Execution Model Introduction
ParSeq is an open-source library for executing async code using Java. Due to its extensibility and simple APIs, it has been widely used inside LinkedIn and integrated as the asynchronous task engine.
Most users will want to use ParSeq for one simple thing: Wrap the Java code that best be executed asynchronously into a Task, then run it with ParSeq Engine. By reading user guides, users can ramp up knowledge about using ParSeq. The examples cover common use cases. However, to understand the scenarios where efficient usage of ParSeq can benefit runtime execution, it might be useful to understand how the ParSeq execution model works. In its design principle, ParSeq is designed to hide implementation for transparency in API and provide abstractions as few as possible. In ParSeq exposed APIs, most users will achieve the goal of running async code by only creating Tasks and working with the Engine. However there are also concepts and abstractions such as Plan and Executor that can be tuned to tweak ParSeq performance and runtime behaviors.
In order to avoid any possible confusions, this documentation uses the following definitions when explaining concurrency concepts of tasks.
Sequential:
What Sequential means for tasks is that each task as a whole, runs completely without interleaving with another task, and all tasks complete in serial order. For example, if CPU Task T1, and CPU Task T2 together run as a sequential task in one single CPU (assume one thread context per CPU), it means T1 runs first and T2 runs after T1 completes, or T2 runs first and T1 runs after T2 completes.
Parallel: Re-using the above example, what Parallel means is that T1 and T2 run simultaneously. For example T1 and T2 can be run in two CPUs, with each task running in one of the CPUS, so they run in parallel.
Concurrent: Concurrency is the abstraction to the user that multiple tasks are "in progress". Though parallelism implies concurrency, concurrency does not necessarily mean Parallelism. Code blocks can start executing and become "in-progress" simultaneously although only a few can be truly run in parallel on the limited thread context resource in the multi-core CPUs. Even with a single-core CPU, tasks can still be running concurrently. For example, in a single CPU, the execution of T1 and T2 can be interleaved. One synonym for concurrent tasks could be "task overlapping".
Serial: Similar to the concept of Serializability, serial means a group of execution units are run sequentially. In ParSeq, because the basic unit of execution is Task, therefore serial execution and sequential execution are the same thing.
In the below example, Let's consider two user job T1 and T2. Let's assume each user job consist of 3 ParSeq tasks. First pictures shows User job T1 and T2 run in sequential, and second picture shows T1's tasks and T2's tasks are interleaved and run in serial.
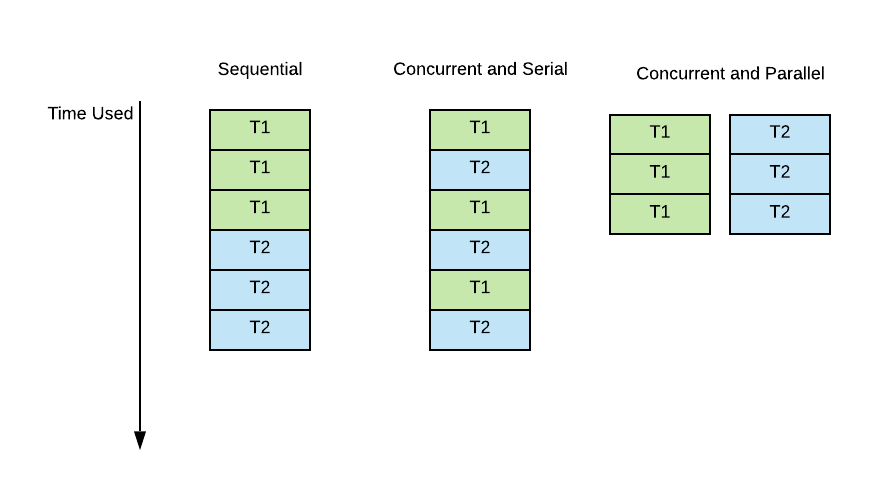
As will be mentioned in the later part of the doc, ParSeq engine ensures that for tasks in one single plan, Task is the basic unit of execution, and tasks in that plan will be run in serial. There will be no parallelism between CPU execution (although I/O can be conducted in parallel). Please don't confuse this definition with Task.par() since Task.par() actually means tasks are submitted to the engine in parallel and their child tasks will be run concurrently. No tasks will be truly running in parallel for one single plan.
