+ + + 【寻找石头】-第37期-20240813-眼里有光 + +
+ + + +
+ 记录过去一周值得记录的“石头”。每周二更新,欢迎关注。它山之石,可以攻玉。
+
+
+
+
+ 共计 115 篇文章
+共计 116 篇文章
共计 115 篇文章
+共计 116 篇文章
共计 115 篇文章
+共计 116 篇文章
共计 115 篇文章
+共计 116 篇文章
共计 115 篇文章
+共计 116 篇文章
共计 115 篇文章
+共计 116 篇文章
共计 115 篇文章
+共计 116 篇文章
共计 115 篇文章
+共计 116 篇文章
共计 115 篇文章
+共计 116 篇文章
共计 115 篇文章
+共计 116 篇文章
共计 115 篇文章
+共计 116 篇文章
共计 115 篇文章
+共计 116 篇文章
共计 115 篇文章
+共计 116 篇文章
共计 115 篇文章
+共计 116 篇文章
共计 115 篇文章
+共计 116 篇文章
共计 115 篇文章
+共计 116 篇文章
共计 115 篇文章
+共计 116 篇文章
共计 115 篇文章
+共计 116 篇文章
共计 115 篇文章
+共计 116 篇文章
共计 115 篇文章
+共计 116 篇文章
共计 115 篇文章
+共计 116 篇文章
共计 115 篇文章
+共计 116 篇文章
共计 115 篇文章
+共计 116 篇文章
共计 115 篇文章
+共计 116 篇文章
共计 115 篇文章
+共计 116 篇文章
共计 115 篇文章
+共计 116 篇文章
共计 115 篇文章
+共计 116 篇文章
共计 115 篇文章
+共计 116 篇文章
共计 115 篇文章
+共计 116 篇文章
共计 115 篇文章
+共计 116 篇文章
共计 115 篇文章
+共计 116 篇文章
共计 115 篇文章
+共计 116 篇文章
共计 115 篇文章
+共计 116 篇文章
共计 115 篇文章
+共计 116 篇文章
共计 115 篇文章
+共计 116 篇文章
共计 115 篇文章
+共计 116 篇文章
共计 115 篇文章
+共计 116 篇文章
共计 115 篇文章
+共计 116 篇文章
共计 115 篇文章
+共计 116 篇文章
共计 115 篇文章
+共计 116 篇文章
共计 115 篇文章
+共计 116 篇文章
共计 115 篇文章
+共计 116 篇文章
2024
+ + +共计 115 篇文章
+共计 116 篇文章
2024
+ + +共计 115 篇文章
+共计 116 篇文章
2024
+ + +共计 115 篇文章
+共计 116 篇文章
2024
+ + +共计 115 篇文章
+共计 116 篇文章
2024
+ + +共计 115 篇文章
+共计 116 篇文章
2024
+ + +共计 115 篇文章
+共计 116 篇文章
2024
+ + +共计 115 篇文章
+共计 116 篇文章
2020
+ + + +2019
@@ -324,12 +333,6 @@共计 115 篇文章
+共计 116 篇文章
2018
+ + +共计 115 篇文章
+共计 116 篇文章
2018
+ + +共计 115 篇文章
+共计 116 篇文章
2024
+ + +共计 115 篇文章
+共计 116 篇文章
2024
+ + +共计 115 篇文章
+共计 116 篇文章
2024
+ + +共计 115 篇文章
+共计 116 篇文章
2024
+ + +共计 115 篇文章
+共计 116 篇文章
2024
+ + + +2023
@@ -321,12 +330,6 @@共计 115 篇文章
+共计 116 篇文章
2023
+ + +共计 115 篇文章
+共计 116 篇文章
2023
+ + +共计 115 篇文章
+共计 116 篇文章
2022
+ + + +2021
@@ -324,12 +333,6 @@
【AI×】AI×可以包括更复杂的AI系统、更广泛的数据集成、更智能的决策支持系统,以及更深入的行业影响和社会变革。| 从“AI+”到“AI×”
【KDD China 2024数智未来研讨会】数字经济浪潮汹涌,AI生成模型正引领新一轮产业革命,其深远影响备受瞩目。响应时代召唤,KDD China 2024年度盛会将于2024年8月16日至17日再次在成都盛大召开,主题聚焦“数据驱动智能,模型生成未来”。| KDD China 2024数智未来研讨会
【人机协同】在人机协同中,自由与计划、自主与规则的平衡至关重要。自由允许机器和人类在不受过多限制的情况下创新和适应,而计划则通过设定框架和目标,确保协同过程的效率和方向性。自主赋予机器和人类一定的决策权,促进灵活性;而规则提供结构和一致性,减少潜在的冲突和错误。成功的人机协同需要在这两对元素之间找到适合的平衡点。因此,在人机协同中,自由与计划、自主与规则之间存在着相互关联但又需要平衡的关系。| 人机协同
【社交】卡尔·荣格(Carl Jung)所描述的那样,性格内向的人通过独处来充电,他们必须有自己的时间才能恢复精力;而性格外向的人则在与人接触的过程中获得能量。大部分人的个性都处在这两极中间的某个水平。比起谈论自己,内向者对他人更感兴趣。内向者具有局外人的视角,将自己定位为观察者,对他人的故事和处境感到好奇。1. 做先发问的那个人 (关于为什么要提问,以及如何提问,可以参考之前一篇博客文章:学会提问);2. 让好奇心发挥作用 (提问以及寻找答案的过程,也是在激发和满足自己好奇心的过程);3. 保持目光锐利(观察身边的人、事、物,让自己具有更强的洞察力)。| 内向者社交法则
【节气养生】立秋
【放下】人生是一场自己和自己的竞技,与人无关,亦与人无尤。不沉溺、不纠结、继续生活,这才是真正的放下。
【桥牌】桥牌是一种涉及多个数学领域的复杂游戏,它要求玩家利用概率论来评估出牌的可能性,运用统计学来分析已出牌并预测剩余牌的分布。玩家还需要掌握组合数学来优化叫牌策略,利用决策理论在不同的选择中做出最佳决策。逻辑推理在推断对手和队友的牌时至关重要,同时策略规划帮助玩家制定长远打法。记忆力在记住已出牌以辅助决策中发挥重要作用,而心理战术则用于影响对手的判断并隐藏自己的决策。
欢迎各位提出建议、问题,我们一起交流、学习、成长。
“问渠那得清如许?为有源头活水来” ヾ(◍°∇°◍)ノ゙
——— 我在半亩方塘等你 ^_^
]]>
立秋是二十四节气中的第十三个节气,标志着夏季的结束和秋季的开始。在这个时节,养生显得尤为重要。以下是从运动、睡眠、饮食、情绪和休息五个方面给出的养生建议:
适度运动:立秋后天气逐渐转凉,但仍有余热。建议选择早晚温度较低时进行运动,如慢跑、散步、太极拳等,避免中午高温时段进行剧烈运动。
增强体质:秋季是锻炼身体、增强体质的好时机,可以逐渐增加运动量,进行一些力量训练和有氧运动,增强身体的抵抗力。
早睡早起:秋季白天渐短,夜晚渐长,应该顺应自然规律,早睡早起,保证充足的睡眠时间,帮助身体恢复和调整。
午休习惯:适当的午休可以补充精力,但时间不宜过长,一般20-30分钟为宜,以免影响夜间睡眠。
清润滋补:立秋后应适当调整饮食,选择一些清润滋补的食物,如百合、银耳、莲子、山药等,帮助润燥。
少辛增酸:避免食用过多辛辣食物,以免生内热。可以适当增加酸味食物,如柠檬、山楂、葡萄等,有助于收敛肺气,增强食欲。
增加蛋白质:适当增加优质蛋白质的摄入,如鱼类、豆类、禽肉等,增强免疫力。
保持愉悦:秋季天气变化较大,容易引发情绪波动。应保持心情愉悦,避免过度忧虑和压力,可以通过阅读、听音乐、与朋友交流等方式放松心情。
调节情绪:遇到不愉快的事情时,应学会调节自己的情绪,保持积极乐观的态度,避免情绪低落对健康产生不利影响。
适度休息:工作和生活中要注意劳逸结合,避免过度劳累。可以通过短暂的休息或小憩来恢复精力。
规律生活:建立规律的生活作息时间,有助于身体的自我调整和恢复,增强免疫力和抗病能力。
立秋是一个过渡的时节,适当调整生活方式,有助于更好地适应季节变化,保持身体健康。
注:使用ChatGPT 4o辅助创作。
欢迎各位提出建议、问题,我们一起交流、学习、成长。
“问渠那得清如许?为有源头活水来” ヾ(◍°∇°◍)ノ゙
——— 我在半亩方塘等你 ^_^
]]>共计 75 篇文章
+共计 76 篇文章
2024
+ + +共计 75 篇文章
+共计 76 篇文章
2024
+ + +共计 75 篇文章
+共计 76 篇文章
2024
+ + +共计 75 篇文章
+共计 76 篇文章
2024
+ + +共计 75 篇文章
+共计 76 篇文章
2024
+ + +共计 75 篇文章
+共计 76 篇文章
2023
+ + +共计 75 篇文章
+共计 76 篇文章
2023
+ + +共计 75 篇文章
+共计 76 篇文章
2022
+ + + +2021
diff --git a/images/ylyg.jpg b/images/ylyg.jpg new file mode 100644 index 00000000..9e056db1 Binary files /dev/null and b/images/ylyg.jpg differ diff --git a/index.html b/index.html index e6b57929..567aac7d 100644 --- a/index.html +++ b/index.html @@ -264,6 +264,69 @@ +
今年准备阅读的12本书如下:
+More: If you want to find more conferences information, you can visit the website (http://www.wikicfp.com/cfp/series?t=c&i=A).
+]]> +疫情之下,保持一个良好的身心状态,对于应对各方面的压力,随地随地可能发生的变化,过好生活就显得至关重要。今天是国庆假期的第一天,由于疫情的缘故,不能安排旅行,就只能待在成都,待在自己平时生活的地方,读书、学习、散步、思考、网上交流。
+趁着这个机会,将之前运动的一些经验和心得记录一下,希望对那些愿意调整自己身心状态,在身体和心理上感觉更加舒服些的朋友们有所帮助。
+从2020年发生疫情以来,今年快到第3年了,时间过得很快,一溜烟的,但是疫情给我们带来的苦闷或者心烦,确实一直持续的,久久难以散去。希望有那么一天,我们可以开心地面对面交谈,热情地问候,幸福地拥抱。
+从2021年12月10日,开始发起#趁年轻 去运动#的活动,到2022年09月29日,保持运动,同时记录的习惯,自己已经运动130天整。最开始在操场跑步,后来在校园里跑步,再后来在室内做无器械运动,身体发生了明显的改变,手臂的肌肉变得更加结实,腿部变得更加有力,精气神变得更加棒。总的来说,一个感受就是,如果室外条件适合,就在室外运动,室内条件合适,就在室内运动,最重要的是,运动起来,注意安全。关于跑步,还在知乎写过一篇文章(空气质量知多少,早上跑步好不好?),感兴趣的朋友也可以去看看。无器械运动推荐这本书(无器械健身)。
+有时候,心情比较烦闷或者比较无聊的时候,也会选择看书、看电影,看纪录片,从年初到现在,大概看了11本书,23部电影,5部纪录片,在身体没法到远方旅行的时候,让思想和心灵去远航也是一次难得的体验,这是一次次穿越时空,跨越江河的旅行,很棒。如果你不知道选什么书看,这里有份书单,供你选阅(2019年书单)。想找经典的电影,可以看看豆瓣电影Top250列表(豆瓣电影Top250),里面很多电影质量很高,值得一看。纪录片的话,自己之前整理了一个列表(纪录片推荐),可以选择自己感兴趣的纪录片来看,挺有意思的。
+如果晚上睡不太好,也会听听轻音乐,助眠音乐,做冥想练习(Now冥想),回到当下,放空自己的大脑,对于缓解压力,睡个好觉,挺有帮助。
+10月的第一天,碎碎念,写了这些。今年剩下的日子还剩3个月,2022年已经过了3/4,希望我们都能安心生活,踏实做事,一点一点,在一件件小事上,修炼自己,保持身心健康,向阳生长。
+欢迎各位提出建议、问题,我们一起交流、学习、成长。
+“问渠那得清如许?为有源头活水来” ヾ(◍°∇°◍)ノ゙
+– 我在半亩方塘等你 ^_^
+]]>
今年准备阅读的12本书如下:
-疫情之下,保持一个良好的身心状态,对于应对各方面的压力,随地随地可能发生的变化,过好生活就显得至关重要。今天是国庆假期的第一天,由于疫情的缘故,不能安排旅行,就只能待在成都,待在自己平时生活的地方,读书、学习、散步、思考、网上交流。
-趁着这个机会,将之前运动的一些经验和心得记录一下,希望对那些愿意调整自己身心状态,在身体和心理上感觉更加舒服些的朋友们有所帮助。
-从2020年发生疫情以来,今年快到第3年了,时间过得很快,一溜烟的,但是疫情给我们带来的苦闷或者心烦,确实一直持续的,久久难以散去。希望有那么一天,我们可以开心地面对面交谈,热情地问候,幸福地拥抱。
-从2021年12月10日,开始发起#趁年轻 去运动#的活动,到2022年09月29日,保持运动,同时记录的习惯,自己已经运动130天整。最开始在操场跑步,后来在校园里跑步,再后来在室内做无器械运动,身体发生了明显的改变,手臂的肌肉变得更加结实,腿部变得更加有力,精气神变得更加棒。总的来说,一个感受就是,如果室外条件适合,就在室外运动,室内条件合适,就在室内运动,最重要的是,运动起来,注意安全。关于跑步,还在知乎写过一篇文章(空气质量知多少,早上跑步好不好?),感兴趣的朋友也可以去看看。无器械运动推荐这本书(无器械健身)。
-有时候,心情比较烦闷或者比较无聊的时候,也会选择看书、看电影,看纪录片,从年初到现在,大概看了11本书,23部电影,5部纪录片,在身体没法到远方旅行的时候,让思想和心灵去远航也是一次难得的体验,这是一次次穿越时空,跨越江河的旅行,很棒。如果你不知道选什么书看,这里有份书单,供你选阅(2019年书单)。想找经典的电影,可以看看豆瓣电影Top250列表(豆瓣电影Top250),里面很多电影质量很高,值得一看。纪录片的话,自己之前整理了一个列表(纪录片推荐),可以选择自己感兴趣的纪录片来看,挺有意思的。
-如果晚上睡不太好,也会听听轻音乐,助眠音乐,做冥想练习(Now冥想),回到当下,放空自己的大脑,对于缓解压力,睡个好觉,挺有帮助。
-10月的第一天,碎碎念,写了这些。今年剩下的日子还剩3个月,2022年已经过了3/4,希望我们都能安心生活,踏实做事,一点一点,在一件件小事上,修炼自己,保持身心健康,向阳生长。
-欢迎各位提出建议、问题,我们一起交流、学习、成长。
-“问渠那得清如许?为有源头活水来” ヾ(◍°∇°◍)ノ゙
-– 我在半亩方塘等你 ^_^
-]]>Given a string, find the length of the longest substring without repeating characters.
- |
Input: “abcabcbb”
Output: 3
Explanation: The answer is “abc”, with the length of 3.
Input: “bbbbb”
Output: 1
Explanation: The answer is “b”, with the length of 1.
Input: “pwwkew”
Output: 3
Explanation: The answer is “wke”, with the length of 3.
Note that the answer must be a substring, “pwke” is a subsequence and not a substring.
该问题可以简化成查找一个字符串中最长的不重复字符子串,返回子串的长度。第一种方法用到了枚举和字典,感觉有点绕,我没有理解清楚;第二种方法采用了字符串的split方法,很巧妙,不过比较难想到。两种方法相比,第二种方法运行时间更短(84ms < 88ms),推荐使用第二种方法,感兴趣的朋友可以研究下第一种方法。
+方法一:
+ |
在官网下载cuda10.0和cudnn7.3.1,两者的版本一定要匹配。
cuda和cudnn匹配列表:
https://developer.nvidia.com/rdp/cudnn-archive#a-collapse731-10
cuda10.0下载地址(选择runfile的文件下载,安装比较方便):
https://developer.nvidia.com/cuda-10.0-download-archive?target_os=Linux&target_arch=x86_64&target_distro=Ubuntu&target_version=1604&target_type=runfilelocal
cudnn7.3.1下载地址:
https://developer.nvidia.com/compute/machine-learning/cudnn/secure/v7.3.1/prod/10.0_2018927/cudnn-10.0-linux-x64-v7.3.1.20
1. 禁用nouveau driver
- |
如果没有结果输出,则代表禁用掉了。如果有内容输出,则代表没有禁用掉。需要执行如下操作,
-1)在/etc/modprobe.d中创建文件blacklist-nouveau.conf,
- |
2)在文件blacklist-nouveau.conf中输入如下内容,
- |
保存并退出后,执行如下命令,
- |
3)执行命令lsmod | grep nouveau 检查是否禁用成功。
2. 进入文本模式
按Ctrl+Alt+F1,进入文本模式,执行如下命令,关闭图形界面,
|
然后进入cuda的安装包所在文件夹,执行如下命令:
- |
输入上述命令后,会显示用户许可证信息,按空格键直到显示为100%,然后输入accept。
-在这个过程中,会遇到如下选项,NVIDIA Accelerated Graphics Driver: 选择n;
openGL(有时不会出现): 选择n;
其他:都选择y;
安装路径可以选择默认:直接回车。
接着,输入命令sudo service lightdm start, 启动图形化界面,按住Alt+Ctrl+F7,返回图形化登录界面,输入账号密码后登录。 或者输入命令sudo reboot,重启回到图形界面。
3. 环境配置
输入如下命令,打开/etc/profile文件,
|
在文件中输入如下内容,
- |
然后,保存并退出文件。接着,执行如下命令,使配置生效,
- |
方法二:
+ |
4. 检查cuda是否安装成功
输入如下命令,查看nvidia驱动的版本:
|
我的版本为410.48。
输入如下命令,查看CUDA Toolkit的版本:
|
我的版本是V10.0.130。
至此,cuda安装成功,接下来安装cudnn。
1. 解压cudnn安装包
- |
2. 配置cudnn
在当前目录输入依次执行如下命令,
|
3. 查看cudnn版本
输入如下命令,查看版本,
|
如果有对应的CUDNN_MAJOR输出,则代表安装成功。
-输入如下命令,
- |
如果出现GPU的信息列表,则说明安装成功。
- |
sudo reboot重启,如果问题依然没有解决,按照上述步骤,重新安装cuda。笔者是在经历了以上三个步骤之后,OneDrive就可以正常登录。如果你遇到不能登录OneDrive,以上方法不能解决或者有新的办法,欢迎留言交流。
]]>Given a string, find the length of the longest substring without repeating characters.
+Input: “abcabcbb”
Output: 3
Explanation: The answer is “abc”, with the length of 3.
Input: “bbbbb”
Output: 1
Explanation: The answer is “b”, with the length of 1.
Input: “pwwkew”
Output: 3
Explanation: The answer is “wke”, with the length of 3.
Note that the answer must be a substring, “pwke” is a subsequence and not a substring.
