Creation and implementation of T4 (quadruplet) object #189
Conversation
|
/run all |
|
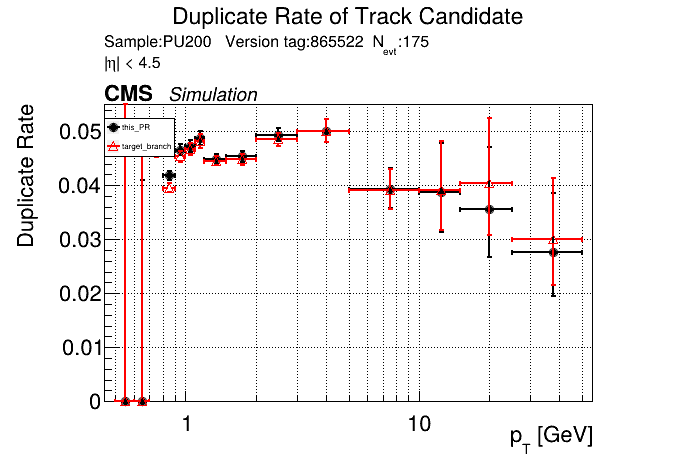
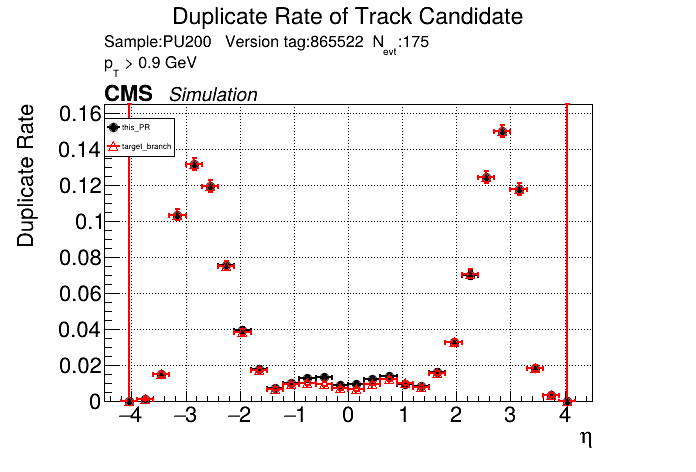
The PR was built and ran successfully in standalone mode. Here are some of the comparison plots.
The full set of validation and comparison plots can be found here. Here is a timing comparison: |
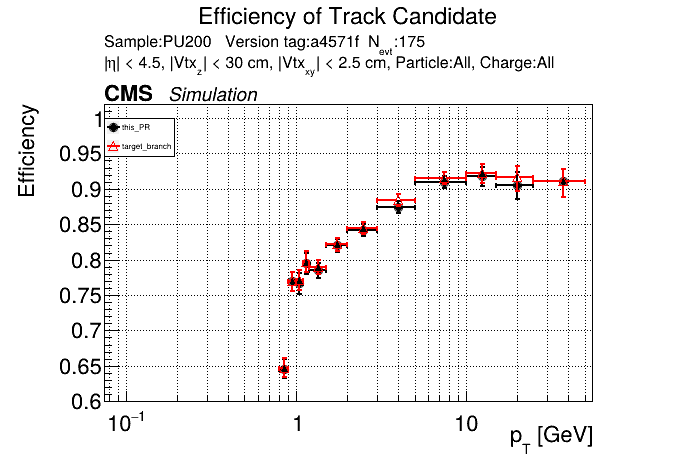
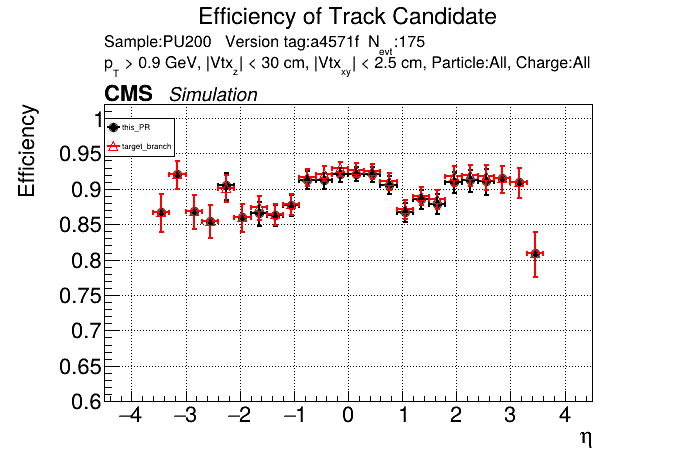
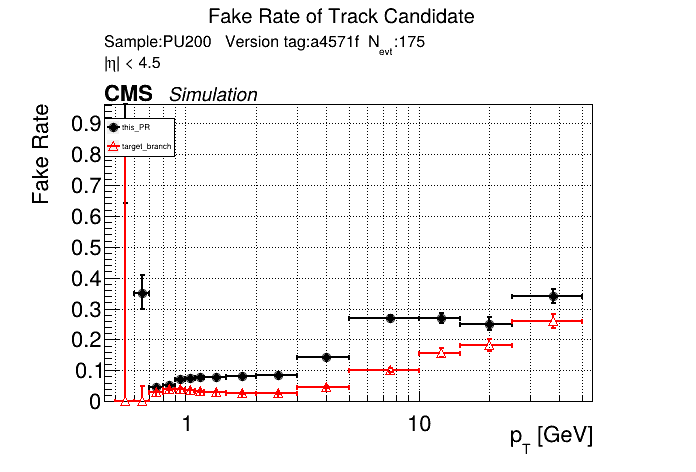
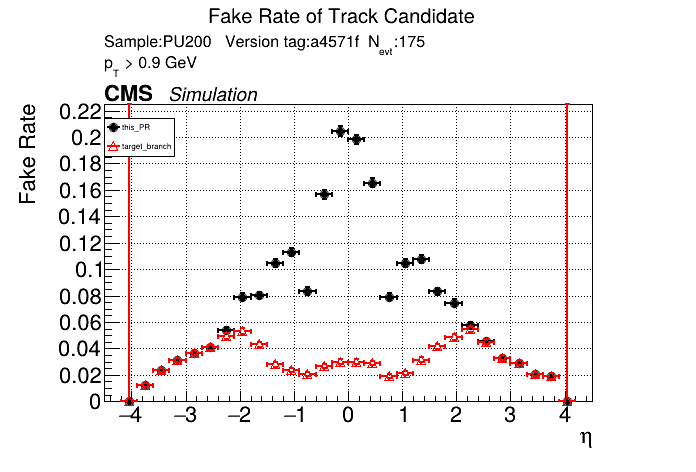
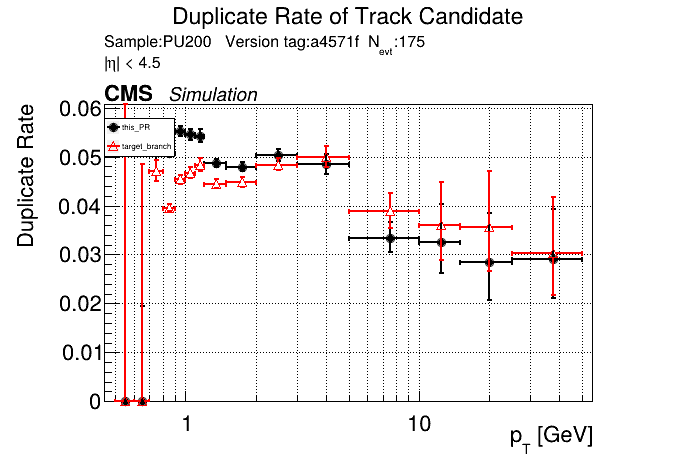
|
There was a problem while building and running with CMSSW. The logs can be found here. |
|
/run cmssw |
|
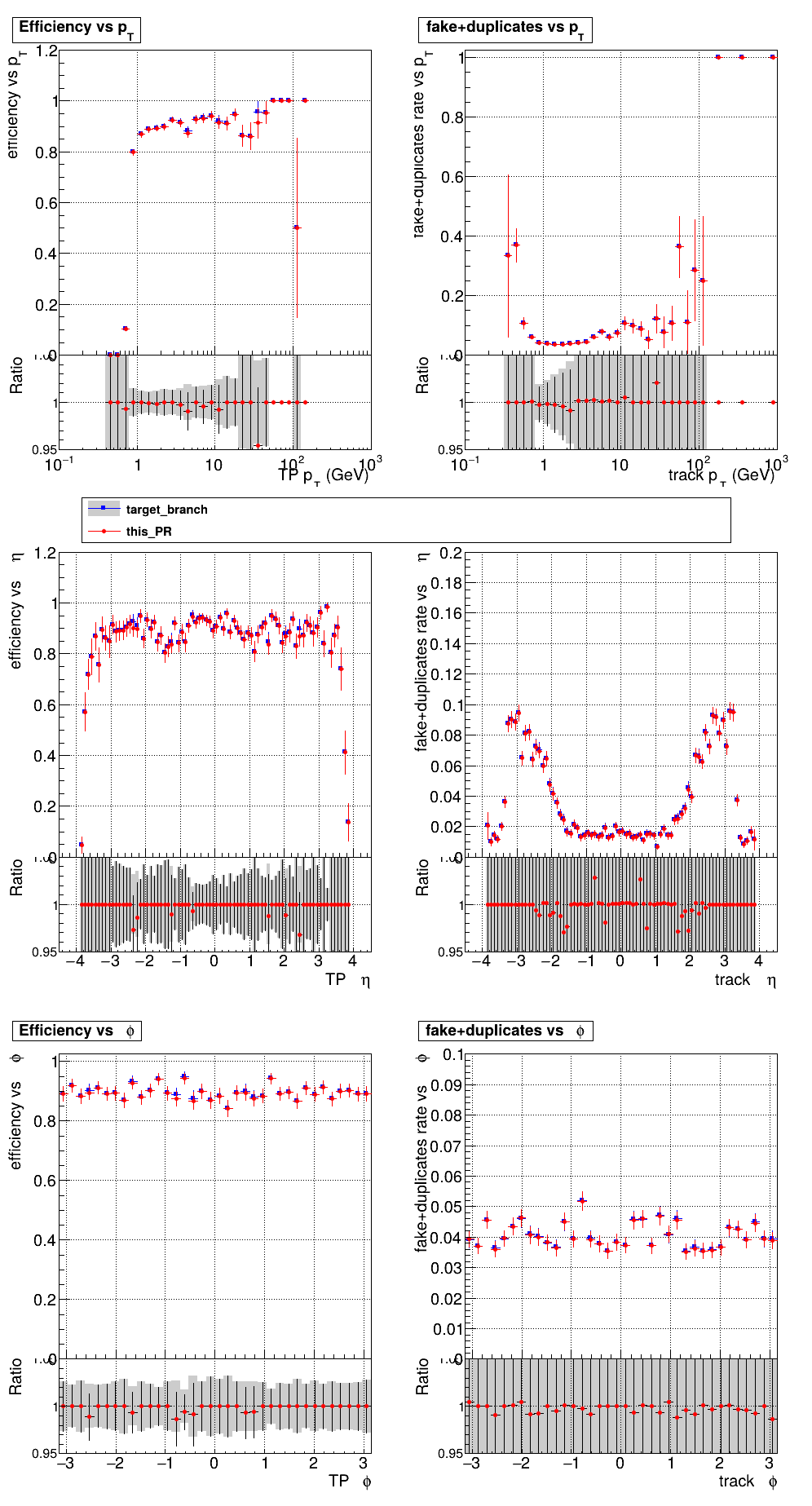
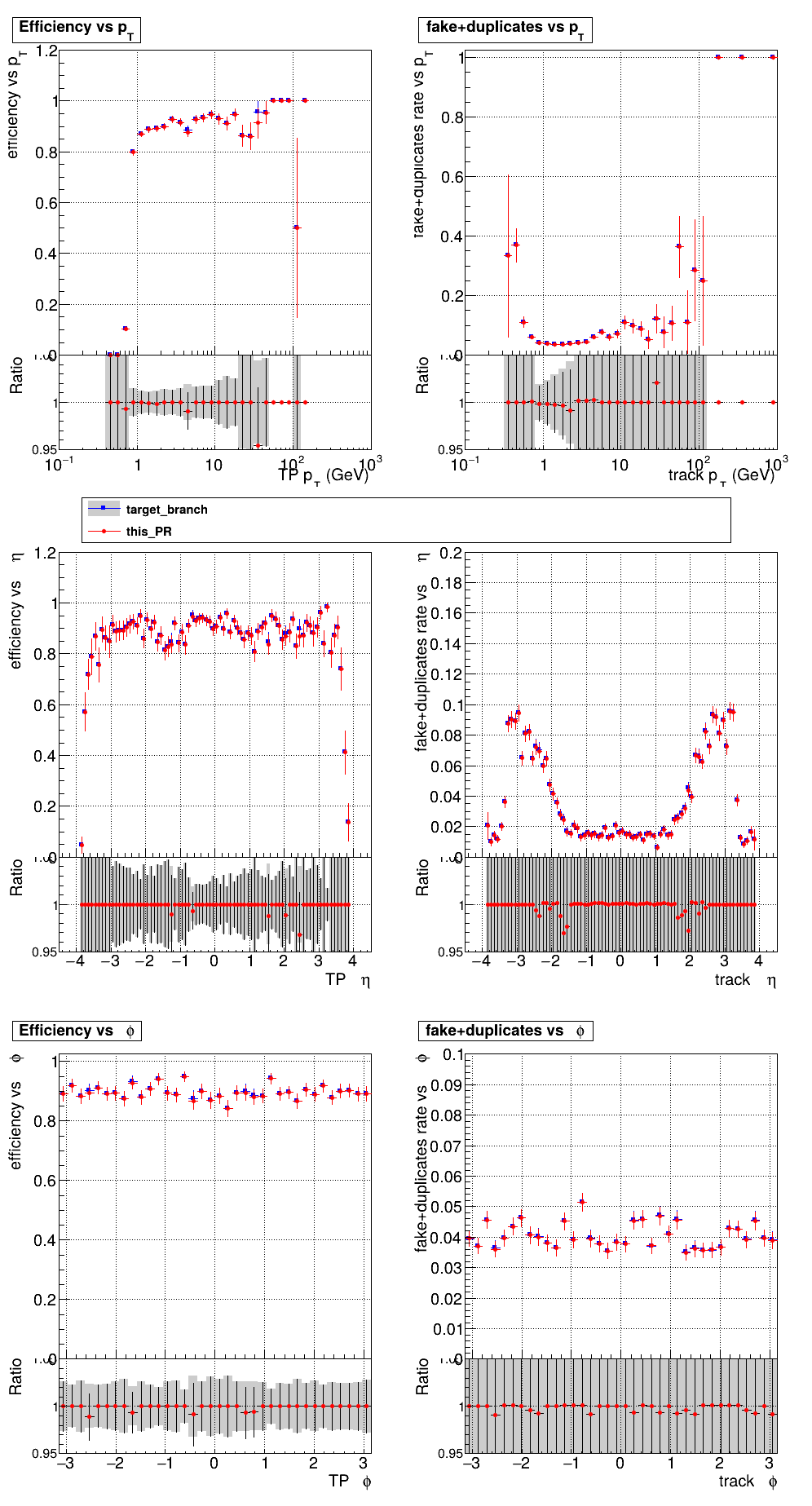
The PR was built and ran successfully with CMSSW. Here are some plots. OOTB All Tracks
The full set of validation and comparison plots can be found here. |
|
/run all |
|
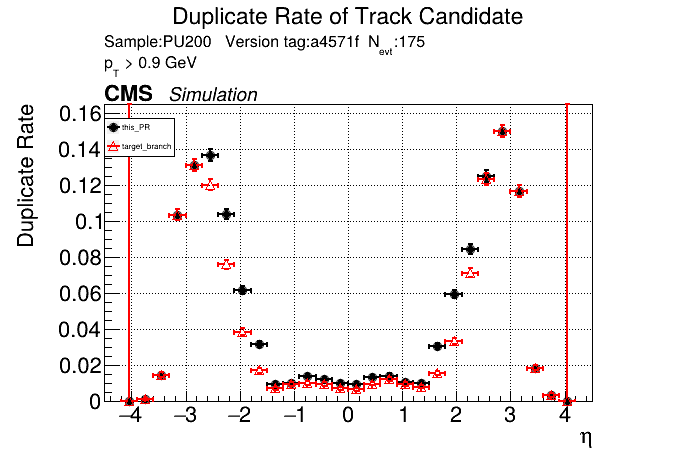
The PR was built and ran successfully in standalone mode. Here are some of the comparison plots.
