LST T5-T5 Duplicate Merging #212
Conversation
0cf65ec to
1b0fe62
Compare
eb1c194 to
ae1e512
Compare
|
Fixed an error where the additional hits weren't being considered in the plots, should see at least some differences now. /run all |
|
/run standalone |
is this ttbar? |
Sorry, just bad plotting formatting if I'm understanding your confusion. There are only bins at x=0, 6, (pLSs and pT3s), 10 (pT5s, T5s), 12 (extended once), and 14 (extended twice). This doesn't factor in if these hits are real or fake, just raw length of the TC's. |
is merging allowed on the same doublet module or in the same layer? |
|
/run standalone |
|
/run gpu-standalone |
|
Speeding up this kernel has been difficult. Moving the code to the existing duplicate cleaning kernel did not give a lot of benefit. Trying to make the kernel less wasteful to speed it up instead. |
|
/run gpu-standalone |
2 similar comments
|
/run gpu-standalone |
|
/run gpu-standalone |
|
Timing is finally fixed. Code is janky though, and still only works in standalone. |
6e40f49 to
314acc9
Compare
|
/run gpu-cmssw |
|
There was a problem while building and running with CMSSW on GPU. The logs can be found here. |
|
/run gpu-cmssw |
0bcdaab to
2cd7d09
Compare
|
/run gpu-cmssw |
|
Plots look good from what I see. |


2cd7d09 to
03d3e78
Compare
|
Marking this PR as ready for review. Will push some final cleanup soon. |
|
The PR was built and ran successfully in standalone mode on GPU. Here are some of the comparison plots.
