Tao Sun *,1, Liyuan Zhu *,1, Shengyu Huang2, Shuran Song1, Iro Armeni1
1Stanford University, 2NVIDIA Research | * denotes equal contribution
TL;DR: Assemble unposed parts into complete objects by learning a point-wise flow model.
- [July 9, 2025] Released training codes.
- [July 1, 2025] Released model checkpoints and inference codes.
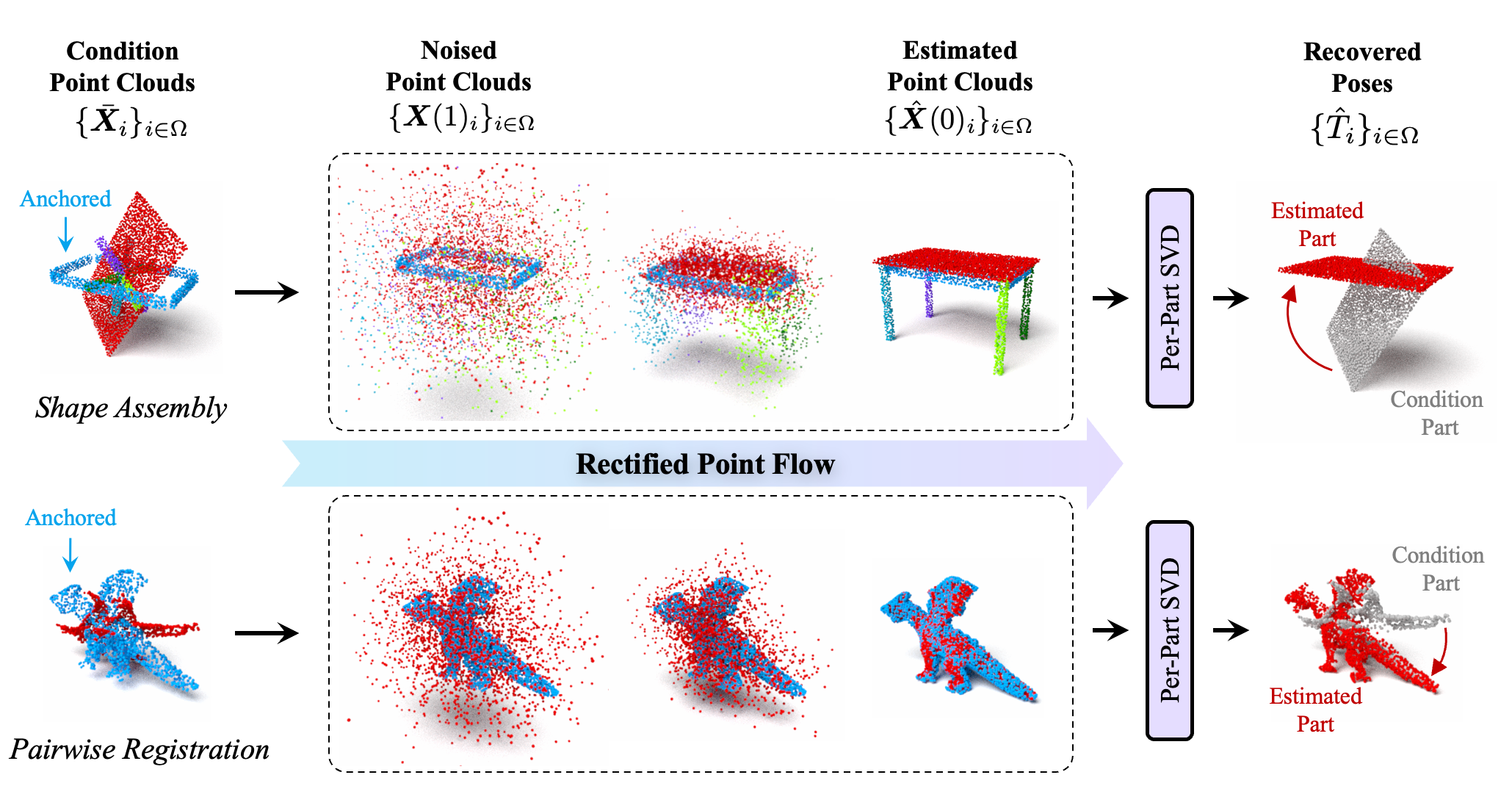
We introduce Rectified Point Flow (RPF), a unified parameterization that formulates pairwise point cloud registration and multi-part shape assembly as a single conditional generative problem. Given unposed point clouds, our method learns a continuous point-wise velocity field that transports noisy points toward their target positions, from which part poses are recovered. In contrast to prior work that regresses part-wise poses with ad-hoc symmetry handling, our method intrinsically learns assembly symmetries without symmetry labels.
