 | A solution of Text Detection/Recognition + SAM that segments every text character, with striking text removal and text inpainting demos driven by diffusion models and Gradio! |
| [MMEditing-SAM](#-mmediting-sam) |
| A solution of Text Detection/Recognition + SAM that segments every text character, with striking text removal and text inpainting demos driven by diffusion models and Gradio! |
| [MMEditing-SAM](#-mmediting-sam) |  | Join SAM and image generation to create awesome images and edit any part of them. |
| [Label-Studio-SAM](#-label-studio-sam) |
| Join SAM and image generation to create awesome images and edit any part of them. |
| [Label-Studio-SAM](#-label-studio-sam) | 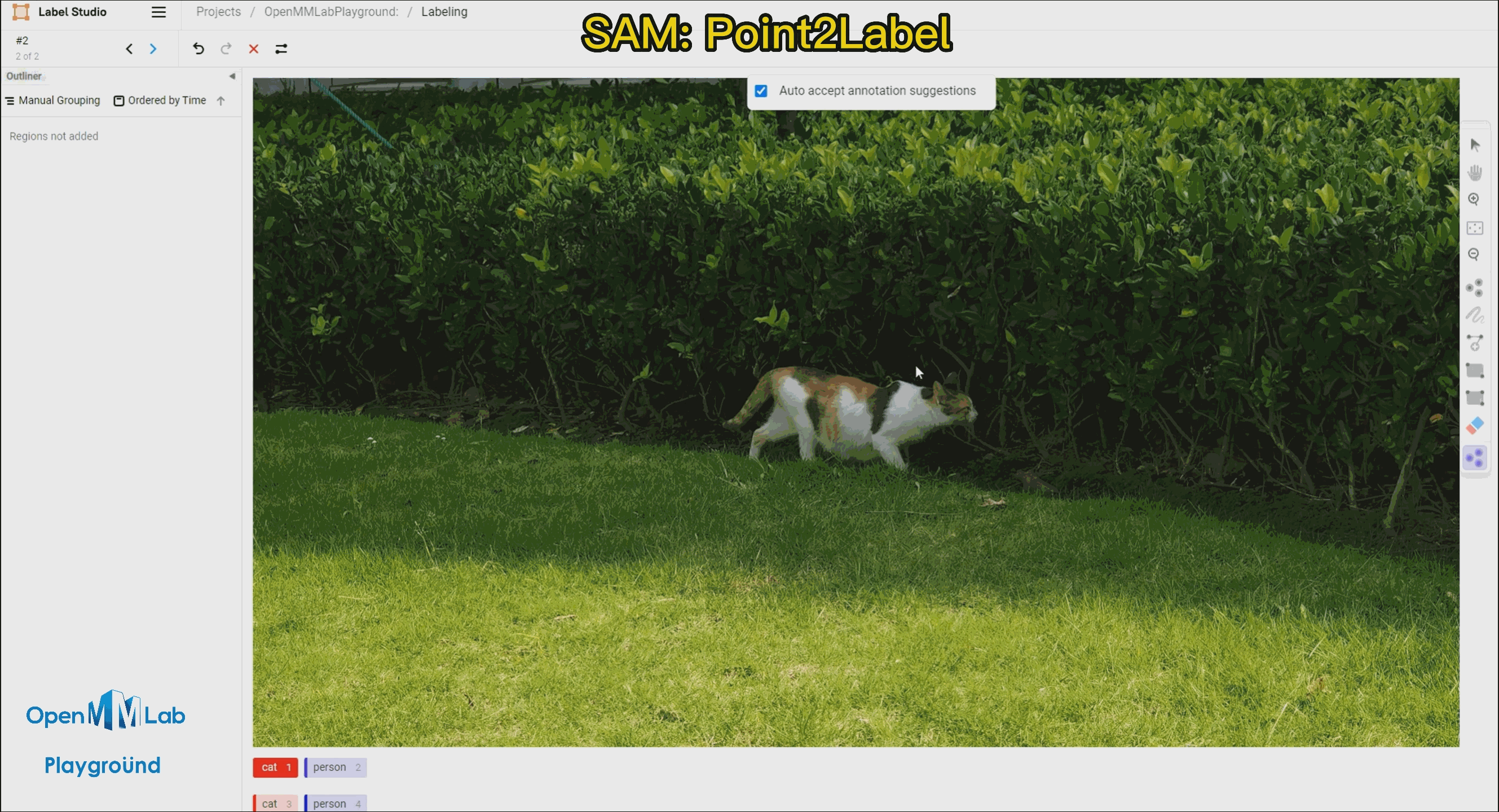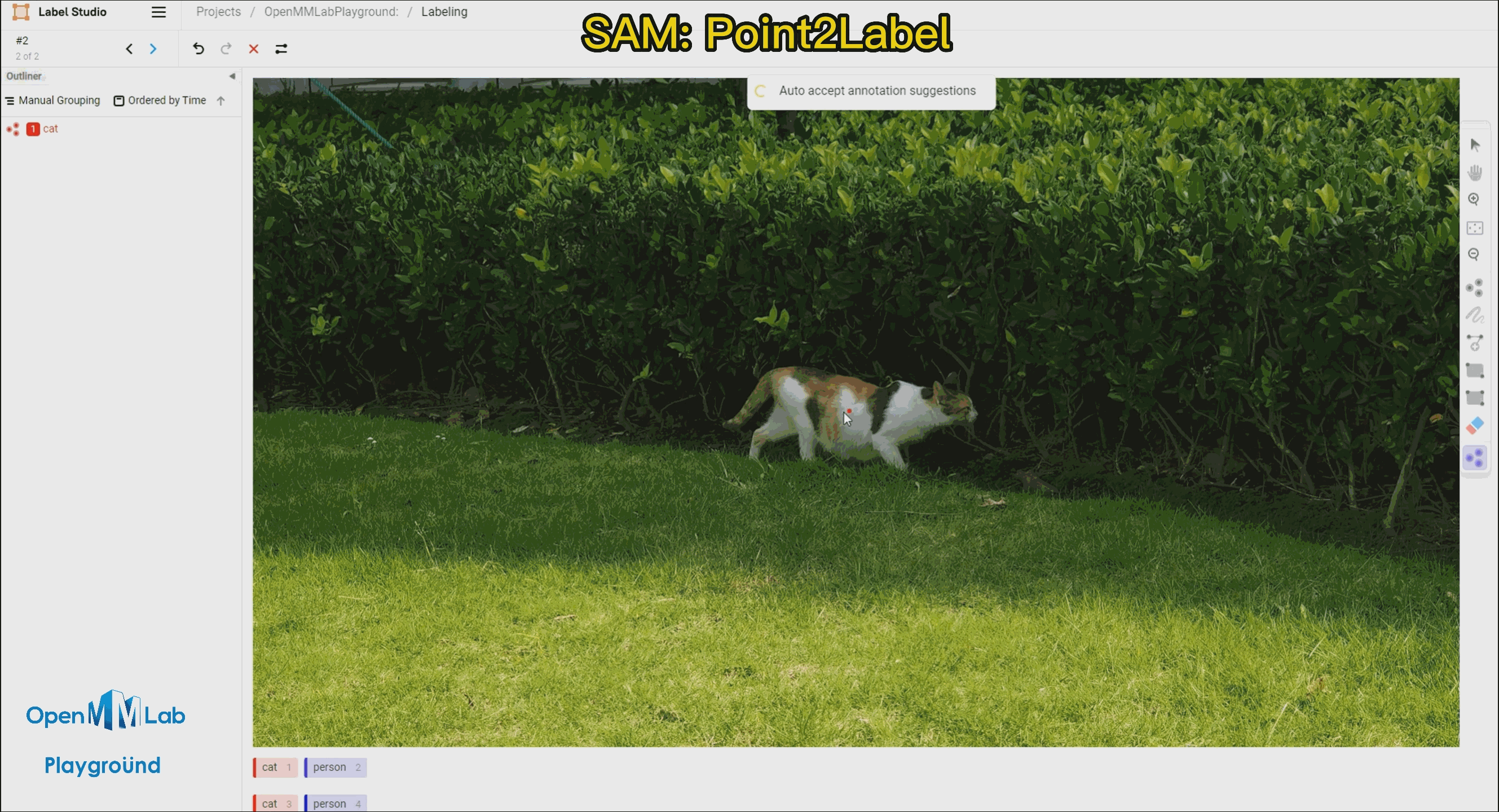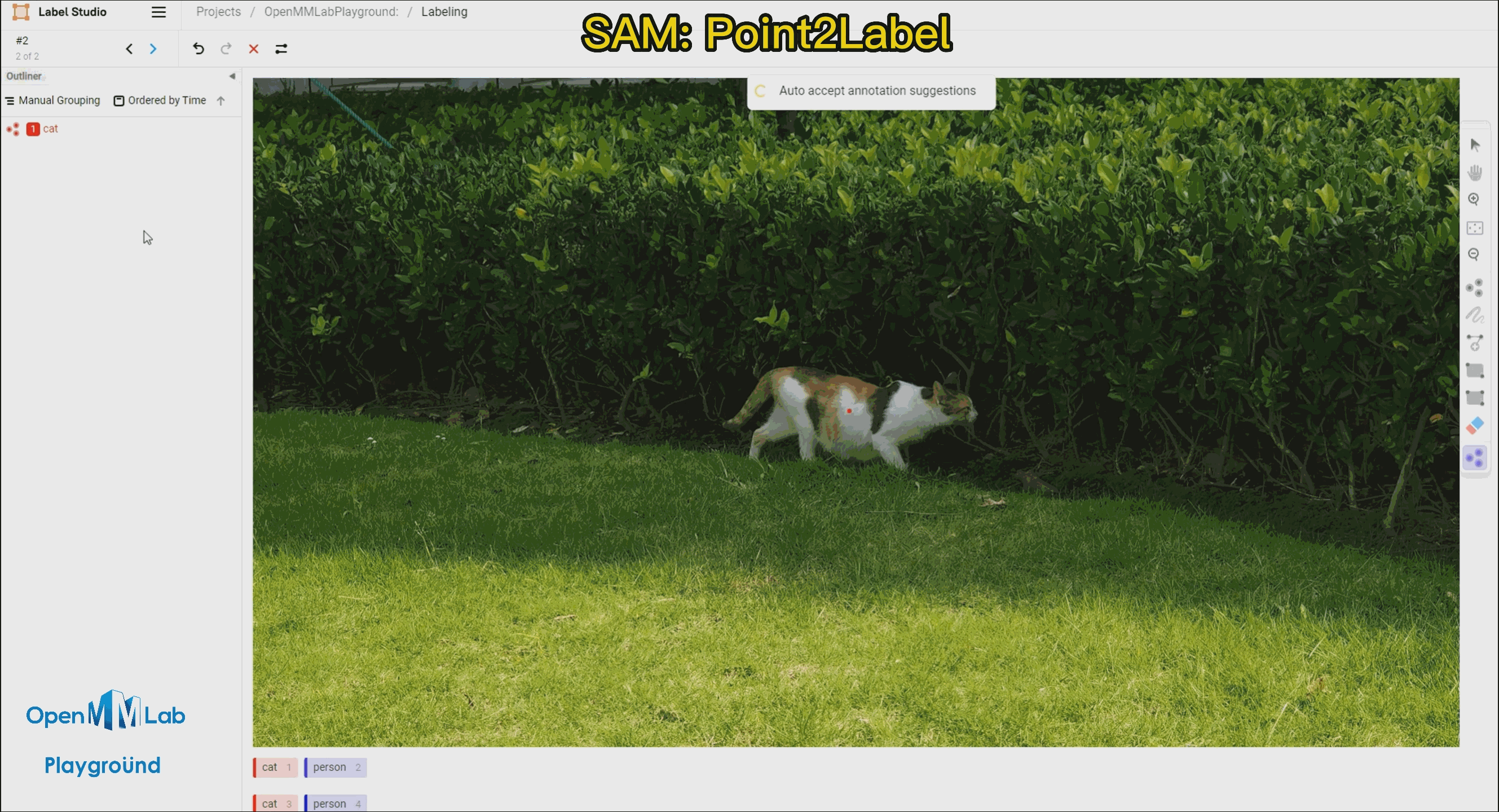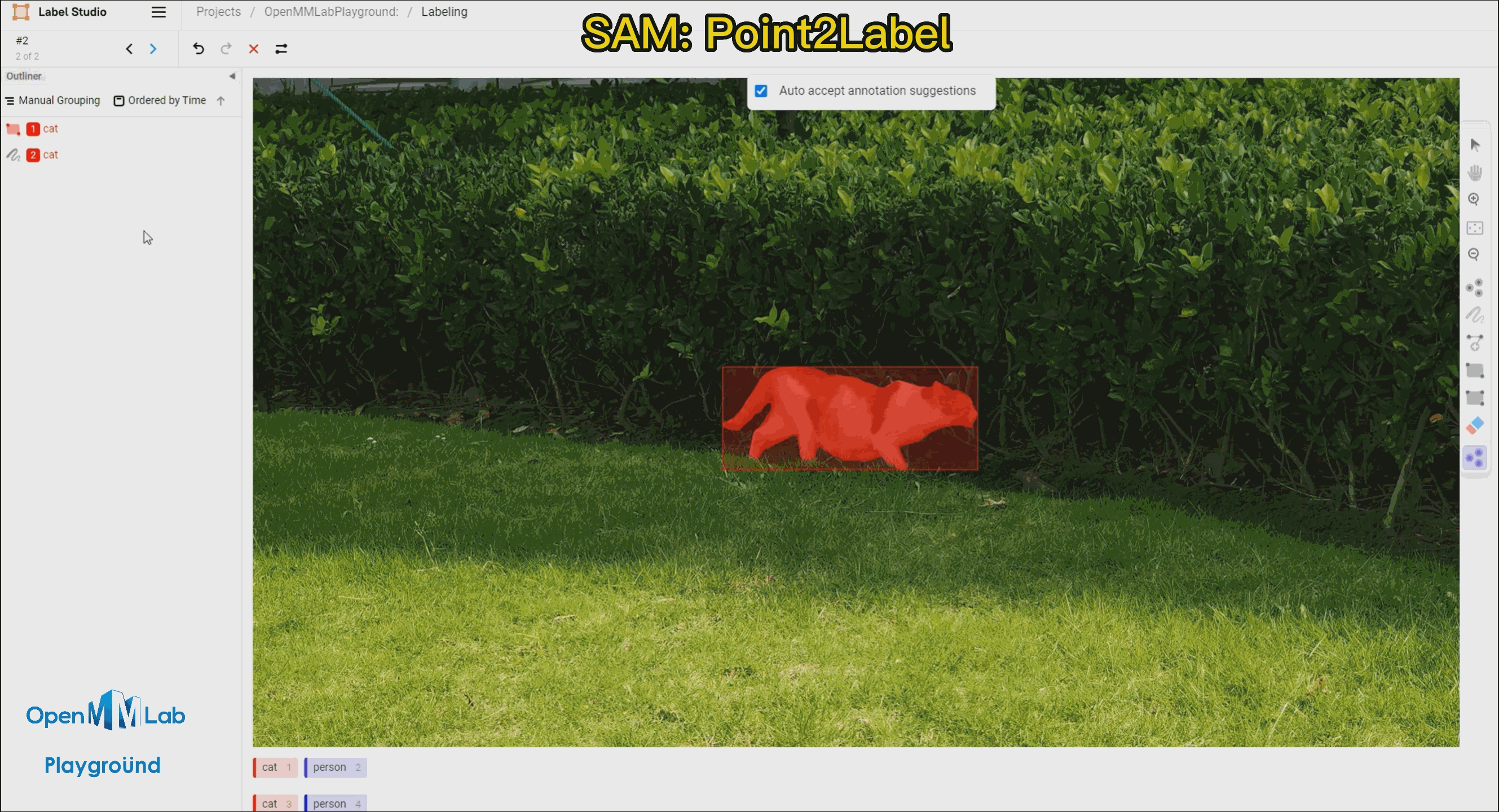 | Combining Label-Studio and SAM to achieve semi-automated annotation. |
+| [InternLM-Langchain](#-internlm-langchain) |
| Combining Label-Studio and SAM to achieve semi-automated annotation. |
+| [InternLM-Langchain](#-internlm-langchain) |  | OpenMMLab Knowledge Base QA based on [internlm/internlm-chat-7b-v1_1](https://huggingface.co/internlm/internlm-chat-7b-v1_1). |
@@ -145,5 +146,12 @@ The solution provides an integration of SAM with Label Studio. The specific feat
2. Bbox2Label: Supports triggering SAM in Label-Studio to generate object masks and axis-aligned bounding box annotations by annotating the object's bounding box.
3. Refine: Supports refining the annotations generated by SAM within Label-Studio.
-Ķ»”µāģĶ¦ü [README](./label_anything/readme.md)ŃĆé
+Please see [README](./label_anything/readme.md) for more information.
+## Ō£© InternLM-Langchain
+
+
+
+ Use [LangChain-Chatchat](https://github.com/chatchat-space/Langchain-Chatchat) to build an OpenMMLab projects knowledge-based question-answering system based on the LLM internlm/[internlm/internlm-chat-7b-v1_1](https://huggingface.co/internlm/internlm-chat-7b-v1_1). It includes multiple projects under OpenMMLab.
+
+Please see [README](./internlm_langchain/README.md) for more information.
diff --git a/README_zh-CN.md b/README_zh-CN.md
index 7b76949a..42467a91 100644
--- a/README_zh-CN.md
+++ b/README_zh-CN.md
@@ -52,7 +52,7 @@
| [MMOCR-SAM](#-mmocr-sam) |
| OpenMMLab Knowledge Base QA based on [internlm/internlm-chat-7b-v1_1](https://huggingface.co/internlm/internlm-chat-7b-v1_1). |
@@ -145,5 +146,12 @@ The solution provides an integration of SAM with Label Studio. The specific feat
2. Bbox2Label: Supports triggering SAM in Label-Studio to generate object masks and axis-aligned bounding box annotations by annotating the object's bounding box.
3. Refine: Supports refining the annotations generated by SAM within Label-Studio.
-Ķ»”µāģĶ¦ü [README](./label_anything/readme.md)ŃĆé
+Please see [README](./label_anything/readme.md) for more information.
+## Ō£© InternLM-Langchain
+
+
+
+ Use [LangChain-Chatchat](https://github.com/chatchat-space/Langchain-Chatchat) to build an OpenMMLab projects knowledge-based question-answering system based on the LLM internlm/[internlm/internlm-chat-7b-v1_1](https://huggingface.co/internlm/internlm-chat-7b-v1_1). It includes multiple projects under OpenMMLab.
+
+Please see [README](./internlm_langchain/README.md) for more information.
diff --git a/README_zh-CN.md b/README_zh-CN.md
index 7b76949a..42467a91 100644
--- a/README_zh-CN.md
+++ b/README_zh-CN.md
@@ -52,7 +52,7 @@
| [MMOCR-SAM](#-mmocr-sam) |  +
+¤Äē langchain-ChatGLM ķĪ╣ńø«ÕŠ«õ┐Īõ║żµĄüńŠż’╝īÕ”éµ×£õĮĀõ╣¤Õ»╣µ£¼ķĪ╣ńø«µä¤Õģ┤ĶČŻ’╝īµ¼óĶ┐ÄÕŖĀÕģźńŠżĶüŖÕÅéõĖÄĶ«©Ķ«║õ║żµĄüŃĆé
diff --git a/internlm_langchain/README.md b/internlm_langchain/README.md
new file mode 100644
index 00000000..cea8b71d
--- /dev/null
+++ b/internlm_langchain/README.md
@@ -0,0 +1,161 @@
+## õ╗ŗń╗Ź
+
+õĮ┐ńö© [LangChain-Chatchat](https://github.com/chatchat-space/Langchain-Chatchat) µÉŁÕ╗║Õ¤║õ║Ä LLM [internlm/internlm-chat-7b-v1_1](https://huggingface.co/internlm/internlm-chat-7b-v1_1) ńÜä OpenMMLab ń¤źĶ»åÕ║ōķŚ«ńŁöŃĆé
+
+ 
+
+## µ©ĪÕ×ŗµö»µīü
+
+µ£¼ķĪ╣ńø«õĖŁķ╗śĶ«żõĮ┐ńö©ńÜä LLM µ©ĪÕ×ŗõĖ║ [internlm/internlm-chat-7b-v1_1](https://huggingface.co/internlm/internlm-chat-7b-v1_1)’╝īķ╗śĶ«żõĮ┐ńö©ńÜä Embedding µ©ĪÕ×ŗõĖ║ [moka-ai/m3e-base](https://huggingface.co/moka-ai/m3e-base) ŃĆé
+
+Ķ«ŠńĮ«µ¢ćõ╗Č `configs/model_configs.py` õĖŁńÜä `llm_model_dict` õĖ║ `internlm-chat-7b`ŃĆé
+
+## Õ╝ĆÕÅæķā©ńĮ▓
+
+### ĶĮ»õ╗Čķ£Ćµ▒é
+
+µ£¼ķĪ╣ńø«ÕĘ▓Õ£© Python 3.8’╝īCUDA 11.7 Ubuntu ńÄ»ÕóāõĖŗÕ«īµłÉµĄŗĶ»ĢŃĆé
+
+### 1. Õ╝ĆÕÅæńÄ»ÕóāÕćåÕżć
+
+ÕÅéĶ¦ü [Õ╝ĆÕÅæńÄ»ÕóāÕćåÕżć](docs/INSTALL.md)ŃĆé
+
+### 2. õĖŗĶĮĮµ©ĪÕ×ŗĶć│µ£¼Õ£░
+
+õĖŗĶĮĮ LLM µ©ĪÕ×ŗ [internlm/internlm-chat-7b-v1_1](https://huggingface.co/internlm/internlm-chat-7b-v1_1) õĖÄ Embedding µ©ĪÕ×ŗ [moka-ai/m3e-base](https://huggingface.co/moka-ai/m3e-base) õĖ║õŠŗ’╝Ü
+
+õĖŗĶĮĮµ©ĪÕ×ŗķ£ĆĶ”üÕģł[Õ«ēĶŻģGit LFS](https://docs.github.com/zh/repositories/working-with-files/managing-large-files/installing-git-large-file-storage)’╝īńäČÕÉÄĶ┐ÉĶĪī
+
+```Shell
+$ git clone https://huggingface.co/internlm/internlm-chat-7b-v1_1
+
+$ git clone https://huggingface.co/moka-ai/m3e-base
+```
+
+### 3. Ķ«ŠńĮ«ķģŹńĮ«ķĪ╣
+
+Õ£©Õ╝ĆÕ¦ŗµē¦ĶĪī Web UI µł¢ÕæĮõ╗żĶĪīõ║żõ║ÆÕēŹ’╝īĶ»ĘÕģłµŻĆµ¤ź `configs/model_config.py` ÕÆī `configs/server_config.py` õĖŁńÜäÕÉäķĪ╣µ©ĪÕ×ŗÕÅéµĢ░Ķ«ŠĶ«Īµś»ÕÉ”ń¼”ÕÉłķ£Ćµ▒é’╝Ü
+
+- Ķ»ĘńĪ«Ķ«żÕĘ▓õĖŗĶĮĮĶć│µ£¼Õ£░ńÜä LLM µ©ĪÕ×ŗµ£¼Õ£░ÕŁśÕé©ĶĘ»ÕŠäÕåÖÕ£© `llm_model_dict` Õ»╣Õ║öµ©ĪÕ×ŗńÜä `local_model_path` Õ▒׵ƦõĖŁ’╝īÕ”é:
+
+```python
+llm_model_dict={
+ "internlm-chat-7b": {
+ "local_model_path": "/root/huggingface/internlm-chat-7b-v1_1",
+ "api_base_url": "http://localhost:8888/v1", # "name"õ┐«µö╣õĖ║ FastChat µ£ŹÕŖĪõĖŁńÜä"api_base_url"
+ "api_key": "EMPTY"
+ },
+ }
+```
+
+- Ķ»ĘńĪ«Ķ«żÕĘ▓õĖŗĶĮĮĶć│µ£¼Õ£░ńÜä Embedding µ©ĪÕ×ŗµ£¼Õ£░ÕŁśÕé©ĶĘ»ÕŠäÕåÖÕ£© `embedding_model_dict` Õ»╣Õ║öµ©ĪÕ×ŗõĮŹńĮ«’╝īÕ”é’╝Ü
+
+```python
+embedding_model_dict = {
+ "m3e-base": "/root/huggingface/m3e-base",
+ }
+```
+
+### 5. ÕÉ»ÕŖ© API µ£ŹÕŖĪµł¢ Web UI
+
+#### 5.1 ÕÉ»ÕŖ© LLM µ£ŹÕŖĪ
+
+Õ”éķ£ĆõĮ┐ńö©Õ╝Ƶ║ɵ©ĪÕ×ŗĶ┐øĶĪīµ£¼Õ£░ķā©ńĮ▓’╝īķ£Ćķ”¢ÕģłÕÉ»ÕŖ© LLM µ£ŹÕŖĪ
+
+Õ£©ķĪ╣ńø«µĀ╣ńø«ÕĮĢõĖŗ’╝īµē¦ĶĪī [server/llm_api.py](server/llm_api.py) Ķäܵ£¼ÕÉ»ÕŖ© **LLM µ©ĪÕ×ŗ**µ£ŹÕŖĪ’╝Ü
+
+```shell
+$ python server/llm_api.py
+```
+
+ķĪ╣ńø«µö»µīüÕżÜÕŹĪÕŖĀĶĮĮ’╝īķ£ĆÕ£© llm_api.py õĖŁõ┐«µö╣ create_model_worker_app ÕćĮµĢ░õĖŁ’╝īõ┐«µö╣Õ”éõĖŗõĖēõĖ¬ÕÅéµĢ░:
+
+```python
+gpus=None,
+num_gpus=1,
+max_gpu_memory="20GiB"
+```
+
+ÕģČõĖŁ’╝ī`gpus` µÄ¦ÕłČõĮ┐ńö©ńÜ䵜ŠÕŹĪńÜäID’╝īÕ”éµ×£ "0,1";
+
+`num_gpus` µÄ¦ÕłČõĮ┐ńö©ńÜäÕŹĪµĢ░;
+
+`max_gpu_memory` µÄ¦ÕłČµ»ÅõĖ¬ÕŹĪõĮ┐ńö©ńÜ䵜ŠÕŁśÕ«╣ķćÅŃĆé
+
+#### 5.2 ÕÉ»ÕŖ© API µ£ŹÕŖĪ
+
+µ£¼Õ£░ķā©ńĮ▓µāģÕåĄõĖŗ’╝īµīēńģ¦ [5.1 ĶŖé](README.md#5.1-ÕÉ»ÕŖ©-LLM-µ£ŹÕŖĪ)**ÕÉ»ÕŖ© LLM µ£ŹÕŖĪÕÉÄ**’╝īÕåŹµē¦ĶĪī [server/api.py](server/api.py) Ķäܵ£¼ÕÉ»ÕŖ© **API** µ£ŹÕŖĪ’╝ø
+
+Õ£©ń║┐Ķ░āńö©APIµ£ŹÕŖĪńÜäµāģÕåĄõĖŗ’╝īńø┤µÄźµē¦µē¦ĶĪī [server/api.py](server/api.py) Ķäܵ£¼ÕÉ»ÕŖ© **API** µ£ŹÕŖĪ’╝ø
+
+Ķ░āńö©ÕæĮõ╗żńż║õŠŗ’╝Ü
+
+```shell
+$ python server/api.py
+```
+
+ÕÉ»ÕŖ© API µ£ŹÕŖĪÕÉÄ’╝īÕÅ»Ķ«┐ķŚ« `localhost:7861` µł¢ `{API µēĆÕ£©µ£ŹÕŖĪÕÖ© IP}:7861` FastAPI Ķć¬ÕŖ©ńö¤µłÉńÜä docs Ķ┐øĶĪīµÄźÕÅŻµ¤źń£ŗõĖĵĄŗĶ»ĢŃĆé
+
+
+
+#### 5.3 ÕÉ»ÕŖ© Web UI µ£ŹÕŖĪ
+
+µīēńģ¦ [5.2 ĶŖé](README.md#5.2-ÕÉ»ÕŖ©-API-µ£ŹÕŖĪ)**ÕÉ»ÕŖ© API µ£ŹÕŖĪÕÉÄ**’╝īµē¦ĶĪī [webui.py](webui.py) ÕÉ»ÕŖ© **Web UI** µ£ŹÕŖĪ’╝łķ╗śĶ«żõĮ┐ńö©ń½»ÕÅŻ `8501`’╝ē
+
+```shell
+$ streamlit run webui.py
+```
+
+õĮ┐ńö© Langchain-Chatchat õĖ╗ķóśĶē▓ÕÉ»ÕŖ© **Web UI** µ£ŹÕŖĪ’╝łķ╗śĶ«żõĮ┐ńö©ń½»ÕÅŻ `8501`’╝ē
+
+```shell
+$ streamlit run webui.py --theme.base "light" --theme.primaryColor "#165dff" --theme.secondaryBackgroundColor "#f5f5f5" --theme.textColor "#000000"
+```
+
+µł¢õĮ┐ńö©õ╗źõĖŗÕæĮõ╗żµīćÕ«ÜÕÉ»ÕŖ© **Web UI** µ£ŹÕŖĪÕ╣ȵīćÕ«Üń½»ÕÅŻÕÅĘ
+
+```shell
+$ streamlit run webui.py --server.port 666
+```
+
+- Web UI Õ»╣Ķ»ØńĢīķØó’╝Ü
+
+ 
+
+---
+
+### 6. õĖĆķö«ÕÉ»ÕŖ©
+
+µø┤µ¢░õĖĆķö«ÕÉ»ÕŖ©Ķäܵ£¼ startup.py,õĖĆķö«ÕÉ»ÕŖ©µēƵ£ē Fastchat µ£ŹÕŖĪŃĆüAPI µ£ŹÕŖĪŃĆüWebUI µ£ŹÕŖĪ’╝īńż║õŠŗõ╗ŻńĀü’╝Ü
+
+```shell
+$ python startup.py -a
+```
+
+Õ╣ČÕÅ»õĮ┐ńö© `Ctrl + C` ńø┤µÄźÕģ│ķŚŁµēƵ£ēĶ┐ÉĶĪīµ£ŹÕŖĪŃĆéÕ”éµ×£õĖƵ¼Īń╗ōµØ¤õĖŹõ║å’╝īÕÅ»õ╗źÕżÜµīēÕćĀµ¼ĪŃĆé
+
+ÕÅ»ķĆēÕÅéµĢ░Õīģµŗ¼ `-a (µł¢--all-webui)`, `--all-api`, `--llm-api`, `-c (µł¢--controller)`, `--openai-api`,
+`-m (µł¢--model-worker)`, `--api`, `--webui`’╝īÕģČõĖŁ’╝Ü
+
+- `--all-webui` õĖ║õĖĆķö«ÕÉ»ÕŖ© WebUI µēƵ£ēõŠØĶĄ¢µ£ŹÕŖĪ’╝ø
+- `--all-api` õĖ║õĖĆķö«ÕÉ»ÕŖ© API µēƵ£ēõŠØĶĄ¢µ£ŹÕŖĪ’╝ø
+- `--llm-api` õĖ║õĖĆķö«ÕÉ»ÕŖ© Fastchat µēƵ£ēõŠØĶĄ¢ńÜä LLM µ£ŹÕŖĪ’╝ø
+- `--openai-api` õĖ║õ╗ģÕÉ»ÕŖ© FastChat ńÜä controller ÕÆī openai-api-server µ£ŹÕŖĪ’╝ø
+- ÕģČõ╗¢õĖ║ÕŹĢńŗ¼µ£ŹÕŖĪÕÉ»ÕŖ©ķĆēķĪ╣ŃĆé
+
+Ķŗźµā│µīćÕ«ÜķØ×ķ╗śĶ«żµ©ĪÕ×ŗ’╝īķ£ĆĶ”üńö© `--model-name` ķĆēķĪ╣’╝īńż║õŠŗ’╝Ü
+
+```shell
+$ python startup.py --all-webui --model-name Qwen-7B-Chat
+```
+
+µø┤ÕżÜõ┐Īµü»ÕÅ»ķĆÜĶ┐ć `python startup.py -h`µ¤źń£ŗŃĆé
+
+**µ│©µäÅ’╝Ü**
+
+**1. startup Ķäܵ£¼ńö©ÕżÜĶ┐øń©ŗµ¢╣Õ╝ÅÕÉ»ÕŖ©ÕÉ䵩ĪÕØŚńÜäµ£ŹÕŖĪ’╝īÕÅ»ĶāĮõ╝ÜÕ»╝Ķć┤µēōÕŹ░ķĪ║Õ║ÅķŚ«ķóś’╝īĶ»ĘńŁēÕŠģÕģ©ķā©µ£ŹÕŖĪÕÅæĶĄĘÕÉÄÕåŹĶ░āńö©’╝īÕ╣ȵĀ╣µŹ«ķ╗śĶ«żµł¢µīćÕ«Üń½»ÕÅŻĶ░āńö©µ£ŹÕŖĪ’╝łķ╗śĶ«ż LLM API µ£ŹÕŖĪń½»ÕÅŻ’╝Ü`127.0.0.1:8888`,ķ╗śĶ«ż API µ£ŹÕŖĪń½»ÕÅŻ’╝Ü`127.0.0.1:7861`,ķ╗śĶ«ż WebUI µ£ŹÕŖĪń½»ÕÅŻ’╝Ü`µ£¼µ£║IP’╝Ü8501`)**
+
+**2.µ£ŹÕŖĪÕÉ»ÕŖ©µŚČķŚ┤ńż║Ķ«ŠÕżćõĖŹÕÉīĶĆīõĖŹÕÉī’╝īń║” 3-10 ÕłåķƤ’╝īÕ”éķĢ┐µŚČķŚ┤µ▓Īµ£ēÕÉ»ÕŖ©Ķ»ĘÕēŹÕŠĆ `./logs`ńø«ÕĮĢõĖŗńøæµÄ¦µŚźÕ┐Ś’╝īÕ«ÜõĮŹķŚ«ķóśŃĆé**
+
+**3. Õ£©LinuxõĖŖõĮ┐ńö©ctrl+CķĆĆÕć║ÕÅ»ĶāĮõ╝Üńö▒õ║ÄlinuxńÜäÕżÜĶ┐øń©ŗµ£║ÕłČÕ»╝Ķć┤multiprocessingķüŚńĢÖÕŁżÕä┐Ķ┐øń©ŗ’╝īÕÅ»ķĆÜĶ┐ćshutdown_all.shĶ┐øĶĪīķĆĆÕć║**
+
diff --git a/internlm_langchain/chains/llmchain_with_history.py b/internlm_langchain/chains/llmchain_with_history.py
new file mode 100644
index 00000000..3d360422
--- /dev/null
+++ b/internlm_langchain/chains/llmchain_with_history.py
@@ -0,0 +1,29 @@
+from langchain.chat_models import ChatOpenAI
+from configs.model_config import llm_model_dict, LLM_MODEL
+from langchain import LLMChain
+from langchain.prompts.chat import (
+ ChatPromptTemplate,
+ HumanMessagePromptTemplate,
+)
+
+model = ChatOpenAI(
+ streaming=True,
+ verbose=True,
+ # callbacks=[callback],
+ openai_api_key=llm_model_dict[LLM_MODEL]["api_key"],
+ openai_api_base=llm_model_dict[LLM_MODEL]["api_base_url"],
+ model_name=LLM_MODEL
+)
+
+
+human_prompt = "{input}"
+human_message_template = HumanMessagePromptTemplate.from_template(human_prompt)
+
+chat_prompt = ChatPromptTemplate.from_messages(
+ [("human", "µłæõ╗¼µØźńÄ®µłÉĶ»ŁµÄźķŠÖ’╝īµłæÕģłµØź’╝īńö¤ķŠÖµ┤╗ĶÖÄ"),
+ ("ai", "ĶÖÄÕż┤ĶÖÄĶäæ"),
+ ("human", "{input}")])
+
+
+chain = LLMChain(prompt=chat_prompt, llm=model, verbose=True)
+print(chain({"input": "µü╝ńŠ×µłÉµĆÆ"}))
\ No newline at end of file
diff --git a/internlm_langchain/common/__init__.py b/internlm_langchain/common/__init__.py
new file mode 100644
index 00000000..e69de29b
diff --git a/internlm_langchain/configs/__init__.py b/internlm_langchain/configs/__init__.py
new file mode 100644
index 00000000..7c105f4e
--- /dev/null
+++ b/internlm_langchain/configs/__init__.py
@@ -0,0 +1,4 @@
+from .model_config import *
+from .server_config import *
+
+VERSION = "v0.2.2"
diff --git a/internlm_langchain/configs/model_config.py b/internlm_langchain/configs/model_config.py
new file mode 100644
index 00000000..ee970d25
--- /dev/null
+++ b/internlm_langchain/configs/model_config.py
@@ -0,0 +1,173 @@
+import os
+import logging
+import torch
+# µŚźÕ┐ŚµĀ╝Õ╝Å
+LOG_FORMAT = "%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s"
+logger = logging.getLogger()
+logger.setLevel(logging.INFO)
+logging.basicConfig(format=LOG_FORMAT)
+
+
+# Õ£©õ╗źõĖŗÕŁŚÕģĖõĖŁõ┐«µö╣Õ▒׵ƦÕĆ╝’╝īõ╗źµīćիܵ£¼Õ£░embeddingµ©ĪÕ×ŗÕŁśÕé©õĮŹńĮ«
+# Õ”éÕ░å "text2vec": "GanymedeNil/text2vec-large-chinese" õ┐«µö╣õĖ║ "text2vec": "User/Downloads/text2vec-large-chinese"
+# µŁżÕżäĶ»ĘÕåÖń╗ØÕ»╣ĶĘ»ÕŠä
+embedding_model_dict = {
+ "ernie-tiny": "nghuyong/ernie-3.0-nano-zh",
+ "ernie-base": "nghuyong/ernie-3.0-base-zh",
+ "text2vec-base": "shibing624/text2vec-base-chinese",
+ "text2vec": "GanymedeNil/text2vec-large-chinese",
+ "text2vec-paraphrase": "shibing624/text2vec-base-chinese-paraphrase",
+ "text2vec-sentence": "shibing624/text2vec-base-chinese-sentence",
+ "text2vec-multilingual": "shibing624/text2vec-base-multilingual",
+ "m3e-small": "moka-ai/m3e-small",
+ "m3e-base": "/root/huggingface/m3e-base",
+ "m3e-large": "moka-ai/m3e-large",
+ "bge-small-zh": "BAAI/bge-small-zh",
+ "bge-base-zh": "BAAI/bge-base-zh",
+ "bge-large-zh": "BAAI/bge-large-zh",
+ "bge-large-zh-noinstruct": "BAAI/bge-large-zh-noinstruct",
+ "text-embedding-ada-002": os.environ.get("OPENAI_API_KEY")
+}
+
+# ķĆēńö©ńÜä Embedding ÕÉŹń¦░
+EMBEDDING_MODEL = "m3e-base"
+
+# Embedding µ©ĪÕ×ŗĶ┐ÉĶĪīĶ«ŠÕżć
+EMBEDDING_DEVICE = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
+
+
+llm_model_dict = {
+ "chatglm-6b": {
+ "local_model_path": "THUDM/chatglm-6b",
+ "api_base_url": "http://localhost:8888/v1", # "name"õ┐«µö╣õĖ║fastchatµ£ŹÕŖĪõĖŁńÜä"api_base_url"
+ "api_key": "EMPTY"
+ },
+
+ "chatglm2-6b": {
+ "local_model_path": "/root/huggingface/chatglm2-6b",
+ "api_base_url": "http://localhost:8123/v1", # URLķ£ĆĶ”üõĖÄĶ┐ÉĶĪīfastchatµ£ŹÕŖĪń½»ńÜäserver_config.FSCHAT_OPENAI_APIõĖĆĶć┤
+ "api_key": "EMPTY"
+ },
+ "internlm-chat-7b": {
+ "local_model_path": "/root/huggingface/internlm-chat-7b-v1_1",
+ "api_base_url": "http://localhost:8123/v1", # URLķ£ĆĶ”üõĖÄĶ┐ÉĶĪīfastchatµ£ŹÕŖĪń½»ńÜäserver_config.FSCHAT_OPENAI_APIõĖĆĶć┤
+ "api_key": "EMPTY"
+ },
+
+ "chatglm2-6b-32k": {
+ "local_model_path": "THUDM/chatglm2-6b-32k", # "THUDM/chatglm2-6b-32k",
+ "api_base_url": "http://localhost:8888/v1", # "URLķ£ĆĶ”üõĖÄĶ┐ÉĶĪīfastchatµ£ŹÕŖĪń½»ńÜäserver_config.FSCHAT_OPENAI_APIõĖĆĶć┤
+ "api_key": "EMPTY"
+ },
+
+ # Ķ░āńö©chatgptµŚČÕ”éµ×£µŖźÕć║’╝Ü urllib3.exceptions.MaxRetryError: HTTPSConnectionPool(host='api.openai.com', port=443):
+ # Max retries exceeded with url: /v1/chat/completions
+ # ÕłÖķ£ĆĶ”üÕ░åurllib3ńēłµ£¼õ┐«µö╣õĖ║1.25.11
+ # Õ”éµ×£õŠØńäȵŖźurllib3.exceptions.MaxRetryError: HTTPSConnectionPool’╝īÕłÖÕ░åhttpsµö╣õĖ║http
+ # ÕÅéĶĆāhttps://zhuanlan.zhihu.com/p/350015032
+
+ # Õ”éµ×£µŖźÕć║’╝Üraise NewConnectionError(
+ # urllib3.exceptions.NewConnectionError:
+
+¤Äē langchain-ChatGLM ķĪ╣ńø«ÕŠ«õ┐Īõ║żµĄüńŠż’╝īÕ”éµ×£õĮĀõ╣¤Õ»╣µ£¼ķĪ╣ńø«µä¤Õģ┤ĶČŻ’╝īµ¼óĶ┐ÄÕŖĀÕģźńŠżĶüŖÕÅéõĖÄĶ«©Ķ«║õ║żµĄüŃĆé
diff --git a/internlm_langchain/README.md b/internlm_langchain/README.md
new file mode 100644
index 00000000..cea8b71d
--- /dev/null
+++ b/internlm_langchain/README.md
@@ -0,0 +1,161 @@
+## õ╗ŗń╗Ź
+
+õĮ┐ńö© [LangChain-Chatchat](https://github.com/chatchat-space/Langchain-Chatchat) µÉŁÕ╗║Õ¤║õ║Ä LLM [internlm/internlm-chat-7b-v1_1](https://huggingface.co/internlm/internlm-chat-7b-v1_1) ńÜä OpenMMLab ń¤źĶ»åÕ║ōķŚ«ńŁöŃĆé
+
+ 
+
+## µ©ĪÕ×ŗµö»µīü
+
+µ£¼ķĪ╣ńø«õĖŁķ╗śĶ«żõĮ┐ńö©ńÜä LLM µ©ĪÕ×ŗõĖ║ [internlm/internlm-chat-7b-v1_1](https://huggingface.co/internlm/internlm-chat-7b-v1_1)’╝īķ╗śĶ«żõĮ┐ńö©ńÜä Embedding µ©ĪÕ×ŗõĖ║ [moka-ai/m3e-base](https://huggingface.co/moka-ai/m3e-base) ŃĆé
+
+Ķ«ŠńĮ«µ¢ćõ╗Č `configs/model_configs.py` õĖŁńÜä `llm_model_dict` õĖ║ `internlm-chat-7b`ŃĆé
+
+## Õ╝ĆÕÅæķā©ńĮ▓
+
+### ĶĮ»õ╗Čķ£Ćµ▒é
+
+µ£¼ķĪ╣ńø«ÕĘ▓Õ£© Python 3.8’╝īCUDA 11.7 Ubuntu ńÄ»ÕóāõĖŗÕ«īµłÉµĄŗĶ»ĢŃĆé
+
+### 1. Õ╝ĆÕÅæńÄ»ÕóāÕćåÕżć
+
+ÕÅéĶ¦ü [Õ╝ĆÕÅæńÄ»ÕóāÕćåÕżć](docs/INSTALL.md)ŃĆé
+
+### 2. õĖŗĶĮĮµ©ĪÕ×ŗĶć│µ£¼Õ£░
+
+õĖŗĶĮĮ LLM µ©ĪÕ×ŗ [internlm/internlm-chat-7b-v1_1](https://huggingface.co/internlm/internlm-chat-7b-v1_1) õĖÄ Embedding µ©ĪÕ×ŗ [moka-ai/m3e-base](https://huggingface.co/moka-ai/m3e-base) õĖ║õŠŗ’╝Ü
+
+õĖŗĶĮĮµ©ĪÕ×ŗķ£ĆĶ”üÕģł[Õ«ēĶŻģGit LFS](https://docs.github.com/zh/repositories/working-with-files/managing-large-files/installing-git-large-file-storage)’╝īńäČÕÉÄĶ┐ÉĶĪī
+
+```Shell
+$ git clone https://huggingface.co/internlm/internlm-chat-7b-v1_1
+
+$ git clone https://huggingface.co/moka-ai/m3e-base
+```
+
+### 3. Ķ«ŠńĮ«ķģŹńĮ«ķĪ╣
+
+Õ£©Õ╝ĆÕ¦ŗµē¦ĶĪī Web UI µł¢ÕæĮõ╗żĶĪīõ║żõ║ÆÕēŹ’╝īĶ»ĘÕģłµŻĆµ¤ź `configs/model_config.py` ÕÆī `configs/server_config.py` õĖŁńÜäÕÉäķĪ╣µ©ĪÕ×ŗÕÅéµĢ░Ķ«ŠĶ«Īµś»ÕÉ”ń¼”ÕÉłķ£Ćµ▒é’╝Ü
+
+- Ķ»ĘńĪ«Ķ«żÕĘ▓õĖŗĶĮĮĶć│µ£¼Õ£░ńÜä LLM µ©ĪÕ×ŗµ£¼Õ£░ÕŁśÕé©ĶĘ»ÕŠäÕåÖÕ£© `llm_model_dict` Õ»╣Õ║öµ©ĪÕ×ŗńÜä `local_model_path` Õ▒׵ƦõĖŁ’╝īÕ”é:
+
+```python
+llm_model_dict={
+ "internlm-chat-7b": {
+ "local_model_path": "/root/huggingface/internlm-chat-7b-v1_1",
+ "api_base_url": "http://localhost:8888/v1", # "name"õ┐«µö╣õĖ║ FastChat µ£ŹÕŖĪõĖŁńÜä"api_base_url"
+ "api_key": "EMPTY"
+ },
+ }
+```
+
+- Ķ»ĘńĪ«Ķ«żÕĘ▓õĖŗĶĮĮĶć│µ£¼Õ£░ńÜä Embedding µ©ĪÕ×ŗµ£¼Õ£░ÕŁśÕé©ĶĘ»ÕŠäÕåÖÕ£© `embedding_model_dict` Õ»╣Õ║öµ©ĪÕ×ŗõĮŹńĮ«’╝īÕ”é’╝Ü
+
+```python
+embedding_model_dict = {
+ "m3e-base": "/root/huggingface/m3e-base",
+ }
+```
+
+### 5. ÕÉ»ÕŖ© API µ£ŹÕŖĪµł¢ Web UI
+
+#### 5.1 ÕÉ»ÕŖ© LLM µ£ŹÕŖĪ
+
+Õ”éķ£ĆõĮ┐ńö©Õ╝Ƶ║ɵ©ĪÕ×ŗĶ┐øĶĪīµ£¼Õ£░ķā©ńĮ▓’╝īķ£Ćķ”¢ÕģłÕÉ»ÕŖ© LLM µ£ŹÕŖĪ
+
+Õ£©ķĪ╣ńø«µĀ╣ńø«ÕĮĢõĖŗ’╝īµē¦ĶĪī [server/llm_api.py](server/llm_api.py) Ķäܵ£¼ÕÉ»ÕŖ© **LLM µ©ĪÕ×ŗ**µ£ŹÕŖĪ’╝Ü
+
+```shell
+$ python server/llm_api.py
+```
+
+ķĪ╣ńø«µö»µīüÕżÜÕŹĪÕŖĀĶĮĮ’╝īķ£ĆÕ£© llm_api.py õĖŁõ┐«µö╣ create_model_worker_app ÕćĮµĢ░õĖŁ’╝īõ┐«µö╣Õ”éõĖŗõĖēõĖ¬ÕÅéµĢ░:
+
+```python
+gpus=None,
+num_gpus=1,
+max_gpu_memory="20GiB"
+```
+
+ÕģČõĖŁ’╝ī`gpus` µÄ¦ÕłČõĮ┐ńö©ńÜ䵜ŠÕŹĪńÜäID’╝īÕ”éµ×£ "0,1";
+
+`num_gpus` µÄ¦ÕłČõĮ┐ńö©ńÜäÕŹĪµĢ░;
+
+`max_gpu_memory` µÄ¦ÕłČµ»ÅõĖ¬ÕŹĪõĮ┐ńö©ńÜ䵜ŠÕŁśÕ«╣ķćÅŃĆé
+
+#### 5.2 ÕÉ»ÕŖ© API µ£ŹÕŖĪ
+
+µ£¼Õ£░ķā©ńĮ▓µāģÕåĄõĖŗ’╝īµīēńģ¦ [5.1 ĶŖé](README.md#5.1-ÕÉ»ÕŖ©-LLM-µ£ŹÕŖĪ)**ÕÉ»ÕŖ© LLM µ£ŹÕŖĪÕÉÄ**’╝īÕåŹµē¦ĶĪī [server/api.py](server/api.py) Ķäܵ£¼ÕÉ»ÕŖ© **API** µ£ŹÕŖĪ’╝ø
+
+Õ£©ń║┐Ķ░āńö©APIµ£ŹÕŖĪńÜäµāģÕåĄõĖŗ’╝īńø┤µÄźµē¦µē¦ĶĪī [server/api.py](server/api.py) Ķäܵ£¼ÕÉ»ÕŖ© **API** µ£ŹÕŖĪ’╝ø
+
+Ķ░āńö©ÕæĮõ╗żńż║õŠŗ’╝Ü
+
+```shell
+$ python server/api.py
+```
+
+ÕÉ»ÕŖ© API µ£ŹÕŖĪÕÉÄ’╝īÕÅ»Ķ«┐ķŚ« `localhost:7861` µł¢ `{API µēĆÕ£©µ£ŹÕŖĪÕÖ© IP}:7861` FastAPI Ķć¬ÕŖ©ńö¤µłÉńÜä docs Ķ┐øĶĪīµÄźÕÅŻµ¤źń£ŗõĖĵĄŗĶ»ĢŃĆé
+
+
+
+#### 5.3 ÕÉ»ÕŖ© Web UI µ£ŹÕŖĪ
+
+µīēńģ¦ [5.2 ĶŖé](README.md#5.2-ÕÉ»ÕŖ©-API-µ£ŹÕŖĪ)**ÕÉ»ÕŖ© API µ£ŹÕŖĪÕÉÄ**’╝īµē¦ĶĪī [webui.py](webui.py) ÕÉ»ÕŖ© **Web UI** µ£ŹÕŖĪ’╝łķ╗śĶ«żõĮ┐ńö©ń½»ÕÅŻ `8501`’╝ē
+
+```shell
+$ streamlit run webui.py
+```
+
+õĮ┐ńö© Langchain-Chatchat õĖ╗ķóśĶē▓ÕÉ»ÕŖ© **Web UI** µ£ŹÕŖĪ’╝łķ╗śĶ«żõĮ┐ńö©ń½»ÕÅŻ `8501`’╝ē
+
+```shell
+$ streamlit run webui.py --theme.base "light" --theme.primaryColor "#165dff" --theme.secondaryBackgroundColor "#f5f5f5" --theme.textColor "#000000"
+```
+
+µł¢õĮ┐ńö©õ╗źõĖŗÕæĮõ╗żµīćÕ«ÜÕÉ»ÕŖ© **Web UI** µ£ŹÕŖĪÕ╣ȵīćÕ«Üń½»ÕÅŻÕÅĘ
+
+```shell
+$ streamlit run webui.py --server.port 666
+```
+
+- Web UI Õ»╣Ķ»ØńĢīķØó’╝Ü
+
+ 
+
+---
+
+### 6. õĖĆķö«ÕÉ»ÕŖ©
+
+µø┤µ¢░õĖĆķö«ÕÉ»ÕŖ©Ķäܵ£¼ startup.py,õĖĆķö«ÕÉ»ÕŖ©µēƵ£ē Fastchat µ£ŹÕŖĪŃĆüAPI µ£ŹÕŖĪŃĆüWebUI µ£ŹÕŖĪ’╝īńż║õŠŗõ╗ŻńĀü’╝Ü
+
+```shell
+$ python startup.py -a
+```
+
+Õ╣ČÕÅ»õĮ┐ńö© `Ctrl + C` ńø┤µÄźÕģ│ķŚŁµēƵ£ēĶ┐ÉĶĪīµ£ŹÕŖĪŃĆéÕ”éµ×£õĖƵ¼Īń╗ōµØ¤õĖŹõ║å’╝īÕÅ»õ╗źÕżÜµīēÕćĀµ¼ĪŃĆé
+
+ÕÅ»ķĆēÕÅéµĢ░Õīģµŗ¼ `-a (µł¢--all-webui)`, `--all-api`, `--llm-api`, `-c (µł¢--controller)`, `--openai-api`,
+`-m (µł¢--model-worker)`, `--api`, `--webui`’╝īÕģČõĖŁ’╝Ü
+
+- `--all-webui` õĖ║õĖĆķö«ÕÉ»ÕŖ© WebUI µēƵ£ēõŠØĶĄ¢µ£ŹÕŖĪ’╝ø
+- `--all-api` õĖ║õĖĆķö«ÕÉ»ÕŖ© API µēƵ£ēõŠØĶĄ¢µ£ŹÕŖĪ’╝ø
+- `--llm-api` õĖ║õĖĆķö«ÕÉ»ÕŖ© Fastchat µēƵ£ēõŠØĶĄ¢ńÜä LLM µ£ŹÕŖĪ’╝ø
+- `--openai-api` õĖ║õ╗ģÕÉ»ÕŖ© FastChat ńÜä controller ÕÆī openai-api-server µ£ŹÕŖĪ’╝ø
+- ÕģČõ╗¢õĖ║ÕŹĢńŗ¼µ£ŹÕŖĪÕÉ»ÕŖ©ķĆēķĪ╣ŃĆé
+
+Ķŗźµā│µīćÕ«ÜķØ×ķ╗śĶ«żµ©ĪÕ×ŗ’╝īķ£ĆĶ”üńö© `--model-name` ķĆēķĪ╣’╝īńż║õŠŗ’╝Ü
+
+```shell
+$ python startup.py --all-webui --model-name Qwen-7B-Chat
+```
+
+µø┤ÕżÜõ┐Īµü»ÕÅ»ķĆÜĶ┐ć `python startup.py -h`µ¤źń£ŗŃĆé
+
+**µ│©µäÅ’╝Ü**
+
+**1. startup Ķäܵ£¼ńö©ÕżÜĶ┐øń©ŗµ¢╣Õ╝ÅÕÉ»ÕŖ©ÕÉ䵩ĪÕØŚńÜäµ£ŹÕŖĪ’╝īÕÅ»ĶāĮõ╝ÜÕ»╝Ķć┤µēōÕŹ░ķĪ║Õ║ÅķŚ«ķóś’╝īĶ»ĘńŁēÕŠģÕģ©ķā©µ£ŹÕŖĪÕÅæĶĄĘÕÉÄÕåŹĶ░āńö©’╝īÕ╣ȵĀ╣µŹ«ķ╗śĶ«żµł¢µīćÕ«Üń½»ÕÅŻĶ░āńö©µ£ŹÕŖĪ’╝łķ╗śĶ«ż LLM API µ£ŹÕŖĪń½»ÕÅŻ’╝Ü`127.0.0.1:8888`,ķ╗śĶ«ż API µ£ŹÕŖĪń½»ÕÅŻ’╝Ü`127.0.0.1:7861`,ķ╗śĶ«ż WebUI µ£ŹÕŖĪń½»ÕÅŻ’╝Ü`µ£¼µ£║IP’╝Ü8501`)**
+
+**2.µ£ŹÕŖĪÕÉ»ÕŖ©µŚČķŚ┤ńż║Ķ«ŠÕżćõĖŹÕÉīĶĆīõĖŹÕÉī’╝īń║” 3-10 ÕłåķƤ’╝īÕ”éķĢ┐µŚČķŚ┤µ▓Īµ£ēÕÉ»ÕŖ©Ķ»ĘÕēŹÕŠĆ `./logs`ńø«ÕĮĢõĖŗńøæµÄ¦µŚźÕ┐Ś’╝īÕ«ÜõĮŹķŚ«ķóśŃĆé**
+
+**3. Õ£©LinuxõĖŖõĮ┐ńö©ctrl+CķĆĆÕć║ÕÅ»ĶāĮõ╝Üńö▒õ║ÄlinuxńÜäÕżÜĶ┐øń©ŗµ£║ÕłČÕ»╝Ķć┤multiprocessingķüŚńĢÖÕŁżÕä┐Ķ┐øń©ŗ’╝īÕÅ»ķĆÜĶ┐ćshutdown_all.shĶ┐øĶĪīķĆĆÕć║**
+
diff --git a/internlm_langchain/chains/llmchain_with_history.py b/internlm_langchain/chains/llmchain_with_history.py
new file mode 100644
index 00000000..3d360422
--- /dev/null
+++ b/internlm_langchain/chains/llmchain_with_history.py
@@ -0,0 +1,29 @@
+from langchain.chat_models import ChatOpenAI
+from configs.model_config import llm_model_dict, LLM_MODEL
+from langchain import LLMChain
+from langchain.prompts.chat import (
+ ChatPromptTemplate,
+ HumanMessagePromptTemplate,
+)
+
+model = ChatOpenAI(
+ streaming=True,
+ verbose=True,
+ # callbacks=[callback],
+ openai_api_key=llm_model_dict[LLM_MODEL]["api_key"],
+ openai_api_base=llm_model_dict[LLM_MODEL]["api_base_url"],
+ model_name=LLM_MODEL
+)
+
+
+human_prompt = "{input}"
+human_message_template = HumanMessagePromptTemplate.from_template(human_prompt)
+
+chat_prompt = ChatPromptTemplate.from_messages(
+ [("human", "µłæõ╗¼µØźńÄ®µłÉĶ»ŁµÄźķŠÖ’╝īµłæÕģłµØź’╝īńö¤ķŠÖµ┤╗ĶÖÄ"),
+ ("ai", "ĶÖÄÕż┤ĶÖÄĶäæ"),
+ ("human", "{input}")])
+
+
+chain = LLMChain(prompt=chat_prompt, llm=model, verbose=True)
+print(chain({"input": "µü╝ńŠ×µłÉµĆÆ"}))
\ No newline at end of file
diff --git a/internlm_langchain/common/__init__.py b/internlm_langchain/common/__init__.py
new file mode 100644
index 00000000..e69de29b
diff --git a/internlm_langchain/configs/__init__.py b/internlm_langchain/configs/__init__.py
new file mode 100644
index 00000000..7c105f4e
--- /dev/null
+++ b/internlm_langchain/configs/__init__.py
@@ -0,0 +1,4 @@
+from .model_config import *
+from .server_config import *
+
+VERSION = "v0.2.2"
diff --git a/internlm_langchain/configs/model_config.py b/internlm_langchain/configs/model_config.py
new file mode 100644
index 00000000..ee970d25
--- /dev/null
+++ b/internlm_langchain/configs/model_config.py
@@ -0,0 +1,173 @@
+import os
+import logging
+import torch
+# µŚźÕ┐ŚµĀ╝Õ╝Å
+LOG_FORMAT = "%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s"
+logger = logging.getLogger()
+logger.setLevel(logging.INFO)
+logging.basicConfig(format=LOG_FORMAT)
+
+
+# Õ£©õ╗źõĖŗÕŁŚÕģĖõĖŁõ┐«µö╣Õ▒׵ƦÕĆ╝’╝īõ╗źµīćիܵ£¼Õ£░embeddingµ©ĪÕ×ŗÕŁśÕé©õĮŹńĮ«
+# Õ”éÕ░å "text2vec": "GanymedeNil/text2vec-large-chinese" õ┐«µö╣õĖ║ "text2vec": "User/Downloads/text2vec-large-chinese"
+# µŁżÕżäĶ»ĘÕåÖń╗ØÕ»╣ĶĘ»ÕŠä
+embedding_model_dict = {
+ "ernie-tiny": "nghuyong/ernie-3.0-nano-zh",
+ "ernie-base": "nghuyong/ernie-3.0-base-zh",
+ "text2vec-base": "shibing624/text2vec-base-chinese",
+ "text2vec": "GanymedeNil/text2vec-large-chinese",
+ "text2vec-paraphrase": "shibing624/text2vec-base-chinese-paraphrase",
+ "text2vec-sentence": "shibing624/text2vec-base-chinese-sentence",
+ "text2vec-multilingual": "shibing624/text2vec-base-multilingual",
+ "m3e-small": "moka-ai/m3e-small",
+ "m3e-base": "/root/huggingface/m3e-base",
+ "m3e-large": "moka-ai/m3e-large",
+ "bge-small-zh": "BAAI/bge-small-zh",
+ "bge-base-zh": "BAAI/bge-base-zh",
+ "bge-large-zh": "BAAI/bge-large-zh",
+ "bge-large-zh-noinstruct": "BAAI/bge-large-zh-noinstruct",
+ "text-embedding-ada-002": os.environ.get("OPENAI_API_KEY")
+}
+
+# ķĆēńö©ńÜä Embedding ÕÉŹń¦░
+EMBEDDING_MODEL = "m3e-base"
+
+# Embedding µ©ĪÕ×ŗĶ┐ÉĶĪīĶ«ŠÕżć
+EMBEDDING_DEVICE = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
+
+
+llm_model_dict = {
+ "chatglm-6b": {
+ "local_model_path": "THUDM/chatglm-6b",
+ "api_base_url": "http://localhost:8888/v1", # "name"õ┐«µö╣õĖ║fastchatµ£ŹÕŖĪõĖŁńÜä"api_base_url"
+ "api_key": "EMPTY"
+ },
+
+ "chatglm2-6b": {
+ "local_model_path": "/root/huggingface/chatglm2-6b",
+ "api_base_url": "http://localhost:8123/v1", # URLķ£ĆĶ”üõĖÄĶ┐ÉĶĪīfastchatµ£ŹÕŖĪń½»ńÜäserver_config.FSCHAT_OPENAI_APIõĖĆĶć┤
+ "api_key": "EMPTY"
+ },
+ "internlm-chat-7b": {
+ "local_model_path": "/root/huggingface/internlm-chat-7b-v1_1",
+ "api_base_url": "http://localhost:8123/v1", # URLķ£ĆĶ”üõĖÄĶ┐ÉĶĪīfastchatµ£ŹÕŖĪń½»ńÜäserver_config.FSCHAT_OPENAI_APIõĖĆĶć┤
+ "api_key": "EMPTY"
+ },
+
+ "chatglm2-6b-32k": {
+ "local_model_path": "THUDM/chatglm2-6b-32k", # "THUDM/chatglm2-6b-32k",
+ "api_base_url": "http://localhost:8888/v1", # "URLķ£ĆĶ”üõĖÄĶ┐ÉĶĪīfastchatµ£ŹÕŖĪń½»ńÜäserver_config.FSCHAT_OPENAI_APIõĖĆĶć┤
+ "api_key": "EMPTY"
+ },
+
+ # Ķ░āńö©chatgptµŚČÕ”éµ×£µŖźÕć║’╝Ü urllib3.exceptions.MaxRetryError: HTTPSConnectionPool(host='api.openai.com', port=443):
+ # Max retries exceeded with url: /v1/chat/completions
+ # ÕłÖķ£ĆĶ”üÕ░åurllib3ńēłµ£¼õ┐«µö╣õĖ║1.25.11
+ # Õ”éµ×£õŠØńäȵŖźurllib3.exceptions.MaxRetryError: HTTPSConnectionPool’╝īÕłÖÕ░åhttpsµö╣õĖ║http
+ # ÕÅéĶĆāhttps://zhuanlan.zhihu.com/p/350015032
+
+ # Õ”éµ×£µŖźÕć║’╝Üraise NewConnectionError(
+ # urllib3.exceptions.NewConnectionError:
+
+
+7B
+ +```shell +python3 -m lmdeploy.serve.turbomind.deploy llama2 /path/to/llama-2-7b-chat-hf +bash workspace/service_docker_up.sh +``` + +
+
+
+13B
+ +```shell +python3 -m lmdeploy.serve.turbomind.deploy llama2 /path/to/llama-2-13b-chat-hf --tp 2 +bash workspace/service_docker_up.sh +``` + +
+
+
+## ķā©ńĮ▓ [LLaMA](https://github.com/facebookresearch/llama) µ£ŹÕŖĪ
+
+Ķ»ĘÕĪ½ÕåÖ[Ķ┐ÖÕ╝ĀĶĪ©](https://docs.google.com/forms/d/e/1FAIpQLSfqNECQnMkycAp2jP4Z9TFX0cGR4uf7b_fBxjY_OjhJILlKGA/viewform)’╝īĶÄĘÕÅ¢ LLaMA µ©ĪÕ×ŗµØāķćŹ
+
+70B
+ +```shell +python3 -m lmdeploy.serve.turbomind.deploy llama2 /path/to/llama-2-70b-chat-hf --tp 8 +bash workspace/service_docker_up.sh +``` + +
+
+
+7B
+ +```shell +python3 -m lmdeploy.serve.turbomind.deploy llama /path/to/llama-7b llama \ + --tokenizer_path /path/to/tokenizer/model +bash workspace/service_docker_up.sh +``` + +
+
+
+13B
+ +```shell +python3 -m lmdeploy.serve.turbomind.deploy llama /path/to/llama-13b llama \ + --tokenizer_path /path/to/tokenizer/model --tp 2 +bash workspace/service_docker_up.sh +``` + +
+
+
+30B
+ +```shell +python3 -m lmdeploy.serve.turbomind.deploy llama /path/to/llama-30b llama \ + --tokenizer_path /path/to/tokenizer/model --tp 4 +bash workspace/service_docker_up.sh +``` + +
+
+
+### ķā©ńĮ▓ [Vicuna](https://lmsys.org/blog/2023-03-30-vicuna/) µ£ŹÕŖĪ
+
+65B
+ +```shell +python3 -m lmdeploy.serve.turbomind.deploy llama /path/to/llama-65b llama \ + --tokenizer_path /path/to/tokenizer/model --tp 8 +bash workspace/service_docker_up.sh +``` + +
+
+
+7B
+ +```shell +python3 -m pip install fschat +python3 -m fastchat.model.apply_delta \ + --base-model-path /path/to/llama-7b \ + --target-model-path /path/to/vicuna-7b \ + --delta-path lmsys/vicuna-7b-delta-v1.1 + +python3 -m lmdeploy.serve.turbomind.deploy vicuna /path/to/vicuna-7b +bash workspace/service_docker_up.sh +``` + +
+
diff --git a/internlm_langchain/knowledge_base/LMDeploy/content/turbomind.md b/internlm_langchain/knowledge_base/LMDeploy/content/turbomind.md
new file mode 100644
index 00000000..e51a0199
--- /dev/null
+++ b/internlm_langchain/knowledge_base/LMDeploy/content/turbomind.md
@@ -0,0 +1,70 @@
+# TurboMind
+
+TurboMind µś»õĖƵ¼ŠÕģ│õ║Ä LLM µÄ©ńÉåńÜäķ½śµĢłµÄ©ńÉåÕ╝ĢµōÄ’╝īÕ¤║õ║ÄĶŗ▒õ╝¤ĶŠŠńÜä [FasterTransformer](https://github.com/NVIDIA/FasterTransformer) ńĀöÕÅæĶĆīµłÉŃĆéÕ«āńÜäõĖ╗Ķ”üÕŖ¤ĶāĮÕīģµŗ¼’╝ÜLLaMa ń╗ōµ×䵩ĪÕ×ŗńÜäµö»µīü’╝īpersistent batch µÄ©ńÉ嵩ĪÕ╝ÅÕÆīÕÅ»µē®Õ▒ĢńÜä KV ń╝ōÕŁśń«ĪńÉåÕÖ©ŃĆé
+
+## TurboMind ń╗ōµ×ä
+
+```
+ +--------------------+
+ | API |
+ +--------------------+
+ | ^
+ Ķ»Ę µ▒é | | µĄüÕ╝ÅÕø×Ķ░ā
+ v |
+ +--------------------+ ĶÄĘÕÅ¢ +-------------------+
+ | Persistent Batch | <-------> | KV Cache ń«ĪńÉåÕÖ© |
+ +--------------------+ µø┤µ¢░ +-------------------+
+ ^
+ |
+ v
++------------------------+
+| LLaMaµÄ©ńÉåÕ«×ńÄ░ |
++------------------------+
+| FT kernels & utilities |
++------------------------+
+```
+
+## Persistent Batch
+
+õĮĀõ╣¤Ķ«ĖÕ£©Õł½ńÜäķĪ╣ńø«õĖŁń£ŗÕł░Ķ┐ÖķĪ╣µ£║ÕłČńÜäÕÅ”õĖĆõĖ¬ÕÉŹÕŁŚ’╝Ü `continuous batching` ŃĆéÕ£©Õ╝ĆÕÅæĶ┐ÖõĖ¬ÕŖ¤ĶāĮµŚČ’╝īµłæõ╗¼Õ░åÕ»╣Ķ»ØÕ╝Å LLM ńÜäµÄ©ńÉåÕ╗║µ©ĪõĖ║õĖĆõĖ¬µīüń╗ŁĶ┐ÉĶĪīńÜä batch ’╝īÕģČńö¤ÕæĮÕ橵£¤ĶĘ©ĶČŖµĢ┤õĖ¬µ£ŹÕŖĪĶ┐ćń©ŗ’╝īµĢģÕ░åÕģČÕæĮÕÉŹõĖ║ `persistent batch` ŃĆéń«ĆÕŹĢµØźĶ»┤µś»Ķ┐ÖµĀĘÕ«×ńÄ░ńÜä’╝Ü
+
+- Ķ»źÕŖ¤ĶāĮõ╝ÜķóäÕģłÕćåÕżćÕźĮ N õĖ¬ batch slotsŃĆé
+- ÕĮōµ£ēń®║ķŚ▓ slots µŚČ’╝ī Ķ»Ęµ▒éÕ░▒õ╝ÜÕŖĀÕģźÕł░ batch õĖŁŃĆéÕĮōĶ»Ęµ▒éÕ»╣Õ║öńÜä tokens ķāĮńö¤µłÉÕ«īµ»ĢÕÉÄ’╝īÕ»╣Õ║öńÜä batch slot õ╝Üń½ŗÕł╗Ķó½ķćŖµöŠ’╝īµÄźµöȵ¢░ńÜäĶ»Ęµ▒éŃĆé
+- **ÕĮōõĖĆõĖ¬ sequence ÕæĮõĖŁń╝ōÕŁśµŚČ’╝łĶ¦üõĖŗµ¢ć’╝ē’╝īÕ«āńÜäÕÄåÕÅ▓ token õĖŹÕ┐ģÕ£©µ»ÅĶĮ«õĖŁķāĮĶ┐øĶĪīĶ¦ŻńĀü’╝īµēĆõ╗źÕ«āńÜä token ńö¤µłÉĶ┐ćń©ŗõ╝ÜÕŹ│Õł╗Õ╝ĆÕ¦ŗ**ŃĆé
+- µĢ┤õĖ¬ batch õ╝ÜĶć¬ÕŖ©µē®ń╝®Õ«╣µØźķü┐ÕģŹõĖŹÕ┐ģĶ”üńÜäĶ«Īń«ŚŃĆé
+
+## KV ń╝ōÕŁśń«ĪńÉåÕÖ©
+
+TurboMind ńÜä [KV ń╝ōÕŁśń«ĪńÉåÕÖ©](https://github.com/InternLM/lmdeploy/blob/main/src/turbomind/models/llama/LlamaCacheManager.h) µś»õĖĆõĖ¬ÕåģÕŁśµ▒Āń▒╗Õ×ŗńÜäÕ»╣Ķ▒Ī’╝īÕ╣ČõĖöÕ£©ÕģČõĖŁÕŖĀÕģźõ║å LRU ńÜäÕ«×ńÄ░’╝īĶ┐ÖµĀʵĢ┤õĖ¬ń«ĪńÉåÕÖ©ÕÅ»õ╗źĶó½ń£ŗõĮ£µś»õĖĆõĖ¬ **KV ń╝ōÕŁśńÜäń╝ōÕŁś**ŃĆéÕż¦Ķć┤ÕĘźõĮ£µ¢╣Õ╝ÅÕ”éõĖŗ’╝Ü
+
+- KV ń╝ōÕŁśńö▒ń«ĪńÉåÕÖ©ÕłåķģŹŃĆéń«ĪńÉåÕÖ©õ╝ܵĀ╣µŹ«ķóäÕģłķģŹńĮ«ÕźĮńÜä slot µĢ░ķćÅÕ╝ĆĶŠ¤ń®║ķŚ┤ŃĆéµ»ÅõĖ¬ slot Õ»╣Õ║öõ║ÄõĖĆõĖ¬ sequence µēĆķ£ĆńÜä KV ń╝ōÕŁśŃĆéÕłåķģŹńÜäÕåģÕŁśÕØŚÕż¦Õ░ÅÕÅ»ķĆÜĶ┐ćķģŹńĮ«µØźÕ«×ńÄ░ķóäÕłåķģŹµł¢ĶĆģµīēķ£ĆÕłåķģŹ’╝łµł¢õ╗ŗõ║ÄõĖżĶĆģõ╣ŗķŚ┤’╝ēŃĆé
+- ÕĮōµ£ēµ¢░ńÜäĶ»Ęµ▒é’╝īõĮåµś»ń╝ōÕŁśµ▒ĀõĖŁµ▓Īµ£ēń®║ķŚ▓ slotµŚČ’╝īµĀ╣µŹ« LRU µ£║ÕłČ’╝īń«ĪńÉåÕÖ©õ╝ÜĶĖóķÖżµ£ĆĶ┐æõĮ┐ńö©µ£ĆÕ░æńÜä sequence’╝īµŖŖÕ«āÕŹĀµŹ«ńÜä slot Õłåń╗Öµ¢░ńÜäĶ»Ęµ▒éŃĆéõĖŹõ╗ģõ╗ģÕ”éµŁż’╝ī
+- sequenceĶÄĘÕÅ¢Õł░õ║åslot’╝īń▒╗õ╝╝ń╝ōÕŁśÕæĮõĖŁŃĆéÕ«āÕ£©ń╝ōÕŁśõĖŁńÜäÕÄåÕÅ▓KVõ╝ÜĶó½ńø┤µÄźĶ┐öÕø×’╝īĶĆīõĖŹńö©Õ£©Ķ┐øĶĪīcontext decoding ŃĆé
+- Ķó½ĶĖóķÖżńÜä sequences õĖŹõ╝ÜĶó½Õ«īÕģ©ńÜäÕłĀķÖż’╝īĶĆīµś»õ╝ÜĶó½ĶĮ¼µŹóµłÉµ£Ćń«Ćµ┤üńÜäÕĮóÕ╝Å’╝īõŠŗÕ”é token IDs ŃĆéÕĮōõ╣ŗÕÉÄĶÄĘÕÅ¢Õł░ńøĖÕÉīńÜä sequence id µŚČ (ÕŹ│ _cache-miss_ ńŖȵĆü)’╝īĶ┐Öõ║ø token IDs Õ░åĶó½ FMHA ńÜä context decoder Ķ¦ŻńĀüÕ╣ČĶó½ĶĮ¼Õø× KV ń╝ōÕŁśŃĆé
+- ĶĖóķÖżÕÆīĶĮ¼µŹóÕØćńö▒ TurboMind Õåģķā©Ķć¬ÕŖ©ń«ĪńÉåµēĆõ╗źÕ»╣ńö©µłĘµØźĶ»┤µś»ķĆŵśÄńÜäŃĆé__õ╗Äńö©µłĘńÜäõĮ┐ńö©Ķ¦ÆÕ║”µØźń£ŗ’╝īõĮ┐ńö©õ║å TurboMind ńÜäń│╗ń╗¤Õ░▒Õāŵś»ÕÅ»õ╗źĶ«┐ķŚ«µŚĀķÖÉńÜäĶ«ŠÕżćÕåģÕŁś__ŃĆé
+
+## TurboMind ńÜä LLaMa Õ«×ńÄ░
+
+µłæõ╗¼Õ»╣ LLaMa ń│╗ÕłŚµ©ĪÕ×ŗńÜäÕ«×ńÄ░µś»õ╗Ä FasterTransformer õĖŁńÜä Gpt-NeX µ©ĪÕ×ŗõ┐«µö╣ĶĆīµØźńÜäŃĆéķÖżõ║åÕ»╣ LLaMa ń│╗ÕłŚĶ┐øĶĪīÕ¤║µ£¼ķ揵×äÕÆīõ┐«µö╣Õż¢’╝īµłæõ╗¼Ķ┐śÕüÜõ║åõĖĆõ║øµö╣Ķ┐øõ╗źÕ«×ńÄ░õ╝ÜĶ»Øµ©ĪÕ×ŗńÜäķ½śµĆ¦ĶāĮµÄ©ńÉå’╝īÕģČõĖŁµ£ĆķćŹĶ”üńÜ䵜»’╝Ü
+
+- µö»µīüÕżÜĶĮ«Õ»╣Ķ»ØõĖŁńÜäÕ┐½ķƤµ¢ćµ£¼Ķ¦ŻńĀüŃĆ鵳æõ╗¼ńö©Õ¤║õ║Ä [cutlass](https://github.com/NVIDIA/cutlass) ńÜä FMHA Õ«×ńÄ░µø┐õ╗Żõ║å context decoder õĖŁńÜäµ│©µäÅÕŖøµ£║ÕłČÕ«×ńÄ░’╝īõ╗ÄĶĆīµö»µīüõ║å Q/K ķĢ┐Õ║”õĖŹÕī╣ķģŹńÜäµāģÕåĄŃĆé
+- µłæõ╗¼Õ£© context FMHA ÕÆī generation FMHA õĖŁķāĮÕŖĀÕģźõ║åķŚ┤µÄźń╝ōÕå▓µīćķÆł’╝īµö»µīü batch õĖŁõĖŹĶ┐×ń╗ŁńÜä KV ń╝ōÕŁśŃĆé
+- õĖ║õ║åµö»µīü persistent batch ńÜäÕ╣ČÕÅæµÄ©ńÉå’╝īµłæõ╗¼Ķ«ŠĶ«Īõ║åµ¢░ńÜäÕÉīµŁźµ£║ÕłČµØźÕŹÅĶ░āÕ£©Õ╝ĀķćÅÕ╣ČÕ×ŗµ©ĪÕ╝ÅõĖŗńÜäÕĘźõĮ£ń║┐ń©ŗŃĆé
+- µłæõ╗¼Õ«×ńÄ░õ║å INT8 KV cache’╝īķÖŹõĮÄõ║åÕåģÕŁśÕ╝ĆķöĆ’╝īµÅÉķ½śõ║åµē╣ÕżäńÉåÕż¦Õ░ÅÕÆīń│╗ń╗¤ÕÉ×ÕÉÉķćÅŃĆéĶ┐ÖÕ£©Õ«×ķÖģÕ£║µÖ»õĖŁķØ×ÕĖĖµ£ēńö©’╝īÕøĀõĖ║ńøĖµ»öµØāķćŹÕÆīÕģČõ╗¢µ┐Ƶ┤╗’╝īKV cache õ╝ܵȳĶĆŚµø┤ÕżÜńÜäÕåģÕŁśÕÆīÕåģÕŁśÕĖ”Õ«ĮŃĆé
+- µłæõ╗¼Ķ¦ŻÕå│õ║åÕŹĢõĖ¬Ķ┐øń©ŗÕåģÕżÜõĖ¬µ©ĪÕ×ŗÕ«×õŠŗÕ£© TP µ©ĪÕ╝ÅõĖŗĶ┐ÉĶĪīµŚČ NCCL ÕŹĪõĮÅńÜäķŚ«ķóśŃĆéNCCL APIs ńÄ░ńö▒ host ń½»ńÜäÕÉīµŁź barriers õ┐صŖżŃĆé
+
+## API
+
+TurboMind ńÜä Python API µö»µīüµĄüÕ╝Åń╗ōµ×£Ķ┐öÕø×ÕÆīÕ╝ĀķćÅÕ╣ČĶĪīµ©ĪÕ╝ÅŃĆé
+
+ÕÉīµŚČ TurboMind õ╣¤ń╗¦µē┐õ║å FasterTransformer ĶāĮÕż¤µ│©ÕåīõĖ║ [Triton Inference Server](https://github.com/triton-inference-server/server) µÄ©ńÉåÕÉÄń½»ńÜäĶāĮÕŖøŃĆéõĮåµś»õĖ║õ║åµö»µīü persistent batch õĖŁńÜäÕ╣ČÕÅæĶ»Ęµ▒é’╝īµłæõ╗¼õĖŹÕåŹÕāÅ FasterTransformer ķ鯵ĀĘõĮ┐ńö© sequence batching µł¢ĶĆģ dynamic batching ŃĆéńøĖÕÅŹ’╝īTurboMind Ķ┤¤Ķ┤ŻĶ«░ÕĮĢÕÆīń«ĪńÉåĶ»Ęµ▒éÕ║ÅÕłŚńÜäńŖȵĆüŃĆé
+
+## TurboMind ÕÆī FasterTransformer ńÜäÕī║Õł½
+
+ķÖżõ║åõĖŖµ¢ćõĖŁµÅÉÕł░ńÜäÕŖ¤ĶāĮÕż¢’╝īTurboMind ńøĖĶŠāõ║Ä FasterTransformer Ķ┐śµ£ēõĖŹÕ░æÕĘ«Õł½ŃĆéĶŁ¼Õ”éõĖŹÕ░æ FasterTransformer ńÜäÕŖ¤ĶāĮÕ£© TurboMind õĖŁķāĮĶó½ÕÄ╗µÄēõ║å’╝īĶ┐ÖÕģČõĖŁÕīģµŗ¼ÕēŹń╝ƵÅÉńż║Ķ»ŹŃĆü beam search ŃĆüõĖŖõĖŗµ¢ć embeddingŃĆüń©Ćń¢ÅÕī¢ GEMM µōŹõĮ£ÕÆīÕ»╣Õ║ö GPT µł¢ T5 ńŁēń╗ōµ×äńÜ䵩ĪÕ×ŗńÜäµö»µīüńŁēńŁēŃĆé
+
+## FAQ
+
+### Õ»╣ Huggingface µ©ĪÕ×ŗńÜäµö»µīü
+
+ÕøĀõĖ║ÕÄåÕÅ▓ÕøĀń┤Ā’╝ī TurboMind ńÜäµØāķćŹĶ«ŠĶ«Īµś»Õ¤║õ║Ä [LLaMa ńÜäÕ«śµ¢╣Õ«×ńÄ░](https://github.com/facebookresearch/llama) Õ«īµłÉńÜä’╝īõĖżĶĆģÕŬńøĖÕĘ«õĖĆõĖ¬ĶĮ¼ńĮ«µōŹõĮ£ŃĆéõĮåµś» Huggingface ńēłµ£¼ńÜäÕ«×ńÄ░ÕŹ┤µś»[ÕÅ”õĖĆń¦ŹÕĮóÕ╝Å](https://github.com/huggingface/transformers/blob/45025d92f815675e483f32812caa28cce3a960e7/src/transformers/models/llama/convert_llama_weights_to_hf.py#L123C76-L123C76)’╝īõĖżń¦ŹµØāķćŹÕ«×ńÄ░µ¢╣Õ╝ÅÕ£© `W_q` ÕÆī `W_k` õĖŖńÜäÕī║Õł½µłæõ╗¼Õ£© [deploy.py](https://github.com/InternLM/lmdeploy/blob/ff4648a1d09e5aec74cf70efef35bfaeeac552e0/lmdeploy/serve/turbomind/deploy.py#L398) Ķ┐øĶĪīõ║åķĆéķģŹÕżäńÉå’╝īńö©µłĘÕÅ»ÕēŹÕŠĆµ¤źń£ŗŃĆé
diff --git a/internlm_langchain/knowledge_base/LMDeploy/content/w4a16.md b/internlm_langchain/knowledge_base/LMDeploy/content/w4a16.md
new file mode 100644
index 00000000..a67304b6
--- /dev/null
+++ b/internlm_langchain/knowledge_base/LMDeploy/content/w4a16.md
@@ -0,0 +1,97 @@
+# W4A16 LLM µ©ĪÕ×ŗķā©ńĮ▓
+
+LMDeploy µö»µīü 4bit µØāķ揵©ĪÕ×ŗńÜäµÄ©ńÉå’╝ī**Õ»╣ NVIDIA µśŠÕŹĪńÜäµ£ĆõĮÄĶ”üµ▒鵜» sm80**’╝īµ»öÕ”éA10’╝īA100’╝īGerforce 30/40ń│╗ÕłŚŃĆé
+
+Õ£©µÄ©ńÉåõ╣ŗÕēŹ’╝īĶ»ĘńĪ«õ┐ØÕ«ēĶŻģõ║å lmdeploy
+
+```shell
+pip install lmdeploy
+```
+
+## 4bit µØāķ揵©ĪÕ×ŗµÄ©ńÉå
+
+õĮĀÕÅ»õ╗źńø┤µÄźõ╗Ä LMDeploy ńÜä [model zoo](https://huggingface.co/lmdeploy) õĖŗĶĮĮÕĘ▓ń╗ÅķćÅÕī¢ÕźĮńÜä 4bit µØāķ揵©ĪÕ×ŗ’╝īńø┤µÄźõĮ┐ńö©õĖŗķØóńÜäÕæĮõ╗żµÄ©ńÉåŃĆéõ╣¤ÕÅ»õ╗źµĀ╣µŹ«["4bit µØāķćŹķćÅÕī¢"](#4bit-µØāķćŹķćÅÕī¢)ń½ĀĶŖéńÜäÕåģÕ«╣’╝īµŖŖ 16bit µØāķćŹķćÅÕī¢õĖ║ 4bit µØāķ插╝īńäČÕÉÄÕåŹµīēõĖŗĶ┐░Ķ»┤µśÄµÄ©ńÉå
+
+õ╗ź 4bit ńÜä Llama-2-chat-7B µ©ĪÕ×ŗõĖ║õŠŗ’╝īÕÅ»õ╗źõ╗Ä model zoo ńø┤µÄźõĖŗĶĮĮ’╝Ü
+
+```shell
+git-lfs install
+git clone https://huggingface.co/lmdeploy/llama2-chat-7b-w4
+```
+
+µē¦ĶĪīõ╗źõĖŗÕæĮõ╗ż’╝īÕŹ│ÕŻգ©ń╗łń½»õĖĵ©ĪÕ×ŗÕ»╣Ķ»Ø’╝Ü
+
+```shell
+
+## ĶĮ¼µŹóµ©ĪÕ×ŗńÜälayout’╝īÕŁśµöŠÕ£©ķ╗śĶ«żĶĘ»ÕŠä ./workspace õĖŗ
+python3 -m lmdeploy.serve.turbomind.deploy \
+ --model-name llama2 \
+ --model-path ./llama2-chat-7b-w4 \
+ --model-format awq \
+ --group-size 128
+
+## µÄ©ńÉå
+python3 -m lmdeploy.turbomind.chat ./workspace
+```
+
+## ÕÉ»ÕŖ© gradio µ£ŹÕŖĪ
+
+Õ”éµ×£µā│ķĆÜĶ┐ć webui õĖĵ©ĪÕ×ŗÕ»╣Ķ»Ø’╝īĶ»Ęµē¦ĶĪīõ╗źõĖŗÕæĮõ╗żÕÉ»ÕŖ© gradio µ£ŹÕŖĪ
+
+```shell
+python3 -m lmdeploy.serve.turbomind ./workspace --server_name {ip_addr} ----server_port {port}
+```
+
+ńäČÕÉÄ’╝īÕ£©µĄÅĶ¦łÕÖ©õĖŁµēōÕ╝Ć http://{ip_addr}:{port}’╝īÕŹ│ÕŻգ©ń║┐Õ»╣Ķ»Ø
+
+## µÄ©ńÉåķƤÕ║”
+
+µłæõ╗¼Õ£© NVIDIA GeForce RTX 4090 õĖŖõĮ┐ńö© [profile_generation.py](https://github.com/InternLM/lmdeploy/blob/main/benchmark/profile_generation.py)’╝īÕłåÕł½µĄŗĶ»Ģõ║å 4-bit Llama-2-7B-chat ÕÆī Llama-2-13B-chat µ©ĪÕ×ŗńÜä token ńö¤µłÉķƤÕ║”ŃĆ鵥ŗĶ»ĢķģŹńĮ«õĖ║ batch size = 1’╝ī(prompt_tokens, completion_tokens) = (1, 512)
+
+| model | llm-awq | mlc-llm | turbomind |
+| ---------------- | ------- | ------- | --------- |
+| Llama-2-7B-chat | 112.9 | 159.4 | 206.4 |
+| Llama-2-13B-chat | N/A | 90.7 | 115.8 |
+
+õĖŖĶ┐░õĖżõĖ¬µ©ĪÕ×ŗńÜä16bit ÕÆī 4bit µØāķ插╝īÕłåÕł½õĮ┐ńö© turbomind µÄ©ńÉåµŚČ’╝īÕÉäĶć¬Õ£©context size õĖ║ 2048 ÕÆī 4096 ķģŹńĮ«õĖŗ’╝īµēĆÕŹĀńÜ䵜ŠÕŁśÕ»╣µ»öÕ”éõĖŗ’╝Ü
+
+| model | 16bit(2048) | 4bit(2048) | 16bit(4096) | 4bit(4096) |
+| ---------------- | ----------- | ---------- | ----------- | ---------- |
+| Llama-2-7B-chat | 15.1 | 6.3 | 16.2 | 7.5 |
+| Llama-2-13B-chat | OOM | 10.3 | OOM | 12.0 |
+
+```shell
+python benchmark/profile_generation.py \
+ ./workspace \
+ --concurrency 1 --input_seqlen 1 --output_seqlen 512
+```
+
+## 4bit µØāķćŹķćÅÕī¢
+
+4bit µØāķćŹķćÅÕī¢Õīģµŗ¼ 2 µŁź’╝Ü
+
+- ńö¤µłÉķćÅÕī¢ÕÅéµĢ░
+- µĀ╣µŹ«ķćÅÕī¢ÕÅéµĢ░’╝īķćÅÕī¢µ©ĪÕ×ŗµØāķćŹ
+
+### ń¼¼õĖƵŁź’╝Üńö¤µłÉķćÅÕī¢ÕÅéµĢ░
+
+```shell
+python3 -m lmdeploy.lite.apis.calibrate \
+ --model $HF_MODEL \
+ --calib_dataset 'c4' \ # µĀĪÕćåµĢ░µŹ«ķøå’╝īµö»µīü c4, ptb, wikitext2, pileval
+ --calib_samples 128 \ # µĀĪÕćåķøåńÜäµĀʵ£¼µĢ░’╝īÕ”éµ×£µśŠÕŁśõĖŹÕż¤’╝īÕÅ»õ╗źķĆéÕĮōĶ░āÕ░Å
+ --calib_seqlen 2048 \ # ÕŹĢµØĪńÜäµ¢ćµ£¼ķĢ┐Õ║”’╝īÕ”éµ×£µśŠÕŁśõĖŹÕż¤’╝īÕÅ»õ╗źķĆéÕĮōĶ░āÕ░Å
+ --work_dir $WORK_DIR \ # õ┐ØÕŁś Pytorch µĀ╝Õ╝ÅķćÅÕī¢ń╗¤Ķ«ĪÕÅéµĢ░ÕÆīķćÅÕī¢ÕÉĵØāķćŹńÜäµ¢ćõ╗ČÕż╣
+```
+
+### ń¼¼õ║īµŁź’╝ÜķćÅÕī¢µØāķ揵©ĪÕ×ŗ
+
+LMDeploy õĮ┐ńö© AWQ ń«Śµ│ĢÕ»╣µ©ĪÕ×ŗµØāķćŹĶ┐øĶĪīķćÅÕī¢ŃĆéÕ£©µē¦ĶĪīõĖŗķØóńÜäÕæĮõ╗żµŚČ’╝īķ£ĆĶ”üµŖŖµŁźķ¬ż1ńÜä`$WORK_DIR`õ╝ĀÕģźŃĆéķćÅÕī¢ń╗ōµØ¤ÕÉÄ’╝īµØāķ揵¢ćõ╗Čõ╣¤õ╝ÜÕŁśµöŠÕ£©Ķ┐ÖõĖ¬ńø«ÕĮĢõĖŁŃĆéńäČÕÉÄÕ░▒ÕÅ»õ╗źµĀ╣µŹ« ["4bitµØāķ揵©ĪÕ×ŗµÄ©ńÉå"](#4bit-µØāķ揵©ĪÕ×ŗµÄ©ńÉå)ń½ĀĶŖéńÜäĶ»┤µśÄ’╝īĶ┐øĶĪīµ©ĪÕ×ŗµÄ©ńÉåŃĆé
+
+```shell
+python3 -m lmdeploy.lite.apis.auto_awq \
+ --model $HF_MODEL \
+ --w_bits 4 \ # µØāķćŹķćÅÕī¢ńÜä bit µĢ░
+ --w_group_size 128 \ # µØāķćŹķćÅÕī¢Õłåń╗äń╗¤Ķ«ĪÕ░║Õ»Ė
+ --work_dir $WORK_DIR \ # µŁźķ¬ż 1 õ┐ØÕŁśķćÅÕī¢ÕÅéµĢ░ńÜäńø«ÕĮĢ
+```
diff --git a/internlm_langchain/knowledge_base/LMDeploy/vector_store/index.faiss b/internlm_langchain/knowledge_base/LMDeploy/vector_store/index.faiss
new file mode 100644
index 00000000..9bcda8dc
Binary files /dev/null and b/internlm_langchain/knowledge_base/LMDeploy/vector_store/index.faiss differ
diff --git a/internlm_langchain/knowledge_base/MMAction/content/DATASET.md b/internlm_langchain/knowledge_base/MMAction/content/DATASET.md
new file mode 100644
index 00000000..df8c4e2d
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMAction/content/DATASET.md
@@ -0,0 +1,69 @@
+## Dataset Preparation
+
+### Notes on Video Data format
+MMAction supports two types of data format: raw frames and video. The former is widely used in previous projects such as [TSN](https://github.com/yjxiong/temporal-segment-networks).
+This is fast (especially when SSD is available) but fails to scale to the fast-growing datasets.
+(For example, the newest edition of [Kinetics](https://deepmind.com/research/open-source/open-source-datasets/kinetics/) has 650K videos and the total frames will take up several TBs.)
+The latter save much space but is slower due to video decoding at execution time.
+To alleviate such issue, we use [decord](https://github.com/zhreshold/decord) for efficient video loading.
+
+For action recognition, both formats are supported.
+For temporal action detection and spatial-temporal action detection, we still recommend the format of raw frames.
+
+
+### Supported datasets
+The supported datasets are listed below.
+We provide shell scripts for data preparation under the path `$MMACTION/data_tools/`.
+To ease usage, we provide tutorials of data deployment for each dataset.
+
+- [HMDB51](http://serre-lab.clps.brown.edu/resource/hmdb-a-large-human-motion-database/): See [PREPARING_HMDB51.md](https://github.com/open-mmlab/mmaction/tree/master/data_tools/hmdb51/PREPARING_HMDB51.md)
+- [UCF101](https://www.crcv.ucf.edu/data/UCF101.php): See [PREPARING_UCF101.md](https://github.com/open-mmlab/mmaction/tree/master/data_tools/ucf101/PREPARING_UCF101.md)
+- [Kinetics400](https://deepmind.com/research/open-source/open-source-datasets/kinetics/): See [PREPARING_KINETICS400.md](https://github.com/open-mmlab/mmaction/tree/master/data_tools/kinetics400/PREPARING_KINETICS400.md)
+- [THUMOS14](https://www.crcv.ucf.edu/THUMOS14/download.html): See [PREPARING_TH14.md](https://github.com/open-mmlab/mmaction/tree/master/data_tools/thumos14/PREPARING_TH14.md)
+- [AVA](https://research.google.com/ava/): See [PREPARING_AVA.md](https://github.com/open-mmlab/mmaction/tree/master/data_tools/ava/PREPARING_AVA.md)
+
+
+Now, you can switch to [GETTING_STARTED.md](https://github.com/open-mmlab/mmaction/tree/master/GETTING_STARTED.md) to train and test the model.
+
+
+**TL;DR** The following guide is helpful when you want to experiment with custom dataset.
+Similar to the datasets stated above, it is recommended organizing in `$MMACTION/data/$DATASET`.
+
+### Prepare annotations
+
+### Prepare videos
+Please refer to the official website and/or the official script to prepare the videos.
+Note that the videos should be arranged in either (1) a two-level directory organized by `${CLASS_NAME}/${VIDEO_ID}` or (2) a single-level directory.
+It is recommended using (1) for action recognition datasets (such as UCF101 and Kinetics) and using (2) for action detection datasets or those with multiple annotations per video (such as THUMOS14 and AVA).
+
+
+### Extract frames
+To extract frames (optical flow, to be specific), [dense_flow](https://github.com/yjxiong/dense_flow) is needed.
+(**TODO**: This will be merged into MMAction in the next version in a smoother way).
+For the time being, please use the following command:
+
+```shell
+python build_rawframes.py $SRC_FOLDER $OUT_FOLDER --df_path $PATH_OF_DENSE_FLOW --level {1, 2}
+```
+- `$SRC_FOLDER` points to the folder of the original video (for example)
+- `$OUT_FOLDER` points to the root folder where the extracted frames and optical flow store
+- `$PATH_OF_DENSE_FLOW` points to the root folder where dense_flow is installed.
+- `--level` is either 1 for the single-level directory or 2 for the two-level directory
+
+The recommended practice is
+
+1. set `$OUT_FOLDER` to be an folder located in SSD
+2. symlink the link `$OUT_FOLDER` to `$MMACTION/data/$DATASET/rawframes`.
+
+```shell
+ln -s ${OUT_FOLDER} $MMACTION/data/$DATASET/rawframes
+```
+
+### Generate filelist
+```shell
+cd $MMACTION
+python data_tools/build_file_list.py ${DATASET} ${SRC_FOLDER} --level {1, 2} --format {rawframes, videos}
+```
+- `${SRC_FOLDER}` should point to the folder of the corresponding to the data format:
+ - "$MMACTION/data/$DATASET/rawframes" if `--format rawframes`
+ - "$MMACTION/data/$DATASET/videos" if `--format videos`
diff --git a/internlm_langchain/knowledge_base/MMAction/content/DOCKER.md b/internlm_langchain/knowledge_base/MMAction/content/DOCKER.md
new file mode 100644
index 00000000..9ce308bf
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMAction/content/DOCKER.md
@@ -0,0 +1,40 @@
+# using Docker to set environment of mmaction
+
+## Requirements
+
+We've been testing/build from ubuntu 18.04 LTS & docker version 19.03.1 (with docker API version 1.40). If you want to building docker images, you could have
+
+- Docker Engine
+- nvidia-docker (to start container with GPUs)
+- Disk space (a lot)
+
+## Install Docker Engine (Ubuntu version)
+
+```
+$ curl -fsSL https://get.docker.com -o get-docker.sh
+$ sh get-docker.sh
+```
+
+## Install Nvidia-Docker
+
+You could update from [nvidia-docker](https://github.com/NVIDIA/nvidia-docker).
+
+## Build the images
+
+You could see the ```Dockerfile``` on [this](https://github.com/open-mmlab/mmaction) repository. So you can copy this file and build as manually or clone this repository.
+
+```
+$ git clone --recursive https://github.com/open-mmlab/mmaction
+$ cd mmaction
+$ docker build -t mmaction .
+```
+
+So when you building this image. The image will not successfully because we want to modified in this code. So you can clone repository in container manually from next step below.
+
+## Run container from images
+
+```
+$ docker run --name mmaction --gpus all -it -v /path/to/your/data:/root mmaction
+```
+
+When run the container, Please follow step [GETTING_STARTED.md](https://github.com/open-mmlab/mmaction/blob/master/GETTING_STARTED.md) to use mmaction.
\ No newline at end of file
diff --git a/internlm_langchain/knowledge_base/MMAction/content/GETTING_STARTED.md b/internlm_langchain/knowledge_base/MMAction/content/GETTING_STARTED.md
new file mode 100644
index 00000000..7c7ca8f9
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMAction/content/GETTING_STARTED.md
@@ -0,0 +1,96 @@
+# Getting Started
+
+This document provides basic tutorials for the usage of MMAction.
+For installation, please refer to [INSTALL.md](https://github.com/open-mmlab/mmaction/blob/master/INSTALL.md).
+For data deployment, please refer to [DATASET.md](https://github.com/open-mmlab/mmaction/blob/master/DATASET.md).
+
+
+## An example on UCF-101
+We first give an example of testing and training action recognition models on UCF101.
+### Prepare data
+First of all, please follow [PREPARING_UCF101.md](https://github.com/open-mmlab/mmaction/blob/master/data_tools/ucf101/PREPARING_UCF101.md) for data preparation.
+
+### Test a reference model
+Reference models are stored in [MODEL_ZOO.md](https://github.com/open-mmlab/mmaction/blob/master/MODEL_ZOO.md).
+We download a reference model spatial stream BN-Inception at `$MMACTION/modelzoo` using:
+```shell
+wget -c https://open-mmlab.s3.ap-northeast-2.amazonaws.com/mmaction/models/ucf101/tsn_2d_rgb_bninception_seg3_f1s1_b32_g8-98160339.pth -P ./modelzoo/
+```
+Then, together with provided configs files, we run the following code to test with multiple GPUs:
+```shell
+./tools/dist_test_recognizer.sh test_configs/TSN/ucf101/tsn_rgb_bninception.py tsn_2d_rgb_bninception_seg3_f1s1_b32_g8-98160339.pth 8
+```
+
+When testing 3D ConvNets, the oversample we used is 10 clips x 3 crops by default. For some extremely large models, it might be difficult for so many samples to fit on 1 GPU. When it happens, you can use commands for heavy test instead:
+```shell
+./tools/dist_test_recognizer_heavy.sh test_configs/CSN\ircsn_kinetics400_se_rgb_r152_seg1_32x2.py ircsn_kinetics400_se_rgb_r152_f32s2_ig65m_fbai-9d6ed879.pth 8 --batch_size=5
+```
+
+
+### Train a model with multiple GPUs
+
+To reproduce the model, we provide training scripts as follows:
+```shell
+./tools/dist_train_recognizer.sh configs/TSN/ucf101/tsn_rgb_bninception.py 8 --validate
+```
+- `--validate`: performs evaluation every k (default=1) epochs during the training, which help diagnose training process.
+
+
+## More examples
+The procedure is not limited to action recognition in UCF101.
+To perform spatial-temporal detection on AVA, we can train a baseline model by running
+```shell
+./tools/dist_train_detector.sh configs/ava/ava_fast_rcnn_nl_r50_c4_1x_kinetics_pretrain_crop.py 8 --validate
+```
+and evaluate a reference model by running
+```shell
+wget -c wget -c https://open-mmlab.s3.ap-northeast-2.amazonaws.com/mmaction/models/ava/fast_rcnn_ava2.1_nl_r50_c4_1x_f32s2_kin-e2495b48.pth -P modelzoo/
+python tools/test_detector.py ava_fast_rcnn_nl_r50_c4_1x_kinetics_pretrain_crop.py modelzoo/fast_rcnn_ava2.1_nl_r50_c4_1x_f32s2_kin-e2495b48.pth --out ava_fast_rcnn_nl_r50_multiscale.pkl --gpus 8 --eval bbox
+```
+
+To perform temporal action detection on THUMOS14, we can training a baseline model by running
+```shell
+./tools/dist_train_localizer.sh configs/thumos14/ssn_thumos14_rgb_bn_inception.py 8
+```
+and evaluate a reference model by running
+```shell
+wget -c wget -c https://open-mmlab.s3.ap-northeast-2.amazonaws.com/mmaction/models/thumos14/ssn_thumos14_rgb_bn_inception_tag-dac9ddb0.pth -P modelzoo/
+python tools/test_detector.py configs/thumos14/ssn_thumos14_rgb_bn_inception.py modelzoo/ssn_thumos14_rgb_bn_inception_tag-dac9ddb0.pth --gpus 8 --out ssn_thumos14_rgb_bn_inception.pkl --eval thumos14
+```
+
+
+## More Abstract Usage
+
+## Inference with pretrained models
+We provide testing scripts to evaluate a whole dataset.
+
+### Test a dataset
+```shell
+python tools/test_${ARCH}.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [--out ${RESULT_FILE}] [other task-specific arguments]
+```
+Arguments:
+- `${ARCH}` could be
+ - "recognizer" for action recognition (TSN, I3D, SlowFast, R(2+1)D, CSN, ...)
+ - "localizer" for temporal action detection/localization (SSN)
+ - "detector" for spatial-temporal action detection (a re-implmented Fast-RCNN baseline)
+- `${CONFIG_FILE}` is the config file stored in `$MMACTION/test_configs`.
+- `${CHECKPOINT_FILE}` is the checkpoint file.
+ Please refer to [MODEL_ZOO.md](https://github.com/open-mmlab/mmaction/blob/master/MODEL_ZOO.md) for more details.
+
+
+## Train a model
+MMAction implements distributed training and non-distributed training, powered by the same engine of [mmdetection](https://github.com/open-mmlab/mmdetection).
+
+
+### Train with multiple GPUs (Recommended)
+Training with multiple GPUs follows the rules below:
+
+```shell
+./tools/dist_train_${ARCH}.sh ${CONFIG_FILE} ${GPU_NUM} [optional arguments]
+```
+- ${ARCH} could be
+ - "recognizer" for action recognition (TSN, I3D, ...)
+ - "localizer" for temporal action detection/localization (SSN)
+ - "detector" for spatial-temporal action detection (a re-implmented Fast-RCNN baseline)
+- ${CONFIG_FILE} is the config file stored in `$MMACTION/configs`.
+- ${GPU_NUM} is the number of GPU (default: 8). If you are using number other than 8, please adjust the learning rate in the config file linearly.
diff --git a/internlm_langchain/knowledge_base/MMAction/content/INSTALL.md b/internlm_langchain/knowledge_base/MMAction/content/INSTALL.md
new file mode 100644
index 00000000..9052d1a1
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMAction/content/INSTALL.md
@@ -0,0 +1,159 @@
+# Installation
+
+```shell
+git clone --recursive https://github.com/open-mmlab/mmaction.git
+```
+
+## Requirements
+
+- Linux
+- Python 3.5+
+- PyTorch 1.0+
+- CUDA 9.0+
+- NVCC 2+
+- GCC 4.9+
+- ffmpeg 4.0+
+- [mmcv](https://github.com/open-mmlab/mmcv).
+ Note that you are strongly recommended to clone the master branch and build from scratch since some of the features have not been added in the latest release.
+- [Decord](https://github.com/zhreshold/decord)
+- [dense_flow](https://github.com/yjxiong/dense_flow)
+
+Note that the last two will be contained in this codebase as a submodule.
+
+## Install Pre-requisites
+### Install Decord (Optional)
+[Decord](https://github.com/zhreshold/decord) is an efficient video loader with smart shuffling.
+This is required when you want to use videos as the input format for training and is more efficient than OpenCV, useds by [mmcv](https://github.com/open-mmlab/mmcv).
+If you just want to have a quick experience with MMAction, you can simply skip this step.
+The installation steps follow decord's documentation.
+
+(a) install the required packages by running:
+
+```shell
+# official PPA comes with ffmpeg 2.8, which lacks tons of features, we use ffmpeg 4.0 here
+sudo apt-get install -y software-properties-common
+sudo add-apt-repository ppa:jonathonf/ffmpeg-4
+sudo apt-get update
+sudo apt-get install -y build-essential python3-dev python3-setuptools make cmake
+libavcodec-dev libavfilter-dev libavformat-dev libavutil-dev
+# note: make sure you have cmake 3.8 or later, you can install from cmake official website if it's too old
+sudo apt-get install ffmpeg
+```
+
+(b) Build the library from source
+
+```shell
+cd third_party/decord
+mkdir build && cd build
+cmake .. -DUSE_CUDA=0
+make
+```
+
+(c) Install python binding
+
+```shell
+cd ../python
+python setup.py install --user
+cd ../../
+```
+
+### Install dense_flow (Optional)
+[Dense_flow](https://github.com/yjxiong/dense_flow) is used to calculate the optical flow of videos.
+If you just want to have a quick experience with MMAction without taking pain of installing opencv, you can skip this step.
+
+Note that Dense_flow now supports OpenCV 4.1.0, 3.1.0 and 2.4.13.
+The master branch is for 4.1.0. For those with 2.4.13, please refer to the lines with strikethrough.
+
+13B
+ +```shell +python3 -m pip install fschat +python3 -m fastchat.model.apply_delta \ + --base-model-path /path/to/llama-13b \ + --target-model-path /path/to/vicuna-13b \ + --delta-path lmsys/vicuna-13b-delta-v1.1 + +python3 -m lmdeploy.serve.turbomind.deploy vicuna /path/to/vicuna-13b +bash workspace/service_docker_up.sh +``` + +õ╗ĵ│©ķćŖµ¢ćõ╗ČõĖŁµ×äÕ╗║µĢ░µŹ«ÕłŚĶĪ©ŃĆé | +| `MMAction2::BaseActionDataset` | `get_data_info(self, idx)`
ń╗ÖÕ«Ü `idx`’╝īõ╗ĵĢ░µŹ«ÕłŚĶĪ©õĖŁĶ┐öÕø×ńøĖÕ║öńÜäµĢ░µŹ«µĀʵ£¼ŃĆé | +| `MMEngine::BaseDataset` | `__getitem__(self, idx)`
ń╗ÖÕ«Ü `idx`’╝īĶ░āńö© `get_data_info` ĶÄĘÕÅ¢µĢ░µŹ«µĀʵ£¼’╝īńäČÕÉÄĶ░āńö© `pipeline` Õ£© `train_pipeline` µł¢ `val_pipeline` õĖŁµē¦ĶĪīµĢ░µŹ«ÕÅśµŹóÕÆīÕó×Õ╝║ŃĆé | + +## Õ«ÜÕłČµ¢░ńÜäµĢ░µŹ«ķøåń▒╗ + +Õż¦ÕżÜµĢ░µāģÕåĄõĖŗ’╝īµŖŖõĮĀńÜäµĢ░µŹ«ķøåń”╗ń║┐ĶĮ¼µŹóµłÉµīćիܵĀ╝Õ╝ŵś»ķ”¢ķĆēµ¢╣µ│Ģ’╝īõĮå MMAction2 µÅÉõŠøõ║åõĖĆõĖ¬µ¢╣õŠ┐ńÜäĶ┐ćń©ŗµØźÕłøÕ╗║õĖĆõĖ¬Õ«ÜÕłČńÜä `Dataset` ń▒╗ŃĆéÕ”éÕēŹµēĆĶ┐░’╝īõ╗╗ÕŖĪńē╣Õ«ÜńÜäµĢ░µŹ«ķøåÕŬķ£ĆĶ”üÕ«×ńÄ░ `load_data_list(self)` µØźõ╗ĵ│©ķćŖµ¢ćõ╗Čńö¤µłÉµĢ░µŹ«ÕłŚĶĪ©ŃĆéĶ»Ęµ│©µäÅ’╝ī`data_list` õĖŁńÜäÕģāń┤Āµś»ÕīģÕɽÕÉÄń╗ŁµĄüń©ŗõĖŁÕ┐ģĶ”üÕŁŚµ«ĄńÜä `dict`ŃĆé + +õ╗ź `VideoDataset` õĖ║õŠŗ’╝ī`train_pipeline`/`val_pipeline` Õ£© `DecordInit` õĖŁķ£ĆĶ”ü `'filename'`’╝īÕ£© `PackActionInputs` õĖŁķ£ĆĶ”ü `'label'`ŃĆéÕøĀµŁż’╝ī`data_list` õĖŁńÜäµĢ░µŹ«µĀʵ£¼Õ┐ģķĪ╗ÕīģÕɽ2õĖ¬ÕŁŚµ«Ą’╝Ü`'filename'`ÕÆī`'label'`ŃĆé +Ķ»ĘÕÅéĶĆā[Õ«ÜÕłČµĢ░µŹ«µĄüµ░┤ń║┐](customize_pipeline.md)õ╗źĶÄĘÕÅ¢µ£ēÕģ│ `pipeline` ńÜäµø┤ÕżÜĶ»”ń╗åõ┐Īµü»ŃĆé + +``` +data_list.append(dict(filename=filename, label=label)) +``` + +`AVADataset` õ╝ܵø┤ÕŖĀÕżŹµØé’╝ī`data_list` õĖŁńÜäµĢ░µŹ«µĀʵ£¼ÕīģÕɽµ£ēÕģ│Ķ¦åķóæµĢ░µŹ«ńÜäÕćĀõĖ¬ÕŁŚµ«ĄŃĆ鵣żÕż¢’╝īÕ«āķćŹÕåÖõ║å `get_data_info(self, idx)` õ╗źĶĮ¼µŹóÕ£©µŚČń®║ÕŖ©õĮ£µŻĆµĄŗµĢ░µŹ«µĄüµ░┤ń║┐õĖŁķ£ĆĶ”üńö©ńÜäÕŁŚµ«ĄŃĆé + +```python + +class AVADataset(BaseActionDataset): + ... + + def load_data_list(self) -> List[dict]: + ... + video_info = dict( + frame_dir=frame_dir, + video_id=video_id, + timestamp=int(timestamp), + img_key=img_key, + shot_info=shot_info, + fps=self._FPS, + ann=ann) + data_list.append(video_info) + data_list.append(video_info) + return data_list + + def get_data_info(self, idx: int) -> dict: + ... + ann = data_info.pop('ann') + data_info['gt_bboxes'] = ann['gt_bboxes'] + data_info['gt_labels'] = ann['gt_labels'] + data_info['entity_ids'] = ann['entity_ids'] + return data_info +``` + +## õĖ║ PoseDataset Ķć¬Õ«Üõ╣ēÕģ│ķö«ńé╣µĀ╝Õ╝Å + +MMAction2 ńø«ÕēŹµö»µīüõĖēń¦ŹÕģ│ķö«ńé╣µĀ╝Õ╝Å’╝Ü`coco`’╝ī`nturgb+d` ÕÆī `openpose`ŃĆéÕ”éµ×£õĮĀõĮ┐ńö©ÕģČõĖŁõĖĆń¦ŹµĀ╝Õ╝Å’╝īõĮĀÕÅ»õ╗źń«ĆÕŹĢÕ£░Õ£©õ╗źõĖŗµ©ĪÕØŚõĖŁµīćÕ«ÜńøĖÕ║öńÜäµĀ╝Õ╝Å’╝Ü + +Õ»╣õ║ÄÕøŠÕŹĘń¦»ńĮæń╗£’╝īÕ”é AAGCN’╝īSTGCN’╝ī... + +- `pipeline`’╝ÜÕ£© `JointToBone` õĖŁńÜäÕÅéµĢ░ `dataset`ŃĆé +- `backbone`’╝ÜÕ£©ÕøŠÕŹĘń¦»ńĮæń╗£õĖŁńÜäÕÅéµĢ░ `graph_cfg`ŃĆé + +Õ»╣õ║Ä PoseC3D’╝Ü + +- `pipeline`’╝ÜÕ£© `Flip` õĖŁ’╝īµĀ╣µŹ«Õģ│ķö«ńé╣ńÜäÕ»╣ń¦░Õģ│ń│╗µīćÕ«Ü `left_kp` ÕÆī `right_kp`ŃĆé +- `pipeline`’╝ÜÕ£© `GeneratePoseTarget` õĖŁ’╝īÕ”éµ×£ `with_limb` õĖ║ `True`’╝īµīćÕ«Ü`skeletons`’╝ī`left_limb`’╝ī`right_limb`’╝īÕ”éµ×£ `with_kp` õĖ║ `True`’╝īµīćÕ«Ü`left_kp` ÕÆī `right_kp`ŃĆé + +Õ”éµ×£õĮ┐ńö©Ķć¬Õ«Üõ╣ēÕģ│ķö«ńé╣µĀ╝Õ╝Å’╝īķ£ĆĶ”üÕ£© `backbone` ÕÆī `pipeline` õĖŁķāĮÕīģÕɽõĖĆõĖ¬µ¢░ńÜäÕøŠÕĖāÕ▒ĆŃĆéĶ┐ÖõĖ¬ÕĖāÕ▒ĆÕ░åÕ«Üõ╣ēÕģ│ķö«ńé╣ÕÅŖÕģČĶ┐׵ğÕģ│ń│╗ŃĆé + +õ╗ź `coco` µĢ░µŹ«ķøåõĖ║õŠŗ’╝īµłæõ╗¼Õ£© `Graph` õĖŁÕ«Üõ╣ēõ║åõĖĆõĖ¬ÕÉŹõĖ║ `coco` ńÜäÕĖāÕ▒ĆŃĆéĶ┐ÖõĖ¬ÕĖāÕ▒ĆńÜä `inward` Ķ┐׵ğÕīģµŗ¼µēƵ£ēĶŖéńé╣Ķ┐׵ğ’╝īµ»ÅõĖ¬**ÕÉæÕ┐ā**Ķ┐׵ğńö▒õĖĆõĖ¬ĶŖéńé╣Õģāń╗äń╗䵳ÉŃĆé`coco`ńÜäķóØÕż¢Ķ«ŠńĮ«Õīģµŗ¼Õ░åĶŖéńé╣µĢ░µīćÕ«ÜõĖ║ `17`’╝īÕ░å `node 0` Ķ«ŠõĖ║õĖŁÕ┐āĶŖéńé╣ŃĆé + +```python + +self.num_node = 17 +self.inward = [(15, 13), (13, 11), (16, 14), (14, 12), (11, 5), + (12, 6), (9, 7), (7, 5), (10, 8), (8, 6), (5, 0), + (6, 0), (1, 0), (3, 1), (2, 0), (4, 2)] +self.center = 0 +``` + +ÕÉīµĀĘ’╝īµłæõ╗¼Õ£© `JointToBone` õĖŁÕ«Üõ╣ēõ║å `pairs`’╝īµĘ╗ÕŖĀõ║åõĖĆõĖ¬ bone `(0, 0)` õ╗źõĮ┐ bone ńÜäµĢ░ķćÅÕ»╣ķĮÉÕł░ jointŃĆécocoµĢ░µŹ«ķøåńÜä `pairs` Õ”éõĖŗµēĆńż║’╝ī`JointToBone` õĖŁńÜä `pairs` ńÜäķĪ║Õ║ŵŚĀÕģ│ń┤¦Ķ”üŃĆé + +```python + +self.pairs = ((0, 0), (1, 0), (2, 0), (3, 1), (4, 2), + (5, 0), (6, 0), (7, 5), (8, 6), (9, 7), + (10, 8), (11, 0), (12, 0), (13, 11), (14, 12), + (15, 13), (16, 14)) +``` + +Ķ”üõĮ┐ńö©õĮĀńÜäĶć¬Õ«Üõ╣ēÕģ│ķö«ńé╣µĀ╝Õ╝Å’╝īÕŬķ£ĆÕ«Üõ╣ēõĖŖĶ┐░Ķ«ŠńĮ«õĖ║õĮĀńÜäÕøŠń╗ōµ×ä’╝īÕ╣ČÕ£©õĮĀńÜäķģŹńĮ«µ¢ćõ╗ČõĖŁµīćÕ«ÜÕ«āõ╗¼’╝īÕ”éõĖŗµēĆńż║ŃĆéÕ£©Ķ┐ÖõĖ¬õŠŗÕŁÉõĖŁ’╝īµłæõ╗¼Õ░åõĮ┐ńö© `STGCN`’╝īÕģČõĖŁ `n` ĶĪ©ńż║ń▒╗Õł½ńÜäµĢ░ķćÅ’╝ī`custom_dataset` Õ£© `Graph` ÕÆī `JointToBone` õĖŁÕ«Üõ╣ēŃĆé + +```python +model = dict( + type='RecognizerGCN', + backbone=dict( + type='STGCN', graph_cfg=dict(layout='custom_dataset', mode='stgcn_spatial')), + cls_head=dict(type='GCNHead', num_classes=n, in_channels=256)) + +train_pipeline = [ + ... + dict(type='GenSkeFeat', dataset='custom_dataset'), + ...] + +val_pipeline = [ + ... + dict(type='GenSkeFeat', dataset='custom_dataset'), + ...] + +test_pipeline = [ + ... + dict(type='GenSkeFeat', dataset='custom_dataset'), + ...] + +``` + +ÕŬķ£Ćń«ĆÕŹĢÕ£░µīćÕ«ÜĶć¬Õ«Üõ╣ēÕĖāÕ▒Ć’╝īõĮĀÕ░▒ÕÅ»õ╗źõĮ┐ńö©õĮĀĶć¬ÕĘ▒ńÜäÕģ│ķö«ńé╣µĀ╝Õ╝ÅĶ┐øĶĪīĶ«Łń╗āÕÆīµĄŗĶ»Ģõ║åŃĆéķĆÜĶ┐ćĶ┐Öń¦Źµ¢╣Õ╝Å’╝īMMAction2 õĖ║ńö©µłĘµÅÉõŠøõ║åÕŠłÕż¦ńÜäńüĄµ┤╗µĆ¦’╝īÕģüĶ«Ėńö©µłĘĶć¬Õ«Üõ╣ēõ╗¢õ╗¼ńÜäµĢ░µŹ«ķøåÕÆīÕģ│ķö«ńé╣µĀ╝Õ╝Å’╝īõ╗źµ╗ĪĶČ│õ╗¢õ╗¼ńē╣Õ«ÜńÜäķ£Ćµ▒éŃĆé + +õ╗źõĖŖÕ░▒µś»Õģ│õ║ÄÕ”éõĮĢĶć¬Õ«Üõ╣ēõĮĀńÜäµĢ░µŹ«ķøåńÜäõĖĆõ║øµ¢╣µ│ĢŃĆéÕĖīµ£øĶ┐ÖõĖ¬µĢÖń©ŗĶāĮÕĖ«ÕŖ®õĮĀńÉåĶ¦ŻMMAction2ńÜäµĢ░µŹ«ķøåń╗ōµ×ä’╝īÕ╣ȵĢÖń╗ÖõĮĀÕ”éõĮĢµĀ╣µŹ«Ķć¬ÕĘ▒ńÜäķ£Ćµ▒éÕłøÕ╗║µ¢░ńÜäµĢ░µŹ«ķøåŃĆéĶÖĮńäČĶ┐ÖÕÅ»ĶāĮķ£ĆĶ”üõĖĆõ║øń╝¢ń©ŗń¤źĶ»å’╝īõĮåµś» MMAction2 Ķ»ĢÕøŠõĮ┐Ķ┐ÖõĖ¬Ķ┐ćń©ŗÕ░ĮÕÅ»ĶāĮń«ĆÕŹĢŃĆéķĆÜĶ┐ćõ║åĶ¦ŻĶ┐Öõ║øÕ¤║µ£¼µ”éÕ┐Ą’╝īõĮĀÕ░åĶāĮÕż¤µø┤ÕźĮÕ£░µÄ¦ÕłČõĮĀńÜäµĢ░µŹ«’╝īõ╗ÄĶĆīµö╣Ķ┐øõĮĀńÜ䵩ĪÕ×ŗµĆ¦ĶāĮŃĆé diff --git a/internlm_langchain/knowledge_base/MMAction2/content/customize_logging.md b/internlm_langchain/knowledge_base/MMAction2/content/customize_logging.md new file mode 100644 index 00000000..badb315c --- /dev/null +++ b/internlm_langchain/knowledge_base/MMAction2/content/customize_logging.md @@ -0,0 +1,163 @@ +# Ķć¬Õ«Üõ╣ēµŚźÕ┐Ś + +MMAction2 Õ£©Ķ┐ÉĶĪīĶ┐ćń©ŗõĖŁõ╝Üõ║¦ńö¤Õż¦ķćÅńÜ䵌źÕ┐Ś’╝īÕ”éµŹ¤Õż▒ŃĆüĶ┐Łõ╗ŻµŚČķŚ┤ŃĆüÕŁ”õ╣ĀńÄćńŁēŃĆéÕ£©Ķ┐ÖõĖĆķā©Õłå’╝īµłæõ╗¼Õ░åÕÉæõĮĀõ╗ŗń╗ŹÕ”éõĮĢĶŠōÕć║Ķć¬Õ«Üõ╣ēµŚźÕ┐ŚŃĆéµ£ēÕģ│µŚźÕ┐Śń│╗ń╗¤ńÜäµø┤ÕżÜĶ»”ń╗åõ┐Īµü»’╝īĶ»ĘÕÅéĶĆā [MMEngine µĢÖń©ŗ](https://mmengine.readthedocs.io/zh_CN/latest/advanced_tutorials/logging.html)ŃĆé + +- [Ķć¬Õ«Üõ╣ēµŚźÕ┐Ś](#Ķć¬Õ«Üõ╣ēµŚźÕ┐Ś) + - [ńüĄµ┤╗ńÜ䵌źÕ┐Śń│╗ń╗¤](#ńüĄµ┤╗ńÜ䵌źÕ┐Śń│╗ń╗¤) + - [Õ«ÜÕłČµŚźÕ┐Ś](#Õ«ÜÕłČµŚźÕ┐Ś) + - [Õ»╝Õć║Ķ░āĶ»ĢµŚźÕ┐Ś](#Õ»╝Õć║Ķ░āĶ»ĢµŚźÕ┐Ś) + +## ńüĄµ┤╗ńÜ䵌źÕ┐Śń│╗ń╗¤ + +ķ╗śĶ«żµāģÕåĄõĖŗ’╝īMMAction2 ńÜ䵌źÕ┐Śń│╗ń╗¤ńö▒ [default_runtime](/configs/_base_/default_runtime.py) õĖŁńÜä `LogProcessor` ķģŹńĮ«’╝Ü + +```python +log_processor = dict(type='LogProcessor', window_size=20, by_epoch=True) +``` + +ķ╗śĶ«żµāģÕåĄõĖŗ’╝ī`LogProcessor` µŹĢĶÄĘ `model.forward` Ķ┐öÕø×ńÜäµēƵ£ēõ╗ź `loss` Õ╝ĆÕż┤ńÜäÕŁŚµ«ĄŃĆéõŠŗÕ”é’╝īÕ£©õ╗źõĖŗµ©ĪÕ×ŗõĖŁ’╝ī`loss1` ÕÆī `loss2` Õ░åÕ£©µ▓Īµ£ēõ╗╗õĮĢķóØÕż¢ķģŹńĮ«ńÜäµāģÕåĄõĖŗĶć¬ÕŖ©Ķ«░ÕĮĢÕł░µŚźÕ┐ŚŃĆé + +```python +from mmengine.model import BaseModel + +class ToyModel(BaseModel): + def __init__(self) -> None: + super().__init__() + self.linear = nn.Linear(1, 1) + + def forward(self, img, label, mode): + feat = self.linear(img) + loss1 = (feat - label).pow(2) + loss2 = (feat - label).abs() + return dict(loss1=loss1, loss2=loss2) +``` + +ĶŠōÕć║µŚźÕ┐ŚķüĄÕŠ¬õ╗źõĖŗµĀ╝Õ╝Å’╝Ü + +``` +08/21 02:58:41 - mmengine - INFO - Epoch(train) [1][10/25] lr: 1.0000e-02 eta: 0:00:00 time: 0.0019 data_time: 0.0004 loss1: 0.8381 loss2: 0.9007 loss: 1.7388 +08/21 02:58:41 - mmengine - INFO - Epoch(train) [1][20/25] lr: 1.0000e-02 eta: 0:00:00 time: 0.0029 data_time: 0.0010 loss1: 0.1978 loss2: 0.4312 loss: 0.6290 +``` + +`LogProcessor` Õ░åµīēõ╗źõĖŗµĀ╝Õ╝ÅĶŠōÕć║µŚźÕ┐Ś’╝Ü + +- µŚźÕ┐ŚńÜäÕēŹń╝Ć’╝Ü + - epoch µ©ĪÕ╝Å(`by_epoch=True`)’╝Ü`Epoch(train) [{current_epoch}/{current_iteration}]/{dataloader_length}` + - iteration µ©ĪÕ╝Å(`by_epoch=False`)’╝Ü`Iter(train) [{current_iteration}/{max_iteration}]` +- ÕŁ”õ╣ĀńÄć (`lr`)’╝ܵ£ĆÕÉÄõĖƵ¼ĪĶ┐Łõ╗ŻńÜäÕŁ”õ╣ĀńÄćŃĆé +- µŚČķŚ┤’╝Ü + - `time`’╝ÜĶ┐ćÕÄ╗ `window_size` µ¼ĪĶ┐Łõ╗ŻńÜäµÄ©ńÉåÕ╣│ÕØ浌ČķŚ┤ŃĆé + - `data_time`’╝ÜĶ┐ćÕÄ╗ `window_size` µ¼ĪĶ┐Łõ╗ŻńÜäµĢ░µŹ«ÕŖĀĶĮĮÕ╣│ÕØ浌ČķŚ┤ŃĆé + - `eta`’╝ÜÕ«īµłÉĶ«Łń╗āńÜäķóäĶ«ĪÕł░ĶŠŠµŚČķŚ┤ŃĆé +- µŹ¤Õż▒’╝ÜĶ┐ćÕÄ╗ `window_size` µ¼ĪĶ┐Łõ╗ŻõĖŁµ©ĪÕ×ŗĶŠōÕć║ńÜäÕ╣│ÕØ浏¤Õż▒ŃĆé + +```{warning} +ķ╗śĶ«żµāģÕåĄõĖŗ’╝īlog_processor ĶŠōÕć║Õ¤║õ║Ä epoch ńÜ䵌źÕ┐Ś(`by_epoch=True`)ŃĆéĶ”üÕŠŚÕł░õĖÄ `train_cfg` Õī╣ķģŹńÜäķóäµ£¤µŚźÕ┐Ś’╝īµłæõ╗¼Õ║öÕ£© `train_cfg` ÕÆī `log_processor` õĖŁĶ«ŠńĮ«ńøĖÕÉīńÜä `by_epoch` ÕĆ╝ŃĆé +``` + +µĀ╣µŹ«õ╗źõĖŖĶ¦äÕłÖ’╝īõ╗ŻńĀüńē浫ĄÕ░åµ»Å20µ¼ĪĶ┐Łõ╗ŻĶ«Īń«Ś loss1 ÕÆī loss2 ńÜäÕ╣│ÕØćÕĆ╝ŃĆéµø┤ÕżÜń▒╗Õ×ŗńÜäń╗¤Ķ«Īµ¢╣µ│Ģ’╝īĶ»ĘÕÅéĶĆā [mmengine.runner.LogProcessor](mmengine.runner.LogProcessor)ŃĆé + +## Õ«ÜÕłČµŚźÕ┐Ś + +µŚźÕ┐Śń│╗ń╗¤õĖŹõ╗ģÕÅ»õ╗źĶ«░ÕĮĢ `loss`’╝ī`lr` ńŁē’╝īĶ┐śÕÅ»õ╗źµöČķøåÕÆīĶŠōÕć║Ķć¬Õ«Üõ╣ēµŚźÕ┐ŚŃĆéõŠŗÕ”é’╝īÕ”éµ×£µłæõ╗¼µā│Ķ”üń╗¤Ķ«ĪõĖŁķŚ┤µŹ¤Õż▒’╝Ü + +`ToyModel` Õ£© forward õĖŁĶ«Īń«Ś `loss_tmp`’╝īõĮåõĖŹÕ░åÕģČõ┐ØÕŁśÕł░Ķ┐öÕø×ÕŁŚÕģĖõĖŁŃĆé + +```python +from mmengine.logging import MessageHub + +class ToyModel(BaseModel): + + def __init__(self) -> None: + super().__init__() + self.linear = nn.Linear(1, 1) + + def forward(self, img, label, mode): + feat = self.linear(img) + loss_tmp = (feat - label).abs() + loss = loss_tmp.pow(2) + + message_hub = MessageHub.get_current_instance() + # Õ£©µČłµü»õĖŁÕ┐āµø┤µ¢░õĖŁķŚ┤ńÜä `loss_tmp` + message_hub.update_scalar('train/loss_tmp', loss_tmp.sum()) + return dict(loss=loss) +``` + +Õ░å `loss_tmp` µĘ╗ÕŖĀÕł░ķģŹńĮ«õĖŁ’╝Ü + +```python +log_processor = dict( + type='LogProcessor', + window_size=20, + by_epoch=True, + custom_cfg=[ + # õĮ┐ńö©Õ╣│ÕØćÕĆ╝ń╗¤Ķ«Ī loss_tmp + dict( + data_src='loss_tmp', + window_size=20, + method_name='mean') + ]) +``` + +`loss_tmp` Õ░åĶó½µĘ╗ÕŖĀÕł░ĶŠōÕć║µŚźÕ┐ŚõĖŁ’╝Ü + +``` +08/21 03:40:31 - mmengine - INFO - Epoch(train) [1][10/25] lr: 1.0000e-02 eta: 0:00:00 time: 0.0026 data_time: 0.0008 loss_tmp: 0.0097 loss: 0.0000 +08/21 03:40:31 - mmengine - INFO - Epoch(train) [1][20/25] lr: 1.0000e-02 eta: 0:00:00 time: 0.0028 data_time: 0.0013 loss_tmp: 0.0065 loss: 0.0000 +``` + +## Õ»╝Õć║Ķ░āĶ»ĢµŚźÕ┐Ś + +Ķ”üÕ░åĶ░āĶ»ĢµŚźÕ┐ŚÕ»╝Õć║Õł░ `work_dir`’╝īõĮĀÕÅ»õ╗źÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁĶ«ŠńĮ«µŚźÕ┐Śń║¦Õł½Õ”éõĖŗ’╝Ü + +``` +log_level='DEBUG' +``` + +``` +08/21 18:16:22 - mmengine - DEBUG - Get class `LocalVisBackend` from "vis_backend" registry in "mmengine" +08/21 18:16:22 - mmengine - DEBUG - An `LocalVisBackend` instance is built from registry, its implementation can be found in mmengine.visualization.vis_backend +08/21 18:16:22 - mmengine - DEBUG - Get class `RuntimeInfoHook` from "hook" registry in "mmengine" +08/21 18:16:22 - mmengine - DEBUG - An `RuntimeInfoHook` instance is built from registry, its implementation can be found in mmengine.hooks.runtime_info_hook +08/21 18:16:22 - mmengine - DEBUG - Get class `IterTimerHook` from "hook" registry in "mmengine" +... +``` + +µŁżÕż¢’╝īÕ”éµ×£õĮĀµŁŻÕ£©õĮ┐ńö©Õģ▒õ║½ÕŁśÕé©Ķ«Łń╗āõĮĀńÜ䵩ĪÕ×ŗ’╝īķéŻõ╣łÕ£© `debug` µ©ĪÕ╝ÅõĖŗ’╝īõĖŹÕÉīµÄÆÕÉŹńÜ䵌źÕ┐ŚÕ░åĶó½õ┐ØÕŁśŃĆ鵌źÕ┐ŚńÜäÕ▒éń║¦ń╗ōµ×äÕ”éõĖŗ’╝Ü + +```text +./tmp +Ōö£ŌöĆŌöĆ tmp.log +Ōö£ŌöĆŌöĆ tmp_rank1.log +Ōö£ŌöĆŌöĆ tmp_rank2.log +Ōö£ŌöĆŌöĆ tmp_rank3.log +Ōö£ŌöĆŌöĆ tmp_rank4.log +Ōö£ŌöĆŌöĆ tmp_rank5.log +Ōö£ŌöĆŌöĆ tmp_rank6.log +ŌööŌöĆŌöĆ tmp_rank7.log +... +ŌööŌöĆŌöĆ tmp_rank63.log +``` + +Õ£©Õģʵ£ēńŗ¼ń½ŗÕŁśÕé©ńÜäÕżÜÕÅ░µ£║ÕÖ©õĖŖńÜ䵌źÕ┐Ś’╝Ü + +```text +# Ķ«ŠÕżć’╝Ü0’╝Ü +work_dir/ +ŌööŌöĆŌöĆ exp_name_logs + Ōö£ŌöĆŌöĆ exp_name.log + Ōö£ŌöĆŌöĆ exp_name_rank1.log + Ōö£ŌöĆŌöĆ exp_name_rank2.log + Ōö£ŌöĆŌöĆ exp_name_rank3.log + ... + ŌööŌöĆŌöĆ exp_name_rank7.log + +# Ķ«ŠÕżć’╝Ü7’╝Ü +work_dir/ +ŌööŌöĆŌöĆ exp_name_logs + Ōö£ŌöĆŌöĆ exp_name_rank56.log + Ōö£ŌöĆŌöĆ exp_name_rank57.log + Ōö£ŌöĆŌöĆ exp_name_rank58.log + ... + ŌööŌöĆŌöĆ exp_name_rank63.log +``` diff --git a/internlm_langchain/knowledge_base/MMAction2/content/customize_models.md b/internlm_langchain/knowledge_base/MMAction2/content/customize_models.md new file mode 100644 index 00000000..c64a6bb3 --- /dev/null +++ b/internlm_langchain/knowledge_base/MMAction2/content/customize_models.md @@ -0,0 +1,3 @@ +# Ķć¬Õ«Üõ╣ēµ©ĪÕ×ŗ + +ÕåģÕ«╣Õ╗║Ķ«ŠõĖŁ... diff --git a/internlm_langchain/knowledge_base/MMAction2/content/customize_optimizer.md b/internlm_langchain/knowledge_base/MMAction2/content/customize_optimizer.md new file mode 100644 index 00000000..5e4279d4 --- /dev/null +++ b/internlm_langchain/knowledge_base/MMAction2/content/customize_optimizer.md @@ -0,0 +1,332 @@ +# Ķć¬Õ«Üõ╣ēõ╝śÕī¢ÕÖ© + +Õ£©µ£¼µĢÖń©ŗõĖŁ’╝īµłæõ╗¼Õ░åõ╗ŗń╗ŹõĖĆõ║øµ×äÕ╗║õ╝śÕī¢ÕÖ©ÕÆīÕŁ”õ╣ĀńÄćńŁ¢ńĢźńÜäµ¢╣µ│Ģ’╝īõ╗źńö©õ║ÄõĮĀńÜäõ╗╗ÕŖĪŃĆé + +- [Ķć¬Õ«Üõ╣ēõ╝śÕī¢ÕÖ©](#Ķć¬Õ«Üõ╣ēõ╝śÕī¢ÕÖ©) + - [õĮ┐ńö© optim_wrapper µ×äÕ╗║õ╝śÕī¢ÕÖ©](#õĮ┐ńö©-optim_wrapper-µ×äÕ╗║õ╝śÕī¢ÕÖ©) + - [õĮ┐ńö© PyTorch µö»µīüńÜäõ╝śÕī¢ÕÖ©](#õĮ┐ńö©-pytorch-µö»µīüńÜäõ╝śÕī¢ÕÖ©) + - [ÕÅéµĢ░Õī¢ń▓Šń╗åķģŹńĮ«](#ÕÅéµĢ░Õī¢ń▓Šń╗åķģŹńĮ«) + - [µó»Õ║”ĶŻüÕē¬](#µó»Õ║”ĶŻüÕē¬) + - [µó»Õ║”ń┤»ń¦»](#µó»Õ║”ń┤»ń¦») + - [Ķć¬Õ«Üõ╣ēÕÅéµĢ░ńŁ¢ńĢź](#Ķć¬Õ«Üõ╣ēÕÅéµĢ░ńŁ¢ńĢź) + - [Ķć¬Õ«Üõ╣ēÕŁ”õ╣ĀńÄćńŁ¢ńĢź](#Ķć¬Õ«Üõ╣ēÕŁ”õ╣ĀńÄćńŁ¢ńĢź) + - [Ķć¬Õ«Üõ╣ēÕŖ©ķćÅńŁ¢ńĢź](#Ķć¬Õ«Üõ╣ēÕŖ©ķćÅńŁ¢ńĢź) + - [µĘ╗ÕŖĀµ¢░ńÜäõ╝śÕī¢ÕÖ©µł¢µ×äķĆĀÕÖ©](#µĘ╗ÕŖĀµ¢░ńÜäõ╝śÕī¢ÕÖ©µł¢µ×äķĆĀÕÖ©) + - [µĘ╗ÕŖĀµ¢░ńÜäõ╝śÕī¢ÕÖ©](#µĘ╗ÕŖĀµ¢░ńÜäõ╝śÕī¢ÕÖ©) + - [1. Õ«×ńÄ░õĖĆõĖ¬µ¢░ńÜäõ╝śÕī¢ÕÖ©](#1-Õ«×ńÄ░õĖĆõĖ¬µ¢░ńÜäõ╝śÕī¢ÕÖ©) + - [2. Õ»╝Õģźõ╝śÕī¢ÕÖ©](#2-Õ»╝Õģźõ╝śÕī¢ÕÖ©) + - [3. Õ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁµīćÕ«Üõ╝śÕī¢ÕÖ©](#3-Õ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁµīćÕ«Üõ╝śÕī¢ÕÖ©) + - [µĘ╗ÕŖĀµ¢░ńÜäõ╝śÕī¢ÕÖ©µ×äķĆĀÕÖ©](#µĘ╗ÕŖĀµ¢░ńÜäõ╝śÕī¢ÕÖ©µ×äķĆĀÕÖ©) + +## õĮ┐ńö© optim_wrapper µ×äÕ╗║õ╝śÕī¢ÕÖ© + +µłæõ╗¼õĮ┐ńö© `optim_wrapper` ÕŁŚµ«ĄµØźķģŹńĮ«õ╝śÕī¢ńŁ¢ńĢź’╝īÕģČõĖŁÕīģµŗ¼ķĆēµŗ®õ╝śÕī¢ÕÖ©ŃĆüÕÅéµĢ░ķĆÉõĖ¬ķģŹńĮ«ŃĆüµó»Õ║”ĶŻüÕē¬ÕÆīµó»Õ║”ń┤»ń¦»ŃĆéõĖĆõĖ¬ń«ĆÕŹĢńÜäńż║õŠŗÕÅ»õ╗źµś»’╝Ü + +```python +optim_wrapper = dict( + type='OptimWrapper', + optimizer=dict(type='SGD', lr=0.0003, weight_decay=0.0001) +) +``` + +Õ£©õĖŖķØóńÜäńż║õŠŗõĖŁ’╝īµłæõ╗¼µ×äÕ╗║õ║åõĖĆõĖ¬ÕŁ”õ╣ĀńÄćõĖ║ 0.0003’╝īµØāķćŹĶĪ░ÕćÅõĖ║ 0.0001 ńÜä SGD õ╝śÕī¢ÕÖ©ŃĆé + +### õĮ┐ńö© PyTorch µö»µīüńÜäõ╝śÕī¢ÕÖ© + +µłæõ╗¼µö»µīü PyTorch Õ«×ńÄ░ńÜäµēƵ£ēõ╝śÕī¢ÕÖ©ŃĆéĶ”üõĮ┐ńö©õĖŹÕÉīńÜäõ╝śÕī¢ÕÖ©’╝īÕŬķ£Ćµø┤µö╣ķģŹńĮ«µ¢ćõ╗ČõĖŁńÜä `optimizer` ÕŁŚµ«ĄŃĆéõŠŗÕ”é’╝īÕ”éµ×£µā│õĮ┐ńö© `torch.optim.Adam`’╝īÕÅ»õ╗źÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁĶ┐øĶĪīÕ”éõĖŗõ┐«µö╣ŃĆé + +```python +optim_wrapper = dict( + type='OptimWrapper', + optimizer = dict( + type='Adam', + lr=0.001, + betas=(0.9, 0.999), + eps=1e-08, + weight_decay=0, + amsgrad=False), +) +``` + +ķ”¢Õģł’╝īµłæõ╗¼ķ£ĆĶ”üÕ░å `type` ńÜäÕĆ╝µø┤µö╣õĖ║ `torch.optim` µö»µīüńÜäµ£¤µ£øõ╝śÕī¢ÕÖ©ÕÉŹń¦░ŃĆéńäČÕÉÄ’╝īÕ░åĶ»źõ╝śÕī¢ÕÖ©ńÜäÕ┐ģĶ”üÕÅéµĢ░µĘ╗ÕŖĀÕł░ `optimizer` ÕŁŚµ«ĄõĖŁŃĆéõĖŖĶ┐░ķģŹńĮ«Õ░åµ×äÕ╗║õ╗źõĖŗõ╝śÕī¢ÕÖ©’╝Ü + +```python +torch.optim.Adam(lr=0.001, + betas=(0.9, 0.999), + eps=1e-08, + weight_decay=0, + amsgrad=False) +``` + +### ÕÅéµĢ░Õī¢ń▓Šń╗åķģŹńĮ« + +õĖĆõ║øµ©ĪÕ×ŗÕÅ»ĶāĮÕ»╣õ╝śÕī¢µ£ēńē╣Õ«ÜńÜäÕÅéµĢ░Ķ«ŠńĮ«’╝īõŠŗÕ”éÕ»╣õ║Ä BatchNorm Õ▒éõĖŹõĮ┐ńö©µØāķćŹĶĪ░ÕćÅ’╝īµł¢ĶĆģÕ»╣õĖŹÕÉīńĮæń╗£Õ▒éõĮ┐ńö©õĖŹÕÉīńÜäÕŁ”õ╣ĀńÄćŃĆéõĖ║õ║åÕ»╣ÕģČĶ┐øĶĪīń╗åĶć┤ķģŹńĮ«’╝īµłæõ╗¼ÕÅ»õ╗źõĮ┐ńö© `optim_wrapper` õĖŁńÜä `paramwise_cfg` ÕÅéµĢ░ŃĆé + +- **õĖ║õĖŹÕÉīń▒╗Õ×ŗńÜäÕÅéµĢ░Ķ«ŠńĮ«õĖŹÕÉīńÜäĶČģÕÅéµĢ░ÕĆŹµĢ░ŃĆé** + + õŠŗÕ”é’╝īµłæõ╗¼ÕÅ»õ╗źÕ£© `paramwise_cfg` õĖŁĶ«ŠńĮ« `norm_decay_mult=0.`’╝īÕ░åÕĮÆõĖĆÕī¢Õ▒éńÜäµØāķćŹĶĪ░ÕćÅĶ«ŠńĮ«õĖ║ķøČŃĆé + + ```python + optim_wrapper = dict( + optimizer=dict(type='SGD', lr=0.8, weight_decay=1e-4), + paramwise_cfg=dict(norm_decay_mult=0.)) + ``` + + Ķ┐śµö»µīüĶ«ŠńĮ«ÕģČõ╗¢ń▒╗Õ×ŗńÜäÕÅéµĢ░’╝īÕīģµŗ¼’╝Ü + + - `lr_mult`’╝ܵēƵ£ēÕÅéµĢ░ńÜäÕŁ”õ╣ĀńÄćõ╣śµĢ░ŃĆé + - `decay_mult`’╝ܵēƵ£ēÕÅéµĢ░ńÜäµØāķćŹĶĪ░ÕćÅõ╣śµĢ░ŃĆé + - `bias_lr_mult`’╝ÜÕüÅńĮ«ķĪ╣ńÜäÕŁ”õ╣ĀńÄćõ╣śµĢ░’╝łõĖŹÕīģµŗ¼ÕĮÆõĖĆÕī¢Õ▒éńÜäÕüÅńĮ«ķĪ╣ÕÆīÕÅ»ÕÅśÕĮóÕŹĘń¦»Õ▒éńÜäÕüÅń¦╗ķćÅ’╝ēŃĆéķ╗śĶ«żõĖ║ 1ŃĆé + - `bias_decay_mult`’╝ÜÕüÅńĮ«ķĪ╣ńÜäµØāķćŹĶĪ░ÕćÅõ╣śµĢ░’╝łõĖŹÕīģµŗ¼ÕĮÆõĖĆÕī¢Õ▒éńÜäÕüÅńĮ«ķĪ╣ÕÆīÕÅ»ÕÅśÕĮóÕŹĘń¦»Õ▒éńÜäÕüÅń¦╗ķćÅ’╝ēŃĆéķ╗śĶ«żõĖ║ 1ŃĆé + - `norm_decay_mult`’╝ÜÕĮÆõĖĆÕī¢Õ▒éµØāķćŹÕÆīÕüÅńĮ«ķĪ╣ńÜäµØāķćŹĶĪ░ÕćÅõ╣śµĢ░ŃĆéķ╗śĶ«żõĖ║ 1ŃĆé + - `dwconv_decay_mult`’╝ܵĘ▒Õ║”ÕŹĘń¦»Õ▒éńÜäµØāķćŹĶĪ░ÕćÅõ╣śµĢ░ŃĆéķ╗śĶ«żõĖ║ 1ŃĆé + - `bypass_duplicate`’╝ܵś»ÕÉ”ĶĘ│Ķ┐ćķćŹÕżŹńÜäÕÅéµĢ░ŃĆéķ╗śĶ«żõĖ║ `False`ŃĆé + - `dcn_offset_lr_mult`’╝ÜÕÅ»ÕÅśÕĮóÕŹĘń¦»Õ▒éńÜäÕŁ”õ╣ĀńÄćõ╣śµĢ░ŃĆéķ╗śĶ«żõĖ║ 1ŃĆé + +- **õĖ║ńē╣Õ«ÜÕÅéµĢ░Ķ«ŠńĮ«õĖŹÕÉīńÜäĶČģÕÅéµĢ░ÕĆŹµĢ░ŃĆé** + + MMAction2 ÕÅ»õ╗źõĮ┐ńö© `paramwise_cfg` õĖŁńÜä `custom_keys` µØźµīćÕ«ÜõĖŹÕÉīńÜäÕÅéµĢ░õĮ┐ńö©õĖŹÕÉīńÜäÕŁ”õ╣ĀńÄ浳¢µØāķćŹĶĪ░ÕćÅŃĆé + + õŠŗÕ”é’╝īĶ”üÕ░å `backbone.layer0` ńÜäµēƵ£ēÕŁ”õ╣ĀńÄćÕÆīµØāķćŹĶĪ░ÕćÅĶ«ŠńĮ«õĖ║ 0’╝īĶĆīõ┐صīü `backbone` ńÜäÕģČõĮÖķā©ÕłåõĖÄõ╝śÕī¢ÕÖ©ńøĖÕÉī’╝īÕ╣ČÕ░å `head` ńÜäÕŁ”õ╣ĀńÄćĶ«ŠńĮ«õĖ║ 0.001’╝īÕÅ»õ╗źõĮ┐ńö©õ╗źõĖŗķģŹńĮ«’╝Ü + + ```python + optim_wrapper = dict( + optimizer=dict(type='SGD', lr=0.01, weight_decay=0.0001), + paramwise_cfg=dict( + custom_keys={ + 'backbone.layer0': dict(lr_mult=0, decay_mult=0), + 'backbone': dict(lr_mult=1), + 'head': dict(lr_mult=0.1) + })) + ``` + +### µó»Õ║”ĶŻüÕē¬ + +Õ£©Ķ«Łń╗āĶ┐ćń©ŗõĖŁ’╝īµŹ¤Õż▒ÕćĮµĢ░ÕÅ»ĶāĮµÄźĶ┐æµé¼Õ┤¢Õī║Õ¤¤’╝īÕ»╝Ķć┤µó»Õ║”ńłåńéĖŃĆéµó»Õ║”ĶŻüÕē¬µ£ēÕŖ®õ║Äń©│Õ«ÜĶ«Łń╗āĶ┐ćń©ŗŃĆéµó»Õ║”ĶŻüÕē¬ńÜäµø┤ÕżÜõ╗ŗń╗ŹÕÅ»õ╗źÕ£©[Ķ┐ÖõĖ¬ķĪĄķØó](https://paperswithcode.com/method/gradient-clipping)µēŠÕł░ŃĆé + +ńø«ÕēŹ’╝īµłæõ╗¼µö»µīü `optim_wrapper` õĖŁńÜä `clip_grad` ķĆēķĪ╣Ķ┐øĶĪīµó»Õ║”ĶŻüÕē¬’╝īÕÅéĶĆā[PyTorch µ¢ćµĪŻ](torch.nn.utils.clip_grad_norm_)ŃĆé + +õ╗źõĖŗµś»õĖĆõĖ¬ńż║õŠŗ’╝Ü + +```python +optim_wrapper = dict( + optimizer=dict(type='SGD', lr=0.01, weight_decay=0.0001), + # norm_type: õĮ┐ńö©ńÜä p-ĶīāµĢ░ńÜäń▒╗Õ×ŗ’╝īĶ┐Öķćī norm_type õĖ║ 2ŃĆé + clip_grad=dict(max_norm=35, norm_type=2)) +``` + +### µó»Õ║”ń┤»ń¦» + +ÕĮōĶ«Īń«ŚĶĄäµ║ɵ£ēķÖɵŚČ’╝īµē╣ķćÅÕż¦Õ░ÅÕŬĶāĮĶ«ŠńĮ«õĖ║ĶŠāÕ░ÅńÜäÕĆ╝’╝īĶ┐ÖÕÅ»ĶāĮõ╝ÜÕĮ▒ÕōŹµ©ĪÕ×ŗńÜäµĆ¦ĶāĮŃĆéÕÅ»õ╗źõĮ┐ńö©µó»Õ║”ń┤»ń¦»µØźĶ¦ŻÕå│Ķ┐ÖõĖ¬ķŚ«ķóśŃĆ鵳æõ╗¼µö»µīü `optim_wrapper` õĖŁńÜä `accumulative_counts` ķĆēķĪ╣Ķ┐øĶĪīµó»Õ║”ń┤»ń¦»ŃĆé + +õ╗źõĖŗµś»õĖĆõĖ¬ńż║õŠŗ’╝Ü + +```python +train_dataloader = dict(batch_size=64) +optim_wrapper = dict( + optimizer=dict(type='SGD', lr=0.01, weight_decay=0.0001), + accumulative_counts=4) +``` + +ĶĪ©ńż║Õ£©Ķ«Łń╗āĶ┐ćń©ŗõĖŁ’╝īµ»Å 4 õĖ¬Ķ┐Łõ╗Żµē¦ĶĪīõĖƵ¼ĪÕÅŹÕÉæõ╝ĀµÆŁŃĆéõĖŖĶ┐░ńż║õŠŗńŁēõ╗Ęõ║Ä’╝Ü + +```python +train_dataloader = dict(batch_size=256) +optim_wrapper = dict( + optimizer=dict(type='SGD', lr=0.01, weight_decay=0.0001)) +``` + +## µ¢░Õó×õ╝śÕī¢ÕÖ©µł¢ĶĆģõ╝śÕī¢ÕÖ©µ×äķĆĀÕÖ© + +Õ£©Ķ«Łń╗āõĖŁ’╝īõ╝śÕī¢ÕÅéµĢ░’╝łÕ”éÕŁ”õ╣ĀńÄćŃĆüÕŖ©ķćÅńŁē’╝ēķĆÜÕĖĖõĖŹµś»Õø║Õ«ÜńÜä’╝īĶĆīµś»ķÜÅńØĆĶ┐Łõ╗Żµł¢Õ橵£¤ńÜäÕÅśÕī¢ĶĆīÕÅśÕī¢ŃĆéPyTorch µö»µīüÕćĀń¦ŹÕŁ”õ╣ĀńÄćńŁ¢ńĢź’╝īõĮåÕ»╣õ║ÄÕżŹµØéńÜäńŁ¢ńĢźÕÅ»ĶāĮõĖŹĶČ│Õż¤ŃĆéÕ£© MMAction2 õĖŁ’╝īµłæõ╗¼µÅÉõŠø `param_scheduler` µØźµø┤ÕźĮÕ£░µÄ¦ÕłČõĖŹÕÉīÕÅéµĢ░ńÜäÕŁ”õ╣ĀńÄćńŁ¢ńĢźŃĆé + +### ķģŹńĮ«ÕŁ”õ╣ĀńÄćĶ░āµĢ┤ńŁ¢ńĢź + +Ķ░āµĢ┤ÕŁ”õ╣ĀńÄćńŁ¢ńĢźĶó½Õ╣┐µ│øńö©õ║ĵÅÉķ½śµĆ¦ĶāĮŃĆ鵳æõ╗¼µö»µīüÕż¦ÕżÜµĢ░ PyTorch ÕŁ”õ╣ĀńÄćńŁ¢ńĢź’╝īÕīģµŗ¼ `ExponentialLR`ŃĆü`LinearLR`ŃĆü`StepLR`ŃĆü`MultiStepLR` ńŁēŃĆé + +µēƵ£ēÕÅ»ńö©ńÜäÕŁ”õ╣ĀńÄćńŁ¢ńĢźÕÅ»õ╗źÕ£©[Ķ┐Öķćī](https://mmaction2.readthedocs.io/en/latest/schedulers.html)µēŠÕł░’╝īÕŁ”õ╣ĀńÄćńŁ¢ńĢźńÜäÕÉŹń¦░õ╗ź `LR` ń╗ōÕ░ŠŃĆé + +- **ÕŹĢõĖĆÕŁ”õ╣ĀńÄćńŁ¢ńĢź** + + Õ£©Õż¦ÕżÜµĢ░µāģÕåĄõĖŗ’╝īµłæõ╗¼ÕŬõĮ┐ńö©õĖĆõĖ¬ÕŁ”õ╣ĀńŁ¢ńĢźõ╗źń«ĆÕī¢ķŚ«ķóśŃĆéõŠŗÕ”é’╝ī`MultiStepLR` Ķó½ńö©õĮ£ ResNet ńÜäķ╗śĶ«żÕŁ”õ╣ĀńÄćńŁ¢ńĢźŃĆéÕ£©Ķ┐Öķćī’╝ī`param_scheduler` µś»õĖĆõĖ¬ÕŁŚÕģĖŃĆé + + ```python + param_scheduler = dict( + type='MultiStepLR', + by_epoch=True, + milestones=[100, 150], + gamma=0.1) + ``` + + µł¢ĶĆģ’╝īµłæõ╗¼µā│õĮ┐ńö© `CosineAnnealingLR` ńŁ¢ńĢźµØźĶĪ░ÕćÅÕŁ”õ╣ĀńÄć’╝Ü + + ```python + param_scheduler = dict( + type='CosineAnnealingLR', + by_epoch=True, + T_max=num_epochs) + ``` + +- **ÕżÜõĖ¬ÕŁ”õ╣ĀńÄćńŁ¢ńĢź** + + Õ£©µ¤Éõ║øĶ«Łń╗āµĪłõŠŗõĖŁ’╝īõĖ║õ║åµÅÉķ½śÕćåńĪ«µĆ¦’╝īõ╝ÜÕ║öńö©ÕżÜõĖ¬ÕŁ”õ╣ĀńÄćńŁ¢ńĢźŃĆéõŠŗÕ”é’╝īÕ£©µŚ®µ£¤ķśČµ«Ą’╝īĶ«Łń╗āÕ«╣µśōõĖŹń©│Õ«Ü’╝īķóäńāŁµś»õĖĆń¦ŹÕćÅÕ░æõĖŹń©│Õ«ÜµĆ¦ńÜäµŖƵ£»ŃĆéÕŁ”õ╣ĀńÄćÕ░åõ╗ÄõĖĆõĖ¬ĶŠāÕ░ÅńÜäÕĆ╝ķĆɵĖÉÕó×ÕŖĀÕł░ķóäµ£¤ÕĆ╝’╝īķĆÜĶ┐ćķóäńāŁĶ┐øĶĪīĶĪ░ÕćÅÕÆīÕģČõ╗¢ńŁ¢ńĢźĶ┐øĶĪīĶĪ░ÕćÅŃĆé + + Õ£© MMAction2 õĖŁ’╝īķĆÜĶ┐ćÕ░åµēĆķ£ĆńÜäńŁ¢ńĢźń╗äÕÉłµłÉ `param_scheduler` ńÜäÕłŚĶĪ©ÕŹ│ÕŻի×ńÄ░ķóäńāŁńŁ¢ńĢźŃĆé + + õ╗źõĖŗµś»õĖĆõ║øńż║õŠŗ’╝Ü + + 1. Õ£©ÕēŹ 50 õĖ¬Ķ┐Łõ╗ŻõĖŁĶ┐øĶĪīń║┐µĆ¦ķóäńāŁŃĆé + + ```python + param_scheduler = [ + # ń║┐µĆ¦ķóäńāŁ + dict(type='LinearLR', + start_factor=0.001, + by_epoch=False, # µīēĶ┐Łõ╗Ż + end=50), # õ╗ģÕ£©ÕēŹ 50 õĖ¬Ķ┐Łõ╗ŻõĖŁĶ┐øĶĪīķóäńāŁ + # õĖ╗Ķ”üńÜäÕŁ”õ╣ĀńÄćńŁ¢ńĢź + dict(type='MultiStepLR', + by_epoch=True, + milestones=[8, 11], + gamma=0.1) + ] + ``` + + 2. Õ£©ÕēŹ 10 õĖ¬Õ橵£¤õĖŁĶ┐øĶĪīń║┐µĆ¦ķóäńāŁ’╝īÕ╣ČÕ£©µ»ÅõĖ¬Õ橵£¤ÕåģµīēĶ┐Łõ╗Żµø┤µ¢░ÕŁ”õ╣ĀńÄćŃĆé + + ```python + param_scheduler = [ + # ń║┐µĆ¦ķóäńāŁ [0, 10) õĖ¬Õ橵£¤ + dict(type='LinearLR', + start_factor=0.001, + by_epoch=True, + end=10, + convert_to_iter_based=True, # µīēĶ┐Łõ╗Żµø┤µ¢░ÕŁ”õ╣ĀńÄć + ), + # Õ£© 10 õĖ¬Õ橵£¤ÕÉÄõĮ┐ńö© CosineAnnealing ńŁ¢ńĢź + dict(type='CosineAnnealingLR', by_epoch=True, begin=10) + ] + ``` + + µ│©µäÅ’╝īµłæõ╗¼Õ£©Ķ┐ÖķćīõĮ┐ńö© `begin` ÕÆī `end` ÕÅéµĢ░µØźµīćիܵ£ēµĢłĶīāÕø┤’╝īĶ»źĶīāÕø┤õĖ║ \[`begin`, `end`)ŃĆéĶīāÕø┤ńÜäÕŹĢõĮŹńö▒ `by_epoch` ÕÅéµĢ░Õ«Üõ╣ēŃĆéÕ”éµ×£µ£¬µīćÕ«Ü’╝īÕłÖ `begin` õĖ║ 0’╝ī`end` õĖ║µ£ĆÕż¦Õ橵£¤µł¢Ķ┐Łõ╗Żµ¼ĪµĢ░ŃĆé + + Õ”éµ×£µēƵ£ēńŁ¢ńĢźńÜäĶīāÕø┤ķāĮõĖŹĶ┐×ń╗Ł’╝īÕłÖÕŁ”õ╣ĀńÄćÕ░åÕ£©Õ┐ĮńĢźńÜäĶīāÕø┤Õåģõ┐صīüõĖŹÕÅś’╝īÕÉ”ÕłÖµēƵ£ēµ£ēµĢłńÜäńŁ¢ńĢźÕ░åµīēńē╣Õ«ÜķśČµ«ĄńÜäķĪ║Õ║ŵē¦ĶĪī’╝īĶ┐ÖõĖÄ PyTorch [`ChainedScheduler`](torch.optim.lr_scheduler.ChainedScheduler) ńÜäĶĪīõĖ║ńøĖÕÉīŃĆé + +### Ķć¬Õ«Üõ╣ēÕŖ©ķćÅńŁ¢ńĢź + +µłæõ╗¼µö»µīüõĮ┐ńö©ÕŖ©ķćÅńŁ¢ńĢźµĀ╣µŹ«ÕŁ”õ╣ĀńÄćõ┐«µö╣õ╝śÕī¢ÕÖ©ńÜäÕŖ©ķćÅ’╝īĶ┐ÖÕÅ»õ╗źõĮ┐µŹ¤Õż▒õ╗źµø┤Õ┐½ńÜäµ¢╣Õ╝ŵöȵĢøŃĆéõĮ┐ńö©µ¢╣µ│ĢõĖÄÕŁ”õ╣ĀńÄćńŁ¢ńĢźńøĖÕÉīŃĆé + +µēƵ£ēÕÅ»ńö©ńÜäÕŁ”õ╣ĀńÄćńŁ¢ńĢźÕÅ»õ╗źÕ£©[Ķ┐Öķćī](https://mmaction2.readthedocs.io/en/latest/schedulers.html)µēŠÕł░’╝īÕŖ©ķćÅńŁ¢ńĢźńÜäÕÉŹń¦░õ╗ź `Momentum` ń╗ōÕ░ŠŃĆé + +õ╗źõĖŗµś»õĖĆõĖ¬ńż║õŠŗ’╝Ü + +```python +param_scheduler = [ + # ÕŁ”õ╣ĀńÄćńŁ¢ńĢź + dict(type='LinearLR', ...), + # ÕŖ©ķćÅńŁ¢ńĢź + dict(type='LinearMomentum', + start_factor=0.001, + by_epoch=False, + begin=0, + end=1000) +] +``` + +## µĘ╗ÕŖĀµ¢░ńÜäõ╝śÕī¢ÕÖ©µł¢µ×äķĆĀÕÖ© + +µ£¼ķā©ÕłåÕ░åõ┐«µö╣ MMAction2 µ║Éõ╗ŻńĀüµł¢ÕÉæ MMAction2 µĪåµ×ČõĖŁµĘ╗ÕŖĀõ╗ŻńĀü’╝īÕłØÕŁ”ĶĆģÕÅ»õ╗źĶĘ│Ķ┐浣żķā©ÕłåŃĆé + +### µĘ╗ÕŖĀµ¢░ńÜäõ╝śÕī¢ÕÖ© + +Õ£©ÕŁ”µ£»ńĀöń®ČÕÆīÕĘźõĖÜÕ«×ĶĘĄõĖŁ’╝īÕÅ»ĶāĮķ£ĆĶ”üõĮ┐ńö© MMAction2 µ£¬Õ«×ńÄ░ńÜäõ╝śÕī¢µ¢╣µ│Ģ’╝īÕÅ»õ╗źķĆÜĶ┐ćõ╗źõĖŗµ¢╣µ│ĢĶ┐øĶĪīµĘ╗ÕŖĀŃĆé + +#### 1. Õ«×ńÄ░õĖĆõĖ¬µ¢░ńÜäõ╝śÕī¢ÕÖ© + +ÕüćĶ«ŠĶ”üµĘ╗ÕŖĀõĖĆõĖ¬ÕÉŹõĖ║ `MyOptimizer` ńÜäõ╝śÕī¢ÕÖ©’╝īÕ«āÕģʵ£ēÕÅéµĢ░ `a`ŃĆü`b` ÕÆī `c`ŃĆéķ£ĆĶ”üÕ£© `mmaction/engine/optimizers` õĖŗÕłøÕ╗║õĖĆõĖ¬µ¢░µ¢ćõ╗Č’╝īÕ╣ČÕ£©µ¢ćõ╗ČõĖŁÕ«×ńÄ░µ¢░ńÜäõ╝śÕī¢ÕÖ©’╝īõŠŗÕ”éÕ£© `mmaction/engine/optimizers/my_optimizer.py` õĖŁ’╝Ü + +```python +from torch.optim import Optimizer +from mmaction.registry import OPTIMIZERS + + +@OPTIMIZERS.register_module() +class MyOptimizer(Optimizer): + + def __init__(self, a, b, c): + ... + + def step(self, closure=None): + ... +``` + +#### 2. Õ»╝Õģźõ╝śÕī¢ÕÖ© + +õĖ║õ║åµēŠÕł░õĖŖĶ┐░Õ«Üõ╣ēńÜ䵩ĪÕØŚ’╝īķ£ĆĶ”üÕ£©Ķ┐ÉĶĪīµŚČÕ»╝ÕģźĶ»źµ©ĪÕØŚŃĆéķ”¢Õģł’╝īÕ£© `mmaction/engine/optimizers/__init__.py` õĖŁÕ»╝ÕģźĶ»źµ©ĪÕØŚ’╝īÕ░åÕģȵĘ╗ÕŖĀÕł░ `mmaction.engine` ÕīģõĖŁŃĆé + +```python +# In mmaction/engine/optimizers/__init__.py +... +from .my_optimizer import MyOptimizer # MyOptimizer ÕÅ»ĶāĮµś»ÕģČõ╗¢ń▒╗ÕÉŹ + +__all__ = [..., 'MyOptimizer'] +``` + +Õ£©Ķ┐ÉĶĪīµŚČ’╝īµłæõ╗¼Õ░åĶć¬ÕŖ©Õ»╝Õģź `mmaction.engine` Õīģ’╝īÕ╣ČÕÉīµŚČµ│©Õåī `MyOptimizer`ŃĆé + +#### 3. Õ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁµīćÕ«Üõ╝śÕī¢ÕÖ© + +ńäČÕÉÄ’╝īÕÅ»õ╗źÕ£©ķģŹńĮ«µ¢ćõ╗ČńÜä `optim_wrapper.optimizer` ÕŁŚµ«ĄõĖŁõĮ┐ńö© `MyOptimizer`ŃĆé + +```python +optim_wrapper = dict( + optimizer=dict(type='MyOptimizer', a=a_value, b=b_value, c=c_value)) +``` + +### µĘ╗ÕŖĀµ¢░ńÜäõ╝śÕī¢ÕÖ©µ×äķĆĀÕÖ© + +õĖĆõ║øµ©ĪÕ×ŗÕÅ»ĶāĮÕ»╣õ╝śÕī¢µ£ēõĖĆõ║øńē╣Õ«ÜńÜäÕÅéµĢ░Ķ«ŠńĮ«’╝īõŠŗÕ”éµēƵ£ē `BatchNorm` Õ▒éńÜäõĖŹÕÉīµØāķćŹĶĪ░ÕćÅńÄćŃĆé + +Õ░Įń«Īµłæõ╗¼ÕĘ▓ń╗ÅÕÅ»õ╗źõĮ┐ńö©[õ╝śÕī¢ÕÖ©µĢÖń©ŗ](#ÕÅéµĢ░Õī¢ń▓Šń╗åķģŹńĮ«)õĖŁńÜä `optim_wrapper.paramwise_cfg` ÕŁŚµ«ĄµØźķģŹńĮ«ÕÉäń¦Źńē╣Õ«ÜÕÅéµĢ░ńÜäõ╝śÕī¢ÕÖ©Ķ«ŠńĮ«’╝īõĮåÕÅ»ĶāĮõ╗ŹµŚĀµ│Ģµ╗ĪĶČ│ķ£Ćµ▒éŃĆé + +ÕĮōńäČ’╝īõĮĀÕÅ»õ╗źõ┐«µö╣Õ«āŃĆéķ╗śĶ«żµāģÕåĄõĖŗ’╝īµłæõ╗¼õĮ┐ńö© [`DefaultOptimWrapperConstructor`](mmengine.optim.DefaultOptimWrapperConstructor) ń▒╗µØźÕżäńÉåõ╝śÕī¢ÕÖ©ńÜäµ×äķĆĀŃĆéÕ£©µ×äķĆĀĶ┐ćń©ŗõĖŁ’╝īÕ«āµĀ╣µŹ« `paramwise_cfg` Õ»╣õĖŹÕÉīÕÅéµĢ░ńÜäõ╝śÕī¢ÕÖ©Ķ«ŠńĮ«Ķ┐øĶĪīń╗åĶć┤ķģŹńĮ«’╝īĶ┐Öõ╣¤ÕÅ»õ╗źõĮ£õĖ║µ¢░õ╝śÕī¢ÕÖ©µ×äķĆĀÕÖ©ńÜ䵩ĪµØ┐ŃĆé + +õĮĀÕÅ»õ╗źķĆÜĶ┐ćµĘ╗ÕŖĀµ¢░ńÜäõ╝śÕī¢ÕÖ©µ×äķĆĀÕÖ©µØźĶ”åńø¢Ķ┐Öõ║øĶĪīõĖ║ŃĆé + +```python +# In mmaction/engine/optimizers/my_optim_constructor.py +from mmengine.optim import DefaultOptimWrapperConstructor +from mmaction.registry import OPTIM_WRAPPER_CONSTRUCTORS + + +@OPTIM_WRAPPER_CONSTRUCTORS.register_module() +class MyOptimWrapperConstructor: + + def __init__(self, optim_wrapper_cfg, paramwise_cfg=None): + ... + + def __call__(self, model): + ... +``` + +ńäČÕÉÄ’╝īÕ»╝ÕģźÕ«āÕ╣ČÕćĀõ╣ÄÕāÅ[õ╝śÕī¢ÕÖ©µĢÖń©ŗ](#µĘ╗ÕŖĀµ¢░ńÜäõ╝śÕī¢ÕÖ©)õĖŁķ鯵ĀĘõĮ┐ńö©Õ«āŃĆé + +1. Õ£© `mmaction/engine/optimizers/__init__.py` õĖŁÕ»╝ÕģźÕ«ā’╝īÕ░åÕģȵĘ╗ÕŖĀÕł░ `mmaction.engine` ÕīģõĖŁŃĆé + + ```python + # In mmaction/engine/optimizers/__init__.py + ... + from .my_optim_constructor import MyOptimWrapperConstructor + + __all__ = [..., 'MyOptimWrapperConstructor'] + ``` + +2. Õ£©ķģŹńĮ«µ¢ćõ╗ČńÜä `optim_wrapper.constructor` ÕŁŚµ«ĄõĖŁõĮ┐ńö© `MyOptimWrapperConstructor`ŃĆé + + ```python + optim_wrapper = dict( + constructor=dict(type='MyOptimWrapperConstructor'), + optimizer=..., + paramwise_cfg=..., + ) + ``` diff --git a/internlm_langchain/knowledge_base/MMAction2/content/customize_pipeline.md b/internlm_langchain/knowledge_base/MMAction2/content/customize_pipeline.md new file mode 100644 index 00000000..4327f96d --- /dev/null +++ b/internlm_langchain/knowledge_base/MMAction2/content/customize_pipeline.md @@ -0,0 +1,144 @@ +# Ķć¬Õ«Üõ╣ēµĢ░µŹ«µĄüµ░┤ń║┐ + +Õ£©µ£¼µĢÖń©ŗõĖŁ’╝īµłæõ╗¼Õ░åõ╗ŗń╗ŹÕ”éõĮĢõĖ║õĮĀńÜäõ╗╗ÕŖĪµ×äÕ╗║µĢ░µŹ«µĄüµ░┤ń║┐’╝łÕŹ│’╝īµĢ░µŹ«ĶĮ¼µŹó’╝ēńÜäõĖĆõ║øµ¢╣µ│ĢŃĆé + +- [Ķć¬Õ«Üõ╣ēµĢ░µŹ«µĄüµ░┤ń║┐](#Ķć¬Õ«Üõ╣ēµĢ░µŹ«µĄüµ░┤ń║┐) + - [µĢ░µŹ«µĄüµ░┤ń║┐Ķ«ŠĶ«Ī](#µĢ░µŹ«µĄüµ░┤ń║┐Ķ«ŠĶ«Ī) + - [õ┐«µö╣Ķ«Łń╗ā/µĄŗĶ»ĢµĢ░µŹ«µĄüµ░┤ń║┐](#õ┐«µö╣Ķ«Łń╗ā/µĄŗĶ»ĢµĢ░µŹ«µĄüµ░┤ń║┐) + - [ÕŖĀĶĮĮ](#ÕŖĀĶĮĮ) + - [ķććµĀĘÕĖ¦ÕÆīÕģČõ╗¢ÕżäńÉå](#ķććµĀĘÕĖ¦ÕÆīÕģČõ╗¢ÕżäńÉå) + - [µĀ╝Õ╝ÅÕī¢](#µĀ╝Õ╝ÅÕī¢) + - [µĘ╗ÕŖĀµ¢░ńÜäµĢ░µŹ«ĶĮ¼µŹó](#µĘ╗ÕŖĀµ¢░ńÜäµĢ░µŹ«ĶĮ¼µŹó) + +## µĢ░µŹ«µĄüµ░┤ń║┐Ķ«ŠĶ«Ī + +µĢ░µŹ«µĄüµ░┤ń║┐µīćńÜ䵜»õ╗ĵĢ░µŹ«ķøåń┤óÕ╝ĢµĀʵ£¼µŚČÕżäńÉåµĢ░µŹ«µĀʵ£¼ÕŁŚÕģĖńÜäĶ┐ćń©ŗ’╝īÕ«āÕīģµŗ¼õĖĆń│╗ÕłŚńÜäµĢ░µŹ«ĶĮ¼µŹóŃĆéµ»ÅõĖ¬µĢ░µŹ«ĶĮ¼µŹóµÄźÕÅŚõĖĆõĖ¬ `dict` õĮ£õĖ║ĶŠōÕģź’╝īÕ»╣ÕģČĶ┐øĶĪīÕżäńÉå’╝īÕ╣Čõ║¦ńö¤õĖĆõĖ¬ `dict` õĮ£õĖ║ĶŠōÕć║’╝īõŠøÕ║ÅÕłŚõĖŁńÜäÕÉÄń╗ŁµĢ░µŹ«ĶĮ¼µŹóõĮ┐ńö©ŃĆé + +õ╗źõĖŗµś»õĖĆõĖ¬õŠŗÕŁÉ’╝īńö©õ║ÄõĮ┐ńö© `VideoDataset` Õ£© Kinetics õĖŖĶ«Łń╗ā SlowFast ńÜäµĢ░µŹ«µĄüµ░┤ń║┐ŃĆéĶ┐ÖõĖ¬µĢ░µŹ«µĄüµ░┤ń║┐ķ”¢ÕģłõĮ┐ńö© [`decord`](https://github.com/dmlc/decord) Ķ»╗ÕÅ¢ÕĤզŗĶ¦åķóæÕ╣ČķÜŵ£║ķććµĀĘõĖĆõĖ¬Ķ¦åķóæÕē¬ĶŠæ’╝īĶ»źÕē¬ĶŠæÕīģÕɽ `32` ÕĖ¦’╝īÕĖ¦ķŚ┤ķÜöõĖ║ `2`ŃĆéńäČÕÉÄ’╝īÕ«āÕ»╣µēƵ£ēÕĖ¦Õ║öńö©ķÜŵ£║Õż¦Õ░ÅĶ░āµĢ┤ńÜäĶŻüÕē¬ÕÆīķÜŵ£║µ░┤Õ╣│ń┐╗ĶĮ¼’╝īńäČÕÉÄÕ░åµĢ░µŹ«ÕĮóńŖȵĀ╝Õ╝ÅÕī¢õĖ║ `NCTHW`’╝īÕ£©Ķ┐ÖõĖ¬õŠŗÕŁÉõĖŁ’╝īÕ«āµś» `(1, 3, 32, 224, 224)`ŃĆé + +```python +train_pipeline = [ + dict(type='DecordInit',), + dict(type='SampleFrames', clip_len=32, frame_interval=2, num_clips=1), + dict(type='DecordDecode'), + dict(type='Resize', scale=(-1, 256)), + dict(type='RandomResizedCrop'), + dict(type='Resize', scale=(224, 224), keep_ratio=False), + dict(type='Flip', flip_ratio=0.5), + dict(type='FormatShape', input_format='NCTHW'), + dict(type='PackActionInputs') +] +``` + +MMAction2 õĖŁµēƵ£ēÕÅ»ńö©ńÜäµĢ░µŹ«ĶĮ¼µŹóńÜäĶ»”ń╗åÕłŚĶĪ©ÕÅ»õ╗źÕ£© [mmaction.datasets.transforms](mmaction.datasets.transforms) õĖŁµēŠÕł░ŃĆé + +## õ┐«µö╣Ķ«Łń╗ā/µĄŗĶ»ĢµĢ░µŹ«µĄüµ░┤ń║┐ + +MMAction2 ńÜäµĢ░µŹ«µĄüµ░┤ń║┐ķØ×ÕĖĖńüĄµ┤╗’╝īÕøĀõĖ║ÕćĀõ╣ĵ»ÅõĖƵŁźńÜäµĢ░µŹ«ķóäÕżäńÉåķāĮÕÅ»õ╗źõ╗ÄķģŹńĮ«µ¢ćõ╗ČõĖŁĶ┐øĶĪīķģŹńĮ«ŃĆéńäČĶĆī’╝īÕ»╣õ║ÄõĖĆõ║øńö©µłĘµØźĶ»┤’╝īĶ┐Öń¦ŹÕżÜµĀʵƦÕÅ»ĶāĮõ╝ÜĶ«®õ║║µä¤Õł░õĖŹń¤źµēƵĬŃĆé + +õ╗źõĖŗµś»õĖĆõ║øńö©õ║ĵ×äÕ╗║ÕŖ©õĮ£Ķ»åÕł½õ╗╗ÕŖĪµĢ░µŹ«µĄüµ░┤ń║┐ńÜäõĖĆĶł¼Õ«×ĶĘĄÕÆīµīćÕŹŚŃĆé + +### ÕŖĀĶĮĮ + +Õ£©µĢ░µŹ«µĄüµ░┤ń║┐ńÜäÕ╝ĆÕ¦ŗ’╝īķĆÜÕĖĖµś»ÕŖĀĶĮĮĶ¦åķóæŃĆéńäČĶĆī’╝īÕ”éµ×£ÕĖ¦ÕĘ▓ń╗ÅĶó½µÅÉÕÅ¢Õć║µØź’╝īõĮĀÕ║öĶ»źõĮ┐ńö© `RawFrameDecode` Õ╣Čõ┐«µö╣µĢ░µŹ«ķøåń▒╗Õ×ŗõĖ║ `RawframeDataset`ŃĆé + +```python +train_pipeline = [ + dict(type='SampleFrames', clip_len=32, frame_interval=2, num_clips=1), + dict(type='RawFrameDecode'), + dict(type='Resize', scale=(-1, 256)), + dict(type='RandomResizedCrop'), + dict(type='Resize', scale=(224, 224), keep_ratio=False), + dict(type='Flip', flip_ratio=0.5), + dict(type='FormatShape', input_format='NCTHW'), + dict(type='PackActionInputs') +] +``` + +Õ”éµ×£õĮĀķ£ĆĶ”üõ╗ÄÕģʵ£ēõĖŹÕÉīµĀ╝Õ╝Å’╝łõŠŗÕ”é’╝ī`pkl`’╝ī`bin`ńŁē’╝ēńÜäµ¢ćõ╗ȵł¢õ╗Äńē╣Õ«ÜõĮŹńĮ«ÕŖĀĶĮĮµĢ░µŹ«’╝īõĮĀÕÅ»õ╗źÕłøÕ╗║õĖĆõĖ¬µ¢░ńÜäÕŖĀĶĮĮĶĮ¼µŹóÕ╣ČÕ░åÕģČÕīģÕɽգ©µĢ░µŹ«µĄüµ░┤ń║┐ńÜäÕ╝ĆÕ¦ŗŃĆéµ£ēÕģ│µø┤ÕżÜĶ»”ń╗åõ┐Īµü»’╝īĶ»ĘÕÅéķśģ[µĘ╗ÕŖĀµ¢░ńÜäµĢ░µŹ«ĶĮ¼µŹó](#µĘ╗ÕŖĀµ¢░ńÜäµĢ░µŹ«ĶĮ¼µŹó)ŃĆé + +### ķććµĀĘÕĖ¦ÕÆīÕģČõ╗¢ÕżäńÉå + +Õ£©Ķ«Łń╗āÕÆīµĄŗĶ»ĢĶ┐ćń©ŗõĖŁ’╝īµłæõ╗¼ÕÅ»ĶāĮõ╝ܵ£ēõ╗ÄĶ¦åķóæõĖŁķććµĀĘÕĖ¦ńÜäõĖŹÕÉīńŁ¢ńĢźŃĆé + +õŠŗÕ”é’╝īÕĮōµĄŗĶ»Ģ SlowFast µŚČ’╝īµłæõ╗¼õ╝ÜÕØćÕīĆÕ£░ķććµĀĘÕżÜõĖ¬Õē¬ĶŠæ’╝īÕ”éõĖŗµēĆńż║’╝Ü + +```python +test_pipeline = [ + ... + dict( + type='SampleFrames', + clip_len=32, + frame_interval=2, + num_clips=10, + test_mode=True), + ... +] +``` + +Õ£©õĖŖĶ┐░õŠŗÕŁÉõĖŁ’╝īµ»ÅõĖ¬Ķ¦åķóæÕ░åÕØćÕīĆÕ£░ķććµĀĘ10õĖ¬Ķ¦åķóæÕē¬ĶŠæ’╝īµ»ÅõĖ¬Õē¬ĶŠæÕīģÕɽ32ÕĖ¦ŃĆé `test_mode=True` ńö©õ║ÄÕ«×ńÄ░Ķ┐ÖõĖĆńé╣’╝īõĖÄĶ«Łń╗āµ£¤ķŚ┤ńÜäķÜŵ£║ķććµĀĘńøĖÕÅŹŃĆé + +ÕÅ”õĖĆõĖ¬õŠŗÕŁÉµČēÕÅŖ `TSN/TSM` µ©ĪÕ×ŗ’╝īÕ«āõ╗¼õ╗ÄĶ¦åķóæõĖŁķććµĀĘÕżÜõĖ¬ńē浫Ą’╝Ü + +```python +train_pipeline = [ + ... + dict(type='SampleFrames', clip_len=1, frame_interval=1, num_clips=8), + ... +] +``` + +ķĆÜÕĖĖ’╝īµĢ░µŹ«µĄüµ░┤ń║┐õĖŁńÜäµĢ░µŹ«Õó×Õ╝║ÕÅ¬ÕżäńÉåĶ¦åķóæń║¦ńÜäĶĮ¼µŹó’╝īõŠŗÕ”éĶ░āµĢ┤Õż¦Õ░ŵł¢ĶŻüÕē¬’╝īĶĆīõĖŹÕżäńÉåÕāÅĶ¦åķóæµĀćÕćåÕī¢µł¢ mixup/cutmix Ķ┐ÖµĀĘńÜäĶĮ¼µŹóŃĆéĶ┐Öµś»ÕøĀõĖ║µłæõ╗¼ÕÅ»õ╗źÕ£©µē╣ķćÅĶ¦åķóæµĢ░µŹ«õĖŖĶ┐øĶĪīĶ¦åķóæµĀćÕćåÕī¢ÕÆī mixup/cutmix’╝īõ╗źõĮ┐ńö© GPU ÕŖĀķĆ¤ÕżäńÉåŃĆéĶ”üķģŹńĮ«Ķ¦åķóæµĀćÕćåÕī¢ÕÆī mixup/cutmix’╝īĶ»ĘõĮ┐ńö© [mmaction.models.utils.data_preprocessor](mmaction.models.utils.data_preprocessor)ŃĆé + +### µĀ╝Õ╝ÅÕī¢ + +µĀ╝Õ╝ÅÕī¢µČēÕÅŖõ╗ĵĢ░µŹ«õ┐Īµü»ÕŁŚÕģĖõĖŁµöČķøåĶ«Łń╗āµĢ░µŹ«’╝īÕ╣ČÕ░åÕģČĶĮ¼µŹóõĖ║õĖĵ©ĪÕ×ŗÕģ╝Õ«╣ńÜäµĀ╝Õ╝ÅŃĆé + +Õ£©Õż¦ÕżÜµĢ░µāģÕåĄõĖŗ’╝īõĮĀÕÅ»õ╗źń«ĆÕŹĢÕ£░õĮ┐ńö© [`PackActionInputs`](mmaction.datasets.transforms.PackActionInputs)’╝īÕ«āÕ░åõ╗ź `NumPy Array` µĀ╝Õ╝ÅńÜäÕøŠÕāÅĶĮ¼µŹóõĖ║ `PyTorch Tensor`’╝īÕ╣ČÕ░åÕ£░ķØóń£¤Õ«×ń▒╗Õł½õ┐Īµü»ÕÆīÕģČõ╗¢Õģāõ┐Īµü»µēōÕīģõĖ║õĖĆõĖ¬ń▒╗õ╝╝ÕŁŚÕģĖńÜäÕ»╣Ķ▒Ī [`ActionDataSample`](mmaction.structures.ActionDataSample)ŃĆé + +```python +train_pipeline = [ + ... + dict(type='PackActionInputs'), +] +``` + +## µĘ╗ÕŖĀµ¢░ńÜäµĢ░µŹ«ĶĮ¼µŹó + +1. Ķ”üÕłøÕ╗║õĖĆõĖ¬µ¢░ńÜäµĢ░µŹ«ĶĮ¼µŹó’╝īń╝¢ÕåÖõĖĆõĖ¬µ¢░ńÜäĶĮ¼µŹóń▒╗Õ£©õĖĆõĖ¬ Python µ¢ćõ╗ČõĖŁ’╝īõŠŗÕ”é’╝īÕÉŹõĖ║ `my_transforms.py`ŃĆéµĢ░µŹ«ĶĮ¼µŹóń▒╗Õ┐ģķĪ╗ń╗¦µē┐ [`mmcv.transforms.BaseTransform`](mmcv.transforms.BaseTransform) ń▒╗’╝īÕ╣ČķćŹÕåÖ `transform` µ¢╣µ│Ģ’╝īĶ»źµ¢╣µ│ĢµÄźÕÅŚõĖĆõĖ¬ `dict` õĮ£õĖ║ĶŠōÕģźÕ╣ČĶ┐öÕø×õĖĆõĖ¬ `dict`ŃĆéµ£ĆÕÉÄ’╝īÕ░å `my_transforms.py` µöŠÕ£© `mmaction/datasets/transforms/` µ¢ćõ╗ČÕż╣õĖŁŃĆé + + ```python + from mmcv.transforms import BaseTransform + from mmaction.datasets import TRANSFORMS + + @TRANSFORMS.register_module() + class MyTransform(BaseTransform): + def __init__(self, msg): + self.msg = msg + + def transform(self, results): + # õ┐«µö╣µĢ░µŹ«õ┐Īµü»ÕŁŚÕģĖ `results`ŃĆé + print(msg, 'MMAction2.') + return results + ``` + +2. Õ£© `mmaction/datasets/transforms/__init__.py` õĖŁÕ»╝Õģźµ¢░ń▒╗ŃĆé + + ```python + ... + from .my_transform import MyTransform + + __all__ = [ + ..., 'MyTransform' + ] + ``` + +3. Õ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁõĮ┐ńö©Õ«āŃĆé + + ```python + train_pipeline = [ + ... + dict(type='MyTransform', msg='Hello!'), + ... + ] + ``` diff --git a/internlm_langchain/knowledge_base/MMAction2/content/dataflow.md b/internlm_langchain/knowledge_base/MMAction2/content/dataflow.md new file mode 100644 index 00000000..29db77f9 --- /dev/null +++ b/internlm_langchain/knowledge_base/MMAction2/content/dataflow.md @@ -0,0 +1,3 @@ +# MMAction2 ńÜäµĢ░µŹ«µĄü + +ÕåģÕ«╣Õ╗║Ķ«ŠõĖŁ... diff --git a/internlm_langchain/knowledge_base/MMAction2/content/depoly.md b/internlm_langchain/knowledge_base/MMAction2/content/depoly.md new file mode 100644 index 00000000..58e9f58e --- /dev/null +++ b/internlm_langchain/knowledge_base/MMAction2/content/depoly.md @@ -0,0 +1,3 @@ +# How to deploy MMAction2 models + +coming soon... diff --git a/internlm_langchain/knowledge_base/MMAction2/content/ecosystem.md b/internlm_langchain/knowledge_base/MMAction2/content/ecosystem.md new file mode 100644 index 00000000..2aafe731 --- /dev/null +++ b/internlm_langchain/knowledge_base/MMAction2/content/ecosystem.md @@ -0,0 +1,23 @@ +# Õ¤║õ║Ä MMAction2 ńÜäńö¤µĆüķĪ╣ńø« + +µ£ēĶ«ĖÕżÜńĀöń®ČÕĘźõĮ£ÕÆīķĪ╣ńø«µś»Õ¤║õ║Ä MMAction2 µ×äÕ╗║ńÜäŃĆé +µłæõ╗¼ÕłŚõĖŠõ║åõĖĆõ║øõŠŗÕŁÉ’╝īÕ▒Ģńż║õ║åÕ”éõĮĢµē®Õ▒Ģ MMAction2 µØźķĆéńö©õ║ĵé©Ķć¬ÕĘ▒ńÜäķĪ╣ńø«ŃĆé +ńö▒õ║ÄķĪĄķØóÕÅ»ĶāĮÕ░ܵ£¬Õ«īµłÉ’╝īµēĆõ╗źĶ»ĘķÜŵŚČķĆÜĶ┐ćµÅÉõ║żPRµØźµø┤µ¢░µŁżķĪĄķØóŃĆé + +## õĮ£õĖ║µē®Õ▒ĢńÜäķĪ╣ńø« + +- [OTEAction2](https://github.com/openvinotoolkit/mmaction2)’╝Üńö©õ║ÄÕŖ©õĮ£Ķ»åÕł½ńÜä OpenVINO Ķ«Łń╗āµē®Õ▒ĢŃĆé +- [PYSKL](https://github.com/kennymckormick/pyskl)’╝ÜõĖĆõĖ¬õĖōµ│©õ║ÄÕ¤║õ║Äķ¬©ķ¬╝ńé╣ÕŖ©õĮ£Ķ»åÕł½ńÜäÕĘźÕģĘń«▒ŃĆé + +## Ķ«║µ¢ćńøĖÕģ│ńÜäķĪ╣ńø« + +Ķ┐śµ£ēõĖĆõ║øõĖÄĶ«║µ¢ćõĖĆĶĄĘÕÅæÕĖāńÜäķĪ╣ńø«ŃĆé +ÕģČõĖŁõĖĆõ║øĶ«║µ¢ćÕÅæĶĪ©Õ£©ķĪČń║¦õ╝ÜĶ««’╝łCVPRŃĆüICCV ÕÆī ECCV’╝ēõĖŖ’╝īÕģČõ╗¢õĖĆõ║øõ╣¤Õģʵ£ēÕŠłķ½śńÜäÕĮ▒ÕōŹÕŖøŃĆé +µłæõ╗¼µīēńģ¦õ╝ÜĶ««µŚČķŚ┤ÕłŚÕć║Õ«āõ╗¼’╝īµ¢╣õŠ┐ńżŠÕī║ÕÅéĶĆāŃĆé + +- Video Swin Transformer’╝īCVPR 2022 [\[Ķ«║µ¢ć\]](https://arxiv.org/abs/2106.13230)[\[github\]](https://github.com/SwinTransformer/Video-Swin-Transformer) +- Evidential Deep Learning for Open Set Action Recognition’╝īICCV 2021 Oral [\[Ķ«║µ¢ć\]](https://arxiv.org/abs/2107.10161)[\[github\]](https://github.com/Cogito2012/DEAR) +- Rethinking Self-supervised Correspondence Learning: A Video Frame-level Similarity Perspective’╝īICCV 2021 Oral [\[Ķ«║µ¢ć\]](https://arxiv.org/abs/2103.17263)[\[github\]](https://github.com/xvjiarui/VFS) +- MGSampler: An Explainable Sampling Strategy for Video Action Recognition’╝īICCV 2021 [\[Ķ«║µ¢ć\]](https://arxiv.org/abs/2104.09952)[\[github\]](https://github.com/MCG-NJU/MGSampler) +- MultiSports: A Multi-Person Video Dataset of Spatio-Temporally Localized Sports Actions’╝īICCV 2021 [\[Ķ«║µ¢ć\]](https://arxiv.org/abs/2105.07404) +- Long Short-Term Transformer for Online Action Detection’╝īNeurIPS 2021 [\[Ķ«║µ¢ć\]](https://arxiv.org/abs/2107.03377)[\[github\]](https://github.com/amazon-research/long-short-term-transformer) diff --git a/internlm_langchain/knowledge_base/MMAction2/content/faq.md b/internlm_langchain/knowledge_base/MMAction2/content/faq.md new file mode 100644 index 00000000..6c785f11 --- /dev/null +++ b/internlm_langchain/knowledge_base/MMAction2/content/faq.md @@ -0,0 +1,125 @@ +# ÕĖĖĶ¦üķŚ«ķóśĶ¦ŻńŁö + +## µ”éĶ┐░ + +µłæõ╗¼Õ£©Ķ┐ÖķćīÕłŚÕć║õ║åĶ«ĖÕżÜńö©µłĘÕĖĖķüćÕł░ńÜäķŚ«ķóśõ╗źÕÅŖńøĖÕ║öńÜäĶ¦ŻÕå│µ¢╣µĪłŃĆé + +- [ÕĖĖĶ¦üķŚ«ķóśĶ¦ŻńŁö](#ÕĖĖĶ¦üķŚ«ķóśĶ¦ŻńŁö) + - [µ”éĶ┐░](#µ”éĶ┐░) + - [Õ«ēĶŻģ](#Õ«ēĶŻģ) + - [µĢ░µŹ«](#µĢ░µŹ«) + - [Ķ«Łń╗ā](#Ķ«Łń╗ā) + - [µĄŗĶ»Ģ](#µĄŗĶ»Ģ) + +Õ”éµ×£µé©ÕÅæńÄ░õ╗╗õĮĢķóæń╣üÕć║ńÄ░ńÜäķŚ«ķóśÕ╣ČõĖöµ£ēĶ¦ŻÕå│µ¢╣µ│Ģ’╝īµ¼óĶ┐ÄÕ£©ÕłŚĶĪ©õĖŁĶĪźÕģģŃĆéÕ”éµ×£Ķ┐ÖķćīńÜäÕåģÕ«╣µ▓Īµ£ēµČĄńø¢µé©ńÜäķŚ«ķóś’╝īĶ»ĘõĮ┐ńö©[µÅÉõŠøńÜ䵩ĪµØ┐](https://github.com/open-mmlab/mmaction2/tree/main/.github/ISSUE_TEMPLATE/error-report.md)ÕłøÕ╗║õĖĆõĖ¬ķŚ«ķóś’╝īÕ╣ČńĪ«õ┐ØÕ£©µ©ĪµØ┐õĖŁÕĪ½ÕåÖµēƵ£ēÕ┐ģĶ”üńÜäõ┐Īµü»ŃĆé + +## Õ«ēĶŻģ + +- **"No module named 'mmcv.ops'"; "No module named 'mmcv.\_ext'"** + + 1. õĮ┐ńö© `pip uninstall mmcv` ÕæĮõ╗żÕŹĖĶĮĮńÄ»ÕóāõĖŁńÜäńÄ░µ£ē mmcvŃĆé + 2. ÕÅéńģ¦[Õ«ēĶŻģĶ»┤µśÄ](https://mmcv.readthedocs.io/en/2.x/get_started/installation.html#install-mmcv)Õ«ēĶŻģ mmcvŃĆé + +- **"OSError: MoviePy Error: creation of None failed because of the following error"** + + õĮ┐ńö© `pip install moviepy` Õ«ēĶŻģŃĆéµø┤ÕżÜõ┐Īµü»ÕÅ»õ╗źÕÅéĶĆā[Õ«śµ¢╣Õ«ēĶŻģµ¢ćµĪŻ](https://zulko.github.io/moviepy/install.html), Ķ»Ęµ│©µäÅ’╝łµĀ╣µŹ«Ķ┐ÖõĖ¬ [issue](https://github.com/Zulko/moviepy/issues/693)’╝ē’╝Ü + + 1. Õ»╣õ║Ä Windows ńö©µłĘ’╝ī[ImageMagick](https://www.imagemagick.org/script/index.php) õĖŹõ╝ÜĶć¬ÕŖ©Ķó½ MoviePy µŻĆµĄŗÕł░’╝īķ£ĆĶ”üõ┐«µö╣ `moviepy/config_defaults.py` µ¢ćõ╗Č’╝īµÅÉõŠø ImageMagick õ║īĶ┐øÕłČµ¢ćõ╗Č `magick` ńÜäĶĘ»ÕŠä’╝īõŠŗÕ”é `IMAGEMAGICK_BINARY = "C:\\Program Files\\ImageMagick_VERSION\\magick.exe"` + 2. Õ»╣õ║Ä Linux ńö©µłĘ’╝īÕ”éµ×£ MoviePy µ▓Īµ£ēµŻĆµĄŗÕł░ ImageMagick’╝īķ£ĆĶ”üõ┐«µö╣ `/etc/ImageMagick-6/policy.xml` µ¢ćõ╗Č’╝īÕ░å `
 +
+ ĶĪīõĖ║Ķ»åÕł½ |
+  + Õ¤║õ║Äķ¬©µ×ČńÜäĶĪīõĖ║Ķ»åÕł½ |
+
 +
+ µŚČń®║ÕŖ©õĮ£µŻĆµĄŗ |
+  + µŚČń®║ÕŖ©õĮ£µŻĆµĄŗ |
+
+
+
+MMAction2 ńÜäÕ¤║ńĪĆńö©µ│Ģ
+ +- [Õ«ēĶŻģ](installation.md) +- [Õ┐½ķƤĶ┐ÉĶĪī](quick_run.md) +- [Õł®ńö©ńÄ░µ£ēµ©ĪÕ×ŗĶ┐øĶĪīµÄ©ńÉå](../user_guides/inference.md) + +
+
+
+Õģ│õ║ÄÕ£©ÕĘ▓µö»µīüńÜäµĢ░µŹ«ķøåõĖŖĶ┐øĶĪīĶ«Łń╗ā
+ +- [õ║åĶ¦ŻķģŹńĮ«µ¢ćõ╗Č](../user_guides/config.md) +- [ÕćåÕżćµĢ░µŹ«ķøå](../user_guides/prepare_dataset.md) +- [Ķ«Łń╗āõĖĵĄŗĶ»Ģ](../user_guides/train_test.md) + +
+
+
+Õģ│õ║ÄõĮ┐ńö©Ķ┐ćń©ŗõĖŁńÜäÕĖĖĶ¦üķŚ«ķóś
+ +- [ÕĖĖĶ¦üķŚ«ķóśĶ¦ŻńŁö](faq.md) +- [µ£ēńö©ńÜäÕĘźÕģĘ](../useful_tools.md) + +
+
+
+Õģ│õ║Ä MMAction2 ńÜäµĪåµ×ČĶ«ŠĶ«Ī
+ +- [20ÕłåķƤ MMAction2 µĪåµ×ȵīćÕŹŚ](guide_to_framework.md) +- [MMAction2 õĖŁńÜäµĢ░µŹ«µĄü](../advanced_guides/dataflow.md) + +
+
+
+Õģ│õ║ÄĶć¬Õ«Üõ╣ēĶ«Łń╗āńÜäķ½śń║¦ńö©µ│Ģ
+ +- [Ķć¬Õ«Üõ╣ēµ©ĪÕ×ŗ](../advanced_guides/customize_models.md) +- [Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøå](../advanced_guides/customize_dataset.md) +- [Ķć¬Õ«Üõ╣ēµĢ░µŹ«ń«Īķüō](../advanced_guides/customize_pipeline.md) +- [Ķć¬Õ«Üõ╣ēõ╝śÕī¢ÕÖ©](../advanced_guides/customize_optimizer.md) +- [Ķć¬Õ«Üõ╣ēµŚźÕ┐ŚĶ«░ÕĮĢ](../advanced_guides/customize_logging.md) + +
+
+
+Õģ│õ║ĵö»µīüńÜ䵩ĪÕ×ŗÕ║ōÕÆīµĢ░µŹ«ķøå
+ +- [µ©ĪÕ×ŗÕ║ō](../modelzoo_statistics.md) +- [µĢ░µŹ«ķøå](../datasetzoo_statistics.md) + +
+
+
+Õģ│õ║Äõ╗Ä MMAction2 0.x Ķ┐üń¦╗
+ +- [õ╗Ä MMAction2 0.x Ķ┐üń¦╗](../migration.md) + +
+
diff --git a/internlm_langchain/knowledge_base/MMAction2/content/prepare_dataset.md b/internlm_langchain/knowledge_base/MMAction2/content/prepare_dataset.md
new file mode 100644
index 00000000..b8cdfee6
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMAction2/content/prepare_dataset.md
@@ -0,0 +1,253 @@
+# ÕćåÕżćµĢ░µŹ«ķøå
+
+MMAction2 µö»µīüĶ«ĖÕżÜńÄ░µ£ēńÜäµĢ░µŹ«ķøåŃĆéÕ£©µ£¼ń½ĀõĖŁ’╝īµłæõ╗¼Õ░åÕ╝ĢÕ»╝µé©ÕćåÕżć MMAction2 ńÜäµĢ░µŹ«ķøåŃĆé
+
+- [ÕćåÕżćµĢ░µŹ«ķøå](#ÕćåÕżćµĢ░µŹ«ķøå)
+ - [Õģ│õ║ÄĶ¦åķóæµĢ░µŹ«µĀ╝Õ╝ÅńÜäĶ»┤µśÄ](#Õģ│õ║ÄĶ¦åķóæµĢ░µŹ«µĀ╝Õ╝ÅńÜäĶ»┤µśÄ)
+ - [õĮ┐ńö©ÕåģńĮ«µĢ░µŹ«ķøå](#õĮ┐ńö©ÕåģńĮ«µĢ░µŹ«ķøå)
+ - [õĮ┐ńö©Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøå](#õĮ┐ńö©Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøå)
+ - [ÕŖ©õĮ£Ķ»åÕł½](#ÕŖ©õĮ£Ķ»åÕł½)
+ - [Õ¤║õ║Äķ¬©ķ¬╝ńÜäÕŖ©õĮ£Ķ»åÕł½](#Õ¤║õ║Äķ¬©ķ¬╝ńÜäÕŖ©õĮ£Ķ»åÕł½)
+ - [µŚČń®║ÕŖ©õĮ£µŻĆµĄŗ](#µŚČń®║ÕŖ©õĮ£µŻĆµĄŗ)
+ - [µŚČÕ║ÅÕŖ©õĮ£Õ«ÜõĮŹ](#µŚČÕ║ÅÕŖ©õĮ£Õ«ÜõĮŹ)
+ - [õĮ┐ńö©µĘĘÕÉłµĢ░µŹ«ķøåĶ┐øĶĪīĶ«Łń╗ā](#õĮ┐ńö©µĘĘÕÉłµĢ░µŹ«ķøåĶ┐øĶĪīĶ«Łń╗ā)
+ - [ķćŹÕżŹµĢ░µŹ«ķøå](#ķćŹÕżŹµĢ░µŹ«ķøå)
+ - [µĄÅĶ¦łµĢ░µŹ«ķøå](#µĄÅĶ¦łµĢ░µŹ«ķøå)
+
+## Õģ│õ║ÄĶ¦åķóæµĢ░µŹ«µĀ╝Õ╝ÅńÜäĶ»┤µśÄ
+
+MMAction2 µö»µīüõĖżń¦Źń▒╗Õ×ŗńÜäµĢ░µŹ«µĀ╝Õ╝Å’╝ÜÕĤզŗÕĖ¦ÕÆīĶ¦åķóæŃĆéÕēŹĶĆģÕ£©õ╣ŗÕēŹńÜäķĪ╣ńø«’╝łÕ”é [TSN](https://github.com/yjxiong/temporal-segment-networks)’╝ēõĖŁĶó½Õ╣┐µ│øõĮ┐ńö©ŃĆéÕĮō SSD ÕÅ»ńö©µŚČ’╝īĶ┐Öń¦Źµ¢╣µ│ĢĶ┐ÉĶĪīķƤÕ║”ÕŠłÕ┐½’╝īõĮåµŚĀµ│Ģµ╗ĪĶČ│µŚźńøŖÕó×ķĢ┐ńÜäµĢ░µŹ«ķøåķ£Ćµ▒é’╝łõŠŗÕ”é’╝īµ£Ćµ¢░ńÜä [Kinetics](https://www.deepmind.com/open-source/kinetics) µĢ░µŹ«ķøåµ£ē 65 õĖćõĖ¬Ķ¦åķóæ’╝īµĆ╗ÕĖ¦µĢ░Õ░åÕŹĀńö©ÕćĀ TB ńÜäń®║ķŚ┤’╝ēŃĆéÕÉÄĶĆģÕÅ»õ╗źĶŖéń£üń®║ķŚ┤’╝īõĮåÕ┐ģķĪ╗Õ£©µē¦ĶĪīµŚČĶ┐øĶĪīĶ«Īń«ŚÕ»åķøåÕ×ŗńÜäĶ¦åķóæĶ¦ŻńĀüŃĆéõĖ║õ║åÕŖĀÕ┐½Ķ¦åķóæĶ¦ŻńĀüķƤÕ║”’╝īµłæõ╗¼µö»µīüÕćĀń¦Źķ½śµĢłńÜäĶ¦åķóæÕŖĀĶĮĮÕ║ō’╝īÕ”é [decord](https://github.com/zhreshold/decord)ŃĆü[PyAV](https://github.com/PyAV-Org/PyAV) ńŁēŃĆé
+
+## õĮ┐ńö©ÕåģńĮ«µĢ░µŹ«ķøå
+
+MMAction2 ÕĘ▓ń╗ŵö»µīüĶ«ĖÕżÜµĢ░µŹ«ķøå’╝īµłæõ╗¼Õ£©ĶĘ»ÕŠä `$MMACTION2/tools/data/` õĖŗµÅÉõŠøõ║åńö©õ║ĵĢ░µŹ«ÕćåÕżćńÜä shell Ķäܵ£¼’╝īĶ»ĘÕÅéĶĆā[µö»µīüńÜäµĢ░µŹ«ķøå](../datasetzoo_satatistics.md)õ╗źĶÄĘÕÅ¢ÕćåÕżćńē╣իܵĢ░µŹ«ķøåńÜäĶ»”ń╗åõ┐Īµü»ŃĆé
+
+## õĮ┐ńö©Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøå
+
+µ£Ćń«ĆÕŹĢńÜäµ¢╣µ│Ģµś»Õ░åµé©ńÜäµĢ░µŹ«ķøåĶĮ¼µŹóõĖ║ńÄ░µ£ēńÜäµĢ░µŹ«ķøåµĀ╝Õ╝Å’╝Ü
+
+- `RawFrameDataset` ÕÆī `VideoDataset` ńö©õ║Ä[ÕŖ©õĮ£Ķ»åÕł½](#ÕŖ©õĮ£Ķ»åÕł½)
+- `PoseDataset` ńö©õ║Ä[Õ¤║õ║Äķ¬©ķ¬╝ńÜäÕŖ©õĮ£Ķ»åÕł½](#Õ¤║õ║Äķ¬©ķ¬╝ńÜäÕŖ©õĮ£Ķ»åÕł½)
+- `AVADataset` ńö©õ║Ä[µŚČń®║ÕŖ©õĮ£µŻĆµĄŗ](#µŚČń®║ÕŖ©õĮ£µŻĆµĄŗ)
+- `ActivityNetDataset` ńö©õ║Ä[µŚČÕ║ÅÕŖ©õĮ£Õ«ÜõĮŹ](#µŚČÕ║ÅÕŖ©õĮ£Õ«ÜõĮŹ)
+
+Õ£©µĢ░µŹ«ķóäÕżäńÉåõ╣ŗÕÉÄ’╝īńö©µłĘķ£ĆĶ”üĶ┐øõĖƵŁźõ┐«µö╣ķģŹńĮ«µ¢ćõ╗Čõ╗źõĮ┐ńö©µĢ░µŹ«ķøåŃĆéõ╗źõĖŗµś»Õ£©ÕĤզŗÕĖ¦µĀ╝Õ╝ÅõĖŁõĮ┐ńö©Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåńÜäńż║õŠŗŃĆé
+
+Õ£© `configs/task/method/my_custom_config.py` õĖŁ’╝Ü
+
+```python
+...
+# µĢ░µŹ«ķøåĶ«ŠńĮ«
+dataset_type = 'RawframeDataset'
+data_root = 'path/to/your/root'
+data_root_val = 'path/to/your/root_val'
+ann_file_train = 'data/custom/custom_train_list.txt'
+ann_file_val = 'data/custom/custom_val_list.txt'
+ann_file_test = 'data/custom/custom_val_list.txt'
+...
+data = dict(
+ videos_per_gpu=32,
+ workers_per_gpu=2,
+ train=dict(
+ type=dataset_type,
+ ann_file=ann_file_train,
+ ...),
+ val=dict(
+ type=dataset_type,
+ ann_file=ann_file_val,
+ ...),
+ test=dict(
+ type=dataset_type,
+ ann_file=ann_file_test,
+ ...))
+...
+```
+
+### ÕŖ©õĮ£Ķ»åÕł½
+
+ÕŖ©õĮ£Ķ»åÕł½µ£ēõĖżń¦Źń▒╗Õ×ŗńÜäµ│©ķćŖµ¢ćõ╗ČŃĆé
+
+- `RawFrameDataset` ńÜäÕĤզŗÕĖ¦µ│©ķćŖ
+
+ ÕĤզŗÕĖ¦µĢ░µŹ«ķøåńÜäµ│©ķćŖµś»õĖĆõĖ¬ÕīģÕÉ½ÕżÜĶĪīńÜäµ¢ćµ£¼µ¢ćõ╗Č’╝īµ»ÅõĖĆĶĪīĶĪ©ńż║õĖĆõĖ¬Ķ¦åķóæńÜä `frame_directory`’╝łńøĖÕ»╣ĶĘ»ÕŠä’╝ēŃĆüĶ¦åķóæńÜä `total_frames` ÕÆīĶ¦åķóæńÜä `label`’╝īńö©ń®║µĀ╝ÕłåķÜöŃĆé
+
+ õ╗źõĖŗµś»õĖĆõĖ¬ńż║õŠŗŃĆé
+
+ ```
+ some/directory-1 163 1
+ some/directory-2 122 1
+ some/directory-3 258 2
+ some/directory-4 234 2
+ some/directory-5 295 3
+ some/directory-6 121 3
+ ```
+
+- `VideoDataset` ńÜäĶ¦åķóæµ│©ķćŖ
+
+ Ķ¦åķóæµĢ░µŹ«ķøåńÜäµ│©ķćŖµś»õĖĆõĖ¬ÕīģÕÉ½ÕżÜĶĪīńÜäµ¢ćµ£¼µ¢ćõ╗Č’╝īµ»ÅõĖĆĶĪīĶĪ©ńż║õĖĆõĖ¬µĀʵ£¼Ķ¦åķóæ’╝īÕīģµŗ¼ `filepath`’╝łńøĖÕ»╣ĶĘ»ÕŠä’╝ēÕÆī `label`’╝īńö©ń®║µĀ╝ÕłåķÜöŃĆé
+
+ õ╗źõĖŗµś»õĖĆõĖ¬ńż║õŠŗŃĆé
+
+ ```
+ some/path/000.mp4 1
+ some/path/001.mp4 1
+ some/path/002.mp4 2
+ some/path/003.mp4 2
+ some/path/004.mp4 3
+ some/path/005.mp4 3
+ ```
+
+### Õ¤║õ║Äķ¬©ķ¬╝ńé╣ńÜäÕŖ©õĮ£Ķ»åÕł½
+
+Ķ»źõ╗╗ÕŖĪÕ¤║õ║Äķ¬©ķ¬╝Õ║ÅÕłŚ’╝łÕģ│ķö«ńé╣ńÜ䵌ČķŚ┤Õ║ÅÕłŚ’╝ēĶ»åÕł½ÕŖ©õĮ£ń▒╗Õł½ŃĆ鵳æõ╗¼µÅÉõŠøõ║åõĖĆõ║øµ¢╣µ│ĢµØźµ×äÕ╗║Ķć¬Õ«Üõ╣ēńÜäķ¬©ķ¬╝µĢ░µŹ«ķøåŃĆé
+
+- õ╗Ä RGB Ķ¦åķóæµĢ░µŹ«µ×äÕ╗║
+
+ µé©ķ£ĆĶ”üõ╗ÄĶ¦åķóæõĖŁµÅÉÕÅ¢Õģ│ķö«ńé╣µĢ░µŹ«’╝īÕ╣ČÕ░åÕģČĶĮ¼µŹóõĖ║µö»µīüńÜäµĀ╝Õ╝ÅŃĆ鵳æõ╗¼µÅÉõŠøõ║åõĖĆõĖ¬[µĢÖń©ŗ](https://github.com/open-mmlab/mmaction2/tree/main/configs/skeleton/posec3d/custom_dataset_training.md)’╝īĶ»”ń╗åõ╗ŗń╗Źõ║åÕ”éõĮĢµē¦ĶĪīŃĆé
+
+- õ╗ÄńÄ░µ£ēÕģ│ķö«ńé╣µĢ░µŹ«µ×äÕ╗║
+
+ ÕüćĶ«Šµé©ÕĘ▓ń╗ŵ£ēõ║å coco µĀ╝Õ╝ÅńÜäÕģ│ķö«ńé╣µĢ░µŹ«’╝īµé©ÕÅ»õ╗źÕ░åÕ«āõ╗¼µöČķøåÕł░õĖĆõĖ¬ pickle µ¢ćõ╗ČõĖŁŃĆé
+
+ µ»ÅõĖ¬ pickle µ¢ćõ╗ČÕ»╣Õ║öõĖĆõĖ¬ÕŖ©õĮ£Ķ»åÕł½µĢ░µŹ«ķøåŃĆépickle µ¢ćõ╗ČńÜäÕåģÕ«╣µś»õĖĆõĖ¬ÕŁŚÕģĖ’╝īÕīģÕɽõĖżõĖ¬ÕŁŚµ«Ą’╝Ü`split` ÕÆī `annotations`
+
+ 1. Split’╝Ü`split` ÕŁŚµ«ĄńÜäÕĆ╝µś»õĖĆõĖ¬ÕŁŚÕģĖ’╝Üķö«µś»µŗåÕłåÕÉŹń¦░’╝īÕĆ╝µś»Õ▒×õ║Äńē╣Õ«ÜÕē¬ĶŠæńÜäĶ¦åķóæµĀćĶ»åń¼”ÕłŚĶĪ©ŃĆé
+ 2. Annotations’╝Ü`annotations` ÕŁŚµ«ĄńÜäÕĆ╝µś»õĖĆõĖ¬ķ¬©ķ¬╝µ│©ķćŖÕłŚĶĪ©’╝īµ»ÅõĖ¬ķ¬©ķ¬╝µ│©ķćŖµś»õĖĆõĖ¬ÕŁŚÕģĖ’╝īÕīģÕɽõ╗źõĖŗÕŁŚµ«Ą’╝Ü
+ - `frame_dir`’╝łstr’╝ē’╝ÜÕ»╣Õ║öĶ¦åķóæńÜäµĀćĶ»åń¼”ŃĆé
+ - `total_frames`’╝łint’╝ē’╝ܵŁżĶ¦åķóæõĖŁńÜäÕĖ¦µĢ░ŃĆé
+ - `img_shape`’╝łtuple\[int\]’╝ē’╝ÜĶ¦åķóæÕĖ¦ńÜäÕĮóńŖČ’╝īõĖĆõĖ¬ÕīģÕɽõĖżõĖ¬Õģāń┤ĀńÜäÕģāń╗ä’╝īµĀ╝Õ╝ÅõĖ║ `(height, width)`ŃĆéõ╗ģÕ»╣ 2D ķ¬©ķ¬╝ķ£ĆĶ”üŃĆé
+ - `original_shape`’╝łtuple\[int\]’╝ē’╝ÜõĖÄ `img_shape` ńøĖÕÉīŃĆé
+ - `label`’╝łint’╝ē’╝ÜÕŖ©õĮ£µĀćńŁŠŃĆé
+ - `keypoint`’╝łnp.ndarray’╝īÕĮóńŖČõĖ║ `[M x T x V x C]`’╝ē’╝ÜÕģ│ķö«ńé╣µ│©ķćŖŃĆé
+ - M’╝Üõ║║µĢ░’╝ø
+ - T’╝ÜÕĖ¦µĢ░’╝łõĖÄ `total_frames` ńøĖÕÉī’╝ē’╝ø
+ - V’╝ÜÕģ│ķö«ńé╣µĢ░ķćÅ’╝łNTURGB+D 3D ķ¬©ķ¬╝õĖ║ 25’╝īCoco õĖ║ 17’╝īOpenPose õĖ║ 18 ńŁē’╝ē’╝ø
+ - C’╝ÜÕģ│ķö«ńé╣ÕØɵĀćńÜäń╗┤µĢ░’╝ł2D Õģ│ķö«ńé╣õĖ║ C=2’╝ī3D Õģ│ķö«ńé╣õĖ║ C=3’╝ēŃĆé
+ - `keypoint_score`’╝łnp.ndarray’╝īÕĮóńŖČõĖ║ `[M x T x V]`’╝ē’╝ÜÕģ│ķö«ńé╣ńÜäńĮ«õ┐ĪÕ║”ÕłåµĢ░ŃĆéõ╗ģÕ»╣ 2D ķ¬©ķ¬╝ķ£ĆĶ”üŃĆé
+
+ õ╗źõĖŗµś»õĖĆõĖ¬ńż║õŠŗ’╝Ü
+
+ ```
+ {
+ "split":
+ {
+ 'xsub_train':
+ ['S001C001P001R001A001', ...],
+ 'xsub_val':
+ ['S001C001P003R001A001', ...],
+ ...
+ }
+
+ "annotations:
+ [
+ {
+ {
+ 'frame_dir': 'S001C001P001R001A001',
+ 'label': 0,
+ 'img_shape': (1080, 1920),
+ 'original_shape': (1080, 1920),
+ 'total_frames': 103,
+ 'keypoint': array([[[[1032. , 334.8], ...]]])
+ 'keypoint_score': array([[[0.934 , 0.9766, ...]]])
+ },
+ {
+ 'frame_dir': 'S001C001P003R001A001',
+ ...
+ },
+ ...
+
+ }
+ ]
+ }
+ ```
+
+ µö»µīüÕģČõ╗¢Õģ│ķö«ńé╣µĀ╝Õ╝Åķ£ĆĶ”üĶ┐øĶĪīĶ┐øõĖƵŁźõ┐«µö╣’╝īĶ»ĘÕÅéĶĆā[Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøå](../advanced_guides/customize_dataset.md)ŃĆé
+
+### µŚČń®║ÕŖ©õĮ£µŻĆµĄŗ
+
+MMAction2 µö»µīüÕ¤║õ║Ä `AVADataset` ńÜ䵌Čń®║ÕŖ©õĮ£µŻĆµĄŗõ╗╗ÕŖĪŃĆéµ│©ķćŖÕīģÕɽń£¤Õ«×ĶŠ╣ńĢīµĪåÕÆīµÅÉĶ««ĶŠ╣ńĢīµĪåŃĆé
+
+- ń£¤Õ«×ĶŠ╣ńĢīµĪå
+ ń£¤Õ«×ĶŠ╣ńĢīµĪåµś»õĖĆõĖ¬ÕīģÕÉ½ÕżÜĶĪīńÜä csv µ¢ćõ╗Č’╝īµ»ÅõĖĆĶĪīµś»õĖĆõĖ¬ÕĖ¦ńÜ䵯ƵĄŗµĀʵ£¼’╝īµĀ╝Õ╝ÅÕ”éõĖŗ’╝Ü
+
+ video_identifier, time_stamp, lt_x, lt_y, rb_x, rb_y, label, entity_id
+ µ»ÅõĖ¬ÕŁŚµ«ĄńÜäÕɽõ╣ēÕ”éõĖŗ’╝Ü
+ `video_identifier`’╝ÜÕ»╣Õ║öĶ¦åķóæńÜäµĀćĶ»åń¼”
+ `time_stamp`’╝ÜÕĮōÕēŹÕĖ¦ńÜ䵌ČķŚ┤µł│
+ `lt_x`’╝ÜÕĘ”õĖŖĶ¦Æńé╣ńÜäĶ¦äĶīāÕī¢ x ÕØɵĀć
+ `lt_y`’╝ÜÕĘ”õĖŖĶ¦Æńé╣ńÜäĶ¦äĶīāÕī¢ y ÕØɵĀć
+ `rb_y`’╝ÜÕÅ│õĖŗĶ¦Æńé╣ńÜäĶ¦äĶīāÕī¢ x ÕØɵĀć
+ `rb_y`’╝ÜÕÅ│õĖŗĶ¦Æńé╣ńÜäĶ¦äĶīāÕī¢ y ÕØɵĀć
+ `label`’╝ÜÕŖ©õĮ£µĀćńŁŠ
+ `entity_id`’╝ÜõĖĆõĖ¬Õö»õĖĆńÜäµĢ┤µĢ░’╝īÕģüĶ«ĖÕ░åµŁżµĪåõĖÄĶ»źĶ¦åķóæńøĖķé╗ÕĖ¦õĖŁµÅÅń╗śÕÉīõĖĆõĖ¬õ║║ńÜäÕģČõ╗¢µĪåĶ┐׵ğĶĄĘµØź
+
+ õ╗źõĖŗµś»õĖĆõĖ¬ńż║õŠŗ’╝Ü
+
+ ```
+ _-Z6wFjXtGQ,0902,0.063,0.049,0.524,0.996,12,0
+ _-Z6wFjXtGQ,0902,0.063,0.049,0.524,0.996,74,0
+ ...
+ ```
+
+- µÅÉĶ««ĶŠ╣ńĢīµĪå
+ µÅÉĶ««ĶŠ╣ńĢīµĪåµś»ńö▒õĖĆõĖ¬õ║║õĮōµŻĆµĄŗÕÖ©ńö¤µłÉńÜä pickle µ¢ćõ╗Č’╝īķĆÜÕĖĖķ£ĆĶ”üÕ£©ńø«µĀćµĢ░µŹ«ķøåõĖŖĶ┐øĶĪīÕŠ«Ķ░āŃĆépickle µ¢ćõ╗ČÕīģÕɽõĖĆõĖ¬ÕĖ”µ£ēõ╗źõĖŗµĢ░µŹ«ń╗ōµ×äńÜäÕŁŚÕģĖ’╝Ü
+
+ `{'video_identifier,time_stamp': bbox_info}`
+
+ video_identifier’╝łstr’╝ē’╝ÜÕ»╣Õ║öĶ¦åķóæńÜäµĀćĶ»åń¼”
+ time_stamp’╝łint’╝ē’╝ÜÕĮōÕēŹÕĖ¦ńÜ䵌ČķŚ┤µł│
+ bbox_info’╝łnp.ndarray’╝īÕĮóńŖČõĖ║`[n, 5]`’╝ē’╝ܵŻĆµĄŗÕł░ńÜäĶŠ╣ńĢīµĪå’╝ī\Õ»╣õ║ÄÕĖīµ£øÕŖĀÕģźÕ╝Ƶ║ÉńżŠÕī║’╝īÕÉæ MMAction2 Ķ┤Īńī«õ╗ŻńĀüńÜäńĀöń®ČĶĆģÕÆīÕ╝ĆÕÅæĶĆģ
+ +- [Õ”éõĮĢõĖ║ MMAction2 ÕüÜÕć║Ķ┤Īńī«](contribution_guide.md) + +
+  +
+
+
++ +```bash +# µÄ©ńÉåń╗ōµ×£ +{'predictions': [{'rec_labels': [[6]], 'rec_scores': [[...]]}]} +``` + +```{note} +Õ”éµ×£µé©Õ£©µ▓Īµ£ē GUI ńÜäµ£ŹÕŖĪÕÖ©õĖŖĶ┐ÉĶĪī MMAction2’╝īµł¢ĶĆģķĆÜĶ┐ćń”üńö© X11 ĶĮ¼ÕÅæńÜä SSH ķܦķüōĶ┐ÉĶĪī MMAction2’╝īÕłÖÕÅ»ĶāĮõĖŹõ╝Üń£ŗÕł░Õ╝╣Õć║ń¬ŚÕÅŻŃĆé +``` + +Õģ│õ║Ä MMAction2 µÄ©ńÉåµÄźÕÅŻńÜäĶ»”ń╗åµÅÅĶ┐░ÕÅ»õ╗źÕ£©[Ķ┐Öķćī](/demo/README.md#inferencer)µēŠÕł░. + +ķÖżõ║åõĮ┐ńö©µłæõ╗¼µÅÉõŠøńÜäķóäĶ«Łń╗āµ©ĪÕ×ŗ’╝īµé©Ķ┐śÕÅ»õ╗źÕ£©Ķć¬ÕĘ▒ńÜäµĢ░µŹ«ķøåõĖŖĶ«Łń╗āµ©ĪÕ×ŗŃĆéÕ£©õĖŗõĖĆĶŖéõĖŁ’╝īµłæõ╗¼Õ░åķĆÜĶ┐ćÕ£©ń▓Šń«Ćńēł [Kinetics](https://download.openmmlab.com/mmaction/kinetics400_tiny.zip) µĢ░µŹ«ķøåõĖŖĶ«Łń╗ā TSN õĖ║õŠŗ’╝īÕĖ”µé©õ║åĶ¦Ż MMAction2 ńÜäÕ¤║µ£¼ÕŖ¤ĶāĮŃĆé + +## ÕćåÕżćµĢ░µŹ«ķøå + +ńö▒õ║ÄĶ¦åķóæµĢ░µŹ«ķøåµĀ╝Õ╝ÅńÜäÕżÜµĀʵƦõĖŹÕł®õ║ĵĢ░µŹ«ķøåńÜäÕłćµŹó’╝īMMAction2 µÅÉÕć║õ║åń╗¤õĖĆńÜä[µĢ░µŹ«µĀ╝Õ╝Å](../user_guides/prepare_dataset.md) ’╝īÕ╣ČõĖ║ÕĖĖńö©ńÜäĶ¦åķóæµĢ░µŹ«ķøåµÅÉõŠøõ║å[µĢ░µŹ«ķøåÕćåÕżćµīćÕŹŚ](../user_guides/data_prepare/dataset_prepare.md)ŃĆéķĆÜÕĖĖ’╝īĶ”üÕ£© MMAction2 õĖŁõĮ┐ńö©Ķ┐Öõ║øµĢ░µŹ«ķøå’╝īõĮĀÕŬķ£ĆĶ”üµīēńģ¦µŁźķ¬żĶ┐øĶĪīÕćåÕżćŃĆé + +```{ń¼öĶ«░} +õĮåÕ£©Ķ┐Öķćī’╝īµĢłńÄćµäÅÕæ│ńØĆõĖĆÕłćŃĆé +``` + +ķ”¢Õģł’╝īĶ»ĘõĖŗĶĮĮµłæõ╗¼ķóäÕģłÕćåÕżćÕźĮńÜä [kinetics400_tiny.zip](https://download.openmmlab.com/mmaction/kinetics400_tiny.zip) ’╝īÕ╣ČÕ░åÕģČĶ¦ŻÕÄŗÕł░ MMAction2 µĀ╣ńø«ÕĮĢõĖŗńÜä `data/` ńø«ÕĮĢŃĆéĶ┐ÖÕ░åõĖ║µé©µÅÉõŠøÕ┐ģĶ”üńÜäĶ¦åķóæÕÆīµ│©ķćŖµ¢ćõ╗ČŃĆé + +```Bash +wget https://download.openmmlab.com/mmaction/kinetics400_tiny.zip +mkdir -p data/ +unzip kinetics400_tiny.zip -d data/ +``` + +## õ┐«µö╣ķģŹńĮ« + +ÕćåÕżćÕźĮµĢ░µŹ«ķøåõ╣ŗÕÉÄ’╝īõĖŗõĖƵŁźµś»õ┐«µö╣ķģŹńĮ«µ¢ćõ╗Č’╝īõ╗źµīćÕ«ÜĶ«Łń╗āķøåÕÆīĶ«Łń╗āÕÅéµĢ░ńÜäõĮŹńĮ«ŃĆé + +Õ£©µ£¼õŠŗõĖŁ’╝īµłæõ╗¼Õ░åõĮ┐ńö© resnet50 õĮ£õĖ║õĖ╗Õ╣▓ńĮæń╗£µØźĶ«Łń╗ā TSNŃĆéńö▒õ║Ä MMAction2 ÕĘ▓ń╗ŵ£ēõ║åÕ«īµĢ┤ńÜä Kinetics400 µĢ░µŹ«ķøåńÜäķģŹńĮ«µ¢ćõ╗Č (`configs/recognition/tsn/tsn_imagenet-pretrained-r50_8xb32-1x1x3-100e_kinetics400-rgb.py`)’╝īµłæõ╗¼ÕŬķ£ĆĶ”üÕ£©ÕģČÕ¤║ńĪĆõĖŖĶ┐øĶĪīõĖĆõ║øõ┐«µö╣ŃĆé + +### õ┐«µö╣µĢ░µŹ«ķøå + +µłæõ╗¼ķ”¢Õģłķ£ĆĶ”üõ┐«µö╣µĢ░µŹ«ķøåńÜäĶĘ»ÕŠäŃĆéµēōÕ╝Ć `configs/recognition/tsn/tsn_imagenet-pretrained-r50_8xb32-1x1x3-100e_kinetics400-rgb.py` ’╝īµīēÕ”éõĖŗµø┐µŹóÕģ│ķö«ÕŁŚ: + +```Python +data_root = 'data/kinetics400_tiny/train' +data_root_val = 'data/kinetics400_tiny/val' +ann_file_train = 'data/kinetics400_tiny/kinetics_tiny_train_video.txt' +ann_file_val = 'data/kinetics400_tiny/kinetics_tiny_val_video.txt' +``` + +### õ┐«µö╣Ķ┐ÉĶĪīķģŹńĮ« + +µŁżÕż¢’╝īńö▒õ║ĵĢ░µŹ«ķøåńÜäÕż¦Õ░ÅÕćÅÕ░æ’╝īµłæõ╗¼Õ╗║Ķ««Õ░åĶ«Łń╗āµē╣Õż¦Õ░ÅÕćÅÕ░æÕł░4õĖ¬’╝īĶ«Łń╗āepochńÜäµĢ░ķćÅńøĖÕ║öÕćÅÕ░æÕł░10õĖ¬ŃĆ鵣żÕż¢’╝īµłæõ╗¼Õ╗║Ķ««Õ░åķ¬īĶ»üÕÆīµØāÕĆ╝ÕŁśÕé©ķŚ┤ķÜöń╝®ń¤ŁõĖ║1ĶĮ«’╝īÕ╣Čõ┐«µö╣ÕŁ”õ╣ĀńÄćĶĪ░ÕćÅńŁ¢ńĢźŃĆéõ┐«µö╣ `configs/recognition/tsn/tsn_imagenet-pretrained-r50_8xb32-1x1x3-100e_kinetics400-rgb.py` õĖŁÕ»╣Õ║öńÜäÕģ│ķö«ÕŁŚ’╝īÕ”éõĖŗµēĆńż║ńö¤µĢłŃĆé + +```python +# Ķ«ŠńĮ«Ķ«Łń╗āµē╣Õż¦Õ░ÅõĖ║ 4 +train_dataloader['batch_size'] = 4 + +# µ»ÅĶĮ«ķāĮõ┐ØÕŁśµØāķ插╝īÕ╣ČõĖöÕŬõ┐ØńĢÖµ£Ćµ¢░ńÜäµØāķćŹ +default_hooks = dict( + checkpoint=dict(type='CheckpointHook', interval=1, max_keep_ckpts=1)) +# Õ░åµ£ĆÕż¦ epoch µĢ░Ķ«ŠńĮ«õĖ║ 10’╝īÕ╣ȵ»Å 1 õĖ¬ epochķ¬īĶ»üµ©ĪÕ×ŗ +train_cfg = dict(type='EpochBasedTrainLoop', max_epochs=10, val_interval=1) +#µĀ╣µŹ« 10 õĖ¬ epochĶ░āµĢ┤ÕŁ”õ╣ĀńÄćĶ░āÕ║” +param_scheduler = [ + dict( + type='MultiStepLR', + begin=0, + end=10, + by_epoch=True, + milestones=[4, 8], + gamma=0.1) +] +``` + +### õ┐«µö╣µ©ĪÕ×ŗķģŹńĮ« + +µŁżÕż¢’╝īńö▒õ║Äń▓Šń«Ćńēł Kinetics µĢ░µŹ«ķøåĶ¦äµ©ĪĶŠāÕ░Å’╝īÕ╗║Ķ««ÕŖĀĶĮĮÕĤզŗ Kinetics µĢ░µŹ«ķøåõĖŖńÜäķóäĶ«Łń╗āµ©ĪÕ×ŗŃĆ鵣żÕż¢’╝īµ©ĪÕ×ŗķ£ĆĶ”üµĀ╣µŹ«Õ«×ķÖģń▒╗Õł½µĢ░Ķ┐øĶĪīõ┐«µö╣ŃĆéĶ»Ęńø┤µÄźÕ░åõ╗źõĖŗõ╗ŻńĀüµĘ╗ÕŖĀÕł░ `configs/recognition/tsn/tsn_imagenet-pretrained-r50_8xb32-1x1x3-100e_kinetics400-rgb.py` õĖŁŃĆé + +```python +model = dict( + cls_head=dict(num_classes=2)) +load_from = 'https://download.openmmlab.com/mmaction/v1.0/recognition/tsn/tsn_imagenet-pretrained-r50_8xb32-1x1x3-100e_kinetics400-rgb/tsn_imagenet-pretrained-r50_8xb32-1x1x3-100e_kinetics400-rgb_20220906-cd10898e.pth' +``` + +Õ£©Ķ┐Öķćī’╝īµłæõ╗¼ńø┤µÄźķĆÜĶ┐ćń╗¦µē┐ ({external+mmengine:doc} `MMEngine: Config
 +
+ +
+| MMCV < 2.0 | +MMCV >= 2.0 | +
|---|---|
| + +```bash +# ÕīģÕɽń«ŚÕŁÉ’╝īÕøĀõĖ║ mmcv-full ńÜäµ£Ćķ½śńēłµ£¼Õ░Åõ║Ä 2.0.0’╝īµēĆõ╗źµŚĀķ£ĆÕŖĀńēłµ£¼ķÖÉÕłČ +pip install openmim +mim install mmcv-full + +# õĖŹÕīģÕɽń«ŚÕŁÉ +pip install openmim +mim install "mmcv < 2.0.0" +``` + + | ++ +```bash +# ÕīģÕɽń«ŚÕŁÉ +pip install openmim +mim install mmcv + +# õĖŹÕīģÕɽń«ŚÕŁÉ’╝īÕøĀõĖ║ mmcv-lite ńÜäĶĄĘÕ¦ŗńēłµ£¼õĖ║ 2.0.0’╝īµēĆõ╗źµŚĀķ£ĆÕŖĀńēłµ£¼ķÖÉÕłČ +pip install openmim +mim install mmcv-lite +``` + + | +
 +
+Õ░åõ╗ŻńĀüÕģŗķÜåÕł░µ£¼Õ£░
+
+```shell
+git clone git@github.com:{username}/mmcv.git
+```
+
+µĘ╗ÕŖĀÕĤõ╗ŻńĀüÕ║ōõĖ║õĖŖµĖĖõ╗ŻńĀüÕ║ō
+
+```bash
+git remote add upstream git@github.com:open-mmlab/mmcv
+```
+
+µŻĆµ¤ź remote µś»ÕÉ”µĘ╗ÕŖĀµłÉÕŖ¤’╝īÕ£©ń╗łń½»ĶŠōÕģź `git remote -v`
+
+```bash
+origin git@github.com:{username}/mmcv.git (fetch)
+origin git@github.com:{username}/mmcv.git (push)
+upstream git@github.com:open-mmlab/mmcv (fetch)
+upstream git@github.com:open-mmlab/mmcv (push)
+```
+
+```{note}
+Ķ┐ÖķćīÕ»╣ origin ÕÆī upstream Ķ┐øĶĪīõĖĆõĖ¬ń«ĆÕŹĢńÜäõ╗ŗń╗Ź’╝īÕĮōµłæõ╗¼õĮ┐ńö© git clone µØźÕģŗķÜåõ╗ŻńĀüµŚČ’╝īõ╝Üķ╗śĶ«żÕłøÕ╗║õĖĆõĖ¬ origin ńÜä remote’╝īÕ«āµīćÕÉæµłæõ╗¼ÕģŗķÜåńÜäõ╗ŻńĀüÕ║ōÕ£░ÕØĆ’╝īĶĆī upstream ÕłÖµś»µłæõ╗¼Ķć¬ÕĘ▒µĘ╗ÕŖĀńÜä’╝īńö©µØźµīćÕÉæÕĤզŗõ╗ŻńĀüÕ║ōÕ£░ÕØĆŃĆéÕĮōńäČÕ”éµ×£õĮĀõĖŹÕ¢£µ¼óõ╗¢ÕŽ upstream’╝īõ╣¤ÕÅ»õ╗źĶć¬ÕĘ▒õ┐«µö╣’╝īµ»öÕ”éÕŽ open-mmlabŃĆ鵳æõ╗¼ķĆÜÕĖĖÕÉæ origin µÅÉõ║żõ╗ŻńĀü’╝łÕŹ│ fork õĖŗµØźńÜäĶ┐£ń©ŗõ╗ōÕ║ō’╝ē’╝īńäČÕÉÄÕÉæ upstream µÅÉõ║żõĖĆõĖ¬ pull requestŃĆéÕ”éµ×£µÅÉõ║żńÜäõ╗ŻńĀüÕÆīµ£Ćµ¢░ńÜäõ╗ŻńĀüÕÅæńö¤Õå▓ń¬ü’╝īÕåŹõ╗Ä upstream µŗēÕÅ¢µ£Ćµ¢░ńÜäõ╗ŻńĀü’╝īÕÆīµ£¼Õ£░Õłåµö»Ķ¦ŻÕå│Õå▓ń¬ü’╝īÕåŹµÅÉõ║żÕł░ originŃĆé
+```
+
+#### 2. ķģŹńĮ« pre-commit
+
+Õ£©µ£¼Õ£░Õ╝ĆÕÅæńÄ»ÕóāõĖŁ’╝īµłæõ╗¼õĮ┐ńö© [pre-commit](https://pre-commit.com/#intro) µØźµŻĆµ¤źõ╗ŻńĀüķŻÄµĀ╝’╝īõ╗źńĪ«õ┐Øõ╗ŻńĀüķŻÄµĀ╝ńÜäń╗¤õĖĆŃĆéÕ£©µÅÉõ║żõ╗ŻńĀü’╝īķ£ĆĶ”üÕģłÕ«ēĶŻģ pre-commit’╝łķ£ĆĶ”üÕ£© MMCV ńø«ÕĮĢõĖŗµē¦ĶĪī’╝ē:
+
+```shell
+pip install -U pre-commit
+pre-commit install
+```
+
+µŻĆµ¤ź pre-commit µś»ÕÉ”ķģŹńĮ«µłÉÕŖ¤’╝īÕ╣ČÕ«ēĶŻģ `.pre-commit-config.yaml` õĖŁńÜäķÆ®ÕŁÉ’╝Ü
+
+```shell
+pre-commit run --all-files
+```
+
+
+
+Õ░åõ╗ŻńĀüÕģŗķÜåÕł░µ£¼Õ£░
+
+```shell
+git clone git@github.com:{username}/mmcv.git
+```
+
+µĘ╗ÕŖĀÕĤõ╗ŻńĀüÕ║ōõĖ║õĖŖµĖĖõ╗ŻńĀüÕ║ō
+
+```bash
+git remote add upstream git@github.com:open-mmlab/mmcv
+```
+
+µŻĆµ¤ź remote µś»ÕÉ”µĘ╗ÕŖĀµłÉÕŖ¤’╝īÕ£©ń╗łń½»ĶŠōÕģź `git remote -v`
+
+```bash
+origin git@github.com:{username}/mmcv.git (fetch)
+origin git@github.com:{username}/mmcv.git (push)
+upstream git@github.com:open-mmlab/mmcv (fetch)
+upstream git@github.com:open-mmlab/mmcv (push)
+```
+
+```{note}
+Ķ┐ÖķćīÕ»╣ origin ÕÆī upstream Ķ┐øĶĪīõĖĆõĖ¬ń«ĆÕŹĢńÜäõ╗ŗń╗Ź’╝īÕĮōµłæõ╗¼õĮ┐ńö© git clone µØźÕģŗķÜåõ╗ŻńĀüµŚČ’╝īõ╝Üķ╗śĶ«żÕłøÕ╗║õĖĆõĖ¬ origin ńÜä remote’╝īÕ«āµīćÕÉæµłæõ╗¼ÕģŗķÜåńÜäõ╗ŻńĀüÕ║ōÕ£░ÕØĆ’╝īĶĆī upstream ÕłÖµś»µłæõ╗¼Ķć¬ÕĘ▒µĘ╗ÕŖĀńÜä’╝īńö©µØźµīćÕÉæÕĤզŗõ╗ŻńĀüÕ║ōÕ£░ÕØĆŃĆéÕĮōńäČÕ”éµ×£õĮĀõĖŹÕ¢£µ¼óõ╗¢ÕŽ upstream’╝īõ╣¤ÕÅ»õ╗źĶć¬ÕĘ▒õ┐«µö╣’╝īµ»öÕ”éÕŽ open-mmlabŃĆ鵳æõ╗¼ķĆÜÕĖĖÕÉæ origin µÅÉõ║żõ╗ŻńĀü’╝łÕŹ│ fork õĖŗµØźńÜäĶ┐£ń©ŗõ╗ōÕ║ō’╝ē’╝īńäČÕÉÄÕÉæ upstream µÅÉõ║żõĖĆõĖ¬ pull requestŃĆéÕ”éµ×£µÅÉõ║żńÜäõ╗ŻńĀüÕÆīµ£Ćµ¢░ńÜäõ╗ŻńĀüÕÅæńö¤Õå▓ń¬ü’╝īÕåŹõ╗Ä upstream µŗēÕÅ¢µ£Ćµ¢░ńÜäõ╗ŻńĀü’╝īÕÆīµ£¼Õ£░Õłåµö»Ķ¦ŻÕå│Õå▓ń¬ü’╝īÕåŹµÅÉõ║żÕł░ originŃĆé
+```
+
+#### 2. ķģŹńĮ« pre-commit
+
+Õ£©µ£¼Õ£░Õ╝ĆÕÅæńÄ»ÕóāõĖŁ’╝īµłæõ╗¼õĮ┐ńö© [pre-commit](https://pre-commit.com/#intro) µØźµŻĆµ¤źõ╗ŻńĀüķŻÄµĀ╝’╝īõ╗źńĪ«õ┐Øõ╗ŻńĀüķŻÄµĀ╝ńÜäń╗¤õĖĆŃĆéÕ£©µÅÉõ║żõ╗ŻńĀü’╝īķ£ĆĶ”üÕģłÕ«ēĶŻģ pre-commit’╝łķ£ĆĶ”üÕ£© MMCV ńø«ÕĮĢõĖŗµē¦ĶĪī’╝ē:
+
+```shell
+pip install -U pre-commit
+pre-commit install
+```
+
+µŻĆµ¤ź pre-commit µś»ÕÉ”ķģŹńĮ«µłÉÕŖ¤’╝īÕ╣ČÕ«ēĶŻģ `.pre-commit-config.yaml` õĖŁńÜäķÆ®ÕŁÉ’╝Ü
+
+```shell
+pre-commit run --all-files
+```
+
+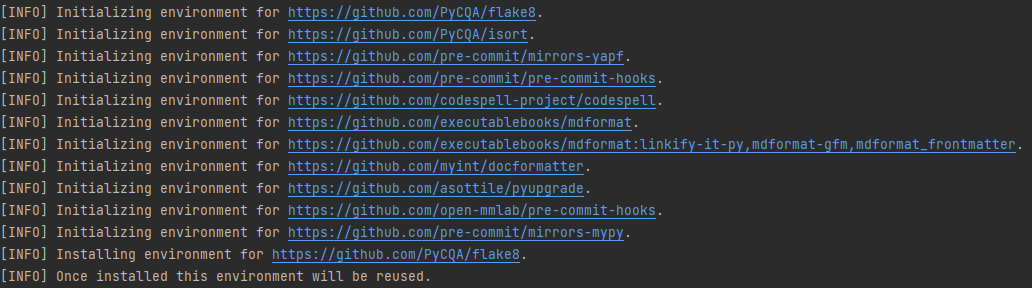 +
+
+
+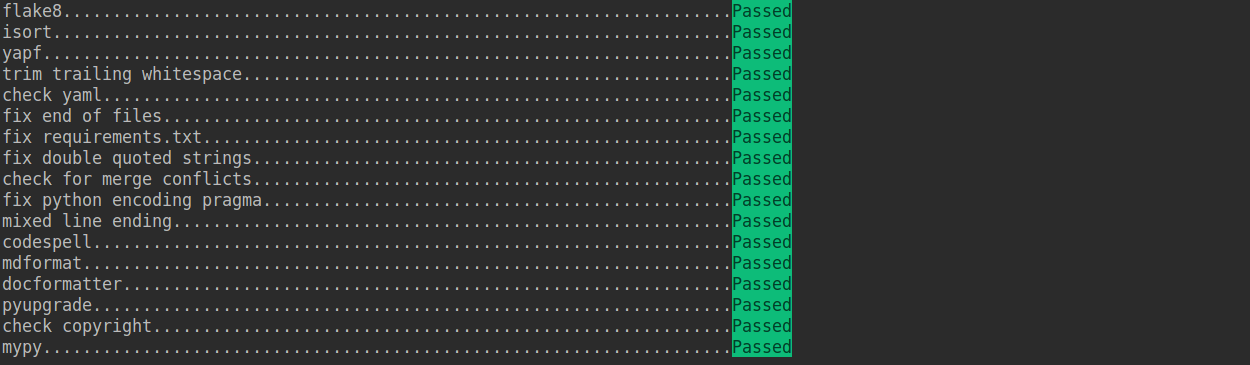 +
+```{note}
+Õ”éµ×£õĮĀµś»õĖŁÕøĮńö©µłĘ’╝īńö▒õ║ÄńĮæń╗£ÕĤÕøĀ’╝īÕÅ»ĶāĮõ╝ÜÕć║ńÄ░Õ«ēĶŻģÕż▒Ķ┤źńÜäµāģÕåĄ’╝īĶ┐ÖµŚČÕÅ»õ╗źõĮ┐ńö©ÕøĮÕåģµ║É
+
+pre-commit install -c .pre-commit-config-zh-cn.yaml
+
+pre-commit run --all-files -c .pre-commit-config-zh-cn.yaml
+```
+
+Õ”éµ×£Õ«ēĶŻģĶ┐ćń©ŗĶó½õĖŁµ¢Ł’╝īÕÅ»õ╗źķćŹÕżŹµē¦ĶĪī `pre-commit run ...` ń╗¦ń╗ŁÕ«ēĶŻģŃĆé
+
+Õ”éµ×£µÅÉõ║żńÜäõ╗ŻńĀüõĖŹń¼”ÕÉłõ╗ŻńĀüķŻÄµĀ╝Ķ¦äĶīā’╝īpre-commit õ╝ÜÕÅæÕć║ĶŁ”ÕæŖ’╝īÕ╣ČĶć¬ÕŖ©õ┐«ÕżŹķā©ÕłåķöÖĶ»»ŃĆé
+
+
+
+```{note}
+Õ”éµ×£õĮĀµś»õĖŁÕøĮńö©µłĘ’╝īńö▒õ║ÄńĮæń╗£ÕĤÕøĀ’╝īÕÅ»ĶāĮõ╝ÜÕć║ńÄ░Õ«ēĶŻģÕż▒Ķ┤źńÜäµāģÕåĄ’╝īĶ┐ÖµŚČÕÅ»õ╗źõĮ┐ńö©ÕøĮÕåģµ║É
+
+pre-commit install -c .pre-commit-config-zh-cn.yaml
+
+pre-commit run --all-files -c .pre-commit-config-zh-cn.yaml
+```
+
+Õ”éµ×£Õ«ēĶŻģĶ┐ćń©ŗĶó½õĖŁµ¢Ł’╝īÕÅ»õ╗źķćŹÕżŹµē¦ĶĪī `pre-commit run ...` ń╗¦ń╗ŁÕ«ēĶŻģŃĆé
+
+Õ”éµ×£µÅÉõ║żńÜäõ╗ŻńĀüõĖŹń¼”ÕÉłõ╗ŻńĀüķŻÄµĀ╝Ķ¦äĶīā’╝īpre-commit õ╝ÜÕÅæÕć║ĶŁ”ÕæŖ’╝īÕ╣ČĶć¬ÕŖ©õ┐«ÕżŹķā©ÕłåķöÖĶ»»ŃĆé
+
+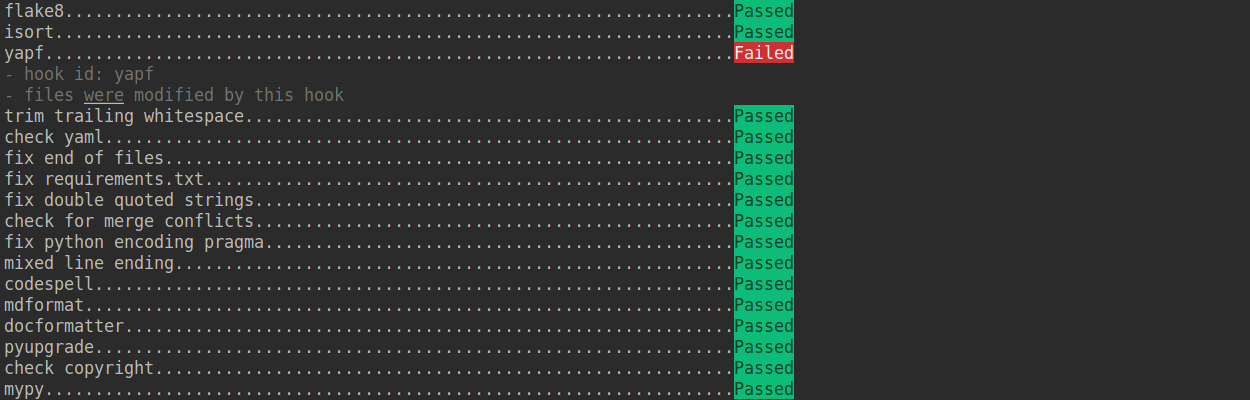 +
+Õ”éµ×£µłæõ╗¼µā│õĖ┤µŚČń╗ĢÕ╝Ć pre-commit ńÜ䵯Ƶ¤źµÅÉõ║żõĖƵ¼Īõ╗ŻńĀü’╝īÕÅ»õ╗źÕ£© `git commit` µŚČÕŖĀõĖŖ `--no-verify`’╝łķ£ĆĶ”üõ┐ØĶ»üµ£ĆÕÉĵĩķĆüĶć│Ķ┐£ń©ŗõ╗ōÕ║ōńÜäõ╗ŻńĀüĶāĮÕż¤ķĆÜĶ┐ć pre-commit µŻĆµ¤ź’╝ēŃĆé
+
+```shell
+git commit -m "xxx" --no-verify
+```
+
+#### 3. ÕłøÕ╗║Õ╝ĆÕÅæÕłåµö»
+
+Õ«ēĶŻģÕ«ī pre-commit õ╣ŗÕÉÄ’╝īµłæõ╗¼ķ£ĆĶ”üÕ¤║õ║Ä main ÕłøÕ╗║Õ╝ĆÕÅæÕłåµö»’╝īÕ╗║Ķ««ńÜäÕłåµö»ÕæĮÕÉŹĶ¦äÕłÖõĖ║ `username/pr_name`ŃĆé
+
+```shell
+git checkout -b yhc/refactor_contributing_doc
+```
+
+Õ£©ÕÉÄń╗ŁńÜäÕ╝ĆÕÅæõĖŁ’╝īÕ”éµ×£µ£¼Õ£░õ╗ōÕ║ōńÜä main Õłåµö»ĶÉĮÕÉÄõ║Ä upstream ńÜä main Õłåµö»’╝īµłæõ╗¼ķ£ĆĶ”üÕģłµŗēÕÅ¢ upstream ńÜäõ╗ŻńĀüĶ┐øĶĪīÕÉīµŁź’╝īÕåŹµē¦ĶĪīõĖŖķØóńÜäÕæĮõ╗ż
+
+```shell
+git pull upstream main
+```
+
+#### 4. µÅÉõ║żõ╗ŻńĀüÕ╣ČÕ£©µ£¼Õ£░ķĆÜĶ┐ćÕŹĢÕģāµĄŗĶ»Ģ
+
+- MMCV Õ╝ĢÕģźõ║å mypy µØźÕüÜķØÖµĆüń▒╗Õ×ŗµŻĆµ¤ź’╝īõ╗źÕó×ÕŖĀõ╗ŻńĀüńÜäķ▓üµŻÆµĆ¦ŃĆéÕøĀµŁżµłæõ╗¼Õ£©µÅÉõ║żõ╗ŻńĀüµŚČ’╝īķ£ĆĶ”üĶĪźÕģģ Type HintsŃĆéÕģĘõĮōĶ¦äÕłÖÕÅ»õ╗źÕÅéĶĆā[µĢÖń©ŗ](https://zhuanlan.zhihu.com/p/519335398)ŃĆé
+
+- µÅÉõ║żńÜäõ╗ŻńĀüÕÉīµĀĘķ£ĆĶ”üķĆÜĶ┐ćÕŹĢÕģāµĄŗĶ»Ģ
+
+ ```shell
+ # ķĆÜĶ┐ćÕģ©ķćÅÕŹĢÕģāµĄŗĶ»Ģ
+ pytest tests
+
+ # µłæõ╗¼ķ£ĆĶ”üõ┐ØĶ»üµÅÉõ║żńÜäõ╗ŻńĀüĶāĮÕż¤ķĆÜĶ┐ćõ┐«µö╣µ©ĪÕØŚńÜäÕŹĢÕģāµĄŗĶ»Ģ’╝īõ╗ź runner õĖ║õŠŗ
+ pytest tests/test_runner/test_runner.py
+ ```
+
+ Õ”éµ×£õĮĀńö▒õ║Äń╝║Õ░æõŠØĶĄ¢µŚĀµ│ĢĶ┐ÉĶĪīõ┐«µö╣µ©ĪÕØŚńÜäÕŹĢÕģāµĄŗĶ»Ģ’╝īÕÅ»õ╗źÕÅéĶĆā[µīćÕ╝Ģ-ÕŹĢÕģāµĄŗĶ»Ģ](#ÕŹĢÕģāµĄŗĶ»Ģ)
+
+- Õ”éµ×£õ┐«µö╣/µĘ╗ÕŖĀõ║åµ¢ćµĪŻ’╝īÕÅéĶĆā[µīćÕ╝Ģ](#µ¢ćµĪŻµĖ▓µ¤ō)ńĪ«Ķ«żµ¢ćµĪŻµĖ▓µ¤ōµŁŻÕĖĖŃĆé
+
+#### 5. µÄ©ķĆüõ╗ŻńĀüÕł░Ķ┐£ń©ŗ
+
+õ╗ŻńĀüķĆÜĶ┐ćÕŹĢÕģāµĄŗĶ»ĢÕÆī pre-commit µŻĆµ¤źÕÉÄ’╝īÕ░åõ╗ŻńĀüµÄ©ķĆüÕł░Ķ┐£ń©ŗõ╗ōÕ║ō’╝īÕ”éµ×£µś»ń¼¼õĖƵ¼ĪµÄ©ķĆü’╝īÕÅ»õ╗źÕ£© `git push` ÕÉÄÕŖĀõĖŖ `-u` ÕÅéµĢ░õ╗źÕģ│ĶüöĶ┐£ń©ŗÕłåµö»
+
+```shell
+git push -u origin {branch_name}
+```
+
+Ķ┐ÖµĀĘõĖŗµ¼ĪÕ░▒ÕÅ»õ╗źńø┤µÄźõĮ┐ńö© `git push` ÕæĮõ╗żµÄ©ķĆüõ╗ŻńĀüõ║å’╝īĶĆīµŚĀķ£ĆµīćÕ«ÜÕłåµö»ÕÆīĶ┐£ń©ŗõ╗ōÕ║ōŃĆé
+
+#### 6. µÅÉõ║żµŗēÕÅ¢Ķ»Ęµ▒é’╝łPR’╝ē
+
+(1) Õ£© GitHub ńÜä Pull request ńĢīķØóÕłøÕ╗║µŗēÕÅ¢Ķ»Ęµ▒é
+
+
+Õ”éµ×£µłæõ╗¼µā│õĖ┤µŚČń╗ĢÕ╝Ć pre-commit ńÜ䵯Ƶ¤źµÅÉõ║żõĖƵ¼Īõ╗ŻńĀü’╝īÕÅ»õ╗źÕ£© `git commit` µŚČÕŖĀõĖŖ `--no-verify`’╝łķ£ĆĶ”üõ┐ØĶ»üµ£ĆÕÉĵĩķĆüĶć│Ķ┐£ń©ŗõ╗ōÕ║ōńÜäõ╗ŻńĀüĶāĮÕż¤ķĆÜĶ┐ć pre-commit µŻĆµ¤ź’╝ēŃĆé
+
+```shell
+git commit -m "xxx" --no-verify
+```
+
+#### 3. ÕłøÕ╗║Õ╝ĆÕÅæÕłåµö»
+
+Õ«ēĶŻģÕ«ī pre-commit õ╣ŗÕÉÄ’╝īµłæõ╗¼ķ£ĆĶ”üÕ¤║õ║Ä main ÕłøÕ╗║Õ╝ĆÕÅæÕłåµö»’╝īÕ╗║Ķ««ńÜäÕłåµö»ÕæĮÕÉŹĶ¦äÕłÖõĖ║ `username/pr_name`ŃĆé
+
+```shell
+git checkout -b yhc/refactor_contributing_doc
+```
+
+Õ£©ÕÉÄń╗ŁńÜäÕ╝ĆÕÅæõĖŁ’╝īÕ”éµ×£µ£¼Õ£░õ╗ōÕ║ōńÜä main Õłåµö»ĶÉĮÕÉÄõ║Ä upstream ńÜä main Õłåµö»’╝īµłæõ╗¼ķ£ĆĶ”üÕģłµŗēÕÅ¢ upstream ńÜäõ╗ŻńĀüĶ┐øĶĪīÕÉīµŁź’╝īÕåŹµē¦ĶĪīõĖŖķØóńÜäÕæĮõ╗ż
+
+```shell
+git pull upstream main
+```
+
+#### 4. µÅÉõ║żõ╗ŻńĀüÕ╣ČÕ£©µ£¼Õ£░ķĆÜĶ┐ćÕŹĢÕģāµĄŗĶ»Ģ
+
+- MMCV Õ╝ĢÕģźõ║å mypy µØźÕüÜķØÖµĆüń▒╗Õ×ŗµŻĆµ¤ź’╝īõ╗źÕó×ÕŖĀõ╗ŻńĀüńÜäķ▓üµŻÆµĆ¦ŃĆéÕøĀµŁżµłæõ╗¼Õ£©µÅÉõ║żõ╗ŻńĀüµŚČ’╝īķ£ĆĶ”üĶĪźÕģģ Type HintsŃĆéÕģĘõĮōĶ¦äÕłÖÕÅ»õ╗źÕÅéĶĆā[µĢÖń©ŗ](https://zhuanlan.zhihu.com/p/519335398)ŃĆé
+
+- µÅÉõ║żńÜäõ╗ŻńĀüÕÉīµĀĘķ£ĆĶ”üķĆÜĶ┐ćÕŹĢÕģāµĄŗĶ»Ģ
+
+ ```shell
+ # ķĆÜĶ┐ćÕģ©ķćÅÕŹĢÕģāµĄŗĶ»Ģ
+ pytest tests
+
+ # µłæõ╗¼ķ£ĆĶ”üõ┐ØĶ»üµÅÉõ║żńÜäõ╗ŻńĀüĶāĮÕż¤ķĆÜĶ┐ćõ┐«µö╣µ©ĪÕØŚńÜäÕŹĢÕģāµĄŗĶ»Ģ’╝īõ╗ź runner õĖ║õŠŗ
+ pytest tests/test_runner/test_runner.py
+ ```
+
+ Õ”éµ×£õĮĀńö▒õ║Äń╝║Õ░æõŠØĶĄ¢µŚĀµ│ĢĶ┐ÉĶĪīõ┐«µö╣µ©ĪÕØŚńÜäÕŹĢÕģāµĄŗĶ»Ģ’╝īÕÅ»õ╗źÕÅéĶĆā[µīćÕ╝Ģ-ÕŹĢÕģāµĄŗĶ»Ģ](#ÕŹĢÕģāµĄŗĶ»Ģ)
+
+- Õ”éµ×£õ┐«µö╣/µĘ╗ÕŖĀõ║åµ¢ćµĪŻ’╝īÕÅéĶĆā[µīćÕ╝Ģ](#µ¢ćµĪŻµĖ▓µ¤ō)ńĪ«Ķ«żµ¢ćµĪŻµĖ▓µ¤ōµŁŻÕĖĖŃĆé
+
+#### 5. µÄ©ķĆüõ╗ŻńĀüÕł░Ķ┐£ń©ŗ
+
+õ╗ŻńĀüķĆÜĶ┐ćÕŹĢÕģāµĄŗĶ»ĢÕÆī pre-commit µŻĆµ¤źÕÉÄ’╝īÕ░åõ╗ŻńĀüµÄ©ķĆüÕł░Ķ┐£ń©ŗõ╗ōÕ║ō’╝īÕ”éµ×£µś»ń¼¼õĖƵ¼ĪµÄ©ķĆü’╝īÕÅ»õ╗źÕ£© `git push` ÕÉÄÕŖĀõĖŖ `-u` ÕÅéµĢ░õ╗źÕģ│ĶüöĶ┐£ń©ŗÕłåµö»
+
+```shell
+git push -u origin {branch_name}
+```
+
+Ķ┐ÖµĀĘõĖŗµ¼ĪÕ░▒ÕÅ»õ╗źńø┤µÄźõĮ┐ńö© `git push` ÕæĮõ╗żµÄ©ķĆüõ╗ŻńĀüõ║å’╝īĶĆīµŚĀķ£ĆµīćÕ«ÜÕłåµö»ÕÆīĶ┐£ń©ŗõ╗ōÕ║ōŃĆé
+
+#### 6. µÅÉõ║żµŗēÕÅ¢Ķ»Ęµ▒é’╝łPR’╝ē
+
+(1) Õ£© GitHub ńÜä Pull request ńĢīķØóÕłøÕ╗║µŗēÕÅ¢Ķ»Ęµ▒é
+ +
+(2) µĀ╣µŹ«µīćÕ╝Ģõ┐«µö╣ PR µÅÅĶ┐░’╝īõ╗źõŠ┐õ║ÄÕģČõ╗¢Õ╝ĆÕÅæĶĆģµø┤ÕźĮÕ£░ńÉåĶ¦ŻõĮĀńÜäõ┐«µö╣
+
+
+
+(2) µĀ╣µŹ«µīćÕ╝Ģõ┐«µö╣ PR µÅÅĶ┐░’╝īõ╗źõŠ┐õ║ÄÕģČõ╗¢Õ╝ĆÕÅæĶĆģµø┤ÕźĮÕ£░ńÉåĶ¦ŻõĮĀńÜäõ┐«µö╣
+
+ +
+µÅÅĶ┐░Ķ¦äĶīāĶ»”Ķ¦ü[µŗēÕÅ¢Ķ»Ęµ▒éĶ¦äĶīā](#µŗēÕÅ¢Ķ»Ęµ▒éĶ¦äĶīā)
+
+
+
+**µ│©µäÅõ║ŗķĪ╣**
+
+(a) PR µÅÅĶ┐░Õ║öĶ»źÕīģÕɽõ┐«µö╣ńÉåńö▒ŃĆüõ┐«µö╣ÕåģÕ«╣õ╗źÕÅŖõ┐«µö╣ÕÉÄÕĖ”µØźńÜäÕĮ▒ÕōŹ’╝īÕ╣ČÕģ│ĶüöńøĖÕģ│ Issue’╝łÕģĘõĮōµ¢╣Õ╝ÅĶ¦ü[µ¢ćµĪŻ](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue)’╝ē
+
+(b) Õ”éµ×£µś»ń¼¼õĖƵ¼ĪõĖ║ OpenMMLab ÕüÜĶ┤Īńī«’╝īķ£ĆĶ”üńŁŠńĮ▓ CLA
+
+
+
+µÅÅĶ┐░Ķ¦äĶīāĶ»”Ķ¦ü[µŗēÕÅ¢Ķ»Ęµ▒éĶ¦äĶīā](#µŗēÕÅ¢Ķ»Ęµ▒éĶ¦äĶīā)
+
+
+
+**µ│©µäÅõ║ŗķĪ╣**
+
+(a) PR µÅÅĶ┐░Õ║öĶ»źÕīģÕɽõ┐«µö╣ńÉåńö▒ŃĆüõ┐«µö╣ÕåģÕ«╣õ╗źÕÅŖõ┐«µö╣ÕÉÄÕĖ”µØźńÜäÕĮ▒ÕōŹ’╝īÕ╣ČÕģ│ĶüöńøĖÕģ│ Issue’╝łÕģĘõĮōµ¢╣Õ╝ÅĶ¦ü[µ¢ćµĪŻ](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue)’╝ē
+
+(b) Õ”éµ×£µś»ń¼¼õĖƵ¼ĪõĖ║ OpenMMLab ÕüÜĶ┤Īńī«’╝īķ£ĆĶ”üńŁŠńĮ▓ CLA
+
+ +
+(c) µŻĆµ¤źµÅÉõ║żńÜä PR µś»ÕÉ”ķĆÜĶ┐ć CI’╝łķøåµłÉµĄŗĶ»Ģ’╝ē
+
+
+
+(c) µŻĆµ¤źµÅÉõ║żńÜä PR µś»ÕÉ”ķĆÜĶ┐ć CI’╝łķøåµłÉµĄŗĶ»Ģ’╝ē
+
+ +
+MMCV õ╝ÜÕ£©õĖŹÕÉīńÜäÕ╣│ÕÅ░’╝łLinuxŃĆüWindowŃĆüMac’╝ē’╝īÕ¤║õ║ÄõĖŹÕÉīńēłµ£¼ńÜä PythonŃĆüPyTorchŃĆüCUDA Õ»╣µÅÉõ║żńÜäõ╗ŻńĀüĶ┐øĶĪīÕŹĢÕģāµĄŗĶ»Ģ’╝īõ╗źõ┐ØĶ»üõ╗ŻńĀüńÜ䵣ŻńĪ«µĆ¦’╝īÕ”éµ×£µ£ēõ╗╗õĮĢõĖĆõĖ¬µ▓Īµ£ēķĆÜĶ┐ć’╝īµłæõ╗¼ÕÅ»ńé╣Õć╗õĖŖÕøŠõĖŁńÜä `Details` µØźµ¤źń£ŗÕģĘõĮōńÜ䵥ŗĶ»Ģõ┐Īµü»’╝īõ╗źõŠ┐õ║ĵłæõ╗¼õ┐«µö╣õ╗ŻńĀüŃĆé
+
+(3) Õ”éµ×£ PR ķĆÜĶ┐ćõ║å CI’╝īķéŻõ╣łÕ░▒ÕÅ»õ╗źńŁēÕŠģÕģČõ╗¢Õ╝ĆÕÅæĶĆģńÜä review’╝īÕ╣ȵĀ╣µŹ« reviewer ńÜäµäÅĶ¦ü’╝īõ┐«µö╣õ╗ŻńĀü’╝īÕ╣ČķćŹÕżŹ [4](#4-µÅÉõ║żõ╗ŻńĀüÕ╣ȵ£¼Õ£░ķĆÜĶ┐ćÕŹĢÕģāµĄŗĶ»Ģ)-[5](#5-µÄ©ķĆüõ╗ŻńĀüÕł░Ķ┐£ń©ŗ) µŁźķ¬ż’╝īńø┤Õł░ reviewer ÕÉīµäÅÕÉłÕģź PRŃĆé
+
+
+
+MMCV õ╝ÜÕ£©õĖŹÕÉīńÜäÕ╣│ÕÅ░’╝łLinuxŃĆüWindowŃĆüMac’╝ē’╝īÕ¤║õ║ÄõĖŹÕÉīńēłµ£¼ńÜä PythonŃĆüPyTorchŃĆüCUDA Õ»╣µÅÉõ║żńÜäõ╗ŻńĀüĶ┐øĶĪīÕŹĢÕģāµĄŗĶ»Ģ’╝īõ╗źõ┐ØĶ»üõ╗ŻńĀüńÜ䵣ŻńĪ«µĆ¦’╝īÕ”éµ×£µ£ēõ╗╗õĮĢõĖĆõĖ¬µ▓Īµ£ēķĆÜĶ┐ć’╝īµłæõ╗¼ÕÅ»ńé╣Õć╗õĖŖÕøŠõĖŁńÜä `Details` µØźµ¤źń£ŗÕģĘõĮōńÜ䵥ŗĶ»Ģõ┐Īµü»’╝īõ╗źõŠ┐õ║ĵłæõ╗¼õ┐«µö╣õ╗ŻńĀüŃĆé
+
+(3) Õ”éµ×£ PR ķĆÜĶ┐ćõ║å CI’╝īķéŻõ╣łÕ░▒ÕÅ»õ╗źńŁēÕŠģÕģČõ╗¢Õ╝ĆÕÅæĶĆģńÜä review’╝īÕ╣ȵĀ╣µŹ« reviewer ńÜäµäÅĶ¦ü’╝īõ┐«µö╣õ╗ŻńĀü’╝īÕ╣ČķćŹÕżŹ [4](#4-µÅÉõ║żõ╗ŻńĀüÕ╣ȵ£¼Õ£░ķĆÜĶ┐ćÕŹĢÕģāµĄŗĶ»Ģ)-[5](#5-µÄ©ķĆüõ╗ŻńĀüÕł░Ķ┐£ń©ŗ) µŁźķ¬ż’╝īńø┤Õł░ reviewer ÕÉīµäÅÕÉłÕģź PRŃĆé
+
+ +
+µēƵ£ē reviewer ÕÉīµäÅÕÉłÕģź PR ÕÉÄ’╝īµłæõ╗¼õ╝ÜÕ░ĮÕ┐½Õ░å PR ÕÉłÕ╣ČÕł░õĖ╗Õłåµö»ŃĆé
+
+#### 7. Ķ¦ŻÕå│Õå▓ń¬ü
+
+ķÜÅńØƵŚČķŚ┤ńÜäµÄ©ń¦╗’╝īµłæõ╗¼ńÜäõ╗ŻńĀüÕ║ōõ╝ÜõĖŹµ¢Łµø┤µ¢░’╝īĶ┐ÖµŚČÕĆÖ’╝īÕ”éµ×£õĮĀńÜä PR õĖÄõĖ╗Õłåµö»ÕŁśÕ£©Õå▓ń¬ü’╝īõĮĀķ£ĆĶ”üĶ¦ŻÕå│Õå▓ń¬ü’╝īĶ¦ŻÕå│Õå▓ń¬üńÜäµ¢╣Õ╝ŵ£ēõĖżń¦Ź’╝Ü
+
+```shell
+git fetch --all --prune
+git rebase upstream/main
+```
+
+µł¢ĶĆģ
+
+```shell
+git fetch --all --prune
+git merge upstream/main
+```
+
+Õ”éµ×£õĮĀķØ×ÕĖĖÕ¢äõ║ÄÕżäńÉåÕå▓ń¬ü’╝īķéŻõ╣łÕÅ»õ╗źõĮ┐ńö© rebase ńÜäµ¢╣Õ╝ÅµØźĶ¦ŻÕå│Õå▓ń¬ü’╝īÕøĀõĖ║Ķ┐ÖĶāĮÕż¤õ┐ØĶ»üõĮĀńÜä commit log ńÜäµĢ┤µ┤üŃĆéÕ”éµ×£õĮĀõĖŹÕż¬ń夵éē `rebase` ńÜäõĮ┐ńö©’╝īķéŻõ╣łÕÅ»õ╗źõĮ┐ńö© `merge` ńÜäµ¢╣Õ╝ÅµØźĶ¦ŻÕå│Õå▓ń¬üŃĆé
+
+### µīćÕ╝Ģ
+
+#### ÕŹĢÕģāµĄŗĶ»Ģ
+
+Õ”éµ×£õĮĀµŚĀµ│ĢµŁŻÕĖĖµē¦ĶĪīķā©Õłåµ©ĪÕØŚńÜäÕŹĢÕģāµĄŗĶ»Ģ’╝īõŠŗÕ”é [video](https://github.com/open-mmlab/mmcv/tree/main/mmcv/video) µ©ĪÕØŚ’╝īÕÅ»ĶāĮµś»õĮĀńÜäÕĮōÕēŹńÄ»Õóāµ▓Īµ£ēÕ«ēĶŻģõ╗źõĖŗõŠØĶĄ¢
+
+```shell
+# Linux
+sudo apt-get update -y
+sudo apt-get install -y libturbojpeg
+sudo apt-get install -y ffmpeg
+
+# Windows
+conda install ffmpeg
+```
+
+Õ£©µÅÉõ║żõ┐«ÕżŹõ╗ŻńĀüķöÖĶ»»µł¢µ¢░Õó×ńē╣µĆ¦ńÜäµŗēÕÅ¢Ķ»Ęµ▒鵌Ȓ╝īµłæõ╗¼Õ║öĶ»źÕ░ĮÕÅ»ĶāĮńÜäĶ«®ÕŹĢÕģāµĄŗĶ»ĢĶ”åńø¢µēƵ£ēµÅÉõ║żńÜäõ╗ŻńĀü’╝īĶ«Īń«ŚÕŹĢÕģāµĄŗĶ»ĢĶ”åńø¢ńÄćńÜäµ¢╣µ│ĢÕ”éõĖŗ
+
+```shell
+python -m coverage run -m pytest /path/to/test_file
+python -m coverage html
+# check file in htmlcov/index.html
+```
+
+#### µ¢ćµĪŻµĖ▓µ¤ō
+
+Õ£©µÅÉõ║żõ┐«ÕżŹõ╗ŻńĀüķöÖĶ»»µł¢µ¢░Õó×ńē╣µĆ¦ńÜäµŗēÕÅ¢Ķ»Ęµ▒鵌Ȓ╝īÕÅ»ĶāĮõ╝Üķ£ĆĶ”üõ┐«µö╣/µ¢░Õó×µ©ĪÕØŚńÜä docstringŃĆ鵳æõ╗¼ķ£ĆĶ”üńĪ«Ķ«żµĖ▓µ¤ōÕÉÄńÜäµ¢ćµĪŻµĀĘÕ╝ŵś»µŁŻńĪ«ńÜäŃĆé
+µ£¼Õ£░ńö¤µłÉµĖ▓µ¤ōÕÉÄńÜäµ¢ćµĪŻńÜäµ¢╣µ│ĢÕ”éõĖŗ
+
+```shell
+pip install -r requirements/docs.txt
+cd docs/zh_cn/
+# or docs/en
+make html
+# check file in ./docs/zh_cn/_build/html/index.html
+```
+
+### õ╗ŻńĀüķŻÄµĀ╝
+
+#### Python
+
+[PEP8](https://www.python.org/dev/peps/pep-0008/) õĮ£õĖ║ OpenMMLab ń«Śµ│ĢÕ║ōķ”¢ķĆēńÜäõ╗ŻńĀüĶ¦äĶīā’╝īµłæõ╗¼õĮ┐ńö©õ╗źõĖŗÕĘźÕģʵŻĆµ¤źÕÆīµĀ╝Õ╝ÅÕī¢õ╗ŻńĀü
+
+- [flake8](https://github.com/PyCQA/flake8): Python Õ«śµ¢╣ÕÅæÕĖāńÜäõ╗ŻńĀüĶ¦äĶīāµŻĆµ¤źÕĘźÕģĘ’╝īµś»ÕżÜõĖ¬µŻĆµ¤źÕĘźÕģĘńÜäÕ░üĶŻģ
+- [isort](https://github.com/timothycrosley/isort): Ķć¬ÕŖ©Ķ░āµĢ┤µ©ĪÕØŚÕ»╝ÕģźķĪ║Õ║ÅńÜäÕĘźÕģĘ
+- [yapf](https://github.com/google/yapf): Google ÕÅæÕĖāńÜäõ╗ŻńĀüĶ¦äĶīāµŻĆµ¤źÕĘźÕģĘ
+- [codespell](https://github.com/codespell-project/codespell): µŻĆµ¤źÕŹĢĶ»Źµŗ╝ÕåÖµś»ÕÉ”µ£ēĶ»»
+- [mdformat](https://github.com/executablebooks/mdformat): µŻĆµ¤ź markdown µ¢ćõ╗ČńÜäÕĘźÕģĘ
+- [docformatter](https://github.com/myint/docformatter): µĀ╝Õ╝ÅÕī¢ docstring ńÜäÕĘźÕģĘ
+
+yapf ÕÆī isort ńÜäķģŹńĮ«ÕÅ»õ╗źÕ£© [setup.cfg](./setup.cfg) µēŠÕł░
+
+ķĆÜĶ┐ćķģŹńĮ« [pre-commit hook](https://pre-commit.com/) ’╝īµłæõ╗¼ÕÅ»õ╗źÕ£©µÅÉõ║żõ╗ŻńĀüµŚČĶć¬ÕŖ©µŻĆµ¤źÕÆīµĀ╝Õ╝ÅÕī¢ `flake8`ŃĆü`yapf`ŃĆü`isort`ŃĆü`trailing whitespaces`ŃĆü`markdown files`’╝ī
+õ┐«ÕżŹ `end-of-files`ŃĆü`double-quoted-strings`ŃĆü`python-encoding-pragma`ŃĆü`mixed-line-ending`’╝īĶ░āµĢ┤ `requirments.txt` ńÜäÕīģķĪ║Õ║ÅŃĆé
+pre-commit ķÆ®ÕŁÉńÜäķģŹńĮ«ÕÅ»õ╗źÕ£© [.pre-commit-config](./.pre-commit-config.yaml) µēŠÕł░ŃĆé
+
+pre-commit ÕģĘõĮōńÜäÕ«ēĶŻģõĮ┐ńö©µ¢╣Õ╝ÅĶ¦ü[µŗēÕÅ¢Ķ»Ęµ▒é](#2-ķģŹńĮ«-pre-commit)ŃĆé
+
+µø┤ÕģĘõĮōńÜäĶ¦äĶīāĶ»ĘÕÅéĶĆā [OpenMMLab õ╗ŻńĀüĶ¦äĶīā](code_style.md)ŃĆé
+
+#### C++ and CUDA
+
+C++ ÕÆī CUDA ńÜäõ╗ŻńĀüĶ¦äĶīāķüĄõ╗Ä [Google C++ Style Guide](https://google.github.io/styleguide/cppguide.html)
+
+### µŗēÕÅ¢Ķ»Ęµ▒éĶ¦äĶīā
+
+1. õĮ┐ńö© [pre-commit hook](https://pre-commit.com)’╝īÕ░ĮķćÅÕćÅÕ░æõ╗ŻńĀüķŻÄµĀ╝ńøĖÕģ│ķŚ«ķóś
+
+2. õĖĆõĖ¬`µŗēÕÅ¢Ķ»Ęµ▒é`Õ»╣Õ║öõĖĆõĖ¬ń¤Łµ£¤Õłåµö»
+
+3. ń▓ÆÕ║”Ķ”üń╗å’╝īõĖĆõĖ¬`µŗēÕÅ¢Ķ»Ęµ▒é`ÕŬÕüÜõĖĆõ╗Čõ║ŗµāģ’╝īķü┐ÕģŹĶČģÕż¦ńÜä`µŗēÕÅ¢Ķ»Ęµ▒é`
+
+ - Bad’╝ÜÕ«×ńÄ░ Faster R-CNN
+ - Acceptable’╝Üń╗Ö Faster R-CNN µĘ╗ÕŖĀõĖĆõĖ¬ box head
+ - Good’╝Üń╗Ö box head Õó×ÕŖĀõĖĆõĖ¬ÕÅéµĢ░µØźµö»µīüĶć¬Õ«Üõ╣ēńÜä conv Õ▒éµĢ░
+
+4. µ»Åµ¼Ī Commit µŚČķ£ĆĶ”üµÅÉõŠøµĖģµÖ░õĖöµ£ēµäÅõ╣ē commit õ┐Īµü»
+
+5. µÅÉõŠøµĖģµÖ░õĖöµ£ēµäÅõ╣ēńÜä`µŗēÕÅ¢Ķ»Ęµ▒é`µÅÅĶ┐░
+
+ - µĀćķóśÕåÖµśÄńÖĮõ╗╗ÕŖĪÕÉŹń¦░’╝īõĖĆĶł¼µĀ╝Õ╝Å:\[Prefix\] Short description of the pull request (Suffix)
+ - prefix: µ¢░Õó×ÕŖ¤ĶāĮ \[Feature\], õ┐« bug \[Fix\], µ¢ćµĪŻńøĖÕģ│ \[Docs\], Õ╝ĆÕÅæõĖŁ \[WIP\] (µÜ鵌ČõĖŹõ╝ÜĶó½review)
+ - µÅÅĶ┐░ķćīõ╗ŗń╗Ź`µŗēÕÅ¢Ķ»Ęµ▒é`ńÜäõĖ╗Ķ”üõ┐«µö╣ÕåģÕ«╣’╝īń╗ōµ×£’╝īõ╗źÕÅŖÕ»╣ÕģČõ╗¢ķā©ÕłåńÜäÕĮ▒ÕōŹ, ÕÅéĶĆā`µŗēÕÅ¢Ķ»Ęµ▒é`µ©ĪµØ┐
+ - Õģ│ĶüöńøĖÕģ│ńÜä`Ķ««ķóś` (issue) ÕÆīÕģČõ╗¢`µŗēÕÅ¢Ķ»Ęµ▒é`
+
+6. Õ”éµ×£Õ╝ĢÕģźõ║åÕģČõ╗¢õĖēµ¢╣Õ║ō’╝īµł¢ÕƤķē┤õ║åõĖēµ¢╣Õ║ōńÜäõ╗ŻńĀü’╝īĶ»ĘńĪ«Ķ«żõ╗¢õ╗¼ńÜäĶ«ĖÕÅ»Ķ»üÕÆī mmcv Õģ╝Õ«╣’╝īÕ╣ČÕ£©ÕƤķē┤ńÜäõ╗ŻńĀüõĖŖĶĪźÕģģ `This code is inspired from http://`
diff --git a/internlm_langchain/knowledge_base/MMCV/content/data_process.md b/internlm_langchain/knowledge_base/MMCV/content/data_process.md
new file mode 100644
index 00000000..7e0afd1e
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMCV/content/data_process.md
@@ -0,0 +1,275 @@
+## µĢ░µŹ«ÕżäńÉå
+
+### ÕøŠÕāÅ
+
+ÕøŠÕāŵ©ĪÕØŚµÅÉõŠøõ║åõĖĆõ║øÕøŠÕāÅķóäÕżäńÉåńÜäÕćĮµĢ░’╝īĶ»źµ©ĪÕØŚõŠØĶĄ¢ `opencv` ŃĆé
+
+#### Ķ»╗ÕÅ¢/õ┐ØÕŁś/µśŠńż║
+
+õĮ┐ńö© `imread` ÕÆī `imwrite` ÕćĮµĢ░ÕÅ»õ╗źĶ»╗ÕÅ¢ÕÆīõ┐ØÕŁśÕøŠÕāÅŃĆé
+
+```python
+import mmcv
+
+img = mmcv.imread('test.jpg')
+img = mmcv.imread('test.jpg', flag='grayscale')
+img_ = mmcv.imread(img) # ńøĖÕĮōõ║Äõ╗Ćõ╣łõ╣¤µ▓ĪÕüÜ
+mmcv.imwrite(img, 'out.jpg')
+```
+
+õ╗Äõ║īĶ┐øÕłČõĖŁĶ»╗ÕÅ¢ÕøŠÕāÅ
+
+```python
+with open('test.jpg', 'rb') as f:
+ data = f.read()
+img = mmcv.imfrombytes(data)
+```
+
+µśŠńż║ÕøŠÕāŵ¢ćõ╗ȵł¢ÕĘ▓Ķ»╗ÕÅ¢ńÜäÕøŠÕāÅ
+
+```python
+mmcv.imshow('tests/data/color.jpg')
+
+for i in range(10):
+ img = np.random.randint(256, size=(100, 100, 3), dtype=np.uint8)
+ mmcv.imshow(img, win_name='test image', wait_time=200)
+```
+
+#### Ķē▓ÕĮ®ń®║ķŚ┤ĶĮ¼µŹó
+
+µö»µīüńÜäĶĮ¼µŹóÕćĮµĢ░’╝Ü
+
+- bgr2gray
+- gray2bgr
+- bgr2rgb
+- rgb2bgr
+- bgr2hsv
+- hsv2bgr
+
+```python
+img = mmcv.imread('tests/data/color.jpg')
+img1 = mmcv.bgr2rgb(img)
+img2 = mmcv.rgb2gray(img1)
+img3 = mmcv.bgr2hsv(img)
+```
+
+#### ń╝®µöŠ
+
+µ£ēõĖēń¦Źń╝®µöŠÕøŠÕāÅńÜäµ¢╣µ│ĢŃĆéµēƵ£ēõ╗ź `imresize_*` Õ╝ĆÕż┤ńÜäÕćĮµĢ░ķāĮµ£ēõĖĆõĖ¬ `return_scale` ÕÅéµĢ░’╝īÕ”éµ×£
+Ķ»źÕÅéµĢ░õĖ║ `False` ’╝īÕćĮµĢ░ńÜäĶ┐öÕø×ÕĆ╝ÕŬµ£ēĶ░āµĢ┤õ╣ŗÕÉÄńÜäÕøŠÕāÅ’╝īÕÉ”ÕłÖµś»õĖĆõĖ¬Õģāń╗ä `(resized_img, scale)` ŃĆé
+
+```python
+# ń╝®µöŠÕøŠÕāÅĶć│ń╗ÖÕ«ÜńÜäÕ░║Õ»Ė
+mmcv.imresize(img, (1000, 600), return_scale=True)
+
+# ń╝®µöŠÕøŠÕāÅĶć│õĖÄń╗ÖÕ«ÜńÜäÕøŠÕāÅÕÉīµĀĘńÜäÕ░║Õ»Ė
+mmcv.imresize_like(img, dst_img, return_scale=False)
+
+# õ╗źõĖĆÕ«ÜńÜäµ»öõŠŗń╝®µöŠÕøŠÕāÅ
+mmcv.imrescale(img, 0.5)
+
+# ń╝®µöŠÕøŠÕāÅĶć│µ£ĆķĢ┐ńÜäĶŠ╣õĖŹÕż¦õ║Ä1000ŃĆüµ£Ćń¤ŁńÜäĶŠ╣õĖŹÕż¦õ║Ä800Õ╣ČõĖöµ▓Īµ£ēµö╣ÕÅśÕøŠÕāÅńÜäķĢ┐Õ«Įµ»ö
+mmcv.imrescale(img, (1000, 800))
+```
+
+#### µŚŗĶĮ¼
+
+µłæõ╗¼ÕÅ»õ╗źõĮ┐ńö© `imrotate` µŚŗĶĮ¼ÕøŠÕāÅõĖĆÕ«ÜńÜäĶ¦ÆÕ║”ŃĆ鵌ŗĶĮ¼ńÜäõĖŁÕ┐āķ£ĆĶ”üµīćÕ«Ü’╝īķ╗śĶ«żÕĆ╝µś»ÕĤզŗÕøŠÕāÅńÜäõĖŁÕ┐āŃĆéµ£ē
+õĖżń¦ŹµŚŗĶĮ¼ńÜ䵩ĪÕ╝Å’╝īõĖĆń¦Źõ┐صīüÕøŠÕāÅńÜäÕ░║Õ»ĖõĖŹÕÅś’╝īÕøĀµŁżµŚŗĶĮ¼ÕÉÄÕĤզŗÕøŠÕāÅõĖŁńÜ䵤Éõ║øķā©Õłåõ╝ÜĶó½ĶŻüÕē¬’╝īÕÅ”õĖĆń¦Źµś»µē®Õż¦
+ÕøŠÕāÅńÜäÕ░║Õ»ĖĶ┐øĶĆīõ┐ØńĢÖÕ«īµĢ┤ńÜäÕĤզŗÕøŠÕāÅŃĆé
+
+```python
+img = mmcv.imread('tests/data/color.jpg')
+
+# ķĪ║µŚČķÆłµŚŗĶĮ¼ÕøŠÕāÅ30Õ║”
+img_ = mmcv.imrotate(img, 30)
+
+# ķĆåµŚČķÆłµŚŗĶĮ¼ÕøŠÕāÅ90Õ║”
+img_ = mmcv.imrotate(img, -90)
+
+# ķĪ║µŚČķÆłµŚŗĶĮ¼ÕøŠÕāÅ30Õ║”Õ╣ČõĖöń╝®µöŠÕøŠÕāÅõĖ║ÕĤզŗÕøŠÕāÅńÜä1.5ÕĆŹ
+img_ = mmcv.imrotate(img, 30, scale=1.5)
+
+# õ╗źÕØɵĀć(100, 100)õĖ║õĖŁÕ┐āķĪ║µŚČķÆłµŚŗĶĮ¼ÕøŠÕāÅ30Õ║”
+img_ = mmcv.imrotate(img, 30, center=(100, 100))
+
+# ķĪ║µŚČķÆłµŚŗĶĮ¼ÕøŠÕāÅ30Õ║”Õ╣ȵē®Õż¦ÕøŠÕāÅńÜäÕ░║Õ»Ė
+img_ = mmcv.imrotate(img, 30, auto_bound=True)
+```
+
+#### ń┐╗ĶĮ¼
+
+µłæõ╗¼ÕÅ»õ╗źõĮ┐ńö© `imflip` ń┐╗ĶĮ¼ÕøŠÕāÅŃĆé
+
+```python
+img = mmcv.imread('tests/data/color.jpg')
+
+# µ░┤Õ╣│ń┐╗ĶĮ¼ÕøŠÕāÅ
+mmcv.imflip(img)
+
+# Õ×éńø┤ń┐╗ĶĮ¼ÕøŠÕāÅ
+mmcv.imflip(img, direction='vertical')
+```
+
+#### ĶŻüÕē¬
+
+`imcrop` ÕÅ»õ╗źĶŻüÕē¬ÕøŠÕāÅńÜäõĖĆõĖ¬µł¢ÕżÜõĖ¬Õī║Õ¤¤’╝īµ»ÅõĖ¬Õī║Õ¤¤ńö©ÕĘ”õĖŖĶ¦ÆÕÆīÕÅ│õĖŗĶ¦ÆÕØɵĀćĶĪ©ńż║’╝īÕĮóÕ”é(x1, y1, x2, y2)
+
+```python
+import mmcv
+import numpy as np
+
+img = mmcv.imread('tests/data/color.jpg')
+
+# ĶŻüÕē¬Õī║Õ¤¤ (10, 10, 100, 120)
+bboxes = np.array([10, 10, 100, 120])
+patch = mmcv.imcrop(img, bboxes)
+
+# ĶŻüÕē¬õĖżõĖ¬Õī║Õ¤¤’╝īÕłåÕł½µś» (10, 10, 100, 120) ÕÆī (0, 0, 50, 50)
+bboxes = np.array([[10, 10, 100, 120], [0, 0, 50, 50]])
+patches = mmcv.imcrop(img, bboxes)
+
+# ĶŻüÕē¬õĖżõĖ¬Õī║Õ¤¤Õ╣ČõĖöń╝®µöŠÕī║Õ¤¤1.2ÕĆŹ
+patches = mmcv.imcrop(img, bboxes, scale=1.2)
+```
+
+#### ÕĪ½Õģģ
+
+`impad` and `impad_to_multiple` ÕÅ»õ╗źńö©ń╗ÖÕ«ÜńÜäÕĆ╝Õ░åÕøŠÕāÅÕĪ½ÕģģĶć│ń╗ÖÕ«ÜńÜäÕ░║Õ»ĖŃĆé
+
+```python
+img = mmcv.imread('tests/data/color.jpg')
+
+# ńö©ń╗ÖÕ«ÜÕĆ╝Õ░åÕøŠÕāÅÕĪ½ÕģģĶć│ (1000, 1200)
+img_ = mmcv.impad(img, shape=(1000, 1200), pad_val=0)
+
+# ńö©ń╗ÖÕ«ÜÕĆ╝ÕłåÕł½ÕĪ½ÕģģÕøŠÕāÅńÜä3õĖ¬ķĆÜķüōĶć│ (1000, 1200)
+img_ = mmcv.impad(img, shape=(1000, 1200), pad_val=(100, 50, 200))
+
+# ńö©ń╗ÖÕ«ÜÕĆ╝ÕĪ½ÕģģÕøŠÕāÅńÜäÕĘ”ŃĆüÕÅ│ŃĆüõĖŖŃĆüõĖŗÕøøµØĪĶŠ╣
+img_ = mmcv.impad(img, padding=(10, 20, 30, 40), pad_val=0)
+
+# ńö©3õĖ¬ÕĆ╝ÕłåÕł½ÕĪ½ÕģģÕøŠÕāÅńÜäÕĘ”ŃĆüÕÅ│ŃĆüõĖŖŃĆüõĖŗÕøøµØĪĶŠ╣ńÜä3õĖ¬ķĆÜķüō
+img_ = mmcv.impad(img, padding=(10, 20, 30, 40), pad_val=(100, 50, 200))
+
+# Õ░åÕøŠÕāÅńÜäÕøøµØĪĶŠ╣ÕĪ½ÕģģĶć│ĶāĮÕż¤Ķó½ń╗ÖÕ«ÜÕĆ╝µĢ┤ķÖż
+img_ = mmcv.impad_to_multiple(img, 32)
+```
+
+### Ķ¦åķóæ
+
+Ķ¦åķó浩ĪÕØŚµÅÉõŠøõ║åõ╗źõĖŗńÜäÕŖ¤ĶāĮ’╝Ü
+
+- õĖĆõĖ¬ `VideoReader` ń▒╗’╝īÕģʵ£ēÕÅŗÕźĮńÜä API µÄźÕÅŻÕÅ»õ╗źĶ»╗ÕÅ¢ÕÆīĶĮ¼µŹóĶ¦åķóæ
+- õĖĆõ║øń╝¢ĶŠæĶ¦åķóæńÜäµ¢╣µ│Ģ’╝īÕīģµŗ¼ `cut` ’╝ī `concat` ’╝ī `resize`
+- ÕģēµĄüńÜäĶ»╗ÕÅ¢/õ┐ØÕŁś/ÕÅśµŹó
+
+#### VideoReader
+
+`VideoReader` ń▒╗µÅÉõŠøõ║åÕÆīÕ║ÅÕłŚõĖƵĀĘńÜäµÄźÕÅŻÕÄ╗ĶÄĘÕÅ¢Ķ¦åķóæÕĖ¦ŃĆéĶ»źń▒╗õ╝Üń╝ōÕŁśµēƵ£ēĶó½Ķ«┐ķŚ«Ķ┐ćńÜäÕĖ¦ŃĆé
+
+```python
+video = mmcv.VideoReader('test.mp4')
+
+# ĶÄĘÕÅ¢Õ¤║µ£¼ńÜäõ┐Īµü»
+print(len(video))
+print(video.width, video.height, video.resolution, video.fps)
+
+# ķüŹÕÄåµēƵ£ēńÜäÕĖ¦
+for frame in video:
+ print(frame.shape)
+
+# Ķ»╗ÕÅ¢õĖŗõĖĆÕĖ¦
+img = video.read()
+
+# õĮ┐ńö©ń┤óÕ╝ĢĶÄĘÕÅ¢ÕĖ¦
+img = video[100]
+
+# ĶÄĘÕÅ¢µīćÕ«ÜĶīāÕø┤ńÜäÕĖ¦
+img = video[5:10]
+```
+
+Õ░åĶ¦åķóæÕłćµłÉÕĖ¦Õ╣Čõ┐ØÕŁśĶć│ń╗ÖÕ«Üńø«ÕĮĢµł¢ĶĆģõ╗Äń╗ÖÕ«Üńø«ÕĮĢõĖŁńö¤µłÉĶ¦åķóæŃĆé
+
+```python
+# Õ░åĶ¦åķóæÕłćµłÉÕĖ¦Õ╣Čõ┐ØÕŁśĶć│ńø«ÕĮĢ
+video = mmcv.VideoReader('test.mp4')
+video.cvt2frames('out_dir')
+
+# õ╗Äń╗ÖÕ«Üńø«ÕĮĢõĖŁńö¤µłÉĶ¦åķóæ
+mmcv.frames2video('out_dir', 'test.avi')
+```
+
+#### ń╝¢ĶŠæÕćĮµĢ░
+
+µ£ēÕćĀõĖ¬ńö©õ║Äń╝¢ĶŠæĶ¦åķóæńÜäÕćĮµĢ░’╝īĶ┐Öõ║øÕćĮµĢ░µś»Õ»╣ `ffmpeg` ńÜäÕ░üĶŻģŃĆé
+
+```python
+# ĶŻüÕē¬Ķ¦åķóæ
+mmcv.cut_video('test.mp4', 'clip1.mp4', start=3, end=10, vcodec='h264')
+
+# Õ░åÕżÜõĖ¬Ķ¦åķóæµŗ╝µÄźµłÉõĖĆõĖ¬Ķ¦åķóæ
+mmcv.concat_video(['clip1.mp4', 'clip2.mp4'], 'joined.mp4', log_level='quiet')
+
+# Õ░åĶ¦åķóæń╝®µöŠĶć│ń╗ÖÕ«ÜńÜäÕ░║Õ»Ė
+mmcv.resize_video('test.mp4', 'resized1.mp4', (360, 240))
+
+# Õ░åĶ¦åķóæń╝®µöŠĶć│ń╗ÖÕ«ÜńÜäÕĆŹńÄć
+mmcv.resize_video('test.mp4', 'resized2.mp4', ratio=2)
+```
+
+#### ÕģēµĄü
+
+`mmcv` µÅÉõŠøõ║åõ╗źõĖŗńö©õ║ĵōŹõĮ£ÕģēµĄüńÜäÕćĮµĢ░’╝Ü
+
+- Ķ»╗ÕÅ¢/õ┐ØÕŁś
+- ÕÅ»Ķ¦åÕī¢
+- µĄüÕÅśµŹó
+
+µłæõ╗¼µÅÉõŠøõ║åõĖżń¦ŹÕ░åÕģēµĄüdumpÕł░µ¢ćõ╗ČńÜäµ¢╣µ│Ģ’╝īÕłåÕł½µś»ķØ×ÕÄŗń╝®ÕÆīÕÄŗń╝®ńÜäµ¢╣µ│ĢŃĆéķØ×ÕÄŗń╝®ńÜäµ¢╣µ│Ģńø┤µÄźÕ░åµĄ«ńé╣µĢ░ÕĆ╝ńÜäÕģēµĄü
+õ┐ØÕŁśĶć│õ║īĶ┐øÕłČµ¢ćõ╗Č’╝īĶÖĮńäČÕģēµĄüµŚĀµŹ¤õĮåµ¢ćõ╗Čõ╝ܵ»öĶŠāÕż¦ŃĆéĶĆīÕÄŗń╝®ńÜäµ¢╣µ│ĢÕģłķćÅÕī¢ÕģēµĄüĶć│ 0-255 µĢ┤ÕĮóµĢ░ÕĆ╝ÕåŹõ┐ØÕŁśõĖ║
+jpegÕøŠÕāÅŃĆéÕģēµĄüńÜäxń╗┤Õ║”ÕÆīyń╗┤Õ║”õ╝ÜĶó½µŗ╝µÄźÕł░ÕøŠÕāÅõĖŁŃĆé
+
+1. Ķ»╗ÕÅ¢/õ┐ØÕŁś
+
+```python
+flow = np.random.rand(800, 600, 2).astype(np.float32)
+# õ┐ØÕŁśÕģēµĄüÕł░floµ¢ćõ╗Č (~3.7M)
+mmcv.flowwrite(flow, 'uncompressed.flo')
+# õ┐ØÕŁśÕģēµĄüõĖ║jpegÕøŠÕāÅ (~230K)’╝īÕøŠÕāÅńÜäÕ░║Õ»ĖõĖ║ (800, 1200)
+mmcv.flowwrite(flow, 'compressed.jpg', quantize=True, concat_axis=1)
+
+# Ķ»╗ÕÅ¢ÕģēµĄüµ¢ćõ╗Č’╝īõ╗źõĖŗõĖżń¦Źµ¢╣Õ╝ÅĶ»╗ÕÅ¢ńÜäÕģēµĄüÕ░║Õ»ĖÕØćõĖ║ (800, 600, 2)
+flow = mmcv.flowread('uncompressed.flo')
+flow = mmcv.flowread('compressed.jpg', quantize=True, concat_axis=1)
+```
+
+2. ÕÅ»Ķ¦åÕī¢
+
+õĮ┐ńö© `mmcv.flowshow()` ÕÅ»Ķ¦åÕī¢ÕģēµĄü
+
+```python
+mmcv.flowshow(flow)
+```
+
+
+
+1. µĄüÕÅśµŹó
+
+```python
+img1 = mmcv.imread('img1.jpg')
+flow = mmcv.flowread('flow.flo')
+warped_img2 = mmcv.flow_warp(img1, flow)
+```
+
+img1 (ÕĘ”) and img2 (ÕÅ│)
+
+
+
+ÕģēµĄü (img2 -> img1)
+
+
+
+ÕÅśµŹóÕÉÄńÜäÕøŠÕāÅÕÆīń£¤Õ«×ÕøŠÕāÅńÜäÕĘ«Õ╝é
+
+
diff --git a/internlm_langchain/knowledge_base/MMCV/content/data_transform.md b/internlm_langchain/knowledge_base/MMCV/content/data_transform.md
new file mode 100644
index 00000000..47d16e1b
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMCV/content/data_transform.md
@@ -0,0 +1,341 @@
+# µĢ░µŹ«ÕÅśµŹó
+
+Õ£© OpenMMLab ń«Śµ│ĢÕ║ōõĖŁ’╝īµĢ░µŹ«ķøåńÜäµ×äÕ╗║ÕÆīµĢ░µŹ«ńÜäÕćåÕżćµś»ńøĖõ║ÆĶ¦ŻĶĆ”ńÜäŃĆéķĆÜÕĖĖ’╝īµĢ░µŹ«ķøåńÜäµ×äÕ╗║ÕŬջ╣µĢ░µŹ«ķøåĶ┐øĶĪīĶ¦Żµ×É’╝īĶ«░ÕĮĢµ»ÅõĖ¬µĀʵ£¼ńÜäÕ¤║µ£¼õ┐Īµü»’╝øĶĆīµĢ░µŹ«ńÜäÕćåÕżćÕłÖµś»ķĆÜĶ┐ćõĖĆń│╗ÕłŚńÜäµĢ░µŹ«ÕÅśµŹó’╝īµĀ╣µŹ«µĀʵ£¼ńÜäÕ¤║µ£¼õ┐Īµü»Ķ┐øĶĪīµĢ░µŹ«ÕŖĀĶĮĮŃĆüķóäÕżäńÉåŃĆüµĀ╝Õ╝ÅÕī¢ńŁēµōŹõĮ£ŃĆé
+
+## µĢ░µŹ«ÕÅśµŹóńÜäĶ«ŠĶ«Ī
+
+Õ£© MMCV õĖŁ’╝īµłæõ╗¼õĮ┐ńö©ÕÉäń¦ŹÕÅ»Ķ░āńö©ńÜäµĢ░µŹ«ÕÅśµŹóń▒╗µØźĶ┐øĶĪīµĢ░µŹ«ńÜäµōŹõĮ£ŃĆéĶ┐Öõ║øµĢ░µŹ«ÕÅśµŹóń▒╗ÕÅ»õ╗źµÄźÕÅŚĶŗźÕ╣▓ķģŹńĮ«ÕÅéµĢ░Ķ┐øĶĪīÕ«×õŠŗÕī¢’╝īõ╣ŗÕÉÄķĆÜĶ┐ćĶ░āńö©ńÜäµ¢╣Õ╝ÅÕ»╣ĶŠōÕģźńÜäµĢ░µŹ«ÕŁŚÕģĖĶ┐øĶĪīÕżäńÉåŃĆéÕÉīµŚČ’╝īµłæõ╗¼ń║”իܵēƵ£ēµĢ░µŹ«ÕÅśµŹóķāĮµÄźÕÅŚõĖĆõĖ¬ÕŁŚÕģĖõĮ£õĖ║ĶŠōÕģź’╝īÕ╣ČÕ░åÕżäńÉåÕÉÄńÜäµĢ░µŹ«ĶŠōÕć║õĖ║õĖĆõĖ¬ÕŁŚÕģĖŃĆéõĖĆõĖ¬ń«ĆÕŹĢńÜäõŠŗÕŁÉÕ”éõĖŗ’╝Ü
+
+```python
+>>> import numpy as np
+>>> from mmcv.transforms import Resize
+>>>
+>>> transform = Resize(scale=(224, 224))
+>>> data_dict = {'img': np.random.rand(256, 256, 3)}
+>>> data_dict = transform(data_dict)
+>>> print(data_dict['img'].shape)
+(224, 224, 3)
+```
+
+µĢ░µŹ«ÕÅśµŹóń▒╗õ╝ÜĶ»╗ÕÅ¢ĶŠōÕģźÕŁŚÕģĖńÜ䵤Éõ║øÕŁŚµ«Ą’╝īÕ╣ČõĖöÕÅ»ĶāĮµĘ╗ÕŖĀŃĆüµł¢ĶĆģµø┤µ¢░µ¤Éõ║øÕŁŚµ«ĄŃĆéĶ┐Öõ║øÕŁŚµ«ĄńÜäķö«Õż¦ķā©ÕłåµāģÕåĄõĖŗµś»Õø║Õ«ÜńÜä’╝īÕ”é `Resize` õ╝ÜÕø║Õ«ÜÕ£░Ķ»╗ÕÅ¢ĶŠōÕģźÕŁŚÕģĖõĖŁńÜä `"img"` ńŁēÕŁŚµ«ĄŃĆ鵳æõ╗¼ÕÅ»õ╗źÕ£©Õ»╣Õ║öń▒╗ńÜäµ¢ćµĪŻõĖŁõ║åĶ¦ŻÕ»╣ĶŠōÕģźĶŠōÕć║ÕŁŚµ«ĄńÜäń║”Õ«ÜŃĆé
+
+```{note}
+ķ╗śĶ«żµāģÕåĄõĖŗ’╝īÕ£©ķ£ĆĶ”üÕøŠÕāÅÕ░║Õ»ĖõĮ£õĖ║**ÕłØÕ¦ŗÕī¢ÕÅéµĢ░**ńÜäµĢ░µŹ«ÕÅśµŹó (Õ”éResize, Pad) õĖŁ’╝īÕøŠÕāÅÕ░║Õ»ĖńÜäķĪ║Õ║ÅÕØćõĖ║ (width, height)ŃĆéÕ£©µĢ░µŹ«ÕÅśµŹó**Ķ┐öÕø×ńÜäÕŁŚÕģĖ**õĖŁ’╝īÕøŠÕāÅńøĖÕģ│ńÜäÕ░║Õ»Ė’╝ī Õ”é `img_shape`ŃĆü`ori_shape`ŃĆü`pad_shape` ńŁē’╝īÕØćõĖ║ (height, width)ŃĆé
+```
+
+MMCV õĖ║µēƵ£ēńÜäµĢ░µŹ«ÕÅśµŹóń▒╗µÅÉõŠøõ║åõĖĆõĖ¬ń╗¤õĖĆńÜäÕ¤║ń▒╗ (`BaseTransform`)’╝Ü
+
+```python
+class BaseTransform(metaclass=ABCMeta):
+
+ def __call__(self, results: dict) -> dict:
+
+ return self.transform(results)
+
+ @abstractmethod
+ def transform(self, results: dict) -> dict:
+ pass
+```
+
+µēƵ£ēńÜäµĢ░µŹ«ÕÅśµŹóń▒╗ķāĮķ£ĆĶ”üń╗¦µē┐ `BaseTransform`’╝īÕ╣ČÕ«×ńÄ░ `transform` µ¢╣µ│ĢŃĆé`transform` µ¢╣µ│ĢńÜäĶŠōÕģźÕÆīĶŠōÕć║ÕØćõĖ║õĖĆõĖ¬ÕŁŚÕģĖŃĆéÕ£©**Ķć¬Õ«Üõ╣ēµĢ░µŹ«ÕÅśµŹóń▒╗**õĖĆĶŖéõĖŁ’╝īµłæõ╗¼õ╝ܵø┤Ķ»”ń╗åÕ£░õ╗ŗń╗ŹÕ”éõĮĢÕ«×ńÄ░õĖĆõĖ¬µĢ░µŹ«ÕÅśµŹóń▒╗ŃĆé
+
+## µĢ░µŹ«µĄüµ░┤ń║┐
+
+Õ”éõĖŖµēĆĶ┐░’╝īµēƵ£ēµĢ░µŹ«ÕÅśµŹóńÜäĶŠōÕģźÕÆīĶŠōÕć║ķāĮµś»õĖĆõĖ¬ÕŁŚÕģĖ’╝īĶĆīõĖöµĀ╣µŹ« OpenMMLab õĖŁ [µ£ēÕģ│µĢ░µŹ«ķøåńÜäń║”Õ«Ü](TODO)’╝īµĢ░µŹ«ķøåõĖŁµ»ÅõĖ¬µĀʵ£¼ńÜäÕ¤║µ£¼õ┐Īµü»ķāĮµś»õĖĆõĖ¬ÕŁŚÕģĖŃĆéĶ┐ÖµĀĘõĖĆµØź’╝īµłæõ╗¼ÕÅ»õ╗źÕ░åµēƵ£ēńÜäµĢ░µŹ«ÕÅśµŹóµōŹõĮ£ķ”¢Õ░ŠńøĖµÄź’╝īń╗äÕÉłµłÉõĖ║õĖƵØĪµĢ░µŹ«µĄüµ░┤ń║┐’╝łdata pipeline’╝ē’╝īĶŠōÕģźµĢ░µŹ«ķøåõĖŁµĀʵ£¼ńÜäõ┐Īµü»ÕŁŚÕģĖ’╝īĶŠōÕć║Õ«īµłÉõĖĆń│╗ÕłŚÕżäńÉåÕÉÄńÜäõ┐Īµü»ÕŁŚÕģĖŃĆé
+
+õ╗źÕłåń▒╗õ╗╗ÕŖĪõĖ║õŠŗ’╝īµłæõ╗¼Õ£©õĖŗÕøŠÕ▒Ģńż║õ║åõĖĆõĖ¬ÕģĖÕ×ŗńÜäµĢ░µŹ«µĄüµ░┤ń║┐ŃĆéÕ»╣µ»ÅõĖ¬µĀʵ£¼’╝īµĢ░µŹ«ķøåõĖŁõ┐ØÕŁśńÜäÕ¤║µ£¼õ┐Īµü»µś»õĖĆõĖ¬Õ”éÕøŠõĖŁµ£ĆÕĘ”õŠ¦µēĆńż║ńÜäÕŁŚÕģĖ’╝īõ╣ŗÕÉĵ»Åń╗ÅĶ┐ćõĖĆõĖ¬ńö▒ĶōØĶē▓ÕØŚõ╗ŻĶĪ©ńÜäµĢ░µŹ«ÕÅśµŹóµōŹõĮ£’╝īµĢ░µŹ«ÕŁŚÕģĖõĖŁķāĮõ╝ÜÕŖĀÕģźµ¢░ńÜäÕŁŚµ«Ą’╝łµĀćĶ«░õĖ║ń╗┐Ķē▓’╝ēµł¢µø┤µ¢░ńÄ░µ£ēńÜäÕŁŚµ«Ą’╝łµĀćĶ«░õĖ║µ®ÖĶē▓’╝ēŃĆé
+
+
+
+µēƵ£ē reviewer ÕÉīµäÅÕÉłÕģź PR ÕÉÄ’╝īµłæõ╗¼õ╝ÜÕ░ĮÕ┐½Õ░å PR ÕÉłÕ╣ČÕł░õĖ╗Õłåµö»ŃĆé
+
+#### 7. Ķ¦ŻÕå│Õå▓ń¬ü
+
+ķÜÅńØƵŚČķŚ┤ńÜäµÄ©ń¦╗’╝īµłæõ╗¼ńÜäõ╗ŻńĀüÕ║ōõ╝ÜõĖŹµ¢Łµø┤µ¢░’╝īĶ┐ÖµŚČÕĆÖ’╝īÕ”éµ×£õĮĀńÜä PR õĖÄõĖ╗Õłåµö»ÕŁśÕ£©Õå▓ń¬ü’╝īõĮĀķ£ĆĶ”üĶ¦ŻÕå│Õå▓ń¬ü’╝īĶ¦ŻÕå│Õå▓ń¬üńÜäµ¢╣Õ╝ŵ£ēõĖżń¦Ź’╝Ü
+
+```shell
+git fetch --all --prune
+git rebase upstream/main
+```
+
+µł¢ĶĆģ
+
+```shell
+git fetch --all --prune
+git merge upstream/main
+```
+
+Õ”éµ×£õĮĀķØ×ÕĖĖÕ¢äõ║ÄÕżäńÉåÕå▓ń¬ü’╝īķéŻõ╣łÕÅ»õ╗źõĮ┐ńö© rebase ńÜäµ¢╣Õ╝ÅµØźĶ¦ŻÕå│Õå▓ń¬ü’╝īÕøĀõĖ║Ķ┐ÖĶāĮÕż¤õ┐ØĶ»üõĮĀńÜä commit log ńÜäµĢ┤µ┤üŃĆéÕ”éµ×£õĮĀõĖŹÕż¬ń夵éē `rebase` ńÜäõĮ┐ńö©’╝īķéŻõ╣łÕÅ»õ╗źõĮ┐ńö© `merge` ńÜäµ¢╣Õ╝ÅµØźĶ¦ŻÕå│Õå▓ń¬üŃĆé
+
+### µīćÕ╝Ģ
+
+#### ÕŹĢÕģāµĄŗĶ»Ģ
+
+Õ”éµ×£õĮĀµŚĀµ│ĢµŁŻÕĖĖµē¦ĶĪīķā©Õłåµ©ĪÕØŚńÜäÕŹĢÕģāµĄŗĶ»Ģ’╝īõŠŗÕ”é [video](https://github.com/open-mmlab/mmcv/tree/main/mmcv/video) µ©ĪÕØŚ’╝īÕÅ»ĶāĮµś»õĮĀńÜäÕĮōÕēŹńÄ»Õóāµ▓Īµ£ēÕ«ēĶŻģõ╗źõĖŗõŠØĶĄ¢
+
+```shell
+# Linux
+sudo apt-get update -y
+sudo apt-get install -y libturbojpeg
+sudo apt-get install -y ffmpeg
+
+# Windows
+conda install ffmpeg
+```
+
+Õ£©µÅÉõ║żõ┐«ÕżŹõ╗ŻńĀüķöÖĶ»»µł¢µ¢░Õó×ńē╣µĆ¦ńÜäµŗēÕÅ¢Ķ»Ęµ▒鵌Ȓ╝īµłæõ╗¼Õ║öĶ»źÕ░ĮÕÅ»ĶāĮńÜäĶ«®ÕŹĢÕģāµĄŗĶ»ĢĶ”åńø¢µēƵ£ēµÅÉõ║żńÜäõ╗ŻńĀü’╝īĶ«Īń«ŚÕŹĢÕģāµĄŗĶ»ĢĶ”åńø¢ńÄćńÜäµ¢╣µ│ĢÕ”éõĖŗ
+
+```shell
+python -m coverage run -m pytest /path/to/test_file
+python -m coverage html
+# check file in htmlcov/index.html
+```
+
+#### µ¢ćµĪŻµĖ▓µ¤ō
+
+Õ£©µÅÉõ║żõ┐«ÕżŹõ╗ŻńĀüķöÖĶ»»µł¢µ¢░Õó×ńē╣µĆ¦ńÜäµŗēÕÅ¢Ķ»Ęµ▒鵌Ȓ╝īÕÅ»ĶāĮõ╝Üķ£ĆĶ”üõ┐«µö╣/µ¢░Õó×µ©ĪÕØŚńÜä docstringŃĆ鵳æõ╗¼ķ£ĆĶ”üńĪ«Ķ«żµĖ▓µ¤ōÕÉÄńÜäµ¢ćµĪŻµĀĘÕ╝ŵś»µŁŻńĪ«ńÜäŃĆé
+µ£¼Õ£░ńö¤µłÉµĖ▓µ¤ōÕÉÄńÜäµ¢ćµĪŻńÜäµ¢╣µ│ĢÕ”éõĖŗ
+
+```shell
+pip install -r requirements/docs.txt
+cd docs/zh_cn/
+# or docs/en
+make html
+# check file in ./docs/zh_cn/_build/html/index.html
+```
+
+### õ╗ŻńĀüķŻÄµĀ╝
+
+#### Python
+
+[PEP8](https://www.python.org/dev/peps/pep-0008/) õĮ£õĖ║ OpenMMLab ń«Śµ│ĢÕ║ōķ”¢ķĆēńÜäõ╗ŻńĀüĶ¦äĶīā’╝īµłæõ╗¼õĮ┐ńö©õ╗źõĖŗÕĘźÕģʵŻĆµ¤źÕÆīµĀ╝Õ╝ÅÕī¢õ╗ŻńĀü
+
+- [flake8](https://github.com/PyCQA/flake8): Python Õ«śµ¢╣ÕÅæÕĖāńÜäõ╗ŻńĀüĶ¦äĶīāµŻĆµ¤źÕĘźÕģĘ’╝īµś»ÕżÜõĖ¬µŻĆµ¤źÕĘźÕģĘńÜäÕ░üĶŻģ
+- [isort](https://github.com/timothycrosley/isort): Ķć¬ÕŖ©Ķ░āµĢ┤µ©ĪÕØŚÕ»╝ÕģźķĪ║Õ║ÅńÜäÕĘźÕģĘ
+- [yapf](https://github.com/google/yapf): Google ÕÅæÕĖāńÜäõ╗ŻńĀüĶ¦äĶīāµŻĆµ¤źÕĘźÕģĘ
+- [codespell](https://github.com/codespell-project/codespell): µŻĆµ¤źÕŹĢĶ»Źµŗ╝ÕåÖµś»ÕÉ”µ£ēĶ»»
+- [mdformat](https://github.com/executablebooks/mdformat): µŻĆµ¤ź markdown µ¢ćõ╗ČńÜäÕĘźÕģĘ
+- [docformatter](https://github.com/myint/docformatter): µĀ╝Õ╝ÅÕī¢ docstring ńÜäÕĘźÕģĘ
+
+yapf ÕÆī isort ńÜäķģŹńĮ«ÕÅ»õ╗źÕ£© [setup.cfg](./setup.cfg) µēŠÕł░
+
+ķĆÜĶ┐ćķģŹńĮ« [pre-commit hook](https://pre-commit.com/) ’╝īµłæõ╗¼ÕÅ»õ╗źÕ£©µÅÉõ║żõ╗ŻńĀüµŚČĶć¬ÕŖ©µŻĆµ¤źÕÆīµĀ╝Õ╝ÅÕī¢ `flake8`ŃĆü`yapf`ŃĆü`isort`ŃĆü`trailing whitespaces`ŃĆü`markdown files`’╝ī
+õ┐«ÕżŹ `end-of-files`ŃĆü`double-quoted-strings`ŃĆü`python-encoding-pragma`ŃĆü`mixed-line-ending`’╝īĶ░āµĢ┤ `requirments.txt` ńÜäÕīģķĪ║Õ║ÅŃĆé
+pre-commit ķÆ®ÕŁÉńÜäķģŹńĮ«ÕÅ»õ╗źÕ£© [.pre-commit-config](./.pre-commit-config.yaml) µēŠÕł░ŃĆé
+
+pre-commit ÕģĘõĮōńÜäÕ«ēĶŻģõĮ┐ńö©µ¢╣Õ╝ÅĶ¦ü[µŗēÕÅ¢Ķ»Ęµ▒é](#2-ķģŹńĮ«-pre-commit)ŃĆé
+
+µø┤ÕģĘõĮōńÜäĶ¦äĶīāĶ»ĘÕÅéĶĆā [OpenMMLab õ╗ŻńĀüĶ¦äĶīā](code_style.md)ŃĆé
+
+#### C++ and CUDA
+
+C++ ÕÆī CUDA ńÜäõ╗ŻńĀüĶ¦äĶīāķüĄõ╗Ä [Google C++ Style Guide](https://google.github.io/styleguide/cppguide.html)
+
+### µŗēÕÅ¢Ķ»Ęµ▒éĶ¦äĶīā
+
+1. õĮ┐ńö© [pre-commit hook](https://pre-commit.com)’╝īÕ░ĮķćÅÕćÅÕ░æõ╗ŻńĀüķŻÄµĀ╝ńøĖÕģ│ķŚ«ķóś
+
+2. õĖĆõĖ¬`µŗēÕÅ¢Ķ»Ęµ▒é`Õ»╣Õ║öõĖĆõĖ¬ń¤Łµ£¤Õłåµö»
+
+3. ń▓ÆÕ║”Ķ”üń╗å’╝īõĖĆõĖ¬`µŗēÕÅ¢Ķ»Ęµ▒é`ÕŬÕüÜõĖĆõ╗Čõ║ŗµāģ’╝īķü┐ÕģŹĶČģÕż¦ńÜä`µŗēÕÅ¢Ķ»Ęµ▒é`
+
+ - Bad’╝ÜÕ«×ńÄ░ Faster R-CNN
+ - Acceptable’╝Üń╗Ö Faster R-CNN µĘ╗ÕŖĀõĖĆõĖ¬ box head
+ - Good’╝Üń╗Ö box head Õó×ÕŖĀõĖĆõĖ¬ÕÅéµĢ░µØźµö»µīüĶć¬Õ«Üõ╣ēńÜä conv Õ▒éµĢ░
+
+4. µ»Åµ¼Ī Commit µŚČķ£ĆĶ”üµÅÉõŠøµĖģµÖ░õĖöµ£ēµäÅõ╣ē commit õ┐Īµü»
+
+5. µÅÉõŠøµĖģµÖ░õĖöµ£ēµäÅõ╣ēńÜä`µŗēÕÅ¢Ķ»Ęµ▒é`µÅÅĶ┐░
+
+ - µĀćķóśÕåÖµśÄńÖĮõ╗╗ÕŖĪÕÉŹń¦░’╝īõĖĆĶł¼µĀ╝Õ╝Å:\[Prefix\] Short description of the pull request (Suffix)
+ - prefix: µ¢░Õó×ÕŖ¤ĶāĮ \[Feature\], õ┐« bug \[Fix\], µ¢ćµĪŻńøĖÕģ│ \[Docs\], Õ╝ĆÕÅæõĖŁ \[WIP\] (µÜ鵌ČõĖŹõ╝ÜĶó½review)
+ - µÅÅĶ┐░ķćīõ╗ŗń╗Ź`µŗēÕÅ¢Ķ»Ęµ▒é`ńÜäõĖ╗Ķ”üõ┐«µö╣ÕåģÕ«╣’╝īń╗ōµ×£’╝īõ╗źÕÅŖÕ»╣ÕģČõ╗¢ķā©ÕłåńÜäÕĮ▒ÕōŹ, ÕÅéĶĆā`µŗēÕÅ¢Ķ»Ęµ▒é`µ©ĪµØ┐
+ - Õģ│ĶüöńøĖÕģ│ńÜä`Ķ««ķóś` (issue) ÕÆīÕģČõ╗¢`µŗēÕÅ¢Ķ»Ęµ▒é`
+
+6. Õ”éµ×£Õ╝ĢÕģźõ║åÕģČõ╗¢õĖēµ¢╣Õ║ō’╝īµł¢ÕƤķē┤õ║åõĖēµ¢╣Õ║ōńÜäõ╗ŻńĀü’╝īĶ»ĘńĪ«Ķ«żõ╗¢õ╗¼ńÜäĶ«ĖÕÅ»Ķ»üÕÆī mmcv Õģ╝Õ«╣’╝īÕ╣ČÕ£©ÕƤķē┤ńÜäõ╗ŻńĀüõĖŖĶĪźÕģģ `This code is inspired from http://`
diff --git a/internlm_langchain/knowledge_base/MMCV/content/data_process.md b/internlm_langchain/knowledge_base/MMCV/content/data_process.md
new file mode 100644
index 00000000..7e0afd1e
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMCV/content/data_process.md
@@ -0,0 +1,275 @@
+## µĢ░µŹ«ÕżäńÉå
+
+### ÕøŠÕāÅ
+
+ÕøŠÕāŵ©ĪÕØŚµÅÉõŠøõ║åõĖĆõ║øÕøŠÕāÅķóäÕżäńÉåńÜäÕćĮµĢ░’╝īĶ»źµ©ĪÕØŚõŠØĶĄ¢ `opencv` ŃĆé
+
+#### Ķ»╗ÕÅ¢/õ┐ØÕŁś/µśŠńż║
+
+õĮ┐ńö© `imread` ÕÆī `imwrite` ÕćĮµĢ░ÕÅ»õ╗źĶ»╗ÕÅ¢ÕÆīõ┐ØÕŁśÕøŠÕāÅŃĆé
+
+```python
+import mmcv
+
+img = mmcv.imread('test.jpg')
+img = mmcv.imread('test.jpg', flag='grayscale')
+img_ = mmcv.imread(img) # ńøĖÕĮōõ║Äõ╗Ćõ╣łõ╣¤µ▓ĪÕüÜ
+mmcv.imwrite(img, 'out.jpg')
+```
+
+õ╗Äõ║īĶ┐øÕłČõĖŁĶ»╗ÕÅ¢ÕøŠÕāÅ
+
+```python
+with open('test.jpg', 'rb') as f:
+ data = f.read()
+img = mmcv.imfrombytes(data)
+```
+
+µśŠńż║ÕøŠÕāŵ¢ćõ╗ȵł¢ÕĘ▓Ķ»╗ÕÅ¢ńÜäÕøŠÕāÅ
+
+```python
+mmcv.imshow('tests/data/color.jpg')
+
+for i in range(10):
+ img = np.random.randint(256, size=(100, 100, 3), dtype=np.uint8)
+ mmcv.imshow(img, win_name='test image', wait_time=200)
+```
+
+#### Ķē▓ÕĮ®ń®║ķŚ┤ĶĮ¼µŹó
+
+µö»µīüńÜäĶĮ¼µŹóÕćĮµĢ░’╝Ü
+
+- bgr2gray
+- gray2bgr
+- bgr2rgb
+- rgb2bgr
+- bgr2hsv
+- hsv2bgr
+
+```python
+img = mmcv.imread('tests/data/color.jpg')
+img1 = mmcv.bgr2rgb(img)
+img2 = mmcv.rgb2gray(img1)
+img3 = mmcv.bgr2hsv(img)
+```
+
+#### ń╝®µöŠ
+
+µ£ēõĖēń¦Źń╝®µöŠÕøŠÕāÅńÜäµ¢╣µ│ĢŃĆéµēƵ£ēõ╗ź `imresize_*` Õ╝ĆÕż┤ńÜäÕćĮµĢ░ķāĮµ£ēõĖĆõĖ¬ `return_scale` ÕÅéµĢ░’╝īÕ”éµ×£
+Ķ»źÕÅéµĢ░õĖ║ `False` ’╝īÕćĮµĢ░ńÜäĶ┐öÕø×ÕĆ╝ÕŬµ£ēĶ░āµĢ┤õ╣ŗÕÉÄńÜäÕøŠÕāÅ’╝īÕÉ”ÕłÖµś»õĖĆõĖ¬Õģāń╗ä `(resized_img, scale)` ŃĆé
+
+```python
+# ń╝®µöŠÕøŠÕāÅĶć│ń╗ÖÕ«ÜńÜäÕ░║Õ»Ė
+mmcv.imresize(img, (1000, 600), return_scale=True)
+
+# ń╝®µöŠÕøŠÕāÅĶć│õĖÄń╗ÖÕ«ÜńÜäÕøŠÕāÅÕÉīµĀĘńÜäÕ░║Õ»Ė
+mmcv.imresize_like(img, dst_img, return_scale=False)
+
+# õ╗źõĖĆÕ«ÜńÜäµ»öõŠŗń╝®µöŠÕøŠÕāÅ
+mmcv.imrescale(img, 0.5)
+
+# ń╝®µöŠÕøŠÕāÅĶć│µ£ĆķĢ┐ńÜäĶŠ╣õĖŹÕż¦õ║Ä1000ŃĆüµ£Ćń¤ŁńÜäĶŠ╣õĖŹÕż¦õ║Ä800Õ╣ČõĖöµ▓Īµ£ēµö╣ÕÅśÕøŠÕāÅńÜäķĢ┐Õ«Įµ»ö
+mmcv.imrescale(img, (1000, 800))
+```
+
+#### µŚŗĶĮ¼
+
+µłæõ╗¼ÕÅ»õ╗źõĮ┐ńö© `imrotate` µŚŗĶĮ¼ÕøŠÕāÅõĖĆÕ«ÜńÜäĶ¦ÆÕ║”ŃĆ鵌ŗĶĮ¼ńÜäõĖŁÕ┐āķ£ĆĶ”üµīćÕ«Ü’╝īķ╗śĶ«żÕĆ╝µś»ÕĤզŗÕøŠÕāÅńÜäõĖŁÕ┐āŃĆéµ£ē
+õĖżń¦ŹµŚŗĶĮ¼ńÜ䵩ĪÕ╝Å’╝īõĖĆń¦Źõ┐صīüÕøŠÕāÅńÜäÕ░║Õ»ĖõĖŹÕÅś’╝īÕøĀµŁżµŚŗĶĮ¼ÕÉÄÕĤզŗÕøŠÕāÅõĖŁńÜ䵤Éõ║øķā©Õłåõ╝ÜĶó½ĶŻüÕē¬’╝īÕÅ”õĖĆń¦Źµś»µē®Õż¦
+ÕøŠÕāÅńÜäÕ░║Õ»ĖĶ┐øĶĆīõ┐ØńĢÖÕ«īµĢ┤ńÜäÕĤզŗÕøŠÕāÅŃĆé
+
+```python
+img = mmcv.imread('tests/data/color.jpg')
+
+# ķĪ║µŚČķÆłµŚŗĶĮ¼ÕøŠÕāÅ30Õ║”
+img_ = mmcv.imrotate(img, 30)
+
+# ķĆåµŚČķÆłµŚŗĶĮ¼ÕøŠÕāÅ90Õ║”
+img_ = mmcv.imrotate(img, -90)
+
+# ķĪ║µŚČķÆłµŚŗĶĮ¼ÕøŠÕāÅ30Õ║”Õ╣ČõĖöń╝®µöŠÕøŠÕāÅõĖ║ÕĤզŗÕøŠÕāÅńÜä1.5ÕĆŹ
+img_ = mmcv.imrotate(img, 30, scale=1.5)
+
+# õ╗źÕØɵĀć(100, 100)õĖ║õĖŁÕ┐āķĪ║µŚČķÆłµŚŗĶĮ¼ÕøŠÕāÅ30Õ║”
+img_ = mmcv.imrotate(img, 30, center=(100, 100))
+
+# ķĪ║µŚČķÆłµŚŗĶĮ¼ÕøŠÕāÅ30Õ║”Õ╣ȵē®Õż¦ÕøŠÕāÅńÜäÕ░║Õ»Ė
+img_ = mmcv.imrotate(img, 30, auto_bound=True)
+```
+
+#### ń┐╗ĶĮ¼
+
+µłæõ╗¼ÕÅ»õ╗źõĮ┐ńö© `imflip` ń┐╗ĶĮ¼ÕøŠÕāÅŃĆé
+
+```python
+img = mmcv.imread('tests/data/color.jpg')
+
+# µ░┤Õ╣│ń┐╗ĶĮ¼ÕøŠÕāÅ
+mmcv.imflip(img)
+
+# Õ×éńø┤ń┐╗ĶĮ¼ÕøŠÕāÅ
+mmcv.imflip(img, direction='vertical')
+```
+
+#### ĶŻüÕē¬
+
+`imcrop` ÕÅ»õ╗źĶŻüÕē¬ÕøŠÕāÅńÜäõĖĆõĖ¬µł¢ÕżÜõĖ¬Õī║Õ¤¤’╝īµ»ÅõĖ¬Õī║Õ¤¤ńö©ÕĘ”õĖŖĶ¦ÆÕÆīÕÅ│õĖŗĶ¦ÆÕØɵĀćĶĪ©ńż║’╝īÕĮóÕ”é(x1, y1, x2, y2)
+
+```python
+import mmcv
+import numpy as np
+
+img = mmcv.imread('tests/data/color.jpg')
+
+# ĶŻüÕē¬Õī║Õ¤¤ (10, 10, 100, 120)
+bboxes = np.array([10, 10, 100, 120])
+patch = mmcv.imcrop(img, bboxes)
+
+# ĶŻüÕē¬õĖżõĖ¬Õī║Õ¤¤’╝īÕłåÕł½µś» (10, 10, 100, 120) ÕÆī (0, 0, 50, 50)
+bboxes = np.array([[10, 10, 100, 120], [0, 0, 50, 50]])
+patches = mmcv.imcrop(img, bboxes)
+
+# ĶŻüÕē¬õĖżõĖ¬Õī║Õ¤¤Õ╣ČõĖöń╝®µöŠÕī║Õ¤¤1.2ÕĆŹ
+patches = mmcv.imcrop(img, bboxes, scale=1.2)
+```
+
+#### ÕĪ½Õģģ
+
+`impad` and `impad_to_multiple` ÕÅ»õ╗źńö©ń╗ÖÕ«ÜńÜäÕĆ╝Õ░åÕøŠÕāÅÕĪ½ÕģģĶć│ń╗ÖÕ«ÜńÜäÕ░║Õ»ĖŃĆé
+
+```python
+img = mmcv.imread('tests/data/color.jpg')
+
+# ńö©ń╗ÖÕ«ÜÕĆ╝Õ░åÕøŠÕāÅÕĪ½ÕģģĶć│ (1000, 1200)
+img_ = mmcv.impad(img, shape=(1000, 1200), pad_val=0)
+
+# ńö©ń╗ÖÕ«ÜÕĆ╝ÕłåÕł½ÕĪ½ÕģģÕøŠÕāÅńÜä3õĖ¬ķĆÜķüōĶć│ (1000, 1200)
+img_ = mmcv.impad(img, shape=(1000, 1200), pad_val=(100, 50, 200))
+
+# ńö©ń╗ÖÕ«ÜÕĆ╝ÕĪ½ÕģģÕøŠÕāÅńÜäÕĘ”ŃĆüÕÅ│ŃĆüõĖŖŃĆüõĖŗÕøøµØĪĶŠ╣
+img_ = mmcv.impad(img, padding=(10, 20, 30, 40), pad_val=0)
+
+# ńö©3õĖ¬ÕĆ╝ÕłåÕł½ÕĪ½ÕģģÕøŠÕāÅńÜäÕĘ”ŃĆüÕÅ│ŃĆüõĖŖŃĆüõĖŗÕøøµØĪĶŠ╣ńÜä3õĖ¬ķĆÜķüō
+img_ = mmcv.impad(img, padding=(10, 20, 30, 40), pad_val=(100, 50, 200))
+
+# Õ░åÕøŠÕāÅńÜäÕøøµØĪĶŠ╣ÕĪ½ÕģģĶć│ĶāĮÕż¤Ķó½ń╗ÖÕ«ÜÕĆ╝µĢ┤ķÖż
+img_ = mmcv.impad_to_multiple(img, 32)
+```
+
+### Ķ¦åķóæ
+
+Ķ¦åķó浩ĪÕØŚµÅÉõŠøõ║åõ╗źõĖŗńÜäÕŖ¤ĶāĮ’╝Ü
+
+- õĖĆõĖ¬ `VideoReader` ń▒╗’╝īÕģʵ£ēÕÅŗÕźĮńÜä API µÄźÕÅŻÕÅ»õ╗źĶ»╗ÕÅ¢ÕÆīĶĮ¼µŹóĶ¦åķóæ
+- õĖĆõ║øń╝¢ĶŠæĶ¦åķóæńÜäµ¢╣µ│Ģ’╝īÕīģµŗ¼ `cut` ’╝ī `concat` ’╝ī `resize`
+- ÕģēµĄüńÜäĶ»╗ÕÅ¢/õ┐ØÕŁś/ÕÅśµŹó
+
+#### VideoReader
+
+`VideoReader` ń▒╗µÅÉõŠøõ║åÕÆīÕ║ÅÕłŚõĖƵĀĘńÜäµÄźÕÅŻÕÄ╗ĶÄĘÕÅ¢Ķ¦åķóæÕĖ¦ŃĆéĶ»źń▒╗õ╝Üń╝ōÕŁśµēƵ£ēĶó½Ķ«┐ķŚ«Ķ┐ćńÜäÕĖ¦ŃĆé
+
+```python
+video = mmcv.VideoReader('test.mp4')
+
+# ĶÄĘÕÅ¢Õ¤║µ£¼ńÜäõ┐Īµü»
+print(len(video))
+print(video.width, video.height, video.resolution, video.fps)
+
+# ķüŹÕÄåµēƵ£ēńÜäÕĖ¦
+for frame in video:
+ print(frame.shape)
+
+# Ķ»╗ÕÅ¢õĖŗõĖĆÕĖ¦
+img = video.read()
+
+# õĮ┐ńö©ń┤óÕ╝ĢĶÄĘÕÅ¢ÕĖ¦
+img = video[100]
+
+# ĶÄĘÕÅ¢µīćÕ«ÜĶīāÕø┤ńÜäÕĖ¦
+img = video[5:10]
+```
+
+Õ░åĶ¦åķóæÕłćµłÉÕĖ¦Õ╣Čõ┐ØÕŁśĶć│ń╗ÖÕ«Üńø«ÕĮĢµł¢ĶĆģõ╗Äń╗ÖÕ«Üńø«ÕĮĢõĖŁńö¤µłÉĶ¦åķóæŃĆé
+
+```python
+# Õ░åĶ¦åķóæÕłćµłÉÕĖ¦Õ╣Čõ┐ØÕŁśĶć│ńø«ÕĮĢ
+video = mmcv.VideoReader('test.mp4')
+video.cvt2frames('out_dir')
+
+# õ╗Äń╗ÖÕ«Üńø«ÕĮĢõĖŁńö¤µłÉĶ¦åķóæ
+mmcv.frames2video('out_dir', 'test.avi')
+```
+
+#### ń╝¢ĶŠæÕćĮµĢ░
+
+µ£ēÕćĀõĖ¬ńö©õ║Äń╝¢ĶŠæĶ¦åķóæńÜäÕćĮµĢ░’╝īĶ┐Öõ║øÕćĮµĢ░µś»Õ»╣ `ffmpeg` ńÜäÕ░üĶŻģŃĆé
+
+```python
+# ĶŻüÕē¬Ķ¦åķóæ
+mmcv.cut_video('test.mp4', 'clip1.mp4', start=3, end=10, vcodec='h264')
+
+# Õ░åÕżÜõĖ¬Ķ¦åķóæµŗ╝µÄźµłÉõĖĆõĖ¬Ķ¦åķóæ
+mmcv.concat_video(['clip1.mp4', 'clip2.mp4'], 'joined.mp4', log_level='quiet')
+
+# Õ░åĶ¦åķóæń╝®µöŠĶć│ń╗ÖÕ«ÜńÜäÕ░║Õ»Ė
+mmcv.resize_video('test.mp4', 'resized1.mp4', (360, 240))
+
+# Õ░åĶ¦åķóæń╝®µöŠĶć│ń╗ÖÕ«ÜńÜäÕĆŹńÄć
+mmcv.resize_video('test.mp4', 'resized2.mp4', ratio=2)
+```
+
+#### ÕģēµĄü
+
+`mmcv` µÅÉõŠøõ║åõ╗źõĖŗńö©õ║ĵōŹõĮ£ÕģēµĄüńÜäÕćĮµĢ░’╝Ü
+
+- Ķ»╗ÕÅ¢/õ┐ØÕŁś
+- ÕÅ»Ķ¦åÕī¢
+- µĄüÕÅśµŹó
+
+µłæõ╗¼µÅÉõŠøõ║åõĖżń¦ŹÕ░åÕģēµĄüdumpÕł░µ¢ćõ╗ČńÜäµ¢╣µ│Ģ’╝īÕłåÕł½µś»ķØ×ÕÄŗń╝®ÕÆīÕÄŗń╝®ńÜäµ¢╣µ│ĢŃĆéķØ×ÕÄŗń╝®ńÜäµ¢╣µ│Ģńø┤µÄźÕ░åµĄ«ńé╣µĢ░ÕĆ╝ńÜäÕģēµĄü
+õ┐ØÕŁśĶć│õ║īĶ┐øÕłČµ¢ćõ╗Č’╝īĶÖĮńäČÕģēµĄüµŚĀµŹ¤õĮåµ¢ćõ╗Čõ╝ܵ»öĶŠāÕż¦ŃĆéĶĆīÕÄŗń╝®ńÜäµ¢╣µ│ĢÕģłķćÅÕī¢ÕģēµĄüĶć│ 0-255 µĢ┤ÕĮóµĢ░ÕĆ╝ÕåŹõ┐ØÕŁśõĖ║
+jpegÕøŠÕāÅŃĆéÕģēµĄüńÜäxń╗┤Õ║”ÕÆīyń╗┤Õ║”õ╝ÜĶó½µŗ╝µÄźÕł░ÕøŠÕāÅõĖŁŃĆé
+
+1. Ķ»╗ÕÅ¢/õ┐ØÕŁś
+
+```python
+flow = np.random.rand(800, 600, 2).astype(np.float32)
+# õ┐ØÕŁśÕģēµĄüÕł░floµ¢ćõ╗Č (~3.7M)
+mmcv.flowwrite(flow, 'uncompressed.flo')
+# õ┐ØÕŁśÕģēµĄüõĖ║jpegÕøŠÕāÅ (~230K)’╝īÕøŠÕāÅńÜäÕ░║Õ»ĖõĖ║ (800, 1200)
+mmcv.flowwrite(flow, 'compressed.jpg', quantize=True, concat_axis=1)
+
+# Ķ»╗ÕÅ¢ÕģēµĄüµ¢ćõ╗Č’╝īõ╗źõĖŗõĖżń¦Źµ¢╣Õ╝ÅĶ»╗ÕÅ¢ńÜäÕģēµĄüÕ░║Õ»ĖÕØćõĖ║ (800, 600, 2)
+flow = mmcv.flowread('uncompressed.flo')
+flow = mmcv.flowread('compressed.jpg', quantize=True, concat_axis=1)
+```
+
+2. ÕÅ»Ķ¦åÕī¢
+
+õĮ┐ńö© `mmcv.flowshow()` ÕÅ»Ķ¦åÕī¢ÕģēµĄü
+
+```python
+mmcv.flowshow(flow)
+```
+
+
+
+1. µĄüÕÅśµŹó
+
+```python
+img1 = mmcv.imread('img1.jpg')
+flow = mmcv.flowread('flow.flo')
+warped_img2 = mmcv.flow_warp(img1, flow)
+```
+
+img1 (ÕĘ”) and img2 (ÕÅ│)
+
+
+
+ÕģēµĄü (img2 -> img1)
+
+
+
+ÕÅśµŹóÕÉÄńÜäÕøŠÕāÅÕÆīń£¤Õ«×ÕøŠÕāÅńÜäÕĘ«Õ╝é
+
+
diff --git a/internlm_langchain/knowledge_base/MMCV/content/data_transform.md b/internlm_langchain/knowledge_base/MMCV/content/data_transform.md
new file mode 100644
index 00000000..47d16e1b
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMCV/content/data_transform.md
@@ -0,0 +1,341 @@
+# µĢ░µŹ«ÕÅśµŹó
+
+Õ£© OpenMMLab ń«Śµ│ĢÕ║ōõĖŁ’╝īµĢ░µŹ«ķøåńÜäµ×äÕ╗║ÕÆīµĢ░µŹ«ńÜäÕćåÕżćµś»ńøĖõ║ÆĶ¦ŻĶĆ”ńÜäŃĆéķĆÜÕĖĖ’╝īµĢ░µŹ«ķøåńÜäµ×äÕ╗║ÕŬջ╣µĢ░µŹ«ķøåĶ┐øĶĪīĶ¦Żµ×É’╝īĶ«░ÕĮĢµ»ÅõĖ¬µĀʵ£¼ńÜäÕ¤║µ£¼õ┐Īµü»’╝øĶĆīµĢ░µŹ«ńÜäÕćåÕżćÕłÖµś»ķĆÜĶ┐ćõĖĆń│╗ÕłŚńÜäµĢ░µŹ«ÕÅśµŹó’╝īµĀ╣µŹ«µĀʵ£¼ńÜäÕ¤║µ£¼õ┐Īµü»Ķ┐øĶĪīµĢ░µŹ«ÕŖĀĶĮĮŃĆüķóäÕżäńÉåŃĆüµĀ╝Õ╝ÅÕī¢ńŁēµōŹõĮ£ŃĆé
+
+## µĢ░µŹ«ÕÅśµŹóńÜäĶ«ŠĶ«Ī
+
+Õ£© MMCV õĖŁ’╝īµłæõ╗¼õĮ┐ńö©ÕÉäń¦ŹÕÅ»Ķ░āńö©ńÜäµĢ░µŹ«ÕÅśµŹóń▒╗µØźĶ┐øĶĪīµĢ░µŹ«ńÜäµōŹõĮ£ŃĆéĶ┐Öõ║øµĢ░µŹ«ÕÅśµŹóń▒╗ÕÅ»õ╗źµÄźÕÅŚĶŗźÕ╣▓ķģŹńĮ«ÕÅéµĢ░Ķ┐øĶĪīÕ«×õŠŗÕī¢’╝īõ╣ŗÕÉÄķĆÜĶ┐ćĶ░āńö©ńÜäµ¢╣Õ╝ÅÕ»╣ĶŠōÕģźńÜäµĢ░µŹ«ÕŁŚÕģĖĶ┐øĶĪīÕżäńÉåŃĆéÕÉīµŚČ’╝īµłæõ╗¼ń║”իܵēƵ£ēµĢ░µŹ«ÕÅśµŹóķāĮµÄźÕÅŚõĖĆõĖ¬ÕŁŚÕģĖõĮ£õĖ║ĶŠōÕģź’╝īÕ╣ČÕ░åÕżäńÉåÕÉÄńÜäµĢ░µŹ«ĶŠōÕć║õĖ║õĖĆõĖ¬ÕŁŚÕģĖŃĆéõĖĆõĖ¬ń«ĆÕŹĢńÜäõŠŗÕŁÉÕ”éõĖŗ’╝Ü
+
+```python
+>>> import numpy as np
+>>> from mmcv.transforms import Resize
+>>>
+>>> transform = Resize(scale=(224, 224))
+>>> data_dict = {'img': np.random.rand(256, 256, 3)}
+>>> data_dict = transform(data_dict)
+>>> print(data_dict['img'].shape)
+(224, 224, 3)
+```
+
+µĢ░µŹ«ÕÅśµŹóń▒╗õ╝ÜĶ»╗ÕÅ¢ĶŠōÕģźÕŁŚÕģĖńÜ䵤Éõ║øÕŁŚµ«Ą’╝īÕ╣ČõĖöÕÅ»ĶāĮµĘ╗ÕŖĀŃĆüµł¢ĶĆģµø┤µ¢░µ¤Éõ║øÕŁŚµ«ĄŃĆéĶ┐Öõ║øÕŁŚµ«ĄńÜäķö«Õż¦ķā©ÕłåµāģÕåĄõĖŗµś»Õø║Õ«ÜńÜä’╝īÕ”é `Resize` õ╝ÜÕø║Õ«ÜÕ£░Ķ»╗ÕÅ¢ĶŠōÕģźÕŁŚÕģĖõĖŁńÜä `"img"` ńŁēÕŁŚµ«ĄŃĆ鵳æõ╗¼ÕÅ»õ╗źÕ£©Õ»╣Õ║öń▒╗ńÜäµ¢ćµĪŻõĖŁõ║åĶ¦ŻÕ»╣ĶŠōÕģźĶŠōÕć║ÕŁŚµ«ĄńÜäń║”Õ«ÜŃĆé
+
+```{note}
+ķ╗śĶ«żµāģÕåĄõĖŗ’╝īÕ£©ķ£ĆĶ”üÕøŠÕāÅÕ░║Õ»ĖõĮ£õĖ║**ÕłØÕ¦ŗÕī¢ÕÅéµĢ░**ńÜäµĢ░µŹ«ÕÅśµŹó (Õ”éResize, Pad) õĖŁ’╝īÕøŠÕāÅÕ░║Õ»ĖńÜäķĪ║Õ║ÅÕØćõĖ║ (width, height)ŃĆéÕ£©µĢ░µŹ«ÕÅśµŹó**Ķ┐öÕø×ńÜäÕŁŚÕģĖ**õĖŁ’╝īÕøŠÕāÅńøĖÕģ│ńÜäÕ░║Õ»Ė’╝ī Õ”é `img_shape`ŃĆü`ori_shape`ŃĆü`pad_shape` ńŁē’╝īÕØćõĖ║ (height, width)ŃĆé
+```
+
+MMCV õĖ║µēƵ£ēńÜäµĢ░µŹ«ÕÅśµŹóń▒╗µÅÉõŠøõ║åõĖĆõĖ¬ń╗¤õĖĆńÜäÕ¤║ń▒╗ (`BaseTransform`)’╝Ü
+
+```python
+class BaseTransform(metaclass=ABCMeta):
+
+ def __call__(self, results: dict) -> dict:
+
+ return self.transform(results)
+
+ @abstractmethod
+ def transform(self, results: dict) -> dict:
+ pass
+```
+
+µēƵ£ēńÜäµĢ░µŹ«ÕÅśµŹóń▒╗ķāĮķ£ĆĶ”üń╗¦µē┐ `BaseTransform`’╝īÕ╣ČÕ«×ńÄ░ `transform` µ¢╣µ│ĢŃĆé`transform` µ¢╣µ│ĢńÜäĶŠōÕģźÕÆīĶŠōÕć║ÕØćõĖ║õĖĆõĖ¬ÕŁŚÕģĖŃĆéÕ£©**Ķć¬Õ«Üõ╣ēµĢ░µŹ«ÕÅśµŹóń▒╗**õĖĆĶŖéõĖŁ’╝īµłæõ╗¼õ╝ܵø┤Ķ»”ń╗åÕ£░õ╗ŗń╗ŹÕ”éõĮĢÕ«×ńÄ░õĖĆõĖ¬µĢ░µŹ«ÕÅśµŹóń▒╗ŃĆé
+
+## µĢ░µŹ«µĄüµ░┤ń║┐
+
+Õ”éõĖŖµēĆĶ┐░’╝īµēƵ£ēµĢ░µŹ«ÕÅśµŹóńÜäĶŠōÕģźÕÆīĶŠōÕć║ķāĮµś»õĖĆõĖ¬ÕŁŚÕģĖ’╝īĶĆīõĖöµĀ╣µŹ« OpenMMLab õĖŁ [µ£ēÕģ│µĢ░µŹ«ķøåńÜäń║”Õ«Ü](TODO)’╝īµĢ░µŹ«ķøåõĖŁµ»ÅõĖ¬µĀʵ£¼ńÜäÕ¤║µ£¼õ┐Īµü»ķāĮµś»õĖĆõĖ¬ÕŁŚÕģĖŃĆéĶ┐ÖµĀĘõĖĆµØź’╝īµłæõ╗¼ÕÅ»õ╗źÕ░åµēƵ£ēńÜäµĢ░µŹ«ÕÅśµŹóµōŹõĮ£ķ”¢Õ░ŠńøĖµÄź’╝īń╗äÕÉłµłÉõĖ║õĖƵØĪµĢ░µŹ«µĄüµ░┤ń║┐’╝łdata pipeline’╝ē’╝īĶŠōÕģźµĢ░µŹ«ķøåõĖŁµĀʵ£¼ńÜäõ┐Īµü»ÕŁŚÕģĖ’╝īĶŠōÕć║Õ«īµłÉõĖĆń│╗ÕłŚÕżäńÉåÕÉÄńÜäõ┐Īµü»ÕŁŚÕģĖŃĆé
+
+õ╗źÕłåń▒╗õ╗╗ÕŖĪõĖ║õŠŗ’╝īµłæõ╗¼Õ£©õĖŗÕøŠÕ▒Ģńż║õ║åõĖĆõĖ¬ÕģĖÕ×ŗńÜäµĢ░µŹ«µĄüµ░┤ń║┐ŃĆéÕ»╣µ»ÅõĖ¬µĀʵ£¼’╝īµĢ░µŹ«ķøåõĖŁõ┐ØÕŁśńÜäÕ¤║µ£¼õ┐Īµü»µś»õĖĆõĖ¬Õ”éÕøŠõĖŁµ£ĆÕĘ”õŠ¦µēĆńż║ńÜäÕŁŚÕģĖ’╝īõ╣ŗÕÉĵ»Åń╗ÅĶ┐ćõĖĆõĖ¬ńö▒ĶōØĶē▓ÕØŚõ╗ŻĶĪ©ńÜäµĢ░µŹ«ÕÅśµŹóµōŹõĮ£’╝īµĢ░µŹ«ÕŁŚÕģĖõĖŁķāĮõ╝ÜÕŖĀÕģźµ¢░ńÜäÕŁŚµ«Ą’╝łµĀćĶ«░õĖ║ń╗┐Ķē▓’╝ēµł¢µø┤µ¢░ńÄ░µ£ēńÜäÕŁŚµ«Ą’╝łµĀćĶ«░õĖ║µ®ÖĶē▓’╝ēŃĆé
+
+
+ +
+
+
+Õ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁ’╝īµĢ░µŹ«µĄüµ░┤ń║┐µś»õĖĆõĖ¬ĶŗźÕ╣▓µĢ░µŹ«ÕÅśµŹóķģŹńĮ«ÕŁŚÕģĖń╗䵳ÉńÜäÕłŚĶĪ©’╝īµ»ÅõĖ¬µĢ░µŹ«ķøåķāĮķ£ĆĶ”üĶ«ŠńĮ«ÕÅéµĢ░ `pipeline` µØźÕ«Üõ╣ēĶ»źµĢ░µŹ«ķøåķ£ĆĶ”üĶ┐øĶĪīńÜäµĢ░µŹ«ÕćåÕżćµōŹõĮ£ŃĆéÕ”éõĖŖµĢ░µŹ«µĄüµ░┤ń║┐Õ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁńÜäķģŹńĮ«Õ”éõĖŗ’╝Ü
+
+```python
+pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='Resize', size=256, keep_ratio=True),
+ dict(type='CenterCrop', crop_size=224),
+ dict(type='Normalize', mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375]),
+ dict(type='ClsFormatBundle')
+]
+
+dataset = dict(
+ ...