该问题可以简化成查找一个字符串中最长的不重复字符子串,返回子串的长度。第一种方法用到了枚举和字典,感觉有点绕,我没有理解清楚;第二种方法采用了字符串的split方法,很巧妙,不过比较难想到。两种方法相比,第二种方法运行时间更短(84ms < 88ms),推荐使用第二种方法,感兴趣的朋友可以研究下第一种方法。
-方法一:
- |
笔者是在经历了以上三个步骤之后,OneDrive就可以正常登录。如果你遇到不能登录OneDrive,以上方法不能解决或者有新的办法,欢迎留言交流。
+]]>方法二:
- |
|
在官网下载cuda10.0和cudnn7.3.1,两者的版本一定要匹配。
cuda和cudnn匹配列表:
https://developer.nvidia.com/rdp/cudnn-archive#a-collapse731-10
cuda10.0下载地址(选择runfile的文件下载,安装比较方便):
https://developer.nvidia.com/cuda-10.0-download-archive?target_os=Linux&target_arch=x86_64&target_distro=Ubuntu&target_version=1604&target_type=runfilelocal
cudnn7.3.1下载地址:
https://developer.nvidia.com/compute/machine-learning/cudnn/secure/v7.3.1/prod/10.0_2018927/cudnn-10.0-linux-x64-v7.3.1.20
1. 禁用nouveau driver
+ |
如果没有结果输出,则代表禁用掉了。如果有内容输出,则代表没有禁用掉。需要执行如下操作,
+1)在/etc/modprobe.d中创建文件blacklist-nouveau.conf,
+ |
2)在文件blacklist-nouveau.conf中输入如下内容,
+ |
保存并退出后,执行如下命令,
+ |
3)执行命令lsmod | grep nouveau 检查是否禁用成功。
2. 进入文本模式
按Ctrl+Alt+F1,进入文本模式,执行如下命令,关闭图形界面,
|
然后进入cuda的安装包所在文件夹,执行如下命令:
+ |
输入上述命令后,会显示用户许可证信息,按空格键直到显示为100%,然后输入accept。
+在这个过程中,会遇到如下选项,NVIDIA Accelerated Graphics Driver: 选择n;
openGL(有时不会出现): 选择n;
其他:都选择y;
安装路径可以选择默认:直接回车。
接着,输入命令sudo service lightdm start, 启动图形化界面,按住Alt+Ctrl+F7,返回图形化登录界面,输入账号密码后登录。 或者输入命令sudo reboot,重启回到图形界面。
3. 环境配置
输入如下命令,打开/etc/profile文件,
|
在文件中输入如下内容,
+ |
然后,保存并退出文件。接着,执行如下命令,使配置生效,
+ |
4. 检查cuda是否安装成功
输入如下命令,查看nvidia驱动的版本:
|
我的版本为410.48。
输入如下命令,查看CUDA Toolkit的版本:
|
我的版本是V10.0.130。
至此,cuda安装成功,接下来安装cudnn。
1. 解压cudnn安装包
+ |
2. 配置cudnn
在当前目录输入依次执行如下命令,
|
3. 查看cudnn版本
输入如下命令,查看版本,
|
如果有对应的CUDNN_MAJOR输出,则代表安装成功。
+输入如下命令,
+ |
如果出现GPU的信息列表,则说明安装成功。
+ |
sudo reboot重启,如果问题依然没有解决,按照上述步骤,重新安装cuda。ICLR 2022完整录用论文列表:https://openreview.net/group?id=ICLR.cc/2022/Conference#oral-submissions
-AAAI 2022录用论文列表:
https://aaai.org/Conferences/AAAI-22/wp-content/uploads/2021/12/AAAI-22_Accepted_Paper_List_Main_Technical_Track.pdf
全文还没有放出来,如果需要,可以在谷歌学术上查找,部分论文已经放在arXiv上。
+NeurIPS 2023论文录用列表: https://openreview.net/group?id=NeurIPS.cc/2023/Conference
-ICLR 2022完整录用论文列表:https://openreview.net/group?id=ICLR.cc/2022/Conference#oral-submissions
+NeurIPS 2023论文录用列表: https://openreview.net/group?id=NeurIPS.cc/2023/Conference
+AAAI 2022录用论文列表:
https://aaai.org/Conferences/AAAI-22/wp-content/uploads/2021/12/AAAI-22_Accepted_Paper_List_Main_Technical_Track.pdf
全文还没有放出来,如果需要,可以在谷歌学术上查找,部分论文已经放在arXiv上。
-
这本书与《少有人走的路:心智成熟的旅程》、《少有人走的路3:与心灵对话》、《少有人走的路4:在焦虑的年代获得精神的成长》、《少有人走的路5:不一样的鼓声》、《少有人走的路6:真诚是生命的药》、《少有人走的路7:靠窗的床》与《少有人走的路8:寻找石头》共同形成了《少有人走的路》系列。
+谎言的本质是掩盖真相。那么为什么会掩盖真相呢?作者认为,是由于人不愿意承受面对问题和解决问题所带来的痛苦。在逃避问题和痛苦的过程中,人会变得颠倒是非,混淆黑白,变得疯狂和邪恶。就像生活(Live)颠倒过来就是邪恶(Evil)。作者希望,我们能勇敢地面对真相,不逃避自己的问题,承受应该承受的痛苦,承担应该承受的责任,促进心灵成长,使得心智成熟。
+ |
这本书与《少有人走的路:心智成熟的旅程》、《少有人走的路3:与心灵对话》、《少有人走的路4:在焦虑的年代获得精神的成长》、《少有人走的路5:不一样的鼓声》、《少有人走的路6:真诚是生命的药》、《少有人走的路7:靠窗的床》与《少有人走的路8:寻找石头》共同形成了《少有人走的路》系列。
-谎言的本质是掩盖真相。那么为什么会掩盖真相呢?作者认为,是由于人不愿意承受面对问题和解决问题所带来的痛苦。在逃避问题和痛苦的过程中,人会变得颠倒是非,混淆黑白,变得疯狂和邪恶。就像生活(Live)颠倒过来就是邪恶(Evil)。作者希望,我们能勇敢地面对真相,不逃避自己的问题,承受应该承受的痛苦,承担应该承受的责任,促进心灵成长,使得心智成熟。
- |
欢迎各位提出建议、问题,我们一起交流、学习、成长。
-“问渠那得清如许?为有源头活水来” ヾ(◍°∇°◍)ノ゙
-——— 我在半亩方塘等你 ^_^
-]]>
欢迎各位提出建议、问题,我们一起交流、学习、成长。
@@ -1461,31 +1434,38 @@一种新的人车交互方式,普渡大学数字孪生实验室发布Talk2Drive框架,通过理解人类的自然语言来控制自动驾驶汽车。| 「人车交互」新突破!普渡大学发布Talk2Drive框架:可学习/定制的「指令识别」系统
-时空数据挖掘领域的大模型相关研究论文汇总 | 时序&时空数据挖掘领域大语言模型相关论文汇总
-大模型怎样重塑社会科学 | 集智俱乐部发起「大语言模型与计算社会科学」读书会
-医疗大模型的应用挑战与未来探索 | 从诊室到云端:医疗大模型的应用挑战与未来探索
+欢迎各位提出建议、问题,我们一起交流、学习、成长。
@@ -1516,36 +1492,32 @@欢迎各位提出建议、问题,我们一起交流、学习、成长。
@@ -1578,64 +1546,50 @@腾讯发布影响2024年的十大科技应用趋势 | 影响2024年的十大科技应用趋势
+微软研究院发布2024年值得关注的三大人工智能趋势 | 2024年值得关注的三大人工智能趋势
+国务院国资委提出中央企业要把发展人工智能放在全局工作中统筹谋划,加快建设一批智能算力中心 | AI赋能产业焕新
+欢迎各位提出建议、问题,我们一起交流、学习、成长。
@@ -1663,50 +1619,31 @@腾讯发布影响2024年的十大科技应用趋势 | 影响2024年的十大科技应用趋势
-一种新的人车交互方式,普渡大学数字孪生实验室发布Talk2Drive框架,通过理解人类的自然语言来控制自动驾驶汽车。| 「人车交互」新突破!普渡大学发布Talk2Drive框架:可学习/定制的「指令识别」系统
微软研究院发布2024年值得关注的三大人工智能趋势 | 2024年值得关注的三大人工智能趋势
-时空数据挖掘领域的大模型相关研究论文汇总 | 时序&时空数据挖掘领域大语言模型相关论文汇总
国务院国资委提出中央企业要把发展人工智能放在全局工作中统筹谋划,加快建设一批智能算力中心 | AI赋能产业焕新
-大模型怎样重塑社会科学 | 集智俱乐部发起「大语言模型与计算社会科学」读书会
+医疗大模型的应用挑战与未来探索 | 从诊室到云端:医疗大模型的应用挑战与未来探索
欢迎各位提出建议、问题,我们一起交流、学习、成长。
@@ -1786,6 +1724,154 @@欢迎各位提出建议、问题,我们一起交流、学习、成长。
“问渠那得清如许?为有源头活水来” ヾ(◍°∇°◍)ノ゙
——— 我在半亩方塘等你 ^_^
+]]>欢迎各位提出建议、问题,我们一起交流、学习、成长。
+“问渠那得清如许?为有源头活水来” ヾ(◍°∇°◍)ノ゙
+——— 我在半亩方塘等你 ^_^
+]]>欢迎各位提出建议、问题,我们一起交流、学习、成长。
+“问渠那得清如许?为有源头活水来” ヾ(◍°∇°◍)ノ゙
+——— 我在半亩方塘等你 ^_^
]]>
每天我们都会刷着看不完的信息,回复着接踵而至的消息,注意力时而停留,手指时而点击。或许今天已经忘了上周的今天在做些什么,在这个容易遗忘的时代,我想我们也需要记录些什么。我们就像航行在汪洋大海的一艘小船,每天既可以看到天空的云卷云舒,也可以看到大海的波涛汹涌,还可以看到水下的神秘多姿。当我们的小船靠岸,岸边的沙粒,路边的石子,家里的人们迎接着我们归来。我期望,在航海归途、在漫漫旅途,寻找到一颗颗“石头”,与你一同分享值得记住的那些人、事、物,也期待你与我分享你所看到的那些人、事、物,让生活丰富多彩、新鲜有趣、意义非凡。——《寻找石头系列》开篇语
【编程助手】CodeGeeX是一款免费的智能编程助手,方便好用 | CodeGeeX 插件在 Visual Studio平台适配上线!成为首个适配VS平台的国产智能编程助手
-【端云协同】端云协同智能新范式,通过将部分智能推理任务或智能推理任务的部分阶段卸载到端侧进行处理,利用端侧本地即时处理的优势,削减响应延时,降低云服务器负载;同时用户原始数据不离开本地,数据安全隐私可以得到良好的保障 | 大规模端云协同智能计算
-【扩散模型】对去噪扩散模型(DDM)进行了解构,发现其关键组件是分词器,而其他组件并非必要。DDM的表现能力主要来自去噪过程而非扩散过程 | 扩散模型的解构研究
-【时空知识图谱】将时空数据整合到知识图谱中,以提高动态信息预测和推荐的准确性和相关性,同时确保模型的可解释性和效率 | SSTKG:简易时空知识图谱:可解释性与多功能动态信息嵌入
-【压缩与泛化】压缩的定义可以被理解为找出数据中的规律性、共性,并用更简洁的方式表示数据,以减少冗余信息 | 泛化即智能,压缩即一切
-【科研素质】做科研的3P(Perception,Persistence,Power)原则——杨振宁
-【商业意识】闽商被誉为“最具冒险性的中国商人”,作风彪悍,最善于抓住机会。不错的商业嗅觉,外加一分大胆、一分赌性的企业家,往往会形成无往不克的自我意识。
+【编程助手】CodeGeeX是一款免费的智能编程助手,方便好用 | CodeGeeX 插件在 Visual Studio平台适配上线!成为首个适配VS平台的国产智能编程助手
+【端云协同】端云协同智能新范式,通过将部分智能推理任务或智能推理任务的部分阶段卸载到端侧进行处理,利用端侧本地即时处理的优势,削减响应延时,降低云服务器负载;同时用户原始数据不离开本地,数据安全隐私可以得到良好的保障 | 大规模端云协同智能计算
+【扩散模型】对去噪扩散模型(DDM)进行了解构,发现其关键组件是分词器,而其他组件并非必要。DDM的表现能力主要来自去噪过程而非扩散过程 | 扩散模型的解构研究
+【时空知识图谱】将时空数据整合到知识图谱中,以提高动态信息预测和推荐的准确性和相关性,同时确保模型的可解释性和效率 | SSTKG:简易时空知识图谱:可解释性与多功能动态信息嵌入
+【压缩与泛化】压缩的定义可以被理解为找出数据中的规律性、共性,并用更简洁的方式表示数据,以减少冗余信息 | 泛化即智能,压缩即一切
+【科研素质】做科研的3P(Perception,Persistence,Power)原则——杨振宁
+【商业意识】闽商被誉为“最具冒险性的中国商人”,作风彪悍,最善于抓住机会。不错的商业嗅觉,外加一分大胆、一分赌性的企业家,往往会形成无往不克的自我意识。
每天我们都会刷着看不完的信息,回复着接踵而至的消息,注意力时而停留,手指时而点击。或许今天已经忘了上周的今天在做些什么,在这个容易遗忘的时代,我想我们也需要记录些什么。我们就像航行在汪洋大海的一艘小船,每天既可以看到天空的云卷云舒,也可以看到大海的波涛汹涌,还可以看到水下的神秘多姿。当我们的小船靠岸,岸边的沙粒,路边的石子,家里的人们迎接着我们归来。我期望,在航海归途、在漫漫旅途,寻找到一颗颗“石头”,与你一同分享值得记住的那些人、事、物,也期待你与我分享你所看到的那些人、事、物,让生活丰富多彩、新鲜有趣、意义非凡。——《寻找石头系列》开篇语
-接下来就是五一劳动节啦,祝大家节日快乐,五月依旧阳光灿烂,活出自己想要的人生。
+

【技术工具】Latent Box,一个AI、创意、艺术工具合集 | Latent Box
-【LSTM与Transformer】LSTM+Transformer,提升模型性能 | LSTM与Transformer技术融合
-【大模型】大模型思辨 | 青春力量,大模型:科研新风潮
+【智慧与智能】当你看到一个苹果,你想到了什么,你真的理解你对面的这个苹果吗?| AI知道苹果是什么吗?DeepMind语言模型科学家正把这些概念变得可量化、可测试
【AI for Science】弦理论家正在利用神经网络的力量将弦的 6D 微观世界与粒子的 4D 宏观世界连接起来 | 探索基本粒子集,人工智能筛选弦理论近乎无限的可能性
-【AI安全】微软亚洲研究院提出了价值观罗盘(Value Compass)项目,研究了一种基于施瓦茨人类基本价值理论的 BaseAlign 对齐算法,从交叉学科的角度切入,充分借鉴伦理学和社会学中的理论,以解决对价值观的定义、评测和对齐问题 | 价值观罗盘:如何让大模型与人类价值观对齐?
-【空间数据智能】中国空间数据智能战略白皮书发布,为促进AGI时代空间数据智能大模型的发展及其在城市、空天遥感、地理、交通等领域的应用,同时推动地理信息科学、计算机科学等领域在空间数据智能大模型交叉研究方面的理论、技术与应用的学术交流,解决空间数据智能大模型产业发展面临的重大挑战和瓶颈问题指明方向 | 《中国空间数据智能战略白皮书》在SpatialDI 2024上正式发布
+【氢能产业】将从科技创新、迭代应用和政策支持三方面推动氢能产业高质量发展 | 工信部:三方面推动氢能产业高质量发展
【数据缺失插补】用LSTM插补气象站缺失的气温数据 | 数据插补之LSTM
+【联邦学习】在个性化联邦学习的范畴中,生成全局模型不再是最终的目的,而以全局模型为知识共享的载体、用全局模型中蕴含的全局信息来提升本地模型效果才是最终的目标 | 开源个性化联邦学习算法库PFLlib
【混合专家模型】混合专家模型用于应对神经网络的稀疏性、神经元的多语义性、计算资源的有限性等问题 | 混合专家: Moe已成为现阶段LLM的新标准
+【AI气候模型】利用 AI 的计算能力和物理定律的基础,来创建一个具有良好可解释性的可学习的气候模型 | 平衡 AI 与物理,中国科学院提出建立可学习的气候模型
【Mamba】即插即用Mamba模块,降低计算复杂度,提高模型的计算效率 | 即插即用Mamba模块小结
+【KAN框架】一种新的基于柯尔莫哥洛夫-阿诺德定理的神经网络框架,具有更少的参数、更强的性能、更好的可解释性 | KAN
【时序大模型】Moirai 的 zero-shot 预测能力具有竞争力甚至表现出更优越的性能 | 首个全开源时序预测基础模型:Zero-shot预测能力比肩从零训练最优模型
+【模拟与数字】生活是模拟的还是数字的?我倾向于认为生活是模拟,是连续的,从哲学上来讲,缺失了过去的任何一个瞬间,都无法成为现在的我。您觉得呢? | 生活是模拟的还是数字的?
【数字经济】近日,国家发展改革委办公厅、国家数据局综合司印发《数字经济2024年工作要点》,对2024年数字经济重点工作作出部署 | 两部门印发《数字经济2024年工作要点》
-【高级机器智能】机器如何能像人类和动物一样高效地学习?机器如何学习世界运作方式并获得常识?机器如何学习推理和规划?| Objective-Driven AI
【技术与哲学】技术与哲学的相互影响,带动技术和哲学的发展 | 心灵渗入世界
+【爱】关于爱、网络技术与道德的访谈,消费主义的盛行,让消费者与商品之间的关系模式正变成人与人之间的关系模式 | 齐格蒙特·鲍曼:我们正在忘记怎样去爱
【创业思维】创业者需要培养的三种核心能力 | 创业思考
-【学问】在追寻大自然奥秘的过程中,找到它最有意义、最有乐趣之处 | 丘成桐:一流人才,始自学问
+【家】“家”是一个牵动复杂情感的词。家是一个有爱的地方 | 孙向晨 | 何以归家:现代性的救赎
+【哲学思维】如果说,科学注重的是观察、实验和归纳思维,艺术注重的是想象力和形象思维,神学(宗教)注重的是天启、信仰和演绎思维,那么,哲学注重的则是人生境界和辩证思维 | 哲学思维的四个纬度




【心智】机器有智无心,人有心有智。心智健全,方才是个成熟的人。
+【生活与生命】如果生活是数字化的,生命就不可能永远存在。如果生命是模拟的,生命可能会永远存在。我认为生命会永远存在,因为生命的本质是灵魂,灵魂不死不灭。
+【健康】我们每个人正是在追求健康的过程中,不断地认识自己,了解世界,调整节奏,越来越健康,达到一个动态的平衡。
+【寻找石头】-第1期-20231113
https://xiepeng21.cn/posts/60a517c0/
【寻找石头】-第21期-20240423
https://xiepeng21.cn/posts/5aad5dcb/
【寻找石头】-第22期-20240430
https://xiepeng21.cn/posts/677551fe/
欢迎各位提出建议、问题,我们一起交流、学习、成长。
@@ -2299,56 +2365,30 @@

【智慧与智能】当你看到一个苹果,你想到了什么,你真的理解你对面的这个苹果吗?| AI知道苹果是什么吗?DeepMind语言模型科学家正把这些概念变得可量化、可测试
-【氢能产业】将从科技创新、迭代应用和政策支持三方面推动氢能产业高质量发展 | 工信部:三方面推动氢能产业高质量发展
-【联邦学习】在个性化联邦学习的范畴中,生成全局模型不再是最终的目的,而以全局模型为知识共享的载体、用全局模型中蕴含的全局信息来提升本地模型效果才是最终的目标 | 开源个性化联邦学习算法库PFLlib
-【AI气候模型】利用 AI 的计算能力和物理定律的基础,来创建一个具有良好可解释性的可学习的气候模型 | 平衡 AI 与物理,中国科学院提出建立可学习的气候模型
-【KAN框架】一种新的基于柯尔莫哥洛夫-阿诺德定理的神经网络框架,具有更少的参数、更强的性能、更好的可解释性 | KAN
+【脑机接口】为什么需要脑机接口?1. 与计算机更好地交流 2. 让计算机理解人类。涉及脑信息采集、计算机科学及信号分析技术、神经科学等 | 脑机接口,为什么不可或缺?
【模拟与数字】生活是模拟的还是数字的?我倾向于认为生活是模拟,是连续的,从哲学上来讲,缺失了过去的任何一个瞬间,都无法成为现在的我。您觉得呢? | 生活是模拟的还是数字的?
+【扩散模型】一篇比较新的扩散模型在时间序列、时空数据中的应用的综述文章 | 扩散模型在时间序列&时空数据的理论、进展、应用与展望
【高级机器智能】机器如何能像人类和动物一样高效地学习?机器如何学习世界运作方式并获得常识?机器如何学习推理和规划?| Objective-Driven AI
+【未来】OpenAI首席执行官山姆·奥特曼(Sam Altman)4月24日参加了斯坦福大学企业思想领袖讲坛ETL(Entrepreneurial Thought Leaders Lecture)的活动,分享了他对人工智能未来的见解 | 奥特曼斯坦福对话万字实录:GPT-5、AGI、核聚变发电、人类未来
【爱】关于爱、网络技术与道德的访谈,消费主义的盛行,让消费者与商品之间的关系模式正变成人与人之间的关系模式 | 齐格蒙特·鲍曼:我们正在忘记怎样去爱
-【学问】在追寻大自然奥秘的过程中,找到它最有意义、最有乐趣之处 | 丘成桐:一流人才,始自学问
-【家】“家”是一个牵动复杂情感的词。家是一个有爱的地方 | 孙向晨 | 何以归家:现代性的救赎
+【爱】关于人机的区别,人具有爱的能力,爱己爱人爱物 | 当人工智能开始拥有思维,人类将何去何从?
【哲学思维】如果说,科学注重的是观察、实验和归纳思维,艺术注重的是想象力和形象思维,神学(宗教)注重的是天启、信仰和演绎思维,那么,哲学注重的则是人生境界和辩证思维 | 哲学思维的四个纬度
+【内卷】爱自己、爱他人,是对抗内卷的底气 | 对于大环境内卷这个问题你怎么看?