The full set of validation and comparison plots can be found here. Here is a timing comparison: |
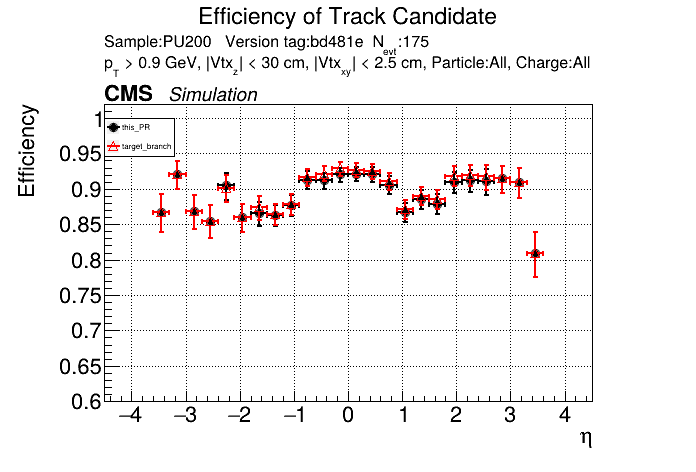
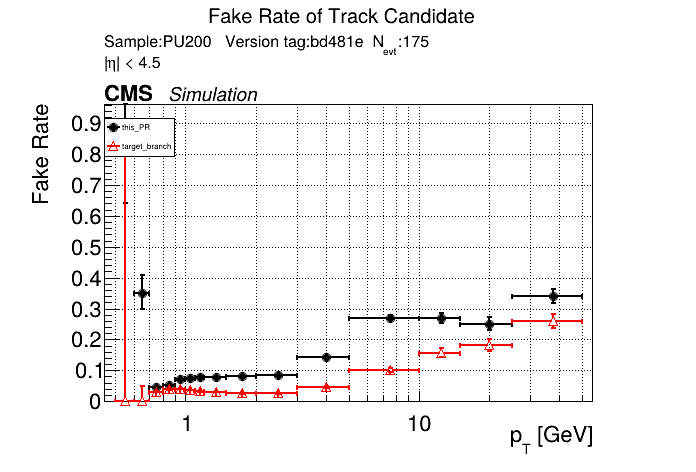
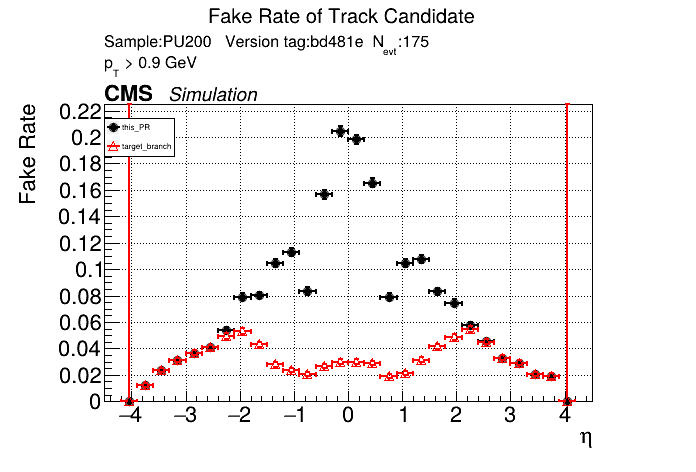
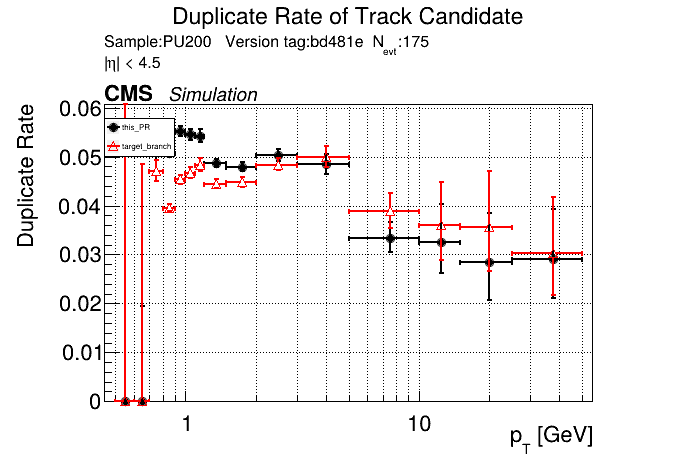
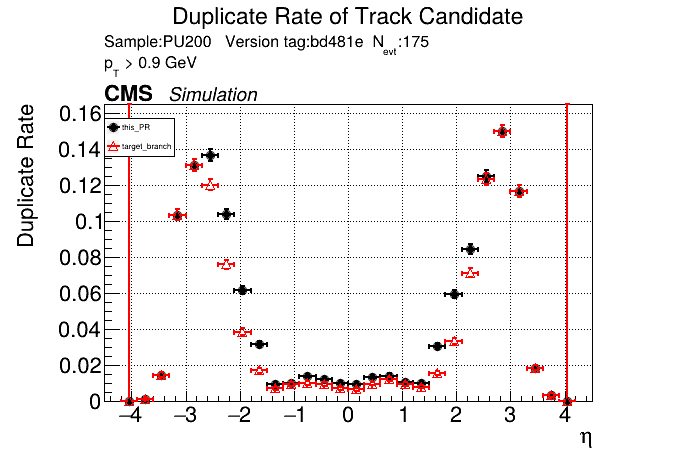
|
The PR was built and ran successfully with CMSSW. Here are some plots. OOTB All Tracks
The full set of validation and comparison plots can be found here. |
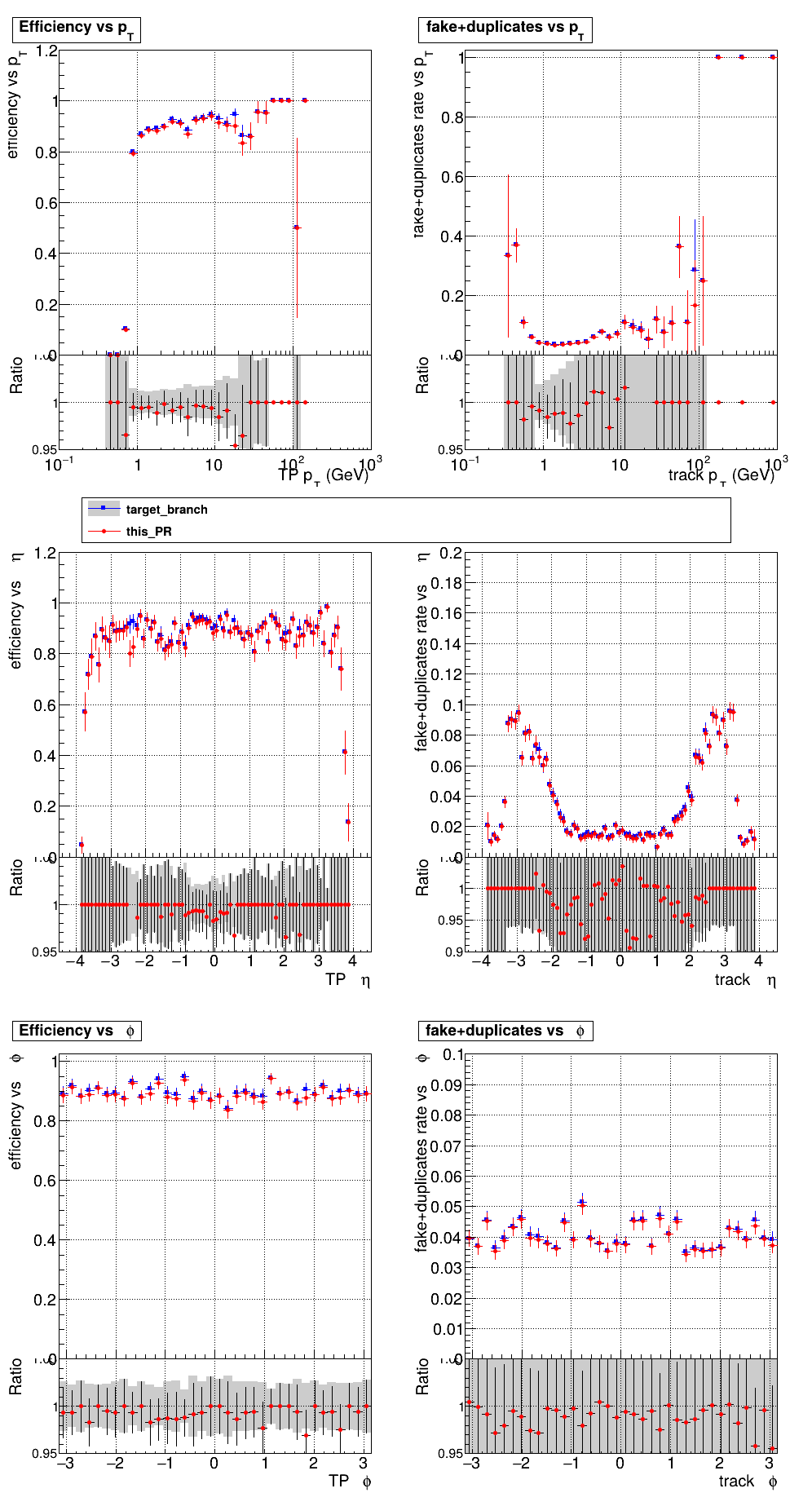
|
/run gpu-all |
|
The PR was built and ran successfully in standalone mode on GPU. Here are some of the comparison plots.
The full set of validation and comparison plots can be found here. Here is a timing comparison: |
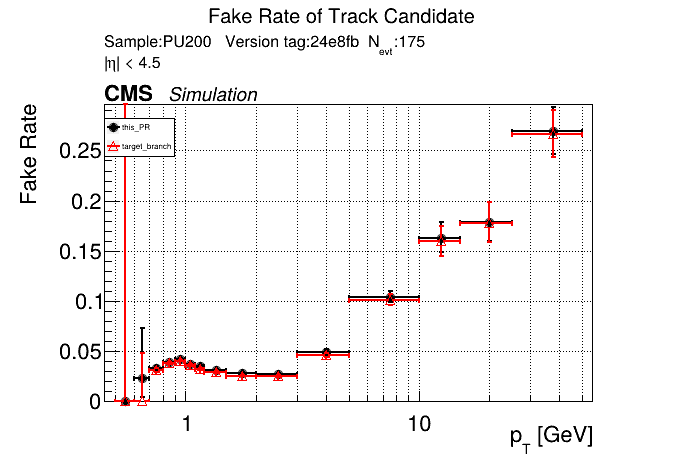
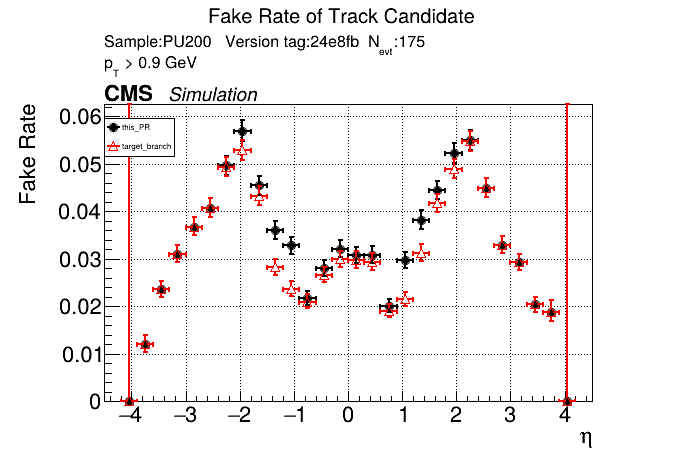
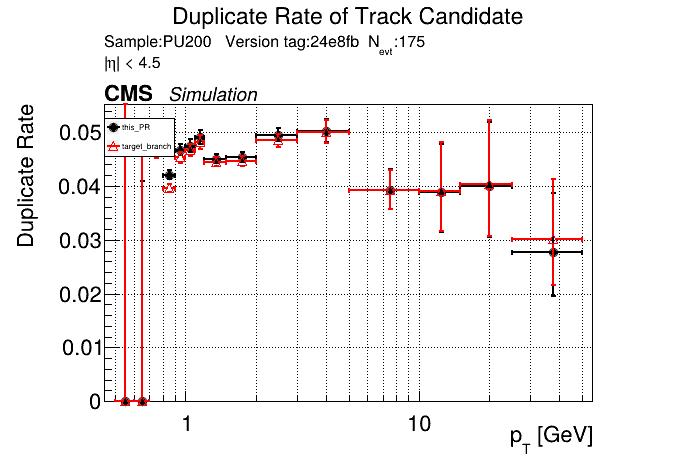
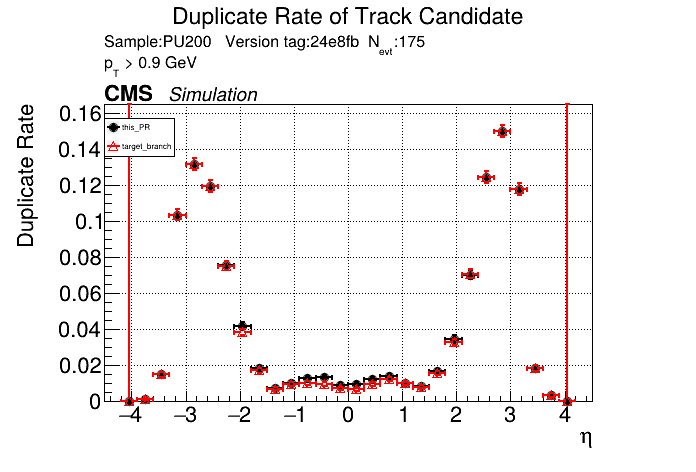
|
The PR was built and ran successfully with CMSSW on GPU. Here are some plots. OOTB All Tracks
The full set of validation and comparison plots can be found here. |
|
/run all |
|
The PR was built and ran successfully in standalone mode. Here are some of the comparison plots.
