本项目的数据来源于10名不同的测试者,他们穿戴IMU设备进行数据收集。共收集了21个IMU节点的数据,对于每一个IMU节点,我们获取一个长度为12的特征向量:包含3x3的位置旋转矩阵和长度为3的加速度向量,。将以上矩阵和向量展平后拼接起来,再将所有节点的特征向量进行拼接,最终拼接测试者的12个身体特征信息(例如躯干长度、臂围、胸围等),最后加上标签,标签是当前正在进行的动作。数据共265维,示例如下:
| head_position_11 | head_position_12 | ... | body_length | ... | label |
|---|---|---|---|---|---|
| -0.27487681 | -0.12415444 | ... | 47 | ... | "引体向上-举手" |
其中每一行为一个时间步,每一列为一个特征。
我们在测量过程中,将测量为None的时间步直接删除。关于为什么会出现测量值为None,我们目前尚不确定是仪器问题还是代码问题。收集数据时,应该尽量保持数据完整性,我们之前的操作失误,之后收集应该尝试先保存这些None值。后续再考虑下采样。
另外,目前我们也不确定数据的时间分辨率,视频流的基准是$25FPS$,最好情况达到$60FPS$。在下次测量应明确分辨率,依次尝试$60FPS,45FPS,30FPS,25FPS,15FPS$。
需要删除一些冗余列(以下为在Excel中显示的列标):GW -- PP;IS -- RL这些冗余列对应的是手指的节点位置.
重新测量后的数据要考虑插值技术,以避免缺失值问题。
- 前向填充法
- 移动平均法
- 插值法(线性插值法、样条插值法)
另外也要考虑平滑技术,以减缓仪器误差、异常值等问题。
- 指数平滑法(霍尔特方法、霍尔特-温特斯平滑法)
- 卡尔曼滤波法
- LOESS(局部散点平滑估计)
针对数据集扩充问题,我们现在已经有了一些样例数据,大约有50000个时间步(500个单独的动作序列),可以先使用这些样本来进行简单的试验。
后续根据需求考虑添加样例,横向扩充与纵向扩充:
-
横向扩充: 添加更多的样本类别,不局限于引体向上动作.





Touch head Sitting down Take off a shoe Eat meal/snack Kick other person 




Hammer throw Clean and jerk Pull ups Tai chi Juggling ball -
纵向扩充: 添加更多的样本数量,拟扩充到万级样本量(500个样本采集所需时间约1小时).
-
数据增强:使用数据增强技术(如噪声加入、时间偏移)扩充数据集,观察其对模型性能的影响。










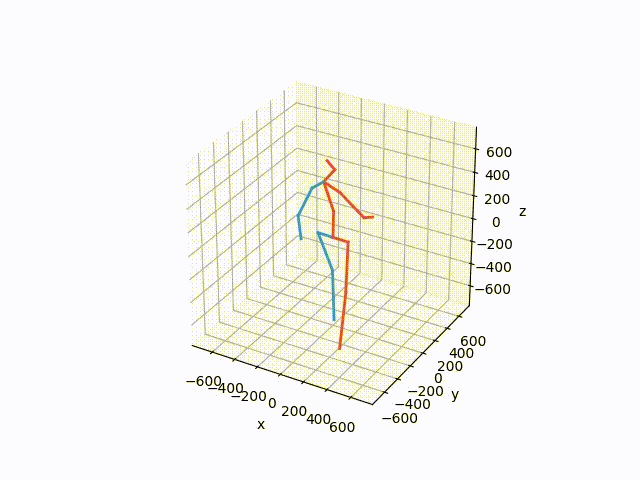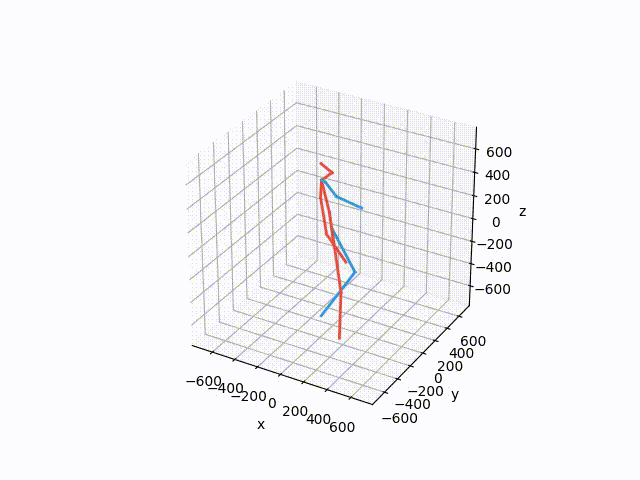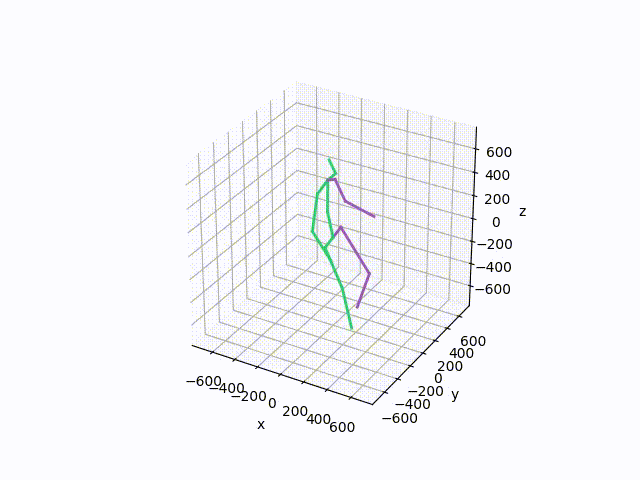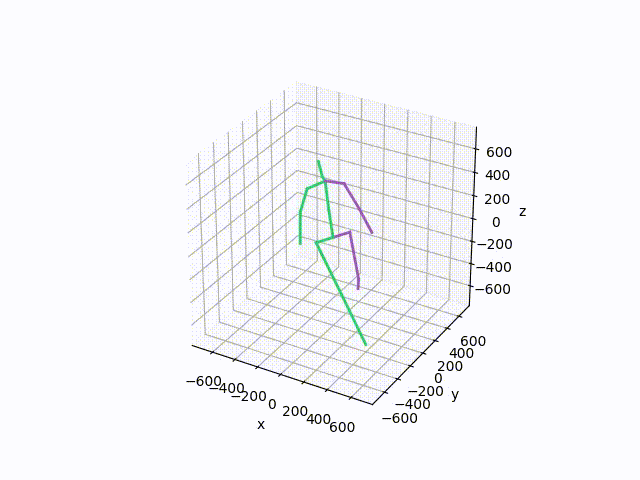
基于已收集到的数据集,应该尝试进行3D可视化,以更好地展示数据真实性。
- 3D Pose Estimation(Human Activity Recognition):给出一段时间序列,识别出当前时间序列对应的动作。
- Pose Tracking:给定一段时间序列,预测下一个时间窗口中的动作。
- 特征选择任务(特征缺失任务): 在上述任务基础上,尝试抛弃一些IMU节点特征,在缺失特征的情况下进行实验.

