⭐⭐⭐⭐⭐ LLM Visualization: https://bbycroft.net/llm
Most of LLMs in market are based variants of the original Vaswani et al. (2017) paper that introduced transformers presented an encoder-decoder architecture.
Transformer models produce a probability distribution over all potential next words given an input string of text.
- The original paper introduced encoder-decoder transformers architecture, which is more geared to tasks like translation.
- ChatGPT and other GPT-series models are decoder-only transformers.
The main architectural innovation of transformers was the introduction of attention heads.
- Transformers Explained Visually (Part 3): Multi-head Attention, deep dive
- A Gentle Introduction to Positional Encoding in Transformer Models, Part 1
- The Illustrated Transformer
- Explaining ChatGPT to Anyone in <20 Minutes
LLaMA2 adopts Rotary Position Embedding (RoPE) in place of traditional absolute positional encoding.
Read more about RoPE at, Rotary Embedding
In self-attention, every word in sequence pays attention to every other word to understand context. Self attention allows the model to relate words each other.
Given a query, lookup for closest keys, return a weighted sum of associated values.

GQA addresess memory bandwidth challenges during the autoregressive decoding of Transformer models. The primary issue stems from the need to load decoder weights and attention keys/values at each processing step, which consumes excessive memory.
Read more about MPA & GPA at, Grouped Query Attention
To solve this memory bandwidth problem, multi-query attention (MQA) was created where only one key-value head exists for multiple query heads. While MQA significantly reduces the memory load and improves inference speed, it comes at the expense of lower quality and training instability.
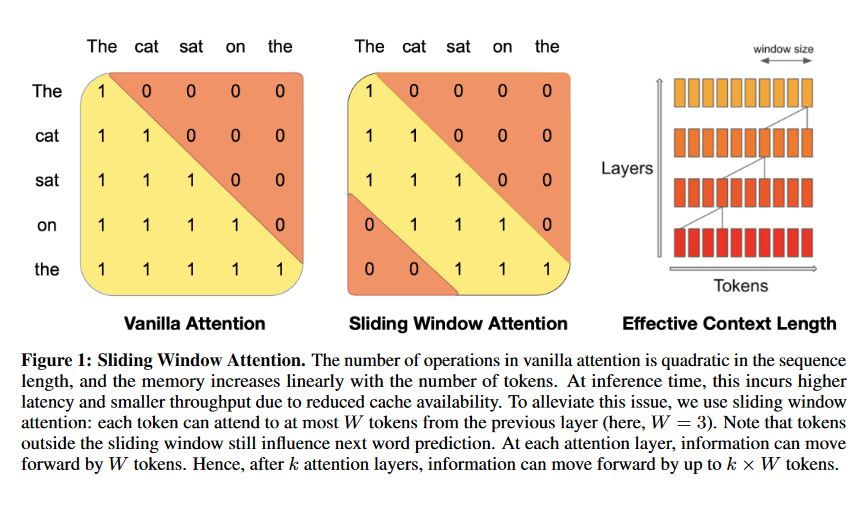
Transformers are slow and memory-hungry on long sequences, since the time and memory complexity of self-attention are quadratic in sequence length.
Flash attention uses two techniques to speedup,
- "tiling" to "restructure the computation of attention" by splitting the input into blocks and performing softmax incrementally.
- I/O aware implementation of attention: Instead of storing the matrix for backpropagation, we simply recalculate it, which is faster than the I/Os.


Source: FlashAttention challenges ML researchers to think about systems-level improvements Long-Sequence Attention with ⚡FlashAttention⚡,
To understand KV caching, it’s important to know how the self-attention mechanism operates within transformers. In each self-attention layer, a given input sequence is projected into three separate matrices: queries (Q), keys (K), and values (V). These projections allow the model to determine which parts of the sequence to attend to by computing attention scores between the queries and keys, which are then applied to the values to yield the output.
Here's a breakdown of how KV caching fits into this process:
- Initial Computation: When generating the first few tokens in a sequence, the model computes the attention matrices—Q, K, and V—for all tokens processed so far. This involves full computation of attention for these initial tokens.
