ISBN Explorer es un proyecto de Data Engineering que automatiza la recolección, fusión y auditoría de metadatos bibliográficos a partir de un CSV.
Soporta múltiples fuentes (Ministerio de Cultura, Google Books, OpenLibrary) y genera fichas individuales que se consolidan en un único archivo JSON listo para análisis o integración.
💡 Este repo incluye ejemplos en
fichas/yfuentes/. Para empezar desde cero ejecuta:python isbn_explorer.py --reset
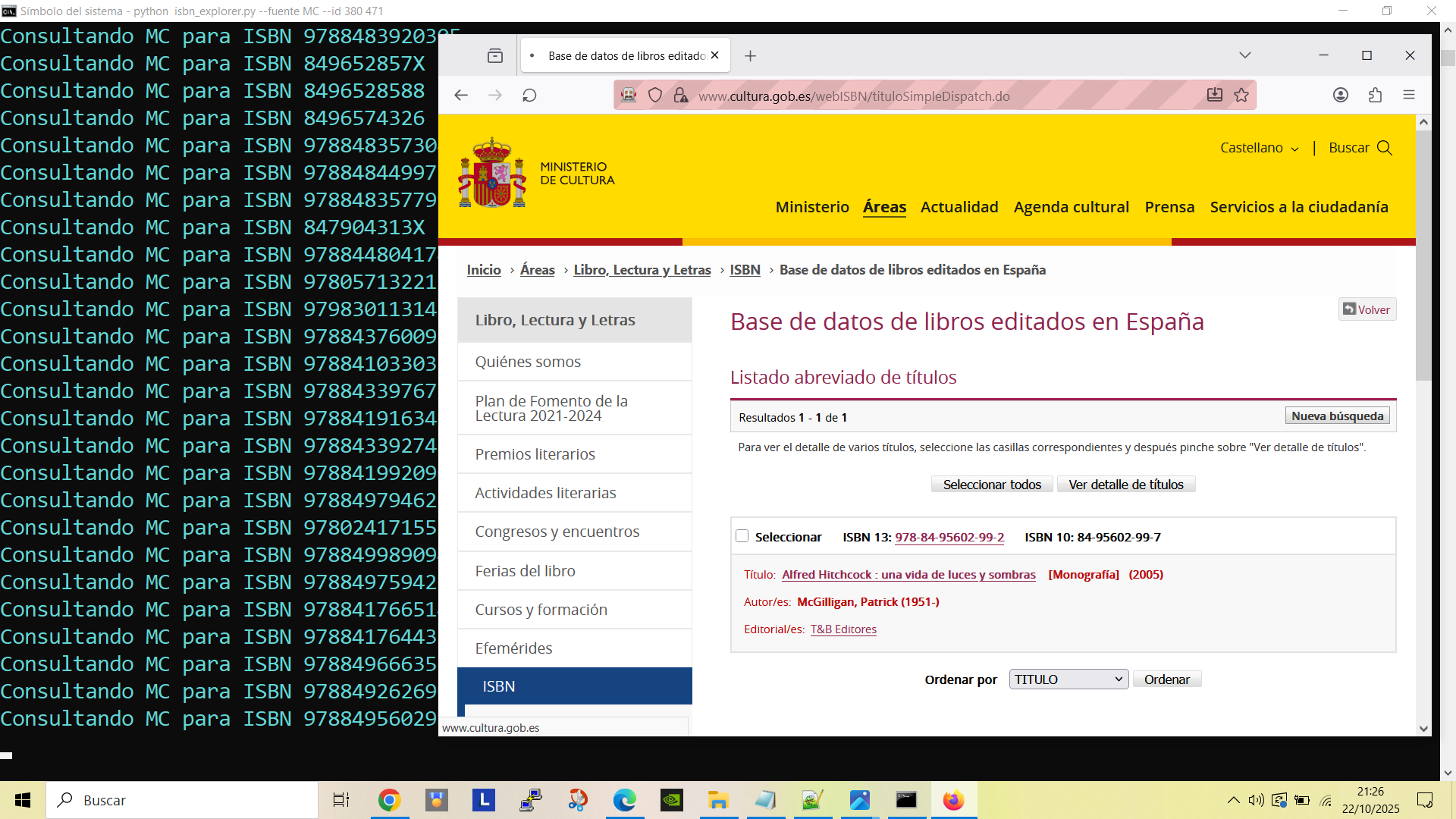
- 00:00 - Presentacion y estructura del proyecto
- 00:50 - Ejecución fuente: Ministerio de Cultura (Selenium)
- 03:40 - Ejecución fuente: Google Books (API)
- 07:22 - Ejecución fuente: OpenLibrary (API)
- 09:32 - Fusion de metadatos
- 11:00 - Auditoria y resultados finales
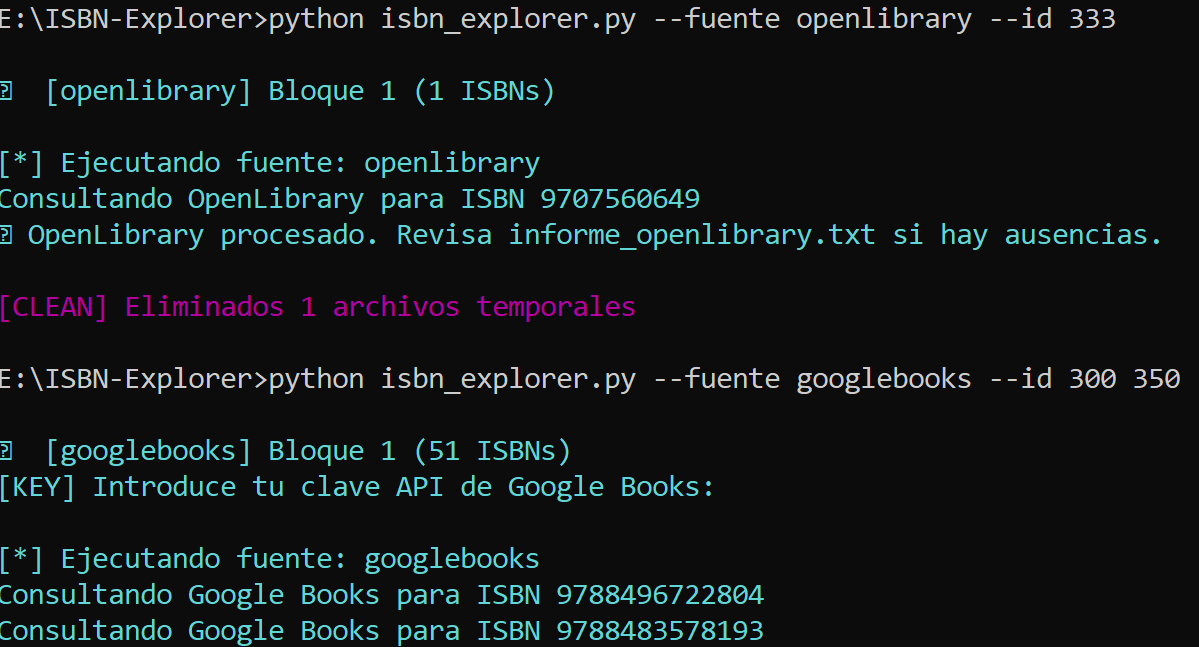
- 00:00 - Limpieza: Borrado de archivos (--reset)
- 01:35 - Uso de --fuente para consultas individuales con rangos --id
- 05:45 - Fusion de fichas individuales
- 07:35 - Consolidacion. Archivo JSON con todos los datos
- 08:30 - Auditoria y estado del sistema
| Categoría | Tecnologías |
|---|---|
| Lenguaje | Python 3.10+ |
| APIs | Google Books API, OpenLibrary API |
| Web Scraping | Selenium, BeautifulSoup |
| Procesamiento | JSON, CSV, manipulación de datos |
| Utilidades | Colorama, python-dotenv, argparse |
- 🔍 Consulta múltiple de fuentes (Ministerio de Cultura, Google Books, OpenLibrary).
- 🔄 Fusión inteligente de metadatos procedentes de distintas fuentes.
- 📊 Auditoría automática de fichas faltantes o incompletas.
- 💾 Consolidación en JSON para análisis o procesamiento posterior.
