diff --git a/.gitignore b/.gitignore
index f894c4c5..455024f8 100644
--- a/.gitignore
+++ b/.gitignore
@@ -67,6 +67,7 @@ studio-pf.log
# Credentials and secrets
.geostudio_config_file
+geostudio_config_file
*.env
.env.local
secrets.yml
diff --git a/workshop/docs/notebooks/lab1-getting-started.ipynb b/workshop/docs/notebooks/lab1-getting-started.ipynb
index f4f76271..46056af7 100644
--- a/workshop/docs/notebooks/lab1-getting-started.ipynb
+++ b/workshop/docs/notebooks/lab1-getting-started.ipynb
@@ -7,6 +7,12 @@
"source": [
"# Lab 1\n",
"\n",
+ "\n",
+ "\n",
+ "  \n",
+ "\n",
+ "\n",
+ "\n",
"**Getting Started with IBM Geospatial Studio**\n",
"\n",
"⏱️ **Estimated Duration:** 10 minutes \n",
@@ -228,6 +234,8 @@
"BASE_STUDIO_UI_URL=https://localhost:4180\n",
"\"\"\"\n",
"\n",
+ "# If you are using jupyter lab, create a normal file to view it on the fileviewer. `geostudio_config_file`\n",
+ "\n",
"# Write to file\n",
"with open('.geostudio_config_file', 'w') as f:\n",
" f.write(config_content)\n",
diff --git a/workshop/docs/notebooks/lab2-onboarding-examples.ipynb b/workshop/docs/notebooks/lab2-onboarding-examples.ipynb
index 2f7eddd8..76a64652 100644
--- a/workshop/docs/notebooks/lab2-onboarding-examples.ipynb
+++ b/workshop/docs/notebooks/lab2-onboarding-examples.ipynb
@@ -7,6 +7,12 @@
"source": [
"# Lab 2\n",
"\n",
+ "\n",
+ "\n",
+ " \n",
+ "\n",
+ "\n",
+ "\n",
"**Onboarding Pre-computed Examples**\n",
"\n",
"⏱️ **Estimated Duration:** 20 minutes \n",
@@ -116,6 +122,8 @@
"outputs": [],
"source": [
"# Initialize the client\n",
+ "# If you are using jupyter lab, create a normal file to view it on the fileviewer. `geostudio_config_file`\n",
+ "\n",
"client = Client(geostudio_config_file=\".geostudio_config_file\")\n",
"\n",
"print(\"✅ Connected to Geospatial Studio!\")"
@@ -403,7 +411,7 @@
"\n",
"2. **Navigate to the Inference Lab:**\n",
" - Click on \"Inference Lab\" in the left sidebar\n",
- " - Or go directly to: `https://localhost:4180/inference`\n",
+ " - Or go directly to: `https://localhost:4180/inference#inference`\n",
"\n",
"3. **Find Your Example:**\n",
" - Look for \"My Examples\" section\n",
diff --git a/workshop/docs/notebooks/lab3-running-inference.ipynb b/workshop/docs/notebooks/lab3-running-inference.ipynb
index c5e196fa..712e6453 100644
--- a/workshop/docs/notebooks/lab3-running-inference.ipynb
+++ b/workshop/docs/notebooks/lab3-running-inference.ipynb
@@ -7,6 +7,11 @@
"source": [
"# Lab 3\n",
"\n",
+ "\n",
+ "\n",
+ " \n",
+ "\n",
+ "\n",
"**Upload Model Checkpoints and Run Inference**\n",
"\n",
"⏱️ **Estimated Duration:** 30 minutes \n",
@@ -132,6 +137,8 @@
"outputs": [],
"source": [
"# Initialize the client\n",
+ "# If you are using jupyter lab, create a normal file to view it on the fileviewer. `geostudio_config_file`\n",
+ "\n",
"client = Client(geostudio_config_file=\".geostudio_config_file\")\n",
"\n",
"print(\"✅ Connected to Geospatial Studio\")"
diff --git a/workshop/docs/notebooks/lab4-burnscars-workflow.ipynb b/workshop/docs/notebooks/lab4-burnscars-workflow.ipynb
index 8f46d9fa..db4b2302 100644
--- a/workshop/docs/notebooks/lab4-burnscars-workflow.ipynb
+++ b/workshop/docs/notebooks/lab4-burnscars-workflow.ipynb
@@ -7,6 +7,12 @@
"source": [
"# Lab 4\n",
"\n",
+ "\n",
+ "\n",
+ " \n",
+ "\n",
+ "\n",
+ "\n",
"**Training a Custom Model for Wildfire Burn Scar Detection**\n",
"\n",
"⏱️ **Estimated Duration:** 60-90 minutes \n",
@@ -127,6 +133,8 @@
"outputs": [],
"source": [
"# Initialize the client\n",
+ "# If you are using jupyter lab, create a normal file to view it on the fileviewer. `geostudio_config_file`\n",
+ "\n",
"client = Client(geostudio_config_file=\".geostudio_config_file\")\n",
"\n",
"print(\"✅ Connected to Geospatial Studio!\")"
@@ -199,8 +207,18 @@
"outputs": [],
"source": [
"# Load the backbone configuration\n",
- "with open(\"../../../populate-studio/payloads/backbones/backbone-Prithvi_EO_V2_300M.json\", \"r\") as f:\n",
- " backbone = json.load(f)\n",
+ "try:\n",
+ " with open(\"../populate-studio/payloads/backbones/backbone-Prithvi_EO_V2_300M.json\", \"r\") as f:\n",
+ " backbone = json.load(f)\n",
+ " \n",
+ "except FileNotFoundError:\n",
+ " backbone = {\n",
+ " \"name\" : \"Prithvi_EO_V2_300M\",\n",
+ " \"description\" : \"Geospatial pre-traineed foundation model Prithvi-EO-V2 (Prithvi_EO_V2_300M)\",\n",
+ " \"checkpoint_filename\" : \"prithvi_eo_v2_300\\/Prithvi_EO_V2_300M.pt\",\n",
+ " \"model_params\" : {\"backbone\": \"prithvi_eo_v2_300\", \"embed_dim\": 768, \"num_heads\": 12, \"tile_size\": 1, \"num_layers\": 12, \"patch_size\": 16, \"tubelet_size\": 1, \"model_category\": \"prithvi\"}\n",
+ " }\n",
+ "\n",
"\n",
"print(\"📋 Backbone Configuration:\")\n",
"print(json.dumps(backbone, indent=2))"
@@ -255,8 +273,54 @@
"outputs": [],
"source": [
"# Load the dataset configuration\n",
- "with open(\"../../../populate-studio/payloads/datasets/dataset-burn_scars.json\", \"r\") as f:\n",
- " wild_fire_dataset = json.load(f)\n",
+ "try:\n",
+ " with open(\"../populate-studio/payloads/datasets/dataset-burn_scars.json\", \"r\") as f:\n",
+ " wild_fire_dataset = json.load(f)\n",
+ "except FileNotFoundError:\n",
+ " wild_fire_dataset = {\n",
+ " \"dataset_name\": \"Wildfire burn scars\",\n",
+ " \"dataset_url\": \"https://s3.us-east.cloud-object-storage.appdomain.cloud/geospatial-studio-example-data/burn-scar-training-data.zip\",\n",
+ " \"label_suffix\": \".mask.tif\",\n",
+ " \"description\": \"A set of wildfire burn scar extent using HLS data. This dataset contains Harmonized Landsat and Sentinel-2 imagery of burn scars and the associated masks for the years 2018-2021 over the contiguous United States. There are 804 512x512 scenes. Its primary purpose is for training geospatial machine learning models. Each tiff file contains a 512x512 pixel tiff file. Scenes contain six bands, and masks have one band. For satellite scenes, each band has already been converted to reflectance.\",\n",
+ " \"purpose\": \"Segmentation\",\n",
+ " \"data_sources\": [\n",
+ " {\n",
+ " \"bands\": [\n",
+ " {\"index\": \"0\", \"band_name\": \"Blue\", \"scaling_factor\": \"0.0001\", \"RGB_band\": \"B\"},\n",
+ " {\"index\": \"1\", \"band_name\": \"Green\", \"scaling_factor\": \"0.0001\", \"RGB_band\": \"G\"},\n",
+ " {\"index\": \"2\", \"band_name\": \"Red\", \"scaling_factor\": \"0.0001\", \"RGB_band\": \"R\"},\n",
+ " {\"index\": \"3\", \"band_name\": \"NIR_Narrow\", \"scaling_factor\": \"0.0001\"},\n",
+ " {\"index\": \"4\", \"band_name\": \"SWIR1\", \"scaling_factor\": \"0.0001\"},\n",
+ " {\"index\": \"5\", \"band_name\": \"SWIR2\", \"scaling_factor\": \"0.0001\"}\n",
+ " ],\n",
+ " \"connector\": \"sentinelhub\",\n",
+ " \"collection\": \"hls_l30\",\n",
+ " \"file_suffix\": \"_merged.tif\",\n",
+ " \"modality_tag\": \"HLS_L30\"\n",
+ " }\n",
+ " ],\n",
+ " \"label_categories\": [\n",
+ " {\n",
+ " \"id\": \"1\",\n",
+ " \"name\": \"Fire Scar\",\n",
+ " \"color\": \"#ab4f4f\",\n",
+ " \"opacity\": 1\n",
+ " },\n",
+ " {\n",
+ " \"id\": \"0\",\n",
+ " \"name\": \"No data\",\n",
+ " \"color\": \"#000000\",\n",
+ " \"opacity\": \"0\"\n",
+ " },\n",
+ " {\n",
+ " \"id\": \"-1\",\n",
+ " \"name\": \"Ignore\",\n",
+ " \"color\": \"#000000\",\n",
+ " \"opacity\": \"0\"\n",
+ " }\n",
+ " ],\n",
+ " \"version\": \"v2\"\n",
+ " }\n",
"\n",
"print(\"📋 Dataset Configuration:\")\n",
"print(json.dumps(wild_fire_dataset, indent=2))"
@@ -371,14 +435,388 @@
"\n",
"# Load the template configuration\n",
"try:\n",
- " with open('../../../populate-studio/payloads/templates/template-seg.json', 'r') as f:\n",
+ " with open('../populate-studio/payloads/templates/template-seg.json', 'r') as f:\n",
" segmentation_template = json.load(f)\n",
" \n",
- " print(\"📋 Segmentation Task Template:\")\n",
- " print(json.dumps(segmentation_template, indent=2))\n",
"except FileNotFoundError:\n",
- " print(\"⚠️ Template file not found. Please check populate-studio/payloads/templates/\")\n",
- " segmentation_template = None"
+ " segmentation_template = {\n",
+ " \"name\": \"Segmentation\",\n",
+ " \"description\": \"Generic template v1 and v2 models: Segmentation\",\n",
+ " \"purpose\": \"Segmentation\",\n",
+ " \"model_params\": {\n",
+ " \"$uri\": \"https://ibm.com/watsonx.ai.geospatial.finetune.segmentation.json\",\n",
+ " \"type\": \"object\",\n",
+ " \"title\": \"Finetune\",\n",
+ " \"$schema\": \"https://json-schema.org/draft/2020-12/schema\",\n",
+ " \"properties\": {\n",
+ " \"data\": {\n",
+ " \"type\": \"object\",\n",
+ " \"default\": {\n",
+ " \"batch_size\": 4,\n",
+ " \"constant_multiply\": 1,\n",
+ " \"workers_per_gpu\": 2,\n",
+ " \"check_stackability\": False\n",
+ " },\n",
+ " \"properties\": {\n",
+ " \"batch_size\": {\n",
+ " \"type\": \"int\",\n",
+ " \"default\": 4,\n",
+ " \"description\": \"Batch size\",\n",
+ " \"studio_name\": \"Batch size\"\n",
+ " },\n",
+ " \"constant_multiply\": {\n",
+ " \"type\": \"float\",\n",
+ " \"default\": 1,\n",
+ " \"description\": \"Constant Scale\",\n",
+ " \"studio_name\": \"Constant Scale\"\n",
+ " },\n",
+ " \"workers_per_gpu\": {\n",
+ " \"studio_name\": \"Workers per GPU\",\n",
+ " \"description\": \"Workers per GPU\",\n",
+ " \"type\": \"int\",\n",
+ " \"default\": 2\n",
+ " },\n",
+ " \"check_stackability\": {\n",
+ " \"studio_name\": \"Check Stackability\",\n",
+ " \"description\": \"Check Stackability\",\n",
+ " \"type\": \"bool\",\n",
+ " \"default\": False\n",
+ " }\n",
+ " },\n",
+ " \"studio_name\": \"Data loading\"\n",
+ " },\n",
+ " \"model\": {\n",
+ " \"type\": \"object\",\n",
+ " \"default\": {\n",
+ " \"decode_head\": {\n",
+ " \"channels\": 256,\n",
+ " \"num_convs\": 4,\n",
+ " \"decoder\": \"UNetDecoder\",\n",
+ " \"loss_decode\": {\n",
+ " \"type\": \"CrossEntropyLoss\",\n",
+ " \"avg_non_ignore\": True\n",
+ " }\n",
+ " },\n",
+ " \"frozen_backbone\": False,\n",
+ " \"tiled_inference_parameters\": {\n",
+ " \"h_crop\": 224,\n",
+ " \"h_stride\": 196,\n",
+ " \"w_crop\": 224,\n",
+ " \"w_stride\": 196,\n",
+ " \"average_patches\": False\n",
+ " }\n",
+ " },\n",
+ " \"properties\": {\n",
+ " \"decode_head\": {\n",
+ " \"type\": \"object\",\n",
+ " \"default\": {\n",
+ " \"channels\": 256,\n",
+ " \"num_convs\": 4,\n",
+ " \"decoder\": \"UperNetDecoder\",\n",
+ " \"loss_decode\": {\n",
+ " \"type\": \"CrossEntropyLoss\",\n",
+ " \"avg_non_ignore\": True\n",
+ " }\n",
+ " },\n",
+ " \"properties\": {\n",
+ " \"channels\": {\n",
+ " \"type\": \"int\",\n",
+ " \"default\": 256,\n",
+ " \"description\": \"Channels at each block of the decode head, except the final one\",\n",
+ " \"studio_name\": \"Channels\"\n",
+ " },\n",
+ " \"num_convs\": {\n",
+ " \"type\": \"int\",\n",
+ " \"default\": 4,\n",
+ " \"description\": \"Number of convolutional blocks in the head (except the final one)\",\n",
+ " \"studio_name\": \"Blocks\"\n",
+ " },\n",
+ " \"decoder\": {\n",
+ " \"enum\": [\n",
+ " \"UperNetDecoder\",\n",
+ " \"UNetDecoder\"\n",
+ " ],\n",
+ " \"type\": \"string\",\n",
+ " \"default\": \"Fixed\",\n",
+ " \"description\": \"Decoder type\",\n",
+ " \"studio_name\": \"Decoder type\"\n",
+ " },\n",