Some background regarding Synchronous and Asynchronous programming might help the user decide and understand when ParSeq should be used. This section can be skipped if the reader already knows when to use and why to use ParSeq in your code. In general, there are two categories of code one will be writing in a program: CPU Bound process and I/O Bound process. The name suggests what limits the scaling of execution speed when codes are executed by computer resources. CPU Bound means the rate at which process progresses is limited by the speed of the CPU. I/O Bound means the rate at which a process progresses is limited by the speed of the I/O subsystem, which requires reading data from an I/O device, such as disk or network.
To optimize CPU bound tasks, splitting the workload and running them in parallel in multiple instances of the CPU will cut the total running time.
However, for I/O tasks, this will not work the best to run the task in parallel since the CPU will be waiting for I/O reading to complete and this is considered as a waste. For optimizing I/O bound tasks, some abstractions have been provided by Operating systems, like Threads and Processes. They are scheduled by Operating system so each Thread and Process will essentially take turns to run an interval of time that not all CPU resources will be wasted while waiting for I/O.
But the parallelism brought by using Threads or Processes are not necessarily most efficient since the scheduling granularity will be coarse in this case. The operating system does not necessarily know your task, and it cannot optimize the best. In I/O bound tasks, multithreading can still waste lots of CPU cycles due to busy waiting on I/O. In order to tackle this problem, finer granularity of concurrency needs to be used so that all CPUs can be efficiently used for running code other than I/O waiting. Some programming languages offer another abstraction, “coroutine", which is essentially a light-weight thread that can be flexibly scheduled in user space (instead of kernel space). By using the coroutine, users can schedule the thread context switching based on language defined primitives. Quite a few async libraries are written in many different languages that help users manage coroutines. By using coroutines and event loops, the concurrency boosts I/O throughput and gives you better performance on I/O bound tasks. To name a few, such techniques have been adopted in Go runtime scheduler, Python Asyncio, Node.Js and Netty's event loop.
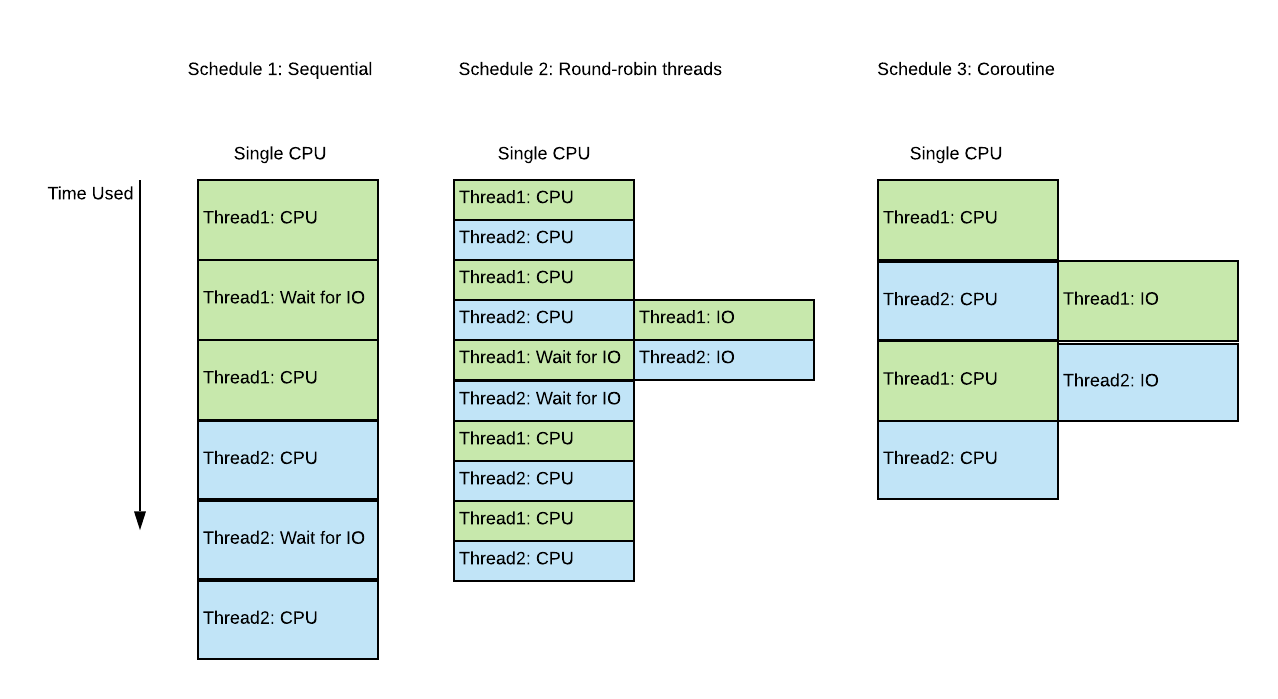
Even though some operations (such as I/O) can be performed asynchronously. Programmers still need to decide how they want to best program the code using programming language. Taking Java as an example, the programmer can write the code in a synchronous way or asynchronous way. Synchronous code can be blocking or non-blocking, meaning the code might be blocking to wait for I/O to complete before running the next lines of code. Or non-blocking meaning the program will poll the I/O result periodically and run the code selectively based on the polling result. Synchronous code always decides the execution flow after