【心智】机器有智无心,人有心有智。心智健全,方才是个成熟的人。
-【生活与生命】如果生活是数字化的,生命就不可能永远存在。如果生命是模拟的,生命可能会永远存在。我认为生命会永远存在,因为生命的本质是灵魂,灵魂不死不灭。
-【健康】我们每个人正是在追求健康的过程中,不断地认识自己,了解世界,调整节奏,越来越健康,达到一个动态的平衡。
-【寻找石头】-第1期-20231113
https://xiepeng21.cn/posts/60a517c0/
【寻找石头】-第22期-20240430
https://xiepeng21.cn/posts/677551fe/
【寻找石头】-第23期-20240507
https://xiepeng21.cn/posts/e68242c/
欢迎各位提出建议、问题,我们一起交流、学习、成长。
@@ -2410,36 +2452,167 @@今日世界读书日,让我们一起阅读吧。通过阅读,遇见全世界,与世界上最智慧、最聪明、最有趣的灵魂对话,了解自己,认识自己,更好地成为自己。💡
+接下来就是五一劳动节啦,祝大家节日快乐,五月依旧阳光灿烂,活出自己想要的人生。
-
分享对我过往人生影响最大的9本书,也欢迎您在评论区留下那些让你印象深刻以及对你有重大影响的书籍,我们一起成长:
-《道德经》
+
【技术工具】Latent Box,一个AI、创意、艺术工具合集 | Latent Box
《论语》
+【LSTM与Transformer】LSTM+Transformer,提升模型性能 | LSTM与Transformer技术融合
《易经》
+【大模型】大模型思辨 | 青春力量,大模型:科研新风潮
+《曾国藩家书》
+【AI for Science】弦理论家正在利用神经网络的力量将弦的 6D 微观世界与粒子的 4D 宏观世界连接起来 | 探索基本粒子集,人工智能筛选弦理论近乎无限的可能性
《毛泽东传》
+【AI安全】微软亚洲研究院提出了价值观罗盘(Value Compass)项目,研究了一种基于施瓦茨人类基本价值理论的 BaseAlign 对齐算法,从交叉学科的角度切入,充分借鉴伦理学和社会学中的理论,以解决对价值观的定义、评测和对齐问题 | 价值观罗盘:如何让大模型与人类价值观对齐?
《红楼梦》
+【空间数据智能】中国空间数据智能战略白皮书发布,为促进AGI时代空间数据智能大模型的发展及其在城市、空天遥感、地理、交通等领域的应用,同时推动地理信息科学、计算机科学等领域在空间数据智能大模型交叉研究方面的理论、技术与应用的学术交流,解决空间数据智能大模型产业发展面临的重大挑战和瓶颈问题指明方向 | 《中国空间数据智能战略白皮书》在SpatialDI 2024上正式发布
《亲密关系》
+【数据缺失插补】用LSTM插补气象站缺失的气温数据 | 数据插补之LSTM
《少有人走的路》
+【混合专家模型】混合专家模型用于应对神经网络的稀疏性、神经元的多语义性、计算资源的有限性等问题 | 混合专家: Moe已成为现阶段LLM的新标准
《为什么长大》
+【Mamba】即插即用Mamba模块,降低计算复杂度,提高模型的计算效率 | 即插即用Mamba模块小结
【交通信号灯控制】利用大模型进行交通信号灯控制 | 港科大(广州)发布大模型交通信号灯控制框架LLMLight
+【时序大模型】Moirai 的 zero-shot 预测能力具有竞争力甚至表现出更优越的性能 | 首个全开源时序预测基础模型:Zero-shot预测能力比肩从零训练最优模型
+【数字经济】近日,国家发展改革委办公厅、国家数据局综合司印发《数字经济2024年工作要点》,对2024年数字经济重点工作作出部署 | 两部门印发《数字经济2024年工作要点》
+【技术与哲学】技术与哲学的相互影响,带动技术和哲学的发展 | 心灵渗入世界
+【创业思维】创业者需要培养的三种核心能力 | 创业思考
+
【寻找石头】-第1期-20231113
https://xiepeng21.cn/posts/60a517c0/
【寻找石头】-第2期-20231117
https://xiepeng21.cn/posts/28c5f201/
【寻找石头】-第3期-20231124
https://xiepeng21.cn/posts/8fbdec1/
【寻找石头】-第4期-20231201
https://xiepeng21.cn/posts/3592f0cd/
【寻找石头】-第5期-20231208
https://xiepeng21.cn/posts/91d891ec/
【寻找石头】-第6期-20231215
https://xiepeng21.cn/posts/4bb8b0de/
【寻找石头】-第7期-20231222
https://xiepeng21.cn/posts/2367af3b/
【寻找石头】-第8期-20240112
https://xiepeng21.cn/posts/27e02ce1/
【寻找石头】-第9期-20240119
https://xiepeng21.cn/posts/6da42cec/
【寻找石头】-第10期-20240126
https://xiepeng21.cn/posts/8dfb97f1/
【寻找石头】-第11期-20240203
https://xiepeng21.cn/posts/10776620/
【寻找石头】-第12期-20240220
https://xiepeng21.cn/posts/68239d6/
【寻找石头】-第13期-20240223
https://xiepeng21.cn/posts/421db1e9/
【寻找石头】-第14期-20240305
https://xiepeng21.cn/posts/e5f91a31/
【寻找石头】-第15期-20240312
https://xiepeng21.cn/posts/bf106756/
【寻找石头】-第16期-20240319
https://xiepeng21.cn/posts/9508d210/
【寻找石头】-第17期-20240326
https://xiepeng21.cn/posts/f30c45c7/
【寻找石头】-第18期-20240402
https://xiepeng21.cn/posts/e46820ec/
【寻找石头】-第19期-20240409
https://xiepeng21.cn/posts/ae2c20e1/
【寻找石头】-第20期-20240416
https://xiepeng21.cn/posts/dc7c2302/
【寻找石头】-第21期-20240423
https://xiepeng21.cn/posts/5aad5dcb/
欢迎各位提出建议、问题,我们一起交流、学习、成长。
+“问渠那得清如许?为有源头活水来” ヾ(◍°∇°◍)ノ゙
+——— 我在半亩方塘等你 ^_^
+]]>今日世界读书日,让我们一起阅读吧。通过阅读,遇见全世界,与世界上最智慧、最聪明、最有趣的灵魂对话,了解自己,认识自己,更好地成为自己。💡
+ + +
分享对我过往人生影响最大的9本书,也欢迎您在评论区留下那些让你印象深刻以及对你有重大影响的书籍,我们一起成长:
+《道德经》
+《论语》
+《易经》
+《曾国藩家书》
+《毛泽东传》
+《红楼梦》
+《亲密关系》
+《少有人走的路》
+《为什么长大》
+【交通信号灯控制】利用大模型进行交通信号灯控制 | 港科大(广州)发布大模型交通信号灯控制框架LLMLight
【基因组语言模型】机器学习在从大量蛋白质序列数据集中学习序列-结构-功能范式背后的潜在关系方面表现出潜力 | 预测蛋白质共调控和功能,哈佛&MIT训练含19层transformer的基因组语言模型
 看起来ChatGPT-4o对于什么是好吃,还不理解,这碗面,你敢吃吗?反正我不敢。
看起来ChatGPT-4o对于什么是好吃,还不理解,这碗面,你敢吃吗?反正我不敢。
【脑机接口】为什么需要脑机接口?1. 与计算机更好地交流 2. 让计算机理解人类。涉及脑信息采集、计算机科学及信号分析技术、神经科学等 | 脑机接口,为什么不可或缺?
+【ChatGPT-4o】使用了一周的ChatGPT-4o之后,给我印象最深的是,她开始在对话中,发起提问了,让我想到了一本书《学会提问》。给你印象最深的功能是什么呢?欢迎在评论区说说看。 | GPT-4o
【扩散模型】一篇比较新的扩散模型在时间序列、时空数据中的应用的综述文章 | 扩散模型在时间序列&时空数据的理论、进展、应用与展望
+【大科学时代】AI几乎可以与所有学科进行交叉融合。青年科学家们跨越传统的学科界限,迈向一个以问题为中心的大科学时代,这个愿景在AI的支持下有了成为现实的可能。我们将会看见更多的多学科融合的新发现、新成果出现。| 大科学时代
【未来】OpenAI首席执行官山姆·奥特曼(Sam Altman)4月24日参加了斯坦福大学企业思想领袖讲坛ETL(Entrepreneurial Thought Leaders Lecture)的活动,分享了他对人工智能未来的见解 | 奥特曼斯坦福对话万字实录:GPT-5、AGI、核聚变发电、人类未来
+【智慧城市】城市是推进数字中国建设的综合载体,推进城市数字化转型、智慧化发展,是面向未来构筑城市竞争新优势的关键之举,也是推动城市治理体系和治理能力现代化的必然要求。| 智慧城市与数字化转型
【爱】关于人机的区别,人具有爱的能力,爱己爱人爱物 | 当人工智能开始拥有思维,人类将何去何从?
-【内卷】爱自己、爱他人,是对抗内卷的底气 | 对于大环境内卷这个问题你怎么看?
-【寻找石头】-第1期-20231113
https://xiepeng21.cn/posts/60a517c0/
【寻找石头】-第23期-20240507
https://xiepeng21.cn/posts/e68242c/
【寻找石头】-第24期-20240514
https://xiepeng21.cn/posts/f309428f/
欢迎各位提出建议、问题,我们一起交流、学习、成长。
@@ -2650,34 +2822,28 @@这篇博客文章是半亩方塘的第100篇。(^-^)V
-2024年已经过半,让我们一起迎接下半场的挑战。ヾ(◍°∇°◍)ノ゙
-
 The piture was generated with ChatGPT-4o.
The piture was generated with ChatGPT-4o.
【生成式AI】看一个东西有没有用,一个容易判断的点,就是你是否会持续用它?这两篇文章展示了生成式AI的百项奇思妙用,比如技术支持与故障排除、 内容创作与编辑、 个人与职业支持、学习与教育、创造力与娱乐、研究、分析与决策等。也欢迎您在评论区说说你平时都用生成式AI工具做些什么?以及它有哪些事情帮不了你做?
- +【神经网络控制器】美国麻省理工学院博士生杨麓洁团队提出可验证型神经网络控制器框架,为复杂非线性系统的稳定控制,提供了新的解决方案,在工业、交通、航空航天等领域都具备潜在应用前景。| 可验证型神经网络控制器框架
【时间序列预测】TFB: 一个全面公平的时间序列预测方法评测基准 | TFB
+【技术进步】君子生非异也,善假于物也。新技术带来更多解决问题的途径。| 新技术
【城市大模型】城市大模型能做些什么?技术驱动下为城市治理带来什么变化?又产生什么问题?如何构建城市大模型?| 城市大模型:认知、应用、展望
+【理性的我们】从“这个行为对我有好处”转变成“这是我参与的集体行为,对我们有好处”。| 合作共赢


【寻找石头】-第1期-20231113
https://xiepeng21.cn/posts/60a517c0/
【寻找石头】-第25期-20240521
https://xiepeng21.cn/posts/75d83c46/
【寻找石头】-第26期-20240528
https://xiepeng21.cn/posts/b1cee82c/
欢迎各位提出建议、问题,我们一起交流、学习、成长。
@@ -2747,28 +2911,34 @@这篇博客文章是半亩方塘的第100篇。(^-^)V
+2024年已经过半,让我们一起迎接下半场的挑战。ヾ(◍°∇°◍)ノ゙
- The piture was generated with ChatGPT-4o.
【神经网络控制器】美国麻省理工学院博士生杨麓洁团队提出可验证型神经网络控制器框架,为复杂非线性系统的稳定控制,提供了新的解决方案,在工业、交通、航空航天等领域都具备潜在应用前景。| 可验证型神经网络控制器框架
+【生成式AI】看一个东西有没有用,一个容易判断的点,就是你是否会持续用它?这两篇文章展示了生成式AI的百项奇思妙用,比如技术支持与故障排除、 内容创作与编辑、 个人与职业支持、学习与教育、创造力与娱乐、研究、分析与决策等。也欢迎您在评论区说说你平时都用生成式AI工具做些什么?以及它有哪些事情帮不了你做?
+【技术进步】君子生非异也,善假于物也。新技术带来更多解决问题的途径。| 新技术
+【时间序列预测】TFB: 一个全面公平的时间序列预测方法评测基准 | TFB
【理性的我们】从“这个行为对我有好处”转变成“这是我参与的集体行为,对我们有好处”。| 合作共赢
+【城市大模型】城市大模型能做些什么?技术驱动下为城市治理带来什么变化?又产生什么问题?如何构建城市大模型?| 城市大模型:认知、应用、展望
【寻找石头】-第1期-20231113
https://xiepeng21.cn/posts/60a517c0/
【寻找石头】-第25期-20240521
https://xiepeng21.cn/posts/75d83c46/
【寻找石头】-第26期-20240528
https://xiepeng21.cn/posts/b1cee82c/
欢迎各位提出建议、问题,我们一起交流、学习、成长。
@@ -2836,41 +3008,30 @@

【时空早期预测】过早得到的预测结果可能会导致较高的误报率,而能够获取更多信息的延迟预测可能会使结果失去时效性。如何平衡准确性和时效性是时空预测领域的一个难点问题,研究者提出一种基于多目标强化学习的时空早期预测模型STEMO,自适应地确定最佳预测时间,达到了时效性和准确性全新的平衡 | 基于多目标强化学习的时空早期预测
-【生成式AI】生成式AI的发展方向,应当是Chat还是Agent?您怎么看?欢迎在评论区留言。前者更擅长说,后者更擅长做,个人观点认为Chat和Agent应该协同起来,达到真正的知行合一 | Chat or Agent or Together
+【时间序列预测】ICML 24论文之揭示线性时间序列预测模型中的简约之美 | An Analysis of Linear Time Series Forecasting Models
【Agent & RAG】Agent & RAG 精选论文、开源项目及产品案例 | Agent & RAG学习资料
+【智能体决策】在心理学、认知神经科学和人工智能等领域,理解并建模人类与动物的行为是一项持续的挑战。研究人员提出了一种贝叶斯行为(Bayesian Behavior)框架,使用变分贝叶斯方法建模了感知运动任务中的行为,其中的核心创新点就在于引入了一个贝叶斯“意图”(intention)变量,从而有效地将习惯性行为与目标导向行为进行了衔接 | 贝叶斯行为框架
【端午节】昨天端午节,通过线上直播观察家乡广安的百舟竞渡端午节活动,滔滔嘉陵江上,百舟竞渡,奋勇争先,智擒活鸭,好不欢快。希望明年有机会到现场感受一下。^_^
【天府艺术公园】上周,饭后去了成都天府艺术公园逛逛,在当代艺术馆看展,下面分享一些照片。您如果有空,也可以去看看,感受艺术之美。
【节气养生】芒种,风吹麦浪,蝉鸣阵阵 | 芒种









【爱自己】真诚不只是唯一的必杀技,爱自己也是。
+【照顾自己】人这辈子要照顾好自己,先照顾好自己,才能面对未来挑战。
【体验】随着AI技术的快速发展,我们感叹于科技改变生活,让生活变得更加便利,获取知识的速度变得越来越快。当我们在生活中,慢下来的时候,独特的生活体验,我认为才是让人变得与众不同和有趣的核心所在。
+【人生积累】人生的成功是一个不断叠加的过程,每一次转型都不是对前一阶段的简单否定,而是以原有的积累为基础再上一个台阶。
【寻找石头】-第27期-20240604-迎接下半场挑战
https://xiepeng21.cn/posts/17dc9243/
【寻找石头】-第28期-20240611-滔滔嘉陵江
https://xiepeng21.cn/posts/d1e9272/
欢迎各位提出建议、问题,我们一起交流、学习、成长。
@@ -2945,172 +3104,41 @@
写的文字:An eagle flying free in the sky.
-生成的视频:
上传的图片:
生成的视频:
2023.11.12 阿里云突发临时宕机 | 阿里云突发全球性严重故障,历经 2.5 小时恢复
-大模型Agent技术发展 | 从第一性原理看大模型Agent技术
-文本生图片工具:gencraft
-文字描述:A boy was riding a cheetah on the prairie.
-生成的图片:
时序大模型
- -时间序列多尺度建模 | 多尺度Patch时序建模总结
-欢迎各位提出建议、问题,我们一起交流、学习、成长。
-“问渠那得清如许?为有源头活水来” ヾ(◍°∇°◍)ノ゙
-——— 我在半亩方塘等你 ^_^
-]]> The piture was generated with ChatGPT-4o. 图中展示了一名学生在阳光明媚的实验室亲身体验学习。
The piture was generated with ChatGPT-4o. 图中展示了一名学生在阳光明媚的实验室亲身体验学习。
【AI与能源】有观点认为“人工智能尽头是能源,未来在于AI与新能源结合”,您怎么看?我认为AI与能源是相互需要,相互促进的过程,前者的发展需要源源不断的能源供给,后者的供给在越来越大的AI算力需求背景下,会存在供不应求的情况,如何通过AI提升能源利用效率,在进一步推动能源电力升级、实现供需良好匹配、可持续环境发展等方面会起到重要的作用 | AI与能源
-【POI数据】有网友分享了一个能够实现零代码获取POI数据的工具,目前支持选择行政区划及指定坐标点周边范围2种方式获取POI数据 | POI数据获取
-【成都人工智能产业发展】提出了成都市人工智能产业高质量发展三年行动计划(2024-2026年),核心亮点在于 1. 紧扣国家战略 2. 直面发展问题 3. 把握发展焦点 4. 瞄准场景需求 | 成都人工智能产业系列政策
-【时空早期预测】过早得到的预测结果可能会导致较高的误报率,而能够获取更多信息的延迟预测可能会使结果失去时效性。如何平衡准确性和时效性是时空预测领域的一个难点问题,研究者提出一种基于多目标强化学习的时空早期预测模型STEMO,自适应地确定最佳预测时间,达到了时效性和准确性全新的平衡 | 基于多目标强化学习的时空早期预测
+【生成式AI】生成式AI的发展方向,应当是Chat还是Agent?您怎么看?欢迎在评论区留言。前者更擅长说,后者更擅长做,个人观点认为Chat和Agent应该协同起来,达到真正的知行合一 | Chat or Agent or Together
+【Agent & RAG】Agent & RAG 精选论文、开源项目及产品案例 | Agent & RAG学习资料
+【节气养生】夏至,嫩荷初绽,万物繁茂。| 夏至养生
+【情绪】情绪就像奔流不息的河流,偶尔波涛汹涌,有时细水长流,没法压抑,只能疏导,推荐《好情绪养成手册》一书,爱自己多一点,睡得更香一些。
+【天府艺术公园】上周,饭后去了成都天府艺术公园逛逛,在当代艺术馆看展,下面分享一些照片。您如果有空,也可以去看看,感受艺术之美。
【实践】唯有实践才是检验真理的唯一标准。
+【爱自己】真诚不只是唯一的必杀技,爱自己也是。
【与众不同】你活那么多年,他活那么多年,肯定有什么事只有你能做,只有你想做。
+【体验】随着AI技术的快速发展,我们感叹于科技改变生活,让生活变得更加便利,获取知识的速度变得越来越快。当我们在生活中,慢下来的时候,独特的生活体验,我认为才是让人变得与众不同和有趣的核心所在。
【寻找石头】-第28期-20240611-滔滔嘉陵江
https://xiepeng21.cn/posts/d1e9272/
【寻找石头】-第29期-20240618-艺术之美
https://xiepeng21.cn/posts/967ff32a/
欢迎各位提出建议、问题,我们一起交流、学习、成长。
@@ -3187,27 +3213,33 @@ 看起来ChatGPT-4o对于什么是好吃,还不理解,这碗面,你敢吃吗?反正我不敢。
The piture was generated with ChatGPT-4o. 图中展示了一名学生在阳光明媚的实验室亲身体验学习。
【ChatGPT-4o】使用了一周的ChatGPT-4o之后,给我印象最深的是,她开始在对话中,发起提问了,让我想到了一本书《学会提问》。给你印象最深的功能是什么呢?欢迎在评论区说说看。 | GPT-4o
+【AI与能源】有观点认为“人工智能尽头是能源,未来在于AI与新能源结合”,您怎么看?我认为AI与能源是相互需要,相互促进的过程,前者的发展需要源源不断的能源供给,后者的供给在越来越大的AI算力需求背景下,会存在供不应求的情况,如何通过AI提升能源利用效率,在进一步推动能源电力升级、实现供需良好匹配、可持续环境发展等方面会起到重要的作用 | AI与能源
【大科学时代】AI几乎可以与所有学科进行交叉融合。青年科学家们跨越传统的学科界限,迈向一个以问题为中心的大科学时代,这个愿景在AI的支持下有了成为现实的可能。我们将会看见更多的多学科融合的新发现、新成果出现。| 大科学时代
+【POI数据】有网友分享了一个能够实现零代码获取POI数据的工具,目前支持选择行政区划及指定坐标点周边范围2种方式获取POI数据 | POI数据获取
【智慧城市】城市是推进数字中国建设的综合载体,推进城市数字化转型、智慧化发展,是面向未来构筑城市竞争新优势的关键之举,也是推动城市治理体系和治理能力现代化的必然要求。| 智慧城市与数字化转型
+【成都人工智能产业发展】提出了成都市人工智能产业高质量发展三年行动计划(2024-2026年),核心亮点在于 1. 紧扣国家战略 2. 直面发展问题 3. 把握发展焦点 4. 瞄准场景需求 | 成都人工智能产业系列政策
【节气养生】夏至,嫩荷初绽,万物繁茂。| 夏至养生
+【情绪】情绪就像奔流不息的河流,偶尔波涛汹涌,有时细水长流,没法压抑,只能疏导,推荐《好情绪养成手册》一书,爱自己多一点,睡得更香一些。
+【实践】唯有实践才是检验真理的唯一标准。
+【与众不同】你活那么多年,他活那么多年,肯定有什么事只有你能做,只有你想做。
+【寻找石头】-第1期-20231113
https://xiepeng21.cn/posts/60a517c0/
【寻找石头】-第24期-20240514
https://xiepeng21.cn/posts/f309428f/
【寻找石头】-第25期-20240521
https://xiepeng21.cn/posts/75d83c46/
【寻找石头】-第26期-20240528
https://xiepeng21.cn/posts/b1cee82c/
【寻找石头】-第27期-20240604-迎接下半场挑战
https://xiepeng21.cn/posts/17dc9243/
【寻找石头】-第28期-20240611-滔滔嘉陵江
https://xiepeng21.cn/posts/d1e9272/
【寻找石头】-第29期-20240618-艺术之美
https://xiepeng21.cn/posts/967ff32a/
欢迎各位提出建议、问题,我们一起交流、学习、成长。
@@ -3273,30 +3315,37 @@
 The piture was generated with ChatGPT-4o.
The piture was generated with ChatGPT-4o.
【时间序列预测】ICML 24论文之揭示线性时间序列预测模型中的简约之美 | An Analysis of Linear Time Series Forecasting Models
+【语言与思维】有研究者认为「语言主要是用于交流的工具,而不是思考的工具,对于任何经过测试的思维形式都不是必需的」,您怎么看? | 语言与思维
【智能体决策】在心理学、认知神经科学和人工智能等领域,理解并建模人类与动物的行为是一项持续的挑战。研究人员提出了一种贝叶斯行为(Bayesian Behavior)框架,使用变分贝叶斯方法建模了感知运动任务中的行为,其中的核心创新点就在于引入了一个贝叶斯“意图”(intention)变量,从而有效地将习惯性行为与目标导向行为进行了衔接 | 贝叶斯行为框架
+【自由能原理】自由能原理提出者Karl Friston从自由能原理视角审视了生物和物理科学中一些重要的大脑理论,包括贝叶斯大脑、预测编码和信息最大化原则、层次推理和注意力理论、神经达尔文主义、信息论和最优控制理论等,表明几种全局性大脑理论可能在自由能框架内得到统一 | 自由能原理
+【学习增强系统】微软亚洲研究院的研究者从两个核心方向,来思考系统应如何不断自我学习和自我进化:“模块化”机器学习模型,与“系统化”大模型的推理思维。目标在于使得模型能够对齐复杂多变的系统环境和需求,并且推理思维能够对齐计算机系统时间和空间上的行为。 | 学习增强系统
【端午节】昨天端午节,通过线上直播观察家乡广安的百舟竞渡端午节活动,滔滔嘉陵江上,百舟竞渡,奋勇争先,智擒活鸭,好不欢快。希望明年有机会到现场感受一下。^_^
+【高考志愿】最近高考生开始填报志愿,有朋友咨询如何选城市、选学校、选专业。我回顾自己在10年前选择的经验,结合近些年对于选择的思考。其中选专业是最令人头疼的,不确定性很大,对其的了解也不够,我认为可以从以下三个维度进行思考选专业,也欢迎大家在留言区,说说您的观点和想法。
+【节气养生】芒种,风吹麦浪,蝉鸣阵阵 | 芒种
+【好书推荐】推荐《好情绪养成手册》一书,读完这本书,我发现情绪无好坏,你不是你的情绪,你的情绪也不是你,好好爱自己,是成长的起点,也是终点。这本书会教你如何爱自己,这个非常重要的技能,但从小家庭和学校都忽略甚至不知道如何教会我们的技能。可搭配《少有人走的路》系列书籍阅读,让我们一起活出自己想要的生活,学会爱自己,爱他人,爱生活,爱社会。
【照顾自己】人这辈子要照顾好自己,先照顾好自己,才能面对未来挑战。
+【焦虑】焦虑的根源在于没有被无条件地爱着,当你感到焦虑的时候,不要慌张,不是你的错。接下来好好爱自己,因为除了自己,很少有人无条件地爱着你。
【人生积累】人生的成功是一个不断叠加的过程,每一次转型都不是对前一阶段的简单否定,而是以原有的积累为基础再上一个台阶。
+【心之所向】越是支持和包容自己,就越能从容地实现每一个心之所向。
【寻找石头】-第27期-20240604-迎接下半场挑战
https://xiepeng21.cn/posts/17dc9243/
【寻找石头】-第28期-20240611-滔滔嘉陵江
https://xiepeng21.cn/posts/d1e9272/
【寻找石头】-第29期-20240618-艺术之美
https://xiepeng21.cn/posts/967ff32a/
【寻找石头】-第30期-20240625-实践出真知
https://xiepeng21.cn/posts/4117bea7/
欢迎各位提出建议、问题,我们一起交流、学习、成长。
@@ -3369,37 +3424,107 @@ The piture was generated with ChatGPT-4o.
写的文字:An eagle flying free in the sky.
+生成的视频:
上传的图片:
生成的视频:
2023.11.12 阿里云突发临时宕机 | 阿里云突发全球性严重故障,历经 2.5 小时恢复
【自由能原理】自由能原理提出者Karl Friston从自由能原理视角审视了生物和物理科学中一些重要的大脑理论,包括贝叶斯大脑、预测编码和信息最大化原则、层次推理和注意力理论、神经达尔文主义、信息论和最优控制理论等,表明几种全局性大脑理论可能在自由能框架内得到统一 | 自由能原理
+大模型Agent技术发展 | 从第一性原理看大模型Agent技术
【学习增强系统】微软亚洲研究院的研究者从两个核心方向,来思考系统应如何不断自我学习和自我进化:“模块化”机器学习模型,与“系统化”大模型的推理思维。目标在于使得模型能够对齐复杂多变的系统环境和需求,并且推理思维能够对齐计算机系统时间和空间上的行为。 | 学习增强系统
+文本生图片工具:gencraft
文字描述:A boy was riding a cheetah on the prairie.
+生成的图片:
时序大模型
+ +时间序列多尺度建模 | 多尺度Patch时序建模总结
+【高考志愿】最近高考生开始填报志愿,有朋友咨询如何选城市、选学校、选专业。我回顾自己在10年前选择的经验,结合近些年对于选择的思考。其中选专业是最令人头疼的,不确定性很大,对其的了解也不够,我认为可以从以下三个维度进行思考选专业,也欢迎大家在留言区,说说您的观点和想法。
- The piture was generated with ChatGPT-4o.
The piture was generated with ChatGPT-4o.
【Embedding技术】Embedding是一种将高维数据映射到低维空间的技术。主要作用是降低数据维度,提升计算效率,使得AI模型可以捕获到数据之间的隐含关系和结构。关于Embedding维度的讨论和分析,可以看一看苏剑林的博客文章最小熵原理(六):词向量的维度应该怎么选择?,挺有意思。知乎也有个话题讨论,关于设计Embedding维数时有什么讲究?,也欢迎您在评论区,讲一讲您的经验和观点。| Embedding技术
【好书推荐】推荐《好情绪养成手册》一书,读完这本书,我发现情绪无好坏,你不是你的情绪,你的情绪也不是你,好好爱自己,是成长的起点,也是终点。这本书会教你如何爱自己,这个非常重要的技能,但从小家庭和学校都忽略甚至不知道如何教会我们的技能。可搭配《少有人走的路》系列书籍阅读,让我们一起活出自己想要的生活,学会爱自己,爱他人,爱生活,爱社会。
+【大模型】腾讯汤道生认为“不是只有做大模型的玩家才是做AI。这就等于认为,只有做手机的企业才在移动时代重要,是很狭隘的。”以及“我们的感受来自体验,自己用一下市面上的产品,Get a feeling到底这个技术发展到什么程度?问题是在哪?”,从个人使用大模型产品的感受来看,非常认同他的观点,此外,我除了关心大模型能帮我们做什么,也关心大模型做不了什么,比如品尝美食、做运动、冥想、徒步、骑行等。在思考的过程中,感悟人活着的意义,以及大模型将给我们的生活方式带来哪些改变。欢迎您在评论区,谈一谈,大模型给你带来的变化,和你的感受。| 对话腾讯汤道生:AI不止于大模型
+【群体智能】涉及多智能体框架,会面临的3个关键问题:1. 先得有单体的 Agent,再利用单体智能组合产生群体智能,对单智能体进行设计和划分,单体智能体划分得越明确,群体智能方案越好做;2. 有了多个单智能体之后,智能体们所在的环境也需要做定义,所有的智能体都在一个环境里面工作;3. 多个智能体之间如何交流,需要定义他们之间的交流链,是串行的或者并行的,要考虑不同应用场景智能体间的通信方式。 | 基于大模型的群体智能解决方案
+【重大科技问题】7月2日,在第二十六届中国科协年会主论坛上,中国科协发布2024重大科学问题、工程技术难题和产业技术问题。| 2024年30个重大科技、产业技术问题难题公布
+【智能时代】智能问题已经打破了科技与非科技的界限,进入了一个超科技的复杂性领域问题,所以在智能时代,不仅仅是要以新的科技视野看待之,而是要呼唤新的思想和思考方式。我认为在智能时代,对人的智能也提出了更高的要求,能否与人、与机器高效沟通、协作,将成为人的智能水平高低的重要分界线。在这些能力里,涉及到独立思考、自主决策、主动行动以及高效协作等。| 智能时代呼唤新的思想和思考
+【未来】未来有哪些发展方向可能会取代当下数学和AI的地位,这篇文章给出了一些思考。也欢迎您在评论区,说一说,今后的科技会走向何方?| 未来取代数学与AI的会是什么?
+【从健身到养生】最近,天气开始变得热起来,雨时而下、时而停,成都的空气中湿度很高,湿热的天气下,流汗过多,更容易让人感到疲乏,加之平日久坐,脖颈酸疼,就在想之前的健身方式(撸铁、骑行、跑步),是不是该因时调整一下。就开始尝试养生运动,比如八段锦、散步、冥想等,发现微微出汗,呼吸之间,身心更加平和,也起到了保养身心的作用,挺好的。
+【好书推荐】推荐《人生很短,做一个有趣的人》一书,这本书是我的床头读物,每晚看一点,不知不觉,就看完了。汪老的人生状态很潇洒,谈美食,论写作,讲画画,细品茶,没有很多波澜壮阔的故事,但给人一种接地气,懂生活的感觉,从文字里,能感受到他提到的“写作,要贴着人物来写”的精髓所在。他当年在西南联大的日子,也很有趣,讲到他和他的老师们的一起学习、生活的故事,令人心驰神往,感触颇深。
+【电影推荐】推荐《阳光灿烂的日子》,一部反映青少年的青春悸动与时代汹涌的片子,带我们近距离感受了那个时代的操蛋和傻逼,也看到了那群人身上的希望和活力,矛盾和冲突不断呈现的喜剧,看完之后,却给人留下对那个时代的回顾反思和一群青少年的成长思考。
+【节气养生】小暑至,盛夏始。| 小暑
【焦虑】焦虑的根源在于没有被无条件地爱着,当你感到焦虑的时候,不要慌张,不是你的错。接下来好好爱自己,因为除了自己,很少有人无条件地爱着你。
+【迷茫】当你感到前路迷茫,不知道未来将去向何方时,不如问问自己,当初为什么出发,也许,你会看到自己是怎么一步步走到现在的,在这个过程中,未来的方向,就会渐渐明朗。就像《西游记》里的唐僧所说,“贫僧从东土大唐而来,去往西天拜佛求经”。
【心之所向】越是支持和包容自己,就越能从容地实现每一个心之所向。
+【焦虑与抑郁】焦虑是自己被困在了未来,抑郁是自己被卡在了过去。未来还没到来,过去已经过去。跳出来看吧,你能把握的只有当下,只有下一步,你想做什么,你要做什么,想好了,就去做吧。
【寻找石头】-第30期-20240625-实践出真知
https://xiepeng21.cn/posts/4117bea7/
【寻找石头】-第31期-20240702-自我关怀
https://xiepeng21.cn/posts/20a61424/
欢迎各位提出建议、问题,我们一起交流、学习、成长。
@@ -3591,53 +3718,136 @@ The piture was generated with ChatGPT-4o.
 The piture was generated with ChatGPT-4o
The piture was generated with ChatGPT-4o
【Embedding技术】Embedding是一种将高维数据映射到低维空间的技术。主要作用是降低数据维度,提升计算效率,使得AI模型可以捕获到数据之间的隐含关系和结构。关于Embedding维度的讨论和分析,可以看一看苏剑林的博客文章最小熵原理(六):词向量的维度应该怎么选择?,挺有意思。知乎也有个话题讨论,关于设计Embedding维数时有什么讲究?,也欢迎您在评论区,讲一讲您的经验和观点。| Embedding技术
+【大自然如何运作】21世纪被称为复杂性科学的世纪。丹麦物理学家帕·巴克和中国物理学家汤超开创的自组织临界性理论,对大自然的复杂性问题进行了系统化探讨,为复杂系统中的跨尺度现象,提供了一种普适而简单的机制上的解释,以其创新性、宏观性和简洁性引起科学界的密切关注。| 自组织临界性
【大模型】腾讯汤道生认为“不是只有做大模型的玩家才是做AI。这就等于认为,只有做手机的企业才在移动时代重要,是很狭隘的。”以及“我们的感受来自体验,自己用一下市面上的产品,Get a feeling到底这个技术发展到什么程度?问题是在哪?”,从个人使用大模型产品的感受来看,非常认同他的观点,此外,我除了关心大模型能帮我们做什么,也关心大模型做不了什么,比如品尝美食、做运动、冥想、徒步、骑行等。在思考的过程中,感悟人活着的意义,以及大模型将给我们的生活方式带来哪些改变。欢迎您在评论区,谈一谈,大模型给你带来的变化,和你的感受。| 对话腾讯汤道生:AI不止于大模型
+【思考快与慢】Meta FAIR 的研究者提出了一种System2(慢速思考)蒸馏方法,该方法在给定一组未标记示例的情况下以无监督的方式执行编译。| System 2蒸馏技术
【群体智能】涉及多智能体框架,会面临的3个关键问题:1. 先得有单体的 Agent,再利用单体智能组合产生群体智能,对单智能体进行设计和划分,单体智能体划分得越明确,群体智能方案越好做;2. 有了多个单智能体之后,智能体们所在的环境也需要做定义,所有的智能体都在一个环境里面工作;3. 多个智能体之间如何交流,需要定义他们之间的交流链,是串行的或者并行的,要考虑不同应用场景智能体间的通信方式。 | 基于大模型的群体智能解决方案
+【大脑如何处理语言】普林斯顿大学的研究者分析电路计算,将这些计算解构为功能专门的「transformations」,将跨词语的上下文信息整合在一起。利用参与者聆听自然故事时获得的功能性MRI数据,验证了这些「transformations」是否可以解释整个皮质语言网络中大脑活动的显著差异。| 大脑如何处理语言
【重大科技问题】7月2日,在第二十六届中国科协年会主论坛上,中国科协发布2024重大科学问题、工程技术难题和产业技术问题。| 2024年30个重大科技、产业技术问题难题公布
-【骑行】前段时间,成都大部分时间在下雨,或者天气很闷热,不适合骑车,今天开始晴朗起来,继续骑车通勤。我们无法预测什么时候能够退休,但我们可以选择一种健康的生活方式,从现在做起,期望我们的退休生活能够更加健康、自在、幸福。
【智能时代】智能问题已经打破了科技与非科技的界限,进入了一个超科技的复杂性领域问题,所以在智能时代,不仅仅是要以新的科技视野看待之,而是要呼唤新的思想和思考方式。我认为在智能时代,对人的智能也提出了更高的要求,能否与人、与机器高效沟通、协作,将成为人的智能水平高低的重要分界线。在这些能力里,涉及到独立思考、自主决策、主动行动以及高效协作等。| 智能时代呼唤新的思想和思考
+【节气养生】大暑,火热的夏季,生活的浪漫。
【未来】未来有哪些发展方向可能会取代当下数学和AI的地位,这篇文章给出了一些思考。也欢迎您在评论区,说一说,今后的科技会走向何方?| 未来取代数学与AI的会是什么?