+ " \"loss_decode\": {\n",
+ " \"type\": \"object\",\n",
+ " \"properties\": {\n",
+ " \"type\": {\n",
+ " \"enum\": [\n",
+ " \"CrossEntropyLoss\"\n",
+ " ],\n",
+ " \"type\": \"string\",\n",
+ " \"default\": \"CrossEntropyLoss\",\n",
+ " \"description\": \"Type of loss function\",\n",
+ " \"studio_name\": \"Loss function\"\n",
+ " },\n",
+ " \"avg_non_ignore\": {\n",
+ " \"type\": \"bool\",\n",
+ " \"default\": True,\n",
+ " \"description\": \"The loss is only averaged over non-ignored targets (ignored targets are usually where labels are missing in the dataset) if this is True\"\n",
+ " }\n",
+ " },\n",
+ " \"description\": \"Loss function to be used\",\n",
+ " \"studio_name\": \"Loss\"\n",
+ " }\n",
+ " },\n",
+ " \"description\": \"Architecture of the decode head\",\n",
+ " \"studio_name\": \"Head\"\n",
+ " },\n",
+ " \"auxiliary_head\": {\n",
+ " \"type\": \"object\",\n",
+ " \"default\": {},\n",
+ " \"properties\": {\n",
+ " \"decoder\": {\n",
+ " \"type\": \"string\",\n",
+ " \"default\": \"FCNDecoder\",\n",
+ " \"description\": \"Decoder function to use\",\n",
+ " \"studio_name\": \"Decoder\"\n",
+ " },\n",
+ " \"channels\": {\n",
+ " \"type\": \"int\",\n",
+ " \"default\": 256,\n",
+ " \"description\": \"Channels at each block of the decode head, except the final one\",\n",
+ " \"studio_name\": \"Channels\"\n",
+ " },\n",
+ " \"num_convs\": {\n",
+ " \"type\": \"int\",\n",
+ " \"default\": 2,\n",
+ " \"description\": \"Number of convolutional blocks in the head (except the final one)\",\n",
+ " \"studio_name\": \"Blocks\"\n",
+ " },\n",
+ " \"in_index\": {\n",
+ " \"type\": \"int\",\n",
+ " \"default\": -1,\n",
+ " \"description\": \"Index of the input list to take. Defaults to -1\",\n",
+ " \"studio_name\": \"In index\"\n",
+ " },\n",
+ " \"dropout\": {\n",
+ " \"type\": \"int\",\n",
+ " \"default\": 0,\n",
+ " \"description\": \"Dropout value to apply. Defaults to 0\",\n",
+ " \"studio_name\": \"Dropout\"\n",
+ " },\n",
+ " \"loss_decode\": {\n",
+ " \"type\": \"object\",\n",
+ " \"properties\": {\n",
+ " \"type\": {\n",
+ " \"enum\": [\n",
+ " \"CrossEntropyLoss\"\n",
+ " ],\n",
+ " \"type\": \"string\",\n",
+ " \"default\": \"CrossEntropyLoss\",\n",
+ " \"description\": \"Type of loss function\",\n",
+ " \"studio_name\": \"Loss function\"\n",
+ " },\n",
+ " \"loss_weight\": {\n",
+ " \"type\": \"float\",\n",
+ " \"default\": 1,\n",
+ " \"description\": \"Multiplicative weight of the loss of the auxiliary head in the loss. The loss is calculated as aux_head_weight * aux_head_loss + decode_head_loss\",\n",
+ " \"studio_name\": \"Loss weight\"\n",
+ " },\n",
+ " \"avg_non_ignore\": {\n",
+ " \"type\": \"bool\",\n",
+ " \"default\": True,\n",
+ " \"description\": \"The loss is only averaged over non-ignored targets (ignored targets are usually where labels are missing in the dataset) if this is True\"\n",
+ " }\n",
+ " },\n",
+ " \"description\": \"Loss function to be used\",\n",
+ " \"studio_name\": \"Loss\"\n",
+ " }\n",
+ " },\n",
+ " \"description\": \"Architecture of the auxiliary head\"\n",
+ " },\n",
+ " \"frozen_backbone\": {\n",
+ " \"type\": \"bool\",\n",
+ " \"default\": False,\n",
+ " \"description\": \"Freeze the weights of the backbone when set to True\",\n",
+ " \"studio_name\": \"Freeze backbone\"\n",
+ " },\n",
+ " \"tiled_inference_parameters\": {\n",
+ " \"type\": \"object\",\n",
+ " \"default\": {\n",
+ " \"h_crop\": 224,\n",
+ " \"h_stride\": 196,\n",
+ " \"w_crop\": 224,\n",
+ " \"w_stride\": 196,\n",
+ " \"average_patches\": False\n",
+ " },\n",
+ " \"properties\": {\n",
+ " \"h_crop\": {\n",
+ " \"type\": \"int\",\n",
+ " \"default\": 224,\n",
+ " \"description\": \"h_crop values for tilling images\",\n",
+ " \"studio_name\": \"h_crop\"\n",
+ " },\n",
+ " \"h_stride\": {\n",
+ " \"type\": \"int\",\n",
+ " \"default\": 196,\n",
+ " \"description\": \"h_stride values for tilling images\",\n",
+ " \"studio_name\": \"h_stride\"\n",
+ " },\n",
+ " \"w_crop\": {\n",
+ " \"type\": \"int\",\n",
+ " \"default\": 224,\n",
+ " \"description\": \"w_crop values for tilling images\",\n",
+ " \"studio_name\": \"w_crop\"\n",
+ " },\n",
+ " \"w_stride\": {\n",
+ " \"type\": \"int\",\n",
+ " \"default\": 196,\n",
+ " \"description\": \"w_stride values for tilling images\",\n",
+ " \"studio_name\": \"w_stride\"\n",
+ " },\n",
+ " \"average_patches\": {\n",
+ " \"type\": \"bool\",\n",
+ " \"default\": False,\n",
+ " \"description\": \"Whether to use average_patches\",\n",
+ " \"studio_name\": \"average_patches\"\n",
+ " }\n",
+ " }\n",
+ " }\n",
+ " },\n",
+ " \"description\": \"Model architecture definition\",\n",
+ " \"studio_name\": \"Architecture\"\n",
+ " },\n",
+ " \"runner\": {\n",
+ " \"type\": \"object\",\n",
+ " \"default\": {\n",
+ " \"max_epochs\": 10,\n",
+ " \"early_stopping_patience\": 20,\n",
+ " \"early_stopping_monitor\": \"val/loss\"\n",
+ " },\n",
+ " \"properties\": {\n",
+ " \"max_epochs\": {\n",
+ " \"type\": \"int\",\n",
+ " \"default\": 10,\n",
+ " \"description\": \"Training epochs\",\n",
+ " \"studio_name\": \"Training epochs\"\n",
+ " },\n",
+ " \"early_stopping_patience\": {\n",
+ " \"type\": \"int\",\n",
+ " \"default\": 20,\n",
+ " \"description\": \"Early stopping patience\",\n",
+ " \"studio_name\": \"Early stopping patience\"\n",
+ " },\n",
+ " \"early_stopping_monitor\": {\n",
+ " \"type\": \"string\",\n",
+ " \"default\": \"val/loss\",\n",
+ " \"description\": \"Monitoring value to determine early stopping\",\n",
+ " \"studio_name\": \"Early stopping monitor\"\n",
+ " }\n",
+ " },\n",
+ " \"studio_name\": \"Runner\"\n",
+ " },\n",
+ " \"lr_config\": {\n",
+ " \"type\": \"object\",\n",
+ " \"default\": {\n",
+ " \"policy\": \"Fixed\"\n",
+ " },\n",
+ " \"required\": [\n",
+ " \"policy\"\n",
+ " ],\n",
+ " \"properties\": {\n",
+ " \"policy\": {\n",
+ " \"enum\": [\n",
+ " \"Fixed\",\n",
+ " \"CosineAnnealing\"\n",
+ " ],\n",
+ " \"type\": \"string\",\n",
+ " \"default\": \"Fixed\",\n",
+ " \"description\": \"Policy type\",\n",
+ " \"studio_name\": \"Policy type\"\n",
+ " },\n",
+ " \"warmup_iters\": {\n",
+ " \"type\": \"int\",\n",
+ " \"default\": 0,\n",
+ " \"description\": \"LR warmup iterations. Valid for some policies\",\n",
+ " \"studio_name\": \"Learning rate warmup iterations\"\n",
+ " },\n",
+ " \"warmup_ratio\": {\n",
+ " \"type\": \"float\",\n",
+ " \"default\": 1,\n",
+ " \"description\": \"Initial lr at warmup will be learning_rate * warmup_ratio\",\n",
+ " \"studio_name\": \"LR warmup initialization ratio\"\n",
+ " }\n",
+ " },\n",
+ " \"description\": \"Learning rate policy\",\n",
+ " \"studio_name\": \"Learning rate policy\"\n",
+ " },\n",
+ " \"optimizer\": {\n",
+ " \"type\": \"object\",\n",
+ " \"default\": {\n",
+ " \"lr\": 6e-05,\n",
+ " \"type\": \"Adam\"\n",
+ " },\n",
+ " \"properties\": {\n",
+ " \"lr\": {\n",
+ " \"type\": \"float\",\n",
+ " \"default\": 6e-05,\n",
+ " \"description\": \"Learning rate\",\n",
+ " \"studio_name\": \"Learning rate\"\n",
+ " },\n",
+ " \"type\": {\n",
+ " \"enum\": [\n",
+ " \"Adam\",\n",
+ " \"SGD\",\n",
+ " \"AdamW\",\n",
+ " \"RMSProp\"\n",
+ " ],\n",
+ " \"default\": \"Adam\",\n",
+ " \"description\": \"Optimizer to be used\",\n",
+ " \"studio_name\": \"Optimizer type\"\n",
+ " },\n",
+ " \"weight_decay\": {\n",
+ " \"type\": \"float\",\n",
+ " \"default\": 0,\n",
+ " \"description\": \"L2 weight regularization (weight decay)\",\n",
+ " \"studio_name\": \"L2 regularization weight\"\n",
+ " }\n",
+ " },\n",
+ " \"description\": \"Optimizer\",\n",
+ " \"studio_name\": \"Optimizer\"\n",
+ " },\n",
+ " \"dataset_id\": {\n",
+ " \"type\": \"string\",\n",
+ " \"description\": \"ID of dataset to use for this finetuning\",\n",
+ " \"studio_name\": \"Dataset\"\n",
+ " },\n",
+ " \"evaluation\": {\n",
+ " \"type\": \"object\",\n",
+ " \"default\": {\n",
+ " \"interval\": 1\n",
+ " },\n",
+ " \"properties\": {\n",
+ " \"interval\": {\n",
+ " \"type\": \"int\",\n",
+ " \"default\": 1,\n",
+ " \"description\": \"Frequency of epochs with which to perform validation\",\n",
+ " \"studio_name\": \"Epoch interval\"\n",
+ " }\n",
+ " },\n",
+ " \"studio_name\": \"Validation\"\n",
+ " },\n",
+ " \"backbone_model_id\": {\n",
+ " \"type\": \"string\",\n",
+ " \"description\": \"ID of the pretrained backbone\"\n",
+ " }\n",
+ " },\n",
+ " \"description\": \"A request sent to the finetuning service to start a finetune task for segmentation\"\n",
+ " },\n",
+ " \"extra_info\": {\n",
+ " \"runtime_image\": \"quay.io/geospatial-studio/terratorch:latest\",\n",
+ " \"model_category\": \"prithvi\",\n",
+ " \"model_framework\": \"terratorch-v2\"\n",
+ " },\n",
+ " \"content\": \"IyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIwojIExpY2Vuc2VkIE1hdGVyaWFscyAtIFByb3BlcnR5IG9mIElCTQojICJSZXN0cmljdGVkIE1hdGVyaWFscyBvZiBJQk0iCiMgQ29weXJpZ2h0IElCTSBDb3JwLiAyMDI1IEFMTCBSSUdIVFMgUkVTRVJWRUQKIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIwoKCiMgbGlnaHRuaW5nLnB5dG9yY2g9PTIuMS4xCnNlZWRfZXZlcnl0aGluZzogMAp0cmFpbmVyOgogIGFjY2VsZXJhdG9yOiBhdXRvCiAgc3RyYXRlZ3k6IGF1dG8KICBkZXZpY2VzOiBhdXRvCiAgbnVtX25vZGVzOiAxCiAgcHJlY2lzaW9uOiAxNi1taXhlZAogIGxvZ2dlcjoKICAgIGNsYXNzX3BhdGg6IGxpZ2h0bmluZy5weXRvcmNoLmxvZ2dlcnMubWxmbG93Lk1MRmxvd0xvZ2dlcgogICAgaW5pdF9hcmdzOgogICAgICBleHBlcmltZW50X25hbWU6IHt7IHR1bmVfaWQgfX0gIyBGdXR1cmUgdmVyc2lvbiwgY2huYWdlIHRoaXMgdG8gdXNlciAvIGVtYWlsCiAgICAgIHJ1bl9uYW1lOiAiVHJhaW4iICAgICMgRnV0dXJlIHZlcnNpb24sIGNobmFnZSB0aGlzIHRvIHR1bmVfaWQKICAgICAgdHJhY2tpbmdfdXJpOiB7eyBtbGZsb3dfdHJhY2tpbmdfdXJsIH19CiAgICAgIHNhdmVfZGlyOiB7eyBtb3VudF9yb290ICsgJ3R1bmUtdGFza3MvJyArIHR1bmVfaWQgKyAnL21sZmxvdycgfX0KICAgICAgeyUgaWYgbWxmbG93X3RhZ3MgLSV9CiAgICAgIHRhZ3M6CiAgICAgICAgeyUgZm9yIGtleSwgdmFsdWUgaW4gbWxmbG93X3RhZ3MuaXRlbXMoKSAtJX0KICAgICAgICB7eyBrZXkgfX06IHt7IHZhbHVlIH19CiAgICAgICAgeyUgZW5kZm9yICV9CiAgICAgIHslLSBlbmRpZiAlfSAgICAgICAKICBjYWxsYmFja3M6CiAgICAtIGNsYXNzX3BhdGg6IFJpY2hQcm9ncmVzc0JhcgogICAgLSBjbGFzc19wYXRoOiBMZWFybmluZ1JhdGVNb25pdG9yCiAgICAgIGluaXRfYXJnczoKICAgICAgICBsb2dnaW5nX2ludGVydmFsOiBlcG9jaAogICAgIyAtLS0tIEVhcmx5IHN0b3AgaWYgLS0tLQogICAgeyUgaWYgcnVubmVyWyJlYXJseV9zdG9wcGluZ19wYXRpZW5jZSJdIC0lfQogICAgLSBjbGFzc19wYXRoOiBFYXJseVN0b3BwaW5nCiAgICAgIGluaXRfYXJnczoKICAgICAgICBtb25pdG9yOiB7eyBydW5uZXJbImVhcmx5X3N0b3BwaW5nX21vbml0b3IiXSB9fQogICAgICAgIHBhdGllbmNlOiB7eyBydW5uZXJbImVhcmx5X3N0b3BwaW5nX3BhdGllbmNlIl0gfX0KICAgIHslLSBlbmRpZiAlfQogICAgICMgLS0tLSBFYXJseSBzdG9wIGVuZGlmIC0tLS0KICAgIC0gY2xhc3NfcGF0aDogTW9kZWxDaGVja3BvaW50CiAgICAgIGluaXRfYXJnczoKICAgICAgICBkaXJwYXRoOiB7eyBtb3VudF9yb290ICsgJ3R1bmUtdGFza3MvJyArIHR1bmVfaWQgICsgJy8nIH19CiAgICAgICAgbW9kZTogbWluCiAgICAgICAgbW9uaXRvcjogdmFsL2xvc3MKICAgICAgICBmaWxlbmFtZToge3sgJ2Jlc3Qtc3RhdGVfZGljdC17ZXBvY2g6MDJkfScgfX0KICAgICAgICBzYXZlX3dlaWdodHNfb25seTogVHJ1ZQogICAgICAKICBtYXhfZXBvY2hzOiB7eyBydW5uZXJbIm1heF9lcG9jaHMiXSB9fQogIGNoZWNrX3ZhbF9ldmVyeV9uX2Vwb2NoOiB7eyBldmFsdWF0aW9uWyJpbnRlcnZhbCJdIH19CiAgbG9nX2V2ZXJ5X25fc3RlcHM6IDUwCiAgZW5hYmxlX2NoZWNrcG9pbnRpbmc6IHRydWUKICBkZWZhdWx0X3Jvb3RfZGlyOiB7eyBtb3VudF9yb290ICsgJ3R1bmUtdGFza3MvJyArIHR1bmVfaWQgfX0KCmRhdGE6CiAgY2xhc3NfcGF0aDogdGVycmF0b3JjaC5kYXRhbW9kdWxlcy5HZW5lcmljTm9uR2VvU2VnbWVudGF0aW9uRGF0YU1vZHVsZQogIGluaXRfYXJnczoKICAgIGJhdGNoX3NpemU6IHt7IGRhdGFbImJhdGNoX3NpemUiXSB9fQogICAgbnVtX3dvcmtlcnM6IHt7IGRhdGFbIndvcmtlcnNfcGVyX2dwdSJdIH19CiAgICBub19sYWJlbF9yZXBsYWNlOiB7eyBsYWJlbF9ub2RhdGEgfX0KICAgIG5vX2RhdGFfcmVwbGFjZToge3sgaW1hZ2Vfbm9kYXRhX3JlcGxhY2UgfX0KICAgIGNvbnN0YW50X3NjYWxlOiB7eyBjb25zdGFudF9tdWx0aXBseSB9fQogICAgZGF0YXNldF9iYW5kczoKICAgICAge3sgYmFuZHMudmFsdWVzKCkgfCBsaXN0IHwgZmlyc3QgfCB0b195YW1sIHwgaW5kZW50KDYpIH19CiAgICBvdXRwdXRfYmFuZHM6CiAgICAgIHt7IG91dHB1dF9iYW5kcy52YWx1ZXMoKSB8IGxpc3QgfCBmaXJzdCB8IHRvX3lhbWwgfCBpbmRlbnQoNikgfX0KICAgIHJnYl9pbmRpY2VzOgogICAgICB7eyByZ2JfYmFuZF9pbmRpY2VzIHwgdG9feWFtbCB8IGluZGVudCg2KSB9fQogICAgdHJhaW5fZGF0YV9yb290OiB7eyBkYXRhX3Jvb3QgfX17eyB0cmFpbl9kYXRhX2Rpci52YWx1ZXMoKSB8IGxpc3QgfCBmaXJzdCB9fQogICAgdHJhaW5fbGFiZWxfZGF0YV9yb290OiB7eyBkYXRhX3Jvb3QgKyB0cmFpbl9sYWJlbHNfZGlyIH19CiAgICB2YWxfZGF0YV9yb290OiB7eyBkYXRhX3Jvb3QgfX17eyB2YWxfZGF0YV9kaXIudmFsdWVzKCkgfCBsaXN0IHwgZmlyc3QgfX0KICAgIHZhbF9sYWJlbF9kYXRhX3Jvb3Q6IHt7IGRhdGFfcm9vdCArIHZhbF9sYWJlbHNfZGlyIH19CiAgICB0ZXN0X2RhdGFfcm9vdDoge3sgZGF0YV9yb290IH19e3sgdGVzdF9kYXRhX2Rpci52YWx1ZXMoKSB8IGxpc3QgfCBmaXJzdCB9fQogICAgdGVzdF9sYWJlbF9kYXRhX3Jvb3Q6IHt7IGRhdGFfcm9vdCArIHRlc3RfbGFiZWxzX2RpciB9fQogICAgeyUgaWYgdHJhaW5fc3BsaXRfcGF0aCAtJX0KICAgIHRyYWluX3NwbGl0OiB7eyBkYXRhX3Jvb3QgKyB0cmFpbl9zcGxpdF9wYXRoIH19CiAgICB7JSBlbmRpZiAtJX0KICAgIHslIGlmIHRlc3Rfc3BsaXRfcGF0aCAtJX0KICAgIHRlc3Rfc3BsaXQ6IHt7IGRhdGFfcm9vdCArIHRlc3Rfc3BsaXRfcGF0aCB9fQogICAgeyUgZW5kaWYgLSV9CiAgICB7JSBpZiB2YWxfc3BsaXRfcGF0aCAtJX0KICAgIHZhbF9zcGxpdDoge3sgZGF0YV9yb290ICsgdmFsX3NwbGl0X3BhdGggfX0KICAgIHslIGVuZGlmIC0lfQogICAgeyUgaWYgaW1nX3N1ZmZpeCAtJX0KICAgIGltZ19ncmVwOiAge3sgaW1nX3N1ZmZpeC52YWx1ZXMoKSB8IGxpc3QgfCBmaXJzdCB8IHRvanNvbiB9fQogICAgeyUgZW5kaWYgLSV9CiAgICB7JSBpZiBzZWdfbWFwX3N1ZmZpeCAtJX0KICAgIGxhYmVsX2dyZXA6ICJ7eyBzZWdfbWFwX3N1ZmZpeCB9fSIKICAgIHslIGVuZGlmIC0lfQogICAgbWVhbnM6IAogICAgICB7eyBub3JtX21lYW5zLnZhbHVlcygpIHwgbGlzdCB8IGZpcnN0fCB0b195YW1sIHwgaW5kZW50KDYpIH19CiAgICBzdGRzOiAKICAgICAge3sgbm9ybV9zdGRzLnZhbHVlcygpIHwgbGlzdCB8IGZpcnN0IHwgdG9feWFtbCB8IGluZGVudCg2KSB9fQogICAgbnVtX2NsYXNzZXM6IHt7IGNsYXNzZXN8bGVuZ3RoIH19CiAgICB7JSBpZiBkYXRhWyJleHBhbmRfdGVtcG9yYWxfZGltZW5zaW9uIl0gaXMgbm90IG5vbmUgLSV9CiAgICBleHBhbmRfdGVtcG9yYWxfZGltZW5zaW9uOiBkYXRhWyJleHBhbmRfdGVtcG9yYWxfZGltZW5zaW9uIl0KICAgIHslIGVuZGlmIC0lfQogICAgeyUgaWYgZGF0YVsiZHJvcF9sYXN0Il0gaXMgbm90IG5vbmUgLSV9CiAgICBkcm9wX2xhc3Q6IGRhdGFbImRyb3BfbGFzdCJdCiAgICB7JSBlbmRpZiAtJX0KICAgICMgLS0tLSB0cmFpbl90cmFuc2Zvcm0gaWYgLS0tLQogICAgeyUgaWYgZGF0YVsidHJhaW5fdHJhbnNmb3JtIl0gLSV9CiAgICB0cmFpbl90cmFuc2Zvcm06CiAgICB7JSBmb3IgdHJhbnNmb3JtIGluIGRhdGFbInRyYWluX3RyYW5zZm9ybSJdICV9CiAgICAtIGNsYXNzX3BhdGg6IHRyYXNuc2Zvcm1bImNsYXNzX3BhdGgiXQogICAgICBpbml0X2FyZ3M6CiAgICAgICAgeyUgaWYgdHJhc25zZm9ybVsiaGVpZ2h0Il0gaXMgbm90IG5vbmUgLSV9CiAgICAgICAgaGVpZ2h0OiB0cmFzbnNmb3JtWyJoZWlnaHQiXQogICAgICAgIHslIGVuZGlmIC0lfQogICAgICAgIHslIGlmIHRyYXNuc2Zvcm1bIndpZHRoIl0gaXMgbm90IG5vbmUgLSV9CiAgICAgICAgd2lkdGg6IHRyYXNuc2Zvcm1bIndpZHRoIl0KICAgICAgICB7JSBlbmRpZiAtJX0KICAgICAgICB7JSBpZiB0cmFzbnNmb3JtWyJhbHdheXNfYXBwbHkiXSBpcyBub3Qgbm9uZSAtJX0KICAgICAgICBhbHdheXNfYXBwbHk6IHRyYXNuc2Zvcm1bImFsd2F5c19hcHBseSJdCiAgICAgICAgeyUgZW5kaWYgLSV9CiAgICAgICAgeyUgaWYgdHJhc25zZm9ybVsidHJhbnNwb3NlX21hc2siXSBpcyBub3Qgbm9uZSAtJX0KICAgICAgICB0cmFuc3Bvc2VfbWFzazogdHJhc25zZm9ybVsidHJhbnNwb3NlX21hc2siXQogICAgICAgIHslIGVuZGlmIC0lfQogICAgICAgIHslIGlmIHRyYXNuc2Zvcm1bInAiXSBpcyBub3Qgbm9uZSAtJX0KICAgICAgICBwOiB0cmFzbnNmb3JtWyJwIl0KICAgICAgICB7JSBlbmRpZiAtJX0KICAgIHslIGVuZGZvciAlfQogICAgeyUgZW5kaWYgLSV9CiAgICAjIC0tLS0gdHJhaW5fdHJhbnNmb3JtIGVuZGlmIC0tLS0KCiAgICAjIGlmIGJhY2tib25lIGlzIHByaXRodmktRU8tdjIKICAgIHRlc3RfdHJhbnNmb3JtOgogICAgICAtIGNsYXNzX3BhdGg6IFRvVGVuc29yVjIKbW9kZWw6CiAgY2xhc3NfcGF0aDogdGVycmF0b3JjaC50YXNrcy5TZW1hbnRpY1NlZ21lbnRhdGlvblRhc2sKICBpbml0X2FyZ3M6CiAgICBtb2RlbF9hcmdzOiAKICAgICAgeyUtIGlmIHByZXRyYWluZWRfbW9kZWxfbmFtZSA9PSAicHJpdGh2aV9lb192MV8xMDAiIG9yIHByZXRyYWluZWRfbW9kZWxfbmFtZSA9PSAicHJpdGh2aV9lb192Ml8zMDAiIG9yIHByZXRyYWluZWRfbW9kZWxfbmFtZSA9PSAicHJpdGh2aV9lb192Ml8zMDBfdGwiIG9yIHByZXRyYWluZWRfbW9kZWxfbmFtZSA9PSAicHJpdGh2aV9lb192Ml82MDAiIG9yIHByZXRyYWluZWRfbW9kZWxfbmFtZSA9PSAicHJpdGh2aV9lb192Ml82MDBfdGwiICV9CiAgICAgIGJhY2tib25lX3ByZXRyYWluZWQ6IHRydWUgCiAgICAgIGJhY2tib25lOiB7eyBwcmV0cmFpbmVkX21vZGVsX25hbWUgfX0KICAgICAgYmFja2JvbmVfZHJvcF9wYXRoOiAwLjEgCiAgICAgIGJhY2tib25lX2JhbmRzOgogICAgICAgIHt7IG91dHB1dF9iYW5kcy52YWx1ZXMoKSB8IGxpc3QgfCBmaXJzdCB8IHRvX3lhbWwgfCBpbmRlbnQoOCkgfX0KICAgICAgbmVja3M6IAogICAgICAgIC0gbmFtZTogU2VsZWN0SW5kaWNlcwogICAgICAgICAgeyUtIGlmIHByZXRyYWluZWRfbW9kZWxfbmFtZSA9PSAicHJpdGh2aV9lb192MV8xMDAiICV9CiAgICAgICAgICBpbmRpY2VzOiBbMiwgNSwgOCwgMTFdICMgMTAwTSBtb2RlbHMKICAgICAgICAgIHslLSBlbGlmIHByZXRyYWluZWRfbW9kZWxfbmFtZSA9PSAicHJpdGh2aV9lb192Ml8zMDAiIG9yIHByZXRyYWluZWRfbW9kZWxfbmFtZSA9PSAicHJpdGh2aV9lb192Ml8zMDBfdGwiICV9CiAgICAgICAgICBpbmRpY2VzOiBbNSwgMTEsIDE3LCAyM10gICMgMzAwTSBtb2RlbHMKICAgICAgICAgIHslLSBlbGlmIHByZXRyYWluZWRfbW9kZWxfbmFtZSA9PSAicHJpdGh2aV9lb192Ml82MDAiIG9yIHByZXRyYWluZWRfbW9kZWxfbmFtZSA9PSAicHJpdGh2aV9lb192Ml82MDBfdGwiICV9CiAgICAgICAgICBpbmRpY2VzOiBbNywgMTUsIDIzLCAzMV0gIyA2MDBNIG1vZGVscyAgICAKICAgICAgICAgIHslIGVuZGlmICV9CiAgICAgICAgLSBuYW1lOiBSZXNoYXBlVG9rZW5zVG9JbWFnZSAjIHJlcXVpcmVkCiAgICAgICAgLSBuYW1lOiBMZWFybmVkSW50ZXJwb2xhdGVUb1B5cmFtaWRhbAogICAgICB7JS0gZWxzZSAlfQogICAgICAjIE9sZCBtb2RlbCB2ZXJzaW9uIGNvbmZpZ3VyYXRpb25zCiAgICAgIHByZXRyYWluZWQ6IHRydWUKICAgICAgYmFja2JvbmU6IHt7IHByZXRyYWluZWRfbW9kZWxfbmFtZSB9fQogICAgICAjIGJhY2tib25lX3RlbXBvcmFsX2VuY29kaW5nOiB0cnVlCiAgICAgIGJhY2tib25lX2Ryb3BfcGF0aF9yYXRlOiAwLjMKICAgICAgYmFja2JvbmVfd2luZG93X3NpemU6IDcKICAgICAgbnVtX2ZyYW1lczoge3sgbnVtX2ZyYW1lcyB9fQogICAgICBoZWFkX2NoYW5uZWxfbGlzdDoKICAgICAgICB7eyBoZWFkX2NoYW5uZWxfbGlzdCB8IHRvX3lhbWwgfCBpbmRlbnQoMTApIH19CiAgICAgIGJhbmRzOgogICAgICAgIHt7IG91dHB1dF9iYW5kcy52YWx1ZXMoKSB8IGxpc3QgfCBmaXJzdCB8IHRvX3lhbWwgfCBpbmRlbnQoOCkgfX0KICAgICAgeyUgZW5kaWYgJX0gCiAgICAgIGRlY29kZXI6IHt7IG1vZGVsWyJkZWNvZGVfaGVhZCJdWyJkZWNvZGVyIl0gfX0KICAgICAgeyUgaWYgIG1vZGVsWyJkZWNvZGVfaGVhZCJdWyJkZWNvZGVyIl0gPT0gIlVwZXJOZXREZWNvZGVyIiAtJX0KICAgICAgZGVjb2Rlcl9jaGFubmVsczogMjU2CiAgICAgIHslIGVsaWYgIG1vZGVsWyJkZWNvZGVfaGVhZCJdWyJkZWNvZGVyIl0gPT0gIlVOZXREZWNvZGVyIiAtJX0KICAgICAgI1RPRE8gdXNlciBwcm92aWRlZCBjaGFubmVscwogICAgICBkZWNvZGVyX2NoYW5uZWxzOiBbNTEyLCAyNTYsIDEyOCwgNjRdCiAgICAgIHslIGVsc2UgJX0KICAgICAgZGVjb2Rlcl9jaGFubmVsczoge3sgbW9kZWxbImRlY29kZV9oZWFkIl1bImNoYW5uZWxzIl0gfX0KICAgICAgeyUgZW5kaWYgLSV9CiAgICAgIG51bV9jbGFzc2VzOiB7eyBjbGFzc2VzfGxlbmd0aCB9fQogICAgICBoZWFkX2Ryb3BvdXQ6IDAuMQogICAgeyUgaWYgcHJldHJhaW5lZF9tb2RlbF9uYW1lID09ICJwcml0aHZpX2VvX3YxXzEwMCIgb3IgcHJldHJhaW5lZF9tb2RlbF9uYW1lID09ICJwcml0aHZpX2VvX3YyXzMwMCIgb3IgcHJldHJhaW5lZF9tb2RlbF9uYW1lID09ICJwcml0aHZpX2VvX3YyXzMwMF90bCIgb3IgcHJldHJhaW5lZF9tb2RlbF9uYW1lID09ICJwcml0aHZpX2VvX3YyXzYwMCIgb3IgcHJldHJhaW5lZF9tb2RlbF9uYW1lID09ICJwcml0aHZpX2VvX3YyXzYwMF90bCIgLSV9CiAgICBtb2RlbF9mYWN0b3J5OiBFbmNvZGVyRGVjb2RlckZhY3RvcnkKICAgIHslLSBlbHNlICV9CiAgICBtb2RlbF9mYWN0b3J5OiBQcml0aHZpTW9kZWxGYWN0b3J5CiAgICB7JSBlbmRpZiAlfSAKICAgIGxvc3M6IHt7IG1vZGVsWyJkZWNvZGVfaGVhZCJdWyJsb3NzX2RlY29kZSJdWyJ0eXBlIl0gfX0KICAgIHBsb3Rfb25fdmFsOiB7eyBydW5uZXJbInBsb3Rfb25fdmFsIl0gfX0KICAgIHslIGlmIG1vZGVsWyJhdXhpbGlhcnlfaGVhZCJdIC0lfQogICAgYXV4X2hlYWRzOgogICAgICAtIG5hbWU6IGF1eF9oZWFkCiAgICAgICAgZGVjb2Rlcjoge3sgbW9kZWxbImF1eGlsaWFyeV9oZWFkIl1bImRlY29kZXIiXSB9fQogICAgICAgIGRlY29kZXJfYXJnczoKICAgICAgICAgIGRlY29kZXJfY2hhbm5lbHM6IHt7IG1vZGVsWyJhdXhpbGlhcnlfaGVhZCJdWyJjaGFubmVscyJdIH19CiAgICAgICAgICBkZWNvZGVyX2luX2luZGV4OiB7eyBtb2RlbFsiYXV4aWxpYXJ5X2hlYWQiXVsiaW5faW5kZXgiXSB9fQogICAgICAgICAgZGVjb2Rlcl9udW1fY29udnM6IHt7IG1vZGVsWyJhdXhpbGlhcnlfaGVhZCJdWyJudW1fY29udnMiXSB9fQogICAgICAgICAgaGVhZF9kcm9wb3V0OiAge3sgbW9kZWxbImF1eGlsaWFyeV9oZWFkIl1bImRyb3BvdXQiXSB9fQogICAgICAgICAgIyBoZWFkX2NoYW5uZWxfbGlzdDoKICAgICAgICAgICMgICAtIDY0CiAgICBhdXhfbG9zczoKICAgICAgYXV4X2hlYWQ6IHt7IG1vZGVsWyJhdXhpbGlhcnlfaGVhZCJdWyJsb3NzX2RlY29kZSJdWyJsb3NzX3dlaWdodCJdIH19CiAgICB7JSBlbmRpZiAtJX0KICAgIGlnbm9yZV9pbmRleDoge3sgaWdub3JlX2luZGV4IH19CiAgICBmcmVlemVfYmFja2JvbmU6IHt7IG1vZGVsWyJmcm96ZW5fYmFja2JvbmUiXSB8IGxvd2VyIH19CiAgICBmcmVlemVfZGVjb2RlcjogZmFsc2UKCiAgICAjIC0tLS0gb3B0aW1pemVyIHN0YXJ0IC0tLS0KICAgIHslIGlmIG1vZGVsWyJvcHRpbWl6ZXIiXSAtJX0KICAgIG9wdGltaXplcjoge3sgbW9kZWxbIm9wdGltaXplciJdWyJ0eXBlIl0gfX0KICAgIGxyOiB7eyBtb2RlbFsib3B0aW1pemVyIl1bImxyIl0gfCBmbG9hdCB9fQogICAgeyUgZW5kaWYgLSV9CiAgICAjIC0tLS0gb3B0aW1pemVyIGVuZCAtLS0tCiAgICB7JSBpZiBtb2RlbFsidGlsZWRfaW5mZXJlbmNlX3BhcmFtZXRlcnMiXSAlfQogICAgdGlsZWRfaW5mZXJlbmNlX3BhcmFtZXRlcnM6IAogICAgICBoX2Nyb3A6IHt7IG1vZGVsWyJ0aWxlZF9pbmZlcmVuY2VfcGFyYW1ldGVycyJdWyJoX2Nyb3AiXSB8IGludH19CiAgICAgIGhfc3RyaWRlOiB7eyBtb2RlbFsidGlsZWRfaW5mZXJlbmNlX3BhcmFtZXRlcnMiXVsiaF9zdHJpZGUiXSB8IGludCB9fQogICAgICB3X2Nyb3A6IHt7IG1vZGVsWyJ0aWxlZF9pbmZlcmVuY2VfcGFyYW1ldGVycyJdWyJ3X2Nyb3AiXSB8IGludH19CiAgICAgIHdfc3RyaWRlOiB7eyBtb2RlbFsidGlsZWRfaW5mZXJlbmNlX3BhcmFtZXRlcnMiXVsid19zdHJpZGUiXSB8IGludCB9fQogICAgICBhdmVyYWdlX3BhdGNoZXM6IHt7IG1vZGVsWyJ0aWxlZF9pbmZlcmVuY2VfcGFyYW1ldGVycyJdWyJhdmVyYWdlX3BhdGNoZXMiXSB9fQogICAgeyUgZWxzZSAlfQogICAgIyBUb0RvOiBSZW1vdmUgdGhlIHRpbGVkX2luZmVyZW5jZSBpZiB1c2VyIG5vdCBwcm92aWRlZC4gCiAgICB0aWxlZF9pbmZlcmVuY2VfcGFyYW1ldGVyczogCiAgICAgIGhfY3JvcDogNTEyCiAgICAgICMgc3RyaWRlIGxvZ2ljID0gd291bGQgYmUgaF9jcm9wIC0gaF9jcm9wICogMC4xMjUKICAgICAgaF9zdHJpZGU6IDQ0OAogICAgICB3X2Nyb3A6IDUxMgogICAgICAjIHN0cmlkZSBsb2dpYyA9IHdvdWxkIGJlIHdfY3JvcCAtIHdfY3JvcCAqIDAuMTI1CiAgICAgIHdfc3RyaWRlOiA0NDgKICAgICAgYXZlcmFnZV9wYXRjaGVzOiB0cnVlCiAgICB7JSBlbmRpZiAlfQpvcHRpbWl6ZXI6CiAgY2xhc3NfcGF0aDoge3sgJ3RvcmNoLm9wdGltLicgKyBvcHRpbWl6ZXJbInR5cGUiXSB9fQogIGluaXRfYXJnczoKICAgICMgLS0tLSBPcHRpbWl6ZXIgc3RhcnQgaWYgLS0tLQogICAgeyUgaWYgb3B0aW1pemVyWyJsciJdIC0lfQogICAgbHI6IHt7IG9wdGltaXplclsibHIiXSB8IGZsb2F0IH19CiAgICB7JSBlbHNlICV9CiAgICBscjogMS5lLTQKICAgIHslIGVuZGlmIC0lfQogICAgeyUgaWYgb3B0aW1pemVyWyJ3ZWlnaHRfZGVjYXkiXSAtJX0KICAgIHdlaWdodF9kZWNheToge3sgb3B0aW1pemVyWyJ3ZWlnaHRfZGVjYXkiXSB9fQogICAgeyUgZWxzZSAlfQogICAgd2VpZ2h0X2RlY2F5OiAwLjA1CiAgICB7JSBlbmRpZiAtJX0KICAgICMgLS0tLSBPcHRpbWl6ZXIgc3RvcCBpZiAtLS0tCmxyX3NjaGVkdWxlcjoKICBjbGFzc19wYXRoOiBSZWR1Y2VMUk9uUGxhdGVhdQogIGluaXRfYXJnczoKICAgIG1vbml0b3I6IHZhbC9sb3NzCg==\"\n",
+ " }\n",
+ "\n",
+ " print(\"📋 Segmentation Task Template:\")\n",
+ "print(json.dumps(segmentation_template, indent=2))"
]
},
{
diff --git a/workshop/docs/notebooks/lab5-gesa-burnscars-workflow.ipynb b/workshop/docs/notebooks/lab5-gesa-burnscars-workflow.ipynb
index 2bbc56af..2bdd595a 100644
--- a/workshop/docs/notebooks/lab5-gesa-burnscars-workflow.ipynb
+++ b/workshop/docs/notebooks/lab5-gesa-burnscars-workflow.ipynb
@@ -8,12 +8,12 @@
"# Lab 5\n",
"\n",
"\n",
- "\n",
+ "\n",
" \n",
"\n",
"\n",
"\n",
- "\n",
+ "\n",
"\n",
"## 🌍 Geospatial Exploration and Orchestration Studio \n",
"\n",
@@ -142,17 +142,17 @@
"Raw satellite data showing the area affected by wildfire:\n",
"\n",
"\n",
- "
\n",
+ "\n",
+ "\n",
+ "\n",
"**Getting Started with IBM Geospatial Studio**\n",
"\n",
"⏱️ **Estimated Duration:** 10 minutes \n",
@@ -228,6 +234,8 @@
"BASE_STUDIO_UI_URL=https://localhost:4180\n",
"\"\"\"\n",
"\n",
+ "# If you are using jupyter lab, create a normal file to view it on the fileviewer. `geostudio_config_file`\n",
+ "\n",
"# Write to file\n",
