{kind=link}
{kind=link}
{kind=link}
Tentar prever admissão na UTI de casos confirmados de COVID-19,
com base nos dados disponíveis. É viável prever quais pacientes precisarão de suporte em unidade de terapia intensiva?
O objetivo é fornecer aos hospitais terciários e trimestrais a resposta mais precisa, para que os recursos da UTI possam ser arranjados ou a transferência do paciente seja agendada.
Utilizando a base de dados de COVID-19 disponibilizada no Kaggle pelo hospital Sírio-Libanês.
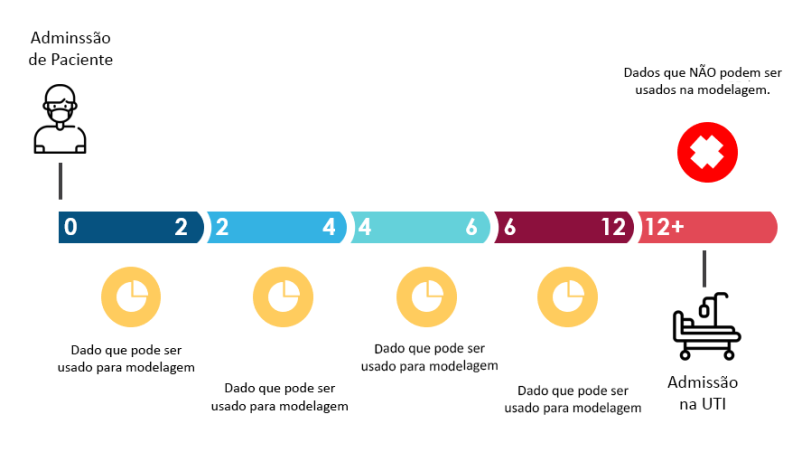
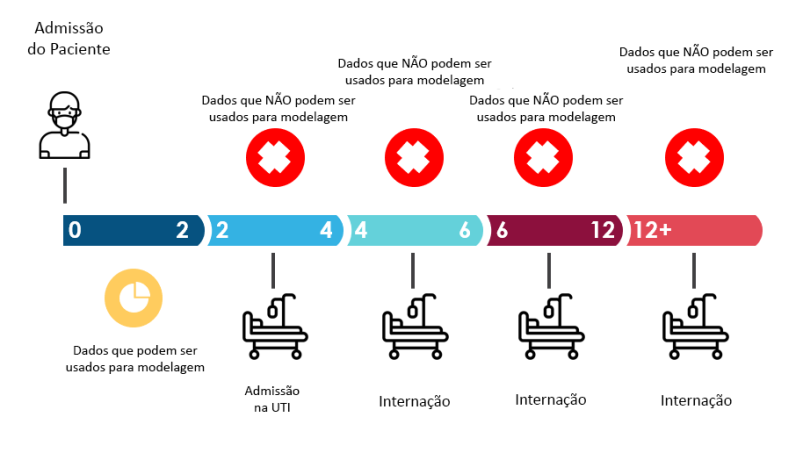
Os dados estão estruturados estão usando o conceito de janela de eventos agrupados da seguinte forma, cada linha representa os dados de um paciente em uma determinada janela de tempo desde a admisão.
| Janela | Descrição |
|---|---|
| 0-2 | De 0 a 2 horas desde a admissão. |
| 2-4 | De 2 a 4 horas desde a admissão. |
| 4-6 | De 4 a 6 horas desde a admissão. |
| 6-12 | De 6 a 12 horas desde a admissão. |
| Above-12 | De 12 horas após a admissão. |
Exemplos:
Os dados foram tratados da seguinte forma:
-
Foram criadas 2 novas features para serem incluídas no Machine Learning:
-
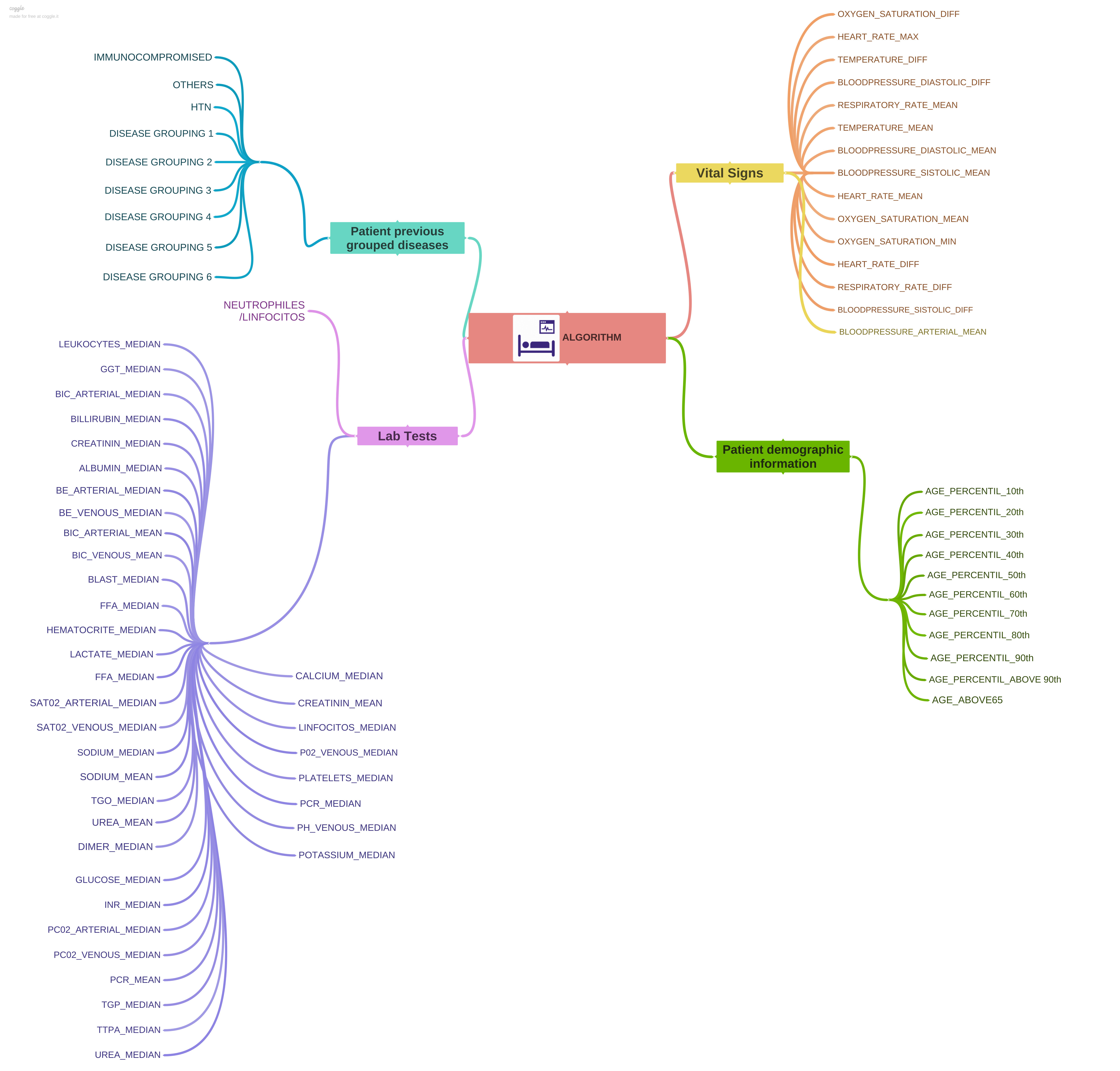