The full set of validation and comparison plots can be found here. Here is a timing comparison: |
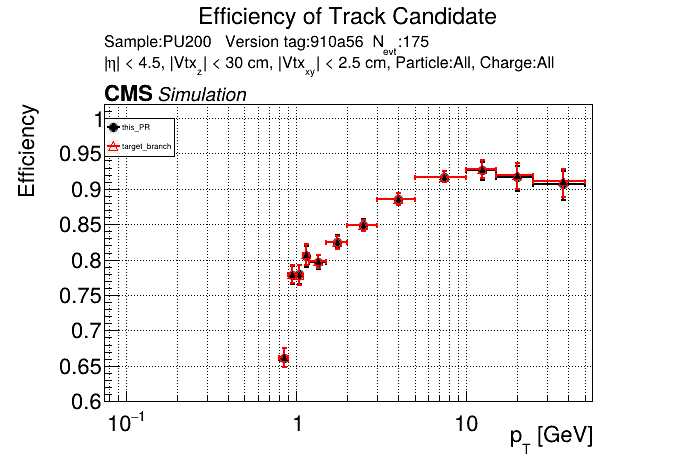
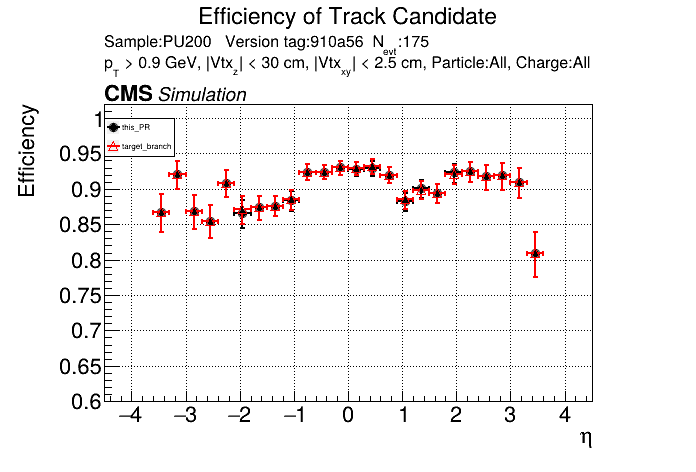
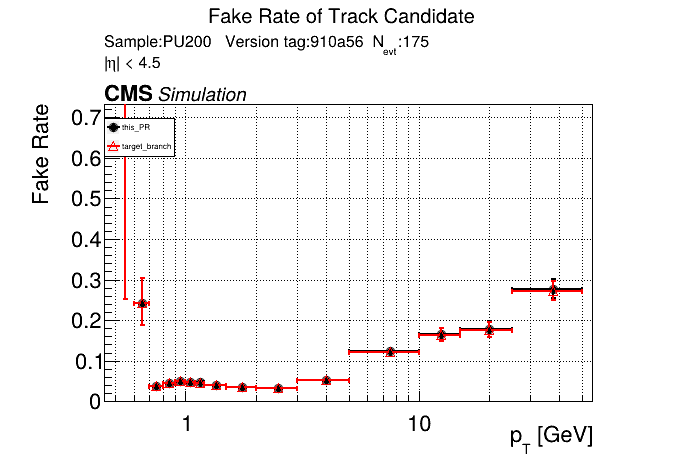
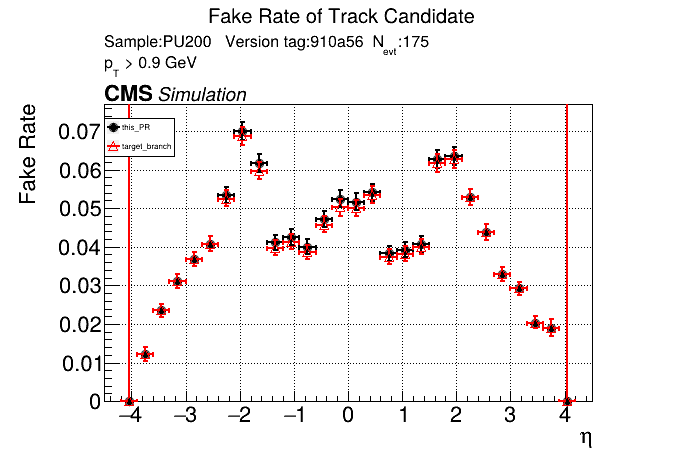
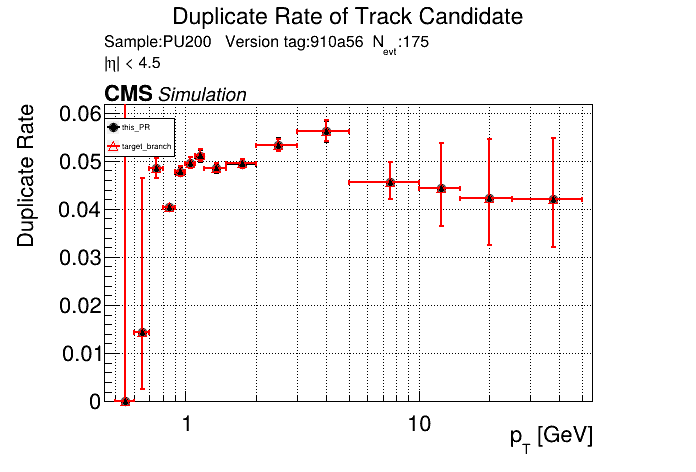
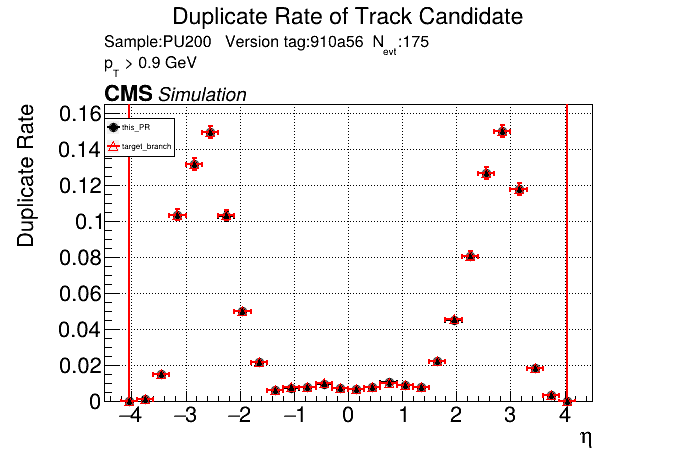
|
The PR was built and ran successfully with CMSSW on GPU. Here are some plots. OOTB All Tracks
The full set of validation and comparison plots can be found here. |
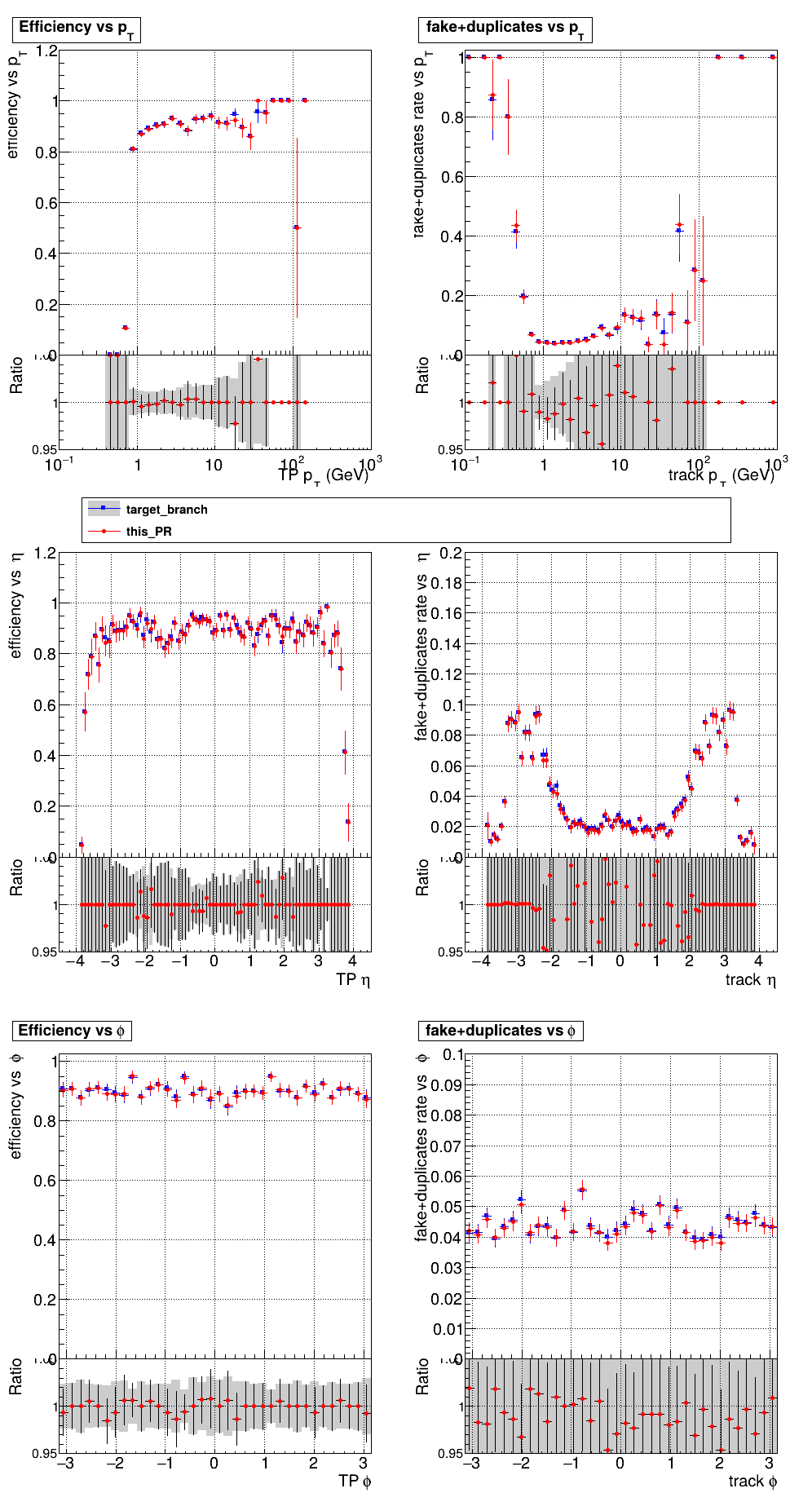
|
@slava77 Let me know if there are any remaining comments. Thanks for the comments so far, I think this PR is a good starting point for me to continue exploring the duplicate merging now (maybe start merging T3's, relax hit sharing requirements, look at adding hits on the same layer etc.). |
| const auto& threadIdx = alpaka::getIdx<alpaka::Block, alpaka::Threads>(acc); | ||
| const auto& blockDim = alpaka::getWorkDiv<alpaka::Block, alpaka::Threads>(acc); | ||
|
|
||
| // Flatten 2D thread indices within the block (Y, X) into one index | ||
| const int threadIndexFlat = threadIdx[1u] * blockDim[2u] + threadIdx[2u]; | ||
| const int blockDimFlat = blockDim[1u] * blockDim[2u]; | ||
|
|
||
| // Scan over lower modules | ||
| for (int lowerModuleIndex = lowerModuleBegin + threadIndexFlat; lowerModuleIndex < lowerModuleEnd; |
There was a problem hiding this comment.
(following on an earlier comment)
Cleaned this code up a bit to be similar to what Yanxi does in the T5 build kernel, but I'm not sure if there's something more clean we can replace this with.
I'm not sure that analogy applies
wouldn't a simple
for (auto lowerModuleIndex : cms::alpakatools::uniform_elements(acc, lowerModuleEnd)) be enough ?
There was a problem hiding this comment.
I don't think this code example works because we start at lowerModuleBegin rather than 0, but I think this gets at the question of why I am using Acc3D when I flatten two of those dimensions. It looks like Acc1D works just as well, I'll push that soon.
There was a problem hiding this comment.
I can't find any cms::alpakatools wrapper functions that would allow me to do the block-level work I use here even in 1D (each block handles its own TC with shared memory for that TC/block, unlike uniform_elements which I think distributes over multiple blocks?). Let me know if you know of one, otherwise I think Acc1D is as clean as this can go.
There was a problem hiding this comment.
since the block direction is aligned with the candidates, perhaps a 2D and use a uniform_elements_x ?
the range can always be over lowerModuleEnd-lowerModuleBegin with an addition.
Note that I expect that having lowerModuleBegin not just 0 the saving is relatively minor and would go away when we start looking for overlap hits on the same layer

this looks problematic.
