In this webproject as a key goal of the SAE Bachelor program 6GST0XD10x I was building a frontend AND backend based modelcar search application with a react framework called next.js using postgres full-text search and semantic quaring with a vector database and last but not least an EXEL-product catalogue with several cars to feed our database with relevant informations to search for. You can also find access to the project on my developer page: www.svendolin-productions.ch
| TYPE | LINK |
|---|---|
| Check out the official video about this project on YOUTUBE: | WATCH NOW |
| Website where the project is going to be implemented in a later period: | www.toycarsaddict.club |
| Website where all my projects are staged: | www.svendolin-productions.club |
A) Why building an own search engine?
- I find the topic extremely interesting and profound. It is a very complex topic that involves many different aspects. Many background processes are not even noticed by users or are not made transparent by the operators of search engines such as Google. Through a project like this, I can get a better picture of how a search engine works, which processes are necessary and how I can build a search engine that is as user-friendly as possible.
- Fortunately, there are a number of research options on the subject, in addition to videos, such as a collection of digital content that I have compiled here: PERLEGO.COM (Btw you need a Perlego account to access the content)
B) What does the project have to do with model cars?
- I have been running a very successful business revolving around 1:64 scale model cars for several years. I have built up a very large community, run several social media channels, a webshop and my own website/blog namely www.toycarsaddict.club . The highlight is a subpage where the collection of me and a friend has been completely digitized. You can click on individual car brands or navigate using the A-Z buttons. You can check out this subpage HERE . This is where I wanted to start with my project.
C) Why not simply install a Wordpress plugin?
- Yes, there are some plugins that are ideal for Wordpress and Elementor (as my website was built with Wordpress). Examples are SearchWP, Relevanssi, Elasticsearch, Jetpack or Ajax Search Pro. However, in addition to many advantages, I also see many construction sites and disadvantages.
- The most obvious point is the fact that I want to find out for myself how a search engine works and how I can optimize it.
- Another point is that I don't just want to have a general search engine but rather a version which is totally focussed on the search for model cars.
- Certain plugins such as Relevanssi take up three times as much storage space when used. This is not ideal for a hoster with limited storage space.
- Only a few plugins are free. Although the basic functions are available, they quickly become expensive. Special features or updates are subject to a charge. So I decided to build my own full stack search engine on a separate subpage.
D) Why on a separate subpage and not directly on the main page of the car collection?
- First and foremost, I want to test and try out the functionality and possibilities of my own search engine. I want to see how I can optimize the search engine so that it is as user-friendly as possible and leads users quickly and easily to the model cars they are looking for. Experimenting also breaks a lot of things!
- It is therefore important to me that I can experiment on a subpage without having to worry about the main page being affected, as there are a lot of users on the main page every day and I have to ensure that everything runs smoothly.
E) What is clearly a MUST HAVE for my search engine?
- Basic Search - The search engine is designed to enable users to quickly and easily search for model cars that interest them: The most basic thing is to be able to enter a search term in a text field and then receive a list of around 3 model cars that contain this search term based on full text of the exact search term.
- Semantic Search – In case of wrong spelling, the search engine should still be able to display relevant results. The Semantic Search should work with a vector database to compare the similarity of the semantical meaning of the search term.
- Instant Search - Smooth loading of search results without reloading the page with caching and routing
F) What is clearly a NICE TO HAVE for my search engine?
- Reverse Image Search - The search engine should have a reverse image search function as a nice to have, so that users can upload a picture and the search engine will show them similar model cars.
- Filtered and faceted search – visitors can filter search results by tags, categories, custom taxonomies, post types, dates, and more.
- Highlighted search terms – The search will add highlights to search terms.
- Spelling correction – if visitors make a typo, the search engine can automatically detect/correct that and will still serve up relevant results.
- Live search instead of Instant search - The search results are displayed live as you type.
G) Why the separation of nice to have and must have?
- The scope of work must be clearly defined. I only have a limited amount of time for this project and have to concentrate on the essentials. You can spend hours and days on a single search feature. That's why I want to include the most important basic functions (MUST HAVE), but these should also work explicitly. The NICE TO HAVE functions are then the features that I can add bit by bit as time permits.