-【健康生活】充足睡眠、健康饮食、规律锻炼、亲近自然和经常冥想。
+【医疗】To Cure Sometimes, To Relieve Often, To Comfort Always.(有时能治愈,常常助缓解,总是去安慰)。
【从健身到养生】最近,天气开始变得热起来,雨时而下、时而停,成都的空气中湿度很高,湿热的天气下,流汗过多,更容易让人感到疲乏,加之平日久坐,脖颈酸疼,就在想之前的健身方式(撸铁、骑行、跑步),是不是该因时调整一下。就开始尝试养生运动,比如八段锦、散步、冥想等,发现微微出汗,呼吸之间,身心更加平和,也起到了保养身心的作用,挺好的。
+【寻找石头】-第1期-20231113
https://xiepeng21.cn/posts/60a517c0/
【好书推荐】推荐《人生很短,做一个有趣的人》一书,这本书是我的床头读物,每晚看一点,不知不觉,就看完了。汪老的人生状态很潇洒,谈美食,论写作,讲画画,细品茶,没有很多波澜壮阔的故事,但给人一种接地气,懂生活的感觉,从文字里,能感受到他提到的“写作,要贴着人物来写”的精髓所在。他当年在西南联大的日子,也很有趣,讲到他和他的老师们的一起学习、生活的故事,令人心驰神往,感触颇深。
+【寻找石头】-第2期-20231117
https://xiepeng21.cn/posts/28c5f201/
【电影推荐】推荐《阳光灿烂的日子》,一部反映青少年的青春悸动与时代汹涌的片子,带我们近距离感受了那个时代的操蛋和傻逼,也看到了那群人身上的希望和活力,矛盾和冲突不断呈现的喜剧,看完之后,却给人留下对那个时代的回顾反思和一群青少年的成长思考。
+【寻找石头】-第3期-20231124
https://xiepeng21.cn/posts/8fbdec1/
【节气养生】小暑至,盛夏始。| 小暑
+【寻找石头】-第4期-20231201
https://xiepeng21.cn/posts/3592f0cd/
【寻找石头】-第5期-20231208
https://xiepeng21.cn/posts/91d891ec/
【寻找石头】-第6期-20231215
https://xiepeng21.cn/posts/4bb8b0de/
【寻找石头】-第7期-20231222
https://xiepeng21.cn/posts/2367af3b/
【寻找石头】-第8期-20240112
https://xiepeng21.cn/posts/27e02ce1/
【寻找石头】-第9期-20240119
https://xiepeng21.cn/posts/6da42cec/
【寻找石头】-第10期-20240126
https://xiepeng21.cn/posts/8dfb97f1/
【寻找石头】-第11期-20240203
https://xiepeng21.cn/posts/10776620/
【寻找石头】-第12期-20240220
https://xiepeng21.cn/posts/68239d6/
【寻找石头】-第13期-20240223
https://xiepeng21.cn/posts/421db1e9/
【寻找石头】-第14期-20240305
https://xiepeng21.cn/posts/e5f91a31/
【寻找石头】-第15期-20240312
https://xiepeng21.cn/posts/bf106756/
【寻找石头】-第16期-20240319
https://xiepeng21.cn/posts/9508d210/
【寻找石头】-第17期-20240326
https://xiepeng21.cn/posts/f30c45c7/
【寻找石头】-第18期-20240402
https://xiepeng21.cn/posts/e46820ec/
【寻找石头】-第19期-20240409
https://xiepeng21.cn/posts/ae2c20e1/
【寻找石头】-第20期-20240416
https://xiepeng21.cn/posts/dc7c2302/
【寻找石头】-第21期-20240423
https://xiepeng21.cn/posts/5aad5dcb/
【寻找石头】-第22期-20240430
https://xiepeng21.cn/posts/677551fe/
【寻找石头】-第23期-20240507
https://xiepeng21.cn/posts/e68242c/
【寻找石头】-第24期-20240514
https://xiepeng21.cn/posts/f309428f/
【寻找石头】-第25期-20240521
https://xiepeng21.cn/posts/75d83c46/
【寻找石头】-第26期-20240528
https://xiepeng21.cn/posts/b1cee82c/
【寻找石头】-第27期-20240604-迎接下半场挑战
https://xiepeng21.cn/posts/17dc9243/
【寻找石头】-第28期-20240611-滔滔嘉陵江
https://xiepeng21.cn/posts/d1e9272/
【寻找石头】-第29期-20240618-艺术之美
https://xiepeng21.cn/posts/967ff32a/
【寻找石头】-第30期-20240625-实践出真知
https://xiepeng21.cn/posts/4117bea7/
【寻找石头】-第31期-20240702-自我关怀
https://xiepeng21.cn/posts/20a61424/
【寻找石头】-第32期-20240709-从健身到养生
https://xiepeng21.cn/posts/67ca5d35/
【寻找石头】-第33期-20240716-自行车
https://xiepeng21.cn/posts/d90d011d/
欢迎各位提出建议、问题,我们一起交流、学习、成长。
+“问渠那得清如许?为有源头活水来” ヾ(◍°∇°◍)ノ゙
+——— 我在半亩方塘等你 ^_^
+]]>
【推理能力】斯坦福大学教授Noah D. Goodman称STaR让AI模型能够通过迭代创建自己的训练数据来“指导”自己进入更高的智能水平,理论上可以让语言模型超越人类水平的智能,成为创造者。| 像人一样思考
+【Mem0】Mem0可实现个性化的AI交互,1. 具有多层次的记忆:它能记住用户的偏好、过去的交互、事情的进展,就像你跟朋友聊天,朋友能记住你喜欢什么、不喜欢什么;2. 自适应的个性化:从交互中持续学习,越用越聪明,真是个贴心的小助手;3. 跨平台、API 友好:支持私有化部署,开发者可以轻松集成到各种平台。| Mem0
+【天气预报】Google Research 研究团队提出一种将传统的基于物理建模与 ML 相结合的新方法——NeuralGCM,可以准确高效地模拟地球大气层。比现有模型更快、计算成本更低、更准确。NeuralGCM 可以生成 2-15 天的天气预报,比目前基于物理的「黄金标准」模型更准确。| 天气预报
+【骑行】上周四独自骑行,绕着成都三环,骑行一圈,目前已经骑完成都二环、三环以及绕城天府绿道,自在骑行,探索世界,耶。
+【电影推荐】《抓娃娃》——闫非/彭大魔,一部关于值得观看的反思家庭教育的影片,从剧中可以看到自己,也可以看到自己希望成为的样子。你愿意如何教育孩子,你希望活出怎样的人生,值得思考。
【迷茫】当你感到前路迷茫,不知道未来将去向何方时,不如问问自己,当初为什么出发,也许,你会看到自己是怎么一步步走到现在的,在这个过程中,未来的方向,就会渐渐明朗。就像《西游记》里的唐僧所说,“贫僧从东土大唐而来,去往西天拜佛求经”。
+【拖延】拖延的最大坏处还不是耽误,而是会使自己变得犹豫,甚至丧失信心。不管什么事,决定了,就立刻去做,这本身就能使人生气勃勃,保持一种主动和快乐的心情。
【焦虑与抑郁】焦虑是自己被困在了未来,抑郁是自己被卡在了过去。未来还没到来,过去已经过去。跳出来看吧,你能把握的只有当下,只有下一步,你想做什么,你要做什么,想好了,就去做吧。
+【淡然】去留无意,望天空云卷云舒。
【寻找石头】-第31期-20240702-自我关怀
https://xiepeng21.cn/posts/20a61424/
【寻找石头】-第32期-20240709-从健身到养生
https://xiepeng21.cn/posts/67ca5d35/
【寻找石头】-第33期-20240716-自行车
https://xiepeng21.cn/posts/d90d011d/
【寻找石头】-第34期-20240723-健康生活
https://xiepeng21.cn/posts/fd3295a5/
欢迎各位提出建议、问题,我们一起交流、学习、成长。
@@ -3829,101 +4045,79 @@
【推理能力】斯坦福大学教授Noah D. Goodman称STaR让AI模型能够通过迭代创建自己的训练数据来“指导”自己进入更高的智能水平,理论上可以让语言模型超越人类水平的智能,成为创造者。| 像人一样思考
+【AI×】AI×可以包括更复杂的AI系统、更广泛的数据集成、更智能的决策支持系统,以及更深入的行业影响和社会变革。| 从“AI+”到“AI×”
【Mem0】Mem0可实现个性化的AI交互,1. 具有多层次的记忆:它能记住用户的偏好、过去的交互、事情的进展,就像你跟朋友聊天,朋友能记住你喜欢什么、不喜欢什么;2. 自适应的个性化:从交互中持续学习,越用越聪明,真是个贴心的小助手;3. 跨平台、API 友好:支持私有化部署,开发者可以轻松集成到各种平台。| Mem0
+【KDD China 2024数智未来研讨会】数字经济浪潮汹涌,AI生成模型正引领新一轮产业革命,其深远影响备受瞩目。响应时代召唤,KDD China 2024年度盛会将于2024年8月16日至17日再次在成都盛大召开,主题聚焦“数据驱动智能,模型生成未来”。| KDD China 2024数智未来研讨会
【天气预报】Google Research 研究团队提出一种将传统的基于物理建模与 ML 相结合的新方法——NeuralGCM,可以准确高效地模拟地球大气层。比现有模型更快、计算成本更低、更准确。NeuralGCM 可以生成 2-15 天的天气预报,比目前基于物理的「黄金标准」模型更准确。| 天气预报
+【人机协同】在人机协同中,自由与计划、自主与规则的平衡至关重要。自由允许机器和人类在不受过多限制的情况下创新和适应,而计划则通过设定框架和目标,确保协同过程的效率和方向性。自主赋予机器和人类一定的决策权,促进灵活性;而规则提供结构和一致性,减少潜在的冲突和错误。成功的人机协同需要在这两对元素之间找到适合的平衡点。因此,在人机协同中,自由与计划、自主与规则之间存在着相互关联但又需要平衡的关系。| 人机协同
【骑行】上周四独自骑行,绕着成都三环,骑行一圈,目前已经骑完成都二环、三环以及绕城天府绿道,自在骑行,探索世界,耶。
+【社交】卡尔·荣格(Carl Jung)所描述的那样,性格内向的人通过独处来充电,他们必须有自己的时间才能恢复精力;而性格外向的人则在与人接触的过程中获得能量。大部分人的个性都处在这两极中间的某个水平。比起谈论自己,内向者对他人更感兴趣。内向者具有局外人的视角,将自己定位为观察者,对他人的故事和处境感到好奇。1. 做先发问的那个人 (关于为什么要提问,以及如何提问,可以参考之前一篇博客文章:学会提问);2. 让好奇心发挥作用 (提问以及寻找答案的过程,也是在激发和满足自己好奇心的过程);3. 保持目光锐利(观察身边的人、事、物,让自己具有更强的洞察力)。| 内向者社交法则
【电影推荐】《抓娃娃》——闫非/彭大魔,一部关于值得观看的反思家庭教育的影片,从剧中可以看到自己,也可以看到自己希望成为的样子。你愿意如何教育孩子,你希望活出怎样的人生,值得思考。
+【节气养生】立秋
【拖延】拖延的最大坏处还不是耽误,而是会使自己变得犹豫,甚至丧失信心。不管什么事,决定了,就立刻去做,这本身就能使人生气勃勃,保持一种主动和快乐的心情。
+【放下】人生是一场自己和自己的竞技,与人无关,亦与人无尤。不沉溺、不纠结、继续生活,这才是真正的放下。
【淡然】去留无意,望天空云卷云舒。
+【桥牌】桥牌是一种涉及多个数学领域的复杂游戏,它要求玩家利用概率论来评估出牌的可能性,运用统计学来分析已出牌并预测剩余牌的分布。玩家还需要掌握组合数学来优化叫牌策略,利用决策理论在不同的选择中做出最佳决策。逻辑推理在推断对手和队友的牌时至关重要,同时策略规划帮助玩家制定长远打法。记忆力在记住已出牌以辅助决策中发挥重要作用,而心理战术则用于影响对手的判断并隐藏自己的决策。
【寻找石头】-第1期-20231113
https://xiepeng21.cn/posts/60a517c0/
【寻找石头】-第2期-20231117
https://xiepeng21.cn/posts/28c5f201/
【寻找石头】-第3期-20231124
https://xiepeng21.cn/posts/8fbdec1/
【寻找石头】-第4期-20231201
https://xiepeng21.cn/posts/3592f0cd/
【寻找石头】-第5期-20231208
https://xiepeng21.cn/posts/91d891ec/
【寻找石头】-第6期-20231215
https://xiepeng21.cn/posts/4bb8b0de/
【寻找石头】-第7期-20231222
https://xiepeng21.cn/posts/2367af3b/
【寻找石头】-第8期-20240112
https://xiepeng21.cn/posts/27e02ce1/
【寻找石头】-第9期-20240119
https://xiepeng21.cn/posts/6da42cec/
【寻找石头】-第10期-20240126
https://xiepeng21.cn/posts/8dfb97f1/
【寻找石头】-第11期-20240203
https://xiepeng21.cn/posts/10776620/
【寻找石头】-第12期-20240220
https://xiepeng21.cn/posts/68239d6/
【寻找石头】-第13期-20240223
https://xiepeng21.cn/posts/421db1e9/
【寻找石头】-第14期-20240305
https://xiepeng21.cn/posts/e5f91a31/
【寻找石头】-第15期-20240312
https://xiepeng21.cn/posts/bf106756/
【寻找石头】-第16期-20240319
https://xiepeng21.cn/posts/9508d210/
【寻找石头】-第17期-20240326
https://xiepeng21.cn/posts/f30c45c7/
【寻找石头】-第18期-20240402
https://xiepeng21.cn/posts/e46820ec/
【寻找石头】-第19期-20240409
https://xiepeng21.cn/posts/ae2c20e1/
【寻找石头】-第20期-20240416
https://xiepeng21.cn/posts/dc7c2302/
【寻找石头】-第21期-20240423
https://xiepeng21.cn/posts/5aad5dcb/
【寻找石头】-第22期-20240430
https://xiepeng21.cn/posts/677551fe/
【寻找石头】-第23期-20240507
https://xiepeng21.cn/posts/e68242c/
【寻找石头】-第24期-20240514
https://xiepeng21.cn/posts/f309428f/
【寻找石头】-第25期-20240521
https://xiepeng21.cn/posts/75d83c46/
【寻找石头】-第26期-20240528
https://xiepeng21.cn/posts/b1cee82c/
【寻找石头】-第27期-20240604-迎接下半场挑战
https://xiepeng21.cn/posts/17dc9243/
【寻找石头】-第28期-20240611-滔滔嘉陵江
https://xiepeng21.cn/posts/d1e9272/
【寻找石头】-第29期-20240618-艺术之美
https://xiepeng21.cn/posts/967ff32a/
【寻找石头】-第30期-20240625-实践出真知
https://xiepeng21.cn/posts/4117bea7/
【寻找石头】-第31期-20240702-自我关怀
https://xiepeng21.cn/posts/20a61424/
【寻找石头】-第32期-20240709-从健身到养生
https://xiepeng21.cn/posts/67ca5d35/
【寻找石头】-第33期-20240716-自行车
https://xiepeng21.cn/posts/d90d011d/
【寻找石头】-第34期-20240723-健康生活
https://xiepeng21.cn/posts/fd3295a5/
欢迎各位提出建议、问题,我们一起交流、学习、成长。
+“问渠那得清如许?为有源头活水来” ヾ(◍°∇°◍)ノ゙
+——— 我在半亩方塘等你 ^_^
+]]>New Bing
Pi
ChatGPT
Claude
文心一言

欢迎各位提出建议、问题,我们一起交流、学习、成长。
“问渠那得清如许?为有源头活水来” ヾ(◍°∇°◍)ノ゙
@@ -3992,39 +4186,41 @@Imagine | 文生图工具,Meta推出 https://imagine.meta.com/?prompt=a+cute+dog+on+mars
+ a cute dog on mars

基于大规模城市交通速度数据,研究发现交通拥堵的消散持续时间近似于幂律分布 | Nat. Commun.速递:交通瓶颈的时空动力学预测严重交通拥堵的早期信号
+充分发挥数据要素的放大、叠加、倍增作用,构建以数据为关键要素的数字经济。数据要素×智能制造、智慧农业、商贸流通、交通运输、金融服务、科技创新、文化旅游、医疗健康、应急管理、气象服务、智慧城市、绿色低碳。| 关于向社会公开征求《“数据要素×”三年行动计划(2024—2026年)(征求意见稿)》意见的公告
+国内外大模型清单,来源:国内外AI大模型(LLMs)排行榜:
New Bing
Pi
ChatGPT
Claude
文心一言
欢迎各位提出建议、问题,我们一起交流、学习、成长。
@@ -4089,38 +4285,47 @@时空AI驱动创新发展 | 院士报告 | 李德仁院士:时空AI驱动创新发展——论数据、算法、算力与应用
+城市智能体 | “四智”融合!全国首个城市智能体@大模型福田创新成果正式发布
+大模型
+国际
+国内
+数据领域建设的五大方向:数据技术、数据应用、三类数商、基础制度、数据价值 | 国家数据局为数据领域建设指明了5大方向
欢迎各位提出建议、问题,我们一起交流、学习、成长。
@@ -4174,397 +4379,48 @@“问渠那得清如许?为有源头活水来” ヾ(◍°∇°◍)ノ゙
——— 我在半亩方塘等你 ^_^
]]>时空AI驱动创新发展 | 院士报告 | 李德仁院士:时空AI驱动创新发展——论数据、算法、算力与应用
-城市智能体 | “四智”融合!全国首个城市智能体@大模型福田创新成果正式发布
-大模型
-国际
-国内
-数据领域建设的五大方向:数据技术、数据应用、三类数商、基础制度、数据价值 | 国家数据局为数据领域建设指明了5大方向
-欢迎各位提出建议、问题,我们一起交流、学习、成长。
-“问渠那得清如许?为有源头活水来” ヾ(◍°∇°◍)ノ゙
-——— 我在半亩方塘等你 ^_^
-]]> The piture was generated with ChatGPT-4o
【大自然如何运作】21世纪被称为复杂性科学的世纪。丹麦物理学家帕·巴克和中国物理学家汤超开创的自组织临界性理论,对大自然的复杂性问题进行了系统化探讨,为复杂系统中的跨尺度现象,提供了一种普适而简单的机制上的解释,以其创新性、宏观性和简洁性引起科学界的密切关注。| 自组织临界性
-【思考快与慢】Meta FAIR 的研究者提出了一种System2(慢速思考)蒸馏方法,该方法在给定一组未标记示例的情况下以无监督的方式执行编译。| System 2蒸馏技术
-【大脑如何处理语言】普林斯顿大学的研究者分析电路计算,将这些计算解构为功能专门的「transformations」,将跨词语的上下文信息整合在一起。利用参与者聆听自然故事时获得的功能性MRI数据,验证了这些「transformations」是否可以解释整个皮质语言网络中大脑活动的显著差异。| 大脑如何处理语言
-【骑行】前段时间,成都大部分时间在下雨,或者天气很闷热,不适合骑车,今天开始晴朗起来,继续骑车通勤。我们无法预测什么时候能够退休,但我们可以选择一种健康的生活方式,从现在做起,期望我们的退休生活能够更加健康、自在、幸福。
-【节气养生】大暑,火热的夏季,生活的浪漫。
-【健康生活】充足睡眠、健康饮食、规律锻炼、亲近自然和经常冥想。
-【医疗】To Cure Sometimes, To Relieve Often, To Comfort Always.(有时能治愈,常常助缓解,总是去安慰)。
-【寻找石头】-第1期-20231113
https://xiepeng21.cn/posts/60a517c0/
【寻找石头】-第2期-20231117
https://xiepeng21.cn/posts/28c5f201/
【寻找石头】-第3期-20231124
https://xiepeng21.cn/posts/8fbdec1/
【寻找石头】-第4期-20231201
https://xiepeng21.cn/posts/3592f0cd/
【寻找石头】-第5期-20231208
https://xiepeng21.cn/posts/91d891ec/
【寻找石头】-第6期-20231215
https://xiepeng21.cn/posts/4bb8b0de/
【寻找石头】-第7期-20231222
https://xiepeng21.cn/posts/2367af3b/
【寻找石头】-第8期-20240112
https://xiepeng21.cn/posts/27e02ce1/
【寻找石头】-第9期-20240119
https://xiepeng21.cn/posts/6da42cec/
【寻找石头】-第10期-20240126
https://xiepeng21.cn/posts/8dfb97f1/
【寻找石头】-第11期-20240203
https://xiepeng21.cn/posts/10776620/
【寻找石头】-第12期-20240220
https://xiepeng21.cn/posts/68239d6/
【寻找石头】-第13期-20240223
https://xiepeng21.cn/posts/421db1e9/
【寻找石头】-第14期-20240305
https://xiepeng21.cn/posts/e5f91a31/
【寻找石头】-第15期-20240312
https://xiepeng21.cn/posts/bf106756/
【寻找石头】-第16期-20240319
https://xiepeng21.cn/posts/9508d210/
【寻找石头】-第17期-20240326
https://xiepeng21.cn/posts/f30c45c7/
【寻找石头】-第18期-20240402
https://xiepeng21.cn/posts/e46820ec/
【寻找石头】-第19期-20240409
https://xiepeng21.cn/posts/ae2c20e1/
【寻找石头】-第20期-20240416
https://xiepeng21.cn/posts/dc7c2302/
【寻找石头】-第21期-20240423
https://xiepeng21.cn/posts/5aad5dcb/
【寻找石头】-第22期-20240430
https://xiepeng21.cn/posts/677551fe/
【寻找石头】-第23期-20240507
https://xiepeng21.cn/posts/e68242c/
【寻找石头】-第24期-20240514
https://xiepeng21.cn/posts/f309428f/
【寻找石头】-第25期-20240521
https://xiepeng21.cn/posts/75d83c46/
【寻找石头】-第26期-20240528
https://xiepeng21.cn/posts/b1cee82c/
【寻找石头】-第27期-20240604-迎接下半场挑战
https://xiepeng21.cn/posts/17dc9243/
【寻找石头】-第28期-20240611-滔滔嘉陵江
https://xiepeng21.cn/posts/d1e9272/
【寻找石头】-第29期-20240618-艺术之美
https://xiepeng21.cn/posts/967ff32a/
【寻找石头】-第30期-20240625-实践出真知
https://xiepeng21.cn/posts/4117bea7/
【寻找石头】-第31期-20240702-自我关怀
https://xiepeng21.cn/posts/20a61424/
【寻找石头】-第32期-20240709-从健身到养生
https://xiepeng21.cn/posts/67ca5d35/
【寻找石头】-第33期-20240716-自行车
https://xiepeng21.cn/posts/d90d011d/
欢迎各位提出建议、问题,我们一起交流、学习、成长。
-“问渠那得清如许?为有源头活水来” ヾ(◍°∇°◍)ノ゙
-——— 我在半亩方塘等你 ^_^
-]]>Imagine | 文生图工具,Meta推出 https://imagine.meta.com/?prompt=a+cute+dog+on+mars
- a cute dog on mars
基于大规模城市交通速度数据,研究发现交通拥堵的消散持续时间近似于幂律分布 | Nat. Commun.速递:交通瓶颈的时空动力学预测严重交通拥堵的早期信号
-充分发挥数据要素的放大、叠加、倍增作用,构建以数据为关键要素的数字经济。数据要素×智能制造、智慧农业、商贸流通、交通运输、金融服务、科技创新、文化旅游、医疗健康、应急管理、气象服务、智慧城市、绿色低碳。| 关于向社会公开征求《“数据要素×”三年行动计划(2024—2026年)(征求意见稿)》意见的公告
-国内外大模型清单,来源:国内外AI大模型(LLMs)排行榜:
欢迎各位提出建议、问题,我们一起交流、学习、成长。
-“问渠那得清如许?为有源头活水来” ヾ(◍°∇°◍)ノ゙
-——— 我在半亩方塘等你 ^_^
-]]>
冬至,『阳气初生』,北半球白天最短,黑夜最长,让过去完全过去,让开始重新开始。
-冬至天气寒冷,患心脏病和高血压的病人容易加重病情,患中风的人也会增多,相关患者人群需注意,做好预防、治疗和康养。
-小知识:每年冬至后的第19天至第27天称为“三九”,是一年中最寒冷的时候。
有首有意思的歌谣:“一九二九不出手,三九四九冰上走,五九六九沿河看柳,七九河开,八九燕来,九九加一九,耕牛遍地走。”
从冬至开始,生命活动由盛转衰,由动转静。
-冬至吃饺子,耳朵冻不坏。有句谚语说,“十月一,冬至到,家家户户吃水饺”。
-欢迎各位提出建议、问题,我们一起交流、学习、成长。
-“问渠那得清如许?为有源头活水来” ヾ(◍°∇°◍)ノ゙
-——— 我在半亩方塘等你 ^_^
-]]>
夏至是二十四节气中的一个重要节气,标志着一年中白天最长、夜晚最短的时期。在这个节气,气温高、湿度大,养生需要注意以下几个方面:
-清晨或傍晚运动:夏至日长夜短,早晨和傍晚的气温相对较低,适合进行户外活动,如散步、跑步、打太极拳等。
-避免剧烈运动:尽量避免中午和下午的高温时段进行剧烈运动,以免中暑。
-适度运动:保持适量的运动强度,选择一些舒缓的运动方式,如瑜伽、游泳等,有助于身体调节。
-保持充足睡眠:虽然白天时间长,但要保证足够的睡眠时间,建议每天至少睡7-8小时。
-午休:由于夜晚时间短,可以适当增加午休时间,15-30分钟的午休有助于恢复精力。
-保持良好睡眠环境:睡觉时保持卧室凉爽、安静、黑暗,有助于提高睡眠质量。
-清淡饮食:夏至时节应以清淡、易消化的食物为主,少吃油腻、辛辣的食物,避免给肠胃增加负担。
-多吃水果蔬菜:适量食用新鲜的瓜果蔬菜,如黄瓜、西瓜、苦瓜等,补充水分和维生素,有助于防暑降温。
-多喝水:保持充足的水分摄入,每天饮水量应在1.5-2升左右,避免脱水。
-少食多餐:适当减少每餐的食量,增加用餐次数,以减轻肠胃负担。
-保持心情愉快:高温容易让人心情烦躁,要学会调节情绪,保持愉快的心情,可以通过听音乐、看书、做自己喜欢的事情来放松心情。
-适当放松:利用闲暇时间进行一些放松活动,如冥想、深呼吸练习等,缓解压力。
-社交活动:多与家人朋友交流,进行一些轻松的社交活动,有助于舒缓情绪。
-通过以上几方面的调养,可以更好地适应夏至的气候变化,保持身体健康。
-注:使用ChatGPT 4o辅助创作。
-欢迎各位提出建议、问题,我们一起交流、学习、成长。
-“问渠那得清如许?为有源头活水来” ヾ(◍°∇°◍)ノ゙
-——— 我在半亩方塘等你 ^_^
-]]>大寒,意味着寒气逆极,这个时节,天气冷到极点,饮食上应转向清淡,注意保暖润燥。有句谚语讲道,“小寒大寒,冷成一团”。
-团团圆圆年夜饭。除夕团聚,在鞭炮声中,一家人围炉而坐,叙旧话新,辞别旧岁尘埃,迎接新岁到来。
-现如今,人们的物质生活得到了极大的改善,然而有时会陷入病痛困扰,有时会陷入情绪低谷,是时候,考虑如何以更好的身心来享受生活。一则,从身体健康出发,关注饮食起居,注重养身。二则,从心理健康出发,关注情绪感受,注重养心。前者,我们可以根据节气养生知识,调整我们的饮食起居,保持健康的身体。后者,我们可以通过阅读、交谈、旅行等,拓宽我们的精神世界,接纳自己,爱自己,恢复健康的心灵。这样,我们就能有一个健康有活力的身心状态去迎接新的一年,拥抱丰富多彩的生活,享受当下的幸福时刻。
-欢迎各位提出建议、问题,我们一起交流、学习、成长。
“问渠那得清如许?为有源头活水来” ヾ(◍°∇°◍)ノ゙
@@ -4574,9 +4430,8 @@从训练样本中尽可能学出适用于所有潜在样本的“普遍规律”,这样才能在遇到新样本时做出正确的判别。然而,当学习器把训练样本学得“太好”了的时候,很可能已经把训练样本自身的一些特点当作了所有潜在样本都会具有的一般性质,这样就会导致泛化性能下降。这种现象在机器学习中称为“过拟合”(overfitting)。
与过拟合相对的是“欠拟合”(underfitting),这是指对训练样本的一般性质尚未学好。
冬至,『阳气初生』,北半球白天最短,黑夜最长,让过去完全过去,让开始重新开始。
+冬至天气寒冷,患心脏病和高血压的病人容易加重病情,患中风的人也会增多,相关患者人群需注意,做好预防、治疗和康养。
+小知识:每年冬至后的第19天至第27天称为“三九”,是一年中最寒冷的时候。
有首有意思的歌谣:“一九二九不出手,三九四九冰上走,五九六九沿河看柳,七九河开,八九燕来,九九加一九,耕牛遍地走。”
从冬至开始,生命活动由盛转衰,由动转静。
+冬至吃饺子,耳朵冻不坏。有句谚语说,“十月一,冬至到,家家户户吃水饺”。
+欢迎各位提出建议、问题,我们一起交流、学习、成长。
+“问渠那得清如许?为有源头活水来” ヾ(◍°∇°◍)ノ゙
+——— 我在半亩方塘等你 ^_^
+]]>
夏至是二十四节气中的一个重要节气,标志着一年中白天最长、夜晚最短的时期。在这个节气,气温高、湿度大,养生需要注意以下几个方面:
+清晨或傍晚运动:夏至日长夜短,早晨和傍晚的气温相对较低,适合进行户外活动,如散步、跑步、打太极拳等。
+避免剧烈运动:尽量避免中午和下午的高温时段进行剧烈运动,以免中暑。
+适度运动:保持适量的运动强度,选择一些舒缓的运动方式,如瑜伽、游泳等,有助于身体调节。
+保持充足睡眠:虽然白天时间长,但要保证足够的睡眠时间,建议每天至少睡7-8小时。
+午休:由于夜晚时间短,可以适当增加午休时间,15-30分钟的午休有助于恢复精力。
+保持良好睡眠环境:睡觉时保持卧室凉爽、安静、黑暗,有助于提高睡眠质量。
+清淡饮食:夏至时节应以清淡、易消化的食物为主,少吃油腻、辛辣的食物,避免给肠胃增加负担。
+多吃水果蔬菜:适量食用新鲜的瓜果蔬菜,如黄瓜、西瓜、苦瓜等,补充水分和维生素,有助于防暑降温。
+多喝水:保持充足的水分摄入,每天饮水量应在1.5-2升左右,避免脱水。
+少食多餐:适当减少每餐的食量,增加用餐次数,以减轻肠胃负担。
+保持心情愉快:高温容易让人心情烦躁,要学会调节情绪,保持愉快的心情,可以通过听音乐、看书、做自己喜欢的事情来放松心情。
+适当放松:利用闲暇时间进行一些放松活动,如冥想、深呼吸练习等,缓解压力。
+社交活动:多与家人朋友交流,进行一些轻松的社交活动,有助于舒缓情绪。
+通过以上几方面的调养,可以更好地适应夏至的气候变化,保持身体健康。
+注:使用ChatGPT 4o辅助创作。
+欢迎各位提出建议、问题,我们一起交流、学习、成长。
+“问渠那得清如许?为有源头活水来” ヾ(◍°∇°◍)ノ゙
+——— 我在半亩方塘等你 ^_^
+]]>从训练样本中尽可能学出适用于所有潜在样本的“普遍规律”,这样才能在遇到新样本时做出正确的判别。然而,当学习器把训练样本学得“太好”了的时候,很可能已经把训练样本自身的一些特点当作了所有潜在样本都会具有的一般性质,这样就会导致泛化性能下降。这种现象在机器学习中称为“过拟合”(overfitting)。
与过拟合相对的是“欠拟合”(underfitting),这是指对训练样本的一般性质尚未学好。
大寒,意味着寒气逆极,这个时节,天气冷到极点,饮食上应转向清淡,注意保暖润燥。有句谚语讲道,“小寒大寒,冷成一团”。
+团团圆圆年夜饭。除夕团聚,在鞭炮声中,一家人围炉而坐,叙旧话新,辞别旧岁尘埃,迎接新岁到来。
+现如今,人们的物质生活得到了极大的改善,然而有时会陷入病痛困扰,有时会陷入情绪低谷,是时候,考虑如何以更好的身心来享受生活。一则,从身体健康出发,关注饮食起居,注重养身。二则,从心理健康出发,关注情绪感受,注重养心。前者,我们可以根据节气养生知识,调整我们的饮食起居,保持健康的身体。后者,我们可以通过阅读、交谈、旅行等,拓宽我们的精神世界,接纳自己,爱自己,恢复健康的心灵。这样,我们就能有一个健康有活力的身心状态去迎接新的一年,拥抱丰富多彩的生活,享受当下的幸福时刻。
+欢迎各位提出建议、问题,我们一起交流、学习、成长。
+“问渠那得清如许?为有源头活水来” ヾ(◍°∇°◍)ノ゙
+——— 我在半亩方塘等你 ^_^
+]]>今日寒露,白露身不露,寒露脚不露。天气渐渐转凉,一层秋雨一层凉,走在路上,感受到秋雨绵绵,远处烟雨蒙蒙的气息。
+养生方面,应注重滋阴润肺,调养精神,保持乐观豁达的心情,天气变凉,注意增添衣物,预防感冒,调整起居,养成早睡早起的习惯,在大雾天气,减少外出运动,在室内运动为主。室内运动推荐做扎马步,俯卧撑,抬腿提膝等,运动前做好热身运动,运动后做好拉伸,不宜过度出汗。
+此外,还有一些养生小妙招,比如早晚泡脚,最好是晚上泡个脚,有助于睡眠,大概20-30分钟,在晚饭后1个小时之后。这个节气,也需要预防肩周炎,按压合谷穴或肩井穴。泡完脚后,可根据自身需要做足底按摩,按压太溪穴,太冲穴,太白穴等,调养肾,肝,脾。
+最后,寒露节气也有吃螃蟹的习俗,赏菊吃蟹,菊黄蟹肥,不过一些不适合吃螃蟹的朋友,要注意忌口。
+欢迎各位提出建议、问题,我们一起交流、学习、成长。
+“问渠那得清如许?为有源头活水来” ヾ(◍°∇°◍)ノ゙
+– 我在半亩方塘等你 ^_^
+]]>今日小雪。寒冷开始的标志,也是到了御寒保暖的时候。小雪,是二十四节气的第20个节气。
-
养生指南:
-小妙招:
-节气习俗:
小雪前后吃糍粑,注意不要过量,可配合萝卜、松花蛋等性冷的食物,以平衡阴阳。
欢迎各位提出建议、问题,我们一起交流、学习、成长。
-“问渠那得清如许?为有源头活水来” ヾ(◍°∇°◍)ノ゙
-——— 我在半亩方塘等你 ^_^
-]]>雨水,是立春以后的第二个节气,在每年的2月19日前后,太阳到达黄经330度。这个时节,气温回升、冰雪融化、降水增多,故名“雨水”。这种忽冷忽热、乍暖还寒的天气,要注意预防感冒。
-雨水遇元宵,团圆吃汤圆。汤圆,与“团圆”字音相近,取团圆之意。象征全家人团团圆圆,和睦幸福,也以此怀念离别的亲人,寄托对未来生活的美好愿望。
-欢迎各位提出建议、问题,我们一起交流、学习、成长。