explicitly dealing with I/O. Asynchronous code on the contrary, has to rely on certain API provided by framework, library (or Kernel for low-level programming), to arrange the notification of I/O completion. The code scheduled after the I/O competition is therefore often called "callback". Callback provides a pattern for Asynchronous programming, but callbacks can sometimes cause bad coding style. There have been several variations or alternatives to callback interface, such as "await" primitives, or "Promise/Future" based interface. ParSeq uses the Promise approach and chain callback functions after the promise is resolved to create new tasks, see user guides regarding how task composition and transformation are achieved. In conclusion, asynchronous code works in par or better than synchronous code regarding performance. The concurrency renders big performance gain in I/O heavy multiple-tasking, as CPUs skips busy-waiting for I/O. On the other hand, async code is also considered harder to maintain, design and debug since it involves concurrency. Simple async code consisting of callbacks can easily introduce "callback hell" issues.
Therefore, as an asynchronous libraries, ParSeq aims to
- provide efficient scheduling mechanisms in executing code flow to improve I/O operation performance.
- provide good interfaces or API to keep code clean and natural for Async programming
- make programmers write concurrent code easier by providing guarantee of no parallelism but only serial execution.
ParSeq users can leverage the asynchronous programming through following APIs to convert code into ParSeq Task to run it asynchronously:
- Submit trunks of synchronous code and the library will wrap the code into a Task. The Task extends an Promise interface, and by doing so. ParSeq can schedule the code asynchronously in its engine. The API to be used are Task.value(), Task.async(), Task.action(), Task.callable(), Task.blocking(), etc.
- One can also provide a callback function and uses the functional programming interface to composite with tasks defined elsewhere. The API to be used are .andThen(), .transform(), .map() .recover(), .withSideEffect(), etc.
- Users can also integrate CompletionStage/CompletableFuture from Java concurrent library to the Promise interface that ParsSeq is using. Please find more info here
- Some tasks such as HTTP requests, are so common that ParSeq provides modules that integrate the clients with the Task APIs.
Once the user coded their logic using ParSeq Task and ran with Engine, this asks the engine to generate a "Plan" to run.
Internally, after tasks are passed to ParSeq Engine, the Engine generates a Context and initializes a PlanContext as part of Context. The engine then runs the Task with Context. The Context manages the lifecycle effect of Task such as cancellation, side-effect, and "runAfter" order relationship between tasks.
All Tasks created and executed as a consequence of invocation of Engine.run() belong to one "Plan" which is physically reflected as belonging to one PlanContext and being executed by a single SerialExecutor. As a consequence (as designed) all Tasks are executed sequentially.