H) To what extent does the general public benefit from this?
- Over the years, the website has been continuously adapted and the scope of the virtual car collection expanded. User testing and feedback from users has shown that we would like to have a faster alternative to the search.
- This is because searching by clicking on the car brands and letters A-Z requires several steps before the desired car is displayed. A search function makes browsing easier, especially if you are looking for models without a specific goal and just want to browse
- The same applies to the reverse image search function. This function is particularly interesting for users who own a model car / a real vehicle but do not know which model it is. By uploading an image, the search engine can display similar models and thus facilitate the search.
- Creating a search engine in this format, especially for the model car sector, is unique and can help other fellow collectors to find information more quickly and easily.
- Such a search system can optimally serve as an important source of information as it covers many different car brands from numerous manufacturers.
- With an additional contact function, users can send me an e-mail and, for example, provide information on how much such a model costs and whether it is still available for purchase. This gives me the opportunity to draw attention to my model car store and the possibility of ordering model cars.
Loading States:
- Smooth loading states while we are waiting for the search results = With Next.js very enjoyable => In Miliseconds getting a list from backend
Implementig the Technique of semantic searching with vector based search results:
- Instant Matches from Database => Also from those which are similar in meaning but dont exactly match the search term
Full Text Search using a regular serverless relational database:
- Super powerful full text search capabilities of PostgreSQL needed for the best performance
- When it matches the search term directly, it will be displayed first on the top as the most relevant result
Advanced Next.js routing patterns:
- URL switches but the core layout stays the same (Car with all the informations and stuff)
- Keep logic in a way which does not require a reload of the page => Good for performance and later on for UX
Caching Search Results:
- Transition back to search page happens instantly => Caching all search results in the background for the best performance
Product Catalogue as a Seeding Script:
- Filled with an ImageID and descriptions out of an EXEL sheet into an Array of Objects (Seeding Script)
- Advantage: It can be easily updated and extended in the EXEL sheet and re-imported into the database again. Or you do it directly in the database with the Drizzle Kit Studio then.
Database:
- Product catalogue with content can be optimally managed using PostgreSQL (Data can be directly deleted there or adjusted without having to change the code or using SQL queries like push where from to thingy)
- Easy access to data, quick queries and simple administration in a safe environment
1) Homepage - Up first it's time to create a basic page without too many details and design elements with following tools:
1.1) React.js is the ideal choice for building a usable user interface as efficiently as possible using components. I had already used other Javascript libraries such as Angular and Vue.js in the past, but I had the most experience with React. Angular was covered in school lessons and used for our PARTUM MEDIA project. That's why I wanted to use something similar.
1.2) Next.js comes into play here as the React Framework, which is based on Node.js and is owned by Vercel. This is ideal if you also want to host or deploy the project on Vercel. There is also a lot on the net about this.
1.3) ShadCN is a UI library for Next.js that I use here to incorporate some standards into the design. For the Bachelor of Science, I can focus on the technical aspects and not waste too much time explaining the UI / UX design.
1.4) Tailwind is a utility-first CSS framework, which provides its users with utility classes and standardized procedures for how the design will behave. So I don't need to spend ages styling individual CSS elements. With the CSS Tailwind Intellisense Extension for Visual Studio Code, I can see and select the utility classes directly in the editor and still have my CSS. But still, Tailwind needs some time to learn and get used to it, so dont judge me too hard if the design is not perfect yet or is buggy here and there. All in all it still should be responsive and user-friendly.
1.5) Lucide.dev is an icon library with a variety of SVG icons that I use here to spice up the design. The elements from ShadCN and Lucide should also behave responsively on the mobile device.
2) Searchbar - Creating an intuitive searchbar which isnt that complicated:
- Intuitive searchbar with a search icon and a text field and accessible to use
- Functional, for example hitting the search will put the state in the URL and the search results will be displayed (also for sharing the URL or reloading), it should keep all the progress
- The entered text should not be lost despite pressing the Escape key
- It should be possible to start the search both by pressing the Enter key and by clicking on the search symbol
- Loading states: When we are in the process of searching and querying our database in the semantic search vector memory, I want to display a loading state. During the process, the user should know that the search is still running and that they can no longer type in anything.