+ pipeline=pipeline,
+ ...
+)
+```
+
+## ÕĖĖńö©ńÜäµĢ░µŹ«ÕÅśµŹóń▒╗
+
+µīēńģ¦ÕŖ¤ĶāĮ’╝īÕĖĖńö©ńÜäµĢ░µŹ«ÕÅśµŹóń▒╗ÕÅ»õ╗źÕż¦Ķć┤ÕłåõĖ║µĢ░µŹ«ÕŖĀĶĮĮŃĆüµĢ░µŹ«ķóäÕżäńÉåõĖÄÕó×Õ╝║ŃĆüµĢ░µŹ«µĀ╝Õ╝ÅÕī¢ŃĆéÕ£© MMCV õĖŁ’╝īµłæõ╗¼µÅÉõŠøõ║åõĖĆõ║øÕĖĖńö©ńÜäµĢ░µŹ«ÕÅśµŹóń▒╗Õ”éõĖŗ’╝Ü
+
+### µĢ░µŹ«ÕŖĀĶĮĮ
+
+õĖ║õ║åµö»µīüÕż¦Ķ¦äµ©ĪµĢ░µŹ«ķøåńÜäÕŖĀĶĮĮ’╝īķĆÜÕĖĖÕ£© `Dataset` ÕłØÕ¦ŗÕī¢µŚČõĖŹÕŖĀĶĮĮµĢ░µŹ«’╝īÕŬÕŖĀĶĮĮńøĖÕ║öńÜäĶĘ»ÕŠäŃĆéÕøĀµŁżķ£ĆĶ”üÕ£©µĢ░µŹ«µĄüµ░┤ń║┐õĖŁĶ┐øĶĪīÕģĘõĮōµĢ░µŹ«ńÜäÕŖĀĶĮĮŃĆé
+
+| class | ÕŖ¤ĶāĮ |
+| :-------------------------: | :---------------------------------------: |
+| [`LoadImageFromFile`](TODO) | µĀ╣µŹ«ĶĘ»ÕŠäÕŖĀĶĮĮÕøŠÕāÅ |
+| [`LoadAnnotations`](TODO) | ÕŖĀĶĮĮÕÆīń╗äń╗ćµĀćµ│©õ┐Īµü»’╝īÕ”é bboxŃĆüĶ»Łõ╣ēÕłåÕē▓ÕøŠńŁē |
+
+### µĢ░µŹ«ķóäÕżäńÉåÕÅŖÕó×Õ╝║
+
+µĢ░µŹ«ķóäÕżäńÉåÕÆīÕó×Õ╝║ķĆÜÕĖĖµś»Õ»╣ÕøŠÕāŵ£¼Ķ║½Ķ┐øĶĪīÕÅśµŹó’╝īÕ”éĶŻüÕē¬ŃĆüÕĪ½ÕģģŃĆüń╝®µöŠńŁēŃĆé
+
+| class | ÕŖ¤ĶāĮ |
+| :------------------------------: | :--------------------------------: |
+| [`Pad`](TODO) | ÕĪ½ÕģģÕøŠÕāÅĶŠ╣ń╝ś |
+| [`CenterCrop`](TODO) | Õ▒ģõĖŁĶŻüÕē¬ |
+| [`Normalize`](TODO) | Õ»╣ÕøŠÕāÅĶ┐øĶĪīÕĮÆõĖĆÕī¢ |
+| [`Resize`](TODO) | µīēńģ¦µīćÕ«ÜÕ░║Õ»Ėµł¢µ»öõŠŗń╝®µöŠÕøŠÕāÅ |
+| [`RandomResize`](TODO) | ń╝®µöŠÕøŠÕāÅĶć│µīćÕ«ÜĶīāÕø┤ńÜäķÜŵ£║Õ░║Õ»Ė |
+| [`RandomMultiscaleResize`](TODO) | ń╝®µöŠÕøŠÕāÅĶć│ÕżÜõĖ¬Õ░║Õ»ĖõĖŁńÜäķÜŵ£║õĖĆõĖ¬Õ░║Õ»Ė |
+| [`RandomGrayscale`](TODO) | ķÜŵ£║ńü░Õ║”Õī¢ |
+| [`RandomFlip`](TODO) | ÕøŠÕāÅķÜŵ£║ń┐╗ĶĮ¼ |
+| [`MultiScaleFlipAug`](TODO) | µö»µīüń╝®µöŠÕÆīń┐╗ĶĮ¼ńÜ䵥ŗĶ»ĢµŚČµĢ░µŹ«Õó×Õ╝║ |
+
+### µĢ░µŹ«µĀ╝Õ╝ÅÕī¢
+
+µĢ░µŹ«µĀ╝Õ╝ÅÕī¢µōŹõĮ£ķĆÜÕĖĖµś»Õ»╣µĢ░µŹ«Ķ┐øĶĪīńÜäń▒╗Õ×ŗĶĮ¼µŹóŃĆé
+
+| class | ÕŖ¤ĶāĮ |
+| :---------------------: | :-------------------------------: |
+| [`ToTensor`](TODO) | Õ░åµīćÕ«ÜńÜäµĢ░µŹ«ĶĮ¼µŹóõĖ║ `torch.Tensor` |
+| [`ImageToTensor`](TODO) | Õ░åÕøŠÕāÅĶĮ¼µŹóõĖ║ `torch.Tensor` |
+
+## Ķć¬Õ«Üõ╣ēµĢ░µŹ«ÕÅśµŹóń▒╗
+
+Ķ”üÕ«×ńÄ░õĖĆõĖ¬µ¢░ńÜäµĢ░µŹ«ÕÅśµŹóń▒╗’╝īķ£ĆĶ”üń╗¦µē┐ `BaseTransform`’╝īÕ╣ČÕ«×ńÄ░ `transform` µ¢╣µ│ĢŃĆéĶ┐Öķćī’╝īµłæõ╗¼õĮ┐ńö©õĖĆõĖ¬ń«ĆÕŹĢńÜäń┐╗ĶĮ¼ÕÅśµŹó’╝ł`MyFlip`’╝ēõĮ£õĖ║ńż║õŠŗ’╝Ü
+
+```python
+import random
+import mmcv
+from mmcv.transforms import BaseTransform, TRANSFORMS
+
+@TRANSFORMS.register_module()
+class MyFlip(BaseTransform):
+ def __init__(self, direction: str):
+ super().__init__()
+ self.direction = direction
+
+ def transform(self, results: dict) -> dict:
+ img = results['img']
+ results['img'] = mmcv.imflip(img, direction=self.direction)
+ return results
+```
+
+õ╗ÄĶĆī’╝īµłæõ╗¼ÕÅ»õ╗źÕ«×õŠŗÕī¢õĖĆõĖ¬ `MyFlip` Õ»╣Ķ▒Ī’╝īÕ╣ČÕ░åõ╣ŗõĮ£õĖ║õĖĆõĖ¬ÕÅ»Ķ░āńö©Õ»╣Ķ▒Ī’╝īµØźÕżäńÉåµłæõ╗¼ńÜäµĢ░µŹ«ÕŁŚÕģĖŃĆé
+
+```python
+import numpy as np
+
+transform = MyFlip(direction='horizontal')
+data_dict = {'img': np.random.rand(224, 224, 3)}
+data_dict = transform(data_dict)
+processed_img = data_dict['img']
+```
+
+ÕÅłµł¢ĶĆģ’╝īÕ£©ķģŹńĮ«µ¢ćõ╗ČńÜä pipeline õĖŁõĮ┐ńö© `MyFlip` ÕÅśµŹó
+
+```python
+pipeline = [
+ ...
+ dict(type='MyFlip', direction='horizontal'),
+ ...
+]
+```
+
+ķ£ĆĶ”üµ│©µäÅńÜ䵜»’╝īÕ”éķ£ĆÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁõĮ┐ńö©’╝īķ£ĆĶ”üõ┐ØĶ»ü `MyFlip` ń▒╗µēĆÕ£©ńÜäµ¢ćõ╗ČÕ£©Ķ┐ÉĶĪīµŚČĶāĮÕż¤Ķó½Õ»╝ÕģźŃĆé
+
+## ÕÅśµŹóÕīģĶŻģ
+
+ÕÅśµŹóÕīģĶŻģµś»õĖĆń¦Źńē╣µ«ŖńÜäµĢ░µŹ«ÕÅśµŹóń▒╗’╝īõ╗¢õ╗¼µ£¼Ķ║½Õ╣ČõĖŹµōŹõĮ£µĢ░µŹ«ÕŁŚÕģĖõĖŁńÜäÕøŠÕāÅŃĆüµĀćńŁŠńŁēõ┐Īµü»’╝īĶĆīµś»Õ»╣ÕģČõĖŁÕ«Üõ╣ēńÜäµĢ░µŹ«ÕÅśµŹóńÜäĶĪīõĖ║Ķ┐øĶĪīÕó×Õ╝║ŃĆé
+
+### ÕŁŚµ«ĄµśĀÕ░ä’╝łKeyMapper’╝ē
+
+ÕŁŚµ«ĄµśĀÕ░äÕīģĶŻģ’╝ł`KeyMapper`’╝ēńö©õ║ÄÕ»╣µĢ░µŹ«ÕŁŚÕģĖõĖŁńÜäÕŁŚµ«ĄĶ┐øĶĪīµśĀÕ░äŃĆéõŠŗÕ”é’╝īõĖĆĶł¼ńÜäÕøŠÕāÅÕżäńÉåÕÅśµŹóķāĮõ╗ĵĢ░µŹ«ÕŁŚÕģĖõĖŁńÜä `"img"` ÕŁŚµ«ĄĶÄĘÕŠŚÕĆ╝ŃĆéõĮåµ£ēõ║øµŚČÕĆÖ’╝īµłæõ╗¼ÕĖīµ£øĶ┐Öõ║øÕÅśµŹóÕżäńÉåµĢ░µŹ«ÕŁŚÕģĖõĖŁÕģČõ╗¢ÕŁŚµ«ĄõĖŁńÜäÕøŠÕāÅ’╝īµ»öÕ”é `"gt_img"` ÕŁŚµ«ĄŃĆé
+
+Õ”éµ×£ķģŹÕÉłµ│©ÕåīÕÖ©ÕÆīķģŹńĮ«µ¢ćõ╗ČõĮ┐ńö©ńÜäĶ»Ø’╝īÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁµĢ░µŹ«ķøåńÜä `pipeline` õĖŁÕ”éõĖŗõŠŗõĮ┐ńö©ÕŁŚµ«ĄµśĀÕ░äÕīģĶŻģ’╝Ü
+
+```python
+pipeline = [
+ ...
+ dict(type='KeyMapper',
+ mapping={
+ 'img': 'gt_img', # Õ░å "gt_img" ÕŁŚµ«ĄµśĀÕ░äĶć│ "img" ÕŁŚµ«Ą
+ 'mask': ..., # õĖŹõĮ┐ńö©ÕĤզŗµĢ░µŹ«õĖŁńÜä "mask" ÕŁŚµ«ĄŃĆéÕŹ│Õ»╣õ║ÄĶó½ÕīģĶŻģńÜäµĢ░µŹ«ÕÅśµŹó’╝īµĢ░µŹ«õĖŁõĖŹÕīģÕɽ "mask" ÕŁŚµ«Ą
+ },
+ auto_remap=True, # Õ£©Õ«īµłÉÕÅśµŹóÕÉÄ’╝īÕ░å "img" ķ揵śĀÕ░äÕø× "gt_img" ÕŁŚµ«Ą
+ transforms=[
+ # Õ£© `RandomFlip` ÕÅśµŹóń▒╗õĖŁ’╝īµłæõ╗¼ÕŬķ£ĆĶ”üµōŹõĮ£ "img" ÕŁŚµ«ĄÕŹ│ÕÅ»
+ dict(type='RandomFlip'),
+ ])
+ ...
+]
+```
+
+Õł®ńö©ÕŁŚµ«ĄµśĀÕ░äÕīģĶŻģ’╝īµłæõ╗¼Õ£©Õ«×ńÄ░µĢ░µŹ«ÕÅśµŹóń▒╗µŚČ’╝īõĖŹķ£ĆĶ”üĶĆāĶÖæÕ£© `transform` µ¢╣µ│ĢõĖŁĶĆāĶÖæÕÉäń¦ŹÕÅ»ĶāĮńÜäĶŠōÕģźÕŁŚµ«ĄÕÉŹ’╝īÕŬķ£ĆĶ”üÕżäńÉåķ╗śĶ«żńÜäÕŁŚµ«ĄÕŹ│ÕÅ»ŃĆé
+
+### ķÜŵ£║ķĆēµŗ®’╝łRandomChoice’╝ēÕÆīķÜŵ£║µē¦ĶĪī’╝łRandomApply’╝ē
+
+ķÜŵ£║ķĆēµŗ®ÕīģĶŻģ’╝ł`RandomChoice`’╝ēńö©õ║Äõ╗ÄõĖĆń│╗ÕłŚµĢ░µŹ«ÕÅśµŹóń╗äÕÉłõĖŁķÜŵ£║Õ║öńö©õĖĆõĖ¬µĢ░µŹ«ÕÅśµŹóń╗äÕÉłŃĆéÕł®ńö©Ķ┐ÖõĖĆÕīģĶŻģ’╝īµłæõ╗¼ÕÅ»õ╗źń«ĆÕŹĢÕ£░Õ«×ńÄ░õĖĆõ║øµĢ░µŹ«Õó×Õ╝║ÕŖ¤ĶāĮ’╝īµ»öÕ”é AutoAugmentŃĆé
+
+Õ”éµ×£ķģŹÕÉłµ│©ÕåīÕÖ©ÕÆīķģŹńĮ«µ¢ćõ╗ČõĮ┐ńö©ńÜäĶ»Ø’╝īÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁµĢ░µŹ«ķøåńÜä `pipeline` õĖŁÕ”éõĖŗõŠŗõĮ┐ńö©ķÜŵ£║ķĆēµŗ®ÕīģĶŻģ’╝Ü
+
+```python
+pipeline = [
+ ...
+ dict(type='RandomChoice',
+ transforms=[
+ [
+ dict(type='Posterize', bits=4),
+ dict(type='Rotate', angle=30.)
+ ], # ń¼¼õĖĆń¦ŹķÜŵ£║ÕÅśÕī¢ń╗äÕÉł
+ [
+ dict(type='Equalize'),
+ dict(type='Rotate', angle=30)
+ ], # ń¼¼õ║īń¦ŹķÜŵ£║ÕÅśµŹóń╗äÕÉł
+ ],
+ prob=[0.4, 0.6] # õĖżń¦ŹķÜŵ£║ÕÅśµŹóń╗äÕÉłÕÉäĶć¬ńÜäķĆēńö©µ”éńÄć
+ )
+ ...
+]
+```
+
+ķÜŵ£║µē¦ĶĪīÕīģĶŻģ’╝ł`RandomApply`’╝ēńö©õ║Äõ╗źµīćիܵ”éńÄćķÜŵ£║µē¦ĶĪīµĢ░µŹ«ÕÅśµŹóń╗äÕÉłŃĆéõŠŗÕ”é’╝Ü
+
+```python
+pipeline = [
+ ...
+ dict(type='RandomApply',
+ transforms=[dict(type='Rotate', angle=30.)],
+ prob=0.3) # õ╗ź 0.3 ńÜäµ”éńÄćµē¦ĶĪīĶó½ÕīģĶŻģńÜäµĢ░µŹ«ÕÅśµŹó
+ ...
+]
+```
+
+### ÕżÜńø«µĀćµē®Õ▒Ģ’╝łTransformBroadcaster’╝ē
+
+ķĆÜÕĖĖ’╝īõĖĆõĖ¬µĢ░µŹ«ÕÅśµŹóń▒╗ÕŬõ╝Üõ╗ÄõĖĆõĖ¬Õø║Õ«ÜńÜäÕŁŚµ«ĄĶ»╗ÕÅ¢µōŹõĮ£ńø«µĀćŃĆéĶÖĮńäȵłæõ╗¼õ╣¤ÕÅ»õ╗źõĮ┐ńö© `KeyMapper` µØźµö╣ÕÅśĶ»╗ÕÅ¢ńÜäÕŁŚµ«Ą’╝īõĮåµŚĀµ│ĢÕ░åÕÅśµŹóõĖƵ¼ĪµĆ¦Õ║öńö©õ║ÄÕżÜõĖ¬ÕŁŚµ«ĄńÜäµĢ░µŹ«ŃĆéõĖ║õ║åÕ«×ńÄ░Ķ┐ÖõĖĆÕŖ¤ĶāĮ’╝īµłæõ╗¼ķ£ĆĶ”üÕƤÕŖ®ÕżÜńø«µĀćµē®Õ▒ĢÕīģĶŻģ’╝ł`TransformBroadcaster`’╝ēŃĆé
+
+ÕżÜńø«µĀćµē®Õ▒ĢÕīģĶŻģ’╝ł`TransformBroadcaster`’╝ēµ£ēõĖżõĖ¬ńö©µ│Ģ’╝īõĖƵś»Õ░åµĢ░µŹ«ÕÅśµŹóõĮ£ńö©õ║ĵīćÕ«ÜńÜäÕżÜõĖ¬ÕŁŚµ«Ą’╝īõ║īµś»Õ░åµĢ░µŹ«ÕÅśµŹóõĮ£ńö©õ║ĵ¤ÉõĖ¬ÕŁŚµ«ĄõĖŗńÜäõĖĆń╗äńø«µĀćõĖŁŃĆé
+
+1. Õ║öńö©õ║ÄÕżÜõĖ¬ÕŁŚµ«Ą
+
+ ÕüćĶ«Šµłæõ╗¼ķ£ĆĶ”üÕ░åµĢ░µŹ«ÕÅśµŹóÕ║öńö©õ║Ä `"lq"` (low-quality) ÕÆī `"gt"` (ground-truth) õĖżõĖ¬ÕŁŚµ«ĄõĖŁńÜäÕøŠÕāÅõĖŖŃĆé
+
+ ```python
+ pipeline = [
+ dict(type='TransformBroadcaster',
+ # ÕłåÕł½Õ║öńö©õ║Ä "lq" ÕÆī "gt" õĖżõĖ¬ÕŁŚµ«Ą’╝īÕ╣ČÕ░åõ║īĶĆģÕ║öĶ«ŠńĮ« "img" ÕŁŚµ«Ą
+ mapping={'img': ['lq', 'gt']},
+ # Õ£©Õ«īµłÉÕÅśµŹóÕÉÄ’╝īÕ░å "img" ÕŁŚµ«Ąķ揵śĀÕ░äÕø×ÕĤÕģłńÜäÕŁŚµ«Ą
+ auto_remap=True,
+ # µś»Õɔգ©Õ»╣ÕÉäńø«µĀćńÜäÕÅśµŹóõĖŁÕģ▒õ║½ķÜŵ£║ÕÅśķćÅ
+ # µø┤ÕżÜõ╗ŗń╗ŹÕÅéÕŖĀÕÉÄń╗Łń½ĀĶŖé’╝łķÜŵ£║ÕÅśķćÅÕģ▒õ║½’╝ē
+ share_random_params=True,
+ transforms=[
+ # Õ£© `RandomFlip` ÕÅśµŹóń▒╗õĖŁ’╝īµłæõ╗¼ÕŬķ£ĆĶ”üµōŹõĮ£ "img" ÕŁŚµ«ĄÕŹ│ÕÅ»
+ dict(type='RandomFlip'),
+ ])
+ ]
+ ```
+
+ Õ£©ÕżÜńø«µĀćµē®Õ▒ĢńÜä `mapping` Ķ«ŠńĮ«õĖŁ’╝īµłæõ╗¼ÕÉīµĀĘÕÅ»õ╗źõĮ┐ńö© `...` µØźÕ┐ĮńĢźµīćÕ«ÜńÜäÕĤզŗÕŁŚµ«ĄŃĆéÕ”éõ╗źõĖŗõŠŗÕŁÉõĖŁ’╝īĶó½ÕīģĶŻ╣ńÜä `RandomCrop` õ╝ÜÕ»╣ÕŁŚµ«Ą `"img"` õĖŁńÜäÕøŠÕāÅĶ┐øĶĪīĶŻüÕē¬’╝īÕ╣ČõĖöÕ£©ÕŁŚµ«Ą `"img_shape"` ÕŁśÕ£©µŚČµø┤µ¢░Õē¬ĶŻüÕÉÄńÜäÕøŠÕāÅÕż¦Õ░ÅŃĆéÕ”éµ×£µłæõ╗¼ÕĖīµ£øÕÉīµŚČÕ»╣õĖżõĖ¬ÕøŠÕāÅÕŁŚµ«Ą `"lq"` ÕÆī `"gt"` Ķ┐øĶĪīńøĖÕÉīńÜäķÜŵ£║ĶŻüÕē¬’╝īõĮåÕŬµø┤µ¢░õĖƵ¼Ī `"img_shape"` ÕŁŚµ«Ą’╝īÕÅ»õ╗źķĆÜĶ┐ćõŠŗÕŁÉõĖŁńÜäµ¢╣Õ╝ÅÕ«×ńÄ░’╝Ü
+
+ ```python
+ pipeline = [
+ dict(type='TransformBroadcaster',
+ mapping={
+ 'img': ['lq', 'gt'],
+ 'img_shape': ['img_shape', ...],
+ },
+ # Õ£©Õ«īµłÉÕÅśµŹóÕÉÄ’╝īÕ░å "img" ÕÆī "img_shape" ÕŁŚµ«Ąķ揵śĀÕ░äÕø×ÕĤÕģłńÜäÕŁŚµ«Ą
+ auto_remap=True,
+ # µś»Õɔգ©Õ»╣ÕÉäńø«µĀćńÜäÕÅśµŹóõĖŁÕģ▒õ║½ķÜŵ£║ÕÅśķćÅ
+ # µø┤ÕżÜõ╗ŗń╗ŹÕÅéÕŖĀÕÉÄń╗Łń½ĀĶŖé’╝łķÜŵ£║ÕÅśķćÅÕģ▒õ║½’╝ē
+ share_random_params=True,
+ transforms=[
+ # `RandomCrop` ń▒╗õĖŁõ╝ܵōŹõĮ£ "img" ÕÆī "img_shape" ÕŁŚµ«ĄŃĆéĶŗź "img_shape" ń®║ń╝║’╝ī
+ # ÕłÖÕŬµōŹõĮ£ "img"
+ dict(type='RandomCrop'),
+ ])
+ ]
+ ```
+
+2. Õ║öńö©õ║ÄõĖĆõĖ¬ÕŁŚµ«ĄńÜäõĖĆń╗äńø«µĀć
+
+ ÕüćĶ«Šµłæõ╗¼ķ£ĆĶ”üÕ░åµĢ░µŹ«ÕÅśµŹóÕ║öńö©õ║Ä `"images"` ÕŁŚµ«Ą’╝īĶ»źÕŁŚµ«ĄõĖ║õĖĆõĖ¬ÕøŠÕāÅń╗䵳ÉńÜä listŃĆé
+
+ ```python
+ pipeline = [
+ dict(type='TransformBroadcaster',
+ # Õ░å "images" ÕŁŚµ«ĄõĖŗńÜäµ»ÅÕ╝ĀÕøŠńē浜ĀÕ░äĶć│ "img" ÕŁŚµ«Ą
+ mapping={'img': 'images'},
+ # Õ£©Õ«īµłÉÕÅśµŹóÕÉÄ’╝īÕ░å "img" ÕŁŚµ«ĄõĖŗńÜäÕøŠńēćķ揵śĀÕ░äÕø× "images" ÕŁŚµ«ĄńÜäÕłŚĶĪ©õĖŁ
+ auto_remap=True,
+ # µś»Õɔգ©Õ»╣ÕÉäńø«µĀćńÜäÕÅśµŹóõĖŁÕģ▒õ║½ķÜŵ£║ÕÅśķćÅ
+ share_random_params=True,
+ transforms=[
+ # Õ£© `RandomFlip` ÕÅśµŹóń▒╗õĖŁ’╝īµłæõ╗¼ÕŬķ£ĆĶ”üµōŹõĮ£ "img" ÕŁŚµ«ĄÕŹ│ÕÅ»
+ dict(type='RandomFlip'),
+ ])
+ ]
+ ```
+
+#### ĶŻģķź░ÕÖ© `cache_randomness`
+
+Õ£© `TransformBroadcaster` õĖŁ’╝īµłæõ╗¼µÅÉõŠøõ║å `share_random_params` ķĆēķĪ╣µØźµö»µīüÕ£©ÕżÜµ¼ĪµĢ░µŹ«ÕÅśµŹóõĖŁÕģ▒õ║½ķÜŵ£║ńŖȵĆüŃĆéõŠŗÕ”é’╝īÕ£©ĶČģÕłåĶŠ©ńÄćõ╗╗ÕŖĪõĖŁ’╝īµłæõ╗¼ÕĖīµ£øÕ░åķÜŵ£║ÕÅśµŹó**ÕÉīµŁź**õĮ£ńö©õ║ÄõĮÄÕłåĶŠ©ńÄćÕøŠÕāÅÕÆīÕĤզŗÕøŠÕāÅŃĆéÕ”éµ×£µłæõ╗¼ÕĖīµ£øÕ£©Ķć¬Õ«Üõ╣ēńÜäµĢ░µŹ«ÕÅśµŹóń▒╗õĖŁõĮ┐ńö©Ķ┐ÖõĖĆÕŖ¤ĶāĮ’╝īķ£ĆĶ”üÕ£©ń▒╗õĖŁµĀćµ│©Õō¬õ║øķÜŵ£║ÕÅśķćŵś»µö»µīüÕģ▒õ║½ńÜäŃĆéĶ┐ÖÕÅ»õ╗źķĆÜĶ┐ćĶŻģķź░ÕÖ© `cache_randomness` µØźÕ«×ńÄ░ŃĆé
+
+õ╗źõĖŖµ¢ćõĖŁńÜä `MyFlip` õĖ║õŠŗ’╝īµłæõ╗¼ÕĖīµ£øõ╗źõĖĆÕ«ÜńÜäµ”éńÄćķÜŵ£║µē¦ĶĪīń┐╗ĶĮ¼’╝Ü
+
+```python
+from mmcv.transforms.utils import cache_randomness
+
+@TRANSFORMS.register_module()
+class MyRandomFlip(BaseTransform):
+ def __init__(self, prob: float, direction: str):
+ super().__init__()
+ self.prob = prob
+ self.direction = direction
+
+ @cache_randomness # µĀćµ│©Ķ»źµ¢╣µ│ĢńÜäĶŠōÕć║õĖ║ÕÅ»Õģ▒õ║½ńÜäķÜŵ£║ÕÅśķćÅ
+ def do_flip(self):
+ flip = True if random.random() > self.prob else False
+ return flip
+
+ def transform(self, results: dict) -> dict:
+ img = results['img']
+ if self.do_flip():
+ results['img'] = mmcv.imflip(img, direction=self.direction)
+ return results
+```
+
+Õ£©õĖŖķØóńÜäõŠŗÕŁÉõĖŁ’╝īµłæõ╗¼ńö©`cache_randomness` ĶŻģķź░ `do_flip`µ¢╣µ│Ģ’╝īÕŹ│Õ░åĶ»źµ¢╣µ│ĢĶ┐öÕø×ÕĆ╝ `flip` µĀćµ│©õĖ║õĖĆõĖ¬µö»µīüÕģ▒õ║½ńÜäķÜŵ£║ÕÅśķćÅŃĆéĶ┐øĶĆī’╝īÕ£© `TransformBroadcaster` Õ»╣ÕżÜõĖ¬ńø«µĀćńÜäÕÅśµŹóõĖŁ’╝īĶ┐ÖõĖĆÕÅśķćÅńÜäÕĆ╝ķāĮõ╝Üõ┐صīüõĖĆĶć┤ŃĆé
+
+#### ĶŻģķź░ÕÖ© `avoid_cache_randomness`
+
+Õ£©õĖĆõ║øµāģÕåĄõĖŗ’╝īµłæõ╗¼µŚĀµ│ĢÕ░åµĢ░µŹ«ÕÅśµŹóõĖŁõ║¦ńö¤ķÜŵ£║ÕÅśķćÅńÜäĶ┐ćń©ŗÕŹĢńŗ¼µöŠÕ£©ń▒╗µ¢╣µ│ĢõĖŁŃĆéõŠŗÕ”éµĢ░µŹ«ÕÅśµŹóõĖŁõĮ┐ńö©ńÜäµØźĶć¬ń¼¼õĖēµ¢╣Õ║ōńÜ䵩ĪÕØŚ’╝īĶ┐Öõ║øµ©ĪÕØŚÕ░åķÜŵ£║ÕÅśķćÅńøĖÕģ│ńÜäķā©ÕłåÕ░üĶŻģÕ£©õ║åÕåģķā©’╝īÕ»╝Ķć┤µŚĀµ│ĢÕ░åÕģȵŖĮÕć║õĖ║µĢ░µŹ«ÕÅśµŹóńÜäń▒╗µ¢╣µ│ĢŃĆéĶ┐ÖµĀĘńÜäµĢ░µŹ«ÕÅśµŹóµŚĀµ│ĢķĆÜĶ┐ćĶŻģķź░ÕÖ© `cache_randomness` µĀćµ│©µö»µīüÕģ▒õ║½ńÜäķÜŵ£║ÕÅśķćÅ’╝īĶ┐øĶĆīµŚĀµ│ĢÕ£©ÕżÜńø«µĀćµē®Õ▒ĢµŚČÕģ▒õ║½ķÜŵ£║ÕÅśķćÅŃĆé
+
+õĖ║õ║åķü┐ÕģŹÕ£©ÕżÜńø«µĀćµē®Õ▒ĢõĖŁĶ»»ńö©µŁżń▒╗µĢ░µŹ«ÕÅśµŹó’╝īµłæõ╗¼µÅÉõŠøõ║åÕÅ”õĖĆõĖ¬ĶŻģķź░ÕÖ© `avoid_cache_randomness`’╝īńö©µØźÕ»╣µŁżń▒╗µĢ░µŹ«ÕÅśµŹóĶ┐øĶĪīµĀćĶ«░’╝Ü
+
+```python
+from mmcv.transforms.utils import avoid_cache_randomness
+
+@TRANSFORMS.register_module()
+@avoid_cache_randomness
+class MyRandomTransform(BaseTransform):
+
+ def transform(self, results: dict) -> dict:
+ ...
+```
+
+ńö© `avoid_cache_randomness` µĀćĶ«░ńÜäµĢ░µŹ«ÕÅśµŹóń▒╗’╝īÕĮōÕģČÕ«×õŠŗĶó½ `TransformBroadcaster` ÕīģĶŻģõĖöÕ░åÕÅéµĢ░ `share_random_params` Ķ«ŠńĮ«õĖ║ True µŚČ’╝īõ╝ܵŖøÕć║Õ╝éÕĖĖ’╝īõ╗źµŁżµÅÉķåÆńö©µłĘõĖŹĶāĮĶ┐ÖµĀĘõĮ┐ńö©ŃĆé
+
+Õ£©õĮ┐ńö© `avoid_cache_randomness` µŚČķ£ĆĶ”üµ│©µäÅõ╗źõĖŗÕćĀńé╣’╝Ü
+
+1. `avoid_cache_randomness` ÕŬńö©õ║ÄĶŻģķź░µĢ░µŹ«ÕÅśµŹóń▒╗’╝łBaseTransfrom ńÜäÕŁÉń▒╗’╝ē’╝īĶĆīõĖŹĶāĮńö©õĖÄĶŻģķź░ÕģČõ╗¢õĖĆĶł¼ńÜäń▒╗ŃĆüń▒╗µ¢╣µ│Ģµł¢ÕćĮµĢ░
+2. Ķó½ `avoid_cache_randomness` õ┐«ķź░ńÜäµĢ░µŹ«ÕÅśµŹóõĮ£õĖ║Õ¤║ń▒╗µŚČ’╝īÕģČÕŁÉń▒╗Õ░å**õĖŹõ╝Üń╗¦µē┐**Ķ┐ÖõĖĆńē╣µĆ¦ŃĆéÕ”éµ×£ÕŁÉń▒╗õ╗ŹµŚĀµ│ĢÕģ▒õ║½ķÜŵ£║ÕÅśķćÅ’╝īÕłÖÕ║öÕåŹµ¼ĪõĮ┐ńö© `avoid_cache_randomness` õ┐«ķź░
+3. ÕŬµ£ēÕĮōõĖĆõĖ¬µĢ░µŹ«ÕÅśµŹóÕģʵ£ēķÜŵ£║µĆ¦’╝īõĖöµŚĀµ│ĢÕģ▒õ║½ķÜŵ£║ÕÅéµĢ░µŚČ’╝īµēŹķ£ĆĶ”üõ╗ź `avoid_cache_randomness` õ┐«ķź░ŃĆ鵌ĀķÜŵ£║µĆ¦ńÜäµĢ░µŹ«ÕÅśµŹóõĖŹķ£ĆĶ”üõ┐«ķź░
diff --git a/internlm_langchain/knowledge_base/MMCV/content/faq.md b/internlm_langchain/knowledge_base/MMCV/content/faq.md
new file mode 100644
index 00000000..6cfb100c
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMCV/content/faq.md
@@ -0,0 +1,91 @@
+## ÕĖĖĶ¦üķŚ«ķóś
+
+Õ£©Ķ┐Öķćīµłæõ╗¼ÕłŚÕć║õ║åńö©µłĘń╗ÅÕĖĖķüćÕł░ńÜäķŚ«ķóśõ╗źÕÅŖÕ»╣Õ║öńÜäĶ¦ŻÕå│µ¢╣µ│ĢŃĆéÕ”éµ×£µé©ķüćÕł░õ║åÕģČõ╗¢ÕĖĖĶ¦üńÜäķŚ«ķóś’╝īÕ╣ČõĖöń¤źķüōÕÅ»õ╗źÕĖ«Õł░Õż¦Õ«ČńÜäĶ¦ŻÕå│ÕŖ×µ│Ģ’╝ī
+µ¼óĶ┐ÄķÜŵŚČõĖ░Õ»īĶ┐ÖõĖ¬ÕłŚĶĪ©ŃĆé
+
+### Õ«ēĶŻģķŚ«ķóś
+
+- KeyError: "xxx: 'yyy is not in the zzz registry'"
+
+ ÕŬµ£ēµ©ĪÕØŚµēĆÕ£©ńÜäµ¢ćõ╗ČĶó½Õ»╝ÕģźµŚČ’╝īµ│©Õåīµ£║ÕłČµēŹõ╝ÜĶó½Ķ¦”ÕÅæ’╝īµēĆõ╗źµé©ķ£ĆĶ”üÕ£©µ¤ÉÕżäÕ»╝ÕģźĶ»źµ¢ćõ╗Č’╝īµø┤ÕżÜĶ»”µāģĶ»Ęµ¤źń£ŗ [KeyError: "MaskRCNN: 'RefineRoIHead is not in the models registry'"](https://github.com/open-mmlab/mmdetection/issues/5974)ŃĆé
+
+- "No module named 'mmcv.ops'"; "No module named 'mmcv.\_ext'"
+
+ 1. õĮ┐ńö© `pip uninstall mmcv` ÕŹĖĶĮĮµé©ńÄ»ÕóāõĖŁńÜä mmcv
+ 2. ÕÅéĶĆā [installation instruction](https://mmcv.readthedocs.io/en/latest/get_started/installation.html) µł¢ĶĆģ [Build MMCV from source](https://mmcv.readthedocs.io/en/latest/get_started/build.html) Õ«ēĶŻģ mmcv-full
+
+- "invalid device function" µł¢ĶĆģ "no kernel image is available for execution"
+
+ 1. µŻĆµ¤ź GPU ńÜä CUDA Ķ«Īń«ŚĶāĮÕŖø
+ 2. Ķ┐ÉĶĪī `python mmdet/utils/collect_env.py` µØźµŻĆµ¤ź PyTorchŃĆütorchvision ÕÆī MMCV µś»ÕÉ”µś»ķÆłÕ»╣µŁŻńĪ«ńÜä GPU µ×ȵ×äµ×äÕ╗║ńÜä’╝īµé©ÕÅ»ĶāĮķ£ĆĶ”üÕÄ╗Ķ«ŠńĮ« `TORCH_CUDA_ARCH_LIST` µØźķ揵¢░Õ«ēĶŻģ MMCVŃĆéÕģ╝Õ«╣µĆ¦ķŚ«ķóśÕÅ»ĶāĮõ╝ÜÕć║ńÄ░Õ£©õĮ┐ńö©µŚ¦ńēłńÜä GPUs’╝īÕ”é’╝Ücolab õĖŖńÜä Tesla K80 (3.7)
+ 3. µŻĆµ¤źĶ┐ÉĶĪīńÄ»Õóāµś»ÕÉ”ÕÆī mmcv/mmdet ń╝¢Ķ»æµŚČńÜäńÄ»ÕóāńøĖÕÉīŃĆéõŠŗÕ”é’╝īµé©ÕÅ»ĶāĮõĮ┐ńö© CUDA 10.0 ń╝¢Ķ»æ mmcv’╝īõĮåÕ£© CUDA 9.0 ńÜäńÄ»ÕóāõĖŁĶ┐ÉĶĪīÕ«ā
+
+- "undefined symbol" µł¢ĶĆģ "cannot open xxx.so"
+
+ 1. Õ”éµ×£ń¼”ÕÅĘÕÆī CUDA/C++ ńøĖÕģ│’╝łõŠŗÕ”é’╝Ülibcudart.so µł¢ĶĆģ GLIBCXX’╝ē’╝īĶ»ĘµŻĆµ¤ź CUDA/GCC Ķ┐ÉĶĪīµŚČńÜäńēłµ£¼µś»ÕÉ”ÕÆīń╝¢Ķ»æ mmcv ńÜäõĖĆĶć┤
+ 2. Õ”éµ×£ń¼”ÕÅĘÕÆī PyTorch ńøĖÕģ│’╝łõŠŗÕ”é’╝Üń¼”ÕÅĘÕīģÕɽ caffeŃĆüaten ÕÆī TH’╝ē’╝īĶ»ĘµŻĆµ¤ź PyTorch Ķ┐ÉĶĪīµŚČńÜäńēłµ£¼µś»ÕÉ”ÕÆīń╝¢Ķ»æ mmcv ńÜäõĖĆĶć┤
+ 3. Ķ┐ÉĶĪī `python mmdet/utils/collect_env.py` õ╗źµŻĆµ¤ź PyTorchŃĆütorchvision ÕÆī MMCV µ×äÕ╗║ÕÆīĶ┐ÉĶĪīńÜäńÄ»Õóāµś»ÕÉ”ńøĖÕÉī
+
+- "RuntimeError: CUDA error: invalid configuration argument"
+
+ Ķ┐ÖõĖ¬ķöÖĶ»»ÕÅ»ĶāĮµś»ńö▒õ║ĵé©ńÜä GPU µĆ¦ĶāĮõĖŹõĮ│ķĆĀµłÉńÜäŃĆéÕ░ØĶ»ĢķÖŹõĮÄ [THREADS_PER_BLOCK](https://github.com/open-mmlab/mmcv/blob/cac22f8cf5a904477e3b5461b1cc36856c2793da/mmcv/ops/csrc/common_cuda_helper.hpp#L10)
+ ńÜäÕĆ╝Õ╣Čķ揵¢░ń╝¢Ķ»æ mmcvŃĆé
+
+- "RuntimeError: nms is not compiled with GPU support"
+
+ Ķ┐ÖõĖ¬ķöÖĶ»»µś»ńö▒õ║ĵé©ńÜä CUDA ńÄ»Õóāµ▓Īµ£ēµŁŻńĪ«Õ«ēĶŻģŃĆé
+ µé©ÕÅ»õ╗źÕ░ØĶ»Ģķ揵¢░Õ«ēĶŻģµé©ńÜä CUDA ńÄ»Õóā’╝īńäČÕÉÄÕłĀķÖż mmcv/build µ¢ćõ╗ČÕż╣Õ╣Čķ揵¢░ń╝¢Ķ»æ mmcvŃĆé
+
+- "Segmentation fault"
+
+ 1. µŻĆµ¤ź GCC ńÜäńēłµ£¼’╝īķĆÜÕĖĖµś»ÕøĀõĖ║ PyTorch ńēłµ£¼õĖÄ GCC ńēłµ£¼õĖŹÕī╣ķģŹ ’╝łõŠŗÕ”é GCC \< 4.9 )’╝īµłæõ╗¼µÄ©ĶŹÉńö©µłĘõĮ┐ńö© GCC 5.4’╝īµłæõ╗¼õ╣¤õĖŹµÄ©ĶŹÉõĮ┐ńö© GCC 5.5’╝ī ÕøĀõĖ║µ£ēÕÅŹķ”ł GCC 5.5 õ╝ÜÕ»╝Ķć┤ "segmentation fault" Õ╣ČõĖöÕłćµŹóÕł░ GCC 5.4 Õ░▒ÕÅ»õ╗źĶ¦ŻÕå│ķŚ«ķóś
+ 2. µŻĆµ¤źµś»ÕÉ”µŁŻńĪ«Õ«ēĶŻģ CUDA ńēłµ£¼ńÜä PyTorcŃĆéĶŠōÕģźõ╗źõĖŗÕæĮõ╗żÕ╣ȵŻĆµ¤źµś»ÕÉ”Ķ┐öÕø× True
+ ```shell
+ python -c 'import torch; print(torch.cuda.is_available())'
+ ```
+ 3. Õ”éµ×£ `torch` Õ«ēĶŻģµłÉÕŖ¤’╝īķéŻõ╣łµŻĆµ¤ź MMCV µś»ÕɔիēĶŻģµłÉÕŖ¤ŃĆéĶŠōÕģźõ╗źõĖŗÕæĮõ╗ż’╝īÕ”éµ×£µ▓Īµ£ēµŖźķöÖĶ»┤µśÄ mmcv-full Õ«ēĶŻģµłÉŃĆé
+ ```shell
+ python -c 'import mmcv; import mmcv.ops'
+ ```
+ 4. Õ”éµ×£ MMCV õĖÄ PyTorch ķāĮÕ«ēĶŻģµłÉÕŖ¤õ║å’╝īÕłÖÕÅ»õ╗źõĮ┐ńö© `ipdb` Ķ«ŠńĮ«µ¢Łńé╣µł¢ĶĆģõĮ┐ńö© `print` ÕćĮµĢ░’╝īÕłåµ×ɵś»Õō¬õĖĆķā©ÕłåńÜäõ╗ŻńĀüÕ»╝Ķć┤õ║å `segmentation fault`
+
+- "libtorch_cuda_cu.so: cannot open shared object file"
+
+ `mmcv-full` õŠØĶĄ¢ `libtorch_cuda_cu.so` µ¢ćõ╗Č’╝īõĮåń©ŗÕ║ÅĶ┐ÉĶĪīµŚČµ▓ĪĶāĮµēŠÕł░Ķ»źµ¢ćõ╗ČŃĆ鵳æõ╗¼ÕÅ»õ╗źµŻĆµ¤źĶ»źµ¢ćõ╗ȵś»ÕÉ”ÕŁśÕ£© `~/miniconda3/envs/{environment-name}/lib/python3.7/site-packages/torch/lib` õ╣¤ÕÅ»õ╗źÕ░ØĶ»ĢķćŹĶŻģ PyTorchŃĆé
+
+- "fatal error C1189: #error: -- unsupported Microsoft Visual Studio version!"
+
+ Õ”éµ×£µé©Õ£© Windows õĖŖń╝¢Ķ»æ mmcv-full Õ╣ČõĖö CUDA ńÜäńēłµ£¼µś» 9.2’╝īµé©ÕŠłÕÅ»ĶāĮõ╝ÜķüćÕł░Ķ┐ÖõĖ¬ķŚ«ķóś `"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.2\include\crt/host_config.h(133): fatal error C1189: #error: -- unsupported Microsoft Visual Studio version! Only the versions 2012, 2013, 2015 and 2017 are supported!"`’╝īµé©ÕÅ»õ╗źÕ░ØĶ»ĢõĮ┐ńö©õĮÄńēłµ£¼ńÜä Microsoft Visual Studio’╝īõŠŗÕ”é vs2017ŃĆé
+
+- "error: member "torch::jit::detail::ModulePolicy::all_slots" may not be initialized"
+
+ Õ”éµ×£µé©Õ£© Windows õĖŖń╝¢Ķ»æ mmcv-full Õ╣ČõĖö PyTorch ńÜäńēłµ£¼µś» 1.5.0’╝īµé©ÕŠłÕÅ»ĶāĮõ╝ÜķüćÕł░Ķ┐ÖõĖ¬ķŚ«ķóś `- torch/csrc/jit/api/module.h(474): error: member "torch::jit::detail::ModulePolicy::all_slots" may not be initialized`ŃĆéĶ¦ŻÕå│Ķ┐ÖõĖ¬ķŚ«ķóśńÜäµ¢╣µ│Ģµś»Õ░å `torch/csrc/jit/api/module.h` µ¢ćõ╗ČõĖŁµēƵ£ē `static constexpr bool all_slots = false;` µø┐µŹóõĖ║ `static bool all_slots = false;`ŃĆéµø┤ÕżÜń╗åĶŖéÕÅ»õ╗źµ¤źń£ŗ [member "torch::jit::detail::AttributePolicy::all_slots" may not be initialized](https://github.com/pytorch/pytorch/issues/39394)ŃĆé
+
+- "error: a member with an in-class initializer must be const"
+
+ Õ”éµ×£µé©Õ£© Windows õĖŖń╝¢Ķ»æ mmcv-full Õ╣ČõĖö PyTorch ńÜäńēłµ£¼µś» 1.6.0’╝īµé©ÕŠłÕÅ»ĶāĮõ╝ÜķüćÕł░Ķ┐ÖõĖ¬ķŚ«ķóś `"- torch/include\torch/csrc/jit/api/module.h(483): error: a member with an in-class initializer must be const"`. Ķ¦ŻÕå│Ķ┐ÖõĖ¬ķŚ«ķóśńÜäµ¢╣µ│Ģµś»Õ░å `torch/include\torch/csrc/jit/api/module.h` µ¢ćõ╗ČõĖŁńÜäµēƵ£ē `CONSTEXPR_EXCEPT_WIN_CUDA ` µø┐µŹóõĖ║ `const`ŃĆéµø┤ÕżÜń╗åĶŖéÕÅ»õ╗źµ¤źń£ŗ [Ninja: build stopped: subcommand failed](https://github.com/open-mmlab/mmcv/issues/575)ŃĆé
+
+- "error: member "torch::jit::ProfileOptionalOp::Kind" may not be initialized"
+
+ Õ”éµ×£µé©Õ£© Windows õĖŖń╝¢Ķ»æ mmcv-full Õ╣ČõĖö PyTorch ńÜäńēłµ£¼µś» 1.7.0’╝īµé©ÕŠłÕÅ»ĶāĮõ╝ÜķüćÕł░Ķ┐ÖõĖ¬ķŚ«ķóś `torch/include\torch/csrc/jit/ir/ir.h(1347): error: member "torch::jit::ProfileOptionalOp::Kind" may not be initialized`. Ķ¦ŻÕå│Ķ┐ÖõĖ¬ķŚ«ķóśńÜäµ¢╣µ│Ģµś»õ┐«µö╣ PyTorch õĖŁńÜäÕćĀõĖ¬µ¢ćõ╗Č’╝Ü
+
+ - ÕłĀķÖż `torch/include\torch/csrc/jit/ir/ir.h` µ¢ćõ╗ČõĖŁńÜä `static constexpr Symbol Kind = ::c10::prim::profile;` ÕÆī `tatic constexpr Symbol Kind = ::c10::prim::profile_optional;`
+ - Õ░å `torch\include\pybind11\cast.h` µ¢ćõ╗ČõĖŁńÜä `explicit operator type&() { return *(this->value); }` µø┐µŹóõĖ║ `explicit operator type&() { return *((type*)this->value); }`
+ - Õ░å `torch/include\torch/csrc/jit/api/module.h` µ¢ćõ╗ČõĖŁńÜä µēƵ£ē `CONSTEXPR_EXCEPT_WIN_CUDA` µø┐µŹóõĖ║ `const`
+
+ µø┤ÕżÜń╗åĶŖéÕÅ»õ╗źµ¤źń£ŗ [Ensure default extra_compile_args](https://github.com/pytorch/pytorch/pull/45956)ŃĆé
+
+- MMCV ÕÆī MMDetection ńÜäÕģ╝Õ«╣µĆ¦ķŚ«ķóś’╝ø"ConvWS is already registered in conv layer"
+
+ Ķ»ĘÕÅéĶĆā [installation instruction](https://mmdetection.readthedocs.io/en/latest/get_started.html#installation) õĖ║µé©ńÜä MMDetection ńēłµ£¼Õ«ēĶŻģµŁŻńĪ«ńēłµ£¼ńÜä MMCVŃĆé
+
+### õĮ┐ńö©ķŚ«ķóś
+
+- "RuntimeError: Expected to have finished reduction in the prior iteration before starting a new one"
+
+ 1. Ķ┐ÖõĖ¬ķöÖĶ»»µś»ÕøĀõĖ║µ£ēõ║øÕÅéµĢ░µ▓Īµ£ēÕÅéõĖÄ loss ńÜäĶ«Īń«Ś’╝īÕÅ»ĶāĮµś»õ╗ŻńĀüõĖŁÕŁśÕ£©ÕżÜõĖ¬Õłåµö»’╝īÕ»╝Ķć┤µ£ēõ║øÕłåµö»µ▓Īµ£ēÕÅéõĖÄ loss ńÜäĶ«Īń«ŚŃĆéµø┤ÕżÜń╗åĶŖéĶ¦ü [Expected to have finished reduction in the prior iteration before starting a new one](https://github.com/pytorch/pytorch/issues/55582)ŃĆé
+ 2. õĮĀÕÅ»õ╗źĶ«ŠńĮ« DDP õĖŁńÜä `find_unused_parameters` õĖ║ `True`’╝īµł¢ĶĆģµēŗÕŖ©µ¤źµēŠÕō¬õ║øÕÅéµĢ░µ▓Īµ£ēńö©Õł░ŃĆé
+
+- "RuntimeError: Trying to backward through the graph a second time"
+
+ õĖŹĶāĮÕÉīµŚČĶ«ŠńĮ« `GradientCumulativeOptimizerHook` ÕÆī `OptimizerHook`’╝īĶ┐Öõ╝ÜÕ»╝Ķć┤ `loss.backward()` Ķó½Ķ░āńö©õĖżµ¼Ī’╝īõ║ĵś»ń©ŗÕ║ŵŖøÕć║ `RuntimeError`ŃĆ鵳æõ╗¼ÕŬķ£ĆĶ«ŠńĮ«ÕģČõĖŁńÜäõĖĆõĖ¬ŃĆéµø┤ÕżÜń╗åĶŖéĶ¦ü [Trying to backward through the graph a second time](https://github.com/open-mmlab/mmcv/issues/1379)ŃĆé
diff --git a/internlm_langchain/knowledge_base/MMCV/content/installation.md b/internlm_langchain/knowledge_base/MMCV/content/installation.md
new file mode 100644
index 00000000..16cb0076
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMCV/content/installation.md
@@ -0,0 +1,369 @@
+## Õ«ēĶŻģ MMCV
+
+MMCV µ£ēõĖżõĖ¬ńēłµ£¼’╝Ü
+
+- **mmcv**: Õ«īµĢ┤ńēł’╝īÕīģÕɽµēƵ£ēńÜäńē╣µĆ¦õ╗źÕÅŖõĖ░Õ»īńÜäÕ╝Ćń«▒ÕŹ│ńö©ńÜä CPU ÕÆī CUDA ń«ŚÕŁÉŃĆéµ│©µäÅ’╝īÕ«īµĢ┤ńēłµ£¼ÕÅ»ĶāĮķ£ĆĶ”üµø┤ķĢ┐µŚČķŚ┤µØźń╝¢Ķ»æŃĆé
+- **mmcv-lite**: ń▓Šń«Ćńēł’╝īõĖŹÕīģÕɽ CPU ÕÆī CUDA ń«ŚÕŁÉõĮåÕīģÕɽÕģČõĮÖµēƵ£ēńē╣µĆ¦ÕÆīÕŖ¤ĶāĮ’╝īń▒╗õ╝╝ MMCV 1.0 õ╣ŗÕēŹńÜäńēłµ£¼ŃĆéÕ”éµ×£õĮĀõĖŹķ£ĆĶ”üõĮ┐ńö©ń«ŚÕŁÉńÜäĶ»Ø’╝īń▓Šń«ĆńēłÕÅ»õ╗źõĮ£õĖ║õĖĆõĖ¬ĶĆāĶÖæķĆēķĪ╣ŃĆé
+
+```{warning}
+Ķ»ĘõĖŹĶ”üÕ£©ÕÉīõĖĆõĖ¬ńÄ»ÕóāõĖŁÕ«ēĶŻģõĖżõĖ¬ńēłµ£¼’╝īÕÉ”ÕłÖÕÅ»ĶāĮõ╝ÜķüćÕł░ń▒╗õ╝╝ `ModuleNotFound` ńÜäķöÖĶ»»ŃĆéÕ£©Õ«ēĶŻģõĖĆõĖ¬ńēłµ£¼õ╣ŗÕēŹ’╝īķ£ĆĶ”üÕģłÕŹĖĶĮĮÕÅ”õĖĆõĖ¬ŃĆé`Õ”éµ×£ CUDA ÕÅ»ńö©’╝īÕ╝║ńāłµÄ©ĶŹÉÕ«ēĶŻģ mmcv`ŃĆé
+```
+
+### Õ«ēĶŻģ mmcv
+
+Õ£©Õ«ēĶŻģ mmcv õ╣ŗÕēŹ’╝īĶ»ĘńĪ«õ┐Ø PyTorch ÕĘ▓ń╗ŵłÉÕŖ¤Õ«ēĶŻģÕ£©ńÄ»ÕóāõĖŁ’╝īÕÅ»õ╗źÕÅéĶĆā [PyTorch Õ«śµ¢╣Õ«ēĶŻģµ¢ćµĪŻ](https://pytorch.org/get-started/locally/#start-locally)ŃĆéÕÅ»õĮ┐ńö©õ╗źõĖŗÕæĮõ╗żķ¬īĶ»ü
+
+```bash
+python -c 'import torch;print(torch.__version__)'
+```
+
+Õ”éµ×£ĶŠōÕć║ńēłµ£¼õ┐Īµü»’╝īÕłÖĶĪ©ńż║ PyTorch ÕĘ▓Õ«ēĶŻģŃĆé
+
+#### õĮ┐ńö© mim Õ«ēĶŻģ’╝łµÄ©ĶŹÉ’╝ē
+
+[mim](https://github.com/open-mmlab/mim) µś» OpenMMLab ķĪ╣ńø«ńÜäÕīģń«ĪńÉåÕĘźÕģĘ’╝īõĮ┐ńö©Õ«āÕÅ»õ╗źÕŠłµ¢╣õŠ┐Õ£░Õ«ēĶŻģ mmcvŃĆé
+
+```bash
+pip install -U openmim
+mim install mmcv
+```
+
+Õ”éµ×£ÕÅæńÄ░õĖŖĶ┐░ńÜäÕ«ēĶŻģÕæĮõ╗żµ▓Īµ£ēõĮ┐ńö©ķóäń╝¢Ķ»æÕīģ’╝łõ╗ź `.whl` ń╗ōÕ░Š’╝ēĶĆīµś»õĮ┐ńö©µ║ÉńĀüÕīģ’╝łõ╗ź `.tar.gz` ń╗ōÕ░Š’╝ēÕ«ēĶŻģ’╝īÕłÖµ£ēÕÅ»ĶāĮµś»µłæõ╗¼µ▓Īµ£ēµÅÉõŠøÕÆīÕĮōÕēŹńÄ»ÕóāńÜä PyTorch ńēłµ£¼ŃĆüCUDA ńēłµ£¼ńøĖÕī╣ķģŹńÜä mmcv ķóäń╝¢Ķ»æÕīģ’╝īµŁżµŚČ’╝īõĮĀÕÅ»õ╗ź[µ║ÉńĀüÕ«ēĶŻģ mmcv](build.md)ŃĆé
+
+
+
+
+Collecting mmcv
+Downloading https://download.openmmlab.com/mmcv/dist/cu102/torch1.8.0/mmcv-2.0.0-cp38-cp38-manylinux1_x86_64.whl + +
+
+õĮ┐ńö©ķóäń╝¢Ķ»æÕīģńÜäÕ«ēĶŻģµŚźÕ┐Ś
+ +Looking in links: https://download.openmmlab.com/mmcv/dist/cu102/torch1.8.0/index.html+Collecting mmcv
+Downloading https://download.openmmlab.com/mmcv/dist/cu102/torch1.8.0/mmcv-2.0.0-cp38-cp38-manylinux1_x86_64.whl + +
+
+Collecting mmcv==2.0.0
+Downloading mmcv-2.0.0.tar.gz + +
+
+Õ”éķ£ĆÕ«ēĶŻģµīćÕ«Üńēłµ£¼ńÜä mmcv’╝īõŠŗÕ”éÕ«ēĶŻģ 2.0.0 ńēłµ£¼ńÜä mmcv’╝īÕÅ»õĮ┐ńö©õ╗źõĖŗÕæĮõ╗ż
+
+```bash
+mim install mmcv==2.0.0
+```
+
+:::{note}
+Õ”éµ×£õĮĀµēōń«ŚõĮ┐ńö© `opencv-python-headless` ĶĆīõĖŹµś» `opencv-python`’╝īõŠŗÕ”éÕ£©õĖĆõĖ¬ÕŠłÕ░ÅńÜäÕ«╣ÕÖ©ńÄ»Õóāµł¢ĶĆģµ▓Īµ£ēÕøŠÕĮóńö©µłĘńĢīķØóńÜäµ£ŹÕŖĪÕÖ©õĖŁ’╝īõĮĀÕÅ»õ╗źÕģłÕ«ēĶŻģ `opencv-python-headless`’╝īĶ┐ÖµĀĘÕ£©Õ«ēĶŻģ mmcv õŠØĶĄ¢ńÜäĶ┐ćń©ŗõĖŁõ╝ÜĶĘ│Ķ┐ć `opencv-python`ŃĆé
+
+ÕÅ”Õż¢’╝īÕ”éµ×£Õ«ēĶŻģõŠØĶĄ¢Õ║ōńÜ䵌ČķŚ┤Ķ┐ćķĢ┐’╝īÕÅ»õ╗źµīćÕ«Ü pypi µ║É
+
+```bash
+mim install "mmcv>=2.0.0rc1" -i https://pypi.tuna.tsinghua.edu.cn/simple
+```
+
+:::
+
+Õ«ēĶŻģÕ«īµłÉÕÉÄÕÅ»õ╗źĶ┐ÉĶĪī [check_installation.py](https://github.com/open-mmlab/mmcv/blob/main/.dev_scripts/check_installation.py) Ķäܵ£¼µŻĆµ¤ź mmcv µś»ÕɔիēĶŻģµłÉÕŖ¤ŃĆé
+
+#### õĮ┐ńö© pip Õ«ēĶŻģ
+
+õĮ┐ńö©õ╗źõĖŗÕæĮõ╗żµ¤źń£ŗ CUDA ÕÆī PyTorch ńÜäńēłµ£¼
+
+```bash
+python -c 'import torch;print(torch.__version__);print(torch.version.cuda)'
+```
+
+µĀ╣µŹ«ń│╗ń╗¤ńÜäń▒╗Õ×ŗŃĆüCUDA ńēłµ£¼ŃĆüPyTorch ńēłµ£¼õ╗źÕÅŖ MMCV ńēłµ£¼ķĆēµŗ®ńøĖÕ║öńÜäÕ«ēĶŻģÕæĮõ╗ż
+
+
+
+
+ õĮ┐ńö©µ║ÉńĀüÕīģńÜäÕ«ēĶŻģµŚźÕ┐Ś
+ +Looking in links: https://download.openmmlab.com/mmcv/dist/cu102/torch1.8.0/index.html+Collecting mmcv==2.0.0
+Downloading mmcv-2.0.0.tar.gz + +
+
+
+
+
+
+
+
+
+
+
+Õ”éµ×£Õ£©õĖŖķØóńÜäõĖŗµŗēµĪåõĖŁµ▓Īµ£ēµēŠÕł░Õ»╣Õ║öńÜäńēłµ£¼’╝īÕłÖÕÅ»ĶāĮµś»µ▓Īµ£ēÕ»╣Õ║ö PyTorch µł¢ĶĆģ CUDA µł¢ĶĆģ mmcv ńēłµ£¼ńÜäķóäń╝¢Ķ»æÕīģ’╝īµŁżµŚČ’╝īõĮĀÕÅ»õ╗ź[µ║ÉńĀüÕ«ēĶŻģ mmcv](build.md)ŃĆé
+
+:::{note}
+PyTorch Õ£© 1.x.0 ÕÆī 1.x.1 õ╣ŗķŚ┤ķĆÜÕĖĖµś»Õģ╝Õ«╣ńÜä’╝īµĢģ mmcv ÕŬµÅÉõŠø 1.x.0 ńÜäń╝¢Ķ»æÕīģŃĆéÕ”éµ×£õĮĀ
+ńÜä PyTorch ńēłµ£¼µś» 1.x.1’╝īõĮĀÕÅ»õ╗źµöŠÕ┐āÕ£░Õ«ēĶŻģÕ£© 1.x.0 ńēłµ£¼ń╝¢Ķ»æńÜä mmcvŃĆéõŠŗÕ”é’╝īÕ”éµ×£õĮĀńÜä
+PyTorch ńēłµ£¼µś» 1.8.1’╝īõĮĀÕÅ»õ╗źµöŠÕ┐āķĆēµŗ® 1.8.xŃĆé
+:::
+
+:::{note}
+Õ”éµ×£õĮĀµēōń«ŚõĮ┐ńö© `opencv-python-headless` ĶĆīõĖŹµś» `opencv-python`’╝īõŠŗÕ”éÕ£©õĖĆõĖ¬ÕŠłÕ░ÅńÜäÕ«╣ÕÖ©ńÄ»Õóāµł¢ĶĆģµ▓Īµ£ēÕøŠÕĮóńö©µłĘńĢīķØóńÜäµ£ŹÕŖĪÕÖ©õĖŁ’╝īõĮĀÕÅ»õ╗źÕģłÕ«ēĶŻģ `opencv-python-headless`’╝īĶ┐ÖµĀĘÕ£©Õ«ēĶŻģ mmcv õŠØĶĄ¢ńÜäĶ┐ćń©ŗõĖŁõ╝ÜĶĘ│Ķ┐ć `opencv-python`ŃĆé
+
+ÕÅ”Õż¢’╝īÕ”éµ×£Õ«ēĶŻģõŠØĶĄ¢Õ║ōńÜ䵌ČķŚ┤Ķ┐ćķĢ┐’╝īÕÅ»õ╗źµīćÕ«Ü pypi µ║É
+
+```bash
+pip install mmcv -f https://download.openmmlab.com/mmcv/dist/cu111/torch1.9.0/index.html -i https://pypi.tuna.tsinghua.edu.cn/simple
+```
+
+:::
+
+Õ«ēĶŻģÕ«īµłÉÕÉÄÕÅ»õ╗źĶ┐ÉĶĪī [check_installation.py](https://github.com/open-mmlab/mmcv/blob/main/.dev_scripts/check_installation.py) Ķäܵ£¼µŻĆµ¤ź mmcv µś»ÕɔիēĶŻģµłÉÕŖ¤ŃĆé
+
+#### õĮ┐ńö© docker ķĢ£ÕāÅ
+
+ÕģłÕ░åń«Śµ│ĢÕ║ōÕģŗķÜåÕł░µ£¼Õ£░ÕåŹµ×äÕ╗║ķĢ£ÕāÅ
+
+```bash
+git clone https://github.com/open-mmlab/mmcv.git && cd mmcv
+docker build -t mmcv -f docker/release/Dockerfile .
+```
+
+õ╣¤ÕÅ»õ╗źńø┤µÄźõĮ┐ńö©õĖŗķØóńÜäÕæĮõ╗żµ×äÕ╗║ķĢ£ÕāÅ
+
+```bash
+docker build -t mmcv https://github.com/open-mmlab/mmcv.git#main:docker/release
+```
+
+[Dockerfile](release/Dockerfile) ķ╗śĶ«żÕ«ēĶŻģµ£Ćµ¢░ńÜä mmcv’╝īÕ”éµ×£õĮĀµā│Ķ”üµīćÕ«Üńēłµ£¼’╝īÕÅ»õ╗źõĮ┐ńö©õĖŗķØóńÜäÕæĮõ╗ż
+
+```bash
+docker image build -t mmcv -f docker/release/Dockerfile --build-arg MMCV=2.0.0 .
+```
+
+Õ”éµ×£õĮĀµā│Ķ”üõĮ┐ńö©ÕģČõ╗¢ńēłµ£¼ńÜä PyTorch ÕÆī CUDA’╝īõĮĀÕÅ»õ╗źÕ£©µ×äÕ╗║ķĢ£ÕāŵŚČµīćÕ«ÜÕ«āõ╗¼ńÜäńēłµ£¼ŃĆé
+
+õŠŗÕ”éµīćÕ«Ü PyTorch ńÜäńēłµ£¼µś» 1.11’╝īCUDA ńÜäńēłµ£¼µś» 11.3
+
+```bash
+docker build -t mmcv -f docker/release/Dockerfile \
+ --build-arg PYTORCH=1.11.0 \
+ --build-arg CUDA=11.3 \
+ --build-arg CUDNN=8 \
+ --build-arg MMCV=2.0.0 .
+```
+
+µø┤ÕżÜ PyTorch ÕÆī CUDA ķĢ£ÕāÅÕÅ»õ╗źńé╣Õć╗ [dockerhub/pytorch](https://hub.docker.com/r/pytorch/pytorch/tags) µ¤źń£ŗŃĆé
+
+### Õ«ēĶŻģ mmcv-lite
+
+Õ”éµ×£õĮĀķ£ĆĶ”üõĮ┐ńö©ÕÆī PyTorch ńøĖÕģ│ńÜ䵩ĪÕØŚ’╝īĶ»ĘńĪ«õ┐Ø PyTorch ÕĘ▓ń╗ŵłÉÕŖ¤Õ«ēĶŻģÕ£©ńÄ»ÕóāõĖŁ’╝īÕÅ»õ╗źÕÅéĶĆā [PyTorch Õ«śµ¢╣Õ«ēĶŻģµ¢ćµĪŻ](https://pytorch.org/get-started/locally/#start-locally)ŃĆé
+
+```python
+pip install mmcv-lite
+```
diff --git a/internlm_langchain/knowledge_base/MMCV/content/introduction.md b/internlm_langchain/knowledge_base/MMCV/content/introduction.md
new file mode 100644
index 00000000..4c735b94
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMCV/content/introduction.md
@@ -0,0 +1,36 @@
+## õ╗ŗń╗Ź MMCV
+
+MMCV µś»õĖĆõĖ¬ķØóÕÉæĶ«Īń«Śµ£║Ķ¦åĶ¦ēńÜäÕ¤║ńĪĆÕ║ō’╝īÕ«āµÅÉõŠøõ║åõ╗źõĖŗÕŖ¤ĶāĮ’╝Ü
+
+- [ÕøŠÕāÅÕÆīĶ¦åķóæÕżäńÉå](../understand_mmcv/data_process.md)
+- [ÕøŠÕāÅÕÆīµĀćµ│©ń╗ōµ×£ÕÅ»Ķ¦åÕī¢](../understand_mmcv/visualization.md)
+- [ÕøŠÕāÅÕÅśµŹó](../understand_mmcv/data_transform.md)
+- [ÕżÜń¦Ź CNN ńĮæń╗£ń╗ōµ×ä](../understand_mmcv/cnn.md)
+- [ķ½śĶ┤©ķćÅÕ«×ńÄ░ńÜäÕĖĖĶ¦ü CUDA ń«ŚÕŁÉ](../understand_mmcv/ops.md)
+
+MMCV µö»µīüÕżÜń¦ŹÕ╣│ÕÅ░’╝īÕīģµŗ¼’╝Ü
+
+- Linux
+- Windows
+- macOS
+
+Õ«āµö»µīüńÜä OpenMMLab ķĪ╣ńø«’╝Ü
+
+- [MMClassification](https://github.com/open-mmlab/mmclassification): OpenMMLab ÕøŠÕāÅÕłåń▒╗ÕĘźÕģĘń«▒
+- [MMDetection](https://github.com/open-mmlab/mmdetection): OpenMMLab ńø«µĀ浯ƵĄŗÕĘźÕģĘń«▒
+- [MMDetection3D](https://github.com/open-mmlab/mmdetection3d): OpenMMLab µ¢░õĖĆõ╗ŻķĆÜńö© 3D ńø«µĀ浯ƵĄŗÕ╣│ÕÅ░
+- [MMRotate](https://github.com/open-mmlab/mmrotate): OpenMMLab µŚŗĶĮ¼µĪåµŻĆµĄŗÕĘźÕģĘń«▒õĖĵĄŗĶ»ĢÕ¤║Õćå
+- [MMYOLO](https://github.com/open-mmlab/mmyolo): OpenMMLab YOLO ń│╗ÕłŚÕĘźÕģĘń«▒õĖĵĄŗĶ»ĢÕ¤║Õćå
+- [MMSegmentation](https://github.com/open-mmlab/mmsegmentation): OpenMMLab Ķ»Łõ╣ēÕłåÕē▓ÕĘźÕģĘń«▒
+- [MMOCR](https://github.com/open-mmlab/mmocr): OpenMMLab Õģ©µĄüń©ŗµ¢ćÕŁŚµŻĆµĄŗĶ»åÕł½ńÉåĶ¦ŻÕĘźÕģĘń«▒
+- [MMPose](https://github.com/open-mmlab/mmpose): OpenMMLab Õ¦┐µĆüõ╝░Ķ«ĪÕĘźÕģĘń«▒
+- [MMHuman3D](https://github.com/open-mmlab/mmhuman3d): OpenMMLab õ║║õĮōÕÅéµĢ░Õī¢µ©ĪÕ×ŗÕĘźÕģĘń«▒õĖĵĄŗĶ»ĢÕ¤║Õćå
+- [MMSelfSup](https://github.com/open-mmlab/mmselfsup): OpenMMLab Ķć¬ńøæńØŻÕŁ”õ╣ĀÕĘźÕģĘń«▒õĖĵĄŗĶ»ĢÕ¤║Õćå
+- [MMRazor](https://github.com/open-mmlab/mmrazor): OpenMMLab µ©ĪÕ×ŗÕÄŗń╝®ÕĘźÕģĘń«▒õĖĵĄŗĶ»ĢÕ¤║Õćå
+- [MMFewShot](https://github.com/open-mmlab/mmfewshot): OpenMMLab Õ░æµĀʵ£¼ÕŁ”õ╣ĀÕĘźÕģĘń«▒õĖĵĄŗĶ»ĢÕ¤║Õćå
+- [MMAction2](https://github.com/open-mmlab/mmaction2): OpenMMLab µ¢░õĖĆõ╗ŻĶ¦åķóæńÉåĶ¦ŻÕĘźÕģĘń«▒
+- [MMTracking](https://github.com/open-mmlab/mmtracking): OpenMMLab õĖĆõĮōÕī¢Ķ¦åķóæńø«µĀćµä¤ń¤źÕ╣│ÕÅ░
+- [MMFlow](https://github.com/open-mmlab/mmflow): OpenMMLab ÕģēµĄüõ╝░Ķ«ĪÕĘźÕģĘń«▒õĖĵĄŗĶ»ĢÕ¤║Õćå
+- [MMEditing](https://github.com/open-mmlab/mmediting): OpenMMLab ÕøŠÕāÅĶ¦åķóæń╝¢ĶŠæÕĘźÕģĘń«▒
+- [MMGeneration](https://github.com/open-mmlab/mmgeneration): OpenMMLab ÕøŠńēćĶ¦åķóæńö¤µłÉµ©ĪÕ×ŗÕĘźÕģĘń«▒
+- [MMDeploy](https://github.com/open-mmlab/mmdeploy): OpenMMLab µ©ĪÕ×ŗķā©ńĮ▓µĪåµ×Č
diff --git a/internlm_langchain/knowledge_base/MMCV/content/ops.md b/internlm_langchain/knowledge_base/MMCV/content/ops.md
new file mode 100644
index 00000000..ba744daf
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMCV/content/ops.md
@@ -0,0 +1,66 @@
+## ń«ŚÕŁÉ
+
+MMCV µÅÉõŠøõ║åµŻĆµĄŗŃĆüÕłåÕē▓ńŁēõ╗╗ÕŖĪõĖŁÕĖĖńö©ńÜäń«ŚÕŁÉ
+
+| Device | CPU | CUDA | MLU | MPS | Ascend |
+| ---------------------------- | --- | ---- | --- | --- | ------ |
+| ActiveRotatedFilter | ŌłÜ | ŌłÜ | | | ŌłÜ |
+| AssignScoreWithK | | ŌłÜ | | | |
+| BallQuery | | ŌłÜ | ŌłÜ | | |
+| BBoxOverlaps | | ŌłÜ | ŌłÜ | ŌłÜ | ŌłÜ |
+| BorderAlign | | ŌłÜ | | | |
+| BoxIouRotated | ŌłÜ | ŌłÜ | ŌłÜ | | ŌłÜ |
+| BoxIouQuadri | ŌłÜ | ŌłÜ | | | |
+| CARAFE | | ŌłÜ | ŌłÜ | | |
+| ChamferDistance | | ŌłÜ | | | |
+| CrissCrossAttention | | ŌłÜ | | | |
+| ContourExpand | ŌłÜ | | | | |
+| ConvexIoU | | ŌłÜ | | | |
+| CornerPool | | ŌłÜ | | | |
+| Correlation | | ŌłÜ | | | |
+| Deformable Convolution v1/v2 | ŌłÜ | ŌłÜ | ŌłÜ | | ŌłÜ |
+| Deformable RoIPool | | ŌłÜ | ŌłÜ | | ŌłÜ |
+| DiffIoURotated | | ŌłÜ | ŌłÜ | | |
+| DynamicScatter | | ŌłÜ | ŌłÜ | | |
+| FurthestPointSample | | ŌłÜ | | | |
+| FurthestPointSampleWithDist | | ŌłÜ | | | |
+| FusedBiasLeakyrelu | | ŌłÜ | | | ŌłÜ |
+| GatherPoints | | ŌłÜ | | | ŌłÜ |
+| GroupPoints | | ŌłÜ | | | |
+| Iou3d | | ŌłÜ | ŌłÜ | | |
+| KNN | | ŌłÜ | | | |
+| MaskedConv | | ŌłÜ | ŌłÜ | | ŌłÜ |
+| MergeCells | | ŌłÜ | | | |
+| MinAreaPolygon | | ŌłÜ | | | |
+| ModulatedDeformConv2d | ŌłÜ | ŌłÜ | ŌłÜ | | ŌłÜ |
+| MultiScaleDeformableAttn | | ŌłÜ | ŌłÜ | | |
+| NMS | ŌłÜ | ŌłÜ | ŌłÜ | | ŌłÜ |
+| NMSRotated | ŌłÜ | ŌłÜ | ŌłÜ | | ŌłÜ |
+| NMSQuadri | ŌłÜ | ŌłÜ | | | |
+| PixelGroup | ŌłÜ | | | | |
+| PointsInBoxes | ŌłÜ | ŌłÜ | | | |
+| PointsInPolygons | | ŌłÜ | | | |
+| PSAMask | ŌłÜ | ŌłÜ | ŌłÜ | | ŌłÜ |
+| RotatedFeatureAlign | ŌłÜ | ŌłÜ | ŌłÜ | | |
+| RoIPointPool3d | | ŌłÜ | ŌłÜ | | |
+| RoIPool | | ŌłÜ | ŌłÜ | | ŌłÜ |
+| RoIAlignRotated | ŌłÜ | ŌłÜ | ŌłÜ | | |
+| RiRoIAlignRotated | | ŌłÜ | | | |
+| RoIAlign | ŌłÜ | ŌłÜ | ŌłÜ | | ŌłÜ |
+| RoIAwarePool3d | | ŌłÜ | ŌłÜ | | |
+| SAConv2d | | ŌłÜ | | | |
+| SigmoidFocalLoss | | ŌłÜ | ŌłÜ | | ŌłÜ |
+| SoftmaxFocalLoss | | ŌłÜ | | | ŌłÜ |
+| SoftNMS | | ŌłÜ | | | |
+| Sparse Convolution | | ŌłÜ | ŌłÜ | | |
+| Synchronized BatchNorm | | ŌłÜ | | | |
+| ThreeInterpolate | | ŌłÜ | | | |
+| ThreeNN | | ŌłÜ | ŌłÜ | | |
+| TINShift | | ŌłÜ | ŌłÜ | | |
+| UpFirDn2d | | ŌłÜ | | | |
+| Voxelization | ŌłÜ | ŌłÜ | ŌłÜ | | ŌłÜ |
+| PrRoIPool | | ŌłÜ | | | |
+| BezierAlign | ŌłÜ | ŌłÜ | | | |
+| BiasAct | | ŌłÜ | | | |
+| FilteredLrelu | | ŌłÜ | | | |
+| Conv2dGradfix | | ŌłÜ | | | |
diff --git a/internlm_langchain/knowledge_base/MMCV/content/pr.md b/internlm_langchain/knowledge_base/MMCV/content/pr.md
new file mode 100644
index 00000000..427fdf9e
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMCV/content/pr.md
@@ -0,0 +1,3 @@
+## µŗēÕÅ¢Ķ»Ęµ▒é
+
+µ£¼µ¢ćµĪŻńÜäÕåģÕ«╣ÕĘ▓Ķ┐üń¦╗Õł░[Ķ┤Īńī«µīćÕŹŚ](contributing.md)ŃĆé
diff --git a/internlm_langchain/knowledge_base/MMCV/content/previous_versions.md b/internlm_langchain/knowledge_base/MMCV/content/previous_versions.md
new file mode 100644
index 00000000..d5438187
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMCV/content/previous_versions.md
@@ -0,0 +1,47 @@
+## ÕģČõ╗¢ńēłµ£¼ńÜä PyTorch
+
+µłæõ╗¼õĖŹÕåŹµÅÉõŠøÕ£©ĶŠāõĮÄńÜä `PyTorch` ńēłµ£¼õĖŗń╝¢Ķ»æńÜä `mmcv-full` Õīģ’╝īõĮåõĖ║õ║åµé©ńÜäµ¢╣õŠ┐’╝īµé©ÕÅ»õ╗źÕ£©õĖŗķØóµēŠÕł░Õ«āõ╗¼ŃĆé
+
+### PyTorch 1.4
+
+| 1.0.0 \<= mmcv_version \<= 1.2.1
+
+#### CUDA 10.1
+
+```bash
+pip install mmcv-full=={mmcv_version} -f https://download.openmmlab.com/mmcv/dist/cu101/torch1.4.0/index.html
+```
+
+#### CUDA 9.2
+
+```bash
+pip install mmcv-full=={mmcv_version} -f https://download.openmmlab.com/mmcv/dist/cu101/torch1.4.0/index.html
+```
+
+#### CPU
+
+```bash
+pip install mmcv-full=={mmcv_version} -f https://download.openmmlab.com/mmcv/dist/cpu/torch1.4.0/index.html
+```
+
+### PyTorch v1.3
+
+| 1.0.0 \<= mmcv_version \<= 1.3.16
+
+#### CUDA 10.1
+
+```bash
+pip install mmcv-full=={mmcv_version} -f https://download.openmmlab.com/mmcv/dist/cu101/torch1.3.0/index.html
+```
+
+#### CUDA 9.2
+
+```bash
+pip install mmcv-full=={mmcv_version} -f https://download.openmmlab.com/mmcv/dist/cu101/torch1.3.0/index.html
+```
+
+#### CPU
+
+```bash
+pip install mmcv-full=={mmcv_version} -f https://download.openmmlab.com/mmcv/dist/cpu/torch1.3.0/index.html
+```
diff --git a/internlm_langchain/knowledge_base/MMCV/content/visualization.md b/internlm_langchain/knowledge_base/MMCV/content/visualization.md
new file mode 100644
index 00000000..9ad26c6a
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMCV/content/visualization.md
@@ -0,0 +1,24 @@
+## ÕÅ»Ķ¦åÕī¢
+
+`mmcv` ÕÅ»õ╗źÕ▒Ģńż║ÕøŠÕāÅõ╗źÕÅŖµĀćµ│©’╝łńø«ÕēŹÕŬµö»µīüµĀćµ│©µĪå’╝ē
+
+```python
+# Õ▒Ģńż║ÕøŠÕāŵ¢ćõ╗Č
+mmcv.imshow('a.jpg')
+
+# Õ▒Ģńż║ÕĘ▓ÕŖĀĶĮĮńÜäÕøŠÕāÅ
+img = np.random.rand(100, 100, 3)
+mmcv.imshow(img)
+
+# Õ▒Ģńż║ÕĖ”µ£ēµĀćµ│©µĪåńÜäÕøŠÕāÅ
+img = np.random.rand(100, 100, 3)
+bboxes = np.array([[0, 0, 50, 50], [20, 20, 60, 60]])
+mmcv.imshow_bboxes(img, bboxes)
+```
+
+`mmcv` õ╣¤ÕÅ»õ╗źÕ▒Ģńż║ńē╣µ«ŖńÜäÕøŠÕāÅ’╝īõŠŗÕ”éÕģēµĄü
+
+```python
+flow = mmcv.flowread('test.flo')
+mmcv.flowshow(flow)
+```
diff --git a/internlm_langchain/knowledge_base/MMCV/vector_store/index.faiss b/internlm_langchain/knowledge_base/MMCV/vector_store/index.faiss
new file mode 100644
index 00000000..c98ec505
Binary files /dev/null and b/internlm_langchain/knowledge_base/MMCV/vector_store/index.faiss differ
diff --git a/internlm_langchain/knowledge_base/MMDeploy/content/01_introduction_to_model_deployment.md b/internlm_langchain/knowledge_base/MMDeploy/content/01_introduction_to_model_deployment.md
new file mode 100644
index 00000000..8ec39adc
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDeploy/content/01_introduction_to_model_deployment.md
@@ -0,0 +1,253 @@
+# ń¼¼õĖĆń½Ā’╝ܵ©ĪÕ×ŗķā©ńĮ▓ń«Ćõ╗ŗ
+
+OpenMMLab ńÜäń«Śµ│ĢÕ”éõĮĢķā©ńĮ▓’╝¤Ķ┐Öµś»ÕŠłÕżÜńżŠÕī║ńö©µłĘńÜäÕø░µāæŃĆéĶĆī[µ©ĪÕ×ŗķā©ńĮ▓ÕĘźÕģĘń«▒ MMDeploy](https://zhuanlan.zhihu.com/p/450342651) ńÜäÕ╝Ƶ║É’╝īÕ╝║ÕŖ┐µēōķĆÜõ║åõ╗Äń«Śµ│Ģµ©ĪÕ×ŗÕł░Õ║öńö©ń©ŗÕ║ÅĶ┐ÖŌĆ£µ£ĆÕÉÄõĖĆÕģ¼ķćīŌĆØ’╝üõ╗ŖÕż®µłæõ╗¼Õ░åÕ╝ĆÕÉ»µ©ĪÕ×ŗķā©ńĮ▓ÕģźķŚ©ń│╗ÕłŚµĢÖń©ŗ’╝īÕ£©µ©ĪÕ×ŗķā©ńĮ▓Õ╝Ƶ║ÉÕ║ō MMDeploy ńÜäĶŠģÕŖ®õĖŗ’╝īõ╗ŗń╗Źõ╗źõĖŗÕåģÕ«╣’╝Ü
+
+- õĖŁķŚ┤ĶĪ©ńż║ ONNX ńÜäÕ«Üõ╣ēµĀćÕćåŃĆé
+- PyTorch µ©ĪÕ×ŗĶĮ¼µŹóÕł░ ONNX µ©ĪÕ×ŗńÜäµ¢╣µ│ĢŃĆé
+- µÄ©ńÉåÕ╝ĢµōÄ ONNX RuntimeŃĆüTensorRT ńÜäõĮ┐ńö©µ¢╣µ│ĢŃĆé
+- ķā©ńĮ▓µĄüµ░┤ń║┐ PyTorch - ONNX - ONNX Runtime/TensorRT ńÜäńż║õŠŗÕÅŖÕĖĖĶ¦üķā©ńĮ▓ķŚ«ķóśńÜäĶ¦ŻÕå│µ¢╣µ│ĢŃĆé
+- MMDeploy C/C++ µÄ©ńÉå SDKŃĆé
+
+ÕĖīµ£øķĆÜĶ┐ćµ£¼ń│╗ÕłŚµĢÖń©ŗ’╝īÕĖ”ķóåÕż¦Õ«ČÕŁ”õ╝ÜÕ”éõĮĢµŖŖĶć¬ÕĘ▒ńÜä PyTorch µ©ĪÕ×ŗķā©ńĮ▓Õł░ ONNX Runtime/TensorRT õĖŖ’╝īÕ╣ČÕŁ”õ╝ÜÕ”éõĮĢµŖŖ OpenMMLab Õ╝Ƶ║ÉõĮōń│╗õĖŁÕÉäõĖ¬Ķ«Īń«Śµ£║Ķ¦åĶ¦ēõ╗╗ÕŖĪńÜ䵩ĪÕ×ŗńö© MMDeploy ķā©ńĮ▓Õł░ÕÉäõĖ¬µÄ©ńÉåÕ╝ĢµōÄõĖŖŃĆé
+
+µłæõ╗¼ķ╗śĶ«żÕż¦Õ«Čń夵éē Python Ķ»ŁĶ©Ć’╝īÕ╣ČÕ»╣ PyTorch µĪåµ×ȵ£ēÕ¤║µ£¼ńÜäĶ«żĶ»å’╝īķÖżµŁżõ╣ŗÕż¢õĖŹķ£ĆĶ”üõ║åĶ¦Żõ╗╗õĮĢµ©ĪÕ×ŗķā©ńĮ▓ńÜäń¤źĶ»åŃĆé
+
+Õ£©ń¼¼õĖĆń»ćµ¢ćń½ĀõĖŁ’╝īµłæõ╗¼Õ░åķā©ńĮ▓õĖĆõĖ¬ń«ĆÕŹĢńÜäĶČģÕłåĶŠ©ńÄ浩ĪÕ×ŗ’╝īĶ«żĶ»åõĖŁķŚ┤ĶĪ©ńż║ŃĆüµÄ©ńÉåÕ╝ĢµōÄńŁēµ©ĪÕ×ŗķā©ńĮ▓õĖŁńÜäµ”éÕ┐ĄŃĆé
+
+## ÕłØĶ»åµ©ĪÕ×ŗķā©ńĮ▓
+
+Õ£©ĶĮ»õ╗ČÕĘźń©ŗõĖŁ’╝īķā©ńĮ▓µīćµŖŖÕ╝ĆÕÅæÕ«īµ»ĢńÜäĶĮ»õ╗ȵŖĢÕģźõĮ┐ńö©ńÜäĶ┐ćń©ŗ’╝īÕīģµŗ¼ńÄ»ÕóāķģŹńĮ«ŃĆüĶĮ»õ╗ČÕ«ēĶŻģńŁēµŁźķ¬żŃĆéń▒╗õ╝╝Õ£░’╝īÕ»╣õ║ĵĘ▒Õ║”ÕŁ”õ╣Āµ©ĪÕ×ŗµØźĶ»┤’╝īµ©ĪÕ×ŗķā©ńĮ▓µīćĶ«®Ķ«Łń╗āÕźĮńÜ䵩ĪÕ×ŗÕ£©ńē╣Õ«ÜńÄ»ÕóāõĖŁĶ┐ÉĶĪīńÜäĶ┐ćń©ŗŃĆéńøĖµ»öõ║ÄĶĮ»õ╗Čķā©ńĮ▓’╝īµ©ĪÕ×ŗķā©ńĮ▓õ╝ÜķØóõĖ┤µø┤ÕżÜńÜäķÜŠķóś’╝Ü
+
+1. Ķ┐ÉĶĪīµ©ĪÕ×ŗµēĆķ£ĆńÜäńÄ»ÕóāķÜŠõ╗źķģŹńĮ«ŃĆéµĘ▒Õ║”ÕŁ”õ╣Āµ©ĪÕ×ŗķĆÜÕĖĖµś»ńö▒õĖĆõ║øµĪåµ×Čń╝¢ÕåÖ’╝īµ»öÕ”é PyTorchŃĆüTensorFlowŃĆéńö▒õ║ĵĪåµ×ČĶ¦äµ©ĪŃĆüõŠØĶĄ¢ńÄ»ÕóāńÜäķÖÉÕłČ’╝īĶ┐Öõ║øµĪåµ×ČõĖŹķĆéÕÉłÕ£©µēŗµ£║ŃĆüÕ╝ĆÕÅæµØ┐ńŁēńö¤õ║¦ńÄ»ÕóāõĖŁÕ«ēĶŻģŃĆé
+2. µĘ▒Õ║”ÕŁ”õ╣Āµ©ĪÕ×ŗńÜäń╗ōµ×äķĆÜÕĖĖµ»öĶŠāÕ║×Õż¦’╝īķ£ĆĶ”üÕż¦ķćÅńÜäń«ŚÕŖøµēŹĶāĮµ╗ĪĶČ│Õ«×µŚČĶ┐ÉĶĪīńÜäķ£Ćµ▒éŃĆ鵩ĪÕ×ŗńÜäĶ┐ÉĶĪīµĢłńÄćķ£ĆĶ”üõ╝śÕī¢ŃĆé
+
+ÕøĀõĖ║Ķ┐Öõ║øķÜŠķóśńÜäÕŁśÕ£©’╝īµ©ĪÕ×ŗķā©ńĮ▓õĖŹĶāĮķØĀń«ĆÕŹĢńÜäńÄ»ÕóāķģŹńĮ«õĖÄÕ«ēĶŻģÕ«īµłÉŃĆéń╗ÅĶ┐ćÕĘźõĖÜńĢīÕÆīÕŁ”µ£»ńĢīµĢ░Õ╣┤ńÜäµÄóń┤ó’╝īµ©ĪÕ×ŗķā©ńĮ▓µ£ēõ║åõĖƵØĪµĄüĶĪīńÜ䵥üµ░┤ń║┐’╝Ü
+
+
+
+õĖ║õ║åĶ«®µ©ĪÕ×ŗµ£Ćń╗łĶāĮÕż¤ķā©ńĮ▓Õł░µ¤ÉõĖĆńÄ»ÕóāõĖŖ’╝īÕ╝ĆÕÅæĶĆģõ╗¼ÕÅ»õ╗źõĮ┐ńö©õ╗╗µäÅõĖĆń¦ŹµĘ▒Õ║”ÕŁ”õ╣ĀµĪåµ×ČµØźÕ«Üõ╣ēńĮæń╗£ń╗ōµ×ä’╝īÕ╣ČķĆÜĶ┐ćĶ«Łń╗āńĪ«Õ«ÜńĮæń╗£õĖŁńÜäÕÅéµĢ░ŃĆéõ╣ŗÕÉÄ’╝īµ©ĪÕ×ŗńÜäń╗ōµ×äÕÆīÕÅéµĢ░õ╝ÜĶó½ĶĮ¼µŹóµłÉõĖĆń¦ŹÕŬµÅÅĶ┐░ńĮæń╗£ń╗ōµ×äńÜäõĖŁķŚ┤ĶĪ©ńż║’╝īõĖĆõ║øķÆłÕ»╣ńĮæń╗£ń╗ōµ×äńÜäõ╝śÕī¢õ╝ÜÕ£©õĖŁķŚ┤ĶĪ©ńż║õĖŖĶ┐øĶĪīŃĆéµ£ĆÕÉÄ’╝īńö©ķØóÕÉæńĪ¼õ╗ČńÜäķ½śµĆ¦ĶāĮń╝¢ń©ŗµĪåµ×Č’╝łÕ”é CUDA’╝īOpenCL’╝ēń╝¢ÕåÖ’╝īĶāĮķ½śµĢłµē¦ĶĪīµĘ▒Õ║”ÕŁ”õ╣ĀńĮæń╗£õĖŁń«ŚÕŁÉńÜäµÄ©ńÉåÕ╝ĢµōÄõ╝ܵŖŖõĖŁķŚ┤ĶĪ©ńż║ĶĮ¼µŹóµłÉńē╣Õ«ÜńÜäµ¢ćõ╗ȵĀ╝Õ╝Å’╝īÕ╣ČÕ£©Õ»╣Õ║öńĪ¼õ╗ČÕ╣│ÕÅ░õĖŖķ½śµĢłĶ┐ÉĶĪīµ©ĪÕ×ŗŃĆé
+
+Ķ┐ÖõĖƵØĪµĄüµ░┤ń║┐Ķ¦ŻÕå│õ║嵩ĪÕ×ŗķā©ńĮ▓õĖŁńÜäõĖżÕż¦ķŚ«ķóś’╝ÜõĮ┐ńö©Õ»╣µÄźµĘ▒Õ║”ÕŁ”õ╣ĀµĪåµ×ČÕÆīµÄ©ńÉåÕ╝ĢµōÄńÜäõĖŁķŚ┤ĶĪ©ńż║’╝īÕ╝ĆÕÅæĶĆģõĖŹÕ┐ģµŗģÕ┐āÕ”éõĮĢÕ£©µ¢░ńÄ»ÕóāõĖŁĶ┐ÉĶĪīÕÉäõĖ¬ÕżŹµØéńÜäµĪåµ×Č’╝øķĆÜĶ┐ćõĖŁķŚ┤ĶĪ©ńż║ńÜäńĮæń╗£ń╗ōµ×äõ╝śÕī¢ÕÆīµÄ©ńÉåÕ╝ĢµōÄÕ»╣Ķ┐Éń«ŚńÜäÕ║ĢÕ▒éõ╝śÕī¢’╝īµ©ĪÕ×ŗńÜäĶ┐Éń«ŚµĢłńÄćÕż¦Õ╣ģµÅÉÕŹćŃĆé
+
+ńÄ░Õ£©’╝īĶ«®µłæõ╗¼õ╗ÄõĖĆõĖ¬µ©ĪÕ×ŗķā©ńĮ▓ńÜäŌĆ£Hello WorldŌĆØķĪ╣ńø«Õģźµēŗ’╝īĶ¦üĶ»åõĖĆõĖŗµ©ĪÕ×ŗķā©ńĮ▓ÕÉäµ¢╣ķØóńÜäń¤źĶ»åÕɦ’╝ü
+
+## ķā©ńĮ▓ń¼¼õĖĆõĖ¬µ©ĪÕ×ŗ
+
+### ÕłøÕ╗║ PyTorch µ©ĪÕ×ŗ
+
+õ╗┐ńģ¦ PyTorch ńÜäÕ«śµ¢╣[ķā©ńĮ▓µĢÖń©ŗ](https://pytorch.org/tutorials/advanced/super_resolution_with_onnxruntime.html)’╝īĶ«®µłæõ╗¼ńö© PyTorch Õ«×ńÄ░õĖĆõĖ¬ĶČģÕłåĶŠ©ńÄ浩ĪÕ×ŗ’╝īÕ╣ȵŖŖµ©ĪÕ×ŗķā©ńĮ▓Õł░ ONNX Runtime Ķ┐ÖõĖ¬µÄ©ńÉåÕ╝ĢµōÄõĖŖŃĆé
+
+ķ”¢Õģł’╝īµłæõ╗¼ķ£ĆĶ”üÕłøÕ╗║õĖĆõĖ¬µ£ē PyTorch Õ║ōńÜä Python ń╝¢ń©ŗńÄ»ÕóāŃĆéÕ”éµ×£õĮĀńÜä PyTorch ńÄ»ÕóāĶ┐śµ▓Īµ£ēĶŻģÕźĮ’╝īÕÅ»õ╗źÕÅéĶĆāÕ«śµ¢╣ńÜä[ÕģźķŚ©µĢÖń©ŗ](https://pytorch.org/get-started/locally/)ŃĆ鵳æõ╗¼Õ╝║ńāłµÄ©ĶŹÉõĮ┐ńö© conda µØźń«ĪńÉå Python Õ║ōŃĆéõĮ┐ńö© conda ÕÅ»õ╗źķØĀÕ”éõĖŗńÜäÕæĮõ╗żÕłØÕ¦ŗÕī¢õĖĆõĖ¬ PyTorch ńÄ»Õóā’╝Ü
+
+```bash
+# ÕłøÕ╗║ķóäÕ«ēĶŻģ Python 3.7 ńÜäÕÉŹÕŽ deploy ĶÖܵŗ¤ńÄ»Õóā
+conda create -n deploy python=3.7 -y
+# Ķ┐øÕģźĶÖܵŗ¤ńÄ»Õóā
+conda activate deploy
+# Õ«ēĶŻģ cpu ńēłµ£¼ńÜä PyTorch
+conda install pytorch torchvision cpuonly -c pytorch
+```
+
+Õ”éµ×£õĮĀńÜäĶ«ŠÕżćµö»µīü cuda ń╝¢ń©ŗ’╝īµłæõ╗¼Õ╗║Ķ««õĮĀÕ£©ķģŹńĮ« cuda ńÄ»ÕóāÕÉÄõĮ┐ńö© gpu õĖŖńÜä PyTorchŃĆéµ»öÕ”éÕ░åõĖŖķØóÕ«ēĶŻģ PyTorch ńÜäÕæĮõ╗żµö╣µłÉ’╝Ü
+
+```bash
+# Õ«ēĶŻģ cuda 11.3 ńÜä PyTorch
+# Õ”éµ×£õĮĀńö©ńÜ䵜»ÕģČõ╗¢ńēłµ£¼ńÜä cuda’╝īĶ»ĘÕÅéĶĆāõĖŖķØó PyTorch ńÜäÕ«śµ¢╣Õ«ēĶŻģµĢÖń©ŗķĆēµŗ®Õ«ēĶŻģÕæĮõ╗ż
+conda install pytorch torchvision cudatoolkit=11.3 -c pytorch
+```
+
+µ£¼µĢÖń©ŗõ╝Üńö©Õł░ÕģČõ╗¢õĖĆõ║øń¼¼õĖēµ¢╣Õ║ōŃĆéõĮĀÕÅ»õ╗źńö©õ╗źõĖŗÕæĮõ╗żµØźÕ«ēĶŻģĶ┐Öõ║øÕ║ō’╝Ü
+
+```bash
+# Õ«ēĶŻģ ONNX Runtime, ONNX, OpenCV
+pip install onnxruntime onnx opencv-python
+```
+
+Õ£©õĖĆÕłćķāĮķģŹńĮ«Õ«īµ»ĢÕÉÄ’╝īńö©õĖŗķØóńÜäõ╗ŻńĀüµØźÕłøÕ╗║õĖĆõĖ¬ĶČģÕłåĶŠ©ńÄ浩ĪÕ×ŗŃĆé
+
+```python
+import os
+
+import cv2
+import numpy as np
+import requests
+import torch
+import torch.onnx
+from torch import nn
+
+class SuperResolutionNet(nn.Module):
+ def __init__(self, upscale_factor):
+ super().__init__()
+ self.upscale_factor = upscale_factor
+ self.img_upsampler = nn.Upsample(
+ scale_factor=self.upscale_factor,
+ mode='bicubic',
+ align_corners=False)
+
+ self.conv1 = nn.Conv2d(3,64,kernel_size=9,padding=4)
+ self.conv2 = nn.Conv2d(64,32,kernel_size=1,padding=0)
+ self.conv3 = nn.Conv2d(32,3,kernel_size=5,padding=2)
+
+ self.relu = nn.ReLU()
+
+ def forward(self, x):
+ x = self.img_upsampler(x)
+ out = self.relu(self.conv1(x))
+ out = self.relu(self.conv2(out))
+ out = self.conv3(out)
+ return out
+
+# Download checkpoint and test image
+urls = ['https://download.openmmlab.com/mmediting/restorers/srcnn/srcnn_x4k915_1x16_1000k_div2k_20200608-4186f232.pth',
+ 'https://raw.githubusercontent.com/open-mmlab/mmagic/master/tests/data/face/000001.png']
+names = ['srcnn.pth', 'face.png']
+for url, name in zip(urls, names):
+ if not os.path.exists(name):
+ open(name, 'wb').write(requests.get(url).content)
+
+def init_torch_model():
+ torch_model = SuperResolutionNet(upscale_factor=3)
+
+ state_dict = torch.load('srcnn.pth')['state_dict']
+
+ # Adapt the checkpoint
+ for old_key in list(state_dict.keys()):
+ new_key = '.'.join(old_key.split('.')[1:])
+ state_dict[new_key] = state_dict.pop(old_key)
+
+ torch_model.load_state_dict(state_dict)
+ torch_model.eval()
+ return torch_model
+
+model = init_torch_model()
+input_img = cv2.imread('face.png').astype(np.float32)
+
+# HWC to NCHW
+input_img = np.transpose(input_img, [2, 0, 1])
+input_img = np.expand_dims(input_img, 0)
+
+# Inference
+torch_output = model(torch.from_numpy(input_img)).detach().numpy()
+
+# NCHW to HWC
+torch_output = np.squeeze(torch_output, 0)
+torch_output = np.clip(torch_output, 0, 255)
+torch_output = np.transpose(torch_output, [1, 2, 0]).astype(np.uint8)
+
+# Show image
+cv2.imwrite("face_torch.png", torch_output)
+```
+
+Õ£©Ķ┐Öõ╗Įõ╗ŻńĀüõĖŁ’╝īµłæõ╗¼ÕłøÕ╗║õ║åõĖĆõĖ¬ń╗ÅÕģĖńÜäĶČģÕłåĶŠ©ńÄćńĮæń╗£ [SRCNN](https://arxiv.org/abs/1501.00092)ŃĆéSRCNN ÕģłµŖŖÕøŠÕāÅõĖŖķććµĀĘÕł░Õ»╣Õ║öÕłåĶŠ©ńÄć’╝īÕåŹńö© 3 õĖ¬ÕŹĘń¦»Õ▒éÕżäńÉåÕøŠÕāÅŃĆéõĖ║õ║åµ¢╣õŠ┐ĶĄĘĶ¦ü’╝īµłæõ╗¼ĶĘ│Ķ┐ćĶ«Łń╗āńĮæń╗£ńÜ䵣źķ¬ż’╝īńø┤µÄźõĖŗĶĮĮµ©ĪÕ×ŗµØāķ插╝łńö▒õ║Ä MMagic õĖŁ SRCNN ńÜäµØāķćŹń╗ōµ×äÕÆīµłæõ╗¼Õ«Üõ╣ēńÜ䵩ĪÕ×ŗõĖŹÕż¬õĖƵĀĘ’╝īµłæõ╗¼õ┐«µö╣õ║åµØāķćŹÕŁŚÕģĖńÜä key µØźķĆéķģŹµłæõ╗¼Õ«Üõ╣ēńÜ䵩ĪÕ×ŗ’╝ē’╝īÕÉīµŚČõĖŗĶĮĮÕźĮĶŠōÕģźÕøŠńēćŃĆéõĖ║õ║åĶ«®µ©ĪÕ×ŗĶŠōÕć║µłÉµŁŻńĪ«ńÜäÕøŠńēćµĀ╝Õ╝Å’╝īµłæõ╗¼µŖŖµ©ĪÕ×ŗńÜäĶŠōÕć║ĶĮ¼µŹóµłÉ HWC µĀ╝Õ╝Å’╝īÕ╣Čõ┐ØĶ»üµ»ÅõĖĆķĆÜķüōńÜäķó£Ķē▓ÕĆ╝ķāĮÕ£© 0~255 õ╣ŗķŚ┤ŃĆéÕ”éµ×£Ķäܵ£¼µŁŻÕĖĖĶ┐ÉĶĪīńÜäĶ»Ø’╝īõĖĆÕ╣ģĶČģÕłåĶŠ©ńÄćńÜäõ║║ĶäĖńģ¦ńēćõ╝Üõ┐ØÕŁśÕ£© `face_torch.png` õĖŁŃĆé
+
+Õ£© PyTorch µ©ĪÕ×ŗµĄŗĶ»ĢµŁŻńĪ«ÕÉÄ’╝īµłæõ╗¼µØźµŁŻÕ╝ÅÕ╝ĆÕ¦ŗķā©ńĮ▓Ķ┐ÖõĖ¬µ©ĪÕ×ŗŃĆ鵳æõ╗¼õĖŗõĖƵŁźńÜäõ╗╗ÕŖĪµś»µŖŖ PyTorch µ©ĪÕ×ŗĶĮ¼µŹóµłÉńö©õĖŁķŚ┤ĶĪ©ńż║ ONNX µÅÅĶ┐░ńÜ䵩ĪÕ×ŗŃĆé
+
+
+
+### õĖŁķŚ┤ĶĪ©ńż║ ŌĆöŌĆö ONNX
+
+Õ£©õ╗ŗń╗Ź ONNX õ╣ŗÕēŹ’╝īµłæõ╗¼Õģłõ╗ĵ£¼Ķ┤©õĖŖµØźĶ«żĶ»åõĖĆõĖŗńź×ń╗ÅńĮæń╗£ńÜäń╗ōµ×äŃĆéńź×ń╗ÅńĮæń╗£Õ«×ķÖģõĖŖÕŬµś»µÅÅĶ┐░õ║åµĢ░µŹ«Ķ«Īń«ŚńÜäĶ┐ćń©ŗ’╝īÕģČń╗ōµ×äÕÅ»õ╗źńö©Ķ«Īń«ŚÕøŠĶĪ©ńż║ŃĆéµ»öÕ”é `a+b` ÕÅ»õ╗źńö©õĖŗķØóńÜäĶ«Īń«ŚÕøŠµØźĶĪ©ńż║’╝Ü
+
+
+
+õĖ║õ║åÕŖĀķƤĶ«Īń«Ś’╝īõĖĆõ║øµĪåµ×Čõ╝ÜõĮ┐ńö©Õ»╣ńź×ń╗ÅńĮæń╗£ŌĆ£Õģłń╝¢Ķ»æ’╝īÕÉĵē¦ĶĪīŌĆØńÜäķØÖµĆüÕøŠµØźµÅÅĶ┐░ńĮæń╗£ŃĆéķØÖµĆüÕøŠńÜäń╝║ńé╣µś»ķÜŠõ╗źµÅÅĶ┐░µÄ¦ÕłČµĄü’╝łµ»öÕ”é if-else Õłåµö»Ķ»ŁÕÅźÕÆī for ÕŠ¬ńÄ»Ķ»ŁÕÅź’╝ē’╝īńø┤µÄźÕ»╣ÕģČÕ╝ĢÕģźµÄ¦ÕłČĶ»ŁÕÅźõ╝ÜÕ»╝Ķć┤õ║¦ńö¤õĖŹÕÉīńÜäĶ«Īń«ŚÕøŠŃĆéµ»öÕ”éÕŠ¬ńÄ»µē¦ĶĪī n µ¼Ī `a=a+b`’╝īÕ»╣õ║ÄõĖŹÕÉīńÜä n’╝īõ╝Üńö¤µłÉõĖŹÕÉīńÜäĶ«Īń«ŚÕøŠ’╝Ü
+
+
+
+ONNX’╝łOpen Neural Network Exchange’╝ēµś» Facebook ÕÆīÕŠ«ĶĮ»Õ£© 2017 Õ╣┤Õģ▒ÕÉīÕÅæÕĖāńÜä’╝īńö©õ║ĵĀćÕćåµÅÅĶ┐░Ķ«Īń«ŚÕøŠńÜäõĖĆń¦ŹµĀ╝Õ╝ÅŃĆéńø«ÕēŹ’╝īÕ£©µĢ░Õ«Čµ£║µ×äńÜäÕģ▒ÕÉīń╗┤µŖżõĖŗ’╝īONNX ÕĘ▓ń╗ÅÕ»╣µÄźõ║åÕżÜń¦ŹµĘ▒Õ║”ÕŁ”õ╣ĀµĪåµ×ČÕÆīÕżÜń¦ŹµÄ©ńÉåÕ╝ĢµōÄŃĆéÕøĀµŁż’╝īONNX Ķó½ÕĮōµłÉõ║åµĘ▒Õ║”ÕŁ”õ╣ĀµĪåµ×ČÕł░µÄ©ńÉåÕ╝ĢµōÄńÜäµĪźµóü’╝īÕ░▒ÕāÅń╝¢Ķ»æÕÖ©ńÜäõĖŁķŚ┤Ķ»ŁĶ©ĆõĖƵĀĘŃĆéńö▒õ║ÄÕÉäµĪåµ×ČÕģ╝Õ«╣µĆ¦õĖŹõĖĆ’╝īµłæõ╗¼ķĆÜÕĖĖÕŬńö© ONNX ĶĪ©ńż║µø┤Õ«╣µśōķā©ńĮ▓ńÜäķØÖµĆüÕøŠŃĆé
+
+Ķ«®µłæõ╗¼ńö©õĖŗķØóńÜäõ╗ŻńĀüµØźµŖŖ PyTorch ńÜ䵩ĪÕ×ŗĶĮ¼µŹóµłÉ ONNX µĀ╝Õ╝ÅńÜ䵩ĪÕ×ŗ’╝Ü
+
+```python
+x = torch.randn(1, 3, 256, 256)
+
+with torch.no_grad():
+ torch.onnx.export(
+ model,
+ x,
+ "srcnn.onnx",
+ opset_version=11,
+ input_names=['input'],
+ output_names=['output'])
+```
+
+ÕģČõĖŁ’╝ī**torch.onnx.export** µś» PyTorch Ķć¬ÕĖ”ńÜäµŖŖµ©ĪÕ×ŗĶĮ¼µŹóµłÉ ONNX µĀ╝Õ╝ÅńÜäÕćĮµĢ░ŃĆéĶ«®µłæõ╗¼Õģłń£ŗõĖĆõĖŗÕēŹõĖēõĖ¬Õ┐ģķĆēÕÅéµĢ░’╝ÜÕēŹõĖēõĖ¬ÕÅéµĢ░ÕłåÕł½µś»Ķ”üĶĮ¼µŹóńÜ䵩ĪÕ×ŗŃĆüµ©ĪÕ×ŗńÜäõ╗╗µäÅõĖĆń╗äĶŠōÕģźŃĆüÕ»╝Õć║ńÜä ONNX µ¢ćõ╗ČńÜäµ¢ćõ╗ČÕÉŹŃĆéĶĮ¼µŹóµ©ĪÕ×ŗµŚČ’╝īķ£ĆĶ”üÕĤµ©ĪÕ×ŗÕÆīĶŠōÕć║µ¢ćõ╗ČÕÉŹµś»ÕŠłÕ«╣µśōńÉåĶ¦ŻńÜä’╝īõĮåõĖ║õ╗Ćõ╣łķ£ĆĶ”üõĖ║µ©ĪÕ×ŗµÅÉõŠøõĖĆń╗äĶŠōÕģźÕæó’╝¤Ķ┐ÖÕ░▒µČēÕÅŖÕł░ ONNX ĶĮ¼µŹóńÜäÕĤńÉåõ║åŃĆéõ╗Ä PyTorch ńÜ䵩ĪÕ×ŗÕł░ ONNX ńÜ䵩ĪÕ×ŗ’╝īµ£¼Ķ┤©õĖŖµś»õĖĆń¦ŹĶ»ŁĶ©ĆõĖŖńÜäń┐╗Ķ»æŃĆéńø┤Ķ¦ēõĖŖńÜäµā│µ│Ģµś»ÕāÅń╝¢Ķ»æÕÖ©õĖƵĀĘÕĮ╗Õ║ĢĶ¦Żµ×ÉÕĤµ©ĪÕ×ŗńÜäõ╗ŻńĀü’╝īĶ«░ÕĮĢµēƵ£ēµÄ¦ÕłČµĄüŃĆéõĮåÕēŹķØóõ╣¤Ķ«▓Õł░’╝īµłæõ╗¼ķĆÜÕĖĖÕŬńö© ONNX Ķ«░ÕĮĢõĖŹĶĆāĶÖæµÄ¦ÕłČµĄüńÜäķØÖµĆüÕøŠŃĆéÕøĀµŁż’╝īPyTorch µÅÉõŠøõ║åõĖĆń¦ŹÕŽÕüÜĶ┐ĮĶĖ¬’╝łtrace’╝ēńÜ䵩ĪÕ×ŗĶĮ¼µŹóµ¢╣µ│Ģ’╝Üń╗ÖÕ«ÜõĖĆń╗äĶŠōÕģź’╝īÕåŹÕ«×ķÖģµē¦ĶĪīõĖĆķüŹµ©ĪÕ×ŗ’╝īÕŹ│µŖŖĶ┐Öń╗äĶŠōÕģźÕ»╣Õ║öńÜäĶ«Īń«ŚÕøŠĶ«░ÕĮĢõĖŗµØź’╝īõ┐ØÕŁśõĖ║ ONNX µĀ╝Õ╝ÅŃĆé**export** ÕćĮµĢ░ńö©ńÜäÕ░▒µś»Ķ┐ĮĶĖ¬Õ»╝Õć║µ¢╣µ│Ģ’╝īķ£ĆĶ”üń╗Öõ╗╗µäÅõĖĆń╗äĶŠōÕģź’╝īĶ«®µ©ĪÕ×ŗĶĘæĶĄĘµØźŃĆ鵳æõ╗¼ńÜ䵥ŗĶ»ĢÕøŠńē浜»õĖēķĆÜķüō’╝ī256x256 Õż¦Õ░ÅńÜä’╝īĶ┐Öķćīõ╣¤µ×äķĆĀõĖĆõĖ¬ÕÉīµĀĘÕĮóńŖČńÜäķÜŵ£║Õ╝ĀķćÅŃĆé
+
+Õē®õĖŗńÜäÕÅéµĢ░õĖŁ’╝ī`opset_version` ĶĪ©ńż║ ONNX ń«ŚÕŁÉķøåńÜäńēłµ£¼ŃĆéµĘ▒Õ║”ÕŁ”õ╣ĀńÜäÕÅæÕ▒Ģõ╝ÜõĖŹµ¢ŁĶ»×ńö¤µ¢░ń«ŚÕŁÉ’╝īõĖ║õ║åµö»µīüĶ┐Öõ║øµ¢░Õó×ńÜäń«ŚÕŁÉ’╝īONNX õ╝Üń╗ÅÕĖĖÕÅæÕĖāµ¢░ńÜäń«ŚÕŁÉķøå’╝īńø«ÕēŹÕĘ▓ń╗ŵø┤µ¢░ 15 õĖ¬ńēłµ£¼ŃĆé µłæõ╗¼õ╗ż `opset_version=11`’╝īÕŹ│õĮ┐ńö©ń¼¼ 11 õĖ¬ ONNX ń«ŚÕŁÉķøå’╝īµś»ÕøĀõĖ║ SRCNN õĖŁńÜä bicubic’╝łÕÅīõĖēµ¼ĪµÅÆÕĆ╝’╝ēÕ£© opset11 õĖŁµēŹÕŠŚÕł░µö»µīüŃĆéÕē®õĖŗńÜäõĖżõĖ¬ÕÅéµĢ░ `input_names`, `output_names` µś»ĶŠōÕģźŃĆüĶŠōÕć║ tensor ńÜäÕÉŹń¦░’╝īµłæõ╗¼ń©ŹÕÉÄõ╝Üńö©Õł░Ķ┐Öõ║øÕÉŹń¦░ŃĆé
+
+Õ”éµ×£õĖŖĶ┐░õ╗ŻńĀüĶ┐ÉĶĪīµłÉÕŖ¤’╝īńø«ÕĮĢõĖŗõ╝ܵ¢░Õó×õĖĆõĖ¬ `srcnn.onnx` ńÜä ONNX µ©ĪÕ×ŗµ¢ćõ╗ČŃĆ鵳æõ╗¼ÕÅ»õ╗źńö©õĖŗķØóńÜäĶäܵ£¼µØźķ¬īĶ»üõĖĆõĖŗµ©ĪÕ×ŗµ¢ćõ╗ȵś»ÕÉ”µŁŻńĪ«ŃĆé
+
+```python
+import onnx
+
+onnx_model = onnx.load("srcnn.onnx")
+try:
+ onnx.checker.check_model(onnx_model)
+except Exception:
+ print("Model incorrect")
+else:
+ print("Model correct")
+```
+
+ÕģČõĖŁ’╝ī**onnx.load** ÕćĮµĢ░ńö©õ║ÄĶ»╗ÕÅ¢õĖĆõĖ¬ ONNX µ©ĪÕ×ŗŃĆé**onnx.checker.check_model** ńö©õ║ĵŻĆµ¤źµ©ĪÕ×ŗµĀ╝Õ╝ŵś»ÕÉ”µŁŻńĪ«’╝īÕ”éµ×£µ£ēķöÖĶ»»ńÜäĶ»ØĶ»źÕćĮµĢ░õ╝Üńø┤µÄźµŖźķöÖŃĆ鵳æõ╗¼ńÜ䵩ĪÕ×ŗµś»µŁŻńĪ«ńÜä’╝īµÄ¦ÕłČÕÅ░õĖŁÕ║öĶ»źõ╝ܵēōÕŹ░Õć║ "Model correct"ŃĆé
+
+µÄźõĖŗµØź’╝īĶ«®µłæõ╗¼µØźń£ŗõĖĆń£ŗ ONNX µ©ĪÕ×ŗÕģĘõĮōńÜäń╗ōµ×䵜»µĆÄõ╣łµĀĘńÜäŃĆ鵳æõ╗¼ÕÅ»õ╗źõĮ┐ńö© Netron’╝łÕ╝Ƶ║ÉńÜ䵩ĪÕ×ŗÕÅ»Ķ¦åÕī¢ÕĘźÕģĘ’╝ēµØźÕÅ»Ķ¦åÕī¢ ONNX µ©ĪÕ×ŗŃĆéµŖŖ `srcnn.onnx` µ¢ćõ╗Čõ╗ĵ£¼Õ£░ńÜäµ¢ćõ╗Čń│╗ń╗¤µŗ¢ÕģźńĮæń½Ö’╝īÕŹ│ÕÅ»ń£ŗÕł░Õ”éõĖŗńÜäÕÅ»Ķ¦åÕī¢ń╗ōµ×£’╝Ü
+
+
+
+ńé╣Õć╗ input µł¢ĶĆģ output’╝īÕÅ»õ╗źµ¤źń£ŗ ONNX µ©ĪÕ×ŗńÜäÕ¤║µ£¼õ┐Īµü»’╝īÕīģµŗ¼µ©ĪÕ×ŗńÜäńēłµ£¼õ┐Īµü»’╝īõ╗źÕÅŖµ©ĪÕ×ŗĶŠōÕģźŃĆüĶŠōÕć║ńÜäÕÉŹń¦░ÕÆīµĢ░µŹ«ń▒╗Õ×ŗŃĆé
+
+
+
+ńé╣Õć╗µ¤ÉõĖĆõĖ¬ń«ŚÕŁÉĶŖéńé╣’╝īÕÅ»õ╗źń£ŗÕł░ń«ŚÕŁÉńÜäÕģĘõĮōõ┐Īµü»ŃĆéµ»öÕ”éńé╣Õć╗ń¼¼õĖĆõĖ¬ Conv ÕÅ»õ╗źń£ŗÕł░’╝Ü
+
+
+
+µ»ÅõĖ¬ń«ŚÕŁÉĶ«░ÕĮĢõ║åń«ŚÕŁÉÕ▒׵ƦŃĆüÕøŠń╗ōµ×äŃĆüµØāķćŹõĖēń▒╗õ┐Īµü»ŃĆé
+
+- ń«ŚÕŁÉÕ▒׵Ʀõ┐Īµü»ÕŹ│ÕøŠõĖŁ attributes ķćīńÜäõ┐Īµü»’╝īÕ»╣õ║ÄÕŹĘń¦»µØźĶ»┤’╝īń«ŚÕŁÉÕ▒׵ƦÕīģµŗ¼õ║åÕŹĘń¦»µĀĖÕż¦Õ░Å’╝łkernel_shape’╝ēŃĆüÕŹĘń¦»µŁźķĢ┐’╝łstrides’╝ēńŁēÕåģÕ«╣ŃĆéĶ┐Öõ║øń«ŚÕŁÉÕ▒׵Ʀµ£Ćń╗łõ╝Üńö©µØźńö¤µłÉõĖĆõĖ¬ÕģĘõĮōńÜäń«ŚÕŁÉŃĆé
+- ÕøŠń╗ōµ×äõ┐Īµü»µīćń«ŚÕŁÉĶŖéńé╣Õ£©Ķ«Īń«ŚÕøŠõĖŁńÜäÕÉŹń¦░ŃĆüķé╗ĶŠ╣ńÜäõ┐Īµü»ŃĆéÕ»╣õ║ÄÕøŠõĖŁńÜäÕŹĘń¦»µØźĶ»┤’╝īĶ»źń«ŚÕŁÉĶŖéńé╣ÕŽÕüÜ Conv_2’╝īĶŠōÕģźµĢ░µŹ«ÕŽÕüÜ 11’╝īĶŠōÕć║µĢ░µŹ«ÕŽÕüÜ 12ŃĆéµĀ╣µŹ«µ»ÅõĖ¬ń«ŚÕŁÉĶŖéńé╣ńÜäÕøŠń╗ōµ×äõ┐Īµü»’╝īÕ░▒ĶāĮÕ«īµĢ┤Õ£░ÕżŹÕĤÕć║ńĮæń╗£ńÜäĶ«Īń«ŚÕøŠŃĆé
+- µØāķćŹõ┐Īµü»µīćńÜ䵜»ńĮæń╗£ń╗ÅĶ┐ćĶ«Łń╗āÕÉÄ’╝īń«ŚÕŁÉÕŁśÕé©ńÜäµØāķćŹõ┐Īµü»ŃĆéÕ»╣õ║ÄÕŹĘń¦»µØźĶ»┤’╝īµØāķćŹõ┐Īµü»Õīģµŗ¼ÕŹĘń¦»µĀĖńÜäµØāķćŹÕĆ╝ÕÆīÕŹĘń¦»ÕÉÄńÜäÕüÅÕĘ«ÕĆ╝ŃĆéńé╣Õć╗ÕøŠõĖŁ conv1.weight, conv1.bias ÕÉÄķØóńÜäÕŖĀÕÅĘÕŹ│ÕÅ»ń£ŗÕł░µØāķćŹõ┐Īµü»ńÜäÕģĘõĮōÕåģÕ«╣ŃĆé
+
+ńÄ░Õ£©’╝īµłæõ╗¼µ£ēõ║å SRCNN ńÜä ONNX µ©ĪÕ×ŗŃĆéĶ«®µłæõ╗¼ń£ŗń£ŗµ£ĆÕÉÄĶ»źÕ”éõĮĢµŖŖĶ┐ÖõĖ¬µ©ĪÕ×ŗĶ┐ÉĶĪīĶĄĘµØźŃĆé
+
+### µÄ©ńÉåÕ╝ĢµōÄ ŌĆöŌĆö ONNX Runtime
+
+**ONNX Runtime** µś»ńö▒ÕŠ«ĶĮ»ń╗┤µŖżńÜäõĖĆõĖ¬ĶĘ©Õ╣│ÕÅ░µ£║ÕÖ©ÕŁ”õ╣ĀµÄ©ńÉåÕŖĀķƤÕÖ©’╝īõ╣¤Õ░▒µś»µłæõ╗¼ÕēŹķØóµÅÉÕł░ńÜäŌĆ£µÄ©ńÉåÕ╝ĢµōÄŌĆØŃĆéONNX Runtime µś»ńø┤µÄźÕ»╣µÄź ONNX ńÜä’╝īÕŹ│ ONNX Runtime ÕÅ»õ╗źńø┤µÄźĶ»╗ÕÅ¢Õ╣ČĶ┐ÉĶĪī `.onnx` µ¢ćõ╗Č’╝īĶĆīõĖŹķ£ĆĶ”üÕåŹµŖŖ `.onnx` µĀ╝Õ╝ÅńÜäµ¢ćõ╗ČĶĮ¼µŹóµłÉÕģČõ╗¢µĀ╝Õ╝ÅńÜäµ¢ćõ╗ČŃĆéõ╣¤Õ░▒µś»Ķ»┤’╝īÕ»╣õ║Ä `PyTorch - ONNX - ONNX Runtime` Ķ┐ÖµØĪķā©ńĮ▓µĄüµ░┤ń║┐’╝īÕŬĶ”üÕ£©ńø«µĀćĶ«ŠÕżćõĖŁÕŠŚÕł░ `.onnx` µ¢ćõ╗Č’╝īÕ╣ČÕ£© ONNX Runtime õĖŖĶ┐ÉĶĪīµ©ĪÕ×ŗ’╝īµ©ĪÕ×ŗķā©ńĮ▓Õ░▒ń«ŚÕż¦ÕŖ¤ÕæŖµłÉõ║åŃĆé
+
+ķĆÜĶ┐ćÕłÜÕłÜńÜäµōŹõĮ£’╝īµłæõ╗¼µŖŖ PyTorch ń╝¢ÕåÖńÜ䵩ĪÕ×ŗĶĮ¼µŹóµłÉõ║å ONNX µ©ĪÕ×ŗ’╝īÕ╣ČķĆÜĶ┐ćÕÅ»Ķ¦åÕī¢µŻĆµ¤źõ║嵩ĪÕ×ŗńÜ䵣ŻńĪ«µĆ¦ŃĆéµ£ĆÕÉÄ’╝īĶ«®µłæõ╗¼ńö© ONNX Runtime Ķ┐ÉĶĪīõĖĆõĖŗµ©ĪÕ×ŗ’╝īÕ«īµłÉµ©ĪÕ×ŗķā©ńĮ▓ńÜäµ£ĆÕÉÄõĖƵŁźŃĆé
+
+ONNX Runtime µÅÉõŠøõ║å Python µÄźÕÅŻŃĆéµÄźńØĆÕłÜµēŹńÜäĶäܵ£¼’╝īµłæõ╗¼ÕÅ»õ╗źµĘ╗ÕŖĀÕ”éõĖŗõ╗ŻńĀüĶ┐ÉĶĪīµ©ĪÕ×ŗ’╝Ü
+
+```python
+import onnxruntime
+
+ort_session = onnxruntime.InferenceSession("srcnn.onnx")
+ort_inputs = {'input': input_img}
+ort_output = ort_session.run(['output'], ort_inputs)[0]
+
+ort_output = np.squeeze(ort_output, 0)
+ort_output = np.clip(ort_output, 0, 255)
+ort_output = np.transpose(ort_output, [1, 2, 0]).astype(np.uint8)
+cv2.imwrite("face_ort.png", ort_output)
+```
+
+Ķ┐Öµ«Ąõ╗ŻńĀüõĖŁ’╝īķÖżÕÄ╗ÕÉÄÕżäńÉåµōŹõĮ£Õż¢’╝īÕÆī ONNX Runtime ńøĖÕģ│ńÜäõ╗ŻńĀüÕŬµ£ēõĖēĶĪīŃĆéĶ«®µłæõ╗¼ń«ĆÕŹĢĶ¦Żµ×ÉõĖĆõĖŗĶ┐ÖõĖēĶĪīõ╗ŻńĀüŃĆé**onnxruntime.InferenceSession** ńö©õ║ÄĶÄĘÕÅ¢õĖĆõĖ¬ ONNX Runtime µÄ©ńÉåÕÖ©’╝īÕģČÕÅéµĢ░µś»ńö©õ║ĵĩńÉåńÜä ONNX µ©ĪÕ×ŗµ¢ćõ╗ČŃĆéµÄ©ńÉåÕÖ©ńÜä run µ¢╣µ│Ģńö©õ║ĵ©ĪÕ×ŗµÄ©ńÉå’╝īÕģČń¼¼õĖĆõĖ¬ÕÅéµĢ░õĖ║ĶŠōÕć║Õ╝ĀķćÅÕÉŹńÜäÕłŚĶĪ©’╝īń¼¼õ║īõĖ¬ÕÅéµĢ░õĖ║ĶŠōÕģźÕĆ╝ńÜäÕŁŚÕģĖŃĆéÕģČõĖŁĶŠōÕģźÕĆ╝ÕŁŚÕģĖńÜä key õĖ║Õ╝ĀķćÅÕÉŹ’╝īvalue õĖ║ numpy ń▒╗Õ×ŗńÜäÕ╝ĀķćÅÕĆ╝ŃĆéĶŠōÕģźĶŠōÕć║Õ╝ĀķćÅńÜäÕÉŹń¦░ķ£ĆĶ”üÕÆī **torch.onnx.export** õĖŁĶ«ŠńĮ«ńÜäĶŠōÕģźĶŠōÕć║ÕÉŹÕ»╣Õ║öŃĆé
+
+Õ”éµ×£õ╗ŻńĀüµŁŻÕĖĖĶ┐ÉĶĪīńÜäĶ»Ø’╝īÕÅ”õĖĆÕ╣ģĶČģÕłåĶŠ©ńÄćńģ¦ńēćõ╝Üõ┐ØÕŁśÕ£© `face_ort.png` õĖŁŃĆéĶ┐ÖÕ╣ģÕøŠńēćÕÆīÕłÜÕłÜÕŠŚÕł░ńÜä `face_torch.png` µś»õĖƵ©ĪõĖƵĀĘńÜäŃĆéĶ┐ÖĶ»┤µśÄ ONNX Runtime µłÉÕŖ¤Ķ┐ÉĶĪīõ║å SRCNN µ©ĪÕ×ŗ’╝īµ©ĪÕ×ŗķā©ńĮ▓Õ«īµłÉõ║å’╝üõ╗źÕÉĵ£ēńö©µłĘµā│Õ«×ńÄ░ĶČģÕłåĶŠ©ńÄćńÜäµōŹõĮ£’╝īµłæõ╗¼ÕŬķ£ĆĶ”üµÅÉõŠøõĖĆõĖ¬ `srcnn.onnx` µ¢ćõ╗Č’╝īÕ╣ČÕĖ«ÕŖ®ńö©µłĘķģŹńĮ«ÕźĮ ONNX Runtime ńÜä Python ńÄ»Õóā’╝īńö©ÕćĀĶĪīõ╗ŻńĀüÕ░▒ÕÅ»õ╗źĶ┐ÉĶĪīµ©ĪÕ×ŗõ║åŃĆ鵳¢ĶĆģĶ┐śµ£ēµø┤ń«ĆõŠ┐ńÜäµ¢╣µ│Ģ’╝īµłæõ╗¼ÕÅ»õ╗źÕł®ńö© ONNX Runtime ń╝¢Ķ»æÕć║õĖĆõĖ¬ÕÅ»õ╗źńø┤µÄźµē¦ĶĪīµ©ĪÕ×ŗńÜäÕ║öńö©ń©ŗÕ║ÅŃĆ鵳æõ╗¼ÕŬķ£ĆĶ”üń╗Öńö©µłĘµÅÉõŠø ONNX µ©ĪÕ×ŗµ¢ćõ╗Č’╝īÕ╣ČĶ«®ńö©µłĘÕ£©Õ║öńö©ń©ŗÕ║ÅķĆēµŗ®Ķ”üµē¦ĶĪīńÜä ONNX µ©ĪÕ×ŗµ¢ćõ╗ČÕÉŹÕ░▒ÕÅ»õ╗źĶ┐ÉĶĪīµ©ĪÕ×ŗõ║åŃĆé
+
+## µĆ╗ń╗ō
+
+Õ£©Ķ┐Öń»ćµĢÖń©ŗķćī’╝īµłæõ╗¼Õł®ńö©µłÉńå¤ńÜ䵩ĪÕ×ŗķā©ńĮ▓ÕĘźÕģĘ’╝īĶĮ╗µØŠķā©ńĮ▓õ║åõĖĆõĖ¬ÕłØÕ¦ŗńēłµ£¼ńÜäĶČģÕłåĶŠ©ńÄ浩ĪÕ×ŗ SRCNNŃĆéõĮåÕ£©Õ«×ķÖģÕ║öńö©Õ£║µÖ»õĖŁ’╝īķÜÅńØƵ©ĪÕ×ŗń╗ōµ×äńÜäÕżŹµØéÕ║”õĖŹµ¢ŁÕŖĀµĘ▒’╝īńó░Õł░ńÜäÕø░ķÜŠńÜäõ╣¤õ╝ÜĶČŖµØźĶČŖÕżÜŃĆéÕ£©õĖŗõĖĆń»ćµĢÖń©ŗķćī’╝īµłæõ╗¼Õ░åŌĆ£ÕŹćń║¦ŌĆØõĖĆõĖŗĶ┐ÖõĖ¬ĶČģÕłåĶŠ©ńÄ浩ĪÕ×ŗ’╝īĶ«®Õ«āµö»µīüÕŖ©µĆüńÜäĶŠōÕģźŃĆé
+
+ń£ŗÕ«īĶ┐Öń»ćµĢÖń©ŗ’╝īµś»õĖŹµś»µä¤Ķ¦ēń¤źĶ»åÕż¬ÕżÜõĖĆõĖŗµČłÕī¢õĖŹĶ┐ćµØź’╝¤µ▓ĪÕģ│ń│╗’╝īµ©ĪÕ×ŗķā©ńĮ▓µ£¼Ķ║½µ£ēķØ×ÕĖĖÕżÜńÜäõĖ£Ķź┐Ķ”üÕŁ”ŃĆéõĖ║õ║åõĖŠõŠŗńÜäµ¢╣õŠ┐’╝īĶ┐Öń»ćµĢÖń©ŗÕīģÕɽõ║åĶ«ĖÕżÜµ£¬µØźµēŹõ╝ÜĶ«▓Õł░ńÜäń¤źĶ»åńé╣ŃĆéõ║ŗÕ«×õĖŖ’╝īĶ»╗Õ«īĶ┐Öń»ćµĢÖń©ŗÕÉÄ’╝īĶ«░õĖŗõ╗źõĖŗń¤źĶ»åńé╣Õ░▒Õż¤õ║å’╝Ü
+
+- µ©ĪÕ×ŗķā©ńĮ▓’╝īµīćµŖŖĶ«Łń╗āÕźĮńÜ䵩ĪÕ×ŗÕ£©ńē╣Õ«ÜńÄ»ÕóāõĖŁĶ┐ÉĶĪīńÜäĶ┐ćń©ŗŃĆ鵩ĪÕ×ŗķā©ńĮ▓Ķ”üĶ¦ŻÕå│µ©ĪÕ×ŗµĪåµ×ČÕģ╝Õ«╣µĆ¦ÕĘ«ÕÆīµ©ĪÕ×ŗĶ┐ÉĶĪīķƤÕ║”µģóĶ┐ÖõĖżÕż¦ķŚ«ķóśŃĆé
+- µ©ĪÕ×ŗķā©ńĮ▓ńÜäÕĖĖĶ¦üµĄüµ░┤ń║┐µś»ŌĆ£µĘ▒Õ║”ÕŁ”õ╣ĀµĪåµ×Č-õĖŁķŚ┤ĶĪ©ńż║-µÄ©ńÉåÕ╝ĢµōÄŌĆØŃĆéÕģČõĖŁµ»öĶŠāÕĖĖńö©ńÜäõĖĆõĖ¬õĖŁķŚ┤ĶĪ©ńż║µś» ONNXŃĆé
+- µĘ▒Õ║”ÕŁ”õ╣Āµ©ĪÕ×ŗÕ«×ķÖģõĖŖÕ░▒µś»õĖĆõĖ¬Ķ«Īń«ŚÕøŠŃĆ鵩ĪÕ×ŗķā©ńĮ▓µŚČķĆÜÕĖĖµŖŖµ©ĪÕ×ŗĶĮ¼µŹóµłÉķØÖµĆüńÜäĶ«Īń«ŚÕøŠ’╝īÕŹ│µ▓Īµ£ēµÄ¦ÕłČµĄü’╝łÕłåµö»Ķ»ŁÕÅźŃĆüÕŠ¬ńÄ»Ķ»ŁÕÅź’╝ēńÜäĶ«Īń«ŚÕøŠŃĆé
+- PyTorch µĪåµ×ČĶć¬ÕĖ”Õ»╣ ONNX ńÜäµö»µīü’╝īÕŬķ£ĆĶ”üµ×äķĆĀõĖĆń╗äķÜŵ£║ńÜäĶŠōÕģź’╝īÕ╣ČÕ»╣µ©ĪÕ×ŗĶ░āńö© **torch.onnx.export** ÕŹ│ÕŻիīµłÉ PyTorch Õł░ ONNX ńÜäĶĮ¼µŹóŃĆé
+- µÄ©ńÉåÕ╝ĢµōÄ ONNX Runtime Õ»╣ ONNX µ©ĪÕ×ŗµ£ēÕĤńö¤ńÜäµö»µīüŃĆéń╗ÖÕ«ÜõĖĆõĖ¬ `.onnx` µ¢ćõ╗Č’╝īÕŬķ£ĆĶ”üń«ĆÕŹĢõĮ┐ńö© ONNX Runtime ńÜä Python API Õ░▒ÕÅ»õ╗źÕ«īµłÉµ©ĪÕ×ŗµÄ©ńÉåŃĆé
+
+õĖ║õ║åÕ«×ńÄ░µĘ▒Õ║”ÕŁ”õ╣Āń«Śµ│ĢńÜäĶÉĮÕ£░’╝īÕģģµ╗ĪµīæµłśńÜ䵩ĪÕ×ŗķā©ńĮ▓µś»õĖĆõĖ¬ķĆāõĖŹÕ╝ĆńÜ䵣źķ¬żŃĆéMMDeploy Õ«×ńÄ░õ║å OpenMMLab õĖŁńø«µĀ浯ƵĄŗŃĆüÕøŠÕāÅÕłåÕē▓ŃĆüĶČģÕłåĶŠ©ńÄćńŁēÕżÜõĖ¬Ķ¦åĶ¦ēõ╗╗ÕŖĪµ©ĪÕ×ŗńÜäķā©ńĮ▓’╝īµö»µīü ONNX Runtime’╝īTensorRT’╝īncnn’╝īopenppl’╝īOpenVINO ńŁēÕżÜõĖ¬µÄ©ńÉåÕ╝ĢµōÄŃĆé
+
+Õ£©ÕÉÄń╗ŁńÜ䵩ĪÕ×ŗķā©ńĮ▓µĢÖń©ŗõĖŁ’╝īµłæõ╗¼Õ░åÕ£©õ╗ŗń╗Źµ©ĪÕ×ŗķā©ńĮ▓µŖƵ£»ńÜäÕÉīµŚČ’╝īõ╗ŗń╗ŹĶ┐Öõ║øµŖƵ£»µś»Õ”éõĮĢĶ┐Éńö©Õ£© MMDeploy õĖŁńÜäŃĆé
diff --git a/internlm_langchain/knowledge_base/MMDeploy/content/02_challenges.md b/internlm_langchain/knowledge_base/MMDeploy/content/02_challenges.md
new file mode 100644
index 00000000..85e4b0c2
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDeploy/content/02_challenges.md
@@ -0,0 +1,356 @@
+# ń¼¼õ║īń½Ā’╝ÜĶ¦ŻÕå│µ©ĪÕ×ŗķā©ńĮ▓õĖŁńÜäķÜŠķóś
+
+Õ£©[ń¼¼õĖĆń½Ā](https://mmdeploy.readthedocs.io/zh_CN/latest/tutorial/01_introduction_to_model_deployment.html)õĖŁ’╝īµłæõ╗¼ķā©ńĮ▓õ║åõĖĆõĖ¬ń«ĆÕŹĢńÜäĶČģÕłåĶŠ©ńÄ浩ĪÕ×ŗ’╝īõĖĆÕłćķāĮÕŹüÕłåķĪ║Õł®ŃĆéõĮåµś»’╝īõĖŖõĖĆõĖ¬µ©ĪÕ×ŗĶ┐śµ£ēõĖĆõ║øń╝║ķÖĘŌĆöŌĆöÕøŠńēćńÜäµöŠÕż¦ÕĆŹµĢ░Õø║իܵś» 4’╝īµłæõ╗¼µŚĀµ│ĢĶ«®ÕøŠńēćµöŠÕż¦õ╗╗µäÅńÜäÕĆŹµĢ░ŃĆéńÄ░Õ£©’╝īµłæõ╗¼µØźÕ░ØĶ»Ģķā©ńĮ▓õĖĆõĖ¬µö»µīüÕŖ©µĆüµöŠÕż¦ÕĆŹµĢ░ńÜ䵩ĪÕ×ŗ’╝īõĮōķ¬īõĖĆõĖŗÕ£©µ©ĪÕ×ŗķā©ńĮ▓õĖŁÕÅ»ĶāĮõ╝Üńó░Õł░ńÜäÕø░ķÜŠŃĆé
+
+## µ©ĪÕ×ŗķā©ńĮ▓õĖŁÕĖĖĶ¦üńÜäķÜŠķóś
+
+Õ£©õ╣ŗÕēŹńÜäÕŁ”õ╣ĀõĖŁ’╝īµłæõ╗¼Õ£©µ©ĪÕ×ŗķā©ńĮ▓õĖŖķĪ║ķŻÄķĪ║µ░┤’╝īµ▓Īµ£ēńó░Õł░õ╗╗õĮĢķŚ«ķóśŃĆéĶ┐Öµś»ÕøĀõĖ║ SRCNN µ©ĪÕ×ŗÕŬÕīģÕɽÕćĀõĖ¬ń«ĆÕŹĢńÜäń«ŚÕŁÉ’╝īĶĆīĶ┐Öõ║øÕŹĘń¦»ŃĆüµÅÆÕĆ╝ń«ŚÕŁÉÕĘ▓ń╗ÅÕ£©ÕÉäõĖ¬õĖŁķŚ┤ĶĪ©ńż║ÕÆīµÄ©ńÉåÕ╝ĢµōÄõĖŖÕŠŚÕł░õ║åÕ«īńŠÄµö»µīüŃĆéÕ”éµ×£µ©ĪÕ×ŗńÜäµōŹõĮ£ń©ŹÕŠ«ÕżŹµØéõĖĆńé╣’╝īµłæõ╗¼ÕÅ»ĶāĮÕ░▒Ķ”üõĖ║Õģ╝Õ«╣µ©ĪÕ×ŗĶĆīõ╗śÕć║Õż¦ķćÅńÜäÕŖ¤Õż½õ║åŃĆéÕ«×ķÖģõĖŖ’╝īµ©ĪÕ×ŗķā©ńĮ▓µŚČõĖĆĶł¼õ╝Üńó░Õł░õ╗źõĖŗÕćĀń▒╗Õø░ķÜŠ’╝Ü
+
+- µ©ĪÕ×ŗńÜäÕŖ©µĆüÕī¢ŃĆéÕć║õ║ĵƦĶāĮńÜäĶĆāĶÖæ’╝īÕÉäµÄ©ńÉåµĪåµ×ČķāĮķ╗śĶ«żµ©ĪÕ×ŗńÜäĶŠōÕģźÕĮóńŖČŃĆüĶŠōÕć║ÕĮóńŖČŃĆüń╗ōµ×䵜»ķØÖµĆüńÜäŃĆéĶĆīõĖ║õ║åĶ«®µ©ĪÕ×ŗńÜäµ│øńö©µĆ¦µø┤Õ╝║’╝īķā©ńĮ▓µŚČķ£ĆĶ”üÕ£©Õ░ĮÕÅ»ĶāĮõĖŹÕĮ▒ÕōŹÕĤµ£ēķĆ╗ĶŠæńÜäÕēŹµÅÉõĖŗ’╝īĶ«®µ©ĪÕ×ŗńÜäĶŠōÕģźĶŠōÕć║µł¢µś»ń╗ōµ×äÕŖ©µĆüÕī¢ŃĆé
+- µ¢░ń«ŚÕŁÉńÜäÕ«×ńÄ░ŃĆéµĘ▒Õ║”ÕŁ”õ╣ĀµŖƵ£»µŚźµ¢░µ£łÕ╝é’╝īµÅÉÕć║µ¢░ń«ŚÕŁÉńÜäķƤÕ║”ÕŠĆÕŠĆÕ┐½õ║Ä ONNX ń╗┤µŖżĶĆģµö»µīüńÜäķƤÕ║”ŃĆéõĖ║õ║åķā©ńĮ▓µ£Ćµ¢░ńÜ䵩ĪÕ×ŗ’╝īķā©ńĮ▓ÕĘźń©ŗÕĖłÕŠĆÕŠĆķ£ĆĶ”üĶć¬ÕĘ▒Õ£© ONNX ÕÆīµÄ©ńÉåÕ╝ĢµōÄõĖŁµö»µīüµ¢░ń«ŚÕŁÉŃĆé
+- õĖŁķŚ┤ĶĪ©ńż║õĖĵĩńÉåÕ╝ĢµōÄńÜäÕģ╝Õ«╣ķŚ«ķóśŃĆéńö▒õ║ÄÕÉäµÄ©ńÉåÕ╝ĢµōÄńÜäÕ«×ńÄ░õĖŹÕÉī’╝īÕ»╣ ONNX ķÜŠõ╗źÕĮóµłÉń╗¤õĖĆńÜäµö»µīüŃĆéõĖ║õ║åńĪ«õ┐ص©ĪÕ×ŗÕ£©õĖŹÕÉīńÜäµÄ©ńÉåÕ╝ĢµōÄõĖŁµ£ēÕÉīµĀĘńÜäĶ┐ÉĶĪīµĢłµ×£’╝īķā©ńĮ▓ÕĘźń©ŗÕĖłÕŠĆÕŠĆÕŠŚõĖ║µ¤ÉõĖ¬µÄ©ńÉåÕ╝ĢµōÄÕ«ÜÕłČµ©ĪÕ×ŗõ╗ŻńĀü’╝īĶ┐ÖõĖ║µ©ĪÕ×ŗķā©ńĮ▓Õ╝ĢÕģźõ║åĶ«ĖÕżÜÕĘźõĮ£ķćÅŃĆé
+
+µłæõ╗¼õ╝ÜÕ£©ÕÉÄń╗ŁµĢÖń©ŗĶ»”ń╗åĶ«▓Ķ┐░Ķ¦ŻÕå│Ķ┐Öõ║øķŚ«ķóśńÜäµ¢╣µ│ĢŃĆéÕ”éµ×£Õ»╣ÕēŹµ¢ćõĖŁ ONNXŃĆüµÄ©ńÉåÕ╝ĢµōÄŃĆüõĖŁķŚ┤ĶĪ©ńż║ŃĆüń«ŚÕŁÉńŁēÕÉŹĶ»Źµä¤Ķ¦ēķÖīńö¤’╝īõĖŹńö©µŗģÕ┐ā’╝īÕÅ»õ╗źķśģĶ»╗[ń¼¼õĖĆń½Ā](https://mmdeploy.readthedocs.io/zh_CN/latest/tutorial/01_introduction_to_model_deployment.html)’╝īõ║åĶ¦Żµ£ēÕģ│µ”éÕ┐ĄŃĆé
+
+ńÄ░Õ£©’╝īĶ«®µłæõ╗¼Õ»╣ÕĤµØźńÜä SRCNN µ©ĪÕ×ŗÕüÜõĖĆõ║øÕ░ÅńÜäõ┐«µö╣’╝īõĮōķ¬īõĖĆõĖŗµ©ĪÕ×ŗÕŖ©µĆüÕī¢Õ»╣µ©ĪÕ×ŗķā©ńĮ▓ķĆĀµłÉńÜäÕø░ķÜŠ’╝īÕ╣ČÕŁ”õ╣ĀĶ¦ŻÕå│Ķ»źķŚ«ķóśńÜäõĖĆń¦Źµ¢╣µ│ĢŃĆé
+
+## ķŚ«ķóś’╝ÜÕ«×ńÄ░ÕŖ©µĆüµöŠÕż¦ńÜäĶČģÕłåĶŠ©ńÄ浩ĪÕ×ŗ
+
+Õ£©ÕĤµØźńÜä SRCNN õĖŁ’╝īÕøŠńēćńÜäµöŠÕż¦µ»öõŠŗµś»ÕåÖµŁ╗Õ£©µ©ĪÕ×ŗķćīńÜä’╝Ü
+
+```python
+class SuperResolutionNet(nn.Module):
+ def __init__(self, upscale_factor):
+ super().__init__()
+ self.upscale_factor = upscale_factor
+ self.img_upsampler = nn.Upsample(
+ scale_factor=self.upscale_factor,
+ mode='bicubic',
+ align_corners=False)
+
+...
+
+def init_torch_model():
+ torch_model = SuperResolutionNet(upscale_factor=3)
+```
+
+µłæõ╗¼õĮ┐ńö© upscale_factor µØźµÄ¦ÕłČµ©ĪÕ×ŗńÜäµöŠÕż¦µ»öõŠŗŃĆéÕłØÕ¦ŗÕī¢µ©ĪÕ×ŗńÜ䵌ČÕĆÖ’╝īµłæõ╗¼ķ╗śĶ«żõ╗ż upscale_factor õĖ║ 3’╝īńö¤µłÉõ║åõĖĆõĖ¬µöŠÕż¦ 3 ÕĆŹńÜä PyTorch µ©ĪÕ×ŗŃĆéĶ┐ÖõĖ¬ PyTorch µ©ĪÕ×ŗµ£Ćń╗łĶó½ĶĮ¼µŹóµłÉõ║å ONNX µĀ╝Õ╝ÅńÜ䵩ĪÕ×ŗŃĆéÕ”éµ×£µłæõ╗¼ķ£ĆĶ”üõĖĆõĖ¬µöŠÕż¦ 4 ÕĆŹńÜ䵩ĪÕ×ŗ’╝īķ£ĆĶ”üķ揵¢░ńö¤µłÉõĖĆķüŹµ©ĪÕ×ŗ’╝īÕåŹÕüÜõĖƵ¼ĪÕł░ ONNX ńÜäĶĮ¼µŹóŃĆé
+
+ńÄ░Õ£©’╝īÕüćĶ«Šµłæõ╗¼Ķ”üÕüÜõĖĆõĖ¬ĶČģÕłåĶŠ©ńÄćńÜäÕ║öńö©ŃĆ鵳æõ╗¼ńÜäńö©µłĘÕĖīµ£øÕøŠńēćńÜäµöŠÕż¦ÕĆŹµĢ░ĶāĮÕż¤Ķć¬ńö▒Ķ«ŠńĮ«ŃĆéĶĆīµłæõ╗¼õ║żń╗Öńö©µłĘńÜä’╝īÕŬµ£ēõĖĆõĖ¬ .onnx µ¢ćõ╗ČÕÆīĶ┐ÉĶĪīĶČģÕłåĶŠ©ńÄ浩ĪÕ×ŗńÜäÕ║öńö©ń©ŗÕ║ÅŃĆ鵳æõ╗¼Õ£©õĖŹõ┐«µö╣ .onnx µ¢ćõ╗ČńÜäÕēŹµÅÉõĖŗµö╣ÕÅśµöŠÕż¦ÕĆŹµĢ░ŃĆé
+
+ÕøĀµŁż’╝īµłæõ╗¼Õ┐ģķĪ╗õ┐«µö╣ÕĤµØźńÜ䵩ĪÕ×ŗ’╝īõ╗żµ©ĪÕ×ŗńÜäµöŠÕż¦ÕĆŹµĢ░ÕÅśµłÉµÄ©ńÉåµŚČńÜäĶŠōÕģźŃĆéÕ£©[ń¼¼õĖĆń½Ā](https://mmdeploy.readthedocs.io/zh_CN/latest/tutorial/01_introduction_to_model_deployment.html)õĖŁńÜä Python Ķäܵ£¼ńÜäÕ¤║ńĪĆõĖŖ’╝īµłæõ╗¼ÕüÜõĖĆõ║øõ┐«µö╣’╝īÕŠŚÕł░Ķ┐ÖµĀĘńÜäĶäܵ£¼’╝Ü
+
+```python
+import torch
+from torch import nn
+from torch.nn.functional import interpolate
+import torch.onnx
+import cv2
+import numpy as np
+
+
+class SuperResolutionNet(nn.Module):
+
+ def __init__(self):
+ super().__init__()
+
+ self.conv1 = nn.Conv2d(3, 64, kernel_size=9, padding=4)
+ self.conv2 = nn.Conv2d(64, 32, kernel_size=1, padding=0)
+ self.conv3 = nn.Conv2d(32, 3, kernel_size=5, padding=2)
+
+ self.relu = nn.ReLU()
+
+ def forward(self, x, upscale_factor):
+ x = interpolate(x,
+ scale_factor=upscale_factor,
+ mode='bicubic',
+ align_corners=False)
+ out = self.relu(self.conv1(x))
+ out = self.relu(self.conv2(out))
+ out = self.conv3(out)
+ return out
+
+
+def init_torch_model():
+ torch_model = SuperResolutionNet()
+
+ # Please read the code about downloading 'srcnn.pth' and 'face.png' in
+ # https://mmdeploy.readthedocs.io/zh_CN/latest/tutorial/01_introduction_to_model_deployment.html#pytorch
+ state_dict = torch.load('srcnn.pth')['state_dict']
+
+ # Adapt the checkpoint
+ for old_key in list(state_dict.keys()):
+ new_key = '.'.join(old_key.split('.')[1:])
+ state_dict[new_key] = state_dict.pop(old_key)
+
+ torch_model.load_state_dict(state_dict)
+ torch_model.eval()
+ return torch_model
+
+
+model = init_torch_model()
+
+input_img = cv2.imread('face.png').astype(np.float32)
+
+# HWC to NCHW
+input_img = np.transpose(input_img, [2, 0, 1])
+input_img = np.expand_dims(input_img, 0)
+
+# Inference
+torch_output = model(torch.from_numpy(input_img), 3).detach().numpy()
+
+# NCHW to HWC
+torch_output = np.squeeze(torch_output, 0)
+torch_output = np.clip(torch_output, 0, 255)
+torch_output = np.transpose(torch_output, [1, 2, 0]).astype(np.uint8)
+
+# Show image
+cv2.imwrite("face_torch_2.png", torch_output)
+```
+
+SuperResolutionNet µ£¬õ┐«µö╣õ╣ŗÕēŹ’╝īnn.Upsample Õ£©ÕłØÕ¦ŗÕī¢ķśČµ«ĄÕø║Õī¢õ║åµöŠÕż¦ÕĆŹµĢ░’╝īĶĆī PyTorch ńÜä interpolate µÅÆÕĆ╝ń«ŚÕŁÉÕÅ»õ╗źÕ£©Ķ┐ÉĶĪīķśČµ«ĄķĆēµŗ®µöŠÕż¦ÕĆŹµĢ░ŃĆéÕøĀµŁż’╝īµłæõ╗¼Õ£©µ¢░Ķäܵ£¼õĖŁõĮ┐ńö© interpolate õ╗Żµø┐ nn.Upsample’╝īõ╗ÄĶĆīĶ«®µ©ĪÕ×ŗµö»µīüÕŖ©µĆüµöŠÕż¦ÕĆŹµĢ░ńÜäĶČģÕłåŃĆé Õ£©ń¼¼ 55 ĶĪīõĮ┐ńö©µ©ĪÕ×ŗµÄ©ńÉåµŚČ’╝īµłæõ╗¼µŖŖµöŠÕż¦ÕĆŹµĢ░Ķ«ŠńĮ«õĖ║ 3ŃĆéµ£ĆÕÉÄ’╝īÕøŠńēćõ┐ØÕŁśÕ£©µ¢ćõ╗Č "face_torch_2.png" õĖŁŃĆéõĖĆÕłćµŁŻÕĖĖńÜäĶ»Ø’╝ī"face_torch_2.png" ÕÆī "face_torch.png" ńÜäÕåģÕ«╣õĖƵ©ĪõĖƵĀĘŃĆé
+
+ķĆÜĶ┐ćń«ĆÕŹĢńÜäõ┐«µö╣’╝īPyTorch µ©ĪÕ×ŗÕĘ▓ń╗ŵö»µīüõ║åÕŖ©µĆüÕłåĶŠ©ńÄćŃĆéńÄ░Õ£©µłæõ╗¼µØźõĖĆõĖŗÕ░ØĶ»ĢÕ»╝Õć║µ©ĪÕ×ŗ’╝Ü
+
+```python
+x = torch.randn(1, 3, 256, 256)
+
+with torch.no_grad():
+ torch.onnx.export(model, (x, 3),
+ "srcnn2.onnx",
+ opset_version=11,
+ input_names=['input', 'factor'],
+ output_names=['output'])
+```
+
+Ķ┐ÉĶĪīĶ┐Öõ║øĶäܵ£¼µŚČ’╝īõ╝ܵŖźõĖĆķĢ┐õĖ▓ķöÖĶ»»ŃĆéµ▓ĪÕŖ×µ│Ģ’╝īµłæõ╗¼ńó░Õł░õ║嵩ĪÕ×ŗķā©ńĮ▓õĖŁńÜäÕģ╝Õ«╣µĆ¦ķŚ«ķóśŃĆé
+
+## Ķ¦ŻÕå│µ¢╣µ│Ģ’╝ÜĶć¬Õ«Üõ╣ēń«ŚÕŁÉ
+
+ńø┤µÄźõĮ┐ńö© PyTorch µ©ĪÕ×ŗńÜäĶ»Ø’╝īµłæõ╗¼õ┐«µö╣ÕćĀĶĪīõ╗ŻńĀüÕ░▒ĶāĮÕ«×ńÄ░µ©ĪÕ×ŗĶŠōÕģźńÜäÕŖ©µĆüÕī¢ŃĆéõĮåÕ£©µ©ĪÕ×ŗķā©ńĮ▓õĖŁ’╝īµłæõ╗¼Ķ”üĶŖ▒µĢ░ÕĆŹńÜ䵌ČķŚ┤µØźĶ«Šµ│ĢĶ¦ŻÕå│Ķ┐ÖõĖĆķŚ«ķóśŃĆéńÄ░Õ£©’╝īĶ«®µłæõ╗¼ķĪ║ńØĆĶ¦ŻÕå│ķŚ«ķóśńÜäµĆØĶĘ»’╝īõĮōķ¬īõĖĆõĖŗµ©ĪÕ×ŗķā©ńĮ▓ńÜäÕø░ķÜŠ’╝īÕ╣ČÕŁ”õ╣ĀõĮ┐ńö©Ķć¬Õ«Üõ╣ēń«ŚÕŁÉńÜäµ¢╣Õ╝Å’╝īĶ¦ŻÕå│ĶČģÕłåĶŠ©ńÄ浩ĪÕ×ŗńÜäÕŖ©µĆüÕī¢ķŚ«ķóśŃĆé
+
+ÕłÜÕłÜńÜäµŖźķöÖµś»ÕøĀõĖ║ PyTorch µ©ĪÕ×ŗÕ£©Õ»╝Õć║Õł░ ONNX µ©ĪÕ×ŗµŚČ’╝īµ©ĪÕ×ŗńÜäĶŠōÕģźÕÅéµĢ░ńÜäń▒╗Õ×ŗÕ┐ģķĪ╗Õģ©ķā©µś» torch.TensorŃĆéĶĆīÕ«×ķÖģõĖŖµłæõ╗¼õ╝ĀÕģźńÜäń¼¼õ║īõĖ¬ÕÅéµĢ░" 3 "µś»õĖĆõĖ¬µĢ┤ÕĮóÕÅśķćÅŃĆéĶ┐ÖõĖŹń¼”ÕÉł PyTorch ĶĮ¼ ONNX ńÜäĶ¦äÕ«ÜŃĆ鵳æõ╗¼Õ┐ģķĪ╗Ķ”üõ┐«µö╣õĖĆõĖŗÕĤµØźńÜ䵩ĪÕ×ŗńÜäĶŠōÕģźŃĆéõĖ║õ║åõ┐ØĶ»üĶŠōÕģźńÜäµēƵ£ēÕÅéµĢ░ķāĮµś» torch.Tensor ń▒╗Õ×ŗńÜä’╝īµłæõ╗¼ÕüÜÕ”éõĖŗõ┐«µö╣’╝Ü
+
+```python
+...
+
+class SuperResolutionNet(nn.Module):
+
+ def forward(self, x, upscale_factor):
+ x = interpolate(x,
+ scale_factor=upscale_factor.item(),
+ mode='bicubic',
+ align_corners=False)
+
+...
+
+# Inference
+# Note that the second input is torch.tensor(3)
+torch_output = model(torch.from_numpy(input_img), torch.tensor(3)).detach().numpy()
+
+...
+
+with torch.no_grad():
+ torch.onnx.export(model, (x, torch.tensor(3)),
+ "srcnn2.onnx",
+ opset_version=11,
+ input_names=['input', 'factor'],
+ output_names=['output'])
+```
+
+ńö▒õ║Ä PyTorch õĖŁ interpolate ńÜä scale_factor ÕÅéµĢ░Õ┐ģķĪ╗µś»õĖĆõĖ¬µĢ░ÕĆ╝’╝īµłæõ╗¼õĮ┐ńö© torch.Tensor.item() µØźµŖŖÕŬµ£ēõĖĆõĖ¬Õģāń┤ĀńÜä torch.Tensor ĶĮ¼µŹóµłÉµĢ░ÕĆ╝ŃĆéõ╣ŗÕÉÄ’╝īÕ£©µ©ĪÕ×ŗµÄ©ńÉåµŚČ’╝īµłæõ╗¼õĮ┐ńö© torch.tensor(3) õ╗Żµø┐ 3’╝īõ╗źõĮ┐ÕŠŚµłæõ╗¼ńÜäµēƵ£ēĶŠōÕģźķāĮµ╗ĪĶČ│Ķ”üµ▒éŃĆéńÄ░Õ£©Ķ┐ÉĶĪīĶäܵ£¼ńÜäĶ»Ø’╝īµŚĀĶ«║µś»ńø┤µÄźĶ┐ÉĶĪīµ©ĪÕ×ŗ’╝īĶ┐śµś»Õ»╝Õć║ ONNX µ©ĪÕ×ŗ’╝īķāĮõĖŹõ╝ܵŖźķöÖõ║åŃĆé
+
+õĮåµś»’╝īÕ»╝Õć║ ONNX µŚČÕŹ┤µŖźõ║åõĖƵØĪ TraceWarning ńÜäĶŁ”ÕæŖŃĆéĶ┐ÖµØĪĶŁ”ÕæŖĶ»┤µ£ēõĖĆõ║øķćÅÕÅ»ĶāĮõ╝ÜĶ┐ĮĶĖ¬Õż▒Ķ┤źŃĆéĶ┐Öµś»µĆÄõ╣łÕø×õ║ŗÕæó’╝¤Ķ«®µłæõ╗¼µŖŖńö¤µłÉńÜä srcnn2.onnx ńö© Netron ÕÅ»Ķ¦åÕī¢õĖĆõĖŗ’╝Ü
+
+
+ÕÅ»õ╗źÕÅæńÄ░’╝īĶÖĮńäȵłæõ╗¼µŖŖµ©ĪÕ×ŗµÄ©ńÉåńÜäĶŠōÕģźĶ«ŠńĮ«õĖ║õ║åõĖżõĖ¬’╝īõĮå ONNX µ©ĪÕ×ŗĶ┐śµś»ķĢ┐ÕŠŚÕÆīÕĤµØźõĖƵ©ĪõĖƵĀĘ’╝īÕŬµ£ēõĖĆõĖ¬ÕŽ " input " ńÜäĶŠōÕģźŃĆéĶ┐Öµś»ńö▒õ║ĵłæõ╗¼õĮ┐ńö©õ║å torch.Tensor.item() µŖŖµĢ░µŹ«õ╗Ä Tensor ķćīÕÅ¢Õć║µØź’╝īĶĆīÕ»╝Õć║ ONNX µ©ĪÕ×ŗµŚČĶ┐ÖõĖ¬µōŹõĮ£µś»µŚĀµ│ĢĶó½Ķ«░ÕĮĢńÜä’╝īÕÅ¬ÕźĮµŖźõ║åõĖƵØĪ TraceWarningŃĆéĶ┐ÖÕ»╝Ķć┤ interpolate µÅÆÕĆ╝ÕćĮµĢ░ńÜäµöŠÕż¦ÕĆŹµĢ░Ķ┐śµś»Ķó½Ķ«ŠńĮ«µłÉõ║å" 3 "Ķ┐ÖõĖ¬Õø║Õ«ÜÕĆ╝’╝īµłæõ╗¼Õ»╝Õć║ńÜä" srcnn2.onnx "ÕÆīµ£ĆÕ╝ĆÕ¦ŗńÜä" srcnn.onnx "Õ«īÕģ©ńøĖÕÉīŃĆé
+
+ńø┤µÄźõ┐«µö╣ÕĤµØźńÜ䵩ĪÕ×ŗõ╝╝õ╣ÄĶĪīõĖŹķĆÜ’╝īµłæõ╗¼ÕŠŚõ╗Ä PyTorch ĶĮ¼ ONNX ńÜäÕĤńÉåÕģźµēŗ’╝īÕ╝║ĶĪīõ╗ż ONNX µ©ĪÕ×ŗµśÄńÖĮµłæõ╗¼ńÜäµā│µ│Ģõ║åŃĆé
+
+õ╗öń╗åĶ¦éÕ»¤ Netron õĖŖÕÅ»Ķ¦åÕī¢Õć║ńÜä ONNX µ©ĪÕ×ŗ’╝īÕÅ»õ╗źÕÅæńÄ░Õ£© PyTorch õĖŁµŚĀĶ«║µś»õĮ┐ńö©µ£ĆµŚ®ńÜä nn.Upsample’╝īĶ┐śµś»ÕÉÄµØźńÜä interpolate’╝īPyTorch ķćīńÜäµÅÆÕĆ╝µōŹõĮ£µ£ĆÕÉÄķāĮõ╝ÜĶĮ¼µŹóµłÉ ONNX Õ«Üõ╣ēńÜä Resize µōŹõĮ£ŃĆéõ╣¤Õ░▒µś»Ķ»┤’╝īµēĆĶ░ō PyTorch ĶĮ¼ ONNX’╝īÕ«×ķÖģõĖŖÕ░▒µś»µŖŖµ»ÅõĖ¬ PyTorch ńÜäµōŹõĮ£µśĀÕ░䵳Éõ║å ONNX Õ«Üõ╣ēńÜäń«ŚÕŁÉŃĆé
+
+ńé╣Õć╗Ķ»źń«ŚÕŁÉ’╝īÕÅ»õ╗źń£ŗÕł░Õ«āńÜäĶ»”ń╗åÕÅéµĢ░Õ”éõĖŗ’╝Ü
+
+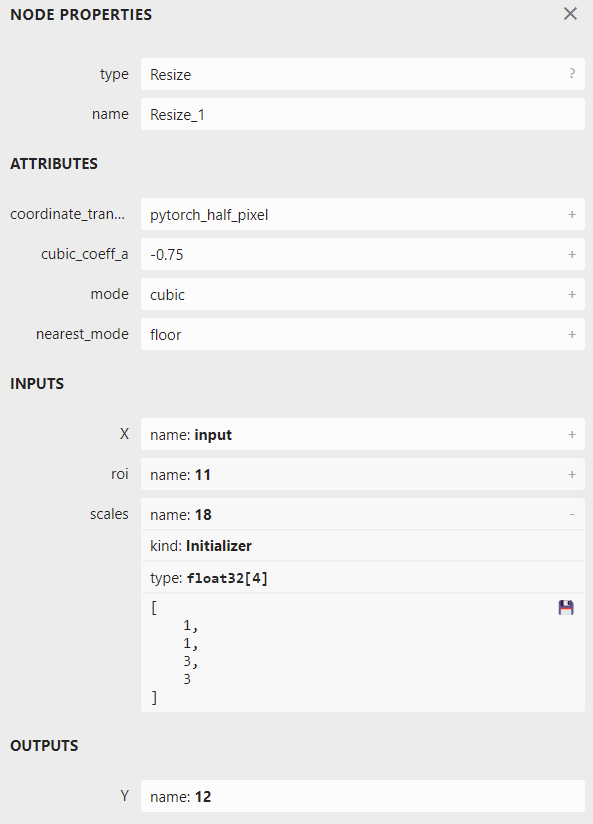
+
+ÕģČõĖŁ’╝īÕ▒ĢÕ╝Ć scales’╝īÕÅ»õ╗źń£ŗÕł░ scales µś»õĖĆõĖ¬ķĢ┐Õ║”õĖ║ 4 ńÜäõĖĆń╗┤Õ╝ĀķćÅ’╝īÕģČÕåģÕ«╣õĖ║ [1, 1, 3, 3], ĶĪ©ńż║ Resize µōŹõĮ£µ»ÅõĖĆõĖ¬ń╗┤Õ║”ńÜäń╝®µöŠń│╗µĢ░’╝øÕģČń▒╗Õ×ŗõĖ║ Initializer’╝īĶĪ©ńż║Ķ┐ÖõĖ¬ÕĆ╝µś»µĀ╣µŹ«ÕĖĖķćÅńø┤µÄźÕłØÕ¦ŗÕī¢Õć║µØźńÜäŃĆéÕ”éµ×£µłæõ╗¼ĶāĮÕż¤Ķć¬ÕĘ▒ńö¤µłÉõĖĆõĖ¬ ONNX ńÜä Resize ń«ŚÕŁÉ’╝īĶ«® scales µłÉõĖ║õĖĆõĖ¬ÕÅ»ÕÅśķćÅĶĆīõĖŹµś»ÕĖĖķćÅ’╝īÕ░▒ÕāÅÕ«āõĖŖķØóńÜä X õĖƵĀĘ’╝īķéŻĶ┐ÖõĖ¬ĶČģÕłåĶŠ©ńÄ浩ĪÕ×ŗÕ░▒ĶāĮÕŖ©µĆüń╝®µöŠõ║åŃĆé
+
+ńÄ░µ£ēÕ«×ńÄ░µÅÆÕĆ╝ńÜä PyTorch ń«ŚÕŁÉµ£ēõĖĆÕźŚĶ¦äÕ«ÜÕźĮńÜ䵜ĀÕ░äÕł░ ONNX Resize ń«ŚÕŁÉńÜäµ¢╣µ│Ģ’╝īĶ┐Öõ║øµśĀÕ░äÕć║ńÜä Resize ń«ŚÕŁÉńÜä scales ÕŬĶāĮµś»ÕĖĖķćÅ’╝īµŚĀµ│Ģµ╗ĪĶČ│µłæõ╗¼ńÜäķ£Ćµ▒éŃĆ鵳æõ╗¼ÕŠŚĶć¬ÕĘ▒Õ«Üõ╣ēõĖĆõĖ¬Õ«×ńÄ░µÅÆÕĆ╝ńÜä PyTorch ń«ŚÕŁÉ’╝īńäČÕÉÄĶ«®Õ«āµśĀÕ░äÕł░õĖĆõĖ¬µłæõ╗¼µ£¤µ£øńÜä ONNX Resize ń«ŚÕŁÉõĖŖŃĆé
+
+õĖŗķØóńÜäĶäܵ£¼Õ«Üõ╣ēõ║åõĖĆõĖ¬ PyTorch µÅÆÕĆ╝ń«ŚÕŁÉ’╝īÕ╣ČÕ£©µ©ĪÕ×ŗķćīõĮ┐ńö©õ║åÕ«āŃĆ鵳æõ╗¼ÕģłķĆÜĶ┐ćĶ┐ÉĶĪīµ©ĪÕ×ŗµØźķ¬īĶ»üĶ»źń«ŚÕŁÉńÜ䵣ŻńĪ«µĆ¦’╝Ü
+
+```python
+import torch
+from torch import nn
+from torch.nn.functional import interpolate
+import torch.onnx
+import cv2
+import numpy as np
+
+
+class NewInterpolate(torch.autograd.Function):
+
+ @staticmethod
+ def symbolic(g, input, scales):
+ return g.op("Resize",
+ input,
+ g.op("Constant",
+ value_t=torch.tensor([], dtype=torch.float32)),
+ scales,
+ coordinate_transformation_mode_s="pytorch_half_pixel",
+ cubic_coeff_a_f=-0.75,
+ mode_s='cubic',
+ nearest_mode_s="floor")
+
+ @staticmethod
+ def forward(ctx, input, scales):
+ scales = scales.tolist()[-2:]
+ return interpolate(input,
+ scale_factor=scales,
+ mode='bicubic',
+ align_corners=False)
+
+
+class StrangeSuperResolutionNet(nn.Module):
+
+ def __init__(self):
+ super().__init__()
+
+ self.conv1 = nn.Conv2d(3, 64, kernel_size=9, padding=4)
+ self.conv2 = nn.Conv2d(64, 32, kernel_size=1, padding=0)
+ self.conv3 = nn.Conv2d(32, 3, kernel_size=5, padding=2)
+
+ self.relu = nn.ReLU()
+
+ def forward(self, x, upscale_factor):
+ x = NewInterpolate.apply(x, upscale_factor)
+ out = self.relu(self.conv1(x))
+ out = self.relu(self.conv2(out))
+ out = self.conv3(out)
+ return out
+
+
+def init_torch_model():
+ torch_model = StrangeSuperResolutionNet()
+
+ state_dict = torch.load('srcnn.pth')['state_dict']
+
+ # Adapt the checkpoint
+ for old_key in list(state_dict.keys()):
+ new_key = '.'.join(old_key.split('.')[1:])
+ state_dict[new_key] = state_dict.pop(old_key)
+
+ torch_model.load_state_dict(state_dict)
+ torch_model.eval()
+ return torch_model
+
+
+model = init_torch_model()
+factor = torch.tensor([1, 1, 3, 3], dtype=torch.float)
+
+input_img = cv2.imread('face.png').astype(np.float32)
+
+# HWC to NCHW
+input_img = np.transpose(input_img, [2, 0, 1])
+input_img = np.expand_dims(input_img, 0)
+
+# Inference
+torch_output = model(torch.from_numpy(input_img), factor).detach().numpy()
+
+# NCHW to HWC
+torch_output = np.squeeze(torch_output, 0)
+torch_output = np.clip(torch_output, 0, 255)
+torch_output = np.transpose(torch_output, [1, 2, 0]).astype(np.uint8)
+
+# Show image
+cv2.imwrite("face_torch_3.png", torch_output)
+```
+
+µ©ĪÕ×ŗĶ┐ÉĶĪīµŁŻÕĖĖńÜäĶ»Ø’╝īõĖĆÕ╣ģµöŠÕż¦3ÕĆŹńÜäĶČģÕłåĶŠ©ńÄćÕøŠńēćõ╝Üõ┐ØÕŁśÕ£©"face_torch_3.png"õĖŁ’╝īÕģČÕåģÕ«╣ÕÆī"face_torch.png"Õ«īÕģ©ńøĖÕÉīŃĆé
+
+Õ£©ÕłÜÕłÜķéŻõĖ¬Ķäܵ£¼õĖŁ’╝īµłæõ╗¼Õ«Üõ╣ē PyTorch µÅÆÕĆ╝ń«ŚÕŁÉńÜäõ╗ŻńĀüÕ”éõĖŗ’╝Ü
+
+```python
+class NewInterpolate(torch.autograd.Function):
+
+ @staticmethod
+ def symbolic(g, input, scales):
+ return g.op("Resize",
+ input,
+ g.op("Constant",
+ value_t=torch.tensor([], dtype=torch.float32)),
+ scales,
+ coordinate_transformation_mode_s="pytorch_half_pixel",
+ cubic_coeff_a_f=-0.75,
+ mode_s='cubic',
+ nearest_mode_s="floor")
+
+ @staticmethod
+ def forward(ctx, input, scales):
+ scales = scales.tolist()[-2:]
+ return interpolate(input,
+ scale_factor=scales,
+ mode='bicubic',
+ align_corners=False)
+```
+
+Õ£©ÕģĘõĮōõ╗ŗń╗ŹĶ┐ÖõĖ¬ń«ŚÕŁÉńÜäÕ«×ńÄ░ÕēŹ’╝īĶ«®µłæõ╗¼ÕģłńÉåµĖģõĖĆõĖŗµĆØĶĘ»ŃĆ鵳æõ╗¼ÕĖīµ£øµ¢░ńÜäµÅÆÕĆ╝ń«ŚÕŁÉµ£ēõĖżõĖ¬ĶŠōÕģź’╝īõĖĆõĖ¬µś»Ķó½ńö©õ║ĵōŹõĮ£ńÜäÕøŠÕāÅ’╝īõĖĆõĖ¬µś»ÕøŠÕāÅńÜäµöŠń╝®µ»öõŠŗŃĆéÕēŹķØóĶ«▓Õł░’╝īõĖ║õ║åÕ»╣µÄź ONNX õĖŁ Resize ń«ŚÕŁÉńÜä scales ÕÅéµĢ░’╝īĶ┐ÖõĖ¬µöŠń╝®µ»öõŠŗµś»õĖĆõĖ¬ [1, 1, x, x] ńÜäÕ╝ĀķćÅ’╝īÕģČõĖŁ x õĖ║µöŠÕż¦ÕĆŹµĢ░ŃĆéÕ£©õ╣ŗÕēŹµöŠÕż¦3ÕĆŹńÜ䵩ĪÕ×ŗõĖŁ’╝īĶ┐ÖõĖ¬ÕÅéµĢ░Ķó½Õø║իܵłÉõ║å[1, 1, 3, 3]ŃĆéÕøĀµŁż’╝īÕ£©µÅÆÕĆ╝ń«ŚÕŁÉõĖŁ’╝īµłæõ╗¼ÕĖīµ£øµ©ĪÕ×ŗńÜäń¼¼õ║īõĖ¬ĶŠōÕģźµś»õĖĆõĖ¬ [1, 1, w, h] ńÜäÕ╝ĀķćÅ’╝īÕģČõĖŁ w ÕÆī h ÕłåÕł½µś»ÕøŠńēćÕ«ĮÕÆīķ½śńÜäµöŠÕż¦ÕĆŹµĢ░ŃĆé
+
+µÉ×µĖģµźÜõ║åµÅÆÕĆ╝ń«ŚÕŁÉńÜäĶŠōÕģź’╝īÕåŹń£ŗõĖĆń£ŗń«ŚÕŁÉńÜäÕģĘõĮōÕ«×ńÄ░ŃĆéń«ŚÕŁÉńÜäµÄ©ńÉåĶĪīõĖ║ńö▒ń«ŚÕŁÉńÜä forward µ¢╣µ│ĢÕå│Õ«ÜŃĆéĶ»źµ¢╣µ│ĢńÜäń¼¼õĖĆõĖ¬ÕÅéµĢ░Õ┐ģķĪ╗õĖ║ ctx’╝īÕÉÄķØóńÜäÕÅéµĢ░õĖ║ń«ŚÕŁÉńÜäĶć¬Õ«Üõ╣ēĶŠōÕģź’╝īµłæõ╗¼Ķ«ŠńĮ«õĖżõĖ¬ĶŠōÕģź’╝īÕłåÕł½õĖ║Ķó½µōŹõĮ£ńÜäÕøŠÕāÅÕÆīµöŠń╝®µ»öõŠŗŃĆéõĖ║õ┐ØĶ»üµÄ©ńÉåµŁŻńĪ«’╝īķ£ĆĶ”üµŖŖ [1, 1, w, h] µĀ╝Õ╝ÅńÜäĶŠōÕģźÕ»╣µÄźÕł░ÕĤµØźńÜä interpolate ÕćĮµĢ░õĖŖŃĆ鵳æõ╗¼ńÜäÕüܵ│Ģµś»µł¬ÕÅ¢ĶŠōÕģźÕ╝ĀķćÅńÜäÕÉÄõĖżõĖ¬Õģāń┤Ā’╝īµŖŖĶ┐ÖõĖżõĖ¬Õģāń┤Āõ╗ź list ńÜäµĀ╝Õ╝Åõ╝ĀÕģź interpolate ńÜä scale_factor ÕÅéµĢ░ŃĆé
+
+µÄźõĖŗµØź’╝īµłæõ╗¼Ķ”üÕå│իܵ¢░ń«ŚÕŁÉµśĀÕ░äÕł░ ONNX ń«ŚÕŁÉńÜäµ¢╣µ│ĢŃĆ鵜ĀÕ░äÕł░ ONNX ńÜäµ¢╣µ│Ģńö▒õĖĆõĖ¬ń«ŚÕŁÉńÜä symbolic µ¢╣µ│ĢÕå│Õ«ÜŃĆésymbolic µ¢╣µ│Ģń¼¼õĖĆõĖ¬ÕÅéµĢ░Õ┐ģķĪ╗µś»g’╝īõ╣ŗÕÉÄńÜäÕÅéµĢ░µś»ń«ŚÕŁÉńÜäĶć¬Õ«Üõ╣ēĶŠōÕģź’╝īÕÆī forward ÕćĮµĢ░õĖƵĀĘŃĆéONNX ń«ŚÕŁÉńÜäÕģĘõĮōÕ«Üõ╣ēńö▒ g.op Õ«×ńÄ░ŃĆég.op ńÜäµ»ÅõĖ¬ÕÅéµĢ░ķāĮÕÅ»õ╗źµśĀÕ░äÕł░ ONNX õĖŁńÜäń«ŚÕŁÉÕ▒׵Ʀ’╝Ü
+
+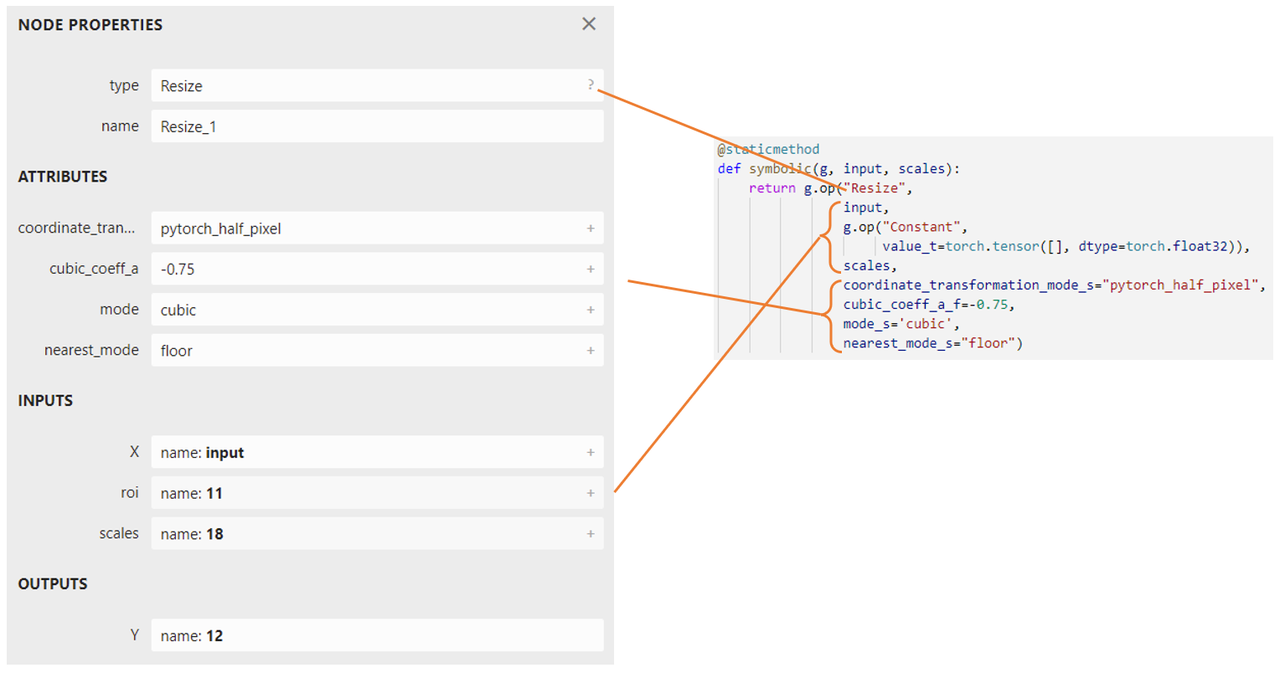
+
+Õ»╣õ║ÄÕģČõ╗¢ÕÅéµĢ░’╝īµłæõ╗¼ÕÅ»õ╗źńģ¦ńØĆńÄ░Õ£©ńÜä [Resize](https://github.com/onnx/onnx/blob/main/docs/Operators.md#Resize) ń«ŚÕŁÉÕĪ½ŃĆéĶĆīĶ”üµ│©µäÅńÜ䵜»’╝īµłæõ╗¼ńÄ░Õ£©ÕĖīµ£ø scales ÕÅéµĢ░µś»ńö▒ĶŠōÕģźÕŖ©µĆüÕå│Õ«ÜńÜäŃĆéÕøĀµŁż’╝īÕ£©ÕĪ½Õģź ONNX ńÜä scales µŚČ’╝īµłæõ╗¼Ķ”üµŖŖ symbolic µ¢╣µ│ĢńÜäĶŠōÕģźÕÅéµĢ░õĖŁńÜä scales ÕĪ½ÕģźŃĆé
+
+µÄźńØĆ’╝īĶ«®µłæõ╗¼µŖŖµ¢░µ©ĪÕ×ŗÕ»╝Õć║µłÉ ONNX µ©ĪÕ×ŗ’╝Ü
+
+```python
+x = torch.randn(1, 3, 256, 256)
+
+with torch.no_grad():
+ torch.onnx.export(model, (x, factor),
+ "srcnn3.onnx",
+ opset_version=11,
+ input_names=['input', 'factor'],
+ output_names=['output'])
+```
+
+µŖŖÕ»╝Õć║ńÜä " srcnn3.onnx " Ķ┐øĶĪīÕÅ»Ķ¦åÕī¢’╝Ü
+
+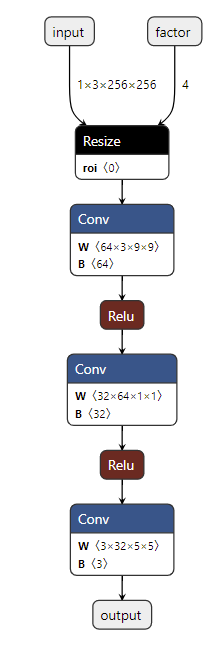
+
+ÕÅ»õ╗źń£ŗÕł░’╝īµŁŻÕ”鵳æõ╗¼µēƵ£¤µ£øńÜä’╝īÕ»╝Õć║ńÜä ONNX µ©ĪÕ×ŗµ£ēõ║åõĖżõĖ¬ĶŠōÕģź’╝üń¼¼õ║īõĖ¬ĶŠōÕģźĶĪ©ńż║ÕøŠÕāÅńÜäµöŠń╝®µ»öõŠŗŃĆé
+
+õ╣ŗÕēŹÕ£©ķ¬īĶ»ü PyTorch µ©ĪÕ×ŗÕÆīÕ»╝Õć║ ONNX µ©ĪÕ×ŗµŚČ’╝īµłæõ╗¼Õ«Įķ½śńÜäń╝®µöŠµ»öõŠŗĶ«ŠńĮ«µłÉõ║å 3x3ŃĆéńÄ░Õ£©’╝īÕ£©ńö© ONNX Runtime µÄ©ńÉåµŚČ’╝īµłæõ╗¼Õ░ØĶ»ĢõĮ┐ńö© 4x4 ńÜäń╝®µöŠµ»öõŠŗ’╝Ü
+
+```python
+import onnxruntime
+
+input_factor = np.array([1, 1, 4, 4], dtype=np.float32)
+ort_session = onnxruntime.InferenceSession("srcnn3.onnx")
+ort_inputs = {'input': input_img, 'factor': input_factor}
+ort_output = ort_session.run(None, ort_inputs)[0]
+
+ort_output = np.squeeze(ort_output, 0)
+ort_output = np.clip(ort_output, 0, 255)
+ort_output = np.transpose(ort_output, [1, 2, 0]).astype(np.uint8)
+cv2.imwrite("face_ort_3.png", ort_output)
+```
+
+Ķ┐ÉĶĪīõĖŖķØóńÜäõ╗ŻńĀü’╝īÕÅ»õ╗źÕŠŚÕł░õĖĆõĖ¬ĶŠ╣ķĢ┐µöŠÕż¦4ÕĆŹńÜäĶČģÕłåĶŠ©ńÄćÕøŠńēć "face_ort_3.png"ŃĆéÕŖ©µĆüńÜäĶČģÕłåĶŠ©ńÄ浩ĪÕ×ŗńö¤µłÉµłÉÕŖ¤õ║å’╝üÕŬĶ”üõ┐«µö╣ input_factor’╝īµłæõ╗¼Õ░▒ÕÅ»õ╗źĶć¬ńö▒Õ£░µÄ¦ÕłČÕøŠńēćńÜäń╝®µöŠµ»öõŠŗŃĆé
+
+µłæõ╗¼ÕłÜÕłÜńÜäÕĘźõĮ£’╝īÕ«×ķÖģõĖŖµś»ń╗ĢĶ┐ć PyTorch µ£¼Ķ║½ńÜäķÖÉÕłČ’╝īÕćŁń®║ŌĆ£µŹÅŌĆØÕć║õ║åõĖĆõĖ¬ ONNX ń«ŚÕŁÉŃĆéõ║ŗÕ«×õĖŖ’╝īµłæõ╗¼õĖŹõ╗ģÕÅ»õ╗źÕłøÕ╗║ńÄ░µ£ēńÜä ONNX ń«ŚÕŁÉ’╝īĶ┐śÕÅ»õ╗źÕ«Üõ╣ēµ¢░ńÜä ONNX ń«ŚÕŁÉõ╗źµŗōÕ▒Ģ ONNX ńÜäĶĪ©ĶŠŠĶāĮÕŖøŃĆéÕÉÄń╗ŁµĢÖń©ŗõĖŁµłæõ╗¼Õ░åõ╗ŗń╗ŹĶć¬Õ«Üõ╣ēµ¢░ ONNX ń«ŚÕŁÉńÜäµ¢╣µ│ĢŃĆé
+
+## µĆ╗ń╗ō
+
+ķĆÜĶ┐ćÕŁ”õ╣ĀÕēŹõĖżń»ćµĢÖń©ŗ’╝īµłæõ╗¼ĶĄ░Õ«īõ║åµĢ┤õĖ¬ķā©ńĮ▓µĄüµ░┤ń║┐’╝īµłÉÕŖ¤ķā©ńĮ▓õ║åµö»µīüÕŖ©µĆüµöŠÕż¦ÕĆŹµĢ░ńÜäĶČģÕłåĶŠ©ńÄ浩ĪÕ×ŗŃĆéÕ£©Ķ┐ÖõĖ¬Ķ┐ćń©ŗõĖŁ’╝īµłæõ╗¼µŚóÕŁ”õ╝Üõ║åÕ”éõĮĢń«ĆÕŹĢÕ£░Ķ░āńö©ÕÉäµĪåµ×ČńÜäAPIÕ«×ńÄ░µ©ĪÕ×ŗķā©ńĮ▓’╝īÕÅłÕŁ”Õł░õ║åÕ”éõĮĢÕłåµ×ÉÕ╣ČÕ░ØĶ»ĢĶ¦ŻÕå│µ©ĪÕ×ŗķā©ńĮ▓µŚČńó░Õł░ńÜäķÜŠķóśŃĆé
+
+ÕÉīµĀĘ’╝īĶ«®µłæõ╗¼µĆ╗ń╗ōõĖĆõĖŗµ£¼ń»ćµĢÖń©ŗńÜäń¤źĶ»åńé╣’╝Ü
+
+- µ©ĪÕ×ŗķā©ńĮ▓õĖŁÕĖĖĶ¦üńÜäÕćĀń▒╗Õø░ķÜŠµ£ē’╝ܵ©ĪÕ×ŗńÜäÕŖ©µĆüÕī¢’╝øµ¢░ń«ŚÕŁÉńÜäÕ«×ńÄ░’╝øµĪåµ×ČķŚ┤ńÜäÕģ╝Õ«╣ŃĆé
+- PyTorch ĶĮ¼ ONNX’╝īÕ«×ķÖģõĖŖÕ░▒µś»µŖŖµ»ÅõĖĆõĖ¬µōŹõĮ£ĶĮ¼Õī¢µłÉ ONNX Õ«Üõ╣ēńÜ䵤ÉõĖĆõĖ¬ń«ŚÕŁÉŃĆéµ»öÕ”éÕ»╣õ║Ä PyTorch õĖŁńÜä Upsample ÕÆī interpolate’╝īÕ£©ĶĮ¼ ONNX ÕÉĵ£Ćń╗łķāĮõ╝ܵłÉõĖ║ ONNX ńÜä Resize ń«ŚÕŁÉŃĆé
+- ķĆÜĶ┐ćõ┐«µö╣ń╗¦µē┐Ķć¬ torch.autograd.Function ńÜäń«ŚÕŁÉńÜä symbolic µ¢╣µ│Ģ’╝īÕÅ»õ╗źµö╣ÕÅśĶ»źń«ŚÕŁÉµśĀÕ░äÕł░ ONNX ń«ŚÕŁÉńÜäĶĪīõĖ║ŃĆé
+
+Ķć│µŁż’╝ī"ķā©ńĮ▓ń¼¼õĖĆõĖ¬µ©ĪÕ×ŗŌĆ£ńÜäµĢÖń©ŗń«Śµś»ÕæŖõĖƵ«ĄĶÉĮõ║åŃĆ鵜»õĖŹµś»Ķ¦ēÕŠŚÕŁ”Õł░ńÜäń¤źĶ»åĶ┐śõĖŹÕż¤ÕżÜ’╝¤µ▓ĪÕģ│ń│╗’╝īÕ£©µÄźõĖŗµØźńÜäÕćĀń»ćµĢÖń©ŗõĖŁ’╝īµłæõ╗¼Õ░åń╗ōÕÉł MMDeploy ’╝īķćŹńé╣õ╗ŗń╗Ź ONNX õĖŁķŚ┤ĶĪ©ńż║ÕÆī ONNX Runtime/TensorRT µÄ©ńÉåÕ╝ĢµōÄńÜäń¤źĶ»å’╝īĶ«®Õż¦Õ«ČÕŁ”õ╝ÜÕ”éõĮĢķā©ńĮ▓µø┤ÕżŹµØéńÜ䵩ĪÕ×ŗŃĆé
diff --git a/internlm_langchain/knowledge_base/MMDeploy/content/03_pytorch2onnx.md b/internlm_langchain/knowledge_base/MMDeploy/content/03_pytorch2onnx.md
new file mode 100644
index 00000000..680b7d97
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDeploy/content/03_pytorch2onnx.md
@@ -0,0 +1,347 @@
+# ń¼¼õĖēń½Ā’╝ÜPyTorch ĶĮ¼ ONNX Ķ»”Ķ¦Ż
+
+ONNX µś»ńø«ÕēŹµ©ĪÕ×ŗķā©ńĮ▓õĖŁµ£ĆķćŹĶ”üńÜäõĖŁķŚ┤ĶĪ©ńż║õ╣ŗõĖĆŃĆéÕŁ”µćéõ║å ONNX ńÜäµŖƵ£»ń╗åĶŖé’╝īÕ░▒ĶāĮĶ¦äķü┐Õż¦ķćÅńÜ䵩ĪÕ×ŗķā©ńĮ▓ķŚ«ķóśŃĆéõ╗ÄĶ┐Öń»ćµ¢ćń½ĀÕ╝ĆÕ¦ŗ’╝īÕ£©µÄźõĖŗµØźńÜäõĖēń»ćµ¢ćń½Āķćī’╝īµłæõ╗¼Õ░åńö▒µĄģÕģźµĘ▒Õ£░õ╗ŗń╗Ź ONNX ńøĖÕģ│ńÜäń¤źĶ»åŃĆéÕ£©ń¼¼õĖĆń»ćµ¢ćń½Āķćī’╝īµłæõ╗¼õ╝Üõ╗ŗń╗Źµø┤ÕżÜ PyTorch ĶĮ¼ ONNX ńÜäń╗åĶŖé’╝īĶ«®Õż¦Õ«ČÕ«īÕģ©µÄīµÅĪµŖŖń«ĆÕŹĢńÜä PyTorch µ©ĪÕ×ŗĶĮ¼µłÉ ONNX µ©ĪÕ×ŗńÜäµ¢╣µ│Ģ’╝øÕ£©ń¼¼õ║īń»ćµ¢ćń½Āķćī’╝īµłæõ╗¼Õ░åõ╗ŗń╗ŹÕ”éõĮĢÕ£© PyTorch õĖŁµö»µīüµø┤ÕżÜńÜä ONNX ń«ŚÕŁÉ’╝īĶ«®Õż¦Õ«ČĶāĮÕĮ╗Õ║ĢĶĄ░ķĆÜ PyTorch Õł░ ONNX Ķ┐ÖµØĪķā©ńĮ▓ĶĘ»ń║┐’╝øń¼¼õĖēń»ćµ¢ćń½Āķćī’╝īµłæõ╗¼Ķ«▓õ╗ŗń╗Ź ONNX µ£¼Ķ║½ńÜäń¤źĶ»å’╝īõ╗źÕÅŖõ┐«µö╣ŃĆüĶ░āĶ»Ģ ONNX µ©ĪÕ×ŗńÜäÕĖĖńö©µ¢╣µ│Ģ’╝īõĮ┐Õż¦Õ«ČĶāĮĶć¬ĶĪīĶ¦ŻÕå│Õż¦ķā©ÕłåÕÆī ONNX µ£ēÕģ│ńÜäķā©ńĮ▓ķŚ«ķóśŃĆé
+
+Õ£©µŖŖ PyTorch µ©ĪÕ×ŗĶĮ¼µŹóµłÉ ONNX µ©ĪÕ×ŗµŚČ’╝īµłæõ╗¼ÕŠĆÕŠĆÕŬķ£ĆĶ”üĶĮ╗µØŠÕ£░Ķ░āńö©õĖĆÕÅź`torch.onnx.export`Õ░▒ĶĪīõ║åŃĆéĶ┐ÖõĖ¬ÕćĮµĢ░ńÜäµÄźÕÅŻń£ŗõĖŖÕÄ╗ń«ĆÕŹĢ’╝īõĮåÕ«āÕ£©õĮ┐ńö©õĖŖĶ┐śµ£ēńØĆĶ»ĖÕżÜńÜäŌĆ£µĮ£Ķ¦äÕłÖŌĆØŃĆéÕ£©Ķ┐Öń»ćµĢÖń©ŗõĖŁ’╝īµłæõ╗¼õ╝ÜĶ»”ń╗åõ╗ŗń╗Ź PyTorch µ©ĪÕ×ŗĶĮ¼ ONNX µ©ĪÕ×ŗńÜäÕĤńÉåÕÅŖµ│©µäÅõ║ŗķĪ╣ŃĆéķÖżµŁżõ╣ŗÕż¢’╝īµłæõ╗¼Ķ┐śõ╝Üõ╗ŗń╗Ź PyTorch õĖÄ ONNX ńÜäń«ŚÕŁÉÕ»╣Õ║öÕģ│ń│╗’╝īõ╗źµĢÖõ╝ÜÕż¦Õ«ČÕ”éõĮĢÕżäńÉå PyTorch µ©ĪÕ×ŗĶĮ¼µŹóµŚČÕÅ»ĶāĮõ╝ÜķüćÕł░ńÜäń«ŚÕŁÉµö»µīüķŚ«ķóśŃĆé
+
+## `torch.onnx.export` ń╗åĶ¦Ż
+
+Õ£©Ķ┐ÖõĖĆĶŖéķćī’╝īµłæõ╗¼Õ░åĶ»”ń╗åõ╗ŗń╗Ź PyTorch Õł░ ONNX ńÜäĶĮ¼µŹóÕćĮµĢ░ŌĆöŌĆö torch.onnx.exportŃĆ鵳æõ╗¼ÕĖīµ£øÕż¦Õ«ČĶāĮÕż¤µø┤ÕŖĀńüĄµ┤╗Õ£░õĮ┐ńö©Ķ┐ÖõĖ¬µ©ĪÕ×ŗĶĮ¼µŹóµÄźÕÅŻ’╝īÕ╣ČķĆÜĶ┐ćõ║åĶ¦ŻÕ«āńÜäÕ«×ńÄ░ÕĤńÉåµØźµø┤ÕźĮÕ£░Õ║öÕ»╣Ķ»źÕćĮµĢ░ńÜäµŖźķöÖ’╝łńö▒õ║ĵ©ĪÕ×ŗķā©ńĮ▓ńÜäÕģ╝Õ«╣µĆ¦ķŚ«ķóś’╝īķā©ńĮ▓ÕżŹµØ鵩ĪÕ×ŗµŚČĶ»źÕćĮµĢ░µŚČÕĖĖõ╝ܵŖźķöÖ’╝ēŃĆé
+
+### Ķ«Īń«ŚÕøŠÕ»╝Õć║µ¢╣µ│Ģ
+
+[TorchScript](https://pytorch.org/docs/stable/jit.html) µś»õĖĆń¦ŹÕ║ÅÕłŚÕī¢ÕÆīõ╝śÕī¢ PyTorch µ©ĪÕ×ŗńÜäµĀ╝Õ╝Å’╝īÕ£©õ╝śÕī¢Ķ┐ćń©ŗõĖŁ’╝īõĖĆõĖ¬`torch.nn.Module`µ©ĪÕ×ŗõ╝ÜĶó½ĶĮ¼µŹóµłÉ TorchScript ńÜä`torch.jit.ScriptModule`µ©ĪÕ×ŗŃĆéńÄ░Õ£©’╝ī TorchScript õ╣¤Ķó½ÕĖĖÕĮōµłÉõĖĆń¦ŹõĖŁķŚ┤ĶĪ©ńż║õĮ┐ńö©ŃĆ鵳æõ╗¼Õ£©[ÕģČõ╗¢µ¢ćń½Ā](https://zhuanlan.zhihu.com/p/486914187)õĖŁÕ»╣ TorchScript µ£ēĶ»”ń╗åńÜäõ╗ŗń╗Ź’╝īĶ┐Öķćīõ╗ŗń╗Ź TorchScript õ╗ģńö©õ║ÄĶ»┤µśÄ PyTorch µ©ĪÕ×ŗĶĮ¼ ONNXńÜäÕĤńÉåŃĆé
+`torch.onnx.export`õĖŁķ£ĆĶ”üńÜ䵩ĪÕ×ŗÕ«×ķÖģõĖŖµś»õĖĆõĖ¬`torch.jit.ScriptModule`ŃĆéĶĆīĶ”üµŖŖµÖ«ķĆÜ PyTorch µ©ĪÕ×ŗĶĮ¼õĖĆõĖ¬Ķ┐ÖµĀĘńÜä TorchScript µ©ĪÕ×ŗ’╝īµ£ēĶʤĶĖ¬’╝łtrace’╝ēÕÆīĶäܵ£¼Õī¢’╝łscript’╝ēõĖżń¦ŹÕ»╝Õć║Ķ«Īń«ŚÕøŠńÜäµ¢╣µ│ĢŃĆéÕ”éµ×£ń╗Ö`torch.onnx.export`õ╝ĀÕģźõ║åõĖĆõĖ¬µÖ«ķĆÜ PyTorch µ©ĪÕ×ŗ’╝ł`torch.nn.Module`)’╝īķéŻõ╣łĶ┐ÖõĖ¬µ©ĪÕ×ŗõ╝Üķ╗śĶ«żõĮ┐ńö©ĶʤĶĖ¬ńÜäµ¢╣µ│ĢÕ»╝Õć║ŃĆéĶ┐ÖõĖĆĶ┐ćń©ŗÕ”éõĖŗÕøŠµēĆńż║’╝Ü
+
+
+
+Õø×Õ┐åõĖĆõĖŗµłæõ╗¼[ń¼¼õĖĆń»ćµĢÖń©ŗ](01_introduction_to_model_deployment.md) ń¤źĶ»å’╝ÜĶʤĶĖ¬µ│ĢÕŬĶāĮķĆÜĶ┐ćÕ«×ķÖģĶ┐ÉĶĪīõĖĆķüŹµ©ĪÕ×ŗńÜäµ¢╣µ│ĢÕ»╝Õć║µ©ĪÕ×ŗńÜäķØÖµĆüÕøŠ’╝īÕŹ│µŚĀµ│ĢĶ»åÕł½Õć║µ©ĪÕ×ŗõĖŁńÜäµÄ¦ÕłČµĄü’╝łÕ”éÕŠ¬ńÄ»’╝ē’╝øĶäܵ£¼Õī¢ÕłÖĶāĮķĆÜĶ┐ćĶ¦Żµ×ɵ©ĪÕ×ŗµØźµŁŻńĪ«Ķ«░ÕĮĢµēƵ£ēńÜäµÄ¦ÕłČµĄüŃĆ鵳æõ╗¼õ╗źõĖŗķØóĶ┐Öµ«Ąõ╗ŻńĀüõĖ║õŠŗµØźń£ŗõĖĆń£ŗĶ┐ÖõĖżń¦ŹĶĮ¼µŹóµ¢╣µ│ĢńÜäÕī║Õł½’╝Ü
+
+```python
+import torch
+
+class Model(torch.nn.Module):
+ def __init__(self, n):
+ super().__init__()
+ self.n = n
+ self.conv = torch.nn.Conv2d(3, 3, 3)
+
+ def forward(self, x):
+ for i in range(self.n):
+ x = self.conv(x)
+ return x
+
+
+
+models = [Model(2), Model(3)]
+model_names = ['model_2', 'model_3']
+
+for model, model_name in zip(models, model_names):
+ dummy_input = torch.rand(1, 3, 10, 10)
+ dummy_output = model(dummy_input)
+ model_trace = torch.jit.trace(model, dummy_input)
+ model_script = torch.jit.script(model)
+
+ # ĶʤĶĖ¬µ│ĢõĖÄńø┤µÄź torch.onnx.export(model, ...)ńŁēõ╗Ę
+ torch.onnx.export(model_trace, dummy_input, f'{model_name}_trace.onnx', example_outputs=dummy_output)
+ # Ķäܵ£¼Õī¢Õ┐ģķĪ╗ÕģłĶ░āńö© torch.jit.sciprt
+ torch.onnx.export(model_script, dummy_input, f'{model_name}_script.onnx', example_outputs=dummy_output)
+```
+
+Õ£©Ķ┐Öµ«Ąõ╗ŻńĀüķćī’╝īµłæõ╗¼Õ«Üõ╣ēõ║åõĖĆõĖ¬ÕĖ”ÕŠ¬ńÄ»ńÜ䵩ĪÕ×ŗ’╝īµ©ĪÕ×ŗķĆÜĶ┐ćÕÅéµĢ░`n`µØźµÄ¦ÕłČĶŠōÕģźÕ╝ĀķćÅĶó½ÕŹĘń¦»ńÜäµ¼ĪµĢ░ŃĆéõ╣ŗÕÉÄ’╝īµłæõ╗¼ÕÉäÕłøÕ╗║õ║åõĖĆõĖ¬`n=2`ÕÆī`n=3`ńÜ䵩ĪÕ×ŗŃĆ鵳æõ╗¼µŖŖĶ┐ÖõĖżõĖ¬µ©ĪÕ×ŗÕłåÕł½ńö©ĶʤĶĖ¬ÕÆīĶäܵ£¼Õī¢ńÜäµ¢╣µ│ĢĶ┐øĶĪīÕ»╝Õć║ŃĆé
+ÕĆ╝ÕŠŚõĖƵÅÉńÜ䵜»’╝īńö▒õ║ÄĶ┐ÖķćīńÜäõĖżõĖ¬µ©ĪÕ×ŗ’╝ł`model_trace`, `model_script`)µś» TorchScript µ©ĪÕ×ŗ’╝ī`export`ÕćĮµĢ░ÕĘ▓ń╗ÅõĖŹķ£ĆĶ”üÕåŹĶ┐ÉĶĪīõĖĆķüŹµ©ĪÕ×ŗõ║åŃĆé’╝łÕ”éµ×£µ©ĪÕ×ŗµś»ńö©ĶʤĶĖ¬µ│ĢÕŠŚÕł░ńÜä’╝īķéŻõ╣łÕ£©µē¦ĶĪī`torch.jit.trace`ńÜ䵌ČÕĆÖÕ░▒Ķ┐ÉĶĪīĶ┐ćõĖĆķüŹõ║å’╝øĶĆīńö©Ķäܵ£¼Õī¢Õ»╝Õć║µŚČ’╝īµ©ĪÕ×ŗõĖŹķ£ĆĶ”üÕ«×ķÖģĶ┐ÉĶĪī’╝ēÕÅéµĢ░õĖŁńÜä`dummy_input`ÕÆī`dummy_output`õ╗ģõ╗ģµś»õĖ║õ║åĶÄĘÕÅ¢ĶŠōÕģźÕÆīĶŠōÕć║Õ╝ĀķćÅńÜäń▒╗Õ×ŗÕÆīÕĮóńŖČŃĆé
+Ķ┐ÉĶĪīõĖŖķØóńÜäõ╗ŻńĀü’╝īµłæõ╗¼µŖŖÕŠŚÕł░ńÜä4õĖ¬ onnx µ¢ćõ╗Čńö© Netron ÕÅ»Ķ¦åÕī¢’╝Ü
+
+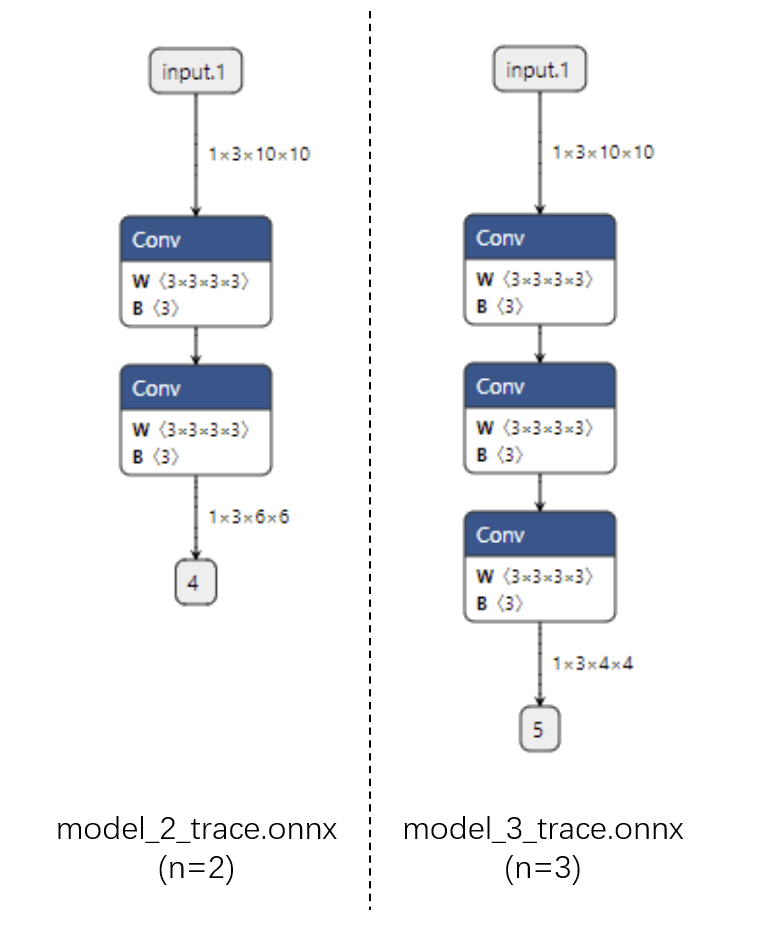
+
+ķ”¢Õģłń£ŗĶʤĶĖ¬µ│ĢÕŠŚÕł░ńÜä ONNX µ©ĪÕ×ŗń╗ōµ×äŃĆéÕÅ»õ╗źń£ŗÕć║µØź’╝īÕ»╣õ║ÄõĖŹÕÉīńÜä `n`,ONNX µ©ĪÕ×ŗńÜäń╗ōµ×䵜»õĖŹõĖƵĀĘńÜäŃĆé
+
+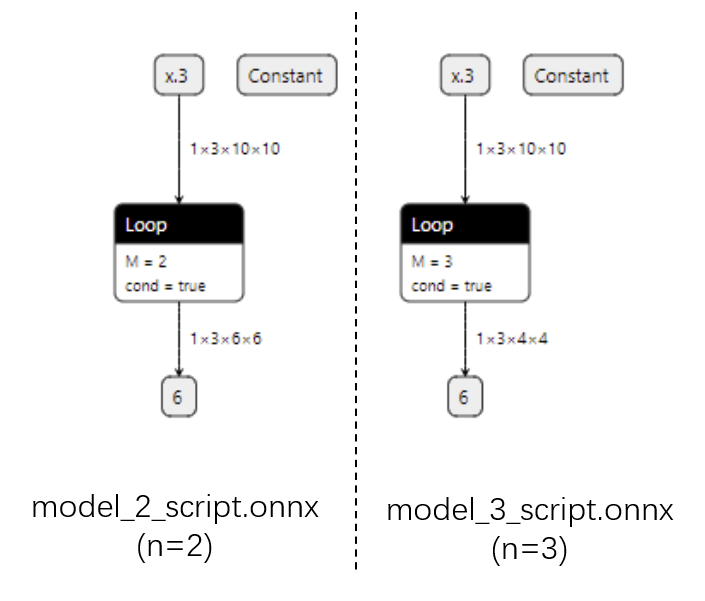
+
+ĶĆīńö©Ķäܵ£¼Õī¢ńÜäĶ»Ø’╝īµ£Ćń╗łńÜä ONNX µ©ĪÕ×ŗńö© `Loop` ĶŖéńé╣µØźĶĪ©ńż║ÕŠ¬ńÄ»ŃĆéĶ┐ÖµĀĘÕō¬µĆĢÕ»╣õ║ÄõĖŹÕÉīńÜä `n`’╝īONNX µ©ĪÕ×ŗõ╣¤µ£ēÕÉīµĀĘńÜäń╗ōµ×äŃĆé
+ńö▒õ║ĵĩńÉåÕ╝ĢµōÄÕ»╣ķØÖµĆüÕøŠńÜäµö»µīüµø┤ÕźĮ’╝īķĆÜÕĖĖµłæõ╗¼Õ£©µ©ĪÕ×ŗķā©ńĮ▓µŚČõĖŹķ£ĆĶ”üµśŠÕ╝ÅÕ£░µŖŖ PyTorch µ©ĪÕ×ŗĶĮ¼µłÉ TorchScript µ©ĪÕ×ŗ’╝īńø┤µÄźµŖŖ PyTorch µ©ĪÕ×ŗńö© `torch.onnx.export` ĶʤĶĖ¬Õ»╝Õć║ÕŹ│ÕÅ»ŃĆéõ║åĶ¦ŻĶ┐Öķā©ÕłåńÜäń¤źĶ»åõĖ╗Ķ”üµś»õĖ║õ║åÕ£©µ©ĪÕ×ŗĶĮ¼µŹóµŖźķöÖµŚČĶāĮÕż¤µø┤ÕźĮÕ£░Õ«ÜõĮŹķŚ«ķ󜵜»ÕÉ”ÕÅæńö¤Õ£© PyTorch ĶĮ¼ TorchScript ķśČµ«ĄŃĆé
+
+### ÕÅéµĢ░Ķ«▓Ķ¦Ż
+
+õ║åĶ¦ŻÕ«īĶĮ¼µŹóÕćĮµĢ░ńÜäÕĤńÉåÕÉÄ’╝īµłæõ╗¼µØźĶ»”ń╗åõ╗ŗń╗ŹõĖĆõĖŗĶ»źÕćĮµĢ░ńÜäõĖ╗Ķ”üÕÅéµĢ░ńÜäõĮ£ńö©ŃĆ鵳æõ╗¼õĖ╗Ķ”üõ╝Üõ╗ÄÕ║öńö©ńÜäĶ¦ÆÕ║”µØźõ╗ŗń╗Źµ»ÅõĖ¬ÕÅéµĢ░Õ£©õĖŹÕÉīńÜ䵩ĪÕ×ŗķā©ńĮ▓Õ£║µÖ»õĖŁÕ║öĶ»źÕ”éõĮĢĶ«ŠńĮ«’╝īĶĆīõĖŹõ╝ÜÕÄ╗ÕłŚÕć║µ»ÅõĖ¬ÕÅéµĢ░ńÜäµēƵ£ēĶ«ŠńĮ«µ¢╣µ│ĢŃĆéĶ»źÕćĮµĢ░Ķ»”ń╗åńÜä API µ¢ćµĪŻÕÅ»ÕÅéĶĆā [torch.onnx ŌĆÆ PyTorch 1.11.0 documentation](https://pytorch.org/docs/stable/onnx.html#functions)
+
+`torch.onnx.export` Õ£© `torch.onnx.__init__.py`µ¢ćõ╗ČõĖŁńÜäÕ«Üõ╣ēÕ”éõĖŗ’╝Ü
+
+```python
+def export(model, args, f, export_params=True, verbose=False, training=TrainingMode.EVAL,
+ input_names=None, output_names=None, aten=False, export_raw_ir=False,
+ operator_export_type=None, opset_version=None, _retain_param_name=True,
+ do_constant_folding=True, example_outputs=None, strip_doc_string=True,
+ dynamic_axes=None, keep_initializers_as_inputs=None, custom_opsets=None,
+ enable_onnx_checker=True, use_external_data_format=False):
+```
+
+ÕēŹõĖēõĖ¬Õ┐ģķĆēÕÅéµĢ░õĖ║µ©ĪÕ×ŗŃĆüµ©ĪÕ×ŗĶŠōÕģźŃĆüÕ»╝Õć║ńÜä onnx µ¢ćõ╗ČÕÉŹ’╝īµłæõ╗¼Õ»╣Ķ┐ÖÕćĀõĖ¬ÕÅéµĢ░ÕĘ▓ń╗ÅÕŠłń夵éēõ║åŃĆ鵳æõ╗¼µØźńØĆķćŹń£ŗõĖĆõĖŗÕÉÄķØóńÜäõĖĆõ║øÕĖĖńö©ÕÅ»ķĆēÕÅéµĢ░ŃĆé
+
+#### export_params
+
+µ©ĪÕ×ŗõĖŁµś»ÕÉ”ÕŁśÕ驵©ĪÕ×ŗµØāķćŹŃĆéõĖĆĶł¼õĖŁķŚ┤ĶĪ©ńż║ÕīģÕɽõĖżÕż¦ń▒╗õ┐Īµü»’╝ܵ©ĪÕ×ŗń╗ōµ×äÕÆīµ©ĪÕ×ŗµØāķ插╝īĶ┐ÖõĖżń▒╗õ┐Īµü»ÕÅ»õ╗źÕ£©ÕÉīõĖĆõĖ¬µ¢ćõ╗ČķćīÕŁśÕé©’╝īõ╣¤ÕÅ»õ╗źÕłåµ¢ćõ╗ČÕŁśÕé©ŃĆéONNX µś»ńö©ÕÉīõĖĆõĖ¬µ¢ćõ╗ČĶĪ©ńż║Ķ«░ÕĮĢµ©ĪÕ×ŗńÜäń╗ōµ×äÕÆīµØāķćŹńÜäŃĆé
+µłæõ╗¼ķā©ńĮ▓µŚČõĖĆĶł¼ķāĮķ╗śĶ«żĶ┐ÖõĖ¬ÕÅéµĢ░õĖ║ TrueŃĆéÕ”éµ×£ onnx µ¢ćõ╗ȵś»ńö©µØźÕ£©õĖŹÕÉīµĪåµ×ČķŚ┤õ╝ĀķĆƵ©ĪÕ×ŗ’╝łµ»öÕ”é PyTorch Õł░ Tensorflow’╝ēĶĆīõĖŹµś»ńö©õ║Äķā©ńĮ▓’╝īÕłÖÕÅ»õ╗źõ╗żĶ┐ÖõĖ¬ÕÅéµĢ░õĖ║ FalseŃĆé
+
+#### input_names, output_names
+
+Ķ«ŠńĮ«ĶŠōÕģźÕÆīĶŠōÕć║Õ╝ĀķćÅńÜäÕÉŹń¦░ŃĆéÕ”éµ×£õĖŹĶ«ŠńĮ«ńÜäĶ»Ø’╝īõ╝ÜĶć¬ÕŖ©ÕłåķģŹõĖĆõ║øń«ĆÕŹĢńÜäÕÉŹÕŁŚ’╝łÕ”éµĢ░ÕŁŚ’╝ēŃĆé
+ONNX µ©ĪÕ×ŗńÜäµ»ÅõĖ¬ĶŠōÕģźÕÆīĶŠōÕć║Õ╝ĀķćÅķāĮµ£ēõĖĆõĖ¬ÕÉŹÕŁŚŃĆéÕŠłÕżÜµÄ©ńÉåÕ╝ĢµōÄÕ£©Ķ┐ÉĶĪī ONNX µ¢ćõ╗ȵŚČ’╝īķāĮķ£ĆĶ”üõ╗źŌĆ£ÕÉŹń¦░-Õ╝ĀķćÅÕĆ╝ŌĆØńÜäµĢ░µŹ«Õ»╣µØźĶŠōÕģźµĢ░µŹ«’╝īÕ╣ȵĀ╣µŹ«ĶŠōÕć║Õ╝ĀķćÅńÜäÕÉŹń¦░µØźĶÄĘÕÅ¢ĶŠōÕć║µĢ░µŹ«ŃĆéÕ£©Ķ┐øĶĪīĶʤÕ╝Āķćŵ£ēÕģ│ńÜäĶ«ŠńĮ«’╝łµ»öÕ”éµĘ╗ÕŖĀÕŖ©µĆüń╗┤Õ║”’╝ēµŚČ’╝īõ╣¤ķ£ĆĶ”üń¤źķüōÕ╝ĀķćÅńÜäÕÉŹÕŁŚŃĆé
+Õ£©Õ«×ķÖģńÜäķā©ńĮ▓µĄüµ░┤ń║┐õĖŁ’╝īµłæõ╗¼ķāĮķ£ĆĶ”üĶ«ŠńĮ«ĶŠōÕģźÕÆīĶŠōÕć║Õ╝ĀķćÅńÜäÕÉŹń¦░’╝īÕ╣Čõ┐ØĶ»ü ONNX ÕÆīµÄ©ńÉåÕ╝ĢµōÄõĖŁõĮ┐ńö©ÕÉīõĖĆÕźŚÕÉŹń¦░ŃĆé
+
+#### opset_version
+
+ĶĮ¼µŹóµŚČÕÅéĶĆāÕō¬õĖ¬ ONNX ń«ŚÕŁÉķøåńēłµ£¼’╝īķ╗śĶ«żõĖ║9ŃĆéÕÉĵ¢ćõ╝ÜĶ»”ń╗åõ╗ŗń╗Ź PyTorch õĖÄ ONNX ńÜäń«ŚÕŁÉÕ»╣Õ║öÕģ│ń│╗ŃĆé
+
+#### dynamic_axes
+
+µīćÕ«ÜĶŠōÕģźĶŠōÕć║Õ╝ĀķćÅńÜäÕō¬õ║øń╗┤Õ║”µś»ÕŖ©µĆüńÜäŃĆé
+õĖ║õ║åĶ┐Įµ▒éµĢłńÄć’╝īONNX ķ╗śĶ«żµēƵ£ēÕÅéõĖÄĶ┐Éń«ŚńÜäÕ╝ĀķćÅķāĮµś»ķØÖµĆüńÜä’╝łÕ╝ĀķćÅńÜäÕĮóńŖČõĖŹÕÅæńö¤µö╣ÕÅś’╝ēŃĆéõĮåÕ£©Õ«×ķÖģÕ║öńö©õĖŁ’╝īµłæõ╗¼ÕÅłÕĖīµ£øµ©ĪÕ×ŗńÜäĶŠōÕģźÕ╝Āķćŵś»ÕŖ©µĆüńÜä’╝īÕ░żÕģȵś»µ£¼µØźÕ░▒µ▓Īµ£ēÕĮóńŖČķÖÉÕłČńÜäÕģ©ÕŹĘń¦»µ©ĪÕ×ŗŃĆéÕøĀµŁż’╝īµłæõ╗¼ķ£ĆĶ”üµśŠÕ╝ÅÕ£░µī浜ÄĶŠōÕģźĶŠōÕć║Õ╝ĀķćÅńÜäÕō¬ÕćĀõĖ¬ń╗┤Õ║”ńÜäÕż¦Õ░ŵś»ÕÅ»ÕÅśńÜäŃĆé
+µłæõ╗¼µØźń£ŗõĖĆõĖ¬`dynamic_axes`ńÜäĶ«ŠńĮ«õŠŗÕŁÉ’╝Ü
+
+```python
+import torch
+
+class Model(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.conv = torch.nn.Conv2d(3, 3, 3)
+
+ def forward(self, x):
+ x = self.conv(x)
+ return x
+
+
+model = Model()
+dummy_input = torch.rand(1, 3, 10, 10)
+model_names = ['model_static.onnx',
+'model_dynamic_0.onnx',
+'model_dynamic_23.onnx']
+
+dynamic_axes_0 = {
+ 'in' : [0],
+ 'out' : [0]
+}
+dynamic_axes_23 = {
+ 'in' : [2, 3],
+ 'out' : [2, 3]
+}
+
+torch.onnx.export(model, dummy_input, model_names[0],
+input_names=['in'], output_names=['out'])
+torch.onnx.export(model, dummy_input, model_names[1],
+input_names=['in'], output_names=['out'], dynamic_axes=dynamic_axes_0)
+torch.onnx.export(model, dummy_input, model_names[2],
+input_names=['in'], output_names=['out'], dynamic_axes=dynamic_axes_23)
+```
+
+ķ”¢Õģł’╝īµłæõ╗¼Õ»╝Õć║3õĖ¬ ONNX µ©ĪÕ×ŗ’╝īÕłåÕł½õĖ║µ▓Īµ£ēÕŖ©µĆüń╗┤Õ║”ŃĆüń¼¼0ń╗┤ÕŖ©µĆüŃĆüń¼¼2ń¼¼3ń╗┤ÕŖ©µĆüńÜ䵩ĪÕ×ŗŃĆé
+Õ£©Ķ┐Öõ╗Įõ╗ŻńĀüķćī’╝īµłæõ╗¼µś»ńö©ÕłŚĶĪ©ńÜäµ¢╣Õ╝ÅĶĪ©ńż║ÕŖ©µĆüń╗┤Õ║”’╝īõŠŗÕ”é’╝Ü
+
+````python
+dynamic_axes_0 = {
+ 'in' : [0],
+ 'out' : [0]
+}
+```
+
+ńö▒õ║Ä ONNX Ķ”üµ▒éµ»ÅõĖ¬ÕŖ©µĆüń╗┤Õ║”ķāĮµ£ēõĖĆõĖ¬ÕÉŹÕŁŚ’╝īĶ┐ÖµĀĘÕåÖńÜäĶ»Øõ╝ÜÕ╝ĢÕć║õĖƵØĪ UserWarning’╝īĶŁ”ÕæŖµłæõ╗¼ķĆÜĶ┐ćÕłŚĶĪ©ńÜäµ¢╣Õ╝ÅĶ«ŠńĮ«ÕŖ©µĆüń╗┤Õ║”ńÜäĶ»Øń│╗ń╗¤õ╝ÜĶć¬ÕŖ©õĖ║Õ«āõ╗¼ÕłåķģŹÕÉŹÕŁŚŃĆéõĖĆń¦ŹµśŠÕ╝ŵĘ╗ÕŖĀÕŖ©µĆüń╗┤Õ║”ÕÉŹÕŁŚńÜäµ¢╣µ│ĢÕ”éõĖŗ’╝Ü
+```python
+dynamic_axes_0 = {
+ 'in' : {0: 'batch'},
+ 'out' : {0: 'batch'}
+}
+````
+
+ńö▒õ║ÄÕ£©Ķ┐Öõ╗Įõ╗ŻńĀüķćīµłæõ╗¼µ▓Īµ£ēµø┤ÕżÜńÜäÕ»╣ÕŖ©µĆüń╗┤Õ║”ńÜäµōŹõĮ£’╝īÕøĀµŁżń«ĆÕŹĢÕ£░ńö©ÕłŚĶĪ©µīćÕ«ÜÕŖ©µĆüń╗┤Õ║”ÕŹ│ÕÅ»ŃĆé
+õ╣ŗÕÉÄ’╝īµłæõ╗¼ńö©õĖŗķØóńÜäõ╗ŻńĀüµØźń£ŗõĖĆń£ŗÕŖ©µĆüń╗┤Õ║”ńÜäõĮ£ńö©’╝Ü
+
+```python
+import onnxruntime
+import numpy as np
+
+origin_tensor = np.random.rand(1, 3, 10, 10).astype(np.float32)
+mult_batch_tensor = np.random.rand(2, 3, 10, 10).astype(np.float32)
+big_tensor = np.random.rand(1, 3, 20, 20).astype(np.float32)
+
+inputs = [origin_tensor, mult_batch_tensor, big_tensor]
+exceptions = dict()
+
+for model_name in model_names:
+ for i, input in enumerate(inputs):
+ try:
+ ort_session = onnxruntime.InferenceSession(model_name)
+ ort_inputs = {'in': input}
+ ort_session.run(['out'], ort_inputs)
+ except Exception as e:
+ exceptions[(i, model_name)] = e
+ print(f'Input[{i}] on model {model_name} error.')
+ else:
+ print(f'Input[{i}] on model {model_name} succeed.')
+```
+
+µłæõ╗¼Õ£©µ©ĪÕ×ŗÕ»╝Õć║Ķ«Īń«ŚÕøŠµŚČńö©ńÜ䵜»õĖĆõĖ¬ÕĮóńŖČõĖ║`(1, 3, 10, 10)`ńÜäÕ╝ĀķćÅŃĆéńÄ░Õ£©’╝īµłæõ╗¼µØźÕ░ØĶ»Ģõ╗źÕĮóńŖČÕłåÕł½µś»`(1, 3, 10, 10), (2, 3, 10, 10), (1, 3, 20, 20)`õĖ║ĶŠōÕģź’╝īńö©ONNX RuntimeĶ┐ÉĶĪīõĖĆõĖŗĶ┐ÖÕćĀõĖ¬µ©ĪÕ×ŗ’╝īń£ŗń£ŗÕō¬õ║øµāģÕåĄõĖŗõ╝ܵŖźķöÖ’╝īÕ╣Čõ┐ØÕŁśÕ»╣Õ║öńÜäµŖźķöÖõ┐Īµü»ŃĆéÕŠŚÕł░ńÜäĶŠōÕć║õ┐Īµü»Õ║öĶ»źÕ”éõĖŗ’╝Ü
+
+```python
+Input[0] on model model_static.onnx succeed.
+Input[1] on model model_static.onnx error.
+Input[2] on model model_static.onnx error.
+Input[0] on model model_dynamic_0.onnx succeed.
+Input[1] on model model_dynamic_0.onnx succeed.
+Input[2] on model model_dynamic_0.onnx error.
+Input[0] on model model_dynamic_23.onnx succeed.
+Input[1] on model model_dynamic_23.onnx error.
+Input[2] on model model_dynamic_23.onnx succeed.
+```
+
+ÕÅ»õ╗źń£ŗÕć║’╝īÕĮóńŖČńøĖÕÉīńÜä`(1, 3, 10, 10)`ńÜäĶŠōÕģźÕ£©µēƵ£ēµ©ĪÕ×ŗõĖŖķāĮµ▓Īµ£ēÕć║ķöÖŃĆéĶĆīÕ»╣õ║Äbatch’╝łń¼¼0ń╗┤’╝ēµł¢ĶĆģķĢ┐Õ«Į’╝łń¼¼2ŃĆü3ń╗┤’╝ēõĖŹÕÉīńÜäĶŠōÕģź’╝īÕŬµ£ēÕ£©Ķ«ŠńĮ«õ║åÕ»╣Õ║öńÜäÕŖ©µĆüń╗┤Õ║”ÕÉĵēŹõĖŹõ╝ÜÕć║ķöÖŃĆ鵳æõ╗¼ÕÅ»õ╗źķöÖĶ»»õ┐Īµü»õĖŁµēŠÕć║µś»Õō¬õ║øń╗┤Õ║”Õć║õ║åķŚ«ķóśŃĆéµ»öÕ”éµłæõ╗¼ÕÅ»õ╗źńö©õ╗źõĖŗõ╗ŻńĀüµ¤źń£ŗ`input[1]`Õ£©`model_static.onnx`õĖŁńÜäµŖźķöÖõ┐Īµü»’╝Ü
+
+```python
+print(exceptions[(1, 'model_static.onnx')])
+
+# output
+# [ONNXRuntimeError] : 2 : INVALID_ARGUMENT : Got invalid dimensions for input: in for the following indices index: 0 Got: 2 Expected: 1 Please fix either the inputs or the model.