- 🧩 Arquitectura modular y extensible, permite añadir nuevas fuentes fácilmente.
- ⚡ Procesamiento por lotes, con control de rango y ejecución segmentada.
- Python 3.10+
- Clave API de Google Books (anadir en
.envcomoGOOGLE_BOOKS_API_KEY=<CLAVE>o introducir interactivamente al iniciar script) - Archivo
biblioteca.csvcon columnas:ID,TITULO,ISBN - Selenium instalado
pip install selenium- Geckodriver instalado y accesible en el PATH (para Firefox).
- Descarga desde: GitHub Releases
- Extrae el ejecutable y colocalo en una carpeta incluida en tu
PATH- Ejemplo:
C:\Program Files\Geckodriver\
- Ejemplo:
- Verifica con:
geckodriver --version- En ministerio.py (línea ~18) indica la ruta del ejecutable:
# Configuracion Selenium
options = Options()
options.headless = True
service = Service(executable_path=r"C:\Users\knock\Programas\geckodriver-v0.36.0-win64\geckodriver.exe")ISBN-Explorer/
├── isbn_explorer.py # Script maestro
├── ministerio.py # Fuente: Ministerio de Cultura
├── googlebooks.py # Fuente: Google Books
├── openlibrary.py # Fuente: OpenLibrary
├── fusiones_fichas.py # Fusión de fichas individuales
├── .env # Clave API de Google Books
├── biblioteca.csv # Archivo principal con ID, TITULO, ISBN
├── fuentes/ # Fichas individuales por fuente
│ ├── MC/
│ ├── googlebooks/
│ └── openlibrary/
├── fichas/ # Fichas fusionadas y consolidadas
│ ├── ficha_ID_ISBN.json
│ └── fichas.json
├── logs/ # Trazas de ejecución
│ └── log_YYYYMMDD_HHMMSS_modo.txt
└── screenshoots/ # Evidencias visuales para el README
El archivo biblioteca.csv debe contener las siguientes columnas:
| Columna | Descripción |
|---|---|
ID |
Número de registro |
TITULO |
Título del libro |
ISBN |
Código ISBN |
💡 Se recomienda mantener encabezados (columnas) en mayusculas y sin espacios extra.
El archivo biblioteca.csv se utiliza como fuente principal de registros. Puedes editarlo manualmente o regenerarlo desde otras fuentes; El script maestro lo carga automaticamente al iniciar cualquier flujo.
💡 El archivo está definido en la línea 21 dentro de
isbn_explorer.py.
CSV_DEFAULT = "biblioteca.csv"| Comando | Descripción |
|---|---|
--fuente |
Ejecuta una fuente específica (MC, googlebooks, openlibrary). |
--full |
Ejecuta el flujo completo sobre todo el CSV. |
--fusionar |
Fusiona fichas individuales en una ficha completa por libro. |
--consolidar |
Genera fichas.json con todas las fichas consolidadas. |
--estado |
Muestra el estado actual del sistema (fichas por fuente, fusionadas, pendientes, etc.). |
--auditar |
Detecta fichas faltantes por ID o ISBN. |
--reset |
Limpia el entorno: elimina fichas, logs e informes previos. |
| Comando | Resultado |
|---|---|
--id 15 |
Procesa únicamente la fila 15 del CSV. |
--id 15 20 |
Procesa del registro 15 al 20 (ambos incluidos). |
Sin --id |
Procesa todo el CSV completo. |
💡 Esta opción puede combinarse con
--fuenteo--fullpara limitar la ejecución a un subconjunto de registros.
