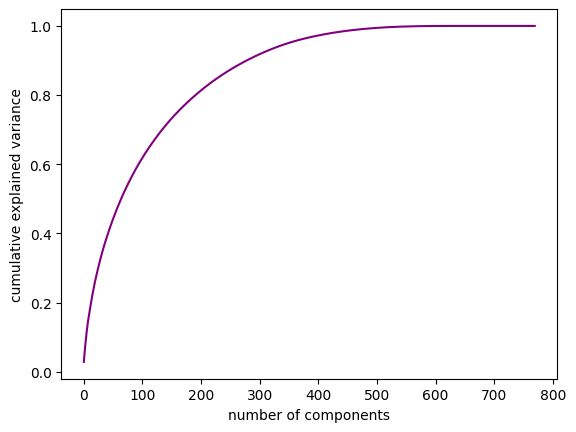
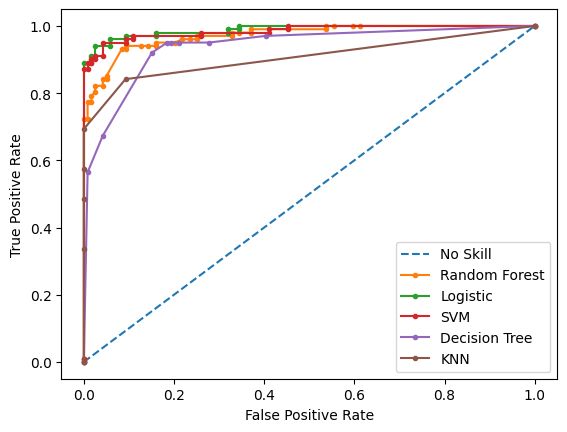
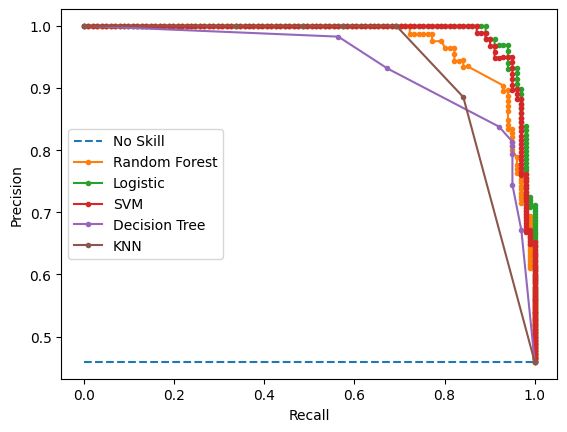
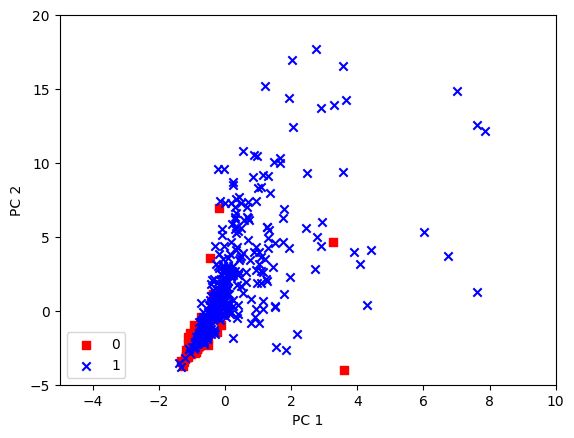
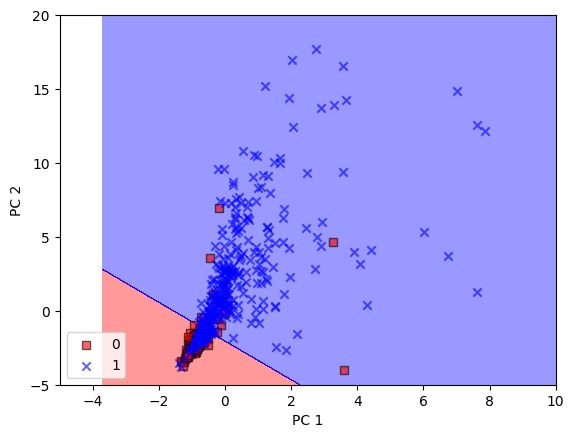
Our goal is to use machine learning techniques to accurately classify products as either food or beauty products based on their ingredient lists. To achieve this, we gathered data by manually collecting ingredient information from 1100 food and beauty products using the ChatGPT API, resulting in a total of 1672 unique ingredients. We conducted pre-processing on the data and tested various classification algorithms. Based on the results, we developed ensemble learning models that were fine-tuned for optimal test performance. We utilized Support Vector Machine (SVM) as the most suitable model for our dataset, and implemented additional techniques such as PCA, GridSearchCV, and Cosine similarity to improve results. We also created a recommendation model that would give a list of similar products based on the given input product from our dataset.
For comparison of all the results generated by different algorithms, check the table in the report.
- Swain, P. H., & Hauska, H. (1977). The decision tree classifier: Design and potential. IEEE Transactions on Geoscience Electronics, 15(3), 142-147.
- Hosmer Jr, D. W., Lemeshow, S., & Sturdivant, R. X. (2013). Applied logistic regression (Vol. 398). John Wiley & Sons.
- Dasu, T., & Johnson, T. (2003). Exploratory data mining and data cleaning. John Wiley & Sons.
- Pal, M. (2005). Random forest classifier for remote sensing classification. International journal of remote sensing, 26(1), 217-222.
- F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay, “Scikit-learn: Machine learning in Python,” Journal of Machine Learning Research, vol. 12, pp. 2825–2830, 2011.