3) Database - Initializing / connecting the application to serverless and vectorized databases:
-
3.1) PostgreSQL Full Text Search:
- Perfect way to implementing quering logic, we filter the products for the search query
- We query for Ferrari: In PostgreSQL we do a complete full-text search based on the title name and the description => Getting the most relevant results by literally matching the search query!
- If the title AND description contain the term Ferrari, we must display the most relevant product at the top
- If the search term corresponds 1:1 to a vehicle in the table (e.g. from the title), e.g. "Ferrari F40", then logically only the exact result is displayed
-
3.2) Semantic Quering:
- If the user makes a spelling mistake, e.g. "Ferari F40", the PostgreSQL full-text search would not display a relevant result => The vector database takes in text and converts this text into a vector with the help of OpenAI to compare the similarity of the semantical meaning
- Vectors, for example, are Javascript arrays, a static data structure: a numerical value is stored in each index, e.g. [0.3,0.8,0.95]
- We define a dimension, e.g. 1536 => So we have 1536 numbers in this array, as long as this is also stored in the array.
- We can solve this numerical representation of the meaning of the text with OpenAI
- Thus “Ferari F40” and “Ferrari F40” are semantically similar in meaning despite spelling mistakes
4) Product Catalogue - Creating a product catalogue with a list of model cars + Product Preview
4.1) Faker.js offers me the possibility to embed a certain amount of realistic but fake data into my table of 50 (alphabetical) units, with wrong prices, wrong content etc.. However, the contents are still read correctly and filled into the tables according to their DNA.
4.2) Drizzle.orm allows me to write SQL queries directly in my code, is highly secure and supports PostgreSQL. It is my bridge between the object-oriented search application and the relational database of Neontech PostgreSQL. With the Drizzle Kit Studio I can make adjustments directly.
4.3) Public Folder is the area where my model car pictures are stored. As I photograph a lot of models for a living, I will save them professionally in a suitable size ratio according to the programming and shoot the photos myself in a well-lit photo box.

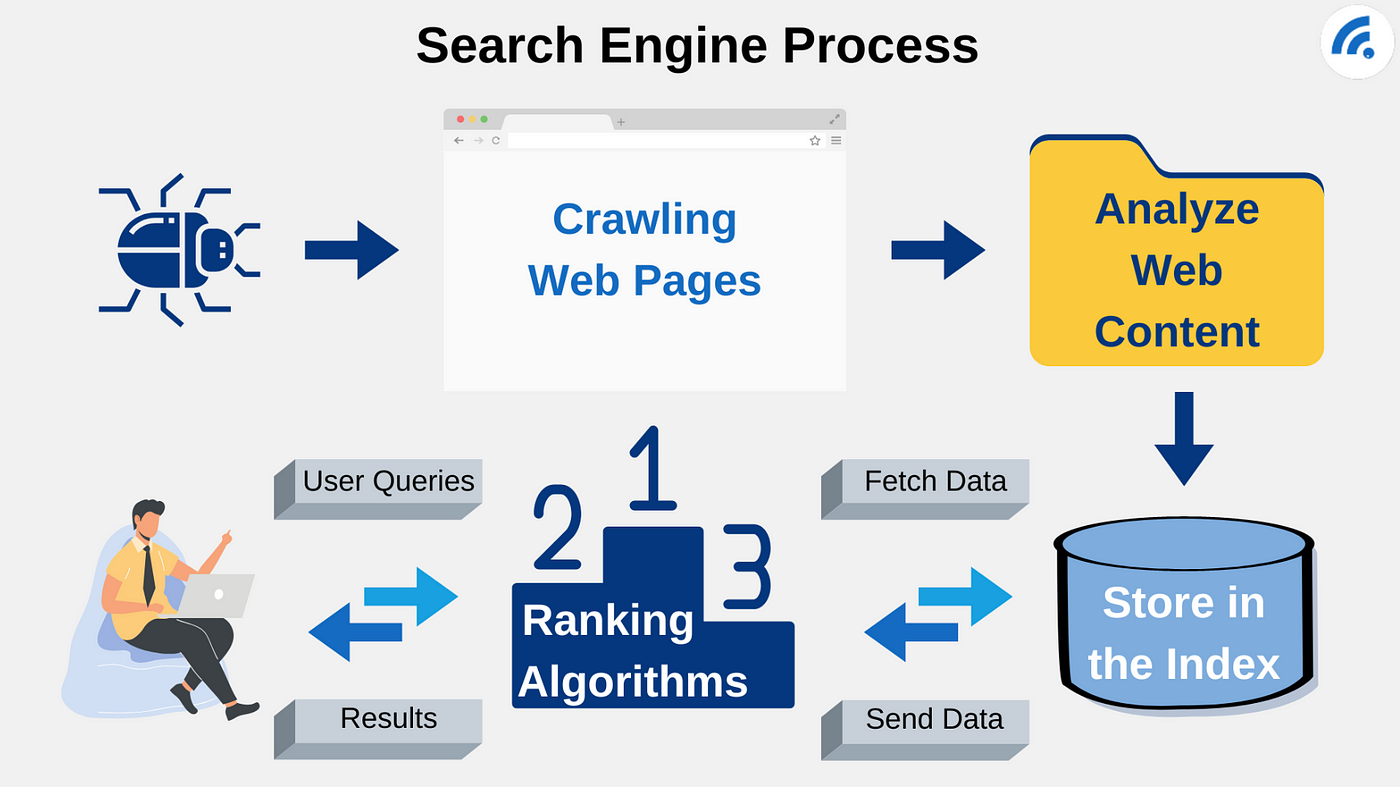
- A good search engine wants to crawl the web pages deeply (as well as high frequently) and analize it page by page
- It should index those pages and store them in a huge database
- It should differentiate between main index and supplemental index
- Main index: Here are the pages that are visited most frequently (e.g. homepage = daily crawl)
- Supplemental index: Here are the pages that are visited less frequently (e.g. imprint = monthly crawl)