python isbn_explorer.py --full
python isbn_explorer.py --fuente openlibrary --id 83 100
python isbn_explorer.py --fusionar
python isbn_explorer.py --consolidar
python isbn_explorer.py --estado
python isbn_explorer.py --auditar
python isbn_explorer.py --reset💬 Todos los comandos pueden combinarse según necesidad. Por ejemplo, para ejecutar una sola fuente sobre un rango específico:
python isbn_explorer.py --fuente MC --id 1 100Puedes consultar la ayuda del script en cualquier momento con:
python isbn_explorer.py --helpSalida:
usage: isbn_explorer.py [-h] [--csv CSV] [--full] [--fuente {MC,googlebooks,openlibrary}]
[--id ID [ID ...]] [--fusionar] [--consolidar]
[--estado] [--auditar] [--reset]
ISBN Explorer
options:
-h, --help Muestra este mensaje de ayuda y termina
--csv CSV Archivo CSV. Por defecto: biblioteca.csv
--full Ejecuta todo el flujo completo
--fuente {MC,googlebooks,openlibrary}
Ejecuta solo una fuente especifica
--id ID [ID ...] Procesa un rango de filas del CSV (ej. --id 200 600) o una sola (ej. --id 30)
--fusionar Fusiona fichas individuales por libro
--consolidar Genera archivo fichas.json con todas las fichas completas
--estado Muestra el estado actual del sistema
--auditar Verifica que fichas completas faltan segun el CSV
--reset Borra todas las fichas, logs e informes
El comando --full ejecuta todo el flujo de procesamiento sobre el archivo CSV principal (biblioteca.csv).
Consulta todas las fuentes disponibles, genera fichas individuales por libro, fusiona los resultados y produce el archivo consolidado fichas.json.
También admite el parámetro --id para limitar la ejecución a una o varias filas específicas del CSV.
Todas las filas del CSV:
python isbn_explorer.py --fullSolo fila con id 230:
python isbn_explorer.py --full --id 230Primeras 200 filas:
python isbn_explorer.py --full --id 1 200- Procesa todas las filas del archivo
biblioteca.csv. - Ejecuta las tres fuentes:
MC,googlebooksyopenlibrary. - Genera fichas individuales por fuente dentro de
fuentes/. - Guarda trazas en
logs/con nombre tipolog_YYYYMMDD_HHMMSS_full.txt.
fuentes/
├── MC/
│ ├── ficha_001_9781234567890.json
│ └── ...
├── googlebooks/
│ ├── ficha_001_9781234567890.json
│ └── ...
└── openlibrary/
├── ficha_001_9781234567890.json
└── ...
logs/
└── log_20251015_2124_full.txt
- Si alguna fuente falla o no responde, el evento se registra en el log correspondiente.
- El tiempo de Ejecución puede variar segun el tamano del CSV y la latencia de las APIs.
- La fusión y la consolidacion se ejecutan automáticamente: aunque también pueden lanzarse de forma independiente con
--fusionary--consolidar
| Paso | Accion |
|---|---|
| 1 | Carga el archivo biblioteca.csv |
| 2 | Ejecuta todas las fuentes (MC, googlebooks, openlibrary) |
| 3 | Genera fichas individuales por fuente en fuentes/ |
| 4 | Fusiona fichas por libro (fusiones_fichas.py) |
| 5 | Crea fichas completas en fichas/ |
| 6 | Consolida todas las fichas en un unico archivo fichas.json |
| 7 | Guarda trazas completas en logs/log_YYYYMMDD_HHMMSS_full.txt |
| 8 | Muestra resumen final en consola con colores y simbolos descriptivos |
El siguiente ejemplo muestra la ejecución completa del flujo (--full), que consulta las tres fuentes, genera fichas individuales, las fusiona y produce el consolidado fichas.json.
E:\ISBN_Explorer>python isbn_explorer.py --full
🔹 [MC] Bloque 1 (100 ISBNs)
🚀 Ejecutando fuente: MC
Consultando MC para ISBN 9788467903317
Consultando MC para ISBN 9788467904680
Consultando MC para ISBN 9788499470115
...
Consultando MC para ISBN 9788483577189
Consultando MC para ISBN 9788433920997
✅ Ministerio procesado. Revisa informe_MC.txt si hay ausencias.