对于分类任务,每一个样本为一个动作对应的一段连续时间内的特征向量。构建出一个元组(Matrix, Label)。
- 基于统计学习方法
- 卡尔曼滤波法:数据来源为IMU,测量的是位姿矩阵和加速度,本身是一种真实世界的与物理、动力相关的数据集(可用机器人学方法来求解轨迹等),所以可以尝试使用卡尔曼滤波法。滤波:根据当前$t$的数据来判断$t$的标签。
- 隐马尔可夫模型:序列问题常用的解决方案,我们已知观测值(序列特征),可以训练出MMG模型(初始状态向量、状态转移矩阵、发射矩阵);之后利用训练完毕的MMG来进行预测。预测:根据$t-1$的数据来生成$t$的数据。
- 基于机器学习方法
- 梯度提升树XGBoost:比较先进和流行的预测器,擅长于时间序列处理。
- LightGBM:另一种流行的工具包。
- 基于深度学习方法
- Transformer
- RNNs(LSTM、GRU)
- STGNN
我们期望使用这些数据完成一个序列到序列任务,具体来说:
- 根据一段时间步的特征向量来预测当前时间步的标签。
- 生成下一段时间步的特征向量和标签。
考虑采用深度学习模型,如LSTM或Transformer,STGNN,进行特征提取和动作预测。具体模型设计可以根据任务的复杂性和数据量来调整。
预处理需要考虑 相对位置编码,节点信息嵌入 等技术.
针对不同的任务应该设置不同的评价指标,例如:
- 分类任务:准确率(Accuracy)
- 生成任务:均方误差(MSE)
-
ST-GCN (Spatial Temporal Graph Convolutional Networks)
- 论文:Spatio-Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition AAAI 2018 (CCF A)
- 方法论:ST-GCN将人体姿态表示为图结构,通过图卷积网络(GCN)来学习时空特征,实现动作识别。
- 评价指标:Accuracy
- 启发式设计:可以基于ST-GCN的思想构建ST-GNN模型,将节点表示为人体关节点,边表示关节点之间的空间关系,通过GCN层和时间维度上的卷积层来学习时空特征。ST-GNN能够有效地捕获人体结构的拓扑关系,并结合时序信息进行建模,从而实现对运动行为的建模和预测。
-
TGNN (Temporal Graph Neural Networks)
- 论文:Temporal Graph Networks for Deep Learning on Dynamic Graphs KDD 2020 (CCF A)
- 方法论:TGNN专注于处理动态图数据,可以有效地处理时序关系,并结合图神经网络来进行建模。
- 评价指标:RSE、CORR(回归任务)
- 启发式设计:借鉴TGNN的思想,设计一个能够动态更新图结构的ST-GNN模型,以适应不同时间步的拓扑关系变化。
-
Hybrid Deep Learning
- 论文:A new hybrid deep learning model for human action recognition Journal of King Saud University - Computer and Information Sciences(SCI Q1,IF 6.9)
- 方法论:使用一种基于GRU(门控循环神经网络)的混合深度学习方法来进行人体动作识别,完成了分类任务。
- 评价指标:Accuracy
-
综述
- 论文: Recent developments in human motion analysis Pattern recognition (SCI Q1, IF 8.0)
-
Human Motion Prediction
- 论文:On Human Motion Prediction Using Recurrent Neural Networks CVPR 2017 (CCF A)
- 方法论:该论文提出了均方误差(MSE)和平均绝对误差(MAE)作为动作预测任务的评价指标,能够有效地评估预测结果与真实值之间的差异。