- It should rank those pages according to the search query
- Google for example uses a PageRank algorithm to rank the pages:
- The PageRank algorithm is based on the number of links that point to a page
- The more links point to a page, the more important it is
- The more important a page is, the higher it is ranked
=> In the Search folder / page.tsx: The first step is the query within our page, this comes from the search parameters that we automatically get passed to the page from next.js. We can simply destructure the search parameters as the props that are passed to the page. The search parameters are objects, each of which has a dynamic key, which is a type of string. The value is a string or a string array or, of course, undefined if the search query is not passed at all (First step is getting the query inside our page, this comes from the search parameters that we get passed automatically be next.js into the page. We can simply destructure the search params as the props that are passed to the page. The search parameters are an Object, each of these has a dynamic key which is a type of string. The Value will be a string or a string array or naturally undefined if the search query is not passed at all)




-
NODE.JS:
- Node.js Info https://www.w3schools.com/nodejs/
- Node.js more Info:https://www.w3schools.com/nodejs/nodejs_intro.asp
- Node.js Website: https://nodejs.org/en
- My Github Repo about node and more: https://github.com/Svendolin/All-about-AJAX-and-Node.js
In a NUTSHELL: Node.js is an open-source, cross-platform, back-end JavaScript runtime environment that runs on the V8 engine and executes JavaScript code outside a web browser.
- Since I want to work with data in the frontend and backend, Node.js is the perfect solution. It allows me to execute JavaScript in the backend and thus process and store data.
- Backend servers use JAVA, PHP, Python, Ruby, C# or Node.js. Node.js is the good choice for me as I already know and use JavaScript. It is also a good choice for applications that have a lot of input and output as it is asynchronous.
- For asynchronous work, Node.js is perfect. It is non-blocking and can handle many requests at the same time. It is also very fast as it is based on the V8 engine from Google. Ajax is used here to transfer data asynchronously. In other words:
- Inserting and loading content from a database/server (e.g. localhost) without refreshing the website each time, or, for example, when clicking on a button, such as the search button, without reloading the page.
- A localhost means “local host” or “local server” and is used to establish an IP connection or a call to a local computer. This is executed here in this React environment on Localhost:3000.