-“问渠那得清如许?为有源头活水来” ヾ(◍°∇°◍)ノ゙
-——— 我在半亩方塘等你 ^_^
-]]>今日寒露,白露身不露,寒露脚不露。天气渐渐转凉,一层秋雨一层凉,走在路上,感受到秋雨绵绵,远处烟雨蒙蒙的气息。
-养生方面,应注重滋阴润肺,调养精神,保持乐观豁达的心情,天气变凉,注意增添衣物,预防感冒,调整起居,养成早睡早起的习惯,在大雾天气,减少外出运动,在室内运动为主。室内运动推荐做扎马步,俯卧撑,抬腿提膝等,运动前做好热身运动,运动后做好拉伸,不宜过度出汗。
-此外,还有一些养生小妙招,比如早晚泡脚,最好是晚上泡个脚,有助于睡眠,大概20-30分钟,在晚饭后1个小时之后。这个节气,也需要预防肩周炎,按压合谷穴或肩井穴。泡完脚后,可根据自身需要做足底按摩,按压太溪穴,太冲穴,太白穴等,调养肾,肝,脾。
-最后,寒露节气也有吃螃蟹的习俗,赏菊吃蟹,菊黄蟹肥,不过一些不适合吃螃蟹的朋友,要注意忌口。
-欢迎各位提出建议、问题,我们一起交流、学习、成长。
-“问渠那得清如许?为有源头活水来” ヾ(◍°∇°◍)ノ゙
-– 我在半亩方塘等你 ^_^
-]]>RNN、LSTM和GRU在序列建模、语言建模和机器翻译等领域被广泛应用。大量的工作来研究如何突破循环语言模型和编码器-解码器模型之间的界限。循环模型通常沿着输入和输出序列的符号位置进行因子计算。在计算时间中将位置与步骤对齐,生成隐含状态$h_t$的一个序列,作为先前的隐含状态$h_{t-1}$和位置$t$的输入的函数。这种固有的顺序特性妨碍了训练样本的并行化,而在较长的序列长度下,并行化就变得至关重要,因为内存约束限制了样本之间的批处理。最近的工作通过因子分解技巧和条件计算在计算效率上取得了显著的提高,同时也提高了后者的模型性能。然而,顺序计算的基本约束仍然存在。
-注意力机制已经成为序列建模和转换模型中引人注目的一个组成部分,允许建模依赖关系而不考虑它们在输入或输出序列中的距离。除了少数情况外,注意力机制往往与循环神经网络一起使用。
-在文章中,作者提出了Transformer模型,该模型避免了循环,而完全依赖于一个注意力机制来刻画输入和输出之间的全局依赖关系。
-Transformer可以实现更大程度的并行化,在8块P100 GPU上只训练了12个小时,就可以在翻译质量方面达到一个新的水平。
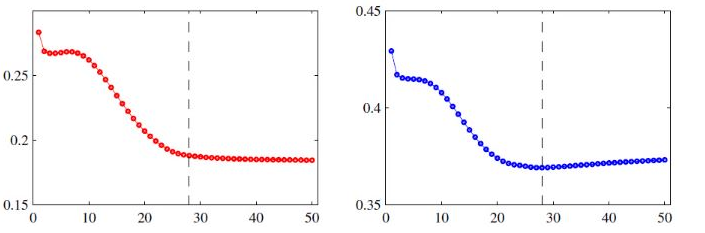
-大多数的经典神经序列转换模型都有一个编码器-解码器的结构。编码器将一个符号表示的输入序列$(x_1,…,x_n)$映射成连续表示的序列$z=(z_1,…,z_n)$。给定$z$,解码器接下来生成符号表示的输出序列$(y_1,…,y_m)$,每次生成一个元素。在每一步,模型都是自回归的,在生成下一个符号时,使用先前生成的符号作为附加输入。Transformer模型沿袭了这种结构,在编码器和解码器中使用堆叠的自注意力、逐点的和全连接层,如下图所示,左边是编码器,右边是解码器。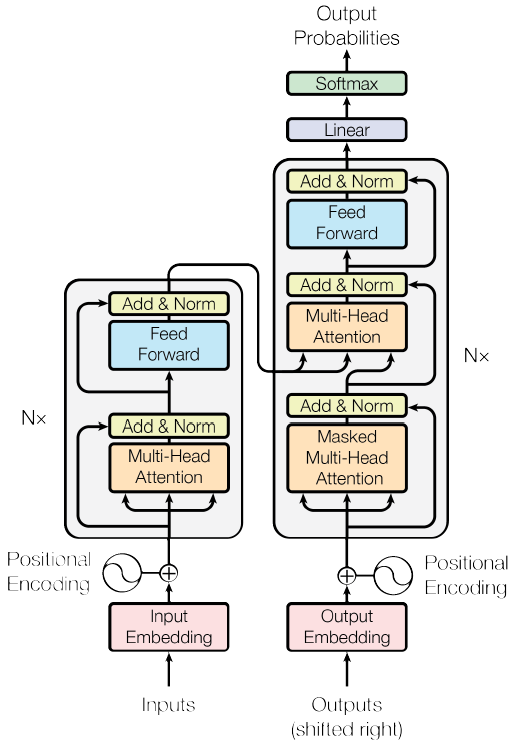
编码器部分: 编码器由6个相同的层堆叠组成。每层有两个子层,由下往上,第一层是一个多头自注意力机制,第二层是逐点式的全连接前馈网络。在每个子层上使用一个残差连接,然后进行层规范化(layer normalization)。也就是说每个子层的输出是LayerNorm($x$+Sublayer($x$))。
-解码器部分: 解码器也由6个相同的层堆叠组成。除了编码器的两个子层,解码器还加入了第三个子层,这个子层在编码器的输出上执行多头注意力操作。与编码器类似,解码器也会在每个子层上使用一个残差连接,然后进行层规范化。修改了解码器堆栈中的自注意力子层,以防止位置注意到后续位置。这个修改,是基于输出嵌入有一个位置偏移的事实考虑,确保了对位置$i$的预测只能依赖于小于$i$的已知输出。
-注意力机制函数可以被描述成将查询(query)、键(key)、值(value)映射到一个输出,其中查询、键、值和输出都是向量。输出以值的加权和的形式计算,其中分配给每个值的权重由查询与相应键的兼容函数计算。
-按比例的点积注意力结构如下图所示。输入包括$d_k$维的查询和键,以及$d_v$维的值。计算公式是$Attention(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{d_{k}}}\right) V$。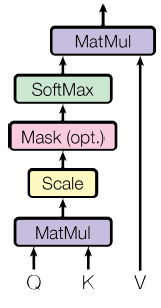
与使用$d_{model}$维的键,值,查询执行单一注意力函数不同,作者发现使用不同的学习线性投影将查询,键,值投影到$d_k, d_k, d_v$维是有益的。然后,对每一个查询、键和值的投影版本并行执行注意力函数,生成$d_v$维的输出值。它们被连接起来并再次投影,从而产生最终的值。如下图所示。多头注意力使模型能够在不同的表示子空间中,在不同的位置共同关注信息。计算公式是
$$
\begin{aligned}
\text { MultiHead }(Q, K, V) &=\text { Concat }\left(\text { head }{1}, \ldots, \text { head }{\mathrm{h}}\right) W^{O} \
\text { where head }{\mathrm{i}} &=\text { Attention }\left(Q W{i}^{Q}, K W_{i}^{K}, V W_{i}^{V}\right)
\end{aligned}
$$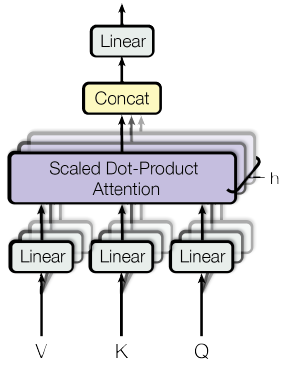
其中,投影是参数矩阵,$W_{i}^{Q} \in \mathbb{R}^{d_{\text {model }} \times d_{k}}$,$W_{i}^{K} \in \mathbb{R}^{d_{\text {model }} \times d_{k}}$,$W_{i}^{V} \in \mathbb{R}^{d_{\text {model }} \times d_{v}}$ and $W^{O} \in \mathbb{R}^{h d_{v} \times d_{model}}$。本文中采用了$h=8$个分布式的注意力层(头),每层的$d_k=d_v=d_{model}/h=64$。由于每个头的维数降低,其总计算代价与全维单头关注的计算代价相似。
这部分包括两个线性转换,中间有一个ReLU激活函数。计算公式是
$$
\mathrm{FFN}(x)=\max \left(0, x W_{1}+b_{1}\right) W_{2}+b_{2}
$$
与其他序列转换模型类似,使用学习到的嵌入将输入符号和输出符号转换为$d_{model}$维的向量。也使用通常学习到的线性变换和Softmax函数将解码器的输出转换为预测的下一个符号的概率。
-由于本模型不包含循环和卷积,为了让模型利用序列的顺序,必须注入一些关于序列中符号的相对或绝对位置的信息。因此,在编码器和解码器堆栈底部的输入嵌入中添加了“位置编码”。位置编码与嵌入具有相同的$d_{model}$维数,因此可以将两者相加。在本文中,使用了不同频率的正弦和余弦函数,如公式所示
$$
\begin{aligned}
P E_{(p o s, 2 i)} &=\sin \left(p o s / 10000^{2 i / d_{\text {model }}}\right) \
P E_{(p o s, 2 i+1)} &=\cos \left(\text { pos } / 10000^{2 i / d_{\text {model }}}\right)
\end{aligned}
$$
其中,$pos$是位置,$i$是维数。也就是说,位置编码的每一维对应一个正弦信号。
在这项工作中,提出了Transformer,这是第一个完全基于注意力机制的序列转换模型,用多头自注意力取代了编码器-解码器结构中最常用的循环层。对于翻译任务,Transformer的训练速度比基于循环层或卷积层的架构要快得多。
-雨水,是立春以后的第二个节气,在每年的2月19日前后,太阳到达黄经330度。这个时节,气温回升、冰雪融化、降水增多,故名“雨水”。这种忽冷忽热、乍暖还寒的天气,要注意预防感冒。
+雨水遇元宵,团圆吃汤圆。汤圆,与“团圆”字音相近,取团圆之意。象征全家人团团圆圆,和睦幸福,也以此怀念离别的亲人,寄托对未来生活的美好愿望。
+欢迎各位提出建议、问题,我们一起交流、学习、成长。
+“问渠那得清如许?为有源头活水来” ヾ(◍°∇°◍)ノ゙
+——— 我在半亩方塘等你 ^_^
+]]>今日小雪。寒冷开始的标志,也是到了御寒保暖的时候。小雪,是二十四节气的第20个节气。
+
养生指南:
+小妙招:
+节气习俗:
小雪前后吃糍粑,注意不要过量,可配合萝卜、松花蛋等性冷的食物,以平衡阴阳。
欢迎各位提出建议、问题,我们一起交流、学习、成长。
+“问渠那得清如许?为有源头活水来” ヾ(◍°∇°◍)ノ゙
+——— 我在半亩方塘等你 ^_^
+]]>提出了一种交通预测深度学习模型——多范围注意力双组分图卷积网络(MRA-BGCN)。该模型首先根据路网距离构建节点向图,根据不同的边相互模式构建边向图。然后利用双组分图卷积实现了节点和边的相互作用建模。此外引入多范围注意力机制,对不同邻域范围内的信息进行聚合,自动学习不同范围的重要性。在两个交通数据集(METR-LA和PEMS-BAY)上的实验结果表明取得了很好的效果。
+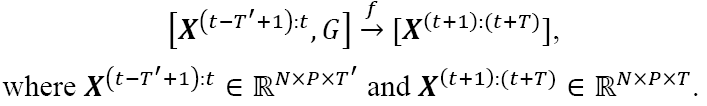
交通预测问题的任务是:学习一个函数$f$, 能够给出$T^{\prime}$历史的图信号和图$G$,预测$T$未来的图信号。
+
METR-LA and PEMS-BAY是两个公开的交通网络数据集。METR-LA记录了从2012年3月1日到2012年6月30日四个月的交通速度统计数据,包括洛杉矶公路上的207个传感器。PEMS-BAY记录了从2017年1月1日到2017年5月31日的5个月的交通速度统计数据,其中包括旧金山湾区的325个传感器。
+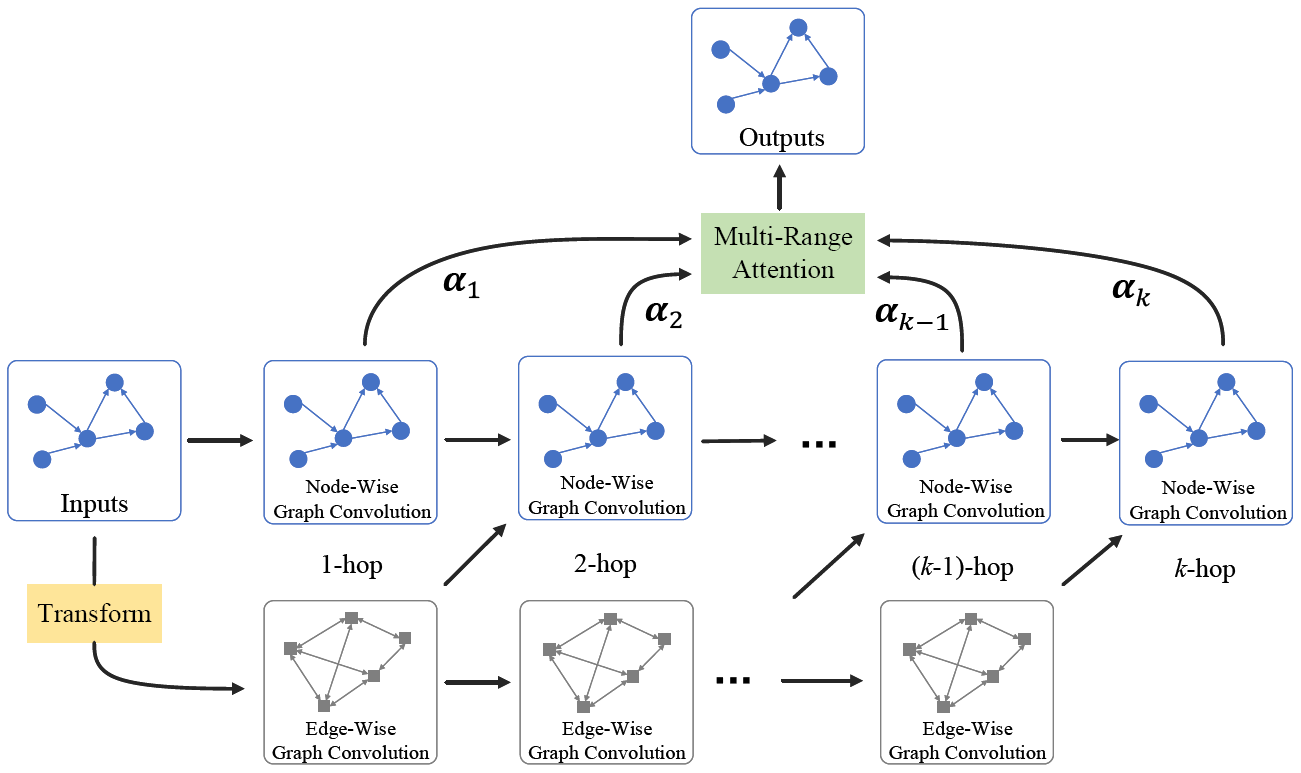
论文中的模型如上图所示,包括2部分,(1)双组分图卷积模块 (2)多范围注意力层。
+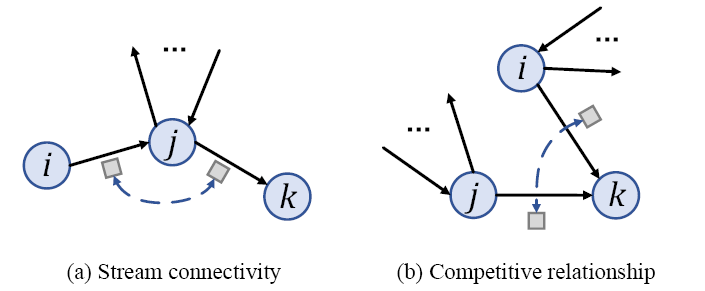
图卷积是对给定图结构的节点间相互作用进行建模的一种有效操作。双组分图卷积可以显式地对节点和边的相互作用进行建模。
+在交通网络中,一个路段可能受到其上下游路段的影响。
+共享同一源节点的道路链路可能会争夺交通资源,产生竞争关系。
+提出了双组分图卷积的多范围注意力机制,能自动学习不同邻域范围的重要性,从而实现对不同邻域范围内信息的聚集,而不仅仅是给定的邻域范围。
+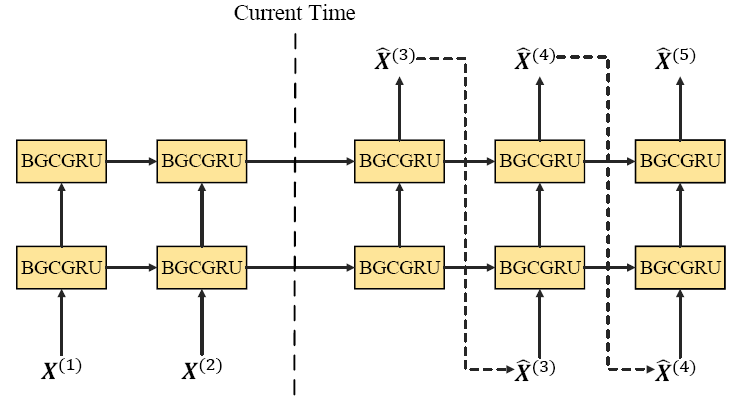
将多个BGCGRU层堆叠起来,并使用Sequence to Sequence体系结构进行多步前向交通预测。
+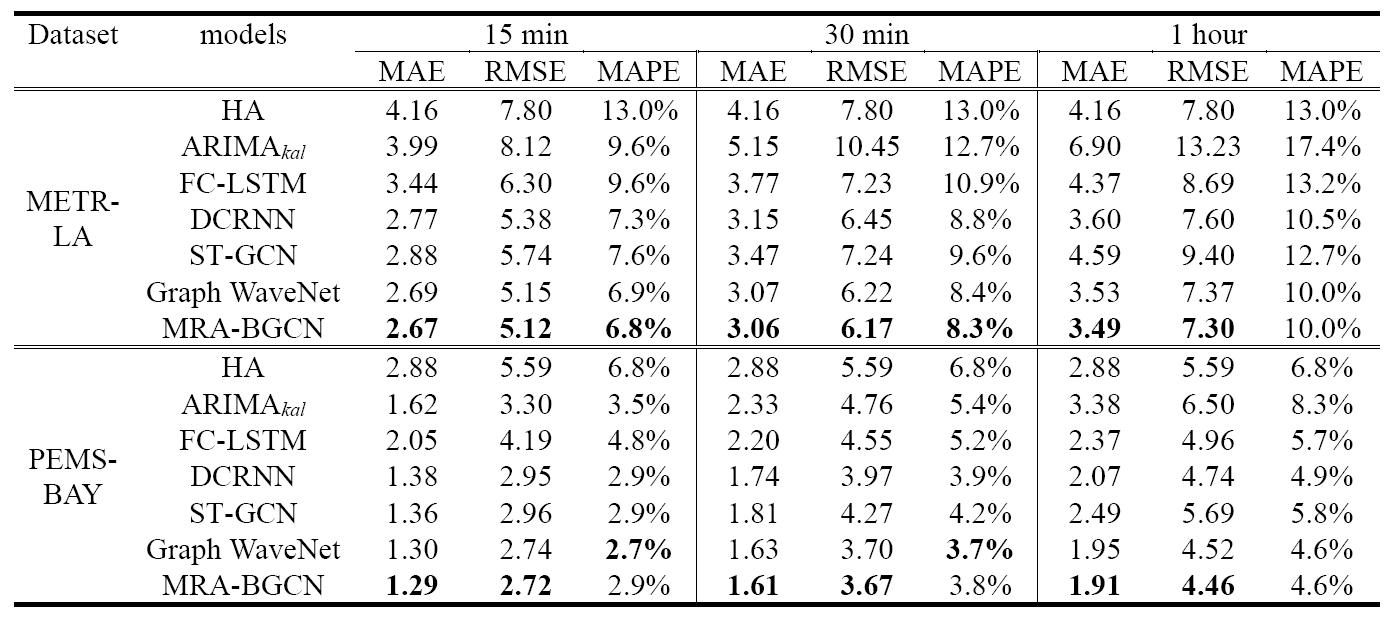
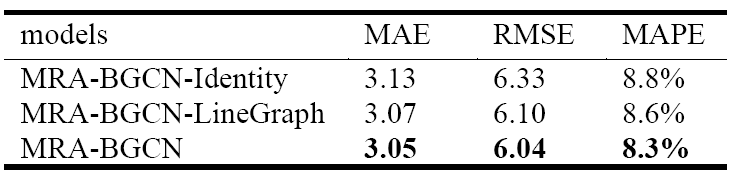
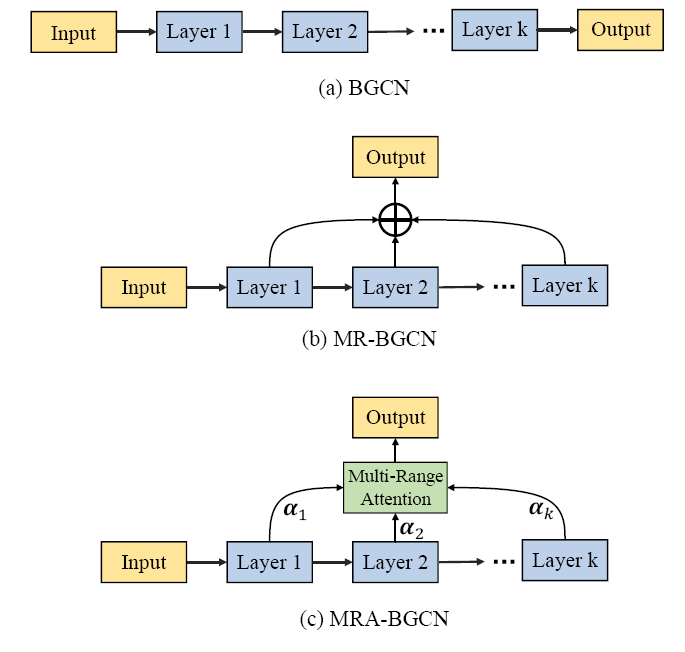
提出了一种用于交通预测的多范围注意力双组分图卷积网络。具体来说,采用双组分图卷积来明确地建模节点和边的相关性,利用一种边向图构造方法来编码边的上下游连通性和竞争关系,使用多范围注意力机制,有效地聚合多个邻域范围信息,生成综合的表示。可以进一步研究的地方是,可以考虑更多的影响因素,比如交通事故以及周围的兴趣点;目前论文中考虑的是单模态输入图,还可以研究多模态输入图。
+]]>RNN、LSTM和GRU在序列建模、语言建模和机器翻译等领域被广泛应用。大量的工作来研究如何突破循环语言模型和编码器-解码器模型之间的界限。循环模型通常沿着输入和输出序列的符号位置进行因子计算。在计算时间中将位置与步骤对齐,生成隐含状态$h_t$的一个序列,作为先前的隐含状态$h_{t-1}$和位置$t$的输入的函数。这种固有的顺序特性妨碍了训练样本的并行化,而在较长的序列长度下,并行化就变得至关重要,因为内存约束限制了样本之间的批处理。最近的工作通过因子分解技巧和条件计算在计算效率上取得了显著的提高,同时也提高了后者的模型性能。然而,顺序计算的基本约束仍然存在。
+注意力机制已经成为序列建模和转换模型中引人注目的一个组成部分,允许建模依赖关系而不考虑它们在输入或输出序列中的距离。除了少数情况外,注意力机制往往与循环神经网络一起使用。
+在文章中,作者提出了Transformer模型,该模型避免了循环,而完全依赖于一个注意力机制来刻画输入和输出之间的全局依赖关系。
+Transformer可以实现更大程度的并行化,在8块P100 GPU上只训练了12个小时,就可以在翻译质量方面达到一个新的水平。
+大多数的经典神经序列转换模型都有一个编码器-解码器的结构。编码器将一个符号表示的输入序列$(x_1,…,x_n)$映射成连续表示的序列$z=(z_1,…,z_n)$。给定$z$,解码器接下来生成符号表示的输出序列$(y_1,…,y_m)$,每次生成一个元素。在每一步,模型都是自回归的,在生成下一个符号时,使用先前生成的符号作为附加输入。Transformer模型沿袭了这种结构,在编码器和解码器中使用堆叠的自注意力、逐点的和全连接层,如下图所示,左边是编码器,右边是解码器。
编码器部分: 编码器由6个相同的层堆叠组成。每层有两个子层,由下往上,第一层是一个多头自注意力机制,第二层是逐点式的全连接前馈网络。在每个子层上使用一个残差连接,然后进行层规范化(layer normalization)。也就是说每个子层的输出是LayerNorm($x$+Sublayer($x$))。
+解码器部分: 解码器也由6个相同的层堆叠组成。除了编码器的两个子层,解码器还加入了第三个子层,这个子层在编码器的输出上执行多头注意力操作。与编码器类似,解码器也会在每个子层上使用一个残差连接,然后进行层规范化。修改了解码器堆栈中的自注意力子层,以防止位置注意到后续位置。这个修改,是基于输出嵌入有一个位置偏移的事实考虑,确保了对位置$i$的预测只能依赖于小于$i$的已知输出。
+注意力机制函数可以被描述成将查询(query)、键(key)、值(value)映射到一个输出,其中查询、键、值和输出都是向量。输出以值的加权和的形式计算,其中分配给每个值的权重由查询与相应键的兼容函数计算。
+按比例的点积注意力结构如下图所示。输入包括$d_k$维的查询和键,以及$d_v$维的值。计算公式是$Attention(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{d_{k}}}\right) V$。
与使用$d_{model}$维的键,值,查询执行单一注意力函数不同,作者发现使用不同的学习线性投影将查询,键,值投影到$d_k, d_k, d_v$维是有益的。然后,对每一个查询、键和值的投影版本并行执行注意力函数,生成$d_v$维的输出值。它们被连接起来并再次投影,从而产生最终的值。如下图所示。多头注意力使模型能够在不同的表示子空间中,在不同的位置共同关注信息。计算公式是
$$
\begin{aligned}
\text { MultiHead }(Q, K, V) &=\text { Concat }\left(\text { head }{1}, \ldots, \text { head }{\mathrm{h}}\right) W^{O} \
\text { where head }{\mathrm{i}} &=\text { Attention }\left(Q W{i}^{Q}, K W_{i}^{K}, V W_{i}^{V}\right)
\end{aligned}
$$
其中,投影是参数矩阵,$W_{i}^{Q} \in \mathbb{R}^{d_{\text {model }} \times d_{k}}$,$W_{i}^{K} \in \mathbb{R}^{d_{\text {model }} \times d_{k}}$,$W_{i}^{V} \in \mathbb{R}^{d_{\text {model }} \times d_{v}}$ and $W^{O} \in \mathbb{R}^{h d_{v} \times d_{model}}$。本文中采用了$h=8$个分布式的注意力层(头),每层的$d_k=d_v=d_{model}/h=64$。由于每个头的维数降低,其总计算代价与全维单头关注的计算代价相似。
这部分包括两个线性转换,中间有一个ReLU激活函数。计算公式是
$$
\mathrm{FFN}(x)=\max \left(0, x W_{1}+b_{1}\right) W_{2}+b_{2}
$$
与其他序列转换模型类似,使用学习到的嵌入将输入符号和输出符号转换为$d_{model}$维的向量。也使用通常学习到的线性变换和Softmax函数将解码器的输出转换为预测的下一个符号的概率。
+由于本模型不包含循环和卷积,为了让模型利用序列的顺序,必须注入一些关于序列中符号的相对或绝对位置的信息。因此,在编码器和解码器堆栈底部的输入嵌入中添加了“位置编码”。位置编码与嵌入具有相同的$d_{model}$维数,因此可以将两者相加。在本文中,使用了不同频率的正弦和余弦函数,如公式所示
$$
\begin{aligned}
P E_{(p o s, 2 i)} &=\sin \left(p o s / 10000^{2 i / d_{\text {model }}}\right) \
P E_{(p o s, 2 i+1)} &=\cos \left(\text { pos } / 10000^{2 i / d_{\text {model }}}\right)
\end{aligned}
$$
其中,$pos$是位置,$i$是维数。也就是说,位置编码的每一维对应一个正弦信号。
在这项工作中,提出了Transformer,这是第一个完全基于注意力机制的序列转换模型,用多头自注意力取代了编码器-解码器结构中最常用的循环层。对于翻译任务,Transformer的训练速度比基于循环层或卷积层的架构要快得多。
+给定两个数组,写一个方法来计算它们的交集。
- -给定 nums1 = [1, 2, 2, 1], nums2 = [2, 2], 返回 [2, 2].