First, please clone the repo:
git clone https://github.com/GradientSpaces/Rectified-Point-Flow.git
cd Rectified-Point-FlowWe use a Python 3.10 environment for compatibility with the dependencies:
conda create -n py310-rpf python=3.10 -y
conda activate py310-rpfThen, use poetry or uv to install the dependencies:
poetry install # or `uv sync`Alternatively, we provide an install.sh script to bootstrap the environment via pip only:
bash install.shThis evironment includes PyTorch 2.5.1, PyTorch3D 0.7.8, and flash-attn 2.7.4. We've tested it on NVIDIA RTX4090/A100/H100 GPUs with CUDA 12.4.

Assembly Generation: To sample the trained RPF model on demo data, please run:
python sample.py data_root=./demo/dataThis saves images of the input (unposed) parts and multiple generations for possible assemblies.
-
Trajectory: To save the flow trajectory as a GIF animation, use
visualizer.save_trajectory=true. -
Renderer: We use Mitsuba for high quality ray-traced rendering, as shown above. For a faster rendering, please switch to PyTorch3D PointsRasterizer by adding
visualizer.renderer=pytorch3d. To disable rendering, usevisualizer.renderer=none. More rendering options are available in config/visualizer. -
Sampler: We support Euler, RK2 (default), and RK4 samplers for inference, set
model.inference_sampler={euler, rk2, rk4}accordingly.
Overlap Prediction: To visualize the overlap probabilities predicted by the encoder, please run:
python predict_overlap.py data_root=./demo/dataCheckpoints: The scripts will automatically download trained checkpoints from our HuggingFace repo:
RPF_base_full_*.ckpt: Full model checkpoint for assembly generation.RPF_base_pretrain_*.ckpt: Only the encoder checkpoint for overlap prediction.
To use custom checkpoints, please set ckpt_path in the config file or pass the argument ckpt_path=... to the command.
The RPF training process consists of two stages:
- Encoder Pretraining: Train the point cloud encoder on the overlap point detection task.
- Flow Model Training: Train the full flow model with the pretrained encoder frozen.
First, pretrain the point cloud encoder (Point Transformer) on the overlap point detection task:
python train.py --config-name "RPF_base_pretrain" \
trainer.num_nodes=1 \
trainer.devices=2 \
data_root="../dataset" \
data.batch_size=200 \
data.num_workers=32 \
data.limit_val_samples=1000 \data.batch_size: Batch size per GPU. Defaults to 200 for 80GB GPU.data.num_workers: Number of data workers per GPU. Defaults to 32.data.limit_val_samples: Limit validation samples per dataset for faster evaluation. Defaults to 1000.
Train the full RPF model with the pretrained encoder:
python train.py --config-name "RPF_base_main" \
trainer.num_nodes=1 \
trainer.devices=8 \
data_root="../dataset" \
data.batch_size=40 \
data.num_workers=16 \
model.encoder_ckpt="./weights/RPF_base_pretrain.ckpt"model.encoder_ckpt: Path to pretrained encoder checkpoint.data.batch_size: Batch size per GPU. Defaults to 40 for 80GB GPU.
Note: RPF's main training and inference logics are in rectified_point_flow/modeling.py.
The model is trained on a combination of following datasets. Please be aware that datasets have different licenses. We will release the processed data files soon.
Click to expand the list of training datasets.
| Dataset | Task | Part segmentation | #Parts | License |
|---|---|---|---|---|
| IKEA-Manual | Shape assembly | Defined by IKEA manuals | [2, 19] | CC BY 4.0 |
| PartNet | Shape assembly | Annotated by human | [2, 64] | MIT License |
| BreakingBad-Everyday | Shape assembly | Simulated fractures via fracture-modes | [2, 49] | MIT License |
| Two-by-Two | Shape assembly | Annotated by human | 2 | MIT License |
| ModelNet-40 | Pairwise registration | Following Predator split | 2 | Custom |
| TUD-L | Pairwise registration | Real scans with partial observations | 2 | CC BY-SA 4.0 |
| Objverse | Overlap prediction | Segmented by PartField | [3, 12] | ODC-BY 1.0 |
RPF supports two data formats: PLY files and HDF5, but we strongly recommend using HDF5 for faster I/O. We provide scripts to help convert between these two formats. See dataset_process/ for more details.