-
NPM and JSON:
In a NUTSHELL: Node.js offers the Node Package Manager NPM, which allows me to install and manage packages. NPM is also a package manager for JavaScript that is installed with Node.js. It consists of a command line client and an online database of public and paid private packages, called the NPM registry. NPM is the world's largest software registry. It consists of more than 1,000,000 packages (as of 2021). These can also be a collection of CSS classes, a package called Matierial Design for example:
- All you need to know what NPM is https://www.w3schools.com/whatis/whatis_npm.asp
- All about the format of JSON https://www.w3schools.com/whatis/whatis_json.asp
2.1 Open VSC > Open in integrated Terminal to use CLI:
#[!] This would be the correct installation, BUT...: npx create-next-app@latest #...I had an issue with the latest version of Next.js 15 and shadcn-ui, look at the bottom of this readme! So at the moment you should use the latest 14 version instead by typing: ====>>> npx [email protected] # Creates an APP with next.js - Then hit YES at using TypeScript / ESLint / Tailwind CSS / etc npm --version # Check the npm version and update it if necessary with: npm install -g npm@latest
2.2 Time to run the DEV Server:
npm run dev // (CTRL + C to stop the server )
What's the difference of RUN DEV and RUN BUILD?

NPM RUN DEV:
- Starts Next.js in development mode.
- Uses hot reloading so that changes are immediately visible in the browser.
- Does not create optimised builds - faster, but less efficient.
- Used locally to work on the app.
NPM RUN BUILD:
- Creates an optimised, static build for production.
- Minifies the code, removes unused files & optimises images/CSS.
- Checks whether the code can be compiled without errors.
- Required before deployment to Vercel, Netlify or own servers
[!] Important note: Always check the path: Rightclick on your folder in VSC > Open with integrated Terminal > Run the server from this path (because in my example I initialized .git outside the folder first which was wrong actually. Be sure to initialize git IN the direct folder!)
-
NEXT.JS and SHADCN:
In a NUTSHELL: It is a React framework and is based on Node.js. Next.JS is owned by Vercel, they also host the projects. Twitch, Tiktok, Ferrari etc. are typical Next.JS users. Hosting via Vercel is as simple as logging in to Vercel and linking to Github so that the project can be uploaded.
-
Next.js Info: https://kinsta.com/de/wissensdatenbank/next-js
-
Next.js is the ideal choice for demonstrating an MVP (Minumum Viable Product) to people for testing purposes on December 28. In the end, it will be a more complex and sophisticated web application, called “Full Stack Search Application”.
-
In addition, Next.JS offers built-in CSS support, which makes my work easier. So I have (theoretically) already created a good basic frontend design in less time and don't waste time on styling or UI/UX design.
3.1 Make things look good with ShadCN (UI library for Next.js, a DEFAULT DESIGN for my project):
-
More infos: https://ui.shadcn.com/docs
-
UI Library for React and Next.js:
npx shadcn@latest init # Installs the latest ShadCN UI package - Then I hit "Default" / "Slate" / "yes" # It then creates a file called "components.json" where this configuration will be added
3.2 STYLING the Search Bar out of the box with full accessability via ShadCN:
-
More infos: https://ui.shadcn.com/docs
-
Part of the UI Library for React and Next.js:
npx shadcn@latest add input # Installs the fully accessibly input component # It then creates a file called "input.tsx" which we can use as a basis for our search bar # It is added at components/ui/input.tsx
-
-
TAILWIND:
In a NUTSHELL: Tailwind is a utility-first CSS framework that provides its users with utility classes. By using these classes, you can quickly and easily create your own unique designs. Tailwind contains the basics for designing websites, such as colors, sizes, margins, positioning, etc. Components must be created by users themselves, so do I. This distinguishes it from other CSS frameworks such as Bootstrap and Bulma, which offer ready-made UI components. Components can be styled inline in Tailwind, which is why it is no longer necessary to create a separate CSS file!- More about React and Tailwind on another repo from me: https://github.com/Svendolin/All-about-React
[+] There is a default configuration that can be easily overwritten with a tailwind.config.js file. = Perfectly customizable.
