diff --git a/README.md b/README.md
index f1c50d97..e5dbfa16 100644
--- a/README.md
+++ b/README.md
@@ -1,383 +1,1079 @@
-# dockprom
+# Dockprom - Docker Monitoring with AI/LLM Observability
-A monitoring solution for Docker hosts and containers with [Prometheus](https://prometheus.io/), [Grafana](http://grafana.org/), [cAdvisor](https://github.com/google/cadvisor),
-[NodeExporter](https://github.com/prometheus/node_exporter) and alerting with [AlertManager](https://github.com/prometheus/alertmanager).
+
-## Install
+
+
+
+
-Clone this repository on your Docker host, cd into dockprom directory and run compose up:
+**A comprehensive monitoring and observability solution for Docker hosts, containers, and AI/LLM applications**
+[Quick Start](#-quick-start) • [Features](#-features) • [AI Observability](#-ai-observability-setup) • [Documentation](#-documentation) • [Contributing](#-contributing)
+
+
+
+---
+
+## 📋 Table of Contents
+
+- [Overview](#-overview)
+- [Features](#-features)
+- [Architecture](#-architecture)
+- [Quick Start](#-quick-start)
+- [AI Observability Setup](#-ai-observability-setup)
+- [Accessing Services](#-accessing-services)
+- [Monitoring Stack Components](#-monitoring-stack-components)
+- [Alerting & Notifications](#-alerting--notifications)
+- [Grafana Dashboards](#-grafana-dashboards)
+- [Advanced Configuration](#-advanced-configuration)
+- [Troubleshooting](#-troubleshooting)
+- [Documentation](#-documentation)
+- [Contributing](#-contributing)
+- [License](#-license)
+
+---
+
+## 🎯 Overview
+
+Dockprom is a **production-ready monitoring solution** that combines traditional infrastructure monitoring with cutting-edge AI/LLM observability. Built on the proven Prometheus + Grafana stack, it extends monitoring capabilities specifically for modern AI applications.
+
+### What Makes This Special?
+
+- ✅ **Drop-in AI Observability**: Monitor Ollama and LLM applications with zero code changes
+- ✅ **Comprehensive Alerting**: 32 pre-configured alerts for infrastructure and AI workloads
+- ✅ **Full Stack Visibility**: Metrics, logs, and traces in one unified platform
+- ✅ **Production Ready**: Battle-tested components with industry best practices
+- ✅ **Easy Deployment**: Single docker-compose command to get started
+
+---
+
+## ⭐ Features
+
+### Infrastructure Monitoring
+- 📊 **Host Metrics**: CPU, memory, disk, network monitoring via Node Exporter
+- 🐳 **Container Metrics**: Docker container resource usage via cAdvisor
+- ⚡ **Real-time Dashboards**: Pre-built Grafana dashboards for immediate insights
+- 🔔 **Smart Alerting**: Intelligent alert routing by severity and service type
+
+### AI/LLM Observability
+- 🤖 **LLM Performance Tracking**: Latency, error rate, token usage, TTFT (Time To First Token)
+- 🚪 **Ollama Gateway**: Transparent proxy with automatic tracing and metrics
+- 📈 **Recording Rules**: Pre-aggregated metrics for AI workload analysis
+- 🔍 **Distributed Tracing**: Full request flow visibility via Tempo
+- 📝 **Log Aggregation**: Centralized logs via Loki and Grafana Alloy
+
+### Observability Platform
+- 📊 **Prometheus**: Time-series metrics database with flexible querying
+- 📈 **Grafana**: Beautiful visualizations and dashboards
+- 📋 **Loki**: Scalable log aggregation system
+- 🔍 **Tempo**: High-scale distributed tracing backend
+- 🔄 **OpenTelemetry**: Vendor-neutral instrumentation and collection
+
+---
+
+## 🏗️ Architecture
+
+```
+┌─────────────────────────────────────────────────────────────────────────┐
+│ Your AI Application │
+│ (Python, Node.js, Go, etc.) │
+└────────────────────────────────┬────────────────────────────────────────┘
+ │
+ ┌────────────┴────────────┐
+ │ Ollama Gateway │ ← Zero-code AI observability
+ │ (Envoy Proxy) │ Automatic tracing/metrics
+ └────────────┬────────────┘
+ │
+ ┌────────────┴────────────┐
+ │ Ollama (Host) │ ← Your LLM inference
+ │ localhost:11434 │
+ └─────────────────────────┘
+
+┌─────────────────────────────────────────────────────────────────────────┐
+│ Observability Pipeline │
+├─────────────────────────────────────────────────────────────────────────┤
+│ │
+│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
+│ │ OTEL │───▶│ Prometheus │───▶│ Grafana │ │
+│ │ Collector │ │ (Metrics) │ │ (Dashboards) │ │
+│ └──────────────┘ └──────────────┘ └──────────────┘ │
+│ │ │ │ │
+│ │ ┌───────┴──────────┐ │ │
+│ │ │ AlertManager │ │ │
+│ │ │ (Notifications) │ │ │
+│ │ └──────────────────┘ │ │
+│ │ │ │
+│ ├────────────────────────────────────────▶│ │
+│ │ │ │
+│ ┌──────▼──────┐ ┌──────────────┐ │ │
+│ │ Tempo │◀───│ Alloy │─────────────┘ │
+│ │ (Traces) │ │ (Log Agent) │ │
+│ └─────────────┘ └──────┬───────┘ │
+│ │ │ │
+│ │ ┌──────▼───────┐ │
+│ └───────────▶│ Loki │ │
+│ │ (Logs) │ │
+│ └──────────────┘ │
+│ │
+│ ┌──────────────┐ ┌──────────────┐ │
+│ │ Node │───▶│ cAdvisor │────────────┐ │
+│ │ Exporter │ │ (Containers) │ │ │
+│ └──────────────┘ └──────────────┘ │ │
+│ ┌────────▼─────────┐ │
+│ │ Prometheus │ │
+│ │ (Aggregation) │ │
+│ └──────────────────┘ │
+└─────────────────────────────────────────────────────────────────────────┘
+```
+
+**Data Flow:**
+1. **AI Application** → Ollama Gateway → Ollama (LLM inference)
+2. **Ollama Gateway** → OTEL Collector (traces, metrics)
+3. **OTEL Collector** → Prometheus (metrics), Tempo (traces)
+4. **Container Logs** → Alloy → Loki
+5. **Host/Container Metrics** → Node Exporter/cAdvisor → Prometheus
+6. **All Data** → Grafana (unified visualization)
+7. **Alerts** → AlertManager → Slack/Teams/Mattermost
+
+---
+
+## 🚀 Quick Start
+
+### Prerequisites
+
+- Docker Engine >= 20.10
+- Docker Compose >= v2.0
+- 4GB RAM minimum (8GB recommended)
+- Host running Ollama on `localhost:11434` (for AI observability)
+
+### Installation
+
+**1. Clone the repository**
```bash
-git clone https://github.com/stefanprodan/dockprom
+git clone https://github.com/waitesgithub/dockprom.git
cd dockprom
+```
+**2. Start the stack**
+```bash
ADMIN_USER='admin' ADMIN_PASSWORD='admin' ADMIN_PASSWORD_HASH='$2a$14$1l.IozJx7xQRVmlkEQ32OeEEfP5mRxTpbDTCTcXRqn19gXD8YK1pO' docker-compose up -d
```
-**Caddy v2 does not accept plaintext passwords. It MUST be provided as a hash value. The above password hash corresponds to ADMIN_PASSWORD 'admin'. To know how to generate hash password, refer [Updating Caddy to v2](#Updating-Caddy-to-v2)**
+**Note:** Caddy v2 requires hashed passwords. The above hash corresponds to password 'admin'. To generate a new hash:
+```bash
+docker run --rm caddy caddy hash-password --plaintext 'your_password'
+```
-Prerequisites:
+**3. Verify deployment**
+```bash
+docker-compose ps
+```
-* Docker Engine >= 1.13
-* Docker Compose >= 1.11
+All services should show as "Up". Access Grafana at `http://localhost:3000` (admin/admin).
-## Updating Caddy to v2
+### First Steps
-Perform a `docker run --rm caddy caddy hash-password --plaintext 'ADMIN_PASSWORD'` in order to generate a hash for your new password.
-ENSURE that you replace `ADMIN_PASSWORD` with new plain text password and `ADMIN_PASSWORD_HASH` with the hashed password references in [docker-compose.yml](./docker-compose.yml) for the caddy container.
+1. **Open Grafana**: Navigate to `http://localhost:3000`
+2. **View Pre-built Dashboards**:
+ - Docker Host Dashboard
+ - Docker Containers Dashboard
+ - Monitor Services Dashboard
+ - AI/LLM Performance Dashboard (if AI observability is configured)
+3. **Check Prometheus**: Visit `http://localhost:9090` to explore metrics
+4. **Configure Alerts**: Follow [Alerting Setup](#alerting--notifications)
-Containers:
+---
-* Prometheus (metrics database) `http://:9090`
-* Prometheus-Pushgateway (push acceptor for ephemeral and batch jobs) `http://:9091`
-* AlertManager (alerts management) `http://:9093`
-* Grafana (visualize metrics) `http://:3000`
-* NodeExporter (host metrics collector)
-* cAdvisor (containers metrics collector)
-* Caddy (reverse proxy and basic auth provider for prometheus and alertmanager)
+## 🤖 AI Observability Setup
-## Setup Grafana
+Monitor your AI/LLM applications with zero code changes using the Ollama Gateway.