+```
+
+Ķ┐Öµ«ĄµŖźķöÖÕæŖĶ»ēµłæõ╗¼ÕÉŹÕŁŚÕŽ`in`ńÜäĶŠōÕģźńÜäń¼¼0ń╗┤õĖŹÕī╣ķģŹŃĆéµ£¼µØźĶ»źń╗┤ńÜäķĢ┐Õ║”Õ║öĶ»źõĖ║1’╝īõĮåµłæõ╗¼ńÜäĶŠōÕģźµś»2ŃĆéÕ«×ķÖģķā©ńĮ▓õĖŁ’╝īÕ”éµ×£µłæõ╗¼ńó░Õł░õ║åń▒╗õ╝╝ńÜäµŖźķöÖ’╝īÕ░▒ÕÅ»õ╗źķĆÜĶ┐ćĶ«ŠńĮ«ÕŖ©µĆüń╗┤Õ║”µØźĶ¦ŻÕå│ķŚ«ķóśŃĆé
+
+### õĮ┐ńö©µŖĆÕʦ
+
+ķĆÜĶ┐ćÕŁ”õ╣Āõ╣ŗÕēŹńÜäń¤źĶ»å’╝īµłæõ╗¼Õ¤║µ£¼µÄīµÅĪõ║å `torch.onnx.export` ÕćĮµĢ░ńÜäķā©ÕłåÕ«×ńÄ░ÕĤńÉåÕÆīÕÅéµĢ░Ķ«ŠńĮ«µ¢╣µ│Ģ’╝īĶČ│õ╗źÕ«īµłÉń«ĆÕŹĢµ©ĪÕ×ŗńÜäĶĮ¼µŹóõ║åŃĆéõĮåÕ£©Õ«×ķÖģÕ║öńö©õĖŁ’╝īõĮ┐ńö©Ķ»źÕćĮµĢ░Ķ┐śõ╝ÜĶĖ®ÕŠłÕżÜÕØæŃĆéĶ┐Öķćīµłæõ╗¼µ©ĪÕ×ŗķā©ńĮ▓Õøóķś¤µŖŖÕ£©Õ«×µłśõĖŁń¦»ń┤»ńÜäõĖĆõ║øń╗Åķ¬īÕłåõ║½ń╗ÖÕż¦Õ«ČŃĆé
+
+#### õĮ┐µ©ĪÕ×ŗÕ£© ONNX ĶĮ¼µŹóµŚČµ£ēõĖŹÕÉīńÜäĶĪīõĖ║
+
+µ£ēõ║øµŚČÕĆÖ’╝īµłæõ╗¼ÕĖīµ£øµ©ĪÕ×ŗÕ£©ńø┤µÄźńö© PyTorch µÄ©ńÉåµŚČµ£ēõĖĆÕźŚķĆ╗ĶŠæ’╝īĶĆīÕ£©Õ»╝Õć║ńÜäONNXµ©ĪÕ×ŗõĖŁµ£ēÕÅ”õĖĆÕźŚķĆ╗ĶŠæŃĆéµ»öÕ”é’╝īµłæõ╗¼ÕÅ»õ╗źµŖŖõĖĆõ║øÕÉÄÕżäńÉåńÜäķĆ╗ĶŠæµöŠÕ£©µ©ĪÕ×ŗķćī’╝īõ╗źń«ĆÕī¢ķÖżĶ┐ÉĶĪīµ©ĪÕ×ŗõ╣ŗÕż¢ńÜäÕģČõ╗¢õ╗ŻńĀüŃĆé`torch.onnx.is_in_onnx_export()`ÕÅ»õ╗źÕ«×ńÄ░Ķ┐ÖõĖĆõ╗╗ÕŖĪ’╝īĶ»źÕćĮµĢ░õ╗ģÕ£©µē¦ĶĪī `torch.onnx.export()`µŚČõĖ║ń£¤ŃĆéõ╗źõĖŗµś»õĖĆõĖ¬õŠŗÕŁÉ’╝Ü
+
+```python
+import torch
+
+class Model(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.conv = torch.nn.Conv2d(3, 3, 3)
+
+ def forward(self, x):
+ x = self.conv(x)
+ if torch.onnx.is_in_onnx_export():
+ x = torch.clip(x, 0, 1)
+ return x
+```
+
+Ķ┐Öķćī’╝īµłæõ╗¼õ╗ģÕ£©µ©ĪÕ×ŗÕ»╝Õć║µŚČµŖŖĶŠōÕć║Õ╝ĀķćÅńÜäµĢ░ÕĆ╝ķÖÉÕłČÕ£©[0, 1]õ╣ŗķŚ┤ŃĆéõĮ┐ńö© `is_in_onnx_export` ńĪ«Õ«×ĶāĮĶ«®µłæõ╗¼µ¢╣õŠ┐Õ£░Õ£©õ╗ŻńĀüõĖŁµĘ╗ÕŖĀÕÆīµ©ĪÕ×ŗķā©ńĮ▓ńøĖÕģ│ńÜäķĆ╗ĶŠæŃĆéõĮåµś»’╝īĶ┐Öõ║øõ╗ŻńĀüÕ»╣ÕŬÕģ│Õ┐āµ©ĪÕ×ŗĶ«Łń╗āńÜäÕ╝ĆÕÅæĶĆģÕÆīńö©µłĘµØźĶ»┤ÕŠłõĖŹÕÅŗÕźĮ’╝īń¬üÕģĆńÜäķā©ńĮ▓ķĆ╗ĶŠæõ╝ÜķÖŹõĮÄõ╗ŻńĀüµĢ┤õĮōńÜäÕÅ»Ķ»╗µĆ¦ŃĆéÕÉīµŚČ’╝ī`is_in_onnx_export` ÕŬĶāĮÕ£©µ»ÅõĖ¬ķ£ĆĶ”üµĘ╗ÕŖĀķā©ńĮ▓ķĆ╗ĶŠæńÜäÕ£░µ¢╣ķāĮŌĆ£µēōĶĪźõĖüŌĆØ’╝īķÜŠõ╗źĶ┐øĶĪīń╗¤õĖĆńÜäń«ĪńÉåŃĆ鵳æõ╗¼õ╣ŗÕÉÄõ╝Üõ╗ŗń╗ŹÕ”éõĮĢõĮ┐ńö© MMDeploy ńÜäķćŹÕåÖµ£║ÕłČµØźĶ¦äķü┐Ķ┐Öõ║øķŚ«ķóśŃĆé
+
+#### Õł®ńö©õĖŁµ¢ŁÕ╝ĀķćÅĶʤĶĖ¬ńÜäµōŹõĮ£
+
+PyTorch ĶĮ¼ ONNX ńÜäĶʤĶĖ¬Õ»╝Õć║µ│Ģµś»õĖŹµś»õĖćĶāĮńÜäŃĆéÕ”éµ×£µłæõ╗¼Õ£©µ©ĪÕ×ŗõĖŁÕüÜõ║åõĖĆõ║øÕŠłŌĆ£Õć║µĀ╝ŌĆØńÜäµōŹõĮ£’╝īĶʤĶĖ¬µ│Ģõ╝ܵŖŖµ¤Éõ║øÕÅ¢Õå│õ║ÄĶŠōÕģźńÜäõĖŁķŚ┤ń╗ōµ×£ÕÅśµłÉÕĖĖķćÅ’╝īõ╗ÄĶĆīõĮ┐Õ»╝Õć║ńÜäONNXµ©ĪÕ×ŗÕÆīÕĤµØźńÜ䵩ĪÕ×ŗµ£ēÕć║ÕģźŃĆéõ╗źõĖŗµś»õĖĆõĖ¬õ╝ÜķĆĀµłÉĶ┐Öń¦ŹŌĆ£ĶʤĶĖ¬õĖŁµ¢ŁŌĆØńÜäõŠŗÕŁÉ’╝Ü
+
+```python
+class Model(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ def forward(self, x):
+ x = x * x[0].item()
+ return x, torch.Tensor([i for i in x])
+
+model = Model()
+dummy_input = torch.rand(10)
+torch.onnx.export(model, dummy_input, 'a.onnx')
+```
+
+Õ”éµ×£õĮĀÕ░ØĶ»ĢÕÄ╗Õ»╝Õć║Ķ┐ÖõĖ¬µ©ĪÕ×ŗ’╝īõ╝ÜÕŠŚÕł░õĖĆÕż¦ÕĀå warning’╝īÕæŖĶ»ēõĮĀĶĮ¼µŹóÕć║µØźńÜ䵩ĪÕ×ŗÕÅ»ĶāĮõĖŹµŁŻńĪ«ŃĆéĶ┐Öõ╣¤ķÜŠµĆ¬’╝īµłæõ╗¼Õ£©Ķ┐ÖõĖ¬µ©ĪÕ×ŗķćīõĮ┐ńö©õ║å`.item()`µŖŖ torch õĖŁńÜäÕ╝ĀķćÅĶĮ¼µŹóµłÉõ║åµÖ«ķĆÜńÜä Python ÕÅśķćÅ’╝īĶ┐śÕ░ØĶ»ĢķüŹÕÄå torch Õ╝ĀķćÅ’╝īÕ╣Čńö©õĖĆõĖ¬ÕłŚĶĪ©µ¢░Õ╗║õĖĆõĖ¬ torch Õ╝ĀķćÅŃĆéĶ┐Öõ║øµČēÕÅŖÕ╝ĀķćÅõĖĵ֫ķĆÜÕÅśķćÅĶĮ¼µŹóńÜäķĆ╗ĶŠæķāĮõ╝ÜÕ»╝Ķć┤µ£Ćń╗łńÜä ONNX µ©ĪÕ×ŗõĖŹÕż¬µŁŻńĪ«ŃĆé
+ÕÅ”õĖƵ¢╣ķØó’╝īµłæõ╗¼õ╣¤ÕÅ»õ╗źÕł®ńö©Ķ┐ÖõĖ¬µĆ¦Ķ┤©’╝īÕ£©õ┐ØĶ»üµŁŻńĪ«µĆ¦ńÜäÕēŹµÅÉõĖŗõ╗żµ©ĪÕ×ŗńÜäõĖŁķŚ┤ń╗ōµ×£ÕÅśµłÉÕĖĖķćÅŃĆéĶ┐ÖõĖ¬µŖĆÕʦÕĖĖÕĖĖńö©õ║ĵ©ĪÕ×ŗńÜäķØÖµĆüÕī¢õĖŖ’╝īÕŹ│õ╗żµ©ĪÕ×ŗõĖŁµēƵ£ēńÜäÕ╝ĀķćÅÕĮóńŖČķāĮÕÅśµłÉÕĖĖķćÅŃĆéÕ£©µ£¬µØźńÜäµĢÖń©ŗõĖŁ’╝īµłæõ╗¼õ╝ÜÕ£©ķā©ńĮ▓Õ«×õŠŗõĖŁĶ»”ń╗åõ╗ŗń╗ŹĶ┐Öõ║øŌĆ£ķ½śń║¦ŌĆصōŹõĮ£ŃĆé
+
+#### õĮ┐ńö©Õ╝ĀķćÅõĖ║ĶŠōÕģź’╝łPyTorchńēłµ£¼ \< 1.9.0’╝ē
+
+µŁŻÕ”鵳æõ╗¼ń¼¼õĖĆń»ćµĢÖń©ŗµēĆÕ▒Ģńż║ńÜä’╝īÕ£©ĶŠāµŚ¦(\< 1.9.0)ńÜä PyTorch õĖŁµŖŖ Python µĢ░ÕĆ╝õĮ£õĖ║ `torch.onnx.export()`ńÜ䵩ĪÕ×ŗĶŠōÕģźµŚČõ╝ܵŖźķöÖŃĆéÕć║õ║ÄÕģ╝Õ«╣µĆ¦ńÜäĶĆāĶÖæ’╝īµłæõ╗¼Ķ┐śµś»µÄ©ĶŹÉõ╗źÕ╝ĀķćÅõĖ║µ©ĪÕ×ŗĶĮ¼µŹóµŚČńÜ䵩ĪÕ×ŗĶŠōÕģźŃĆé
+
+## PyTorch Õ»╣ ONNX ńÜäń«ŚÕŁÉµö»µīü
+
+Õ£©ńĪ«õ┐Ø`torch.onnx.export()`ńÜäĶ░āńö©µ¢╣µ│ĢµŚĀĶ»»ÕÉÄ’╝īPyTorch ĶĮ¼ ONNX µŚČµ£ĆÕ«╣µśōÕć║ńÄ░ńÜäķŚ«ķóśÕ░▒µś»ń«ŚÕŁÉõĖŹÕģ╝Õ«╣õ║åŃĆéĶ┐Öķćīµłæõ╗¼õ╝Üõ╗ŗń╗ŹÕ”éõĮĢÕłżµ¢Łµ¤ÉõĖ¬ PyTorch ń«ŚÕŁÉÕ£© ONNX õĖŁµś»ÕÉ”Õģ╝Õ«╣’╝īõ╗źÕŖ®Õż¦Õ«ČÕ£©ńó░Õł░µŖźķöÖµŚČĶāĮµø┤ÕźĮÕ£░µŖŖķöÖĶ»»ÕĮÆń▒╗ŃĆéĶĆīÕģĘõĮōµĘ╗ÕŖĀń«ŚÕŁÉńÜäµ¢╣µ│Ģµłæõ╗¼õ╝ÜÕ£©õ╣ŗÕÉÄńÜäµ¢ćń½Āķćīõ╗ŗń╗ŹŃĆé
+Õ£©ĶĮ¼µŹóµÖ«ķĆÜńÜä`torch.nn.Module`µ©ĪÕ×ŗµŚČ’╝īPyTorch õĖƵ¢╣ķØóõ╝Üńö©ĶʤĶĖ¬µ│Ģµē¦ĶĪīÕēŹÕÉæµÄ©ńÉå’╝īµŖŖķüćÕł░ńÜäń«ŚÕŁÉµĢ┤ÕÉłµłÉĶ«Īń«ŚÕøŠ’╝øÕÅ”õĖƵ¢╣ķØó’╝īPyTorch Ķ┐śõ╝ܵŖŖķüćÕł░ńÜäµ»ÅõĖ¬ń«ŚÕŁÉń┐╗Ķ»æµłÉ ONNX õĖŁÕ«Üõ╣ēńÜäń«ŚÕŁÉŃĆéÕ£©Ķ┐ÖõĖ¬ń┐╗Ķ»æĶ┐ćń©ŗõĖŁ’╝īÕÅ»ĶāĮõ╝Üńó░Õł░õ╗źõĖŗµāģÕåĄ’╝Ü
+
+- Ķ»źń«ŚÕŁÉÕÅ»õ╗źõĖĆÕ»╣õĖĆÕ£░ń┐╗Ķ»æµłÉõĖĆõĖ¬ ONNX ń«ŚÕŁÉŃĆé
+- Ķ»źń«ŚÕŁÉÕ£© ONNX õĖŁµ▓Īµ£ēńø┤µÄźÕ»╣Õ║öńÜäń«ŚÕŁÉ’╝īõ╝Üń┐╗Ķ»æµłÉõĖĆĶć│ÕżÜõĖ¬ ONNX ń«ŚÕŁÉŃĆé
+- Ķ»źń«ŚÕŁÉµ▓Īµ£ēÕ«Üõ╣ēń┐╗Ķ»æµłÉ ONNX ńÜäĶ¦äÕłÖ’╝īµŖźķöÖŃĆé
+
+ķéŻõ╣ł’╝īĶ»źÕ”éõĮĢµ¤źń£ŗ PyTorch ń«ŚÕŁÉõĖÄ ONNX ń«ŚÕŁÉńÜäÕ»╣Õ║öµāģÕåĄÕæó’╝¤ńö▒õ║Ä PyTorch ń«ŚÕŁÉµś»ÕÉæ ONNX Õ»╣ķĮÉńÜä’╝īĶ┐Öķćīµłæõ╗¼Õģłń£ŗõĖĆõĖŗ ONNX ń«ŚÕŁÉńÜäÕ«Üõ╣ēµāģÕåĄ’╝īÕåŹń£ŗõĖĆõĖŗ PyTorch Õ«Üõ╣ēńÜäń«ŚÕŁÉµśĀÕ░äÕģ│ń│╗ŃĆé
+
+### ONNX ń«ŚÕŁÉµ¢ćµĪŻ
+
+ONNX ń«ŚÕŁÉńÜäÕ«Üõ╣ēµāģÕåĄ’╝īķāĮÕÅ»õ╗źÕ£©Õ«śµ¢╣ńÜä[ń«ŚÕŁÉµ¢ćµĪŻ](https://github.com/onnx/onnx/blob/main/docs/Operators.md)õĖŁµ¤źń£ŗŃĆéĶ┐Öõ╗Įµ¢ćµĪŻÕŹüÕłåķćŹĶ”ü’╝īµłæõ╗¼ńó░Õł░õ╗╗õĮĢÕÆī ONNX ń«ŚÕŁÉµ£ēÕģ│ńÜäķŚ«ķóśķāĮÕŠŚµØźŌĆØĶ»ĘµĢÖŌĆ£Ķ┐Öõ╗Įµ¢ćµĪŻŃĆé
+
+
+
+Ķ┐Öõ╗Įµ¢ćµĪŻõĖŁµ£ĆķćŹĶ”üńÜäÕ╝ĆÕż┤ńÜäĶ┐ÖõĖ¬ń«ŚÕŁÉÕÅśµø┤ĶĪ©µĀ╝ŃĆéĶĪ©µĀ╝ńÜäń¼¼õĖĆÕłŚµś»ń«ŚÕŁÉÕÉŹ’╝īń¼¼õ║īÕłŚµś»Ķ»źń«ŚÕŁÉÕÅæńö¤ÕÅśÕŖ©ńÜäń«ŚÕŁÉķøåńēłµ£¼ÕÅĘ’╝īõ╣¤Õ░▒µś»µłæõ╗¼õ╣ŗÕēŹÕ£©`torch.onnx.export`õĖŁµÅÉÕł░ńÜä`opset_version`ĶĪ©ńż║ńÜäń«ŚÕŁÉķøåńēłµ£¼ÕÅĘŃĆéķĆÜĶ┐浤źń£ŗń«ŚÕŁÉń¼¼õĖƵ¼ĪÕÅæńö¤ÕÅśÕŖ©ńÜäńēłµ£¼ÕÅĘ’╝īµłæõ╗¼ÕÅ»õ╗źń¤źķüōµ¤ÉõĖ¬ń«ŚÕŁÉµś»õ╗ÄÕō¬õĖ¬ńēłµ£¼Õ╝ĆÕ¦ŗµö»µīüńÜä’╝øķĆÜĶ┐浤źń£ŗµ¤Éń«ŚÕŁÉÕ░Åõ║ÄńŁēõ║Ä`opset_version`ńÜäń¼¼õĖĆõĖ¬µö╣ÕŖ©Ķ«░ÕĮĢ’╝īµłæõ╗¼ÕÅ»õ╗źń¤źķüōÕĮōÕēŹń«ŚÕŁÉķøåńēłµ£¼õĖŁĶ»źń«ŚÕŁÉńÜäÕ«Üõ╣ēĶ¦äÕłÖŃĆé
+
+
+
+ķĆÜĶ┐ćńé╣Õć╗ĶĪ©µĀ╝õĖŁńÜäķōŠµÄź’╝īµłæõ╗¼ÕÅ»õ╗źµ¤źń£ŗµ¤ÉõĖ¬ń«ŚÕŁÉńÜäĶŠōÕģźŃĆüĶŠōÕć║ÕÅéµĢ░Ķ¦äÕ«ÜÕÅŖõĮ┐ńö©ńż║õŠŗŃĆéµ»öÕ”éõĖŖÕøŠµś»ReluÕ£© ONNX õĖŁńÜäÕ«Üõ╣ēĶ¦äÕłÖ’╝īĶ┐Öõ╗ĮÕ«Üõ╣ēĶĪ©µśÄ Relu Õ║öĶ»źµ£ēõĖĆõĖ¬ĶŠōÕģźÕÆīõĖĆõĖ¬ĶŠōÕģź’╝īĶŠōÕģźĶŠōÕć║ńÜäń▒╗Õ×ŗńøĖÕÉī’╝īÕØćõĖ║ tensorŃĆé
+
+### PyTorch Õ»╣ ONNX ń«ŚÕŁÉńÜ䵜ĀÕ░ä
+
+Õ£© PyTorch õĖŁ’╝īÕÆī ONNX µ£ēÕģ│ńÜäÕ«Üõ╣ēÕģ©ķā©µöŠÕ£© [torch.onnx ńø«ÕĮĢ](https://github.com/pytorch/pytorch/tree/main/torch/onnx)õĖŁ’╝īÕ”éõĖŗÕøŠµēĆńż║’╝Ü
+
+
+
+ÕģČõĖŁ’╝ī`symbloic_opset{n}.py`’╝łń¼”ÕÅĘĶĪ©µ¢ćõ╗Č’╝ēÕŹ│ĶĪ©ńż║ PyTorch Õ£©µö»µīüń¼¼ n ńēł ONNX ń«ŚÕŁÉķøåµŚČµ¢░ÕŖĀÕģźńÜäÕåģÕ«╣ŃĆ鵳æõ╗¼õ╣ŗÕēŹĶ«▓Ķ┐ć’╝ī bicubic µÅÆÕĆ╝µś»Õ£©ń¼¼ 11 õĖ¬ńēłµ£¼Õ╝ĆÕ¦ŗµö»µīüńÜäŃĆ鵳æõ╗¼õ╗źÕ«āõĖ║õŠŗµØźń£ŗń£ŗÕ”éõĮĢµ¤źµēŠń«ŚÕŁÉńÜ䵜ĀÕ░äµāģÕåĄŃĆé
+ķ”¢Õģł’╝īõĮ┐ńö©µÉ£ń┤óÕŖ¤ĶāĮ’╝īÕ£©`torch/onnx`µ¢ćõ╗ČÕż╣µÉ£ń┤ó"bicubic"’╝īÕÅ»õ╗źÕÅæńÄ░Ķ┐ÖõĖ¬Ķ┐ÖõĖ¬µÅÆÕĆ╝Õ£©ń¼¼ 11 õĖ¬ńēłµ£¼ńÜäÕ«Üõ╣ēµ¢ćõ╗ČõĖŁ’╝Ü
+
+
+
+õ╣ŗÕÉÄ’╝īµłæõ╗¼µīēńģ¦õ╗ŻńĀüńÜäĶ░āńö©ķĆ╗ĶŠæ’╝īķĆɵŁźĶĘ│ĶĮ¼ńø┤Õł░µ£ĆÕ║ĢÕ▒éńÜä ONNX µśĀÕ░äÕćĮµĢ░’╝Ü
+
+```python
+upsample_bicubic2d = _interpolate("upsample_bicubic2d", 4, "cubic")
+
+->
+
+def _interpolate(name, dim, interpolate_mode):
+ return sym_help._interpolate_helper(name, dim, interpolate_mode)
+
+->
+
+def _interpolate_helper(name, dim, interpolate_mode):
+ def symbolic_fn(g, input, output_size, *args):
+ ...
+
+ return symbolic_fn
+```
+
+µ£ĆÕÉÄ’╝īÕ£©`symbolic_fn`õĖŁ’╝īµłæõ╗¼ÕÅ»õ╗źń£ŗÕł░µÅÆÕĆ╝ń«ŚÕŁÉµś»µĆÄõ╣łµĀĘĶó½µśĀÕ░䵳ÉÕżÜõĖ¬ ONNX ń«ŚÕŁÉńÜäŃĆéÕģČõĖŁ’╝īµ»ÅõĖĆõĖ¬`g.op`Õ░▒µś»õĖĆõĖ¬ ONNX ńÜäÕ«Üõ╣ēŃĆéµ»öÕ”éÕģČõĖŁńÜä `Resize` ń«ŚÕŁÉÕ░▒µś»Ķ┐ÖµĀĘÕåÖńÜä’╝Ü
+
+```python
+ return g.op("Resize",
+ input,
+ empty_roi,
+ empty_scales,
+ output_size,
+ coordinate_transformation_mode_s=coordinate_transformation_mode,
+ cubic_coeff_a_f=-0.75, # only valid when mode="cubic"
+ mode_s=interpolate_mode, # nearest, linear, or cubic
+ nearest_mode_s="floor") # only valid when mode="nearest"
+```
+
+ķĆÜĶ┐ćÕ£©ÕēŹķØóµÅÉÕł░ńÜä ONNX ń«ŚÕŁÉµ¢ćµĪŻõĖŁµ¤źµēŠ [Resize ń«ŚÕŁÉńÜäÕ«Üõ╣ē](https://github.com/onnx/onnx/blob/main/docs/Operators.md#resize)’╝īµłæõ╗¼Õ░▒ÕÅ»õ╗źń¤źķüōĶ┐Öµ»ÅõĖĆõĖ¬ÕÅéµĢ░ńÜäÕɽõ╣ēõ║åŃĆéńö©ń▒╗õ╝╝ńÜäµ¢╣µ│Ģ’╝īµłæõ╗¼ÕÅ»õ╗źÕÄ╗µ¤źĶ»óÕģČõ╗¢ ONNX ń«ŚÕŁÉńÜäÕÅéµĢ░Õɽõ╣ē’╝īĶ┐øĶĆīń¤źķüō PyTorch õĖŁńÜäÕÅéµĢ░µś»µĆĵĀĘõĖƵŁźõĖƵŁźõ╝ĀÕģźÕł░µ»ÅõĖ¬ ONNX ń«ŚÕŁÉõĖŁńÜäŃĆé
+µÄīµÅĪõ║åÕ”éõĮĢµ¤źĶ»ó PyTorch µśĀÕ░äÕł░ ONNX ńÜäÕģ│ń│╗ÕÉÄ’╝īµłæõ╗¼Õ£©Õ«×ķÖģÕ║öńö©µŚČÕ░▒ÕÅ»õ╗źÕ£© `torch.onnx.export()`ńÜä`opset_version`õĖŁÕģłķóäĶ«ŠõĖĆõĖ¬ńēłµ£¼ÕÅĘ’╝īńó░Õł░õ║åķŚ«ķóśÕ░▒ÕÄ╗Õ»╣Õ║öńÜä PyTorch ń¼”ÕÅĘĶĪ©µ¢ćõ╗ČķćīÕÄ╗µ¤źŃĆéÕ”éµ×£µ¤Éń«ŚÕŁÉńĪ«Õ«×õĖŹÕŁśÕ£©’╝īµł¢ĶĆģń«ŚÕŁÉńÜ䵜ĀÕ░äÕģ│ń│╗õĖŹµ╗ĪĶČ│µłæõ╗¼ńÜäĶ”üµ▒é’╝īµłæõ╗¼Õ░▒ÕÅ»ĶāĮÕŠŚńö©ÕģČõ╗¢ńÜäń«ŚÕŁÉń╗ĢĶ┐ćÕÄ╗’╝īµł¢ĶĆģĶć¬Õ«Üõ╣ēń«ŚÕŁÉõ║åŃĆé
+
+## µĆ╗ń╗ō
+
+Õ£©Ķ┐Öń»ćµĢÖń©ŗõĖŁ’╝īµłæõ╗¼ń│╗ń╗¤Õ£░õ╗ŗń╗Źõ║å PyTorch ĶĮ¼ ONNX ńÜäÕĤńÉåŃĆ鵳æõ╗¼Õģłµś»ńØĆķćŹĶ«▓Ķ¦Żõ║åõĮ┐ńö©µ£Ćķóæń╣üńÜä `torch.onnx.export`ÕćĮµĢ░’╝īÕÅłń╗ÖÕć║õ║嵤źĶ»ó PyTorch Õ»╣ ONNX ń«ŚÕŁÉµö»µīüµāģÕåĄńÜäµ¢╣µ│ĢŃĆéķĆÜĶ┐ćµ£¼µ¢ć’╝īµłæõ╗¼ÕĖīµ£øÕż¦Õ«ČĶāĮÕż¤µłÉÕŖ¤ĶĮ¼µŹóÕć║Õż¦ķā©ÕłåõĖŹķ£ĆĶ”üµĘ╗ÕŖĀµ¢░ń«ŚÕŁÉńÜä ONNX µ©ĪÕ×ŗ’╝īÕ╣ČÕ£©ńó░Õł░ń«ŚÕŁÉķŚ«ķ󜵌ČĶāĮÕż¤µ£ēµĢłÕ«ÜõĮŹķŚ«ķóśÕĤÕøĀŃĆéÕģĘõĮōĶĆīĶ©Ć’╝īÕż¦Õ«ČĶ»╗Õ«īµ£¼µ¢ćÕÉÄÕ║öĶ»źõ║åĶ¦Żõ╗źõĖŗńÜäń¤źĶ»å’╝Ü
+
+- ĶʤĶĖ¬µ│ĢÕÆīĶäܵ£¼Õī¢Õ£©Õ»╝Õć║ÕĖ”µÄ¦ÕłČĶ»ŁÕÅźńÜäĶ«Īń«ŚÕøŠµŚČµ£ēõ╗Ćõ╣łÕī║Õł½ŃĆé
+- `torch.onnx.export()`õĖŁĶ»źÕ”éõĮĢĶ«ŠńĮ« `input_names, output_names, dynamic_axes`ŃĆé
+- õĮ┐ńö© `torch.onnx.is_in_onnx_export()`µØźõĮ┐µ©ĪÕ×ŗÕ£©ĶĮ¼µŹóÕł░ ONNX µŚČµ£ēõĖŹÕÉīńÜäĶĪīõĖ║ŃĆé
+- Õ”éõĮĢµ¤źĶ»ó [ONNX ń«ŚÕŁÉµ¢ćµĪŻ](https://github.com/onnx/onnx/blob/main/docs/Operators.md)ŃĆé
+- Õ”éõĮĢµ¤źĶ»ó PyTorch Õ»╣µ¤ÉõĖ¬ ONNX ńēłµ£¼ńÜäµ¢░ńē╣µĆ¦µö»µīüµāģÕåĄŃĆé
+- Õ”éõĮĢÕłżµ¢Ł PyTorch Õ»╣µ¤ÉõĖ¬ ONNX ń«ŚÕŁÉµś»ÕÉ”µö»µīü’╝īµö»µīüńÜäµ¢╣µ│Ģµś»µĆĵĀĘńÜäŃĆé
+
+Ķ┐Öµ£¤õ╗ŗń╗ŹńÜäń¤źĶ»åµ»öĶŠāµŖĮĶ▒Ī’╝īÕż¦Õ«Čõ╝ÜõĖŹõ╝ÜĶ¦ēÕŠŚµ£ēńé╣ŌĆ£µ░┤ŌĆØ’╝¤µ▓ĪÕģ│ń│╗’╝īõĖŗõĖĆń»ćµĢÖń©ŗõĖŁ’╝īµłæõ╗¼Õ░åõ╗źń╗ÖÕć║õ╗ŻńĀüÕ«×õŠŗńÜäÕĮóÕ╝Å’╝īõ╗ŗń╗ŹÕżÜń¦ŹõĖ║ PyTorch ĶĮ¼ ONNX µĘ╗ÕŖĀń«ŚÕŁÉµö»µīüńÜäµ¢╣µ│Ģ’╝īõĖ║Õż¦Õ«ČÕ£© PyTorch ĶĮ¼ ONNX Ķ┐ÖµØĪĶĘ»õĖŖµē½ķÖżµø┤ÕżÜńÜäķÜ£ńóŹŃĆé
+
+## ń╗āõ╣Ā
+
+1. Asinh ń«ŚÕŁÉÕć║ńÄ░õ║Äń¼¼ 9 õĖ¬ ONNX ń«ŚÕŁÉķøåŃĆéPyTorch Õ£© 9 ÕÅĘńēłµ£¼ńÜäń¼”ÕÅĘĶĪ©µ¢ćõ╗ČõĖŁµś»µĆĵĀʵö»µīüĶ┐ÖõĖ¬ń«ŚÕŁÉńÜä’╝¤
+2. BitShift ń«ŚÕŁÉÕć║ńÄ░õ║Äń¼¼11õĖ¬ ONNX ń«ŚÕŁÉķøåŃĆéPyTorch Õ£© 11 ÕÅĘńēłµ£¼ńÜäń¼”ÕÅĘĶĪ©µ¢ćõ╗ČõĖŁµś»µĆĵĀʵö»µīüĶ┐ÖõĖ¬ń«ŚÕŁÉńÜä’╝¤
+3. Õ£© [ń¼¼õĖĆń»ćµĢÖń©ŗ](01_introduction_to_model_deployment.md) õĖŁ’╝īµłæõ╗¼Ķ«▓Ķ┐ć PyTorch ’╝łµł¬Ķć│ń¼¼ 11 ÕÅĘń«ŚÕŁÉķøå’╝ēõĖŹµö»µīüÕ£©µÅÆÕĆ╝õĖŁĶ«ŠńĮ«ÕŖ©µĆüńÜäµöŠń╝®ń│╗µĢ░ŃĆéĶ┐ÖõĖ¬ń│╗µĢ░Õ»╣Õ║ö `torch.onnx.symbolic_helper._interpolate_helper`ńÜäsymbolic_fnńÜäResizeń«ŚÕŁÉµśĀÕ░äÕģ│ń│╗õĖŁńÜäÕō¬õĖ¬ÕÅéµĢ░’╝¤µłæõ╗¼µś»Õ”éõĮĢõ┐«µö╣Ķ┐ÖõĖĆÕÅéµĢ░ńÜä’╝¤
+
+ń╗āõ╣ĀńÜäńŁöµĪłõ╝ÜÕ£©õĖŗµ£¤µĢÖń©ŗõĖŁµÅŁµÖōŃĆé
diff --git a/internlm_langchain/knowledge_base/MMDeploy/content/04_onnx_custom_op.md b/internlm_langchain/knowledge_base/MMDeploy/content/04_onnx_custom_op.md
new file mode 100644
index 00000000..54ebe9e7
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDeploy/content/04_onnx_custom_op.md
@@ -0,0 +1,473 @@
+# ń¼¼Õøøń½Ā’╝ÜÕ£© PyTorch õĖŁµö»µīüµø┤ÕżÜ ONNX ń«ŚÕŁÉ
+
+Õ£©[õĖŖõĖĆń»ćµĢÖń©ŗ](03_pytorch2onnx.md)õĖŁ’╝īµłæõ╗¼ń│╗ń╗¤Õ£░ÕŁ”õ╣Āõ║å PyTorch ĶĮ¼ ONNX ńÜäµ¢╣µ│Ģ’╝īÕÅ»õ╗źÕÅæńÄ░ PyTorch Õ»╣ ONNX ńÜäµö»µīüĶ┐śõĖŹķöÖŃĆéõĮåÕ£©Õ«×ķÖģńÜäķā©ńĮ▓Ķ┐ćń©ŗõĖŁ’╝īķÜŠÕģŹńó░Õł░µ©ĪÕ×ŗµŚĀµ│Ģńö©ÕĤńö¤ PyTorch ń«ŚÕŁÉĶĪ©ńż║ńÜäµāģÕåĄŃĆéĶ┐ÖõĖ¬µŚČÕĆÖ’╝īµłæõ╗¼Õ░▒ÕŠŚĶĆāĶÖæµē®Õģģ PyTorch’╝īÕŹ│Õ£© PyTorch õĖŁµö»µīüµø┤ÕżÜ ONNX ń«ŚÕŁÉŃĆé
+
+ĶĆīĶ”üõĮ┐ PyTorch ń«ŚÕŁÉķĪ║Õł®ĶĮ¼µŹóÕł░ ONNX ’╝īµłæõ╗¼ķ£ĆĶ”üõ┐ØĶ»üõ╗źõĖŗõĖēõĖ¬ńÄ»ĶŖéķāĮõĖŹÕć║ķöÖ’╝Ü
+
+- ń«ŚÕŁÉÕ£© PyTorch õĖŁµ£ēÕ«×ńÄ░
+- µ£ēµŖŖĶ»ź PyTorch ń«ŚÕŁÉµśĀÕ░䵳ÉõĖĆõĖ¬µł¢ÕżÜõĖ¬ ONNX ń«ŚÕŁÉńÜäµ¢╣µ│Ģ
+- ONNX µ£ēńøĖÕ║öńÜäń«ŚÕŁÉ
+
+ÕŻգ©Õ«×ķÖģķā©ńĮ▓õĖŁ’╝īĶ┐ÖõĖēķā©ÕłåńÜäÕåģÕ«╣ķāĮÕÅ»ĶāĮµ£ēµēĆń╝║Õż▒ŃĆéÕģČõĖŁµ£ĆÕØÅńÜäµāģÕåĄµś»’╝ܵłæõ╗¼Õ«Üõ╣ēõ║åõĖĆõĖ¬Õģ©µ¢░ńÜäń«ŚÕŁÉ’╝īÕ«āõĖŹõ╗ģń╝║Õ░æ PyTorch Õ«×ńÄ░’╝īĶ┐śń╝║Õ░æ PyTorch Õł░ ONNX ńÜ䵜ĀÕ░äÕģ│ń│╗ŃĆéõĮåµēĆĶ░ōĶĮ”Õł░Õ▒▒ÕēŹÕ┐ģµ£ēĶĘ»’╝īÕ»╣õ║ÄĶ┐ÖõĖēõĖ¬ńÄ»ĶŖé’╝īµłæõ╗¼õ╣¤ÕłåÕł½ķāĮµ£ēõ╗źõĖŗńÜäµĘ╗ÕŖĀµö»µīüńÜäµ¢╣µ│Ģ’╝Ü
+
+- PyTorch ń«ŚÕŁÉ
+ - ń╗äÕÉłńÄ░µ£ēń«ŚÕŁÉ
+ - µĘ╗ÕŖĀ TorchScript ń«ŚÕŁÉ
+ - µĘ╗ÕŖĀµÖ«ķĆÜ C++ µŗōÕ▒Ģń«ŚÕŁÉ
+- µśĀÕ░äµ¢╣µ│Ģ
+ - õĖ║ ATen ń«ŚÕŁÉµĘ╗ÕŖĀń¼”ÕÅĘÕćĮµĢ░
+ - õĖ║ TorchScript ń«ŚÕŁÉµĘ╗ÕŖĀń¼”ÕÅĘÕćĮµĢ░
+ - Õ░üĶŻģµłÉ torch.autograd.Function Õ╣ȵĘ╗ÕŖĀń¼”ÕÅĘÕćĮµĢ░
+- ONNX ń«ŚÕŁÉ
+ - õĮ┐ńö©ńÄ░µ£ē ONNX ń«ŚÕŁÉ
+ - Õ«Üõ╣ēµ¢░ ONNX ń«ŚÕŁÉ
+
+ķéŻõ╣ł’╝īķØóÕ»╣õĖŹÕÉīńÜäµāģÕåĄµŚČ’╝īÕ░▒ķ£ĆĶ”üµłæõ╗¼ńüĄµ┤╗Õ£░ķĆēńö©ÕÆīń╗äÕÉłĶ┐Öõ║øµ¢╣µ│ĢŃĆéÕɼĶĄĘµØźµś»õĖŹµś»ÕŠłÕżŹµØé’╝¤Õł½µŗģÕ┐ā’╝īµ£¼ń»ćµ¢ćń½ĀõĖŁ’╝īµłæõ╗¼Õ░åÕø┤ń╗ĢńØĆõĖēń¦Źń«ŚÕŁÉµśĀÕ░äµ¢╣µ│Ģ’╝īÕŁ”õ╣ĀõĖēõĖ¬µĘ╗ÕŖĀń«ŚÕŁÉµö»µīüńÜäÕ«×õŠŗ’╝īµØźńÉåµĖģÕ”éõĮĢõĖ║ PyTorch ń«ŚÕŁÉĶĮ¼ ONNX ń«ŚÕŁÉńÜäõĖēõĖ¬ńÄ»ĶŖéµĘ╗ÕŖĀµö»µīüŃĆé
+
+## µö»µīü ATen ń«ŚÕŁÉ
+
+Õ«×ķÖģńÜäķā©ńĮ▓Ķ┐ćń©ŗõĖŁ’╝īµłæõ╗¼ķāĮµ£ēÕÅ»ĶāĮõ╝Üńó░Õł░õĖĆõĖ¬µ£Ćń«ĆÕŹĢńÜäń«ŚÕŁÉń╝║Õż▒ķŚ«ķóś’╝Ü ń«ŚÕŁÉÕ£© ATen õĖŁÕĘ▓ń╗ÅÕ«×ńÄ░õ║å’╝īONNX õĖŁõ╣¤µ£ēńøĖÕģ│ń«ŚÕŁÉńÜäÕ«Üõ╣ē’╝īõĮåµś»ńøĖÕģ│ń«ŚÕŁÉµśĀÕ░äµłÉ ONNX ńÜäĶ¦äÕłÖµ▓Īµ£ēÕåÖŃĆéÕ£©Ķ┐Öń¦ŹµāģÕåĄõĖŗ’╝īµłæõ╗¼ÕŬķ£ĆĶ”ü**õĖ║ ATen ń«ŚÕŁÉĶĪźÕģģµÅÅĶ┐░µśĀÕ░äĶ¦äÕłÖńÜäń¼”ÕÅĘÕćĮµĢ░**Õ░▒ĶĪīõ║åŃĆé
+
+> [ATen](https://pytorch.org/cppdocs/#aten) µś» PyTorch ÕåģńĮ«ńÜä C++ Õ╝ĀķćÅĶ«Īń«ŚÕ║ō’╝īPyTorch ń«ŚÕŁÉÕ£©Õ║ĢÕ▒éń╗ØÕż¦ÕżÜµĢ░Ķ«Īń«ŚķāĮµś»ńö© ATen Õ«×ńÄ░ńÜäŃĆé
+
+õĖŖµ£¤õ╣ĀķóśõĖŁ’╝īµłæõ╗¼µøŠń╗ŵÅÉÕł░õ║å ONNX ńÜä `Asinh` ń«ŚÕŁÉŃĆéĶ┐ÖõĖ¬ń«ŚÕŁÉÕ£© ATen õĖŁµ£ēÕ«×ńÄ░’╝īÕŹ┤ń╝║Õ░æõ║åµśĀÕ░äÕł░ ONNX ń«ŚÕŁÉńÜäń¼”ÕÅĘÕćĮµĢ░ŃĆéÕ£©Ķ┐Öķćī’╝īµłæõ╗¼µØźÕ░ØĶ»ĢõĖ║Õ«āĶĪźÕģģń¼”ÕÅĘÕćĮµĢ░’╝īÕ╣ČÕ»╝Õć║õĖĆõĖ¬ÕīģÕɽĶ┐ÖõĖ¬ń«ŚÕŁÉńÜä ONNX µ©ĪÕ×ŗŃĆé
+
+### ĶÄĘÕÅ¢ ATen õĖŁń«ŚÕŁÉµÄźÕÅŻÕ«Üõ╣ē
+
+õĖ║õ║åń╝¢ÕåÖń¼”ÕÅĘÕćĮµĢ░’╝īµłæõ╗¼ķ£ĆĶ”üĶÄĘÕŠŚ `asinh` µÄ©ńÉåµÄźÕÅŻńÜäĶŠōÕģźÕÅéµĢ░Õ«Üõ╣ēŃĆéĶ┐ÖµŚČ’╝īµłæõ╗¼Ķ”üÕÄ╗ `torch/_C/_VariableFunctions.pyi` ÕÆī `torch/nn/functional.pyi` Ķ┐ÖõĖżõĖ¬µ¢ćõ╗ČõĖŁµÉ£ń┤óµłæõ╗¼ÕłÜÕłÜÕŠŚÕł░ńÜäĶ┐ÖõĖ¬ń«ŚÕŁÉÕÉŹŃĆéĶ┐ÖõĖżõĖ¬µ¢ćõ╗ȵś»ń╝¢Ķ»æ PyTorch µŚČµ£¼Õ£░Ķć¬ÕŖ©ńö¤µłÉńÜäµ¢ćõ╗Č’╝īķćīķØóÕīģÕɽõ║å ATen ń«ŚÕŁÉńÜä PyTorch Ķ░āńö©µÄźÕÅŻŃĆéķĆÜĶ┐ćµÉ£ń┤ó’╝īµłæõ╗¼ÕÅ»õ╗źń¤źķüō `asinh` Õ£©µ¢ćõ╗Č `torch/_C/_VariableFunctions.pyi` õĖŁ’╝īÕģȵğÕÅŻÕ«Üõ╣ēõĖ║:
+
+```python
+def asinh(input: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...
+```
+
+ń╗ÅĶ┐ćĶ┐Öõ║øµŁźķ¬ż’╝īµłæõ╗¼ńĪ«Ķ«żõ║åń╝║Õż▒ńÜäń«ŚÕŁÉÕÉŹõĖ║ `asinh`’╝īÕ«āµś»õĖĆõĖ¬µ£ēÕ«×ńÄ░ńÜä ATen ń«ŚÕŁÉŃĆ鵳æõ╗¼Ķ┐śĶ«░õĖŗõ║å `asinh` ńÜäĶ░āńö©µÄźÕÅŻŃĆéµÄźõĖŗµØź’╝īµłæõ╗¼Ķ”üõĖ║Õ«āĶĪźÕģģń¼”ÕÅĘÕćĮµĢ░’╝īõĮ┐Õ«āÕ£©ĶĮ¼µŹóµłÉ ONNX µ©ĪÕ×ŗµŚČõĖŹÕåŹµŖźķöÖŃĆé
+
+### µĘ╗ÕŖĀń¼”ÕÅĘÕćĮµĢ░
+
+Õł░ńø«ÕēŹõĖ║µŁó’╝īµłæõ╗¼ÕĘ▓ń╗ÅÕżÜµ¼ĪµÄźĶ¦”õ║åÕ«Üõ╣ē PyTorch Õł░ ONNX µśĀÕ░äĶ¦äÕłÖńÜäń¼”ÕÅĘÕćĮµĢ░õ║åŃĆéńÄ░Õ£©’╝īµłæõ╗¼ÕÉæÕż¦Õ«ČµŁŻÕ╝Åõ╗ŗń╗ŹõĖĆõĖŗń¼”ÕÅĘÕćĮµĢ░ŃĆé
+
+ń¼”ÕÅĘÕćĮµĢ░’╝īÕÅ»õ╗źń£ŗµłÉµś» PyTorch ń«ŚÕŁÉń▒╗ńÜäõĖĆõĖ¬ķØÖµĆüµ¢╣µ│ĢŃĆéÕ£©µŖŖ PyTorch µ©ĪÕ×ŗĶĮ¼µŹóµłÉ ONNX µ©ĪÕ×ŗµŚČ’╝īÕÉäõĖ¬ PyTorch ń«ŚÕŁÉńÜäń¼”ÕÅĘÕćĮµĢ░õ╝ÜĶó½õŠØµ¼ĪĶ░āńö©’╝īõ╗źÕ«īµłÉ PyTorch ń«ŚÕŁÉÕł░ ONNX ń«ŚÕŁÉńÜäĶĮ¼µŹóŃĆéń¼”ÕÅĘÕćĮµĢ░ńÜäÕ«Üõ╣ēõĖĆĶł¼Õ”éõĖŗ’╝Ü
+
+```python
+def symbolic(g: torch._C.Graph, input_0: torch._C.Value, input_1: torch._C.Value, ...):
+```
+
+ÕģČõĖŁ’╝ī`torch._C.Graph` ÕÆī `torch._C.Value` ķāĮÕ»╣Õ║ö PyTorch ńÜä C++ Õ«×ńÄ░ķćīńÜäõĖĆõ║øń▒╗ŃĆ鵳æõ╗¼Õ£©Ķ┐Öń»ćµ¢ćń½ĀõĖŹµĘ▒ń®ČÕ«āõ╗¼ńÜäń╗åĶŖé’╝īÕŬķ£ĆĶ”üń¤źķüōń¼¼õĖĆõĖ¬ÕÅéµĢ░Õ░▒Õø║Õ«ÜÕŽ `g`’╝īÕ«āĶĪ©ńż║ÕÆīĶ«Īń«ŚÕøŠńøĖÕģ│ńÜäÕåģÕ«╣’╝øÕÉÄķØóńÜäµ»ÅõĖ¬ÕÅéµĢ░ķāĮĶĪ©ńż║ń«ŚÕŁÉńÜäĶŠōÕģź’╝īķ£ĆĶ”üÕÆīń«ŚÕŁÉńÜäÕēŹÕÉæµÄ©ńÉåµÄźÕÅŻńÜäĶŠōÕģźńøĖÕÉīŃĆéÕ»╣õ║Ä ATen ń«ŚÕŁÉµØźĶ»┤’╝īÕ«āõ╗¼ńÜäÕēŹÕÉæµÄ©ńÉåµÄźÕÅŻÕ░▒µś»õĖŖĶ┐░õĖżõĖ¬ `.pyi` µ¢ćõ╗ČķćīńÜäÕćĮµĢ░µÄźÕÅŻŃĆé
+
+`g` µ£ēõĖĆõĖ¬µ¢╣µ│Ģ `op`ŃĆéÕ£©µŖŖ PyTorch ń«ŚÕŁÉĶĮ¼µŹóµłÉ ONNX ń«ŚÕŁÉµŚČ’╝īķ£ĆĶ”üÕ£©ń¼”ÕÅĘÕćĮµĢ░õĖŁĶ░āńö©µŁżµ¢╣µ│ĢµØźõĖ║µ£Ćń╗łńÜäĶ«Īń«ŚÕøŠµĘ╗ÕŖĀõĖĆõĖ¬ ONNX ń«ŚÕŁÉŃĆéÕģČÕ«Üõ╣ēÕ”éõĖŗ’╝Ü
+
+```python
+def op(name: str, input_0: torch._C.Value, input_1: torch._C.Value, ...)
+```
+
+ÕģČõĖŁ’╝īń¼¼õĖĆõĖ¬ÕÅéµĢ░µś»ń«ŚÕŁÉÕÉŹń¦░ŃĆéÕ”éµ×£Ķ»źń«ŚÕŁÉµś»µÖ«ķĆÜńÜä ONNX ń«ŚÕŁÉ’╝īÕŬķ£ĆĶ”üµŖŖÕ«āÕ£© ONNX Õ«śµ¢╣µ¢ćµĪŻķćīńÜäÕÉŹń¦░ÕĪ½Ķ┐øÕÄ╗ÕŹ│ÕÅ»’╝łµłæõ╗¼ń©ŹÕÉÄÕåŹĶ«▓ÕģČõ╗¢µāģÕåĄ’╝ēŃĆé
+
+Õ£©µ£Ćń«ĆÕŹĢńÜäµāģÕåĄõĖŗ’╝īµłæõ╗¼ÕŬĶ”üµŖŖ PyTorch ń«ŚÕŁÉńÜäĶŠōÕģźńö©`g.op()`õĖĆõĖĆÕ»╣Õ║öÕł░ ONNX ń«ŚÕŁÉõĖŖÕŹ│ÕÅ»’╝īÕ╣ȵŖŖ`g.op()`ńÜäĶ┐öÕø×ÕĆ╝õĮ£õĖ║ń¼”ÕÅĘÕćĮµĢ░ńÜäĶ┐öÕø×ÕĆ╝ŃĆéÕ£©µāģÕåĄµø┤ÕżŹµØ鵌Ȓ╝īµłæõ╗¼ĶĮ¼µŹóõĖĆõĖ¬ PyTorch ń«ŚÕŁÉÕÅ»ĶāĮĶ”üµ¢░Õ╗║ĶŗźÕ╣▓õĖ¬ ONNX ń«ŚÕŁÉŃĆé
+
+ĶĪźÕģģÕ«īõ║åĶāīµÖ»ń¤źĶ»å’╝īĶ«®µłæõ╗¼Õø×Õł░ `asinh` ń«ŚÕŁÉõĖŖ’╝īµØźõĖ║Õ«āń╝¢ÕåÖń¼”ÕÅĘÕćĮµĢ░ŃĆ鵳æõ╗¼ÕģłÕÄ╗ń┐╗ķśģõĖĆõĖŗ ONNX ń«ŚÕŁÉµ¢ćµĪŻ’╝īÕŁ”õ╣ĀõĖĆõĖŗµłæõ╗¼Õ£©ń¼”ÕÅĘÕćĮµĢ░ķćīńÜ䵜ĀÕ░äÕģ│ń│╗ `g.op()` ķćīÕ║öĶ»źµĆÄõ╣łÕåÖŃĆé[`Asinh` ńÜäµ¢ćµĪŻ](https://github.com/onnx/onnx/blob/main/docs/Operators.md#asinh)ÕåÖķüō’╝ÜĶ»źń«ŚÕŁÉµ£ēõĖĆõĖ¬ĶŠōÕģź `input`’╝īõĖĆõĖ¬ĶŠōÕć║ `output`’╝īõ║īĶĆģńÜäń▒╗Õ×ŗķāĮõĖ║Õ╝ĀķćÅŃĆé
+
+Õł░Ķ┐Öķćī’╝īµłæõ╗¼ÕĘ▓ń╗ÅÕ«īµłÉõ║åõ┐Īµü»µöČķøåńÄ»ĶŖéŃĆ鵳æõ╗¼Õ£©õĖŖõĖĆÕ░ÅĶŖéÕŠŚń¤źõ║å `asinh` ńÜäµÄ©ńÉåµÄźÕÅŻÕ«Üõ╣ē’╝īÕ£©Ķ┐ÖõĖĆÕ░ÅĶŖéķćīµöČķøåõ║å ONNX ń«ŚÕŁÉ `Asinh` ńÜäÕ«Üõ╣ēŃĆéńÄ░Õ£©’╝īµłæõ╗¼ÕÅ»õ╗źńö©õ╗ŻńĀüµØźĶĪźÕģģĶ┐Öõ║īĶĆģńÜ䵜ĀÕ░äÕģ│ń│╗õ║åŃĆéÕ£©ÕłÜÕłÜÕ»╝Õć║ `asinh` ń«ŚÕŁÉńÜäõ╗ŻńĀüõĖŁ’╝īµłæõ╗¼µĘ╗ÕŖĀõ╗źõĖŗÕåģÕ«╣’╝Ü
+
+```python
+from torch.onnx.symbolic_registry import register_op
+
+def asinh_symbolic(g, input, *, out=None):
+ return g.op("Asinh", input)
+
+register_op('asinh', asinh_symbolic, '', 9)
+```
+
+Ķ┐ÖķćīńÜä`asinh_symbolic`Õ░▒µś»`asinh`ńÜäń¼”ÕÅĘÕćĮµĢ░ŃĆéõ╗ÄķÖż`g`õ╗źÕż¢ńÜäń¼¼õ║īõĖ¬ĶŠōÕģźÕÅéµĢ░Õ╝ĆÕ¦ŗ’╝īÕģČĶŠōÕģźÕÅéµĢ░Õ║öĶ»źõĖźµĀ╝Õ»╣Õ║öÕ«āÕ£© ATen õĖŁńÜäÕ«Üõ╣ē’╝Ü
+
+```python
+def asinh(input: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...
+```
+
+Õ£©ń¼”ÕÅĘÕćĮµĢ░ńÜäÕćĮµĢ░õĮōõĖŁ’╝ī`g.op("Asinh", input)`ÕłÖÕ«īµłÉõ║å ONNX ń«ŚÕŁÉńÜäÕ«Üõ╣ēŃĆéÕģČõĖŁ’╝īń¼¼õĖĆõĖ¬ÕÅéµĢ░`"Asinh"`µś»ń«ŚÕŁÉÕ£© ONNX õĖŁńÜäÕÉŹń¦░ŃĆéĶć│õ║Äń¼¼õ║īõĖ¬ÕÅéµĢ░ `input`’╝īÕ”éµłæõ╗¼ÕłÜÕłÜÕ£©µ¢ćµĪŻķćīµēĆĶ¦ü’╝īĶ┐ÖõĖ¬ń«ŚÕŁÉÕŬµ£ēõĖĆõĖ¬ĶŠōÕģź’╝īÕøĀµŁżµłæõ╗¼ÕŬĶ”üµŖŖń¼”ÕÅĘÕćĮµĢ░ńÜäĶŠōÕģźÕÅéµĢ░ `input` Õ»╣Õ║öĶ┐ćÕÄ╗Õ░▒ĶĪīŃĆéONNX ńÜä `Asinh` ńÜäĶŠōÕć║ÕÆī ATen ńÜä `asinh` ńÜäĶŠōÕć║µś»õĖĆĶć┤ńÜä’╝īÕøĀµŁżµłæõ╗¼ńø┤µÄźµŖŖ `g.op()` ńÜäń╗ōµ×£Ķ┐öÕø×ÕŹ│ÕÅ»ŃĆé
+
+Õ«Üõ╣ēÕ«īń¼”ÕÅĘÕćĮµĢ░ÕÉÄ’╝īµłæõ╗¼Ķ”üµŖŖĶ┐ÖõĖ¬ń¼”ÕÅĘÕćĮµĢ░ÕÆīÕĤµØźńÜä ATen ń«ŚÕŁÉŌĆ£ń╗æÕ«ÜŌĆØĶĄĘµØźŃĆéĶ┐Öķćī’╝īµłæõ╗¼Ķ”üńö©Õł░ `register_op` Ķ┐ÖõĖ¬ PyTorch API µØźÕ«īµłÉń╗æÕ«ÜŃĆéÕ”éńż║õŠŗµēĆńż║’╝īÕŬķ£ĆĶ”üõĖĆĶĪīń«ĆÕŹĢńÜäõ╗ŻńĀüÕŹ│ÕÅ»µŖŖń¼”ÕÅĘÕćĮµĢ░ `asinh_symbolic` ń╗æÕ«ÜÕł░ń«ŚÕŁÉ `asinh` õĖŖ’╝Ü
+
+```python
+register_op('asinh', asinh_symbolic, '', 9)
+```
+
+`register_op`ńÜäń¼¼õĖĆõĖ¬ÕÅéµĢ░µś»ńø«µĀć ATen ń«ŚÕŁÉÕÉŹ’╝īń¼¼õ║īõĖ¬µś»Ķ”üµ│©ÕåīńÜäń¼”ÕÅĘÕćĮµĢ░’╝īĶ┐ÖõĖżõĖ¬ÕÅéµĢ░ÕŠłÕźĮńÉåĶ¦ŻŃĆéń¼¼õĖēõĖ¬ÕÅéµĢ░µś»ń«ŚÕŁÉńÜäŌĆ£Õ¤¤ŌĆØ’╝īÕ»╣õ║ĵ֫ķĆÜ ONNX ń«ŚÕŁÉ’╝īńø┤µÄźÕĪ½ń®║ÕŁŚń¼”õĖ▓ÕŹ│ÕÅ»ŃĆéń¼¼ÕøøõĖ¬ÕÅéµĢ░ĶĪ©ńż║ÕÉæÕō¬õĖ¬ń«ŚÕŁÉķøåńēłµ£¼µ│©ÕåīŃĆ鵳æõ╗¼ķüĄńģ¦ ONNX µĀćÕćå’╝īÕÉæń¼¼ 9 ÕÅĘń«ŚÕŁÉķøåµ│©ÕåīŃĆéÕĆ╝ÕŠŚµ│©µäÅńÜ䵜»’╝īĶ┐ÖķćīÕÉæń¼¼ 9 ÕÅĘń«ŚÕŁÉķøåµ│©Õåī’╝īõĖŹõ╗ŻĶĪ©ĶŠāµ¢░ńÜäń«ŚÕŁÉķøå’╝łń¼¼ 10 ÕÅĘŃĆüń¼¼ 11 ÕÅĘŌĆ”ŌĆ”’╝ēķāĮÕŠŚÕł░õ║åµ│©ÕåīŃĆéÕ£©ńż║õŠŗõĖŁ’╝īµłæõ╗¼ÕģłÕŬÕÉæń¼¼ 9 ÕÅĘń«ŚÕŁÉķøåµ│©ÕåīŃĆé
+
+µĢ┤ńÉåõĖĆõĖŗ’╝īµłæõ╗¼µ£Ćń╗łńÜäõ╗ŻńĀüÕ”éõĖŗ’╝Ü
+
+```python
+import torch
+
+class Model(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ def forward(self, x):
+ return torch.asinh(x)
+
+from torch.onnx.symbolic_registry import register_op
+
+def asinh_symbolic(g, input, *, out=None):
+ return g.op("Asinh", input)
+
+register_op('asinh', asinh_symbolic, '', 9)
+
+model = Model()
+input = torch.rand(1, 3, 10, 10)
+torch.onnx.export(model, input, 'asinh.onnx')
+```
+
+µłÉÕŖ¤Õ»╝Õć║ńÜäĶ»Ø’╝ī`asinh.onnx` Õ║öĶ»źķĢ┐Ķ┐ÖõĖ¬µĀĘÕŁÉ’╝Ü
+
+
+
+### µĄŗĶ»Ģń«ŚÕŁÉ
+
+Õ£©Õ«īµłÉõ║åõĖĆõ╗ĮĶć¬Õ«Üõ╣ēń«ŚÕŁÉÕÉÄ’╝īµłæõ╗¼õĖĆÕ«ÜĶ”üµĄŗĶ»ĢõĖĆõĖŗń«ŚÕŁÉńÜ䵣ŻńĪ«µĆ¦ŃĆéõĖĆĶł¼µłæõ╗¼Ķ”üńö© PyTorch Ķ┐ÉĶĪīõĖĆķüŹÕĤń«ŚÕŁÉ’╝īÕåŹńö©µÄ©ńÉåÕ╝ĢµōÄ’╝łµ»öÕ”é ONNX Runtime’╝ēĶ┐ÉĶĪīõĖĆõĖŗ ONNX ń«ŚÕŁÉ’╝īµ£ĆÕÉĵ»öÕ»╣õĖżµ¼ĪńÜäĶ┐ÉĶĪīń╗ōµ×£ŃĆéÕ»╣õ║ĵłæõ╗¼ÕłÜÕłÜÕŠŚÕł░ńÜä `asinh.onnx`’╝īÕÅ»õ╗źńö©Õ”éõĖŗõ╗ŻńĀüµØźķ¬īĶ»ü’╝Ü
+
+```python
+import onnxruntime
+import torch
+import numpy as np
+
+class Model(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ def forward(self, x):
+ return torch.asinh(x)
+
+model = Model()
+input = torch.rand(1, 3, 10, 10)
+torch_output = model(input).detach().numpy()
+
+sess = onnxruntime.InferenceSession('asinh.onnx')
+ort_output = sess.run(None, {'0': input.numpy()})[0]
+
+assert np.allclose(torch_output, ort_output)
+```
+
+Õ£©Ķ┐Öõ╗Įõ╗ŻńĀüķćī’╝īµłæõ╗¼ńö© PyTorch ÕüÜõ║åõĖĆķüŹµÄ©ńÉå’╝īÕ╣ȵŖŖń╗ōµ×£ĶĮ¼µłÉõ║å numpy µĀ╝Õ╝ÅŃĆéõ╣ŗÕÉÄ’╝īµłæõ╗¼ÕÅłńö© ONNX Runtime Õ»╣ onnx µ¢ćõ╗ČÕüÜõ║åõĖƵ¼ĪµÄ©ńÉåŃĆéµ£ĆÕÉÄ’╝īµłæõ╗¼õĮ┐ńö© `np.allclose` µØźõ┐ØĶ»üõĖżõĖ¬ń╗ōµ×£Õ╝ĀķćÅńÜäĶ»»ÕĘ«Õ£©õĖĆõĖ¬ÕÅ»õ╗źÕģüĶ«ĖńÜäĶīāÕø┤ÕåģŃĆéõĖĆÕłćµŁŻÕĖĖńÜäĶ»Ø’╝īĶ┐ÉĶĪīĶ┐Öµ«Ąõ╗ŻńĀüÕÉÄ’╝ī`assert` µēĆÕ£©ĶĪīõĖŹõ╝ܵŖźķöÖ’╝īń©ŗÕ║ÅÕ║öĶ»źµ▓Īµ£ēõ╗╗õĮĢĶŠōÕć║ŃĆé
+
+## µö»µīü TorchScript ń«ŚÕŁÉ
+
+Õ»╣õ║ÄõĖĆõ║øµ»öĶŠāÕżŹµØéńÜäĶ┐Éń«Ś’╝īõ╗ģõĮ┐ńö© PyTorch ÕĤńö¤ń«ŚÕŁÉµś»µŚĀµ│ĢÕ«×ńÄ░ńÜäŃĆéĶ┐ÖõĖ¬µŚČÕĆÖ’╝īÕ░▒Ķ”üĶĆāĶÖæĶć¬Õ«Üõ╣ēõĖĆõĖ¬ PyTorch ń«ŚÕŁÉ’╝īÕåŹµŖŖÕ«āĶĮ¼µŹóÕł░ ONNX õĖŁõ║åŃĆéµ¢░Õó× PyTorch ń«ŚÕŁÉńÜäµ¢╣µ│Ģµ£ēÕŠłÕżÜ’╝īPyTorch Õ«śµ¢╣µ»öĶŠāµÄ©ĶŹÉńÜäõĖĆń¦ŹÕüܵ│Ģµś»[µĘ╗ÕŖĀ TorchScript ń«ŚÕŁÉ](https://pytorch.org/tutorials/advanced/torch_script_custom_ops.html) ŃĆé
+
+ńö▒õ║ĵĘ╗ÕŖĀń«ŚÕŁÉńÜäµ¢╣µ│ĢĶŠāń╣üńÉÉ’╝īµłæõ╗¼õ╗ŖÕż®ĶĘ│Ķ┐ćµ¢░Õó× TorchScript ń«ŚÕŁÉńÜäÕåģÕ«╣’╝īõ╗źÕÅ»ÕÅśÕĮóÕŹĘń¦»’╝łDeformable Convolution’╝ēń«ŚÕŁÉõĖ║õŠŗ’╝īõ╗ŗń╗ŹõĖ║ńÄ░µ£ē TorchScript ń«ŚÕŁÉµĘ╗ÕŖĀ ONNX µö»µīüńÜäµ¢╣µ│ĢŃĆé
+
+> ÕÅ»ÕÅśÕĮóÕŹĘń¦»’╝łDeformable Convolution’╝ēµś»Õ£© Torchvision õĖŁÕ«×ńÄ░ńÜä TorchScript ń«ŚÕŁÉ’╝īĶÖĮńäČÕ░ܵ£¬ÕŠŚÕł░Õ╣┐µ│øµö»µīü’╝īõĮåµś»Õć║ńÄ░Õ£©Ķ«ĖÕżÜµ©ĪÕ×ŗõĖŁŃĆé
+
+µ£ēõ║åµö»µīü ATen ń«ŚÕŁÉńÜäń╗Åķ¬īõ╣ŗÕÉÄ’╝īµłæõ╗¼ÕÅ»õ╗źń¤źķüōõĖ║ń«ŚÕŁÉµĘ╗ÕŖĀń¼”ÕÅĘÕćĮµĢ░õĖĆĶł¼Ķ”üń╗ÅĶ┐ćõ╗źõĖŗÕćĀµŁź’╝Ü
+
+1. ĶÄĘÕÅ¢ÕĤń«ŚÕŁÉńÜäÕēŹÕÉæµÄ©ńÉåµÄźÕÅŻŃĆé
+2. ĶÄĘÕÅ¢ńø«µĀć ONNX ń«ŚÕŁÉńÜäÕ«Üõ╣ēŃĆé
+3. ń╝¢ÕåÖń¼”ÕÅĘÕćĮµĢ░Õ╣Čń╗æÕ«ÜŃĆé
+
+Õ£©õĖ║ÕÅ»ÕÅśÕĮóÕŹĘń¦»µĘ╗ÕŖĀń¼”ÕÅĘÕćĮµĢ░µŚČ’╝īµłæõ╗¼õ╣¤ÕÅ»õ╗źÕ░ØĶ»ĢĶĄ░õĖĆķüŹĶ┐ÖõĖ¬µĄüń©ŗŃĆé
+
+### õĮ┐ńö© TorchScript ń«ŚÕŁÉ
+
+ÕÆīõ╣ŗÕēŹõĖƵĀĘ’╝īµłæõ╗¼ķ”¢ÕģłÕ«Üõ╣ēõĖĆõĖ¬ÕīģÕɽõ║åń«ŚÕŁÉńÜ䵩ĪÕ×ŗ’╝īõĖ║õ╣ŗÕÉÄĶĮ¼µŹó ONNX µ©ĪÕ×ŗÕüÜÕćåÕżćŃĆé
+
+```python
+import torch
+import torchvision
+
+class Model(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.conv1 = torch.nn.Conv2d(3, 18, 3)
+ self.conv2 = torchvision.ops.DeformConv2d(3, 3, 3)
+
+ def forward(self, x):
+ return self.conv2(x, self.conv1(x))
+```
+
+ÕģČõĖŁ’╝ī`torchvision.ops.DeformConv2d` Õ░▒µś» Torchvision õĖŁńÜäÕÅ»ÕÅśÕĮóÕŹĘń¦»Õ▒éŃĆéńøĖµ»öõ║ĵ֫ķĆÜÕŹĘń¦»’╝īÕÅ»ÕÅśÕĮóÕŹĘń¦»ńÜäÕģČõ╗¢ÕÅéµĢ░ķāĮÕż¦Ķć┤ńøĖÕÉī’╝īÕö»õĖĆńÜäÕī║Õł½Õ░▒µś»Õ£©µÄ©ńÉåµŚČķ£ĆĶ”üÕżÜĶŠōÕģźõĖĆõĖ¬ĶĪ©ńż║ÕüÅń¦╗ķćÅńÜäÕ╝ĀķćÅŃĆé
+
+ńäČÕÉÄ’╝īµłæõ╗¼µ¤źĶ»óń«ŚÕŁÉńÜäÕēŹÕÉæµÄ©ńÉåµÄźÕÅŻŃĆé`DeformConv2d` Õ▒éµ£Ćń╗łõ╝ÜĶ░āńö© `deform_conv2d` Ķ┐ÖõĖ¬ń«ŚÕŁÉŃĆ鵳æõ╗¼ÕÅ»õ╗źÕ£© `torchvision/csrc/ops/deform_conv2d.cpp` õĖŁµ¤źÕł░Ķ»źń«ŚÕŁÉńÜäĶ░āńö©µÄźÕÅŻ’╝Ü
+
+```python
+m.def(TORCH_SELECTIVE_SCHEMA(
+ "torchvision::deform_conv2d(Tensor input,
+ Tensor weight,
+ Tensor offset,
+ ......
+ bool use_mask) -> Tensor"));
+```
+
+ķéŻõ╣łµÄźõĖŗµØź’╝īµĀ╣µŹ«õ╣ŗÕēŹńÜäń╗Åķ¬ī’╝īµłæõ╗¼Õ░▒µś»Ķ”üÕÄ╗ ONNX Õ«śµ¢╣µ¢ćµĪŻõĖŁµ¤źµēŠń«ŚÕŁÉńÜäÕ«Üõ╣ēõ║åŃĆé
+
+### Ķć¬Õ«Üõ╣ē ONNX ń«ŚÕŁÉ
+
+ÕŠłķüŚµåŠńÜ䵜»’╝īÕ”éµ×£µłæõ╗¼ÕÄ╗ ONNX ńÜäÕ«śµ¢╣ń«ŚÕŁÉķĪĄķØóµÉ£ń┤ó "deform"’╝īÕ░åµÉ£õĖŹÕć║õ╗╗õĮĢÕåģÕ«╣ŃĆéńø«ÕēŹ’╝īONNX Ķ┐śµ▓Īµ£ēµÅÉõŠøÕÅ»ÕÅśÕĮóÕŹĘń¦»ńÜäń«ŚÕŁÉ’╝īµłæõ╗¼Ķ”üĶć¬ÕĘ▒Õ«Üõ╣ēõĖĆõĖ¬ ONNX ń«ŚÕŁÉõ║åŃĆé
+
+µłæõ╗¼Õ£©ÕēŹķØóĶ«▓Ķ┐ć’╝ī`g.op()` µś»ńö©µØźÕ«Üõ╣ē ONNX ń«ŚÕŁÉńÜäÕćĮµĢ░ŃĆéÕ»╣õ║Ä ONNX Õ«śµ¢╣Õ«Üõ╣ēńÜäń«ŚÕŁÉ’╝ī`g.op()` ńÜäń¼¼õĖĆõĖ¬ÕÅéµĢ░Õ░▒µś»Ķ»źń«ŚÕŁÉńÜäÕÉŹń¦░ŃĆéĶĆīÕ»╣õ║ÄõĖĆõĖ¬Ķć¬Õ«Üõ╣ēń«ŚÕŁÉ’╝ī`g.op()` ńÜäń¼¼õĖĆõĖ¬ÕÅéµĢ░µś»õĖĆõĖ¬ÕĖ”ÕæĮÕÉŹń®║ķŚ┤ńÜäń«ŚÕŁÉÕÉŹ’╝īµ»öÕ”é’╝Ü
+
+```python
+g.op("custom::deform_conv2d, ...)
+```
+
+ÕģČõĖŁ’╝ī"::"ÕēŹķØóńÜäÕåģÕ«╣Õ░▒µś»µłæõ╗¼ńÜäÕæĮÕÉŹń®║ķŚ┤ŃĆéĶ»źµ”éÕ┐ĄÕÆī C++ ńÜäÕæĮÕÉŹń®║ķŚ┤ń▒╗õ╝╝’╝īµś»õĖ║õ║åķś▓µŁóÕæĮÕÉŹÕå▓ń¬üĶĆīĶ«ŠÕ«ÜńÜäŃĆéÕ”éµ×£Õ£© `g.op()` ķćīõĖŹÕŖĀÕēŹķØóńÜäÕæĮÕÉŹń®║ķŚ┤’╝īÕłÖń«ŚÕŁÉõ╝ÜĶó½ķ╗śĶ«żµłÉ ONNX ńÜäÕ«śµ¢╣ń«ŚÕŁÉŃĆé
+
+PyTorch Õ£©Ķ┐ÉĶĪī `g.op()` µŚČõ╝ÜÕ»╣Õ«śµ¢╣ńÜäń«ŚÕŁÉÕüܵŻĆµ¤ź’╝īÕ”éµ×£ń«ŚÕŁÉÕÉŹµ£ēĶ»»’╝īµł¢ĶĆģń«ŚÕŁÉńÜäĶŠōÕģźń▒╗Õ×ŗõĖŹµŁŻńĪ«’╝ī `g.op()` Õ░▒õ╝ܵŖźķöÖŃĆéõĖ║õ║åĶ«®µłæõ╗¼ķÜÅÕ┐āµēƵ¼▓Õ£░Õ«Üõ╣ēµ¢░ ONNX ń«ŚÕŁÉ’╝īµłæõ╗¼Õ┐ģķĪ╗Ķ«ŠÕ«ÜõĖĆõĖ¬ÕæĮÕÉŹń®║ķŚ┤’╝īń╗Öń«ŚÕŁÉÕÅ¢õĖ¬ÕÉŹ’╝īÕåŹÕ«Üõ╣ēĶć¬ÕĘ▒ńÜäń«ŚÕŁÉŃĆé
+
+µłæõ╗¼Õ£©[ń¼¼õĖĆń»ćµĢÖń©ŗ](01_introduction_to_model_deployment.md)ÕŁ”Ķ┐ć’╝ÜONNX µś»õĖĆÕźŚµĀćÕćå’╝īµ£¼Ķ║½Õ╣ČõĖŹÕīģµŗ¼Õ«×ńÄ░ŃĆéÕ£©Ķ┐Öķćī’╝īµłæõ╗¼Õ░▒ń«ĆńĢźÕ£░Õ«Üõ╣ēõĖĆõĖ¬ ONNX ÕÅ»ÕÅśÕĮóÕŹĘń¦»ń«ŚÕŁÉ’╝īĶĆīõĖŹÕÄ╗ÕåÖÕ«āÕ£©µ¤ÉõĖ¬µÄ©ńÉåÕ╝ĢµōÄõĖŖńÜäÕ«×ńÄ░ŃĆéÕ£©õ╣ŗÕÉÄńÜäµĢÖń©ŗõĖŁ’╝īµłæõ╗¼ÕåŹÕŁ”õ╣ĀÕ£©ÕÉäõĖ¬µÄ©ńÉåÕ╝ĢµōÄõĖŁµĘ╗ÕŖĀµ¢░ ONNX ń«ŚÕŁÉµö»µīüńÜäµ¢╣µ│ĢŃĆ鵣żÕżä’╝īµłæõ╗¼ÕŬÕģ│Õ┐āÕ”éõĮĢÕ»╝Õć║õĖĆõĖ¬ÕīģÕɽµ¢░ ONNX ń«ŚÕŁÉĶŖéńé╣ńÜä onnx µ¢ćõ╗ČŃĆéÕøĀµŁż’╝īµłæõ╗¼ÕÅ»õ╗źõĖ║µ¢░ń«ŚÕŁÉń╝¢ÕåÖÕ”éõĖŗń«ĆÕŹĢńÜäń¼”ÕÅĘÕćĮµĢ░’╝Ü
+
+```python
+@parse_args("v", "v", "v", "v", "v", "i", "i", "i", "i", "i", "i", "i", "i", "none")
+def symbolic(g,
+ input,
+ weight,
+ offset,
+ mask,
+ bias,
+ stride_h, stride_w,
+ pad_h, pad_w,
+ dil_h, dil_w,
+ n_weight_grps,
+ n_offset_grps,
+ use_mask):
+ return g.op("custom::deform_conv2d", input, offset)
+```
+
+Õ£©Ķ┐ÖõĖ¬ń¼”ÕÅĘÕćĮµĢ░õĖŁ’╝īµłæõ╗¼õ╗źÕłÜÕłÜµÉ£ń┤óÕł░ńÜäń«ŚÕŁÉĶŠōÕģźÕÅéµĢ░õĮ£õĖ║ń¼”ÕÅĘÕćĮµĢ░ńÜäĶŠōÕģźÕÅéµĢ░’╝īÕ╣ČÕŬńö© `input` ÕÆī `offset` µØźµ×äķĆĀõĖĆõĖ¬ń«ĆÕŹĢńÜä ONNX ń«ŚÕŁÉŃĆé
+
+Ķ┐Öµ«Ąõ╗ŻńĀüõĖŁ’╝īµ£Ćõ╗żõ║║ń¢æµāæńÜäÕ░▒µś»ĶŻģķź░ÕÖ© `@parse_args` õ║åŃĆéń«ĆÕŹĢµØźĶ»┤’╝īTorchScript ń«ŚÕŁÉńÜäń¼”ÕÅĘÕćĮµĢ░Ķ”üµ▒éµĀćµ│©Õć║µ»ÅõĖĆõĖ¬ĶŠōÕģźÕÅéµĢ░ńÜäń▒╗Õ×ŗŃĆéµ»öÕ”é"v"ĶĪ©ńż║ Torch Õ║ōķćīńÜä `value` ń▒╗Õ×ŗ’╝īõĖĆĶł¼ńö©õ║ĵĀćµ│©Õ╝ĀķćÅ’╝īĶĆī"i"ĶĪ©ńż║ int ń▒╗Õ×ŗ’╝ī"f"ĶĪ©ńż║ float ń▒╗Õ×ŗ’╝ī"none"ĶĪ©ńż║Ķ»źÕÅéµĢ░õĖ║ń®║ŃĆéÕģĘõĮōńÜäń▒╗Õ×ŗÕɽõ╣ēÕÅ»õ╗źÕ£© [torch.onnx.symbolic_helper.py](https://github.com/pytorch/pytorch/blob/main/torch/onnx/symbolic_helper.py)õĖŁµ¤źń£ŗŃĆéĶ┐ÖķćīĶŠōÕģźÕÅéµĢ░õĖŁńÜä `input, weight, offset, mask, bias` ķāĮµś»Õ╝ĀķćÅ’╝īµēĆõ╗źńö©"v"ĶĪ©ńż║ŃĆéÕÉÄķØóńÜäÕģČõ╗¢ÕÅéµĢ░ÕÉīńÉåŃĆ鵳æõ╗¼õĖŹÕ┐ģń║Āń╗ōõ║Ä `@parse_args`ńÜäÕĤńÉå’╝īµĀ╣µŹ«Õ«×ķÖģµāģÕåĄÕ»╣ń¼”ÕÅĘÕćĮµĢ░ńÜäÕÅéµĢ░µĀćµ│©ń▒╗Õ×ŗÕŹ│ÕÅ»ŃĆé
+
+µ£ēõ║åń¼”ÕÅĘÕćĮµĢ░ÕÉÄ’╝īµłæõ╗¼ķĆÜĶ┐ćÕ”éõĖŗńÜäµ¢╣Õ╝ŵ│©Õåīń¼”ÕÅĘÕćĮµĢ░’╝Ü
+
+```python
+register_custom_op_symbolic("torchvision::deform_conv2d", symbolic, 9)
+```
+
+ÕÆīÕēŹķØóńÜä `register_op` ń▒╗õ╝╝’╝īµ│©Õåīń¼”ÕÅĘÕćĮµĢ░µŚČ’╝īµłæõ╗¼Ķ”üĶŠōÕģźń«ŚÕŁÉÕÉŹŃĆüń¼”ÕÅĘÕćĮµĢ░ŃĆüń«ŚÕŁÉķøåńēłµ£¼ŃĆéõĖÄÕēŹķØóõĖŹÕÉīńÜ䵜»’╝īĶ┐ÖķćīńÜäń«ŚÕŁÉķøåńēłµ£¼µś»µ£ĆµŚ®ńö¤µĢłńēłµ£¼’╝īÕ£©Ķ┐ÖķćīĶ«ŠÕ«Üńēłµ£¼ 9’╝īµäÅÕæ│ńØĆõ╣ŗÕÉÄńÜäń¼¼ 10 ÕÅĘŃĆüń¼¼ 11 ÕÅĘŌĆ”ŌĆ”ńēłµ£¼ķøåķāĮĶāĮõĮ┐ńö©Ķ┐ÖõĖ¬µ¢░ń«ŚÕŁÉŃĆé
+
+µ£ĆÕÉÄ’╝īµłæõ╗¼Õ«īµĢ┤ńÜ䵩ĪÕ×ŗÕ»╝Õć║õ╗ŻńĀüÕ”éõĖŗ’╝Ü
+
+```python
+import torch
+import torchvision
+
+class Model(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.conv1 = torch.nn.Conv2d(3, 18, 3)
+ self.conv2 = torchvision.ops.DeformConv2d(3, 3, 3)
+
+ def forward(self, x):
+ return self.conv2(x, self.conv1(x))
+
+from torch.onnx import register_custom_op_symbolic
+from torch.onnx.symbolic_helper import parse_args
+
+@parse_args("v", "v", "v", "v", "v", "i", "i", "i", "i", "i", "i", "i", "i", "none")
+def symbolic(g,
+ input,
+ weight,
+ offset,
+ mask,
+ bias,
+ stride_h, stride_w,
+ pad_h, pad_w,
+ dil_h, dil_w,
+ n_weight_grps,
+ n_offset_grps,
+ use_mask):
+ return g.op("custom::deform_conv2d", input, offset)
+
+register_custom_op_symbolic("torchvision::deform_conv2d", symbolic, 9)
+
+model = Model()
+input = torch.rand(1, 3, 10, 10)
+torch.onnx.export(model, input, 'dcn.onnx')
+```
+
+õ╗ŻńĀüµłÉÕŖ¤Ķ┐ÉĶĪīńÜäĶ»Ø’╝īµłæõ╗¼Õ║öĶ»źĶāĮÕŠŚÕł░Õ”éõĖŗńÜä ONNX µ©ĪÕ×ŗ’╝Ü
+
+
+
+ÕÅ»õ╗źń£ŗÕł░’╝īµłæõ╗¼Ķć¬Õ«Üõ╣ēńÜä ONNX ń«ŚÕŁÉ `deform_conv2d` ÕīģÕɽõ║åõĖżõĖ¬ĶŠōÕģź’╝īõĖĆõĖ¬ĶŠōÕć║’╝īÕÆīµłæõ╗¼ķóäµā│ÕŠŚõĖƵĀĘŃĆé
+
+## õĮ┐ńö© torch.autograd.Function
+
+µ£ĆÕÉÄ’╝īµłæõ╗¼µØźÕŁ”õ╣ĀõĖĆń¦Źń«ĆÕŹĢńÜäõĖ║ PyTorch µĘ╗ÕŖĀ C++ ń«ŚÕŁÉÕ«×ńÄ░ńÜäµ¢╣µ│Ģ’╝īµØźõ╗Żµø┐ĶŠāõĖ║ÕżŹµØéńÜäµ¢░Õó× TorchScript ń«ŚÕŁÉŃĆéÕÉīµŚČ’╝īµłæõ╗¼õ╝Üńö© torch.autograd.Function Õ░üĶŻģĶ┐ÖõĖ¬µ¢░ń«ŚÕŁÉŃĆétorch.autograd.Function ĶāĮÕ«īµłÉń«ŚÕŁÉÕ«×ńÄ░ÕÆīń«ŚÕŁÉĶ░āńö©ńÜäķÜöń”╗ŃĆéõĖŹń«Īń«ŚÕŁÉµś»µĆÄõ╣łÕ«×ńÄ░ńÜä’╝īÕ«āÕ░üĶŻģÕÉÄńÜäõĮ┐ńö©õĮōķ¬īõ╗źÕÅŖ ONNX Õ»╝Õć║µ¢╣µ│Ģõ╝ÜÕÆīÕĤńö¤ńÜä PyTorch ń«ŚÕŁÉõĖƵĀĘŃĆéĶ┐Öµś»µłæõ╗¼µ»öĶŠāµÄ©ĶŹÉńÜäõĖ║ń«ŚÕŁÉµĘ╗ÕŖĀ ONNX µö»µīüńÜäµ¢╣µ│ĢŃĆé
+
+õĖ║õ║åÕ║öÕ»╣µø┤ÕżŹµØéńÜäµāģÕåĄ’╝īµłæõ╗¼µØźĶć¬Õ«Üõ╣ēõĖĆõĖ¬ÕźćµĆ¬ńÜä `my_add` ń«ŚÕŁÉŃĆéĶ┐ÖõĖ¬ń«ŚÕŁÉńÜäĶŠōÕģźÕ╝ĀķćÅ a, b ’╝īĶŠōÕć║ `2a + b` ńÜäÕĆ╝ŃĆ鵳æõ╗¼õ╝ÜÕģłµŖŖÕ«āÕ£© PyTorch õĖŁÕ«×ńÄ░’╝īÕåŹµŖŖÕ«āÕ»╝Õć║Õł░ ONNX õĖŁŃĆé
+
+### õĖ║ PyTorch µĘ╗ÕŖĀ C++ µŗōÕ▒Ģ
+
+õĖ║ PyTorch µĘ╗ÕŖĀń«ĆÕŹĢńÜä C++ µŗōÕ▒ĢĶ┐śµś»ÕŠłµ¢╣õŠ┐ńÜäŃĆéÕ»╣õ║ĵłæõ╗¼Õ«Üõ╣ēńÜä my_add ń«ŚÕŁÉ’╝īÕÅ»õ╗źńö©õ╗źõĖŗńÜä C++ µ║ɵ¢ćõ╗ČµØźÕ«×ńÄ░ŃĆ鵳æõ╗¼µŖŖĶ»źµ¢ćõ╗ČÕæĮÕÉŹõĖ║ "my_add.cpp"’╝Ü
+
+```C++
+// my_add.cpp
+
+#include
+  +
+
+
+ńø┤µÄźÕ░åĶ»źµ©ĪÕ×ŗĶĮ¼µŹóµłÉTensorRTµ©ĪÕ×ŗõ╣¤µś»õĖŹÕÅ»ĶĪīńÜä’╝īĶ┐Öµś»ÕøĀõĖ║TensorRTĶ┐śµŚĀµ│ĢĶ¦Żµ×É `DynamicTRTResize` ĶŖéńé╣ŃĆéĶĆīµā│Ķ”üĶ¦Żµ×ÉĶ»źĶŖéńé╣’╝īµłæõ╗¼Õ┐ģķĪ╗õĖ║TensorRTµĘ╗ÕŖĀc++õ╗ŻńĀü’╝īÕ«×ńÄ░Ķ»źµÅÆõ╗ČŃĆé
+
+### C++Õ«×ńÄ░
+
+ÕøĀõĖ║MMDeployõĖŁÕĘ▓ń╗ÅÕ«×ńÄ░õ║åBicubic Interpolateń«ŚÕŁÉ’╝īµēĆõ╗źµłæõ╗¼ÕÅ»õ╗źÕżŹńö©ÕģČõĖŁńÜäCUDAķā©Õłåõ╗ŻńĀü’╝īÕŬķÆłÕ»╣TensorRTÕ«×ńÄ░µö»µīüÕŖ©µĆüscaleńÜäµÅÆõ╗ČÕŹ│ÕÅ»ŃĆéÕ»╣CUDAń╝¢ń©ŗµä¤Õģ┤ĶČŻńÜäÕ░Åõ╝Öõ╝┤ÕÅ»õ╗źÕÅéĶĆāCUDAńÜä[Õ«śµ¢╣µĢÖń©ŗ](https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html)ŃĆéÕøĀõĖ║ `csrc/backend_ops/tensorrt/bicubic_interpolate` õĖŁµ£ēµłæõ╗¼ķ£ĆĶ”üńÜäCUDAõ╗ŻńĀü’╝īµēĆõ╗źµłæõ╗¼ÕÅ»õ╗źńø┤µÄźÕ£©Ķ»źµ¢ćõ╗ČÕż╣ÕŖĀµĘ╗ÕŖĀTensorRTńøĖÕģ│ńÜätrt_dynamic_resize.hppÕÆītrt_dynamic_resize.cppµ¢ćõ╗Č’╝īÕ£©Ķ┐ÖõĖżõĖ¬µ¢ćõ╗ČõĖŁÕłåÕł½ÕŻ░µśÄÕÆīÕ«×ńÄ░µÅÆõ╗ČÕ░▒ÕÅ»õ╗źõ║åŃĆ鵳æõ╗¼õ╣¤ÕÅ»õ╗źµ¢░Õ╗║µ¢ćõ╗ČÕż╣ `csrc/backend_ops/tensorrt/dynamic_resize`’╝īÕ░åĶ┐ÖõĖżõĖ¬µ¢ćõ╗Čńø┤µÄźµöŠÕł░Ķ┐ÖõĖ¬µ¢ćõ╗ČÕż╣õĖŗŃĆé
+
+Õ»╣TensorRT 7+’╝īĶ”üÕ«×ńÄ░Ķ┐ÖµĀĘõĖĆõĖ¬Ķć¬Õ«Üõ╣ēµÅÆõ╗Č’╝īµłæõ╗¼ķ£ĆĶ”üÕåÖõĖżõĖ¬ń▒╗ŃĆé
+
+- `DynamicTRTResize`’╝īń╗¦µē┐Ķć¬[nvinfer1::IPluginV2DynamicExt](https://docs.nvidia.com/deeplearning/tensorrt/api/c_api/classnvinfer1_1_1_i_plugin_v2_dynamic_ext.html)’╝īÕ«īµłÉµÅÆõ╗ČńÜäÕģĘõĮōÕ«×ńÄ░
+- `DynamicTRTResizeCreator`’╝īń╗¦µē┐Ķć¬[nvinfer1::IPluginCreator](https://docs.nvidia.com/deeplearning/tensorrt/api/c_api/classnvinfer1_1_1_i_plugin_creator.html)’╝īµś»µÅÆõ╗ČńÜäÕĘźÕÄéń▒╗’╝īńö©õ║ÄÕłøÕ╗║`DynamicTRTResize`µÅÆõ╗ČńÜäÕ«×õŠŗŃĆé
+
+Õ£©MMDeployõĖŁ’╝īńö▒õ║ĵ£ēĶŗźÕ╣▓µÅÆõ╗Čķ£ĆĶ”üÕ«×ńÄ░’╝īµēĆõ╗źµłæõ╗¼Õ£©`mmdeploy/csrc/backend_ops/tensorrt/common/trt_plugin_base.hpp`õĖŁÕ«×ńÄ░õ║å`TRTPluginBase`ÕÆī`TRTPluginCreatorBase`õĖżõĖ¬ń▒╗’╝īńö©õ║Äń«ĪńÉåõĖĆõ║øµēƵ£ēµÅÆõ╗ČÕģ▒µ£ēńÜäÕ▒׵Ʀµ¢╣µ│ĢŃĆéÕģČõĖŁ’╝ī`TRTPluginBase`µś»ń╗¦µē┐Ķć¬`nvinfer1::IPluginV2DynamicExt`’╝īĶĆī`TRTPluginCreatorBase`µś»ń╗¦µē┐Ķć¬`nvinfer1::IPluginCreator`ŃĆéĶ┐ÖµĀĘ’╝īńö©µłĘÕ«×ńÄ░µÅÆõ╗ȵŚČÕŬķ£Ćń╗¦µē┐Ķ┐ÖõĖżõĖ¬µ¢░ńÜäń▒╗ÕŹ│ÕÅ»ŃĆéµēĆõ╗źµłæõ╗¼ÕŬķ£ĆÕ£©`dynamic_resize`µ¢ćõ╗ČÕż╣õĖŗ.hppµ¢ćõ╗ČõĖŁ’╝īÕ╝Ģńö©`trt_plugin_base.hpp`Õż┤µ¢ćõ╗Č’╝īńäČÕÉÄÕ«×ńÄ░ń▒╗Õ”éõĖŗ’╝Ü
+
+```cpp
+class DynamicTRTResize : public TRTPluginBase{}
+class DynamicTRTResizeCreator : public TRTPluginCreatorBase{}
+```
+
+Õ£©trt_dynamic_resize.hppõĖŁ’╝īµłæõ╗¼ÕŻ░µśÄÕ”éõĖŗÕåģÕ«╣’╝Ü
+
+```cpp
+#ifndef TRT_DYNAMIC_RESIZE_HPP
+#define TRT_DYNAMIC_RESIZE_HPP
+#include
+
+  +
+
+
+õ╗ÄõĖŖķØóńÜäÕøŠńēćÕÆīõ╗ŻńĀüõĖŁµłæõ╗¼ÕÅæńÄ░’╝īµÅÆõ╗Čń▒╗`DynamicTRTResize`õĖŁµłæõ╗¼Õ«Üõ╣ēõ║åń¦üµ£ēÕÅśķćÅ`mAlignCorners`’╝īĶ»źÕÅśķćÅĶĪ©ńż║µś»ÕÉ”`align corners`ŃĆ鵣żÕż¢ÕŬĶ”üÕ«×ńÄ░µ×äķĆĀµ×ɵ×äÕćĮµĢ░ÕÆīTensoRTõĖŁõĖēõĖ¬Õ¤║ń▒╗ńÜäµ¢╣µ│ĢÕŹ│ÕÅ»ŃĆéÕģČõĖŁµ×äķĆĀÕćĮµĢ░µ£ēõ║ī’╝īÕłåÕł½ńö©õ║ÄÕłøÕ╗║µÅÆõ╗ČÕÆīÕÅŹÕ║ÅÕłŚÕī¢µÅÆõ╗ČŃĆéĶĆīÕ¤║ń▒╗µ¢╣µ│ĢõĖŁ’╝Ü
+
+1. Õ¤║ń▒╗`IPluginV2DynamicExt`ńÜäµ¢╣µ│ĢĶŠāõĖ║ÕĆ╝ÕŠŚÕģ│µ│©’╝ī`getOutputDimensions`ĶÄĘÕÅ¢ĶŠōÕć║Õ╝ĀķćÅńÜäÕĮóńŖČ’╝ī`enqueue`ń£¤µŁŻĶ┤¤Ķ┤Żµē¦ĶĪīµłæõ╗¼ńÜäń«Śµ│Ģ’╝īÕåģķā©õĖĆĶł¼õ╝ÜĶ░āńö©CUDAµĀĖÕćĮµĢ░ŃĆéµ£¼µ¢ćÕ«×ńÄ░ńÜäµÅÆõ╗Čńø┤µÄźĶ░āńö©MMDeployÕĘ▓Õ«Üõ╣ēÕ£©`csrc/backend_ops/tensorrt/bicubic_interpolate`ńÜäµĀĖÕćĮµĢ░`bicubic_interpolate`ŃĆé
+2. Õ¤║ń▒╗`IPluginV2Ext`ńÜäµ¢╣µ│Ģ’╝īµłæõ╗¼ÕŬĶ”üÕ«×ńÄ░ĶÄĘÕÅ¢ĶŠōÕć║µĢ░µŹ«ń▒╗Õ×ŗńÜä`getOutputDataType`ÕŹ│ÕÅ»ŃĆé
+3. Õ¤║ń▒╗`IPluginV2`ÕłÖµś»õ║øĶÄĘÕÅ¢µÅÆõ╗Čń▒╗Õ×ŗÕÆīńēłµ£¼ÕÅĘńÜäµ¢╣µ│Ģ’╝īµŁżÕż¢ÕłÖµś»Õ║ÅÕłŚÕī¢ĶŠōÕģźµÅÆõ╗ČńÜäÕÅéµĢ░ńÜäÕćĮµĢ░`serialize`ÕÆīĶ«Īń«ŚĶ»źÕÅéµĢ░ńÜäÕ║ÅÕłŚÕī¢ÕÉÄ`buffer`Õż¦Õ░ÅńÜäÕćĮµĢ░`getSerializationSize`’╝īõ╗źÕÅŖĶÄĘÕÅ¢ĶŠōÕć║Õ╝ĀķćÅõĖ¬µĢ░ńÜäµ¢╣µ│Ģ`getNbOutputs`ŃĆéĶ┐śµ£ēķā©ÕłåÕģ¼Õģ▒µ¢╣µ│ĢĶó½Õ«Üõ╣ēÕ£©`TRTPluginBase`ń▒╗Õåģõ║åŃĆé
+
+Õ£©µÅÆõ╗ČÕĘźÕÄéń▒╗ `DynamicTRTResizeCreator` õĖŁ’╝īµłæõ╗¼ķ£ĆĶ”üÕŻ░µśÄĶÄĘÕÅ¢µÅÆõ╗ČÕÉŹń¦░ÕÆīńēłµ£¼ńÜäµ¢╣µ│Ģ `getPluginName` ÕÆī `getPluginVersion`ŃĆéÕÉīµŚČµłæõ╗¼Ķ┐śķ£ĆĶ”üÕŻ░µśÄÕłøÕ╗║µÅÆõ╗ČÕÆīÕÅŹÕ║ÅÕłŚÕī¢µÅÆõ╗ČńÜäµ¢╣µ│Ģ `createPlugin` ÕÆī `deserializePlugin`’╝īÕēŹĶĆģĶ░āńö© `DynamicTRTResize` õĖŁÕłøÕ╗║µÅÆõ╗ČńÜäµ¢╣µ│Ģ’╝īÕÉÄĶĆģĶ░āńö©ÕÅŹÕ║ÅÕłŚÕī¢µÅÆõ╗ČńÜäµ¢╣µ│ĢŃĆé
+
+µÄźõĖŗµØź’╝īµłæõ╗¼Õ░▒Õ«×ńÄ░õĖŖĶ┐░ÕŻ░µśÄÕɦŃĆéÕ£©.cppµ¢ćõ╗ČõĖŁµłæõ╗¼Õ«×ńÄ░õ╗ŻńĀüÕ”éõĖŗ’╝Ü
+
+```cpp
+// Copyright (c) OpenMMLab. All rights reserved
+#include "trt_dynamic_resize.hpp"
+
+#include
+| ÕÉŹń¦░ | +Õ«ēĶŻģµ¢╣Õ╝Å | +
|---|---|
| OpenCV (>=3.0) |
+
+ |
+
+
| ncnn | +ncnn µś»µö»µīü android Õ╣│ÕÅ░ńÜäķ½śµĢłńź×ń╗ÅńĮæń╗£µÄ©ńÉåĶ«Īń«ŚµĪåµ×Č
+ ńø«ÕēŹ, MMDeploy µö»µīü ncnn ńÜä 20220721 ńēłµ£¼, õĖöÕ┐ģķĪ╗õĮ┐ńö©git clone õĖŗĶĮĮµ║ÉńĀüńÜäµ¢╣Õ╝ÅÕ«ēĶŻģŃĆéĶ»ĘÕł░ Ķ┐Öķćī µ¤źĶ»ó ncnn µö»µīüńÜä android ABIŃĆé+ + |
+
| OpenJDK | +ń╝¢Ķ»æJava APIõ╣ŗÕēŹķ£ĆĶ”üÕģłÕćåÕżćOpenJDKÕ╝ĆÕÅæńÄ»Õóā + Ķ»ĘÕÅéĶĆā Java API ń╝¢Ķ»æ Ķ┐øĶĪīµ×äÕ╗║. + | +
+
+
+
+
+
+
+
+
+| mmpretrain | +TensorRT(ms) | +PPLNN(ms) | +ncnn(ms) | +Ascend(ms) | +|||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| model | +spatial | +T4 | +JetsonNano2GB | +Jetson TX2 | +T4 | +SnapDragon888 | +Adreno660 | +Ascend310 | +|||
| fp32 | +fp16 | +int8 | +fp32 | +fp16 | +fp32 | +fp16 | +fp32 | +fp32 | +fp32 | +||
| ResNet | +224x224 | +2.97 | +1.26 | +1.21 | +59.32 | +30.54 | +24.13 | +1.30 | +33.91 | +25.93 | +2.49 | +
| ResNeXt | +224x224 | +4.31 | +1.42 | +1.37 | +88.10 | +49.18 | +37.45 | +1.36 | +133.44 | +69.38 | +- | +
| SE-ResNet | +224x224 | +3.41 | +1.66 | +1.51 | +74.59 | +48.78 | +29.62 | +1.91 | +107.84 | +80.85 | +- | +
| ShuffleNetV2 | +224x224 | +1.37 | +1.19 | +1.13 | +15.26 | +10.23 | +7.37 | +4.69 | +9.55 | +10.66 | +- | +
| mmdet part1 | +TensorRT(ms) | +PPLNN(ms) | +||||
|---|---|---|---|---|---|---|
| model | +spatial | +T4 | +Jetson TX2 | +T4 | +||
| fp32 | +fp16 | +int8 | +fp32 | +fp16 | +||
| YOLOv3 | +320x320 | +14.76 | +24.92 | +24.92 | +- | +18.07 | +
| SSD-Lite | +320x320 | +8.84 | +9.21 | +8.04 | +1.28 | +19.72 | +
| RetinaNet | +800x1344 | +97.09 | +25.79 | +16.88 | +780.48 | +38.34 | +
| FCOS | +800x1344 | +84.06 | +23.15 | +17.68 | +- | +- | +
| FSAF | +800x1344 | +82.96 | +21.02 | +13.50 | +- | +30.41 | +
| Faster R-CNN | +800x1344 | +88.08 | +26.52 | +19.14 | +733.81 | +65.40 | +
| Mask R-CNN | +800x1344 | +104.83 | +58.27 | +- | +- | +86.80 | +
+
+
+
+
+
+| mmdet part2 | +ncnn | +||
|---|---|---|---|
| model | +spatial | +SnapDragon888 | +Adreno660 | +
| fp32 | +fp32 | +||
| MobileNetv2-YOLOv3 | +320x320 | +48.57 | +66.55 | +
| SSD-Lite | +320x320 | +44.91 | +66.19 | +
| YOLOX | +416x416 | +111.60 | +134.50 | +
+
+
+
+
+
+| mmagic | +TensorRT(ms) | +PPLNN(ms) | +||||
|---|---|---|---|---|---|---|
| model | +spatial | +T4 | +Jetson TX2 | +T4 | +||
| fp32 | +fp16 | +int8 | +fp32 | +fp16 | +||
| ESRGAN | +32x32 | +12.64 | +12.42 | +12.45 | +- | +7.67 | +
| SRCNN | +32x32 | +0.70 | +0.35 | +0.26 | +58.86 | +0.56 | +
+
+
+
+
+
+| mmocr | +TensorRT(ms) | +PPLNN(ms) | +ncnn(ms) | +||||
|---|---|---|---|---|---|---|---|
| model | +spatial | +T4 | +T4 | +SnapDragon888 | +Adreno660 | +||
| fp32 | +fp16 | +int8 | +fp16 | +fp32 | +fp32 | +||
| DBNet | +640x640 | +10.70 | +5.62 | +5.00 | +34.84 | +- | +- | +
| CRNN | +32x32 | +1.93 | +1.40 | +1.36 | +- | +10.57 | +20.00 | +
+
+
+
+
+
+## ń▓ŠÕ║”µĄŗĶ»Ģ
+
+| mmseg | +TensorRT(ms) | +PPLNN(ms) | +||||
|---|---|---|---|---|---|---|
| model | +spatial | +T4 | +Jetson TX2 | +T4 | +||
| fp32 | +fp16 | +int8 | +fp32 | +fp16 | +||
| FCN | +512x1024 | +128.42 | +23.97 | +18.13 | +1682.54 | +27.00 | +
| PSPNet | +1x3x512x1024 | +119.77 | +24.10 | +16.33 | +1586.19 | +27.26 | +
| DeepLabV3 | +512x1024 | +226.75 | +31.80 | +19.85 | +- | +36.01 | +
| DeepLabV3+ | +512x1024 | +151.25 | +47.03 | +50.38 | +2534.96 | +34.80 | +
+
+
+
+
+| mmpretrain | +PyTorch | +TorchScript | +ONNX Runtime | +TensorRT | +PPLNN | +Ascend | +|||
|---|---|---|---|---|---|---|---|---|---|
| model | +metric | +fp32 | +fp32 | +fp32 | +fp32 | +fp16 | +int8 | +fp16 | +fp32 | +
| ResNet-18 | +top-1 | +69.90 | +69.90 | +69.88 | +69.88 | +69.86 | +69.86 | +69.86 | +69.91 | +
| top-5 | +89.43 | +89.43 | +89.34 | +89.34 | +89.33 | +89.38 | +89.34 | +89.43 | +|
| ResNeXt-50 | +top-1 | +77.90 | +77.90 | +77.90 | +77.90 | +- | +77.78 | +77.89 | +- | +
| top-5 | +93.66 | +93.66 | +93.66 | +93.66 | +- | +93.64 | +93.65 | +- | +|
| SE-ResNet-50 | +top-1 | +77.74 | +77.74 | +77.74 | +77.74 | +77.75 | +77.63 | +77.73 | +- | +
| top-5 | +93.84 | +93.84 | +93.84 | +93.84 | +93.83 | +93.72 | +93.84 | +- | +|
| ShuffleNetV1 1.0x | +top-1 | +68.13 | +68.13 | +68.13 | +68.13 | +68.13 | +67.71 | +68.11 | +- | +
| top-5 | +87.81 | +87.81 | +87.81 | +87.81 | +87.81 | +87.58 | +87.80 | +- | +|
| ShuffleNetV2 1.0x | +top-1 | +69.55 | +69.55 | +69.55 | +69.55 | +69.54 | +69.10 | +69.54 | +- | +
| top-5 | +88.92 | +88.92 | +88.92 | +88.92 | +88.91 | +88.58 | +88.92 | +- | +|
| MobileNet V2 | +top-1 | +71.86 | +71.86 | +71.86 | +71.86 | +71.87 | +70.91 | +71.84 | +71.87 | +
| top-5 | +90.42 | +90.42 | +90.42 | +90.42 | +90.40 | +89.85 | +90.41 | +90.42 | +|
| Vision Transformer | +top-1 | +85.43 | +85.43 | +- | +85.43 | +85.42 | +- | +- | +85.43 | +
| top-5 | +97.77 | +97.77 | +- | +97.77 | +97.76 | +- | +- | +97.77 | +|
| Swin Transformer | +top-1 | +81.18 | +81.18 | +81.18 | +81.18 | +81.18 | +- | +- | +- | +
| top-5 | +95.61 | +95.61 | +95.61 | +95.61 | +95.61 | +- | +- | +- | +|
| EfficientFormer | +top-1 | +80.46 | +80.45 | +80.46 | +80.46 | +- | +- | +- | +- | +
| top-5 | +94.99 | +94.98 | +94.99 | +94.99 | +- | +- | +- | +- | +|
+
+
+
+
+| mmdet | +Pytorch | +TorchScript | +ONNXRuntime | +TensorRT | +PPLNN | +Ascend | +OpenVINO | +|||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| model | +task | +dataset | +metric | +fp32 | +fp32 | +fp32 | +fp32 | +fp16 | +int8 | +fp16 | +fp32 | +fp32 | +
| YOLOV3 | +Object Detection | +COCO2017 | +box AP | +33.7 | +33.7 | +- | +33.5 | +33.5 | +33.5 | +- | +- | +- | +
| SSD | +Object Detection | +COCO2017 | +box AP | +25.5 | +25.5 | +- | +25.5 | +25.5 | +- | +- | +- | +- | +
| RetinaNet | +Object Detection | +COCO2017 | +box AP | +36.5 | +36.4 | +- | +36.4 | +36.4 | +36.3 | +36.5 | +36.4 | +- | +
| FCOS | +Object Detection | +COCO2017 | +box AP | +36.6 | +- | +- | +36.6 | +36.5 | +- | +- | +- | +- | +
| FSAF | +Object Detection | +COCO2017 | +box AP | +37.4 | +37.4 | +- | +37.4 | +37.4 | +37.2 | +37.4 | +- | +- | +
| CenterNet | +Object Detection | +COCO2017 | +box AP | +25.9 | +26.0 | +26.0 | +26.0 | +25.8 | +- | +- | +- | +- | +
| YOLOX | +Object Detection | +COCO2017 | +box AP | +40.5 | +40.3 | +- | +40.3 | +40.3 | +29.3 | +- | +- | +- | +
| Faster R-CNN | +Object Detection | +COCO2017 | +box AP | +37.4 | +37.3 | +- | +37.3 | +37.3 | +37.1 | +37.3 | +37.2 | +- | +
| ATSS | +Object Detection | +COCO2017 | +box AP | +39.4 | +- | +- | +39.4 | +39.4 | +- | +- | +- | +- | +
| Cascade R-CNN | +Object Detection | +COCO2017 | +box AP | +40.4 | +- | +- | +40.4 | +40.4 | +- | +40.4 | +- | +- | +
| GFL | +Object Detection | +COCO2017 | +box AP | +40.2 | +- | +40.2 | +40.2 | +40.0 | +- | +- | +- | +- | +
| RepPoints | +Object Detection | +COCO2017 | +box AP | +37.0 | +- | +- | +36.9 | +- | +- | +- | +- | +- | +
| DETR | +Object Detection | +COCO2017 | +box AP | +40.1 | +40.1 | +- | +40.1 | +40.1 | +- | +- | +- | +- | +
| Mask R-CNN | +Instance Segmentation | +COCO2017 | +box AP | +38.2 | +38.1 | +- | +38.1 | +38.1 | +- | +38.0 | +- | +- | +
| mask AP | +34.7 | +34.7 | +- | +33.7 | +33.7 | +- | +- | +- | +- | +|||
| Swin-Transformer | +Instance Segmentation | +COCO2017 | +box AP | +42.7 | +- | +42.7 | +42.5 | +37.7 | +- | +- | +- | +- | +
| mask AP | +39.3 | +- | +39.3 | +39.3 | +35.4 | +- | +- | +- | +- | +|||
| SOLO | +Instance Segmentation | +COCO2017 | +mask AP | +33.1 | +- | +32.7 | +- | +- | +- | +- | +- | +32.7 | +
| SOLOv2 | +Instance Segmentation | +COCO2017 | +mask AP | +34.8 | +- | +34.5 | +- | +- | +- | +- | +- | +34.5 | +
+
+
+
+
+| mmagic | +Pytorch | +TorchScript | +ONNX Runtime | +TensorRT | +PPLNN | +|||||
|---|---|---|---|---|---|---|---|---|---|---|
| model | +task | +dataset | +metric | +fp32 | +fp32 | +fp32 | +fp32 | +fp16 | +int8 | +fp16 | +
| SRCNN | +Super Resolution | +Set5 | +PSNR | +28.4316 | +28.4120 | +28.4323 | +28.4323 | +28.4286 | +28.1995 | +28.4311 | +
| SSIM | +0.8099 | +0.8106 | +0.8097 | +0.8097 | +0.8096 | +0.7934 | +0.8096 | +|||
| ESRGAN | +Super Resolution | +Set5 | +PSNR | +28.2700 | +28.2619 | +28.2592 | +28.2592 | +- | +- | +28.2624 | +
| SSIM | +0.7778 | +0.7784 | +0.7764 | +0.7774 | +- | +- | +0.7765 | +|||
| ESRGAN-PSNR | +Super Resolution | +Set5 | +PSNR | +30.6428 | +30.6306 | +30.6444 | +30.6430 | +- | +- | +27.0426 | +
| SSIM | +0.8559 | +0.8565 | +0.8558 | +0.8558 | +- | +- | +0.8557 | +|||
| SRGAN | +Super Resolution | +Set5 | +PSNR | +27.9499 | +27.9252 | +27.9408 | +27.9408 | +- | +- | +27.9388 | +
| SSIM | +0.7846 | +0.7851 | +0.7839 | +0.7839 | +- | +- | +0.7839 | +|||
| SRResNet | +Super Resolution | +Set5 | +PSNR | +30.2252 | +30.2069 | +30.2300 | +30.2300 | +- | +- | +30.2294 | +
| SSIM | +0.8491 | +0.8497 | +0.8488 | +0.8488 | +- | +- | +0.8488 | +|||
| Real-ESRNet | +Super Resolution | +Set5 | +PSNR | +28.0297 | +- | +27.7016 | +27.7016 | +- | +- | +27.7049 | +
| SSIM | +0.8236 | +- | +0.8122 | +0.8122 | +- | +- | +0.8123 | +|||
| EDSR | +Super Resolution | +Set5 | +PSNR | +30.2223 | +30.2192 | +30.2214 | +30.2214 | +30.2211 | +30.1383 | +- | +
| SSIM | +0.8500 | +0.8507 | +0.8497 | +0.8497 | +0.8497 | +0.8469 | +- | +|||
+
+
+
+
+| mmocr | +Pytorch | +TorchScript | +ONNXRuntime | +TensorRT | +PPLNN | +OpenVINO | +|||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| model | +task | +dataset | +metric | +fp32 | +fp32 | +fp32 | +fp32 | +fp16 | +int8 | +fp16 | +fp32 | +
| DBNet* | +TextDetection | +ICDAR2015 | +recall | +0.7310 | +0.7308 | +0.7304 | +0.7198 | +0.7179 | +0.7111 | +0.7304 | +0.7309 | +
| precision | +0.8714 | +0.8718 | +0.8714 | +0.8677 | +0.8674 | +0.8688 | +0.8718 | +0.8714 | +|||
| hmean | +0.7950 | +0.7949 | +0.7950 | +0.7868 | +0.7856 | +0.7821 | +0.7949 | +0.7950 | +|||
| DBNetpp | +TextDetection | +ICDAR2015 | +recall | +0.8209 | +0.8209 | +0.8209 | +0.8199 | +0.8204 | +0.8204 | +- | +0.8209 | +
| precision | +0.9079 | +0.9079 | +0.9079 | +0.9117 | +0.9117 | +0.9142 | +- | +0.9079 | +|||
| hmean | +0.8622 | +0.8622 | +0.8622 | +0.8634 | +0.8637 | +0.8648 | +- | +0.8622 | +|||
| PSENet | +TextDetection | +ICDAR2015 | +recall | +0.7526 | +0.7526 | +0.7526 | +0.7526 | +0.7520 | +0.7496 | +- | +0.7526 | +
| precision | +0.8669 | +0.8669 | +0.8669 | +0.8669 | +0.8668 | +0.8550 | +- | +0.8669 | +|||
| hmean | +0.8057 | +0.8057 | +0.8057 | +0.8057 | +0.8054 | +0.7989 | +- | +0.8057 | +|||
| PANet | +TextDetection | +ICDAR2015 | +recall | +0.7401 | +0.7401 | +0.7401 | +0.7357 | +0.7366 | +- | +- | +0.7401 | +
| precision | +0.8601 | +0.8601 | +0.8601 | +0.8570 | +0.8586 | +- | +- | +0.8601 | +|||
| hmean | +0.7955 | +0.7955 | +0.7955 | +0.7917 | +0.7930 | +- | +- | +0.7955 | +|||
| TextSnake | +TextDetection | +CTW1500 | +recall | +0.8052 | +0.8052 | +0.8052 | +0.8055 | +- | +- | +- | +- | +
| precision | +0.8535 | +0.8535 | +0.8535 | +0.8538 | +- | +- | +- | +- | +|||
| hmean | +0.8286 | +0.8286 | +0.8286 | +0.8290 | +- | +- | +- | +- | +|||
| MaskRCNN | +TextDetection | +ICDAR2015 | +recall | +0.7766 | +0.7766 | +0.7766 | +0.7766 | +0.7761 | +0.7670 | +- | +- | +
| precision | +0.8644 | +0.8644 | +0.8644 | +0.8644 | +0.8630 | +0.8705 | +- | +- | +|||
| hmean | +0.8182 | +0.8182 | +0.8182 | +0.8182 | +0.8172 | +0.8155 | +- | +- | +|||
| CRNN | +TextRecognition | +IIIT5K | +acc | +0.8067 | +0.8067 | +0.8067 | +0.8067 | +0.8063 | +0.8067 | +0.8067 | +- | +
| SAR | +TextRecognition | +IIIT5K | +acc | +0.9517 | +- | +0.9287 | +- | +- | +- | +- | +- | +
| SATRN | +TextRecognition | +IIIT5K | +acc | +0.9470 | +0.9487 | +0.9487 | +0.9487 | +0.9483 | +0.9483 | +- | +- | +
| ABINet | +TextRecognition | +IIIT5K | +acc | +0.9603 | +0.9563 | +0.9563 | +0.9573 | +0.9507 | +0.9510 | +- | +- | +
+
+
+
+
+| mmseg | +Pytorch | +TorchScript | +ONNXRuntime | +TensorRT | +PPLNN | +Ascend | +||||
|---|---|---|---|---|---|---|---|---|---|---|
| model | +dataset | +metric | +fp32 | +fp32 | +fp32 | +fp32 | +fp16 | +int8 | +fp16 | +fp32 | +
| FCN | +Cityscapes | +mIoU | +72.25 | +72.36 | +- | +72.36 | +72.35 | +74.19 | +72.35 | +72.35 | +
| PSPNet | +Cityscapes | +mIoU | +78.55 | +78.66 | +- | +78.26 | +78.24 | +77.97 | +78.09 | +78.67 | +
| deeplabv3 | +Cityscapes | +mIoU | +79.09 | +79.12 | +- | +79.12 | +79.12 | +78.96 | +79.12 | +79.06 | +
| deeplabv3+ | +Cityscapes | +mIoU | +79.61 | +79.60 | +- | +79.60 | +79.60 | +79.43 | +79.60 | +79.51 | +
| Fast-SCNN | +Cityscapes | +mIoU | +70.96 | +70.96 | +- | +70.93 | +70.92 | +66.00 | +70.92 | +- | +
| UNet | +Cityscapes | +mIoU | +69.10 | +- | +- | +69.10 | +69.10 | +68.95 | +- | +- | +
| ANN | +Cityscapes | +mIoU | +77.40 | +- | +- | +77.32 | +77.32 | +- | +- | +- | +
| APCNet | +Cityscapes | +mIoU | +77.40 | +- | +- | +77.32 | +77.32 | +- | +- | +- | +
| BiSeNetV1 | +Cityscapes | +mIoU | +74.44 | +- | +- | +74.44 | +74.43 | +- | +- | +- | +
| BiSeNetV2 | +Cityscapes | +mIoU | +73.21 | +- | +- | +73.21 | +73.21 | +- | +- | +- | +
| CGNet | +Cityscapes | +mIoU | +68.25 | +- | +- | +68.27 | +68.27 | +- | +- | +- | +
| EMANet | +Cityscapes | +mIoU | +77.59 | +- | +- | +77.59 | +77.6 | +- | +- | +- | +
| EncNet | +Cityscapes | +mIoU | +75.67 | +- | +- | +75.66 | +75.66 | +- | +- | +- | +
| ERFNet | +Cityscapes | +mIoU | +71.08 | +- | +- | +71.08 | +71.07 | +- | +- | +- | +
| FastFCN | +Cityscapes | +mIoU | +79.12 | +- | +- | +79.12 | +79.12 | +- | +- | +- | +
| GCNet | +Cityscapes | +mIoU | +77.69 | +- | +- | +77.69 | +77.69 | +- | +- | +- | +
| ICNet | +Cityscapes | +mIoU | +76.29 | +- | +- | +76.36 | +76.36 | +- | +- | +- | +
| ISANet | +Cityscapes | +mIoU | +78.49 | +- | +- | +78.49 | +78.49 | +- | +- | +- | +
| OCRNet | +Cityscapes | +mIoU | +74.30 | +- | +- | +73.66 | +73.67 | +- | +- | +- | +
| PointRend | +Cityscapes | +mIoU | +76.47 | +76.47 | +- | +76.41 | +76.42 | +- | +- | +- | +
| Semantic FPN | +Cityscapes | +mIoU | +74.52 | +- | +- | +74.52 | +74.52 | +- | +- | +- | +
| STDC | +Cityscapes | +mIoU | +75.10 | +- | +- | +75.10 | +75.10 | +- | +- | +- | +
| STDC | +Cityscapes | +mIoU | +77.17 | +- | +- | +77.17 | +77.17 | +- | +- | +- | +
| UPerNet | +Cityscapes | +mIoU | +77.10 | +- | +- | +77.19 | +77.18 | +- | +- | +- | +
| Segmenter | +ADE20K | +mIoU | +44.32 | +44.29 | +44.29 | +44.29 | +43.34 | +43.35 | +- | +- | +
+
+
+
+
+
+| mmpose | +Pytorch | +ONNXRuntime | +TensorRT | +PPLNN | +OpenVINO | +||||
|---|---|---|---|---|---|---|---|---|---|
| model | +task | +dataset | +metric | +fp32 | +fp32 | +fp32 | +fp16 | +fp16 | +fp32 | +
| HRNet | +Pose Detection | +COCO | +AP | +0.748 | +0.748 | +0.748 | +0.748 | +- | +0.748 | +
| AR | +0.802 | +0.802 | +0.802 | +0.802 | +- | +0.802 | +|||
| LiteHRNet | +Pose Detection | +COCO | +AP | +0.663 | +0.663 | +0.663 | +- | +- | +0.663 | +
| AR | +0.728 | +0.728 | +0.728 | +- | +- | +0.728 | +|||
| MSPN | +Pose Detection | +COCO | +AP | +0.762 | +0.762 | +0.762 | +0.762 | +- | +0.762 | +
| AR | +0.825 | +0.825 | +0.825 | +0.825 | +- | +0.825 | +|||
| Hourglass | +Pose Detection | +COCO | +AP | +0.717 | +0.717 | +0.717 | +0.717 | +- | +0.717 | +
| AR | +0.774 | +0.774 | +0.774 | +0.774 | +- | +0.774 | +|||
| SimCC | +Pose Detection | +COCO | +AP | +0.607 | +- | +0.608 | +- | +- | +- | +
| AR | +0.668 | +- | +0.672 | +- | +- | +- | +|||
+
+
+
+
+
+| mmrotate | +Pytorch | +ONNXRuntime | +TensorRT | +PPLNN | +OpenVINO | +||||
|---|---|---|---|---|---|---|---|---|---|
| model | +task | +dataset | +metrics | +fp32 | +fp32 | +fp32 | +fp16 | +fp16 | +fp32 | +
| RotatedRetinaNet | +Rotated Detection | +DOTA-v1.0 | +mAP | +0.698 | +0.698 | +0.698 | +0.697 | +- | +- | +
| Oriented RCNN | +Rotated Detection | +DOTA-v1.0 | +mAP | +0.756 | +0.756 | +0.758 | +0.730 | +- | +- | +
| GlidingVertex | +Rotated Detection | +DOTA-v1.0 | +mAP | +0.732 | +- | +0.733 | +0.731 | +- | +- | +
| RoI Transformer | +Rotated Detection | +DOTA-v1.0 | +mAP | +0.761 | +- | +0.758 | +- | +- | +- | +
+
+
+
+
+## Õżćµ│©
+
+- ńö▒õ║ĵ¤Éõ║øµĢ░µŹ«ķøåÕ£©õ╗ŻńĀüÕ║ōõĖŁÕīģÕɽÕÉäń¦ŹÕłåĶŠ©ńÄćńÜäÕøŠÕāÅ’╝īõŠŗÕ”é MMDet’╝īķƤÕ║”Õ¤║Õćåµś»ķĆÜĶ┐ć MMDeploy õĖŁńÜäķØÖµĆüķģŹńĮ«ĶÄĘÕŠŚńÜä’╝īĶĆīµĆ¦ĶāĮÕ¤║Õćåµś»ķĆÜĶ┐ćÕŖ©µĆüķģŹńĮ«ĶÄĘÕŠŚńÜä
+- TensorRT ńÜäõĖĆõ║ø int8 µĆ¦ĶāĮÕ¤║ÕćåµĄŗĶ»Ģķ£ĆĶ”üµ£ē tensor core ńÜä Nvidia ÕŹĪ’╝īÕÉ”ÕłÖµĆ¦ĶāĮõ╝ÜÕż¦Õ╣ģõĖŗķÖŹ
+- DBNet Õ£©µ©ĪÕ×ŗ `neck` õĮ┐ńö©õ║å`nearest` µÅÆÕĆ╝’╝īTensorRT-7 ńö©õ║åõĖÄ Pytorch Õ«īÕģ©õĖŹÕÉīńÜäńŁ¢ńĢźŃĆéõĖ║õ║åõĮ┐õĖÄ TensorRT-7 Õģ╝Õ«╣’╝īµłæõ╗¼ķćŹÕåÖõ║å`neck`õ╗źõĮ┐ńö©`bilinear`µÅÆÕĆ╝’╝īĶ┐ÖµÅÉķ½śõ║åµŻĆµĄŗµĆ¦ĶāĮŃĆéõĖ║õ║åĶÄĘÕŠŚõĖÄ Pytorch Õī╣ķģŹńÜäµĆ¦ĶāĮ’╝īµÄ©ĶŹÉõĮ┐ńö© TensorRT-8+’╝īÕģȵÅÆÕĆ╝µ¢╣µ│ĢõĖÄ Pytorch ńøĖÕÉīŃĆé
+- Õ»╣õ║Ä mmpose µ©ĪÕ×ŗ’╝īÕ£©µ©ĪÕ×ŗķģŹńĮ«µ¢ćõ╗ČõĖŁ `flip_test` ķ£ĆĶ«ŠńĮ«õĖ║ `False`
+- ķā©Õłåµ©ĪÕ×ŗÕ£© fp16 µ©ĪÕ╝ÅõĖŗÕÅ»ĶāĮÕŁśÕ£©ĶŠāÕż¦ńÜäń▓ŠÕ║”µŹ¤Õż▒’╝īĶ»ĘµĀ╣µŹ«ÕģĘõĮōµāģÕåĄÕ»╣µ©ĪÕ×ŗĶ┐øĶĪīĶ░āµĢ┤ŃĆé
diff --git a/internlm_langchain/knowledge_base/MMDeploy/content/benchmark_edge.md b/internlm_langchain/knowledge_base/MMDeploy/content/benchmark_edge.md
new file mode 100644
index 00000000..1a539273
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDeploy/content/benchmark_edge.md
@@ -0,0 +1,58 @@
+# ĶŠ╣ŃĆüń½»Ķ«ŠÕżćµĄŗĶ»Ģń╗ōµ×£
+
+Ķ┐Öķćīń╗ÖÕć║µłæõ╗¼ĶŠ╣ŃĆüń½»Ķ«ŠÕżćńÜ䵥ŗĶ»Ģń╗ōĶ«║’╝īńö©µłĘÕÅ»õ╗źńø┤µÄźķĆÜĶ┐ć [model profiling](../02-how-to-run/profile_model.md) ĶÄĘÕŠŚĶć¬ÕĘ▒ńÄ»ÕóāńÜäń╗ōµ×£ŃĆé
+
+## ĶĮ»ńĪ¼õ╗ČńÄ»Õóā
+
+- host OS ubuntu 18.04
+- backend SNPE-1.59
+- device Mi11 (qcom 888)
+
+## mmpretrain µ©ĪÕ×ŗ
+
+| model | dataset | spatial | fp32 top-1 (%) | snpe gpu hybrid fp32 top-1 (%) | latency (ms) |
+| :----------------------------------------------------------------------------------------------------------------------: | :---------: | :-----: | :------------: | :----------------------------: | :----------: |
+| [ShuffleNetV2](https://github.com/open-mmlab/mmpretrain/blob/main/configs/shufflenet_v2/shufflenet-v2-1x_16xb64_in1k.py) | ImageNet-1k | 224x224 | 69.55 | 69.83\* | 20┬▒7 |
+| [MobilenetV2](https://github.com/open-mmlab/mmpretrain/blob/main/configs/mobilenet_v2/mobilenet-v2_8xb32_in1k.py) | ImageNet-1k | 224x224 | 71.86 | 72.14\* | 15┬▒6 |
+
+tips:
+
+1. ImageNet-1k µĢ░µŹ«ķøåĶŠāÕż¦’╝īõ╗ģõĮ┐ńö©õĖĆķā©ÕłåµĄŗĶ»Ģ’╝ł8000/50000’╝ē
+2. ĶŠ╣ŃĆüń½»Ķ«ŠÕżćÕÅæńāŁõ╝ÜķÖŹķóæ’╝īÕøĀµŁżĶĆŚµŚČÕ«×ķÖģõĖŖõ╝ܵ│óÕŖ©ŃĆéĶ┐Öķćīń╗ÖÕć║Ķ┐ÉĶĪīõĖƵ«ĄµŚČķŚ┤ÕÉÄŃĆüń©│Õ«ÜńÜäµĢ░ÕĆ╝ŃĆéĶ┐ÖõĖ¬ń╗ōµ×£µø┤Ķ┤┤Ķ┐æÕ«×ķÖģķ£Ćµ▒é
+
+## mmocr µŻĆµĄŗ
+
+| model | dataset | spatial | fp32 hmean | snpe gpu hybrid hmean | latency(ms) |
+| :--------------------------------------------------------------------------------------------------------------------: | :-------: | :------: | :--------: | :-------------------: | :---------: |
+| [PANet](https://github.com/open-mmlab/mmocr/blob/main/configs/textdet/panet/panet_resnet18_fpem-ffm_600e_icdar2015.py) | ICDAR2015 | 1312x736 | 0.795 | 0.785 @thr=0.9 | 3100┬▒100 |
+
+## mmpose µ©ĪÕ×ŗ
+
+| model | dataset | spatial | snpe hybrid AR@IoU=0.50 | snpe hybrid AP@IoU=0.50 | latency(ms) |
+| :---------------------------------------------------------------------------------------------------------------------------------------------------------------------: | :--------: | :-----: | :---------------------: | :---------------------: | :---------: |
+| [pose_hrnet_w32](https://github.com/open-mmlab/mmpose/blob/main/configs/animal_2d_keypoint/topdown_heatmap/animalpose/td-hm_hrnet-w32_8xb64-210e_animalpose-256x256.py) | Animalpose | 256x256 | 0.997 | 0.989 | 630┬▒50 |
+
+tips:
+
+- µĄŗĶ»Ģ pose_hrnet ńö©ńÜ䵜» AnimalPose ńÜä test dataset’╝īĶĆīķØ× val dataset
+
+## mmseg
+
+| model | dataset | spatial | mIoU | latency(ms) |
+| :------------------------------------------------------------------------------------------------------------------: | :--------: | :------: | :---: | :---------: |
+| [fcn](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/fcn/fcn_r18-d8_4xb2-80k_cityscapes-512x1024.py) | Cityscapes | 512x1024 | 71.11 | 4915┬▒500 |
+
+tips:
+
+- fcn ńö© 512x1024 Õ░║Õ»ĖĶ┐ÉĶĪīµŁŻÕĖĖŃĆéCityscapes µĢ░µŹ«ķøå 1024x2048 ÕłåĶŠ©ńÄćõ╝ÜÕ»╝Ķć┤Ķ«ŠÕżćķćŹÕÉ»
+
+## ÕģČõ╗¢µ©ĪÕ×ŗ
+
+- mmdet ķ£ĆĶ”üµēŗÕŖ©µŖŖµ©ĪÕ×ŗµŗåµłÉõĖżķā©ÕłåŃĆéÕøĀõĖ║
+ - snpe µ║ÉńĀüõĖŁ `onnx_to_ir.py` õ╗ģĶāĮĶ¦Żµ×ÉĶŠōÕģź’╝ī`ir_to_dlc.py` Ķ┐śõĖŹµö»µīü topk
+ - UDO ’╝łńö©µłĘĶć¬Õ«Üõ╣ēń«ŚÕŁÉ’╝ēµŚĀµ│ĢÕÆī `snpe-onnx-to-dlc` ķģŹÕÉłõĮ┐ńö©
+- mmagic µ©ĪÕ×ŗ
+ - srcnn ķ£ĆĶ”ü cubic resize’╝īsnpe õĖŹµö»µīü
+ - esrgan ÕÅ»µŁŻÕĖĖĶĮ¼µŹó’╝īõĮåÕŖĀĶĮĮµ©ĪÕ×ŗõ╝ÜÕ»╝Ķć┤Ķ«ŠÕżćķćŹÕÉ»
+- mmrotate õŠØĶĄ¢ [e2cnn](https://pypi.org/project/e2cnn/) ’╝īķ£ĆĶ”üµēŗÕŖ©Õ«ēĶŻģ [ÕģČ Python3.6
+ Õģ╝Õ«╣Õłåµö»](https://github.com/QUVA-Lab/e2cnn)
diff --git a/internlm_langchain/knowledge_base/MMDeploy/content/benchmark_tvm.md b/internlm_langchain/knowledge_base/MMDeploy/content/benchmark_tvm.md
new file mode 100644
index 00000000..d58c9c9b
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDeploy/content/benchmark_tvm.md
@@ -0,0 +1,51 @@
+# TVM µĄŗĶ»Ģ
+
+## µö»µīüµ©ĪÕ×ŗÕłŚĶĪ©
+
+| Model | Codebase | Model config |
+| :---------------- | :------------- | :-------------------------------------------------------------------------------------: |
+| RetinaNet | MMDetection | [config](https://github.com/open-mmlab/mmdetection/tree/main/configs/retinanet) |
+| Faster R-CNN | MMDetection | [config](https://github.com/open-mmlab/mmdetection/tree/main/configs/faster_rcnn) |
+| YOLOv3 | MMDetection | [config](https://github.com/open-mmlab/mmdetection/tree/main/configs/yolo) |
+| YOLOX | MMDetection | [config](https://github.com/open-mmlab/mmdetection/tree/main/configs/yolox) |
+| Mask R-CNN | MMDetection | [config](https://github.com/open-mmlab/mmdetection/tree/main/configs/mask_rcnn) |
+| SSD | MMDetection | [config](https://github.com/open-mmlab/mmdetection/tree/main/configs/ssd) |
+| ResNet | MMPretrain | [config](https://github.com/open-mmlab/mmpretrain/tree/main/configs/resnet) |
+| ResNeXt | MMPretrain | [config](https://github.com/open-mmlab/mmpretrain/tree/main/configs/resnext) |
+| SE-ResNet | MMPretrain | [config](https://github.com/open-mmlab/mmpretrain/tree/main/configs/seresnet) |
+| MobileNetV2 | MMPretrain | [config](https://github.com/open-mmlab/mmpretrain/tree/main/configs/mobilenet_v2) |
+| ShuffleNetV1 | MMPretrain | [config](https://github.com/open-mmlab/mmpretrain/tree/main/configs/shufflenet_v1) |
+| ShuffleNetV2 | MMPretrain | [config](https://github.com/open-mmlab/mmpretrain/tree/main/configs/shufflenet_v2) |
+| VisionTransformer | MMPretrain | [config](https://github.com/open-mmlab/mmpretrain/tree/main/configs/vision_transformer) |
+| FCN | MMSegmentation | [config](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/fcn) |
+| PSPNet | MMSegmentation | [config](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/pspnet) |
+| DeepLabV3 | MMSegmentation | [config](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/deeplabv3) |
+| DeepLabV3+ | MMSegmentation | [config](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/deeplabv3plus) |
+| UNet | MMSegmentation | [config](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/unet) |
+
+ĶĪ©õĖŁõ╗ģÕłŚÕć║ÕĘ▓µĄŗĶ»Ģµ©ĪÕ×ŗ’╝īµ£¬ÕłŚÕć║ńÜ䵩ĪÕ×ŗÕÅ»ĶāĮÕÉīµĀʵö»µīü’╝īÕÅ»õ╗źĶć¬ĶĪīÕ░ØĶ»ĢĶĮ¼µŹóŃĆé
+
+## Test
+
+- Ubuntu 20.04
+- tvm 0.9.0
+
+| mmpretrain | metric | PyTorch | TVM |
+| :-----------------------------------------------------------------------------------------------------------------------: | :----: | :-----: | :---: |
+| [ResNet-18](https://github.com/open-mmlab/mmpretrain/blob/main/configs/resnet/resnet18_8xb32_in1k.py) | top-1 | 69.90 | 69.90 |
+| [ResNeXt-50](https://github.com/open-mmlab/mmpretrain/blob/main/configs/resnext/resnext50-32x4d_8xb32_in1k.py) | top-1 | 77.90 | 77.90 |
+| [ShuffleNet V2](https://github.com/open-mmlab/mmpretrain/blob/main/configs/shufflenet_v2/shufflenet-v2-1x_16xb64_in1k.py) | top-1 | 69.55 | 69.55 |
+| [MobileNet V2](https://github.com/open-mmlab/mmpretrain/tree/main/configs/mobilenet_v2/mobilenet-v2_8xb32_in1k.py) | top-1 | 71.86 | 71.86 |
+
+
+
+| mmdet(\*) | metric | PyTorch | TVM |
+| :-----------------------------------------------------------------------------------: | :----: | :-----: | :--: |
+| [SSD](https://github.com/open-mmlab/mmdetection/tree/main/configs/ssd/ssd300_coco.py) | box AP | 25.5 | 25.5 |
+
+\*: ńö▒õ║ĵÜ鵌ČõĖŹµö»µīüÕŖ©µĆüĶĮ¼µŹó’╝īÕøĀµŁżõ╗ģµÅÉõŠø SSD ńÜäń▓ŠÕ║”µĄŗĶ»Ģń╗ōµ×£ŃĆé
+
+| mmseg | metric | PyTorch | TVM |
+| :---------------------------------------------------------------------------------------------------------------------------: | :----: | :-----: | :---: |
+| [FCN](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/fcn/fcn_r50-d8_4xb2-40k_cityscapes-512x1024.py) | mIoU | 72.25 | 72.36 |
+| [PSPNet](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/pspnet/pspnet_r50-d8_4xb2-80k_cityscapes-512x1024.py) | mIoU | 78.55 | 77.90 |
diff --git a/internlm_langchain/knowledge_base/MMDeploy/content/build_from_docker.md b/internlm_langchain/knowledge_base/MMDeploy/content/build_from_docker.md
new file mode 100644
index 00000000..4813dad1
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDeploy/content/build_from_docker.md
@@ -0,0 +1,68 @@
+# õĮ┐ńö© Docker ķĢ£ÕāÅ
+
+µ£¼µ¢ćń«ĆĶ┐░Õ”éõĮĢõĮ┐ńö©[Docker](https://docs.docker.com/get-docker/)Õ«ēĶŻģmmdeploy
+
+## ĶÄĘÕÅ¢ķĢ£ÕāÅ
+
+õĖ║õ║åµ¢╣õŠ┐ńö©µłĘ’╝īmmdeployÕ£©[Docker Hub](https://hub.docker.com/r/openmmlab/mmdeploy)õĖŖµÅÉõŠøõ║åÕżÜõĖ¬ńēłµ£¼ńÜäķĢ£ÕāÅ’╝īõŠŗÕ”éÕ»╣õ║Ä`mmdeploy==1.2.0`’╝ī
+ÕģČķĢ£ÕāŵĀćńŁŠõĖ║`openmmlab/mmdeploy:ubuntu20.04-cuda11.3-mmdeploy1.2.0`’╝īĶĆīµ£Ćµ¢░ńÜäķĢ£ÕāŵĀćńŁŠõĖ║`openmmlab/mmdeploy:ubuntu20.04-cuda11.3-mmdeploy`ŃĆé
+ķĢ£ÕāÅńøĖÕģ│Ķ¦äµĀ╝õ┐Īµü»Õ”éõĖŗĶĪ©µēĆńż║’╝Ü
+
+| Item | Version |
+| :---------: | :---------: |
+| OS | Ubuntu20.04 |
+| CUDA | 11.3 |
+| CUDNN | 8.2 |
+| Python | 3.8.10 |
+| Torch | 1.10.0 |
+| TorchVision | 0.11.0 |
+| TorchScript | 1.10.0 |
+| TensorRT | 8.2.3.0 |
+| ONNXRuntime | 1.8.1 |
+| OpenVINO | 2022.3.0 |
+| ncnn | 20221128 |
+| openppl | 0.8.1 |
+
+ńö©µłĘÕÅ»ķĆēµŗ®õĖĆõĖ¬[ķĢ£ÕāÅ](https://hub.docker.com/r/openmmlab/mmdeploy/tags)Õ╣ČĶ┐ÉĶĪī`docker pull`µŗēÕÅ¢ķĢ£ÕāÅÕł░µ£¼Õ£░’╝Ü
+
+```shell
+export TAG=openmmlab/mmdeploy:ubuntu20.04-cuda11.3-mmdeploy
+docker pull $TAG
+```
+
+## µ×äÕ╗║ķĢ£ÕāÅ(ÕÅ»ķĆē)
+
+Õ”éµ×£ÕĘ▓µÅÉõŠøńÜäķĢ£ÕāŵŚĀµ│Ģµ╗ĪĶČ│Ķ”üµ▒é’╝īńö©µłĘÕÅ»õ┐«µö╣`docker/Release/Dockerfile`Õ╣ČÕ£©µ£¼Õ£░µ×äÕ╗║ķĢ£ÕāÅŃĆéÕģČõĖŁ’╝īµ×äÕ╗║ÕÅéµĢ░`MMDEPLOY_VERSION`ÕÅ»õ╗źµś»[mmdeploy](https://github.com/open-mmlab/mmdeploy)ķĪ╣ńø«ńÜäõĖĆõĖ¬[µĀćńŁŠ](https://github.com/open-mmlab/mmdeploy/tags)µł¢ĶĆģÕłåµö»ŃĆé
+
+```shell
+export MMDEPLOY_VERSION=main
+export TAG=mmdeploy-${MMDEPLOY_VERSION}
+docker build docker/Release/ -t ${TAG} --build-arg MMDEPLOY_VERSION=${MMDEPLOY_VERSION}
+```
+
+## Ķ┐ÉĶĪī docker Õ«╣ÕÖ©
+
+ÕĮōµŗēÕÅ¢µł¢µ×äÕ╗║ docker ķĢ£ÕāÅÕÉÄ’╝īńö©µłĘÕÅ»õĮ┐ńö© `docker run` ÕÉ»ÕŖ© docker µ£ŹÕŖĪ’╝Ü
+
+```shell
+export TAG=openmmlab/mmdeploy:ubuntu20.04-cuda11.3-mmdeploy
+docker run --gpus=all -it --rm $TAG
+```
+
+## ÕĖĖĶ¦üķŚ«ńŁö
+
+1. CUDA error: the provided PTX was compiled with an unsupported toolchain:
+
+ Õ”é [Ķ┐Öķćī](https://forums.developer.nvidia.com/t/cuda-error-the-provided-ptx-was-compiled-with-an-unsupported-toolchain/185754)µēĆĶ»┤’╝īµø┤µ¢░ GPU ńÜäķ®▒ÕŖ©Õł░µé©ńÜäGPUĶāĮõĮ┐ńö©ńÜäµ£Ćµ¢░ńēłµ£¼ŃĆé
+
+2. docker: Error response from daemon: could not select device driver "" with capabilities: [gpu].
+
+ ```shell
+ # Add the package repositories
+ distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
+ curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
+ curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
+
+ sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
+ sudo systemctl restart docker
+ ```
diff --git a/internlm_langchain/knowledge_base/MMDeploy/content/build_from_script.md b/internlm_langchain/knowledge_base/MMDeploy/content/build_from_script.md
new file mode 100644
index 00000000..3d563649
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDeploy/content/build_from_script.md
@@ -0,0 +1,53 @@
+# õĖĆķö«Õ╝ÅĶäܵ£¼Õ«ēĶŻģ
+
+ķĆÜĶ┐ćńö©µłĘĶ░āńĀö’╝īµłæõ╗¼ÕŠŚń¤źÕżÜµĢ░õĮ┐ńö©ĶĆģÕ£©õ║åĶ¦Ż mmdeploy ÕēŹ’╝īÕĘ▓ń╗Åńå¤ń¤ź python ÕÆī torch ńö©µ│ĢŃĆéÕøĀµŁżµłæõ╗¼µÅÉõŠøĶäܵ£¼ń«ĆÕī¢ mmdeploy Õ«ēĶŻģŃĆé
+
+ÕüćĶ«Šµé©ÕĘ▓ń╗ÅÕćåÕżćÕźĮ
+
+- python3 -m pip’╝łÕ┐ģķĪ╗’╝īconda µł¢ pyenv ńÜåÕÅ»’╝ē
+- nvcc’╝łÕÅ¢Õå│õ║ĵĩńÉåÕÉÄń½»’╝ē
+- torch’╝łķØ×Õ┐ģķĪ╗’╝īÕÅ»Õ╗ČÕÉÄÕ«ēĶŻģ’╝ē
+
+Ķ┐ÉĶĪīĶ┐ÖõĖ¬Ķäܵ£¼µØźÕ«ēĶŻģ mmdeploy + ncnn backend’╝ī`nproc` ÕÅ»õ╗źõĖŹµīćÕ«ÜŃĆé
+
+```bash
+$ cd /path/to/mmdeploy
+$ python3 tools/scripts/build_ubuntu_x64_ncnn.py
+..
+```
+
+µ£¤ķŚ┤ÕÅ»ĶāĮķ£ĆĶ”ü sudo Õ»åńĀü’╝īĶäܵ£¼õ╝ÜÕ░Įµ£ĆÕż¦ÕŖ¬ÕŖøÕ«īµłÉ mmdeploy SDK ÕÆī demo’╝Ü
+
+- µŻĆµĄŗń│╗ń╗¤ńēłµ£¼ŃĆümake õĮ┐ńö©ńÜä job õĖ¬µĢ░ŃĆüµś»ÕÉ” root ńö©µłĘ’╝īõ╣¤õ╝ÜĶć¬ÕŖ©õ┐«ÕżŹ pip ķŚ«ķóś
+- Õ»╗µēŠÕ┐ģķĪ╗ńÜäÕ¤║ńĪĆÕĘźÕģĘ’╝īÕ”é g++-7ŃĆücmakeŃĆüwget ńŁē
+- ń╝¢Ķ»æÕ┐ģķĪ╗ńÜäõŠØĶĄ¢’╝īÕ”é pyncnnŃĆü protobuf
+
+Ķäܵ£¼õ╣¤õ╝ÜÕ░ĮķćÅķü┐ÕģŹÕĮ▒ÕōŹ host ńÄ»Õóā’╝Ü
+
+- µ║ÉńĀüń╝¢Ķ»æńÜäõŠØĶĄ¢’╝īķāĮµöŠÕ£©õĖÄ mmdeploy ÕÉīń║¦ńÜä `mmdeploy-dep` ńø«ÕĮĢõĖŁ
+- õĖŹõ╝ÜõĖ╗ÕŖ©õ┐«µö╣ PATHŃĆüLD_LIBRARY_PATHŃĆüPYTHONPATH ńŁēÕÅśķćÅ
+- õ╝ܵēōÕŹ░ķ£ĆĶ”üõ┐«µö╣ńÜäńÄ»ÕóāÕÅśķćÅ’╝ī**ķ£ĆĶ”üµ│©µäŵ£Ćń╗łńÜäĶŠōÕć║õ┐Īµü»**
+
+Ķäܵ£¼µ£Ćń╗łõ╝ܵē¦ĶĪī `python3 tools/check_env.py`’╝īÕ«ēĶŻģµłÉÕŖ¤Õ║öµśŠńż║Õ»╣Õ║ö backend ńÜäńēłµ£¼ÕÅĘÕÆī `ops_is_available: True`’╝īõŠŗÕ”é’╝Ü
+
+```bash
+$ python3 tools/check_env.py
+..
+2022-09-13 14:49:13,767 - mmdeploy - INFO - **********Backend information**********
+2022-09-13 14:49:14,116 - mmdeploy - INFO - onnxruntime: 1.8.0 ops_is_avaliable : True
+2022-09-13 14:49:14,131 - mmdeploy - INFO - tensorrt: 8.4.1.5 ops_is_avaliable : True
+2022-09-13 14:49:14,139 - mmdeploy - INFO - ncnn: 1.0.20220901 ops_is_avaliable : True
+2022-09-13 14:49:14,150 - mmdeploy - INFO - pplnn_is_avaliable: True
+..
+```
+
+Ķ┐Öµś»ÕĘ▓ķ¬īĶ»üńÜäÕ«ēĶŻģĶäܵ£¼ŃĆéÕ”éµ×£µā│Ķ«® mmdeploy ÕÉīµŚČµö»µīüÕżÜń¦Ź backend’╝īµ»ÅõĖ¬Ķäܵ£¼µē¦ĶĪīõĖƵ¼ĪÕŹ│ÕÅ»’╝Ü
+
+| script | OS version |
+| :-----------------------------: | :-----------------: |
+| build_ubuntu_x64_ncnn.py | 18.04/20.04 |
+| build_ubuntu_x64_ort.py | 18.04/20.04 |
+| build_ubuntu_x64_pplnn.py | 18.04/20.04 |
+| build_ubuntu_x64_torchscript.py | 18.04/20.04 |
+| build_ubuntu_x64_tvm.py | 18.04/20.04 |
+| build_jetson_orin_python38.sh | JetPack5.0 L4T 34.1 |
diff --git a/internlm_langchain/knowledge_base/MMDeploy/content/build_from_source.md b/internlm_langchain/knowledge_base/MMDeploy/content/build_from_source.md
new file mode 100644
index 00000000..04c85655
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDeploy/content/build_from_source.md
@@ -0,0 +1,51 @@
+# µ║ÉńĀüµēŗÕŖ©Õ«ēĶŻģ
+
+Õ”éµ×£ńĮæń╗£Ķē»ÕźĮ’╝īµłæõ╗¼Õ╗║Ķ««õĮ┐ńö© [docker](build_from_docker.md) µł¢ [õĖĆķö«Õ╝ÅĶäܵ£¼](build_from_script.md) µ¢╣Õ╝ÅŃĆé
+
+## õĖŗĶĮĮ
+
+```bash
+git clone -b main git@github.com:open-mmlab/mmdeploy.git --recursive
+```
+
+### FAQ
+
+- Õ”éµ×£ńö▒õ║ÄńĮæń╗£ńŁēÕĤÕøĀÕ»╝Ķć┤µŗēÕÅ¢õ╗ōÕ║ōÕŁÉµ©ĪÕØŚÕż▒Ķ┤ź’╝īÕÅ»õ╗źÕ░ØĶ»ĢķĆÜĶ┐ćÕ”éõĖŗµīćõ╗żµēŗÕŖ©ÕåŹµ¼ĪÕ«ēĶŻģÕŁÉµ©ĪÕØŚ:
+
+ ```bash
+ git clone git@github.com:NVIDIA/cub.git third_party/cub
+ cd third_party/cub
+ git checkout c3cceac115
+
+ # Ķ┐öÕø×Ķć│ third_party ńø«ÕĮĢ, ÕģŗķÜå pybind11
+ cd ..
+ git clone git@github.com:pybind/pybind11.git pybind11
+ cd pybind11
+ git checkout 70a58c5
+
+ cd ..
+ git clone git@github.com:gabime/spdlog.git spdlog
+ cd spdlog
+ git checkout 9e8e52c048
+ ```
+
+- Õ”éµ×£õ╗ź `SSH` µ¢╣Õ╝Å `git clone` õ╗ŻńĀüÕż▒Ķ┤ź’╝īµé©ÕÅ»õ╗źÕ░ØĶ»ĢõĮ┐ńö© `HTTPS` ÕŹÅĶ««õĖŗĶĮĮõ╗ŻńĀü’╝Ü
+
+ ```bash
+ git clone -b main https://github.com/open-mmlab/mmdeploy.git MMDeploy
+ cd MMDeploy
+ git submodule update --init --recursive
+ ```
+
+## ń╝¢Ķ»æ
+
+µĀ╣µŹ«µé©ńÜäńø«µĀćÕ╣│ÕÅ░’╝īńé╣Õć╗Õ”éõĖŗÕ»╣Õ║öńÜäķōŠµÄź’╝īµīēńģ¦Ķ»┤µśÄń╝¢Ķ»æ MMDeploy
+
+- [Linux-x86_64](linux-x86_64.md)
+- [Windows](windows.md)
+- [MacOS](macos-arm64.md)
+- [Android-aarch64](android.md)
+- [NVIDIA Jetson](jetsons.md)
+- [Qcom SNPE](snpe.md)
+- [RISC-V](riscv.md)
+- [Rockchip](rockchip.md)
diff --git a/internlm_langchain/knowledge_base/MMDeploy/content/cmake_option.md b/internlm_langchain/knowledge_base/MMDeploy/content/cmake_option.md
new file mode 100644
index 00000000..7c10bb20
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDeploy/content/cmake_option.md
@@ -0,0 +1,129 @@
+# cmake ń╝¢Ķ»æķĆēķĪ╣Ķ»┤µśÄ
+
+| mmaction2 | +Pytorch | +ONNXRuntime | +TensorRT | +PPLNN | +OpenVINO | +||||
|---|---|---|---|---|---|---|---|---|---|
| model | +task | +dataset | +metrics | +fp32 | +fp32 | +fp32 | +fp16 | +fp16 | +fp32 | +
| TSN | +Recognition | +Kinetics-400 | +top-1 | +69.71 | +- | +69.71 | +- | +- | +- | +
| top-5 | +88.75 | +- | +88.75 | +- | +- | +- | +|||
| SlowFast | +Recognition | +Kinetics-400 | +top-1 | +74.45 | +- | +75.62 | +- | +- | +- | +
| top-5 | +91.55 | +- | +92.10 | +- | +- | +- | +|||
| ķĆēķĪ╣ | +ÕÅ¢ÕĆ╝ĶīāÕø┤ | +ń╝║ń£üÕĆ╝ | +Ķ»┤µśÄ | +
|---|---|---|---|
| MMDEPLOY_SHARED_LIBS | +{ON, OFF} | +ON | +ÕŖ©µĆüÕ║ōńÜäń╝¢Ķ»æÕ╝ĆÕģ│ŃĆéĶ«ŠńĮ«OFFµŚČ’╝īń╝¢Ķ»æķØÖµĆüÕ║ō | +
| MMDEPLOY_BUILD_SDK | +{ON, OFF} | +OFF | +MMDeploy SDK ń╝¢Ķ»æÕ╝ĆÕģ│ | +
| MMDEPLOY_BUILD_SDK_MONOLITHIC | +{ON, OFF} | +OFF | +ń╝¢Ķ»æńö¤µłÉÕŹĢõĖ¬ lib µ¢ćõ╗Č | +
| MMDEPLOY_BUILD_TEST | +{ON, OFF} | +OFF | +MMDeploy SDK ńÜäÕŹĢÕģāµĄŗĶ»Ģń©ŗÕ║Åń╝¢Ķ»æÕ╝ĆÕģ│ | +
| MMDEPLOY_BUILD_SDK_PYTHON_API | +{ON, OFF} | +OFF | +SDK python packageńÜäń╝¢Ķ»æÕ╝ĆÕģ│ | +
| MMDEPLOY_BUILD_SDK_CSHARP_API | +{ON, OFF} | +OFF | +SDK C# packageńÜäń╝¢Ķ»æÕ╝ĆÕģ│ | +
| MMDEPLOY_BUILD_SDK_JAVA_API | +{ON, OFF} | +OFF | +SDK Java packageńÜäń╝¢Ķ»æÕ╝ĆÕģ│ | +
| MMDEPLOY_BUILD_EXAMPLES | +{ON, OFF} | +OFF | +µś»ÕÉ”ń╝¢Ķ»æ demo | +
| MMDEPLOY_SPDLOG_EXTERNAL | +{ON, OFF} | +OFF | +µś»ÕÉ”õĮ┐ńö©ń│╗ń╗¤Ķć¬ÕĖ”ńÜä spdlog Õ«ēĶŻģÕīģ | +
| MMDEPLOY_ZIP_MODEL | +{ON, OFF} | +OFF | +µś»ÕÉ”õĮ┐ńö© zip µĀ╝Õ╝ÅńÜä sdk ńø«ÕĮĢ | +
| MMDEPLOY_COVERAGE | +{ON, OFF} | +OFF | +ķóØÕż¢Õó×ÕŖĀń╝¢Ķ»æķĆēķĪ╣’╝īõ╗źńö¤µłÉõ╗ŻńĀüĶ”åńø¢ńÄćµŖźĶĪ© | +
| MMDEPLOY_TARGET_DEVICES | +{"cpu", "cuda"} | +cpu | +Ķ«ŠńĮ«ńø«µĀćĶ«ŠÕżćŃĆéÕĮōµ£ēÕżÜõĖ¬Ķ«ŠÕżćµŚČ’╝īĶ«ŠÕżćÕÉŹń¦░õ╣ŗķŚ┤õĮ┐ńö©ÕłåÕÅĘķÜöÕ╝ĆŃĆé µ»öÕ”é’╝ī-DMMDEPLOY_TARGET_DEVICES="cpu;cuda" | +
| MMDEPLOY_TARGET_BACKENDS | +{"trt", "ort", "pplnn", "ncnn", "openvino", "torchscript", "snpe", "coreml", "tvm"} | +N/A | + ķ╗śĶ«żµāģÕåĄõĖŗ’╝īSDKõĖŹĶ«ŠńĮ«õ╗╗õĮĢÕÉÄń½», ÕøĀõĖ║Õ«āõĖÄÕ║öńö©Õ£║µÖ»ķ½śÕ║”ńøĖÕģ│ŃĆé ÕĮōķĆēµŗ®ÕżÜõĖ¬ÕÉÄń½»µŚČ’╝ī õĖŁķŚ┤õĮ┐ńö©ÕłåÕÅĘķÜöÕ╝ĆŃĆéµ»öÕ”é’╝ī+ 1. trt: ĶĪ©ńż║ TensorRTŃĆéķ£ĆĶ”üĶ«ŠńĮ« TENSORRT_DIR ÕÆī CUDNN_DIRŃĆé
+ONNXRUNTIME_DIRŃĆé
+pplnn_DIRŃĆé+ 4. ncnn’╝ÜĶĪ©ńż║ ncnnŃĆéķ£ĆĶ”üĶ«ŠńĮ« ncnn_DIRŃĆé + 5. openvino: ĶĪ©ńż║ OpenVINOŃĆéķ£ĆĶ”üĶ«ŠńĮ« InferenceEngine_DIRŃĆé+ 6. torchscript: ĶĪ©ńż║ TorchScriptŃĆéķ£ĆĶ”üĶ«ŠńĮ« Torch_DIRŃĆé+ 7. snpe: ĶĪ©ńż║ qcom snpeŃĆéķ£ĆĶ”üńÄ»ÕóāÕÅśķćÅĶ«ŠńĮ« SNPE_ROOTŃĆé + 8. coreml: ĶĪ©ńż║ Core MLŃĆéńø«ÕēŹÕ£©Ķ┐øĶĪīµ©ĪÕ×ŗĶĮ¼µŹóµŚČķ£ĆĶ”üĶ«ŠńĮ« Torch_DIRŃĆé + 9. tvm: ĶĪ©ńż║ TVMŃĆéķ£ĆĶ”üĶ«ŠńĮ« TVM_DIRŃĆé+ |
+
| MMDEPLOY_CODEBASES | +{"mmpretrain", "mmdet", "mmseg", "mmagic", "mmocr", "all"} | +all | +ńö©µØźĶ«ŠńĮ«SDKÕÉÄÕżäńÉåń╗äõ╗Č’╝īÕŖĀĶĮĮ OpenMMLab ń«Śµ│Ģõ╗ōÕ║ōńÜäÕÉÄÕżäńÉåÕŖ¤ĶāĮŃĆéÕ”éµ×£ķĆēµŗ®ÕżÜõĖ¬ codebase’╝īõĖŁķŚ┤õĮ┐ńö©ÕłåÕÅĘķÜöÕ╝ĆŃĆéµ»öÕ”é’╝ī-DMMDEPLOY_CODEBASES="mmcls;mmdet"ŃĆéõ╣¤ÕÅ»õ╗źķĆÜĶ┐ć -DMMDEPLOY_CODEBASES=all µ¢╣Õ╝Å’╝īÕŖĀĶĮĮµēƵ£ē codebaseŃĆé |
+
| OS-Arch | +Device | +ONNX Runtime | +TensorRT | +
|---|---|---|---|
| Linux-x86_64 | +CPU | +Y | +N/A | +
| CUDA | +Y | +Y | +|
| Windows-x86_64 | +CPU | +Y | +N/A | +
| CUDA | +Y | +Y | +
+
+
+Linux-x86_64
+ +```shell +# 1. Õ«ēĶŻģ MMDeploy µ©ĪÕ×ŗĶĮ¼µŹóÕĘźÕģĘ’╝łÕɽtrt/ortĶć¬Õ«Üõ╣ēń«ŚÕŁÉ’╝ē +pip install mmdeploy==1.2.0 + +# 2. Õ«ēĶŻģ MMDeploy SDKµÄ©ńÉåÕĘźÕģĘ +# µĀ╣µŹ«µś»ÕÉ”ķ£ĆĶ”üGPUµÄ©ńÉåÕÅ»õ╗╗ķĆēÕģČõĖĆĶ┐øĶĪīõĖŗĶĮĮÕ«ēĶŻģ +# 2.1 µö»µīü onnxruntime µÄ©ńÉå +pip install mmdeploy-runtime==1.2.0 +# 2.2 µö»µīü onnxruntime-gpu tensorrt µÄ©ńÉå +pip install mmdeploy-runtime-gpu==1.2.0 + +# 3. Õ«ēĶŻģµÄ©ńÉåÕ╝ĢµōÄ +# 3.1 Õ«ēĶŻģµÄ©ńÉåÕ╝ĢµōÄ TensorRT +# !!! ĶŗźĶ”üĶ┐øĶĪī TensorRT µ©ĪÕ×ŗńÜäĶĮ¼µŹóõ╗źÕÅŖµÄ©ńÉå’╝īõ╗Ä NVIDIA Õ«śńĮæõĖŗĶĮĮ TensorRT-8.2.3.0 CUDA 11.x Õ«ēĶŻģÕīģÕ╣ČĶ¦ŻÕÄŗÕł░ÕĮōÕēŹńø«ÕĮĢŃĆé +pip install TensorRT-8.2.3.0/python/tensorrt-8.2.3.0-cp38-none-linux_x86_64.whl +pip install pycuda +export TENSORRT_DIR=$(pwd)/TensorRT-8.2.3.0 +export LD_LIBRARY_PATH=${TENSORRT_DIR}/lib:$LD_LIBRARY_PATH +# !!! ÕÅ”Õż¢Ķ┐śķ£ĆĶ”üõ╗Ä NVIDIA Õ«śńĮæõĖŗĶĮĮ cuDNN 8.2.1 CUDA 11.x Õ«ēĶŻģÕīģÕ╣ČĶ¦ŻÕÄŗÕł░ÕĮōÕēŹńø«ÕĮĢ +export CUDNN_DIR=$(pwd)/cuda +export LD_LIBRARY_PATH=$CUDNN_DIR/lib64:$LD_LIBRARY_PATH + +# 3.2 Õ«ēĶŻģµÄ©ńÉåÕ╝ĢµōÄ ONNX Runtime +# µĀ╣µŹ«µś»ÕÉ”ķ£ĆĶ”üGPUµÄ©ńÉåÕÅ»õ╗╗ķĆēÕģČõĖĆĶ┐øĶĪīõĖŗĶĮĮÕ«ēĶŻģ +# 3.2.1 onnxruntime +wget https://github.com/microsoft/onnxruntime/releases/download/v1.8.1/onnxruntime-linux-x64-1.8.1.tgz +tar -zxvf onnxruntime-linux-x64-1.8.1.tgz +export ONNXRUNTIME_DIR=$(pwd)/onnxruntime-linux-x64-1.8.1 +export LD_LIBRARY_PATH=$ONNXRUNTIME_DIR/lib:$LD_LIBRARY_PATH +# 3.2.2 onnxruntime-gpu +pip install onnxruntime-gpu==1.8.1 +wget https://github.com/microsoft/onnxruntime/releases/download/v1.8.1/onnxruntime-linux-x64-gpu-1.8.1.tgz +tar -zxvf onnxruntime-linux-x64-gpu-1.8.1.tgz +export ONNXRUNTIME_DIR=$(pwd)/onnxruntime-linux-x64-gpu-1.8.1 +export LD_LIBRARY_PATH=$ONNXRUNTIME_DIR/lib:$LD_LIBRARY_PATH +``` + +
+
+
+Ķ»ĘķśģĶ»╗ [Ķ┐Öķćī](02-how-to-run/prebuilt_package_windows.md)’╝īõ║åĶ¦Ż MMDeploy ķóäń╝¢Ķ»æÕīģÕ£© Windows Õ╣│ÕÅ░õĖŗńÜäõĮ┐ńö©µ¢╣µ│ĢŃĆé
+
+## µ©ĪÕ×ŗĶĮ¼µŹó
+
+Õ£©ÕćåÕżćÕĘźõĮ£Õ░▒ń╗¬ÕÉÄ’╝īµłæõ╗¼ÕÅ»õ╗źõĮ┐ńö© MMDeploy õĖŁńÜäÕĘźÕģĘ `tools/deploy.py`’╝īÕ░å OpenMMLab ńÜä PyTorch µ©ĪÕ×ŗĶĮ¼µŹóµłÉµÄ©ńÉåÕÉÄń½»µö»µīüńÜäµĀ╝Õ╝ÅŃĆé
+Õ»╣õ║Ä`tools/deploy.py` ńÜäõĮ┐ńö©ń╗åĶŖé’╝īĶ»ĘÕÅéĶĆā [Õ”éõĮĢĶĮ¼µŹóµ©ĪÕ×ŗ](02-how-to-run/convert_model.md)ŃĆé
+
+õ╗ź [MMDetection](https://github.com/open-mmlab/mmdetection) õĖŁńÜä `Faster R-CNN` õĖ║õŠŗ’╝īµłæõ╗¼ÕÅ»õ╗źõĮ┐ńö©Õ”éõĖŗÕæĮõ╗ż’╝īÕ░å PyTorch µ©ĪÕ×ŗĶĮ¼µŹóõĖ║ TenorRT µ©ĪÕ×ŗ’╝īõ╗ÄĶĆīķā©ńĮ▓Õł░ NVIDIA GPU õĖŖ.
+
+```shell
+# ÕģŗķÜå mmdeploy õ╗ōÕ║ōŃĆéĶĮ¼µŹóµŚČ’╝īķ£ĆĶ”üõĮ┐ńö© mmdeploy õ╗ōÕ║ōõĖŁńÜäķģŹńĮ«µ¢ćõ╗Č’╝īÕ╗║ń½ŗĶĮ¼µŹóµĄüµ░┤ń║┐, `--recursive` õĖŹµś»Õ┐ģķĪ╗ńÜä
+git clone -b main --recursive https://github.com/open-mmlab/mmdeploy.git
+
+# Õ«ēĶŻģ mmdetectionŃĆéĶĮ¼µŹóµŚČ’╝īķ£ĆĶ”üõĮ┐ńö© mmdetection õ╗ōÕ║ōõĖŁńÜ䵩ĪÕ×ŗķģŹńĮ«µ¢ćõ╗Č’╝īµ×äÕ╗║ PyTorch nn module
+git clone -b 3.x https://github.com/open-mmlab/mmdetection.git
+cd mmdetection
+mim install -v -e .
+cd ..
+
+# õĖŗĶĮĮ Faster R-CNN µ©ĪÕ×ŗµØāķćŹ
+wget -P checkpoints https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth
+
+# µē¦ĶĪīĶĮ¼µŹóÕæĮõ╗ż’╝īÕ«×ńÄ░ń½»Õł░ń½»ńÜäĶĮ¼µŹó
+python mmdeploy/tools/deploy.py \
+ mmdeploy/configs/mmdet/detection/detection_tensorrt_dynamic-320x320-1344x1344.py \
+ mmdetection/configs/faster_rcnn/faster-rcnn_r50_fpn_1x_coco.py \
+ checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \
+ mmdetection/demo/demo.jpg \
+ --work-dir mmdeploy_model/faster-rcnn \
+ --device cuda \
+ --dump-info
+```
+
+ĶĮ¼µŹóń╗ōµ×£Ķó½õ┐ØÕŁśÕ£© `--work-dir` µīćÕÉæńÜäµ¢ćõ╗ČÕż╣õĖŁŃĆé**Ķ»źµ¢ćõ╗ČÕż╣õĖŁõĖŹõ╗ģÕīģÕɽµÄ©ńÉåÕÉÄń½»µ©ĪÕ×ŗ’╝īĶ┐śÕīģµŗ¼µÄ©ńÉåÕģāõ┐Īµü»ŃĆéĶ┐Öõ║øÕåģÕ«╣ńÜäµĢ┤õĮōĶó½Õ«Üõ╣ēõĖ║ SDK ModelŃĆéµÄ©ńÉå SDK Õ░åńö©Õ«āĶ┐øĶĪīµ©ĪÕ×ŗµÄ©ńÉåŃĆé**
+
+```{tip}
+µŖŖõĖŖĶ┐░ĶĮ¼µŹóÕæĮõ╗żõĖŁńÜädetection_tensorrt_dynamic-320x320-1344x1344.py µŹóµłÉ detection_onnxruntime_dynamic.py’╝īÕ╣Čõ┐«µö╣ --device õĖ║ cpu’╝ī
+ÕŹ│ÕÅ»õ╗źĶĮ¼Õć║ onnx µ©ĪÕ×ŗ’╝īÕ╣Čńö© ONNXRuntime Ķ┐øĶĪīµÄ©ńÉå
+```
+
+## µ©ĪÕ×ŗµÄ©ńÉå
+
+Õ£©ĶĮ¼µŹóÕ«īµłÉÕÉÄ’╝īõĮĀµŚóÕÅ»õ╗źõĮ┐ńö© Model Converter Ķ┐øĶĪīµÄ©ńÉå’╝īõ╣¤ÕÅ»õ╗źõĮ┐ńö© Inference SDKŃĆé
+
+### õĮ┐ńö© Model Converter ńÜäµÄ©ńÉå API
+
+Model Converter Õ▒ÅĶöĮõ║åµÄ©ńÉåÕÉÄń½»µÄźÕÅŻńÜäÕĘ«Õ╝é’╝īÕ»╣ÕģȵĩńÉå API Ķ┐øĶĪīõ║åń╗¤õĖĆÕ░üĶŻģ’╝īµÄźÕÅŻÕÉŹń¦░õĖ║ `inference_model`ŃĆé
+
+õ╗źõĖŖµ¢ćõĖŁ Faster R-CNN ńÜä TensorRT µ©ĪÕ×ŗõĖ║õŠŗ’╝īõĮĀÕÅ»õ╗źõĮ┐ńö©Õ”éõĖŗµ¢╣Õ╝ÅĶ┐øĶĪīµ©ĪÕ×ŗµÄ©ńÉåÕĘźõĮ£’╝Ü
+
+```python
+from mmdeploy.apis import inference_model
+result = inference_model(
+ model_cfg='mmdetection/configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py',
+ deploy_cfg='mmdeploy/configs/mmdet/detection/detection_tensorrt_dynamic-320x320-1344x1344.py',
+ backend_files=['mmdeploy_model/faster-rcnn/end2end.engine'],
+ img='mmdetection/demo/demo.jpg',
+ device='cuda:0')
+```
+
+```{note}
+µÄźÕÅŻõĖŁńÜä model_path µīćńÜ䵜»µÄ©ńÉåÕ╝Ģµōĵ¢ćõ╗ČńÜäĶĘ»ÕŠä’╝īµ»öÕ”éõŠŗÕŁÉÕĮōõĖŁend2end.engineµ¢ćõ╗ČńÜäĶĘ»ÕŠäŃĆéĶĘ»ÕŠäÕ┐ģķĪ╗µöŠÕ£© list õĖŁ’╝īÕøĀõĖ║µ£ēńÜäµÄ©ńÉåÕ╝Ģµōĵ©ĪÕ×ŗń╗ōµ×äÕÆīµØāķ揵ś»ÕłåÕ╝ĆÕŁśÕé©ńÜäŃĆé
+```
+
+### õĮ┐ńö©µÄ©ńÉå SDK
+
+õĮĀÕÅ»õ╗źńø┤µÄźĶ┐ÉĶĪīķóäń╝¢Ķ»æÕīģõĖŁńÜä demo ń©ŗÕ║Å’╝īĶŠōÕģź SDK Model ÕÆīÕøŠÕāÅ’╝īĶ┐øĶĪīµÄ©ńÉå’╝īÕ╣ȵ¤źń£ŗµÄ©ńÉåń╗ōµ×£ŃĆé
+
+```shell
+wget https://github.com/open-mmlab/mmdeploy/releases/download/v1.2.0/mmdeploy-1.2.0-linux-x86_64-cuda11.3.tar.gz
+tar xf mmdeploy-1.2.0-linux-x86_64-cuda11.3
+
+cd mmdeploy-1.2.0-linux-x86_64-cuda11.3
+# Ķ┐ÉĶĪī python demo
+python example/python/object_detection.py cuda ../mmdeploy_model/faster-rcnn ../mmdetection/demo/demo.jpg
+# Ķ┐ÉĶĪī C/C++ demo
+# µĀ╣µŹ«µ¢ćõ╗ČÕż╣ÕåģńÜä README.md Ķ┐øĶĪīń╝¢Ķ»æ
+./bin/object_detection cuda ../mmdeploy_model/faster-rcnn ../mmdetection/demo/demo.jpg
+```
+
+```{note}
+õ╗źõĖŖĶ┐░ÕæĮõ╗żõĖŁ’╝īĶŠōÕģźµ©ĪÕ×ŗµś» SDK Model ńÜäĶĘ»ÕŠä’╝łõ╣¤Õ░▒µś» Model Converter õĖŁ --work-dir ÕÅéµĢ░’╝ē’╝īĶĆīõĖŹµś»µÄ©ńÉåÕ╝Ģµōĵ¢ćõ╗ČńÜäĶĘ»ÕŠäŃĆé
+ÕøĀõĖ║ SDK õĖŹõ╗ģĶ”üĶÄĘÕÅ¢µÄ©ńÉåÕ╝Ģµōĵ¢ćõ╗Č’╝īĶ┐śķ£ĆĶ”üµÄ©ńÉåÕģāõ┐Īµü»’╝łdeploy.json, pipeline.json’╝ēŃĆéÕ«āõ╗¼ÕÉłÕ£©õĖĆĶĄĘ’╝īµ×äµłÉ SDK Model’╝īÕŁśÕé©Õ£© --work-dir õĖŗ
+```
+
+ķÖżõ║å demo ń©ŗÕ║Å’╝īķóäń╝¢Ķ»æÕīģĶ┐śµÅÉõŠøõ║å SDK ÕżÜĶ»ŁĶ©ĆµÄźÕÅŻŃĆéõĮĀÕÅ»õ╗źµĀ╣µŹ«Ķć¬ÕĘ▒ńÜäķĪ╣ńø«ķ£Ćµ▒é’╝īķĆēµŗ®ÕÉłķĆéńÜäĶ»ŁĶ©ĆµÄźÕÅŻ’╝ī
+µŖŖ MMDeploy SDK ķøåµłÉÕł░Ķć¬ÕĘ▒ńÜäķĪ╣ńø«õĖŁ’╝īĶ┐øĶĪīõ║īµ¼ĪÕ╝ĆÕÅæŃĆé
+
+#### Python API
+
+Õ»╣õ║ĵŻĆµĄŗÕŖ¤ĶāĮ’╝īõĮĀõ╣¤ÕÅ»õ╗źÕÅéĶĆāÕ”éõĖŗõ╗ŻńĀü’╝īķøåµłÉ MMDeploy SDK Python API Õł░Ķć¬ÕĘ▒ńÜäķĪ╣ńø«õĖŁ’╝Ü
+
+```python
+from mmdeploy_runtime import Detector
+import cv2
+
+# Ķ»╗ÕÅ¢ÕøŠńēć
+img = cv2.imread('mmdetection/demo/demo.jpg')
+
+# ÕłøÕ╗║µŻĆµĄŗÕÖ©
+detector = Detector(model_path='mmdeploy_models/faster-rcnn', device_name='cuda', device_id=0)
+# µē¦ĶĪīµÄ©ńÉå
+bboxes, labels, _ = detector(img)
+# õĮ┐ńö©ķśłÕĆ╝Ķ┐ćµ╗żµÄ©ńÉåń╗ōµ×£’╝īÕ╣Čń╗śÕłČÕł░ÕĤÕøŠõĖŁ
+indices = [i for i in range(len(bboxes))]
+for index, bbox, label_id in zip(indices, bboxes, labels):
+ [left, top, right, bottom], score = bbox[0:4].astype(int), bbox[4]
+ if score < 0.3:
+ continue
+ cv2.rectangle(img, (left, top), (right, bottom), (0, 255, 0))
+
+cv2.imwrite('output_detection.png', img)
+```
+
+µø┤ÕżÜńż║õŠŗ’╝īĶ»Ęµ¤źķśģ[Ķ┐Öķćī](https://github.com/open-mmlab/mmdeploy/tree/main/demo/python)ŃĆé
+
+#### C++ API
+
+õĮ┐ńö© C++ API Ķ┐øĶĪīµ©ĪÕ×ŗµÄ©ńÉåńÜ䵥üń©ŗń¼”ÕÉłõĖŗķØóńÜ䵩ĪÕ╝Å’╝Ü
+
+
+õ╗źõĖŗµś»ÕģĘõĮōĶ┐ćń©ŗ’╝Ü
+
+```C++
+#include Windows-x86_64
+| ÕÉŹń¦░ | +Õ«ēĶŻģĶ»┤µśÄ | +
|---|---|
| conda | +Ķ»ĘÕÅéĶĆāÕ«śµ¢╣Ķ»┤µśÄÕ«ēĶŻģ condaŃĆé ķĆÜĶ┐ć conda ÕłøÕ╗║Õ╣ȵ┐Ƶ┤╗ Python ńÄ»ÕóāŃĆé + |
+
| PyTorch (>=1.8.0) |
+ Õ«ēĶŻģ PyTorch’╝īĶ”üµ▒éńēłµ£¼µś» torch>=1.8.0ŃĆéÕÅ»µ¤źń£ŗÕ«śńĮæĶÄĘÕÅ¢µø┤ÕżÜĶ»”ń╗åńÜäÕ«ēĶŻģµĢÖń©ŗŃĆéĶ»ĘńĪ«õ┐Ø PyTorch Ķ”üµ▒éńÜä CUDA ńēłµ£¼ÕÆīµé©õĖ╗µ£║ńÜä CUDA ńēłµ£¼µś»õĖĆĶć┤ + |
+
| mmcv | +ÕÅéĶĆāÕ”éõĖŗÕæĮõ╗żÕ«ēĶŻģ mmcvŃĆéµø┤ÕżÜÕ«ēĶŻģµ¢╣Õ╝Å’╝īÕÅ»µ¤źń£ŗ mmcv Õ«śńĮæ + |
+
| ÕÉŹń¦░ | +Õ«ēĶŻģĶ»┤µśÄ | +
|---|---|
| OpenCV (>=3.0) |
+
+ Õ£© Ubuntu 18.04 ÕÅŖõ╗źõĖŖńēłµ£¼
+ |
+
+
| pplcv | +pplcv µś» openPPL Õ╝ĆÕÅæńÜäķ½śµĆ¦ĶāĮÕøŠÕāÅÕżäńÉåÕ║ōŃĆé µŁżõŠØĶĄ¢ķĪ╣õĖ║ÕÅ»ķĆēķĪ╣’╝īÕŬµ£ēÕ£© cuda Õ╣│ÕÅ░õĖŗ’╝īµēŹķ£ĆÕ«ēĶŻģŃĆé + |
+
| ÕÉŹń¦░ | +Õ«ēĶŻģÕīģ | +Õ«ēĶŻģĶ»┤µśÄ | +
|---|---|---|
| ONNXRuntime | +onnxruntime (>=1.8.1) |
+
+ 1. Õ«ēĶŻģ onnxruntime ńÜä python Õīģ
+ |
+
| TensorRT |
+ TensorRT |
+
+ 1. ńÖ╗ÕĮĢ NVIDIA Õ«śńĮæ’╝īõ╗ÄĶ┐ÖķćīķĆēÕÅ¢Õ╣ČõĖŗĶĮĮ TensorRT tar ÕīģŃĆéĶ”üõ┐ØĶ»üÕ«āÕÆīµé©µ£║ÕÖ©ńÜä CPU µ×ȵ×äõ╗źÕÅŖ CUDA ńēłµ£¼µś»Õī╣ķģŹńÜäŃĆé + µé©ÕÅ»õ╗źÕÅéĶĆāĶ┐Öõ╗ĮµīćÕŹŚÕ«ēĶŻģ TensorRTŃĆé + 1. Ķ┐Öķćīõ╣¤µ£ēõĖĆõ╗Į TensorRT 8.2 GA Update 2 Õ£© Linux x86_64 ÕÆī CUDA 11.x õĖŗńÜäÕ«ēĶŻģńż║õŠŗ’╝īõŠøµé©ÕÅéĶĆāŃĆéķ”¢Õģł’╝īńé╣Õć╗µŁżÕżäõĖŗĶĮĮ CUDA 11.x TensorRT 8.2.3.0ŃĆéńäČÕÉÄ’╝īµĀ╣µŹ«Õ”éõĖŗÕæĮõ╗ż’╝īÕ«ēĶŻģÕ╣ČķģŹńĮ« TensorRT õ╗źÕÅŖńøĖÕģ│õŠØĶĄ¢ŃĆé + |
+
| cuDNN | +
+ 1. õ╗Ä cuDNN Archive ķĆēµŗ®ÕÆīµé©ńÄ»ÕóāõĖŁ CPU µ×ȵ×äŃĆüCUDA ńēłµ£¼õ╗źÕÅŖ TensorRT ńēłµ£¼ķģŹÕźŚńÜä cuDNNŃĆéõ╗źÕēŹµ¢ć TensorRT Õ«ēĶŻģĶ»┤µśÄõĖ║õŠŗ’╝īÕ«āķ£ĆĶ”ü cudnn8.2ŃĆéÕøĀµŁż’╝īÕÅ»õ╗źõĖŗĶĮĮ CUDA 11.x cuDNN 8.2 + 2. Ķ¦ŻÕÄŗÕÄŗń╝®Õīģ’╝īÕ╣ČĶ«ŠńĮ«ńÄ»ÕóāÕÅśķćÅ + |
+ |
| PPL.NN | +ppl.nn | +
+ 1. Ķ»ĘÕÅéĶĆā ppl.nn ńÜä Õ«ēĶŻģµ¢ćµĪŻ ń╝¢Ķ»æ ppl.nn’╝īÕ╣ČÕ«ēĶŻģ pyppl + 2. Õ░å pplnn ńÜäµĀ╣ńø«ÕĮĢÕåÖÕģźńÄ»ÕóāÕÅśķćÅ + |
+
| OpenVINO | +openvino | +1. Õ«ēĶŻģ OpenVINO
+ |
+
| ncnn | +ncnn | +1. Ķ»ĘÕÅéĶĆā ncnnńÜä wiki ń╝¢Ķ»æ ncnnŃĆé
+ń╝¢Ķ»æµŚČ’╝īĶ»ĘµēōÕ╝Ć-DNCNN_PYTHON=ON+2. Õ░å ncnn ńÜäµĀ╣ńø«ÕĮĢÕåÖÕģźńÄ»ÕóāÕÅśķćÅ + |
+
| TorchScript | +libtorch | +
+ 1. Download libtorch from here. Please note that only Pre-cxx11 ABI and version 1.8.1+ on Linux platform are supported by now. For previous versions of libtorch, you can find them in the issue comment. + 2. Take Libtorch1.8.1+cu111 as an example. You can install it like this: + |
+
| Ascend | +CANN | +
+ 1. µīēńģ¦ Õ«śµ¢╣µīćÕ╝Ģ Õ«ēĶŻģ CANN ÕĘźÕģĘķøå. + 2. ķģŹńĮ«ńÄ»Õóā + |
+
| TVM | +TVM | +
+ 1. µīēńģ¦ Õ«śµ¢╣µīćÕ╝ĢÕ«ēĶŻģ TVM. + 2. ķģŹńĮ«ńÄ»Õóā + |
+
+Õ”éµ×£µé©µā│õĮ┐õĖŖĶ┐░ńÄ»ÕóāÕÅśķćŵ░Ėõ╣ģµ£ēµĢł’╝īÕÅ»õ╗źµŖŖÕ«āõ╗¼ÕŖĀÕģź
~/.bashrcŃĆéõ╗ź ONNXRuntime ńÜäńÄ»ÕóāÕÅśķćÅõĖ║õŠŗ’╝ī
+
+```bash
+echo '# set env for onnxruntime' >> ~/.bashrc
+echo "export ONNXRUNTIME_DIR=${ONNXRUNTIME_DIR}" >> ~/.bashrc
+echo "export LD_LIBRARY_PATH=$ONNXRUNTIME_DIR/lib:$LD_LIBRARY_PATH" >> ~/.bashrc
+source ~/.bashrc
+```
+
+### ń╝¢Ķ»æ MMDeploy
+
+```bash
+cd /the/root/path/of/MMDeploy
+export MMDEPLOY_DIR=$(pwd)
+```
+
+#### ń╝¢Ķ»æ Model Converter
+
+Õ”éµ×£µé©ķĆēµŗ®õ║åONNXRuntime’╝īTensorRT’╝īncnn ÕÆī torchscript õ╗╗õĖĆń¦ŹµÄ©ńÉåÕÉÄń½»’╝īµé©ķ£ĆĶ”üń╝¢Ķ»æÕ»╣Õ║öńÜäĶć¬Õ«Üõ╣ēń«ŚÕŁÉÕ║ōŃĆé
+
+- **ONNXRuntime** Ķć¬Õ«Üõ╣ēń«ŚÕŁÉ
+
+ ```bash
+ cd ${MMDEPLOY_DIR}
+ mkdir -p build && cd build
+ cmake -DCMAKE_CXX_COMPILER=g++-7 -DMMDEPLOY_TARGET_BACKENDS=ort -DONNXRUNTIME_DIR=${ONNXRUNTIME_DIR} ..
+ make -j$(nproc) && make install
+ ```
+
+- **TensorRT** Ķć¬Õ«Üõ╣ēń«ŚÕŁÉ
+
+ ```bash
+ cd ${MMDEPLOY_DIR}
+ mkdir -p build && cd build
+ cmake -DCMAKE_CXX_COMPILER=g++-7 -DMMDEPLOY_TARGET_BACKENDS=trt -DTENSORRT_DIR=${TENSORRT_DIR} -DCUDNN_DIR=${CUDNN_DIR} ..
+ make -j$(nproc) && make install
+ ```
+
+- **ncnn** Ķć¬Õ«Üõ╣ēń«ŚÕŁÉ
+
+ ```bash
+ cd ${MMDEPLOY_DIR}
+ mkdir -p build && cd build
+ cmake -DCMAKE_CXX_COMPILER=g++-7 -DMMDEPLOY_TARGET_BACKENDS=ncnn -Dncnn_DIR=${NCNN_DIR}/build/install/lib/cmake/ncnn ..
+ make -j$(nproc) && make install
+ ```
+
+- **torchscript** Ķć¬Õ«Üõ╣ēń«ŚÕŁÉ
+
+ ```bash
+ cd ${MMDEPLOY_DIR}
+ mkdir -p build && cd build
+ cmake -DMMDEPLOY_TARGET_BACKENDS=torchscript -DTorch_DIR=${Torch_DIR} ..
+ make -j$(nproc) && make install
+ ```
+
+ÕÅéĶĆā [cmake ķĆēķĪ╣Ķ»┤µśÄ](cmake_option.md)
+
+#### Õ«ēĶŻģ Model Converter
+
+```bash
+cd ${MMDEPLOY_DIR}
+mim install -e .
+```
+
+**µ│©µäÅ**
+
+- µ£ēõ║øõŠØĶĄ¢ķĪ╣µś»ÕÅ»ķĆēńÜäŃĆéĶ┐ÉĶĪī `pip install -e .` Õ░åĶ┐øĶĪīµ£ĆÕ░ÅÕī¢õŠØĶĄ¢Õ«ēĶŻģŃĆé Õ”éµ×£ķ£ĆÕ«ēĶŻģÕģČõ╗¢ÕÅ»ķĆēõŠØĶĄ¢ķĪ╣’╝īĶ»Ęµē¦ĶĪī`pip install -r requirements/optional.txt`’╝ī
+ µł¢ĶĆģ `pip install -e .[optional]`ŃĆéÕģČõĖŁ’╝ī`[optional]`ÕÅ»õ╗źµø┐µŹóõĖ║’╝Ü`all`ŃĆü`tests`ŃĆü`build` µł¢ `optional`ŃĆé
+- cuda10 Õ╗║Ķ««Õ«ēĶŻģ[ĶĪźõĖüÕīģ](https://developer.nvidia.com/cuda-10.2-download-archive?target_os=Linux&target_arch=x86_64&target_distro=Ubuntu&target_version=1804&target_type=runfilelocal)’╝īÕÉ”ÕłÖµ©ĪÕ×ŗĶ┐ÉĶĪīÕÅ»ĶāĮÕć║ńÄ░ GEMM ńøĖÕģ│ķöÖĶ»»
+
+#### ń╝¢Ķ»æ SDK ÕÆī Demos
+
+õĖŗµ¢ćÕ▒Ģńż║2õĖ¬µ×äÕ╗║SDKńÜäµĀĘõŠŗ’╝īÕłåÕł½ńö© ONNXRuntime ÕÆī TensorRT õĮ£õĖ║µÄ©ńÉåÕ╝ĢµōÄŃĆéµé©ÕÅ»õ╗źÕÅéĶĆāÕ«āõ╗¼’╝īµ┐Ƶ┤╗ÕģČõ╗¢ńÜäµÄ©ńÉåÕ╝ĢµōÄŃĆé
+
+- cpu + ONNXRuntime
+
+ ```Bash
+ cd ${MMDEPLOY_DIR}
+ mkdir -p build && cd build
+ cmake .. \
+ -DCMAKE_CXX_COMPILER=g++-7 \
+ -DMMDEPLOY_BUILD_SDK=ON \
+ -DMMDEPLOY_BUILD_EXAMPLES=ON \
+ -DMMDEPLOY_BUILD_SDK_PYTHON_API=ON \
+ -DMMDEPLOY_TARGET_DEVICES=cpu \
+ -DMMDEPLOY_TARGET_BACKENDS=ort \
+ -DONNXRUNTIME_DIR=${ONNXRUNTIME_DIR}
+
+ make -j$(nproc) && make install
+ ```
+
+- cuda + TensorRT
+
+ ```Bash
+ cd ${MMDEPLOY_DIR}
+ mkdir -p build && cd build
+ cmake .. \
+ -DCMAKE_CXX_COMPILER=g++-7 \
+ -DMMDEPLOY_BUILD_SDK=ON \
+ -DMMDEPLOY_BUILD_EXAMPLES=ON \
+ -DMMDEPLOY_BUILD_SDK_PYTHON_API=ON \
+ -DMMDEPLOY_TARGET_DEVICES="cuda;cpu" \
+ -DMMDEPLOY_TARGET_BACKENDS=trt \
+ -Dpplcv_DIR=${PPLCV_DIR}/cuda-build/install/lib/cmake/ppl \
+ -DTENSORRT_DIR=${TENSORRT_DIR} \
+ -DCUDNN_DIR=${CUDNN_DIR}
+
+ make -j$(nproc) && make install
+ ```
+
+- pplnn
+
+ ```Bash
+ cd ${MMDEPLOY_DIR}
+ mkdir -p build && cd build
+ cmake .. \
+ -DCMAKE_CXX_COMPILER=g++-7 \
+ -DMMDEPLOY_BUILD_SDK=ON \
+ -DMMDEPLOY_BUILD_EXAMPLES=ON \
+ -DMMDEPLOY_BUILD_SDK_PYTHON_API=ON \
+ -DMMDEPLOY_TARGET_DEVICES="cuda;cpu" \
+ -DMMDEPLOY_TARGET_BACKENDS=pplnn \
+ -Dpplcv_DIR=${PPLCV_DIR}/cuda-build/install/lib/cmake/ppl \
+ -Dpplnn_DIR=${PPLNN_DIR}/pplnn-build/install/lib/cmake/ppl
+
+ make -j$(nproc) && make install
+ ```
diff --git a/internlm_langchain/knowledge_base/MMDeploy/content/macos-arm64.md b/internlm_langchain/knowledge_base/MMDeploy/content/macos-arm64.md
new file mode 100644
index 00000000..8aa162db
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDeploy/content/macos-arm64.md
@@ -0,0 +1,177 @@
+# macOS-arm64 õĖŗµ×äÕ╗║µ¢╣Õ╝Å
+
+- [macOS-arm64 õĖŗµ×äÕ╗║µ¢╣Õ╝Å](#macos-arm64-õĖŗµ×äÕ╗║µ¢╣Õ╝Å)
+ - [µ║ÉńĀüÕ«ēĶŻģ](#µ║ÉńĀüÕ«ēĶŻģ)
+ - [Õ«ēĶŻģµ×äÕ╗║ÕÆīń╝¢Ķ»æÕĘźÕģĘķōŠ](#Õ«ēĶŻģµ×äÕ╗║ÕÆīń╝¢Ķ»æÕĘźÕģĘķōŠ)
+ - [Õ«ēĶŻģõŠØĶĄ¢Õīģ](#Õ«ēĶŻģõŠØĶĄ¢Õīģ)
+ - [Õ«ēĶŻģ MMDeploy Converter õŠØĶĄ¢](#Õ«ēĶŻģ-mmdeploy-converter-õŠØĶĄ¢)
+ - [Õ«ēĶŻģ MMDeploy SDK õŠØĶĄ¢](#Õ«ēĶŻģ-mmdeploy-sdk-õŠØĶĄ¢)
+ - [Õ«ēĶŻģµÄ©ńÉåÕ╝ĢµōÄ](#Õ«ēĶŻģµÄ©ńÉåÕ╝ĢµōÄ)
+ - [ń╝¢Ķ»æ MMDeploy](#ń╝¢Ķ»æ-mmdeploy)
+ - [ń╝¢Ķ»æ Model Converter](#ń╝¢Ķ»æ-model-converter)
+ - [Õ«ēĶŻģ Model Converter](#Õ«ēĶŻģ-model-converter)
+ - [ń╝¢Ķ»æ SDK ÕÆī Demos](#ń╝¢Ķ»æ-sdk-ÕÆī-demos)
+
+## µ║ÉńĀüÕ«ēĶŻģ
+
+### Õ«ēĶŻģµ×äÕ╗║ÕÆīń╝¢Ķ»æÕĘźÕģĘķōŠ
+
+- cmake
+
+ ```
+ brew install cmake
+ ```
+
+- clang
+
+ Õ«ēĶŻģ Xcode µł¢ĶĆģķĆÜĶ┐ćÕ”éõĖŗÕæĮõ╗żÕ«ēĶŻģ Command Line Tools
+
+ ```
+ xcode-select --install
+ ```
+
+### Õ«ēĶŻģõŠØĶĄ¢Õīģ
+
+#### Õ«ēĶŻģ MMDeploy Converter õŠØĶĄ¢
+
+ÕÅéĶĆā[get_started](../get_started.md)µ¢ćµĪŻ’╝īÕ«ēĶŻģcondaŃĆé
+
+```bash
+# install pytoch & mmcv
+conda install pytorch==1.9.0 torchvision==0.10.0 -c pytorch
+pip install -U openmim
+mim install mmengine
+mim install "mmcv>=2.0.0rc2"
+```
+
+#### Õ«ēĶŻģ MMDeploy SDK õŠØĶĄ¢
+
+Õ”éµ×£µé©ÕŬջ╣µ©ĪÕ×ŗĶĮ¼µŹóµä¤Õģ┤ĶČŻ’╝īķéŻõ╣łÕÅ»õ╗źĶĘ│Ķ┐ćµ£¼ń½ĀĶŖéŃĆé
+
+| ÕÉŹń¦░ | +Õ«ēĶŻģĶ»┤µśÄ | +
|---|---|
| OpenCV (>=3.0) |
+
+ |
+
| ÕÉŹń¦░ | +Õ«ēĶŻģÕīģ | +Õ«ēĶŻģĶ»┤µśÄ | +
|---|---|---|
| Core ML | +coremltools | +
+ |
+
| TorchScript | +libtorch | +
+ 1. libtorchµÜéõĖŹµÅÉõŠøarmńēłµ£¼ńÜälibrary’╝īµĢģķ£ĆĶ”üĶć¬ĶĪīń╝¢Ķ»æŃĆéń╝¢Ķ»æµŚČµ│©µäÅlibtorchĶ”üÕÆīpytorchńÜäńēłµ£¼õ┐صīüõĖĆĶć┤’╝īĶ┐ÖµĀĘń╝¢Ķ»æÕć║ńÜäĶć¬Õ«Üõ╣ēń«ŚÕŁÉµēŹÕÅ»õ╗źÕŖĀĶĮĮµłÉÕŖ¤ŃĆé + 2. õ╗źlibtorch 1.9.0õĖ║õŠŗ’╝īÕÅ»ķĆÜĶ┐ćÕ”éõĖŗÕæĮõ╗żÕ«ēĶŻģ: + |
+
+  +
+
+
+mmdeploy Õ¤║õ║ÄķØÖµĆüÕøŠ’╝łonnx’╝ēńö¤µłÉµÄ©ńÉåµĪåµ×ȵēĆķ£ĆńÜäķćÅÕī¢ĶĪ©’╝īÕåŹńö©ÕÉÄń½»ÕĘźÕģʵŖŖµĄ«ńé╣µ©ĪÕ×ŗĶĮ¼õĖ║Õ«Üńé╣ŃĆé
+
+ńø«ÕēŹ mmdeploy µö»µīü ncnn PTQŃĆé
+
+## µ©ĪÕ×ŗµĆÄõ╣łĶĮ¼Õ«Üńé╣
+
+[mmdeploy Õ«ēĶŻģ](../01-how-to-build/build_from_source.md)Õ«īµłÉÕÉÄ’╝īÕŖĀĶĮĮ ppq Õ╣ČÕ«ēĶŻģ
+
+```bash
+git clone https://github.com/openppl-public/ppq.git
+cd ppq
+pip install -r requirements.txt
+python3 setup.py install
+```
+
+Õø×Õł░ mmdeploy, õĮ┐ńö© `tools/deploy.py --quant` ķĆēķĪ╣Õ╝ĆÕÉ»ķćÅÕī¢ŃĆé
+
+```bash
+cd /path/to/mmdeploy
+export MODEL_CONFIG=/path/to/mmpretrain/configs/resnet/resnet18_8xb16_cifar10.py
+export MODEL_PATH=https://download.openmmlab.com/mmclassification/v0/resnet/resnet18_b16x8_cifar10_20210528-bd6371c8.pth
+
+# µēŠõĖĆõ║ø imagenet µĀĘõŠŗÕøŠ
+git clone https://github.com/nihui/imagenet-sample-images --depth=1
+
+# ķćÅÕī¢µ©ĪÕ×ŗ
+python3 tools/deploy.py configs/mmpretrain/classification_ncnn-int8_static.py ${MODEL_CONFIG} ${MODEL_PATH} /path/to/self-test.png --work-dir work_dir --device cpu --quant --quant-image-dir /path/to/imagenet-sample-images
+...
+```
+
+ÕÅéµĢ░Ķ»┤µśÄ
+
+| ÕÅéµĢ░ | Õɽõ╣ē |
+| :---------------: | :----------------------------------------------: |
+| --quant | µś»ÕÉ”Õ╝ĆÕÉ»ķćÅÕī¢’╝īķ╗śĶ«żõĖ║ False |
+| --quant-image-dir | µĀĪÕćåµĢ░µŹ«ķøå’╝īķ╗śĶ«żõĮ┐ńö© MODEL_CONFIG õĖŁńÜä**ķ¬īĶ»üķøå** |
+
+## Ķć¬Õ╗║µĀĪÕćåµĢ░µŹ«ķøå
+
+µĀĪÕćåķøåµś»ńö©µØźĶ«Īń«ŚķćÅÕī¢Õ▒éÕÅéµĢ░ńÜä’╝īµ¤Éõ║ø DFQ’╝łData Free Quantization’╝ēµ¢╣µ│ĢńöÜĶć│õĖŹķ£ĆĶ”üµĀĪÕćåķøå
+
+- µ¢░Õ╗║µ¢ćõ╗ČÕż╣’╝īńø┤µÄźµöŠÕģźÕøŠńēćÕŹ│ÕÅ»’╝łõĖŹķ£ĆĶ”üńø«ÕĮĢń╗ōµ×äŃĆüõĖŹĶ”üĶ┤¤õŠŗŃĆüµ▓Īµ£ēÕæĮÕÉŹĶ”üµ▒é’╝ē
+- ÕøŠńēćķ£ĆõĖ║ń£¤Õ«×õĖÜÕŖĪÕ£║µÖ»õĖŁńÜäµĢ░µŹ«’╝īńøĖÕĘ«Ķ┐ćĶ┐£õ╝ÜÕ»╝Ķć┤ń▓ŠÕ║”õĖŗķÖŹ
+- õĖŹĶāĮńø┤µÄźµŗ┐µĄŗĶ»ĢķøåÕüÜķćÅÕī¢’╝īÕÉ”ÕłÖµś»Ķ┐ćµŗ¤ÕÉł
+ | ń▒╗Õ×ŗ | Ķ«Łń╗āķøå | ķ¬īĶ»üķøå | µĄŗĶ»Ģķøå | µĀĪÕćåķøå |
+ | ---- | ------ | ------ | -------- | ------ |
+ | ńö©µ│Ģ | QAT | PTQ | µĄŗĶ»Ģń▓ŠÕ║” | PTQ |
+
+**Õ╝║ńāłÕ╗║Ķ««**ķćÅÕī¢ń╗ōµØ¤ÕÉÄ’╝ī[µīēµŁżµ¢ćµĪŻ](profile_model.md) ķ¬īĶ»üµ©ĪÕ×ŗń▓ŠÕ║”ŃĆé[Ķ┐Öķćī](../03-benchmark/quantization.md) µś»õĖĆõ║øķćÅÕī¢µ©ĪÕ×ŗµĄŗĶ»Ģń╗ōµ×£ŃĆé
diff --git a/internlm_langchain/knowledge_base/MMDeploy/content/quick_start.md b/internlm_langchain/knowledge_base/MMDeploy/content/quick_start.md
new file mode 100644
index 00000000..f19df4cf
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDeploy/content/quick_start.md
@@ -0,0 +1,83 @@
+# Õ┐½ķƤÕ╝ĆÕ¦ŗ
+
+Õż¦ÕżÜµĢ░ ML µ©ĪÕ×ŗķÖżõ║åµÄ©ńÉåÕż¢’╝īķ£ĆĶ”üÕ»╣ĶŠōÕģźµĢ░µŹ«Ķ┐øĶĪīõĖĆõ║øķóäÕżäńÉå’╝īÕ╣ČÕ»╣ĶŠōÕć║Ķ┐øĶĪīõĖĆõ║øÕÉÄÕżäńÉåµŁźķ¬ż’╝īõ╗źĶÄĘÕŠŚń╗ōµ×äÕī¢ĶŠōÕć║ŃĆé MMDeploy sdk µÅÉõŠøõ║åÕĖĖĶ¦üńÜäķóäÕżäńÉåÕÆīÕÉÄÕżäńÉåµŁźķ¬żŃĆé ÕĮōµé©õĮ┐ńö© MMDeploy Ķ┐øĶĪīµ©ĪÕ×ŗĶĮ¼µŹóÕÉÄ’╝īµé©ÕÅ»õ╗źńø┤µÄźõĮ┐ńö©mmdeploy sdk Ķ┐øĶĪīµÄ©ńÉåŃĆé
+
+## µ©ĪÕ×ŗĶĮ¼µŹó
+
+ÕÅ»ÕÅéĶĆā [convert model](../02-how-to-run/convert_model.md) ĶÄĘÕŠŚµø┤ÕżÜõ┐Īµü».
+
+ĶĮ¼µ©ĪÕ×ŗµŚČķĆÜĶ┐ćÕó×ÕŖĀ `--dump-info` ÕÅéµĢ░ÕŠŚÕł░Õ”éõĖŗńÜäńø«ÕĮĢń╗ōµ×ä(tensorrt)ŃĆé Õ”éµ×£ĶĮ¼µŹóõĖ║ÕģČõ╗¢ÕÉÄń½»’╝īń╗ōµ×äõ╝ÜńĢźµ£ēõĖŹÕÉīŃĆéÕģČõĖŁõĖżõĖ¬ÕøŠńēćõĖ║õĖŹÕÉīÕÉÄń½»µÄ©ńÉåń╗ōµ×£
+
+```bash
+Ōö£ŌöĆŌöĆ deploy.json
+Ōö£ŌöĆŌöĆ detail.json
+Ōö£ŌöĆŌöĆ pipeline.json
+Ōö£ŌöĆŌöĆ end2end.onnx
+Ōö£ŌöĆŌöĆ end2end.engine
+Ōö£ŌöĆŌöĆ output_pytorch.jpg
+ŌööŌöĆŌöĆ output_tensorrt.jpg
+```
+
+ÕÆīSDKńøĖÕģ│ńÜäµ¢ćõ╗ȵ£ē’╝Ü
+
+- deploy.json // µ©ĪÕ×ŗõ┐Īµü».
+- pipeline.json // pipelineõ┐Īµü»’╝īÕīģµŗ¼ÕēŹÕżäńÉåŃĆüµ©ĪÕ×ŗõ╗źÕÅŖÕÉÄÕżäńÉå.
+- end2end.engine // µ©ĪÕ×ŗµ¢ćõ╗Č
+
+SDK ÕÅ»õ╗źńø┤µÄźĶ»╗ÕÅ¢µ©ĪÕ×ŗńø«ÕĮĢ’╝īõ╣¤ÕÅ»õ╗źĶ»╗ÕÅ¢ńøĖÕģ│µ¢ćõ╗ȵēōÕīģµłÉ zip ÕÄŗń╝®ÕīģŃĆé Ķ”üĶ»╗ÕÅ¢ zip µ¢ćõ╗Č’╝īsdk Õ£©ń╝¢Ķ»æµŚČĶ”üĶ«ŠńĮ« `-DMMDEPLOY_ZIP_MODEL=ON`
+
+## SDK µÄ©ńÉå
+
+õĖĆĶł¼µØźĶ«▓’╝īµ©ĪÕ×ŗµÄ©ńÉåÕīģÕɽõ╗źõĖŗõĖēõĖ¬ķā©ÕłåŃĆé
+
+- ÕłøÕ╗║ pipeline
+- Ķ»╗ÕÅ¢µĢ░µŹ«
+- µ©ĪÕ×ŗµÄ©ńÉå
+
+õ╗źõĖŗõĮ┐ńö© `classifier` õĮ£õĖ║õŠŗÕŁÉµØźÕ▒Ģńż║õĖēõĖ¬µŁźķ¬ż.
+
+### ÕłøÕ╗║ pipeline
+
+#### õ╗ÄńĪ¼ńøśõĖŁÕŖĀĶĮĮµ©ĪÕ×ŗ
+
+```cpp
+
+std::string model_path = "/data/resnet"; // or "/data/resnet.zip" if build with `-DMMDEPLOY_ZIP_MODEL=ON`
+mmdeploy_model_t model;
+mmdeploy_model_create_by_path(model_path, &model);
+
+mmdeploy_classifier_t classifier{};
+mmdeploy_classifier_create(model, "cpu", 0, &classifier);
+```
+
+#### õ╗ÄÕåģÕŁśõĖŁÕŖĀĶĮĮµ©ĪÕ×ŗ
+
+```cpp
+std::string model_path = "/data/resnet.zip"
+std::ifstream ifs(model_path, std::ios::binary); // /path/to/zipmodel
+ifs.seekg(0, std::ios::end);
+auto size = ifs.tellg();
+ifs.seekg(0, std::ios::beg);
+std::string str(size, '\0'); // binary data, should decrypt if it's encrypted
+ifs.read(str.data(), size);
+
+mmdeploy_model_t model;
+mmdeploy_model_create(str.data(), size, &model);
+
+mmdeploy_classifier_t classifier{};
+mmdeploy_classifier_create(model, "cpu", 0, &classifier);
+```
+
+### Ķ»╗ÕÅ¢µĢ░µŹ«
+
+```cpp
+cv::Mat img = cv::imread(image_path);
+```
+
+### µ©ĪÕ×ŗµÄ©ńÉå
+
+```cpp
+mmdeploy_classification_t* res{};
+int* res_count{};
+mmdeploy_classifier_apply(classifier, &mat, 1, &res, &res_count);
+```
diff --git a/internlm_langchain/knowledge_base/MMDeploy/content/regression_test.md b/internlm_langchain/knowledge_base/MMDeploy/content/regression_test.md
new file mode 100644
index 00000000..cc7150f7
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDeploy/content/regression_test.md
@@ -0,0 +1,285 @@
+# Õ”éõĮĢĶ┐øĶĪīÕø×ÕĮƵĄŗĶ»Ģ
+
+
+
+Ķ┐Öń»ćµĢÖń©ŗõ╗ŗń╗Źõ║åÕ”éõĮĢĶ┐øĶĪīÕø×ÕĮƵĄŗĶ»ĢŃĆéķā©ńĮ▓ķģŹńĮ«µ¢ćõ╗Čńö▒`µ»ÅõĖ¬codebaseńÜäÕø×ÕĮÆķģŹńĮ«µ¢ćõ╗Č`’╝ī`µÄ©ńÉåµĪåµ×ČķģŹńĮ«õ┐Īµü»`ń╗䵳ÉŃĆé
+
+
+
+- [Õ”éõĮĢĶ┐øĶĪīÕø×ÕĮƵĄŗĶ»Ģ](#Õ”éõĮĢĶ┐øĶĪīÕø×ÕĮƵĄŗĶ»Ģ)
+ - [1. ńÄ»ÕóāµÉŁÕ╗║](#1-ńÄ»ÕóāµÉŁÕ╗║)
+ - [MMDeployńÜäÕ«ēĶŻģÕÅŖķģŹńĮ«](#mmdeployńÜäÕ«ēĶŻģÕÅŖķģŹńĮ«)
+ - [PythonńÄ»ÕóāõŠØĶĄ¢](#pythonńÄ»ÕóāõŠØĶĄ¢)
+ - [2. ńö©µ│Ģ](#2-ńö©µ│Ģ)
+ - [ÕÅéµĢ░Ķ¦Żµ×É](#ÕÅéµĢ░Ķ¦Żµ×É)
+ - [µ│©µäÅõ║ŗķĪ╣](#µ│©µäÅõ║ŗķĪ╣)
+ - [õŠŗÕŁÉ](#õŠŗÕŁÉ)
+ - [3. Õø×ÕĮƵĄŗĶ»ĢķģŹńĮ«µ¢ćõ╗Č](#3-Õø×ÕĮƵĄŗĶ»ĢķģŹńĮ«µ¢ćõ╗Č)
+ - [ńż║õŠŗÕÅŖÕÅéµĢ░Ķ¦Żµ×É](#ńż║õŠŗÕÅŖÕÅéµĢ░Ķ¦Żµ×É)
+ - [4. ńö¤µłÉńÜäµŖźÕæŖ](#4-ńö¤µłÉńÜäµŖźÕæŖ)
+ - [µ©ĪµØ┐](#µ©ĪµØ┐)
+ - [ńż║õŠŗ](#ńż║õŠŗ)
+ - [5. µö»µīüńÜäÕÉÄń½»](#5-µö»µīüńÜäÕÉÄń½»)
+ - [6. µö»µīüńÜäCodebaseÕÅŖÕģČMetric](#6-µö»µīüńÜäcodebaseÕÅŖÕģČmetric)
+ - [7. µ│©µäÅõ║ŗķĪ╣](#7-µ│©µäÅõ║ŗķĪ╣)
+ - [8. ÕĖĖĶ¦üķŚ«ķóś](#8-ÕĖĖĶ¦üķŚ«ķóś)
+
+
+
+## 1. ńÄ»ÕóāµÉŁÕ╗║
+
+### MMDeployńÜäÕ«ēĶŻģÕÅŖķģŹńĮ«
+
+µ£¼ń½ĀĶŖéńÜäÕåģÕ«╣’╝īķ£ĆĶ”üµÅÉÕēŹµĀ╣µŹ«[build µ¢ćµĪŻ](../01-how-to-build/build_from_source.md)Õ░å MMDeploy Õ«ēĶŻģķģŹńĮ«ÕźĮõ╣ŗÕÉÄ’╝īµēŹĶāĮĶ┐øĶĪīŃĆé
+
+### PythonńÄ»ÕóāõŠØĶĄ¢
+
+ķ£ĆĶ”üÕ«ēĶŻģ test ńÜäńÄ»Õóā
+
+```shell
+pip install -r requirements/tests.txt
+```
+
+Õ”éµ×£Õ£©õĮ┐ńö©Ķ┐ćń©ŗµś» numpy µŖźķöÖ’╝īÕłÖµø┤µ¢░õĖĆõĖŗ numpy
+
+```shell
+pip install -U numpy
+```
+
+## 2. ńö©µ│Ģ
+
+```shell
+python ./tools/regression_test.py \
+ --codebase "${CODEBASE_NAME}" \
+ --backends "${BACKEND}" \
+ [--models "${MODELS}"] \
+ --work-dir "${WORK_DIR}" \
+ --device "${DEVICE}" \
+ --log-level INFO \
+ [--performance µł¢ -p] \
+ [--checkpoint-dir "$CHECKPOINT_DIR"]
+```
+
+### ÕÅéµĢ░Ķ¦Żµ×É
+
+- `--codebase` : ķ£ĆĶ”üµĄŗĶ»ĢńÜä codebase’╝īeg.`mmdet`, µĄŗĶ»ĢÕżÜõĖ¬ `mmpretrain mmdet ...`
+- `--backends` : ńŁøķĆēµĄŗĶ»ĢńÜäÕÉÄń½», ķ╗śĶ«żµĄŗÕģ©ķā©`backend`, õ╣¤ÕÅ»õ╝ĀÕģźĶŗźÕ╣▓õĖ¬ÕÉÄń½»’╝īõŠŗÕ”é `onnxruntime tesnsorrt`ŃĆéÕ”éµ×£ķ£ĆĶ”üõĖĆÕÉīĶ┐øĶĪī SDK ńÜ䵥ŗĶ»Ģ’╝īķ£ĆĶ”üÕ£© `tests/regression/${codebase}.yml` ķćīķØóńÜä `sdk_config` Ķ┐øĶĪīķģŹńĮ«ŃĆé
+- `--models` : µīćիܵĄŗĶ»ĢńÜ䵩ĪÕ×ŗ, ķ╗śĶ«żµĄŗĶ»Ģ `yml` õĖŁµēƵ£ēµ©ĪÕ×ŗ, õ╣¤ÕÅ»õ╝ĀÕģźĶŗźÕ╣▓õĖ¬µ©ĪÕ×ŗÕÉŹń¦░’╝īµ©ĪÕ×ŗÕÉŹń¦░ÕÅ»ÕÅéĶĆāńøĖÕģ│ymlķģŹńĮ«µ¢ćõ╗ČŃĆéõŠŗÕ”é `ResNet SE-ResNet "Mask R-CNN"`ŃĆéµ│©µäÅńÜ䵜»’╝īÕÅ»õ╝ĀÕģźÕŬµ£ēÕŁŚµ»ŹÕÆīµĢ░ÕŁŚń╗䵳ɵ©ĪÕ×ŗÕÉŹń¦░’╝īõŠŗÕ”é `resnet seresnet maskrcnn`ŃĆé
+- `--work-dir` : µ©ĪÕ×ŗĶĮ¼µŹóŃĆüµŖźÕæŖńö¤µłÉńÜäĶĘ»ÕŠä’╝īķ╗śĶ«żµś»`../mmdeploy_regression_working_dir`’╝īµ│©µäÅĶĘ»ÕŠäõĖŁõĖŹĶ”üÕɽń®║µĀ╝ńŁēńē╣µ«ŖÕŁŚń¼”ŃĆé
+- `--checkpoint-dir`: PyTorch µ©ĪÕ×ŗµ¢ćõ╗ČõĖŗĶĮĮõ┐ØÕŁśĶĘ»ÕŠä’╝īķ╗śĶ«żµś»`../mmdeploy_checkpoints`’╝īµ│©µäÅĶĘ»ÕŠäõĖŁõĖŹĶ”üÕɽń®║µĀ╝ńŁēńē╣µ«ŖÕŁŚń¼”ŃĆé
+- `--device` : õĮ┐ńö©ńÜäĶ«ŠÕżć’╝īķ╗śĶ«ż `cuda`ŃĆé
+- `--log-level` : Ķ«ŠńĮ«µŚźĶ«░ńÜäńŁēń║¦’╝īķĆēķĪ╣Õīģµŗ¼`'CRITICAL'’╝ī 'FATAL'’╝ī 'ERROR'’╝ī 'WARN'’╝ī 'WARNING'’╝ī 'INFO'’╝ī 'DEBUG'’╝ī 'NOTSET'`ŃĆéķ╗śĶ«żµś»`INFO`ŃĆé
+- `-p` µł¢ `--performance` : µś»ÕÉ”µĄŗĶ»Ģń▓ŠÕ║”’╝īÕŖĀõĖŖÕłÖµĄŗĶ»ĢĶĮ¼µŹó+ń▓ŠÕ║”’╝īõĖŹÕŖĀõĖŖÕłÖÕŬµĄŗĶ»ĢĶĮ¼µŹó
+
+### µ│©µäÅõ║ŗķĪ╣
+
+Õ»╣õ║Ä Windows ńö©µłĘ’╝Ü
+
+1. Ķ”üÕ£© shell ÕæĮõ╗żõĖŁõĮ┐ńö© `&&` Ķ┐׵ğń¼”’╝īķ£ĆĶ”üõĖŗĶĮĮÕ╣ČõĮ┐ńö© `PowerShell 7 Preview 5+`ŃĆé
+2. Õ”éµ×£µé©õĮ┐ńö© conda env’╝īÕÅ»ĶāĮķ£ĆĶ”üÕ£© regression_test.py õĖŁÕ░å `python3` µø┤µö╣õĖ║ `python`’╝īÕøĀõĖ║ `%USERPROFILE%\AppData\Local\Microsoft\WindowsApps` ńø«ÕĮĢõĖŁµ£ē `python3.exe`ŃĆé
+
+## õŠŗÕŁÉ
+
+1. µĄŗĶ»Ģ mmdet ÕÆī mmpose ńÜäµēƵ£ē backend ńÜä **ĶĮ¼µŹó+ń▓ŠÕ║”**
+
+```shell
+python ./tools/regression_test.py \
+ --codebase mmdet mmpose \
+ --work-dir "../mmdeploy_regression_working_dir" \
+ --device "cuda" \
+ --log-level INFO \
+ --performance
+```
+
+2. µĄŗĶ»Ģ mmdet ÕÆī mmpose ńÜ䵤ÉÕćĀõĖ¬ backend ńÜä **ĶĮ¼µŹó+ń▓ŠÕ║”**
+
+```shell
+python ./tools/regression_test.py \
+ --codebase mmdet mmpose \
+ --backends onnxruntime tensorrt \
+ --work-dir "../mmdeploy_regression_working_dir" \
+ --device "cuda" \
+ --log-level INFO \
+ -p
+```
+
+3. µĄŗĶ»Ģ mmdet ÕÆī mmpose ńÜ䵤ÉÕćĀõĖ¬ backend’╝ī**ÕŬµĄŗĶ»ĢĶĮ¼µŹó**
+
+```shell
+python ./tools/regression_test.py \
+ --codebase mmdet mmpose \
+ --backends onnxruntime tensorrt \
+ --work-dir "../mmdeploy_regression_working_dir" \
+ --device "cuda" \
+ --log-level INFO
+```
+
+4. µĄŗĶ»Ģ mmdet ÕÆī mmpretrain ńÜ䵤ÉÕćĀõĖ¬ models’╝ī**ÕŬµĄŗĶ»ĢĶĮ¼µŹó**
+
+```shell
+python ./tools/regression_test.py \
+ --codebase mmdet mmpose \
+ --models ResNet SE-ResNet "Mask R-CNN" \
+ --work-dir "../mmdeploy_regression_working_dir" \
+ --device "cuda" \
+ --log-level INFO
+```
+
+## 3. Õø×ÕĮƵĄŗĶ»ĢķģŹńĮ«µ¢ćõ╗Č
+
+### ńż║õŠŗÕÅŖÕÅéµĢ░Ķ¦Żµ×É
+
+```yaml
+globals:
+ codebase_dir: ../mmocr # Õø×ÕĮƵĄŗĶ»ĢńÜä codebase ĶĘ»ÕŠä
+ checkpoint_force_download: False # Õø×ÕĮƵĄŗĶ»Ģµś»ÕÉ”ķ揵¢░õĖŗĶĮĮµ©ĪÕ×ŗÕŹ│õĮ┐ÕģČÕĘ▓ń╗ÅÕŁśÕ£©
+ images: # µĄŗĶ»ĢõĮ┐ńö©ÕøŠńēć
+ img_densetext_det: &img_densetext_det ../mmocr/demo/demo_densetext_det.jpg
+ img_demo_text_det: &img_demo_text_det ../mmocr/demo/demo_text_det.jpg
+ img_demo_text_ocr: &img_demo_text_ocr ../mmocr/demo/demo_text_ocr.jpg
+ img_demo_text_recog: &img_demo_text_recog ../mmocr/demo/demo_text_recog.jpg
+ metric_info: &metric_info # µīćµĀćÕÅéµĢ░
+ hmean-iou: # ÕæĮÕÉŹµĀ╣µŹ« metafile.Results.Metrics
+ eval_name: hmean-iou # ÕæĮÕÉŹµĀ╣µŹ« test.py --metrics args ÕģźÕÅéÕÉŹń¦░
+ metric_key: 0_hmean-iou:hmean # ÕæĮÕÉŹµĀ╣µŹ« eval ÕåÖÕģź log ńÜä key name
+ tolerance: 0.1 # Õ«╣Õ┐ŹńÜäķśłÕĆ╝Õī║ķŚ┤
+ task_name: Text Detection # ÕæĮÕÉŹµĀ╣µŹ«µ©ĪÕ×ŗ metafile.Results.Task
+ dataset: ICDAR2015 #ÕæĮÕÉŹµĀ╣µŹ«µ©ĪÕ×ŗ metafile.Results.Dataset
+ word_acc: # ÕÉīõĖŖ
+ eval_name: acc
+ metric_key: 0_word_acc_ignore_case
+ tolerance: 0.2
+ task_name: Text Recognition
+ dataset: IIIT5K
+ convert_image_det: &convert_image_det # detĶĮ¼µŹóõ╝ÜõĮ┐ńö©Õł░ńÜäÕøŠńēć
+ input_img: *img_densetext_det
+ test_img: *img_demo_text_det
+ convert_image_rec: &convert_image_rec
+ input_img: *img_demo_text_recog
+ test_img: *img_demo_text_recog
+ backend_test: &default_backend_test True # µś»Õɔջ╣ backend Ķ┐øĶĪīń▓ŠÕ║”µĄŗĶ»Ģ
+ sdk: # SDK ķģŹńĮ«µ¢ćõ╗Č
+ sdk_detection_dynamic: &sdk_detection_dynamic configs/mmocr/text-detection/text-detection_sdk_dynamic.py
+ sdk_recognition_dynamic: &sdk_recognition_dynamic configs/mmocr/text-recognition/text-recognition_sdk_dynamic.py
+
+onnxruntime:
+ pipeline_ort_recognition_static_fp32: &pipeline_ort_recognition_static_fp32
+ convert_image: *convert_image_rec # ĶĮ¼µŹóĶ┐ćń©ŗõĖŁõĮ┐ńö©ńÜäÕøŠńēć
+ backend_test: *default_backend_test # µś»ÕÉ”Ķ┐øĶĪīÕÉÄń½»µĄŗĶ»Ģ’╝īÕŁśÕ£©ÕłÖÕłżµ¢Ł’╝īõĖŹÕŁśÕ£©ÕłÖĶ¦åõĖ║ False
+ sdk_config: *sdk_recognition_dynamic # µś»ÕÉ”Ķ┐øĶĪīSDKµĄŗĶ»Ģ’╝īÕŁśÕ£©ÕłÖõĮ┐ńö©ńē╣Õ«ÜńÜä SDK config Ķ┐øĶĪīµĄŗĶ»Ģ’╝īõĖŹÕŁśÕ£©ÕłÖĶ¦åõĖ║õĖŹĶ┐øĶĪī SDK µĄŗĶ»Ģ
+ deploy_config: configs/mmocr/text-recognition/text-recognition_onnxruntime_static.py # õĮ┐ńö©ńÜä deploy cfg ĶĘ»ÕŠä’╝īÕ¤║õ║Ä mmdeploy ńÜäĶĘ»ÕŠä
+
+ pipeline_ort_recognition_dynamic_fp32: &pipeline_ort_recognition_dynamic_fp32
+ convert_image: *convert_image_rec
+ backend_test: *default_backend_test
+ sdk_config: *sdk_recognition_dynamic
+ deploy_config: configs/mmocr/text-recognition/text-recognition_onnxruntime_dynamic.py
+
+ pipeline_ort_detection_dynamic_fp32: &pipeline_ort_detection_dynamic_fp32
+ convert_image: *convert_image_det
+ deploy_config: configs/mmocr/text-detection/text-detection_onnxruntime_dynamic.py
+
+tensorrt:
+ pipeline_trt_recognition_dynamic_fp16: &pipeline_trt_recognition_dynamic_fp16
+ convert_image: *convert_image_rec
+ backend_test: *default_backend_test
+ sdk_config: *sdk_recognition_dynamic
+ deploy_config: configs/mmocr/text-recognition/text-recognition_tensorrt-fp16_dynamic-1x32x32-1x32x640.py
+
+ pipeline_trt_detection_dynamic_fp16: &pipeline_trt_detection_dynamic_fp16
+ convert_image: *convert_image_det
+ backend_test: *default_backend_test
+ sdk_config: *sdk_detection_dynamic
+ deploy_config: configs/mmocr/text-detection/text-detection_tensorrt-fp16_dynamic-320x320-2240x2240.py
+
+openvino:
+ # µŁżÕżäń£üńĢź’╝īÕåģÕ«╣ÕÉīõĖŖ
+ncnn:
+ # µŁżÕżäń£üńĢź’╝īÕåģÕ«╣ÕÉīõĖŖ
+pplnn:
+ # µŁżÕżäń£üńĢź’╝īÕåģÕ«╣ÕÉīõĖŖ
+torchscript:
+ # µŁżÕżäń£üńĢź’╝īÕåģÕ«╣ÕÉīõĖŖ
+
+
+models:
+ - name: crnn # µ©ĪÕ×ŗÕÉŹń¦░
+ metafile: configs/textrecog/crnn/metafile.yml # µ©ĪÕ×ŗÕ»╣Õ║öńÜä metafile ńÜäĶĘ»ÕŠä’╝īńøĖÕ»╣õ║Ä codebase ńÜäĶĘ»ÕŠä
+ codebase_model_config_dir: configs/textrecog/crnn # `model_configs` ńÜäńłČµ¢ćõ╗ČÕż╣ĶĘ»ÕŠä’╝īńøĖÕ»╣õ║Ä codebase ńÜäĶĘ»ÕŠä
+ model_configs: # ķ£ĆĶ”üµĄŗĶ»ĢńÜä config ÕÉŹń¦░
+ - crnn_academic_dataset.py
+ pipelines: # õĮ┐ńö©ńÜä pipeline
+ - *pipeline_ort_recognition_dynamic_fp32
+
+ - name: dbnet
+ metafile: configs/textdet/dbnet/metafile.yml
+ codebase_model_config_dir: configs/textdet/dbnet
+ model_configs:
+ - dbnet_r18_fpnc_1200e_icdar2015.py
+ pipelines:
+ - *pipeline_ort_detection_dynamic_fp32
+ - *pipeline_trt_detection_dynamic_fp16
+
+ # ńē╣µ«ŖńÜä pipeline ÕÅ»õ╗źĶ┐ÖµĀĘÕŖĀÕģź
+ - convert_image: xxx
+ backend_test: xxx
+ sdk_config: xxx
+ deploy_config: configs/mmocr/text-detection/xxx
+```
+
+## 4. ńö¤µłÉńÜäµŖźÕæŖ
+
+### µ©ĪµØ┐
+
+| | Model | Model Config | Task | Checkpoint | Dataset | Backend | Deploy Config | Static or Dynamic | Precision Type | Conversion Result | metric_1 | metric_2 | metric_n | Test Pass |
+| ---- | -------- | ----------------- | ---------------- | -------------- | ---------- | -------- | --------------- | ----------------- | -------------- | ----------------- | ----------- | ----------- | ----------- | ------------ |
+| Õ║ÅÕÅĘ | µ©ĪÕ×ŗÕÉŹń¦░ | model config ĶĘ»ÕŠä | µē¦ĶĪīńÜä task name | `.pth`µ©ĪÕ×ŗĶĘ»ÕŠä | µĢ░µŹ«ķøåÕÉŹń¦░ | ÕÉÄń½»ÕÉŹń¦░ | deploy cfg ĶĘ»ÕŠä | ÕŖ©µĆü or ķØÖµĆü | µĄŗĶ»Ģń▓ŠÕ║” | µ©ĪÕ×ŗĶĮ¼µŹóń╗ōµ×£ | µīćµĀć 1 µĢ░ÕĆ╝ | µīćµĀć 2 µĢ░ÕĆ╝ | µīćµĀć n µĢ░ÕĆ╝ | ÕÉÄń½»µĄŗĶ»Ģń╗ōµ×£ |
+
+### ńż║õŠŗ
+
+Ķ┐Öµś» MMOCR ńö¤µłÉńÜäµŖźÕæŖ
+
+| | Model | Model Config | Task | Checkpoint | Dataset | Backend | Deploy Config | Static or Dynamic | Precision Type | Conversion Result | hmean-iou | word_acc | Test Pass |
+| --- | ----- | ---------------------------------------------------------------- | ---------------- | ------------------------------------------------------------------------------------------------------------ | --------- | --------------- | -------------------------------------------------------------------------------------- | ----------------- | -------------- | ----------------- | --------- | -------- | --------- |
+| 0 | crnn | ../mmocr/configs/textrecog/crnn/crnn_academic_dataset.py | Text Recognition | ../mmdeploy_checkpoints/mmocr/crnn/crnn_academic-a723a1c5.pth | IIIT5K | Pytorch | - | - | - | - | - | 80.5 | - |
+| 1 | crnn | ../mmocr/configs/textrecog/crnn/crnn_academic_dataset.py | Text Recognition | ${WORK_DIR}/mmocr/crnn/onnxruntime/static/crnn_academic-a723a1c5/end2end.onnx | x | onnxruntime | configs/mmocr/text-recognition/text-recognition_onnxruntime_dynamic.py | static | fp32 | True | - | 80.67 | True |
+| 2 | crnn | ../mmocr/configs/textrecog/crnn/crnn_academic_dataset.py | Text Recognition | ${WORK_DIR}/mmocr/crnn/onnxruntime/static/crnn_academic-a723a1c5 | x | SDK-onnxruntime | configs/mmocr/text-recognition/text-recognition_sdk_dynamic.py | static | fp32 | True | - | x | False |
+| 3 | dbnet | ../mmocr/configs/textdet/dbnet/dbnet_r18_fpnc_1200e_icdar2015.py | Text Detection | ../mmdeploy_checkpoints/mmocr/dbnet/dbnet_r18_fpnc_sbn_1200e_icdar2015_20210329-ba3ab597.pth | ICDAR2015 | Pytorch | - | - | - | - | 0.795 | - | - |
+| 4 | dbnet | ../mmocr/configs/textdet/dbnet/dbnet_r18_fpnc_1200e_icdar2015.py | Text Detection | ../mmdeploy_checkpoints/mmocr/dbnet/dbnet_r18_fpnc_sbn_1200e_icdar2015_20210329-ba3ab597.pth | ICDAR | onnxruntime | configs/mmocr/text-detection/text-detection_onnxruntime_dynamic.py | dynamic | fp32 | True | - | - | True |
+| 5 | dbnet | ../mmocr/configs/textdet/dbnet/dbnet_r18_fpnc_1200e_icdar2015.py | Text Detection | ${WORK_DIR}/mmocr/dbnet/tensorrt/dynamic/dbnet_r18_fpnc_sbn_1200e_icdar2015_20210329-ba3ab597/end2end.engine | ICDAR | tensorrt | configs/mmocr/text-detection/text-detection_tensorrt-fp16_dynamic-320x320-2240x2240.py | dynamic | fp16 | True | 0.793302 | - | True |
+| 6 | dbnet | ../mmocr/configs/textdet/dbnet/dbnet_r18_fpnc_1200e_icdar2015.py | Text Detection | ${WORK_DIR}/mmocr/dbnet/tensorrt/dynamic/dbnet_r18_fpnc_sbn_1200e_icdar2015_20210329-ba3ab597 | ICDAR | SDK-tensorrt | configs/mmocr/text-detection/text-detection_sdk_dynamic.py | dynamic | fp16 | True | 0.795073 | - | True |
+
+## 5. µö»µīüńÜäÕÉÄń½»
+
+- [x] ONNX Runtime
+- [x] TensorRT
+- [x] PPLNN
+- [x] ncnn
+- [x] OpenVINO
+- [x] TorchScript
+- [x] SNPE
+- [x] MMDeploy SDK
+
+## 6. µö»µīüńÜäCodebaseÕÅŖÕģČMetric
+
+| Codebase | Metric | Support |
+| ---------- | -------- | ------------------ |
+| mmdet | bbox | :heavy_check_mark: |
+| | segm | :heavy_check_mark: |
+| | PQ | :x: |
+| mmpretrain | accuracy | :heavy_check_mark: |
+| mmseg | mIoU | :heavy_check_mark: |
+| mmpose | AR | :heavy_check_mark: |
+| | AP | :heavy_check_mark: |
+| mmocr | hmean | :heavy_check_mark: |
+| | acc | :heavy_check_mark: |
+| mmagic | PSNR | :heavy_check_mark: |
+| | SSIM | :heavy_check_mark: |
+
+## 7. µ│©µäÅõ║ŗķĪ╣
+
+µÜ鵌Ā
+
+## 8. ÕĖĖĶ¦üķŚ«ķóś
+
+µÜ鵌Ā
diff --git a/internlm_langchain/knowledge_base/MMDeploy/content/riscv.md b/internlm_langchain/knowledge_base/MMDeploy/content/riscv.md
new file mode 100644
index 00000000..b1af8dff
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDeploy/content/riscv.md
@@ -0,0 +1,107 @@
+# µö»µīü RISC-V
+
+MMDeploy ķĆēµŗ® ncnn õĮ£õĖ║ RISC-V Õ╣│ÕÅ░õĖŗńÜäµÄ©ńÉåÕÉÄń½»ŃĆéÕ«īµĢ┤ńÜäķā©ńĮ▓Ķ┐ćń©ŗÕīģÕɽõĖżõĖ¬µŁźķ¬ż’╝Ü
+
+µ©ĪÕ×ŗĶĮ¼µŹó’╝ÜÕ£© Host ń½»Õ░å PyTorch µ©ĪÕ×ŗĶĮ¼õĖ║ ncnn µ©ĪÕ×ŗŃĆéÕ╣ČÕ░åĶĮ¼µŹóÕÉÄńÜ䵩ĪÕ×ŗõ╝ĀÕł░ deviceŃĆé
+
+µ©ĪÕ×ŗķā©ńĮ▓’╝ÜÕ£© Host ń½»õ╗źõ║żÕÅēń╝¢Ķ»æµ¢╣Õ╝Åń╝¢Ķ»æ ncnn ÕÆī MMDeployŃĆéõ╝ĀÕł░ Device ń½»Ķ┐øĶĪīµÄ©ńÉåŃĆé
+
+## 1. µ©ĪÕ×ŗĶĮ¼µŹó
+
+a) Õ«ēĶŻģ MMDeploy
+
+ÕÅ»ÕÅéĶĆā [BUILD µ¢ćµĪŻ](./linux-x86_64.md)’╝īÕ«ēĶŻģ ncnn µÄ©ńÉåÕ╝ĢµōÄõ╗źÕÅŖ MMDeployŃĆé
+
+b) µ©ĪÕ×ŗĶĮ¼µŹó
+
+õ╗ź Resnet-18 õĖ║õŠŗŃĆéÕģłÕÅéńģ¦[µ¢ćµĪŻ](https://github.com/open-mmlab/mmpretrain)Õ«ēĶŻģ mmpretrain’╝īńäČÕÉÄõĮ┐ńö© `tools/deploy.py` ĶĮ¼µŹóµ©ĪÕ×ŗŃĆé
+
+```bash
+export MODEL_CONFIG=/path/to/mmpretrain/configs/resnet/resnet18_8xb32_in1k.py
+export MODEL_PATH=https://download.openmmlab.com/mmclassification/v0/resnet/resnet18_8xb32_in1k_20210831-fbbb1da6.pth
+
+# µ©ĪÕ×ŗĶĮ¼µŹó
+cd /path/to/mmdeploy
+python tools/deploy.py \
+ configs/mmpretrain/classification_ncnn_static.py \
+ $MODEL_CONFIG \
+ $MODEL_PATH \
+ tests/data/tiger.jpeg \
+ --work-dir resnet18 \
+ --device cpu \
+ --dump-info
+```
+
+## 2. µ©ĪÕ×ŗķā©ńĮ▓
+
+a) õĖŗĶĮĮõ║żÕÅēń╝¢Ķ»æÕĘźÕģĘķōŠ’╝īĶ«ŠńĮ«ńÄ»ÕóāÕÅśķćÅ
+
+```bash
+# õĖŗĶĮĮ Xuantie-900-gcc-linux-5.10.4-glibc-x86_64-V2.2.6-20220516.tar.gz
+# https://occ.t-head.cn/community/download?id=4046947553902661632
+tar xf Xuantie-900-gcc-linux-5.10.4-glibc-x86_64-V2.2.6-20220516.tar.gz
+export RISCV_ROOT_PATH=`realpath Xuantie-900-gcc-linux-5.10.4-glibc-x86_64-V2.2.6`
+```
+
+b) ń╝¢Ķ»æ ncnn & opencv
+
+```bash
+# ncnn
+# ÕÅ»ÕÅéĶĆā https://github.com/Tencent/ncnn/wiki/how-to-build#build-for-allwinner-d1
+
+# opencv
+git clone https://github.com/opencv/opencv.git
+mkdir build_riscv && cd build_riscv
+cmake .. \
+ -DCMAKE_TOOLCHAIN_FILE=/path/to/mmdeploy/cmake/toolchains/riscv64-unknown-linux-gnu.cmake \
+ -DCMAKE_INSTALL_PREFIX=install \
+ -DBUILD_PERF_TESTS=OFF \
+ -DBUILD_SHARED_LIBS=OFF \
+ -DBUILD_TESTS=OFF \
+ -DCMAKE_BUILD_TYPE=Release
+
+make -j$(nproc) && make install
+```
+
+c) ń╝¢Ķ»æ mmdeploy SDK & demo
+
+```bash
+cd /path/to/mmdeploy
+mkdir build_riscv && cd build_riscv
+cmake .. \
+ -DCMAKE_TOOLCHAIN_FILE=../cmake/toolchains/riscv64-unknown-linux-gnu.cmake \
+ -DMMDEPLOY_BUILD_SDK=ON \
+ -DMMDEPLOY_SHARED_LIBS=OFF \
+ -DMMDEPLOY_BUILD_EXAMPLES=ON \
+ -DMMDEPLOY_TARGET_DEVICES="cpu" \
+ -DMMDEPLOY_TARGET_BACKENDS="ncnn" \
+ -Dncnn_DIR=${ncnn_DIR}/build-c906/install/lib/cmake/ncnn/ \
+ -DMMDEPLOY_CODEBASES=all \
+ -DOpenCV_DIR=${OpenCV_DIR}/build_riscv/install/lib/cmake/opencv4
+
+make -j$(nproc) && make install
+```
+
+µē¦ĶĪī `make install` õ╣ŗÕÉÄ, examplesńÜäÕÅ»µē¦ĶĪīµ¢ćõ╗Čõ╝Üõ┐ØÕŁśÕ£© `install/bin`
+
+```
+tree -L 1 install/bin/
+.
+Ōö£ŌöĆŌöĆ image_classification
+Ōö£ŌöĆŌöĆ image_restorer
+Ōö£ŌöĆŌöĆ image_segmentation
+Ōö£ŌöĆŌöĆ object_detection
+Ōö£ŌöĆŌöĆ ocr
+Ōö£ŌöĆŌöĆ pose_detection
+ŌööŌöĆŌöĆ rotated_object_detection
+```
+
+d) Ķ┐ÉĶĪī demo
+
+ÕģłńĪ«Ķ«żµĄŗĶ»Ģµ©ĪÕ×ŗńö©õ║å `--dump-info`’╝īĶ┐ÖµĀĘ `resnet18` ńø«ÕĮĢµēŹµ£ē `pipeline.json` ńŁē SDK µēĆķ£Ćµ¢ćõ╗ČŃĆé
+
+µŖŖ dump ÕźĮńÜ䵩ĪÕ×ŗńø«ÕĮĢ(resnet18)ŃĆüÕÅ»µē¦ĶĪīµ¢ćõ╗Č(image_classification)ŃĆüµĄŗĶ»ĢÕøŠńēć(tests/data/tiger.jpeg)µŗĘĶ┤ØÕł░Ķ«ŠÕżćõĖŁ
+
+```bash
+./image_classification cpu ./resnet18 tiger.jpeg
+```
diff --git a/internlm_langchain/knowledge_base/MMDeploy/content/rknn.md b/internlm_langchain/knowledge_base/MMDeploy/content/rknn.md
new file mode 100644
index 00000000..159d8718
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDeploy/content/rknn.md
@@ -0,0 +1,9 @@
+# µö»µīüńÜä RKNN ńē╣ÕŠü
+
+ńø«ÕēŹ, MMDeploy ÕŬգ© rk3588 ÕÆī rv1126 ńÜä linux Õ╣│ÕÅ░õĖŖµĄŗĶ»ĢĶ┐ć.
+
+õ╗źõĖŗńē╣µĆ¦ķ£ĆĶ”üµēŗÕŖ©Õ£© MMDeploy Ķć¬ĶĪīķģŹńĮ«’╝īÕ”é[Ķ┐Öķćī](https://github.com/open-mmlab/mmdeploy/tree/main/configs/_base_/backends/rknn.py).
+
+- target_platform ’╝ü= default
+- quantization settings
+- optimization level ’╝ü= 1
diff --git a/internlm_langchain/knowledge_base/MMDeploy/content/rockchip.md b/internlm_langchain/knowledge_base/MMDeploy/content/rockchip.md
new file mode 100644
index 00000000..b44e10b8
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDeploy/content/rockchip.md
@@ -0,0 +1,342 @@
+# ńæ×ĶŖ»ÕŠ« NPU ķā©ńĮ▓
+
+- [ńæ×ĶŖ»ÕŠ« NPU ķā©ńĮ▓](#ńæ×ĶŖ»ÕŠ«-npu-ķā©ńĮ▓)
+ - [µ©ĪÕ×ŗĶĮ¼µŹó](#µ©ĪÕ×ŗĶĮ¼µŹó)
+ - [Õ«ēĶŻģńÄ»Õóā](#Õ«ēĶŻģńÄ»Õóā)
+ - [Õłåń▒╗µ©ĪÕ×ŗĶĮ¼µŹó](#Õłåń▒╗µ©ĪÕ×ŗĶĮ¼µŹó)
+ - [µŻĆµĄŗµ©ĪÕ×ŗĶĮ¼µŹó](#µŻĆµĄŗµ©ĪÕ×ŗĶĮ¼µŹó)
+ - [ķā©ńĮ▓ config Ķ»┤µśÄ](#ķā©ńĮ▓-config-Ķ»┤µśÄ)
+ - [ķŚ«ķóśĶ»┤µśÄ](#ķŚ«ķóśĶ»┤µśÄ)
+ - [µ©ĪÕ×ŗµÄ©ńÉå](#µ©ĪÕ×ŗµÄ©ńÉå)
+ - [Host õ║żÕÅēń╝¢Ķ»æ](#host-õ║żÕÅēń╝¢Ķ»æ)
+ - [Device µē¦ĶĪīµÄ©ńÉå](#device-µē¦ĶĪīµÄ©ńÉå)
+
+______________________________________________________________________
+
+MMDeploy µö»µīüµŖŖµ©ĪÕ×ŗķā©ńĮ▓Õł░ńæ×ĶŖ»ÕŠ«Ķ«ŠÕżćõĖŖŃĆéÕĘ▓µö»µīüńÜäĶŖ»ńēć’╝ÜRV1126ŃĆüRK3588ŃĆé
+
+Õ«īµĢ┤ńÜäķā©ńĮ▓Ķ┐ćń©ŗÕīģÕɽõĖżõĖ¬µŁźķ¬ż’╝Ü
+
+1. µ©ĪÕ×ŗĶĮ¼µŹó
+
+ - Õ£©õĖ╗µ£║õĖŖ’╝īÕ░å PyTorch µ©ĪÕ×ŗĶĮ¼µŹóõĖ║ RKNN µ©ĪÕ×ŗ
+
+2. µ©ĪÕ×ŗµÄ©ńÉå
+
+ - Õ£©õĖ╗µ£║õĖŖ’╝ī õĮ┐ńö©õ║żÕÅēń╝¢Ķ»æÕĘźÕģĘÕŠŚÕł░Ķ«ŠÕżćµēĆķ£ĆńÜä SDK ÕÆī bin
+ - µŖŖĶĮ¼ÕźĮńÜ䵩ĪÕ×ŗÕÆīń╝¢ÕźĮńÜä SDKŃĆübin’╝īõ╝ĀÕł░Ķ«ŠÕżć’╝īĶ┐øĶĪīµÄ©ńÉå
+
+## µ©ĪÕ×ŗĶĮ¼µŹó
+
+### Õ«ēĶŻģńÄ»Õóā
+
+1. Ķ»ĘÕÅéĶĆā[Õ┐½ķƤÕģźķŚ©](../get_started.md)’╝īÕłøÕ╗║ conda ĶÖܵŗ¤ńÄ»Õóā’╝īÕ╣ČÕ«ēĶŻģ PyTorchŃĆümmcv-full
+
+2. Õ«ēĶŻģ RKNN Toolkit
+
+ Õ”éõĖŗĶĪ©µēĆńż║’╝īńæ×ĶŖ»ÕŠ«µÅÉõŠøõ║å 2 ÕźŚ RKNN Toolkit’╝īÕ»╣Õ║öõ║ÄõĖŹÕÉīńÜäĶŖ»ńēćÕ×ŗÕÅĘ
+
+
+| Device | +RKNN-Toolkit | +Installation Guide | +
|---|---|---|
| RK1808 / RK1806 / RV1109 / RV1126 | +git clone https://github.com/rockchip-linux/rknn-toolkit |
+ Õ«ēĶŻģµīćÕŹŚ | +
| RK3566 / RK3568 / RK3588 / RV1103 / RV1106 | +git clone https://github.com/rockchip-linux/rknn-toolkit2 |
+ Õ«ēĶŻģµīćÕŹŚ | +
+2. µŖŖ cmake ĶĘ»ÕŠäÕŖĀÕģźÕł░ńÄ»ÕóāÕÅśķćÅ PATH õĖŁ, "C:\\Program Files (x86)\\Microsoft Visual Studio\\2019\\Community\\Common7\\IDE\\CommonExtensions\\Microsoft\\CMake\\CMake\\bin"
+3. Õ”éµ×£ń│╗ń╗¤õĖŁķģŹńĮ«õ║å NVIDIA µśŠÕŹĪ’╝īµĀ╣µŹ«[Õ«śńĮæµĢÖń©ŗ](https://developer.nvidia.com\/cuda-downloads)’╝īõĖŗĶĮĮÕ╣ČÕ«ēĶŻģ cuda toolkitŃĆé
+ +### Õ«ēĶŻģõŠØĶĄ¢Õīģ + +#### Õ«ēĶŻģ MMDeploy Converter õŠØĶĄ¢ + +
| ÕÉŹń¦░ | +Õ«ēĶŻģµ¢╣µ│Ģ | +
|---|---|
| conda | +Ķ»ĘÕÅéĶĆā Ķ┐Öķćī Õ«ēĶŻģ condaŃĆéÕ«ēĶŻģÕ«īµ»ĢÕÉÄ’╝īµēōÕ╝Ćń│╗ń╗¤Õ╝ĆÕ¦ŗĶÅ£ÕŹĢ’╝īõ╗źń«ĪńÉåÕæśńÜäĶ║½õ╗ĮµēōÕ╝Ć anaconda powershell promptŃĆé ÕøĀõĖ║’╝ī +1. õĖŗµ¢ćõĖŁńÜäÕ«ēĶŻģÕæĮõ╗żÕØ浜»Õ£© anaconda powershell õĖŁµĄŗĶ»Ģķ¬īĶ»üńÜäŃĆé +2. õĮ┐ńö©ń«ĪńÉåÕæśµØāķÖÉ’╝īÕÅ»õ╗źµŖŖń¼¼õĖēµ¢╣Õ║ōÕ«ēĶŻģÕł░ń│╗ń╗¤ńø«ÕĮĢŃĆéĶāĮÕż¤ń«ĆÕī¢ MMDeploy ń╝¢Ķ»æÕæĮõ╗żŃĆé +Ķ»┤µśÄ’╝ÜÕ”éµ×£õĮĀÕ»╣ cmake ÕĘźõĮ£ÕĤńÉåÕŠłń夵éē’╝īõ╣¤ÕÅ»õ╗źõĮ┐ńö©µÖ«ķĆÜńö©µłĘµØāķÖɵēōÕ╝Ć anaconda powershell promptŃĆé + |
+
| PyTorch (>=1.8.0) |
+ Õ«ēĶŻģ PyTorch’╝īĶ”üµ▒éńēłµ£¼µś» torch>=1.8.0ŃĆéÕÅ»µ¤źń£ŗÕ«śńĮæĶÄĘÕÅ¢µø┤ÕżÜĶ»”ń╗åńÜäÕ«ēĶŻģµĢÖń©ŗŃĆéĶ»ĘńĪ«õ┐Ø PyTorch Ķ”üµ▒éńÜä CUDA ńēłµ£¼ÕÆīµé©õĖ╗µ£║ńÜä CUDA ńēłµ£¼µś»õĖĆĶć┤ + |
+
| mmcv | +ÕÅéĶĆāÕ”éõĖŗÕæĮõ╗żÕ«ēĶŻģ mmcvŃĆéµø┤ÕżÜÕ«ēĶŻģµ¢╣Õ╝Å’╝īÕÅ»µ¤źń£ŗ mmcv Õ«śńĮæ + |
+
| ÕÉŹń¦░ | +Õ«ēĶŻģµ¢╣µ│Ģ | +
|---|---|
| OpenCV | +
+ 1. õ╗ÄĶ┐ÖķćīõĖŗĶĮĮ OpenCV 3+ŃĆé
+ 2. µé©ÕÅ»õ╗źõĖŗĶĮĮÕ╣ČÕ«ēĶŻģ OpenCV ķóäń╝¢Ķ»æÕīģÕł░µīćÕ«ÜńÜäńø«ÕĮĢõĖŗŃĆéõ╣¤ÕÅ»õ╗źķĆēµŗ®µ║ÉńĀüń╝¢Ķ»æÕ«ēĶŻģńÜäµ¢╣Õ╝Å
+ 3. Õ£©Õ«ēĶŻģńø«ÕĮĢõĖŁ’╝īµēŠÕł░ OpenCVConfig.cmake’╝īÕ╣ȵŖŖÕ«āńÜäĶĘ»ÕŠäµĘ╗ÕŖĀÕł░ńÄ»ÕóāÕÅśķćÅ PATH õĖŁŃĆéÕāÅĶ┐ÖµĀĘ’╝Ü
+ |
+
| pplcv | +pplcv µś» openPPL Õ╝ĆÕÅæńÜäķ½śµĆ¦ĶāĮÕøŠÕāÅÕżäńÉåÕ║ōŃĆé µŁżõŠØĶĄ¢ķĪ╣õĖ║ÕÅ»ķĆēķĪ╣’╝īÕŬµ£ēÕ£© cuda Õ╣│ÕÅ░õĖŗ’╝īµēŹķ£ĆÕ«ēĶŻģŃĆé + |
+
| µÄ©ńÉåÕ╝ĢµōÄ | +õŠØĶĄ¢Õīģ | +Õ«ēĶŻģµ¢╣µ│Ģ | +
|---|---|---|
| ONNXRuntime | +onnxruntime (>=1.8.1) |
+
+ 1. Õ«ēĶŻģ onnxruntime ńÜä python Õīģ
+ |
+
| TensorRT |
+ TensorRT |
+
+ 1. ńÖ╗ÕĮĢ NVIDIA Õ«śńĮæ’╝īõ╗ÄĶ┐ÖķćīķĆēÕÅ¢Õ╣ČõĖŗĶĮĮ TensorRT tar ÕīģŃĆéĶ”üõ┐ØĶ»üÕ«āÕÆīµé©µ£║ÕÖ©ńÜä CPU µ×ȵ×äõ╗źÕÅŖ CUDA ńēłµ£¼µś»Õī╣ķģŹńÜäŃĆéµé©ÕÅ»õ╗źÕÅéĶĆāĶ┐Öõ╗Į µīćÕŹŚ Õ«ēĶŻģ TensorRTŃĆé + 2. Ķ┐Öķćīõ╣¤µ£ēõĖĆõ╗Į TensorRT 8.2 GA Update 2 Õ£© Windows x86_64 ÕÆī CUDA 11.x õĖŗńÜäÕ«ēĶŻģńż║õŠŗ’╝īõŠøµé©ÕÅéĶĆāŃĆéķ”¢Õģł’╝īńé╣Õć╗µŁżÕżäõĖŗĶĮĮ CUDA 11.x TensorRT 8.2.3.0ŃĆéńäČÕÉÄ’╝īµĀ╣µŹ«Õ”éõĖŗÕæĮõ╗ż’╝īÕ«ēĶŻģÕ╣ČķģŹńĮ« TensorRT õ╗źÕÅŖńøĖÕģ│õŠØĶĄ¢ŃĆé + |
+
| cudnn | +
+ 1. õ╗Ä cuDNN Archive õĖŁķĆēµŗ®ÕÆīµé©ńÄ»ÕóāõĖŁ CPU µ×ȵ×äŃĆüCUDA ńēłµ£¼õ╗źÕÅŖ TensorRT ńēłµ£¼ķģŹÕźŚńÜä cuDNNŃĆéõ╗źÕēŹµ¢ć TensorRT Õ«ēĶŻģĶ»┤µśÄõĖ║õŠŗ’╝īÕ«āķ£ĆĶ”ü cudnn8.2ŃĆéÕøĀµŁż’╝īÕÅ»õ╗źõĖŗĶĮĮ CUDA 11.x cuDNN 8.2 + 2. Ķ¦ŻÕÄŗÕÄŗń╝®Õīģ’╝īÕ╣ČĶ«ŠńĮ«ńÄ»ÕóāÕÅśķćÅ + |
+ |
| PPL.NN | +ppl.nn | +TODO | +
| OpenVINO | +openvino | +TODO | +
| ncnn | +ncnn | +TODO | +
| Õ£© v2.25.0 õ╣ŗÕēŹ | +v2.25.0 ÕÅŖõ╣ŗÕÉÄ | +
| + +``` +'mask2former_xxx_coco.py' õ╗ŻĶĪ©Õģ©µÖ»ÕłåÕē▓ńÜäķģŹńĮ«µ¢ćõ╗Č +``` + + | ++ +``` +'mask2former_xxx_coco.py' õ╗ŻĶĪ©Õ«×õŠŗÕłåÕē▓ńÜäķģŹńĮ«µ¢ćõ╗Č +'mask2former_xxx_coco-panoptic.py' õ╗ŻĶĪ©Õģ©µÖ»ÕłåÕē▓ńÜäķģŹńĮ«µ¢ćõ╗Č +``` + + |
|---|
| ÕĤķģŹńĮ« | ++ +```python +# ÕøŠÕāÅÕĮÆõĖĆÕī¢ÕÅéµĢ░ +img_norm_cfg = dict( + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + to_rgb=True) +pipeline=[ + ..., + dict(type='Normalize', **img_norm_cfg), + dict(type='Pad', size_divisor=32), # ÕøŠÕāÅ padding Õł░ 32 ńÜäÕĆŹµĢ░ + ... +] +``` + + | +
| µ¢░ķģŹńĮ« | ++ +```python +model = dict( + data_preprocessor=dict( + type='DetDataPreprocessor', + # ÕøŠÕāÅÕĮÆõĖĆÕī¢ÕÅéµĢ░ + mean=[123.675, 116.28, 103.53], + std=[58.395, 57.12, 57.375], + bgr_to_rgb=True, + # ÕøŠÕāÅ padding ÕÅéµĢ░ + pad_mask=True, # Õ£©Õ«×õŠŗÕłåÕē▓õĖŁ’╝īķ£ĆĶ”üÕ░å mask õ╣¤Ķ┐øĶĪī padding + pad_size_divisor=32) # ÕøŠÕāÅ padding Õł░ 32 ńÜäÕĆŹµĢ░ +) +``` + + | +
| ÕĤķģŹńĮ« | ++ +```python +data = dict( + samples_per_gpu=2, + workers_per_gpu=2, + train=dict( + type=dataset_type, + ann_file=data_root + 'annotations/instances_train2017.json', + img_prefix=data_root + 'train2017/', + pipeline=train_pipeline), + val=dict( + type=dataset_type, + ann_file=data_root + 'annotations/instances_val2017.json', + img_prefix=data_root + 'val2017/', + pipeline=test_pipeline), + test=dict( + type=dataset_type, + ann_file=data_root + 'annotations/instances_val2017.json', + img_prefix=data_root + 'val2017/', + pipeline=test_pipeline)) +``` + + | +
| µ¢░ķģŹńĮ« | ++ +```python +train_dataloader = dict( + batch_size=2, + num_workers=2, + persistent_workers=True, # ķü┐ÕģŹµ»Åµ¼ĪĶ┐Łõ╗ŻÕÉÄ dataloader ķ揵¢░ÕłøÕ╗║ÕŁÉĶ┐øń©ŗ + sampler=dict(type='DefaultSampler', shuffle=True), # ķ╗śĶ«żńÜä sampler’╝īÕÉīµŚČµö»µīüÕłåÕĖāÕ╝ÅĶ«Łń╗āÕÆīķØ×ÕłåÕĖāÕ╝ÅĶ«Łń╗ā + batch_sampler=dict(type='AspectRatioBatchSampler'), # ķ╗śĶ«żńÜä batch_sampler’╝īńö©õ║Äõ┐ØĶ»ü batch õĖŁńÜäÕøŠńēćÕģʵ£ēńøĖõ╝╝ńÜäķĢ┐Õ«Įµ»ö’╝īõ╗ÄĶĆīÕÅ»õ╗źµø┤ÕźĮÕ£░Õł®ńö©µśŠÕŁś + dataset=dict( + type=dataset_type, + data_root=data_root, + ann_file='annotations/instances_train2017.json', + data_prefix=dict(img='train2017/'), + filter_cfg=dict(filter_empty_gt=True, min_size=32), + pipeline=train_pipeline)) +# Õ£© 3.x ńēłµ£¼õĖŁÕÅ»õ╗źńŗ¼ń½ŗķģŹńĮ«ķ¬īĶ»üÕÆīµĄŗĶ»ĢńÜä dataloader +val_dataloader = dict( + batch_size=1, + num_workers=2, + persistent_workers=True, + drop_last=False, + sampler=dict(type='DefaultSampler', shuffle=False), + dataset=dict( + type=dataset_type, + data_root=data_root, + ann_file='annotations/instances_val2017.json', + data_prefix=dict(img='val2017/'), + test_mode=True, + pipeline=test_pipeline)) +test_dataloader = val_dataloader # µĄŗĶ»Ģ dataloader ńÜäķģŹńĮ«õĖÄķ¬īĶ»ü dataloader ńÜäķģŹńĮ«ńøĖÕÉī’╝īĶ┐Öķćīń£üńĢź +``` + + | +
| ÕĤķģŹńĮ« | ++ +```python +img_norm_cfg = dict( + mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True) +train_pipeline = [ + dict(type='LoadImageFromFile'), + dict(type='LoadAnnotations', with_bbox=True), + dict(type='Resize', img_scale=(1333, 800), keep_ratio=True), + dict(type='RandomFlip', flip_ratio=0.5), + dict(type='Normalize', **img_norm_cfg), + dict(type='Pad', size_divisor=32), + dict(type='DefaultFormatBundle'), + dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']), +] +``` + + | +
| µ¢░ķģŹńĮ« | ++ +```python +train_pipeline = [ + dict(type='LoadImageFromFile'), + dict(type='LoadAnnotations', with_bbox=True), + dict(type='Resize', scale=(1333, 800), keep_ratio=True), + dict(type='RandomFlip', prob=0.5), + dict(type='PackDetInputs') +] +``` + + | +
| ÕĤķģŹńĮ« | ++ +```python +test_pipeline = [ + dict(type='LoadImageFromFile'), + dict( + type='MultiScaleFlipAug', + img_scale=(1333, 800), + flip=False, + transforms=[ + dict(type='Resize', keep_ratio=True), + dict(type='RandomFlip'), + dict(type='Normalize', **img_norm_cfg), + dict(type='Pad', size_divisor=32), + dict(type='ImageToTensor', keys=['img']), + dict(type='Collect', keys=['img']), + ]) +] +``` + + | +
| µ¢░ķģŹńĮ« | ++ +```python +test_pipeline = [ + dict(type='LoadImageFromFile'), + dict(type='Resize', scale=(1333, 800), keep_ratio=True), + dict( + type='PackDetInputs', + meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', + 'scale_factor')) +] +``` + + | +
| ÕÉŹń¦░ | +ÕĤķģŹńĮ« | +µ¢░ķģŹńĮ« | +
|---|---|---|
| Resize | ++ +```python +dict(type='Resize', + img_scale=(1333, 800), + keep_ratio=True) +``` + + | + ++ +```python +dict(type='Resize', + scale=(1333, 800), + keep_ratio=True) +``` + + | +
| RandomResize | ++ +```python +dict( + type='Resize', + img_scale=[ + (1333, 640), (1333, 800)], + multiscale_mode='range', + keep_ratio=True) +``` + + | ++ +```python +dict( + type='RandomResize', + scale=[ + (1333, 640), (1333, 800)], + keep_ratio=True) +``` + + | +
| RandomChoiceResize | ++ +```python +dict( + type='Resize', + img_scale=[ + (1333, 640), (1333, 672), + (1333, 704), (1333, 736), + (1333, 768), (1333, 800)], + multiscale_mode='value', + keep_ratio=True) +``` + + | ++ +```python +dict( + type='RandomChoiceResize', + scales=[ + (1333, 640), (1333, 672), + (1333, 704), (1333, 736), + (1333, 768), (1333, 800)], + keep_ratio=True) +``` + + | +
| RandomFlip | ++ +```python +dict(type='RandomFlip', + flip_ratio=0.5) +``` + + | ++ +```python +dict(type='RandomFlip', + prob=0.5) +``` + + | +
| Ķ»äµĄŗµīćµĀćÕÉŹń¦░ | +ÕĤķģŹńĮ« | +µ¢░ķģŹńĮ« | +
|---|---|---|
| COCO | ++ +```python +data = dict( + val=dict( + type='CocoDataset', + ann_file=data_root + 'annotations/instances_val2017.json')) +evaluation = dict(metric=['bbox', 'segm']) +``` + + | + ++ +```python +val_evaluator = dict( + type='CocoMetric', + ann_file=data_root + 'annotations/instances_val2017.json', + metric=['bbox', 'segm'], + format_only=False) +``` + + | +
| Pascal VOC | ++ +```python +data = dict( + val=dict( + type=dataset_type, + ann_file=data_root + 'VOC2007/ImageSets/Main/test.txt')) +evaluation = dict(metric='mAP') +``` + + | ++ +```python +val_evaluator = dict( + type='VOCMetric', + metric='mAP', + eval_mode='11points') +``` + + | +
| OpenImages | ++ +```python +data = dict( + val=dict( + type='OpenImagesDataset', + ann_file=data_root + 'annotations/validation-annotations-bbox.csv', + img_prefix=data_root + 'OpenImages/validation/', + label_file=data_root + 'annotations/class-descriptions-boxable.csv', + hierarchy_file=data_root + + 'annotations/bbox_labels_600_hierarchy.json', + meta_file=data_root + 'annotations/validation-image-metas.pkl', + image_level_ann_file=data_root + + 'annotations/validation-annotations-human-imagelabels-boxable.csv')) +evaluation = dict(interval=1, metric='mAP') +``` + + | ++ +```python +val_evaluator = dict( + type='OpenImagesMetric', + iou_thrs=0.5, + ioa_thrs=0.5, + use_group_of=True, + get_supercategory=True) +``` + + | +
| CityScapes | ++ +```python +data = dict( + val=dict( + type='CityScapesDataset', + ann_file=data_root + + 'annotations/instancesonly_filtered_gtFine_val.json', + img_prefix=data_root + 'leftImg8bit/val/', + pipeline=test_pipeline)) +evaluation = dict(metric=['bbox', 'segm']) +``` + + | ++ +```python +val_evaluator = [ + dict( + type='CocoMetric', + ann_file=data_root + + 'annotations/instancesonly_filtered_gtFine_val.json', + metric=['bbox', 'segm']), + dict( + type='CityScapesMetric', + ann_file=data_root + + 'annotations/instancesonly_filtered_gtFine_val.json', + seg_prefix=data_root + '/gtFine/val', + outfile_prefix='./work_dirs/cityscapes_metric/instance') +] +``` + + | +
| ÕĤķģŹńĮ« | ++ +```python +runner = dict( + type='EpochBasedRunner', # Ķ«Łń╗āÕŠ¬ńÄ»ńÜäń▒╗Õ×ŗ + max_epochs=12) # µ£ĆÕż¦Ķ«Łń╗āĶĮ«µ¼Ī +evaluation = dict(interval=2) # ķ¬īĶ»üķŚ┤ķÜöŃĆ鵻Š2 õĖ¬ epoch ķ¬īĶ»üõĖƵ¼Ī +``` + + | +
| µ¢░ķģŹńĮ« | ++ +```python +train_cfg = dict( + type='EpochBasedTrainLoop', # Ķ«Łń╗āÕŠ¬ńÄ»ńÜäń▒╗Õ×ŗ’╝īĶ»ĘÕÅéĶĆā https://github.com/open-mmlab/mmengine/blob/main/mmengine/runner/loops.py + max_epochs=12, # µ£ĆÕż¦Ķ«Łń╗āĶĮ«µ¼Ī + val_interval=2) # ķ¬īĶ»üķŚ┤ķÜöŃĆ鵻Š2 õĖ¬ epoch ķ¬īĶ»üõĖƵ¼Ī +val_cfg = dict(type='ValLoop') # ķ¬īĶ»üÕŠ¬ńÄ»ńÜäń▒╗Õ×ŗ +test_cfg = dict(type='TestLoop') # µĄŗĶ»ĢÕŠ¬ńÄ»ńÜäń▒╗Õ×ŗ +``` + + | +
| ÕĤķģŹńĮ« | ++ +```python +optimizer = dict( + type='SGD', # ķÜŵ£║µó»Õ║”õĖŗķÖŹõ╝śÕī¢ÕÖ© + lr=0.02, # Õ¤║ńĪĆÕŁ”õ╣ĀńÄć + momentum=0.9, # ÕĖ”ÕŖ©ķćÅńÜäķÜŵ£║µó»Õ║”õĖŗķÖŹ + weight_decay=0.0001) # µØāķćŹĶĪ░ÕćÅ +optimizer_config = dict(grad_clip=None) # µó»Õ║”ĶŻüÕē¬ńÜäķģŹńĮ«’╝īĶ«ŠńĮ«õĖ║ None Õģ│ķŚŁµó»Õ║”ĶŻüÕē¬ +``` + + | +
| µ¢░ķģŹńĮ« | ++ +```python +optim_wrapper = dict( # õ╝śÕī¢ÕÖ©Õ░üĶŻģńÜäķģŹńĮ« + type='OptimWrapper', # õ╝śÕī¢ÕÖ©Õ░üĶŻģńÜäń▒╗Õ×ŗŃĆéÕÅ»õ╗źÕłćµŹóĶć│ AmpOptimWrapper µØźÕÉ»ńö©µĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗ā + optimizer=dict( # õ╝śÕī¢ÕÖ©ķģŹńĮ«ŃĆéµö»µīü PyTorch ńÜäÕÉäń¦Źõ╝śÕī¢ÕÖ©ŃĆéĶ»ĘÕÅéĶĆā https://pytorch.org/docs/stable/optim.html#algorithms + type='SGD', # ķÜŵ£║µó»Õ║”õĖŗķÖŹõ╝śÕī¢ÕÖ© + lr=0.02, # Õ¤║ńĪĆÕŁ”õ╣ĀńÄć + momentum=0.9, # ÕĖ”ÕŖ©ķćÅńÜäķÜŵ£║µó»Õ║”õĖŗķÖŹ + weight_decay=0.0001), # µØāķćŹĶĪ░ÕćÅ + clip_grad=None, # µó»Õ║”ĶŻüÕē¬ńÜäķģŹńĮ«’╝īĶ«ŠńĮ«õĖ║ None Õģ│ķŚŁµó»Õ║”ĶŻüÕē¬ŃĆéõĮ┐ńö©µ¢╣µ│ĢĶ»ĘĶ¦ü https://mmengine.readthedocs.io/en/latest/tutorials/optimizer.html + ) +``` + + | +
| ÕĤķģŹńĮ« | ++ +```python +lr_config = dict( + policy='step', # Õ£©Ķ«Łń╗āĶ┐ćń©ŗõĖŁõĮ┐ńö© multi step ÕŁ”õ╣ĀńÄćńŁ¢ńĢź + warmup='linear', # õĮ┐ńö©ń║┐µĆ¦ÕŁ”õ╣ĀńÄćķóäńāŁ + warmup_iters=500, # Õł░ń¼¼ 500 õĖ¬ iteration ń╗ōµØ¤ķóäńāŁ + warmup_ratio=0.001, # ÕŁ”õ╣ĀńÄćķóäńāŁńÜäń│╗µĢ░ + step=[8, 11], # Õ£©Õō¬ÕćĀõĖ¬ epoch Ķ┐øĶĪīÕŁ”õ╣ĀńÄćĶĪ░ÕćÅ + gamma=0.1) # ÕŁ”õ╣ĀńÄćĶĪ░ÕćÅń│╗µĢ░ +``` + + | +
| µ¢░ķģŹńĮ« | ++ +```python +param_scheduler = [ + dict( + type='LinearLR', # õĮ┐ńö©ń║┐µĆ¦ÕŁ”õ╣ĀńÄćķóäńāŁ + start_factor=0.001, # ÕŁ”õ╣ĀńÄćķóäńāŁńÜäń│╗µĢ░ + by_epoch=False, # µīē iteration µø┤µ¢░ķóäńāŁÕŁ”õ╣ĀńÄć + begin=0, # õ╗Äń¼¼õĖĆõĖ¬ iteration Õ╝ĆÕ¦ŗ + end=500), # Õł░ń¼¼ 500 õĖ¬ iteration ń╗ōµØ¤ + dict( + type='MultiStepLR', # Õ£©Ķ«Łń╗āĶ┐ćń©ŗõĖŁõĮ┐ńö© multi step ÕŁ”õ╣ĀńÄćńŁ¢ńĢź + by_epoch=True, # µīē epoch µø┤µ¢░ÕŁ”õ╣ĀńÄć + begin=0, # õ╗Äń¼¼õĖĆõĖ¬ epoch Õ╝ĆÕ¦ŗ + end=12, # Õł░ń¼¼ 12 õĖ¬ epoch ń╗ōµØ¤ + milestones=[8, 11], # Õ£©Õō¬ÕćĀõĖ¬ epoch Ķ┐øĶĪīÕŁ”õ╣ĀńÄćĶĪ░ÕćÅ + gamma=0.1) # ÕŁ”õ╣ĀńÄćĶĪ░ÕćÅń│╗µĢ░ +] +``` + + | +
| ÕŖ¤ĶāĮ | +ÕĤķģŹńĮ« | +µ¢░ķģŹńĮ« | +
|---|---|---|
| Ķ«ŠńĮ«õ┐ØÕŁśķŚ┤ķÜö | ++ +```python +checkpoint_config = dict( + interval=1) +``` + + | + ++ +```python +default_hooks = dict( + checkpoint=dict( + type='CheckpointHook', + interval=1)) +``` + + | +
| õ┐ØÕŁśµ£ĆõĮ│µ©ĪÕ×ŗ | ++ +```python +evaluation = dict( + save_best='auto') +``` + + | ++ +```python +default_hooks = dict( + checkpoint=dict( + type='CheckpointHook', + save_best='auto')) +``` + + | +
| ÕŬõ┐ØńĢÖµ£Ćµ¢░ńÜäÕćĀõĖ¬µ©ĪÕ×ŗ | ++ +```python +checkpoint_config = dict( + max_keep_ckpts=3) +``` + + | ++ +```python +default_hooks = dict( + checkpoint=dict( + type='CheckpointHook', + max_keep_ckpts=3)) +``` + + | +
| ÕŖ¤ĶāĮ | +ÕĤķģŹńĮ« | +µ¢░ķģŹńĮ« | +
|---|---|---|
| Ķ«ŠńĮ«µŚźÕ┐ŚµēōÕŹ░ķŚ┤ķÜö | ++ +```python +log_config = dict( + interval=50) +``` + + | + ++ +```python +default_hooks = dict( + logger=dict( + type='LoggerHook', + interval=50)) +# ÕÅ»ķĆē’╝Ü ķģŹńĮ«µŚźÕ┐ŚµēōÕŹ░µĢ░ÕĆ╝ńÜäÕ╣│µ╗æń¬ŚÕÅŻÕż¦Õ░Å +log_processor = dict( + type='LogProcessor', + window_size=50) +``` + + | +
| õĮ┐ńö© TensorBoard µł¢ WandB ÕÅ»Ķ¦åÕī¢µŚźÕ┐Ś | ++ +```python +log_config = dict( + interval=50, + hooks=[ + dict(type='TextLoggerHook'), + dict(type='TensorboardLoggerHook'), + dict(type='MMDetWandbHook', + init_kwargs={ + 'project': 'mmdetection', + 'group': 'maskrcnn-r50-fpn-1x-coco' + }, + interval=50, + log_checkpoint=True, + log_checkpoint_metadata=True, + num_eval_images=100) + ]) +``` + + | ++ +```python +vis_backends = [ + dict(type='LocalVisBackend'), + dict(type='TensorboardVisBackend'), + dict(type='WandbVisBackend', + init_kwargs={ + 'project': 'mmdetection', + 'group': 'maskrcnn-r50-fpn-1x-coco' + }) +] +visualizer = dict( + type='DetLocalVisualizer', vis_backends=vis_backends, name='visualizer') +``` + + | +
| ÕĤķģŹńĮ« | +µ¢░ķģŹńĮ« | +
|---|---|
| + +```python +cudnn_benchmark = False +opencv_num_threads = 0 +mp_start_method = 'fork' +dist_params = dict(backend='nccl') +log_level = 'INFO' +load_from = None +resume_from = None + + +``` + + | ++ +```python +env_cfg = dict( + cudnn_benchmark=False, + mp_cfg=dict(mp_start_method='fork', + opencv_num_threads=0), + dist_cfg=dict(backend='nccl')) +log_level = 'INFO' +load_from = None +resume = False +``` + + | +
+ +
+
+
+Õ”éµ×£µā│Ķ┐øĶĪīÕżÜń¦Źń▒╗Õ×ŗńÜäĶ»åÕł½’╝īķ£ĆĶ”üõĮ┐ńö© `xx . xx .` ńÜäµĀ╝Õ╝ÅÕ£© `--texts` ÕŁŚµ«ĄÕÉÄÕŻ░µśÄńø«µĀćń▒╗Õ×ŗ:
+
+```shell
+python demo/image_demo.py demo/demo.jpg glip_tiny_a_mmdet-b3654169.pth --texts 'bench . car .'
+```
+
+ń╗ōµ×£Õ”éõĖŗÕøŠµēĆńż║’╝Ü
+
+
+
+ +
+
+
+µÄ©ńÉåĶäܵ£¼Ķ┐śµö»µīüĶŠōÕģźõĖĆõĖ¬ÕÅźÕŁÉõĮ£õĖ║ `--texts` ÕŁŚµ«ĄńÜäĶŠōÕģź’╝Ü
+
+```shell
+python demo/image_demo.py demo/demo.jpg glip_tiny_a_mmdet-b3654169.pth --texts 'There are a lot of cars here.'
+```
+
+ń╗ōµ×£ÕÅ»õ╗źÕÅéĶĆāõĖŗÕøŠ’╝Ü
+
+
+
+ +
+
+
+### ķ¬īĶ»üµ╝öńż║
+
+MMDetection µö»µīüÕÉÄńÜä GLIP ń«Śµ│ĢÕ»╣µ»öÕ«śµ¢╣ńēłµ£¼µ▓Īµ£ēń▓ŠÕ║”õĖŖńÜ䵏¤Õż▒’╝ī benchmark Õ”éõĖŗµēĆńż║’╝Ü
+
+| Model | official mAP | mmdet mAP |
+| ----------------------- | :----------: | :-------: |
+| glip_A_Swin_T_O365.yaml | 42.9 | 43.0 |
+| glip_Swin_T_O365.yaml | 44.9 | 44.9 |
+| glip_Swin_L.yaml | 51.4 | 51.3 |
+
+ńö©µłĘÕÅ»õ╗źõĮ┐ńö© `test.py` Ķäܵ£¼Õ»╣µ©ĪÕ×ŗń▓ŠÕ║”Ķ┐øĶĪīķ¬īĶ»ü’╝īõĮ┐ńö©Õ”éõĖŗµēĆńż║’╝Ü
+
+```shell
+# 1 gpu
+python tools/test.py configs/glip/glip_atss_swin-t_fpn_dyhead_pretrain_obj365.py glip_tiny_a_mmdet-b3654169.pth
+
+# 8 GPU
+./tools/dist_test.sh configs/glip/glip_atss_swin-t_fpn_dyhead_pretrain_obj365.py glip_tiny_a_mmdet-b3654169.pth 8
+```
+
+ķ¬īĶ»üń╗ōµ×£Õż¦Ķć┤Õ”éõĖŗ’╝Ü
+
+```shell
+Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.428
+Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=1000 ] = 0.594
+Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=1000 ] = 0.466
+Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = 0.300
+Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.477
+Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.534
+Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.634
+Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=300 ] = 0.634
+Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=1000 ] = 0.634
+Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = 0.473
+Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.690
+Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.789
+```
diff --git a/internlm_langchain/knowledge_base/MMDetection/content/init_cfg.md b/internlm_langchain/knowledge_base/MMDetection/content/init_cfg.md
new file mode 100644
index 00000000..b58b19d5
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection/content/init_cfg.md
@@ -0,0 +1,161 @@
+# µØāķćŹÕłØÕ¦ŗÕī¢
+
+Õ£©Ķ«Łń╗āĶ┐ćń©ŗõĖŁ’╝īķĆéÕĮōńÜäÕłØÕ¦ŗÕī¢ńŁ¢ńĢźµ£ēÕł®õ║ÄÕŖĀÕ┐½Ķ«Łń╗āķƤÕ║”µł¢ĶÄĘÕŠŚ’żüŌŠ╝ńÜäµĆ¦ĶāĮŃĆé [MMCV](https://github.com/open-mmlab/mmcv/blob/master/mmcv/cnn/utils/weight_init.py) µÅÉõŠøõ║åõĖĆõ║øÕĖĖŌĮżńÜäÕłØÕ¦ŗÕī¢µ©ĪÕØŚńÜäŌĮģµ│Ģ’╝īÕ”é `nn.Conv2d`ŃĆé MMdetection õĖŁńÜ䵩ĪÕ×ŗÕłØÕ¦ŗÕī¢õĖ╗Ķ”üõĮ┐ŌĮż `init_cfg`ŃĆéŌĮżŌ╝ŠÕÅ»õ╗źķĆÜĶ┐ćõ╗źõĖŗõĖżõĖ¬µŁźķ¬żµØźÕłØÕ¦ŗÕī¢µ©ĪÕ×ŗ’╝Ü
+
+1. Õ£© `model_cfg` õĖŁõĖ║µ©ĪÕ×ŗµł¢ÕģČń╗äõ╗ČÕ«Üõ╣ē `init_cfg`’╝īõĮåŌ╝”ń╗äõ╗ČńÜä `init_cfg` õ╝śÕģłń║¦’żüŌŠ╝’╝īõ╝ÜĶ”åńø¢ŌĮŚµ©ĪÕØŚńÜä `init_cfg` ŃĆé
+2. ÕāÅÕŠĆÕĖĖõĖƵĀʵ×äÕ╗║µ©ĪÕ×ŗ’╝īńäČÕÉĵśŠÕ╝ÅĶ░āŌĮż `model.init_weights()` ŌĮģµ│Ģ’╝īµŁżµŚČµ©ĪÕ×ŗÕÅéµĢ░Õ░åõ╝ÜĶó½µīēńģ¦ķģŹńĮ«µ¢ćõ╗ČÕåÖµ│ĢĶ┐øĶĪīÕłØÕ¦ŗÕī¢ŃĆé
+
+MMdetection ÕłØÕ¦ŗÕī¢ÕĘźõĮ£µĄüńÜäķ½śÕ▒é API Ķ░āńö©µĄüń©ŗµś»’╝Ü
+
+model_cfg(init_cfg) -> build_from_cfg -> model -> init_weight() -> initialize(self, self.init_cfg) -> children's init_weight()
+
+### µÅÅĶ┐░
+
+Õ«āńÜäµĢ░µŹ«ń▒╗Õ×ŗµś» dict µł¢ĶĆģ list\[dict\]’╝īÕīģÕɽõ║åõĖŗÕłŚķö«ÕĆ╝:
+
+- `type` (str)’╝īÕīģÕɽ `INTIALIZERS` õĖŁńÜäÕłØÕ¦ŗÕī¢ÕÖ©ÕÉŹń¦░’╝īÕÉÄķØóĶʤńØĆÕłØÕ¦ŗÕī¢ÕÖ©ńÜäÕÅéµĢ░ŃĆé
+- `layer`’╝łstr µł¢ list\[str\]’╝ē’╝īÕīģÕɽ Pytorch µł¢ MMCV õĖŁÕ¤║µ£¼Õ▒éńÜäÕÉŹń¦░’╝īõ╗źÕÅŖÕ░åĶó½ÕłØÕ¦ŗÕī¢ńÜäÕÅ»ÕŁ”õ╣ĀÕÅéµĢ░’╝īõŠŗÕ”é `'Conv2d'`’╝ī`'DeformConv2d'`ŃĆé
+- `override` (dict µł¢ list\[dict\])’╝īÕīģÕɽ’ź¦ń╗¦µē┐ŌŠā `BaseModule` õĖöÕģČÕłØÕ¦ŗÕī¢ķģŹńĮ«õĖÄ `layer` ķö«õĖŁńÜäÕģČõ╗¢Õ▒é’ź¦ÕÉīńÜäŌ╝”µ©ĪÕØŚŃĆé `type` õĖŁÕ«Üõ╣ēńÜäÕłØÕ¦ŗÕī¢ÕÖ©Õ░åķĆéŌĮżõ║Ä `layer` õĖŁÕ«Üõ╣ēńÜäµēƵ£ēÕ▒é’╝īÕøĀµŁżÕ”éµ×£Ō╝”µ©ĪÕØŚ’ź¦µś» `BaseModule` ńÜäµ┤ŠŌĮŻń▒╗õĮåÕÅ»õ╗źõĖÄ `layer` õĖŁńÜäÕ▒éńøĖÕÉīńÜäŌĮģÕ╝ÅÕłØÕ¦ŗÕī¢’╝īÕłÖ’ź¦ķ£ĆĶ”üõĮ┐ŌĮż `override`ŃĆé`override` ÕīģÕɽõ║å’╝Ü
+ - `type` ÕÉÄĶĘ¤ÕłØÕ¦ŗÕī¢ÕÖ©ńÜäÕÅéµĢ░’╝ø
+ - `name` ńö©õ╗źµīćŌĮ░Õ░åĶó½ÕłØÕ¦ŗÕī¢ńÜäŌ╝”µ©ĪÕØŚŃĆé
+
+### ÕłØÕ¦ŗÕī¢ÕÅéµĢ░
+
+õ╗Ä `mmcv.runner.BaseModule` µł¢ `mmdet.models` ń╗¦µē┐õĖĆõĖ¬µ¢░µ©ĪÕ×ŗŃĆéĶ┐Öķćīµłæõ╗¼ńö© FooModel µØźõĖŠõĖ¬õŠŗÕŁÉŃĆé
+
+```python
+import torch.nn as nn
+from mmcv.runner import BaseModule
+
+class FooModel(BaseModule)
+ def __init__(self,
+ arg1,
+ arg2,
+ init_cfg=None):
+ super(FooModel, self).__init__(init_cfg)
+ ...
+```
+
+- ńø┤µÄźÕ£©õ╗ŻńĀüõĖŁõĮ┐ŌĮż `init_cfg` ÕłØÕ¦ŗÕī¢µ©ĪÕ×ŗ
+
+ ```python
+ import torch.nn as nn
+ from mmcv.runner import BaseModule
+ # or directly inherit mmdet models
+
+ class FooModel(BaseModule)
+ def __init__(self,
+ arg1,
+ arg2,
+ init_cfg=XXX):
+ super(FooModel, self).__init__(init_cfg)
+ ...
+ ```
+
+- Õ£© `mmcv.Sequential` µł¢ `mmcv.ModuleList` õ╗ŻńĀüõĖŁńø┤µÄźõĮ┐ŌĮż `init_cfg` ÕłØÕ¦ŗÕī¢µ©ĪÕ×ŗ
+
+ ```python
+ from mmcv.runner import BaseModule, ModuleList
+
+ class FooModel(BaseModule)
+ def __init__(self,
+ arg1,
+ arg2,
+ init_cfg=None):
+ super(FooModel, self).__init__(init_cfg)
+ ...
+ self.conv1 = ModuleList(init_cfg=XXX)
+ ```
+
+- õĮ┐ŌĮżķģŹńĮ«ŌĮéõ╗ČõĖŁńÜä `init_cfg` ÕłØÕ¦ŗÕī¢µ©ĪÕ×ŗ
+
+ ```python
+ model = dict(
+ ...
+ model = dict(
+ type='FooModel',
+ arg1=XXX,
+ arg2=XXX,
+ init_cfg=XXX),
+ ...
+ ```
+
+### init_cfg ńÜäõĮ┐ńö©
+
+1. ńö© `layer` ķö«ÕłØÕ¦ŗÕī¢µ©ĪÕ×ŗ
+
+ Õ”éµ×£µłæõ╗¼ÕŬիÜõ╣ēõ║å `layer`, Õ«āÕŬõ╝ÜÕ£© `layer` ķö«õĖŁÕłØÕ¦ŗÕī¢ńĮæń╗£Õ▒éŃĆé
+
+ µ│©µäÅ’╝Ü `layer` ķö«Õ»╣Õ║öńÜäÕĆ╝µś» Pytorch ńÜäÕĖ”µ£ē weights ÕÆī bias Õ▒׵ƦńÜäń▒╗ÕÉŹ’╝łÕøĀµŁż’ź¦ŌĮƵīü `MultiheadAttention` Õ▒é’╝ēŃĆé
+
+- Õ«Üõ╣ēŌĮżõ║ÄÕłØÕ¦ŗÕī¢Õģʵ£ēńøĖÕÉīķģŹńĮ«ńÜ䵩ĪÕØŚńÜä `layer` ķö«ŃĆé
+
+ ```python
+ init_cfg = dict(type='Constant', layer=['Conv1d', 'Conv2d', 'Linear'], val=1)
+ # ŌĮżńøĖÕÉīńÜäķģŹńĮ«ÕłØÕ¦ŗÕī¢µĢ┤õĖ¬µ©ĪÕØŚ
+ ```
+
+- Õ«Üõ╣ēŌĮżõ║ÄÕłØÕ¦ŗÕī¢Õģʵ£ē’ź¦ÕÉīķģŹńĮ«ńÜäÕ▒éńÜä `layer` ķö«ŃĆé
+
+ ```python
+ init_cfg = [dict(type='Constant', layer='Conv1d', val=1),
+ dict(type='Constant', layer='Conv2d', val=2),
+ dict(type='Constant', layer='Linear', val=3)]
+ # nn.Conv1d Õ░åĶó½ÕłØÕ¦ŗÕī¢õĖ║ dict(type='Constant', val=1)
+ # nn.Conv2d Õ░åĶó½ÕłØÕ¦ŗÕī¢õĖ║ dict(type='Constant', val=2)
+ # nn.Linear Õ░åĶó½ÕłØÕ¦ŗÕī¢õĖ║ dict(type='Constant', val=3)
+ ```
+
+2. õĮ┐ŌĮż `override` ķö«ÕłØÕ¦ŗÕī¢µ©ĪÕ×ŗ
+
+- ÕĮōõĮ┐ŌĮżÕ▒׵ƦÕÉŹÕłØÕ¦ŗÕī¢µ¤Éõ║øńē╣Õ«Üķā©ÕłåµŚČ’╝īµłæõ╗¼ÕÅ»õ╗źõĮ┐ŌĮż `override` ķö«’╝ī `override` õĖŁńÜäÕĆ╝Õ░åÕ┐ĮńĢź init_cfg õĖŁńÜäÕĆ╝ŃĆé
+
+ ```python
+ # layers’╝Ü
+ # self.feat = nn.Conv1d(3, 1, 3)
+ # self.reg = nn.Conv2d(3, 3, 3)
+ # self.cls = nn.Linear(1,2)
+
+ init_cfg = dict(type='Constant',
+ layer=['Conv1d','Conv2d'], val=1, bias=2,
+ override=dict(type='Constant', name='reg', val=3, bias=4))
+ # self.feat and self.cls Õ░åĶó½ÕłØÕ¦ŗÕī¢õĖ║ dict(type='Constant', val=1, bias=2)
+ # ÕŽ 'reg' ńÜ䵩ĪÕØŚÕ░åĶó½ÕłØÕ¦ŗÕī¢õĖ║ dict(type='Constant', val=3, bias=4)
+ ```
+
+- Õ”éµ×£ init_cfg õĖŁńÜä `layer` õĖ║ None’╝īÕłÖÕŬõ╝ÜÕłØÕ¦ŗÕī¢ override õĖŁµ£ē name ńÜäŌ╝”µ©ĪÕØŚ’╝īŌĮĮ override õĖŁńÜä type ÕÆīÕģČõ╗¢ÕÅéµĢ░ÕÅ»õ╗źń£üńĢźŃĆé
+
+ ```python
+ # layers’╝Ü
+ # self.feat = nn.Conv1d(3, 1, 3)
+ # self.reg = nn.Conv2d(3, 3, 3)
+ # self.cls = nn.Linear(1,2)
+
+ init_cfg = dict(type='Constant', val=1, bias=2, override=dict(name='reg'))
+
+ # self.feat and self.cls Õ░åĶó½ Pytorch ÕłØÕ¦ŗÕī¢
+ # ÕŽ 'reg' ńÜ䵩ĪÕØŚÕ░åĶó½ dict(type='Constant', val=1, bias=2) ÕłØÕ¦ŗÕī¢
+ ```
+
+- Õ”éµ×£µłæõ╗¼’ź¦Õ«Üõ╣ē `layer` µł¢ `override` ķö«’╝īÕ«ā’ź¦õ╝ÜÕłØÕ¦ŗÕī¢õ╗╗õĮĢõĖ£Ķź┐ŃĆé
+
+- µŚĀµĢłńÜäõĮ┐ńö©
+
+ ```python
+ # override µ▓Īµ£ē name ķö«ńÜäĶ»Øµś»µŚĀµĢłńÜä
+ init_cfg = dict(type='Constant', layer=['Conv1d','Conv2d'], val=1, bias=2,
+ override=dict(type='Constant', val=3, bias=4))
+
+ # override µ£ē name ķö«ÕÆīÕģČõ╗¢ÕÅéµĢ░õĮåµś»µ▓Īµ£ē type ķö«õ╣¤µś»µŚĀµĢłńÜä
+ init_cfg = dict(type='Constant', layer=['Conv1d','Conv2d'], val=1, bias=2,
+ override=dict(name='reg', val=3, bias=4))
+ ```
+
+3. õĮ┐ŌĮżķóäĶ«Łń╗āµ©ĪÕ×ŗÕłØÕ¦ŗÕī¢µ©ĪÕ×ŗ
+
+ ```python
+ init_cfg = dict(type='Pretrained',
+ checkpoint='torchvision://resnet50')
+ ```
+
+µø┤ÕżÜń╗åĶŖéÕÅ»õ╗źÕÅéĶĆā [MMEngine](https://mmengine.readthedocs.io/zh_CN/latest/advanced_tutorials/initialize.html) ńÜäµ¢ćµĪŻ
diff --git a/internlm_langchain/knowledge_base/MMDetection/content/label_studio.md b/internlm_langchain/knowledge_base/MMDetection/content/label_studio.md
new file mode 100644
index 00000000..202122f6
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection/content/label_studio.md
@@ -0,0 +1,255 @@
+# õĮ┐ńö© MMDetection ÕÆī Label-Studio Ķ┐øĶĪīÕŹŖĶć¬ÕŖ©Õī¢ńø«µĀ浯ƵĄŗµĀćµ│©
+
+µĀćµ│©µĢ░µŹ«µś»õĖĆõĖ¬Ķ┤╣µŚČĶ┤╣ÕŖøńÜäõ╗╗ÕŖĪ’╝īµ£¼µ¢ćõ╗ŗń╗Źõ║åÕ”éõĮĢõĮ┐ńö© MMDetection õĖŁńÜä RTMDet ń«Śµ│ĢĶüöÕÉł Label-Studio ĶĮ»õ╗ČĶ┐øĶĪīÕŹŖĶć¬ÕŖ©Õī¢µĀćµ│©ŃĆéÕģĘõĮōµØźĶ»┤’╝īõĮ┐ńö© RTMDet ķó䵥ŗÕøŠńēćńö¤µłÉµĀćµ│©’╝īńäČÕÉÄõĮ┐ńö© Label-Studio Ķ┐øĶĪīÕŠ«Ķ░āµĀćµ│©’╝īńżŠÕī║ńö©µłĘÕÅ»õ╗źÕÅéĶĆāµŁżµĄüń©ŗÕÆīµ¢╣µ│Ģ’╝īÕ░åÕģČÕ║öńö©Õł░ÕģČõ╗¢ķóåÕ¤¤ŃĆé
+
+- RTMDet’╝ÜRTMDet µś» OpenMMLab Ķć¬ńĀöńÜäķ½śń▓ŠÕ║”ÕŹĢķśČµ«ĄńÜäńø«µĀ浯ƵĄŗń«Śµ│Ģ’╝īÕ╝Ƶ║Éõ║Ä MMDetection ńø«µĀ浯ƵĄŗÕĘźÕģĘń«▒õĖŁ’╝īÕģČÕ╝Ƶ║ÉÕŹÅĶ««õĖ║ Apache 2.0’╝īÕĘźõĖÜńĢīńÜäńö©µłĘÕÅ»õ╗źõĖŹÕÅŚķÖÉńÜäÕģŹĶ┤╣õĮ┐ńö©ŃĆé
+- [Label Studio](https://github.com/heartexlabs/label-studio) µś»õĖƵ¼Šõ╝śń¦ĆńÜäµĀćµ│©ĶĮ»õ╗Č’╝īĶ”åńø¢ÕøŠÕāÅÕłåń▒╗ŃĆüńø«µĀ浯ƵĄŗŃĆüÕłåÕē▓ńŁēķóåÕ¤¤µĢ░µŹ«ķøåµĀćµ│©ńÜäÕŖ¤ĶāĮŃĆé
+
+µ£¼µ¢ćÕ░åõĮ┐ńö©[Õ¢ĄÕ¢ĄµĢ░µŹ«ķøå](https://download.openmmlab.com/mmyolo/data/cat_dataset.zip)ńÜäÕøŠńēć’╝īĶ┐øĶĪīÕŹŖĶć¬ÕŖ©Õī¢µĀćµ│©ŃĆé
+
+## ńÄ»ÕóāķģŹńĮ«
+
+ķ”¢Õģłķ£ĆĶ”üÕłøÕ╗║õĖĆõĖ¬ĶÖܵŗ¤ńÄ»Õóā’╝īńäČÕÉÄÕ«ēĶŻģ PyTorch ÕÆī MMCVŃĆéÕ£©µ£¼µ¢ćõĖŁ’╝īµłæõ╗¼Õ░åµīćÕ«Ü PyTorch ÕÆī MMCV ńÜäńēłµ£¼ŃĆéµÄźõĖŗµØźÕ«ēĶŻģ MMDetectionŃĆüLabel-Studio ÕÆī label-studio-ml-backend’╝īÕģĘõĮōµŁźķ¬żÕ”éõĖŗ’╝Ü
+
+ÕłøÕ╗║ĶÖܵŗ¤ńÄ»Õóā’╝Ü
+
+```shell
+conda create -n rtmdet python=3.9 -y
+conda activate rtmdet
+```
+
+Õ«ēĶŻģ PyTorch
+
+```shell
+# Linux and Windows CPU only
+pip install torch==1.10.1+cpu torchvision==0.11.2+cpu torchaudio==0.10.1 -f https://download.pytorch.org/whl/cpu/torch_stable.html
+# Linux and Windows CUDA 11.3
+pip install torch==1.10.1+cu113 torchvision==0.11.2+cu113 torchaudio==0.10.1 -f https://download.pytorch.org/whl/cu113/torch_stable.html
+# OSX
+pip install torch==1.10.1 torchvision==0.11.2 torchaudio==0.10.1
+```
+
+Õ«ēĶŻģ MMCV
+
+```shell
+pip install -U openmim
+mim install "mmcv>=2.0.0"
+# Õ«ēĶŻģ mmcv ńÜäĶ┐ćń©ŗõĖŁõ╝ÜĶć¬ÕŖ©Õ«ēĶŻģ mmengine
+```
+
+Õ«ēĶŻģ MMDetection
+
+```shell
+git clone https://github.com/open-mmlab/mmdetection
+cd mmdetection
+pip install -v -e .
+```
+
+Õ«ēĶŻģ Label-Studio ÕÆī label-studio-ml-backend
+
+```shell
+# Õ«ēĶŻģ label-studio ķ£ĆĶ”üõĖƵ«ĄµŚČķŚ┤,Õ”éµ×£µēŠõĖŹÕł░ńēłµ£¼Ķ»ĘõĮ┐ńö©Õ«śµ¢╣µ║É
+pip install label-studio==1.7.2
+pip install label-studio-ml==1.0.9
+```
+
+õĖŗĶĮĮrtmdetµØāķćŹ
+
+```shell
+cd path/to/mmetection
+mkdir work_dirs
+cd work_dirs
+wget https://download.openmmlab.com/mmdetection/v3.0/rtmdet/rtmdet_m_8xb32-300e_coco/rtmdet_m_8xb32-300e_coco_20220719_112220-229f527c.pth
+```
+
+## ÕÉ»ÕŖ©µ£ŹÕŖĪ
+
+ÕÉ»ÕŖ© RTMDet ÕÉÄń½»µÄ©ńÉåµ£ŹÕŖĪ’╝Ü
+
+```shell
+cd path/to/mmetection
+
+label-studio-ml start projects/LabelStudio/backend_template --with \
+config_file=configs/rtmdet/rtmdet_m_8xb32-300e_coco.py \
+checkpoint_file=./work_dirs/rtmdet_m_8xb32-300e_coco_20220719_112220-229f527c.pth \
+device=cpu \
+--port 8003
+# device=cpu õĖ║õĮ┐ńö© CPU µÄ©ńÉå’╝īÕ”éµ×£õĮ┐ńö© GPU µÄ©ńÉå’╝īÕ░å cpu µø┐µŹóõĖ║ cuda:0
+```
+
+
+
+µŁżµŚČ’╝īRTMDet ÕÉÄń½»µÄ©ńÉåµ£ŹÕŖĪÕĘ▓ń╗ÅÕÉ»ÕŖ©’╝īÕÉÄń╗ŁÕ£© Label-Studio Web ń│╗ń╗¤õĖŁķģŹńĮ« http://localhost:8003 ÕÉÄń½»µÄ©ńÉåµ£ŹÕŖĪÕŹ│ÕÅ»ŃĆé
+
+ńÄ░Õ£©ÕÉ»ÕŖ© Label-Studio ńĮæķĪĄµ£ŹÕŖĪ’╝Ü
+
+```shell
+label-studio start
+```
+
+
+
+µēōÕ╝ƵĄÅĶ¦łÕÖ©Ķ«┐ķŚ« [http://localhost:8080/](http://localhost:8080/) ÕŹ│ÕÅ»ń£ŗÕł░ Label-Studio ńÜäńĢīķØóŃĆé
+
+
+
+µłæõ╗¼µ│©ÕåīõĖĆõĖ¬ńö©µłĘ’╝īńäČÕÉÄÕłøÕ╗║õĖĆõĖ¬ RTMDet-Semiautomatic-Label ķĪ╣ńø«ŃĆé
+
+
+
+µłæõ╗¼ķĆÜĶ┐ćõĖŗķØóńÜäµ¢╣Õ╝ÅõĖŗĶĮĮÕźĮńż║õŠŗńÜäÕ¢ĄÕ¢ĄÕøŠńēć’╝īńé╣Õć╗ Data Import Õ»╝Õģźķ£ĆĶ”üµĀćµ│©ńÜäńī½ÕøŠńēćŃĆé
+
+```shell
+cd path/to/mmetection
+mkdir data && cd data
+
+wget https://download.openmmlab.com/mmyolo/data/cat_dataset.zip && unzip cat_dataset.zip
+```
+
+
+
+
+
+ńäČÕÉÄķĆēµŗ® Object Detection With Bounding Boxes µ©ĪµØ┐
+
+
+
+```shell
+airplane
+apple
+backpack
+banana
+baseball_bat
+baseball_glove
+bear
+bed
+bench
+bicycle
+bird
+boat
+book
+bottle
+bowl
+broccoli
+bus
+cake
+car
+carrot
+cat
+cell_phone
+chair
+clock
+couch
+cow
+cup
+dining_table
+dog
+donut
+elephant
+fire_hydrant
+fork
+frisbee
+giraffe
+hair_drier
+handbag
+horse
+hot_dog
+keyboard
+kite
+knife
+laptop
+microwave
+motorcycle
+mouse
+orange
+oven
+parking_meter
+person
+pizza
+potted_plant
+refrigerator
+remote
+sandwich
+scissors
+sheep
+sink
+skateboard
+skis
+snowboard
+spoon
+sports_ball
+stop_sign
+suitcase
+surfboard
+teddy_bear
+tennis_racket
+tie
+toaster
+toilet
+toothbrush
+traffic_light
+train
+truck
+tv
+umbrella
+vase
+wine_glass
+zebra
+```
+
+ńäČÕÉÄÕ░åõĖŖĶ┐░ń▒╗Õł½ÕżŹÕłČµĘ╗ÕŖĀÕł░ Label-Studio’╝īńäČÕÉÄńé╣Õć╗ SaveŃĆé
+
+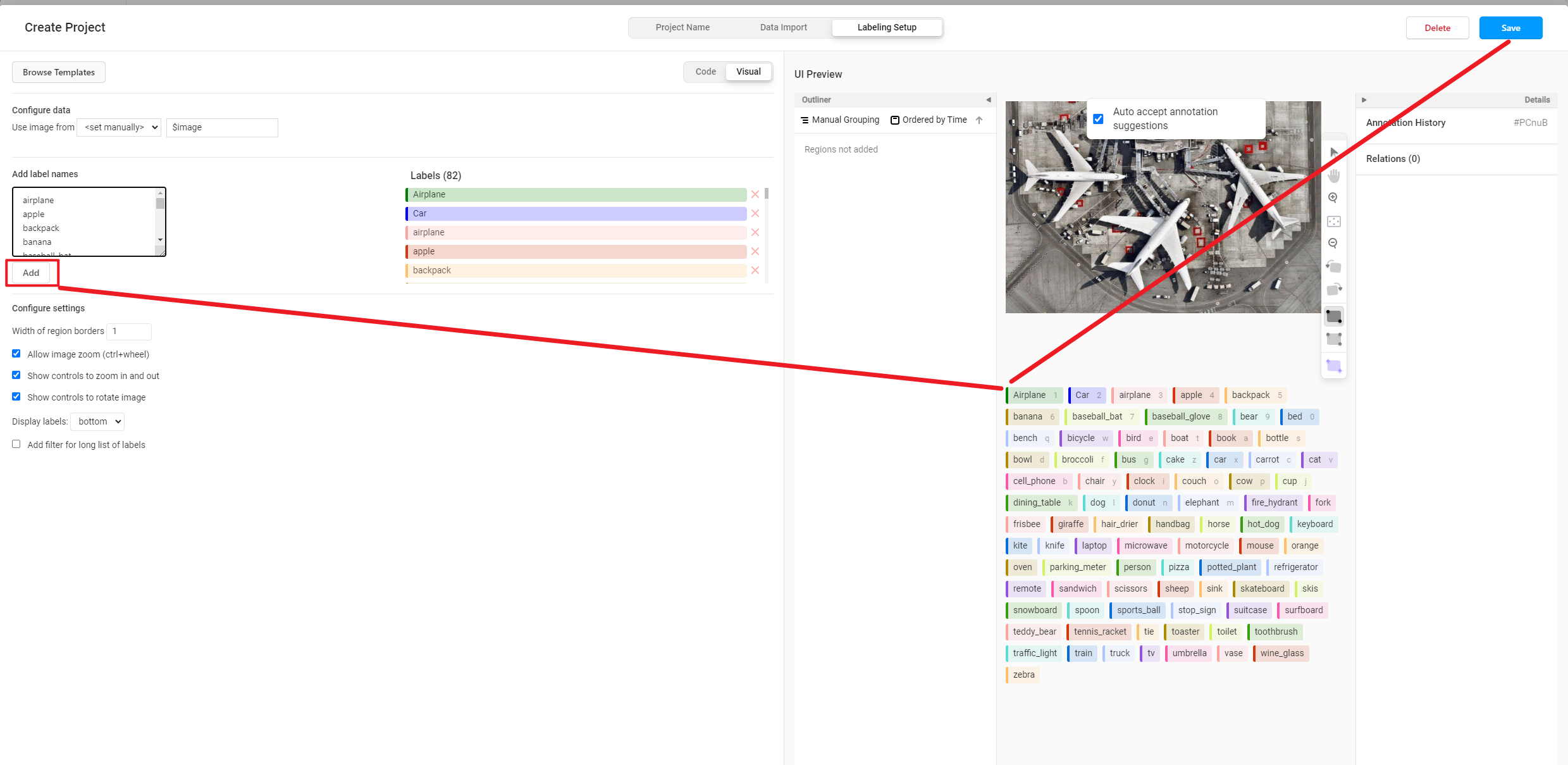
+
+ńäČÕÉÄÕ£©Ķ«ŠńĮ«õĖŁńé╣Õć╗ Add Model µĘ╗ÕŖĀ RTMDet ÕÉÄń½»µÄ©ńÉåµ£ŹÕŖĪŃĆé
+
+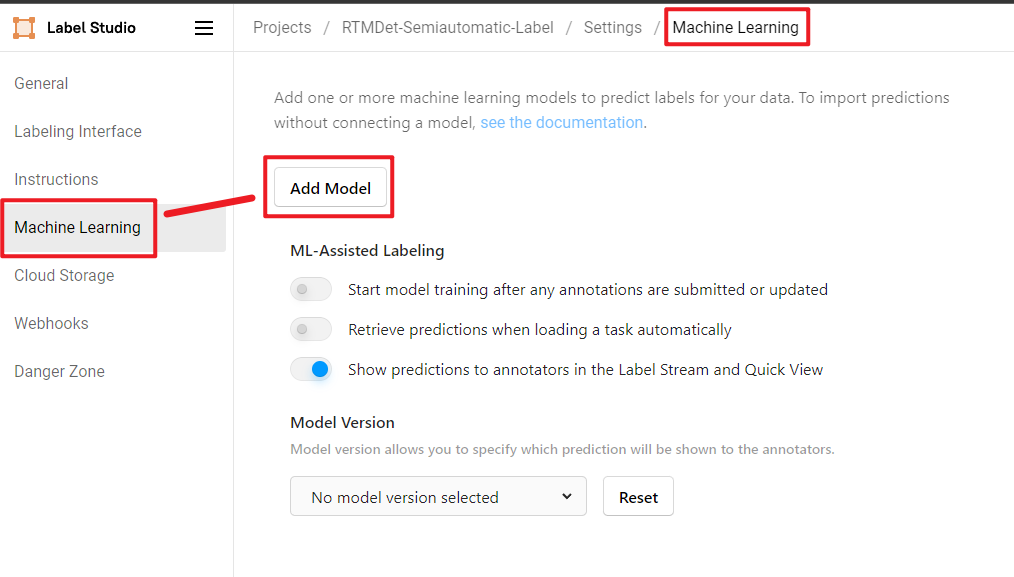
+
+ńé╣Õć╗ Validate and Save’╝īńäČÕÉÄńé╣Õć╗ Start LabelingŃĆé
+
+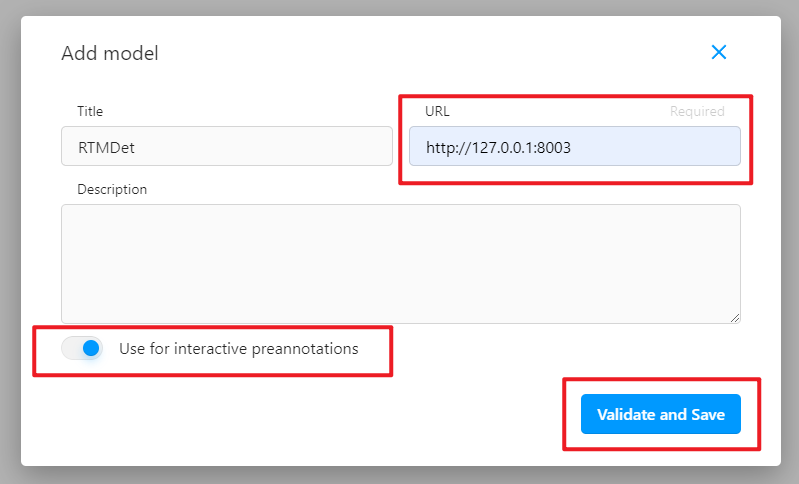
+
+ń£ŗÕł░Õ”éõĖŗ Connected Õ░▒Ķ»┤µśÄÕÉÄń½»µÄ©ńÉåµ£ŹÕŖĪµĘ╗ÕŖĀµłÉÕŖ¤ŃĆé
+
+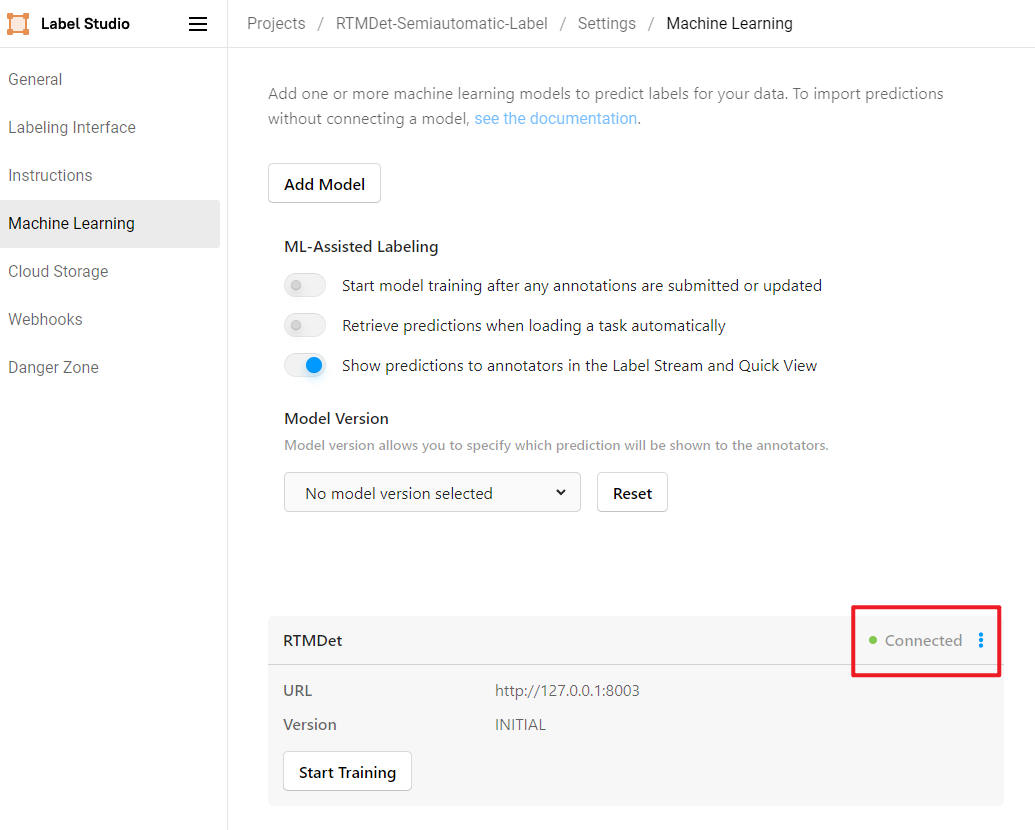
+
+## Õ╝ĆÕ¦ŗÕŹŖĶć¬ÕŖ©Õī¢µĀćµ│©
+
+ńé╣Õć╗ Label Õ╝ĆÕ¦ŗµĀćµ│©
+
+
+
+µłæõ╗¼ÕÅ»õ╗źń£ŗÕł░ RTMDet ÕÉÄń½»µÄ©ńÉåµ£ŹÕŖĪÕĘ▓ń╗ŵłÉÕŖ¤Ķ┐öÕø×õ║åķó䵥ŗń╗ōµ×£Õ╣ȵśŠńż║Õ£©ÕøŠńēćõĖŖ’╝īµłæõ╗¼ÕÅ»õ╗źÕÅæńÄ░Ķ┐ÖõĖ¬Õ¢ĄÕ¢Ąķó䵥ŗńÜäµĪåµ£ēńé╣Õż¦ŃĆé
+
+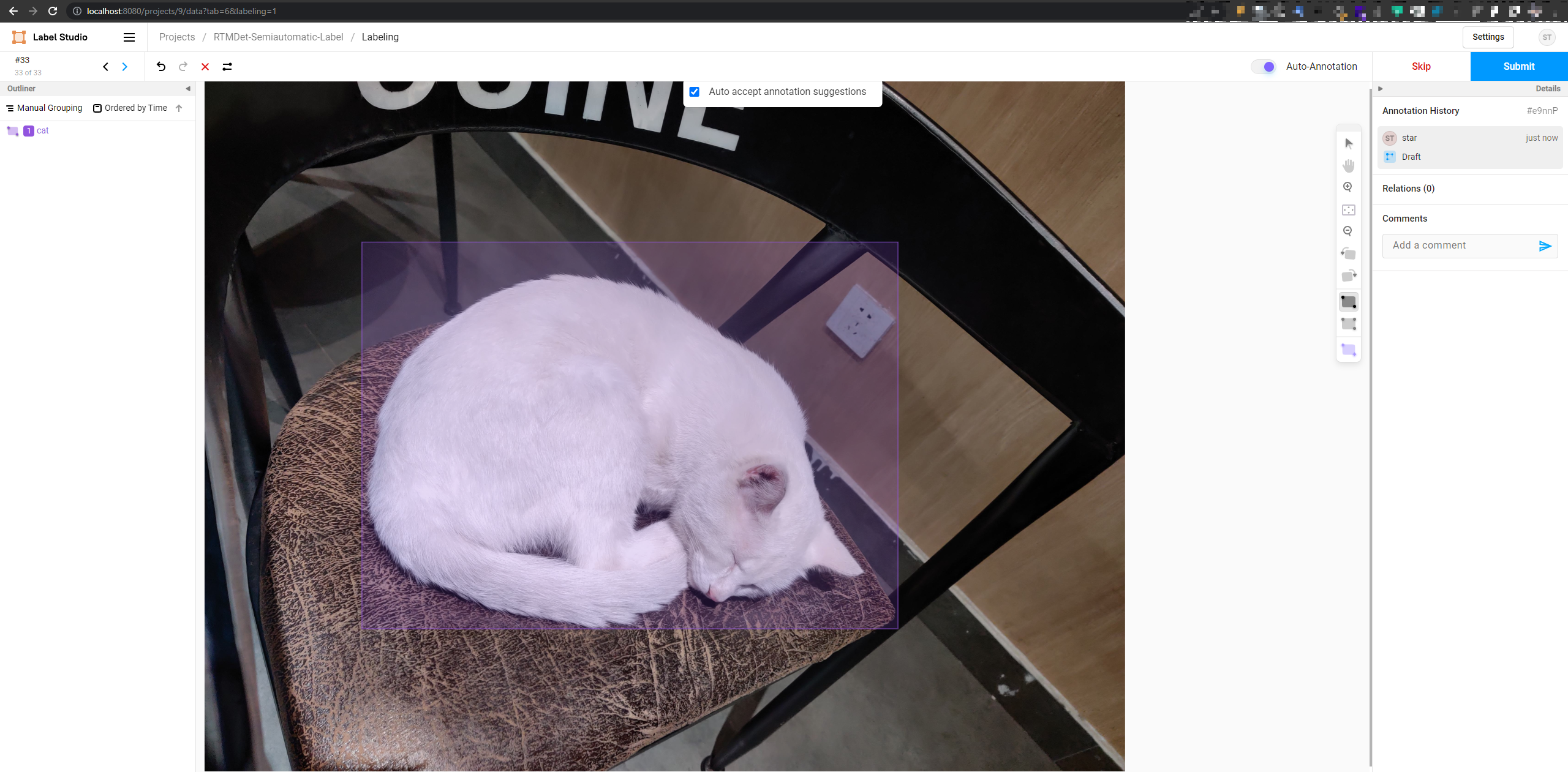
+
+µłæõ╗¼µēŗÕĘźµŗ¢ÕŖ©µĪå’╝īõ┐«µŁŻõĖĆõĖŗµĪåńÜäõĮŹńĮ«’╝īÕŠŚÕł░õ╗źõĖŗõ┐«µŁŻĶ┐ćÕÉÄńÜäµĀćµ│©’╝īńäČÕÉÄńé╣Õć╗ Submit’╝īµ£¼Õ╝ĀÕøŠńēćÕ░▒µĀćµ│©Õ«īµ»Ģõ║åŃĆé
+
+
+
+µłæõ╗¼ submit Õ«īµ»ĢµēƵ£ēÕøŠńēćÕÉÄ’╝īńé╣Õć╗ exprot Õ»╝Õć║ COCO µĀ╝Õ╝ÅńÜäµĢ░µŹ«ķøå’╝īÕ░▒ĶāĮµŖŖµĀćµ│©ÕźĮńÜäµĢ░µŹ«ķøåńÜäÕÄŗń╝®ÕīģÕ»╝Õć║µØźõ║åŃĆé
+
+
+
+ńö© vscode µēōÕ╝ĆĶ¦ŻÕÄŗÕÉÄńÜäµ¢ćõ╗ČÕż╣’╝īÕÅ»õ╗źń£ŗÕł░µĀćµ│©ÕźĮńÜäµĢ░µŹ«ķøå’╝īÕīģÕɽõ║åÕøŠńēćÕÆī json µĀ╝Õ╝ÅńÜäµĀćµ│©µ¢ćõ╗ČŃĆé
+
+
+
+Õł░µŁżÕŹŖĶć¬ÕŖ©Õī¢µĀćµ│©Õ░▒Õ«īµłÉõ║å’╝īµłæõ╗¼ÕÅ»õ╗źńö©Ķ┐ÖõĖ¬µĢ░µŹ«ķøåÕ£© MMDetection Ķ«Łń╗āń▓ŠÕ║”µø┤ķ½śńÜ䵩ĪÕ×ŗõ║å’╝īĶ«Łń╗āÕć║µø┤ÕźĮńÜ䵩ĪÕ×ŗ’╝īńäČÕÉÄÕåŹńö©Ķ┐ÖõĖ¬µ©ĪÕ×ŗń╗¦ń╗ŁÕŹŖĶć¬ÕŖ©Õī¢µĀćµ│©µ¢░ķććķøåńÜäÕøŠńēć’╝īĶ┐ÖµĀĘÕ░▒ÕÅ»õ╗źõĖŹµ¢ŁĶ┐Łõ╗Ż’╝īµē®Õģģķ½śĶ┤©ķćŵĢ░µŹ«ķøå’╝īµÅÉķ½śµ©ĪÕ×ŗńÜäń▓ŠÕ║”ŃĆé
+
+## õĮ┐ńö© MMYOLO õĮ£õĖ║ÕÉÄń½»µÄ©ńÉåµ£ŹÕŖĪ
+
+Õ”éµ×£µā│Õ£© MMYOLO õĖŁõĮ┐ńö© Label-Studio’╝īÕÅ»õ╗źÕÅéĶĆāÕ£©ÕÉ»ÕŖ©ÕÉÄń½»µÄ©ńÉåµ£ŹÕŖĪµŚČ’╝īÕ░å config_file ÕÆī checkpoint_file µø┐µŹóõĖ║ MMYOLO ńÜäķģŹńĮ«µ¢ćõ╗ČÕÆīµØāķ揵¢ćõ╗ČÕŹ│ÕÅ»ŃĆé
+
+```shell
+cd path/to/mmetection
+
+label-studio-ml start projects/LabelStudio/backend_template --with \
+config_file= path/to/mmyolo_config.py \
+checkpoint_file= path/to/mmyolo_weights.pth \
+device=cpu \
+--port 8003
+# device=cpu õĖ║õĮ┐ńö© CPU µÄ©ńÉå’╝īÕ”éµ×£õĮ┐ńö© GPU µÄ©ńÉå’╝īÕ░å cpu µø┐µŹóõĖ║ cuda:0
+```
+
+µŚŗĶĮ¼ńø«µĀ浯ƵĄŗÕÆīÕ«×õŠŗÕłåÕē▓Ķ┐śÕ£©µö»µīüõĖŁ’╝īµĢ¼Ķ»Ęµ£¤ÕŠģŃĆé
diff --git a/internlm_langchain/knowledge_base/MMDetection/content/migration.md b/internlm_langchain/knowledge_base/MMDetection/content/migration.md
new file mode 100644
index 00000000..d706856f
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection/content/migration.md
@@ -0,0 +1,12 @@
+# õ╗Ä MMDetection 2.x Ķ┐üń¦╗Ķć│ 3.x
+
+MMDetection 3.x ńēłµ£¼µś»õĖĆõĖ¬ķćŹÕż¦µø┤µ¢░’╝īÕīģÕɽõ║åĶ«ĖÕżÜ API ÕÆīķģŹńĮ«µ¢ćõ╗ČńÜäÕÅśÕī¢ŃĆéµ£¼µ¢ćµĪŻµŚ©Õ£©ÕĖ«ÕŖ®ńö©µłĘõ╗Ä MMDetection 2.x ńēłµ£¼Ķ┐üń¦╗Õł░ 3.x ńēłµ£¼ŃĆé
+µłæõ╗¼Õ░åĶ┐üń¦╗µīćÕŹŚÕłåõĖ║õ╗źõĖŗÕćĀõĖ¬ķā©Õłå’╝Ü
+
+- [ķģŹńĮ«µ¢ćõ╗ČĶ┐üń¦╗](./config_migration.md)
+- [API ÕÆī Registry Ķ┐üń¦╗](./api_and_registry_migration.md)
+- [µĢ░µŹ«ķøåĶ┐üń¦╗](./dataset_migration.md)
+- [µ©ĪÕ×ŗĶ┐üń¦╗](./model_migration.md)
+- [ÕĖĖĶ¦üķŚ«ķóś](./migration_faq.md)
+
+Õ”éµ×£µé©Õ£©Ķ┐üń¦╗Ķ┐ćń©ŗõĖŁķüćÕł░õ╗╗õĮĢķŚ«ķóś’╝īµ¼óĶ┐ÄÕ£© issue õĖŁµÅÉÕć║ŃĆ鵳æõ╗¼õ╣¤µ¼óĶ┐ĵé©õĖ║µ£¼µ¢ćµĪŻÕüÜÕć║Ķ┤Īńī«ŃĆé
diff --git a/internlm_langchain/knowledge_base/MMDetection/content/migration_faq.md b/internlm_langchain/knowledge_base/MMDetection/content/migration_faq.md
new file mode 100644
index 00000000..208a138b
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection/content/migration_faq.md
@@ -0,0 +1 @@
+# Ķ┐üń¦╗ FAQ
diff --git a/internlm_langchain/knowledge_base/MMDetection/content/model_migration.md b/internlm_langchain/knowledge_base/MMDetection/content/model_migration.md
new file mode 100644
index 00000000..d7992440
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection/content/model_migration.md
@@ -0,0 +1 @@
+# Õ░嵩ĪÕ×ŗõ╗Ä MMDetection 2.x Ķ┐üń¦╗Ķć│ 3.x
diff --git a/internlm_langchain/knowledge_base/MMDetection/content/model_zoo.md b/internlm_langchain/knowledge_base/MMDetection/content/model_zoo.md
new file mode 100644
index 00000000..b5376152
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection/content/model_zoo.md
@@ -0,0 +1,333 @@
+# µ©ĪÕ×ŗÕ║ō
+
+## ķĢ£ÕāÅÕ£░ÕØĆ
+
+õ╗Ä MMDetection V2.0 ĶĄĘ’╝īµłæõ╗¼ÕŬķĆÜĶ┐ćķś┐ķćīõ║æń╗┤µŖżµ©ĪÕ×ŗÕ║ōŃĆéV1.x ńēłµ£¼ńÜ䵩ĪÕ×ŗÕĘ▓ń╗ÅÕ╝āńö©ŃĆé
+
+## Õģ▒ÕÉīĶ«ŠńĮ«
+
+- µēƵ£ēµ©ĪÕ×ŗķāĮµś»Õ£© `coco_2017_train` õĖŖĶ«Łń╗ā’╝īÕ£© `coco_2017_val` õĖŖµĄŗĶ»ĢŃĆé
+- µłæõ╗¼õĮ┐ńö©ÕłåÕĖāÕ╝ÅĶ«Łń╗āŃĆé
+- µēƵ£ē pytorch-style ńÜä ImageNet ķóäĶ«Łń╗āõĖ╗Õ╣▓ńĮæń╗£µØźĶć¬ PyTorch ńÜ䵩ĪÕ×ŗÕ║ō’╝īcaffe-style ńÜäķóäĶ«Łń╗āõĖ╗Õ╣▓ńĮæń╗£µØźĶć¬ detectron2 µ£Ćµ¢░Õ╝Ƶ║ÉńÜ䵩ĪÕ×ŗŃĆé
+- õĖ║õ║åõĖÄÕģČõ╗¢õ╗ŻńĀüÕ║ōÕģ¼Õ╣│µ»öĶŠā’╝īµ¢ćµĪŻõĖŁµēĆÕåÖńÜä GPU ÕåģÕŁśµś»8õĖ¬ GPU ńÜä `torch.cuda.max_memory_allocated()` ńÜäµ£ĆÕż¦ÕĆ╝’╝īµŁżÕĆ╝ķĆÜÕĖĖÕ░Åõ║Ä nvidia-smi µśŠńż║ńÜäÕĆ╝ŃĆé
+- µłæõ╗¼õ╗źńĮæń╗£ forward ÕÆīÕÉÄÕżäńÉåńÜ䵌ČķŚ┤ÕŖĀÕÆīõĮ£õĖ║µÄ©ńÉåµŚČķŚ┤’╝īõĖŹÕīģÕɽµĢ░µŹ«ÕŖĀĶĮĮµŚČķŚ┤ŃĆéµēƵ£ēń╗ōµ×£ķĆÜĶ┐ć [benchmark.py](https://github.com/open-mmlab/mmdetection/blob/main/tools/analysis_tools/benchmark.py) Ķäܵ£¼Ķ«Īń«ŚµēĆÕŠŚŃĆéĶ»źĶäܵ£¼õ╝ÜĶ«Īń«ŚµÄ©ńÉå 2000 Õ╝ĀÕøŠÕāÅńÜäÕ╣│ÕØ浌ČķŚ┤ŃĆé
+
+## ImageNet ķóäĶ«Łń╗āµ©ĪÕ×ŗ
+
+ķĆÜĶ┐ć ImageNet Õłåń▒╗õ╗╗ÕŖĪķóäĶ«Łń╗āńÜäõĖ╗Õ╣▓ńĮæń╗£Ķ┐øĶĪīÕłØÕ¦ŗÕī¢µś»ÕŠłÕĖĖĶ¦üńÜäµōŹõĮ£ŃĆéµēƵ£ēķóäĶ«Łń╗āµ©ĪÕ×ŗńÜäķōŠµÄźķāĮÕÅ»õ╗źÕ£© [open_mmlab](https://github.com/open-mmlab/mmcv/blob/master/mmcv/model_zoo/open_mmlab.json) õĖŁµēŠÕł░ŃĆéµĀ╣µŹ« `img_norm_cfg` ÕÆīÕĤզŗµØāķ插╝īµłæõ╗¼ÕÅ»õ╗źÕ░åµēƵ£ē ImageNet ķóäĶ«Łń╗āµ©ĪÕ×ŗÕłåõĖ║õ╗źõĖŗÕćĀń¦ŹµāģÕåĄ’╝Ü
+
+- TorchVision’╝Ütorchvision µ©ĪÕ×ŗµØāķ插╝īÕīģÕɽ ResNet50, ResNet101ŃĆé`img_norm_cfg` õĖ║ `dict(mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)`ŃĆé
+- Pycls’╝Ü[pycls](https://github.com/facebookresearch/pycls) µ©ĪÕ×ŗµØāķ插╝īÕīģÕɽ RegNetXŃĆé`img_norm_cfg` õĖ║ `dict( mean=[103.530, 116.280, 123.675], std=[57.375, 57.12, 58.395], to_rgb=False)`ŃĆé
+- MSRA styles’╝Ü[MSRA](https://github.com/KaimingHe/deep-residual-networks) µ©ĪÕ×ŗµØāķ插╝īÕīģÕɽ ResNet50_Caffe’╝īResNet101_CaffeŃĆé`img_norm_cfg` õĖ║ `dict( mean=[103.530, 116.280, 123.675], std=[1.0, 1.0, 1.0], to_rgb=False)`ŃĆé
+- Caffe2 styles’╝ÜńÄ░ķśČµ«ĄÕŬÕīģÕɽ ResNext101_32x8dŃĆé`img_norm_cfg` õĖ║ `dict(mean=[103.530, 116.280, 123.675], std=[57.375, 57.120, 58.395], to_rgb=False)`ŃĆé
+- Other styles: SSD ńÜä `img_norm_cfg` õĖ║ `dict(mean=[123.675, 116.28, 103.53], std=[1, 1, 1], to_rgb=True)`’╝īYOLOv3 ńÜä `img_norm_cfg` õĖ║ `dict(mean=[0, 0, 0], std=[255., 255., 255.], to_rgb=True)`ŃĆé
+
+MMdetection ÕĖĖńö©Õł░ńÜäõĖ╗Õ╣▓ńĮæń╗£ń╗åĶŖéÕ”éõĖŗĶĪ©µēĆńż║’╝Ü
+
+| µ©ĪÕ×ŗ | µØźµ║É | ķōŠµÄź | µÅÅĶ┐░ |
+| ---------------- | ----------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| ResNet50 | TorchVision | [torchvision õĖŁńÜä ResNet-50](https://download.pytorch.org/models/resnet50-19c8e357.pth) | µØźĶć¬ [torchvision õĖŁńÜä ResNet-50](https://download.pytorch.org/models/resnet50-19c8e357.pth)ŃĆé |
+| ResNet101 | TorchVision | [torchvision õĖŁńÜä ResNet-101](https://download.pytorch.org/models/resnet101-5d3b4d8f.pth) | µØźĶć¬ [torchvision õĖŁńÜä ResNet-101](https://download.pytorch.org/models/resnet101-5d3b4d8f.pth)ŃĆé |
+| RegNetX | Pycls | [RegNetX_3.2gf](https://download.openmmlab.com/pretrain/third_party/regnetx_3.2gf-c2599b0f.pth)’╝ī[RegNetX_800mf](https://download.openmmlab.com/pretrain/third_party/regnetx_800mf-1f4be4c7.pth) ńŁē | µØźĶć¬ [pycls](https://github.com/facebookresearch/pycls)ŃĆé |
+| ResNet50_Caffe | MSRA | [MSRA õĖŁńÜä ResNet-50](https://download.openmmlab.com/pretrain/third_party/resnet50_caffe-788b5fa3.pth) | ńö▒ [Detectron2 õĖŁńÜä R-50.pkl](https://dl.fbaipublicfiles.com/detectron2/ImageNetPretrained/MSRA/R-50.pkl) ĶĮ¼Õī¢ńÜäÕē»µ£¼ŃĆéÕĤզŗµØāķ揵¢ćõ╗ČµØźĶć¬ [MSRA õĖŁńÜäÕĤզŗ ResNet-50](https://github.com/KaimingHe/deep-residual-networks)ŃĆé |
+| ResNet101_Caffe | MSRA | [MSRA õĖŁńÜä ResNet-101](https://download.openmmlab.com/pretrain/third_party/resnet101_caffe-3ad79236.pth) | ńö▒ [Detectron2 õĖŁńÜä R-101.pkl](https://dl.fbaipublicfiles.com/detectron2/ImageNetPretrained/MSRA/R-101.pkl) ĶĮ¼Õī¢ńÜäÕē»µ£¼ŃĆéÕĤզŗµØāķ揵¢ćõ╗ČµØźĶć¬ [MSRA õĖŁńÜäÕĤզŗ ResNet-101](https://github.com/KaimingHe/deep-residual-networks)ŃĆé |
+| ResNext101_32x8d | Caffe2 | [Caffe2 ResNext101_32x8d](https://download.openmmlab.com/pretrain/third_party/resnext101_32x8d-1516f1aa.pth) | ńö▒ [Detectron2 õĖŁńÜä X-101-32x8d.pkl](https://dl.fbaipublicfiles.com/detectron2/ImageNetPretrained/FAIR/X-101-32x8d.pkl) ĶĮ¼Õī¢ńÜäÕē»µ£¼ŃĆéÕĤզŗ ResNeXt-101-32x8d ńö▒ FB õĮ┐ńö© Caffe2 Ķ«Łń╗āŃĆé |
+
+## Baselines
+
+### RPN
+
+Ķ»ĘÕÅéĶĆā [RPN](https://github.com/open-mmlab/mmdetection/blob/main/configs/rpn)ŃĆé
+
+### Faster R-CNN
+
+Ķ»ĘÕÅéĶĆā [Faster R-CNN](https://github.com/open-mmlab/mmdetection/blob/main/configs/faster_rcnn)ŃĆé
+
+### Mask R-CNN
+
+Ķ»ĘÕÅéĶĆā [Mask R-CNN](https://github.com/open-mmlab/mmdetection/blob/main/configs/mask_rcnn)ŃĆé
+
+### Fast R-CNN (õĮ┐ńö©µÅÉÕēŹĶ«Īń«ŚńÜä proposals)
+
+Ķ»ĘÕÅéĶĆā [Fast R-CNN](https://github.com/open-mmlab/mmdetection/blob/main/configs/fast_rcnn)ŃĆé
+
+### RetinaNet
+
+Ķ»ĘÕÅéĶĆā [RetinaNet](https://github.com/open-mmlab/mmdetection/blob/main/configs/retinanet)ŃĆé
+
+### Cascade R-CNN and Cascade Mask R-CNN
+
+Ķ»ĘÕÅéĶĆā [Cascade R-CNN](https://github.com/open-mmlab/mmdetection/blob/main/configs/cascade_rcnn)ŃĆé
+
+### Hybrid Task Cascade (HTC)
+
+Ķ»ĘÕÅéĶĆā [HTC](https://github.com/open-mmlab/mmdetection/blob/main/configs/htc)ŃĆé
+
+### SSD
+
+Ķ»ĘÕÅéĶĆā [SSD](https://github.com/open-mmlab/mmdetection/blob/main/configs/ssd)ŃĆé
+
+### Group Normalization (GN)
+
+Ķ»ĘÕÅéĶĆā [Group Normalization](https://github.com/open-mmlab/mmdetection/blob/main/configs/gn)ŃĆé
+
+### Weight Standardization
+
+Ķ»ĘÕÅéĶĆā [Weight Standardization](https://github.com/open-mmlab/mmdetection/blob/main/configs/gn+ws)ŃĆé
+
+### Deformable Convolution v2
+
+Ķ»ĘÕÅéĶĆā [Deformable Convolutional Networks](https://github.com/open-mmlab/mmdetection/blob/main/configs/dcn)ŃĆé
+
+### CARAFE: Content-Aware ReAssembly of FEatures
+
+Ķ»ĘÕÅéĶĆā [CARAFE](https://github.com/open-mmlab/mmdetection/blob/main/configs/carafe)ŃĆé
+
+### Instaboost
+
+Ķ»ĘÕÅéĶĆā [Instaboost](https://github.com/open-mmlab/mmdetection/blob/main/configs/instaboost)ŃĆé
+
+### Libra R-CNN
+
+Ķ»ĘÕÅéĶĆā [Libra R-CNN](https://github.com/open-mmlab/mmdetection/blob/main/configs/libra_rcnn)ŃĆé
+
+### Guided Anchoring
+
+Ķ»ĘÕÅéĶĆā [Guided Anchoring](https://github.com/open-mmlab/mmdetection/blob/main/configs/guided_anchoring)ŃĆé
+
+### FCOS
+
+Ķ»ĘÕÅéĶĆā [FCOS](https://github.com/open-mmlab/mmdetection/blob/main/configs/fcos)ŃĆé
+
+### FoveaBox
+
+Ķ»ĘÕÅéĶĆā [FoveaBox](https://github.com/open-mmlab/mmdetection/blob/main/configs/foveabox)ŃĆé
+
+### RepPoints
+
+Ķ»ĘÕÅéĶĆā [RepPoints](https://github.com/open-mmlab/mmdetection/blob/main/configs/reppoints)ŃĆé
+
+### FreeAnchor
+
+Ķ»ĘÕÅéĶĆā [FreeAnchor](https://github.com/open-mmlab/mmdetection/blob/main/configs/free_anchor)ŃĆé
+
+### Grid R-CNN (plus)
+
+Ķ»ĘÕÅéĶĆā [Grid R-CNN](https://github.com/open-mmlab/mmdetection/blob/main/configs/grid_rcnn)ŃĆé
+
+### GHM
+
+Ķ»ĘÕÅéĶĆā [GHM](https://github.com/open-mmlab/mmdetection/blob/main/configs/ghm)ŃĆé
+
+### GCNet
+
+Ķ»ĘÕÅéĶĆā [GCNet](https://github.com/open-mmlab/mmdetection/blob/main/configs/gcnet)ŃĆé
+
+### HRNet
+
+Ķ»ĘÕÅéĶĆā [HRNet](https://github.com/open-mmlab/mmdetection/blob/main/configs/hrnet)ŃĆé
+
+### Mask Scoring R-CNN
+
+Ķ»ĘÕÅéĶĆā [Mask Scoring R-CNN](https://github.com/open-mmlab/mmdetection/blob/main/configs/ms_rcnn)ŃĆé
+
+### Train from Scratch
+
+Ķ»ĘÕÅéĶĆā [Rethinking ImageNet Pre-training](https://github.com/open-mmlab/mmdetection/blob/main/configs/scratch)ŃĆé
+
+### NAS-FPN
+
+Ķ»ĘÕÅéĶĆā [NAS-FPN](https://github.com/open-mmlab/mmdetection/blob/main/configs/nas_fpn)ŃĆé
+
+### ATSS
+
+Ķ»ĘÕÅéĶĆā [ATSS](https://github.com/open-mmlab/mmdetection/blob/main/configs/atss)ŃĆé
+
+### FSAF
+
+Ķ»ĘÕÅéĶĆā [FSAF](https://github.com/open-mmlab/mmdetection/blob/main/configs/fsaf)ŃĆé
+
+### RegNetX
+
+Ķ»ĘÕÅéĶĆā [RegNet](https://github.com/open-mmlab/mmdetection/blob/main/configs/regnet)ŃĆé
+
+### Res2Net
+
+Ķ»ĘÕÅéĶĆā [Res2Net](https://github.com/open-mmlab/mmdetection/blob/main/configs/res2net)ŃĆé
+
+### GRoIE
+
+Ķ»ĘÕÅéĶĆā [GRoIE](https://github.com/open-mmlab/mmdetection/blob/main/configs/groie)ŃĆé
+
+### Dynamic R-CNN
+
+Ķ»ĘÕÅéĶĆā [Dynamic R-CNN](https://github.com/open-mmlab/mmdetection/blob/main/configs/dynamic_rcnn)ŃĆé
+
+### PointRend
+
+Ķ»ĘÕÅéĶĆā [PointRend](https://github.com/open-mmlab/mmdetection/blob/main/configs/point_rend)ŃĆé
+
+### DetectoRS
+
+Ķ»ĘÕÅéĶĆā [DetectoRS](https://github.com/open-mmlab/mmdetection/blob/main/configs/detectors)ŃĆé
+
+### Generalized Focal Loss
+
+Ķ»ĘÕÅéĶĆā [Generalized Focal Loss](https://github.com/open-mmlab/mmdetection/blob/main/configs/gfl)ŃĆé
+
+### CornerNet
+
+Ķ»ĘÕÅéĶĆā [CornerNet](https://github.com/open-mmlab/mmdetection/blob/main/configs/cornernet)ŃĆé
+
+### YOLOv3
+
+Ķ»ĘÕÅéĶĆā [YOLOv3](https://github.com/open-mmlab/mmdetection/blob/main/configs/yolo)ŃĆé
+
+### PAA
+
+Ķ»ĘÕÅéĶĆā [PAA](https://github.com/open-mmlab/mmdetection/blob/main/configs/paa)ŃĆé
+
+### SABL
+
+Ķ»ĘÕÅéĶĆā [SABL](https://github.com/open-mmlab/mmdetection/blob/main/configs/sabl)ŃĆé
+
+### CentripetalNet
+
+Ķ»ĘÕÅéĶĆā [CentripetalNet](https://github.com/open-mmlab/mmdetection/blob/main/configs/centripetalnet)ŃĆé
+
+### ResNeSt
+
+Ķ»ĘÕÅéĶĆā [ResNeSt](https://github.com/open-mmlab/mmdetection/blob/main/configs/resnest)ŃĆé
+
+### DETR
+
+Ķ»ĘÕÅéĶĆā [DETR](https://github.com/open-mmlab/mmdetection/blob/main/configs/detr)ŃĆé
+
+### Deformable DETR
+
+Ķ»ĘÕÅéĶĆā [Deformable DETR](https://github.com/open-mmlab/mmdetection/blob/main/configs/deformable_detr)ŃĆé
+
+### AutoAssign
+
+Ķ»ĘÕÅéĶĆā [AutoAssign](https://github.com/open-mmlab/mmdetection/blob/main/configs/autoassign)ŃĆé
+
+### YOLOF
+
+Ķ»ĘÕÅéĶĆā [YOLOF](https://github.com/open-mmlab/mmdetection/blob/main/configs/yolof)ŃĆé
+
+### Seesaw Loss
+
+Ķ»ĘÕÅéĶĆā [Seesaw Loss](https://github.com/open-mmlab/mmdetection/blob/main/configs/seesaw_loss)ŃĆé
+
+### CenterNet
+
+Ķ»ĘÕÅéĶĆā [CenterNet](https://github.com/open-mmlab/mmdetection/blob/main/configs/centernet)ŃĆé
+
+### YOLOX
+
+Ķ»ĘÕÅéĶĆā [YOLOX](https://github.com/open-mmlab/mmdetection/blob/main/configs/yolox)ŃĆé
+
+### PVT
+
+Ķ»ĘÕÅéĶĆā [PVT](https://github.com/open-mmlab/mmdetection/blob/main/configs/pvt)ŃĆé
+
+### SOLO
+
+Ķ»ĘÕÅéĶĆā [SOLO](https://github.com/open-mmlab/mmdetection/blob/main/configs/solo)ŃĆé
+
+### QueryInst
+
+Ķ»ĘÕÅéĶĆā [QueryInst](https://github.com/open-mmlab/mmdetection/blob/main/configs/queryinst)ŃĆé
+
+### Other datasets
+
+µłæõ╗¼Ķ┐śÕ£© [PASCAL VOC](https://github.com/open-mmlab/mmdetection/blob/main/configs/pascal_voc)’╝ī[Cityscapes](https://github.com/open-mmlab/mmdetection/blob/main/configs/cityscapes) ÕÆī [WIDER FACE](https://github.com/open-mmlab/mmdetection/blob/main/configs/wider_face) õĖŖÕ»╣õĖĆõ║øµ¢╣µ│ĢĶ┐øĶĪīõ║åÕ¤║ÕćåµĄŗĶ»ĢŃĆé
+
+### Pre-trained Models
+
+µłæõ╗¼Ķ┐śķĆÜĶ┐ćÕżÜÕ░║Õ║”Ķ«Łń╗āÕÆīµø┤ķĢ┐ńÜäĶ«Łń╗āńŁ¢ńĢźµØźĶ«Łń╗āńö© ResNet-50 ÕÆī [RegNetX-3.2G](https://github.com/open-mmlab/mmdetection/blob/main/configs/regnet) õĮ£õĖ║õĖ╗Õ╣▓ńĮæń╗£ńÜä [Faster R-CNN](https://github.com/open-mmlab/mmdetection/blob/main/configs/faster_rcnn) ÕÆī [Mask R-CNN](https://github.com/open-mmlab/mmdetection/blob/main/configs/mask_rcnn)ŃĆéĶ┐Öõ║øµ©ĪÕ×ŗÕÅ»õ╗źõĮ£õĖ║õĖŗµĖĖõ╗╗ÕŖĪńÜäķóäĶ«Łń╗āµ©ĪÕ×ŗŃĆé
+
+## ķƤÕ║”Õ¤║Õćå
+
+### Ķ«Łń╗āķƤÕ║”Õ¤║Õćå
+
+µłæõ╗¼µÅÉõŠø [analyze_logs.py](https://github.com/open-mmlab/mmdetection/blob/main/tools/analysis_tools/analyze_logs.py) µØźÕŠŚÕł░Ķ«Łń╗āõĖŁµ»ÅõĖƵ¼ĪĶ┐Łõ╗ŻńÜäÕ╣│ÕØ浌ČķŚ┤ŃĆéńż║õŠŗĶ»ĘÕÅéĶĆā [Log Analysis](https://mmdetection.readthedocs.io/en/latest/useful_tools.html#log-analysis)ŃĆé
+
+µłæõ╗¼õĖÄÕģČõ╗¢µĄüĶĪīµĪåµ×ČńÜä Mask R-CNN Ķ«Łń╗āķƤÕ║”Ķ┐øĶĪīµ»öĶŠā’╝łµĢ░µŹ«µś»õ╗Ä [detectron2](https://github.com/facebookresearch/detectron2/blob/main/docs/notes/benchmarks.md/) ÕżŹÕłČĶĆīµØź’╝ēŃĆéÕ£© mmdetection õĖŁ’╝īµłæõ╗¼õĮ┐ńö© [mask-rcnn_r50-caffe_fpn_poly-1x_coco_v1.py](https://github.com/open-mmlab/mmdetection/blob/main/configs/mask_rcnn/mask-rcnn_r50-caffe_fpn_poly-1x_coco_v1.py) Ķ┐øĶĪīÕ¤║ÕćåµĄŗĶ»ĢŃĆéÕ«āõĖÄ detectron2 ńÜä [mask_rcnn_R_50_FPN_noaug_1x.yaml](https://github.com/facebookresearch/detectron2/blob/main/configs/Detectron1-Comparisons/mask_rcnn_R_50_FPN_noaug_1x.yaml) Ķ«ŠńĮ«Õ«īÕģ©õĖƵĀĘŃĆéÕÉīµŚČ’╝īµłæõ╗¼Ķ┐śµÅÉõŠøõ║å[µ©ĪÕ×ŗµØāķćŹ](https://download.openmmlab.com/mmdetection/v2.0/benchmark/mask_rcnn_r50_caffe_fpn_poly_1x_coco_no_aug/mask_rcnn_r50_caffe_fpn_poly_1x_coco_no_aug_compare_20200518-10127928.pth)ÕÆī[Ķ«Łń╗ā log](https://download.openmmlab.com/mmdetection/v2.0/benchmark/mask_rcnn_r50_caffe_fpn_poly_1x_coco_no_aug/mask_rcnn_r50_caffe_fpn_poly_1x_coco_no_aug_20200518_105755.log.json) õĮ£õĖ║ÕÅéĶĆāŃĆéõĖ║õ║åĶĘ│Ķ┐ć GPU ķóäńāŁµŚČķŚ┤’╝īÕÉ×ÕÉÉķćŵīēńģ¦100-500µ¼ĪĶ┐Łõ╗Żõ╣ŗķŚ┤ńÜäÕ╣│ÕØćÕÉ×ÕÉÉķćÅµØźĶ«Īń«ŚŃĆé
+
+| µĪåµ×Č | ÕÉ×ÕÉÉķćÅ (img/s) |
+| -------------------------------------------------------------------------------------- | -------------- |
+| [Detectron2](https://github.com/facebookresearch/detectron2) | 62 |
+| [MMDetection](https://github.com/open-mmlab/mmdetection) | 61 |
+| [maskrcnn-benchmark](https://github.com/facebookresearch/maskrcnn-benchmark/) | 53 |
+| [tensorpack](https://github.com/tensorpack/tensorpack/tree/master/examples/FasterRCNN) | 50 |
+| [simpledet](https://github.com/TuSimple/simpledet/) | 39 |
+| [Detectron](https://github.com/facebookresearch/Detectron) | 19 |
+| [matterport/Mask_RCNN](https://github.com/matterport/Mask_RCNN/) | 14 |
+
+### µÄ©ńÉåµŚČķŚ┤Õ¤║Õćå
+
+µłæõ╗¼µÅÉõŠø [benchmark.py](https://github.com/open-mmlab/mmdetection/blob/main/tools/analysis_tools/benchmark.py) Õ»╣µÄ©ńÉåµŚČķŚ┤Ķ┐øĶĪīÕ¤║ÕćåµĄŗĶ»ĢŃĆ鵣żĶäܵ£¼Õ░åµÄ©ńÉå 2000 Õ╝ĀÕøŠńēćÕ╣ČĶ«Īń«ŚÕ┐ĮńĢźÕēŹ 5 µ¼ĪµÄ©ńÉåńÜäÕ╣│ÕØćµÄ©ńÉåµŚČķŚ┤ŃĆéÕÅ»õ╗źķĆÜĶ┐ćĶ«ŠńĮ« `LOG-INTERVAL` µØźµö╣ÕÅś log ĶŠōÕć║ķŚ┤ķÜö’╝łķ╗śĶ«żõĖ║ 50’╝ēŃĆé
+
+```shell
+python tools/benchmark.py ${CONFIG} ${CHECKPOINT} [--log-interval $[LOG-INTERVAL]] [--fuse-conv-bn]
+```
+
+µ©ĪÕ×ŗÕ║ōõĖŁ’╝īµēƵ£ēµ©ĪÕ×ŗÕ£©Õ¤║ÕćåµĄŗķćŵĩńÉåµŚČķŚ┤µŚČķāĮµ▓ĪĶ«ŠńĮ« `fuse-conv-bn`, µŁżĶ«ŠńĮ«ÕÅ»õ╗źõĮ┐µÄ©ńÉåµŚČķŚ┤µø┤ń¤ŁŃĆé
+
+## õĖÄ Detectron2 Õ»╣µ»ö
+
+µłæõ╗¼Õ£©ķƤÕ║”ÕÆīń▓ŠÕ║”µ¢╣ķØóÕ»╣ mmdetection ÕÆī [Detectron2](https://github.com/facebookresearch/detectron2.git) Ķ┐øĶĪīÕ»╣µ»öŃĆéÕ»╣µ»öµēĆõĮ┐ńö©ńÜä detectron2 ńÜä commit id õĖ║ [185c27e](https://github.com/facebookresearch/detectron2/tree/185c27e4b4d2d4c68b5627b3765420c6d7f5a659)(30/4/2020)ŃĆé
+õĖ║õ║åÕģ¼Õ╣│Õ»╣µ»ö’╝īµłæõ╗¼µēƵ£ēńÜäÕ«×ķ¬īķāĮÕ£©ÕÉīõĖƵ£║ÕÖ©õĖŗĶ┐øĶĪīŃĆé
+
+### ńĪ¼õ╗Č
+
+- 8 NVIDIA Tesla V100 (32G) GPUs
+- Intel(R) Xeon(R) Gold 6148 CPU @ 2.40GHz
+
+### ĶĮ»õ╗ČńÄ»Õóā
+
+- Python 3.7
+- PyTorch 1.4
+- CUDA 10.1
+- CUDNN 7.6.03
+- NCCL 2.4.08
+
+### ń▓ŠÕ║”
+
+| µ©ĪÕ×ŗ | Ķ«Łń╗āńŁ¢ńĢź | Detectron2 | mmdetection | õĖŗĶĮĮ |
+| ------------------------------------------------------------------------------------------------------------------------------- | -------- | -------------------------------------------------------------------------------------------------------------------------------------- | ----------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| [Faster R-CNN](https://github.com/open-mmlab/mmdetection/blob/main/configs/faster_rcnn/faster-rcnn_r50-caffe_fpn_ms-1x_coco.py) | 1x | [37.9](https://github.com/facebookresearch/detectron2/blob/main/configs/COCO-Detection/faster_rcnn_R_50_FPN_1x.yaml) | 38.0 | [model](https://download.openmmlab.com/mmdetection/v2.0/benchmark/faster_rcnn_r50_caffe_fpn_mstrain_1x_coco/faster_rcnn_r50_caffe_fpn_mstrain_1x_coco-5324cff8.pth) \| [log](https://download.openmmlab.com/mmdetection/v2.0/benchmark/faster_rcnn_r50_caffe_fpn_mstrain_1x_coco/faster_rcnn_r50_caffe_fpn_mstrain_1x_coco_20200429_234554.log.json) |
+| [Mask R-CNN](https://github.com/open-mmlab/mmdetection/blob/main/configs/mask_rcnn/mask-rcnn_r50-caffe_fpn_ms-poly-1x_coco.py) | 1x | [38.6 & 35.2](https://github.com/facebookresearch/detectron2/blob/master/configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_1x.yaml) | 38.8 & 35.4 | [model](https://download.openmmlab.com/mmdetection/v2.0/benchmark/mask_rcnn_r50_caffe_fpn_mstrain-poly_1x_coco/mask_rcnn_r50_caffe_fpn_mstrain-poly_1x_coco-dbecf295.pth) \| [log](https://download.openmmlab.com/mmdetection/v2.0/benchmark/mask_rcnn_r50_caffe_fpn_mstrain-poly_1x_coco/mask_rcnn_r50_caffe_fpn_mstrain-poly_1x_coco_20200430_054239.log.json) |
+| [Retinanet](https://github.com/open-mmlab/mmdetection/blob/main/configs/retinanet/retinanet_r50-caffe_fpn_ms-1x_coco.py) | 1x | [36.5](https://github.com/facebookresearch/detectron2/blob/master/configs/COCO-Detection/retinanet_R_50_FPN_1x.yaml) | 37.0 | [model](https://download.openmmlab.com/mmdetection/v2.0/benchmark/retinanet_r50_caffe_fpn_mstrain_1x_coco/retinanet_r50_caffe_fpn_mstrain_1x_coco-586977a0.pth) \| [log](https://download.openmmlab.com/mmdetection/v2.0/benchmark/retinanet_r50_caffe_fpn_mstrain_1x_coco/retinanet_r50_caffe_fpn_mstrain_1x_coco_20200430_014748.log.json) |
+
+### Ķ«Łń╗āķƤÕ║”
+
+Ķ«Łń╗āķƤÕ║”õĮ┐ńö© s/iter µØźÕ║”ķćÅŃĆéń╗ōµ×£ĶČŖõĮÄĶČŖÕźĮŃĆé
+
+| µ©ĪÕ×ŗ | Detectron2 | mmdetection |
+| ------------ | ---------- | ----------- |
+| Faster R-CNN | 0.210 | 0.216 |
+| Mask R-CNN | 0.261 | 0.265 |
+| Retinanet | 0.200 | 0.205 |
+
+### µÄ©ńÉåķƤÕ║”
+
+µÄ©ńÉåķƤÕ║”ķĆÜĶ┐ćÕŹĢÕ╝Ā GPU õĖŗńÜä fps(img/s) µØźÕ║”ķćÅ’╝īĶČŖķ½śĶČŖÕźĮŃĆé
+õĖ║õ║åõĖÄ Detectron2 õ┐صīüõĖĆĶć┤’╝īµłæõ╗¼µēĆÕåÖńÜäµÄ©ńÉåµŚČķŚ┤ķÖżÕÄ╗õ║åµĢ░µŹ«ÕŖĀĶĮĮµŚČķŚ┤ŃĆé
+Õ»╣õ║Ä Mask RCNN’╝īµłæõ╗¼ÕÄ╗ķÖżõ║åÕÉÄÕżäńÉåõĖŁ RLE ń╝¢ńĀüńÜ䵌ČķŚ┤ŃĆé
+µłæõ╗¼Õ£©µŗ¼ÕÅĘõĖŁń╗ÖÕć║õ║åÕ«śµ¢╣ń╗ÖÕć║ńÜäķƤÕ║”ŃĆéńö▒õ║ÄńĪ¼õ╗ČÕĘ«Õ╝é’╝īÕ«śµ¢╣ń╗ÖÕć║ńÜäķƤÕ║”õ╝ܵ»öµłæõ╗¼µēƵĄŗĶ»ĢÕŠŚÕł░ńÜäķƤÕ║”Õ┐½õĖĆõ║øŃĆé
+
+| µ©ĪÕ×ŗ | Detectron2 | mmdetection |
+| ------------ | ----------- | ----------- |
+| Faster R-CNN | 25.6 (26.3) | 22.2 |
+| Mask R-CNN | 22.5 (23.3) | 19.6 |
+| Retinanet | 17.8 (18.2) | 20.6 |
+
+### Ķ«Łń╗āÕåģÕŁś
+
+| µ©ĪÕ×ŗ | Detectron2 | mmdetection |
+| ------------ | ---------- | ----------- |
+| Faster R-CNN | 3.0 | 3.8 |
+| Mask R-CNN | 3.4 | 3.9 |
+| Retinanet | 3.9 | 3.4 |
diff --git a/internlm_langchain/knowledge_base/MMDetection/content/models.md b/internlm_langchain/knowledge_base/MMDetection/content/models.md
new file mode 100644
index 00000000..c5119d06
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection/content/models.md
@@ -0,0 +1 @@
+# µ©ĪÕ×ŗ’╝łÕŠģµø┤µ¢░’╝ē
diff --git a/internlm_langchain/knowledge_base/MMDetection/content/new_model.md b/internlm_langchain/knowledge_base/MMDetection/content/new_model.md
new file mode 100644
index 00000000..424c4f90
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection/content/new_model.md
@@ -0,0 +1,289 @@
+# Õ£©µĀćÕćåµĢ░µŹ«ķøåõĖŖĶ«Łń╗āĶć¬Õ«Üõ╣ēµ©ĪÕ×ŗ’╝łÕŠģµø┤µ¢░’╝ē
+
+Õ£©µ£¼µ¢ćõĖŁ’╝īõĮĀÕ░åń¤źķüōÕ”éõĮĢÕ£©µĀćÕćåµĢ░µŹ«ķøåõĖŖĶ«Łń╗āŃĆüµĄŗĶ»ĢÕÆīµÄ©ńÉåĶć¬Õ«Üõ╣ēµ©ĪÕ×ŗŃĆ鵳æõ╗¼Õ░åÕ£© cityscapes µĢ░µŹ«ķøåõĖŖõ╗źĶć¬Õ«Üõ╣ē Cascade Mask R-CNN R50 µ©ĪÕ×ŗõĖ║õŠŗµ╝öńż║µĢ┤õĖ¬Ķ┐ćń©ŗ’╝īõĖ║õ║åµ¢╣õŠ┐Ķ»┤µśÄ’╝īµłæõ╗¼Õ░å neck µ©ĪÕØŚõĖŁńÜä `FPN` µø┐µŹóõĖ║ `AugFPN`’╝īÕ╣ČõĖöÕ£©Ķ«Łń╗āõĖŁńÜäĶć¬ÕŖ©Õó×Õ╝║ń▒╗õĖŁÕó×ÕŖĀ `Rotate` µł¢ `TranslateX`ŃĆé
+
+Õ¤║µ£¼µŁźķ¬żÕ”éõĖŗµēĆńż║’╝Ü
+
+1. ÕćåÕżćµĀćÕćåµĢ░µŹ«ķøå
+2. ÕćåÕżćõĮĀńÜäĶć¬Õ«Üõ╣ēµ©ĪÕ×ŗ
+3. ÕćåÕżćķģŹńĮ«µ¢ćõ╗Č
+4. Õ£©µĀćÕćåµĢ░µŹ«ķøåõĖŖÕ»╣µ©ĪÕ×ŗĶ┐øĶĪīĶ«Łń╗āŃĆüµĄŗĶ»ĢÕÆīµÄ©ńÉå
+
+## ÕćåÕżćµĀćÕćåµĢ░µŹ«ķøå
+
+Õ£©µ£¼µ¢ćõĖŁ’╝īµłæõ╗¼õĮ┐ńö© cityscapes µĀćÕćåµĢ░µŹ«ķøåõĖ║õŠŗĶ┐øĶĪīĶ»┤µśÄŃĆé
+
+µÄ©ĶŹÉÕ░åµĢ░µŹ«ķøåµĀ╣ĶĘ»ÕŠäķććńö©ń¼”ÕÅĘķōŠµÄźµ¢╣Õ╝ÅķōŠµÄźÕł░ `$MMDETECTION/data`ŃĆé
+
+Õ”éµ×£õĮĀńÜäµ¢ćõ╗Čń╗ōµ×äõĖŹÕÉī’╝īõĮĀÕÅ»ĶāĮķ£ĆĶ”üÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁĶ┐øĶĪīńøĖÕ║öńÜäĶĘ»ÕŠäµø┤µö╣ŃĆéµĀćÕćåńÜäµ¢ćõ╗Čń╗äń╗ćµĀ╝Õ╝ÅÕ”éõĖŗµēĆńż║’╝Ü
+
+```none
+mmdetection
+Ōö£ŌöĆŌöĆ mmdet
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+Ōö£ŌöĆŌöĆ data
+Ōöé Ōö£ŌöĆŌöĆ coco
+Ōöé Ōöé Ōö£ŌöĆŌöĆ annotations
+Ōöé Ōöé Ōö£ŌöĆŌöĆ train2017
+Ōöé Ōöé Ōö£ŌöĆŌöĆ val2017
+Ōöé Ōöé Ōö£ŌöĆŌöĆ test2017
+Ōöé Ōö£ŌöĆŌöĆ cityscapes
+Ōöé Ōöé Ōö£ŌöĆŌöĆ annotations
+Ōöé Ōöé Ōö£ŌöĆŌöĆ leftImg8bit
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ train
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ val
+Ōöé Ōöé Ōö£ŌöĆŌöĆ gtFine
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ train
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ val
+Ōöé Ōö£ŌöĆŌöĆ VOCdevkit
+Ōöé Ōöé Ōö£ŌöĆŌöĆ VOC2007
+Ōöé Ōöé Ōö£ŌöĆŌöĆ VOC2012
+```
+
+õĮĀõ╣¤ÕÅ»õ╗źķĆÜĶ┐ćÕ”éõĖŗµ¢╣Õ╝ÅĶ«ŠÕ«ÜµĢ░µŹ«ķøåµĀ╣ĶĘ»ÕŠä
+
+```bash
+export MMDET_DATASETS=$data_root
+```
+
+µłæõ╗¼Õ░åõ╝ÜõĮ┐ńö©ńÄ»ÕóāõŠ┐ÕÅśķćÅ `$MMDET_DATASETS` õĮ£õĖ║µĢ░µŹ«ķøåńÜäµĀ╣ńø«ÕĮĢ’╝īÕøĀµŁżõĮĀµŚĀķ£ĆÕåŹõ┐«µö╣ńøĖÕ║öķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠäõ┐Īµü»ŃĆé
+
+õĮĀķ£ĆĶ”üõĮ┐ńö©Ķäܵ£¼ `tools/dataset_converters/cityscapes.py` Õ░å cityscapes µĀćµ│©ĶĮ¼Õī¢õĖ║ coco µĀćµ│©µĀ╝Õ╝ÅŃĆé
+
+```shell
+pip install cityscapesscripts
+python tools/dataset_converters/cityscapes.py ./data/cityscapes --nproc 8 --out-dir ./data/cityscapes/annotations
+```
+
+ńø«ÕēŹÕ£© `cityscapes `µ¢ćõ╗ČÕż╣õĖŁńÜäķģŹńĮ«µ¢ćõ╗ȵēĆÕ»╣Õ║öµ©ĪÕ×ŗµś»ķććńö© COCO ķóäĶ«Łń╗āµØāķćŹĶ┐øĶĪīÕłØÕ¦ŗÕī¢ńÜäŃĆé
+
+Õ”éµ×£õĮĀńÜäńĮæń╗£õĖŹÕÅ»ńö©µł¢ĶĆģµ»öĶŠāµģó’╝īÕ╗║Ķ««õĮĀÕģłµēŗÕŖ©õĖŗĶĮĮÕ»╣Õ║öńÜäķóäĶ«Łń╗āµØāķ插╝īÕÉ”ÕłÖÕÅ»ĶāĮÕ£©Ķ«Łń╗āÕ╝ĆÕ¦ŗµŚČÕĆÖÕć║ńÄ░ķöÖĶ»»ŃĆé
+
+## ÕćåÕżćõĮĀńÜäĶć¬Õ«Üõ╣ēµ©ĪÕ×ŗ
+
+ń¼¼õ║īµŁźµś»ÕćåÕżćõĮĀńÜäĶć¬Õ«Üõ╣ēµ©ĪÕ×ŗµł¢ĶĆģĶ«Łń╗āńøĖÕģ│ķģŹńĮ«ŃĆéÕüćĶ«ŠõĮĀµā│Õ£©ÕĘ▓µ£ēńÜä Cascade Mask R-CNN R50 µŻĆµĄŗµ©ĪÕ×ŗÕ¤║ńĪĆõĖŖ’╝īµ¢░Õó×õĖĆõĖ¬µ¢░ńÜä neck µ©ĪÕØŚ `AugFPN` ÕÄ╗õ╗Żµø┐ķ╗śĶ«żńÜä `FPN`’╝īõ╗źõĖŗµś»ÕģĘõĮōÕ«×ńÄ░’╝Ü
+
+### 1 Õ«Üõ╣ēµ¢░ńÜä neck (õŠŗÕ”é AugFPN)
+
+ķ”¢ÕģłÕłøÕ╗║µ¢░µ¢ćõ╗Č `mmdet/models/necks/augfpn.py`.
+
+```python
+import torch.nn as nn
+from mmdet.registry import MODELS
+
+@MODELS.register_module()
+class AugFPN(nn.Module):
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ num_outs,
+ start_level=0,
+ end_level=-1,
+ add_extra_convs=False):
+ pass
+
+ def forward(self, inputs):
+ # implementation is ignored
+ pass
+```
+
+### 2 Õ»╝Õģźµ©ĪÕØŚ
+
+õĮĀÕÅ»õ╗źķććńö©õĖżń¦Źµ¢╣Õ╝ÅÕ»╝Õģźµ©ĪÕØŚ’╝īń¼¼õĖĆń¦Źµś»Õ£© `mmdet/models/necks/__init__.py` õĖŁµĘ╗ÕŖĀÕ”éõĖŗÕåģÕ«╣
+
+```python
+from .augfpn import AugFPN
+```
+
+ń¼¼õ║īń¦Źµś»Õó×ÕŖĀÕ”éõĖŗõ╗ŻńĀüÕł░Õ»╣Õ║öķģŹńĮ«õĖŁ’╝īĶ┐Öń¦Źµ¢╣Õ╝ÅńÜäÕźĮÕżäµś»õĖŹķ£ĆĶ”üµö╣ÕŖ©õ╗ŻńĀü
+
+```python
+custom_imports = dict(
+ imports=['mmdet.models.necks.augfpn'],
+ allow_failed_imports=False)
+```
+
+### 3 õ┐«µö╣ķģŹńĮ«
+
+```python
+neck=dict(
+ type='AugFPN',
+ in_channels=[256, 512, 1024, 2048],
+ out_channels=256,
+ num_outs=5)
+```
+
+Õģ│õ║ÄĶć¬Õ«Üõ╣ēµ©ĪÕ×ŗÕģČõĮÖńøĖÕģ│ń╗åĶŖéõŠŗÕ”éÕ«×ńÄ░µ¢░ńÜäķ¬©µ×ČńĮæń╗£’╝īÕż┤ķā©ńĮæń╗£ŃĆüµŹ¤Õż▒ÕćĮµĢ░’╝īõ╗źÕÅŖĶ┐ÉĶĪīµŚČĶ«Łń╗āķģŹńĮ«õŠŗÕ”éÕ«Üõ╣ēµ¢░ńÜäõ╝śÕī¢ÕÖ©ŃĆüõĮ┐ńö©µó»Õ║”ĶŻüÕē¬ŃĆüÕ«ÜÕłČĶ«Łń╗āĶ░āÕ║”ńŁ¢ńĢźÕÆīķÆ®ÕŁÉńŁē’╝īĶ»ĘÕÅéĶĆāµ¢ćµĪŻ [Ķć¬Õ«Üõ╣ēµ©ĪÕ×ŗ](tutorials/customize_models.md) ÕÆī [Ķć¬Õ«Üõ╣ēĶ┐ÉĶĪīµŚČĶ«Łń╗āķģŹńĮ«](tutorials/customize_runtime.md)ŃĆé
+
+## ÕćåÕżćķģŹńĮ«µ¢ćõ╗Č
+
+ń¼¼õĖēµŁźµś»ÕćåÕżćĶ«Łń╗āķģŹńĮ«µēĆķ£ĆĶ”üńÜäķģŹńĮ«µ¢ćõ╗ČŃĆéÕüćĶ«ŠõĮĀµēōń«ŚÕ¤║õ║Ä cityscapes µĢ░µŹ«ķøå’╝īÕ£© Cascade Mask R-CNN R50 õĖŁµ¢░Õó× `AugFPN` µ©ĪÕØŚ’╝īÕÉīµŚČÕó×ÕŖĀ `Rotate` µł¢ĶĆģ `Translate` µĢ░µŹ«Õó×Õ╝║ńŁ¢ńĢź’╝īÕüćĶ«ŠõĮĀńÜäķģŹńĮ«µ¢ćõ╗ČõĮŹõ║Ä `configs/cityscapes/` ńø«ÕĮĢõĖŗ’╝īÕ╣ČõĖöÕÅ¢ÕÉŹõĖ║ `cascade-mask-rcnn_r50_augfpn_autoaug-10e_cityscapes.py`’╝īÕłÖķģŹńĮ«õ┐Īµü»Õ”éõĖŗ’╝Ü
+
+```python
+# ń╗¦µē┐ base ķģŹńĮ«’╝īńäČÕÉÄĶ┐øĶĪīķÆłÕ»╣µĆ¦õ┐«µö╣
+_base_ = [
+ '../_base_/models/cascade-mask-rcnn_r50_fpn.py',
+ '../_base_/datasets/cityscapes_instance.py', '../_base_/default_runtime.py'
+]
+
+model = dict(
+ # Ķ«ŠńĮ« `init_cfg` õĖ║ None’╝īĶĪ©ńż║õĖŹÕŖĀĶĮĮ ImageNet ķóäĶ«Łń╗āµØāķ插╝ī
+ # ÕÉÄń╗ŁÕÅ»õ╗źĶ«ŠńĮ« `load_from` ÕÅéµĢ░ńö©µØźÕŖĀĶĮĮ COCO ķóäĶ«Łń╗āµØāķćŹ
+ backbone=dict(init_cfg=None),
+ # õĮ┐ńö©µ¢░Õó×ńÜä `AugFPN` µ©ĪÕØŚõ╗Żµø┐ķ╗śĶ«żńÜä `FPN`
+ neck=dict(
+ type='AugFPN',
+ in_channels=[256, 512, 1024, 2048],
+ out_channels=256,
+ num_outs=5),
+ # µłæõ╗¼õ╣¤ķ£ĆĶ”üÕ░å num_classes õ╗Ä 80 õ┐«µö╣õĖ║ 8 µØźÕī╣ķģŹ cityscapes µĢ░µŹ«ķøåµĀćµ│©
+ # Ķ┐ÖõĖ¬õ┐«µö╣Õīģµŗ¼ `bbox_head` ÕÆī `mask_head`.
+ roi_head=dict(
+ bbox_head=[
+ dict(
+ type='Shared2FCBBoxHead',
+ in_channels=256,
+ fc_out_channels=1024,
+ roi_feat_size=7,
+ # Õ░å COCO ń▒╗Õł½õ┐«µö╣õĖ║ cityscapes ń▒╗Õł½
+ num_classes=8,
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[0., 0., 0., 0.],
+ target_stds=[0.1, 0.1, 0.2, 0.2]),
+ reg_class_agnostic=True,
+ loss_cls=dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=False,
+ loss_weight=1.0),
+ loss_bbox=dict(type='SmoothL1Loss', beta=1.0,
+ loss_weight=1.0)),
+ dict(
+ type='Shared2FCBBoxHead',
+ in_channels=256,
+ fc_out_channels=1024,
+ roi_feat_size=7,
+ # Õ░å COCO ń▒╗Õł½õ┐«µö╣õĖ║ cityscapes ń▒╗Õł½
+ num_classes=8,
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[0., 0., 0., 0.],
+ target_stds=[0.05, 0.05, 0.1, 0.1]),
+ reg_class_agnostic=True,
+ loss_cls=dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=False,
+ loss_weight=1.0),
+ loss_bbox=dict(type='SmoothL1Loss', beta=1.0,
+ loss_weight=1.0)),
+ dict(
+ type='Shared2FCBBoxHead',
+ in_channels=256,
+ fc_out_channels=1024,
+ roi_feat_size=7,
+ # Õ░å COCO ń▒╗Õł½õ┐«µö╣õĖ║ cityscapes ń▒╗Õł½
+ num_classes=8,
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[0., 0., 0., 0.],
+ target_stds=[0.033, 0.033, 0.067, 0.067]),
+ reg_class_agnostic=True,
+ loss_cls=dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=False,
+ loss_weight=1.0),
+ loss_bbox=dict(type='SmoothL1Loss', beta=1.0, loss_weight=1.0))
+ ],
+ mask_head=dict(
+ type='FCNMaskHead',
+ num_convs=4,
+ in_channels=256,
+ conv_out_channels=256,
+ # Õ░å COCO ń▒╗Õł½õ┐«µö╣õĖ║ cityscapes ń▒╗Õł½
+ num_classes=8,
+ loss_mask=dict(
+ type='CrossEntropyLoss', use_mask=True, loss_weight=1.0))))
+
+# Ķ”åÕåÖ `train_pipeline`’╝īńäČÕÉĵ¢░Õó× `AutoAugment` Ķ«Łń╗āķģŹńĮ«
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations', with_bbox=True, with_mask=True),
+ dict(
+ type='AutoAugment',
+ policies=[
+ [dict(
+ type='Rotate',
+ level=5,
+ img_border_value=(124, 116, 104),
+ prob=0.5)
+ ],
+ [dict(type='Rotate', level=7, img_border_value=(124, 116, 104)),
+ dict(
+ type='TranslateX',
+ level=5,
+ prob=0.5,
+ img_border_value=(124, 116, 104))
+ ],
+ ]),
+ dict(
+ type='RandomResize',
+ scale=[(2048, 800), (2048, 1024)],
+ keep_ratio=True),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='PackDetInputs'),
+]
+
+# Ķ«ŠńĮ«µ»ÅÕ╝ĀµśŠÕŹĪńÜäµē╣ÕżäńÉåÕż¦Õ░Å’╝īÕÉīµŚČĶ«ŠńĮ«µ¢░ńÜäĶ«Łń╗ā pipeline
+data = dict(
+ samples_per_gpu=1,
+ workers_per_gpu=3,
+ train=dict(dataset=dict(pipeline=train_pipeline)))
+
+# Ķ«ŠńĮ«õ╝śÕī¢ÕÖ©
+optim_wrapper = dict(
+ type='OptimWrapper',
+ optimizer=dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0001))
+
+# Ķ«ŠńĮ«Õ«ÜÕłČńÜäÕŁ”õ╣ĀńÄćńŁ¢ńĢź
+param_scheduler = [
+ dict(
+ type='LinearLR', start_factor=0.001, by_epoch=False, begin=0, end=500),
+ dict(
+ type='MultiStepLR',
+ begin=0,
+ end=10,
+ by_epoch=True,
+ milestones=[8],
+ gamma=0.1)
+]
+
+# Ķ«Łń╗ā’╝īķ¬īĶ»ü’╝īµĄŗĶ»ĢķģŹńĮ«
+train_cfg = dict(type='EpochBasedTrainLoop', max_epochs=10, val_interval=1)
+val_cfg = dict(type='ValLoop')
+test_cfg = dict(type='TestLoop')
+
+# µłæõ╗¼ķććńö© COCO ķóäĶ«Łń╗āĶ┐ćńÜä Cascade Mask R-CNN R50 µ©ĪÕ×ŗµØāķćŹõĮ£õĖ║ÕłØÕ¦ŗÕī¢µØāķ插╝īÕÅ»õ╗źÕŠŚÕł░µø┤ÕŖĀń©│Õ«ÜńÜäµĆ¦ĶāĮ
+load_from = 'https://download.openmmlab.com/mmdetection/v2.0/cascade_rcnn/cascade_mask_rcnn_r50_fpn_1x_coco/cascade_mask_rcnn_r50_fpn_1x_coco_20200203-9d4dcb24.pth'
+```
+
+## Ķ«Łń╗āµ¢░µ©ĪÕ×ŗ
+
+õĖ║õ║åĶāĮÕż¤õĮ┐ńö©µ¢░Õó×ķģŹńĮ«µØźĶ«Łń╗āµ©ĪÕ×ŗ’╝īõĮĀÕÅ»õ╗źĶ┐ÉĶĪīÕ”éõĖŗÕæĮõ╗ż’╝Ü
+
+```shell
+python tools/train.py configs/cityscapes/cascade-mask-rcnn_r50_augfpn_autoaug-10e_cityscapes.py
+```
+
+Õ”éµ×£µā│õ║åĶ¦Żµø┤ÕżÜńö©µ│Ģ’╝īÕÅ»õ╗źÕÅéĶĆā [õŠŗÕŁÉ1](1_exist_data_model.md)ŃĆé
+
+## µĄŗĶ»ĢÕÆīµÄ©ńÉå
+
+õĖ║õ║åĶāĮÕż¤µĄŗĶ»ĢĶ«Łń╗āÕźĮńÜ䵩ĪÕ×ŗ’╝īõĮĀÕÅ»õ╗źĶ┐ÉĶĪīÕ”éõĖŗÕæĮõ╗ż’╝Ü
+
+```shell
+python tools/test.py configs/cityscapes/cascade-mask-rcnn_r50_augfpn_autoaug-10e_cityscapes.py work_dirs/cascade-mask-rcnn_r50_augfpn_autoaug-10e_cityscapes/epoch_10.pth
+```
+
+Õ”éµ×£µā│õ║åĶ¦Żµø┤ÕżÜńö©µ│Ģ’╝īÕÅ»õ╗źÕÅéĶĆā [õŠŗÕŁÉ1](1_exist_data_model.md)ŃĆé
diff --git a/internlm_langchain/knowledge_base/MMDetection/content/overview.md b/internlm_langchain/knowledge_base/MMDetection/content/overview.md
new file mode 100644
index 00000000..5269aed8
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection/content/overview.md
@@ -0,0 +1,54 @@
+# µ”éĶ┐░
+
+µ£¼ń½ĀÕÉæµé©õ╗ŗń╗Ź MMDetection ńÜäµĢ┤õĮōµĪåµ×Č’╝īÕ╣ȵÅÉõŠøĶ»”ń╗åńÜäµĢÖń©ŗķōŠµÄźŃĆé
+
+## õ╗Ćõ╣łµś» MMDetection
+
+
+
+MMDetection µś»õĖĆõĖ¬ńø«µĀ浯ƵĄŗÕĘźÕģĘń«▒’╝īÕīģÕɽõ║åõĖ░Õ»īńÜäńø«µĀ浯ƵĄŗŃĆüÕ«×õŠŗÕłåÕē▓ŃĆüÕģ©µÖ»ÕłåÕē▓ń«Śµ│Ģõ╗źÕÅŖńøĖÕģ│ńÜäń╗äõ╗ČÕÆīµ©ĪÕØŚ’╝īõĖŗķØóµś»Õ«āńÜäµĢ┤õĮōµĪåµ×Č’╝Ü
+
+MMDetection ńö▒ 7 õĖ¬õĖ╗Ķ”üķā©Õłåń╗䵳ɒ╝īapisŃĆüstructuresŃĆüdatasetsŃĆümodelsŃĆüengineŃĆüevaluation ÕÆī visualizationŃĆé
+
+- **apis** õĖ║µ©ĪÕ×ŗµÄ©ńÉåµÅÉõŠøķ½śń║¦ APIŃĆé
+- **structures** µÅÉõŠø bboxŃĆümask ÕÆī DetDataSample ńŁēµĢ░µŹ«ń╗ōµ×äŃĆé
+- **datasets** µö»µīüńö©õ║Äńø«µĀ浯ƵĄŗŃĆüÕ«×õŠŗÕłåÕē▓ÕÆīÕģ©µÖ»ÕłåÕē▓ńÜäÕÉäń¦ŹµĢ░µŹ«ķøåŃĆé
+ - **transforms** ÕīģÕɽÕÉäń¦ŹµĢ░µŹ«Õó×Õ╝║ÕÅśµŹóŃĆé
+ - **samplers** Õ«Üõ╣ēõ║åõĖŹÕÉīńÜäµĢ░µŹ«ÕŖĀĶĮĮÕÖ©ķććµĀĘńŁ¢ńĢźŃĆé
+- **models** µś»µŻĆµĄŗÕÖ©µ£ĆķćŹĶ”üńÜäķā©Õłå’╝īÕīģÕɽµŻĆµĄŗÕÖ©ńÜäõĖŹÕÉīń╗äõ╗ČŃĆé
+ - **detectors** Õ«Üõ╣ēµēƵ£ēµŻĆµĄŗµ©ĪÕ×ŗń▒╗ŃĆé
+ - **data_preprocessors** ńö©õ║ÄķóäÕżäńÉ嵩ĪÕ×ŗńÜäĶŠōÕģźµĢ░µŹ«ŃĆé
+ - **backbones** ÕīģÕɽÕÉäń¦Źķ¬©Õ╣▓ńĮæń╗£ŃĆé
+ - **necks** ÕīģÕɽÕÉäń¦Źµ©ĪÕ×ŗķółķā©ń╗äõ╗ČŃĆé
+ - **dense_heads** ÕīģÕɽµē¦ĶĪīÕ»åķøåķó䵥ŗńÜäÕÉäń¦ŹµŻĆµĄŗÕż┤ŃĆé
+ - **roi_heads** ÕīģÕɽõ╗Ä RoI ķó䵥ŗńÜäÕÉäń¦ŹµŻĆµĄŗÕż┤ŃĆé
+ - **seg_heads** ÕīģÕɽÕÉäń¦ŹÕłåÕē▓Õż┤ŃĆé
+ - **losses** ÕīģÕɽÕÉäń¦ŹµŹ¤Õż▒ÕćĮµĢ░ŃĆé
+ - **task_modules** õĖ║µŻĆµĄŗõ╗╗ÕŖĪµÅÉõŠøµ©ĪÕØŚ’╝īõŠŗÕ”é assignersŃĆüsamplersŃĆübox coders ÕÆī prior generatorsŃĆé
+ - **layers** µÅÉõŠøõ║åõĖĆõ║øÕ¤║µ£¼ńÜäńź×ń╗ÅńĮæń╗£Õ▒éŃĆé
+- **engine** µś»Ķ┐ÉĶĪīµŚČń╗äõ╗ČńÜäõĖĆķā©ÕłåŃĆé
+ - **runner** õĖ║ [MMEngine ńÜäµē¦ĶĪīÕÖ©](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/runner.html)µÅÉõŠøµē®Õ▒ĢŃĆé
+ - **schedulers** µÅÉõŠøńö©õ║ÄĶ░āµĢ┤õ╝śÕī¢ĶČģÕÅéµĢ░ńÜäĶ░āÕ║”ń©ŗÕ║ÅŃĆé
+ - **optimizers** µÅÉõŠøõ╝śÕī¢ÕÖ©ÕÆīõ╝śÕī¢ÕÖ©Õ░üĶŻģŃĆé
+ - **hooks** µÅÉõŠøµē¦ĶĪīÕÖ©ńÜäÕÉäń¦ŹķÆ®ÕŁÉŃĆé
+- **evaluation** õĖ║Ķ»äõ╝░µ©ĪÕ×ŗµĆ¦ĶāĮµÅÉõŠøõĖŹÕÉīńÜäµīćµĀćŃĆé
+- **visualization** ńö©õ║ÄÕÅ»Ķ¦åÕī¢µŻĆµĄŗń╗ōµ×£ŃĆé
+
+## Õ”éõĮĢõĮ┐ńö©µ£¼µīćÕŹŚ
+
+õ╗źõĖŗµś» MMDetection ńÜäĶ»”ń╗åµīćÕŹŚ’╝Ü
+
+1. Õ«ēĶŻģĶ»┤µśÄĶ¦ü[Õ╝ĆÕ¦ŗõĮĀńÜäń¼¼õĖƵŁź](get_started.md)ŃĆé
+
+2. MMDetection ńÜäÕ¤║µ£¼õĮ┐ńö©µ¢╣µ│ĢĶ»ĘÕÅéĶĆāõ╗źõĖŗµĢÖń©ŗŃĆé
+
+ - [Ķ«Łń╗āÕÆīµĄŗĶ»Ģ](https://mmdetection.readthedocs.io/zh_CN/latest/user_guides/index.html#train-test)
+
+ - [Õ«×ńö©ÕĘźÕģĘ](https://mmdetection.readthedocs.io/zh_CN/latest/user_guides/index.html#useful-tools)
+
+3. ÕÅéĶĆāõ╗źõĖŗµĢÖń©ŗµĘ▒Õģźõ║åĶ¦Ż’╝Ü
+
+ - [Õ¤║ńĪƵ”éÕ┐Ą](https://mmdetection.readthedocs.io/zh_CN/latest/advanced_guides/index.html#basic-concepts)
+ - [ń╗äõ╗ČÕ«ÜÕłČ](https://mmdetection.readthedocs.io/zh_CN/latest/advanced_guides/index.html#component-customization)
+
+4. Õ»╣õ║Ä MMDetection 2.x ńēłµ£¼ńÜäńö©µłĘ’╝īµłæõ╗¼µÅÉõŠøõ║å[Ķ┐üń¦╗µīćÕŹŚ](./migration/migration.md)’╝īÕĖ«ÕŖ®µé©Õ«īµłÉµ¢░ńēłµ£¼ńÜäķĆéķģŹŃĆé
diff --git a/internlm_langchain/knowledge_base/MMDetection/content/projects.md b/internlm_langchain/knowledge_base/MMDetection/content/projects.md
new file mode 100644
index 00000000..6b9d300d
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection/content/projects.md
@@ -0,0 +1,48 @@
+# Õ¤║õ║Ä MMDetection ńÜäķĪ╣ńø«
+
+µ£ēĶ«ĖÕżÜÕ╝Ƶ║ÉķĪ╣ńø«ķāĮµś»Õ¤║õ║Ä MMDetection µÉŁÕ╗║ńÜä’╝īµłæõ╗¼Õ£©Ķ┐ÖķćīÕłŚõĖŠõĖĆķā©ÕłåõĮ£õĖ║µĀĘõŠŗ’╝īÕ▒Ģńż║Õ”éõĮĢÕ¤║õ║Ä MMDetection µÉŁÕ╗║µé©Ķć¬ÕĘ▒ńÜäķĪ╣ńø«ŃĆé
+ńö▒õ║ÄĶ┐ÖõĖ¬ķĪĄķØóÕłŚõĖŠńÜäķĪ╣ńø«Õ╣ČõĖŹÕ«īÕģ©’╝īµłæõ╗¼µ¼óĶ┐ÄńżŠÕī║µÅÉõ║ż Pull Request µØźµø┤µ¢░Ķ┐ÖõĖ¬µ¢ćµĪŻŃĆé
+
+## MMDetection ńÜäµŗōÕ▒ĢķĪ╣ńø«
+
+õĖĆõ║øķĪ╣ńø«µŗōÕ▒Ģõ║å MMDetection ńÜäĶŠ╣ńĢī’╝īÕ”éÕ░å MMDetection µŗōÕ▒Ģµö»µīü 3D µŻĆµĄŗµł¢ĶĆģÕ░å MMDetection ńö©õ║Äķā©ńĮ▓ŃĆé
+Õ«āõ╗¼Õ▒Ģńż║õ║å MMDetection ńÜäĶ«ĖÕżÜÕÅ»ĶāĮµĆ¦’╝īµēĆõ╗źµłæõ╗¼Õ£©Ķ┐Öķćīõ╣¤ÕłŚõĖŠõĖĆõ║øŃĆé
+
+- [OTEDetection](https://github.com/opencv/mmdetection): OpenVINO training extensions for object detection.
+- [MMDetection3d](https://github.com/open-mmlab/mmdetection3d): OpenMMLab's next-generation platform for general 3D object detection.
+
+## ńĀöń®ČķĪ╣ńø«
+
+ÕÉīµĀʵ£ēĶ«ĖÕżÜńĀöń®ČĶ«║µ¢ćµś»Õ¤║õ║Ä MMDetection Ķ┐øĶĪīńÜäŃĆéĶ«ĖÕżÜĶ«║µ¢ćķāĮÕÅæĶĪ©Õ£©õ║åķĪČń║¦ńÜäõ╝ÜĶ««µł¢µ£¤ÕłŖõĖŖ’╝īµł¢ĶĆģÕ»╣ńżŠÕī║õ║¦ńö¤õ║åµĘ▒Ķ┐£ńÜäÕĮ▒ÕōŹŃĆé
+õĖ║õ║åÕÉæńżŠÕī║µÅÉõŠøõĖĆõĖ¬ÕÅ»õ╗źÕÅéĶĆāńÜäĶ«║µ¢ćÕłŚĶĪ©’╝īÕĖ«ÕŖ®Õż¦Õ«ČÕ╝ĆÕÅæµł¢ĶĆģµ»öĶŠāµ¢░ńÜäÕēŹµ▓┐ń«Śµ│Ģ’╝īµłæõ╗¼Õ£©Ķ┐Öķćīõ╣¤ķüĄÕŠ¬õ╝ÜĶ««ńÜ䵌ČķŚ┤ķĪ║Õ║ÅÕłŚõĖŠõ║åõĖĆõ║øĶ«║µ¢ćŃĆé
+MMDetection õĖŁÕĘ▓ń╗ŵö»µīüńÜäń«Śµ│ĢõĖŹÕ£©µŁżÕłŚŃĆé
+
+- Involution: Inverting the Inherence of Convolution for Visual Recognition, CVPR21. [\[paper\]](https://arxiv.org/abs/2103.06255)[\[github\]](https://github.com/d-li14/involution)
+- Multiple Instance Active Learning for Object Detection, CVPR 2021. [\[paper\]](https://openaccess.thecvf.com/content/CVPR2021/papers/Yuan_Multiple_Instance_Active_Learning_for_Object_Detection_CVPR_2021_paper.pdf)[\[github\]](https://github.com/yuantn/MI-AOD)
+- Adaptive Class Suppression Loss for Long-Tail Object Detection, CVPR 2021. [\[paper\]](https://arxiv.org/abs/2104.00885)[\[github\]](https://github.com/CASIA-IVA-Lab/ACSL)
+- Generalizable Pedestrian Detection: The Elephant In The Room, CVPR2021. [\[paper\]](https://arxiv.org/abs/2003.08799)[\[github\]](https://github.com/hasanirtiza/Pedestron)
+- Group Fisher Pruning for Practical Network Compression, ICML2021. [\[paper\]](https://github.com/jshilong/FisherPruning/blob/main/resources/paper.pdf)[\[github\]](https://github.com/jshilong/FisherPruning)
+- Overcoming Classifier Imbalance for Long-tail Object Detection with Balanced Group Softmax, CVPR2020. [\[paper\]](http://openaccess.thecvf.com/content_CVPR_2020/papers/Li_Overcoming_Classifier_Imbalance_for_Long-Tail_Object_Detection_With_Balanced_Group_CVPR_2020_paper.pdf)[\[github\]](https://github.com/FishYuLi/BalancedGroupSoftmax)
+- Coherent Reconstruction of Multiple Humans from a Single Image, CVPR2020. [\[paper\]](https://jiangwenpl.github.io/multiperson/)[\[github\]](https://github.com/JiangWenPL/multiperson)
+- Look-into-Object: Self-supervised Structure Modeling for Object Recognition, CVPR 2020. [\[paper\]](http://openaccess.thecvf.com/content_CVPR_2020/papers/Zhou_Look-Into-Object_Self-Supervised_Structure_Modeling_for_Object_Recognition_CVPR_2020_paper.pdf)[\[github\]](https://github.com/JDAI-CV/LIO)
+- Video Panoptic Segmentation, CVPR2020. [\[paper\]](https://arxiv.org/abs/2006.11339)[\[github\]](https://github.com/mcahny/vps)
+- D2Det: Towards High Quality Object Detection and Instance Segmentation, CVPR2020. [\[paper\]](http://openaccess.thecvf.com/content_CVPR_2020/html/Cao_D2Det_Towards_High_Quality_Object_Detection_and_Instance_Segmentation_CVPR_2020_paper.html)[\[github\]](https://github.com/JialeCao001/D2Det)
+- CentripetalNet: Pursuing High-quality Keypoint Pairs for Object Detection, CVPR2020. [\[paper\]](https://arxiv.org/abs/2003.09119)[\[github\]](https://github.com/KiveeDong/CentripetalNet)
+- Learning a Unified Sample Weighting Network for Object Detection, CVPR 2020. [\[paper\]](http://openaccess.thecvf.com/content_CVPR_2020/html/Cai_Learning_a_Unified_Sample_Weighting_Network_for_Object_Detection_CVPR_2020_paper.html)[\[github\]](https://github.com/caiqi/sample-weighting-network)
+- Scale-equalizing Pyramid Convolution for Object Detection, CVPR2020. [\[paper\]](https://arxiv.org/abs/2005.03101) [\[github\]](https://github.com/jshilong/SEPC)
+- Revisiting the Sibling Head in Object Detector, CVPR2020. [\[paper\]](https://arxiv.org/abs/2003.07540)[\[github\]](https://github.com/Sense-X/TSD)
+- PolarMask: Single Shot Instance Segmentation with Polar Representation, CVPR2020. [\[paper\]](https://arxiv.org/abs/1909.13226)[\[github\]](https://github.com/xieenze/PolarMask)
+- Hit-Detector: Hierarchical Trinity Architecture Search for Object Detection, CVPR2020. [\[paper\]](https://arxiv.org/abs/2003.11818)[\[github\]](https://github.com/ggjy/HitDet.pytorch)
+- ZeroQ: A Novel Zero Shot Quantization Framework, CVPR2020. [\[paper\]](https://arxiv.org/abs/2001.00281)[\[github\]](https://github.com/amirgholami/ZeroQ)
+- CBNet: A Novel Composite Backbone Network Architecture for Object Detection, AAAI2020. [\[paper\]](https://aaai.org/Papers/AAAI/2020GB/AAAI-LiuY.1833.pdf)[\[github\]](https://github.com/VDIGPKU/CBNet)
+- RDSNet: A New Deep Architecture for Reciprocal Object Detection and Instance Segmentation, AAAI2020. [\[paper\]](https://arxiv.org/abs/1912.05070)[\[github\]](https://github.com/wangsr126/RDSNet)
+- Training-Time-Friendly Network for Real-Time Object Detection, AAAI2020. [\[paper\]](https://arxiv.org/abs/1909.00700)[\[github\]](https://github.com/ZJULearning/ttfnet)
+- Cascade RPN: Delving into High-Quality Region Proposal Network with Adaptive Convolution, NeurIPS 2019. [\[paper\]](https://arxiv.org/abs/1909.06720)[\[github\]](https://github.com/thangvubk/Cascade-RPN)
+- Reasoning R-CNN: Unifying Adaptive Global Reasoning into Large-scale Object Detection, CVPR2019. [\[paper\]](http://openaccess.thecvf.com/content_CVPR_2019/papers/Xu_Reasoning-RCNN_Unifying_Adaptive_Global_Reasoning_Into_Large-Scale_Object_Detection_CVPR_2019_paper.pdf)[\[github\]](https://github.com/chanyn/Reasoning-RCNN)
+- Learning RoI Transformer for Oriented Object Detection in Aerial Images, CVPR2019. [\[paper\]](https://arxiv.org/abs/1812.00155)[\[github\]](https://github.com/dingjiansw101/AerialDetection)
+- SOLO: Segmenting Objects by Locations. [\[paper\]](https://arxiv.org/abs/1912.04488)[\[github\]](https://github.com/WXinlong/SOLO)
+- SOLOv2: Dynamic, Faster and Stronger. [\[paper\]](https://arxiv.org/abs/2003.10152)[\[github\]](https://github.com/WXinlong/SOLO)
+- Dense Peppoints: Representing Visual Objects with Dense Point Sets. [\[paper\]](https://arxiv.org/abs/1912.11473)[\[github\]](https://github.com/justimyhxu/Dense-RepPoints)
+- IterDet: Iterative Scheme for Object Detection in Crowded Environments. [\[paper\]](https://arxiv.org/abs/2005.05708)[\[github\]](https://github.com/saic-vul/iterdet)
+- Cross-Iteration Batch Normalization. [\[paper\]](https://arxiv.org/abs/2002.05712)[\[github\]](https://github.com/Howal/Cross-iterationBatchNorm)
+- A Ranking-based, Balanced Loss Function Unifying Classification and Localisation in Object Detection, NeurIPS2020 [\[paper\]](https://arxiv.org/abs/2009.13592)[\[github\]](https://github.com/kemaloksuz/aLRPLoss)
diff --git a/internlm_langchain/knowledge_base/MMDetection/content/robustness_benchmarking.md b/internlm_langchain/knowledge_base/MMDetection/content/robustness_benchmarking.md
new file mode 100644
index 00000000..e95c79a9
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection/content/robustness_benchmarking.md
@@ -0,0 +1,109 @@
+# µŻĆµĄŗÕÖ©ķ▓üµŻÆµĆ¦µŻĆµ¤ź
+
+## õ╗ŗń╗Ź
+
+µłæõ╗¼µÅÉõŠøõ║åÕ£© [Benchmarking Robustness in Object Detection: Autonomous Driving when Winter is Coming](https://arxiv.org/abs/1907.07484) õĖŁÕ«Üõ╣ēńÜäŃĆīÕøŠÕāŵŹ¤ÕØÅÕ¤║ÕćåµĄŗĶ»ĢŃĆŹõĖŖµĄŗĶ»Ģńø«µĀ浯ƵĄŗÕÆīÕ«×õŠŗÕłåÕē▓µ©ĪÕ×ŗńÜäÕĘźÕģĘŃĆé
+µŁżķĪĄķØóµÅÉõŠøõ║åÕ”éõĮĢõĮ┐ńö©Ķ»źÕ¤║ÕćåµĄŗĶ»ĢńÜäÕ¤║µ£¼µĢÖń©ŗŃĆé
+
+```latex
+@article{michaelis2019winter,
+ title={Benchmarking Robustness in Object Detection:
+ Autonomous Driving when Winter is Coming},
+ author={Michaelis, Claudio and Mitzkus, Benjamin and
+ Geirhos, Robert and Rusak, Evgenia and
+ Bringmann, Oliver and Ecker, Alexander S. and
+ Bethge, Matthias and Brendel, Wieland},
+ journal={arXiv:1907.07484},
+ year={2019}
+}
+```
+
+
+
+## Õģ│õ║ÄÕ¤║ÕćåµĄŗĶ»Ģ
+
+Ķ”üÕ░åń╗ōµ×£µÅÉõ║żÕł░Õ¤║ÕćåµĄŗĶ»Ģ’╝īĶ»ĘĶ«┐ķŚ«[Õ¤║ÕćåµĄŗĶ»ĢõĖ╗ķĪĄ](https://github.com/bethgelab/robust-detection-benchmark)
+
+Õ¤║ÕćåµĄŗĶ»Ģµś»õ╗┐ńģ¦ [imagenet-c Õ¤║ÕćåµĄŗĶ»Ģ](https://github.com/hendrycks/robustness)’╝īńö▒ Dan Hendrycks ÕÆī Thomas Dietterich Õ£©[Benchmarking Neural Network Robustness to Common Corruptions and Perturbations](https://arxiv.org/abs/1903.12261)(ICLR 2019)õĖŁÕÅæĶĪ©ŃĆé
+
+ÕøŠÕāŵŹ¤ÕØÅÕÅśµŹóÕŖ¤ĶāĮÕīģÕɽգ©µŁżÕ║ōõĖŁ’╝īõĮåÕÅ»õ╗źõĮ┐ńö©õ╗źõĖŗµ¢╣µ│ĢÕŹĢńŗ¼Õ«ēĶŻģ’╝Ü
+
+```shell
+pip install imagecorruptions
+```
+
+õĖÄ imagenet-c ńøĖµ»ö’╝īµłæõ╗¼Õ┐ģķĪ╗Ķ┐øĶĪīõĖĆõ║øµø┤µö╣õ╗źÕżäńÉåõ╗╗µäÅÕż¦Õ░ÅńÜäÕøŠÕāÅÕÆīńü░Õ║”ÕøŠÕāÅŃĆé
+µłæõ╗¼Ķ┐śõ┐«µö╣õ║åŌĆ£Ķ┐ÉÕŖ©µ©Īń│ŖŌĆØÕÆīŌĆ£ķø¬ŌĆصŹ¤ÕØÅ’╝īõ╗źĶ¦ŻķÖżÕ»╣õ║Ä linux ńē╣Õ«ÜÕ║ōńÜäõŠØĶĄ¢’╝ī
+ÕÉ”ÕłÖÕ┐ģķĪ╗ÕŹĢńŗ¼Õ«ēĶŻģĶ┐Öõ║øÕ║ōŃĆéµ£ēÕģ│Ķ»”ń╗åõ┐Īµü»’╝īĶ»ĘÕÅéķśģ [imagecorruptions](https://github.com/bethgelab/imagecorruptions)ŃĆé
+
+## õĮ┐ńö©ķóäĶ«Łń╗āµ©ĪÕ×ŗĶ┐øĶĪīµÄ©ńÉå
+
+µłæõ╗¼µÅÉõŠøõ║åõĖĆõĖ¬µĄŗĶ»ĢĶäܵ£¼µØźĶ»äõ╝░µ©ĪÕ×ŗÕ£©Õ¤║ÕćåµĄŗĶ»ĢõĖŁµÅÉõŠøńÜäÕÉäń¦ŹµŹ¤ÕØÅÕÅśµŹóń╗äÕÉłõĖŗńÜäµĆ¦ĶāĮŃĆé
+
+### Õ£©µĢ░µŹ«ķøåõĖŖµĄŗĶ»Ģ
+
+- [x] ÕŹĢÕ╝Ā GPU µĄŗĶ»Ģ
+- [ ] ÕżÜÕ╝Ā GPU µĄŗĶ»Ģ
+- [ ] ÕÅ»Ķ¦åÕī¢µŻĆµĄŗń╗ōµ×£
+
+µé©ÕÅ»õ╗źõĮ┐ńö©õ╗źõĖŗÕæĮõ╗żÕ£©Õ¤║ÕćåµĄŗĶ»ĢõĖŁõĮ┐ńö© 15 ń¦ŹµŹ¤ÕØÅÕÅśµŹóµØźµĄŗĶ»Ģµ©ĪÕ×ŗµĆ¦ĶāĮŃĆé
+
+```shell
+# single-gpu testing
+python tools/analysis_tools/test_robustness.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [--out ${RESULT_FILE}] [--eval ${EVAL_METRICS}]
+```
+
+õ╣¤ÕÅ»õ╗źķĆēµŗ®ÕģČÕ«āõĖŹÕÉīń▒╗Õ×ŗńÜ䵏¤ÕØÅÕÅśµŹóŃĆé
+
+```shell
+# noise
+python tools/analysis_tools/test_robustness.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [--out ${RESULT_FILE}] [--eval ${EVAL_METRICS}] --corruptions noise
+
+# blur
+python tools/analysis_tools/test_robustness.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [--out ${RESULT_FILE}] [--eval ${EVAL_METRICS}] --corruptions blur
+
+# wetaher
+python tools/analysis_tools/test_robustness.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [--out ${RESULT_FILE}] [--eval ${EVAL_METRICS}] --corruptions weather
+
+# digital
+python tools/analysis_tools/test_robustness.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [--out ${RESULT_FILE}] [--eval ${EVAL_METRICS}] --corruptions digital
+```
+
+µł¢ĶĆģõĮ┐ńö©õĖĆń╗äĶć¬Õ«Üõ╣ēńÜ䵏¤ÕØÅÕÅśµŹó’╝īõŠŗÕ”é’╝Ü
+
+```shell
+# gaussian noise, zoom blur and snow
+python tools/analysis_tools/test_robustness.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [--out ${RESULT_FILE}] [--eval ${EVAL_METRICS}] --corruptions gaussian_noise zoom_blur snow
+```
+
+µ£ĆÕÉÄ’╝īµłæõ╗¼õ╣¤ÕÅ»õ╗źķĆēµŗ®µ¢ĮÕŖĀÕ£©ÕøŠÕāÅõĖŖńÜ䵏¤ÕØÅÕÅśµŹóńÜäõĖźķćŹń©ŗÕ║”ŃĆé
+õĖźķćŹń©ŗÕ║”õ╗Ä 1 Õł░ 5 ķĆÉń║¦Õó×Õ╝║’╝ī0 ĶĪ©ńż║õĖŹÕ»╣ÕøŠÕāŵ¢ĮÕŖĀµŹ¤ÕØÅÕÅśµŹó’╝īÕŹ│ÕĤզŗÕøŠÕāŵĢ░µŹ«ŃĆé
+
+```shell
+# severity 1
+python tools/analysis_tools/test_robustness.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [--out ${RESULT_FILE}] [--eval ${EVAL_METRICS}] --severities 1
+
+# severities 0,2,4
+python tools/analysis_tools/test_robustness.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [--out ${RESULT_FILE}] [--eval ${EVAL_METRICS}] --severities 0 2 4
+```
+
+## µ©ĪÕ×ŗµĄŗĶ»Ģń╗ōµ×£
+
+õĖŗĶĪ©µś»ÕÉ䵩ĪÕ×ŗÕ£© COCO 2017val õĖŖńÜ䵥ŗĶ»Ģń╗ōµ×£ŃĆé
+
+| Model | Backbone | Style | Lr schd | box AP clean | box AP corr. | box % | mask AP clean | mask AP corr. | mask % |
+| :-----------------: | :-----------------: | :-----: | :-----: | :----------: | :----------: | :---: | :-----------: | :-----------: | :----: |
+| Faster R-CNN | R-50-FPN | pytorch | 1x | 36.3 | 18.2 | 50.2 | - | - | - |
+| Faster R-CNN | R-101-FPN | pytorch | 1x | 38.5 | 20.9 | 54.2 | - | - | - |
+| Faster R-CNN | X-101-32x4d-FPN | pytorch | 1x | 40.1 | 22.3 | 55.5 | - | - | - |
+| Faster R-CNN | X-101-64x4d-FPN | pytorch | 1x | 41.3 | 23.4 | 56.6 | - | - | - |
+| Faster R-CNN | R-50-FPN-DCN | pytorch | 1x | 40.0 | 22.4 | 56.1 | - | - | - |
+| Faster R-CNN | X-101-32x4d-FPN-DCN | pytorch | 1x | 43.4 | 26.7 | 61.6 | - | - | - |
+| Mask R-CNN | R-50-FPN | pytorch | 1x | 37.3 | 18.7 | 50.1 | 34.2 | 16.8 | 49.1 |
+| Mask R-CNN | R-50-FPN-DCN | pytorch | 1x | 41.1 | 23.3 | 56.7 | 37.2 | 20.7 | 55.7 |
+| Cascade R-CNN | R-50-FPN | pytorch | 1x | 40.4 | 20.1 | 49.7 | - | - | - |
+| Cascade Mask R-CNN | R-50-FPN | pytorch | 1x | 41.2 | 20.7 | 50.2 | 35.7 | 17.6 | 49.3 |
+| RetinaNet | R-50-FPN | pytorch | 1x | 35.6 | 17.8 | 50.1 | - | - | - |
+| Hybrid Task Cascade | X-101-64x4d-FPN-DCN | pytorch | 1x | 50.6 | 32.7 | 64.7 | 43.8 | 28.1 | 64.0 |
+
+ńö▒õ║ÄÕ»╣ÕøŠÕāÅńÜ䵏¤ÕØÅÕÅśµŹóÕŁśÕ£©ķÜŵ£║µĆ¦’╝īµĄŗĶ»Ģń╗ōµ×£ÕÅ»ĶāĮńĢźµ£ēõĖŹÕÉīŃĆé
diff --git a/internlm_langchain/knowledge_base/MMDetection/content/semi_det.md b/internlm_langchain/knowledge_base/MMDetection/content/semi_det.md
new file mode 100644
index 00000000..a2235237
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection/content/semi_det.md
@@ -0,0 +1,320 @@
+# ÕŹŖńøæńØŻńø«µĀ浯ƵĄŗ
+
+ÕŹŖńøæńØŻńø«µĀ浯ƵĄŗÕÉīµŚČÕł®ńö©µĀćńŁŠµĢ░µŹ«ÕÆīµŚĀµĀćńŁŠµĢ░µŹ«Ķ┐øĶĪīĶ«Łń╗ā’╝īõĖƵ¢╣ķØóÕÅ»õ╗źÕćÅÕ░浩ĪÕ×ŗÕ»╣µŻĆµĄŗµĪåµĢ░ķćÅńÜäõŠØĶĄ¢’╝īÕÅ”õĖƵ¢╣ķØóõ╣¤ÕÅ»õ╗źÕł®ńö©Õż¦ķćÅńÜäµ£¬µĀćĶ«░µĢ░µŹ«Ķ┐øõĖƵŁźµÅÉķ½śµ©ĪÕ×ŗŃĆé
+
+µīēńģ¦õ╗źõĖŗµĄüń©ŗĶ┐øĶĪīÕŹŖńøæńØŻńø«µĀ浯ƵĄŗ’╝Ü
+
+- [ÕŹŖńøæńØŻńø«µĀ浯ƵĄŗ](#ÕŹŖńøæńØŻńø«µĀ浯ƵĄŗ)
+ - [ÕćåÕżćÕÆīµŗåÕłåµĢ░µŹ«ķøå](#ÕćåÕżćÕÆīµŗåÕłåµĢ░µŹ«ķøå)
+ - [ķģŹńĮ«ÕżÜÕłåµö»µĢ░µŹ«µĄüń©ŗ](#ķģŹńĮ«ÕżÜÕłåµö»µĢ░µŹ«µĄüń©ŗ)
+ - [ķģŹńĮ«ÕŹŖńøæńØŻµĢ░µŹ«ÕŖĀĶĮĮ](#ķģŹńĮ«ÕŹŖńøæńØŻµĢ░µŹ«ÕŖĀĶĮĮ)
+ - [ķģŹńĮ«ÕŹŖńøæńØŻµ©ĪÕ×ŗ](#ķģŹńĮ«ÕŹŖńøæńØŻµ©ĪÕ×ŗ)
+ - [ķģŹńĮ«MeanTeacherHook](#ķģŹńĮ«meanteacherhook)
+ - [ķģŹńĮ«TeacherStudentValLoop](#ķģŹńĮ«teacherstudentvalloop)
+
+## ÕćåÕżćÕÆīµŗåÕłåµĢ░µŹ«ķøå
+
+µłæõ╗¼µÅÉõŠøõ║åµĢ░µŹ«ķøåõĖŗĶĮĮĶäܵ£¼’╝īķ╗śĶ«żõĖŗĶĮĮ coco2017 µĢ░µŹ«ķøå’╝īÕ╣ČõĖöĶć¬ÕŖ©Ķ¦ŻÕÄŗŃĆé
+
+```shell
+python tools/misc/download_dataset.py
+```
+
+Ķ¦ŻÕÄŗÕÉÄńÜäµĢ░µŹ«ķøåńø«ÕĮĢÕ”éõĖŗ’╝Ü
+
+```plain
+mmdetection
+Ōö£ŌöĆŌöĆ data
+Ōöé Ōö£ŌöĆŌöĆ coco
+Ōöé Ōöé Ōö£ŌöĆŌöĆ annotations
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ image_info_unlabeled2017.json
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ instances_train2017.json
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ instances_val2017.json
+Ōöé Ōöé Ōö£ŌöĆŌöĆ test2017
+Ōöé Ōöé Ōö£ŌöĆŌöĆ train2017
+Ōöé Ōöé Ōö£ŌöĆŌöĆ unlabeled2017
+Ōöé Ōöé Ōö£ŌöĆŌöĆ val2017
+```
+
+ÕŹŖńøæńØŻńø«µĀ浯ƵĄŗÕ£© coco µĢ░µŹ«ķøåõĖŖµ£ēõĖżń¦Źµ»öĶŠāķĆÜńö©ńÜäÕ«×ķ¬īĶ«ŠńĮ«’╝Ü
+
+’╝ł1’╝ēÕ░å `train2017` µīēńģ¦Õø║Õ«ÜńÖŠÕłåµ»ö’╝ł1%’╝ī2%’╝ī5% ÕÆī 10%’╝ēÕłÆÕłåÕć║õĖĆķā©ÕłåµĢ░µŹ«õĮ£õĖ║µĀćńŁŠµĢ░µŹ«ķøå’╝īÕē®õĮÖńÜäĶ«Łń╗āķøåµĢ░µŹ«õĮ£õĖ║µŚĀµĀćńŁŠµĢ░µŹ«ķøå’╝īÕÉīµŚČĶĆāĶÖæÕłÆÕłåõĖŹÕÉīńÜäĶ«Łń╗āķøåµĢ░µŹ«õĮ£õĖ║µĀćńŁŠµĢ░µŹ«ķøåÕ»╣ÕŹŖńøæńØŻĶ«Łń╗āńÜäń╗ōµ×£ÕĮ▒ÕōŹĶŠāÕż¦’╝īµēĆõ╗źķććńö©õ║öµŖśõ║żÕÅēķ¬īĶ»üµØźĶ»äõ╝░ń«Śµ│ĢµĆ¦ĶāĮŃĆ鵳æõ╗¼µÅÉõŠøõ║åµĢ░µŹ«ķøåÕłÆÕłåĶäܵ£¼’╝Ü
+
+```shell
+python tools/misc/split_coco.py
+```
+
+Ķ»źĶäܵ£¼ķ╗śĶ«żõ╝ܵīēńģ¦ 1%’╝ī2%’╝ī5% ÕÆī 10% ńÜäµĀćńŁŠµĢ░µŹ«ÕŹĀµ»öÕłÆÕłå `train2017`’╝īµ»ÅõĖĆń¦ŹÕłÆÕłåõ╝ÜķÜŵ£║ķćŹÕżŹ 5 µ¼Ī’╝īńö©õ║Äõ║żÕÅēķ¬īĶ»üŃĆéńö¤µłÉńÜäÕŹŖńøæńØŻµĀćµ│©µ¢ćõ╗ČÕÉŹń¦░µĀ╝Õ╝ÅÕ”éõĖŗ’╝Ü
+
+- µĀćńŁŠµĢ░µŹ«ķøåµĀćµ│©ÕÉŹń¦░µĀ╝Õ╝Å’╝Ü`instances_train2017.{fold}@{percent}.json`
+
+- µŚĀµĀćńŁŠµĢ░µŹ«ķøåÕÉŹń¦░µĀćµ│©’╝Ü`instances_train2017.{fold}@{percent}-unlabeled.json`
+
+ÕģČõĖŁ’╝ī`fold` ńö©õ║Äõ║żÕÅēķ¬īĶ»ü’╝ī`percent` ĶĪ©ńż║µĀćńŁŠµĢ░µŹ«ńÜäÕŹĀµ»öŃĆé ÕłÆÕłåÕÉÄńÜäµĢ░µŹ«ķøåńø«ÕĮĢń╗ōµ×äÕ”éõĖŗ’╝Ü
+
+```plain
+mmdetection
+Ōö£ŌöĆŌöĆ data
+Ōöé Ōö£ŌöĆŌöĆ coco
+Ōöé Ōöé Ōö£ŌöĆŌöĆ annotations
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ image_info_unlabeled2017.json
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ instances_train2017.json
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ instances_val2017.json
+Ōöé Ōöé Ōö£ŌöĆŌöĆ semi_anns
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ instances_train2017.1@1.json
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ instances_train2017.1@1-unlabeled.json
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ instances_train2017.1@2.json
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ instances_train2017.1@2-unlabeled.json
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ instances_train2017.1@5.json
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ instances_train2017.1@5-unlabeled.json
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ instances_train2017.1@10.json
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ instances_train2017.1@10-unlabeled.json
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ instances_train2017.2@1.json
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ instances_train2017.2@1-unlabeled.json
+Ōöé Ōöé Ōö£ŌöĆŌöĆ test2017
+Ōöé Ōöé Ōö£ŌöĆŌöĆ train2017
+Ōöé Ōöé Ōö£ŌöĆŌöĆ unlabeled2017
+Ōöé Ōöé Ōö£ŌöĆŌöĆ val2017
+```
+
+’╝ł2’╝ēÕ░å `train2017` õĮ£õĖ║µĀćńŁŠµĢ░µŹ«ķøå’╝ī`unlabeled2017` õĮ£õĖ║µŚĀµĀćńŁŠµĢ░µŹ«ķøåŃĆéńö▒õ║Ä `image_info_unlabeled2017.json` µ▓Īµ£ē `categories` õ┐Īµü»’╝īµŚĀµ│ĢÕłØÕ¦ŗÕī¢ `CocoDataset` ’╝īµēĆõ╗źķ£ĆĶ”üÕ░å `instances_train2017.json` ńÜä `categories` ÕåÖÕģź `image_info_unlabeled2017.json` ’╝īÕÅ”ÕŁśõĖ║ `instances_unlabeled2017.json`’╝īńøĖÕģ│Ķäܵ£¼Õ”éõĖŗ’╝Ü
+
+```python
+from mmengine.fileio import load, dump
+
+anns_train = load('instances_train2017.json')
+anns_unlabeled = load('image_info_unlabeled2017.json')
+anns_unlabeled['categories'] = anns_train['categories']
+dump(anns_unlabeled, 'instances_unlabeled2017.json')
+```
+
+ÕżäńÉåÕÉÄńÜäµĢ░µŹ«ķøåńø«ÕĮĢÕ”éõĖŗ’╝Ü
+
+```plain
+mmdetection
+Ōö£ŌöĆŌöĆ data
+Ōöé Ōö£ŌöĆŌöĆ coco
+Ōöé Ōöé Ōö£ŌöĆŌöĆ annotations
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ image_info_unlabeled2017.json
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ instances_train2017.json
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ instances_unlabeled2017.json
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ instances_val2017.json
+Ōöé Ōöé Ōö£ŌöĆŌöĆ test2017
+Ōöé Ōöé Ōö£ŌöĆŌöĆ train2017
+Ōöé Ōöé Ōö£ŌöĆŌöĆ unlabeled2017
+Ōöé Ōöé Ōö£ŌöĆŌöĆ val2017
+```
+
+## ķģŹńĮ«ÕżÜÕłåµö»µĢ░µŹ«µĄüń©ŗ
+
+ÕŹŖńøæńØŻÕŁ”õ╣Āµ£ēõĖżõĖ¬õĖ╗Ķ”üńÜäµ¢╣µ│Ģ’╝īÕłåÕł½µś»
+[õĖĆĶć┤µĆ¦µŁŻÕłÖÕī¢](https://research.nvidia.com/sites/default/files/publications/laine2017iclr_paper.pdf)
+ÕÆī[õ╝¬µĀćńŁŠ](https://www.researchgate.net/profile/Dong-Hyun-Lee/publication/280581078_Pseudo-Label_The_Simple_and_Efficient_Semi-Supervised_Learning_Method_for_Deep_Neural_Networks/links/55bc4ada08ae092e9660b776/Pseudo-Label-The-Simple-and-Efficient-Semi-Supervised-Learning-Method-for-Deep-Neural-Networks.pdf) ŃĆé
+õĖĆĶć┤µĆ¦µŁŻÕłÖÕī¢ÕŠĆÕŠĆķ£ĆĶ”üõĖĆõ║øń▓ŠÕ┐āńÜäĶ«ŠĶ«Ī’╝īĶĆīõ╝¬µĀćńŁŠńÜäÕĮóÕ╝ŵ»öĶŠāń«ĆÕŹĢ’╝īµø┤Õ«╣µśōµŗōÕ▒ĢÕł░õĖŗµĖĖõ╗╗ÕŖĪŃĆ鵳æõ╗¼õĖ╗Ķ”üķććńö©õ║åÕ¤║õ║Äõ╝¬µĀćńŁŠńÜäµĢÖÕĖłÕŁ”ńö¤ĶüöÕÉłĶ«Łń╗āńÜäÕŹŖńøæńØŻńø«µĀ浯ƵĄŗµĪåµ×Č’╝īÕ»╣õ║ĵĀćńŁŠµĢ░µŹ«ÕÆīµŚĀµĀćńŁŠµĢ░µŹ«ķ£ĆĶ”üķģŹńĮ«õĖŹÕÉīńÜäµĢ░µŹ«µĄüń©ŗ’╝Ü
+’╝ł1’╝ēµĀćńŁŠµĢ░µŹ«ńÜäµĢ░µŹ«µĄüń©ŗ’╝Ü
+
+```python
+# pipeline used to augment labeled data,
+# which will be sent to student model for supervised training.
+sup_pipeline = [
+ dict(type='LoadImageFromFile',backend_args = backend_args),
+ dict(type='LoadAnnotations', with_bbox=True),
+ dict(type='RandomResize', scale=scale, keep_ratio=True),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='RandAugment', aug_space=color_space, aug_num=1),
+ dict(type='FilterAnnotations', min_gt_bbox_wh=(1e-2, 1e-2)),
+ dict(type='MultiBranch', sup=dict(type='PackDetInputs'))
+]
+```
+
+’╝ł2’╝ēµŚĀµĀćńŁŠńÜäµĢ░µŹ«µĄüń©ŗ’╝Ü
+
+```python
+# pipeline used to augment unlabeled data weakly,
+# which will be sent to teacher model for predicting pseudo instances.
+weak_pipeline = [
+ dict(type='RandomResize', scale=scale, keep_ratio=True),
+ dict(type='RandomFlip', prob=0.5),
+ dict(
+ type='PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor', 'flip', 'flip_direction',
+ 'homography_matrix')),
+]
+
+# pipeline used to augment unlabeled data strongly,
+# which will be sent to student model for unsupervised training.
+strong_pipeline = [
+ dict(type='RandomResize', scale=scale, keep_ratio=True),
+ dict(type='RandomFlip', prob=0.5),
+ dict(
+ type='RandomOrder',
+ transforms=[
+ dict(type='RandAugment', aug_space=color_space, aug_num=1),
+ dict(type='RandAugment', aug_space=geometric, aug_num=1),
+ ]),
+ dict(type='RandomErasing', n_patches=(1, 5), ratio=(0, 0.2)),
+ dict(type='FilterAnnotations', min_gt_bbox_wh=(1e-2, 1e-2)),
+ dict(
+ type='PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor', 'flip', 'flip_direction',
+ 'homography_matrix')),
+]
+
+# pipeline used to augment unlabeled data into different views
+unsup_pipeline = [
+ dict(type='LoadImageFromFile', backend_args = backend_args),
+ dict(type='LoadEmptyAnnotations'),
+ dict(
+ type='MultiBranch',
+ unsup_teacher=weak_pipeline,
+ unsup_student=strong_pipeline,
+ )
+]
+```
+
+## ķģŹńĮ«ÕŹŖńøæńØŻµĢ░µŹ«ÕŖĀĶĮĮ
+
+’╝ł1’╝ēµ×äÕ╗║ÕŹŖńøæńØŻµĢ░µŹ«ķøåŃĆéõĮ┐ńö© `ConcatDataset` µŗ╝µÄźµĀćńŁŠµĢ░µŹ«ķøåÕÆīµŚĀµĀćńŁŠµĢ░µŹ«ķøåŃĆé
+
+```python
+labeled_dataset = dict(
+ type=dataset_type,
+ data_root=data_root,
+ ann_file='annotations/instances_train2017.json',
+ data_prefix=dict(img='train2017/'),
+ filter_cfg=dict(filter_empty_gt=True, min_size=32),
+ pipeline=sup_pipeline)
+
+unlabeled_dataset = dict(
+ type=dataset_type,
+ data_root=data_root,
+ ann_file='annotations/instances_unlabeled2017.json',
+ data_prefix=dict(img='unlabeled2017/'),
+ filter_cfg=dict(filter_empty_gt=False),
+ pipeline=unsup_pipeline)
+
+train_dataloader = dict(
+ batch_size=batch_size,
+ num_workers=num_workers,
+ persistent_workers=True,
+ sampler=dict(
+ type='GroupMultiSourceSampler',
+ batch_size=batch_size,
+ source_ratio=[1, 4]),
+ dataset=dict(
+ type='ConcatDataset', datasets=[labeled_dataset, unlabeled_dataset]))
+```
+
+’╝ł2’╝ēõĮ┐ńö©ÕżÜµ║ɵĢ░µŹ«ķøåķććµĀĘÕÖ©ŃĆé õĮ┐ńö© `GroupMultiSourceSampler` õ╗Ä `labeled_dataset` ÕÆī `labeled_dataset` ķććµĀʵĢ░µŹ«ń╗äµłÉ batch , `source_ratio` µÄ¦ÕłČ batch õĖŁµĀćńŁŠµĢ░µŹ«ÕÆīµŚĀµĀćńŁŠµĢ░µŹ«ńÜäÕŹĀµ»öŃĆé`GroupMultiSourceSampler` Ķ┐śõ┐ØĶ»üõ║åÕÉīõĖĆõĖ¬ batch õĖŁńÜäÕøŠńēćÕģʵ£ēńøĖĶ┐æńÜäķĢ┐Õ«Įµ»öõŠŗ’╝īÕ”éµ×£õĖŹķ£ĆĶ”üõ┐ØĶ»übatchÕåģÕøŠńēćńÜäķĢ┐Õ«Įµ»öõŠŗ’╝īÕÅ»õ╗źõĮ┐ńö© `MultiSourceSampler`ŃĆé`GroupMultiSourceSampler` ķććµĀĘńż║µäÅÕøŠÕ”éõĖŗ’╝Ü
+
+
+
+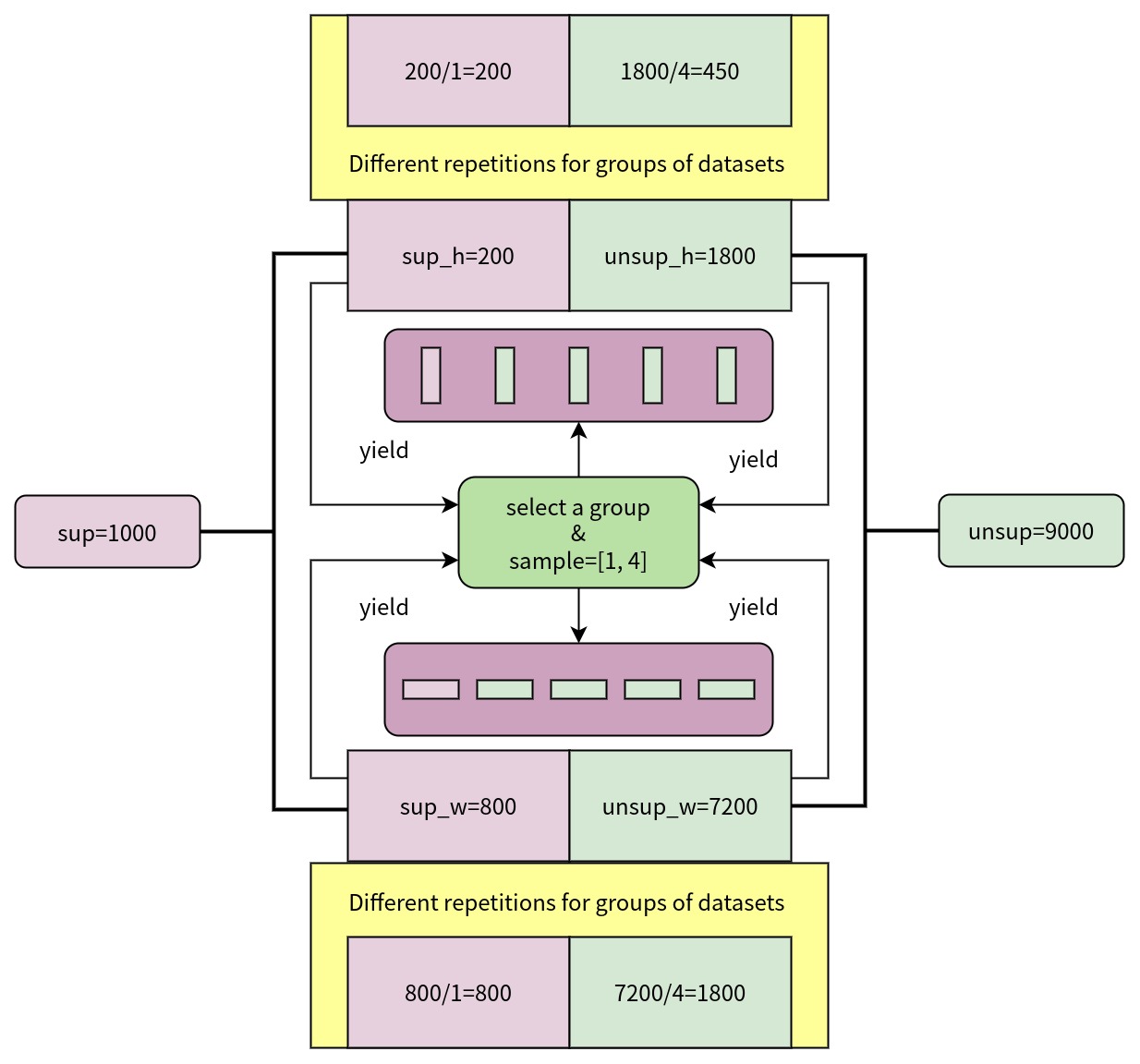 +
+
+
+`sup=1000` ĶĪ©ńż║µĀćńŁŠµĢ░µŹ«ķøåńÜäĶ¦äµ©ĪõĖ║ 1000 ’╝ī`sup_h=200` ĶĪ©ńż║µĀćńŁŠµĢ░µŹ«ķøåõĖŁķĢ┐Õ«Įµ»öÕż¦õ║ÄńŁēõ║Ä1ńÜäÕøŠńēćĶ¦äµ©ĪõĖ║ 200’╝ī`sup_w=800` ĶĪ©ńż║µĀćńŁŠµĢ░µŹ«ķøåõĖŁķĢ┐Õ«Įµ»öÕ░Åõ║Ä1ńÜäÕøŠńēćĶ¦äµ©ĪõĖ║ 800 ’╝ī`unsup=9000` ĶĪ©ńż║µŚĀµĀćńŁŠµĢ░µŹ«ķøåńÜäĶ¦äµ©ĪõĖ║ 9000 ’╝ī`unsup_h=1800` ĶĪ©ńż║µŚĀµĀćńŁŠµĢ░µŹ«ķøåõĖŁķĢ┐Õ«Įµ»öÕż¦õ║ÄńŁēõ║Ä1ńÜäÕøŠńēćĶ¦äµ©ĪõĖ║ 1800’╝ī`unsup_w=7200` ĶĪ©ńż║µĀćńŁŠµĢ░µŹ«ķøåõĖŁķĢ┐Õ«Įµ»öÕ░Åõ║Ä1ńÜäÕøŠńēćĶ¦äµ©ĪõĖ║ 7200 ’╝ī`GroupMultiSourceSampler` µ»Åµ¼Īµīēńģ¦µĀćńŁŠµĢ░µŹ«ķøåÕÆīµŚĀµĀćńŁŠµĢ░µŹ«ķøåńÜäÕøŠńēćńÜäµĆ╗õĮōķĢ┐Õ«Įµ»öÕłåÕĖāķÜŵ£║ķĆēµŗ®õĖĆń╗ä’╝īńäČÕÉĵīēńģ¦ `source_ratio` õ╗ÄõĖżõĖ¬µĢ░µŹ«ķøåõĖŁķććµĀĘń╗äµłÉ batch ’╝īÕøĀµŁżµĀćńŁŠµĢ░µŹ«ķøåÕÆīµŚĀµĀćńŁŠµĢ░µŹ«ķøåķćŹÕżŹķććµĀʵ¼ĪµĢ░õĖŹÕÉīŃĆé
+
+## ķģŹńĮ«ÕŹŖńøæńØŻµ©ĪÕ×ŗ
+
+µłæõ╗¼ķĆēµŗ® `Faster R-CNN` õĮ£õĖ║ `detector` Ķ┐øĶĪīÕŹŖńøæńØŻĶ«Łń╗ā’╝īõ╗źÕŹŖńøæńØŻńø«µĀ浯ƵĄŗń«Śµ│Ģ `SoftTeacher` õĖ║õŠŗ’╝īµ©ĪÕ×ŗńÜäķģŹńĮ«ÕÅ»õ╗źń╗¦µē┐ `_base_/models/faster-rcnn_r50_fpn.py`’╝īÕ░åµŻĆµĄŗÕÖ©ńÜäķ¬©Õ╣▓ńĮæń╗£µø┐µŹóµłÉ `caffe` ķŻÄµĀ╝ŃĆé
+µ│©µäÅ’╝īõĖÄńøæńØŻĶ«Łń╗āńÜäķģŹńĮ«µ¢ćõ╗ČõĖŹÕÉīńÜ䵜»’╝ī`Faster R-CNN` õĮ£õĖ║ `detector`’╝īµś»õĮ£õĖ║ `model`ńÜäõĖĆõĖ¬Õ▒׵Ʀ’╝īĶĆīõĖŹµś» `model` ŃĆ鵣żÕż¢’╝īĶ┐śķ£ĆĶ”üÕ░å`data_preprocessor`Ķ«ŠńĮ«õĖ║`MultiBranchDataPreprocessor`’╝īńö©õ║ÄÕżäńÉåõĖŹÕÉīµĢ░µŹ«µĄüń©ŗÕøŠńēćńÜäÕĪ½ÕģģÕÆīÕĮÆõĖĆÕī¢ŃĆé
+µ£ĆÕÉÄ’╝īÕÅ»õ╗źķĆÜĶ┐ć `semi_train_cfg` ÕÆī `semi_test_cfg` ķģŹńĮ«ÕŹŖńøæńØŻĶ«Łń╗āÕÆīµĄŗĶ»Ģķ£ĆĶ”üńÜäÕÅéµĢ░ŃĆé
+
+```python
+_base_ = [
+ '../_base_/models/faster-rcnn_r50_fpn.py', '../_base_/default_runtime.py',
+ '../_base_/datasets/semi_coco_detection.py'
+]
+
+detector = _base_.model
+detector.data_preprocessor = dict(
+ type='DetDataPreprocessor',
+ mean=[103.530, 116.280, 123.675],
+ std=[1.0, 1.0, 1.0],
+ bgr_to_rgb=False,
+ pad_size_divisor=32)
+detector.backbone = dict(
+ type='ResNet',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ frozen_stages=1,
+ norm_cfg=dict(type='BN', requires_grad=False),
+ norm_eval=True,
+ style='caffe',
+ init_cfg=dict(
+ type='Pretrained',
+ checkpoint='open-mmlab://detectron2/resnet50_caffe'))
+
+model = dict(
+ _delete_=True,
+ type='SoftTeacher',
+ detector=detector,
+ data_preprocessor=dict(
+ type='MultiBranchDataPreprocessor',
+ data_preprocessor=detector.data_preprocessor),
+ semi_train_cfg=dict(
+ freeze_teacher=True,
+ sup_weight=1.0,
+ unsup_weight=4.0,
+ pseudo_label_initial_score_thr=0.5,
+ rpn_pseudo_thr=0.9,
+ cls_pseudo_thr=0.9,
+ reg_pseudo_thr=0.02,
+ jitter_times=10,
+ jitter_scale=0.06,
+ min_pseudo_bbox_wh=(1e-2, 1e-2)),
+ semi_test_cfg=dict(predict_on='teacher'))
+```
+
+µŁżÕż¢’╝īµłæõ╗¼õ╣¤µö»µīüÕģČõ╗¢µŻĆµĄŗµ©ĪÕ×ŗĶ┐øĶĪīÕŹŖńøæńØŻĶ«Łń╗ā’╝īµ»öÕ”é’╝ī`RetinaNet` ÕÆī `Cascade R-CNN`ŃĆéńö▒õ║Ä `SoftTeacher` õ╗ģµö»µīü `Faster R-CNN`’╝īµēĆõ╗źķ£ĆĶ”üÕ░åÕģȵø┐µŹóõĖ║ `SemiBaseDetector`’╝īńż║õŠŗÕ”éõĖŗ’╝Ü
+
+```python
+_base_ = [
+ '../_base_/models/retinanet_r50_fpn.py', '../_base_/default_runtime.py',
+ '../_base_/datasets/semi_coco_detection.py'
+]
+
+detector = _base_.model
+
+model = dict(
+ _delete_=True,
+ type='SemiBaseDetector',
+ detector=detector,
+ data_preprocessor=dict(
+ type='MultiBranchDataPreprocessor',
+ data_preprocessor=detector.data_preprocessor),
+ semi_train_cfg=dict(
+ freeze_teacher=True,
+ sup_weight=1.0,
+ unsup_weight=1.0,
+ cls_pseudo_thr=0.9,
+ min_pseudo_bbox_wh=(1e-2, 1e-2)),
+ semi_test_cfg=dict(predict_on='teacher'))
+```
+
+µ▓┐ńö© `SoftTeacher` ńÜäÕŹŖńøæńØŻĶ«Łń╗āķģŹńĮ«’╝īÕ░å `batch_size` µö╣õĖ║ 2 ’╝ī`source_ratio` µö╣õĖ║ `[1, 1]`’╝ī`RetinaNet`’╝ī`Faster R-CNN`’╝ī `Cascade R-CNN` õ╗źÕÅŖ `SoftTeacher` Õ£© 10% coco Ķ«Łń╗āķøåõĖŖńÜäńøæńØŻĶ«Łń╗āÕÆīÕŹŖńøæńØŻĶ«Łń╗āńÜäÕ«×ķ¬īń╗ōµ×£Õ”éõĖŗ’╝Ü
+
+| Model | Detector | BackBone | Style | sup-0.1-coco mAP | semi-0.1-coco mAP |
+| :--------------: | :-----------: | :------: | :---: | :--------------: | :---------------: |
+| SemiBaseDetector | RetinaNet | R-50-FPN | caffe | 23.5 | 27.7 |
+| SemiBaseDetector | Faster R-CNN | R-50-FPN | caffe | 26.7 | 28.4 |
+| SemiBaseDetector | Cascade R-CNN | R-50-FPN | caffe | 28.0 | 29.7 |
+| SoftTeacher | Faster R-CNN | R-50-FPN | caffe | 26.7 | 31.1 |
+
+## ķģŹńĮ«MeanTeacherHook
+
+ķĆÜÕĖĖ’╝īµĢÖÕĖłµ©ĪÕ×ŗķććńö©Õ»╣ÕŁ”ńö¤µ©ĪÕ×ŗµīćµĢ░µ╗æÕŖ©Õ╣│ÕØć’╝łEMA’╝ēńÜäµ¢╣Õ╝ÅĶ┐øĶĪīµø┤µ¢░’╝īĶ┐øĶĆīµĢÖÕĖłµ©ĪÕ×ŗķÜÅńØĆÕŁ”ńö¤µ©ĪÕ×ŗńÜäõ╝śÕī¢ĶĆīõ╝śÕī¢’╝īÕÅ»õ╗źķĆÜĶ┐ćķģŹńĮ« `custom_hooks` Õ«×ńÄ░’╝Ü
+
+```python
+custom_hooks = [dict(type='MeanTeacherHook')]
+```
+
+## ķģŹńĮ«TeacherStudentValLoop
+
+ńö▒õ║ĵĢÖÕĖłÕŁ”ńö¤ĶüöÕÉłĶ«Łń╗āµĪåµ×ČÕŁśÕ£©õĖżõĖ¬µ©ĪÕ×ŗ’╝īµłæõ╗¼ÕÅ»õ╗źńö© `TeacherStudentValLoop` µø┐µŹó `ValLoop`’╝īÕ£©Ķ«Łń╗āńÜäĶ┐ćń©ŗõĖŁÕÉīµŚČµŻĆķ¬īõĖżõĖ¬µ©ĪÕ×ŗńÜäń▓ŠÕ║”ŃĆé
+
+```python
+val_cfg = dict(type='TeacherStudentValLoop')
+```
diff --git a/internlm_langchain/knowledge_base/MMDetection/content/single_stage_as_rpn.md b/internlm_langchain/knowledge_base/MMDetection/content/single_stage_as_rpn.md
new file mode 100644
index 00000000..39db35c2
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection/content/single_stage_as_rpn.md
@@ -0,0 +1,171 @@
+# Õ░åÕŹĢķśČµ«ĄµŻĆµĄŗÕÖ©õĮ£õĖ║ RPN
+
+ÕĆÖķĆēÕī║Õ¤¤ńĮæń╗£ (Region Proposal Network, RPN) õĮ£õĖ║ [Faster R-CNN](https://arxiv.org/abs/1506.01497) ńÜäõĖĆõĖ¬ÕŁÉµ©ĪÕØŚ’╝īÕ░åõĖ║ Faster R-CNN ńÜäń¼¼õ║īķśČµ«Ąõ║¦ńö¤ÕĆÖķĆēÕī║Õ¤¤ŃĆéÕ£© MMDetection ķćīÕż¦ÕżÜµĢ░ńÜäõ║īķśČµ«ĄµŻĆµĄŗÕÖ©õĮ┐ńö© [`RPNHead`](../../../mmdet/models/dense_heads/rpn_head.py)õĮ£õĖ║ÕĆÖķĆēÕī║Õ¤¤ńĮæń╗£µØźõ║¦ńö¤ÕĆÖķĆēÕī║Õ¤¤ŃĆéńäČĶĆī’╝īõ╗╗õĮĢńÜäÕŹĢķśČµ«ĄµŻĆµĄŗÕÖ©ķāĮÕÅ»õ╗źõĮ£õĖ║ÕĆÖķĆēÕī║Õ¤¤ńĮæń╗£’╝īµś»ÕøĀõĖ║õ╗¢õ╗¼Õ»╣ĶŠ╣ńĢīµĪåńÜäķó䵥ŗÕÅ»õ╗źĶó½Ķ¦åõĖ║µś»õĖĆń¦ŹÕĆÖķĆēÕī║Õ¤¤’╝īÕ╣ČõĖöÕøĀµŁżĶāĮÕż¤Õ£© R-CNN õĖŁÕŠŚÕł░µö╣Ķ┐øŃĆéÕøĀµŁżÕ£© MMDetection v3.0 õĖŁõ╝ܵö»µīüÕ░åÕŹĢķśČµ«ĄµŻĆµĄŗÕÖ©õĮ£õĖ║ RPN õĮ┐ńö©ŃĆé
+
+µÄźõĖŗµØźµłæõ╗¼ķĆÜĶ┐ćõĖĆõĖ¬õŠŗÕŁÉ’╝īÕŹ│Õ”éõĮĢÕ£© [Faster R-CNN](../../../configs/faster_rcnn/faster-rcnn_r50_fpn_fcos-rpn_1x_coco.py) õĖŁõĮ┐ńö©õĖĆõĖ¬µŚĀķöܵĪåńÜäÕŹĢķśČµ«ĄńÜ䵯ƵĄŗÕÖ©µ©ĪÕ×ŗ [FCOS](../../../configs/fcos/fcos_r50-caffe_fpn_gn-head_1x_coco.py) õĮ£õĖ║ RPN ’╝īĶ»”ń╗åķśÉĶ┐░ÕģĘõĮōńÜäÕģ©ķā©µĄüń©ŗŃĆé
+
+õĖ╗Ķ”üµĄüń©ŗÕ”éõĖŗ:
+
+1. Õ£© Faster R-CNN õĖŁõĮ┐ńö© `FCOSHead` õĮ£õĖ║ `RPNHead`
+2. Ķ»äõ╝░ÕĆÖķĆēÕī║Õ¤¤
+3. ńö©ķóäÕģłĶ«Łń╗āńÜä FCOS Ķ«Łń╗āÕ«ÜÕłČńÜä Faster R-CNN
+
+## Õ£© Faster R-CNN õĖŁõĮ┐ńö© `FCOSHead` õĮ£õĖ║` RPNHead`
+
+õĖ║õ║åÕ£© Faster R-CNN õĖŁõĮ┐ńö© `FCOSHead` õĮ£õĖ║ `RPNHead` ’╝īµłæõ╗¼Õ║öĶ»źÕłøÕ╗║õĖĆõĖ¬ÕÉŹõĖ║ `configs/faster_rcnn/faster-rcnn_r50_fpn_fcos-rpn_1x_coco.py` ńÜäķģŹńĮ«µ¢ćõ╗Č’╝īÕ╣ČõĖöÕ£© `configs/faster_rcnn/faster-rcnn_r50_fpn_fcos-rpn_1x_coco.py` õĖŁÕ░å `rpn_head` ńÜäĶ«ŠńĮ«µø┐µŹóõĖ║ `bbox_head` ńÜäĶ«ŠńĮ«’╝īµŁżÕż¢µłæõ╗¼õ╗ŹńäČõĮ┐ńö© FCOS ńÜäńōČķółĶ«ŠńĮ«’╝īµŁźÕ╣ģõĖ║`[8,16,32,64,128]`’╝īÕ╣ČõĖöµø┤µ¢░ `bbox_roi_extractor` ńÜä `featmap_stride` õĖ║ ` [8,16,32,64,128]`ŃĆéõĖ║õ║åķü┐ÕģŹµŹ¤Õż▒ÕÅśµģó’╝īµłæõ╗¼Õ£©ÕēŹ1000µ¼ĪĶ┐Łõ╗ŻĶĆīõĖŹµś»ÕēŹ500µ¼ĪĶ┐Łõ╗ŻõĖŁÕ║öńö©ķóäńāŁ’╝īĶ┐ÖµäÅÕæ│ńØĆ lr Õó×ķĢ┐ÕŠŚµø┤µģóŃĆéńøĖÕģ│ķģŹńĮ«Õ”éõĖŗ:
+
+```python
+_base_ = [
+ '../_base_/models/faster-rcnn_r50_fpn.py',
+ '../_base_/datasets/coco_detection.py',
+ '../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py'
+]
+model = dict(
+ # õ╗Ä configs/fcos/fcos_r50-caffe_fpn_gn-head_1x_coco.py ÕżŹÕłČ
+ neck=dict(
+ start_level=1,
+ add_extra_convs='on_output', # õĮ┐ńö© P5
+ relu_before_extra_convs=True),
+ rpn_head=dict(
+ _delete_=True, # Õ┐ĮńĢźµ£¬õĮ┐ńö©ńÜ䵌¦Ķ«ŠńĮ«
+ type='FCOSHead',
+ num_classes=1, # Õ»╣õ║Ä rpn, num_classes = 1’╝īÕ”éµ×£ num_classes > 1’╝īÕ«āÕ░åÕ£© TwoStageDetector õĖŁĶć¬ÕŖ©Ķ«ŠńĮ«õĖ║1
+ in_channels=256,
+ stacked_convs=4,
+ feat_channels=256,
+ strides=[8, 16, 32, 64, 128],
+ loss_cls=dict(
+ type='FocalLoss',
+ use_sigmoid=True,
+ gamma=2.0,
+ alpha=0.25,
+ loss_weight=1.0),
+ loss_bbox=dict(type='IoULoss', loss_weight=1.0),
+ loss_centerness=dict(
+ type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0)),
+ roi_head=dict( # featmap_strides ńÜäµø┤µ¢░ÕÅ¢Õå│õ║Äõ║Äķółķā©ńÜ䵣źõ╝É
+ bbox_roi_extractor=dict(featmap_strides=[8, 16, 32, 64, 128])))
+# ÕŁ”õ╣ĀńÄć
+param_scheduler = [
+ dict(
+ type='LinearLR', start_factor=0.001, by_epoch=False, begin=0,
+ end=1000), # µģóµģóÕó×ÕŖĀ lr’╝īÕÉ”ÕłÖµŹ¤Õż▒ÕÅśµłÉ NAN
+ dict(
+ type='MultiStepLR',
+ begin=0,
+ end=12,
+ by_epoch=True,
+ milestones=[8, 11],
+ gamma=0.1)
+]
+```
+
+ńäČÕÉÄ’╝īµłæõ╗¼ÕÅ»õ╗źõĮ┐ńö©õĖŗķØóńÜäÕæĮõ╗żµØźĶ«Łń╗āµłæõ╗¼ńÜäÕ«ÜÕłČµ©ĪÕ×ŗŃĆéµø┤ÕżÜĶ«Łń╗āÕæĮõ╗ż’╝īĶ»ĘÕÅéĶĆā[Ķ┐Öķćī](train.md)ŃĆé
+
+```python
+# õĮ┐ńö©8õĖ¬ GPU Ķ┐øĶĪīĶ«Łń╗ā
+bash
+tools/dist_train.sh
+configs/faster_rcnn/faster-rcnn_r50_fpn_fcos-rpn_1x_coco.py
+--work-dir /work_dirs/faster-rcnn_r50_fpn_fcos-rpn_1x_coco
+```
+
+## Ķ»äõ╝░ÕĆÖķĆēÕī║Õ¤¤
+
+ÕĆÖķĆēÕī║Õ¤¤ńÜäĶ┤©ķćÅÕ»╣µŻĆµĄŗÕÖ©ńÜäµĆ¦ĶāĮµ£ēķćŹĶ”üÕĮ▒ÕōŹ’╝īÕøĀµŁż’╝īµłæõ╗¼õ╣¤µÅÉõŠøõ║åõĖĆń¦ŹĶ»äõ╝░ÕĆÖķĆēÕī║Õ¤¤ńÜäµ¢╣µ│ĢŃĆéÕÆīõĖŖķØóõĖƵĀĘÕłøÕ╗║õĖĆõĖ¬µ¢░ńÜäÕÉŹõĖ║ `configs/rpn/fcos-rpn_r50_fpn_1x_coco.py` ńÜäķģŹńĮ«µ¢ćõ╗Č’╝īÕ╣ČõĖöÕ£© `configs/rpn/fcos-rpn_r50_fpn_1x_coco.py` õĖŁÕ░å `rpn_head` ńÜäĶ«ŠńĮ«µø┐µŹóõĖ║ `bbox_head` ńÜäĶ«ŠńĮ«ŃĆé
+
+```python
+_base_ = [
+ '../_base_/models/rpn_r50_fpn.py', '../_base_/datasets/coco_detection.py',
+ '../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py'
+]
+val_evaluator = dict(metric='proposal_fast')
+test_evaluator = val_evaluator
+model = dict(
+ # õ╗Ä configs/fcos/fcos_r50-caffe_fpn_gn-head_1x_coco.py ÕżŹÕłČ
+ neck=dict(
+ start_level=1,
+ add_extra_convs='on_output', # õĮ┐ńö© P5
+ relu_before_extra_convs=True),
+ rpn_head=dict(
+ _delete_=True, # Õ┐ĮńĢźµ£¬õĮ┐ńö©ńÜ䵌¦Ķ«ŠńĮ«
+ type='FCOSHead',
+ num_classes=1, # Õ»╣õ║Ä rpn, num_classes = 1’╝īÕ”éµ×£ num_classes >õĖ║1’╝īÕ«āÕ░åÕ£© rpn õĖŁĶć¬ÕŖ©Ķ«ŠńĮ«õĖ║1
+ in_channels=256,
+ stacked_convs=4,
+ feat_channels=256,
+ strides=[8, 16, 32, 64, 128],
+ loss_cls=dict(
+ type='FocalLoss',
+ use_sigmoid=True,
+ gamma=2.0,
+ alpha=0.25,
+ loss_weight=1.0),
+ loss_bbox=dict(type='IoULoss', loss_weight=1.0),
+ loss_centerness=dict(
+ type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0)))
+```
+
+ÕüćĶ«Šµłæõ╗¼Õ£©Ķ«Łń╗āõ╣ŗÕÉĵ£ēµŻĆµ¤źńé╣ `./work_dirs/faster-rcnn_r50_fpn_fcos-rpn_1x_coco/epoch_12.pth` ’╝īńäČÕÉÄ’╝īµłæõ╗¼ÕÅ»õ╗źõĮ┐ńö©õĖŗķØóńÜäÕæĮõ╗żµØźĶ»äõ╝░Õ╗║Ķ««ńÜäĶ┤©ķćÅŃĆé
+
+```python
+# õĮ┐ńö©8õĖ¬ GPU Ķ┐øĶĪīµĄŗĶ»Ģ
+bash
+tools/dist_test.sh
+configs/rpn/fcos-rpn_r50_fpn_1x_coco.py
+--work_dirs /faster-rcnn_r50_fpn_fcos-rpn_1x_coco/epoch_12.pth
+```
+
+## ńö©ķóäÕģłĶ«Łń╗āńÜä FCOS Ķ«Łń╗āÕ«ÜÕłČńÜä Faster R-CNN
+
+ķóäĶ«Łń╗āõĖŹõ╗ģÕŖĀÕ┐½õ║åĶ«Łń╗āńÜäµöȵĢøķƤÕ║”’╝īĶĆīõĖöµÅÉķ½śõ║åµŻĆµĄŗÕÖ©ńÜäµĆ¦ĶāĮŃĆéÕøĀµŁż’╝īµłæõ╗¼Õ£©Ķ┐Öķćīń╗ÖÕć║õĖĆõĖ¬õŠŗÕŁÉµØźĶ»┤µśÄÕ”éõĮĢõĮ┐ńö©ķóäÕģłĶ«Łń╗āńÜä FCOS õĮ£õĖ║ RPN µØźÕŖĀķƤĶ«Łń╗āÕÆīµÅÉķ½śń▓ŠÕ║”ŃĆéÕüćĶ«Šµłæõ╗¼µā│Õ£© Faster R-CNN õĖŁõĮ┐ńö© `FCOSHead` õĮ£õĖ║ `rpn_head`’╝īÕ╣ČÕŖĀĶĮĮķóäÕģłĶ«Łń╗āµØāķćŹµØźĶ┐øĶĪīĶ«Łń╗ā [`fcos_r50-caffe_fpn_gn-head_1x_coco`](https://download.openmmlab.com/mmdetection/v2.0/fcos/fcos_r50_caffe_fpn_gn-head_1x_coco/fcos_r50_caffe_fpn_gn-head_1x_coco-821213aa.pth)ŃĆé ķģŹńĮ«µ¢ćõ╗Č `configs/faster_rcnn/faster-rcnn_r50-caffe_fpn_fcos- rpn_1x_copy .py` ńÜäÕåģÕ«╣Õ”éõĖŗµēĆńż║ŃĆéµ│©µäÅ’╝ī`fcos_r50-caffe_fpn_gn-head_1x_coco` õĮ┐ńö© ResNet50 ńÜä caffe ńēłµ£¼’╝īÕøĀµŁżķ£ĆĶ”üµø┤µ¢░ `data_preprocessor` õĖŁńÜäÕāÅń┤ĀÕ╣│ÕØćÕĆ╝ÕÆī stdŃĆé
+
+```python
+_base_ = [
+ '../_base_/models/faster-rcnn_r50_fpn.py',
+ '../_base_/datasets/coco_detection.py',
+ '../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py'
+]
+model = dict(
+ data_preprocessor=dict(
+ mean=[103.530, 116.280, 123.675],
+ std=[1.0, 1.0, 1.0],
+ bgr_to_rgb=False),
+ backbone=dict(
+ norm_cfg=dict(type='BN', requires_grad=False),
+ style='caffe',
+ init_cfg=None), # the checkpoint in ``load_from`` contains the weights of backbone
+ neck=dict(
+ start_level=1,
+ add_extra_convs='on_output', # õĮ┐ńö© P5
+ relu_before_extra_convs=True),
+ rpn_head=dict(
+ _delete_=True, # Õ┐ĮńĢźµ£¬õĮ┐ńö©ńÜ䵌¦Ķ«ŠńĮ«
+ type='FCOSHead',
+ num_classes=1, # Õ»╣õ║Ä rpn, num_classes = 1’╝īÕ”éµ×£ num_classes > 1’╝īÕ«āÕ░åÕ£© TwoStageDetector õĖŁĶć¬ÕŖ©Ķ«ŠńĮ«õĖ║1
+ in_channels=256,
+ stacked_convs=4,
+ feat_channels=256,
+ strides=[8, 16, 32, 64, 128],
+ loss_cls=dict(
+ type='FocalLoss',
+ use_sigmoid=True,
+ gamma=2.0,
+ alpha=0.25,
+ loss_weight=1.0),
+ loss_bbox=dict(type='IoULoss', loss_weight=1.0),
+ loss_centerness=dict(
+ type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0)),
+ roi_head=dict( # update featmap_strides due to the strides in neck
+ bbox_roi_extractor=dict(featmap_strides=[8, 16, 32, 64, 128])))
+load_from = 'https://download.openmmlab.com/mmdetection/v2.0/fcos/fcos_r50_caffe_fpn_gn-head_1x_coco/fcos_r50_caffe_fpn_gn-head_1x_coco-821213aa.pth'
+```
+
+Ķ«Łń╗āÕæĮõ╗żÕ”éõĖŗŃĆé
+
+```python
+bash
+tools/dist_train.sh
+configs/faster_rcnn/faster-rcnn_r50-caffe_fpn_fcos-rpn_1x_coco.py \
+--work-dir /work_dirs/faster-rcnn_r50-caffe_fpn_fcos-rpn_1x_coco
+```
diff --git a/internlm_langchain/knowledge_base/MMDetection/content/structures.md b/internlm_langchain/knowledge_base/MMDetection/content/structures.md
new file mode 100644
index 00000000..c2118c34
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection/content/structures.md
@@ -0,0 +1 @@
+# µĢ░µŹ«ń╗ōµ×ä’╝łÕŠģµø┤µ¢░’╝ē
diff --git a/internlm_langchain/knowledge_base/MMDetection/content/test.md b/internlm_langchain/knowledge_base/MMDetection/content/test.md
new file mode 100644
index 00000000..1b165b04
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection/content/test.md
@@ -0,0 +1,285 @@
+# µĄŗĶ»ĢńÄ░µ£ēµ©ĪÕ×ŗ
+
+µłæõ╗¼µÅÉõŠøõ║åµĄŗĶ»ĢĶäܵ£¼’╝īĶāĮÕż¤µĄŗĶ»ĢõĖĆõĖ¬ńÄ░µ£ēµ©ĪÕ×ŗÕ£©µēƵ£ēµĢ░µŹ«ķøå’╝łCOCO’╝īPascal VOC’╝īCityscapes ńŁē’╝ēõĖŖńÜäµĆ¦ĶāĮŃĆ鵳æõ╗¼µö»µīüÕ£©Õ”éõĖŗńÄ»ÕóāõĖŗµĄŗĶ»Ģ’╝Ü
+
+- ÕŹĢ GPU µĄŗĶ»Ģ
+- CPU µĄŗĶ»Ģ
+- ÕŹĢĶŖéńé╣ÕżÜ GPU µĄŗĶ»Ģ
+- ÕżÜĶŖéńé╣µĄŗĶ»Ģ
+
+µĀ╣µŹ«õ╗źõĖŖµĄŗĶ»ĢńÄ»Õóā’╝īķĆēµŗ®ÕÉłķĆéńÜäĶäܵ£¼µØźµē¦ĶĪīµĄŗĶ»ĢĶ┐ćń©ŗŃĆé
+
+```shell
+# ÕŹĢ GPU µĄŗĶ»Ģ
+python tools/test.py \
+ ${CONFIG_FILE} \
+ ${CHECKPOINT_FILE} \
+ [--out ${RESULT_FILE}] \
+ [--show]
+
+# CPU µĄŗĶ»Ģ’╝Üń”üńö© GPU Õ╣ČĶ┐ÉĶĪīÕŹĢ GPU µĄŗĶ»ĢĶäܵ£¼
+export CUDA_VISIBLE_DEVICES=-1
+python tools/test.py \
+ ${CONFIG_FILE} \
+ ${CHECKPOINT_FILE} \
+ [--out ${RESULT_FILE}] \
+ [--show]
+
+# ÕŹĢĶŖéńé╣ÕżÜ GPU µĄŗĶ»Ģ
+bash tools/dist_test.sh \
+ ${CONFIG_FILE} \
+ ${CHECKPOINT_FILE} \
+ ${GPU_NUM} \
+ [--out ${RESULT_FILE}]
+```
+
+`tools/dist_test.sh` õ╣¤µö»µīüÕżÜĶŖéńé╣µĄŗĶ»Ģ’╝īõĖŹĶ┐ćķ£ĆĶ”üõŠØĶĄ¢ PyTorch ńÜä [ÕÉ»ÕŖ©ÕĘźÕģĘ](https://pytorch.org/docs/stable/distributed.html#launch-utility) ŃĆé
+
+ÕÅ»ķĆēÕÅéµĢ░’╝Ü
+
+- `RESULT_FILE`: ń╗ōµ×£µ¢ćõ╗ČÕÉŹń¦░’╝īķ£Ćõ╗ź .pkl ÕĮóÕ╝ÅÕŁśÕé©ŃĆéÕ”éµ×£µ▓Īµ£ēÕŻ░µśÄ’╝īÕłÖõĖŹÕ░åń╗ōµ×£ÕŁśÕé©Õł░µ¢ćõ╗ČŃĆé
+- `--show`: Õ”éµ×£Õ╝ĆÕÉ»’╝īµŻĆµĄŗń╗ōµ×£Õ░åĶó½ń╗śÕłČÕ£©ÕøŠÕāÅõĖŖ’╝īõ╗źõĖĆõĖ¬µ¢░ń¬ŚÕÅŻńÜäÕĮóÕ╝ÅÕ▒Ģńż║ŃĆéÕ«āÕŬķĆéńö©õ║ÄÕŹĢ GPU ńÜ䵥ŗĶ»Ģ’╝īµś»ńö©õ║ÄĶ░āĶ»ĢÕÆīÕÅ»Ķ¦åÕī¢ńÜäŃĆéĶ»ĘńĪ«õ┐ØõĮ┐ńö©µŁżÕŖ¤ĶāĮµŚČ’╝īõĮĀńÜä GUI ÕÅ»õ╗źÕ£©ńÄ»ÕóāõĖŁµēōÕ╝ĆŃĆéÕÉ”ÕłÖ’╝īõĮĀÕÅ»ĶāĮõ╝ÜķüćÕł░Ķ┐Öõ╣łõĖĆõĖ¬ķöÖĶ»» `cannot connect to X server`ŃĆé
+- `--show-dir`: Õ”éµ×£µī浜Ē╝īµŻĆµĄŗń╗ōµ×£Õ░åõ╝ÜĶó½ń╗śÕłČÕ£©ÕøŠÕāÅõĖŖÕ╣Čõ┐ØÕŁśÕł░µīćÕ«Üńø«ÕĮĢŃĆéÕ«āÕŬķĆéńö©õ║ÄÕŹĢ GPU ńÜ䵥ŗĶ»Ģ’╝īµś»ńö©õ║ÄĶ░āĶ»ĢÕÆīÕÅ»Ķ¦åÕī¢ńÜäŃĆéÕŹ│õĮ┐õĮĀńÜäńÄ»ÕóāõĖŁµ▓Īµ£ē GUI’╝īĶ┐ÖõĖ¬ķĆēķĪ╣õ╣¤ÕÅ»õĮ┐ńö©ŃĆé
+- `--cfg-options`: Õ”éµ×£µī浜Ē╝īĶ┐ÖķćīńÜäķö«ÕĆ╝Õ»╣Õ░åõ╝ÜĶó½ÕÉłÕ╣ČÕł░ķģŹńĮ«µ¢ćõ╗ČõĖŁŃĆé
+
+### µĀĘõŠŗ
+
+ÕüćĶ«ŠõĮĀÕĘ▓ń╗ÅõĖŗĶĮĮõ║å checkpoint µ¢ćõ╗ČÕł░ `checkpoints/` µ¢ćõ╗ČõĖŗõ║åŃĆé
+
+1. µĄŗĶ»Ģ RTMDet Õ╣ČÕÅ»Ķ¦åÕī¢ÕģČń╗ōµ×£ŃĆéµīēõ╗╗µäÅķö«ń╗¦ń╗ŁõĖŗÕ╝ĀÕøŠńēćńÜ䵥ŗĶ»ĢŃĆéķģŹńĮ«µ¢ćõ╗ČÕÆī checkpoint µ¢ćõ╗Č [Õ£©µŁż](https://github.com/open-mmlab/mmdetection/tree/main/configs/rtmdet) ŃĆé
+
+ ```shell
+ python tools/test.py \
+ configs/rtmdet/rtmdet_l_8xb32-300e_coco.py \
+ checkpoints/rtmdet_l_8xb32-300e_coco_20220719_112030-5a0be7c4.pth \
+ --show
+ ```
+
+2. µĄŗĶ»Ģ RTMDet’╝īÕ╣ČõĖ║õ║åõ╣ŗÕÉÄńÜäÕÅ»Ķ¦åÕī¢õ┐ØÕŁśń╗śÕłČńÜäÕøŠÕāÅŃĆéķģŹńĮ«µ¢ćõ╗ČÕÆī checkpoint µ¢ćõ╗Č [Õ£©µŁż](https://github.com/open-mmlab/mmdetection/tree/main/configs/rtmdet) ŃĆé
+
+ ```shell
+ python tools/test.py \
+ configs/rtmdet/rtmdet_l_8xb32-300e_coco.py \
+ checkpoints/rtmdet_l_8xb32-300e_coco_20220719_112030-5a0be7c4.pth \
+ --show-dir rtmdet_l_8xb32-300e_coco_results
+ ```
+
+3. Õ£© Pascal VOC µĢ░µŹ«ķøåõĖŖµĄŗĶ»Ģ Faster R-CNN’╝īõĖŹõ┐ØÕŁśµĄŗĶ»Ģń╗ōµ×£’╝īµĄŗĶ»Ģ `mAP`ŃĆéķģŹńĮ«µ¢ćõ╗ČÕÆī checkpoint µ¢ćõ╗Č [Õ£©µŁż](../../../configs/pascal_voc) ŃĆé
+
+ ```shell
+ python tools/test.py \
+ configs/pascal_voc/faster-rcnn_r50_fpn_1x_voc0712.py \
+ checkpoints/faster_rcnn_r50_fpn_1x_voc0712_20200624-c9895d40.pth
+ ```
+
+4. õĮ┐ńö© 8 ÕØŚ GPU µĄŗĶ»Ģ Mask R-CNN’╝īµĄŗĶ»Ģ `bbox` ÕÆī `mAP` ŃĆéķģŹńĮ«µ¢ćõ╗ČÕÆī checkpoint µ¢ćõ╗Č [Õ£©µŁż](../../../configs/mask_rcnn) ŃĆé
+
+ ```shell
+ ./tools/dist_test.sh \
+ configs/mask-rcnn_r50_fpn_1x_coco.py \
+ checkpoints/mask_rcnn_r50_fpn_1x_coco_20200205-d4b0c5d6.pth \
+ 8 \
+ --out results.pkl
+ ```
+
+5. õĮ┐ńö© 8 ÕØŚ GPU µĄŗĶ»Ģ Mask R-CNN’╝īµĄŗĶ»Ģ**µ»Åń▒╗**ńÜä `bbox` ÕÆī `mAP`ŃĆéķģŹńĮ«µ¢ćõ╗ČÕÆī checkpoint µ¢ćõ╗Č [Õ£©µŁż](../../../configs/mask_rcnn) ŃĆé
+
+ ```shell
+ ./tools/dist_test.sh \
+ configs/mask_rcnn/mask-rcnn_r50_fpn_1x_coco.py \
+ checkpoints/mask_rcnn_r50_fpn_1x_coco_20200205-d4b0c5d6.pth \
+ 8
+ ```
+
+ Ķ»źÕæĮõ╗żńö¤µłÉõĖżõĖ¬JSONµ¢ćõ╗Č `./work_dirs/coco_instance/test.bbox.json` ÕÆī `./work_dirs/coco_instance/test.segm.json`ŃĆé
+
+6. Õ£© COCO test-dev µĢ░µŹ«ķøåõĖŖ’╝īõĮ┐ńö© 8 ÕØŚ GPU µĄŗĶ»Ģ Mask R-CNN’╝īÕ╣Čńö¤µłÉ JSON µ¢ćõ╗ȵÅÉõ║żÕł░Õ«śµ¢╣Ķ»äµĄŗµ£ŹÕŖĪÕÖ©’╝īķģŹńĮ«µ¢ćõ╗ČÕÆī checkpoint µ¢ćõ╗Č [Õ£©µŁż](../../../configs/mask_rcnnn) ŃĆéõĮĀÕÅ»õ╗źÕ£© [config](./././configs/_base_/datasets/coco_instance.py) ńÜäµ│©ķćŖõĖŁńö© test_evaluator ÕÆī test_dataloader µø┐µŹóÕĤµØźńÜä test_evaluator ÕÆī test_dataloader’╝īńäČÕÉÄĶ┐ÉĶĪī’╝Ü
+
+ ```shell
+ ./tools/dist_test.sh \
+ configs/cityscapes/mask-rcnn_r50_fpn_1x_cityscapes.py \
+ checkpoints/mask_rcnn_r50_fpn_1x_cityscapes_20200227-afe51d5a.pth \
+ 8
+ ```
+
+ Ķ┐ÖĶĪīÕæĮõ╗żńö¤µłÉõĖżõĖ¬ JSON µ¢ćõ╗Č `mask_rcnn_test-dev_results.bbox.json` ÕÆī `mask_rcnn_test-dev_results.segm.json`ŃĆé
+
+7. Õ£© Cityscapes µĢ░µŹ«ķøåõĖŖ’╝īõĮ┐ńö© 8 ÕØŚ GPU µĄŗĶ»Ģ Mask R-CNN’╝īńö¤µłÉ txt ÕÆī png µ¢ćõ╗Č’╝īÕ╣ČõĖŖõ╝ĀÕł░Õ«śµ¢╣Ķ»äµĄŗµ£ŹÕŖĪÕÖ©ŃĆéķģŹńĮ«µ¢ćõ╗ČÕÆī checkpoint µ¢ćõ╗Č [Õ£©µŁż](../../../configs/cityscapes) ŃĆé õĮĀÕÅ»õ╗źÕ£© [config](./././configs/_base_/datasets/cityscapes_instance.py) ńÜäµ│©ķćŖõĖŁńö© test_evaluator ÕÆī test_dataloader µø┐µŹóÕĤµØźńÜä test_evaluator ÕÆī test_dataloader’╝īńäČÕÉÄĶ┐ÉĶĪī’╝Ü
+
+ ```shell
+ ./tools/dist_test.sh \
+ configs/cityscapes/mask-rcnn_r50_fpn_1x_cityscapes.py \
+ checkpoints/mask_rcnn_r50_fpn_1x_cityscapes_20200227-afe51d5a.pth \
+ 8
+ ```
+
+ ńö¤µłÉńÜä png ÕÆī txt µ¢ćõ╗ČÕ£© `./work_dirs/cityscapes_metric` µ¢ćõ╗ČÕż╣õĖŗŃĆé
+
+### õĖŹõĮ┐ńö© Ground Truth µĀćµ│©Ķ┐øĶĪīµĄŗĶ»Ģ
+
+MMDetection µö»µīüÕ£©õĖŹõĮ┐ńö© ground-truth µĀćµ│©ńÜäµāģÕåĄõĖŗÕ»╣µ©ĪÕ×ŗĶ┐øĶĪīµĄŗĶ»Ģ’╝īĶ┐Öķ£ĆĶ”üńö©Õł░ `CocoDataset`ŃĆéÕ”éµ×£õĮĀńÜäµĢ░µŹ«ķøåµĀ╝Õ╝ÅõĖŹµś» COCO µĀ╝Õ╝ÅńÜä’╝īĶ»ĘÕ░åÕģČĶĮ¼Õī¢µłÉ COCO µĀ╝Õ╝ÅŃĆéÕ”éµ×£õĮĀńÜäµĢ░µŹ«ķøåµĀ╝Õ╝ŵś» VOC µł¢ĶĆģ Cityscapes’╝īõĮĀÕÅ»õ╗źõĮ┐ńö© [tools/dataset_converters](https://github.com/open-mmlab/mmdetection/tree/main/tools/dataset_converters) ÕåģńÜäĶäܵ£¼ńø┤µÄźÕ░åÕģČĶĮ¼Õī¢µłÉ COCO µĀ╝Õ╝ÅŃĆéÕ”éµ×£µś»ÕģČõ╗¢µĀ╝Õ╝Å’╝īÕÅ»õ╗źõĮ┐ńö© [images2coco Ķäܵ£¼](https://github.com/open-mmlab/mmdetection/tree/master/tools/dataset_converters/images2coco.py) Ķ┐øĶĪīĶĮ¼µŹóŃĆé
+
+```shell
+python tools/dataset_converters/images2coco.py \
+ ${IMG_PATH} \
+ ${CLASSES} \
+ ${OUT} \
+ [--exclude-extensions]
+```
+
+ÕÅéµĢ░’╝Ü
+
+- `IMG_PATH`: ÕøŠńēćµĀ╣ĶĘ»ÕŠäŃĆé
+- `CLASSES`: ń▒╗ÕłŚĶĪ©µ¢ćµ£¼µ¢ćõ╗ČÕÉŹŃĆéµ¢ćµ£¼õĖŁµ»ÅõĖĆĶĪīÕŁśÕé©õĖĆõĖ¬ń▒╗Õł½ŃĆé
+- `OUT`: ĶŠōÕć║ json µ¢ćõ╗ČÕÉŹŃĆé ķ╗śĶ«żõ┐ØÕŁśńø«ÕĮĢÕÆī `IMG_PATH` Õ£©ÕÉīõĖĆń║¦ŃĆé
+- `exclude-extensions`: ÕŠģµÄÆķÖżńÜäµ¢ćõ╗ČÕÉÄń╝ĆÕÉŹŃĆé
+
+Õ£©ĶĮ¼µŹóÕ«īµłÉÕÉÄ’╝īõĮ┐ńö©Õ”éõĖŗÕæĮõ╗żĶ┐øĶĪīµĄŗĶ»Ģ
+
+```shell
+# ÕŹĢ GPU µĄŗĶ»Ģ
+python tools/test.py \
+ ${CONFIG_FILE} \
+ ${CHECKPOINT_FILE} \
+ [--show]
+
+# CPU µĄŗĶ»Ģ’╝Üń”üńö© GPU Õ╣ČĶ┐ÉĶĪīÕŹĢ GPU µĄŗĶ»ĢĶäܵ£¼
+export CUDA_VISIBLE_DEVICES=-1
+python tools/test.py \
+ ${CONFIG_FILE} \
+ ${CHECKPOINT_FILE} \
+ [--out ${RESULT_FILE}] \
+ [--show]
+
+# ÕŹĢĶŖéńé╣ÕżÜ GPU µĄŗĶ»Ģ
+bash tools/dist_test.sh \
+ ${CONFIG_FILE} \
+ ${CHECKPOINT_FILE} \
+ ${GPU_NUM} \
+ [--show]
+```
+
+ÕüćĶ«Š [model zoo](https://mmdetection.readthedocs.io/en/latest/modelzoo_statistics.html) õĖŁńÜä checkpoint µ¢ćõ╗ČĶó½õĖŗĶĮĮÕł░õ║å `checkpoints/` µ¢ćõ╗ČÕż╣õĖŗ’╝ī
+µłæõ╗¼ÕÅ»õ╗źõĮ┐ńö©õ╗źõĖŗÕæĮõ╗ż’╝īńö© 8 ÕØŚ GPU Õ£© COCO test-dev µĢ░µŹ«ķøåõĖŖµĄŗĶ»Ģ Mask R-CNN’╝īÕ╣ČõĖöńö¤µłÉ JSON µ¢ćõ╗ČŃĆé
+
+```sh
+./tools/dist_test.sh \
+ configs/mask_rcnn/mask-rcnn_r50_fpn_1x_coco.py \
+ checkpoints/mask_rcnn_r50_fpn_1x_coco_20200205-d4b0c5d6.pth \
+ 8
+```
+
+Ķ┐ÖĶĪīÕæĮõ╗żńö¤µłÉõĖżõĖ¬ JSON µ¢ćõ╗Č `./work_dirs/coco_instance/test.bbox.jso` ÕÆī `./work_dirs/coco_instance/test.segm.jsonn`ŃĆé
+
+### µē╣ķćŵĩńÉå
+
+MMDetection Õ£©µĄŗĶ»Ģµ©ĪÕ╝ÅõĖŗ’╝īµŚóµö»µīüÕŹĢÕ╝ĀÕøŠńēćńÜäµÄ©ńÉå’╝īõ╣¤µö»µīüÕ»╣ÕøŠÕāÅĶ┐øĶĪīµē╣ķćŵĩńÉåŃĆéķ╗śĶ«żµāģÕåĄõĖŗ’╝īµłæõ╗¼õĮ┐ńö©ÕŹĢÕ╝ĀÕøŠńēćńÜ䵥ŗĶ»Ģ’╝īõĮĀÕÅ»õ╗źķĆÜĶ┐ćõ┐«µö╣µĄŗĶ»ĢµĢ░µŹ«ķģŹńĮ«µ¢ćõ╗ČõĖŁńÜä `samples_per_gpu` µØźÕ╝ĆÕÉ»µē╣ķćŵĄŗĶ»ĢŃĆé
+Õ╝ĆÕÉ»µē╣ķćŵĩńÉåńÜäķģŹńĮ«µ¢ćõ╗Čõ┐«µö╣µ¢╣µ│ĢõĖ║’╝Ü
+
+```shell
+data = dict(train_dataloader=dict(...), val_dataloader=dict(...), test_dataloader=dict(batch_size=2, ...))
+```
+
+µł¢ĶĆģõĮĀÕÅ»õ╗źķĆÜĶ┐ćÕ░å `--cfg-options` Ķ«ŠńĮ«õĖ║ `--cfg-options test_dataloader.batch_size=` µØźÕ╝ĆÕɻիāŃĆé
+
+## µĄŗĶ»ĢµŚČÕó×Õ╝║ (TTA)
+
+µĄŗĶ»ĢµŚČÕó×Õ╝║ (TTA) µś»õĖĆń¦ŹÕ£©µĄŗĶ»ĢķśČµ«ĄõĮ┐ńö©ńÜäµĢ░µŹ«Õó×Õ╝║ńŁ¢ńĢźŃĆéÕ«āÕ»╣ÕÉīõĖĆÕ╝ĀÕøŠńēćÕ║öńö©õĖŹÕÉīńÜäÕó×Õ╝║’╝īõŠŗÕ”éń┐╗ĶĮ¼ÕÆīń╝®µöŠ’╝īńö©õ║ĵ©ĪÕ×ŗµÄ©ńÉå’╝īńäČÕÉÄÕ░åµ»ÅõĖ¬Õó×Õ╝║ÕÉÄńÜäÕøŠÕāÅńÜäķó䵥ŗń╗ōµ×£ÕÉłÕ╣Č’╝īõ╗źĶÄĘÕŠŚµø┤ÕćåńĪ«ńÜäķó䵥ŗń╗ōµ×£ŃĆéõĖ║õ║åĶ«®ńö©µłĘµø┤Õ«╣µśōõĮ┐ńö© TTA’╝īMMEngine µÅÉõŠøõ║å [BaseTTAModel](https://mmengine.readthedocs.io/en/latest/api/generated/mmengine.model.BaseTTAModel.html#mmengine.model.BaseTTAModel) ń▒╗’╝īÕģüĶ«Ėńö©µłĘµĀ╣µŹ«Ķć¬ÕĘ▒ńÜäķ£Ćµ▒éķĆÜĶ┐ćń«ĆÕŹĢÕ£░µē®Õ▒Ģ BaseTTAModel ń▒╗µØźÕ«×ńÄ░õĖŹÕÉīńÜä TTA ńŁ¢ńĢźŃĆé
+
+Õ£© MMDetection õĖŁ’╝īµłæõ╗¼µÅÉõŠøõ║å [DetTTAModel](../../../mmdet/models/test_time_augs/det_tta.py) ń▒╗’╝īÕ«āń╗¦µē┐Ķć¬ BaseTTAModelŃĆé
+
+### õĮ┐ńö©µĪłõŠŗ
+
+õĮ┐ńö© TTA ķ£ĆĶ”üõĖżõĖ¬µŁźķ¬żŃĆéķ”¢Õģł’╝īõĮĀķ£ĆĶ”üÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁµĘ╗ÕŖĀ `tta_model` ÕÆī `tta_pipeline`’╝Ü
+
+```shell
+tta_model = dict(
+ type='DetTTAModel',
+ tta_cfg=dict(nms=dict(
+ type='nms',
+ iou_threshold=0.5),
+ max_per_img=100))
+
+tta_pipeline = [
+ dict(type='LoadImageFromFile',
+ backend_args=None),
+ dict(
+ type='TestTimeAug',
+ transforms=[[
+ dict(type='Resize', scale=(1333, 800), keep_ratio=True)
+ ], [ # It uses 2 flipping transformations (flipping and not flipping).
+ dict(type='RandomFlip', prob=1.),
+ dict(type='RandomFlip', prob=0.)
+ ], [
+ dict(
+ type='PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape',
+ 'img_shape', 'scale_factor', 'flip',
+ 'flip_direction'))
+ ]])]
+```
+
+ń¼¼õ║īµŁź’╝īĶ┐ÉĶĪīµĄŗĶ»ĢĶäܵ£¼µŚČ’╝īĶ«ŠńĮ« `--tta` ÕÅéµĢ░’╝īÕ”éõĖŗµēĆńż║’╝Ü
+
+```shell
+# ÕŹĢ GPU µĄŗĶ»Ģ
+python tools/test.py \
+ ${CONFIG_FILE} \
+ ${CHECKPOINT_FILE} \
+ [--tta]
+
+# CPU µĄŗĶ»Ģ’╝Üń”üńö© GPU Õ╣ČĶ┐ÉĶĪīÕŹĢ GPU µĄŗĶ»ĢĶäܵ£¼
+export CUDA_VISIBLE_DEVICES=-1
+python tools/test.py \
+ ${CONFIG_FILE} \
+ ${CHECKPOINT_FILE} \
+ [--out ${RESULT_FILE}] \
+ [--tta]
+
+# ÕżÜ GPU µĄŗĶ»Ģ
+bash tools/dist_test.sh \
+ ${CONFIG_FILE} \
+ ${CHECKPOINT_FILE} \
+ ${GPU_NUM} \
+ [--tta]
+```
+
+õĮĀõ╣¤ÕÅ»õ╗źĶć¬ÕĘ▒õ┐«µö╣ TTA ķģŹńĮ«’╝īõŠŗÕ”éµĘ╗ÕŖĀń╝®µöŠÕó×Õ╝║’╝Ü
+
+```shell
+tta_model = dict(
+ type='DetTTAModel',
+ tta_cfg=dict(nms=dict(
+ type='nms',
+ iou_threshold=0.5),
+ max_per_img=100))
+
+img_scales = [(1333, 800), (666, 400), (2000, 1200)]
+tta_pipeline = [
+ dict(type='LoadImageFromFile',
+ backend_args=None),
+ dict(
+ type='TestTimeAug',
+ transforms=[[
+ dict(type='Resize', scale=s, keep_ratio=True) for s in img_scales
+ ], [
+ dict(type='RandomFlip', prob=1.),
+ dict(type='RandomFlip', prob=0.)
+ ], [
+ dict(
+ type='PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape',
+ 'img_shape', 'scale_factor', 'flip',
+ 'flip_direction'))
+ ]])]
+```
+
+õ╗źõĖŖµĢ░µŹ«Õó×Õ╝║ń«ĪķüōÕ░åķ”¢ÕģłÕ»╣ÕøŠÕāŵē¦ĶĪī 3 õĖ¬ÕżÜÕ░║Õ║”ĶĮ¼µŹó’╝īńäČÕÉĵē¦ĶĪī 2 õĖ¬ń┐╗ĶĮ¼ĶĮ¼µŹó’╝łń┐╗ĶĮ¼ÕÆīõĖŹń┐╗ĶĮ¼’╝ē’╝īµ£ĆÕÉÄõĮ┐ńö© PackDetInputs Õ░åÕøŠÕāŵēōÕīģÕł░µ£Ćń╗łń╗ōµ×£õĖŁŃĆé
+Ķ┐Öķćīµ£ēµø┤ÕżÜńÜä TTA õĮ┐ńö©µĪłõŠŗõŠøµé©ÕÅéĶĆā’╝Ü
+
+- [RetinaNet](../../../configs/retinanet/retinanet_tta.py)
+- [CenterNet](../../../configs/centernet/centernet_tta.py)
+- [YOLOX](../../../configs/rtmdet/rtmdet_tta.py)
+- [RTMDet](../../../configs/yolox/yolox_tta.py)
+
+µø┤ÕżÜķ½śń║¦ńö©µ│ĢÕÆī TTA ńÜäµĢ░µŹ«µĄü’╝īĶ»ĘÕÅéĶĆā [MMEngine](https://mmengine.readthedocs.io/en/latest/advanced_tutorials/test_time_augmentation.html#data-flow)ŃĆ鵳æõ╗¼Õ░åÕ£©ÕÉÄń╗Łµö»µīüÕ«×õŠŗÕłåÕē▓ TTAŃĆé
diff --git a/internlm_langchain/knowledge_base/MMDetection/content/test_results_submission.md b/internlm_langchain/knowledge_base/MMDetection/content/test_results_submission.md
new file mode 100644
index 00000000..7a076585
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection/content/test_results_submission.md
@@ -0,0 +1,174 @@
+# µÅÉõ║żµĄŗĶ»Ģń╗ōµ×£
+
+## Õģ©µÖ»ÕłåÕē▓µĄŗĶ»Ģń╗ōµ×£µÅÉõ║ż
+
+õĖŗķØóÕćĀĶŖéõ╗ŗń╗ŹÕ”éõĮĢÕ£© COCO µĄŗĶ»ĢÕ╝ĆÕÅæķøåõĖŖńö¤µłÉµ│øĶ¦åÕłåÕē▓µ©ĪÕ×ŗńÜäķó䵥ŗń╗ōµ×£’╝īÕ╣ČÕ░åķó䵥ŗµÅÉõ║żÕł░ [COCOĶ»äõ╝░µ£ŹÕŖĪÕÖ©](https://competitions.codalab.org/competitions/19507)
+
+### ÕēŹµÅɵØĪõ╗Č
+
+- õĖŗĶĮĮ [COCOµĄŗĶ»ĢµĢ░µŹ«ķøåÕøŠÕāÅ](http://images.cocodataset.org/zips/test2017.zip)’╝ī[µĄŗĶ»ĢÕøŠÕāÅõ┐Īµü»](http://images.cocodataset.org/annotations/image_info_test2017.zip)’╝īÕÆī[Õģ©µÖ»Ķ«Łń╗ā/ńøĖÕģ│µ│©ķćŖ](http://images.cocodataset.org/annotations/panoptic_annotations_trainval2017.zip)’╝īńäČÕÉÄĶ¦ŻÕÄŗń╝®Õ«āõ╗¼’╝īµŖŖ `test2017` µöŠÕł░ `data/coco/`’╝īµŖŖ json µ¢ćõ╗ČÕÆīµ│©ķćŖµ¢ćõ╗ȵöŠÕł░ `data/coco/annotations/` ŃĆé
+
+```shell
+# ÕüćĶ«Š data/coco/ õĖŹÕŁśÕ£©
+mkdir -pv data/coco/
+# õĖŗĶĮĮ test2017
+wget -P data/coco/ http://images.cocodataset.org/zips/test2017.zip
+wget -P data/coco/ http://images.cocodataset.org/annotations/image_info_test2017.zip
+wget -P data/coco/ http://images.cocodataset.org/annotations/panoptic_annotations_trainval2017.zip
+# Ķ¦ŻÕÄŗń╝®Õ«āõ╗¼
+unzip data/coco/test2017.zip -d data/coco/
+unzip data/coco/image_info_test2017.zip -d data/coco/
+unzip data/coco/panoptic_annotations_trainval2017.zip -d data/coco/
+# ÕłĀķÖż zip µ¢ćõ╗Č(ÕÅ»ķĆē)
+rm -rf data/coco/test2017.zip data/coco/image_info_test2017.zip data/coco/panoptic_annotations_trainval2017.zip
+```
+
+- Ķ┐ÉĶĪīõ╗źõĖŗõ╗ŻńĀüµø┤µ¢░µĄŗĶ»ĢÕøŠÕāÅõ┐Īµü»õĖŁńÜäń▒╗Õł½õ┐Īµü»ŃĆéńö▒õ║Ä `image_info_test-dev2017.json` ńÜäń▒╗Õł½õ┐Īµü»õĖŁń╝║Õ░æÕ▒׵Ʀ `isthing` ’╝īµłæõ╗¼ķ£ĆĶ”üńö© `panoptic_val2017.json` õĖŁńÜäń▒╗Õł½õ┐Īµü»µø┤µ¢░Õ«āŃĆé
+
+```shell
+python tools/misc/gen_coco_panoptic_test_info.py data/coco/annotations
+```
+
+Õ£©Õ«īµłÉõĖŖĶ┐░ÕćåÕżćõ╣ŗÕÉÄ’╝īõĮĀńÜä `data` ńø«ÕĮĢń╗ōµ×äÕ║öĶ»źµś»Ķ┐ÖµĀĘ:
+
+```text
+data
+`-- coco
+ |-- annotations
+ | |-- image_info_test-dev2017.json
+ | |-- image_info_test2017.json
+ | |-- panoptic_image_info_test-dev2017.json
+ | |-- panoptic_train2017.json
+ | |-- panoptic_train2017.zip
+ | |-- panoptic_val2017.json
+ | `-- panoptic_val2017.zip
+ `-- test2017
+```
+
+### coco µĄŗĶ»ĢÕ╝ĆÕÅæńÜäµÄ©ńÉå
+
+Ķ”üÕ£© coco test-dev õĖŖĶ┐øĶĪīµÄ©µ¢Ł’╝īµłæõ╗¼Õ║öĶ»źķ”¢Õģłµø┤µ¢░ `test_dataloder` ÕÆī `test_evaluator` ńÜäĶ«ŠńĮ«ŃĆéµ£ēõĖżń¦Źµ¢╣µ│ĢÕÅ»õ╗źÕüÜÕł░Ķ┐ÖõĖĆńé╣:1. Õ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁµø┤µ¢░Õ«āõ╗¼;2. Õ£©ÕæĮõ╗żĶĪīõĖŁµø┤µ¢░Õ«āõ╗¼ŃĆé
+
+#### Õ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁµø┤µ¢░Õ«āõ╗¼
+
+ńøĖÕģ│ńÜäĶ«ŠńĮ«Õ£© `configs/_base_/datasets/ coco_panoptical .py` ńÜäµ£½Õ░Š’╝īÕ”éõĖŗµēĆńż║ŃĆé
+
+```python
+test_dataloader = dict(
+ batch_size=1,
+ num_workers=1,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ ann_file='annotations/panoptic_image_info_test-dev2017.json',
+ data_prefix=dict(img='test2017/'),
+ test_mode=True,
+ pipeline=test_pipeline))
+test_evaluator = dict(
+ type='CocoPanopticMetric',
+ format_only=True,
+ ann_file=data_root + 'annotations/panoptic_image_info_test-dev2017.json',
+ outfile_prefix='./work_dirs/coco_panoptic/test')
+```
+
+õ╗źõĖŗõ╗╗õĮĢõĖĆń¦Źµ¢╣µ│ĢķāĮÕÅ»õ╗źńö©õ║ĵø┤µ¢░ coco test-dev ķøåõĖŖńÜäµÄ©ńÉåĶ«ŠńĮ«
+
+µāģÕåĄ1:ńø┤µÄźÕÅ¢µČłµ│©ķćŖ `configs/_base_/datasets/ coco_panoptical .py` õĖŁńÜäĶ«ŠńĮ«ŃĆé
+
+µāģÕåĄ2:Õ░åõ╗źõĖŗĶ«ŠńĮ«ÕżŹÕłČÕł░µé©ńÄ░Õ£©õĮ┐ńö©ńÜäķģŹńĮ«µ¢ćõ╗ČõĖŁŃĆé
+
+```python
+test_dataloader = dict(
+ dataset=dict(
+ ann_file='annotations/panoptic_image_info_test-dev2017.json',
+ data_prefix=dict(img='test2017/', _delete_=True)))
+test_evaluator = dict(
+ format_only=True,
+ ann_file=data_root + 'annotations/panoptic_image_info_test-dev2017.json',
+ outfile_prefix='./work_dirs/coco_panoptic/test')
+```
+
+ńäČÕÉÄķĆÜĶ┐ćõ╗źõĖŗÕæĮõ╗żÕ»╣ coco test-dev et Ķ┐øĶĪīµÄ©µ¢ŁŃĆé
+
+```shell
+python tools/test.py \
+ ${CONFIG_FILE} \
+ ${CHECKPOINT_FILE}
+```
+
+#### Õ£©ÕæĮõ╗żĶĪīõĖŁµø┤µ¢░Õ«āõ╗¼
+
+coco test-dev õĖŖµø┤µ¢░ńøĖÕģ│Ķ«ŠńĮ«ÕÆīµÄ©ńÉåńÜäÕæĮõ╗żÕ”éõĖŗµēĆńż║ŃĆé
+
+```shell
+# ńö©õĖĆõĖ¬ gpu µĄŗĶ»Ģ
+CUDA_VISIBLE_DEVICES=0 python tools/test.py \
+ ${CONFIG_FILE} \
+ ${CHECKPOINT_FILE} \
+ --cfg-options \
+ test_dataloader.dataset.ann_file=annotations/panoptic_image_info_test-dev2017.json \
+ test_dataloader.dataset.data_prefix.img=test2017 \
+ test_dataloader.dataset.data_prefix._delete_=True \
+ test_evaluator.format_only=True \
+ test_evaluator.ann_file=data/coco/annotations/panoptic_image_info_test-dev2017.json \
+ test_evaluator.outfile_prefix=${WORK_DIR}/results
+# ńö©ÕøøõĖ¬ gpu µĄŗĶ»Ģ
+CUDA_VISIBLE_DEVICES=0,1,3,4 bash tools/dist_test.sh \
+ ${CONFIG_FILE} \
+ ${CHECKPOINT_FILE} \
+ 8 \ # eights gpus
+ --cfg-options \
+ test_dataloader.dataset.ann_file=annotations/panoptic_image_info_test-dev2017.json \
+ test_dataloader.dataset.data_prefix.img=test2017 \
+ test_dataloader.dataset.data_prefix._delete_=True \
+ test_evaluator.format_only=True \
+ test_evaluator.ann_file=data/coco/annotations/panoptic_image_info_test-dev2017.json \
+ test_evaluator.outfile_prefix=${WORK_DIR}/results
+# ńö© slurm µĄŗĶ»Ģ
+GPUS=8 tools/slurm_test.sh \
+ ${Partition} \
+ ${JOB_NAME} \
+ ${CONFIG_FILE} \
+ ${CHECKPOINT_FILE} \
+ --cfg-options \
+ test_dataloader.dataset.ann_file=annotations/panoptic_image_info_test-dev2017.json \
+ test_dataloader.dataset.data_prefix.img=test2017 \
+ test_dataloader.dataset.data_prefix._delete_=True \
+ test_evaluator.format_only=True \
+ test_evaluator.ann_file=data/coco/annotations/panoptic_image_info_test-dev2017.json \
+ test_evaluator.outfile_prefix=${WORK_DIR}/results
+```
+
+õŠŗÕŁÉ:ÕüćĶ«Šµłæõ╗¼õĮ┐ńö©ķóäÕģłĶ«Łń╗āńÜäÕĖ”µ£ē ResNet-50 ķ¬©Õ╣▓ńĮæńÜä MaskFormer Õ»╣ `test2017` µē¦ĶĪīµÄ©µ¢ŁŃĆé
+
+```shell
+# ÕŹĢ gpu µĄŗĶ»Ģ
+CUDA_VISIBLE_DEVICES=0 python tools/test.py \
+ configs/maskformer/maskformer_r50_mstrain_16x1_75e_coco.py \
+ checkpoints/maskformer_r50_mstrain_16x1_75e_coco_20220221_141956-bc2699cb.pth \
+ --cfg-options \
+ test_dataloader.dataset.ann_file=annotations/panoptic_image_info_test-dev2017.json \
+ test_dataloader.dataset.data_prefix.img=test2017 \
+ test_dataloader.dataset.data_prefix._delete_=True \
+ test_evaluator.format_only=True \
+ test_evaluator.ann_file=data/coco/annotations/panoptic_image_info_test-dev2017.json \
+ test_evaluator.outfile_prefix=work_dirs/maskformer/results
+```
+
+### ķćŹÕæĮÕÉŹµ¢ćõ╗ČÕ╣ČÕÄŗń╝®ń╗ōµ×£
+
+µÄ©ńÉåõ╣ŗÕÉÄ’╝īÕģ©µÖ»ÕłåÕē▓ń╗ōµ×£(õĖĆõĖ¬ json µ¢ćõ╗ČÕÆīõĖĆõĖ¬ÕŁśÕ驵ĮńĀüńÜäńø«ÕĮĢ)Õ░åÕ£© `WORK_DIR` õĖŁŃĆ鵳æõ╗¼Õ║öĶ»źµīēńģ¦ [COCO's Website](https://cocodataset.org/#upload)õĖŖńÜäÕæĮÕÉŹń║”Õ«Üķ揵¢░ÕæĮÕÉŹÕ«āõ╗¼ŃĆéµ£ĆÕÉÄ’╝īµłæõ╗¼ķ£ĆĶ”üÕ░å json ÕÆīÕŁśÕ驵ĮńĀüńÜäńø«ÕĮĢÕÄŗń╝®Õł░ zip µ¢ćõ╗ČõĖŁ’╝īÕ╣ȵĀ╣µŹ«ÕæĮÕÉŹń║”Õ«ÜķćŹÕæĮÕÉŹĶ»ź zip µ¢ćõ╗ČŃĆéµ│©µäÅ’╝ī zip µ¢ćõ╗ČÕ║öĶ»ź**ńø┤µÄź**ÕīģÕɽõĖŖĶ┐░õĖżõĖ¬µ¢ćõ╗ČŃĆé
+
+ķćŹÕæĮÕÉŹµ¢ćõ╗ČÕÆīÕÄŗń╝®ń╗ōµ×£ńÜäÕæĮõ╗ż:
+
+```shell
+# Õ£© WORK_DIR õĖŁ’╝īµłæõ╗¼µ£ē panoptic ÕłåÕē▓ń╗ōµ×£: 'panoptic' ÕÆī 'results. panoptical .json'ŃĆé
+cd ${WORK_DIR}
+# Õ░å '[algorithm_name]' µø┐µŹóõĖ║µé©õĮ┐ńö©ńÜäń«Śµ│ĢÕÉŹń¦░
+mv ./panoptic ./panoptic_test-dev2017_[algorithm_name]_results
+mv ./results.panoptic.json ./panoptic_test-dev2017_[algorithm_name]_results.json
+zip panoptic_test-dev2017_[algorithm_name]_results.zip -ur panoptic_test-dev2017_[algorithm_name]_results panoptic_test-dev2017_[algorithm_name]_results.json
+```
diff --git a/internlm_langchain/knowledge_base/MMDetection/content/train.md b/internlm_langchain/knowledge_base/MMDetection/content/train.md
new file mode 100644
index 00000000..8feb1aa6
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection/content/train.md
@@ -0,0 +1,451 @@
+# Õ£©µĀćÕćåµĢ░µŹ«ķøåõĖŖĶ«Łń╗āķóäÕ«Üõ╣ēńÜ䵩ĪÕ×ŗ
+
+MMDetection õ╣¤õĖ║Ķ«Łń╗āµŻĆµĄŗµ©ĪÕ×ŗµÅÉõŠøõ║åÕ╝Ćńø¢ÕŹ│ķŻ¤ńÜäÕĘźÕģĘŃĆéµ£¼ĶŖéÕ░åÕ▒Ģńż║Õ£©µĀćÕćåµĢ░µŹ«ķøå’╝łµ»öÕ”é COCO’╝ēõĖŖÕ”éõĮĢĶ«Łń╗āõĖĆõĖ¬ķóäÕ«Üõ╣ēńÜ䵩ĪÕ×ŗŃĆé
+
+### µĢ░µŹ«ķøå
+
+Ķ«Łń╗āķ£ĆĶ”üÕćåÕżćÕźĮµĢ░µŹ«ķøå’╝īń╗åĶŖéĶ»ĘÕÅéĶĆā [µĢ░µŹ«ķøåÕćåÕżć](#%E6%95%B0%E6%8D%AE%E9%9B%86%E5%87%86%E5%A4%87) ŃĆé
+
+**µ│©µäÅ**’╝Ü
+ńø«ÕēŹ’╝ī`configs/cityscapes` µ¢ćõ╗ČÕż╣õĖŗńÜäķģŹńĮ«µ¢ćõ╗ČķāĮµś»õĮ┐ńö© COCO ķóäĶ«Łń╗āµØāÕĆ╝Ķ┐øĶĪīÕłØÕ¦ŗÕī¢ńÜäŃĆéÕ”éµ×£ńĮæń╗£Ķ┐׵ğõĖŹÕÅ»ńö©µł¢ĶĆģķƤÕ║”ÕŠłµģó’╝īõĮĀÕÅ»õ╗źµÅÉÕēŹõĖŗĶĮĮńÄ░ÕŁśńÜ䵩ĪÕ×ŗŃĆéÕÉ”ÕłÖÕÅ»ĶāĮÕ£©Ķ«Łń╗āńÜäÕ╝ĆÕ¦ŗõ╝ܵ£ēķöÖĶ»»ÕÅæńö¤ŃĆé
+
+### ÕŁ”õ╣ĀńÄćĶć¬ÕŖ©ń╝®µöŠ
+
+**µ│©µäÅ**’╝ÜÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁńÜäÕŁ”õ╣ĀńÄ浜»Õ£© 8 ÕØŚ GPU’╝īµ»ÅÕØŚ GPU µ£ē 2 Õ╝ĀÕøŠÕāÅ’╝łµē╣Õż¦Õ░ÅõĖ║ 8\*2=16’╝ēńÜäµāģÕåĄõĖŗĶ«ŠńĮ«ńÜäŃĆéÕģČÕĘ▓ń╗ÅĶ«ŠńĮ«Õ£© `config/_base_/schedules/schedule_1x.py` õĖŁńÜä `auto_scale_lr.base_batch_size`ŃĆéÕŁ”õ╣ĀńÄćõ╝ÜÕ¤║õ║ĵē╣µ¼ĪÕż¦Õ░ÅõĖ║ `16`µŚČńÜäÕĆ╝Ķ┐øĶĪīĶć¬ÕŖ©ń╝®µöŠŃĆéÕÉīµŚČ’╝īõĖ║õ║åõĖŹÕĮ▒ÕōŹÕģČõ╗¢Õ¤║õ║Ä mmdet ńÜä codebase’╝īÕÉ»ńö©Ķć¬ÕŖ©ń╝®µöŠµĀćÕ┐Ś `auto_scale_lr.enable` ķ╗śĶ«żĶ«ŠńĮ«õĖ║ `False`ŃĆé
+
+Õ”éµ×£Ķ”üÕÉ»ńö©µŁżÕŖ¤ĶāĮ’╝īķ£ĆÕ£©ÕæĮõ╗żµĘ╗ÕŖĀÕÅéµĢ░ `--auto-scale-lr`ŃĆéÕ╣ČõĖöÕ£©ÕÉ»ÕŖ©ÕæĮõ╗żõ╣ŗÕēŹ’╝īĶ»ĘµŻĆµ¤źõĖŗÕŹ│Õ░åõĮ┐ńö©ńÜäķģŹńĮ«µ¢ćõ╗ČńÜäÕÉŹń¦░’╝īÕøĀõĖ║ķģŹńĮ«ÕÉŹń¦░µīćńż║ķ╗śĶ«żńÜäµē╣ÕżäńÉåÕż¦Õ░ÅŃĆé
+Õ£©ķ╗śĶ«żµāģÕåĄõĖŗ’╝īµē╣µ¼ĪÕż¦Õ░ŵś» `8 x 2 = 16`’╝īõŠŗÕ”é’╝Ü`faster_rcnn_r50_caffe_fpn_90k_coco.py` µł¢ĶĆģ `pisa_faster_rcnn_x101_32x4d_fpn_1x_coco.py`’╝øĶŗźõĖŹµś»ķ╗śĶ«żµē╣µ¼Ī’╝īõĮĀÕÅ»õ╗źÕ£©ķģŹńĮ«µ¢ćõ╗Čń£ŗÕł░ÕāÅ `_NxM_` ÕŁŚµĀĘńÜä’╝īõŠŗÕ”é’╝Ü`cornernet_hourglass104_mstest_32x3_210e_coco.py` ńÜäµē╣µ¼ĪÕż¦Õ░ŵś» `32 x 3 = 96`, µł¢ĶĆģ `scnet_x101_64x4d_fpn_8x1_20e_coco.py` ńÜäµē╣µ¼ĪÕż¦Õ░ŵś» `8 x 1 = 8`ŃĆé
+
+**Ķ»ĘĶ«░õĮÅ’╝ÜÕ”éµ×£õĮ┐ńö©õĖŹµś»ķ╗śĶ«żµē╣µ¼ĪÕż¦Õ░ÅõĖ║ `16`ńÜäķģŹńĮ«µ¢ćõ╗Č’╝īĶ»ĘµŻĆµ¤źķģŹńĮ«µ¢ćõ╗ČõĖŁńÜäÕ║Ģķā©’╝īõ╝ܵ£ē `auto_scale_lr.base_batch_size`ŃĆéÕ”éµ×£µēŠõĖŹÕł░’╝īÕÅ»õ╗źÕ£©ÕģČń╗¦µē┐ńÜä `_base_=[xxx]` µ¢ćõ╗ČõĖŁµēŠÕł░ŃĆéÕÅ”Õż¢’╝īÕ”éµ×£µā│õĮ┐ńö©Ķć¬ÕŖ©ń╝®µöŠÕŁ”õ╣ĀńÄćńÜäÕŖ¤ĶāĮ’╝īĶ»ĘõĖŹĶ”üõ┐«µö╣Ķ┐Öõ║øÕĆ╝ŃĆé**
+
+ÕŁ”õ╣ĀńÄćĶć¬ÕŖ©ń╝®µöŠÕ¤║µ£¼ńö©µ│ĢÕ”éõĖŗ’╝Ü
+
+```shell
+python tools/train.py \
+ ${CONFIG_FILE} \
+ --auto-scale-lr \
+ [optional arguments]
+```
+
+µē¦ĶĪīÕæĮõ╗żõ╣ŗÕÉÄ’╝īõ╝ܵĀ╣µŹ«µ£║ÕÖ©ńÜäGPUµĢ░ķćÅÕÆīĶ«Łń╗āńÜäµē╣µ¼ĪÕż¦Õ░ÅÕ»╣ÕŁ”õ╣ĀńÄćĶ┐øĶĪīĶć¬ÕŖ©ń╝®µöŠ’╝īń╝®µöŠµ¢╣Õ╝ÅĶ»”Ķ¦ü [ń║┐µĆ¦µē®Õ▒ĢĶ¦äÕłÖ](https://arxiv.org/abs/1706.02677) ’╝īµ»öÕ”é’╝ÜÕ£© 4 ÕØŚ GPU Õ╣ČõĖöµ»ÅÕ╝Ā GPU õĖŖµ£ē 2 Õ╝ĀÕøŠńēćńÜäµāģÕåĄõĖŗ `lr=0.01`’╝īķéŻõ╣łÕ£© 16 ÕØŚ GPU Õ╣ČõĖöµ»ÅÕ╝Ā GPU õĖŖµ£ē 4 Õ╝ĀÕøŠńēćńÜäµāģÕåĄõĖŗ, LR õ╝ÜĶć¬ÕŖ©ń╝®µöŠĶć│ `lr=0.08`ŃĆé
+
+Õ”éµ×£õĖŹÕÉ»ńö©Ķ»źÕŖ¤ĶāĮ’╝īÕłÖķ£ĆĶ”üµĀ╣µŹ« [ń║┐µĆ¦µē®Õ▒ĢĶ¦äÕłÖ](https://arxiv.org/abs/1706.02677) µØźµēŗÕŖ©Ķ«Īń«ŚÕ╣Čõ┐«µö╣ķģŹńĮ«µ¢ćõ╗ČķćīķØó `optimizer.lr` ńÜäÕĆ╝ŃĆé
+
+### õĮ┐ńö©ÕŹĢ GPU Ķ«Łń╗ā
+
+µłæõ╗¼µÅÉõŠøõ║å `tools/train.py` µØźÕ╝ĆÕɻգ©ÕŹĢÕ╝Ā GPU õĖŖńÜäĶ«Łń╗āõ╗╗ÕŖĪŃĆéÕ¤║µ£¼õĮ┐ńö©Õ”éõĖŗ’╝Ü
+
+```shell
+python tools/train.py \
+ ${CONFIG_FILE} \
+ [optional arguments]
+```
+
+Õ£©Ķ«Łń╗āµ£¤ķŚ┤’╝īµŚźÕ┐Śµ¢ćõ╗ČÕÆī checkpoint µ¢ćõ╗ČÕ░åõ╝ÜĶó½õ┐ØÕŁśÕ£©ÕĘźõĮ£ńø«ÕĮĢõĖŗ’╝īÕ«āķ£ĆĶ”üķĆÜĶ┐ćķģŹńĮ«µ¢ćõ╗ČõĖŁńÜä `work_dir` µł¢ĶĆģ CLI ÕÅéµĢ░õĖŁńÜä `--work-dir` µØźµīćÕ«ÜŃĆé
+
+ķ╗śĶ«żµāģÕåĄõĖŗ’╝īµ©ĪÕ×ŗÕ░åÕ£©µ»ÅĶĮ«Ķ«Łń╗āõ╣ŗÕÉÄÕ£© validation ķøåõĖŖĶ┐øĶĪīµĄŗĶ»Ģ’╝īµĄŗĶ»ĢńÜäķóæńÄćÕÅ»õ╗źķĆÜĶ┐ćĶ«ŠńĮ«ķģŹńĮ«µ¢ćõ╗ČµØźµīćÕ«Ü’╝Ü
+
+```python
+# µ»Å 12 ĶĮ«Ķ┐Łõ╗ŻĶ┐øĶĪīõĖƵ¼ĪµĄŗĶ»ĢĶ»äõ╝░
+train_cfg = dict(val_interval=12)
+```
+
+Ķ┐ÖõĖ¬ÕĘźÕģʵğÕÅŚõ╗źõĖŗÕÅéµĢ░’╝Ü
+
+- `--work-dir ${WORK_DIR}`: Ķ”åńø¢ÕĘźõĮ£ńø«ÕĮĢ.
+- `--resume`’╝ÜĶć¬ÕŖ©õ╗Äwork_dirõĖŁńÜäµ£Ćµ¢░µŻĆµ¤źńé╣µüóÕżŹ.
+- `--resume ${CHECKPOINT_FILE}`: õ╗ĵ¤ÉõĖ¬ checkpoint µ¢ćõ╗Čń╗¦ń╗ŁĶ«Łń╗ā.
+- `--cfg-options 'Key=value'`: Ķ”åńø¢õĮ┐ńö©ńÜäķģŹńĮ«µ¢ćõ╗ČõĖŁńÜäÕģČõ╗¢Ķ«ŠńĮ«.
+
+**µ│©µäÅ**’╝Ü
+`resume` ÕÆī `load-from` ńÜäÕī║Õł½’╝Ü
+
+`resume` µŚóÕŖĀĶĮĮõ║嵩ĪÕ×ŗńÜäµØāķćŹÕÆīõ╝śÕī¢ÕÖ©ńÜäńŖȵĆü’╝īõ╣¤õ╝Üń╗¦µē┐µīćÕ«Ü checkpoint ńÜäĶ┐Łõ╗Żµ¼ĪµĢ░’╝īõĖŹõ╝Üķ揵¢░Õ╝ĆÕ¦ŗĶ«Łń╗āŃĆé`load-from` ÕłÖµś»ÕŬÕŖĀĶĮĮµ©ĪÕ×ŗńÜäµØāķ插╝īÕ«āńÜäĶ«Łń╗āµś»õ╗ÄÕż┤Õ╝ĆÕ¦ŗńÜä’╝īń╗ÅÕĖĖĶó½ńö©õ║ÄÕŠ«Ķ░āµ©ĪÕ×ŗŃĆéÕģČõĖŁload-fromķ£ĆĶ”üÕåÖÕģźķģŹńĮ«µ¢ćõ╗ČõĖŁ’╝īĶĆīresumeõĮ£õĖ║ÕæĮõ╗żĶĪīÕÅéµĢ░õ╝ĀÕģźŃĆé
+
+### õĮ┐ńö© CPU Ķ«Łń╗ā
+
+õĮ┐ńö© CPU Ķ«Łń╗āńÜ䵥üń©ŗÕÆīõĮ┐ńö©ÕŹĢ GPU Ķ«Łń╗āńÜ䵥üń©ŗõĖĆĶć┤’╝īµłæõ╗¼õ╗ģķ£ĆĶ”üÕ£©Ķ«Łń╗āµĄüń©ŗÕ╝ĆÕ¦ŗÕēŹń”üńö© GPUŃĆé
+
+```shell
+export CUDA_VISIBLE_DEVICES=-1
+```
+
+õ╣ŗÕÉÄĶ┐ÉĶĪīÕŹĢ GPU Ķ«Łń╗āĶäܵ£¼ÕŹ│ÕÅ»ŃĆé
+
+**µ│©µäÅ**’╝Ü
+
+µłæõ╗¼õĖŹµÄ©ĶŹÉńö©µłĘõĮ┐ńö© CPU Ķ┐øĶĪīĶ«Łń╗ā’╝īĶ┐ÖÕż¬Ķ┐ćń╝ōµģóŃĆ鵳æõ╗¼µö»µīüĶ┐ÖõĖ¬ÕŖ¤ĶāĮµś»õĖ║õ║åµ¢╣õŠ┐ńö©µłĘÕ£©µ▓Īµ£ē GPU ńÜäµ£║ÕÖ©õĖŖĶ┐øĶĪīĶ░āĶ»ĢŃĆé
+
+### Õ£©ÕżÜ GPU õĖŖĶ«Łń╗ā
+
+µłæõ╗¼µÅÉõŠøõ║å `tools/dist_train.sh` µØźÕ╝ĆÕɻգ©ÕżÜ GPU õĖŖńÜäĶ«Łń╗āŃĆéÕ¤║µ£¼õĮ┐ńö©Õ”éõĖŗ’╝Ü
+
+```shell
+bash ./tools/dist_train.sh \
+ ${CONFIG_FILE} \
+ ${GPU_NUM} \
+ [optional arguments]
+```
+
+ÕÅ»ķĆēÕÅéµĢ░ÕÆīÕŹĢ GPU Ķ«Łń╗āńÜäÕÅ»ķĆēÕÅéµĢ░õĖĆĶć┤ŃĆé
+
+#### ÕÉīµŚČÕÉ»ÕŖ©ÕżÜõĖ¬õ╗╗ÕŖĪ
+
+Õ”éµ×£õĮĀµā│Õ£©õĖĆÕÅ░µ£║ÕÖ©õĖŖÕÉ»ÕŖ©ÕżÜõĖ¬õ╗╗ÕŖĪńÜäĶ»Ø’╝īµ»öÕ”éÕ£©õĖĆõĖ¬µ£ē 8 ÕØŚ GPU ńÜäµ£║ÕÖ©õĖŖÕÉ»ÕŖ© 2 õĖ¬ķ£ĆĶ”ü 4 ÕØŚGPUńÜäõ╗╗ÕŖĪ’╝īõĮĀķ£ĆĶ”üń╗ÖõĖŹÕÉīńÜäĶ«Łń╗āõ╗╗ÕŖĪµīćÕ«ÜõĖŹÕÉīńÜäń½»ÕÅŻ’╝łķ╗śĶ«żõĖ║ 29500’╝ēµØźķü┐ÕģŹÕå▓ń¬üŃĆé
+
+Õ”éµ×£õĮĀõĮ┐ńö© `dist_train.sh` µØźÕÉ»ÕŖ©Ķ«Łń╗āõ╗╗ÕŖĪ’╝īõĮĀÕÅ»õ╗źõĮ┐ńö©ÕæĮõ╗żµØźĶ«ŠńĮ«ń½»ÕÅŻŃĆé
+
+```shell
+CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 ./tools/dist_train.sh ${CONFIG_FILE} 4
+CUDA_VISIBLE_DEVICES=4,5,6,7 PORT=29501 ./tools/dist_train.sh ${CONFIG_FILE} 4
+```
+
+### õĮ┐ńö©ÕżÜÕÅ░µ£║ÕÖ©Ķ«Łń╗ā
+
+Õ”éµ×£µé©µā│õĮ┐ńö©ńö▒ ethernet Ķ┐׵ğĶĄĘµØźńÜäÕżÜÕÅ░µ£║ÕÖ©’╝ī µé©ÕÅ»õ╗źõĮ┐ńö©õ╗źõĖŗÕæĮõ╗ż:
+
+Õ£©ń¼¼õĖĆÕÅ░µ£║ÕÖ©õĖŖ:
+
+```shell
+NNODES=2 NODE_RANK=0 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR sh tools/dist_train.sh $CONFIG $GPUS
+```
+
+Õ£©ń¼¼õ║īÕÅ░µ£║ÕÖ©õĖŖ:
+
+```shell
+NNODES=2 NODE_RANK=1 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR sh tools/dist_train.sh $CONFIG $GPUS
+```
+
+õĮåµś»’╝īÕ”éµ×£µé©õĖŹõĮ┐ńö©ķ½śķƤńĮæĶĘ»Ķ┐׵ğĶ┐ÖÕćĀÕÅ░µ£║ÕÖ©ńÜäĶ»Ø’╝īĶ«Łń╗āÕ░åõ╝ÜķØ×ÕĖĖµģóŃĆé
+
+### õĮ┐ńö© Slurm µØźń«ĪńÉåõ╗╗ÕŖĪ
+
+Slurm µś»õĖĆõĖ¬ÕĖĖĶ¦üńÜäĶ«Īń«ŚķøåńŠżĶ░āÕ║”ń│╗ń╗¤ŃĆéÕ£© Slurm ń«ĪńÉåńÜäķøåńŠżõĖŖ’╝īõĮĀÕÅ»õ╗źõĮ┐ńö© `slurm.sh` µØźÕ╝ĆÕÉ»Ķ«Łń╗āõ╗╗ÕŖĪŃĆéÕ«āµŚóµö»µīüÕŹĢĶŖéńé╣Ķ«Łń╗āõ╣¤µö»µīüÕżÜĶŖéńé╣Ķ«Łń╗āŃĆé
+
+Õ¤║µ£¼õĮ┐ńö©Õ”éõĖŗ’╝Ü
+
+```shell
+[GPUS=${GPUS}] ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} ${CONFIG_FILE} ${WORK_DIR}
+```
+
+õ╗źõĖŗµś»Õ£©õĖĆõĖ¬ÕÉŹń¦░õĖ║ _dev_ ńÜä Slurm ÕłåÕī║õĖŖ’╝īõĮ┐ńö© 16 ÕØŚ GPU µØźĶ«Łń╗ā Mask R-CNN ńÜäõŠŗÕŁÉ’╝īÕ╣ČõĖöÕ░å `work-dir` Ķ«ŠńĮ«Õ£©õ║嵤Éõ║øÕģ▒õ║½µ¢ćõ╗Čń│╗ń╗¤õĖŗŃĆé
+
+```shell
+GPUS=16 ./tools/slurm_train.sh dev mask_r50_1x configs/mask_rcnn_r50_fpn_1x_coco.py /nfs/xxxx/mask_rcnn_r50_fpn_1x
+```
+
+õĮĀÕÅ»õ╗źµ¤źń£ŗ [µ║ÉńĀü](https://github.com/open-mmlab/mmdetection/blob/main/tools/slurm_train.sh) µØźµŻĆµ¤źÕģ©ķā©ńÜäÕÅéµĢ░ÕÆīńÄ»ÕóāÕÅśķćÅ.
+
+Õ£©õĮ┐ńö© Slurm µŚČ’╝īń½»ÕÅŻķ£ĆĶ”üõ╗źõĖŗµ¢╣ńÜ䵤ÉõĖ¬µ¢╣µ│Ģõ╣ŗõĖĆµØźĶ«ŠńĮ«ŃĆé
+
+1. ķĆÜĶ┐ć `--options` µØźĶ«ŠńĮ«ń½»ÕÅŻŃĆ鵳æõ╗¼ķØ×ÕĖĖÕ╗║Ķ««ńö©Ķ┐Öń¦Źµ¢╣µ│Ģ’╝īÕøĀõĖ║Õ«āµŚĀķ£Ćµö╣ÕÅśÕĤզŗńÜäķģŹńĮ«µ¢ćõ╗ČŃĆé
+
+ ```shell
+ CUDA_VISIBLE_DEVICES=0,1,2,3 GPUS=4 ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} config1.py ${WORK_DIR} --cfg-options 'dist_params.port=29500'
+ CUDA_VISIBLE_DEVICES=4,5,6,7 GPUS=4 ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} config2.py ${WORK_DIR} --cfg-options 'dist_params.port=29501'
+ ```
+
+2. õ┐«µö╣ķģŹńĮ«µ¢ćõ╗ČµØźĶ«ŠńĮ«õĖŹÕÉīńÜäõ║żµĄüń½»ÕÅŻŃĆé
+
+ Õ£© `config1.py` õĖŁ’╝īĶ«ŠńĮ«’╝Ü
+
+ ```python
+ dist_params = dict(backend='nccl', port=29500)
+ ```
+
+ Õ£© `config2.py` õĖŁ’╝īĶ«ŠńĮ«’╝Ü
+
+ ```python
+ dist_params = dict(backend='nccl', port=29501)
+ ```
+
+ ńäČÕÉÄõĮĀÕÅ»õ╗źõĮ┐ńö© `config1.py` ÕÆī `config2.py` µØźÕÉ»ÕŖ©õĖżõĖ¬õ╗╗ÕŖĪõ║åŃĆé
+
+ ```shell
+ CUDA_VISIBLE_DEVICES=0,1,2,3 GPUS=4 ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} config1.py ${WORK_DIR}
+ CUDA_VISIBLE_DEVICES=4,5,6,7 GPUS=4 ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} config2.py ${WORK_DIR}
+ ```
+
+# Õ£©Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåõĖŖĶ┐øĶĪīĶ«Łń╗ā
+
+ķĆÜĶ┐ćµ£¼µ¢ćµĪŻ’╝īõĮĀÕ░åõ╝Üń¤źķüōÕ”éõĮĢõĮ┐ńö©Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåÕ»╣ķóäÕģłÕ«Üõ╣ēÕźĮńÜ䵩ĪÕ×ŗĶ┐øĶĪīµÄ©ńÉå’╝īµĄŗĶ»Ģõ╗źÕÅŖĶ«Łń╗āŃĆ鵳æõ╗¼õĮ┐ńö© [balloon dataset](https://github.com/matterport/Mask_RCNN/tree/master/samples/balloon) õĮ£õĖ║õŠŗÕŁÉµØźµÅÅĶ┐░µĢ┤õĖ¬Ķ┐ćń©ŗŃĆé
+
+Õ¤║µ£¼µŁźķ¬żÕ”éõĖŗ’╝Ü
+
+1. ÕćåÕżćĶć¬Õ«Üõ╣ēµĢ░µŹ«ķøå
+2. ÕćåÕżćķģŹńĮ«µ¢ćõ╗Č
+3. Õ£©Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåõĖŖĶ┐øĶĪīĶ«Łń╗ā’╝īµĄŗĶ»ĢÕÆīµÄ©ńÉåŃĆé
+
+## ÕćåÕżćĶć¬Õ«Üõ╣ēµĢ░µŹ«ķøå
+
+MMDetection õĖĆÕģ▒µö»µīüõĖēń¦ŹÕĮóÕ╝ÅÕ║öńö©µ¢░µĢ░µŹ«ķøå’╝Ü
+
+1. Õ░åµĢ░µŹ«ķøåķ揵¢░ń╗äń╗ćõĖ║ COCO µĀ╝Õ╝ÅŃĆé
+2. Õ░åµĢ░µŹ«ķøåķ揵¢░ń╗äń╗ćõĖ║õĖĆõĖ¬õĖŁķŚ┤µĀ╝Õ╝ÅŃĆé
+3. Õ«×ńÄ░õĖĆõĖ¬µ¢░ńÜäµĢ░µŹ«ķøåŃĆé
+
+µłæõ╗¼ķĆÜÕĖĖÕ╗║Ķ««õĮ┐ńö©ÕēŹķØóõĖżń¦Źµ¢╣µ│Ģ’╝īÕøĀõĖ║Õ«āõ╗¼ķĆÜÕĖĖµØźĶ»┤µ»öń¼¼õĖēń¦Źµ¢╣µ│ĢĶ”üń«ĆÕŹĢŃĆé
+
+Õ£©µ£¼µ¢ćµĪŻõĖŁ’╝īµłæõ╗¼Õ▒Ģńż║õĖĆõĖ¬õŠŗÕŁÉµØźĶ»┤µśÄÕ”éõĮĢÕ░åµĢ░µŹ«ĶĮ¼Õī¢õĖ║ COCO µĀ╝Õ╝ÅŃĆé
+
+**µ│©µäÅ**’╝ÜÕ£© MMDetection 3.0 õ╣ŗÕÉÄ’╝īµĢ░µŹ«ķøåÕÆīµīćµĀćÕĘ▓ń╗ÅĶ¦ŻĶĆ”’╝łķÖżõ║å CityScapes’╝ēŃĆéÕøĀµŁż’╝īńö©µłĘÕ£©ķ¬īĶ»üķśČµ«ĄõĮ┐ńö©õ╗╗µäÅńÜäĶ»äõ╗ʵīćµĀćµØźĶ»äõ╗ʵ©ĪÕ×ŗÕ£©õ╗╗µäŵĢ░µŹ«ķøåõĖŖńÜäµĆ¦ĶāĮŃĆéµ»öÕ”é’╝īńö© VOC Ķ»äõ╗ʵīćµĀćµØźĶ»äõ╗ʵ©ĪÕ×ŗÕ£© COCO µĢ░µŹ«ķøåńÜäµĆ¦ĶāĮ’╝īµł¢ĶĆģÕÉīµŚČõĮ┐ńö© VOC Ķ»äõ╗ʵīćµĀćÕÆī COCO Ķ»äõ╗ʵīćµĀćµØźĶ»äõ╗ʵ©ĪÕ×ŗÕ£© OpenImages µĢ░µŹ«ķøåõĖŖńÜäµĆ¦ĶāĮŃĆé
+
+### COCOµĀćµ│©µĀ╝Õ╝Å
+
+ńö©õ║ÄÕ«×õŠŗÕłåÕē▓ńÜä COCO µĢ░µŹ«ķøåµĀ╝Õ╝ÅÕ”éõĖŗµēĆńż║’╝īÕģČõĖŁńÜäķö«’╝łkey’╝ēķāĮµś»Õ┐ģĶ”üńÜä’╝īÕÅéĶĆā[Ķ┐Öķćī](https://cocodataset.org/#format-data)µØźĶÄĘÕÅ¢µø┤ÕżÜń╗åĶŖéŃĆé
+
+```json
+{
+ "images": [image],
+ "annotations": [annotation],
+ "categories": [category]
+}
+
+
+image = {
+ "id": int,
+ "width": int,
+ "height": int,
+ "file_name": str,
+}
+
+annotation = {
+ "id": int,
+ "image_id": int,
+ "category_id": int,
+ "segmentation": RLE or [polygon],
+ "area": float,
+ "bbox": [x,y,width,height], # (x, y) õĖ║ bbox ÕĘ”õĖŖĶ¦ÆńÜäÕØɵĀć
+ "iscrowd": 0 or 1,
+}
+
+categories = [{
+ "id": int,
+ "name": str,
+ "supercategory": str,
+}]
+```
+
+ńÄ░Õ£©ÕüćĶ«Šµłæõ╗¼õĮ┐ńö© balloon datasetŃĆé
+
+õĖŗĶĮĮõ║åµĢ░µŹ«ķøåõ╣ŗÕÉÄ’╝īµłæõ╗¼ķ£ĆĶ”üÕ«×ńÄ░õĖĆõĖ¬ÕćĮµĢ░Õ░åµĀćµ│©µĀ╝Õ╝ÅĶĮ¼Õī¢õĖ║ COCO µĀ╝Õ╝ÅŃĆéńäČÕÉĵłæõ╗¼Õ░▒ÕÅ»õ╗źõĮ┐ńö©ÕĘ▓ń╗ÅÕ«×ńÄ░ńÜä `CocoDataset` ń▒╗µØźÕŖĀĶĮĮµĢ░µŹ«Õ╣ČĶ┐øĶĪīĶ«Łń╗āõ╗źÕÅŖĶ»äµĄŗŃĆé
+
+Õ”éµ×£õĮĀµĄÅĶ¦łĶ┐ćµ¢░µĢ░µŹ«ķøå’╝īõĮĀõ╝ÜÕÅæńÄ░µĀ╝Õ╝ÅÕ”éõĖŗ’╝Ü
+
+```json
+{'base64_img_data': '',
+ 'file_attributes': {},
+ 'filename': '34020010494_e5cb88e1c4_k.jpg',
+ 'fileref': '',
+ 'regions': {'0': {'region_attributes': {},
+ 'shape_attributes': {'all_points_x': [1020,
+ 1000,
+ 994,
+ 1003,
+ 1023,
+ 1050,
+ 1089,
+ 1134,
+ 1190,
+ 1265,
+ 1321,
+ 1361,
+ 1403,
+ 1428,
+ 1442,
+ 1445,
+ 1441,
+ 1427,
+ 1400,
+ 1361,
+ 1316,
+ 1269,
+ 1228,
+ 1198,
+ 1207,
+ 1210,
+ 1190,
+ 1177,
+ 1172,
+ 1174,
+ 1170,
+ 1153,
+ 1127,
+ 1104,
+ 1061,
+ 1032,
+ 1020],
+ 'all_points_y': [963,
+ 899,
+ 841,
+ 787,
+ 738,
+ 700,
+ 663,
+ 638,
+ 621,
+ 619,
+ 643,
+ 672,
+ 720,
+ 765,
+ 800,
+ 860,
+ 896,
+ 942,
+ 990,
+ 1035,
+ 1079,
+ 1112,
+ 1129,
+ 1134,
+ 1144,
+ 1153,
+ 1166,
+ 1166,
+ 1150,
+ 1136,
+ 1129,
+ 1122,
+ 1112,
+ 1084,
+ 1037,
+ 989,
+ 963],
+ 'name': 'polygon'}}},
+ 'size': 1115004}
+```
+
+µĀćµ│©µ¢ćõ╗ȵŚČµś» JSON µĀ╝Õ╝ÅńÜä’╝īÕģČõĖŁµēƵ£ēķö«’╝łkey’╝ēń╗䵳Éõ║åõĖĆÕ╝ĀÕøŠńēćńÜäµēƵ£ēµĀćµ│©ŃĆé
+
+ÕģČõĖŁÕ░å balloon dataset ĶĮ¼Õī¢õĖ║ COCO µĀ╝Õ╝ÅńÜäõ╗ŻńĀüÕ”éõĖŗµēĆńż║ŃĆé
+
+```python
+import os.path as osp
+
+import mmcv
+
+from mmengine.fileio import dump, load
+from mmengine.utils import track_iter_progress
+
+
+def convert_balloon_to_coco(ann_file, out_file, image_prefix):
+ data_infos = load(ann_file)
+
+ annotations = []
+ images = []
+ obj_count = 0
+ for idx, v in enumerate(track_iter_progress(data_infos.values())):
+ filename = v['filename']
+ img_path = osp.join(image_prefix, filename)
+ height, width = mmcv.imread(img_path).shape[:2]
+
+ images.append(
+ dict(id=idx, file_name=filename, height=height, width=width))
+
+ for _, obj in v['regions'].items():
+ assert not obj['region_attributes']
+ obj = obj['shape_attributes']
+ px = obj['all_points_x']
+ py = obj['all_points_y']
+ poly = [(x + 0.5, y + 0.5) for x, y in zip(px, py)]
+ poly = [p for x in poly for p in x]
+
+ x_min, y_min, x_max, y_max = (min(px), min(py), max(px), max(py))
+
+ data_anno = dict(
+ image_id=idx,
+ id=obj_count,
+ category_id=0,
+ bbox=[x_min, y_min, x_max - x_min, y_max - y_min],
+ area=(x_max - x_min) * (y_max - y_min),
+ segmentation=[poly],
+ iscrowd=0)
+ annotations.append(data_anno)
+ obj_count += 1
+
+ coco_format_json = dict(
+ images=images,
+ annotations=annotations,
+ categories=[{
+ 'id': 0,
+ 'name': 'balloon'
+ }])
+ dump(coco_format_json, out_file)
+
+
+if __name__ == '__main__':
+ convert_balloon_to_coco(ann_file='data/balloon/train/via_region_data.json',
+ out_file='data/balloon/train/annotation_coco.json',
+ image_prefix='data/balloon/train')
+ convert_balloon_to_coco(ann_file='data/balloon/val/via_region_data.json',
+ out_file='data/balloon/val/annotation_coco.json',
+ image_prefix='data/balloon/val')
+```
+
+õĮ┐ńö©Õ”éõĖŖńÜäÕćĮµĢ░’╝īńö©µłĘÕÅ»õ╗źµłÉÕŖ¤Õ░åµĀćµ│©µ¢ćõ╗ČĶĮ¼Õī¢õĖ║ JSON µĀ╝Õ╝Å’╝īõ╣ŗÕÉÄÕÅ»õ╗źõĮ┐ńö© `CocoDataset` Õ»╣µ©ĪÕ×ŗĶ┐øĶĪīĶ«Łń╗ā’╝īÕ╣Čńö© `CocoMetric` Ķ»äµĄŗŃĆé
+
+## ÕćåÕżćķģŹńĮ«µ¢ćõ╗Č
+
+ń¼¼õ║īµŁźķ£ĆĶ”üÕćåÕżćõĖĆõĖ¬ķģŹńĮ«µ¢ćõ╗ČµØźµłÉÕŖ¤ÕŖĀĶĮĮµĢ░µŹ«ķøåŃĆéÕüćĶ«Šµłæõ╗¼µā│Ķ”üńö© balloon dataset µØźĶ«Łń╗āķģŹÕżćõ║å FPN ńÜä Mask R-CNN ’╝īÕ”éõĖŗµś»µłæõ╗¼ńÜäķģŹńĮ«µ¢ćõ╗ČŃĆéÕüćĶ«ŠķģŹńĮ«µ¢ćõ╗ČÕæĮÕÉŹõĖ║ `mask-rcnn_r50-caffe_fpn_ms-poly-1x_balloon.py`’╝īńøĖÕ║öõ┐ØÕŁśĶĘ»ÕŠäõĖ║ `configs/balloon/`’╝īķģŹńĮ«µ¢ćõ╗ČÕåģÕ«╣Õ”éõĖŗµēĆńż║ŃĆéĶ»”ń╗åńÜäķģŹńĮ«µ¢ćõ╗ȵ¢╣µ│ĢÕÅ»õ╗źÕÅéĶĆā[ÕŁ”õ╣ĀķģŹńĮ«µ¢ćõ╗Č ŌĆö MMDetection 3.0.0 µ¢ćµĪŻ](https://mmdetection.readthedocs.io/zh_CN/latest/user_guides/config.html#base)ŃĆé
+
+```python
+# µ¢░ķģŹńĮ«ń╗¦µē┐õ║åÕ¤║µ£¼ķģŹńĮ«’╝īÕ╣ČÕüÜõ║åÕ┐ģĶ”üńÜäõ┐«µö╣
+_base_ = '../mask_rcnn/mask-rcnn_r50-caffe_fpn_ms-poly-1x_coco.py'
+
+# µłæõ╗¼Ķ┐śķ£ĆĶ”üµø┤µö╣ head õĖŁńÜä num_classes õ╗źÕī╣ķģŹµĢ░µŹ«ķøåõĖŁńÜäń▒╗Õł½µĢ░
+model = dict(
+ roi_head=dict(
+ bbox_head=dict(num_classes=1), mask_head=dict(num_classes=1)))
+
+# õ┐«µö╣µĢ░µŹ«ķøåńøĖÕģ│ķģŹńĮ«
+data_root = 'data/balloon/'
+metainfo = {
+ 'classes': ('balloon', ),
+ 'palette': [
+ (220, 20, 60),
+ ]
+}
+train_dataloader = dict(
+ batch_size=1,
+ dataset=dict(
+ data_root=data_root,
+ metainfo=metainfo,
+ ann_file='train/annotation_coco.json',
+ data_prefix=dict(img='train/')))
+val_dataloader = dict(
+ dataset=dict(
+ data_root=data_root,
+ metainfo=metainfo,
+ ann_file='val/annotation_coco.json',
+ data_prefix=dict(img='val/')))
+test_dataloader = val_dataloader
+
+# õ┐«µö╣Ķ»äõ╗ʵīćµĀćńøĖÕģ│ķģŹńĮ«
+val_evaluator = dict(ann_file=data_root + 'val/annotation_coco.json')
+test_evaluator = val_evaluator
+
+# õĮ┐ńö©ķóäĶ«Łń╗āńÜä Mask R-CNN µ©ĪÕ×ŗµØāķćŹµØźÕüÜÕłØÕ¦ŗÕī¢’╝īÕÅ»õ╗źµÅÉķ½śµ©ĪÕ×ŗµĆ¦ĶāĮ
+load_from = 'https://download.openmmlab.com/mmdetection/v2.0/mask_rcnn/mask_rcnn_r50_caffe_fpn_mstrain-poly_3x_coco/mask_rcnn_r50_caffe_fpn_mstrain-poly_3x_coco_bbox_mAP-0.408__segm_mAP-0.37_20200504_163245-42aa3d00.pth'
+
+```
+
+## Ķ«Łń╗āõĖĆõĖ¬µ¢░ńÜ䵩ĪÕ×ŗ
+
+õĖ║õ║åõĮ┐ńö©µ¢░ńÜäķģŹńĮ«µ¢╣µ│ĢµØźÕ»╣µ©ĪÕ×ŗĶ┐øĶĪīĶ«Łń╗ā’╝īõĮĀÕŬķ£ĆĶ”üĶ┐ÉĶĪīÕ”éõĖŗÕæĮõ╗żŃĆé
+
+```shell
+python tools/train.py configs/balloon/mask-rcnn_r50-caffe_fpn_ms-poly-1x_balloon.py
+```
+
+ÕÅéĶĆā [Õ£©µĀćÕćåµĢ░µŹ«ķøåõĖŖĶ«Łń╗āķóäÕ«Üõ╣ēńÜ䵩ĪÕ×ŗ](https://mmdetection.readthedocs.io/zh_CN/latest/user_guides/train.html#id1) µØźĶÄĘÕÅ¢µø┤ÕżÜĶ»”ń╗åńÜäõĮ┐ńö©µ¢╣µ│ĢŃĆé
+
+## µĄŗĶ»Ģõ╗źÕÅŖµÄ©ńÉå
+
+õĖ║õ║åµĄŗĶ»ĢĶ«Łń╗āÕ«īµ»ĢńÜ䵩ĪÕ×ŗ’╝īõĮĀÕŬķ£ĆĶ”üĶ┐ÉĶĪīÕ”éõĖŗÕæĮõ╗żŃĆé
+
+```shell
+python tools/test.py configs/balloon/mask-rcnn_r50-caffe_fpn_ms-poly-1x_balloon.py work_dirs/mask-rcnn_r50-caffe_fpn_ms-poly-1x_balloon/epoch_12.pth
+```
+
+ÕÅéĶĆā [µĄŗĶ»ĢńÄ░µ£ēµ©ĪÕ×ŗ](https://mmdetection.readthedocs.io/zh_CN/latest/user_guides/test.html) µØźĶÄĘÕÅ¢µø┤ÕżÜĶ»”ń╗åńÜäõĮ┐ńö©µ¢╣µ│ĢŃĆé
diff --git a/internlm_langchain/knowledge_base/MMDetection/content/transforms.md b/internlm_langchain/knowledge_base/MMDetection/content/transforms.md
new file mode 100644
index 00000000..07d7db24
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection/content/transforms.md
@@ -0,0 +1,43 @@
+# µĢ░µŹ«ÕÅśµŹó’╝łÕŠģµø┤µ¢░’╝ē
+
+µīēńģ¦µā»õŠŗ’╝īµłæõ╗¼õĮ┐ńö© `Dataset` ÕÆī `DataLoader` Ķ┐øĶĪīÕżÜĶ┐øń©ŗńÜäµĢ░µŹ«ÕŖĀĶĮĮŃĆé`Dataset` Ķ┐öÕø×ÕŁŚÕģĖń▒╗Õ×ŗńÜäµĢ░µŹ«’╝īµĢ░µŹ«ÕåģÕ«╣õĖ║µ©ĪÕ×ŗ `forward` µ¢╣µ│ĢńÜäÕÉäõĖ¬ÕÅéµĢ░ŃĆéńö▒õ║ÄÕ£©ńø«µĀ浯ƵĄŗõĖŁ’╝īĶŠōÕģźńÜäÕøŠÕāŵĢ░µŹ«Õģʵ£ēõĖŹÕÉīńÜäÕż¦Õ░Å’╝īµłæõ╗¼Õ£© `MMCV` ķćīÕ╝ĢÕģźõĖĆõĖ¬µ¢░ńÜä `DataContainer` ń▒╗ÕÄ╗µöČķøåÕÆīÕłåÕÅæõĖŹÕÉīÕż¦Õ░ÅńÜäĶŠōÕģźµĢ░µŹ«ŃĆéµø┤ÕżÜń╗åĶŖéĶ»ĘÕÅéĶĆā[Ķ┐Öķćī](https://github.com/open-mmlab/mmcv/blob/master/mmcv/parallel/data_container.py)ŃĆé
+
+µĢ░µŹ«ńÜäÕćåÕżćµĄüń©ŗÕÆīµĢ░µŹ«ķøåµś»Ķ¦ŻĶĆ”ńÜäŃĆéķĆÜÕĖĖõĖĆõĖ¬µĢ░µŹ«ķøåÕ«Üõ╣ēõ║åÕ”éõĮĢÕżäńÉåµĀćµ│©µĢ░µŹ«’╝łannotations’╝ēõ┐Īµü»’╝īĶĆīõĖĆõĖ¬µĢ░µŹ«µĄüń©ŗÕ«Üõ╣ēõ║åÕćåÕżćõĖĆõĖ¬µĢ░µŹ«ÕŁŚÕģĖńÜäµēƵ£ēµŁźķ¬żŃĆéõĖĆõĖ¬µĄüń©ŗÕīģµŗ¼õĖĆń│╗ÕłŚńÜäµōŹõĮ£’╝īµ»ÅõĖ¬µōŹõĮ£ķāĮµŖŖõĖĆõĖ¬ÕŁŚÕģĖõĮ£õĖ║ĶŠōÕģź’╝īńäČÕÉÄÕåŹĶŠōÕć║õĖĆõĖ¬µ¢░ńÜäÕŁŚÕģĖń╗ÖõĖŗõĖĆõĖ¬ÕÅśµŹóµōŹõĮ£ŃĆé
+
+µłæõ╗¼Õ£©õĖŗÕøŠÕ▒Ģńż║õ║åõĖĆõĖ¬ń╗ÅÕģĖńÜäµĢ░µŹ«ÕżäńÉåµĄüń©ŗŃĆéĶōØĶē▓ÕØŚµś»µĢ░µŹ«ÕżäńÉåµōŹõĮ£’╝īķÜÅńØƵĢ░µŹ«µĄüń©ŗńÜäÕżäńÉå’╝īµ»ÅõĖ¬µōŹõĮ£ķāĮÕÅ»õ╗źÕ£©ń╗ōµ×£ÕŁŚÕģĖõĖŁÕŖĀÕģźµ¢░ńÜäķö«’╝łµĀćĶ«░õĖ║ń╗┐Ķē▓’╝ēµł¢µø┤µ¢░ńÄ░µ£ēńÜäķö«’╝łµĀćĶ«░õĖ║µ®ÖĶē▓’╝ēŃĆé
+
+
+
+Ķ┐Öõ║øµōŹõĮ£ÕÅ»õ╗źÕłåõĖ║µĢ░µŹ«ÕŖĀĶĮĮ’╝łdata loading’╝ēŃĆüķóäÕżäńÉå’╝łpre-processing’╝ēŃĆüµĀ╝Õ╝ÅÕÅśÕī¢’╝łformatting’╝ēÕÆīµĄŗĶ»ĢµŚČµĢ░µŹ«Õó×Õ╝║’╝łtest-time augmentation’╝ēŃĆé
+
+õĖŗķØóńÜäõŠŗÕŁÉµś» `Faster R-CNN` ńÜäõĖĆõĖ¬µĄüń©ŗ’╝Ü
+
+```python
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations', with_bbox=True),
+ dict(type='Resize', img_scale=(1333, 800), keep_ratio=True),
+ dict(type='RandomFlip', flip_ratio=0.5),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size_divisor=32),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']),
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(1333, 800),
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size_divisor=32),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img']),
+ ])
+]
+```
diff --git a/internlm_langchain/knowledge_base/MMDetection/content/useful_hooks.md b/internlm_langchain/knowledge_base/MMDetection/content/useful_hooks.md
new file mode 100644
index 00000000..07a59df2
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection/content/useful_hooks.md
@@ -0,0 +1,107 @@
+# Õ«×ńö©ńÜäķÆ®ÕŁÉ
+
+MMDetection ÕÆī MMEngine õĖ║ńö©µłĘµÅÉõŠøõ║åÕżÜń¦ŹÕżÜµĀĘÕ«×ńö©ńÜäķÆ®ÕŁÉ’╝łHook’╝ē’╝īÕīģµŗ¼ `MemoryProfilerHook`ŃĆü`NumClassCheckHook` ńŁēńŁēŃĆé
+Ķ┐Öń»ćµĢÖń©ŗõ╗ŗń╗Źõ║å MMDetection õĖŁÕ«×ńÄ░ńÜäķÆ®ÕŁÉÕŖ¤ĶāĮÕÅŖõĮ┐ńö©µ¢╣Õ╝ÅŃĆéĶŗźõĮ┐ńö© MMEngine Õ«Üõ╣ēńÜäķÆ®ÕŁÉĶ»ĘÕÅéĶĆā [MMEngine ńÜäķÆ®ÕŁÉAPIµ¢ćµĪŻ](https://github.com/open-mmlab/mmengine/tree/main/docs/en/tutorials/hook.md).
+
+## CheckInvalidLossHook
+
+## NumClassCheckHook
+
+## MemoryProfilerHook
+
+[ÕåģÕŁśÕłåµ×ÉķÆ®ÕŁÉ](https://github.com/open-mmlab/mmdetection/blob/main/mmdet/engine/hooks/memory_profiler_hook.py)
+Ķ«░ÕĮĢõ║åÕīģµŗ¼ĶÖܵŗ¤ÕåģÕŁśŃĆüõ║żµŹóÕåģÕŁśŃĆüÕĮōÕēŹĶ┐øń©ŗÕ£©ÕåģńÜäµēƵ£ēÕåģÕŁśõ┐Īµü»’╝īÕ«āĶāĮÕż¤ÕĖ«ÕŖ®µŹĢµŹēń│╗ń╗¤ńÜäõĮ┐ńö©ńŖČÕåĄõĖÄÕÅæńÄ░ķÜÉĶŚÅńÜäÕåģÕŁśµ│äķ£▓ķŚ«ķóśŃĆéõĖ║õ║åõĮ┐ńö©Ķ┐ÖõĖ¬ķÆ®ÕŁÉ’╝īõĮĀķ£ĆĶ”üÕģłķĆÜĶ┐ć `pip install memory_profiler psutil` ÕæĮõ╗żÕ«ēĶŻģ `memory_profiler` ÕÆī `psutil`ŃĆé
+
+### õĮ┐ńö©
+
+õĖ║õ║åõĮ┐ńö©Ķ┐ÖõĖ¬ķÆ®ÕŁÉ’╝īõĮ┐ńö©ĶĆģķ£ĆĶ”üµĘ╗ÕŖĀÕ”éõĖŗõ╗ŻńĀüĶć│ config µ¢ćõ╗Č
+
+```python
+custom_hooks = [
+ dict(type='MemoryProfilerHook', interval=50)
+]
+```
+
+### ń╗ōµ×£
+
+Õ£©Ķ«Łń╗āõĖŁ’╝īõĮĀõ╝Üń£ŗÕł░ `MemoryProfilerHook` Ķ«░ÕĮĢńÜäÕ”éõĖŗõ┐Īµü»’╝Ü
+
+```text
+The system has 250 GB (246360 MB + 9407 MB) of memory and 8 GB (5740 MB + 2452 MB) of swap memory in total. Currently 9407 MB (4.4%) of memory and 5740 MB (29.9%) of swap memory were consumed. And the current training process consumed 5434 MB of memory.
+```
+
+```text
+2022-04-21 08:49:56,881 - mmengine - INFO - Memory information available_memory: 246360 MB, used_memory: 9407 MB, memory_utilization: 4.4 %, available_swap_memory: 5740 MB, used_swap_memory: 2452 MB, swap_memory_utilization: 29.9 %, current_process_memory: 5434 MB
+```
+
+## SetEpochInfoHook
+
+## SyncNormHook
+
+## SyncRandomSizeHook
+
+## YOLOXLrUpdaterHook
+
+## YOLOXModeSwitchHook
+
+## Õ”éõĮĢÕ«×ńÄ░Ķć¬Õ«Üõ╣ēķÆ®ÕŁÉ
+
+ķĆÜÕĖĖ’╝īõ╗ĵ©ĪÕ×ŗĶ«Łń╗āńÜäÕ╝ĆÕ¦ŗÕł░ń╗ōµØ¤’╝īÕģ▒µ£ē20õĖ¬ńé╣õĮŹÕÅ»õ╗źµē¦ĶĪīķÆ®ÕŁÉŃĆ鵳æõ╗¼ÕÅ»õ╗źÕ«×ńÄ░Ķć¬Õ«Üõ╣ēķÆ®ÕŁÉÕ£©õĖŹÕÉīńé╣õĮŹµē¦ĶĪī’╝īõ╗źõŠ┐Õ£©Ķ«Łń╗āõĖŁÕ«×ńÄ░Ķć¬Õ«Üõ╣ēµōŹõĮ£ŃĆé
+
+- global points: `before_run`, `after_run`
+- points in training: `before_train`, `before_train_epoch`, `before_train_iter`, `after_train_iter`, `after_train_epoch`, `after_train`
+- points in validation: `before_val`, `before_val_epoch`, `before_val_iter`, `after_val_iter`, `after_val_epoch`, `after_val`
+- points at testing: `before_test`, `before_test_epoch`, `before_test_iter`, `after_test_iter`, `after_test_epoch`, `after_test`
+- other points: `before_save_checkpoint`, `after_save_checkpoint`
+
+µ»öÕ”é’╝īµłæõ╗¼Ķ”üÕ«×ńÄ░õĖĆõĖ¬µŻĆµ¤ź loss ńÜäķÆ®ÕŁÉ’╝īÕĮōµŹ¤Õż▒õĖ║ NaN µŚČĶć¬ÕŖ©ń╗ōµØ¤Ķ«Łń╗āŃĆ鵳æõ╗¼ÕÅ»õ╗źµŖŖĶ┐ÖõĖ¬Ķ┐ćń©ŗÕłåõĖ║õĖēµŁź’╝Ü
+
+1. Õ£© MMEngine Õ«×ńÄ░õĖĆõĖ¬ń╗¦µē┐õ║Ä `Hook` ń▒╗ńÜäµ¢░ķÆ®ÕŁÉ’╝īÕ╣ČÕ«×ńÄ░ `after_train_iter` µ¢╣µ│Ģńö©õ║ĵŻĆµ¤źµ»Å `n` µ¼ĪĶ«Łń╗āĶ┐Łõ╗ŻÕÉĵŹ¤Õż▒µś»ÕÉ”ÕÅśõĖ║ NaN ŃĆé
+2. õĮ┐ńö© `@HOOKS.register_module()` µ│©ÕåīÕ«×ńÄ░ÕźĮõ║åńÜäĶć¬Õ«Üõ╣ēķÆ®ÕŁÉ’╝īÕ”éõĖŗÕłŚõ╗ŻńĀüµēĆńż║ŃĆé
+3. Õ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁµĘ╗ÕŖĀ `custom_hooks = [dict(type='MemoryProfilerHook', interval=50)]`
+
+```python
+from typing import Optional
+
+import torch
+from mmengine.hooks import Hook
+from mmengine.runner import Runner
+
+from mmdet.registry import HOOKS
+
+
+@HOOKS.register_module()
+class CheckInvalidLossHook(Hook):
+ """Check invalid loss hook.
+
+ This hook will regularly check whether the loss is valid
+ during training.
+
+ Args:
+ interval (int): Checking interval (every k iterations).
+ Default: 50.
+ """
+
+ def __init__(self, interval: int = 50) -> None:
+ self.interval = interval
+
+ def after_train_iter(self,
+ runner: Runner,
+ batch_idx: int,
+ data_batch: Optional[dict] = None,
+ outputs: Optional[dict] = None) -> None:
+ """Regularly check whether the loss is valid every n iterations.
+
+ Args:
+ runner (:obj:`Runner`): The runner of the training process.
+ batch_idx (int): The index of the current batch in the train loop.
+ data_batch (dict, Optional): Data from dataloader.
+ Defaults to None.
+ outputs (dict, Optional): Outputs from model. Defaults to None.
+ """
+ if self.every_n_train_iters(runner, self.interval):
+ assert torch.isfinite(outputs['loss']), \
+ runner.logger.info('loss become infinite or NaN!')
+```
+
+Ķ»ĘÕÅéĶĆā [Ķć¬Õ«Üõ╣ēĶ«Łń╗āķģŹńĮ«](../advanced_guides/customize_runtime.md) õ║åĶ¦Żµø┤ÕżÜõĖÄĶć¬Õ«Üõ╣ēķÆ®ÕŁÉńøĖÕģ│ńÜäÕåģÕ«╣ŃĆé
diff --git a/internlm_langchain/knowledge_base/MMDetection/content/useful_tools.md b/internlm_langchain/knowledge_base/MMDetection/content/useful_tools.md
new file mode 100644
index 00000000..e53ffdfc
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection/content/useful_tools.md
@@ -0,0 +1,562 @@
+ķÖżõ║åĶ«Łń╗āÕÆīµĄŗĶ»ĢĶäܵ£¼’╝īµłæõ╗¼Ķ┐śÕ£© `tools/` ńø«ÕĮĢõĖŗµÅÉõŠøõ║åĶ«ĖÕżÜµ£ēńö©ńÜäÕĘźÕģĘŃĆé
+
+## µŚźÕ┐ŚÕłåµ×É
+
+`tools/analysis_tools/analyze_logs.py` ÕÅ»Õł®ńö©µīćÕ«ÜńÜäĶ«Łń╗ā log µ¢ćõ╗Čń╗śÕłČ loss/mAP µø▓ń║┐ÕøŠ’╝ī
+ń¼¼õĖƵ¼ĪĶ┐ÉĶĪīÕēŹĶ»ĘÕģłĶ┐ÉĶĪī `pip install seaborn` Õ«ēĶŻģÕ┐ģĶ”üõŠØĶĄ¢.
+
+```shell
+python tools/analysis_tools/analyze_logs.py plot_curve [--keys ${KEYS}] [--eval-interval ${EVALUATION_INTERVAL}] [--title ${TITLE}] [--legend ${LEGEND}] [--backend ${BACKEND}] [--style ${STYLE}] [--out ${OUT_FILE}]
+```
+
+
+
+µĀĘõŠŗ:
+
+- ń╗śÕłČÕłåń▒╗µŹ¤Õż▒µø▓ń║┐ÕøŠ
+
+ ```shell
+ python tools/analysis_tools/analyze_logs.py plot_curve log.json --keys loss_cls --legend loss_cls
+ ```
+
+- ń╗śÕłČÕłåń▒╗µŹ¤Õż▒ŃĆüÕø×ÕĮƵŹ¤Õż▒µø▓ń║┐ÕøŠ’╝īõ┐ØÕŁśÕøŠńēćõĖ║Õ»╣Õ║öńÜä pdf µ¢ćõ╗Č
+
+ ```shell
+ python tools/analysis_tools/analyze_logs.py plot_curve log.json --keys loss_cls loss_bbox --out losses.pdf
+ ```
+
+- Õ£©ńøĖÕÉīÕøŠÕāÅõĖŁµ»öĶŠāõĖżµ¼ĪĶ┐ÉĶĪīń╗ōµ×£ńÜä bbox mAP
+
+ ```shell
+ python tools/analysis_tools/analyze_logs.py plot_curve log1.json log2.json --keys bbox_mAP --legend run1 run2
+ ```
+
+- Ķ«Īń«ŚÕ╣│ÕØćĶ«Łń╗āķƤÕ║”
+
+ ```shell
+ python tools/analysis_tools/analyze_logs.py cal_train_time log.json [--include-outliers]
+ ```
+
+ ĶŠōÕć║õ╗źÕ”éõĖŗÕĮóÕ╝ÅÕ▒Ģńż║
+
+ ```text
+ -----Analyze train time of work_dirs/some_exp/20190611_192040.log.json-----
+ slowest epoch 11, average time is 1.2024
+ fastest epoch 1, average time is 1.1909
+ time std over epochs is 0.0028
+ average iter time: 1.1959 s/iter
+ ```
+
+## ń╗ōµ×£Õłåµ×É
+
+õĮ┐ńö© `tools/analysis_tools/analyze_results.py` ÕÅ»Ķ«Īń«Śµ»ÅõĖ¬ÕøŠÕāÅ mAP’╝īķÜÅÕÉĵĀ╣µŹ«ń£¤Õ«×µĀćµ│©µĪåõĖÄķó䵥ŗµĪåńÜäµ»öĶŠāń╗ōµ×£’╝īÕ▒Ģńż║µł¢õ┐ØÕŁśµ£Ćķ½śõĖĵ£ĆõĮÄ top-k ÕŠŚÕłåńÜäķó䵥ŗÕøŠÕāÅŃĆé
+
+**õĮ┐ńö©µ¢╣µ│Ģ**
+
+```shell
+python tools/analysis_tools/analyze_results.py \
+ ${CONFIG} \
+ ${PREDICTION_PATH} \
+ ${SHOW_DIR} \
+ [--show] \
+ [--wait-time ${WAIT_TIME}] \
+ [--topk ${TOPK}] \
+ [--show-score-thr ${SHOW_SCORE_THR}] \
+ [--cfg-options ${CFG_OPTIONS}]
+```
+
+ÕÉäõĖ¬ÕÅéµĢ░ķĆēķĪ╣ńÜäõĮ£ńö©:
+
+- `config`: model config µ¢ćõ╗ČńÜäĶĘ»ÕŠäŃĆé
+- `prediction_path`: õĮ┐ńö© `tools/test.py` ĶŠōÕć║ńÜä pickle µĀ╝Õ╝Åń╗ōµ×£µ¢ćõ╗ČŃĆé
+- `show_dir`: ń╗śÕłČń£¤Õ«×µĀćµ│©µĪåõĖÄķó䵥ŗµĪåńÜäÕøŠÕāÅÕŁśµöŠńø«ÕĮĢŃĆé
+- `--show`’╝ÜÕå│իܵś»ÕÉ”Õ▒Ģńż║ń╗śÕłČ box ÕÉÄńÜäÕøŠńēć’╝īķ╗śĶ«żÕĆ╝õĖ║ `False`ŃĆé
+- `--wait-time`: show µŚČķŚ┤ńÜäķŚ┤ķÜö’╝īĶŗźõĖ║ 0 ĶĪ©ńż║µīüń╗ŁµśŠńż║ŃĆé
+- `--topk`: µĀ╣µŹ«µ£Ćķ½śµł¢µ£ĆõĮÄ `topk` µ”éńÄćµÄÆÕ║Åõ┐ØÕŁśńÜäÕøŠńēćµĢ░ķćÅ’╝īĶŗźõĖŹµīćÕ«Ü’╝īķ╗śĶ«żĶ«ŠńĮ«õĖ║ `20`ŃĆé
+- `--show-score-thr`: ĶāĮÕż¤Õ▒Ģńż║ńÜäµ”éńÄćķśłÕĆ╝’╝īķ╗śĶ«żõĖ║ `0`ŃĆé
+- `--cfg-options`: Õ”éµ×£µīćÕ«Ü’╝īÕÅ»µĀ╣µŹ«µīćÕ«Üķö«ÕĆ╝Õ»╣Ķ”åńø¢µø┤µ¢░ķģŹńĮ«µ¢ćõ╗ČńÜäÕ»╣Õ║öķĆēķĪ╣
+
+**µĀĘõŠŗ**:
+ÕüćĶ«ŠõĮĀÕĘ▓ń╗ÅķĆÜĶ┐ć `tools/test.py` ÕŠŚÕł░õ║å pickle µĀ╝Õ╝ÅńÜäń╗ōµ×£µ¢ćõ╗Č’╝īĶĘ»ÕŠäõĖ║ './result.pkl'ŃĆé
+
+1. µĄŗĶ»Ģ Faster R-CNN Õ╣ČÕÅ»Ķ¦åÕī¢ń╗ōµ×£’╝īõ┐ØÕŁśÕøŠńēćĶć│ `results/`
+
+```shell
+python tools/analysis_tools/analyze_results.py \
+ configs/faster_rcnn/faster-rcnn_r50_fpn_1x_coco.py \
+ result.pkl \
+ results \
+ --show
+```
+
+2. µĄŗĶ»Ģ Faster R-CNN Õ╣ȵīćÕ«Ü top-k ÕÅéµĢ░õĖ║ 50’╝īõ┐ØÕŁśń╗ōµ×£ÕøŠńēćĶć│ `results/`
+
+```shell
+python tools/analysis_tools/analyze_results.py \
+ configs/faster_rcnn/faster-rcnn_r50_fpn_1x_coco.py \
+ result.pkl \
+ results \
+ --topk 50
+```
+
+3. Õ”éµ×£õĮĀµā│Ķ┐ćµ╗żõĮĵ”éńÄćńÜäķó䵥ŗń╗ōµ×£’╝īµīćÕ«Ü `show-score-thr` ÕÅéµĢ░
+
+```shell
+python tools/analysis_tools/analyze_results.py \
+ configs/faster_rcnn/faster-rcnn_r50_fpn_1x_coco.py \
+ result.pkl \
+ results \
+ --show-score-thr 0.3
+```
+
+## ÕÅ»Ķ¦åÕī¢
+
+### ÕÅ»Ķ¦åÕī¢µĢ░µŹ«ķøå
+
+`tools/analysis_tools/browse_dataset.py` ÕÅ»ÕĖ«ÕŖ®õĮ┐ńö©ĶĆģµŻĆµ¤źµēĆõĮ┐ńö©ńÜ䵯ƵĄŗµĢ░µŹ«ķøå’╝łÕīģµŗ¼ÕøŠÕāÅÕÆīµĀćµ│©’╝ē’╝īµł¢õ┐ØÕŁśÕøŠÕāÅĶć│µīćÕ«Üńø«ÕĮĢŃĆé
+
+```shell
+python tools/misc/browse_dataset.py ${CONFIG} [-h] [--skip-type ${SKIP_TYPE[SKIP_TYPE...]}] [--output-dir ${OUTPUT_DIR}] [--not-show] [--show-interval ${SHOW_INTERVAL}]
+```
+
+### ÕÅ»Ķ¦åÕī¢µ©ĪÕ×ŗ
+
+Õ£©ÕÅ»Ķ¦åÕī¢õ╣ŗÕēŹ’╝īķ£ĆĶ”üÕģłĶĮ¼µŹóµ©ĪÕ×ŗĶć│ ONNX µĀ╝Õ╝Å’╝ī[ÕÅ»ÕÅéĶĆāµŁżÕżä](#convert-mmdetection-model-to-onnx-experimental)ŃĆé
+µ│©µäÅ’╝īńÄ░Õ£©ÕŬµö»µīü RetinaNet’╝īõ╣ŗÕÉÄńÜäńēłµ£¼Õ░åõ╝ܵö»µīüÕģČõ╗¢µ©ĪÕ×ŗ
+ĶĮ¼µŹóÕÉÄńÜ䵩ĪÕ×ŗÕÅ»õ╗źĶó½ÕģČõ╗¢ÕĘźÕģĘÕÅ»Ķ¦åÕī¢[Netron](https://github.com/lutzroeder/netron)ŃĆé
+
+### ÕÅ»Ķ¦åÕī¢ķó䵥ŗń╗ōµ×£
+
+Õ”éµ×£õĮĀµā│Ķ”üõĖĆõĖ¬ĶĮ╗ķćÅ GUI ÕÅ»Ķ¦åÕī¢µŻĆµĄŗń╗ōµ×£’╝īõĮĀÕÅ»õ╗źÕÅéĶĆā [DetVisGUI project](https://github.com/Chien-Hung/DetVisGUI/tree/mmdetection)ŃĆé
+
+## Ķ»»ÕĘ«Õłåµ×É
+
+`tools/analysis_tools/coco_error_analysis.py` õĮ┐ńö©õĖŹÕÉīµĀćÕćåÕłåµ×ɵ»ÅõĖ¬ń▒╗Õł½ńÜä COCO Ķ»äõ╝░ń╗ōµ×£ŃĆéÕÉīµŚČÕ░åõĖĆõ║øµ£ēÕĖ«ÕŖ®ńÜäõ┐Īµü»õĮōńÄ░Õ£©ÕøŠĶĪ©õĖŖŃĆé
+
+```shell
+python tools/analysis_tools/coco_error_analysis.py ${RESULT} ${OUT_DIR} [-h] [--ann ${ANN}] [--types ${TYPES[TYPES...]}]
+```
+
+µĀĘõŠŗ:
+
+ÕüćĶ«ŠõĮĀÕĘ▓ń╗ŵŖŖ [Mask R-CNN checkpoint file](https://download.openmmlab.com/mmdetection/v2.0/mask_rcnn/mask_rcnn_r50_fpn_1x_coco/mask_rcnn_r50_fpn_1x_coco_20200205-d4b0c5d6.pth) µöŠńĮ«Õ£©µ¢ćõ╗ČÕż╣ 'checkpoint' õĖŁ’╝łÕģČõ╗¢µ©ĪÕ×ŗĶ»ĘÕ£© [model zoo](./model_zoo.md) õĖŁĶÄĘÕÅ¢’╝ēŃĆé
+
+õĖ║õ║åõ┐ØÕŁś bbox ń╗ōµ×£õ┐Īµü»’╝īµłæõ╗¼ķ£ĆĶ”üńö©õĖŗÕłŚµ¢╣Õ╝Åõ┐«µö╣ `test_evaluator` :
+
+1. µ¤źµēŠÕĮōÕēŹ config µ¢ćõ╗ČńøĖÕ»╣Õ║öńÜä 'configs/base/datasets' µĢ░µŹ«ķøåõ┐Īµü»ŃĆé
+2. ńö©ÕĮōÕēŹµĢ░µŹ«ķøå config õĖŁńÜä test_evaluator õ╗źÕÅŖ test_dataloader µø┐µŹóÕĤզŗµ¢ćõ╗ČńÜä test_evaluator õ╗źÕÅŖ test_dataloaderŃĆé
+3. õĮ┐ńö©õ╗źõĖŗÕæĮõ╗żÕŠŚÕł░ bbox µł¢ segmentation ńÜä json µĀ╝Õ╝ŵ¢ćõ╗ČŃĆé
+
+```shell
+python tools/test.py \
+ configs/mask_rcnn/mask-rcnn_r50_fpn_1x_coco.py \
+ checkpoint/mask_rcnn_r50_fpn_1x_coco_20200205-d4b0c5d6.pth \
+```
+
+1. ÕŠŚÕł░µ»ÅõĖĆń▒╗ńÜä COCO bbox Ķ»»ÕĘ«ń╗ōµ×£’╝īÕ╣Čõ┐ØÕŁśÕłåµ×Éń╗ōµ×£ÕøŠÕāÅĶć│µīćÕ«Üńø«ÕĮĢŃĆé’╝łÕ£© [config](../../../configs/_base_/datasets/coco_instance.py) õĖŁķ╗śĶ«żńø«ÕĮĢµś» './work_dirs/coco_instance/test')
+
+```shell
+python tools/analysis_tools/coco_error_analysis.py \
+ results.bbox.json \
+ results \
+ --ann=data/coco/annotations/instances_val2017.json \
+```
+
+2. ÕŠŚÕł░µ»ÅõĖĆń▒╗ńÜä COCO ÕłåÕē▓Ķ»»ÕĘ«ń╗ōµ×£’╝īÕ╣Čõ┐ØÕŁśÕłåµ×Éń╗ōµ×£ÕøŠÕāÅĶć│µīćÕ«Üńø«ÕĮĢŃĆé
+
+```shell
+python tools/analysis_tools/coco_error_analysis.py \
+ results.segm.json \
+ results \
+ --ann=data/coco/annotations/instances_val2017.json \
+ --types='segm'
+```
+
+## µ©ĪÕ×ŗµ£ŹÕŖĪķā©ńĮ▓
+
+Õ”éµ×£õĮĀµā│õĮ┐ńö© [`TorchServe`](https://pytorch.org/serve/) µÉŁÕ╗║õĖĆõĖ¬ `MMDetection` µ©ĪÕ×ŗµ£ŹÕŖĪ’╝īÕÅ»õ╗źÕÅéĶĆāõ╗źõĖŗµŁźķ¬ż’╝Ü
+
+### 1. Õ«ēĶŻģ TorchServe
+
+ÕüćĶ«ŠõĮĀÕĘ▓ń╗ŵłÉÕŖ¤Õ«ēĶŻģõ║åÕīģÕɽ `PyTorch` ÕÆī `MMDetection` ńÜä `Python` ńÄ»Õóā’╝īķéŻõ╣łõĮĀÕÅ»õ╗źĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗żµØźÕ«ēĶŻģ `TorchServe` ÕÅŖÕģČõŠØĶĄ¢ķĪ╣ŃĆéµ£ēÕģ│µø┤ÕżÜÕģČõ╗¢Õ«ēĶŻģķĆēķĪ╣’╝īĶ»ĘÕÅéĶĆā[Õ┐½ķƤÕģźķŚ©](https://github.com/pytorch/serve/blob/master/README.md#serve-a-model)ŃĆé
+
+```shell
+python -m pip install torchserve torch-model-archiver torch-workflow-archiver nvgpu
+```
+
+**µ│©µäÅ**: Õ”éµ×£õĮĀµā│Õ£© docker õĖŁõĮ┐ńö©`TorchServe`’╝īĶ»ĘÕÅéĶĆā[torchserve docker](https://github.com/pytorch/serve/blob/master/docker/README.md)ŃĆé
+
+### 2. µŖŖ MMDetection µ©ĪÕ×ŗĶĮ¼µŹóĶć│ TorchServe
+
+```shell
+python tools/deployment/mmdet2torchserve.py ${CONFIG_FILE} ${CHECKPOINT_FILE} \
+--output-folder ${MODEL_STORE} \
+--model-name ${MODEL_NAME}
+```
+
+### 3. ÕÉ»ÕŖ© `TorchServe`
+
+```shell
+torchserve --start --ncs \
+ --model-store ${MODEL_STORE} \
+ --models ${MODEL_NAME}.mar
+```
+
+### 4. µĄŗĶ»Ģķā©ńĮ▓µĢłµ×£
+
+```shell
+curl -O curl -O https://raw.githubusercontent.com/pytorch/serve/master/docs/images/3dogs.jpg
+curl http://127.0.0.1:8080/predictions/${MODEL_NAME} -T 3dogs.jpg
+```
+
+õĮĀÕÅ»õ╗źÕŠŚÕł░õĖŗÕłŚ json õ┐Īµü»’╝Ü
+
+```json
+[
+ {
+ "class_label": 16,
+ "class_name": "dog",
+ "bbox": [
+ 294.63409423828125,
+ 203.99111938476562,
+ 417.048583984375,
+ 281.62744140625
+ ],
+ "score": 0.9987992644309998
+ },
+ {
+ "class_label": 16,
+ "class_name": "dog",
+ "bbox": [
+ 404.26019287109375,
+ 126.0080795288086,
+ 574.5091552734375,
+ 293.6662292480469
+ ],
+ "score": 0.9979367256164551
+ },
+ {
+ "class_label": 16,
+ "class_name": "dog",
+ "bbox": [
+ 197.2144775390625,
+ 93.3067855834961,
+ 307.8505554199219,
+ 276.7560119628906
+ ],
+ "score": 0.993338406085968
+ }
+]
+```
+
+#### ń╗ōµ×£Õ»╣µ»ö
+
+õĮĀõ╣¤ÕÅ»õ╗źõĮ┐ńö© `test_torchserver.py` µØźµ»öĶŠā `TorchServe` ÕÆī `PyTorch` ńÜäń╗ōµ×£’╝īÕ╣ČÕÅ»Ķ¦åÕī¢’╝Ü
+
+```shell
+python tools/deployment/test_torchserver.py ${IMAGE_FILE} ${CONFIG_FILE} ${CHECKPOINT_FILE} ${MODEL_NAME}
+[--inference-addr ${INFERENCE_ADDR}] [--device ${DEVICE}] [--score-thr ${SCORE_THR}] [--work-dir ${WORK_DIR}]
+```
+
+µĀĘõŠŗ:
+
+```shell
+python tools/deployment/test_torchserver.py \
+demo/demo.jpg \
+configs/yolo/yolov3_d53_8xb8-320-273e_coco.py \
+checkpoint/yolov3_d53_320_273e_coco-421362b6.pth \
+yolov3 \
+--work-dir ./work-dir
+```
+
+### 5. Õü£µŁó `TorchServe`
+
+```shell
+torchserve --stop
+```
+
+## µ©ĪÕ×ŗÕżŹµØéÕ║”
+
+`tools/analysis_tools/get_flops.py` ÕĘźÕģĘÕÅ»ńö©õ║ÄĶ«Īń«Śµīćիܵ©ĪÕ×ŗńÜä FLOPsŃĆüÕÅéµĢ░ķćÅÕż¦Õ░Å’╝łµö╣ń╝¢Ķć¬ [flops-counter.pytorch](https://github.com/sovrasov/flops-counter.pytorch) ’╝ēŃĆé
+
+```shell
+python tools/analysis_tools/get_flops.py ${CONFIG_FILE} [--shape ${INPUT_SHAPE}]
+```
+
+ĶÄĘÕŠŚńÜäń╗ōµ×£Õ”éõĖŗ’╝Ü
+
+```text
+==============================
+Input shape: (3, 1280, 800)
+Flops: 239.32 GFLOPs
+Params: 37.74 M
+==============================
+```
+
+**µ│©µäÅ**’╝ÜĶ┐ÖõĖ¬ÕĘźÕģĘĶ┐śÕŬµś»Õ«×ķ¬īµĆ¦Ķ┤©’╝īµłæõ╗¼õĖŹõ┐ØĶ»üĶ┐ÖõĖ¬µĢ░ÕĆ╝µś»ń╗ØÕ»╣µŁŻńĪ«ńÜäŃĆéõĮĀÕÅ»õ╗źÕ░åõ╗¢ńö©õ║Äń«ĆÕŹĢńÜäµ»öĶŠā’╝īõĮåÕ”éµ×£ńö©õ║Äń¦æµŖĆĶ«║µ¢ćµŖźÕæŖķ£ĆĶ”üÕåŹõĖēµŻĆµ¤źńĪ«Ķ«żŃĆé
+
+1. FLOPs õĖÄĶŠōÕģźńÜäÕĮóńŖČÕż¦Õ░ÅńøĖÕģ│’╝īÕÅéµĢ░ķćŵ▓Īµ£ēĶ┐ÖõĖ¬Õģ│ń│╗’╝īķ╗śĶ«żńÜäĶŠōÕģźÕĮóńŖČÕż¦Õ░ÅõĖ║ (1, 3, 1280, 800) ŃĆé
+2. õĖĆõ║øń«ŚÕŁÉÕ╣ČõĖŹĶ«ĪÕģź FLOPs’╝īµ»öÕ”é GN µł¢ÕģČõ╗¢Ķć¬Õ«Üõ╣ēńÜäń«ŚÕŁÉŃĆéõĮĀÕÅ»õ╗źÕÅéĶĆā [`mmcv.cnn.get_model_complexity_info()`](https://github.com/open-mmlab/mmcv/blob/2.x/mmcv/cnn/utils/flops_counter.py) µ¤źń£ŗµø┤Ķ»”ń╗åńÜäĶ»┤µśÄŃĆé
+3. õĖżķśČµ«ĄµŻĆµĄŗńÜä FLOPs Õż¦Õ░ÅÕÅ¢Õå│õ║Ä proposal ńÜäµĢ░ķćÅŃĆé
+
+## µ©ĪÕ×ŗĶĮ¼µŹó
+
+### MMDetection µ©ĪÕ×ŗĶĮ¼µŹóĶć│ ONNX µĀ╝Õ╝Å
+
+µłæõ╗¼µÅÉõŠøõ║åõĖĆõĖ¬Ķäܵ£¼ńö©õ║ÄĶĮ¼µŹóµ©ĪÕ×ŗĶć│ [ONNX](https://github.com/onnx/onnx) µĀ╝Õ╝ÅŃĆéÕÉīµŚČĶ┐śµö»µīüµ»öĶŠā Pytorch õĖÄ ONNX µ©ĪÕ×ŗńÜäĶŠōÕć║ń╗ōµ×£õ╗źõŠ┐Õ»╣ńģ¦ŃĆéµø┤Ķ»”ń╗åńÜäÕåģÕ«╣ÕÅ»õ╗źÕÅéĶĆā [mmdeploy](https://github.com/open-mmlab/mmdeploy)ŃĆé
+
+### MMDetection 1.x µ©ĪÕ×ŗĶĮ¼µŹóĶć│ MMDetection 2.x µ©ĪÕ×ŗ
+
+`tools/model_converters/upgrade_model_version.py` ÕÅ»Õ░åµŚ¦ńēłµ£¼ńÜä MMDetection checkpoints ĶĮ¼µŹóĶć│µ¢░ńēłµ£¼ŃĆéõĮåĶ”üµ│©µäŵŁżĶäܵ£¼õĖŹõ┐ØĶ»üÕ£©µ¢░ńēłµ£¼ÕŖĀÕģźķØ×Õģ╝Õ«╣µø┤µ¢░ÕÉÄĶ┐śĶāĮµŁŻÕĖĖĶĮ¼µŹó’╝īÕ╗║Ķ««µé©ńø┤µÄźõĮ┐ńö©µ¢░ńēłµ£¼ńÜä checkpointsŃĆé
+
+```shell
+python tools/model_converters/upgrade_model_version.py ${IN_FILE} ${OUT_FILE} [-h] [--num-classes NUM_CLASSES]
+```
+
+### RegNet µ©ĪÕ×ŗĶĮ¼µŹóĶć│ MMDetection µ©ĪÕ×ŗ
+
+`tools/model_converters/regnet2mmdet.py` Õ░å pycls ń╝¢ńĀüńÜäķóäĶ«Łń╗ā RegNet µ©ĪÕ×ŗĶĮ¼µŹóõĖ║ MMDetection ķŻÄµĀ╝ŃĆé
+
+```shell
+python tools/model_converters/regnet2mmdet.py ${SRC} ${DST} [-h]
+```
+
+### Detectron ResNet µ©ĪÕ×ŗĶĮ¼µŹóĶć│ Pytorch µ©ĪÕ×ŗ
+
+`tools/model_converters/detectron2pytorch.py` Õ░å detectron ńÜäÕĤզŗķóäĶ«Łń╗ā RegNet µ©ĪÕ×ŗĶĮ¼µŹóõĖ║ MMDetection ķŻÄµĀ╝ŃĆé
+
+```shell
+python tools/model_converters/detectron2pytorch.py ${SRC} ${DST} ${DEPTH} [-h]
+```
+
+### ÕłČõĮ£ÕÅæÕĖāńö©µ©ĪÕ×ŗ
+
+`tools/model_converters/publish_model.py` ÕÅ»ńö©µØźÕłČõĮ£õĖĆõĖ¬ÕÅæÕĖāńö©ńÜ䵩ĪÕ×ŗŃĆé
+
+Õ£©ÕÅæÕĖāµ©ĪÕ×ŗĶć│ AWS õ╣ŗÕēŹ’╝īõĮĀÕÅ»ĶāĮķ£ĆĶ”ü’╝Ü
+
+1. Õ░嵩ĪÕ×ŗĶĮ¼µŹóĶć│ CPU Õ╝ĀķćÅ
+2. ÕłĀķÖżõ╝śÕī¢ÕÖ©ńŖȵĆü
+3. Ķ«Īń«Ś checkpoint µ¢ćõ╗ČńÜä hash ÕĆ╝’╝īÕ╣ČÕ░å hash ÕÅĘńĀüĶ«░ÕĮĢĶć│µ¢ćõ╗ČÕÉŹŃĆé
+
+```shell
+python tools/model_converters/publish_model.py ${INPUT_FILENAME} ${OUTPUT_FILENAME}
+```
+
+µĀĘõŠŗ’╝Ü
+
+```shell
+python tools/model_converters/publish_model.py work_dirs/faster_rcnn/latest.pth faster_rcnn_r50_fpn_1x_20190801.pth
+```
+
+µ£ĆÕÉÄĶŠōÕć║ńÜäµ¢ćõ╗ČÕÉŹÕ”éõĖŗµēĆńż║’╝Ü `faster_rcnn_r50_fpn_1x_20190801-{hash id}.pth`.
+
+## µĢ░µŹ«ķøåĶĮ¼µŹó
+
+`tools/data_converters/` µÅÉõŠøõ║åÕ░å Cityscapes µĢ░µŹ«ķøåõĖÄ Pascal VOC µĢ░µŹ«ķøåĶĮ¼µŹóĶć│ COCO µĢ░µŹ«ķøåµĀ╝Õ╝ÅńÜäÕĘźÕģĘ
+
+```shell
+python tools/dataset_converters/cityscapes.py ${CITYSCAPES_PATH} [-h] [--img-dir ${IMG_DIR}] [--gt-dir ${GT_DIR}] [-o ${OUT_DIR}] [--nproc ${NPROC}]
+python tools/dataset_converters/pascal_voc.py ${DEVKIT_PATH} [-h] [-o ${OUT_DIR}]
+```
+
+## µĢ░µŹ«ķøåõĖŗĶĮĮ
+
+`tools/misc/download_dataset.py` ÕÅ»õ╗źõĖŗĶĮĮÕÉäń▒╗ÕĮóÕ”é COCO’╝ī VOC’╝ī LVIS µĢ░µŹ«ķøåŃĆé
+
+```shell
+python tools/misc/download_dataset.py --dataset-name coco2017
+python tools/misc/download_dataset.py --dataset-name voc2007
+python tools/misc/download_dataset.py --dataset-name lvis
+```
+
+Õ»╣õ║ÄõĖŁÕøĮÕóāÕåģńÜäńö©µłĘ’╝īµłæõ╗¼õ╣¤µÄ©ĶŹÉõĮ┐ńö©Õ╝Ƶ║ɵĢ░µŹ«Õ╣│ÕÅ░ [OpenDataLab](https://opendatalab.com/?source=OpenMMLab%20GitHub) µØźĶÄĘÕÅ¢Ķ┐Öõ║øµĢ░µŹ«ķøå’╝īõ╗źĶÄĘÕŠŚµø┤ÕźĮńÜäõĖŗĶĮĮõĮōķ¬ī:
+
+- [COCO2017](https://opendatalab.com/COCO_2017/download?source=OpenMMLab%20GitHub)
+- [VOC2007](https://opendatalab.com/PASCAL_VOC2007/download?source=OpenMMLab%20GitHub)
+- [VOC2012](https://opendatalab.com/PASCAL_VOC2012/download?source=OpenMMLab%20GitHub)
+- [LVIS](https://opendatalab.com/LVIS/download?source=OpenMMLab%20GitHub)
+
+## Õ¤║ÕćåµĄŗĶ»Ģ
+
+### ķ▓üµŻÆµĆ¦µĄŗĶ»ĢÕ¤║Õćå
+
+`tools/analysis_tools/test_robustness.py` ÕÅŖ `tools/analysis_tools/robustness_eval.py` ÕĖ«ÕŖ®õĮ┐ńö©ĶĆģĶĪĪķćŵ©ĪÕ×ŗńÜäķ▓üµŻÆµĆ¦ŃĆéÕģȵĀĖÕ┐āµĆصā│µØźµ║Éõ║Ä [Benchmarking Robustness in Object Detection: Autonomous Driving when Winter is Coming](https://arxiv.org/abs/1907.07484)ŃĆéÕ”éµ×£õĮĀµā│õ║åĶ¦ŻÕ”éõĮĢÕ£©µ▒ĪµŹ¤ÕøŠÕāÅõĖŖĶ»äõ╝░µ©ĪÕ×ŗńÜäµĢłµ×£’╝īõ╗źÕÅŖÕÅéĶĆāĶ»źÕ¤║ÕćåńÜäõĖĆń╗äµĀćÕć嵩ĪÕ×ŗ’╝īĶ»ĘÕÅéńģ¦ [robustness_benchmarking.md](robustness_benchmarking.md)ŃĆé
+
+### FPS µĄŗĶ»ĢÕ¤║Õćå
+
+`tools/analysis_tools/benchmark.py` ÕÅ»ÕĖ«ÕŖ®õĮ┐ńö©ĶĆģĶ«Īń«Ś FPS’╝īFPS Ķ«Īń«ŚÕīģµŗ¼õ║嵩ĪÕ×ŗÕÉæÕēŹõ╝ĀµÆŁõĖÄÕÉÄÕżäńÉåĶ┐ćń©ŗŃĆéõĖ║õ║åÕŠŚÕł░µø┤ń▓ŠńĪ«ńÜäĶ«Īń«ŚÕĆ╝’╝īńÄ░Õ£©ńÜäÕłåÕĖāÕ╝ÅĶ«Īń«Śµ©ĪÕ╝ÅÕŬµö»µīüõĖĆõĖ¬ GPUŃĆé
+
+```shell
+python -m torch.distributed.launch --nproc_per_node=1 --master_port=${PORT} tools/analysis_tools/benchmark.py \
+ ${CONFIG} \
+ [--checkpoint ${CHECKPOINT}] \
+ [--repeat-num ${REPEAT_NUM}] \
+ [--max-iter ${MAX_ITER}] \
+ [--log-interval ${LOG_INTERVAL}] \
+ --launcher pytorch
+```
+
+µĀĘõŠŗ’╝ÜÕüćĶ«ŠõĮĀÕĘ▓ń╗ÅõĖŗĶĮĮõ║å `Faster R-CNN` µ©ĪÕ×ŗ checkpoint Õ╣ȵöŠńĮ«Õ£© `checkpoints/` ńø«ÕĮĢõĖŗŃĆé
+
+```shell
+python -m torch.distributed.launch --nproc_per_node=1 --master_port=29500 tools/analysis_tools/benchmark.py \
+ configs/faster_rcnn/faster-rcnn_r50_fpn_1x_coco.py \
+ checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \
+ --launcher pytorch
+```
+
+## µø┤ÕżÜÕĘźÕģĘ
+
+### õ╗źµ¤ÉõĖ¬Ķ»äõ╝░µĀćÕćåĶ┐øĶĪīĶ»äõ╝░
+
+`tools/analysis_tools/eval_metric.py` µĀ╣µŹ«ķģŹńĮ«µ¢ćõ╗ČõĖŁńÜäĶ»äõ╝░µ¢╣Õ╝ÅÕ»╣ pkl ń╗ōµ×£µ¢ćõ╗ČĶ┐øĶĪīĶ»äõ╝░ŃĆé
+
+```shell
+python tools/analysis_tools/eval_metric.py ${CONFIG} ${PKL_RESULTS} [-h] [--format-only] [--eval ${EVAL[EVAL ...]}]
+ [--cfg-options ${CFG_OPTIONS [CFG_OPTIONS ...]}]
+ [--eval-options ${EVAL_OPTIONS [EVAL_OPTIONS ...]}]
+```
+
+### µēōÕŹ░Õģ©ķā© config
+
+`tools/misc/print_config.py` ÕÅ»Õ░åµēƵ£ēķģŹńĮ«ń╗¦µē┐Õģ│ń│╗Õ▒ĢÕ╝Ć’╝īÕ«īÕģ©µēōÕŹ░ńøĖÕ║öńÜäķģŹńĮ«µ¢ćõ╗ČŃĆé
+
+```shell
+python tools/misc/print_config.py ${CONFIG} [-h] [--options ${OPTIONS [OPTIONS...]}]
+```
+
+## ĶČģÕÅéµĢ░õ╝śÕī¢
+
+### YOLO Anchor õ╝śÕī¢
+
+`tools/analysis_tools/optimize_anchors.py` µÅÉõŠøõ║åõĖżń¦Źµ¢╣µ│Ģõ╝śÕī¢ YOLO ńÜä anchorsŃĆé
+
+ÕģČõĖŁõĖĆń¦Źµ¢╣µ│ĢõĮ┐ńö© K ÕØćÕĆ╝ anchor ĶüÜń▒╗’╝łk-means anchor cluster’╝ē’╝īµ║ÉĶć¬ [darknet](https://github.com/AlexeyAB/darknet/blob/master/src/detector.c#L1421)ŃĆé
+
+```shell
+python tools/analysis_tools/optimize_anchors.py ${CONFIG} --algorithm k-means --input-shape ${INPUT_SHAPE [WIDTH HEIGHT]} --output-dir ${OUTPUT_DIR}
+```
+
+ÕÅ”õĖĆń¦Źµ¢╣µ│ĢõĮ┐ńö©ÕĘ«ÕłåĶ┐øÕī¢ń«Śµ│Ģõ╝śÕī¢ anchorsŃĆé
+
+```shell
+python tools/analysis_tools/optimize_anchors.py ${CONFIG} --algorithm differential_evolution --input-shape ${INPUT_SHAPE [WIDTH HEIGHT]} --output-dir ${OUTPUT_DIR}
+```
+
+µĀĘõŠŗ’╝Ü
+
+```shell
+python tools/analysis_tools/optimize_anchors.py configs/yolo/yolov3_d53_8xb8-320-273e_coco.py --algorithm differential_evolution --input-shape 608 608 --device cuda --output-dir work_dirs
+```
+
+õĮĀÕÅ»ĶāĮõ╝Üń£ŗÕł░Õ”éõĖŗń╗ōµ×£’╝Ü
+
+```
+loading annotations into memory...
+Done (t=9.70s)
+creating index...
+index created!
+2021-07-19 19:37:20,951 - mmdet - INFO - Collecting bboxes from annotation...
+[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 117266/117266, 15874.5 task/s, elapsed: 7s, ETA: 0s
+
+2021-07-19 19:37:28,753 - mmdet - INFO - Collected 849902 bboxes.
+differential_evolution step 1: f(x)= 0.506055
+differential_evolution step 2: f(x)= 0.506055
+......
+
+differential_evolution step 489: f(x)= 0.386625
+2021-07-19 19:46:40,775 - mmdet - INFO Anchor evolution finish. Average IOU: 0.6133754253387451
+2021-07-19 19:46:40,776 - mmdet - INFO Anchor differential evolution result:[[10, 12], [15, 30], [32, 22], [29, 59], [61, 46], [57, 116], [112, 89], [154, 198], [349, 336]]
+2021-07-19 19:46:40,798 - mmdet - INFO Result saved in work_dirs/anchor_optimize_result.json
+```
+
+## µĘʵĘåń¤®ķśĄ
+
+µĘʵĘåń¤®ķśĄµś»Õ»╣µŻĆµĄŗń╗ōµ×£ńÜäµ”éĶ¦łŃĆé
+`tools/analysis_tools/confusion_matrix.py` ÕŻջ╣ķó䵥ŗń╗ōµ×£Ķ┐øĶĪīÕłåµ×É’╝īń╗śÕłČµłÉµĘʵĘåń¤®ķśĄĶĪ©ŃĆé
+ķ”¢Õģł’╝īĶ┐ÉĶĪī `tools/test.py` õ┐ØÕŁś `.pkl` ķó䵥ŗń╗ōµ×£ŃĆé
+õ╣ŗÕÉÄÕåŹĶ┐ÉĶĪī’╝Ü
+
+```
+python tools/analysis_tools/confusion_matrix.py ${CONFIG} ${DETECTION_RESULTS} ${SAVE_DIR} --show
+```
+
+µ£ĆÕÉÄõĮĀÕÅ»õ╗źÕŠŚÕł░Õ”éÕøŠńÜäµĘʵĘåń¤®ķśĄ’╝Ü
+
+
+
+## COCO Õłåń”╗ÕÆīķü«µīĪÕ«×õŠŗÕłåÕē▓µĆ¦ĶāĮĶ»äõ╝░
+
+Õ»╣õ║ĵ£ĆÕģłĶ┐øńÜäńø«µĀ浯ƵĄŗÕÖ©µØźĶ»┤’╝īµŻĆµĄŗĶó½ķü«µīĪńÜäńē®õĮōõ╗Źńäȵś»õĖĆõĖ¬µīæµłśŃĆé
+µłæõ╗¼Õ«×ńÄ░õ║åĶ«║µ¢ć [A Tri-Layer Plugin to Improve Occluded Detection](https://arxiv.org/abs/2210.10046) õĖŁµÅÉÕć║ńÜäµīćµĀćµØźĶ«Īń«ŚÕłåń”╗ÕÆīķü«µīĪńø«µĀćńÜäÕżÕø×ńÄćŃĆé
+
+õĮ┐ńö©µŁżĶ»äõ╗ʵīćµĀćµ£ēõĖżń¦Źµ¢╣µ│Ģ’╝Ü
+
+### ń”╗ń║┐Ķ»äµĄŗ
+
+µłæõ╗¼µÅÉõŠøõ║åõĖĆõĖ¬Ķäܵ£¼Õ»╣ÕŁśÕé©ÕÉÄńÜ䵯ƵĄŗń╗ōµ×£µ¢ćõ╗ČĶ«Īń«ŚµīćµĀćŃĆé
+
+ķ”¢Õģł’╝īõĮ┐ńö© `tools/test.py` Ķäܵ£¼ÕŁśÕ驵ŻĆµĄŗń╗ōµ×£’╝Ü
+
+```shell
+python tools/test.py ${CONFIG} ${MODEL_PATH} --out results.pkl
+```
+
+ńäČÕÉÄ’╝īĶ┐ÉĶĪī `tools/analysis_tools/coco_occluded_separated_recall.py` Ķäܵ£¼µØźĶ«Īń«ŚÕłåń”╗ÕÆīķü«µīĪńø«µĀćńÜäµÄ®ńĀüńÜäÕżÕø×ńÄć:
+
+```shell
+python tools/analysis_tools/coco_occluded_separated_recall.py results.pkl --out occluded_separated_recall.json
+```
+
+ĶŠōÕć║Õ”éõĖŗ’╝Ü
+
+```
+loading annotations into memory...
+Done (t=0.51s)
+creating index...
+index created!
+processing detection results...
+[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 5000/5000, 109.3 task/s, elapsed: 46s, ETA: 0s
+computing occluded mask recall...
+[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 5550/5550, 780.5 task/s, elapsed: 7s, ETA: 0s
+COCO occluded mask recall: 58.79%
+COCO occluded mask success num: 3263
+computing separated mask recall...
+[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 3522/3522, 778.3 task/s, elapsed: 5s, ETA: 0s
+COCO separated mask recall: 31.94%
+COCO separated mask success num: 1125
+
++-----------+--------+-------------+
+| mask type | recall | num correct |
++-----------+--------+-------------+
+| occluded | 58.79% | 3263 |
+| separated | 31.94% | 1125 |
++-----------+--------+-------------+
+Evaluation results have been saved to occluded_separated_recall.json.
+```
+
+### Õ£©ń║┐Ķ»äµĄŗ
+
+µłæõ╗¼Õ«×ńÄ░ń╗¦µē┐Ķć¬ `CocoMetic` ńÜä `CocoOccludedSeparatedMetric`ŃĆé
+Ķ”üÕ£©Ķ«Łń╗āµ£¤ķŚ┤Ķ»äõ╝░Õłåń”╗ÕÆīķü«µīĪµÄ®ńĀüńÜäÕżÕø×ńÄć’╝īÕŬķ£ĆÕ£©ķģŹńĮ«õĖŁÕ░å evaluator ń▒╗Õ×ŗµø┐µŹóõĖ║ `CocoOccludedSeparatedMetric`’╝Ü
+
+```python
+val_evaluator = dict(
+ type='CocoOccludedSeparatedMetric', # õ┐«µö╣µŁżÕżä
+ ann_file=data_root + 'annotations/instances_val2017.json',
+ metric=['bbox', 'segm'],
+ format_only=False)
+test_evaluator = val_evaluator
+```
+
+Õ”éµ×£µé©õĮ┐ńö©õ║åµŁżµīćµĀć’╝īĶ»ĘÕ╝Ģńö©Ķ«║µ¢ć’╝Ü
+
+```latex
+@article{zhan2022triocc,
+ title={A Tri-Layer Plugin to Improve Occluded Detection},
+ author={Zhan, Guanqi and Xie, Weidi and Zisserman, Andrew},
+ journal={British Machine Vision Conference},
+ year={2022}
+}
+```
diff --git a/internlm_langchain/knowledge_base/MMDetection/content/visualization.md b/internlm_langchain/knowledge_base/MMDetection/content/visualization.md
new file mode 100644
index 00000000..f90ab6d4
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection/content/visualization.md
@@ -0,0 +1,93 @@
+# ÕÅ»Ķ¦åÕī¢
+
+Õ£©ķśģĶ»╗µ£¼µĢÖń©ŗõ╣ŗÕēŹ’╝īÕ╗║Ķ««ÕģłķśģĶ»╗ MMEngine ńÜä [Visualization](https://github.com/open-mmlab/mmengine/blob/main/docs/en/advanced_tutorials/visualization.md) µ¢ćµĪŻ’╝īõ╗źÕ»╣ `Visualizer` ńÜäÕ«Üõ╣ēÕÆīńö©µ│Ģµ£ēõĖĆõĖ¬ÕłØµŁźńÜäõ║åĶ¦ŻŃĆé
+
+ń«ĆĶĆīĶ©Ćõ╣ŗ’╝ī`Visualizer` Õ£© MMEngine õĖŁÕ«×ńÄ░õ╗źµ╗ĪĶČ│µŚźÕĖĖÕÅ»Ķ¦åÕī¢ķ£Ćµ▒é’╝īÕ╣ČÕīģÕɽõ╗źõĖŗõĖēõĖ¬õĖ╗Ķ”üÕŖ¤ĶāĮ’╝Ü
+
+- Õ«×ńÄ░ķĆÜńö©ńÜäń╗śÕøŠ API’╝īõŠŗÕ”é [`draw_bboxes`](mmengine.visualization.Visualizer.draw_bboxes) Õ«×ńÄ░õ║åń╗śÕłČĶŠ╣ńĢīµĪåńÜäÕŖ¤ĶāĮ’╝ī[`draw_lines`](mmengine.visualization.Visualizer.draw_lines) Õ«×ńÄ░õ║åń╗śÕłČń║┐µØĪńÜäÕŖ¤ĶāĮŃĆé
+- µö»µīüÕ░åÕÅ»Ķ¦åÕī¢ń╗ōµ×£ŃĆüÕŁ”õ╣ĀńÄćµø▓ń║┐ŃĆüµŹ¤Õż▒ÕćĮµĢ░µø▓ń║┐õ╗źÕÅŖķ¬īĶ»üń▓ŠÕ║”µø▓ń║┐ÕåÖÕģźÕł░ÕÉäń¦ŹÕÉÄń½»õĖŁ’╝īÕīģµŗ¼µ£¼Õ£░ńŻüńøśõ╗źÕÅŖÕĖĖĶ¦üńÜäµĘ▒Õ║”ÕŁ”õ╣ĀĶ«Łń╗āµŚźÕ┐ŚÕĘźÕģĘ’╝īõŠŗÕ”é [TensorBoard](https://www.tensorflow.org/tensorboard) ÕÆī [Wandb](https://wandb.ai/site)ŃĆé
+- µö»µīüÕ£©õ╗ŻńĀüńÜäõ╗╗õĮĢõĮŹńĮ«Ķ░āńö©õ╗źÕÅ»Ķ¦åÕī¢µł¢Ķ«░ÕĮĢµ©ĪÕ×ŗÕ£©Ķ«Łń╗āµł¢µĄŗĶ»Ģµ£¤ķŚ┤ńÜäõĖŁķŚ┤ńŖȵĆü’╝īõŠŗÕ”éńē╣ÕŠüÕøŠÕÆīķ¬īĶ»üń╗ōµ×£ŃĆé
+
+Õ¤║õ║Ä MMEngine ńÜä `Visualizer`’╝īMMDet µÅÉõŠøõ║åÕÉäń¦Źķóäµ×äÕ╗║ńÜäÕÅ»Ķ¦åÕī¢ÕĘźÕģĘ’╝īńö©µłĘÕÅ»õ╗źķĆÜĶ┐ćń«ĆÕŹĢÕ£░õ┐«µö╣õ╗źõĖŗķģŹńĮ«µ¢ćõ╗ČµØźõĮ┐ńö©Õ«āõ╗¼ŃĆé
+
+- `tools/analysis_tools/browse_dataset.py` Ķäܵ£¼µÅÉõŠøõ║åõĖĆõĖ¬µĢ░µŹ«ķøåÕÅ»Ķ¦åÕī¢ÕŖ¤ĶāĮ’╝īÕÅ»õ╗źÕ£©µĢ░µŹ«ń╗ÅĶ┐ćµĢ░µŹ«ĶĮ¼µŹóÕÉÄń╗śÕłČÕøŠÕāÅÕÆīńøĖÕ║öńÜäµ│©ķćŖ’╝īÕģĘõĮōµÅÅĶ┐░Ķ»ĘÕÅéĶ¦ü[`browse_dataset.py`](useful_tools.md#Visualization)ŃĆé
+
+- MMEngineÕ«×ńÄ░õ║å`LoggerHook`’╝īõĮ┐ńö©`Visualizer`Õ░åÕŁ”õ╣ĀńÄćŃĆüµŹ¤Õż▒ÕÆīĶ»äõ╝░ń╗ōµ×£ÕåÖÕģźńö▒`Visualizer`Ķ«ŠńĮ«ńÜäÕÉÄń½»ŃĆéÕøĀµŁż’╝īķĆÜĶ┐ćõ┐«µö╣ķģŹńĮ«µ¢ćõ╗ČõĖŁńÜä`Visualizer`ÕÉÄń½»’╝īõŠŗÕ”éõ┐«µö╣õĖ║`TensorBoardVISBackend`µł¢`WandbVISBackend`’╝īÕÅ»õ╗źÕ«×ńÄ░µŚźÕ┐ŚĶ«░ÕĮĢÕł░ÕĖĖńö©ńÜäĶ«Łń╗āµŚźÕ┐ŚÕĘźÕģĘ’╝īÕ”é`TensorBoard`µł¢`WandB`’╝īõ╗ÄĶĆīµ¢╣õŠ┐ńö©µłĘõĮ┐ńö©Ķ┐Öõ║øÕÅ»Ķ¦åÕī¢ÕĘźÕģĘµØźÕłåµ×ÉÕÆīńøæµÄ¦Ķ«Łń╗āĶ┐ćń©ŗŃĆé
+
+- Õ£©MMDetõĖŁÕ«×ńÄ░õ║å`VisualizerHook`’╝īÕ«āõĮ┐ńö©`Visualizer`Õ░åķ¬īĶ»üµł¢ķó䵥ŗķśČµ«ĄńÜäķó䵥ŗń╗ōµ×£ÕÅ»Ķ¦åÕī¢µł¢ÕŁśÕé©Õł░ńö▒`Visualizer`Ķ«ŠńĮ«ńÜäÕÉÄń½»ŃĆéÕøĀµŁż’╝īķĆÜĶ┐ćõ┐«µö╣ķģŹńĮ«µ¢ćõ╗ČõĖŁńÜä`Visualizer`ÕÉÄń½»’╝īõŠŗÕ”éõ┐«µö╣õĖ║`TensorBoardVISBackend`µł¢`WandbVISBackend`’╝īÕÅ»õ╗źÕ░åķó䵥ŗÕøŠÕāÅÕŁśÕé©Õł░`TensorBoard`µł¢`Wandb`õĖŁŃĆé
+
+## ķģŹńĮ«
+
+ńö▒õ║ÄõĮ┐ńö©õ║åµ│©Õåīµ£║ÕłČ’╝īÕ£©MMDetõĖŁµłæõ╗¼ÕÅ»õ╗źķĆÜĶ┐ćõ┐«µö╣ķģŹńĮ«µ¢ćõ╗ČµØźĶ«ŠńĮ«`Visualizer`ńÜäĶĪīõĖ║ŃĆéķĆÜÕĖĖ’╝īµłæõ╗¼õ╝ÜÕ£©`configs/_base_/default_runtime.py`õĖŁõĖ║ÕÅ»Ķ¦åÕī¢ÕÖ©Õ«Üõ╣ēķ╗śĶ«żķģŹńĮ«’╝īĶ»”ń╗åõ┐Īµü»Ķ»ĘÕÅéĶ¦ü[ķģŹńĮ«µĢÖń©ŗ](config.md)ŃĆé
+
+```Python
+vis_backends = [dict(type='LocalVisBackend')]
+visualizer = dict(
+ type='DetLocalVisualizer',
+ vis_backends=vis_backends,
+ name='visualizer')
+```
+
+Õ¤║õ║ÄõĖŖķØóńÜäõŠŗÕŁÉ’╝īµłæõ╗¼ÕÅ»õ╗źń£ŗÕł░`Visualizer`ńÜäķģŹńĮ«ńö▒õĖżõĖ¬õĖ╗Ķ”üķā©Õłåń╗䵳ɒ╝īÕŹ│`Visualizer`ń▒╗Õ×ŗÕÆīÕģČõĮ┐ńö©ńÜäÕÅ»Ķ¦åÕī¢ÕÉÄń½»`vis_backends`ŃĆé
+
+- ńö©µłĘÕÅ»ńø┤µÄźõĮ┐ńö©`DetLocalVisualizer`µØźÕÅ»Ķ¦åÕī¢µö»µīüõ╗╗ÕŖĪńÜäµĀćńŁŠµł¢ķó䵥ŗń╗ōµ×£ŃĆé
+- MMDetķ╗śĶ«żÕ░åÕÅ»Ķ¦åÕī¢ÕÉÄń½»`vis_backend`Ķ«ŠńĮ«õĖ║µ£¼Õ£░ÕÅ»Ķ¦åÕī¢ÕÉÄń½»`LocalVisBackend`’╝īÕ░åµēƵ£ēÕÅ»Ķ¦åÕī¢ń╗ōµ×£ÕÆīÕģČõ╗¢Ķ«Łń╗āõ┐Īµü»õ┐ØÕŁśÕ£©µ£¼Õ£░µ¢ćõ╗ČÕż╣õĖŁŃĆé
+
+## ÕŁśÕé©
+
+MMDetķ╗śĶ«żõĮ┐ńö©µ£¼Õ£░ÕÅ»Ķ¦åÕī¢ÕÉÄń½»[`LocalVisBackend`](mmengine.visualization.LocalVisBackend)’╝ī`VisualizerHook`ÕÆī`LoggerHook`õĖŁÕŁśÕé©ńÜ䵩ĪÕ×ŗµŹ¤Õż▒ŃĆüÕŁ”õ╣ĀńÄćŃĆüµ©ĪÕ×ŗĶ»äõ╝░ń▓ŠÕ║”ÕÆīÕÅ»Ķ¦åÕī¢õ┐Īµü»’╝īÕīģµŗ¼µŹ¤Õż▒ŃĆüÕŁ”õ╣ĀńÄćŃĆüĶ»äõ╝░ń▓ŠÕ║”Õ░åķ╗śĶ«żõ┐ØÕŁśÕł░`{work_dir}/{config_name}/{time}/{vis_data}`µ¢ćõ╗ČÕż╣õĖŁŃĆ鵣żÕż¢’╝īMMDetĶ┐śµö»µīüÕģČõ╗¢ÕĖĖĶ¦üńÜäÕÅ»Ķ¦åÕī¢ÕÉÄń½»’╝īõŠŗÕ”é`TensorboardVisBackend`ÕÆī`WandbVisBackend`’╝īµé©ÕŬķ£ĆĶ”üÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁµø┤µö╣`vis_backends`ń▒╗Õ×ŗõĖ║ńøĖÕ║öńÜäÕÅ»Ķ¦åÕī¢ÕÉÄń½»ÕŹ│ÕÅ»ŃĆéõŠŗÕ”é’╝īÕŬķ£ĆÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁµÅÆÕģźõ╗źõĖŗõ╗ŻńĀüÕØŚÕŹ│ÕÅ»Õ░åµĢ░µŹ«ÕŁśÕé©Õł░`TensorBoard`ÕÆī`Wandb`õĖŁŃĆé
+
+```Python
+# https://mmengine.readthedocs.io/en/latest/api/visualization.html
+_base_.visualizer.vis_backends = [
+ dict(type='LocalVisBackend'), #
+ dict(type='TensorboardVisBackend'),
+ dict(type='WandbVisBackend'),]
+```
+
+## ń╗śÕøŠ
+
+### ń╗śÕłČķó䵥ŗń╗ōµ×£
+
+MMDetõĖ╗Ķ”üõĮ┐ńö©[`DetVisualizationHook`](mmdet.engine.hooks.DetVisualizationHook)µØźń╗śÕłČķ¬īĶ»üÕÆīµĄŗĶ»ĢńÜäķó䵥ŗń╗ōµ×£’╝īķ╗śĶ«żµāģÕåĄõĖŗ`DetVisualizationHook`µś»Õģ│ķŚŁńÜä’╝īÕģČķ╗śĶ«żķģŹńĮ«Õ”éõĖŗŃĆé
+
+```Python
+visualization=dict( #ńö©µłĘÕÅ»Ķ¦åÕī¢ķ¬īĶ»üÕÆīµĄŗĶ»Ģń╗ōµ×£
+ type='DetVisualizationHook',
+ draw=False,
+ interval=1,
+ show=False)
+```
+
+õ╗źõĖŗĶĪ©µĀ╝Õ▒Ģńż║õ║å`DetVisualizationHook`µö»µīüńÜäÕÅéµĢ░ŃĆé
+
+| ÕÅéµĢ░ | µÅÅĶ┐░ |
+| :------: | :------------------------------------------------------------------------------: |
+| draw | DetVisualizationHookķĆÜĶ┐ćenableÕÅéµĢ░µēōÕ╝ĆÕÆīÕģ│ķŚŁ’╝īķ╗śĶ«żńŖȵĆüõĖ║Õģ│ķŚŁŃĆé |
+| interval | µÄ¦ÕłČÕ£©DetVisualizationHookÕÉ»ńö©µŚČÕŁśÕ驵ł¢µśŠńż║ķ¬īĶ»üµł¢µĄŗĶ»Ģń╗ōµ×£ńÜäķŚ┤ķÜö’╝īÕŹĢõĮŹõĖ║Ķ┐Łõ╗Żµ¼ĪµĢ░ŃĆé |
+| show | µÄ¦ÕłČµś»ÕÉ”ÕÅ»Ķ¦åÕī¢ķ¬īĶ»üµł¢µĄŗĶ»ĢńÜäń╗ōµ×£ŃĆé |
+
+Õ”éµ×£µé©µā│Õ£©Ķ«Łń╗āµł¢µĄŗĶ»Ģµ£¤ķŚ┤ÕÉ»ńö© `DetVisualizationHook` ńøĖÕģ│ÕŖ¤ĶāĮÕÆīķģŹńĮ«’╝īµé©ÕŬķ£ĆĶ”üõ┐«µö╣ķģŹńĮ«µ¢ćõ╗Č’╝īõ╗ź `configs/rtmdet/rtmdet_tiny_8xb32-300e_coco.py` õĖ║õŠŗ’╝īÕÉīµŚČń╗śÕłČµ│©ķćŖÕÆīķó䵥ŗ’╝īÕ╣ȵśŠńż║ÕøŠÕāÅ’╝īķģŹńĮ«µ¢ćõ╗ČÕÅ»õ╗źõ┐«µö╣Õ”éõĖŗ’╝Ü
+
+```Python
+visualization = _base_.default_hooks.visualization
+visualization.update(dict(draw=True, show=True))
+```
+
+
+
+ +
+
+
+`test.py`ń©ŗÕ║ŵÅÉõŠøõ║å`--show`ÕÆī`--show-dir`ÕÅéµĢ░’╝īÕÅ»õ╗źÕ£©µĄŗĶ»ĢĶ┐ćń©ŗõĖŁÕÅ»Ķ¦åÕī¢µ│©ķćŖÕÆīķó䵥ŗń╗ōµ×£’╝īĶĆīõĖŹķ£ĆĶ”üõ┐«µö╣ķģŹńĮ«µ¢ćõ╗Č’╝īõ╗ÄĶĆīĶ┐øõĖƵŁźń«ĆÕī¢õ║åµĄŗĶ»ĢĶ┐ćń©ŗŃĆé
+
+```Shell
+# Õ▒Ģńż║µĄŗĶ»Ģń╗ōµ×£
+python tools/test.py configs/rtmdet/rtmdet_tiny_8xb32-300e_coco.py https://download.openmmlab.com/mmdetection/v3.0/rtmdet/rtmdet_tiny_8xb32-300e_coco/rtmdet_tiny_8xb32-300e_coco_20220902_112414-78e30dcc.pth --show
+
+# µīćÕ«ÜÕŁśÕé©ķó䵥ŗń╗ōµ×£ńÜäõĮŹńĮ«
+python tools/test.py configs/rtmdet/rtmdet_tiny_8xb32-300e_coco.py https://download.openmmlab.com/mmdetection/v3.0/rtmdet/rtmdet_tiny_8xb32-300e_coco/rtmdet_tiny_8xb32-300e_coco_20220902_112414-78e30dcc.pth --show-dir imgs/
+```
+
+
+
+
+
diff --git a/internlm_langchain/knowledge_base/MMDetection/vector_store/index.faiss b/internlm_langchain/knowledge_base/MMDetection/vector_store/index.faiss
new file mode 100644
index 00000000..dd3b34cf
Binary files /dev/null and b/internlm_langchain/knowledge_base/MMDetection/vector_store/index.faiss differ
diff --git a/internlm_langchain/knowledge_base/MMDetection3D/content/backends_support.md b/internlm_langchain/knowledge_base/MMDetection3D/content/backends_support.md
new file mode 100644
index 00000000..80c535de
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection3D/content/backends_support.md
@@ -0,0 +1,154 @@
+# ÕÉÄń½»µö»µīü
+
+µłæõ╗¼µö»µīüõĖŹÕÉīńÜäµ¢ćõ╗ČÕ«óµłĘń½»ÕÉÄń½»’╝ÜńŻüńøśŃĆüCeph ÕÆī LMDB ńŁēŃĆéõĖŗķØ󵜻õ┐«µö╣ķģŹńĮ«õĮ┐õ╣ŗõ╗Ä Ceph ÕŖĀĶĮĮÕÆīõ┐ØÕŁśµĢ░µŹ«ńÜäńż║õŠŗŃĆé
+
+## õ╗Ä Ceph Ķ»╗ÕÅ¢µĢ░µŹ«ÕÆīµĀćµ│©µ¢ćõ╗Č
+
+µłæõ╗¼µö»µīüõ╗Ä Ceph ÕŖĀĶĮĮµĢ░µŹ«ÕÆīńö¤µłÉńÜäµĀćµ│©õ┐Īµü»µ¢ćõ╗Č’╝łpkl ÕÆī json’╝ē’╝Ü
+
+```python
+# set file client backends as Ceph
+backend_args = dict(
+ backend='petrel',
+ path_mapping=dict({
+ './data/nuscenes/':
+ 's3://openmmlab/datasets/detection3d/nuscenes/', # replace the path with your data path on Ceph
+ 'data/nuscenes/':
+ 's3://openmmlab/datasets/detection3d/nuscenes/' # replace the path with your data path on Ceph
+ }))
+
+db_sampler = dict(
+ data_root=data_root,
+ info_path=data_root + 'kitti_dbinfos_train.pkl',
+ rate=1.0,
+ prepare=dict(filter_by_difficulty=[-1], filter_by_min_points=dict(Car=5)),
+ sample_groups=dict(Car=15),
+ classes=class_names,
+ # set file client for points loader to load training data
+ points_loader=dict(
+ type='LoadPointsFromFile',
+ coord_type='LIDAR',
+ load_dim=4,
+ use_dim=4,
+ backend_args=backend_args),
+ # set file client for data base sampler to load db info file
+ backend_args=backend_args)
+
+train_pipeline = [
+ # set file client for loading training data
+ dict(type='LoadPointsFromFile', coord_type='LIDAR', load_dim=4, use_dim=4, backend_args=backend_args),
+ # set file client for loading training data annotations
+ dict(type='LoadAnnotations3D', with_bbox_3d=True, with_label_3d=True, backend_args=backend_args),
+ dict(type='ObjectSample', db_sampler=db_sampler),
+ dict(
+ type='ObjectNoise',
+ num_try=100,
+ translation_std=[0.25, 0.25, 0.25],
+ global_rot_range=[0.0, 0.0],
+ rot_range=[-0.15707963267, 0.15707963267]),
+ dict(type='RandomFlip3D', flip_ratio_bev_horizontal=0.5),
+ dict(
+ type='GlobalRotScaleTrans',
+ rot_range=[-0.78539816, 0.78539816],
+ scale_ratio_range=[0.95, 1.05]),
+ dict(type='PointsRangeFilter', point_cloud_range=point_cloud_range),
+ dict(type='ObjectRangeFilter', point_cloud_range=point_cloud_range),
+ dict(type='PointShuffle'),
+ dict(type='DefaultFormatBundle3D', class_names=class_names),
+ dict(type='Collect3D', keys=['points', 'gt_bboxes_3d', 'gt_labels_3d'])
+]
+test_pipeline = [
+ # set file client for loading validation/testing data
+ dict(type='LoadPointsFromFile', coord_type='LIDAR', load_dim=4, use_dim=4, backend_args=backend_args),
+ dict(
+ type='MultiScaleFlipAug3D',
+ img_scale=(1333, 800),
+ pts_scale_ratio=1,
+ flip=False,
+ transforms=[
+ dict(
+ type='GlobalRotScaleTrans',
+ rot_range=[0, 0],
+ scale_ratio_range=[1., 1.],
+ translation_std=[0, 0, 0]),
+ dict(type='RandomFlip3D'),
+ dict(
+ type='PointsRangeFilter', point_cloud_range=point_cloud_range),
+ dict(
+ type='DefaultFormatBundle3D',
+ class_names=class_names,
+ with_label=False),
+ dict(type='Collect3D', keys=['points'])
+ ])
+]
+
+data = dict(
+ # set file client for loading training info files (.pkl)
+ train=dict(
+ type='RepeatDataset',
+ times=2,
+ dataset=dict(pipeline=train_pipeline, classes=class_names, backend_args=backend_args)),
+ # set file client for loading validation info files (.pkl)
+ val=dict(pipeline=test_pipeline, classes=class_names,backend_args=backend_args),
+ # set file client for loading testing info files (.pkl)
+ test=dict(pipeline=test_pipeline, classes=class_names, backend_args=backend_args))
+```
+
+## õ╗Ä Ceph Ķ»╗ÕÅ¢ķóäĶ«Łń╗āµ©ĪÕ×ŗ
+
+```python
+model = dict(
+ pts_backbone=dict(
+ _delete_=True,
+ type='NoStemRegNet',
+ arch='regnetx_1.6gf',
+ init_cfg=dict(
+ type='Pretrained', checkpoint='s3://openmmlab/checkpoints/mmdetection3d/regnetx_1.6gf'), # replace the path with your pretrained model path on Ceph
+ ...
+```
+
+## õ╗Ä Ceph Ķ»╗ÕÅ¢µ©ĪÕ×ŗµØāķ揵¢ćõ╗Č
+
+```python
+# replace the path with your checkpoint path on Ceph
+load_from = 's3://openmmlab/checkpoints/mmdetection3d/v0.1.0_models/pointpillars/hv_pointpillars_secfpn_6x8_160e_kitti-3d-car/hv_pointpillars_secfpn_6x8_160e_kitti-3d-car_20200620_230614-77663cd6.pth'
+resume_from = None
+workflow = [('train', 1)]
+```
+
+## õ┐ØÕŁśµ©ĪÕ×ŗµØāķ揵¢ćõ╗ČĶć│ Ceph
+
+```python
+# checkpoint saving
+# replace the path with your checkpoint saving path on Ceph
+checkpoint_config = dict(interval=1, max_keep_ckpts=2, out_dir='s3://openmmlab/mmdetection3d')
+```
+
+## EvalHook õ┐ØÕŁśµ£Ćõ╝śµ©ĪÕ×ŗµØāķ揵¢ćõ╗ČĶć│ Ceph
+
+```python
+# replace the path with your checkpoint saving path on Ceph
+evaluation = dict(interval=1, save_best='bbox', out_dir='s3://openmmlab/mmdetection3d')
+```
+
+## Ķ«Łń╗āµŚźÕ┐Śõ┐ØÕŁśĶć│ Ceph
+
+Ķ«Łń╗āÕÉÄńÜäĶ«Łń╗āµŚźÕ┐Śõ╝ÜÕżćõ╗ĮÕł░µīćÕ«ÜńÜä Ceph ĶĘ»ÕŠäŃĆé
+
+```python
+log_config = dict(
+ interval=50,
+ hooks=[
+ dict(type='TextLoggerHook', out_dir='s3://openmmlab/mmdetection3d'),
+ ])
+```
+
+µé©Ķ┐śÕÅ»õ╗źķĆÜĶ┐ćĶ«ŠńĮ« `keep_local = False` Õżćõ╗ĮÕł░µīćÕ«ÜńÜä Ceph ĶĘ»ÕŠäÕÉÄÕłĀķÖżµ£¼Õ£░Ķ«Łń╗āµŚźÕ┐ŚŃĆé
+
+```python
+log_config = dict(
+ interval=50,
+ hooks=[
+ dict(type='TextLoggerHook', out_dir='s3://openmmlab/mmdetection3d', keep_local=False),
+ ])
+```
diff --git a/internlm_langchain/knowledge_base/MMDetection3D/content/benchmarks.md b/internlm_langchain/knowledge_base/MMDetection3D/content/benchmarks.md
new file mode 100644
index 00000000..52b92270
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection3D/content/benchmarks.md
@@ -0,0 +1,285 @@
+# Õ¤║ÕćåµĄŗĶ»Ģ
+
+Ķ┐Öķćīµłæõ╗¼Õ»╣ MMDetection3D ÕÆīÕģČõ╗¢Õ╝Ƶ║É 3D ńø«µĀ浯ƵĄŗõ╗ŻńĀüÕ║ōõĖŁµ©ĪÕ×ŗńÜäĶ«Łń╗āķƤÕ║”ÕÆīµĄŗĶ»ĢķƤÕ║”Ķ┐øĶĪīõ║åÕ¤║ÕćåµĄŗĶ»ĢŃĆé
+
+## ķģŹńĮ«
+
+- ńĪ¼õ╗Č’╝Ü8 NVIDIA Tesla V100 (32G) GPUs, Intel(R) Xeon(R) Gold 6148 CPU @ 2.40GHz
+- ĶĮ»õ╗Č’╝ÜPython 3.7, CUDA 10.1, cuDNN 7.6.5, PyTorch 1.3, numba 0.48.0.
+- µ©ĪÕ×ŗ’╝Üńö▒õ║ÄõĖŹÕÉīõ╗ŻńĀüÕ║ōµēĆÕ«×ńÄ░ńÜ䵩ĪÕ×ŗń¦Źń▒╗µ£ēµēĆõĖŹÕÉī’╝īÕ£©Õ¤║ÕćåµĄŗĶ»ĢõĖŁµłæõ╗¼ķĆēµŗ®õ║å SECONDŃĆüPointPillarsŃĆüPart-A2 ÕÆī VoteNet ÕćĀń¦Źµ©ĪÕ×ŗ’╝īÕłåÕł½õĖÄÕģČõ╗¢õ╗ŻńĀüÕ║ōõĖŁńÜäńøĖÕ║öµ©ĪÕ×ŗÕ«×ńÄ░Ķ┐øĶĪīõ║åÕ»╣µ»öŃĆé
+- Õ║”ķćŵ¢╣µ│Ģ’╝ܵłæõ╗¼õĮ┐ńö©µĢ┤õĖ¬Ķ«Łń╗āĶ┐ćń©ŗõĖŁńÜäÕ╣│ÕØćÕÉ×ÕÉÉķćÅõĮ£õĖ║Õ║”ķćŵ¢╣µ│Ģ’╝īÕ╣ČĶĘ│Ķ┐ćµ»ÅõĖ¬ epoch ńÜäÕēŹ 50 µ¼ĪĶ┐Łõ╗Żõ╗źµČłķÖżĶ«Łń╗āķóäńāŁńÜäÕĮ▒ÕōŹŃĆé
+
+## õĖ╗Ķ”üń╗ōµ×£
+
+Õ»╣õ║ĵ©ĪÕ×ŗńÜäĶ«Łń╗āķƤÕ║”’╝łµĀʵ£¼/ń¦Æ’╝ē’╝īµłæõ╗¼Õ░å MMDetection3D õĖÄÕģČõ╗¢Õ«×ńÄ░õ║åńøĖÕÉīµ©ĪÕ×ŗńÜäõ╗ŻńĀüÕ║ōĶ┐øĶĪīõ║åÕ»╣µ»öŃĆéń╗ōµ×£Õ”éõĖŗµēĆńż║’╝īĶĪ©µĀ╝ÕåģńÜäµĢ░ÕŁŚĶČŖÕż¦’╝īõ╗ŻĶĪ©µ©ĪÕ×ŗńÜäĶ«Łń╗āķƤÕ║”ĶČŖÕ┐½ŃĆéõ╗ŻńĀüÕ║ōõĖŁõĖŹµö»µīüńÜ䵩ĪÕ×ŗõĮ┐ńö© `├Ś` Ķ┐øĶĪīµĀćĶ»åŃĆé
+
+| µ©ĪÕ×ŗ | MMDetection3D | OpenPCDet | votenet | Det3D |
+| :-----------------: | :-----------: | :-------: | :-----: | :---: |
+| VoteNet | 358 | ├Ś | 77 | ├Ś |
+| PointPillars-car | 141 | ├Ś | ├Ś | 140 |
+| PointPillars-3class | 107 | 44 | ├Ś | ├Ś |
+| SECOND | 40 | 30 | ├Ś | ├Ś |
+| Part-A2 | 17 | 14 | ├Ś | ├Ś |
+
+## µĄŗĶ»Ģń╗åĶŖé
+
+### õĖ║õ║åĶ«Īń«ŚķƤÕ║”µēĆÕüÜńÜäõ┐«µö╣
+
+- __MMDetection3D__’╝ܵłæõ╗¼Õ░ØĶ»ĢõĮ┐ńö©õĖÄÕģČõ╗¢õ╗ŻńĀüÕ║ōõĖŁÕ░ĮÕÅ»ĶāĮńøĖÕÉīńÜäķģŹńĮ«’╝īÕģĘõĮōķģŹńĮ«ń╗åĶŖéĶ¦ü [Õ¤║ÕćåµĄŗĶ»ĢķģŹńĮ«](https://github.com/open-mmlab/MMDetection3D/blob/main/configs/benchmark)ŃĆé
+
+- __Det3D__’╝ÜõĖ║õ║åõĖÄ Det3D Ķ┐øĶĪīµ»öĶŠā’╝īµłæõ╗¼õĮ┐ńö©õ║å commit [519251e](https://github.com/poodarchu/Det3D/tree/519251e72a5c1fdd58972eabeac67808676b9bb7) µēĆÕ»╣Õ║öńÜäõ╗ŻńĀüńēłµ£¼ŃĆé
+
+- __OpenPCDet__’╝ÜõĖ║õ║åõĖÄ OpenPCDet Ķ┐øĶĪīµ»öĶŠā’╝īµłæõ╗¼õĮ┐ńö©õ║å commit [b32fbddb](https://github.com/open-mmlab/OpenPCDet/tree/b32fbddbe06183507bad433ed99b407cbc2175c2) µēĆÕ»╣Õ║öńÜäõ╗ŻńĀüńēłµ£¼ŃĆé
+
+ õĖ║õ║åĶ«Īń«ŚĶ«Łń╗āķƤÕ║”’╝īµłæõ╗¼Õ£© `./tools/train_utils/train_utils.py` µ¢ćõ╗ČõĖŁµĘ╗ÕŖĀõ║åńö©õ║ÄĶ«░ÕĮĢĶ┐ÉĶĪīµŚČķŚ┤ńÜäõ╗ŻńĀüŃĆ鵳æõ╗¼Õ»╣µ»ÅõĖ¬ epoch ńÜäĶ«Łń╗āķƤÕ║”Ķ┐øĶĪīĶ«Īń«Ś’╝īÕ╣ȵŖźÕæŖµēƵ£ē epoch ńÜäÕ╣│ÕØćķƤÕ║”ŃĆé
+
+
+
+
+
+### VoteNet
+
+- __MMDetection3D__’╝ÜÕ£© v0.1.0 ńēłµ£¼õĖŗ, µē¦ĶĪīÕ”éõĖŗÕæĮõ╗ż’╝Ü
+
+ ```bash
+ ./tools/dist_train.sh configs/votenet/votenet_8xb16_sunrgbd-3d.py 8 --no-validate
+ ```
+
+- __votenet__’╝ÜÕ£© commit [2f6d6d3](https://github.com/facebookresearch/votenet/tree/2f6d6d36ff98d96901182e935afe48ccee82d566) ńēłµ£¼õĖŗ’╝īµē¦ĶĪīÕ”éõĖŗÕæĮõ╗ż’╝Ü
+
+ ```bash
+ python train.py --dataset sunrgbd --batch_size 16
+ ```
+
+ ńäČÕÉĵē¦ĶĪīÕ”éõĖŗÕæĮõ╗ż’╝īÕ»╣µĄŗĶ»ĢķƤÕ║”Ķ┐øĶĪīĶ»äõ╝░’╝Ü
+
+ ```bash
+ python eval.py --dataset sunrgbd --checkpoint_path log_sunrgbd/checkpoint.tar --batch_size 1 --dump_dir eval_sunrgbd --cluster_sampling seed_fps --use_3d_nms --use_cls_nms --per_class_proposal
+ ```
+
+ µ│©µäÅ’╝īõĖ║õ║åĶ«Īń«ŚµÄ©ńÉåķƤÕ║”’╝īµłæõ╗¼Õ»╣ `eval.py` Ķ┐øĶĪīõ║åõ┐«µö╣ŃĆé
+
+ + ’╝łõĖ║õ║åõĮ┐ńö©ńøĖÕÉīµ¢╣µ│ĢĶ┐øĶĪīµĄŗĶ»ĢµēĆÕüÜńÜäÕģĘõĮōõ┐«µö╣ - ńé╣Õć╗Õ▒ĢÕ╝Ć’╝ē +
+ + ```diff + diff --git a/tools/train_utils/train_utils.py b/tools/train_utils/train_utils.py + index 91f21dd..021359d 100644 + --- a/tools/train_utils/train_utils.py + +++ b/tools/train_utils/train_utils.py + @@ -2,6 +2,7 @@ import torch + import os + import glob + import tqdm + +import datetime + from torch.nn.utils import clip_grad_norm_ + + + @@ -13,7 +14,10 @@ def train_one_epoch(model, optimizer, train_loader, model_func, lr_scheduler, ac + if rank == 0: + pbar = tqdm.tqdm(total=total_it_each_epoch, leave=leave_pbar, desc='train', dynamic_ncols=True) + + + start_time = None + for cur_it in range(total_it_each_epoch): + + if cur_it > 49 and start_time is None: + + start_time = datetime.datetime.now() + try: + batch = next(dataloader_iter) + except StopIteration: + @@ -55,9 +59,11 @@ def train_one_epoch(model, optimizer, train_loader, model_func, lr_scheduler, ac + tb_log.add_scalar('learning_rate', cur_lr, accumulated_iter) + for key, val in tb_dict.items(): + tb_log.add_scalar('train_' + key, val, accumulated_iter) + + endtime = datetime.datetime.now() + + speed = (endtime - start_time).seconds / (total_it_each_epoch - 50) + if rank == 0: + pbar.close() + - return accumulated_iter + + return accumulated_iter, speed + + + def train_model(model, optimizer, train_loader, model_func, lr_scheduler, optim_cfg, + @@ -65,6 +71,7 @@ def train_model(model, optimizer, train_loader, model_func, lr_scheduler, optim_ + lr_warmup_scheduler=None, ckpt_save_interval=1, max_ckpt_save_num=50, + merge_all_iters_to_one_epoch=False): + accumulated_iter = start_iter + + speeds = [] + with tqdm.trange(start_epoch, total_epochs, desc='epochs', dynamic_ncols=True, leave=(rank == 0)) as tbar: + total_it_each_epoch = len(train_loader) + if merge_all_iters_to_one_epoch: + @@ -82,7 +89,7 @@ def train_model(model, optimizer, train_loader, model_func, lr_scheduler, optim_ + cur_scheduler = lr_warmup_scheduler + else: + cur_scheduler = lr_scheduler + - accumulated_iter = train_one_epoch( + + accumulated_iter, speed = train_one_epoch( + model, optimizer, train_loader, model_func, + lr_scheduler=cur_scheduler, + accumulated_iter=accumulated_iter, optim_cfg=optim_cfg, + @@ -91,7 +98,7 @@ def train_model(model, optimizer, train_loader, model_func, lr_scheduler, optim_ + total_it_each_epoch=total_it_each_epoch, + dataloader_iter=dataloader_iter + ) + - + + speeds.append(speed) + # save trained model + trained_epoch = cur_epoch + 1 + if trained_epoch % ckpt_save_interval == 0 and rank == 0: + @@ -107,6 +114,8 @@ def train_model(model, optimizer, train_loader, model_func, lr_scheduler, optim_ + save_checkpoint( + checkpoint_state(model, optimizer, trained_epoch, accumulated_iter), filename=ckpt_name, + ) + + print(speed) + + print(f'*******{sum(speeds) / len(speeds)}******') + + + def model_state_to_cpu(model_state): + ``` + +
+ kitti
+```
+
+**Õ░ÅĶ┤┤ÕŻ½**’╝Ü
+
+- **ńÄ░µłÉńÜäµĀćµ│©µ¢ćõ╗Č**’╝ܵłæõ╗¼ÕĘ▓ń╗ŵÅÉõŠøõ║åń”╗ń║┐ÕżäńÉåÕźĮńÜä [KITTI µĀćµ│©µ¢ćõ╗Č](#µĢ░µŹ«ķøåµĀćµ│©µ¢ćõ╗ČÕłŚĶĪ©)ŃĆéµé©ńø┤µÄźõĖŗĶĮĮõ╗¢õ╗¼Õ╣ȵöŠÕł░ `data/kitti/` ńø«ÕĮĢõĖŗŃĆéńäČĶĆī’╝īÕ”éµ×£õĮĀµā│Õ£©ńé╣õ║æµŻĆµĄŗµ¢╣µ│ĢõĖŁõĮ┐ńö© `ObjectSample` Ķ┐ÖõĖƵĢ░µŹ«Õó×Õ╝║’╝īõĮĀÕÅ»õ╗źÕåŹķóØÕż¢õĮ┐ńö©õ╗źõĖŗÕæĮõ╗żµØźńö¤µłÉńē®õĮōµĀćµ│©µĪåµĢ░µŹ«Õ║ō’╝Ü
+
+```bash
+python tools/create_data.py kitti --root-path ./data/kitti --out-dir ./data/kitti --extra-tag kitti --only-gt-database
+```
+
+### Waymo
+
+Õ£©[Ķ┐Öķćī](https://waymo.com/open/download/)õĖŗĶĮĮ Waymo Õģ¼Õ╝ƵĢ░µŹ«ķøå 1.2 ńēłµ£¼’╝īÕ£©[Ķ┐Öķćī](https://drive.google.com/drive/folders/18BVuF_RYJF0NjZpt8SnfzANiakoRMf0o?usp=sharing)õĖŗĶĮĮÕģȵĢ░µŹ«ÕłÆÕłåµ¢ćõ╗ČŃĆéńäČÕÉÄ’╝īÕ░å `.tfrecord` µ¢ćõ╗ČńĮ«õ║Ä `data/waymo/waymo_format/` ńø«ÕĮĢõĖŗńÜäńøĖÕ║öõĮŹńĮ«’╝īÕ╣ČÕ░åµĢ░µŹ«ÕłÆÕłåńÜä `.txt` µ¢ćõ╗ČńĮ«õ║Ä `data/waymo/kitti_format/ImageSets` ńø«ÕĮĢõĖŗŃĆéÕ£©[Ķ┐Öķćī](https://console.cloud.google.com/storage/browser/waymo_open_dataset_v_1_2_0/validation/ground_truth_objects)õĖŗĶĮĮķ¬īĶ»üķøåńÜäń£¤Õ«×µĀćńŁŠ’╝ł`.bin` µ¢ćõ╗Č’╝ēÕ╣ČÕ░åÕģČńĮ«õ║Ä `data/waymo/waymo_format/`ŃĆéµÅÉńż║’╝ÜõĮĀÕÅ»õ╗źõĮ┐ńö© `gsutil` µØźńö©ÕæĮõ╗żõĖŗĶĮĮÕż¦Ķ¦äµ©ĪńÜäµĢ░µŹ«ķøåŃĆéµø┤ÕżÜń╗åĶŖéĶ»ĘÕÅéĶĆāµŁż[ÕĘźÕģĘ](https://github.com/RalphMao/Waymo-Dataset-Tool)ŃĆéÕ«īµłÉõ╗źõĖŖÕÉ䵣źÕÉÄ’╝īÕÅ»õ╗źķĆÜĶ┐ćĶ┐ÉĶĪīõ╗źõĖŗµīćõ╗żÕ»╣ Waymo µĢ░µŹ«Ķ┐øĶĪīķóäÕżäńÉå’╝Ü
+
+```bash
+python tools/create_data.py waymo --root-path ./data/waymo/ --out-dir ./data/waymo/ --workers 128 --extra-tag waymo
+```
+
+µ│©µäÅ:
+
+- Õ”éµ×£õĮĀńÜäńĪ¼ńøśń®║ķŚ┤Õż¦Õ░ÅõĖŹĶČ│õ╗źÕŁśÕé©ĶĮ¼µŹóÕÉÄńÜäµĢ░µŹ«’╝īõĮĀÕÅ»õ╗źÕ░å `--out-dir` ÕÅéµĢ░Ķ«ŠÕ«ÜõĖ║Õł½ńÜäĶĘ»ÕŠäŃĆéõĮĀÕŬķ£ĆĶ”üĶ«░ÕŠŚÕ£©ķéŻõĖ¬ĶĘ»ÕŠäõĖŗÕłøÕ╗║µ¢ćõ╗ČÕż╣Õ╣ČõĖŗĶĮĮµĢ░µŹ«’╝īńäČÕÉÄÕ£©µĢ░µŹ«ķóäÕżäńÉåÕ«īµłÉÕÉÄÕ░åÕģČķōŠµÄźÕø× `data/waymo/kitti_format` ÕŹ│ÕÅ»ŃĆé
+
+**Õ░ÅĶ┤┤ÕŻ½**’╝Ü
+
+- **ńÄ░µłÉńÜäµĀćµ│©µ¢ćõ╗Č**: µłæõ╗¼ÕĘ▓ń╗ŵÅÉõŠøõ║åń”╗ń║┐ÕżäńÉåÕźĮńÜä [Waymo µĀćµ│©µ¢ćõ╗Č](#µĢ░µŹ«ķøåµĀćµ│©µ¢ćõ╗ČÕłŚĶĪ©)ŃĆéµé©ńø┤µÄźõĖŗĶĮĮõ╗¢õ╗¼Õ╣ȵöŠÕł░ `data/waymo/kitti_format/` ńø«ÕĮĢõĖŗŃĆéńäČĶĆī’╝īµé©Ķ┐śµś»ķ£ĆĶ”üĶć¬ÕĘ▒õĮ┐ńö©õĖŖķØóńÜäĶäܵ£¼Õ░å Waymo ńÜäÕĤզŗµĢ░µŹ«Ķ┐śķ£ĆĶ”üĶĮ¼µłÉ kitti µĀ╝Õ╝ÅŃĆé
+
+- **Waymo-mini**’╝Ü Õ”éµ×£õĮĀÕŬµś»õĖ║õ║åķ¬īĶ»üµ¤Éõ║øµ¢╣µ│Ģµł¢ĶĆģ debug, õĮĀÕÅ»õ╗źõĮ┐ńö©µłæõ╗¼µÅÉõŠøńÜä [Waymo-mini](https://download.openmmlab.com/mmdetection3d/data/waymo/waymo_mini_kitti_format.tar.gz)ŃĆéÕ«āÕŬÕīģÕɽÕĤզŗµĢ░µŹ«ķøåõĖŁĶ«Łń╗āķøåõĖŁńÜä 2 õĖ¬ segments ÕÆī ķ¬īĶ»üķøåõĖŁńÜä 1 õĖ¬ segmentŃĆéµé©ÕŬķ£ĆĶ”üõĖŗĶĮĮÕ╣ČõĖöĶ¦ŻÕÄŗÕł░ `data/waymo/`’╝īÕŹ│ÕÅ»õĮ┐ńö©Õ«ā’╝Ü
+
+ ```bash
+ tar -xzvf waymo_mini_kitti_format.tar.gz -C ./data/waymo
+ ```
+
+- **µø┤Õ┐½ńÜäĶ»äõ╝░**’╝Ü Õ”éµ×£õĮĀµā│Õ£© Waymo õĖŖĶ┐øĶĪīµø┤Õ┐½ńÜäĶ»äõ╝░’╝īõĮĀÕÅ»õ╗źõĖŗĶĮĮÕĘ▓ń╗ÅķóäÕżäńÉåÕźĮńÜä[Õģāõ┐Īµü»µ¢ćõ╗Č](https://download.openmmlab.com/mmdetection3d/data/waymo/idx2metainfo.pkl)Õ╣ČÕ░åÕģȵöŠńĮ«Õ£© `data/waymo/waymo_format/` ńø«ÕĮĢõĖŗŃĆéµÄźńØĆ’╝īõĮĀÕÅ»õ╗źµīēńģ¦õ╗źõĖŗµØźõ┐«µö╣µĢ░µŹ«ķøåńÜäķģŹńĮ«’╝Ü
+
+ ```python
+ val_evaluator = dict(
+ type='WaymoMetric',
+ ann_file='./data/waymo/kitti_format/waymo_infos_val.pkl',
+ waymo_bin_file='./data/waymo/waymo_format/gt.bin',
+ data_root='./data/waymo/waymo_format',
+ backend_args=backend_args,
+ convert_kitti_format=True,
+ idx2metainfo='data/waymo/waymo_format/idx2metainfo.pkl'
+ )
+ ```
+
+ ńø«ÕēŹĶ┐Öń¦Źµ¢╣Õ╝Åõ╗ģķÖÉõ║Äń║»ńé╣õ║æµŻĆµĄŗõ╗╗ÕŖĪŃĆé
+
+### NuScenes
+
+Õ£©[Ķ┐Öķćī](https://www.nuscenes.org/download)õĖŗĶĮĮ nuScenes µĢ░µŹ«ķøå 1.0 ńēłµ£¼ńÜäÕ«īµĢ┤µĢ░µŹ«µ¢ćõ╗ČŃĆéķĆÜĶ┐ćĶ┐ÉĶĪīõ╗źõĖŗµīćõ╗żÕ»╣ nuScenes µĢ░µŹ«Ķ┐øĶĪīķóäÕżäńÉå’╝Ü
+
+```bash
+python tools/create_data.py nuscenes --root-path ./data/nuscenes --out-dir ./data/nuscenes --extra-tag nuscenes
+```
+
+**Õ░ÅĶ┤┤ÕŻ½**’╝Ü
+
+- **ńÄ░µłÉńÜäµĀćµ│©µ¢ćõ╗Č**’╝ܵłæõ╗¼ÕĘ▓ń╗ŵÅÉõŠøõ║åń”╗ń║┐ÕżäńÉåÕźĮńÜä [NuScenes µĀćµ│©µ¢ćõ╗Č](#µĢ░µŹ«ķøåµĀćµ│©µ¢ćõ╗ČÕłŚĶĪ©)ŃĆéµé©ńø┤µÄźõĖŗĶĮĮõ╗¢õ╗¼Õ╣ȵöŠÕł░ `data/nuscenes/` ńø«ÕĮĢõĖŗŃĆéńäČĶĆī’╝īÕ”éµ×£õĮĀµā│Õ£©ńé╣õ║æµŻĆµĄŗµ¢╣µ│ĢõĖŁõĮ┐ńö© `ObjectSample` Ķ┐ÖõĖƵĢ░µŹ«Õó×Õ╝║’╝īõĮĀÕÅ»õ╗źÕåŹķóØÕż¢õĮ┐ńö©õ╗źõĖŗÕæĮõ╗żµØźńö¤µłÉńē®õĮōµĀćµ│©µĪåµĢ░µŹ«Õ║ō’╝Ü
+
+```bash
+python tools/create_data.py nuscenes --root-path ./data/nuscenes --out-dir ./data/nuscenes --extra-tag nuscenes --only-gt-database
+```
+
+### Lyft
+
+Õ£©[Ķ┐Öķćī](https://www.kaggle.com/c/3d-object-detection-for-autonomous-vehicles/data)õĖŗĶĮĮ Lyft 3D µŻĆµĄŗµĢ░µŹ«ŃĆéķĆÜĶ┐ćĶ┐ÉĶĪīõ╗źõĖŗµīćõ╗żÕ»╣ Lyft µĢ░µŹ«Ķ┐øĶĪīķóäÕżäńÉå’╝Ü
+
+```bash
+python tools/create_data.py lyft --root-path ./data/lyft --out-dir ./data/lyft --extra-tag lyft --version v1.01
+python tools/data_converter/lyft_data_fixer.py --version v1.01 --root-folder ./data/lyft
+```
+
+µ│©µäÅ’╝īõĖ║õ║åµ¢ćõ╗Čń╗ōµ×äńÜäµĖģµÖ░µĆ¦’╝īµłæõ╗¼ķüĄõ╗Äõ║å Lyft µĢ░µŹ«ÕĤÕģłńÜäµ¢ćõ╗ČÕż╣ÕÉŹń¦░ŃĆéĶ»Ęµīēńģ¦õĖŖķØóÕ▒Ģńż║Õć║ńÜäµ¢ćõ╗Čń╗ōµ×äÕ»╣ÕĤզŗµ¢ćõ╗ČÕż╣Ķ┐øĶĪīķćŹÕæĮÕÉŹŃĆéÕÉīµĀĘÕĆ╝ÕŠŚµ│©µäÅńÜ䵜»’╝īń¼¼õ║īĶĪīÕæĮõ╗żńÜäńø«ńÜ䵜»õĖ║õ║åõ┐«ÕżŹõĖĆõĖ¬µŹ¤ÕØÅńÜäµ┐ĆÕģēķøĘĶŠŠµĢ░µŹ«µ¢ćõ╗ČŃĆéµø┤ÕżÜń╗åĶŖéĶ»ĘÕÅéĶĆā[Ķ»źĶ«©Ķ«║](https://www.kaggle.com/c/3d-object-detection-for-autonomous-vehicles/discussion/110000)ŃĆé
+
+### SemanticKITTI
+
+Õ£©[Ķ┐Öķćī](http://semantic-kitti.org/dataset.html#download)õĖŗĶĮĮ SemanticKITTI µĢ░µŹ«ķøåÕ╣ČĶ¦ŻÕÄŗµēƵ£ēµ¢ćõ╗ČŃĆéķĆÜĶ┐ćĶ┐ÉĶĪīõ╗źõĖŗµīćõ╗żÕ»╣ SemanticKITTI µĢ░µŹ«Ķ┐øĶĪīķóäÕżäńÉå’╝Ü
+
+```bash
+python ./tools/create_data.py semantickitti --root-path ./data/semantickitti --out-dir ./data/semantickitti --extra-tag semantickitti
+```
+
+**Õ░ÅĶ┤┤ÕŻ½**’╝Ü
+
+- **ńÄ░µłÉńÜäµĀćµ│©µ¢ćõ╗Č**. µłæõ╗¼ÕĘ▓ń╗ŵÅÉõŠøõ║åń”╗ń║┐ÕżäńÉåÕźĮńÜä [SemanticKITTI µĀćµ│©µ¢ćõ╗Č](#µĢ░µŹ«ķøåµĀćµ│©µ¢ćõ╗ČÕłŚĶĪ©)ŃĆéµé©ńø┤µÄźõĖŗĶĮĮõ╗¢õ╗¼Õ╣ȵöŠÕł░ `data/semantickitti` ńø«ÕĮĢõĖŗŃĆé
+
+### S3DISŃĆüScanNet ÕÆī SUN RGB-D
+
+Ķ»ĘÕÅéĶĆā S3DIS [README](https://github.com/open-mmlab/mmdetection3d/blob/dev-1.x/data/s3dis/README.md) µ¢ćõ╗Čõ╗źÕ»╣ÕģČĶ┐øĶĪīµĢ░µŹ«ķóäÕżäńÉåŃĆé
+
+Ķ»ĘÕÅéĶĆā ScanNet [README](https://github.com/open-mmlab/mmdetection3d/blob/dev-1.x/data/scannet/README.md) µ¢ćõ╗Čõ╗źÕ»╣ÕģČĶ┐øĶĪīµĢ░µŹ«ķóäÕżäńÉåŃĆé
+
+Ķ»ĘÕÅéĶĆā SUN RGB-D [README](https://github.com/open-mmlab/mmdetection3d/blob/dev-1.x/data/sunrgbd/README.md) µ¢ćõ╗Čõ╗źÕ»╣ÕģČĶ┐øĶĪīµĢ░µŹ«ķóäÕżäńÉåŃĆé
+
+**Õ░ÅĶ┤┤ÕŻ½**’╝ÜÕ»╣õ║Ä S3DIS, ScanNet ÕÆī SUN RGB-D µĢ░µŹ«ķøå’╝īµłæõ╗¼ÕĘ▓ń╗ŵÅÉõŠøõ║åń”╗ń║┐ÕżäńÉåÕźĮńÜä [µĀćµ│©µ¢ćõ╗Č](#µĢ░µŹ«ķøåµĀćµ│©µ¢ćõ╗ČÕłŚĶĪ©)ŃĆéµé©ÕÅ»õ╗źńø┤µÄźõĖŗĶĮĮõ╗¢õ╗¼Õ╣ȵöŠÕł░ `data/${DATASET}/` ńø«ÕĮĢõĖŗŃĆéńäČĶĆī’╝īµé©Ķ┐śµś»ķ£ĆĶ”üĶć¬ÕĘ▒Õł®ńö©µłæõ╗¼ńÜäĶäܵ£¼µØźńö¤µłÉńé╣õ║æµ¢ćõ╗Čõ╗źÕÅŖĶ»Łõ╣ēµÄ®Ķ壵¢ćõ╗Č(Õ”éµ×£Ķ»źµĢ░µŹ«ķøåµ£ēńÜäĶ»Ø)ŃĆé
+
+### Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøå
+
+Õģ│õ║ÄÕ”éõĮĢõĮ┐ńö©Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøå’╝īĶ»ĘÕÅéĶĆā[Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøå](https://github.com/open-mmlab/mmdetection3d/blob/dev-1.x/docs/zh_cn/advanced_guides/customize_dataset.md)ŃĆé
+
+### µø┤µ¢░µĢ░µŹ«õ┐Īµü»
+
+Õ”éµ×£õĮĀõ╣ŗÕēŹÕĘ▓ń╗ÅõĮ┐ńö© v1.0.0rc1-v1.0.0rc4 ńēłńÜä mmdetection3d ÕłøÕ╗║µĢ░µŹ«õ┐Īµü»’╝īńÄ░Õ£©õĮĀµā│õĮ┐ńö©µ£Ćµ¢░ńÜä v1.1.0 ńēł mmdetection3d’╝īõĮĀķ£ĆĶ”üµø┤µ¢░µĢ░µŹ«õ┐Īµü»µ¢ćõ╗ČŃĆé
+
+```bash
+python tools/dataset_converters/update_infos_to_v2.py --dataset ${DATA_SET} --pkl-path ${PKL_PATH} --out-dir ${OUT_DIR}
+```
+
+- `--dataset`’╝ܵĢ░µŹ«ķøåÕÉŹŃĆé
+- `--pkl-path`’╝ܵīćիܵĢ░µŹ«õ┐Īµü» pkl µ¢ćõ╗ČĶĘ»ÕŠäŃĆé
+- `--out-dir`’╝ÜĶŠōÕć║µĢ░µŹ«õ┐Īµü» pkl µ¢ćõ╗Čńø«ÕĮĢŃĆé
+
+õŠŗÕ”é’╝Ü
+
+```bash
+python tools/dataset_converters/update_infos_to_v2.py --dataset kitti --pkl-path ./data/kitti/kitti_infos_trainval.pkl --out-dir ./data/kitti
+```
+
+### µĢ░µŹ«ķøåµĀćµ│©µ¢ćõ╗ČÕłŚĶĪ©
+
+µłæõ╗¼µÅÉõŠøõ║åń”╗ń║┐ńö¤µłÉÕźĮńÜäµĢ░µŹ«ķøåµĀćµ│©µ¢ćõ╗Čõ╗źõŠøÕÅéĶĆāŃĆéõĖ║õ║åµ¢╣õŠ┐’╝īµé©õ╣¤ÕÅ»õ╗źńø┤µÄźõĮ┐ńö©õ╗¢õ╗¼ŃĆé
+
+| µĢ░µŹ«ķøå | Ķ«Łń╗āķøåµĀćµ│©µ¢ćõ╗Č | ķ¬īĶ»üķøåµĀćµ│©µ¢ćõ╗Č | µĄŗĶ»ĢķøåµĀćµ│©µ¢ćõ╗Č |
+| :--------------------------------------------------------------------------------------------------------------------: | :---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: | :--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: | :--------------------------------------------------------------------------------------------------------------------------: |
+| KITTI | [kitti_infos_train.pkl](https://download.openmmlab.com/mmdetection3d/data/kitti/kitti_infos_train.pkl) | [kitti_infos_val.pkl](https://download.openmmlab.com/mmdetection3d/data/kitti/kitti_infos_val.pkl) | [kitti_infos_test](https://download.openmmlab.com/mmdetection3d/data/kitti/kitti_infos_test.pkl) |
+| NuScenes | [nuscenes_infos_train.pkl](https://download.openmmlab.com/mmdetection3d/data/nuscenes/nuscenes_infos_train.pkl) [nuscenes_mini_infos_train.pkl](https://download.openmmlab.com/mmdetection3d/data/nuscenes/nuscenes_mini_infos_train.pkl) | [nuscenes_infos_val.pkl](https://download.openmmlab.com/mmdetection3d/data/nuscenes/nuscenes_infos_val.pkl) [nuscenes_mini_infos_val.pkl](https://download.openmmlab.com/mmdetection3d/data/nuscenes/nuscenes_mini_infos_val.pkl) | |
+| Waymo | [waymo_infos_train.pkl](https://download.openmmlab.com/mmdetection3d/data/waymo/waymo_infos_train.pkl) [waymo_mini_infos_train.pkl](https://download.openmmlab.com/mmdetection3d/data/waymo/waymo_mini_infos_train.pkl) | [waymo_infos_val.pkl](https://download.openmmlab.com/mmdetection3d/data/waymo/waymo_infos_val.pkl) [waymo_mini_infos_val.pkl](https://download.openmmlab.com/mmdetection3d/data/waymo/waymo_mini_infos_val.pkl) | [waymo_infos_test.pkl](https://download.openmmlab.com/mmdetection3d/data/waymo/waymo_infos_test.pkl) |
+| [Waymo-mini kitti-format data](https://download.openmmlab.com/mmdetection3d/data/waymo/waymo_mini_kitti_format.tar.gz) | | | |
+| SUN RGB-D | [sunrgbd_infos_train.pkl](https://download.openmmlab.com/mmdetection3d/data/sunrgbd/sunrgbd_infos_train.pkl) | [sunrgbd_infos_val.pkl](https://download.openmmlab.com/mmdetection3d/data/sunrgbd/sunrgbd_infos_val.pkl) | |
+| ScanNet | [scannet_infos_train.pkl](https://download.openmmlab.com/mmdetection3d/data/scannet/scannet_infos_train.pkl) | [scannet_infos_val.pkl](https://download.openmmlab.com/mmdetection3d/data/scannet/scannet_infos_val.pkl) | [scannet_infos_test.pkl](https://download.openmmlab.com/mmdetection3d/data/scannet/scannet_infos_test.pkl) |
+| SemanticKitti | [semantickitti_infos_train.pkl](https://download.openmmlab.com/mmdetection3d/data/semantickitti/semantickitti_infos_train.pkl) | [semantickitti_infos_val.pkl](https://download.openmmlab.com/mmdetection3d/data/semantickitti/semantickitti_infos_val.pkl) | [semantickitti_infos_test.pkl](https://download.openmmlab.com/mmdetection3d/data/semantickitti/semantickitti_infos_test.pkl) |
diff --git a/internlm_langchain/knowledge_base/MMDetection3D/content/faq.md b/internlm_langchain/knowledge_base/MMDetection3D/content/faq.md
new file mode 100644
index 00000000..6b5a9896
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection3D/content/faq.md
@@ -0,0 +1,58 @@
+# ÕĖĖĶ¦üķŚ«ķóśĶ¦ŻńŁö
+
+µłæõ╗¼ÕłŚÕć║õ║åõĖĆõ║øńö©µłĘÕÆīÕ╝ĆÕÅæĶĆģÕ£©Õ╝ĆÕÅæĶ┐ćń©ŗõĖŁõ╝ÜķüćÕł░ńÜäÕĖĖĶ¦üķŚ«ķóśõ╗źÕÅŖÕ»╣Õ║öńÜäĶ¦ŻÕå│µ¢╣µĪł’╝īÕ”éµ×£µé©ÕÅæńÄ░õ║åõ╗╗õĮĢķóæń╣üÕć║ńÄ░ńÜäķŚ«ķóś’╝īĶ»ĘķÜŵŚČµē®Õģģµ£¼ÕłŚĶĪ©’╝īķØ×ÕĖĖµ¼óĶ┐ĵ驵ÅÉÕć║ńÜäõ╗╗õĮĢĶ¦ŻÕå│µ¢╣µĪłŃĆéÕ”éµ×£µé©Õ£©ńÄ»ÕóāķģŹńĮ«ŃĆüµ©ĪÕ×ŗĶ«Łń╗āńŁēÕĘźõĮ£õĖŁķüćÕł░õ╗╗õĮĢńÜäķŚ«ķóś’╝īĶ»ĘõĮ┐ńö©[ķŚ«ķ󜵩ĪµØ┐](https://github.com/open-mmlab/mmdetection3d/blob/master/.github/ISSUE_TEMPLATE/error-report.md)µØźÕłøÕ╗║ńøĖÕ║öńÜä issue’╝īÕ╣ČÕ░åµēĆķ£ĆńÜäµēƵ£ēõ┐Īµü»ÕĪ½ÕģźÕł░ķŚ«ķ󜵩ĪµØ┐õĖŁ’╝īµłæõ╗¼õ╝ÜÕ░ĮÕ┐½Ķ¦ŻÕå│µé©ńÜäķŚ«ķóśŃĆé
+
+## MMEngine/MMCV/MMDet/MMDet3D Õ«ēĶŻģ
+
+- Ķʤ MMEngine, MMCV, MMDetection ÕÆī MMDetection3D ńøĖÕģ│ńÜäń╝¢Ķ»æķŚ«ķóś; "ConvWS is already registered in conv layer"; "AssertionError: MMCV==xxx is used but incompatible. Please install mmcv>=xxx, \<=xxx."
+
+- MMDetection3D ķ£ĆĶ”üńÜä MMEngine, MMCV ÕÆī MMDetection ńÜäńēłµ£¼ÕłŚÕ£©õ║åõĖŗķØóŃĆéĶ»ĘÕ«ēĶŻģµŁŻńĪ«ńēłµ£¼ńÜä MMEngineŃĆüMMCV ÕÆī MMDetection õ╗źķü┐ÕģŹńøĖÕģ│ńÜäÕ«ēĶŻģķŚ«ķóśŃĆé
+
+ | MMDetection3D ńēłµ£¼ | MMEngine ńēłµ£¼ | MMCV ńēłµ£¼ | MMDetection ńēłµ£¼ |
+ | ------------------ | :----------------------: | :---------------------: | :----------------------: |
+ | dev-1.x | mmengine>=0.7.1, \<1.0.0 | mmcv>=2.0.0rc4, \<2.1.0 | mmdet>=3.0.0, \<3.1.0 |
+ | main | mmengine>=0.7.1, \<1.0.0 | mmcv>=2.0.0rc4, \<2.1.0 | mmdet>=3.0.0, \<3.1.0 |
+ | v1.1.0rc3 | mmengine>=0.1.0, \<1.0.0 | mmcv>=2.0.0rc3, \<2.1.0 | mmdet>=3.0.0rc0, \<3.1.0 |
+ | v1.1.0rc2 | mmengine>=0.1.0, \<1.0.0 | mmcv>=2.0.0rc3, \<2.1.0 | mmdet>=3.0.0rc0, \<3.1.0 |
+ | v1.1.0rc1 | mmengine>=0.1.0, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 | mmdet>=3.0.0rc0, \<3.1.0 |
+ | v1.1.0rc0 | mmengine>=0.1.0, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 | mmdet>=3.0.0rc0, \<3.1.0 |
+
+ **µ│©µäÅ**’╝ÜÕ”éµ×£õĮĀµā│Õ«ēĶŻģ mmdet3d-v1.0.0rcx’╝īÕÅ»õ╗źÕ£©[µŁżÕżä](https://mmdetection3d.readthedocs.io/en/latest/faq.html#mmcv-mmdet-mmdet3d-installation)µēŠÕł░ MMDetection’╝īMMSegmentation ÕÆī MMCV ńÜäÕģ╝Õ«╣ńēłµ£¼ŃĆéĶ»ĘķĆēµŗ®µŁŻńĪ«ńēłµ£¼ńÜä MMCVŃĆüMMDetection ÕÆī MMSegmentation õ╗źķü┐ÕģŹÕ«ēĶŻģķŚ«ķóśŃĆé
+
+- Õ”éµ×£µé©Õ£© `import open3d` µŚČķüćÕł░õĖŗķØóńÜäķŚ«ķóś’╝Ü
+
+ `OSError: /lib/x86_64-linux-gnu/libm.so.6: version 'GLIBC_2.27' not found`
+
+ Ķ»ĘÕ░å open3d ńÜäńēłµ£¼ķÖŹń║¦Ķć│ 0.9.0.0’╝īÕøĀõĖ║µ£Ćµ¢░ńēł open3d ķ£ĆĶ”ü 'GLIBC_2.27' µ¢ćõ╗ČńÜäµö»µīü’╝ī Ubuntu 16.04 ń│╗ń╗¤õĖŁń╝║Õż▒Ķ»źµ¢ćõ╗Č’╝īõĖöĶ»źµ¢ćõ╗Čõ╗ģÕŁśÕ£©õ║Ä Ubuntu 18.04 ÕÅŖõ╣ŗÕÉÄńÜäń│╗ń╗¤õĖŁŃĆé
+
+- Õ”éµ×£µé©Õ£© `import pycocotools` µŚČķüćÕł░ńēłµ£¼ķöÖĶ»»ńÜäķŚ«ķóś’╝īĶ┐Öµś»ńö▒õ║Ä nuscenes-devkit ķ£ĆĶ”üÕ«ēĶŻģ pycocotools’╝īńäČĶĆī mmdet õŠØĶĄ¢õ║Ä mmpycocotools’╝īÕĮōÕēŹńÜäĶ¦ŻÕå│µ¢╣µĪłÕ”éõĖŗµēĆńż║’╝īµłæõ╗¼Õ░åõ╝ÜÕ£©õ╣ŗÕÉÄÕģ©ķØóµö»µīü pycocotools ’╝Ü
+
+ ```shell
+ pip uninstall pycocotools mmpycocotools
+ pip install mmpycocotools
+ ```
+
+ **µ│©µäÅ**’╝Ü µłæõ╗¼ÕĘ▓ń╗ÅÕ£© 0.13.0 ÕÅŖõ╣ŗÕÉÄńÜäńēłµ£¼õĖŁÕģ©ķØóµö»µīü pycocotoolsŃĆé
+
+- Õ”éµ×£µé©Õ£©Õ»╝Õģź pycocotools ńøĖÕģ│ÕīģµŚČķüćÕł░õĖŗķØóńÜäķŚ«ķóś’╝Ü
+
+ `ValueError: numpy.ndarray size changed, may indicate binary incompatibility. Expected 88 from C header, got 80 from PyObject`
+
+ Ķ»ĘÕ░å pycocotools ńÜäńēłµ£¼ķÖŹń║¦Ķć│ 2.0.1’╝īĶ┐Öµś»ńö▒õ║ĵ£Ćµ¢░ńēłµ£¼ńÜä pycocotools õĖÄ numpy \< 1.20.0 õĖŹÕģ╝Õ«╣ŃĆ鵳¢ĶĆģķĆÜĶ┐ćõĖŗķØóńÜäµ¢╣Õ╝Åõ╗ĵ║ÉńĀüĶ┐øĶĪīń╝¢Ķ»æµØźÕ«ēĶŻģµ£Ćµ¢░ńēłµ£¼ńÜä pycocotools ’╝Ü
+
+ `pip install -e "git+https://github.com/cocodataset/cocoapi#egg=pycocotools&subdirectory=PythonAPI"`
+
+ µł¢ĶĆģ
+
+ `pip install -e "git+https://github.com/ppwwyyxx/cocoapi#egg=pycocotools&subdirectory=PythonAPI"`
+
+- Õ”éµ×£µé©õĮ┐ńö© cuda-9.0 ńÜäńÄ»ÕóāÕ╣ČķüćÕł░Õģ│õ║Ä numba ńÜäķöÖĶ»»’╝ī µé©Õ║öĶ»źµŻĆµ¤źõĖŗ numba ńÜäńēłµ£¼ŃĆéÕ£© cuda-9.0 ńÄ»ÕóāõĖŁ’╝īķ½śńēłµ£¼ńÜä numba µś»õĖŹµö»µīüńÜä’╝īµłæõ╗¼Õ╗║Ķ««Õ«ēĶŻģ numba==0.53.0.
+
+## Õ”éõĮĢµĀćµ│©ńé╣õ║æ’╝¤
+
+MMDetection3D õĖŹµö»µīüńé╣õ║æµĀćµ│©ŃĆ鵳æõ╗¼µÅÉõŠøõĖĆõ║øÕ╝Ƶ║ÉńÜäµĀćµ│©ÕĘźÕģĘõŠøÕÅéĶĆā’╝Ü
+
+- [SUSTechPOINTS](https://github.com/naurril/SUSTechPOINTS)
+- [LATTE](https://github.com/bernwang/latte)
+
+µŁżÕż¢’╝īµłæõ╗¼µö╣Ķ┐øõ║å [LATTE](https://github.com/bernwang/latte) õ╗źõŠ┐µø┤µ¢╣õŠ┐ńÜäµĀćµ│©ŃĆéµø┤ÕżÜńÜäń╗åĶŖéĶ»ĘÕÅéĶĆā[Ķ┐Öķćī](https://arxiv.org/abs/2011.10174)ŃĆé
diff --git a/internlm_langchain/knowledge_base/MMDetection3D/content/get_started.md b/internlm_langchain/knowledge_base/MMDetection3D/content/get_started.md
new file mode 100644
index 00000000..9f0c1cb5
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection3D/content/get_started.md
@@ -0,0 +1,294 @@
+# Õ╝ĆÕ¦ŗõĮĀńÜäń¼¼õĖƵŁź
+
+## õŠØĶĄ¢
+
+Õ£©µ£¼ĶŖéõĖŁ’╝īµłæõ╗¼Õ░åÕ▒Ģńż║Õ”éõĮĢõĮ┐ńö© PyTorch ÕćåÕżćńÄ»ÕóāŃĆé
+
+MMDetection3D µö»µīüÕ£© Linux’╝īWindows’╝łÕ«×ķ¬īµĆ¦µö»µīü’╝ē’╝īMacOS õĖŖĶ┐ÉĶĪī’╝īÕ«āķ£ĆĶ”ü Python 3.7 õ╗źõĖŖ’╝īCUDA 9.2 õ╗źõĖŖÕÆī PyTorch 1.6 õ╗źõĖŖŃĆé
+
+```{note}
+Õ”éµ×£µé©Õ»╣ PyTorch µ£ēń╗Åķ¬īÕ╣ČõĖöÕĘ▓ń╗ÅÕ«ēĶŻģõ║åÕ«ā’╝īµé©ÕÅ»õ╗źńø┤µÄźĶĘ│ĶĮ¼Õł░[õĖŗõĖĆÕ░ÅĶŖé](#Õ«ēĶŻģµĄüń©ŗ)ŃĆéÕÉ”ÕłÖ’╝īµé©ÕÅ»õ╗źµīēńģ¦õĖŗĶ┐░µŁźķ¬żĶ┐øĶĪīÕćåÕżćŃĆé
+```
+
+**µŁźķ¬ż 0.** õ╗Ä[Õ«śµ¢╣ńĮæń½Ö](https://docs.conda.io/en/latest/miniconda.html)õĖŗĶĮĮÕ╣ČÕ«ēĶŻģ MinicondaŃĆé
+
+**µŁźķ¬ż 1.** ÕłøÕ╗║Õ╣ȵ┐Ƶ┤╗õĖĆõĖ¬ conda ńÄ»ÕóāŃĆé
+
+```shell
+conda create --name openmmlab python=3.8 -y
+conda activate openmmlab
+```
+
+**µŁźķ¬ż 2.** Õ¤║õ║Ä [PyTorch Õ«śµ¢╣Ķ»┤µśÄ](https://pytorch.org/get-started/locally/)Õ«ēĶŻģ PyTorch’╝īõŠŗÕ”é’╝Ü
+
+Õ£© GPU Õ╣│ÕÅ░õĖŖ’╝Ü
+
+```shell
+conda install pytorch torchvision -c pytorch
+```
+
+Õ£© CPU Õ╣│ÕÅ░õĖŖ’╝Ü
+
+```shell
+conda install pytorch torchvision cpuonly -c pytorch
+```
+
+## Õ«ēĶŻģµĄüń©ŗ
+
+µłæõ╗¼µÄ©ĶŹÉńö©µłĘÕÅéńģ¦µłæõ╗¼ńÜäµ£ĆõĮ│Õ«×ĶĘĄÕ«ēĶŻģ MMDetection3DŃĆéõĖŹĶ┐ć’╝īµĢ┤õĖ¬Ķ┐ćń©ŗõ╣¤µś»ÕŻիÜÕłČÕī¢ńÜä’╝īµø┤ÕżÜõ┐Īµü»Ķ»ĘÕÅéĶĆā[Ķć¬Õ«Üõ╣ēÕ«ēĶŻģ](#Ķć¬Õ«Üõ╣ēÕ«ēĶŻģ)ń½ĀĶŖéŃĆé
+
+### µ£ĆõĮ│Õ«×ĶĘĄ
+
+**µŁźķ¬ż 0.** õĮ┐ńö© [MIM](https://github.com/open-mmlab/mim) Õ«ēĶŻģ [MMEngine](https://github.com/open-mmlab/mmengine)’╝ī[MMCV](https://github.com/open-mmlab/mmcv) ÕÆī [MMDetection](https://github.com/open-mmlab/mmdetection)ŃĆé
+
+```shell
+pip install -U openmim
+mim install mmengine
+mim install 'mmcv>=2.0.0rc4'
+mim install 'mmdet>=3.0.0'
+```
+
+**µ│©µäÅ**’╝ÜÕ£© MMCV-v2.x õĖŁ’╝ī`mmcv-full` µö╣ÕÉŹõĖ║ `mmcv`’╝īÕ”éµ×£µé©µā│Õ«ēĶŻģõĖŹÕīģÕɽ CUDA ń«ŚÕŁÉńÜä `mmcv`’╝īµé©ÕÅ»õ╗źõĮ┐ńö© `mim install "mmcv-lite>=2.0.0rc4"` Õ«ēĶŻģń▓Šń«ĆńēłŃĆé
+
+**µŁźķ¬ż 1.** Õ«ēĶŻģ MMDetection3DŃĆé
+
+µ¢╣µĪł a’╝ÜÕ”éµ×£µé©Õ╝ĆÕÅæÕ╣Čńø┤µÄźĶ┐ÉĶĪī mmdet3d’╝īõ╗ĵ║ÉńĀüÕ«ēĶŻģÕ«ā’╝Ü
+
+```shell
+git clone https://github.com/open-mmlab/mmdetection3d.git -b dev-1.x
+# "-b dev-1.x" ĶĪ©ńż║ÕłćµŹóÕł░ `dev-1.x` Õłåµö»ŃĆé
+cd mmdetection3d
+pip install -v -e .
+# "-v" µīćĶ»”ń╗åĶ»┤µśÄ’╝īµł¢µø┤ÕżÜńÜäĶŠōÕć║
+# "-e" ĶĪ©ńż║Õ£©ÕÅ»ń╝¢ĶŠæµ©ĪÕ╝ÅõĖŗÕ«ēĶŻģķĪ╣ńø«’╝īÕøĀµŁżÕ»╣õ╗ŻńĀüµēĆÕüÜńÜäõ╗╗õĮĢµ£¼Õ£░õ┐«µö╣ķāĮõ╝Üńö¤µĢł’╝īõ╗ÄĶĆīµŚĀķ£Ćķ揵¢░Õ«ēĶŻģŃĆé
+```
+
+µ¢╣µĪł b’╝ÜÕ”éµ×£µé©Õ░å mmdet3d õĮ£õĖ║õŠØĶĄ¢µł¢ń¼¼õĖēµ¢╣ Python ÕīģõĮ┐ńö©’╝īõĮ┐ńö© MIM Õ«ēĶŻģ’╝Ü
+
+```shell
+mim install "mmdet3d>=1.1.0rc0"
+```
+
+µ│©µäÅ’╝Ü
+
+1. Õ”éµ×£µé©ÕĖīµ£øõĮ┐ńö© `opencv-python-headless` ĶĆīõĖŹµś» `opencv-python`’╝īµé©ÕÅ»õ╗źÕ£©Õ«ēĶŻģ MMCV õ╣ŗÕēŹÕ«ēĶŻģÕ«āŃĆé
+
+2. õĖĆõ║øÕ«ēĶŻģõŠØĶĄ¢µś»ÕÅ»ķĆēńÜäŃĆéń«ĆÕŹĢÕ£░Ķ┐ÉĶĪī `pip install -v -e .` Õ░åõ╝ÜÕ«ēĶŻģµ£ĆõĮÄĶ┐ÉĶĪīĶ”üµ▒éńÜäńēłµ£¼ŃĆéÕ”éµ×£µā│Ķ”üõĮ┐ńö©õĖĆõ║øÕÅ»ķĆēõŠØĶĄ¢ķĪ╣’╝īõŠŗÕ”é `albumentations` ÕÆī `imagecorruptions`’╝īÕÅ»õ╗źõĮ┐ńö© `pip install -r requirements/optional.txt` Ķ┐øĶĪīµēŗÕŖ©Õ«ēĶŻģ’╝īµł¢ĶĆģÕ£©õĮ┐ńö© `pip` µŚČµīćիܵēĆķ£ĆńÜäķÖäÕŖĀÕŖ¤ĶāĮ’╝łõŠŗÕ”é `pip install -v -e .[optional]`’╝ē’╝īµö»µīüķÖäÕŖĀÕŖ¤ĶāĮńÜäµ£ēµĢłķö«ÕĆ╝Õīģµŗ¼ `all`ŃĆü`tests`ŃĆü`build` õ╗źÕÅŖ `optional`ŃĆé
+
+ µłæõ╗¼ÕĘ▓ń╗ŵö»µīü `spconv 2.0`ŃĆéÕ”éµ×£ńö©µłĘÕĘ▓ń╗ÅÕ«ēĶŻģ `spconv 2.0`’╝īõ╗ŻńĀüõ╝Üķ╗śĶ«żõĮ┐ńö© `spconv 2.0`’╝īÕ«āõ╝ܵ»öÕĤńö¤ `mmcv spconv` õĮ┐ńö©µø┤Õ░æńÜä GPU ÕåģÕŁśŃĆéńö©µłĘÕÅ»õ╗źõĮ┐ńö©õĖŗÕłŚńÜäÕæĮõ╗żµØźÕ«ēĶŻģ `spconv 2.0`’╝Ü
+
+ ```shell
+ pip install cumm-cuxxx
+ pip install spconv-cuxxx
+ ```
+
+ `xxx` ĶĪ©ńż║ńÄ»ÕóāõĖŁńÜä CUDA ńēłµ£¼ŃĆé
+
+ õŠŗÕ”é’╝īõĮ┐ńö© CUDA 10.2’╝īÕ»╣Õ║öÕæĮõ╗żµś» `pip install cumm-cu102 && pip install spconv-cu102`ŃĆé
+
+ µö»µīüńÜä CUDA ńēłµ£¼Õīģµŗ¼ 10.2’╝ī11.1’╝ī11.3 ÕÆī 11.4ŃĆéńö©µłĘõ╣¤ÕÅ»õ╗źķĆÜĶ┐ćµ║ÉńĀüń╝¢Ķ»æµØźÕ«ēĶŻģŃĆéµø┤ÕżÜń╗åĶŖéĶ»ĘÕÅéĶĆā[spconv v2.x](https://github.com/traveller59/spconv)ŃĆé
+
+ µłæõ╗¼õ╣¤µö»µīü `Minkowski Engine` õĮ£õĖ║ń©Ćń¢ÅÕŹĘń¦»ńÜäÕÉÄń½»ŃĆéÕ”éµ×£ķ£ĆĶ”ü’╝īĶ»ĘÕÅéĶĆā[Õ«ēĶŻģµīćÕŹŚ](https://github.com/NVIDIA/MinkowskiEngine#installation) µł¢ĶĆģõĮ┐ńö© `pip` µØźÕ«ēĶŻģ’╝Ü
+
+ ```shell
+ conda install openblas-devel -c anaconda
+ export CPLUS_INCLUDE_PATH=CPLUS_INCLUDE_PATH:${YOUR_CONDA_ENVS_DIR}/include
+ # replace ${YOUR_CONDA_ENVS_DIR} to your anaconda environment path e.g. `/home/username/anaconda3/envs/openmmlab`.
+ pip install -U git+https://github.com/NVIDIA/MinkowskiEngine -v --no-deps --install-option="--blas_include_dirs=/opt/conda/include" --install-option="--blas=openblas"
+ ```
+
+ µłæõ╗¼Ķ┐śµö»µīü `Torchsparse` õĮ£õĖ║ń©Ćń¢ÅÕŹĘń¦»ńÜäÕÉÄń½»ŃĆéÕ”éµ×£ķ£ĆĶ”ü’╝īĶ»ĘÕÅéĶĆā[Õ«ēĶŻģµīćÕŹŚ](https://github.com/mit-han-lab/torchsparse#installation) µł¢ĶĆģõĮ┐ńö© `pip` µØźÕ«ēĶŻģ’╝Ü
+
+ ```shell
+ sudo apt install libsparsehash-dev
+ pip install --upgrade git+https://github.com/mit-han-lab/torchsparse.git@v1.4.0
+ ```
+
+ µł¢ĶĆģķĆÜĶ┐ćõ╗źõĖŗÕ«ēĶŻģń╗ĢĶ┐ćsudoµØāķÖÉ
+
+ ```shell
+ conda install -c bioconda sparsehash
+ export CPLUS_INCLUDE_PATH=CPLUS_INCLUDE_PATH:${YOUR_CONDA_ENVS_DIR}/include
+ # replace ${YOUR_CONDA_ENVS_DIR} to your anaconda environment path e.g. `/home/username/anaconda3/envs/openmmlab`.
+ pip install --upgrade git+https://github.com/mit-han-lab/torchsparse.git@v1.4.0
+ ```
+
+3. µłæõ╗¼ńÜäõ╗ŻńĀüńø«ÕēŹõĖŹĶāĮÕ£©ÕŬµ£ē CPU ńÜäńÄ»Õóā’╝łCUDA õĖŹÕÅ»ńö©’╝ēõĖŗń╝¢Ķ»æŃĆé
+
+### ķ¬īĶ»üÕ«ēĶŻģ
+
+õĖ║õ║åķ¬īĶ»ü MMDetection3D µś»ÕɔիēĶŻģµŁŻńĪ«’╝īµłæõ╗¼µÅÉõŠøõ║åõĖĆõ║øńż║õŠŗõ╗ŻńĀüµØźµē¦ĶĪīµ©ĪÕ×ŗµÄ©ńÉåŃĆé
+
+**µŁźķ¬ż 1.** µłæõ╗¼ķ£ĆĶ”üõĖŗĶĮĮķģŹńĮ«µ¢ćõ╗ČÕÆīµ©ĪÕ×ŗµØāķ揵¢ćõ╗ČŃĆé
+
+```shell
+mim download mmdet3d --config pointpillars_hv_secfpn_8xb6-160e_kitti-3d-car --dest .
+```
+
+õĖŗĶĮĮÕ░åķ£ĆĶ”üÕćĀń¦ÆķƤµł¢µø┤ķĢ┐µŚČķŚ┤’╝īĶ┐ÖÕÅ¢Õå│õ║ĵé©ńÜäńĮæń╗£ńÄ»ÕóāŃĆéÕ«īµłÉÕÉÄ’╝īµé©õ╝ÜÕ£©ÕĮōÕēŹµ¢ćõ╗ČÕż╣õĖŁÕÅæńÄ░õĖżõĖ¬µ¢ćõ╗Č `pointpillars_hv_secfpn_8xb6-160e_kitti-3d-car.py` ÕÆī `hv_pointpillars_secfpn_6x8_160e_kitti-3d-car_20220331_134606-d42d15ed.pth`ŃĆé
+
+**µŁźķ¬ż 2.** µÄ©ńÉåķ¬īĶ»üŃĆé
+
+µ¢╣µĪł a’╝ÜÕ”éµ×£µé©õ╗ĵ║ÉńĀüÕ«ēĶŻģ MMDetection3D’╝īķéŻõ╣łńø┤µÄźĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗żĶ┐øĶĪīķ¬īĶ»ü’╝Ü
+
+```shell
+python demo/pcd_demo.py demo/data/kitti/000008.bin pointpillars_hv_secfpn_8xb6-160e_kitti-3d-car.py hv_pointpillars_secfpn_6x8_160e_kitti-3d-car_20220331_134606-d42d15ed.pth --show
+```
+
+µé©õ╝Üń£ŗÕł░õĖĆõĖ¬ÕĖ”µ£ēńé╣õ║æńÜäÕÅ»Ķ¦åÕī¢ńĢīķØó’╝īÕģČõĖŁÕīģÕɽµ£ēÕ£©µ▒ĮĶĮ”õĖŖń╗śÕłČńÜ䵯ƵĄŗµĪåŃĆé
+
+**µ│©µäÅ**’╝Ü
+
+Õ”éµ×£µé©µā│ĶŠōÕģźõĖĆõĖ¬ `.ply` µ¢ćõ╗Č’╝īµé©ÕÅ»õ╗źõĮ┐ńö©Õ”éõĖŗÕćĮµĢ░Õ░åÕ«āĶĮ¼µŹóµłÉ `.bin` µĀ╝Õ╝ÅŃĆéńäČÕÉĵé©ÕÅ»õ╗źõĮ┐ńö©ĶĮ¼Õī¢ńÜä `.bin` µ¢ćõ╗ČµØźĶ┐ÉĶĪīµĀĘõŠŗŃĆéĶ»Ęµ│©µäÅÕ£©õĮ┐ńö©µŁżĶäܵ£¼õ╣ŗÕēŹ’╝īµé©ķ£ĆĶ”üÕ«ēĶŻģ `pandas` ÕÆī `plyfile`ŃĆéĶ┐ÖõĖ¬ÕćĮµĢ░õ╣¤ÕÅ»õ╗źńö©õ║ÄĶ«Łń╗ā `ply µĢ░µŹ«`µŚČõĮ£õĖ║µĢ░µŹ«ķóäÕżäńÉåµØźõĮ┐ńö©ŃĆé
+
+```python
+import numpy as np
+import pandas as pd
+from plyfile import PlyData
+
+def convert_ply(input_path, output_path):
+ plydata = PlyData.read(input_path) # Ķ»╗ÕÅ¢µ¢ćõ╗Č
+ data = plydata.elements[0].data # Ķ»╗ÕÅ¢µĢ░µŹ«
+ data_pd = pd.DataFrame(data) # ĶĮ¼µŹóµłÉ DataFrame
+ data_np = np.zeros(data_pd.shape, dtype=np.float) # ÕłØÕ¦ŗÕī¢µĢ░ń╗äµØźÕŁśÕ驵Ģ░µŹ«
+ property_names = data[0].dtype.names # Ķ»╗ÕÅ¢Õ▒׵ƦÕÉŹń¦░
+ for i, name in enumerate(
+ property_names): # ķĆÜĶ┐ćÕ▒׵ƦĶ»╗ÕÅ¢µĢ░µŹ«
+ data_np[:, i] = data_pd[name]
+ data_np.astype(np.float32).tofile(output_path)
+```
+
+õŠŗÕ”é’╝Ü
+
+```python
+convert_ply('./test.ply', './test.bin')
+```
+
+Õ”éµ×£µé©µ£ēÕģČõ╗¢µĀ╝Õ╝ÅńÜäńé╣õ║æµĢ░µŹ«’╝ł`.off`’╝ī`.obj` ńŁē’╝ē’╝īµé©ÕÅ»õ╗źõĮ┐ńö© `trimesh` Õ░åÕ«āõ╗¼ĶĮ¼Õī¢µłÉ `.ply`ŃĆé
+
+```python
+import trimesh
+
+def to_ply(input_path, output_path, original_type):
+ mesh = trimesh.load(input_path, file_type=original_type) # Ķ»╗ÕÅ¢µ¢ćõ╗Č
+ mesh.export(output_path, file_type='ply') # ĶĮ¼µŹóµłÉ ply
+```
+
+õŠŗÕ”é’╝Ü
+
+```python
+to_ply('./test.obj', './test.ply', 'obj')
+```
+
+µ¢╣µĪł b’╝ÜÕ”éµ×£µé©õĮ┐ńö© MIM Õ«ēĶŻģ MMDetection3D’╝īķéŻõ╣łÕÅ»õ╗źµēōÕ╝Ƶé©ńÜä Python Ķ¦Żµ×ÉÕÖ©’╝īÕżŹÕłČÕ╣Čń▓śĶ┤┤õ╗źõĖŗõ╗ŻńĀü’╝Ü
+
+```python
+from mmdet3d.apis import init_model, inference_detector
+
+config_file = 'pointpillars_hv_secfpn_8xb6-160e_kitti-3d-car.py'
+checkpoint_file = 'hv_pointpillars_secfpn_6x8_160e_kitti-3d-car_20220331_134606-d42d15ed.pth'
+model = init_model(config_file, checkpoint_file)
+inference_detector(model, 'demo/data/kitti/000008.bin')
+```
+
+µé©Õ░åõ╝Üń£ŗÕł░õĖĆõĖ¬ÕīģÕɽ `Det3DDataSample` ńÜäÕłŚĶĪ©’╝īķó䵥ŗń╗ōµ×£Õ£© `pred_instances_3d` ķćīķØó’╝īÕīģÕɽµ£ēµŻĆµĄŗµĪå’╝īń▒╗Õł½ÕÆīÕŠŚÕłåŃĆé
+
+### Ķć¬Õ«Üõ╣ēÕ«ēĶŻģ
+
+#### CUDA ńēłµ£¼
+
+Õ£©Õ«ēĶŻģ PyTorch µŚČ’╝īµé©ķ£ĆĶ”üµīćÕ«Ü CUDA ńÜäńēłµ£¼ŃĆéÕ”éµ×£µé©õĖŹµĖģµźÜÕ║öĶ»źķĆēµŗ®Õō¬õĖĆõĖ¬’╝īĶ»ĘķüĄÕŠ¬µłæõ╗¼ńÜäÕ╗║Ķ««’╝Ü
+
+- Õ»╣õ║Ä Ampere µ×ȵ×äńÜä NVIDIA GPU’╝īõŠŗÕ”é GeForce 30 ń│╗ÕłŚõ╗źÕÅŖ NVIDIA A100’╝īCUDA 11 µś»Õ┐ģķ£ĆńÜäŃĆé
+- Õ»╣õ║ĵø┤µŚ®ńÜä NVIDIA GPU’╝īCUDA 11 µś»ÕÉæÕÉÄÕģ╝Õ«╣ńÜä’╝īõĮå CUDA 10.2 µÅÉõŠøµø┤ÕźĮńÜäÕģ╝Õ«╣µĆ¦’╝īÕ╣ČõĖöµø┤ĶĮ╗ķćÅŃĆé
+
+Ķ»ĘńĪ«õ┐Ø GPU ķ®▒ÕŖ©ńēłµ£¼µ╗ĪĶČ│µ£ĆõĮÄńÜäńēłµ£¼ķ£Ćµ▒éŃĆéµø┤ÕżÜõ┐Īµü»Ķ»ĘÕÅéĶĆāµŁż[ĶĪ©µĀ╝](https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html#cuda-major-component-versions__table-cuda-toolkit-driver-versions)ŃĆé
+
+```{note}
+Õ”éµ×£µé©ķüĄÕŠ¬µłæõ╗¼ńÜäµ£ĆõĮ│Õ«×ĶĘĄ’╝īµé©ÕŬķ£ĆĶ”üÕ«ēĶŻģ CUDA Ķ┐ÉĶĪīÕ║ō’╝īĶ┐Öµś»ÕøĀõĖ║õĖŹķ£ĆĶ”üÕ£©µ£¼Õ£░ń╝¢Ķ»æ CUDA õ╗ŻńĀüŃĆéõĮåÕ”éµ×£µé©ÕĖīµ£øõ╗ĵ║ÉńĀüń╝¢Ķ»æ MMCV’╝īµł¢ĶĆģÕ╝ĆÕÅæÕģČõ╗¢ CUDA ń«ŚÕŁÉ’╝īķéŻõ╣łµé©ķ£ĆĶ”üõ╗Ä NVIDIA ńÜä[Õ«śńĮæ](https://developer.nvidia.com/cuda-downloads)Õ«ēĶŻģÕ«īµĢ┤ńÜä CUDA ÕĘźÕģĘķōŠ’╝īÕ╣ČõĖöĶ»źńēłµ£¼Õ║öĶ»źõĖÄ PyTorch ńÜä CUDA ńēłµ£¼ńøĖÕī╣ķģŹ’╝īµ»öÕ”éÕ£© `conda install` µīćõ╗żķćīµīćÕ«Ü cudatoolkit ńēłµ£¼ŃĆé
+```
+
+#### õĖŹķĆÜĶ┐ć MIM Õ«ēĶŻģ MMEngine
+
+Õ”éµ×£µā│Ķ”üõĮ┐ńö© pip ĶĆīõĖŹµś» MIM Õ«ēĶŻģ MMEngine’╝īĶ»ĘÕÅéĶĆā [MMEngine Õ«ēĶŻģµīćÕŹŚ](https://mmengine.readthedocs.io/zh_CN/latest/get_started/installation.html)ŃĆé
+
+õŠŗÕ”é’╝īµé©ÕÅ»õ╗źķĆÜĶ┐ćõ╗źõĖŗµīćõ╗żÕ«ēĶŻģ MMEngine’╝Ü
+
+```shell
+pip install mmengine
+```
+
+#### õĖŹķĆÜĶ┐ć MIM Õ«ēĶŻģ MMCV
+
+MMCV ÕīģÕɽ C++ ÕÆī CUDA µŗōÕ▒Ģ’╝īÕøĀµŁżÕģČÕ»╣ PyTorch ńÜäõŠØĶĄ¢µø┤ÕżŹµØéŃĆéMIM õ╝ÜĶć¬ÕŖ©Ķ¦ŻÕå│µŁżń▒╗õŠØĶĄ¢Õģ│ń│╗Õ╣ČõĮ┐Õ«ēĶŻģµø┤Õ«╣µśōŃĆéõĮåĶ┐ÖõĖŹµś»Õ┐ģķ£ĆńÜäŃĆé
+
+Õ”éµ×£µā│Ķ”üõĮ┐ńö© pip ĶĆīõĖŹµś» MIM Õ«ēĶŻģ MMCV’╝īĶ»ĘÕÅéĶĆā [MMCV Õ«ēĶŻģµīćÕŹŚ](https://mmcv.readthedocs.io/zh_CN/2.x/get_started/installation.html)ŃĆéĶ┐Öķ£ĆĶ”üńö©µīćÕ«Ü url ńÜäÕĮóÕ╝ŵēŗÕŖ©µīćÕ«ÜÕ»╣Õ║öńÜä PyTorch ÕÆī CUDA ńēłµ£¼ŃĆé
+
+õŠŗÕ”é’╝īõĖŗĶ┐░µīćõ╗żÕ░åõ╝ÜÕ«ēĶŻģÕ¤║õ║Ä PyTorch 1.12.x ÕÆī CUDA 11.6 ń╝¢Ķ»æńÜä MMCV’╝Ü
+
+```shell
+pip install "mmcv>=2.0.0rc4" -f https://download.openmmlab.com/mmcv/dist/cu116/torch1.12.0/index.html
+```
+
+#### Õ£© Google Colab õĖŁÕ«ēĶŻģ
+
+[Google Colab](https://colab.research.google.com/) ķĆÜÕĖĖÕĘ▓ń╗ÅÕ«ēĶŻģõ║å PyTorch’╝īÕøĀµŁżµłæõ╗¼ÕŬķ£ĆĶ”üńö©Õ”éõĖŗÕæĮõ╗żÕ«ēĶŻģ MMEngine’╝īMMCV’╝īMMDetection ÕÆī MMDetection3D ÕŹ│ÕÅ»ŃĆé
+
+**µŁźķ¬ż 1.** õĮ┐ńö© [MIM](https://github.com/open-mmlab/mim) Õ«ēĶŻģ [MMEngine](https://github.com/open-mmlab/mmengine)’╝ī[MMCV](https://github.com/open-mmlab/mmcv) ÕÆī [MMDetection](https://github.com/open-mmlab/mmdetection)ŃĆé
+
+```shell
+!pip3 install openmim
+!mim install mmengine
+!mim install "mmcv>=2.0.0rc4,<2.1.0"
+!mim install "mmdet>=3.0.0,<3.1.0"
+```
+
+**µŁźķ¬ż 2.** õ╗ĵ║ÉńĀüÕ«ēĶŻģ MMDetection3DŃĆé
+
+```shell
+!git clone https://github.com/open-mmlab/mmdetection3d.git -b dev-1.x
+%cd mmdetection3d
+!pip install -e .
+```
+
+**µŁźķ¬ż 3.** ķ¬īĶ»üÕ«ēĶŻģµś»ÕÉ”µłÉÕŖ¤ŃĆé
+
+```python
+import mmdet3d
+print(mmdet3d.__version__)
+# ķóäµ£¤ĶŠōÕć║’╝Ü1.1.0rc0 µł¢ÕģČÕ«āńēłµ£¼ÕÅĘŃĆé
+```
+
+```{note}
+Õ£© Jupyter Notebook õĖŁ’╝īµä¤ÕÅ╣ÕÅĘ `!` ńö©õ║ĵē¦ĶĪīÕż¢ķā©ÕæĮõ╗ż’╝īĶĆī `%cd` µś»õĖĆõĖ¬[ķŁöµ£»ÕæĮõ╗ż](https://ipython.readthedocs.io/en/stable/interactive/magics.html#magic-cd)’╝īńö©õ║ÄÕłćµŹó Python ńÜäÕĘźõĮ£ĶĘ»ÕŠäŃĆé
+```
+
+#### ķĆÜĶ┐ć Docker õĮ┐ńö© MMDetection3D
+
+µłæõ╗¼µÅÉõŠøõ║å [Dockerfile](https://github.com/open-mmlab/mmdetection3d/blob/dev-1.x/docker/Dockerfile) µØźµ×äÕ╗║õĖĆõĖ¬ķĢ£ÕāÅŃĆéĶ»ĘńĪ«õ┐صé©ńÜä [docker ńēłµ£¼](https://docs.docker.com/engine/install/) >= 19.03ŃĆé
+
+```shell
+# Õ¤║õ║Ä PyTorch 1.9’╝īCUDA 11.1 µ×äÕ╗║ķĢ£ÕāÅ
+# Õ”éµ×£µé©µā│Ķ”üÕģČõ╗¢ńēłµ£¼’╝īÕŬķ£ĆĶ”üõ┐«µö╣ Dockerfile
+docker build -t mmdetection3d docker/
+```
+
+ńö©õ╗źõĖŗÕæĮõ╗żĶ┐ÉĶĪī Docker ķĢ£ÕāÅ’╝Ü
+
+```shell
+docker run --gpus all --shm-size=8g -it -v {DATA_DIR}:/mmdetection3d/data mmdetection3d
+```
+
+### µĢģķÜ£µÄÆķÖż
+
+Õ”éµ×£µé©Õ£©Õ«ēĶŻģĶ┐ćń©ŗõĖŁķüćÕł░õĖĆõ║øķŚ«ķóś’╝īĶ»ĘÕģłÕÅéĶĆā [FAQ](notes/faq.md) ķĪĄķØóŃĆéÕ”éµ×£µ▓Īµ£ēµēŠÕł░Õ»╣Õ║öńÜäĶ¦ŻÕå│µ¢╣µĪł’╝īµé©õ╣¤ÕÅ»õ╗źÕ£© GitHub [µÅÉõĖĆõĖ¬ķŚ«ķóś](https://github.com/open-mmlab/mmdetection3d/issues/new/choose)ŃĆé
+
+### õĮ┐ńö©ÕżÜõĖ¬ MMDetection3D ńēłµ£¼Ķ┐øĶĪīÕ╝ĆÕÅæ
+
+Ķ«Łń╗āÕÆīµĄŗĶ»ĢńÜäĶäܵ£¼ÕĘ▓ń╗ÅÕ£© `PYTHONPATH` õĖŁĶ┐øĶĪīõ║åõ┐«µö╣’╝īõ╗źńĪ«õ┐ØĶäܵ£¼õĮ┐ńö©ÕĮōÕēŹńø«ÕĮĢõĖŁńÜä MMDetection3DŃĆé
+
+Ķ”üõĮ┐ńÄ»ÕóāõĖŁÕ«ēĶŻģķ╗śĶ«żńēłµ£¼ńÜä MMDetection3D ĶĆīõĖŹµś»ÕĮōÕēŹµŁŻÕ£©õĮ┐ńö©ńÜä’╝īÕÅ»õ╗źÕłĀķÖżÕć║ńÄ░Õ£©ńøĖÕģ│Ķäܵ£¼õĖŁńÜäõ╗ŻńĀü’╝Ü
+
+```shell
+PYTHONPATH="$(dirname $0)/..":$PYTHONPATH
+```
diff --git a/internlm_langchain/knowledge_base/MMDetection3D/content/inference.md b/internlm_langchain/knowledge_base/MMDetection3D/content/inference.md
new file mode 100644
index 00000000..a3a62b53
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection3D/content/inference.md
@@ -0,0 +1,101 @@
+# µÄ©ńÉå
+
+## õ╗ŗń╗Ź
+
+µłæõ╗¼µÅÉõŠøõ║åÕżÜµ©ĪµĆü/ÕŹĢµ©ĪµĆü’╝łÕ¤║õ║ĵ┐ĆÕģēķøĘĶŠŠ/ÕøŠÕāÅ’╝ēŃĆüÕ«żÕåģ/Õ«żÕż¢Õ£║µÖ»ńÜä 3D µŻĆµĄŗÕÆī 3D Ķ»Łõ╣ēÕłåÕē▓µĀĘõŠŗńÜäĶäܵ£¼’╝īķóäĶ«Łń╗āµ©ĪÕ×ŗÕÅ»õ╗źõ╗Ä [Model Zoo](https://github.com/open-mmlab/mmdetection3d/blob/dev-1.x/docs/zh_cn/model_zoo.md) õĖŗĶĮĮŃĆ鵳æõ╗¼õ╣¤µÅÉõŠøõ║å KITTIŃĆüSUN RGB-DŃĆünuScenes ÕÆī ScanNet µĢ░µŹ«ķøåńÜäķóäÕżäńÉåµĀʵ£¼µĢ░µŹ«’╝īõĮĀÕÅ»õ╗źµĀ╣µŹ«µłæõ╗¼ńÜäķóäÕżäńÉåµŁźķ¬żõĮ┐ńö©õ╗╗õĮĢÕģČÕ«āµĢ░µŹ«ŃĆé
+
+## µĄŗĶ»Ģ
+
+### 3D µŻĆµĄŗ
+
+#### ńé╣õ║æµĀĘõŠŗ
+
+Õ£©ńé╣õ║æµĢ░µŹ«õĖŖµĄŗĶ»Ģ 3D µŻĆµĄŗÕÖ©’╝īĶ┐ÉĶĪī’╝Ü
+
+```shell
+python demo/pcd_demo.py ${PCD_FILE} ${CONFIG_FILE} ${CHECKPOINT_FILE} [--device ${GPU_ID}] [--score-thr ${SCORE_THR}] [--out-dir ${OUT_DIR}] [--show]
+```
+
+ńé╣õ║æÕÆīķó䵥ŗ 3D µĪåńÜäÕÅ»Ķ¦åÕī¢ń╗ōµ×£õ╝ÜĶó½õ┐ØÕŁśÕ£© `${OUT_DIR}/PCD_NAME`’╝īÕ«āÕÅ»õ╗źõĮ┐ńö© [MeshLab](http://www.meshlab.net/) µēōÕ╝ĆŃĆéµ│©µäÅÕ”éµ×£õĮĀĶ«ŠńĮ«õ║å `--show`’╝īķĆÜĶ┐ć [Open3D](http://www.open3d.org/) ÕÅ»õ╗źÕ£©ń║┐µśŠńż║ķó䵥ŗń╗ōµ×£ŃĆé
+
+Õ£© KITTI µĢ░µŹ«õĖŖµĄŗĶ»Ģ [PointPillars µ©ĪÕ×ŗ](https://download.openmmlab.com/mmdetection3d/v1.0.0_models/pointpillars/hv_pointpillars_secfpn_6x8_160e_kitti-3d-car/hv_pointpillars_secfpn_6x8_160e_kitti-3d-car_20220331_134606-d42d15ed.pth)’╝Ü
+
+```shell
+python demo/pcd_demo.py demo/data/kitti/000008.bin configs/pointpillars/pointpillars_hv_secfpn_8xb6-160e_kitti-3d-car.py ${CHECKPOINT_FILE} --show
+```
+
+Õ£© SUN RGB-D µĢ░µŹ«õĖŖµĄŗĶ»Ģ [VoteNet µ©ĪÕ×ŗ](https://download.openmmlab.com/mmdetection3d/v1.0.0_models/votenet/votenet_16x8_sunrgbd-3d-10class/votenet_16x8_sunrgbd-3d-10class_20210820_162823-bf11f014.pth)’╝Ü
+
+```shell
+python demo/pcd_demo.py demo/data/sunrgbd/sunrgbd_000017.bin configs/votenet/votenet_8xb16_sunrgbd-3d.py ${CHECKPOINT_FILE} --show
+```
+
+#### ÕŹĢńø« 3D µĀĘõŠŗ
+
+Õ£©ÕøŠÕāŵĢ░µŹ«õĖŖµĄŗĶ»ĢÕŹĢńø« 3D µŻĆµĄŗÕÖ©’╝īĶ┐ÉĶĪī’╝Ü
+
+```shell
+python demo/mono_det_demo.py ${IMAGE_FILE} ${ANNOTATION_FILE} ${CONFIG_FILE} ${CHECKPOINT_FILE} [--device ${GPU_ID}] [--out-dir ${OUT_DIR}] [--show]
+```
+
+`ANNOTATION_FILE` ķ£ĆĶ”üµÅÉõŠø 3D Õł░ 2D ńÜäõ╗┐Õ░äń¤®ķśĄ’╝łńøĖµ£║ÕåģÕÅéń¤®ķśĄ’╝ē’╝īÕÅ»Ķ¦åÕī¢ń╗ōµ×£õ╝ÜĶó½õ┐ØÕŁśÕ£© `${OUT_DIR}/PCD_NAME`’╝īÕģČõĖŁÕīģµŗ¼ÕøŠÕāÅõ╗źÕÅŖķó䵥ŗ 3D µĪåÕ£©ÕøŠÕāÅõĖŖńÜäµŖĢÕĮ▒ŃĆé
+
+Õ£© KITTI µĢ░µŹ«õĖŖµĄŗĶ»Ģ [PGD µ©ĪÕ×ŗ](https://download.openmmlab.com/mmdetection3d/v1.0.0_models/pgd/pgd_r101_caffe_fpn_gn-head_3x4_4x_kitti-mono3d/pgd_r101_caffe_fpn_gn-head_3x4_4x_kitti-mono3d_20211022_102608-8a97533b.pth)’╝Ü
+
+```shell
+python demo/mono_det_demo.py demo/data/kitti/000008.png demo/data/kitti/000008.pkl configs/pgd/pgd_r101-caffe_fpn_head-gn_4xb3-4x_kitti-mono3d.py ${CHECKPOINT_FILE} --show --cam-type CAM2 --score-thr 8
+```
+
+**µ│©µäÅ**’╝Ü PGD µ¢╣µ│ĢńÜäķó䵥ŗµĪåÕłåµĢ░Õ╣ČõĖŹµś»Õ£© (0, 1) õ╣ŗķŚ┤
+
+Õ£© nuScenes µĢ░µŹ«õĖŖµĄŗĶ»Ģ [FCOS3D µ©ĪÕ×ŗ](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/fcos3d/fcos3d_r101_caffe_fpn_gn-head_dcn_2x8_1x_nus-mono3d_finetune/fcos3d_r101_caffe_fpn_gn-head_dcn_2x8_1x_nus-mono3d_finetune_20210717_095645-8d806dc2.pth)’╝Ü
+
+```shell
+python demo/mono_det_demo.py demo/data/nuscenes/n015-2018-07-24-11-22-45+0800__CAM_BACK__1532402927637525.jpg demo/data/nuscenes/n015-2018-07-24-11-22-45+0800.pkl configs/fcos3d/fcos3d_r101-caffe-dcn_fpn_head-gn_8xb2-1x_nus-mono3d_finetune.py ${CHECKPOINT_FILE} --show --cam-type CAM_BACK
+```
+
+**µ│©µäÅ**’╝Ü ÕĮōÕ»╣ń┐╗ĶĮ¼ÕøŠÕāÅÕÅ»Ķ¦åÕī¢ÕŹĢńø« 3D µŻĆµĄŗń╗ōµ×£µś»’╝īńøĖµ£║ÕåģÕÅéń¤®ķśĄõ╣¤Õ║öĶ»źńøĖÕ║öõ┐«µö╣ŃĆéÕ£© PR [#744](https://github.com/open-mmlab/mmdetection3d/pull/744) õĖŁÕÅ»õ╗źõ║åĶ¦Żµø┤ÕżÜń╗åĶŖéÕÆīńż║õŠŗŃĆé
+
+#### ÕżÜµ©ĪµĆüµĀĘõŠŗ
+
+Õ£©ÕżÜµ©ĪµĆüµĢ░µŹ«’╝łķĆÜÕĖĖµś»ńé╣õ║æÕÆīÕøŠÕāÅ’╝ēõĖŖµĄŗĶ»Ģ 3D µŻĆµĄŗÕÖ©’╝īĶ┐ÉĶĪī’╝Ü
+
+```shell
+python demo/multi_modality_demo.py ${PCD_FILE} ${IMAGE_FILE} ${ANNOTATION_FILE} ${CONFIG_FILE} ${CHECKPOINT_FILE} [--device ${GPU_ID}] [--score-thr ${SCORE_THR}] [--out-dir ${OUT_DIR}] [--show]
+```
+
+`ANNOTATION_FILE` ķ£ĆĶ”üµÅÉõŠø 3D Õł░ 2D ńÜäõ╗┐Õ░äń¤®ķśĄ’╝īÕÅ»Ķ¦åÕī¢ń╗ōµ×£õ╝ÜĶó½õ┐ØÕŁśÕ£© `${OUT_DIR}/PCD_NAME`’╝īÕģČõĖŁÕīģµŗ¼ńé╣õ║æŃĆüÕøŠÕāÅŃĆüķó䵥ŗńÜä 3D µĪåõ╗źÕÅŖÕ«āõ╗¼Õ£©ÕøŠÕāÅõĖŖńÜäµŖĢÕĮ▒ŃĆé
+
+Õ£© KITTI µĢ░µŹ«õĖŖµĄŗĶ»Ģ [MVX-Net µ©ĪÕ×ŗ](https://download.openmmlab.com/mmdetection3d/v1.1.0_models/mvxnet/mvxnet_fpn_dv_second_secfpn_8xb2-80e_kitti-3d-3class/mvxnet_fpn_dv_second_secfpn_8xb2-80e_kitti-3d-3class-8963258a.pth)’╝Ü
+
+```shell
+python demo/multi_modality_demo.py demo/data/kitti/000008.bin demo/data/kitti/000008.png demo/data/kitti/000008.pkl configs/mvxnet/mvxnet_fpn_dv_second_secfpn_8xb2-80e_kitti-3d-3class.py ${CHECKPOINT_FILE} --cam-type CAM2 --show
+```
+
+Õ£© SUN RGB-D µĢ░µŹ«õĖŖµĄŗĶ»Ģ [ImVoteNet µ©ĪÕ×ŗ](https://download.openmmlab.com/mmdetection3d/v1.0.0_models/imvotenet/imvotenet_stage2_16x8_sunrgbd-3d-10class/imvotenet_stage2_16x8_sunrgbd-3d-10class_20210819_192851-1bcd1b97.pth)’╝Ü
+
+```shell
+python demo/multi_modality_demo.py demo/data/sunrgbd/000017.bin demo/data/sunrgbd/000017.jpg demo/data/sunrgbd/sunrgbd_000017_infos.pkl configs/imvotenet/imvotenet_stage2_8xb16_sunrgbd-3d.py ${CHECKPOINT_FILE} --cam-type CAM0 --show --score-thr 0.6
+```
+
+Õ£© NuScenes µĢ░µŹ«õĖŖµĄŗĶ»Ģ [BEVFusion µ©ĪÕ×ŗ](https://drive.google.com/file/d/1QkvbYDk4G2d6SZoeJqish13qSyXA4lp3/view?usp=share_link)
+
+```shell
+python demo/multi_modality_demo.py demo/data/nuscenes/n015-2018-07-24-11-22-45+0800__LIDAR_TOP__1532402927647951.pcd.bin demo/data/nuscenes/ demo/data/nuscenes/n015-2018-07-24-11-22-45+0800.pkl projects/BEVFusion/configs/bevfusion_voxel0075_second_secfpn_8xb4-cyclic-20e_nus-3d.py ${CHECKPOINT_FILE} --cam-type all --score-thr 0.2 --show
+```
+
+### 3D ÕłåÕē▓
+
+Õ£©ńé╣õ║æµĢ░µŹ«õĖŖµĄŗĶ»Ģ 3D ÕłåÕē▓ÕÖ©’╝īĶ┐ÉĶĪī’╝Ü
+
+```shell
+python demo/pc_seg_demo.py ${PCD_FILE} ${CONFIG_FILE} ${CHECKPOINT_FILE} [--device ${GPU_ID}] [--out-dir ${OUT_DIR}] [--show]
+```
+
+ÕÅ»Ķ¦åÕī¢ń╗ōµ×£õ╝ÜĶó½õ┐ØÕŁśÕ£© `${OUT_DIR}/PCD_NAME`’╝īÕģČõĖŁÕīģµŗ¼ńé╣õ║æõ╗źÕÅŖķó䵥ŗńÜä 3D ÕłåÕē▓µÄ®ńĀüŃĆé
+
+Õ£© ScanNet µĢ░µŹ«õĖŖµĄŗĶ»Ģ [PointNet++ (SSG) µ©ĪÕ×ŗ](https://download.openmmlab.com/mmdetection3d/v0.1.0_models/pointnet2/pointnet2_ssg_16x2_cosine_200e_scannet_seg-3d-20class/pointnet2_ssg_16x2_cosine_200e_scannet_seg-3d-20class_20210514_143644-ee73704a.pth)’╝Ü
+
+```shell
+python demo/pcd_seg_demo.py demo/data/scannet/scene0000_00.bin configs/pointnet2/pointnet2_ssg_2xb16-cosine-200e_scannet-seg.py ${CHECKPOINT_FILE} --show
+```
diff --git a/internlm_langchain/knowledge_base/MMDetection3D/content/kitti.md b/internlm_langchain/knowledge_base/MMDetection3D/content/kitti.md
new file mode 100644
index 00000000..4b86215b
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection3D/content/kitti.md
@@ -0,0 +1,206 @@
+# KITTI µĢ░µŹ«ķøå
+
+µ£¼ķĪĄµÅÉõŠøõ║åµ£ēÕģ│Õ£© MMDetection3D õĖŁõĮ┐ńö© KITTI µĢ░µŹ«ķøåńÜäÕģĘõĮōµĢÖń©ŗŃĆé
+
+## µĢ░µŹ«ÕćåÕżć
+
+µé©ÕÅ»õ╗źÕ£©[Ķ┐Öķćī](http://www.cvlibs.net/datasets/kitti/eval_object.php?obj_benchmark=3d)õĖŗĶĮĮ KITTI 3D µŻĆµĄŗµĢ░µŹ«Õ╣ČĶ¦ŻÕÄŗń╝®µēƵ£ē zip µ¢ćõ╗ČŃĆ鵣żÕż¢’╝īµé©ÕÅ»õ╗źÕ£©[Ķ┐Öķćī](https://download.openmmlab.com/mmdetection3d/data/train_planes.zip)õĖŗĶĮĮķüōĶĘ»Õ╣│ķØóõ┐Īµü»’╝īÕģČÕ£©Ķ«Łń╗āĶ┐ćń©ŗõĖŁõĮ£õĖ║õĖĆõĖ¬ÕÅ»ķĆēķĪ╣’╝īńö©µØźµÅÉķ½śµ©ĪÕ×ŗńÜäµĆ¦ĶāĮŃĆéķüōĶĘ»Õ╣│ķØóõ┐Īµü»ńö▒ [AVOD](https://github.com/kujason/avod) ńö¤µłÉ’╝īµø┤ÕżÜń╗åĶŖéĶ»ĘÕÅéĶĆā[µŁżÕżä](https://github.com/kujason/avod/issues/19)ŃĆé
+
+ÕāÅÕćåÕżćµĢ░µŹ«ķøåńÜäõĖĆĶł¼µ¢╣µ│ĢõĖƵĀĘ’╝īÕ╗║Ķ««Õ░åµĢ░µŹ«ķøåµĀ╣ńø«ÕĮĢķōŠµÄźÕł░ `$MMDETECTION3D/data`ŃĆé
+
+Õ£©µłæõ╗¼ÕżäńÉåõ╣ŗÕēŹ’╝īµ¢ćõ╗ČÕż╣ń╗ōµ×äÕ║öµīēÕ”éõĖŗµ¢╣Õ╝Åń╗äń╗ć’╝Ü
+
+```
+mmdetection3d
+Ōö£ŌöĆŌöĆ mmdet3d
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+Ōö£ŌöĆŌöĆ data
+Ōöé Ōö£ŌöĆŌöĆ kitti
+Ōöé Ōöé Ōö£ŌöĆŌöĆ ImageSets
+Ōöé Ōöé Ōö£ŌöĆŌöĆ testing
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ calib
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ image_2
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ velodyne
+Ōöé Ōöé Ōö£ŌöĆŌöĆ training
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ calib
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ image_2
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ label_2
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ velodyne
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ planes (optional)
+```
+
+### ÕłøÕ╗║ KITTI µĢ░µŹ«ķøå
+
+õĖ║õ║åÕłøÕ╗║ KITTI ńé╣õ║æµĢ░µŹ«’╝īķ”¢Õģłķ£ĆĶ”üÕŖĀĶĮĮÕĤզŗńÜäńé╣õ║æµĢ░µŹ«Õ╣Čńö¤µłÉńøĖÕģ│ńÜäÕīģÕɽńø«µĀćµĀćńŁŠÕÆīµĀćµ│©µĪåńÜäµĢ░µŹ«µĀćµ│©µ¢ćõ╗Č’╝īÕÉīµŚČĶ┐śķ£ĆĶ”üõĖ║ KITTI µĢ░µŹ«ķøåńö¤µłÉµ»ÅõĖ¬ÕŹĢńŗ¼ńÜäĶ«Łń╗āńø«µĀćńÜäńé╣õ║æµĢ░µŹ«’╝īÕ╣ČÕ░åÕģČÕŁśÕé©Õ£© `data/kitti/kitti_gt_database` ńÜä `.bin` µĀ╝Õ╝ÅńÜäµ¢ćõ╗ČõĖŁ’╝īµŁżÕż¢’╝īķ£ĆĶ”üõĖ║Ķ«Łń╗āµĢ░µŹ«µł¢ĶĆģķ¬īĶ»üµĢ░µŹ«ńö¤µłÉ `.pkl` µĀ╝Õ╝ÅńÜäÕīģÕɽµĢ░µŹ«õ┐Īµü»ńÜäµ¢ćõ╗ČŃĆéķÜÅÕÉÄ’╝īķĆÜĶ┐ćĶ┐ÉĶĪīõĖŗķØóńÜäÕæĮõ╗żµØźÕłøÕ╗║µ£Ćń╗łńÜä KITTI µĢ░µŹ«’╝Ü
+
+```bash
+mkdir ./data/kitti/ && mkdir ./data/kitti/ImageSets
+
+# õĖŗĶĮĮµĢ░µŹ«ÕłÆÕłå
+wget -c https://raw.githubusercontent.com/traveller59/second.pytorch/master/second/data/ImageSets/test.txt --no-check-certificate --content-disposition -O ./data/kitti/ImageSets/test.txt
+wget -c https://raw.githubusercontent.com/traveller59/second.pytorch/master/second/data/ImageSets/train.txt --no-check-certificate --content-disposition -O ./data/kitti/ImageSets/train.txt
+wget -c https://raw.githubusercontent.com/traveller59/second.pytorch/master/second/data/ImageSets/val.txt --no-check-certificate --content-disposition -O ./data/kitti/ImageSets/val.txt
+wget -c https://raw.githubusercontent.com/traveller59/second.pytorch/master/second/data/ImageSets/trainval.txt --no-check-certificate --content-disposition -O ./data/kitti/ImageSets/trainval.txt
+
+python tools/create_data.py kitti --root-path ./data/kitti --out-dir ./data/kitti --extra-tag kitti --with-plane
+```
+
+ķ£ĆĶ”üµ│©µäÅńÜ䵜»’╝īÕ”éµ×£µé©ńÜäµ£¼Õ£░ńŻüńøśµ▓Īµ£ēÕģģĶČ│ńÜäÕŁśÕé©ń®║ķŚ┤µØźÕŁśÕé©ĶĮ¼µŹóÕÉÄńÜäµĢ░µŹ«’╝īµé©ÕÅ»õ╗źķĆÜĶ┐ćµö╣ÕÅś `--out-dir` µØźµīćÕ«ÜÕģČõ╗¢õ╗╗µäÅńÜäÕŁśÕé©ĶĘ»ÕŠäŃĆéÕ”éµ×£µé©µ▓Īµ£ēÕćåÕżć `planes` µĢ░µŹ«’╝īµé©ķ£ĆĶ”üń¦╗ķÖż `--with-plane` µĀćÕ┐ŚŃĆé
+
+ÕżäńÉåÕÉÄńÜäµ¢ćõ╗ČÕż╣ń╗ōµ×äÕ║öĶ»źÕ”éõĖŗ’╝Ü
+
+```
+kitti
+Ōö£ŌöĆŌöĆ ImageSets
+Ōöé Ōö£ŌöĆŌöĆ test.txt
+Ōöé Ōö£ŌöĆŌöĆ train.txt
+Ōöé Ōö£ŌöĆŌöĆ trainval.txt
+Ōöé Ōö£ŌöĆŌöĆ val.txt
+Ōö£ŌöĆŌöĆ testing
+Ōöé Ōö£ŌöĆŌöĆ calib
+Ōöé Ōö£ŌöĆŌöĆ image_2
+Ōöé Ōö£ŌöĆŌöĆ velodyne
+Ōöé Ōö£ŌöĆŌöĆ velodyne_reduced
+Ōö£ŌöĆŌöĆ training
+Ōöé Ōö£ŌöĆŌöĆ calib
+Ōöé Ōö£ŌöĆŌöĆ image_2
+Ōöé Ōö£ŌöĆŌöĆ label_2
+Ōöé Ōö£ŌöĆŌöĆ velodyne
+Ōöé Ōö£ŌöĆŌöĆ velodyne_reduced
+Ōöé Ōö£ŌöĆŌöĆ planes (optional)
+Ōö£ŌöĆŌöĆ kitti_gt_database
+Ōöé Ōö£ŌöĆŌöĆ xxxxx.bin
+Ōö£ŌöĆŌöĆ kitti_infos_train.pkl
+Ōö£ŌöĆŌöĆ kitti_infos_val.pkl
+Ōö£ŌöĆŌöĆ kitti_dbinfos_train.pkl
+Ōö£ŌöĆŌöĆ kitti_infos_test.pkl
+Ōö£ŌöĆŌöĆ kitti_infos_trainval.pkl
+```
+
+- `kitti_gt_database/xxxxx.bin`’╝ÜĶ«Łń╗āµĢ░µŹ«ķøåõĖŁÕīģÕɽգ© 3D µĀćµ│©µĪåõĖŁńÜäńé╣õ║æµĢ░µŹ«ŃĆé
+- `kitti_infos_train.pkl`’╝ÜĶ«Łń╗āµĢ░µŹ«ķøå’╝īĶ»źÕŁŚÕģĖÕīģÕɽõ║åõĖżõĖ¬ķö«ÕĆ╝’╝Ü`metainfo` ÕÆī `data_list`ŃĆé`metainfo` ÕīģÕɽµĢ░µŹ«ķøåńÜäÕ¤║µ£¼õ┐Īµü»’╝īõŠŗÕ”é `categories`, `dataset` ÕÆī `info_version`ŃĆé`data_list` µś»ńö▒ÕŁŚÕģĖń╗䵳ÉńÜäÕłŚĶĪ©’╝īµ»ÅõĖ¬ÕŁŚÕģĖ’╝łõ╗źõĖŗń«Ćń¦░ `info`’╝ēÕīģÕɽõ║åÕŹĢõĖ¬µĀʵ£¼ńÜäµēƵ£ēĶ»”ń╗åõ┐Īµü»ŃĆé
+ - info\['sample_idx'\]’╝ÜĶ»źµĀʵ£¼Õ£©µĢ┤õĖ¬µĢ░µŹ«ķøåńÜäń┤óÕ╝ĢŃĆé
+ - info\['images'\]’╝ÜÕżÜõĖ¬ńøĖµ£║µŹĢĶÄĘńÜäÕøŠÕāÅõ┐Īµü»ŃĆ鵜»õĖĆõĖ¬ÕŁŚÕģĖ’╝īÕīģÕɽ 5 õĖ¬ķö«ÕĆ╝’╝Ü`CAM0`, `CAM1`, `CAM2`, `CAM3`, `R0_rect`ŃĆé
+ - info\['images'\]\['R0_rect'\]’╝ܵĀĪÕćåµŚŗĶĮ¼ń¤®ķśĄ’╝īµś»õĖĆõĖ¬ 4x4 µĢ░ń╗äŃĆé
+ - info\['images'\]\['CAM2'\]’╝ÜÕīģÕɽ `CAM2` ńøĖµ£║õ╝Āµä¤ÕÖ©ńÜäõ┐Īµü»ŃĆé
+ - info\['images'\]\['CAM2'\]\['img_path'\]’╝ÜÕøŠÕāÅńÜäµ¢ćõ╗ČÕÉŹŃĆé
+ - info\['images'\]\['CAM2'\]\['height'\]’╝ÜÕøŠÕāÅńÜäķ½śŃĆé
+ - info\['images'\]\['CAM2'\]\['width'\]’╝ÜÕøŠÕāÅńÜäÕ«ĮŃĆé
+ - info\['images'\]\['CAM2'\]\['cam2img'\]’╝ÜńøĖµ£║Õł░ÕøŠÕāÅńÜäÕÅśµŹóń¤®ķśĄ’╝īµś»õĖĆõĖ¬ 4x4 µĢ░ń╗äŃĆé
+ - info\['images'\]\['CAM2'\]\['lidar2cam'\]’╝ܵ┐ĆÕģēķøĘĶŠŠÕł░ńøĖµ£║ńÜäÕÅśµŹóń¤®ķśĄ’╝īµś»õĖĆõĖ¬ 4x4 µĢ░ń╗äŃĆé
+ - info\['images'\]\['CAM2'\]\['lidar2img'\]’╝ܵ┐ĆÕģēķøĘĶŠŠÕł░ÕøŠÕāÅńÜäÕÅśµŹóń¤®ķśĄ’╝īµś»õĖĆõĖ¬ 4x4 µĢ░ń╗äŃĆé
+ - info\['lidar_points'\]’╝ܵś»õĖĆõĖ¬ÕŁŚÕģĖ’╝īÕīģÕɽõ║åµ┐ĆÕģēķøĘĶŠŠńé╣ńøĖÕģ│ńÜäõ┐Īµü»ŃĆé
+ - info\['lidar_points'\]\['lidar_path'\]’╝ܵ┐ĆÕģēķøĘĶŠŠńé╣õ║æµĢ░µŹ«ńÜäµ¢ćõ╗ČÕÉŹŃĆé
+ - info\['lidar_points'\]\['num_pts_feats'\]’╝Üńé╣ńÜäńē╣ÕŠüń╗┤Õ║”ŃĆé
+ - info\['lidar_points'\]\['Tr_velo_to_cam'\]’╝ÜVelodyne ÕØɵĀćÕł░ńøĖµ£║ÕØɵĀćńÜäÕÅśµŹóń¤®ķśĄ’╝īµś»õĖĆõĖ¬ 4x4 µĢ░ń╗äŃĆé
+ - info\['lidar_points'\]\['Tr_imu_to_velo'\]’╝ÜIMU ÕØɵĀćÕł░ Velodyne ÕØɵĀćńÜäÕÅśµŹóń¤®ķśĄ’╝īµś»õĖĆõĖ¬ 4x4 µĢ░ń╗äŃĆé
+ - info\['instances'\]’╝ܵś»õĖĆõĖ¬ÕŁŚÕģĖń╗䵳ÉńÜäÕłŚĶĪ©ŃĆéµ»ÅõĖ¬ÕŁŚÕģĖÕīģÕÉ½ÕŹĢõĖ¬Õ«×õŠŗńÜäµēƵ£ēµĀćµ│©õ┐Īµü»ŃĆéÕ»╣õ║ÄÕģČõĖŁńÜäń¼¼ i õĖ¬Õ«×õŠŗ’╝īµłæõ╗¼µ£ē’╝Ü
+ - info\['instances'\]\[i\]\['bbox'\]’╝ÜķĢ┐Õ║”õĖ║ 4 ńÜäÕłŚĶĪ©’╝īõ╗ź (x1, y1, x2, y2) ńÜäķĪ║Õ║ÅĶĪ©ńż║Õ«×õŠŗńÜä 2D ĶŠ╣ńĢīµĪåŃĆé
+ - info\['instances'\]\[i\]\['bbox_3d'\]’╝ÜķĢ┐Õ║”õĖ║ 7 ńÜäÕłŚĶĪ©’╝īõ╗ź (x, y, z, l, h, w, yaw) ńÜäķĪ║Õ║ÅĶĪ©ńż║Õ«×õŠŗńÜä 3D ĶŠ╣ńĢīµĪåŃĆé
+ - info\['instances'\]\[i\]\['bbox_label'\]’╝ܵś»õĖĆõĖ¬µĢ┤µĢ░’╝īĶĪ©ńż║Õ«×õŠŗńÜä 2D µĀćńŁŠ’╝ī-1 õ╗ŻĶĪ©Õ┐ĮńĢźŃĆé
+ - info\['instances'\]\[i\]\['bbox_label_3d'\]’╝ܵś»õĖĆõĖ¬µĢ┤µĢ░’╝īĶĪ©ńż║Õ«×õŠŗńÜä 3D µĀćńŁŠ’╝ī-1 õ╗ŻĶĪ©Õ┐ĮńĢźŃĆé
+ - info\['instances'\]\[i\]\['depth'\]’╝Ü3D ĶŠ╣ńĢīµĪåµŖĢÕĮ▒Õł░ńøĖÕģ│ÕøŠÕāÅÕ╣│ķØóńÜäõĖŁÕ┐āńé╣ńÜäµĘ▒Õ║”ŃĆé
+ - info\['instances'\]\[i\]\['num_lidar_pts'\]’╝Ü3D ĶŠ╣ńĢīµĪåÕåģńÜäµ┐ĆÕģēķøĘĶŠŠńé╣µĢ░ŃĆé
+ - info\['instances'\]\[i\]\['center_2d'\]’╝Ü3D ĶŠ╣ńĢīµĪåµŖĢÕĮ▒ńÜä 2D õĖŁÕ┐āŃĆé
+ - info\['instances'\]\[i\]\['difficulty'\]’╝ÜKITTI Õ«śµ¢╣Õ«Üõ╣ēńÜäÕø░ķÜŠÕ║”’╝īÕīģµŗ¼ń«ĆÕŹĢŃĆüķĆéõĖŁŃĆüÕø░ķÜŠŃĆé
+ - info\['instances'\]\[i\]\['truncated'\]’╝Üõ╗Ä 0’╝łķØ×µł¬µ¢Ł’╝ēÕł░ 1’╝łµł¬µ¢Ł’╝ēńÜ䵥«ńé╣µĢ░’╝īÕģČõĖŁµł¬µ¢ŁµīćńÜ䵜»ń”╗Õ╝ƵŻĆµĄŗÕøŠÕāÅĶŠ╣ńĢīńÜ䵯ƵĄŗńø«µĀćŃĆé
+ - info\['instances'\]\[i\]\['occluded'\]’╝ܵĢ┤µĢ░ (0,1,2,3) ĶĪ©ńż║ńø«µĀćńÜäķü«µīĪńŖȵĆü’╝Ü0 = Õ«īÕģ©ÕÅ»Ķ¦ü’╝ī1 = ķā©Õłåķü«µīĪ’╝ī2 = Õż¦ķØóń¦»ķü«µīĪ’╝ī3 = µ£¬ń¤źŃĆé
+ - info\['instances'\]\[i\]\['group_ids'\]’╝Üńö©õ║ÄÕżÜķā©ÕłåńÜäńē®õĮōŃĆé
+ - info\['plane'\]’╝łÕÅ»ķĆē’╝ē’╝ÜÕ£░Õ╣│ķØóõ┐Īµü»ŃĆé
+
+µø┤ÕżÜń╗åĶŖéĶ»ĘÕÅéĶĆā [kitti_converter.py](https://github.com/open-mmlab/mmdetection3d/blob/dev-1.x/tools/dataset_converters/kitti_converter.py) ÕÆī [update_infos_to_v2.py](https://github.com/open-mmlab/mmdetection3d/blob/dev-1.x/tools/dataset_converters/update_infos_to_v2.py)ŃĆé
+
+## Ķ«Łń╗āµĄüń©ŗ
+
+õĖŗķØóÕ▒Ģńż║õ║åõĖĆõĖ¬õĮ┐ńö© KITTI µĢ░µŹ«ķøåĶ┐øĶĪī 3D ńø«µĀ浯ƵĄŗńÜäÕģĖÕ×ŗµĄüń©ŗ’╝Ü
+
+```python
+train_pipeline = [
+ dict(
+ type='LoadPointsFromFile',
+ coord_type='LIDAR',
+ load_dim=4, # x, y, z, intensity
+ use_dim=4),
+ dict(
+ type='LoadAnnotations3D', with_bbox_3d=True, with_label_3d=True),
+ dict(type='ObjectSample', db_sampler=db_sampler),
+ dict(
+ type='ObjectNoise',
+ num_try=100,
+ translation_std=[1.0, 1.0, 0.5],
+ global_rot_range=[0.0, 0.0],
+ rot_range=[-0.78539816, 0.78539816]),
+ dict(type='RandomFlip3D', flip_ratio_bev_horizontal=0.5),
+ dict(
+ type='GlobalRotScaleTrans',
+ rot_range=[-0.78539816, 0.78539816],
+ scale_ratio_range=[0.95, 1.05]),
+ dict(type='PointsRangeFilter', point_cloud_range=point_cloud_range),
+ dict(type='ObjectRangeFilter', point_cloud_range=point_cloud_range),
+ dict(type='PointShuffle'),
+ dict(
+ type='Pack3DDetInputs',
+ keys=['points', 'gt_bboxes_3d', 'gt_labels_3d'])
+]
+```
+
+- µĢ░µŹ«Õó×Õ╝║’╝Ü
+ - `ObjectNoise`’╝ÜÕ»╣Õ£║µÖ»õĖŁńÜäµ»ÅõĖ¬ń£¤Õ«×µĀćµ│©µĪåńø«µĀćµĘ╗ÕŖĀÕÖ¬ķ¤│ŃĆé
+ - `RandomFlip3D`’╝ÜÕ»╣ĶŠōÕģźńé╣õ║æµĢ░µŹ«Ķ┐øĶĪīķÜŵ£║Õ£░µ░┤Õ╣│ń┐╗ĶĮ¼µł¢ĶĆģÕ×éńø┤ń┐╗ĶĮ¼ŃĆé
+ - `GlobalRotScaleTrans`’╝ÜÕ»╣ĶŠōÕģźńé╣õ║æµĢ░µŹ«Ķ┐øĶĪīµŚŗĶĮ¼ŃĆé
+
+## Ķ»äõ╝░
+
+õĮ┐ńö© 8 õĖ¬ GPU õ╗źÕÅŖ KITTI µīćµĀćĶ»äõ╝░ńÜä PointPillars ńÜäńż║õŠŗÕ”éõĖŗ’╝Ü
+
+```shell
+bash tools/dist_test.sh configs/pointpillars/pointpillars_hv_secfpn_8xb6-160e_kitti-3d-3class.py work_dirs/pointpillars_hv_secfpn_8xb6-160e_kitti-3d-3class/latest.pth 8
+```
+
+## Õ║”ķćŵīćµĀć
+
+KITTI Õ«śµ¢╣õĮ┐ńö©Õģ©ń▒╗Õ╣│ÕØćń▓ŠÕ║”’╝łmAP’╝ēÕÆīÕ╣│ÕØćµ¢╣ÕÉæńøĖõ╝╝Õ║”’╝łAOS’╝ēµØźĶ»äõ╝░ 3D ńø«µĀ浯ƵĄŗńÜäµĆ¦ĶāĮ’╝īµø┤ÕżÜń╗åĶŖéĶ»ĘÕÅéĶĆā[Õ«śµ¢╣ńĮæń½Ö](http://www.cvlibs.net/datasets/kitti/eval_3dobject.php)ÕÆī[Ķ«║µ¢ć](http://www.cvlibs.net/publications/Geiger2012CVPR.pdf)ŃĆé
+
+MMDetection3D ķććńö©ńøĖÕÉīńÜäµ¢╣µ│ĢÕ£© KITTI µĢ░µŹ«ķøåõĖŖĶ┐øĶĪīĶ»äõ╝░’╝īõĖŗķØóÕ▒Ģńż║õ║åõĖĆõĖ¬Ķ»äõ╝░ń╗ōµ×£ńÜäõŠŗÕŁÉ’╝Ü
+
+```
+Car AP@0.70, 0.70, 0.70:
+bbox AP:97.9252, 89.6183, 88.1564
+bev AP:90.4196, 87.9491, 85.1700
+3d AP:88.3891, 77.1624, 74.4654
+aos AP:97.70, 89.11, 87.38
+Car AP@0.70, 0.50, 0.50:
+bbox AP:97.9252, 89.6183, 88.1564
+bev AP:98.3509, 90.2042, 89.6102
+3d AP:98.2800, 90.1480, 89.4736
+aos AP:97.70, 89.11, 87.38
+```
+
+## µĄŗĶ»ĢÕÆīµÅÉõ║ż
+
+õĮ┐ńö© 8 õĖ¬ GPU Õ£© KITTI õĖŖµĄŗĶ»Ģ PointPillars Õ╣Čńö¤µłÉÕ»╣µÄÆĶĪīµ”£ńÜäµÅÉõ║żńÜäńż║õŠŗÕ”éõĖŗ’╝Ü
+
+- ķ”¢Õģł’╝īõĮĀķ£ĆĶ”üÕ£©õĮĀńÜäķģŹńĮ«µ¢ćõ╗ČõĖŁõ┐«µö╣ `test_dataloader` ÕÆī `test_evaluator` ÕŁŚÕģĖ’╝īÕ”éõĖŗµēĆńż║’╝Ü
+
+ ```python
+ data_root = 'data/kitti/'
+ test_dataloader = dict(
+ dataset=dict(
+ ann_file='kitti_infos_test.pkl',
+ load_eval_anns=False,
+ data_prefix=dict(pts='testing/velodyne_reduced')))
+ test_evaluator = dict(
+ ann_file=data_root + 'kitti_infos_test.pkl',
+ format_only=True,
+ pklfile_prefix='results/kitti-3class/kitti_results',
+ submission_prefix='results/kitti-3class/kitti_results')
+ ```
+
+- µÄźõĖŗµØź’╝īõĮĀÕÅ»õ╗źĶ┐ÉĶĪīÕ”éõĖŗµĄŗĶ»ĢĶäܵ£¼ŃĆé
+
+ ```shell
+ ./tools/dist_test.sh configs/pointpillars/pointpillars_hv_secfpn_8xb6-160e_kitti-3d-3class.py work_dirs/pointpillars_hv_secfpn_8xb6-160e_kitti-3d-3class/latest.pth 8
+ ```
+
+Õ£©ńö¤µłÉ `results/kitti-3class/kitti_results/xxxxx.txt` ÕÉÄ’╝īµé©ÕÅ»õ╗źµÅÉõ║żĶ┐Öõ║øµ¢ćõ╗ČÕł░ KITTI Õ«śµ¢╣ńĮæń½ÖĶ┐øĶĪīÕ¤║ÕćåµĄŗĶ»Ģ’╝īµø┤ÕżÜń╗åĶŖéĶ»ĘÕÅéĶĆā [KITTI Õ«śµ¢╣ńĮæń½Ö](http://www.cvlibs.net/datasets/kitti/index.php)ŃĆé
diff --git a/internlm_langchain/knowledge_base/MMDetection3D/content/lidar_det3d.md b/internlm_langchain/knowledge_base/MMDetection3D/content/lidar_det3d.md
new file mode 100644
index 00000000..1277e310
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection3D/content/lidar_det3d.md
@@ -0,0 +1,83 @@
+# Õ¤║õ║ĵ┐ĆÕģēķøĘĶŠŠńÜä 3D µŻĆµĄŗ
+
+Õ¤║õ║ĵ┐ĆÕģēķøĘĶŠŠńÜä 3D µŻĆµĄŗµś» MMDetection3D µö»µīüńÜäµ£ĆÕ¤║ńĪĆńÜäõ╗╗ÕŖĪõ╣ŗõĖĆŃĆéÕ«āµ£¤µ£øń╗ÖÕ«ÜńÜ䵩ĪÕ×ŗõ╗źµ┐ĆÕģēķøĘĶŠŠķććķøåńÜäõ╗╗µäŵĢ░ķćÅńÜäńē╣ÕŠüńé╣õĖ║ĶŠōÕģź’╝īÕ╣ČõĖ║µ»ÅõĖĆõĖ¬µä¤Õģ┤ĶČŻńÜäńø«µĀćķó䵥ŗ 3D µĪåÕÅŖń▒╗Õł½µĀćńŁŠŃĆéµÄźõĖŗµØź’╝īµłæõ╗¼õ╗ź KITTI µĢ░µŹ«ķøåõĖŖńÜä PointPillars õĖ║õŠŗ’╝īÕ▒Ģńż║Õ”éõĮĢÕćåÕżćµĢ░µŹ«’╝īÕ£©µĀćÕćåńÜä 3D µŻĆµĄŗÕ¤║ÕćåõĖŖĶ«Łń╗āÕ╣ȵĄŗĶ»Ģµ©ĪÕ×ŗ’╝īõ╗źÕÅŖÕÅ»Ķ¦åÕī¢Õ╣Čķ¬īĶ»üń╗ōµ×£ŃĆé
+
+## µĢ░µŹ«ÕćåÕżć
+
+ķ”¢Õģł’╝īµłæõ╗¼ķ£ĆĶ”üõĖŗĶĮĮÕĤզŗµĢ░µŹ«Õ╣ȵīēńģ¦[µĢ░µŹ«ÕćåÕżćµ¢ćµĪŻ](https://mmdetection3d.readthedocs.io/zh_CN/dev-1.x/user_guides/dataset_prepare.html)õĖŁµÅÉõŠøńÜäµĀćÕćåµ¢╣Õ╝Åķ揵¢░ń╗äń╗ćµĢ░µŹ«ŃĆé
+
+ńö▒õ║ÄõĖŹÕÉīµĢ░µŹ«ķøåńÜäÕĤզŗµĢ░µŹ«µ£ēõĖŹÕÉīńÜäń╗äń╗ćµ¢╣Õ╝Å’╝īµłæõ╗¼ķĆÜÕĖĖķ£ĆĶ”üńö© `.pkl` µ¢ćõ╗ȵöČķøåµ£ēńö©ńÜäµĢ░µŹ«õ┐Īµü»ŃĆéÕøĀµŁż’╝īÕ£©ÕćåÕżćÕźĮµēƵ£ēńÜäÕĤզŗµĢ░µŹ«õ╣ŗÕÉÄ’╝īµłæõ╗¼ķ£ĆĶ”üĶ┐ÉĶĪī `create_data.py` õĖŁµÅÉõŠøńÜäĶäܵ£¼µØźõĖ║õĖŹÕÉīńÜäµĢ░µŹ«ķøåńö¤µłÉµĢ░µŹ«ķøåõ┐Īµü»ŃĆéõŠŗÕ”é’╝īÕ»╣õ║Ä KITTI’╝īµłæõ╗¼ķ£ĆĶ”üĶ┐ÉĶĪīÕ”éõĖŗÕæĮõ╗ż’╝Ü
+
+```shell
+python tools/create_data.py kitti --root-path ./data/kitti --out-dir ./data/kitti --extra-tag kitti
+```
+
+ķÜÅÕÉÄ’╝īńøĖÕģ│ńÜäńø«ÕĮĢń╗ōµ×äÕ░åÕ”éõĖŗµēĆńż║’╝Ü
+
+```
+mmdetection3d
+Ōö£ŌöĆŌöĆ mmdet3d
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+Ōö£ŌöĆŌöĆ data
+Ōöé Ōö£ŌöĆŌöĆ kitti
+Ōöé Ōöé Ōö£ŌöĆŌöĆ ImageSets
+Ōöé Ōöé Ōö£ŌöĆŌöĆ testing
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ calib
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ image_2
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ velodyne
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ velodyne_reduced
+Ōöé Ōöé Ōö£ŌöĆŌöĆ training
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ calib
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ image_2
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ label_2
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ velodyne
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ velodyne_reduced
+Ōöé Ōöé Ōö£ŌöĆŌöĆ kitti_gt_database
+Ōöé Ōöé Ōö£ŌöĆŌöĆ kitti_infos_train.pkl
+Ōöé Ōöé Ōö£ŌöĆŌöĆ kitti_infos_trainval.pkl
+Ōöé Ōöé Ōö£ŌöĆŌöĆ kitti_infos_val.pkl
+Ōöé Ōöé Ōö£ŌöĆŌöĆ kitti_infos_test.pkl
+Ōöé Ōöé Ōö£ŌöĆŌöĆ kitti_dbinfos_train.pkl
+```
+
+## Ķ«Łń╗ā
+
+µÄźńØĆ’╝īµłæõ╗¼Õ░åõĮ┐ńö©µÅÉõŠøńÜäķģŹńĮ«µ¢ćõ╗ČĶ«Łń╗ā PointPillarsŃĆéÕĮōµé©õĮ┐ńö©õĖŹÕÉīńÜä GPU Ķ«ŠńĮ«Ķ┐øĶĪīĶ«Łń╗āµŚČ’╝īµé©ÕÅ»õ╗źµīēńģ¦Ķ┐ÖõĖ¬[µĢÖń©ŗ](https://mmdetection3d.readthedocs.io/en/dev-1.x/user_guides/train_test.html)ńÜäńż║õŠŗŃĆéÕüćĶ«Šµłæõ╗¼Õ£©õĖĆÕÅ░Õģʵ£ē 8 ÕØŚ GPU ńÜäµ£║ÕÖ©õĖŖõĮ┐ńö©ÕłåÕĖāÕ╝ÅĶ«Łń╗ā’╝Ü
+
+```shell
+./tools/dist_train.sh configs/pointpillars/pointpillars_hv_secfpn_8xb6-160e_kitti-3d-3class.py 8
+```
+
+µ│©µäÅ’╝īķģŹńĮ«µ¢ćõ╗ČÕÉŹõĖŁńÜä `8xb6` µś»µīćĶ«Łń╗āńö©õ║å 8 ÕØŚ GPU’╝īµ»ÅÕØŚ GPU õĖŖµ£ē 6 õĖ¬µĢ░µŹ«µĀʵ£¼ŃĆéÕ”éµ×£µé©ńÜäĶć¬Õ«Üõ╣ēĶ«ŠńĮ«õĖŹÕÉīõ║ĵŁż’╝īķéŻõ╣łµ£ēµŚČÕĆÖµé©ķ£ĆĶ”üńøĖÕ║öÕ£░Ķ░āµĢ┤ÕŁ”õ╣ĀńÄćŃĆéÕ¤║µ£¼Ķ¦äÕłÖÕÅ»õ╗źÕÅéĶĆā[µŁżÕżä](https://arxiv.org/abs/1706.02677)ŃĆ鵳æõ╗¼ÕĘ▓ń╗ŵö»µīüõ║åõĮ┐ńö© `--auto-scale-lr` µØźĶć¬ÕŖ©ń╝®µöŠÕŁ”õ╣ĀńÄćŃĆé
+
+## Õ«ÜķćÅĶ»äõ╝░
+
+Õ£©Ķ«Łń╗āµ£¤ķŚ┤’╝īµ©ĪÕ×ŗµØāķ揵¢ćõ╗ČÕ░åõ╝ܵĀ╣µŹ«ķģŹńĮ«µ¢ćõ╗ČõĖŁńÜä `train_cfg = dict(val_interval=xxx)` Ķ«ŠńĮ«Ķó½Õ橵£¤µĆ¦Õ£░Ķ»äõ╝░ŃĆ鵳æõ╗¼µö»µīüõĖŹÕÉīµĢ░µŹ«ķøåńÜäÕ«śµ¢╣Ķ»äõ╝░µ¢╣µĪłŃĆéÕ»╣õ║Ä KITTI’╝īÕ░åÕ»╣ 3 õĖ¬ń▒╗Õł½õĮ┐ńö©õ║żÕ╣ȵ»ö’╝łIoU’╝ēķśłÕĆ╝ÕłåÕł½õĖ║ 0.5/0.7 ńÜäÕ╣│ÕØćń▓ŠÕ║”’╝łmAP’╝ēµØźĶ»äõ╝░µ©ĪÕ×ŗŃĆéĶ»äõ╝░ń╗ōµ×£Õ░åõ╝ÜĶó½µēōÕŹ░Õł░ń╗łń½»õĖŁ’╝īÕ”éõĖŗµēĆńż║’╝Ü
+
+```
+Car AP@0.70, 0.70, 0.70:
+bbox AP:98.1839, 89.7606, 88.7837
+bev AP:89.6905, 87.4570, 85.4865
+3d AP:87.4561, 76.7569, 74.1302
+aos AP:97.70, 88.73, 87.34
+Car AP@0.70, 0.50, 0.50:
+bbox AP:98.1839, 89.7606, 88.7837
+bev AP:98.4400, 90.1218, 89.6270
+3d AP:98.3329, 90.0209, 89.4035
+aos AP:97.70, 88.73, 87.34
+```
+
+µŁżÕż¢’╝īÕ£©Ķ«Łń╗āÕ«īµłÉÕÉĵé©õ╣¤ÕÅ»õ╗źĶ»äõ╝░ńē╣Õ«ÜńÜ䵩ĪÕ×ŗµØāķ揵¢ćõ╗ČŃĆéµé©ÕÅ»õ╗źń«ĆÕŹĢÕ£░µē¦ĶĪīõ╗źõĖŗĶäܵ£¼’╝Ü
+
+```shell
+./tools/dist_test.sh configs/pointpillars/pointpillars_hv_secfpn_8xb6-160e_kitti-3d-3class.py work_dirs/pointpillars/latest.pth 8
+```
+
+## µĄŗĶ»ĢõĖĵÅÉõ║ż
+
+Õ”éµ×£µé©ÕŬµā│Õ£©Õ£©ń║┐Õ¤║ÕćåõĖŖĶ┐øĶĪīµÄ©ńÉåµł¢µĄŗĶ»Ģµ©ĪÕ×ŗµĆ¦ĶāĮ’╝īµé©ķ£ĆĶ”üÕ£©ńøĖÕ║öńÜäĶ»äõ╝░ÕÖ©õĖŁµīćÕ«Ü `submission_prefix`’╝īõŠŗÕ”é’╝īÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁµĘ╗ÕŖĀ `test_evaluator = dict(type='KittiMetric', ann_file=data_root + 'kitti_infos_test.pkl', format_only=True, pklfile_prefix='results/kitti-3class/kitti_results', submission_prefix='results/kitti-3class/kitti_results')`’╝īńäČÕÉÄÕÅ»õ╗źÕŠŚÕł░ń╗ōµ×£µ¢ćõ╗ČŃĆéĶ»ĘńĪ«õ┐ØķģŹńĮ«µ¢ćõ╗ČõĖŁńÜä[µĄŗĶ»Ģõ┐Īµü»](https://github.com/open-mmlab/mmdetection3d/blob/dev-1.x/configs/_base_/datasets/kitti-3d-3class.py#L117)ńÜä `data_prefix` ÕÆī `ann_file` ńö▒ķ¬īĶ»üķøåńøĖÕ║öÕ£░µö╣õĖ║µĄŗĶ»ĢķøåŃĆéÕ£©ńö¤µłÉń╗ōµ×£ÕÉÄ’╝īµé©ÕÅ»õ╗źÕÄŗń╝®µ¢ćõ╗ČÕż╣Õ╣ČõĖŖõ╝ĀĶć│ KITTI Ķ»äõ╝░µ£ŹÕŖĪÕÖ©õĖŖŃĆé
+
+## Õ«ÜµĆ¦Ķ»äõ╝░
+
+MMDetection3D Ķ┐śµÅÉõŠøõ║åķĆÜńö©ńÜäÕÅ»Ķ¦åÕī¢ÕĘźÕģĘ’╝īõ╗źõŠ┐õ║ĵłæõ╗¼ÕÅ»õ╗źÕ»╣Ķ«Łń╗āÕźĮńÜ䵩ĪÕ×ŗķó䵥ŗńÜ䵯ƵĄŗń╗ōµ×£µ£ēõĖĆõĖ¬ńø┤Ķ¦éńÜäµä¤ÕÅŚŃĆéµé©õ╣¤ÕÅ»õ╗źÕ£©Ķ»äõ╝░ķśČµ«ĄķĆÜĶ┐ćĶ«ŠńĮ« `--show` µØźÕ£©ń║┐ÕÅ»Ķ¦åÕī¢µŻĆµĄŗń╗ōµ×£’╝īµł¢ĶĆģõĮ┐ńö© `tools/misc/visualize_results.py` µØźń”╗ń║┐Õ£░Ķ┐øĶĪīÕÅ»Ķ¦åÕī¢ŃĆ鵣żÕż¢’╝īµłæõ╗¼Ķ┐śµÅÉõŠøõ║åĶäܵ£¼ `tools/misc/browse_dataset.py` ńö©õ║ÄÕÅ»Ķ¦åÕī¢µĢ░µŹ«ķøåĶĆīõĖŹÕüܵĩńÉåŃĆéµø┤ÕżÜńÜäń╗åĶŖéĶ»ĘÕÅéĶĆā[ÕÅ»Ķ¦åÕī¢µ¢ćµĪŻ](https://mmdetection3d.readthedocs.io/zh_CN/dev-1.x/user_guides/visualization.html)ŃĆé
diff --git a/internlm_langchain/knowledge_base/MMDetection3D/content/lidar_sem_seg3d.md b/internlm_langchain/knowledge_base/MMDetection3D/content/lidar_sem_seg3d.md
new file mode 100644
index 00000000..d35636ad
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection3D/content/lidar_sem_seg3d.md
@@ -0,0 +1,78 @@
+# Õ¤║õ║ĵ┐ĆÕģēķøĘĶŠŠńÜä 3D Ķ»Łõ╣ēÕłåÕē▓
+
+Õ¤║õ║ĵ┐ĆÕģēķøĘĶŠŠńÜä 3D Ķ»Łõ╣ēÕłåÕē▓µś» MMDetection3D µö»µīüńÜäµ£ĆÕ¤║ńĪĆńÜäõ╗╗ÕŖĪõ╣ŗõĖĆŃĆéÕ«āµ£¤µ£øń╗ÖÕ«ÜńÜ䵩ĪÕ×ŗõ╗źµ┐ĆÕģēķøĘĶŠŠķććķøåńÜäõ╗╗µäŵĢ░ķćÅńÜäńē╣ÕŠüńé╣õĖ║ĶŠōÕģź’╝īÕ╣Čķó䵥ŗµ»ÅõĖ¬ĶŠōÕģźńé╣ńÜäĶ»Łõ╣ēµĀćńŁŠŃĆéµÄźõĖŗµØź’╝īµłæõ╗¼õ╗ź ScanNet µĢ░µŹ«ķøåõĖŖńÜä PointNet++ (SSG) õĖ║õŠŗ’╝īÕ▒Ģńż║Õ”éõĮĢÕćåÕżćµĢ░µŹ«’╝īÕ£©µĀćÕćåńÜä 3D Ķ»Łõ╣ēÕłåÕē▓Õ¤║ÕćåõĖŖĶ«Łń╗āÕ╣ȵĄŗĶ»Ģµ©ĪÕ×ŗ’╝īõ╗źÕÅŖÕÅ»Ķ¦åÕī¢Õ╣Čķ¬īĶ»üń╗ōµ×£ŃĆé
+
+## µĢ░µŹ«ÕćåÕżć
+
+ķ”¢Õģł’╝īµłæõ╗¼ķ£ĆĶ”üõ╗Ä ScanNet [Õ«śµ¢╣ńĮæń½Ö](http://kaldir.vc.in.tum.de/scannet_benchmark/documentation)õĖŗĶĮĮÕĤզŗµĢ░µŹ«ŃĆé
+
+ńö▒õ║ÄõĖŹÕÉīµĢ░µŹ«ķøåńÜäÕĤզŗµĢ░µŹ«µ£ēõĖŹÕÉīńÜäń╗äń╗ćµ¢╣Õ╝Å’╝īµłæõ╗¼ķĆÜÕĖĖķ£ĆĶ”üńö© pkl µł¢ json µ¢ćõ╗ȵöČķøåµ£ēńö©ńÜäµĢ░µŹ«õ┐Īµü»ŃĆé
+
+ÕøĀµŁż’╝īÕ£©ÕćåÕżćÕźĮµēƵ£ēńÜäÕĤզŗµĢ░µŹ«õ╣ŗÕÉÄ’╝īµłæõ╗¼ÕÅ»õ╗źķüĄÕŠ¬ [ScanNet µ¢ćµĪŻ](https://github.com/open-mmlab/mmdetection3d/blob/master/data/scannet/README.md/)õĖŁńÜäĶ»┤µśÄńö¤µłÉµĢ░µŹ«õ┐Īµü»ŃĆé
+
+ķÜÅÕÉÄ’╝īńøĖÕģ│ńÜäńø«ÕĮĢń╗ōµ×äÕ░åÕ”éõĖŗµēĆńż║’╝Ü
+
+```
+mmdetection3d
+Ōö£ŌöĆŌöĆ mmdet3d
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+Ōö£ŌöĆŌöĆ data
+Ōöé Ōö£ŌöĆŌöĆ scannet
+Ōöé Ōöé Ōö£ŌöĆŌöĆ scannet_utils.py
+Ōöé Ōöé Ōö£ŌöĆŌöĆ batch_load_scannet_data.py
+Ōöé Ōöé Ōö£ŌöĆŌöĆ load_scannet_data.py
+Ōöé Ōöé Ōö£ŌöĆŌöĆ scannet_utils.py
+Ōöé Ōöé Ōö£ŌöĆŌöĆ README.md
+Ōöé Ōöé Ōö£ŌöĆŌöĆ scans
+Ōöé Ōöé Ōö£ŌöĆŌöĆ scans_test
+Ōöé Ōöé Ōö£ŌöĆŌöĆ scannet_instance_data
+Ōöé Ōöé Ōö£ŌöĆŌöĆ points
+Ōöé Ōöé Ōö£ŌöĆŌöĆ instance_mask
+Ōöé Ōöé Ōö£ŌöĆŌöĆ semantic_mask
+Ōöé Ōöé Ōö£ŌöĆŌöĆ seg_info
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ train_label_weight.npy
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ train_resampled_scene_idxs.npy
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ val_label_weight.npy
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ val_resampled_scene_idxs.npy
+Ōöé Ōöé Ōö£ŌöĆŌöĆ scannet_infos_train.pkl
+Ōöé Ōöé Ōö£ŌöĆŌöĆ scannet_infos_val.pkl
+Ōöé Ōöé Ōö£ŌöĆŌöĆ scannet_infos_test.pkl
+```
+
+## Ķ«Łń╗ā
+
+µÄźńØĆ’╝īµłæõ╗¼Õ░åõĮ┐ńö©µÅÉõŠøńÜäķģŹńĮ«µ¢ćõ╗ČĶ«Łń╗ā PointNet++ (SSG) µ©ĪÕ×ŗŃĆéÕĮōõĮĀõĮ┐ńö©õĖŹÕÉīńÜä GPU Ķ«ŠńĮ«Ķ┐øĶĪīĶ«Łń╗āµŚČ’╝īõĮĀÕ¤║µ£¼õĖŖÕÅ»õ╗źµīēńģ¦Ķ┐ÖõĖ¬[µĢÖń©ŗ](https://mmdetection3d.readthedocs.io/zh_CN/latest/1_exist_data_model.html#inference-with-existing-models)ńÜäńż║õŠŗĶäܵ£¼ŃĆéÕüćĶ«Šµłæõ╗¼Õ£©õĖĆÕÅ░Õģʵ£ē 2 ÕØŚ GPU ńÜäµ£║ÕÖ©õĖŖõĮ┐ńö©ÕłåÕĖāÕ╝ÅĶ«Łń╗ā’╝Ü
+
+```
+./tools/dist_train.sh configs/pointnet2/pointnet2_ssg_2xb16-cosine-200e_scannet-seg.py 2
+```
+
+µ│©µäÅ’╝īķģŹńĮ«µ¢ćõ╗ČÕÉŹõĖŁńÜä `16x2` µś»µīćĶ«Łń╗āµŚČńö©õ║å 2 ÕØŚ GPU’╝īµ»ÅÕØŚ GPU õĖŖµ£ē 16 õĖ¬µĀʵ£¼ŃĆéÕ”éµ×£õĮĀńÜäĶć¬Õ«Üõ╣ēĶ«ŠńĮ«õĖŹÕÉīõ║ĵŁż’╝īķéŻõ╣łµ£ēµŚČÕĆÖõĮĀķ£ĆĶ”üńøĖÕ║öńÜäĶ░āµĢ┤ÕŁ”õ╣ĀńÄćŃĆéÕ¤║µ£¼Ķ¦äÕłÖÕÅ»õ╗źÕÅéĶĆā[µŁżÕżä](https://arxiv.org/abs/1706.02677)ŃĆé
+
+## Õ«ÜķćÅĶ»äõ╝░
+
+Õ£©Ķ«Łń╗āµ£¤ķŚ┤’╝īµ©ĪÕ×ŗµØāķćŹÕ░åõ╝ܵĀ╣µŹ«ķģŹńĮ«µ¢ćõ╗ČõĖŁńÜä `train_cfg = dict(val_interval=xxx)` Ķ«ŠńĮ«Ķó½Õ橵£¤µĆ¦Õ£░Ķ»äõ╝░ŃĆ鵳æõ╗¼µö»µīüõĖŹÕÉīµĢ░µŹ«ķøåńÜäÕ«śµ¢╣Ķ»äõ╝░µ¢╣µĪłŃĆéÕ»╣õ║Ä ScanNet’╝īÕ░åõĮ┐ńö© 20 õĖ¬ń▒╗Õł½ńÜäÕ╣│ÕØćõ║żÕ╣ȵ»ö (mIoU) Õ»╣µ©ĪÕ×ŗĶ┐øĶĪīĶ»äõ╝░ŃĆéĶ»äõ╝░ń╗ōµ×£Õ░åõ╝ÜĶó½µēōÕŹ░Õł░ń╗łń½»õĖŁ’╝īÕ”éõĖŗµēĆńż║’╝Ü
+
+```
++---------+--------+--------+---------+--------+--------+--------+--------+--------+--------+-----------+---------+---------+--------+---------+--------------+----------------+--------+--------+---------+----------------+--------+--------+---------+
+| classes | wall | floor | cabinet | bed | chair | sofa | table | door | window | bookshelf | picture | counter | desk | curtain | refrigerator | showercurtrain | toilet | sink | bathtub | otherfurniture | miou | acc | acc_cls |
++---------+--------+--------+---------+--------+--------+--------+--------+--------+--------+-----------+---------+---------+--------+---------+--------------+----------------+--------+--------+---------+----------------+--------+--------+---------+
+| results | 0.7257 | 0.9373 | 0.4625 | 0.6613 | 0.7707 | 0.5562 | 0.5864 | 0.4010 | 0.4558 | 0.7011 | 0.2500 | 0.4645 | 0.4540 | 0.5399 | 0.2802 | 0.3488 | 0.7359 | 0.4971 | 0.6922 | 0.3681 | 0.5444 | 0.8118 | 0.6695 |
++---------+--------+--------+---------+--------+--------+--------+--------+--------+--------+-----------+---------+---------+--------+---------+--------------+----------------+--------+--------+---------+----------------+--------+--------+---------+
+```
+
+µŁżÕż¢’╝īÕ£©Ķ«Łń╗āÕ«īµłÉÕÉÄõĮĀõ╣¤ÕÅ»õ╗źĶ»äõ╝░ńē╣Õ«ÜńÜ䵩ĪÕ×ŗµØāķ揵¢ćõ╗ČŃĆéõĮĀÕÅ»õ╗źń«ĆÕŹĢÕ£░µē¦ĶĪīõ╗źõĖŗĶäܵ£¼’╝Ü
+
+```
+./tools/dist_test.sh configs/pointnet2/pointnet2_ssg_16x2_cosine_200e_scannet-seg.py work_dirs/pointnet2_ssg/latest.pth 8
+```
+
+## µĄŗĶ»ĢõĖĵÅÉõ║ż
+
+Õ”éµ×£õĮĀÕŬµā│Õ£©Õ£©ń║┐Õ¤║ÕćåõĖŖĶ┐øĶĪīµÄ©ńÉåµł¢µĄŗĶ»Ģµ©ĪÕ×ŗµĆ¦ĶāĮ’╝īõĮĀķ£ĆĶ”üÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁńÜä `test_evalutor` ÕŁŚµ«ĄÕó×ÕŖĀ `submission_prefix`’╝ī õŠŗÕ”éķģŹńĮ«µ¢ćõ╗ČÕó×ÕŖĀ `test_evaluator = dict(type='SegMetric',submission_prefix=work_dirs/pointnet2_ssg/test_submission`)ŃĆé
+Õ╣ČÕ░å ScanNet µĢ░µŹ«ķøå[ķģŹńĮ«µ¢ćõ╗Č](https://github.com/open-mmlab/mmdetection3d/blob/main/configs/_base_/datasets/scannet-seg.py#L129)õĖŁńÜä `ann_file=scannet_infos_val.pkl` ÕÅśµłÉ `ann_file=scannet_infos_test.pkl`ŃĆéÕ£©ńö¤µłÉń╗ōµ×£ÕÉÄ’╝īõĮĀÕÅ»õ╗źÕÄŗń╝®µ¢ćõ╗ČÕż╣Õ╣ČõĖŖõ╝ĀĶć│ [ScanNet Ķ»äõ╝░µ£ŹÕŖĪÕÖ©](http://kaldir.vc.in.tum.de/scannet_benchmark/semantic_label_3d)õĖŖŃĆé
+
+## Õ«ÜµĆ¦Ķ»äõ╝░
+
+MMDetection3D Ķ┐śµÅÉõŠøõ║åķĆÜńö©ńÜäÕÅ»Ķ¦åÕī¢ÕĘźÕģĘ’╝īõ╗źõŠ┐õ║ĵłæõ╗¼ÕÅ»õ╗źÕ»╣Ķ«Łń╗āÕźĮńÜ䵩ĪÕ×ŗķó䵥ŗńÜäÕłåÕē▓ń╗ōµ×£µ£ēõĖĆõĖ¬ńø┤Ķ¦éńÜäµä¤ÕÅŚŃĆéõĮĀõ╣¤ÕÅ»õ╗źÕ£©Ķ»äõ╝░ķśČµ«ĄķĆÜĶ┐ćĶ«ŠńĮ« `--eval-options 'show=True' 'out_dir=${SHOW_DIR}'` µØźÕ£©ń║┐ÕÅ»Ķ¦åÕī¢ÕłåÕē▓ń╗ōµ×£’╝īµł¢ĶĆģõĮ┐ńö© `tools/misc/visualize_results.py` µØźń”╗ń║┐Õ£░Ķ┐øĶĪīÕÅ»Ķ¦åÕī¢ŃĆ鵣żÕż¢’╝īµłæõ╗¼Ķ┐śµÅÉõŠøõ║åĶäܵ£¼ `tools/misc/browse_dataset.py` ńö©õ║ÄÕÅ»Ķ¦åÕī¢µĢ░µŹ«ķøåĶĆīõĖŹÕüܵĩńÉåŃĆéµø┤ÕżÜńÜäń╗åĶŖéĶ»ĘÕÅéĶĆā[ÕÅ»Ķ¦åÕī¢µ¢ćµĪŻ](https://mmdetection3d.readthedocs.io/zh_CN/latest/useful_tools.html#visualization)ŃĆé
diff --git a/internlm_langchain/knowledge_base/MMDetection3D/content/lyft.md b/internlm_langchain/knowledge_base/MMDetection3D/content/lyft.md
new file mode 100644
index 00000000..eab8b529
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection3D/content/lyft.md
@@ -0,0 +1,195 @@
+# Lyft µĢ░µŹ«ķøå
+
+µ£¼ķĪĄµÅÉõŠøõ║åµ£ēÕģ│Õ£© MMDetection3D õĖŁõĮ┐ńö© Lyft µĢ░µŹ«ķøåńÜäÕģĘõĮōµĢÖń©ŗŃĆé
+
+## ÕćåÕżćõ╣ŗÕēŹ
+
+µé©ÕÅ»õ╗źÕ£©[Ķ┐Öķćī](https://www.kaggle.com/c/3d-object-detection-for-autonomous-vehicles/data)õĖŗĶĮĮ Lyft 3D µŻĆµĄŗµĢ░µŹ«Õ╣ČĶ¦ŻÕÄŗń╝®µēƵ£ē zip µ¢ćõ╗ČŃĆé
+
+ÕāÅÕćåÕżćµĢ░µŹ«ķøåńÜäõĖĆĶł¼µ¢╣µ│ĢõĖƵĀĘ’╝īÕ╗║Ķ««Õ░åµĢ░µŹ«ķøåµĀ╣ńø«ÕĮĢķōŠµÄźÕł░ `$MMDETECTION3D/data`ŃĆé
+
+Õ£©Ķ┐øĶĪīÕżäńÉåõ╣ŗÕēŹ’╝īµ¢ćõ╗ČÕż╣ń╗ōµ×äÕ║öµīēÕ”éõĖŗµ¢╣Õ╝Åń╗äń╗ć’╝Ü
+
+```
+mmdetection3d
+Ōö£ŌöĆŌöĆ mmdet3d
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+Ōö£ŌöĆŌöĆ data
+Ōöé Ōö£ŌöĆŌöĆ lyft
+Ōöé Ōöé Ōö£ŌöĆŌöĆ v1.01-train
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ v1.01-train (train_data)
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ lidar (train_lidar)
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ images (train_images)
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ maps (train_maps)
+Ōöé Ōöé Ōö£ŌöĆŌöĆ v1.01-test
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ v1.01-test (test_data)
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ lidar (test_lidar)
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ images (test_images)
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ maps (test_maps)
+Ōöé Ōöé Ōö£ŌöĆŌöĆ train.txt
+Ōöé Ōöé Ōö£ŌöĆŌöĆ val.txt
+Ōöé Ōöé Ōö£ŌöĆŌöĆ test.txt
+Ōöé Ōöé Ōö£ŌöĆŌöĆ sample_submission.csv
+```
+
+ÕģČõĖŁ `v1.01-train` ÕÆī `v1.01-test` ÕīģÕɽõĖÄ nuScenes µĢ░µŹ«ķøåńøĖÕÉīńÜäÕģāµ¢ćõ╗Č’╝ī`.txt` µ¢ćõ╗ČÕīģÕɽµĢ░µŹ«ÕłÆÕłåńÜäõ┐Īµü»ŃĆéLyft õĖŹµÅÉõŠøĶ«Łń╗āķøåÕÆīķ¬īĶ»üķøåńÜäÕ«śµ¢╣ÕłÆÕłåµ¢╣µĪł’╝īÕøĀµŁż MMDetection3D Õ»╣õĖŹÕÉīÕ£║µÖ»õĖŗńÜäõĖŹÕÉīń▒╗Õł½ńÜäńø«µĀćµĢ░ķćÅĶ┐øĶĪīÕłåµ×É’╝īÕ╣ȵÅÉõŠøõ║åõĖĆõĖ¬µĢ░µŹ«ķøåÕłÆÕłåµ¢╣µĪłŃĆé`sample_submission.csv` µś»ńö©õ║ĵÅÉõ║żÕł░ Kaggle Ķ»äõ╝░µ£ŹÕŖĪÕÖ©ńÜäÕ¤║µ£¼µ¢ćõ╗ČŃĆéķ£ĆĶ”üµ│©µäÅńÜ䵜»’╝īµłæõ╗¼ķüĄÕŠ¬õ║å Lyft µ£ĆÕłØńÜäµ¢ćõ╗ČÕż╣ÕæĮÕÉŹõ╗źÕ«×ńÄ░µø┤µĖģµźÜńÜäµ¢ćõ╗Čń╗äń╗ćŃĆéĶ»ĘÕ░åõĖŗĶĮĮõĖŗµØźńÜäÕĤզŗµ¢ćõ╗ČÕż╣µīēńģ¦õĖŖĶ┐░ń╗äń╗ćń╗ōµ×äķ揵¢░ÕæĮÕÉŹŃĆé
+
+## µĢ░µŹ«ÕćåÕżć
+
+ń╗äń╗ć Lyft µĢ░µŹ«ķøåńÜäµ¢╣Õ╝ÅÕÆīń╗äń╗ć nuScenes ńÜäµ¢╣Õ╝ÅńøĖÕÉī’╝īķ”¢Õģłõ╝Üńö¤µłÉÕćĀõ╣ÄÕģʵ£ēńøĖÕÉīń╗ōµ×äńÜä `.pkl` µ¢ćõ╗Č’╝īµÄźńØĆķ£ĆĶ”üķćŹńé╣Õģ│µ│©Ķ┐ÖõĖżõĖ¬µĢ░µŹ«ķøåõ╣ŗķŚ┤ńÜäõĖŹÕÉīńé╣’╝īµø┤ÕżÜÕģ│õ║ĵĢ░µŹ«ķøåõ┐Īµü»µ¢ćõ╗Čń╗ōµ×äńÜäĶ»┤µśÄĶ»ĘÕÅéĶĆā [nuScenes µĢÖń©ŗ](https://github.com/open-mmlab/mmdetection3d/blob/dev-1.x/docs/zh_cn/advanced_guides/datasets/nuscenes_det.md)ŃĆé
+
+Ķ»ĘķĆÜĶ┐ćĶ┐ÉĶĪīõĖŗķØóńÜäÕæĮõ╗żµØźńö¤µłÉ Lyft ńÜäµĢ░µŹ«ķøåõ┐Īµü»µ¢ćõ╗Č’╝Ü
+
+```bash
+python tools/create_data.py lyft --root-path ./data/lyft --out-dir ./data/lyft --extra-tag lyft --version v1.01
+python tools/data_converter/lyft_data_fixer.py --version v1.01 --root-folder ./data/lyft
+```
+
+Ķ»Ęµ│©µäÅ’╝īõĖŖķØóńÜäń¼¼õ║īĶĪīÕæĮõ╗żńö©õ║Äõ┐«ÕżŹµŹ¤ÕØÅńÜä lidar µĢ░µŹ«µ¢ćõ╗Č’╝īµø┤ÕżÜń╗åĶŖéĶ»ĘÕÅéĶĆāµŁżÕżä[Ķ«©Ķ«║](https://www.kaggle.com/c/3d-object-detection-for-autonomous-vehicles/discussion/110000)ŃĆé
+
+ÕżäńÉåÕÉÄńÜäµ¢ćõ╗ČÕż╣ń╗ōµ×äÕ║öĶ»źÕ”éõĖŗ’╝Ü
+
+```
+mmdetection3d
+Ōö£ŌöĆŌöĆ mmdet3d
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+Ōö£ŌöĆŌöĆ data
+Ōöé Ōö£ŌöĆŌöĆ lyft
+Ōöé Ōöé Ōö£ŌöĆŌöĆ v1.01-train
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ v1.01-train (train_data)
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ lidar (train_lidar)
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ images (train_images)
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ maps (train_maps)
+Ōöé Ōöé Ōö£ŌöĆŌöĆ v1.01-test
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ v1.01-test (test_data)
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ lidar (test_lidar)
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ images (test_images)
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ maps (test_maps)
+Ōöé Ōöé Ōö£ŌöĆŌöĆ train.txt
+Ōöé Ōöé Ōö£ŌöĆŌöĆ val.txt
+Ōöé Ōöé Ōö£ŌöĆŌöĆ test.txt
+Ōöé Ōöé Ōö£ŌöĆŌöĆ sample_submission.csv
+Ōöé Ōöé Ōö£ŌöĆŌöĆ lyft_infos_train.pkl
+Ōöé Ōöé Ōö£ŌöĆŌöĆ lyft_infos_val.pkl
+Ōöé Ōöé Ōö£ŌöĆŌöĆ lyft_infos_test.pkl
+```
+
+- `lyft_infos_train.pkl`’╝ÜĶ«Łń╗āµĢ░µŹ«ķøåõ┐Īµü»’╝īĶ»źÕŁŚÕģĖÕīģÕɽõĖżõĖ¬Õģ│ķö«ÕŁŚ’╝Ü`metainfo` ÕÆī `data_list`ŃĆé`metainfo` ÕīģÕɽµĢ░µŹ«ķøåńÜäÕ¤║µ£¼õ┐Īµü»’╝īõŠŗÕ”é `categories`, `dataset` ÕÆī `info_version`ŃĆé`data_list` µś»ńö▒ÕŁŚÕģĖń╗䵳ÉńÜäÕłŚĶĪ©’╝īµ»ÅõĖ¬ÕŁŚÕģĖ’╝łõ╗źõĖŗń«Ćń¦░ `info`’╝ēÕīģÕɽõ║åÕŹĢõĖ¬µĀʵ£¼ńÜäµēƵ£ēĶ»”ń╗åõ┐Īµü»ŃĆé
+ - info\['sample_idx'\]’╝ܵĀʵ£¼Õ£©µĢ┤õĖ¬µĢ░µŹ«ķøåńÜäń┤óÕ╝ĢŃĆé
+ - info\['token'\]’╝ܵĀʵ£¼µĢ░µŹ«µĀćĶ«░ŃĆé
+ - info\['timestamp'\]’╝ܵĀʵ£¼µĢ░µŹ«µŚČķŚ┤µł│ŃĆé
+ - info\['lidar_points'\]’╝ܵś»õĖĆõĖ¬ÕŁŚÕģĖ’╝īÕīģÕɽõ║åµēƵ£ēõĖĵ┐ĆÕģēķøĘĶŠŠńé╣ńøĖÕģ│ńÜäõ┐Īµü»ŃĆé
+ - info\['lidar_points'\]\['lidar_path'\]’╝ܵ┐ĆÕģēķøĘĶŠŠńé╣õ║æµĢ░µŹ«ńÜäµ¢ćõ╗ČÕÉŹŃĆé
+ - info\['lidar_points'\]\['num_pts_feats'\]’╝Üńé╣ńÜäńē╣ÕŠüń╗┤Õ║”ŃĆé
+ - info\['lidar_points'\]\['lidar2ego'\]’╝ÜĶ»źµ┐ĆÕģēķøĘĶŠŠõ╝Āµä¤ÕÖ©Õł░Ķć¬ĶĮ”ńÜäÕÅśµŹóń¤®ķśĄŃĆé’╝ł4x4 ÕłŚĶĪ©’╝ē
+ - info\['lidar_points'\]\['ego2global'\]’╝ÜĶć¬ĶĮ”Õł░Õģ©Õ▒ĆÕØɵĀćńÜäÕÅśµŹóń¤®ķśĄŃĆé’╝ł4x4 ÕłŚĶĪ©’╝ē
+ - info\['lidar_sweeps'\]’╝ܵś»õĖĆõĖ¬ÕłŚĶĪ©’╝īÕīģÕɽõ║åµē½µÅÅõ┐Īµü»’╝łµ▓Īµ£ēµĀćµ│©ńÜäõĖŁķŚ┤ÕĖ¦’╝ēŃĆé
+ - info\['lidar_sweeps'\]\[i\]\['lidar_points'\]\['data_path'\]’╝Üń¼¼ i µ¼Īµē½µÅÅńÜäµ┐ĆÕģēķøĘĶŠŠµĢ░µŹ«ńÜäµ¢ćõ╗ČĶĘ»ÕŠäŃĆé
+ - info\['lidar_sweeps'\]\[i\]\['lidar_points'\]\[lidar2ego''\]’╝ÜÕĮōÕēŹµ┐ĆÕģēķøĘĶŠŠõ╝Āµä¤ÕÖ©Õł░Ķć¬ĶĮ”Õ£©ń¼¼ i µ¼Īµē½µÅÅńÜäÕÅśµŹóń¤®ķśĄŃĆé’╝ł4x4 ÕłŚĶĪ©’╝ē
+ - info\['lidar_sweeps'\]\[i\]\['lidar_points'\]\['ego2global'\]’╝ÜĶć¬ĶĮ”Õ£©ń¼¼ i µ¼Īµē½µÅÅÕł░Õģ©Õ▒ĆÕØɵĀćńÜäÕÅśµŹóń¤®ķśĄŃĆé’╝ł4x4 ÕłŚĶĪ©’╝ē
+ - info\['lidar_sweeps'\]\[i\]\['lidar2sensor'\]’╝Üõ╗ÄÕĮōÕēŹÕĖ¦õĖ╗µ┐ĆÕģēķøĘĶŠŠÕł░ń¼¼ i ÕĖ¦µē½µÅŵ┐ĆÕģēķøĘĶŠŠńÜäÕÅśµŹóń¤®ķśĄŃĆé’╝ł4x4 ÕłŚĶĪ©’╝ē
+ - info\['lidar_sweeps'\]\[i\]\['timestamp'\]’╝ܵē½µÅŵĢ░µŹ«ńÜ䵌ČķŚ┤µł│ŃĆé
+ - info\['lidar_sweeps'\]\[i\]\['sample_data_token'\]’╝ܵē½µÅŵĀʵ£¼µĢ░µŹ«µĀćĶ«░ŃĆé
+ - info\['images'\]’╝ܵś»õĖĆõĖ¬ÕŁŚÕģĖ’╝īÕīģÕɽõĖĵ»ÅõĖ¬ńøĖµ£║Õ»╣Õ║öńÜäÕģŁõĖ¬ķö«ÕĆ╝’╝Ü`'CAM_FRONT'`, `'CAM_FRONT_RIGHT'`, `'CAM_FRONT_LEFT'`, `'CAM_BACK'`, `'CAM_BACK_LEFT'`, `'CAM_BACK_RIGHT'`ŃĆéµ»ÅõĖ¬ÕŁŚÕģĖÕīģÕɽõ║åÕ»╣Õ║öńøĖµ£║ńÜäµēƵ£ēµĢ░µŹ«õ┐Īµü»ŃĆé
+ - info\['images'\]\['CAM_XXX'\]\['img_path'\]’╝ÜÕøŠÕāÅńÜäµ¢ćõ╗ČÕÉŹŃĆé
+ - info\['images'\]\['CAM_XXX'\]\['cam2img'\]’╝ÜÕĮō 3D ńé╣µŖĢÕĮ▒Õł░ÕøŠÕāÅÕ╣│ķØóµŚČķ£ĆĶ”üńÜäÕåģÕÅéõ┐Īµü»ńøĖÕģ│ńÜäÕÅśµŹóń¤®ķśĄŃĆé’╝ł3x3 ÕłŚĶĪ©’╝ē
+ - info\['images'\]\['CAM_XXX'\]\['sample_data_token'\]’╝ÜÕøŠÕāŵĀʵ£¼µĢ░µŹ«µĀćĶ«░ŃĆé
+ - info\['images'\]\['CAM_XXX'\]\['timestamp'\]’╝ÜÕøŠÕāÅńÜ䵌ČķŚ┤µł│ŃĆé
+ - info\['images'\]\['CAM_XXX'\]\['cam2ego'\]’╝ÜĶ»źńøĖµ£║õ╝Āµä¤ÕÖ©Õł░Ķć¬ĶĮ”ńÜäÕÅśµŹóń¤®ķśĄŃĆé’╝ł4x4 ÕłŚĶĪ©’╝ē
+ - info\['images'\]\['CAM_XXX'\]\['lidar2cam'\]’╝ܵ┐ĆÕģēķøĘĶŠŠõ╝Āµä¤ÕÖ©Õł░Ķ»źńøĖµ£║ńÜäÕÅśµŹóń¤®ķśĄŃĆé’╝ł4x4 ÕłŚĶĪ©’╝ē
+ - info\['instances'\]’╝ܵś»õĖĆõĖ¬ÕŁŚÕģĖń╗䵳ÉńÜäÕłŚĶĪ©ŃĆéµ»ÅõĖ¬ÕŁŚÕģĖÕīģÕÉ½ÕŹĢõĖ¬Õ«×õŠŗńÜäµēƵ£ēµĀćµ│©õ┐Īµü»ŃĆéÕ»╣õ║ÄÕģČõĖŁńÜäń¼¼ i õĖ¬Õ«×õŠŗ’╝īµłæõ╗¼µ£ē’╝Ü
+ - info\['instances'\]\[i\]\['bbox_3d'\]’╝ÜķĢ┐Õ║”õĖ║ 7 ńÜäÕłŚĶĪ©’╝īõ╗ź (x, y, z, l, w, h, yaw) ńÜäķĪ║Õ║ÅĶĪ©ńż║Õ«×õŠŗÕ£©µ┐ĆÕģēķøĘĶŠŠÕØɵĀćń│╗õĖŗńÜä 3D ĶŠ╣ńĢīµĪåŃĆé
+ - info\['instances'\]\[i\]\['bbox_label_3d'\]’╝ܵĢ┤µĢ░õ╗Ä 0 Õ╝ĆÕ¦ŗĶĪ©ńż║Õ«×õŠŗńÜäµĀćńŁŠ’╝īÕģČõĖŁ -1 õ╗ŻĶĪ©Õ┐ĮńĢźĶ»źń▒╗Õł½ŃĆé
+ - info\['instances'\]\[i\]\['bbox_3d_isvalid'\]’╝ܵ»ÅõĖ¬ÕīģÕø┤µĪåµś»ÕÉ”µ£ēµĢłŃĆéõĖĆĶł¼µāģÕåĄõĖŗ’╝īµłæõ╗¼ÕŬÕ░åÕīģÕɽĶć│Õ░æõĖĆõĖ¬µ┐ĆÕģēķøĘĶŠŠµł¢ķøĘĶŠŠńé╣ńÜä 3D µĪåõĮ£õĖ║µ£ēµĢłµĪåŃĆé
+
+µÄźõĖŗµØźÕ░åĶ»”ń╗åõ╗ŗń╗Ź Lyft µĢ░µŹ«ķøåÕÆī nuScenes µĢ░µŹ«ķøåõ╣ŗķŚ┤ńÜäµĢ░µŹ«ķøåõ┐Īµü»µ¢ćõ╗ČõĖŁńÜäõĖŹÕÉīńé╣’╝Ü
+
+- `lyft_database/xxxxx.bin` µ¢ćõ╗ČõĖŹÕŁśÕ£©’╝Üńö▒õ║Äń£¤Õ«×µĀćµ│©µĪåńÜäķććµĀĘÕ»╣Õ«×ķ¬īńÜäÕĮ▒ÕōŹÕÅ»õ╗źÕ┐ĮńĢźõĖŹĶ«Ī’╝īÕ£© Lyft µĢ░µŹ«ķøåõĖŁõĖŹõ╝ܵÅÉÕÅ¢Ķ»źńø«ÕĮĢÕÆīńøĖÕģ│ńÜä `.bin` µ¢ćõ╗ČŃĆé
+
+- `lyft_infos_train.pkl`
+
+ - info\['instances'\]\[i\]\['velocity'\] õĖŹÕŁśÕ£©’╝ÜLyft µĢ░µŹ«ķøåõĖŁõĖŹÕŁśÕ£©ķƤÕ║”Ķ»äõ╝░õ┐Īµü»ŃĆé
+ - info\['instances'\]\[i\]\['num_lidar_pts'\] ÕÅŖ info\['instances'\]\[i\]\['num_radar_pts'\] õĖŹÕŁśÕ£©ŃĆé
+
+Ķ┐Öķćīõ╗ģõ╗ŗń╗ŹÕŁśÕé©Õ£©Ķ«Łń╗āµĢ░µŹ«µ¢ćõ╗ČńÜäµĢ░µŹ«Ķ«░ÕĮĢõ┐Īµü»ŃĆéĶ┐ÖÕÉīµĀĘķĆéńö©õ║Äķ¬īĶ»üķøåÕÆīµĄŗĶ»Ģķøå’╝łµ▓Īµ£ēÕ«×õŠŗ’╝ēŃĆé
+
+µø┤ÕżÜÕģ│õ║Ä `lyft_infos_xxx.pkl` ńÜäń╗ōµ×äõ┐Īµü»Ķ»ĘÕÅéĶĆā [lyft_converter.py](https://github.com/open-mmlab/mmdetection3d/blob/dev-1.x/tools/dataset_converters/lyft_converter.py)ŃĆé
+
+## Ķ«Łń╗āµĄüń©ŗ
+
+### Õ¤║õ║Ä LiDAR ńÜäµ¢╣µ│Ģ
+
+Lyft õĖŖÕ¤║õ║Ä LiDAR ńÜä 3D µŻĆµĄŗ’╝łÕīģµŗ¼ÕżÜµ©ĪµĆüµ¢╣µ│Ģ’╝ēńÜäĶ«Łń╗āµĄüń©ŗõĖÄ nuScenes ÕćĀõ╣ÄńøĖÕÉī’╝īÕ”éõĖŗµēĆńż║’╝Ü
+
+```python
+train_pipeline = [
+ dict(
+ type='LoadPointsFromFile',
+ coord_type='LIDAR',
+ load_dim=5,
+ use_dim=5),
+ dict(
+ type='LoadPointsFromMultiSweeps',
+ sweeps_num=10),
+ dict(type='LoadAnnotations3D', with_bbox_3d=True, with_label_3d=True),
+ dict(
+ type='GlobalRotScaleTrans',
+ rot_range=[-0.3925, 0.3925],
+ scale_ratio_range=[0.95, 1.05],
+ translation_std=[0, 0, 0]),
+ dict(type='RandomFlip3D', flip_ratio_bev_horizontal=0.5),
+ dict(type='PointsRangeFilter', point_cloud_range=point_cloud_range),
+ dict(type='ObjectRangeFilter', point_cloud_range=point_cloud_range),
+ dict(type='PointShuffle'),
+ dict(
+ type='Pack3DDetInputs',
+ keys=['points', 'gt_bboxes_3d', 'gt_labels_3d'])
+]
+```
+
+õĖÄ nuScenes ńøĖõ╝╝’╝īÕ£© Lyft õĖŖĶ┐øĶĪīĶ«Łń╗āńÜ䵩ĪÕ×ŗõ╣¤ķ£ĆĶ”ü `LoadPointsFromMultiSweeps` µŁźķ¬żµØźõ╗ÄĶ┐×ń╗ŁÕĖ¦õĖŁÕŖĀĶĮĮńé╣õ║æµĢ░µŹ«ŃĆéÕÅ”Õż¢’╝īĶĆāĶÖæÕł░ Lyft õĖŁµēƵöČķøåńÜäµ┐ĆÕģēķøĘĶŠŠńé╣ńÜäÕ╝║Õ║”µś»µŚĀµĢłńÜä’╝īÕøĀµŁżÕ░å `LoadPointsFromMultiSweeps` õĖŁńÜä `use_dim` ķ╗śĶ«żÕĆ╝Ķ«ŠńĮ«õĖ║ `[0, 1, 2, 4]`’╝īÕģČõĖŁÕēŹõĖēõĖ¬ń╗┤Õ║”ĶĪ©ńż║ńé╣ńÜäÕØɵĀć’╝īµ£ĆÕÉÄõĖĆõĖ¬ń╗┤Õ║”ĶĪ©ńż║µŚČķŚ┤µł│ńÜäÕĘ«Õ╝éŃĆé
+
+## Ķ»äõ╝░
+
+õĮ┐ńö© 8 õĖ¬ GPU õ╗źÕÅŖ Lyft µīćµĀćĶ»äõ╝░ńÜä PointPillars ńÜäńż║õŠŗÕ”éõĖŗ’╝Ü
+
+```shell
+bash ./tools/dist_test.sh configs/pointpillars/pointpillars_hv_fpn_sbn-all_8xb2-2x_lyft-3d.py checkpoints/hv_pointpillars_fpn_sbn-all_2x8_2x_lyft-3d_20210517_202818-fc6904c3.pth 8
+```
+
+## Õ║”ķćŵīćµĀć
+
+Lyft µÅÉÕć║õ║åõĖĆõĖ¬µø┤ÕŖĀõĖźµĀ╝ńÜäńö©õ╗źĶ»äõ╝░µēĆķó䵥ŗńÜä 3D µŻĆµĄŗµĪåńÜäÕ║”ķćŵīćµĀćŃĆéÕłżµ¢ŁõĖĆõĖ¬ķó䵥ŗµĪåµś»ÕÉ”µś»µŁŻń▒╗ńÜäÕ¤║µ£¼Ķ»äÕłżµĀćÕćåÕÆī KITTI õĖƵĀĘ’╝īÕ”éÕ¤║õ║Ä 3D õ║żÕ╣ȵ»öĶ┐øĶĪīĶ»äõ╝░’╝īńäČĶĆī’╝īLyft ķććńö©õĖÄ COCO ńøĖõ╝╝ńÜäµ¢╣Õ╝ÅµØźĶ«Īń«ŚÕ╣│ÕØćń▓ŠÕ║” -- Ķ«Īń«Ś 3D õ║żÕ╣ȵ»öÕ£© 0.5-0.95 õ╣ŗķŚ┤ńÜäõĖŹÕÉīķśłÕĆ╝õĖŗńÜäÕ╣│ÕØćń▓ŠÕ║”ŃĆéÕ«×ķÖģõĖŖ’╝īķćŹÕÅĀķā©ÕłåÕż¦õ║Ä 0.7 ńÜä 3D õ║żÕ╣ȵ»öµś»õĖĆķĪ╣Õ»╣õ║Ä 3D µŻĆµĄŗµ¢╣µ│Ģµ»öĶŠāõĖźµĀ╝ńÜäµĀćÕćå’╝īÕøĀµŁżµĢ┤õĮōńÜäµĆ¦ĶāĮõ╝╝õ╣Äõ╝ÜÕüÅõĮÄŃĆéńøĖµ»öõ║ÄÕģČõ╗¢µĢ░µŹ«ķøå’╝īLyft õĖŖõĖŹÕÉīń▒╗Õł½ńÜäµĀćµ│©õĖŹÕ╣│ĶĪĪµś»Õ»╝Ķć┤µ£Ćń╗łń╗ōµ×£ÕüÅõĮÄńÜäÕÅ”õĖĆõĖ¬ķćŹĶ”üÕĤÕøĀŃĆéµø┤ÕżÜÕģ│õ║ÄÕ║”ķćŵīćµĀćńÜäÕ«Üõ╣ēĶ»ĘÕÅéĶĆā[Õ«śµ¢╣ńĮæÕØĆ](https://www.kaggle.com/c/3d-object-detection-for-autonomous-vehicles/overview/evaluation)ŃĆé
+
+Ķ┐ÖķćīÕ░åķććńö©Õ«śµ¢╣µ¢╣µ│ĢÕ»╣ Lyft Ķ┐øĶĪīĶ»äõ╝░’╝īõĖŗķØóÕ▒Ģńż║õ║åõĖĆõĖ¬Ķ»äõ╝░ń╗ōµ×£ńÜäõŠŗÕŁÉ’╝Ü
+
+```
++mAPs@0.5:0.95------+--------------+
+| class | mAP@0.5:0.95 |
++-------------------+--------------+
+| animal | 0.0 |
+| bicycle | 0.099 |
+| bus | 0.177 |
+| car | 0.422 |
+| emergency_vehicle | 0.0 |
+| motorcycle | 0.049 |
+| other_vehicle | 0.359 |
+| pedestrian | 0.066 |
+| truck | 0.176 |
+| Overall | 0.15 |
++-------------------+--------------+
+```
+
+## µĄŗĶ»ĢÕÆīµÅÉõ║ż
+
+õĮ┐ńö© 8 õĖ¬ GPU Õ£© Lyft õĖŖµĄŗĶ»Ģ PointPillars Õ╣Čńö¤µłÉÕ»╣µÄÆĶĪīµ”£ńÜäµÅÉõ║żńÜäńż║õŠŗÕ”éõĖŗ’╝Ü
+
+```shell
+./tools/dist_test.sh configs/pointpillars/pointpillars_hv_fpn_sbn-all_8xb2-2x_lyft-3d.py work_dirs/pp-lyft/latest.pth 8 --cfg-options test_evaluator.jsonfile_prefix=work_dirs/pp-lyft/results_challenge test_evaluator.csv_savepath=results/pp-lyft/results_challenge.csv
+```
+
+Õ£©ńö¤µłÉ `work_dirs/pp-lyft/results_challenge.csv`’╝īµé©ÕÅ»õ╗źÕ░åńö¤µłÉńÜäµ¢ćõ╗ȵÅÉõ║żÕł░ Kaggle Ķ»äõ╝░µ£ŹÕŖĪÕÖ©’╝īĶ»ĘÕÅéĶĆā[Õ«śµ¢╣ńĮæÕØĆ](https://www.kaggle.com/c/3d-object-detection-for-autonomous-vehicles)ĶÄĘÕÅ¢µø┤ÕżÜń╗åĶŖéŃĆé
+
+ÕÉīµŚČĶ┐śÕÅ»õ╗źõĮ┐ńö©ÕÅ»Ķ¦åÕī¢ÕĘźÕģĘÕ░åķó䵥ŗń╗ōµ×£Ķ┐øĶĪīÕÅ»Ķ¦åÕī¢’╝īµø┤ÕżÜń╗åĶŖéĶ»ĘÕÅéĶĆā[ÕÅ»Ķ¦åÕī¢µ¢ćµĪŻ](https://mmdetection3d.readthedocs.io/zh_CN/latest/useful_tools.html#visualization)ŃĆé
diff --git a/internlm_langchain/knowledge_base/MMDetection3D/content/model_deployment.md b/internlm_langchain/knowledge_base/MMDetection3D/content/model_deployment.md
new file mode 100644
index 00000000..f66172c1
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection3D/content/model_deployment.md
@@ -0,0 +1,4 @@
+# µ©ĪÕ×ŗķā©ńĮ▓’╝łÕŠģµø┤µ¢░’╝ē
+
+MMDet3D 1.1 Õ«īÕģ©Õ¤║õ║Ä [MMDeploy](https://mmdeploy.readthedocs.io/) õŠåķā©ńĮ▓µ©ĪÕ×ŗŃĆé
+µłæõ╗¼Õ░åÕ£©õĖŗõĖĆõĖ¬ńēłµ£¼Õ«īÕ¢äĶ┐ÖõĖ¬µ¢ćµĪŻŃĆé
diff --git a/internlm_langchain/knowledge_base/MMDetection3D/content/model_zoo.md b/internlm_langchain/knowledge_base/MMDetection3D/content/model_zoo.md
new file mode 100644
index 00000000..ec08bb25
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection3D/content/model_zoo.md
@@ -0,0 +1,141 @@
+# µ©ĪÕ×ŗÕ║ō
+
+## ķĆÜńö©Ķ«ŠńĮ«
+
+- õĮ┐ńö©ÕłåÕĖāÕ╝ÅĶ«Łń╗ā’╝ø
+- õĖ║õ║åÕÆīÕģČõ╗¢õ╗ŻńĀüÕ║ōÕüÜÕģ¼Õ╣│Õ»╣µ»ö’╝īµ£¼µ¢ćÕ▒Ģńż║ńÜ䵜»õĮ┐ńö© `torch.cuda.max_memory_allocated()` Õ£© 8 õĖ¬ GPUs õĖŖÕŠŚÕł░ńÜäµ£ĆÕż¦ GPU µśŠÕŁśÕŹĀńö©ÕĆ╝’╝īķ£ĆĶ”üµ│©µäÅńÜ䵜»’╝īĶ┐Öõ║øµśŠÕŁśÕŹĀńö©ÕĆ╝ķĆÜÕĖĖÕ░Åõ║Ä `nvidia-smi` µśŠńż║Õć║µØźńÜ䵜ŠÕŁśÕŹĀńö©ÕĆ╝’╝ø
+- Õ£©µ©ĪÕ×ŗÕ║ōõĖŁµēĆÕ▒Ģńż║ńÜäµÄ©ńÉåµŚČķŚ┤µś»Õīģµŗ¼ńĮæń╗£ÕēŹÕÉæõ╝ĀµÆŁÕÆīÕÉÄÕżäńÉåµēĆķ£ĆńÜäµĆ╗µŚČķŚ┤’╝īõĖŹÕīģµŗ¼µĢ░µŹ«ÕŖĀĶĮĮµēĆķ£ĆńÜ䵌ČķŚ┤’╝īµ©ĪÕ×ŗÕ║ōõĖŁµēĆÕ▒Ģńż║ńÜäń╗ōµ×£ÕØćńö▒ [benchmark.py](https://github.com/open-mmlab/mmdetection/blob/master/tools/analysis_tools/benchmark.py) Ķäܵ£¼µ¢ćõ╗ČÕ£© 2000 Õ╝ĀÕøŠÕāÅõĖŖµēĆĶ«Īń«ŚńÜäÕ╣│ÕØ浌ČķŚ┤ŃĆé
+
+## Õ¤║Õćåń╗ōµ×£
+
+### SECOND
+
+Ķ»ĘÕÅéĶĆā [SECOND](https://github.com/open-mmlab/mmdetection3d/blob/main/configs/second) ĶÄĘÕÅ¢µø┤ÕżÜńÜäń╗åĶŖé’╝īµłæõ╗¼Õ£© KITTI ÕÆī Waymo µĢ░µŹ«ķøåõĖŖķāĮń╗ÖÕć║õ║åńøĖÕ║öńÜäÕ¤║Õćåń╗ōµ×£ŃĆé
+
+### PointPillars
+
+Ķ»ĘÕÅéĶĆā [PointPillars](https://github.com/open-mmlab/mmdetection3d/blob/main/configs/pointpillars) ĶÄĘÕÅ¢µø┤ÕżÜń╗åĶŖé’╝īµłæõ╗¼Õ£© KITTI ŃĆünuScenes ŃĆüLyft ŃĆüWaymo µĢ░µŹ«ķøåõĖŖń╗ÖÕć║õ║åńøĖÕ║öńÜäÕ¤║Õćåń╗ōµ×£ŃĆé
+
+### Part-A2
+
+Ķ»ĘÕÅéĶĆā [Part-A2](https://github.com/open-mmlab/mmdetection3d/blob/main/configs/parta2) ĶÄĘÕÅ¢µø┤ÕżÜń╗åĶŖéŃĆé
+
+### VoteNet
+
+Ķ»ĘÕÅéĶĆā [VoteNet](https://github.com/open-mmlab/mmdetection3d/blob/main/configs/votenet) ĶÄĘÕÅ¢µø┤ÕżÜń╗åĶŖé’╝īµłæõ╗¼Õ£© ScanNet ÕÆī SUNRGBD µĢ░µŹ«ķøåõĖŖń╗ÖÕć║õ║åńøĖÕ║öńÜäÕ¤║Õćåń╗ōµ×£ŃĆé
+
+### Dynamic Voxelization
+
+Ķ»ĘÕÅéĶĆā [Dynamic Voxelization](https://github.com/open-mmlab/mmdetection3d/blob/main/configs/dynamic_voxelization) ĶÄĘÕÅ¢µø┤ÕżÜń╗åĶŖéŃĆé
+
+### MVXNet
+
+Ķ»ĘÕÅéĶĆā [MVXNet](https://github.com/open-mmlab/mmdetection3d/blob/main/configs/mvxnet) ĶÄĘÕÅ¢µø┤ÕżÜń╗åĶŖéŃĆé
+
+### RegNetX
+
+Ķ»ĘÕÅéĶĆā [RegNet](https://github.com/open-mmlab/mmdetection3d/blob/main/configs/regnet) ĶÄĘÕÅ¢µø┤ÕżÜń╗åĶŖé’╝īµłæõ╗¼Õ░å pointpillars ńÜäõĖ╗Õ╣▓ńĮæń╗£µø┐µŹóµłÉ RegNetX’╝īÕ╣ČÕ£© nuScenes ÕÆī Lyft µĢ░µŹ«ķøåõĖŖń╗ÖÕć║õ║åńøĖÕ║öńÜäÕ¤║Õćåń╗ōµ×£ŃĆé
+
+### nuImages
+
+µłæõ╗¼Õ£© [nuImages µĢ░µŹ«ķøå](https://www.nuscenes.org/nuimages) õĖŖõ╣¤µÅÉõŠøÕ¤║Õć嵩ĪÕ×ŗ’╝īĶ»ĘÕÅéĶĆā [nuImages](https://github.com/open-mmlab/mmdetection3d/blob/main/configs/nuimages) ĶÄĘÕÅ¢µø┤ÕżÜń╗åĶŖé’╝īµłæõ╗¼Õ£©Ķ»źµĢ░µŹ«ķøåõĖŖµÅÉõŠø Mask R-CNN ’╝ī Cascade Mask R-CNN ÕÆī HTC ńÜäń╗ōµ×£ŃĆé
+
+### H3DNet
+
+Ķ»ĘÕÅéĶĆā [H3DNet](https://github.com/open-mmlab/mmdetection3d/blob/main/configs/h3dnet) ĶÄĘÕÅ¢µø┤ÕżÜń╗åĶŖéŃĆé
+
+### 3DSSD
+
+Ķ»ĘÕÅéĶĆā [3DSSD](https://github.com/open-mmlab/mmdetection3d/blob/main/configs/3dssd) ĶÄĘÕÅ¢µø┤ÕżÜń╗åĶŖéŃĆé
+
+### CenterPoint
+
+Ķ»ĘÕÅéĶĆā [CenterPoint](https://github.com/open-mmlab/mmdetection3d/blob/main/configs/centerpoint) ĶÄĘÕÅ¢µø┤ÕżÜń╗åĶŖéŃĆé
+
+### SSN
+
+Ķ»ĘÕÅéĶĆā [SSN](https://github.com/open-mmlab/mmdetection3d/blob/main/configs/ssn) ĶÄĘÕÅ¢µø┤ÕżÜń╗åĶŖé’╝īµłæõ╗¼Õ░å pointpillars õĖŁńÜ䵯ƵĄŗÕż┤µø┐µŹóµłÉ SSN µ©ĪÕ×ŗõĖŁµēĆõĮ┐ńö©ńÜä ŌĆśshape-aware grouping headsŌĆÖ’╝īÕ╣ČÕ£© nuScenes ÕÆī Lyft µĢ░µŹ«ķøåõĖŖń╗ÖÕć║õ║åńøĖÕ║öńÜäÕ¤║Õćåń╗ōµ×£ŃĆé
+
+### ImVoteNet
+
+Ķ»ĘÕÅéĶĆā [ImVoteNet](https://github.com/open-mmlab/mmdetection3d/blob/main/configs/imvotenet) ĶÄĘÕÅ¢µø┤ÕżÜń╗åĶŖé’╝īµłæõ╗¼Õ£© SUNRGBD µĢ░µŹ«ķøåõĖŖń╗ÖÕć║õ║åńøĖÕ║öńÜäń╗ōµ×£ŃĆé
+
+### FCOS3D
+
+Ķ»ĘÕÅéĶĆā [FCOS3D](https://github.com/open-mmlab/mmdetection3d/blob/main/configs/fcos3d) ĶÄĘÕÅ¢µø┤ÕżÜń╗åĶŖé’╝īµłæõ╗¼Õ£© nuScenes µĢ░µŹ«ķøåõĖŖń╗ÖÕć║õ║åńøĖÕ║öńÜäń╗ōµ×£ŃĆé
+
+### PointNet++
+
+Ķ»ĘÕÅéĶĆā [PointNet++](https://github.com/open-mmlab/mmdetection3d/blob/main/configs/pointnet2) ĶÄĘÕÅ¢µø┤ÕżÜń╗åĶŖé’╝īµłæõ╗¼Õ£© ScanNet ÕÆī S3DIS µĢ░µŹ«ķøåõĖŖń╗ÖÕć║õ║åńøĖÕ║öńÜäń╗ōµ×£ŃĆé
+
+### Group-Free-3D
+
+Ķ»ĘÕÅéĶĆā [Group-Free-3D](https://github.com/open-mmlab/mmdetection3d/blob/main/configs/groupfree3d) ĶÄĘÕÅ¢µø┤ÕżÜń╗åĶŖé’╝īµłæõ╗¼Õ£© ScanNet µĢ░µŹ«ķøåõĖŖń╗ÖÕć║õ║åńøĖÕ║öńÜäń╗ōµ×£ŃĆé
+
+### ImVoxelNet
+
+Ķ»ĘÕÅéĶĆā [ImVoxelNet](https://github.com/open-mmlab/mmdetection3d/blob/main/configs/imvoxelnet) ĶÄĘÕÅ¢µø┤ÕżÜń╗åĶŖé’╝īµłæõ╗¼Õ£© KITTI µĢ░µŹ«ķøåõĖŖń╗ÖÕć║õ║åńøĖÕ║öńÜäń╗ōµ×£ŃĆé
+
+### PAConv
+
+Ķ»ĘÕÅéĶĆā [PAConv](https://github.com/open-mmlab/mmdetection3d/blob/main/configs/paconv) ĶÄĘÕÅ¢µø┤ÕżÜń╗åĶŖé’╝īµłæõ╗¼Õ£© S3DIS µĢ░µŹ«ķøåõĖŖń╗ÖÕć║õ║åńøĖÕ║öńÜäń╗ōµ×£ŃĆé
+
+### DGCNN
+
+Ķ»ĘÕÅéĶĆā [DGCNN](https://github.com/open-mmlab/mmdetection3d/blob/main/configs/dgcnn) ĶÄĘÕÅ¢µø┤ÕżÜń╗åĶŖé’╝īµłæõ╗¼Õ£© S3DIS µĢ░µŹ«ķøåõĖŖń╗ÖÕć║õ║åńøĖÕ║öńÜäń╗ōµ×£ŃĆé
+
+### SMOKE
+
+Ķ»ĘÕÅéĶĆā [SMOKE](https://github.com/open-mmlab/mmdetection3d/blob/main/configs/smoke) ĶÄĘÕÅ¢µø┤ÕżÜń╗åĶŖé’╝īµłæõ╗¼Õ£© KITTI µĢ░µŹ«ķøåõĖŖń╗ÖÕć║õ║åńøĖÕ║öńÜäń╗ōµ×£ŃĆé
+
+### PGD
+
+Ķ»ĘÕÅéĶĆā [PGD](https://github.com/open-mmlab/mmdetection3d/blob/main/configs/pgd) ĶÄĘÕÅ¢µø┤ÕżÜń╗åĶŖé’╝īµłæõ╗¼Õ£© KITTI ÕÆī nuScenes µĢ░µŹ«ķøåõĖŖń╗ÖÕć║õ║åńøĖÕ║öńÜäń╗ōµ×£ŃĆé
+
+### PointRCNN
+
+Ķ»ĘÕÅéĶĆā [PointRCNN](https://github.com/open-mmlab/mmdetection3d/blob/main/configs/point_rcnn) ĶÄĘÕÅ¢µø┤ÕżÜń╗åĶŖé’╝īµłæõ╗¼Õ£© KITTI µĢ░µŹ«ķøåõĖŖń╗ÖÕć║õ║åńøĖÕ║öńÜäń╗ōµ×£ŃĆé
+
+### MonoFlex
+
+Ķ»ĘÕÅéĶĆā [MonoFlex](https://github.com/open-mmlab/mmdetection3d/blob/main/configs/monoflex) ĶÄĘÕÅ¢µø┤ÕżÜń╗åĶŖé’╝īµłæõ╗¼Õ£© KITTI µĢ░µŹ«ķøåõĖŖń╗ÖÕć║õ║åńøĖÕ║öńÜäń╗ōµ×£ŃĆé
+
+### SA-SSD
+
+Ķ»ĘÕÅéĶĆā [SA-SSD](https://github.com/open-mmlab/mmdetection3d/blob/main/configs/sassd) ĶÄĘÕÅ¢µø┤ÕżÜńÜäń╗åĶŖé’╝īµłæõ╗¼Õ£© KITTI µĢ░µŹ«ķøåõĖŖń╗ÖÕć║õ║åńøĖÕ║öńÜäÕ¤║Õćåń╗ōµ×£ŃĆé
+
+### FCAF3D
+
+Ķ»ĘÕÅéĶĆā [FCAF3D](https://github.com/open-mmlab/mmdetection3d/blob/main/configs/fcaf3d) ĶÄĘÕÅ¢µø┤ÕżÜńÜäń╗åĶŖé’╝īµłæõ╗¼Õ£© ScanNet, S3DIS ÕÆī SUN RGB-D µĢ░µŹ«ķøåõĖŖń╗ÖÕć║õ║åńøĖÕ║öńÜäÕ¤║Õćåń╗ōµ×£ŃĆé
+
+### PV-RCNN
+
+Ķ»ĘÕÅéĶĆā [PV-RCNN](https://github.com/open-mmlab/mmdetection3d/blob/dev-1.x/configs/pv_rcnn) ĶÄĘÕÅ¢µø┤ÕżÜńÜäń╗åĶŖé’╝īµłæõ╗¼Õ£© KITTI µĢ░µŹ«ķøåõĖŖń╗ÖÕć║õ║åńøĖÕ║öńÜäÕ¤║Õćåń╗ōµ×£ŃĆé
+
+### BEVFusion
+
+Ķ»ĘÕÅéĶĆā [BEVFusion](https://github.com/open-mmlab/mmdetection3d/blob/dev-1.x/projects/BEVFusion) ĶÄĘÕÅ¢µø┤ÕżÜńÜäń╗åĶŖé, µłæõ╗¼Õ£© NuScenes µĢ░µŹ«ķøåõĖŖń╗ÖÕć║õ║åńøĖÕ║öńÜäÕ¤║Õćåń╗ōµ×£ŃĆé
+
+### CenterFormer
+
+Ķ»ĘÕÅéĶĆā [CenterFormer](https://github.com/open-mmlab/mmdetection3d/blob/dev-1.x/projects/CenterFormer) ĶÄĘÕÅ¢µø┤ÕżÜńÜäń╗åĶŖé, µłæõ╗¼Õ£© Waymo µĢ░µŹ«ķøåõĖŖń╗ÖÕć║õ║åńøĖÕ║öńÜäÕ¤║Õćåń╗ōµ×£ŃĆé
+
+### TR3D
+
+Ķ»ĘÕÅéĶĆā [TR3D](https://github.com/open-mmlab/mmdetection3d/blob/dev-1.x/projects/TR3D) ĶÄĘÕÅ¢µø┤ÕżÜńÜäń╗åĶŖé, µłæõ╗¼Õ£© ScanNet, SUN RGB-D ÕÆī S3DIS µĢ░µŹ«ķøåõĖŖń╗ÖÕć║õ║åńøĖÕ║öńÜäÕ¤║Õćåń╗ōµ×£ŃĆé
+
+### DETR3D
+
+Ķ»ĘÕÅéĶĆā [DETR3D](https://github.com/open-mmlab/mmdetection3d/blob/dev-1.x/projects/DETR3D) ĶÄĘÕÅ¢µø┤ÕżÜńÜäń╗åĶŖé, µłæõ╗¼Õ£© NuScenes µĢ░µŹ«ķøåõĖŖń╗ÖÕć║õ║åńøĖÕ║öńÜäÕ¤║Õćåń╗ōµ×£ŃĆé
+
+### PETR
+
+Ķ»ĘÕÅéĶĆā [PETR](https://github.com/open-mmlab/mmdetection3d/blob/dev-1.x/projects/PETR) ĶÄĘÕÅ¢µø┤ÕżÜńÜäń╗åĶŖé, µłæõ╗¼Õ£© NuScenes µĢ░µŹ«ķøåõĖŖń╗ÖÕć║õ║åńøĖÕ║öńÜäÕ¤║Õćåń╗ōµ×£ŃĆé
+
+### TPVFormer
+
+Ķ»ĘÕÅéĶĆā [TPVFormer](https://github.com/open-mmlab/mmdetection3d/blob/dev-1.x/projects/TPVFormer) ĶÄĘÕÅ¢µø┤ÕżÜńÜäń╗åĶŖé, µłæõ╗¼Õ£© NuScenes µĢ░µŹ«ķøåõĖŖń╗ÖÕć║õ║åńøĖÕ║öńÜäÕ¤║Õćåń╗ōµ×£ŃĆé
+
+### Mixed Precision (FP16) Training
+
+ń╗åĶŖéĶ»ĘÕÅéĶĆā [Mixed Precision (FP16) Training Õ£© PointPillars Ķ«Łń╗āńÜäµĀĘõŠŗ](https://github.com/open-mmlab/mmdetection3d/blob/main/configs/pointpillars/pointpillars_hv_fpn_sbn-all_8xb2-amp-2x_nus-3d.py)ŃĆé
diff --git a/internlm_langchain/knowledge_base/MMDetection3D/content/new_data_model.md b/internlm_langchain/knowledge_base/MMDetection3D/content/new_data_model.md
new file mode 100644
index 00000000..add2fe5e
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection3D/content/new_data_model.md
@@ -0,0 +1,102 @@
+# Õ£©Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåõĖŖĶ┐øĶĪīĶ«Łń╗ā
+
+µ£¼µ¢ćÕ░åõĖ╗Ķ”üõ╗ŗń╗ŹÕ”éõĮĢõĮ┐ńö©Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåµØźĶ┐øĶĪīµ©ĪÕ×ŗńÜäĶ«Łń╗āÕÆīµĄŗĶ»Ģ’╝īõ╗ź Waymo µĢ░µŹ«ķøåõĮ£õĖ║ńż║õŠŗµØźĶ»┤µśÄµĢ┤õĖ¬µĄüń©ŗŃĆé
+
+Õ¤║µ£¼µŁźķ¬żÕ”éõĖŗµēĆńż║’╝Ü
+
+1. ÕćåÕżćĶć¬Õ«Üõ╣ēµĢ░µŹ«ķøå’╝ø
+2. ÕćåÕżćķģŹńĮ«µ¢ćõ╗Č’╝ø
+3. Õ£©Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåõĖŖĶ┐øĶĪīµ©ĪÕ×ŗńÜäĶ«Łń╗āŃĆüµĄŗĶ»ĢÕÆīµÄ©ńÉåŃĆé
+
+## ÕćåÕżćĶć¬Õ«Üõ╣ēµĢ░µŹ«ķøå
+
+Õ£© MMDetection3D õĖŁµ£ēõĖēń¦Źµ¢╣Õ╝ÅµØźĶć¬Õ«Üõ╣ēõĖĆõĖ¬µ¢░ńÜäµĢ░µŹ«ķøå’╝Ü
+
+1. Õ░åµ¢░µĢ░µŹ«ķøåńÜäµĢ░µŹ«µĀ╝Õ╝Åķ揵¢░ń╗äń╗浳ÉÕĘ▓µö»µīüńÜäµĢ░µŹ«ķøåµĀ╝Õ╝Å’╝ø
+2. Õ░åµ¢░µĢ░µŹ«ķøåńÜäµĢ░µŹ«µĀ╝Õ╝Åķ揵¢░ń╗äń╗浳ÉÕĘ▓µö»µīüńÜäõĖĆń¦ŹõĖŁķŚ┤µĀ╝Õ╝Å’╝ø
+3. õ╗ÄÕż┤Õ╝ĆÕ¦ŗÕłøÕ╗║õĖĆõĖ¬µ¢░ńÜäµĢ░µŹ«ķøåŃĆé
+
+ńö▒õ║ÄÕēŹõĖżń¦Źµ¢╣Õ╝ŵ»öń¼¼õĖēń¦Źµ¢╣Õ╝ŵø┤ÕŖĀÕ«╣µśō’╝īµłæõ╗¼µø┤ÕŖĀÕ╗║Ķ««ķććńö©ÕēŹõĖżń¦Źµ¢╣Õ╝ÅµØźĶć¬Õ«Üõ╣ēµĢ░µŹ«ķøåŃĆé
+
+Õ£©µ£¼µ¢ćõĖŁ’╝īµłæõ╗¼ń╗ÖÕć║ńż║õŠŗÕ░åµĢ░µŹ«ĶĮ¼µŹóµłÉ KITTI µĢ░µŹ«ķøåńÜäµĢ░µŹ«µĀ╝Õ╝Å’╝īõĮĀÕÅ»õ╗źÕÅéĶĆāµŁżÕżäÕ░åõĮĀńÜäµĢ░µŹ«ķøåķ揵¢░ń╗äń╗ćµłÉ KITTI µĀ╝Õ╝ÅŃĆéÕģ│õ║ĵĀćÕćåµĀ╝Õ╝ÅńÜäµĢ░µŹ«ķøå’╝īõĮĀÕÅ»õ╗źÕÅéĶĆā[Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåµ¢ćµĪŻ](https://github.com/open-mmlab/mmdetection3d/blob/dev-1.x/docs/zh_cn/advanced_guides/customize_dataset.md)ŃĆé
+
+**µ│©µäÅ**’╝ÜĶĆāĶÖæÕł░ Waymo µĢ░µŹ«ķøåńÜäµĀ╝Õ╝ÅõĖÄńÄ░µ£ēńÜäÕģČõ╗¢µĢ░µŹ«ķøåńÜäµĀ╝Õ╝ÅńÜäÕĘ«Õł½ĶŠāÕż¦’╝īÕøĀµŁżµ£¼µ¢ćõ╗źĶ»źµĢ░µŹ«ķøåõĖ║õŠŗµØźĶ«▓Ķ¦ŻÕ”éõĮĢĶć¬Õ«Üõ╣ēµĢ░µŹ«ķøå’╝īõ╗ÄĶĆīµ¢╣õŠ┐ńÉåĶ¦ŻµĢ░µŹ«ķøåĶć¬Õ«Üõ╣ēńÜäĶ┐ćń©ŗŃĆéĶŗźķ£ĆĶ”üÕłøÕ╗║ńÜäµ¢░µĢ░µŹ«ķøåõĖÄńÄ░µ£ēńÜäµĢ░µŹ«ķøåńÜäń╗äń╗ćµĀ╝Õ╝ÅĶŠāõĖ║ńøĖõ╝╝’╝īÕ”é Lyft µĢ░µŹ«ķøåÕÆī nuScenes µĢ░µŹ«ķøå’╝īķććńö©Õ»╣µĢ░µŹ«ķøåńÜäõĖŁķŚ┤µĀ╝Õ╝ÅĶ┐øĶĪīĶĮ¼µŹóńÜäµ¢╣Õ╝Å’╝łń¼¼õ║īń¦Źµ¢╣Õ╝Å’╝ēńøĖµ»öõ║Äķććńö©Õ»╣µĢ░µŹ«µĀ╝Õ╝ÅĶ┐øĶĪīĶĮ¼µŹóńÜäµ¢╣Õ╝Å’╝łń¼¼õĖĆń¦Źµ¢╣Õ╝Å’╝ēõ╝ܵø┤ÕŖĀń«ĆÕŹĢµśōĶĪīŃĆé
+
+### KITTI µĢ░µŹ«ķøåµĀ╝Õ╝Å
+
+Õ║öńö©õ║Ä 3D ńø«µĀ浯ƵĄŗńÜä KITTI ÕĤզŗµĢ░µŹ«ķøåńÜäń╗äń╗ćµ¢╣Õ╝ÅķĆÜÕĖĖÕ”éõĖŗµēĆńż║’╝īÕģČõĖŁ `ImageSets` ÕīģÕɽµĢ░µŹ«ķøåÕłÆÕłåµ¢ćõ╗Č’╝īńö©õ╗źÕłÆÕłåĶ«Łń╗āķøå/ķ¬īĶ»üķøå/µĄŗĶ»Ģķøå’╝ī`calib` ÕīģÕɽջ╣õ║ĵ»ÅõĖ¬µĢ░µŹ«µĀʵ£¼ńÜäµĀćÕ«Üõ┐Īµü»’╝ī`image_2` ÕÆī `velodyne` ÕłåÕł½ÕīģÕɽÕøŠÕāŵĢ░µŹ«ÕÆīńé╣õ║æµĢ░µŹ«’╝ī`label_2` ÕīģÕɽõĖÄ 3D ńø«µĀ浯ƵĄŗńøĖÕģ│ńÜäµĀćµ│©µ¢ćõ╗ČŃĆé
+
+```
+mmdetection3d
+Ōö£ŌöĆŌöĆ mmdet3d
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+Ōö£ŌöĆŌöĆ data
+Ōöé Ōö£ŌöĆŌöĆ kitti
+Ōöé Ōöé Ōö£ŌöĆŌöĆ ImageSets
+Ōöé Ōöé Ōö£ŌöĆŌöĆ testing
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ calib
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ image_2
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ velodyne
+Ōöé Ōöé Ōö£ŌöĆŌöĆ training
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ calib
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ image_2
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ label_2
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ velodyne
+```
+
+KITTI Õ«śµ¢╣µÅÉõŠøńÜäńø«µĀ浯ƵĄŗÕ╝ĆÕÅæ[ÕĘźÕģĘÕīģ](https://s3.eu-central-1.amazonaws.com/avg-kitti/devkit_object.zip)Ķ»”ń╗åµÅÅĶ┐░õ║å KITTI µĢ░µŹ«ķøåńÜäµĀćµ│©µĀ╝Õ╝Å’╝īõŠŗÕ”é’╝īKITTI µĀćµ│©µĀ╝Õ╝ÅÕīģÕɽõ║åõ╗źõĖŗńÜäµĀćµ│©õ┐Īµü»’╝Ü
+
+```
+# ÕĆ╝ ÕÉŹń¦░ µÅÅĶ┐░
+----------------------------------------------------------------------------
+ 1 ń▒╗Õ×ŗ µÅÅĶ┐░µŻĆµĄŗńø«µĀćńÜäń▒╗Õ×ŗ’╝Ü'Car'’╝ī'Van'’╝ī'Truck'’╝ī
+ 'Pedestrian'’╝ī'Person_sitting'’╝ī'Cyclist'’╝ī'Tram'’╝ī
+ 'Misc' µł¢ 'DontCare'
+ 1 µł¬µ¢Łń©ŗÕ║”ŃĆĆ õ╗Ä 0’╝łķØ×µł¬µ¢Ł’╝ēÕł░ 1’╝łµł¬µ¢Ł’╝ēńÜ䵥«ńé╣µĢ░’╝īÕģČõĖŁµł¬µ¢ŁµīćńÜ䵜»ń”╗Õ╝ƵŻĆµĄŗÕøŠÕāÅĶŠ╣ńĢīńÜ䵯ƵĄŗńø«µĀć
+ 1 ķü«µīĪń©ŗÕ║”ŃĆĆ ńö©µØźĶĪ©ńż║ķü«µīĪńŖȵĆüńÜäÕøøń¦ŹµĢ┤µĢ░’╝ł0’╝ī1’╝ī2’╝ī3’╝ē:
+ 0 = ÕÅ»Ķ¦ü’╝ī1 = ķā©Õłåķü«µīĪ
+ 2 = Õż¦ķØóń¦»ķü«µīĪ’╝ī3 = µ£¬ń¤ź
+ 1 Ķ¦éµĄŗĶ¦Æ Ķ¦éµĄŗńø«µĀćńÜäĶ¦ÆÕ║”’╝īÕÅ¢ÕĆ╝ĶīāÕø┤õĖ║ [-pi..pi]
+ 4 µĀćµ│©µĪå µŻĆµĄŗńø«µĀćÕ£©ÕøŠÕāÅõĖŁńÜäõ║īń╗┤µĀćµ│©µĪå’╝łõ╗ź0õĖ║ÕłØÕ¦ŗõĖŗµĀć’╝ē’╝ÜÕīģµŗ¼µ»ÅõĖ¬µŻĆµĄŗńø«µĀćńÜäÕĘ”õĖŖĶ¦ÆÕÆīÕÅ│õĖŗĶ¦ÆńÜäÕØɵĀć
+ 3 ń╗┤Õ║”ŃĆĆ µŻĆµĄŗńø«µĀćńÜäõĖēń╗┤ń╗┤Õ║”’╝Üķ½śÕ║”ŃĆüÕ«ĮÕ║”ŃĆüķĢ┐Õ║”’╝łõ╗źń▒│õĖ║ÕŹĢõĮŹ’╝ē
+ 3 õĮŹńĮ«ŃĆĆ ńøĖµ£║ÕØɵĀćń│╗õĖŗńÜäõĖēń╗┤õĮŹńĮ« x’╝īy’╝īz’╝łõ╗źń▒│õĖ║ÕŹĢõĮŹ’╝ē
+ 1 y µŚŗĶĮ¼ŃĆĆ ńøĖµ£║ÕØɵĀćń│╗õĖŗµŻĆµĄŗńø«µĀćń╗ĢńØĆYĶĮ┤ńÜ䵌ŗĶĮ¼Ķ¦Æ’╝īÕÅ¢ÕĆ╝ĶīāÕø┤õĖ║ [-pi..pi]
+ 1 ÕŠŚÕłåŃĆĆ õ╗ģÕ£©Ķ«Īń«Śń╗ōµ×£µŚČõĮ┐ńö©’╝īµŻĆµĄŗõĖŁĶĪ©ńż║ńĮ«õ┐ĪÕ║”ńÜ䵥«ńé╣µĢ░’╝īńö©õ║Äńö¤µłÉ p/r µø▓ń║┐’╝īÕ£©p/r ÕøŠõĖŁ’╝īĶČŖķ½śńÜäµø▓ń║┐ĶĪ©ńż║ń╗ōµ×£ĶČŖÕźĮŃĆé
+```
+
+Õüćիܵłæõ╗¼õĮ┐ńö© Waymo µĢ░µŹ«ķøåŃĆé
+
+Õ£©õĖŗĶĮĮÕźĮµĢ░µŹ«ķøåÕÉÄ’╝īµłæõ╗¼ķ£ĆĶ”üÕ«×ńÄ░õĖĆõĖ¬ÕćĮµĢ░ńö©µØźÕ░åĶŠōÕģźµĢ░µŹ«ÕÆīµĀćµ│©µ¢ćõ╗ČĶĮ¼µŹóµłÉ KITTI ķŻÄµĀ╝ŃĆéńäČÕÉĵłæõ╗¼ÕÅ»õ╗źķĆÜĶ┐ćń╗¦µē┐ `KittiDataset` Õ«×ńÄ░ `WaymoDataset`’╝īńö©µØźÕŖĀĶĮĮµĢ░µŹ«õ╗źÕÅŖĶ«Łń╗āµ©ĪÕ×ŗ’╝īķĆÜĶ┐ćń╗¦µē┐ `KittiMetric` Õ«×ńÄ░ `WaymoMetric` µØźÕüܵ©ĪÕ×ŗńÜäĶ»äõ╝░ŃĆé
+
+ÕģĘõĮōµØźĶ»┤’╝īķ”¢ÕģłõĮ┐ńö©[µĢ░µŹ«ĶĮ¼µŹóÕÖ©](https://github.com/open-mmlab/mmdetection3d/blob/dev-1.x/tools/dataset_converters/waymo_converter.py)Õ░å Waymo µĢ░µŹ«ķøåĶĮ¼µŹóµłÉ KITTI µĢ░µŹ«ķøåńÜäµĀ╝Õ╝Å’╝īÕ╣ČÕ«Üõ╣ē [Waymo ń▒╗](https://github.com/open-mmlab/mmdetection3d/blob/dev-1.x/mmdet3d/datasets/waymo_dataset.py)Õ»╣ĶĮ¼µŹóńÜäµĢ░µŹ«Ķ┐øĶĪīÕżäńÉåŃĆ鵣żÕż¢ķ£ĆĶ”üµĘ╗ÕŖĀ waymo [Ķ»äõ╝░ń▒╗](https://github.com/open-mmlab/mmdetection3d/blob/dev-1.x/mmdet3d/evaluation/metrics/waymo_metric.py)µØźĶ»äõ╝░ń╗ōµ×£ŃĆéÕøĀõĖ║µłæõ╗¼Õ░å Waymo ÕĤզŗµĢ░µŹ«ķøåĶ┐øĶĪīķóäÕżäńÉåÕ╣Čķ揵¢░ń╗äń╗ćµłÉ KITTI µĢ░µŹ«ķøåńÜäµĀ╝Õ╝Å’╝īÕøĀµŁżÕÅ»õ╗źµ»öĶŠāÕ«╣µśōķĆÜĶ┐ćń╗¦µē┐ KittiDataset ń▒╗µØźÕ«×ńÄ░ WaymoDataset ń▒╗ŃĆéķ£ĆĶ”üµ│©µäÅńÜ䵜»’╝īńö▒õ║Ä Waymo µĢ░µŹ«ķøåµ£ēńøĖÕ║öńÜäÕ«śµ¢╣Ķ»äõ╝░µ¢╣µ│Ģ’╝īµłæõ╗¼ķ£ĆĶ”üĶ┐øõĖƵŁźÕ«×ńÄ░µ¢░ńÜä Waymo Ķ»äõ╝░µ¢╣µ│Ģ’╝īµø┤ÕżÜÕģ│õ║ÄĶ»äõ╝░µ¢╣µ│ĢÕÅéĶĆā[Ķ»äõ╝░µ¢ćµĪŻ](https://github.com/open-mmlab/mmengine/blob/main/docs/en/tutorials/metric_and_evaluator.md)ŃĆéµ£ĆÕÉÄ’╝īńö©µłĘÕÅ»õ╗źµłÉÕŖ¤Õ£░ĶĮ¼µŹóµĢ░µŹ«Õ╣ČõĮ┐ńö© `WaymoDataset` Ķ«Łń╗āõ╗źÕÅŖ `WaymoMetric` Ķ»äõ╝░µ©ĪÕ×ŗŃĆé
+
+µø┤ÕżÜÕģ│õ║Ä Waymo µĢ░µŹ«ķøåķóäÕżäńÉåńÜäõĖŁķŚ┤ń╗ōµ×£ńÜäń╗åĶŖé’╝īĶ»ĘÕÅéńģ¦Õ»╣Õ║öńÜä[Ķ»┤µśÄµ¢ćµĪŻ](https://mmdetection3d.readthedocs.io/zh_CN/latest/datasets/waymo_det.html)ŃĆé
+
+## ÕćåÕżćķģŹńĮ«µ¢ćõ╗Č
+
+ń¼¼õ║īµŁźµś»ÕćåÕżćķģŹńĮ«µ¢ćõ╗ČµØźÕĖ«ÕŖ®µĢ░µŹ«ķøåńÜäĶ»╗ÕÅ¢ÕÆīõĮ┐ńö©’╝īÕÅ”Õż¢’╝īõĖ║õ║åÕ£© 3D µŻĆµĄŗõĖŁĶÄĘÕŠŚõĖŹķöÖńÜäµĆ¦ĶāĮ’╝īĶ░āµĢ┤ĶČģÕÅéµĢ░ķĆÜÕĖĖµś»Õ┐ģĶ”üńÜäŃĆé
+
+ÕüćĶ«Šµłæõ╗¼µā│Ķ”üõĮ┐ńö© PointPillars µ©ĪÕ×ŗÕ£© Waymo µĢ░µŹ«ķøåõĖŖÕ«×ńÄ░õĖēń▒╗ńÜä 3D ńø«µĀ浯ƵĄŗ’╝ÜvehicleŃĆücyclistŃĆüpedestrian’╝īÕÅéńģ¦ KITTI µĢ░µŹ«ķøå[ķģŹńĮ«µ¢ćõ╗Č](https://github.com/open-mmlab/mmdetection3d/blob/dev-1.x/configs/_base_/datasets/kitti-3d-3class.py)ŃĆüµ©ĪÕ×ŗ[ķģŹńĮ«µ¢ćõ╗Č](https://github.com/open-mmlab/mmdetection3d/blob/dev-1.x/configs/_base_/models/pointpillars_hv_secfpn_kitti.py)ÕÆī[µĢ┤õĮōķģŹńĮ«µ¢ćõ╗Č](https://github.com/open-mmlab/mmdetection3d/blob/dev-1.x/configs/pointpillars/pointpillars_hv_secfpn_8xb6-160e_kitti-3d-3class.py)’╝īµłæõ╗¼ķ£ĆĶ”üÕćåÕżć[µĢ░µŹ«ķøåķģŹńĮ«µ¢ćõ╗Č](https://github.com/open-mmlab/mmdetection3d/blob/dev-1.x/configs/_base_/datasets/waymoD5-3d-3class.py)ŃĆü[µ©ĪÕ×ŗķģŹńĮ«µ¢ćõ╗Č](https://github.com/open-mmlab/mmdetection3d/blob/dev-1.x/configs/_base_/models/pointpillars_hv_secfpn_waymo.py)’╝īÕ╣ČÕ░åĶ┐ÖõĖżń¦Źµ¢ćõ╗ČĶ┐øĶĪīń╗ōÕÉłÕŠŚÕł░[µĢ┤õĮōķģŹńĮ«µ¢ćõ╗Č](https://github.com/open-mmlab/mmdetection3d/blob/dev-1.x/configs/pointpillars/pointpillars_hv_secfpn_sbn-all_16xb2-2x_waymoD5-3d-3class.py)ŃĆé
+
+## Ķ«Łń╗āõĖĆõĖ¬µ¢░ńÜ䵩ĪÕ×ŗ
+
+õĖ║õ║åõĮ┐ńö©õĖĆõĖ¬µ¢░ńÜäķģŹńĮ«µ¢ćõ╗ČµØźĶ«Łń╗āµ©ĪÕ×ŗ’╝īÕÅ»õ╗źķĆÜĶ┐ćõĖŗķØóńÜäÕæĮõ╗żµØźÕ«×ńÄ░’╝Ü
+
+```shell
+python tools/train.py configs/pointpillars/pointpillars_hv_secfpn_sbn-all_16xb2-2x_waymoD5-3d-3class.py
+```
+
+µø┤ÕżÜńÜäõĮ┐ńö©ń╗åĶŖé’╝īĶ»ĘÕÅéĶĆā[µĪłõŠŗ 1](https://mmdetection3d.readthedocs.io/zh_CN/latest/1_exist_data_model.html)ŃĆé
+
+## µĄŗĶ»ĢÕÆīµÄ©ńÉå
+
+õĖ║õ║åµĄŗĶ»ĢÕĘ▓ń╗ÅĶ«Łń╗āÕźĮńÜ䵩ĪÕ×ŗńÜäµĆ¦ĶāĮ’╝īÕÅ»õ╗źķĆÜĶ┐ćõĖŗķØóńÜäÕæĮõ╗żµØźÕ«×ńÄ░’╝Ü
+
+```shell
+python tools/test.py configs/pointpillars/pointpillars_hv_secfpn_sbn-all_16xb2-2x_waymoD5-3d-3class.py work_dirs/pointpillars_hv_secfpn_sbn-all_16xb2-2x_waymoD5-3d-3class/latest.pth
+```
+
+**µ│©µäÅ**’╝ÜõĖ║õ║åõĮ┐ńö© Waymo µĢ░µŹ«ķøåńÜäĶ»äõ╝░µ¢╣µ│Ģ’╝īķ£ĆĶ”üÕÅéĶĆā[Ķ»┤µśÄµ¢ćµĪŻ](https://mmdetection3d.readthedocs.io/zh_CN/latest/datasets/waymo_det.html)Õ╣ȵīēńģ¦Õ«śµ¢╣µīćÕ»╝µØźÕćåÕżćõĖÄĶ»äõ╝░ńøĖÕģ│ĶüöńÜäµ¢ćõ╗ČŃĆé
+
+µø┤ÕżÜµ£ēÕģ│µĄŗĶ»ĢÕÆīµÄ©ńÉåńÜäõĮ┐ńö©ń╗åĶŖé’╝īĶ»ĘÕÅéĶĆā[µĪłõŠŗ 1](https://mmdetection3d.readthedocs.io/zh_CN/latest/1_exist_data_model.html) ŃĆé
diff --git a/internlm_langchain/knowledge_base/MMDetection3D/content/nuscenes.md b/internlm_langchain/knowledge_base/MMDetection3D/content/nuscenes.md
new file mode 100644
index 00000000..dcac78b2
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection3D/content/nuscenes.md
@@ -0,0 +1,239 @@
+# NuScenes µĢ░µŹ«ķøå
+
+µ£¼ķĪĄµÅÉõŠøõ║åµ£ēÕģ│Õ£© MMDetection3D õĖŁõĮ┐ńö© nuScenes µĢ░µŹ«ķøåńÜäÕģĘõĮōµĢÖń©ŗŃĆé
+
+## ÕćåÕżćõ╣ŗÕēŹ
+
+µé©ÕÅ»õ╗źÕ£©[Ķ┐Öķćī](https://www.nuscenes.org/download)õĖŗĶĮĮ nuScenes 3D µŻĆµĄŗµĢ░µŹ« Full dataset (v1.0) Õ╣ČĶ¦ŻÕÄŗń╝®µēƵ£ē zip µ¢ćõ╗ČŃĆé
+
+Õ”éµ×£µé©µā│Ķ┐øĶĪī 3D Ķ»Łõ╣ēÕłåÕē▓õ╗╗ÕŖĪ’╝īķ£ĆĶ”üķóØÕż¢õĖŗĶĮĮ nuScenes-lidarseg µĢ░µŹ«µĀćµ│©’╝īÕ╣ČÕ░åĶ¦ŻÕÄŗńÜäµ¢ćõ╗ȵöŠÕģź nuScenes Õ»╣Õ║öńÜäµ¢ćõ╗ČÕż╣õĖŗŃĆé
+
+**µ│©µäÅ**’╝ÜnuScenes-lidarseg õĖŁńÜä v1.0trainval(test)/categroy.json õ╝ܵø┐µŹóÕĤÕģł Full dataset (v1.0) ÕĤÕģłńÜä v1.0trainval(test)/categroy.json’╝īõĮåµś»õĖŹõ╝ÜÕ»╣ 3D ńø«µĀ浯ƵĄŗõ╗╗ÕŖĪķĆĀµłÉÕĮ▒ÕōŹŃĆé
+
+ÕāÅÕćåÕżćµĢ░µŹ«ķøåńÜäõĖĆĶł¼µ¢╣µ│ĢõĖƵĀĘ’╝īÕ╗║Ķ««Õ░åµĢ░µŹ«ķøåµĀ╣ńø«ÕĮĢķōŠµÄźÕł░ `$MMDETECTION3D/data`ŃĆé
+
+Õ£©µłæõ╗¼ÕżäńÉåõ╣ŗÕēŹ’╝īµ¢ćõ╗ČÕż╣ń╗ōµ×äÕ║öµīēÕ”éõĖŗµ¢╣Õ╝Åń╗äń╗ćŃĆé
+
+```
+mmdetection3d
+Ōö£ŌöĆŌöĆ mmdet3d
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+Ōö£ŌöĆŌöĆ data
+Ōöé Ōö£ŌöĆŌöĆ nuscenes
+Ōöé Ōöé Ōö£ŌöĆŌöĆ maps
+Ōöé Ōöé Ōö£ŌöĆŌöĆ samples
+Ōöé Ōöé Ōö£ŌöĆŌöĆ sweeps
+Ōöé Ōöé Ōö£ŌöĆŌöĆ lidarseg (optional)
+Ōöé Ōöé Ōö£ŌöĆŌöĆ v1.0-test
+| | Ōö£ŌöĆŌöĆ v1.0-trainval
+```
+
+## µĢ░µŹ«ÕćåÕżć
+
+µłæõ╗¼ķĆÜÕĖĖķ£ĆĶ”üķĆÜĶ┐ćńē╣իܵĀĘÕ╝ÅµØźõĮ┐ńö© `.pkl` µ¢ćõ╗Čń╗äń╗ćµ£ēńö©ńÜäµĢ░µŹ«õ┐Īµü»ŃĆéĶ”üõĖ║ nuScenes ÕćåÕżćĶ┐Öõ║øµ¢ćõ╗Č’╝īĶ»ĘĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗ż’╝Ü
+
+```bash
+python tools/create_data.py nuscenes --root-path ./data/nuscenes --out-dir ./data/nuscenes --extra-tag nuscenes
+```
+
+ÕżäńÉåÕÉÄńÜäµ¢ćõ╗ČÕż╣ń╗ōµ×äÕ║öĶ»źÕ”éõĖŗŃĆé
+
+```
+mmdetection3d
+Ōö£ŌöĆŌöĆ mmdet3d
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+Ōö£ŌöĆŌöĆ data
+Ōöé Ōö£ŌöĆŌöĆ nuscenes
+Ōöé Ōöé Ōö£ŌöĆŌöĆ maps
+Ōöé Ōöé Ōö£ŌöĆŌöĆ samples
+Ōöé Ōöé Ōö£ŌöĆŌöĆ sweeps
+Ōöé Ōöé Ōö£ŌöĆŌöĆ lidarseg (optional)
+Ōöé Ōöé Ōö£ŌöĆŌöĆ v1.0-test
+| | Ōö£ŌöĆŌöĆ v1.0-trainval
+Ōöé Ōöé Ōö£ŌöĆŌöĆ nuscenes_database
+Ōöé Ōöé Ōö£ŌöĆŌöĆ nuscenes_infos_train.pkl
+Ōöé Ōöé Ōö£ŌöĆŌöĆ nuscenes_infos_val.pkl
+Ōöé Ōöé Ōö£ŌöĆŌöĆ nuscenes_infos_test.pkl
+Ōöé Ōöé Ōö£ŌöĆŌöĆ nuscenes_dbinfos_train.pkl
+```
+
+- `nuscenes_database/xxxxx.bin`’╝ÜĶ«Łń╗āµĢ░µŹ«ķøåńÜäµ»ÅõĖ¬ 3D ÕīģÕø┤µĪåõĖŁÕīģÕɽńÜäńé╣õ║æµĢ░µŹ«ŃĆé
+- `nuscenes_infos_train.pkl`’╝ÜĶ«Łń╗āµĢ░µŹ«ķøå’╝īĶ»źÕŁŚÕģĖÕīģÕɽõ║åõĖżõĖ¬ķö«ÕĆ╝’╝Ü`metainfo` ÕÆī `data_list`ŃĆé`metainfo` ÕīģÕɽµĢ░µŹ«ķøåńÜäÕ¤║µ£¼õ┐Īµü»’╝īõŠŗÕ”é `categories`, `dataset` ÕÆī `info_version`ŃĆé`data_list` µś»ńö▒ÕŁŚÕģĖń╗䵳ÉńÜäÕłŚĶĪ©’╝īµ»ÅõĖ¬ÕŁŚÕģĖ’╝łõ╗źõĖŗń«Ćń¦░ `info`’╝ēÕīģÕɽõ║åÕŹĢõĖ¬µĀʵ£¼ńÜäµēƵ£ēĶ»”ń╗åõ┐Īµü»ŃĆé
+ - info\['sample_idx'\]’╝ܵĀʵ£¼Õ£©µĢ┤õĖ¬µĢ░µŹ«ķøåńÜäń┤óÕ╝ĢŃĆé
+ - info\['token'\]’╝ܵĀʵ£¼µĢ░µŹ«µĀćĶ«░ŃĆé
+ - info\['timestamp'\]’╝ܵĀʵ£¼µĢ░µŹ«µŚČķŚ┤µł│ŃĆé
+ - info\['ego2global'\]’╝ÜĶć¬ĶĮ”Õł░Õģ©Õ▒ĆÕØɵĀćńÜäÕÅśµŹóń¤®ķśĄŃĆé’╝ł4x4 ÕłŚĶĪ©’╝ē
+ - info\['lidar_points'\]’╝ܵś»õĖĆõĖ¬ÕŁŚÕģĖ’╝īÕīģÕɽõ║åµēƵ£ēõĖĵ┐ĆÕģēķøĘĶŠŠńé╣ńøĖÕģ│ńÜäõ┐Īµü»ŃĆé
+ - info\['lidar_points'\]\['lidar_path'\]’╝ܵ┐ĆÕģēķøĘĶŠŠńé╣õ║æµĢ░µŹ«ńÜäµ¢ćõ╗ČÕÉŹŃĆé
+ - info\['lidar_points'\]\['num_pts_feats'\]’╝Üńé╣ńÜäńē╣ÕŠüń╗┤Õ║”ŃĆé
+ - info\['lidar_points'\]\['lidar2ego'\]’╝ÜĶ»źµ┐ĆÕģēķøĘĶŠŠõ╝Āµä¤ÕÖ©Õł░Ķć¬ĶĮ”ńÜäÕÅśµŹóń¤®ķśĄŃĆé’╝ł4x4 ÕłŚĶĪ©’╝ē
+ - info\['lidar_sweeps'\]’╝ܵś»õĖĆõĖ¬ÕłŚĶĪ©’╝īÕīģÕɽõ║åµē½µÅÅõ┐Īµü»’╝łµ▓Īµ£ēµĀćµ│©ńÜäõĖŁķŚ┤ÕĖ¦’╝ēŃĆé
+ - info\['lidar_sweeps'\]\[i\]\['lidar_points'\]\['data_path'\]’╝Üń¼¼ i µ¼Īµē½µÅÅńÜäµ┐ĆÕģēķøĘĶŠŠµĢ░µŹ«ńÜäµ¢ćõ╗ČĶĘ»ÕŠäŃĆé
+ - info\['lidar_sweeps'\]\[i\]\['lidar_points'\]\[lidar2ego''\]’╝ÜÕĮōÕēŹµ┐ĆÕģēķøĘĶŠŠõ╝Āµä¤ÕÖ©Õł░Ķć¬ĶĮ”ńÜäÕÅśµŹóń¤®ķśĄŃĆé’╝ł4x4 ÕłŚĶĪ©’╝ē
+ - info\['lidar_sweeps'\]\[i\]\['lidar_points'\]\['ego2global'\]’╝ÜĶć¬ĶĮ”Õł░Õģ©Õ▒ĆÕØɵĀćńÜäÕÅśµŹóń¤®ķśĄŃĆé’╝ł4x4 ÕłŚĶĪ©’╝ē
+ - info\['lidar_sweeps'\]\[i\]\['lidar2sensor'\]’╝Üõ╗ÄõĖ╗µ┐ĆÕģēķøĘĶŠŠõ╝Āµä¤ÕÖ©Õł░ÕĮōÕēŹõ╝Āµä¤ÕÖ©’╝łńö©õ║ĵöČķøåµē½µÅŵĢ░µŹ«’╝ēńÜäÕÅśµŹóń¤®ķśĄŃĆé’╝ł4x4 ÕłŚĶĪ©’╝ē
+ - info\['lidar_sweeps'\]\[i\]\['timestamp'\]’╝ܵē½µÅŵĢ░µŹ«ńÜ䵌ČķŚ┤µł│ŃĆé
+ - info\['lidar_sweeps'\]\[i\]\['sample_data_token'\]’╝ܵē½µÅŵĀʵ£¼µĢ░µŹ«µĀćĶ«░ŃĆé
+ - info\['images'\]’╝ܵś»õĖĆõĖ¬ÕŁŚÕģĖ’╝īÕīģÕɽõĖĵ»ÅõĖ¬ńøĖµ£║Õ»╣Õ║öńÜäÕģŁõĖ¬ķö«ÕĆ╝’╝Ü`'CAM_FRONT'`, `'CAM_FRONT_RIGHT'`, `'CAM_FRONT_LEFT'`, `'CAM_BACK'`, `'CAM_BACK_LEFT'`, `'CAM_BACK_RIGHT'`ŃĆéµ»ÅõĖ¬ÕŁŚÕģĖÕīģÕɽõ║åÕ»╣Õ║öńøĖµ£║ńÜäµēƵ£ēµĢ░µŹ«õ┐Īµü»ŃĆé
+ - info\['images'\]\['CAM_XXX'\]\['img_path'\]’╝ÜÕøŠÕāÅńÜäµ¢ćõ╗ČÕÉŹŃĆé
+ - info\['images'\]\['CAM_XXX'\]\['cam2img'\]’╝ÜÕĮō 3D ńé╣µŖĢÕĮ▒Õł░ÕøŠÕāÅÕ╣│ķØóµŚČķ£ĆĶ”üńÜäÕåģÕÅéõ┐Īµü»ńøĖÕģ│ńÜäÕÅśµŹóń¤®ķśĄŃĆé’╝ł3x3 ÕłŚĶĪ©’╝ē
+ - info\['images'\]\['CAM_XXX'\]\['sample_data_token'\]’╝ÜÕøŠÕāŵĀʵ£¼µĢ░µŹ«µĀćĶ«░ŃĆé
+ - info\['images'\]\['CAM_XXX'\]\['timestamp'\]’╝ÜÕøŠÕāÅńÜ䵌ČķŚ┤µł│ŃĆé
+ - info\['images'\]\['CAM_XXX'\]\['cam2ego'\]’╝ÜĶ»źńøĖµ£║õ╝Āµä¤ÕÖ©Õł░Ķć¬ĶĮ”ńÜäÕÅśµŹóń¤®ķśĄŃĆé’╝ł4x4 ÕłŚĶĪ©’╝ē
+ - info\['images'\]\['CAM_XXX'\]\['lidar2cam'\]’╝ܵ┐ĆÕģēķøĘĶŠŠõ╝Āµä¤ÕÖ©Õł░Ķ»źńøĖµ£║ńÜäÕÅśµŹóń¤®ķśĄŃĆé’╝ł4x4 ÕłŚĶĪ©’╝ē
+ - info\['instances'\]’╝ܵś»õĖĆõĖ¬ÕŁŚÕģĖń╗䵳ÉńÜäÕłŚĶĪ©ŃĆéµ»ÅõĖ¬ÕŁŚÕģĖÕīģÕÉ½ÕŹĢõĖ¬Õ«×õŠŗńÜäµēƵ£ēµĀćµ│©õ┐Īµü»ŃĆéÕ»╣õ║ÄÕģČõĖŁńÜäń¼¼ i õĖ¬Õ«×õŠŗ’╝īµłæõ╗¼µ£ē’╝Ü
+ - info\['instances'\]\[i\]\['bbox_3d'\]’╝ÜķĢ┐Õ║”õĖ║ 7 ńÜäÕłŚĶĪ©’╝īõ╗ź (x, y, z, l, w, h, yaw) ńÜäķĪ║Õ║ÅĶĪ©ńż║Õ«×õŠŗńÜä 3D ĶŠ╣ńĢīµĪåŃĆé
+ - info\['instances'\]\[i\]\['bbox_label_3d'\]’╝ܵĢ┤µĢ░ĶĪ©ńż║Õ«×õŠŗńÜäµĀćńŁŠ’╝ī-1 õ╗ŻĶĪ©Õ┐ĮńĢźŃĆé
+ - info\['instances'\]\[i\]\['velocity'\]’╝Ü3D ĶŠ╣ńĢīµĪåńÜäķƤÕ║”’╝łńö▒õ║ÄõĖŹµŁŻńĪ«’╝īµ▓Īµ£ēÕ×éńø┤µĄŗķćÅ’╝ē’╝īÕż¦Õ░ÅõĖ║ (2, ) ńÜäÕłŚĶĪ©ŃĆé
+ - info\['instances'\]\[i\]\['num_lidar_pts'\]’╝ܵ»ÅõĖ¬ 3D ĶŠ╣ńĢīµĪåÕåģÕīģÕɽńÜäµ┐ĆÕģēķøĘĶŠŠńé╣µĢ░ŃĆé
+ - info\['instances'\]\[i\]\['num_radar_pts'\]’╝ܵ»ÅõĖ¬ 3D ĶŠ╣ńĢīµĪåÕåģÕīģÕɽńÜäķøĘĶŠŠńé╣µĢ░ŃĆé
+ - info\['instances'\]\[i\]\['bbox_3d_isvalid'\]’╝ܵ»ÅõĖ¬ÕīģÕø┤µĪåµś»ÕÉ”µ£ēµĢłŃĆéõĖĆĶł¼µāģÕåĄõĖŗ’╝īµłæõ╗¼ÕŬÕ░åÕīģÕɽĶć│Õ░æõĖĆõĖ¬µ┐ĆÕģēķøĘĶŠŠµł¢ķøĘĶŠŠńé╣ńÜä 3D µĪåõĮ£õĖ║µ£ēµĢłµĪåŃĆé
+ - info\['cam_instances'\]’╝ܵś»õĖĆõĖ¬ÕŁŚÕģĖ’╝īÕīģÕɽõ╗źõĖŗķö«ÕĆ╝’╝Ü`'CAM_FRONT'`, `'CAM_FRONT_RIGHT'`, `'CAM_FRONT_LEFT'`, `'CAM_BACK'`, `'CAM_BACK_LEFT'`, `'CAM_BACK_RIGHT'`ŃĆéÕ»╣õ║ÄÕ¤║õ║ÄĶ¦åĶ¦ēńÜä 3D ńø«µĀ浯ƵĄŗõ╗╗ÕŖĪ’╝īµłæõ╗¼Õ░åµĢ┤õĖ¬Õ£║µÖ»ńÜä 3D µĀćµ│©ÕłÆÕłåĶć│Õ«āõ╗¼µēĆÕ▒×õ║ÄńÜäńøĖÕ║öńøĖµ£║õĖŁŃĆéÕ»╣õ║ÄÕģČõĖŁńÜäń¼¼ i õĖ¬Õ«×õŠŗ’╝īµłæõ╗¼µ£ē’╝Ü
+ - info\['cam_instances'\]\['CAM_XXX'\]\[i\]\['bbox_label'\]’╝ÜÕ«×õŠŗµĀćńŁŠŃĆé
+ - info\['cam_instances'\]\['CAM_XXX'\]\[i\]\['bbox_label_3d'\]’╝ÜÕ«×õŠŗµĀćńŁŠŃĆé
+ - info\['cam_instances'\]\['CAM_XXX'\]\[i\]\['bbox'\]’╝Ü2D ĶŠ╣ńĢīµĪåµĀćµ│©’╝ł3D µĪåµŖĢÕĮ▒ńÜäń¤®ÕĮóµĪå’╝ē’╝īķĪ║Õ║ÅõĖ║ \[x1, y1, x2, y2\] ńÜäÕłŚĶĪ©ŃĆé
+ - info\['cam_instances'\]\['CAM_XXX'\]\[i\]\['center_2d'\]’╝Ü3D µĪåµŖĢÕĮ▒Õł░ÕøŠÕāÅõĖŖńÜäõĖŁÕ┐āńé╣’╝īÕż¦Õ░ÅõĖ║ (2, ) ńÜäÕłŚĶĪ©ŃĆé
+ - info\['cam_instances'\]\['CAM_XXX'\]\[i\]\['depth'\]’╝Ü3D µĪåµŖĢÕĮ▒õĖŁÕ┐āńÜäµĘ▒Õ║”ŃĆé
+ - info\['cam_instances'\]\['CAM_XXX'\]\[i\]\['velocity'\]’╝Ü3D ĶŠ╣ńĢīµĪåńÜäķƤÕ║”’╝łńö▒õ║ÄõĖŹµŁŻńĪ«’╝īµ▓Īµ£ēÕ×éńø┤µĄŗķćÅ’╝ē’╝īÕż¦Õ░ÅõĖ║ (2, ) ńÜäÕłŚĶĪ©ŃĆé
+ - info\['cam_instances'\]\['CAM_XXX'\]\[i\]\['attr_label'\]’╝ÜÕ«×õŠŗńÜäÕ▒׵ƦµĀćńŁŠŃĆ鵳æõ╗¼õĖ║Õ▒×µĆ¦Õłåń▒╗ń╗┤µŖżõ║åõĖĆõĖ¬Õ▒׵ƦķøåÕÉłÕÆīµśĀÕ░äŃĆé
+ - info\['cam_instances'\]\['CAM_XXX'\]\[i\]\['bbox_3d'\]’╝ÜķĢ┐Õ║”õĖ║ 7 ńÜäÕłŚĶĪ©’╝īõ╗ź (x, y, z, l, h, w, yaw) ńÜäķĪ║Õ║ÅĶĪ©ńż║Õ«×õŠŗńÜä 3D ĶŠ╣ńĢīµĪåŃĆé
+ - info\['pts_semantic_mask_path'\]’╝ܵ┐ĆÕģēķøĘĶŠŠĶ»Łõ╣ēÕłåÕē▓µĀćµ│©ńÜäµ¢ćõ╗ČÕÉŹŃĆé
+
+µ│©µäÅ’╝Ü
+
+1. `instances` ÕÆī `cam_instances` õĖŁ `bbox_3d` ńÜäÕī║Õł½ŃĆé`bbox_3d` ķāĮĶó½ĶĮ¼µŹóÕł░ MMDet3D Õ«Üõ╣ēńÜäÕØɵĀćń│╗õĖŗ’╝ī`instances` õĖŁńÜä `bbox_3d` µś»Õ£©µ┐ĆÕģēķøĘĶŠŠÕØɵĀćń│╗õĖŗ’╝īĶĆī `cam_instances` µś»Õ£©ńøĖµ£║ÕØɵĀćń│╗õĖŗŃĆéµ│©µäÅÕ«āõ╗¼ 3D µĪåõĖŁĶĪ©ńż║ńÜäõĖŹÕÉī’╝ł'l, w, h' ÕÆī 'l, h, w'’╝ēŃĆé
+
+2. Ķ┐Öķćīµłæõ╗¼ÕŬĶ¦ŻķćŖĶ«Łń╗āõ┐Īµü»µ¢ćõ╗ČõĖŁĶ«░ÕĮĢńÜäµĢ░µŹ«ŃĆéĶ┐ÖÕÉīµĀĘķĆéńö©õ║Äķ¬īĶ»üķøåÕÆīµĄŗĶ»Ģķøå’╝łµĄŗĶ»ĢķøåńÜä `.pkl` µ¢ćõ╗ČõĖŁõĖŹÕīģÕɽ `instances` õ╗źÕÅŖ `cam_instances`’╝ēŃĆé
+
+ĶÄĘÕÅ¢ `nuscenes_infos_xxx.pkl` ńÜäµĀĖÕ┐āÕćĮµĢ░õĖ║ [\_fill_trainval_infos](https://github.com/open-mmlab/mmdetection3d/blob/dev-1.x/tools/dataset_converters/nuscenes_converter.py#L146)ŃĆéµø┤ÕżÜń╗åĶŖéĶ»ĘÕÅéĶĆā [nuscenes_converter.py](https://github.com/open-mmlab/mmdetection3d/blob/dev-1.x/tools/dataset_converters/nuscenes_converter.py)ŃĆé
+
+## Ķ«Łń╗āµĄüń©ŗ
+
+### Õ¤║õ║Ä LiDAR ńÜäµ¢╣µ│Ģ
+
+nuScenes õĖŖÕ¤║õ║Ä LiDAR ńÜä 3D µŻĆµĄŗ’╝łÕīģµŗ¼ÕżÜµ©ĪµĆüµ¢╣µ│Ģ’╝ēńÜäÕģĖÕ×ŗĶ«Łń╗āµĄüń©ŗÕ”éõĖŗŃĆé
+
+```python
+train_pipeline = [
+ dict(
+ type='LoadPointsFromFile',
+ coord_type='LIDAR',
+ load_dim=5,
+ use_dim=5),
+ dict(
+ type='LoadPointsFromMultiSweeps',
+ sweeps_num=10),
+ dict(type='LoadAnnotations3D', with_bbox_3d=True, with_label_3d=True),
+ dict(
+ type='GlobalRotScaleTrans',
+ rot_range=[-0.3925, 0.3925],
+ scale_ratio_range=[0.95, 1.05],
+ translation_std=[0, 0, 0]),
+ dict(type='RandomFlip3D', flip_ratio_bev_horizontal=0.5),
+ dict(type='PointsRangeFilter', point_cloud_range=point_cloud_range),
+ dict(type='ObjectRangeFilter', point_cloud_range=point_cloud_range),
+ dict(type='ObjectNameFilter', classes=class_names),
+ dict(type='PointShuffle'),
+ dict(
+ type='Pack3DDetInputs',
+ keys=['points', 'gt_bboxes_3d', 'gt_labels_3d'])
+]
+```
+
+õĖÄõĖĆĶł¼µāģÕåĄńøĖµ»ö’╝īnuScenes µ£ēõĖĆõĖ¬ńē╣Õ«ÜńÜä `'LoadPointsFromMultiSweeps'` µĄüµ░┤ń║┐µØźõ╗ÄĶ┐×ń╗ŁÕĖ¦ÕŖĀĶĮĮńé╣õ║æŃĆéĶ┐Öµś»µŁżĶ«ŠńĮ«õĖŁõĮ┐ńö©ńÜäÕĖĖĶ¦üÕüܵ│ĢŃĆéµø┤ÕżÜń╗åĶŖéĶ»ĘÕÅéĶĆā nuScenes [ÕĤզŗĶ«║µ¢ć](https://arxiv.org/abs/1903.11027)ŃĆé`'LoadPointsFromMultiSweeps'` õĖŁńÜäķ╗śĶ«ż `use_dim` µś» `[0, 1, 2, 4]`’╝īÕģČõĖŁÕēŹ 3 õĖ¬ń╗┤Õ║”µś»µīćńé╣ÕØɵĀć’╝īµ£ĆÕÉÄõĖĆõĖ¬µś»µī浌ČķŚ┤µł│ÕĘ«Õ╝éŃĆéńö▒õ║ÄÕ£©µŗ╝µÄźµØźĶć¬õĖŹÕÉīÕĖ¦ńÜäńé╣µŚČõĮ┐ńö©ńé╣õ║æńÜäÕ╝║Õ║”õ┐Īµü»õ╝Üõ║¦ńö¤ÕÖ¬ÕŻ░’╝īÕøĀµŁżķ╗śĶ«żµāģÕåĄõĖŗõĖŹõĮ┐ńö©ńé╣õ║æńÜäÕ╝║Õ║”õ┐Īµü»ŃĆé
+
+### Õ¤║õ║ÄĶ¦åĶ¦ēńÜäµ¢╣µ│Ģ
+
+nuScenes õĖŖÕ¤║õ║ÄÕøŠÕāÅńÜä 3D µŻĆµĄŗńÜäÕģĖÕ×ŗĶ«Łń╗āµĄüµ░┤ń║┐Õ”éõĖŗŃĆé
+
+```python
+train_pipeline = [
+ dict(type='LoadImageFromFileMono3D'),
+ dict(
+ type='LoadAnnotations3D',
+ with_bbox=True,
+ with_label=True,
+ with_attr_label=True,
+ with_bbox_3d=True,
+ with_label_3d=True,
+ with_bbox_depth=True),
+ dict(type='mmdet.Resize', img_scale=(1600, 900), keep_ratio=True),
+ dict(type='RandomFlip3D', flip_ratio_bev_horizontal=0.5),
+ dict(
+ type='Pack3DDetInputs',
+ keys=[
+ 'img', 'gt_bboxes', 'gt_bboxes_labels', 'attr_labels', 'gt_bboxes_3d',
+ 'gt_labels_3d', 'centers_2d', 'depths'
+ ]),
+]
+```
+
+Õ«āķüĄÕŠ¬ 2D µŻĆµĄŗńÜäõĖĆĶł¼µĄüµ░┤ń║┐’╝īõĮåÕ£©õĖĆõ║øń╗åĶŖéõĖŖµ£ēµēĆõĖŹÕÉī’╝Ü
+
+- Õ«āõĮ┐ńö©ÕŹĢńø«µĄüµ░┤ń║┐ÕŖĀĶĮĮÕøŠÕāÅ’╝īÕģČõĖŁÕīģµŗ¼ķóØÕż¢ńÜäÕ┐ģķ£Ćõ┐Īµü»’╝īÕ”éńøĖµ£║ÕåģÕÅéń¤®ķśĄŃĆé
+- Õ«āķ£ĆĶ”üÕŖĀĶĮĮ 3D µĀćµ│©ŃĆé
+- õĖĆõ║øµĢ░µŹ«Õó×Õ╝║µŖƵ£»ķ£ĆĶ”üĶ░āµĢ┤’╝īõŠŗÕ”é`RandomFlip3D`ŃĆéńø«ÕēŹµłæõ╗¼õĖŹµö»µīüµø┤ÕżÜńÜäÕó×Õ╝║µ¢╣µ│Ģ’╝īÕøĀõĖ║Õ”éõĮĢĶ┐üń¦╗ÕÆīÕ║öńö©ÕģČõ╗¢µŖƵ£»õ╗ŹÕ£©µÄóń┤óõĖŁŃĆé
+
+## Ķ»äõ╝░
+
+õĮ┐ńö© 8 õĖ¬ GPU õ╗źÕÅŖ nuScenes µīćµĀćĶ»äõ╝░ńÜä PointPillars ńÜäńż║õŠŗÕ”éõĖŗ
+
+```shell
+bash ./tools/dist_test.sh configs/pointpillars/pointpillars_hv_fpn_sbn-all_8xb4-2x_nus-3d.py checkpoints/hv_pointpillars_fpn_sbn-all_4x8_2x_nus-3d_20200620_230405-2fa62f3d.pth 8
+```
+
+## µīćµĀć
+
+NuScenes µÅÉÕć║õ║åõĖĆõĖ¬ń╗╝ÕÉłµīćµĀć’╝īÕŹ│ nuScenes µŻĆµĄŗÕłåµĢ░’╝łNDS’╝ē’╝īõ╗źĶ»äõ╝░õĖŹÕÉīńÜäµ¢╣µ│ĢÕ╣ČĶ«ŠńĮ«Õ¤║ÕćåµĄŗĶ»ĢŃĆéÕ«āńö▒Õ╣│ÕØćń▓ŠÕ║”’╝łmAP’╝ēŃĆüÕ╣│ÕØćÕ╣│ń¦╗Ķ»»ÕĘ«’╝łATE’╝ēŃĆüÕ╣│ÕØćÕ░║Õ║”Ķ»»ÕĘ«’╝łASE’╝ēŃĆüÕ╣│ÕØćµ¢╣ÕÉæĶ»»ÕĘ«’╝łAOE’╝ēŃĆüÕ╣│ÕØćķƤÕ║”Ķ»»ÕĘ«’╝łAVE’╝ēÕÆīÕ╣│ÕØćÕ▒׵ƦĶ»»ÕĘ«’╝łAAE’╝ēń╗䵳ÉŃĆéµø┤ÕżÜń╗åĶŖéĶ»ĘÕÅéĶĆāÕģČ[Õ«śµ¢╣ńĮæń½Ö](https://www.nuscenes.org/object-detection?externalData=all&mapData=all&modalities=Any)ŃĆé
+
+µłæõ╗¼õ╣¤ķććńö©Ķ┐Öń¦Źµ¢╣µ│ĢÕ»╣ nuScenes Ķ┐øĶĪīĶ»äõ╝░ŃĆéµēōÕŹ░ńÜäĶ»äõ╝░ń╗ōµ×£ńż║õŠŗÕ”éõĖŗ’╝Ü
+
+```
+mAP: 0.3197
+mATE: 0.7595
+mASE: 0.2700
+mAOE: 0.4918
+mAVE: 1.3307
+mAAE: 0.1724
+NDS: 0.3905
+Eval time: 170.8s
+
+Per-class results:
+Object Class AP ATE ASE AOE AVE AAE
+car 0.503 0.577 0.152 0.111 2.096 0.136
+truck 0.223 0.857 0.224 0.220 1.389 0.179
+bus 0.294 0.855 0.204 0.190 2.689 0.283
+trailer 0.081 1.094 0.243 0.553 0.742 0.167
+construction_vehicle 0.058 1.017 0.450 1.019 0.137 0.341
+pedestrian 0.392 0.687 0.284 0.694 0.876 0.158
+motorcycle 0.317 0.737 0.265 0.580 2.033 0.104
+bicycle 0.308 0.704 0.299 0.892 0.683 0.010
+traffic_cone 0.555 0.486 0.309 nan nan nan
+barrier 0.466 0.581 0.269 0.169 nan nan
+```
+
+## µĄŗĶ»ĢÕÆīµÅÉõ║ż
+
+õĮ┐ńö© 8 õĖ¬ GPU Õ£© nuScenes õĖŖµĄŗĶ»Ģ PointPillars Õ╣Čńö¤µłÉÕ»╣µÄÆĶĪīµ”£ńÜäµÅÉõ║żńÜäńż║õŠŗÕ”éõĖŗ
+
+õĮĀķ£ĆĶ”üÕ£©Õ»╣Õ║öńÜäķģŹńĮ«µ¢ćõ╗ČõĖŁńÜä `test_evaluator` ķćīõ┐«µö╣ `jsonfile_prefix`ŃĆéõĖŠõĖ¬õŠŗÕŁÉ’╝īµĘ╗ÕŖĀ `test_evaluator = dict(type='NuScenesMetric', jsonfile_prefix='work_dirs/pp-nus/results_eval.json')` µł¢Õ£©µĄŗĶ»ĢÕæĮõ╗żÕÉÄõĮ┐ńö© `--cfg-options "test_evaluator.jsonfile_prefix=work_dirs/pp-nus/results_eval.json)`ŃĆé
+
+```shell
+./tools/dist_test.sh configs/pointpillars/pointpillars_hv_fpn_sbn-all_8xb4-2x_nus-3d.py work_dirs/pp-nus/latest.pth 8 --cfg-options 'test_evaluator.jsonfile_prefix=work_dirs/pp-nus/results_eval'
+```
+
+Ķ»Ęµ│©µäÅ’╝īÕ£©[Ķ┐Öķćī](https://github.com/open-mmlab/mmdetection3d/blob/dev-1.x/configs/_base_/datasets/nus-3d.py#L132)µĄŗĶ»Ģõ┐Īµü»Õ║öµø┤µö╣õĖ║µĄŗĶ»ĢķøåĶĆīõĖŹµś»ķ¬īĶ»üķøåŃĆé
+
+ńö¤µłÉ `work_dirs/pp-nus/results_eval.json` ÕÉÄ’╝īµé©ÕÅ»õ╗źÕÄŗń╝®Õ╣ȵÅÉõ║żń╗Ö nuScenes Õ¤║ÕćåµĄŗĶ»ĢŃĆéµø┤ÕżÜõ┐Īµü»Ķ»ĘÕÅéĶĆā [nuScenes Õ«śµ¢╣ńĮæń½Ö](https://www.nuscenes.org/object-detection?externalData=all&mapData=all&modalities=Any)ŃĆé
+
+µłæõ╗¼Ķ┐śÕÅ»õ╗źõĮ┐ńö©µłæõ╗¼Õ╝ĆÕÅæńÜäÕÅ»Ķ¦åÕī¢ÕĘźÕģĘÕ░åķó䵥ŗń╗ōµ×£ÕÅ»Ķ¦åÕī¢ŃĆéµø┤ÕżÜń╗åĶŖéĶ»ĘÕÅéĶĆā[ÕÅ»Ķ¦åÕī¢µ¢ćµĪŻ](https://mmdetection3d.readthedocs.io/zh_CN/latest/useful_tools.html#id2)ŃĆé
+
+## µ│©µäÅ
+
+### `NuScenesBox` ÕÆīµłæõ╗¼ńÜä `CameraInstanceBoxes` õ╣ŗķŚ┤ńÜäĶĮ¼µŹóŃĆé
+
+µĆ╗ńÜäµØźĶ»┤’╝ī`NuScenesBox` ÕÆīµłæõ╗¼ńÜä `CameraInstanceBoxes` ńÜäõĖ╗Ķ”üÕī║Õł½õĖ╗Ķ”üõĮōńÄ░Õ£©ĶĮ¼ÕÉæĶ¦Æ’╝łyaw’╝ēÕ«Üõ╣ēõĖŖŃĆé `NuScenesBox` Õ«Üõ╣ēõ║åõĖĆõĖ¬ÕøøÕģāµĢ░µł¢õĖēõĖ¬µ¼¦µŗēĶ¦ÆńÜ䵌ŗĶĮ¼’╝īĶĆīµłæõ╗¼ńÜäńö▒õ║ÄÕ«×ķÖģµāģÕåĄÕŬիÜõ╣ēõ║åõĖĆõĖ¬ĶĮ¼ÕÉæĶ¦Æ’╝łyaw’╝ē’╝īÕ«āķ£ĆĶ”üµłæõ╗¼Õ£©ķóäÕżäńÉåÕÆīÕÉÄÕżäńÉåõĖŁµēŗÕŖ©µĘ╗ÕŖĀõĖĆõ║øķóØÕż¢ńÜ䵌ŗĶĮ¼’╝īõŠŗÕ”é[Ķ┐Öķćī](https://github.com/open-mmlab/mmdetection3d/blob/master/mmdet3d/datasets/nuscenes_mono_dataset.py#L673)ŃĆé
+
+ÕÅ”Õż¢’╝īĶ»Ęµ│©µäÅ’╝īĶ¦Æńé╣ÕÆīõĮŹńĮ«ńÜäÕ«Üõ╣ēÕ£© `NuScenesBox` õĖŁµś»Õłåń”╗ńÜäŃĆéõŠŗÕ”é’╝īÕ£©ÕŹĢńø« 3D µŻĆµĄŗõĖŁ’╝īµĪåõĮŹńĮ«ńÜäÕ«Üõ╣ēÕ£©ÕģČńøĖµ£║ÕØɵĀćõĖŁ’╝łµ£ēÕģ│µ▒ĮĶĮ”Ķ«ŠńĮ«’╝īĶ»ĘÕÅéķśģÕģČÕ«śµ¢╣[µÅÆÕøŠ](https://www.nuscenes.org/nuscenes#data-collection)’╝ē’╝īÕŹ│õĖÄ[µłæõ╗¼ńÜä](https://github.com/open-mmlab/mmdetection3d/blob/master/mmdet3d/core/bbox/structures/cam_box3d.py)õĖĆĶć┤ŃĆéńøĖµ»öõ╣ŗõĖŗ’╝īÕ«āńÜäĶ¦Æńé╣µś»ķĆÜĶ┐ć[µā»õŠŗ](https://github.com/nutonomy/nuscenes-devkit/blob/02e9200218977193a1058dd7234f935834378319/python-sdk/nuscenes/utils/data_classes.py#L527) Õ«Üõ╣ēńÜä’╝īŌĆ£x ÕÉæÕēŹ’╝ī y ÕÉæÕĘ”’╝ī z ÕÉæõĖŖŌĆØŃĆéÕ«āÕ»╝Ķć┤õ║åõĖĵłæõ╗¼ńÜä `CameraInstanceBoxes` õĖŹÕÉīńÜäń╗┤Õ║”ÕÆīµŚŗĶĮ¼Õ«Üõ╣ēńÉåÕ┐ĄŃĆéõĖĆõĖ¬ń¦╗ķÖżńøĖõ╝╝Õå▓ń¬üńÜäõŠŗÕŁÉµś» PR [#744](https://github.com/open-mmlab/mmdetection3d/pull/744)ŃĆéÕÉīµĀĘńÜäķŚ«ķóśõ╣¤ÕŁśÕ£©õ║Ä LiDAR ń│╗ń╗¤õĖŁŃĆéõĖ║õ║åĶ¦ŻÕå│Õ«āõ╗¼’╝īµłæõ╗¼ķĆÜÕĖĖõ╝ÜÕ£©ķóäÕżäńÉåÕÆīÕÉÄÕżäńÉåõĖŁµĘ╗ÕŖĀõĖĆõ║øĶĮ¼µŹó’╝īõ╗źõ┐ØĶ»üÕ£©µĢ┤õĖ¬Ķ«Łń╗āÕÆīµÄ©ńÉåĶ┐ćń©ŗõĖŁµĪåķāĮÕ£©µłæõ╗¼ńÜäÕØɵĀćń│╗ń│╗ń╗¤ķćīŃĆé
diff --git a/internlm_langchain/knowledge_base/MMDetection3D/content/s3dis.md b/internlm_langchain/knowledge_base/MMDetection3D/content/s3dis.md
new file mode 100644
index 00000000..7af22390
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection3D/content/s3dis.md
@@ -0,0 +1,271 @@
+# S3DIS µĢ░µŹ«ķøå
+
+## µĢ░µŹ«ķøåńÜäÕćåÕżć
+
+Õ»╣õ║ĵĢ░µŹ«ķøåÕćåÕżćńÜäµĢ┤õĮōµĄüń©ŗ’╝īĶ»ĘÕÅéĶĆā S3DIS ńÜä[µīćÕŹŚ](https://github.com/open-mmlab/mmdetection3d/blob/master/data/s3dis/README.md/)ŃĆé
+
+### µÅÉÕÅ¢ S3DIS µĢ░µŹ«
+
+ķĆÜĶ┐ćõ╗ÄÕĤզŗµĢ░µŹ«õĖŁµÅÉÕÅ¢ S3DIS µĢ░µŹ«’╝īµłæõ╗¼Õ░åńé╣õ║æµĢ░µŹ«Ķ»╗ÕÅ¢Õ╣Čõ┐ØÕŁśõĖŗńøĖÕģ│ńÜäµĀćµ│©õ┐Īµü»’╝īõŠŗÕ”éĶ»Łõ╣ēÕłåÕē▓µĀćńŁŠÕÆīÕ«×õŠŗÕłåÕē▓µĀćńŁŠŃĆé
+
+µĢ░µŹ«µÅÉÕÅ¢ÕēŹńÜäńø«ÕĮĢń╗ōµ×äÕ║öĶ»źÕ”éõĖŗµēĆńż║’╝Ü
+
+```
+mmdetection3d
+Ōö£ŌöĆŌöĆ mmdet3d
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+Ōö£ŌöĆŌöĆ data
+Ōöé Ōö£ŌöĆŌöĆ s3dis
+Ōöé Ōöé Ōö£ŌöĆŌöĆ meta_data
+Ōöé Ōöé Ōö£ŌöĆŌöĆ Stanford3dDataset_v1.2_Aligned_Version
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ Area_1
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ conferenceRoom_1
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ office_1
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ ...
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ Area_2
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ Area_3
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ Area_4
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ Area_5
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ Area_6
+Ōöé Ōöé Ōö£ŌöĆŌöĆ indoor3d_util.py
+Ōöé Ōöé Ōö£ŌöĆŌöĆ collect_indoor3d_data.py
+Ōöé Ōöé Ōö£ŌöĆŌöĆ README.md
+```
+
+Õ£© `Stanford3dDataset_v1.2_Aligned_Version` ńø«ÕĮĢõĖŗ’╝īµēƵ£ēµł┐ķŚ┤õŠØµŹ«µēĆÕ▒×Õī║Õ¤¤Ķó½ÕłåõĖ║ 6 ń╗äŃĆé
+µłæõ╗¼ķĆÜÕĖĖõĮ┐ńö© 5 õĖ¬Õī║Õ¤¤Ķ┐øĶĪīĶ«Łń╗ā’╝īńäČÕÉÄÕ£©õĮÖõĖŗ 1 õĖ¬Õī║Õ¤¤õĖŖĶ┐øĶĪīµĄŗĶ»Ģ (Ķó½õĮÖõĖŗńÜä 1 õĖ¬Õī║Õ¤¤ķĆÜÕĖĖõĖ║Õī║Õ¤¤ 5)ŃĆé
+Õ£©µ»ÅõĖ¬Õī║Õ¤¤ńÜäńø«ÕĮĢõĖŗÕīģÕɽµ£ēÕżÜõĖ¬µł┐ķŚ┤ńÜäµ¢ćõ╗ČÕż╣’╝īµ»ÅõĖ¬µ¢ćõ╗ČÕż╣µś»õĖĆõĖ¬µł┐ķŚ┤ńÜäÕĤզŗńé╣õ║æµĢ░µŹ«ÕÆīńøĖÕģ│ńÜäµĀćµ│©õ┐Īµü»ŃĆé
+õŠŗÕ”é’╝īÕ£© `Area_1/office_1` ńø«ÕĮĢõĖŗńÜäµ¢ćõ╗ČÕ”éõĖŗµēĆńż║’╝Ü
+
+- `office_1.txt`’╝ÜõĖĆõĖ¬ txt µ¢ćõ╗ČÕŁśÕé©ńØĆÕĤզŗńé╣õ║æµĢ░µŹ«µ»ÅõĖ¬ńé╣ńÜäÕØɵĀćÕÆīķó£Ķē▓õ┐Īµü»ŃĆé
+
+- `Annotations/`’╝ÜĶ┐ÖõĖ¬µ¢ćõ╗ČÕż╣ķćīÕīģÕɽµ£ēµŁżµł┐ķŚ┤õĖŁÕ«×õŠŗńē®õĮōńÜäõ┐Īµü» (õ╗ź txt µ¢ćõ╗ČńÜäÕĮóÕ╝ÅÕŁśÕé©)ŃĆéµ»ÅõĖ¬ txt µ¢ćõ╗ČĶĪ©ńż║õĖĆõĖ¬Õ«×õŠŗ’╝īõŠŗÕ”é’╝Ü
+
+ - `chair_1.txt`’╝ÜÕŁśÕ驵£ēĶ»źµł┐ķŚ┤õĖŁõĖƵŖŖµżģÕŁÉńÜäńé╣õ║æµĢ░µŹ«ŃĆé
+
+ Õ”éµ×£µłæõ╗¼Õ░å `Annotations/` õĖŗńÜäµēƵ£ē txt µ¢ćõ╗ČÕÉłÕ╣ČĶĄĘµØź’╝īÕŠŚÕł░ńÜäńé╣õ║æÕ░▒ÕÆī `office_1.txt` õĖŁńÜäńé╣õ║æµś»õĖĆĶć┤ńÜäŃĆé
+
+õĮĀÕÅ»õ╗źķĆÜĶ┐ć `python collect_indoor3d_data.py` µīćõ╗żĶ┐øĶĪī S3DIS µĢ░µŹ«ńÜäµÅÉÕÅ¢ŃĆé
+õĖ╗Ķ”üµŁźķ¬żÕīģµŗ¼’╝Ü
+
+- õ╗ÄÕĤզŗ txt µ¢ćõ╗ČõĖŁĶ»╗ÕÅ¢ńé╣õ║æµĢ░µŹ«ŃĆüĶ»Łõ╣ēÕłåÕē▓µĀćńŁŠÕÆīÕ«×õŠŗÕłåÕē▓µĀćńŁŠŃĆé
+- Õ░åńé╣õ║æµĢ░µŹ«ÕÆīńøĖÕģ│µĀćµ│©µ¢ćõ╗ČÕŁśÕé©õĖŗµØźŃĆé
+
+Ķ┐ÖÕģČõĖŁńÜäµĀĖÕ┐āÕćĮµĢ░ `indoor3d_util.py` õĖŁńÜä `export` ÕćĮµĢ░Õ«×ńÄ░Õ”éõĖŗ’╝Ü
+
+```python
+def export(anno_path, out_filename):
+ """Õ░åÕĤզŗµĢ░µŹ«ķøåńÜäµ¢ćõ╗ČĶĮ¼Õī¢õĖ║ńé╣õ║æŃĆüĶ»Łõ╣ēÕłåÕē▓µĀćńŁŠÕÆīÕ«×õŠŗÕłåÕē▓µÄ®ńĀüµ¢ćõ╗ČŃĆé
+ µłæõ╗¼Õ░åÕÉīõĖƵł┐ķŚ┤õĖŁµēƵ£ēÕ«×õŠŗńÜäńé╣Ķ┐øĶĪīĶüÜÕÉłŃĆé
+
+ ÕÅéµĢ░ÕłŚĶĪ©:
+ anno_path (str): µĀćµ│©õ┐Īµü»ńÜäĶĘ»ÕŠä’╝īõŠŗÕ”é Area_1/office_2/Annotations/
+ out_filename (str): õ┐ØÕŁśńé╣õ║æÕÆīµĀćńŁŠńÜäĶĘ»ÕŠä
+ file_format (str): txt µł¢ numpy’╝īµīćÕ«Üõ┐ØÕŁśńÜäµ¢ćõ╗ȵĀ╝Õ╝Å
+
+ µ│©µäÅ:
+ ńé╣õ║æÕ£©ÕżäńÉåĶ┐ćń©ŗõĖŁĶó½µĢ┤õĮōń¦╗ÕŖ©õ║å’╝īõ┐ØÕŁśõĖŗńÜäńé╣µ£ĆÕ░ÅõĮŹõ║ÄÕĤńé╣ (ÕŹ│µ▓Īµ£ēĶ┤¤µĢ░ÕØɵĀćÕĆ╝)
+ """
+ points_list = []
+ ins_idx = 1 # Õ«×õŠŗµĀćńŁŠõ╗Ä 1 Õ╝ĆÕ¦ŗ’╝īÕøĀµŁżµ£Ćń╗łÕ«×õŠŗµĀćńŁŠõĖ║ 0 ńÜäńé╣Õ░▒µś»µŚĀµĀćµ│©ńÜäńé╣
+
+ # `anno_path` ńÜäõĖĆõĖ¬õŠŗÕŁÉ’╝ÜArea_1/office_1/Annotations
+ # ÕģČõĖŁõ╗ź txt µ¢ćõ╗ČÕŁśÕ驵£ēĶ»źµł┐ķŚ┤õĖŁµēƵ£ēÕ«×õŠŗńē®õĮōńÜäńé╣õ║æ
+ for f in glob.glob(osp.join(anno_path, '*.txt')):
+ # get class name of this instance
+ one_class = osp.basename(f).split('_')[0]
+ if one_class not in class_names: # µ¤Éõ║øµł┐ķŚ┤µ£ē 'staris' ń▒╗ńē®õĮō
+ one_class = 'clutter'
+ points = np.loadtxt(f)
+ labels = np.ones((points.shape[0], 1)) * class2label[one_class]
+ ins_labels = np.ones((points.shape[0], 1)) * ins_idx
+ ins_idx += 1
+ points_list.append(np.concatenate([points, labels, ins_labels], 1))
+
+ data_label = np.concatenate(points_list, 0) # [N, 8], (pts, rgb, sem, ins)
+ # Õ░åńé╣õ║æÕ»╣ķĮÉÕł░ÕĤńé╣
+ xyz_min = np.amin(data_label, axis=0)[0:3]
+ data_label[:, 0:3] -= xyz_min
+
+ np.save(f'{out_filename}_point.npy', data_label[:, :6].astype(np.float32))
+ np.save(f'{out_filename}_sem_label.npy', data_label[:, 6].astype(np.int64))
+ np.save(f'{out_filename}_ins_label.npy', data_label[:, 7].astype(np.int64))
+
+```
+
+õĖŖĶ┐░õ╗ŻńĀüõĖŁ’╝īµłæõ╗¼Ķ»╗ÕÅ¢ `Annotations/` õĖŗńÜäµēƵ£ēńé╣õ║æÕ«×õŠŗ’╝īÕ░åÕģČÕÉłÕ╣ČÕŠŚÕł░µĢ┤õĮōµł┐Õ▒ŗńÜäńé╣õ║æ’╝īÕÉīµŚČńö¤µłÉĶ»Łõ╣ē/Õ«×õŠŗÕłåÕē▓ńÜäµĀćńŁŠŃĆé
+Õ£©µÅÉÕÅ¢Õ«īµ»ÅõĖ¬µł┐ķŚ┤ńÜäµĢ░µŹ«ÕÉÄ’╝īńé╣õ║æŃĆüĶ»Łõ╣ēÕłåÕē▓ÕÆīÕ«×õŠŗÕłåÕē▓ńÜäµĀćńŁŠµ¢ćõ╗ČÕ║öõ╗ź `.npy` ńÜäµĀ╝Õ╝ÅĶó½õ┐ØÕŁśõĖŗµØźŃĆé
+
+### ÕłøÕ╗║µĢ░µŹ«ķøå
+
+```shell
+python tools/create_data.py s3dis --root-path ./data/s3dis \
+--out-dir ./data/s3dis --extra-tag s3dis
+```
+
+õĖŖĶ┐░µīćõ╗żķ”¢ÕģłĶ»╗ÕÅ¢õ╗ź `.npy` µĀ╝Õ╝ÅÕŁśÕé©ńÜäńé╣õ║æŃĆüĶ»Łõ╣ēÕłåÕē▓ÕÆīÕ«×õŠŗÕłåÕē▓µĀćńŁŠµ¢ćõ╗Č’╝īńäČÕÉÄĶ┐øõĖƵŁźÕ░åÕ«āõ╗¼õ╗ź `.bin` µĀ╝Õ╝Åõ┐ØÕŁśŃĆé
+ÕÉīµŚČ’╝īµ»ÅõĖ¬Õī║Õ¤¤ `.pkl` µĀ╝Õ╝ÅńÜäõ┐Īµü»µ¢ćõ╗Čõ╣¤õ╝ÜĶó½õ┐ØÕŁśõĖŗµØźŃĆé
+
+µĢ░µŹ«ķóäÕżäńÉåÕÉÄńÜäńø«ÕĮĢń╗ōµ×äÕ”éõĖŗµēĆńż║’╝Ü
+
+```
+s3dis
+Ōö£ŌöĆŌöĆ meta_data
+Ōö£ŌöĆŌöĆ indoor3d_util.py
+Ōö£ŌöĆŌöĆ collect_indoor3d_data.py
+Ōö£ŌöĆŌöĆ README.md
+Ōö£ŌöĆŌöĆ Stanford3dDataset_v1.2_Aligned_Version
+Ōö£ŌöĆŌöĆ s3dis_data
+Ōö£ŌöĆŌöĆ points
+Ōöé Ōö£ŌöĆŌöĆ xxxxx.bin
+Ōö£ŌöĆŌöĆ instance_mask
+Ōöé Ōö£ŌöĆŌöĆ xxxxx.bin
+Ōö£ŌöĆŌöĆ semantic_mask
+Ōöé Ōö£ŌöĆŌöĆ xxxxx.bin
+Ōö£ŌöĆŌöĆ seg_info
+Ōöé Ōö£ŌöĆŌöĆ Area_1_label_weight.npy
+Ōöé Ōö£ŌöĆŌöĆ Area_1_resampled_scene_idxs.npy
+Ōöé Ōö£ŌöĆŌöĆ Area_2_label_weight.npy
+Ōöé Ōö£ŌöĆŌöĆ Area_2_resampled_scene_idxs.npy
+Ōöé Ōö£ŌöĆŌöĆ Area_3_label_weight.npy
+Ōöé Ōö£ŌöĆŌöĆ Area_3_resampled_scene_idxs.npy
+Ōöé Ōö£ŌöĆŌöĆ Area_4_label_weight.npy
+Ōöé Ōö£ŌöĆŌöĆ Area_4_resampled_scene_idxs.npy
+Ōöé Ōö£ŌöĆŌöĆ Area_5_label_weight.npy
+Ōöé Ōö£ŌöĆŌöĆ Area_5_resampled_scene_idxs.npy
+Ōöé Ōö£ŌöĆŌöĆ Area_6_label_weight.npy
+Ōöé Ōö£ŌöĆŌöĆ Area_6_resampled_scene_idxs.npy
+Ōö£ŌöĆŌöĆ s3dis_infos_Area_1.pkl
+Ōö£ŌöĆŌöĆ s3dis_infos_Area_2.pkl
+Ōö£ŌöĆŌöĆ s3dis_infos_Area_3.pkl
+Ōö£ŌöĆŌöĆ s3dis_infos_Area_4.pkl
+Ōö£ŌöĆŌöĆ s3dis_infos_Area_5.pkl
+Ōö£ŌöĆŌöĆ s3dis_infos_Area_6.pkl
+```
+
+- `points/xxxxx.bin`’╝ܵÅÉÕÅ¢ńÜäńé╣õ║æµĢ░µŹ«ŃĆé
+- `instance_mask/xxxxx.bin`’╝ܵ»ÅõĖ¬ńé╣õ║æńÜäÕ«×õŠŗµĀćńŁŠ’╝īÕÅ¢ÕĆ╝ĶīāÕø┤õĖ║ \[0, ${Õ«×õŠŗõĖ¬µĢ░}\]’╝īÕģČõĖŁ 0 õ╗ŻĶĪ©µ£¬µĀćµ│©ńÜäńé╣ŃĆé
+- `semantic_mask/xxxxx.bin`’╝ܵ»ÅõĖ¬ńé╣õ║æńÜäĶ»Łõ╣ēµĀćńŁŠ’╝īÕÅ¢ÕĆ╝ĶīāÕø┤õĖ║ \[0, 12\]ŃĆé
+- `s3dis_infos_Area_1.pkl`’╝ÜÕī║Õ¤¤ 1 ńÜäµĢ░µŹ«õ┐Īµü»’╝īµ»ÅõĖ¬µł┐ķŚ┤ńÜäĶ»”ń╗åõ┐Īµü»Õ”éõĖŗ’╝Ü
+ - info\['point_cloud'\]: {'num_features': 6, 'lidar_idx': sample_idx}.