[+] The auxiliary classes provided by Tailwind save you having to name classes, which makes your work easier
[+] With the IntelliSense Tailwind CSS Extension for Visual Studio Code, users can see and select the utility classes directly in the editor, so I can see the original CSS class names when hovering.
[+] Tailwind CSS is an open source project and can be used free of charge.
-
LUCIDE.REACT:
In a NUTSHELL: Lucide.dev is an icon library with tons of SVG icons to style and implement with our react project- Simply install it with npm in your terminal:
npm install lucide-react
-
NEON.TECH PostgreSQL Database + Fulltext Search:
In a NUTSHELL: neon.tech is a modern serverless PostgresQL platform that enables databases to be created and managed quickly and easily. Databases and branches can be started at different cloud providers and regions. In line with the serverless approach, each branch stops automatically when the traffic stops. Neon is a serverless, scalable implementation of PostgreSQL that you can run on-premise or try through its managed service.Why not MYSQL or MongoDB as I usuallly did?
[+] Branching: Free experimentation without effects on the main branch main
[+] Immediate backup of the database. If data is accidentally lost, we can switch to the last good branch.
[+] Simplified integration tests. Developers can run tests in test-specific branches.
[+] Safe testing of automated database migrations in production.
[+] Isolated execution of analysis or machine learning processes.
[+] Connection capability with Drizzle-Kit-Studio to manage everything under the hood!
[!] None of this is possible with conventional database engines. At least not without further ado. Some database engines like SQL Server have snapshots that can actually create instant copies of a database. But snapshots are read-only, and that limits their usefulness. With most database engines, we have to resort to more complicated mechanisms such as backup and restore or replication.
-
More infos: https://neon.tech/home
-
Pricing will be set at Free Plan due to testing purposes which can be seen HERE
-
Neon automatically scales my project's compute resources up or down to meet demand. The recommended settings for my free plan are currently selected at 2vCPU and 8GB RAM max.
-
Don't forget to copy the unique database URL from the Neon.tech dashboard and paste it into the .env file (as a connection string) which wont be uploaded to Github for security reasons.
6.1 Install the NEON Serverless Driver:
- More infos: https://neon.tech/docs/serverless/serverless-driver- Connect to Neon from serverless environments over HTTP. The Neon serverless driver uses the neon function for queries over HTTP:
npm install @neondatabase/serverless # Installs the fully accessibly input component ```
-
-
DRIZZLE.ORM
In a NUTSHELL: Drizzle ORM is a TypeScript-based data framework. ORMs like Drizzle help to connect to a database server and execute queries and operations via object-based APIs. In a JavaScript/TypeScript ORM, each type of database entity is represented by a JS/TS prototype. Tables are created for each prototype, columns are represented by fields and attributes, while rows are created for each instance of the prototype.- Drizzle's official website and docs: https://orm.drizzle.team/docs/overview => "Drizzle is the only ORM with relational and SQL-like query APIs that gives you the best of both worlds when it comes to accessing your relational data. Drizzle is lightweight, performant, text-safe, lactose-free, gluten-free, sober, flexible and serverless-ready. Drizzle is not just a library, it's an experience."
# Install Note-Postgres Package npm install drizzle-orm # Install Note-Postgres Package kit, a studio for managing and interacting to the database npm install -D drizzle-kit # m audit fix is intended to automatically upgrade / fix vulnerabilities in npm packages because I had 1 vulnerability npm audit fix
Time to push our Schema (the datatable) to the database of PostgreSQL by Neon:
# Went through all this: https://orm.drizzle.team/docs/get-started/postgresql-new and directly applied changes to my database using: npx drizzle-kit push

-
FAKER @faker-js/faker
In a NUTSHELL: faker-js generates massive amounts of fake (but realistic) data for testing and development. More about that here: https://www.npmjs.com/package/@faker-js/faker- Simply install it with npm in your terminal:
npm install --save-dev @faker-js/faker
-
VECTOR / TSX:
In a NUTSHELL: A serverless vector database designed for working with vector embeddings. In the domain of databases, a vector database is essential for managing numeric representations of objects (images, sounds, text, etc.) in a multi-dimensional space. These databases are focused on efficiently handling vectors for storage, retrieval, and, most importantly, querying based on similarity.With other words: I will implement a semantic search querying to increase the search accuracy by querying semantically related results. More about that: https://upstash.com/docs/vector/overall/whatisvector
9.1 Installment of a vexctor database:
- Simply install it with npm in your terminal:
npm install @upstash/vector
9.2 TSX installation:
- TypeScript Execute (tsx): The easiest way to run TypeScript in Node.js
- More about that here: https://www.npmjs.com/package/tsx
- Getting started: https://tsx.is/getting-started
npm install -D tsx # And add to the JSON file: "tsx": "tsx", in the scripts section9.3 Continue with Drizzle (as we knew it from chapter 7.):
- Time to add some randomly seeded data to the database:
- More Infos: https://dev.to/anasrin/seeding-database-with-drizzle-orm-fga
npm run drizzle:seed # And add to the JSON file: "tsx": "tsx", in the scripts section- Time to launch Drizzle-Kit Studio, which is a new way for you to explore SQL database on Drizzle projects.