"with open('.geostudio_config_file', 'w') as f:\n",
" f.write(config_content)\n",
diff --git a/workshop/docs/notebooks/lab2-onboarding-examples.ipynb b/workshop/docs/notebooks/lab2-onboarding-examples.ipynb
index 2f7eddd8..76a64652 100644
--- a/workshop/docs/notebooks/lab2-onboarding-examples.ipynb
+++ b/workshop/docs/notebooks/lab2-onboarding-examples.ipynb
@@ -7,6 +7,12 @@
"source": [
"# Lab 2\n",
"\n",
+ "\n",
+ "\n",
+ " \n",
+ "\n",
+ "\n",
+ "\n",
"**Onboarding Pre-computed Examples**\n",
"\n",
"⏱️ **Estimated Duration:** 20 minutes \n",
@@ -116,6 +122,8 @@
"outputs": [],
"source": [
"# Initialize the client\n",
+ "# If you are using jupyter lab, create a normal file to view it on the fileviewer. `geostudio_config_file`\n",
+ "\n",
"client = Client(geostudio_config_file=\".geostudio_config_file\")\n",
"\n",
"print(\"✅ Connected to Geospatial Studio!\")"
@@ -403,7 +411,7 @@
"\n",
"2. **Navigate to the Inference Lab:**\n",
" - Click on \"Inference Lab\" in the left sidebar\n",
- " - Or go directly to: `https://localhost:4180/inference`\n",
+ " - Or go directly to: `https://localhost:4180/inference#inference`\n",
"\n",
"3. **Find Your Example:**\n",
" - Look for \"My Examples\" section\n",
diff --git a/workshop/docs/notebooks/lab3-running-inference.ipynb b/workshop/docs/notebooks/lab3-running-inference.ipynb
index c5e196fa..712e6453 100644
--- a/workshop/docs/notebooks/lab3-running-inference.ipynb
+++ b/workshop/docs/notebooks/lab3-running-inference.ipynb
@@ -7,6 +7,11 @@
"source": [
"# Lab 3\n",
"\n",
+ "\n",
+ "\n",
+ " \n",
+ "\n",
+ "\n",
"**Upload Model Checkpoints and Run Inference**\n",
"\n",
"⏱️ **Estimated Duration:** 30 minutes \n",
@@ -132,6 +137,8 @@
"outputs": [],
"source": [
"# Initialize the client\n",
+ "# If you are using jupyter lab, create a normal file to view it on the fileviewer. `geostudio_config_file`\n",
+ "\n",
"client = Client(geostudio_config_file=\".geostudio_config_file\")\n",
"\n",
"print(\"✅ Connected to Geospatial Studio\")"
diff --git a/workshop/docs/notebooks/lab4-burnscars-workflow.ipynb b/workshop/docs/notebooks/lab4-burnscars-workflow.ipynb
index 8f46d9fa..db4b2302 100644
--- a/workshop/docs/notebooks/lab4-burnscars-workflow.ipynb
+++ b/workshop/docs/notebooks/lab4-burnscars-workflow.ipynb
@@ -7,6 +7,12 @@
"source": [
"# Lab 4\n",
"\n",
+ "\n",
+ "\n",
+ " \n",
+ "\n",
+ "\n",
+ "\n",
"**Training a Custom Model for Wildfire Burn Scar Detection**\n",
"\n",
"⏱️ **Estimated Duration:** 60-90 minutes \n",
@@ -127,6 +133,8 @@
"outputs": [],
"source": [
"# Initialize the client\n",
+ "# If you are using jupyter lab, create a normal file to view it on the fileviewer. `geostudio_config_file`\n",
+ "\n",
"client = Client(geostudio_config_file=\".geostudio_config_file\")\n",
"\n",
"print(\"✅ Connected to Geospatial Studio!\")"
@@ -199,8 +207,18 @@
"outputs": [],
"source": [
"# Load the backbone configuration\n",
- "with open(\"../../../populate-studio/payloads/backbones/backbone-Prithvi_EO_V2_300M.json\", \"r\") as f:\n",
- " backbone = json.load(f)\n",
+ "try:\n",
+ " with open(\"../populate-studio/payloads/backbones/backbone-Prithvi_EO_V2_300M.json\", \"r\") as f:\n",
+ " backbone = json.load(f)\n",
+ " \n",
+ "except FileNotFoundError:\n",
+ " backbone = {\n",
+ " \"name\" : \"Prithvi_EO_V2_300M\",\n",
+ " \"description\" : \"Geospatial pre-traineed foundation model Prithvi-EO-V2 (Prithvi_EO_V2_300M)\",\n",
+ " \"checkpoint_filename\" : \"prithvi_eo_v2_300\\/Prithvi_EO_V2_300M.pt\",\n",
+ " \"model_params\" : {\"backbone\": \"prithvi_eo_v2_300\", \"embed_dim\": 768, \"num_heads\": 12, \"tile_size\": 1, \"num_layers\": 12, \"patch_size\": 16, \"tubelet_size\": 1, \"model_category\": \"prithvi\"}\n",
+ " }\n",
+ "\n",
"\n",
"print(\"📋 Backbone Configuration:\")\n",
"print(json.dumps(backbone, indent=2))"
@@ -255,8 +273,54 @@
"outputs": [],
"source": [
"# Load the dataset configuration\n",
- "with open(\"../../../populate-studio/payloads/datasets/dataset-burn_scars.json\", \"r\") as f:\n",
- " wild_fire_dataset = json.load(f)\n",
+ "try:\n",
+ " with open(\"../populate-studio/payloads/datasets/dataset-burn_scars.json\", \"r\") as f:\n",
+ " wild_fire_dataset = json.load(f)\n",
+ "except FileNotFoundError:\n",
+ " wild_fire_dataset = {\n",
+ " \"dataset_name\": \"Wildfire burn scars\",\n",
+ " \"dataset_url\": \"https://s3.us-east.cloud-object-storage.appdomain.cloud/geospatial-studio-example-data/burn-scar-training-data.zip\",\n",
+ " \"label_suffix\": \".mask.tif\",\n",
+ " \"description\": \"A set of wildfire burn scar extent using HLS data. This dataset contains Harmonized Landsat and Sentinel-2 imagery of burn scars and the associated masks for the years 2018-2021 over the contiguous United States. There are 804 512x512 scenes. Its primary purpose is for training geospatial machine learning models. Each tiff file contains a 512x512 pixel tiff file. Scenes contain six bands, and masks have one band. For satellite scenes, each band has already been converted to reflectance.\",\n",
+ " \"purpose\": \"Segmentation\",\n",
+ " \"data_sources\": [\n",
+ " {\n",
+ " \"bands\": [\n",
+ " {\"index\": \"0\", \"band_name\": \"Blue\", \"scaling_factor\": \"0.0001\", \"RGB_band\": \"B\"},\n",
+ " {\"index\": \"1\", \"band_name\": \"Green\", \"scaling_factor\": \"0.0001\", \"RGB_band\": \"G\"},\n",
+ " {\"index\": \"2\", \"band_name\": \"Red\", \"scaling_factor\": \"0.0001\", \"RGB_band\": \"R\"},\n",
+ " {\"index\": \"3\", \"band_name\": \"NIR_Narrow\", \"scaling_factor\": \"0.0001\"},\n",
+ " {\"index\": \"4\", \"band_name\": \"SWIR1\", \"scaling_factor\": \"0.0001\"},\n",
+ " {\"index\": \"5\", \"band_name\": \"SWIR2\", \"scaling_factor\": \"0.0001\"}\n",
+ " ],\n",
+ " \"connector\": \"sentinelhub\",\n",
+ " \"collection\": \"hls_l30\",\n",
+ " \"file_suffix\": \"_merged.tif\",\n",
+ " \"modality_tag\": \"HLS_L30\"\n",
+ " }\n",
+ " ],\n",
+ " \"label_categories\": [\n",
+ " {\n",
+ " \"id\": \"1\",\n",
+ " \"name\": \"Fire Scar\",\n",
+ " \"color\": \"#ab4f4f\",\n",
+ " \"opacity\": 1\n",
+ " },\n",
+ " {\n",
+ " \"id\": \"0\",\n",
+ " \"name\": \"No data\",\n",
+ " \"color\": \"#000000\",\n",
+ " \"opacity\": \"0\"\n",
+ " },\n",
+ " {\n",
+ " \"id\": \"-1\",\n",
+ " \"name\": \"Ignore\",\n",
+ " \"color\": \"#000000\",\n",
+ " \"opacity\": \"0\"\n",
+ " }\n",
+ " ],\n",
+ " \"version\": \"v2\"\n",
+ " }\n",
"\n",
"print(\"📋 Dataset Configuration:\")\n",
"print(json.dumps(wild_fire_dataset, indent=2))"
@@ -371,14 +435,388 @@
"\n",
"# Load the template configuration\n",
"try:\n",
- " with open('../../../populate-studio/payloads/templates/template-seg.json', 'r') as f:\n",
+ " with open('../populate-studio/payloads/templates/template-seg.json', 'r') as f:\n",
" segmentation_template = json.load(f)\n",
" \n",
- " print(\"📋 Segmentation Task Template:\")\n",
- " print(json.dumps(segmentation_template, indent=2))\n",
"except FileNotFoundError:\n",
- " print(\"⚠️ Template file not found. Please check populate-studio/payloads/templates/\")\n",
- " segmentation_template = None"
+ " segmentation_template = {\n",
+ " \"name\": \"Segmentation\",\n",
+ " \"description\": \"Generic template v1 and v2 models: Segmentation\",\n",
+ " \"purpose\": \"Segmentation\",\n",
+ " \"model_params\": {\n",
+ " \"$uri\": \"https://ibm.com/watsonx.ai.geospatial.finetune.segmentation.json\",\n",
+ " \"type\": \"object\",\n",
+ " \"title\": \"Finetune\",\n",
+ " \"$schema\": \"https://json-schema.org/draft/2020-12/schema\",\n",
+ " \"properties\": {\n",
+ " \"data\": {\n",
+ " \"type\": \"object\",\n",
+ " \"default\": {\n",
+ " \"batch_size\": 4,\n",
+ " \"constant_multiply\": 1,\n",
+ " \"workers_per_gpu\": 2,\n",
+ " \"check_stackability\": False\n",
+ " },\n",
+ " \"properties\": {\n",
+ " \"batch_size\": {\n",
+ " \"type\": \"int\",\n",
+ " \"default\": 4,\n",
+ " \"description\": \"Batch size\",\n",
+ " \"studio_name\": \"Batch size\"\n",
+ " },\n",
+ " \"constant_multiply\": {\n",
+ " \"type\": \"float\",\n",
+ " \"default\": 1,\n",
+ " \"description\": \"Constant Scale\",\n",
+ " \"studio_name\": \"Constant Scale\"\n",
+ " },\n",
+ " \"workers_per_gpu\": {\n",
+ " \"studio_name\": \"Workers per GPU\",\n",
+ " \"description\": \"Workers per GPU\",\n",
+ " \"type\": \"int\",\n",
+ " \"default\": 2\n",
+ " },\n",
+ " \"check_stackability\": {\n",
+ " \"studio_name\": \"Check Stackability\",\n",
+ " \"description\": \"Check Stackability\",\n",
+ " \"type\": \"bool\",\n",
+ " \"default\": False\n",
+ " }\n",
+ " },\n",
+ " \"studio_name\": \"Data loading\"\n",
+ " },\n",
+ " \"model\": {\n",
+ " \"type\": \"object\",\n",
+ " \"default\": {\n",
+ " \"decode_head\": {\n",
+ " \"channels\": 256,\n",
+ " \"num_convs\": 4,\n",
+ " \"decoder\": \"UNetDecoder\",\n",
+ " \"loss_decode\": {\n",
+ " \"type\": \"CrossEntropyLoss\",\n",
+ " \"avg_non_ignore\": True\n",
+ " }\n",
+ " },\n",
+ " \"frozen_backbone\": False,\n",
+ " \"tiled_inference_parameters\": {\n",
+ " \"h_crop\": 224,\n",
+ " \"h_stride\": 196,\n",
+ " \"w_crop\": 224,\n",
+ " \"w_stride\": 196,\n",
+ " \"average_patches\": False\n",
+ " }\n",
+ " },\n",
+ " \"properties\": {\n",
+ " \"decode_head\": {\n",
+ " \"type\": \"object\",\n",
+ " \"default\": {\n",
+ " \"channels\": 256,\n",
+ " \"num_convs\": 4,\n",
+ " \"decoder\": \"UperNetDecoder\",\n",
+ " \"loss_decode\": {\n",
+ " \"type\": \"CrossEntropyLoss\",\n",
+ " \"avg_non_ignore\": True\n",
+ " }\n",
+ " },\n",
+ " \"properties\": {\n",
+ " \"channels\": {\n",
+ " \"type\": \"int\",\n",
+ " \"default\": 256,\n",
+ " \"description\": \"Channels at each block of the decode head, except the final one\",\n",
+ " \"studio_name\": \"Channels\"\n",
+ " },\n",
+ " \"num_convs\": {\n",
+ " \"type\": \"int\",\n",
+ " \"default\": 4,\n",
+ " \"description\": \"Number of convolutional blocks in the head (except the final one)\",\n",
+ " \"studio_name\": \"Blocks\"\n",
+ " },\n",
+ " \"decoder\": {\n",
+ " \"enum\": [\n",
+ " \"UperNetDecoder\",\n",
+ " \"UNetDecoder\"\n",
+ " ],\n",
+ " \"type\": \"string\",\n",
+ " \"default\": \"Fixed\",\n",
+ " \"description\": \"Decoder type\",\n",
+ " \"studio_name\": \"Decoder type\"\n",
+ " },\n",
+ " \"loss_decode\": {\n",
+ " \"type\": \"object\",\n",
+ " \"properties\": {\n",
+ " \"type\": {\n",
+ " \"enum\": [\n",
+ " \"CrossEntropyLoss\"\n",
+ " ],\n",
+ " \"type\": \"string\",\n",
+ " \"default\": \"CrossEntropyLoss\",\n",
+ " \"description\": \"Type of loss function\",\n",
+ " \"studio_name\": \"Loss function\"\n",
+ " },\n",
+ " \"avg_non_ignore\": {\n",
+ " \"type\": \"bool\",\n",
+ " \"default\": True,\n",
+ " \"description\": \"The loss is only averaged over non-ignored targets (ignored targets are usually where labels are missing in the dataset) if this is True\"\n",
+ " }\n",
+ " },\n",
+ " \"description\": \"Loss function to be used\",\n",
+ " \"studio_name\": \"Loss\"\n",
+ " }\n",
+ " },\n",
+ " \"description\": \"Architecture of the decode head\",\n",
+ " \"studio_name\": \"Head\"\n",
+ " },\n",
+ " \"auxiliary_head\": {\n",
+ " \"type\": \"object\",\n",
+ " \"default\": {},\n",