The full set of validation and comparison plots can be found here. Here is a timing comparison: |
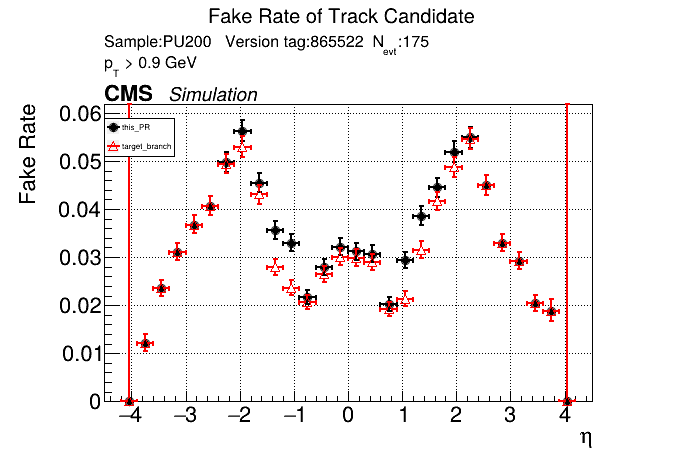
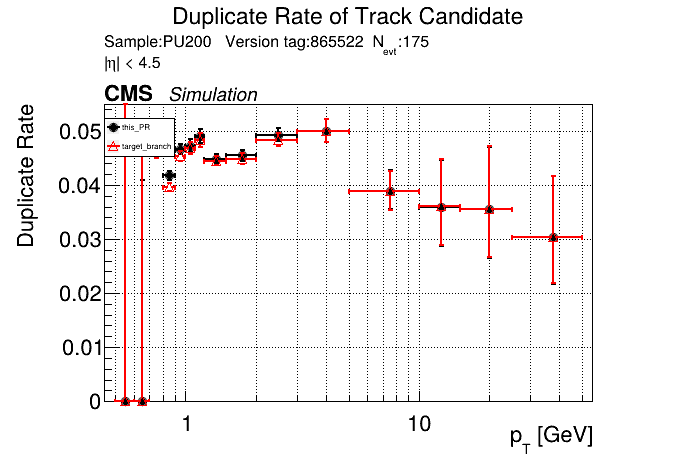
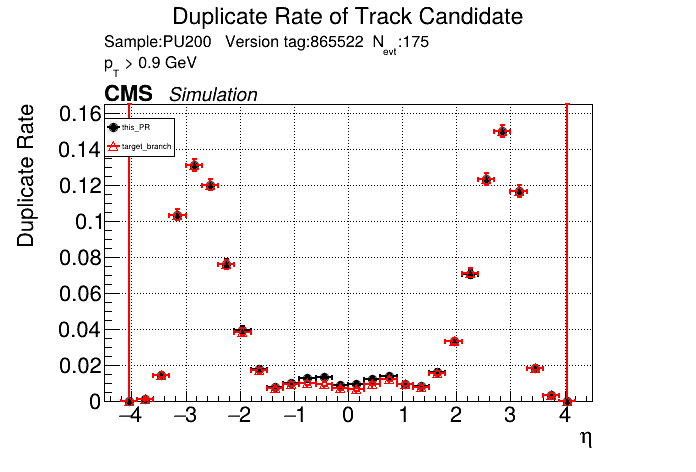
|
The PR was built and ran successfully with CMSSW. Here are some plots. OOTB All Tracks
The full set of validation and comparison plots can be found here. |
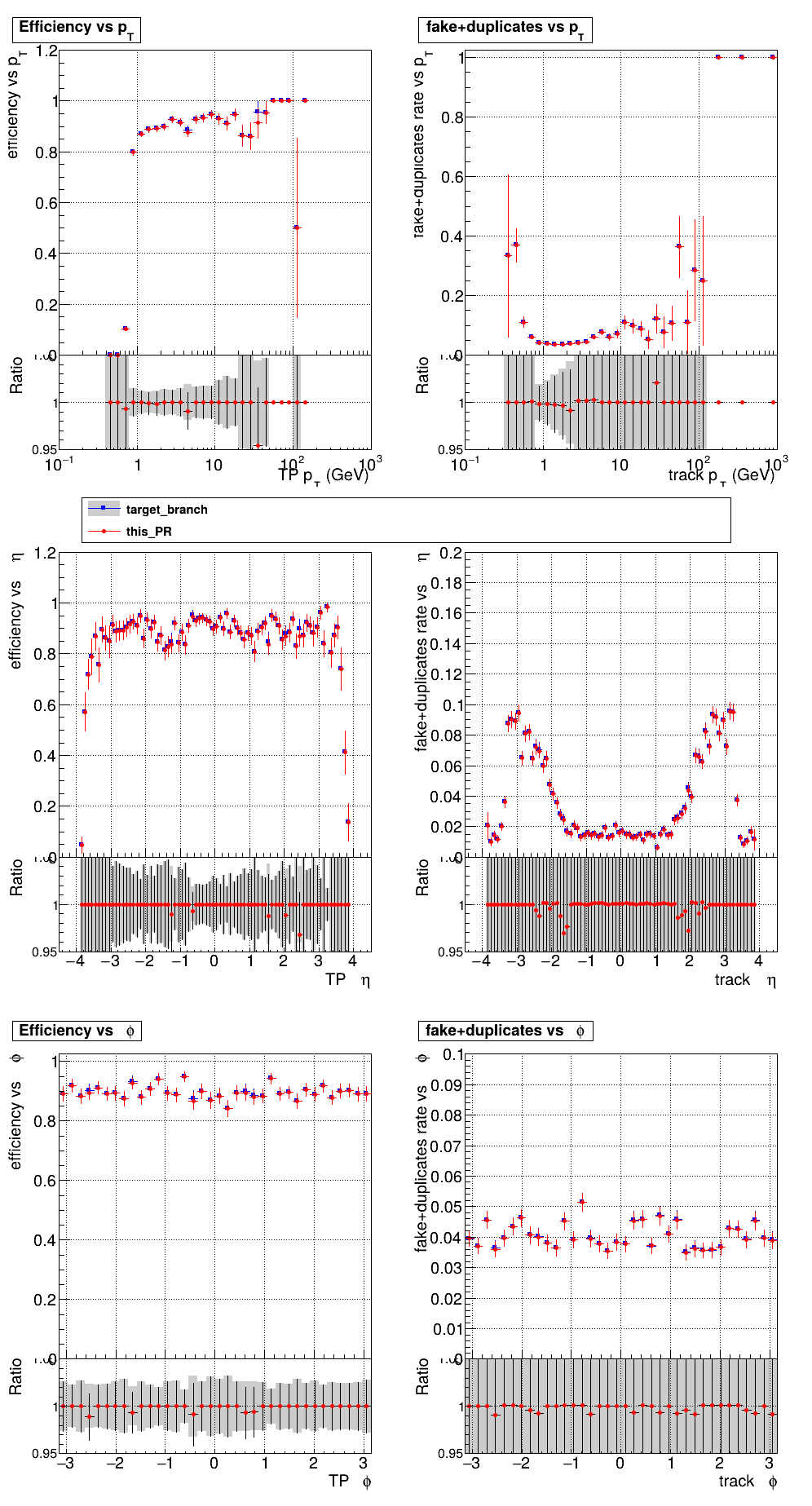
|
/run gpu-all |
|
The PR was built and ran successfully in standalone mode on GPU. Here are some of the comparison plots.
The full set of validation and comparison plots can be found here. Here is a timing comparison: |
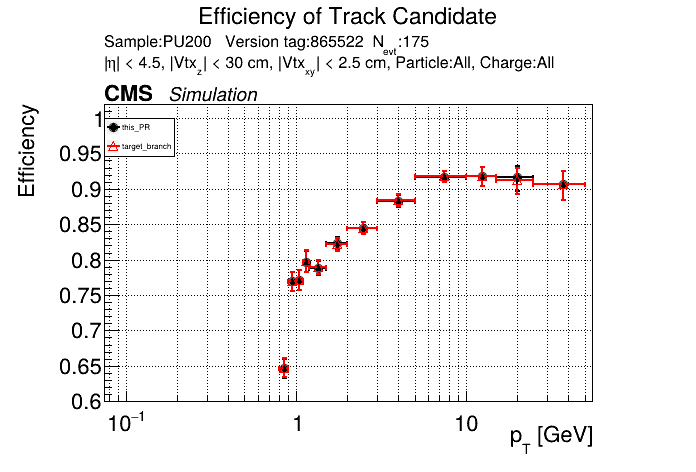
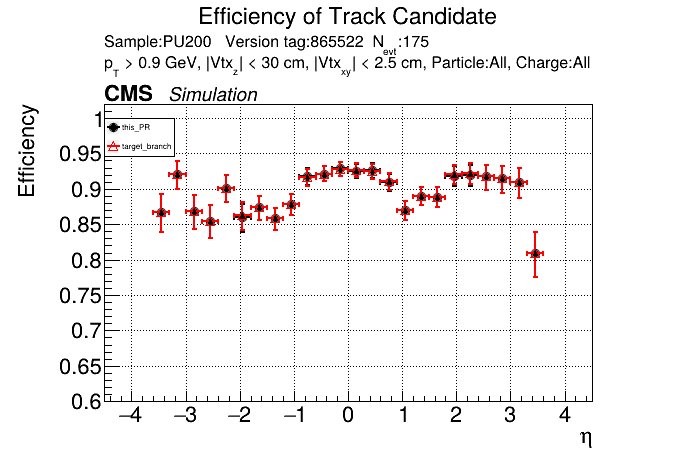
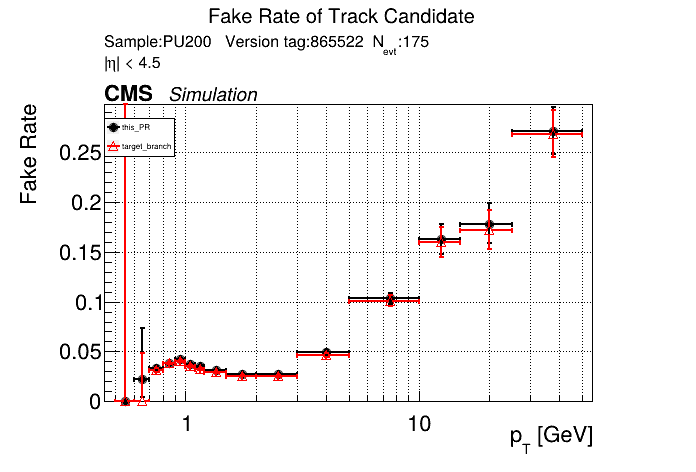
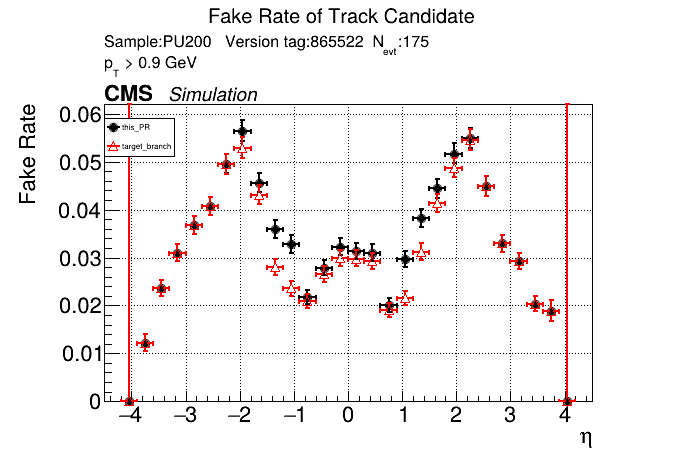
|
The PR was built and ran successfully with CMSSW on GPU. Here are some plots. OOTB All Tracks
The full set of validation and comparison plots can be found here. |
|
/run cmssw |
|
instead of adding T4s in parallel in CMSSW, I'd rather we keep them together with T5s. |
|
The PR was built and ran successfully with CMSSW. Here are some plots. OOTB All Tracks