-Navigate to `http://:3000` and login with user ***admin*** password ***admin***. You can change the credentials in the compose file or by supplying the `ADMIN_USER` and `ADMIN_PASSWORD` environment variables on compose up. The config file can be added directly in grafana part like this
+### Step 1: Configure Host Ollama
-```yaml
-grafana:
- image: grafana/grafana:7.2.0
- env_file:
- - config
+Ensure Ollama is accessible from Docker containers:
+
+```bash
+# For Linux, Ollama must listen on a non-loopback interface
+export OLLAMA_HOST=0.0.0.0:11434
+ollama serve
+
+# Verify it's running
+curl http://localhost:11434/api/tags
```
-and the config file format should have this content
+### Step 2: Use Ollama Gateway (Zero-Code Option)
-```yaml
-GF_SECURITY_ADMIN_USER=admin
-GF_SECURITY_ADMIN_PASSWORD=changeme
-GF_USERS_ALLOW_SIGN_UP=false
+**Instead of connecting to `localhost:11434`, connect to the gateway at port `8080`:**
+
+```python
+# Before (direct Ollama connection)
+client = OpenAI(base_url="http://localhost:11434/v1")
+
+# After (with observability)
+client = OpenAI(base_url="http://localhost:8080/v1")
```
-If you want to change the password, you have to remove this entry, otherwise the change will not take effect
+The gateway automatically:
+- ✅ Captures all requests/responses as traces
+- ✅ Measures Time To First Token (TTFT)
+- ✅ Tracks token usage and throughput
+- ✅ Monitors error rates and latency
+- ✅ Forwards requests to Ollama unchanged
+
+### Step 3: Instrument Your Application (Full Observability)
+
+For custom metrics and traces, instrument with OpenTelemetry:
+
+**Python Example:**
+```python
+from opentelemetry import trace
+from opentelemetry.sdk.trace import TracerProvider
+from opentelemetry.sdk.trace.export import BatchSpanProcessor
+from opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporter
+
+# Configure OTLP exporter
+provider = TracerProvider()
+processor = BatchSpanProcessor(
+ OTLPSpanExporter(endpoint="http://localhost:4317", insecure=True)
+)
+provider.add_span_processor(processor)
+trace.set_tracer_provider(provider)
+
+# Use in your code
+tracer = trace.get_tracer(__name__)
+
+with tracer.start_as_current_span("llm_request"):
+ response = client.chat.completions.create(
+ model="llama2",
+ messages=[{"role": "user", "content": "Hello!"}]
+ )
+```
-```yaml
-- grafana_data:/var/lib/grafana
+**Node.js Example:**
+```javascript
+const { NodeTracerProvider } = require('@opentelemetry/sdk-trace-node');
+const { OTLPTraceExporter } = require('@opentelemetry/exporter-trace-otlp-grpc');
+const { BatchSpanProcessor } = require('@opentelemetry/sdk-trace-base');
+
+const provider = new NodeTracerProvider();
+provider.addSpanProcessor(
+ new BatchSpanProcessor(
+ new OTLPTraceExporter({
+ url: 'http://localhost:4317'
+ })
+ )
+);
+provider.register();
+```
+
+### Step 4: View Your Data
+
+**Grafana Dashboards:**
+- AI/LLM Performance Dashboard: `http://localhost:3000`
+- Distributed Traces: Navigate to **Explore** → Select **Tempo** datasource
+- Logs: Navigate to **Explore** → Select **Loki** datasource
+
+**Query Examples:**
+
+```promql
+# Average LLM latency (PromQL)
+ai:llm:latency_p95_ms
+
+# Error rate
+ai:llm:error_rate
+
+# Time to first token
+ai:llm:ttft_p95_ms
+
+# Throughput
+ai:llm:throughput_rpm
```
-Grafana is preconfigured with dashboards and Prometheus as the default data source:
+---
+
+## 🌐 Accessing Services
-* Name: Prometheus
-* Type: Prometheus
-* Url: [http://prometheus:9090](http://prometheus:9090)
-* Access: proxy
+| Service | URL | Credentials | Purpose |
+|---------|-----|-------------|---------|
+| **Grafana** | http://localhost:3000 | admin/admin | Dashboards & visualization |
+| **Prometheus** | http://localhost:9090 | admin/admin (via Caddy) | Metrics & queries |
+| **AlertManager** | http://localhost:9093 | admin/admin (via Caddy) | Alert management |
+| **Loki** | http://localhost:3100 | admin/admin (via Caddy) | Log aggregation API |
+| **Tempo** | http://localhost:3200 | admin/admin (via Caddy) | Distributed tracing API |
+| **OTEL Collector** | http://localhost:4317 | - | OTLP gRPC endpoint |
+| **Ollama Gateway** | http://localhost:8080 | - | AI observability proxy |
+| **cAdvisor** | http://localhost:8081 | - | Container metrics UI |
+| **Node Exporter** | http://localhost:9100 | - | Host metrics API |
+| **Pushgateway** | http://localhost:9091 | admin/admin (via Caddy) | Batch job metrics |
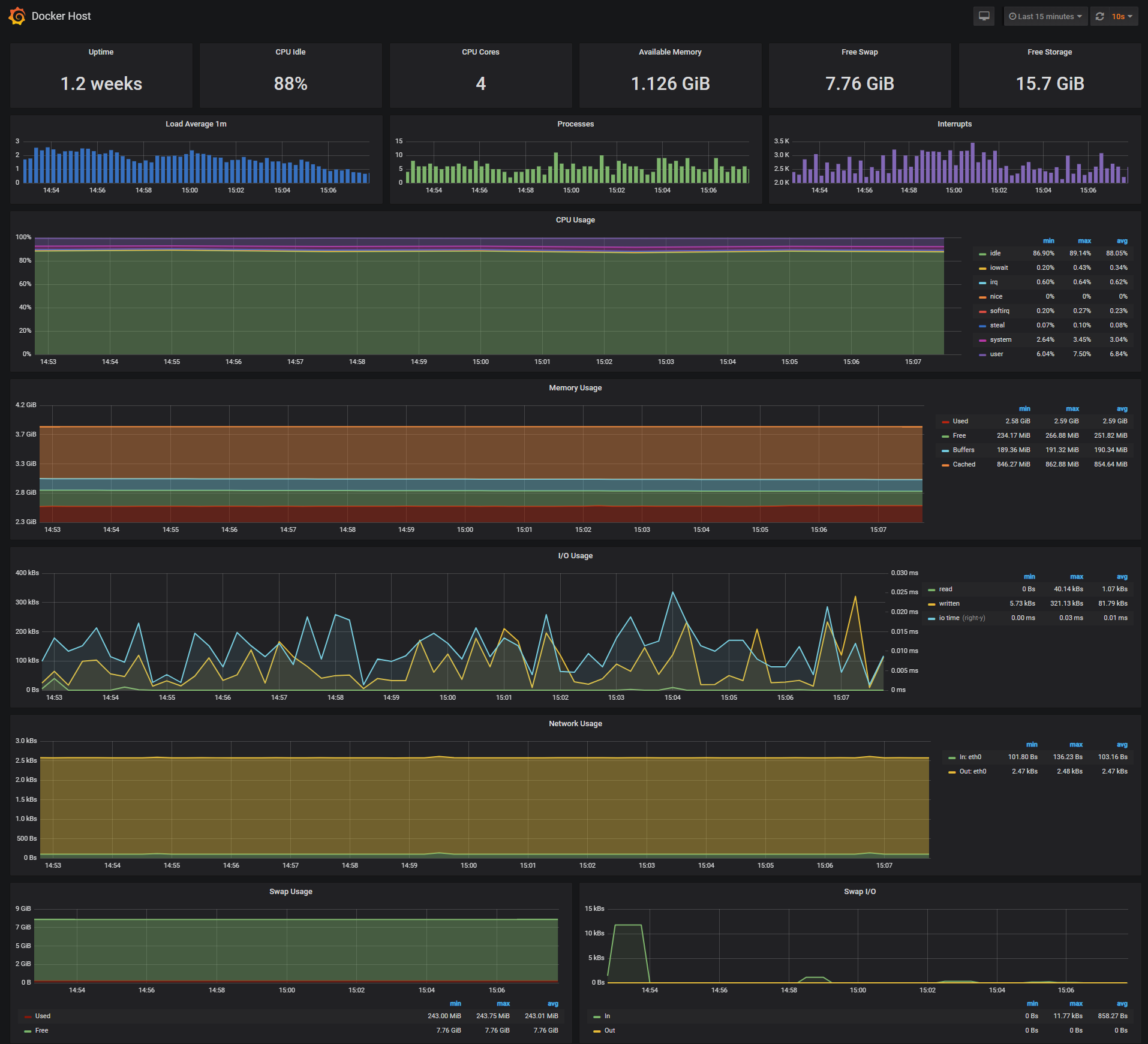
-***Docker Host Dashboard***
+**Default Credentials:**
+- Grafana: `admin` / `admin` (change on first login)
+- Caddy protected services: `admin` / `admin` (configure via environment variables)
-
+---
-The Docker Host Dashboard shows key metrics for monitoring the resource usage of your server:
+## 📦 Monitoring Stack Components
-* Server uptime, CPU idle percent, number of CPU cores, available memory, swap and storage
-* System load average graph, running and blocked by IO processes graph, interrupts graph
-* CPU usage graph by mode (guest, idle, iowait, irq, nice, softirq, steal, system, user)
-* Memory usage graph by distribution (used, free, buffers, cached)
-* IO usage graph (read Bps, read Bps and IO time)
-* Network usage graph by device (inbound Bps, Outbound Bps)
-* Swap usage and activity graphs
+### Core Monitoring
-For storage and particularly Free Storage graph, you have to specify the fstype in grafana graph request.
-You can find it in `grafana/provisioning/dashboards/docker_host.json`, at line 480 :
+#### Prometheus
+**Purpose:** Time-series metrics database and alerting engine
+
+**Features:**
+- Multi-dimensional data model with time series
+- Flexible query language (PromQL)
+- Pull-based metrics collection
+- Service discovery and target monitoring
+- Built-in alerting rules
+
+**Configuration:** `prometheus/prometheus.yml`
+
+#### Grafana
+**Purpose:** Analytics and monitoring visualization platform
+
+**Features:**
+- Interactive dashboards with drill-down capabilities
+- Multiple datasource support (Prometheus, Loki, Tempo)
+- Alert visualization and management
+- User authentication and RBAC
+- Dashboard provisioning and sharing
+
+**Configuration:** `grafana/provisioning/`
+
+#### Node Exporter
+**Purpose:** Host-level metrics exporter
+
+**Metrics:**
+- CPU usage, load average
+- Memory and swap utilization
+- Disk I/O, space usage
+- Network statistics
+- System uptime and processes
+
+#### cAdvisor
+**Purpose:** Container resource usage and performance metrics
+
+**Metrics:**
+- Container CPU, memory, network, disk usage
+- Per-container resource limits
+- Historical resource usage
+- Docker container lifecycle events
+
+### AI/LLM Observability
+
+#### Ollama Gateway (Envoy Proxy)
+**Purpose:** Transparent proxy for AI observability
+
+**Features:**
+- Zero-code instrumentation for Ollama requests
+- Automatic distributed tracing via OpenTelemetry
+- Request/response capture with span attributes
+- Performance metrics (latency, throughput)
+- Error tracking and rate limiting
+
+**Port:** 8080 (proxies to host.docker.internal:11434)
+
+#### OpenTelemetry Collector
+**Purpose:** Vendor-neutral telemetry data pipeline
+
+**Features:**
+- OTLP protocol receiver (gRPC and HTTP)
+- Data processing and enrichment
+- Export to multiple backends (Prometheus, Tempo, Loki)
+- Trace sampling and filtering
+- Metrics aggregation
+
+**Configuration:** `otel-collector/config.yaml`
+
+#### Tempo
+**Purpose:** High-scale distributed tracing backend
+
+**Features:**
+- Cost-effective trace storage
+- Integration with Loki for trace-to-log correlation
+- TraceQL for querying traces
+- Compatible with OpenTelemetry, Jaeger, Zipkin
+- No indexing required (search by trace ID)
+
+**Configuration:** `tempo/tempo.yaml`
+
+#### Loki
+**Purpose:** Log aggregation and querying system
+
+**Features:**
+- Label-based log indexing (like Prometheus for logs)
+- LogQL query language
+- Integration with Grafana for log visualization
+- Cost-effective storage (object storage compatible)
+- Multi-tenancy support
+
+**Configuration:** `loki/loki-config.yaml`
+
+#### Grafana Alloy
+**Purpose:** Lightweight log collection agent
+
+**Features:**
+- Docker container log collection
+- Log parsing and enrichment
+- Forwarding to Loki
+- Low resource footprint
+- Dynamic configuration reload
+
+### Alerting & Notifications
+
+#### AlertManager
+**Purpose:** Alert routing, grouping, and notification management
+
+**Features:**
+- Intelligent alert grouping and deduplication
+- Multiple notification channels (Slack, Teams, Mattermost, email)
+- Alert silencing and inhibition
+- Routing based on labels and severity
+- Template-based notifications
+
+**Configuration:** `alertmanager/config.yml`
+
+#### Pushgateway
+**Purpose:** Metrics gateway for batch jobs and short-lived processes
+
+**Features:**
+- Accept metrics pushed from batch jobs
+- Preserve metrics for Prometheus scraping
+- Support for multiple job metrics
+- Metric expiration and cleanup
+
+---
+
+## 🔔 Alerting & Notifications
+
+### Alert Coverage
+
+This stack includes **32 pre-configured alerts** covering all critical aspects:
+
+| Category | # Alerts | Severity Levels | Examples |
+|----------|----------|-----------------|----------|
+| **Service Health** | 2 | Critical | ServiceDown, ObservabilityStackDown |
+| **Infrastructure** | 6 | Warning, Critical | HighCPULoad, CriticalMemoryUsage, HighDiskUsage |
+| **AI/LLM Performance** | 5 | Warning, Critical | HighLLMErrorRate, SlowTimeToFirstToken, HighLLMLatency |
+| **Ollama Gateway** | 4 | Warning, Critical | HighGateway5xxRate, GatewayHighLatency |
+| **RAG Tools** | 4 | Warning | HighRAGRetrievalLatency, LowRAGRelevanceScore |
+| **AI Safety & Security** | 3 | Critical | ContentModerationSpikeDetected, UnusualModelAccessPattern |
+| **Observability Stack** | 5 | Warning, Critical | PrometheusHighMemory, LokiHighIngestionRate |
+| **Container Health** | 3 | Warning, Critical | ContainerHighMemory, ContainerHighCPU |
+
+### Notification Channels
+
+**Supported Integrations:**
+- 💬 **Slack**: Real-time notifications to channels
+- 👥 **Microsoft Teams**: Webhook-based alerts with rich formatting
+- 💻 **Mattermost**: Slack-compatible webhook integration
+- 📧 **Email**: SMTP-based notifications (configure in AlertManager)
+
+### Alert Routing Strategy
```yaml
-"expr": "sum(node_filesystem_free_bytes{fstype=\"btrfs\"})",
+# Critical alerts → Immediate notification (10s wait, 1m interval, 4h repeat)
+# Warning alerts → Standard notification (30s wait, 5m interval, 12h repeat)
+
+Routes:
+├─ Critical Alerts (severity=critical)
+│ ├─ AI/LLM Critical → ai-llm-critical receiver
+│ ├─ Infrastructure Critical → infrastructure-critical receiver
+│ └─ Security Critical → security-critical receiver
+│
+└─ Warning Alerts (severity=warning)
+ ├─ AI/LLM Warnings → ai-llm-warnings receiver
+ └─ Infrastructure Warnings → infrastructure-warnings receiver
```
-I work on BTRFS, so i need to change `aufs` to `btrfs`.