+ " \"properties\": {\n",
+ " \"decoder\": {\n",
+ " \"type\": \"string\",\n",
+ " \"default\": \"FCNDecoder\",\n",
+ " \"description\": \"Decoder function to use\",\n",
+ " \"studio_name\": \"Decoder\"\n",
+ " },\n",
+ " \"channels\": {\n",
+ " \"type\": \"int\",\n",
+ " \"default\": 256,\n",
+ " \"description\": \"Channels at each block of the decode head, except the final one\",\n",
+ " \"studio_name\": \"Channels\"\n",
+ " },\n",
+ " \"num_convs\": {\n",
+ " \"type\": \"int\",\n",
+ " \"default\": 2,\n",
+ " \"description\": \"Number of convolutional blocks in the head (except the final one)\",\n",
+ " \"studio_name\": \"Blocks\"\n",
+ " },\n",
+ " \"in_index\": {\n",
+ " \"type\": \"int\",\n",
+ " \"default\": -1,\n",
+ " \"description\": \"Index of the input list to take. Defaults to -1\",\n",
+ " \"studio_name\": \"In index\"\n",
+ " },\n",
+ " \"dropout\": {\n",
+ " \"type\": \"int\",\n",
+ " \"default\": 0,\n",
+ " \"description\": \"Dropout value to apply. Defaults to 0\",\n",
+ " \"studio_name\": \"Dropout\"\n",
+ " },\n",
+ " \"loss_decode\": {\n",
+ " \"type\": \"object\",\n",
+ " \"properties\": {\n",
+ " \"type\": {\n",
+ " \"enum\": [\n",
+ " \"CrossEntropyLoss\"\n",
+ " ],\n",
+ " \"type\": \"string\",\n",
+ " \"default\": \"CrossEntropyLoss\",\n",
+ " \"description\": \"Type of loss function\",\n",
+ " \"studio_name\": \"Loss function\"\n",
+ " },\n",
+ " \"loss_weight\": {\n",
+ " \"type\": \"float\",\n",
+ " \"default\": 1,\n",
+ " \"description\": \"Multiplicative weight of the loss of the auxiliary head in the loss. The loss is calculated as aux_head_weight * aux_head_loss + decode_head_loss\",\n",
+ " \"studio_name\": \"Loss weight\"\n",
+ " },\n",
+ " \"avg_non_ignore\": {\n",
+ " \"type\": \"bool\",\n",
+ " \"default\": True,\n",
+ " \"description\": \"The loss is only averaged over non-ignored targets (ignored targets are usually where labels are missing in the dataset) if this is True\"\n",
+ " }\n",
+ " },\n",
+ " \"description\": \"Loss function to be used\",\n",
+ " \"studio_name\": \"Loss\"\n",
+ " }\n",
+ " },\n",
+ " \"description\": \"Architecture of the auxiliary head\"\n",
+ " },\n",
+ " \"frozen_backbone\": {\n",
+ " \"type\": \"bool\",\n",
+ " \"default\": False,\n",
+ " \"description\": \"Freeze the weights of the backbone when set to True\",\n",
+ " \"studio_name\": \"Freeze backbone\"\n",
+ " },\n",
+ " \"tiled_inference_parameters\": {\n",
+ " \"type\": \"object\",\n",
+ " \"default\": {\n",
+ " \"h_crop\": 224,\n",
+ " \"h_stride\": 196,\n",
+ " \"w_crop\": 224,\n",
+ " \"w_stride\": 196,\n",
+ " \"average_patches\": False\n",
+ " },\n",
+ " \"properties\": {\n",
+ " \"h_crop\": {\n",
+ " \"type\": \"int\",\n",
+ " \"default\": 224,\n",
+ " \"description\": \"h_crop values for tilling images\",\n",
+ " \"studio_name\": \"h_crop\"\n",
+ " },\n",
+ " \"h_stride\": {\n",
+ " \"type\": \"int\",\n",
+ " \"default\": 196,\n",
+ " \"description\": \"h_stride values for tilling images\",\n",
+ " \"studio_name\": \"h_stride\"\n",
+ " },\n",
+ " \"w_crop\": {\n",
+ " \"type\": \"int\",\n",
+ " \"default\": 224,\n",
+ " \"description\": \"w_crop values for tilling images\",\n",
+ " \"studio_name\": \"w_crop\"\n",
+ " },\n",
+ " \"w_stride\": {\n",
+ " \"type\": \"int\",\n",
+ " \"default\": 196,\n",
+ " \"description\": \"w_stride values for tilling images\",\n",
+ " \"studio_name\": \"w_stride\"\n",
+ " },\n",
+ " \"average_patches\": {\n",
+ " \"type\": \"bool\",\n",
+ " \"default\": False,\n",
+ " \"description\": \"Whether to use average_patches\",\n",
+ " \"studio_name\": \"average_patches\"\n",
+ " }\n",
+ " }\n",
+ " }\n",
+ " },\n",
+ " \"description\": \"Model architecture definition\",\n",
+ " \"studio_name\": \"Architecture\"\n",
+ " },\n",
+ " \"runner\": {\n",
+ " \"type\": \"object\",\n",
+ " \"default\": {\n",
+ " \"max_epochs\": 10,\n",
+ " \"early_stopping_patience\": 20,\n",
+ " \"early_stopping_monitor\": \"val/loss\"\n",
+ " },\n",
+ " \"properties\": {\n",
+ " \"max_epochs\": {\n",
+ " \"type\": \"int\",\n",
+ " \"default\": 10,\n",
+ " \"description\": \"Training epochs\",\n",
+ " \"studio_name\": \"Training epochs\"\n",
+ " },\n",
+ " \"early_stopping_patience\": {\n",
+ " \"type\": \"int\",\n",
+ " \"default\": 20,\n",
+ " \"description\": \"Early stopping patience\",\n",
+ " \"studio_name\": \"Early stopping patience\"\n",
+ " },\n",
+ " \"early_stopping_monitor\": {\n",
+ " \"type\": \"string\",\n",
+ " \"default\": \"val/loss\",\n",
+ " \"description\": \"Monitoring value to determine early stopping\",\n",
+ " \"studio_name\": \"Early stopping monitor\"\n",
+ " }\n",
+ " },\n",
+ " \"studio_name\": \"Runner\"\n",
+ " },\n",
+ " \"lr_config\": {\n",
+ " \"type\": \"object\",\n",
+ " \"default\": {\n",
+ " \"policy\": \"Fixed\"\n",
+ " },\n",
+ " \"required\": [\n",
+ " \"policy\"\n",
+ " ],\n",
+ " \"properties\": {\n",
+ " \"policy\": {\n",
+ " \"enum\": [\n",
+ " \"Fixed\",\n",
+ " \"CosineAnnealing\"\n",
+ " ],\n",
+ " \"type\": \"string\",\n",
+ " \"default\": \"Fixed\",\n",
+ " \"description\": \"Policy type\",\n",
+ " \"studio_name\": \"Policy type\"\n",
+ " },\n",
+ " \"warmup_iters\": {\n",
+ " \"type\": \"int\",\n",
+ " \"default\": 0,\n",
+ " \"description\": \"LR warmup iterations. Valid for some policies\",\n",
+ " \"studio_name\": \"Learning rate warmup iterations\"\n",
+ " },\n",
+ " \"warmup_ratio\": {\n",
+ " \"type\": \"float\",\n",
+ " \"default\": 1,\n",
+ " \"description\": \"Initial lr at warmup will be learning_rate * warmup_ratio\",\n",
+ " \"studio_name\": \"LR warmup initialization ratio\"\n",
+ " }\n",
+ " },\n",
+ " \"description\": \"Learning rate policy\",\n",
+ " \"studio_name\": \"Learning rate policy\"\n",
+ " },\n",
+ " \"optimizer\": {\n",
+ " \"type\": \"object\",\n",
+ " \"default\": {\n",
+ " \"lr\": 6e-05,\n",
+ " \"type\": \"Adam\"\n",
+ " },\n",
+ " \"properties\": {\n",
+ " \"lr\": {\n",
+ " \"type\": \"float\",\n",
+ " \"default\": 6e-05,\n",
+ " \"description\": \"Learning rate\",\n",
+ " \"studio_name\": \"Learning rate\"\n",
+ " },\n",
+ " \"type\": {\n",
+ " \"enum\": [\n",
+ " \"Adam\",\n",
+ " \"SGD\",\n",
+ " \"AdamW\",\n",
+ " \"RMSProp\"\n",
+ " ],\n",
+ " \"default\": \"Adam\",\n",
+ " \"description\": \"Optimizer to be used\",\n",
+ " \"studio_name\": \"Optimizer type\"\n",
+ " },\n",
+ " \"weight_decay\": {\n",
+ " \"type\": \"float\",\n",
+ " \"default\": 0,\n",
+ " \"description\": \"L2 weight regularization (weight decay)\",\n",
+ " \"studio_name\": \"L2 regularization weight\"\n",
+ " }\n",
+ " },\n",
+ " \"description\": \"Optimizer\",\n",
+ " \"studio_name\": \"Optimizer\"\n",
+ " },\n",
+ " \"dataset_id\": {\n",
+ " \"type\": \"string\",\n",
+ " \"description\": \"ID of dataset to use for this finetuning\",\n",
+ " \"studio_name\": \"Dataset\"\n",
+ " },\n",
+ " \"evaluation\": {\n",
+ " \"type\": \"object\",\n",
+ " \"default\": {\n",
+ " \"interval\": 1\n",
+ " },\n",
+ " \"properties\": {\n",
+ " \"interval\": {\n",
+ " \"type\": \"int\",\n",
+ " \"default\": 1,\n",
+ " \"description\": \"Frequency of epochs with which to perform validation\",\n",
+ " \"studio_name\": \"Epoch interval\"\n",
+ " }\n",
+ " },\n",
+ " \"studio_name\": \"Validation\"\n",
+ " },\n",
+ " \"backbone_model_id\": {\n",
+ " \"type\": \"string\",\n",
+ " \"description\": \"ID of the pretrained backbone\"\n",
+ " }\n",
+ " },\n",
+ " \"description\": \"A request sent to the finetuning service to start a finetune task for segmentation\"\n",
+ " },\n",
+ " \"extra_info\": {\n",
+ " \"runtime_image\": \"quay.io/geospatial-studio/terratorch:latest\",\n",
+ " \"model_category\": \"prithvi\",\n",
+ " \"model_framework\": \"terratorch-v2\"\n",
+ " },\n",
+ " \"content\": \"IyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIwojIExpY2Vuc2VkIE1hdGVyaWFscyAtIFByb3BlcnR5IG9mIElCTQojICJSZXN0cmljdGVkIE1hdGVyaWFscyBvZiBJQk0iCiMgQ29weXJpZ2h0IElCTSBDb3JwLiAyMDI1IEFMTCBSSUdIVFMgUkVTRVJWRUQKIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIwoKCiMgbGlnaHRuaW5nLnB5dG9yY2g9PTIuMS4xCnNlZWRfZXZlcnl0aGluZzogMAp0cmFpbmVyOgogIGFjY2VsZXJhdG9yOiBhdXRvCiAgc3RyYXRlZ3k6IGF1dG8KICBkZXZpY2VzOiBhdXRvCiAgbnVtX25vZGVzOiAxCiAgcHJlY2lzaW9uOiAxNi1taXhlZAogIGxvZ2dlcjoKICAgIGNsYXNzX3BhdGg6IGxpZ2h0bmluZy5weXRvcmNoLmxvZ2dlcnMubWxmbG93Lk1MRmxvd0xvZ2dlcgogICAgaW5pdF9hcmdzOgogICAgICBleHBlcmltZW50X25hbWU6IHt7IHR1bmVfaWQgfX0gIyBGdXR1cmUgdmVyc2lvbiwgY2huYWdlIHRoaXMgdG8gdXNlciAvIGVtYWlsCiAgICAgIHJ1bl9uYW1lOiAiVHJhaW4iICAgICMgRnV0dXJlIHZlcnNpb24sIGNobmFnZSB0aGlzIHRvIHR1bmVfaWQKICAgICAgdHJhY2tpbmdfdXJpOiB7eyBtbGZsb3dfdHJhY2tpbmdfdXJsIH19CiAgICAgIHNhdmVfZGlyOiB7eyBtb3VudF9yb290ICsgJ3R1bmUtdGFza3MvJyArIHR1bmVfaWQgKyAnL21sZmxvdycgfX0KICAgICAgeyUgaWYgbWxmbG93X3RhZ3MgLSV9CiAgICAgIHRhZ3M6CiAgICAgICAgeyUgZm9yIGtleSwgdmFsdWUgaW4gbWxmbG93X3RhZ3MuaXRlbXMoKSAtJX0KICAgICAgICB7eyBrZXkgfX06IHt7IHZhbHVlIH19CiAgICAgICAgeyUgZW5kZm9yICV9CiAgICAgIHslLSBlbmRpZiAlfSAgICAgICAKICBjYWxsYmFja3M6CiAgICAtIGNsYXNzX3BhdGg6IFJpY2hQcm9ncmVzc0JhcgogICAgLSBjbGFzc19wYXRoOiBMZWFybmluZ1JhdGVNb25pdG9yCiAgICAgIGluaXRfYXJnczoKICAgICAgICBsb2dnaW5nX2ludGVydmFsOiBlcG9jaAogICAgIyAtLS0tIEVhcmx5IHN0b3AgaWYgLS0tLQogICAgeyUgaWYgcnVubmVyWyJlYXJseV9zdG9wcGluZ19wYXRpZW5jZSJdIC0lfQogICAgLSBjbGFzc19wYXRoOiBFYXJseVN0b3BwaW5nCiAgICAgIGluaXRfYXJnczoKICAgICAgICBtb25pdG9yOiB7eyBydW5uZXJbImVhcmx5X3N0b3BwaW5nX21vbml0b3IiXSB9fQogICAgICAgIHBhdGllbmNlOiB7eyBydW5uZXJbImVhcmx5X3N0b3BwaW5nX3BhdGllbmNlIl0gfX0KICAgIHslLSBlbmRpZiAlfQogICAgICMgLS0tLSBFYXJseSBzdG9wIGVuZGlmIC0tLS0KICAgIC0gY2xhc3NfcGF0aDogTW9kZWxDaGVja3BvaW50CiAgICAgIGluaXRfYXJnczoKICAgICAgICBkaXJwYXRoOiB7eyBtb3VudF9yb290ICsgJ3R1bmUtdGFza3MvJyArIHR1bmVfaWQgICsgJy8nIH19CiAgICAgICAgbW9kZTogbWluCiAgICAgICAgbW9uaXRvcjogdmFsL2xvc3MKICAgICAgICBmaWxlbmFtZToge3sgJ2Jlc3Qtc3RhdGVfZGljdC17ZXBvY2g6MDJkfScgfX0KICAgICAgICBzYXZlX3dlaWdodHNfb25seTogVHJ1ZQogICAgICAKICBtYXhfZXBvY2hzOiB7eyBydW5uZXJbIm1heF9lcG9jaHMiXSB9fQogIGNoZWNrX3ZhbF9ldmVyeV9uX2Vwb2NoOiB7eyBldmFsdWF0aW9uWyJpbnRlcnZhbCJdIH19CiAgbG9nX2V2ZXJ5X25fc3RlcHM6IDUwCiAgZW5hYmxlX2NoZWNrcG9pbnRpbmc6IHRydWUKICBkZWZhdWx0X3Jvb3RfZGlyOiB7eyBtb3VudF9yb290ICsgJ3R1bmUtdGFza3MvJyArIHR1bmVfaWQgfX0KCmRhdGE6CiAgY2xhc3NfcGF0aDogdGVycmF0b3JjaC5kYXRhbW9kdWxlcy5HZW5lcmljTm9uR2VvU2VnbWVudGF0aW9uRGF0YU1vZHVsZQogIGluaXRfYXJnczoKICAgIGJhdGNoX3NpemU6IHt7IGRhdGFbImJhdGNoX3NpemUiXSB9fQogICAgbnVtX3dvcmtlcnM6IHt7IGRhdGFbIndvcmtlcnNfcGVyX2dwdSJdIH19CiAgICBub19sYWJlbF9yZXBsYWNlOiB7eyBsYWJlbF9ub2RhdGEgfX0KICAgIG5vX2RhdGFfcmVwbGFjZToge3sgaW1hZ2Vfbm9kYXRhX3JlcGxhY2UgfX0KICAgIGNvbnN0YW50X3NjYWxlOiB7eyBjb25zdGFudF9tdWx0aXBseSB9fQogICAgZGF0YXNldF9iYW5kczoKICAgICAge3sgYmFuZHMudmFsdWVzKCkgfCBsaXN0IHwgZmlyc3QgfCB0b195YW1sIHwgaW5kZW50KDYpIH19CiAgICBvdXRwdXRfYmFuZHM6CiAgICAgIHt7IG91dHB1dF9iYW5kcy52YWx1ZXMoKSB8IGxpc3QgfCBmaXJzdCB8IHRvX3lhbWwgfCBpbmRlbnQoNikgfX0KICAgIHJnYl9pbmRpY2VzOgogICAgICB7eyByZ2JfYmFuZF9pbmRpY2VzIHwgdG9feWFtbCB8IGluZGVudCg2KSB9fQogICAgdHJhaW5fZGF0YV9yb290OiB7eyBkYXRhX3Jvb3QgfX17eyB0cmFpbl9kYXRhX2Rpci52YWx1ZXMoKSB8IGxpc3QgfCBmaXJzdCB9fQogICAgdHJhaW5fbGFiZWxfZGF0YV9yb290OiB7eyBkYXRhX3Jvb3QgKyB0cmFpbl9sYWJlbHNfZGlyIH19CiAgICB2YWxfZGF0YV9yb290OiB7eyBkYXRhX3Jvb3QgfX17eyB2YWxfZGF0YV9kaXIudmFsdWVzKCkgfCBsaXN0IHwgZmlyc3QgfX0KICAgIHZhbF9sYWJlbF9kYXRhX3Jvb3Q6IHt7IGRhdGFfcm9vdCArIHZhbF9sYWJlbHNfZGlyIH19CiAgICB0ZXN0X2RhdGFfcm9vdDoge3sgZGF0YV9yb290IH19e3sgdGVzdF9kYXRhX2Rpci52YWx1ZXMoKSB8IGxpc3QgfCBmaXJzdCB9fQogICAgdGVzdF9sYWJlbF9kYXRhX3Jvb3Q6IHt7IGRhdGFfcm9vdCArIHRlc3RfbGFiZWxzX2RpciB9fQogICAgeyUgaWYgdHJhaW5fc3BsaXRfcGF0aCAtJX0KICAgIHRyYWluX3NwbGl0OiB7eyBkYXRhX3Jvb3QgKyB0cmFpbl9zcGxpdF9wYXRoIH19CiAgICB7JSBlbmRpZiAtJX0KICAgIHslIGlmIHRlc3Rfc3BsaXRfcGF0aCAtJX0KICAgIHRlc3Rfc3BsaXQ6IHt7IGRhdGFfcm9vdCArIHRlc3Rfc3BsaXRfcGF0aCB9fQogICAgeyUgZW5kaWYgLSV9CiAgICB7JSBpZiB2YWxfc3BsaXRfcGF0aCAtJX0KICAgIHZhbF9zcGxpdDoge3sgZGF0YV9yb290ICsgdmFsX3NwbGl0X3BhdGggfX0KICAgIHslIGVuZGlmIC0lfQogICAgeyUgaWYgaW1nX3N1ZmZpeCAtJX0KICAgIGltZ19ncmVwOiAge3sgaW1nX3N1ZmZpeC52YWx1ZXMoKSB8IGxpc3QgfCBmaXJzdCB8IHRvanNvbiB9fQogICAgeyUgZW5kaWYgLSV9CiAgICB7JSBpZiBzZWdfbWFwX3N1ZmZpeCAtJX0KICAgIGxhYmVsX2dyZXA6ICJ7eyBzZWdfbWFwX3N1ZmZpeCB9fSIKICAgIHslIGVuZGlmIC0lfQogICAgbWVhbnM6IAogICAgICB7eyBub3JtX21lYW5zLnZhbHVlcygpIHwgbGlzdCB8IGZpcnN0fCB0b195YW1sIHwgaW5kZW50KDYpIH19CiAgICBzdGRzOiAKICAgICAge3sgbm9ybV9zdGRzLnZhbHVlcygpIHwgbGlzdCB8IGZpcnN0IHwgdG9feWFtbCB8IGluZGVudCg2KSB9fQogICAgbnVtX2NsYXNzZXM6IHt7IGNsYXNzZXN8bGVuZ3RoIH19CiAgICB7JSBpZiBkYXRhWyJleHBhbmRfdGVtcG9yYWxfZGltZW5zaW9uIl0gaXMgbm90IG5vbmUgLSV9CiAgICBleHBhbmRfdGVtcG9yYWxfZGltZW5zaW9uOiBkYXRhWyJleHBhbmRfdGVtcG9yYWxfZGltZW5zaW9uIl0KICAgIHslIGVuZGlmIC0lfQogICAgeyUgaWYgZGF0YVsiZHJvcF9sYXN0Il0gaXMgbm90IG5vbmUgLSV9CiAgICBkcm9wX2xhc3Q6IGRhdGFbImRyb3BfbGFzdCJdCiAgICB7JSBlbmRpZiAtJX0KICAgICMgLS0tLSB0cmFpbl90cmFuc2Zvcm0gaWYgLS0tLQogICAgeyUgaWYgZGF0YVsidHJhaW5fdHJhbnNmb3JtIl0gLSV9CiAgICB0cmFpbl90cmFuc2Zvcm06CiAgICB7JSBmb3IgdHJhbnNmb3JtIGluIGRhdGFbInRyYWluX3RyYW5zZm9ybSJdICV9CiAgICAtIGNsYXNzX3BhdGg6IHRyYXNuc2Zvcm1bImNsYXNzX3BhdGgiXQogICAgICBpbml0X2FyZ3M6CiAgICAgICAgeyUgaWYgdHJhc25zZm9ybVsiaGVpZ2h0Il0gaXMgbm90IG5vbmUgLSV9CiAgICAgICAgaGVpZ2h0OiB0cmFzbnNmb3JtWyJoZWlnaHQiXQogICAgICAgIHslIGVuZGlmIC0lfQogICAgICAgIHslIGlmIHRyYXNuc2Zvcm1bIndpZHRoIl0gaXMgbm90IG5vbmUgLSV9CiAgICAgICAgd2lkdGg6IHRyYXNuc2Zvcm1bIndpZHRoIl0KICAgICAgICB7JSBlbmRpZiAtJX0KICAgICAgICB7JSBpZiB0cmFzbnNmb3JtWyJhbHdheXNfYXBwbHkiXSBpcyBub3Qgbm9uZSAtJX0KICAgICAgICBhbHdheXNfYXBwbHk6IHRyYXNuc2Zvcm1bImFsd2F5c19hcHBseSJdCiAgICAgICAgeyUgZW5kaWYgLSV9CiAgICAgICAgeyUgaWYgdHJhc25zZm9ybVsidHJhbnNwb3NlX21hc2siXSBpcyBub3Qgbm9uZSAtJX0KICAgICAgICB0cmFuc3Bvc2VfbWFzazogdHJhc25zZm9ybVsidHJhbnNwb3NlX21hc2siXQogICAgICAgIHslIGVuZGlmIC0lfQogICAgICAgIHslIGlmIHRyYXNuc2Zvcm1bInAiXSBpcyBub3Qgbm9uZSAtJX0KICAgICAgICBwOiB0cmFzbnNmb3JtWyJwIl0KICAgICAgICB7JSBlbmRpZiAtJX0KICAgIHslIGVuZGZvciAlfQogICAgeyUgZW5kaWYgLSV9CiAgICAjIC0tLS0gdHJhaW5fdHJhbnNmb3JtIGVuZGlmIC0tLS0KCiAgICAjIGlmIGJhY2tib25lIGlzIHByaXRodmktRU8tdjIKICAgIHRlc3RfdHJhbnNmb3JtOgogICAgICAtIGNsYXNzX3BhdGg6IFRvVGVuc29yVjIKbW9kZWw6CiAgY2xhc3NfcGF0aDogdGVycmF0b3JjaC50YXNrcy5TZW1hbnRpY1NlZ21lbnRhdGlvblRhc2sKICBpbml0X2FyZ3M6CiAgICBtb2RlbF9hcmdzOiAKICAgICAgeyUtIGlmIHByZXRyYWluZWRfbW9kZWxfbmFtZSA9PSAicHJpdGh2aV9lb192MV8xMDAiIG9yIHByZXRyYWluZWRfbW9kZWxfbmFtZSA9PSAicHJpdGh2aV9lb192Ml8zMDAiIG9yIHByZXRyYWluZWRfbW9kZWxfbmFtZSA9PSAicHJpdGh2aV9lb192Ml8zMDBfdGwiIG9yIHByZXRyYWluZWRfbW9kZWxfbmFtZSA9PSAicHJpdGh2aV9lb192Ml82MDAiIG9yIHByZXRyYWluZWRfbW9kZWxfbmFtZSA9PSAicHJpdGh2aV9lb192Ml82MDBfdGwiICV9CiAgICAgIGJhY2tib25lX3ByZXRyYWluZWQ6IHRydWUgCiAgICAgIGJhY2tib25lOiB7eyBwcmV0cmFpbmVkX21vZGVsX25hbWUgfX0KICAgICAgYmFja2JvbmVfZHJvcF9wYXRoOiAwLjEgCiAgICAgIGJhY2tib25lX2JhbmRzOgogICAgICAgIHt7IG91dHB1dF9iYW5kcy52YWx1ZXMoKSB8IGxpc3QgfCBmaXJzdCB8IHRvX3lhbWwgfCBpbmRlbnQoOCkgfX0KICAgICAgbmVja3M6IAogICAgICAgIC0gbmFtZTogU2VsZWN0SW5kaWNlcwogICAgICAgICAgeyUtIGlmIHByZXRyYWluZWRfbW9kZWxfbmFtZSA9PSAicHJpdGh2aV9lb192MV8xMDAiICV9CiAgICAgICAgICBpbmRpY2VzOiBbMiwgNSwgOCwgMTFdICMgMTAwTSBtb2RlbHMKICAgICAgICAgIHslLSBlbGlmIHByZXRyYWluZWRfbW9kZWxfbmFtZSA9PSAicHJpdGh2aV9lb192Ml8zMDAiIG9yIHByZXRyYWluZWRfbW9kZWxfbmFtZSA9PSAicHJpdGh2aV9lb192Ml8zMDBfdGwiICV9CiAgICAgICAgICBpbmRpY2VzOiBbNSwgMTEsIDE3LCAyM10gICMgMzAwTSBtb2RlbHMKICAgICAgICAgIHslLSBlbGlmIHByZXRyYWluZWRfbW9kZWxfbmFtZSA9PSAicHJpdGh2aV9lb192Ml82MDAiIG9yIHByZXRyYWluZWRfbW9kZWxfbmFtZSA9PSAicHJpdGh2aV9lb192Ml82MDBfdGwiICV9CiAgICAgICAgICBpbmRpY2VzOiBbNywgMTUsIDIzLCAzMV0gIyA2MDBNIG1vZGVscyAgICAKICAgICAgICAgIHslIGVuZGlmICV9CiAgICAgICAgLSBuYW1lOiBSZXNoYXBlVG9rZW5zVG9JbWFnZSAjIHJlcXVpcmVkCiAgICAgICAgLSBuYW1lOiBMZWFybmVkSW50ZXJwb2xhdGVUb1B5cmFtaWRhbAogICAgICB7JS0gZWxzZSAlfQogICAgICAjIE9sZCBtb2RlbCB2ZXJzaW9uIGNvbmZpZ3VyYXRpb25zCiAgICAgIHByZXRyYWluZWQ6IHRydWUKICAgICAgYmFja2JvbmU6IHt7IHByZXRyYWluZWRfbW9kZWxfbmFtZSB9fQogICAgICAjIGJhY2tib25lX3RlbXBvcmFsX2VuY29kaW5nOiB0cnVlCiAgICAgIGJhY2tib25lX2Ryb3BfcGF0aF9yYXRlOiAwLjMKICAgICAgYmFja2JvbmVfd2luZG93X3NpemU6IDcKICAgICAgbnVtX2ZyYW1lczoge3sgbnVtX2ZyYW1lcyB9fQogICAgICBoZWFkX2NoYW5uZWxfbGlzdDoKICAgICAgICB7eyBoZWFkX2NoYW5uZWxfbGlzdCB8IHRvX3lhbWwgfCBpbmRlbnQoMTApIH19CiAgICAgIGJhbmRzOgogICAgICAgIHt7IG91dHB1dF9iYW5kcy52YWx1ZXMoKSB8IGxpc3QgfCBmaXJzdCB8IHRvX3lhbWwgfCBpbmRlbnQoOCkgfX0KICAgICAgeyUgZW5kaWYgJX0gCiAgICAgIGRlY29kZXI6IHt7IG1vZGVsWyJkZWNvZGVfaGVhZCJdWyJkZWNvZGVyIl0gfX0KICAgICAgeyUgaWYgIG1vZGVsWyJkZWNvZGVfaGVhZCJdWyJkZWNvZGVyIl0gPT0gIlVwZXJOZXREZWNvZGVyIiAtJX0KICAgICAgZGVjb2Rlcl9jaGFubmVsczogMjU2CiAgICAgIHslIGVsaWYgIG1vZGVsWyJkZWNvZGVfaGVhZCJdWyJkZWNvZGVyIl0gPT0gIlVOZXREZWNvZGVyIiAtJX0KICAgICAgI1RPRE8gdXNlciBwcm92aWRlZCBjaGFubmVscwogICAgICBkZWNvZGVyX2NoYW5uZWxzOiBbNTEyLCAyNTYsIDEyOCwgNjRdCiAgICAgIHslIGVsc2UgJX0KICAgICAgZGVjb2Rlcl9jaGFubmVsczoge3sgbW9kZWxbImRlY29kZV9oZWFkIl1bImNoYW5uZWxzIl0gfX0KICAgICAgeyUgZW5kaWYgLSV9CiAgICAgIG51bV9jbGFzc2VzOiB7eyBjbGFzc2VzfGxlbmd0aCB9fQogICAgICBoZWFkX2Ryb3BvdXQ6IDAuMQogICAgeyUgaWYgcHJldHJhaW5lZF9tb2RlbF9uYW1lID09ICJwcml0aHZpX2VvX3YxXzEwMCIgb3IgcHJldHJhaW5lZF9tb2RlbF9uYW1lID09ICJwcml0aHZpX2VvX3YyXzMwMCIgb3IgcHJldHJhaW5lZF9tb2RlbF9uYW1lID09ICJwcml0aHZpX2VvX3YyXzMwMF90bCIgb3IgcHJldHJhaW5lZF9tb2RlbF9uYW1lID09ICJwcml0aHZpX2VvX3YyXzYwMCIgb3IgcHJldHJhaW5lZF9tb2RlbF9uYW1lID09ICJwcml0aHZpX2VvX3YyXzYwMF90bCIgLSV9CiAgICBtb2RlbF9mYWN0b3J5OiBFbmNvZGVyRGVjb2RlckZhY3RvcnkKICAgIHslLSBlbHNlICV9CiAgICBtb2RlbF9mYWN0b3J5OiBQcml0aHZpTW9kZWxGYWN0b3J5CiAgICB7JSBlbmRpZiAlfSAKICAgIGxvc3M6IHt7IG1vZGVsWyJkZWNvZGVfaGVhZCJdWyJsb3NzX2RlY29kZSJdWyJ0eXBlIl0gfX0KICAgIHBsb3Rfb25fdmFsOiB7eyBydW5uZXJbInBsb3Rfb25fdmFsIl0gfX0KICAgIHslIGlmIG1vZGVsWyJhdXhpbGlhcnlfaGVhZCJdIC0lfQogICAgYXV4X2hlYWRzOgogICAgICAtIG5hbWU6IGF1eF9oZWFkCiAgICAgICAgZGVjb2Rlcjoge3sgbW9kZWxbImF1eGlsaWFyeV9oZWFkIl1bImRlY29kZXIiXSB9fQogICAgICAgIGRlY29kZXJfYXJnczoKICAgICAgICAgIGRlY29kZXJfY2hhbm5lbHM6IHt7IG1vZGVsWyJhdXhpbGlhcnlfaGVhZCJdWyJjaGFubmVscyJdIH19CiAgICAgICAgICBkZWNvZGVyX2luX2luZGV4OiB7eyBtb2RlbFsiYXV4aWxpYXJ5X2hlYWQiXVsiaW5faW5kZXgiXSB9fQogICAgICAgICAgZGVjb2Rlcl9udW1fY29udnM6IHt7IG1vZGVsWyJhdXhpbGlhcnlfaGVhZCJdWyJudW1fY29udnMiXSB9fQogICAgICAgICAgaGVhZF9kcm9wb3V0OiAge3sgbW9kZWxbImF1eGlsaWFyeV9oZWFkIl1bImRyb3BvdXQiXSB9fQogICAgICAgICAgIyBoZWFkX2NoYW5uZWxfbGlzdDoKICAgICAgICAgICMgICAtIDY0CiAgICBhdXhfbG9zczoKICAgICAgYXV4X2hlYWQ6IHt7IG1vZGVsWyJhdXhpbGlhcnlfaGVhZCJdWyJsb3NzX2RlY29kZSJdWyJsb3NzX3dlaWdodCJdIH19CiAgICB7JSBlbmRpZiAtJX0KICAgIGlnbm9yZV9pbmRleDoge3sgaWdub3JlX2luZGV4IH19CiAgICBmcmVlemVfYmFja2JvbmU6IHt7IG1vZGVsWyJmcm96ZW5fYmFja2JvbmUiXSB8IGxvd2VyIH19CiAgICBmcmVlemVfZGVjb2RlcjogZmFsc2UKCiAgICAjIC0tLS0gb3B0aW1pemVyIHN0YXJ0IC0tLS0KICAgIHslIGlmIG1vZGVsWyJvcHRpbWl6ZXIiXSAtJX0KICAgIG9wdGltaXplcjoge3sgbW9kZWxbIm9wdGltaXplciJdWyJ0eXBlIl0gfX0KICAgIGxyOiB7eyBtb2RlbFsib3B0aW1pemVyIl1bImxyIl0gfCBmbG9hdCB9fQogICAgeyUgZW5kaWYgLSV9CiAgICAjIC0tLS0gb3B0aW1pemVyIGVuZCAtLS0tCiAgICB7JSBpZiBtb2RlbFsidGlsZWRfaW5mZXJlbmNlX3BhcmFtZXRlcnMiXSAlfQogICAgdGlsZWRfaW5mZXJlbmNlX3BhcmFtZXRlcnM6IAogICAgICBoX2Nyb3A6IHt7IG1vZGVsWyJ0aWxlZF9pbmZlcmVuY2VfcGFyYW1ldGVycyJdWyJoX2Nyb3AiXSB8IGludH19CiAgICAgIGhfc3RyaWRlOiB7eyBtb2RlbFsidGlsZWRfaW5mZXJlbmNlX3BhcmFtZXRlcnMiXVsiaF9zdHJpZGUiXSB8IGludCB9fQogICAgICB3X2Nyb3A6IHt7IG1vZGVsWyJ0aWxlZF9pbmZlcmVuY2VfcGFyYW1ldGVycyJdWyJ3X2Nyb3AiXSB8IGludH19CiAgICAgIHdfc3RyaWRlOiB7eyBtb2RlbFsidGlsZWRfaW5mZXJlbmNlX3BhcmFtZXRlcnMiXVsid19zdHJpZGUiXSB8IGludCB9fQogICAgICBhdmVyYWdlX3BhdGNoZXM6IHt7IG1vZGVsWyJ0aWxlZF9pbmZlcmVuY2VfcGFyYW1ldGVycyJdWyJhdmVyYWdlX3BhdGNoZXMiXSB9fQogICAgeyUgZWxzZSAlfQogICAgIyBUb0RvOiBSZW1vdmUgdGhlIHRpbGVkX2luZmVyZW5jZSBpZiB1c2VyIG5vdCBwcm92aWRlZC4gCiAgICB0aWxlZF9pbmZlcmVuY2VfcGFyYW1ldGVyczogCiAgICAgIGhfY3JvcDogNTEyCiAgICAgICMgc3RyaWRlIGxvZ2ljID0gd291bGQgYmUgaF9jcm9wIC0gaF9jcm9wICogMC4xMjUKICAgICAgaF9zdHJpZGU6IDQ0OAogICAgICB3X2Nyb3A6IDUxMgogICAgICAjIHN0cmlkZSBsb2dpYyA9IHdvdWxkIGJlIHdfY3JvcCAtIHdfY3JvcCAqIDAuMTI1CiAgICAgIHdfc3RyaWRlOiA0NDgKICAgICAgYXZlcmFnZV9wYXRjaGVzOiB0cnVlCiAgICB7JSBlbmRpZiAlfQpvcHRpbWl6ZXI6CiAgY2xhc3NfcGF0aDoge3sgJ3RvcmNoLm9wdGltLicgKyBvcHRpbWl6ZXJbInR5cGUiXSB9fQogIGluaXRfYXJnczoKICAgICMgLS0tLSBPcHRpbWl6ZXIgc3RhcnQgaWYgLS0tLQogICAgeyUgaWYgb3B0aW1pemVyWyJsciJdIC0lfQogICAgbHI6IHt7IG9wdGltaXplclsibHIiXSB8IGZsb2F0IH19CiAgICB7JSBlbHNlICV9CiAgICBscjogMS5lLTQKICAgIHslIGVuZGlmIC0lfQogICAgeyUgaWYgb3B0aW1pemVyWyJ3ZWlnaHRfZGVjYXkiXSAtJX0KICAgIHdlaWdodF9kZWNheToge3sgb3B0aW1pemVyWyJ3ZWlnaHRfZGVjYXkiXSB9fQogICAgeyUgZWxzZSAlfQogICAgd2VpZ2h0X2RlY2F5OiAwLjA1CiAgICB7JSBlbmRpZiAtJX0KICAgICMgLS0tLSBPcHRpbWl6ZXIgc3RvcCBpZiAtLS0tCmxyX3NjaGVkdWxlcjoKICBjbGFzc19wYXRoOiBSZWR1Y2VMUk9uUGxhdGVhdQogIGluaXRfYXJnczoKICAgIG1vbml0b3I6IHZhbC9sb3NzCg==\"\n",
+ " }\n",
+ "\n",
+ " print(\"📋 Segmentation Task Template:\")\n",
+ "print(json.dumps(segmentation_template, indent=2))"
]
},
{
diff --git a/workshop/docs/notebooks/lab5-gesa-burnscars-workflow.ipynb b/workshop/docs/notebooks/lab5-gesa-burnscars-workflow.ipynb
index 2bbc56af..2bdd595a 100644
--- a/workshop/docs/notebooks/lab5-gesa-burnscars-workflow.ipynb
+++ b/workshop/docs/notebooks/lab5-gesa-burnscars-workflow.ipynb
@@ -8,12 +8,12 @@
"# Lab 5\n",
"\n",
"\n",
- "\n",
+ "\n",
" \n",
"\n",
"\n",
"\n",
- "\n",
+ "\n",
"\n",
"## 🌍 Geospatial Exploration and Orchestration Studio \n",
"\n",
@@ -142,17 +142,17 @@
"Raw satellite data showing the area affected by wildfire:\n",
"\n",
"\n",
- " \n",
+ "
\n",
+ " \n",
"\n",
"#### Model Prediction\n",
"The fine-tuned model identifies burn scar areas:\n",
"\n",
- "
\n",
"\n",
"#### Model Prediction\n",
"The fine-tuned model identifies burn scar areas:\n",
"\n",
- " \n",
+ "
\n",
+ " \n",
"\n",
"#### Prediction Overlay\n",
"Burn scar predictions overlaid on the original imagery for validation:\n",
"\n",
- "
\n",
"\n",
"#### Prediction Overlay\n",
"Burn scar predictions overlaid on the original imagery for validation:\n",
"\n",
- " \n",
+ "
\n",
+ " \n",
"\n",
"\n",
"\n",
@@ -259,7 +259,9 @@
"#############################################################\n",
"# Initialize Geostudio client using a geostudio config file\n",
"#############################################################\n",
- "gfm_client = Client(geostudio_config_file=\".geostudio_config_file\")"
+ "# If you are using jupyter lab, create a normal file to view it on the fileviewer. `geostudio_config_file`\n",
+ "\n",
+ "gfm_client = Client(geostudio_config_file=\"geostudio_config_file\")"
]
},
{
@@ -280,12 +282,6 @@
"In this section, we'll explore how to review datasets that have already been prepared and onboarded to the Geospatial Studio. This is useful for understanding what data is available before starting a fine-tuning task."