Click to expand more usage examples.
Override any configuration parameter from the command line:
# Adjust learning rate and batch size
python train.py --config-name "RPF_base_main" \
model.optimizer.lr=1e-4 \
data.batch_size=32 \
trainer.max_epochs=2000 \
trainer.accumulate_grad_batches=2 \
# Use different dataset combination
python train.py --config-name "RPF_base_main" \
data=ikea \
data.dataset_paths.ikea="../dataset/ikea.hdf5"Finetuning the flow model from a checkpoint:
python train.py --config-name "RPF_base_main" \
model.flow_model_ckpt="./weights/RPF_base.ckpt"Resume interrupted training from a Lightning checkpoint:
python train.py --config-name "RPF_base_main" \
ckpt_path="./output/RPF_base_joint/last.ckpt"Our code supports distributed training across multiple GPUs:
# Default: DDP with automatic multi-GPU detection, which uses all available GPUs.
python train.py --config-name "RPF_base_main" \
trainer.devices="auto" \
trainer.strategy="ddp"
# You can specify number of GPUs and nodes.
python train.py --config-name "RPF_base_main" \
trainer.num_nodes=2 \
trainer.devices=8 \
trainer.strategy="ddp"RPF uses Hydra for configuration management.
The configuration is organized into following groups. Click to expand.
RPF_base_pretrain.yaml: Root config for encoder pretraining.RPF_base_main.yaml: Root config for flow model training.
Relevant parameters:
data_root: Path to the directory containing HDF5 files.experiment_name: The name used for WandB run.log_dir: Directory for checkpoints and logs (default:./output/${experiment_name}).seed: Random seed for reproducibility (default: 42).
rectified_point_flow.yaml: Main RPF model configurationoptimizer: AdamW optimizer settings (lr: 1e-4, weight_decay: 1e-6)lr_scheduler: MultiStepLR with milestones at [1000, 1300, 1600, 1900]timestep_sampling: Timestep sampling strategy ("u_shaped")inference_sampling_steps: Number of inference steps (default: 20)
encoder/ptv3_object.yaml: Point Transformer V3 encoder configurationflow_model/point_cloud_dit.yaml: Diffusion Transformer (DiT) configuration
ikea.yaml: Single dataset configuration exampleikea_partnet_everyday_twobytwo_modelnet_tudl.yaml: Multi-dataset config for flow model training.ikea_partnet_everyday_twobytwo_modelnet_tudl_objverse.yaml: Multi-dataset config for encoder pretraining.
Relevant parameters:
num_points_to_sample: Points to sample per part (default: 5000)min_parts/max_parts: Range of parts per scene (2-64)min_points_per_part: Minimum points required per part (default: 20)multi_anchor: Enable multi-anchor training (default: true)
Define parameters for Lightning's Trainer. You can add/adjust all the settings supported by Trainer.
main.yaml: Flow model training settings.pretrain.yaml: Pretraining settings.
wandb.yaml: Weights & Biases logging configuration
Slow I/O: We find that the flow model training can be bound by the I/O. This typically leads to a low GPU utilization (e.g., < 80%). We've optimized the setting based on our systems (one node of 8xH100 with 112 CPU cores) and you may need to adjust your own settings. Here are some suggestions:
- More threads per worker: Increase
num_threads=2in rectified_point_flow/data/dataset.py. - More workers per GPU: Increase
data.num_workers=32based on your CPU cores. - Use point-cloud-utils for faster point sampling: Enable with
USE_PCU=1 python train.py .... - Use HDF5 format and store the files on faster storage (e.g., SSD or NVMe).
Loss overflow: We do find numerical instabilities during training, especially loss overflowing to NaN. If you encounter this when training, you may try to use bf16 precision by adding trainer.precision=bf16.
- Release model & demo code
- Release full training code & checkpoints
- Release processed dataset files
- Support running without flash-attn
- Online demo
If you find the code or data useful for your research, please cite our paper:
@inproceedings{sun2025_rpf,
author = {Sun, Tao and Zhu, Liyuan and Huang, Shengyu and Song, Shuran and Armeni, Iro},
title = {Rectified Point Flow: Generic Point Cloud Pose Estimation},
booktitle = {arxiv preprint arXiv:2506.05282},
year = {2025},
}Some codes in this repo are borrowed from open-source projects, including DiT, PointTransformer, and GARF. We appreciate their valuable contributions!
This project is licensed under the Apache License 2.0 - see the LICENSE file for details.