네트워크 유량 알고리즘에 대표적인 알고리즘 포드 포커슨과 에드몬트 카프 알고리즘이 있다.
포드 포커슨은 네트워크 유량 알고리즘의 증가 경로 탐색을 DFS를 이용한 것이고 에드몬트 카프 알고리즘은 네트워크 유량 알고리즘을 BFS를 이용한 것이다.
그렇다면 두 알고리즘을 포괄하고 있는 네트워크 유량에 대해서 먼저 간단히 알아본다.
시작점에서부터 도착점으로 동시에 보낼 수 있는 데이터나 사물의 최대 양을 구하는 알고리즘이다.
Source: 시작점 , Sink: 도착점
Capacity: 용량 (정해진 용량에서 가능한 용량의 양)
Flow: 유량 (용량을 점유하고 있는 유량 값)
c(a, b): 정점 a 에서 b로 정해진 용량에서 아직 쓸 수 있는 용량 값
f(a, b): 정점 a 에서 b로 흐르고 있는 유량 값
네트워크 유량 알고리즘을 이해하기 위해서는 네트워크 유량을 대표하는 3가지 특징을 알아야 한다.
-각 간선에 흐르는 유량은 해당되는 간선의 용량을 넘어서 흐를 수 없다.
의사코드 : f(a,b) <= c(a,b)
-각 정점에 들어오고 나가는 유량의 합은 같다.
-의사코드 : f(a,b) == -f(b,a) ※네트워크 유량 알고리즘에서 경로를 다 구했으면 끝이 아니다. 이 유량의 대칭 특징에 의하여 음의 유량을 계산해 주어야 한다. 최대 유량 알고리즘은 모든 가능한 경로를 다 계산해주기 위해서 음의 유량도 계산해주어야 한다. 우리가 단순하게 유량을 더해주는 과정에서 사실은 보이지 않게 반대로 가는 유량이 빼지고 있다고 생각해야 .
#include <iostream>
#include <vector>
#include <cstring>
#define MAX 100 //노드 개수
#define INF 1000000000//무한대값 설정
using namespace std; //c++문법 쓰기 위해
int c[MAX][MAX], f[MAX][MAX], visit[MAX];
vector<int> adj[MAX]; //인접 노드 배열
int dfs(int a, int T, int flow) {
if (visit[a]) return 0;
visit[a] = 1;
if(a==T) return flow;
for(int i=0; i< adj[a].size(); i++) {
int b = adj[a][i], now_flow = c[a][b] - f[a][b];
if (now_flow <= 0) continue;
int result = dfs(b,T,min(flow,now_flow));
if (result) { //최소 유량 추가
f[a][b] += result;
f[b][a] -= result;
return result;
}
}
return 0;
}
int maxFlow(int S, int T) {
int result = 0;
while(1) {
memset(visit,0,sizeof(visit));
int flow = dfs(S,T,INF);
if(!flow) break;
result += flow;
}
return result;
}
int main()
{
int n,source,sink;
cin >> n;
cin >> source >> sink;
for(int i=0; i<n; i++) {
int n1,n2,n3;
cin >> n1 >> n2 >> n3;
adj[n1].push_back(n2);
adj[n2].push_back(n1);
c[n1][n2] = n3;
}
int result = maxFlow(source,sink);
cout << result;
return 0;
}- maxflow
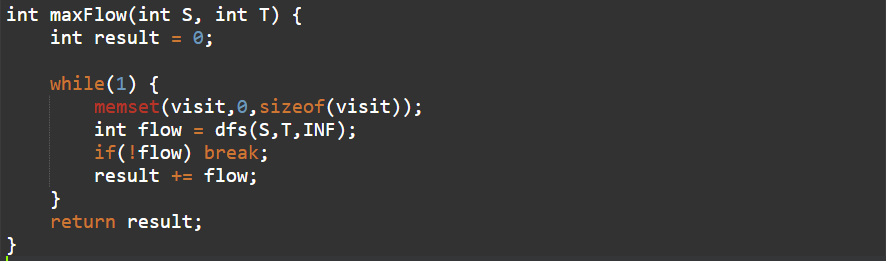
위 사진은 최대유량을 계산하기 위해 만들어진 함수이다.
