use TCN and Transformer model for forecasting on "Hourly Energy Consumption" data
- Advantages of TCN over RNN
- Parallelism
TCN can process data in parallel without requiring sequential processing like RNN. - Flexible receptive field
The size of the receptive field of TCN is determined by the number of layers, the size of the convolution kernel, and the expansion coefficient. It can be flexibly customized according to different characteristics of different tasks. - Stable gradient
RNNs often have problems of gradient disappearance and gradient explosion, which are mainly caused by shared parameters in different time periods. Like traditional convolutional neural networks, TCNs are less prone to gradient disappearance and explosion problems. - The memory is lower
When RNN is used, it needs to save the information of each step, which will occupy a lot of memory. The convolution kernel of TCN is shared in one layer, and the memory usage is lower.
- Parallelism
ex : kernel size=2,dilations=[1,2,4,8]

In order to effectively deal with long historical information

(kernel size=3)

Adaptive model depth, alleviating the phenomenon of gradient vanishing and exploding

Prevent units from co-adapting too much, and turn on all neurons during Inference, so that the average value of each small neural network can be easily estimated, using dropout can greatly reduce the possibility of overfitting

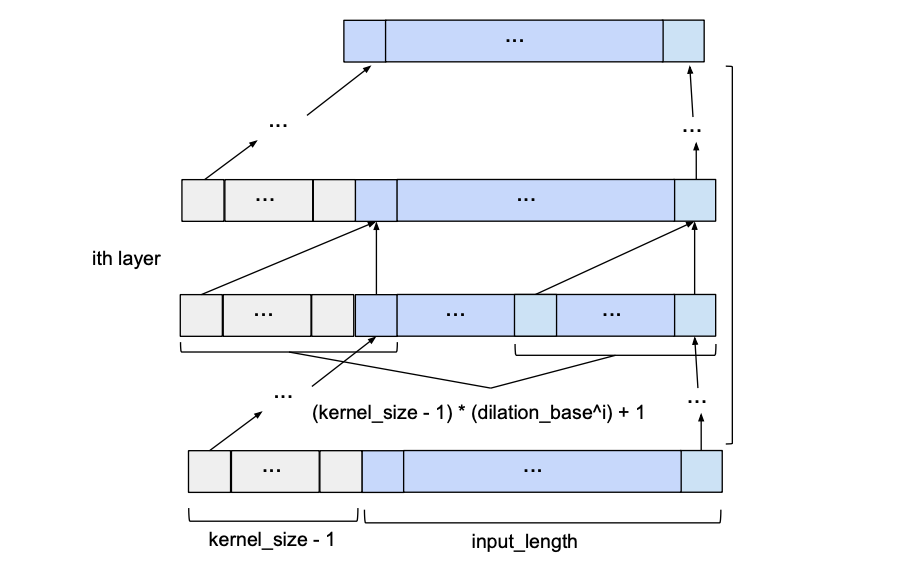
Given input_length, kernel_size, dilation_base and the minimum number of layers required for full history coverage, the basic TCN network would look something like this:
- The motivation of Transformer is to solve the following problems of RNNs:
- Sequential computation is difficult to parallelize.
- Use the attention mechanism to solve the problem that RNNs cannot rely on long distances. The farther the words are, the harder it is to find each other's information.
- Excessive RNN architecture may cause the gradient to disappear
Transformer consists of Encoder and Decoder, which are very different in nature and should be understood separately. The former is used to compress sequence information, and the latter is used to convert (decompress) the information extracted by the former into information required by the task.

The role of Query and Key is to determine the weight of Value, and Key and Value form a token. When Query and Key are strongly related to the task, the Value corresponding to Key will be enlarged.

The advantage of this is that each head (q, k, v) can focus on different information, some focus on local, some focus on global information, etc.

Since the input and output have the same shape, we can use residual connection to add the output to the input. And use LayerNorm to normalize in the direction of each instance.

Layer Normalization (LN) is often used in RNN. The concept is similar to BN. The difference is that LN normalizes each sample.

The Decoder is not allowed to see future messages, so we have to cover up the vectors after i+1.

https://unit8.com/resources/temporal-convolutional-networks-and-forecasting/
https://www.twblogs.net/a/5d6dc709bd9eee541c33c0b2
https://meetonfriday.com/posts/7c0020de/
https://medium.com/@a5560648/dropout-5fb2105dbf7c
https://zhuanlan.zhihu.com/p/52477665
https://ithelp.ithome.com.tw/articles/10206317
https://medium.com/%E5%B7%A5%E4%BA%BA%E6%99%BA%E6%85%A7/review-attention-is-all-you-need-62a1c93c48a5
https://medium.com/ching-i/transformer-attention-is-all-you-need-c7967f38af14