The full set of validation and comparison plots can be found here. |
Got it, I'll do that instead. |
|
/run cmssw |
|
The PR was built and ran successfully with CMSSW. Here are some plots. OOTB All Tracks
The full set of validation and comparison plots can be found here. |
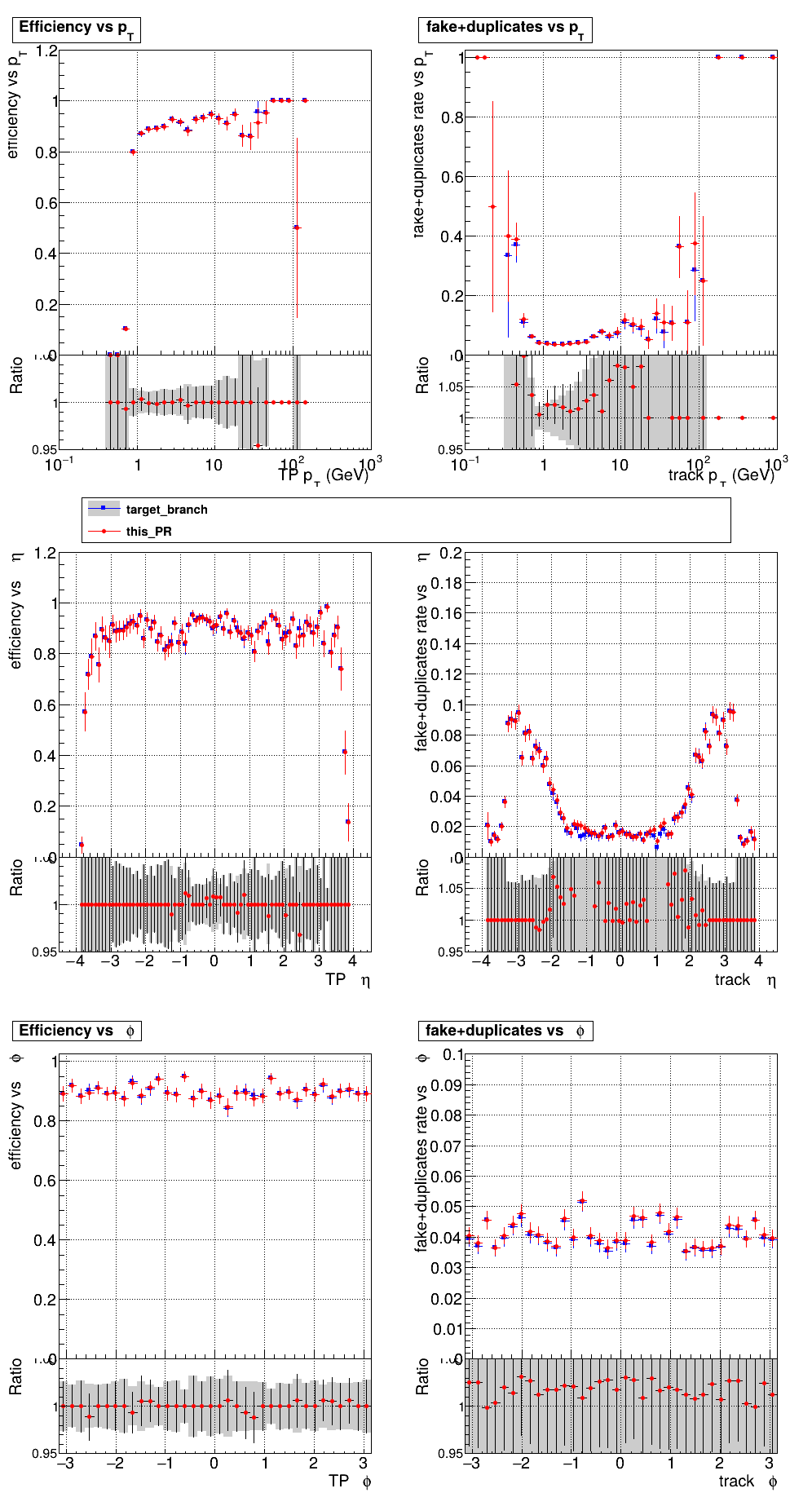
|
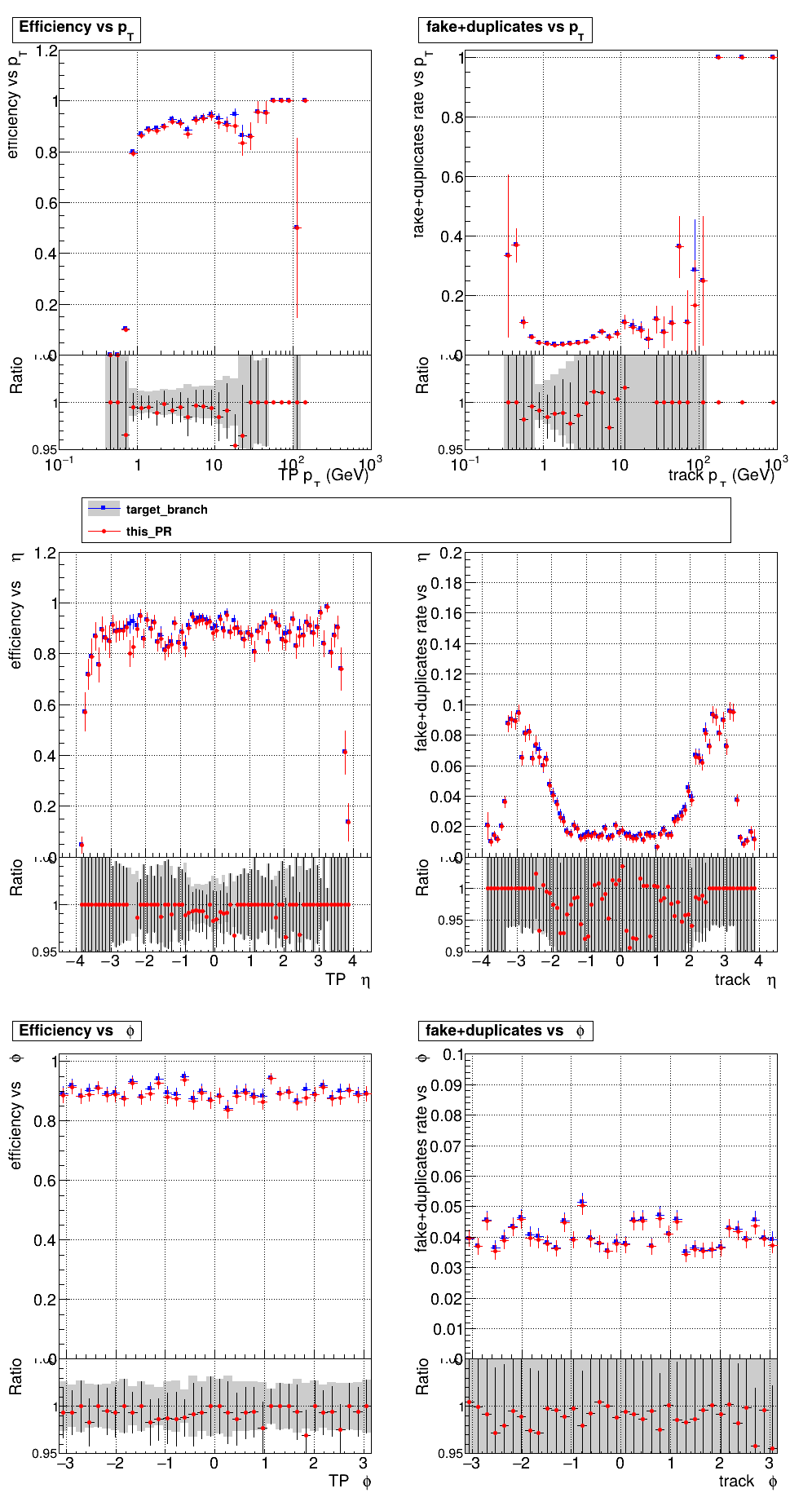
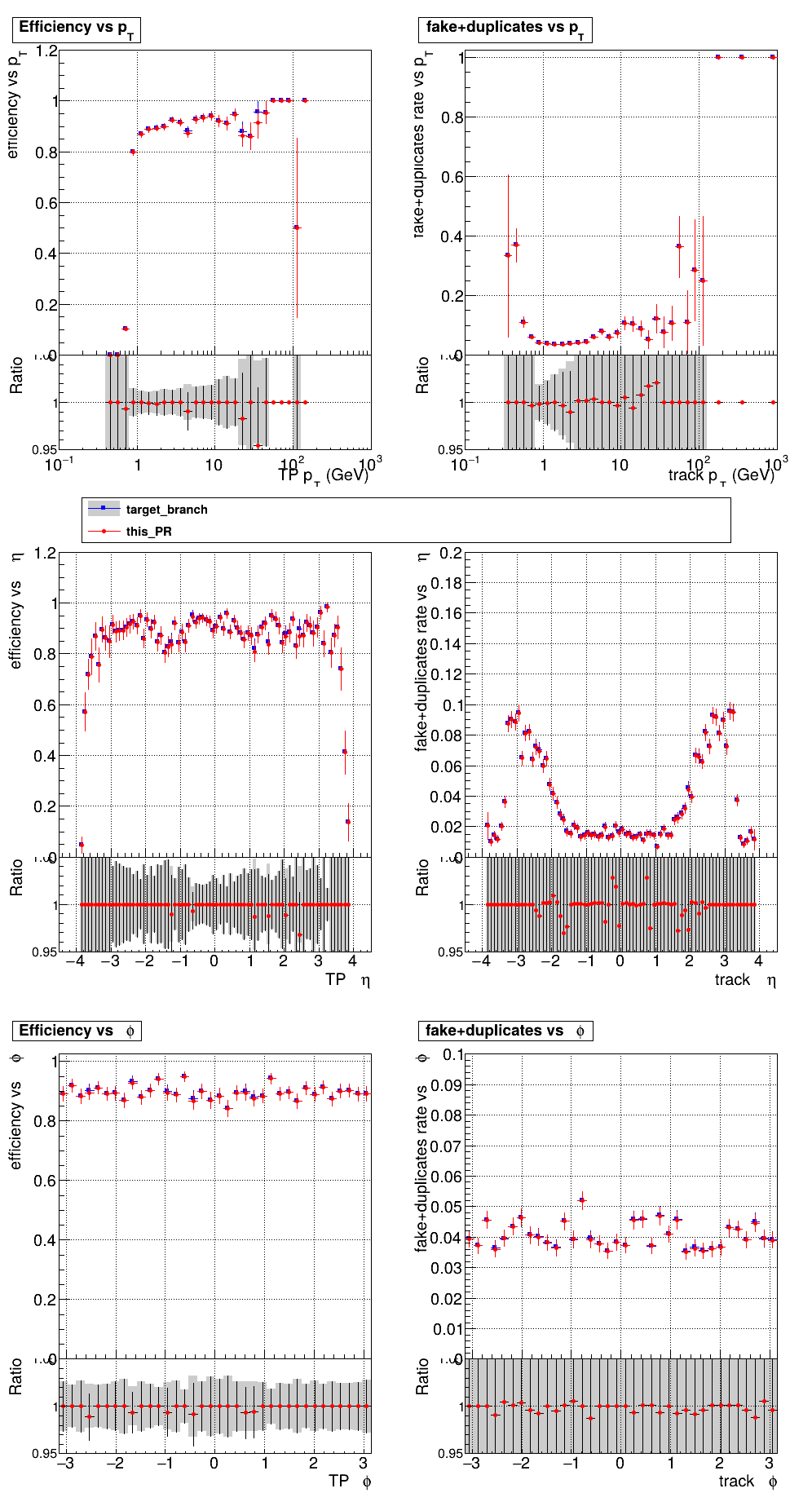
Adding the charge cut to the T5's causes a big drop in efficiency? Any ideas why it works for T4s? @slava77 Commit here, added to counting + creation kernels: d9b77ef I get the same plots only adding the cut to the creation kernel. 
|
How large is the inefficiency? I can speculate that at T4 level some inefficiency was acceptable; also, having two MDs in common probably reduces the inefficiency of this cut |
This is just the normal PU200 setup, you can see the pT5 efficiency drops drastically. pT5 markers are at like ~20% above. Here is the same plot without that charge cut for comparison: 
|
ah, indeed, this looks broken |
I didn't notice a bug. |
|
The PR was built and ran successfully in standalone mode. Here are some of the comparison plots.
The full set of validation and comparison plots can be found here. Here is a timing comparison: |
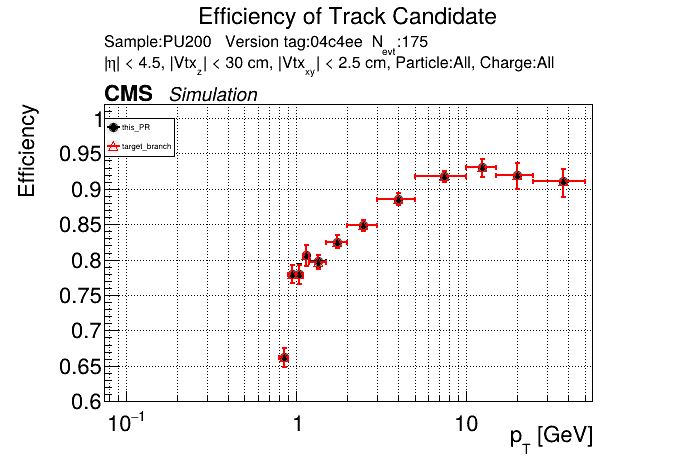
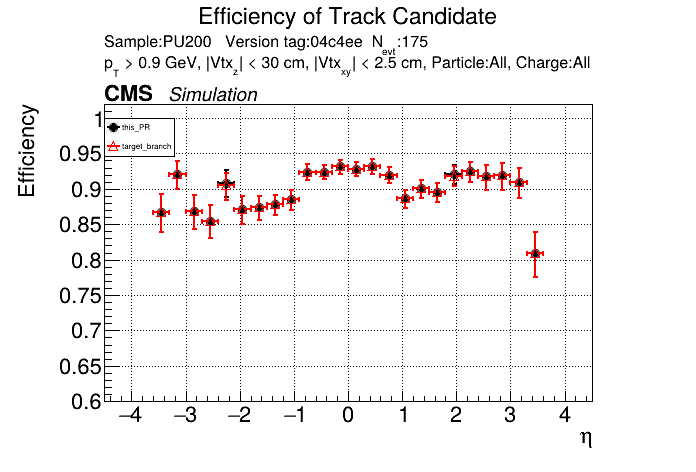
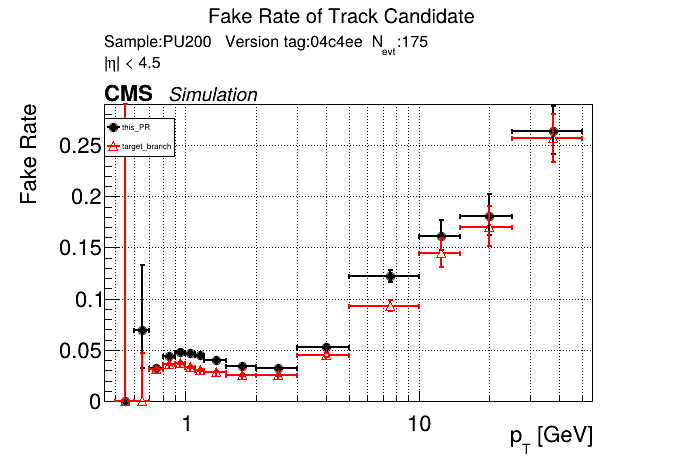
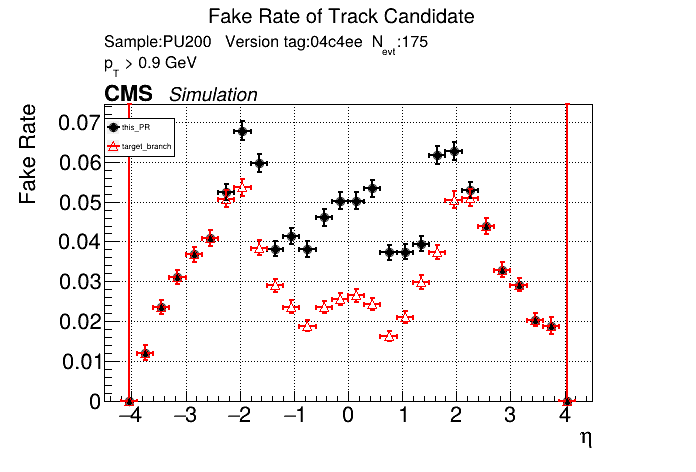
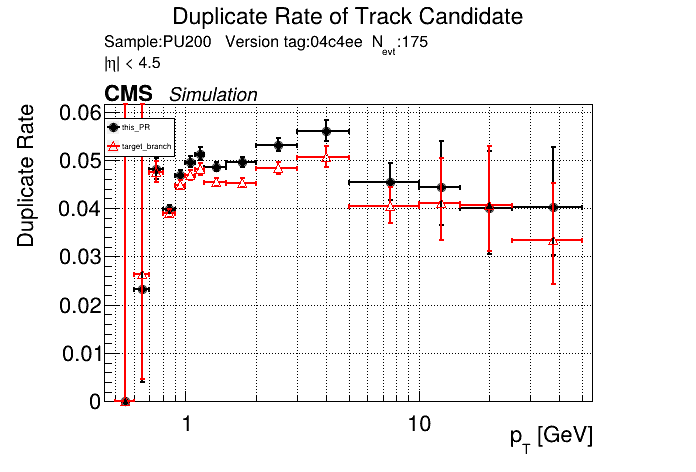
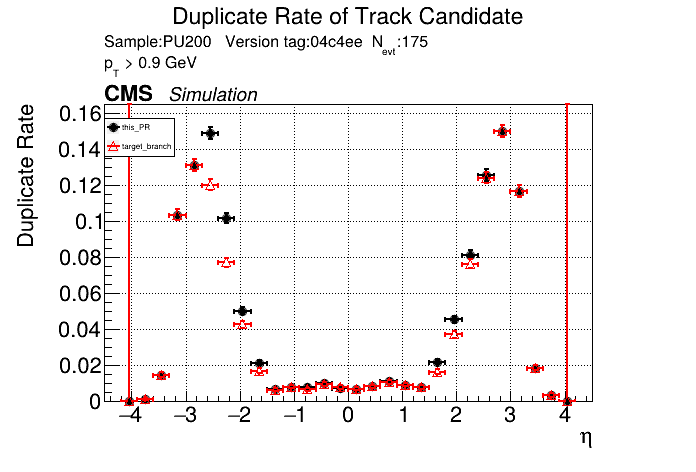
|
The PR was built and ran successfully with CMSSW. Here are some plots. OOTB All Tracks
The full set of validation and comparison plots can be found here. |
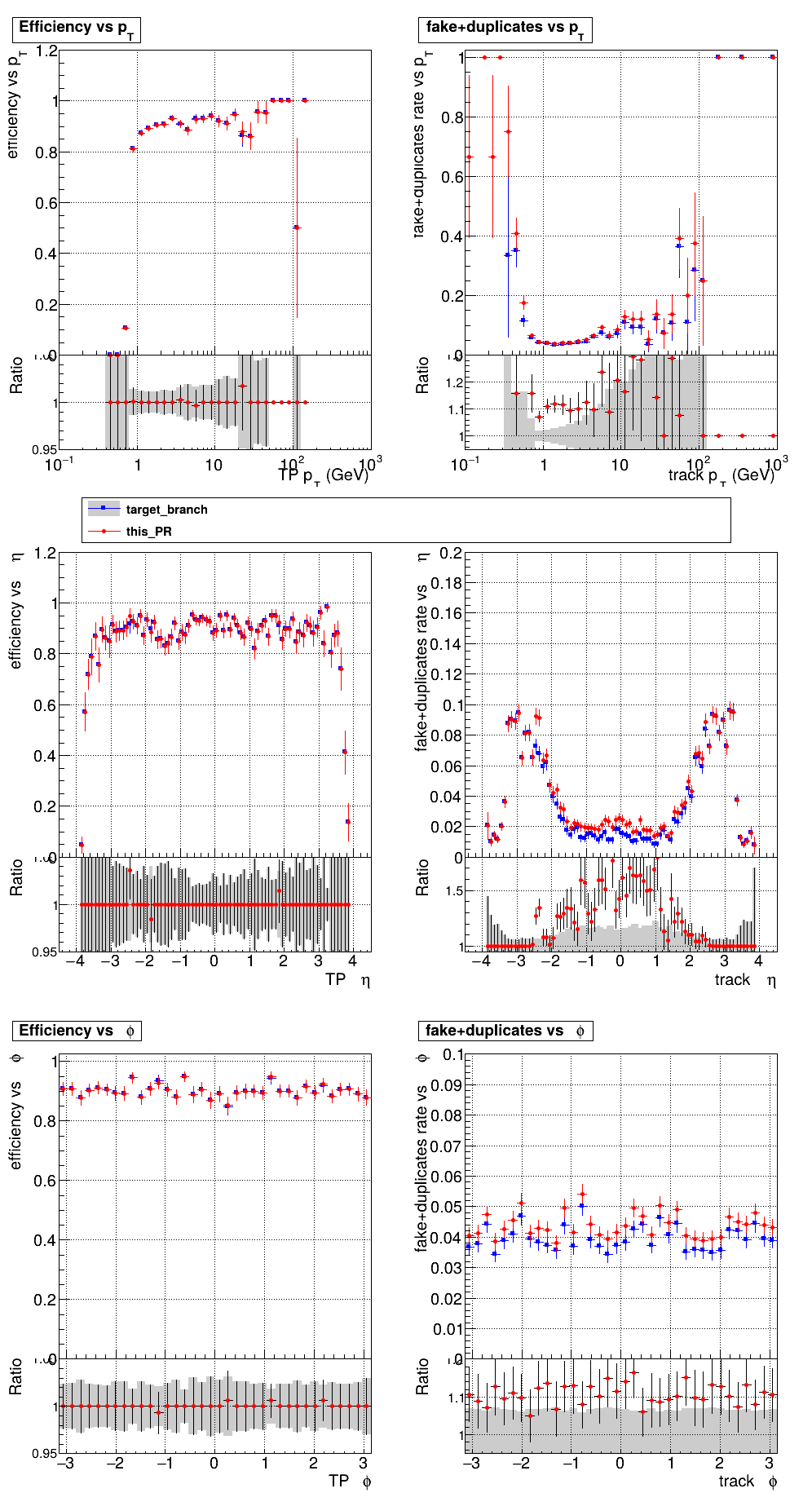
 slava77
left a comment
slava77
left a comment
There was a problem hiding this comment.
many comments related to formatting are not repeated; please check for similar patterns in the added code
| namespace lst { | ||
| using QuadrupletsHostCollection = PortableHostMultiCollection<QuadrupletsSoA, QuadrupletsOccupancySoA>; | ||
| } // namespace lst | ||
| #endif No newline at end of file |
| struct Params_T4 { | ||
| static constexpr int kLayers = 4, kHits = 8; | ||
| using ArrayU8xLayers = edm::StdArray<uint8_t, kLayers>; | ||
| using ArrayU16xLayers = edm::StdArray<uint16_t, kLayers>; | ||
| using ArrayUxHits = edm::StdArray<unsigned int, kHits>; | ||
| }; |
There was a problem hiding this comment.
I'd move this up, between T3 and T5 to be in more logical order
| // only when required by a flag for other pT objects. | ||
| if (includeNonpLSTSs_ || lstOutput_view.trackCandidateType()[i] == lst::LSTObjType::T5) { | ||
| if (includeNonpLSTSs_ || (lstOutput_view.trackCandidateType()[i] == lst::LSTObjType::T5) || | ||
| (lstOutput_view.trackCandidateType()[i] == lst::LSTObjType::T4)) { |
There was a problem hiding this comment.
6 lines below is if (lstOutput_view.trackCandidateType()[i] == lst::LSTObjType::T5) {
I think that this check should stay for T4s that still have 2 first PS layers, if that logic is still required.
The barrel-3 T4s should be OK to require just the first P-side hit and pick up the second only on the next layer.
OTOH, perhaps it's worth to revisit that P-side selection for the first two hits, if it is still required.
I recall that it was needed due to the features of the initial state estimator (done using the first two hits) in the seed generator from hits (used below).
But maybe things changed since the initial introduction of this code.
There was a problem hiding this comment.
This is an old comment but I think it might be still relevant. Currently the T4s aren't included in the check for having the first 2 hits be PS (in L218-222 in the current LSTOutputConverter.cc). Should I include them? From my understanding if it's just checking the first 2 hits then it should have no impact on any of the T4s.
There was a problem hiding this comment.
this comment was indeed from the time when I started the review in August
There was a problem hiding this comment.
(since the very early version), now that all barrel T4s start from B3, this requirement would kill all T4s.
The fact that we see something (visible in the fake+dr plots though) looks like using P+S for the first two hits still works.
But it could be that the lack of any change in efficiency is still indicative of a problem.
The logic should be less that "the first two should be P-side", but rather that if one of the two first hits is "S", it has to be on another layer and not in the same doublet module stack.
There was a problem hiding this comment.
@jchismar
what do you see in the cube sample vs eta in CMSSW? (just to use a sample where T4s are expected to contribute)
There was a problem hiding this comment.
I haven't checked on the cube sample in CMSSW, only ttbar with and without PU. I don't think I know which input file to use for the cube sample, do you know of one?
There was a problem hiding this comment.
it may need to be remade.
@VourMa @GNiendorf did you make a cube sample relatively recently (to perhaps still have the step1 config around) ?
There was a problem hiding this comment.
since the goal for the test in my question/request is not so much the cube but rather to see T4s vs eta, perhaps running a local test on ttbar with T5s disabled (during building) would be enough ... or even also pT3s as well.
This way the potential issue with the hit selection in the output converter would be more clear.
There was a problem hiding this comment.
ttbar with T5s disabled (during building) would be enough ... or even also pT3s as well.
uhm, no, don't disable pT3s: the reference should have something to compare with
| const int flatThreadExtent = blockSize; // total threads per block | ||
|
|
||
| for (int iter : cms::alpakatools::uniform_groups_z(acc, nEligibleT4Modules)) { | ||
| uint16_t lowerModule1 = ranges.indicesOfEligibleT4Modules()[iter]; |
There was a problem hiding this comment.
| uint16_t lowerModule1 = ranges.indicesOfEligibleT4Modules()[iter]; | |
| const uint16_t lowerModule1 = ranges.indicesOfEligibleT4Modules()[iter]; |
check the rest of the code to more systematically keep things const if they are supposed to be
| unsigned int innerOuterInnerMiniDoubletIndex = | ||
| segments.mdIndices()[secondSegmentIndex][0]; //inner triplet outer segment inner MD index |
There was a problem hiding this comment.
please try to keep the names more compact or at least more readable: innerOuterInner requires the comment to be understood.
if the name was more clear the comment is not necessary
| unsigned int innerOuterInnerMiniDoubletIndex = | |
| segments.mdIndices()[secondSegmentIndex][0]; //inner triplet outer segment inner MD index | |
| unsigned int innerT3OuterLSInnerMDIndex = segments.mdIndices()[secondSegmentIndex][0]; |
or
| unsigned int innerOuterInnerMiniDoubletIndex = | |
| segments.mdIndices()[secondSegmentIndex][0]; //inner triplet outer segment inner MD index | |
| unsigned int innerT3MD2Index = segments.mdIndices()[secondSegmentIndex][0]; |
| } | ||
|
|
||
| //___________________________________________________________________________________________________________________________________________________________________________________________ | ||
| float runQuadruplet(LSTEvent* event) { |
| timing_total_short += timing[7] * 1000; // pT3 | ||
| timing_total_short += timing[8] * 1000; // TC | ||
| timing_total_short += timing[9] * 1000; // Reset | ||
| timing_total += timing[0] * 1000; // Hits |
| } | ||
|
|
||
| //________________________________________________________________________________________________________________________________ | ||
| void createQuadrupletBranches() { |
There was a problem hiding this comment.
keep closer to T5 (similar code to be closer together)
| } | ||
|
|
||
| //________________________________________________________________________________________________________________________________ | ||
| std::map<unsigned int, unsigned int> setQuadrupletBranches(LSTEvent* event, |
| std::vector<float> const& trk_ph2_z) { | ||
| auto const trackCandidatesExtended = event->getTrackCandidatesExtended(); | ||
| auto const quadruplets = event->getQuadruplets<QuadrupletsSoA>(); | ||
| unsigned int T4 = trackCandidatesExtended.directObjectIndices()[idx]; |
There was a problem hiding this comment.
| unsigned int T4 = trackCandidatesExtended.directObjectIndices()[idx]; | |
| unsigned int t4 = trackCandidatesExtended.directObjectIndices()[idx]; |
here and elsewhere to match the CMSSW code style (only types are capitalized first letter)
| auto hType = tracker.getDetectorType(hit.geographicalId()); | ||
| if (hType != TrackerGeometry::ModuleType::Ph2PSP && n < 2) | ||
| continue; // the first two should be P |
There was a problem hiding this comment.
Do I recall correctly that all T4s start on a PS layer?
In this case the logic may be just if (hType == TrackerGeometry::ModuleType::Ph2PSS && n < 1) continue;
and change the comment to assume the first layer is a PS; skip the first S-side hit
There was a problem hiding this comment.
ah, no, if (hType == TrackerGeometry::ModuleType::Ph2PSS && n < 1) is not enough to skip the first S; need to count the total hits so far.
There was a problem hiding this comment.
Manos pointed me to here to get the layer info. I'll take a look at it tomorrow, and also double check about T4s only starting on a PS layer.
There was a problem hiding this comment.
During the meeting I was talking about layer index that we can get given a detId; it needs a tracker topology though.