|
|
/run all |
|
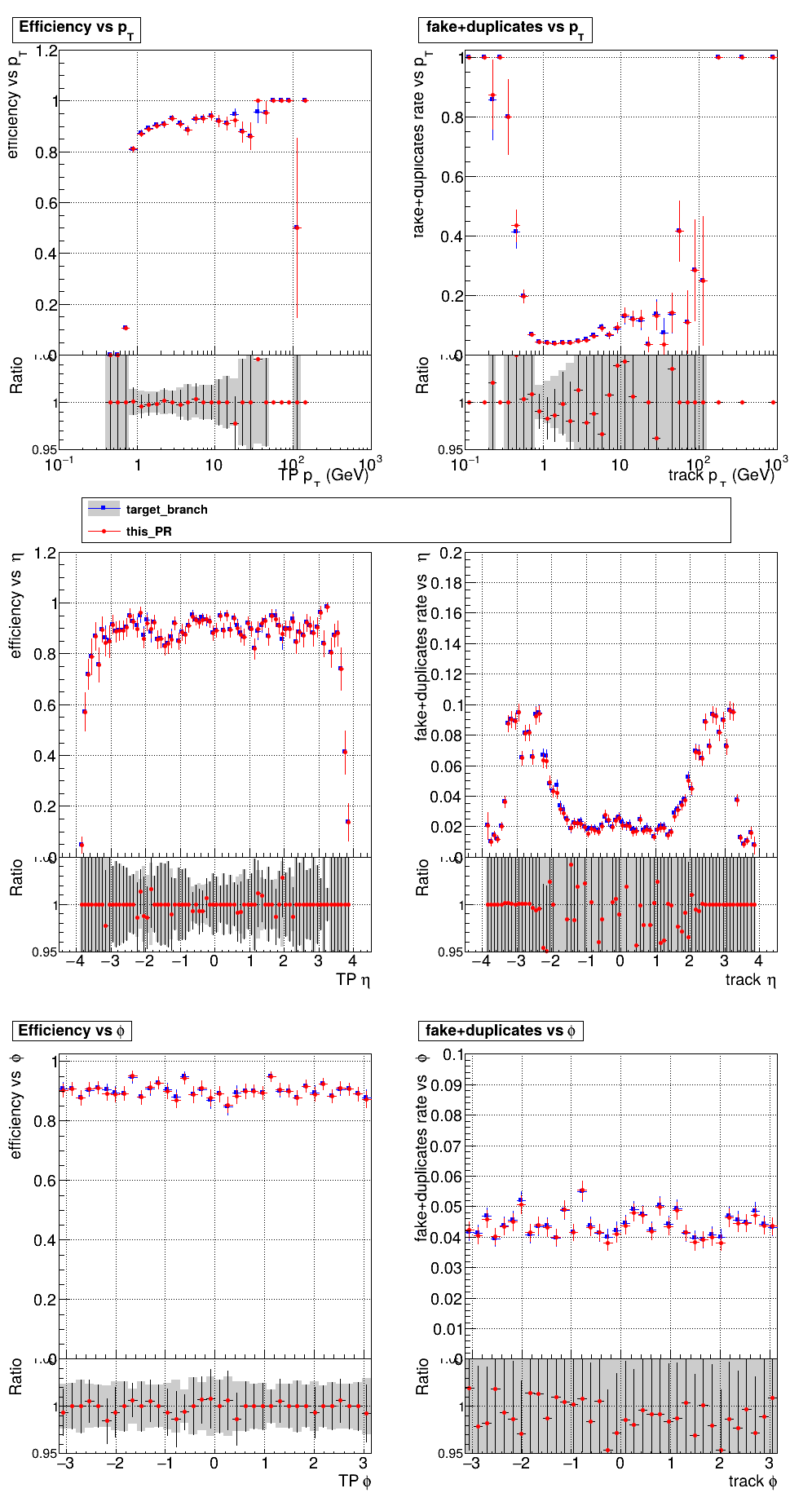
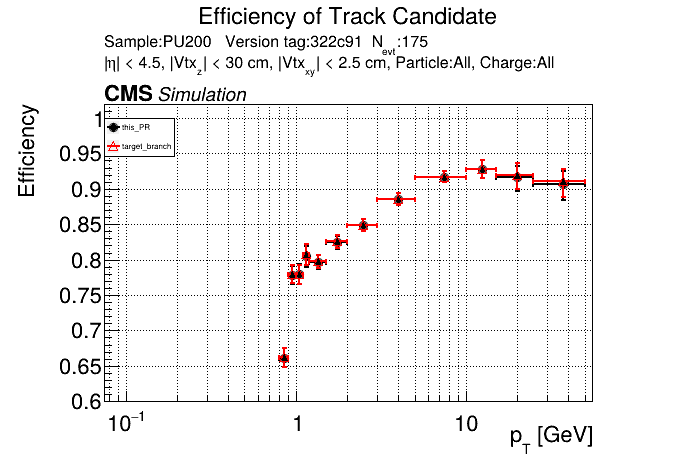
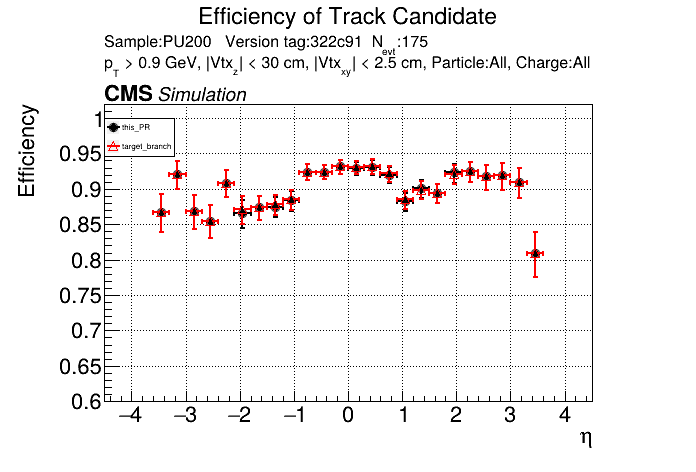
The PR was built and ran successfully in standalone mode. Here are some of the comparison plots.
