peftee (PEFT-ee) is a lightweight Python library for efficient LLM fine-tuning, built on top of Hugging Face Transformers and PyTorch. It enables fine-tuning models like Llama3-8B on 8 GB GPUs with minimal speed loss ⚡ (~9s per 200 samples at 2k context length) while saving ~14 GB (7.6 vs 21.8) of VRAM
💡 Intuition
Today, LLM fine-tuning is mostly about adapting style, structure, and behavior, rather than inserting new knowledge — for that, RAG is a better approach. Moreover, in most cases, there’s no need to fine-tune all transformer layers; updating only the last few (typically 4–8) with an adapter such as LoRA is sufficient. peftee is built precisely for this scenario.
⭐ How do we achieve this:
- Intelligently using Disk (SSD preferable) and CPU offloading with minimal overhead
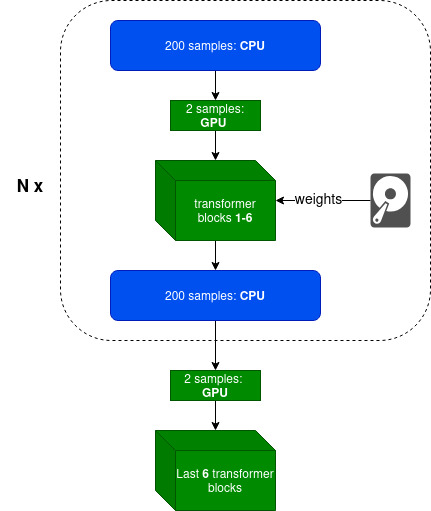
- Parameter efficient fine-tuning techniques like LoRA
- Gradient checkpointing
- Optimizer states offloading (experimental)
- FlashAttention-2 with online softmax. Full attention matrix is never materialized.
Supported model families:
- ✅ Llama3 (ex, meta-llama/Meta-Llama-3-8B)
- ✅ Gemma3 (ex, google/gemma-3-12b-it)
Supported GPUs: NVIDIA, AMD, and Apple Silicon (MacBook).
It is recommended to create venv or conda environment first
python3 -m venv peftee_env
source peftee_env/bin/activateInstall peftee with pip install peftee or from source:
git clone https://github.com/Mega4alik/peftee.git
cd peftee
pip install --no-build-isolation -e .# download the model first
huggingface-cli download "meta-llama/Llama-3.2-1B" --local-dir "./models/Llama-3.2-1B/" --local-dir-use-symlinks FalseTraining sample
import torch
from torch.utils.data import DataLoader
from datasets import load_dataset
from transformers import AutoTokenizer, TextStreamer
from peft import LoraConfig
from peftee import SFTTrainer, DefaultDataCollator
model_dir = "./models/Llama-3.2-1B/"
# initialize tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_dir)
tokenizer.pad_token = tokenizer.eos_token
# load dataset (sample)
def preprocess(ex):
return {
"prompt": f"Given schema {ex['schema']}, extract the fields from: {ex['text']}",
"completion": ex["item"]
}
dataset = load_dataset("paraloq/json_data_extraction")
dataset = dataset.map(preprocess, batched=False)
dataset = dataset.filter(lambda x: len(x["prompt"]) + len(x["completion"]) < 1500*5) #filter
dataset = dataset["train"].train_test_split(test_size=0.06, seed=42)
train_dataset, test_dataset = dataset["train"], dataset["test"]
print("Dataset train, test sizes:", len(train_dataset), len(test_dataset))
# Training
data_collator = DefaultDataCollator(tokenizer, is_eval=False, logging=True) #input: {prompt, completion}. output: {input_ids, attention_mask, labels}
peft_config = LoraConfig(
target_modules=["self_attn.q_proj", "self_attn.v_proj"], # it will automatically apply to last trainable layers
r=8, #8-32
lora_alpha=16, #r*2 normally
task_type="CAUSAL_LM"
)
trainer = SFTTrainer(
model_dir,
output_dir="./mymodel/",
device="cuda:0",
trainable_layers_num=4, #4-8, last layers
offload_cpu_layers_num=0, #99 for maximum offload to CPU
peft_config=peft_config,
epochs=3,
samples_per_step=100, #100-500, depending on available RAM
batch_size=2,
gradient_accumulation_batch_steps=2,
gradient_checkpointing=True,
learning_rate=2e-4,
eval_steps=4,
save_steps=4,
data_collator=data_collator,
train_dataset=train_dataset,
eval_dataset=test_dataset
)
trainer.train(resume_from_checkpoint=None) #checkpoint dirFor Evaluation/Inference, we will be using oLLM, LLM inference library
# Install ollm
pip install --no-build-isolation ollmfrom ollm import AutoInference
data_collator = DefaultDataCollator(tokenizer, is_eval=True, logging=False)
o = AutoInference(model_dir, adapter_dir="./mymodel/checkpoint-20/", device="cuda:0", logging=False)
text_streamer = TextStreamer(o.tokenizer, skip_prompt=True, skip_special_tokens=False)
test_ds = DataLoader(test_dataset, batch_size=1, shuffle=True)
for sample in test_ds:
x = data_collator(sample)
outputs = o.model.generate(input_ids=x["input_ids"].to(o.device), max_new_tokens=500, streamer=text_streamer).cpu()
answer = o.tokenizer.decode(outputs[0][x["input_ids"].shape[-1]:], skip_special_tokens=False)
print(answer)If there’s a model you’d like to see supported, feel free to suggest it in the discussion — I’ll do my best to make it happen.