[cudadev] Update the CUDA implementation to the version in CMSSW 12.0.0-pre3 #191
Conversation
|
Mhm, I seem to have broken something: |
b923a0e to
fb9033e
Compare
|
OK, I had picked one change too much (from cms-sw/cmssw#33889, which is post-CMSSW_12_0_0_pre3) in the vertex finder. |
|
|
Note that the new code is measurable slower. cudacudadev |
|
Comparing the throughput of the
|
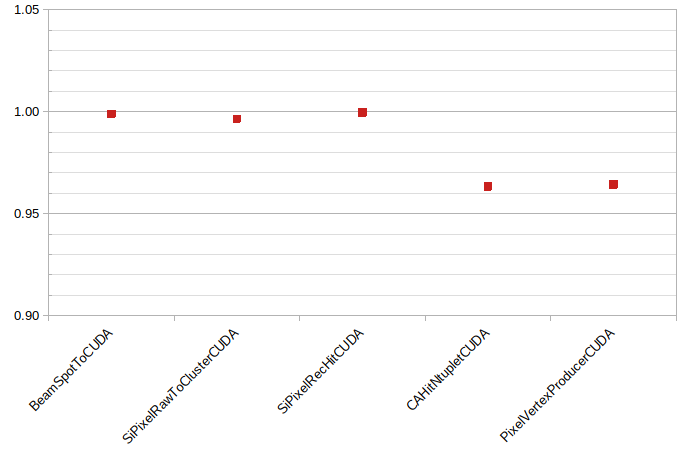
|
@VinInn @felicepantaleo @makortel can you think of anything that may have slowed down the |
|
can you run nvprof (or equivalent nsight)? |
|
any metric or settings in particular ? here is the output of ncu --print-summary per-kernel ./cuda --maxEvents 10and here is the result of |
|
too much info to digest (at least in txt form) |
|
ah, ok - it's also much faster to generate :-) |
|
maybe some sort of numeric diff out of the logs |
|
from the nsys logs, the main offender seems to be Time(%) Total Time (ns) Instances Average Minimum Maximum Name
------- --------------- --------- --------- ------- ------- ----------------------------------------------------------------------------------------------------
- 22.9 366,054,748 1,000 366,054.7 113,823 755,099 kernel_find_ntuplets(TrackingRecHit2DSOAView const*, GPUCACell*, unsigned int const*, cms::cuda::Si…
+ 25.2 415,254,529 1,000 415,254.5 123,263 874,844 kernel_find_ntuplets(TrackingRecHit2DSOAView const*, GPUCACell*, unsigned int const*, cms::cuda::Si… |
|
can standalone print the stat? |
|
yes, it just needs to be recompiled: vs |
|
identical (good)! |
|
or yes, it just needs to be recompiled: cuda
cudadev
|
|
the only difference seems in |
|
The meaning changed... |
|
one can compare the details in the ".log". Clearly "dev" is spending more cycles |
|
we changed some int16 in int32 and maybe the size of some arrays. Plus made the hits dynamically allocated. |
| public: | ||
| static constexpr uint32_t maxHits() { return gpuClustering::MaxNumClusters; } | ||
| using hindex_type = uint16_t; // if above is <=2^16 | ||
| using hindex_type = uint32_t; // if above is <=2^32 |
There was a problem hiding this comment.
if I change this I get a failed assert:
/data/user/fwyzard/pixeltrack-standalone/src/cudadev/CUDADataFormats/TrackingRecHit2DHeterogeneous.h:111:62: error: static assertion failed
static_assert(sizeof(TrackingRecHit2DSOAView::hindex_type) == sizeof(float));
There was a problem hiding this comment.
ok. the storing area changed as well. so not so trivial
There was a problem hiding this comment.
maybe there is a not so hard way to revert the full PR....
There was a problem hiding this comment.
not obvious, was done BEFORE the merge (or at least not by me in CMSSW master)
There was a problem hiding this comment.
Yes, I think it was done in the Patatrack branch - before the merge in the upstream CMSSW and the following clean up.
| // types | ||
| using hindex_type = uint16_t; // FIXME from siPixelRecHitsHeterogeneousProduct | ||
| using tindex_type = uint16_t; // for tuples | ||
| using hindex_type = uint32_t; // FIXME from siPixelRecHitsHeterogeneousProduct |
There was a problem hiding this comment.
all these changes and still in two places....
There was a problem hiding this comment.
if I change this I can run fine, but I still have a ~3.5% loss in performance
There was a problem hiding this comment.
so this is not the cause of the regression
| thisCell.theUsed |= 1; | ||
| oc.theUsed |= 1; | ||
| thisCell.setUsedBit(1); | ||
| oc.setUsedBit(1); |
There was a problem hiding this comment.
hope these mods are just esthetic
There was a problem hiding this comment.
I assume so, given that it's defined as
__device__ __forceinline__ void setUsedBit(uint16_t bit) { theUsed_ |= bit; }
| //to implement | ||
| // endcap pixel | ||
|
|
||
| class TrackerTopology { |
There was a problem hiding this comment.
I wonder why TrackerTopology is needed? I did notice the added #include in SiPixelRawToClusterGPUKernel.cu but by quick look on the diff the reason wasn't evident (e.g. the full). If only a subset of this header is needed, could the copy be limited to that?
There was a problem hiding this comment.
Good point, I'll check if it can be reduced.
There was a problem hiding this comment.
OK, the only part that uses the topology is
so I can copy those three constants and avoid including the full topology.
There was a problem hiding this comment.
The PixelSubdetector::PixelBarrel is defined in PixelSubdetector.h (added in this PR), and the DetId::* in DetId.h (added in this PR), so maybe the TrackerTopology could be avoided completely?
There was a problem hiding this comment.
Thanks for the suggestion, I've update the PR dropping DataFormats/TrackerTopology.h and including the other headers directly.
|
Overall this PR looks ok for |
|
Hi Matti, I've prepared this update for two reasons:
I don't know if we want to do regular updates. If we do (on a regular basis or not) the next ones might be easier, now that all code is in CMSSW and we can check the upstream PRs. |
|
If one dumps the ptr for the two versions of |
|
Took me a bit, but here they are: |
... and I'm happy to report that the same issue is still there after the update (but somewhat harder to trigger) :-) |
|
On the other hand, if I run multiple jobs concurrently, the So maybe we don't need to worry too much about the single job slowdown. |
Thanks for the clarifications, makes sense. I have also been planning to use the
Ok. I suppose the current "update when there is demand" can be good-enough for now. |
Co-authored-by: Angela Czirkos <[email protected]> Co-authored-by: Eric Cano <[email protected]> Co-authored-by: Felice Pantaleo <[email protected]> Co-authored-by: Marco Musich <[email protected]> Co-authored-by: Matti Kortelainen <[email protected]> Co-authored-by: Tamas Vami <[email protected]> Co-authored-by: Vincenzo Innocente <[email protected]>
fb9033e to
fe2bc62
Compare
No description provided.