The full set of validation and comparison plots can be found here. Here is a timing comparison: |
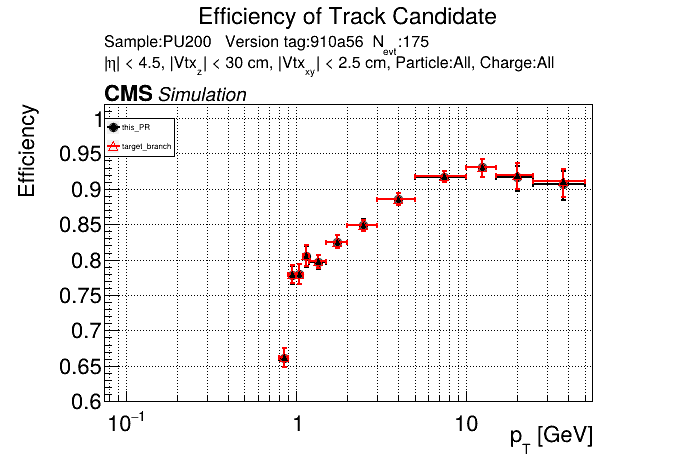
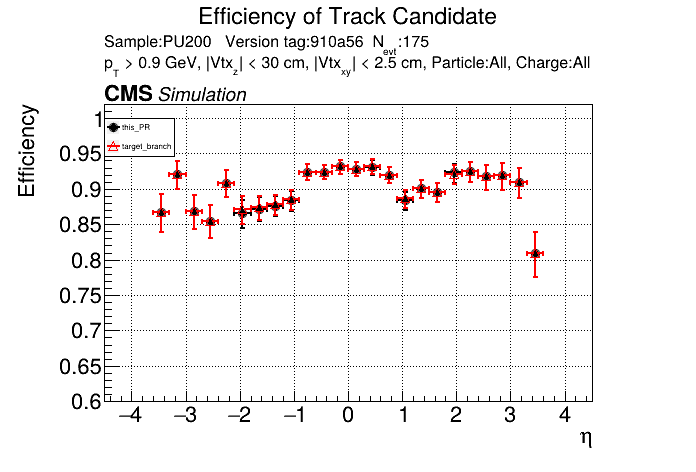
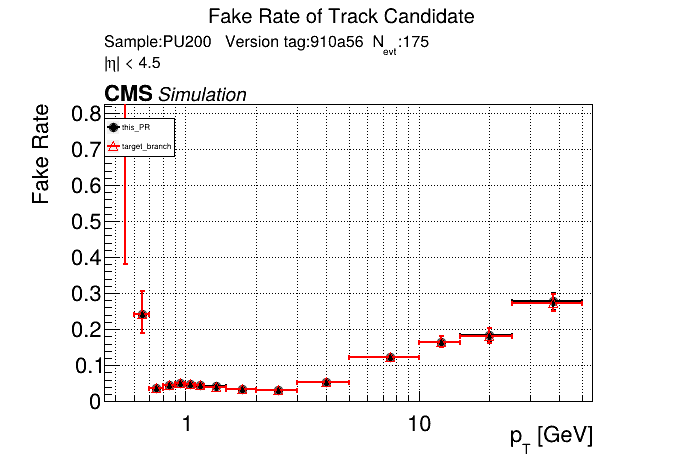
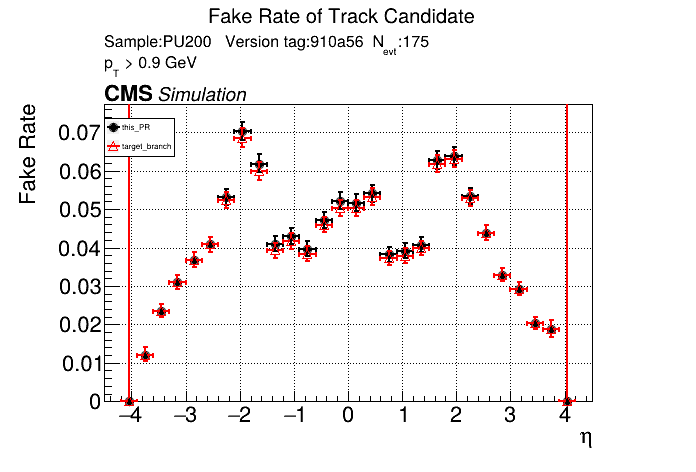
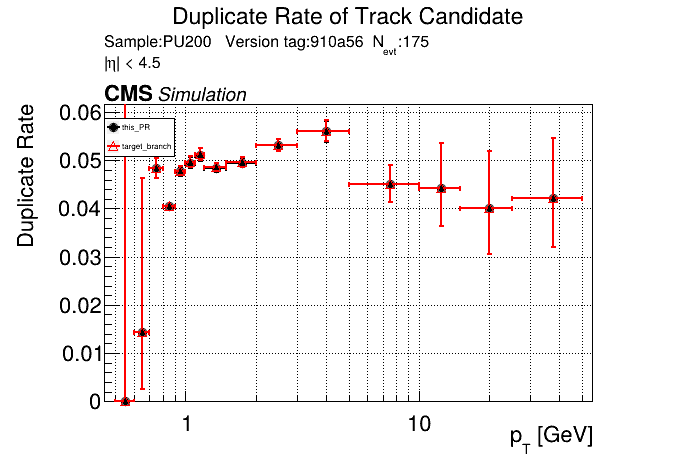
|
The PR was built and ran successfully with CMSSW. Here are some plots. OOTB All Tracks
The full set of validation and comparison plots can be found here. |
910a568 to
80827e7
Compare
|
/run gpu-all |
|
The PR was built and ran successfully in standalone mode on GPU. Here are some of the comparison plots.
The full set of validation and comparison plots can be found here. Here is a timing comparison: |
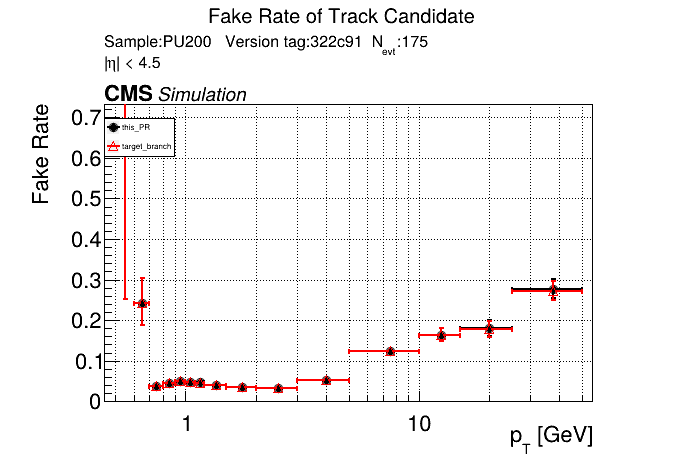
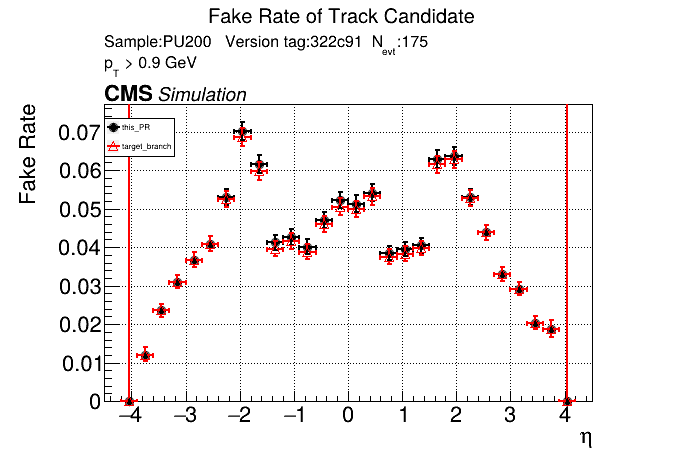
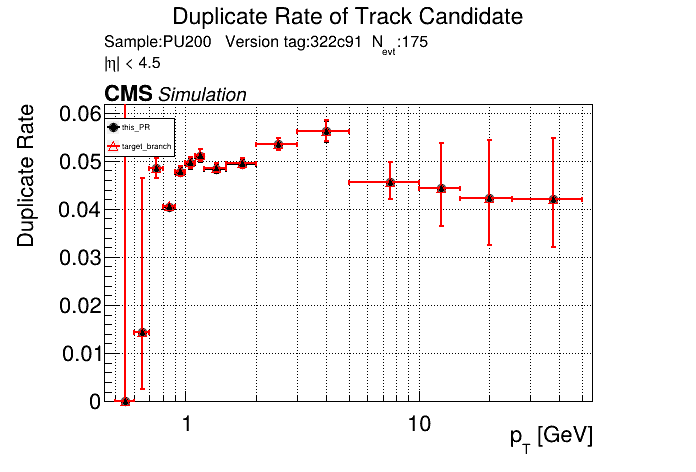
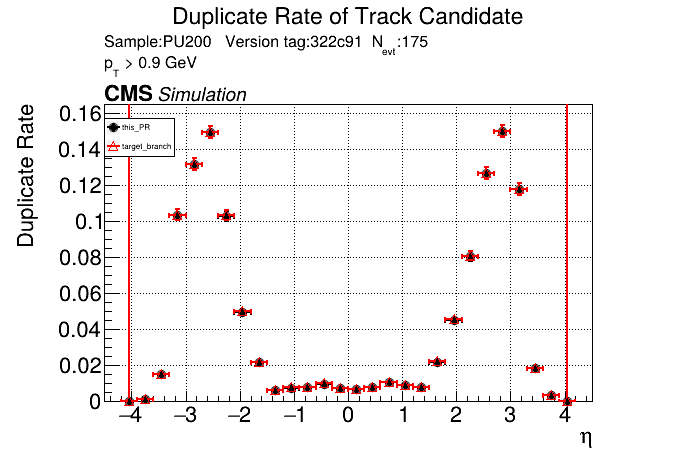
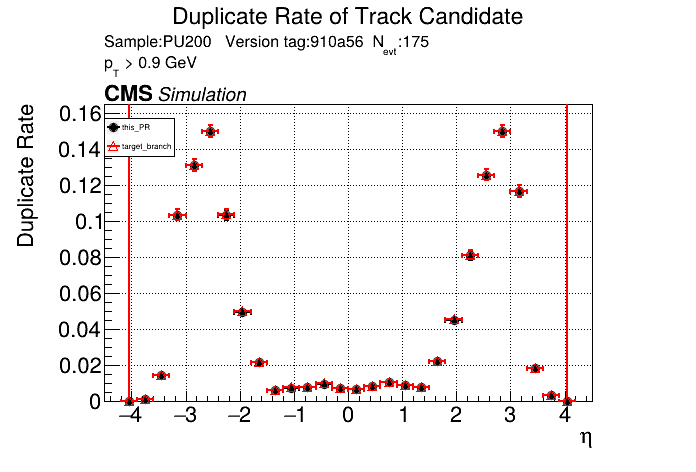
I've seen this bump in the CMSSW plots since the beginning of this PR for both CPU/GPU. I don't see the bump on the standalone plots, so I assumed it had something to do with like the final fit or similar that CMSSW does different from standalone. Edit: I guess there are 11 OT layers so 22 hits + 3/4 pixel hits causing this? So maybe some bug where all hits get read as non-empty? |
322c916 to
e2602d4
Compare
|
The PR was built and ran successfully with CMSSW on GPU. Here are some plots. OOTB All Tracks
The full set of validation and comparison plots can be found here. |
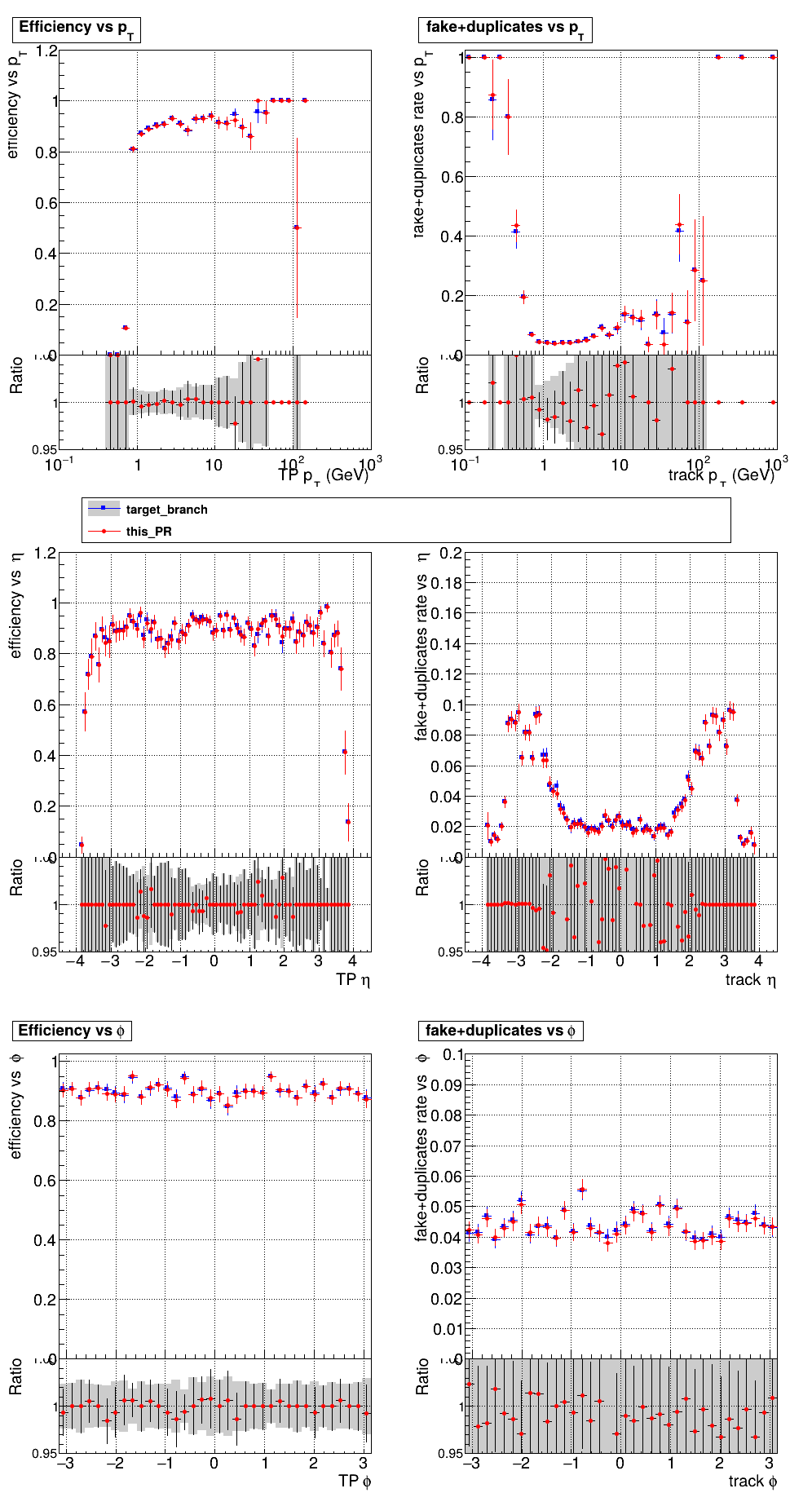
that's my guess. I don't see an explosion in fakes In the CMSSW setup we are supposedly using the LST candidates directly to next run a fit on them. So, there is no path to add more hits (there is a way to lose some due to fitting). |

02e949a to
d55821d
Compare
d55821d to
a32b82c
Compare
a32b82c to
4cb70db
Compare
|
/run gpu-CMSSW |
|
note to self: updates so far since the last review in one place https://github.com/SegmentLinking/cmssw/compare/910a5688c32655115ee1b24c38bdd67ac8725a29..4cb70dbb59988ef9bc97b7ea6b73fd7692347204 |
|
The PR was built and ran successfully with CMSSW on GPU. Here are some plots. OOTB All Tracks
The full set of validation and comparison plots can be found here. |
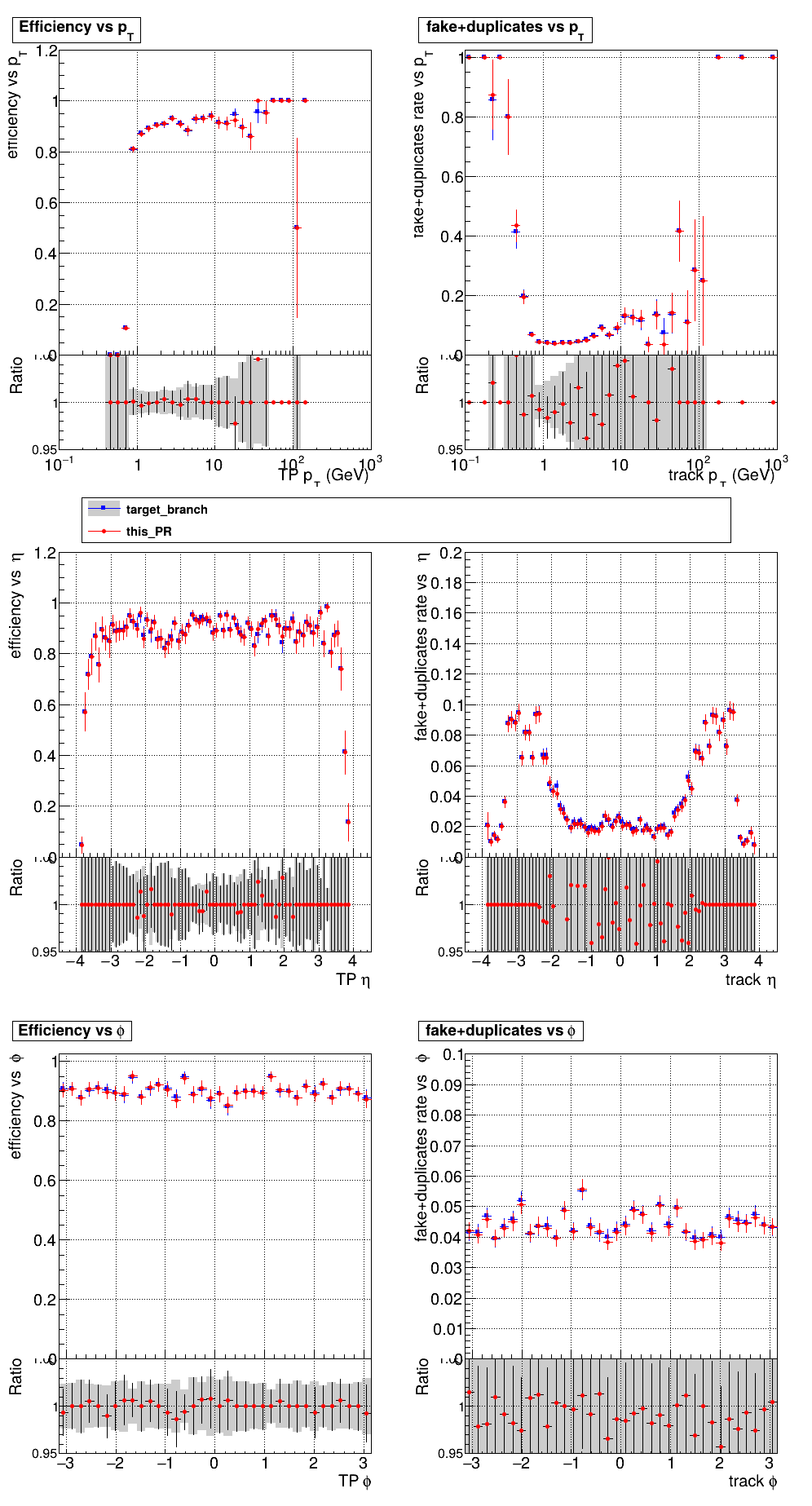

@slava77 Looks good now after adding resets to pLS function + some other cleanup. |
this kind of disproves my older "intuition" arguments (in a different context) that adding hits to a pT5 should not improve the momentum resolution. |

Introduces a new kernel that merges built T5s on top of T5 and pT5 Track Candidates. Changes the LST TC data structure to accommodate longer tracks.
Zoom in:

Histogram of Lengths:

Purity of extensions looks good.
Plots below are the same, just one has y-scale set to log. Only a small decrease in pMatched of the track candidates.