The actual execution of the task is carried out by the SerialExecutor initialized in the Plan. SerialExecutor is an abstraction that makes sure that all Runnables submitted to it are executed sequentially. It has its own queue and a reference to underlying j.u.c.Executor. There might be many SerialExecutors running in parallel and one SerialExecutor might continue to be executed on different threads but all Runnables submitted to one SerialExecutor are executed sequentially. SerialExecutor submits itself for execution to the underlying Executor.
Engine also contains a ScheduledExecutor. It is mainly used to implement Task.withTimeout() functionality

Let's consider a simple example:
Task t = Task.action(() -> System.out.println("Hello World"));
engine.run(t)When t is submitted to engine a new SerialExecutor is created and t is started:
-
t'srun()method is submitted to it's Plan's SerialExecutor. SerialExecutor submits itself to the underlying Executor. At this point execution Context is captured and stored together with a Runnable. - One of the Executor's threads picks up a Runnable, restores execution Context on current thread and starts a Runnable. Runnable is SerialExecutor's run loop.
- It picks up the first item from it's queue (there is only one item on it) and executes it. The item from the queue is Task.action() implementation with captured callable:
System.out.println("Hello World"). Callable is executed:System.out.println("Hello World"). - Because there is nothing else on SerialExecutor's queue, its run loop exits. Executor's thread removes execution Context from the current thread and returns itself to the Executor's pool.
Task t1 = ..., t2 = ..., t3 = ...;
Task t = Task.par(t1, t2, t2);
engine.run(t)When t is submitted to the engine a new SerialExecutor is created and t is started:
- t's run() method is submitted to it's Plan's SerialExecutor. SerialExecutor submits itself to the underlying Executor. At this point execution Context is captured and stored together with a Runnable.
- One of the Executor's threads picks up a Runnable, restores execution Context on current thread and starts a Runnable. Runnable is SerialExecutor's run loop.
- It picks up the first item from it's queue (there is only one item on it) and executes it. The item from the queue is a par() implementation. It captured 3 tasks that are supposed to be executed in parallel: t1, t2, t3.
- It invokes t1's run(), t2's run(), t3's run() in an arbitrary order. Each of them is submitted to Plan's SerialExecutor. In each case SerialExecutor adds the Runnable to it's queue because it is already being executed. par() implementation completes and returns control to SerialExecutor's run loop.
- At this point there are 3 items on SerialExecutor's queue. SerialExecutor's run loop will iterate over every item on the queue and execute it one by one on the executor(note they are not necessarily executed on the same thread).
- After that the queue is empty. Because there is nothing else on SerialExecutor's queue, its run loop exits. Executor's thread removes execution Context from the current thread and returns itself to the Executor's pool.
Task is the basic execution unit in the ParSeq engine. The APIs which composites, or transform tasks would actually create more tasks, and the newly created task will depend on initiating tasks. Each time the task composition API is called, one or more new tasks will be created. Newly created tasks might have their own result and exception, which might or might not propagate to their predecessors tasks. The user might not need to know this detail if he only wants the return result. These implementation details might be useful if users want to manage exceptions, or cancel previous tasks.
A simple example:
Task t1 = Task.async(() -> { SettablePromise p = ...; ...; return p; });
Task t2 = ...;
Task t = t1.andThen(t2);
engine.run(t)When t is submitted to the engine a new SerialExecutor is created and t is started:
- t's run() method is submitted to it's Plan's SerialExecutor. SerialExecutor submits itself to the underlying Executor. At this point execution Context is captured and stored together with a Runnable.
- One of the Executor's threads picks up a Runnable, restores execution Context on current thread and starts a Runnable. Runnable is SerialExecutor's run loop. It picks up the first item from it's queue (there is only one item on it) and executes it. The item from the queue is a andThen() implementation.