+ - info\['pts_path'\]: `points/xxxxx.bin` ńé╣õ║æńÜäĶĘ»ÕŠäŃĆé
+ - info\['pts_instance_mask_path'\]: `instance_mask/xxxxx.bin` Õ«×õŠŗµĀćńŁŠńÜäĶĘ»ÕŠäŃĆé
+ - info\['pts_semantic_mask_path'\]: `semantic_mask/xxxxx.bin` Ķ»Łõ╣ēµĀćńŁŠńÜäĶĘ»ÕŠäŃĆé
+- `seg_info`’╝ÜõĖ║µö»µīüĶ»Łõ╣ēÕłåÕē▓õ╗╗ÕŖĪµēĆńö¤µłÉńÜäõ┐Īµü»µ¢ćõ╗ČŃĆé
+ - `Area_1_label_weight.npy`’╝ܵ»ÅõĖĆĶ»Łõ╣ēń▒╗Õł½ńÜäµØāķćŹń│╗µĢ░ŃĆéÕøĀõĖ║ S3DIS õĖŁÕ▒×õ║ÄõĖŹÕÉīń▒╗ńÜäńé╣ńÜäµĢ░ķćÅńøĖÕĘ«ÕŠłÕż¦’╝īõĖĆõĖ¬ÕĖĖĶ¦üńÜäµōŹõĮ£µś»Õ£©Ķ«Īń«ŚµŹ¤Õż▒µŚČÕ»╣õĖŹÕÉīń▒╗Õł½Ķ┐øĶĪīÕŖĀµØā (label re-weighting) õ╗źÕŠŚÕł░µø┤ÕźĮńÜäÕłåÕē▓µĆ¦ĶāĮŃĆé
+ - `Area_1_resampled_scene_idxs.npy`’╝ܵ»ÅõĖĆõĖ¬Õ£║µÖ» (µł┐ķŚ┤) ńÜäķćŹķććµĀʵĀćńŁŠŃĆéÕ£©Ķ«Łń╗āĶ┐ćń©ŗõĖŁ’╝īµłæõ╗¼õŠØµŹ«µ»ÅõĖ¬Õ£║µÖ»ńÜäńé╣ńÜäµĢ░ķćÅ’╝īõ╝ÜÕ»╣ÕģČĶ┐øĶĪīõĖŹÕÉīµ¼ĪµĢ░ńÜäķćŹķććµĀĘ’╝īõ╗źõ┐ØĶ»üĶ«Łń╗āµĢ░µŹ«ÕØćĶĪĪŃĆé
+
+## Ķ«Łń╗āµĄüń©ŗ
+
+S3DIS õĖŖ 3D Ķ»Łõ╣ēÕłåÕē▓ńÜäõĖĆń¦ŹÕģĖÕ×ŗµĢ░µŹ«ĶĮĮÕģźµĄüń©ŗÕ”éõĖŗµēĆńż║’╝Ü
+
+```python
+class_names = ('ceiling', 'floor', 'wall', 'beam', 'column', 'window', 'door',
+ 'table', 'chair', 'sofa', 'bookcase', 'board', 'clutter')
+num_points = 4096
+train_pipeline = [
+ dict(
+ type='LoadPointsFromFile',
+ coord_type='DEPTH',
+ shift_height=False,
+ use_color=True,
+ load_dim=6,
+ use_dim=[0, 1, 2, 3, 4, 5]),
+ dict(
+ type='LoadAnnotations3D',
+ with_bbox_3d=False,
+ with_label_3d=False,
+ with_mask_3d=False,
+ with_seg_3d=True),
+ dict(
+ type='PointSegClassMapping'),
+ dict(
+ type='IndoorPatchPointSample',
+ num_points=num_points,
+ block_size=1.0,
+ ignore_index=None,
+ use_normalized_coord=True,
+ enlarge_size=None,
+ min_unique_num=num_points // 4,
+ eps=0.0),
+ dict(type='NormalizePointsColor', color_mean=None),
+ dict(
+ type='GlobalRotScaleTrans',
+ rot_range=[-3.141592653589793, 3.141592653589793], # [-pi, pi]
+ scale_ratio_range=[0.8, 1.2],
+ translation_std=[0, 0, 0]),
+ dict(
+ type='RandomJitterPoints',
+ jitter_std=[0.01, 0.01, 0.01],
+ clip_range=[-0.05, 0.05]),
+ dict(type='RandomDropPointsColor', drop_ratio=0.2),
+ dict(type='Pack3DDetInputs', keys=['points', 'pts_semantic_mask'])
+]
+```
+
+- `PointSegClassMapping`’╝ÜÕ£©Ķ«Łń╗āĶ┐ćń©ŗõĖŁ’╝īÕŬµ£ēĶó½õĮ┐ńö©ńÜäń▒╗Õł½ńÜäÕ║ÅÕÅĘõ╝ÜĶó½µśĀÕ░äÕł░ń▒╗õ╝╝ \[0, 13) ĶīāÕø┤ÕåģńÜäń▒╗Õł½µĀćńŁŠŃĆéÕģČõĮÖńÜäń▒╗Õł½Õ║ÅÕÅĘõ╝ÜĶó½ĶĮ¼µŹóõĖ║ `ignore_index` µēĆÕłČÕ«ÜńÜäÕ┐ĮńĢźµĀćńŁŠ’╝īÕ£©µ£¼õŠŗõĖŁµś» `13`ŃĆé
+- `IndoorPatchPointSample`’╝Üõ╗ÄĶŠōÕģźńé╣õ║æõĖŁĶŻüÕē¬õĖĆõĖ¬Õɽµ£ēÕø║իܵĢ░ķćÅńé╣ńÜäÕ░ÅÕØŚ (patch)ŃĆé`block_size` µīćÕ«Üõ║åĶŻüÕē¬ÕØŚńÜäĶŠ╣ķĢ┐’╝īÕ£© S3DIS õĖŖĶ┐ÖõĖ¬µĢ░ÕĆ╝õĖĆĶł¼Ķ«ŠńĮ«õĖ║ `1.0`ŃĆé
+- `NormalizePointsColor`’╝ÜÕ░åĶŠōÕģźńé╣ńÜäķó£Ķē▓õ┐Īµü»ÕĮÆõĖĆÕī¢’╝īķĆÜĶ┐ćÕ░å RGB ÕĆ╝ķÖżõ╗ź `255` µØźÕ«×ńÄ░ŃĆé
+- µĢ░µŹ«Õó×Õ╣┐’╝Ü
+ - `GlobalRotScaleTrans`’╝ÜÕ»╣ĶŠōÕģźńé╣õ║æĶ┐øĶĪīķÜŵ£║µŚŗĶĮ¼ÕÆīµöŠń╝®ÕÅśµŹóŃĆé
+ - `RandomJitterPoints`’╝ÜķĆÜĶ┐ćÕ»╣µ»ÅõĖĆõĖ¬ńé╣µ¢ĮÕŖĀõĖŹÕÉīńÜäÕÖ¬ÕŻ░ÕÉæķćÅõ╗źÕ«×ńÄ░Õ»╣ńé╣õ║æńÜäķÜŵ£║µē░ÕŖ©ŃĆé
+ - `RandomDropPointsColor`’╝Üõ╗ź `drop_ratio` ńÜäµ”éńÄćķÜŵ£║Õ░åńé╣õ║æńÜäķó£Ķē▓ÕĆ╝Õģ©ķā©ńĮ«ķøČŃĆé
+
+## Õ║”ķćŵīćµĀć
+
+ķĆÜÕĖĖµłæõ╗¼õĮ┐ńö©Õ╣│ÕØćõ║żÕ╣ȵ»ö (mean Intersection over Union, mIoU) õĮ£õĖ║ S3DIS Ķ»Łõ╣ēÕłåÕē▓õ╗╗ÕŖĪńÜäÕ║”ķćŵīćµĀćŃĆé
+ÕģĘõĮōĶĆīĶ©Ć’╝īµłæõ╗¼ÕģłĶ«Īń«ŚµēƵ£ēń▒╗Õł½ńÜä IoU’╝īńäČÕÉÄÕÅ¢Õ╣│ÕØćÕĆ╝õĮ£õĖ║ mIoUŃĆé
+µø┤ÕżÜÕ«×ńÄ░ń╗åĶŖéĶ»ĘÕÅéĶĆā [seg_eval.py](https://github.com/open-mmlab/mmdetection3d/blob/dev-1.x/mmdet3d/evaluation/functional/seg_eval.py)ŃĆé
+
+µŁŻÕ”éÕ£© `µÅÉÕÅ¢ S3DIS µĢ░µŹ«` õĖĆĶŖéõĖŁµēƵÅÉÕÅŖńÜä’╝īS3DIS ķĆÜÕĖĖÕ£© 5 õĖ¬Õī║Õ¤¤õĖŖĶ┐øĶĪīĶ«Łń╗ā’╝īńäČÕÉÄÕ£©õĮÖõĖŗńÜä 1 õĖ¬Õī║Õ¤¤õĖŖĶ┐øĶĪīµĄŗĶ»ĢŃĆéõĮåµś»Õ£©ÕģČõ╗¢Ķ«║µ¢ćõĖŁ’╝īõ╣¤µ£ēõĖŹÕÉīńÜäÕłÆÕłåµ¢╣Õ╝ÅŃĆé
+õĖ║õ║åõŠ┐õ║ÄńüĄµ┤╗ÕłÆÕłåĶ«Łń╗āÕÆīµĄŗĶ»ĢńÜäÕŁÉķøå’╝īµłæõ╗¼ķ”¢ÕģłÕ«Üõ╣ēÕŁÉµĢ░µŹ«ķøå (sub-dataset) µØźĶĪ©ńż║µ»ÅõĖĆõĖ¬Õī║Õ¤¤’╝īńäČÕÉĵĀ╣µŹ«Õī║Õ¤¤ÕłÆÕłåÕ»╣ÕģČĶ┐øĶĪīÕÉłÕ╣Č’╝īõ╗źÕŠŚÕł░Õ«īµĢ┤ńÜäĶ«Łń╗āķøåŃĆé
+õ╗źõĖŗµś»Õ£©Õī║Õ¤¤ 1ŃĆü2ŃĆü3ŃĆü4ŃĆü6 õĖŖĶ«Łń╗āÕ╣ČÕ£©Õī║Õ¤¤ 5 õĖŖµĄŗĶ»ĢńÜäõĖĆõĖ¬ķģŹńĮ«µ¢ćõ╗ČõŠŗÕŁÉ’╝Ü
+
+```python
+dataset_type = 'S3DISSegDataset'
+data_root = './data/s3dis/'
+class_names = ('ceiling', 'floor', 'wall', 'beam', 'column', 'window', 'door',
+ 'table', 'chair', 'sofa', 'bookcase', 'board', 'clutter')
+train_area = [1, 2, 3, 4, 6]
+test_area = 5
+train_dataloader = dict(
+ batch_size=8,
+ num_workers=4,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ ann_files=[f's3dis_infos_Area_{i}.pkl' for i in train_area],
+ metainfo=metainfo,
+ data_prefix=data_prefix,
+ pipeline=train_pipeline,
+ modality=input_modality,
+ ignore_index=len(class_names),
+ scene_idxs=[
+ f'seg_info/Area_{i}_resampled_scene_idxs.npy' for i in train_area
+ ],
+ test_mode=False))
+test_dataloader = dict(
+ batch_size=1,
+ num_workers=1,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ ann_files=f's3dis_infos_Area_{test_area}.pkl',
+ metainfo=metainfo,
+ data_prefix=data_prefix,
+ pipeline=test_pipeline,
+ modality=input_modality,
+ ignore_index=len(class_names),
+ scene_idxs=f'seg_info/Area_{test_area}_resampled_scene_idxs.npy',
+ test_mode=True))
+val_dataloader = test_dataloader
+```
+
+ÕÅ»õ╗źń£ŗÕł░’╝īµłæõ╗¼ķĆÜĶ┐ćÕ░åÕżÜõĖ¬ńøĖÕ║öĶĘ»ÕŠäµ×䵳ÉńÜäÕłŚĶĪ© (list) ĶŠōÕģź `ann_files` ÕÆī `scene_idxs` õ╗źÕ«×ńÄ░Ķ«Łń╗āµĄŗĶ»ĢķøåńÜäÕłÆÕłåŃĆé
+Õ”éµ×£õ┐«µö╣Ķ«Łń╗āµĄŗĶ»ĢÕī║Õ¤¤ńÜäÕłÆÕłå’╝īÕŬķ£ĆĶ”üń«ĆÕŹĢõ┐«µö╣ `train_area` ÕÆī `test_area` ÕŹ│ÕÅ»ŃĆé
diff --git a/internlm_langchain/knowledge_base/MMDetection3D/content/scannet.md b/internlm_langchain/knowledge_base/MMDetection3D/content/scannet.md
new file mode 100644
index 00000000..bbba255a
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection3D/content/scannet.md
@@ -0,0 +1,354 @@
+# ScanNet µĢ░µŹ«ķøå
+
+MMDetection3D µö»µīüÕ£© ScanNet µĢ░µŹ«ķøåõĖŖĶ┐øĶĪī 3D ńø«µĀ浯ƵĄŗ\\Ķ»Łõ╣ēÕłåÕē▓ õ╗╗ÕŖĪŃĆéµ£¼ķĪĄµÅÉõŠøõ║åµ£ēÕģ│Õ£© MMDetection3D õĖŁõĮ┐ńö© ScanNet µĢ░µŹ«ķøåńÜäÕģĘõĮōµĢÖń©ŗŃĆé
+
+## µĢ░µŹ«ķøåÕćåÕżć
+
+Ķ»ĘÕÅéĶĆā ScanNet ńÜä[µīćÕŹŚ](https://github.com/open-mmlab/mmdetection3d/blob/master/data/scannet/README.md)õ╗źµ¤źń£ŗµĆ╗õĮōµĄüń©ŗŃĆé
+
+### µÅÉÕÅ¢ ScanNet ńé╣õ║æµĢ░µŹ«
+
+ķĆÜĶ┐ćµÅÉÕÅ¢ ScanNet µĢ░µŹ«’╝īµłæõ╗¼ÕŖĀĶĮĮÕĤզŗńé╣õ║æµ¢ćõ╗Č’╝īÕ╣Čńö¤µłÉÕīģµŗ¼Ķ»Łõ╣ēµĀćńŁŠŃĆüÕ«×õŠŗµĀćńŁŠÕÆīń£¤Õ«×ńē®õĮōÕīģÕø┤µĪåÕ£©ÕåģńÜäńøĖÕģ│µĀćµ│©ŃĆé
+
+```shell
+python batch_load_scannet_data.py
+```
+
+µĢ░µŹ«ÕżäńÉåõ╣ŗÕēŹńÜäµ¢ćõ╗Čńø«ÕĮĢń╗ōµ×äÕ”éõĖŗ’╝Ü
+
+```
+mmdetection3d
+Ōö£ŌöĆŌöĆ mmdet3d
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+Ōö£ŌöĆŌöĆ data
+Ōöé Ōö£ŌöĆŌöĆ scannet
+Ōöé Ōöé Ōö£ŌöĆŌöĆ meta_data
+Ōöé Ōöé Ōö£ŌöĆŌöĆ scans
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ scenexxxx_xx
+Ōöé Ōöé Ōö£ŌöĆŌöĆ batch_load_scannet_data.py
+Ōöé Ōöé Ōö£ŌöĆŌöĆ load_scannet_data.py
+Ōöé Ōöé Ōö£ŌöĆŌöĆ scannet_utils.py
+Ōöé Ōöé Ōö£ŌöĆŌöĆ README.md
+```
+
+Õ£© `scans` µ¢ćõ╗ČÕż╣õĖŗµĆ╗Õģ▒µ£ē 1201 õĖ¬Ķ«Łń╗āµĀʵ£¼µ¢ćõ╗ČÕż╣ÕÆī 312 õĖ¬ķ¬īĶ»üµĀʵ£¼µ¢ćõ╗ČÕż╣’╝īÕģČõĖŁÕŁśµ£ēµ£¬ÕżäńÉåńÜäńé╣õ║æµĢ░µŹ«ÕÆīńøĖÕģ│ńÜäµĀćµ│©ŃĆéµ»öÕ”éĶ»┤’╝īÕ£©µ¢ćõ╗ČÕż╣ `scene0001_01` õĖŗµ¢ćõ╗ȵś»Ķ┐ÖµĀĘń╗äń╗ćńÜä’╝Ü
+
+- `scene0001_01_vh_clean_2.ply`’╝ÜÕŁśµ£ēµ»ÅõĖ¬ķĪČńé╣ÕØɵĀćÕÆīķó£Ķē▓ńÜäńĮæµĀ╝µ¢ćõ╗ČŃĆéńĮæµĀ╝ńÜäķĪČńé╣Ķó½ńø┤µÄźńö©õĮ£µ£¬ÕżäńÉåńÜäńé╣õ║æµĢ░µŹ«ŃĆé
+- `scene0001_01.aggregation.json`’╝ÜÕīģÕɽńē®õĮō IDŃĆüÕłåÕē▓ķā©Õłå IDŃĆüµĀćńŁŠńÜäµĀćµ│©µ¢ćõ╗ČŃĆé
+- `scene0001_01_vh_clean_2.0.010000.segs.json`’╝ÜÕīģÕÉ½ÕłåÕē▓ķā©Õłå ID ÕÆīķĪČńé╣ńÜäÕłåÕē▓µĀćµ│©µ¢ćõ╗ČŃĆé
+- `scene0001_01.txt`’╝ÜÕīģµŗ¼Õ»╣ķĮÉń¤®ķśĄńŁēńÜäÕģāµ¢ćõ╗ČŃĆé
+- `scene0001_01_vh_clean_2.labels.ply`’╝ÜÕīģÕɽµ»ÅõĖ¬ķĪČńé╣ń▒╗Õł½ńÜäµĀćµ│©µ¢ćõ╗ČŃĆé
+
+ķĆÜĶ┐ćĶ┐ÉĶĪī `python batch_load_scannet_data.py` µØźµÅÉÕÅ¢ ScanNet µĢ░µŹ«ńÜäÕżäńÉåĶ┐ćń©ŗõĖ╗Ķ”üÕīģÕɽõ╗źõĖŗÕćĀµŁź’╝Ü
+
+- õ╗ÄÕĤզŗµ¢ćõ╗ČõĖŁµÅÉÕÅ¢Õć║ńé╣õ║æŃĆüÕ«×õŠŗµĀćńŁŠŃĆüĶ»Łõ╣ēµĀćńŁŠÕÆīÕīģÕø┤µĪåµĀćńŁŠµ¢ćõ╗ČŃĆé
+- õĖŗķććµĀĘÕĤզŗńé╣õ║æÕ╣ČĶ┐ćµ╗żµÄēõĖŹÕÉłµ│ĢńÜäń▒╗Õł½ŃĆé
+- õ┐ØÕŁśÕżäńÉåÕÉÄńÜäńé╣õ║æµĢ░µŹ«ÕÆīńøĖÕģ│ńÜäµĀćµ│©µ¢ćõ╗ČŃĆé
+
+`load_scannet_data.py` õĖŁńÜäµĀĖÕ┐āÕćĮµĢ░ `export` Õ”éõĖŗ’╝Ü
+
+```python
+def export(mesh_file,
+ agg_file,
+ seg_file,
+ meta_file,
+ label_map_file,
+ output_file=None,
+ test_mode=False):
+
+ # µĀćńŁŠµśĀÕ░äµ¢ćõ╗Č’╝Ü./data/scannet/meta_data/scannetv2-labels.combined.tsv
+ # Ķ»źµĀćńŁŠµśĀÕ░äµ¢ćõ╗ČõĖŁµ£ēÕżÜń¦ŹµĀćńŁŠµĀćÕćå’╝īµ»öÕ”é 'nyu40id'
+ label_map = scannet_utils.read_label_mapping(
+ label_map_file, label_from='raw_category', label_to='nyu40id')
+ # ÕŖĀĶĮĮÕĤզŗńé╣õ║æµĢ░µŹ«’╝īńē╣ÕŠüÕīģµŗ¼6ń╗┤’╝ÜXYZRGB
+ mesh_vertices = scannet_utils.read_mesh_vertices_rgb(mesh_file)
+
+ # ÕŖĀĶĮĮÕ£║µÖ»ÕØɵĀćĶĮ┤Õ»╣ķĮÉń¤®ķśĄ’╝ÜõĖĆõĖ¬ 4x4 ńÜäÕÅśµŹóń¤®ķśĄ
+ # Õ░åõ╝Āµä¤ÕÖ©ÕØɵĀćń│╗õĖŗńÜäÕĤզŗńé╣ĶĮ¼Õī¢Õł░ÕÅ”õĖĆõĖ¬ÕØɵĀćń│╗õĖŗ
+ # Ķ»źÕØɵĀćń│╗õĖĵł┐Õ▒ŗńÜäõĖżĶŠ╣Õ╣│ĶĪī’╝łõ╣¤Õ░▒µś»õĖÄÕØɵĀćĶĮ┤Õ╣│ĶĪī’╝ē
+ lines = open(meta_file).readlines()
+ # µĄŗĶ»ĢķøåńÜäµĢ░µŹ«µ▓Īµ£ēÕ»╣ķĮÉń¤®ķśĄ
+ axis_align_matrix = np.eye(4)
+ for line in lines:
+ if 'axisAlignment' in line:
+ axis_align_matrix = [
+ float(x)
+ for x in line.rstrip().strip('axisAlignment = ').split(' ')
+ ]
+ break
+ axis_align_matrix = np.array(axis_align_matrix).reshape((4, 4))
+
+ # Õ»╣ńĮæµĀ╝ķĪČńé╣Ķ┐øĶĪīÕģ©Õ▒ĆńÜäÕ»╣ķĮÉ
+ pts = np.ones((mesh_vertices.shape[0], 4))
+ # ÕÉīń¦Źń▒╗ÕØɵĀćõĖŗńÜäÕĤզŗńé╣õ║æ’╝īµ»ÅõĖĆĶĪīńÜäµĢ░µŹ«µś» [x, y, z, 1]
+ pts[:, 0:3] = mesh_vertices[:, 0:3]
+ # Õ░åÕĤզŗńĮæµĀ╝ķĪČńé╣ĶĮ¼µŹóõĖ║Õ»╣ķĮÉÕÉÄńÜäķĪČńé╣
+ pts = np.dot(pts, axis_align_matrix.transpose()) # Nx4
+ aligned_mesh_vertices = np.concatenate([pts[:, 0:3], mesh_vertices[:, 3:]],
+ axis=1)
+
+ # ÕŖĀĶĮĮĶ»Łõ╣ēõĖÄÕ«×õŠŗµĀćńŁŠ
+ if not test_mode:
+ # µ»ÅõĖ¬ńē®õĮōķāĮµ£ēõĖĆõĖ¬Ķ»Łõ╣ēµĀćńŁŠ’╝īÕ╣ČõĖöÕīģÕɽÕćĀõĖ¬ÕłåÕē▓ķā©Õłå
+ object_id_to_segs, label_to_segs = read_aggregation(agg_file)
+ # ÕŠłÕżÜńé╣Õ▒×õ║ÄÕÉīõĖĆÕłåÕē▓ķā©Õłå
+ seg_to_verts, num_verts = read_segmentation(seg_file)
+ label_ids = np.zeros(shape=(num_verts), dtype=np.uint32)
+ object_id_to_label_id = {}
+ for label, segs in label_to_segs.items():
+ label_id = label_map[label]
+ for seg in segs:
+ verts = seg_to_verts[seg]
+ # µ»ÅõĖ¬ńé╣ķāĮµ£ēõĖĆõĖ¬Ķ»Łõ╣ēµĀćńŁŠ
+ label_ids[verts] = label_id
+ instance_ids = np.zeros(
+ shape=(num_verts), dtype=np.uint32) # 0’╝ܵ£¬µĀćµ│©ńÜä
+ for object_id, segs in object_id_to_segs.items():
+ for seg in segs:
+ verts = seg_to_verts[seg]
+ # object_id õ╗Ä 1 Õ╝ĆÕ¦ŗĶ«ĪµĢ░’╝īµ»öÕ”é 1,2,3,.,,,.NUM_INSTANCES
+ # µ»ÅõĖ¬ńé╣ķāĮÕ▒×õ║ÄõĖĆõĖ¬ńē®õĮō
+ instance_ids[verts] = object_id
+ if object_id not in object_id_to_label_id:
+ object_id_to_label_id[object_id] = label_ids[verts][0]
+ # ÕīģÕø┤µĪåµĀ╝Õ╝ÅõĖ║ [x, y, z, dx, dy, dz, label_id]
+ # [x, y, z] µś»ÕīģÕø┤µĪåńÜäķćŹÕŖøõĖŁÕ┐ā, [dx, dy, dz] µś»õĖÄÕØɵĀćĶĮ┤Õ╣│ĶĪīńÜä
+ # [label_id] µś» 'nyu40id' µĀćÕćåõĖŗńÜäĶ»Łõ╣ēµĀćńŁŠ
+ # µ│©µäÅ’╝ÜÕøĀõĖ║õĖēń╗┤ÕīģÕø┤µĪåµś»õĖÄÕØɵĀćĶĮ┤Õ╣│ĶĪīńÜä’╝īµēĆõ╗źµŚŗĶĮ¼Ķ¦Æµś» 0
+ unaligned_bboxes = extract_bbox(mesh_vertices, object_id_to_segs,
+ object_id_to_label_id, instance_ids)
+ aligned_bboxes = extract_bbox(aligned_mesh_vertices, object_id_to_segs,
+ object_id_to_label_id, instance_ids)
+ ...
+
+ return mesh_vertices, label_ids, instance_ids, unaligned_bboxes, \
+ aligned_bboxes, object_id_to_label_id, axis_align_matrix
+
+```
+
+Õ£©õ╗ĵ»ÅõĖ¬Õ£║µÖ»ńÜäµē½µÅŵ¢ćõ╗ȵÅÉÕÅ¢µĢ░µŹ«ÕÉÄ’╝īÕ”éµ×£ÕĤզŗńé╣õ║æńé╣µĢ░Ķ┐ćÕżÜ’╝īÕÅ»õ╗źÕ░åÕģČõĖŗķććµĀĘ’╝łµ»öÕ”éÕł░ 50000 õĖ¬ńé╣’╝ē’╝īõĮåÕ£©õĖēń╗┤Ķ»Łõ╣ēÕłåÕē▓õ╗╗ÕŖĪõĖŁ’╝īńé╣õ║æõĖŹõ╝ÜĶó½õĖŗķććµĀĘŃĆ鵣żÕż¢’╝īÕ£© `nyu40id` µĀćÕćåõ╣ŗÕż¢ńÜäõĖŹÕÉłµ│ĢĶ»Łõ╣ēµĀćńŁŠµł¢ĶĆģÕÅ»ķĆēńÜä `DONOT CARE` ń▒╗Õł½µĀćńŁŠÕ║öĶó½Ķ┐ćµ╗żŃĆéµ£Ćń╗ł’╝īńé╣õ║æµ¢ćõ╗ČŃĆüĶ»Łõ╣ēµĀćńŁŠŃĆüÕ«×õŠŗµĀćńŁŠÕÆīń£¤Õ«×ńē®õĮōńÜäķøåÕÉłÕ║öĶó½ÕŁśÕé©õ║Ä `.npy` µ¢ćõ╗ČõĖŁŃĆé
+
+### µÅÉÕÅ¢ ScanNet RGB Ķē▓ÕĮ®µĢ░µŹ«’╝łÕÅ»ķĆēńÜä’╝ē
+
+ķĆÜĶ┐ćµÅÉÕÅ¢ ScanNet RGB Ķē▓ÕĮ®µĢ░µŹ«’╝īÕ»╣õ║ĵ»ÅõĖ¬Õ£║µÖ»µłæõ╗¼ÕŖĀĶĮĮ RGB ÕøŠÕāÅõĖÄķģŹÕźŚ 4x4 õĮŹÕ¦┐ń¤®ķśĄŃĆüÕŹĢõĖ¬ 4x4 ńøĖµ£║ÕåģÕÅéń¤®ķśĄńÜäķøåÕÉłŃĆéĶ»Ęµ│©µäÅ’╝īĶ┐ÖõĖƵŁźµś»ÕÅ»ķĆēńÜä’╝īķÖżķØ×Ķ”üĶ┐ÉĶĪīÕżÜĶ¦åÕøŠńē®õĮōµŻĆµĄŗ’╝īÕÉ”ÕłÖÕÅ»õ╗źńĢźÕÄ╗Ķ┐ÖµŁźŃĆé
+
+```shell
+python extract_posed_images.py
+```
+
+1201 õĖ¬Ķ«Łń╗āµĀʵ£¼’╝ī312 õĖ¬ķ¬īĶ»üµĀʵ£¼ÕÆī 100 õĖ¬µĄŗĶ»ĢµĀʵ£¼õĖŁńÜäµ»ÅõĖĆõĖ¬ķāĮÕīģÕɽõĖĆõĖ¬ÕŹĢńŗ¼ńÜä `.sens` µ¢ćõ╗ČŃĆéµ»öÕ”éĶ»┤’╝īÕ»╣õ║ÄÕ£║µÖ» `0001_01` µłæõ╗¼µ£ē `data/scannet/scans/scene0001_01/0001_01.sens`ŃĆéÕ»╣õ║ÄĶ┐ÖõĖ¬Õ£║µÖ»µēƵ£ēÕøŠÕāÅÕÆīõĮŹÕ¦┐µĢ░µŹ«ķāĮĶó½µÅÉÕÅ¢Ķć│ `data/scannet/posed_images/scene0001_01`ŃĆéÕģĘõĮōµØźĶ»┤’╝īĶ»źµ¢ćõ╗ČÕż╣õĖŗõ╝ܵ£ē 300 õĖ¬ xxxxx.jpg µĀ╝Õ╝ÅńÜäÕøŠÕāŵĢ░µŹ«’╝ī300 õĖ¬ xxxxx.txt µĀ╝Õ╝ÅńÜäńøĖµ£║õĮŹÕ¦┐µĢ░µŹ«ÕÆīõĖĆõĖ¬ÕŹĢńŗ¼ńÜä `intrinsic.txt` ÕåģÕÅéµ¢ćõ╗ČŃĆéķĆÜÕĖĖµØźĶ»┤’╝īõĖĆõĖ¬Õ£║µÖ»ÕīģÕɽµĢ░ÕŹāÕ╝ĀÕøŠÕāÅŃĆéķ╗śĶ«żµāģÕåĄõĖŗ’╝īµłæõ╗¼ÕŬõ╝ܵÅÉÕÅ¢ÕģČõĖŁńÜä 300 Õ╝Ā’╝īõ╗ÄĶĆīÕÅ¬ÕŹĀńö©Õ░æõ║Ä 100 Gb ńÜäń®║ķŚ┤ŃĆéĶ”üµā│µÅÉÕÅ¢µø┤ÕżÜÕøŠÕāÅ’╝īĶ»ĘõĮ┐ńö© `--max-images-per-scene` ÕÅéµĢ░ŃĆé
+
+### ÕłøÕ╗║µĢ░µŹ«ķøå
+
+```shell
+python tools/create_data.py scannet --root-path ./data/scannet \
+--out-dir ./data/scannet --extra-tag scannet
+```
+
+õĖŖĶ┐░µÅÉÕÅ¢ńÜäńé╣õ║æµ¢ćõ╗Č’╝īĶ»Łõ╣ēń▒╗Õł½µĀćµ│©µ¢ćõ╗Č’╝īÕÆīńē®õĮōÕ«×õŠŗµĀćµ│©µ¢ćõ╗ČĶó½Ķ┐øõĖƵŁźõ╗ź `.bin` µĀ╝Õ╝Åõ┐ØÕŁśŃĆéõĖĵŁżÕÉīµŚČ `.pkl` µĀ╝Õ╝ÅńÜäµ¢ćõ╗ČĶó½ńö¤µłÉÕ╣Čńö©õ║ÄĶ«Łń╗āÕÆīķ¬īĶ»üŃĆéĶÄĘÕÅ¢µĢ░µŹ«õ┐Īµü»ńÜäµĀĖÕ┐āÕćĮµĢ░ `process_single_scene` Õ”éõĖŗ’╝Ü
+
+```python
+def process_single_scene(sample_idx):
+
+ # ÕłåÕł½õ╗ź .bin µĀ╝Õ╝Åõ┐ØÕŁśńé╣õ║æµ¢ćõ╗Č’╝īĶ»Łõ╣ēń▒╗Õł½µĀćµ│©µ¢ćõ╗ČÕÆīńē®õĮōÕ«×õŠŗµĀćµ│©µ¢ćõ╗Č
+ # ĶÄĘÕÅ¢ info['pts_path']’╝īinfo['pts_instance_mask_path'] ÕÆī info['pts_semantic_mask_path']
+ ...
+
+ # ĶÄĘÕÅ¢µĀćµ│©
+ if has_label:
+ annotations = {}
+ # ÕīģÕø┤µĪåńÜäÕĮóńŖČõĖ║ [k, 6 + class]
+ aligned_box_label = self.get_aligned_box_label(sample_idx)
+ unaligned_box_label = self.get_unaligned_box_label(sample_idx)
+ annotations['gt_num'] = aligned_box_label.shape[0]
+ if annotations['gt_num'] != 0:
+ aligned_box = aligned_box_label[:, :-1] # k, 6
+ unaligned_box = unaligned_box_label[:, :-1]
+ classes = aligned_box_label[:, -1] # k
+ annotations['name'] = np.array([
+ self.label2cat[self.cat_ids2class[classes[i]]]
+ for i in range(annotations['gt_num'])
+ ])
+ # õĖ║õ║åÕÉæÕÉÄÕģ╝Õ«╣’╝īķ╗śĶ«żńÜäÕÅéµĢ░ÕÉŹĶĄŗõ║łõ║åõĖÄÕØɵĀćĶĮ┤Õ╣│ĶĪīńÜäÕīģÕø┤µĪå
+ # µłæõ╗¼ÕÉīµŚČõ┐ØÕŁśõ║åÕ»╣Õ║öńÜäõĖÄÕØɵĀćĶĮ┤õĖŹÕ╣│ĶĪīńÜäÕīģÕø┤µĪåńÜäõ┐Īµü»
+ annotations['location'] = aligned_box[:, :3]
+ annotations['dimensions'] = aligned_box[:, 3:6]
+ annotations['gt_boxes_upright_depth'] = aligned_box
+ annotations['unaligned_location'] = unaligned_box[:, :3]
+ annotations['unaligned_dimensions'] = unaligned_box[:, 3:6]
+ annotations[
+ 'unaligned_gt_boxes_upright_depth'] = unaligned_box
+ annotations['index'] = np.arange(
+ annotations['gt_num'], dtype=np.int32)
+ annotations['class'] = np.array([
+ self.cat_ids2class[classes[i]]
+ for i in range(annotations['gt_num'])
+ ])
+ axis_align_matrix = self.get_axis_align_matrix(sample_idx)
+ annotations['axis_align_matrix'] = axis_align_matrix # 4x4
+ info['annos'] = annotations
+ return info
+```
+
+Õ”éõĖŖµĢ░µŹ«ÕżäńÉåÕÉÄ’╝īµ¢ćõ╗Čńø«ÕĮĢń╗ōµ×äÕ║öÕ”éõĖŗ’╝Ü
+
+```
+scannet
+Ōö£ŌöĆŌöĆ meta_data
+Ōö£ŌöĆŌöĆ batch_load_scannet_data.py
+Ōö£ŌöĆŌöĆ load_scannet_data.py
+Ōö£ŌöĆŌöĆ scannet_utils.py
+Ōö£ŌöĆŌöĆ README.md
+Ōö£ŌöĆŌöĆ scans
+Ōö£ŌöĆŌöĆ scans_test
+Ōö£ŌöĆŌöĆ scannet_instance_data
+Ōö£ŌöĆŌöĆ points
+Ōöé Ōö£ŌöĆŌöĆ xxxxx.bin
+Ōö£ŌöĆŌöĆ instance_mask
+Ōöé Ōö£ŌöĆŌöĆ xxxxx.bin
+Ōö£ŌöĆŌöĆ semantic_mask
+Ōöé Ōö£ŌöĆŌöĆ xxxxx.bin
+Ōö£ŌöĆŌöĆ seg_info
+Ōöé Ōö£ŌöĆŌöĆ train_label_weight.npy
+Ōöé Ōö£ŌöĆŌöĆ train_resampled_scene_idxs.npy
+Ōöé Ōö£ŌöĆŌöĆ val_label_weight.npy
+Ōöé Ōö£ŌöĆŌöĆ val_resampled_scene_idxs.npy
+Ōö£ŌöĆŌöĆ posed_images
+Ōöé Ōö£ŌöĆŌöĆ scenexxxx_xx
+Ōöé Ōöé Ōö£ŌöĆŌöĆ xxxxxx.txt
+Ōöé Ōöé Ōö£ŌöĆŌöĆ xxxxxx.jpg
+Ōöé Ōöé Ōö£ŌöĆŌöĆ intrinsic.txt
+Ōö£ŌöĆŌöĆ scannet_infos_train.pkl
+Ōö£ŌöĆŌöĆ scannet_infos_val.pkl
+Ōö£ŌöĆŌöĆ scannet_infos_test.pkl
+```
+
+- `points/xxxxx.bin`’╝ÜõĖŗķććµĀĘÕÉÄ’╝īµ£¬õĖÄÕØɵĀćĶĮ┤Õ╣│ĶĪī’╝łÕŹ│µ▓Īµ£ēÕ»╣ķĮÉ’╝ēńÜäńé╣õ║æŃĆéÕøĀõĖ║ ScanNet 3D µŻĆµĄŗõ╗╗ÕŖĪÕ░åõĖÄÕØɵĀćĶĮ┤Õ╣│ĶĪīńÜäńé╣õ║æõĮ£õĖ║ĶŠōÕģź’╝īĶĆī ScanNet 3D Ķ»Łõ╣ēÕłåÕē▓õ╗╗ÕŖĪÕ░åÕ»╣ķĮÉÕēŹńÜäńé╣õ║æõĮ£õĖ║ĶŠōÕģź’╝īµłæõ╗¼ķĆēµŗ®ÕŁśÕé©Õ»╣ķĮÉÕēŹńÜäńé╣õ║æÕÆīÕ«āõ╗¼ńÜäÕ»╣ķĮÉń¤®ķśĄŃĆéĶ»Ęµ│©µäÅ’╝ÜÕ£© 3D µŻĆµĄŗńÜäķóäÕżäńÉåµĄüń©ŗ [`GlobalAlignment`](https://github.com/open-mmlab/mmdetection3d/blob/9f0b01caf6aefed861ef4c3eb197c09362d26b32/mmdet3d/datasets/pipelines/transforms_3d.py#L423) ÕÉÄ’╝īńé╣õ║æÕ░▒ķāĮµś»õĖÄÕØɵĀćĶĮ┤Õ╣│ĶĪīńÜäõ║åŃĆé
+- `instance_mask/xxxxx.bin`’╝ܵ»ÅõĖ¬ńé╣ńÜäÕ«×õŠŗµĀćńŁŠ’╝īÕĆ╝ńÜäĶīāÕø┤õĖ║’╝Ü\[0, NUM_INSTANCES\]’╝īÕģČõĖŁ 0 ĶĪ©ńż║µ▓Īµ£ēµĀćµ│©ŃĆé
+- `semantic_mask/xxxxx.bin`’╝ܵ»ÅõĖ¬ńé╣ńÜäĶ»Łõ╣ēµĀćńŁŠ’╝īÕĆ╝ńÜäĶīāÕø┤õĖ║’╝Ü\[1, 40\], õ╣¤Õ░▒µś» `nyu40id` ńÜäµĀćÕćåŃĆéĶ»Ęµ│©µäÅ’╝ÜÕ£©Ķ«Łń╗āµĄüń©ŗ `PointSegClassMapping` õĖŁ’╝ī`nyu40id` ńÜä ID õ╝ÜĶó½µśĀÕ░äÕł░Ķ«Łń╗ā IDŃĆé
+- `seg_info`’╝ÜõĖ║µö»µīüĶ»Łõ╣ēÕłåÕē▓õ╗╗ÕŖĪµēĆńö¤µłÉńÜäõ┐Īµü»µ¢ćõ╗ČŃĆé
+ - `train_label_weight.npy`’╝ܵ»ÅõĖĆĶ»Łõ╣ēń▒╗Õł½ńÜäµØāķćŹń│╗µĢ░ŃĆéÕøĀõĖ║ ScanNet õĖŁÕ▒×õ║ÄõĖŹÕÉīń▒╗ńÜäńé╣ńÜäµĢ░ķćÅńøĖÕĘ«ÕŠłÕż¦’╝īõĖĆõĖ¬ÕĖĖĶ¦üńÜäµōŹõĮ£µś»Õ£©Ķ«Īń«ŚµŹ¤Õż▒µŚČÕ»╣õĖŹÕÉīń▒╗Õł½Ķ┐øĶĪīÕŖĀµØā (label re-weighting) õ╗źÕŠŚÕł░µø┤ÕźĮńÜäÕłåÕē▓µĆ¦ĶāĮŃĆé
+ - `train_resampled_scene_idxs.npy`’╝ܵ»ÅõĖĆõĖ¬Õ£║µÖ» (µł┐ķŚ┤) ńÜäķćŹķććµĀʵĀćńŁŠŃĆéÕ£©Ķ«Łń╗āĶ┐ćń©ŗõĖŁ’╝īµłæõ╗¼õŠØµŹ«µ»ÅõĖ¬Õ£║µÖ»ńÜäńé╣ńÜäµĢ░ķćÅ’╝īõ╝ÜÕ»╣ÕģČĶ┐øĶĪīõĖŹÕÉīµ¼ĪµĢ░ńÜäķćŹķććµĀĘ’╝īõ╗źõ┐ØĶ»üĶ«Łń╗āµĢ░µŹ«ÕØćĶĪĪŃĆé
+- `posed_images/scenexxxx_xx`’╝Ü`.jpg` ÕøŠÕāÅńÜäķøåÕÉł’╝īĶ┐śÕīģÕɽ `.txt` µĀ╝Õ╝ÅńÜä 4x4 ńøĖµ£║Õ¦┐µĆüÕÆīÕŹĢõĖ¬ `.txt` µĀ╝Õ╝ÅńÜäńøĖµ£║ÕåģÕÅéń¤®ķśĄµ¢ćõ╗ČŃĆé
+- `scannet_infos_train.pkl`’╝ÜĶ«Łń╗āķøåńÜäµĢ░µŹ«õ┐Īµü»’╝īµ»ÅõĖ¬Õ£║µÖ»ńÜäÕģĘõĮōõ┐Īµü»Õ”éõĖŗ’╝Ü
+ - info\['lidar_points'\]’╝ÜÕŁŚÕģĖÕīģÕɽõĖĵ┐ĆÕģēķøĘĶŠŠńé╣ńøĖÕģ│ńÜäõ┐Īµü»ŃĆé
+ - info\['lidar_points'\]\['lidar_path'\]’╝ܵ┐ĆÕģēķøĘĶŠŠńé╣õ║æµĢ░µŹ«ńÜäµ¢ćõ╗ČÕÉŹŃĆé
+ - info\['lidar_points'\]\['num_pts_feats'\]’╝Üńé╣ńÜäńē╣ÕŠüń╗┤Õ║”ŃĆé
+ - info\['lidar_points'\]\['axis_align_matrix'\]’╝Üńö©õ║ÄÕ»╣ķĮÉÕØɵĀćĶĮ┤ńÜäÕÅśµŹóń¤®ķśĄŃĆé
+ - info\['pts_semantic_mask_path'\]’╝ÜĶ»Łõ╣ēÕłåÕē▓µĀćµ│©ńÜäµ¢ćõ╗ČÕÉŹŃĆé
+ - info\['pts_instance_mask_path'\]’╝ÜÕ«×õŠŗÕłåÕē▓µĀćµ│©ńÜäµ¢ćõ╗ČÕÉŹŃĆé
+ - info\['instances'\]’╝ÜÕŁŚÕģĖń╗䵳ÉńÜäÕłŚĶĪ©’╝īµ»ÅõĖ¬ÕŁŚÕģĖÕīģÕɽõĖĆõĖ¬Õ«×õŠŗńÜäµēƵ£ēµĀćµ│©õ┐Īµü»ŃĆéÕ»╣õ║ÄÕģČõĖŁńÜäń¼¼ i õĖ¬Õ«×õŠŗ’╝īµłæõ╗¼µ£ē’╝Ü
+ - info\['instances'\]\[i\]\['bbox_3d'\]’╝ÜķĢ┐Õ║”õĖ║ 6 ńÜäÕłŚĶĪ©’╝īõ╗ź (x, y, z, l, w, h) ńÜäķĪ║Õ║ÅĶĪ©ńż║µĘ▒Õ║”ÕØɵĀćń│╗õĖŗõĖÄÕØɵĀćĶĮ┤Õ╣│ĶĪīńÜä 3D ĶŠ╣ńĢīµĪåŃĆé
+ - info\[instances\]\[i\]\['bbox_label_3d'\]’╝Ü3D ĶŠ╣ńĢīµĪåńÜäµĀćńŁŠŃĆé
+- `scannet_infos_val.pkl`’╝Üķ¬īĶ»üķøåõĖŖńÜäµĢ░µŹ«õ┐Īµü»’╝īõĖÄ `scannet_infos_train.pkl` µĀ╝Õ╝ÅÕ«īÕģ©õĖĆĶć┤ŃĆé
+- `scannet_infos_test.pkl`’╝ܵĄŗĶ»ĢķøåõĖŖńÜäµĢ░µŹ«õ┐Īµü»’╝īõĖÄ `scannet_infos_train.pkl` µĀ╝Õ╝ÅÕćĀõ╣ÄÕ«īÕģ©õĖĆĶć┤’╝īķÖżõ║åń╝║Õ░æµĀćµ│©ŃĆé
+
+## Ķ«Łń╗āµĄüń©ŗ
+
+ScanNet Ķ┐øĶĪī **3D ńø«µĀ浯ƵĄŗ**ńÜäõĖĆń¦ŹÕģĖÕ×ŗµĢ░µŹ«ĶĮĮÕģźµĄüń©ŗÕ”éõĖŗµēĆńż║’╝Ü
+
+```python
+train_pipeline = [
+ dict(
+ type='LoadPointsFromFile',
+ coord_type='DEPTH',
+ shift_height=True,
+ load_dim=6,
+ use_dim=[0, 1, 2]),
+ dict(
+ type='LoadAnnotations3D',
+ with_bbox_3d=True,
+ with_label_3d=True,
+ with_mask_3d=True,
+ with_seg_3d=True),
+ dict(type='GlobalAlignment', rotation_axis=2),
+ dict(type='PointSegClassMapping'),
+ dict(type='PointSample', num_points=40000),
+ dict(
+ type='RandomFlip3D',
+ sync_2d=False,
+ flip_ratio_bev_horizontal=0.5,
+ flip_ratio_bev_vertical=0.5),
+ dict(
+ type='GlobalRotScaleTrans',
+ rot_range=[-0.087266, 0.087266],
+ scale_ratio_range=[1.0, 1.0],
+ shift_height=True),
+ dict(
+ type='Pack3DDetInputs',
+ keys=[
+ 'points', 'gt_bboxes_3d', 'gt_labels_3d', 'pts_semantic_mask',
+ 'pts_instance_mask'
+ ])
+]
+```
+
+- `GlobalAlignment`’╝ÜĶŠōÕģźńÜäńé╣õ║æÕ£©µ¢ĮÕŖĀõ║åÕØɵĀćĶĮ┤Õ╣│ĶĪīńÜäń¤®ķśĄÕÉÄÕ║öĶó½ĶĮ¼µŹóõĖ║õĖÄÕØɵĀćĶĮ┤Õ╣│ĶĪīńÜäÕĮóÕ╝ÅŃĆé
+- `PointSegClassMapping`’╝ÜĶ«Łń╗āõĖŁ’╝īÕŬµ£ēÕÉłµ│ĢńÜäń▒╗Õł½ ID µēŹõ╝ÜĶó½µśĀÕ░äÕł░ń▒╗Õł½µĀćńŁŠ’╝īµ»öÕ”é \[0, 18)ŃĆé
+- µĢ░µŹ«Õó×Õ╝║:
+ - `PointSample`’╝ÜõĖŗķććµĀĘĶŠōÕģźńé╣õ║æŃĆé
+ - `RandomFlip3D`’╝ÜķÜŵ£║ÕĘ”ÕÅ│µł¢ÕēŹÕÉÄń┐╗ĶĮ¼ńé╣õ║æŃĆé
+ - `GlobalRotScaleTrans`’╝ܵŚŗĶĮ¼ĶŠōÕģźńé╣õ║æ’╝īÕ»╣õ║Ä ScanNet Ķ¦ÆÕ║”ķĆÜÕĖĖĶÉĮÕģź \[-5, 5\]’╝łÕ║”’╝ēńÜäĶīāÕø┤’╝øÕ╣ȵöŠń╝®ĶŠōÕģźńé╣õ║æ’╝īÕ»╣õ║Ä ScanNet µ»öõŠŗķĆÜÕĖĖõĖ║ 1.0’╝łÕŹ│õĖŹÕüÜń╝®µöŠ’╝ē’╝øµ£ĆÕÉÄÕ╣│ń¦╗ĶŠōÕģźńé╣õ║æ’╝īÕ»╣õ║Ä ScanNet ķĆÜÕĖĖõĮŹń¦╗ķćÅõĖ║ 0’╝łÕŹ│õĖŹÕüÜõĮŹń¦╗’╝ēŃĆé
+
+ScanNet Ķ┐øĶĪī **3D Ķ»Łõ╣ēÕłåÕē▓**ńÜäõĖĆń¦ŹÕģĖÕ×ŗµĢ░µŹ«ĶĮĮÕģźµĄüń©ŗÕ”éõĖŗµēĆńż║’╝Ü
+
+```python
+train_pipeline = [
+ dict(
+ type='LoadPointsFromFile',
+ coord_type='DEPTH',
+ shift_height=False,
+ use_color=True,
+ load_dim=6,
+ use_dim=[0, 1, 2, 3, 4, 5]),
+ dict(
+ type='LoadAnnotations3D',
+ with_bbox_3d=False,
+ with_label_3d=False,
+ with_mask_3d=False,
+ with_seg_3d=True),
+ dict(
+ type='PointSegClassMapping'),
+ dict(
+ type='IndoorPatchPointSample',
+ num_points=num_points,
+ block_size=1.5,
+ ignore_index=len(class_names),
+ use_normalized_coord=False,
+ enlarge_size=0.2,
+ min_unique_num=None),
+ dict(type='NormalizePointsColor', color_mean=None),
+ dict(type='Pack3DDetInputs', keys=['points', 'pts_semantic_mask'])
+]
+```
+
+- `PointSegClassMapping`’╝ÜÕ£©Ķ«Łń╗āĶ┐ćń©ŗõĖŁ’╝īÕŬµ£ēĶó½õĮ┐ńö©ńÜäń▒╗Õł½ńÜäÕ║ÅÕÅĘõ╝ÜĶó½µśĀÕ░äÕł░ń▒╗õ╝╝ \[0, 20) ĶīāÕø┤ÕåģńÜäń▒╗Õł½µĀćńŁŠŃĆéÕģČõĮÖńÜäń▒╗Õł½Õ║ÅÕÅĘõ╝ÜĶó½ĶĮ¼µŹóõĖ║ `ignore_index` µēĆÕłČÕ«ÜńÜäÕ┐ĮńĢźµĀćńŁŠ’╝īÕ£©µ£¼õŠŗõĖŁµś» `20`ŃĆé
+- `IndoorPatchPointSample`’╝Üõ╗ÄĶŠōÕģźńé╣õ║æõĖŁĶŻüÕē¬õĖĆõĖ¬Õɽµ£ēÕø║իܵĢ░ķćÅńé╣ńÜäÕ░ÅÕØŚ (patch)ŃĆé`block_size` µīćÕ«Üõ║åĶŻüÕē¬ÕØŚńÜäĶŠ╣ķĢ┐’╝īÕ£© ScanNet õĖŖĶ┐ÖõĖ¬µĢ░ÕĆ╝õĖĆĶł¼Ķ«ŠńĮ«õĖ║ `1.5`ŃĆé
+- `NormalizePointsColor`’╝ÜÕ░åĶŠōÕģźńé╣ńÜäķó£Ķē▓õ┐Īµü»ÕĮÆõĖĆÕī¢’╝īķĆÜĶ┐ćÕ░å RGB ÕĆ╝ķÖżõ╗ź `255` µØźÕ«×ńÄ░ŃĆé
+
+## Ķ»äõ╝░µīćµĀć
+
+- **ńø«µĀ浯ƵĄŗ**’╝ÜķĆÜÕĖĖõĮ┐ńö©Õģ©ń▒╗Õ╣│ÕØćń▓ŠÕ║”’╝łmAP’╝ēµØźĶ»äõ╝░ ScanNet ńÜä 3D µŻĆµĄŗõ╗╗ÕŖĪńÜäµĆ¦ĶāĮ’╝īµ»öÕ”é `mAP@0.25` ÕÆī `mAP@0.5`ŃĆéÕģĘõĮōµØźĶ»┤’╝īĶ»äõ╝░µŚČĶ░āńö©õĖĆõĖ¬ķĆÜńö©ńÜäĶ«Īń«Ś 3D ńē®õĮōµŻĆµĄŗÕżÜõĖ¬ń▒╗Õł½ńÜäń▓ŠÕ║”ÕÆīÕżÕø×ńÄćńÜäÕćĮµĢ░ŃĆéµø┤ÕżÜń╗åĶŖéĶ»ĘÕÅéĶĆā [indoor_eval](https://github.com/open-mmlab/mmdetection3d/blob/dev-1.x/mmdet3d/evaluation/functional/indoor_eval.py)ŃĆé
+
+ **µ│©µäÅ**’╝ÜõĖÄÕ£©ń½ĀĶŖé`µÅÉÕÅ¢ ScanNet µĢ░µŹ«`õĖŁõ╗ŗń╗ŹńÜäķ鯵ĀĘ’╝īµēƵ£ēń£¤Õ«×ńē®õĮōńÜäõĖēń╗┤ÕīģÕø┤µĪåµś»õĖÄÕØɵĀćĶĮ┤Õ╣│ĶĪīńÜä’╝īõ╣¤Õ░▒µś»Ķ»┤µŚŗĶĮ¼Ķ¦ÆõĖ║ 0ŃĆéÕøĀµŁż’╝īķó䵥ŗÕīģÕø┤µĪåńÜäńĮæń╗£µÄźÕÅŚńÜäÕīģÕø┤µĪåµŚŗĶĮ¼Ķ¦ÆńøæńØŻõ╣¤µś» 0’╝īõĖöÕ£©ÕÉÄÕżäńÉåķśČµ«Ąµłæõ╗¼õĮ┐ńö©ķĆéńö©õ║ÄõĖÄÕØɵĀćĶĮ┤Õ╣│ĶĪīńÜäÕīģÕø┤µĪåńÜäķØ×µ×üÕż¦ÕĆ╝µŖæÕłČ’╝łNMS’╝ē’╝īĶ»źĶ┐ćń©ŗõĖŹõ╝ÜĶĆāĶÖæÕīģÕø┤µĪåńÜ䵌ŗĶĮ¼ŃĆé
+
+- **Ķ»Łõ╣ēÕłåÕē▓**’╝ÜķĆÜÕĖĖõĮ┐ńö©Õ╣│ÕØćõ║żÕ╣ȵ»ö (mean Intersection over Union, mIoU) µØźĶ»äõ╝░ ScanNet ńÜä 3D Ķ»Łõ╣ēÕłåÕē▓õ╗╗ÕŖĪńÜäµĆ¦ĶāĮŃĆéÕģĘõĮōĶĆīĶ©Ć’╝īµłæõ╗¼ÕģłĶ«Īń«ŚµēƵ£ēń▒╗Õł½ńÜä IoU’╝īńäČÕÉÄÕÅ¢Õ╣│ÕØćÕĆ╝õĮ£õĖ║ mIoUŃĆéµø┤ÕżÜÕ«×ńÄ░ń╗åĶŖéĶ»ĘÕÅéĶĆā [seg_eval.py](https://github.com/open-mmlab/mmdetection3d/blob/dev-1.x/mmdet3d/evaluation/functional/seg_eval.py)ŃĆé
+
+## Õ£©µĄŗĶ»ĢķøåõĖŖµĄŗĶ»ĢÕ╣ȵÅÉõ║żń╗ōµ×£
+
+ķ╗śĶ«żµāģÕåĄõĖŗ’╝īMMDet3D ńÜäõ╗ŻńĀüµś»Õ£©Ķ«Łń╗āķøåõĖŖĶ┐øĶĪīµ©ĪÕ×ŗĶ«Łń╗ā’╝īńäČÕÉÄÕ£©ķ¬īĶ»üķøåõĖŖĶ┐øĶĪīµ©ĪÕ×ŗµĄŗĶ»ĢŃĆé
+
+Õ”éµ×£õĮĀõ╣¤µā│Õ£©Õ£©ń║┐Õ¤║ÕćåõĖŖµĄŗĶ»Ģµ©ĪÕ×ŗńÜäµĆ¦ĶāĮ’╝łõ╗ģµö»µīüĶ»Łõ╣ēÕłåÕē▓’╝ē’╝īĶ»ĘÕ£©µĄŗĶ»ĢÕæĮõ╗żõĖŁÕŖĀõĖŖ `--format-only` ńÜäµĀćĶ«░’╝īÕÉīµŚČõ╣¤Ķ”üÕ░å ScanNet µĢ░µŹ«ķøå[ķģŹńĮ«µ¢ćõ╗Č](https://github.com/open-mmlab/mmdetection3d/blob/main/configs/_base_/datasets/scannet-seg.py#L126)õĖŁńÜä `ann_file=data_root + 'scannet_infos_val.pkl'` µö╣µłÉ `ann_file=data_root + 'scannet_infos_test.pkl'`ŃĆé
+
+Ķ»ĘĶ«░ÕŠŚķĆÜĶ┐ć `txt_prefix` µØźµīćիܵā│Ķ”üõ┐ØÕŁśµĄŗĶ»Ģń╗ōµ×£ńÜäµ¢ćõ╗ČÕż╣ÕÉŹń¦░ŃĆé
+
+õ╗ź PointNet++ (SSG) Õ£© ScanNet õĖŖńÜ䵥ŗĶ»ĢõĖ║õŠŗ’╝īõĮĀÕÅ»õ╗źĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗żµØźÕ«īµłÉµĄŗĶ»Ģń╗ōµ×£ńÜäõ┐ØÕŁś’╝Ü
+
+```
+./tools/dist_test.sh configs/pointnet2/pointnet2_ssg_16x2_cosine_200e_scannet-seg.py \
+ work_dirs/pointnet2_ssg/latest.pth --format-only \
+ --eval-options txt_prefix=work_dirs/pointnet2_ssg/test_submission
+```
+
+Õ£©õ┐ØÕŁśµĄŗĶ»Ģń╗ōµ×£ÕÉÄ’╝īõĮĀÕÅ»õ╗źÕ░åĶ»źµ¢ćõ╗ČÕż╣ÕÄŗń╝®’╝īńäČÕÉĵÅÉõ║żÕł░ [ScanNet Õ£©ń║┐µĄŗĶ»Ģµ£ŹÕŖĪÕÖ©](http://kaldir.vc.in.tum.de/scannet_benchmark/semantic_label_3d)õĖŖĶ┐øĶĪīķ¬īĶ»üŃĆé
diff --git a/internlm_langchain/knowledge_base/MMDetection3D/content/semantickitti.md b/internlm_langchain/knowledge_base/MMDetection3D/content/semantickitti.md
new file mode 100644
index 00000000..cd4f4dcb
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection3D/content/semantickitti.md
@@ -0,0 +1,129 @@
+# SemanticKITTI µĢ░µŹ«ķøå
+
+µ£¼ķĪĄµÅÉõŠøõ║åµ£ēÕģ│Õ£© MMDetection3D õĖŁõĮ┐ńö© SemanticKITTI µĢ░µŹ«ķøåńÜäÕģĘõĮōµĢÖń©ŗŃĆé
+
+## µĢ░µŹ«ķøåÕćåÕżć
+
+µé©ÕÅ»õ╗źÕ£©[Ķ┐Öķćī](http://semantic-kitti.org/dataset.html#download)õĖŗĶĮĮ SemanticKITTI µĢ░µŹ«ķøåÕ╣ČĶ¦ŻÕÄŗń╝®µēƵ£ē zip µ¢ćõ╗ČŃĆé
+
+ÕāÅÕćåÕżćµĢ░µŹ«ķøåńÜäõĖĆĶł¼µ¢╣µ│ĢõĖƵĀĘ’╝īÕ╗║Ķ««Õ░åµĢ░µŹ«ķøåµĀ╣ńø«ÕĮĢķōŠµÄźÕł░ `$MMDETECTION3D/data`ŃĆé
+
+Õ£©µłæõ╗¼ÕżäńÉåõ╣ŗÕēŹ’╝īµ¢ćõ╗ČÕż╣ń╗ōµ×äÕ║öµīēÕ”éõĖŗµ¢╣Õ╝Åń╗äń╗ć’╝Ü
+
+```
+mmdetection3d
+Ōö£ŌöĆŌöĆ mmdet3d
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+Ōö£ŌöĆŌöĆ data
+Ōöé Ōö£ŌöĆŌöĆ semantickitti
+Ōöé Ōöé Ōö£ŌöĆŌöĆ sequences
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ 00
+Ōöé Ōöé Ōöé Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ labels
+Ōöé Ōöé Ōöé Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ velodyne
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ 01
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ ..
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ 22
+```
+
+SemanticKITTI µĢ░µŹ«ķøåÕīģÕɽ 23 õĖ¬Õ║ÅÕłŚ’╝īÕģČõĖŁÕ║ÅÕłŚ \[0-7\] , \[9-10\] õĮ£õĖ║Ķ«Łń╗āķøå’╝łń║” 19k Ķ«Łń╗āµĀʵ£¼’╝ē’╝īÕ║ÅÕłŚ 8 õĮ£õĖ║ķ¬īĶ»üķøå’╝łń║” 4k ķ¬īĶ»üµĀʵ£¼’╝ē’╝ī\[11-22\] õĮ£õĖ║µĄŗĶ»Ģķøå ’╝łń║”20kµĄŗĶ»ĢµĀʵ£¼’╝ēŃĆéÕģČõĖŁµ»ÅõĖ¬Õ║ÅÕłŚÕłåÕł½ÕīģÕɽ velodyne ÕÆī labels õĖżõĖ¬µ¢ćõ╗ČÕż╣ÕłåÕł½ÕŁśµöŠµ┐ĆÕģēķøĘĶŠŠńé╣õ║æµĢ░µŹ«ÕÆīÕłåÕē▓µĀćµ│© (ÕģČõĖŁķ½ś16õĮŹÕŁśµöŠÕ«×õŠŗÕłåÕē▓µĀćµ│©’╝īõĮÄ16õĮŹÕŁśµöŠĶ»Łõ╣ēÕłåÕē▓µĀćµ│©)ŃĆé
+
+### ÕłøÕ╗║ SemanticKITTI µĢ░µŹ«ķøå
+
+µłæõ╗¼µÅÉõŠøõ║åńö¤µłÉµĢ░µŹ«ķøåõ┐Īµü»ńÜäĶäܵ£¼’╝īńö©õ║ĵĄŗĶ»ĢÕÆīĶ«Łń╗āŃĆéķĆÜĶ┐ćõ╗źõĖŗÕæĮõ╗żńö¤µłÉ `.pkl` µ¢ćõ╗Č’╝Ü
+
+```bash
+python ./tools/create_data.py semantickitti --root-path ./data/semantickitti --out-dir ./data/semantickitti --extra-tag semantickitti
+```
+
+ÕżäńÉåÕÉÄńÜäµ¢ćõ╗ČÕż╣ń╗ōµ×äÕ║öĶ»źÕ”éõĖŗ’╝Ü
+
+```
+mmdetection3d
+Ōö£ŌöĆŌöĆ mmdet3d
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+Ōö£ŌöĆŌöĆ data
+Ōöé Ōö£ŌöĆŌöĆ semantickitti
+Ōöé Ōöé Ōö£ŌöĆŌöĆ sequences
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ 00
+Ōöé Ōöé Ōöé Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ labels
+Ōöé Ōöé Ōöé Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ velodyne
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ 01
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ ..
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ 22
+Ōöé Ōöé Ōö£ŌöĆŌöĆ semantickitti_infos_test.pkl
+Ōöé Ōöé Ōö£ŌöĆŌöĆ semantickitti_infos_train.pkl
+Ōöé Ōöé Ōö£ŌöĆŌöĆ semantickitti_infos_val.pkl
+```
+
+- `semantickitti_infos_train.pkl`: Ķ«Łń╗āµĢ░µŹ«ķøå, Ķ»źÕŁŚÕģĖÕīģÕɽõĖżõĖ¬ķö«ÕĆ╝: `metainfo` ÕÆī `data_list`.
+ `metainfo` ÕīģÕɽĶ»źµĢ░µŹ«ķøåńÜäÕ¤║µ£¼õ┐Īµü»ŃĆé `data_list` µś»ńö▒ÕŁŚÕģĖń╗䵳ÉńÜäÕłŚĶĪ©’╝īµ»ÅõĖ¬ÕŁŚÕģĖ’╝łõ╗źõĖŗń«Ćń¦░ `info`’╝ēÕīģÕɽõ║åÕŹĢõĖ¬µĀʵ£¼ńÜäµēƵ£ēĶ»”ń╗åõ┐Īµü»ŃĆé
+ - info\['sample_id'\]’╝ÜĶ»źµĀʵ£¼Õ£©µĢ┤õĖ¬µĢ░µŹ«ķøåńÜäń┤óÕ╝ĢŃĆé
+ - info\['lidar_points'\]’╝ܵś»õĖĆõĖ¬ÕŁŚÕģĖ’╝īÕīģÕɽõ║åµ┐ĆÕģēķøĘĶŠŠńé╣ńøĖÕģ│ńÜäõ┐Īµü»ŃĆé
+ - info\['lidar_points'\]\['lidar_path'\]’╝ܵ┐ĆÕģēķøĘĶŠŠńé╣õ║æµĢ░µŹ«ńÜäµ¢ćõ╗ČÕÉŹŃĆé
+ - info\['lidar_points'\]\['num_pts_feats'\]’╝Üńé╣ńÜäńē╣ÕŠüń╗┤Õ║”
+ - info\['pts_semantic_mask_pth'\]’╝ÜõĖēń╗┤Ķ»Łõ╣ēÕłåÕē▓ńÜäµĀćµ│©µ¢ćõ╗ČńÜäµ¢ćõ╗ČĶĘ»ÕŠä
+
+µø┤ÕżÜń╗åĶŖéĶ»ĘÕÅéĶĆā [semantickitti_converter.py](https://github.com/open-mmlab/mmdetection3d/blob/dev-1.x/tools/dataset_converters/semantickitti_converter.py) ÕÆī [update_infos_to_v2.py ](https://github.com/open-mmlab/mmdetection3d/blob/dev-1.x/tools/dataset_converters/update_infos_to_v2.py) ŃĆé
+
+## Train pipeline
+
+õĖŗķØóÕ▒Ģńż║õ║åõĖĆõĖ¬õĮ┐ńö© SemanticKITTI µĢ░µŹ«ķøåĶ┐øĶĪī 3D Ķ»Łõ╣ēÕłåÕē▓ńÜäÕģĖÕ×ŗµĄüń©ŗ’╝Ü
+
+```python
+train_pipeline = [
+ dict(
+ type='LoadPointsFromFile',
+ coord_type='LIDAR',
+ load_dim=4,
+ use_dim=4,
+ backend_args=backend_args),
+ dict(
+ type='LoadAnnotations3D',
+ with_bbox_3d=False,
+ with_label_3d=False,
+ with_seg_3d=True,
+ seg_3d_dtype='np.int32',
+ seg_offset=2**16,
+ dataset_type='semantickitti',
+ backend_args=backend_args),
+ dict(type='PointSegClassMapping'),
+ dict(
+ type='RandomFlip3D',
+ sync_2d=False,
+ flip_ratio_bev_horizontal=0.5,
+ flip_ratio_bev_vertical=0.5),
+ dict(
+ type='GlobalRotScaleTrans',
+ rot_range=[-0.78539816, 0.78539816],
+ scale_ratio_range=[0.95, 1.05],
+ translation_std=[0.1, 0.1, 0.1],
+ ),
+ dict(type='Pack3DDetInputs', keys=['points', 'pts_semantic_mask'])
+]
+```
+
+- µĢ░µŹ«Õó×Õ╝║:
+ - `RandomFlip3D`’╝ÜÕ»╣ĶŠōÕģźńé╣õ║æµĢ░µŹ«Ķ┐øĶĪīķÜŵ£║Õ£░µ░┤Õ╣│ń┐╗ĶĮ¼µł¢ĶĆģÕ×éńø┤ń┐╗ĶĮ¼ŃĆé
+ - `GlobalRotScaleTrans`’╝ÜÕ»╣ĶŠōÕģźńé╣õ║æµĢ░µŹ«Ķ┐øĶĪīµŚŗĶĮ¼ŃĆüń╝®µöŠŃĆüÕ╣│ń¦╗ŃĆé
+
+## Ķ»äõ╝░
+
+õĮ┐ńö© 8 õĖ¬ GPU õ╗źÕÅŖ SemanticKITTI µīćµĀćĶ»äõ╝░ńÜä MinkUNet ńÜäńż║õŠŗÕ”éõĖŗ’╝Ü
+
+```shell
+bash tools/dist_test.sh configs/minkunet/minkunet_w32_8xb2-15e_semantickitti.py checkpoints/minkunet_w32_8xb2-15e_semantickitti_20230309_160710-7fa0a6f1.pth 8
+```
+
+## Õ║”ķćŵīćµĀć
+
+ķĆÜÕĖĖµłæõ╗¼õĮ┐ńö©Õ╣│ÕØćõ║żÕ╣ȵ»ö (mean Intersection over Union, mIoU) õĮ£õĖ║ SemanticKITTI Ķ»Łõ╣ēÕłåÕē▓õ╗╗ÕŖĪńÜäÕ║”ķćŵīćµĀćŃĆé
+ÕģĘõĮōĶĆīĶ©Ć’╝īµłæõ╗¼ÕģłĶ«Īń«ŚµēƵ£ēń▒╗Õł½ńÜä IoU’╝īńäČÕÉÄÕÅ¢Õ╣│ÕØćÕĆ╝õĮ£õĖ║ mIoUŃĆé
+µø┤ÕżÜÕ«×ńÄ░ń╗åĶŖéĶ»ĘÕÅéĶĆā [seg_eval.py](https://github.com/open-mmlab/mmdetection3d/blob/dev-1.x/mmdet3d/evaluation/functional/seg_eval.py)ŃĆé
+
+õ╗źõĖŗµś»õĖĆõĖ¬Ķ»äõ╝░ń╗ōµ×£ńÜäµĀĘõŠŗ:
+
+| classes | car | bicycle | motorcycle | truck | bus | person | bicyclist | motorcyclist | road | parking | sidewalk | other-ground | building | fence | vegetation | trunck | terrian | pole | traffic-sign | miou | acc | acc_cls |
+| ------- | ------ | ------- | ---------- | ------ | ------ | ------ | --------- | ------------ | ------ | ------- | -------- | ------------ | -------- | ------ | ---------- | ------ | ------- | ------ | ------------ | ------ | ------ | ------- |
+| results | 0.9687 | 0.1908 | 0.6313 | 0.8580 | 0.6359 | 0.6818 | 0.8444 | 0.0002 | 0.9353 | 0.4854 | 0.8106 | 0.0024 | 0.9050 | 0.6111 | 0.8822 | 0.6605 | 0.7493 | 0.6442 | 0.4837 | 0.6306 | 0.9202 | 0.6924 |
diff --git a/internlm_langchain/knowledge_base/MMDetection3D/content/sunrgbd.md b/internlm_langchain/knowledge_base/MMDetection3D/content/sunrgbd.md
new file mode 100644
index 00000000..3c3875e5
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection3D/content/sunrgbd.md
@@ -0,0 +1,250 @@
+# SUN RGB-D µĢ░µŹ«ķøå
+
+## µĢ░µŹ«ķøåńÜäÕćåÕżć
+
+Õ»╣õ║ĵĢ░µŹ«ķøåÕćåÕżćńÜäµĢ┤õĮōµĄüń©ŗ’╝īĶ»ĘÕÅéĶĆā SUN RGB-D ńÜä[µīćÕŹŚ](https://github.com/open-mmlab/mmdetection3d/blob/master/data/sunrgbd/README.md)ŃĆé
+
+### õĖŗĶĮĮ SUN RGB-D µĢ░µŹ«õĖÄÕĘźÕģĘÕīģ
+
+Õ£©[Ķ┐Öķćī](http://rgbd.cs.princeton.edu/data/)õĖŗĶĮĮ SUN RGB-D ńÜäµĢ░µŹ«ŃĆéµÄźõĖŗµØź’╝īÕ░å `SUNRGBD.zip`ŃĆü`SUNRGBDMeta2DBB_v2.mat`ŃĆü`SUNRGBDMeta3DBB_v2.mat` ÕÆī `SUNRGBDtoolbox.zip` ń¦╗ÕŖ©Õł░ `OFFICIAL_SUNRGBD` µ¢ćõ╗ČÕż╣’╝īÕ╣ČĶ¦ŻÕÄŗµ¢ćõ╗ČŃĆé
+
+õĖŗĶĮĮÕ«īµłÉÕÉÄ’╝īµĢ░µŹ«ÕżäńÉåõ╣ŗÕēŹńÜäµ¢ćõ╗Čńø«ÕĮĢń╗ōµ×äÕ”éõĖŗ’╝Ü
+
+```
+sunrgbd
+Ōö£ŌöĆŌöĆ README.md
+Ōö£ŌöĆŌöĆ matlab
+Ōöé Ōö£ŌöĆŌöĆ extract_rgbd_data_v1.m
+Ōöé Ōö£ŌöĆŌöĆ extract_rgbd_data_v2.m
+Ōöé Ōö£ŌöĆŌöĆ extract_split.m
+Ōö£ŌöĆŌöĆ OFFICIAL_SUNRGBD
+Ōöé Ōö£ŌöĆŌöĆ SUNRGBD
+Ōöé Ōö£ŌöĆŌöĆ SUNRGBDMeta2DBB_v2.mat
+Ōöé Ōö£ŌöĆŌöĆ SUNRGBDMeta3DBB_v2.mat
+Ōöé Ōö£ŌöĆŌöĆ SUNRGBDtoolbox
+```
+
+### õ╗ÄÕĤզŗµĢ░µŹ«õĖŁµÅÉÕÅ¢ 3D µŻĆµĄŗµēĆķ£ĆµĢ░µŹ«õĖĵĀćµ│©
+
+ķĆÜĶ┐ćĶ┐ÉĶĪīÕ”éõĖŗµīćõ╗żõ╗ÄÕĤզŗµ¢ćõ╗ČõĖŁµÅÉÕÅ¢Õć║ SUN RGB-D ńÜäµĀćµ│©’╝łĶ┐Öķ£ĆĶ”üµé©ńÜäµ£║ÕÖ©õĖŁÕ«ēĶŻģõ║å MATLAB’╝ē’╝Ü
+
+```bash
+matlab -nosplash -nodesktop -r 'extract_split;quit;'
+matlab -nosplash -nodesktop -r 'extract_rgbd_data_v2;quit;'
+matlab -nosplash -nodesktop -r 'extract_rgbd_data_v1;quit;'
+```
+
+õĖ╗Ķ”üńÜ䵣źķ¬żÕīģµŗ¼’╝Ü
+
+- µÅÉÕÅ¢Õć║Ķ«Łń╗āķøåÕÆīķ¬īĶ»üķøåńÜäń┤óÕ╝Ģµ¢ćõ╗Č’╝ø
+- õ╗ÄÕĤզŗµĢ░µŹ«õĖŁµÅÉÕÅ¢Õć║ 3D µŻĆµĄŗµēĆķ£ĆĶ”üńÜäµĢ░µŹ«’╝ø
+- õ╗ÄÕĤզŗńÜäµĀćµ│©µĢ░µŹ«õĖŁµÅÉÕÅ¢Õ╣Čń╗äń╗浯ƵĄŗõ╗╗ÕŖĪõĮ┐ńö©ńÜäµĀćµ│©µĢ░µŹ«ŃĆé
+
+ńö©õ║Äõ╗ĵĘ▒Õ║”ÕøŠõĖŁµÅÉÕÅ¢ńé╣õ║æµĢ░µŹ«ńÜä `extract_rgbd_data_v2.m` ńÜäõĖ╗Ķ”üķā©ÕłåÕ”éõĖŗ’╝Ü
+
+```matlab
+data = SUNRGBDMeta(imageId);
+data.depthpath(1:16) = '';
+data.depthpath = strcat('../OFFICIAL_SUNRGBD', data.depthpath);
+data.rgbpath(1:16) = '';
+data.rgbpath = strcat('../OFFICIAL_SUNRGBD', data.rgbpath);
+
+% õ╗ĵĘ▒Õ║”ÕøŠĶÄĘÕÅ¢ńé╣õ║æ
+[rgb,points3d,depthInpaint,imsize]=read3dPoints(data);
+rgb(isnan(points3d(:,1)),:) = [];
+points3d(isnan(points3d(:,1)),:) = [];
+points3d_rgb = [points3d, rgb];
+
+% MAT µ¢ćõ╗ȵ»ö TXT µ¢ćõ╗ČÕ░ÅõĖēÕĆŹŃĆéÕ£© Python õĖŁµłæõ╗¼ÕÅ»õ╗źõĮ┐ńö©
+% scipy.io.loadmat('xxx.mat')['points3d_rgb'] µØźÕŖĀĶĮĮµĢ░µŹ«
+mat_filename = strcat(num2str(imageId,'%06d'), '.mat');
+txt_filename = strcat(num2str(imageId,'%06d'), '.txt');
+% õ┐ØÕŁśńé╣õ║æµĢ░µŹ«
+parsave(strcat(depth_folder, mat_filename), points3d_rgb);
+```
+
+ńö©õ║ĵÅÉÕÅ¢Õ╣Čń╗äń╗浯ƵĄŗõ╗╗ÕŖĪµĀćµ│©ńÜä `extract_rgbd_data_v1.m` ńÜäõĖ╗Ķ”üķā©ÕłåÕ”éõĖŗ’╝Ü
+
+```matlab
+% ĶŠōÕć║ 2D ÕÆī 3D ÕīģÕø┤µĪå
+data2d = data;
+fid = fopen(strcat(det_label_folder, txt_filename), 'w');
+for j = 1:length(data.groundtruth3DBB)
+ centroid = data.groundtruth3DBB(j).centroid; % 3D ÕīģÕø┤µĪåõĖŁÕ┐ā
+ classname = data.groundtruth3DBB(j).classname; % ń▒╗ÕÉŹ
+ orientation = data.groundtruth3DBB(j).orientation; % 3D ÕīģÕø┤µĪåµ¢╣ÕÉæ
+ coeffs = abs(data.groundtruth3DBB(j).coeffs); % 3D ÕīģÕø┤µĪåÕż¦Õ░Å
+ box2d = data2d.groundtruth2DBB(j).gtBb2D; % 2D ÕīģÕø┤µĪå
+ fprintf(fid, '%s %d %d %d %d %f %f %f %f %f %f %f %f\n', classname, box2d(1), box2d(2), box2d(3), box2d(4), centroid(1), centroid(2), centroid(3), coeffs(1), coeffs(2), coeffs(3), orientation(1), orientation(2));
+end
+fclose(fid);
+```
+
+õĖŖķØóńÜäõĖżõĖ¬Ķäܵ£¼Ķ░āńö©õ║å SUN RGB-D µÅÉõŠøńÜä[ÕĘźÕģĘÕīģ](https://rgbd.cs.princeton.edu/data/SUNRGBDtoolbox.zip)õĖŁńÜäõĖĆõ║øÕćĮµĢ░’╝īÕ”é `read3dPoints`ŃĆé
+
+õĮ┐ńö©õĖŖĶ┐░Ķäܵ£¼µÅÉÕÅ¢µĢ░µŹ«ÕÉÄ’╝īµ¢ćõ╗Čńø«ÕĮĢń╗ōµ×äÕ║öÕ”éõĖŗ’╝Ü
+
+```
+sunrgbd
+Ōö£ŌöĆŌöĆ README.md
+Ōö£ŌöĆŌöĆ matlab
+Ōöé Ōö£ŌöĆŌöĆ extract_rgbd_data_v1.m
+Ōöé Ōö£ŌöĆŌöĆ extract_rgbd_data_v2.m
+Ōöé Ōö£ŌöĆŌöĆ extract_split.m
+Ōö£ŌöĆŌöĆ OFFICIAL_SUNRGBD
+Ōöé Ōö£ŌöĆŌöĆ SUNRGBD
+Ōöé Ōö£ŌöĆŌöĆ SUNRGBDMeta2DBB_v2.mat
+Ōöé Ōö£ŌöĆŌöĆ SUNRGBDMeta3DBB_v2.mat
+Ōöé Ōö£ŌöĆŌöĆ SUNRGBDtoolbox
+Ōö£ŌöĆŌöĆ sunrgbd_trainval
+Ōöé Ōö£ŌöĆŌöĆ calib
+Ōöé Ōö£ŌöĆŌöĆ depth
+Ōöé Ōö£ŌöĆŌöĆ image
+Ōöé Ōö£ŌöĆŌöĆ label
+Ōöé Ōö£ŌöĆŌöĆ label_v1
+Ōöé Ōö£ŌöĆŌöĆ seg_label
+Ōöé Ōö£ŌöĆŌöĆ train_data_idx.txt
+Ōöé Ōö£ŌöĆŌöĆ val_data_idx.txt
+```
+
+Õ£©Õ”éõĖŗµ»ÅõĖ¬µ¢ćõ╗ČÕż╣õĖŗ’╝īķāĮµ£ēµĆ╗Ķ«Ī 5285 õĖ¬Ķ«Łń╗āķøåµĀʵ£¼ÕÆī 5050 õĖ¬ķ¬īĶ»üķøåµĀʵ£¼’╝Ü
+
+- `calib`’╝Ü`.txt` ÕÉÄń╝ĆńÜäńøĖµ£║µĀćիܵ¢ćõ╗ČŃĆé
+- `depth`’╝Ü`.mat` ÕÉÄń╝ĆńÜäńé╣õ║æµ¢ćõ╗Č’╝īÕīģÕɽ xyz ÕØɵĀćÕÆī rgb Ķē▓ÕĮ®ÕĆ╝ŃĆé
+- `image`’╝Ü`.jpg` ÕÉÄń╝ĆńÜäõ║īń╗┤ÕøŠÕāŵ¢ćõ╗ČŃĆé
+- `label`’╝Ü`.txt` ÕÉÄń╝ĆńÜäńö©õ║ĵŻĆµĄŗõ╗╗ÕŖĪńÜäµĀćµ│©µĢ░µŹ«’╝łńēłµ£¼õ║ī’╝ēŃĆé
+- `label_v1`’╝Ü`.txt` ÕÉÄń╝ĆńÜäńö©õ║ĵŻĆµĄŗõ╗╗ÕŖĪńÜäµĀćµ│©µĢ░µŹ«’╝łńēłµ£¼õĖĆ’╝ēŃĆé
+- `seg_label`’╝Ü`.txt` ÕÉÄń╝ĆńÜäńö©õ║ÄÕłåÕē▓õ╗╗ÕŖĪńÜäµĀćµ│©µĢ░µŹ«ŃĆé
+
+ńø«ÕēŹ’╝īµłæõ╗¼õĮ┐ńö©ńēłµ£¼õĖĆńÜäµĢ░µŹ«ńö©õ║ÄĶ«Łń╗āõĖĵĄŗĶ»Ģ’╝īÕøĀµŁżńēłµ£¼õ║īńÜäµĀćµ│©Õ╣ȵ£¬õĮ┐ńö©ŃĆé
+
+### ÕłøÕ╗║µĢ░µŹ«ķøå
+
+Ķ»ĘĶ┐ÉĶĪīÕ”éõĖŗµīćõ╗żÕłøÕ╗║µĢ░µŹ«ķøå’╝Ü
+
+```shell
+python tools/create_data.py sunrgbd --root-path ./data/sunrgbd \
+--out-dir ./data/sunrgbd --extra-tag sunrgbd
+```
+
+µł¢ĶĆģ’╝īÕ”éµ×£õĮ┐ńö© slurm’╝īÕÅ»õ╗źõĮ┐ńö©Õ”éõĖŗµīćõ╗żµø┐õ╗Ż’╝Ü
+
+```
+bash tools/create_data.sh sunrgbd
+```
+
+õ╣ŗÕēŹµÅÉÕł░ńÜäńé╣õ║æµĢ░µŹ«Õ░▒õ╝ÜĶó½ÕżäńÉåÕ╣Čõ╗ź `.bin` µĀ╝Õ╝Åķ揵¢░ÕŁśÕé©ŃĆéõĖĵŁżÕÉīµŚČ’╝ī`.pkl` µ¢ćõ╗Čõ╣¤Ķó½ńö¤µłÉ’╝īńö©õ║ÄÕŁśÕ驵Ģ░µŹ«µĀćµ│©ÕÆīÕģāõ┐Īµü»ŃĆé
+
+Õ”éõĖŖµĢ░µŹ«ÕżäńÉåÕÉÄ’╝īµ¢ćõ╗Čńø«ÕĮĢń╗ōµ×äÕ║öÕ”éõĖŗ’╝Ü
+
+```
+sunrgbd
+Ōö£ŌöĆŌöĆ README.md
+Ōö£ŌöĆŌöĆ matlab
+Ōöé Ōö£ŌöĆŌöĆ ...
+Ōö£ŌöĆŌöĆ OFFICIAL_SUNRGBD
+Ōöé Ōö£ŌöĆŌöĆ ...
+Ōö£ŌöĆŌöĆ sunrgbd_trainval
+Ōöé Ōö£ŌöĆŌöĆ ...
+Ōö£ŌöĆŌöĆ points
+Ōö£ŌöĆŌöĆ sunrgbd_infos_train.pkl
+Ōö£ŌöĆŌöĆ sunrgbd_infos_val.pkl
+```
+
+- `points/xxxxxx.bin`’╝ÜķÖŹķććµĀĘÕÉÄńÜäńé╣õ║æµĢ░µŹ«ŃĆé
+- `sunrgbd_infos_train.pkl`’╝ÜĶ«Łń╗āķøåµĢ░µŹ«õ┐Īµü»’╝łµĀćµ│©õĖÄÕģāõ┐Īµü»’╝ē’╝īµ»ÅõĖ¬Õ£║µÖ»µēĆÕɽµĢ░µŹ«õ┐Īµü»ÕģĘõĮōÕ”éõĖŗ’╝Ü
+ - info\['lidar_points'\]’╝ÜÕŁŚÕģĖÕīģÕɽõ║åõĖĵ┐ĆÕģēķøĘĶŠŠńé╣ńøĖÕģ│ńÜäõ┐Īµü»ŃĆé
+ - info\['lidar_points'\]\['num_pts_feats'\]’╝Üńé╣ńÜäńē╣ÕŠüń╗┤Õ║”ŃĆé
+ - info\['lidar_points'\]\['lidar_path'\]’╝ܵ┐ĆÕģēķøĘĶŠŠńé╣õ║æµĢ░µŹ«ńÜäµ¢ćõ╗ČÕÉŹŃĆé
+ - info\['images'\]’╝ÜÕŁŚÕģĖÕīģÕɽõ║åõĖÄÕøŠÕāŵĢ░µŹ«ńøĖÕģ│ńÜäõ┐Īµü»ŃĆé
+ - info\['images'\]\['CAM0'\]\['img_path'\]’╝ÜÕøŠÕāÅńÜäµ¢ćõ╗ČÕÉŹŃĆé
+ - info\['images'\]\['CAM0'\]\['depth2img'\]’╝ܵĘ▒Õ║”Õł░ÕøŠÕāÅńÜäÕÅśµŹóń¤®ķśĄ’╝īÕĮóńŖČõĖ║ (4, 4)ŃĆé
+ - info\['images'\]\['CAM0'\]\['height'\]’╝ÜÕøŠÕāÅńÜäķ½śŃĆé
+ - info\['images'\]\['CAM0'\]\['width'\]’╝ÜÕøŠÕāÅńÜäÕ«ĮŃĆé
+ - info\['instances'\]’╝Üńö▒ÕŁŚÕģĖń╗䵳ÉńÜäÕłŚĶĪ©’╝īÕīģÕɽõ║åĶ»źÕĖ¦ńÜäµēƵ£ēµĀćµ│©õ┐Īµü»ŃĆéµ»ÅõĖ¬ÕŁŚÕģĖõĖÄÕŹĢõĖ¬Õ«×õŠŗńÜäµĀćµ│©ńøĖÕģ│ŃĆéÕ»╣õ║ÄÕģČõĖŁńÜäń¼¼ i õĖ¬Õ«×õŠŗ’╝īµłæõ╗¼µ£ē’╝Ü
+ - info\['instances'\]\[i\]\['bbox_3d'\]’╝ÜķĢ┐Õ║”õĖ║ 7 ńÜäÕłŚĶĪ©’╝īĶĪ©ńż║µĘ▒Õ║”ÕØɵĀćń│╗õĖŗńÜä 3D ĶŠ╣ńĢīµĪåŃĆé
+ - info\['instances'\]\[i\]\['bbox'\]’╝ÜķĢ┐Õ║”õĖ║ 4 ńÜäÕłŚĶĪ©’╝īõ╗ź (x1, y1, x2, y2) ńÜäķĪ║Õ║ÅĶĪ©ńż║Õ«×õŠŗńÜä 2D ĶŠ╣ńĢīµĪåŃĆé
+ - info\['instances'\]\[i\]\['bbox_label_3d'\]’╝ܵĢ┤µĢ░ĶĪ©ńż║Õ«×õŠŗńÜä 3D µĀćńŁŠ’╝ī-1 ĶĪ©ńż║Õ┐ĮńĢźĶ»źń▒╗Õł½ŃĆé
+ - info\['instances'\]\[i\]\['bbox_label'\]’╝ܵĢ┤µĢ░ĶĪ©ńż║Õ«×õŠŗńÜä 2D µĀćńŁŠ’╝ī-1 ĶĪ©ńż║Õ┐ĮńĢźĶ»źń▒╗Õł½ŃĆé
+- `sunrgbd_infos_val.pkl`’╝Üķ¬īĶ»üķøåõĖŖńÜäµĢ░µŹ«õ┐Īµü»’╝īõĖÄ `sunrgbd_infos_train.pkl` µĀ╝Õ╝ÅÕ«īÕģ©õĖĆĶć┤ŃĆé
+
+## Ķ«Łń╗āµĄüń©ŗ
+
+SUN RGB-D õĖŖń║»ńé╣õ║æ 3D ńē®õĮōµŻĆµĄŗńÜäÕģĖÕ×ŗµĄüń©ŗÕ”éõĖŗ’╝Ü
+
+```python
+train_pipeline = [
+ dict(
+ type='LoadPointsFromFile',
+ coord_type='DEPTH',
+ shift_height=True,
+ load_dim=6,
+ use_dim=[0, 1, 2]),
+ dict(type='LoadAnnotations3D'),
+ dict(
+ type='RandomFlip3D',
+ sync_2d=False,
+ flip_ratio_bev_horizontal=0.5,
+ ),
+ dict(
+ type='GlobalRotScaleTrans',
+ rot_range=[-0.523599, 0.523599],
+ scale_ratio_range=[0.85, 1.15],
+ shift_height=True),
+ dict(type='PointSample', num_points=20000),
+ dict(
+ type='Pack3DDetInputs',
+ keys=['points', 'gt_bboxes_3d', 'gt_labels_3d'])
+]
+```
+
+ńé╣õ║æõĖŖńÜäµĢ░µŹ«Õó×Õ╝║
+
+- `RandomFlip3D`’╝ÜķÜŵ£║ÕĘ”ÕÅ│µł¢ÕēŹÕÉÄń┐╗ĶĮ¼ĶŠōÕģźńé╣õ║æŃĆé
+- `GlobalRotScaleTrans`’╝ܵŚŗĶĮ¼ĶŠōÕģźńé╣õ║æ’╝īÕ»╣õ║Ä SUN RGB-D Ķ¦ÆÕ║”ķĆÜÕĖĖĶÉĮÕģź \[-30, 30\]’╝łÕ║”’╝ēńÜäĶīāÕø┤’╝øÕ╣ȵöŠń╝®ĶŠōÕģźńé╣õ║æ’╝īÕ»╣õ║Ä SUN RGB-D µ»öõŠŗķĆÜÕĖĖĶÉĮÕģź \[0.85, 1.15\] ńÜäĶīāÕø┤’╝øµ£ĆÕÉÄÕ╣│ń¦╗ĶŠōÕģźńé╣õ║æ’╝īÕ»╣õ║Ä SUN RGB-D ķĆÜÕĖĖõĮŹń¦╗ķćÅõĖ║ 0’╝łÕŹ│õĖŹÕüÜõĮŹń¦╗’╝ēŃĆé
+- `PointSample`’╝ÜķÖŹķććµĀĘĶŠōÕģźńé╣õ║æŃĆé
+
+SUN RGB-D õĖŖÕżÜµ©ĪµĆü’╝łńé╣õ║æÕÆīÕøŠÕāÅ’╝ē3D ńē®õĮōµŻĆµĄŗńÜäÕģĖÕ×ŗµĄüń©ŗÕ”éõĖŗ’╝Ü
+
+```python
+train_pipeline = [
+ dict(
+ type='LoadPointsFromFile',
+ coord_type='DEPTH',
+ shift_height=True,
+ load_dim=6,
+ use_dim=[0, 1, 2]),
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations3D'),
+ dict(type='LoadAnnotations', with_bbox=True),
+ dict(type='Resize', scale=(1333, 600), keep_ratio=True),
+ dict(type='RandomFlip', flip_ratio=0.0),
+ dict(type='Pad', size_divisor=32),
+ dict(
+ type='RandomFlip3D',
+ sync_2d=False,
+ flip_ratio_bev_horizontal=0.5,
+ ),
+ dict(
+ type='GlobalRotScaleTrans',
+ rot_range=[-0.523599, 0.523599],
+ scale_ratio_range=[0.85, 1.15],
+ shift_height=True),
+ dict(
+ type='Pack3DDetInputs',
+ keys=['points', 'gt_bboxes_3d', 'gt_labels_3d','img', 'gt_bboxes', 'gt_bboxes_labels'])
+]
+```
+
+ÕøŠÕāÅõĖŖńÜäµĢ░µŹ«Õó×Õ╝║
+
+- `Resize`’╝ܵö╣ÕÅśĶŠōÕģźÕøŠÕāÅńÜäÕż¦Õ░Å’╝ī`keep_ratio=True` µäÅÕæ│ńØĆÕøŠÕāÅńÜäµ»öõŠŗõĖŹµö╣ÕÅśŃĆé
+- `RandomFlip`’╝ÜķÜŵ£║Õ£░ń┐╗µŖśÕøŠÕāÅŃĆé
+
+ÕøŠÕāÅÕó×Õ╝║ńÜäÕ«×ńÄ░ÕÅ¢Ķć¬ [MMDetection](https://github.com/open-mmlab/mmdetection/tree/dev-3.x/mmdet/datasets/transforms)ŃĆé
+
+## Õ║”ķćŵīćµĀć
+
+õĖÄ ScanNet õĖƵĀĘ’╝īķĆÜÕĖĖõĮ┐ńö© mAP’╝łÕģ©ń▒╗Õ╣│ÕØćń▓ŠÕ║”’╝ēµØźĶ»äõ╝░ SUN RGB-D ńÜ䵯ƵĄŗõ╗╗ÕŖĪńÜäµĆ¦ĶāĮ’╝īµ»öÕ”é `mAP@0.25` ÕÆī `mAP@0.5`ŃĆéÕģĘõĮōµØźĶ»┤’╝īĶ»äõ╝░µŚČĶ░āńö©õĖĆõĖ¬ķĆÜńö©ńÜäĶ«Īń«Ś 3D ńē®õĮōµŻĆµĄŗÕżÜõĖ¬ń▒╗Õł½ńÜäń▓ŠÕ║”ÕÆīÕżÕø×ńÄćńÜäÕćĮµĢ░ŃĆéµø┤ÕżÜń╗åĶŖéĶ»ĘÕÅéĶĆā [`indoor_eval.py`](https://github.com/open-mmlab/mmdetection3d/blob/dev-1.x/mmdet3d/evaluation/functional/indoor_eval.py)ŃĆé
+
+ÕøĀõĖ║ SUN RGB-D ÕīģÕɽµ£ēÕøŠÕāŵĢ░µŹ«’╝īµēĆõ╗źÕøŠÕāÅõĖŖńÜäńē®õĮōµŻĆµĄŗõ╣¤µś»ÕÅ»ĶĪīńÜäŃĆéõĖŠõĖ¬õŠŗÕŁÉ’╝īÕ£© ImVoteNet õĖŁ’╝īµłæõ╗¼ķ”¢ÕģłĶ«Łń╗āõ║åõĖĆõĖ¬ÕøŠÕāŵŻĆµĄŗÕÖ©’╝īÕ╣ČõĖöõ╣¤õĮ┐ńö© mAP µīćµĀć’╝īÕ”é `mAP@0.5`’╝īµØźĶ»äõ╝░ÕģČĶĪ©ńÄ░ŃĆ鵳æõ╗¼õĮ┐ńö© [MMDetection](https://github.com/open-mmlab/mmdetection) Õ║ōõĖŁńÜä `eval_map` ÕćĮµĢ░µØźĶ«Īń«Ś mAPŃĆé
diff --git a/internlm_langchain/knowledge_base/MMDetection3D/content/train_test.md b/internlm_langchain/knowledge_base/MMDetection3D/content/train_test.md
new file mode 100644
index 00000000..3b475a44
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection3D/content/train_test.md
@@ -0,0 +1,254 @@
+# Õ£©µĀćµ│©µĢ░µŹ«ķøåõĖŖµĄŗĶ»ĢÕÆīĶ«Łń╗ā
+
+### Õ£©µĀćÕćåµĢ░µŹ«ķøåõĖŖµĄŗĶ»ĢÕĘ▓µ£ēµ©ĪÕ×ŗ
+
+- ÕŹĢµśŠÕŹĪ
+- CPU
+- ÕŹĢĶŖéńé╣ÕżÜµśŠÕŹĪ
+- ÕżÜĶŖéńé╣
+
+õĮĀÕÅ»õ╗źķĆÜĶ┐ćõ╗źõĖŗÕæĮõ╗żµØźµĄŗĶ»ĢµĢ░µŹ«ķøå’╝Ü
+
+```shell
+# ÕŹĢÕØŚµśŠÕŹĪµĄŗĶ»Ģ
+python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [--out ${RESULT_FILE}] [--eval ${EVAL_METRICS}] [--show] [--show-dir ${SHOW_DIR}]
+
+# CPU’╝Üń”üńö©µśŠÕŹĪÕ╣ČĶ┐ÉĶĪīÕŹĢÕØŚ CPU µĄŗĶ»ĢĶäܵ£¼’╝łÕ«×ķ¬īµĆ¦’╝ē
+export CUDA_VISIBLE_DEVICES=-1
+python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [--out ${RESULT_FILE}] [--eval ${EVAL_METRICS}] [--show] [--show-dir ${SHOW_DIR}]
+
+# ÕżÜÕØŚµśŠÕŹĪµĄŗĶ»Ģ
+./tools/dist_test.sh ${CONFIG_FILE} ${CHECKPOINT_FILE} ${GPU_NUM} [--out ${RESULT_FILE}] [--eval ${EVAL_METRICS}]
+```
+
+**µ│©µäÅ**:
+
+ńø«ÕēŹµłæõ╗¼ÕŬµö»µīü SMOKE ńÜä CPU µÄ©ńÉåµĄŗĶ»ĢŃĆé
+
+ÕÅ»ķĆēÕÅéµĢ░’╝Ü
+
+- `--show`’╝ÜÕ”éµ×£Ķó½µīćÕ«Ü’╝īµŻĆµĄŗń╗ōµ×£õ╝ÜÕ£©ķØÖķ╗śµ©ĪÕ╝ÅõĖŗĶó½õ┐ØÕŁś’╝īńö©õ║ÄĶ░āĶ»ĢÕÆīÕÅ»Ķ¦åÕī¢’╝īõĮåÕŬգ©ÕŹĢÕØŚ GPU µĄŗĶ»ĢńÜäµāģÕåĄõĖŗńö¤µĢł’╝īÕÆī `--show-dir` µÉŁķģŹõĮ┐ńö©ŃĆé
+- `--show-dir`’╝ÜÕ”éµ×£Ķó½µīćÕ«Ü’╝īµŻĆµĄŗń╗ōµ×£õ╝ÜĶó½õ┐ØÕŁśÕ£©µīćիܵ¢ćõ╗ČÕż╣õĖŗńÜä `***_points.obj` ÕÆī `***_pred.obj` µ¢ćõ╗ČõĖŁ’╝īńö©õ║ÄĶ░āĶ»ĢÕÆīÕÅ»Ķ¦åÕī¢’╝īõĮåÕŬգ©ÕŹĢÕØŚ GPU µĄŗĶ»ĢńÜäµāģÕåĄõĖŗńö¤µĢł’╝īÕ»╣õ║ÄĶ┐ÖõĖ¬ķĆēķĪ╣’╝īÕøŠÕĮóÕī¢ńĢīķØóÕ£©õĮĀńÜäńÄ»ÕóāõĖŁõĖŹµś»Õ┐ģķ£ĆńÜäŃĆé
+
+µēƵ£ēÕÆīĶ»äõ╝░ńøĖÕģ│ńÜäÕÅéµĢ░Õ£©ńøĖÕ║öńÜäµĢ░µŹ«ķøåķģŹńĮ«ńÜä `test_evaluator` õĖŁĶ«ŠńĮ«ŃĆéõŠŗÕ”é `test_evaluator = dict(type='KittiMetric', ann_file=data_root + 'kitti_infos_val.pkl', pklfile_prefix=None, submission_prefix=None)`
+
+ÕÅéµĢ░’╝Ü
+
+- `type`’╝ÜńøĖÕ»╣Õ║öńÜäĶ»äõ╗ʵīćµĀćÕÉŹ’╝īķĆÜÕĖĖÕÆīµĢ░µŹ«ķøåńøĖÕģ│ĶüöŃĆé
+- `ann_file`’╝ܵĀćµ│©µ¢ćõ╗ČĶĘ»ÕŠäŃĆé
+- `pklfile_prefix`’╝ÜÕÅ»ķĆēÕÅéµĢ░ŃĆéĶŠōÕć║ń╗ōµ×£õ┐ØÕŁśµłÉ pickle µĀ╝Õ╝ÅńÜäµ¢ćõ╗ČÕÉŹŃĆéÕ”éµ×£µ▓Īµ£ēµīćÕ«Ü’╝īń╗ōµ×£Õ░åõĖŹõ╝Üõ┐ØÕŁśµłÉµ¢ćõ╗ČŃĆé
+- `submission_prefix`’╝ÜÕÅ»ķĆēÕÅéµĢ░ŃĆéń╗ōµ×£Õ░åĶó½õ┐ØÕŁśÕł░µ¢ćõ╗ČõĖŁ’╝īńäČÕÉÄõĮĀÕÅ»õ╗źÕ░åÕ«āõĖŖõ╝ĀÕł░Õ«śµ¢╣Ķ»äõ╝░µ£ŹÕŖĪÕÖ©õĖŁŃĆé
+
+ńż║õŠŗ’╝Ü
+
+ÕüćÕ«ÜõĮĀÕĘ▓ń╗ŵŖŖµ©ĪÕ×ŗµØāķ揵¢ćõ╗ČõĖŗĶĮĮÕł░ `checkpoints/` µ¢ćõ╗ČÕż╣õĖŗ’╝ī
+
+1. Õ£© ScanNet µĢ░µŹ«ķøåõĖŖµĄŗĶ»Ģ VoteNet’╝īõ┐ØÕŁśµ©ĪÕ×ŗ’╝īÕÅ»Ķ¦åÕī¢ķó䵥ŗń╗ōµ×£
+
+ ```shell
+ python tools/test.py configs/votenet/votenet_8xb8_scannet-3d.py \
+ checkpoints/votenet_8x8_scannet-3d-18class_20200620_230238-2cea9c3a.pth \
+ --show --show-dir ./data/scannet/show_results
+ ```
+
+2. Õ£© ScanNet µĢ░µŹ«ķøåõĖŖµĄŗĶ»Ģ VoteNet’╝īõ┐ØÕŁśµ©ĪÕ×ŗ’╝īÕÅ»Ķ¦åÕī¢ķó䵥ŗń╗ōµ×£’╝īÕÅ»Ķ¦åÕī¢ń£¤Õ«×µĀćńŁŠ’╝īĶ«Īń«Ś mAP
+
+ ```shell
+ python tools/test.py configs/votenet/votenet_8xb8_scannet-3d.py \
+ checkpoints/votenet_8x8_scannet-3d-18class_20200620_230238-2cea9c3a.pth \
+ --show --show-dir ./data/scannet/show_results
+ ```
+
+3. Õ£© ScanNet µĢ░µŹ«ķøåõĖŖµĄŗĶ»Ģ VoteNet’╝łõĖŹõ┐ØÕŁśµĄŗĶ»Ģń╗ōµ×£’╝ē’╝īĶ«Īń«Ś mAP
+
+ ```shell
+ python tools/test.py configs/votenet/votenet_8xb8_scannet-3d.py \
+ checkpoints/votenet_8x8_scannet-3d-18class_20200620_230238-2cea9c3a.pth
+ ```
+
+4. õĮ┐ńö© 8 ÕØŚµśŠÕŹĪÕ£© KITTI µĢ░µŹ«ķøåõĖŖµĄŗĶ»Ģ SECOND’╝īĶ«Īń«Ś mAP
+
+ ```shell
+ ./tools/slurm_test.sh ${PARTITION} ${JOB_NAME} configs/second/second_hv_secfpn_8xb6-80e_kitti-3d-3class.py \
+ checkpoints/hv_second_secfpn_6x8_80e_kitti-3d-3class_20200620_230238-9208083a.pth
+ ```
+
+5. õĮ┐ńö© 8 ÕØŚµśŠÕŹĪÕ£© nuScenes µĢ░µŹ«ķøåõĖŖµĄŗĶ»Ģ PointPillars’╝īńö¤µłÉµÅÉõ║żń╗ÖÕ«śµ¢╣Ķ»äµĄŗµ£ŹÕŖĪÕÖ©ńÜä json µ¢ćõ╗Č
+
+ ```shell
+ ./tools/slurm_test.sh ${PARTITION} ${JOB_NAME} configs/pointpillars/pointpillars_hv_secfpn_sbn-all_8xb4-2x_nus-3d.py \
+ checkpoints/hv_pointpillars_fpn_sbn-all_4x8_2x_nus-3d_20200620_230405-2fa62f3d.pth \
+ --cfg-options 'test_evaluator.jsonfile_prefix=./pointpillars_nuscenes_results'
+ ```
+
+ ńö¤µłÉńÜäń╗ōµ×£õ╝Üõ┐ØÕŁśÕ£© `./pointpillars_nuscenes_results` ńø«ÕĮĢŃĆé
+
+6. õĮ┐ńö© 8 ÕØŚµśŠÕŹĪÕ£© KITTI µĢ░µŹ«ķøåõĖŖµĄŗĶ»Ģ SECOND’╝īńö¤µłÉµÅÉõ║żń╗ÖÕ«śµ¢╣Ķ»äµĄŗµ£ŹÕŖĪÕÖ©ńÜä txt µ¢ćõ╗Č
+
+ ```shell
+ ./tools/slurm_test.sh ${PARTITION} ${JOB_NAME} configs/second/second_hv_secfpn_8xb6-80e_kitti-3d-3class.py \
+ checkpoints/hv_second_secfpn_6x8_80e_kitti-3d-3class_20200620_230238-9208083a.pth \
+ --cfg-options 'test_evaluator.pklfile_prefix=./second_kitti_results' 'submission_prefix=./second_kitti_results'
+ ```
+
+ ńö¤µłÉńÜäń╗ōµ×£õ╝Üõ┐ØÕŁśÕ£© `./second_kitti_results` ńø«ÕĮĢŃĆé
+
+7. õĮ┐ńö© 8 ÕØŚµśŠÕŹĪÕ£© Lyft µĢ░µŹ«ķøåõĖŖµĄŗĶ»Ģ PointPillars’╝īńö¤µłÉµÅÉõ║żń╗ÖµÄÆĶĪīµ”£ńÜä pkl µ¢ćõ╗Č
+
+ ```shell
+ ./tools/slurm_test.sh ${PARTITION} ${JOB_NAME} configs/pointpillars/hv_pointpillars_fpn_sbn-2x8_2x_lyft-3d.py \
+ checkpoints/hv_pointpillars_fpn_sbn-2x8_2x_lyft-3d_latest.pth \
+ --cfg-options 'test_evaluator.jsonfile_prefix=results/pp_lyft/results_challenge' \
+ 'test_evaluator.csv_savepath=results/pp_lyft/results_challenge.csv' \
+ 'test_evaluator.pklfile_prefix=results/pp_lyft/results_challenge.pkl'
+ ```
+
+ **µ│©µäÅ**’╝ÜõĖ║õ║åńö¤µłÉ Lyft µĢ░µŹ«ķøåńÜäµÅÉõ║żń╗ōµ×£’╝ī`--eval-options` Õ┐ģķĪ╗µīćÕ«Ü `csv_savepath`ŃĆéńö¤µłÉ csv µ¢ćõ╗ČÕÉÄ’╝īõĮĀÕÅ»õ╗źõĮ┐ńö©[ńĮæń½Ö](https://www.kaggle.com/c/3d-object-detection-for-autonomous-vehicles/submit)õĖŖń╗ÖÕć║ńÜä kaggle ÕæĮõ╗żµÅÉõ║żń╗ōµ×£ŃĆé
+
+ µ│©µäÅÕ£© [Lyft µĢ░µŹ«ķøåńÜäķģŹńĮ«µ¢ćõ╗Č](../../configs/_base_/datasets/lyft-3d.py)’╝ī`test` õĖŁńÜä `ann_file` ÕĆ╝õĖ║ `lyft_infos_test.pkl`’╝īµś»µ▓Īµ£ēµĀćµ│©ńÜä Lyft Õ«śµ¢╣µĄŗĶ»ĢķøåŃĆéĶ”üÕ£©ķ¬īĶ»üµĢ░µŹ«ķøåõĖŖµĄŗĶ»Ģ’╝īĶ»ĘµŖŖÕ«āµö╣õĖ║ `lyft_infos_val.pkl`ŃĆé
+
+8. õĮ┐ńö© 8 ÕØŚµśŠÕŹĪÕ£© waymo µĢ░µŹ«ķøåõĖŖµĄŗĶ»Ģ PointPillars’╝īõĮ┐ńö© waymo Õ║”ķćŵ¢╣µ│ĢĶ«Īń«Ś mAP
+
+ ```shell
+ ./tools/slurm_test.sh ${PARTITION} ${JOB_NAME} configs/pointpillars/pointpillars_hv_secfpn_sbn-all_16xb2-2x_waymo-3d-car.py \
+ checkpoints/hv_pointpillars_secfpn_sbn-2x16_2x_waymo-3d-car_latest.pth \
+ --cfg-options 'test_evaluator.pklfile_prefix=results/waymo-car/kitti_results' \
+ 'test_evaluator.submission_prefix=results/waymo-car/kitti_results'
+ ```
+
+ **µ│©µäÅ**’╝ÜÕ»╣õ║Ä waymo µĢ░µŹ«ķøåõĖŖńÜäĶ»äõ╝░’╝īĶ»ĘµĀ╣µŹ«[Ķ»┤µśÄ](https://github.com/waymo-research/waymo-open-dataset/blob/master/docs/quick_start.md/)µ×äÕ╗║õ║īĶ┐øÕłČµ¢ćõ╗Č `compute_detection_metrics_main` µØźÕüÜÕ║”ķćÅĶ«Īń«Ś’╝īÕ╣ȵŖŖÕ«āµöŠÕ£© `mmdet3d/core/evaluation/waymo_utils/`ŃĆé’╝łÕ£©õĮ┐ńö© bazel µ×äÕ╗║ `compute_detection_metrics_main` µŚČ’╝īµ£ēµŚČõ╝ÜÕć║ńÄ░ `'round' is not a member of 'std'` ńÜäķöÖĶ»»’╝īµłæõ╗¼ÕŬķ£ĆĶ”üµŖŖķéŻõĖ¬µ¢ćõ╗ČõĖŁ `round` ÕēŹńÜä `std::` ÕÄ╗µÄēŃĆé’╝ēõ║īĶ┐øÕłČµ¢ćõ╗Čńö¤µłÉµŚČķ£ĆĶ”üÕ£© `--eval-options` õĖŁń╗ÖÕ«Ü `pklfile_prefix`ŃĆéÕ»╣õ║ÄÕ║”ķćŵ¢╣µ│Ģ’╝ī`waymo` µś»µÄ©ĶŹÉńÜäÕ«śµ¢╣Ķ»äõ╝░ńŁ¢ńĢź’╝īńø«ÕēŹ `kitti` Ķ»äõ╝░µś»õŠØńģ¦ KITTI ĶĆīµØźńÜä’╝īµ»ÅõĖ¬ķÜŠÕ║”ńÜäń╗ōµ×£ÕÆī KITTI ńÜäÕ«Üõ╣ēÕ╣ČõĖŹÕ«īÕģ©õĖĆĶć┤ŃĆéńø«ÕēŹÕż¦ÕżÜµĢ░ńē®õĮōķāĮĶó½µĀćĶ«░õĖ║0ķÜŠÕ║”’╝īõ╝ÜÕ£©µ£¬µØźõ┐«ÕżŹŃĆéÕ«āńÜäõĖŹń©│Õ«ÜÕĤÕøĀÕīģµŗ¼Ķ»äõ╝░ńÜäĶ«Īń«ŚÕż¦ŃĆüĶĮ¼µŹóÕÉÄńÜäµĢ░µŹ«ń╝║õ╣Åķü«µīĪÕÆīµł¬µ¢ŁŃĆüķÜŠÕ║”ńÜäÕ«Üõ╣ēõĖŹÕÉīõ╗źÕÅŖÕ╣│ÕØćń▓ŠÕ║”ńÜäĶ«Īń«Śµ¢╣µ│ĢõĖŹÕÉīŃĆé
+
+9. õĮ┐ńö© 8 ÕØŚµśŠÕŹĪÕ£© waymo µĢ░µŹ«ķøåõĖŖµĄŗĶ»Ģ PointPillars’╝īńö¤µłÉ bin µ¢ćõ╗ČÕ╣ȵÅÉõ║żÕł░µÄÆĶĪīµ”£
+
+ ```shell
+ ./tools/slurm_test.sh ${PARTITION} ${JOB_NAME} configs/pointpillars/pointpillars_hv_secfpn_sbn-all_16xb2-2x_waymo-3d-car.py \
+ checkpoints/hv_pointpillars_secfpn_sbn-2x16_2x_waymo-3d-car_latest.pth \
+ --cfg-options 'test_evaluator.pklfile_prefix=results/waymo-car/kitti_results' \
+ 'test_evaluator.submission_prefix=results/waymo-car/kitti_results'
+ ```
+
+ **µ│©µäÅ**’╝Üńö¤µłÉ bin µ¢ćõ╗ČÕÉÄ’╝īõĮĀÕÅ»õ╗źń«ĆÕŹĢÕ£░µ×äÕ╗║õ║īĶ┐øÕłČµ¢ćõ╗Č `create_submission`’╝īÕ╣ȵĀ╣µŹ«[Ķ»┤µśÄ](https://github.com/waymo-research/waymo-open-dataset/blob/master/docs/quick_start.md/)ÕłøÕ╗║µÅÉõ║żńÜäµ¢ćõ╗ČŃĆéĶ”üÕ£©ķ¬īĶ»üµ£ŹÕŖĪÕÖ©õĖŖĶ»äµĄŗķ¬īĶ»üµĢ░µŹ«ķøå’╝īõĮĀõ╣¤ÕÅ»õ╗źńö©ÕÉīµĀĘńÜäµ¢╣Õ╝Åńö¤µłÉµÅÉõ║żńÜäµ¢ćõ╗ČŃĆé
+
+## Õ£©µĀćÕćåµĢ░µŹ«ķøåõĖŖĶ«Łń╗āķóäÕ«Üõ╣ēµ©ĪÕ×ŗ
+
+MMDetection3D ÕłåÕł½ńö© `MMDistributedDataParallel` and `MMDataParallel` Õ«×ńÄ░õ║åÕłåÕĖāÕ╝ÅĶ«Łń╗āÕÆīķØ×ÕłåÕĖāÕ╝ÅĶ«Łń╗āŃĆé
+
+µēƵ£ēńÜäĶŠōÕć║’╝łµŚźÕ┐Śµ¢ćõ╗ČÕÆīµ©ĪÕ×ŗµØāķ揵¢ćõ╗Č’╝ēķāĮõ╝ÜĶó½õ┐ØÕŁśÕł░ÕĘźõĮ£ńø«ÕĮĢõĖŗ’╝īķĆÜĶ┐ćķģŹńĮ«µ¢ćõ╗ČķćīńÜä `work_dir` µīćÕ«ÜŃĆé
+
+ķ╗śĶ«żµłæõ╗¼µ»ÅĶ┐ćõĖĆõĖ¬Õ橵£¤ķāĮÕ£©ķ¬īĶ»üµĢ░µŹ«ķøåõĖŖĶ»äµĄŗµ©ĪÕ×ŗ’╝īõĮĀÕÅ»õ╗źķĆÜĶ┐ćÕ£©Ķ«Łń╗āķģŹńĮ«ķćīµĘ╗ÕŖĀķŚ┤ķÜöÕÅéµĢ░µØźµö╣ÕÅśĶ»äµĄŗńÜ䵌ČķŚ┤ķŚ┤ķÜö’╝Ü
+
+```python
+train_cfg = dict(type='EpochBasedTrainLoop', val_interval=1) # µ»Å12õĖ¬Õ橵£¤Ķ»äõ╝░õĖƵ¼Īµ©ĪÕ×ŗ
+```
+
+**ķćŹĶ”ü**’╝ÜķģŹńĮ«µ¢ćõ╗ČõĖŁńÜäķ╗śĶ«żÕŁ”õ╣ĀńÄćÕ»╣Õ║ö 8 ÕØŚµśŠÕŹĪ’╝īķģŹńĮ«µ¢ćõ╗ČÕÉŹķćīµ£ēÕģĘõĮōńÜäµē╣ķćÅÕż¦Õ░Å’╝īµ»öÕ”é '2xb8' ĶĪ©ńż║õĖĆÕģ▒ 8 ÕØŚµśŠÕŹĪ’╝īµ»ÅÕØŚµśŠÕŹĪ 2 õĖ¬µĀʵ£¼ŃĆé
+µĀ╣µŹ« [Linear Scaling Rule](https://arxiv.org/abs/1706.02677)’╝īÕĮōõĮĀõĮ┐ńö©õĖŹÕÉīµĢ░ķćÅńÜ䵜ŠÕŹĪµł¢µ»ÅÕØŚµśŠÕŹĪµ£ēõĖŹÕÉīµĢ░ķćÅńÜäÕøŠÕāŵŚČ’╝īķ£ĆĶ”üõŠØµē╣ķćÅÕż¦Õ░ŵīēµ»öõŠŗĶ░āµĢ┤ÕŁ”õ╣ĀńÄćŃĆéÕ”éµ×£ńö© 4 ÕØŚµśŠÕŹĪŃĆüµ»ÅÕØŚµśŠÕŹĪ 2 Õ╣ģÕøŠÕāŵŚČÕŁ”õ╣ĀńÄćõĖ║ 0.01’╝īķéŻõ╣łńö© 16 ÕØŚµśŠÕŹĪŃĆüµ»ÅÕØŚµśŠÕŹĪ 4 Õ╣ģÕøŠÕāŵŚČÕŁ”õ╣ĀńÄćÕ║öĶ«ŠõĖ║ 0.08ŃĆéńäČĶĆī’╝īńö▒õ║ÄÕż¦ÕżÜµĢ░µ©ĪÕ×ŗõĮ┐ńö© ADAM ĶĆīõĖŹµś» SGD Ķ┐øĶĪīõ╝śÕī¢’╝īõĖŖĶ┐░Ķ¦äÕłÖÕÅ»ĶāĮÕ╣ČõĖŹķĆéńö©’╝īńö©µłĘķ£ĆĶ”üĶć¬ÕĘ▒Ķ░āµĢ┤ÕŁ”õ╣ĀńÄćŃĆé
+
+### õĮ┐ńö©ÕŹĢÕØŚµśŠÕŹĪĶ┐øĶĪīĶ«Łń╗ā
+
+```shell
+python tools/train.py ${CONFIG_FILE} [optional arguments]
+```
+
+Õ”éµ×£õĮĀµā│Õ£©ÕæĮõ╗żõĖŁµīćÕ«ÜÕĘźõĮ£ńø«ÕĮĢ’╝īµĘ╗ÕŖĀÕÅéµĢ░ `--work-dir ${YOUR_WORK_DIR}`ŃĆé
+
+### õĮ┐ńö© CPU Ķ┐øĶĪīĶ«Łń╗ā (Õ«×ķ¬īµĆ¦)
+
+Õ£© CPU õĖŖĶ«Łń╗āńÜäĶ┐ćń©ŗõĖÄÕŹĢ GPU Ķ«Łń╗āõĖĆĶć┤ŃĆé µłæõ╗¼ÕŬķ£ĆĶ”üÕ£©Ķ«Łń╗āĶ┐ćń©ŗõ╣ŗÕēŹń”üńö©µśŠÕŹĪŃĆé
+
+```shell
+export CUDA_VISIBLE_DEVICES=-1
+```
+
+õ╣ŗÕÉÄĶ┐ÉĶĪīÕŹĢµśŠÕŹĪĶ«Łń╗āĶäܵ£¼ÕŹ│ÕÅ»ŃĆé
+
+**µ│©µäÅ**’╝Ü
+
+ńø«ÕēŹ’╝īÕż¦ÕżÜµĢ░ńé╣õ║æńøĖÕģ│ń«Śµ│ĢķāĮõŠØĶĄ¢õ║Ä 3D CUDA ń«ŚÕŁÉ’╝īµŚĀµ│ĢÕ£© CPU õĖŖĶ┐øĶĪīĶ«Łń╗āŃĆé õĖĆõ║øÕŹĢńø« 3D ńē®õĮōµŻĆµĄŗń«Śµ│Ģ’╝īõŠŗÕ”é FCOS3DŃĆüSMOKE ÕÅ»õ╗źÕ£© CPU õĖŖĶ┐øĶĪīĶ«Łń╗āŃĆ鵳æõ╗¼õĖŹµÄ©ĶŹÉńö©µłĘõĮ┐ńö© CPU Ķ┐øĶĪīĶ«Łń╗ā’╝īĶ┐ÖÕż¬Ķ┐ćń╝ōµģóŃĆ鵳æõ╗¼µö»µīüĶ┐ÖõĖ¬ÕŖ¤ĶāĮµś»õĖ║õ║åµ¢╣õŠ┐ńö©µłĘÕ£©µ▓Īµ£ēµśŠÕŹĪńÜäµ£║ÕÖ©õĖŖĶ░āĶ»Ģµ¤Éõ║øńē╣Õ«ÜńÜäµ¢╣µ│ĢŃĆé
+
+### õĮ┐ńö©ÕżÜÕØŚµśŠÕŹĪĶ┐øĶĪīĶ«Łń╗ā
+
+```shell
+./tools/dist_train.sh ${CONFIG_FILE} ${GPU_NUM} [optional arguments]
+```
+
+ÕÅ»ķĆēÕÅéµĢ░’╝Ü
+
+- `--cfg-options 'Key=value'`’╝ÜĶ”åńø¢õĮ┐ńö©ńÜäķģŹńĮ«õĖŁńÜäõĖĆõ║øĶ«ŠÕ«ÜŃĆé
+
+### õĮ┐ńö©ÕżÜõĖ¬µ£║ÕÖ©Ķ┐øĶĪīĶ«Łń╗ā
+
+Õ”éµ×£Ķ”üÕ£© [slurm](https://slurm.schedmd.com/) ń«ĪńÉåńÜäķøåńŠżõĖŖĶ┐ÉĶĪī MMDectection3D’╝īõĮĀÕÅ»õ╗źõĮ┐ńö© `slurm_train.sh` Ķäܵ£¼’╝łĶ»źĶäܵ£¼õ╣¤µö»µīüÕŹĢµ£║Ķ«Łń╗ā’╝ē
+
+```shell
+[GPUS=${GPUS}] ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} ${CONFIG_FILE} ${WORK_DIR}
+```
+
+õĖŗķØ󵜻õĖĆõĖ¬õĮ┐ńö© 16 ÕØŚµśŠÕŹĪÕ£© dev ÕłåÕī║õĖŖĶ«Łń╗ā Mask R-CNN ńÜäńż║õŠŗ’╝Ü
+
+```shell
+GPUS=16 ./tools/slurm_train.sh dev pp_kitti_3class configs/pointpillars/pointpillars_hv_secfpn_8xb6-160e_kitti-3d-3class.py /nfs/xxxx/pp_kitti_3class
+```
+
+õĮĀÕÅ»õ╗źµ¤źń£ŗ [slurm_train.sh](https://github.com/open-mmlab/mmdetection/blob/master/tools/slurm_train.sh) µØźĶÄĘÕÅ¢µēƵ£ēńÜäÕÅéµĢ░ÕÆīńÄ»ÕóāÕÅśķćÅŃĆé
+
+Õ”éµ×£µé©µā│õĮ┐ńö©ńö▒ ethernet Ķ┐׵ğĶĄĘµØźńÜäÕżÜÕÅ░µ£║ÕÖ©’╝ī µé©ÕÅ»õ╗źõĮ┐ńö©õ╗źõĖŗÕæĮõ╗ż:
+
+Õ£©ń¼¼õĖĆÕÅ░µ£║ÕÖ©õĖŖ:
+
+```shell
+NNODES=2 NODE_RANK=0 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR ./tools/dist_train.sh $CONFIG $GPUS
+```
+
+Õ£©ń¼¼õ║īÕÅ░µ£║ÕÖ©õĖŖ:
+
+```shell
+NNODES=2 NODE_RANK=1 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR ./tools/dist_train.sh $CONFIG $GPUS
+```
+
+õĮåµś»’╝īÕ”éµ×£µé©õĖŹõĮ┐ńö©ķ½śķƤńĮæĶĘ»Ķ┐׵ğĶ┐ÖÕćĀÕÅ░µ£║ÕÖ©ńÜäĶ»Ø’╝īĶ«Łń╗āÕ░åõ╝ÜķØ×ÕĖĖµģóŃĆé
+
+### Õ£©ÕŹĢõĖ¬µ£║ÕÖ©õĖŖÕÉ»ÕŖ©ÕżÜõĖ¬õ╗╗ÕŖĪ
+
+Õ”éµ×£õĮĀÕ£©ÕŹĢõĖ¬µ£║ÕÖ©õĖŖÕÉ»ÕŖ©ÕżÜõĖ¬õ╗╗ÕŖĪ’╝īµ»öÕ”é’╝īÕ£©Õģʵ£ē8ÕØŚµśŠÕŹĪńÜäµ£║ÕÖ©õĖŖĶ┐øĶĪī2õĖ¬4ÕØŚµśŠÕŹĪĶ«Łń╗āńÜäõ╗╗ÕŖĪ’╝īõĮĀķ£ĆĶ”üõĖ║µ»ÅõĖ¬õ╗╗ÕŖĪµīćÕ«ÜõĖŹÕÉīńÜäń½»ÕÅŻ’╝łķ╗śĶ«żõĖ║29500’╝ēõ╗źķü┐ÕģŹķĆÜõ┐ĪÕå▓ń¬üŃĆé
+
+Õ”éµ×£õĮĀõĮ┐ńö© `dist_train.sh` ÕÉ»ÕŖ©Ķ«Łń╗āõ╗╗ÕŖĪ’╝īÕÅ»õ╗źÕ£©ÕæĮõ╗żõĖŁĶ«ŠńĮ«ń½»ÕÅŻ’╝Ü
+
+```shell
+CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 ./tools/dist_train.sh ${CONFIG_FILE} 4
+CUDA_VISIBLE_DEVICES=4,5,6,7 PORT=29501 ./tools/dist_train.sh ${CONFIG_FILE} 4
+```
+
+Õ”éµ×£õĮĀõĮ┐ńö© Slurm ÕÉ»ÕŖ©Ķ«Łń╗āõ╗╗ÕŖĪ’╝īµ£ēõĖżń¦Źµ¢╣Õ╝ŵīćÕ«Üń½»ÕÅŻ’╝Ü
+
+1. ķĆÜĶ┐ć `--cfg-options` Ķ«ŠńĮ«ń½»ÕÅŻ’╝īĶ┐Öµś»µø┤µÄ©ĶŹÉńÜä’╝īÕøĀõĖ║Õ«āõĖŹµö╣ÕÅśÕĤµØźńÜäķģŹńĮ«
+
+ ```shell
+ CUDA_VISIBLE_DEVICES=0,1,2,3 GPUS=4 ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} config1.py ${WORK_DIR} --cfg-options 'env_cfg.dist_cfg.port=29500'
+ CUDA_VISIBLE_DEVICES=4,5,6,7 GPUS=4 ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} config2.py ${WORK_DIR} --cfg-options 'env_cfg.dist_cfg.port=29501'
+ ```
+
+2. õ┐«µö╣ķģŹńĮ«µ¢ćõ╗Č’╝łķĆÜÕĖĖÕ£©ķģŹńĮ«µ¢ćõ╗ČńÜäÕĆƵĢ░ń¼¼6ĶĪī’╝ēµØźĶ«ŠńĮ«õĖŹÕÉīńÜäķĆÜõ┐Īń½»ÕÅŻ
+
+ Õ£© `config1.py` õĖŁ’╝ī
+
+ ```python
+ env_cfg = dict(
+ dist_cfg=dict(backend='nccl', port=29500)
+ )
+ ```
+
+ Õ£© `config2.py` õĖŁ’╝ī
+
+ ```python
+ env_cfg = dict(
+ dist_cfg=dict(backend='nccl', port=29501)
+ )
+ ```
+
+ ńäČÕÉÄ’╝īõĮĀÕÅ»õ╗źõĮ┐ńö© `config1.py` and `config2.py` ÕÉ»ÕŖ©õĖżõĖ¬õ╗╗ÕŖĪ
+
+ ```shell
+ CUDA_VISIBLE_DEVICES=0,1,2,3 GPUS=4 ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} config1.py ${WORK_DIR}
+ CUDA_VISIBLE_DEVICES=4,5,6,7 GPUS=4 ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} config2.py ${WORK_DIR}
+ ```
diff --git a/internlm_langchain/knowledge_base/MMDetection3D/content/useful_tools.md b/internlm_langchain/knowledge_base/MMDetection3D/content/useful_tools.md
new file mode 100644
index 00000000..5cd256c7
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection3D/content/useful_tools.md
@@ -0,0 +1,211 @@
+µłæõ╗¼Õ£© `tools/` µ¢ćõ╗ČÕż╣ĶĘ»ÕŠäõĖŗµÅÉõŠøõ║åĶ«ĖÕżÜµ£ēńö©ńÜäÕĘźÕģĘŃĆé
+
+## µŚźÕ┐ŚÕłåµ×É
+
+ń╗ÖÕ«ÜõĖĆõĖ¬Ķ«Łń╗āńÜ䵌źÕ┐Śµ¢ćõ╗Č’╝īµé©ÕÅ»õ╗źń╗śÕłČÕć║ loss/mAP µø▓ń║┐ŃĆéķ”¢Õģłķ£ĆĶ”üĶ┐ÉĶĪī `pip install seaborn` Õ«ēĶŻģõŠØĶĄ¢ÕīģŃĆé
+
+
+
+```shell
+python tools/analysis_tools/analyze_logs.py plot_curve [--keys ${KEYS}] [--title ${TITLE}] [--legend ${LEGEND}] [--backend ${BACKEND}] [--style ${STYLE}] [--out ${OUT_FILE}] [--mode ${MODE}] [--interval ${INTERVAL}]
+```
+
+**µ│©µäÅ**: Õ”éµ×£µé©µā│ń╗śÕłČńÜäµīćµĀ浜»Õ£©ķ¬īĶ»üķśČµ«ĄĶ«Īń«ŚÕŠŚÕł░ńÜä’╝īµé©ķ£ĆĶ”üµĘ╗ÕŖĀõĖĆõĖ¬µĀćÕ┐Ś `--mode eval` ’╝īÕ”éµ×£µé©µ»Åń╗ÅĶ┐ćõĖĆõĖ¬ `${INTERVAL}` ńÜäķŚ┤ķÜöĶ┐øĶĪīĶ»äõ╝░’╝īµé©ķ£ĆĶ”üÕó×ÕŖĀõĖĆõĖ¬ÕÅéµĢ░ `--interval ${INTERVAL}`ŃĆé
+
+ńż║õŠŗ’╝Ü
+
+- ń╗śÕłČÕć║µ¤Éµ¼ĪĶ┐ÉĶĪīńÜäÕłåń▒╗ lossŃĆé
+
+ ```shell
+ python tools/analysis_tools/analyze_logs.py plot_curve log.json --keys loss_cls --legend loss_cls
+ ```
+
+- ń╗śÕłČÕć║µ¤Éµ¼ĪĶ┐ÉĶĪīńÜäÕłåń▒╗ÕÆīÕø×ÕĮÆ loss’╝īÕ╣ČõĖöõ┐ØÕŁśÕøŠńēćõĖ║ pdf µĀ╝Õ╝ÅŃĆé
+
+ ```shell
+ python tools/analysis_tools/analyze_logs.py plot_curve log.json --keys loss_cls loss_bbox --out losses.pdf
+ ```
+
+- Õ£©ÕÉīõĖĆÕ╝ĀÕøŠńēćõĖŁµ»öĶŠāõĖżµ¼ĪĶ┐ÉĶĪīńÜä bbox mAPŃĆé
+
+ ```shell
+ # µĀ╣µŹ« Car_3D_moderate_strict Õ£© KITTI õĖŖĶ»äõ╝░ PartA2 ÕÆī secondŃĆé
+ python tools/analysis_tools/analyze_logs.py plot_curve tools/logs/PartA2.log.json tools/logs/second.log.json --keys KITTI/Car_3D_moderate_strict --legend PartA2 second --mode eval --interval 1
+ # µĀ╣µŹ« Car_3D_moderate_strict Õ£© KITTI õĖŖÕłåÕł½Õ»╣ĶĮ”ÕÆī 3 ń▒╗Ķ»äõ╝░ PointPillarsŃĆé
+ python tools/analysis_tools/analyze_logs.py plot_curve tools/logs/pp-3class.log.json tools/logs/pp.log.json --keys KITTI/Car_3D_moderate_strict --legend pp-3class pp --mode eval --interval 2
+ ```
+
+µé©õ╣¤ĶāĮĶ«Īń«ŚÕ╣│ÕØćĶ«Łń╗āķƤÕ║”ŃĆé
+
+```shell
+python tools/analysis_tools/analyze_logs.py cal_train_time log.json [--include-outliers]
+```
+
+ķóäµ£¤ĶŠōÕć║Õ║öĶ»źÕ”éõĖŗµēĆńż║ŃĆé
+
+```
+-----Analyze train time of work_dirs/some_exp/20190611_192040.log.json-----
+slowest epoch 11, average time is 1.2024
+fastest epoch 1, average time is 1.1909
+time std over epochs is 0.0028
+average iter time: 1.1959 s/iter
+```
+
+
+
+## µ©ĪÕ×ŗķā©ńĮ▓
+
+**µ│©µäÅ**’╝ܵŁżÕĘźÕģĘõ╗ŹńäČÕżäõ║ÄĶ»Ģķ¬īķśČµ«Ą’╝īńø«ÕēŹÕŬµ£ē SECOND µö»µīüńö© [`TorchServe`](https://pytorch.org/serve/) ķā©ńĮ▓’╝īµłæõ╗¼Õ░åõ╝ÜÕ£©µ£¬µØźµö»µīüµø┤ÕżÜńÜ䵩ĪÕ×ŗŃĆé
+
+õĖ║õ║åõĮ┐ńö© [`TorchServe`](https://pytorch.org/serve/) ķā©ńĮ▓ `MMDetection3D` µ©ĪÕ×ŗ’╝īµé©ÕÅ»õ╗źķüĄÕŠ¬õ╗źõĖŗµŁźķ¬ż’╝Ü
+
+### 1. Õ░嵩ĪÕ×ŗõ╗Ä MMDetection3D ĶĮ¼µŹóÕł░ TorchServe
+
+```shell
+python tools/deployment/mmdet3d2torchserve.py ${CONFIG_FILE} ${CHECKPOINT_FILE} \
+--output-folder ${MODEL_STORE} \
+--model-name ${MODEL_NAME}
+```
+
+**Note**: ${MODEL_STORE} ķ£ĆĶ”üõĖ║µ¢ćõ╗ČÕż╣ńÜäń╗ØÕ»╣ĶĘ»ÕŠäŃĆé
+
+### 2. µ×äÕ╗║ `mmdet3d-serve` ķĢ£ÕāÅ
+
+```shell
+docker build -t mmdet3d-serve:latest docker/serve/
+```
+
+### 3. Ķ┐ÉĶĪī `mmdet3d-serve`
+
+µ¤źń£ŗÕ«śńĮæµ¢ćµĪŻµØź [õĮ┐ńö© docker Ķ┐ÉĶĪī TorchServe](https://github.com/pytorch/serve/blob/master/docker/README.md#running-torchserve-in-a-production-docker-environment)ŃĆé
+
+õĖ║õ║åÕ£© GPU õĖŖĶ┐ÉĶĪī’╝īµé©ķ£ĆĶ”üÕ«ēĶŻģ [nvidia-docker](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html)ŃĆéµé©ÕÅ»õ╗źÕ┐ĮńĢź `--gpus` ÕÅéµĢ░’╝īõ╗ÄĶĆīÕ£© CPU õĖŖĶ┐ÉĶĪīŃĆé
+
+õŠŗÕŁÉ’╝Ü
+
+```shell
+docker run --rm \
+--cpus 8 \
+--gpus device=0 \
+-p8080:8080 -p8081:8081 -p8082:8082 \
+--mount type=bind,source=$MODEL_STORE,target=/home/model-server/model-store \
+mmdet3d-serve:latest
+```
+
+[ķśģĶ»╗µ¢ćµĪŻ](https://github.com/pytorch/serve/blob/072f5d088cce9bb64b2a18af065886c9b01b317b/docs/rest_api.md/) Õģ│õ║Ä Inference (8080), Management (8081) and Metrics (8082) µÄźÕÅŻŃĆé
+
+### 4. µĄŗĶ»Ģķā©ńĮ▓
+
+µé©ÕÅ»õ╗źõĮ┐ńö© `test_torchserver.py` Ķ┐øĶĪīķā©ńĮ▓’╝ī ÕÉīµŚČµ»öĶŠā torchserver ÕÆī pytorch ńÜäń╗ōµ×£ŃĆé
+
+```shell
+python tools/deployment/test_torchserver.py ${IMAGE_FILE} ${CONFIG_FILE} ${CHECKPOINT_FILE} ${MODEL_NAME}
+[--inference-addr ${INFERENCE_ADDR}] [--device ${DEVICE}] [--score-thr ${SCORE_THR}]
+```
+
+õŠŗÕŁÉ:
+
+```shell
+python tools/deployment/test_torchserver.py demo/data/kitti/kitti_000008.bin configs/second/hv_second_secfpn_6x8_80e_kitti-3d-car.py checkpoints/hv_second_secfpn_6x8_80e_kitti-3d-car_20200620_230238-393f000c.pth second
+```
+
+
+
+# µ©ĪÕ×ŗÕżŹµØéÕ║”
+
+µé©ÕÅ»õ╗źõĮ┐ńö© MMDetection õĖŁńÜä `tools/analysis_tools/get_flops.py` Ķ┐ÖõĖ¬Ķäܵ£¼µ¢ćõ╗Č’╝īÕ¤║õ║Ä [flops-counter.pytorch](https://github.com/sovrasov/flops-counter.pytorch) Ķ«Īń«ŚõĖĆõĖ¬ń╗Öիܵ©ĪÕ×ŗńÜäĶ«Īń«ŚķćÅ (FLOPS) ÕÆīÕÅéµĢ░ķćÅ (params)ŃĆé
+
+```shell
+python tools/analysis_tools/get_flops.py ${CONFIG_FILE} [--shape ${INPUT_SHAPE}]
+```
+
+µé©Õ░åõ╝ÜÕŠŚÕł░Õ”éõĖŗńÜäń╗ōµ×£’╝Ü
+
+```text
+==============================
+Input shape: (4000, 4)
+Flops: 5.78 GFLOPs
+Params: 953.83 k
+==============================
+```
+
+**µ│©µäÅ**’╝ܵŁżÕĘźÕģĘõ╗ŹńäČÕżäõ║ÄĶ»Ģķ¬īķśČµ«Ą’╝īµłæõ╗¼õĖŹĶāĮõ┐ØĶ»üµĢ░ÕĆ╝µś»ń╗ØÕ»╣µŁŻńĪ«ńÜäŃĆéµé©ÕÅ»õ╗źÕ░åń╗ōµ×£ńö©õ║Äń«ĆÕŹĢńÜäµ»öĶŠā’╝īõĮåÕ£©ÕåÖµŖƵ£»µ¢ćµĪŻµŖźÕæŖµł¢ĶĆģĶ«║µ¢ćõ╣ŗÕēŹµé©ķ£ĆĶ”üÕåŹµ¼ĪńĪ«Ķ«żõĖĆõĖŗŃĆé
+
+1. Ķ«Īń«ŚķćÅ (FLOPs) ÕÆīĶŠōÕģźÕĮóńŖȵ£ēÕģ│’╝īõĮåµś»ÕÅéµĢ░ķćÅ (params) ÕłÖÕÆīĶŠōÕģźÕĮóńŖȵŚĀÕģ│ŃĆéķ╗śĶ«żńÜäĶŠōÕģźÕĮóńŖČõĖ║ (1, 40000, 4)ŃĆé
+2. õĖĆõ║øĶ┐Éń«ŚµōŹõĮ£õĖŹĶ«ĪÕģźĶ«Īń«ŚķćÅ (FLOPs)’╝īµ»öÕ”éĶ»┤ÕāÅGNÕÆīÕ«ÜÕłČńÜäĶ┐Éń«ŚµōŹõĮ£’╝īĶ»”ń╗åń╗åĶŖéĶ»ĘÕÅéĶĆā [`mmcv.cnn.get_model_complexity_info()`](https://github.com/open-mmlab/mmcv/blob/master/mmcv/cnn/utils/flops_counter.py)ŃĆé
+3. µłæõ╗¼ńÄ░Õ£©õ╗ģõ╗ģµö»µīüÕŹĢµ©ĪµĆüĶŠōÕģź’╝łńé╣õ║æµł¢ĶĆģÕøŠńēć’╝ēńÜäÕŹĢķśČµ«Ąµ©ĪÕ×ŗńÜäĶ«Īń«ŚķćÅ (FLOPs) Ķ«Īń«Ś’╝īµłæõ╗¼Õ░åõ╝ÜÕ£©µ£¬µØźµö»µīüõĖżķśČµ«ĄÕÆīÕżÜµ©ĪµĆüµ©ĪÕ×ŗńÜäĶ«Īń«ŚŃĆé
+
+
+
+## µ©ĪÕ×ŗĶĮ¼µŹó
+
+### RegNet µ©ĪÕ×ŗĶĮ¼µŹóÕł░ MMDetection
+
+`tools/model_converters/regnet2mmdet.py` Õ░å pycls ķóäĶ«Łń╗ā RegNet µ©ĪÕ×ŗõĖŁńÜäķö«ĶĮ¼µŹóõĖ║ MMDetection ķŻÄµĀ╝ŃĆé
+
+```shell
+python tools/model_converters/regnet2mmdet.py ${SRC} ${DST} [-h]
+```
+
+### Detectron ResNet ĶĮ¼µŹóÕł░ Pytorch
+
+MMDetection õĖŁńÜä `tools/detectron2pytorch.py` ĶāĮÕż¤µŖŖÕĤզŗńÜä detectron õĖŁķóäĶ«Łń╗āńÜä ResNet µ©ĪÕ×ŗńÜäķö«ĶĮ¼µŹóõĖ║ PyTorch ķŻÄµĀ╝ŃĆé
+
+```shell
+python tools/detectron2pytorch.py ${SRC} ${DST} ${DEPTH} [-h]
+```
+
+### ÕćåÕżćĶ”üÕÅæÕĖāńÜ䵩ĪÕ×ŗ
+
+`tools/model_converters/publish_model.py` ÕĖ«ÕŖ®ńö©µłĘÕćåÕżćõ╗¢õ╗¼ńö©õ║ÄÕÅæÕĖāńÜ䵩ĪÕ×ŗŃĆé
+
+Õ£©µé©õĖŖõ╝ĀõĖĆõĖ¬µ©ĪÕ×ŗÕł░õ║æµ£ŹÕŖĪÕÖ© (AWS) õ╣ŗÕēŹ’╝īµé©ķ£ĆĶ”üÕüÜõ╗źõĖŗÕćĀµŁź’╝Ü
+
+1. Õ░嵩ĪÕ×ŗµØāķćŹĶĮ¼µŹóõĖ║ CPU Õ╝ĀķćÅ
+2. ÕłĀķÖżĶ«░ÕĮĢõ╝śÕī¢ÕÖ©ńŖȵĆü (optimizer states) ńÜäńøĖÕģ│õ┐Īµü»
+3. Ķ«Īń«ŚµŻĆµ¤źńé╣ (checkpoint) µ¢ćõ╗ČńÜäÕōłÕĖīń╝¢ńĀü (hash id) Õ╣ČõĖöµŖŖÕōłÕĖīń╝¢ńĀüÕŖĀÕł░µ¢ćõ╗ČÕÉŹķćī
+
+```shell
+python tools/model_converters/publish_model.py ${INPUT_FILENAME} ${OUTPUT_FILENAME}
+```
+
+õŠŗÕ”é’╝ī
+
+```shell
+python tools/model_converters/publish_model.py work_dirs/faster_rcnn/latest.pth faster_rcnn_r50_fpn_1x_20190801.pth
+```
+
+µ£Ćń╗łńÜäĶŠōÕć║µ¢ćõ╗ČÕÉŹÕ░åõ╝ܵś» `faster_rcnn_r50_fpn_1x_20190801-{hash id}.pth`ŃĆé
+
+
+
+# µĢ░µŹ«ķøåĶĮ¼µŹó
+
+`tools/dataset_converters/` ÕīģÕɽĶĮ¼µŹóµĢ░µŹ«ķøåõĖ║ÕģČõ╗¢µĀ╝Õ╝ÅńÜäõĖĆõ║øÕĘźÕģĘŃĆéÕģČõĖŁÕż¦ÕżÜµĢ░ĶĮ¼µŹóµĢ░µŹ«ķøåõĖ║Õ¤║õ║Ä pickle ńÜäõ┐Īµü»µ¢ćõ╗Č’╝īµ»öÕ”é KITTI’╝īnuscense ÕÆī lyftŃĆéWaymo ĶĮ¼µŹóÕÖ©Ķó½ńö©µØźķ揵¢░ń╗äń╗ć waymo ÕĤզŗµĢ░µŹ«õĖ║ KITTI ķŻÄµĀ╝ŃĆéńö©µłĘĶāĮÕż¤ÕÅéĶĆāÕ«āõ╗¼õ║åĶ¦Żµłæõ╗¼ĶĮ¼µŹóµĢ░µŹ«µĀ╝Õ╝ÅńÜäµ¢╣µ│ĢŃĆéÕ░åÕ«āõ╗¼õ┐«µö╣õĖ║ nuImages ĶĮ¼µŹóÕÖ©ńŁēĶäܵ£¼õ╣¤ÕŠłµ¢╣õŠ┐ŃĆé
+
+õĖ║õ║åĶĮ¼µŹó nuImages µĢ░µŹ«ķøåõĖ║ COCO µĀ╝Õ╝Å’╝īĶ»ĘõĮ┐ńö©õĖŗķØóńÜäµīćõ╗ż’╝Ü
+
+```shell
+python -u tools/dataset_converters/nuimage_converter.py --data-root ${DATA_ROOT} --version ${VERSIONS} \
+ --out-dir ${OUT_DIR} --nproc ${NUM_WORKERS} --extra-tag ${TAG}
+```
+
+- `--data-root`: µĢ░µŹ«ķøåńÜäµĀ╣ńø«ÕĮĢ’╝īķ╗śĶ«żõĖ║ `./data/nuimages`ŃĆé
+- `--version`: µĢ░µŹ«ķøåńÜäńēłµ£¼’╝īķ╗śĶ«żõĖ║ `v1.0-mini`ŃĆéĶ”üĶÄĘÕÅ¢Õ«īµĢ┤µĢ░µŹ«ķøå’╝īĶ»ĘõĮ┐ńö© `--version v1.0-train v1.0-val v1.0-mini`ŃĆé
+- `--out-dir`: µ│©ķćŖÕÆīĶ»Łõ╣ēµÄ®ńĀüńÜäĶŠōÕć║ńø«ÕĮĢ’╝īķ╗śĶ«żõĖ║ `./data/nuimages/annotations/`ŃĆé
+- `--nproc`: µĢ░µŹ«ÕćåÕżćńÜäĶ┐øń©ŗµĢ░’╝īķ╗śĶ«żõĖ║ `4`ŃĆéńö▒õ║ÄÕøŠńē浜»Õ╣ČĶĪīÕżäńÉåńÜä’╝īµø┤Õż¦ńÜäĶ┐øń©ŗµĢ░ńø«ĶāĮÕż¤ÕćÅÕ░æÕćåÕżćµŚČķŚ┤ŃĆé
+- `--extra-tag`: µ│©ķćŖńÜäķóØÕż¢µĀćńŁŠ’╝īķ╗śĶ«żõĖ║ `nuimages`ŃĆéĶ┐ÖÕÅ»ńö©õ║ÄÕ░åõĖŹÕÉīµŚČķŚ┤ÕżäńÉåńÜäõĖŹÕÉīµ│©ķćŖÕłåÕ╝Ćõ╗źõŠøńĀöń®ČŃĆé
+
+µø┤ÕżÜńÜäµĢ░µŹ«ÕćåÕżćń╗åĶŖéÕÅéĶĆā [doc](https://mmdetection3d.readthedocs.io/zh_CN/latest/data_preparation.html)’╝īnuImages µĢ░µŹ«ķøåńÜäń╗åĶŖéÕÅéĶĆā [README](https://github.com/open-mmlab/mmdetection3d/blob/main/configs/nuimages/README.md/)ŃĆé
+
+
+
+# ÕģČõ╗¢ÕåģÕ«╣
+
+## µēōÕŹ░Õ«īµĢ┤ńÜäķģŹńĮ«µ¢ćõ╗Č
+
+`tools/misc/print_config.py` ķĆÉÕŁŚµēōÕŹ░µĢ┤õĖ¬ķģŹńĮ«µ¢ćõ╗Č’╝īÕ▒ĢÕ╝ƵēƵ£ēńÜäÕ»╝ÕģźŃĆé
+
+```shell
+python tools/misc/print_config.py ${CONFIG} [-h] [--options ${OPTIONS [OPTIONS...]}]
+```
diff --git a/internlm_langchain/knowledge_base/MMDetection3D/content/vision_det3d.md b/internlm_langchain/knowledge_base/MMDetection3D/content/vision_det3d.md
new file mode 100644
index 00000000..ff5917ca
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection3D/content/vision_det3d.md
@@ -0,0 +1,114 @@
+# Õ¤║õ║ÄĶ¦åĶ¦ēńÜä 3D µŻĆµĄŗ
+
+Õ¤║õ║ÄĶ¦åĶ¦ēńÜä 3D µŻĆµĄŗµś»µīćÕ¤║õ║Äń║»Ķ¦åĶ¦ēĶŠōÕģźńÜä 3D µŻĆµĄŗµ¢╣µ│Ģ’╝īõŠŗÕ”éÕ¤║õ║ÄÕŹĢńø«ŃĆüÕÅīńø«ÕÆīÕżÜĶ¦åÕøŠÕøŠÕāÅńÜä 3D µŻĆµĄŗŃĆéńø«ÕēŹ’╝īµłæõ╗¼ÕŬµö»µīüÕŹĢńø«ÕÆīÕżÜĶ¦åÕøŠńÜä 3D µŻĆµĄŗµ¢╣µ│ĢŃĆéÕģČõ╗¢µ¢╣µ│Ģõ╣¤Õ║öĶ»źõĖĵłæõ╗¼ńÜäµĪåµ×ČÕģ╝Õ«╣’╝īÕ╣ČÕ£©Õ░åµØźÕŠŚÕł░µö»µīüŃĆé
+
+Õ«āµ£¤µ£øń╗ÖÕ«ÜńÜ䵩ĪÕ×ŗõ╗źõ╗╗µäŵĢ░ķćÅńÜäÕøŠÕāÅõĮ£õĖ║ĶŠōÕģź’╝īÕ╣ČõĖ║µ»ÅõĖĆõĖ¬µä¤Õģ┤ĶČŻńÜäńø«µĀćķó䵥ŗ 3D µĪåÕÅŖń▒╗Õł½µĀćńŁŠŃĆéõ╗ź nuScenes µĢ░µŹ«ķøå FCOS3D õĖ║õŠŗ’╝īµłæõ╗¼Õ░åÕ▒Ģńż║Õ”éõĮĢÕćåÕżćµĢ░µŹ«’╝īÕ£©µĀćÕćåńÜä 3D µŻĆµĄŗÕ¤║ÕćåõĖŖĶ«Łń╗āÕ╣ȵĄŗĶ»Ģµ©ĪÕ×ŗ’╝īõ╗źÕÅŖÕÅ»Ķ¦åÕī¢Õ╣Čķ¬īĶ»üń╗ōµ×£ŃĆé
+
+## µĢ░µŹ«ÕćåÕżć
+
+ķ”¢Õģł’╝īµłæõ╗¼ķ£ĆĶ”üõĖŗĶĮĮÕĤզŗµĢ░µŹ«Õ╣ȵīēńģ¦[µĢ░µŹ«ÕćåÕżćµ¢ćµĪŻ](https://mmdetection3d.readthedocs.io/zh_CN/latest/data_preparation.html)õĖŁµÅÉõŠøńÜäµĀćÕćåµ¢╣Õ╝Åķ揵¢░ń╗äń╗ćµĢ░µŹ«ŃĆé
+
+ńö▒õ║ÄõĖŹÕÉīµĢ░µŹ«ķøåńÜäÕĤզŗµĢ░µŹ«µ£ēõĖŹÕÉīńÜäń╗äń╗ćµ¢╣Õ╝Å’╝īµłæõ╗¼ķĆÜÕĖĖķ£ĆĶ”üńö© pkl µł¢ json µ¢ćõ╗ȵöČķøåµ£ēńö©ńÜäµĢ░µŹ«õ┐Īµü»ŃĆéÕøĀµŁż’╝īÕ£©ÕćåÕżćÕźĮµēƵ£ēńÜäÕĤզŗµĢ░µŹ«õ╣ŗÕÉÄ’╝īµłæõ╗¼ķ£ĆĶ”üĶ┐ÉĶĪī `create_data.py` õĖŁµÅÉõŠøńÜäĶäܵ£¼µØźõĖ║õĖŹÕÉīńÜäµĢ░µŹ«ķøåńö¤µłÉµĢ░µŹ«õ┐Īµü»ŃĆéõŠŗÕ”é’╝īÕ»╣õ║Ä nuScenes’╝īµłæõ╗¼ķ£ĆĶ”üĶ┐ÉĶĪīÕ”éõĖŗÕæĮõ╗ż’╝Ü
+
+```
+python tools/create_data.py nuscenes --root-path ./data/nuscenes --out-dir ./data/nuscenes --extra-tag nuscenes
+```
+
+ķÜÅÕÉÄ’╝īńøĖÕģ│ńÜäńø«ÕĮĢń╗ōµ×äÕ░åÕ”éõĖŗµēĆńż║’╝Ü
+
+```
+mmdetection3d
+Ōö£ŌöĆŌöĆ mmdet3d
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+Ōö£ŌöĆŌöĆ data
+Ōöé Ōö£ŌöĆŌöĆ nuscenes
+Ōöé Ōöé Ōö£ŌöĆŌöĆ maps
+Ōöé Ōöé Ōö£ŌöĆŌöĆ samples
+Ōöé Ōöé Ōö£ŌöĆŌöĆ sweeps
+Ōöé Ōöé Ōö£ŌöĆŌöĆ v1.0-test
+| | Ōö£ŌöĆŌöĆ v1.0-trainval
+Ōöé Ōöé Ōö£ŌöĆŌöĆ nuscenes_database
+Ōöé Ōöé Ōö£ŌöĆŌöĆ nuscenes_infos_train.pkl
+Ōöé Ōöé Ōö£ŌöĆŌöĆ nuscenes_infos_trainval.pkl
+Ōöé Ōöé Ōö£ŌöĆŌöĆ nuscenes_infos_val.pkl
+Ōöé Ōöé Ōö£ŌöĆŌöĆ nuscenes_infos_test.pkl
+Ōöé Ōöé Ōö£ŌöĆŌöĆ nuscenes_dbinfos_train.pkl
+Ōöé Ōöé Ōö£ŌöĆŌöĆ nuscenes_infos_train_mono3d.coco.json
+Ōöé Ōöé Ōö£ŌöĆŌöĆ nuscenes_infos_trainval_mono3d.coco.json
+Ōöé Ōöé Ōö£ŌöĆŌöĆ nuscenes_infos_val_mono3d.coco.json
+Ōöé Ōöé Ōö£ŌöĆŌöĆ nuscenes_infos_test_mono3d.coco.json
+```
+
+µ│©µäÅ’╝īµŁżÕżäńÜä pkl µ¢ćõ╗ČõĖ╗Ķ”üńö©õ║ÄõĮ┐ńö© LiDAR µĢ░µŹ«ńÜäµ¢╣µ│Ģ’╝ījson µ¢ćõ╗Čńö©õ║Ä 2D µŻĆµĄŗ/ń║»Ķ¦åĶ¦ēńÜä 3D µŻĆµĄŗŃĆéÕ£© v0.13.0 µö»µīüÕŹĢńø« 3D µŻĆµĄŗõ╣ŗÕēŹ’╝ījson µ¢ćõ╗ČÕŬÕīģÕɽ 2D µŻĆµĄŗńÜäõ┐Īµü»’╝īÕøĀµŁżÕ”éµ×£õĮĀķ£ĆĶ”üµ£Ćµ¢░ńÜäõ┐Īµü»’╝īĶ»ĘÕłćµŹóÕł░ v0.13.0 õ╣ŗÕÉÄńÜäÕłåµö»ŃĆé
+
+## Ķ«Łń╗ā
+
+µÄźńØĆ’╝īµłæõ╗¼Õ░åõĮ┐ńö©µÅÉõŠøńÜäķģŹńĮ«µ¢ćõ╗ČĶ«Łń╗ā FCOS3DŃĆéÕ¤║µ£¼ńÜäĶäܵ£¼õĖÄÕģČõ╗¢µ©ĪÕ×ŗõĖƵĀĘŃĆéÕĮōõĮĀõĮ┐ńö©õĖŹÕÉīńÜä GPU Ķ«ŠńĮ«Ķ┐øĶĪīĶ«Łń╗āµŚČ’╝īõĮĀÕ¤║µ£¼õĖŖÕÅ»õ╗źµīēńģ¦Ķ┐ÖõĖ¬[µĢÖń©ŗ](https://mmdetection3d.readthedocs.io/zh_CN/latest/1_exist_data_model.html#inference-with-existing-models)ńÜäńż║õŠŗŃĆéÕüćĶ«Šµłæõ╗¼Õ£©õĖĆÕÅ░Õģʵ£ē 8 ÕØŚ GPU ńÜäµ£║ÕÖ©õĖŖõĮ┐ńö©ÕłåÕĖāÕ╝ÅĶ«Łń╗ā’╝Ü
+
+```
+./tools/dist_train.sh configs/fcos3d/fcos3d_r101_caffe_fpn_gn-head_dcn_2x8_1x_nus-mono3d.py 8
+```
+
+µ│©µäÅ’╝īķģŹńĮ«µ¢ćõ╗ČÕÉŹõĖŁńÜä `2x8` µś»µīćĶ«Łń╗āµŚČńö©õ║å 8 ÕØŚ GPU’╝īµ»ÅÕØŚ GPU õĖŖµ£ē 2 õĖ¬µĢ░µŹ«µĀʵ£¼ŃĆéÕ”éµ×£õĮĀńÜäĶć¬Õ«Üõ╣ēĶ«ŠńĮ«õĖŹÕÉīõ║ĵŁż’╝īķéŻõ╣łµ£ēµŚČÕĆÖõĮĀķ£ĆĶ”üńøĖÕ║öńÜäĶ░āµĢ┤ÕŁ”õ╣ĀńÄćŃĆéÕ¤║µ£¼Ķ¦äÕłÖÕÅ»õ╗źÕÅéĶĆā[µŁżÕżä](https://arxiv.org/abs/1706.02677)ŃĆé
+
+µłæõ╗¼õ╣¤ÕÅ»õ╗źķĆÜĶ┐ćĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗żÕŠ«Ķ░ā FCOS3D’╝īõ╗ÄĶĆīĶŠŠÕł░µø┤ÕźĮńÜäµĆ¦ĶāĮ’╝Ü
+
+```
+./tools/dist_train.sh fcos3d_r101_caffe_fpn_gn-head_dcn_2x8_1x_nus-mono3d_finetune.py 8
+```
+
+ķĆÜĶ┐ćÕģłÕēŹńÜäĶäܵ£¼Ķ«Łń╗āÕźĮõĖĆõĖ¬Õ¤║Õć嵩ĪÕ×ŗÕÉÄ’╝īĶ»ĘĶ«░ÕŠŚńøĖÕ║öńÜäõ┐«µö╣[µŁżÕżä](https://github.com/open-mmlab/mmdetection3d/blob/main/configs/fcos3d/fcos3d_r101_caffe_fpn_gn-head_dcn_2x8_1x_nus-mono3d_finetune.py#L8)ńÜäĶĘ»ÕŠäŃĆé
+
+## Õ«ÜķćÅĶ»äõ╝░
+
+Õ£©Ķ«Łń╗āµ£¤ķŚ┤’╝īµ©ĪÕ×ŗµØāķ揵¢ćõ╗ČÕ░åõ╝ܵĀ╣µŹ«ķģŹńĮ«µ¢ćõ╗ČõĖŁńÜä `evaluation = dict(interval=xxx)` Ķ«ŠńĮ«Ķó½Õ橵£¤µĆ¦Õ£░Ķ»äõ╝░ŃĆé
+
+µłæõ╗¼µö»µīüõĖŹÕÉīµĢ░µŹ«ķøåńÜäÕ«śµ¢╣Ķ»äõ╝░µ¢╣µĪłŃĆéńö▒õ║ÄĶŠōÕć║µĀ╝Õ╝ÅõĖÄÕ¤║õ║ÄÕģČõ╗¢µ©ĪµĆüńÜä 3D µŻĆµĄŗńøĖÕÉī’╝īÕøĀµŁżĶ»äõ╝░µ¢╣µ│Ģõ╣¤µś»õĖƵĀĘńÜäŃĆé
+
+Õ»╣õ║Ä nuScenes’╝īÕ░åõĮ┐ńö©Õ¤║õ║ÄĶĘØń”╗ńÜäÕ╣│ÕØćń▓ŠÕ║”’╝łmAP’╝ēõ╗źÕÅŖ nuScenes µŻĆµĄŗÕłåµĢ░’╝łNDS’╝ēÕłåÕł½Õ»╣ 10 õĖ¬ń▒╗Õł½Ķ┐øĶĪīĶ»äõ╝░ŃĆéĶ»äõ╝░ń╗ōµ×£Õ░åõ╝ÜĶó½µēōÕŹ░Õł░ń╗łń½»õĖŁ’╝īÕ”éõĖŗµēĆńż║’╝Ü
+
+```
+mAP: 0.3197
+mATE: 0.7595
+mASE: 0.2700
+mAOE: 0.4918
+mAVE: 1.3307
+mAAE: 0.1724
+NDS: 0.3905
+Eval time: 170.8s
+
+Per-class results:
+Object Class AP ATE ASE AOE AVE AAE
+car 0.503 0.577 0.152 0.111 2.096 0.136
+truck 0.223 0.857 0.224 0.220 1.389 0.179
+bus 0.294 0.855 0.204 0.190 2.689 0.283
+trailer 0.081 1.094 0.243 0.553 0.742 0.167
+construction_vehicle 0.058 1.017 0.450 1.019 0.137 0.341
+pedestrian 0.392 0.687 0.284 0.694 0.876 0.158
+motorcycle 0.317 0.737 0.265 0.580 2.033 0.104
+bicycle 0.308 0.704 0.299 0.892 0.683 0.010
+traffic_cone 0.555 0.486 0.309 nan nan nan
+barrier 0.466 0.581 0.269 0.169 nan nan
+```
+
+µŁżÕż¢’╝īÕ£©Ķ«Łń╗āÕ«īµłÉÕÉÄõĮĀõ╣¤ÕÅ»õ╗źĶ»äõ╝░ńē╣Õ«ÜńÜ䵩ĪÕ×ŗµØāķ揵¢ćõ╗ČŃĆéõĮĀÕÅ»õ╗źń«ĆÕŹĢÕ£░µē¦ĶĪīõ╗źõĖŗĶäܵ£¼’╝Ü
+
+```
+./tools/dist_test.sh configs/fcos3d/fcos3d_r101_caffe_fpn_gn-head_dcn_2x8_1x_nus-mono3d.py \
+ work_dirs/fcos3d/latest.pth --eval mAP
+```
+
+## µĄŗĶ»ĢõĖĵÅÉõ║ż
+
+Õ”éµ×£õĮĀÕŬµā│Õ£©Õ£©ń║┐Õ¤║ÕćåõĖŖĶ┐øĶĪīµÄ©ńÉåµł¢µĄŗĶ»Ģµ©ĪÕ×ŗµĆ¦ĶāĮ’╝īõĮĀķ£ĆĶ”üÕ░åõ╣ŗÕēŹĶ»äõ╝░Ķäܵ£¼õĖŁńÜä `--eval mAP` µø┐µŹóµłÉ `--format-only`’╝īÕ╣ČÕ£©ķ£ĆĶ”üńÜäµāģÕåĄõĖŗµīćÕ«Ü `jsonfile_prefix`’╝īõŠŗÕ”é’╝īµĘ╗ÕŖĀķĆēķĪ╣ `--eval-options jsonfile_prefix=work_dirs/fcos3d/test_submission`ŃĆéĶ»ĘńĪ«õ┐ØķģŹńĮ«µ¢ćõ╗ČõĖŁńÜä[µĄŗĶ»Ģõ┐Īµü»](https://github.com/open-mmlab/mmdetection3d/blob/main/configs/_base_/datasets/nus-mono3d.py#L93)ńö▒ķ¬īĶ»üķøåńøĖÕ║öÕ£░µö╣õĖ║µĄŗĶ»ĢķøåŃĆé
+
+Õ£©ńö¤µłÉń╗ōµ×£ÕÉÄ’╝īõĮĀÕÅ»õ╗źÕÄŗń╝®µ¢ćõ╗ČÕż╣Õ╣ČõĖŖõ╝ĀĶć│ nuScenes 3D µŻĆµĄŗµīæµłśńÜä evalAI Ķ»äõ╝░µ£ŹÕŖĪÕÖ©õĖŖŃĆé
+
+## Õ«ÜµĆ¦Ķ»äõ╝░
+
+MMDetection3D Ķ┐śµÅÉõŠøõ║åķĆÜńö©ńÜäÕÅ»Ķ¦åÕī¢ÕĘźÕģĘ’╝īõ╗źõŠ┐õ║ĵłæõ╗¼ÕÅ»õ╗źÕ»╣Ķ«Łń╗āÕźĮńÜ䵩ĪÕ×ŗķó䵥ŗńÜ䵯ƵĄŗń╗ōµ×£µ£ēõĖĆõĖ¬ńø┤Ķ¦éńÜäµä¤ÕÅŚŃĆéõĮĀõ╣¤ÕÅ»õ╗źÕ£©Ķ»äõ╝░ķśČµ«ĄķĆÜĶ┐ćĶ«ŠńĮ« `--eval-options 'show=True' 'out_dir=${SHOW_DIR}'` µØźÕ£©ń║┐ÕÅ»Ķ¦åÕī¢µŻĆµĄŗń╗ōµ×£’╝īµł¢ĶĆģõĮ┐ńö© `tools/misc/visualize_results.py` µØźń”╗ń║┐Õ£░Ķ┐øĶĪīÕÅ»Ķ¦åÕī¢ŃĆé
+
+µŁżÕż¢’╝īµłæõ╗¼Ķ┐śµÅÉõŠøõ║åĶäܵ£¼ `tools/misc/browse_dataset.py` ńö©õ║ÄÕÅ»Ķ¦åÕī¢µĢ░µŹ«ķøåĶĆīõĖŹÕüܵĩńÉåŃĆéµø┤ÕżÜńÜäń╗åĶŖéĶ»ĘÕÅéĶĆā[ÕÅ»Ķ¦åÕī¢µ¢ćµĪŻ](https://mmdetection3d.readthedocs.io/zh_CN/latest/useful_tools.html#visualization)ŃĆé
+
+µ│©µäÅ’╝īńø«ÕēŹµłæõ╗¼õ╗ģµö»µīüń║»Ķ¦åĶ¦ēµ¢╣µ│ĢÕ£©ÕøŠÕāÅõĖŖńÜäÕÅ»Ķ¦åÕī¢ŃĆéÕ░åµØźµłæõ╗¼Õ░åķøåµłÉÕ£©ÕēŹµÖ»ÕøŠõ╗źÕÅŖķĖ¤ń×░ÕøŠ’╝łBEV’╝ēõĖŁńÜäÕÅ»Ķ¦åÕī¢ŃĆé
diff --git a/internlm_langchain/knowledge_base/MMDetection3D/content/visualization.md b/internlm_langchain/knowledge_base/MMDetection3D/content/visualization.md
new file mode 100644
index 00000000..d09c4571
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection3D/content/visualization.md
@@ -0,0 +1,202 @@
+# ÕÅ»Ķ¦åÕī¢
+
+MMDetection3D µÅÉõŠøõ║å `Det3DLocalVisualizer` ńö©µØźÕ£©Ķ«Łń╗āÕÅŖµĄŗĶ»ĢķśČµ«ĄÕÅ»Ķ¦åÕī¢ÕÆīÕŁśÕ驵©ĪÕ×ŗńÜäńŖȵĆüõ╗źÕÅŖń╗ōµ×£’╝īÕģČÕģʵ£ēõ╗źõĖŗńē╣µĆ¦’╝Ü
+
+1. µö»µīüÕżÜµ©ĪµĆüµĢ░µŹ«ÕÆīÕżÜõ╗╗ÕŖĪńÜäÕ¤║µ£¼ń╗śÕøŠńĢīķØóŃĆé
+2. µö»µīüÕżÜõĖ¬ÕÉÄń½»’╝łÕ”é local’╝īTensorBoard’╝ē’╝īÕ░åĶ«Łń╗āńŖȵĆü’╝łÕ”é `loss`’╝ī`lr`’╝ēµł¢µ©ĪÕ×ŗĶ»äõ╝░µīćµĀćÕåÖÕģźµīćÕ«ÜńÜäõĖĆõĖ¬µł¢ÕżÜõĖ¬ÕÉÄń½»õĖŁŃĆé
+3. µö»µīüÕżÜµ©ĪµĆüµĢ░µŹ«ń£¤Õ«×µĀćńŁŠńÜäÕÅ»Ķ¦åÕī¢’╝ī3D µŻĆµĄŗń╗ōµ×£ńÜäĶĘ©µ©ĪµĆüÕÅ»Ķ¦åÕī¢ŃĆé
+
+## Õ¤║µ£¼ń╗śÕłČńĢīķØó
+
+ń╗¦µē┐Ķć¬ `DetLocalVisualizer`’╝ī`Det3DLocalVisualizer` µÅÉõŠøõ║åÕ£© 2D ÕøŠÕāÅõĖŖń╗śÕłČÕĖĖĶ¦üńø«µĀćńÜäńĢīķØó’╝īõŠŗÕ”éń╗śÕłČµŻĆµĄŗµĪåŃĆüńé╣ŃĆüµ¢ćµ£¼ŃĆüń║┐ŃĆüÕ£åŃĆüÕżÜĶŠ╣ÕĮóŃĆüõ║īĶ┐øÕłČµÄ®ńĀüńŁēŃĆéÕģ│õ║Ä 2D ń╗śÕłČńÜäµø┤ÕżÜń╗åĶŖé’╝īĶ»ĘÕÅéĶĆā MMDetection õĖŁńÜä[ÕÅ»Ķ¦åÕī¢µ¢ćµĪŻ](https://mmengine.readthedocs.io/zh_CN/latest/advanced_tutorials/visualization.html)ŃĆéĶ┐Öķćīµłæõ╗¼õ╗ŗń╗Ź 3D ń╗śÕłČńĢīķØóŃĆé
+
+### Õ£©ÕøŠÕāÅõĖŖń╗śÕłČńé╣õ║æ
+
+ķĆÜĶ┐ćõĮ┐ńö© `draw_points_on_image`’╝īµłæõ╗¼µö»µīüÕ£©ÕøŠÕāÅõĖŖń╗śÕłČńé╣õ║æŃĆé
+
+```python
+import mmcv
+import numpy as np
+from mmengine import load
+
+from mmdet3d.visualization import Det3DLocalVisualizer
+
+info_file = load('demo/data/kitti/000008.pkl')
+points = np.fromfile('demo/data/kitti/000008.bin', dtype=np.float32)
+points = points.reshape(-1, 4)[:, :3]
+lidar2img = np.array(info_file['data_list'][0]['images']['CAM2']['lidar2img'], dtype=np.float32)
+
+visualizer = Det3DLocalVisualizer()
+img = mmcv.imread('demo/data/kitti/000008.png')
+img = mmcv.imconvert(img, 'bgr', 'rgb')
+visualizer.set_image(img)
+visualizer.draw_points_on_image(points, lidar2img)
+visualizer.show()
+```
+
+
+
+### Õ£©ńé╣õ║æõĖŖń╗śÕłČ 3D µĪå
+
+ķĆÜĶ┐ćõĮ┐ńö© `draw_bboxes_3d`’╝īµłæõ╗¼µö»µīüÕ£©ńé╣õ║æõĖŖń╗śÕłČ 3D µĪåŃĆé
+
+```python
+import torch
+import numpy as np
+
+from mmdet3d.visualization import Det3DLocalVisualizer
+from mmdet3d.structures import LiDARInstance3DBoxes
+
+points = np.fromfile('demo/data/kitti/000008.bin', dtype=np.float32)
+points = points.reshape(-1, 4)
+visualizer = Det3DLocalVisualizer()
+# set point cloud in visualizer
+visualizer.set_points(points)
+bboxes_3d = LiDARInstance3DBoxes(
+ torch.tensor([[8.7314, -1.8559, -1.5997, 4.2000, 3.4800, 1.8900,
+ -1.5808]]))
+# Draw 3D bboxes
+visualizer.draw_bboxes_3d(bboxes_3d)
+visualizer.show()
+```
+
+
+
+### Õ£©ÕøŠÕāÅõĖŖń╗śÕłČµŖĢÕĮ▒ńÜä 3D µĪå
+
+ķĆÜĶ┐ćõĮ┐ńö© `draw_proj_bboxes_3d`’╝īµłæõ╗¼µö»µīüÕ£©ÕøŠÕāÅõĖŖń╗śÕłČµŖĢÕĮ▒ńÜä 3D µĪåŃĆé
+
+```python
+import mmcv
+import numpy as np
+from mmengine import load
+
+from mmdet3d.visualization import Det3DLocalVisualizer
+from mmdet3d.structures import CameraInstance3DBoxes
+
+info_file = load('demo/data/kitti/000008.pkl')
+cam2img = np.array(info_file['data_list'][0]['images']['CAM2']['cam2img'], dtype=np.float32)
+bboxes_3d = []
+for instance in info_file['data_list'][0]['instances']:
+ bboxes_3d.append(instance['bbox_3d'])
+gt_bboxes_3d = np.array(bboxes_3d, dtype=np.float32)
+gt_bboxes_3d = CameraInstance3DBoxes(gt_bboxes_3d)
+input_meta = {'cam2img': cam2img}
+
+visualizer = Det3DLocalVisualizer()
+
+img = mmcv.imread('demo/data/kitti/000008.png')
+img = mmcv.imconvert(img, 'bgr', 'rgb')
+visualizer.set_image(img)
+# project 3D bboxes to image
+visualizer.draw_proj_bboxes_3d(gt_bboxes_3d, input_meta)
+visualizer.show()
+```
+
+### ń╗śÕłČ BEV Ķ¦åĶ¦ÆńÜäµĪå
+
+ķĆÜĶ┐ćõĮ┐ńö© `draw_bev_bboxes`’╝īµłæõ╗¼µö»µīüń╗śÕłČ BEV Ķ¦åĶ¦ÆõĖŗńÜäµĪåŃĆé
+
+```python
+import numpy as np
+from mmengine import load
+
+from mmdet3d.visualization import Det3DLocalVisualizer
+from mmdet3d.structures import CameraInstance3DBoxes
+
+info_file = load('demo/data/kitti/000008.pkl')
+bboxes_3d = []
+for instance in info_file['data_list'][0]['instances']:
+ bboxes_3d.append(instance['bbox_3d'])
+gt_bboxes_3d = np.array(bboxes_3d, dtype=np.float32)
+gt_bboxes_3d = CameraInstance3DBoxes(gt_bboxes_3d)
+
+visualizer = Det3DLocalVisualizer()
+# set bev image in visualizer
+visualizer.set_bev_image()
+# draw bev bboxes
+visualizer.draw_bev_bboxes(gt_bboxes_3d, edge_colors='orange')
+visualizer.show()
+```
+
+### ń╗śÕłČ 3D ÕłåÕē▓µÄ®ńĀü
+
+ķĆÜĶ┐ćõĮ┐ńö© `draw_seg_mask`’╝īµłæõ╗¼µö»µīüķĆÜĶ┐ćķĆÉńé╣ńØĆĶē▓µØźń╗śÕłČÕłåÕē▓µÄ®ńĀüŃĆé
+
+```python
+import numpy as np
+
+from mmdet3d.visualization import Det3DLocalVisualizer
+
+points = np.fromfile('demo/data/sunrgbd/000017.bin', dtype=np.float32)
+points = points.reshape(-1, 3)
+visualizer = Det3DLocalVisualizer()
+mask = np.random.rand(points.shape[0], 3)
+points_with_mask = np.concatenate((points, mask), axis=-1)
+# Draw 3D points with mask
+visualizer.set_points(points, pcd_mode=2, vis_mode='add')
+visualizer.draw_seg_mask(points_with_mask)
+visualizer.show()
+```
+
+## ń╗ōµ×£
+
+Õ”éµ×£µā│Ķ”üÕÅ»Ķ¦åÕī¢Ķ«Łń╗āµ©ĪÕ×ŗńÜäķó䵥ŗń╗ōµ×£’╝īõĮĀÕÅ»õ╗źĶ┐ÉĶĪīÕ”éõĖŗµīćõ╗ż’╝Ü
+
+```bash
+python tools/test.py ${CONFIG_FILE} ${CKPT_PATH} --show --show-dir ${SHOW_DIR}
+```
+
+Ķ┐ÉĶĪīĶ»źµīćõ╗żÕÉÄ’╝īń╗śÕłČńÜäń╗ōµ×£’╝łÕīģµŗ¼ĶŠōÕģźµĢ░µŹ«ÕÆīńĮæń╗£ĶŠōÕć║Õ£©ĶŠōÕģźõĖŖńÜäÕÅ»Ķ¦åÕī¢’╝ēÕ░åõ╝ÜĶó½õ┐ØÕŁśÕ£© `${SHOW_DIR}` õĖŁŃĆé
+
+Ķ┐ÉĶĪīĶ»źµīćõ╗żÕÉÄ’╝īõĮĀÕ░åÕ£© `${SHOW_DIR}` õĖŁĶÄĘÕŠŚĶŠōÕģźµĢ░µŹ«’╝īńĮæń╗£ĶŠōÕć║ÕÆīń£¤µś»µĀćńŁŠÕ£©ĶŠōÕģźõĖŖńÜäÕÅ»Ķ¦åÕī¢’╝łÕ”éÕ£©ÕżÜµ©ĪµĆüµŻĆµĄŗõ╗╗ÕŖĪÕÆīÕ¤║õ║ÄĶ¦åĶ¦ēńÜ䵯ƵĄŗõ╗╗ÕŖĪõĖŁńÜä `***_gt.png` ÕÆī `***_pred.png`’╝ēŃĆéÕĮōÕÉ»ńö© `show` µŚČ’╝ī[Open3D](http://www.open3d.org/) Õ░åõ╝Üńö©õ║ÄÕ£©ń║┐ÕÅ»Ķ¦åÕī¢ń╗ōµ×£ŃĆéÕ”éµ×£õĮĀµś»Õ£©µ▓Īµ£ē GUI ńÜäĶ┐£ń©ŗµ£ŹÕŖĪÕÖ©õĖŖµĄŗĶ»ĢµŚČ’╝īÕ£©ń║┐ÕÅ»Ķ¦åÕī¢µś»õĖŹĶó½µö»µīüńÜäŃĆéõĮĀÕÅ»õ╗źõ╗ÄĶ┐£ń©ŗµ£ŹÕŖĪÕÖ©õĖŁõĖŗĶĮĮ `results.pkl`’╝īÕ╣ČÕ£©µ£¼Õ£░µ£║ÕÖ©õĖŖń”╗ń║┐ÕÅ»Ķ¦åÕī¢ķó䵥ŗń╗ōµ×£ŃĆé
+
+õĮ┐ńö© `Open3D` ÕÉÄń½»ń”╗ń║┐ÕÅ»Ķ¦åÕī¢ń╗ōµ×£’╝īõĮĀÕÅ»õ╗źĶ┐ÉĶĪīÕ”éõĖŗµīćõ╗ż’╝Ü
+
+```bash
+python tools/misc/visualize_results.py ${CONFIG_FILE} --result ${RESULTS_PATH} --show-dir ${SHOW_DIR}
+```
+
+
+
+Ķ┐Öķ£ĆĶ”üÕ£©Ķ┐£ń©ŗµ£ŹÕŖĪÕÖ©õĖŁĶāĮÕż¤µÄ©ńÉåÕ╣Čńö¤µłÉń╗ōµ×£’╝īńäČÕÉÄńö©µłĘÕ£©õĖ╗µ£║õĖŁõĮ┐ńö© GUI µēōÕ╝ĆŃĆé
+
+## µĢ░µŹ«ķøå
+
+µłæõ╗¼õ╣¤µÅÉõŠøõ║åĶäܵ£¼µØźÕÅ»Ķ¦åÕī¢µĢ░µŹ«ķøåĶĆīµŚĀķ£ĆµÄ©ńÉåŃĆéõĮĀÕÅ»õ╗źõĮ┐ńö© `tools/misc/browse_dataset.py` µØźÕ£©ń║┐ÕÅ»Ķ¦åÕī¢ÕŖĀĶĮĮńÜäµĢ░µŹ«ńÜäń£¤Õ«×µĀćńŁŠ’╝īÕ╣Čõ┐ØÕŁśÕ£©ńĪ¼ńøśõĖŁŃĆéńø«ÕēŹµłæõ╗¼µö»µīüµēƵ£ēµĢ░µŹ«ķøåńÜäÕŹĢµ©ĪµĆü 3D µŻĆµĄŗÕÆī 3D ÕłåÕē▓’╝īKITTI ÕÆī SUN RGB-D ńÜäÕżÜµ©ĪµĆü 3D µŻĆµĄŗ’╝īõ╗źÕÅŖ nuScenes ńÜäÕŹĢńø« 3D µŻĆµĄŗŃĆéÕ”éµ×£µā│Ķ”üµĄÅĶ¦ł KITTI µĢ░µŹ«ķøå’╝īõĮĀÕÅ»õ╗źĶ┐ÉĶĪīÕ”éõĖŗµīćõ╗ż’╝Ü
+
+```shell
+python tools/misc/browse_dataset.py configs/_base_/datasets/kitti-3d-3class.py --task lidar_det --output-dir ${OUTPUT_DIR}
+```
+
+**µ│©µäÅ**’╝ÜõĖƵŚ”µīćÕ«Üõ║å `--output-dir`’╝īÕĮōÕ£© open3d ń¬ŚÕÅŻõĖŁµīēõĖŗ `_ESC_` µŚČ’╝īńö©µłĘµīćÕ«ÜńÜäĶ¦åÕøŠÕøŠÕāÅÕ░åõ╝ÜĶó½õ┐ØÕŁśõĖŗµØźŃĆéÕ”éµ×£õĮĀµā│Ķ”üÕ»╣ńé╣õ║æĶ┐øĶĪīń╝®µöŠµōŹõĮ£õ╗źĶ¦éÕ»¤µø┤ÕżÜń╗åĶŖé’╝ī õĮĀÕÅ»õ╗źÕ£©ÕæĮõ╗żõĖŁµīćÕ«Ü `--show-interval=0`ŃĆé
+
+õĖ║õ║åķ¬īĶ»üµĢ░µŹ«ńÜäõĖĆĶć┤µĆ¦ÕÆīµĢ░µŹ«Õó×Õ╝║ńÜäµĢłµ×£’╝īõĮĀÕÅ»õ╗źÕŖĀõĖŖ `--aug` µØźÕÅ»Ķ¦åÕī¢µĢ░µŹ«Õó×Õ╝║ÕÉÄńÜäµĢ░µŹ«’╝īµīćõ╗żÕ”éõĖŗµēĆńż║’╝Ü
+
+```shell
+python tools/misc/browse_dataset.py configs/_base_/datasets/kitti-3d-3class.py --task det --aug --output-dir ${OUTPUT_DIR}
+```
+
+Õ”éµ×£õĮĀµā│µśŠńż║ÕĖ”µ£ēµŖĢÕĮ▒ńÜä 3D ĶŠ╣ńĢīµĪåńÜä 2D ÕøŠÕāÅ’╝īõĮĀķ£ĆĶ”üõĖĆõĖ¬µö»µīüÕżÜµ©ĪµĆüµĢ░µŹ«ÕŖĀĶĮĮńÜäķģŹńĮ«µ¢ćõ╗Č’╝īÕ╣ČÕ░å `--task` ÕÅéµĢ░µö╣õĖ║ `multi-modality_det`ŃĆéńż║õŠŗÕ”éõĖŗ’╝Ü
+
+```shell
+python tools/misc/browse_dataset.py configs/mvxnet/mvxnet_fpn_dv_second_secfpn_8xb2-80e_kitti-3d-3class.py --task multi-modality_det --output-dir ${OUTPUT_DIR}
+```
+
+
+
+õĮĀÕÅ»õ╗źõĮ┐ńö©õĖŹÕÉīńÜäķģŹńĮ«µĄÅĶ¦łõĖŹÕÉīńÜäµĢ░µŹ«ķøå’╝īõŠŗÕ”éÕ£© 3D Ķ»Łõ╣ēÕłåÕē▓õ╗╗ÕŖĪõĖŁÕÅ»Ķ¦åÕī¢ ScanNet µĢ░µŹ«ķøå’╝Ü
+
+```shell
+python tools/misc/browse_dataset.py configs/_base_/datasets/scannet-seg.py --task lidar_seg --output-dir ${OUTPUT_DIR}
+```
+
+
+
+Õ£©ÕŹĢńø« 3D µŻĆµĄŗõ╗╗ÕŖĪõĖŁµĄÅĶ¦ł nuScenes µĢ░µŹ«ķøå’╝Ü
+
+```shell
+python tools/misc/browse_dataset.py configs/_base_/datasets/nus-mono3d.py --task mono_det --output-dir ${OUTPUT_DIR}
+```
+
+
diff --git a/internlm_langchain/knowledge_base/MMDetection3D/content/waymo.md b/internlm_langchain/knowledge_base/MMDetection3D/content/waymo.md
new file mode 100644
index 00000000..577ec151
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection3D/content/waymo.md
@@ -0,0 +1,168 @@
+# Waymo µĢ░µŹ«ķøå
+
+µ£¼µ¢ćµĪŻķĪĄÕīģÕɽõ║åÕģ│õ║Ä MMDetection3D õĖŁ Waymo µĢ░µŹ«ķøåńö©µ│ĢńÜäµĢÖń©ŗŃĆé
+
+## µĢ░µŹ«ķøåÕćåÕżć
+
+Õ£©ÕćåÕżć Waymo µĢ░µŹ«ķøåõ╣ŗÕēŹ’╝īÕ”éµ×£µé©õ╣ŗÕēŹÕŬիēĶŻģõ║å `requirements/build.txt` ÕÆī `requirements/runtime.txt` õĖŁńÜäõŠØĶĄ¢’╝īĶ»ĘķĆÜĶ┐ćĶ┐ÉĶĪīÕ”éõĖŗµīćõ╗żķóØÕż¢Õ«ēĶŻģ Waymo µĢ░µŹ«ķøåµēĆõŠØĶĄ¢ńÜäÕ«śµ¢╣Õīģ’╝Ü
+
+```
+# tf 2.1.0.
+pip install waymo-open-dataset-tf-2-1-0==1.2.0
+# tf 2.0.0
+# pip install waymo-open-dataset-tf-2-0-0==1.2.0
+# tf 1.15.0
+# pip install waymo-open-dataset-tf-1-15-0==1.2.0
+```
+
+µł¢ĶĆģ
+
+```
+pip install -r requirements/optional.txt
+```
+
+ÕÆīÕćåÕżćµĢ░µŹ«ķøåńÜäķĆÜńö©µ¢╣µ│ĢõĖĆĶć┤’╝īµłæõ╗¼µÄ©ĶŹÉÕ░åµĢ░µŹ«ķøåµĀ╣ńø«ÕĮĢĶĮ»ķōŠµÄźĶć│ `$MMDETECTION3D/data`ŃĆé
+ńö▒õ║ÄÕĤզŗ Waymo µĢ░µŹ«ńÜäµĀ╝Õ╝ÅÕ¤║õ║Ä `tfrecord`’╝īµłæõ╗¼ķ£ĆĶ”üÕ░åÕĤզŗµĢ░µŹ«Ķ┐øĶĪīķóäÕżäńÉå’╝īõ╗źõŠ┐õ║ÄĶ«Łń╗āÕÆīµĄŗĶ»ĢµŚČõĮ┐ńö©ŃĆ鵳æõ╗¼ńÜäµ¢╣µ│Ģµś»Õ░åÕ«āõ╗¼ĶĮ¼µŹóõĖ║ KITTI µĀ╝Õ╝ÅŃĆé
+
+ÕżäńÉåõ╣ŗÕēŹ’╝īµ¢ćõ╗Čńø«ÕĮĢń╗ōµ×äń╗äń╗ćÕ”éõĖŗ’╝Ü
+
+```
+mmdetection3d
+Ōö£ŌöĆŌöĆ mmdet3d
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+Ōö£ŌöĆŌöĆ data
+Ōöé Ōö£ŌöĆŌöĆ waymo
+Ōöé Ōöé Ōö£ŌöĆŌöĆ waymo_format
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ training
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ validation
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ testing
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ gt.bin
+Ōöé Ōöé Ōö£ŌöĆŌöĆ kitti_format
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ ImageSets
+
+```
+
+µé©ÕÅ»õ╗źÕ£©[Ķ┐Öķćī](https://waymo.com/open/download/)õĖŗĶĮĮ 1.2 ńēłµ£¼ńÜä Waymo Õģ¼Õ╝ƵĢ░µŹ«ķøå’╝īÕ╣ČÕ£©[Ķ┐Öķćī](https://drive.google.com/drive/folders/18BVuF_RYJF0NjZpt8SnfzANiakoRMf0o?usp=sharing)õĖŗĶĮĮÕģČĶ«Łń╗ā/ķ¬īĶ»ü/µĄŗĶ»ĢķøåµŗåÕłåµ¢ćõ╗ČŃĆéµÄźõĖŗµØź’╝īĶ»ĘÕ░å `tfrecord` µ¢ćõ╗ȵöŠÕģź `data/waymo/waymo_format/` õĖŗńÜäÕ»╣Õ║öµ¢ćõ╗ČÕż╣’╝īÕ╣ČÕ░å txt µĀ╝Õ╝ÅńÜäµĢ░µŹ«ķøåµŗåÕłåµ¢ćõ╗ȵöŠÕģź `data/waymo/kitti_format/ImageSets`ŃĆéÕ£©[Ķ┐Öķćī](https://console.cloud.google.com/storage/browser/waymo_open_dataset_v_1_2_0/validation/ground_truth_objects)õĖŗĶĮĮķ¬īĶ»üķøåõĮ┐ńö©ńÜä bin µĀ╝Õ╝Åń£¤Õ«×µĀćµ│© (Ground Truth) µ¢ćõ╗ČÕ╣ȵöŠÕģź `data/waymo/waymo_format/`ŃĆéÕ░Åń¬ŹķŚ©’╝ܵé©ÕÅ»õ╗źõĮ┐ńö© `gsutil` µØźÕ£©ÕæĮõ╗żĶĪīõĖŗĶĮĮÕż¦Ķ¦äµ©ĪµĢ░µŹ«ķøåŃĆéµé©ÕÅ»õ╗źÕ░åĶ»ź[ÕĘźÕģĘ](https://github.com/RalphMao/Waymo-Dataset-Tool) õĮ£õĖ║õĖĆõĖ¬õŠŗÕŁÉµØźµ¤źń£ŗµø┤ÕżÜń╗åĶŖéŃĆéõ╣ŗÕÉÄ’╝īķĆÜĶ┐ćĶ┐ÉĶĪīÕ”éõĖŗµīćõ╗żÕćåÕżć Waymo µĢ░µŹ«’╝Ü
+
+```bash
+python tools/create_data.py waymo --root-path ./data/waymo/ --out-dir ./data/waymo/ --workers 128 --extra-tag waymo
+```
+
+Ķ»Ęµ│©µäÅ’╝īÕ”éµ×£µé©ńÜäµ£¼Õ£░ńŻüńøśµ▓Īµ£ēĶČ│Õż¤ń®║ķŚ┤õ┐ØÕŁśĶĮ¼µŹóÕÉÄńÜäµĢ░µŹ«’╝īµé©ÕÅ»õ╗źÕ░å `--out-dir` µö╣õĖ║ÕģČõ╗¢ńø«ÕĮĢ’╝øÕŬĶ”üÕ£©ÕłøÕ╗║µ¢ćõ╗ČÕż╣ŃĆüÕćåÕżćµĢ░µŹ«Õ╣ČĶĮ¼µŹóµĀ╝Õ╝ÅÕÉÄ’╝īÕ░åµĢ░µŹ«µ¢ćõ╗ČķōŠµÄźÕł░ `data/waymo/kitti_format` ÕŹ│ÕÅ»ŃĆé
+
+Õ£©µĢ░µŹ«ĶĮ¼µŹóÕÉÄ’╝īµ¢ćõ╗Čńø«ÕĮĢń╗ōµ×äÕ║öń╗äń╗ćÕ”éõĖŗ’╝Ü
+
+```
+mmdetection3d
+Ōö£ŌöĆŌöĆ mmdet3d
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+Ōö£ŌöĆŌöĆ data
+Ōöé Ōö£ŌöĆŌöĆ waymo
+Ōöé Ōöé Ōö£ŌöĆŌöĆ waymo_format
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ training
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ validation
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ testing
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ gt.bin
+Ōöé Ōöé Ōö£ŌöĆŌöĆ kitti_format
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ ImageSets
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ training
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ calib
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ image_0
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ image_1
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ image_2
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ image_3
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ image_4
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ label_0
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ label_1
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ label_2
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ label_3
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ label_4
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ label_all
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ pose
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ velodyne
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ testing
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ (the same as training)
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ waymo_gt_database
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ waymo_infos_trainval.pkl
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ waymo_infos_train.pkl
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ waymo_infos_val.pkl
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ waymo_infos_test.pkl
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ waymo_dbinfos_train.pkl
+
+```
+
+ÕøĀõĖ║ Waymo µĢ░µŹ«ńÜäµØźµ║ÉÕīģÕɽµĢ░õĖ¬ńøĖµ£║’╝īĶ┐Öķćīµłæõ╗¼Õ░åµ»ÅõĖ¬ńøĖµ£║Õ»╣Õ║öńÜäÕøŠÕāÅÕÆīµĀćńŁŠµ¢ćõ╗ČÕłåÕł½ÕŁśÕé©’╝īÕ╣ČÕ░åńøĖµ£║õĮŹÕ¦┐ (pose) µ¢ćõ╗ČÕŁśÕé©õĖŗµØźõ╗źõŠøÕÉÄń╗ŁÕżäńÉåĶ┐×ń╗ŁÕżÜÕĖ¦ńÜäńé╣õ║æŃĆ鵳æõ╗¼õĮ┐ńö© `{a}{bbb}{ccc}` ńÜäÕÉŹń¦░ń╝¢ńĀüµ¢╣Õ╝ÅõĖ║µ»ÅÕĖ¦µĢ░µŹ«ÕæĮÕÉŹ’╝īÕģČõĖŁ `a` µś»õĖŹÕÉīµĢ░µŹ«µŗåÕłåńÜäÕēŹń╝Ć’╝ł`0` µīćõ╗ŻĶ«Łń╗āķøå’╝ī`1` µīćõ╗Żķ¬īĶ»üķøå’╝ī`2` µīćõ╗ŻµĄŗĶ»Ģķøå’╝ē’╝ī`bbb` µś»ÕłåÕē▓ķā©Õłå (segment) ńÜäń┤óÕ╝Ģ’╝īĶĆī `ccc` µś»ÕĖ¦ń┤óÕ╝ĢŃĆéµé©ÕÅ»õ╗źĶĮ╗ĶĆīµśōõĖŠÕ£░µīēńģ¦Õ”éõĖŖÕæĮÕÉŹĶ¦äÕłÖÕ«ÜõĮŹÕł░µēĆķ£ĆńÜäÕĖ¦ŃĆ鵳æõ╗¼Õ░åĶ«Łń╗āÕÆīķ¬īĶ»üµēĆķ£ĆµĢ░µŹ«µīē KITTI ńÜäµ¢╣Õ╝ÅķøåÕÉłÕ£©õĖĆĶĄĘ’╝īńäČÕÉÄÕ░åĶ«Łń╗āķøå/ķ¬īĶ»üķøå/µĄŗĶ»ĢķøåńÜäń┤óÕ╝ĢÕŁśÕé©Õ£© `ImageSet` õĖŗńÜäµ¢ćõ╗ČõĖŁŃĆé
+
+## Ķ«Łń╗ā
+
+ĶĆāĶÖæÕł░ÕĤզŗµĢ░µŹ«ķøåõĖŁńÜäµĢ░µŹ«µ£ēÕŠłÕżÜńøĖõ╝╝ńÜäÕĖ¦’╝īµłæõ╗¼Õ¤║µ£¼õĖŖÕÅ»õ╗źõĖ╗Ķ”üõĮ┐ńö©õĖĆõĖ¬ÕŁÉķøåµØźĶ«Łń╗āµłæõ╗¼ńÜ䵩ĪÕ×ŗŃĆéÕ£©µłæõ╗¼ÕłØµŁźńÜäÕ¤║ń║┐õĖŁ’╝īµłæõ╗¼Õ£©µ»Åõ║öÕĖ¦ÕøŠńēćõĖŁÕŖĀĶĮĮõĖĆÕĖ¦ŃĆéÕŠŚńøŖõ║ĵłæõ╗¼ńÜäĶČģÕÅéµĢ░Ķ«ŠńĮ«ÕÆīµĢ░µŹ«Õó×Õ╝║µ¢╣µĪł’╝īµłæõ╗¼ÕŠŚÕł░õ║åµ»ö Waymo [ÕĤĶ«║µ¢ć](https://arxiv.org/pdf/1912.04838.pdf)õĖŁµø┤ÕźĮńÜäµĆ¦ĶāĮŃĆéĶ»Ęń¦╗µŁź `configs/pointpillars/` õĖŗńÜä README.md õ╗źµ¤źń£ŗµø┤ÕżÜķģŹńĮ«ÕÆīµĆ¦ĶāĮńøĖÕģ│ńÜäń╗åĶŖéŃĆ鵳æõ╗¼õ╝ÜÕ░ĮÕ┐½ÕÅæÕĖāõĖĆõĖ¬µø┤Õ«īµĢ┤ńÜä Waymo Õ¤║Õćåµ”£ÕŹĢ (benchmark)ŃĆé
+
+## Ķ»äõ╝░
+
+õĖ║õ║åÕ£© Waymo µĢ░µŹ«ķøåõĖŖĶ┐øĶĪīµŻĆµĄŗµĆ¦ĶāĮĶ»äõ╝░’╝īĶ»Ęµīēńģ¦[µŁżÕżäµīćńż║](https://github.com/waymo-research/waymo-open-dataset/blob/master/docs/quick_start.md)µ×äÕ╗║ńö©õ║ÄĶ«Īń«ŚĶ»äõ╝░µīćµĀćńÜäõ║īĶ┐øÕłČµ¢ćõ╗Č `compute_detection_metrics_main`’╝īÕ╣ČÕ░åÕ«āńĮ«õ║Ä `mmdet3d/core/evaluation/waymo_utils/` õĖŗŃĆéµé©Õ¤║µ£¼õĖŖÕÅ»õ╗źµīēńģ¦õĖŗµ¢╣ÕæĮõ╗żÕ«ēĶŻģ `bazel`’╝īńäČÕÉĵ×äÕ╗║õ║īĶ┐øÕłČµ¢ćõ╗Č’╝Ü
+
+```shell
+# download the code and enter the base directory
+git clone https://github.com/waymo-research/waymo-open-dataset.git waymo-od
+# git clone https://github.com/Abyssaledge/waymo-open-dataset-master waymo-od # if you want to use faster multi-thread version.
+cd waymo-od
+git checkout remotes/origin/master
+
+# use the Bazel build system
+sudo apt-get install --assume-yes pkg-config zip g++ zlib1g-dev unzip python3 python3-pip
+BAZEL_VERSION=3.1.0
+wget https://github.com/bazelbuild/bazel/releases/download/${BAZEL_VERSION}/bazel-${BAZEL_VERSION}-installer-linux-x86_64.sh
+sudo bash bazel-${BAZEL_VERSION}-installer-linux-x86_64.sh
+sudo apt install build-essential
+
+# configure .bazelrc
+./configure.sh
+# delete previous bazel outputs and reset internal caches
+bazel clean
+
+bazel build waymo_open_dataset/metrics/tools/compute_detection_metrics_main
+cp bazel-bin/waymo_open_dataset/metrics/tools/compute_detection_metrics_main ../mmdetection3d/mmdet3d/evaluation/functional/waymo_utils/
+```
+
+µÄźõĖŗµØź’╝īµé©Õ░▒ÕÅ»õ╗źÕ£© Waymo õĖŖĶ»äõ╝░µé©ńÜ䵩ĪÕ×ŗõ║åŃĆéÕ”éõĖŗńż║õŠŗµś»õĮ┐ńö© 8 õĖ¬ÕøŠÕĮóÕżäńÉåÕÖ© (GPU) Õ£© Waymo õĖŖńö© Waymo Ķ»äõ╗ʵīćµĀćĶ»äõ╝░ PointPillars µ©ĪÕ×ŗńÜäµāģµÖ»’╝Ü
+
+```shell
+./tools/dist_test.sh configs/pointpillars/pointpillars_hv_secfpn_sbn-all_16xb2-2x_waymo-3d-car.py checkpoints/hv_pointpillars_secfpn_sbn-2x16_2x_waymo-3d-car_latest.pth
+```
+
+Õ”éµ×£ķ£ĆĶ”üńö¤µłÉ bin µ¢ćõ╗Č’╝īķ£ĆĶ”üÕ£©ķģŹńĮ«µ¢ćõ╗ČńÜä `test_evaluator` õĖŁµīćÕ«Ü `pklfile_prefix`’╝īÕøĀµŁżõĮĀÕÅ»õ╗źÕ£©ÕæĮõ╗żÕÉĵĘ╗ÕŖĀ `--cfg-options "test_evaluator.pklfile_prefix=xxxx"`ŃĆé
+
+**µ│©µäÅ**:
+
+1. µ£ēµŚČńö© `bazel` µ×äÕ╗║ `compute_detection_metrics_main` ńÜäĶ┐ćń©ŗõĖŁõ╝ÜÕć║ńÄ░Õ”éõĖŗķöÖĶ»»’╝Ü`'round' õĖŹµś» 'std' ńÜ䵳ÉÕæś` (`'round' is not a member of 'std'`)ŃĆ鵳æõ╗¼ÕŬķ£ĆĶ”üń¦╗ķÖżĶ»źµ¢ćõ╗ČõĖŁ’╝ī`round` ÕēŹńÜä `std::`ŃĆé
+
+2. ĶĆāĶÖæÕł░ Waymo õĖŖĶ»äõ╝░õĖƵ¼ĪĶĆŚµŚČõĖŹń¤Ł’╝īµłæõ╗¼Õ╗║Ķ««ÕŬգ©µ©ĪÕ×ŗĶ«Łń╗āń╗ōµØ¤µŚČĶ┐øĶĪīĶ»äõ╝░ŃĆé
+
+3. õĖ║õ║åÕ£© CUDA 9 ńÄ»ÕóāõĮ┐ńö© TensorFlow’╝īµłæõ╗¼Õ╗║Ķ««ķĆÜĶ┐ćń╝¢Ķ»æ TensorFlow µ║ÉńĀüńÜäµ¢╣Õ╝ÅõĮ┐ńö©ŃĆéķÖżõ║åÕ«śµ¢╣µĢÖń©ŗõ╣ŗÕż¢’╝īµé©Ķ┐śÕÅ»õ╗źÕÅéĶĆāĶ»ź[ķōŠµÄź](https://github.com/SmileTM/Tensorflow2.X-GPU-CUDA9.0)õ╗źÕ»╗µēŠÕÅ»ĶāĮÕÉłķĆéńÜäķóäń╝¢Ķ»æÕīģõ╗źÕÅŖń╝¢Ķ»æµ║ÉńĀüńÜäÕ«×ńö©µö╗ńĢźŃĆé
+
+## µĄŗĶ»ĢÕ╣ȵÅÉõ║żÕł░Õ«śµ¢╣µ£ŹÕŖĪÕÖ©
+
+Õ”éõĖŗµś»õĖĆõĖ¬õĮ┐ńö© 8 õĖ¬ÕøŠÕĮóÕżäńÉåÕÖ©Õ£© Waymo õĖŖµĄŗĶ»Ģ PointPillars’╝īńö¤µłÉ bin µ¢ćõ╗ČÕ╣ȵÅÉõ║żń╗ōµ×£Õł░Õ«śµ¢╣µ”£ÕŹĢńÜäõŠŗÕŁÉ’╝Ü
+
+Õ”éµ×£õĮĀµā│ńö¤µłÉ bin µ¢ćõ╗ČÕ╣ȵÅÉõ║żÕł░µ£ŹÕŖĪÕÖ©õĖŁ’╝īÕ£©Ķ┐ÉĶĪīµĄŗĶ»Ģµīćõ╗żÕēŹõĮĀķ£ĆĶ”üÕ£©ķģŹńĮ«µ¢ćõ╗ČńÜä `test_evaluator` õĖŁµīćÕ«Ü `submission_prefix`ŃĆé
+
+Õ£©ńö¤µłÉ bin µ¢ćõ╗ČÕÉÄ’╝īµé©ÕÅ»õ╗źń«ĆÕŹĢÕ£░µ×äÕ╗║õ║īĶ┐øÕłČµ¢ćõ╗Č `create_submission`’╝īÕ╣ȵīēńģ¦[µīćńż║](https://github.com/waymo-research/waymo-open-dataset/blob/master/docs/quick_start.md/)ÕłøÕ╗║õĖĆõĖ¬µÅÉõ║żµ¢ćõ╗ČŃĆéõĖŗķØ󵜻õĖĆõ║øńż║õŠŗ’╝Ü
+
+```shell
+cd ../waymo-od/
+bazel build waymo_open_dataset/metrics/tools/create_submission
+cp bazel-bin/waymo_open_dataset/metrics/tools/create_submission ../mmdetection3d/mmdet3d/core/evaluation/waymo_utils/
+vim waymo_open_dataset/metrics/tools/submission.txtpb # set the metadata information
+cp waymo_open_dataset/metrics/tools/submission.txtpb ../mmdetection3d/mmdet3d/evaluation/functional/waymo_utils/
+
+cd ../mmdetection3d
+# suppose the result bin is in `results/waymo-car/submission`
+mmdet3d/core/evaluation/waymo_utils/create_submission --input_filenames='results/waymo-car/kitti_results_test.bin' --output_filename='results/waymo-car/submission/model' --submission_filename='mmdet3d/evaluation/functional/waymo_utils/submission.txtpb'
+
+tar cvf results/waymo-car/submission/my_model.tar results/waymo-car/submission/my_model/
+gzip results/waymo-car/submission/my_model.tar
+```
+
+Õ”éµ×£µā│ńö©Õ«śµ¢╣Ķ»äõ╝░µ£ŹÕŖĪÕÖ©Ķ»äõ╝░µé©Õ£©ķ¬īĶ»üķøåõĖŖńÜäń╗ōµ×£’╝īµé©ÕÅ»õ╗źõĮ┐ńö©ÕÉīµĀĘńÜäµ¢╣µ│Ģńö¤µłÉµÅÉõ║żµ¢ćõ╗Č’╝īÕŬķ£ĆńĪ«õ┐صé©Õ£©Ķ┐ÉĶĪīÕ”éõĖŖµīćõ╗żÕēŹµø┤µö╣ `submission.txtpb` õĖŁńÜäÕŁŚµ«ĄÕĆ╝ÕŹ│ÕÅ»ŃĆé
diff --git a/internlm_langchain/knowledge_base/MMDetection3D/vector_store/index.faiss b/internlm_langchain/knowledge_base/MMDetection3D/vector_store/index.faiss
new file mode 100644
index 00000000..d7fe9427
Binary files /dev/null and b/internlm_langchain/knowledge_base/MMDetection3D/vector_store/index.faiss differ
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/15_minutes.md b/internlm_langchain/knowledge_base/MMEngine/content/15_minutes.md
new file mode 100644
index 00000000..8ca102f5
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/15_minutes.md
@@ -0,0 +1,242 @@
+# 15 ÕłåķƤõĖŖµēŗ MMEngine
+
+õ╗źÕ£© CIFAR-10 µĢ░µŹ«ķøåõĖŖĶ«Łń╗āõĖĆõĖ¬ ResNet-50 µ©ĪÕ×ŗõĖ║õŠŗ’╝īµłæõ╗¼Õ░åõĮ┐ńö© 80 ĶĪīõ╗źÕåģńÜäõ╗ŻńĀü’╝īÕł®ńö© MMEngine µ×äÕ╗║õĖĆõĖ¬Õ«īµĢ┤ńÜäŃĆü
+ÕÅ»ķģŹńĮ«ńÜäĶ«Łń╗āÕÆīķ¬īĶ»üµĄüń©ŗ’╝īµĢ┤õĖ¬µĄüń©ŗÕīģÕɽՔéõĖŗµŁźķ¬ż’╝Ü
+
+1. [µ×äÕ╗║µ©ĪÕ×ŗ](#µ×äÕ╗║µ©ĪÕ×ŗ)
+2. [µ×äÕ╗║µĢ░µŹ«ķøåÕÆīµĢ░µŹ«ÕŖĀĶĮĮÕÖ©](#µ×äÕ╗║µĢ░µŹ«ķøåÕÆīµĢ░µŹ«ÕŖĀĶĮĮÕÖ©)
+3. [µ×äÕ╗║Ķ»äµĄŗµīćµĀć](#µ×äÕ╗║Ķ»äµĄŗµīćµĀć)
+4. [µ×äÕ╗║µē¦ĶĪīÕÖ©Õ╣ȵē¦ĶĪīõ╗╗ÕŖĪ](#µ×äÕ╗║µē¦ĶĪīÕÖ©Õ╣ȵē¦ĶĪīõ╗╗ÕŖĪ)
+
+## µ×äÕ╗║µ©ĪÕ×ŗ
+
+ķ”¢Õģł’╝īµłæõ╗¼ķ£ĆĶ”üµ×äÕ╗║õĖĆõĖ¬**µ©ĪÕ×ŗ**’╝īÕ£© MMEngine õĖŁ’╝īµłæõ╗¼ń║”Õ«ÜĶ┐ÖõĖ¬µ©ĪÕ×ŗÕ║öÕĮōń╗¦µē┐ `BaseModel`’╝īÕ╣ČõĖöÕģČ `forward` µ¢╣µ│ĢķÖżõ║åµÄźÕÅŚµØźĶ欵Ģ░µŹ«ķøåńÜäĶŗźÕ╣▓ÕÅéµĢ░Õż¢’╝īĶ┐śķ£ĆĶ”üµÄźÕÅŚķóØÕż¢ńÜäÕÅéµĢ░ `mode`’╝ÜÕ»╣õ║ÄĶ«Łń╗ā’╝īµłæõ╗¼ķ£ĆĶ”ü `mode` µÄźÕÅŚÕŁŚń¼”õĖ▓ "loss"’╝īÕ╣ČĶ┐öÕø×õĖĆõĖ¬ÕīģÕɽ "loss" ÕŁŚµ«ĄńÜäÕŁŚÕģĖ’╝øÕ»╣õ║Äķ¬īĶ»ü’╝īµłæõ╗¼ķ£ĆĶ”ü `mode` µÄźÕÅŚÕŁŚń¼”õĖ▓ "predict"’╝īÕ╣ČĶ┐öÕø×ÕÉīµŚČÕīģÕɽķó䵥ŗõ┐Īµü»ÕÆīń£¤Õ«×õ┐Īµü»ńÜäń╗ōµ×£ŃĆé
+
+```python
+import torch.nn.functional as F
+import torchvision
+from mmengine.model import BaseModel
+
+
+class MMResNet50(BaseModel):
+ def __init__(self):
+ super().__init__()
+ self.resnet = torchvision.models.resnet50()
+
+ def forward(self, imgs, labels, mode):
+ x = self.resnet(imgs)
+ if mode == 'loss':
+ return {'loss': F.cross_entropy(x, labels)}
+ elif mode == 'predict':
+ return x, labels
+```
+
+## µ×äÕ╗║µĢ░µŹ«ķøåÕÆīµĢ░µŹ«ÕŖĀĶĮĮÕÖ©
+
+Õģȵ¼Ī’╝īµłæõ╗¼ķ£ĆĶ”üµ×äÕ╗║Ķ«Łń╗āÕÆīķ¬īĶ»üµēĆķ£ĆĶ”üńÜä**µĢ░µŹ«ķøå (Dataset)**ÕÆī**µĢ░µŹ«ÕŖĀĶĮĮÕÖ© (DataLoader)**ŃĆé
+Õ»╣õ║ÄÕ¤║ńĪĆńÜäĶ«Łń╗āÕÆīķ¬īĶ»üÕŖ¤ĶāĮ’╝īµłæõ╗¼ÕÅ»õ╗źńø┤µÄźõĮ┐ńö©ń¼”ÕÉł PyTorch µĀćÕćåńÜäµĢ░µŹ«ÕŖĀĶĮĮÕÖ©ÕÆīµĢ░µŹ«ķøåŃĆé
+
+```python
+import torchvision.transforms as transforms
+from torch.utils.data import DataLoader
+
+norm_cfg = dict(mean=[0.491, 0.482, 0.447], std=[0.202, 0.199, 0.201])
+train_dataloader = DataLoader(batch_size=32,
+ shuffle=True,
+ dataset=torchvision.datasets.CIFAR10(
+ 'data/cifar10',
+ train=True,
+ download=True,
+ transform=transforms.Compose([
+ transforms.RandomCrop(32, padding=4),
+ transforms.RandomHorizontalFlip(),
+ transforms.ToTensor(),
+ transforms.Normalize(**norm_cfg)
+ ])))
+
+val_dataloader = DataLoader(batch_size=32,
+ shuffle=False,
+ dataset=torchvision.datasets.CIFAR10(
+ 'data/cifar10',
+ train=False,
+ download=True,
+ transform=transforms.Compose([
+ transforms.ToTensor(),
+ transforms.Normalize(**norm_cfg)
+ ])))
+```
+
+## µ×äÕ╗║Ķ»äµĄŗµīćµĀć
+
+õĖ║õ║åĶ┐øĶĪīķ¬īĶ»üÕÆīµĄŗĶ»Ģ’╝īµłæõ╗¼ķ£ĆĶ”üÕ«Üõ╣ēµ©ĪÕ×ŗµÄ©ńÉåń╗ōµ×£ńÜä**Ķ»äµĄŗµīćµĀć**ŃĆ鵳æõ╗¼ń║”Õ«ÜĶ┐ÖõĖĆĶ»äµĄŗµīćµĀćķ£ĆĶ”üń╗¦µē┐ `BaseMetric`’╝īÕ╣ČÕ«×ńÄ░ `process` ÕÆī `compute_metrics` µ¢╣µ│ĢŃĆéÕģČõĖŁ `process` µ¢╣µ│ĢµÄźÕÅŚµĢ░µŹ«ķøåńÜäĶŠōÕć║ÕÆīµ©ĪÕ×ŗ `mode="predict"`
+µŚČńÜäĶŠōÕć║’╝īµŁżµŚČńÜäµĢ░µŹ«õĖ║õĖĆõĖ¬µē╣µ¼ĪńÜäµĢ░µŹ«’╝īÕ»╣Ķ┐ÖõĖƵē╣µ¼ĪńÜäµĢ░µŹ«Ķ┐øĶĪīÕżäńÉåÕÉÄ’╝īõ┐ØÕŁśõ┐Īµü»Ķć│ `self.results` Õ▒׵ƦŃĆé
+ĶĆī `compute_metrics` µÄźÕÅŚ `results` ÕÅéµĢ░’╝īĶ┐ÖõĖĆÕÅéµĢ░ńÜäĶŠōÕģźõĖ║ `process` õĖŁõ┐ØÕŁśńÜäµēƵ£ēõ┐Īµü»
+’╝łÕ”éµ×£µś»ÕłåÕĖāÕ╝ÅńÄ»Õóā’╝ī`results` õĖŁõĖ║ÕĘ▓µöČķøåńÜä’╝īÕīģµŗ¼ÕÉäõĖ¬Ķ┐øń©ŗ `process` õ┐ØÕŁśõ┐Īµü»ńÜäń╗ōµ×£’╝ē’╝īÕł®ńö©Ķ┐Öõ║øõ┐Īµü»Ķ«Īń«ŚÕ╣ČĶ┐öÕø×õ┐ØÕŁśµ£ēĶ»äµĄŗµīćµĀćń╗ōµ×£ńÜäÕŁŚÕģĖŃĆé
+
+```python
+from mmengine.evaluator import BaseMetric
+
+class Accuracy(BaseMetric):
+ def process(self, data_batch, data_samples):
+ score, gt = data_samples
+ # Õ░åõĖĆõĖ¬µē╣µ¼ĪńÜäõĖŁķŚ┤ń╗ōµ×£õ┐ØÕŁśĶć│ `self.results`
+ self.results.append({
+ 'batch_size': len(gt),
+ 'correct': (score.argmax(dim=1) == gt).sum().cpu(),
+ })
+
+ def compute_metrics(self, results):
+ total_correct = sum(item['correct'] for item in results)
+ total_size = sum(item['batch_size'] for item in results)
+ # Ķ┐öÕø×õ┐ØÕŁśµ£ēĶ»äµĄŗµīćµĀćń╗ōµ×£ńÜäÕŁŚÕģĖ’╝īÕģČõĖŁķö«õĖ║µīćµĀćÕÉŹń¦░
+ return dict(accuracy=100 * total_correct / total_size)
+```
+
+## µ×äÕ╗║µē¦ĶĪīÕÖ©Õ╣ȵē¦ĶĪīõ╗╗ÕŖĪ
+
+µ£ĆÕÉÄ’╝īµłæõ╗¼Õł®ńö©µ×äÕ╗║ÕźĮńÜä**µ©ĪÕ×ŗ**’╝ī**µĢ░µŹ«ÕŖĀĶĮĮÕÖ©**’╝ī**Ķ»äµĄŗµīćµĀć**µ×äÕ╗║õĖĆõĖ¬**µē¦ĶĪīÕÖ© (Runner)**’╝īÕÉīµŚČÕ£©ÕģČõĖŁķģŹńĮ«
+**õ╝śÕī¢ÕÖ©**ŃĆü**ÕĘźõĮ£ĶĘ»ÕŠä**ŃĆü**Ķ«Łń╗āõĖÄķ¬īĶ»üķģŹńĮ«**ńŁēķĆēķĪ╣’╝īÕŹ│ÕÅ»ķĆÜĶ┐ćĶ░āńö© `train()` µÄźÕÅŻÕÉ»ÕŖ©Ķ«Łń╗ā’╝Ü
+
+```python
+from torch.optim import SGD
+from mmengine.runner import Runner
+
+runner = Runner(
+ # ńö©õ╗źĶ«Łń╗āÕÆīķ¬īĶ»üńÜ䵩ĪÕ×ŗ’╝īķ£ĆĶ”üµ╗ĪĶČ│ńē╣Õ«ÜńÜäµÄźÕÅŻķ£Ćµ▒é
+ model=MMResNet50(),
+ # ÕĘźõĮ£ĶĘ»ÕŠä’╝īńö©õ╗źõ┐ØÕŁśĶ«Łń╗āµŚźÕ┐ŚŃĆüµØāķ揵¢ćõ╗Čõ┐Īµü»
+ work_dir='./work_dir',
+ # Ķ«Łń╗āµĢ░µŹ«ÕŖĀĶĮĮÕÖ©’╝īķ£ĆĶ”üµ╗ĪĶČ│ PyTorch µĢ░µŹ«ÕŖĀĶĮĮÕÖ©ÕŹÅĶ««
+ train_dataloader=train_dataloader,
+ # õ╝śÕī¢ÕÖ©ÕīģĶŻģ’╝īńö©õ║ĵ©ĪÕ×ŗõ╝śÕī¢’╝īÕ╣ȵÅÉõŠø AMPŃĆüµó»Õ║”ń┤»ń¦»ńŁēķÖäÕŖĀÕŖ¤ĶāĮ
+ optim_wrapper=dict(optimizer=dict(type=SGD, lr=0.001, momentum=0.9)),
+ # Ķ«Łń╗āķģŹńĮ«’╝īńö©õ║ĵīćÕ«ÜĶ«Łń╗āÕ橵£¤ŃĆüķ¬īĶ»üķŚ┤ķÜöńŁēõ┐Īµü»
+ train_cfg=dict(by_epoch=True, max_epochs=5, val_interval=1),
+ # ķ¬īĶ»üµĢ░µŹ«ÕŖĀĶĮĮÕÖ©’╝īķ£ĆĶ”üµ╗ĪĶČ│ PyTorch µĢ░µŹ«ÕŖĀĶĮĮÕÖ©ÕŹÅĶ««
+ val_dataloader=val_dataloader,
+ # ķ¬īĶ»üķģŹńĮ«’╝īńö©õ║ĵīćÕ«Üķ¬īĶ»üµēĆķ£ĆĶ”üńÜäķóØÕż¢ÕÅéµĢ░
+ val_cfg=dict(),
+ # ńö©õ║Äķ¬īĶ»üńÜäĶ»äµĄŗÕÖ©’╝īĶ┐ÖķćīõĮ┐ńö©ķ╗śĶ«żĶ»äµĄŗÕÖ©’╝īÕ╣ČĶ»äµĄŗµīćµĀć
+ val_evaluator=dict(type=Accuracy),
+)
+
+runner.train()
+```
+
+µ£ĆÕÉÄ’╝īĶ«®µłæõ╗¼µŖŖõ╗źõĖŖķā©Õłåµ▒ćµĆ╗µłÉõĖ║õĖĆõĖ¬Õ«īµĢ┤ńÜä’╝īÕł®ńö© MMEngine µē¦ĶĪīÕÖ©Ķ┐øĶĪīĶ«Łń╗āÕÆīķ¬īĶ»üńÜäĶäܵ£¼’╝Ü
+
+ +
+```python
+import torch.nn.functional as F
+import torchvision
+import torchvision.transforms as transforms
+from torch.optim import SGD
+from torch.utils.data import DataLoader
+
+from mmengine.evaluator import BaseMetric
+from mmengine.model import BaseModel
+from mmengine.runner import Runner
+
+
+class MMResNet50(BaseModel):
+ def __init__(self):
+ super().__init__()
+ self.resnet = torchvision.models.resnet50()
+
+ def forward(self, imgs, labels, mode):
+ x = self.resnet(imgs)
+ if mode == 'loss':
+ return {'loss': F.cross_entropy(x, labels)}
+ elif mode == 'predict':
+ return x, labels
+
+
+class Accuracy(BaseMetric):
+ def process(self, data_batch, data_samples):
+ score, gt = data_samples
+ self.results.append({
+ 'batch_size': len(gt),
+ 'correct': (score.argmax(dim=1) == gt).sum().cpu(),
+ })
+
+ def compute_metrics(self, results):
+ total_correct = sum(item['correct'] for item in results)
+ total_size = sum(item['batch_size'] for item in results)
+ return dict(accuracy=100 * total_correct / total_size)
+
+
+norm_cfg = dict(mean=[0.491, 0.482, 0.447], std=[0.202, 0.199, 0.201])
+train_dataloader = DataLoader(batch_size=32,
+ shuffle=True,
+ dataset=torchvision.datasets.CIFAR10(
+ 'data/cifar10',
+ train=True,
+ download=True,
+ transform=transforms.Compose([
+ transforms.RandomCrop(32, padding=4),
+ transforms.RandomHorizontalFlip(),
+ transforms.ToTensor(),
+ transforms.Normalize(**norm_cfg)
+ ])))
+
+val_dataloader = DataLoader(batch_size=32,
+ shuffle=False,
+ dataset=torchvision.datasets.CIFAR10(
+ 'data/cifar10',
+ train=False,
+ download=True,
+ transform=transforms.Compose([
+ transforms.ToTensor(),
+ transforms.Normalize(**norm_cfg)
+ ])))
+
+runner = Runner(
+ model=MMResNet50(),
+ work_dir='./work_dir',
+ train_dataloader=train_dataloader,
+ optim_wrapper=dict(optimizer=dict(type=SGD, lr=0.001, momentum=0.9)),
+ train_cfg=dict(by_epoch=True, max_epochs=5, val_interval=1),
+ val_dataloader=val_dataloader,
+ val_cfg=dict(),
+ val_evaluator=dict(type=Accuracy),
+)
+runner.train()
+```
+
+ĶŠōÕć║ńÜäĶ«Łń╗āµŚźÕ┐ŚÕ”éõĖŗ’╝Ü
+
+```
+2022/08/22 15:51:53 - mmengine - INFO -
+------------------------------------------------------------
+System environment:
+ sys.platform: linux
+ Python: 3.8.12 (default, Oct 12 2021, 13:49:34) [GCC 7.5.0]
+ CUDA available: True
+ numpy_random_seed: 1513128759
+ GPU 0: NVIDIA GeForce GTX 1660 SUPER
+ CUDA_HOME: /usr/local/cuda
+...
+
+2022/08/22 15:51:54 - mmengine - INFO - Checkpoints will be saved to /home/mazerun/work_dir by HardDiskBackend.
+2022/08/22 15:51:56 - mmengine - INFO - Epoch(train) [1][10/1563] lr: 1.0000e-03 eta: 0:18:23 time: 0.1414 data_time: 0.0077 memory: 392 loss: 5.3465
+2022/08/22 15:51:56 - mmengine - INFO - Epoch(train) [1][20/1563] lr: 1.0000e-03 eta: 0:11:29 time: 0.0354 data_time: 0.0077 memory: 392 loss: 2.7734
+2022/08/22 15:51:56 - mmengine - INFO - Epoch(train) [1][30/1563] lr: 1.0000e-03 eta: 0:09:10 time: 0.0352 data_time: 0.0076 memory: 392 loss: 2.7789
+2022/08/22 15:51:57 - mmengine - INFO - Epoch(train) [1][40/1563] lr: 1.0000e-03 eta: 0:08:00 time: 0.0353 data_time: 0.0073 memory: 392 loss: 2.5725
+2022/08/22 15:51:57 - mmengine - INFO - Epoch(train) [1][50/1563] lr: 1.0000e-03 eta: 0:07:17 time: 0.0347 data_time: 0.0073 memory: 392 loss: 2.7382
+2022/08/22 15:51:57 - mmengine - INFO - Epoch(train) [1][60/1563] lr: 1.0000e-03 eta: 0:06:49 time: 0.0347 data_time: 0.0072 memory: 392 loss: 2.5956
+2022/08/22 15:51:58 - mmengine - INFO - Epoch(train) [1][70/1563] lr: 1.0000e-03 eta: 0:06:28 time: 0.0348 data_time: 0.0072 memory: 392 loss: 2.7351
+...
+2022/08/22 15:52:50 - mmengine - INFO - Saving checkpoint at 1 epochs
+2022/08/22 15:52:51 - mmengine - INFO - Epoch(val) [1][10/313] eta: 0:00:03 time: 0.0122 data_time: 0.0047 memory: 392
+2022/08/22 15:52:51 - mmengine - INFO - Epoch(val) [1][20/313] eta: 0:00:03 time: 0.0122 data_time: 0.0047 memory: 308
+2022/08/22 15:52:51 - mmengine - INFO - Epoch(val) [1][30/313] eta: 0:00:03 time: 0.0123 data_time: 0.0047 memory: 308
+...
+2022/08/22 15:52:54 - mmengine - INFO - Epoch(val) [1][313/313] accuracy: 35.7000
+```
+
+Õ¤║õ║Ä PyTorch ÕÆīÕ¤║õ║Ä MMEngine ńÜäĶ«Łń╗āµĄüń©ŗÕ»╣µ»öÕ”éõĖŗ’╝Ü
+
+
+
+ķÖżõ║åõ╗źõĖŖÕ¤║ńĪĆń╗äõ╗Č’╝īõĮĀĶ┐śÕÅ»õ╗źÕł®ńö©**µē¦ĶĪīÕÖ©**ĶĮ╗µØŠÕ£░ń╗äÕÉłķģŹńĮ«ÕÉäń¦ŹĶ«Łń╗āµŖĆÕʦ’╝īÕ”éÕ╝ĆÕÉ»µĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗āÕÆīµó»Õ║”ń┤»ń¦»’╝łĶ¦ü [õ╝śÕī¢ÕÖ©Õ░üĶŻģ’╝łOptimWrapper’╝ē](../tutorials/optim_wrapper.md)’╝ēŃĆüķģŹńĮ«ÕŁ”õ╣ĀńÄćĶĪ░Õćŵø▓ń║┐’╝łĶ¦ü [Ķ»äµĄŗµīćµĀćõĖÄĶ»äµĄŗÕÖ©’╝łMetrics & Evaluator’╝ē](../tutorials/evaluation.md)’╝ēńŁēŃĆé
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/basedataset.md b/internlm_langchain/knowledge_base/MMEngine/content/basedataset.md
new file mode 100644
index 00000000..1e069826
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/basedataset.md
@@ -0,0 +1,501 @@
+# µĢ░µŹ«ķøåÕ¤║ń▒╗’╝łBaseDataset’╝ē
+
+## Õ¤║µ£¼õ╗ŗń╗Ź
+
+ń«Śµ│ĢÕ║ōõĖŁńÜäµĢ░µŹ«ķøåń▒╗Ķ┤¤Ķ┤ŻÕ£©Ķ«Łń╗ā/µĄŗĶ»ĢĶ┐ćń©ŗõĖŁõĖ║µ©ĪÕ×ŗµÅÉõŠøĶŠōÕģźµĢ░µŹ«’╝īOpenMMLab õĖŗÕÉäõĖ¬ń«Śµ│ĢÕ║ōõĖŁńÜäµĢ░µŹ«ķøåµ£ēõĖĆõ║øÕģ▒ÕÉīńÜäńē╣ńé╣ÕÆīķ£Ćµ▒é’╝īµ»öÕ”éķ£ĆĶ”üķ½śµĢłńÜäÕåģķā©µĢ░µŹ«ÕŁśÕ驵Ā╝Õ╝Å’╝īķ£ĆĶ”üµö»µīüµĢ░µŹ«ķøåµŗ╝µÄźŃĆüµĢ░µŹ«ķøåķćŹÕżŹķććµĀĘńŁēÕŖ¤ĶāĮŃĆé
+
+ÕøĀµŁż **MMEngine** Õ«×ńÄ░õ║åõĖĆõĖ¬µĢ░µŹ«ķøåÕ¤║ń▒╗’╝łBaseDataset’╝ēÕ╣ČÕ«Üõ╣ēõ║åõĖĆõ║øÕ¤║µ£¼µÄźÕÅŻ’╝īõĖöÕ¤║õ║ÄĶ┐ÖÕźŚµÄźÕÅŻÕ«×ńÄ░õ║åõĖĆõ║øµĢ░µŹ«ķøåÕīģĶŻģ’╝łDatasetWrapper’╝ēŃĆéOpenMMLab ń«Śµ│ĢÕ║ōõĖŁńÜäÕż¦ķā©ÕłåµĢ░µŹ«ķøåķāĮõ╝ܵ╗ĪĶČ│Ķ┐ÖÕźŚµĢ░µŹ«ķøåÕ¤║ń▒╗Õ«Üõ╣ēńÜäµÄźÕÅŻ’╝īÕ╣ČõĮ┐ńö©ń╗¤õĖĆńÜäµĢ░µŹ«ķøåÕīģĶŻģŃĆé
+
+µĢ░µŹ«ķøåÕ¤║ń▒╗ńÜäÕ¤║µ£¼ÕŖ¤ĶāĮµś»ÕŖĀĶĮĮµĢ░µŹ«ķøåõ┐Īµü»’╝īĶ┐Öķćīµłæõ╗¼Õ░åµĢ░µŹ«ķøåõ┐Īµü»ÕłåµłÉõĖżń▒╗’╝īõĖĆń¦Źµś»Õģāõ┐Īµü» (meta information)’╝īõ╗ŻĶĪ©µĢ░µŹ«ķøåĶć¬Ķ║½ńøĖÕģ│ńÜäõ┐Īµü»’╝īµ£ēµŚČķ£ĆĶ”üĶ󽵩ĪÕ×ŗµł¢ÕģČõ╗¢Õż¢ķā©ń╗äõ╗ČĶÄĘÕÅ¢’╝īµ»öÕ”éÕ£©ÕøŠÕāÅÕłåń▒╗õ╗╗ÕŖĪõĖŁ’╝īµĢ░µŹ«ķøåńÜäÕģāõ┐Īµü»õĖĆĶł¼ÕīģÕɽń▒╗Õł½õ┐Īµü» `classes`’╝īÕøĀõĖ║Õłåń▒╗µ©ĪÕ×ŗ `model` õĖĆĶł¼ķ£ĆĶ”üĶ«░ÕĮĢµĢ░µŹ«ķøåńÜäń▒╗Õł½õ┐Īµü»’╝øÕÅ”õĖĆń¦ŹõĖ║µĢ░µŹ«õ┐Īµü» (data information)’╝īÕ£©µĢ░µŹ«õ┐Īµü»õĖŁ’╝īÕ«Üõ╣ēõ║åÕģĘõĮōµĀʵ£¼ńÜäµ¢ćõ╗ČĶĘ»ÕŠäŃĆüÕ»╣Õ║öµĀćńŁŠńŁēńÜäõ┐Īµü»ŃĆéķÖżµŁżõ╣ŗÕż¢’╝īµĢ░µŹ«ķøåÕ¤║ń▒╗ńÜäÕÅ”õĖĆõĖ¬ÕŖ¤ĶāĮõĖ║õĖŹµ¢ŁÕ£░Õ░åµĢ░µŹ«ķĆüÕģźµĢ░µŹ«µĄüµ░┤ń║┐’╝łdata pipeline’╝ēõĖŁ’╝īĶ┐øĶĪīµĢ░µŹ«ķóäÕżäńÉåŃĆé
+
+### µĢ░µŹ«µĀćµ│©µ¢ćõ╗ČĶ¦äĶīā
+
+õĖ║õ║åń╗¤õĖĆõĖŹÕÉīõ╗╗ÕŖĪńÜäµĢ░µŹ«ķøåµÄźÕÅŻ’╝īõŠ┐õ║ÄÕżÜõ╗╗ÕŖĪńÜäń«Śµ│Ģµ©ĪÕ×ŗĶ«Łń╗ā’╝īOpenMMLab ÕłČÕ«Üõ║å **OpenMMLab 2.0 µĢ░µŹ«ķøåµĀ╝Õ╝ÅĶ¦äĶīā**’╝ī µĢ░µŹ«ķøåµĀćµ│©µ¢ćõ╗Čķ£Ćń¼”ÕÉłĶ»źĶ¦äĶīā’╝īµĢ░µŹ«ķøåÕ¤║ń▒╗Õ¤║õ║ÄĶ»źĶ¦äĶīāÕÄ╗Ķ»╗ÕÅ¢õĖÄĶ¦Żµ×ɵĢ░µŹ«µĀćµ│©µ¢ćõ╗ČŃĆéÕ”éµ×£ńö©µłĘµÅÉõŠøńÜäµĢ░µŹ«µĀćµ│©µ¢ćõ╗ČõĖŹń¼”ÕÉłĶ¦äիܵĀ╝Õ╝Å’╝īńö©µłĘÕÅ»õ╗źķĆēµŗ®Õ░åÕģČĶĮ¼Õī¢õĖ║Ķ¦äիܵĀ╝Õ╝Å’╝īÕ╣ČõĮ┐ńö© OpenMMLab ńÜäń«Śµ│ĢÕ║ōÕ¤║õ║ÄĶ»źµĢ░µŹ«µĀćµ│©µ¢ćõ╗ČĶ┐øĶĪīń«Śµ│ĢĶ«Łń╗āÕÆīµĄŗĶ»ĢŃĆé
+
+OpenMMLab 2.0 µĢ░µŹ«ķøåµĀ╝Õ╝ÅĶ¦äĶīāĶ¦äÕ«Ü’╝īµĀćµ│©µ¢ćõ╗ČÕ┐ģķĪ╗õĖ║ `json` µł¢ `yaml`’╝ī`yml` µł¢ `pickle`’╝ī`pkl` µĀ╝Õ╝Å’╝øµĀćµ│©µ¢ćõ╗ČõĖŁÕŁśÕé©ńÜäÕŁŚÕģĖÕ┐ģķĪ╗ÕīģÕɽ `metainfo` ÕÆī `data_list` õĖżõĖ¬ÕŁŚµ«ĄŃĆéÕģČõĖŁ `metainfo` µś»õĖĆõĖ¬ÕŁŚÕģĖ’╝īķćīķØóÕīģÕɽµĢ░µŹ«ķøåńÜäÕģāõ┐Īµü»’╝ø`data_list` µś»õĖĆõĖ¬ÕłŚĶĪ©’╝īÕłŚĶĪ©õĖŁµ»ÅõĖ¬Õģāń┤Āµś»õĖĆõĖ¬ÕŁŚÕģĖ’╝īĶ»źÕŁŚÕģĖÕ«Üõ╣ēõ║åõĖĆõĖ¬ÕĤզŗµĢ░µŹ«’╝łraw data’╝ē’╝īµ»ÅõĖ¬ÕĤզŗµĢ░µŹ«ÕīģÕɽõĖĆõĖ¬µł¢ĶŗźÕ╣▓õĖ¬Ķ«Łń╗ā/µĄŗĶ»ĢµĀʵ£¼ŃĆé
+
+õ╗źõĖŗµś»õĖĆõĖ¬ JSON µĀćµ│©µ¢ćõ╗ČńÜäõŠŗÕŁÉ’╝łĶ»źõŠŗÕŁÉõĖŁµ»ÅõĖ¬ÕĤզŗµĢ░µŹ«ÕŬÕīģÕɽõĖĆõĖ¬Ķ«Łń╗ā/µĄŗĶ»ĢµĀʵ£¼’╝ē:
+
+```json
+
+{
+ "metainfo":
+ {
+ "classes": ["cat", "dog"]
+ },
+ "data_list":
+ [
+ {
+ "img_path": "xxx/xxx_0.jpg",
+ "img_label": 0
+ },
+ {
+ "img_path": "xxx/xxx_1.jpg",
+ "img_label": 1
+ }
+ ]
+}
+```
+
+ÕÉīµŚČÕüćĶ«ŠµĢ░µŹ«ÕŁśµöŠĶĘ»ÕŠäÕ”éõĖŗ’╝Ü
+
+```text
+data
+Ōö£ŌöĆŌöĆ annotations
+Ōöé Ōö£ŌöĆŌöĆ train.json
+Ōö£ŌöĆŌöĆ train
+Ōöé Ōö£ŌöĆŌöĆ xxx/xxx_0.jpg
+Ōöé Ōö£ŌöĆŌöĆ xxx/xxx_1.jpg
+Ōöé Ōö£ŌöĆŌöĆ ...
+```
+
+### µĢ░µŹ«ķøåÕ¤║ń▒╗ńÜäÕłØÕ¦ŗÕī¢µĄüń©ŗ
+
+µĢ░µŹ«ķøåÕ¤║ń▒╗ńÜäÕłØÕ¦ŗÕī¢µĄüń©ŗÕ”éõĖŗÕøŠµēĆńż║’╝Ü
+
+
+
+```python
+import torch.nn.functional as F
+import torchvision
+import torchvision.transforms as transforms
+from torch.optim import SGD
+from torch.utils.data import DataLoader
+
+from mmengine.evaluator import BaseMetric
+from mmengine.model import BaseModel
+from mmengine.runner import Runner
+
+
+class MMResNet50(BaseModel):
+ def __init__(self):
+ super().__init__()
+ self.resnet = torchvision.models.resnet50()
+
+ def forward(self, imgs, labels, mode):
+ x = self.resnet(imgs)
+ if mode == 'loss':
+ return {'loss': F.cross_entropy(x, labels)}
+ elif mode == 'predict':
+ return x, labels
+
+
+class Accuracy(BaseMetric):
+ def process(self, data_batch, data_samples):
+ score, gt = data_samples
+ self.results.append({
+ 'batch_size': len(gt),
+ 'correct': (score.argmax(dim=1) == gt).sum().cpu(),
+ })
+
+ def compute_metrics(self, results):
+ total_correct = sum(item['correct'] for item in results)
+ total_size = sum(item['batch_size'] for item in results)
+ return dict(accuracy=100 * total_correct / total_size)
+
+
+norm_cfg = dict(mean=[0.491, 0.482, 0.447], std=[0.202, 0.199, 0.201])
+train_dataloader = DataLoader(batch_size=32,
+ shuffle=True,
+ dataset=torchvision.datasets.CIFAR10(
+ 'data/cifar10',
+ train=True,
+ download=True,
+ transform=transforms.Compose([
+ transforms.RandomCrop(32, padding=4),
+ transforms.RandomHorizontalFlip(),
+ transforms.ToTensor(),
+ transforms.Normalize(**norm_cfg)
+ ])))
+
+val_dataloader = DataLoader(batch_size=32,
+ shuffle=False,
+ dataset=torchvision.datasets.CIFAR10(
+ 'data/cifar10',
+ train=False,
+ download=True,
+ transform=transforms.Compose([
+ transforms.ToTensor(),
+ transforms.Normalize(**norm_cfg)
+ ])))
+
+runner = Runner(
+ model=MMResNet50(),
+ work_dir='./work_dir',
+ train_dataloader=train_dataloader,
+ optim_wrapper=dict(optimizer=dict(type=SGD, lr=0.001, momentum=0.9)),
+ train_cfg=dict(by_epoch=True, max_epochs=5, val_interval=1),
+ val_dataloader=val_dataloader,
+ val_cfg=dict(),
+ val_evaluator=dict(type=Accuracy),
+)
+runner.train()
+```
+
+ĶŠōÕć║ńÜäĶ«Łń╗āµŚźÕ┐ŚÕ”éõĖŗ’╝Ü
+
+```
+2022/08/22 15:51:53 - mmengine - INFO -
+------------------------------------------------------------
+System environment:
+ sys.platform: linux
+ Python: 3.8.12 (default, Oct 12 2021, 13:49:34) [GCC 7.5.0]
+ CUDA available: True
+ numpy_random_seed: 1513128759
+ GPU 0: NVIDIA GeForce GTX 1660 SUPER
+ CUDA_HOME: /usr/local/cuda
+...
+
+2022/08/22 15:51:54 - mmengine - INFO - Checkpoints will be saved to /home/mazerun/work_dir by HardDiskBackend.
+2022/08/22 15:51:56 - mmengine - INFO - Epoch(train) [1][10/1563] lr: 1.0000e-03 eta: 0:18:23 time: 0.1414 data_time: 0.0077 memory: 392 loss: 5.3465
+2022/08/22 15:51:56 - mmengine - INFO - Epoch(train) [1][20/1563] lr: 1.0000e-03 eta: 0:11:29 time: 0.0354 data_time: 0.0077 memory: 392 loss: 2.7734
+2022/08/22 15:51:56 - mmengine - INFO - Epoch(train) [1][30/1563] lr: 1.0000e-03 eta: 0:09:10 time: 0.0352 data_time: 0.0076 memory: 392 loss: 2.7789
+2022/08/22 15:51:57 - mmengine - INFO - Epoch(train) [1][40/1563] lr: 1.0000e-03 eta: 0:08:00 time: 0.0353 data_time: 0.0073 memory: 392 loss: 2.5725
+2022/08/22 15:51:57 - mmengine - INFO - Epoch(train) [1][50/1563] lr: 1.0000e-03 eta: 0:07:17 time: 0.0347 data_time: 0.0073 memory: 392 loss: 2.7382
+2022/08/22 15:51:57 - mmengine - INFO - Epoch(train) [1][60/1563] lr: 1.0000e-03 eta: 0:06:49 time: 0.0347 data_time: 0.0072 memory: 392 loss: 2.5956
+2022/08/22 15:51:58 - mmengine - INFO - Epoch(train) [1][70/1563] lr: 1.0000e-03 eta: 0:06:28 time: 0.0348 data_time: 0.0072 memory: 392 loss: 2.7351
+...
+2022/08/22 15:52:50 - mmengine - INFO - Saving checkpoint at 1 epochs
+2022/08/22 15:52:51 - mmengine - INFO - Epoch(val) [1][10/313] eta: 0:00:03 time: 0.0122 data_time: 0.0047 memory: 392
+2022/08/22 15:52:51 - mmengine - INFO - Epoch(val) [1][20/313] eta: 0:00:03 time: 0.0122 data_time: 0.0047 memory: 308
+2022/08/22 15:52:51 - mmengine - INFO - Epoch(val) [1][30/313] eta: 0:00:03 time: 0.0123 data_time: 0.0047 memory: 308
+...
+2022/08/22 15:52:54 - mmengine - INFO - Epoch(val) [1][313/313] accuracy: 35.7000
+```
+
+Õ¤║õ║Ä PyTorch ÕÆīÕ¤║õ║Ä MMEngine ńÜäĶ«Łń╗āµĄüń©ŗÕ»╣µ»öÕ”éõĖŗ’╝Ü
+
+
+
+ķÖżõ║åõ╗źõĖŖÕ¤║ńĪĆń╗äõ╗Č’╝īõĮĀĶ┐śÕÅ»õ╗źÕł®ńö©**µē¦ĶĪīÕÖ©**ĶĮ╗µØŠÕ£░ń╗äÕÉłķģŹńĮ«ÕÉäń¦ŹĶ«Łń╗āµŖĆÕʦ’╝īÕ”éÕ╝ĆÕÉ»µĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗āÕÆīµó»Õ║”ń┤»ń¦»’╝łĶ¦ü [õ╝śÕī¢ÕÖ©Õ░üĶŻģ’╝łOptimWrapper’╝ē](../tutorials/optim_wrapper.md)’╝ēŃĆüķģŹńĮ«ÕŁ”õ╣ĀńÄćĶĪ░Õćŵø▓ń║┐’╝łĶ¦ü [Ķ»äµĄŗµīćµĀćõĖÄĶ»äµĄŗÕÖ©’╝łMetrics & Evaluator’╝ē](../tutorials/evaluation.md)’╝ēńŁēŃĆé
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/basedataset.md b/internlm_langchain/knowledge_base/MMEngine/content/basedataset.md
new file mode 100644
index 00000000..1e069826
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/basedataset.md
@@ -0,0 +1,501 @@
+# µĢ░µŹ«ķøåÕ¤║ń▒╗’╝łBaseDataset’╝ē
+
+## Õ¤║µ£¼õ╗ŗń╗Ź
+
+ń«Śµ│ĢÕ║ōõĖŁńÜäµĢ░µŹ«ķøåń▒╗Ķ┤¤Ķ┤ŻÕ£©Ķ«Łń╗ā/µĄŗĶ»ĢĶ┐ćń©ŗõĖŁõĖ║µ©ĪÕ×ŗµÅÉõŠøĶŠōÕģźµĢ░µŹ«’╝īOpenMMLab õĖŗÕÉäõĖ¬ń«Śµ│ĢÕ║ōõĖŁńÜäµĢ░µŹ«ķøåµ£ēõĖĆõ║øÕģ▒ÕÉīńÜäńē╣ńé╣ÕÆīķ£Ćµ▒é’╝īµ»öÕ”éķ£ĆĶ”üķ½śµĢłńÜäÕåģķā©µĢ░µŹ«ÕŁśÕ驵Ā╝Õ╝Å’╝īķ£ĆĶ”üµö»µīüµĢ░µŹ«ķøåµŗ╝µÄźŃĆüµĢ░µŹ«ķøåķćŹÕżŹķććµĀĘńŁēÕŖ¤ĶāĮŃĆé
+
+ÕøĀµŁż **MMEngine** Õ«×ńÄ░õ║åõĖĆõĖ¬µĢ░µŹ«ķøåÕ¤║ń▒╗’╝łBaseDataset’╝ēÕ╣ČÕ«Üõ╣ēõ║åõĖĆõ║øÕ¤║µ£¼µÄźÕÅŻ’╝īõĖöÕ¤║õ║ÄĶ┐ÖÕźŚµÄźÕÅŻÕ«×ńÄ░õ║åõĖĆõ║øµĢ░µŹ«ķøåÕīģĶŻģ’╝łDatasetWrapper’╝ēŃĆéOpenMMLab ń«Śµ│ĢÕ║ōõĖŁńÜäÕż¦ķā©ÕłåµĢ░µŹ«ķøåķāĮõ╝ܵ╗ĪĶČ│Ķ┐ÖÕźŚµĢ░µŹ«ķøåÕ¤║ń▒╗Õ«Üõ╣ēńÜäµÄźÕÅŻ’╝īÕ╣ČõĮ┐ńö©ń╗¤õĖĆńÜäµĢ░µŹ«ķøåÕīģĶŻģŃĆé
+
+µĢ░µŹ«ķøåÕ¤║ń▒╗ńÜäÕ¤║µ£¼ÕŖ¤ĶāĮµś»ÕŖĀĶĮĮµĢ░µŹ«ķøåõ┐Īµü»’╝īĶ┐Öķćīµłæõ╗¼Õ░åµĢ░µŹ«ķøåõ┐Īµü»ÕłåµłÉõĖżń▒╗’╝īõĖĆń¦Źµś»Õģāõ┐Īµü» (meta information)’╝īõ╗ŻĶĪ©µĢ░µŹ«ķøåĶć¬Ķ║½ńøĖÕģ│ńÜäõ┐Īµü»’╝īµ£ēµŚČķ£ĆĶ”üĶ󽵩ĪÕ×ŗµł¢ÕģČõ╗¢Õż¢ķā©ń╗äõ╗ČĶÄĘÕÅ¢’╝īµ»öÕ”éÕ£©ÕøŠÕāÅÕłåń▒╗õ╗╗ÕŖĪõĖŁ’╝īµĢ░µŹ«ķøåńÜäÕģāõ┐Īµü»õĖĆĶł¼ÕīģÕɽń▒╗Õł½õ┐Īµü» `classes`’╝īÕøĀõĖ║Õłåń▒╗µ©ĪÕ×ŗ `model` õĖĆĶł¼ķ£ĆĶ”üĶ«░ÕĮĢµĢ░µŹ«ķøåńÜäń▒╗Õł½õ┐Īµü»’╝øÕÅ”õĖĆń¦ŹõĖ║µĢ░µŹ«õ┐Īµü» (data information)’╝īÕ£©µĢ░µŹ«õ┐Īµü»õĖŁ’╝īÕ«Üõ╣ēõ║åÕģĘõĮōµĀʵ£¼ńÜäµ¢ćõ╗ČĶĘ»ÕŠäŃĆüÕ»╣Õ║öµĀćńŁŠńŁēńÜäõ┐Īµü»ŃĆéķÖżµŁżõ╣ŗÕż¢’╝īµĢ░µŹ«ķøåÕ¤║ń▒╗ńÜäÕÅ”õĖĆõĖ¬ÕŖ¤ĶāĮõĖ║õĖŹµ¢ŁÕ£░Õ░åµĢ░µŹ«ķĆüÕģźµĢ░µŹ«µĄüµ░┤ń║┐’╝łdata pipeline’╝ēõĖŁ’╝īĶ┐øĶĪīµĢ░µŹ«ķóäÕżäńÉåŃĆé
+
+### µĢ░µŹ«µĀćµ│©µ¢ćõ╗ČĶ¦äĶīā
+
+õĖ║õ║åń╗¤õĖĆõĖŹÕÉīõ╗╗ÕŖĪńÜäµĢ░µŹ«ķøåµÄźÕÅŻ’╝īõŠ┐õ║ÄÕżÜõ╗╗ÕŖĪńÜäń«Śµ│Ģµ©ĪÕ×ŗĶ«Łń╗ā’╝īOpenMMLab ÕłČÕ«Üõ║å **OpenMMLab 2.0 µĢ░µŹ«ķøåµĀ╝Õ╝ÅĶ¦äĶīā**’╝ī µĢ░µŹ«ķøåµĀćµ│©µ¢ćõ╗Čķ£Ćń¼”ÕÉłĶ»źĶ¦äĶīā’╝īµĢ░µŹ«ķøåÕ¤║ń▒╗Õ¤║õ║ÄĶ»źĶ¦äĶīāÕÄ╗Ķ»╗ÕÅ¢õĖÄĶ¦Żµ×ɵĢ░µŹ«µĀćµ│©µ¢ćõ╗ČŃĆéÕ”éµ×£ńö©µłĘµÅÉõŠøńÜäµĢ░µŹ«µĀćµ│©µ¢ćõ╗ČõĖŹń¼”ÕÉłĶ¦äիܵĀ╝Õ╝Å’╝īńö©µłĘÕÅ»õ╗źķĆēµŗ®Õ░åÕģČĶĮ¼Õī¢õĖ║Ķ¦äիܵĀ╝Õ╝Å’╝īÕ╣ČõĮ┐ńö© OpenMMLab ńÜäń«Śµ│ĢÕ║ōÕ¤║õ║ÄĶ»źµĢ░µŹ«µĀćµ│©µ¢ćõ╗ČĶ┐øĶĪīń«Śµ│ĢĶ«Łń╗āÕÆīµĄŗĶ»ĢŃĆé
+
+OpenMMLab 2.0 µĢ░µŹ«ķøåµĀ╝Õ╝ÅĶ¦äĶīāĶ¦äÕ«Ü’╝īµĀćµ│©µ¢ćõ╗ČÕ┐ģķĪ╗õĖ║ `json` µł¢ `yaml`’╝ī`yml` µł¢ `pickle`’╝ī`pkl` µĀ╝Õ╝Å’╝øµĀćµ│©µ¢ćõ╗ČõĖŁÕŁśÕé©ńÜäÕŁŚÕģĖÕ┐ģķĪ╗ÕīģÕɽ `metainfo` ÕÆī `data_list` õĖżõĖ¬ÕŁŚµ«ĄŃĆéÕģČõĖŁ `metainfo` µś»õĖĆõĖ¬ÕŁŚÕģĖ’╝īķćīķØóÕīģÕɽµĢ░µŹ«ķøåńÜäÕģāõ┐Īµü»’╝ø`data_list` µś»õĖĆõĖ¬ÕłŚĶĪ©’╝īÕłŚĶĪ©õĖŁµ»ÅõĖ¬Õģāń┤Āµś»õĖĆõĖ¬ÕŁŚÕģĖ’╝īĶ»źÕŁŚÕģĖÕ«Üõ╣ēõ║åõĖĆõĖ¬ÕĤզŗµĢ░µŹ«’╝łraw data’╝ē’╝īµ»ÅõĖ¬ÕĤզŗµĢ░µŹ«ÕīģÕɽõĖĆõĖ¬µł¢ĶŗźÕ╣▓õĖ¬Ķ«Łń╗ā/µĄŗĶ»ĢµĀʵ£¼ŃĆé
+
+õ╗źõĖŗµś»õĖĆõĖ¬ JSON µĀćµ│©µ¢ćõ╗ČńÜäõŠŗÕŁÉ’╝łĶ»źõŠŗÕŁÉõĖŁµ»ÅõĖ¬ÕĤզŗµĢ░µŹ«ÕŬÕīģÕɽõĖĆõĖ¬Ķ«Łń╗ā/µĄŗĶ»ĢµĀʵ£¼’╝ē:
+
+```json
+
+{
+ "metainfo":
+ {
+ "classes": ["cat", "dog"]
+ },
+ "data_list":
+ [
+ {
+ "img_path": "xxx/xxx_0.jpg",
+ "img_label": 0
+ },
+ {
+ "img_path": "xxx/xxx_1.jpg",
+ "img_label": 1
+ }
+ ]
+}
+```
+
+ÕÉīµŚČÕüćĶ«ŠµĢ░µŹ«ÕŁśµöŠĶĘ»ÕŠäÕ”éõĖŗ’╝Ü
+
+```text
+data
+Ōö£ŌöĆŌöĆ annotations
+Ōöé Ōö£ŌöĆŌöĆ train.json
+Ōö£ŌöĆŌöĆ train
+Ōöé Ōö£ŌöĆŌöĆ xxx/xxx_0.jpg
+Ōöé Ōö£ŌöĆŌöĆ xxx/xxx_1.jpg
+Ōöé Ōö£ŌöĆŌöĆ ...
+```
+
+### µĢ░µŹ«ķøåÕ¤║ń▒╗ńÜäÕłØÕ¦ŗÕī¢µĄüń©ŗ
+
+µĢ░µŹ«ķøåÕ¤║ń▒╗ńÜäÕłØÕ¦ŗÕī¢µĄüń©ŗÕ”éõĖŗÕøŠµēĆńż║’╝Ü
+
+`_.
+
+ # ÕżŹÕłČõ╗ŻńĀü
+ # This code was copied from the `ubelt
+ # library`_.
+
+ # Õ╝Ģńö©Ķ«║µ¢ć & µĘ╗ÕŖĀÕģ¼Õ╝Å
+ class LabelSmoothLoss(nn.Module):
+ r"""Initializer for the label smoothed cross entropy loss.
+
+ Refers to `Rethinking the Inception Architecture for Computer Vision
+ `_.
+
+ This decreases gap between output scores and encourages generalization.
+ Labels provided to forward can be one-hot like vectors (NxC) or class
+ indices (Nx1).
+ And this accepts linear combination of one-hot like labels from mixup or
+ cutmix except multi-label task.
+
+ Args:
+ label_smooth_val (float): The degree of label smoothing.
+ num_classes (int, optional): Number of classes. Defaults to None.
+ mode (str): Refers to notes, Options are "original", "classy_vision",
+ "multi_label". Defaults to "classy_vision".
+ reduction (str): The method used to reduce the loss.
+ Options are "none", "mean" and "sum". Defaults to 'mean'.
+ loss_weight (float): Weight of the loss. Defaults to 1.0.
+
+ Note:
+ if the ``mode`` is "original", this will use the same label smooth
+ method as the original paper as:
+
+ .. math::
+ (1-\epsilon)\delta_{k, y} + \frac{\epsilon}{K}
+
+ where :math:`\epsilon` is the ``label_smooth_val``, :math:`K` is
+ the ``num_classes`` and :math:`\delta_{k,y}` is Dirac delta,
+ which equals 1 for k=y and 0 otherwise.
+
+ if the ``mode`` is "classy_vision", this will use the same label
+ smooth method as the `facebookresearch/ClassyVision
+ `_ repo as:
+
+ .. math::
+ \frac{\delta_{k, y} + \epsilon/K}{1+\epsilon}
+
+ if the ``mode`` is "multi_label", this will accept labels from
+ multi-label task and smoothing them as:
+
+ .. math::
+ (1-2\epsilon)\delta_{k, y} + \epsilon
+ ```
+
+```{note}
+µ│©µäÅ \`\`here\`\`ŃĆü\`here\`ŃĆü"here" õĖēń¦ŹÕ╝ĢÕÅĘÕŖ¤ĶāĮµś»õĖŹÕÉīŃĆé
+
+Õ£© reStructured Ķ»Łµ│ĢõĖŁ’╝ī\`\`here\`\` ĶĪ©ńż║õĖƵ«Ąõ╗ŻńĀü’╝ø\`here\` ĶĪ©ńż║µ¢£õĮō’╝ø"here" µŚĀńē╣µ«ŖÕɽõ╣ē’╝īõĖĆĶł¼ÕÅ»ńö©µØźĶĪ©ńż║ÕŁŚń¼”õĖ▓ŃĆéÕģČõĖŁ \`here\` ńÜäńö©µ│ĢõĖÄ Markdown õĖŁõĖŹÕÉī’╝īķ£ĆĶ”üÕżÜÕŖĀńĢÖµäÅŃĆé
+ÕÅ”Õż¢Ķ┐śµ£ē :obj:\`type\` Ķ┐Öń¦Źµø┤Ķ¦äĶīāńÜäĶĪ©ńż║ń▒╗ńÜäÕåÖµ│Ģ’╝īõĮåķē┤õ║ÄķĢ┐Õ║”’╝īõĖŹÕüÜńē╣Õł½Ķ”üµ▒é’╝īõĖĆĶł¼õ╗ģńö©õ║ÄĶĪ©ńż║ķØ×ÕĖĖńö©ń▒╗Õ×ŗŃĆé
+```
+
+3. µ¢╣µ│Ģ’╝łÕćĮµĢ░’╝ēµ¢ćµĪŻ
+
+ ÕćĮµĢ░µ¢ćµĪŻõĖÄń▒╗µ¢ćµĪŻńÜäń╗ōµ×äÕ¤║µ£¼õĖĆĶć┤’╝īõĮåķ£ĆĶ”üÕŖĀÕģźĶ┐öÕø×ÕĆ╝µ¢ćµĪŻŃĆéÕ»╣õ║ÄĶŠāõĖ║ÕżŹµØéńÜäÕćĮµĢ░ÕÆīń▒╗’╝īÕÅ»õ╗źõĮ┐ńö© Examples ÕŁŚµ«ĄÕŖĀÕģźńż║õŠŗ’╝øÕ”éµ×£ķ£ĆĶ”üÕ»╣ÕÅéµĢ░ÕŖĀÕģźõĖĆõ║øĶŠāķĢ┐ńÜäÕżćµ│©’╝īÕÅ»õ╗źÕŖĀÕģź Note ÕŁŚµ«ĄĶ┐øĶĪīĶ»┤µśÄŃĆé
+
+ Õ»╣õ║ÄõĮ┐ńö©ĶŠāõĖ║ÕżŹµØéńÜäń▒╗µł¢ÕćĮµĢ░’╝īµ»öĶĄĘń£ŗÕż¦µ«ĄÕż¦µ«ĄńÜäĶ»┤µśÄµ¢ćÕŁŚÕÆīÕÅéµĢ░µ¢ćµĪŻ’╝īµĘ╗ÕŖĀÕÉłķĆéńÜäńż║õŠŗµø┤ĶāĮÕĖ«ÕŖ®ńö©µłĘĶ┐ģķƤõ║åĶ¦ŻÕģČńö©µ│ĢŃĆéķ£ĆĶ”üµ│©µäÅńÜ䵜»’╝īĶ┐Öõ║øńż║õŠŗµ£ĆÕźĮµś»ĶāĮÕż¤ńø┤µÄźÕ£© Python õ║żõ║ÆÕ╝ÅńÄ»ÕóāõĖŁĶ┐ÉĶĪīńÜä’╝īÕ╣Čń╗ÖÕć║õĖĆõ║øńøĖÕ»╣Õ║öńÜäń╗ōµ×£ŃĆéÕ”éµ×£ÕŁśÕ£©ÕżÜõĖ¬ńż║õŠŗ’╝īÕÅ»õ╗źõĮ┐ńö©µ│©ķćŖń«ĆÕŹĢĶ»┤µśÄµ»Åµ«Ąńż║õŠŗ’╝īõ╣¤ĶāĮĶĄĘÕł░ÕłåķÜöõĮ£ńö©ŃĆé
+
+ ```python
+ def import_modules_from_strings(imports, allow_failed_imports=False):
+ """Import modules from the given list of strings.
+
+ Args:
+ imports (list | str | None): The given module names to be imported.
+ allow_failed_imports (bool): If True, the failed imports will return
+ None. Otherwise, an ImportError is raise. Defaults to False.
+
+ Returns:
+ List[module] | module | None: The imported modules.
+ All these three lines in docstring will be compiled into the same
+ line in readthedocs.
+
+ Examples:
+ >>> osp, sys = import_modules_from_strings(
+ ... ['os.path', 'sys'])
+ >>> import os.path as osp_
+ >>> import sys as sys_
+ >>> assert osp == osp_
+ >>> assert sys == sys_
+ """
+ ...
+ ```
+
+ Õ”éµ×£ÕćĮµĢ░µÄźÕÅŻÕ£©µ¤ÉõĖ¬ńēłµ£¼ÕÅæńö¤õ║åÕÅśÕī¢’╝īķ£ĆĶ”üÕ£© docstring õĖŁÕŖĀÕģźńøĖÕģ│ńÜäĶ»┤µśÄ’╝īÕ┐ģĶ”üµŚČµĘ╗ÕŖĀ Note µł¢ĶĆģ Warning Ķ┐øĶĪīĶ»┤µśÄ’╝īõŠŗÕ”é’╝Ü
+
+ ```python
+ class CheckpointHook(Hook):
+ """Save checkpoints periodically.
+
+ Args:
+ out_dir (str, optional): The root directory to save checkpoints. If
+ not specified, ``runner.work_dir`` will be used by default. If
+ specified, the ``out_dir`` will be the concatenation of
+ ``out_dir`` and the last level directory of ``runner.work_dir``.
+ Defaults to None. `Changed in version 1.3.15.`
+ file_client_args (dict, optional): Arguments to instantiate a
+ FileClient. See :class:`mmcv.fileio.FileClient` for details.
+ Defaults to None. `New in version 1.3.15.`
+
+ Warning:
+ Before v1.3.15, the ``out_dir`` argument indicates the path where the
+ checkpoint is stored. However, in v1.3.15 and later, ``out_dir``
+ indicates the root directory and the final path to save checkpoint is
+ the concatenation of out_dir and the last level directory of
+ ``runner.work_dir``. Suppose the value of ``out_dir`` is
+ "/path/of/A" and the value of ``runner.work_dir`` is "/path/of/B",
+ then the final path will be "/path/of/A/B".
+ ```
+
+ Õ”éµ×£ÕÅéµĢ░µł¢Ķ┐öÕø×ÕĆ╝ķćīÕĖ”µ£ēķ£ĆĶ”üÕ▒ĢÕ╝ƵÅÅĶ┐░ÕŁŚµ«ĄńÜä dict’╝īÕłÖÕ║öĶ»źķććńö©Õ”éõĖŗµĀ╝Õ╝Å’╝Ü
+
+ ```python
+ def func(x):
+ r"""
+ Args:
+ x (None): A dict with 2 keys, ``padded_targets``, and ``targets``.
+
+ - ``targets`` (list[Tensor]): A list of tensors.
+ Each tensor has the shape of :math:`(T_i)`. Each
+ element is the index of a character.
+ - ``padded_targets`` (Tensor): A tensor of shape :math:`(N)`.
+ Each item is the length of a word.
+
+ Returns:
+ dict: A dict with 2 keys, ``padded_targets``, and ``targets``.
+
+ - ``targets`` (list[Tensor]): A list of tensors.
+ Each tensor has the shape of :math:`(T_i)`. Each
+ element is the index of a character.
+ - ``padded_targets`` (Tensor): A tensor of shape :math:`(N)`.
+ Each item is the length of a word.
+ """
+ return x
+ ```
+
+```{important}
+õĖ║õ║åńö¤µłÉ readthedocs µ¢ćµĪŻ’╝īµ¢ćµĪŻńÜäń╝¢ÕåÖķ£ĆĶ”üµīēńģ¦ ReStructrued µ¢ćµĪŻµĀ╝Õ╝Å’╝īÕÉ”ÕłÖõ╝Üõ║¦ńö¤µ¢ćµĪŻµĖ▓µ¤ōķöÖĶ»»’╝īÕ£©µÅÉõ║ż PR ÕēŹ’╝īµ£ĆÕźĮńö¤µłÉÕ╣ČķóäĶ¦łõĖĆõĖŗµ¢ćµĪŻµĢłµ×£ŃĆé
+Ķ»Łµ│ĢĶ¦äĶīāÕÅéĶĆā’╝Ü
+
+- [reStructuredText Primer - Sphinx documentation](https://www.sphinx-doc.org/en/master/usage/restructuredtext/basics.html#)
+- [Example Google Style Python Docstrings ŌĆÆ napoleon 0.7 documentation](https://sphinxcontrib-napoleon.readthedocs.io/en/latest/example_google.html#example-google)
+```
+
+## µ│©ķćŖĶ¦äĶīā
+
+### õĖ║õ╗Ćõ╣łĶ”üÕåÖµ│©ķćŖ
+
+Õ»╣õ║ÄõĖĆõĖ¬Õ╝Ƶ║ÉķĪ╣ńø«’╝īÕøóķś¤ÕÉłõĮ£õ╗źÕÅŖńżŠÕī║õ╣ŗķŚ┤ńÜäÕÉłõĮ£µś»Õ┐ģõĖŹÕÅ»Õ░æńÜä’╝īÕøĀĶĆīÕ░żÕģČĶ”üķćŹĶ¦åÕÉłńÉåńÜäµ│©ķćŖŃĆéõĖŹÕåÖµ│©ķćŖńÜäõ╗ŻńĀü’╝īÕŠłµ£ēÕÅ»ĶāĮĶ┐ćÕćĀõĖ¬µ£łĶć¬ÕĘ▒õ╣¤ķÜŠõ╗źńÉåĶ¦Ż’╝īķĆĀµłÉķóØÕż¢ńÜäķśģĶ»╗ÕÆīõ┐«µö╣µłÉµ£¼ŃĆé
+
+### Õ”éõĮĢÕåÖµ│©ķćŖ
+
+µ£Ćķ£ĆĶ”üÕåÖµ│©ķćŖńÜ䵜»õ╗ŻńĀüõĖŁķéŻõ║øµŖĆÕʦµĆ¦ńÜäķā©ÕłåŃĆéÕ”éµ×£õĮĀÕ£©õĖŗµ¼Īõ╗ŻńĀüÕ«Īµ¤źńÜ䵌ČÕĆÖÕ┐ģķĪ╗Ķ¦ŻķćŖõĖĆõĖŗ’╝īķéŻõ╣łõĮĀÕ║öĶ»źńÄ░Õ£©Õ░▒ń╗ÖÕ«āÕåÖµ│©ķćŖŃĆéÕ»╣õ║ÄÕżŹµØéńÜäµōŹõĮ£’╝īÕ║öĶ»źÕ£©ÕģȵōŹõĮ£Õ╝ĆÕ¦ŗÕēŹÕåÖõĖŖĶŗźÕ╣▓ĶĪīµ│©ķćŖŃĆéÕ»╣õ║ÄõĖŹµś»õĖĆńø«õ║åńäČńÜäõ╗ŻńĀü’╝īÕ║öÕ£©ÕģČĶĪīÕ░ŠµĘ╗ÕŖĀµ│©ķćŖŃĆé
+ŌĆöŌĆö Google Õ╝Ƶ║ÉķĪ╣ńø«ķŻÄµĀ╝µīćÕŹŚ
+
+```python
+# We use a weighted dictionary search to find out where i is in
+# the array. We extrapolate position based on the largest num
+# in the array and the array size and then do binary search to
+# get the exact number.
+if i & (i-1) == 0: # True if i is 0 or a power of 2.
+```
+
+õĖ║õ║åµÅÉķ½śÕÅ»Ķ»╗µĆ¦, µ│©ķćŖÕ║öĶ»źĶć│Õ░æń”╗Õ╝Ćõ╗ŻńĀü2õĖ¬ń®║µĀ╝.
+ÕÅ”õĖƵ¢╣ķØó, ń╗ØõĖŹĶ”üµÅÅĶ┐░õ╗ŻńĀü. ÕüćĶ«ŠķśģĶ»╗õ╗ŻńĀüńÜäõ║║µ»öõĮĀµø┤µćéPython, õ╗¢ÕŬµś»õĖŹń¤źķüōõĮĀńÜäõ╗ŻńĀüĶ”üÕüÜõ╗Ćõ╣ł.
+ŌĆöŌĆö Google Õ╝Ƶ║ÉķĪ╣ńø«ķŻÄµĀ╝µīćÕŹŚ
+
+```python
+# Wrong:
+# Now go through the b array and make sure whenever i occurs
+# the next element is i+1
+
+# Wrong:
+if i & (i-1) == 0: # True if i bitwise and i-1 is 0.
+```
+
+Õ£©µ│©ķćŖõĖŁ’╝īÕÅ»õ╗źõĮ┐ńö© Markdown Ķ»Łµ│Ģ’╝īÕøĀõĖ║Õ╝ĆÕÅæõ║║ÕæśķĆÜÕĖĖń夵éē Markdown Ķ»Łµ│Ģ’╝īĶ┐ÖµĀĘÕÅ»õ╗źõŠ┐õ║Äõ║żµĄüńÉåĶ¦Ż’╝īÕ”éÕÅ»õĮ┐ńö©ÕŹĢÕÅŹÕ╝ĢÕÅĘĶĪ©ńż║õ╗ŻńĀüÕÆīÕÅśķćÅ’╝łµ│©µäÅõĖŹĶ”üÕÆī docstring õĖŁńÜä ReStructured Ķ»Łµ│ĢµĘʵĘå’╝ē
+
+```python
+# `_reversed_padding_repeated_twice` is the padding to be passed to
+# `F.pad` if needed (e.g., for non-zero padding types that are
+# implemented as two ops: padding + conv). `F.pad` accepts paddings in
+# reverse order than the dimension.
+self._reversed_padding_repeated_twice = _reverse_repeat_tuple(self.padding, 2)
+```
+
+### µ│©ķćŖńż║õŠŗ
+
+1. Õć║Ķć¬ `mmcv/utils/registry.py`’╝īÕ»╣õ║ÄĶŠāõĖ║ÕżŹµØéńÜäķĆ╗ĶŠæń╗ōµ×ä’╝īķĆÜĶ┐ćµ│©ķćŖ’╝īµśÄńĪ«õ║åõ╝śÕģłń║¦Õģ│ń│╗ŃĆé
+
+ ```python
+ # self.build_func will be set with the following priority:
+ # 1. build_func
+ # 2. parent.build_func
+ # 3. build_from_cfg
+ if build_func is None:
+ if parent is not None:
+ self.build_func = parent.build_func
+ else:
+ self.build_func = build_from_cfg
+ else:
+ self.build_func = build_func
+ ```
+
+2. Õć║Ķć¬ `mmcv/runner/checkpoint.py`’╝īÕ»╣õ║Ä bug õ┐«ÕżŹõĖŁńÜäõĖĆõ║øńē╣µ«ŖÕżäńÉå’╝īÕÅ»õ╗źķÖäÕĖ”ńøĖÕģ│ńÜä issue ķōŠµÄź’╝īÕĖ«ÕŖ®ÕģČõ╗¢õ║║õ║åĶ¦Ż bug ĶāīµÖ»ŃĆé
+
+ ```python
+ def _save_ckpt(checkpoint, file):
+ # The 1.6 release of PyTorch switched torch.save to use a new
+ # zipfile-based file format. It will cause RuntimeError when a
+ # checkpoint was saved in high version (PyTorch version>=1.6.0) but
+ # loaded in low version (PyTorch version<1.6.0). More details at
+ # https://github.com/open-mmlab/mmpose/issues/904
+ if digit_version(TORCH_VERSION) >= digit_version('1.6.0'):
+ torch.save(checkpoint, file, _use_new_zipfile_serialization=False)
+ else:
+ torch.save(checkpoint, file)
+ ```
+
+## ń▒╗Õ×ŗµ│©Ķ¦Ż
+
+### õĖ║õ╗Ćõ╣łĶ”üÕåÖń▒╗Õ×ŗµ│©Ķ¦Ż
+
+ń▒╗Õ×ŗµ│©Ķ¦Żµś»Õ»╣ÕćĮµĢ░õĖŁÕÅśķćÅńÜäń▒╗Õ×ŗÕüÜķÖÉիܵł¢µÅÉńż║’╝īõĖ║õ╗ŻńĀüńÜäÕ«ēÕģ©µĆ¦µÅÉõŠøõ┐ØķÜ£ŃĆüÕó×Õ╝║õ╗ŻńĀüńÜäÕÅ»Ķ»╗µĆ¦ŃĆüķü┐ÕģŹÕć║ńÄ░ń▒╗Õ×ŗńøĖÕģ│ńÜäķöÖĶ»»ŃĆé
+Python µ▓Īµ£ēÕ»╣ń▒╗Õ×ŗÕüÜÕ╝║ÕłČķÖÉÕłČ’╝īń▒╗Õ×ŗµ│©Ķ¦ŻÕŬĶĄĘÕł░õĖĆõĖ¬µÅÉńż║õĮ£ńö©’╝īķĆÜÕĖĖõĮĀńÜä IDE õ╝ÜĶ¦Żµ×ÉĶ┐Öõ║øń▒╗Õ×ŗµ│©Ķ¦Ż’╝īńäČÕÉÄÕ£©õĮĀĶ░āńö©ńøĖÕģ│õ╗ŻńĀüµŚČÕ»╣ń▒╗Õ×ŗÕüܵÅÉńż║ŃĆéÕÅ”Õż¢õ╣¤µ£ēń▒╗Õ×ŗµ│©Ķ¦ŻµŻĆµ¤źÕĘźÕģĘ’╝īĶ┐Öõ║øÕĘźÕģĘõ╝ܵĀ╣µŹ«ń▒╗Õ×ŗµ│©Ķ¦Ż’╝īÕ»╣õ╗ŻńĀüõĖŁÕÅ»ĶāĮÕć║ńÄ░ńÜäķŚ«ķóśĶ┐øĶĪīµŻĆµ¤ź’╝īÕćÅÕ░æ bug ńÜäÕć║ńÄ░ŃĆé
+ķ£ĆĶ”üµ│©µäÅńÜ䵜»’╝īķĆÜÕĖĖµłæõ╗¼õĖŹķ£ĆĶ”üµ│©ķćŖµ©ĪÕØŚõĖŁńÜäµēƵ£ēÕćĮµĢ░’╝Ü
+
+1. Õģ¼Õģ▒ńÜä API ķ£ĆĶ”üµ│©ķćŖ
+2. Õ£©õ╗ŻńĀüńÜäÕ«ēÕģ©µĆ¦’╝īµĖģµÖ░µĆ¦ÕÆīńüĄµ┤╗µĆ¦õĖŖĶ┐øĶĪīµØāĶĪĪµś»ÕÉ”µ│©ķćŖ
+3. Õ»╣õ║ÄÕ«╣µśōÕć║ńÄ░ń▒╗Õ×ŗńøĖÕģ│ńÜäķöÖĶ»»ńÜäõ╗ŻńĀüĶ┐øĶĪīµ│©ķćŖ
+4. ķÜŠõ╗źńÉåĶ¦ŻńÜäõ╗ŻńĀüĶ»ĘĶ┐øĶĪīµ│©ķćŖ
+5. Ķŗźõ╗ŻńĀüõĖŁńÜäń▒╗Õ×ŗÕĘ▓ń╗Åń©│Õ«Ü’╝īÕÅ»õ╗źĶ┐øĶĪīµ│©ķćŖ. Õ»╣õ║ÄõĖĆõ╗ĮµłÉńå¤ńÜäõ╗ŻńĀü’╝īÕżÜµĢ░µāģÕåĄõĖŗ’╝īÕŹ│õĮ┐µ│©ķćŖõ║åµēƵ£ēńÜäÕćĮµĢ░’╝īõ╣¤õĖŹõ╝ÜõĖ¦Õż▒Õż¬ÕżÜńÜäńüĄµ┤╗µĆ¦.
+
+### Õ”éõĮĢÕåÖń▒╗Õ×ŗµ│©Ķ¦Ż
+
+1. ÕćĮµĢ░ / µ¢╣µ│Ģń▒╗Õ×ŗµ│©Ķ¦Ż’╝īķĆÜÕĖĖõĖŹÕ»╣ self ÕÆī cls µ│©ķćŖŃĆé
+
+ ```python
+ from typing import Optional, List, Tuple
+
+ # Õģ©ķā©õĮŹõ║ÄõĖĆĶĪī
+ def my_method(self, first_var: int) -> int:
+ pass
+
+ # ÕÅ”ĶĄĘõĖĆĶĪī
+ def my_method(
+ self, first_var: int,
+ second_var: float) -> Tuple[MyLongType1, MyLongType1, MyLongType1]:
+ pass
+
+ # ÕŹĢńŗ¼µłÉĶĪī’╝łÕģĘõĮōńÜäÕ║öńö©Õ£║ÕÉłõĖÄĶĪīÕ«Įµ£ēÕģ│’╝īÕ╗║Ķ««ń╗ōÕÉł yapf Ķć¬ÕŖ©Õī¢µĀ╝Õ╝ÅõĮ┐ńö©’╝ē
+ def my_method(
+ self, first_var: int, second_var: float
+ ) -> Tuple[MyLongType1, MyLongType1, MyLongType1]:
+ pass
+
+ # Õ╝Ģńö©Õ░ܵ£¬Ķó½Õ«Üõ╣ēńÜäń▒╗Õ×ŗ
+ class MyClass:
+ def __init__(self,
+ stack: List["MyClass"]) -> None:
+ pass
+ ```
+
+ µ│©’╝Üń▒╗Õ×ŗµ│©Ķ¦ŻõĖŁńÜäń▒╗Õ×ŗÕÅ»õ╗źµś» Python ÕåģńĮ«ń▒╗Õ×ŗ’╝īõ╣¤ÕÅ»õ╗źµś»Ķć¬Õ«Üõ╣ēń▒╗’╝īĶ┐śÕÅ»õ╗źõĮ┐ńö© Python µÅÉõŠøńÜä wrapper ń▒╗Õ»╣ń▒╗Õ×ŗµ│©Ķ¦ŻĶ┐øĶĪīĶŻģķź░’╝īõĖĆõ║øÕĖĖĶ¦üńÜäµ│©Ķ¦ŻÕ”éõĖŗ’╝Ü
+
+ ```python
+ # µĢ░ÕĆ╝ń▒╗Õ×ŗ
+ from numbers import Number
+
+ # ÕÅ»ķĆēń▒╗Õ×ŗ’╝īµīćÕÅéµĢ░ÕÅ»õ╗źõĖ║ None
+ from typing import Optional
+ def foo(var: Optional[int] = None):
+ pass
+
+ # ĶüöÕÉłń▒╗Õ×ŗ’╝īµīćÕÉīµŚČµÄźÕÅŚÕżÜń¦Źń▒╗Õ×ŗ
+ from typing import Union
+ def foo(var: Union[float, str]):
+ pass
+
+ from typing import Sequence # Õ║ÅÕłŚń▒╗Õ×ŗ
+ from typing import Iterable # ÕÅ»Ķ┐Łõ╗Żń▒╗Õ×ŗ
+ from typing import Any # õ╗╗µäÅń▒╗Õ×ŗ
+ from typing import Callable # ÕÅ»Ķ░āńö©ń▒╗Õ×ŗ
+
+ from typing import List, Dict # ÕłŚĶĪ©ÕÆīÕŁŚÕģĖńÜäµ│øÕ×ŗń▒╗Õ×ŗ
+ from typing import Tuple # Õģāń╗äńÜäńē╣µ«ŖµĀ╝Õ╝Å
+ # ĶÖĮńäČÕ£© Python 3.9 õĖŁ’╝īlist, tuple ÕÆī dict µ£¼Ķ║½ÕĘ▓µö»µīüµ│øÕ×ŗ’╝īõĮåõĖ║õ║åµö»µīüõ╣ŗÕēŹńÜäńēłµ£¼
+ # µłæõ╗¼Õ£©Ķ┐øĶĪīń▒╗Õ×ŗµ│©Ķ¦ŻµŚČĶ┐śµś»ķ£ĆĶ”üõĮ┐ńö© List, Tuple, Dict ń▒╗Õ×ŗ
+ # ÕÅ”Õż¢’╝īÕ£©Õ»╣ÕÅéµĢ░ń▒╗Õ×ŗĶ┐øĶĪīµ│©Ķ¦ŻµŚČ’╝īÕ░ĮķćÅõĮ┐ńö© Sequence & Iterable & Mapping
+ # List, Tuple, Dict õĖ╗Ķ”üńö©õ║ÄĶ┐öÕø×ÕĆ╝ń▒╗Õ×ŗµ│©Ķ¦Ż
+ # ÕÅéĶ¦ü https://docs.python.org/3/library/typing.html#typing.List
+ ```
+
+2. ÕÅśķćÅń▒╗Õ×ŗµ│©Ķ¦Ż’╝īõĖĆĶł¼ńö©õ║ÄķÜŠõ╗źńø┤µÄźµÄ©µ¢ŁÕģČń▒╗Õ×ŗµŚČ
+
+ ```python
+ # Recommend: ÕĖ”ń▒╗Õ×ŗµ│©Ķ¦ŻńÜäĶĄŗÕĆ╝
+ a: Foo = SomeUndecoratedFunction()
+ a: List[int]: [1, 2, 3] # List ÕŬµö»µīüÕŹĢõĖĆń▒╗Õ×ŗµ│øÕ×ŗ’╝īÕÅ»õĮ┐ńö© Union
+ b: Tuple[int, int] = (1, 2) # ķĢ┐Õ║”Õø║Õ«ÜõĖ║ 2
+ c: Tuple[int, ...] = (1, 2, 3) # ÕÅśķĢ┐
+ d: Dict[str, int] = {'a': 1, 'b': 2}
+
+ # Not Recommend’╝ÜĶĪīÕ░Šń▒╗Õ×ŗµ│©ķćŖ
+ # ĶÖĮńäČĶ┐Öń¦Źµ¢╣Õ╝ÅĶó½ÕåÖÕ£©õ║å Google Õ╝Ƶ║ɵīćÕŹŚõĖŁ’╝īõĮåĶ┐Öµś»õĖĆń¦ŹõĖ║õ║åµö»µīü Python 2.7 ńēłµ£¼
+ # ĶĆīĶĪźÕģģńÜäµ│©ķćŖµ¢╣Õ╝Å’╝īķē┤õ║ĵłæõ╗¼ÕŬµö»µīü Python 3, õĖ║õ║åķŻÄµĀ╝ń╗¤õĖĆ’╝īõĖŹµÄ©ĶŹÉõĮ┐ńö©Ķ┐Öń¦Źµ¢╣Õ╝ÅŃĆé
+ a = SomeUndecoratedFunction() # type: Foo
+ a = [1, 2, 3] # type: List[int]
+ b = (1, 2, 3) # type: Tuple[int, ...]
+ c = (1, "2", 3.5) # type: Tuple[int, Text, float]
+ ```
+
+3. µ│øÕ×ŗ
+
+ õĖŖµ¢ćõĖŁµłæõ╗¼ń¤źķüō’╝ītyping õĖŁµÅÉõŠøõ║å list ÕÆī dict ńÜäµ│øÕ×ŗń▒╗Õ×ŗ’╝īķéŻõ╣łµłæõ╗¼Ķć¬ÕĘ▒µś»ÕÉ”ÕÅ»õ╗źÕ«Üõ╣ēń▒╗õ╝╝ńÜäµ│øÕ×ŗÕæó’╝¤
+
+ ```python
+ from typing import TypeVar, Generic
+
+ KT = TypeVar('KT')
+ VT = TypeVar('VT')
+
+ class Mapping(Generic[KT, VT]):
+ def __init__(self, data: Dict[KT, VT]):
+ self._data = data
+
+ def __getitem__(self, key: KT) -> VT:
+ return self._data[key]
+ ```
+
+ õĮ┐ńö©õĖŖĶ┐░µ¢╣µ│Ģ’╝īµłæõ╗¼Õ«Üõ╣ēõ║åõĖĆõĖ¬µŗźµ£ēµ│øÕ×ŗĶāĮÕŖøńÜ䵜ĀÕ░äń▒╗’╝īÕ«×ķÖģńö©µ│ĢÕ”éõĖŗ’╝Ü
+
+ ```python
+ mapping = Mapping[str, float]({'a': 0.5})
+ value: float = example['a']
+ ```
+
+ ÕÅ”Õż¢’╝īµłæõ╗¼õ╣¤ÕÅ»õ╗źÕł®ńö© TypeVar Õ£©ÕćĮµĢ░ńŁŠÕÉŹõĖŁµīćÕ«ÜĶüöÕŖ©ńÜäÕżÜõĖ¬ń▒╗Õ×ŗ’╝Ü
+
+ ```python
+ from typing import TypeVar, List
+
+ T = TypeVar('T') # Can be anything
+ A = TypeVar('A', str, bytes) # Must be str or bytes
+
+
+ def repeat(x: T, n: int) -> List[T]:
+ """Return a list containing n references to x."""
+ return [x]*n
+
+
+ def longest(x: A, y: A) -> A:
+ """Return the longest of two strings."""