🧹 Eliminados 1 archivos temporales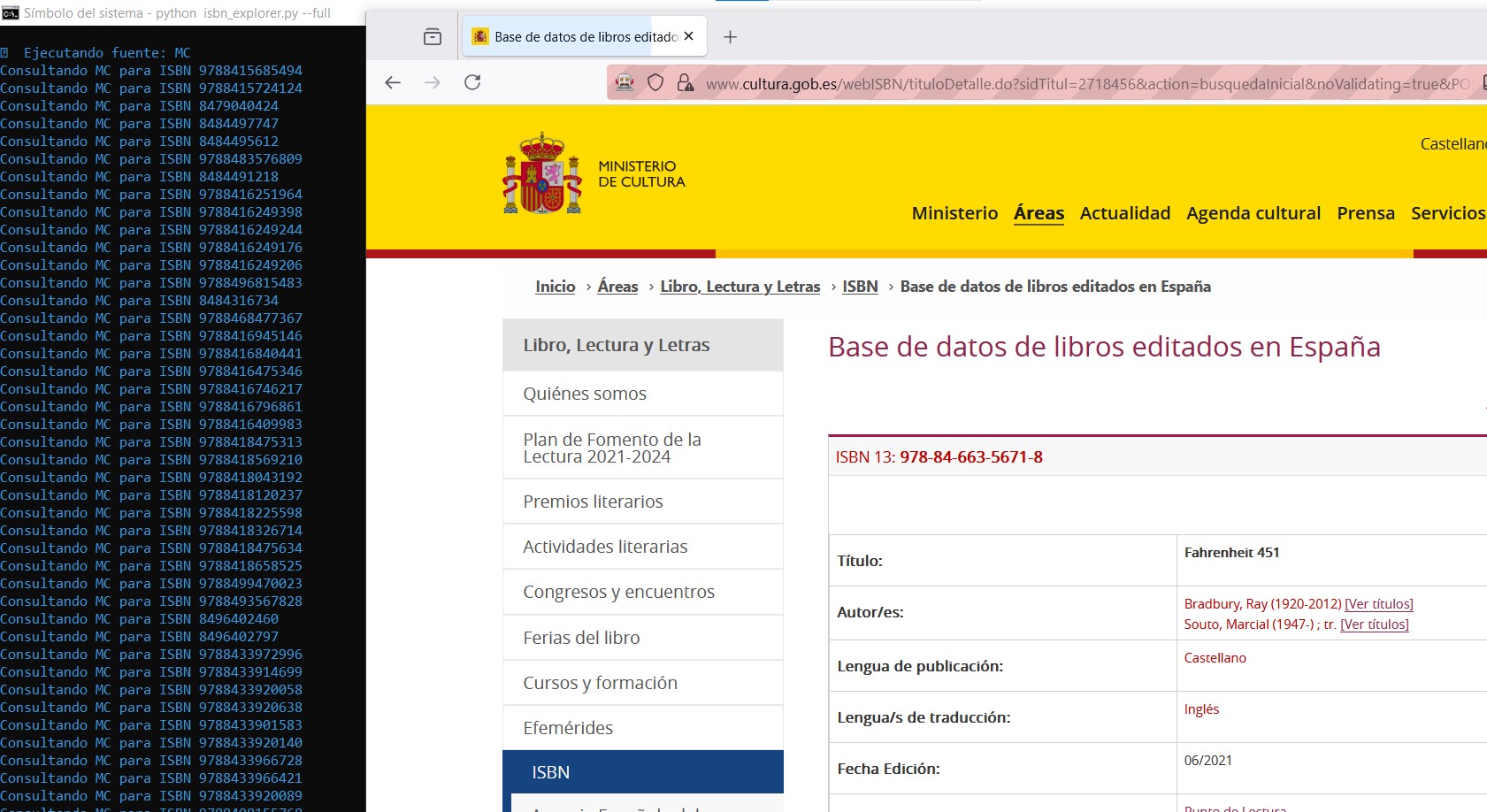
🔹 [googlebooks] Bloque 1 (100 ISBNs)
🚀 Ejecutando fuente: googlebooks
Consultando Google Books para ISBN 9788467903317
Consultando Google Books para ISBN 9788467904680
Consultando Google Books para ISBN 9788499470115
...
Consultando Google Books para ISBN 9788483577189
Consultando Google Books para ISBN 9788433920997
✅ Google Books procesado. Revisa informe_googlebooks.txt si hay ausencias.
🧹 Eliminados 1 archivos temporales
🚀 Ejecutando fuente: openlibrary
Consultando OpenLibrary para ISBN 9788467903317
Consultando OpenLibrary para ISBN 9788467904680
Consultando OpenLibrary para ISBN 9788499470115
...