처음에 사전 용어정리를 할 때 말했던 source(시작점)와 sink(도착점)를 매개변수로 받는다. 그리고 결과 값으로 나올 result 값을 0으로 초기화 해준다.
무한루프를 돌 껀데 이 while문으로 다시 들어올때마다 매번 visit함수를 초기화 해 줄 것이다. 그 이유는 밑에 코드를 보면 dfs함수를 쓸 껀데 밑에서 dfs코드에 대해서 설명하겠지만 출발점에 대해서 visit값을 1로 즉 방문했다고 초기화 해준다. 그럼 다시 maxflow 함수로 돌아와서 이 코드가 돌아갈 때 매번 visit값을 0으로 초기화 해주지 않는다면 오류가 날 것이다.
int flow=dfs(S,T,INF) 코드를 그대로 해석한다면 'flow는 유량 값이고 유량 값을 dfs함수 에게 보내서 찾아준다.'라는 말이지만 dfs함수를 써서 증가경로를 하나 찾고 증가경로를 하나 찾았다면 돌아와서 flow에다가 값을 넣어준다라는 의미이다.
if(!flow) break; 더 이상 증가경로를 찾지 못했다면 이 함수를 빠져나오는 것이고 각 증가경로 별 흐르는 유량 값이 존재한다면 result에 계속 더해주는 함수이다.
- dfs
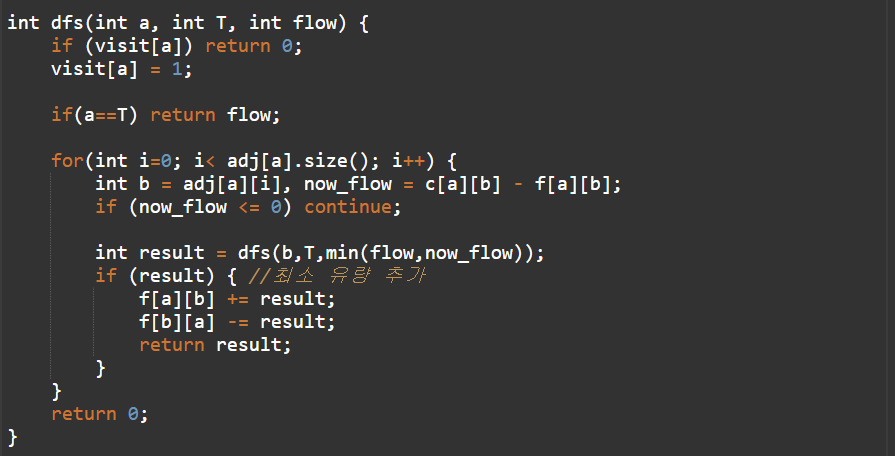
위 사진은 각 경로별 흐를 유량을 계산해 줄 함수이다.
먼저 출발점(시작점이 아니다)과 도착점 그리고 유량을 매개변수로 받는다.
if(visit[a])로 이미 방문을 했다면 return 0을 해주고 하지 않았다면 1값을 넣어서 방문했다고 초기화를 해준다. if(a==T) 출발점이 만약 도착점이라면 즉 dfs 함수를 돌면서 증가경로를 하나 찾았고 그걸로 도착점까지 도착했다면 지금까지 계산했던 flow함수를 리턴해 줄 것이다.