]
},
- {
- "cell_type": "markdown",
- "id": "ae7d34b9",
- "metadata": {},
- "source": []
- },
{
"cell_type": "code",
"execution_count": null,
@@ -309,10 +305,16 @@
"source": [
"# Get detailed information about a specific burn scars dataset\n",
"# If you know the dataset name or ID, you can retrieve its details\n",
- "burn_scars_dataset_id = \"geodata-e8hwqfrvtsgwfgsx7agvgk\"\n",
+ "burn_scars_dataset_id = \"select-dataset_id-from-DataFrame-above\"\n",
"burn_scars_dataset_id"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "31fee87f",
+ "metadata": {},
+ "source": []
+ },
{
"cell_type": "code",
"execution_count": null,
@@ -381,10 +383,18 @@
"source": [
"# List all the base models onboarded in the cluster\n",
"base_models = gfm_client.list_base_models()['results']\n",
- "display(DataFrame(base_models))\n",
- "\n",
+ "display(DataFrame(base_models))\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "06dfa760",
+ "metadata": {},
+ "outputs": [],
+ "source": [
"# Select Prithvi_EO_V2_300M model\n",
- "prithvi_eo_v2_300m_base_model_id = \"28ad8b4f-13ba-4567-b28f-bb16758324c3\""
+ "prithvi_eo_v2_300m_base_model_id = \"select-base_model-id-from-DataFrame-above\""
]
},
{
@@ -429,10 +439,18 @@
"source": [
"# List all the templates onboarded in the cluster\n",
"tune_templates = gfm_client.list_tune_templates()['results']\n",
- "display(DataFrame(tune_templates))\n",
- "\n",
+ "display(DataFrame(tune_templates))\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7aecd8db",
+ "metadata": {},
+ "outputs": [],
+ "source": [
"# Select segmentation template\n",
- "segmentation_template_id = \"8573acf1-5ee7-4291-bcfe-357408080445\""
+ "segmentation_template_id = \"select-template-id-from-DataFrame-above\""
]
},
{
@@ -512,6 +530,8 @@
"5. **Completion**: Finalizing and storing the trained model\n",
"\n",
"**Expected Duration:**\n",
+ "\n",
+ "These times are dependent on the tuning config e.g. number of epochs, batch size, dataset size, etc.\n",
"- Modern GPU (V100/A100): 30-45 minutes\n",
"- Older GPU: 45-90 minutes\n",
"- CPU: Not recommended (2 hrs + Using Terramind tiny )\n",
@@ -727,7 +747,7 @@
" \"visible_by_default\": \"True\"\n",
" }\n",
" ],\n",
- " \"tune_id\" : \"geotune-k9xhhztv6rqub8usa4xjdp\"\n",
+ " \"tune_id\" : tune_id\n",
"}\n",
"\n",
"print(\"📋 Inference Configuration:\")\n",
@@ -745,7 +765,6 @@
"source": [
"# Submit the inference request\n",
"print(\"\\n🚀 Submitting inference request...\\n\")\n",
- "tune_id = \"geotune-k9xhhztv6rqub8usa4xjdp\"\n",
"\n",
"inference_response = gfm_client.try_out_tune(tune_id=tune_id, data=inference_payload)\n",
"\n",
@@ -824,20 +843,72 @@
"outputs": [],
"source": [
"# The best model already onboarded in the cluster\n",
- "best_burnscars_model = \"geotune-mgmshlc8b9mwksedrghray\"\n",
+ "best_burnscars_model = \"replace-with-best-burnscars_model_id\" \n",
"# Run an inference on the best model\n",
- "gfm_client.try_out_tune(tune_id=tune_id, data={**inference_payload, \"description\": \"Best Model Inference\", \"tune_id\":best_burnscars_model})\n",
+ "gfm_client.try_out_tune(tune_id=tune_id, data={**inference_payload, \"description\": \"Burns Best Model Inference\", \"tune_id\":best_burnscars_model})\n",
"\n",
"\n",
"# Use 5.1 instructions to view the results in the UI"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "44a8b962",
+ "metadata": {},
+ "source": [
+ "## 7.0 Download artifacts : Download our trained model artifacts\n",
+ "\n",
+ "With the trained model, we will download the checkpoint and config that we can re-use for running inferences. \n",
+ "\n",
+ "We will use wget/curl to download the artifacts. Otherwise, you can grab the links and download directly to your local machine.\n",
+ "\n",
+ "---"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "33e73e49",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Get the download URLs for the trained model artifacts\n",
+ "artifact_urls = gfm_client.download_tune(tune_id=tune_id)\n",
+ "artifact_urls"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "download-artifacts",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Extract URLs\n",
+ "config_url = artifact_urls['config_url']\n",
+ "checkpoint_url = artifact_urls['checkpoint_url']\n",
+ "\n",
+ "print(f\"Config URL: {config_url}\")\n",
+ "print(f\"Checkpoint URL: {checkpoint_url}\")\n",
+ "print(\"\\n--- Download Commands ---\\n\")\n",
+ "\n",
+ "# Using wget\n",
+ "print(\"Using wget:\")\n",
+ "print(f\"wget -O config_deploy.yaml '{config_url}'\")\n",
+ "print(f\"wget -O model_checkpoint.ckpt '{checkpoint_url}'\")\n",
+ "\n",
+ "# Using wget\n",
+ "print(\"\\nUsing curl:\")\n",
+ "print(f\"curl -o config_deploy.yaml '{config_url}'\")\n",
+ "print(f\"curl -o model_checkpoint.ckpt '{checkpoint_url}'\")"
+ ]
+ },
{
"cell_type": "markdown",
"id": "summary-section-2",
"metadata": {},
"source": [
- "## 7. Summary and Key Takeaways\n",
+ "## 8. Summary and Key Takeaways\n",
"\n",
"Congratulations! You've completed an end-to-end machine learning workflow for geospatial AI with a burnscars example. 🎉\n",
"\n",
diff --git a/workshop/docs/notebooks/lab6-gesa-floods-workflow.ipynb b/workshop/docs/notebooks/lab6-gesa-floods-workflow.ipynb
index 8e264513..ac97dc6b 100644
--- a/workshop/docs/notebooks/lab6-gesa-floods-workflow.ipynb
+++ b/workshop/docs/notebooks/lab6-gesa-floods-workflow.ipynb
@@ -7,7 +7,7 @@
"source": [
"# Lab 6\n",
"\n",
- "\n",
+ "\n",
" \n",
"\n"
]
@@ -17,7 +17,7 @@
"id": "d61fa1ff",
"metadata": {},
"source": [
- "\n",
+ "\n",
"\n",
"## 🌍 Geospatial Exploration and Orchestration Studio \n",
"\n",
@@ -27,36 +27,36 @@
"
\n",
"\n",
"\n",
"\n",
@@ -259,7 +259,9 @@
"#############################################################\n",
"# Initialize Geostudio client using a geostudio config file\n",
"#############################################################\n",
- "gfm_client = Client(geostudio_config_file=\".geostudio_config_file\")"
+ "# If you are using jupyter lab, create a normal file to view it on the fileviewer. `geostudio_config_file`\n",
+ "\n",
+ "gfm_client = Client(geostudio_config_file=\"geostudio_config_file\")"
]
},
{
@@ -280,12 +282,6 @@
"In this section, we'll explore how to review datasets that have already been prepared and onboarded to the Geospatial Studio. This is useful for understanding what data is available before starting a fine-tuning task."
]
},
- {
- "cell_type": "markdown",
- "id": "ae7d34b9",
- "metadata": {},
- "source": []
- },
{
"cell_type": "code",
"execution_count": null,
@@ -309,10 +305,16 @@
"source": [
"# Get detailed information about a specific burn scars dataset\n",
"# If you know the dataset name or ID, you can retrieve its details\n",
- "burn_scars_dataset_id = \"geodata-e8hwqfrvtsgwfgsx7agvgk\"\n",
+ "burn_scars_dataset_id = \"select-dataset_id-from-DataFrame-above\"\n",
"burn_scars_dataset_id"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "31fee87f",
+ "metadata": {},
+ "source": []
+ },
{
"cell_type": "code",
"execution_count": null,
@@ -381,10 +383,18 @@
"source": [
"# List all the base models onboarded in the cluster\n",
"base_models = gfm_client.list_base_models()['results']\n",
- "display(DataFrame(base_models))\n",
- "\n",
+ "display(DataFrame(base_models))\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "06dfa760",
+ "metadata": {},
+ "outputs": [],
+ "source": [
"# Select Prithvi_EO_V2_300M model\n",
- "prithvi_eo_v2_300m_base_model_id = \"28ad8b4f-13ba-4567-b28f-bb16758324c3\""
+ "prithvi_eo_v2_300m_base_model_id = \"select-base_model-id-from-DataFrame-above\""
]
},
{
@@ -429,10 +439,18 @@
"source": [
"# List all the templates onboarded in the cluster\n",
"tune_templates = gfm_client.list_tune_templates()['results']\n",
- "display(DataFrame(tune_templates))\n",
- "\n",
+ "display(DataFrame(tune_templates))\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7aecd8db",
+ "metadata": {},
+ "outputs": [],
+ "source": [
"# Select segmentation template\n",
- "segmentation_template_id = \"8573acf1-5ee7-4291-bcfe-357408080445\""
+ "segmentation_template_id = \"select-template-id-from-DataFrame-above\""
]
},
{
@@ -512,6 +530,8 @@
"5. **Completion**: Finalizing and storing the trained model\n",
"\n",
"**Expected Duration:**\n",
+ "\n",
+ "These times are dependent on the tuning config e.g. number of epochs, batch size, dataset size, etc.\n",
"- Modern GPU (V100/A100): 30-45 minutes\n",
"- Older GPU: 45-90 minutes\n",
"- CPU: Not recommended (2 hrs + Using Terramind tiny )\n",
@@ -727,7 +747,7 @@
" \"visible_by_default\": \"True\"\n",
" }\n",
" ],\n",
- " \"tune_id\" : \"geotune-k9xhhztv6rqub8usa4xjdp\"\n",
+ " \"tune_id\" : tune_id\n",
"}\n",
"\n",
"print(\"📋 Inference Configuration:\")\n",
@@ -745,7 +765,6 @@
"source": [
"# Submit the inference request\n",
"print(\"\\n🚀 Submitting inference request...\\n\")\n",
- "tune_id = \"geotune-k9xhhztv6rqub8usa4xjdp\"\n",
"\n",
"inference_response = gfm_client.try_out_tune(tune_id=tune_id, data=inference_payload)\n",
"\n",
@@ -824,20 +843,72 @@
"outputs": [],
"source": [
"# The best model already onboarded in the cluster\n",
- "best_burnscars_model = \"geotune-mgmshlc8b9mwksedrghray\"\n",
+ "best_burnscars_model = \"replace-with-best-burnscars_model_id\" \n",
"# Run an inference on the best model\n",
- "gfm_client.try_out_tune(tune_id=tune_id, data={**inference_payload, \"description\": \"Best Model Inference\", \"tune_id\":best_burnscars_model})\n",
+ "gfm_client.try_out_tune(tune_id=tune_id, data={**inference_payload, \"description\": \"Burns Best Model Inference\", \"tune_id\":best_burnscars_model})\n",
"\n",
"\n",
"# Use 5.1 instructions to view the results in the UI"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "44a8b962",
+ "metadata": {},
+ "source": [
+ "## 7.0 Download artifacts : Download our trained model artifacts\n",
+ "\n",
+ "With the trained model, we will download the checkpoint and config that we can re-use for running inferences. \n",
+ "\n",
+ "We will use wget/curl to download the artifacts. Otherwise, you can grab the links and download directly to your local machine.\n",
+ "\n",
+ "---"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "33e73e49",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Get the download URLs for the trained model artifacts\n",
+ "artifact_urls = gfm_client.download_tune(tune_id=tune_id)\n",
+ "artifact_urls"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "download-artifacts",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Extract URLs\n",
+ "config_url = artifact_urls['config_url']\n",
+ "checkpoint_url = artifact_urls['checkpoint_url']\n",
+ "\n",
+ "print(f\"Config URL: {config_url}\")\n",
+ "print(f\"Checkpoint URL: {checkpoint_url}\")\n",
+ "print(\"\\n--- Download Commands ---\\n\")\n",
+ "\n",
+ "# Using wget\n",
+ "print(\"Using wget:\")\n",
+ "print(f\"wget -O config_deploy.yaml '{config_url}'\")\n",
+ "print(f\"wget -O model_checkpoint.ckpt '{checkpoint_url}'\")\n",
+ "\n",
+ "# Using wget\n",
+ "print(\"\\nUsing curl:\")\n",
+ "print(f\"curl -o config_deploy.yaml '{config_url}'\")\n",
+ "print(f\"curl -o model_checkpoint.ckpt '{checkpoint_url}'\")"
+ ]
+ },
{
"cell_type": "markdown",
"id": "summary-section-2",
"metadata": {},
"source": [
- "## 7. Summary and Key Takeaways\n",
+ "## 8. Summary and Key Takeaways\n",
"\n",
"Congratulations! You've completed an end-to-end machine learning workflow for geospatial AI with a burnscars example. 🎉\n",
"\n",
diff --git a/workshop/docs/notebooks/lab6-gesa-floods-workflow.ipynb b/workshop/docs/notebooks/lab6-gesa-floods-workflow.ipynb
index 8e264513..ac97dc6b 100644
--- a/workshop/docs/notebooks/lab6-gesa-floods-workflow.ipynb
+++ b/workshop/docs/notebooks/lab6-gesa-floods-workflow.ipynb
@@ -7,7 +7,7 @@
"source": [
"# Lab 6\n",
"\n",
- "\n",
+ "\n",
" \n",
"\n"
]
@@ -17,7 +17,7 @@
"id": "d61fa1ff",
"metadata": {},
"source": [
- "\n",
+ "\n",
"\n",
"## 🌍 Geospatial Exploration and Orchestration Studio \n",
"\n",
@@ -27,36 +27,36 @@
"\n",
" | License | \n",
" \n",
- "  \n",
+ " \n",
" \n",
+ " \n",
" | \n",
"
\n",
"\n",
" | TerraStackAI | \n",
" \n",
- "  \n",
- " \n",
- "  \n",
- " \n",
- "  \n",
+ " \n",
+ " \n",
+ " \n",
" \n",
+ " \n",
+ " \n",
+ " \n",
" | \n",
"
\n",
"\n",
" | Built With | \n",
" \n",
- "  \n",
- " \n",
- "  \n",
- " \n",
- "  \n",
+ " \n",
+ " \n",
+ " \n",
+ " \n",
+ " \n",
+ "  \n",
"\n",
" \n",
"\n",
" | \n",
"
\n",
"\n",
" | Deployment | \n",
" \n",
- "  \n",
- " \n",
- "  \n",
- " \n",
- "  \n",
- " \n",
- "  \n",
- " \n",
- "  \n",
- " \n",
- "  \n",
- " \n",
- "  \n",
+ " \n",
+ " \n",
+ " \n",
+ " \n",
+ " \n",
+ " \n",
+ " \n",
" \n",
+ " \n",
+ " \n",
+ " \n",
+ " \n",
+ " \n",
+ " \n",
+ " \n",
" | \n",
"
\n",
"\n",
@@ -145,17 +145,17 @@
"#### Input Satellite Imagery\n",
"Raw satellite data showing the area affected by wildfire:\n",
"\n",
- "\n",
+ "\n",
"\n",
"#### Model Prediction\n",
"The fine-tuned model identifies floods areas:\n",
"\n",
- "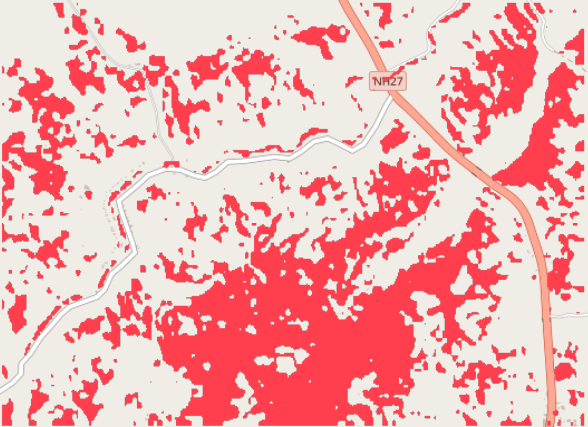\n",
+ "\n",
"\n",
"#### Prediction Overlay\n",
"floods predictions overlaid on the original imagery for validation:\n",
"\n",
- "\n",
+ "\n",
"\n",
"This workflow demonstrates the power of geospatial foundation models in identifying and mapping wildfire-affected areas, which is crucial for disaster response, environmental monitoring, and recovery planning.\n",
"\n",
@@ -260,6 +260,8 @@
"#############################################################\n",
"# Initialize Geostudio client using a geostudio config file\n",
"#############################################################\n",
+ "# If you are using jupyter lab, create a normal file to view it on the fileviewer. `geostudio_config_file`\n",
+ "\n",
"gfm_client = Client(geostudio_config_file=\".geostudio_config_file\")"
]
},
@@ -310,7 +312,7 @@
"source": [
"# Get detailed information about a specific floodss dataset\n",
"# If you know the dataset name or ID, you can retrieve its details\n",
- "floods_dataset_id = \"geodata-4vdk3x6pyfvr59zxki6kcc\"\n",
+ "floods_dataset_id = \"select-dataset_id-from-above\"\n",
"floods_dataset_id"
]
},
@@ -396,10 +398,18 @@
"source": [
"# List all the base models onboarded in the cluster\n",
"base_models = gfm_client.list_base_models()['results']\n",
- "display(DataFrame(base_models))\n",
- "\n",
+ "display(DataFrame(base_models))\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d04ca019",
+ "metadata": {},
+ "outputs": [],
+ "source": [
"# Select Terramind Tiny model\n",
- "terramind_tiny_base_model_id = \"fdf47e1e-aa27-42c2-b5da-b82e8f608c9d\""
+ "terramind_tiny_base_model_id = \"select-base_model-id-from-DataFrame-above\""
]
},
{
@@ -444,10 +454,18 @@
"source": [
"# List all the templates onboarded in the cluster\n",
"tune_templates = gfm_client.list_tune_templates()['results']\n",
- "display(DataFrame(tune_templates))\n",