Consultando OpenLibrary para ISBN 9788449344251
Consultando OpenLibrary para ISBN 9788433920997
✅ OpenLibrary procesado. Revisa informe_openlibrary.txt si hay ausencias.
🧹 Eliminados 1 archivos temporales
FUSIÓN
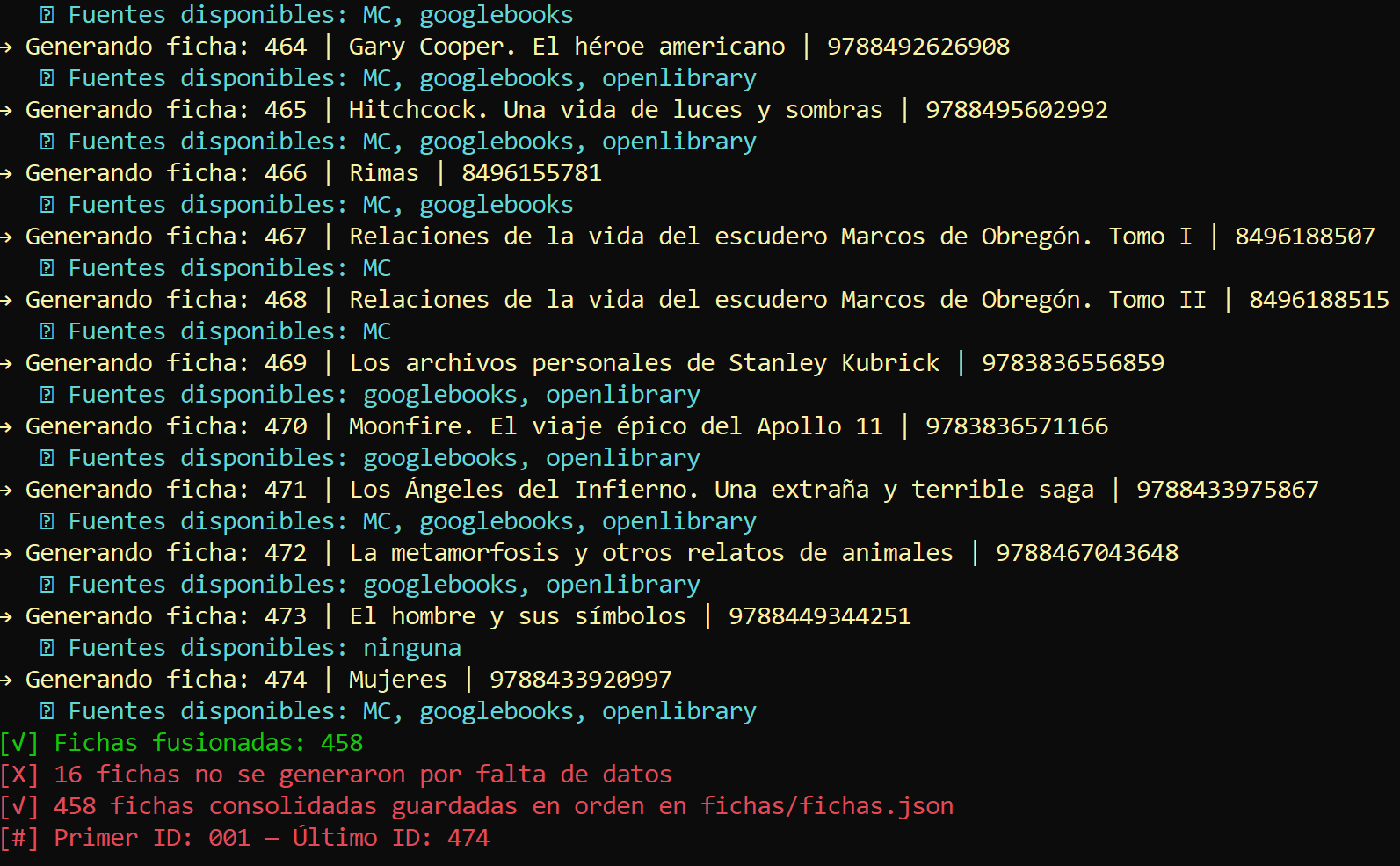
Este comando imprime un resumen del entorno actual, útil para verificar el progreso antes de ejecutar acciones como --fusionar, --consolidar o --validar.