-先对两个数组由小到大排序,用两个指针index1和index2遍历两个数组,比较对应元素的大小,如果相等,则添加进result数组,如果不相等,元素小的数组指针加一,最终其中一个数组遍历结束,就停止程序。
- |
1、两数组的交 II https://blog.csdn.net/guoziqing506/article/details/51569488
-]]>提出了一种交通预测深度学习模型——多范围注意力双组分图卷积网络(MRA-BGCN)。该模型首先根据路网距离构建节点向图,根据不同的边相互模式构建边向图。然后利用双组分图卷积实现了节点和边的相互作用建模。此外引入多范围注意力机制,对不同邻域范围内的信息进行聚合,自动学习不同范围的重要性。在两个交通数据集(METR-LA和PEMS-BAY)上的实验结果表明取得了很好的效果。
-
交通预测问题的任务是:学习一个函数$f$, 能够给出$T^{\prime}$历史的图信号和图$G$,预测$T$未来的图信号。
-
METR-LA and PEMS-BAY是两个公开的交通网络数据集。METR-LA记录了从2012年3月1日到2012年6月30日四个月的交通速度统计数据,包括洛杉矶公路上的207个传感器。PEMS-BAY记录了从2017年1月1日到2017年5月31日的5个月的交通速度统计数据,其中包括旧金山湾区的325个传感器。
-
论文中的模型如上图所示,包括2部分,(1)双组分图卷积模块 (2)多范围注意力层。
-
图卷积是对给定图结构的节点间相互作用进行建模的一种有效操作。双组分图卷积可以显式地对节点和边的相互作用进行建模。
-在交通网络中,一个路段可能受到其上下游路段的影响。
-共享同一源节点的道路链路可能会争夺交通资源,产生竞争关系。
-提出了双组分图卷积的多范围注意力机制,能自动学习不同邻域范围的重要性,从而实现对不同邻域范围内信息的聚集,而不仅仅是给定的邻域范围。
-
将多个BGCGRU层堆叠起来,并使用Sequence to Sequence体系结构进行多步前向交通预测。
-提出了一种用于交通预测的多范围注意力双组分图卷积网络。具体来说,采用双组分图卷积来明确地建模节点和边的相关性,利用一种边向图构造方法来编码边的上下游连通性和竞争关系,使用多范围注意力机制,有效地聚合多个邻域范围信息,生成综合的表示。可以进一步研究的地方是,可以考虑更多的影响因素,比如交通事故以及周围的兴趣点;目前论文中考虑的是单模态输入图,还可以研究多模态输入图。
+ +随着ChatGPT等大模型的兴起,关于城市大模型的讨论和研究兴趣也在不断增加,然而这一迅速发展起来的领域,也面临许多挑战,比如缺乏对城市大模型的清晰定义、系统的研究梳理、通用的解决方案。
+本文提出了城市大模型的概念,讨论了构建城市大模型面临的挑战、将城市大模型相关的研究工作按照数据(模态、类型)进行分类,并给出了城市大模型框架图,最后从应用的角度,探讨了大模型对不同应用场景的可能影响。相关的论文和开源资料发布在了GitHub库 https://github.com/usail-hkust/Awesome-Urban-Foundation-Models
+
这个框架图包含三个部分,1. 多源多粒度多模态城市数据,如城市文本语料、街景图像、空间轨迹、时间序列数据、城市知识图谱等;2. 城市基础模型; 3. 下游应用场景,涵盖交通、城市规划、能源管理、环境监测及公共安全等领域。
+
将城市大模型按照数据的模态、类型进行分类,包括基于语言的、视觉的、轨迹的、时间序列的、多模态的以及其他类型的城市大模型。
+
从城市数据的集成、融合到多模态城市大模型构建,再到不同的城市应用场景。提升城市大模型的时空推理以及隐私保护能力。
+随着ChatGPT等大模型的兴起,关于城市大模型的讨论和研究兴趣也在不断增加,然而这一迅速发展起来的领域,也面临许多挑战,比如缺乏对城市大模型的清晰定义、系统的研究梳理、通用的解决方案。
-本文提出了城市大模型的概念,讨论了构建城市大模型面临的挑战、将城市大模型相关的研究工作按照数据(模态、类型)进行分类,并给出了城市大模型框架图,最后从应用的角度,探讨了大模型对不同应用场景的可能影响。相关的论文和开源资料发布在了GitHub库 https://github.com/usail-hkust/Awesome-Urban-Foundation-Models
-
这个框架图包含三个部分,1. 多源多粒度多模态城市数据,如城市文本语料、街景图像、空间轨迹、时间序列数据、城市知识图谱等;2. 城市基础模型; 3. 下游应用场景,涵盖交通、城市规划、能源管理、环境监测及公共安全等领域。
-
将城市大模型按照数据的模态、类型进行分类,包括基于语言的、视觉的、轨迹的、时间序列的、多模态的以及其他类型的城市大模型。
-
从城市数据的集成、融合到多模态城市大模型构建,再到不同的城市应用场景。提升城市大模型的时空推理以及隐私保护能力。
-
安装pyecharts(以Ubuntu系统为例):
- |
代码实现
- |
最后,还要提到的一点是,以上只是简单的示例,仅供学习,实际使用过程中,需要适当调整代码,达到更好的效果,或选用其他可视化方式。
-给定两个数组,写一个方法来计算它们的交集。
+ +给定 nums1 = [1, 2, 2, 1], nums2 = [2, 2], 返回 [2, 2].
+先对两个数组由小到大排序,用两个指针index1和index2遍历两个数组,比较对应元素的大小,如果相等,则添加进result数组,如果不相等,元素小的数组指针加一,最终其中一个数组遍历结束,就停止程序。
+ |
1、两数组的交 II https://blog.csdn.net/guoziqing506/article/details/51569488
]]>给定一个排序数组,你需要在原地删除重复出现的元素,使得每个元素只出现一次,返回移除后数组的新长度。(不要使用额外的数组空间,你必须在原地修改输入数组并在使用O(1)额外空间的条件下完成)。
+给定一个数组,它的第 i 个元素是一支给定股票第 i 天的价格。
设计一个算法来计算你所能获取的最大利润。你可以尽可能地完成更多的交易(多次买卖一支股票)。
注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
给定数组 nums = [1,1,2],
函数应该返回新的长度 2, 并且原数组 nums 的前两个元素被修改为 1, 2。你不需要考虑数组中超出新长度后面的元素。
遍历一遍数组,将不重复的数字保留,重复的数字覆盖,并删除末尾剩余的数字。
- |
1、LintCode(100)删除排序数组中的重复数字 https://blog.csdn.net/fly_yr/article/details/51548657
+(1)输入: [7,1,5,3,6,4]
输出: 7
解释: 在第 2 天(股票价格 = 1)的时候买入,在第 3 天(股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。
随后,在第 4 天(股票价格 = 3)的时候买入,在第 5 天(股票价格 = 6)的时候卖出, 这笔交易所能获得利润 = 6-3 = 3 。
(2)输入: [1,2,3,4,5]
输出: 4
解释: 在第 1 天(股票价格 = 1)的时候买入,在第 5 天 (股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。
注意你不能在第 1 天和第 2 天接连购买股票,之后再将它们卖出。
因为这样属于同时参与了多笔交易,你必须在再次购买前出售掉之前的股票。
(3)输入: [7,6,4,3,1]
输出: 0
解释: 在这种情况下, 没有交易完成, 所以最大利润为 0。
通过比较相邻两个值的大小,低价买入,高价卖出,然后计算收益,另外考虑不买入和不卖出的特殊情况。
+ |
1、买卖股票的最佳时机 II-Python-LeetCode https://blog.csdn.net/linfeng886/article/details/80070804
]]>给定一个排序数组,你需要在原地删除重复出现的元素,使得每个元素只出现一次,返回移除后数组的新长度。(不要使用额外的数组空间,你必须在原地修改输入数组并在使用O(1)额外空间的条件下完成)。
- -库恩提出的科学范式是一种科学规范、规则,也是一种科学理论,从实践中来,又能够经得起历史和实践的检验。科学的发展,不仅仅是科学知识的积累,还应当是科学范式的传承和发展。另外,学科和科学看似是两个相同的字组成,但两者包含的研究方法和理念,应当是有区别的。学科代表分而治之的观念,分科治学,能让学科走向更深的深度,更大限度拓深人的专长,解决某个专门领域的问题。而科学不仅仅是一种理论,也是一种体制机制下追求真理的精神,是一种理念、文化和氛围,能够在全社会广泛认可,取得广泛的影响。
-由科学产生的范式,犹如大海航行中的海图,犹如探险家的攻略,也代表着进行科研的一种规则,通用的理念与方法,它是经过无数科学家在科研实践中,总结、提炼、升华出来的一种理论,并经过了历史与实践的检验,能引领后来的科研工作者,站在巨人的肩上,继续探索科学,为我们指明了科学发现与研究的路线,也为我们指出了科学的界限、层次与禁忌。
-作为计算机科学与技术专业的一名研究生,正如在专业名字中体现出的内涵一致,研究计算机,不仅要当作一门学科,也要注重它的技术应用,更重要的是了解它的起源、研究规则、规范、该领域优秀科学家的思想和理念,这也就涉及到了范式。在一定的科研规范、路径下,遵循前人的科研理念,方法,在已有的科研基础上,继承与发展科研范式,创新开展科研工作,形成新时代、新阶段下的科研范式,进而提升为该学科、各学科通用,并能有效融合的,大家公认的具有广泛理论应用基础的科学范式。
-科学与学科,分久必合,合久必分,在这个过程中,范式调整与发展、传承与创新、范式一直在发展,变得适合科学,助力科学发展。
-注:感悟来自《自然辩证法》课程。
-给定数组 nums = [1,1,2],
函数应该返回新的长度 2, 并且原数组 nums 的前两个元素被修改为 1, 2。你不需要考虑数组中超出新长度后面的元素。
遍历一遍数组,将不重复的数字保留,重复的数字覆盖,并删除末尾剩余的数字。
+ |
1、LintCode(100)删除排序数组中的重复数字 https://blog.csdn.net/fly_yr/article/details/51548657
]]>给定一个数组,它的第 i 个元素是一支给定股票第 i 天的价格。
设计一个算法来计算你所能获取的最大利润。你可以尽可能地完成更多的交易(多次买卖一支股票)。
注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
(1)输入: [7,1,5,3,6,4]
输出: 7
解释: 在第 2 天(股票价格 = 1)的时候买入,在第 3 天(股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。
随后,在第 4 天(股票价格 = 3)的时候买入,在第 5 天(股票价格 = 6)的时候卖出, 这笔交易所能获得利润 = 6-3 = 3 。
(2)输入: [1,2,3,4,5]
输出: 4
解释: 在第 1 天(股票价格 = 1)的时候买入,在第 5 天 (股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。
注意你不能在第 1 天和第 2 天接连购买股票,之后再将它们卖出。
因为这样属于同时参与了多笔交易,你必须在再次购买前出售掉之前的股票。
(3)输入: [7,6,4,3,1]
输出: 0
解释: 在这种情况下, 没有交易完成, 所以最大利润为 0。
通过比较相邻两个值的大小,低价买入,高价卖出,然后计算收益,另外考虑不买入和不卖出的特殊情况。
- |
1、买卖股票的最佳时机 II-Python-LeetCode https://blog.csdn.net/linfeng886/article/details/80070804
+
安装pyecharts(以Ubuntu系统为例):
+ |
代码实现
+ |
最后,还要提到的一点是,以上只是简单的示例,仅供学习,实际使用过程中,需要适当调整代码,达到更好的效果,或选用其他可视化方式。
+给定一个非空整数数组,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。(算法应该具有线性时间复杂度)
+(1)
输入: [2,2,1]
输出: 1
(2)
输入: [4,1,2,1,2]
输出: 4
为了找出只出现一次的元素,可以先将所有元素出现的次数变为一次,然后对所有元素求和,乘以2倍,减去原来数组元素的和,即为只出现一次的元素的值。
- |
1、LeetCode 136. 只出现一次的数字 Python https://blog.csdn.net/ma412410029/article/details/80511684
+ +库恩提出的科学范式是一种科学规范、规则,也是一种科学理论,从实践中来,又能够经得起历史和实践的检验。科学的发展,不仅仅是科学知识的积累,还应当是科学范式的传承和发展。另外,学科和科学看似是两个相同的字组成,但两者包含的研究方法和理念,应当是有区别的。学科代表分而治之的观念,分科治学,能让学科走向更深的深度,更大限度拓深人的专长,解决某个专门领域的问题。而科学不仅仅是一种理论,也是一种体制机制下追求真理的精神,是一种理念、文化和氛围,能够在全社会广泛认可,取得广泛的影响。
+由科学产生的范式,犹如大海航行中的海图,犹如探险家的攻略,也代表着进行科研的一种规则,通用的理念与方法,它是经过无数科学家在科研实践中,总结、提炼、升华出来的一种理论,并经过了历史与实践的检验,能引领后来的科研工作者,站在巨人的肩上,继续探索科学,为我们指明了科学发现与研究的路线,也为我们指出了科学的界限、层次与禁忌。
+作为计算机科学与技术专业的一名研究生,正如在专业名字中体现出的内涵一致,研究计算机,不仅要当作一门学科,也要注重它的技术应用,更重要的是了解它的起源、研究规则、规范、该领域优秀科学家的思想和理念,这也就涉及到了范式。在一定的科研规范、路径下,遵循前人的科研理念,方法,在已有的科研基础上,继承与发展科研范式,创新开展科研工作,形成新时代、新阶段下的科研范式,进而提升为该学科、各学科通用,并能有效融合的,大家公认的具有广泛理论应用基础的科学范式。
+科学与学科,分久必合,合久必分,在这个过程中,范式调整与发展、传承与创新、范式一直在发展,变得适合科学,助力科学发展。
+注:感悟来自《自然辩证法》课程。
+给定一个非空整数数组,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。(算法应该具有线性时间复杂度)
+ +(1)
输入: [2,2,1]
输出: 1
(2)
输入: [4,1,2,1,2]
输出: 4
为了找出只出现一次的元素,可以先将所有元素出现的次数变为一次,然后对所有元素求和,乘以2倍,减去原来数组元素的和,即为只出现一次的元素的值。
+ |
1、LeetCode 136. 只出现一次的数字 Python https://blog.csdn.net/ma412410029/article/details/80511684
+]]>给定一个数组,将数组中的元素向右移动 k 个位置,其中 k 是非负数。
- -机器学习是通过设计算法来自动地从数据中提取有价值的信息。由于机器学习是一类数据驱动的方法,所以数据是机器学习的核心。机器学习涉及到三个重要的组成核心:数据、模型和学习。
-那么对于数据、模型和学习这三个重要的概念,本书有三个重要的观点:
-这种书分为了两个部分,第一部分是数学基础部分,第二部分是机器学习任务及方法。可以根据自己的实际需求,选择阅读方法,我推荐自底向上的方式,当然也可以两种方式结合。
-接下来介绍数学基础部分和机器学习四大支柱(常见任务)的关系,如图所示: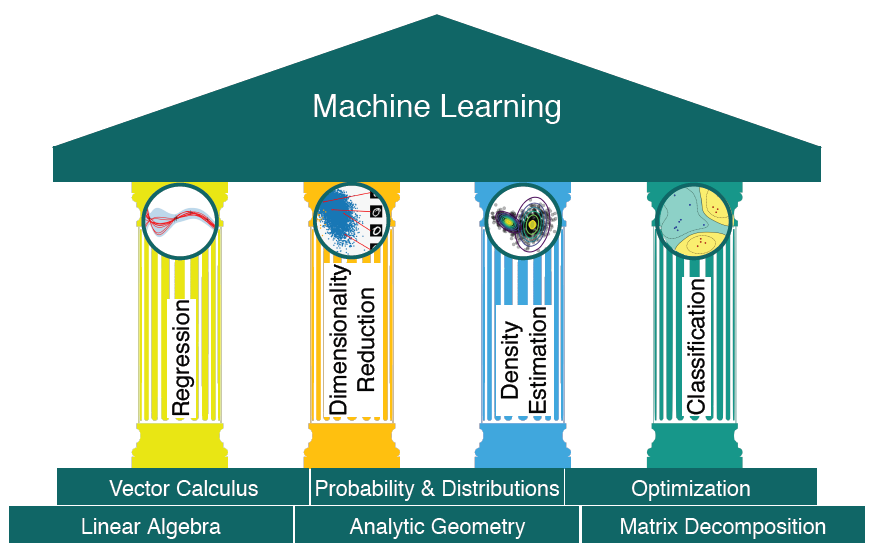
这本书可以从https://mml-book.com这个网站下载。第一部分主要适用笔和纸完成练习,第二部分提供有编程的代码用于加深机器学习算法的理解。
-]]>(1)
输入: [1,2,3,4,5,6,7] 和 k = 3
输出: [5,6,7,1,2,3,4]解释:
向右旋转 1 步: [7,1,2,3,4,5,6]
向右旋转 2 步: [6,7,1,2,3,4,5]
向右旋转 3 步: [5,6,7,1,2,3,4]
(2)
输入: [-1,-100,3,99] 和 k = 2
输出: [3,99,-1,-100]
解释:
向右旋转 1 步: [99,-1,-100,3]
向右旋转 2 步: [3,99,-1,-100]
将前k个元素移动到数组的后半部分,将后(n-k)个元素移动到数组的前半部分。
+ |
1、这是一个直观的算法操作,以切片(分块)的方式操作数组,比较符合人的思维,但是要注重观察示例特征,否则容易陷入单个元素移动的怪圈。
2、nums[:] = 和 nums = 的区别:
|
给定一个数组,将数组中的元素向右移动 k 个位置,其中 k 是非负数。
- -(1)
输入: [1,2,3,4,5,6,7] 和 k = 3
输出: [5,6,7,1,2,3,4]解释:
向右旋转 1 步: [7,1,2,3,4,5,6]
向右旋转 2 步: [6,7,1,2,3,4,5]
向右旋转 3 步: [5,6,7,1,2,3,4]
(2)
输入: [-1,-100,3,99] 和 k = 2
输出: [3,99,-1,-100]
解释:
向右旋转 1 步: [99,-1,-100,3]
向右旋转 2 步: [3,99,-1,-100]
将前k个元素移动到数组的后半部分,将后(n-k)个元素移动到数组的前半部分。
- |
1、这是一个直观的算法操作,以切片(分块)的方式操作数组,比较符合人的思维,但是要注重观察示例特征,否则容易陷入单个元素移动的怪圈。
2、nums[:] = 和 nums = 的区别:
|

在这本书里,见证了大量的诗词、中医养生的内容以及人物言谈对话,感受到了荣、宁二府由兴到衰再到“兴”的过程,还有贾宝玉、林黛玉、薛宝钗、老太太以及王熙凤等人生命历程。
其中,给我印象最深的是薛宝钗,她不仅担负起薛家的家庭重担,也要承受着贾宝玉无心功名、沉迷闺阁的反传统压力。而她自己却是旧传统下的知书达理、贤良之妻。这个世界给了她不公,但她却从容应对,不刻薄他人,维持着家庭的和睦,不失高贵和优雅。
总的来说,这本书,包含的内容及其丰富,从日常生活到社会万象,囊括万千,值得一读,甚至多读。
注: 这本书,我看的是Kindle电子书版本(《红楼梦》(古典名著普及文库)),在当当上搜索了一下,红楼梦有不同版本,推荐人民文学出版社的《红楼梦》。
机器学习是通过设计算法来自动地从数据中提取有价值的信息。由于机器学习是一类数据驱动的方法,所以数据是机器学习的核心。机器学习涉及到三个重要的组成核心:数据、模型和学习。
+那么对于数据、模型和学习这三个重要的概念,本书有三个重要的观点:
+这种书分为了两个部分,第一部分是数学基础部分,第二部分是机器学习任务及方法。可以根据自己的实际需求,选择阅读方法,我推荐自底向上的方式,当然也可以两种方式结合。
+接下来介绍数学基础部分和机器学习四大支柱(常见任务)的关系,如图所示:
这本书可以从https://mml-book.com这个网站下载。第一部分主要适用笔和纸完成练习,第二部分提供有编程的代码用于加深机器学习算法的理解。
]]>
在这本书里,见证了大量的诗词、中医养生的内容以及人物言谈对话,感受到了荣、宁二府由兴到衰再到“兴”的过程,还有贾宝玉、林黛玉、薛宝钗、老太太以及王熙凤等人生命历程。
其中,给我印象最深的是薛宝钗,她不仅担负起薛家的家庭重担,也要承受着贾宝玉无心功名、沉迷闺阁的反传统压力。而她自己却是旧传统下的知书达理、贤良之妻。这个世界给了她不公,但她却从容应对,不刻薄他人,维持着家庭的和睦,不失高贵和优雅。
总的来说,这本书,包含的内容及其丰富,从日常生活到社会万象,囊括万千,值得一读,甚至多读。
注: 这本书,我看的是Kindle电子书版本(《红楼梦》(古典名著普及文库)),在当当上搜索了一下,红楼梦有不同版本,推荐人民文学出版社的《红楼梦》。
共计 36 篇文章
+共计 37 篇文章
2024
+ + +共计 36 篇文章
+共计 37 篇文章
2024
+ + +共计 36 篇文章
+共计 37 篇文章
2024
+ + +2023
- - - -共计 36 篇文章
+共计 37 篇文章
2023
+ + +共计 36 篇文章
+共计 37 篇文章
2024
+ + +共计 36 篇文章
+共计 37 篇文章
2024
+ + +共计 36 篇文章
+共计 37 篇文章
2024
+ + +2023
- - - -共计 36 篇文章
+共计 37 篇文章
2023
+ + +