- "\n",
+ "display(DataFrame(tune_templates))\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "956e3be2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
"# Select segmentation template\n",
- "terramind_segmentation_template_id = \"ccf91f72-0a17-41f0-b835-5be3c901fe34\""
+ "terramind_segmentation_template_id = \"select-template-id-from-DataFrame-above\""
]
},
{
@@ -527,6 +545,8 @@
"5. **Completion**: Finalizing and storing the trained model\n",
"\n",
"**Expected Duration:**\n",
+ "\n",
+ "These times are dependent on the tuning config e.g. number of epochs, batch size, dataset size, etc.\n",
"- Modern GPU (V100/A100): 30-45 minutes\n",
"- Older GPU: 45-90 minutes\n",
"- CPU: Not recommended (2 hrs + Using Terramind tiny )\n",
@@ -606,7 +626,7 @@
" \"polygons\": []\n",
" },\n",
" \"temporal_domain\": [\n",
- " \"2024-04-30,2024-05-07\"\n",
+ " \"2024-04-30_2024-05-07\"\n",
" ],\n",
" \"pipeline_steps\": [\n",
" {\n",
@@ -904,6 +924,58 @@
"---"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "6b9f8e09",
+ "metadata": {},
+ "source": [
+ "## 7.0 Download artifacts : Download our trained model artifacts\n",
+ "\n",
+ "With the trained model, we will download the checkpoint and config that we can re-use for running inferences. \n",
+ "\n",
+ "We will use wget/curl to download the artifacts. Otherwise, you can grab the links and download directly to your local machine.\n",
+ "\n",
+ "---"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f02b97ce",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Get the download URLs for the trained model artifacts\n",
+ "artifact_urls = gfm_client.download_tune(tune_id=tune_id)\n",
+ "artifact_urls"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "cbb4b98a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Extract URLs\n",
+ "config_url = artifact_urls['config_url']\n",
+ "checkpoint_url = artifact_urls['checkpoint_url']\n",
+ "\n",
+ "print(f\"Config URL: {config_url}\")\n",
+ "print(f\"Checkpoint URL: {checkpoint_url}\")\n",
+ "print(\"\\n--- Download Commands ---\\n\")\n",
+ "\n",
+ "# Using wget\n",
+ "print(\"Using wget:\")\n",
+ "print(f\"wget -O config_deploy.yaml '{config_url}'\")\n",
+ "print(f\"wget -O model_checkpoint.ckpt '{checkpoint_url}'\")\n",
+ "\n",
+ "# Using wget\n",
+ "print(\"\\nUsing curl:\")\n",
+ "print(f\"curl -o config_deploy.yaml '{config_url}'\")\n",
+ "print(f\"curl -o model_checkpoint.ckpt '{checkpoint_url}'\")"
+ ]
+ },
{
"cell_type": "code",
"execution_count": null,
@@ -912,9 +984,9 @@
"outputs": [],
"source": [
"# The best model already onboarded in the cluster\n",
- "best_floods_model = \"geotune-mgmshlc8b9mwksedrghray\"\n",
+ "best_floods_model = \"replace-with-best-floods_model_id\"\n",
"# Run an inference on the best model\n",
- "gfm_client.try_out_tune(tune_id=tune_id, data={**inference_payload, \"description\": \"Best Model Inference\",\"tune_id\":best_floods_model})\n",
+ "gfm_client.try_out_tune(tune_id=tune_id, data={**inference_payload, \"description\": \"Floods Best Model Inference\",\"tune_id\":best_floods_model})\n",
"\n",
"\n",
"# Use 5.1 instructions to view the results in the UI"
@@ -925,7 +997,7 @@
"id": "summary-section-2",
"metadata": {},
"source": [
- "## 7. Summary and Key Takeaways\n",
+ "## 8. Summary and Key Takeaways\n",
"\n",
"Congratulations! You've completed an end-to-end machine learning workflow for geospatial AI with a Multimodal Floods example. 🎉\n",
"\n",
@@ -950,8 +1022,8 @@
"---\n",
"### Next Steps\n",
"\n",
- "- **Lab 6**: Complete end-to-end workflow with floods usecase\n",
- "- **Explore**: Using Multimodal models for predicting floods. \n",
+ "- **Lab 7**: Complete end-to-end workflow with buildings usecase\n",
+ "- **Explore**: Using convnext model for building detection. \n",
"\n",
"\n",
"Thank you for participating! We hope you found this workshop valuable and are excited to build geospatial AI applications with IBM Geospatial Studio.\n",
diff --git a/workshop/docs/notebooks/lab7-gesa-buildings-workflow.ipynb b/workshop/docs/notebooks/lab7-gesa-buildings-workflow.ipynb
index 05860557..cb6e05fc 100644
--- a/workshop/docs/notebooks/lab7-gesa-buildings-workflow.ipynb
+++ b/workshop/docs/notebooks/lab7-gesa-buildings-workflow.ipynb
@@ -7,9 +7,9 @@
"source": [
"# Lab 7\n",
"\n",
- "\n",
+ "\n",
"\n",
- "\n",
+ "\n",
" \n",
"\n"
]
@@ -19,7 +19,7 @@
"id": "d61fa1ff",
"metadata": {},
"source": [
- "\n",
+ "\n",
"## 🌍 Geospatial Exploration and Orchestration Studio \n",
"\n",
"## Training a Custom Model for Buildings Detection Detection\n",
@@ -145,18 +145,18 @@
"#### Input Satellite Imagery\n",
"Raw satellite data showing labelled buildings:\n",
"\n",
- " \n",
+ "
\n",
+ " \n",
"\n",
"#### Model Prediction\n",
"The fine-tuned model identifies buildings :\n",
"\n",
"\n",
- "
\n",
"\n",
"#### Model Prediction\n",
"The fine-tuned model identifies buildings :\n",
"\n",
"\n",
- " \n",
+ "
\n",
+ " \n",
"\n",
"#### Prediction Overlay\n",
"Buildings predictions overlaid on the original imagery for validation:\n",
"\n",
- "
\n",
"\n",
"#### Prediction Overlay\n",
"Buildings predictions overlaid on the original imagery for validation:\n",
"\n",
- " \n",
+ "
\n",
+ " \n",
"\n",
"This workflow demonstrates the power of geospatial foundation models in identifying buildings which is crucial for disaster response, environmental monitoring, and recovery planning.\n",
"\n",
@@ -261,6 +261,8 @@
"#############################################################\n",
"# Initialize Geostudio client using a geostudio config file\n",
"#############################################################\n",
+ "# If you are using jupyter lab, create a normal file to view it on the fileviewer. `geostudio_config_file`\n",
+ "\n",
"gfm_client = Client(geostudio_config_file=\".geostudio_config_file\")"
]
},
@@ -312,7 +314,7 @@
"source": [
"# Get detailed information about a specific buildings detections dataset\n",
"# If you know the dataset name or ID, you can retrieve its details\n",
- "buildings_detection_dataset_id = \"geodata-mtst5e5yh8zdg3azhcj6he\"\n",
+ "buildings_detection_dataset_id = \"select-dataset_id-from-DataFrame-above\"\n",
"buildings_detection_dataset_id"
]
},
@@ -394,9 +396,18 @@
"source": [
"# List all the base models onboarded in the cluster\n",
"base_models = gfm_client.list_base_models(output='df')\n",
- "base_models\n",
+ "display(DataFrame(base_models))\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "668204eb",
+ "metadata": {},
+ "outputs": [],
+ "source": [
"# Select Prithvi_EO_V2_300M model\n",
- "convnext_base_model_id = \"69791dd1-cb10-440a-a34f-f4c00bf74697\""
+ "convnext_base_model_id = \"select-base_model-id-from-DataFrame-above\""
]
},
{
@@ -441,10 +452,18 @@
"source": [
"# List all the templates onboarded in the cluster\n",
"tune_templates = gfm_client.list_tune_templates(output='df')\n",
- "tune_templates\n",
- "\n",
+ "display(DataFrame(tune_templates))\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "777f2c45",
+ "metadata": {},
+ "outputs": [],
+ "source": [
"# Select segmentation template\n",
- "convnext_segmentation_template_id = \"83fd6d96-2f25-4293-b6a7-f47d86724549\""
+ "convnext_segmentation_template_id = \"select-template_id-from-DataFrame-above\""
]
},
{
@@ -524,6 +543,8 @@
"5. **Completion**: Finalizing and storing the trained model\n",
"\n",
"**Expected Duration:**\n",
+ "\n",
+ "These times are dependent on the tuning config e.g. number of epochs, batch size, dataset size, etc.\n",
"- Modern GPU (V100/A100): 30-45 minutes\n",
"- Older GPU: 45-90 minutes\n",
"- CPU: Not recommended (2 hrs + Using Terramind tiny )\n",
@@ -835,20 +856,72 @@
"outputs": [],
"source": [
"# The best model already onboarded in the cluster\n",
- "best_floods_model = \"geotune-mgmshlc8b9mwksedrghray\"\n",
+ "best_floods_model = \"replace-with-best-buildings_model_id\"\n",
"# Run an inference on the best model\n",
- "gfm_client.try_out_tune(tune_id=tune_id, data={**inference_payload, \"description\": \"Best Model Inference\"})\n",
+ "gfm_client.try_out_tune(tune_id=tune_id, data={**inference_payload, \"description\": \"Buildings Best Model Inference\"})\n",
"\n",
"\n",
"# Use 5.1 instructions to view the results in the UI"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "0bda7a5a",
+ "metadata": {},
+ "source": [
+ "## 7.0 Download artifacts : Download our trained model artifacts\n",
+ "\n",
+ "With the trained model, we will download the checkpoint and config that we can re-use for running inferences. \n",
+ "\n",
+ "We will use wget/curl to download the artifacts. Otherwise, you can grab the links and download directly to your local machine.\n",
+ "\n",
+ "---"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8f8cf9e3",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Get the download URLs for the trained model artifacts\n",
+ "artifact_urls = gfm_client.download_tune(tune_id=tune_id)\n",
+ "artifact_urls"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "aed0836a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Extract URLs\n",
+ "config_url = artifact_urls['config_url']\n",
+ "checkpoint_url = artifact_urls['checkpoint_url']\n",
+ "\n",
+ "print(f\"Config URL: {config_url}\")\n",
+ "print(f\"Checkpoint URL: {checkpoint_url}\")\n",
+ "print(\"\\n--- Download Commands ---\\n\")\n",
+ "\n",
+ "# Using wget\n",
+ "print(\"Using wget:\")\n",
+ "print(f\"wget -O config_deploy.yaml '{config_url}'\")\n",
+ "print(f\"wget -O model_checkpoint.ckpt '{checkpoint_url}'\")\n",
+ "\n",
+ "# Using wget\n",
+ "print(\"\\nUsing curl:\")\n",
+ "print(f\"curl -o config_deploy.yaml '{config_url}'\")\n",
+ "print(f\"curl -o model_checkpoint.ckpt '{checkpoint_url}'\")"
+ ]
+ },
{
"cell_type": "markdown",
"id": "summary-section-2",
"metadata": {},
"source": [
- "## 7. Summary and Key Takeaways\n",
+ "## 8. Summary and Key Takeaways\n",
"\n",
"Congratulations! You've completed an end-to-end machine learning workflow for geospatial AI with a burnscars example. 🎉\n",
"\n",
\n",
"\n",
"This workflow demonstrates the power of geospatial foundation models in identifying buildings which is crucial for disaster response, environmental monitoring, and recovery planning.\n",
"\n",
@@ -261,6 +261,8 @@
"#############################################################\n",
"# Initialize Geostudio client using a geostudio config file\n",
"#############################################################\n",
+ "# If you are using jupyter lab, create a normal file to view it on the fileviewer. `geostudio_config_file`\n",
+ "\n",
"gfm_client = Client(geostudio_config_file=\".geostudio_config_file\")"
]
},
@@ -312,7 +314,7 @@
"source": [
"# Get detailed information about a specific buildings detections dataset\n",
"# If you know the dataset name or ID, you can retrieve its details\n",
- "buildings_detection_dataset_id = \"geodata-mtst5e5yh8zdg3azhcj6he\"\n",
+ "buildings_detection_dataset_id = \"select-dataset_id-from-DataFrame-above\"\n",
"buildings_detection_dataset_id"
]
},
@@ -394,9 +396,18 @@
"source": [
"# List all the base models onboarded in the cluster\n",
"base_models = gfm_client.list_base_models(output='df')\n",
- "base_models\n",
+ "display(DataFrame(base_models))\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "668204eb",
+ "metadata": {},
+ "outputs": [],
+ "source": [
"# Select Prithvi_EO_V2_300M model\n",
- "convnext_base_model_id = \"69791dd1-cb10-440a-a34f-f4c00bf74697\""
+ "convnext_base_model_id = \"select-base_model-id-from-DataFrame-above\""
]
},
{
@@ -441,10 +452,18 @@
"source": [
"# List all the templates onboarded in the cluster\n",
"tune_templates = gfm_client.list_tune_templates(output='df')\n",
- "tune_templates\n",
- "\n",
+ "display(DataFrame(tune_templates))\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "777f2c45",
+ "metadata": {},
+ "outputs": [],
+ "source": [
"# Select segmentation template\n",
- "convnext_segmentation_template_id = \"83fd6d96-2f25-4293-b6a7-f47d86724549\""
+ "convnext_segmentation_template_id = \"select-template_id-from-DataFrame-above\""
]
},
{
@@ -524,6 +543,8 @@
"5. **Completion**: Finalizing and storing the trained model\n",
"\n",
"**Expected Duration:**\n",
+ "\n",
+ "These times are dependent on the tuning config e.g. number of epochs, batch size, dataset size, etc.\n",
"- Modern GPU (V100/A100): 30-45 minutes\n",
"- Older GPU: 45-90 minutes\n",
"- CPU: Not recommended (2 hrs + Using Terramind tiny )\n",
@@ -835,20 +856,72 @@
"outputs": [],
"source": [
"# The best model already onboarded in the cluster\n",
- "best_floods_model = \"geotune-mgmshlc8b9mwksedrghray\"\n",
+ "best_floods_model = \"replace-with-best-buildings_model_id\"\n",
"# Run an inference on the best model\n",
- "gfm_client.try_out_tune(tune_id=tune_id, data={**inference_payload, \"description\": \"Best Model Inference\"})\n",
+ "gfm_client.try_out_tune(tune_id=tune_id, data={**inference_payload, \"description\": \"Buildings Best Model Inference\"})\n",
"\n",
"\n",
"# Use 5.1 instructions to view the results in the UI"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "0bda7a5a",
+ "metadata": {},
+ "source": [
+ "## 7.0 Download artifacts : Download our trained model artifacts\n",
+ "\n",
+ "With the trained model, we will download the checkpoint and config that we can re-use for running inferences. \n",
+ "\n",
+ "We will use wget/curl to download the artifacts. Otherwise, you can grab the links and download directly to your local machine.\n",
+ "\n",
+ "---"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8f8cf9e3",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Get the download URLs for the trained model artifacts\n",
+ "artifact_urls = gfm_client.download_tune(tune_id=tune_id)\n",
+ "artifact_urls"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "aed0836a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Extract URLs\n",
+ "config_url = artifact_urls['config_url']\n",
+ "checkpoint_url = artifact_urls['checkpoint_url']\n",
+ "\n",
+ "print(f\"Config URL: {config_url}\")\n",
+ "print(f\"Checkpoint URL: {checkpoint_url}\")\n",
+ "print(\"\\n--- Download Commands ---\\n\")\n",
+ "\n",
+ "# Using wget\n",
+ "print(\"Using wget:\")\n",
+ "print(f\"wget -O config_deploy.yaml '{config_url}'\")\n",
+ "print(f\"wget -O model_checkpoint.ckpt '{checkpoint_url}'\")\n",
+ "\n",
+ "# Using wget\n",
+ "print(\"\\nUsing curl:\")\n",
+ "print(f\"curl -o config_deploy.yaml '{config_url}'\")\n",
+ "print(f\"curl -o model_checkpoint.ckpt '{checkpoint_url}'\")"
+ ]
+ },
{
"cell_type": "markdown",
"id": "summary-section-2",
"metadata": {},
"source": [
- "## 7. Summary and Key Takeaways\n",
+ "## 8. Summary and Key Takeaways\n",
"\n",
"Congratulations! You've completed an end-to-end machine learning workflow for geospatial AI with a burnscars example. 🎉\n",
"\n",