- Caching of Keys and Values: After computing K and V for each token, these matrices are stored in a KV cache. This cache holds the keys and values for each token in the sequence, indexed by their position.
- Reuse in Subsequent Tokens: For each new token generated (in sequential text generation or conversation), the model only computes the query (Q) for the current token. Instead of recalculating K and V for the entire sequence, it retrieves the cached K and V matrices from the previous steps.
- Attention Calculation: The attention is then computed using the new query (Q) and the cached keys (K) and values (V). This allows the model to attend to the entire history of tokens without recomputing each one from scratch.
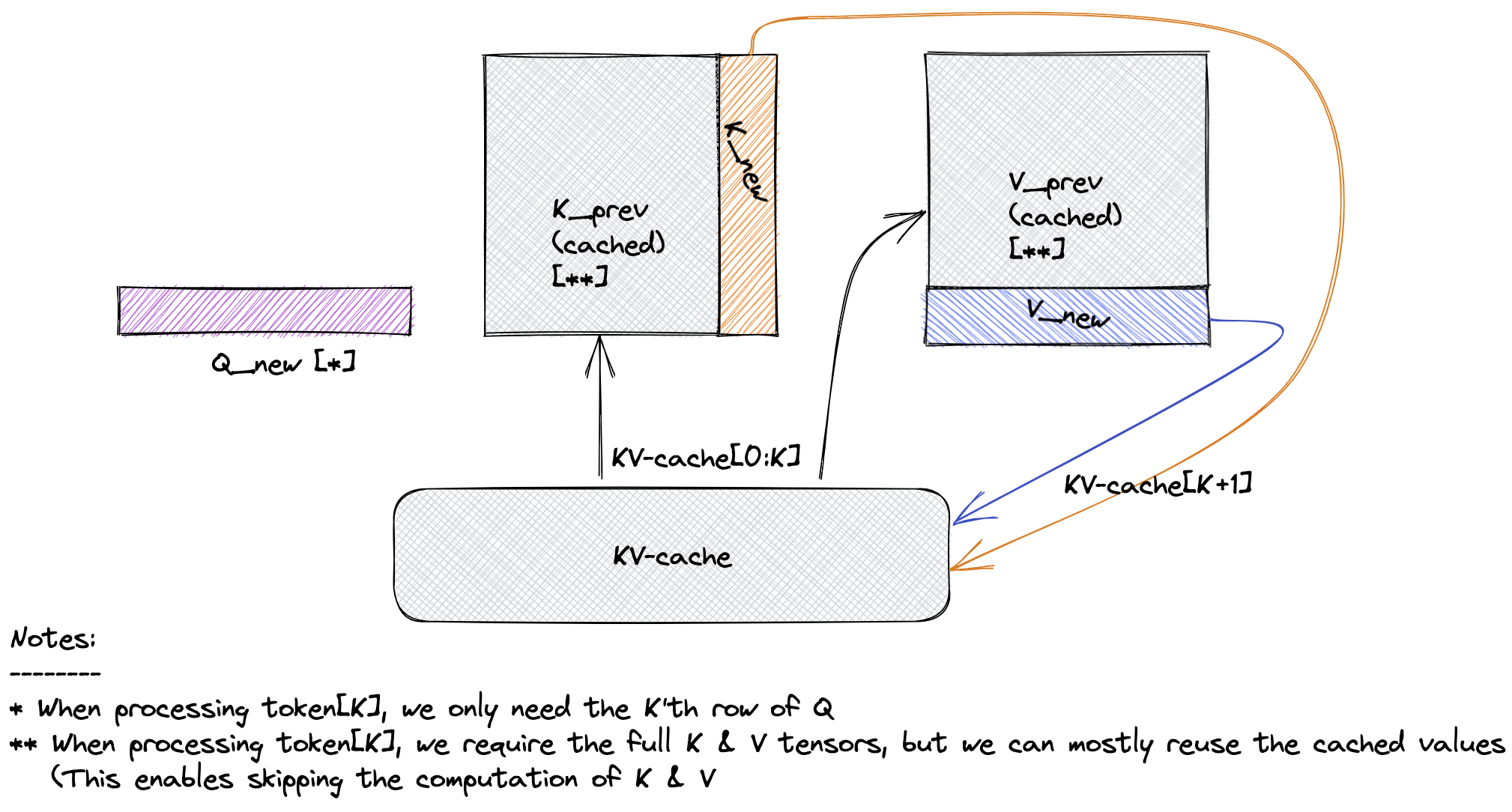
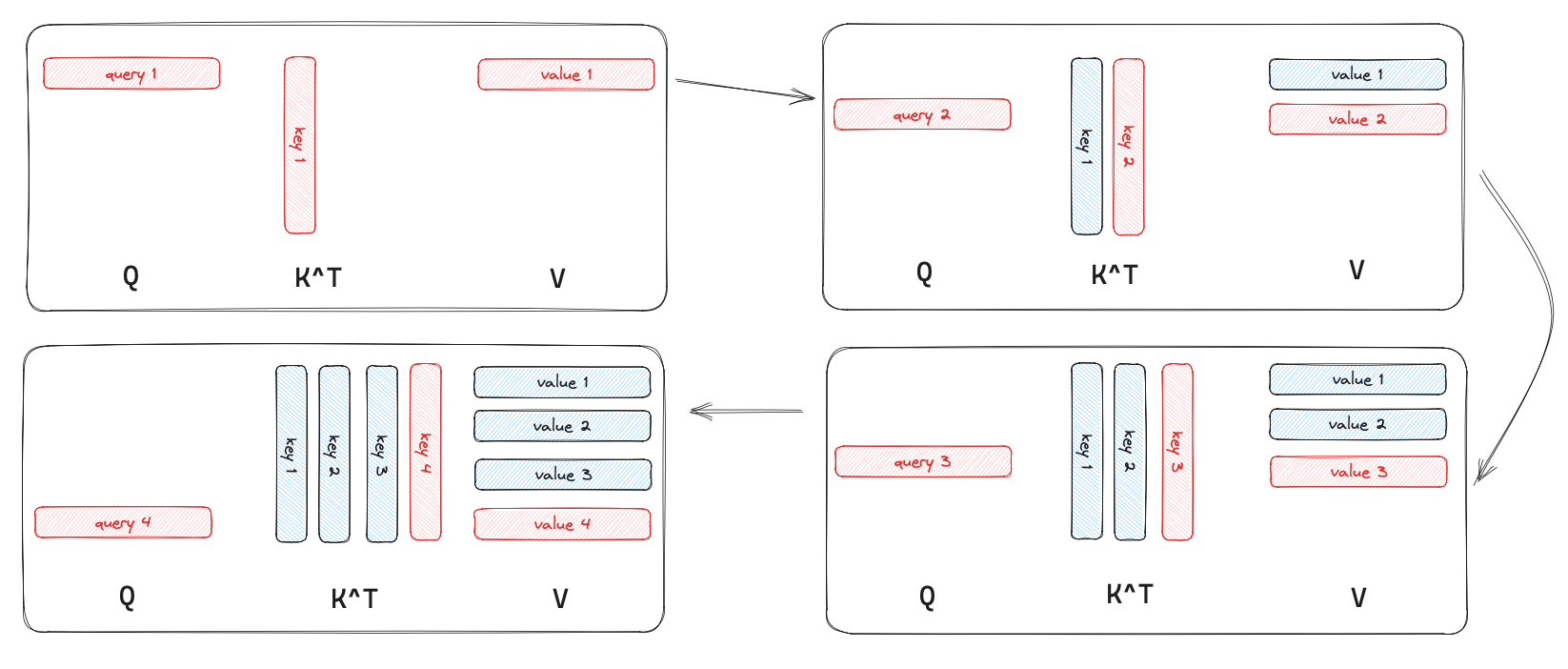
One challenge with KV caching is that it requires memory for each token generated, which can be substantial for long sequences. Some approaches to manage this include:
