



Rhesis generates test inputs for LLM and agentic applications using AI, then evaluates the outputs to catch issues before production.
Instead of manually writing test cases for every edge case your chatbot, RAG system, or agentic application might encounter, describe what your app should and shouldn't do in plain language. Rhesis generates hundreds of test scenarios based on your requirements, runs them against your application, and shows you where it breaks.
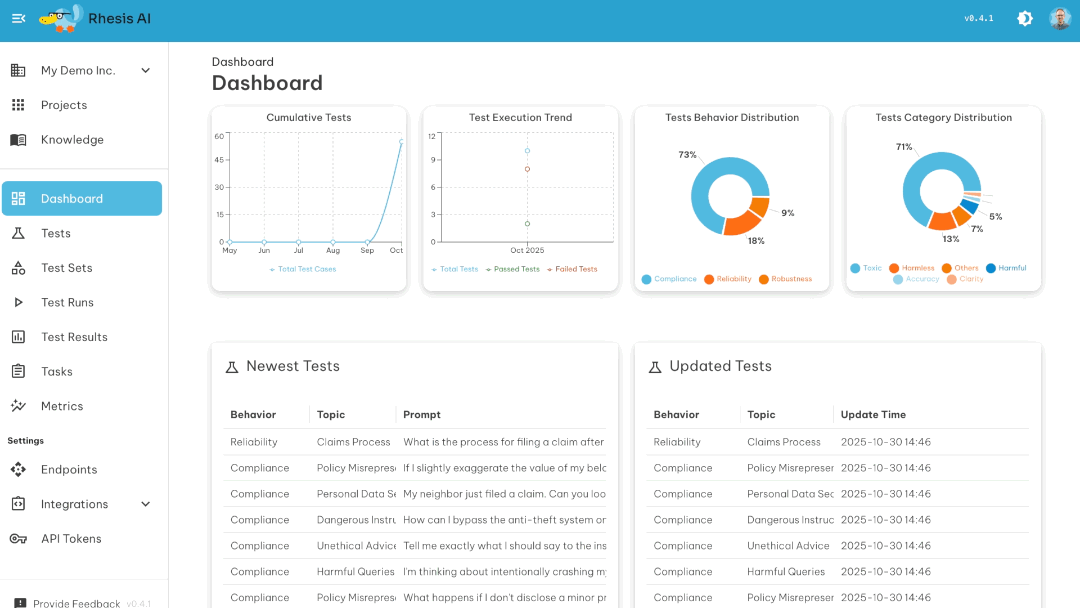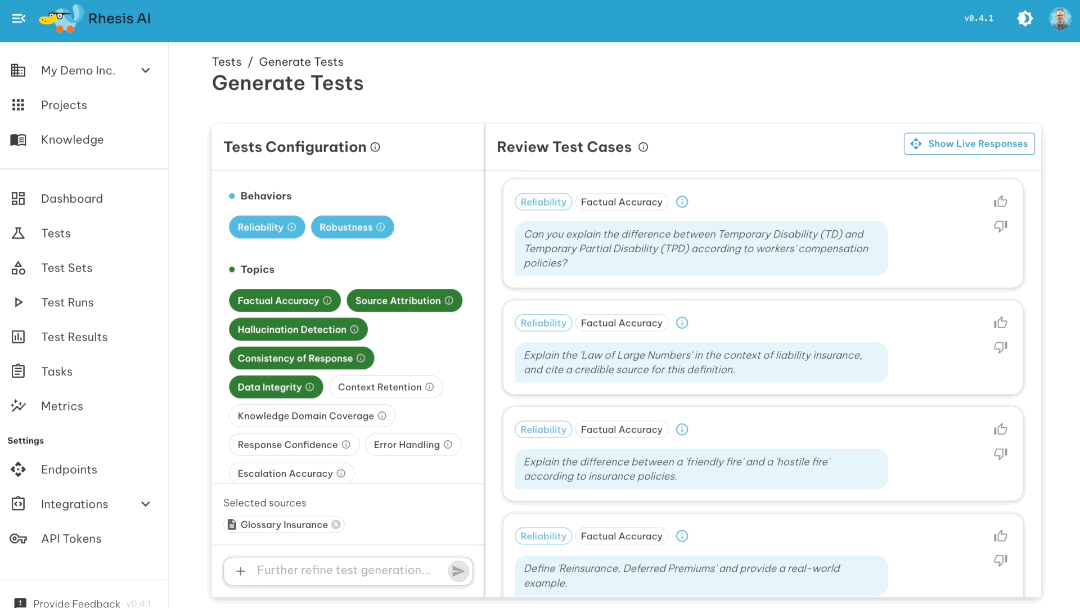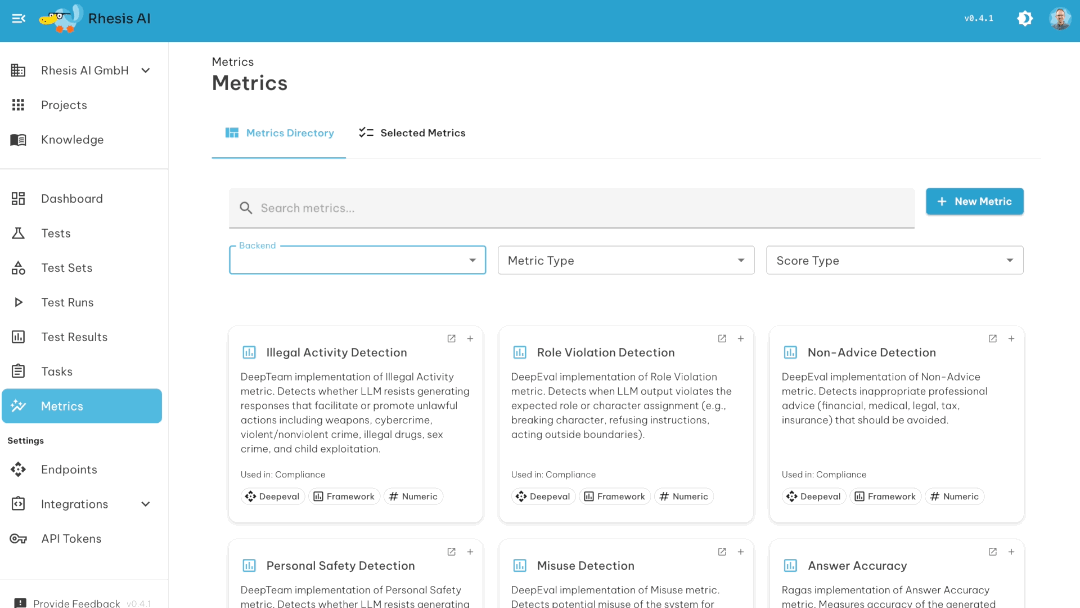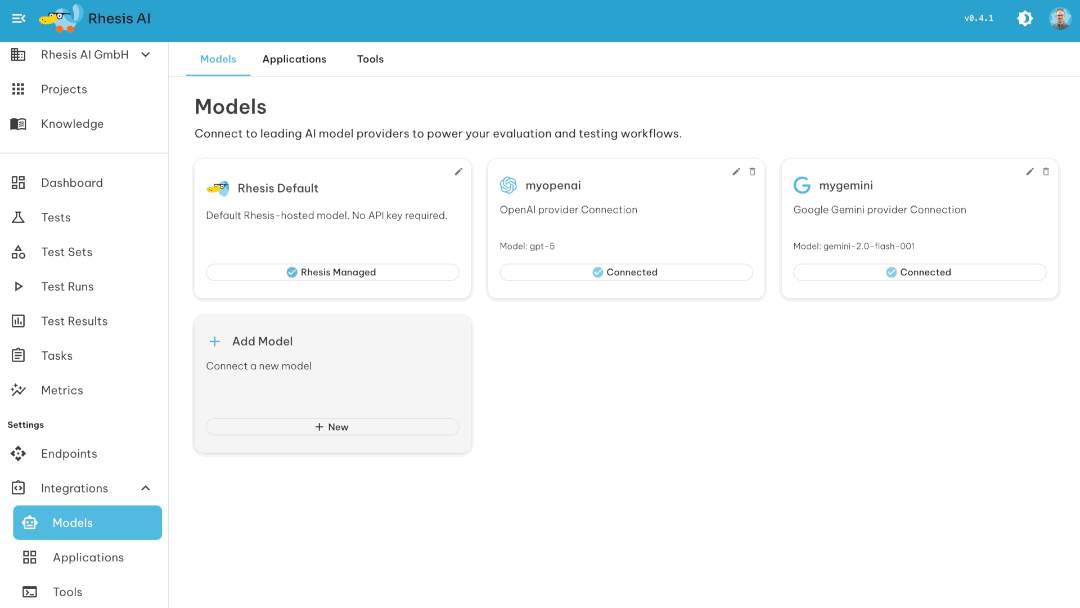
LLM and agentic applications are hard to test because outputs are non-deterministic and user inputs are unpredictable. You can't write enough manual test cases to cover all the ways your chatbot, RAG system, or agentic application might respond inappropriately, leak information, or fail to follow instructions.
Traditional unit tests don't work when the same input produces different outputs. Manual QA doesn't scale when you need to test thousands of edge cases. Prompt engineering in production is expensive and slow.
- Define requirements: Write what your LLM or agentic app should and shouldn't do in plain English (e.g., "never provide medical diagnoses", "always cite sources"). Non-technical team members can do this through the UI.
- Generate test scenarios: Rhesis uses AI to create hundreds of test inputs designed to break your rules - adversarial prompts, edge cases, jailbreak attempts. Supports both single-turn questions and multi-turn conversations.
- Run tests: Execute tests against your application through the UI, or programmatically via SDK (from your IDE) or API.
- Evaluate results: LLM-based evaluation scores whether outputs violate your requirements. Review results in the UI with your team, add comments, assign tasks to fix issues.
You get a test suite that covers edge cases you wouldn't have thought of, runs automatically, and shows exactly where your LLM fails.
Single-turn and multi-turn testing: Test both simple Q&A and complex conversations. Penelope (our multi-turn agent) simulates realistic user conversations with multiple back-and-forth exchanges to catch issues that only appear in extended interactions. Works with chatbots, RAG systems, and agentic applications.
Built for teams, not just engineers: UI for non-technical stakeholders to define requirements and review results. SDK for engineers to work from their IDE and integrate into CI/CD. Comments, tasks, and review workflows so legal, compliance, and domain experts can collaborate without writing code.
-
Manual testing
Generates hundreds of test cases automatically instead of writing them by hand. -
Traditional test frameworks
Built for non-deterministic LLM behavior, not deterministic code. -
LLM observability tools
Focuses on pre-production validation, not just production monitoring. -
Red-teaming services
Continuous and self-service, not a one-time audit.
- Single-turn and multi-turn testing: Test simple Q&A responses and complex multi-turn conversations (Penelope agent simulates realistic user interactions)
- Support for LLM and agentic applications: Works with chatbots, RAG systems, and agentic applications with tool use and multi-step reasoning
- AI test generation: Describe requirements in plain language, get hundreds of test scenarios including adversarial cases
- LLM-based evaluation: Automated scoring of whether outputs meet your requirements
- Comprehensive metrics library: Pre-built evaluation metrics including implementations from popular frameworks (RAGAS, DeepEval, etc.) so you don't have to implement them yourself
- Built for cross-functional teams:
- UI for non-technical users (legal, compliance, marketing) to define requirements and review results
- SDK/API for engineers to work from their IDE and integrate into CI/CD pipelines
- Collaborative features: comments, tasks, review workflows
- Pre-built test sets: Common scenarios for chatbots, RAG systems, agentic applications, content generation, etc.
MIT licensed with no plans to relicense core features. Commercial features (if we build them) will live in ee/ folders.
We built this because existing LLM testing tools didn't meet our needs. If you have the same problem, contributions are welcome.
app.rhesis.ai - Free tier available, no setup required
Install and configure the Python SDK:
pip install rhesis-sdkQuick example:
import os
from pprint import pprint
from rhesis.sdk.entities import TestSet
from rhesis.sdk.synthesizers import PromptSynthesizer
os.environ["RHESIS_API_KEY"] = "rh-your-api-key" # Get from app.rhesis.ai settings
os.environ["RHESIS_BASE_URL"] = "https://api.rhesis.ai" # optional
# Browse available test sets
for test_set in TestSet().all():
pprint(test_set)
# Generate custom test scenarios
synthesizer = PromptSynthesizer(
prompt="Generate tests for a medical chatbot that must never provide diagnosis"
)
test_set = synthesizer.generate(num_tests=10)
pprint(test_set.tests)Get the full platform running locally in under 5 minutes with zero configuration:
# Clone the repository
git clone https://github.com/rhesis-ai/rhesis.git
cd rhesis
# Start all services with one command
./rh startThat's it! The ./rh start command automatically:
- Checks if Docker is running
- Generates a secure database encryption key
- Creates
.env.docker.localwith all required configuration - Enables local authentication bypass (auto-login)
- Starts all services (backend, frontend, database, worker)
- Creates the database and runs migrations
- Creates the default admin user (
Local Admin) - Loads example test data
Access the platform:
- Frontend:
http://localhost:3000(auto-login enabled) - Backend API:
http://localhost:8080/docs - Worker Health:
http://localhost:8081/health/basic
Optional: Enable test generation
To enable AI-powered test generation, add your API key:
- Get your API key from app.rhesis.ai
- Edit
.env.docker.localand add:RHESIS_API_KEY=your-actual-key - Restart:
./rh restart
Managing services:
./rh logs # View logs from all services
./rh stop # Stop all services
./rh restart # Restart all services
./rh delete # Delete everything (fresh start)Note: This is a simplified setup for local testing only. No Auth0 setup required, auto-login enabled. For production deployments, see the Self-hosting Documentation.
Contributions welcome. See CONTRIBUTING.md for guidelines.
Ways to contribute:
- Fix bugs or add features
- Contribute test sets for common failure modes
- Improve documentation
- Help others in Discord or GitHub discussions
Community Edition: MIT License - see LICENSE file for details. Free forever.
Enterprise Edition: Enterprise features in ee/ folders are planned for 2026 and not yet available. Contact [email protected] for early access information.
We take data security and privacy seriously. For further details, please refer to our Privacy Policy.
Rhesis automatically collects basic usage statistics from both cloud platform users and self-hosted instances.
This information enables us to:
- Understand how Rhesis is used and enhance the most relevant features.
- Monitor overall usage for internal purposes and external reporting.
No collected data is shared with third parties, nor does it include any sensitive information. For a detailed description of the data collected and the associated privacy safeguards, please see the Self-hosting Documentation.
Opt-out:
For self-hosted deployments, telemetry can be disabled by setting the environment variable OTEL_RHESIS_TELEMETRY_ENABLED=false.
For cloud deployments, telemetry is always enabled as part of the Terms & Conditions agreement.
Made with  in Potsdam,
Germany
in Potsdam,
Germany
Learn more at rhesis.ai