E:\ISBN_Explorer>python isbn_explorer.py --estado
📊 Estado actual del sistema:
MC: 362 fichas individuales
googlebooks: 404 fichas individuales
openlibrary: 167 fichas individuales
🔄 Fichas fusionadas: 458
💾 fichas.json contiene 458 registros consolidados
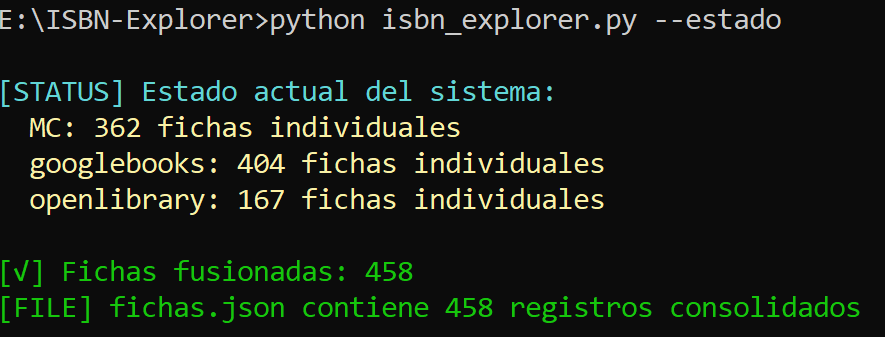
Combina las respuestas de MC, googlebooks y openlibrary en fichas consolidadas únicas por registro.
python isbn_explorer.py --fusionar
Permite revisar y validar las fichas generadas tras la fusión, aplicando correcciones o normalizaciones automáticas.
E:\ISBN_Explorer>python isbn_explorer.py --consolidar
✅ 10 fichas consolidadas guardadas en orden en fichas/fichas.json
📊 Primer ID: 300 — ultimo ID: 310
E:\ISBN_Explorer>python isbn_explorer.py --estado