Need to add const edm::ESGetToken<TrackerTopology, TrackerTopologyRcd> tTopoToken_; to the member data and call esConsumes on it in the constructor (similar to the geometry token). Then
const TrackerTopology& tTopo = iSetup.getData(tTopoToken_); at the start of ::produce and then tTopo.layer(hit.geographicalId()) will give you the layer.
I'd then get the first hit layer index and if (hType == TrackerGeometry::ModuleType::Ph2PSS && hitLayer == firstLayer) continue;
8b51a41 to
2358fff
Compare
|
/run all |
|
There was a problem while building and running in standalone mode. The logs can be found here. |
2358fff to
7840d07
Compare
|
/run all |
7840d07 to
3ec1f23
Compare
|
/run all |
|
The PR was built and ran successfully in standalone mode. Here are some of the comparison plots.
The full set of validation and comparison plots can be found here. Here is a timing comparison: |
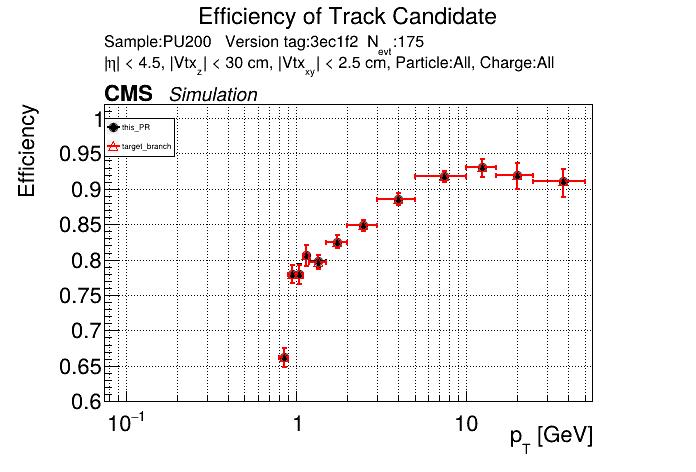
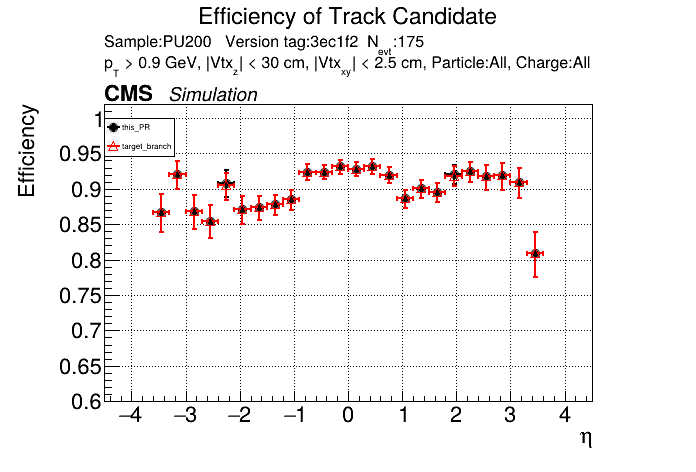
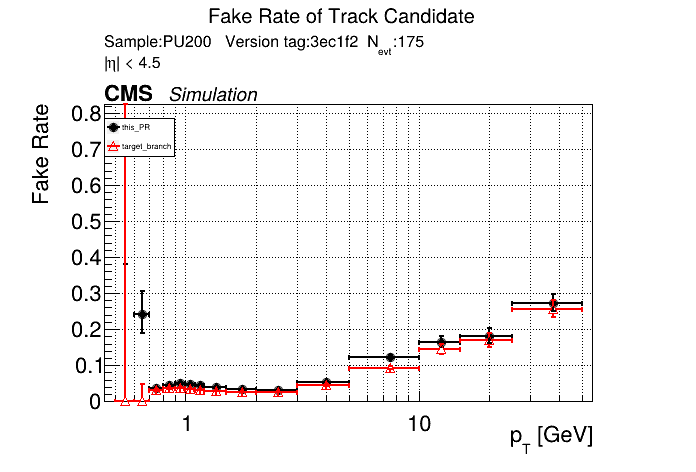
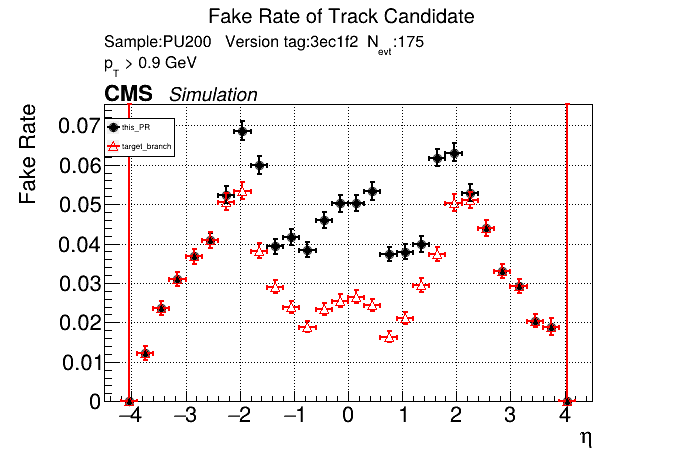
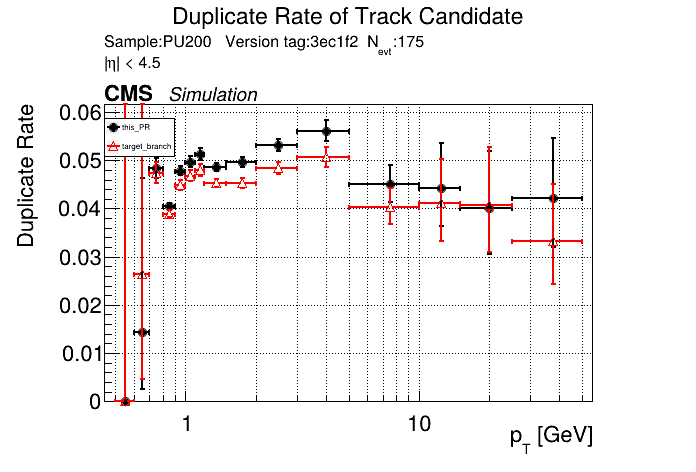
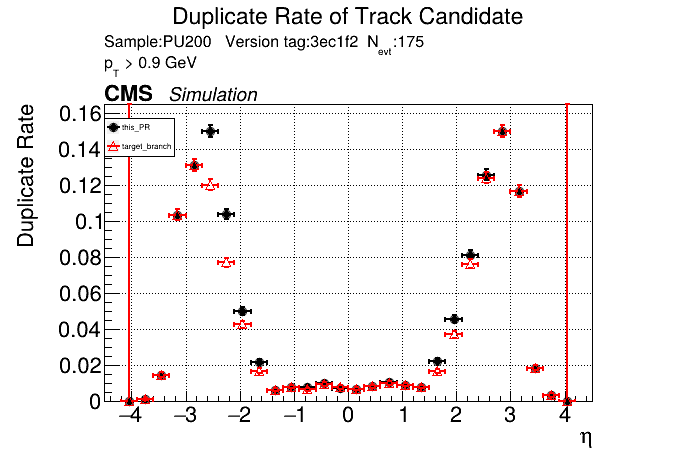
|
The PR was built and ran successfully with CMSSW. Here are some plots. OOTB All Tracks
The full set of validation and comparison plots can be found here. |
3ec1f23 to
45e831b
Compare
|
/run all |
|
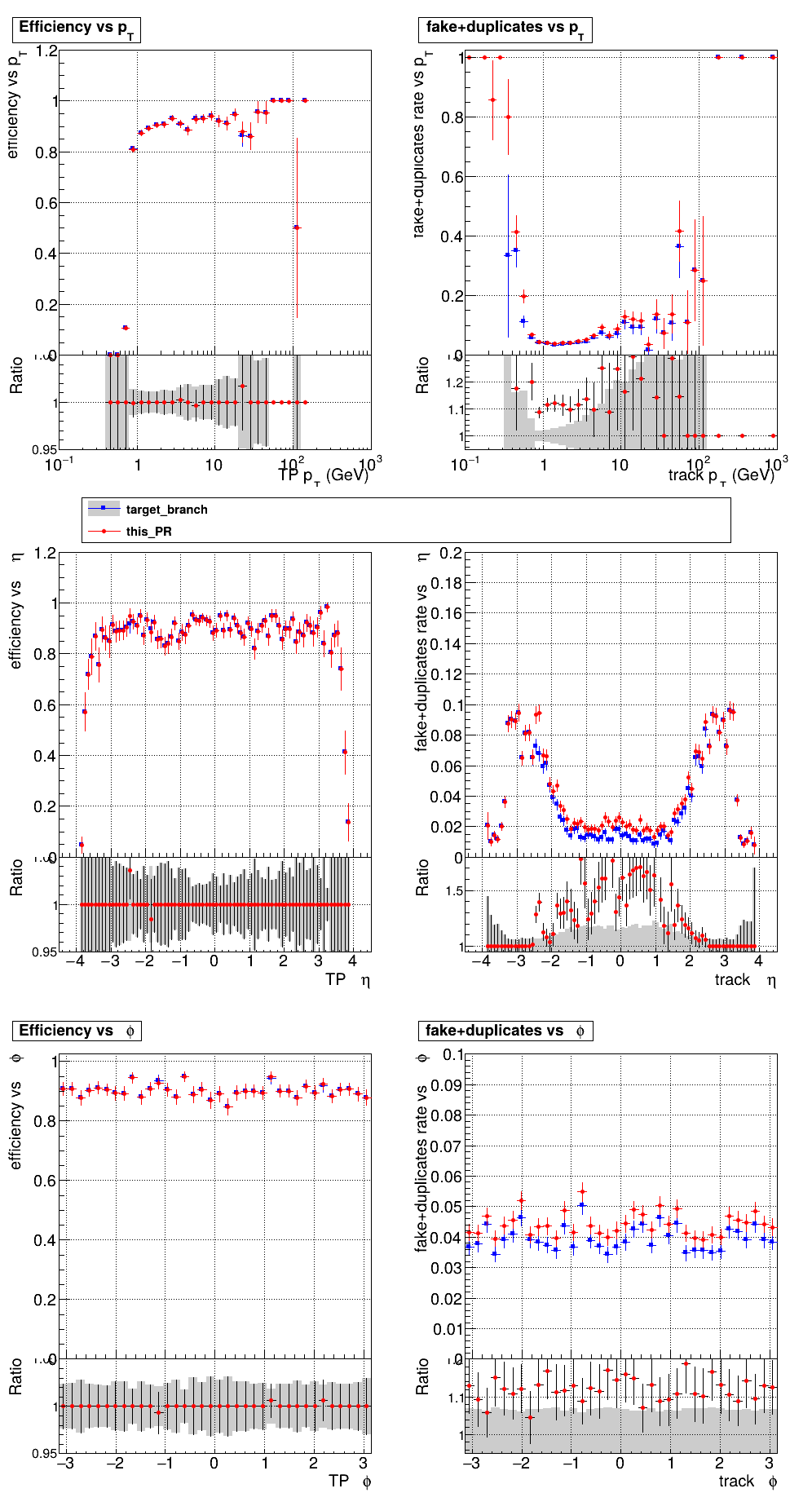
The PR was built and ran successfully in standalone mode. Here are some of the comparison plots.