+**Inhibit Rules:** Critical alerts suppress related warnings to prevent alert fatigue.
+
+### Configuration Files
+
+- **Alert Rules**: `prometheus/alert.rules` (32 alerts)
+- **AlertManager Config**: `alertmanager/config.yml` (routing & receivers)
+- **Recording Rules**: `prometheus/recording.rules` (pre-aggregated AI metrics)
+
+**Setup Guide:** See [WEBHOOK_SETUP.md](./WEBHOOK_SETUP.md) for webhook configuration
+**Runbooks:** See [ALERT_RUNBOOKS.md](./ALERT_RUNBOOKS.md) for troubleshooting steps
+
+---
+
+## 📊 Grafana Dashboards
+
+### Pre-built Dashboards
+
+#### 1. Docker Host Dashboard
+**Metrics:**
+- CPU usage (overall, per-core)
+- Memory utilization and swap
+- Disk I/O, space usage, inode usage
+- Network traffic (RX/TX)
+- System load and uptime
+
+**Note:** Update `fstype` in dashboard JSON based on your filesystem (e.g., `ext4`, `xfs`, `btrfs`).
+
+#### 2. Docker Containers Dashboard
+**Metrics:**
+- Per-container CPU usage
+- Memory usage and limits
+- Network I/O by container
+- Container lifecycle events
+- Resource quotas and throttling
+
+#### 3. Monitor Services Dashboard
+**Metrics:**
+- Service availability (up/down status)
+- Scrape duration and success rate
+- Target health across all jobs
+- Prometheus internal metrics
+
+#### 4. AI/LLM Performance Dashboard
+**Metrics:**
+- LLM request rate and error rate
+- Latency percentiles (p50, p95, p99)
+- Time To First Token (TTFT) tracking
+- Token usage and throughput
+- Model-specific performance breakdown
+
+#### 5. Alert Monitoring Dashboard
+**Panels:**
+- Critical vs warning alert counts
+- Alert firing rate over time
+- Active alerts table with details
+- Alerts by service/category
+- Alert pattern heatmap
-You can find right value for your system in Prometheus `http://:9090` launching this request :
+**Import Guide:** See [GRAFANA_DASHBOARD_SETUP.md](./GRAFANA_DASHBOARD_SETUP.md)
+
+### Dashboard JSON Files
+
+Pre-configured dashboard JSON files are available in `grafana/provisioning/dashboards/`:
+- `docker-host-dashboard.json`
+- `docker-containers-dashboard.json`
+- `monitor-services-dashboard.json`
+- `ai-llm-dashboard.json`
+- `alert-monitoring-dashboard.json`
+
+**Auto-provisioning:** Dashboards are automatically loaded on Grafana startup.
+
+---
+
+## ⚙️ Advanced Configuration
+
+### Custom Recording Rules
+
+Add custom pre-aggregated metrics for AI workloads in `prometheus/recording.rules`:
```yaml
-node_filesystem_free_bytes
+groups:
+ - name: custom_ai_metrics
+ interval: 30s
+ rules:
+ # Custom model-specific error rate
+ - record: ai:llm:model_error_rate:5m
+ expr: |
+ sum by (model) (rate(llm_request_errors_total[5m]))
+ / sum by (model) (rate(llm_requests_total[5m]))
+
+ # Average tokens per request
+ - record: ai:llm:avg_tokens_per_request
+ expr: |
+ sum(rate(llm_tokens_total[5m]))
+ / sum(rate(llm_requests_total[5m]))
```
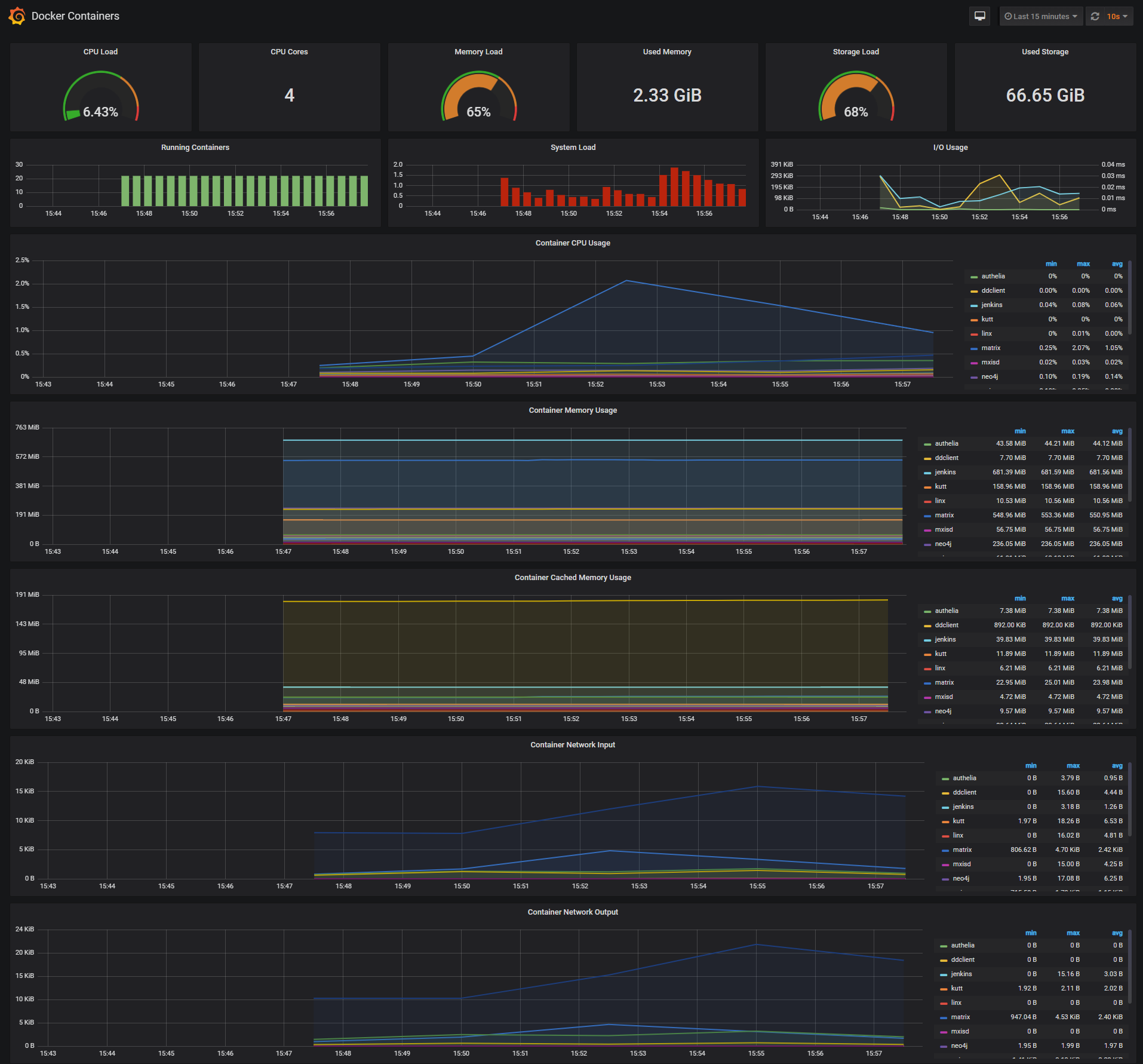
-***Docker Containers Dashboard***
+### Environment Variables
+
+Configure stack behavior via environment variables:
-
+```bash
+# Prometheus
+PROMETHEUS_RETENTION=15d
-The Docker Containers Dashboard shows key metrics for monitoring running containers:
+# Grafana
+ADMIN_USER=admin
+ADMIN_PASSWORD=your_secure_password
+ADMIN_PASSWORD_HASH=$(docker run --rm caddy caddy hash-password --plaintext 'your_secure_password')
-* Total containers CPU load, memory and storage usage
-* Running containers graph, system load graph, IO usage graph
-* Container CPU usage graph
-* Container memory usage graph
-* Container cached memory usage graph
-* Container network inbound usage graph
-* Container network outbound usage graph
+# Grafana additional settings
+GF_SERVER_ROOT_URL=https://grafana.yourdomain.com
+GF_AUTH_ANONYMOUS_ENABLED=false
+```
-Note that this dashboard doesn't show the containers that are part of the monitoring stack.
+### Scaling Considerations
+
+**For Production Deployments:**
+
+1. **Persistent Storage:**
+ ```yaml
+ volumes:
+ - prometheus-data:/prometheus
+ - grafana-data:/var/lib/grafana
+ - loki-data:/loki
+ ```
+
+2. **Resource Limits:**
+ ```yaml
+ deploy:
+ resources:
+ limits:
+ cpus: '2'
+ memory: 4G
+ reservations:
+ memory: 2G
+ ```
+
+3. **High Availability:**
+ - Run multiple AlertManager instances with clustering
+ - Use external Prometheus remote storage (Thanos, Cortex)
+ - Configure Loki with object storage backend (S3, GCS)
+
+### Security Hardening
+
+**1. Enable Authentication:**
+```yaml
+# Prometheus (via Caddy)
+# Already configured with basic auth
-For storage and particularly Storage Load graph, you have to specify the fstype in grafana graph request.
-You can find it in `grafana/provisioning/dashboards/docker_containers.json`, at line 406 :
+# Grafana
+GF_AUTH_ANONYMOUS_ENABLED=false
+GF_SECURITY_ADMIN_PASSWORD=
+```
+**2. Network Isolation:**
```yaml
-"expr": "(node_filesystem_size_bytes{fstype=\"btrfs\"} - node_filesystem_free_bytes{fstype=\"btrfs\"}) / node_filesystem_size_bytes{fstype=\"btrfs\"} * 100",
+networks:
+ monitor-net:
+ driver: bridge
+ internal: false # Set to true for isolation (requires external proxy)
```
-I work on BTRFS, so i need to change `aufs` to `btrfs`.