+ return x if len(x) >= len(y) else y
+ ```
+
+µø┤ÕżÜÕģ│õ║Äń▒╗Õ×ŗµ│©Ķ¦ŻńÜäÕåÖµ│ĢĶ»ĘÕÅéĶĆā [typing](https://docs.python.org/3/library/typing.html)ŃĆé
+
+### ń▒╗Õ×ŗµ│©Ķ¦ŻµŻĆµ¤źÕĘźÕģĘ
+
+[mypy](https://mypy.readthedocs.io/en/stable/) µś»õĖĆõĖ¬ Python ķØÖµĆüń▒╗Õ×ŗµŻĆµ¤źÕĘźÕģĘŃĆéµĀ╣µŹ«õĮĀńÜäń▒╗Õ×ŗµ│©Ķ¦Ż’╝īmypy õ╝ܵŻĆµ¤źõ╝ĀÕÅéŃĆüĶĄŗÕĆ╝ńŁēµōŹõĮ£µś»ÕÉ”ń¼”ÕÉłń▒╗Õ×ŗµ│©Ķ¦Ż’╝īõ╗ÄĶĆīķü┐ÕģŹÕÅ»ĶāĮÕć║ńÄ░ńÜä bugŃĆé
+
+õŠŗÕ”éÕ”éõĖŗńÜäõĖĆõĖ¬ Python Ķäܵ£¼µ¢ćõ╗Č test.py:
+
+```python
+def foo(var: int) -> float:
+ return float(var)
+
+a: str = foo('2.0')
+b: int = foo('3.0') # type: ignore
+```
+
+Ķ┐ÉĶĪī mypy test.py ÕÅ»õ╗źÕŠŚÕł░Õ”éõĖŗµŻĆµ¤źń╗ōµ×£’╝īÕłåÕł½µīćÕć║õ║åń¼¼ 4 ĶĪīÕ£©ÕćĮµĢ░Ķ░āńö©ÕÆīĶ┐öÕø×ÕĆ╝ĶĄŗÕĆ╝õĖżÕżäń▒╗Õ×ŗķöÖĶ»»ŃĆéĶĆīń¼¼ 5 ĶĪīÕÉīµĀĘÕŁśÕ£©õĖżõĖ¬ń▒╗Õ×ŗķöÖĶ»»’╝īńö▒õ║ÄõĮ┐ńö©õ║å type: ignore ĶĆīĶó½Õ┐ĮńĢźõ║å’╝īÕŬµ£ēķā©Õłåńē╣µ«ŖµāģÕåĄÕÅ»ĶāĮķ£ĆĶ”üµŁżń▒╗Õ┐ĮńĢźŃĆé
+
+```
+test.py:4: error: Incompatible types in assignment (expression has type "float", variable has type "int")
+test.py:4: error: Argument 1 to "foo" has incompatible type "str"; expected "int"
+Found 2 errors in 1 file (checked 1 source file)
+```
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/config.md b/internlm_langchain/knowledge_base/MMEngine/content/config.md
new file mode 100644
index 00000000..82302b28
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/config.md
@@ -0,0 +1,1174 @@
+# ķģŹńĮ«’╝łConfig’╝ē
+
+- [ķģŹńĮ«’╝łConfig’╝ē](#ķģŹńĮ«config)
+ - [ķģŹńĮ«µ¢ćõ╗ČĶ»╗ÕÅ¢](#ķģŹńĮ«µ¢ćõ╗ČĶ»╗ÕÅ¢)
+ - [ķģŹńĮ«µ¢ćõ╗ČńÜäõĮ┐ńö©](#ķģŹńĮ«µ¢ćõ╗ČńÜäõĮ┐ńö©)
+ - [ķģŹńĮ«µ¢ćõ╗ČńÜäń╗¦µē┐](#ķģŹńĮ«µ¢ćõ╗ČńÜäń╗¦µē┐)
+ - [ń╗¦µē┐µ£║ÕłČµ”éĶ┐░](#ń╗¦µē┐µ£║ÕłČµ”éĶ┐░)
+ - [õ┐«µö╣ń╗¦µē┐ÕŁŚµ«Ą](#õ┐«µö╣ń╗¦µē┐ÕŁŚµ«Ą)
+ - [ÕłĀķÖżÕŁŚÕģĖõĖŁńÜä key](#ÕłĀķÖżÕŁŚÕģĖõĖŁńÜä-key)
+ - [Õ╝Ģńö©Ķó½ń╗¦µē┐µ¢ćõ╗ČõĖŁńÜäÕÅśķćÅ](#Õ╝Ģńö©Ķó½ń╗¦µē┐µ¢ćõ╗ČõĖŁńÜäÕÅśķćÅ)
+ - [ķģŹńĮ«µ¢ćõ╗ČńÜäÕ»╝Õć║](#ķģŹńĮ«µ¢ćõ╗ČńÜäÕ»╝Õć║)
+ - [ÕģČõ╗¢Ķ┐øķśČńö©µ│Ģ](#ÕģČõ╗¢Ķ┐øķśČńö©µ│Ģ)
+ - [ķóäÕ«Üõ╣ēÕŁŚµ«Ą](#ķóäÕ«Üõ╣ēÕŁŚµ«Ą)
+ - [ÕæĮõ╗żĶĪīõ┐«µö╣ķģŹńĮ«](#ÕæĮõ╗żĶĪīõ┐«µö╣ķģŹńĮ«)
+ - [õĮ┐ńö©ńÄ»ÕóāÕÅśķćŵø┐µŹóķģŹńĮ«](#õĮ┐ńö©ńÄ»ÕóāÕÅśķćŵø┐µŹóķģŹńĮ«)
+ - [Õ»╝ÕģźĶć¬Õ«Üõ╣ē Python µ©ĪÕØŚ](#Õ»╝ÕģźĶć¬Õ«Üõ╣ē-python-µ©ĪÕØŚ)
+ - [ĶĘ©ķĪ╣ńø«ń╗¦µē┐ķģŹńĮ«µ¢ćõ╗Č](#ĶĘ©ķĪ╣ńø«ń╗¦µē┐ķģŹńĮ«µ¢ćõ╗Č)
+ - [ĶĘ©ķĪ╣ńø«ĶÄĘÕÅ¢ķģŹńĮ«µ¢ćõ╗Č](#ĶĘ©ķĪ╣ńø«ĶÄĘÕÅ¢ķģŹńĮ«µ¢ćõ╗Č)
+ - [ń║» Python ķŻÄµĀ╝ńÜäķģŹńĮ«µ¢ćõ╗Č’╝łBeta’╝ē](#ń║»-python-ķŻÄµĀ╝ńÜäķģŹńĮ«µ¢ćõ╗Čbeta)
+ - [Õ¤║µ£¼Ķ»Łµ│Ģ](#Õ¤║µ£¼Ķ»Łµ│Ģ)
+ - [µ©ĪÕØŚµ×äÕ╗║](#µ©ĪÕØŚµ×äÕ╗║)
+ - [ń╗¦µē┐](#ń╗¦µē┐)
+ - [ķģŹńĮ«µ¢ćõ╗ČńÜäÕ»╝Õć║](#ķģŹńĮ«µ¢ćõ╗ČńÜäÕ»╝Õć║-1)
+ - [õ╗Ćõ╣łµś» lazy import](#õ╗Ćõ╣łµś»-lazy-import)
+ - [ÕŖ¤ĶāĮķÖÉÕłČ](#ÕŖ¤ĶāĮķÖÉÕłČ)
+ - [Ķ┐üń¦╗µīćÕŹŚ](#Ķ┐üń¦╗µīćÕŹŚ)
+
+MMEngine Õ«×ńÄ░õ║åµŖĮĶ▒ĪńÜäķģŹńĮ«ń▒╗’╝łConfig’╝ē’╝īõĖ║ńö©µłĘµÅÉõŠøń╗¤õĖĆńÜäķģŹńĮ«Ķ«┐ķŚ«µÄźÕÅŻŃĆéķģŹńĮ«ń▒╗ĶāĮÕż¤µö»µīüõĖŹÕÉīµĀ╝Õ╝ÅńÜäķģŹńĮ«µ¢ćõ╗Č’╝īÕīģµŗ¼ `python`’╝ī`json`’╝ī`yaml`’╝īńö©µłĘÕÅ»õ╗źµĀ╣µŹ«ķ£Ćµ▒éķĆēµŗ®Ķć¬ÕĘ▒ÕüÅÕźĮńÜäµĀ╝Õ╝ÅŃĆéķģŹńĮ«ń▒╗µÅÉõŠøõ║åń▒╗õ╝╝ÕŁŚÕģĖµł¢ĶĆģ Python Õ»╣Ķ▒ĪÕ▒׵ƦńÜäĶ«┐ķŚ«µÄźÕÅŻ’╝īńö©µłĘÕÅ»õ╗źÕŹüÕłåĶć¬ńäČÕ£░Ķ┐øĶĪīķģŹńĮ«ÕŁŚµ«ĄńÜäĶ»╗ÕÅ¢ÕÆīõ┐«µö╣ŃĆéõĖ║õ║åµ¢╣õŠ┐ń«Śµ│ĢµĪåµ×Čń«ĪńÉåķģŹńĮ«µ¢ćõ╗Č’╝īķģŹńĮ«ń▒╗õ╣¤Õ«×ńÄ░õ║åõĖĆõ║øńē╣µĆ¦’╝īõŠŗÕ”éķģŹńĮ«µ¢ćõ╗ČńÜäÕŁŚµ«Ąń╗¦µē┐ńŁēŃĆé
+
+Õ£©Õ╝ĆÕ¦ŗµĢÖń©ŗõ╣ŗÕēŹ’╝īµłæõ╗¼ÕģłÕ░åµĢÖń©ŗõĖŁķ£ĆĶ”üńö©Õł░ńÜäķģŹńĮ«µ¢ćõ╗ČõĖŗĶĮĮÕł░µ£¼Õ£░’╝łÕ╗║Ķ««Õ£©õĖ┤µŚČńø«ÕĮĢõĖŗµē¦ĶĪī’╝īµ¢╣õŠ┐ÕÉÄń╗ŁÕłĀķÖżńż║õŠŗķģŹńĮ«µ¢ćõ╗Č’╝ē’╝Ü
+
+```bash
+wget https://raw.githubusercontent.com/open-mmlab/mmengine/main/docs/resources/config/config_sgd.py
+wget https://raw.githubusercontent.com/open-mmlab/mmengine/main/docs/resources/config/cross_repo.py
+wget https://raw.githubusercontent.com/open-mmlab/mmengine/main/docs/resources/config/custom_imports.py
+wget https://raw.githubusercontent.com/open-mmlab/mmengine/main/docs/resources/config/demo_train.py
+wget https://raw.githubusercontent.com/open-mmlab/mmengine/main/docs/resources/config/example.py
+wget https://raw.githubusercontent.com/open-mmlab/mmengine/main/docs/resources/config/learn_read_config.py
+wget https://raw.githubusercontent.com/open-mmlab/mmengine/main/docs/resources/config/my_module.py
+wget https://raw.githubusercontent.com/open-mmlab/mmengine/main/docs/resources/config/optimizer_cfg.py
+wget https://raw.githubusercontent.com/open-mmlab/mmengine/main/docs/resources/config/predefined_var.py
+wget https://raw.githubusercontent.com/open-mmlab/mmengine/main/docs/resources/config/refer_base_var.py
+wget https://raw.githubusercontent.com/open-mmlab/mmengine/main/docs/resources/config/replace_data_root.py
+wget https://raw.githubusercontent.com/open-mmlab/mmengine/main/docs/resources/config/replace_num_classes.py
+wget https://raw.githubusercontent.com/open-mmlab/mmengine/main/docs/resources/config/resnet50_delete_key.py
+wget https://raw.githubusercontent.com/open-mmlab/mmengine/main/docs/resources/config/resnet50_lr0.01.py
+wget https://raw.githubusercontent.com/open-mmlab/mmengine/main/docs/resources/config/resnet50_runtime.py
+wget https://raw.githubusercontent.com/open-mmlab/mmengine/main/docs/resources/config/resnet50.py
+wget https://raw.githubusercontent.com/open-mmlab/mmengine/main/docs/resources/config/runtime_cfg.py
+wget https://raw.githubusercontent.com/open-mmlab/mmengine/main/docs/resources/config/modify_base_var.py
+```
+
+```{note}
+ķģŹńĮ«ń▒╗µö»µīüõĖżń¦ŹķŻÄµĀ╝ńÜäķģŹńĮ«µ¢ćõ╗Č’╝īÕŹ│ń║»µ¢ćµ£¼ķŻÄµĀ╝ńÜäķģŹńĮ«µ¢ćõ╗ČÕÆīń║» Python ķŻÄµĀ╝ńÜäķģŹńĮ«µ¢ćõ╗Č’╝łv0.8.0 ńÜäµ¢░ńē╣µĆ¦’╝ē’╝īõ║īĶĆģÕ£©Ķ░āńö©µÄźÕÅŻń╗¤õĖĆńÜäÕēŹµÅÉõĖŗÕÉäµ£ēńē╣Ķē▓ŃĆéÕ»╣õ║ÄÕ░ÜõĖöõĖŹõ║åĶ¦ŻķģŹńĮ«ń▒╗Õ¤║µ£¼ńö©µ│Ģńö©µłĘ’╝īÕ╗║Ķ««õ╗Ä[ķģŹńĮ«µ¢ćõ╗ČĶ»╗ÕÅ¢](#ķģŹńĮ«µ¢ćõ╗ČĶ»╗ÕÅ¢) õĖĆĶŖéÕ╝ĆÕ¦ŗķśģĶ»╗’╝īõ╗źõ║åĶ¦ŻķģŹńĮ«ń▒╗ńÜäÕŖ¤ĶāĮÕÆīń║»µ¢ćµ£¼ķģŹńĮ«µ¢ćõ╗ČńÜäĶ»Łµ│ĢŃĆéÕ£©õĖĆõ║øµāģÕåĄõĖŗ’╝īń║»µ¢ćµ£¼ķŻÄµĀ╝ńÜäķģŹńĮ«µ¢ćõ╗ČÕåÖµ│Ģµø┤ÕŖĀń«Ćµ┤ü’╝īĶ»Łµ│ĢÕģ╝Õ«╣µĆ¦µø┤ÕźĮ’╝ł`json`ŃĆü`yaml` ķĆÜńö©’╝ēŃĆéÕ”éµ×£õĮĀÕĖīµ£øķģŹńĮ«µ¢ćõ╗ČńÜäÕåÖµ│ĢÕÅ»õ╗źµø┤ÕŖĀńüĄµ┤╗’╝īÕ╗║Ķ««ķśģĶ»╗Õ╣ČõĮ┐ńö©[ń║» Python ķŻÄµĀ╝ńÜäķģŹńĮ«µ¢ćõ╗Č](#ń║»-python-ķŻÄµĀ╝ńÜäķģŹńĮ«µ¢ćõ╗Čbeta)’╝łbeta’╝ē
+```
+
+## ķģŹńĮ«µ¢ćõ╗ČĶ»╗ÕÅ¢
+
+ķģŹńĮ«ń▒╗µÅÉõŠøõ║åń╗¤õĖĆńÜäµÄźÕÅŻ `Config.fromfile()`’╝īµØźĶ»╗ÕÅ¢ÕÆīĶ¦Żµ×ÉķģŹńĮ«µ¢ćõ╗ČŃĆé
+
+ÕÉłµ│ĢńÜäķģŹńĮ«µ¢ćõ╗ČÕ║öĶ»źÕ«Üõ╣ēõĖĆń│╗ÕłŚķö«ÕĆ╝Õ»╣’╝īĶ┐ÖķćīõĖŠÕćĀõĖ¬õĖŹÕÉīµĀ╝Õ╝ÅķģŹńĮ«µ¢ćõ╗ČńÜäõŠŗÕŁÉŃĆé
+
+Python µĀ╝Õ╝Å’╝Ü
+
+```Python
+test_int = 1
+test_list = [1, 2, 3]
+test_dict = dict(key1='value1', key2=0.1)
+```
+
+Json µĀ╝Õ╝Å’╝Ü
+
+```json
+{
+ "test_int": 1,
+ "test_list": [1, 2, 3],
+ "test_dict": {"key1": "value1", "key2": 0.1}
+}
+```
+
+YAML µĀ╝Õ╝Å’╝Ü
+
+```yaml
+test_int: 1
+test_list: [1, 2, 3]
+test_dict:
+ key1: "value1"
+ key2: 0.1
+```
+
+Õ»╣õ║Äõ╗źõĖŖõĖēń¦ŹµĀ╝Õ╝ÅńÜäµ¢ćõ╗Č’╝īÕüćĶ«Šµ¢ćõ╗ČÕÉŹÕłåÕł½õĖ║ `config.py`’╝ī`config.json`’╝ī`config.yml`’╝īĶ░āńö© `Config.fromfile('config.xxx')` µÄźÕÅŻÕŖĀĶĮĮĶ┐ÖõĖēõĖ¬µ¢ćõ╗ČķāĮõ╝ÜÕŠŚÕł░ńøĖÕÉīńÜäń╗ōµ×£’╝īµ×äķĆĀõ║åÕīģÕɽ 3 õĖ¬ÕŁŚµ«ĄńÜäķģŹńĮ«Õ»╣Ķ▒ĪŃĆ鵳æõ╗¼õ╗ź `config.py` õĖ║õŠŗ’╝īµłæõ╗¼ÕģłÕ░åńż║õŠŗķģŹńĮ«µ¢ćõ╗ČõĖŗĶĮĮÕł░µ£¼Õ£░’╝Ü
+
+ńäČÕÉÄķĆÜĶ┐ćķģŹńĮ«ń▒╗ńÜä `fromfile` µÄźÕÅŻĶ»╗ÕÅ¢ķģŹńĮ«µ¢ćõ╗Č’╝Ü
+
+```python
+from mmengine.config import Config
+
+cfg = Config.fromfile('learn_read_config.py')
+print(cfg)
+```
+
+```
+Config (path: learn_read_config.py): {'test_int': 1, 'test_list': [1, 2, 3], 'test_dict': {'key1': 'value1', 'key2': 0.1}}
+```
+
+## ķģŹńĮ«µ¢ćõ╗ČńÜäõĮ┐ńö©
+
+ķĆÜĶ┐ćĶ»╗ÕÅ¢ķģŹńĮ«µ¢ćõ╗ČµØźÕłØÕ¦ŗÕī¢ķģŹńĮ«Õ»╣Ķ▒ĪÕÉÄ’╝īÕ░▒ÕÅ»õ╗źÕāÅõĮ┐ńö©µÖ«ķĆÜÕŁŚÕģĖµł¢ĶĆģ Python ń▒╗õĖƵĀĘµØźõĮ┐ńö©Ķ┐ÖõĖ¬ÕÅśķćÅõ║åŃĆ鵳æõ╗¼µÅÉõŠøõ║åõĖżń¦ŹĶ«┐ķŚ«µÄźÕÅŻ’╝īÕŹ│ń▒╗õ╝╝ÕŁŚÕģĖńÜäµÄźÕÅŻ `cfg['key']` µł¢ĶĆģń▒╗õ╝╝ Python Õ»╣Ķ▒ĪÕ▒׵ƦńÜäµÄźÕÅŻ `cfg.key`ŃĆéĶ┐ÖõĖżń¦ŹµÄźÕÅŻķāĮµö»µīüĶ»╗ÕåÖŃĆé
+
+```python
+print(cfg.test_int)
+print(cfg.test_list)
+print(cfg.test_dict)
+cfg.test_int = 2
+
+print(cfg['test_int'])
+print(cfg['test_list'])
+print(cfg['test_dict'])
+cfg['test_list'][1] = 3
+print(cfg['test_list'])
+```
+
+```
+1
+[1, 2, 3]
+{'key1': 'value1', 'key2': 0.1}
+2
+[1, 2, 3]
+{'key1': 'value1', 'key2': 0.1}
+[1, 3, 3]
+```
+
+µ│©µäÅ’╝īķģŹńĮ«µ¢ćõ╗ČõĖŁÕ«Üõ╣ēńÜäÕĄīÕźŚÕŁŚµ«Ą’╝łÕŹ│ń▒╗õ╝╝ÕŁŚÕģĖńÜäÕŁŚµ«Ą’╝ē’╝īÕ£© Config õĖŁõ╝ÜÕ░åÕģČĶĮ¼Õī¢õĖ║ ConfigDict ń▒╗’╝īĶ»źń▒╗ń╗¦µē┐õ║å Python ÕåģńĮ«ÕŁŚÕģĖń▒╗Õ×ŗńÜäÕģ©ķā©µÄźÕÅŻ’╝īÕÉīµŚČõ╣¤µö»µīüõ╗źÕ»╣Ķ▒ĪÕ▒׵ƦńÜäµ¢╣Õ╝ÅĶ«┐ķŚ«µĢ░µŹ«ŃĆé
+
+Õ£©ń«Śµ│ĢÕ║ōõĖŁ’╝īÕÅ»õ╗źÕ░åķģŹńĮ«õĖĵ│©ÕåīÕÖ©ń╗ōÕÉłĶĄĘµØźõĮ┐ńö©’╝īĶŠŠÕł░ķĆÜĶ┐ćķģŹńĮ«µ¢ćõ╗ČµØźµÄ¦ÕłČµ©ĪÕØŚµ×äķĆĀńÜäńø«ńÜäŃĆéĶ┐ÖķćīõĖŠõĖĆõĖ¬Õ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁÕ«Üõ╣ēõ╝śÕī¢ÕÖ©ńÜäõŠŗÕŁÉŃĆé
+
+ÕüćĶ«Šµłæõ╗¼ÕĘ▓ń╗ÅÕ«Üõ╣ēõ║åõĖĆõĖ¬õ╝śÕī¢ÕÖ©ńÜäµ│©ÕåīÕÖ© OPTIMIZERS’╝īÕīģµŗ¼õ║åÕÉäń¦Źõ╝śÕī¢ÕÖ©ŃĆéķéŻõ╣łķ”¢ÕģłÕåÖõĖĆõĖ¬ `config_sgd.py`’╝Ü
+
+```python
+optimizer = dict(type='SGD', lr=0.1, momentum=0.9, weight_decay=0.0001)
+```
+
+ńäČÕÉÄÕ£©ń«Śµ│ĢÕ║ōõĖŁÕÅ»õ╗źķĆÜĶ┐ćÕ”éõĖŗõ╗ŻńĀüµ×äķĆĀõ╝śÕī¢ÕÖ©Õ»╣Ķ▒ĪŃĆé
+
+```python
+from mmengine import Config, optim
+from mmengine.registry import OPTIMIZERS
+
+import torch.nn as nn
+
+cfg = Config.fromfile('config_sgd.py')
+
+model = nn.Conv2d(1, 1, 1)
+cfg.optimizer.params = model.parameters()
+optimizer = OPTIMIZERS.build(cfg.optimizer)
+print(optimizer)
+```
+
+```
+SGD (
+Parameter Group 0
+ dampening: 0
+ foreach: None
+ lr: 0.1
+ maximize: False
+ momentum: 0.9
+ nesterov: False
+ weight_decay: 0.0001
+)
+```
+
+## ķģŹńĮ«µ¢ćõ╗ČńÜäń╗¦µē┐
+
+µ£ēµŚČÕĆÖ’╝īõĖżõĖ¬õĖŹÕÉīńÜäķģŹńĮ«µ¢ćõ╗Čõ╣ŗķŚ┤ńÜäÕĘ«Õ╝éÕŠłÕ░Å’╝īÕÅ»ĶāĮõ╗ģõ╗ģÕŬµö╣õ║åõĖĆõĖ¬ÕŁŚµ«Ą’╝īµłæõ╗¼Õ░▒ķ£ĆĶ”üÕ░åµēƵ£ēÕåģÕ«╣ÕżŹÕłČń▓śĶ┤┤õĖƵ¼Ī’╝īĶĆīõĖöÕ£©ÕÉÄń╗ŁĶ¦éÕ»¤ńÜ䵌ČÕĆÖ’╝īõĖŹÕ«╣µśōÕ«ÜõĮŹÕł░ÕģĘõĮōÕĘ«Õ╝éńÜäÕŁŚµ«ĄŃĆéÕÅłµ£ēõ║øµāģÕåĄõĖŗ’╝īÕżÜõĖ¬ķģŹńĮ«µ¢ćõ╗ČÕÅ»ĶāĮķāĮµ£ēńøĖÕÉīńÜäõĖƵē╣ÕŁŚµ«Ą’╝īµłæõ╗¼õĖŹÕŠŚõĖŹÕ£©Ķ┐Öõ║øķģŹńĮ«µ¢ćõ╗ČõĖŁĶ┐øĶĪīÕżŹÕłČń▓śĶ┤┤’╝īń╗ÖÕÉÄń╗ŁńÜäõ┐«µö╣ÕÆīń╗┤µŖżÕĖ”µØźõ║åõĖŹõŠ┐ŃĆé
+
+õĖ║õ║åĶ¦ŻÕå│Ķ┐Öõ║øķŚ«ķóś’╝īµłæõ╗¼ń╗ÖķģŹńĮ«µ¢ćõ╗ČÕó×ÕŖĀõ║åń╗¦µē┐ńÜäµ£║ÕłČ’╝īÕŹ│õĖĆõĖ¬ķģŹńĮ«µ¢ćõ╗Č A ÕÅ»õ╗źÕ░åÕÅ”õĖĆõĖ¬ķģŹńĮ«µ¢ćõ╗Č B õĮ£õĖ║Ķć¬ÕĘ▒ńÜäÕ¤║ńĪĆ’╝īńø┤µÄźń╗¦µē┐õ║å B õĖŁµēƵ£ēÕŁŚµ«Ą’╝īĶĆīõĖŹÕ┐ģµśŠÕ╝ÅÕżŹÕłČń▓śĶ┤┤ŃĆé
+
+### ń╗¦µē┐µ£║ÕłČµ”éĶ┐░
+
+Ķ┐Öķćīµłæõ╗¼õĖŠõĖĆõĖ¬õŠŗÕŁÉµØźĶ»┤µśÄń╗¦µē┐µ£║ÕłČŃĆéÕ«Üõ╣ēÕ”éõĖŗõĖżõĖ¬ķģŹńĮ«µ¢ćõ╗Č’╝ī
+
+`optimizer_cfg.py`’╝Ü
+
+```python
+optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
+```
+
+`resnet50.py`’╝Ü
+
+```python
+_base_ = ['optimizer_cfg.py']
+model = dict(type='ResNet', depth=50)
+```
+
+ĶÖĮńäȵłæõ╗¼Õ£© `resnet50.py` õĖŁµ▓Īµ£ēÕ«Üõ╣ē optimizer ÕŁŚµ«Ą’╝īõĮåńö▒õ║ĵłæõ╗¼ÕåÖõ║å `_base_ = ['optimizer_cfg.py']`’╝īõ╝ÜõĮ┐Ķ┐ÖõĖ¬ķģŹńĮ«µ¢ćõ╗ČĶÄĘÕŠŚ `optimizer_cfg.py` õĖŁńÜäµēƵ£ēÕŁŚµ«ĄŃĆé
+
+```python
+cfg = Config.fromfile('resnet50.py')
+print(cfg.optimizer)
+```
+
+```
+{'type': 'SGD', 'lr': 0.02, 'momentum': 0.9, 'weight_decay': 0.0001}
+```
+
+Ķ┐Öķćī `_base_` µś»ķģŹńĮ«µ¢ćõ╗ČńÜäõ┐ØńĢÖÕŁŚµ«Ą’╝īµīćÕ«Üõ║åĶ»źķģŹńĮ«µ¢ćõ╗ČńÜäń╗¦µē┐µØźµ║ÉŃĆéµö»µīüń╗¦µē┐ÕżÜõĖ¬µ¢ćõ╗Č’╝īÕ░åÕÉīµŚČĶÄĘÕŠŚĶ┐ÖÕżÜõĖ¬µ¢ćõ╗ČõĖŁńÜäµēƵ£ēÕŁŚµ«Ą’╝īõĮåµś»Ķ”üµ▒éń╗¦µē┐ńÜäÕżÜõĖ¬µ¢ćõ╗ČõĖŁ**µ▓Īµ£ē**ńøĖÕÉīÕÉŹń¦░ńÜäÕŁŚµ«Ą’╝īÕÉ”ÕłÖõ╝ܵŖźķöÖŃĆé
+
+`runtime_cfg.py`’╝Ü
+
+```python
+gpu_ids = [0, 1]
+```
+
+`resnet50_runtime.py`’╝Ü
+
+```python
+_base_ = ['optimizer_cfg.py', 'runtime_cfg.py']
+model = dict(type='ResNet', depth=50)
+```
+
+Ķ┐ÖµŚČ’╝īĶ»╗ÕÅ¢ķģŹńĮ«µ¢ćõ╗Č `resnet50_runtime.py` õ╝ÜĶÄĘÕŠŚ 3 õĖ¬ÕŁŚµ«Ą `model`’╝ī`optimizer`’╝ī`gpu_ids`ŃĆé
+
+```python
+cfg = Config.fromfile('resnet50_runtime.py')
+print(cfg.optimizer)
+```
+
+```
+{'type': 'SGD', 'lr': 0.02, 'momentum': 0.9, 'weight_decay': 0.0001}
+```
+
+ķĆÜĶ┐ćĶ┐Öń¦Źµ¢╣Õ╝Å’╝īµłæõ╗¼ÕÅ»õ╗źÕ░åķģŹńĮ«µ¢ćõ╗ČĶ┐øĶĪīµŗåÕłå’╝īÕ«Üõ╣ēõĖĆõ║øķĆÜńö©ķģŹńĮ«µ¢ćõ╗Č’╝īÕ£©Õ«×ķÖģķģŹńĮ«µ¢ćõ╗ČõĖŁń╗¦µē┐ÕÉäń¦ŹķĆÜńö©ķģŹńĮ«µ¢ćõ╗Č’╝īÕÅ»õ╗źÕćÅÕ░æÕģĘõĮōõ╗╗ÕŖĪńÜäķģŹńĮ«µĄüń©ŗŃĆé
+
+### õ┐«µö╣ń╗¦µē┐ÕŁŚµ«Ą
+
+µ£ēµŚČÕĆÖ’╝īµłæõ╗¼ń╗¦µē┐õĖĆõĖ¬ķģŹńĮ«µ¢ćõ╗Čõ╣ŗÕÉÄ’╝īÕÅ»ĶāĮķ£ĆĶ”üÕ»╣ÕģČõĖŁõĖ¬Õł½ÕŁŚµ«ĄĶ┐øĶĪīõ┐«µö╣’╝īõŠŗÕ”éń╗¦µē┐õ║å `optimizer_cfg.py` õ╣ŗÕÉÄ’╝īµā│Õ░åÕŁ”õ╣ĀńÄćõ╗Ä 0.02 õ┐«µö╣õĖ║ 0.01ŃĆé
+
+Ķ┐ÖµŚČÕĆÖ’╝īÕŬķ£ĆĶ”üÕ£©µ¢░ńÜäķģŹńĮ«µ¢ćõ╗ČõĖŁ’╝īķ揵¢░Õ«Üõ╣ēõĖĆõĖŗķ£ĆĶ”üõ┐«µö╣ńÜäÕŁŚµ«ĄÕŹ│ÕÅ»ŃĆéµ│©µäÅńö▒õ║Ä optimizer Ķ┐ÖõĖ¬ÕŁŚµ«Ąµś»õĖĆõĖ¬ÕŁŚÕģĖ’╝īµłæõ╗¼ÕŬķ£ĆĶ”üķ揵¢░Õ«Üõ╣ēĶ┐ÖõĖ¬ÕŁŚÕģĖķćīķØóķ£Ćõ┐«µö╣ńÜäõĖŗń║¦ÕŁŚµ«ĄÕŹ│ÕÅ»ŃĆéĶ┐ÖõĖ¬Ķ¦äÕłÖõ╣¤ķĆéńö©õ║ÄÕó×ÕŖĀõĖĆõ║øõĖŗń║¦ÕŁŚµ«ĄŃĆé
+
+`resnet50_lr0.01.py`’╝Ü
+
+```python
+_base_ = ['optimizer_cfg.py', 'runtime_cfg.py']
+model = dict(type='ResNet', depth=50)
+optimizer = dict(lr=0.01)
+```
+
+Ķ»╗ÕÅ¢Ķ┐ÖõĖ¬ķģŹńĮ«µ¢ćõ╗Čõ╣ŗÕÉÄ’╝īÕ░▒ÕÅ»õ╗źÕŠŚÕł░µ£¤µ£øńÜäń╗ōµ×£ŃĆé
+
+```python
+cfg = Config.fromfile('resnet50_lr0.01.py')
+print(cfg.optimizer)
+```
+
+```
+{'type': 'SGD', 'lr': 0.01, 'momentum': 0.9, 'weight_decay': 0.0001}
+```
+
+Õ»╣õ║ÄķØ×ÕŁŚÕģĖń▒╗Õ×ŗńÜäÕŁŚµ«Ą’╝īõŠŗÕ”éµĢ┤µĢ░’╝īÕŁŚń¼”õĖ▓’╝īÕłŚĶĪ©ńŁē’╝īķ揵¢░Õ«Üõ╣ēÕŹ│ÕŻիīÕģ©Ķ”åńø¢’╝īõŠŗÕ”éõĖŗķØóńÜäÕåÖµ│ĢÕ░▒Õ░å `gpu_ids` Ķ┐ÖõĖ¬ÕŁŚµ«ĄńÜäÕĆ╝õ┐«µö╣µłÉõ║å `[0]`ŃĆé
+
+```python
+_base_ = ['optimizer_cfg.py', 'runtime_cfg.py']
+model = dict(type='ResNet', depth=50)
+gpu_ids = [0]
+```
+
+### ÕłĀķÖżÕŁŚÕģĖõĖŁńÜä key
+
+µ£ēµŚČÕĆÖµłæõ╗¼Õ»╣õ║Äń╗¦µē┐Ķ┐ćµØźńÜäÕŁŚÕģĖń▒╗Õ×ŗÕŁŚµ«Ą’╝īõĖŹõ╗ģõ╗ģµś»µā│õ┐«µö╣ÕģČõĖŁµ¤Éõ║ø key’╝īÕÅ»ĶāĮĶ┐śķ£ĆĶ”üÕłĀķÖżÕģČõĖŁńÜäõĖĆõ║ø keyŃĆéĶ┐ÖµŚČÕĆÖÕ£©ķ揵¢░Õ«Üõ╣ēĶ┐ÖõĖ¬ÕŁŚÕģĖµŚČ’╝īķ£ĆĶ”üµīćÕ«Ü `_delete_=True`’╝īĶĪ©ńż║Õ░åµ▓Īµ£ēÕ£©µ¢░Õ«Üõ╣ēńÜäÕŁŚÕģĖõĖŁÕć║ńÄ░ńÜä key Õģ©ķā©ÕłĀķÖżŃĆé
+
+`resnet50_delete_key.py`’╝Ü
+
+```python
+_base_ = ['optimizer_cfg.py', 'runtime_cfg.py']
+model = dict(type='ResNet', depth=50)
+optimizer = dict(_delete_=True, type='SGD', lr=0.01)
+```
+
+Ķ┐ÖµŚČÕĆÖ’╝ī`optimizer` Ķ┐ÖõĖ¬ÕŁŚÕģĖõĖŁÕ░▒ÕŬµ£ē `type` ÕÆī `lr` Ķ┐ÖõĖżõĖ¬ key’╝ī`momentum` ÕÆī `weight_decay` Õ░åõĖŹÕåŹĶó½ń╗¦µē┐ŃĆé
+
+```python
+cfg = Config.fromfile('resnet50_delete_key.py')
+print(cfg.optimizer)
+```
+
+```
+{'type': 'SGD', 'lr': 0.01}
+```
+
+### Õ╝Ģńö©Ķó½ń╗¦µē┐µ¢ćõ╗ČõĖŁńÜäÕÅśķćÅ
+
+µ£ēµŚČµłæõ╗¼µā│ķćŹÕżŹÕł®ńö© `_base_` õĖŁÕ«Üõ╣ēńÜäÕŁŚµ«ĄÕåģÕ«╣’╝īÕ░▒ÕÅ»õ╗źķĆÜĶ┐ć `{{_base_.xxxx}}` ĶÄĘÕÅ¢µØźĶÄĘÕÅ¢Õ»╣Õ║öÕÅśķćÅńÜäµŗĘĶ┤ØŃĆéõŠŗÕ”é’╝Ü
+
+`refer_base_var.py`
+
+```python
+_base_ = ['resnet50.py']
+a = {{_base_.model}}
+```
+
+Ķ¦Żµ×ÉÕÉÄÕÅæńÄ░’╝ī`a` ńÜäÕĆ╝ÕÅśµłÉõ║å `resnet50.py` õĖŁÕ«Üõ╣ēńÜä `model`
+
+```python
+cfg = Config.fromfile('refer_base_var.py')
+print(cfg.a)
+```
+
+```
+{'type': 'ResNet', 'depth': 50}
+```
+
+µłæõ╗¼ÕÅ»õ╗źÕ£© `json`ŃĆü`yaml`ŃĆü`python` õĖēń¦Źń▒╗Õ×ŗńÜäķģŹńĮ«µ¢ćõ╗ČõĖŁ’╝īõĮ┐ńö©Ķ┐Öń¦Źµ¢╣Õ╝ÅµØźĶÄĘÕÅ¢ `_base_` õĖŁÕ«Üõ╣ēńÜäÕÅśķćÅŃĆé
+
+Õ░Įń«ĪĶ┐Öń¦ŹĶÄĘÕÅ¢ `_base_` õĖŁÕ«Üõ╣ēÕÅśķćÅńÜäµ¢╣Õ╝ÅķØ×ÕĖĖķĆÜńö©’╝īõĮåµś»Õ£©Ķ»Łµ│ĢõĖŖÕŁśÕ£©õĖĆõ║øķÖÉÕłČ’╝īµŚĀµ│ĢÕģģÕłåÕł®ńö© `python` ń▒╗ķģŹńĮ«µ¢ćõ╗ČńÜäÕŖ©µĆüńē╣µĆ¦ŃĆéµ»öÕ”éµłæõ╗¼µā│Õ£© `python` ń▒╗ķģŹńĮ«µ¢ćõ╗ČõĖŁ’╝īõ┐«µö╣ `_base_` õĖŁÕ«Üõ╣ēńÜäÕÅśķćÅ’╝Ü
+
+```python
+_base_ = ['resnet50.py']
+a = {{_base_.model}}
+a['type'] = 'MobileNet'
+```
+
+ķģŹńĮ«ń▒╗µś»µŚĀµ│ĢĶ¦Żµ×ÉĶ┐ÖµĀĘńÜäķģŹńĮ«µ¢ćõ╗ČńÜä’╝łĶ¦Żµ×ɵŚČµŖźķöÖ’╝ēŃĆéķģŹńĮ«ń▒╗µÅÉõŠøõ║åõĖĆń¦Źµø┤ `pythonic` ńÜäµ¢╣Õ╝Å’╝īĶ«®µłæõ╗¼ĶāĮÕż¤Õ£© `python` ń▒╗ķģŹńĮ«µ¢ćõ╗ČõĖŁõ┐«µö╣ `_base_` õĖŁÕ«Üõ╣ēńÜäÕÅśķćÅ’╝ł`python` ń▒╗ķģŹńĮ«µ¢ćõ╗ČõĖōÕ▒×ńē╣µĆ¦’╝īńø«ÕēŹõĖŹµö»µīüÕ£© `json`ŃĆü`yaml` ķģŹńĮ«µ¢ćõ╗ČõĖŁõ┐«µö╣ `_base_` õĖŁÕ«Üõ╣ēńÜäÕÅśķćÅ’╝ēŃĆé
+
+`modify_base_var.py`’╝Ü
+
+```python
+_base_ = ['resnet50.py']
+a = _base_.model
+a.type = 'MobileNet'
+```
+
+```python
+cfg = Config.fromfile('modify_base_var.py')
+print(cfg.a)
+```
+
+```
+{'type': 'MobileNet', 'depth': 50}
+```
+
+Ķ¦Żµ×ÉÕÉÄÕÅæńÄ░’╝ī`a` ńÜä type ÕÅśµłÉõ║å `MobileNet`ŃĆé
+
+## ķģŹńĮ«µ¢ćõ╗ČńÜäÕ»╝Õć║
+
+Õ£©ÕÉ»ÕŖ©Ķ«Łń╗āĶäܵ£¼µŚČ’╝īńö©µłĘÕÅ»ĶāĮķĆÜĶ┐ćõ╝ĀÕÅéńÜäµ¢╣Õ╝ÅµØźõ┐«µö╣ķģŹńĮ«µ¢ćõ╗ČńÜäķā©ÕłåÕŁŚµ«Ą’╝īõĖ║µŁżµłæõ╗¼µÅÉõŠøõ║å `dump` µÄźÕÅŻµØźÕ»╝Õć║µø┤µö╣ÕÉÄńÜäķģŹńĮ«µ¢ćõ╗ČŃĆéõĖÄĶ»╗ÕÅ¢ķģŹńĮ«µ¢ćõ╗Čń▒╗õ╝╝’╝īńö©µłĘÕÅ»õ╗źķĆÜĶ┐ć `cfg.dump('config.xxx')` µØźķĆēµŗ®Õ»╝Õć║µ¢ćõ╗ČńÜäµĀ╝Õ╝ÅŃĆé`dump` ÕÉīµĀĘÕÅ»õ╗źÕ»╝Õć║µ£ēń╗¦µē┐Õģ│ń│╗ńÜäķģŹńĮ«µ¢ćõ╗Č’╝īÕ»╝Õć║ńÜäµ¢ćõ╗ČÕÅ»õ╗źĶó½ńŗ¼ń½ŗõĮ┐ńö©’╝īõĖŹÕåŹõŠØĶĄ¢õ║Ä `_base_` õĖŁÕ«Üõ╣ēńÜäµ¢ćõ╗ČŃĆé
+
+Õ¤║õ║Äń╗¦µē┐õĖĆĶŖéÕ«Üõ╣ēńÜä `resnet50.py`’╝īµłæõ╗¼Õ░åÕģČÕŖĀĶĮĮÕÉÄÕ»╝Õć║’╝Ü
+
+```python
+cfg = Config.fromfile('resnet50.py')
+cfg.dump('resnet50_dump.py')
+```
+
+`resnet50_dump.py`
+
+```python
+optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
+model = dict(type='ResNet', depth=50)
+```
+
+ń▒╗õ╝╝ńÜä’╝īµłæõ╗¼ÕÅ»õ╗źÕ»╝Õć║ jsonŃĆüyaml µĀ╝Õ╝ÅńÜäķģŹńĮ«µ¢ćõ╗Č
+
+`resnet50_dump.yaml`
+
+```yaml
+model:
+ depth: 50
+ type: ResNet
+optimizer:
+ lr: 0.02
+ momentum: 0.9
+ type: SGD
+ weight_decay: 0.0001
+```
+
+`resnet50_dump.json`
+
+```json
+{"optimizer": {"type": "SGD", "lr": 0.02, "momentum": 0.9, "weight_decay": 0.0001}, "model": {"type": "ResNet", "depth": 50}}
+```
+
+µŁżÕż¢’╝ī`dump` õĖŹõ╗ģĶāĮÕ»╝Õć║ÕŖĀĶĮĮĶ欵¢ćõ╗ČńÜä `cfg`’╝īĶ┐śĶāĮÕ»╝Õć║ÕŖĀĶĮĮĶć¬ÕŁŚÕģĖńÜä `cfg`
+
+```python
+cfg = Config(dict(a=1, b=2))
+cfg.dump('dump_dict.py')
+```
+
+`dump_dict.py`
+
+```python
+a=1
+b=2
+```
+
+## ÕģČõ╗¢Ķ┐øķśČńö©µ│Ģ
+
+Ķ┐Öķćīõ╗ŗń╗ŹõĖĆõĖŗķģŹńĮ«ń▒╗ńÜäĶ┐øķśČńö©µ│Ģ’╝īĶ┐Öõ║øÕ░ŵŖĆÕʦÕÅ»ĶāĮõĮ┐ńö©µłĘÕ╝ĆÕÅæÕÆīõĮ┐ńö©ń«Śµ│ĢÕ║ōµø┤ń«ĆÕŹĢµ¢╣õŠ┐ŃĆé
+
+```{note}
+ķ£ĆĶ”üµ│©µäÅńÜ䵜»’╝īÕ”éµ×£õĮĀńö©ńÜ䵜»ń║» Python ķŻÄµĀ╝ńÜäķģŹńĮ«µ¢ćõ╗Č’╝īÕŬµ£ēŌĆ£ÕæĮõ╗żĶĪīõ┐«µö╣ķģŹńĮ«ŌĆØõĖĆĶŖéõĖŁµÅÉÕł░ÕŖ¤ĶāĮµś»µ£ēµĢłńÜäŃĆé
+```
+
+### ķóäÕ«Üõ╣ēÕŁŚµ«Ą
+
+```{note}
+Ķ»źńö©µ│Ģõ╗ģķĆéńö©õ║ÄķØ× `lazy_import` µ©ĪÕ╝Å’╝īÕģĘõĮōĶ¦üń║» Python ķŻÄµĀ╝ńÜäķģŹńĮ«µ¢ćõ╗ČõĖĆĶŖé
+```
+
+µ£ēµŚČÕĆÖµłæõ╗¼ÕĖīµ£øķģŹńĮ«µ¢ćõ╗ČõĖŁńÜäõĖĆõ║øÕŁŚµ«ĄÕÆīÕĮōÕēŹĶĘ»ÕŠäµł¢ĶĆģµ¢ćõ╗ČÕÉŹńŁēńøĖÕģ│’╝īĶ┐ÖķćīõĖŠõĖĆõĖ¬ÕģĖÕ×ŗõĮ┐ńö©Õ£║µÖ»ńÜäõŠŗÕŁÉŃĆéÕ£©Ķ«Łń╗āµ©ĪÕ×ŗµŚČ’╝īµłæõ╗¼õ╝ÜÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁÕ«Üõ╣ēõĖĆõĖ¬ÕĘźõĮ£ńø«ÕĮĢ’╝īÕŁśµöŠĶ┐Öń╗äÕ«×ķ¬īķģŹńĮ«ńÜ䵩ĪÕ×ŗÕÆīµŚźÕ┐Ś’╝īķéŻõ╣łÕ»╣õ║ÄõĖŹÕÉīńÜäķģŹńĮ«µ¢ćõ╗Č’╝īµłæõ╗¼µ£¤µ£øÕ«Üõ╣ēõĖŹÕÉīńÜäÕĘźõĮ£ńø«ÕĮĢŃĆéńö©µłĘńÜäõĖĆń¦ŹÕĖĖĶ¦üķĆēµŗ®µś»’╝īńø┤µÄźõĮ┐ńö©ķģŹńĮ«µ¢ćõ╗ČÕÉŹõĮ£õĖ║ÕĘźõĮ£ńø«ÕĮĢÕÉŹńÜäõĖĆķā©Õłå’╝īõŠŗÕ”éÕ»╣õ║ÄķģŹńĮ«µ¢ćõ╗Č `predefined_var.py`’╝īÕĘźõĮ£ńø«ÕĮĢÕ░▒µś» `./work_dir/predefined_var`ŃĆé
+
+õĮ┐ńö©ķóäÕ«Üõ╣ēÕŁŚµ«ĄÕÅ»õ╗źµ¢╣õŠ┐Õ£░Õ«×ńÄ░Ķ┐Öń¦Źķ£Ćµ▒é’╝īÕ£©ķģŹńĮ«µ¢ćõ╗Č `predefined_var.py` õĖŁÕÅ»õ╗źĶ┐ÖµĀĘÕåÖ’╝Ü
+
+```Python
+work_dir = './work_dir/{{fileBasenameNoExtension}}'
+```
+
+Ķ┐Öķćī `{{fileBasenameNoExtension}}` ĶĪ©ńż║Ķ»źķģŹńĮ«µ¢ćõ╗ČńÜäµ¢ćõ╗ČÕÉŹ’╝łõĖŹÕɽµŗōÕ▒ĢÕÉŹ’╝ē’╝īÕ£©ķģŹńĮ«ń▒╗Ķ»╗ÕÅ¢ķģŹńĮ«µ¢ćõ╗ČńÜ䵌ČÕĆÖ’╝īõ╝ÜÕ░åĶ┐Öń¦Źńö©ÕÅīĶŖ▒µŗ¼ÕÅĘÕīģĶĄĘµØźńÜäÕŁŚń¼”õĖ▓Ķć¬ÕŖ©Ķ¦Żµ×ÉõĖ║Õ»╣Õ║öńÜäÕ«×ķÖģÕĆ╝ŃĆé
+
+```python
+cfg = Config.fromfile('./predefined_var.py')
+print(cfg.work_dir)
+```
+
+```
+./work_dir/predefined_var
+```
+
+ńø«ÕēŹµö»µīüńÜäķóäÕ«Üõ╣ēÕŁŚµ«Ąµ£ēõ╗źõĖŗÕøøń¦Ź’╝īÕÅśķćÅÕÉŹÕÅéĶĆāĶć¬ [VS Code](https://code.visualstudio.com/docs/editor/variables-reference) õĖŁńÜäńøĖÕģ│ÕŁŚµ«Ą’╝Ü
+
+- `{{fileDirname}}` - ÕĮōÕēŹµ¢ćõ╗ČńÜäńø«ÕĮĢÕÉŹ’╝īõŠŗÕ”é `/home/your-username/your-project/folder`
+- `{{fileBasename}}` - ÕĮōÕēŹµ¢ćõ╗ČńÜäµ¢ćõ╗ČÕÉŹ’╝īõŠŗÕ”é `file.py`
+- `{{fileBasenameNoExtension}}` - ÕĮōÕēŹµ¢ćõ╗ČõĖŹÕīģÕɽµē®Õ▒ĢÕÉŹńÜäµ¢ćõ╗ČÕÉŹ’╝īõŠŗÕ”é `file`
+- `{{fileExtname}}` - ÕĮōÕēŹµ¢ćõ╗ČńÜäµē®Õ▒ĢÕÉŹ’╝īõŠŗÕ”é `.py`
+
+### ÕæĮõ╗żĶĪīõ┐«µö╣ķģŹńĮ«
+
+µ£ēµŚČÕĆÖµłæõ╗¼ÕŬÕĖīµ£øõ┐«µö╣ķā©ÕłåķģŹńĮ«’╝īĶĆīõĖŹµā│õ┐«µö╣ķģŹńĮ«µ¢ćõ╗ȵ£¼Ķ║½’╝īõŠŗÕ”éÕ«×ķ¬īĶ┐ćń©ŗõĖŁµā│µø┤µŹóÕŁ”õ╣ĀńÄć’╝īõĮåµś»ÕÅłõĖŹµā│ķ揵¢░ÕåÖõĖĆõĖ¬ķģŹńĮ«µ¢ćõ╗Č’╝īÕĖĖńö©ńÜäÕüܵ│Ģµś»Õ£©ÕæĮõ╗żĶĪīõ╝ĀÕģźÕÅéµĢ░µØźĶ”åńø¢ńøĖÕģ│ķģŹńĮ«ŃĆéĶĆāĶÖæÕł░µłæõ╗¼µā│õ┐«µö╣ńÜäķģŹńĮ«ķĆÜÕĖĖµś»õĖĆõ║øÕåģÕ▒éÕÅéµĢ░’╝īÕ”éõ╝śÕī¢ÕÖ©ńÜäÕŁ”õ╣ĀńÄćŃĆüµ©ĪÕ×ŗÕŹĘń¦»Õ▒éńÜäķĆÜķüōµĢ░ńŁē’╝īÕøĀµŁż MMEngine µÅÉõŠøõ║åõĖĆÕźŚµĀćÕćåńÜ䵥üń©ŗ’╝īĶ«®µłæõ╗¼ĶāĮÕż¤Õ£©ÕæĮõ╗żĶĪīķćīĶĮ╗µØŠõ┐«µö╣ķģŹńĮ«µ¢ćõ╗ČõĖŁõ╗╗µäÅÕ▒éń║¦ńÜäÕÅéµĢ░ŃĆé
+
+1. õĮ┐ńö© `argparse` Ķ¦Żµ×ÉĶäܵ£¼Ķ┐ÉĶĪīńÜäÕÅéµĢ░
+2. õĮ┐ńö© `argparse.ArgumentParser.add_argument` µ¢╣µ│ĢµŚČ’╝īĶ«® `action` ÕÅéµĢ░ńÜäÕĆ╝õĖ║ [DictAction](mmengine.config.DictAction)’╝īńö©Õ«āµØźĶ┐øõĖƵŁźĶ¦Żµ×ÉÕæĮõ╗żĶĪīÕÅéµĢ░õĖŁńö©õ║Äõ┐«µö╣ķģŹńĮ«µ¢ćõ╗ČńÜäÕÅéµĢ░
+3. õĮ┐ńö©ķģŹńĮ«ń▒╗ńÜä `merge_from_dict` µ¢╣µ│ĢµØźµø┤µ¢░ķģŹńĮ«
+
+ÕÉ»ÕŖ©Ķäܵ£¼ńż║õŠŗÕ”éõĖŗ’╝Ü
+
+`demo_train.py`
+
+```python
+import argparse
+
+from mmengine.config import Config, DictAction
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Train a model')
+ parser.add_argument('config', help='train config file path')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ cfg = Config.fromfile(args.config)
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+ print(cfg)
+
+
+if __name__ == '__main__':
+ main()
+```
+
+ńż║õŠŗķģŹńĮ«µ¢ćõ╗ČÕ”éõĖŗ’╝Ü
+
+`example.py`
+
+```python
+model = dict(type='CustomModel', in_channels=[1, 2, 3])
+optimizer = dict(type='SGD', lr=0.01)
+```
+
+µłæõ╗¼Õ£©ÕæĮõ╗żĶĪīķćīķĆÜĶ┐ć `.` ńÜäµ¢╣Õ╝ÅµØźĶ«┐ķŚ«ķģŹńĮ«µ¢ćõ╗ČõĖŁńÜäµĘ▒Õ▒éķģŹńĮ«’╝īõŠŗÕ”éµłæõ╗¼µā│õ┐«µö╣ÕŁ”õ╣ĀńÄć’╝īÕŬķ£ĆĶ”üÕ£©ÕæĮõ╗żĶĪīµē¦ĶĪī’╝Ü
+
+```bash
+python demo_train.py ./example.py --cfg-options optimizer.lr=0.1
+```
+
+```
+Config (path: ./example.py): {'model': {'type': 'CustomModel', 'in_channels': [1, 2, 3]}, 'optimizer': {'type': 'SGD', 'lr': 0.1}}
+```
+
+µłæõ╗¼µłÉÕŖ¤Õ£░µŖŖÕŁ”õ╣ĀńÄćõ╗Ä 0.01 õ┐«µö╣µłÉ 0.1ŃĆéÕ”éµ×£µā│µö╣ÕÅśÕłŚĶĪ©ŃĆüÕģāń╗äń▒╗Õ×ŗńÜäķģŹńĮ«’╝īÕ”éõĖŖõŠŗõĖŁńÜä `in_channels`’╝īÕłÖķ£ĆĶ”üÕ£©ÕæĮõ╗żĶĪīĶĄŗÕĆ╝µŚČń╗Ö `()`’╝ī`[]` Õż¢ÕŖĀõĖŖÕÅīÕ╝ĢÕÅĘ’╝Ü
+
+```bash
+python demo_train.py ./example.py --cfg-options model.in_channels="[1, 1, 1]"
+```
+
+```
+Config (path: ./example.py): {'model': {'type': 'CustomModel', 'in_channels': [1, 1, 1]}, 'optimizer': {'type': 'SGD', 'lr': 0.01}}
+```
+
+`model.in_channels` ÕĘ▓ń╗Åõ╗Ä \[1, 2, 3\] õ┐«µö╣µłÉ \[1, 1, 1\]ŃĆé
+
+```{note}
+õĖŖĶ┐░µĄüń©ŗÕŬµö»µīüÕ£©ÕæĮõ╗żĶĪīķćīõ┐«µö╣ÕŁŚń¼”õĖ▓ŃĆüµĢ┤Õ×ŗŃĆüµĄ«ńé╣Õ×ŗŃĆüÕĖāÕ░öÕ×ŗŃĆüNoneŃĆüÕłŚĶĪ©ŃĆüÕģāń╗äń▒╗Õ×ŗńÜäķģŹńĮ«ķĪ╣ŃĆéÕ»╣õ║ÄÕłŚĶĪ©ŃĆüÕģāń╗äń▒╗Õ×ŗńÜäķģŹńĮ«’╝īķćīķØóµ»ÅõĖ¬Õģāń┤ĀńÜäń▒╗Õ×ŗõ╣¤Õ┐ģķĪ╗õĖ║õĖŖĶ┐░õĖāń¦Źń▒╗Õ×ŗõ╣ŗõĖĆŃĆé
+```
+
+:::{note}
+`DictAction` ńÜäĶĪīõĖ║õĖÄ `"extend"` ńøĖõ╝╝’╝īµö»µīüÕżÜµ¼Īõ╝ĀķĆÆ’╝īÕ╣Čõ┐ØÕŁśÕ£©ÕÉīõĖĆõĖ¬ÕłŚĶĪ©õĖŁŃĆéÕ”é
+
+```bash
+python demo_train.py ./example.py --cfg-options optimizer.type="Adam" --cfg-options model.in_channels="[1, 1, 1]"
+```
+
+```
+Config (path: ./example.py): {'model': {'type': 'CustomModel', 'in_channels': [1, 1, 1]}, 'optimizer': {'type': 'Adam', 'lr': 0.01}}
+```
+
+:::
+
+### õĮ┐ńö©ńÄ»ÕóāÕÅśķćŵø┐µŹóķģŹńĮ«
+
+ÕĮōĶ”üõ┐«µö╣ńÜäķģŹńĮ«ÕĄīÕźŚÕŠłµĘ▒µŚČ’╝īµłæõ╗¼Õ£©ÕæĮõ╗żĶĪīõĖŁķ£ĆĶ”üÕŖĀõĖŖÕŠłķĢ┐ńÜäÕēŹń╝ĆµØźĶ┐øĶĪīÕ«ÜõĮŹŃĆéõĖ║õ║åµø┤µ¢╣õŠ┐Õ£░Õ£©ÕæĮõ╗żĶĪīõĖŁõ┐«µö╣ķģŹńĮ«’╝īMMEngine µÅÉõŠøõ║åõĖĆÕźŚķĆÜĶ┐ćńÄ»ÕóāÕÅśķćÅµØźµø┐µŹóķģŹńĮ«ńÜäµ¢╣µ│ĢŃĆé
+
+Õ£©Ķ¦Żµ×ÉķģŹńĮ«µ¢ćõ╗Čõ╣ŗÕēŹ’╝īMMEngine õ╝ܵɣń┤óµēƵ£ēńÜä `{{$ENV_VAR:DEF_VAL}}` ÕŁŚµ«Ą’╝īÕ╣ČõĮ┐ńö©ńē╣Õ«ÜńÜäńÄ»ÕóāÕÅśķćÅµØźµø┐µŹóĶ┐ÖõĖĆķā©ÕłåŃĆéĶ┐Öķćī `ENV_VAR` õĖ║µø┐µŹóĶ┐ÖõĖĆķā©ÕłåµēĆńö©ńÜäńÄ»ÕóāÕÅśķćÅ’╝ī`DEF_VAL` õĖ║µ▓Īµ£ēĶ«ŠńĮ«ńÄ»ÕóāÕÅśķćŵŚČńÜäķ╗śĶ«żÕĆ╝ŃĆé
+
+õŠŗÕ”é’╝īÕĮōµłæõ╗¼µā│Õ£©ÕæĮõ╗żĶĪīõĖŁõ┐«µö╣µĢ░µŹ«ķøåĶĘ»ÕŠäµŚČ’╝īµłæõ╗¼ÕÅ»õ╗źÕ£©ķģŹńĮ«µ¢ćõ╗Č `replace_data_root.py` õĖŁĶ┐ÖµĀĘÕåÖ’╝Ü
+
+```python
+dataset_type = 'CocoDataset'
+data_root = '{{$DATASET:/data/coco/}}'
+dataset=dict(ann_file= data_root + 'train.json')
+```
+
+ÕĮōµłæõ╗¼Ķ┐ÉĶĪī `demo_train.py` µØźĶ»╗ÕÅ¢Ķ┐ÖõĖ¬ķģŹńĮ«µ¢ćõ╗ȵŚČ’╝Ü
+
+```bash
+python demo_train.py replace_data_root.py
+```
+
+```
+Config (path: replace_data_root.py): {'dataset_type': 'CocoDataset', 'data_root': '/data/coco/', 'dataset': {'ann_file': '/data/coco/train.json'}}
+```
+
+Ķ┐Öķćīµ▓Īµ£ēĶ«ŠńĮ«ńÄ»ÕóāÕÅśķćÅ `DATASET`, ń©ŗÕ║Åńø┤µÄźõĮ┐ńö©ķ╗śĶ«żÕĆ╝ `/data/coco/` µØźµø┐µŹó `{{$DATASET:/data/coco/}}`ŃĆéÕ”éµ×£Õ£©ÕæĮõ╗żĶĪīÕēŹĶ«ŠńĮ«Ķ«ŠńĮ«ńÄ»ÕóāÕÅśķćÅÕłÖõ╝ܵ£ēÕ”éõĖŗń╗ōµ×£’╝Ü
+
+```bash
+DATASET=/new/dataset/path/ python demo_train.py replace_data_root.py
+```
+
+```
+Config (path: replace_data_root.py): {'dataset_type': 'CocoDataset', 'data_root': '/new/dataset/path/', 'dataset': {'ann_file': '/new/dataset/path/train.json'}}
+```
+
+`data_root` Ķó½µø┐µŹóµłÉõ║åńÄ»ÕóāÕÅśķćÅ `DATASET` ńÜäÕĆ╝ `/new/dataset/path/`ŃĆé
+
+ÕĆ╝ÕŠŚµ│©µäÅńÜ䵜»’╝ī`--cfg-options` õĖÄ `{{$ENV_VAR:DEF_VAL}}` ķāĮÕÅ»õ╗źÕ£©ÕæĮõ╗żĶĪīµö╣ÕÅśķģŹńĮ«µ¢ćõ╗ČńÜäÕĆ╝’╝īõĮåõ╗¢õ╗¼Ķ┐śµ£ēõĖĆõ║øÕī║Õł½ŃĆéńÄ»ÕóāÕÅśķćÅńÜäµø┐µŹóÕÅæńö¤Õ£©ķģŹńĮ«µ¢ćõ╗ČĶ¦Żµ×Éõ╣ŗÕēŹŃĆéÕ”éµ×£Ķ»źķģŹńĮ«Ķ┐śÕÅéõĖÄÕł░ÕģČõ╗¢ķģŹńĮ«ńÜäÕ«Üõ╣ēµŚČ’╝īńÄ»ÕóāÕÅśķćŵø┐µŹóõ╣¤õ╝ÜÕĮ▒ÕōŹÕł░ÕģČõ╗¢ķģŹńĮ«’╝īĶĆī `--cfg-options` ÕŬõ╝ܵö╣ÕÅśĶ”üõ┐«µö╣ńÜäķģŹńĮ«µ¢ćõ╗ČńÜäÕĆ╝ŃĆé
+
+µłæõ╗¼õ╗ź `demo_train.py` õĖÄ `replace_data_root.py` õĖ║õŠŗŃĆé Õ”éµ×£µłæõ╗¼ķĆÜĶ┐ćķģŹńĮ« `--cfg-options data_root='/new/dataset/path'` µØźõ┐«µö╣ `data_root`’╝Ü
+
+```bash
+python demo_train.py replace_data_root.py --cfg-options data_root='/new/dataset/path/'
+```
+
+```
+Config (path: replace_data_root.py): {'dataset_type': 'CocoDataset', 'data_root': '/new/dataset/path/', 'dataset': {'ann_file': '/data/coco/train.json'}}
+```
+
+õ╗ÄĶŠōÕć║ń╗ōµ×£õĖŖń£ŗ’╝īÕŬµ£ē `data_root` Ķó½õ┐«µö╣õĖ║µ¢░ńÜäÕĆ╝ŃĆé`dataset.ann_file` õŠØńäČõ┐صīüÕĤզŗÕĆ╝ŃĆé
+
+õĮ£õĖ║Õ»╣µ»ö’╝īÕ”éµ×£µłæõ╗¼ķĆÜĶ┐ćķģŹńĮ« `DATASET=/new/dataset/path` µØźõ┐«µö╣ `data_root`:
+
+```bash
+DATASET=/new/dataset/path/ python demo_train.py replace_data_root.py
+```
+
+```
+Config (path: replace_data_root.py): {'dataset_type': 'CocoDataset', 'data_root': '/new/dataset/path/', 'dataset': {'ann_file': '/new/dataset/path/train.json'}}
+```
+
+`data_root` õĖÄ `dataset.ann_file` ÕÉīµŚČĶó½õ┐«µö╣õ║åŃĆé
+
+ńÄ»ÕóāÕÅśķćÅõ╣¤ÕÅ»õ╗źńö©µØźµø┐µŹóÕŁŚń¼”õĖ▓õ╗źÕż¢ńÜäķģŹńĮ«’╝īĶ┐ÖµŚČÕÅ»õ╗źõĮ┐ńö© `{{'$ENV_VAR:DEF_VAL'}}` µł¢ĶĆģ `{{"$ENV_VAR:DEF_VAL"}}` µĀ╝Õ╝ÅŃĆé`''` õĖÄ `""` ńö©µØźõ┐ØĶ»üķģŹńĮ«µ¢ćõ╗ČÕÉłõ╣Ä python Ķ»Łµ│ĢŃĆé
+
+õŠŗÕ”é’╝īÕĮōµłæõ╗¼µā│µø┐µŹóµ©ĪÕ×ŗķó䵥ŗńÜäń▒╗Õł½µĢ░µŚČ’╝īÕÅ»õ╗źÕ£©ķģŹńĮ«µ¢ćõ╗Č `replace_num_classes.py` õĖŁĶ┐ÖµĀĘÕåÖ’╝Ü
+
+```
+model=dict(
+ bbox_head=dict(
+ num_classes={{'$NUM_CLASSES:80'}}))
+```
+
+ÕĮōµłæõ╗¼Ķ┐ÉĶĪī `demo_train.py` µØźĶ»╗ÕÅ¢Ķ┐ÖõĖ¬ķģŹńĮ«µ¢ćõ╗ȵŚČ’╝Ü
+
+```bash
+python demo_train.py replace_num_classes.py
+```
+
+```
+Config (path: replace_num_classes.py): {'model': {'bbox_head': {'num_classes': 80}}}
+```
+
+ÕĮōĶ«ŠńĮ« `NUM_CLASSES` ńÄ»ÕóāÕÅśķćÅÕÉÄ’╝Ü
+
+```bash
+NUM_CLASSES=20 python demo_train.py replace_num_classes.py
+```
+
+```
+Config (path: replace_num_classes.py): {'model': {'bbox_head': {'num_classes': 20}}}
+```
+
+### Õ»╝ÕģźĶć¬Õ«Üõ╣ē Python µ©ĪÕØŚ
+
+Õ░åķģŹńĮ«õĖĵ│©ÕåīÕÖ©ń╗ōÕÉłĶĄĘµØźõĮ┐ńö©µŚČ’╝īÕ”éµ×£µłæõ╗¼ÕŠĆµ│©ÕåīÕÖ©õĖŁµ│©Õåīõ║åõĖĆõ║øĶć¬Õ«Üõ╣ēńÜäń▒╗’╝īÕ░▒ÕÅ»ĶāĮõ╝ÜķüćÕł░õĖĆõ║øķŚ«ķóśŃĆéÕøĀõĖ║Ķ»╗ÕÅ¢ķģŹńĮ«µ¢ćõ╗ČńÜ䵌ČÕĆÖ’╝īĶ┐Öķā©Õłåõ╗ŻńĀüÕÅ»ĶāĮĶ┐śµ▓Īµ£ēĶó½µē¦ĶĪīÕł░’╝īµēĆõ╗źÕ╣ȵ£¬Õ«īµłÉµ│©ÕåīĶ┐ćń©ŗ’╝īõ╗ÄĶĆīÕ»╝Ķć┤µ×äÕ╗║Ķć¬Õ«Üõ╣ēń▒╗ńÜ䵌ČÕĆÖµŖźķöÖŃĆé
+
+õŠŗÕ”éµłæõ╗¼µ¢░Õ«×ńÄ░õ║åõĖĆń¦Źõ╝śÕī¢ÕÖ© `CustomOptim`’╝īńøĖÕ║öõ╗ŻńĀüÕ£© `my_module.py` õĖŁŃĆé
+
+```python
+from mmengine.registry import OPTIMIZERS
+
+@OPTIMIZERS.register_module()
+class CustomOptim:
+ pass
+```
+
+µłæõ╗¼õĖ║Ķ┐ÖõĖ¬õ╝śÕī¢ÕÖ©ńÜäõĮ┐ńö©ÕåÖõ║åõĖĆõĖ¬µ¢░ńÜäķģŹńĮ«µ¢ćõ╗Č `custom_imports.py`’╝Ü
+
+```python
+optimizer = dict(type='CustomOptim')
+```
+
+ķéŻõ╣łÕ░▒ķ£ĆĶ”üÕ£©Ķ»╗ÕÅ¢ķģŹńĮ«µ¢ćõ╗ČÕÆīµ×äķĆĀõ╝śÕī¢ÕÖ©õ╣ŗÕēŹ’╝īÕó×ÕŖĀõĖĆĶĪī `import my_module` µØźõ┐ØĶ»üÕ░åĶć¬Õ«Üõ╣ēńÜäń▒╗ `CustomOptim` µ│©ÕåīÕł░ OPTIMIZERS µ│©ÕåīÕÖ©õĖŁ’╝ÜõĖ║õ║åĶ¦ŻÕå│Ķ┐ÖõĖ¬ķŚ«ķóś’╝īµłæõ╗¼ń╗ÖķģŹńĮ«µ¢ćõ╗ČÕ«Üõ╣ēõ║åõĖĆõĖ¬õ┐ØńĢÖÕŁŚµ«Ą `custom_imports`’╝īńö©õ║ÄÕ░åķ£ĆĶ”üµÅÉÕēŹÕ»╝ÕģźńÜä Python µ©ĪÕØŚ’╝īńø┤µÄźÕåÖÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁŃĆéÕ»╣õ║ÄõĖŖĶ┐░õŠŗÕŁÉ’╝īÕ░▒ÕÅ»õ╗źÕ░åķģŹńĮ«µ¢ćõ╗ČÕåÖµłÉÕ”éõĖŗ’╝Ü
+
+`custom_imports.py`
+
+```python
+custom_imports = dict(imports=['my_module'], allow_failed_imports=False)
+optimizer = dict(type='CustomOptim')
+```
+
+Ķ┐ÖµĀʵłæõ╗¼Õ░▒õĖŹńö©Õ£©Ķ«Łń╗āõ╗ŻńĀüõĖŁÕó×ÕŖĀÕ»╣Õ║öńÜä import Ķ»ŁÕÅź’╝īÕŬķ£ĆĶ”üõ┐«µö╣ķģŹńĮ«µ¢ćõ╗ČÕ░▒ÕÅ»õ╗źÕ«×ńÄ░ķØ×õŠĄÕģźÕ╝ÅÕ»╝ÕģźĶć¬Õ«Üõ╣ēµ│©Õåīµ©ĪÕØŚŃĆé
+
+```python
+cfg = Config.fromfile('custom_imports.py')
+
+from mmengine.registry import OPTIMIZERS
+
+custom_optim = OPTIMIZERS.build(cfg.optimizer)
+print(custom_optim)
+```
+
+```
+
+```
+
+### ĶĘ©ķĪ╣ńø«ń╗¦µē┐ķģŹńĮ«µ¢ćõ╗Č
+
+õĖ║õ║åķü┐ÕģŹÕ¤║õ║ÄÕĘ▓µ£ēń«Śµ│ĢÕ║ōÕ╝ĆÕÅæµ¢░ķĪ╣ńø«µŚČķ£ĆĶ”üÕżŹÕłČÕż¦ķćÅńÜäķģŹńĮ«µ¢ćõ╗Č’╝īMMEngine ńÜäķģŹńĮ«ń▒╗µö»µīüķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ©ķĪ╣ńø«ń╗¦µē┐ŃĆéõŠŗÕ”éµłæõ╗¼Õ¤║õ║Ä MMDetection Õ╝ĆÕÅæµ¢░ńÜäń«Śµ│ĢÕ║ō’╝īķ£ĆĶ”üõĮ┐ńö©õ╗źõĖŗ MMDetection ńÜäķģŹńĮ«µ¢ćõ╗Č’╝Ü
+
+```text
+configs/_base_/schedules/schedule_1x.py
+configs/_base_/datasets.coco_instance.py
+configs/_base_/default_runtime.py
+configs/_base_/models/faster-rcnn_r50_fpn.py
+```
+
+Õ”éµ×£µ▓Īµ£ēķģŹńĮ«µ¢ćõ╗ČĶĘ©ķĪ╣ńø«ń╗¦µē┐ńÜäÕŖ¤ĶāĮ’╝īµłæõ╗¼Õ░▒ķ£ĆĶ”üµŖŖ MMDetection ńÜäķģŹńĮ«µ¢ćõ╗ȵŗĘĶ┤ØÕł░ÕĮōÕēŹķĪ╣ńø«’╝īĶĆīµłæõ╗¼ńÄ░Õ£©ÕŬķ£ĆĶ”üÕ«ēĶŻģ MMDetection’╝łÕ”éõĮ┐ńö© `mim install mmdet`’╝ē’╝īÕ£©µ¢░ķĪ╣ńø«ńÜäķģŹńĮ«µ¢ćõ╗ČõĖŁµīēńģ¦õ╗źõĖŗµ¢╣Õ╝Åń╗¦µē┐ MMDetection ńÜäķģŹńĮ«µ¢ćõ╗Č’╝Ü
+
+`cross_repo.py`
+
+```python
+_base_ = [
+ 'mmdet::_base_/schedules/schedule_1x.py',
+ 'mmdet::_base_/datasets/coco_instance.py',
+ 'mmdet::_base_/default_runtime.py',
+ 'mmdet::_base_/models/faster-rcnn_r50_fpn.py',
+]
+```
+
+µłæõ╗¼ÕÅ»õ╗źÕāÅÕŖĀĶĮĮµÖ«ķĆÜķģŹńĮ«µ¢ćõ╗ČõĖƵĀĘÕŖĀĶĮĮ `cross_repo.py`
+
+```python
+cfg = Config.fromfile('cross_repo.py')
+print(cfg.train_cfg)
+```
+
+```
+{'type': 'EpochBasedTrainLoop', 'max_epochs': 12, 'val_interval': 1, '_scope_': 'mmdet'}
+```
+
+ķĆÜĶ┐ćµīćÕ«Ü `mmdet::`’╝īConfig ń▒╗õ╝ÜÕÄ╗µŻĆń┤ó mmdet ÕīģõĖŁńÜäķģŹńĮ«µ¢ćõ╗Čńø«ÕĮĢ’╝īÕ╣Čń╗¦µē┐µīćÕ«ÜńÜäķģŹńĮ«µ¢ćõ╗ČŃĆéÕ«×ķÖģõĖŖ’╝īÕŬĶ”üń«Śµ│ĢÕ║ōńÜä `setup.py` µ¢ćõ╗Čń¼”ÕÉł [MMEngine Õ«ēĶŻģĶ¦äĶīā](todo)’╝īÕ£©µŁŻńĪ«Õ«ēĶŻģń«Śµ│ĢÕ║ōõ╗źÕÉÄ’╝īµ¢░ńÜäķĪ╣ńø«Õ░▒ÕÅ»õ╗źõĮ┐ńö©õĖŖĶ┐░ńö©µ│ĢÕÄ╗ń╗¦µē┐ÕĘ▓µ£ēń«Śµ│ĢÕ║ōńÜäķģŹńĮ«µ¢ćõ╗ČĶĆīµŚĀķ£ĆµŗĘĶ┤ØŃĆé
+
+### ĶĘ©ķĪ╣ńø«ĶÄĘÕÅ¢ķģŹńĮ«µ¢ćõ╗Č
+
+MMEngine Ķ┐śµÅÉõŠøõ║å `get_config` ÕÆī `get_model` õĖżõĖ¬µÄźÕÅŻ’╝īµö»µīüÕ»╣ń¼”ÕÉł [MMEngine Õ«ēĶŻģĶ¦äĶīā](todo) ńÜäń«Śµ│ĢÕ║ōõĖŁńÜ䵩ĪÕ×ŗÕÆīķģŹńĮ«µ¢ćõ╗ČÕüÜń┤óÕ╝ĢÕ╣ČĶ┐øĶĪī API Ķ░āńö©ŃĆéķĆÜĶ┐ć `get_model` µÄźÕÅŻÕÅ»õ╗źĶÄĘÕŠŚµ×äÕ╗║ÕźĮńÜ䵩ĪÕ×ŗŃĆéķĆÜĶ┐ć `get_config` µÄźÕÅŻÕÅ»õ╗źĶÄĘÕŠŚķģŹńĮ«µ¢ćõ╗ČŃĆé
+
+`get_model` ńÜäõĮ┐ńö©µĀĘõŠŗÕ”éõĖŗµēĆńż║’╝īõĮ┐ńö©ÕÆīĶĘ©ķĪ╣ńø«ń╗¦µē┐ķģŹńĮ«µ¢ćõ╗ČńøĖÕÉīńÜäĶ»Łµ│Ģ’╝īµīćÕ«Ü `mmdet::`’╝īÕŹ│ÕŻգ© mmdet ÕīģõĖŁµŻĆń┤óÕ»╣Õ║öńÜäķģŹńĮ«µ¢ćõ╗ČÕ╣ȵ×äÕ╗║ÕÆīÕłØÕ¦ŗÕī¢ńøĖÕ║öµ©ĪÕ×ŗŃĆéńö©µłĘÕÅ»õ╗źķĆÜĶ┐ćµīćÕ«Ü `pretrained=True` ĶÄĘÕŠŚÕĘ▓ń╗ÅÕŖĀĶĮĮķóäĶ«Łń╗āµØāķćŹńÜ䵩ĪÕ×ŗõ╗źĶ┐øĶĪīĶ«Łń╗āµł¢ĶĆģµÄ©ńÉåŃĆé
+
+```python
+from mmengine.hub import get_model
+
+model = get_model(
+ 'mmdet::faster_rcnn/faster-rcnn_r50_fpn_1x_coco.py', pretrained=True)
+print(type(model))
+```
+
+```
+http loads checkpoint from path: https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth
+
+```
+
+`get_config` ńÜäõĮ┐ńö©µĀĘõŠŗÕ”éõĖŗµēĆńż║’╝īõĮ┐ńö©ÕÆīĶĘ©ķĪ╣ńø«ń╗¦µē┐ķģŹńĮ«µ¢ćõ╗ČńøĖÕÉīńÜäĶ»Łµ│Ģ’╝īµīćÕ«Ü `mmdet::`’╝īÕŹ│ÕŻի×ńÄ░ÕÄ╗ mmdet ÕīģõĖŁµŻĆń┤óÕ╣ČÕŖĀĶĮĮÕ»╣Õ║öńÜäķģŹńĮ«µ¢ćõ╗ČŃĆéńö©µłĘÕÅ»õ╗źÕ¤║õ║ÄĶ┐ÖµĀĘÕŠŚÕł░ńÜäķģŹńĮ«µ¢ćõ╗ČĶ┐øĶĪīµÄ©ńÉåõ┐«µö╣Õ╣ČĶć¬Õ«Üõ╣ēĶć¬ÕĘ▒ńÜäń«Śµ│Ģµ©ĪÕ×ŗŃĆéÕÉīµŚČ’╝īÕ”éµ×£ńö©µłĘµīćÕ«Ü `pretrained=True`’╝īÕŠŚÕł░ńÜäķģŹńĮ«µ¢ćõ╗ČõĖŁõ╝ܵ¢░Õó× `model_path` ÕŁŚµ«Ą’╝īµīćÕ«Üõ║åÕ»╣Õ║öµ©ĪÕ×ŗķóäĶ«Łń╗āµØāķćŹńÜäĶĘ»ÕŠäŃĆé
+
+```python
+from mmengine.hub import get_config
+
+cfg = get_config(
+ 'mmdet::faster_rcnn/faster-rcnn_r50_fpn_1x_coco.py', pretrained=True)
+print(cfg.model_path)
+
+```
+
+```
+https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth
+```
+
+## ń║» Python ķŻÄµĀ╝ńÜäķģŹńĮ«µ¢ćõ╗Č’╝łBeta’╝ē
+
+Õ£©õ╣ŗÕēŹńÜäµĢÖń©ŗķćī’╝īµłæõ╗¼õ╗ŗń╗Źõ║åÕ”éõĮĢõĮ┐ńö©ķģŹńĮ«µ¢ćõ╗Č’╝īµÉŁķģŹµ│©ÕåīÕÖ©µØźµ×äÕ╗║µ©ĪÕØŚ’╝øÕ”éõĮĢõĮ┐ńö© `_base_` µØźń╗¦µē┐ķģŹńĮ«µ¢ćõ╗ČŃĆéĶ┐Öõ║øń║»µ¢ćµ£¼ķŻÄµĀ╝ńÜäķģŹńĮ«µ¢ćõ╗ČÕø║ńäČĶāĮÕż¤µ╗ĪĶČ│µłæõ╗¼Õ╣│µŚČÕ╝ĆÕÅæńÜäÕż¦ķā©Õłåķ£Ćµ▒é’╝īÕ╣ČõĖöõĖĆõ║øµ©ĪÕØŚńÜä alias õ╣¤Õż¦Õż¦ń«ĆÕī¢õ║åķģŹńĮ«µ¢ćõ╗Č’╝łõŠŗÕ”é `ResNet` Õ░▒ĶāĮµīćõ╗Ż `mmcls.models.ResNet`’╝ēŃĆéõĮåµś»õ╣¤ÕŁśÕ£©õĖĆõ║øÕ╝Ŗń½»’╝Ü
+
+1. ķģŹńĮ«µ¢ćõ╗ČõĖŁ’╝ītype ÕŁŚµ«Ąµś»ķĆÜĶ┐ćÕŁŚń¼”õĖ▓µØźµīćÕ«ÜńÜä’╝īÕ£© IDE õĖŁµŚĀµ│Ģńø┤µÄźĶĘ│ĶĮ¼Õł░Õ»╣Õ║öńÜäń▒╗Õ«Üõ╣ēÕżä’╝īõĖŹÕł®õ║Äõ╗ŻńĀüķśģĶ»╗ÕÆīĶĘ│ĶĮ¼
+2. ķģŹńĮ«µ¢ćõ╗ČńÜäń╗¦µē┐’╝īõ╣¤µś»ķĆÜĶ┐ćÕŁŚń¼”õĖ▓µØźµīćÕ«ÜńÜä’╝īIDE µŚĀµ│Ģńø┤µÄźĶĘ│ĶĮ¼Õł░Ķó½ń╗¦µē┐ńÜäµ¢ćõ╗ČõĖŁ’╝īÕĮōķģŹńĮ«µ¢ćõ╗Čń╗¦µē┐ń╗ōµ×äÕżŹµØ鵌Ȓ╝īõĖŹÕł®õ║ÄķģŹńĮ«µ¢ćõ╗ČńÜäķśģĶ»╗ÕÆīĶĘ│ĶĮ¼
+3. ń╗¦µē┐Ķ¦äÕłÖĶŠāõĖ║ķÜÉÕ╝Å’╝īÕłØÕŁ”ĶĆģÕŠłķÜŠńÉåĶ¦ŻķģŹńĮ«µ¢ćõ╗ȵś»Õ”éõĮĢÕ»╣ńøĖÕÉīÕŁŚµ«ĄńÜäÕÅśķćÅĶ┐øĶĪīĶ׏ÕÉł’╝īõĖöĶĪŹńö¤Õć║ `_delete_` Ķ┐Öń▒╗ńē╣µ«ŖĶ»Łµ│Ģ’╝īÕŁ”õ╣ĀµłÉµ£¼ĶŠāķ½ś
+4. ńö©µłĘÕ┐śĶ«░µ│©Õåīµ©ĪÕØŚµŚČ’╝īÕ«╣µśōÕÅæńö¤ module not found ńÜä error
+5. Õ£©Õ░ÜõĖöµ▓Īµ£ēµÅÉÕł░ńÜäĶĘ©Õ║ōń╗¦µē┐õĖŁ’╝īscope ńÜäÕ╝ĢÕģźÕ»╝Ķć┤ķģŹńĮ«µ¢ćõ╗ČńÜäń╗¦µē┐Ķ¦äÕłÖµø┤ÕŖĀÕżŹµØé’╝īÕłØÕŁ”ĶĆģÕŠłķÜŠńÉåĶ¦Ż
+
+ń╗╝õĖŖµēĆĶ┐░’╝īÕ░Įń«Īń║»µ¢ćµ£¼ķŻÄµĀ╝ńÜäķģŹńĮ«µ¢ćõ╗ČĶāĮÕż¤õĖ║ `python`ŃĆü`json`ŃĆü`yaml` µĀ╝Õ╝ÅńÜäķģŹńĮ«µÅÉõŠøńøĖÕÉīńÜäĶ»Łµ│ĢĶ¦äÕłÖ’╝īõĮåµś»ÕĮōķģŹńĮ«µ¢ćõ╗ČÕÅśÕŠŚÕżŹµØ鵌Ȓ╝īń║»µ¢ćµ£¼ķŻÄµĀ╝ńÜäķģŹńĮ«µ¢ćõ╗Čõ╝ܵśŠÕŠŚÕŖøõĖŹõ╗ÄÕ┐āŃĆéõĖ║µŁż’╝īµłæõ╗¼µÅÉõŠøõ║åń║» Python ķŻÄµĀ╝ńÜäķģŹńĮ«µ¢ćõ╗Č’╝īÕŹ│ `lazy import` µ©ĪÕ╝Å’╝īÕ«āĶāĮÕż¤ÕģģÕłåÕł®ńö© Python ńÜäĶ»Łµ│ĢĶ¦äÕłÖ’╝īĶ¦ŻÕå│õĖŖĶ┐░ķŚ«ķóśŃĆéõĖĵŁżÕÉīµŚČ’╝īń║» Python ķŻÄµĀ╝ńÜäķģŹńĮ«µ¢ćõ╗Čõ╣¤µö»µīüÕ»╝Õć║µłÉ `json` ÕÆī `yaml` µĀ╝Õ╝ÅŃĆé
+
+### Õ¤║µ£¼Ķ»Łµ│Ģ
+
+õ╣ŗÕēŹńÜäµĢÖń©ŗÕłåÕł½õ╗ŗń╗Źõ║åÕ¤║õ║Äń║»µ¢ćµ£¼ķŻÄµĀ╝ķģŹńĮ«µ¢ćõ╗ČńÜ䵩ĪÕØŚµ×äÕ╗║ŃĆüń╗¦µē┐ÕÆīÕ»╝Õć║’╝īµ£¼ĶŖéÕ░åÕ¤║õ║ÄĶ┐ÖõĖēõĖ¬µ¢╣ķØóµØźõ╗ŗń╗Źń║» Python ķŻÄµĀ╝ńÜäķģŹńĮ«µ¢ćõ╗ČŃĆé
+
+#### µ©ĪÕØŚµ×äÕ╗║
+
+µłæõ╗¼ķĆÜĶ┐ćõĖĆõĖ¬ń«ĆÕŹĢńÜäõŠŗÕŁÉµØźÕ»╣µ»öń║» Python ķŻÄµĀ╝ÕÆīń║»µ¢ćµ£¼ķŻÄµĀ╝ńÜäķģŹńĮ«µ¢ćõ╗Č’╝Ü
+
+```{eval-rst}
+.. tabs::
+ .. tabs::
+
+ .. code-tab:: python ń║» Python ķŻÄµĀ╝
+
+ # µŚĀķ£Ćµ│©Õåī
+
+ .. code-tab:: python ń║»µ¢ćµ£¼ķŻÄµĀ╝
+
+ # µ│©ÕåīµĄüń©ŗ
+ from torch.optim import SGD
+ from mmengine.registry import OPTIMIZERS
+
+ OPTIMIZERS.register_module(module=SGD, name='SGD')
+
+ .. tabs::
+
+ .. code-tab:: python ń║» Python ķŻÄµĀ╝
+
+ # ķģŹńĮ«µ¢ćõ╗ČÕåÖµ│Ģ
+ from torch.optim import SGD
+
+
+ optimizer = dict(type=SGD, lr=0.1)
+
+ .. code-tab:: python ń║»µ¢ćµ£¼ķŻÄµĀ╝
+
+ # ķģŹńĮ«µ¢ćõ╗ČÕåÖµ│Ģ
+ optimizer = dict(type='SGD', lr=0.1)
+
+ .. tabs::
+
+ .. code-tab:: python ń║» Python ķŻÄµĀ╝
+
+ # µ×äÕ╗║µĄüń©ŗÕ«īÕģ©õĖĆĶć┤
+ import torch.nn as nn
+ from mmengine.registry import OPTIMIZERS
+
+
+ cfg = Config.fromfile('optimizer.py')
+ model = nn.Conv2d(1, 1, 1)
+ cfg.optimizer.params = model.parameters()
+ optimizer = OPTIMIZERS.build(cfg.optimizer)
+
+ .. code-tab:: python ń║»µ¢ćµ£¼ķŻÄµĀ╝
+
+ # µ×äÕ╗║µĄüń©ŗÕ«īÕģ©õĖĆĶć┤
+ import torch.nn as nn
+ from mmengine.registry import OPTIMIZERS
+
+
+ cfg = Config.fromfile('optimizer.py')
+ model = nn.Conv2d(1, 1, 1)
+ cfg.optimizer.params = model.parameters()
+ optimizer = OPTIMIZERS.build(cfg.optimizer)
+```
+
+õ╗ÄõĖŖķØóńÜäõŠŗÕŁÉÕÅ»õ╗źń£ŗÕć║’╝īń║» Python ķŻÄµĀ╝ńÜäķģŹńĮ«µ¢ćõ╗ČÕÆīń║»µ¢ćµ£¼ķŻÄµĀ╝ńÜäķģŹńĮ«µ¢ćõ╗ČńÜäÕī║Õł½Õ£©õ║Ä’╝Ü
+
+1. ń║» Python ķŻÄµĀ╝ńÜäķģŹńĮ«µ¢ćõ╗ȵŚĀķ£Ćµ│©Õåīµ©ĪÕØŚ
+2. ń║» Python ķŻÄµĀ╝ńÜäķģŹńĮ«µ¢ćõ╗ČõĖŁ’╝ītype ÕŁŚµ«ĄõĖŹÕåŹµś»ÕŁŚń¼”õĖ▓’╝īĶĆīµś»ńø┤µÄźµīćõ╗Żµ©ĪÕØŚŃĆéńøĖÕ║öńÜäķģŹńĮ«µ¢ćõ╗Čķ£ĆĶ”üÕżÜÕć║ import Ķ»Łµ│Ģ
+
+ķ£ĆĶ”üµ│©µäÅńÜ䵜»’╝īOpenMMLab ń│╗ÕłŚń«Śµ│ĢÕ║ōÕ£©µ¢░Õó×µ©ĪÕØŚµŚČõ╗Źõ╝Üõ┐ØńĢÖµ│©ÕåīĶ┐ćń©ŗ’╝īńö©µłĘÕ¤║õ║Ä MMEngine µ×äÕ╗║Ķć¬ÕĘ▒ńÜäķĪ╣ńø«µŚČ’╝īÕ”éµ×£õĮ┐ńö©ń║» Python ķŻÄµĀ╝ńÜäķģŹńĮ«µ¢ćõ╗Č’╝īÕłÖµŚĀķ£Ćµ│©ÕåīŃĆéń£ŗÕł░Ķ┐ÖõĮĀõ╝ܵł¢Ķ«Ėõ╝ÜÕźĮÕźć’╝īĶ┐ÖµĀʵ▓Īµ£ēÕ«ēĶŻģ PyTorch ńÜäńÄ»ÕóāõĖŹÕ░▒µ▓Īµ│ĢĶ¦Żµ×ɵĀĘõŠŗķģŹńĮ«µ¢ćõ╗Čõ║åõ╣ł’╝īĶ┐ÖµĀĘńÜäķģŹńĮ«µ¢ćõ╗ČĶ┐śÕŽķģŹńĮ«µ¢ćõ╗Čõ╣ł’╝¤õĖŹĶ”üńØƵƟ’╝īĶ┐Öķā©ÕłåńÜäÕåģÕ«╣µłæõ╗¼õ╝ÜÕ£©ÕÉÄķØóõ╗ŗń╗ŹŃĆé
+
+#### ń╗¦µē┐
+
+ń║» Python ķŻÄµĀ╝ńÜäķģŹńĮ«µ¢ćõ╗Čń╗¦µē┐Ķ»Łµ│Ģµ£ēµēĆõĖŹÕÉī’╝Ü
+
+```{eval-rst}
+.. tabs::
+
+ .. code-tab:: python ń║» Python ķŻÄµĀ╝ń╗¦µē┐
+
+ from mmengine.config import read_base
+
+
+ with read_base():
+ from .optimizer import *
+
+ .. code-tab:: python ń║»µ¢ćµ£¼ķŻÄµĀ╝ń╗¦µē┐
+
+ _base_ = [./optimizer.py]
+
+```
+
+ń║» Python ķŻÄµĀ╝ńÜäķģŹńĮ«µ¢ćõ╗ČķĆÜĶ┐ć import Ķ»Łµ│ĢµØźÕ«×ńÄ░ń╗¦µē┐’╝īĶ┐ÖµĀĘÕüÜńÜäÕźĮÕżäµś»’╝īµłæõ╗¼ÕÅ»õ╗źńø┤µÄźĶĘ│ĶĮ¼Õł░Ķó½ń╗¦µē┐ńÜäķģŹńĮ«µ¢ćõ╗ČõĖŁ’╝īµ¢╣õŠ┐ķśģĶ»╗ÕÆīĶĘ│ĶĮ¼ŃĆéÕÅśķćÅńÜäń╗¦µē┐Ķ¦äÕłÖ’╝łÕó×ÕłĀµö╣µ¤ź’╝ēÕ«īÕģ©Õ»╣ķĮÉ Python Ķ»Łµ│Ģ’╝īõŠŗÕ”éµłæµā│õ┐«µö╣ base ķģŹńĮ«µ¢ćõ╗ČõĖŁ optimizer ńÜäÕŁ”õ╣ĀńÄć’╝Ü
+
+```python
+from mmengine.config import read_base
+
+
+with read_base():
+ from .optimizer import *
+
+# optimizer õĖ║ base ķģŹńĮ«µ¢ćõ╗ČÕ«Üõ╣ēńÜäÕÅśķćÅ
+optimizer.update(
+ lr=0.01,
+)
+```
+
+ÕĮōńäČõ║å’╝īÕ”éµ×£õĮĀÕĘ▓ń╗Åõ╣Āµā»õ║åń║»µ¢ćµ£¼ķŻÄµĀ╝ńÜäń╗¦µē┐Ķ¦äÕłÖ’╝īõĖöĶ»źÕÅśķćÅÕ£© _base_ ķģŹńĮ«µ¢ćõ╗ČõĖŁõĖ║ `dict` ń▒╗Õ×ŗ’╝īõ╣¤ÕÅ»õ╗źķĆÜĶ┐ć merge Ķ»Łµ│ĢµØźÕ«×ńÄ░ÕÆīń║»µ¢ćµ£¼ķŻÄµĀ╝ķģŹńĮ«µ¢ćõ╗ČõĖĆĶć┤ńÜäń╗¦µē┐Ķ¦äÕłÖ’╝Ü
+
+```python
+from mmengine.config import read_base
+
+
+with read_base():
+ from .optimizer import *
+
+# optimizer õĖ║ base ķģŹńĮ«µ¢ćõ╗ČÕ«Üõ╣ēńÜäÕÅśķćÅ
+optimizer.merge(
+ _delete_=True,
+ lr=0.01,
+ type='SGD'
+)
+
+# ńŁēõ╗ĘńÜä python ķŻÄµĀ╝ÕåÖµ│ĢÕ”éõĖŗ’╝īõĖÄ Python ńÜä import Ķ¦äÕłÖÕ«īÕģ©õĖĆĶć┤
+# optimizer = dict(
+# lr=0.01,
+# type='SGD'
+# )
+```
+
+````{note}
+ķ£ĆĶ”üµ│©µäÅńÜ䵜»’╝īń║» Python ķŻÄµĀ╝ńÜäķģŹńĮ«µ¢ćõ╗ČõĖŁ’╝īÕŁŚÕģĖńÜä `update` µ¢╣µ│ĢõĖÄ `dict.update` ń©Źµ£ēõĖŹÕÉīŃĆéń║» Python ķŻÄµĀ╝ńÜä update õ╝ÜķĆÆÕĮÆÕ£░ÕÄ╗µø┤µ¢░ÕŁŚÕģĖõĖŁńÜäÕåģÕ«╣’╝īõŠŗÕ”é’╝Ü
+
+```python
+x = dict(a=1, b=dict(c=2, d=3))
+
+x.update(dict(b=dict(d=4)))
+# ķģŹńĮ«µ¢ćõ╗ČõĖŁńÜä update Ķ¦äÕłÖ’╝Ü
+# {a: 1, b: {c: 2, d: 4}}
+# µÖ«ķĆÜ dict ńÜä update Ķ¦äÕłÖ’╝Ü
+# {a: 1, b: {d: 4}}
+```
+
+ÕÅ»Ķ¦üÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁõĮ┐ńö© update µ¢╣µ│Ģõ╝ÜķĆÆÕĮÆÕ£░ÕÄ╗µø┤µ¢░ÕŁŚµ«Ą’╝īĶĆīõĖŹµś»ń«ĆÕŹĢńÜäĶ”åńø¢ŃĆé
+````
+
+õĖÄń║»µ¢ćµ£¼ķŻÄµĀ╝ńÜäķģŹńĮ«µ¢ćõ╗ČńøĖµ»ö’╝īń║» Python ķŻÄµĀ╝ńÜäķģŹńĮ«µ¢ćõ╗ČńÜäń╗¦µē┐Ķ¦äÕłÖÕ«īÕģ©Õ»╣ķĮÉ import Ķ»Łµ│Ģ’╝īµø┤Õ«╣µśōńÉåĶ¦Ż’╝īõĖöµö»µīüķģŹńĮ«µ¢ćõ╗Čõ╣ŗķŚ┤ńÜäĶĘ│ĶĮ¼ŃĆéõĮĀµł¢Ķ«Ėõ╝ÜÕźĮÕźćµŚóńäČń╗¦µē┐ÕÆīµ©ĪÕØŚńÜäÕ»╝ÕģźķāĮõĮ┐ńö©õ║å import Ķ»Łµ│Ģ’╝īõĖ║õ╗Ćõ╣łń╗¦µē┐ķģŹńĮ«µ¢ćõ╗ČĶ┐śķ£ĆĶ”üķóØÕż¢ńÜä `with read_base():` Ķ┐ÖõĖ¬õĖŖõĖŗµ¢ćń«ĪńÉåÕÖ©Õæó’╝¤õĖƵ¢╣ķØóĶ┐ÖµĀĘÕÅ»õ╗źµÅÉÕŹćķģŹńĮ«µ¢ćõ╗ČńÜäÕÅ»Ķ»╗µĆ¦’╝īÕÅ»õ╗źĶ«®ń╗¦µē┐ńÜäķģŹńĮ«µ¢ćõ╗ȵø┤ÕŖĀń¬üÕć║’╝īÕÅ”õĖƵ¢╣ķØóõ╣¤µś»ÕÅŚķÖÉõ║Ä lazy_import ńÜäĶ¦äÕłÖ’╝īĶ┐ÖõĖ¬õ╝ÜÕ£©ÕÉÄķØóĶ«▓Õł░ŃĆé
+
+#### ķģŹńĮ«µ¢ćõ╗ČńÜäÕ»╝Õć║
+
+ń║» python ķŻÄµĀ╝ķģŹńĮ«µ¢ćõ╗Čõ╣¤ķĆÜĶ┐ć dump µÄźÕÅŻÕ»╝Õć║’╝īõĮ┐ńö©õĖŖµ▓Īµ£ēõ╗╗õĮĢÕī║Õł½’╝īõĮåµś»Õ»╝Õć║ńÜäÕåģÕ«╣õ╝ܵ£ēµēĆõĖŹÕÉī’╝Ü
+
+```{eval-rst}
+.. tabs::
+
+ .. tabs::
+
+ .. code-tab:: python ń║» Python ķŻÄµĀ╝Õ»╝Õć║
+
+ optimizer = dict(type='torch.optim.SGD', lr=0.1)
+
+ .. code-tab:: python ń║»µ¢ćµ£¼ķŻÄµĀ╝Õ»╝Õć║
+
+ optimizer = dict(type='SGD', lr=0.1)
+
+ .. tabs::
+
+ .. code-tab:: yaml ń║» Python ķŻÄµĀ╝Õ»╝Õć║
+
+ optimizer:
+ type: torch.optim.SGD
+ lr: 0.1
+
+ .. code-tab:: yaml ń║»µ¢ćµ£¼ķŻÄµĀ╝Õ»╝Õć║
+
+ optimizer:
+ type: SGD
+ lr: 0.1
+
+ .. tabs::
+
+ .. code-tab:: json ń║» Python ķŻÄµĀ╝Õ»╝Õć║
+
+ {"optimizer": "torch.optim.SGD", "lr": 0.1}
+
+ .. code-tab:: json ń║»µ¢ćµ£¼ķŻÄµĀ╝Õ»╝Õć║
+
+ {"optimizer": "SGD", "lr": 0.1}
+```
+
+ÕÅ»õ╗źń£ŗÕł░’╝īń║» Python ķŻÄµĀ╝Õ»╝Õć║ńÜä type ÕŁŚµ«Ąõ╝ÜÕīģÕɽµ©ĪÕØŚńÜäÕģ©ķćÅõ┐Īµü»ŃĆéÕ»╝Õć║ńÜäķģŹńĮ«µ¢ćõ╗Čõ╣¤ÕÅ»õ╗źĶó½ńø┤µÄźÕŖĀĶĮĮ’╝īķĆÜĶ┐ćµ│©ÕåīÕÖ©µØźµ×äÕ╗║Õ«×õŠŗŃĆé
+
+### õ╗Ćõ╣łµś» lazy import
+
+ń£ŗÕł░Ķ┐ÖõĮĀÕÅ»ĶāĮõ╝ÜÕÉɵ¦Į’╝īĶ┐Öń║» Python ķŻÄµĀ╝ńÜäķģŹńĮ«µ¢ćõ╗ȵä¤Ķ¦ēÕ░▒Õāŵś»ńö©ń║» Python Ķ»Łµ│ĢµØźń╗äń╗ćķģŹńĮ«µ¢ćõ╗ČÕśøŃĆéĶ┐ÖµĀʵłæÕō¬Ķ┐śķ£ĆĶ”üķģŹńĮ«ń▒╗’╝īńø┤µÄźńö© Python Ķ»Łµ│ĢµØźÕ»╝ÕģźķģŹńĮ«µ¢ćõ╗ČõĖŹÕ░▒ÕźĮõ║åŃĆéÕ”éµ×£õĮĀµ£ēĶ┐ÖµĀĘńÜäµä¤ÕÅŚ’╝īķéŻń£¤µś»õĖĆõ╗ČÕĆ╝ÕŠŚÕ║åńźØńÜäõ║ŗ’╝īÕøĀõĖ║Ķ┐ÖµŁŻµś»µłæõ╗¼µā│Ķ”üńÜäµĢłµ×£ŃĆé
+
+µŁŻÕ”éÕēŹķØóµēƵÅÉÕł░ńÜä’╝īĶ¦Żµ×ÉķģŹńĮ«µ¢ćõ╗Čķ£ĆĶ”üõŠØĶĄ¢ķģŹńĮ«µ¢ćõ╗ČõĖŁÕ╝Ģńö©ńÜäõĖēµ¢╣Õ║ō’╝īĶ┐ÖÕģČÕ«×µś»õĖĆõ╗ČķØ×ÕĖĖõĖŹÕÉłńÉåńÜäõ║ŗŃĆéõŠŗÕ”éµłæÕ¤║õ║Ä MMagic Ķ«Łń╗āõ║åõĖĆõĖ¬µ©ĪÕ×ŗ’╝īµā│õĮ┐ńö© MMDeploy ńÜä onnxruntime ÕÉÄń½»ķā©ńĮ▓ŃĆéńö▒õ║Äķā©ńĮ▓ńÄ»ÕóāõĖŁµ▓Īµ£ē torch’╝īĶĆīķģŹńĮ«µ¢ćõ╗ČĶ¦Żµ×ÉĶ┐ćń©ŗõĖŁķ£ĆĶ”ü torch’╝īĶ┐ÖÕ░▒Õ»╝Ķć┤õ║åµłæµŚĀµ│Ģńø┤µÄźõĮ┐ńö© MMagic ńÜäķģŹńĮ«µ¢ćõ╗ČõĮ£õĖ║ķā©ńĮ▓ńÜäķģŹńĮ«’╝īĶ┐Öµś»ķØ×ÕĖĖõĖŹµ¢╣õŠ┐ńÜäŃĆéõĖ║õ║åĶ¦ŻÕå│Ķ┐ÖõĖ¬ķŚ«ķóś’╝īµłæõ╗¼Õ╝ĢÕģźõ║å lazy_import ńÜäµ”éÕ┐ĄŃĆé
+
+Ķ”üĶüŖ lazy_import ńÜäÕģĘõĮōÕ«×ńÄ░µś»õĖĆõ╗ȵ»öĶŠāÕżŹµØéńÜäõ║ŗ’╝īÕ£©µŁżµłæõ╗¼õ╗ģÕ»╣ÕģČÕŖ¤ĶāĮÕüÜń«ĆĶ”üõ╗ŗń╗ŹŃĆélazy_import ńÜäµĀĖÕ┐āµĆصā│µś»’╝īÕ░åķģŹńĮ«µ¢ćõ╗ČõĖŁńÜä import Ķ»ŁÕÅźÕ╗ČĶ┐¤Õł░ķģŹńĮ«µ¢ćõ╗ČĶó½Ķ¦Żµ×ɵŚČµēŹµē¦ĶĪī’╝īĶ┐ÖµĀĘÕ░▒ÕÅ»õ╗źķü┐ÕģŹķģŹńĮ«µ¢ćõ╗ČõĖŁńÜä import Ķ»ŁÕÅźÕ»╝Ķć┤ńÜäõĖēµ¢╣Õ║ōõŠØĶĄ¢ķŚ«ķóśŃĆéķģŹńĮ«µ¢ćõ╗ČĶ¦Żµ×ÉĶ┐ćń©ŗµŚČ’╝īPython Ķ¦ŻķćŖÕÖ©Õ«×ķÖģµē¦ĶĪīńÜäńŁēµĢłõ╗ŻńĀüÕ”éõĖŗ
+
+```{eval-rst}
+.. tabs::
+ .. code-tab:: python ÕĤզŗķģŹńĮ«µ¢ćõ╗Č
+
+ from torch.optim import SGD
+
+
+ optimizer = dict(type=SGD)
+
+ .. code-tab:: python ķĆÜĶ┐ćķģŹńĮ«ń▒╗’╝īPython Ķ¦ŻķćŖÕÖ©Õ«×ķÖģµē¦ĶĪīńÜäõ╗ŻńĀü
+
+ lazy_obj = LazyObject('torch.optim', 'SGD')
+
+ optimizer = dict(type=lazy_obj)
+```
+
+LazyObject õĮ£õĖ║ `Config` µ©ĪÕØŚńÜäÕģ¦ķā©ń▒╗Õ×ŗ’╝īµŚĀµ│ĢĶó½ńö©µłĘńø┤µÄźĶ«┐ķŚ«ŃĆéńö©µłĘÕ£©Ķ«┐ķŚ« type ÕŁŚµ«ĄµŚČ’╝īõ╝Üń╗ÅĶ┐ćõĖĆń│╗ÕłŚńÜäĶĮ¼µŹó’╝īÕ░å `LazyObject` ĶĮ¼Õī¢µłÉń£¤µŁŻńÜä `torch.optim.SGD` ń▒╗Õ×ŗŃĆéĶ┐ÖµĀĘõĖĆµØź’╝īķģŹńĮ«µ¢ćõ╗ČńÜäĶ¦Żµ×ÉõĖŹõ╝ÜĶ¦”ÕÅæõĖēµ¢╣Õ║ōńÜäÕ»╝Õģź’╝īĶĆīńö©µłĘõĮ┐ńö©ķģŹńĮ«µ¢ćõ╗ȵŚČ’╝īÕÅłÕÅ»õ╗źµŁŻÕĖĖĶ«┐ķŚ«õĖēµ¢╣Õ║ōńÜäń▒╗Õ×ŗŃĆé
+
+Ķ”üµā│Ķ«┐ķŚ« `LazyObject` ńÜäÕåģķā©ń▒╗Õ×ŗ’╝īÕÅ»õ╗źķĆÜĶ┐ć `Config.to_dict` µÄźÕÅŻ’╝Ü
+
+```python
+cfg = Config.fromfile('optimizer.py').to_dict()
+print(type(cfg['optimizer']['type']))
+# mmengine.config.lazy.LazyObject
+```
+
+µŁżµŚČÕŠŚÕł░ńÜä type Õ░▒µś» `LazyObject` ń▒╗Õ×ŗŃĆé
+
+ńäČĶĆīÕ»╣õ║Ä base µ¢ćõ╗ČńÜäń╗¦µē┐’╝łÕ»╝Õģź’╝īimport’╝ē’╝īµłæõ╗¼õĖŹĶāĮÕż¤ķććÕÅ¢ lazy import ńÜäńŁ¢ńĢź’╝īĶ┐Öµś»ÕøĀõĖ║µłæõ╗¼ÕĖīµ£øĶ¦Żµ×ÉÕÉÄńÜäķģŹńĮ«µ¢ćõ╗ČĶāĮÕż¤ÕīģÕɽ base ķģŹńĮ«µ¢ćõ╗ČÕ«Üõ╣ēńÜäÕŁŚµ«Ą’╝īķ£ĆĶ”üń£¤µŁŻńÜäĶ¦”ÕÅæ importŃĆéÕøĀµŁżµłæõ╗¼Õ»╣ base µ¢ćõ╗ČńÜäÕ»╝ÕģźÕŖĀõ║åõĖĆÕ▒éķÖÉÕłČ’╝īÕŹ│Õ┐ģķĪ╗Õ£© `with read_base()'` ńÜäõĖŖõĖŗµ¢ćõĖŁÕ»╝ÕģźŃĆé
+
+### ÕŖ¤ĶāĮķÖÉÕłČ
+
+1. õĖŹĶāĮÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁÕ«Üõ╣ēÕćĮµĢ░ŃĆüń▒╗ńŁē
+2. ķģŹńĮ«µ¢ćõ╗ČÕÉŹÕ┐ģķĪ╗ń¼”ÕÉł Python µ©ĪÕØŚÕÉŹńÜäÕæĮÕÉŹĶ¦äĶīā’╝īÕŹ│ÕŬĶāĮÕīģÕÉ½ÕŁŚµ»ŹŃĆüµĢ░ÕŁŚŃĆüõĖŗÕłÆń║┐’╝īõĖöõĖŹĶāĮõ╗źµĢ░ÕŁŚÕ╝ĆÕż┤
+3. Õ»╝Õģź base ķģŹńĮ«µ¢ćõ╗ČõĖŁńÜäÕÅśķćŵŚČ’╝īõŠŗÕ”é `from ._base_.alpha import beta`’╝īµŁżÕżäńÜä `alpha` Õ┐ģķĪ╗µś»µ©ĪÕØŚ’╝łmodule’╝ēÕÉŹ’╝īÕŹ│ Python µ¢ćõ╗Č’╝īĶĆīõĖŹĶāĮµś»Õɽµ£ē `__init__.py` ńÜäÕīģ’╝łpackage’╝ēÕÉŹ
+4. õĖŹµö»µīüÕ£© absolute import Ķ»ŁÕÅźõĖŁÕÉīµŚČÕ»╝ÕģźÕżÜõĖ¬ÕÅśķćÅ’╝īõŠŗÕ”é `import torch, numpy, os`ŃĆéķ£ĆĶ”üķĆÜĶ┐ćÕżÜõĖ¬ import Ķ»ŁÕÅźµØźÕ«×ńÄ░’╝īõŠŗÕ”é `import torch; import numpy; import os`
+
+### Ķ┐üń¦╗µīćÕŹŚ
+
+õ╗Äń║»µ¢ćµ£¼ķŻÄµĀ╝ńÜäķģŹńĮ«µ¢ćõ╗ČĶ┐üń¦╗Õł░ń║» Python ķŻÄµĀ╝ńÜäķģŹńĮ«µ¢ćõ╗Č’╝īķ£ĆĶ”üķüĄÕ«łõ╗źõĖŗĶ¦äÕłÖ’╝Ü
+
+1. type õ╗ÄÕŁŚń¼”õĖ▓µø┐µŹóµłÉÕģĘõĮōńÜäń▒╗’╝Ü
+
+ - õ╗ŻńĀüõĖŹõŠØĶĄ¢ type ÕŁŚµ«Ąµś»ÕŁŚń¼”õĖ▓’╝īõĖöµ▓Īµ£ēÕ»╣ type ÕŁŚµ«ĄÕüÜńē╣µ«ŖÕżäńÉå’╝īÕłÖÕÅ»õ╗źÕ░åÕŁŚń¼”õĖ▓ń▒╗Õ×ŗńÜä type µø┐µŹóµłÉÕģĘõĮōńÜäń▒╗’╝īÕ╣ČÕ£©ķģŹńĮ«µ¢ćõ╗ČńÜäÕ╝ĆÕż┤Õ»╝ÕģźĶ»źń▒╗
+ - õ╗ŻńĀüõŠØĶĄ¢ type ÕŁŚµ«Ąµś»ÕŁŚń¼”õĖ▓’╝īÕłÖķ£ĆĶ”üõ┐«µö╣õ╗ŻńĀü’╝īµł¢õ┐صīüÕĤµ£ēńÜäÕŁŚń¼”õĖ▓µĀ╝Õ╝ÅńÜä type
+
+2. ķćŹÕæĮÕÉŹķģŹńĮ«µ¢ćõ╗Č’╝īķģŹńĮ«µ¢ćõ╗ČÕæĮÕÉŹķ£ĆĶ”üń¼”ÕÉł Python µ©ĪÕØŚÕÉŹńÜäÕæĮÕÉŹĶ¦äĶīā’╝īÕŹ│ÕŬĶāĮÕīģÕÉ½ÕŁŚµ»ŹŃĆüµĢ░ÕŁŚŃĆüõĖŗÕłÆń║┐’╝īõĖöõĖŹĶāĮõ╗źµĢ░ÕŁŚÕ╝ĆÕż┤
+
+3. ÕłĀķÖż scope ńøĖÕģ│ķģŹńĮ«ŃĆéń║» Python ķŻÄµĀ╝ńÜäķģŹńĮ«µ¢ćõ╗ČõĖŹÕåŹķ£ĆĶ”üķĆÜĶ┐ć scope µØźĶĘ©Õ║ōĶ░āńö©µ©ĪÕØŚ’╝īńø┤µÄźķĆÜĶ┐ć import Õ»╝ÕģźÕŹ│ÕÅ»ŃĆéÕć║õ║ÄÕģ╝Õ«╣µĆ¦µ¢╣ķØóńÜäĶĆāĶÖæ’╝īµłæõ╗¼õ╗ŹńäČĶ«® Runner ńÜä default_scope ÕÅéµĢ░õĖ║ `mmengine`’╝īńö©µłĘķ£ĆĶ”üÕ░åÕģȵēŗÕŖ©Ķ«ŠńĮ«õĖ║ `None`
+
+4. Õ»╣õ║ĵ│©ÕåīÕÖ©õĖŁÕŁśÕ£©Õł½ÕÉŹńÜä’╝łalias’╝ēńÜ䵩ĪÕØŚ’╝īÕ░åÕģČÕł½ÕÉŹµø┐µŹóµłÉÕģČÕ»╣Õ║öńÜäń£¤Õ«×µ©ĪÕØŚÕŹ│ÕÅ»’╝īõ╗źõĖŗµś»ÕĖĖńö©ńÜäÕł½ÕÉŹµø┐µŹóĶĪ©’╝Ü
+
+
+
+
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/contributing.md b/internlm_langchain/knowledge_base/MMEngine/content/contributing.md
new file mode 100644
index 00000000..a5e52fd8
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/contributing.md
@@ -0,0 +1,257 @@
+# Ķ┤Īńī«õ╗ŻńĀü
+
+µ¼óĶ┐ÄÕŖĀÕģź MMEngine ńżŠÕī║’╝īµłæõ╗¼Ķć┤ÕŖøõ║ĵēōķĆĀµ£ĆÕēŹµ▓┐ńÜäµĘ▒Õ║”ÕŁ”õ╣Āµ©ĪÕ×ŗĶ«Łń╗āńÜäÕ¤║ńĪĆÕ║ō’╝īµłæõ╗¼µ¼óĶ┐Äõ╗╗õĮĢń▒╗Õ×ŗńÜäĶ┤Īńī«’╝īÕīģµŗ¼õĮåõĖŹķÖÉõ║Ä
+
+**õ┐«ÕżŹķöÖĶ»»**
+
+õ┐«ÕżŹõ╗ŻńĀüÕ«×ńÄ░ķöÖĶ»»ńÜ䵣źķ¬żÕ”éõĖŗ’╝Ü
+
+1. Õ”éµ×£µÅÉõ║żńÜäõ╗ŻńĀüµö╣ÕŖ©ĶŠāÕż¦’╝īÕ╗║Ķ««ÕģłµÅÉõ║ż issue’╝īÕ╣ȵŁŻńĪ«µÅÅĶ┐░ issue ńÜäńÄ░Ķ▒ĪŃĆüÕĤÕøĀÕÆīÕżŹńÄ░µ¢╣Õ╝Å’╝īĶ«©Ķ«║ÕÉÄńĪ«Ķ«żõ┐«ÕżŹµ¢╣µĪłŃĆé
+2. õ┐«ÕżŹķöÖĶ»»Õ╣ČĶĪźÕģģńøĖÕ║öńÜäÕŹĢÕģāµĄŗĶ»Ģ’╝īµÅÉõ║żµŗēÕÅ¢Ķ»Ęµ▒éŃĆé
+
+**µ¢░Õó×ÕŖ¤ĶāĮµł¢ń╗äõ╗Č**
+
+1. Õ”éµ×£µ¢░ÕŖ¤ĶāĮµł¢µ©ĪÕØŚµČēÕÅŖĶŠāÕż¦ńÜäõ╗ŻńĀüµö╣ÕŖ©’╝īÕ╗║Ķ««ÕģłµÅÉõ║ż issue’╝īńĪ«Ķ«żÕŖ¤ĶāĮńÜäÕ┐ģĶ”üµĆ¦ŃĆé
+2. Õ«×ńÄ░µ¢░Õó×ÕŖ¤ĶāĮÕ╣ȵĘ╗ÕŹĢÕģāµĄŗĶ»Ģ’╝īµÅÉõ║żµŗēÕÅ¢Ķ»Ęµ▒éŃĆé
+
+**µ¢ćµĪŻĶĪźÕģģ**
+
+õ┐«ÕżŹµ¢ćµĪŻÕÅ»õ╗źńø┤µÄźµÅÉõ║żµŗēÕÅ¢Ķ»Ęµ▒é
+
+µĘ╗ÕŖĀµ¢ćµĪŻµł¢Õ░åµ¢ćµĪŻń┐╗Ķ»æµłÉÕģČõ╗¢Ķ»ŁĶ©ĆµŁźķ¬żÕ”éõĖŗ
+
+1. µÅÉõ║ż issue’╝īńĪ«Ķ«żµĘ╗ÕŖĀµ¢ćµĪŻńÜäÕ┐ģĶ”üµĆ¦ŃĆé
+2. µĘ╗ÕŖĀµ¢ćµĪŻ’╝īµÅÉõ║żµŗēÕÅ¢Ķ»Ęµ▒éŃĆé
+
+## µŗēÕÅ¢Ķ»Ęµ▒éÕĘźõĮ£µĄü
+
+Õ”éµ×£õĮĀÕ»╣µŗēÕÅ¢Ķ»Ęµ▒éõĖŹõ║åĶ¦Ż’╝īµ▓ĪÕģ│ń│╗’╝īµÄźõĖŗµØźńÜäÕåģÕ«╣Õ░åõ╝Üõ╗ÄķøČÕ╝ĆÕ¦ŗ’╝īõĖƵŁźõĖƵŁźÕ£░µīćÕ╝ĢõĮĀÕ”éõĮĢÕłøÕ╗║õĖĆõĖ¬µŗēÕÅ¢Ķ»Ęµ▒éŃĆéÕ”éµ×£õĮĀµā│µĘ▒Õģźõ║åĶ¦ŻµŗēÕÅ¢Ķ»Ęµ▒éńÜäÕ╝ĆÕÅ浩ĪÕ╝Å’╝īÕÅ»õ╗źÕÅéĶĆā github [Õ«śµ¢╣µ¢ćµĪŻ](https://docs.github.com/en/github/collaborating-with-issues-and-pull-requests/about-pull-requests)
+
+### 1. ÕżŹÕł╗õ╗ōÕ║ō
+
+ÕĮōõĮĀń¼¼õĖƵ¼ĪµÅÉõ║żµŗēÕÅ¢Ķ»Ęµ▒鵌Ȓ╝īÕģłÕżŹÕł╗ OpenMMLab ÕĤõ╗ŻńĀüÕ║ō’╝īńé╣Õć╗ GitHub ķĪĄķØóÕÅ│õĖŖĶ¦ÆńÜä **Fork** µīēķÆ«’╝īÕżŹÕł╗ÕÉÄńÜäõ╗ŻńĀüÕ║ōÕ░åõ╝ÜÕć║ńÄ░Õ£©õĮĀńÜä GitHub õĖ¬õ║║õĖ╗ķĪĄõĖŗŃĆé
+
+
+
+Õ░åõ╗ŻńĀüÕģŗķÜåÕł░µ£¼Õ£░
+
+```shell
+git clone git@github.com:{username}/mmengine.git
+```
+
+µĘ╗ÕŖĀÕĤõ╗ŻńĀüÕ║ōõĖ║õĖŖµĖĖõ╗ŻńĀüÕ║ō
+
+```bash
+git remote add upstream git@github.com:open-mmlab/mmengine
+```
+
+µŻĆµ¤ź remote µś»ÕÉ”µĘ╗ÕŖĀµłÉÕŖ¤’╝īÕ£©ń╗łń½»ĶŠōÕģź `git remote -v`
+
+```bash
+origin git@github.com:{username}/mmengine.git (fetch)
+origin git@github.com:{username}/mmengine.git (push)
+upstream git@github.com:open-mmlab/mmengine (fetch)
+upstream git@github.com:open-mmlab/mmengine (push)
+```
+
+```{note}
+Ķ┐ÖķćīÕ»╣ origin ÕÆī upstream Ķ┐øĶĪīõĖĆõĖ¬ń«ĆÕŹĢńÜäõ╗ŗń╗Ź’╝īÕĮōµłæõ╗¼õĮ┐ńö© git clone µØźÕģŗķÜåõ╗ŻńĀüµŚČ’╝īõ╝Üķ╗śĶ«żÕłøÕ╗║õĖĆõĖ¬ origin ńÜä remote’╝īÕ«āµīćÕÉæµłæõ╗¼ÕģŗķÜåńÜäõ╗ŻńĀüÕ║ōÕ£░ÕØĆ’╝īĶĆī upstream ÕłÖµś»µłæõ╗¼Ķć¬ÕĘ▒µĘ╗ÕŖĀńÜä’╝īńö©µØźµīćÕÉæÕĤզŗõ╗ŻńĀüÕ║ōÕ£░ÕØĆŃĆéÕĮōńäČÕ”éµ×£õĮĀõĖŹÕ¢£µ¼óõ╗¢ÕŽ upstream’╝īõ╣¤ÕÅ»õ╗źĶć¬ÕĘ▒õ┐«µö╣’╝īµ»öÕ”éÕŽ open-mmlabŃĆ鵳æõ╗¼ķĆÜÕĖĖÕÉæ origin µÅÉõ║żõ╗ŻńĀü’╝łÕŹ│ fork õĖŗµØźńÜäĶ┐£ń©ŗõ╗ōÕ║ō’╝ē’╝īńäČÕÉÄÕÉæ upstream µÅÉõ║żõĖĆõĖ¬ pull requestŃĆéÕ”éµ×£µÅÉõ║żńÜäõ╗ŻńĀüÕÆīµ£Ćµ¢░ńÜäõ╗ŻńĀüÕÅæńö¤Õå▓ń¬ü’╝īÕåŹõ╗Ä upstream µŗēÕÅ¢µ£Ćµ¢░ńÜäõ╗ŻńĀü’╝īÕÆīµ£¼Õ£░Õłåµö»Ķ¦ŻÕå│Õå▓ń¬ü’╝īÕåŹµÅÉõ║żÕł░ originŃĆé
+```
+
+### 2. ķģŹńĮ« pre-commit
+
+Õ£©µ£¼Õ£░Õ╝ĆÕÅæńÄ»ÕóāõĖŁ’╝īµłæõ╗¼õĮ┐ńö© [pre-commit](https://pre-commit.com/#intro) µØźµŻĆµ¤źõ╗ŻńĀüķŻÄµĀ╝’╝īõ╗źńĪ«õ┐Øõ╗ŻńĀüķŻÄµĀ╝ńÜäń╗¤õĖĆŃĆéÕ£©µÅÉõ║żõ╗ŻńĀü’╝īķ£ĆĶ”üÕģłÕ«ēĶŻģ pre-commit’╝łķ£ĆĶ”üÕ£© mmengine ńø«ÕĮĢõĖŗµē¦ĶĪī’╝ē:
+
+```shell
+pip install -U pre-commit
+pre-commit install
+```
+
+µŻĆµ¤ź pre-commit µś»ÕÉ”ķģŹńĮ«µłÉÕŖ¤’╝īÕ╣ČÕ«ēĶŻģ `.pre-commit-config.yaml` õĖŁńÜäķÆ®ÕŁÉ’╝Ü
+
+```shell
+pre-commit run --all-files
+```
+
+
+
+
+
+```{note}
+Õ”éµ×£õĮĀµś»õĖŁÕøĮńö©µłĘ’╝īńö▒õ║ÄńĮæń╗£ÕĤÕøĀ’╝īÕÅ»ĶāĮõ╝ÜÕć║ńÄ░Õ«ēĶŻģÕż▒Ķ┤źńÜäµāģÕåĄ’╝īĶ┐ÖµŚČÕÅ»õ╗źõĮ┐ńö©ÕøĮÕåģµ║É
+pre-commit install -c .pre-commit-config-zh-cn.yaml
+pre-commit run --all-files -c .pre-commit-config-zh-cn.yaml
+```
+
+Õ”éµ×£Õ«ēĶŻģĶ┐ćń©ŗĶó½õĖŁµ¢Ł’╝īÕÅ»õ╗źķćŹÕżŹµē¦ĶĪī `pre-commit run ...` ń╗¦ń╗ŁÕ«ēĶŻģŃĆé
+
+Õ”éµ×£µÅÉõ║żńÜäõ╗ŻńĀüõĖŹń¼”ÕÉłõ╗ŻńĀüķŻÄµĀ╝Ķ¦äĶīā’╝īpre-commit õ╝ÜÕÅæÕć║ĶŁ”ÕæŖ’╝īÕ╣ČĶć¬ÕŖ©õ┐«ÕżŹķā©ÕłåķöÖĶ»»ŃĆé
+
+
+
+Õ”éµ×£µłæõ╗¼µā│õĖ┤µŚČń╗ĢÕ╝Ć pre-commit ńÜ䵯Ƶ¤źµÅÉõ║żõĖƵ¼Īõ╗ŻńĀü’╝īÕÅ»õ╗źÕ£© `git commit` µŚČÕŖĀõĖŖ `--no-verify`’╝łķ£ĆĶ”üõ┐ØĶ»üµ£ĆÕÉĵĩķĆüĶć│Ķ┐£ń©ŗõ╗ōÕ║ōńÜäõ╗ŻńĀüĶāĮÕż¤ķĆÜĶ┐ć pre-commit µŻĆµ¤ź’╝ēŃĆé
+
+```shell
+git commit -m "xxx" --no-verify
+```
+
+### 3. ÕłøÕ╗║Õ╝ĆÕÅæÕłåµö»
+
+Õ«ēĶŻģÕ«ī pre-commit õ╣ŗÕÉÄ’╝īµłæõ╗¼ķ£ĆĶ”üÕ¤║õ║Ä master ÕłøÕ╗║Õ╝ĆÕÅæÕłåµö»’╝īÕ╗║Ķ««ńÜäÕłåµö»ÕæĮÕÉŹĶ¦äÕłÖõĖ║ `username/pr_name`ŃĆé
+
+```shell
+git checkout -b yhc/refactor_contributing_doc
+```
+
+Õ£©ÕÉÄń╗ŁńÜäÕ╝ĆÕÅæõĖŁ’╝īÕ”éµ×£µ£¼Õ£░õ╗ōÕ║ōńÜä master Õłåµö»ĶÉĮÕÉÄõ║Ä upstream ńÜä master Õłåµö»’╝īµłæõ╗¼ķ£ĆĶ”üÕģłµŗēÕÅ¢ upstream ńÜäõ╗ŻńĀüĶ┐øĶĪīÕÉīµŁź’╝īÕåŹµē¦ĶĪīõĖŖķØóńÜäÕæĮõ╗ż
+
+```shell
+git pull upstream master
+```
+
+### 4. µÅÉõ║żõ╗ŻńĀüÕ╣ČÕ£©µ£¼Õ£░ķĆÜĶ┐ćÕŹĢÕģāµĄŗĶ»Ģ
+
+- MMEngine Õ╝ĢÕģźõ║å mypy µØźÕüÜķØÖµĆüń▒╗Õ×ŗµŻĆµ¤ź’╝īõ╗źÕó×ÕŖĀõ╗ŻńĀüńÜäķ▓üµŻÆµĆ¦ŃĆéÕøĀµŁżµłæõ╗¼Õ£©µÅÉõ║żõ╗ŻńĀüµŚČ’╝īķ£ĆĶ”üĶĪźÕģģ Type HintsŃĆéÕģĘõĮōĶ¦äÕłÖÕÅ»õ╗źÕÅéĶĆā[µĢÖń©ŗ](https://zhuanlan.zhihu.com/p/519335398)ŃĆé
+
+- µÅÉõ║żńÜäõ╗ŻńĀüÕÉīµĀĘķ£ĆĶ”üķĆÜĶ┐ćÕŹĢÕģāµĄŗĶ»Ģ
+
+ ```shell
+ # ķĆÜĶ┐ćÕģ©ķćÅÕŹĢÕģāµĄŗĶ»Ģ
+ pytest tests
+
+ # µłæõ╗¼ķ£ĆĶ”üõ┐ØĶ»üµÅÉõ║żńÜäõ╗ŻńĀüĶāĮÕż¤ķĆÜĶ┐ćõ┐«µö╣µ©ĪÕØŚńÜäÕŹĢÕģāµĄŗĶ»Ģ’╝īõ╗ź runner õĖ║õŠŗ
+ pytest tests/test_runner/test_runner.py
+ ```
+
+ Õ”éµ×£õĮĀńö▒õ║Äń╝║Õ░æõŠØĶĄ¢µŚĀµ│ĢĶ┐ÉĶĪīõ┐«µö╣µ©ĪÕØŚńÜäÕŹĢÕģāµĄŗĶ»Ģ’╝īÕÅ»õ╗źÕÅéĶĆā[µīćÕ╝Ģ-ÕŹĢÕģāµĄŗĶ»Ģ](#ÕŹĢÕģāµĄŗĶ»Ģ)
+
+- Õ”éµ×£õ┐«µö╣/µĘ╗ÕŖĀõ║åµ¢ćµĪŻ’╝īÕÅéĶĆā[µīćÕ╝Ģ](#µ¢ćµĪŻµĖ▓µ¤ō)ńĪ«Ķ«żµ¢ćµĪŻµĖ▓µ¤ōµŁŻÕĖĖŃĆé
+
+### 5. µÄ©ķĆüõ╗ŻńĀüÕł░Ķ┐£ń©ŗ
+
+õ╗ŻńĀüķĆÜĶ┐ćÕŹĢÕģāµĄŗĶ»ĢÕÆī pre-commit µŻĆµ¤źÕÉÄ’╝īÕ░åõ╗ŻńĀüµÄ©ķĆüÕł░Ķ┐£ń©ŗõ╗ōÕ║ō’╝īÕ”éµ×£µś»ń¼¼õĖƵ¼ĪµÄ©ķĆü’╝īÕÅ»õ╗źÕ£© `git push` ÕÉÄÕŖĀõĖŖ `-u` ÕÅéµĢ░õ╗źÕģ│ĶüöĶ┐£ń©ŗÕłåµö»
+
+```shell
+git push -u origin {branch_name}
+```
+
+Ķ┐ÖµĀĘõĖŗµ¼ĪÕ░▒ÕÅ»õ╗źńø┤µÄźõĮ┐ńö© `git push` ÕæĮõ╗żµÄ©ķĆüõ╗ŻńĀüõ║å’╝īĶĆīµŚĀķ£ĆµīćÕ«ÜÕłåµö»ÕÆīĶ┐£ń©ŗõ╗ōÕ║ōŃĆé
+
+### 6. µÅÉõ║żµŗēÕÅ¢Ķ»Ęµ▒é’╝łPR’╝ē
+
+(1) Õ£© GitHub ńÜä Pull request ńĢīķØóÕłøÕ╗║µŗēÕÅ¢Ķ»Ęµ▒é
+
+
+(2) µĀ╣µŹ«µīćÕ╝Ģõ┐«µö╣ PR µÅÅĶ┐░’╝īõ╗źõŠ┐õ║ÄÕģČõ╗¢Õ╝ĆÕÅæĶĆģµø┤ÕźĮÕ£░ńÉåĶ¦ŻõĮĀńÜäõ┐«µö╣
+
+
+
+µÅÅĶ┐░Ķ¦äĶīāĶ»”Ķ¦ü[µŗēÕÅ¢Ķ»Ęµ▒éĶ¦äĶīā](#µŗēÕÅ¢Ķ»Ęµ▒éĶ¦äĶīā)
+
+
+
+**µ│©µäÅõ║ŗķĪ╣**
+
+(a) PR µÅÅĶ┐░Õ║öĶ»źÕīģÕɽõ┐«µö╣ńÉåńö▒ŃĆüõ┐«µö╣ÕåģÕ«╣õ╗źÕÅŖõ┐«µö╣ÕÉÄÕĖ”µØźńÜäÕĮ▒ÕōŹ’╝īÕ╣ČÕģ│ĶüöńøĖÕģ│ Issue’╝łÕģĘõĮōµ¢╣Õ╝ÅĶ¦ü[µ¢ćµĪŻ](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue)’╝ē
+
+(b) Õ”éµ×£µś»ń¼¼õĖƵ¼ĪõĖ║ OpenMMLab ÕüÜĶ┤Īńī«’╝īķ£ĆĶ”üńŁŠńĮ▓ CLA
+
+
+
+(c) µŻĆµ¤źµÅÉõ║żńÜä PR µś»ÕÉ”ķĆÜĶ┐ć CI’╝łķøåµłÉµĄŗĶ»Ģ’╝ē
+
+
+
+MMEngine õ╝ÜÕ£©õĖŹÕÉīńÜäÕ╣│ÕÅ░’╝łLinuxŃĆüWindowŃĆüMac’╝ē’╝īÕ¤║õ║ÄõĖŹÕÉīńēłµ£¼ńÜä PythonŃĆüPyTorchŃĆüCUDA Õ»╣µÅÉõ║żńÜäõ╗ŻńĀüĶ┐øĶĪīÕŹĢÕģāµĄŗĶ»Ģ’╝īõ╗źõ┐ØĶ»üõ╗ŻńĀüńÜ䵣ŻńĪ«µĆ¦’╝īÕ”éµ×£µ£ēõ╗╗õĮĢõĖĆõĖ¬µ▓Īµ£ēķĆÜĶ┐ć’╝īµłæõ╗¼ÕÅ»ńé╣Õć╗õĖŖÕøŠõĖŁńÜä `Details` µØźµ¤źń£ŗÕģĘõĮōńÜ䵥ŗĶ»Ģõ┐Īµü»’╝īõ╗źõŠ┐õ║ĵłæõ╗¼õ┐«µö╣õ╗ŻńĀüŃĆé
+
+(3) Õ”éµ×£ PR ķĆÜĶ┐ćõ║å CI’╝īķéŻõ╣łÕ░▒ÕÅ»õ╗źńŁēÕŠģÕģČõ╗¢Õ╝ĆÕÅæĶĆģńÜä review’╝īÕ╣ȵĀ╣µŹ« reviewer ńÜäµäÅĶ¦ü’╝īõ┐«µö╣õ╗ŻńĀü’╝īÕ╣ČķćŹÕżŹ [4](#4-µÅÉõ║żõ╗ŻńĀüÕ╣ČÕ£©µ£¼Õ£░ķĆÜĶ┐ćÕŹĢÕģāµĄŗĶ»Ģ)-[5](#5-µÄ©ķĆüõ╗ŻńĀüÕł░Ķ┐£ń©ŗ) µŁźķ¬ż’╝īńø┤Õł░ reviewer ÕÉīµäÅÕÉłÕģź PRŃĆé
+
+
+
+µēƵ£ē reviewer ÕÉīµäÅÕÉłÕģź PR ÕÉÄ’╝īµłæõ╗¼õ╝ÜÕ░ĮÕ┐½Õ░å PR ÕÉłÕ╣ČÕł░õĖ╗Õłåµö»ŃĆé
+
+### 7. Ķ¦ŻÕå│Õå▓ń¬ü
+
+ķÜÅńØƵŚČķŚ┤ńÜäµÄ©ń¦╗’╝īµłæõ╗¼ńÜäõ╗ŻńĀüÕ║ōõ╝ÜõĖŹµ¢Łµø┤µ¢░’╝īĶ┐ÖµŚČÕĆÖ’╝īÕ”éµ×£õĮĀńÜä PR õĖÄõĖ╗Õłåµö»ÕŁśÕ£©Õå▓ń¬ü’╝īõĮĀķ£ĆĶ”üĶ¦ŻÕå│Õå▓ń¬ü’╝īĶ¦ŻÕå│Õå▓ń¬üńÜäµ¢╣Õ╝ŵ£ēõĖżń¦Ź’╝Ü
+
+```shell
+git fetch --all --prune
+git rebase upstream/master
+```
+
+µł¢ĶĆģ
+
+```shell
+git fetch --all --prune
+git merge upstream/master
+```
+
+Õ”éµ×£õĮĀķØ×ÕĖĖÕ¢äõ║ÄÕżäńÉåÕå▓ń¬ü’╝īķéŻõ╣łÕÅ»õ╗źõĮ┐ńö© rebase ńÜäµ¢╣Õ╝ÅµØźĶ¦ŻÕå│Õå▓ń¬ü’╝īÕøĀõĖ║Ķ┐ÖĶāĮÕż¤õ┐ØĶ»üõĮĀńÜä commit log ńÜäµĢ┤µ┤üŃĆéÕ”éµ×£õĮĀõĖŹÕż¬ń夵éē `rebase` ńÜäõĮ┐ńö©’╝īķéŻõ╣łÕÅ»õ╗źõĮ┐ńö© `merge` ńÜäµ¢╣Õ╝ÅµØźĶ¦ŻÕå│Õå▓ń¬üŃĆé
+
+## µīćÕ╝Ģ
+
+### ÕŹĢÕģāµĄŗĶ»Ģ
+
+Õ£©µÅÉõ║żõ┐«ÕżŹõ╗ŻńĀüķöÖĶ»»µł¢µ¢░Õó×ńē╣µĆ¦ńÜäµŗēÕÅ¢Ķ»Ęµ▒鵌Ȓ╝īµłæõ╗¼Õ║öĶ»źÕ░ĮÕÅ»ĶāĮńÜäĶ«®ÕŹĢÕģāµĄŗĶ»ĢĶ”åńø¢µēƵ£ēµÅÉõ║żńÜäõ╗ŻńĀü’╝īĶ«Īń«ŚÕŹĢÕģāµĄŗĶ»ĢĶ”åńø¢ńÄćńÜäµ¢╣µ│ĢÕ”éõĖŗ
+
+```shell
+python -m coverage run -m pytest /path/to/test_file
+python -m coverage html
+# check file in htmlcov/index.html
+```
+
+### µ¢ćµĪŻµĖ▓µ¤ō
+
+Õ£©µÅÉõ║żõ┐«ÕżŹõ╗ŻńĀüķöÖĶ»»µł¢µ¢░Õó×ńē╣µĆ¦ńÜäµŗēÕÅ¢Ķ»Ęµ▒鵌Ȓ╝īÕÅ»ĶāĮõ╝Üķ£ĆĶ”üõ┐«µö╣/µ¢░Õó×µ©ĪÕØŚńÜä docstringŃĆ鵳æõ╗¼ķ£ĆĶ”üńĪ«Ķ«żµĖ▓µ¤ōÕÉÄńÜäµ¢ćµĪŻµĀĘÕ╝ŵś»µŁŻńĪ«ńÜäŃĆé
+µ£¼Õ£░ńö¤µłÉµĖ▓µ¤ōÕÉÄńÜäµ¢ćµĪŻńÜäµ¢╣µ│ĢÕ”éõĖŗ
+
+```shell
+pip install -r requirements/docs.txt
+cd docs/zh_cn/
+# or docs/en
+make html
+# check file in ./docs/zh_cn/_build/html/index.html
+```
+
+## Python õ╗ŻńĀüķŻÄµĀ╝
+
+[PEP8](https://www.python.org/dev/peps/pep-0008/) õĮ£õĖ║ OpenMMLab ń«Śµ│ĢÕ║ōķ”¢ķĆēńÜäõ╗ŻńĀüĶ¦äĶīā’╝īµłæõ╗¼õĮ┐ńö©õ╗źõĖŗÕĘźÕģʵŻĆµ¤źÕÆīµĀ╝Õ╝ÅÕī¢õ╗ŻńĀü
+
+- [flake8](https://github.com/PyCQA/flake8): Python Õ«śµ¢╣ÕÅæÕĖāńÜäõ╗ŻńĀüĶ¦äĶīāµŻĆµ¤źÕĘźÕģĘ’╝īµś»ÕżÜõĖ¬µŻĆµ¤źÕĘźÕģĘńÜäÕ░üĶŻģ
+- [isort](https://github.com/timothycrosley/isort): Ķć¬ÕŖ©Ķ░āµĢ┤µ©ĪÕØŚÕ»╝ÕģźķĪ║Õ║ÅńÜäÕĘźÕģĘ
+- [yapf](https://github.com/google/yapf): Google ÕÅæÕĖāńÜäõ╗ŻńĀüĶ¦äĶīāµŻĆµ¤źÕĘźÕģĘ
+- [codespell](https://github.com/codespell-project/codespell): µŻĆµ¤źÕŹĢĶ»Źµŗ╝ÕåÖµś»ÕÉ”µ£ēĶ»»
+- [mdformat](https://github.com/executablebooks/mdformat): µŻĆµ¤ź markdown µ¢ćõ╗ČńÜäÕĘźÕģĘ
+- [docformatter](https://github.com/myint/docformatter): µĀ╝Õ╝ÅÕī¢ docstring ńÜäÕĘźÕģĘ
+
+yapf ÕÆī isort ńÜäķģŹńĮ«ÕÅ»õ╗źÕ£© [setup.cfg](https://github.com/open-mmlab/mmengine/blob/main/setup.cfg) µēŠÕł░
+
+ķĆÜĶ┐ćķģŹńĮ« [pre-commit hook](https://pre-commit.com/) ’╝īµłæõ╗¼ÕÅ»õ╗źÕ£©µÅÉõ║żõ╗ŻńĀüµŚČĶć¬ÕŖ©µŻĆµ¤źÕÆīµĀ╝Õ╝ÅÕī¢ `flake8`ŃĆü`yapf`ŃĆü`isort`ŃĆü`trailing whitespaces`ŃĆü`markdown files`’╝īõ┐«ÕżŹ `end-of-files`ŃĆü`double-quoted-strings`ŃĆü`python-encoding-pragma`ŃĆü`mixed-line-ending`’╝īĶ░āµĢ┤ `requirments.txt` ńÜäÕīģķĪ║Õ║ÅŃĆé
+pre-commit ķÆ®ÕŁÉńÜäķģŹńĮ«ÕÅ»õ╗źÕ£© [.pre-commit-config](https://github.com/open-mmlab/mmengine/blob/main/.pre-commit-config-zh-cn.yaml) µēŠÕł░ŃĆé
+
+pre-commit ÕģĘõĮōńÜäÕ«ēĶŻģõĮ┐ńö©µ¢╣Õ╝ÅĶ¦ü[µŗēÕÅ¢Ķ»Ęµ▒é](#2-ķģŹńĮ«-pre-commit)ŃĆé
+
+µø┤ÕģĘõĮōńÜäĶ¦äĶīāĶ»ĘÕÅéĶĆā [OpenMMLab õ╗ŻńĀüĶ¦äĶīā](code_style.md)ŃĆé
+
+## µŗēÕÅ¢Ķ»Ęµ▒éĶ¦äĶīā
+
+1. õĮ┐ńö© [pre-commit hook](https://pre-commit.com)’╝īÕ░ĮķćÅÕćÅÕ░æõ╗ŻńĀüķŻÄµĀ╝ńøĖÕģ│ķŚ«ķóś
+
+2. õĖĆõĖ¬`µŗēÕÅ¢Ķ»Ęµ▒é`Õ»╣Õ║öõĖĆõĖ¬ń¤Łµ£¤Õłåµö»
+
+3. ń▓ÆÕ║”Ķ”üń╗å’╝īõĖĆõĖ¬`µŗēÕÅ¢Ķ»Ęµ▒é`ÕŬÕüÜõĖĆõ╗Čõ║ŗµāģ’╝īķü┐ÕģŹĶČģÕż¦ńÜä`µŗēÕÅ¢Ķ»Ęµ▒é`
+
+ - Bad’╝ÜÕ«×ńÄ░ Faster R-CNN
+ - Acceptable’╝Üń╗Ö Faster R-CNN µĘ╗ÕŖĀõĖĆõĖ¬ box head
+ - Good’╝Üń╗Ö box head Õó×ÕŖĀõĖĆõĖ¬ÕÅéµĢ░µØźµö»µīüĶć¬Õ«Üõ╣ēńÜä conv Õ▒éµĢ░
+
+4. µ»Åµ¼Ī Commit µŚČķ£ĆĶ”üµÅÉõŠøµĖģµÖ░õĖöµ£ēµäÅõ╣ē commit õ┐Īµü»
+
+5. µÅÉõŠøµĖģµÖ░õĖöµ£ēµäÅõ╣ēńÜä`µŗēÕÅ¢Ķ»Ęµ▒é`µÅÅĶ┐░
+
+ - µĀćķóśÕåÖµśÄńÖĮõ╗╗ÕŖĪÕÉŹń¦░’╝īõĖĆĶł¼µĀ╝Õ╝Å:\[Prefix\] Short description of the pull request (Suffix)
+ - prefix: µ¢░Õó×ÕŖ¤ĶāĮ \[Feature\], õ┐« bug \[Fix\], µ¢ćµĪŻńøĖÕģ│ \[Docs\], Õ╝ĆÕÅæõĖŁ \[WIP\] (µÜ鵌ČõĖŹõ╝ÜĶó½review)
+ - µÅÅĶ┐░ķćīõ╗ŗń╗Ź`µŗēÕÅ¢Ķ»Ęµ▒é`ńÜäõĖ╗Ķ”üõ┐«µö╣ÕåģÕ«╣’╝īń╗ōµ×£’╝īõ╗źÕÅŖÕ»╣ÕģČõ╗¢ķā©ÕłåńÜäÕĮ▒ÕōŹ, ÕÅéĶĆā`µŗēÕÅ¢Ķ»Ęµ▒é`µ©ĪµØ┐
+ - Õģ│ĶüöńøĖÕģ│ńÜä`Ķ««ķóś` (issue) ÕÆīÕģČõ╗¢`µŗēÕÅ¢Ķ»Ęµ▒é`
+
+6. Õ”éµ×£Õ╝ĢÕģźõ║åÕģČõ╗¢õĖēµ¢╣Õ║ō’╝īµł¢ÕƤķē┤õ║åõĖēµ¢╣Õ║ōńÜäõ╗ŻńĀü’╝īĶ»ĘńĪ«Ķ«żõ╗¢õ╗¼ńÜäĶ«ĖÕÅ»Ķ»üÕÆī MMEngine Õģ╝Õ«╣’╝īÕ╣ČÕ£©ÕƤķē┤ńÜäõ╗ŻńĀüõĖŖĶĪźÕģģ `This code is inspired from http://`
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/cross_library.md b/internlm_langchain/knowledge_base/MMEngine/content/cross_library.md
new file mode 100644
index 00000000..a70dc728
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/cross_library.md
@@ -0,0 +1,94 @@
+# ĶĘ©Õ║ōĶ░āńö©µ©ĪÕØŚ
+
+ķĆÜĶ┐ćõĮ┐ńö© MMEngine ńÜä[µ│©ÕåīÕÖ©’╝łRegistry’╝ē](registry.md)ÕÆī[ķģŹńĮ«µ¢ćõ╗Č’╝łConfig’╝ē](config.md)’╝īńö©µłĘÕÅ»õ╗źÕ«×ńÄ░ĶĘ©ĶĮ»õ╗ČÕīģńÜ䵩ĪÕØŚµ×äÕ╗║ŃĆé
+õŠŗÕ”é’╝īÕ£© [MMDetection](https://github.com/open-mmlab/mmdetection) õĖŁõĮ┐ńö© [MMPretrain](https://github.com/open-mmlab/mmpretrain) ńÜä Backbone’╝īµł¢ĶĆģÕ£© [MMRotate](https://github.com/open-mmlab/mmrotate) õĖŁõĮ┐ńö© [MMDetection](https://github.com/open-mmlab/mmdetection) ńÜä Transform’╝īµł¢ĶĆģÕ£© [MMTracking](https://github.com/open-mmlab/mmtracking) õĖŁõĮ┐ńö© [MMDetection](https://github.com/open-mmlab/mmdetection) ńÜä DetectorŃĆé
+õĖĆĶł¼µØźĶ»┤’╝īÕÉīń▒╗µ©ĪÕØŚķāĮÕÅ»õ╗źĶ┐øĶĪīĶĘ©Õ║ōĶ░āńö©’╝īÕŬķ£ĆĶ”üÕ£©ķģŹńĮ«µ¢ćõ╗ČńÜ䵩ĪÕØŚń▒╗Õ×ŗÕēŹÕŖĀõĖŖĶĮ»õ╗ČÕīģÕÉŹńÜäÕēŹń╝ĆÕŹ│ÕÅ»ŃĆéõĖŗķØóõĖŠÕćĀõĖ¬ÕĖĖĶ¦üńÜäõŠŗÕŁÉ’╝Ü
+
+## ĶĘ©Õ║ōĶ░āńö© Backbone:
+
+õ╗źÕ£© MMDetection õĖŁĶ░āńö© MMPretrain ńÜä ConvNeXt õĖ║õŠŗ’╝īķ”¢Õģłķ£ĆĶ”üÕ£©ķģŹńĮ«õĖŁÕŖĀÕģź `custom_imports` ÕŁŚµ«ĄÕ░å MMPretrain ńÜä Backbone µĘ╗ÕŖĀĶ┐øµ│©ÕåīÕÖ©’╝īńäČÕÉÄÕŬķ£ĆĶ”üÕ£© Backbone ńÜäķģŹńĮ«õĖŁńÜä `type` ÕŖĀõĖŖ MMPretrain ńÜäĶĮ»õ╗ČÕīģÕÉŹ `mmpretrain` õĮ£õĖ║ÕēŹń╝Ć’╝īÕŹ│ `mmpretrain.ConvNeXt` ÕŹ│ÕÅ»’╝Ü
+
+```python
+# õĮ┐ńö© custom_imports Õ░å mmpretrain ńÜä models µĘ╗ÕŖĀĶ┐øµ│©ÕåīÕÖ©
+custom_imports = dict(imports=['mmpretrain.models'], allow_failed_imports=False)
+
+model = dict(
+ type='MaskRCNN',
+ data_preprocessor=dict(...),
+ backbone=dict(
+ type='mmpretrain.ConvNeXt', # µĘ╗ÕŖĀ mmpretrain ÕēŹń╝ĆÕ«īµłÉĶĘ©Õ║ōĶ░āńö©
+ arch='tiny',
+ out_indices=[0, 1, 2, 3],
+ drop_path_rate=0.4,
+ layer_scale_init_value=1.0,
+ gap_before_final_norm=False,
+ init_cfg=dict(
+ type='Pretrained',
+ checkpoint=
+ 'https://download.openmmlab.com/mmclassification/v0/convnext/downstream/convnext-tiny_3rdparty_32xb128-noema_in1k_20220301-795e9634.pth',
+ prefix='backbone.')),
+ neck=dict(...),
+ rpn_head=dict(...))
+```
+
+## ĶĘ©Õ║ōĶ░āńö© Transform:
+
+õĖÄõĖŖµ¢ćńÜäĶĘ©Õ║ōĶ░āńö© Backbone õĖƵĀĘ’╝īõĮ┐ńö© custom_imports ÕÆīµĘ╗ÕŖĀÕēŹń╝ĆÕŹ│ÕŻի×ńÄ░ĶĘ©Õ║ōĶ░āńö©’╝Ü
+
+```python
+# õĮ┐ńö© custom_imports Õ░å mmdet ńÜä transforms µĘ╗ÕŖĀĶ┐øµ│©ÕåīÕÖ©
+custom_imports = dict(imports=['mmdet.datasets.transforms'], allow_failed_imports=False)
+
+# µĘ╗ÕŖĀ mmdet ÕēŹń╝ĆÕ«īµłÉĶĘ©Õ║ōĶ░āńö©
+train_pipeline=[
+ dict(type='mmdet.LoadImageFromFile'),
+ dict(type='mmdet.LoadAnnotations', with_bbox=True, box_type='qbox'),
+ dict(type='ConvertBoxType', box_type_mapping=dict(gt_bboxes='rbox')),
+ dict(type='mmdet.Resize', scale=(1024, 2014), keep_ratio=True),
+ dict(type='mmdet.RandomFlip', prob=0.5),
+ dict(type='mmdet.PackDetInputs')
+]
+```
+
+## ĶĘ©Õ║ōĶ░āńö© Detector:
+
+ĶĘ©Õ║ōĶ░āńö©ń«Śµ│Ģµś»õĖĆõĖ¬µ»öĶŠāÕżŹµØéńÜäõŠŗÕŁÉ’╝īõĖĆõĖ¬ń«Śµ│Ģõ╝ÜÕīģÕÉ½ÕżÜõĖ¬ÕŁÉµ©ĪÕØŚ’╝īÕøĀµŁżµ»ÅõĖ¬ÕŁÉµ©ĪÕØŚõ╣¤ķ£ĆĶ”üÕ£©`type`õĖŁÕó×ÕŖĀÕēŹń╝Ć’╝īõ╗źÕ£© MMTracking õĖŁĶ░āńö© MMDetection ńÜä YOLOX õĖ║õŠŗ’╝Ü
+
+```python
+# õĮ┐ńö© custom_imports Õ░å mmdet ńÜä models µĘ╗ÕŖĀĶ┐øµ│©ÕåīÕÖ©
+custom_imports = dict(imports=['mmdet.models'], allow_failed_imports=False)
+model = dict(
+ type='mmdet.YOLOX',
+ backbone=dict(type='mmdet.CSPDarknet', deepen_factor=1.33, widen_factor=1.25),
+ neck=dict(
+ type='mmdet.YOLOXPAFPN',
+ in_channels=[320, 640, 1280],
+ out_channels=320,
+ num_csp_blocks=4),
+ bbox_head=dict(
+ type='mmdet.YOLOXHead', num_classes=1, in_channels=320, feat_channels=320),
+ train_cfg=dict(assigner=dict(type='mmdet.SimOTAAssigner', center_radius=2.5)))
+```
+
+õĖ║õ║åķü┐ÕģŹń╗Öµ»ÅõĖ¬ÕŁÉµ©ĪÕØŚµēŗÕŖ©Õó×ÕŖĀÕēŹń╝Ć’╝īķģŹńĮ«µ¢ćõ╗ČõĖŁÕ╝ĢÕģźõ║å `_scope_` Õģ│ķö«ÕŁŚ’╝īÕĮōµ¤ÉõĖƵ©ĪÕØŚńÜäķģŹńĮ«õĖŁµĘ╗ÕŖĀõ║å `_scope_` Õģ│ķö«ÕŁŚÕÉÄ’╝īĶ»źµ©ĪÕØŚķģŹńĮ«µ¢ćõ╗ČõĖŗķØóńÜäµēƵ£ēÕŁÉµ©ĪÕØŚķģŹńĮ«ķāĮõ╝Üõ╗ÄĶ»źÕģ│ķö«ÕŁŚµēĆÕ»╣Õ║öńÜäĶĮ»õ╗ČÕīģÕåģÕÄ╗µ×äÕ╗║’╝Ü
+
+```python
+# õĮ┐ńö© custom_imports Õ░å mmdet ńÜä models µĘ╗ÕŖĀĶ┐øµ│©ÕåīÕÖ©
+custom_imports = dict(imports=['mmdet.models'], allow_failed_imports=False)
+model = dict(
+ _scope_='mmdet', # õĮ┐ńö© _scope_ Õģ│ķö«ÕŁŚ’╝īķü┐ÕģŹń╗ÖµēƵ£ēÕŁÉµ©ĪÕØŚµĘ╗ÕŖĀÕēŹń╝Ć
+ type='YOLOX',
+ backbone=dict(type='CSPDarknet', deepen_factor=1.33, widen_factor=1.25),
+ neck=dict(
+ type='YOLOXPAFPN',
+ in_channels=[320, 640, 1280],
+ out_channels=320,
+ num_csp_blocks=4),
+ bbox_head=dict(
+ type='YOLOXHead', num_classes=1, in_channels=320, feat_channels=320),
+ train_cfg=dict(assigner=dict(type='SimOTAAssigner', center_radius=2.5)))
+```
+
+õ╗źõĖŖĶ┐ÖõĖżń¦ŹÕåÖµ│Ģõ║ÆńøĖńŁēõ╗ĘŃĆé
+
+ĶŗźÕĖīµ£øõ║åĶ¦Żµø┤ÕżÜÕģ│õ║ĵ│©ÕåīÕÖ©ÕÆīķģŹńĮ«µ¢ćõ╗ČńÜäÕåģÕ«╣’╝īĶ»ĘÕÅéĶĆā[ķģŹńĮ«µ¢ćõ╗ȵĢÖń©ŗ](config.md)ÕÆī[µ│©ÕåīÕÖ©µĢÖń©ŗ](registry.md)
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/data_element.md b/internlm_langchain/knowledge_base/MMEngine/content/data_element.md
new file mode 100644
index 00000000..7574a925
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/data_element.md
@@ -0,0 +1,1098 @@
+# µŖĮĶ▒ĪµĢ░µŹ«µÄźÕÅŻ
+
+Õ£©µ©ĪÕ×ŗńÜäĶ«Łń╗ā/µĄŗĶ»ĢĶ┐ćń©ŗõĖŁ’╝īń╗äõ╗Čõ╣ŗķŚ┤ÕŠĆÕŠĆµ£ēÕż¦ķćÅńÜäµĢ░µŹ«ķ£ĆĶ”üõ╝ĀķĆÆ’╝īõĖŹÕÉīńÜäń«Śµ│Ģķ£ĆĶ”üõ╝ĀķĆÆńÜäµĢ░µŹ«ń╗ÅÕĖĖµś»õĖŹõĖƵĀĘńÜä’╝īõŠŗÕ”é’╝īĶ«Łń╗āÕŹĢķśČµ«ĄµŻĆµĄŗÕÖ©ķ£ĆĶ”üĶÄĘÕŠŚµĢ░µŹ«ķøåńÜäµĀćµ│©µĪå’╝łground truth bounding boxes’╝ēÕÆīµĀćńŁŠ’╝łground truth box labels’╝ē’╝īĶ«Łń╗ā Mask R-CNN µŚČĶ┐śķ£ĆĶ”üÕ«×õŠŗµÄ®ńĀü’╝łinstance masks’╝ēŃĆé
+Ķ«Łń╗āĶ┐Öõ║øµ©ĪÕ×ŗµŚČńÜäõ╗ŻńĀüÕ”éõĖŗµēĆńż║
+
+```python
+for img, img_metas, gt_bboxes, gt_labels in data_loader:
+ loss = retinanet(img, img_metas, gt_bboxes, gt_labels)
+```
+
+```python
+for img, img_metas, gt_bboxes, gt_masks, gt_labels in data_loader:
+ loss = mask_rcnn(img, img_metas, gt_bboxes, gt_masks, gt_labels)
+```
+
+ÕÅ»õ╗źÕÅæńÄ░’╝īÕ£©õĖŹÕŖĀÕ░üĶŻģńÜäµāģÕåĄõĖŗ’╝īõĖŹÕÉīń«Śµ│ĢµēĆķ£ĆµĢ░µŹ«ńÜäõĖŹõĖĆĶć┤Õ»╝Ķć┤õ║åõĖŹÕÉīń«Śµ│Ģµ©ĪÕØŚõ╣ŗķŚ┤µÄźÕÅŻńÜäõĖŹõĖĆĶć┤’╝īÕĮ▒ÕōŹõ║åń«Śµ│ĢÕ║ōńÜäµŗōÕ▒ĢµĆ¦’╝īÕÉīµŚČõĖĆõĖ¬ń«Śµ│ĢÕ║ōÕåģńÜ䵩ĪÕØŚõĖ║õ║åõ┐صīüÕģ╝Õ«╣µĆ¦ÕŠĆÕŠĆÕ£©µÄźÕÅŻõĖŖÕŁśÕ£©ÕåŚõĮÖŃĆé
+õĖŖĶ┐░Õ╝Ŗń½»Õ£©ń«Śµ│ĢÕ║ōõ╣ŗķŚ┤õ╝ÜõĮōńÄ░Õ£░µø┤ÕŖĀµśÄµśŠ’╝īÕ»╝Ķć┤Õ£©Õ«×ńÄ░ÕżÜõ╗╗ÕŖĪ’╝łÕÉīµŚČĶ┐øĶĪīÕ”éĶ»Łõ╣ēÕłåÕē▓ŃĆüµŻĆµĄŗŃĆüÕģ│ķö«ńé╣µŻĆµĄŗńŁēÕżÜõĖ¬õ╗╗ÕŖĪ’╝ēµä¤ń¤źµ©ĪÕ×ŗµŚČµ©ĪÕØŚķÜŠõ╗źÕżŹńö©’╝īµÄźÕÅŻķÜŠõ╗źµŗōÕ▒ĢŃĆé
+
+õĖ║õ║åĶ¦ŻÕå│õĖŖĶ┐░ķŚ«ķóś’╝īMMEngine Õ«Üõ╣ēõ║åõĖĆÕźŚµŖĮĶ▒ĪńÜäµĢ░µŹ«µÄźÕÅŻµØźÕ░üĶŻģµ©ĪÕ×ŗĶ┐ÉĶĪīĶ┐ćń©ŗõĖŁńÜäÕÉäń¦ŹµĢ░µŹ«ŃĆéÕüćĶ«ŠÕ░åõĖŖĶ┐░õĖŹÕÉīńÜäµĢ░µŹ«Õ░üĶŻģĶ┐ø `data_sample` ’╝īõĖŹÕÉīń«Śµ│ĢńÜäĶ«Łń╗āķāĮÕÅ»õ╗źĶó½µŖĮĶ▒ĪÕÆīń╗¤õĖƵłÉÕ”éõĖŗõ╗ŻńĀü
+
+```python
+for img, data_sample in dataloader:
+ loss = model(img, data_sample)
+```
+
+ķĆÜĶ┐ćÕ»╣ÕÉäń¦ŹµĢ░µŹ«µÅÉõŠøń╗¤õĖĆńÜäÕ░üĶŻģ’╝īµŖĮĶ▒ĪµĢ░µŹ«µÄźÕÅŻń╗¤õĖĆÕ╣Čń«ĆÕī¢õ║åń«Śµ│ĢÕ║ōõĖŁÕÉäõĖ¬µ©ĪÕØŚńÜäµÄźÕÅŻ’╝īÕÅ»õ╗źĶó½ńö©õ║Äń«Śµ│ĢÕ║ōõĖŁ dataset’╝īmodel’╝īvisualizer’╝īÕÆī evaluator ń╗äõ╗Čõ╣ŗķŚ┤’╝īµł¢ĶĆģ model ÕåģÕÉäõĖ¬µ©ĪÕØŚõ╣ŗķŚ┤ńÜäµĢ░µŹ«õ╝ĀķĆÆŃĆé
+µŖĮĶ▒ĪµĢ░µŹ«µÄźÕÅŻÕ«×ńÄ░õ║åÕ¤║µ£¼ńÜäÕó×/ÕłĀ/µö╣/µ¤źÕŖ¤ĶāĮ’╝īÕÉīµŚČµö»µīüõĖŹÕÉīĶ«ŠÕżćõ╣ŗķŚ┤ńÜäĶ┐üń¦╗’╝īµö»µīüń▒╗ÕŁŚÕģĖÕÆīÕ╝ĀķćÅńÜäµōŹõĮ£’╝īÕÅ»õ╗źÕģģÕłåµ╗ĪĶČ│ń«Śµ│ĢÕ║ōÕ»╣õ║ÄĶ┐Öõ║øµĢ░µŹ«ńÜäõĮ┐ńö©Ķ”üµ▒éŃĆé
+Õ¤║õ║Ä MMEngine ńÜäń«Śµ│ĢÕ║ōÕÅ»õ╗źń╗¦µē┐Ķ┐ÖÕźŚµŖĮĶ▒ĪµĢ░µŹ«µÄźÕÅŻÕ╣ČÕ«×ńÄ░Ķć¬ÕĘ▒ńÜäµŖĮĶ▒ĪµĢ░µŹ«µÄźÕÅŻµØźķĆéÕ║öõĖŹÕÉīń«Śµ│ĢõĖŁµĢ░µŹ«ńÜäńē╣ńé╣õĖÄÕ«×ķÖģķ£ĆĶ”ü’╝īÕ£©õ┐صīüń╗¤õĖƵğÕÅŻńÜäÕÉīµŚČµÅÉķ½śõ║åń«Śµ│Ģµ©ĪÕØŚńÜäµŗōÕ▒ĢµĆ¦ŃĆé
+
+Õ£©Õ«×ķÖģÕ«×ńÄ░Ķ┐ćń©ŗõĖŁ’╝īń«Śµ│ĢÕ║ōõĖŁńÜäÕÉäõĖ¬ń╗äõ╗ȵēĆÕģĘÕżćńÜäµĢ░µŹ«µÄźÕÅŻ’╝īõĖĆĶł¼õĖ║õ╗źõĖŗõĖżń¦Ź’╝Ü
+
+- õĖĆõĖ¬Ķ«Łń╗āµł¢µĄŗĶ»ĢµĀʵ£¼’╝łõŠŗÕ”éõĖĆÕ╝ĀÕøŠÕāÅ’╝ēńÜäµēƵ£ēńÜäµĀćµ│©õ┐Īµü»ÕÆīķó䵥ŗõ┐Īµü»ńÜäķøåÕÉł’╝īõŠŗÕ”éµĢ░µŹ«ķøåńÜäĶŠōÕć║ŃĆüµ©ĪÕ×ŗõ╗źÕÅŖÕÅ»Ķ¦åÕī¢ÕÖ©ńÜäĶŠōÕģźõĖĆĶł¼õĖ║ÕŹĢõĖ¬Ķ«Łń╗āµł¢µĄŗĶ»ĢµĀʵ£¼ńÜäµēƵ£ēõ┐Īµü»ŃĆéMMEngine Õ░åÕģČÕ«Üõ╣ēõĖ║µĢ░µŹ«µĀʵ£¼’╝łDataSample’╝ē
+- ÕŹĢõĖĆń▒╗Õ×ŗńÜäķó䵥ŗµł¢µĀćµ│©’╝īõĖĆĶł¼µś»ń«Śµ│Ģµ©ĪÕ×ŗõĖŁµ¤ÉõĖ¬ÕŁÉµ©ĪÕØŚńÜäĶŠōÕć║, õŠŗÕ”éõ║īķśČµ«ĄµŻĆµĄŗõĖŁRPNńÜäĶŠōÕć║ŃĆüĶ»Łõ╣ēÕłåÕē▓µ©ĪÕ×ŗńÜäĶŠōÕć║ŃĆüÕģ│ķö«ńé╣Õłåµö»ńÜäĶŠōÕć║’╝īGANõĖŁńö¤µłÉÕÖ©ńÜäĶŠōÕć║ńŁēŃĆéMMEngine Õ░åÕģČÕ«Üõ╣ēõĖ║µĢ░µŹ«Õģāń┤Ā’╝łXXXData’╝ē
+
+õĖŗĶŠ╣ķ”¢Õģłõ╗ŗń╗ŹõĖĆõĖŗµĢ░µŹ«µĀʵ£¼õĖĵĢ░µŹ«Õģāń┤ĀńÜäÕ¤║ń▒╗ [BaseDataElement](mmengine.structures.BaseDataElement)ŃĆé
+
+## µĢ░µŹ«Õ¤║ń▒╗(BaseDataElement)
+
+`BaseDataElement` õĖŁÕŁśÕ£©õĖżń¦Źń▒╗Õ×ŗńÜäµĢ░µŹ«’╝īõĖĆń¦Źµś» `data` ń▒╗Õ×ŗ’╝īÕ”éµĀćµ│©µĪåŃĆüµĪåńÜäµĀćńŁŠŃĆüÕÆīÕ«×õŠŗµÄ®ńĀüńŁē’╝øÕÅ”õĖĆń¦Źµś» `metainfo` ń▒╗Õ×ŗ’╝īÕīģÕɽµĢ░µŹ«ńÜäÕģāõ┐Īµü»õ╗źńĪ«õ┐صĢ░µŹ«ńÜäÕ«īµĢ┤µĆ¦’╝īÕ”é `img_shape`, `img_id` ńŁēµĢ░µŹ«µēĆÕ£©ÕøŠńēćńÜäõĖĆõ║øÕ¤║µ£¼õ┐Īµü»’╝īµ¢╣õŠ┐ÕÅ»Ķ¦åÕī¢ńŁēµāģÕåĄõĖŗÕ»╣µĢ░µŹ«Ķ┐øĶĪīµüóÕżŹÕÆīõĮ┐ńö©ŃĆéńö©µłĘÕ£©ÕłøÕ╗║ `BaseDataElement` ńÜäĶ┐ćń©ŗõĖŁķ£ĆĶ”üÕ»╣Ķ┐ÖõĖżń▒╗Õ▒׵ƦńÜäµĢ░µŹ«Ķ┐øĶĪīµśŠÕ╝ÅÕ£░Õī║ÕłåÕÆīÕŻ░µśÄŃĆé
+
+õĖ║õ║åĶāĮÕż¤µø┤ÕŖĀµ¢╣õŠ┐Õ£░õĮ┐ńö© `BaseDataElement`’╝ī`data` ÕÆī `metainfo` õĖŁńÜäµĢ░µŹ«ÕØćõĖ║ `BaseDataElement` ńÜäÕ▒׵ƦŃĆ鵳æõ╗¼ÕÅ»õ╗źķĆÜĶ┐ćĶ«┐ķŚ«ń▒╗Õ▒׵ƦńÜäµ¢╣Õ╝Åńø┤µÄźĶ«┐ķŚ« `data` ÕÆī `metainfo` õĖŁńÜäµĢ░µŹ«ŃĆ鵣żÕż¢’╝ī`BaseDataElement` Ķ┐śµÅÉõŠøõ║åÕŠłÕżÜµ¢╣µ│Ģ’╝īµ¢╣õŠ┐µłæõ╗¼µōŹõĮ£ `data` ÕåģńÜäµĢ░µŹ«’╝Ü
+
+- Õó×/ÕłĀ/µö╣/µ¤ź `data` õĖŁõĖŹÕÉīÕŁŚµ«ĄńÜäµĢ░µŹ«
+- Õ░å `data` Ķ┐üń¦╗Ķć│ńø«µĀćĶ«ŠÕżć
+- µö»µīüÕāÅĶ«┐ķŚ«ÕŁŚÕģĖ/Õ╝ĀķćÅõĖƵĀĘĶ«┐ķŚ« data ÕåģńÜäµĢ░µŹ«õ╗źÕģģÕłåµ╗ĪĶČ│ń«Śµ│ĢÕ║ōÕ»╣õ║ÄĶ┐Öõ║øµĢ░µŹ«ńÜäõĮ┐ńö©Ķ”üµ▒éŃĆé
+
+### 1. µĢ░µŹ«Õģāń┤ĀńÜäÕłøÕ╗║
+
+`BaseDataElement` ńÜä data ÕÅéµĢ░ÕÅ»õ╗źńø┤µÄźķĆÜĶ┐ć `key=value` ńÜäµ¢╣Õ╝ÅĶć¬ńö▒µĘ╗ÕŖĀ’╝īmetainfo ńÜäÕŁŚµ«Ąķ£ĆĶ”üµśŠÕ╝ÅķĆÜĶ┐ćÕģ│ķö«ÕŁŚ `metainfo` µīćÕ«ÜŃĆé
+
+```python
+import torch
+from mmengine.structures import BaseDataElement
+# ÕÅ»õ╗źÕŻ░µśÄõĖĆõĖ¬ń®║ńÜä object
+data_element = BaseDataElement()
+
+bboxes = torch.rand((5, 4)) # ÕüćÕ«Ü bboxes µś»õĖĆõĖ¬ Nx4 ń╗┤ńÜä tensor’╝īN õ╗ŻĶĪ©µĪåńÜäõĖ¬µĢ░
+scores = torch.rand((5,)) # ÕüćիܵĪåńÜäÕłåµĢ░µś»õĖĆõĖ¬ N ń╗┤ńÜä tensor’╝īN õ╗ŻĶĪ©µĪåńÜäõĖ¬µĢ░
+img_id = 0 # ÕøŠÕāÅńÜä ID
+H = 800 # ÕøŠÕāÅńÜäķ½śÕ║”
+W = 1333 # ÕøŠÕāÅńÜäÕ«ĮÕ║”
+
+# ńø┤µÄźĶ«ŠńĮ« BaseDataElement ńÜä data ÕÅéµĢ░
+data_element = BaseDataElement(bboxes=bboxes, scores=scores)
+
+# µśŠÕ╝ÅÕŻ░µśÄµØźĶ«ŠńĮ« BaseDataElement ńÜäÕÅéµĢ░ metainfo
+data_element = BaseDataElement(
+ bboxes=bboxes,
+ scores=scores,
+ metainfo=dict(img_id=img_id, img_shape=(H, W)))
+```
+
+### 2. `new` õĖÄ `clone` ÕćĮµĢ░
+
+ńö©µłĘÕÅ»õ╗źõĮ┐ńö© `new()` µ¢╣µ│ĢÕ¤║õ║ÄÕĘ▓µ£ēńÜä `BaseDataElement` ÕłøÕ╗║õĖĆõĖ¬Õģʵ£ēńøĖÕÉī `data` ÕÆī `metainfo` ńÜä `BaseDataElement`ŃĆéńö©µłĘõ╣¤ÕÅ»õ╗źÕ£©Ķ░āńö© `new` µ¢╣µ│ĢµŚČõ╝ĀÕģźµ¢░ńÜä `data` ÕÆī `metainfo`’╝īõŠŗÕ”é `new(metainfo=xx)` ’╝īµŁżµŚČÕłøÕ╗║ńÜä `BaseDataElement` ńøĖĶŠāõ║ÄÕĘ▓µ£ēńÜä `BaseDataElement`’╝ī`data` Õ«īÕģ©õĖĆĶć┤ ’╝īĶĆī `metainfo` ÕłÖõĖ║µ¢░Ķ«ŠńĮ«ńÜäÕåģÕ«╣ŃĆé
+õ╣¤ÕÅ»õ╗źńø┤µÄźõĮ┐ńö© `clone()` µØźĶÄĘÕŠŚõĖĆõ╗ĮµĘ▒µŗĘĶ┤Ø’╝ī`clone()` ÕćĮµĢ░ńÜäĶĪīõĖ║õĖÄ PyTorch õĖŁ Tensor ńÜä `clone()` ÕÅéµĢ░õ┐صīüõĖĆĶć┤ŃĆé
+
+```python
+data_element = BaseDataElement(
+ bboxes=torch.rand((5, 4)),
+ scores=torch.rand((5,)),
+ metainfo=dict(img_id=1, img_shape=(640, 640)))
+
+# ÕÅ»õ╗źÕ£©ÕłøÕ╗║µ¢░ `BaseDataElement` µŚČĶ«ŠńĮ« metainfo ÕÆī data’╝īõĮ┐ÕŠŚµ¢░ńÜä BaseDataElement µ£ēńøĖÕÉīµ£¬Ķó½Ķ«ŠńĮ«ńÜäµĢ░µŹ«
+data_element1 = data_element.new(metainfo=dict(img_id=2, img_shape=(320, 320)))
+print('bboxes is in data_element1:', 'bboxes' in data_element1) # True
+print('bboxes in data_element1 is same as bbox in data_element', (data_element1.bboxes == data_element.bboxes).all())
+print('img_id in data_element1 is', data_element1.img_id == 2) # True
+
+data_element2 = data_element.new(label=torch.rand(5,))
+print('bboxes is not in data_element2', 'bboxes' not in data_element2) # True
+print('img_id in data_element2 is same as img_id in data_element', data_element2.img_id == data_element.img_id)
+print('label in data_element2 is', 'label' in data_element2)
+
+# õ╣¤ÕÅ»õ╗źķĆÜĶ┐ć `clone` µ×äÕ╗║õĖĆõĖ¬µ¢░ńÜä object’╝īµ¢░ńÜä object õ╝ܵŗźµ£ēÕÆī data_element ńøĖÕÉīńÜä data ÕÆī metainfo ÕåģÕ«╣õ╗źÕÅŖńŖȵĆüŃĆé
+data_element2 = data_element1.clone()
+```
+
+```
+bboxes is in data_element1: True
+bboxes in data_element1 is same as bbox in data_element tensor(True)
+img_id in data_element1 is True
+bboxes is not in data_element2 True
+img_id in data_element2 is same as img_id in data_element True
+label in data_element2 is True
+```
+
+### 3. Õ▒׵ƦńÜäÕó×ÕŖĀõĖĵ¤źĶ»ó
+
+Õ»╣Õó×ÕŖĀÕ▒׵ƦĶĆīĶ©Ć’╝īńö©µłĘÕÅ»õ╗źÕāÅÕó×ÕŖĀń▒╗Õ▒׵Ʀķ鯵ĀĘÕó×ÕŖĀ `data` ÕåģńÜäÕ▒׵Ʀ’╝øÕ»╣ `metainfo` ĶĆīĶ©Ć’╝īõĖĆĶł¼Õé©ÕŁśńÜäõĖ║õĖĆõ║øÕøŠÕāÅńÜäÕģāõ┐Īµü»’╝īõĖĆĶł¼µāģÕåĄõĖŗõĖŹõ╝Üõ┐«µö╣’╝īÕ”éµ×£ķ£ĆĶ”üÕó×ÕŖĀ’╝īńö©µłĘÕ║öÕĮōõĮ┐ńö© `set_metainfo` µÄźÕÅŻµśŠńż║Õ£░õ┐«µö╣ŃĆé
+
+Õ»╣µ¤źĶ»óĶĆīĶ©Ć’╝īńö©µłĘÕÅ»õ╗źÕÅ»õ╗źķĆÜĶ┐ć `keys`’╝ī`values`’╝īÕÆī `items` µØźĶ«┐ķŚ«ÕÅ¬ÕŁśÕ£©õ║Ä data õĖŁńÜäķö«ÕĆ╝’╝īõ╣¤ÕÅ»õ╗źķĆÜĶ┐ć `metainfo_keys`’╝ī`metainfo_values`’╝īÕÆī`metainfo_items` µØźĶ«┐ķŚ«ÕÅ¬ÕŁśÕ£©õ║Ä metainfo õĖŁńÜäķö«ÕĆ╝ŃĆé
+ńö©µłĘĶ┐śĶāĮķĆÜĶ┐ć `all_keys`’╝ī`all_values`’╝ī `all_items` µØźĶ«┐ķŚ« `BaseDataElement` ńÜäµēƵ£ēńÜäÕ▒׵ƦÕ╣ČõĖöõĖŹÕī║Õłåõ╗¢õ╗¼ńÜäń▒╗Õ×ŗŃĆé
+
+ÕÉīµŚČõĖ║õ║åµ¢╣õŠ┐õĮ┐ńö©’╝īńö©µłĘÕÅ»õ╗źÕāÅĶ«┐ķŚ«ń▒╗Õ▒׵ƦõĖƵĀĘĶ«┐ķŚ« data õĖÄ metainfo ÕåģńÜäµĢ░µŹ«’╝īµł¢ńØĆń▒╗ÕŁŚÕģĖµ¢╣Õ╝ÅķĆÜĶ┐ć `get()` µÄźÕÅŻĶ«┐ķŚ«µĢ░µŹ«ŃĆé
+
+**µ│©µäÅ’╝Ü**
+
+1. `BaseDataElement` õĖŹµö»µīü metainfo ÕÆī data Õ▒׵ƦõĖŁµ£ēÕÉīÕÉŹńÜäÕŁŚµ«Ą’╝īµēĆõ╗źńö©µłĘÕ║öÕĮōķü┐ÕģŹ metainfo ÕÆī data Õ▒׵ƦõĖŁĶ«ŠńĮ«ńøĖÕÉīńÜäÕŁŚµ«Ą’╝īÕÉ”ÕłÖ `BaseDataElement` õ╝ܵŖźķöÖŃĆé
+2. ĶĆāĶÖæÕł░ `InstanceData` ÕÆī `PixelData` µö»µīüÕ»╣µĢ░µŹ«Ķ┐øĶĪīÕłćńēćµōŹõĮ£’╝īõĖ║õ║åķü┐ÕģŹ `[]` ńö©µ│ĢńÜäõĖŹõĖĆĶć┤’╝īÕÉīµŚČÕćÅÕ░æÕÉīń¦Źķ£Ćµ▒éńÜäõĖŹÕÉīµ¢╣µ│Ģ’╝ī`BaseDataElement` õĖŹµö»µīüÕāÅÕŁŚÕģĖķ鯵ĀĘĶ«┐ķŚ«ÕÆīĶ«ŠńĮ«Õ«āńÜäÕ▒׵Ʀ’╝īµēĆõ╗źń▒╗õ╝╝ `BaseDataElement[name]` ńÜäÕÅ¢ÕĆ╝ĶĄŗÕĆ╝µōŹõĮ£µś»õĖŹĶó½µö»µīüńÜäŃĆé
+
+```python
+data_element = BaseDataElement()
+# ķĆÜĶ┐ć `set_metainfo`Ķ«ŠńĮ« data_element ńÜä metainfo ÕŁŚµ«Ą’╝ī
+# ÕÉīµŚČ img_id ÕÆī img_shape µłÉõĖ║ data_element ńÜäÕ▒׵Ʀ
+data_element.set_metainfo(dict(img_id=9, img_shape=(100, 100)))
+# µ¤źń£ŗ metainfo ńÜä key, value ÕÆī item
+print("metainfo'keys are", data_element.metainfo_keys())
+print("metainfo'values are", data_element.metainfo_values())
+for k, v in data_element.metainfo_items():
+ print(f'{k}: {v}')
+
+print("ķĆÜĶ┐ćń▒╗Õ▒׵Ʀµ¤źń£ŗ img_id ÕÆī img_shape")
+print('img_id:', data_element.img_id)
+print('img_shape:', data_element.img_shape)
+```
+
+```
+metainfo'keys are ['img_id', 'img_shape']
+metainfo'values are [9, (100, 100)]
+img_id: 9
+img_shape: (100, 100)
+ķĆÜĶ┐ćń▒╗Õ▒׵Ʀµ¤źń£ŗ img_id ÕÆī img_shape
+img_id: 9
+img_shape: (100, 100)
+```
+
+```python
+
+# ķĆÜĶ┐ćń▒╗Õ▒׵Ʀńø┤µÄźĶ«ŠńĮ« BaseDataElement õĖŁńÜä data ÕŁŚµ«Ą
+data_element.scores = torch.rand((5,))
+data_element.bboxes = torch.rand((5, 4))
+
+print("data's key is:", data_element.keys())
+print("data's value is:", data_element.values())
+for k, v in data_element.items():
+ print(f'{k}: {v}')
+
+print("ķĆÜĶ┐ćń▒╗Õ▒׵Ʀµ¤źń£ŗ scores ÕÆī bboxes")
+print('scores:', data_element.scores)
+print('bboxes:', data_element.bboxes)
+
+print("ķĆÜĶ┐ć get() µ¤źń£ŗ scores ÕÆī bboxes")
+print('scores:', data_element.get('scores', None))
+print('bboxes:', data_element.get('bboxes', None))
+print('fake:', data_element.get('fake', 'not exist'))
+```
+
+```
+data's key is: ['scores', 'bboxes']
+data's value is: [tensor([0.7937, 0.6307, 0.3682, 0.4425, 0.8515]), tensor([[0.9204, 0.2110, 0.2886, 0.7925],
+ [0.7993, 0.8982, 0.5698, 0.4120],
+ [0.7085, 0.7016, 0.3069, 0.3216],
+ [0.0206, 0.5253, 0.1376, 0.9322],
+ [0.2512, 0.7683, 0.3010, 0.2672]])]
+scores: tensor([0.7937, 0.6307, 0.3682, 0.4425, 0.8515])
+bboxes: tensor([[0.9204, 0.2110, 0.2886, 0.7925],
+ [0.7993, 0.8982, 0.5698, 0.4120],
+ [0.7085, 0.7016, 0.3069, 0.3216],
+ [0.0206, 0.5253, 0.1376, 0.9322],
+ [0.2512, 0.7683, 0.3010, 0.2672]])
+ķĆÜĶ┐ćń▒╗Õ▒׵Ʀµ¤źń£ŗ scores ÕÆī bboxes
+scores: tensor([0.7937, 0.6307, 0.3682, 0.4425, 0.8515])
+bboxes: tensor([[0.9204, 0.2110, 0.2886, 0.7925],
+ [0.7993, 0.8982, 0.5698, 0.4120],
+ [0.7085, 0.7016, 0.3069, 0.3216],
+ [0.0206, 0.5253, 0.1376, 0.9322],
+ [0.2512, 0.7683, 0.3010, 0.2672]])
+ķĆÜĶ┐ć get() µ¤źń£ŗ scores ÕÆī bboxes
+scores: tensor([0.7937, 0.6307, 0.3682, 0.4425, 0.8515])
+bboxes: tensor([[0.9204, 0.2110, 0.2886, 0.7925],
+ [0.7993, 0.8982, 0.5698, 0.4120],
+ [0.7085, 0.7016, 0.3069, 0.3216],
+ [0.0206, 0.5253, 0.1376, 0.9322],
+ [0.2512, 0.7683, 0.3010, 0.2672]])
+fake: not exist
+```
+
+```python
+
+print("All key in data_element is:", data_element.all_keys())
+print("The length of values in data_element is", len(data_element.all_values()))
+for k, v in data_element.all_items():
+ print(f'{k}: {v}')
+```
+
+```
+All key in data_element is: ['img_id', 'img_shape', 'scores', 'bboxes']
+The length of values in data_element is 4
+img_id: 9
+img_shape: (100, 100)
+scores: tensor([0.7937, 0.6307, 0.3682, 0.4425, 0.8515])
+bboxes: tensor([[0.9204, 0.2110, 0.2886, 0.7925],
+ [0.7993, 0.8982, 0.5698, 0.4120],
+ [0.7085, 0.7016, 0.3069, 0.3216],
+ [0.0206, 0.5253, 0.1376, 0.9322],
+ [0.2512, 0.7683, 0.3010, 0.2672]])
+```
+
+### 4. Õ▒׵ƦńÜäÕłĀµö╣
+
+ńö©µłĘÕÅ»õ╗źÕāÅõ┐«µö╣Õ«×õŠŗÕ▒׵ƦõĖƵĀĘõ┐«µö╣ `BaseDataElement` ńÜä `data`, Õ»╣`metainfo` ĶĆīĶ©Ć’╝īõĖĆĶł¼Õé©ÕŁśńÜäõĖ║õĖĆõ║øÕøŠÕāÅńÜäÕģāõ┐Īµü»’╝īõĖĆĶł¼µāģÕåĄõĖŗõĖŹõ╝Üõ┐«µö╣’╝īÕ”éµ×£ķ£ĆĶ”üõ┐«µö╣’╝īńö©µłĘÕ║öÕĮōõĮ┐ńö© `set_metainfo` µÄźÕÅŻµśŠńż║ńÜäõ┐«µö╣ŃĆé
+
+ÕÉīµŚČõĖ║õ║åµōŹõĮ£ńÜäõŠ┐µŹĘµĆ¦’╝īÕ»╣ `data` ÕÆī `metainfo` õĖŁńÜäµĢ░µŹ«ÕÅ»õ╗źķĆÜĶ┐ć `del` ńø┤µÄźÕłĀķÖż’╝īõ╣¤µö»µīü `pop` Õ£©Ķ«┐ķŚ«Õ▒׵ƦÕÉÄÕłĀķÖżÕ▒׵ƦŃĆé
+
+```python
+data_element = BaseDataElement(
+ bboxes=torch.rand((6, 4)), scores=torch.rand((6,)),
+ metainfo=dict(img_id=0, img_shape=(640, 640))
+)
+for k, v in data_element.all_items():
+ print(f'{k}: {v}')
+```
+
+```
+img_id: 0
+img_shape: (640, 640)
+scores: tensor([0.8445, 0.6678, 0.8172, 0.9125, 0.7186, 0.5462])
+bboxes: tensor([[0.5773, 0.0289, 0.4793, 0.7573],
+ [0.8187, 0.8176, 0.3455, 0.3368],
+ [0.6947, 0.5592, 0.7285, 0.0281],
+ [0.7710, 0.9867, 0.7172, 0.5815],
+ [0.3999, 0.9192, 0.7817, 0.2535],
+ [0.2433, 0.0132, 0.1757, 0.6196]])
+```
+
+```python
+# Õ»╣ data Ķ┐øĶĪīõ┐«µö╣
+data_element.bboxes = data_element.bboxes * 2
+data_element.scores = data_element.scores * -1
+for k, v in data_element.items():
+ print(f'{k}: {v}')
+
+# ÕłĀķÖż data õĖŁńÜäÕ▒׵Ʀ
+del data_element.bboxes
+for k, v in data_element.items():
+ print(f'{k}: {v}')
+
+data_element.pop('scores', None)
+print('The keys in data is', data_element.keys())
+```
+
+```
+scores: tensor([-0.8445, -0.6678, -0.8172, -0.9125, -0.7186, -0.5462])
+bboxes: tensor([[1.1546, 0.0578, 0.9586, 1.5146],
+ [1.6374, 1.6352, 0.6911, 0.6735],
+ [1.3893, 1.1185, 1.4569, 0.0562],
+ [1.5420, 1.9734, 1.4344, 1.1630],
+ [0.7999, 1.8384, 1.5635, 0.5070],
+ [0.4867, 0.0264, 0.3514, 1.2392]])
+scores: tensor([-0.8445, -0.6678, -0.8172, -0.9125, -0.7186, -0.5462])
+The keys in data is []
+```
+
+```python
+# Õ»╣ metainfo Ķ┐øĶĪīõ┐«µö╣
+data_element.set_metainfo(dict(img_shape = (1280, 1280), img_id=10))
+print(data_element.img_shape) # (1280, 1280)
+for k, v in data_element.metainfo_items():
+ print(f'{k}: {v}')
+
+# µÅÉõŠøõ║åõŠ┐µŹĘńÜäÕ▒×µĆ¦ÕłĀķÖżÕÆīĶ«┐ķŚ«µōŹõĮ£ pop
+del data_element.img_shape
+for k, v in data_element.metainfo_items():
+ print(f'{k}: {v}')
+
+data_element.pop('img_id')
+print('The keys in metainfo is', data_element.metainfo_keys())
+```
+
+```
+(1280, 1280)
+img_id: 10
+img_shape: (1280, 1280)
+img_id: 10
+The keys in metainfo is []
+```
+
+### 5. ń▒╗Õ╝ĀķćŵōŹõĮ£
+
+ńö©µłĘÕÅ»õ╗źÕāÅ torch.Tensor ķ鯵ĀĘÕ»╣ `BaseDataElement` ńÜä data Ķ┐øĶĪīńŖȵĆüĶĮ¼µŹó’╝īńø«ÕēŹµö»µīü `cuda`’╝ī `cpu`’╝ī `to`’╝ī `numpy` ńŁēµōŹõĮ£ŃĆé
+ÕģČõĖŁ’╝ī`to` ÕćĮµĢ░µŗźµ£ēÕÆī `torch.Tensor.to()` ńøĖÕÉīńÜäµÄźÕÅŻ’╝īõĮ┐ÕŠŚńö©µłĘÕÅ»õ╗źńüĄµ┤╗Õ£░Õ░åĶó½Õ░üĶŻģńÜä tensor Ķ┐øĶĪīńŖȵĆüĶĮ¼µŹóŃĆé
+**µ│©µäÅ’╝Ü** Ķ┐Öõ║øµÄźÕÅŻÕŬõ╝ÜÕżäńÉåń▒╗Õ×ŗõĖ║ np.array’╝ītorch.Tensor’╝īµł¢ĶĆģµĢ░ÕŁŚńÜäÕ║ÅÕłŚ’╝īÕģČõ╗¢Õ▒׵ƦńÜäµĢ░µŹ«’╝łÕ”éÕŁŚń¼”õĖ▓’╝ēõ╝ÜĶó½ĶĘ│Ķ┐ćÕżäńÉåŃĆé
+
+```python
+data_element = BaseDataElement(
+ bboxes=torch.rand((6, 4)), scores=torch.rand((6,)),
+ metainfo=dict(img_id=0, img_shape=(640, 640))
+)
+# Õ░åµēƵ£ē data ĶĮ¼ń¦╗Õł░ GPU õĖŖ
+cuda_element_1 = data_element.cuda()
+print('cuda_element_1 is on the device of', cuda_element_1.bboxes.device) # cuda:0
+cuda_element_2 = data_element.to('cuda:0')
+print('cuda_element_1 is on the device of', cuda_element_2.bboxes.device) # cuda:0
+
+# Õ░åµēƵ£ē data ĶĮ¼ń¦╗Õł░ cpu õĖŖ
+cpu_element_1 = cuda_element_1.cpu()
+print('cpu_element_1 is on the device of', cpu_element_1.bboxes.device) # cpu
+cpu_element_2 = cuda_element_2.to('cpu')
+print('cpu_element_2 is on the device of', cpu_element_2.bboxes.device) # cpu
+
+# Õ░åµēƵ£ē data ÕÅśµłÉ FP16
+fp16_instances = cuda_element_1.to(
+ device=None, dtype=torch.float16, non_blocking=False, copy=False,
+ memory_format=torch.preserve_format)
+print('The type of bboxes in fp16_instances is', fp16_instances.bboxes.dtype) # torch.float16
+
+# ķś╗µ¢ŁµēƵ£ē data ńÜäµó»Õ║”
+cuda_element_3 = cuda_element_2.detach()
+print('The data in cuda_element_3 requires grad: ', cuda_element_3.bboxes.requires_grad)
+# ĶĮ¼ń¦╗ data Õł░ numpy array
+np_instances = cpu_element_1.numpy()
+print('The type of cpu_element_1 is convert to', type(np_instances.bboxes))
+```
+
+```
+cuda_element_1 is on the device of cuda:0
+cuda_element_1 is on the device of cuda:0
+cpu_element_1 is on the device of cpu
+cpu_element_2 is on the device of cpu
+The type of bboxes in fp16_instances is torch.float16
+The data in cuda_element_3 requires grad: False
+The type of cpu_element_1 is convert to
+```
+
+### 6. Õ▒׵ƦńÜäÕ▒Ģńż║
+
+`BaseDataElement` Ķ┐śÕ«×ńÄ░õ║å `__repr__`’╝īÕøĀµŁż’╝īńö©µłĘÕÅ»õ╗źńø┤µÄźķĆÜĶ┐ć `print` ÕćĮµĢ░ń£ŗÕł░ÕģČõĖŁńÜäµēƵ£ēµĢ░µŹ«õ┐Īµü»ŃĆé
+ÕÉīµŚČ’╝īõĖ║õ║åõŠ┐µŹĘÕ╝ĆÕÅæĶĆģ debug’╝ī`BaseDataElement` õĖŁńÜäÕ▒׵ƦķāĮõ╝ܵĘ╗ÕŖĀĶ┐ø `__dict__` õĖŁ’╝īµ¢╣õŠ┐ńö©µłĘÕ£© IDE ńĢīķØóÕÅ»õ╗źńø┤Ķ¦éń£ŗÕł░ `BaseDataElement` õĖŁńÜäÕåģÕ«╣ŃĆé
+õĖĆõĖ¬Õ«īµĢ┤ńÜäÕ▒׵ƦÕ▒Ģńż║Õ”éõĖŗ
+
+```python
+img_meta = dict(img_shape=(800, 1196, 3), pad_shape=(800, 1216, 3))
+instance_data = BaseDataElement(metainfo=img_meta)
+instance_data.det_labels = torch.LongTensor([0, 1, 2, 3])
+instance_data.det_scores = torch.Tensor([0.01, 0.1, 0.2, 0.3])
+print(instance_data)
+```
+
+```
+
+```
+
+## µĢ░µŹ«Õģāń┤Ā(xxxData)
+
+MMEngine Õ░åµĢ░µŹ«Õģāń┤ĀµāģÕåĄÕłÆÕłåõĖ║õĖēõĖ¬ń▒╗Õł½’╝Ü
+
+- Õ«×õŠŗµĢ░µŹ« (InstanceData) : õĖ╗Ķ”üķÆłÕ»╣ńÜ䵜»õĖŖÕ▒éõ╗╗ÕŖĪ (high-level) õĖŁ’╝īÕ»╣ÕøŠÕāÅõĖŁµēƵ£ēÕ«×õŠŗńøĖÕģ│ńÜäµĢ░µŹ«Ķ┐øĶĪīÕ░üĶŻģ’╝īµ»öÕ”éµŻĆµĄŗµĪå (bounding boxes)’╝īńē®õĮōń▒╗Õł½ (box labels)’╝īÕ«×õŠŗµÄ®ńĀü (instance masks)’╝īÕģ│ķö«ńé╣ (key points)’╝īµ¢ćÕŁŚĶŠ╣ńĢī (polygons)’╝īĶʤĶĖ¬ id (tracking ids) ńŁēŃĆéµēƵ£ēÕ«×õŠŗńøĖÕģ│ńÜäµĢ░µŹ«ńÜä**ķĢ┐Õ║”õĖĆĶć┤**’╝īÕØćõĖ║ÕøŠÕāÅõĖŁÕ«×õŠŗńÜäõĖ¬µĢ░ŃĆé
+- ÕāÅń┤ĀµĢ░µŹ« (PixelData) : õĖ╗Ķ”üķÆłÕ»╣Õ║ĢÕ▒éõ╗╗ÕŖĪ (low-level) õ╗źÕÅŖķ£ĆĶ”üµä¤ń¤źÕāÅń┤Āń║¦Õł½µĀćńŁŠńÜäķā©ÕłåõĖŖÕ▒éõ╗╗ÕŖĪŃĆéÕāÅń┤ĀµĢ░µŹ«Õ»╣ÕāÅń┤Āń║¦ńøĖÕģ│ńÜäµĢ░µŹ«Ķ┐øĶĪīÕ░üĶŻģ’╝īµ»öÕ”éĶ»Łõ╣ēÕłåÕē▓õĖŁńÜäÕłåÕē▓ÕøŠ (segmentation map), ÕģēµĄüõ╗╗ÕŖĪõĖŁńÜäÕģēµĄüÕøŠ (flow map), Õģ©µÖ»ÕłåÕē▓õĖŁńÜäÕģ©µÖ»ÕłåÕē▓ÕøŠ (panoptic seg map)’╝øÕ║ĢÕ▒éõ╗╗ÕŖĪõĖŁńö¤µłÉńÜäÕÉäń¦ŹÕøŠÕāÅ’╝īµ»öÕ”éĶČģÕłåĶŠ©ÕøŠ’╝īÕÄ╗ÕÖ¬ÕøŠ’╝īõ╗źÕÅŖńö¤µłÉńÜäÕÉäń¦ŹķŻÄµĀ╝ÕøŠŃĆéĶ┐Öõ║øµĢ░µŹ«ńÜäńē╣ńé╣µś»ķāĮµś»õĖēń╗┤µł¢Õøøń╗┤µĢ░ń╗ä’╝īµ£ĆÕÉÄõĖżń╗┤Õ║”õĖ║µĢ░µŹ«ńÜäķ½śÕ║” (height) ÕÆīÕ«ĮÕ║” (width)’╝īõĖöÕģʵ£ēńøĖÕÉīńÜä height ÕÆī width
+- µĀćńŁŠµĢ░µŹ« (LabelData) : õĖ╗Ķ”üķÆłÕ»╣µĀćńŁŠń║¦Õł½ńÜäµĢ░µŹ«Ķ┐øĶĪīÕ░üĶŻģ’╝īµ»öÕ”éÕøŠÕāÅÕłåń▒╗’╝īÕżÜÕłåń▒╗õĖŁńÜäń▒╗Õł½’╝īÕøŠÕāÅńö¤µłÉõĖŁńö¤µłÉÕøŠÕāÅńÜäń▒╗Õł½ÕåģÕ«╣’╝īµł¢ĶĆģµ¢ćÕŁŚĶ»åÕł½õĖŁńÜäµ¢ćµ£¼ńŁēŃĆé
+
+### InstanceData
+
+[`InstanceData`](mmengine.structures.InstanceData) Õ£© `BaseDataElement` ńÜäÕ¤║ńĪĆõĖŖÕ»╣ `data` ÕŁśÕé©ńÜäµĢ░µŹ«ÕüÜõ║åķÖÉÕłČ’╝īĶ”üµ▒éÕŁśÕé©Õ£© `data` õĖŁńÜäµĢ░µŹ«ńÜäķĢ┐Õ║”õĖĆĶć┤ŃĆéµ»öÕ”éÕ£©ńø«µĀ浯ƵĄŗõĖŁ, ÕüćĶ«ŠõĖĆÕ╝ĀÕøŠÕāÅõĖŁµ£ē N õĖ¬ńø«µĀć (instance)’╝īÕÅ»õ╗źÕ░åÕøŠÕāÅńÜäµēƵ£ēĶŠ╣ńĢīµĪå (bbox)’╝īń▒╗Õł½ (label) ńŁēÕŁśÕé©Õ£© `InstanceData` õĖŁ, `InstanceData` ńÜä bbox ÕÆī label ńÜäķĢ┐Õ║”ńøĖÕÉīŃĆé
+MMEngine Õ»╣ `InstanceData` ÕŖĀÕģźõ║åÕ”éõĖŗµö»µīü’╝Ü
+
+- Õ»╣ `InstanceData` õĖŁ data µēĆÕŁśÕé©ńÜäµĢ░µŹ«Ķ┐øĶĪīõ║åķĢ┐Õ║”µĀĪķ¬ī
+- data ķā©Õłåµö»µīüń▒╗ÕŁŚÕģĖĶ«┐ķŚ«ÕÆīĶ«ŠńĮ«Õ«āńÜäÕ▒׵Ʀ
+- µö»µīüÕ¤║ńĪĆń┤óÕ╝Ģ’╝īÕłćńēćõ╗źÕÅŖķ½śń║¦ń┤óÕ╝ĢÕŖ¤ĶāĮ
+- µö»µīüÕģʵ£ē**ńøĖÕÉīńÜä `key`** õĮåµś»õĖŹÕÉīńÜä `InstanceData` Ķ┐øĶĪīµŗ╝µÄźńÜäÕŖ¤ĶāĮŃĆé
+
+Ķ┐Öõ║øµē®Õ▒ĢÕŖ¤ĶāĮķÖżõ║åµö»µīüÕ¤║ńĪĆńÜäµĢ░µŹ«ń╗ōµ×ä’╝ī µ»öÕ”é `torch.tensor`, `numpy.dnarray`, `list`, `str` ÕÆī `tuple`, õ╣¤ÕÅ»õ╗źµś»Ķć¬Õ«Üõ╣ēńÜäµĢ░µŹ«ń╗ōµ×ä’╝īÕŬĶ”üĶć¬Õ«Üõ╣ēµĢ░µŹ«ń╗ōµ×äÕ«×ńÄ░õ║å `__len__`, `__getitem__` ÕÆī `cat` µ¢╣µ│ĢŃĆé
+
+#### µĢ░µŹ«µĀĪķ¬ī
+
+`InstanceData` õĖŁ data ńÜäµĢ░µŹ«ķĢ┐Õ║”Ķ”üõ┐صīüõĖĆĶć┤’╝īÕ”éµ×£õ╝ĀÕģźõĖŹÕÉīķĢ┐Õ║”ńÜäµ¢░µĢ░µŹ«’╝īÕ░åõ╝ܵŖźķöÖŃĆé
+
+```python
+from mmengine.structures import InstanceData
+import torch
+import numpy as np
+
+img_meta = dict(img_shape=(800, 1196, 3), pad_shape=(800, 1216, 3))
+instance_data = InstanceData(metainfo=img_meta)
+instance_data.det_labels = torch.LongTensor([2, 3])
+instance_data.det_scores = torch.Tensor([0.8, 0.7])
+instance_data.bboxes = torch.rand((2, 4))
+print('The length of instance_data is', len(instance_data)) # 2
+
+instance_data.bboxes = torch.rand((3, 4))
+```
+
+```
+The length of instance_data is 2
+AssertionError: the length of values 3 is not consistent with the length of this :obj:`InstanceData` 2
+```
+
+#### ń▒╗ÕŁŚÕģĖĶ«┐ķŚ«ÕÆīĶ«ŠńĮ«Õ▒׵Ʀ
+
+`InstanceData` µö»µīüń▒╗õ╝╝ÕŁŚÕģĖńÜäµōŹõĮ£Ķ«┐ķŚ«ÕÆīĶ«ŠńĮ«ÕģČ **data** Õ▒׵ƦŃĆé
+
+```python
+img_meta = dict(img_shape=(800, 1196, 3), pad_shape=(800, 1216, 3))
+instance_data = InstanceData(metainfo=img_meta)
+instance_data["det_labels"] = torch.LongTensor([2, 3])
+instance_data["det_scores"] = torch.Tensor([0.8, 0.7])
+instance_data.bboxes = torch.rand((2, 4))
+print(instance_data)
+```
+
+```
+
+```
+
+#### ń┤óÕ╝ĢõĖÄÕłćńēć
+
+`InstanceData` µö»µīü Python õĖŁń▒╗õ╝╝ÕłŚĶĪ©ńÜäń┤óÕ╝ĢõĖÄÕłćńēć’╝īÕÉīµŚČõ╣¤µö»µīüń▒╗õ╝╝ numpy ńÜäķ½śń║¦ń┤óÕ╝ĢµōŹõĮ£ŃĆé
+
+```python
+img_meta = dict(img_shape=(800, 1196, 3), pad_shape=(800, 1216, 3))
+instance_data = InstanceData(metainfo=img_meta)
+instance_data.det_labels = torch.LongTensor([2, 3])
+instance_data.det_scores = torch.Tensor([0.8, 0.7])
+instance_data.bboxes = torch.rand((2, 4))
+print(instance_data)
+```
+
+```
+
+```
+
+1. ń┤óÕ╝Ģ
+
+```python
+print(instance_data[1])
+```
+
+```
+
+```
+
+2. Õłćńēć
+
+```python
+print(instance_data[0:1])
+```
+
+```
+
+```
+
+3. ķ½śń║¦ń┤óÕ╝Ģ
+
+- ÕłŚĶĪ©ń┤óÕ╝Ģ
+
+```python
+sorted_results = instance_data[instance_data.det_scores.sort().indices]
+print(sorted_results)
+```
+
+```
+
+```
+
+- ÕĖāÕ░öń┤óÕ╝Ģ
+
+```python
+filter_results = instance_data[instance_data.det_scores > 0.75]
+print(filter_results)
+```
+
+```
+
+```
+
+4. ń╗ōµ×£õĖ║ń®║
+
+```python
+empty_results = instance_data[instance_data.det_scores > 1]
+print(empty_results)
+```
+
+```
+
+```
+
+#### µŗ╝µÄź(cat)
+
+ńö©µłĘÕÅ»õ╗źÕ░åõĖżõĖ¬Õģʵ£ēńøĖÕÉī key ńÜä `InstanceData` µŗ╝µÄźµłÉõĖĆõĖ¬ `InstanceData`ŃĆéÕ»╣õ║ÄķĢ┐Õ║”ÕłåÕł½õĖ║ N ÕÆī M ńÜäõĖżõĖ¬ `InstanceData`’╝ī µŗ╝µÄźÕÉÄõĖ║ķĢ┐Õ║” N + M ńÜäµ¢░ńÜä `InstanceData`
+
+```python
+img_meta = dict(img_shape=(800, 1196, 3), pad_shape=(800, 1216, 3))
+instance_data = InstanceData(metainfo=img_meta)
+instance_data.det_labels = torch.LongTensor([2, 3])
+instance_data.det_scores = torch.Tensor([0.8, 0.7])
+instance_data.bboxes = torch.rand((2, 4))
+print('The length of instance_data is', len(instance_data))
+cat_results = InstanceData.cat([instance_data, instance_data])
+print('The length of instance_data is', len(cat_results))
+print(cat_results)
+```
+
+```
+The length of instance_data is 2
+The length of instance_data is 4
+
+```
+
+#### Ķć¬Õ«Üõ╣ēµĢ░µŹ«ń╗ōµ×ä
+
+Õ»╣õ║ÄĶć¬Õ«Üõ╣ēń╗ōµ×äÕ”éµ×£µā│õĮ┐ńö©õĖŖĶ┐░µē®Õ▒ĢĶ”üµ▒éķ£ĆĶ”üÕ«×ńÄ░`__len__`, `__getitem__` ÕÆī `cat`õĖēõĖ¬µÄźÕÅŻ.
+
+```python
+import itertools
+
+class TmpObject:
+ def __init__(self, tmp) -> None:
+ assert isinstance(tmp, list)
+ self.tmp = tmp
+
+ def __len__(self):
+ return len(self.tmp)
+
+ def __getitem__(self, item):
+ if type(item) == int:
+ if item >= len(self) or item < -len(self): # type:ignore
+ raise IndexError(f'Index {item} out of range!')
+ else:
+ # keep the dimension
+ item = slice(item, None, len(self))
+ return TmpObject(self.tmp[item])
+
+ @staticmethod
+ def cat(tmp_objs):
+ assert all(isinstance(results, TmpObject) for results in tmp_objs)
+ if len(tmp_objs) == 1:
+ return tmp_objs[0]
+ tmp_list = [tmp_obj.tmp for tmp_obj in tmp_objs]
+ tmp_list = list(itertools.chain(*tmp_list))
+ new_data = TmpObject(tmp_list)
+ return new_data
+
+ def __repr__(self):
+ return str(self.tmp)
+```
+
+```python
+img_meta = dict(img_shape=(800, 1196, 3), pad_shape=(800, 1216, 3))
+instance_data = InstanceData(metainfo=img_meta)
+instance_data.det_labels = torch.LongTensor([2, 3])
+instance_data["det_scores"] = torch.Tensor([0.8, 0.7])
+instance_data.bboxes = torch.rand((2, 4))
+instance_data.polygons = TmpObject([[1, 2, 3, 4], [5, 6, 7, 8]])
+print(instance_data)
+```
+
+```
+
+```
+
+```python
+# ķ½śń║¦ń┤óÕ╝Ģ
+print(instance_data[instance_data.det_scores > 0.75])
+```
+
+```
+
+```
+
+```python
+# µŗ╝µÄź
+print(InstanceData.cat([instance_data, instance_data]))
+```
+
+```
+
+```
+
+### PixelData
+
+[`PixelData`](mmengine.structures.PixelData) Õ£© `BaseDataElement` ńÜäÕ¤║ńĪĆõĖŖ’╝īÕÉīµĀĘÕ»╣ data õĖŁÕŁśÕé©ńÜäµĢ░µŹ«ÕüÜõ║åķÖÉÕłČ:
+
+- µēƵ£ē data ÕåģńÜäµĢ░µŹ«ÕØćõĖ║ 3 ń╗┤’╝īÕ╣ČõĖöķĪ║Õ║ÅõĖ║ (ķĆÜķüō’╝īķ½ś’╝īÕ«Į)
+- µēƵ£ēÕ£© data ÕåģńÜäµĢ░µŹ«Ķ”üµ£ēńøĖÕÉīńÜäķĢ┐ÕÆīÕ«Į
+
+Õ¤║õ║ÄõĖŖĶ┐░ÕüćÕ«ÜÕ»╣ `PixelData`Ķ┐øĶĪīõ║åµē®Õ▒Ģ’╝īÕīģµŗ¼’╝Ü
+
+- Õ»╣ `PixelData` õĖŁ data µēĆÕŁśÕé©ńÜäµĢ░µŹ«Ķ┐øĶĪīõ║åÕ░║Õ»ĖńÜäµĀĪķ¬ī
+- µö»µīüÕ»╣ data ķā©ÕłåńÜäµĢ░µŹ«Õ»╣Õ«×õŠŗĶ┐øĶĪīń®║ķŚ┤ń╗┤Õ║”ńÜäń┤óÕ╝ĢÕÆīÕłćńēćŃĆé
+
+#### µĢ░µŹ«µĀĪķ¬ī
+
+`PixelData` õ╝ÜÕ»╣õ╝ĀÕģźÕł░ data ńÜäµĢ░µŹ«Ķ┐øĶĪīń╗┤Õ║”õĖÄķĢ┐Õ«ĮńÜäµĀĪķ¬īŃĆé
+
+```python
+from mmengine.structures import PixelData
+import random
+import torch
+import numpy as np
+metainfo = dict(
+ img_id=random.randint(0, 100),
+ img_shape=(random.randint(400, 600), random.randint(400, 600)))
+image = np.random.randint(0, 255, (4, 20, 40))
+featmap = torch.randint(0, 255, (10, 20, 40))
+pixel_data = PixelData(metainfo=metainfo,
+ image=image,
+ featmap=featmap)
+print('The shape of pixel_data is', pixel_data.shape)
+# set
+pixel_data.map3 = torch.randint(0, 255, (20, 40))
+print('The shape of pixel_data is', pixel_data.map3.shape)
+```
+
+```
+The shape of pixel_data is (20, 40)
+The shape of pixel_data is torch.Size([1, 20, 40])
+```
+
+```python
+pixel_data.map2 = torch.randint(0, 255, (3, 20, 30))
+# AssertionError: the height and width of values (20, 30) is not consistent with the length of this :obj:`PixelData` (20, 40)
+```
+
+```
+AssertionError: the height and width of values (20, 30) is not consistent with the length of this :obj:`PixelData` (20, 40)
+```
+
+```python
+pixel_data.map2 = torch.randint(0, 255, (1, 3, 20, 40))
+# AssertionError: The dim of value must be 2 or 3, but got 4
+```
+
+```
+AssertionError: The dim of value must be 2 or 3, but got 4
+```
+
+#### ń®║ķŚ┤ń╗┤Õ║”ń┤óÕ╝Ģ
+
+`PixelData` µö»µīüÕ»╣ data ķā©ÕłåńÜäµĢ░µŹ«Õ»╣Õ«×õŠŗĶ┐øĶĪīń®║ķŚ┤ń╗┤Õ║”ńÜäń┤óÕ╝ĢÕÆīÕłćńēć’╝īÕŬķ£Ćõ╝ĀÕģźķĢ┐Õ«ĮńÜäń┤óÕ╝ĢÕŹ│ÕÅ»ŃĆé
+
+```python
+metainfo = dict(
+ img_id=random.randint(0, 100),
+ img_shape=(random.randint(400, 600), random.randint(400, 600)))
+image = np.random.randint(0, 255, (4, 20, 40))
+featmap = torch.randint(0, 255, (10, 20, 40))
+pixel_data = PixelData(metainfo=metainfo,
+ image=image,
+ featmap=featmap)
+print('The shape of pixel_data is', pixel_data.shape)
+```
+
+```
+The shape of pixel_data is (20, 40)
+```
+
+- ń┤óÕ╝Ģ
+
+```python
+index_data = pixel_data[10, 20]
+print('The shape of index_data is', index_data.shape)
+```
+
+```
+The shape of index_data is (1, 1)
+```
+
+- Õłćńēć
+
+```python
+slice_data = pixel_data[10:20, 20:40]
+print('The shape of slice_data is', slice_data.shape)
+```
+
+```
+The shape of slice_data is (10, 20)
+```
+
+### LabelData
+
+[`LabelData`](mmengine.structures.LabelData) õĖ╗Ķ”üńö©µØźÕ░üĶŻģµĀćńŁŠµĢ░µŹ«’╝īÕ”éÕ£║µÖ»Õłåń▒╗µĀćńŁŠ’╝īµ¢ćÕŁŚĶ»åÕł½µĀćńŁŠńŁēŃĆé`LabelData` µ▓Īµ£ēÕ»╣ data ÕüÜõ╗╗õĮĢķÖÉÕłČ’╝īÕŬµÅÉõŠøõ║åõĖżõĖ¬ķóØÕż¢ÕŖ¤ĶāĮ’╝Üonehot õĖÄ index ńÜäĶĮ¼µŹóŃĆé
+
+```python
+from mmengine.structures import LabelData
+import torch
+
+item = torch.tensor([1], dtype=torch.int64)
+num_classes = 10
+
+```
+
+```python
+onehot = LabelData.label_to_onehot(label=item, num_classes=num_classes)
+print(f'{num_classes} is convert to ', onehot)
+
+index = LabelData.onehot_to_label(onehot=onehot)
+print(f'{onehot} is convert to ', index)
+```
+
+```
+10 is convert to tensor([0, 1, 0, 0, 0, 0, 0, 0, 0, 0])
+tensor([0, 1, 0, 0, 0, 0, 0, 0, 0, 0]) is convert to tensor([1])
+```
+
+## µĢ░µŹ«µĀʵ£¼(xxxDataSample)
+
+õĖĆõ╗ĮµĀʵ£¼õĖŁÕÅ»ĶāĮÕŁśÕ£©õĖŹÕÉīń▒╗Õ×ŗńÜäµĀćńŁŠ’╝īõŠŗÕ”éõĖĆÕ╝ĀÕøŠńēćķćīÕÅ»ĶāĮÕÉīµŚČÕŁśÕ£©Õ«×õŠŗń║¦Õł½ńÜäµĀćńŁŠ’╝łBox’╝ē’╝īÕāÅń┤Āń║¦Õł½ńÜäµĀćńŁŠ’╝łSegMap’╝ē’╝īÕøĀµŁżÕ£© PixelDataŃĆüInstanceDataŃĆüPixelData õ╣ŗõĖŖ’╝īĶ┐śõ╝ܵ£ēõĖĆÕ▒éµø┤ÕŖĀķ½śń║¦Õ░üĶŻģ’╝īńö©µØźĶĪ©ńż║ÕøŠÕāÅń║¦Õł½ńÜäµĀćńŁŠŃĆéOpenMMLab ń│╗ÕłŚķĪ╣ńø«Õ░åĶ┐ÖÕ▒éÕ░üĶŻģÕæĮÕÉŹõĖ║ `XXDataSample`ŃĆéõ╗źµŻĆµĄŗõ╗╗ÕŖĪõĖ║õŠŗ’╝īMMDet Õ░▒Õ«×ńÄ░õ║å DetDataSampleŃĆéĶ«Łń╗āĶ┐ćń©ŗõĖŁµēƵ£ēńÜäµĀćńŁŠķāĮõ╝ÜĶó½Õ░üĶŻģÕ£© XXXDataSample õĖŁ’╝īĶ┐ÖµĀĘĶāĮÕż¤õ┐ØĶ»üõĖŹÕÉīńÜäµĘ▒Õ║”ÕŁ”õ╣Āõ╗╗ÕŖĪĶāĮÕż¤õ┐صīüń╗¤õĖĆńÜäµĢ░µŹ«µĄüÕÆīń╗¤õĖĆńÜäµĢ░µŹ«µōŹõĮ£µ¢╣Õ╝ÅŃĆé
+
+### õĖŗµĖĖÕ║ōõĮ┐ńö©
+
+õ╗ź MMDet õĖ║õŠŗ’╝īĶ»┤µśÄõĖŗµĖĖÕ║ōõĖŁµĢ░µŹ«µĀʵ£¼ńÜäõĮ┐ńö©’╝īõ╗źÕÅŖµĢ░µŹ«µĀʵ£¼ÕŁŚµ«ĄńÜäń║”µØ¤ÕÆīÕæĮÕÉŹŃĆéMMDet õĖŁÕ«Üõ╣ēõ║å `DetDataSample`, ÕÉīµŚČÕ«Üõ╣ēõ║å 7 õĖ¬ÕŁŚµ«Ą’╝īÕłåÕł½õĖ║’╝Ü
+
+- µĀćµ│©õ┐Īµü»
+ - gt_instance(InstanceData): Õ«×õŠŗµĀćµ│©õ┐Īµü»’╝īÕīģµŗ¼Õ«×õŠŗńÜäń▒╗Õł½ŃĆüĶŠ╣ńĢīµĪåńŁē’╝ī ń▒╗Õ×ŗń║”µØ¤õĖ║ `InstanceData`ŃĆé
+ - gt_panoptic_seg(PixelData): Õģ©µÖ»ÕłåÕē▓ńÜäµĀćµ│©õ┐Īµü»’╝īń▒╗Õ×ŗń║”µØ¤õĖ║ `PixelData`ŃĆé
+ - gt_semantic_seg(PixelData): Ķ»Łõ╣ēÕłåÕē▓ńÜäµĀćµ│©õ┐Īµü»’╝ī ń▒╗Õ×ŗń║”µØ¤õĖ║ `PixelData`ŃĆé
+- ķó䵥ŗń╗ōµ×£
+ - pred_instance(InstanceData): Õ«×õŠŗķó䵥ŗń╗ōµ×£’╝īÕīģµŗ¼Õ«×õŠŗńÜäń▒╗Õł½ŃĆüĶŠ╣ńĢīµĪåńŁē’╝ī ń▒╗Õ×ŗń║”µØ¤õĖ║ `InstanceData`ŃĆé
+ - pred_panoptic_seg(PixelData): Õģ©µÖ»ÕłåÕē▓ńÜäķó䵥ŗń╗ōµ×£’╝īń▒╗Õ×ŗń║”µØ¤õĖ║ `PixelData`ŃĆé
+ - pred_semantic_seg(PixelData): Ķ»Łõ╣ēÕłåÕē▓ńÜäķó䵥ŗń╗ōµ×£’╝ī ń▒╗Õ×ŗń║”µØ¤õĖ║ `PixelData`ŃĆé
+- õĖŁķŚ┤ń╗ōµ×£
+ - proposal(InstanceData): õĖ╗Ķ”üõĖ║õ║īķśČµ«ĄõĖŁ RPN ńÜäķó䵥ŗń╗ōµ×£’╝ī ń▒╗Õ×ŗń║”µØ¤õĖ║ `InstanceData`ŃĆé
+
+```python
+from mmengine.structures import BaseDataElement
+import torch
+
+class DetDataSample(BaseDataElement):
+
+ # µĀćµ│©
+ @property
+ def gt_instances(self) -> InstanceData:
+ return self._gt_instances
+
+ @gt_instances.setter
+ def gt_instances(self, value: InstanceData):
+ self.set_field(value, '_gt_instances', dtype=InstanceData)
+
+ @gt_instances.deleter
+ def gt_instances(self):
+ del self._gt_instances
+
+ @property
+ def gt_panoptic_seg(self) -> PixelData:
+ return self._gt_panoptic_seg
+
+ @gt_panoptic_seg.setter
+ def gt_panoptic_seg(self, value: PixelData):
+ self.set_field(value, '_gt_panoptic_seg', dtype=PixelData)
+
+ @gt_panoptic_seg.deleter
+ def gt_panoptic_seg(self):
+ del self._gt_panoptic_seg
+
+ @property
+ def gt_sem_seg(self) -> PixelData:
+ return self._gt_sem_seg
+
+ @gt_sem_seg.setter
+ def gt_sem_seg(self, value: PixelData):
+ self.set_field(value, '_gt_sem_seg', dtype=PixelData)
+
+ @gt_sem_seg.deleter
+ def gt_sem_seg(self):
+ del self._gt_sem_seg
+
+ # ķó䵥ŗ
+ @property
+ def pred_instances(self) -> InstanceData:
+ return self._pred_instances
+
+ @pred_instances.setter
+ def pred_instances(self, value: InstanceData):
+ self.set_field(value, '_pred_instances', dtype=InstanceData)
+
+ @pred_instances.deleter
+ def pred_instances(self):
+ del self._pred_instances
+
+ @property
+ def pred_panoptic_seg(self) -> PixelData:
+ return self._pred_panoptic_seg
+
+ @pred_panoptic_seg.setter
+ def pred_panoptic_seg(self, value: PixelData):
+ self.set_field(value, '_pred_panoptic_seg', dtype=PixelData)
+
+ @pred_panoptic_seg.deleter
+ def pred_panoptic_seg(self):
+ del self._pred_panoptic_seg
+
+ # õĖŁķŚ┤ń╗ōµ×£
+ @property
+ def pred_sem_seg(self) -> PixelData:
+ return self._pred_sem_seg
+
+ @pred_sem_seg.setter
+ def pred_sem_seg(self, value: PixelData):
+ self.set_field(value, '_pred_sem_seg', dtype=PixelData)
+
+ @pred_sem_seg.deleter
+ def pred_sem_seg(self):
+ del self._pred_sem_seg
+
+ @property
+ def proposals(self) -> InstanceData:
+ return self._proposals
+
+ @proposals.setter
+ def proposals(self, value: InstanceData):
+ self.set_field(value, '_proposals', dtype=InstanceData)
+
+ @proposals.deleter
+ def proposals(self):
+ del self._proposals
+
+```
+
+### ń▒╗Õ×ŗń║”µØ¤
+
+DetDataSample ńÜäńö©µ│ĢÕ”éõĖŗµēĆńż║’╝īÕ£©µĢ░µŹ«ń▒╗Õ×ŗõĖŹń¼”ÕÉłĶ”üµ▒éńÜ䵌ČÕĆÖ(õŠŗÕ”éńö© torch.Tensor ĶĆīķØ× InstanceData Õ«Üõ╣ē proposals µŚČ)’╝īDetDataSample Õ░▒õ╝ܵŖźķöÖŃĆé
+
+```python
+data_sample = DetDataSample()
+
+data_sample.proposals = InstanceData(data=dict(bboxes=torch.rand((5,4))))
+print(data_sample)
+```
+
+```
+
+) at 0x7f9f1c090430>
+```
+
+```python
+data_sample.proposals = torch.rand((5, 4))
+```
+
+```
+AssertionError: tensor([[0.4370, 0.1661, 0.0902, 0.8421],
+ [0.4947, 0.1668, 0.0083, 0.1111],
+ [0.2041, 0.8663, 0.0563, 0.3279],
+ [0.7817, 0.1938, 0.2499, 0.6748],
+ [0.4524, 0.8265, 0.4262, 0.2215]]) should be a but got
+```
+
+## µÄźÕÅŻńÜäń«ĆÕī¢
+
+õĖŗķØóõ╗ź MMDetection õĖ║õŠŗµø┤ÕģĘõĮōÕ£░Ķ»┤µśÄ OpenMMLab ńÜäń«Śµ│ĢÕ║ōÕ░åÕ”éõĮĢĶ┐üń¦╗õĮ┐ńö©µŖĮĶ▒ĪµĢ░µŹ«µÄźÕÅŻ’╝īõ╗źń«ĆÕī¢µ©ĪÕØŚÕÆīń╗äõ╗ȵğÕÅŻńÜäŃĆ鵳æõ╗¼ÕüćÕ«Ü MMDetection ÕÆī MMEngine õĖŁÕ«×ńÄ░õ║å DetDataSample ÕÆī InstanceDataŃĆé
+
+### 1. ń╗äõ╗ȵğÕÅŻńÜäń«ĆÕī¢
+
+µŻĆµĄŗÕÖ©ńÜäÕż¢ķā©µÄźÕÅŻÕÅ»õ╗źÕŠŚÕł░µśŠĶæŚńÜäń«ĆÕī¢ÕÆīń╗¤õĖĆŃĆéMMDet 2.X õĖŁÕŹĢķśČµ«ĄµŻĆµĄŗÕÖ©ÕÆīÕŹĢķśČµ«ĄÕłåÕē▓ń«Śµ│ĢńÜäµÄźÕÅŻÕ”éõĖŗŃĆéÕ£©Ķ«Łń╗āĶ┐ćń©ŗõĖŁ’╝ī`SingleStageDetector` ķ£ĆĶ”üĶÄĘÕÅ¢
+`img`’╝ī `img_metas`’╝ī `gt_bboxes`’╝ī `gt_labels`’╝ī `gt_bboxes_ignore` õĮ£õĖ║ĶŠōÕģź’╝īõĮåµś» `SingleStageInstanceSegmentor` Ķ┐śķ£ĆĶ”ü `gt_masks`’╝īÕ»╝Ķć┤ detector ńÜäĶ«Łń╗āµÄźÕÅŻõĖŹõĖĆĶć┤’╝īÕĮ▒ÕōŹõ║åõ╗ŻńĀüńÜäńüĄµ┤╗µĆ¦ŃĆé
+
+```python
+class SingleStageDetector(BaseDetector):
+ ...
+
+ def forward_train(self,
+ img,
+ img_metas,
+ gt_bboxes,
+ gt_labels,
+ gt_bboxes_ignore=None):
+
+
+class SingleStageInstanceSegmentor(BaseDetector):
+ ...
+
+ def forward_train(self,
+ img,
+ img_metas,
+ gt_masks,
+ gt_labels,
+ gt_bboxes=None,
+ gt_bboxes_ignore=None,
+ **kwargs):
+```
+
+Õ£© MMDet 3.0 õĖŁ’╝īµēƵ£ēµŻĆµĄŗÕÖ©ńÜäĶ«Łń╗āµÄźÕÅŻķāĮÕÅ»õ╗źõĮ┐ńö© DetDataSample ń╗¤õĖĆń«ĆÕī¢õĖ║ `img` ÕÆī `data_samples`’╝īõĖŹÕÉīµ©ĪÕØŚÕÅ»õ╗źµĀ╣µŹ«ķ£ĆĶ”üÕÄ╗Ķ«┐ķŚ« `data_samples` Õ░üĶŻģńÜäÕÉäń¦ŹµēĆķ£ĆĶ”üńÜäÕ▒׵ƦŃĆé
+
+```python
+class SingleStageDetector(BaseDetector):
+ ...
+
+ def forward_train(self,
+ img,
+ data_samples):
+
+class SingleStageInstanceSegmentor(BaseDetector):
+ ...
+
+ def forward_train(self,
+ img,
+ data_samples):
+
+```
+
+### 2. µ©ĪÕØŚµÄźÕÅŻńÜäń«ĆÕī¢
+
+MMDet 2.X õĖŁ `HungarianAssigner` ÕÆī `MaskHungarianAssigner` ÕłåÕł½ńö©õ║ÄÕ£©Ķ«Łń╗āĶ┐ćń©ŗõĖŁÕ░åµŻĆµĄŗµĪåÕÆīÕ«×õŠŗµÄ®ńĀüÕÆīµĀćµ│©ńÜäÕ«×õŠŗĶ┐øĶĪīÕī╣ķģŹŃĆéõ╗¢õ╗¼Õåģķā©ńÜäÕī╣ķģŹķĆ╗ĶŠæÕ«×ńÄ░µś»õĖƵĀĘńÜä’╝īÕŬµś»µÄźÕÅŻÕÆīµŹ¤Õż▒ÕćĮµĢ░ńÜäĶ«Īń«ŚõĖŹÕÉīŃĆé
+õĮåµś»’╝īµÄźÕÅŻńÜäõĖŹÕÉīõĮ┐ÕŠŚ `HungarianAssigner` õĖŁńÜäõ╗ŻńĀüµŚĀµ│ĢĶó½ÕżŹńö©’╝ī`MaskHungarianAssigner` õĖŁķćŹÕåÖõ║åÕŠłÕżÜÕåŚõĮÖńÜäķĆ╗ĶŠæŃĆé
+
+```python
+class HungarianAssigner(BaseAssigner):
+
+ def assign(self,
+ bbox_pred,
+ cls_pred,
+ gt_bboxes,
+ gt_labels,
+ img_meta,
+ gt_bboxes_ignore=None,
+ eps=1e-7):
+
+class MaskHungarianAssigner(BaseAssigner):
+
+ def assign(self,
+ cls_pred,
+ mask_pred,
+ gt_labels,
+ gt_mask,
+ img_meta,
+ gt_bboxes_ignore=None,
+ eps=1e-7):
+```
+
+`InstanceData` ÕÅ»õ╗źÕ░üĶŻģÕ«×õŠŗńÜäµĪåŃĆüÕłåµĢ░ŃĆüÕÆīµÄ®ńĀü’╝īÕ░å `HungarianAssigner` ńÜäµĀĖÕ┐āÕÅéµĢ░ń«ĆÕī¢µłÉ `pred_instances`’╝ī`gt_instances`’╝īÕÆī `gt_instances_ignore`
+õĮ┐ÕŠŚ `HungarianAssigner` ÕÆī `MaskHungarianAssigner` ÕÅ»õ╗źÕÉłÕ╣ȵłÉõĖĆõĖ¬ķĆÜńö©ńÜä `HungarianAssigner`ŃĆé
+
+```python
+class HungarianAssigner(BaseAssigner):
+
+ def assign(self,
+ pred_instances,
+ gt_instancess,
+ gt_instances_ignore=None,
+ eps=1e-7):
+```
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/data_transform.md b/internlm_langchain/knowledge_base/MMEngine/content/data_transform.md
new file mode 100644
index 00000000..ff6ce852
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/data_transform.md
@@ -0,0 +1,136 @@
+# µĢ░µŹ«ÕÅśµŹó (Data Transform)
+
+Õ£© OpenMMLab ń«Śµ│ĢÕ║ōõĖŁ’╝īµĢ░µŹ«ķøåńÜäµ×äÕ╗║ÕÆīµĢ░µŹ«ńÜäÕćåÕżćµś»ńøĖõ║ÆĶ¦ŻĶĆ”ńÜäŃĆéķĆÜÕĖĖ’╝īµĢ░µŹ«ķøåńÜäµ×äÕ╗║ÕŬջ╣µĢ░µŹ«ķøåĶ┐øĶĪīĶ¦Żµ×É’╝īĶ«░ÕĮĢµ»ÅõĖ¬µĀʵ£¼ńÜäÕ¤║µ£¼õ┐Īµü»’╝øĶĆīµĢ░µŹ«ńÜäÕćåÕżćÕłÖµś»ķĆÜĶ┐ćõĖĆń│╗ÕłŚńÜäµĢ░µŹ«ÕÅśµŹó’╝īµĀ╣µŹ«µĀʵ£¼ńÜäÕ¤║µ£¼õ┐Īµü»Ķ┐øĶĪīµĢ░µŹ«ÕŖĀĶĮĮŃĆüķóäÕżäńÉåŃĆüµĀ╝Õ╝ÅÕī¢ńŁēµōŹõĮ£ŃĆé
+
+## õĮ┐ńö©µĢ░µŹ«ÕÅśµŹóń▒╗
+
+Õ£© MMEngine õĖŁ’╝īµłæõ╗¼õĮ┐ńö©ÕÉäń¦ŹÕÅ»Ķ░āńö©ńÜäµĢ░µŹ«ÕÅśµŹóń▒╗µØźĶ┐øĶĪīµĢ░µŹ«ńÜäµōŹõĮ£ŃĆéĶ┐Öõ║øµĢ░µŹ«ÕÅśµŹóń▒╗ÕÅ»õ╗źµÄźÕÅŚĶŗźÕ╣▓ķģŹńĮ«ÕÅéµĢ░Ķ┐øĶĪīÕ«×õŠŗÕī¢’╝īõ╣ŗÕÉÄķĆÜĶ┐ćĶ░āńö©ńÜäµ¢╣Õ╝ÅÕ»╣ĶŠōÕģźńÜäµĢ░µŹ«ÕŁŚÕģĖĶ┐øĶĪīÕżäńÉåŃĆéÕÉīµŚČ’╝īµłæõ╗¼ń║”իܵēƵ£ēµĢ░µŹ«ÕÅśµŹóķāĮµÄźÕÅŚõĖĆõĖ¬ÕŁŚÕģĖõĮ£õĖ║ĶŠōÕģź’╝īÕ╣ČÕ░åÕżäńÉåÕÉÄńÜäµĢ░µŹ«ĶŠōÕć║õĖ║õĖĆõĖ¬ÕŁŚÕģĖŃĆéõĖĆõĖ¬ń«ĆÕŹĢńÜäõŠŗÕŁÉÕ”éõĖŗ’╝Ü
+
+```{note}
+MMEngine õĖŁõ╗ģń║”Õ«Üõ║åµĢ░µŹ«ÕÅśµŹóń▒╗ńÜäĶ¦äĶīā’╝īÕĖĖńö©ńÜäµĢ░µŹ«ÕÅśµŹóń▒╗Õ«×ńÄ░ÕÅŖÕ¤║ń▒╗ķāĮÕ£© MMCV õĖŁ’╝īÕøĀµŁżÕ£©µ£¼ń»ćµĢÖń©ŗķ£ĆĶ”üµÅÉÕēŹÕ«ēĶŻģÕźĮ MMCV’╝īÕÅéĶ¦ü {external+mmcv:doc}`MMCV Õ«ēĶŻģµĢÖń©ŗ `ŃĆé
+```
+
+```python
+>>> import numpy as np
+>>> from mmcv.transforms import Resize
+>>>
+>>> transform = Resize(scale=(224, 224))
+>>> data_dict = {'img': np.random.rand(256, 256, 3)}
+>>> data_dict = transform(data_dict)
+>>> print(data_dict['img'].shape)
+(224, 224, 3)
+```
+
+## Õ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁõĮ┐ńö©
+
+Õ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁ’╝īµłæõ╗¼Õ░åõĖĆń│╗ÕłŚµĢ░µŹ«ÕÅśµŹóń╗äÕÉłµłÉõĖ║õĖĆõĖ¬ÕłŚĶĪ©’╝īń¦░õĖ║µĢ░µŹ«µĄüµ░┤ń║┐’╝łData Pipeline’╝ē’╝īõ╝Āń╗ÖµĢ░µŹ«ķøåńÜä `pipeline` ÕÅéµĢ░ŃĆéķĆÜÕĖĖµĢ░µŹ«µĄüµ░┤ń║┐ńö▒õ╗źõĖŗÕćĀõĖ¬ķā©Õłåń╗䵳ɒ╝Ü
+
+1. µĢ░µŹ«ÕŖĀĶĮĮ’╝īķĆÜÕĖĖõĮ┐ńö© [`LoadImageFromFile`](mmcv.transforms.LoadImageFromFile)
+2. µĀćńŁŠÕŖĀĶĮĮ’╝īķĆÜÕĖĖõĮ┐ńö© [`LoadAnnotations`](mmcv.transforms.LoadAnnotations)
+3. µĢ░µŹ«ÕżäńÉåÕÅŖÕó×Õ╝║’╝īõŠŗÕ”é [`RandomResize`](mmcv.transforms.RandomResize)
+4. µĢ░µŹ«µĀ╝Õ╝ÅÕī¢’╝īµĀ╣µŹ«õ╗╗ÕŖĪõĖŹÕÉī’╝īÕ£©ÕÉäõĖ¬õ╗ōÕ║ōõĮ┐ńö©Ķć¬ÕĘ▒ńÜäÕÅśµŹóµōŹõĮ£’╝īķĆÜÕĖĖÕÉŹõĖ║ `PackXXXInputs`’╝īÕģČõĖŁ XXX µś»õ╗╗ÕŖĪńÜäÕÉŹń¦░’╝īÕ”éÕłåń▒╗õ╗╗ÕŖĪõĖŁńÜä `PackClsInputs`ŃĆé
+
+õ╗źÕłåń▒╗õ╗╗ÕŖĪõĖ║õŠŗ’╝īµłæõ╗¼Õ£©õĖŗÕøŠÕ▒Ģńż║õ║åõĖĆõĖ¬ÕģĖÕ×ŗńÜäµĢ░µŹ«µĄüµ░┤ń║┐ŃĆéÕ»╣µ»ÅõĖ¬µĀʵ£¼’╝īµĢ░µŹ«ķøåõĖŁõ┐ØÕŁśńÜäÕ¤║µ£¼õ┐Īµü»µś»õĖĆõĖ¬Õ”éÕøŠõĖŁµ£ĆÕĘ”õŠ¦µēĆńż║ńÜäÕŁŚÕģĖ’╝īõ╣ŗÕÉĵ»Åń╗ÅĶ┐ćõĖĆõĖ¬ńö▒ĶōØĶē▓ÕØŚõ╗ŻĶĪ©ńÜäµĢ░µŹ«ÕÅśµŹóµōŹõĮ£’╝īµĢ░µŹ«ÕŁŚÕģĖõĖŁķāĮõ╝ÜÕŖĀÕģźµ¢░ńÜäÕŁŚµ«Ą’╝łµĀćĶ«░õĖ║ń╗┐Ķē▓’╝ēµł¢µø┤µ¢░ńÄ░µ£ēńÜäÕŁŚµ«Ą’╝łµĀćĶ«░õĖ║µ®ÖĶē▓’╝ēŃĆé
+
+
+
+
+
+```{note}
+Õ”éµ×£Õ¤║ńĪĆķģŹńĮ«µ¢ćõ╗ČõĖ║ train_dataloader ķģŹńĮ«õ║åÕ¤║õ║Ä iteration/epoch ķććµĀĘńÜä sampler’╝īÕłÖķ£ĆĶ”üÕ£©ÕĮōÕēŹķģŹńĮ«µ¢ćõ╗ČõĖŁÕ░åÕģȵø┤µö╣õĖ║µīćÕ«Üń▒╗Õ×ŗńÜä sampler’╝īµł¢Õ░åÕģČĶ«ŠńĮ«õĖ║ NoneŃĆéÕĮō dataloader õĖŁńÜä sampler õĖ║ None’╝īMMEngine µł¢µĀ╣µŹ« train_cfg õĖŁńÜä by_epoch ÕÅéµĢ░ķĆēµŗ® `InfiniteSampler`’╝łFalse’╝ē µł¢ `DefaultSampler`’╝łTrue’╝ēŃĆé
+```
+
+```{note}
+Õ”éµ×£Õ¤║ńĪĆķģŹńĮ«µ¢ćõ╗ČÕ£© train_cfg õĖŁµīćÕ«Üõ║å type’╝īķéŻõ╣łÕ┐ģķĪ╗Õ£©ÕĮōÕēŹķģŹńĮ«µ¢ćõ╗ČõĖŁÕ░å type Ķ”åńø¢õĖ║’╝łIterBasedTrainLoop µł¢ EpochBasedTrainLoop’╝ē’╝īĶĆīõĖŹĶāĮń«ĆÕŹĢńÜäµīćÕ«Ü by_epoch ÕÅéµĢ░ŃĆé
+```
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/evaluation.md b/internlm_langchain/knowledge_base/MMEngine/content/evaluation.md
new file mode 100644
index 00000000..a3a9ae72
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/evaluation.md
@@ -0,0 +1,88 @@
+# µ©ĪÕ×ŗń▓ŠÕ║”Ķ»äµĄŗ
+
+## Ķ»äµĄŗµīćµĀćõĖÄĶ»äµĄŗÕÖ©
+
+Õ£©µ©ĪÕ×ŗķ¬īĶ»üÕÆīµ©ĪÕ×ŗµĄŗĶ»ĢõĖŁ’╝īķĆÜÕĖĖķ£ĆĶ”üÕ»╣µ©ĪÕ×ŗń▓ŠÕ║”ÕüÜÕ«ÜķćÅĶ»äµĄŗŃĆéÕ£© MMEngine õĖŁÕ«×ńÄ░õ║åĶ»äµĄŗµīćµĀć’╝łMetric’╝ēÕÆīĶ»äµĄŗÕÖ©’╝łEvaluator’╝ēµØźÕ«īµłÉĶ┐ÖõĖĆÕŖ¤ĶāĮŃĆé
+
+- **Ķ»äµĄŗµīćµĀć** ńö©õ║ĵĀ╣µŹ«µĄŗĶ»ĢµĢ░µŹ«ÕÆīµ©ĪÕ×ŗķó䵥ŗń╗ōµ×£’╝īÕ«īµłÉńē╣իܵ©ĪÕ×ŗń▓ŠÕ║”µīćµĀćńÜäĶ«Īń«ŚŃĆéÕ£© OpenMMLab ÕÉäń«Śµ│ĢÕ║ōõĖŁµÅÉõŠøõ║åÕ»╣Õ║öõ╗╗ÕŖĪńÜäÕĖĖńö©Ķ»äµĄŗµīćµĀć’╝īÕ”é [MMPretrain](https://github.com/open-mmlab/mmpretrain) õĖŁµÅÉõŠøõ║å[Accuracy](https://mmpretrain.readthedocs.io/en/latest/api/generated/mmpretrain.evaluation.Accuracy.html#mmpretrain.evaluation.Accuracy) ńö©õ║ÄĶ«Īń«ŚÕłåń▒╗µ©ĪÕ×ŗńÜä Top-k Õłåń▒╗µŁŻńĪ«ńÄć’╝ø[MMDetection](https://github.com/open-mmlab/mmdetection) õĖŁµÅÉõŠøõ║å [COCOMetric](https://github.com/open-mmlab/mmdetection/blob/main/mmdet/evaluation/metrics/coco_metric.py) ńö©õ║ÄĶ«Īń«Śńø«µĀ浯ƵĄŗµ©ĪÕ×ŗńÜä AP’╝īAR ńŁēĶ»äµĄŗµīćµĀćŃĆéĶ»äµĄŗµīćµĀćõĖĵĢ░µŹ«ķøåĶ¦ŻĶĆ”’╝īÕ”é COCOMetric õ╣¤ÕÅ»ńö©õ║Ä COCO õ╗źÕż¢ńÜäńø«µĀ浯ƵĄŗµĢ░µŹ«ķøåõĖŖŃĆé
+
+- **Ķ»äµĄŗÕÖ©** µś»Ķ»äµĄŗµīćµĀćńÜäõĖŖÕ▒鵩ĪÕØŚ’╝īķĆÜÕĖĖÕīģÕɽõĖĆõĖ¬µł¢ÕżÜõĖ¬Ķ»äµĄŗµīćµĀćŃĆéĶ»äµĄŗÕÖ©ńÜäõĮ£ńö©µś»Õ£©µ©ĪÕ×ŗĶ»äµĄŗµŚČÕ«īµłÉÕ┐ģĶ”üńÜäµĢ░µŹ«µĀ╝Õ╝ÅĶĮ¼µŹó’╝īÕ╣ČĶ░āńö©Ķ»äµĄŗµīćµĀćĶ«Īń«Śµ©ĪÕ×ŗń▓ŠÕ║”ŃĆéĶ»äµĄŗÕÖ©ķĆÜÕĖĖńö▒[µē¦ĶĪīÕÖ©](../tutorials/runner.md)µł¢µĄŗĶ»ĢĶäܵ£¼µ×äÕ╗║’╝īÕłåÕł½ńö©õ║ÄÕ£©ń║┐Ķ»äµĄŗÕÆīń”╗ń║┐Ķ»äµĄŗŃĆé
+
+### Ķ»äµĄŗµīćµĀćÕ¤║ń▒╗ `BaseMetric`
+
+Ķ»äµĄŗµīćµĀćÕ¤║ń▒╗ `BaseMetric` µś»õĖĆõĖ¬µŖĮĶ▒Īń▒╗’╝īÕłØÕ¦ŗÕī¢ÕÅéµĢ░Õ”éõĖŗ:
+
+- `collect_device`’╝ÜÕ£©ÕłåÕĖāÕ╝ÅĶ»äµĄŗõĖŁńö©õ║ÄÕÉīµŁźń╗ōµ×£ńÜäĶ«ŠÕżćÕÉŹ’╝īÕ”é `'cpu'` µł¢ `'gpu'`ŃĆé
+- `prefix`’╝ÜĶ»äµĄŗµīćµĀćÕÉŹÕēŹń╝Ć’╝īńö©õ╗źÕī║Õł½ÕżÜõĖ¬ÕÉīÕÉŹńÜäĶ»äµĄŗµīćµĀćŃĆéÕ”éµ×£Ķ»źÕÅéµĢ░µ£¬ń╗ÖÕ«Ü’╝īÕłÖõ╝ÜÕ░ØĶ»ĢõĮ┐ńö©ń▒╗Õ▒׵Ʀ `default_prefix` õĮ£õĖ║ÕēŹń╝ĆŃĆé
+
+```python
+class BaseMetric(metaclass=ABCMeta):
+
+ default_prefix: Optional[str] = None
+
+ def __init__(self,
+ collect_device: str = 'cpu',
+ prefix: Optional[str] = None) -> None:
+ ...
+```
+
+`BaseMetric` µ£ēõ╗źõĖŗ 2 õĖ¬ķćŹĶ”üńÜäµ¢╣µ│Ģķ£ĆĶ”üÕ£©ÕŁÉń▒╗õĖŁķćŹÕåÖ’╝Ü
+
+- **`process()`** ńö©õ║ÄÕżäńÉåµ»ÅõĖ¬µē╣µ¼ĪńÜ䵥ŗĶ»ĢµĢ░µŹ«ÕÆīµ©ĪÕ×ŗķó䵥ŗń╗ōµ×£ŃĆéÕżäńÉåń╗ōµ×£Õ║öÕŁśµöŠÕ£© `self.results` ÕłŚĶĪ©õĖŁ’╝īńö©õ║ÄÕ£©ÕżäńÉåÕ«īµēƵ£ēµĄŗĶ»ĢµĢ░µŹ«ÕÉÄĶ«Īń«ŚĶ»äµĄŗµīćµĀćŃĆéĶ»źµ¢╣µ│ĢÕģʵ£ēõ╗źõĖŗ 2 õĖ¬ÕÅéµĢ░’╝Ü
+
+ - `data_batch`’╝ÜõĖĆõĖ¬µē╣µ¼ĪńÜ䵥ŗĶ»ĢµĢ░µŹ«µĀʵ£¼’╝īķĆÜÕĖĖńø┤µÄźµØźĶć¬õĖĵĢ░µŹ«ÕŖĀĶĮĮÕÖ©
+ - `data_samples`’╝ÜÕ»╣Õ║öńÜ䵩ĪÕ×ŗķó䵥ŗń╗ōµ×£
+ Ķ»źµ¢╣µ│Ģµ▓Īµ£ēĶ┐öÕø×ÕĆ╝ŃĆéÕćĮµĢ░µÄźÕÅŻÕ«Üõ╣ēÕ”éõĖŗ’╝Ü
+
+ ```python
+ @abstractmethod
+ def process(self, data_batch: Any, data_samples: Sequence[dict]) -> None:
+ """Process one batch of data samples and predictions. The processed
+ results should be stored in ``self.results``, which will be used to
+ compute the metrics when all batches have been processed.
+ Args:
+ data_batch (Any): A batch of data from the dataloader.
+ data_samples (Sequence[dict]): A batch of outputs from the model.
+ """
+ ```
+
+- **`compute_metrics()`** ńö©õ║ÄĶ«Īń«ŚĶ»äµĄŗµīćµĀć’╝īÕ╣ČÕ░åµēĆĶ»äµĄŗµīćµĀćÕŁśµöŠÕ£©õĖĆõĖ¬ÕŁŚÕģĖõĖŁĶ┐öÕø×ŃĆéĶ»źµ¢╣µ│Ģµ£ēõ╗źõĖŗ 1 õĖ¬ÕÅéµĢ░’╝Ü
+
+ - `results`’╝ÜÕłŚĶĪ©ń▒╗Õ×ŗ’╝īÕŁśµöŠõ║åµēƵ£ēµē╣µ¼ĪµĄŗĶ»ĢµĢ░µŹ«ń╗ÅĶ┐ć `process()` µ¢╣µ│ĢÕżäńÉåÕÉÄÕŠŚÕł░ńÜäń╗ōµ×£
+ Ķ»źµ¢╣µ│ĢĶ┐öÕø×õĖĆõĖ¬ÕŁŚÕģĖ’╝īķćīķØóõ┐ØÕŁśõ║åĶ»äµĄŗµīćµĀćńÜäÕÉŹń¦░ÕÆīÕ»╣Õ║öńÜäĶ»äµĄŗÕĆ╝ŃĆéÕćĮµĢ░µÄźÕÅŻÕ«Üõ╣ēÕ”éõĖŗ’╝Ü
+
+ ```python
+ @abstractmethod
+ def compute_metrics(self, results: list) -> dict:
+ """Compute the metrics from processed results.
+
+ Args:
+ results (list): The processed results of each batch.
+
+ Returns:
+ dict: The computed metrics. The keys are the names of the metrics,
+ and the values are corresponding results.
+ """
+ ```
+
+ÕģČõĖŁ’╝ī`compute_metrics()` õ╝ÜÕ£© `evaluate()` µ¢╣µ│ĢõĖŁĶó½Ķ░āńö©’╝øÕÉÄĶĆģÕ£©Ķ«Īń«ŚĶ»äµĄŗµīćµĀćÕēŹ’╝īõ╝ÜÕ£©ÕłåÕĖāÕ╝ŵĄŗĶ»ĢµŚČµöČķøåÕÆīµ▒ćµĆ╗õĖŹÕÉī rank ńÜäõĖŁķŚ┤ÕżäńÉåń╗ōµ×£ŃĆé
+
+ķ£ĆĶ”üµ│©µäÅńÜ䵜»’╝ī`self.results` õĖŁÕŁśµöŠńÜäÕģĘõĮōń▒╗Õ×ŗÕÅ¢Õå│õ║ÄĶ»äµĄŗµīćµĀćÕŁÉń▒╗ńÜäÕ«×ńÄ░ŃĆéõŠŗÕ”é’╝īÕĮōµĄŗĶ»ĢµĀʵ£¼µł¢µ©ĪÕ×ŗĶŠōÕć║µĢ░µŹ«ķćÅĶŠāÕż¦’╝łÕ”éĶ»Łõ╣ēÕłåÕē▓ŃĆüÕøŠÕāÅńö¤µłÉńŁēõ╗╗ÕŖĪ’╝ē’╝īõĖŹÕ«£Õģ©ķā©ÕŁśµöŠÕ£©ÕåģÕŁśõĖŁµŚČ’╝īÕÅ»õ╗źÕ£© `self.results` õĖŁÕŁśµöŠµ»ÅõĖ¬µē╣µ¼ĪĶ«Īń«ŚÕŠŚÕł░ńÜäµīćµĀć’╝īÕ╣ČÕ£© `compute_metrics()` õĖŁµ▒ćµĆ╗’╝øµł¢Õ░åµ»ÅõĖ¬µē╣µ¼ĪńÜäõĖŁķŚ┤ń╗ōµ×£ÕŁśÕé©Õł░õĖ┤µŚČµ¢ćõ╗ČõĖŁ’╝īÕ╣ČÕ£© `self.results` õĖŁÕŁśµöŠõĖ┤µŚČµ¢ćõ╗ČĶĘ»ÕŠä’╝īµ£ĆÕÉÄńö▒ `compute_metrics()` õ╗ĵ¢ćõ╗ČõĖŁĶ»╗ÕÅ¢µĢ░µŹ«Õ╣ČĶ«Īń«ŚµīćµĀćŃĆé
+
+## µ©ĪÕ×ŗń▓ŠÕ║”Ķ»äµĄŗµĄüń©ŗ
+
+ķĆÜÕĖĖ’╝īµ©ĪÕ×ŗń▓ŠÕ║”Ķ»äµĄŗńÜäĶ┐ćń©ŗÕ”éõĖŗÕøŠµēĆńż║ŃĆé
+
+**Õ£©ń║┐Ķ»äµĄŗ**’╝ܵĄŗĶ»ĢµĢ░µŹ«ķĆÜÕĖĖõ╝ÜĶó½ÕłÆÕłåõĖ║ĶŗźÕ╣▓µē╣µ¼Ī’╝łbatch’╝ēŃĆéķĆÜĶ┐ćõĖĆõĖ¬ÕŠ¬ńÄ»’╝īõŠØµ¼ĪÕ░åµ»ÅõĖ¬µē╣µ¼ĪńÜäµĢ░µŹ«ķĆüÕģźµ©ĪÕ×ŗ’╝īÕŠŚÕł░Õ»╣Õ║öńÜäķó䵥ŗń╗ōµ×£’╝īÕ╣ČÕ░åµĄŗĶ»ĢµĢ░µŹ«ÕÆīµ©ĪÕ×ŗķó䵥ŗń╗ōµ×£ķĆüÕģźĶ»äµĄŗÕÖ©ŃĆéĶ»äµĄŗÕÖ©õ╝ÜĶ░āńö©Ķ»äµĄŗµīćµĀćńÜä `process()` µ¢╣µ│ĢÕ»╣µĢ░µŹ«ÕÆīķó䵥ŗń╗ōµ×£Ķ┐øĶĪīÕżäńÉåŃĆéÕĮōÕŠ¬ńÄ»ń╗ōµØ¤ÕÉÄ’╝īĶ»äµĄŗÕÖ©õ╝ÜĶ░āńö©Ķ»äµĄŗµīćµĀćńÜä `evaluate()` µ¢╣µ│Ģ’╝īÕÅ»Ķ«Īń«ŚÕŠŚÕł░Õ»╣Õ║öµīćµĀćńÜ䵩ĪÕ×ŗń▓ŠÕ║”ŃĆé
+
+**ń”╗ń║┐Ķ»äµĄŗ**’╝ÜõĖÄÕ£©ń║┐Ķ»äµĄŗĶ┐ćń©ŗń▒╗õ╝╝’╝īÕī║Õł½µś»ńø┤µÄźĶ»╗ÕÅ¢ķóäÕģłõ┐ØÕŁśńÜ䵩ĪÕ×ŗķó䵥ŗń╗ōµ×£µØźĶ┐øĶĪīĶ»äµĄŗŃĆéĶ»äµĄŗÕÖ©µÅÉõŠøõ║å `offline_evaluate` µÄźÕÅŻ’╝īńö©õ║ÄÕ£©ń”╗ń║┐µ¢╣Õ╝ÅõĖŗĶ░āńö©Ķ»äµĄŗµīćµĀćµØźĶ«Īń«Śµ©ĪÕ×ŗń▓ŠÕ║”ŃĆéõĖ║õ║åķü┐ÕģŹÕÉīµŚČÕżäńÉåÕż¦ķćŵĢ░µŹ«Õ»╝Ķć┤ÕåģÕŁśµ║óÕć║’╝īń”╗ń║┐Ķ»äµĄŗµŚČõ╝ÜÕ░åµĄŗĶ»ĢµĢ░µŹ«ÕÆīķó䵥ŗń╗ōµ×£ÕłåµłÉĶŗźÕ╣▓õĖ¬ÕØŚ’╝łchunk’╝ēĶ┐øĶĪīÕżäńÉå’╝īń▒╗õ╝╝Õ£©ń║┐Ķ»äµĄŗõĖŁńÜäµē╣µ¼ĪŃĆé
+
+)
+```
+
+ÕÅ»õ╗źń£ŗÕł░µ│©ÕåīÕł░ Linear µ©ĪÕØŚńÜä `forward_hook_fn` ķÆ®ÕŁÉĶó½Ķ░āńö©’╝īÕ£©Ķ»źķÆ®ÕŁÉõĖŁµēōÕŹ░õ║å Linear µ©ĪÕØŚńÜäµØāķćŹŃĆüÕüÅńĮ«ŃĆüµ©ĪÕØŚńÜäĶŠōÕģźõ╗źÕÅŖĶŠōÕć║ŃĆéµø┤ÕżÜÕģ│õ║Ä PyTorch ķÆ®ÕŁÉńÜäńö©µ│ĢÕÅ»õ╗źķśģĶ»╗ [nn.Module](https://pytorch.org/docs/stable/generated/torch.nn.Module.html)ŃĆé
+
+## MMEngine õĖŁķÆ®ÕŁÉńÜäĶ«ŠĶ«Ī
+
+Õ£©õ╗ŗń╗Ź MMEngine õĖŁķÆ®ÕŁÉńÜäĶ«ŠĶ«Īõ╣ŗÕēŹ’╝īÕģłń«ĆÕŹĢõ╗ŗń╗ŹõĮ┐ńö© PyTorch Õ«×ńÄ░µ©ĪÕ×ŗĶ«Łń╗āńÜäÕ¤║µ£¼µŁźķ¬ż’╝łńż║õŠŗõ╗ŻńĀüµØźĶć¬ [PyTorch Tutorials](https://pytorch.org/tutorials/beginner/blitz/cifar10_tutorial.html#sphx-glr-beginner-blitz-cifar10-tutorial-py)’╝ē’╝Ü
+
+```python
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import torch.optim as optim
+import torchvision.transforms as transforms
+from torch.utils.data import Dataset, DataLoader
+
+class CustomDataset(Dataset):
+ pass
+
+class Net(nn.Module):
+ pass
+
+def main():
+ transform = transforms.ToTensor()
+ train_dataset = CustomDataset(transform=transform, ...)
+ val_dataset = CustomDataset(transform=transform, ...)
+ test_dataset = CustomDataset(transform=transform, ...)
+ train_dataloader = DataLoader(train_dataset, ...)
+ val_dataloader = DataLoader(val_dataset, ...)
+ test_dataloader = DataLoader(test_dataset, ...)
+
+ net = Net()
+ criterion = nn.CrossEntropyLoss()
+ optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
+
+ for i in range(max_epochs):
+ for inputs, labels in train_dataloader:
+ optimizer.zero_grad()
+ outputs = net(inputs)
+ loss = criterion(outputs, labels)
+ loss.backward()
+ optimizer.step()
+
+ with torch.no_grad():
+ for inputs, labels in val_dataloader:
+ outputs = net(inputs)
+ loss = criterion(outputs, labels)
+
+ with torch.no_grad():
+ for inputs, labels in test_dataloader:
+ outputs = net(inputs)
+ accuracy = ...
+```
+
+õĖŖķØóńÜäõ╝¬õ╗ŻńĀüµś»Ķ«Łń╗āµ©ĪÕ×ŗńÜäÕ¤║µ£¼µŁźķ¬żŃĆéÕ”éµ×£Ķ”üÕ£©õĖŖķØóńÜäõ╗ŻńĀüõĖŁÕŖĀÕģźÕ«ÜÕłČÕī¢ńÜäķĆ╗ĶŠæ’╝īµłæõ╗¼ķ£ĆĶ”üõĖŹµ¢Łõ┐«µö╣ÕÆīµŗōÕ▒Ģ `main` ÕćĮµĢ░ŃĆéõĖ║õ║åµÅÉķ½ś `main` ÕćĮµĢ░ńÜäńüĄµ┤╗µĆ¦ÕÆīµŗōÕ▒ĢµĆ¦’╝īµłæõ╗¼ÕÅ»õ╗źÕ£© `main` µ¢╣µ│ĢõĖŁµÅÆÕģźõĮŹńé╣’╝īÕ╣ČÕ£©Õ»╣Õ║öõĮŹńé╣Õ«×ńÄ░Ķ░āńö© hook ńÜäµŖĮĶ▒ĪķĆ╗ĶŠæŃĆ鵣żµŚČÕŬķ£ĆÕ£©Ķ┐Öõ║øõĮŹńé╣µÅÆÕģź hook µØźÕ«×ńÄ░Õ«ÜÕłČÕī¢ķĆ╗ĶŠæ’╝īÕŹ│ÕÅ»µĘ╗ÕŖĀÕ«ÜÕłČÕī¢ÕŖ¤ĶāĮ’╝īõŠŗÕ”éÕŖĀĶĮĮµ©ĪÕ×ŗµØāķćŹŃĆüµø┤µ¢░µ©ĪÕ×ŗÕÅéµĢ░ńŁēŃĆé
+
+```python
+def main():
+ ...
+ call_hooks('before_run', hooks) # õ╗╗ÕŖĪÕ╝ĆÕ¦ŗÕēŹµē¦ĶĪīńÜäķĆ╗ĶŠæ
+ call_hooks('after_load_checkpoint', hooks) # ÕŖĀĶĮĮµØāķćŹÕÉĵē¦ĶĪīńÜäķĆ╗ĶŠæ
+ call_hooks('before_train', hooks) # Ķ«Łń╗āÕ╝ĆÕ¦ŗÕēŹµē¦ĶĪīńÜäķĆ╗ĶŠæ
+ for i in range(max_epochs):
+ call_hooks('before_train_epoch', hooks) # ķüŹÕÄåĶ«Łń╗āµĢ░µŹ«ķøåÕēŹµē¦ĶĪīńÜäķĆ╗ĶŠæ
+ for inputs, labels in train_dataloader:
+ call_hooks('before_train_iter', hooks) # µ©ĪÕ×ŗÕēŹÕÉæĶ«Īń«ŚÕēŹµē¦ĶĪīńÜäķĆ╗ĶŠæ
+ outputs = net(inputs)
+ loss = criterion(outputs, labels)
+ call_hooks('after_train_iter', hooks) # µ©ĪÕ×ŗÕēŹÕÉæĶ«Īń«ŚÕÉĵē¦ĶĪīńÜäķĆ╗ĶŠæ
+ loss.backward()
+ optimizer.step()
+ call_hooks('after_train_epoch', hooks) # ķüŹÕÄåÕ«īĶ«Łń╗āµĢ░µŹ«ķøåÕÉĵē¦ĶĪīńÜäķĆ╗ĶŠæ
+
+ call_hooks('before_val_epoch', hooks) # ķüŹÕÄåķ¬īĶ»üµĢ░µŹ«ķøåÕēŹµē¦ĶĪīńÜäķĆ╗ĶŠæ
+ with torch.no_grad():
+ for inputs, labels in val_dataloader:
+ call_hooks('before_val_iter', hooks) # µ©ĪÕ×ŗÕēŹÕÉæĶ«Īń«ŚÕēŹµē¦ĶĪī
+ outputs = net(inputs)
+ loss = criterion(outputs, labels)
+ call_hooks('after_val_iter', hooks) # µ©ĪÕ×ŗÕēŹÕÉæĶ«Īń«ŚÕÉĵē¦ĶĪī
+ call_hooks('after_val_epoch', hooks) # ķüŹÕÄåÕ«īķ¬īĶ»üµĢ░µŹ«ķøåÕēŹµē¦ĶĪī
+
+ call_hooks('before_save_checkpoint', hooks) # õ┐ØÕŁśµØāķćŹÕēŹµē¦ĶĪīńÜäķĆ╗ĶŠæ
+ call_hooks('after_train', hooks) # Ķ«Łń╗āń╗ōµØ¤ÕÉĵē¦ĶĪīńÜäķĆ╗ĶŠæ
+
+ call_hooks('before_test_epoch', hooks) # ķüŹÕÄåµĄŗĶ»ĢµĢ░µŹ«ķøåÕēŹµē¦ĶĪīńÜäķĆ╗ĶŠæ
+ with torch.no_grad():
+ for inputs, labels in test_dataloader:
+ call_hooks('before_test_iter', hooks) # µ©ĪÕ×ŗÕēŹÕÉæĶ«Īń«ŚÕÉĵē¦ĶĪīńÜäķĆ╗ĶŠæ
+ outputs = net(inputs)
+ accuracy = ...
+ call_hooks('after_test_iter', hooks) # ķüŹÕÄåÕ«īµłÉµĄŗĶ»ĢµĢ░µŹ«ķøåÕÉĵē¦ĶĪīńÜäķĆ╗ĶŠæ
+ call_hooks('after_test_epoch', hooks) # ķüŹÕÄåÕ«īµĄŗĶ»ĢµĢ░µŹ«ķøåÕÉĵē¦ĶĪī
+
+ call_hooks('after_run', hooks) # õ╗╗ÕŖĪń╗ōµØ¤ÕÉĵē¦ĶĪīńÜäķĆ╗ĶŠæ
+```
+
+Õ£© MMEngine õĖŁ’╝īµłæõ╗¼Õ░åĶ«Łń╗āĶ┐ćń©ŗµŖĮĶ▒ĪµłÉµē¦ĶĪīÕÖ©’╝łRunner’╝ē’╝īµē¦ĶĪīÕÖ©ķÖżõ║åÕ«īµłÉńÄ»ÕóāńÜäÕłØÕ¦ŗÕī¢’╝īÕÅ”õĖĆõĖ¬ÕŖ¤ĶāĮµś»Õ£©ńē╣Õ«ÜńÜäõĮŹńé╣Ķ░āńö©ķÆ®ÕŁÉÕ«īµłÉÕ«ÜÕłČÕī¢ķĆ╗ĶŠæŃĆéµø┤ÕżÜÕģ│õ║ĵē¦ĶĪīÕÖ©ńÜäõ╗ŗń╗ŹĶ»ĘķśģĶ»╗[µē¦ĶĪīÕÖ©µ¢ćµĪŻ](../tutorials/runner.md)ŃĆé
+
+õĖ║õ║åµ¢╣õŠ┐ń«ĪńÉå’╝īMMEngine Õ░åõĮŹńé╣Õ«Üõ╣ēõĖ║µ¢╣µ│ĢÕ╣ČķøåµłÉÕł░[ķÆ®ÕŁÉÕ¤║ń▒╗’╝łHook’╝ē](mmengine.hooks.Hook)õĖŁ’╝īµłæõ╗¼ÕŬķ£Ćń╗¦µē┐ķÆ®ÕŁÉÕ¤║ń▒╗Õ╣ȵĀ╣µŹ«ķ£Ćµ▒éÕ£©ńē╣Õ«ÜõĮŹńé╣Õ«×ńÄ░Õ«ÜÕłČÕī¢ķĆ╗ĶŠæ’╝īÕåŹÕ░åķÆ®ÕŁÉµ│©ÕåīÕł░µē¦ĶĪīÕÖ©õĖŁ’╝īõŠ┐ÕÅ»Ķć¬ÕŖ©Ķ░āńö©ķÆ®ÕŁÉõĖŁńøĖÕ║öõĮŹńé╣ńÜäµ¢╣µ│ĢŃĆé
+
+ķÆ®ÕŁÉõĖŁõĖĆÕģ▒µ£ē 22 õĖ¬õĮŹńé╣’╝Ü
+
+- before_run
+- after_run
+- before_train
+- after_train
+- before_train_epoch
+- after_train_epoch
+- before_train_iter
+- after_train_iter
+- before_val
+- after_val
+- before_val_epoch
+- after_val_epoch
+- before_val_iter
+- after_val_iter
+- before_test
+- after_test
+- before_test_epoch
+- after_test_epoch
+- before_test_iter
+- after_test_iter
+- before_save_checkpoint
+- after_load_checkpoint
+
+õĮĀÕÅ»ĶāĮĶ┐śµā│ķśģĶ»╗[ķÆ®ÕŁÉńÜäńö©µ│Ģ](../tutorials/hook.md)µł¢ĶĆģ[ķÆ®ÕŁÉńÜä API µ¢ćµĪŻ](../api/hooks)ŃĆé
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/infer.md b/internlm_langchain/knowledge_base/MMEngine/content/infer.md
new file mode 100644
index 00000000..ffc1a0b7
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/infer.md
@@ -0,0 +1,244 @@
+# µÄ©ńÉåµÄźÕÅŻ
+
+Õ¤║õ║Ä MMEngine Õ╝ĆÕÅæµŚČ’╝īµłæõ╗¼ķĆÜÕĖĖõ╝ÜõĖ║ÕģĘõĮōń«Śµ│ĢÕ«Üõ╣ēõĖĆõĖ¬ķģŹńĮ«µ¢ćõ╗Č’╝īµĀ╣µŹ«ķģŹńĮ«µ¢ćõ╗ČÕÄ╗µ×äÕ╗║[µē¦ĶĪīÕÖ©](./runner.md)’╝īµē¦ĶĪīĶ«Łń╗āŃĆüµĄŗĶ»ĢµĄüń©ŗ’╝īÕ╣Čõ┐ØÕŁśĶ«Łń╗āÕźĮńÜäµØāķćŹŃĆéÕ¤║õ║ÄĶ«Łń╗āÕźĮńÜ䵩ĪÕ×ŗĶ┐øĶĪīµÄ©ńÉåµŚČ’╝īķĆÜÕĖĖķ£ĆĶ”üµē¦ĶĪīõ╗źõĖŗµŁźķ¬ż’╝Ü
+
+1. Õ¤║õ║ÄķģŹńĮ«µ¢ćõ╗ȵ×äÕ╗║µ©ĪÕ×ŗ
+2. ÕŖĀĶĮĮµ©ĪÕ×ŗµØāķćŹ
+3. µÉŁÕ╗║µĢ░µŹ«ķóäÕżäńÉåµĄüń©ŗ
+4. µē¦ĶĪīµ©ĪÕ×ŗÕēŹÕÉæµÄ©ńÉå
+5. ÕÅ»Ķ¦åÕī¢µÄ©ńÉåń╗ōµ×£
+6. ĶŠōÕć║µÄ©ńÉåń╗ōµ×£
+
+Õ»╣õ║ĵŁżń▒╗µĀćÕćåńÜäµÄ©ńÉåµĄüń©ŗ’╝īMMEngine µÅÉõŠøõ║åń╗¤õĖĆńÜäµÄ©ńÉåµÄźÕÅŻ’╝īÕ╣ČõĖöÕ╗║Ķ««ńö©µłĘÕ¤║õ║ÄĶ┐ÖõĖĆÕźŚµÄźÕÅŻĶ¦äĶīāµØźÕ╝ĆÕÅæµÄ©ńÉåõ╗ŻńĀüŃĆé
+
+## õĮ┐ńö©µĀĘõŠŗ
+
+### Õ«Üõ╣ēµÄ©ńÉåÕÖ©
+
+**Õ¤║õ║Ä `BaseInferencer` Õ«×ńÄ░Ķć¬Õ«Üõ╣ēńÜäµÄ©ńÉåÕÖ©**
+
+```python
+from mmengine.infer import BaseInferencer
+
+class CustomInferencer(BaseInferencer)
+ ...
+```
+
+ÕģĘõĮōń╗åĶŖéÕÅéĶĆā[Õ╝ĆÕÅæĶ¦äĶīā](#µÄ©ńÉåµÄźÕÅŻÕ╝ĆÕÅæĶ¦äĶīā)
+
+### µ×äÕ╗║µÄ©ńÉåÕÖ©
+
+**Õ¤║õ║ÄķģŹńĮ«µ¢ćõ╗ČĶĘ»ÕŠäµ×äÕ╗║µÄ©ńÉåÕÖ©**
+
+```python
+cfg = 'path/to/config.py'
+weight = 'path/to/weight.pth'
+
+inferencer = CustomInferencer(model=cfg, weight=weight)
+```
+
+**Õ¤║õ║ÄķģŹńĮ«ń▒╗Õ«×õŠŗµ×äÕ╗║µÄ©ńÉåÕÖ©**
+
+```python
+from mmengine import Config
+
+cfg = Config.fromfile('path/to/config.py')
+weight = 'path/to/weight.pth'
+
+inferencer = CustomInferencer(model=cfg, weight=weight)
+```
+
+**Õ¤║õ║Ä model-index õĖŁÕ«Üõ╣ēńÜä model name µ×äÕ╗║µÄ©ńÉåÕÖ©**’╝īõ╗ź MMDetection õĖŁńÜä [atss µŻĆµĄŗÕÖ©õĖ║õŠŗ](https://github.com/open-mmlab/mmdetection/blob/31c84958f54287a8be2b99cbf87a6dcf12e57753/configs/atss/metafile.yml#L22)’╝īmodel name õĖ║ `atss_r50_fpn_1x_coco`’╝īńö▒õ║Ä model-index õĖŁÕĘ▓ń╗ÅÕ«Üõ╣ēõ║å weight ńÜäĶĘ»ÕŠä’╝īÕøĀµŁżÕÅ»õ╗źõĖŹķģŹńĮ« weight ÕÅéµĢ░ŃĆé
+
+```python
+inferencer = CustomInferencer(model='atss_r50_fpn_1x_coco')
+```
+
+### µē¦ĶĪīµÄ©ńÉå
+
+**µÄ©ńÉåÕŹĢÕ╝ĀÕøŠńēć**
+
+```python
+# ĶŠōÕģźõĖ║ÕøŠńēćĶĘ»ÕŠä
+img = 'path/to/img.jpg'
+result = inferencer(img)
+
+# ĶŠōÕģźõĖ║Ķ»╗ÕÅ¢ńÜäÕøŠńēć(ń▒╗Õ×ŗõĖ║ np.ndarray)
+img = cv2.imread('path/to/img.jpg')
+result = inferencer(img)
+
+# ĶŠōÕģźõĖ║ url
+img = 'https://xxx.com/img.jpg'
+result = inferencer(img)
+```
+
+**µÄ©ńÉåÕżÜÕ╝ĀÕøŠńēć**
+
+```python
+img_dir = 'path/to/directory'
+result = inferencer(img_dir)
+```
+
+```{note}
+OpenMMLab ń│╗ÕłŚń«Śµ│ĢÕ║ōĶ”üµ▒é `inferencer(img)` ĶŠōÕć║õĖĆõĖ¬ `dict`’╝īÕģČõĖŁÕīģÕɽ `visualization: list` ÕÆī `predictions: list` õĖżõĖ¬ÕŁŚµ«Ą’╝īÕłåÕł½Õ»╣Õ║öÕÅ»Ķ¦åÕī¢ń╗ōµ×£ÕÆīķó䵥ŗń╗ōµ×£ŃĆé
+```
+
+## µÄ©ńÉåµÄźÕÅŻÕ╝ĆÕÅæĶ¦äĶīā
+
+inferencer µē¦ĶĪīµÄ©ńÉåµŚČ’╝īķĆÜÕĖĖõ╝ܵē¦ĶĪīõ╗źõĖŗµŁźķ¬ż’╝Ü
+
+1. preprocess’╝ÜĶŠōÕģźµĢ░µŹ«ķóäÕżäńÉå’╝īÕīģµŗ¼µĢ░µŹ«Ķ»╗ÕÅ¢ŃĆüµĢ░µŹ«ķóäÕżäńÉåŃĆüµĢ░µŹ«µĀ╝Õ╝ÅĶĮ¼µŹóńŁē
+2. forward: µ©ĪÕ×ŗÕēŹÕÉæµÄ©ńÉå
+3. visualize’╝Üķó䵥ŗń╗ōµ×£ÕÅ»Ķ¦åÕī¢
+4. postprocess’╝Üķó䵥ŗń╗ōµ×£ÕÉÄÕżäńÉå’╝īÕīģµŗ¼ń╗ōµ×£µĀ╝Õ╝ÅĶĮ¼µŹóŃĆüÕ»╝Õć║ķó䵥ŗń╗ōµ×£ńŁē
+
+õĖ║õ║åõ╝śÕī¢ inferencer ńÜäõĮ┐ńö©õĮōķ¬ī’╝īµłæõ╗¼õĖŹÕĖīµ£øõĮ┐ńö©ĶĆģÕ£©µē¦ĶĪīµÄ©ńÉåµŚČ’╝īķ£ĆĶ”üõĖ║µ»ÅõĖ¬Ķ┐ćń©ŗķāĮķģŹńĮ«õĖĆķüŹÕÅéµĢ░ŃĆ鵏óÕÅźĶ»ØĶ»┤’╝īµłæõ╗¼ÕĖīµ£øõĮ┐ńö©ĶĆģÕÅ»õ╗źÕ£©õĖŹµä¤ń¤źõĖŖĶ┐░µĄüń©ŗńÜäµāģÕåĄõĖŗ’╝īń«ĆÕŹĢõĖ║ `__call__` µÄźÕÅŻķģŹńĮ«ÕÅéµĢ░’╝īÕŹ│ÕŻիīµłÉµÄ©ńÉåŃĆé
+
+`__call__` µÄźÕÅŻõ╝ܵīēńģ¦ķĪ║Õ║ŵē¦ĶĪīõĖŖĶ┐░µŁźķ¬ż’╝īõĮåµś»µ£¼Ķ║½ÕŹ┤õĖŹń¤źķüōõĮ┐ńö©ĶĆģõ╝ĀÕģźńÜäÕÅéµĢ░ķ£ĆĶ”üÕłåÕÅæń╗ÖÕō¬õĖ¬µŁźķ¬ż’╝īÕøĀµŁżÕ╝ĆÕÅæĶĆģÕ£©Õ«×ńÄ░ `CustomInferencer` µŚČ’╝īķ£ĆĶ”üÕ«Üõ╣ē `preprocess_kwargs`’╝ī`forward_kwargs`’╝ī`visualize_kwargs`’╝ī`postprocess_kwargs` 4 õĖ¬ń▒╗Õ▒׵Ʀ’╝īµ»ÅõĖ¬Õ▒׵ƦÕØćõĖ║õĖĆõĖ¬ÕŁŚń¼”ķøåÕÉł’╝ł`Set[str]`’╝ē’╝īńö©õ║ĵīćÕ«Ü `__call__` µÄźÕÅŻõĖŁńÜäÕÅéµĢ░Õ»╣Õ║öÕō¬õĖ¬µŁźķ¬ż’╝Ü
+
+```python
+class CustomInferencer(BaseInferencer):
+ preprocess_kwargs = {'a'}
+ forward_kwargs = {'b'}
+ visualize_kwargs = {'c'}
+ postprocess_kwargs = {'d'}
+
+ def preprocess(self, inputs, batch_size=1, a=None):
+ pass
+
+ def forward(self, inputs, b=None):
+ pass
+
+ def visualize(self, inputs, preds, show, c=None):
+ pass
+
+ def postprocess(self, preds, visualization, return_datasample=False, d=None):
+ pass
+
+ def __call__(
+ self,
+ inputs,
+ batch_size=1,
+ show=True,
+ return_datasample=False,
+ a=None,
+ b=None,
+ c=None,
+ d=None):
+ return super().__call__(
+ inputs, batch_size, show, return_datasample, a=a, b=b, c=c, d=d)
+```
+
+õĖŖĶ┐░õ╗ŻńĀüõĖŁ’╝ī`preprocess`’╝ī`forward`’╝ī`visualize`’╝ī`postprocess` ÕøøõĖ¬ÕćĮµĢ░ńÜä `a`’╝ī`b`’╝ī`c`’╝ī`d` õĖ║ńö©µłĘÕÅ»õ╗źõ╝ĀÕģźńÜäķóØÕż¢ÕÅéµĢ░’╝ł`inputs`, `preds` ńŁēÕÅéµĢ░Õ£© `__call__` ńÜäµē¦ĶĪīĶ┐ćń©ŗõĖŁõ╝ÜĶó½Ķć¬ÕŖ©ÕĪ½Õģź’╝ē’╝īÕøĀµŁżÕ╝ĆÕÅæĶĆģķ£ĆĶ”üÕ£©ń▒╗Õ▒׵Ʀ `preprocess_kwargs`’╝ī`forward_kwargs`’╝ī`visualize_kwargs`’╝ī`postprocess_kwargs` õĖŁµīćÕ«ÜĶ┐Öõ║øÕÅéµĢ░’╝īĶ┐ÖµĀĘ `__call__` ķśČµ«Ąńö©µłĘõ╝ĀÕģźńÜäÕÅéµĢ░Õ░▒ÕÅ»õ╗źĶó½µŁŻńĪ«ÕłåÕÅæń╗ÖÕ»╣Õ║öńÜ䵣źķ¬żŃĆéÕłåÕÅæĶ┐ćń©ŗńö▒ `BaseInferencer.__call__` ÕćĮµĢ░Õ«×ńÄ░’╝īÕ╝ĆÕÅæĶĆģµŚĀķ£ĆÕģ│Õ┐āŃĆé
+
+µŁżÕż¢’╝īµłæõ╗¼ķ£ĆĶ”üÕ░å `CustomInferencer` µ│©ÕåīÕł░Ķć¬Õ«Üõ╣ēµ│©ÕåīÕÖ©µł¢ĶĆģ MMEngine ńÜäµ│©ÕåīÕÖ©õĖŁ
+
+```python
+from mmseg.registry import INFERENCERS
+# õ╣¤ÕÅ»õ╗źµ│©ÕåīÕł░ MMEngine ńÜäµ│©ÕåīõĖŁ
+# from mmengine.registry import INFERENCERS
+
+@INFERENCERS.register_module()
+class CustomInferencer(BaseInferencer):
+ ...