- More Infos: https://orm.drizzle.team/drizzle-studio/overview
npx drizzle-kit studio # And add to the JSON file: "tsx": "tsx", in the scripts section # After compiling, it's important to copy paste the URL in the browser https://local.drizzle.studio/
- => IMPORTANT: Now we can host the database content here https://local.drizzle.studio/ or directly in the Neon.tech PostgreSQL dashboard which is connected with each other: https://console.neon.tech/app/projects/dry-heart-80939055/branches/br-withered-fog-a240j34l/tables?database=searchapplication
9.4 Creating an account:
- We define a few things such as dimension count* (1536) and Similarity Function* (cosine) and then we can create a new database.
- The token we get can be connected and pasted into the .env file for security reasons.
- Now we should have a postgres database and a Upstash vector database running in parallel.
# https://console.upstash.com/vector/472ec71e-d8f0-4281-bc1c-9dae9212e1bd?teamid=0
-
OpenAI - OpenAI TypeScript and JavaScript API Library
In a NUTSHELL: The OpenAI API provides a simple interface to state-of-the-art AI models for natural language processing, image generation, semantic search, and speech recognition. We will need it for the semantic search querying with Upstash Vector to increase the search accuracy by querying semantically related results.But what is an API? => The API - also known as the programming interface - therefore enables applications to communicate with each other. The API is not the database or even the server, but the code that regulates the access points for the server and enables communication. This speeds up and simplifies data exchange between different systems many times over.
- Simply install it with npm in your terminal:
npm install openai
10.1 Getting used to the OpenAI developer Platform:
- We need our API key to connect to the OpenAI API. We can find it in the dashboard: https://platform.openai.com/docs/overview
- Searching for "API keys" and copy the secret key to the .env file
-
Vercel - Publishing projects with Vercel
In a NUTSHELL: Vercel is known for its outstanding deployment and hosting of web applications. With a strong focus on speed and ease of use, Vercel enables developers to publish and manage their projects effortlessly. As with the other applications, a GitHub account is required. More about that here: https://vercel.com/docs
NPM RUN BUILD ERROR => At the moment NPM RUN BUILD is not working due to a bug that we have raised in the issues section. Therefore the project cannot be uploaded to Vercel yet.
if ('generateMetadata' in entry) { Next.js build worker exited with code: 1 and signal: null
| must | Name | Creator | |
|---|---|---|---|
| ✔️ | Prettier - Code formatter | Prettier | link |
| ✔️ | Tailwind CSS intellisense - CSS tooling. Hover on Tailwind ClassNames to see the regular CSS names | Tailwind Labs | link |

| ELEMENT | Library / Component Links |
|---|---|
| ICONS | LUCIDE |
| SEARCH BAR INPUT | SHADCN |
| BUTTON | SHADCN |
Feel free to contact me if you've seen something wrong, found some errors or struggled on some mistakes! Always happy to have a clean sheet here! :)
6 issues have been detected, 6 answers have been given, 5 solutions have been made. Check out our ISSUES SECTION for more information: HERE
| Questions / Issues | Anwers | Solutions |
|---|---|---|
| 6 | 6 | 5 |