v4.0.0: Algorithm Benchmark, Analysis, API simplification
This release corrects and optimizes all the algorithms from benchmarking on Atari. New metrics are introduced. The lab's API is also redesigned for simplicity.
Benchmark
- full algorithm benchmark on 4 core Atari environments #396
- LunarLander benchmark #388 and BipedalWalker benchmark #377
This benchmark table is pulled from PR396. See the full benchmark results here.
| Env. \ Alg. | A2C (GAE) | A2C (n-step) | PPO | DQN | DDQN+PER |
|---|---|---|---|---|---|
Breakout graph  |
389.99 graph |
391.32 graph |
425.89 graph |
65.04 graph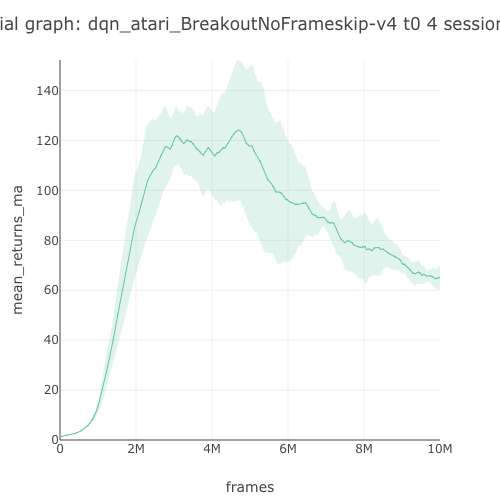 |
181.72 graph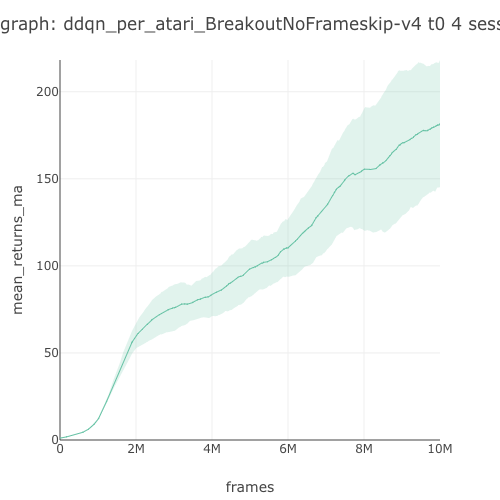 |
Pong graph  |
20.04 graph |
19.66 graph |
20.09 graph |
18.34 graph |
20.44 graph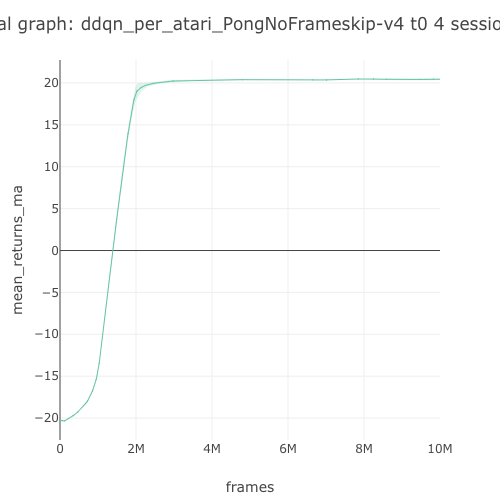 |
Qbert graph 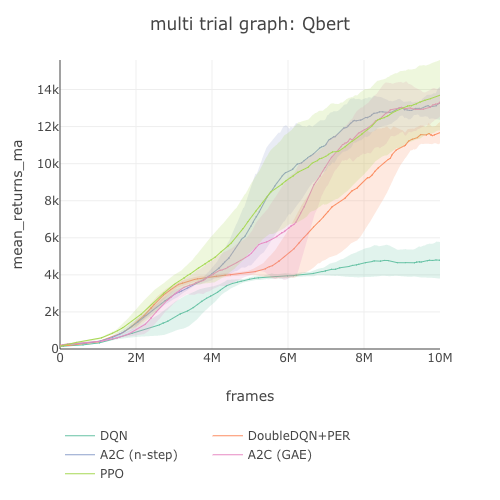 |
13,328.32 graph |
13,259.19 graph |
13,691.89 graph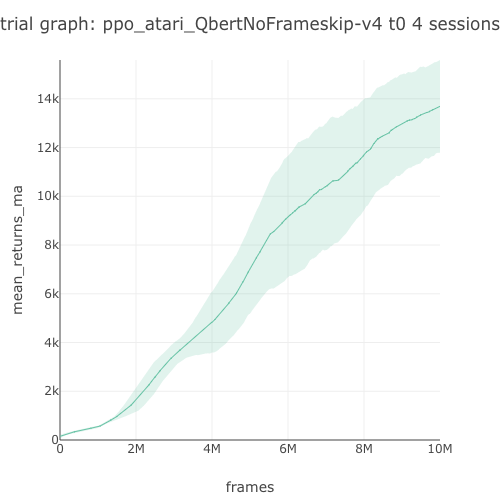 |
4,787.79 graph |
11,673.52 graph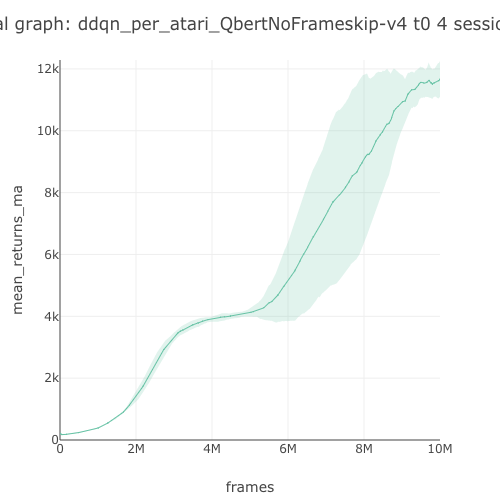 |
Seaquest graph  |
892.68 graph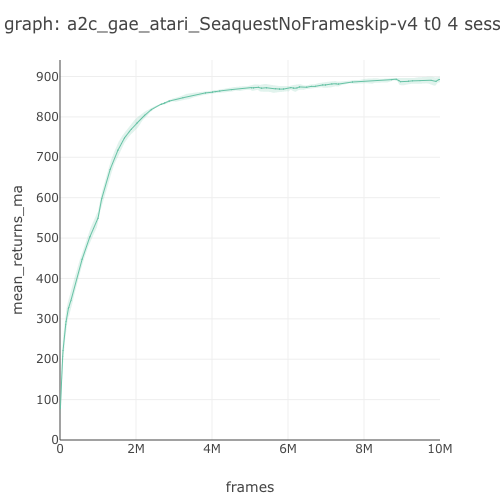 |
1,686.08 graph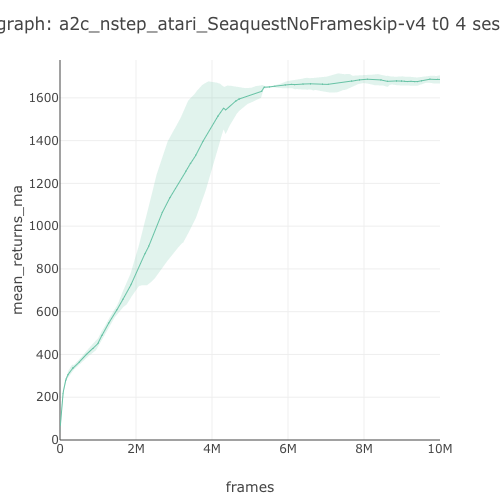 |
1,583.04 graph |
1,118.50 graph |
3,751.34 graph |
Algorithms
- correct and optimize all algorithms with benchmarking #315 #327 #328 #361
- introduce "shared" and "synced" Hogwild modes for distributed training #337 #340
- streamline and optimize agent components too
Now, the full list of algorithms are:
- SARSA
- DQN, distributed-DQN
- Double-DQN, Dueling-DQN, PER-DQN
- REINFORCE
- A2C, A3C (N-step & GAE)
- PPO, distributed-PPO
- SIL (A2C, PPO)
All the algorithms can be ran in distributed mode also; which in some cases they have their special names (mentioned above)
Environments
- implement vector environments #302
- implement more environment wrappers for preprocessing. Some replay memories are retired. #303 #330 #331 #342
- make Lab Env wrapper interface identical to gym #304, #305, #306, #307
API
- all the Space objects (AgentSpace, EnvSpace, AEBSpace, InfoSpace) are retired, to opt for a much simpler interface. #335 #348
- major API simplification throughout
Analysis
- rework analysis, introduce new metrics: strength, sample efficiency, training efficiency, stability, consistency #347 #349
- fast evaluation using vectorized env for
rigorous_eval#390 , and using inference for fast eval #391