+**3. TLS Encryption:**
+Caddy automatically handles TLS. Configure your domain in the Caddyfile:
+```
+https://grafana.yourdomain.com {
+ reverse_proxy grafana:3000
+ basicauth /* {
+ {$ADMIN_USER} {$ADMIN_PASSWORD_HASH}
+ }
+}
+```
+
+### Custom Alert Rules
-You can find right value for your system in Prometheus `http://:9090` launching this request :
+Add your own alerts in `prometheus/alert.rules`:
```yaml
-node_filesystem_size_bytes
-node_filesystem_free_bytes
+groups:
+ - name: custom_alerts
+ rules:
+ - alert: CustomHighErrorRate
+ expr: rate(http_requests_total{status=~"5.."}[5m]) > 0.05
+ for: 5m
+ labels:
+ severity: warning
+ annotations:
+ summary: "High error rate detected"
+ description: "Error rate is {{ $value | humanizePercentage }}"
+ runbook_url: "https://github.com/waitesgithub/dockprom/blob/master/docs/runbooks/CustomHighErrorRate.md"
```
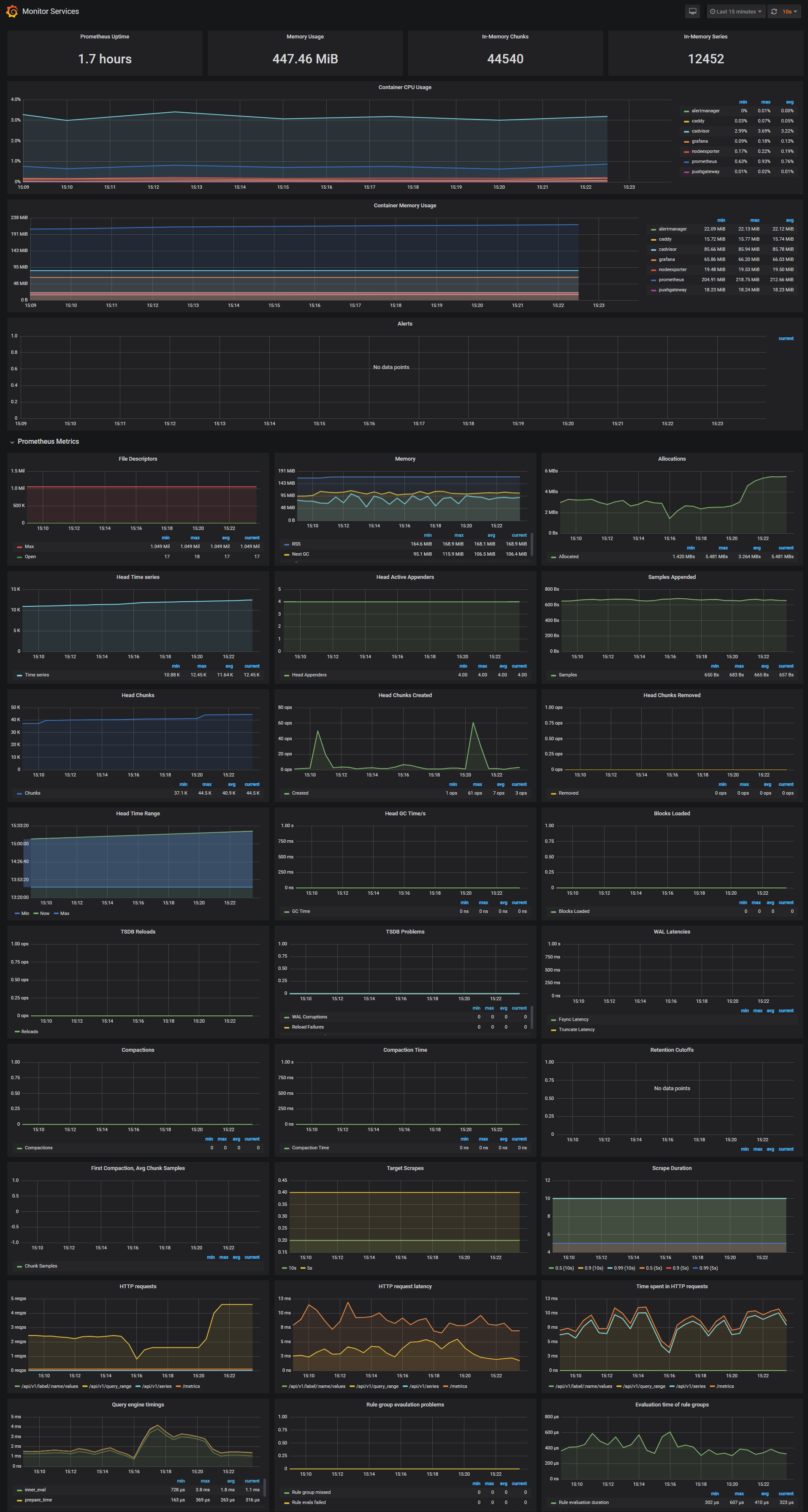
-***Monitor Services Dashboard***
+---
+
+## 🔧 Troubleshooting
-
+### Common Issues
-The Monitor Services Dashboard shows key metrics for monitoring the containers that make up the monitoring stack:
+#### 1. Services Not Starting
-* Prometheus container uptime, monitoring stack total memory usage, Prometheus local storage memory chunks and series
-* Container CPU usage graph
-* Container memory usage graph
-* Prometheus chunks to persist and persistence urgency graphs
-* Prometheus chunks ops and checkpoint duration graphs
-* Prometheus samples ingested rate, target scrapes and scrape duration graphs
-* Prometheus HTTP requests graph
-* Prometheus alerts graph
+**Symptom:** Containers exit immediately or show "unhealthy" status
-## Define alerts
+**Solutions:**
+```bash
+# Check logs
+docker-compose logs
-Three alert groups have been setup within the [alert.rules](https://github.com/stefanprodan/dockprom/blob/master/prometheus/alert.rules) configuration file:
+# Common issues:
+# - Port conflicts: Change ports in docker-compose.yml
+# - Permission issues: Check volume mount permissions
+# - Resource constraints: Increase Docker memory limit
+```
-* Monitoring services alerts [targets](https://github.com/stefanprodan/dockprom/blob/master/prometheus/alert.rules#L2-L11)
-* Docker Host alerts [host](https://github.com/stefanprodan/dockprom/blob/master/prometheus/alert.rules#L13-L40)
-* Docker Containers alerts [containers](https://github.com/stefanprodan/dockprom/blob/master/prometheus/alert.rules#L42-L69)
+#### 2. Ollama Gateway Can't Connect to Host
-You can modify the alert rules and reload them by making a HTTP POST call to Prometheus:
+**Symptom:** Gateway returns 503 errors or connection refused
+**Solutions:**
```bash
-curl -X POST http://admin:admin@:9090/-/reload
+# Verify Ollama is running and accessible
+curl http://localhost:11434/api/tags
+
+# For Linux, ensure Ollama listens on 0.0.0.0
+export OLLAMA_HOST=0.0.0.0:11434
+ollama serve
+
+# Check gateway can reach host
+docker exec ollama-gateway curl http://host.docker.internal:11434/api/tags
+
+# Update docker-compose.yml if needed:
+extra_hosts:
+ - "host.docker.internal:host-gateway"
```
-***Monitoring services alerts***
+#### 3. No Metrics in Grafana
-Trigger an alert if any of the monitoring targets (node-exporter and cAdvisor) are down for more than 30 seconds:
+**Symptom:** Dashboards show "No data" or empty graphs
-```yaml
-- alert: monitor_service_down
- expr: up == 0
- for: 30s
- labels:
- severity: critical
- annotations:
- summary: "Monitor service non-operational"
- description: "Service {{ $labels.instance }} is down."
+**Solutions:**
+```bash
+# Verify Prometheus is scraping targets
+# Visit http://localhost:9090/targets
+
+# Check Prometheus logs
+docker-compose logs prometheus
+
+# Verify datasource configuration in Grafana
+# Settings → Data Sources → Prometheus
+# URL should be: http://prometheus:9090
```
-***Docker Host alerts***
+#### 4. Alerts Not Firing
-Trigger an alert if the Docker host CPU is under high load for more than 30 seconds:
+**Symptom:** Expected alerts don't appear in AlertManager
-```yaml
-- alert: high_cpu_load
- expr: node_load1 > 1.5
- for: 30s
- labels:
- severity: warning
- annotations:
- summary: "Server under high load"
- description: "Docker host is under high load, the avg load 1m is at {{ $value}}. Reported by instance {{ $labels.instance }} of job {{ $labels.job }}."
+**Solutions:**
+```bash
+# Validate alert rules syntax
+docker exec prometheus promtool check rules /etc/prometheus/alert.rules
+
+# Check if rules are loaded
+curl http://admin:admin@localhost:9090/api/v1/rules
+
+# Verify AlertManager is receiving alerts
+curl http://admin:admin@localhost:9093/api/v1/alerts
+
+# Reload Prometheus configuration
+curl -X POST http://admin:admin@localhost:9090/-/reload
```
-Modify the load threshold based on your CPU cores.
+#### 5. High Memory Usage
-Trigger an alert if the Docker host memory is almost full:
+**Symptom:** Prometheus or Loki consuming excessive memory
+**Solutions:**
```yaml
-- alert: high_memory_load
- expr: (sum(node_memory_MemTotal_bytes) - sum(node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes) ) / sum(node_memory_MemTotal_bytes) * 100 > 85
- for: 30s
- labels:
- severity: warning
- annotations:
- summary: "Server memory is almost full"
- description: "Docker host memory usage is {{ humanize $value}}%. Reported by instance {{ $labels.instance }} of job {{ $labels.job }}."
+# Adjust retention periods in prometheus/prometheus.yml
+global:
+ scrape_interval: 15s
+
+# Add storage configuration
+storage:
+ tsdb:
+ retention.time: 15d # Reduce from default 30d
+ retention.size: 10GB # Add size-based retention
+
+# For Loki, adjust in loki/loki-config.yaml
+limits_config:
+ retention_period: 168h # 7 days
```
-Trigger an alert if the Docker host storage is almost full:
+#### 6. Traces Not Appearing in Tempo
-```yaml
-- alert: high_storage_load
- expr: (node_filesystem_size_bytes{fstype="aufs"} - node_filesystem_free_bytes{fstype="aufs"}) / node_filesystem_size_bytes{fstype="aufs"} * 100 > 85
- for: 30s
- labels:
- severity: warning
- annotations:
- summary: "Server storage is almost full"
- description: "Docker host storage usage is {{ humanize $value}}%. Reported by instance {{ $labels.instance }} of job {{ $labels.job }}."
+**Symptom:** No traces visible in Grafana Explore → Tempo
+
+**Solutions:**
+```bash
+# Verify OTEL Collector is receiving traces
+docker-compose logs otel-collector | grep -i trace
+
+# Check Tempo ingestion
+curl http://admin:admin@localhost:3200/api/search
+
+# Verify application is sending to correct endpoint
+# OTLP gRPC: localhost:4317
+# OTLP HTTP: localhost:4318
+
+# Check trace sampling (might be sampling out spans)
```
-***Docker Containers alerts***
+#### 7. Filesystem Type Issues
-Trigger an alert if a container is down for more than 30 seconds:
+**Symptom:** Disk metrics showing "No data" in dashboards
-```yaml
-- alert: jenkins_down
- expr: absent(container_memory_usage_bytes{name="jenkins"})
- for: 30s
- labels:
- severity: critical
- annotations:
- summary: "Jenkins down"
- description: "Jenkins container is down for more than 30 seconds."
+**Solution:**
+```bash
+# Find your filesystem type
+node_filesystem_free_bytes
+
+# Update grafana dashboard JSON files:
+# Replace fstype="aufs" with your actual filesystem type
+# Common types: ext4, xfs, btrfs, overlay2
+
+# Example in docker_host.json:
+"expr": "sum(node_filesystem_free_bytes{fstype=\"ext4\"})"
+```
+
+### Verification Commands
+
+```bash
+# Check all services are running
+docker-compose ps
+
+# View service logs
+docker-compose logs -f
+
+# Test Prometheus targets
+curl http://admin:admin@localhost:9090/api/v1/targets | jq .
+
+# Test AlertManager configuration
+docker exec alertmanager amtool check-config /etc/alertmanager/config.yml
+
+# Verify Grafana datasources
+curl -u admin:admin http://localhost:3000/api/datasources
+
+# Test OTLP endpoint
+grpcurl -plaintext -d '{}' localhost:4317 list
```
-Trigger an alert if a container is using more than 10% of total CPU cores for more than 30 seconds:
+### Performance Optimization
+**1. Reduce Metrics Cardinality:**
```yaml
-- alert: jenkins_high_cpu
- expr: sum(rate(container_cpu_usage_seconds_total{name="jenkins"}[1m])) / count(node_cpu_seconds_total{mode="system"}) * 100 > 10
- for: 30s
- labels:
- severity: warning
- annotations:
- summary: "Jenkins high CPU usage"
- description: "Jenkins CPU usage is {{ humanize $value}}%."
+# Drop unnecessary labels in prometheus/prometheus.yml
+metric_relabel_configs:
+ - source_labels: [__name__]
+ regex: 'high_cardinality_metric.*'
+ action: drop
```
-Trigger an alert if a container is using more than 1.2GB of RAM for more than 30 seconds:
+**2. Adjust Scrape Intervals:**
+```yaml
+# For less critical metrics, increase interval
+scrape_configs:
+ - job_name: 'low-priority-job'
+ scrape_interval: 60s # Instead of default 15s
+```
+**3. Enable Query Caching:**
```yaml
-- alert: jenkins_high_memory
- expr: sum(container_memory_usage_bytes{name="jenkins"}) > 1200000000
- for: 30s
- labels:
- severity: warning
- annotations:
- summary: "Jenkins high memory usage"
- description: "Jenkins memory consumption is at {{ humanize $value}}."
+# In grafana/grafana.ini
+[caching]
+enabled = true
```
-## Setup alerting
+---
-The AlertManager service is responsible for handling alerts sent by Prometheus server.
-AlertManager can send notifications via email, Pushover, Slack, HipChat or any other system that exposes a webhook interface.
-A complete list of integrations can be found [here](https://prometheus.io/docs/alerting/configuration).
+## 📚 Documentation
-You can view and silence notifications by accessing `http://:9093`.
+### Quick Links
-The notification receivers can be configured in [alertmanager/config.yml](https://github.com/stefanprodan/dockprom/blob/master/alertmanager/config.yml) file.
+- **Alert Rules Reference**: [alert.rules](./prometheus/alert.rules)
+- **Recording Rules**: [recording.rules](./prometheus/recording.rules)
+- **Prometheus Config**: [prometheus.yml](./prometheus/prometheus.yml)
+- **AlertManager Config**: [alertmanager/config.yml](./alertmanager/config.yml)
+- **Docker Compose**: [docker-compose.yml](./docker-compose.yml)
-To receive alerts via Slack you need to make a custom integration by choose ***incoming web hooks*** in your Slack team app page.
-You can find more details on setting up Slack integration [here](http://www.robustperception.io/using-slack-with-the-alertmanager/).
+### Implementation Guides
-Copy the Slack Webhook URL into the ***api_url*** field and specify a Slack ***channel***.
+- **[IMPLEMENTATION_SUMMARY.md](./IMPLEMENTATION_SUMMARY.md)** - Complete deployment checklist
+- **[WEBHOOK_SETUP.md](./WEBHOOK_SETUP.md)** - Teams & Mattermost webhook configuration
+- **[ALERT_RUNBOOKS.md](./ALERT_RUNBOOKS.md)** - Troubleshooting guide for each alert
+- **[GRAFANA_DASHBOARD_SETUP.md](./GRAFANA_DASHBOARD_SETUP.md)** - Dashboard creation guide
-```yaml
-route:
- receiver: 'slack'
-
-receivers:
- - name: 'slack'
- slack_configs:
- - send_resolved: true
- text: "{{ .CommonAnnotations.description }}"
- username: 'Prometheus'
- channel: '#'
- api_url: 'https://hooks.slack.com/services/'
-```
+### External Resources
+
+- [Prometheus Documentation](https://prometheus.io/docs/)
+- [Grafana Documentation](https://grafana.com/docs/)
+- [OpenTelemetry Collector](https://opentelemetry.io/docs/collector/)
+- [Loki Documentation](https://grafana.com/docs/loki/)
+- [Tempo Documentation](https://grafana.com/docs/tempo/)
+- [Ollama Documentation](https://github.com/ollama/ollama/tree/main/docs)
-
+---
-## Sending metrics to the Pushgateway
+## 🤝 Contributing
-The [pushgateway](https://github.com/prometheus/pushgateway) is used to collect data from batch jobs or from services.
+We welcome contributions! Here's how you can help:
-To push data, simply execute:
+### Reporting Issues
+
+1. Check existing [issues](https://github.com/waitesgithub/dockprom/issues)
+2. Create detailed bug reports with:
+ - Dockprom version
+ - Docker version
+ - Steps to reproduce
+ - Expected vs actual behavior
+ - Relevant logs
+
+### Submitting Changes
+
+1. **Fork the repository**
+2. **Create a feature branch**
+ ```bash
+ git checkout -b feature/your-feature-name
+ ```
+3. **Make your changes**
+ - Follow existing code style
+ - Update documentation
+ - Add tests if applicable
+4. **Commit with clear messages**
+ ```bash
+ git commit -m "feat: add support for new LLM metrics"
+ ```
+5. **Push and create a Pull Request**
+ ```bash
+ git push origin feature/your-feature-name
+ ```
+
+### Development Setup
```bash
-echo "some_metric 3.14" | curl --data-binary @- http://user:password@localhost:9091/metrics/job/some_job
+# Clone your fork
+git clone https://github.com/YOUR_USERNAME/dockprom.git
+cd dockprom
+
+# Add upstream remote
+git remote add upstream https://github.com/waitesgithub/dockprom.git
+
+# Start development environment
+docker-compose up -d
+
+# Make changes and test
+docker-compose restart
```
-Please replace the `user:password` part with your user and password set in the initial configuration (default: `admin:admin`).
+### Areas for Contribution
-## Updating Grafana to v5.2.2
+- 📊 New Grafana dashboards for specific use cases
+- 🔔 Additional alert rules and runbooks
+- 🤖 Support for more LLM providers (OpenAI, Anthropic, etc.)
+- 📝 Documentation improvements and translations
+- 🧪 Test coverage and CI/CD improvements
+- 🔧 Performance optimizations
-[In Grafana versions >= 5.1 the id of the grafana user has been changed](http://docs.grafana.org/installation/docker/#migration-from-a-previous-version-of-the-docker-container-to-5-1-or-later). Unfortunately this means that files created prior to 5.1 won’t have the correct permissions for later versions.
+### Code of Conduct
-| Version | User | User ID |
-|:-------:|:-------:|:-------:|
-| < 5.1 | grafana | 104 |
-| \>= 5.1 | grafana | 472 |
+- Be respectful and inclusive
+- Provide constructive feedback
+- Focus on what is best for the community
+- Show empathy towards other community members
-There are two possible solutions to this problem.
+---
-1. Change ownership from 104 to 472
-2. Start the upgraded container as user 104
+## 📄 License
-## Specifying a user in docker-compose.yml
+This project is licensed under the **MIT License** - see the [LICENSE](./LICENSE) file for details.
-To change ownership of the files run your grafana container as root and modify the permissions.
+### MIT License Summary
-First perform a `docker-compose down` then modify your docker-compose.yml to include the `user: root` option:
+- ✅ Commercial use
+- ✅ Modification
+- ✅ Distribution
+- ✅ Private use
+- ⚠️ Liability and warranty disclaimers apply
-```yaml
- grafana:
- image: grafana/grafana:5.2.2
- container_name: grafana
- volumes:
- - grafana_data:/var/lib/grafana
- - ./grafana/datasources:/etc/grafana/datasources
- - ./grafana/dashboards:/etc/grafana/dashboards
- - ./grafana/setup.sh:/setup.sh
- entrypoint: /setup.sh
- user: root
- environment:
- - GF_SECURITY_ADMIN_USER=${ADMIN_USER:-admin}
- - GF_SECURITY_ADMIN_PASSWORD=${ADMIN_PASSWORD:-admin}
- - GF_USERS_ALLOW_SIGN_UP=false
- restart: unless-stopped
- expose:
- - 3000
- networks:
- - monitor-net
- labels:
- org.label-schema.group: "monitoring"
-```
+---
-Perform a `docker-compose up -d` and then issue the following commands:
+## 🙏 Acknowledgments
-```bash
-docker exec -it --user root grafana bash
+This project builds upon the excellent work of:
-# in the container you just started:
-chown -R root:root /etc/grafana && \
-chmod -R a+r /etc/grafana && \
-chown -R grafana:grafana /var/lib/grafana && \
-chown -R grafana:grafana /usr/share/grafana
-```
+- **Stefan Prodan** - Original [dockprom](https://github.com/stefanprodan/dockprom) creator
+- **Prometheus Team** - For the amazing monitoring system
+- **Grafana Labs** - For Grafana, Loki, Tempo, and Alloy
+- **OpenTelemetry Community** - For vendor-neutral observability standards
+- **Ollama Team** - For accessible local LLM deployment
+- **Docker Community** - For containerization excellence
-To run the grafana container as `user: 104` change your `docker-compose.yml` like such:
+### Special Thanks
-```yaml
- grafana:
- image: grafana/grafana:5.2.2
- container_name: grafana
- volumes:
- - grafana_data:/var/lib/grafana
- - ./grafana/datasources:/etc/grafana/datasources
- - ./grafana/dashboards:/etc/grafana/dashboards
- - ./grafana/setup.sh:/setup.sh
- entrypoint: /setup.sh
- user: "104"
- environment:
- - GF_SECURITY_ADMIN_USER=${ADMIN_USER:-admin}
- - GF_SECURITY_ADMIN_PASSWORD=${ADMIN_PASSWORD:-admin}
- - GF_USERS_ALLOW_SIGN_UP=false
- restart: unless-stopped
- expose:
- - 3000
- networks:
- - monitor-net
- labels:
- org.label-schema.group: "monitoring"
-```
+- All contributors who have helped improve this project
+- The DevOps and AI/ML communities for feedback and testing
+- Open source maintainers whose tools make this possible
+
+---
+
+## 📊 Project Stats
+
+
+
+
+
+
+---
+
+## 🔗 Related Projects
+
+- [Netdata](https://github.com/netdata/netdata) - Real-time performance monitoring
+- [VictoriaMetrics](https://github.com/VictoriaMetrics/VictoriaMetrics) - High-performance Prometheus alternative
+- [Thanos](https://github.com/thanos-io/thanos) - Prometheus long-term storage
+- [Cortex](https://github.com/cortexproject/cortex) - Horizontally scalable Prometheus
+- [OpenLLMetry](https://github.com/traceloop/openllmetry) - OpenTelemetry for LLMs
+
+---
+
+## 🗺️ Roadmap
+
+### Planned Features
+
+- [ ] **Multi-LLM Provider Support**: OpenAI, Anthropic, Cohere gateway adapters
+- [ ] **Cost Tracking Dashboard**: Token costs and usage analytics
+- [ ] **Automated Performance Testing**: Load testing framework for LLMs
+- [ ] **Enhanced Security Monitoring**: Content moderation dashboards
+- [ ] **Mobile Alerts**: Push notifications via mobile apps
+- [ ] **GitOps Integration**: Flux/ArgoCD deployment examples
+- [ ] **Kubernetes Support**: Helm charts and operator
+- [ ] **Advanced RAG Metrics**: Vector database performance tracking
+
+### Recently Added
+
+- ✅ Comprehensive alert rules (32 alerts)
+- ✅ Multi-channel notifications (Slack, Teams, Mattermost)
+- ✅ AI/LLM observability with Ollama Gateway
+- ✅ Distributed tracing with Tempo
+- ✅ Log aggregation with Loki and Alloy
+- ✅ Pre-aggregated AI metrics via recording rules
+
+---
+
+## 💬 Community & Support
+
+### Getting Help
+
+- **Documentation**: Check this README and documentation files
+- **Issues**: [GitHub Issues](https://github.com/waitesgithub/dockprom/issues)
+- **Discussions**: [GitHub Discussions](https://github.com/waitesgithub/dockprom/discussions)
+
+### Stay Updated
+
+- ⭐ **Star this repo** to stay notified of updates
+- 👁️ **Watch releases** for new versions
+- 🔄 **Follow the project** for development updates
+
+---
+
+
+
+## 🌟 Show Your Support
+
+If you find this project useful, please consider:
+
+- ⭐ **Starring the repository**
+- 🔄 **Sharing with your network**
+- 🐛 **Reporting bugs and issues**
+- 💡 **Suggesting new features**
+- 🤝 **Contributing code or documentation**
+
+---
+
+**Built with ❤️ for the DevOps and AI/ML communities**
+
+*Making observability accessible for everyone*
+
+---
+
+**Questions?** Open an [issue](https://github.com/waitesgithub/dockprom/issues) • **Want to contribute?** Check our [contributing guidelines](#-contributing)
+
+
diff --git a/alloy/config.alloy b/alloy/config.alloy
new file mode 100644
index 00000000..9d09d026
--- /dev/null
+++ b/alloy/config.alloy
@@ -0,0 +1,43 @@
+// Grafana Alloy: discover Docker containers and ship logs to Loki.
+
+discovery.docker "containers" {
+ host = "unix:///var/run/docker.sock"
+}
+
+// Optional: add useful labels.