The full set of validation and comparison plots can be found here. Here is a timing comparison: |
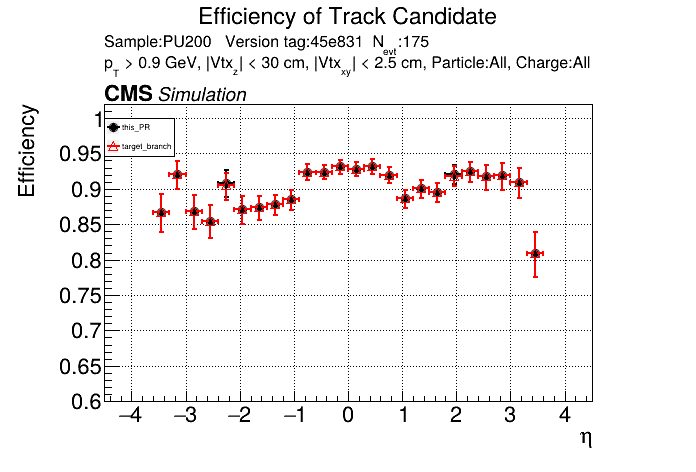
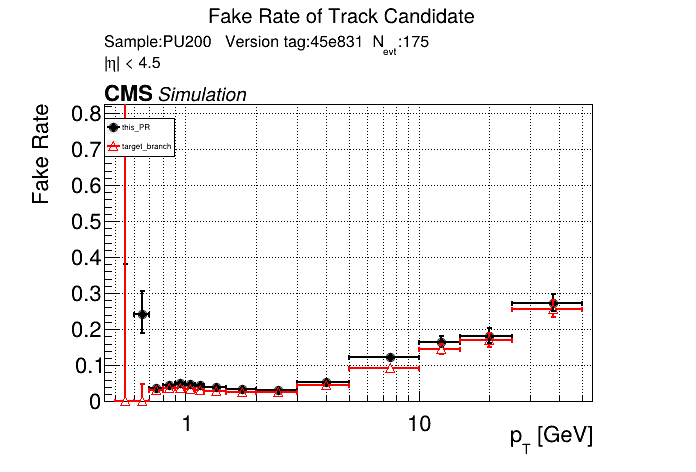
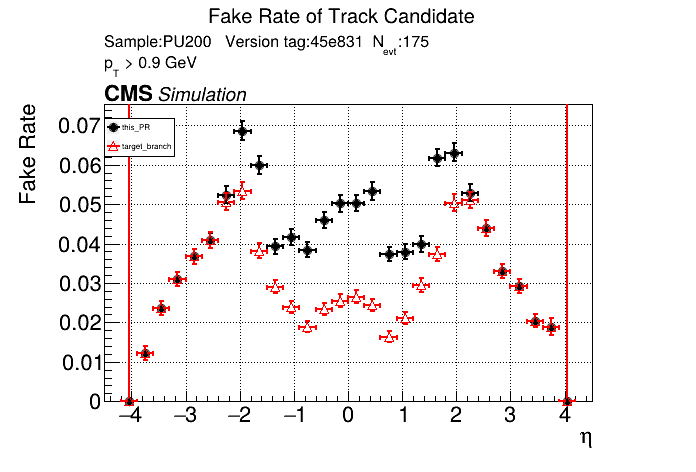
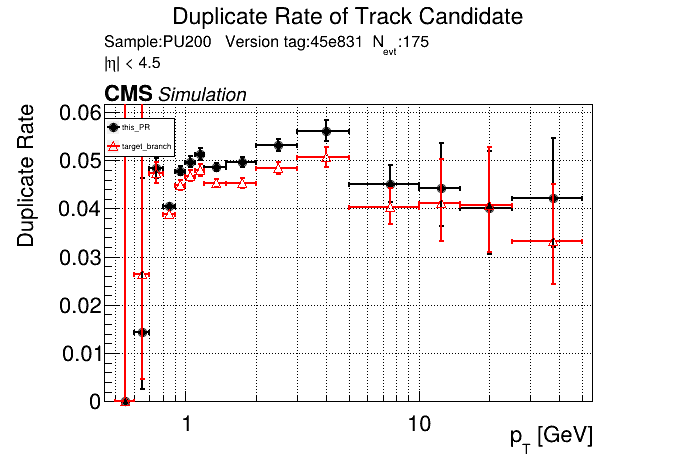
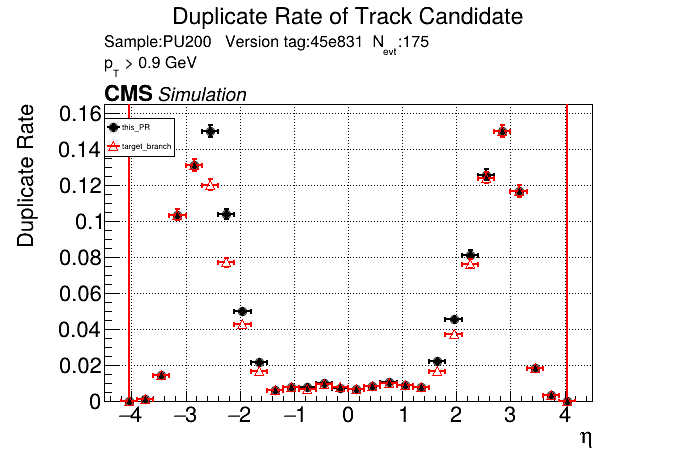
|
The PR was built and ran successfully with CMSSW. Here are some plots. OOTB All Tracks
The full set of validation and comparison plots can be found here. |
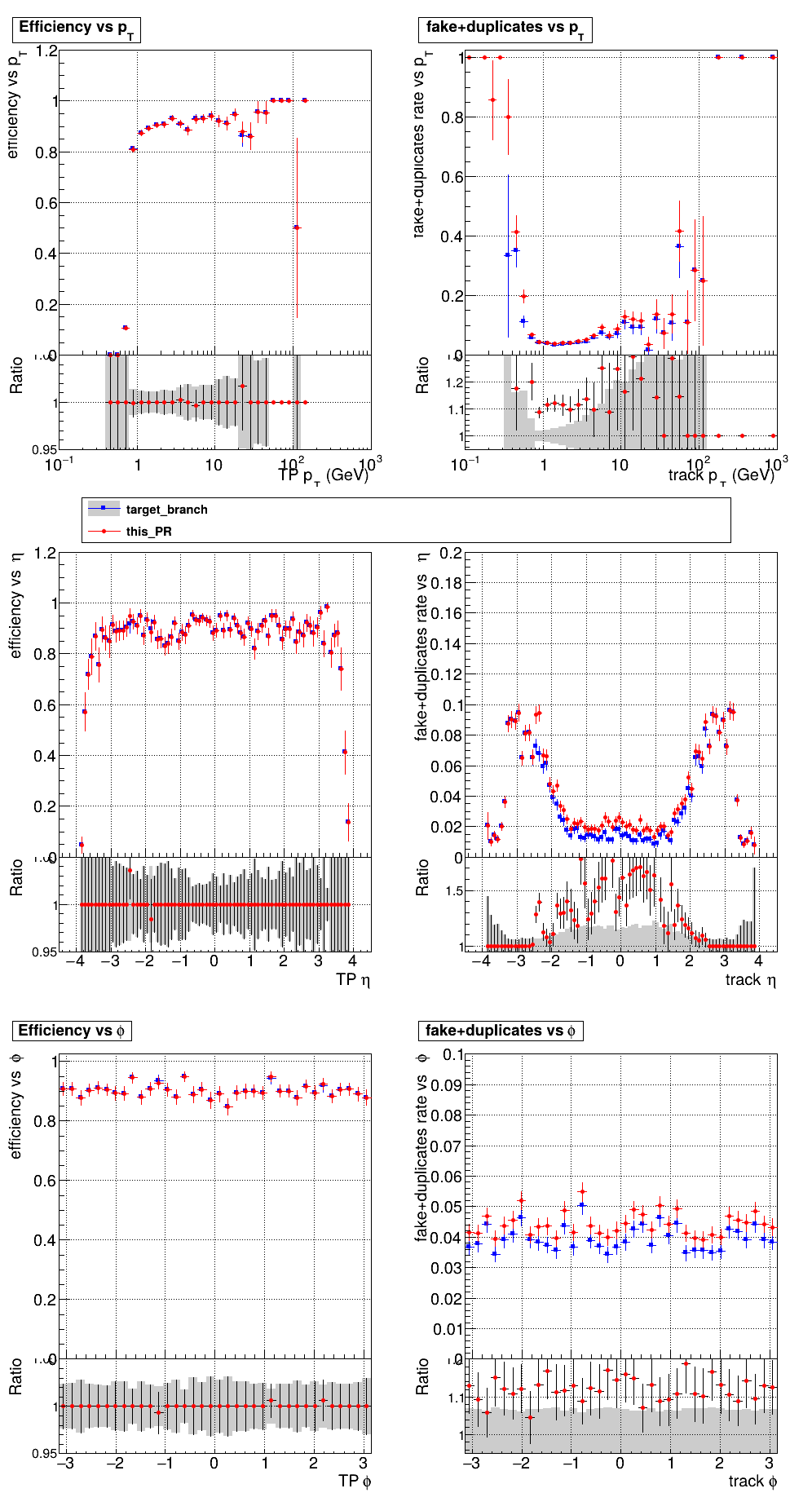
|
/run all |
|
The PR was built and ran successfully in standalone mode. Here are some of the comparison plots.
The full set of validation and comparison plots can be found here. Here is a timing comparison: |






|
The PR was built and ran successfully in standalone mode on GPU. Here are some of the comparison plots.
The full set of validation and comparison plots can be found here. Here is a timing comparison: |
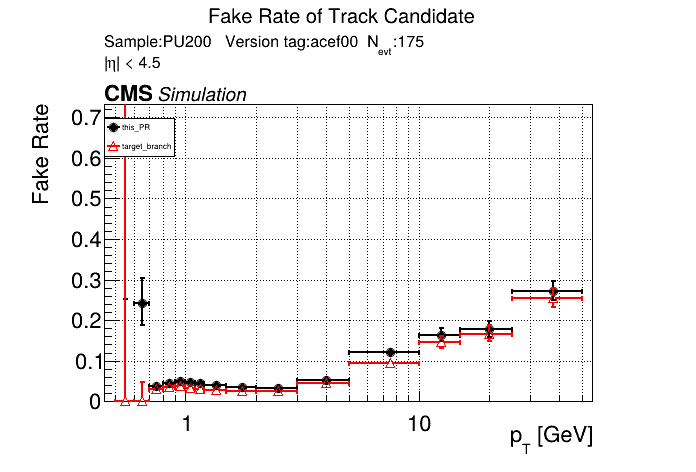
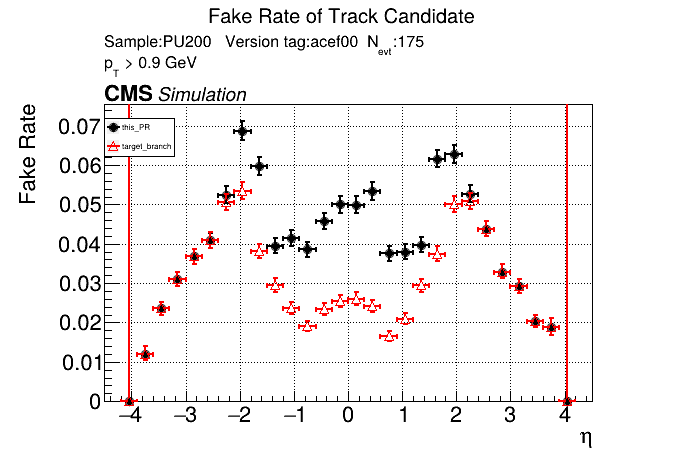
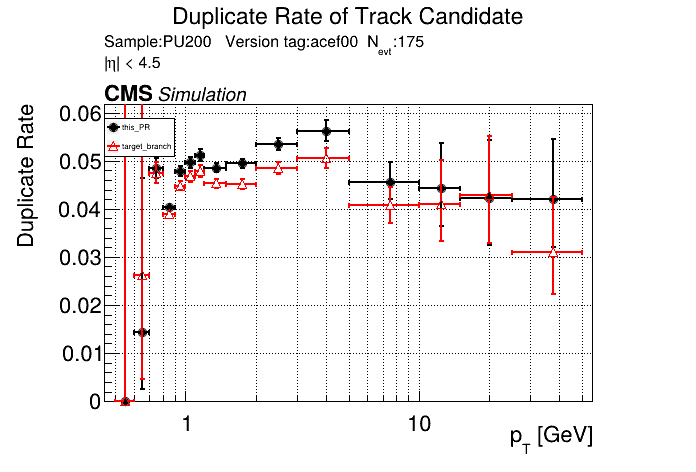
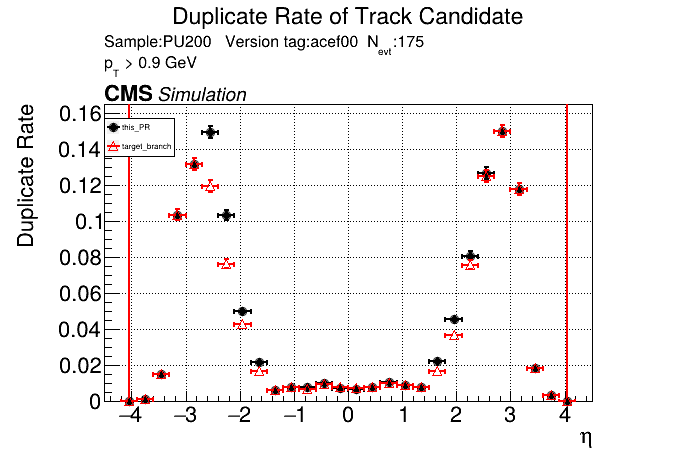

it looks like s=8 is slower by about 10%. |
|
The PR was built and ran successfully with CMSSW on GPU. Here are some plots. OOTB All Tracks
The full set of validation and comparison plots can be found here. |
Here is the timing from a local run: |



|
The PR was built and ran successfully with CMSSW. Here are some plots. OOTB All Tracks
The full set of validation and comparison plots can be found here. |
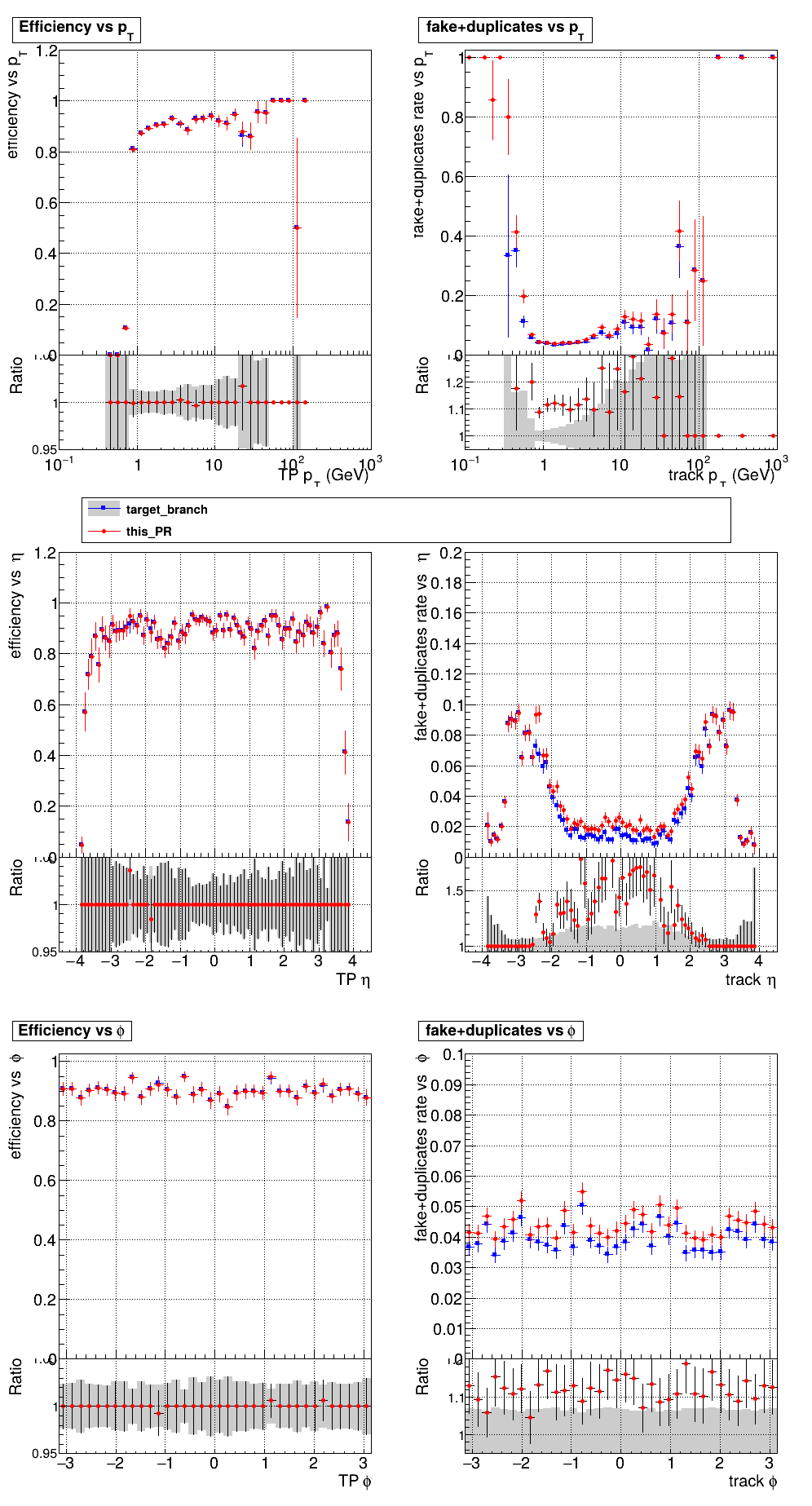
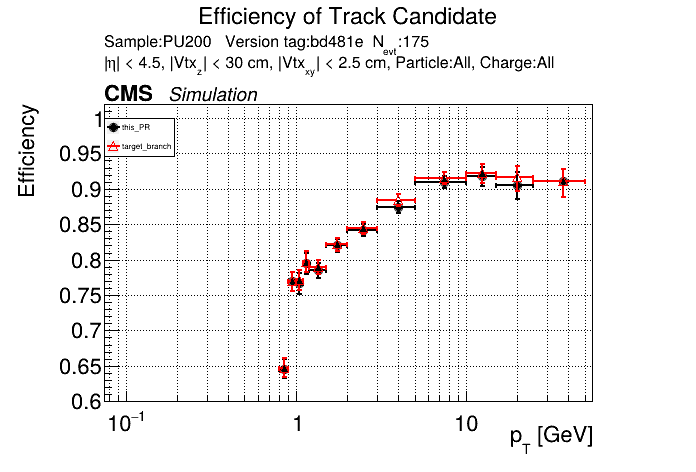
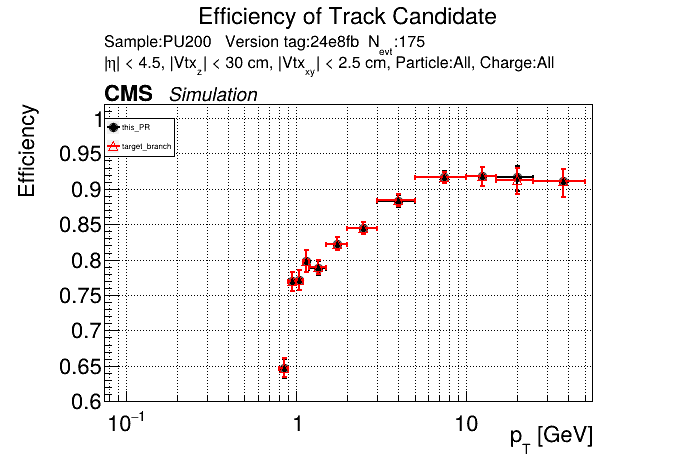