BLOODPRESSURE_ARTERIAL_MEAN = (BLOODPRESSURE_SISTOLIC_MEAN + 2* BLOODPRESSURE_DIASTOLIC_MEAN)/3
-
NEUTROPHILES/LINFOCITOS = NEUTROPHILES_MEAN/LINFOCITOS_MEAN
Estas Features foram criadas com base nos artigos abaixo:
BLOODPRESSURE ARTERIAL MEAN, Nature, Ago/2020
NEUTROPHILES/LINFOCITOS, Revista Brasileira de Análises Clínicas, Ago/2020 -
-
Se o paciente foi para a UTI em qualquer janela de tempo o valor da coluna ICU da primeira janela (0-2) desse paciente foi alterada para 1, pois queremos saber se o paciente ira precisar de UTI o logo na primeira janela de tempo.
-
Foi aplicada a tecnica one-hot-encoding na coluna AGE_PERCENTIL para tornar o processo de Machine Learning mais preciso.
-
Features com correlações maiores que 0,95 foram removidas.
-
Pacientes que tem a coluna ICU igual 1 na primeira janela (0-2) foram descartados.
-
Pacientes que não possuem nenhuma feature preechida foram descartados.
-
Para pacientes que possuem valores de algumas features como NaN, na janela 0-2, mas possuem valores nas janelas subsequentes, estes foram preenchidos com usando a tecnica back-fill e foward-fill.
Dados disponíveis:
Foi escolhido o modelo RandomForestClassifier.
No qual obtivemos uma precisão media final de 73.17%, curva ROC, AUC de 77% e recall de 65.7%.