- It captured t1 and t2 instances. It adds a PromiseListener to t1. This promiseListener, when called, will run t2's run() method. After adding PromiseListener, andThen's run() method invokes t1's run(). It is submitted to Plan's SerialExecutor. Since SerialExecutor's run loop is already running, the t1's run() method is added to SerialExecutor's queue. andThen's implementation completes and returns control to SerialExecutor's run loop.
- At this point there is one item on SerialExecutor's queue: t1's run() method. SerialExecutor's run loop picks it up and executes it. During execution t1 creates a Promise that, when completed, will complete t1. t1's run() completes and returns control to SerialExecutor's run loop.
- Because there is nothing else on SerialExecutor's queue, its run loop exits. Executor's thread removes execution Context from the current thread and returns itself to the Executor's pool.
After some time t1's Promise is completed on an arbitrary thread e.g. R2 thread.
- It invokes all registered PromiseListeners. One of them executes t2's run() method. It is submitted to it's Plan's SerialExecutor. SerialExecutor submits itself to the underlying Executor.
- At this point execution Context is captured and stored together with a Runnable. One of the Executor's threads picks up a Runnable, restores execution Context on current thread and starts a Runnable (please note that execution Context used here comes from the thread that completed t1's Promise). Runnable is SerialExecutor's run loop. It picks up the first item from it's queue (there is only one item on it) and executes it. The item from the queue is t2's run() method.
- SerialExecutor's run loop executes it and exits because there is nothing else on SerialExecutor's queue. Executor's thread removes execution Context from the current thread and returns itself to the Executor's pool.
A more complicated example which includes failure handling:
Task<String> task1 = fetchByUrl("https://www.google.com");
Task<String> task2 = task1.withTimeOut(10);
Task<String> task3 = task2.recover(() -> Systems.out.println("TimedOut"));
// equivalent to the following
task3 = fetchByUrl("https://www.google.com").withTimeOut(10).recover(() -> System.out.println("TimedOut"));Three tasks, task1, task2, task3 are created, no matter whether explicitly named. But one simply needs to pass task3 to the engine, i.e. run engine.run(task3)
The tasks might not be handled in the same way when results returned or exceptions happened. For example, when the timeout happens, task1 is considered cancelled, task2 is considered failed with TimeoutException and task3 is considered completed.
Last, for transformation such as .map(), it is quite similar although slightly different in implementation, e.g.
Task<Integer> task4 = task3.map("length", s -> s.length())
Underneath the hood, this creates a "PropagetResult" task to propagate results from task3 to task4.
Likewise, Task.par() or Tasks.seq() are also tasks created to wrap tasks so these tasks being wrapped can be composed parallely(Task.par()) or sequentially(Task.seq()).
As mentioned earlier in the doc, ParSeq works best for I/O intensive tasks. When running these tasks in the engine, it takes a relatively long time for the promise to complete due to the waiting for I/O and ParSeq doesn't wait for the Promise to complete before running another Task. Therefore the time for waiting I/O is utilized and not wasted. The following examples can help illustrate this point:
The example is to run CPU intensive blocking code and starts the tasks concurrently using Task.par():
Task.par(
Task.callable("1000th prime", () -> nthPrime(1000)),
Task.callable("1000th prime", () -> nthPrime(1000)),
Task.callable("1000th prime", () -> nthPrime(1000))
);As can be seen from the trace below, though the tasks are launched in parallel and run in concurrent, because the code is blocking the engine picking up another task, the three tasks created by Task.callable actually execute one after another, which defeated the purpose of Task.par(). There is no chance for optimization here because they are all CPU intensive and interleaving the execution of them does not bring any benefits. The ParSeq engine will work with this blocking task as a basic unit of execution.