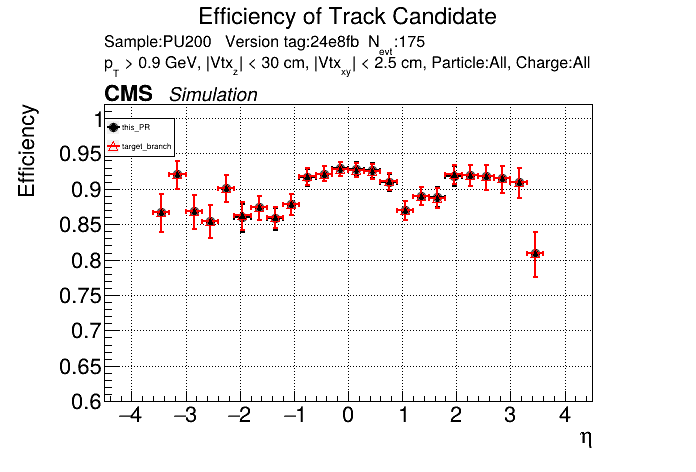
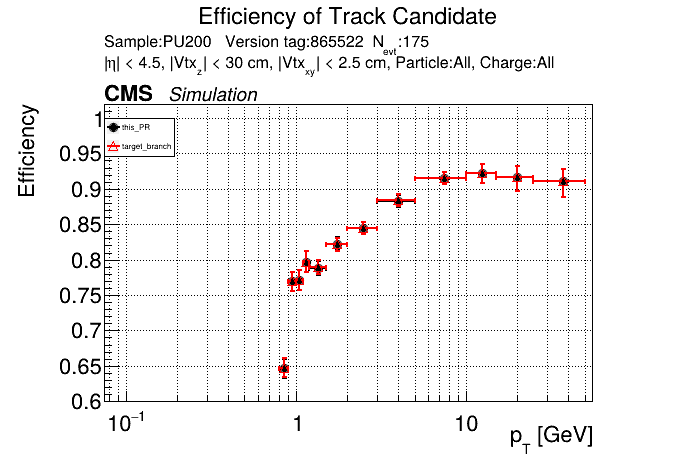
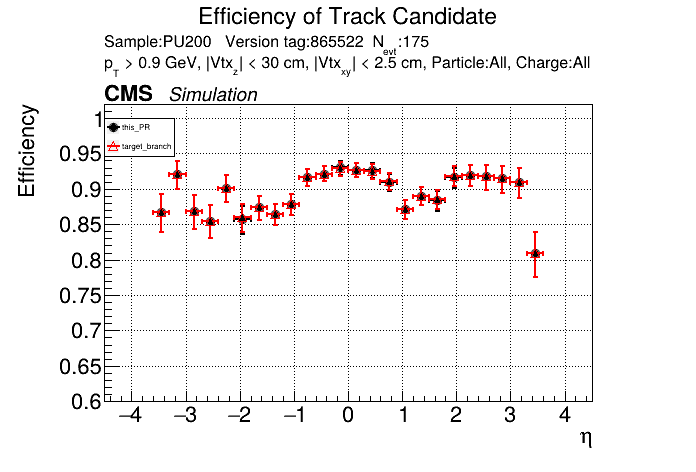
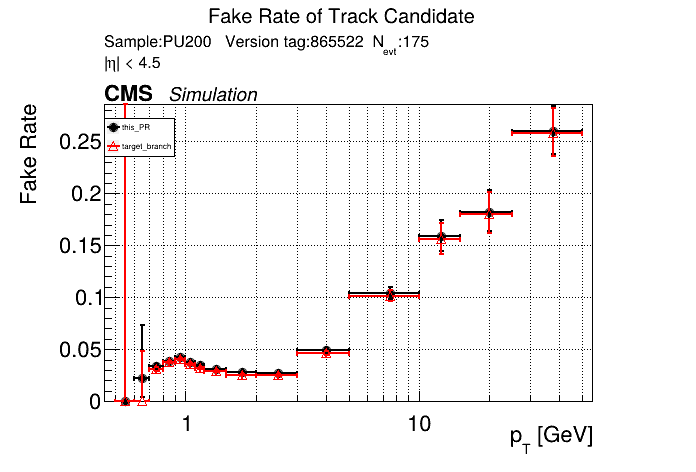
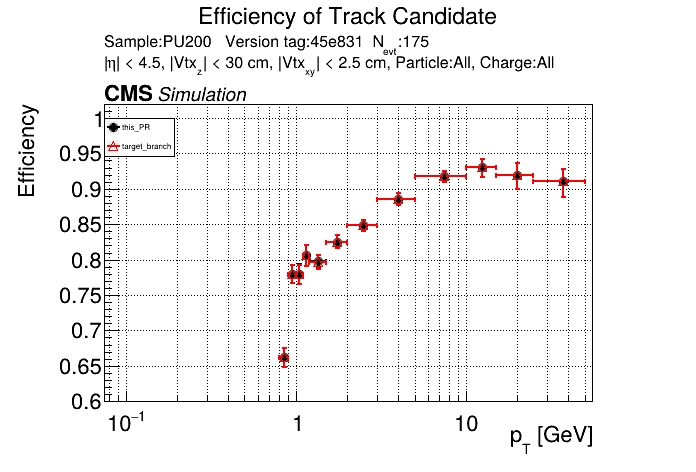
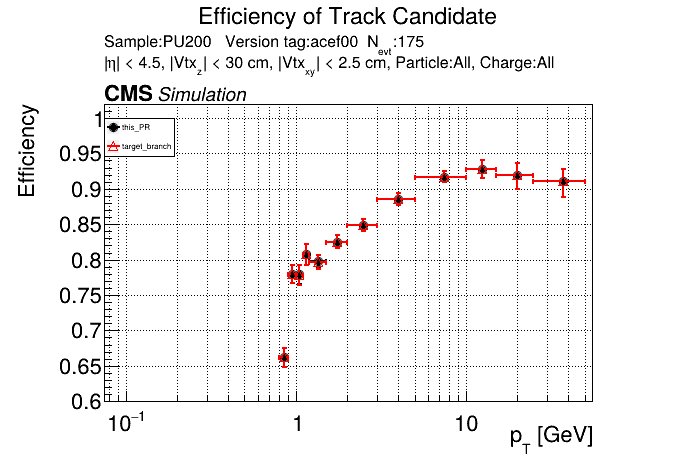
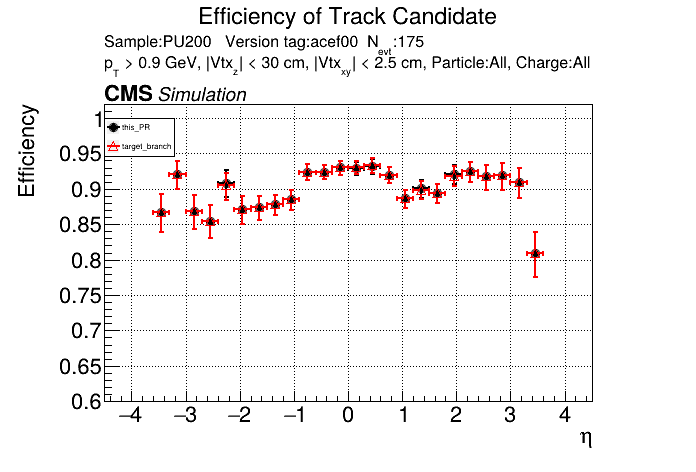
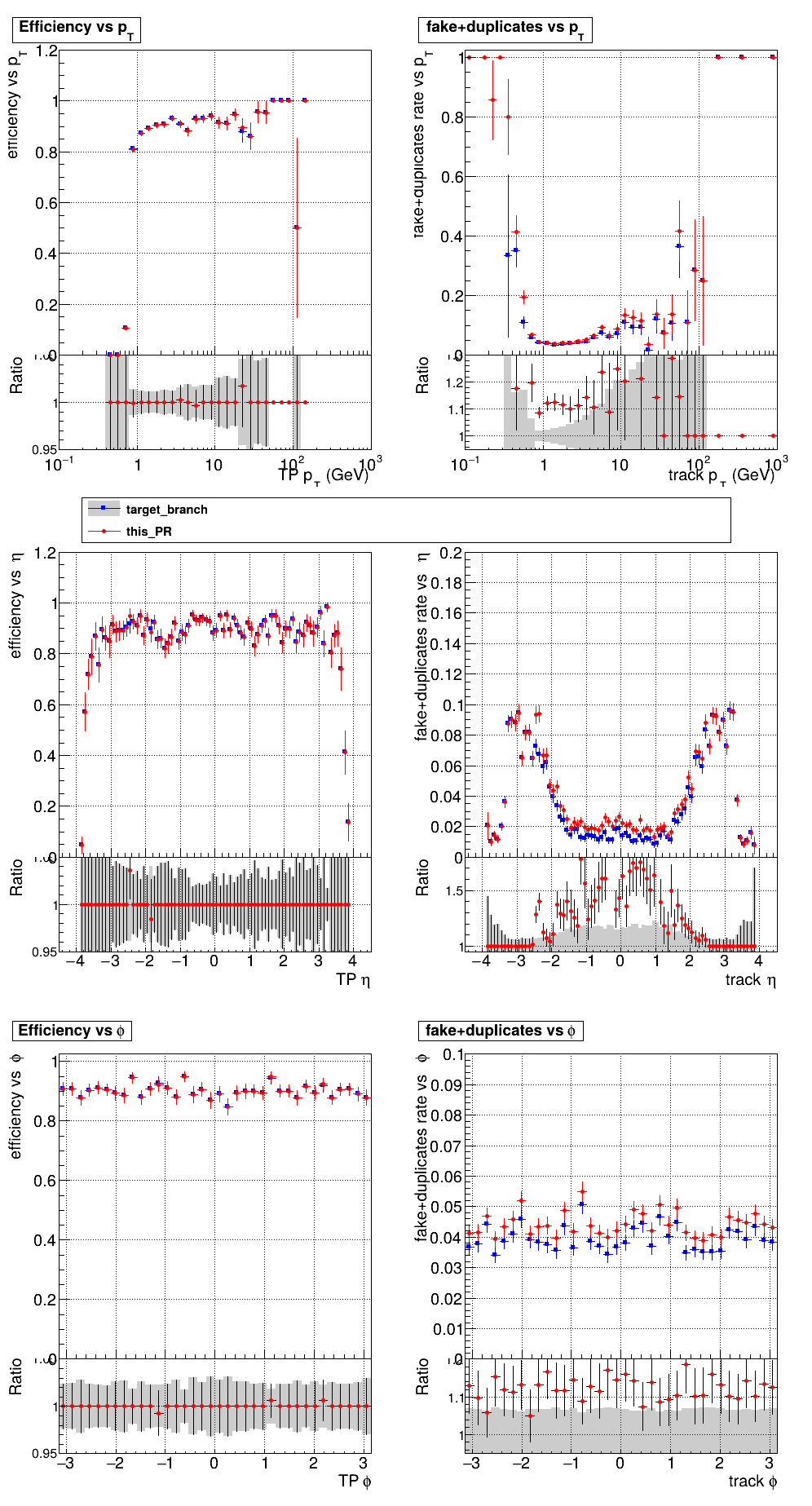
This PR introduces the T4 (quadruplet) object to increase efficiency at large displacement. T4s are built from two T3s that share a common LS. Only T3s that are not used in pT5s, pT3s or T5s are considered, and the T3s must start in either the endcap or on barrel layer 3 to reduce duplicates with the other objects. T4s are added as an additional track candidate so that the final TC collection is in the following order: pT5, pT3, T5, T4, and pLS. Motivation for the introduction of T4s was presented at the Tracking POG meeting on 30 Sep 2025.
5 selections are applied to T4s: requiring that the charges of the two T3s must be the same, a DNN classifier, a beta cut for consistency with a circle in r-phi (identical to that used for T5s), a chi-squared cut for consistency with a helix in r-z, and a cut on the impact parameter (dxy). The T4 DNN uses a multi-class architecture (similar to the T3 DNN) which classifies T4s as fake, real prompt, and real displaced. The DNN and dxy cut values are set to keep real displaced tracks while rejecting fake and real prompt tracks.
The displaced efficiency gain on a 50cm cube muon gun sample is shown below, where the current configuration is shown in blue and the addition of T4s is shown in red.

Full plots can be found here for ttbar PU200 and 50cm cube muon gun.