+discovery.relabel "docker_labels" {
+ targets = discovery.docker.containers.targets
+
+ rule {
+ source_labels = ["__meta_docker_container_name"]
+ regex = "/(.*)"
+ target_label = "container"
+ }
+
+ rule {
+ source_labels = ["__meta_docker_container_image"]
+ target_label = "image"
+ }
+
+ rule {
+ source_labels = ["__meta_docker_container_id"]
+ target_label = "container_id"
+ }
+}
+
+loki.source.docker "docker" {
+ host = "unix:///var/run/docker.sock"
+ targets = discovery.relabel.docker_labels.output
+ forward_to = [loki.process.docker.receiver]
+}
+
+loki.process "docker" {
+ stage.docker {}
+ forward_to = [loki.write.loki.receiver]
+}
+
+loki.write "loki" {
+ endpoint {
+ url = "http://loki:3100/loki/api/v1/push"
+ }
+}
diff --git a/caddy/Caddyfile b/caddy/Caddyfile
index 6fd77388..018a3ed1 100644
--- a/caddy/Caddyfile
+++ b/caddy/Caddyfile
@@ -29,3 +29,17 @@
}
reverse_proxy pushgateway:9091
}
+
+:3100 {
+ basicauth /* {
+ {$ADMIN_USER} {$ADMIN_PASSWORD_HASH}
+ }
+ reverse_proxy loki:3100
+}
+
+:3200 {
+ basicauth /* {
+ {$ADMIN_USER} {$ADMIN_PASSWORD_HASH}
+ }
+ reverse_proxy tempo:3200
+}
diff --git a/core b/core
new file mode 100644
index 00000000..dcabbf1b
Binary files /dev/null and b/core differ
diff --git a/docker-compose.yml b/docker-compose.yml
index 34cb822e..176134c2 100644
--- a/docker-compose.yml
+++ b/docker-compose.yml
@@ -5,6 +5,8 @@ networks:
volumes:
prometheus_data: {}
grafana_data: {}
+ loki_data: {}
+ tempo_data: {}
services:
@@ -104,6 +106,90 @@ services:
labels:
org.label-schema.group: "monitoring"
+ loki:
+ image: grafana/loki:2.9.8
+ container_name: loki
+ command: -config.file=/etc/loki/loki.yml
+ volumes:
+ - ./loki:/etc/loki:ro
+ - loki_data:/loki
+ restart: unless-stopped
+ expose:
+ - 3100
+ networks:
+ - monitor-net
+ labels:
+ org.label-schema.group: "monitoring"
+
+ tempo:
+ image: grafana/tempo:2.3.1
+ container_name: tempo
+ command: -config.file=/etc/tempo/tempo.yml
+ volumes:
+ - ./tempo:/etc/tempo:ro
+ - tempo_data:/var/tempo
+ restart: unless-stopped
+ expose:
+ - 3200
+ - 4317
+ - 4318
+ networks:
+ - monitor-net
+ labels:
+ org.label-schema.group: "monitoring"
+
+ otel-collector:
+ image: otel/opentelemetry-collector-contrib:0.96.0
+ container_name: otel-collector
+ command: ["--config=/etc/otel-collector/config.yml"]
+ volumes:
+ - ./otel-collector:/etc/otel-collector:ro
+ restart: unless-stopped
+ ports:
+ # OTLP endpoints for apps (host -> collector)
+ - "4317:4317" # OTLP gRPC
+ - "4318:4318" # OTLP HTTP
+ expose:
+ - 8889 # Prometheus scrape (OTLP metrics -> Prometheus exporter)
+ networks:
+ - monitor-net
+ labels:
+ org.label-schema.group: "monitoring"
+
+ ollama-gateway:
+ image: envoyproxy/envoy:v1.30.4
+ container_name: ollama-gateway
+ command: ["/usr/local/bin/envoy", "-c", "/etc/envoy/envoy.yml", "--log-level", "info"]
+ volumes:
+ - ./envoy:/etc/envoy:ro
+ extra_hosts:
+ # Linux Docker: maps to host gateway IP (Docker 20.10+)
+ - "host.docker.internal:host-gateway"
+ ports:
+ # Local Ollama gateway for users/apps (host -> gateway)
+ - "11435:11434"
+ expose:
+ # Envoy admin (/stats/prometheus)
+ - 9901
+ restart: unless-stopped
+ networks:
+ - monitor-net
+ labels:
+ org.label-schema.group: "monitoring"
+
+ alloy:
+ image: grafana/alloy:v1.3.0
+ container_name: alloy
+ command: ["run", "--server.http.listen-addr=0.0.0.0:12345", "/etc/alloy/config.alloy"]
+ volumes:
+ - ./alloy:/etc/alloy:ro
+ - /var/run/docker.sock:/var/run/docker.sock:ro
+ restart: unless-stopped
+ networks:
+ - monitor-net
+ labels:
+ org.label-schema.group: "monitoring"
+
pushgateway:
image: prom/pushgateway:v1.11.0
container_name: pushgateway
@@ -124,6 +210,8 @@ services:
- "9090:9090"
- "9093:9093"
- "9091:9091"
+ - "3100:3100"
+ - "3200:3200"
volumes:
- ./caddy:/etc/caddy
environment:
diff --git a/envoy/envoy.yml b/envoy/envoy.yml
new file mode 100644
index 00000000..1e056ba6
--- /dev/null
+++ b/envoy/envoy.yml
@@ -0,0 +1,77 @@
+static_resources:
+ listeners:
+ - name: listener_ollama
+ address:
+ socket_address:
+ address: 0.0.0.0
+ port_value: 11434
+ filter_chains:
+ - filters:
+ - name: envoy.filters.network.http_connection_manager
+ typed_config:
+ "@type": type.googleapis.com/envoy.extensions.filters.network.http_connection_manager.v3.HttpConnectionManager
+ stat_prefix: ollama_gateway
+ generate_request_id: true
+ tracing:
+ provider:
+ name: envoy.tracers.opentelemetry
+ typed_config:
+ "@type": type.googleapis.com/envoy.config.trace.v3.OpenTelemetryConfig
+ grpc_service:
+ envoy_grpc:
+ cluster_name: otel_collector
+ timeout: 0.25s
+ service_name: ollama-gateway
+ access_log:
+ - name: envoy.access_loggers.stdout
+ typed_config:
+ "@type": type.googleapis.com/envoy.extensions.access_loggers.stream.v3.StdoutAccessLog
+ route_config:
+ name: local_route
+ virtual_hosts:
+ - name: ollama
+ domains: ["*"]
+ routes:
+ - match:
+ prefix: "/"
+ route:
+ cluster: ollama_upstream
+ timeout: 0s
+ http_filters:
+ - name: envoy.filters.http.router
+ typed_config:
+ "@type": type.googleapis.com/envoy.extensions.filters.http.router.v3.Router
+
+ clusters:
+ - name: ollama_upstream
+ type: STRICT_DNS
+ connect_timeout: 2s
+ load_assignment:
+ cluster_name: ollama_upstream
+ endpoints:
+ - lb_endpoints:
+ - endpoint:
+ address:
+ socket_address:
+ address: host.docker.internal
+ port_value: 11434
+
+ - name: otel_collector
+ type: STRICT_DNS
+ connect_timeout: 1s
+ http2_protocol_options: {}
+ load_assignment:
+ cluster_name: otel_collector
+ endpoints:
+ - lb_endpoints:
+ - endpoint:
+ address:
+ socket_address:
+ address: otel-collector
+ port_value: 4317
+
+admin:
+ address:
+ socket_address:
+ address: 0.0.0.0
+ port_value: 9901
diff --git a/grafana/provisioning/dashboards/ai_llm_observability.json b/grafana/provisioning/dashboards/ai_llm_observability.json
new file mode 100644
index 00000000..011108bf
--- /dev/null
+++ b/grafana/provisioning/dashboards/ai_llm_observability.json
@@ -0,0 +1,415 @@
+{
+ "uid": "ai-llm-observability",
+ "title": "AI - LLM Observability (Model-agnostic)",
+ "tags": [
+ "ai",
+ "llm",
+ "observability",
+ "prometheus"
+ ],
+ "timezone": "browser",
+ "schemaVersion": 39,
+ "version": 1,
+ "refresh": "10s",
+ "time": {
+ "from": "now-15m",
+ "to": "now"
+ },
+ "templating": {
+ "list": [
+ {
+ "name": "service",
+ "type": "query",
+ "datasource": {
+ "type": "prometheus",
+ "uid": "prometheus"
+ },
+ "query": {
+ "query": "label_values(llm_requests_total, service)",
+ "refId": "service"
+ },
+ "includeAll": true,
+ "multi": true,
+ "hide": 0
+ },
+ {
+ "name": "model",
+ "type": "query",
+ "datasource": {
+ "type": "prometheus",
+ "uid": "prometheus"
+ },
+ "query": {
+ "query": "label_values(llm_requests_total, model)",
+ "refId": "model"
+ },
+ "includeAll": true,
+ "multi": true,
+ "hide": 0
+ },
+ {
+ "name": "provider",
+ "type": "query",
+ "datasource": {
+ "type": "prometheus",
+ "uid": "prometheus"
+ },
+ "query": {
+ "query": "label_values(llm_requests_total, provider)",
+ "refId": "provider"
+ },
+ "includeAll": true,
+ "multi": true,
+ "hide": 2
+ }
+ ]
+ },
+ "panels": [
+ {
+ "type": "stat",
+ "title": "LLM RPS",
+ "gridPos": {
+ "x": 0,
+ "y": 0,
+ "w": 6,
+ "h": 4
+ },
+ "datasource": {
+ "type": "prometheus",
+ "uid": "prometheus"
+ },
+ "targets": [
+ {
+ "refId": "A",
+ "expr": "sum(ai:llm:rps{service=~\"$service\", model=~\"$model\", provider=~\"$provider\"})"
+ }
+ ]
+ },
+ {
+ "type": "stat",
+ "title": "Error Rate (%)",
+ "gridPos": {
+ "x": 6,
+ "y": 0,
+ "w": 6,
+ "h": 4
+ },
+ "datasource": {
+ "type": "prometheus",
+ "uid": "prometheus"
+ },
+ "targets": [
+ {
+ "refId": "A",
+ "expr": "sum(ai:llm:error_rate{service=~\"$service\", model=~\"$model\", provider=~\"$provider\"}) * 100"
+ }
+ ]
+ },
+ {
+ "type": "stat",
+ "title": "p95 End-to-end Latency (ms)",
+ "gridPos": {
+ "x": 12,
+ "y": 0,
+ "w": 6,
+ "h": 4
+ },
+ "datasource": {
+ "type": "prometheus",
+ "uid": "prometheus"
+ },
+ "targets": [
+ {
+ "refId": "A",
+ "expr": "max(ai:llm:latency_p95_ms{stage=\"end_to_end\", service=~\"$service\", model=~\"$model\", provider=~\"$provider\"})"
+ }
+ ]
+ },
+ {
+ "type": "stat",
+ "title": "Tokens / sec",
+ "gridPos": {
+ "x": 18,
+ "y": 0,
+ "w": 6,
+ "h": 4
+ },
+ "datasource": {
+ "type": "prometheus",
+ "uid": "prometheus"
+ },
+ "targets": [
+ {
+ "refId": "A",
+ "expr": "sum(ai:llm:tokens_per_sec{type=~\"prompt|completion\", service=~\"$service\", model=~\"$model\", provider=~\"$provider\"})"
+ }
+ ]
+ },
+ {
+ "type": "timeseries",
+ "title": "Requests / sec by status",
+ "gridPos": {
+ "x": 0,
+ "y": 4,
+ "w": 12,
+ "h": 8
+ },
+ "datasource": {
+ "type": "prometheus",
+ "uid": "prometheus"
+ },
+ "targets": [
+ {
+ "refId": "A",
+ "expr": "sum by (status) (ai:llm:rps_by_status{service=~\"$service\", model=~\"$model\", provider=~\"$provider\"})",
+ "legendFormat": "{{status}}"
+ }
+ ]
+ },
+ {
+ "type": "timeseries",
+ "title": "Latency percentiles (end_to_end)",
+ "gridPos": {