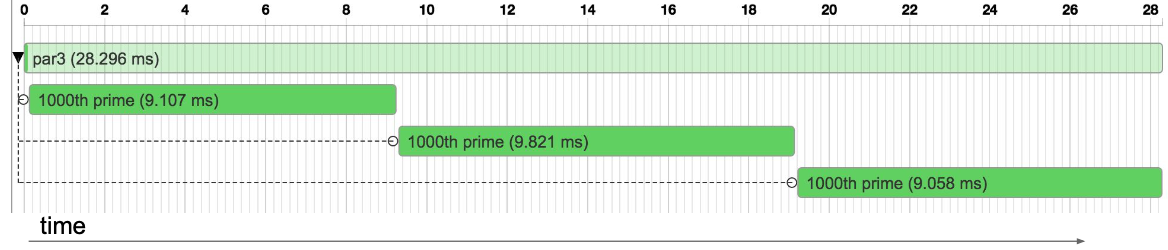
On the other hand, for I/O task, most of the time spent on waiting I/O to complete, so for I/O tasks launched by Task.par(), after the Task starts, and I/O completes, the result needs to be propagated back to be set to the Promise. The trace visualization shows how the time is spent on completing tasks, which can tell most of the time was spent on waiting for the Promise to complete.
Task<String> fetchGoogle = fetchBody("http://www.google.com");
Task<String> fetchBing = fetchBody("http://www.bing.com");
Task<String> fetchYahoo = fetchBody("http://www.yahoo.com");
Task<?> par3 = Task.par(fetchBing, fetchGoogle, fetchYahoo)
As mentioned in the User Guide, Task.par is a parallel composition method. There are also other sequential composition methods, such as Tasks.seq. Users can provide ParSeq Engine the task created by these composition methods in order to compose multiple tasks to run in a single plan. The following example will be used to illustrate the order at which the tasks are scheduled.
Task<String> task1_1= fetchUrl(httpClient, "http://www.google.com", 10000);
Task<Integer> task1_2 = task1_1.map("length", s -> s.length());
Task<String> task2_1= fetchUrl(httpClient, "http://www.bing.com", 10000);
Task<Integer> task2_2 = task2_1.map("length", s -> s.length());
Tasks composed from Tasks.seq() will be sequentially executed. This code tells the engine to run all children tasks of tasks1_2 sequentially, and then runs all children tasks of task2_2. Task 1 will be completed all at once, before Task 2.
Engine.run(Tasks.seq(task1_2, task2_2))
Tasks composed from Task.par() will be started concurrently
Engine.run(Task.par(task1_2, task2_2))
This line of code tells the engine to start running task1_2 and task2_2 concurrently. What happens underneath the hood is that the two tasks will be added to a queue one by one for execution. The number in the diagram tells the order of which the task should be picked up by the engine from the queue (assuming first task started should be scheduled first, i.e. FIFO).

In summary, the tasks inside one single plan get following runtime behavior:
- Serial execution: Tasks inside one plan are executed in serial order, and only one task is being executed at any real time. This means for tasks in one single plan, there is no parallelism, but only concurrency, any time during the execution. (Note: with Task.Blocking() as an exception since this API requires you to provide an executor service, the blocking task therefore runs in another executor service)
- When the tasks are running concurrently, the execution will use different threads, so it is not single-threaded.
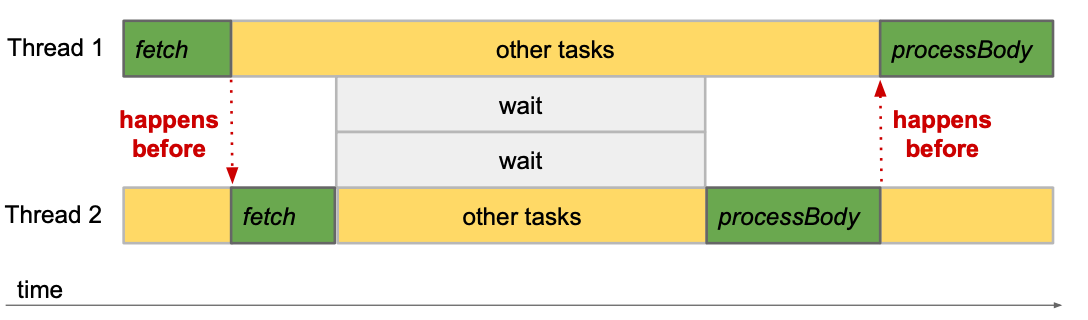
An example to illustrate these two properties is as followed:
Task<String> fetchGoogle = fetchBody("http://www.google.com");
Task<String> fetchBing = fetchBody("http://www.bing.com");
Task<String> processGoogle = fetchGoogle.andThen(this::processBody);
Task<String> processBing = fetchBing.andThen(this::processBody);The above example created 4 tasks, when they are run internally by an engine, they will run one after another, but not necessarily on the same thread.