다음으로 반복을 돌 것이다. 출발점에서 갈 수 있는 첫 인덱스부터 끝까지 반복하며 b와 now_flow를 초기화 해줄 것이다. (now_flow가 0과 같다면 즉 유량이 더 이상 흐를 수 없다면 밑은 생략하고 다음 반복을 돌라는 의미이다.) result 값을 dfs함수를 돌면서 초기화를 해 줄 것인데 여기서 첫 인덱스 값이 b로 바뀐다. b는 보시다시피 처음 들어왔을 때 출발점과 연결되어 있는 노드이다. b가 다시 새롭게 출발점이 되어 dfs함수를 도는 것이다. 이렇게 반복을 하다보면 위에서 설명했다시피 출발점이 도착점과 같아지는 경우가 생기고 flow를 리턴받을 것이고 result값은 리턴 받은 flow값으로 초기화 해준다. 그 다음에 result값이 존재한다면 해당경로에 유량을 흘려 보내주면 된다. 유량의 대칭 특징에 의하여 음의 유량도 반대로 흘려 보내준다. result를 돌려주어 dfs함수에서 받고 result를 점점 증가시켜준다.
- main
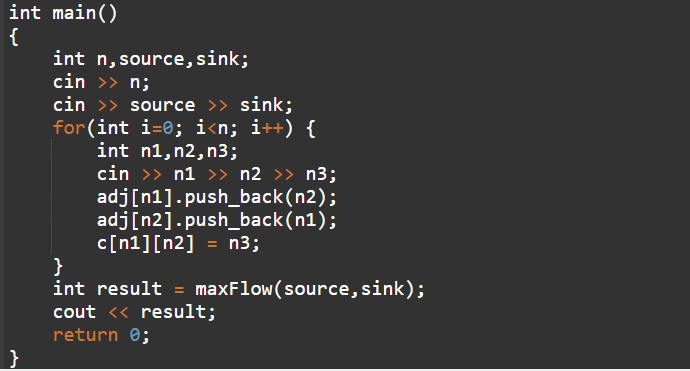
main함수는 n으로 몇개의 간선이 있는지를 입력 받을 것이고 source와 sink로 시작점과 도착점을 입력 받을 것이다.
그리고 간선의 개수만큼 반복문을 돌면서 n1과 n2로 노드들을 연결해줄 것이고 n3로 그 노드사이에 용량의 크기를 넣어준다.
result에 maxflow함수로 리턴 받은 최대 유량을 넣어줄 것이다.
마지막으로 result 최대 유량을 출력해 줄 것이다.
- 출력값

위 실행화면을 보면 간선은 10개이고 시작점과 도착점은 1,6이고 노드들을 연결해주고 있다.
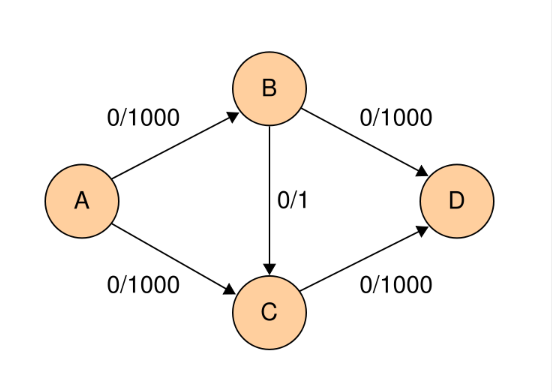
위 그림은 포드 포커슨 알고리즘에서 대표되는 최악의 경우에 대한 예시이다. 먼저 A->B->C->D 경로를 찾아 flow1을 흘려보낸다. 2.역간선을 이용하여 A->C->B->D를 찾는다. 그럼 B->C로 흐르는 유량이 0으로 초기화 되어진다. 그럼 결국 1000번의 루프를 타야 무한루프를 탈출할 수 있다.
위 포드 포커슨 알고리즘의 단점 때문에 맨 위에서 네트워크 유량의 대표적인 알고리즘이 포드 포커슨과 에드몬트 카프가 있다고 언급했었다.
에드몬트 카프 알고리즘이 포드 포커슨 알고리즘과 연관이 있어서 언급하였는데 지금부터 에드몬트 카프에 대해서는 간단히 코드 옆에 주석으로 설명하겠다.