+ "x": 12,
+ "y": 4,
+ "w": 12,
+ "h": 8
+ },
+ "datasource": {
+ "type": "prometheus",
+ "uid": "prometheus"
+ },
+ "targets": [
+ {
+ "refId": "A",
+ "expr": "max(ai:llm:latency_p50_ms{stage=\"end_to_end\", service=~\"$service\", model=~\"$model\", provider=~\"$provider\"})",
+ "legendFormat": "p50"
+ },
+ {
+ "refId": "B",
+ "expr": "max(ai:llm:latency_p95_ms{stage=\"end_to_end\", service=~\"$service\", model=~\"$model\", provider=~\"$provider\"})",
+ "legendFormat": "p95"
+ },
+ {
+ "refId": "C",
+ "expr": "max(ai:llm:latency_p99_ms{stage=\"end_to_end\", service=~\"$service\", model=~\"$model\", provider=~\"$provider\"})",
+ "legendFormat": "p99"
+ }
+ ]
+ },
+ {
+ "type": "timeseries",
+ "title": "Latency breakdown percentiles (model / retrieval / tool)",
+ "gridPos": {
+ "x": 0,
+ "y": 12,
+ "w": 24,
+ "h": 8
+ },
+ "datasource": {
+ "type": "prometheus",
+ "uid": "prometheus"
+ },
+ "targets": [
+ {
+ "refId": "A",
+ "expr": "max(ai:llm:latency_p95_ms{stage=\"model\", service=~\"$service\", model=~\"$model\", provider=~\"$provider\"})",
+ "legendFormat": "model p95"
+ },
+ {
+ "refId": "B",
+ "expr": "max(ai:llm:latency_p95_ms{stage=\"retrieval\", service=~\"$service\", model=~\"$model\", provider=~\"$provider\"})",
+ "legendFormat": "retrieval p95"
+ },
+ {
+ "refId": "C",
+ "expr": "max(ai:llm:latency_p95_ms{stage=\"tool\", service=~\"$service\", model=~\"$model\", provider=~\"$provider\"})",
+ "legendFormat": "tool p95"
+ }
+ ]
+ },
+ {
+ "type": "timeseries",
+ "title": "Tokens (prompt vs completion)",
+ "gridPos": {
+ "x": 0,
+ "y": 20,
+ "w": 12,
+ "h": 8
+ },
+ "datasource": {
+ "type": "prometheus",
+ "uid": "prometheus"
+ },
+ "targets": [
+ {
+ "refId": "A",
+ "expr": "sum by (type) (ai:llm:tokens_per_sec{service=~\"$service\", model=~\"$model\", provider=~\"$provider\"})",
+ "legendFormat": "{{type}}"
+ }
+ ]
+ },
+ {
+ "type": "timeseries",
+ "title": "Retries / cancellations",
+ "gridPos": {
+ "x": 12,
+ "y": 20,
+ "w": 12,
+ "h": 8
+ },
+ "datasource": {
+ "type": "prometheus",
+ "uid": "prometheus"
+ },
+ "targets": [
+ {
+ "refId": "A",
+ "expr": "sum(ai:llm:retries_per_sec{service=~\"$service\", model=~\"$model\", provider=~\"$provider\"})",
+ "legendFormat": "retries"
+ },
+ {
+ "refId": "B",
+ "expr": "sum(ai:llm:cancellations_per_sec{service=~\"$service\", model=~\"$model\", provider=~\"$provider\"})",
+ "legendFormat": "cancellations"
+ }
+ ]
+ },
+ {
+ "type": "timeseries",
+ "title": "Streaming: time to first token p95 (ms)",
+ "gridPos": {
+ "x": 0,
+ "y": 28,
+ "w": 12,
+ "h": 8
+ },
+ "datasource": {
+ "type": "prometheus",
+ "uid": "prometheus"
+ },
+ "targets": [
+ {
+ "refId": "A",
+ "expr": "max(ai:llm:ttft_p95_ms{service=~\"$service\", model=~\"$model\", provider=~\"$provider\"})",
+ "legendFormat": "p95"
+ }
+ ]
+ },
+ {
+ "type": "timeseries",
+ "title": "Queue wait p95 (ms)",
+ "gridPos": {
+ "x": 12,
+ "y": 28,
+ "w": 12,
+ "h": 8
+ },
+ "datasource": {
+ "type": "prometheus",
+ "uid": "prometheus"
+ },
+ "targets": [
+ {
+ "refId": "A",
+ "expr": "max(ai:llm:queue_wait_p95_ms{service=~\"$service\", model=~\"$model\", provider=~\"$provider\"})",
+ "legendFormat": "p95"
+ }
+ ]
+ },
+ {
+ "type": "timeseries",
+ "title": "RAG: retrieval latency p95 (ms)",
+ "gridPos": {
+ "x": 0,
+ "y": 36,
+ "w": 12,
+ "h": 8
+ },
+ "datasource": {
+ "type": "prometheus",
+ "uid": "prometheus"
+ },
+ "targets": [
+ {
+ "refId": "A",
+ "expr": "max(ai:rag:retrieval_latency_p95_ms{service=~\"$service\"})",
+ "legendFormat": "p95"
+ }
+ ]
+ },
+ {
+ "type": "timeseries",
+ "title": "RAG: empty retrieval rate",
+ "gridPos": {
+ "x": 12,
+ "y": 36,
+ "w": 12,
+ "h": 8
+ },
+ "datasource": {
+ "type": "prometheus",
+ "uid": "prometheus"
+ },
+ "targets": [
+ {
+ "refId": "A",
+ "expr": "sum(ai:rag:empty_retrieval_per_sec{service=~\"$service\"})",
+ "legendFormat": "empty_retrieval"
+ }
+ ]
+ },
+ {
+ "type": "timeseries",
+ "title": "Tools: calls and failures",
+ "gridPos": {
+ "x": 0,
+ "y": 44,
+ "w": 24,
+ "h": 8
+ },
+ "datasource": {
+ "type": "prometheus",
+ "uid": "prometheus"
+ },
+ "targets": [
+ {
+ "refId": "A",
+ "expr": "sum by (tool) (ai:tool:calls_per_sec{service=~\"$service\", status=\"success\"})",
+ "legendFormat": "{{tool}} success"
+ },
+ {
+ "refId": "B",
+ "expr": "sum by (tool) (ai:tool:calls_per_sec{service=~\"$service\", status=\"error\"})",
+ "legendFormat": "{{tool}} error"
+ }
+ ]
+ },
+ {
+ "type": "timeseries",
+ "title": "Safety: guardrail blocks / PII redactions",
+ "gridPos": {
+ "x": 0,
+ "y": 52,
+ "w": 24,
+ "h": 8
+ },
+ "datasource": {
+ "type": "prometheus",
+ "uid": "prometheus"
+ },
+ "targets": [
+ {
+ "refId": "A",
+ "expr": "sum by (policy) (ai:safety:guardrail_blocks_per_sec{service=~\"$service\"})",
+ "legendFormat": "blocked {{policy}}"
+ },
+ {
+ "refId": "B",
+ "expr": "sum by (type) (ai:safety:pii_redactions_per_sec{service=~\"$service\"})",
+ "legendFormat": "pii {{type}}"
+ }
+ ]
+ }
+ ]
+}
diff --git a/grafana/provisioning/dashboards/ai_ollama_gateway.json b/grafana/provisioning/dashboards/ai_ollama_gateway.json
new file mode 100644
index 00000000..e073dce6
--- /dev/null
+++ b/grafana/provisioning/dashboards/ai_ollama_gateway.json
@@ -0,0 +1,294 @@
+{
+ "uid": "ai-ollama-gateway",
+ "title": "AI - Ollama Gateway (Envoy)",
+ "tags": [
+ "ai",
+ "ollama",
+ "envoy",
+ "prometheus"
+ ],
+ "timezone": "browser",
+ "schemaVersion": 39,
+ "version": 1,
+ "refresh": "10s",
+ "time": {
+ "from": "now-15m",
+ "to": "now"
+ },
+ "templating": {
+ "list": [
+ {
+ "name": "job",
+ "type": "query",
+ "datasource": {
+ "type": "prometheus",
+ "uid": "prometheus"
+ },
+ "query": {
+ "query": "label_values(envoy_server_uptime, job)",
+ "refId": "job"
+ },
+ "current": {
+ "text": "ollama-gateway",
+ "value": "ollama-gateway"
+ },
+ "hide": 0
+ },
+ {
+ "name": "cluster",
+ "type": "query",
+ "datasource": {
+ "type": "prometheus",
+ "uid": "prometheus"
+ },
+ "query": {
+ "query": "label_values(envoy_cluster_upstream_rq_total{job=\"$job\"}, envoy_cluster_name)",
+ "refId": "cluster"
+ },
+ "current": {
+ "text": "ollama_upstream",
+ "value": "ollama_upstream"
+ },
+ "hide": 0
+ }
+ ]
+ },
+ "panels": [
+ {
+ "type": "stat",
+ "title": "Gateway Up",
+ "gridPos": {
+ "x": 0,
+ "y": 0,
+ "w": 4,
+ "h": 4
+ },
+ "datasource": {
+ "type": "prometheus",
+ "uid": "prometheus"
+ },
+ "targets": [
+ {
+ "refId": "A",
+ "expr": "up{job=\"$job\"}",
+ "instant": true
+ }
+ ],
+ "fieldConfig": {
+ "defaults": {
+ "mappings": [
+ {
+ "type": "value",
+ "options": {
+ "0": {
+ "text": "DOWN"
+ },
+ "1": {
+ "text": "UP"
+ }
+ }
+ }
+ ],
+ "thresholds": {
+ "mode": "absolute",
+ "steps": [
+ {
+ "color": "red",
+ "value": null
+ },
+ {
+ "color": "green",
+ "value": 1
+ }
+ ]
+ }
+ },
+ "overrides": []
+ }
+ },
+ {
+ "type": "stat",
+ "title": "RPS",
+ "gridPos": {
+ "x": 4,
+ "y": 0,
+ "w": 5,
+ "h": 4
+ },
+ "datasource": {
+ "type": "prometheus",
+ "uid": "prometheus"
+ },
+ "targets": [
+ {
+ "refId": "A",
+ "expr": "ai:envoy:downstream_rps{job=\"$job\"}"
+ }
+ ]
+ },
+ {
+ "type": "stat",
+ "title": "5xx Rate",
+ "gridPos": {
+ "x": 9,
+ "y": 0,
+ "w": 5,
+ "h": 4
+ },
+ "datasource": {
+ "type": "prometheus",
+ "uid": "prometheus"
+ },
+ "targets": [
+ {
+ "refId": "A",
+ "expr": "ai:envoy:downstream_5xx_rps{job=\"$job\"}"
+ }
+ ]
+ },
+ {
+ "type": "stat",
+ "title": "p95 Downstream Latency (ms)",
+ "gridPos": {
+ "x": 14,
+ "y": 0,
+ "w": 5,
+ "h": 4
+ },
+ "datasource": {
+ "type": "prometheus",
+ "uid": "prometheus"
+ },
+ "targets": [
+ {
+ "refId": "A",
+ "expr": "ai:envoy:downstream_latency_p95_ms{job=\"$job\"}"
+ }
+ ]
+ },
+ {
+ "type": "stat",
+ "title": "Active Requests",
+ "gridPos": {
+ "x": 19,
+ "y": 0,
+ "w": 5,
+ "h": 4
+ },
+ "datasource": {
+ "type": "prometheus",
+ "uid": "prometheus"
+ },
+ "targets": [
+ {
+ "refId": "A",
+ "expr": "ai:envoy:active_requests{job=\"$job\"}"
+ }
+ ]
+ },
+ {
+ "type": "timeseries",
+ "title": "RPS by response code class",
+ "gridPos": {
+ "x": 0,
+ "y": 4,
+ "w": 12,
+ "h": 8
+ },
+ "datasource": {
+ "type": "prometheus",
+ "uid": "prometheus"
+ },
+ "targets": [
+ {
+ "refId": "A",
+ "expr": "ai:envoy:downstream_rps_by_codeclass{job=\"$job\"}",
+ "legendFormat": "{{envoy_response_code_class}}xx"
+ }
+ ]
+ },
+ {
+ "type": "timeseries",
+ "title": "Downstream latency percentiles (ms)",
+ "gridPos": {
+ "x": 12,
+ "y": 4,
+ "w": 12,
+ "h": 8
+ },
+ "datasource": {
+ "type": "prometheus",
+ "uid": "prometheus"
+ },
+ "targets": [
+ {
+ "refId": "A",
+ "expr": "ai:envoy:downstream_latency_p50_ms{job=\"$job\"}",
+ "legendFormat": "p50"
+ },
+ {
+ "refId": "B",
+ "expr": "ai:envoy:downstream_latency_p95_ms{job=\"$job\"}",
+ "legendFormat": "p95"
+ },
+ {
+ "refId": "C",
+ "expr": "ai:envoy:downstream_latency_p99_ms{job=\"$job\"}",
+ "legendFormat": "p99"
+ }
+ ]
+ },
+ {
+ "type": "timeseries",
+ "title": "Upstream requests (to Ollama)",
+ "gridPos": {
+ "x": 0,
+ "y": 12,
+ "w": 12,