During initialization of Engine, the TaskQueueFactory attribute can be chosen between default (which implies a LIFOPriorityQueue) versus a FIFOPriorityQueue. This does not necessarily impact your execution performance if your tasks are asynchronous in nature. However if your task is synchronous and blocking, then you might see the impact of order of execution. Everytime when one task creates a child task, it will add to the Queue in SerialExecutor so the ExecutorLoop can run it later. In the default implementation, the LIFOPriorityQueue is used. The rationale behind using a LIFO queue as default is to leverage temporal and spatial locality of parent task and its child task.
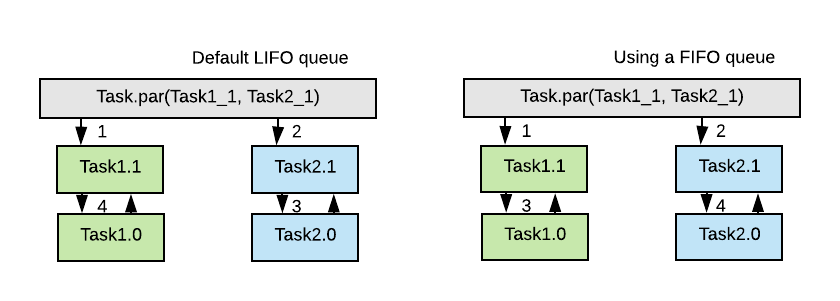
Created Task can stop running due to mainly two reasons
- Exception
- Cancellation
Note from ParSeq API's point of view, cancellation should be considered as failure. and Task created by failure handling API, such as the tasks returned by .recover(), .failure(), will not run if the originating task was cancelled. For the curious, underneath the hood, "cancellation" is indeed a failure with EarlyFinishException, but .recover(), .failure() will not respond to this type of exception.
Note if the current task throws an exception, the task which s the predecessor of the current task will be cancelled.
Task<String> task1 = fetchByUrl("https://www.google.com");
Task<String> task2 = task1.withTimeOut(10). // If task2 fail due to timeout, task1 will be "cancelled"Sometime this behavior is not desired, for example in Task.par(), one task should not cause all task to fail
final Task <Response> google = HttpClient.get("http://google.com").task();
final Task <Response> bing = HttpClient.get("http://bing.com").task();
// this task will fail because google task will timeout after 10ms
// as a consequence bing task will be cancelled
final Task both = Task.par(google.withTimeout(10, TimeUnit.MILLISECONDS), bing);In this case, if google task timed out, it will cause the Task.par(), i.e. that both task to be cancelled and bing task will be cancelled as well. If the user does not want this behavior, one can use shareable:
// this "both" task will fail because wrapped google task will timeout after 10ms
// notice however that original google and bing tasks were not cancelled
final Task both =
Task.par(google.shareable().withTimeout(10, TimeUnit.MILLISECONDS), bing.shareable());Task provides an API to perform side effects. The side effect task can be created by chaining an existing task with .withSideEffect().
Note that side effect tasks have behavior that is very different from "non side effect task", such as Task.action(). The side effect task has following properties:
- The side effect will complete successfully even though the underlying Task fails.
- The side effect will always complete with a null value
- If an exception is thrown in the Task supplying Callable then the entire plan would fail with that exception and any subsequent tasks won't run. If this is not desired, one should use
.withSafeSideEffect()
In implementation the side effect task starts asynchronously and it is started in a separate forked planContext.
If the user submits multiple plans to the ParSeq engine, those plans will be running on different threads in parallel. That means multiple tasks will be running at the same time. But for each single plan, the aforementioned guarantees still apply.