📊 Estado actual del sistema:
MC: 9 fichas individuales
googlebooks: 10 fichas individuales
openlibrary: 8 fichas individuales
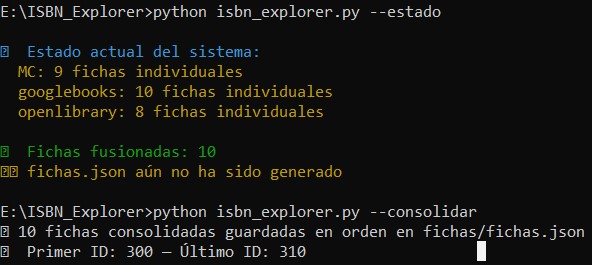
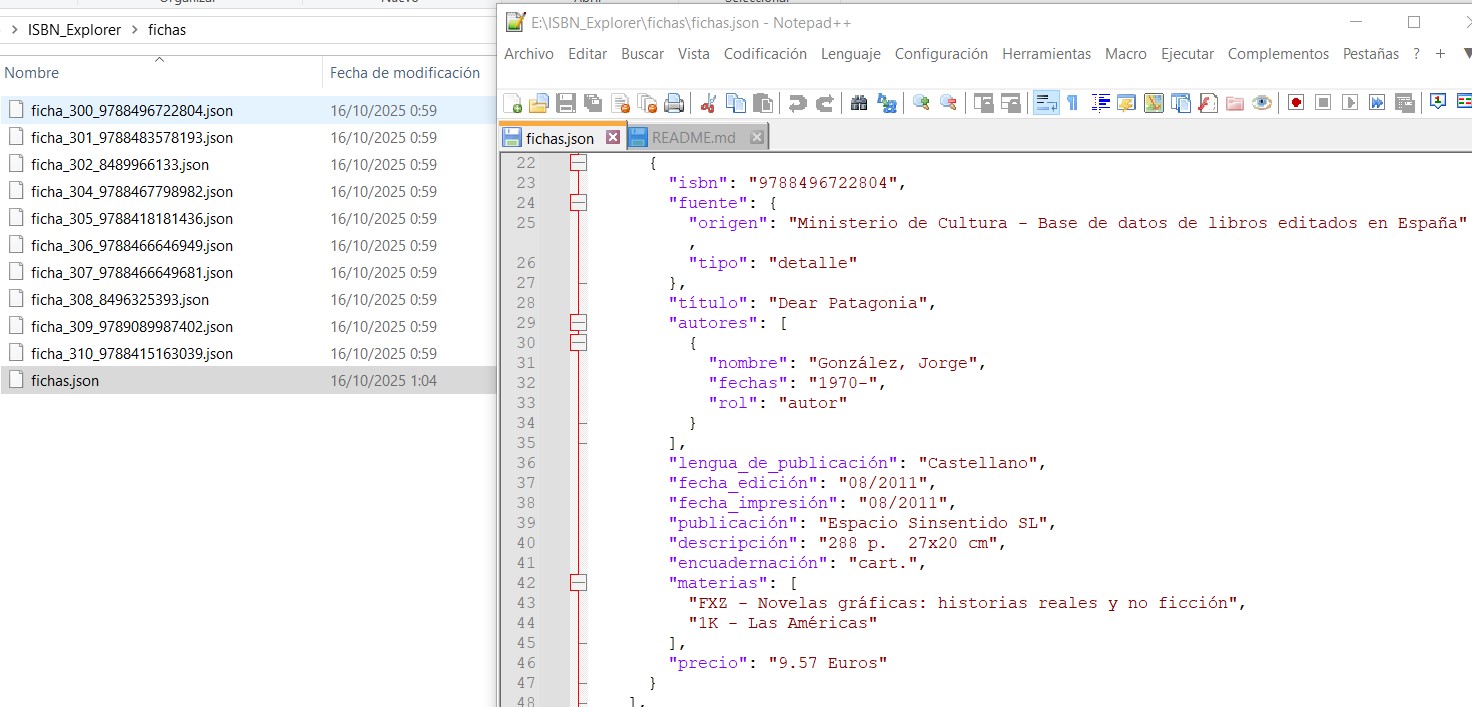
Elimina todos los archivos generados (fichas, fuentes, logs) y deja el entorno limpio para una nueva ejecución.
E:\ISBN_Explorer>python isbn_explorer.py --reset
🧹 Ejecutando limpieza total de archivos...
🗑️ Fichas eliminadas: 458
🗑️ Logs eliminados: 12
🗑️ Informes eliminados: 0
✅ Limpieza completa.
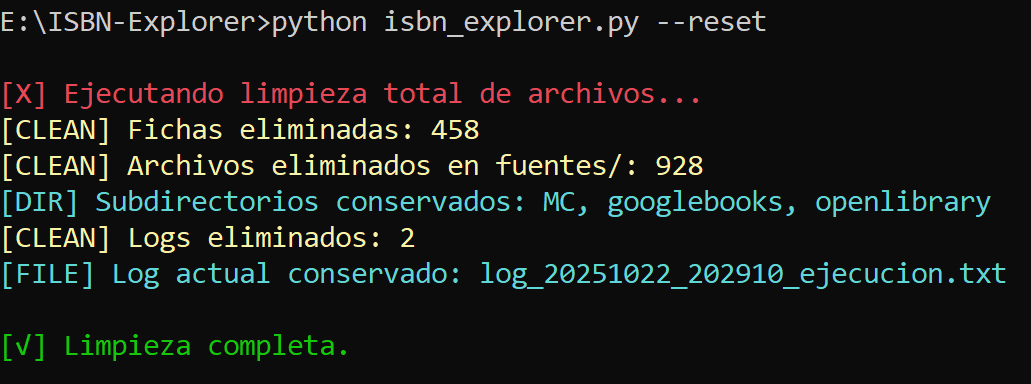
- Base de datos NoSQL para almacenamiento escalable
- Interfaz web con Flask/FastAPI
- Dashboard para visualización de resultados
- Nuevas fuentes (Amazon, GoodReads, etc.)
- Despliegue en cloud