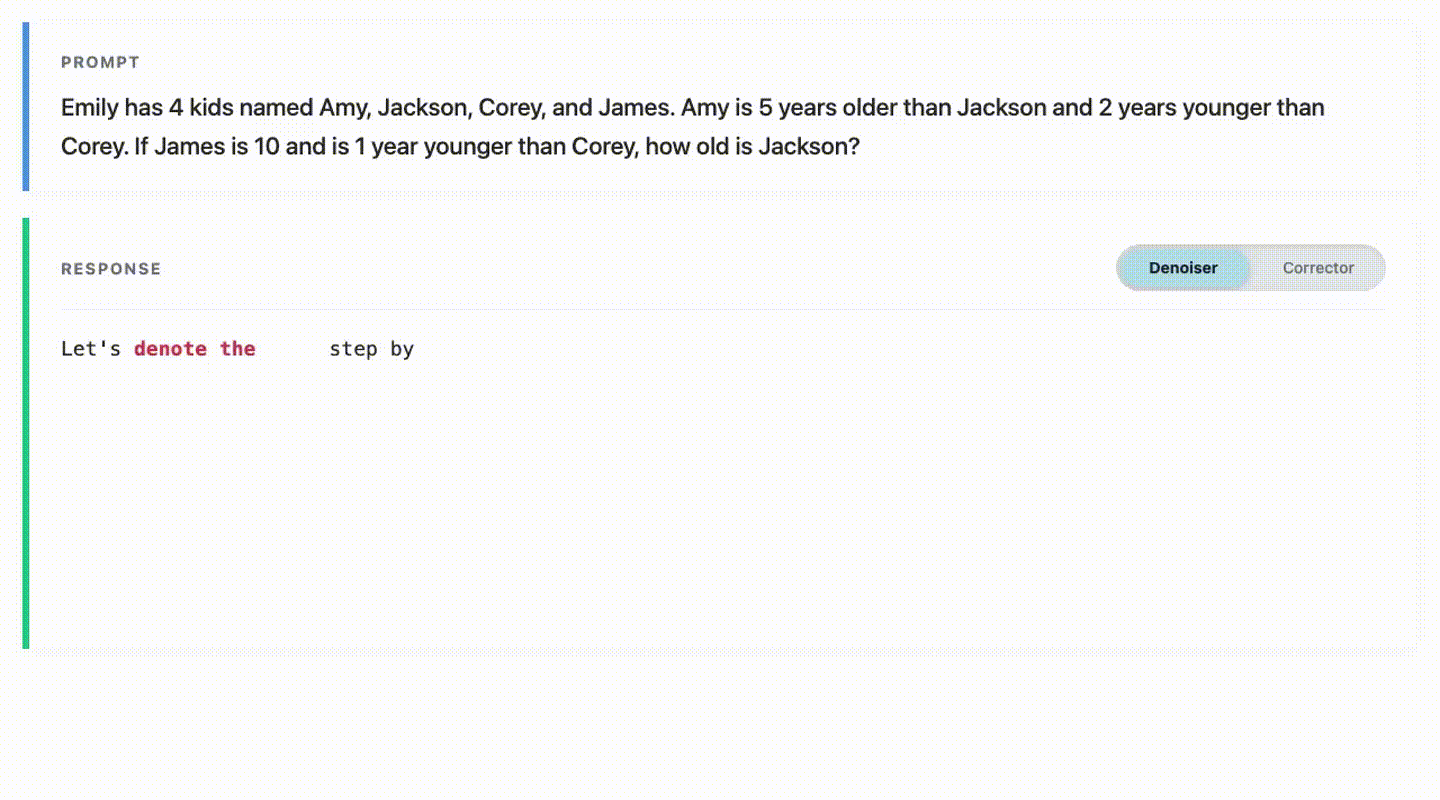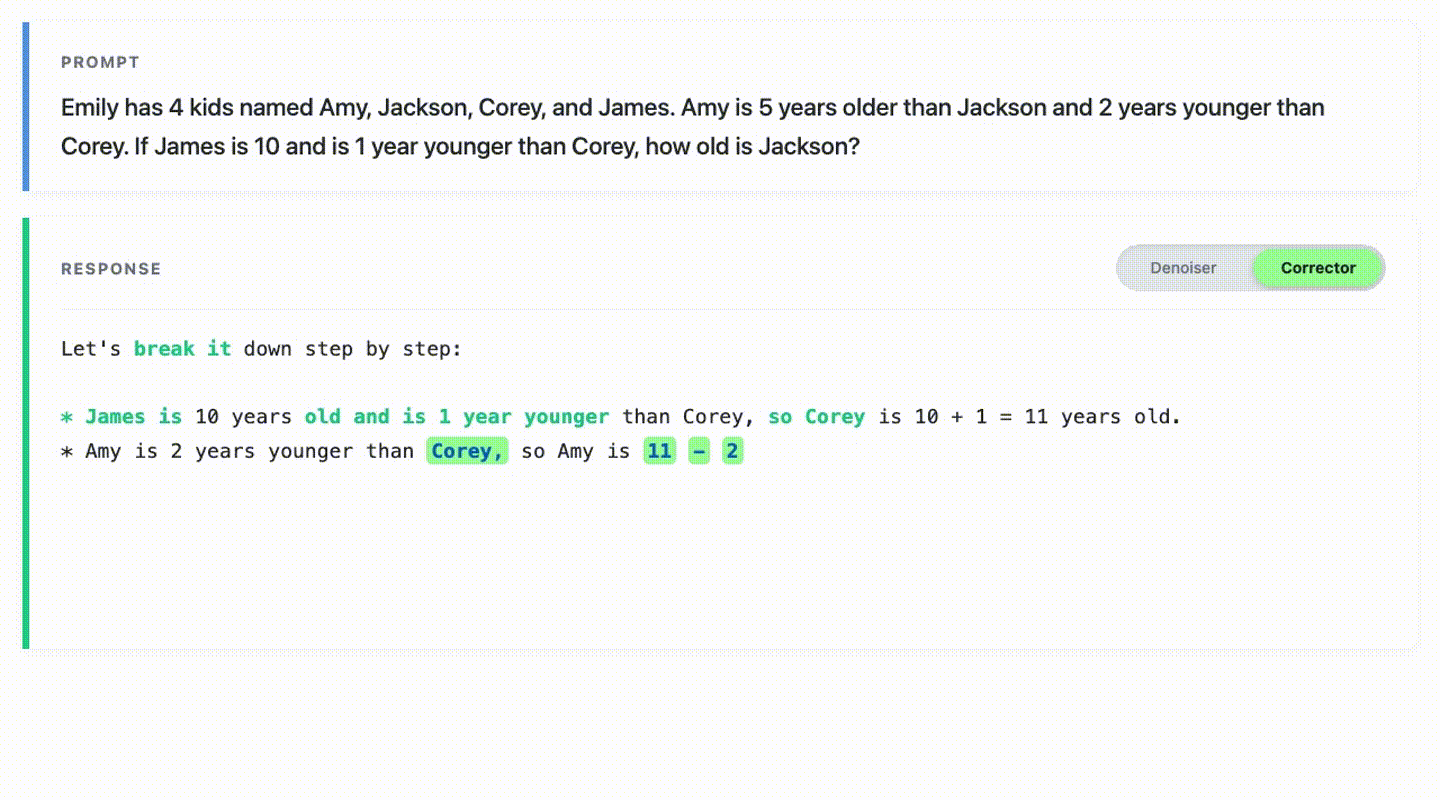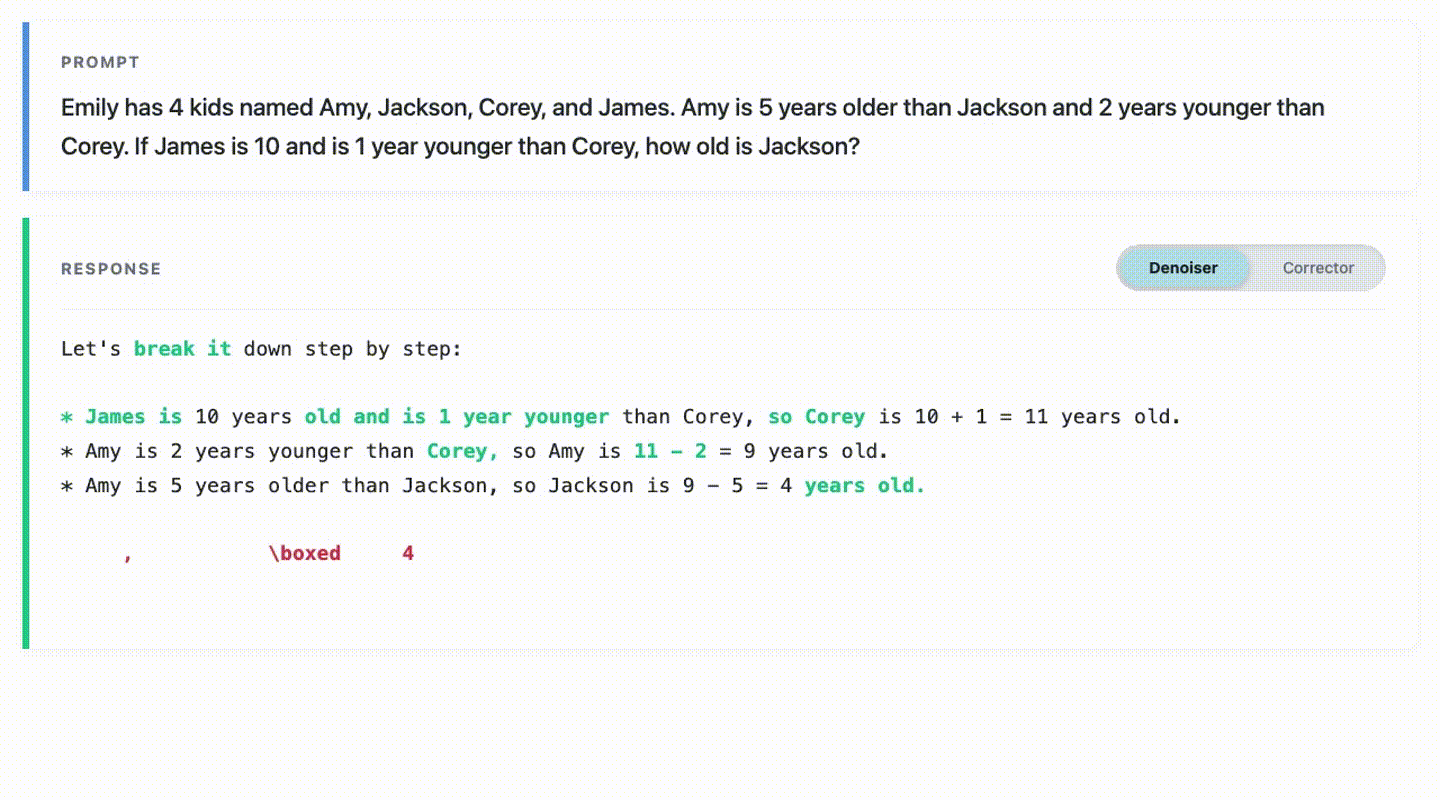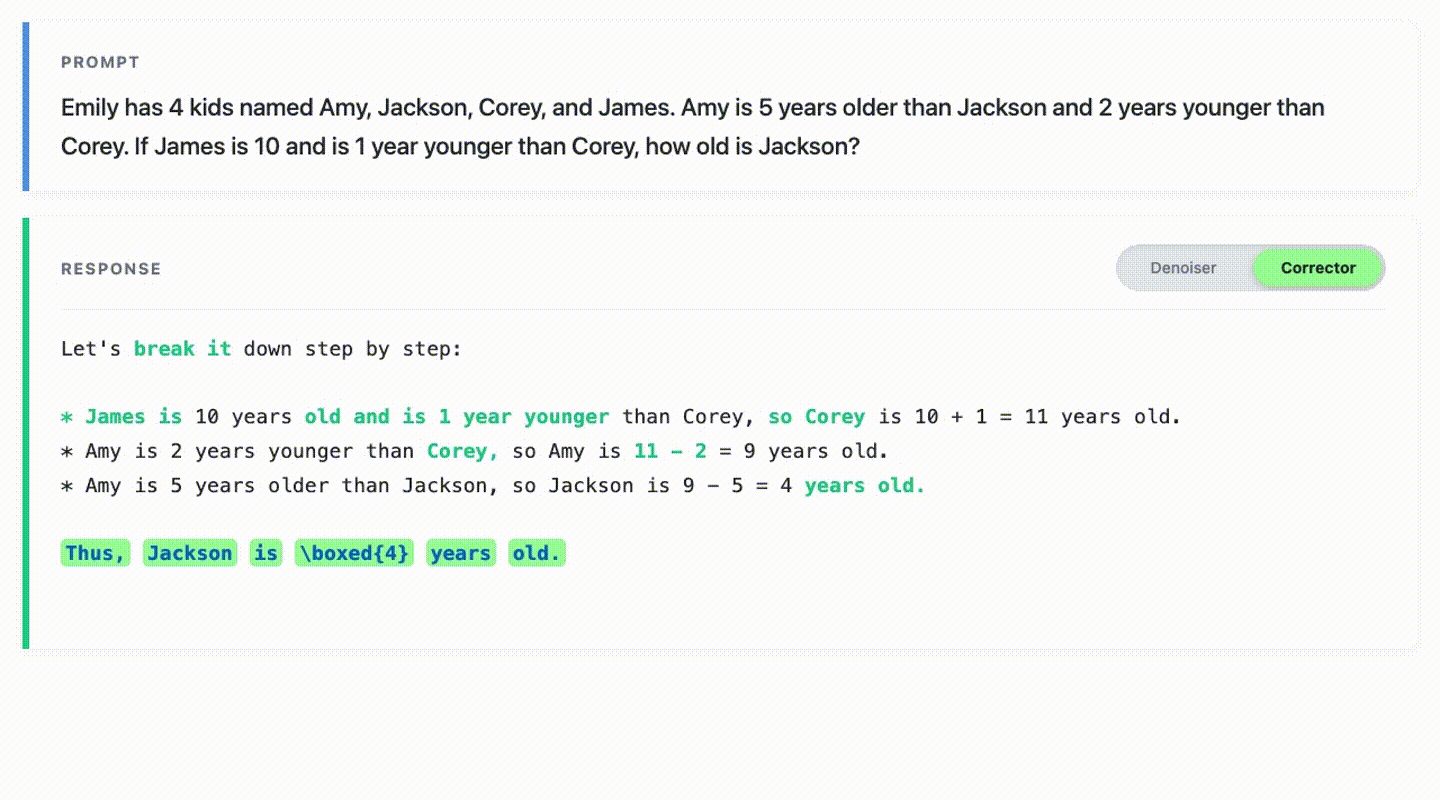
This repository contains code for reproducing experiments in the paper Learn from Your Mistakes: Self-Correcting Masked Diffusion Models
We also share trained models on HuggingFace 🤗 and support intergration with these models. See the "Using HuggingFace Models" section below.