+ "h": 8
+ },
+ "datasource": {
+ "type": "prometheus",
+ "uid": "prometheus"
+ },
+ "targets": [
+ {
+ "refId": "A",
+ "expr": "ai:envoy:upstream_rps{job=\"$job\", envoy_cluster_name=\"$cluster\"}",
+ "legendFormat": "upstream_rq"
+ },
+ {
+ "refId": "B",
+ "expr": "ai:envoy:upstream_5xx_rps{job=\"$job\", envoy_cluster_name=\"$cluster\"}",
+ "legendFormat": "upstream_5xx"
+ }
+ ]
+ },
+ {
+ "type": "timeseries",
+ "title": "Upstream latency percentiles (ms)",
+ "gridPos": {
+ "x": 12,
+ "y": 12,
+ "w": 12,
+ "h": 8
+ },
+ "datasource": {
+ "type": "prometheus",
+ "uid": "prometheus"
+ },
+ "targets": [
+ {
+ "refId": "A",
+ "expr": "ai:envoy:upstream_latency_p95_ms{job=\"$job\", envoy_cluster_name=\"$cluster\"}",
+ "legendFormat": "p95"
+ },
+ {
+ "refId": "B",
+ "expr": "ai:envoy:upstream_latency_p99_ms{job=\"$job\", envoy_cluster_name=\"$cluster\"}",
+ "legendFormat": "p99"
+ }
+ ]
+ }
+ ]
+}
diff --git a/grafana/provisioning/datasources/datasource.yml b/grafana/provisioning/datasources/datasource.yml
index bb37f13d..d52acdd4 100644
--- a/grafana/provisioning/datasources/datasource.yml
+++ b/grafana/provisioning/datasources/datasource.yml
@@ -2,10 +2,43 @@ apiVersion: 1
datasources:
- name: Prometheus
+ uid: prometheus
type: prometheus
access: proxy
orgId: 1
url: http://prometheus:9090
basicAuth: false
isDefault: true
- editable: true
\ No newline at end of file
+ editable: true
+
+ - name: Loki
+ uid: loki
+ type: loki
+ access: proxy
+ orgId: 1
+ url: http://loki:3100
+ basicAuth: false
+ isDefault: false
+ editable: true
+
+ - name: Tempo
+ uid: tempo
+ type: tempo
+ access: proxy
+ orgId: 1
+ url: http://tempo:3200
+ basicAuth: false
+ isDefault: false
+ editable: true
+ jsonData:
+ tracesToLogsV2:
+ datasourceUid: loki
+ spanStartTimeShift: "-1m"
+ spanEndTimeShift: "1m"
+ tags:
+ - key: "service.name"
+ value: "service"
+ - key: "service.instance.id"
+ value: "instance"
+ lokiSearch:
+ datasourceUid: loki
\ No newline at end of file
diff --git a/loki/loki.yml b/loki/loki.yml
new file mode 100644
index 00000000..135b965f
--- /dev/null
+++ b/loki/loki.yml
@@ -0,0 +1,32 @@
+auth_enabled: false
+
+server:
+ http_listen_port: 3100
+
+common:
+ path_prefix: /loki
+ storage:
+ filesystem:
+ chunks_directory: /loki/chunks
+ rules_directory: /loki/rules
+ replication_factor: 1
+ ring:
+ kvstore:
+ store: inmemory
+
+schema_config:
+ configs:
+ - from: 2023-01-01
+ store: boltdb-shipper
+ object_store: filesystem
+ schema: v13
+ index:
+ prefix: index_
+ period: 24h
+
+limits_config:
+ retention_period: 168h
+ allow_structured_metadata: true
+
+ruler:
+ alertmanager_url: http://alertmanager:9093
diff --git a/otel-collector/config.yml b/otel-collector/config.yml
new file mode 100644
index 00000000..b4fbfe2b
--- /dev/null
+++ b/otel-collector/config.yml
@@ -0,0 +1,40 @@
+receivers:
+ otlp:
+ protocols:
+ grpc:
+ http:
+
+processors:
+ memory_limiter:
+ check_interval: 1s
+ limit_mib: 512
+ spike_limit_mib: 128
+ batch: {}
+
+exporters:
+ otlp:
+ endpoint: tempo:4317
+ tls:
+ insecure: true
+ loki:
+ endpoint: http://loki:3100/loki/api/v1/push
+ prometheus:
+ endpoint: 0.0.0.0:8889
+
+service:
+ telemetry:
+ logs:
+ level: info
+ pipelines:
+ traces:
+ receivers: [otlp]
+ processors: [memory_limiter, batch]
+ exporters: [otlp]
+ logs:
+ receivers: [otlp]
+ processors: [memory_limiter, batch]
+ exporters: [loki]
+ metrics:
+ receivers: [otlp]
+ processors: [memory_limiter, batch]
+ exporters: [prometheus]
diff --git a/prometheus/prometheus.yml b/prometheus/prometheus.yml
index 79069633..783ae15c 100644
--- a/prometheus/prometheus.yml
+++ b/prometheus/prometheus.yml
@@ -10,6 +10,7 @@ global:
# Load and evaluate rules in this file every 'evaluation_interval' seconds.
rule_files:
- "alert.rules"
+ - "recording.rules"
# A scrape configuration containing exactly one endpoint to scrape.
scrape_configs:
@@ -34,6 +35,17 @@ scrape_configs:
static_configs:
- targets: ['pushgateway:9091']
+ - job_name: 'otel-collector'
+ scrape_interval: 10s
+ static_configs:
+ - targets: ['otel-collector:8889']
+
+ - job_name: 'ollama-gateway'
+ scrape_interval: 10s
+ metrics_path: /stats/prometheus
+ static_configs:
+ - targets: ['ollama-gateway:9901']
+
alerting:
alertmanagers:
diff --git a/prometheus/recording.rules b/prometheus/recording.rules
new file mode 100644
index 00000000..322fdeb7
--- /dev/null
+++ b/prometheus/recording.rules
@@ -0,0 +1,96 @@
+groups:
+ - name: ai_observability_envoy_gateway
+ interval: 30s
+ rules:
+ - record: ai:envoy:downstream_rps
+ expr: sum by (job) (rate(envoy_http_downstream_rq_total[1m]))
+
+ - record: ai:envoy:downstream_rps_by_codeclass
+ expr: sum by (job, envoy_response_code_class) (rate(envoy_http_downstream_rq_xx[1m]))
+
+ - record: ai:envoy:downstream_5xx_rps
+ expr: sum by (job) (rate(envoy_http_downstream_rq_xx{envoy_response_code_class="5"}[5m]))
+
+ - record: ai:envoy:downstream_latency_p50_ms
+ expr: histogram_quantile(0.50, sum by (job, le) (rate(envoy_http_downstream_rq_time_bucket[5m]))) * 1000
+
+ - record: ai:envoy:downstream_latency_p95_ms
+ expr: histogram_quantile(0.95, sum by (job, le) (rate(envoy_http_downstream_rq_time_bucket[5m]))) * 1000
+
+ - record: ai:envoy:downstream_latency_p99_ms
+ expr: histogram_quantile(0.99, sum by (job, le) (rate(envoy_http_downstream_rq_time_bucket[5m]))) * 1000
+
+ - record: ai:envoy:active_requests
+ expr: sum by (job) (envoy_http_downstream_rq_active)
+
+ - record: ai:envoy:upstream_rps
+ expr: sum by (job, envoy_cluster_name) (rate(envoy_cluster_upstream_rq_total[1m]))
+
+ - record: ai:envoy:upstream_5xx_rps
+ expr: sum by (job, envoy_cluster_name) (rate(envoy_cluster_upstream_rq_xx{envoy_response_code_class="5"}[5m]))
+
+ - record: ai:envoy:upstream_latency_p95_ms
+ expr: histogram_quantile(0.95, sum by (job, envoy_cluster_name, le) (rate(envoy_cluster_upstream_rq_time_bucket[5m]))) * 1000
+
+ - record: ai:envoy:upstream_latency_p99_ms
+ expr: histogram_quantile(0.99, sum by (job, envoy_cluster_name, le) (rate(envoy_cluster_upstream_rq_time_bucket[5m]))) * 1000
+
+ - name: ai_observability_llm_model_agnostic
+ interval: 30s
+ rules:
+ - record: ai:llm:rps
+ expr: sum by (service, model, provider) (rate(llm_requests_total[1m]))
+
+ - record: ai:llm:rps_by_status
+ expr: sum by (service, model, provider, status) (rate(llm_requests_total[1m]))
+
+ - record: ai:llm:error_rate
+ expr: |
+ (sum by (service, model, provider) (rate(llm_errors_total[5m])))
+ /
+ clamp_min(sum by (service, model, provider) (rate(llm_requests_total[5m])), 1)
+
+ - record: ai:llm:latency_p50_ms
+ expr: histogram_quantile(0.50, sum by (le, service, model, provider, stage) (rate(llm_latency_seconds_bucket[5m]))) * 1000
+
+ - record: ai:llm:latency_p95_ms
+ expr: histogram_quantile(0.95, sum by (le, service, model, provider, stage) (rate(llm_latency_seconds_bucket[5m]))) * 1000
+
+ - record: ai:llm:latency_p99_ms
+ expr: histogram_quantile(0.99, sum by (le, service, model, provider, stage) (rate(llm_latency_seconds_bucket[5m]))) * 1000
+
+ - record: ai:llm:ttft_p95_ms
+ expr: histogram_quantile(0.95, sum by (le, service, model, provider) (rate(llm_time_to_first_token_seconds_bucket[5m]))) * 1000
+
+ - record: ai:llm:queue_wait_p95_ms
+ expr: histogram_quantile(0.95, sum by (le, service, model, provider) (rate(llm_queue_wait_seconds_bucket[5m]))) * 1000
+
+ - record: ai:llm:tokens_per_sec
+ expr: sum by (service, model, provider, type) (rate(llm_tokens_total[1m]))
+
+ - record: ai:llm:tokens_per_request
+ expr: |
+ (sum by (service, model, provider) (rate(llm_tokens_total[5m])))
+ /
+ clamp_min(sum by (service, model, provider) (rate(llm_requests_total[5m])), 1)
+
+ - record: ai:llm:retries_per_sec
+ expr: sum by (service, model, provider) (rate(llm_retries_total[5m]))
+
+ - record: ai:llm:cancellations_per_sec
+ expr: sum by (service, model, provider) (rate(llm_cancellations_total[5m]))
+
+ - record: ai:rag:retrieval_latency_p95_ms
+ expr: histogram_quantile(0.95, sum by (le, service) (rate(rag_retrieval_latency_seconds_bucket[5m]))) * 1000
+
+ - record: ai:rag:empty_retrieval_per_sec
+ expr: sum by (service) (rate(rag_empty_retrieval_total[5m]))
+
+ - record: ai:tool:calls_per_sec
+ expr: sum by (service, tool, status) (rate(llm_tool_calls_total[5m]))
+
+ - record: ai:safety:guardrail_blocks_per_sec
+ expr: sum by (service, policy) (rate(llm_guardrail_blocks_total[5m]))
+
+ - record: ai:safety:pii_redactions_per_sec
+ expr: sum by (service, type) (rate(llm_pii_redactions_total[5m]))
diff --git a/tempo/tempo.yml b/tempo/tempo.yml
new file mode 100644
index 00000000..1cf54eff
--- /dev/null
+++ b/tempo/tempo.yml
@@ -0,0 +1,25 @@
+server:
+ http_listen_port: 3200
+
+distributor:
+ receivers:
+ otlp:
+ protocols:
+ grpc:
+ http:
+
+ingester:
+ max_block_duration: 5m
+ trace_idle_period: 10s
+
+compactor:
+ compaction:
+ block_retention: 24h
+
+storage:
+ trace:
+ backend: local
+ local:
+ path: /var/tempo/traces
+ wal:
+ path: /var/tempo/wal