#include <iostream>
#include <vector>
#include <queue>
#define MAX 100 //노드 개수
#define INF 1000000000//무한대값 설정
using namespace std; //c++문법 쓰기 위해
int result; //result는 결과 변수
int c[MAX][MAX], f[MAX][MAX],d[MAX]; //c는 용량 변수 f는 유량 변수 d는 특정한 노드를 방문했는지 알려주는 변수이다.
vector<int> adj[MAX]; //연결된 간선을 표현할 수 있도록 a라는 변수 설정
//최대 유량을 구하는 함수이다. 시작점과 끝 점을 받는다.
void maxFlow(int start,int end) {
while(1) { //반복적으로 모든 경로를 탐색할 수 있도록 무한루프를 설정해준다.
fill(d,d+MAX,-1); //모든 정점은 방문하지 않은 상태로 -1로 초기화해준다.
queue<int> q; //q를 하나 만들어서 모든 경로를 확인해본다.
q.push(start);//시작점을 큐에 넣어준다.
while(!q.empty()) {
int x = q.front();//큐에서 한개를 꺼낸다음
q.pop();
for(int i=0; i < adj[x].size();i++) {
int y = adj[x][i];
// 방문하지 않은 노드 중에서 용량이 남은 경우
if(c[x][y] - f[x][y] > 0 && d[y] == -1) {//용량이 유량보다 많으면서 방문하지 않았을 경우
q.push(y); //큐에 넣어준다.
d[y] = x; //경로를 기억한다.
if(y == end) break; //도착지에 도달을 한 경우
}
}
}//도착지까지는 도달하지 않기 때문에 -1이 담겨 있다.
if(d[end] == -1) break;//모든 경우를 찾았을 경우 탈출한다.
int flow = INF; //가능한 용량중 작은 것을 넣어야하기 때문에 무한값을 넣어놓는다.
for(int i=end;i != start; i = d[i]) {//거꾸로 최소 유량을 탐색합니다.
flow = min(flow,c[d[i]][i] - f[d[i]][i]);
}
//최소 유량만큼 추가합니다.
for(int i=end;i != start; i = d[i]) {
f[d[i]][i] += flow;
f[i][d[i]] -= flow;
}
result += flow; //최대 유량값을 구했다.
}
}
int main()
{
int n,source,sink;
cin >> n;
cin >> source >> sink;
for(int i=0; i<n; i++) {
int n1,n2,n3;
cin >> n1 >> n2 >> n3;
adj[n1].push_back(n2);
adj[n2].push_back(n1);
c[n1][n2] = n3;
}
maxFlow(source,sink);
cout << result;
return 0;
return 0;
}
- 두 알고리즘의 차이
포드 포커슨은 네트워크 유량을 경로 탐색을 할때 DFS를 이용하여 푼 것이고 에드몬트 카프 알고리즘은 BFS를 이용하여 경로 탐색을 한 것이다. 위 최악의 경우 때문에 대부분의 사람들이 에드몬트 카프 알고리즘을 사용한다. 많은 사람들이 오해하고 있는 것 이 위 포드 포커슨에 최악의 경우 때문에 에드몬트 카프 알고리즘이 포드 포커슨 알고리즘보다 상위호환이라고 생각하고 있는데 무조건 좋은 것이 아니라 상황에 따라서 선택해야한다.
그 이유는 시간 복잡도가 포드 포커슨의 시간 복잡도는 O(V+E)F(포드 포커슨 시간 복잡도에서 정점의 개수는 간선의 개수보다 현전히 작기 때문에 O(E)F라고 할 수 있다.)이고 에드몬트 카프의 시간 복잡도는 O(VE^2)이다. 즉 포드 포커슨 알고리즘의 시간 복잡도는 FLOW값에 영향을 많이 받고 에드몬트 카프 알고리즘은 간선의 개수의 영향을 많이 받는다. 이래서 상황에 따라 선택해야 하는 것이다.