main.py: Routines for training (language models and classifiers)noise_schedule.py: Noise schedulesdiffusion.py: Forward/reverse diffusion- Absorbing state / uniform noise diffusion
- AR
dataloader.py: Dataloadersutils.py: LR scheduler, logging,fsspechandlingmodels/: Denoising network architectures.configs/: Config files for datasets/denoising networks/noise schedules/LR schedulesscripts/: Shell scripts for training/evaluationguidance_eval/: Guidance evaluation scriptsllada/: Code to reproduce evaluation of LLaDA SFT models
To enable ProSeCo training, set the corrector_training flag in
config.yaml to True.
Additional parameters that can be tuned include the following:
corrector_training: True #
use_weighted_corrector_loss: True # Whether to apply the αt' / 1 - αt weight to corrector loss
use_model_outputs_as_corrector_input: False # Whether to pass denoiser outputs at all positions, or just masked ones
use_argmax_for_corrector: True # Whether to use argmax sampling to create corrector inputs
corrector_training_start_step: 0 # What (global) step to start applying corrector loss
mdlm_loss_weight: 1.0 # Additional optional weighting for MDLM loss
corrector_loss_weight: 1.0 # Additional optional weighting for corrector loss
corrector_loss_errors_upweighted: False # Whether to prioritize mistakes in corrector loss (see Appendix C.3 for details)
Below we detail the parameters one can use when applying corrector steps during
inference.
These parameters can be found under sampling in config.yaml:
corrector_prior_is_argmax: True # Use argmax from denoiser as corrector input
corrector_sampling: 'argmax' # Sampling scheme for corrector steps
corrector_every_n_steps: 1 # Frequency for applying corrector loops
corrector_steps: 0 # Max number of corrector steps per loop
corrector_start_iter: 0 # Can be used to delay when corrector steps are eligible to start
corrector_top_k: 0 # Used in conjunction with `select_top_k` strategy for corrector samplingWe also provide code for reproducing the evaluations with our LLaDA-SFT model in the llada directory. See the README file there for more details, and download the model from HuggingFace.
To get started, create a conda environment containing the required dependencies.
conda env create -f requirements.yaml
conda activate discdiffCreate the following directories to store saved models and slurm logs:
mkdir outputs
mkdir watch_folderWe rely on wandb integration
to log experiments and eval curves.
Throughout, the main entry point for running experiments is the main.py script.
We also provide sample slurm scripts for launching pre-training and evaluation experiments in the scrips/ directory.
We provide pre-trained models on HuggingFace 🤗:
- We release the LLaDA + ProSeCO SFT model: kuleshov-group/proseco-llada-sft
- We release the ProSeCo model trained from scratch on OWT: kuleshov-group/proseco-owt
Please see the README pages for these models on HuggingFace or our paper for more details about the training of these models.
To use these models, you can load them using the HuggingFace API, e.g.,
from transformers import AutoModelForCausalLM, AutoModelForMaskedLM
model = AutoModelForCausalLM.from_pretrained("kuleshov-group/proseco-llada-sft")
model = AutoModelForMaskedLM.from_pretrained("kuleshov-group/proseco-owt")To use these models in our repository, set the following config parameters:
backbone="hf_dit"
model="hf"
model.pretrained_model_name_or_path="kuleshov-group/proseco-owt"This repository was built off of UDLM and MDLM.
@article{schiff2026learn,
title={Learn from Your Mistakes: Self-Correcting Masked Diffusion Models},
author={Schiff, Yair and Belhasin, Omer and Uziel, Roy and Wang, Guanghan and Arriola, Marianne and Turok, Gilad and Elad, Michael and Kuleshov, Volodymyr},
journal={arXiv preprint arXiv:2602.11590},
year={2026}
}