+```
+
+```{note}
+OpenMMLab ń│╗ÕłŚń«Śµ│Ģõ╗ōÕ║ōÕ┐ģķĪ╗Õ░å Inferencer µ│©ÕåīÕł░õĖŗµĖĖõ╗ōÕ║ōńÜäµ│©ÕåīÕÖ©’╝īĶĆīõĖŹĶāĮµ│©ÕåīÕł░ MMEngine ńÜäµĀ╣µ│©ÕåīÕÖ©’╝łķü┐ÕģŹķćŹÕÉŹ’╝ēŃĆé
+```
+
+## µĀĖÕ┐āµÄźÕÅŻĶ»┤µśÄ’╝Ü
+
+### `__init__()`
+
+`BaseInferencer.__init__` ÕĘ▓ń╗ÅÕ«×ńÄ░õ║å[õĮ┐ńö©µĀĘõŠŗ](#µ×äÕ╗║µÄ©ńÉåÕÖ©)õĖŁµ×äÕ╗║µÄ©ńÉåÕÖ©ńÜäķĆ╗ĶŠæ’╝īÕøĀµŁżķĆÜÕĖĖµāģÕåĄõĖŗõĖŹķ£ĆĶ”üķćŹÕåÖ `__init__` ÕćĮµĢ░ŃĆéÕ”éµ×£µā│Õ«×ńÄ░Ķć¬Õ«Üõ╣ēńÜäÕŖĀĶĮĮķģŹńĮ«µ¢ćõ╗ČŃĆüµØāķćŹÕłØÕ¦ŗÕī¢ŃĆüpipeline ÕłØÕ¦ŗÕī¢ńŁēķĆ╗ĶŠæ’╝īõ╣¤ÕÅ»õ╗źķćŹÕåÖ `__init__` µ¢╣µ│ĢŃĆé
+
+### `_init_pipeline()`
+
+```{note}
+µŖĮĶ▒Īµ¢╣µ│Ģ’╝īÕŁÉń▒╗Õ┐ģķĪ╗Õ«×ńÄ░
+```
+
+ÕłØÕ¦ŗÕī¢Õ╣ČĶ┐öÕø× inferencer µēĆķ£ĆńÜä pipelineŃĆépipeline ńö©õ║ÄÕŹĢÕ╝ĀÕøŠńēć’╝īń▒╗õ╝╝õ║Ä OpenMMLab ń│╗ÕłŚń«Śµ│ĢÕ║ōõĖŁÕ«Üõ╣ēńÜä `train_pipeline`’╝ī`test_pipeline`ŃĆéõĮ┐ńö©ĶĆģĶ░āńö© `__call__` µÄźÕÅŻõ╝ĀÕģźńÜäµ»ÅõĖ¬ `inputs`’╝īķāĮõ╝Üń╗ÅĶ┐ć pipeline ÕżäńÉå’╝īń╗äµłÉ batch data’╝īńäČÕÉÄõ╝ĀÕģź `forward` µ¢╣µ│ĢŃĆé
+
+### `_init_collate()`
+
+ÕłØÕ¦ŗÕī¢Õ╣ČĶ┐öÕø× inferencer µēĆķ£ĆńÜä `collate_fn`’╝īÕģČÕĆ╝ńŁēõ╗Ęõ║ÄĶ«Łń╗āĶ┐ćń©ŗõĖŁ Dataloader ńÜä `collate_fn`ŃĆé`BaseInferencer` ķ╗śĶ«żõ╝Üõ╗Ä `test_dataloader` ńÜäķģŹńĮ«õĖŁĶÄĘÕÅ¢ `collate_fn`’╝īÕøĀµŁżķĆÜÕĖĖµāģÕåĄõĖŗõĖŹķ£ĆĶ”üķćŹÕåÖ `_init_collate` ÕćĮµĢ░ŃĆé
+
+### `_init_visualizer()`
+
+ÕłØÕ¦ŗÕī¢Õ╣ČĶ┐öÕø× inferencer µēĆķ£ĆńÜä `visualizer`’╝īÕģČÕĆ╝ńŁēõ╗Ęõ║ÄĶ«Łń╗āĶ┐ćń©ŗõĖŁ `visualizer`ŃĆé`BaseInferencer` ķ╗śĶ«żõ╝Üõ╗Ä `visualizer` ńÜäķģŹńĮ«õĖŁĶÄĘÕÅ¢ `visualizer`’╝īÕøĀµŁżķĆÜÕĖĖµāģÕåĄõĖŗõĖŹķ£ĆĶ”üķćŹÕåÖ `_init_visualizer` ÕćĮµĢ░ŃĆé
+
+### `preprocess()`
+
+ÕģźÕÅé’╝Ü
+
+- inputs’╝ÜĶŠōÕģźµĢ░µŹ«’╝īńö▒ `__call__` õ╝ĀÕģź’╝īķĆÜÕĖĖõĖ║ÕøŠńēćĶĘ»ÕŠäµł¢ĶĆģÕøŠńēćµĢ░µŹ«ń╗䵳ÉńÜäÕłŚĶĪ©
+- batch_size’╝Übatch Õż¦Õ░Å’╝īńö▒õĮ┐ńö©ĶĆģÕ£©Ķ░āńö© `__call__` µŚČõ╝ĀÕģź
+- ÕģČõ╗¢ÕÅéµĢ░’╝Üńö▒ńö©µłĘõ╝ĀÕģź’╝īõĖöÕ£© `preprocess_kwargs` õĖŁµīćÕ«Ü
+
+Ķ┐öÕø×ÕĆ╝’╝Ü
+
+- ńö¤µłÉÕÖ©’╝īµ»Åµ¼ĪĶ┐Łõ╗ŻĶ┐öÕø×õĖĆõĖ¬ batch ńÜäµĢ░µŹ«ŃĆé
+
+`preprocess` ķ╗śĶ«żµś»õĖĆõĖ¬ńö¤µłÉÕÖ©ÕćĮµĢ░’╝īÕ░å `pipeline` ÕÅŖ `collate_fn` Õ║öńö©õ║ÄĶŠōÕģźµĢ░µŹ«’╝īńö¤µłÉÕÖ©Ķ┐Łõ╗ŻĶ┐öÕø×ńÜ䵜»ń╗äÕ«ī batch’╝īķóäÕżäńÉåÕÉÄńÜäń╗ōµ×£ŃĆéķĆÜÕĖĖµāģÕåĄõĖŗÕŁÉń▒╗µŚĀķ£ĆķćŹÕåÖŃĆé
+
+### `forward()`
+
+ÕģźÕÅé’╝Ü
+
+- inputs’╝ÜĶŠōÕģźµĢ░µŹ«’╝īńö▒ `preprocess` ÕżäńÉåÕÉÄńÜä batch data
+- ÕģČõ╗¢ÕÅéµĢ░’╝Üńö▒ńö©µłĘõ╝ĀÕģź’╝īõĖöÕ£© `forward_kwargs` õĖŁµīćÕ«Ü
+
+Ķ┐öÕø×ÕĆ╝’╝Ü
+
+- ķó䵥ŗń╗ōµ×£’╝īķ╗śĶ«żń▒╗Õ×ŗõĖ║ `List[BaseDataElement]`
+
+Ķ░āńö© `model.test_step` µē¦ĶĪīÕēŹÕÉæµÄ©ńÉå’╝īÕ╣ČĶ┐öÕø׵ĩńÉåń╗ōµ×£ŃĆéķĆÜÕĖĖµāģÕåĄõĖŗÕŁÉń▒╗µŚĀķ£ĆķćŹÕåÖŃĆé
+
+### `visualize()`
+
+```{note}
+µŖĮĶ▒Īµ¢╣µ│Ģ’╝īÕŁÉń▒╗Õ┐ģķĪ╗Õ«×ńÄ░
+```
+
+ÕģźÕÅé’╝Ü
+
+- inputs’╝ÜĶŠōÕģźµĢ░µŹ«’╝īµ£¬ń╗ÅĶ┐ćķóäÕżäńÉåńÜäÕĤզŗµĢ░µŹ«ŃĆé
+- preds’╝ܵ©ĪÕ×ŗńÜäķó䵥ŗń╗ōµ×£
+- show’╝ܵś»ÕÉ”ÕÅ»Ķ¦åÕī¢
+- ÕģČõ╗¢ÕÅéµĢ░’╝Üńö▒ńö©µłĘõ╝ĀÕģź’╝īõĖöÕ£© `visualize_kwargs` õĖŁµīćÕ«Ü
+
+Ķ┐öÕø×ÕĆ╝’╝Ü
+
+- ÕÅ»Ķ¦åÕī¢ń╗ōµ×£’╝īń▒╗Õ×ŗķĆÜÕĖĖõĖ║ `List[np.ndarray]`’╝īõ╗źńø«µĀ浯ƵĄŗõ╗╗ÕŖĪõĖ║õŠŗ’╝īÕłŚĶĪ©õĖŁńÜäµ»ÅõĖ¬Õģāń┤ĀÕ║öĶ»źµś»ńö╗Õ«īµŻĆµĄŗµĪåÕÉÄńÜäÕøŠÕāÅ’╝īńø┤µÄźõĮ┐ńö© `cv2.imshow` Õ░▒ĶāĮÕÅ»Ķ¦åÕī¢µŻĆµĄŗń╗ōµ×£ŃĆéõĖŹÕÉīõ╗╗ÕŖĪńÜäÕÅ»Ķ¦åÕī¢µĄüń©ŗµ£ēµēĆõĖŹÕÉī’╝ī`visualize` Õ║öĶ»źĶ┐öÕø×Ķ»źķóåÕ¤¤Õåģ’╝īķĆéńö©õ║ÄÕĖĖĶ¦üÕÅ»Ķ¦åÕī¢µĄüń©ŗńÜäń╗ōµ×£ŃĆé
+
+### `postprocess()`
+
+```{note}
+µŖĮĶ▒Īµ¢╣µ│Ģ’╝īÕŁÉń▒╗Õ┐ģķĪ╗Õ«×ńÄ░
+```
+
+ÕģźÕÅé’╝Ü
+
+- preds’╝ܵ©ĪÕ×ŗķó䵥ŗń╗ōµ×£’╝īń▒╗Õ×ŗõĖ║ `list`’╝īÕłŚĶĪ©õĖŁńÜäµ»ÅõĖ¬Õģāń┤ĀĶĪ©ńż║õĖĆõĖ¬µĢ░µŹ«ńÜäķó䵥ŗń╗ōµ×£ŃĆéOpenMMLab ń│╗ÕłŚń«Śµ│ĢÕ║ōõĖŁ’╝īķó䵥ŗń╗ōµ×£õĖŁµ»ÅõĖ¬Õģāń┤ĀńÜäń▒╗Õ×ŗÕØćõĖ║ `BaseDataElement`
+- visualization’╝ÜÕÅ»Ķ¦åÕī¢ń╗ōµ×£
+- return_datasample’╝ܵś»ÕÉ”ń╗┤µīü datasample Ķ┐öÕø×ŃĆé`False` µŚČĶĮ¼µŹóµłÉ `dict` Ķ┐öÕø×
+- ÕģČõ╗¢ÕÅéµĢ░’╝Üńö▒ńö©µłĘõ╝ĀÕģź’╝īõĖöÕ£© `postprocess_kwargs` õĖŁµīćÕ«Ü
+
+Ķ┐öÕø×ÕĆ╝’╝Ü
+
+- ÕÅ»Ķ¦åÕī¢ń╗ōµ×£ÕÆīķó䵥ŗń╗ōµ×£’╝īń▒╗Õ×ŗõĖ║õĖĆõĖ¬ÕŁŚÕģĖŃĆéOpenMMLab ń│╗ÕłŚń«Śµ│ĢÕ║ōĶ”üµ▒éĶ┐öÕø×ńÜäÕŁŚÕģĖÕīģÕɽ `predictions` ÕÆī `visualization` õĖżõĖ¬ keyŃĆé
+
+### `__call__()`
+
+ÕģźÕÅé’╝Ü
+
+- inputs’╝ÜĶŠōÕģźµĢ░µŹ«’╝īķĆÜÕĖĖõĖ║ÕøŠńēćĶĘ»ÕŠäŃĆüµł¢ĶĆģÕøŠńēćµĢ░µŹ«ń╗䵳ÉńÜäÕłŚĶĪ©ŃĆé`inputs` õĖŁńÜäµ»ÅõĖ¬Õģāń┤Āõ╣¤ÕÅ»õ╗źµś»ÕģČõ╗¢ń▒╗Õ×ŗńÜäµĢ░µŹ«’╝īÕŬķ£ĆĶ”üõ┐ØĶ»üµĢ░µŹ«ĶāĮÕż¤Ķó½ [\_init_pipeline](#_init_pipeline) Ķ┐öÕø×ńÜä `pipeline` ÕżäńÉåÕŹ│ÕÅ»ŃĆéÕĮō `inputs` ÕŬÕɽõĖĆõĖ¬µÄ©ńÉåµĢ░µŹ«µŚČ’╝īÕ«āÕÅ»õ╗źõĖŹµś»õĖĆõĖ¬ `list`’╝ī`__call__` õ╝ÜÕ£©Õåģķā©Õ░å `inputs` ÕīģĶŻģµłÉÕłŚĶĪ©’╝īõ╗źõŠ┐õ║ÄÕÉÄń╗ŁÕżäńÉå
+- return_datasample’╝ܵś»ÕÉ”Õ░å datasample ĶĮ¼µŹóµłÉ `dict` Ķ┐öÕø×
+- batch_size’╝ܵĩńÉåńÜä batch size’╝īõ╝ÜĶó½Ķ┐øõĖƵŁźõ╝Āń╗Ö `preprocess` ÕćĮµĢ░
+- ÕģČõ╗¢ÕÅéµĢ░’╝ÜÕłåÕÅæń╗Ö `preprocess`ŃĆü`forward`ŃĆü`visualize`ŃĆü`postprocess` ÕćĮµĢ░ńÜäķóØÕż¢ÕÅéµĢ░
+
+Ķ┐öÕø×ÕĆ╝’╝Ü
+
+- `postprocess` Ķ┐öÕø×ńÜäÕÅ»Ķ¦åÕī¢ń╗ōµ×£ÕÆīķó䵥ŗń╗ōµ×£’╝īń▒╗Õ×ŗõĖ║õĖĆõĖ¬ÕŁŚÕģĖŃĆéOpenMMLab ń│╗ÕłŚń«Śµ│ĢÕ║ōĶ”üµ▒éĶ┐öÕø×ńÜäÕŁŚÕģĖÕīģÕɽ `predictions` ÕÆī `visualization` õĖżõĖ¬ key
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/initialize.md b/internlm_langchain/knowledge_base/MMEngine/content/initialize.md
new file mode 100644
index 00000000..f8d8f0a3
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/initialize.md
@@ -0,0 +1,417 @@
+# µØāķćŹÕłØÕ¦ŗÕī¢
+
+Õ¤║õ║Ä Pytorch µ×äÕ╗║µ©ĪÕ×ŗµŚČ’╝īµłæõ╗¼ķĆÜÕĖĖõ╝ÜķĆēµŗ® [nn.Module](https://pytorch.org/docs/stable/nn.html?highlight=nn%20module#module-torch.nn.modules) õĮ£õĖ║µ©ĪÕ×ŗńÜäÕ¤║ń▒╗’╝īµÉŁķģŹõĮ┐ńö© Pytorch ńÜäÕłØÕ¦ŗÕī¢µ©ĪÕØŚ [torch.nn.init](https://pytorch.org/docs/stable/nn.init.html?highlight=kaiming#torch.nn.init.kaiming_normal_)’╝īÕ«īµłÉµ©ĪÕ×ŗńÜäÕłØÕ¦ŗÕī¢ŃĆéMMEngine Õ£©µŁżÕ¤║ńĪĆõĖŖµŖĮĶ▒ĪÕć║Õ¤║ńĪƵ©ĪÕØŚ’╝łBaseModule’╝ē,Ķ«®µłæõ╗¼ĶāĮÕż¤ķĆÜĶ┐ćõ╝ĀÕÅ鵳¢ķģŹńĮ«µ¢ćõ╗ČµØźķĆēµŗ®µ©ĪÕ×ŗńÜäÕłØÕ¦ŗÕī¢µ¢╣Õ╝ÅŃĆ鵣żÕż¢’╝ī`MMEngine` Ķ┐śµÅÉõŠøõ║åõĖĆń│╗ÕłŚµ©ĪÕØŚÕłØÕ¦ŗÕī¢ÕćĮµĢ░’╝īĶ«®µłæõ╗¼ĶāĮÕż¤µø┤ÕŖĀµ¢╣õŠ┐ńüĄµ┤╗Õ£░ÕłØÕ¦ŗÕī¢µ©ĪÕ×ŗÕÅéµĢ░ŃĆé
+
+## ķģŹńĮ«Õ╝ÅÕłØÕ¦ŗÕī¢
+
+õĖ║õ║åĶāĮÕż¤µø┤ÕŖĀńüĄµ┤╗Õ£░ÕłØÕ¦ŗÕī¢µ©ĪÕ×ŗµØāķ插╝ī`MMEngine` µŖĮĶ▒ĪÕć║õ║嵩ĪÕØŚÕ¤║ń▒╗ `BaseModule`ŃĆ鵩ĪÕØŚÕ¤║ń▒╗ń╗¦µē┐Ķć¬ `nn.Module`’╝īÕ£©ÕģĘÕżć `nn.Module` Õ¤║ńĪĆÕŖ¤ĶāĮńÜäÕÉīµŚČ’╝īĶ┐śµö»µīüÕ£©µ×äķĆĀµŚČµÄźÕÅŚÕÅéµĢ░’╝īõ╗źµŁżµØźķĆēµŗ®µØāķćŹÕłØÕ¦ŗÕī¢µ¢╣Õ╝ÅŃĆéń╗¦µē┐Ķć¬ `BaseModule` ńÜ䵩ĪÕ×ŗÕÅ»õ╗źÕ£©Õ«×õŠŗÕī¢ķśČµ«ĄµÄźÕÅŚ `init_cfg` ÕÅéµĢ░’╝īµłæõ╗¼ÕÅ»õ╗źķĆÜĶ┐ćķģŹńĮ« `init_cfg` õĖ║µ©ĪÕ×ŗõĖŁõ╗╗µäÅń╗äõ╗ČńüĄµ┤╗Õ£░ķĆēµŗ®ÕłØÕ¦ŗÕī¢µ¢╣Õ╝ÅŃĆéńø«ÕēŹµłæõ╗¼ÕÅ»õ╗źÕ£© `init_cfg` õĖŁķģŹńĮ«õ╗źõĖŗÕłØÕ¦ŗÕī¢ÕÖ©’╝Ü
+
+
+
+
+
+µłæõ╗¼ķĆÜĶ┐ćÕćĀõĖ¬õŠŗÕŁÉµØźńÉåĶ¦ŻÕ”éõĮĢÕ£© `init_cfg` ķćīķģŹńĮ«ÕłØÕ¦ŗÕī¢ÕÖ©’╝īµØźķĆēµŗ®µ©ĪÕ×ŗńÜäÕłØÕ¦ŗÕī¢µ¢╣Õ╝ÅŃĆé
+
+### õĮ┐ńö©ķóäĶ«Łń╗āµØāķćŹÕłØÕ¦ŗÕī¢
+
+ÕüćĶ«Šµłæõ╗¼Õ«Üõ╣ēõ║嵩ĪÕ×ŗń▒╗ `ToyNet`’╝īÕ«āń╗¦µē┐Ķ欵©ĪÕØŚÕ¤║ń▒╗’╝ł`BaseModule`’╝ēŃĆ鵣żµŚČµłæõ╗¼ÕÅ»õ╗źÕ£© `ToyNet` ÕłØÕ¦ŗÕī¢µŚČõ╝ĀÕģź `init_cfg` ÕÅéµĢ░µØźķĆēµŗ®µ©ĪÕ×ŗńÜäÕłØÕ¦ŗÕī¢µ¢╣Õ╝Å’╝īÕ«×õŠŗÕī¢ÕÉÄÕåŹĶ░āńö© `init_weights` µ¢╣µ│Ģ’╝īÕ«īµłÉµØāķćŹńÜäÕłØÕ¦ŗÕī¢ŃĆéõ╗źÕŖĀĶĮĮķóäĶ«Łń╗āµØāķćŹõĖ║õŠŗ’╝Ü
+
+```python
+import torch
+import torch.nn as nn
+
+from mmengine.model import BaseModule
+
+
+class ToyNet(BaseModule):
+
+ def __init__(self, init_cfg=None):
+ super().__init__(init_cfg)
+ self.conv1 = nn.Linear(1, 1)
+
+
+# õ┐ØÕŁśķóäĶ«Łń╗āµØāķćŹ
+toy_net = ToyNet()
+torch.save(toy_net.state_dict(), './pretrained.pth')
+pretrained = './pretrained.pth'
+
+# ķģŹńĮ«ÕŖĀĶĮĮķóäĶ«Łń╗āµØāķćŹńÜäÕłØÕ¦ŗÕī¢µ¢╣Õ╝Å
+toy_net = ToyNet(init_cfg=dict(type='Pretrained', checkpoint=pretrained))
+# ÕŖĀĶĮĮµØāķćŹ
+toy_net.init_weights()
+```
+
+```
+08/19 16:50:24 - mmengine - INFO - load model from: ./pretrained.pth
+08/19 16:50:24 - mmengine - INFO - local loads checkpoint from path: ./pretrained.pth
+```
+
+ÕĮō `init_cfg` µś»õĖĆõĖ¬ÕŁŚÕģĖµŚČ’╝ī`type` ÕŁŚµ«ĄÕ░▒ĶĪ©ńż║õĖĆń¦ŹÕłØÕ¦ŗÕī¢ÕÖ©’╝īÕ«āķ£ĆĶ”üĶó½µ│©ÕåīÕł░ `WEIGHT_INITIALIZERS` [µ│©ÕåīÕÖ©](registry.md)ŃĆ鵳æõ╗¼ÕÅ»õ╗źķĆÜĶ┐ćµīćÕ«Ü `init_cfg=dict(type='Pretrained', checkpoint='path/to/ckpt')` µØźÕŖĀĶĮĮķóäĶ«Łń╗āµØāķ插╝īÕģČõĖŁ `Pretrained` õĖ║ `PretrainedInit` ÕłØÕ¦ŗÕī¢ÕÖ©ńÜäń╝®ÕåÖ’╝īĶ┐ÖõĖ¬µśĀÕ░äÕÉŹńö▒ `WEIGHT_INITIALIZERS` ń╗┤µŖż’╝ø`checkpoint` µś» `PretrainedInit` ńÜäÕłØÕ¦ŗÕī¢ÕÅéµĢ░’╝īńö©õ║ĵīćիܵØāķćŹńÜäÕŖĀĶĮĮĶĘ»ÕŠä’╝īÕ«āÕÅ»õ╗źµś»µ£¼Õ£░ńŻüńøśĶĘ»ÕŠä’╝īõ╣¤ÕÅ»õ╗źµś» URLŃĆé
+
+```{note}
+Õ£©µēƵ£ēńÜäÕłØÕ¦ŗÕī¢ÕÖ©õĖŁ’╝ī`PretrainedInit` µŗźµ£ēµ£Ćķ½śńÜäõ╝śÕģłń║¦ŃĆé`init_cfg` õĖŁÕģČõ╗¢ÕłØÕ¦ŗÕī¢ÕÖ©ÕłØÕ¦ŗÕī¢ńÜäµØāķćŹõ╝ÜĶó½ `PretrainedInit` ÕŖĀĶĮĮńÜäķóäĶ«Łń╗āµØāķćŹĶ”åńø¢ŃĆé
+```
+
+### ÕĖĖńö©ńÜäÕłØÕ¦ŗÕī¢µ¢╣Õ╝Å
+
+ÕÆīõĮ┐ńö© `PretrainedInit` ÕłØÕ¦ŗÕī¢ÕÖ©ń▒╗õ╝╝’╝īÕ”éµ×£µłæõ╗¼µā│Õ»╣ÕŹĘń¦»ÕüÜ `Kaiming` ÕłØÕ¦ŗÕī¢’╝īķ£ĆĶ”üõ╗ż `init_cfg=dict(type='Kaiming', layer='Conv2d')`ŃĆéĶ┐ÖµĀʵ©ĪÕ×ŗÕłØÕ¦ŗÕī¢µŚČ’╝īÕ░▒õ╝Üõ╗ź `Kaiming` ÕłØÕ¦ŗÕī¢ńÜäµ¢╣Õ╝ÅµØźÕłØÕ¦ŗÕī¢ń▒╗Õ×ŗõĖ║ `Conv2d` ńÜ䵩ĪÕØŚŃĆé
+
+µ£ēµŚČÕĆÖµłæõ╗¼ÕÅ»ĶāĮķ£ĆĶ”üńö©õĖŹÕÉīńÜäÕłØÕ¦ŗÕī¢µ¢╣Õ╝ÅÕÄ╗ÕłØÕ¦ŗÕī¢õĖŹÕÉīń▒╗Õ×ŗńÜ䵩ĪÕØŚ’╝īõŠŗÕ”éÕ»╣ÕŹĘń¦»õĮ┐ńö© `Kaiming` ÕłØÕ¦ŗÕī¢’╝īÕ»╣ń║┐µĆ¦Õ▒éõĮ┐ńö© `Xavier`
+ÕłØÕ¦ŗÕī¢ŃĆ鵣żµŚČµłæõ╗¼ÕÅ»õ╗źõĮ┐ `init_cfg` µłÉõĖ║õĖĆõĖ¬ÕłŚĶĪ©’╝īÕģČõĖŁńÜäµ»ÅõĖĆõĖ¬Õģāń┤ĀķāĮĶĪ©ńż║Õ»╣µ¤Éõ║øÕ▒éõĮ┐ńö©ńē╣Õ«ÜńÜäÕłØÕ¦ŗÕī¢µ¢╣Õ╝ÅŃĆé
+
+```python
+import torch.nn as nn
+
+from mmengine.model import BaseModule
+
+
+class ToyNet(BaseModule):
+
+ def __init__(self, init_cfg=None):
+ super().__init__(init_cfg)
+ self.linear = nn.Linear(1, 1)
+ self.conv = nn.Conv2d(1, 1, 1)
+
+
+# Õ»╣ÕŹĘń¦»ÕüÜ Kaiming ÕłØÕ¦ŗÕī¢’╝īń║┐µĆ¦Õ▒éÕüÜ Xavier ÕłØÕ¦ŗÕī¢
+toy_net = ToyNet(
+ init_cfg=[
+ dict(type='Kaiming', layer='Conv2d'),
+ dict(type='Xavier', layer='Linear')
+ ], )
+toy_net.init_weights()
+```
+
+```
+08/19 16:50:24 - mmengine - INFO -
+linear.weight - torch.Size([1, 1]):
+XavierInit: gain=1, distribution=normal, bias=0
+
+08/19 16:50:24 - mmengine - INFO -
+linear.bias - torch.Size([1]):
+XavierInit: gain=1, distribution=normal, bias=0
+
+08/19 16:50:24 - mmengine - INFO -
+conv.weight - torch.Size([1, 1, 1, 1]):
+KaimingInit: a=0, mode=fan_out, nonlinearity=relu, distribution =normal, bias=0
+
+08/19 16:50:24 - mmengine - INFO -
+conv.bias - torch.Size([1]):
+KaimingInit: a=0, mode=fan_out, nonlinearity=relu, distribution =normal, bias=0
+```
+
+ń▒╗õ╝╝Õ£░’╝ī`layer` ÕÅéµĢ░õ╣¤ÕÅ»õ╗źµś»õĖĆõĖ¬ÕłŚĶĪ©’╝īĶĪ©ńż║ÕłŚĶĪ©õĖŁńÜäÕżÜń¦ŹõĖŹÕÉīńÜä `layer` ÕØćõĮ┐ńö© `type` µīćÕ«ÜńÜäÕłØÕ¦ŗÕī¢µ¢╣Õ╝Å
+
+```python
+# Õ»╣ÕŹĘń¦»ÕÆīń║┐µĆ¦Õ▒éÕüÜ Kaiming ÕłØÕ¦ŗÕī¢
+toy_net = ToyNet(init_cfg=[dict(type='Kaiming', layer=['Conv2d', 'Linear'])], )
+toy_net.init_weights()
+```
+
+```
+08/19 16:50:24 - mmengine - INFO -
+linear.weight - torch.Size([1, 1]):
+KaimingInit: a=0, mode=fan_out, nonlinearity=relu, distribution =normal, bias=0
+
+08/19 16:50:24 - mmengine - INFO -
+linear.bias - torch.Size([1]):
+KaimingInit: a=0, mode=fan_out, nonlinearity=relu, distribution =normal, bias=0
+
+08/19 16:50:24 - mmengine - INFO -
+conv.weight - torch.Size([1, 1, 1, 1]):
+KaimingInit: a=0, mode=fan_out, nonlinearity=relu, distribution =normal, bias=0
+
+08/19 16:50:24 - mmengine - INFO -
+conv.bias - torch.Size([1]):
+KaimingInit: a=0, mode=fan_out, nonlinearity=relu, distribution =normal, bias=0
+```
+
+### µø┤ń╗åń▓ÆÕ║”ńÜäÕłØÕ¦ŗÕī¢
+
+µ£ēµŚČÕÉīõĖĆń▒╗Õ×ŗńÜäõĖŹÕÉīµ©ĪÕØŚµ£ēõĖŹÕÉīÕłØÕ¦ŗÕī¢µ¢╣Õ╝Å’╝īõŠŗÕ”éńÄ░Õ£©µ£ē `conv1` ÕÆī `conv2` õĖżõĖ¬µ©ĪÕØŚ’╝īõ╗¢õ╗¼ńÜäń▒╗Õ×ŗÕØćõĖ║ `Conv2d`
+ŃĆ鵳æõ╗¼ķ£ĆĶ”üÕ»╣ conv1 Ķ┐øĶĪī `Kaiming` ÕłØÕ¦ŗÕī¢’╝īconv2 Ķ┐øĶĪī `Xavier` ÕłØÕ¦ŗÕī¢’╝īÕłÖÕÅ»õ╗źķĆÜĶ┐ćķģŹńĮ« `override` ÕÅéµĢ░µØźµ╗ĪĶČ│Ķ┐ÖµĀĘńÜäķ£Ćµ▒é’╝Ü
+
+```python
+import torch.nn as nn
+
+from mmengine.model import BaseModule
+
+
+class ToyNet(BaseModule):
+
+ def __init__(self, init_cfg=None):
+ super().__init__(init_cfg)
+ self.conv1 = nn.Conv2d(1, 1, 1)
+ self.conv2 = nn.Conv2d(1, 1, 1)
+
+
+# Õ»╣ conv1 ÕüÜ Kaiming ÕłØÕ¦ŗÕī¢’╝īÕ»╣ õ╗Ä conv2 ÕüÜ Xavier ÕłØÕ¦ŗÕī¢
+toy_net = ToyNet(
+ init_cfg=[
+ dict(
+ type='Kaiming',
+ layer=['Conv2d'],
+ override=dict(name='conv2', type='Xavier')),
+ ], )
+toy_net.init_weights()
+```
+
+```
+08/19 16:50:24 - mmengine - INFO -
+conv1.weight - torch.Size([1, 1, 1, 1]):
+KaimingInit: a=0, mode=fan_out, nonlinearity=relu, distribution =normal, bias=0
+
+08/19 16:50:24 - mmengine - INFO -
+conv1.bias - torch.Size([1]):
+KaimingInit: a=0, mode=fan_out, nonlinearity=relu, distribution =normal, bias=0
+
+08/19 16:50:24 - mmengine - INFO -
+conv2.weight - torch.Size([1, 1, 1, 1]):
+XavierInit: gain=1, distribution=normal, bias=0
+
+08/19 16:50:24 - mmengine - INFO -
+conv2.bias - torch.Size([1]):
+KaimingInit: a=0, mode=fan_out, nonlinearity=relu, distribution =normal, bias=0
+```
+
+`override` ÕÅ»õ╗źńÉåĶ¦ŻµłÉõĖĆõĖ¬ÕĄīÕźŚńÜä `init_cfg`’╝ī õ╗¢ÕÉīµĀĘÕÅ»õ╗źµś» `list` µł¢ĶĆģ `dict`’╝īõ╣¤ķ£ĆĶ”üķĆÜĶ┐ć `type`
+ÕŁŚµ«ĄµīćÕ«ÜÕłØÕ¦ŗÕī¢µ¢╣Õ╝ÅŃĆéõĖŹÕÉīńÜ䵜» `override` Õ┐ģķĪ╗µīćÕ«Ü `name`’╝ī`name` ńøĖÕĮōõ║Ä `override`
+ńÜäõĮ£ńö©Õ¤¤’╝īÕ”éõĖŖõŠŗõĖŁ’╝ī`override` ńÜäõĮ£ńö©Õ¤¤õĖ║ `toy_net.conv2`’╝īµłæõ╗¼õ╝Üõ╗ź `Xavier` ÕłØÕ¦ŗÕī¢µ¢╣Õ╝ÅÕłØÕ¦ŗÕī¢ `toy_net.conv2` õĖŗńÜäµēƵ£ēÕÅéµĢ░’╝īĶĆīõĖŹõ╝ÜÕĮ▒ÕōŹõĮ£ńö©Õ¤¤õ╗źÕż¢ńÜ䵩ĪÕØŚŃĆé
+
+### Ķć¬Õ«Üõ╣ēńÜäÕłØÕ¦ŗÕī¢µ¢╣Õ╝Å
+
+Õ░Įń«Ī `init_cfg` ĶāĮÕż¤µÄ¦ÕłČÕÉäõĖ¬µ©ĪÕØŚńÜäÕłØÕ¦ŗÕī¢µ¢╣Õ╝Å’╝īõĮåµś»Õ£©õĖŹµē®Õ▒Ģ `WEIGHT_INITIALIZERS`
+ńÜäµāģÕåĄõĖŗ’╝īµłæõ╗¼µś»µŚĀµ│ĢÕłØÕ¦ŗÕī¢õĖĆõ║øĶć¬Õ«Üõ╣ēµ©ĪÕØŚńÜä’╝īõŠŗÕ”éĶĪ©µĀ╝õĖŁµÅÉÕł░ńÜäÕż¦ÕżÜµĢ░ÕłØÕ¦ŗÕī¢ÕÖ©’╝īķāĮķ£ĆĶ”üÕ»╣Õ║öńÜ䵩ĪÕØŚµ£ē `weight` ÕÆī `bias` Õ▒׵Ʀ ŃĆéÕ»╣õ║ÄĶ┐Öń¦ŹµāģÕåĄ’╝īµłæõ╗¼Õ╗║Ķ««Ķ«®Ķć¬Õ«Üõ╣ēµ©ĪÕØŚÕ«×ńÄ░ `init_weights` µ¢╣µ│ĢŃĆ鵩ĪÕ×ŗĶ░āńö© `init_weights`
+µŚČ’╝īõ╝ÜķōŠÕ╝ÅÕ£░Ķ░āńö©µēƵ£ēÕŁÉµ©ĪÕØŚńÜä `init_weights`ŃĆé
+
+ÕüćĶ«Šµłæõ╗¼Õ«Üõ╣ēõ║åõ╗źõĖŗµ©ĪÕØŚ’╝Ü
+
+- ń╗¦µē┐Ķć¬ `nn.Module` ńÜä `ToyConv`’╝īÕ«×ńÄ░õ║å `init_weights` µ¢╣µ│Ģ’╝īĶ«® `custom_weight` ÕłØÕ¦ŗÕī¢õĖ║ 1’╝ī`custom_bias` ÕłØÕ¦ŗÕī¢õĖ║ 0
+
+- ń╗¦µē┐Ķ欵©ĪÕØŚÕ¤║ń▒╗ńÜ䵩ĪÕ×ŗ `ToyNet`’╝īõĖöÕɽµ£ē `ToyConv` ÕŁÉµ©ĪÕØŚ
+
+µłæõ╗¼Õ£©Ķ░āńö© `ToyNet` ńÜä `init_weights` µ¢╣µ│ĢµŚČ’╝īõ╝ÜķōŠÕ╝ÅńÜäĶ░āńö©ńÜäÕŁÉµ©ĪÕØŚ `ToyConv` ńÜä `init_weights` µ¢╣µ│Ģ’╝īÕ«×ńÄ░Ķć¬Õ«Üõ╣ēµ©ĪÕØŚńÜäÕłØÕ¦ŗÕī¢ŃĆé
+
+```python
+import torch
+import torch.nn as nn
+
+from mmengine.model import BaseModule
+
+
+class ToyConv(nn.Module):
+
+ def __init__(self):
+ super().__init__()
+ self.custom_weight = nn.Parameter(torch.empty(1, 1, 1, 1))
+ self.custom_bias = nn.Parameter(torch.empty(1))
+
+ def init_weights(self):
+ with torch.no_grad():
+ self.custom_weight = self.custom_weight.fill_(1)
+ self.custom_bias = self.custom_bias.fill_(0)
+
+
+class ToyNet(BaseModule):
+
+ def __init__(self, init_cfg=None):
+ super().__init__(init_cfg)
+ self.conv1 = nn.Conv2d(1, 1, 1)
+ self.conv2 = nn.Conv2d(1, 1, 1)
+ self.custom_conv = ToyConv()
+
+
+toy_net = ToyNet(
+ init_cfg=[
+ dict(
+ type='Kaiming',
+ layer=['Conv2d'],
+ override=dict(name='conv2', type='Xavier'))
+ ])
+# ķōŠÕ╝ÅĶ░āńö© `ToyConv.init_weights()`’╝īõ╗źĶć¬Õ«Üõ╣ēńÜäµ¢╣Õ╝ÅÕłØÕ¦ŗÕī¢
+toy_net.init_weights()
+```
+
+```
+08/19 16:50:24 - mmengine - INFO -
+conv1.weight - torch.Size([1, 1, 1, 1]):
+KaimingInit: a=0, mode=fan_out, nonlinearity=relu, distribution =normal, bias=0
+
+08/19 16:50:24 - mmengine - INFO -
+conv1.bias - torch.Size([1]):
+KaimingInit: a=0, mode=fan_out, nonlinearity=relu, distribution =normal, bias=0
+
+08/19 16:50:24 - mmengine - INFO -
+conv2.weight - torch.Size([1, 1, 1, 1]):
+XavierInit: gain=1, distribution=normal, bias=0
+
+08/19 16:50:24 - mmengine - INFO -
+conv2.bias - torch.Size([1]):
+KaimingInit: a=0, mode=fan_out, nonlinearity=relu, distribution =normal, bias=0
+
+08/19 16:50:24 - mmengine - INFO -
+custom_conv.custom_weight - torch.Size([1, 1, 1, 1]):
+Initialized by user-defined `init_weights` in ToyConv
+
+08/19 16:50:24 - mmengine - INFO -
+custom_conv.custom_bias - torch.Size([1]):
+Initialized by user-defined `init_weights` in ToyConv
+```
+
+### Õ░Åń╗ō
+
+µ£ĆÕÉĵłæõ╗¼Õ»╣ `init_cfg` ÕÆī `init_weights` õĖżń¦ŹÕłØÕ¦ŗÕī¢µ¢╣Õ╝ÅÕüÜõĖĆõ║øµĆ╗ń╗ō’╝Ü
+
+**1. ķģŹńĮ« `init_cfg` µÄ¦ÕłČÕłØÕ¦ŗÕī¢**
+
+- ķĆÜÕĖĖńö©õ║ÄÕłØÕ¦ŗÕī¢õĖĆõ║øµ»öĶŠāÕ║ĢÕ▒éńÜ䵩ĪÕØŚ’╝īõŠŗÕ”éÕŹĘń¦»ŃĆüń║┐µĆ¦Õ▒éńŁēŃĆéÕ”éµ×£µā│ķĆÜĶ┐ć `init_cfg` ķģŹńĮ«Ķć¬Õ«Üõ╣ēµ©ĪÕØŚńÜäÕłØÕ¦ŗÕī¢µ¢╣Õ╝Å’╝īķ£ĆĶ”üÕ░åńøĖÕ║öńÜäÕłØÕ¦ŗÕī¢ÕÖ©µ│©ÕåīÕł░ `WEIGHT_INITIALIZERS` ķćīŃĆé
+- ÕŖ©µĆüÕłØÕ¦ŗÕī¢ńē╣µĆ¦’╝īÕłØÕ¦ŗÕī¢µ¢╣Õ╝ÅķÜÅ `init_cfg` ńÜäÕĆ╝µö╣ÕÅśŃĆé
+
+**2. Õ«×ńÄ░ `init_weights` µ¢╣µ│Ģ**
+
+- ķĆÜÕĖĖńö©õ║ÄÕłØÕ¦ŗÕī¢Ķć¬Õ«Üõ╣ēµ©ĪÕØŚŃĆéńøĖµ»öõ║Ä `init_cfg` ńÜäĶć¬Õ«Üõ╣ēÕłØÕ¦ŗÕī¢’╝īÕ«×ńÄ░ `init_weights` µ¢╣µ│Ģµø┤ÕŖĀń«ĆÕŹĢ’╝īµŚĀķ£Ćµ│©ÕåīŃĆéńäČĶĆī’╝īÕ«āńÜäńüĄµ┤╗µĆ¦õĖŹÕÅŖ `init_cfg`’╝īµŚĀµ│ĢÕŖ©µĆüÕ£░µīćÕ«Üõ╗╗µäŵ©ĪÕØŚńÜäÕłØÕ¦ŗÕī¢µ¢╣Õ╝ÅŃĆé
+
+```{note}
+- init_weights ńÜäõ╝śÕģłń║¦µ»ö `init_cfg` ķ½ś
+- µē¦ĶĪīÕÖ©õ╝ÜÕ£© train() ÕćĮµĢ░õĖŁĶ░āńö© init_weightsŃĆé
+```
+
+## ÕćĮµĢ░Õ╝ÅÕłØÕ¦ŗÕī¢
+
+Õ£©[Ķć¬Õ«Üõ╣ēńÜäÕłØÕ¦ŗÕī¢µ¢╣Õ╝Å](#Ķć¬Õ«Üõ╣ēńÜäÕłØÕ¦ŗÕī¢µ¢╣Õ╝Å)õĖĆĶŖéµÅÉÕł░’╝īµłæõ╗¼ÕÅ»õ╗źÕ£© `init_weights` ķćīÕ«×ńÄ░Ķć¬Õ«Üõ╣ēńÜäÕÅéµĢ░ÕłØÕ¦ŗÕī¢ķĆ╗ĶŠæŃĆéõĖ║õ║åĶāĮÕż¤µø┤ÕŖĀµ¢╣õŠ┐Õ£░Õ«×ńÄ░ÕÅéµĢ░ÕłØÕ¦ŗÕī¢’╝īMMEngine Õ£© `torch.nn.init`ńÜäÕ¤║ńĪĆõĖŖ’╝īµÅÉõŠøõ║åõĖĆń│╗ÕłŚ**µ©ĪÕØŚÕłØÕ¦ŗÕī¢ÕćĮµĢ░**µØźÕłØÕ¦ŗÕī¢µĢ┤õĖ¬µ©ĪÕØŚŃĆéõŠŗÕ”éµłæõ╗¼Õ»╣ÕŹĘń¦»Õ▒éńÜäµØāķ插╝ł`weight`’╝ēĶ┐øĶĪīµŁŻµĆüÕłåÕĖāÕłØÕ¦ŗÕī¢’╝īÕŹĘń¦»Õ▒éńÜäÕüÅńĮ«’╝ł`bias`’╝ēĶ┐øĶĪīÕĖĖµĢ░ÕłØÕ¦ŗÕī¢’╝īÕ¤║õ║Ä `torch.nn.init` ńÜäÕ«×ńÄ░Õ”éõĖŗ’╝Ü
+
+```python
+from torch.nn.init import normal_, constant_
+import torch.nn as nn
+
+model = nn.Conv2d(1, 1, 1)
+normal_(model.weight, mean=0, std=0.01)
+constant_(model.bias, val=0)
+```
+
+```
+Parameter containing:
+tensor([0.], requires_grad=True)
+```
+
+õĖŖĶ┐░µĄüń©ŗÕ«×ķÖģõĖŖµś»ÕŹĘń¦»µŁŻµĆüÕłåÕĖāÕłØÕ¦ŗÕī¢ńÜäµĀćÕćåµĄüń©ŗ’╝īÕøĀµŁż MMEngine Õ£©µŁżÕ¤║ńĪĆõĖŖÕüÜõ║åĶ┐øõĖƵŁźÕ£░ń«ĆÕī¢’╝īÕ«×ńÄ░õ║åõĖĆń│╗ÕłŚÕĖĖńö©ńÜä**µ©ĪÕØŚ**ÕłØÕ¦ŗÕī¢ÕćĮµĢ░ŃĆéńøĖµ»ö `torch.nn.init`’╝īMMEngine µÅÉõŠøńÜäÕłØÕ¦ŗÕī¢ÕćĮµĢ░ńø┤µÄźµÄźÕÅŚÕŹĘń¦»µ©ĪÕØŚ’╝īõĖĆĶĪīõ╗ŻńĀüĶāĮÕ«×ńÄ░ÕÉīµĀĘńÜäÕłØÕ¦ŗÕī¢ķĆ╗ĶŠæ’╝Ü
+
+```python
+from mmengine.model import normal_init
+
+normal_init(model, mean=0, std=0.01, bias=0)
+```
+
+ń▒╗õ╝╝Õ£░’╝īµłæõ╗¼õ╣¤ÕÅ»õ╗źńö© [Kaiming](http://proceedings.mlr.press/v9/glorot10a/glorot10a.pdf) ÕłØÕ¦ŗÕī¢ÕÆī [Xavier](http://proceedings.mlr.press/v9/glorot10a/glorot10a.pdf) ÕłØÕ¦ŗÕī¢’╝Ü
+
+```python
+from mmengine.model import kaiming_init, xavier_init
+
+kaiming_init(model)
+xavier_init(model)
+```
+
+ńø«ÕēŹ MMEngine µÅÉõŠøõ║åõ╗źõĖŗÕłØÕ¦ŗÕī¢ÕćĮµĢ░’╝Ü
+
+
+
+
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/installation.md b/internlm_langchain/knowledge_base/MMEngine/content/installation.md
new file mode 100644
index 00000000..917a2567
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/installation.md
@@ -0,0 +1,75 @@
+# Õ«ēĶŻģ
+
+## ńÄ»ÕóāõŠØĶĄ¢
+
+- Python 3.7+
+- PyTorch 1.6+
+- CUDA 9.2+
+- GCC 5.4+
+
+## ÕćåÕżćńÄ»Õóā
+
+1. õĮ┐ńö© conda µ¢░Õ╗║ĶÖܵŗ¤ńÄ»Õóā’╝īÕ╣ČĶ┐øÕģźĶ»źĶÖܵŗ¤ńÄ»Õóā’╝ø
+
+ ```bash
+ conda create -n open-mmlab python=3.7 -y
+ conda activate open-mmlab
+ ```
+
+2. Õ«ēĶŻģ PyTorch
+
+ Õ£©Õ«ēĶŻģ MMEngine õ╣ŗÕēŹ’╝īĶ»ĘńĪ«õ┐Ø PyTorch ÕĘ▓ń╗ŵłÉÕŖ¤Õ«ēĶŻģÕ£©ńÄ»ÕóāõĖŁ’╝īÕÅ»õ╗źÕÅéĶĆā [PyTorch Õ«śµ¢╣Õ«ēĶŻģµ¢ćµĪŻ](https://pytorch.org/get-started/locally/#start-locally)ŃĆéõĮ┐ńö©õ╗źõĖŗÕæĮõ╗żķ¬īĶ»ü PyTorch µś»ÕɔիēĶŻģ
+
+ ```bash
+ python -c 'import torch;print(torch.__version__)'
+ ```
+
+## Õ«ēĶŻģ MMEngine
+
+### õĮ┐ńö© mim Õ«ēĶŻģ
+
+[mim](https://github.com/open-mmlab/mim) µś» OpenMMLab ķĪ╣ńø«ńÜäÕīģń«ĪńÉåÕĘźÕģĘ’╝īõĮ┐ńö©Õ«āÕÅ»õ╗źÕŠłµ¢╣õŠ┐Õ£░Õ«ēĶŻģ OpenMMLab ķĪ╣ńø«ŃĆé
+
+```bash
+pip install -U openmim
+mim install mmengine
+```
+
+### õĮ┐ńö© pip Õ«ēĶŻģ
+
+```bash
+pip install mmengine
+```
+
+### õĮ┐ńö© docker ķĢ£ÕāÅ
+
+1. µ×äÕ╗║ķĢ£ÕāÅ
+
+ ```bash
+ docker build -t mmengine https://github.com/open-mmlab/mmengine.git#main:docker/release
+ ```
+
+ µø┤ÕżÜµ×äÕ╗║µ¢╣Õ╝ÅĶ»ĘÕÅéĶĆā [mmengine/docker](https://github.com/open-mmlab/mmengine/tree/main/docker)ŃĆé
+
+2. Ķ┐ÉĶĪīķĢ£ÕāÅ
+
+ ```bash
+ docker run --gpus all --shm-size=8g -it mmengine
+ ```
+
+### µ║ÉńĀüÕ«ēĶŻģ
+
+```bash
+# Õ”éµ×£ÕģŗķÜåõ╗ŻńĀüõ╗ōÕ║ōńÜäķƤÕ║”Ķ┐ćµģó’╝īÕÅ»õ╗źõ╗Ä https://gitee.com/open-mmlab/mmengine.git ÕģŗķÜå
+git clone https://github.com/open-mmlab/mmengine.git
+cd mmengine
+pip install -e . -v
+```
+
+## ķ¬īĶ»üÕ«ēĶŻģ
+
+õĖ║õ║åķ¬īĶ»üµś»ÕÉ”µŁŻńĪ«Õ«ēĶŻģõ║å MMEngine ÕÆīµēĆķ£ĆńÜäńÄ»Õóā’╝īµłæõ╗¼ÕÅ»õ╗źĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗ż
+
+```bash
+python -c 'import mmengine;print(mmengine.__version__)'
+```
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/introduction.md b/internlm_langchain/knowledge_base/MMEngine/content/introduction.md
new file mode 100644
index 00000000..e3958151
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/introduction.md
@@ -0,0 +1,58 @@
+# õ╗ŗń╗Ź
+
+MMEngine µś»õĖĆõĖ¬Õ¤║õ║Ä PyTorch Õ«×ńÄ░ńÜä’╝īńö©õ║ÄĶ«Łń╗āµĘ▒Õ║”ÕŁ”õ╣Āµ©ĪÕ×ŗńÜäÕ¤║ńĪĆÕ║ō’╝īµö»µīüÕ£© LinuxŃĆüWindowsŃĆümacOS õĖŖĶ┐ÉĶĪīŃĆéÕ«āÕģʵ£ēÕ”éõĖŗõĖēõĖ¬ńē╣µĆ¦’╝Ü
+
+1. **ķĆÜńö©õĖöÕ╝║Õż¦ńÜäµē¦ĶĪīÕÖ©**’╝Ü
+
+ - µö»µīüńö©Õ░æķćÅõ╗ŻńĀüĶ«Łń╗āõĖŹÕÉīńÜäõ╗╗ÕŖĪ’╝īõŠŗÕ”éõ╗ģõĮ┐ńö© 80 ĶĪīõ╗ŻńĀüÕ░▒ÕÅ»õ╗źĶ«Łń╗ā ImageNet’╝łÕĤզŗ PyTorch ńż║õŠŗķ£ĆĶ”ü 400 ĶĪī’╝ēŃĆé
+ - ĶĮ╗µØŠÕģ╝Õ«╣µĄüĶĪīńÜäń«Śµ│ĢÕ║ō’╝łÕ”é TIMMŃĆüTorchVision ÕÆī Detectron2’╝ēõĖŁńÜ䵩ĪÕ×ŗŃĆé
+
+2. **µÄźÕÅŻń╗¤õĖĆńÜäÕ╝ƵöŠµ×ȵ×ä**’╝Ü
+
+ - õĮ┐ńö©ń╗¤õĖĆńÜäµÄźÕÅŻÕżäńÉåõĖŹÕÉīńÜäń«Śµ│Ģõ╗╗ÕŖĪ’╝īõŠŗÕ”é’╝īÕ«×ńÄ░õĖĆõĖ¬µ¢╣µ│ĢÕ╣ČÕ║öńö©õ║ĵēƵ£ēńÜäÕģ╝Õ«╣µĆ¦µ©ĪÕ×ŗŃĆé
+ - õĖŖõĖŗµĖĖńÜäÕ»╣µÄźµø┤ÕŖĀń╗¤õĖĆõŠ┐µŹĘ’╝īÕ£©õĖ║õĖŖÕ▒éń«Śµ│ĢÕ║ōµÅÉõŠøń╗¤õĖƵŖĮĶ▒ĪńÜäÕÉīµŚČ’╝īµö»µīüÕżÜń¦ŹÕÉÄń½»Ķ«ŠÕżćŃĆéńø«ÕēŹ MMEngine µö»µīü Nvidia CUDAŃĆüMac MPSŃĆüAMDŃĆüMLU ńŁēĶ«ŠÕżćĶ┐øĶĪīµ©ĪÕ×ŗĶ«Łń╗āŃĆé
+
+3. **ÕŻիÜÕłČńÜäĶ«Łń╗āµĄüń©ŗ**’╝Ü
+
+ - Õ«Üõ╣ēõ║åŌĆ£õ╣Éķ½śŌĆØÕ╝ÅńÜäĶ«Łń╗āµĄüń©ŗŃĆé
+ - µÅÉõŠøõ║åõĖ░Õ»īńÜäń╗äõ╗ČÕÆīńŁ¢ńĢźŃĆé
+ - õĮ┐ńö©õĖŹÕÉīńŁēń║¦ńÜä API µÄ¦ÕłČĶ«Łń╗āĶ┐ćń©ŗŃĆé
+
+## µ×ȵ×ä
+
+
+
+õĖŖÕøŠÕ▒Ģńż║õ║å MMEngine Õ£© OpenMMLab 2.0 õĖŁńÜäÕ▒éµ¼ĪŃĆéMMEngine Õ«×ńÄ░õ║å OpenMMLab ń«Śµ│ĢÕ║ōńÜäµ¢░õĖĆõ╗ŻĶ«Łń╗āµ×ȵ×ä’╝īõĖ║ OpenMMLab õĖŁńÜä 30 ÕżÜõĖ¬ń«Śµ│ĢÕ║ōµÅÉõŠøõ║åń╗¤õĖĆńÜäµē¦ĶĪīÕ¤║Õ║¦ŃĆéÕģȵĀĖÕ┐āń╗äõ╗ČÕīģÕɽĶ«Łń╗āÕ╝ĢµōÄŃĆüĶ»äµĄŗÕ╝ĢµōÄÕÆīµ©ĪÕØŚń«ĪńÉåńŁēŃĆé
+
+## µ©ĪÕØŚõ╗ŗń╗Ź
+
+ +
+MMEngine Õ░åĶ«Łń╗āĶ┐ćń©ŗõĖŁµČēÕÅŖńÜäń╗äõ╗ČÕÆīÕ«āõ╗¼ńÜäÕģ│ń│╗Ķ┐øĶĪīõ║åµŖĮĶ▒Ī’╝īÕ”éõĖŖÕøŠµēĆńż║ŃĆéõĖŹÕÉīń«Śµ│ĢÕ║ōõĖŁńÜäÕÉīń▒╗Õ×ŗń╗äõ╗ČÕģʵ£ēńøĖÕÉīńÜäµÄźÕÅŻÕ«Üõ╣ēŃĆé
+
+### µĀĖÕ┐āµ©ĪÕØŚõĖÄńøĖÕģ│ń╗äõ╗Č
+
+Ķ«Łń╗āÕ╝ĢµōÄńÜäµĀĖÕ┐āµ©ĪÕØŚµś»[µē¦ĶĪīÕÖ©’╝łRunner’╝ē](../tutorials/runner.md)ŃĆéµē¦ĶĪīÕÖ©Ķ┤¤Ķ┤Żµē¦ĶĪīĶ«Łń╗āŃĆüµĄŗĶ»ĢÕÆīµÄ©ńÉåõ╗╗ÕŖĪÕ╣Čń«ĪńÉåĶ┐Öõ║øĶ┐ćń©ŗõĖŁµēĆķ£ĆĶ”üńÜäÕÉäõĖ¬ń╗äõ╗ČŃĆéÕ£©Ķ«Łń╗āŃĆüµĄŗĶ»ĢŃĆüµÄ©ńÉåõ╗╗ÕŖĪµē¦ĶĪīĶ┐ćń©ŗõĖŁńÜäńē╣Õ«ÜõĮŹńĮ«’╝īµē¦ĶĪīÕÖ©Ķ«ŠńĮ«õ║å[ķÆ®ÕŁÉ’╝łHook’╝ē](../tutorials/hook.md)µØźÕģüĶ«Ėńö©µłĘµŗōÕ▒ĢŃĆüµÅÆÕģźÕÆīµē¦ĶĪīĶć¬Õ«Üõ╣ēķĆ╗ĶŠæŃĆéµē¦ĶĪīÕÖ©õĖ╗Ķ”üĶ░āńö©Õ”éõĖŗń╗äõ╗ČµØźÕ«īµłÉĶ«Łń╗āÕÆīµÄ©ńÉåĶ┐ćń©ŗõĖŁńÜäÕŠ¬ńÄ»’╝Ü
+
+- [µĢ░µŹ«ķøå’╝łDataset’╝ē](../tutorials/dataset.md)’╝ÜĶ┤¤Ķ┤ŻÕ£©Ķ«Łń╗āŃĆüµĄŗĶ»ĢŃĆüµÄ©ńÉåõ╗╗ÕŖĪõĖŁµ×äÕ╗║µĢ░µŹ«ķøå’╝īÕ╣ČÕ░åµĢ░µŹ«ķĆüń╗Öµ©ĪÕ×ŗŃĆéÕ«×ķÖģõĮ┐ńö©Ķ┐ćń©ŗõĖŁõ╝ÜĶó½µĢ░µŹ«ÕŖĀĶĮĮÕÖ©’╝łDataLoader’╝ēÕ░üĶŻģõĖĆÕ▒é’╝īµĢ░µŹ«ÕŖĀĶĮĮÕÖ©õ╝ÜÕÉ»ÕŖ©ÕżÜõĖ¬ÕŁÉĶ┐øń©ŗµØźÕŖĀĶĮĮµĢ░µŹ«ŃĆé
+- [µ©ĪÕ×ŗ’╝łModel’╝ē](../tutorials/model.md)’╝ÜÕ£©Ķ«Łń╗āĶ┐ćń©ŗõĖŁµÄźÕÅŚµĢ░µŹ«Õ╣ČĶŠōÕć║ loss’╝øÕ£©µĄŗĶ»ĢŃĆüµÄ©ńÉåõ╗╗ÕŖĪõĖŁµÄźÕÅŚµĢ░µŹ«’╝īÕ╣ČĶ┐øĶĪīķó䵥ŗŃĆéÕłåÕĖāÕ╝ÅĶ«Łń╗āńŁēµāģÕåĄõĖŗõ╝ÜĶ󽵩ĪÕ×ŗńÜäÕ░üĶŻģÕÖ©’╝łModel Wrapper’╝īÕ”é `MMDistributedDataParallel`’╝ēÕ░üĶŻģõĖĆÕ▒éŃĆé
+- [õ╝śÕī¢ÕÖ©Õ░üĶŻģ’╝łOptimizer’╝ē](../tutorials/optim_wrapper.md)’╝Üõ╝śÕī¢ÕÖ©Õ░üĶŻģĶ┤¤Ķ┤ŻÕ£©Ķ«Łń╗āĶ┐ćń©ŗõĖŁµē¦ĶĪīÕÅŹÕÉæõ╝ĀµÆŁõ╝śÕī¢µ©ĪÕ×ŗ’╝īÕ╣ČõĖöõ╗źń╗¤õĖĆńÜäµÄźÕÅŻµö»µīüõ║åµĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗āÕÆīµó»Õ║”ń┤»ÕŖĀŃĆé
+- [ÕÅéµĢ░Ķ░āÕ║”ÕÖ©’╝łParameter Scheduler’╝ē](../tutorials/param_scheduler.md)’╝ÜĶ«Łń╗āĶ┐ćń©ŗõĖŁ’╝īÕ»╣ÕŁ”õ╣ĀńÄćŃĆüÕŖ©ķćÅńŁēõ╝śÕī¢ÕÖ©ĶČģÕÅéµĢ░Ķ┐øĶĪīÕŖ©µĆüĶ░āµĢ┤ŃĆé
+
+Õ£©Ķ«Łń╗āķŚ┤ķÜÖµł¢ĶĆģµĄŗĶ»ĢķśČµ«Ą’╝ī[Ķ»äµĄŗµīćµĀćõĖÄĶ»äµĄŗÕÖ©’╝łMetrics & Evaluator’╝ē](../tutorials/evaluation.md)õ╝ÜĶ┤¤Ķ┤ŻÕ»╣µ©ĪÕ×ŗµĆ¦ĶāĮĶ┐øĶĪīĶ»äµĄŗŃĆéÕģČõĖŁĶ»äµĄŗÕÖ©Ķ┤¤Ķ┤ŻÕ¤║õ║ĵĢ░µŹ«ķøåÕ»╣µ©ĪÕ×ŗńÜäķó䵥ŗĶ┐øĶĪīĶ»äõ╝░ŃĆéĶ»äµĄŗÕÖ©ÕåģĶ┐śµ£ēõĖĆÕ▒éµŖĮĶ▒Īµś»Ķ»äµĄŗµīćµĀć’╝īĶ┤¤Ķ┤ŻĶ«Īń«ŚÕģĘõĮōńÜäõĖĆõĖ¬µł¢ÕżÜõĖ¬Ķ»äµĄŗµīćµĀć’╝łÕ”éÕżÕø×ńÄćŃĆüµŁŻńĪ«ńÄćńŁē’╝ēŃĆé
+
+õĖ║õ║åń╗¤õĖƵğÕÅŻ’╝īOpenMMLab 2.0 õĖŁÕÉäõĖ¬ń«Śµ│ĢÕ║ōńÜäĶ»äµĄŗÕÖ©’╝īµ©ĪÕ×ŗÕÆīµĢ░µŹ«õ╣ŗķŚ┤õ║żµĄüńÜäµÄźÕÅŻķāĮõĮ┐ńö©õ║å[µĢ░µŹ«Õģāń┤Ā’╝łData Element’╝ē](../advanced_tutorials/data_element.md)µØźĶ┐øĶĪīÕ░üĶŻģŃĆé
+
+Õ£©Ķ«Łń╗āŃĆüµÄ©ńÉåµē¦ĶĪīĶ┐ćń©ŗõĖŁ’╝īõĖŖĶ┐░ÕÉäõĖ¬ń╗äõ╗ČķāĮÕÅ»õ╗źĶ░āńö©µŚźÕ┐Śń«ĪńÉ嵩ĪÕØŚÕÆīÕÅ»Ķ¦åÕī¢ÕÖ©Ķ┐øĶĪīń╗ōµ×äÕī¢ÕÆīķØ×ń╗ōµ×äÕī¢µŚźÕ┐ŚńÜäÕŁśÕé©õĖÄÕ▒Ģńż║ŃĆé[µŚźÕ┐Śń«ĪńÉå’╝łLogging Modules’╝ē](../advanced_tutorials/logging.md)’╝ÜĶ┤¤Ķ┤Żń«ĪńÉåµē¦ĶĪīÕÖ©Ķ┐ÉĶĪīĶ┐ćń©ŗõĖŁõ║¦ńö¤ńÜäÕÉäń¦ŹµŚźÕ┐Śõ┐Īµü»ŃĆéÕģČõĖŁµČłµü»µ×óń║Į’╝łMessageHub’╝ēĶ┤¤Ķ┤ŻÕ«×ńÄ░ń╗äõ╗ČõĖÄń╗äõ╗ČŃĆüµē¦ĶĪīÕÖ©õĖĵē¦ĶĪīÕÖ©õ╣ŗķŚ┤ńÜäµĢ░µŹ«Õģ▒õ║½’╝īµŚźÕ┐ŚÕżäńÉåÕÖ©’╝łLog Processor’╝ēĶ┤¤Ķ┤ŻÕ»╣µŚźÕ┐Śõ┐Īµü»Ķ┐øĶĪīÕżäńÉå’╝īÕżäńÉåÕÉÄńÜ䵌źÕ┐Śõ╝ÜÕłåÕł½ÕÅæķĆüń╗Öµē¦ĶĪīÕÖ©ńÜ䵌źÕ┐ŚÕÖ©’╝łLogger’╝ēÕÆīÕÅ»Ķ¦åÕī¢ÕÖ©’╝łVisualizer’╝ēĶ┐øĶĪīµŚźÕ┐ŚńÜäń«ĪńÉåõĖÄÕ▒Ģńż║ŃĆé[ÕÅ»Ķ¦åÕī¢ÕÖ©’╝łVisualizer’╝ē](../advanced_tutorials/visualization.md)’╝ÜÕÅ»Ķ¦åÕī¢ÕÖ©Ķ┤¤Ķ┤ŻÕ»╣µ©ĪÕ×ŗńÜäńē╣ÕŠüÕøŠŃĆüķó䵥ŗń╗ōµ×£ÕÆīĶ«Łń╗āĶ┐ćń©ŗõĖŁõ║¦ńö¤ńÜäń╗ōµ×äÕī¢µŚźÕ┐ŚĶ┐øĶĪīÕÅ»Ķ¦åÕī¢’╝īµö»µīü Tensorboard ÕÆī WanDB ńŁēÕżÜń¦ŹÕÅ»Ķ¦åÕī¢ÕÉÄń½»ŃĆé
+
+### Õģ¼Õģ▒Õ¤║ńĪƵ©ĪÕØŚ
+
+MMEngine õĖŁĶ┐śÕ«×ńÄ░õ║åÕÉäń¦Źń«Śµ│Ģµ©ĪÕ×ŗµē¦ĶĪīĶ┐ćń©ŗõĖŁķ£ĆĶ”üńö©Õł░ńÜäÕģ¼Õģ▒Õ¤║ńĪƵ©ĪÕØŚ’╝īÕīģµŗ¼
+
+- [ķģŹńĮ«ń▒╗’╝łConfig’╝ē](../advanced_tutorials/config.md)’╝ÜÕ£© OpenMMLab ń«Śµ│ĢÕ║ōõĖŁ’╝īńö©µłĘÕÅ»õ╗źķĆÜĶ┐ćń╝¢ÕåÖ config µØźķģŹńĮ«Ķ«Łń╗āŃĆüµĄŗĶ»ĢĶ┐ćń©ŗõ╗źÕÅŖńøĖÕģ│ńÜäń╗äõ╗ČŃĆé
+- [µ│©ÕåīÕÖ©’╝łRegistry’╝ē](../advanced_tutorials/registry.md)’╝ÜĶ┤¤Ķ┤Żń«ĪńÉåń«Śµ│ĢÕ║ōõĖŁÕģʵ£ēńøĖÕÉīÕŖ¤ĶāĮńÜ䵩ĪÕØŚŃĆéMMEngine µĀ╣µŹ«Õ»╣ń«Śµ│ĢÕ║ōµ©ĪÕØŚńÜäµŖĮĶ▒Ī’╝īÕ«Üõ╣ēõ║åõĖĆÕźŚµĀ╣µ│©ÕåīÕÖ©’╝īń«Śµ│ĢÕ║ōõĖŁńÜäµ│©ÕåīÕÖ©ÕÅ»õ╗źń╗¦µē┐Ķć¬Ķ┐ÖÕźŚµĀ╣µ│©ÕåīÕÖ©’╝īÕ«×ńÄ░µ©ĪÕØŚńÜäĶĘ©ń«Śµ│ĢÕ║ōĶ░āńö©ŃĆé
+- [µ¢ćõ╗ČĶ»╗ÕåÖ’╝łFile I/O’╝ē](../advanced_tutorials/fileio.md)’╝ÜõĖ║ÕÉäõĖ¬µ©ĪÕØŚńÜäµ¢ćõ╗ČĶ»╗ÕåÖµÅÉõŠøõ║åń╗¤õĖĆńÜäµÄźÕÅŻ’╝īõ╗źń╗¤õĖĆńÜäÕĮóÕ╝ŵö»µīüõ║åÕżÜń¦Źµ¢ćõ╗ČĶ»╗ÕåÖÕÉÄń½»ÕÆīÕżÜń¦Źµ¢ćõ╗ȵĀ╝Õ╝Å’╝īÕ╣ČÕģĘÕżćµē®Õ▒ĢµĆ¦ŃĆé
+- [ÕłåÕĖāÕ╝ÅķĆÜõ┐ĪÕĤĶ»Ł’╝łDistributed Communication Primitives’╝ē](../advanced_tutorials/distributed.md)’╝ÜĶ┤¤Ķ┤ŻÕ£©ń©ŗÕ║ÅÕłåÕĖāÕ╝ÅĶ┐ÉĶĪīĶ┐ćń©ŗõĖŁõĖŹÕÉīĶ┐øń©ŗķŚ┤ńÜäķĆÜõ┐ĪŃĆéĶ┐ÖÕźŚµÄźÕÅŻÕ▒ÅĶöĮõ║åÕłåÕĖāÕ╝ÅÕÆīķØ×ÕłåÕĖāÕ╝ÅńÄ»ÕóāńÜäÕī║Õł½’╝īÕÉīµŚČõ╣¤Ķć¬ÕŖ©ÕżäńÉåõ║åµĢ░µŹ«ńÜäĶ«ŠÕżćÕÆīķĆÜõ┐ĪÕÉÄń½»ŃĆé
+- [ÕģČõ╗¢ÕĘźÕģĘ’╝łUtils’╝ē](../advanced_tutorials/manager_mixin.md)’╝ÜĶ┐śµ£ēõĖĆõ║øÕĘźÕģʵƦńÜ䵩ĪÕØŚ’╝īÕ”é ManagerMixin’╝īÕ«āÕ«×ńÄ░õ║åõĖĆń¦ŹÕģ©Õ▒ĆÕÅśķćÅńÜäÕłøÕ╗║ÕÆīĶÄĘÕÅ¢µ¢╣Õ╝Å’╝īµē¦ĶĪīÕÖ©ÕåģÕŠłÕżÜÕģ©Õ▒ĆÕÅ»Ķ¦üÕ»╣Ķ▒ĪńÜäÕ¤║ń▒╗Õ░▒µś» ManagerMixinŃĆé
+
+ńö©µłĘÕÅ»õ╗źĶ┐øõĖƵŁźķśģĶ»╗[µĢÖń©ŗ](../tutorials/runner.md)µØźõ║åĶ¦ŻĶ┐Öõ║øµ©ĪÕØŚńÜäķ½śń║¦ńö©µ│Ģ’╝īõ╣¤ÕÅ»õ╗źÕÅéĶĆā[Ķ«ŠĶ«Īµ¢ćµĪŻ](../design/hook.md) õ║åĶ¦ŻÕ«āõ╗¼ńÜäĶ«ŠĶ«ĪµĆØĶĘ»õĖÄń╗åĶŖéŃĆé
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/large_model_training.md b/internlm_langchain/knowledge_base/MMEngine/content/large_model_training.md
new file mode 100644
index 00000000..6539d1a2
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/large_model_training.md
@@ -0,0 +1,265 @@
+# Õż¦µ©ĪÕ×ŗĶ«Łń╗ā
+
+Õ£©Ķ«Łń╗āÕż¦µ©ĪÕ×ŗµŚČ’╝īķ£ĆĶ”üÕ║×Õż¦ńÜäĶĄäµ║ÉŃĆéÕŹĢÕŹĪµśŠÕŁśķĆÜÕĖĖõĖŹĶāĮµ╗ĪĶČ│Ķ«Łń╗āńÜäķ£ĆĶ”ü’╝īÕøĀµŁżÕć║ńÄ░õ║åÕż¦µ©ĪÕ×ŗĶ«Łń╗āµŖƵ£»’╝īÕģČõĖŁÕģĖÕ×ŗńÜäõĖĆń¦Źµś» [DeepSpeed ZeRO](https://www.deepspeed.ai/tutorials/zero/#zero-overview)ŃĆéDeepSpedd ZeRO µö»µīüÕłćÕłåõ╝śÕī¢ÕÖ©ŃĆüµó»Õ║”õ╗źÕÅŖÕÅéµĢ░ŃĆé
+
+õĖ║õ║åµø┤ÕŖĀńüĄµ┤╗Õ£░µö»µīüÕż¦µ©ĪÕ×ŗĶ«Łń╗āµŖƵ£»’╝īõ╗Ä MMEngine v0.8.0 Õ╝ĆÕ¦ŗ’╝īµłæõ╗¼µÅÉõŠøõ║åµ¢░ńÜäµē¦ĶĪīÕÖ© [FlexibleRunner](mmengine.runner.FlexibleRunner) ÕÆīÕżÜõĖ¬µŖĮĶ▒ĪńŁ¢ńĢź [Strategy](../api/strategy)ŃĆé
+
+```{warning}
+µ¢░ńÜäµē¦ĶĪīÕÖ© FlexibleRunner ÕÆī Strategy Ķ┐śÕżäõ║ÄÕ«×ķ¬īµĆ¦ķśČµ«Ą’╝īÕ£©Õ░åµØźńÜäńēłµ£¼õĖŁ’╝īÕ«āõ╗¼ńÜäµÄźÕÅŻµ£ēÕÅ»ĶāĮõ╝ÜÕÅæńö¤ÕÅśÕī¢ŃĆé
+```
+
+õĖŗķØóńÜäńż║õŠŗõ╗ŻńĀüµæśĶć¬ [examples/distributed_training_with_flexible_runner.py](https://github.com/open-mmlab/mmengine/blob/main/examples/distributed_training_with_flexible_runner.py)ŃĆé
+
+## DeepSpeed
+
+[DeepSpeed](https://github.com/microsoft/DeepSpeed/tree/master) µś»ÕŠ«ĶĮ»Õ╝Ƶ║ÉńÜäÕ¤║õ║Ä PyTorch ńÜäÕłåÕĖāÕ╝ŵĪåµ×Č’╝īÕģȵö»µīüõ║å `ZeRO`, `3D-Parallelism`, `DeepSpeed-MoE`, `ZeRO-Infinity` ńŁēĶ«Łń╗āńŁ¢ńĢźŃĆé
+MMEngine Ķć¬ v0.8.0 Õ╝ĆÕ¦ŗµö»µīüõĮ┐ńö© DeepSpeed Ķ┐øĶĪīµ©ĪÕ×ŗńÜäĶ«Łń╗āŃĆé
+
+õĮ┐ńö© DeepSpeed ÕēŹķ£ĆÕ«ēĶŻģ deepspeed’╝Ü
+
+```bash
+pip install deepspeed
+```
+
+Õ«ēĶŻģÕźĮ deepspeed ÕÉÄ’╝īķ£ĆķģŹńĮ« FlexibleRunner ńÜä strategy ÕÆī optim_wrapper ÕÅéµĢ░’╝Ü
+
+- strategy’╝ܵīćÕ«Ü `type='DeepSpeedStrategy'` Õ╣ČķģŹńĮ«ÕÅéµĢ░ŃĆéÕÅéµĢ░ńÜäĶ»”ń╗åõ╗ŗń╗ŹÕÅ»ķśģĶ»╗ [DeepSpeedStrategy](mmengine._strategy.DeepSpeedStrategy)ŃĆé
+- optim_wrapper’╝ܵīćÕ«Ü `type='DeepSpeedOptimWrapper'` Õ╣ČķģŹńĮ«ÕÅéµĢ░ŃĆéÕÅéµĢ░ńÜäĶ»”ń╗åõ╗ŗń╗ŹÕÅ»ķśģĶ»╗ [DeepSpeedOptimWrapper](mmengine._strategy.deepspeed.DeepSpeedOptimWrapper)ŃĆé
+
+õĖŗķØ󵜻 DeepSpeed ńøĖÕģ│ńÜäķģŹńĮ«’╝Ü
+
+```python
+from mmengine.runner._flexible_runner import FlexibleRunner
+
+# µīćÕ«Ü DeepSpeedStrategy Õ╣ČķģŹńĮ«ÕÅéµĢ░
+strategy = dict(
+ type='DeepSpeedStrategy',
+ fp16=dict(
+ enabled=True,
+ fp16_master_weights_and_grads=False,
+ loss_scale=0,
+ loss_scale_window=500,
+ hysteresis=2,
+ min_loss_scale=1,
+ initial_scale_power=15,
+ ),
+ inputs_to_half=[0],
+ zero_optimization=dict(
+ stage=3,
+ allgather_partitions=True,
+ reduce_scatter=True,
+ allgather_bucket_size=50000000,
+ reduce_bucket_size=50000000,
+ overlap_comm=True,
+ contiguous_gradients=True,
+ cpu_offload=False),
+)
+
+# µīćÕ«Ü DeepSpeedOptimWrapper Õ╣ČķģŹńĮ«ÕÅéµĢ░
+optim_wrapper = dict(
+ type='DeepSpeedOptimWrapper',
+ optimizer=dict(type='AdamW', lr=1e-3))
+
+# ÕłØÕ¦ŗÕī¢ FlexibleRunner
+runner = FlexibleRunner(
+ model=MMResNet50(),
+ work_dir='./work_dirs',
+ strategy=strategy,
+ train_dataloader=train_dataloader,
+ optim_wrapper=optim_wrapper,
+ param_scheduler=dict(type='LinearLR'),
+ train_cfg=dict(by_epoch=True, max_epochs=10, val_interval=1),
+ val_dataloader=val_dataloader,
+ val_cfg=dict(),
+ val_evaluator=dict(type=Accuracy))
+
+# Õ╝ĆÕ¦ŗĶ«Łń╗ā
+runner.train()
+```
+
+õĮ┐ńö©õĖżÕ╝ĀÕŹĪÕÉ»ÕŖ©ÕłåÕĖāÕ╝ÅĶ«Łń╗ā’╝Ü
+
+```bash
+torchrun --nproc-per-node 2 examples/distributed_training_with_flexible_runner.py --use-deepspeed
+```
+
+
+
+MMEngine Õ░åĶ«Łń╗āĶ┐ćń©ŗõĖŁµČēÕÅŖńÜäń╗äõ╗ČÕÆīÕ«āõ╗¼ńÜäÕģ│ń│╗Ķ┐øĶĪīõ║åµŖĮĶ▒Ī’╝īÕ”éõĖŖÕøŠµēĆńż║ŃĆéõĖŹÕÉīń«Śµ│ĢÕ║ōõĖŁńÜäÕÉīń▒╗Õ×ŗń╗äõ╗ČÕģʵ£ēńøĖÕÉīńÜäµÄźÕÅŻÕ«Üõ╣ēŃĆé
+
+### µĀĖÕ┐āµ©ĪÕØŚõĖÄńøĖÕģ│ń╗äõ╗Č
+
+Ķ«Łń╗āÕ╝ĢµōÄńÜäµĀĖÕ┐āµ©ĪÕØŚµś»[µē¦ĶĪīÕÖ©’╝łRunner’╝ē](../tutorials/runner.md)ŃĆéµē¦ĶĪīÕÖ©Ķ┤¤Ķ┤Żµē¦ĶĪīĶ«Łń╗āŃĆüµĄŗĶ»ĢÕÆīµÄ©ńÉåõ╗╗ÕŖĪÕ╣Čń«ĪńÉåĶ┐Öõ║øĶ┐ćń©ŗõĖŁµēĆķ£ĆĶ”üńÜäÕÉäõĖ¬ń╗äõ╗ČŃĆéÕ£©Ķ«Łń╗āŃĆüµĄŗĶ»ĢŃĆüµÄ©ńÉåõ╗╗ÕŖĪµē¦ĶĪīĶ┐ćń©ŗõĖŁńÜäńē╣Õ«ÜõĮŹńĮ«’╝īµē¦ĶĪīÕÖ©Ķ«ŠńĮ«õ║å[ķÆ®ÕŁÉ’╝łHook’╝ē](../tutorials/hook.md)µØźÕģüĶ«Ėńö©µłĘµŗōÕ▒ĢŃĆüµÅÆÕģźÕÆīµē¦ĶĪīĶć¬Õ«Üõ╣ēķĆ╗ĶŠæŃĆéµē¦ĶĪīÕÖ©õĖ╗Ķ”üĶ░āńö©Õ”éõĖŗń╗äõ╗ČµØźÕ«īµłÉĶ«Łń╗āÕÆīµÄ©ńÉåĶ┐ćń©ŗõĖŁńÜäÕŠ¬ńÄ»’╝Ü
+
+- [µĢ░µŹ«ķøå’╝łDataset’╝ē](../tutorials/dataset.md)’╝ÜĶ┤¤Ķ┤ŻÕ£©Ķ«Łń╗āŃĆüµĄŗĶ»ĢŃĆüµÄ©ńÉåõ╗╗ÕŖĪõĖŁµ×äÕ╗║µĢ░µŹ«ķøå’╝īÕ╣ČÕ░åµĢ░µŹ«ķĆüń╗Öµ©ĪÕ×ŗŃĆéÕ«×ķÖģõĮ┐ńö©Ķ┐ćń©ŗõĖŁõ╝ÜĶó½µĢ░µŹ«ÕŖĀĶĮĮÕÖ©’╝łDataLoader’╝ēÕ░üĶŻģõĖĆÕ▒é’╝īµĢ░µŹ«ÕŖĀĶĮĮÕÖ©õ╝ÜÕÉ»ÕŖ©ÕżÜõĖ¬ÕŁÉĶ┐øń©ŗµØźÕŖĀĶĮĮµĢ░µŹ«ŃĆé
+- [µ©ĪÕ×ŗ’╝łModel’╝ē](../tutorials/model.md)’╝ÜÕ£©Ķ«Łń╗āĶ┐ćń©ŗõĖŁµÄźÕÅŚµĢ░µŹ«Õ╣ČĶŠōÕć║ loss’╝øÕ£©µĄŗĶ»ĢŃĆüµÄ©ńÉåõ╗╗ÕŖĪõĖŁµÄźÕÅŚµĢ░µŹ«’╝īÕ╣ČĶ┐øĶĪīķó䵥ŗŃĆéÕłåÕĖāÕ╝ÅĶ«Łń╗āńŁēµāģÕåĄõĖŗõ╝ÜĶ󽵩ĪÕ×ŗńÜäÕ░üĶŻģÕÖ©’╝łModel Wrapper’╝īÕ”é `MMDistributedDataParallel`’╝ēÕ░üĶŻģõĖĆÕ▒éŃĆé
+- [õ╝śÕī¢ÕÖ©Õ░üĶŻģ’╝łOptimizer’╝ē](../tutorials/optim_wrapper.md)’╝Üõ╝śÕī¢ÕÖ©Õ░üĶŻģĶ┤¤Ķ┤ŻÕ£©Ķ«Łń╗āĶ┐ćń©ŗõĖŁµē¦ĶĪīÕÅŹÕÉæõ╝ĀµÆŁõ╝śÕī¢µ©ĪÕ×ŗ’╝īÕ╣ČõĖöõ╗źń╗¤õĖĆńÜäµÄźÕÅŻµö»µīüõ║åµĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗āÕÆīµó»Õ║”ń┤»ÕŖĀŃĆé
+- [ÕÅéµĢ░Ķ░āÕ║”ÕÖ©’╝łParameter Scheduler’╝ē](../tutorials/param_scheduler.md)’╝ÜĶ«Łń╗āĶ┐ćń©ŗõĖŁ’╝īÕ»╣ÕŁ”õ╣ĀńÄćŃĆüÕŖ©ķćÅńŁēõ╝śÕī¢ÕÖ©ĶČģÕÅéµĢ░Ķ┐øĶĪīÕŖ©µĆüĶ░āµĢ┤ŃĆé
+
+Õ£©Ķ«Łń╗āķŚ┤ķÜÖµł¢ĶĆģµĄŗĶ»ĢķśČµ«Ą’╝ī[Ķ»äµĄŗµīćµĀćõĖÄĶ»äµĄŗÕÖ©’╝łMetrics & Evaluator’╝ē](../tutorials/evaluation.md)õ╝ÜĶ┤¤Ķ┤ŻÕ»╣µ©ĪÕ×ŗµĆ¦ĶāĮĶ┐øĶĪīĶ»äµĄŗŃĆéÕģČõĖŁĶ»äµĄŗÕÖ©Ķ┤¤Ķ┤ŻÕ¤║õ║ĵĢ░µŹ«ķøåÕ»╣µ©ĪÕ×ŗńÜäķó䵥ŗĶ┐øĶĪīĶ»äõ╝░ŃĆéĶ»äµĄŗÕÖ©ÕåģĶ┐śµ£ēõĖĆÕ▒éµŖĮĶ▒Īµś»Ķ»äµĄŗµīćµĀć’╝īĶ┤¤Ķ┤ŻĶ«Īń«ŚÕģĘõĮōńÜäõĖĆõĖ¬µł¢ÕżÜõĖ¬Ķ»äµĄŗµīćµĀć’╝łÕ”éÕżÕø×ńÄćŃĆüµŁŻńĪ«ńÄćńŁē’╝ēŃĆé
+
+õĖ║õ║åń╗¤õĖƵğÕÅŻ’╝īOpenMMLab 2.0 õĖŁÕÉäõĖ¬ń«Śµ│ĢÕ║ōńÜäĶ»äµĄŗÕÖ©’╝īµ©ĪÕ×ŗÕÆīµĢ░µŹ«õ╣ŗķŚ┤õ║żµĄüńÜäµÄźÕÅŻķāĮõĮ┐ńö©õ║å[µĢ░µŹ«Õģāń┤Ā’╝łData Element’╝ē](../advanced_tutorials/data_element.md)µØźĶ┐øĶĪīÕ░üĶŻģŃĆé
+
+Õ£©Ķ«Łń╗āŃĆüµÄ©ńÉåµē¦ĶĪīĶ┐ćń©ŗõĖŁ’╝īõĖŖĶ┐░ÕÉäõĖ¬ń╗äõ╗ČķāĮÕÅ»õ╗źĶ░āńö©µŚźÕ┐Śń«ĪńÉ嵩ĪÕØŚÕÆīÕÅ»Ķ¦åÕī¢ÕÖ©Ķ┐øĶĪīń╗ōµ×äÕī¢ÕÆīķØ×ń╗ōµ×äÕī¢µŚźÕ┐ŚńÜäÕŁśÕé©õĖÄÕ▒Ģńż║ŃĆé[µŚźÕ┐Śń«ĪńÉå’╝łLogging Modules’╝ē](../advanced_tutorials/logging.md)’╝ÜĶ┤¤Ķ┤Żń«ĪńÉåµē¦ĶĪīÕÖ©Ķ┐ÉĶĪīĶ┐ćń©ŗõĖŁõ║¦ńö¤ńÜäÕÉäń¦ŹµŚźÕ┐Śõ┐Īµü»ŃĆéÕģČõĖŁµČłµü»µ×óń║Į’╝łMessageHub’╝ēĶ┤¤Ķ┤ŻÕ«×ńÄ░ń╗äõ╗ČõĖÄń╗äõ╗ČŃĆüµē¦ĶĪīÕÖ©õĖĵē¦ĶĪīÕÖ©õ╣ŗķŚ┤ńÜäµĢ░µŹ«Õģ▒õ║½’╝īµŚźÕ┐ŚÕżäńÉåÕÖ©’╝łLog Processor’╝ēĶ┤¤Ķ┤ŻÕ»╣µŚźÕ┐Śõ┐Īµü»Ķ┐øĶĪīÕżäńÉå’╝īÕżäńÉåÕÉÄńÜ䵌źÕ┐Śõ╝ÜÕłåÕł½ÕÅæķĆüń╗Öµē¦ĶĪīÕÖ©ńÜ䵌źÕ┐ŚÕÖ©’╝łLogger’╝ēÕÆīÕÅ»Ķ¦åÕī¢ÕÖ©’╝łVisualizer’╝ēĶ┐øĶĪīµŚźÕ┐ŚńÜäń«ĪńÉåõĖÄÕ▒Ģńż║ŃĆé[ÕÅ»Ķ¦åÕī¢ÕÖ©’╝łVisualizer’╝ē](../advanced_tutorials/visualization.md)’╝ÜÕÅ»Ķ¦åÕī¢ÕÖ©Ķ┤¤Ķ┤ŻÕ»╣µ©ĪÕ×ŗńÜäńē╣ÕŠüÕøŠŃĆüķó䵥ŗń╗ōµ×£ÕÆīĶ«Łń╗āĶ┐ćń©ŗõĖŁõ║¦ńö¤ńÜäń╗ōµ×äÕī¢µŚźÕ┐ŚĶ┐øĶĪīÕÅ»Ķ¦åÕī¢’╝īµö»µīü Tensorboard ÕÆī WanDB ńŁēÕżÜń¦ŹÕÅ»Ķ¦åÕī¢ÕÉÄń½»ŃĆé
+
+### Õģ¼Õģ▒Õ¤║ńĪƵ©ĪÕØŚ
+
+MMEngine õĖŁĶ┐śÕ«×ńÄ░õ║åÕÉäń¦Źń«Śµ│Ģµ©ĪÕ×ŗµē¦ĶĪīĶ┐ćń©ŗõĖŁķ£ĆĶ”üńö©Õł░ńÜäÕģ¼Õģ▒Õ¤║ńĪƵ©ĪÕØŚ’╝īÕīģµŗ¼
+
+- [ķģŹńĮ«ń▒╗’╝łConfig’╝ē](../advanced_tutorials/config.md)’╝ÜÕ£© OpenMMLab ń«Śµ│ĢÕ║ōõĖŁ’╝īńö©µłĘÕÅ»õ╗źķĆÜĶ┐ćń╝¢ÕåÖ config µØźķģŹńĮ«Ķ«Łń╗āŃĆüµĄŗĶ»ĢĶ┐ćń©ŗõ╗źÕÅŖńøĖÕģ│ńÜäń╗äõ╗ČŃĆé
+- [µ│©ÕåīÕÖ©’╝łRegistry’╝ē](../advanced_tutorials/registry.md)’╝ÜĶ┤¤Ķ┤Żń«ĪńÉåń«Śµ│ĢÕ║ōõĖŁÕģʵ£ēńøĖÕÉīÕŖ¤ĶāĮńÜ䵩ĪÕØŚŃĆéMMEngine µĀ╣µŹ«Õ»╣ń«Śµ│ĢÕ║ōµ©ĪÕØŚńÜäµŖĮĶ▒Ī’╝īÕ«Üõ╣ēõ║åõĖĆÕźŚµĀ╣µ│©ÕåīÕÖ©’╝īń«Śµ│ĢÕ║ōõĖŁńÜäµ│©ÕåīÕÖ©ÕÅ»õ╗źń╗¦µē┐Ķć¬Ķ┐ÖÕźŚµĀ╣µ│©ÕåīÕÖ©’╝īÕ«×ńÄ░µ©ĪÕØŚńÜäĶĘ©ń«Śµ│ĢÕ║ōĶ░āńö©ŃĆé
+- [µ¢ćõ╗ČĶ»╗ÕåÖ’╝łFile I/O’╝ē](../advanced_tutorials/fileio.md)’╝ÜõĖ║ÕÉäõĖ¬µ©ĪÕØŚńÜäµ¢ćõ╗ČĶ»╗ÕåÖµÅÉõŠøõ║åń╗¤õĖĆńÜäµÄźÕÅŻ’╝īõ╗źń╗¤õĖĆńÜäÕĮóÕ╝ŵö»µīüõ║åÕżÜń¦Źµ¢ćõ╗ČĶ»╗ÕåÖÕÉÄń½»ÕÆīÕżÜń¦Źµ¢ćõ╗ȵĀ╝Õ╝Å’╝īÕ╣ČÕģĘÕżćµē®Õ▒ĢµĆ¦ŃĆé
+- [ÕłåÕĖāÕ╝ÅķĆÜõ┐ĪÕĤĶ»Ł’╝łDistributed Communication Primitives’╝ē](../advanced_tutorials/distributed.md)’╝ÜĶ┤¤Ķ┤ŻÕ£©ń©ŗÕ║ÅÕłåÕĖāÕ╝ÅĶ┐ÉĶĪīĶ┐ćń©ŗõĖŁõĖŹÕÉīĶ┐øń©ŗķŚ┤ńÜäķĆÜõ┐ĪŃĆéĶ┐ÖÕźŚµÄźÕÅŻÕ▒ÅĶöĮõ║åÕłåÕĖāÕ╝ÅÕÆīķØ×ÕłåÕĖāÕ╝ÅńÄ»ÕóāńÜäÕī║Õł½’╝īÕÉīµŚČõ╣¤Ķć¬ÕŖ©ÕżäńÉåõ║åµĢ░µŹ«ńÜäĶ«ŠÕżćÕÆīķĆÜõ┐ĪÕÉÄń½»ŃĆé
+- [ÕģČõ╗¢ÕĘźÕģĘ’╝łUtils’╝ē](../advanced_tutorials/manager_mixin.md)’╝ÜĶ┐śµ£ēõĖĆõ║øÕĘźÕģʵƦńÜ䵩ĪÕØŚ’╝īÕ”é ManagerMixin’╝īÕ«āÕ«×ńÄ░õ║åõĖĆń¦ŹÕģ©Õ▒ĆÕÅśķćÅńÜäÕłøÕ╗║ÕÆīĶÄĘÕÅ¢µ¢╣Õ╝Å’╝īµē¦ĶĪīÕÖ©ÕåģÕŠłÕżÜÕģ©Õ▒ĆÕÅ»Ķ¦üÕ»╣Ķ▒ĪńÜäÕ¤║ń▒╗Õ░▒µś» ManagerMixinŃĆé
+
+ńö©µłĘÕÅ»õ╗źĶ┐øõĖƵŁźķśģĶ»╗[µĢÖń©ŗ](../tutorials/runner.md)µØźõ║åĶ¦ŻĶ┐Öõ║øµ©ĪÕØŚńÜäķ½śń║¦ńö©µ│Ģ’╝īõ╣¤ÕÅ»õ╗źÕÅéĶĆā[Ķ«ŠĶ«Īµ¢ćµĪŻ](../design/hook.md) õ║åĶ¦ŻÕ«āõ╗¼ńÜäĶ«ŠĶ«ĪµĆØĶĘ»õĖÄń╗åĶŖéŃĆé
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/large_model_training.md b/internlm_langchain/knowledge_base/MMEngine/content/large_model_training.md
new file mode 100644
index 00000000..6539d1a2
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/large_model_training.md
@@ -0,0 +1,265 @@
+# Õż¦µ©ĪÕ×ŗĶ«Łń╗ā
+
+Õ£©Ķ«Łń╗āÕż¦µ©ĪÕ×ŗµŚČ’╝īķ£ĆĶ”üÕ║×Õż¦ńÜäĶĄäµ║ÉŃĆéÕŹĢÕŹĪµśŠÕŁśķĆÜÕĖĖõĖŹĶāĮµ╗ĪĶČ│Ķ«Łń╗āńÜäķ£ĆĶ”ü’╝īÕøĀµŁżÕć║ńÄ░õ║åÕż¦µ©ĪÕ×ŗĶ«Łń╗āµŖƵ£»’╝īÕģČõĖŁÕģĖÕ×ŗńÜäõĖĆń¦Źµś» [DeepSpeed ZeRO](https://www.deepspeed.ai/tutorials/zero/#zero-overview)ŃĆéDeepSpedd ZeRO µö»µīüÕłćÕłåõ╝śÕī¢ÕÖ©ŃĆüµó»Õ║”õ╗źÕÅŖÕÅéµĢ░ŃĆé
+
+õĖ║õ║åµø┤ÕŖĀńüĄµ┤╗Õ£░µö»µīüÕż¦µ©ĪÕ×ŗĶ«Łń╗āµŖƵ£»’╝īõ╗Ä MMEngine v0.8.0 Õ╝ĆÕ¦ŗ’╝īµłæõ╗¼µÅÉõŠøõ║åµ¢░ńÜäµē¦ĶĪīÕÖ© [FlexibleRunner](mmengine.runner.FlexibleRunner) ÕÆīÕżÜõĖ¬µŖĮĶ▒ĪńŁ¢ńĢź [Strategy](../api/strategy)ŃĆé
+
+```{warning}
+µ¢░ńÜäµē¦ĶĪīÕÖ© FlexibleRunner ÕÆī Strategy Ķ┐śÕżäõ║ÄÕ«×ķ¬īµĆ¦ķśČµ«Ą’╝īÕ£©Õ░åµØźńÜäńēłµ£¼õĖŁ’╝īÕ«āõ╗¼ńÜäµÄźÕÅŻµ£ēÕÅ»ĶāĮõ╝ÜÕÅæńö¤ÕÅśÕī¢ŃĆé
+```
+
+õĖŗķØóńÜäńż║õŠŗõ╗ŻńĀüµæśĶć¬ [examples/distributed_training_with_flexible_runner.py](https://github.com/open-mmlab/mmengine/blob/main/examples/distributed_training_with_flexible_runner.py)ŃĆé
+
+## DeepSpeed
+
+[DeepSpeed](https://github.com/microsoft/DeepSpeed/tree/master) µś»ÕŠ«ĶĮ»Õ╝Ƶ║ÉńÜäÕ¤║õ║Ä PyTorch ńÜäÕłåÕĖāÕ╝ŵĪåµ×Č’╝īÕģȵö»µīüõ║å `ZeRO`, `3D-Parallelism`, `DeepSpeed-MoE`, `ZeRO-Infinity` ńŁēĶ«Łń╗āńŁ¢ńĢźŃĆé
+MMEngine Ķć¬ v0.8.0 Õ╝ĆÕ¦ŗµö»µīüõĮ┐ńö© DeepSpeed Ķ┐øĶĪīµ©ĪÕ×ŗńÜäĶ«Łń╗āŃĆé
+
+õĮ┐ńö© DeepSpeed ÕēŹķ£ĆÕ«ēĶŻģ deepspeed’╝Ü
+
+```bash
+pip install deepspeed
+```
+
+Õ«ēĶŻģÕźĮ deepspeed ÕÉÄ’╝īķ£ĆķģŹńĮ« FlexibleRunner ńÜä strategy ÕÆī optim_wrapper ÕÅéµĢ░’╝Ü
+
+- strategy’╝ܵīćÕ«Ü `type='DeepSpeedStrategy'` Õ╣ČķģŹńĮ«ÕÅéµĢ░ŃĆéÕÅéµĢ░ńÜäĶ»”ń╗åõ╗ŗń╗ŹÕÅ»ķśģĶ»╗ [DeepSpeedStrategy](mmengine._strategy.DeepSpeedStrategy)ŃĆé
+- optim_wrapper’╝ܵīćÕ«Ü `type='DeepSpeedOptimWrapper'` Õ╣ČķģŹńĮ«ÕÅéµĢ░ŃĆéÕÅéµĢ░ńÜäĶ»”ń╗åõ╗ŗń╗ŹÕÅ»ķśģĶ»╗ [DeepSpeedOptimWrapper](mmengine._strategy.deepspeed.DeepSpeedOptimWrapper)ŃĆé
+
+õĖŗķØ󵜻 DeepSpeed ńøĖÕģ│ńÜäķģŹńĮ«’╝Ü
+
+```python
+from mmengine.runner._flexible_runner import FlexibleRunner
+
+# µīćÕ«Ü DeepSpeedStrategy Õ╣ČķģŹńĮ«ÕÅéµĢ░
+strategy = dict(
+ type='DeepSpeedStrategy',
+ fp16=dict(
+ enabled=True,
+ fp16_master_weights_and_grads=False,
+ loss_scale=0,
+ loss_scale_window=500,
+ hysteresis=2,
+ min_loss_scale=1,
+ initial_scale_power=15,
+ ),
+ inputs_to_half=[0],
+ zero_optimization=dict(
+ stage=3,
+ allgather_partitions=True,
+ reduce_scatter=True,
+ allgather_bucket_size=50000000,
+ reduce_bucket_size=50000000,
+ overlap_comm=True,
+ contiguous_gradients=True,
+ cpu_offload=False),
+)
+
+# µīćÕ«Ü DeepSpeedOptimWrapper Õ╣ČķģŹńĮ«ÕÅéµĢ░
+optim_wrapper = dict(
+ type='DeepSpeedOptimWrapper',
+ optimizer=dict(type='AdamW', lr=1e-3))
+
+# ÕłØÕ¦ŗÕī¢ FlexibleRunner
+runner = FlexibleRunner(
+ model=MMResNet50(),
+ work_dir='./work_dirs',
+ strategy=strategy,
+ train_dataloader=train_dataloader,
+ optim_wrapper=optim_wrapper,
+ param_scheduler=dict(type='LinearLR'),
+ train_cfg=dict(by_epoch=True, max_epochs=10, val_interval=1),
+ val_dataloader=val_dataloader,
+ val_cfg=dict(),
+ val_evaluator=dict(type=Accuracy))
+
+# Õ╝ĆÕ¦ŗĶ«Łń╗ā
+runner.train()
+```
+
+õĮ┐ńö©õĖżÕ╝ĀÕŹĪÕÉ»ÕŖ©ÕłåÕĖāÕ╝ÅĶ«Łń╗ā’╝Ü
+
+```bash
+torchrun --nproc-per-node 2 examples/distributed_training_with_flexible_runner.py --use-deepspeed
+```
+
+
+
+
+
+ÕģČõĖŁ `window_size` ńÜäÕĆ╝ÕÅ»õ╗źµś»’╝Ü
+
+- µĢ░ÕŁŚ’╝ÜĶĪ©ńż║ń╗¤Ķ«Īń¬ŚÕÅŻńÜäÕż¦Õ░Å
+- `global`’╝Üń╗¤Ķ«ĪÕģ©Õ▒ĆńÜäµ£ĆÕż¦ŃĆüµ£ĆÕ░ÅÕÆīÕØćÕĆ╝
+- `epoch`’╝Üń╗¤Ķ«ĪõĖĆõĖ¬ epoch ÕåģńÜäµ£ĆÕż¦ŃĆüµ£ĆÕ░ÅÕÆīÕØćÕĆ╝
+
+ÕĮōńäȵłæõ╗¼õ╣¤ÕÅ»õ╗źķĆēµŗ®Ķć¬Õ«Üõ╣ēńÜäń╗¤Ķ«Īµ¢╣µ│Ģ’╝īĶ»”ń╗åµŁźķ¬żĶ¦ü[µŚźÕ┐ŚĶ«ŠĶ«Ī](../design/logging.md)ŃĆé
+
+Õ”éµ×£µłæõ╗¼µŚóµā│ń╗¤Ķ«Īń¬ŚÕÅŻõĖ║ 10 ńÜä `loss1` ńÜäÕ▒Ćķā©ÕØćÕĆ╝’╝īÕÅłµā│ń╗¤Ķ«Ī `loss1` ńÜäÕģ©Õ▒ĆÕØćÕĆ╝’╝īÕłÖķ£ĆĶ”üķóØÕż¢µīćÕ«Ü `log_name`’╝Ü
+
+```python
+runner = Runner(
+ model=ToyModel(),
+ work_dir='tmp_dir',
+ train_dataloader=train_dataloader,
+ train_cfg=dict(by_epoch=True, max_epochs=1),
+ optim_wrapper=dict(optimizer=dict(type='SGD', lr=0.01)),
+ log_processor=dict(
+ custom_cfg=[
+ # log_name ĶĪ©ńż║ loss1 ķ揵¢░ń╗¤Ķ«ĪÕÉÄńÜ䵌źÕ┐ŚÕÉŹ
+ dict(data_src='loss1', log_name='loss1_global', method_name='mean', window_size='global')])
+)
+runner.train()
+```
+
+```
+08/21 18:39:32 - mmengine - INFO - Epoch(train) [1][10/25] lr: 1.0000e-02 eta: 0:00:00 time: 0.0016 data_time: 0.0004 loss1: 0.1512 loss2: 0.3751 loss: 0.5264 loss1_global: 0.1512
+08/21 18:39:32 - mmengine - INFO - Epoch(train) [1][20/25] lr: 1.0000e-02 eta: 0:00:00 time: 0.0051 data_time: 0.0036 loss1: 0.0113 loss2: 0.0856 loss: 0.0970 loss1_global: 0.0813
+```
+
+ń▒╗õ╝╝Õ£░’╝īµłæõ╗¼õ╣¤ÕÅ»õ╗źń╗¤Ķ«Ī `loss1` ńÜäÕ▒Ćķā©µ£ĆÕż¦ÕĆ╝ÕÆīÕģ©Õ▒Ƶ£ĆÕż¦ÕĆ╝’╝Ü
+
+```python
+runner = Runner(
+ model=ToyModel(),
+ work_dir='tmp_dir',
+ train_dataloader=train_dataloader,
+ train_cfg=dict(by_epoch=True, max_epochs=1),
+ optim_wrapper=dict(optimizer=dict(type='SGD', lr=0.01)),
+ log_processor=dict(custom_cfg=[
+ # ń╗¤Ķ«Ī loss1 ńÜäÕ▒Ćķā©µ£ĆÕż¦ÕĆ╝’╝īń╗¤Ķ«Īń¬ŚÕÅŻõĖ║ 10’╝īÕ╣ČÕ£©µŚźÕ┐ŚõĖŁķćŹÕæĮÕÉŹõĖ║ loss1_local_max
+ dict(data_src='loss1',
+ log_name='loss1_local_max',
+ window_size=10,
+ method_name='max'),
+ # ń╗¤Ķ«Ī loss1 ńÜäÕģ©Õ▒Ƶ£ĆÕż¦ÕĆ╝’╝īÕ╣ČÕ£©µŚźÕ┐ŚõĖŁķćŹÕæĮÕÉŹõĖ║ loss1_local_max
+ dict(
+ data_src='loss1',
+ log_name='loss1_global_max',
+ method_name='max',
+ window_size='global')
+ ]))
+runner.train()
+```
+
+```
+08/21 03:17:26 - mmengine - INFO - Epoch(train) [1][10/25] lr: 1.0000e-02 eta: 0:00:00 time: 0.0021 data_time: 0.0006 loss1: 1.8495 loss2: 1.3427 loss: 3.1922 loss1_local_max: 2.8872 loss1_global_max: 2.8872
+08/21 03:17:26 - mmengine - INFO - Epoch(train) [1][20/25] lr: 1.0000e-02 eta: 0:00:00 time: 0.0024 data_time: 0.0010 loss1: 0.5464 loss2: 0.7251 loss: 1.2715 loss1_local_max: 2.8872 loss1_global_max: 2.8872
+```
+
+µø┤ÕżÜķģŹńĮ«Ķ¦äÕłÖĶ¦ü[µŚźÕ┐ŚÕżäńÉåÕÖ©µ¢ćµĪŻ](mmengine.runner.LogProcessor)
+
+## Ķć¬Õ«Üõ╣ēń╗¤Ķ«ĪÕåģÕ«╣
+
+ķÖżõ║å MMEngine ķ╗śĶ«żńÜ䵌źÕ┐Śń╗¤Ķ«Īń▒╗Õ×ŗ’╝īÕ”éµŹ¤Õż▒ŃĆüĶ┐Łõ╗ŻµŚČķŚ┤ŃĆüÕŁ”õ╣ĀńÄć’╝īńö©µłĘõ╣¤ÕÅ»õ╗źĶć¬ĶĪīµĘ╗ÕŖĀµŚźÕ┐ŚńÜäń╗¤Ķ«ĪÕåģÕ«╣ŃĆéõŠŗÕ”éµłæõ╗¼µā│ń╗¤Ķ«ĪµŹ¤Õż▒ńÜäõĖŁķŚ┤ń╗ōµ×£’╝īÕÅ»õ╗źĶ┐ÖµĀĘÕüÜ’╝Ü
+
+```python
+from mmengine.logging import MessageHub
+
+
+class ToyModel(BaseModel):
+
+ def __init__(self) -> None:
+ super().__init__()
+ self.linear = nn.Linear(1, 1)
+
+ def forward(self, img, label, mode):
+ feat = self.linear(img)
+ loss_tmp = (feat - label).abs()
+ loss = loss_tmp.pow(2)
+
+ message_hub = MessageHub.get_current_instance()
+ # Õ£©µŚźÕ┐ŚõĖŁķóØÕż¢ń╗¤Ķ«Ī `loss_tmp`
+ message_hub.update_scalar('train/loss_tmp', loss_tmp.sum())
+ return dict(loss=loss)
+
+
+runner = Runner(
+ model=ToyModel(),
+ work_dir='tmp_dir',
+ train_dataloader=train_dataloader,
+ train_cfg=dict(by_epoch=True, max_epochs=1),
+ optim_wrapper=dict(optimizer=dict(type='SGD', lr=0.01)),
+ log_processor=dict(
+ custom_cfg=[
+ # ń╗¤Ķ«Ī loss_tmp ńÜäÕ▒Ćķā©ÕØćÕĆ╝
+ dict(
+ data_src='loss_tmp',
+ window_size=10,
+ method_name='mean')
+ ]
+ )
+)
+runner.train()
+```
+
+```
+08/21 03:40:31 - mmengine - INFO - Epoch(train) [1][10/25] lr: 1.0000e-02 eta: 0:00:00 time: 0.0026 data_time: 0.0008 loss_tmp: 0.0097 loss: 0.0000
+08/21 03:40:31 - mmengine - INFO - Epoch(train) [1][20/25] lr: 1.0000e-02 eta: 0:00:00 time: 0.0028 data_time: 0.0013 loss_tmp: 0.0065 loss: 0.0000
+```
+
+ķĆÜĶ┐ćĶ░āńö©[µČłµü»µ×óń║Į](mmengine.logging.MessageHub)ńÜäµÄźÕÅŻÕ«×ńÄ░Ķć¬Õ«Üõ╣ēµŚźÕ┐ŚńÜäń╗¤Ķ«Ī’╝īÕģĘõĮōµŁźķ¬żÕ”éõĖŗ’╝Ü
+
+1. Ķ░āńö© `get_current_instance` µÄźÕÅŻĶÄĘÕÅ¢µē¦ĶĪīÕÖ©ńÜäµČłµü»µ×óń║ĮŃĆé
+2. Ķ░āńö© `update_scalar` µÄźÕÅŻµø┤µ¢░µŚźÕ┐ŚÕåģÕ«╣’╝īÕģČõĖŁń¼¼õĖĆõĖ¬ÕÅéµĢ░õĖ║µŚźÕ┐ŚńÜäÕÉŹń¦░’╝īµŚźÕ┐ŚÕÉŹń¦░õ╗ź `train/`’╝ī`val/`’╝ī`test/` ÕēŹń╝ƵēōÕż┤’╝īńö©õ║ÄÕī║ÕłåĶ«Łń╗āńŖȵĆü’╝īńäČÕÉĵēŹµś»Õ«×ķÖģńÜ䵌źÕ┐ŚÕÉŹ’╝īÕ”éõĖŖõŠŗõĖŁńÜä `train/loss_tmp`,Ķ┐ÖµĀĘń╗¤Ķ«ĪńÜ䵌źÕ┐ŚõĖŁÕ░▒õ╝ÜÕć║ńÄ░ `loss_tmp`ŃĆé
+3. ķģŹńĮ«µŚźÕ┐ŚÕżäńÉåÕÖ©’╝īõ╗źÕØćÕĆ╝ńÜäµ¢╣Õ╝Åń╗¤Ķ«Ī `loss_tmp`ŃĆéÕ”éµ×£õĖŹķģŹńĮ«’╝īµŚźÕ┐ŚķćīµśŠńż║ `loss_tmp` µ£ĆĶ┐æõĖƵ¼Īµø┤µ¢░ńÜäÕĆ╝ŃĆé
+
+## ĶŠōÕć║Ķ░āĶ»ĢµŚźÕ┐Ś
+
+ÕłØÕ¦ŗÕī¢µē¦ĶĪīÕÖ©’╝łRunner’╝ēµŚČ’╝īÕ░å `log_level` Ķ«ŠńĮ«µłÉ `debug`ŃĆéĶ┐ÖµĀĘń╗łń½»õĖŖÕ░▒õ╝ÜķóØÕż¢ĶŠōÕć║µŚźÕ┐ŚńŁēń║¦õĖ║ `debug` ńÜ䵌źÕ┐Ś
+
+```python
+runner = Runner(
+ model=ToyModel(),
+ work_dir='tmp_dir',
+ train_dataloader=train_dataloader,
+ log_level='DEBUG',
+ train_cfg=dict(by_epoch=True, max_epochs=1),
+ optim_wrapper=dict(optimizer=dict(type='SGD', lr=0.01)))
+runner.train()
+```
+
+```
+08/21 18:16:22 - mmengine - DEBUG - Get class `LocalVisBackend` from "vis_backend" registry in "mmengine"
+08/21 18:16:22 - mmengine - DEBUG - An `LocalVisBackend` instance is built from registry, its implementation can be found in mmengine.visualization.vis_backend
+08/21 18:16:22 - mmengine - DEBUG - Get class `RuntimeInfoHook` from "hook" registry in "mmengine"
+08/21 18:16:22 - mmengine - DEBUG - An `RuntimeInfoHook` instance is built from registry, its implementation can be found in mmengine.hooks.runtime_info_hook
+08/21 18:16:22 - mmengine - DEBUG - Get class `IterTimerHook` from "hook" registry in "mmengine"
+...
+```
+
+µŁżÕż¢’╝īÕłåÕĖāÕ╝ÅĶ«Łń╗āµŚČ’╝ī`DEBUG` µ©ĪÕ╝ÅĶ┐śõ╝ÜÕłåĶ┐øń©ŗÕŁśÕ驵ŚźÕ┐ŚŃĆéÕŹĢµ£║ÕżÜÕŹĪ’╝īµł¢ĶĆģÕżÜµ£║ÕżÜÕŹĪõĮåµś»Õģ▒õ║½ÕŁśÕé©ńÜäµāģÕåĄõĖŗ’╝īÕ»╝Õć║ńÜäÕłåÕĖāÕ╝ŵŚźÕ┐ŚĶĘ»ÕŠäÕ”éõĖŗ
+
+```text
+# Õģ▒õ║½ÕŁśÕé©
+./tmp
+Ōö£ŌöĆŌöĆ tmp.log
+Ōö£ŌöĆŌöĆ tmp_rank1.log
+Ōö£ŌöĆŌöĆ tmp_rank2.log
+Ōö£ŌöĆŌöĆ tmp_rank3.log
+Ōö£ŌöĆŌöĆ tmp_rank4.log
+Ōö£ŌöĆŌöĆ tmp_rank5.log
+Ōö£ŌöĆŌöĆ tmp_rank6.log
+ŌööŌöĆŌöĆ tmp_rank7.log
+...
+ŌööŌöĆŌöĆ tmp_rank63.log
+```
+
+ÕżÜµ£║ÕżÜÕŹĪ’╝īńŗ¼ń½ŗÕŁśÕé©ńÜäµāģÕåĄ’╝Ü
+
+```text
+# ńŗ¼ń½ŗÕŁśÕé©
+# Ķ«ŠÕżć 0’╝Ü
+work_dir/
+ŌööŌöĆŌöĆ exp_name_logs
+ Ōö£ŌöĆŌöĆ exp_name.log
+ Ōö£ŌöĆŌöĆ exp_name_rank1.log
+ Ōö£ŌöĆŌöĆ exp_name_rank2.log
+ Ōö£ŌöĆŌöĆ exp_name_rank3.log
+ ...
+ ŌööŌöĆŌöĆ exp_name_rank7.log
+
+# Ķ«ŠÕżć 7’╝Ü
+work_dir/
+ŌööŌöĆŌöĆ exp_name_logs
+ Ōö£ŌöĆŌöĆ exp_name_rank56.log
+ Ōö£ŌöĆŌöĆ exp_name_rank57.log
+ Ōö£ŌöĆŌöĆ exp_name_rank58.log
+ ...
+ ŌööŌöĆŌöĆ exp_name_rank63.log
+```
+
+Õ”éµ×£µā│Ķ”üµø┤ÕŖĀµĘ▒ÕģźńÜäõ║åĶ¦Ż MMEngine ńÜ䵌źÕ┐Śń│╗ń╗¤’╝īÕÅ»õ╗źÕÅéĶĆā[µŚźÕ┐Śń│╗ń╗¤Ķ«ŠĶ«Ī](../design/logging.md)ŃĆé
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/manager_mixin.md b/internlm_langchain/knowledge_base/MMEngine/content/manager_mixin.md
new file mode 100644
index 00000000..4395d84a
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/manager_mixin.md
@@ -0,0 +1,55 @@
+# Õģ©Õ▒Ćń«ĪńÉåÕÖ©’╝łManagerMixin’╝ē
+
+Runner Õ£©Ķ«Łń╗āĶ┐ćń©ŗõĖŁ’╝īķÜŠÕģŹõ╝ÜõĮ┐ńö©Õģ©Õ▒ĆÕÅśķćÅµØźÕģ▒õ║½õ┐Īµü»’╝īõŠŗÕ”éµłæõ╗¼õ╝ÜÕ£© model õĖŁĶÄĘÕÅ¢Õģ©Õ▒ĆńÜä [logger](mmengine.logging.MMLogger) µØźµēōÕŹ░ÕłØÕ¦ŗÕī¢õ┐Īµü»’╝øÕ£© model õĖŁĶÄĘÕÅ¢Õģ©Õ▒ĆńÜä [Visualizer](./visualization.md) µØźÕÅ»Ķ¦åÕī¢ķó䵥ŗń╗ōµ×£ŃĆüńē╣ÕŠüÕøŠ’╝øÕ£© [Registry](../advanced_tutorials/registry.md) õĖŁĶÄĘÕÅ¢Õģ©Õ▒ĆńÜä [DefaultScope](mmengine.registry.DefaultScope) µØźńĪ«Õ«Üµ│©ÕåīÕ¤¤ŃĆéõĖ║õ║åń«ĪńÉåĶ┐Öõ║øÕŖ¤ĶāĮńøĖõ╝╝ńÜ䵩ĪÕØŚ’╝īMMEngine Ķ«ŠĶ«Īõ║åń«ĪńÉåÕÖ© [ManagerMix](mmengine.utils.ManagerMixin) µØźń╗¤õĖĆÕģ©Õ▒ĆÕÅśķćÅńÜäÕłøÕ╗║ÕÆīĶÄĘÕÅ¢µ¢╣Õ╝ÅŃĆé
+
+
+
+## µÄźÕÅŻõ╗ŗń╗Ź
+
+- get_instance(name='', \*\*kwargs)’╝ÜÕłøÕ╗║µł¢ĶĆģĶ┐öÕø×Õ»╣Õ║öÕÉŹÕŁŚńÜäńÜäÕ«×õŠŗŃĆé
+- get_current_instance()’╝ÜĶ┐öÕø×µ£ĆĶ┐æĶó½ÕłøÕ╗║ńÜäÕ«×õŠŗŃĆé
+- instance_name’╝ÜĶÄĘÕÅ¢Õ»╣Õ║öÕ«×õŠŗńÜä nameŃĆé
+
+## õĮ┐ńö©µ¢╣µ│Ģ
+
+1. Õ«Üõ╣ēµ£ēÕģ©Õ▒ĆĶ«┐ķŚ«ķ£Ćµ▒éńÜäń▒╗
+
+```python
+from mmengine.utils import ManagerMixin
+
+
+class GlobalClass(ManagerMixin):
+ def __init__(self, name, value):
+ super().__init__(name)
+ self.value = value
+```
+
+µ│©µäÅÕģ©Õ▒Ćń▒╗ńÜäµ×äķĆĀÕćĮµĢ░Õ┐ģķĪ╗ÕĖ”µ£ē name ÕÅéµĢ░’╝īÕ╣ČÕ£©µ×äķĆĀÕćĮµĢ░õĖŁĶ░āńö© `super().__init__(name)`’╝īõ╗źńĪ«õ┐ØÕÉÄń╗ŁĶāĮÕż¤µĀ╣µŹ« name µØźĶÄĘÕÅ¢Õ»╣Õ║öńÜäÕ«×õŠŗŃĆé
+
+2. Õ£©õ╗╗µäÅõĮŹńĮ«Õ«×õŠŗÕī¢Ķ»źÕ»╣Ķ▒Ī’╝īõ╗ź Hook õĖ║õŠŗ’╝łĶ”üńĪ«õ┐ØĶ«┐ķŚ«Ķ»źÕ«×õŠŗµŚČ’╝īÕ»╣Ķ▒ĪÕĘ▓ń╗ÅĶó½ÕłøÕ╗║’╝ē’╝Ü
+
+```python
+from mmengine import Hook
+
+class CustomHook(Hook):
+ def before_run(self, runner):
+ GlobalClass.get_instance('mmengine', value=50)
+ GlobalClass.get_instance(runner.experiment_name, value=100)
+```
+
+ÕĮōµłæõ╗¼Ķ░āńö©ÕŁÉń▒╗ńÜä `get_instance` µÄźÕÅŻµŚČ’╝ī`ManagerMixin` õ╝ܵĀ╣µŹ«ÕÉŹÕŁŚµØźÕłżµ¢ŁÕ»╣Õ║öÕ«×õŠŗµś»ÕÉ”ÕĘ▓ń╗ÅÕŁśÕ£©’╝īĶ┐øĶĆīÕłøÕ╗║/ĶÄĘÕÅ¢Õ«×õŠŗŃĆéÕ”éõĖŖõŠŗµēĆńż║’╝īÕĮōµłæõ╗¼ń¼¼õĖƵ¼ĪĶ░āńö© `GlobalClass.get_instance('mmengine', value=50)` µŚČ’╝īõ╝ÜÕłøÕ╗║õĖĆõĖ¬ÕÉŹõĖ║ "mmengine" ńÜä `GlobalClass` Õ«×õŠŗ’╝īÕģČÕłØÕ¦ŗ value õĖ║ 50ŃĆéõĖ║õ║åµ¢╣õŠ┐ÕÉÄń╗Łõ╗ŗń╗Ź `get_current_instance` µÄźÕÅŻ’╝īĶ┐Öķćīµłæõ╗¼ÕłøÕ╗║õ║åõĖżõĖ¬ `GlobalClass` Õ«×õŠŗŃĆé
+
+3. Õ£©õ╗╗µäÅń╗äõ╗ČõĖŁĶ«┐ķŚ«Ķ»źÕ«×õŠŗ
+
+```python
+import torch.nn as nn
+
+
+class CustomModule(nn.Module):
+ def forward(self, x):
+ value = GlobalClass.get_current_instance().value # µ£ĆĶ┐æõĖƵ¼ĪĶó½ÕłøÕ╗║ńÜäÕ«×õŠŗ value õĖ║ 100’╝łµŁźķ¬żõ║īõĖŁµīēķĪ║Õ║ÅÕłøÕ╗║’╝ē
+ value = GlobalClass.get_instance('mmengine').value # ÕÉŹõĖ║ mmengine ńÜäÕ«×õŠŗ value õĖ║ 50
+ # value = GlobalClass.get_instance('mmengine', 1000).value # mmengine ÕĘ▓ń╗ÅĶó½ÕłøÕ╗║’╝īõĖŹĶāĮÕåŹµÄźÕÅŚķóØÕż¢ÕÅéµĢ░
+```
+
+Õ£©ÕÉīõĖĆĶ┐øń©ŗķćī’╝īµłæõ╗¼ÕÅ»õ╗źÕ£©õĖŹÕÉīń╗äõ╗ČõĖŁĶ«┐ķŚ« `GlobalClass` Õ«×õŠŗŃĆéõŠŗÕ”éµłæõ╗¼Õ£© `CustomModule` õĖŁ’╝īĶ░āńö© `get_instance` ÕÆī `get_current_instance` µÄźÕÅŻµØźĶÄĘÕÅ¢Õ»╣Õ║öÕÉŹÕŁŚńÜäÕ«×õŠŗÕÆīµ£ĆĶ┐æĶó½ÕłøÕ╗║ńÜäÕ«×õŠŗŃĆéķ£ĆĶ”üµ│©µäÅńÜ䵜»’╝īńö▒õ║Ä "mmengine" Õ«×õŠŗÕĘ▓ń╗ÅĶó½ÕłøÕ╗║’╝īÕåŹµ¼ĪĶ░āńö©µŚČõĖŹĶāĮÕåŹõ╝ĀÕģźķóØÕż¢ÕÅéµĢ░’╝īÕÉ”ÕłÖõ╝ܵŖźķöÖŃĆé
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/model.md b/internlm_langchain/knowledge_base/MMEngine/content/model.md
new file mode 100644
index 00000000..1da42c17
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/model.md
@@ -0,0 +1,443 @@
+# Ķ┐üń¦╗ MMCV µ©ĪÕ×ŗÕł░ MMEngine
+
+## ń«Ćõ╗ŗ
+
+MMCV µŚ®µ£¤µö»µīüńÜäĶ«Īń«Śµ£║Ķ¦åĶ¦ēõ╗╗ÕŖĪ’╝īõŠŗÕ”éńø«µĀ浯ƵĄŗŃĆüńē®õĮōĶ»åÕł½ńŁē’╝īķāĮķććńö©õ║åõĖĆń¦ŹÕģĖÕ×ŗńÜ䵩ĪÕ×ŗÕÅéµĢ░õ╝śÕī¢µĄüń©ŗ’╝īÕÅ»õ╗źĶó½ÕĮÆń║│õĖ║õ╗źõĖŗÕøøõĖ¬µŁźķ¬ż’╝Ü
+
+1. Ķ«Īń«ŚµŹ¤Õż▒
+2. Ķ«Īń«Śµó»Õ║”
+3. µø┤µ¢░ÕÅéµĢ░
+4. µó»Õ║”µĖģķøČ
+
+õĖŖĶ┐░µĄüń©ŗńÜäõĖĆÕż¦ńē╣ńé╣Õ░▒µś»Ķ░āńö©õĮŹńĮ«ń╗¤õĖĆ’╝łÕ£©Ķ«Łń╗āĶ┐Łõ╗ŻÕÉÄĶ░āńö©’╝ēŃĆüµē¦ĶĪīµŁźķ¬żń╗¤õĖĆ’╝łõŠØµ¼Īµē¦ĶĪīµŁźķ¬ż 1->2->3->4’╝ē’╝īķØ×ÕĖĖÕźæÕÉł[ķÆ®ÕŁÉ’╝łHook’╝ē](../design/hook.md)ńÜäĶ«ŠĶ«ĪÕÄ¤ÕłÖ’╝īÕøĀµŁżĶ┐Öń▒╗õ╗╗ÕŖĪķĆÜÕĖĖõ╝ÜõĮ┐ńö© `Hook`
+µØźõ╝śÕī¢µ©ĪÕ×ŗŃĆéMMCV õĖ║µŁżÕ«×ńÄ░õ║åõĖĆń│╗ÕłŚńÜä `Hook`’╝īõŠŗÕ”é `OptimizerHook`’╝łÕŹĢń▓ŠÕ║”Ķ«Łń╗ā’╝ēŃĆü`Fp16OptimizerHook`’╝łµĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗ā’╝ē ÕÆī `GradientCumulativeFp16OptimizerHook`’╝łµĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗ā + µó»Õ║”ń┤»ÕŖĀ’╝ē’╝īõĖ║Ķ┐Öń▒╗õ╗╗ÕŖĪµÅÉõŠøÕÉäń¦Źõ╝śÕī¢ńŁ¢ńĢźŃĆé
+
+õĖĆõ║øõŠŗÕ”éńö¤µłÉÕ»╣µŖŚńĮæń╗£’╝łGAN’╝ē’╝īĶć¬ńøæńØŻ’╝łSelf-supervision’╝ēńŁēķóåÕ¤¤ńÜäń«Śµ│ĢõĖĆĶł¼µ£ēµø┤ÕŖĀńüĄµ┤╗ńÜäĶ«Łń╗āµĄüń©ŗ’╝īĶ┐Öń▒╗µĄüń©ŗÕ╣ČõĖŹµ╗ĪĶČ│Ķ░āńö©õĮŹńĮ«ń╗¤õĖĆŃĆüµē¦ĶĪīµŁźķ¬żń╗¤õĖĆńÜäÕÄ¤ÕłÖ’╝īķÜŠõ╗źõĮ┐ńö© `Hook` Õ»╣ÕÅéµĢ░Ķ┐øĶĪīõ╝śÕī¢ŃĆéõĖ║õ║åµö»µīüĶ«Łń╗āĶ┐Öń▒╗õ╗╗ÕŖĪ’╝īMMCV ńÜäµē¦ĶĪīÕÖ©õ╝ÜÕ£©Ķ░āńö© `model.train_step` µŚČ’╝īķóØÕż¢õ╝ĀÕģź `optimizer` ÕÅéµĢ░’╝īĶ«®µ©ĪÕ×ŗÕ£© `train_step` ķćīÕ«×ńÄ░Ķć¬Õ«Üõ╣ēńÜäõ╝śÕī¢µĄüń©ŗŃĆéĶ┐ÖµĀĘĶÖĮńäČÕÅ»õ╗źµö»µīüĶ«Łń╗āĶ┐Öń▒╗õ╗╗ÕŖĪ’╝īõĮåõ╣¤õ╝ÜÕ»╝Ķć┤µŚĀµ│ĢõĮ┐ńö©ÕÉäń¦Ź `OptimizerHook`’╝īķ£ĆĶ”üń«Śµ│ĢÕ£© `train_step` õĖŁÕ«×ńÄ░µĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗āŃĆüµó»Õ║”ń┤»ÕŖĀńŁēĶ«Łń╗āńŁ¢ńĢźŃĆé
+
+õĖ║õ║åń╗¤õĖƵĘ▒Õ║”ÕŁ”õ╣Āõ╗╗ÕŖĪńÜäÕÅéµĢ░õ╝śÕī¢µĄüń©ŗ’╝īMMEngine Ķ«ŠĶ«Īõ║å[õ╝śÕī¢ÕÖ©Õ░üĶŻģ](mmengine.optim.OptimWrapper)’╝īķøåµłÉõ║åµĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗āŃĆüµó»Õ║”ń┤»ÕŖĀńŁēĶ«Łń╗āńŁ¢ńĢź’╝īÕÉäń▒╗µĘ▒Õ║”ÕŁ”õ╣Āõ╗╗ÕŖĪõĖĆÕŠŗÕ£© `model.train_step` ķćīµē¦ĶĪīÕÅéµĢ░õ╝śÕī¢µĄüń©ŗŃĆé
+
+## õ╝śÕī¢µĄüń©ŗńÜäĶ┐üń¦╗
+
+### ÕĖĖńö©ńÜäÕÅéµĢ░µø┤µ¢░µĄüń©ŗ
+
+ĶĆāĶÖæÕł░ńø«µĀ浯ƵĄŗŃĆüńē®õĮōĶ»åÕł½õĖĆń▒╗ńÜäµĘ▒Õ║”ÕŁ”õ╣Āõ╗╗ÕŖĪÕÅéµĢ░õ╝śÕī¢ńÜ䵥üń©ŗÕ¤║µ£¼õĖĆĶć┤’╝īµłæõ╗¼ÕÅ»õ╗źķĆÜĶ┐ćń╗¦µē┐[µ©ĪÕ×ŗÕ¤║ń▒╗](../tutorials/model.md)µØźÕ«īµłÉĶ┐üń¦╗ŃĆé
+
+**Õ¤║õ║Ä MMCV µē¦ĶĪīÕÖ©ńÜ䵩ĪÕ×ŗ**
+
+Õ£©õ╗ŗń╗ŹÕ”éõĮĢĶ┐üń¦╗µ©ĪÕ×ŗõ╣ŗÕēŹ’╝īµłæõ╗¼ÕģłµØźń£ŗõĖĆõĖ¬Õ¤║õ║Ä MMCV µē¦ĶĪīÕÖ©Ķ«Łń╗āµ©ĪÕ×ŗńÜäµ£Ćń«Ćńż║õŠŗ’╝Ü
+
+```python
+import torch
+import torch.nn as nn
+from torch.optim import SGD
+from torch.utils.data import DataLoader
+
+from mmcv.runner import Runner
+from mmcv.utils.logging import get_logger
+
+
+train_dataset = [(torch.ones(1, 1), torch.ones(1, 1))] * 50
+train_dataloader = DataLoader(train_dataset, batch_size=2)
+
+
+class MMCVToyModel(nn.Module):
+ def __init__(self) -> None:
+ super().__init__()
+ self.linear = nn.Linear(1, 1)
+
+ def forward(self, img, label, return_loss=False):
+ feat = self.linear(img)
+ loss1 = (feat - label).pow(2)
+ loss2 = (feat - label).abs()
+ loss = (loss1 + loss2).sum()
+ return dict(loss=loss,
+ num_samples=len(img),
+ log_vars=dict(
+ loss1=loss1.sum().item(),
+ loss2=loss2.sum().item()))
+
+ def train_step(self, data, optimizer=None):
+ return self(*data, return_loss=True)
+
+ def val_step(self, data, optimizer=None):
+ return self(*data, return_loss=False)
+
+
+model = MMCVToyModel()
+optimizer = SGD(model.parameters(), lr=0.01)
+logger = get_logger('demo')
+
+lr_config = dict(policy='step', step=[2, 3])
+optimizer_config = dict(grad_clip=None)
+log_config = dict(interval=10, hooks=[dict(type='TextLoggerHook')])
+
+
+runner = Runner(
+ model=model,
+ work_dir='tmp_dir',
+ optimizer=optimizer,
+ logger=logger,
+ max_epochs=5)
+
+runner.register_training_hooks(
+ lr_config=lr_config,
+ optimizer_config=optimizer_config,
+ log_config=log_config)
+runner.run([train_dataloader], [('train', 1)])
+```
+
+Õ¤║õ║Ä MMCV µē¦ĶĪīÕÖ©Ķ«Łń╗āµ©ĪÕ×ŗµŚČ’╝īµłæõ╗¼Õ┐ģķĪ╗Õ«×ńÄ░ `train_step` µÄźÕÅŻ’╝īÕ╣ČĶ┐öÕø×õĖĆõĖ¬ÕŁŚÕģĖ’╝īÕŁŚÕģĖķ£ĆĶ”üÕīģÕɽõ╗źõĖŗõĖēõĖ¬ÕŁŚµ«Ą’╝Ü
+
+- loss’╝Üõ╝Āń╗Ö `OptimizerHook` Ķ«Īń«Śµó»Õ║”
+- num_samples’╝Üõ╝Āń╗Ö `LogBuffer`’╝īńö©õ║ÄĶ«Īń«ŚÕ╣│µ╗æÕÉÄńÜ䵏¤Õż▒
+- log_vars’╝Üõ╝Āń╗Ö `LogBuffer` ńö©õ║ÄĶ«Īń«ŚÕ╣│µ╗æÕÉÄńÜ䵏¤Õż▒
+
+**Õ¤║õ║Ä MMEngine µē¦ĶĪīÕÖ©ńÜ䵩ĪÕ×ŗ**
+
+Õ¤║õ║Ä MMEngine ńÜäµē¦ĶĪīÕÖ©’╝īÕ«×ńÄ░ÕÉīµĀĘķĆ╗ĶŠæńÜäõ╗ŻńĀü’╝Ü
+
+```python
+import torch
+import torch.nn as nn
+from torch.utils.data import DataLoader
+
+from mmengine.runner import Runner
+from mmengine.model import BaseModel
+
+train_dataset = [(torch.ones(1, 1), torch.ones(1, 1))] * 50
+train_dataloader = DataLoader(train_dataset, batch_size=2)
+
+
+class MMEngineToyModel(BaseModel):
+
+ def __init__(self) -> None:
+ super().__init__()
+ self.linear = nn.Linear(1, 1)
+
+ def forward(self, img, label, mode):
+ feat = self.linear(img)
+ # Ķó½ `train_step` Ķ░āńö©’╝īĶ┐öÕø×ńö©õ║ĵø┤µ¢░ÕÅéµĢ░ńÜ䵏¤Õż▒ÕŁŚÕģĖ
+ if mode == 'loss':
+ loss1 = (feat - label).pow(2)
+ loss2 = (feat - label).abs()
+ return dict(loss1=loss1, loss2=loss2)
+ # Ķó½ `val_step` Ķ░āńö©’╝īĶ┐öÕø×õ╝Āń╗Ö `evaluator` ńÜäķó䵥ŗń╗ōµ×£
+ elif mode == 'predict':
+ return [_feat for _feat in feat]
+ # tensor µ©ĪÕ╝Å’╝īÕŖ¤ĶāĮĶ»”Ķ¦üµ©ĪÕ×ŗµĢÖń©ŗµ¢ćµĪŻ’╝Ü tutorials/model.md
+ else:
+ pass
+
+
+runner = Runner(
+ model=MMEngineToyModel(),
+ work_dir='tmp_dir',
+ train_dataloader=train_dataloader,
+ train_cfg=dict(by_epoch=True, max_epochs=5),
+ optim_wrapper=dict(optimizer=dict(type='SGD', lr=0.01)))
+runner.train()
+```
+
+MMEngine Õ«×ńÄ░õ║嵩ĪÕ×ŗÕ¤║ń▒╗’╝īµ©ĪÕ×ŗÕ¤║ń▒╗Õ£© `train_step` ķćīÕ«×ńÄ░õ║å `OptimizerHook` ńÜäõ╝śÕī¢µĄüń©ŗŃĆéÕøĀµŁżõĖŖõŠŗõĖŁ’╝īµłæõ╗¼µŚĀķ£ĆÕ«×ńÄ░ `train_step`’╝īĶ┐ÉĶĪīµŚČńø┤µÄźĶ░āńö©Õ¤║ń▒╗ńÜä `train_step`ŃĆé
+
+
+
+
+
+Õģ│õ║ÄńŁēµĢłõ╗ŻńĀüõĖŁńÜä[µĢ░µŹ«ÕżäńÉåÕÖ©’╝łdata_preprocessor’╝ē](mmengine.model.BaseDataPreprocessor)ÕÆī[õ╝śÕī¢ÕÖ©Õ░üĶŻģ’╝łoptim_wrapper’╝ē](mmengine.optim.OptimWrapper)ńÜäĶ»┤µśÄ’╝īĶ»”Ķ¦ü[µ©ĪÕ×ŗµĢÖń©ŗ](../tutorials/model.md#µĢ░µŹ«ķóäÕżäńÉåÕÖ©datapreprocessor)ÕÆī[õ╝śÕī¢ÕÖ©Õ░üĶŻģµĢÖń©ŗ](../tutorials/optim_wrapper.md)ŃĆé
+
+µ©ĪÕ×ŗÕģĘõĮōÕĘ«Õ╝éÕ”éõĖŗ’╝Ü
+
+- `MMCVToyModel` ń╗¦µē┐Ķć¬ `nn.Module`’╝īĶĆī `MMEngineToyModel` ń╗¦µē┐Ķć¬ `BaseModel`
+- `MMCVToyModel` Õ┐ģķĪ╗Õ«×ńÄ░ `train_step`’╝īõĖöÕ┐ģķĪ╗Ķ┐öÕø×µŹ¤Õż▒ÕŁŚÕģĖ’╝īµŹ¤Õż▒ÕŁŚÕģĖÕīģÕɽ `loss` ÕÆī `log_vars` ÕÆī `num_samples` ÕŁŚµ«ĄŃĆé`MMEngineToyModel` ń╗¦µē┐Ķć¬ `BaseModel`’╝īÕŬķ£ĆĶ”üÕ«×ńÄ░ `forward` µÄźÕÅŻ’╝īÕ╣ČĶ┐öÕø×µŹ¤Õż▒ÕŁŚÕģĖ’╝īµŹ¤Õż▒ÕŁŚÕģĖńÜäµ»ÅõĖĆõĖ¬ÕĆ╝Õ┐ģķĪ╗µś»ÕŻՊ«ńÜäÕ╝ĀķćÅ
+- `MMCVToyModel` ÕÆī `MMEngineModel` ńÜä `forward` ńÜäµÄźÕÅŻķ£ĆĶ”üÕī╣ķģŹ `train_step` õĖŁńÜäĶ░āńö©µ¢╣Õ╝Å’╝īńö▒õ║Ä `MMEngineToyModel` ńø┤µÄźĶ░āńö©Õ¤║ń▒╗ńÜä `train_step` µ¢╣µ│Ģ’╝īÕøĀµŁż `forward` ķ£ĆĶ”üµÄźÕÅŚÕÅéµĢ░ `mode`’╝īÕģĘõĮōĶ¦äÕłÖĶ»”Ķ¦ü[µ©ĪÕ×ŗµĢÖń©ŗµ¢ćµĪŻ](../tutorials/model.md)
+
+### Ķć¬Õ«Üõ╣ēńÜäÕÅéµĢ░µø┤µ¢░µĄüń©ŗ
+
+õ╗źĶ«Łń╗āńö¤µłÉÕ»╣µŖŚńĮæń╗£õĖ║õŠŗ’╝īńö¤µłÉÕÖ©ÕÆīÕłżÕł½ÕÖ©ńÜäõ╝śÕī¢ķ£ĆĶ”üõ║żµø┐Ķ┐øĶĪī’╝īõĖöõ╝śÕī¢µĄüń©ŗÕÅ»ĶāĮõ╝ÜķÜÅńØĆĶ┐Łõ╗Żµ¼ĪµĢ░ńÜäÕó×ÕżÜÕÅæńö¤ÕÅśÕī¢’╝īÕøĀµŁżÕŠłķÜŠõĮ┐ńö© `OptimizerHook` µØźµ╗ĪĶČ│Ķ┐Öń¦Źķ£Ćµ▒éŃĆéÕ£©Õ¤║õ║Ä MMCV Ķ«Łń╗āńö¤µłÉÕ»╣µŖŚńĮæń╗£µŚČ’╝īķĆÜÕĖĖõ╝ÜÕ£©µ©ĪÕ×ŗńÜä `train_step` µÄźÕÅŻõĖŁõ╝ĀÕģź `optimizer`’╝īńäČÕÉÄÕ£© `train_step` ķćīÕ«×ńÄ░Ķć¬Õ«Üõ╣ēńÜäÕÅéµĢ░µø┤µ¢░ķĆ╗ĶŠæŃĆéĶ┐Öń¦ŹĶ«Łń╗āµĄüń©ŗÕÆī MMEngine ķØ×ÕĖĖńøĖõ╝╝’╝īÕŬõĖŹĶ┐ć MMEngine Õ£© `train_step` µÄźÕÅŻõĖŁõ╝ĀÕģź[õ╝śÕī¢ÕÖ©Õ░üĶŻģ](../tutorials/optim_wrapper.md)’╝īĶāĮÕż¤µø┤ÕŖĀń«ĆÕŹĢÕ£░õ╝śÕī¢µ©ĪÕ×ŗŃĆé
+
+ÕÅéĶĆā[Ķ«Łń╗āńö¤µłÉÕ»╣µŖŚńĮæń╗£](../examples/train_a_gan.md)’╝īMMCV ÕÆī MMEngine ńÜäÕ»╣µ»öÕ«×ńÄ░Õ”éõĖŗ’╝Ü
+
+
+
+
+
+õ║īĶĆģńÜäÕī║Õł½õĖ╗Ķ”üÕ£©õ║Äõ╝śÕī¢ÕÖ©ńÜäõĮ┐ńö©µ¢╣Õ╝ÅŃĆ鵣żÕż¢’╝ī`train_step` µÄźÕÅŻĶ┐öÕø×ÕĆ╝ńÜäÕĘ«Õ╝éÕÆī[õĖŖõĖĆĶŖé](#ÕĖĖńö©ńÜäÕÅéµĢ░µø┤µ¢░µĄüń©ŗ)µÅÉÕł░ńÜäõĖĆĶć┤ŃĆé
+
+## ķ¬īĶ»ü/µĄŗĶ»ĢµĄüń©ŗńÜäĶ┐üń¦╗
+
+Õ¤║õ║Ä MMCV µē¦ĶĪīÕÖ©Õ«×ńÄ░ńÜ䵩ĪÕ×ŗķĆÜÕĖĖõĖŹķ£ĆĶ”üõĖ║ķ¬īĶ»üŃĆüµĄŗĶ»ĢµĄüń©ŗµÅÉõŠøńŗ¼ń½ŗńÜä `val_step`ŃĆü`test_step`’╝łµĄŗĶ»ĢµĄüń©ŗńö▒ `EvalHook` Õ«×ńÄ░’╝īĶ┐ÖķćīõĖŹÕüÜÕ▒ĢÕ╝Ć’╝ēŃĆéÕ¤║õ║Ä MMEngine µē¦ĶĪīÕÖ©Õ«×ńÄ░ńÜ䵩ĪÕ×ŗÕłÖµ£ēµēĆõĖŹÕÉī’╝ī[ValLoop](mmengine.runner.ValLoop)ŃĆü[TestLoop](mmengine.runner.TestLoop) õ╝ÜÕłåÕł½Ķ░āńö©µ©ĪÕ×ŗńÜä `val_step` ÕÆī `test_step` µÄźÕÅŻ’╝īĶŠōÕć║õ╝ÜĶ┐øõĖƵŁźõ╝Āń╗Ö [Evaluator.process](mmengine.evaluator.Evaluator.process)ŃĆéÕøĀµŁżµ©ĪÕ×ŗńÜä `val_step` ÕÆī `test_step` µÄźÕÅŻĶŠōÕć║ķ£ĆĶ”üÕÆī `Evaluator.process` ńÜäÕģźÕÅé’╝łń¼¼õĖĆõĖ¬ÕÅéµĢ░’╝ēÕ»╣ķĮÉ’╝īÕŹ│Ķ┐öÕø×ÕłŚĶĪ©’╝łµÄ©ĶŹÉ’╝īõ╣¤ÕÅ»õ╗źµś»ÕģČõ╗¢ÕÅ»Ķ┐Łõ╗Żń▒╗Õ×ŗ’╝ēń▒╗Õ×ŗńÜäń╗ōµ×£ŃĆéÕłŚĶĪ©õĖŁńÜäµ»ÅõĖĆõĖ¬Õģāń┤Āõ╗ŻĶĪ©õĖĆõĖ¬µē╣µ¼Ī’╝łbatch’╝ēµĢ░µŹ«õĖŁµ»ÅõĖ¬µĀʵ£¼ńÜäķó䵥ŗń╗ōµ×£ŃĆ鵩ĪÕ×ŗńÜä `test_step` ÕÆī `val_step` õ╝ÜĶ░ā `forward` µÄźÕÅŻ’╝łĶ»”Ķ¦ü[µ©ĪÕ×ŗµĢÖń©ŗµ¢ćµĪŻ](../tutorials/model.md)’╝ē’╝īÕøĀµŁżÕ£©õĖŖõĖĆĶŖéńÜ䵩ĪÕ×ŗńż║õŠŗõĖŁ’╝īµ©ĪÕ×ŗ `forward` ńÜä `predict` µ©ĪÕ╝Åõ╝ÜÕ░å `feat` ÕłćńēćÕÉÄ’╝īõ╗źÕłŚĶĪ©ńÜäÕĮóÕ╝ÅĶ┐öÕø×ķó䵥ŗń╗ōµ×£ŃĆé
+
+```python
+
+class MMEngineToyModel(BaseModel):
+
+ ...
+ def forward(self, img, label, mode):
+ if mode == 'loss':
+ ...
+ elif mode == 'predict':
+ # µŖŖõĖĆõĖ¬ batch ńÜäķó䵥ŗń╗ōµ×£Õłćńē浳ÉÕłŚĶĪ©’╝īµ»ÅõĖ¬Õģāń┤Āõ╗ŻĶĪ©õĖĆõĖ¬µĀʵ£¼ńÜäķó䵥ŗń╗ōµ×£
+ return [_feat for _feat in feat]
+ else:
+ ...
+ # tensor µ©ĪÕ╝Å’╝īÕŖ¤ĶāĮĶ»”Ķ¦üµ©ĪÕ×ŗµĢÖń©ŗµ¢ćµĪŻ’╝Ü tutorials/model.md
+```
+
+## Ķ┐üń¦╗ÕłåÕĖāÕ╝ÅĶ«Łń╗ā
+
+MMCV ķ£ĆĶ”üÕ£©µē¦ĶĪīÕÖ©µ×äÕ╗║õ╣ŗÕēŹ,õĮ┐ńö© `MMDistributedDataParallel` Õ»╣µ©ĪÕ×ŗĶ┐øĶĪīÕłåÕĖāÕ╝ÅÕ░üĶŻģŃĆéMMEngine Õ«×ńÄ░õ║å [MMDistributedDataParallel](mmengine.model.MMDistributedDataParallel) ÕÆī [MMSeparateDistributedDataParallel](mmengine.model.MMSeparateDistributedDataParallel) õĖżń¦ŹÕłåÕĖāÕ╝ŵ©ĪÕ×ŗÕ░üĶŻģ’╝īõŠøõĖŹÕÉīń▒╗Õ×ŗńÜäõ╗╗ÕŖĪķĆēµŗ®ŃĆéµē¦ĶĪīÕÖ©õ╝ÜÕ£©µ×äÕ╗║µŚČÕ»╣µ©ĪÕ×ŗĶ┐øĶĪīÕłåÕĖāÕ╝ÅÕ░üĶŻģŃĆé
+
+1. **ÕĖĖńö©Ķ«Łń╗āµĄüń©ŗ**
+
+ Õ»╣õ║Ä[ń«Ćõ╗ŗ](#ń«Ćõ╗ŗ)õĖŁµÅÉÕł░ńÜäÕĖĖńö©õ╝śÕī¢µĄüń©ŗńÜäĶ«Łń╗āõ╗╗ÕŖĪ’╝īÕŹ│õĖƵ¼ĪÕÅéµĢ░µø┤µ¢░ÕÅ»õ╗źĶó½µŗåĶ¦ŻµłÉµó»Õ║”Ķ«Īń«ŚŃĆüÕÅéµĢ░õ╝śÕī¢ŃĆüµó»Õ║”µĖģķøČńÜäõ╗╗ÕŖĪ’╝īõĮ┐ńö© Runner ķ╗śĶ«żńÜä `MMDistributedDataParallel` ÕŹ│ÕÅ»µ╗ĪĶČ│ķ£Ćµ▒é’╝īµŚĀķ£ĆõĖ║ runner ÕģČõ╗¢ķóØÕż¢ÕÅéµĢ░ŃĆé
+
+
+
+
+
+
+
+2. **õ╗źĶć¬Õ«Üõ╣ēµĄüń©ŗÕłåµ©ĪÕØŚõ╝śÕī¢µ©ĪÕ×ŗńÜäÕŁ”õ╣Āõ╗╗ÕŖĪ**
+
+ ÕÉīµĀĘõ╗źĶ«Łń╗āńö¤µłÉÕ»╣µŖŚńĮæń╗£õĖ║õŠŗ’╝īńö¤µłÉÕ»╣µŖŚńĮæń╗£µ£ēõĖżõĖ¬ķ£ĆĶ”üÕłåÕł½õ╝śÕī¢ńÜäÕŁÉµ©ĪÕØŚ’╝īÕŹ│ńö¤µłÉÕÖ©ÕÆīÕłżÕł½ÕÖ©ŃĆéÕøĀµŁżķ£ĆĶ”üõĮ┐ńö© `MMSeparateDistributedDataParallel` Õ»╣µ©ĪÕ×ŗĶ┐øĶĪīÕ░üĶŻģŃĆ鵳æõ╗¼ķ£ĆĶ”üÕ£©µ×äÕ╗║µē¦ĶĪīÕÖ©µŚČµīćÕ«Ü’╝Ü
+
+ ```python
+ cfg = dict(model_wrapper_cfg='MMSeparateDistributedDataParallel')
+ runner = Runner(
+ model=model,
+ ...,
+ launcher='pytorch',
+ cfg=cfg)
+ ```
+
+ ÕŹ│ÕÅ»Ķ┐øĶĪīÕłåÕĖāÕ╝ÅĶ«Łń╗āŃĆé
+
+
+
+3. **õ╗źĶć¬Õ«Üõ╣ēµĄüń©ŗõ╝śÕī¢µĢ┤õĖ¬µ©ĪÕ×ŗńÜäµĘ▒Õ║”ÕŁ”õ╣Āõ╗╗ÕŖĪ**
+
+ µ£ēµŚČÕĆÖµłæõ╗¼ķ£ĆĶ”üńö©Ķć¬Õ«Üõ╣ēńÜäõ╝śÕī¢µĄüń©ŗµØźõ╝śÕī¢ÕŹĢõĖ¬µ©ĪÕØŚ’╝īĶ┐ÖµŚČÕĆÖµłæõ╗¼Õ░▒õĖŹĶāĮÕżŹńö©µ©ĪÕ×ŗÕ¤║ń▒╗ńÜä `train_step`’╝īĶĆīķ£ĆĶ”üķ揵¢░Õ«×ńÄ░’╝īõŠŗÕ”éµłæõ╗¼µā│ńö©ÕÉīõĖƵē╣ÕøŠńēćÕ»╣µ©ĪÕ×ŗõ╝śÕī¢õĖżµ¼Ī’╝īń¼¼õĖƵ¼ĪÕ╝ĆÕÉ»µē╣µĢ░µŹ«Õó×Õ╝║’╝īń¼¼õ║īµ¼ĪÕģ│ķŚŁ’╝Ü
+
+ ```python
+ class CustomModel(BaseModel):
+
+ def train_step(self, data, optim_wrapper):
+ data = self.data_preprocessor(data, training=True) # Õ╝ĆÕÉ»µē╣µĢ░µŹ«Õó×Õ╝║
+ loss = self(data, mode='loss')
+ optim_wrapper.update_params(loss)
+ data = self.data_preprocessor(data, training=False) # Õģ│ķŚŁµē╣µĢ░µŹ«Õó×Õ╝║
+ loss = self(data, mode='loss')
+ optim_wrapper.update_params(loss)
+ ```
+
+ Ķ”üµā│ÕÉ»ńö©ÕłåÕĖāÕ╝ÅĶ«Łń╗ā’╝īµłæõ╗¼Õ░▒ķ£ĆĶ”üķćŹĶĮĮ `MMSeparateDistributedDataParallel`’╝īÕ╣ČÕ£© `train_step` õĖŁÕ«×ńÄ░ÕÆī `CustomModel.train_step` ńøĖÕÉīńÜ䵥üń©ŗ’╝ł`test_step`ŃĆü`val_step` ÕÉīńÉå’╝ēŃĆé
+
+ ```python
+ class CustomDistributedDataParallel(MMSeparateDistributedDataParallel):
+
+ def train_step(self, data, optim_wrapper):
+ data = self.data_preprocessor(data, training=True) # Õ╝ĆÕÉ»µē╣µĢ░µŹ«Õó×Õ╝║
+ loss = self(data, mode='loss')
+ optim_wrapper.update_params(loss)
+ data = self.data_preprocessor(data, training=False) # Õģ│ķŚŁµē╣µĢ░µŹ«Õó×Õ╝║
+ loss = self(data, mode='loss')
+ optim_wrapper.update_params(loss)
+ ```
+
+ µ£ĆÕÉÄÕ£©µ×äÕ╗║ `runner` µŚČµīćÕ«Ü’╝Ü
+
+ ```python
+ # µīćÕ«ÜÕ░üĶŻģń▒╗Õ×ŗõĖ║ `CustomDistributedDataParallel`’╝īÕ╣ČÕ¤║õ║Äķ╗śĶ«żÕÅéµĢ░Õ░üĶŻģµ©ĪÕ×ŗŃĆé
+ cfg = dict(model_wrapper_cfg=dict(type='CustomDistributedDataParallel'))
+ runner = Runner(
+ model=model,
+ ...,
+ launcher='pytorch',
+ cfg=cfg
+ )
+ ```
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/model_analysis.md b/internlm_langchain/knowledge_base/MMEngine/content/model_analysis.md
new file mode 100644
index 00000000..c3867933
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/model_analysis.md
@@ -0,0 +1,184 @@
+# µ©ĪÕ×ŗÕżŹµØéÕ║”Õłåµ×É
+
+µłæõ╗¼µÅÉõŠøõ║åõĖĆõĖ¬ÕĘźÕģĘµØźÕĖ«ÕŖ®Õłåµ×ÉńĮæń╗£ńÜäÕżŹµØéµĆ¦ŃĆ鵳æõ╗¼ÕƤķē┤õ║å [fvcore](https://github.com/facebookresearch/fvcore) ńÜäÕ«×ńÄ░µĆØĶĘ»µØźµ×äÕ╗║Ķ┐ÖõĖ¬ÕĘźÕģĘ’╝īÕ╣ČĶ«ĪÕłÆÕ£©µ£¬µØźµö»µīüµø┤ÕżÜńÜäĶć¬Õ«Üõ╣ēń«ŚÕŁÉŃĆéńø«ÕēŹńÜäÕĘźÕģʵÅÉõŠøõ║åńö©õ║ÄĶ«Īń«Śń╗Öիܵ©ĪÕ×ŗńÜ䵥«ńé╣Ķ┐Éń«ŚķćÅ’╝łFLOPs’╝ēŃĆüµ┐Ƶ┤╗ķćÅ’╝łActivations’╝ēÕÆīÕÅéµĢ░ķćÅ’╝łParameters’╝ēńÜäµÄźÕÅŻ’╝īÕ╣ȵö»µīüõ╗źńĮæń╗£ń╗ōµ×䵳¢ĶĪ©µĀ╝ńÜäÕĮóÕ╝ÅķĆÉÕ▒éµēōÕŹ░ńøĖÕģ│õ┐Īµü»’╝īÕÉīµŚČµÅÉõŠøõ║åń«ŚÕŁÉń║¦Õł½’╝łoperator’╝ēÕÆīµ©ĪÕØŚń║¦Õł½’╝łModule’╝ēńÜäń╗¤Ķ«ĪŃĆéÕ”éµ×£µé©Õ»╣ń╗¤Ķ«ĪµĄ«ńé╣Ķ┐Éń«ŚķćÅńÜäÕ«×ńÄ░ń╗åĶŖéµä¤Õģ┤ĶČŻ’╝īĶ»ĘÕÅéĶĆā [Flop Count](https://github.com/facebookresearch/fvcore/blob/main/docs/flop_count.md)ŃĆé
+
+## Õ«Üõ╣ē
+
+µ©ĪÕ×ŗÕżŹµØéÕ║”µ£ē 3 õĖ¬µīćµĀć’╝īÕłåÕł½µś»µĄ«ńé╣Ķ┐Éń«ŚķćÅ’╝łFLOPs’╝ēŃĆüµ┐Ƶ┤╗ķćÅ’╝łActivations’╝ēõ╗źÕÅŖÕÅéµĢ░ķćÅ’╝łParameters’╝ē’╝īÕ«āõ╗¼ńÜäÕ«Üõ╣ēÕ”éõĖŗ’╝Ü
+
+- µĄ«ńé╣Ķ┐Éń«ŚķćÅ
+
+ µĄ«ńé╣Ķ┐Éń«ŚķćÅõĖŹµś»õĖĆõĖ¬Õ«Üõ╣ēķØ×ÕĖĖµśÄńĪ«ńÜäµīćµĀć’╝īÕ£©Ķ┐ÖķćīÕÅéĶĆā [detectron2](https://detectron2.readthedocs.io/en/latest/modules/fvcore.html#fvcore.nn.FlopCountAnalysis) ńÜäµÅÅĶ┐░’╝īÕ░åõĖĆń╗äõ╣śÕŖĀĶ┐Éń«ŚÕ«Üõ╣ēõĖ║ 1 õĖ¬ flopŃĆé
+
+- µ┐Ƶ┤╗ķćÅ
+
+ µ┐Ƶ┤╗ķćÅńö©õ║ÄĶĪĪķćŵ¤ÉõĖĆÕ▒éõ║¦ńö¤ńÜäńē╣ÕŠüµĢ░ķćÅŃĆé
+
+- ÕÅéµĢ░ķćÅ
+
+ µ©ĪÕ×ŗńÜäÕÅéµĢ░ķćÅŃĆé
+
+õŠŗÕ”é’╝īń╗ÖÕ«ÜĶŠōÕģźÕ░║Õ»Ė `inputs = torch.randn((1, 3, 10, 10))`’╝īÕÆīõĖĆõĖ¬ÕŹĘń¦»Õ▒é `conv = nn.Conv2d(in_channels=3, out_channels=10, kernel_size=3)`’╝īķéŻõ╣łÕ«āĶŠōÕć║ńÜäńē╣ÕŠüÕøŠÕ░║Õ»ĖõĖ║ `(1, 10, 8, 8)`’╝īÕłÖÕ«āńÜ䵥«ńé╣Ķ┐Éń«Śķćŵś» `17280 = 10*8*8*3*3*3`’╝ł10*8*8 ĶĪ©ńż║ĶŠōÕć║ńÜäńē╣ÕŠüÕøŠÕż¦Õ░ÅŃĆü3*3*3 ĶĪ©ńż║µ»ÅõĖĆõĖ¬ĶŠōÕć║ķ£ĆĶ”üńÜäĶ«Īń«ŚķćÅ’╝ēŃĆüµ┐Ƶ┤╗ķćŵś» `640 = 10*8*8`ŃĆüÕÅéµĢ░ķćŵś» `280 = 3*10*3*3 + 10`’╝ł3*10*3\*3 ĶĪ©ńż║µØāķćŹńÜäÕ░║Õ»ĖŃĆü10 ĶĪ©ńż║ÕüÅńĮ«ÕĆ╝ńÜäÕ░║Õ»Ė’╝ēŃĆé
+
+## ńö©µ│Ģ
+
+### Õ¤║õ║Ä `nn.Module` µ×äÕ╗║ńÜ䵩ĪÕ×ŗ
+
+µ×äÕ╗║µ©ĪÕ×ŗ
+
+```python
+from torch import nn
+
+from mmengine.analysis import get_model_complexity_info
+
+
+# õ╗źÕŁŚÕģĖńÜäÕĮóÕ╝ÅĶ┐öÕø×Õłåµ×Éń╗ōµ×£’╝īÕīģµŗ¼:
+# ['flops', 'flops_str', 'activations', 'activations_str', 'params', 'params_str', 'out_table', 'out_arch']
+class InnerNet(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.fc1 = nn.Linear(10, 10)
+ self.fc2 = nn.Linear(10, 10)
+
+ def forward(self, x):
+ return self.fc1(self.fc2(x))
+
+
+class TestNet(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.fc1 = nn.Linear(10, 10)
+ self.fc2 = nn.Linear(10, 10)
+ self.inner = InnerNet()
+
+ def forward(self, x):
+ return self.fc1(self.fc2(self.inner(x)))
+
+
+input_shape = (1, 10)
+model = TestNet()
+```
+
+`get_model_complexity_info` Ķ┐öÕø×ńÜä `analysis_results` µś»õĖĆõĖ¬ÕīģÕɽ 7 õĖ¬ÕĆ╝ńÜäÕŁŚÕģĖ:
+
+- `flops`: flop ńÜäµĆ╗µĢ░, õŠŗÕ”é, 1000, 1000000
+- `flops_str`: µĀ╝Õ╝ÅÕī¢ńÜäÕŁŚń¼”õĖ▓, õŠŗÕ”é, 1.0G, 1.0M
+- `params`: Õģ©ķā©ÕÅéµĢ░ńÜäµĢ░ķćÅ, õŠŗÕ”é, 1000, 1000000
+- `params_str`: µĀ╝Õ╝ÅÕī¢ńÜäÕŁŚń¼”õĖ▓, õŠŗÕ”é, 1.0K, 1M
+- `activations`: µ┐Ƶ┤╗ķćÅńÜäµĆ╗µĢ░, õŠŗÕ”é, 1000, 1000000
+- `activations_str`: µĀ╝Õ╝ÅÕī¢ńÜäÕŁŚń¼”õĖ▓, õŠŗÕ”é, 1.0G, 1M
+- `out_table`: õ╗źĶĪ©µĀ╝ÕĮóÕ╝ŵēōÕŹ░ńøĖÕģ│õ┐Īµü»
+
+µēōÕŹ░ń╗ōµ×£
+
+- õ╗źĶĪ©µĀ╝ÕĮóÕ╝ŵēōÕŹ░ńøĖÕģ│õ┐Īµü»
+
+ ```python
+ print(analysis_results['out_table'])
+ ```
+
+ ```text
+ +---------------------+----------------------+--------+--------------+
+ | module | #parameters or shape | #flops | #activations |
+ +---------------------+----------------------+--------+--------------+
+ | model | 0.44K | 0.4K | 40 |
+ | fc1 | 0.11K | 100 | 10 |
+ | fc1.weight | (10, 10) | | |
+ | fc1.bias | (10,) | | |
+ | fc2 | 0.11K | 100 | 10 |
+ | fc2.weight | (10, 10) | | |
+ | fc2.bias | (10,) | | |
+ | inner | 0.22K | 0.2K | 20 |
+ | inner.fc1 | 0.11K | 100 | 10 |
+ | inner.fc1.weight | (10, 10) | | |
+ | inner.fc1.bias | (10,) | | |
+ | inner.fc2 | 0.11K | 100 | 10 |
+ | inner.fc2.weight | (10, 10) | | |
+ | inner.fc2.bias | (10,) | | |
+ +---------------------+----------------------+--------+--------------+
+ ```
+
+- õ╗źńĮæń╗£Õ▒éń║¦ń╗ōµ×äµēōÕŹ░ńøĖÕģ│õ┐Īµü»
+
+ ```python
+ print(analysis_results['out_arch'])
+ ```
+
+ ```bash
+ TestNet(
+ #params: 0.44K, #flops: 0.4K, #acts: 40
+ (fc1): Linear(
+ in_features=10, out_features=10, bias=True
+ #params: 0.11K, #flops: 100, #acts: 10
+ )
+ (fc2): Linear(
+ in_features=10, out_features=10, bias=True
+ #params: 0.11K, #flops: 100, #acts: 10
+ )
+ (inner): InnerNet(
+ #params: 0.22K, #flops: 0.2K, #acts: 20
+ (fc1): Linear(
+ in_features=10, out_features=10, bias=True
+ #params: 0.11K, #flops: 100, #acts: 10
+ )
+ (fc2): Linear(
+ in_features=10, out_features=10, bias=True
+ #params: 0.11K, #flops: 100, #acts: 10
+ )
+ )
+ )
+ ```
+
+- õ╗źÕŁŚń¼”õĖ▓ńÜäÕĮóÕ╝ŵēōÕŹ░ń╗ōµ×£
+
+ ```python
+ print("Model Flops:{}".format(analysis_results['flops_str']))
+ # Model Flops:0.4K
+ print("Model Parameters:{}".format(analysis_results['params_str']))
+ # Model Parameters:0.44K
+ ```
+
+### Õ¤║õ║Ä BaseModel’╝łµØźĶć¬ MMEngine’╝ēµ×äÕ╗║ńÜ䵩ĪÕ×ŗ
+
+```python
+import torch.nn.functional as F
+import torchvision
+from mmengine.model import BaseModel
+from mmengine.analysis import get_model_complexity_info
+
+
+class MMResNet50(BaseModel):
+ def __init__(self):
+ super().__init__()
+ self.resnet = torchvision.models.resnet50()
+
+ def forward(self, imgs, labels=None, mode='tensor'):
+ x = self.resnet(imgs)
+ if mode == 'loss':
+ return {'loss': F.cross_entropy(x, labels)}
+ elif mode == 'predict':
+ return x, labels
+ elif mode == 'tensor':
+ return x
+
+
+input_shape = (3, 224, 224)
+model = MMResNet50()
+
+analysis_results = get_model_complexity_info(model, input_shape)
+
+print("Model Flops:{}".format(analysis_results['flops_str']))
+# Model Flops:4.145G
+print("Model Parameters:{}".format(analysis_results['params_str']))
+# Model Parameters:25.557M
+```
+
+## ÕģČõ╗¢µÄźÕÅŻ
+
+ķÖżõ║åõĖŖĶ┐░Õ¤║µ£¼ńö©µ│Ģ’╝ī`get_model_complexity_info` Ķ┐śĶāĮµÄźÕÅŚõ╗źõĖŗÕÅéµĢ░’╝īĶŠōÕć║Õ«ÜÕłČÕī¢ńÜäń╗¤Ķ«Īń╗ōµ×£’╝Ü
+
+- `model`: (nn.Module) ÕŠģÕłåµ×ÉńÜ䵩ĪÕ×ŗ
+- `input_shape`: (tuple) ĶŠōÕģźÕ░║Õ»Ė’╝īõŠŗÕ”é (3, 224, 224)
+- `inputs`: (optional: torch.Tensor), Õ”éµ×£õ╝ĀÕģźĶ»źÕÅéµĢ░, `input_shape` õ╝ÜĶó½Õ┐ĮńĢź
+- `show_table`: (bool) µś»ÕÉ”õ╗źĶĪ©µĀ╝ÕĮóÕ╝ÅĶ┐öÕø×ń╗¤Ķ«Īń╗ōµ×£’╝īķ╗śĶ«żÕĆ╝’╝ÜTrue
+- `show_arch`: (bool) µś»ÕÉ”õ╗źńĮæń╗£ń╗ōµ×äÕĮóÕ╝ÅĶ┐öÕø×ń╗¤Ķ«Īń╗ōµ×£’╝īķ╗śĶ«żÕĆ╝’╝ÜTrue
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/optim_wrapper.md b/internlm_langchain/knowledge_base/MMEngine/content/optim_wrapper.md
new file mode 100644
index 00000000..2c9c7d6b
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/optim_wrapper.md
@@ -0,0 +1,502 @@
+# õ╝śÕī¢ÕÖ©Õ░üĶŻģ’╝łOptimWrapper’╝ē
+
+Õ£©[µē¦ĶĪīÕÖ©µĢÖń©ŗ](./runner.md)ÕÆī[µ©ĪÕ×ŗµĢÖń©ŗ](./model.md)õĖŁ’╝īµłæõ╗¼µł¢ÕżÜµł¢Õ░æÕ£░µÅÉÕł░õ║åõ╝śÕī¢ÕÖ©Õ░üĶŻģ’╝łOptimWrapper’╝ēńÜäµ”éÕ┐Ą’╝īõĮåµś»ÕŹ┤µ▓Īµ£ēõ╗ŗń╗ŹõĖ║õ╗Ćõ╣łµłæõ╗¼ķ£ĆĶ”üõ╝śÕī¢ÕÖ©Õ░üĶŻģ’╝īńøĖµ»öõ║Ä Pytorch ÕĤńö¤ńÜäõ╝śÕī¢ÕÖ©’╝īõ╝śÕī¢ÕÖ©Õ░üĶŻģÕÅłµ£ēµĆĵĀĘńÜäõ╝śÕŖ┐’╝īĶ┐Öõ║øķŚ«ķóśõ╝ÜÕ£©µ£¼µĢÖń©ŗõĖŁÕŠŚÕł░õĖĆõĖĆĶ¦ŻńŁöŃĆ鵳æõ╗¼Õ░åķĆÜĶ┐ćÕ»╣µ»öńÜäµ¢╣Õ╝ÅÕĖ«ÕŖ®Õż¦Õ«ČńÉåĶ¦Ż’╝īõ╝śÕī¢ÕÖ©Õ░üĶŻģńÜäõ╝śÕŖ┐’╝īõ╗źÕÅŖÕ”éõĮĢõĮ┐ńö©Õ«āŃĆé
+
+õ╝śÕī¢ÕÖ©Õ░üĶŻģķĪŠÕÉŹµĆØõ╣ē’╝īµś» Pytorch ÕĤńö¤õ╝śÕī¢ÕÖ©’╝łOptimizer’╝ēķ½śń║¦µŖĮĶ▒Ī’╝īÕ«āÕ£©Õó×ÕŖĀõ║åµø┤ÕżÜÕŖ¤ĶāĮńÜäÕÉīµŚČ’╝īµÅÉõŠøõ║åõĖĆÕźŚń╗¤õĖĆńÜäµÄźÕÅŻŃĆéõ╝śÕī¢ÕÖ©Õ░üĶŻģµö»µīüõĖŹÕÉīńÜäĶ«Łń╗āńŁ¢ńĢź’╝īÕīģµŗ¼µĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗āŃĆüµó»Õ║”ń┤»ÕŖĀÕÆīµó»Õ║”µł¬µ¢ŁŃĆ鵳æõ╗¼ÕÅ»õ╗źµĀ╣µŹ«ķ£Ćµ▒éķĆēµŗ®ÕÉłķĆéńÜäĶ«Łń╗āńŁ¢ńĢźŃĆéõ╝śÕī¢ÕÖ©Õ░üĶŻģĶ┐śÕ«Üõ╣ēõ║åõĖĆÕźŚµĀćÕćåńÜäÕÅéµĢ░µø┤µ¢░µĄüń©ŗ’╝īńö©µłĘÕÅ»õ╗źÕ¤║õ║ÄĶ┐ÖõĖĆÕźŚµĄüń©ŗ’╝īÕ«×ńÄ░ÕÉīõĖĆÕźŚõ╗ŻńĀü’╝īõĖŹÕÉīĶ«Łń╗āńŁ¢ńĢźńÜäÕłćµŹóŃĆé
+
+## õ╝śÕī¢ÕÖ©Õ░üĶŻģ vs õ╝śÕī¢ÕÖ©
+
+Ķ┐Öķćīµłæõ╗¼ÕłåÕł½Õ¤║õ║Ä Pytorch ÕåģńĮ«ńÜäõ╝śÕī¢ÕÖ©ÕÆī MMEngine ńÜäõ╝śÕī¢ÕÖ©Õ░üĶŻģĶ┐øĶĪīÕŹĢń▓ŠÕ║”Ķ«Łń╗āŃĆüµĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗āÕÆīµó»Õ║”ń┤»ÕŖĀ’╝īÕ»╣µ»öõ║īĶĆģÕ«×ńÄ░õĖŖńÜäÕī║Õł½ŃĆé
+
+### Ķ«Łń╗āµ©ĪÕ×ŗ
+
+**1.1 Õ¤║õ║Ä Pytorch ńÜä SGD õ╝śÕī¢ÕÖ©Õ«×ńÄ░ÕŹĢń▓ŠÕ║”Ķ«Łń╗ā**
+
+```python
+import torch
+from torch.optim import SGD
+import torch.nn as nn
+import torch.nn.functional as F
+
+inputs = [torch.zeros(10, 1, 1)] * 10
+targets = [torch.ones(10, 1, 1)] * 10
+model = nn.Linear(1, 1)
+optimizer = SGD(model.parameters(), lr=0.01)
+optimizer.zero_grad()
+
+for input, target in zip(inputs, targets):
+ output = model(input)
+ loss = F.l1_loss(output, target)
+ loss.backward()
+ optimizer.step()
+ optimizer.zero_grad()
+```
+
+**1.2 õĮ┐ńö© MMEngine ńÜäõ╝śÕī¢ÕÖ©Õ░üĶŻģÕ«×ńÄ░ÕŹĢń▓ŠÕ║”Ķ«Łń╗ā**
+
+```python
+from mmengine.optim import OptimWrapper
+
+optim_wrapper = OptimWrapper(optimizer=optimizer)
+
+for input, target in zip(inputs, targets):
+ output = model(input)
+ loss = F.l1_loss(output, target)
+ optim_wrapper.update_params(loss)
+```
+
+
+
+õ╝śÕī¢ÕÖ©Õ░üĶŻģńÜä `update_params` Õ«×ńÄ░õ║åµĀćÕćåńÜäµó»Õ║”Ķ«Īń«ŚŃĆüÕÅéµĢ░µø┤µ¢░ÕÆīµó»Õ║”µĖģķøȵĄüń©ŗ’╝īÕÅ»õ╗źńø┤µÄźńö©µØźµø┤µ¢░µ©ĪÕ×ŗÕÅéµĢ░ŃĆé
+
+**2.1 Õ¤║õ║Ä Pytorch ńÜä SGD õ╝śÕī¢ÕÖ©Õ«×ńÄ░µĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗ā**
+
+```python
+from torch.cuda.amp import autocast
+
+model = model.cuda()
+inputs = [torch.zeros(10, 1, 1, 1)] * 10
+targets = [torch.ones(10, 1, 1, 1)] * 10
+
+for input, target in zip(inputs, targets):
+ with autocast():
+ output = model(input.cuda())
+ loss = F.l1_loss(output, target.cuda())
+ loss.backward()
+ optimizer.step()
+ optimizer.zero_grad()
+```
+
+**2.2 Õ¤║õ║Ä MMEngine ńÜä õ╝śÕī¢ÕÖ©Õ░üĶŻģÕ«×ńÄ░µĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗ā**
+
+```python
+from mmengine.optim import AmpOptimWrapper
+
+optim_wrapper = AmpOptimWrapper(optimizer=optimizer)
+
+for input, target in zip(inputs, targets):
+ with optim_wrapper.optim_context(model):
+ output = model(input.cuda())
+ loss = F.l1_loss(output, target.cuda())
+ optim_wrapper.update_params(loss)
+```
+
+
+
+Õ╝ĆÕÉ»µĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗āķ£ĆĶ”üõĮ┐ńö© `AmpOptimWrapper`’╝īõ╗¢ńÜä optim_context µÄźÕÅŻń▒╗õ╝╝ `autocast`’╝īõ╝ÜÕ╝ĆÕÉ»µĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗āńÜäõĖŖõĖŗµ¢ćŃĆéķÖżµŁżõ╣ŗÕż¢õ╗¢Ķ┐śĶāĮÕŖĀķĆ¤ÕłåÕĖāÕ╝ÅĶ«Łń╗āµŚČńÜäµó»Õ║”ń┤»ÕŖĀ’╝īĶ┐ÖõĖ¬µłæõ╗¼õ╝ÜÕ£©õĖŗõĖĆõĖ¬ńż║õŠŗõĖŁõ╗ŗń╗ŹŃĆé
+
+**3.1 Õ¤║õ║Ä Pytorch ńÜä SGD õ╝śÕī¢ÕÖ©Õ«×ńÄ░µĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗āÕÆīµó»Õ║”ń┤»ÕŖĀ**
+
+```python
+for idx, (input, target) in enumerate(zip(inputs, targets)):
+ with autocast():
+ output = model(input.cuda())
+ loss = F.l1_loss(output, target.cuda())
+ loss.backward()
+ if idx % 2 == 0:
+ optimizer.step()
+ optimizer.zero_grad()
+```
+
+**3.2 Õ¤║õ║Ä MMEngine ńÜäõ╝śÕī¢ÕÖ©Õ░üĶŻģÕ«×ńÄ░µĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗āÕÆīµó»Õ║”ń┤»ÕŖĀ**
+
+```python
+optim_wrapper = AmpOptimWrapper(optimizer=optimizer, accumulative_counts=2)
+
+for input, target in zip(inputs, targets):
+ with optim_wrapper.optim_context(model):
+ output = model(input.cuda())
+ loss = F.l1_loss(output, target.cuda())
+ optim_wrapper.update_params(loss)
+```
+
+
+
+µłæõ╗¼ÕŬķ£ĆĶ”üķģŹńĮ« `accumulative_counts` ÕÅéµĢ░’╝īÕ╣ČĶ░āńö© `update_params` µÄźÕÅŻÕ░▒ĶāĮÕ«×ńÄ░µó»Õ║”ń┤»ÕŖĀńÜäÕŖ¤ĶāĮŃĆéķÖżµŁżõ╣ŗÕż¢’╝īÕłåÕĖāÕ╝ÅĶ«Łń╗āµāģÕåĄõĖŗ’╝īÕ”éµ×£µłæõ╗¼ķģŹńĮ«µó»Õ║”ń┤»ÕŖĀńÜäÕÉīµŚČÕ╝ĆÕÉ»õ║å `optim_wrapper` õĖŖõĖŗµ¢ć’╝īÕÅ»õ╗źķü┐ÕģŹµó»Õ║”ń┤»ÕŖĀķśČµ«ĄõĖŹÕ┐ģĶ”üńÜäµó»Õ║”ÕÉīµŁźŃĆé
+
+õ╝śÕī¢ÕÖ©Õ░üĶŻģÕÉīµĀʵÅÉõŠøõ║åµø┤ń╗åń▓ÆÕ║”ńÜäµÄźÕÅŻ’╝īµ¢╣õŠ┐ńö©µłĘÕ«×ńÄ░õĖĆõ║øĶć¬Õ«Üõ╣ēńÜäÕÅéµĢ░µø┤µ¢░ķĆ╗ĶŠæ’╝Ü
+
+- `backward`’╝Üõ╝ĀÕģźµŹ¤Õż▒’╝īńö©õ║ÄĶ«Īń«ŚÕÅéµĢ░µó»Õ║”ŃĆé
+- `step`’╝ÜÕÉī `optimizer.step`’╝īńö©õ║ĵø┤µ¢░ÕÅéµĢ░ŃĆé
+- `zero_grad`’╝ÜÕÉī `optimizer.zero_grad`’╝īńö©õ║ÄÕÅéµĢ░ńÜäµó»Õ║”ŃĆé
+
+µłæõ╗¼ÕÅ»õ╗źõĮ┐ńö©õĖŖĶ┐░µÄźÕÅŻÕ«×ńÄ░ÕÆī Pytorch õ╝śÕī¢ÕÖ©ńøĖÕÉīńÜäÕÅéµĢ░µø┤µ¢░ķĆ╗ĶŠæ’╝Ü
+
+```python
+for idx, (input, target) in enumerate(zip(inputs, targets)):
+ optimizer.zero_grad()
+ with optim_wrapper.optim_context(model):
+ output = model(input.cuda())
+ loss = F.l1_loss(output, target.cuda())
+ optim_wrapper.backward(loss)
+ if idx % 2 == 0:
+ optim_wrapper.step()
+ optim_wrapper.zero_grad()
+```
+
+µłæõ╗¼ÕÉīµĀĘÕÅ»õ╗źõĖ║õ╝śÕī¢ÕÖ©Õ░üĶŻģķģŹńĮ«µó»Õ║”ĶŻüÕćÅńŁ¢ńĢź’╝Ü
+
+```python
+# Õ¤║õ║Ä torch.nn.utils.clip_grad_norm_ Õ»╣µó»Õ║”Ķ┐øĶĪīĶŻüÕćÅ
+optim_wrapper = AmpOptimWrapper(
+ optimizer=optimizer, clip_grad=dict(max_norm=1))
+
+# Õ¤║õ║Ä torch.nn.utils.clip_grad_value_ Õ»╣µó»Õ║”Ķ┐øĶĪīĶŻüÕćÅ
+optim_wrapper = AmpOptimWrapper(
+ optimizer=optimizer, clip_grad=dict(clip_value=0.2))
+```
+
+### ĶÄĘÕÅ¢ÕŁ”õ╣ĀńÄć/ÕŖ©ķćÅ
+
+õ╝śÕī¢ÕÖ©Õ░üĶŻģµÅÉõŠøõ║å `get_lr` ÕÆī `get_momentum` µÄźÕÅŻńö©õ║ÄĶÄĘÕÅ¢õ╝śÕī¢ÕÖ©ńÜäõĖĆõĖ¬ÕÅéµĢ░ń╗äńÜäÕŁ”õ╣ĀńÄć’╝Ü
+
+```python
+import torch.nn as nn
+from torch.optim import SGD
+
+from mmengine.optim import OptimWrapper
+
+model = nn.Linear(1, 1)
+optimizer = SGD(model.parameters(), lr=0.01)
+optim_wrapper = OptimWrapper(optimizer)
+
+print(optimizer.param_groups[0]['lr']) # 0.01
+print(optimizer.param_groups[0]['momentum']) # 0
+print(optim_wrapper.get_lr()) # {'lr': [0.01]}
+print(optim_wrapper.get_momentum()) # {'momentum': [0]}
+```
+
+```
+0.01
+0
+{'lr': [0.01]}
+{'momentum': [0]}
+```
+
+### Õ»╝Õć║/ÕŖĀĶĮĮńŖȵĆüÕŁŚÕģĖ
+
+õ╝śÕī¢ÕÖ©Õ░üĶŻģÕÆīõ╝śÕī¢ÕÖ©õĖƵĀĘ’╝īµÅÉõŠøõ║å `state_dict` ÕÆī `load_state_dict` µÄźÕÅŻ’╝īńö©õ║ÄÕ»╝Õć║/ÕŖĀĶĮĮõ╝śÕī¢ÕÖ©ńŖȵĆü’╝īÕ»╣õ║Ä `AmpOptimWrapper`’╝īõ╝śÕī¢ÕÖ©Õ░üĶŻģĶ┐śõ╝ÜķóØÕż¢Õ»╝Õć║µĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗āńøĖÕģ│ńÜäÕÅéµĢ░’╝Ü
+
+```python
+import torch.nn as nn
+from torch.optim import SGD
+from mmengine.optim import OptimWrapper, AmpOptimWrapper
+
+model = nn.Linear(1, 1)
+optimizer = SGD(model.parameters(), lr=0.01)
+
+optim_wrapper = OptimWrapper(optimizer=optimizer)
+amp_optim_wrapper = AmpOptimWrapper(optimizer=optimizer)
+
+# Õ»╝Õć║ńŖȵĆüÕŁŚÕģĖ
+optim_state_dict = optim_wrapper.state_dict()
+amp_optim_state_dict = amp_optim_wrapper.state_dict()
+
+print(optim_state_dict)
+print(amp_optim_state_dict)
+optim_wrapper_new = OptimWrapper(optimizer=optimizer)
+amp_optim_wrapper_new = AmpOptimWrapper(optimizer=optimizer)
+
+# ÕŖĀĶĮĮńŖȵĆüÕŁŚÕģĖ
+amp_optim_wrapper_new.load_state_dict(amp_optim_state_dict)
+optim_wrapper_new.load_state_dict(optim_state_dict)
+```
+
+```
+{'state': {}, 'param_groups': [{'lr': 0.01, 'momentum': 0, 'dampening': 0, 'weight_decay': 0, 'nesterov': False, 'maximize': False, 'foreach': None, 'params': [0, 1]}]}
+{'state': {}, 'param_groups': [{'lr': 0.01, 'momentum': 0, 'dampening': 0, 'weight_decay': 0, 'nesterov': False, 'maximize': False, 'foreach': None, 'params': [0, 1]}], 'loss_scaler': {'scale': 65536.0, 'growth_factor': 2.0, 'backoff_factor': 0.5, 'growth_interval': 2000, '_growth_tracker': 0}}
+```
+
+### õĮ┐ńö©ÕżÜõĖ¬õ╝śÕī¢ÕÖ©
+
+ĶĆāĶÖæÕł░ńö¤µłÉÕ»╣µŖŚńĮæń╗£õ╣ŗń▒╗ńÜäń«Śµ│ĢķĆÜÕĖĖķ£ĆĶ”üõĮ┐ńö©ÕżÜõĖ¬õ╝śÕī¢ÕÖ©µØźĶ«Łń╗āńö¤µłÉÕÖ©ÕÆīÕłżÕł½ÕÖ©’╝īÕøĀµŁżõ╝śÕī¢ÕÖ©Õ░üĶŻģµÅÉõŠøõ║åõ╝śÕī¢ÕÖ©Õ░üĶŻģńÜäÕ«╣ÕÖ©ń▒╗’╝Ü`OptimWrapperDict` µØźń«ĪńÉåÕżÜõĖ¬õ╝śÕī¢ÕÖ©Õ░üĶŻģŃĆé`OptimWrapperDict` õ╗źÕŁŚÕģĖńÜäÕĮóÕ╝ÅÕŁśÕé©õ╝śÕī¢ÕÖ©Õ░üĶŻģ’╝īÕ╣ČÕģüĶ«Ėńö©µłĘÕāÅÕŁŚÕģĖõĖƵĀĘĶ«┐ķŚ«ŃĆüķüŹÕÄåÕģČõĖŁńÜäÕģāń┤Ā’╝īÕŹ│õ╝śÕī¢ÕÖ©Õ░üĶŻģÕ«×õŠŗŃĆé
+
+õĖĵ֫ķĆÜńÜäõ╝śÕī¢ÕÖ©Õ░üĶŻģõĖŹÕÉī’╝ī`OptimWrapperDict` µ▓Īµ£ēÕ«×ńÄ░ `update_params`ŃĆü `optim_context`, `backward`ŃĆü`step` ńŁēµ¢╣µ│Ģ’╝īµŚĀµ│ĢĶó½ńø┤µÄźńö©õ║ÄĶ«Łń╗āµ©ĪÕ×ŗŃĆ鵳æõ╗¼Õ╗║Ķ««ńø┤µÄźĶ«┐ķŚ« `OptimWrapperDict` ń«ĪńÉåńÜäõ╝śÕī¢ÕÖ©Õ«×õŠŗ’╝īµØźÕ«×ńÄ░ÕÅéµĢ░µø┤µ¢░ķĆ╗ĶŠæŃĆé
+
+õĮĀµł¢Ķ«Ėõ╝ÜÕźĮÕźć’╝īµŚóńäČ `OptimWrapperDict` µ▓Īµ£ēĶ«Łń╗āńÜäÕŖ¤ĶāĮ’╝īķéŻõĖ║õ╗Ćõ╣łõĖŹńø┤µÄźõĮ┐ńö© `dict` µØźń«ĪńÉåÕżÜõĖ¬õ╝śÕī¢ÕÖ©’╝¤õ║ŗÕ«×õĖŖ’╝ī`OptimWrapperDict` ńÜäµĀĖÕ┐āÕŖ¤ĶāĮµś»µö»µīüµē╣ķćÅÕ»╝Õć║/ÕŖĀĶĮĮµēƵ£ēõ╝śÕī¢ÕÖ©Õ░üĶŻģńÜäńŖȵĆüÕŁŚÕģĖ’╝øµö»µīüĶÄĘÕÅ¢ÕżÜõĖ¬õ╝śÕī¢ÕÖ©Õ░üĶŻģńÜäÕŁ”õ╣ĀńÄćŃĆüÕŖ©ķćÅŃĆéÕ”éµ×£µ▓Īµ£ē `OptimWrapperDict`’╝ī`MMEngine` Õ░▒ķ£ĆĶ”üÕ£©ÕŠłÕżÜõĮŹńĮ«Õ»╣õ╝śÕī¢ÕÖ©Õ░üĶŻģńÜäń▒╗Õ×ŗÕüÜ `if else` Õłżµ¢Ł’╝īõ╗źĶÄĘÕÅ¢µēƵ£ēõ╝śÕī¢ÕÖ©Õ░üĶŻģńÜäńŖȵĆüŃĆé
+
+```python
+from torch.optim import SGD
+import torch.nn as nn
+
+from mmengine.optim import OptimWrapper, OptimWrapperDict
+
+gen = nn.Linear(1, 1)
+disc = nn.Linear(1, 1)
+optimizer_gen = SGD(gen.parameters(), lr=0.01)
+optimizer_disc = SGD(disc.parameters(), lr=0.01)
+
+optim_wapper_gen = OptimWrapper(optimizer=optimizer_gen)
+optim_wapper_disc = OptimWrapper(optimizer=optimizer_disc)
+optim_dict = OptimWrapperDict(gen=optim_wapper_gen, disc=optim_wapper_disc)
+
+print(optim_dict.get_lr()) # {'gen.lr': [0.01], 'disc.lr': [0.01]}
+print(optim_dict.get_momentum()) # {'gen.momentum': [0], 'disc.momentum': [0]}
+```
+
+```
+{'gen.lr': [0.01], 'disc.lr': [0.01]}
+{'gen.momentum': [0], 'disc.momentum': [0]}
+```
+
+Õ”éõĖŖõŠŗµēĆńż║’╝ī`OptimWrapperDict` ÕÅ»õ╗źķØ×ÕĖĖµ¢╣õŠ┐ńÜäÕ»╝Õć║µēƵ£ēõ╝śÕī¢ÕÖ©Õ░üĶŻģńÜäÕŁ”õ╣ĀńÄćÕÆīÕŖ©ķćÅ’╝īÕÉīµĀĘńÜä’╝īõ╝śÕī¢ÕÖ©Õ░üĶŻģõ╣¤ĶāĮÕż¤Õ»╝Õć║/ÕŖĀĶĮĮµēƵ£ēõ╝śÕī¢ÕÖ©Õ░üĶŻģńÜäńŖȵĆüÕŁŚÕģĖŃĆé
+
+### Õ£©[µē¦ĶĪīÕÖ©](./runner.md)õĖŁķģŹńĮ«õ╝śÕī¢ÕÖ©Õ░üĶŻģ
+
+õ╝śÕī¢ÕÖ©Õ░üĶŻģķ£ĆĶ”üµÄźÕÅŚ `optimizer` ÕÅéµĢ░’╝īÕøĀµŁżµłæõ╗¼ķ”¢Õģłķ£ĆĶ”üõĖ║õ╝śÕī¢ÕÖ©Õ░üĶŻģķģŹńĮ« `optimizer`ŃĆéMMEngine õ╝ÜĶć¬ÕŖ©Õ░å PyTorch õĖŁńÜäµēƵ£ēõ╝śÕī¢ÕÖ©ķāĮµĘ╗ÕŖĀĶ┐ø `OPTIMIZERS` µ│©ÕåīĶĪ©õĖŁ’╝īńö©µłĘÕÅ»õ╗źńö©ÕŁŚÕģĖńÜäÕĮóÕ╝ÅµØźµīćÕ«Üõ╝śÕī¢ÕÖ©’╝īµēƵ£ēµö»µīüńÜäõ╝śÕī¢ÕÖ©Ķ¦ü [PyTorch õ╝śÕī¢ÕÖ©ÕłŚĶĪ©](https://pytorch.org/docs/stable/optim.html#algorithms)ŃĆé
+
+õ╗źķģŹńĮ«õĖĆõĖ¬ SGD õ╝śÕī¢ÕÖ©Õ░üĶŻģõĖ║õŠŗ’╝Ü
+
+```python
+optimizer = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0001)
+optim_wrapper = dict(type='OptimWrapper', optimizer=optimizer)
+```
+
+Ķ┐ÖµĀʵłæõ╗¼Õ░▒ķģŹńĮ«ÕźĮõ║åõĖĆõĖ¬õ╝śÕī¢ÕÖ©ń▒╗Õ×ŗõĖ║ SGD ńÜäõ╝śÕī¢ÕÖ©Õ░üĶŻģ’╝īÕŁ”õ╣ĀńÄćŃĆüÕŖ©ķćÅńŁēÕÅéµĢ░Õ”éķģŹńĮ«µēĆńż║ŃĆéĶĆāĶÖæÕł░ `OptimWrapper` õĖ║µĀćÕćåńÜäÕŹĢń▓ŠÕ║”Ķ«Łń╗ā’╝īÕøĀµŁżµłæõ╗¼õ╣¤ÕÅ»õ╗źõĖŹķģŹńĮ« `type` ÕŁŚµ«Ą’╝Ü
+
+```python
+optimizer = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0001)
+optim_wrapper = dict(optimizer=optimizer)
+```
+
+Ķ”üµā│Õ╝ĆÕÉ»µĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗āÕÆīµó»Õ║”ń┤»ÕŖĀ’╝īķ£ĆĶ”üÕ░å `type` ÕłćµŹóµłÉ `AmpOptimWrapper`’╝īÕ╣ȵīćÕ«Ü `accumulative_counts` ÕÅéµĢ░’╝Ü
+
+```python
+optimizer = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0001)
+optim_wrapper = dict(type='AmpOptimWrapper', optimizer=optimizer, accumulative_counts=2)
+```
+
+```{note}
+Õ”éµ×£õĮĀµś»ń¼¼õĖƵ¼ĪķśģĶ»╗ MMEngine ńÜäµĢÖń©ŗµ¢ćµĪŻ’╝īÕ╣ČõĖöÕ░ܵ£¬õ║åĶ¦Ż[ķģŹńĮ«ń▒╗](../advanced_tutorials/config.md)ŃĆü[µ│©ÕåīÕÖ©](../advanced_tutorials/registry.md) ńŁēµ”éÕ┐Ą’╝īÕ╗║Ķ««ÕÅ»õ╗źÕģłĶĘ│Ķ┐ćõ╗źõĖŗĶ┐øķśČµĢÖń©ŗ’╝īÕģłÕÄ╗ķśģĶ»╗ÕģČõ╗¢µ¢ćµĪŻŃĆéÕĮōńäČõ║å’╝īÕ”éµ×£õĮĀÕĘ▓ń╗ÅÕģĘÕżćõ║åĶ┐Öõ║øÕé©Õżćń¤źĶ»å’╝īµłæõ╗¼Õ╝║ńāłÕ╗║Ķ««ķśģĶ»╗Ķ┐øķśČµĢÖń©ŗ’╝īÕ£©Ķ┐øķśČµĢÖń©ŗõĖŁ’╝īµłæõ╗¼Õ░åÕŁ”õ╝Ü’╝Ü
+
+1. Õ”éõĮĢÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁÕ«ÜÕłČÕī¢Õ£░Õ£©õ╝śÕī¢ÕÖ©õĖŁķģŹńĮ«µ©ĪÕ×ŗÕÅéµĢ░ńÜäÕŁ”õ╣ĀńÄćŃĆüĶĪ░ÕćÅń│╗µĢ░ńŁēŃĆé
+2. Õ”éõĮĢĶć¬Õ«Üõ╣ēõĖĆõĖ¬õ╝śÕī¢ÕÖ©µ×äķĆĀńŁ¢ńĢź’╝īÕ«×ńÄ░ń£¤µŁŻµäÅõ╣ēõĖŖńÜäŌĆ£õ╝śÕī¢ÕÖ©ķģŹńĮ«Ķć¬ńö▒ŌĆØŃĆé
+
+ķÖżõ║åķģŹńĮ«ń▒╗ÕÆīµ│©ÕåīÕÖ©ńŁēÕēŹńĮ«ń¤źĶ»å’╝īµłæõ╗¼Õ╗║Ķ««Õ£©Õ╝ĆÕ¦ŗĶ┐øķśČµĢÖń©ŗõ╣ŗÕēŹ’╝īÕģłµĘ▒Õģźõ║åĶ¦Ż Pytorch ÕĤńö¤õ╝śÕī¢ÕÖ©µ×äķĆĀµŚČńÜä params ÕÅéµĢ░ŃĆé
+```
+
+## Ķ┐øķśČķģŹńĮ«
+
+PyTorch ńÜäõ╝śÕī¢ÕÖ©µö»µīüÕ»╣µ©ĪÕ×ŗõĖŁńÜäõĖŹÕÉīÕÅéµĢ░Ķ«ŠńĮ«õĖŹÕÉīńÜäĶČģÕÅéµĢ░’╝īõŠŗÕ”éÕ»╣õĖĆõĖ¬Õłåń▒╗µ©ĪÕ×ŗńÜäķ¬©Õ╣▓’╝łbackbone’╝ēÕÆīÕłåń▒╗Õż┤’╝łhead’╝ēĶ«ŠńĮ«õĖŹÕÉīńÜäÕŁ”õ╣ĀńÄć’╝Ü
+
+```python
+from torch.optim import SGD
+import torch.nn as nn
+
+model = nn.ModuleDict(dict(backbone=nn.Linear(1, 1), head=nn.Linear(1, 1)))
+optimizer = SGD([{'params': model.backbone.parameters()},
+ {'params': model.head.parameters(), 'lr': 1e-3}],
+ lr=0.01,
+ momentum=0.9)
+```
+
+õĖŖķØóńÜäõŠŗÕŁÉõĖŁ’╝īµ©ĪÕ×ŗńÜäķ¬©Õ╣▓ķā©ÕłåõĮ┐ńö©õ║å 0.01 ÕŁ”õ╣ĀńÄć’╝īĶĆīµ©ĪÕ×ŗńÜäÕż┤ķā©ÕłÖõĮ┐ńö©õ║å 1e-3 ÕŁ”õ╣ĀńÄćŃĆéńö©µłĘÕÅ»õ╗źÕ░嵩ĪÕ×ŗńÜäõĖŹÕÉīķā©ÕłåÕÅéµĢ░ÕÆīÕ»╣Õ║öńÜäĶČģÕÅéń╗䵳ÉõĖĆõĖ¬ÕŁŚÕģĖńÜäÕłŚĶĪ©õ╝Āń╗Öõ╝śÕī¢ÕÖ©’╝īµØźÕ«×ńÄ░Õ»╣µ©ĪÕ×ŗõ╝śÕī¢ńÜäń╗åń▓ÆÕ║”Ķ░āµĢ┤ŃĆé
+
+Õ£© MMEngine õĖŁ’╝īµłæõ╗¼ķĆÜĶ┐ćõ╝śÕī¢ÕÖ©Õ░üĶŻģµ×äķĆĀÕÖ©’╝łoptimizer wrapper constructor’╝ē’╝īĶ«®ńö©µłĘĶāĮÕż¤ńø┤µÄźķĆÜĶ┐ćĶ«ŠńĮ«õ╝śÕī¢ÕÖ©Õ░üĶŻģķģŹńĮ«µ¢ćõ╗ČõĖŁńÜä `paramwise_cfg` ÕŁŚµ«ĄĶĆīķØ×õ┐«µö╣õ╗ŻńĀüµØźÕ«×ńÄ░Õ»╣µ©ĪÕ×ŗńÜäõĖŹÕÉīķā©ÕłåĶ«ŠńĮ«õĖŹÕÉīńÜäĶČģÕÅéŃĆé
+
+### õĖ║õĖŹÕÉīń▒╗Õ×ŗńÜäÕÅéµĢ░Ķ«ŠńĮ«õĖŹÕÉīńÜäĶČģÕÅéń│╗µĢ░
+
+MMEngine µÅÉõŠøńÜäķ╗śĶ«żõ╝śÕī¢ÕÖ©Õ░üĶŻģµ×äķĆĀÕÖ©µö»µīüÕ»╣µ©ĪÕ×ŗõĖŁõĖŹÕÉīń▒╗Õ×ŗńÜäÕÅéµĢ░Ķ«ŠńĮ«õĖŹÕÉīńÜäĶČģÕÅéń│╗µĢ░ŃĆéõŠŗÕ”é’╝īµłæõ╗¼ÕÅ»õ╗źÕ£© `paramwise_cfg` õĖŁĶ«ŠńĮ« `norm_decay_mult=0`’╝īõ╗ÄĶĆīÕ░åµŁŻÕłÖÕī¢Õ▒é’╝łnormalization layer’╝ēńÜäµØāķ插╝łweight’╝ēÕÆīÕüÅńĮ«’╝łbias’╝ēńÜäµØāÕĆ╝ĶĪ░ÕćÅń│╗µĢ░’╝łweight decay’╝ēĶ«ŠńĮ«õĖ║ 0’╝īµØźÕ«×ńÄ░ [Bag of Tricks](https://arxiv.org/abs/1812.01187) Ķ«║µ¢ćõĖŁµÅÉÕł░ńÜäõĖŹÕ»╣µŁŻÕłÖÕī¢Õ▒éĶ┐øĶĪīµØāÕĆ╝ĶĪ░ÕćÅńÜäµŖĆÕʦŃĆé
+
+ÕģĘõĮōńż║õŠŗÕ”éõĖŗ’╝īµłæõ╗¼Õ░å `ToyModel` õĖŁµēƵ£ēµŁŻÕłÖÕī¢Õ▒é’╝ł`head.bn`’╝ēńÜäµØāķćŹĶĪ░ÕćÅń│╗µĢ░Ķ«ŠńĮ«õĖ║ 0’╝Ü
+
+```python
+from mmengine.optim import build_optim_wrapper
+from collections import OrderedDict
+
+class ToyModel(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.backbone = nn.ModuleDict(
+ dict(layer0=nn.Linear(1, 1), layer1=nn.Linear(1, 1)))
+ self.head = nn.Sequential(
+ OrderedDict(
+ linear=nn.Linear(1, 1),
+ bn=nn.BatchNorm1d(1)))
+
+
+optim_wrapper = dict(
+ optimizer=dict(type='SGD', lr=0.01, weight_decay=0.0001),
+ paramwise_cfg=dict(norm_decay_mult=0))
+optimizer = build_optim_wrapper(ToyModel(), optim_wrapper)
+```
+
+```
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- backbone.layer0.bias:lr=0.01
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- backbone.layer0.bias:weight_decay=0.0001
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- backbone.layer1.bias:lr=0.01
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- backbone.layer1.bias:weight_decay=0.0001
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- head.linear.bias:lr=0.01
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- head.linear.bias:weight_decay=0.0001
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- head.bn.weight:weight_decay=0.0
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- head.bn.bias:weight_decay=0.0
+```
+
+ķÖżõ║åÕÅ»õ╗źÕ»╣µŁŻÕłÖÕī¢Õ▒éńÜäµØāķćŹĶĪ░ÕćÅĶ┐øĶĪīķģŹńĮ«Õż¢’╝īMMEngine ńÜäķ╗śĶ«żõ╝śÕī¢ÕÖ©Õ░üĶŻģµ×äķĆĀÕÖ©ńÜä `paramwise_cfg` Ķ┐śµö»µīüÕ»╣µø┤ÕżÜõĖŹÕÉīń▒╗Õ×ŗńÜäÕÅéµĢ░Ķ«ŠńĮ«ĶČģÕÅéń│╗µĢ░’╝īµö»µīüńÜäķģŹńĮ«Õ”éõĖŗ’╝Ü
+
+`lr_mult`’╝ܵēƵ£ēÕÅéµĢ░ńÜäÕŁ”õ╣ĀńÄćń│╗µĢ░
+
+`decay_mult`’╝ܵēƵ£ēÕÅéµĢ░ńÜäĶĪ░ÕćÅń│╗µĢ░
+
+`bias_lr_mult`’╝ÜÕüÅńĮ«ńÜäÕŁ”õ╣ĀńÄćń│╗µĢ░’╝łõĖŹÕīģµŗ¼µŁŻÕłÖÕī¢Õ▒éńÜäÕüÅńĮ«õ╗źÕÅŖÕÅ»ÕÅśÕĮóÕŹĘń¦»ńÜä offset’╝ē
+
+`bias_decay_mult`’╝ÜÕüÅńĮ«ńÜäµØāÕĆ╝ĶĪ░ÕćÅń│╗µĢ░’╝łõĖŹÕīģµŗ¼µŁŻÕłÖÕī¢Õ▒éńÜäÕüÅńĮ«õ╗źÕÅŖÕÅ»ÕÅśÕĮóÕŹĘń¦»ńÜä offset’╝ē
+
+`norm_decay_mult`’╝ܵŁŻÕłÖÕī¢Õ▒éµØāķćŹÕÆīÕüÅńĮ«ńÜäµØāÕĆ╝ĶĪ░ÕćÅń│╗µĢ░
+
+`flat_decay_mult`’╝ÜõĖĆń╗┤ÕÅéµĢ░ńÜäµØāÕĆ╝ĶĪ░ÕćÅń│╗µĢ░
+
+`dwconv_decay_mult`’╝ÜDepth-wise ÕŹĘń¦»ńÜäµØāÕĆ╝ĶĪ░ÕćÅń│╗µĢ░
+
+`bypass_duplicate`’╝ܵś»ÕÉ”ĶĘ│Ķ┐ćķćŹÕżŹńÜäÕÅéµĢ░’╝īķ╗śĶ«żõĖ║ `False`
+
+`dcn_offset_lr_mult`’╝ÜÕÅ»ÕÅśÕĮóÕŹĘń¦»’╝łDeformable Convolution’╝ēńÜäÕŁ”õ╣ĀńÄćń│╗µĢ░
+
+### õĖ║µ©ĪÕ×ŗõĖŹÕÉīķā©ÕłåńÜäÕÅéµĢ░Ķ«ŠńĮ«õĖŹÕÉīńÜäĶČģÕÅéń│╗µĢ░
+
+µŁżÕż¢’╝īõĖÄõĖŖµ¢ć PyTorch ńÜäńż║õŠŗõĖƵĀĘ’╝īÕ£© MMEngine õĖŁµłæõ╗¼õ╣¤ÕÉīµĀĘÕÅ»õ╗źÕ»╣µ©ĪÕ×ŗõĖŁńÜäõ╗╗µäŵ©ĪÕØŚĶ«ŠńĮ«õĖŹÕÉīńÜäĶČģÕÅé’╝īÕŬķ£ĆĶ”üÕ£© `paramwise_cfg` õĖŁĶ«ŠńĮ« `custom_keys` ÕŹ│ÕÅ»ŃĆé
+
+õŠŗÕ”éµłæõ╗¼µā│Õ░å `backbone.layer0` µēƵ£ēÕÅéµĢ░ńÜäÕŁ”õ╣ĀńÄćĶ«ŠńĮ«õĖ║ 0’╝īĶĪ░ÕćÅń│╗µĢ░Ķ«ŠńĮ«õĖ║ 0’╝ī`backbone` ÕģČõĮÖÕŁÉµ©ĪÕØŚńÜäÕŁ”õ╣ĀńÄćĶ«ŠńĮ«õĖ║ 0.01’╝ø`head` µēƵ£ēÕÅéµĢ░ńÜäÕŁ”õ╣ĀńÄćĶ«ŠńĮ«õĖ║ 0.001’╝īÕÅ»õ╗źĶ┐ÖµĀĘķģŹńĮ«’╝Ü
+
+```python
+optim_wrapper = dict(
+ optimizer=dict(type='SGD', lr=0.01, weight_decay=0.0001),
+ paramwise_cfg=dict(
+ custom_keys={
+ 'backbone.layer0': dict(lr_mult=0, decay_mult=0),
+ 'backbone': dict(lr_mult=1),
+ 'head': dict(lr_mult=0.1)
+ }))
+optimizer = build_optim_wrapper(ToyModel(), optim_wrapper)
+```
+
+```
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- backbone.layer0.weight:lr=0.0
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- backbone.layer0.weight:weight_decay=0.0
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- backbone.layer0.weight:lr_mult=0
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- backbone.layer0.weight:decay_mult=0
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- backbone.layer0.bias:lr=0.0
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- backbone.layer0.bias:weight_decay=0.0
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- backbone.layer0.bias:lr_mult=0
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- backbone.layer0.bias:decay_mult=0
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- backbone.layer1.weight:lr=0.01
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- backbone.layer1.weight:weight_decay=0.0001
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- backbone.layer1.weight:lr_mult=1
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- backbone.layer1.bias:lr=0.01
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- backbone.layer1.bias:weight_decay=0.0001
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- backbone.layer1.bias:lr_mult=1
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- head.linear.weight:lr=0.001
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- head.linear.weight:weight_decay=0.0001
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- head.linear.weight:lr_mult=0.1
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- head.linear.bias:lr=0.001
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- head.linear.bias:weight_decay=0.0001
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- head.linear.bias:lr_mult=0.1
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- head.bn.weight:lr=0.001
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- head.bn.weight:weight_decay=0.0001
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- head.bn.weight:lr_mult=0.1
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- head.bn.bias:lr=0.001
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- head.bn.bias:weight_decay=0.0001
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- head.bn.bias:lr_mult=0.1
+```
+
+õĖŖõŠŗõĖŁ’╝īµ©ĪÕ×ŗńÜäńŖȵĆüÕŁŚÕģĖńÜä `key` Õ”éõĖŗ’╝Ü
+
+```python
+for name, val in ToyModel().named_parameters():
+ print(name)
+```
+
+```
+backbone.layer0.weight
+backbone.layer0.bias
+backbone.layer1.weight
+backbone.layer1.bias
+head.linear.weight
+head.linear.bias
+head.bn.weight
+head.bn.bias
+```
+
+custom_keys õĖŁµ»ÅõĖĆõĖ¬ÕŁŚµ«ĄńÜäÕɽõ╣ēÕ”éõĖŗ’╝Ü
+
+1. `'backbone': dict(lr_mult=1)`’╝ÜÕ░åÕÉŹÕŁŚÕēŹń╝ĆõĖ║ `backbone` ńÜäÕÅéµĢ░ńÜäÕŁ”õ╣ĀńÄćń│╗µĢ░Ķ«ŠńĮ«õĖ║ 1
+2. `'backbone.layer0': dict(lr_mult=0, decay_mult=0)`’╝ÜÕ░åÕÉŹÕŁŚÕēŹń╝ĆõĖ║ `backbone.layer0` ńÜäÕÅéµĢ░ÕŁ”õ╣ĀńÄćń│╗µĢ░Ķ«ŠńĮ«õĖ║ 0’╝īĶĪ░ÕćÅń│╗µĢ░Ķ«ŠńĮ«õĖ║ 0’╝īĶ»źķģŹńĮ«õ╝śÕģłń║¦µ»öń¼¼õĖƵØĪķ½ś
+3. `'head': dict(lr_mult=0.1)`’╝ÜÕ░åÕÉŹÕŁŚÕēŹń╝ĆõĖ║ `head` ńÜäÕÅéµĢ░ńÜäÕŁ”õ╣ĀńÄćń│╗µĢ░Ķ«ŠńĮ«õĖ║ 0.1
+
+### Ķć¬Õ«Üõ╣ēõ╝śÕī¢ÕÖ©µ×äķĆĀńŁ¢ńĢź
+
+õĖÄ MMEngine õĖŁńÜäÕģČõ╗¢µ©ĪÕØŚõĖƵĀĘ’╝īõ╝śÕī¢ÕÖ©Õ░üĶŻģµ×äķĆĀÕÖ©õ╣¤ÕÉīµĀĘńö▒[µ│©ÕåīĶĪ©](../advanced_tutorials/registry.md)ń«ĪńÉåŃĆ鵳æõ╗¼ÕÅ»õ╗źķĆÜĶ┐ćÕ«×ńÄ░Ķć¬Õ«Üõ╣ēńÜäõ╝śÕī¢ÕÖ©Õ░üĶŻģµ×äķĆĀÕÖ©µØźÕ«×ńÄ░Ķć¬Õ«Üõ╣ēńÜäĶČģÕÅéĶ«ŠńĮ«ńŁ¢ńĢźŃĆé
+
+õŠŗÕ”é’╝īµłæõ╗¼µā│Õ«×ńÄ░õĖĆõĖ¬ÕŽÕüÜ `LayerDecayOptimWrapperConstructor` ńÜäõ╝śÕī¢ÕÖ©Õ░üĶŻģµ×äķĆĀÕÖ©’╝īĶāĮÕż¤Õ»╣µ©ĪÕ×ŗõĖŹÕÉīµĘ▒Õ║”ńÜäÕ▒éĶć¬ÕŖ©Ķ«ŠńĮ«ķĆÆÕćÅńÜäÕŁ”õ╣ĀńÄć’╝Ü
+
+```python
+from mmengine.optim import DefaultOptimWrapperConstructor
+from mmengine.registry import OPTIM_WRAPPER_CONSTRUCTORS
+from mmengine.logging import print_log
+
+
+@OPTIM_WRAPPER_CONSTRUCTORS.register_module(force=True)
+class LayerDecayOptimWrapperConstructor(DefaultOptimWrapperConstructor):
+
+ def __init__(self, optim_wrapper_cfg, paramwise_cfg=None):
+ super().__init__(optim_wrapper_cfg, paramwise_cfg=None)
+ self.decay_factor = paramwise_cfg.get('decay_factor', 0.5)
+
+ super().__init__(optim_wrapper_cfg, paramwise_cfg)
+
+ def add_params(self, params, module, prefix='' ,lr=None):
+ if lr is None:
+ lr = self.base_lr
+
+ for name, param in module.named_parameters(recurse=False):
+ param_group = dict()
+ param_group['params'] = [param]
+ param_group['lr'] = lr
+ params.append(param_group)
+ full_name = f'{prefix}.{name}' if prefix else name
+ print_log(f'{full_name} : lr={lr}', logger='current')
+
+ for name, module in module.named_children():
+ chiled_prefix = f'{prefix}.{name}' if prefix else name
+ self.add_params(
+ params, module, chiled_prefix, lr=lr * self.decay_factor)
+
+
+class ToyModel(nn.Module):
+
+ def __init__(self) -> None:
+ super().__init__()
+ self.layer = nn.ModuleDict(dict(linear=nn.Linear(1, 1)))
+ self.linear = nn.Linear(1, 1)
+
+
+model = ToyModel()
+
+optim_wrapper = dict(
+ optimizer=dict(type='SGD', lr=0.01, weight_decay=0.0001),
+ paramwise_cfg=dict(decay_factor=0.5),
+ constructor='LayerDecayOptimWrapperConstructor')
+
+optimizer = build_optim_wrapper(model, optim_wrapper)
+```
+
+```
+08/23 22:20:26 - mmengine - INFO - layer.linear.weight : lr=0.0025
+08/23 22:20:26 - mmengine - INFO - layer.linear.bias : lr=0.0025
+08/23 22:20:26 - mmengine - INFO - linear.weight : lr=0.005
+08/23 22:20:26 - mmengine - INFO - linear.bias : lr=0.005
+```
+
+`add_params` Ķó½ń¼¼õĖƵ¼ĪĶ░āńö©µŚČ’╝ī`params` ÕÅéµĢ░õĖ║ń®║ÕłŚĶĪ©’╝ł`list`’╝ē’╝ī`module` õĖ║µ©ĪÕ×ŗ’╝ł`model`’╝ēŃĆéĶ»”ń╗åńÜäķćŹĶĮĮĶ¦äÕłÖÕÅéĶĆā[õ╝śÕī¢ÕÖ©Õ░üĶŻģµ×äķĆĀÕÖ©µ¢ćµĪŻ](mmengine.optim.DefaultOptimWrapperConstructor)ŃĆé
+
+ń▒╗õ╝╝Õ£░’╝īÕ”éµ×£µā│µ×äķĆĀÕżÜõĖ¬õ╝śÕī¢ÕÖ©’╝īõ╣¤ķ£ĆĶ”üÕ«×ńÄ░Ķć¬Õ«Üõ╣ēńÜäµ×äķĆĀÕÖ©’╝Ü
+
+```python
+@OPTIM_WRAPPER_CONSTRUCTORS.register_module()
+class MultipleOptimiWrapperConstructor:
+ ...
+```
+
+### Õ£©Ķ«Łń╗āĶ┐ćń©ŗõĖŁĶ░āµĢ┤ĶČģÕÅé
+
+õ╝śÕī¢ÕÖ©õĖŁńÜäĶČģÕÅéµĢ░Õ£©µ×äķĆĀµŚČÕŬĶāĮĶ«ŠńĮ«õĖ║õĖĆõĖ¬Õ«ÜÕĆ╝’╝īõ╗ģõ╗ģõĮ┐ńö©õ╝śÕī¢ÕÖ©Õ░üĶŻģ’╝īÕ╣ČõĖŹĶāĮÕ£©Ķ«Łń╗āĶ┐ćń©ŗõĖŁĶ░āµĢ┤ÕŁ”õ╣ĀńÄćńŁēÕÅéµĢ░ŃĆéÕ£© MMEngine õĖŁ’╝īµłæõ╗¼Õ«×ńÄ░õ║åÕÅéµĢ░Ķ░āÕ║”ÕÖ©’╝łParameter Scheduler’╝ē’╝īõ╗źõŠ┐ĶāĮÕż¤Õ£©Ķ«Łń╗āĶ┐ćń©ŗõĖŁĶ░āµĢ┤ÕÅéµĢ░ŃĆéÕģ│õ║ÄÕÅéµĢ░Ķ░āÕ║”ÕÖ©ńÜäńö©µ│ĢĶ»ĘĶ¦ü[õ╝śÕī¢ÕÖ©ÕÅéµĢ░Ķ░āµĢ┤ńŁ¢ńĢź](./param_scheduler.md)
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/param_scheduler.md b/internlm_langchain/knowledge_base/MMEngine/content/param_scheduler.md
new file mode 100644
index 00000000..fd9f1842
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/param_scheduler.md
@@ -0,0 +1,563 @@
+# Ķ┐üń¦╗ MMCV ÕÅéµĢ░Ķ░āÕ║”ÕÖ©Õł░ MMEngine
+
+MMCV 1.x ńēłµ£¼õĮ┐ńö© [LrUpdaterHook](https://mmcv.readthedocs.io/zh_CN/v1.6.0/api.html#mmcv.runner.LrUpdaterHook) ÕÆī [MomentumUpdaterHook](https://mmcv.readthedocs.io/zh_CN/v1.6.0/api.html#mmcv.runner.MomentumUpdaterHook) µØźĶ░āµĢ┤ÕŁ”õ╣ĀńÄćÕÆīÕŖ©ķćÅŃĆé
+õĮåķÜÅńØƵĘ▒Õ║”ÕŁ”õ╣Āń«Śµ│ĢĶ«Łń╗āµ¢╣Õ╝ÅńÜäõĖŹµ¢ŁÕÅæÕ▒Ģ’╝īõĮ┐ńö© Hook õ┐«µö╣ÕŁ”õ╣ĀńÄćÕĘ▓ń╗ÅķÜŠõ╗źµ╗ĪĶČ│µø┤ÕŖĀõĖ░Õ»īńÜäĶć¬Õ«Üõ╣ēķ£Ćµ▒é’╝īÕøĀµŁż MMEngine µÅÉõŠøõ║åÕÅéµĢ░Ķ░āÕ║”ÕÖ©’╝łParamScheduler’╝ēŃĆé
+õĖƵ¢╣ķØó’╝īÕÅéµĢ░Ķ░āÕ║”ÕÖ©ńÜäµÄźÕÅŻõĖÄ PyTroch ńÜäÕŁ”õ╣ĀńÄćĶ░āÕ║”ÕÖ©’╝łLRScheduler’╝ēÕ»╣ķĮÉ’╝īÕÅ”õĖƵ¢╣ķØó’╝īÕÅéµĢ░Ķ░āÕ║”ÕÖ©µÅÉõŠøõ║åµø┤õĖ░Õ»īńÜäÕŖ¤ĶāĮ’╝īĶ»”ń╗åĶ»ĘÕÅéĶĆā[ÕÅéµĢ░Ķ░āÕ║”ÕÖ©õĮ┐ńö©µīćÕŹŚ](../tutorials/param_scheduler.md)ŃĆé
+
+## ÕŁ”õ╣ĀńÄćĶ░āÕ║”ÕÖ©’╝łLrUpdater’╝ēĶ┐üń¦╗
+
+MMEngine õĖŁõĮ┐ńö© LRScheduler µø┐õ╗Ż LrUpdaterHook’╝īķģŹńĮ«µ¢ćõ╗ČõĖŁńÜäÕŁŚµ«Ąõ╗ÄÕĤµ£¼ńÜä `lr_config` õ┐«µö╣õĖ║ `param_scheduler`ŃĆé
+MMCV õĖŁńÜäÕŁ”õ╣ĀńÄćķģŹńĮ«õĖÄ MMEngine õĖŁńÜäÕÅéµĢ░Ķ░āÕ║”ÕÖ©ķģŹńĮ«Õ»╣Õ║öÕģ│ń│╗Õ”éõĖŗ’╝Ü
+
+### ÕŁ”õ╣ĀńÄćķóäńāŁ’╝łWarmup’╝ēĶ┐üń¦╗
+
+ńö▒õ║Ä MMEngine õĖŁńÜäÕŁ”õ╣ĀńÄćĶ░āÕ║”ÕÖ©Õ£©Õ«×ńÄ░µŚČÕó×ÕŖĀõ║å begin ÕÆī end ÕÅéµĢ░’╝īµīćÕ«Üõ║åĶ░āÕ║”ÕÖ©ńÜäńö¤µĢłÕī║ķŚ┤’╝īµēĆõ╗źÕÅ»õ╗źķĆÜĶ┐ćĶ░āÕ║”ÕÖ©ń╗äÕÉłńÜäµ¢╣Õ╝ÅÕ«×ńÄ░ÕŁ”õ╣ĀńÄćķóäńāŁŃĆéMMCV õĖŁµ£ē 3 ń¦ŹÕŁ”õ╣ĀńÄćķóäńāŁµ¢╣Õ╝Å’╝īÕłåÕł½µś» `'constant'`, `'linear'`, `'exp'`’╝īÕ£© MMEngine õĖŁÕ»╣Õ║öńÜäķģŹńĮ«Õ║öõ┐«µö╣õĖ║:
+
+#### ÕĖĖµĢ░ķóäńāŁ(constant)
+
+
+
+
+
+#### ń║┐µĆ¦ķóäńāŁ(linear)
+
+
+
+
+
+#### µīćµĢ░ķóäńāŁ(exp)
+
+
+
+
+
+### fixed ÕŁ”õ╣ĀńÄć’╝łFixedLrUpdaterHook’╝ēĶ┐üń¦╗
+
+
+
+
+
+### step ÕŁ”õ╣ĀńÄć’╝łStepLrUpdaterHook’╝ēĶ┐üń¦╗
+
+
+
+
+
+### poly ÕŁ”õ╣ĀńÄć’╝łPolyLrUpdaterHook’╝ēĶ┐üń¦╗
+
+
+
+
+
+### exp ÕŁ”õ╣ĀńÄć’╝łExpLrUpdaterHook’╝ēĶ┐üń¦╗
+
+
+
+
+
+### CosineAnnealing ÕŁ”õ╣ĀńÄć’╝łCosineAnnealingLrUpdaterHook’╝ēĶ┐üń¦╗
+
+
+
+
+
+### FlatCosineAnnealing ÕŁ”õ╣ĀńÄć’╝łFlatCosineAnnealingLrUpdaterHook’╝ēĶ┐üń¦╗
+
+ÕāÅ FlatCosineAnnealing Ķ┐Öń¦Źńö▒ÕżÜõĖ¬ÕŁ”õ╣ĀńÄćńŁ¢ńĢźµŗ╝µÄźĶĆīµłÉńÜäÕŁ”õ╣ĀńÄć’╝īÕĤµ£¼ķ£ĆĶ”üķćŹÕåÖ Hook µØźÕ«×ńÄ░’╝īĶĆīÕ£© MMEngine õĖŁÕŬķ£ĆÕ░åõĖżõĖ¬ÕÅéµĢ░Ķ░āÕ║”ÕÖ©ń╗äÕÉłÕŹ│ÕÅ»
+
+
+
+
+
+### CosineRestart ÕŁ”õ╣ĀńÄć’╝łCosineRestartLrUpdaterHook’╝ēĶ┐üń¦╗
+
+
+
+
+
+### OneCycle ÕŁ”õ╣ĀńÄć’╝łOneCycleLrUpdaterHook’╝ēĶ┐üń¦╗
+
+
+
+
+
+ķ£ĆĶ”üµ│©µäÅńÜ䵜» `by_epoch` ÕÅéµĢ░ MMCV ķ╗śĶ«żµś» `False`, MMEngine ķ╗śĶ«żµś» `True`
+
+### LinearAnnealing ÕŁ”õ╣ĀńÄć’╝łLinearAnnealingLrUpdaterHook’╝ēĶ┐üń¦╗
+
+
+
+
+
+## ÕŖ©ķćÅĶ░āÕ║”ÕÖ©’╝łMomentumUpdater’╝ēĶ┐üń¦╗
+
+MMCV õĮ┐ńö© `momentum_config` ÕŁŚµ«ĄÕÆī MomentumUpdateHook Ķ░āµĢ┤ÕŖ©ķćÅŃĆé MMEngine õĖŁÕŖ©ķćÅÕÉīµĀĘńö▒ÕÅéµĢ░Ķ░āÕ║”ÕÖ©µÄ¦ÕłČŃĆéńö©µłĘÕÅ»õ╗źń«ĆÕŹĢÕ░åÕŁ”õ╣ĀńÄćĶ░āÕ║”ÕÖ©ÕÉÄńÜä `LR` õ┐«µö╣õĖ║ `Momentum`’╝īÕŹ│ÕÅ»õĮ┐ńö©ÕÉīµĀĘńÜäńŁ¢ńĢźµØźĶ░āµĢ┤ÕŖ©ķćÅŃĆéÕŖ©ķćÅĶ░āÕ║”ÕÖ©ÕŬķ£ĆĶ”üÕÆīÕŁ”õ╣ĀńÄćĶ░āÕ║”ÕÖ©õĖƵĀʵĘ╗ÕŖĀĶ┐ø `param_scheduler` ÕłŚĶĪ©õĖŁÕŹ│ÕÅ»ŃĆéõĖŠõĖĆõĖ¬ń«ĆÕŹĢńÜäõŠŗÕŁÉ’╝Ü
+
+
+
+
+
+## ÕÅéµĢ░µø┤µ¢░ķóæńÄćńøĖÕģ│ķģŹńĮ«Ķ┐üń¦╗
+
+Õ”éµ×£Õ£©õĮ┐ńö© epoch-based Ķ«Łń╗āÕŠ¬ńÄ»õĖöķģŹńĮ«µ¢ćõ╗ČõĖŁµīē epoch Ķ«ŠńĮ«ńö¤µĢłÕī║ķŚ┤’╝ł`begin`’╝ī`end`’╝ēµł¢Õ橵£¤’╝ł`T_max`’╝ēńŁēÕÅśķćÅńÜäÕÉīµŚČÕĖīµ£øÕÅéµĢ░ńÄćµīē iteration µø┤µ¢░’╝īÕ£© MMCV õĖŁķ£ĆĶ”üÕ░å `by_epoch` Ķ«ŠńĮ«õĖ║ FalseŃĆéĶĆīÕ£© MMEngine õĖŁķ£ĆĶ”üµ│©µäÅ’╝īķģŹńĮ«õĖŁńÜä `by_epoch` õ╗Źķ£ĆĶ«ŠńĮ«õĖ║ True’╝īķĆÜĶ┐ćÕ£©ķģŹńĮ«õĖŁµĘ╗ÕŖĀ `convert_to_iter_based=True` µØźµ×äÕ╗║µīē iteration µø┤µ¢░ńÜäÕÅéµĢ░Ķ░āÕ║”ÕÖ©’╝īÕģ│õ║ĵŁżķģŹńĮ«Ķ»”Ķ¦ü[ÕÅéµĢ░Ķ░āÕ║”ÕÖ©µĢÖń©ŗ](../tutorials/param_scheduler.md)ŃĆé
+õ╗źĶ┐üń¦╗CosineAnnealingõĖ║õŠŗ’╝Ü
+
+
+
+
+
+õĮĀÕÅ»ĶāĮĶ┐śµā│ķśģĶ»╗[ÕÅéµĢ░Ķ░āÕ║”ÕÖ©ńÜäµĢÖń©ŗ](../tutorials/param_scheduler.md)µł¢ĶĆģ[ÕÅéµĢ░Ķ░āÕ║”ÕÖ©ńÜä API µ¢ćµĪŻ](../api/optim)ŃĆé
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/registry.md b/internlm_langchain/knowledge_base/MMEngine/content/registry.md
new file mode 100644
index 00000000..f44b9d53
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/registry.md
@@ -0,0 +1,311 @@
+# µ│©ÕåīÕÖ©’╝łRegistry’╝ē
+
+OpenMMLab ńÜäń«Śµ│ĢÕ║ōµö»µīüõ║åõĖ░Õ»īńÜäń«Śµ│ĢÕÆīµĢ░µŹ«ķøå’╝īÕøĀµŁżÕ«×ńÄ░õ║åÕŠłÕżÜÕŖ¤ĶāĮńøĖĶ┐æńÜ䵩ĪÕØŚŃĆéõŠŗÕ”é ResNet ÕÆī SE-ResNet ńÜäń«Śµ│ĢÕ«×ńÄ░ÕłåÕł½Õ¤║õ║Ä `ResNet` ÕÆī `SEResNet` ń▒╗’╝īĶ┐Öõ║øń▒╗µ£ēńøĖõ╝╝ńÜäÕŖ¤ĶāĮÕÆīµÄźÕÅŻ’╝īķāĮÕ▒×õ║Äń«Śµ│ĢÕ║ōõĖŁńÜ䵩ĪÕ×ŗń╗äõ╗ČŃĆéõĖ║õ║åń«ĪńÉåĶ┐Öõ║øÕŖ¤ĶāĮńøĖõ╝╝ńÜ䵩ĪÕØŚ’╝īMMEngine Õ«×ńÄ░õ║å [µ│©ÕåīÕÖ©](mmengine.registry.Registry)ŃĆéOpenMMLab Õż¦ÕżÜµĢ░ń«Śµ│ĢÕ║ōÕØćõĮ┐ńö©µ│©ÕåīÕÖ©µØźń«ĪńÉåÕ«āõ╗¼ńÜäõ╗ŻńĀüµ©ĪÕØŚ’╝īÕīģµŗ¼ [MMDetection](https://github.com/open-mmlab/mmdetection)’╝ī [MMDetection3D](https://github.com/open-mmlab/mmdetection3d)’╝ī[MMPretrain](https://github.com/open-mmlab/mmpretrain) ÕÆī [MMagic](https://github.com/open-mmlab/mmagic) ńŁēŃĆé
+
+## õ╗Ćõ╣łµś»µ│©ÕåīÕÖ©
+
+MMEngine Õ«×ńÄ░ńÜä[µ│©ÕåīÕÖ©](mmengine.registry.Registry)ÕÅ»õ╗źń£ŗõĮ£õĖĆõĖ¬µśĀÕ░äĶĪ©ÕÆīµ©ĪÕØŚµ×äÕ╗║µ¢╣µ│Ģ’╝łbuild function’╝ēńÜäń╗äÕÉłŃĆ鵜ĀÕ░äĶĪ©ń╗┤µŖżõ║åõĖĆõĖ¬ÕŁŚń¼”õĖ▓Õł░**ń▒╗µł¢ĶĆģÕćĮµĢ░ńÜ䵜ĀÕ░ä**’╝īõĮ┐ÕŠŚńö©µłĘÕÅ»õ╗źÕƤÕŖ®ÕŁŚń¼”õĖ▓µ¤źµēŠÕł░ńøĖÕ║öńÜäń▒╗µł¢ÕćĮµĢ░’╝īõŠŗÕ”éń╗┤µŖżÕŁŚń¼”õĖ▓ `"ResNet"` Õł░ `ResNet` ń▒╗µł¢ÕćĮµĢ░ńÜ䵜ĀÕ░ä’╝īõĮ┐ÕŠŚńö©µłĘÕÅ»õ╗źķĆÜĶ┐ć `"ResNet"` µēŠÕł░ `ResNet` ń▒╗’╝øĶĆīµ©ĪÕØŚµ×äÕ╗║µ¢╣µ│ĢÕłÖÕ«Üõ╣ēõ║åÕ”éõĮĢµĀ╣µŹ«ÕŁŚń¼”õĖ▓µ¤źµēŠÕł░Õ»╣Õ║öńÜäń▒╗µł¢ÕćĮµĢ░õ╗źÕÅŖÕ”éõĮĢÕ«×õŠŗÕī¢Ķ┐ÖõĖ¬ń▒╗µł¢ĶĆģĶ░āńö©Ķ┐ÖõĖ¬ÕćĮµĢ░’╝īõŠŗÕ”é’╝īķĆÜĶ┐ćÕŁŚń¼”õĖ▓ `"bn"` µēŠÕł░ `nn.BatchNorm2d` Õ╣ČÕ«×õŠŗÕī¢ `BatchNorm2d` µ©ĪÕØŚ’╝øÕÅłµł¢ĶĆģķĆÜĶ┐ćÕŁŚń¼”õĖ▓ `"build_batchnorm2d"` µēŠÕł░ `build_batchnorm2d` ÕćĮµĢ░Õ╣ČĶ┐öÕø×Ķ»źÕćĮµĢ░ńÜäĶ░āńö©ń╗ōµ×£ŃĆéMMEngine õĖŁńÜäµ│©ÕåīÕÖ©ķ╗śĶ«żõĮ┐ńö© [build_from_cfg](mmengine.registry.build_from_cfg) ÕćĮµĢ░µØźµ¤źµēŠÕ╣ČÕ«×õŠŗÕī¢ÕŁŚń¼”õĖ▓Õ»╣Õ║öńÜäń▒╗µł¢ĶĆģÕćĮµĢ░ŃĆé
+
+õĖĆõĖ¬µ│©ÕåīÕÖ©ń«ĪńÉåńÜäń▒╗µł¢ÕćĮµĢ░ķĆÜÕĖĖµ£ēńøĖõ╝╝ńÜäµÄźÕÅŻÕÆīÕŖ¤ĶāĮ’╝īÕøĀµŁżĶ»źµ│©ÕåīÕÖ©ÕÅ»õ╗źĶó½Ķ¦åõĮ£Ķ┐Öõ║øń▒╗µł¢ÕćĮµĢ░ńÜäµŖĮĶ▒ĪŃĆéõŠŗÕ”éµ│©ÕåīÕÖ© `MODELS` ÕÅ»õ╗źĶó½Ķ¦åõĮ£µēƵ£ēµ©ĪÕ×ŗńÜäµŖĮĶ▒Ī’╝īń«ĪńÉåõ║å `ResNet`’╝ī`SEResNet` ÕÆī `RegNetX` ńŁēÕłåń▒╗ńĮæń╗£ńÜäń▒╗õ╗źÕÅŖ `build_ResNet`, `build_SEResNet` ÕÆī `build_RegNetX` ńŁēÕłåń▒╗ńĮæń╗£ńÜäµ×äÕ╗║ÕćĮµĢ░ŃĆé
+
+## ÕģźķŚ©ńö©µ│Ģ
+
+õĮ┐ńö©µ│©ÕåīÕÖ©ń«ĪńÉåõ╗ŻńĀüÕ║ōõĖŁńÜ䵩ĪÕØŚ’╝īķ£ĆĶ”üõ╗źõĖŗõĖēõĖ¬µŁźķ¬żŃĆé
+
+1. ÕłøÕ╗║µ│©ÕåīÕÖ©
+2. ÕłøÕ╗║õĖĆõĖ¬ńö©õ║ÄÕ«×õŠŗÕī¢ń▒╗ńÜäµ×äÕ╗║µ¢╣µ│Ģ’╝łÕÅ»ķĆē’╝īÕ£©Õż¦ÕżÜµĢ░µāģÕåĄõĖŗÕÅ»õ╗źÕŬõĮ┐ńö©ķ╗śĶ«żµ¢╣µ│Ģ’╝ē
+3. Õ░嵩ĪÕØŚÕŖĀÕģźµ│©ÕåīÕÖ©õĖŁ
+
+ÕüćĶ«Šµłæõ╗¼Ķ”üÕ«×ńÄ░õĖĆń│╗ÕłŚµ┐Ƶ┤╗µ©ĪÕØŚÕ╣ČõĖöÕĖīµ£øõ╗ģõ┐«µö╣ķģŹńĮ«Õ░▒ĶāĮÕż¤õĮ┐ńö©õĖŹÕÉīńÜäµ┐Ƶ┤╗µ©ĪÕØŚĶĆīµŚĀķ£Ćõ┐«µö╣õ╗ŻńĀüŃĆé
+
+ķ”¢ÕģłÕłøÕ╗║µ│©ÕåīÕÖ©’╝ī
+
+```python
+from mmengine import Registry
+# scope ĶĪ©ńż║µ│©ÕåīÕÖ©ńÜäõĮ£ńö©Õ¤¤’╝īÕ”éµ×£õĖŹĶ«ŠńĮ«’╝īķ╗śĶ«żõĖ║ÕīģÕÉŹ’╝īõŠŗÕ”éÕ£© mmdetection õĖŁ’╝īÕ«āńÜä scope õĖ║ mmdet
+# locations ĶĪ©ńż║µ│©ÕåīÕ£©µŁżµ│©ÕåīÕÖ©ńÜ䵩ĪÕØŚµēĆÕŁśµöŠńÜäõĮŹńĮ«’╝īµ│©ÕåīÕÖ©õ╝ܵĀ╣µŹ«ķóäÕģłÕ«Üõ╣ēńÜäõĮŹńĮ«Õ£©µ×äÕ╗║µ©ĪÕØŚµŚČĶć¬ÕŖ© import
+ACTIVATION = Registry('activation', scope='mmengine', locations=['mmengine.models.activations'])
+```
+
+`locations` µīćÕ«ÜńÜ䵩ĪÕØŚ `mmengine.models.activations` Õ»╣Õ║öõ║å `mmengine/models/activations.py` µ¢ćõ╗ČŃĆéÕ£©õĮ┐ńö©µ│©ÕåīÕÖ©µ×äÕ╗║µ©ĪÕØŚńÜ䵌ČÕĆÖ’╝īACTIVATION µ│©ÕåīÕÖ©õ╝ÜĶć¬ÕŖ©õ╗ÄĶ»źµ¢ćõ╗ČõĖŁÕ»╝ÕģźÕ«×ńÄ░ńÜ䵩ĪÕØŚŃĆéÕøĀµŁż’╝īµłæõ╗¼ÕÅ»õ╗źÕ£© `mmengine/models/activations.py` µ¢ćõ╗ČõĖŁÕ«×ńÄ░õĖŹÕÉīńÜäµ┐Ƶ┤╗ÕćĮµĢ░’╝īõŠŗÕ”é `Sigmoid`’╝ī`ReLU` ÕÆī `Softmax`ŃĆé
+
+```python
+import torch.nn as nn
+
+# õĮ┐ńö©µ│©ÕåīÕÖ©ń«ĪńÉ嵩ĪÕØŚ
+@ACTIVATION.register_module()
+class Sigmoid(nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ def forward(self, x):
+ print('call Sigmoid.forward')
+ return x
+
+@ACTIVATION.register_module()
+class ReLU(nn.Module):
+ def __init__(self, inplace=False):
+ super().__init__()
+
+ def forward(self, x):
+ print('call ReLU.forward')
+ return x
+
+@ACTIVATION.register_module()
+class Softmax(nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ def forward(self, x):
+ print('call Softmax.forward')
+ return x
+```
+
+õĮ┐ńö©µ│©ÕåīÕÖ©ń«ĪńÉ嵩ĪÕØŚńÜäÕģ│ķö«µŁźķ¬żµś»’╝īÕ░åÕ«×ńÄ░ńÜ䵩ĪÕØŚµ│©ÕåīÕł░µ│©ÕåīĶĪ© `ACTIVATION` õĖŁŃĆéķĆÜĶ┐ć `@ACTIVATION.register_module()` ĶŻģķź░µēĆÕ«×ńÄ░ńÜ䵩ĪÕØŚ’╝īÕŁŚń¼”õĖ▓ÕÆīń▒╗µł¢ÕćĮµĢ░õ╣ŗķŚ┤ńÜ䵜ĀÕ░äÕ░▒ÕÅ»õ╗źńö▒ `ACTIVATION` µ×äÕ╗║ÕÆīń╗┤µŖż’╝īµłæõ╗¼õ╣¤ÕÅ»õ╗źķĆÜĶ┐ć `ACTIVATION.register_module(module=ReLU)` Õ«×ńÄ░ÕÉīµĀĘńÜäÕŖ¤ĶāĮŃĆé
+
+ķĆÜĶ┐ćµ│©Õåī’╝īµłæõ╗¼Õ░▒ÕÅ»õ╗źķĆÜĶ┐ć `ACTIVATION` Õ╗║ń½ŗÕŁŚń¼”õĖ▓õĖÄń▒╗µł¢ÕćĮµĢ░õ╣ŗķŚ┤ńÜ䵜ĀÕ░ä’╝ī
+
+```python
+print(ACTIVATION.module_dict)
+# {
+# 'Sigmoid': __main__.Sigmoid,
+# 'ReLU': __main__.ReLU,
+# 'Softmax': __main__.Softmax
+# }
+```
+
+```{note}
+ÕŬµ£ēµ©ĪÕØŚµēĆÕ£©ńÜäµ¢ćõ╗ČĶó½Õ»╝ÕģźµŚČ’╝īµ│©Õåīµ£║ÕłČµēŹõ╝ÜĶó½Ķ¦”ÕÅæ’╝īńö©µłĘÕÅ»õ╗źķĆÜĶ┐ćõĖēń¦Źµ¢╣Õ╝ÅÕ░嵩ĪÕØŚµĘ╗ÕŖĀÕł░µ│©ÕåīÕÖ©õĖŁ’╝Ü
+
+1. Õ£© ``locations`` µīćÕÉæńÜäµ¢ćõ╗ČõĖŁÕ«×ńÄ░µ©ĪÕØŚŃĆéµ│©ÕåīÕÖ©Õ░åĶć¬ÕŖ©Õ£©ķóäÕģłÕ«Üõ╣ēńÜäõĮŹńĮ«Õ»╝Õģźµ©ĪÕØŚŃĆéĶ┐Öń¦Źµ¢╣Õ╝ŵś»õĖ║õ║åń«ĆÕī¢ń«Śµ│ĢÕ║ōńÜäõĮ┐ńö©’╝īõ╗źõŠ┐ńö©µłĘÕÅ»õ╗źńø┤µÄźõĮ┐ńö© ``REGISTRY.build(cfg)``ŃĆé
+
+2. µēŗÕŖ©Õ»╝Õģźµ¢ćõ╗ČŃĆéÕĖĖńö©õ║Äńö©µłĘÕ£©ń«Śµ│ĢÕ║ōõ╣ŗÕåģµł¢õ╣ŗÕż¢Õ«×ńÄ░µ¢░ńÜ䵩ĪÕØŚŃĆé
+
+3. Õ£©ķģŹńĮ«õĖŁõĮ┐ńö© ``custom_imports`` ÕŁŚµ«ĄŃĆé Ķ»”µāģĶ»ĘÕÅéĶĆā[Õ»╝ÕģźĶć¬Õ«Üõ╣ēPythonµ©ĪÕØŚ](config.md#Õ»╝ÕģźĶć¬Õ«Üõ╣ē-python-µ©ĪÕØŚ)ŃĆé
+```
+
+µ©ĪÕØŚµłÉÕŖ¤µ│©ÕåīÕÉÄ’╝īµłæõ╗¼ÕÅ»õ╗źķĆÜĶ┐ćķģŹńĮ«µ¢ćõ╗ČõĮ┐ńö©Ķ┐ÖõĖ¬µ┐Ƶ┤╗µ©ĪÕØŚŃĆé
+
+```python
+import torch
+
+input = torch.randn(2)
+
+act_cfg = dict(type='Sigmoid')
+activation = ACTIVATION.build(act_cfg)
+output = activation(input)
+# call Sigmoid.forward
+print(output)
+```
+
+Õ”éµ×£µłæõ╗¼µā│õĮ┐ńö© `ReLU`’╝īõ╗ģķ£Ćõ┐«µö╣ķģŹńĮ«ŃĆé
+
+```python
+act_cfg = dict(type='ReLU', inplace=True)
+activation = ACTIVATION.build(act_cfg)
+output = activation(input)
+# call ReLU.forward
+print(output)
+```
+
+Õ”éµ×£µłæõ╗¼ÕĖīµ£øÕ£©ÕłøÕ╗║Õ«×õŠŗÕēŹµŻĆµ¤źĶŠōÕģźÕÅéµĢ░ńÜäń▒╗Õ×ŗ’╝łµł¢ĶĆģõ╗╗õĮĢÕģČõ╗¢µōŹõĮ£’╝ē’╝īµłæõ╗¼ÕÅ»õ╗źÕ«×ńÄ░õĖĆõĖ¬µ×äÕ╗║µ¢╣µ│ĢÕ╣ČÕ░åÕģČõ╝ĀķĆÆń╗Öµ│©ÕåīÕÖ©õ╗ÄĶĆīÕ«×ńÄ░Ķć¬Õ«Üõ╣ēµ×äÕ╗║µĄüń©ŗŃĆé
+
+ÕłøÕ╗║õĖĆõĖ¬µ×äÕ╗║µ¢╣µ│Ģ’╝ī
+
+```python
+
+def build_activation(cfg, registry, *args, **kwargs):
+ cfg_ = cfg.copy()
+ act_type = cfg_.pop('type')
+ print(f'build activation: {act_type}')
+ act_cls = registry.get(act_type)
+ act = act_cls(*args, **kwargs, **cfg_)
+ return act
+```
+
+Õ╣ČÕ░å `build_activation` õ╝ĀķĆÆń╗Ö `build_func` ÕÅéµĢ░
+
+```python
+ACTIVATION = Registry('activation', build_func=build_activation, scope='mmengine', locations=['mmengine.models.activations'])
+
+@ACTIVATION.register_module()
+class Tanh(nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ def forward(self, x):
+ print('call Tanh.forward')
+ return x
+
+act_cfg = dict(type='Tanh')
+activation = ACTIVATION.build(act_cfg)
+output = activation(input)
+# build activation: Tanh
+# call Tanh.forward
+print(output)
+```
+
+```{note}
+Õ£©Ķ┐ÖõĖ¬õŠŗÕŁÉõĖŁ’╝īµłæõ╗¼µ╝öńż║õ║åÕ”éõĮĢõĮ┐ńö©ÕÅéµĢ░ `build_func` Ķć¬Õ«Üõ╣ēµ×äÕ╗║ń▒╗ńÜäÕ«×õŠŗńÜäµ¢╣µ│ĢŃĆé
+Ķ»źÕŖ¤ĶāĮń▒╗õ╝╝õ║Äķ╗śĶ«żńÜä `build_from_cfg` µ¢╣µ│ĢŃĆéÕ£©Õż¦ÕżÜµĢ░µāģÕåĄõĖŗ’╝īõĮ┐ńö©ķ╗śĶ«żńÜäµ¢╣µ│ĢÕ░▒ÕÅ»õ╗źõ║åŃĆé
+```
+
+MMEngine ńÜäµ│©ÕåīÕÖ©ķÖżõ║åÕÅ»õ╗źµ│©Õåīń▒╗’╝īõ╣¤ÕÅ»õ╗źµ│©ÕåīÕćĮµĢ░ŃĆé
+
+```python
+FUNCTION = Registry('function', scope='mmengine')
+
+@FUNCTION.register_module()
+def print_args(**kwargs):
+ print(kwargs)
+
+func_cfg = dict(type='print_args', a=1, b=2)
+func_res = FUNCTION.build(func_cfg)
+```
+
+## Ķ┐øķśČńö©µ│Ģ
+
+MMEngine ńÜäµ│©ÕåīÕÖ©µö»µīüÕ▒éń║¦µ│©Õåī’╝īÕł®ńö©Ķ»źÕŖ¤ĶāĮÕŻի×ńÄ░ĶĘ©ķĪ╣ńø«Ķ░āńö©’╝īÕŹ│ÕÅ»õ╗źÕ£©õĖĆõĖ¬ķĪ╣ńø«õĖŁõĮ┐ńö©ÕÅ”õĖĆõĖ¬ķĪ╣ńø«ńÜ䵩ĪÕØŚŃĆéĶÖĮńäČĶĘ©ķĪ╣ńø«Ķ░āńö©õ╣¤µ£ēÕģČõ╗¢µ¢╣µ│ĢńÜäÕÅ»õ╗źÕ«×ńÄ░’╝īõĮå MMEngine µ│©ÕåīÕÖ©µÅÉõŠøõ║åµø┤õĖ║ń«ĆõŠ┐ńÜäµ¢╣µ│ĢŃĆé
+
+õĖ║õ║åµ¢╣õŠ┐ĶĘ©Õ║ōĶ░āńö©’╝īMMEngine µÅÉõŠøõ║å 22 õĖ¬µĀ╣µ│©ÕåīÕÖ©’╝Ü
+
+- RUNNERS: Runner ńÜäµ│©ÕåīÕÖ©
+- RUNNER_CONSTRUCTORS: Runner ńÜäµ×äķĆĀÕÖ©
+- LOOPS: ń«ĪńÉåĶ«Łń╗āŃĆüķ¬īĶ»üõ╗źÕÅŖµĄŗĶ»ĢµĄüń©ŗ’╝īÕ”é `EpochBasedTrainLoop`
+- HOOKS: ķÆ®ÕŁÉ’╝īÕ”é `CheckpointHook`, `ParamSchedulerHook`
+- DATASETS: µĢ░µŹ«ķøå
+- DATA_SAMPLERS: `DataLoader` ńÜä `Sampler`’╝īńö©õ║ÄķććµĀʵĢ░µŹ«
+- TRANSFORMS: ÕÉäń¦ŹµĢ░µŹ«ķóäÕżäńÉå’╝īÕ”é `Resize`, `Reshape`
+- MODELS: µ©ĪÕ×ŗńÜäÕÉäń¦Źµ©ĪÕØŚ
+- MODEL_WRAPPERS: µ©ĪÕ×ŗńÜäÕīģĶŻģÕÖ©’╝īÕ”é `MMDistributedDataParallel`’╝īńö©õ║ÄÕ»╣ÕłåÕĖāÕ╝ŵĢ░µŹ«Õ╣ČĶĪī
+- WEIGHT_INITIALIZERS: µØāķćŹÕłØÕ¦ŗÕī¢ńÜäÕĘźÕģĘ
+- OPTIMIZERS: µ│©Õåīõ║å PyTorch õĖŁµēƵ£ēńÜä `Optimizer` õ╗źÕÅŖĶć¬Õ«Üõ╣ēńÜä `Optimizer`
+- OPTIM_WRAPPER: Õ»╣ Optimizer ńøĖÕģ│µōŹõĮ£ńÜäÕ░üĶŻģ’╝īÕ”é `OptimWrapper`’╝ī`AmpOptimWrapper`
+- OPTIM_WRAPPER_CONSTRUCTORS: optimizer wrapper ńÜäµ×äķĆĀÕÖ©
+- PARAM_SCHEDULERS: ÕÉäń¦ŹÕÅéµĢ░Ķ░āÕ║”ÕÖ©’╝īÕ”é `MultiStepLR`
+- METRICS: ńö©õ║ÄĶ«Īń«Śµ©ĪÕ×ŗń▓ŠÕ║”ńÜäĶ»äõ╝░µīćµĀć’╝īÕ”é `Accuracy`
+- EVALUATOR: ńö©õ║ÄĶ«Īń«Śµ©ĪÕ×ŗń▓ŠÕ║”ńÜäõĖĆõĖ¬µł¢ÕżÜõĖ¬Ķ»äõ╝░µīćµĀć
+- TASK_UTILS: õ╗╗ÕŖĪÕ╝║ńøĖÕģ│ńÜäõĖĆõ║øń╗äõ╗Č’╝īÕ”é `AnchorGenerator`, `BboxCoder`
+- VISUALIZERS: ń«ĪńÉåń╗śÕłČµ©ĪÕØŚ’╝īÕ”é `DetVisualizer` ÕŻգ©ÕøŠńēćõĖŖń╗śÕłČķó䵥ŗµĪå
+- VISBACKENDS: ÕŁśÕé©Ķ«Łń╗āµŚźÕ┐ŚńÜäÕÉÄń½»’╝īÕ”é `LocalVisBackend`, `TensorboardVisBackend`
+- LOG_PROCESSORS: µÄ¦ÕłČµŚźÕ┐ŚńÜäń╗¤Ķ«Īń¬ŚÕÅŻÕÆīń╗¤Ķ«Īµ¢╣µ│Ģ’╝īķ╗śĶ«żõĮ┐ńö© `LogProcessor`’╝īՔ鵣ēńē╣µ«Ŗķ£Ćµ▒éÕÅ»Ķć¬Õ«Üõ╣ē `LogProcessor`
+- FUNCTIONS: µ│©Õåīõ║åÕÉäń¦ŹÕćĮµĢ░’╝īÕ”é Dataloader õĖŁõ╝ĀÕģźńÜä `collate_fn`
+- INFERENCERS: µ│©Õåīõ║åÕÉäń¦Źõ╗╗ÕŖĪńÜäµÄ©ńÉåÕÖ©’╝īÕ”é `DetInferencer`’╝īĶ┤¤Ķ┤ŻµŻĆµĄŗõ╗╗ÕŖĪńÜäµÄ©ńÉå
+
+### Ķ░āńö©ńłČĶŖéńé╣ńÜ䵩ĪÕØŚ
+
+`MMEngine` õĖŁÕ«Üõ╣ēµ©ĪÕØŚ `RReLU`’╝īÕ╣ČÕŠĆ `MODELS` µĀ╣µ│©ÕåīÕÖ©µ│©ÕåīŃĆé
+
+```python
+import torch.nn as nn
+from mmengine import Registry, MODELS
+
+@MODELS.register_module()
+class RReLU(nn.Module):
+ def __init__(self, lower=0.125, upper=0.333, inplace=False):
+ super().__init__()
+
+ def forward(self, x):
+ print('call RReLU.forward')
+ return x
+```
+
+ÕüćĶ«Šµ£ēõĖ¬ķĪ╣ńø«ÕŽ `MMAlpha`’╝īÕ«āõ╣¤Õ«Üõ╣ēõ║å `MODELS`’╝īÕ╣ČĶ«ŠńĮ«ÕģČńłČĶŖéńé╣õĖ║ `MMEngine` ńÜä `MODELS`’╝īĶ┐ÖµĀĘÕ░▒Õ╗║ń½ŗõ║åÕ▒éń║¦ń╗ōµ×äŃĆé
+
+```python
+from mmengine import Registry, MODELS as MMENGINE_MODELS
+
+MODELS = Registry('model', parent=MMENGINE_MODELS, scope='mmalpha', locations=['mmalpha.models'])
+```
+
+õĖŗÕøŠµś» `MMEngine` ÕÆī `MMAlpha` ńÜäµ│©ÕåīÕÖ©Õ▒éń║¦ń╗ōµ×äŃĆé
+
+ +
+Ķ┐ÉĶĪīĶ┐ćń©ŗõĖŁÕģĘõĮōńÜäĶ░āńö©µĀłÕ”éõĖŗµēĆńż║’╝Ü
+
+
+
+Ķ┐ÉĶĪīĶ┐ćń©ŗõĖŁÕģĘõĮōńÜäĶ░āńö©µĀłÕ”éõĖŗµēĆńż║’╝Ü
+
+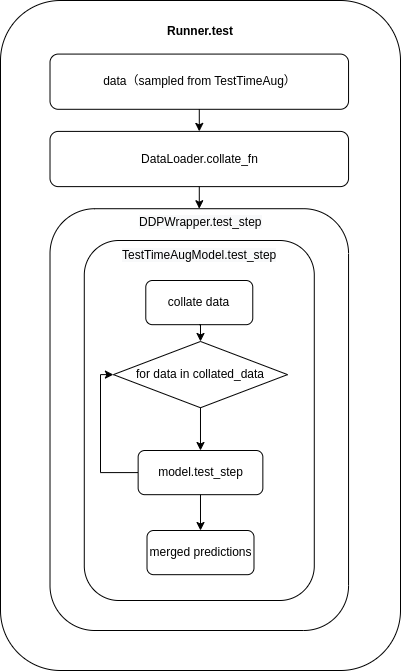 +
+### µĢ░µŹ«µĄü
+
+µĢ░µŹ«ń╗Å `TestTimeAug` Õó×Õ╝║ÕÉÄ’╝īÕģȵĢ░µŹ«µĀ╝Õ╝ÅõĖ║’╝Ü
+
+```python
+image1 = dict(
+ inputs=[data_1_1, data_1_2],
+ data_sample=[data_sample1_1, data_sample1_2]
+)
+
+image2 = dict(
+ inputs=[data_2_1, data_2_2],
+ data_sample=[data_sample2_1, data_sample2_2]
+)
+
+
+image3 = dict(
+ inputs=[data_3_1, data_3_2],
+ data_sample=[data_sample3_1, data_sample3_2]
+)
+
+```
+
+ÕģČõĖŁ `data_{i}_{j}` õĖ║Õó×Õ╝║ÕÉÄńÜäµĢ░µŹ«’╝ī`data_sample_{i}_{j}` õĖ║Õó×Õ╝║ÕÉĵĢ░µŹ«ńÜäµĀćńŁŠõ┐Īµü»ŃĆé
+µĢ░µŹ«ń╗ÅĶ┐ć DataLoader ÕżäńÉåÕÉÄ’╝īµĀ╝Õ╝ÅĶĮ¼ÕÅśõĖ║’╝Ü
+
+```python
+data_batch = dict(
+ inputs = [
+ (data_1_1, data_2_1, data_3_1),
+ (data_1_2, data_2_2, data_3_2),
+ ]
+ data_samples=[
+ (data_samples1_1, data_samples2_1, data_samples3_1),
+ (data_samples1_2, data_samples2_2, data_samples3_2)
+ ]
+)
+```
+
+õĖ║õ║åµ¢╣õŠ┐µ©ĪÕ×ŗµÄ©ńÉå’╝īBaseTTAModel õ╝ÜÕ£©µ©ĪÕ×ŗµÄ©ńÉåÕēŹÕ░åÕ░åµĢ░µŹ«ĶĮ¼µŹóõĖ║’╝Ü
+
+```python
+data_batch_aug1 = dict(
+ inputs = (data_1_1, data_2_1, data_3_1),
+ data_samples=(data_samples1_1, data_samples2_1, data_samples3_1)
+)
+
+data_batch_aug2 = dict(
+ inputs = (data_1_2, data_2_2, data_3_2),
+ data_samples=(data_samples1_2, data_samples2_2, data_samples3_2)
+)
+```
+
+µŁżµŚČµ»ÅõĖ¬ `data_batch_aug` ÕØćÕÅ»õ╗źńø┤µÄźõ╝ĀÕģźµ©ĪÕ×ŗĶ┐øĶĪīµÄ©ńÉåŃĆ鵩ĪÕ×ŗµÄ©ńÉåÕÉÄ’╝ī`BaseTTAModel` õ╝ÜÕ░åµÄ©ńÉåń╗ōµ×£µĢ┤ńÉåµłÉ’╝Ü
+
+```python
+preds = [
+ [data_samples1_1, data_samples_1_2],
+ [data_samples2_1, data_samples_2_2],
+ [data_samples3_1, data_samples_3_2],
+]
+```
+
+µ¢╣õŠ┐ńö©µłĘĶ┐øĶĪīń╗ōµ×£Ķ׏ÕÉłŃĆéõ║åĶ¦Ż TTA ńÜäµĢ░µŹ«µĄüÕÉÄ’╝īµłæõ╗¼Õ░▒ÕÅ»õ╗źµĀ╣µŹ«ÕģĘõĮōńÜäķ£Ćµ▒é’╝īķćŹĶĮĮ `BaseTTAModel.test_step()`’╝īõ╗źÕ«×ńÄ░µø┤ÕŖĀÕżŹµØéńÜäĶ׏ÕÉłńŁ¢ńĢźŃĆé
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/train_a_gan.md b/internlm_langchain/knowledge_base/MMEngine/content/train_a_gan.md
new file mode 100644
index 00000000..9b19331a
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/train_a_gan.md
@@ -0,0 +1,308 @@
+# Ķ«Łń╗āńö¤µłÉÕ»╣µŖŚńĮæń╗£
+
+ńö¤µłÉÕ»╣µŖŚńĮæń╗£(Generative Adversarial Network, GAN)ÕÅ»õ╗źńö©µØźńö¤µłÉÕøŠÕāÅĶ¦åķóæńŁēµĢ░µŹ«ŃĆéĶ┐Öń»ćµĢÖń©ŗÕ░åÕĖ”õĮĀõĖƵŁźµŁźńö© MMEngine Ķ«Łń╗ā GAN ’╝ü
+
+µłæõ╗¼ÕÅ»õ╗źķĆÜĶ┐ćõ╗źõĖŗµŁźķ¬żµØźĶ«Łń╗āõĖĆõĖ¬ńö¤µłÉÕ»╣µŖŚńĮæń╗£ŃĆé
+
+- [Ķ«Łń╗āńö¤µłÉÕ»╣µŖŚńĮæń╗£](#Ķ«Łń╗āńö¤µłÉÕ»╣µŖŚńĮæń╗£)
+ - [µ×äÕ╗║µĢ░µŹ«ÕŖĀĶĮĮÕÖ©](#µ×äÕ╗║µĢ░µŹ«ÕŖĀĶĮĮÕÖ©)
+ - [µ×äÕ╗║µĢ░µŹ«ķøå](#µ×äÕ╗║µĢ░µŹ«ķøå)
+ - [µ×äÕ╗║ńö¤µłÉÕÖ©ńĮæń╗£ÕÆīÕłżÕł½ÕÖ©ńĮæń╗£](#µ×äÕ╗║ńö¤µłÉÕÖ©ńĮæń╗£ÕÆīÕłżÕł½ÕÖ©ńĮæń╗£)
+ - [µ×äÕ╗║õĖĆõĖ¬ńö¤µłÉÕ»╣µŖŚńĮæń╗£µ©ĪÕ×ŗ](#µ×äÕ╗║õĖĆõĖ¬ńö¤µłÉÕ»╣µŖŚńĮæń╗£µ©ĪÕ×ŗ)
+ - [µ×äÕ╗║õ╝śÕī¢ÕÖ©](#µ×äÕ╗║õ╝śÕī¢ÕÖ©)
+ - [õĮ┐ńö©µē¦ĶĪīÕÖ©Ķ┐øĶĪīĶ«Łń╗ā](#õĮ┐ńö©µē¦ĶĪīÕÖ©Ķ┐øĶĪīĶ«Łń╗ā)
+
+## µ×äÕ╗║µĢ░µŹ«ÕŖĀĶĮĮÕÖ©
+
+### µ×äÕ╗║µĢ░µŹ«ķøå
+
+µÄźõĖŗµØź, µłæõ╗¼õĖ║ MNIST µĢ░µŹ«ķøåµ×äÕ╗║õĖĆõĖ¬µĢ░µŹ«ķøåń▒╗ `MNISTDataset`, ń╗¦µē┐Ķ欵Ģ░µŹ«ķøåÕ¤║ń▒╗ [BaseDataset](mmengine.dataset.BaseDataset), Õ╣ČõĖöķćŹĶĮĮµĢ░µŹ«ķøåÕ¤║ń▒╗ńÜä `load_data_list` ÕćĮµĢ░, õ┐ØĶ»üĶ┐öÕø×ÕĆ╝õĖ║ `list[dict]`’╝īÕģČõĖŁµ»ÅõĖ¬ `dict` õ╗ŻĶĪ©õĖĆõĖ¬µĢ░µŹ«µĀʵ£¼ŃĆéµø┤ÕżÜÕģ│õ║Ä MMEngine õĖŁµĢ░µŹ«ķøåńÜäńö©µ│Ģ’╝īÕÅ»õ╗źÕÅéĶĆā[µĢ░µŹ«ķøåµĢÖń©ŗ](../advanced_tutorials/basedataset.md)ŃĆé
+
+```python
+import numpy as np
+from mmcv.transforms import to_tensor
+from torch.utils.data import random_split
+from torchvision.datasets import MNIST
+
+from mmengine.dataset import BaseDataset
+
+
+class MNISTDataset(BaseDataset):
+
+ def __init__(self, data_root, pipeline, test_mode=False):
+ # õĖŗĶĮĮ MNIST µĢ░µŹ«ķøå
+ if test_mode:
+ mnist_full = MNIST(data_root, train=True, download=True)
+ self.mnist_dataset, _ = random_split(mnist_full, [55000, 5000])
+ else:
+ self.mnist_dataset = MNIST(data_root, train=False, download=True)
+
+ super().__init__(
+ data_root=data_root, pipeline=pipeline, test_mode=test_mode)
+
+ @staticmethod
+ def totensor(img):
+ if len(img.shape) < 3:
+ img = np.expand_dims(img, -1)
+ img = np.ascontiguousarray(img.transpose(2, 0, 1))
+ return to_tensor(img)
+
+ def load_data_list(self):
+ return [
+ dict(inputs=self.totensor(np.array(x[0]))) for x in self.mnist_dataset
+ ]
+
+
+dataset = MNISTDataset("./data", [])
+
+```
+
+õĮ┐ńö© Runner õĖŁńÜäÕćĮµĢ░ build_dataloader µØźµ×äÕ╗║µĢ░µŹ«ÕŖĀĶĮĮÕÖ©ŃĆé
+
+```python
+import os
+import torch
+from mmengine.runner import Runner
+
+NUM_WORKERS = int(os.cpu_count() / 2)
+BATCH_SIZE = 256 if torch.cuda.is_available() else 64
+
+train_dataloader = dict(
+ batch_size=BATCH_SIZE,
+ num_workers=NUM_WORKERS,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dataset)
+train_dataloader = Runner.build_dataloader(train_dataloader)
+```
+
+## µ×äÕ╗║ńö¤µłÉÕÖ©ńĮæń╗£ÕÆīÕłżÕł½ÕÖ©ńĮæń╗£
+
+õĖŗķØóńÜäõ╗ŻńĀüµ×äÕ╗║Õ╣ČÕ«×õŠŗÕī¢õ║åõĖĆõĖ¬ńö¤µłÉÕÖ©(Generator)ÕÆīõĖĆõĖ¬ÕłżÕł½ÕÖ©(Discriminator)ŃĆé
+
+```python
+import torch.nn as nn
+
+class Generator(nn.Module):
+ def __init__(self, noise_size, img_shape):
+ super().__init__()
+ self.img_shape = img_shape
+ self.noise_size = noise_size
+
+ def block(in_feat, out_feat, normalize=True):
+ layers = [nn.Linear(in_feat, out_feat)]
+ if normalize:
+ layers.append(nn.BatchNorm1d(out_feat, 0.8))
+ layers.append(nn.LeakyReLU(0.2, inplace=True))
+ return layers
+
+ self.model = nn.Sequential(
+ *block(noise_size, 128, normalize=False),
+ *block(128, 256),
+ *block(256, 512),
+ *block(512, 1024),
+ nn.Linear(1024, int(np.prod(img_shape))),
+ nn.Tanh(),
+ )
+
+ def forward(self, z):
+ img = self.model(z)
+ img = img.view(img.size(0), *self.img_shape)
+ return img
+```
+
+```python
+class Discriminator(nn.Module):
+ def __init__(self, img_shape):
+ super().__init__()
+
+ self.model = nn.Sequential(
+ nn.Linear(int(np.prod(img_shape)), 512),
+ nn.LeakyReLU(0.2, inplace=True),
+ nn.Linear(512, 256),
+ nn.LeakyReLU(0.2, inplace=True),
+ nn.Linear(256, 1),
+ nn.Sigmoid(),
+ )
+
+ def forward(self, img):
+ img_flat = img.view(img.size(0), -1)
+ validity = self.model(img_flat)
+
+ return validity
+```
+
+```python
+generator = Generator(100, (1, 28, 28))
+discriminator = Discriminator((1, 28, 28))
+```
+
+## µ×äÕ╗║õĖĆõĖ¬ńö¤µłÉÕ»╣µŖŚńĮæń╗£µ©ĪÕ×ŗ
+
+Õ£©õĮ┐ńö© MMEngine µŚČ’╝īµłæõ╗¼ńö© [ImgDataPreprocessor](mmengine.model.ImgDataPreprocessor) µØźÕ»╣µĢ░µŹ«Ķ┐øĶĪīÕĮÆõĖĆÕī¢ÕÆīķó£Ķē▓ķĆÜķüōńÜäĶĮ¼µŹóŃĆé
+
+```python
+from mmengine.model import ImgDataPreprocessor
+
+data_preprocessor = ImgDataPreprocessor(mean=([127.5]), std=([127.5]))
+```
+
+õĖŗķØóńÜäõ╗ŻńĀüÕ«×ńÄ░õ║åÕ¤║ńĪĆ GAN ńÜäń«Śµ│ĢŃĆéõĮ┐ńö© MMEngine Õ«×ńÄ░ń«Śµ│Ģń▒╗’╝īķ£ĆĶ”üń╗¦µē┐ [BaseModel](mmengine.model.BaseModel) Õ¤║ń▒╗’╝īÕ£© train_step õĖŁÕ«×ńÄ░Ķ«Łń╗āĶ┐ćń©ŗŃĆéGAN ķ£ĆĶ”üõ║żµø┐Ķ«Łń╗āńö¤µłÉÕÖ©ÕÆīÕłżÕł½ÕÖ©’╝īÕłåÕł½ńö▒ train_discriminator ÕÆī train_generator Õ«×ńÄ░’╝īÕ╣ČÕ«×ńÄ░ disc_loss ÕÆī gen_loss Ķ«Īń«ŚÕłżÕł½ÕÖ©µŹ¤Õż▒ÕćĮµĢ░ÕÆīńö¤µłÉÕÖ©µŹ¤Õż▒ÕćĮµĢ░ŃĆé
+Õģ│õ║Ä BaseModel ńÜäµø┤ÕżÜõ┐Īµü»’╝īĶ»ĘÕÅéĶĆā[µ©ĪÕ×ŗµĢÖń©ŗ](../tutorials/model.md).
+
+```python
+import torch.nn.functional as F
+from mmengine.model import BaseModel
+
+class GAN(BaseModel):
+
+ def __init__(self, generator, discriminator, noise_size,
+ data_preprocessor):
+ super().__init__(data_preprocessor=data_preprocessor)
+ assert generator.noise_size == noise_size
+ self.generator = generator
+ self.discriminator = discriminator
+ self.noise_size = noise_size
+
+ def train_step(self, data, optim_wrapper):
+ # ĶÄĘÕÅ¢µĢ░µŹ«ÕÆīµĢ░µŹ«ķóäÕżäńÉå
+ inputs_dict = self.data_preprocessor(data, True)
+ # Ķ«Łń╗āÕłżÕł½ÕÖ©
+ disc_optimizer_wrapper = optim_wrapper['discriminator']
+ with disc_optimizer_wrapper.optim_context(self.discriminator):
+ log_vars = self.train_discriminator(inputs_dict,
+ disc_optimizer_wrapper)
+
+ # Ķ«Łń╗āńö¤µłÉÕÖ©
+ set_requires_grad(self.discriminator, False)
+ gen_optimizer_wrapper = optim_wrapper['generator']
+ with gen_optimizer_wrapper.optim_context(self.generator):
+ log_vars_gen = self.train_generator(inputs_dict,
+ gen_optimizer_wrapper)
+
+ set_requires_grad(self.discriminator, True)
+ log_vars.update(log_vars_gen)
+
+ return log_vars
+
+ def forward(self, batch_inputs, data_samples=None, mode=None):
+ return self.generator(batch_inputs)
+
+ def disc_loss(self, disc_pred_fake, disc_pred_real):
+ losses_dict = dict()
+ losses_dict['loss_disc_fake'] = F.binary_cross_entropy(
+ disc_pred_fake, 0. * torch.ones_like(disc_pred_fake))
+ losses_dict['loss_disc_real'] = F.binary_cross_entropy(
+ disc_pred_real, 1. * torch.ones_like(disc_pred_real))
+
+ loss, log_var = self.parse_losses(losses_dict)
+ return loss, log_var
+
+ def gen_loss(self, disc_pred_fake):
+ losses_dict = dict()
+ losses_dict['loss_gen'] = F.binary_cross_entropy(
+ disc_pred_fake, 1. * torch.ones_like(disc_pred_fake))
+ loss, log_var = self.parse_losses(losses_dict)
+ return loss, log_var
+
+ def train_discriminator(self, inputs, optimizer_wrapper):
+ real_imgs = inputs['inputs']
+ z = torch.randn(
+ (real_imgs.shape[0], self.noise_size)).type_as(real_imgs)
+ with torch.no_grad():
+ fake_imgs = self.generator(z)
+
+ disc_pred_fake = self.discriminator(fake_imgs)
+ disc_pred_real = self.discriminator(real_imgs)
+
+ parsed_losses, log_vars = self.disc_loss(disc_pred_fake,
+ disc_pred_real)
+ optimizer_wrapper.update_params(parsed_losses)
+ return log_vars
+
+ def train_generator(self, inputs, optimizer_wrapper):
+ real_imgs = inputs['inputs']
+ z = torch.randn(real_imgs.shape[0], self.noise_size).type_as(real_imgs)
+
+ fake_imgs = self.generator(z)
+
+ disc_pred_fake = self.discriminator(fake_imgs)
+ parsed_loss, log_vars = self.gen_loss(disc_pred_fake)
+
+ optimizer_wrapper.update_params(parsed_loss)
+ return log_vars
+```
+
+ÕģČõĖŁõĖĆõĖ¬ÕćĮµĢ░ set_requires_grad ńö©µØźķöüÕ«ÜĶ«Łń╗āńö¤µłÉÕÖ©µŚČÕłżÕł½ÕÖ©ńÜäµØāķćŹŃĆé
+
+```python
+def set_requires_grad(nets, requires_grad=False):
+ """Set requires_grad for all the networks.
+
+ Args:
+ nets (nn.Module | list[nn.Module]): A list of networks or a single
+ network.
+ requires_grad (bool): Whether the networks require gradients or not.
+ """
+ if not isinstance(nets, list):
+ nets = [nets]
+ for net in nets:
+ if net is not None:
+ for param in net.parameters():
+ param.requires_grad = requires_grad
+```
+
+```python
+
+model = GAN(generator, discriminator, 100, data_preprocessor)
+
+```
+
+## µ×äÕ╗║õ╝śÕī¢ÕÖ©
+
+MMEngine õĮ┐ńö© [OptimWrapper](mmengine.optim.OptimWrapper) µØźÕ░üĶŻģõ╝śÕī¢ÕÖ©’╝īÕ»╣õ║ÄÕżÜõĖ¬õ╝śÕī¢ÕÖ©ńÜäµāģÕåĄ’╝īõĮ┐ńö© [OptimWrapperDict](mmengine.optim.OptimWrapperDict) Õ»╣ OptimWrapper ÕåŹĶ┐øĶĪīõĖƵ¼ĪÕ░üĶŻģŃĆé
+Õģ│õ║Äõ╝śÕī¢ÕÖ©ńÜäµø┤ÕżÜõ┐Īµü»’╝īĶ»ĘÕÅéĶĆā[õ╝śÕī¢ÕÖ©µĢÖń©ŗ](../tutorials/optim_wrapper.md).
+
+```python
+from mmengine.optim import OptimWrapper, OptimWrapperDict
+
+opt_g = torch.optim.Adam(generator.parameters(), lr=0.0001, betas=(0.5, 0.999))
+opt_g_wrapper = OptimWrapper(opt_g)
+
+opt_d = torch.optim.Adam(
+ discriminator.parameters(), lr=0.0001, betas=(0.5, 0.999))
+opt_d_wrapper = OptimWrapper(opt_d)
+
+opt_wrapper_dict = OptimWrapperDict(
+ generator=opt_g_wrapper, discriminator=opt_d_wrapper)
+
+```
+
+## õĮ┐ńö©µē¦ĶĪīÕÖ©Ķ┐øĶĪīĶ«Łń╗ā
+
+õĖŗķØóńÜäõ╗ŻńĀüµ╝öńż║õ║åÕ”éõĮĢõĮ┐ńö© Runner Ķ┐øĶĪīµ©ĪÕ×ŗĶ«Łń╗āŃĆéÕģ│õ║Ä Runner ńÜäµø┤ÕżÜõ┐Īµü»’╝īĶ»ĘÕÅéĶĆā[µē¦ĶĪīÕÖ©µĢÖń©ŗ](../tutorials/runner.md)ŃĆé
+
+```python
+train_cfg = dict(by_epoch=True, max_epochs=220)
+runner = Runner(
+ model,
+ work_dir='runs/gan/',
+ train_dataloader=train_dataloader,
+ train_cfg=train_cfg,
+ optim_wrapper=opt_wrapper_dict)
+runner.train()
+```
+
+Õł░Ķ┐Öķćī’╝īµłæõ╗¼Õ░▒Õ«īµłÉõ║åõĖĆõĖ¬ GAN ńÜäĶ«Łń╗ā’╝īķĆÜĶ┐ćõĖŗķØóńÜäõ╗ŻńĀüÕÅ»õ╗źµ¤źń£ŗÕłÜµēŹĶ«Łń╗āńÜä GAN ńö¤µłÉńÜäń╗ōµ×£ŃĆé
+
+```python
+z = torch.randn(64, 100).cuda()
+img = model(z)
+
+from torchvision.utils import save_image
+save_image(img, "result.png", normalize=True)
+```
+
+
+
+Õ”éµ×£õĮĀµā│õ║åĶ¦Żµø┤ÕżÜÕ”éõĮĢõĮ┐ńö© MMEngine Õ«×ńÄ░ GAN ÕÆīńö¤µłÉµ©ĪÕ×ŗ’╝īµłæõ╗¼Õ╝║ńāłÕ╗║Ķ««õĮĀõĮ┐ńö©ÕÉīµĀĘÕ¤║õ║Ä MMEngine Õ╝ĆÕÅæńÜäńö¤µłÉµĪåµ×Č [MMGen](https://github.com/open-mmlab/mmgeneration/tree/dev-1.x)ŃĆé
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/train_seg.md b/internlm_langchain/knowledge_base/MMEngine/content/train_seg.md
new file mode 100644
index 00000000..2b125447
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/train_seg.md
@@ -0,0 +1,290 @@
+# Ķ«Łń╗āĶ»Łõ╣ēÕłåÕē▓µ©ĪÕ×ŗ
+
+Ķ»Łõ╣ēÕłåÕē▓ńÜäµĀĘõŠŗÕż¦õĮōÕÅ»õ╗źÕłåµłÉÕøøõĖ¬µŁźķ¬ż:
+
+- [õĖŗĶĮĮ Camvid µĢ░µŹ«ķøå](#õĖŗĶĮĮ-camvid-µĢ░µŹ«ķøå)
+- [Õ«×ńÄ░ Camvid µĢ░µŹ«ń▒╗](#Õ«×ńÄ░-camvid-µĢ░µŹ«ń▒╗)
+- [Õ«×ńÄ░Ķ»Łõ╣ēÕłåÕē▓µ©ĪÕ×ŗ](#Õ«×ńÄ░Ķ»Łõ╣ēÕłåÕē▓µ©ĪÕ×ŗ)
+- [õĮ┐ńö© Runner Ķ«Łń╗āµ©ĪÕ×ŗ](#õĮ┐ńö©-runner-Ķ«Łń╗āµ©ĪÕ×ŗ)
+
+```{note}
+Õ”éµ×£õĮĀµø┤Õ¢£µ¼ó notebook ķŻÄµĀ╝ńÜäµĀĘõŠŗ’╝īõ╣¤ÕÅ»õ╗źÕ£©[µŁżÕżä](https://colab.research.google.com/github/open-mmlab/mmengine/blob/main/examples/segmentation/train.ipynb) õĮōķ¬īŃĆé
+```
+
+## õĖŗĶĮĮ Camvid µĢ░µŹ«ķøå
+
+ķ”¢Õģł’╝īõ╗Ä opendatalab õĖŗĶĮĮ Camvid µĢ░µŹ«ķøå:
+
+```bash
+# https://opendatalab.com/CamVid
+# Configure install
+pip install opendatalab
+# Upgraded version
+pip install -U opendatalab
+# Login
+odl login
+# Download this dataset
+mkdir data
+odl get CamVid -d data
+# Preprocess data in Linux. You should extract the files to data manually in
+# Windows
+tar -xzvf data/CamVid/raw/CamVid.tar.gz.00 -C ./data
+```
+
+## Õ«×ńÄ░ Camvid µĢ░µŹ«ń▒╗
+
+Õ«×ńÄ░ń╗¦µē┐Ķć¬ VisionDataset ńÜä CamVid µĢ░µŹ«ń▒╗ŃĆéÕ£©Ķ┐ÖõĖ¬ń▒╗õĖŁ’╝īµłæõ╗¼ķćŹÕåÖõ║å`__getitem__`ÕÆī`__len__`µ¢╣µ│Ģ’╝īõ╗źńĪ«õ┐ص»ÅõĖ¬ń┤óÕ╝ĢĶ┐öÕø×õĖĆõĖ¬ÕīģÕɽÕøŠÕāÅÕÆīµĀćńŁŠńÜäÕŁŚÕģĖŃĆ鵣żÕż¢’╝īµłæõ╗¼Ķ┐śÕ«×ńÄ░õ║åcolor_to_classÕŁŚÕģĖ’╝īÕ░å mask ńÜäķó£Ķē▓µśĀÕ░äÕł░ń▒╗Õł½ń┤óÕ╝ĢŃĆé
+
+```python
+import os
+import numpy as np
+from torchvision.datasets import VisionDataset
+from PIL import Image
+import csv
+
+
+def create_palette(csv_filepath):
+ color_to_class = {}
+ with open(csv_filepath, newline='') as csvfile:
+ reader = csv.DictReader(csvfile)
+ for idx, row in enumerate(reader):
+ r, g, b = int(row['r']), int(row['g']), int(row['b'])
+ color_to_class[(r, g, b)] = idx
+ return color_to_class
+
+class CamVid(VisionDataset):
+
+ def __init__(self,
+ root,
+ img_folder,
+ mask_folder,
+ transform=None,
+ target_transform=None):
+ super().__init__(
+ root, transform=transform, target_transform=target_transform)
+ self.img_folder = img_folder
+ self.mask_folder = mask_folder
+ self.images = list(
+ sorted(os.listdir(os.path.join(self.root, img_folder))))
+ self.masks = list(
+ sorted(os.listdir(os.path.join(self.root, mask_folder))))
+ self.color_to_class = create_palette(
+ os.path.join(self.root, 'class_dict.csv'))
+
+ def __getitem__(self, index):
+ img_path = os.path.join(self.root, self.img_folder, self.images[index])
+ mask_path = os.path.join(self.root, self.mask_folder,
+ self.masks[index])
+
+ img = Image.open(img_path).convert('RGB')
+ mask = Image.open(mask_path).convert('RGB') # Convert to RGB
+
+ if self.transform is not None:
+ img = self.transform(img)
+
+ # Convert the RGB values to class indices
+ mask = np.array(mask)
+ mask = mask[:, :, 0] * 65536 + mask[:, :, 1] * 256 + mask[:, :, 2]
+ labels = np.zeros_like(mask, dtype=np.int64)
+ for color, class_index in self.color_to_class.items():
+ rgb = color[0] * 65536 + color[1] * 256 + color[2]
+ labels[mask == rgb] = class_index
+
+ if self.target_transform is not None:
+ labels = self.target_transform(labels)
+ data_samples = dict(
+ labels=labels, img_path=img_path, mask_path=mask_path)
+ return img, data_samples
+
+ def __len__(self):
+ return len(self.images)
+
+```
+
+Õ¤║õ║Ä CamVid µĢ░µŹ«ń▒╗’╝īķĆēµŗ®ńøĖÕ║öńÜäµĢ░µŹ«Õó×Õ╝║µ¢╣Õ╝Å’╝īµ×äÕ╗║ train_dataloader ÕÆī val_dataloader’╝īõŠøÕÉÄń╗Ł runner õĮ┐ńö©
+
+```python
+import torch
+import torchvision.transforms as transforms
+
+norm_cfg = dict(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
+transform = transforms.Compose(
+ [transforms.ToTensor(),
+ transforms.Normalize(**norm_cfg)])
+
+target_transform = transforms.Lambda(
+ lambda x: torch.tensor(np.array(x), dtype=torch.long))
+
+train_set = CamVid(
+ 'data/CamVid',
+ img_folder='train',
+ mask_folder='train_labels',
+ transform=transform,
+ target_transform=target_transform)
+
+valid_set = CamVid(
+ 'data/CamVid',
+ img_folder='val',
+ mask_folder='val_labels',
+ transform=transform,
+ target_transform=target_transform)
+
+train_dataloader = dict(
+ batch_size=3,
+ dataset=train_set,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ collate_fn=dict(type='default_collate'))
+
+val_dataloader = dict(
+ batch_size=3,
+ dataset=valid_set,
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ collate_fn=dict(type='default_collate'))
+```
+
+## Õ«×ńÄ░Ķ»Łõ╣ēÕłåÕē▓µ©ĪÕ×ŗ
+
+Õ«Üõ╣ēõĖĆõĖ¬ÕÉŹõĖ║`MMDeeplabV3`ńÜ䵩ĪÕ×ŗń▒╗ŃĆéĶ»źń▒╗ń╗¦µē┐Ķć¬`BaseModel`’╝īÕ╣ČķøåµłÉõ║åDeepLabV3µ×ȵ×äńÜäÕłåÕē▓µ©ĪÕ×ŗŃĆé`MMDeeplabV3` ķćŹÕåÖõ║å`forward`µ¢╣µ│Ģ’╝īõ╗źÕżäńÉåĶŠōÕģźÕøŠÕāÅÕÆīµĀćńŁŠ’╝īÕ╣ȵö»µīüÕ£©Ķ«Łń╗āÕÆīķó䵥ŗµ©ĪÕ╝ÅõĖŗĶ«Īń«ŚµŹ¤Õż▒ÕÆīĶ┐öÕø×ķó䵥ŗń╗ōµ×£ŃĆé
+
+Õģ│õ║Ä`BaseModel`ńÜäµø┤ÕżÜõ┐Īµü»’╝īĶ»ĘÕÅéĶĆā[µ©ĪÕ×ŗµĢÖń©ŗ](../tutorials/model.md)ŃĆé
+
+```python
+from mmengine.model import BaseModel
+from torchvision.models.segmentation import deeplabv3_resnet50
+import torch.nn.functional as F
+
+
+class MMDeeplabV3(BaseModel):
+
+ def __init__(self, num_classes):
+ super().__init__()
+ self.deeplab = deeplabv3_resnet50()
+ self.deeplab.classifier[4] = torch.nn.Conv2d(
+ 256, num_classes, kernel_size=(1, 1), stride=(1, 1))
+
+ def forward(self, imgs, data_samples=None, mode='tensor'):
+ x = self.deeplab(imgs)['out']
+ if mode == 'loss':
+ return {'loss': F.cross_entropy(x, data_samples['labels'])}
+ elif mode == 'predict':
+ return x, data_samples
+```
+
+## õĮ┐ńö© Runner Ķ«Łń╗āµ©ĪÕ×ŗ
+
+Õ£©õĮ┐ńö© Runner Ķ┐øĶĪīĶ«Łń╗āõ╣ŗÕēŹ’╝īµłæõ╗¼ķ£ĆĶ”üÕ«×ńÄ░ IoU’╝łõ║żÕ╣ȵ»ö’╝ēµīćµĀćµØźĶ»äõ╝░µ©ĪÕ×ŗńÜäµĆ¦ĶāĮŃĆé
+
+```python
+from mmengine.evaluator import BaseMetric
+
+class IoU(BaseMetric):
+
+ def process(self, data_batch, data_samples):
+ preds, labels = data_samples[0], data_samples[1]['labels']
+ preds = torch.argmax(preds, dim=1)
+ intersect = (labels == preds).sum()
+ union = (torch.logical_or(preds, labels)).sum()
+ iou = (intersect / union).cpu()
+ self.results.append(
+ dict(batch_size=len(labels), iou=iou * len(labels)))
+
+ def compute_metrics(self, results):
+ total_iou = sum(result['iou'] for result in self.results)
+ num_samples = sum(result['batch_size'] for result in self.results)
+ return dict(iou=total_iou / num_samples)
+```
+
+Õ«×ńÄ░ÕÅ»Ķ¦åÕī¢ķÆ®ÕŁÉ’╝łHook’╝ēõ╣¤ÕŠłķćŹĶ”ü’╝īÕ«āÕÅ»õ╗źõŠ┐õ║ĵø┤ĶĮ╗µØŠÕ£░µ»öĶŠāµ©ĪÕ×ŗķó䵥ŗńÜäÕźĮÕØÅŃĆé
+
+```python
+from mmengine.hooks import Hook
+import shutil
+import cv2
+import os.path as osp
+
+
+class SegVisHook(Hook):
+
+ def __init__(self, data_root, vis_num=1) -> None:
+ super().__init__()
+ self.vis_num = vis_num
+ self.palette = create_palette(osp.join(data_root, 'class_dict.csv'))
+
+ def after_val_iter(self,
+ runner,
+ batch_idx: int,
+ data_batch=None,
+ outputs=None) -> None:
+ if batch_idx > self.vis_num:
+ return
+ preds, data_samples = outputs
+ img_paths = data_samples['img_path']
+ mask_paths = data_samples['mask_path']
+ _, C, H, W = preds.shape
+ preds = torch.argmax(preds, dim=1)
+ for idx, (pred, img_path,
+ mask_path) in enumerate(zip(preds, img_paths, mask_paths)):
+ pred_mask = np.zeros((H, W, 3), dtype=np.uint8)
+ runner.visualizer.set_image(pred_mask)
+ for color, class_id in self.palette.items():
+ runner.visualizer.draw_binary_masks(
+ pred == class_id,
+ colors=[color],
+ alphas=1.0,
+ )
+ # Convert RGB to BGR
+ pred_mask = runner.visualizer.get_image()[..., ::-1]
+ saved_dir = osp.join(runner.log_dir, 'vis_data', str(idx))
+ os.makedirs(saved_dir, exist_ok=True)
+
+ shutil.copyfile(img_path,
+ osp.join(saved_dir, osp.basename(img_path)))
+ shutil.copyfile(mask_path,
+ osp.join(saved_dir, osp.basename(mask_path)))
+ cv2.imwrite(
+ osp.join(saved_dir, f'pred_{osp.basename(img_path)}'),
+ pred_mask)
+```
+
+ÕćåÕżćÕ«īµ»Ģ’╝īĶ«®µłæõ╗¼ńö© Runner Õ╝ĆÕ¦ŗĶ«Łń╗āÕɦ’╝ü
+
+```python
+from torch.optim import AdamW
+from mmengine.optim import AmpOptimWrapper
+from mmengine.runner import Runner
+
+
+num_classes = 32 # Modify to actual number of categories.
+
+runner = Runner(
+ model=MMDeeplabV3(num_classes),
+ work_dir='./work_dir',
+ train_dataloader=train_dataloader,
+ optim_wrapper=dict(
+ type=AmpOptimWrapper, optimizer=dict(type=AdamW, lr=2e-4)),
+ train_cfg=dict(by_epoch=True, max_epochs=10, val_interval=10),
+ val_dataloader=val_dataloader,
+ val_cfg=dict(),
+ val_evaluator=dict(type=IoU),
+ custom_hooks=[SegVisHook('data/CamVid')],
+ default_hooks=dict(checkpoint=dict(type='CheckpointHook', interval=1)),
+)
+runner.train()
+```
+
+Ķ«Łń╗āÕ«īµłÉÕÉÄ’╝īõĮĀÕÅ»õ╗źÕ£© `./work_dir/{timestamp}/vis_data` µ¢ćõ╗ČÕż╣õĖŁµēŠÕł░ÕÅ»Ķ¦åÕī¢ń╗ōµ×£’╝īÕ”éõĖŗÕøŠµēĆńż║’╝Ü
+
+
+
+### µĢ░µŹ«µĄü
+
+µĢ░µŹ«ń╗Å `TestTimeAug` Õó×Õ╝║ÕÉÄ’╝īÕģȵĢ░µŹ«µĀ╝Õ╝ÅõĖ║’╝Ü
+
+```python
+image1 = dict(
+ inputs=[data_1_1, data_1_2],
+ data_sample=[data_sample1_1, data_sample1_2]
+)
+
+image2 = dict(
+ inputs=[data_2_1, data_2_2],
+ data_sample=[data_sample2_1, data_sample2_2]
+)
+
+
+image3 = dict(
+ inputs=[data_3_1, data_3_2],
+ data_sample=[data_sample3_1, data_sample3_2]
+)
+
+```
+
+ÕģČõĖŁ `data_{i}_{j}` õĖ║Õó×Õ╝║ÕÉÄńÜäµĢ░µŹ«’╝ī`data_sample_{i}_{j}` õĖ║Õó×Õ╝║ÕÉĵĢ░µŹ«ńÜäµĀćńŁŠõ┐Īµü»ŃĆé
+µĢ░µŹ«ń╗ÅĶ┐ć DataLoader ÕżäńÉåÕÉÄ’╝īµĀ╝Õ╝ÅĶĮ¼ÕÅśõĖ║’╝Ü
+
+```python
+data_batch = dict(
+ inputs = [
+ (data_1_1, data_2_1, data_3_1),
+ (data_1_2, data_2_2, data_3_2),
+ ]
+ data_samples=[
+ (data_samples1_1, data_samples2_1, data_samples3_1),
+ (data_samples1_2, data_samples2_2, data_samples3_2)
+ ]
+)
+```
+
+õĖ║õ║åµ¢╣õŠ┐µ©ĪÕ×ŗµÄ©ńÉå’╝īBaseTTAModel õ╝ÜÕ£©µ©ĪÕ×ŗµÄ©ńÉåÕēŹÕ░åÕ░åµĢ░µŹ«ĶĮ¼µŹóõĖ║’╝Ü
+
+```python
+data_batch_aug1 = dict(
+ inputs = (data_1_1, data_2_1, data_3_1),
+ data_samples=(data_samples1_1, data_samples2_1, data_samples3_1)
+)
+
+data_batch_aug2 = dict(
+ inputs = (data_1_2, data_2_2, data_3_2),
+ data_samples=(data_samples1_2, data_samples2_2, data_samples3_2)
+)
+```
+
+µŁżµŚČµ»ÅõĖ¬ `data_batch_aug` ÕØćÕÅ»õ╗źńø┤µÄźõ╝ĀÕģźµ©ĪÕ×ŗĶ┐øĶĪīµÄ©ńÉåŃĆ鵩ĪÕ×ŗµÄ©ńÉåÕÉÄ’╝ī`BaseTTAModel` õ╝ÜÕ░åµÄ©ńÉåń╗ōµ×£µĢ┤ńÉåµłÉ’╝Ü
+
+```python
+preds = [
+ [data_samples1_1, data_samples_1_2],
+ [data_samples2_1, data_samples_2_2],
+ [data_samples3_1, data_samples_3_2],
+]
+```
+
+µ¢╣õŠ┐ńö©µłĘĶ┐øĶĪīń╗ōµ×£Ķ׏ÕÉłŃĆéõ║åĶ¦Ż TTA ńÜäµĢ░µŹ«µĄüÕÉÄ’╝īµłæõ╗¼Õ░▒ÕÅ»õ╗źµĀ╣µŹ«ÕģĘõĮōńÜäķ£Ćµ▒é’╝īķćŹĶĮĮ `BaseTTAModel.test_step()`’╝īõ╗źÕ«×ńÄ░µø┤ÕŖĀÕżŹµØéńÜäĶ׏ÕÉłńŁ¢ńĢźŃĆé
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/train_a_gan.md b/internlm_langchain/knowledge_base/MMEngine/content/train_a_gan.md
new file mode 100644
index 00000000..9b19331a
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/train_a_gan.md
@@ -0,0 +1,308 @@
+# Ķ«Łń╗āńö¤µłÉÕ»╣µŖŚńĮæń╗£
+
+ńö¤µłÉÕ»╣µŖŚńĮæń╗£(Generative Adversarial Network, GAN)ÕÅ»õ╗źńö©µØźńö¤µłÉÕøŠÕāÅĶ¦åķóæńŁēµĢ░µŹ«ŃĆéĶ┐Öń»ćµĢÖń©ŗÕ░åÕĖ”õĮĀõĖƵŁźµŁźńö© MMEngine Ķ«Łń╗ā GAN ’╝ü
+
+µłæõ╗¼ÕÅ»õ╗źķĆÜĶ┐ćõ╗źõĖŗµŁźķ¬żµØźĶ«Łń╗āõĖĆõĖ¬ńö¤µłÉÕ»╣µŖŚńĮæń╗£ŃĆé
+
+- [Ķ«Łń╗āńö¤µłÉÕ»╣µŖŚńĮæń╗£](#Ķ«Łń╗āńö¤µłÉÕ»╣µŖŚńĮæń╗£)
+ - [µ×äÕ╗║µĢ░µŹ«ÕŖĀĶĮĮÕÖ©](#µ×äÕ╗║µĢ░µŹ«ÕŖĀĶĮĮÕÖ©)
+ - [µ×äÕ╗║µĢ░µŹ«ķøå](#µ×äÕ╗║µĢ░µŹ«ķøå)
+ - [µ×äÕ╗║ńö¤µłÉÕÖ©ńĮæń╗£ÕÆīÕłżÕł½ÕÖ©ńĮæń╗£](#µ×äÕ╗║ńö¤µłÉÕÖ©ńĮæń╗£ÕÆīÕłżÕł½ÕÖ©ńĮæń╗£)
+ - [µ×äÕ╗║õĖĆõĖ¬ńö¤µłÉÕ»╣µŖŚńĮæń╗£µ©ĪÕ×ŗ](#µ×äÕ╗║õĖĆõĖ¬ńö¤µłÉÕ»╣µŖŚńĮæń╗£µ©ĪÕ×ŗ)
+ - [µ×äÕ╗║õ╝śÕī¢ÕÖ©](#µ×äÕ╗║õ╝śÕī¢ÕÖ©)
+ - [õĮ┐ńö©µē¦ĶĪīÕÖ©Ķ┐øĶĪīĶ«Łń╗ā](#õĮ┐ńö©µē¦ĶĪīÕÖ©Ķ┐øĶĪīĶ«Łń╗ā)
+
+## µ×äÕ╗║µĢ░µŹ«ÕŖĀĶĮĮÕÖ©
+
+### µ×äÕ╗║µĢ░µŹ«ķøå
+
+µÄźõĖŗµØź, µłæõ╗¼õĖ║ MNIST µĢ░µŹ«ķøåµ×äÕ╗║õĖĆõĖ¬µĢ░µŹ«ķøåń▒╗ `MNISTDataset`, ń╗¦µē┐Ķ欵Ģ░µŹ«ķøåÕ¤║ń▒╗ [BaseDataset](mmengine.dataset.BaseDataset), Õ╣ČõĖöķćŹĶĮĮµĢ░µŹ«ķøåÕ¤║ń▒╗ńÜä `load_data_list` ÕćĮµĢ░, õ┐ØĶ»üĶ┐öÕø×ÕĆ╝õĖ║ `list[dict]`’╝īÕģČõĖŁµ»ÅõĖ¬ `dict` õ╗ŻĶĪ©õĖĆõĖ¬µĢ░µŹ«µĀʵ£¼ŃĆéµø┤ÕżÜÕģ│õ║Ä MMEngine õĖŁµĢ░µŹ«ķøåńÜäńö©µ│Ģ’╝īÕÅ»õ╗źÕÅéĶĆā[µĢ░µŹ«ķøåµĢÖń©ŗ](../advanced_tutorials/basedataset.md)ŃĆé
+
+```python
+import numpy as np
+from mmcv.transforms import to_tensor
+from torch.utils.data import random_split
+from torchvision.datasets import MNIST
+
+from mmengine.dataset import BaseDataset
+
+
+class MNISTDataset(BaseDataset):
+
+ def __init__(self, data_root, pipeline, test_mode=False):
+ # õĖŗĶĮĮ MNIST µĢ░µŹ«ķøå
+ if test_mode:
+ mnist_full = MNIST(data_root, train=True, download=True)
+ self.mnist_dataset, _ = random_split(mnist_full, [55000, 5000])
+ else:
+ self.mnist_dataset = MNIST(data_root, train=False, download=True)
+
+ super().__init__(
+ data_root=data_root, pipeline=pipeline, test_mode=test_mode)
+
+ @staticmethod
+ def totensor(img):
+ if len(img.shape) < 3:
+ img = np.expand_dims(img, -1)
+ img = np.ascontiguousarray(img.transpose(2, 0, 1))
+ return to_tensor(img)
+
+ def load_data_list(self):
+ return [
+ dict(inputs=self.totensor(np.array(x[0]))) for x in self.mnist_dataset
+ ]
+
+
+dataset = MNISTDataset("./data", [])
+
+```
+
+õĮ┐ńö© Runner õĖŁńÜäÕćĮµĢ░ build_dataloader µØźµ×äÕ╗║µĢ░µŹ«ÕŖĀĶĮĮÕÖ©ŃĆé
+
+```python
+import os
+import torch
+from mmengine.runner import Runner
+
+NUM_WORKERS = int(os.cpu_count() / 2)
+BATCH_SIZE = 256 if torch.cuda.is_available() else 64
+
+train_dataloader = dict(
+ batch_size=BATCH_SIZE,
+ num_workers=NUM_WORKERS,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dataset)
+train_dataloader = Runner.build_dataloader(train_dataloader)
+```
+
+## µ×äÕ╗║ńö¤µłÉÕÖ©ńĮæń╗£ÕÆīÕłżÕł½ÕÖ©ńĮæń╗£
+
+õĖŗķØóńÜäõ╗ŻńĀüµ×äÕ╗║Õ╣ČÕ«×õŠŗÕī¢õ║åõĖĆõĖ¬ńö¤µłÉÕÖ©(Generator)ÕÆīõĖĆõĖ¬ÕłżÕł½ÕÖ©(Discriminator)ŃĆé
+
+```python
+import torch.nn as nn
+
+class Generator(nn.Module):
+ def __init__(self, noise_size, img_shape):
+ super().__init__()
+ self.img_shape = img_shape
+ self.noise_size = noise_size
+
+ def block(in_feat, out_feat, normalize=True):
+ layers = [nn.Linear(in_feat, out_feat)]
+ if normalize:
+ layers.append(nn.BatchNorm1d(out_feat, 0.8))
+ layers.append(nn.LeakyReLU(0.2, inplace=True))
+ return layers
+
+ self.model = nn.Sequential(
+ *block(noise_size, 128, normalize=False),
+ *block(128, 256),
+ *block(256, 512),
+ *block(512, 1024),
+ nn.Linear(1024, int(np.prod(img_shape))),
+ nn.Tanh(),
+ )
+
+ def forward(self, z):
+ img = self.model(z)
+ img = img.view(img.size(0), *self.img_shape)
+ return img
+```
+
+```python
+class Discriminator(nn.Module):
+ def __init__(self, img_shape):
+ super().__init__()
+
+ self.model = nn.Sequential(
+ nn.Linear(int(np.prod(img_shape)), 512),
+ nn.LeakyReLU(0.2, inplace=True),
+ nn.Linear(512, 256),
+ nn.LeakyReLU(0.2, inplace=True),
+ nn.Linear(256, 1),
+ nn.Sigmoid(),
+ )
+
+ def forward(self, img):
+ img_flat = img.view(img.size(0), -1)
+ validity = self.model(img_flat)
+
+ return validity
+```
+
+```python
+generator = Generator(100, (1, 28, 28))
+discriminator = Discriminator((1, 28, 28))
+```
+
+## µ×äÕ╗║õĖĆõĖ¬ńö¤µłÉÕ»╣µŖŚńĮæń╗£µ©ĪÕ×ŗ
+
+Õ£©õĮ┐ńö© MMEngine µŚČ’╝īµłæõ╗¼ńö© [ImgDataPreprocessor](mmengine.model.ImgDataPreprocessor) µØźÕ»╣µĢ░µŹ«Ķ┐øĶĪīÕĮÆõĖĆÕī¢ÕÆīķó£Ķē▓ķĆÜķüōńÜäĶĮ¼µŹóŃĆé
+
+```python
+from mmengine.model import ImgDataPreprocessor
+
+data_preprocessor = ImgDataPreprocessor(mean=([127.5]), std=([127.5]))
+```
+
+õĖŗķØóńÜäõ╗ŻńĀüÕ«×ńÄ░õ║åÕ¤║ńĪĆ GAN ńÜäń«Śµ│ĢŃĆéõĮ┐ńö© MMEngine Õ«×ńÄ░ń«Śµ│Ģń▒╗’╝īķ£ĆĶ”üń╗¦µē┐ [BaseModel](mmengine.model.BaseModel) Õ¤║ń▒╗’╝īÕ£© train_step õĖŁÕ«×ńÄ░Ķ«Łń╗āĶ┐ćń©ŗŃĆéGAN ķ£ĆĶ”üõ║żµø┐Ķ«Łń╗āńö¤µłÉÕÖ©ÕÆīÕłżÕł½ÕÖ©’╝īÕłåÕł½ńö▒ train_discriminator ÕÆī train_generator Õ«×ńÄ░’╝īÕ╣ČÕ«×ńÄ░ disc_loss ÕÆī gen_loss Ķ«Īń«ŚÕłżÕł½ÕÖ©µŹ¤Õż▒ÕćĮµĢ░ÕÆīńö¤µłÉÕÖ©µŹ¤Õż▒ÕćĮµĢ░ŃĆé
+Õģ│õ║Ä BaseModel ńÜäµø┤ÕżÜõ┐Īµü»’╝īĶ»ĘÕÅéĶĆā[µ©ĪÕ×ŗµĢÖń©ŗ](../tutorials/model.md).
+
+```python
+import torch.nn.functional as F
+from mmengine.model import BaseModel
+
+class GAN(BaseModel):
+
+ def __init__(self, generator, discriminator, noise_size,
+ data_preprocessor):
+ super().__init__(data_preprocessor=data_preprocessor)
+ assert generator.noise_size == noise_size
+ self.generator = generator
+ self.discriminator = discriminator
+ self.noise_size = noise_size
+
+ def train_step(self, data, optim_wrapper):
+ # ĶÄĘÕÅ¢µĢ░µŹ«ÕÆīµĢ░µŹ«ķóäÕżäńÉå
+ inputs_dict = self.data_preprocessor(data, True)
+ # Ķ«Łń╗āÕłżÕł½ÕÖ©
+ disc_optimizer_wrapper = optim_wrapper['discriminator']
+ with disc_optimizer_wrapper.optim_context(self.discriminator):
+ log_vars = self.train_discriminator(inputs_dict,
+ disc_optimizer_wrapper)
+
+ # Ķ«Łń╗āńö¤µłÉÕÖ©
+ set_requires_grad(self.discriminator, False)
+ gen_optimizer_wrapper = optim_wrapper['generator']
+ with gen_optimizer_wrapper.optim_context(self.generator):
+ log_vars_gen = self.train_generator(inputs_dict,
+ gen_optimizer_wrapper)
+
+ set_requires_grad(self.discriminator, True)
+ log_vars.update(log_vars_gen)
+
+ return log_vars
+
+ def forward(self, batch_inputs, data_samples=None, mode=None):
+ return self.generator(batch_inputs)
+
+ def disc_loss(self, disc_pred_fake, disc_pred_real):
+ losses_dict = dict()
+ losses_dict['loss_disc_fake'] = F.binary_cross_entropy(
+ disc_pred_fake, 0. * torch.ones_like(disc_pred_fake))
+ losses_dict['loss_disc_real'] = F.binary_cross_entropy(
+ disc_pred_real, 1. * torch.ones_like(disc_pred_real))
+
+ loss, log_var = self.parse_losses(losses_dict)
+ return loss, log_var
+
+ def gen_loss(self, disc_pred_fake):
+ losses_dict = dict()
+ losses_dict['loss_gen'] = F.binary_cross_entropy(
+ disc_pred_fake, 1. * torch.ones_like(disc_pred_fake))
+ loss, log_var = self.parse_losses(losses_dict)
+ return loss, log_var
+
+ def train_discriminator(self, inputs, optimizer_wrapper):
+ real_imgs = inputs['inputs']
+ z = torch.randn(
+ (real_imgs.shape[0], self.noise_size)).type_as(real_imgs)
+ with torch.no_grad():
+ fake_imgs = self.generator(z)
+
+ disc_pred_fake = self.discriminator(fake_imgs)
+ disc_pred_real = self.discriminator(real_imgs)
+
+ parsed_losses, log_vars = self.disc_loss(disc_pred_fake,
+ disc_pred_real)
+ optimizer_wrapper.update_params(parsed_losses)
+ return log_vars
+
+ def train_generator(self, inputs, optimizer_wrapper):
+ real_imgs = inputs['inputs']
+ z = torch.randn(real_imgs.shape[0], self.noise_size).type_as(real_imgs)
+
+ fake_imgs = self.generator(z)
+
+ disc_pred_fake = self.discriminator(fake_imgs)
+ parsed_loss, log_vars = self.gen_loss(disc_pred_fake)
+
+ optimizer_wrapper.update_params(parsed_loss)
+ return log_vars
+```
+
+ÕģČõĖŁõĖĆõĖ¬ÕćĮµĢ░ set_requires_grad ńö©µØźķöüÕ«ÜĶ«Łń╗āńö¤µłÉÕÖ©µŚČÕłżÕł½ÕÖ©ńÜäµØāķćŹŃĆé
+
+```python
+def set_requires_grad(nets, requires_grad=False):
+ """Set requires_grad for all the networks.
+
+ Args:
+ nets (nn.Module | list[nn.Module]): A list of networks or a single
+ network.
+ requires_grad (bool): Whether the networks require gradients or not.
+ """
+ if not isinstance(nets, list):
+ nets = [nets]
+ for net in nets:
+ if net is not None:
+ for param in net.parameters():
+ param.requires_grad = requires_grad
+```
+
+```python
+
+model = GAN(generator, discriminator, 100, data_preprocessor)
+
+```
+
+## µ×äÕ╗║õ╝śÕī¢ÕÖ©
+
+MMEngine õĮ┐ńö© [OptimWrapper](mmengine.optim.OptimWrapper) µØźÕ░üĶŻģõ╝śÕī¢ÕÖ©’╝īÕ»╣õ║ÄÕżÜõĖ¬õ╝śÕī¢ÕÖ©ńÜäµāģÕåĄ’╝īõĮ┐ńö© [OptimWrapperDict](mmengine.optim.OptimWrapperDict) Õ»╣ OptimWrapper ÕåŹĶ┐øĶĪīõĖƵ¼ĪÕ░üĶŻģŃĆé
+Õģ│õ║Äõ╝śÕī¢ÕÖ©ńÜäµø┤ÕżÜõ┐Īµü»’╝īĶ»ĘÕÅéĶĆā[õ╝śÕī¢ÕÖ©µĢÖń©ŗ](../tutorials/optim_wrapper.md).
+
+```python
+from mmengine.optim import OptimWrapper, OptimWrapperDict
+
+opt_g = torch.optim.Adam(generator.parameters(), lr=0.0001, betas=(0.5, 0.999))
+opt_g_wrapper = OptimWrapper(opt_g)
+
+opt_d = torch.optim.Adam(
+ discriminator.parameters(), lr=0.0001, betas=(0.5, 0.999))
+opt_d_wrapper = OptimWrapper(opt_d)
+
+opt_wrapper_dict = OptimWrapperDict(
+ generator=opt_g_wrapper, discriminator=opt_d_wrapper)
+
+```
+
+## õĮ┐ńö©µē¦ĶĪīÕÖ©Ķ┐øĶĪīĶ«Łń╗ā
+
+õĖŗķØóńÜäõ╗ŻńĀüµ╝öńż║õ║åÕ”éõĮĢõĮ┐ńö© Runner Ķ┐øĶĪīµ©ĪÕ×ŗĶ«Łń╗āŃĆéÕģ│õ║Ä Runner ńÜäµø┤ÕżÜõ┐Īµü»’╝īĶ»ĘÕÅéĶĆā[µē¦ĶĪīÕÖ©µĢÖń©ŗ](../tutorials/runner.md)ŃĆé
+
+```python
+train_cfg = dict(by_epoch=True, max_epochs=220)
+runner = Runner(
+ model,
+ work_dir='runs/gan/',
+ train_dataloader=train_dataloader,
+ train_cfg=train_cfg,
+ optim_wrapper=opt_wrapper_dict)
+runner.train()
+```
+
+Õł░Ķ┐Öķćī’╝īµłæõ╗¼Õ░▒Õ«īµłÉõ║åõĖĆõĖ¬ GAN ńÜäĶ«Łń╗ā’╝īķĆÜĶ┐ćõĖŗķØóńÜäõ╗ŻńĀüÕÅ»õ╗źµ¤źń£ŗÕłÜµēŹĶ«Łń╗āńÜä GAN ńö¤µłÉńÜäń╗ōµ×£ŃĆé
+
+```python
+z = torch.randn(64, 100).cuda()
+img = model(z)
+
+from torchvision.utils import save_image
+save_image(img, "result.png", normalize=True)
+```
+
+
+
+Õ”éµ×£õĮĀµā│õ║åĶ¦Żµø┤ÕżÜÕ”éõĮĢõĮ┐ńö© MMEngine Õ«×ńÄ░ GAN ÕÆīńö¤µłÉµ©ĪÕ×ŗ’╝īµłæõ╗¼Õ╝║ńāłÕ╗║Ķ««õĮĀõĮ┐ńö©ÕÉīµĀĘÕ¤║õ║Ä MMEngine Õ╝ĆÕÅæńÜäńö¤µłÉµĪåµ×Č [MMGen](https://github.com/open-mmlab/mmgeneration/tree/dev-1.x)ŃĆé
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/train_seg.md b/internlm_langchain/knowledge_base/MMEngine/content/train_seg.md
new file mode 100644
index 00000000..2b125447
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/train_seg.md
@@ -0,0 +1,290 @@
+# Ķ«Łń╗āĶ»Łõ╣ēÕłåÕē▓µ©ĪÕ×ŗ
+
+Ķ»Łõ╣ēÕłåÕē▓ńÜäµĀĘõŠŗÕż¦õĮōÕÅ»õ╗źÕłåµłÉÕøøõĖ¬µŁźķ¬ż:
+
+- [õĖŗĶĮĮ Camvid µĢ░µŹ«ķøå](#õĖŗĶĮĮ-camvid-µĢ░µŹ«ķøå)
+- [Õ«×ńÄ░ Camvid µĢ░µŹ«ń▒╗](#Õ«×ńÄ░-camvid-µĢ░µŹ«ń▒╗)
+- [Õ«×ńÄ░Ķ»Łõ╣ēÕłåÕē▓µ©ĪÕ×ŗ](#Õ«×ńÄ░Ķ»Łõ╣ēÕłåÕē▓µ©ĪÕ×ŗ)
+- [õĮ┐ńö© Runner Ķ«Łń╗āµ©ĪÕ×ŗ](#õĮ┐ńö©-runner-Ķ«Łń╗āµ©ĪÕ×ŗ)
+
+```{note}
+Õ”éµ×£õĮĀµø┤Õ¢£µ¼ó notebook ķŻÄµĀ╝ńÜäµĀĘõŠŗ’╝īõ╣¤ÕÅ»õ╗źÕ£©[µŁżÕżä](https://colab.research.google.com/github/open-mmlab/mmengine/blob/main/examples/segmentation/train.ipynb) õĮōķ¬īŃĆé
+```
+
+## õĖŗĶĮĮ Camvid µĢ░µŹ«ķøå
+
+ķ”¢Õģł’╝īõ╗Ä opendatalab õĖŗĶĮĮ Camvid µĢ░µŹ«ķøå:
+
+```bash
+# https://opendatalab.com/CamVid
+# Configure install
+pip install opendatalab
+# Upgraded version
+pip install -U opendatalab
+# Login
+odl login
+# Download this dataset
+mkdir data
+odl get CamVid -d data
+# Preprocess data in Linux. You should extract the files to data manually in
+# Windows
+tar -xzvf data/CamVid/raw/CamVid.tar.gz.00 -C ./data
+```
+
+## Õ«×ńÄ░ Camvid µĢ░µŹ«ń▒╗
+
+Õ«×ńÄ░ń╗¦µē┐Ķć¬ VisionDataset ńÜä CamVid µĢ░µŹ«ń▒╗ŃĆéÕ£©Ķ┐ÖõĖ¬ń▒╗õĖŁ’╝īµłæõ╗¼ķćŹÕåÖõ║å`__getitem__`ÕÆī`__len__`µ¢╣µ│Ģ’╝īõ╗źńĪ«õ┐ص»ÅõĖ¬ń┤óÕ╝ĢĶ┐öÕø×õĖĆõĖ¬ÕīģÕɽÕøŠÕāÅÕÆīµĀćńŁŠńÜäÕŁŚÕģĖŃĆ鵣żÕż¢’╝īµłæõ╗¼Ķ┐śÕ«×ńÄ░õ║åcolor_to_classÕŁŚÕģĖ’╝īÕ░å mask ńÜäķó£Ķē▓µśĀÕ░äÕł░ń▒╗Õł½ń┤óÕ╝ĢŃĆé
+
+```python
+import os
+import numpy as np
+from torchvision.datasets import VisionDataset
+from PIL import Image
+import csv
+
+
+def create_palette(csv_filepath):
+ color_to_class = {}
+ with open(csv_filepath, newline='') as csvfile:
+ reader = csv.DictReader(csvfile)
+ for idx, row in enumerate(reader):
+ r, g, b = int(row['r']), int(row['g']), int(row['b'])
+ color_to_class[(r, g, b)] = idx
+ return color_to_class
+
+class CamVid(VisionDataset):
+
+ def __init__(self,
+ root,
+ img_folder,
+ mask_folder,
+ transform=None,
+ target_transform=None):
+ super().__init__(
+ root, transform=transform, target_transform=target_transform)
+ self.img_folder = img_folder
+ self.mask_folder = mask_folder
+ self.images = list(
+ sorted(os.listdir(os.path.join(self.root, img_folder))))
+ self.masks = list(
+ sorted(os.listdir(os.path.join(self.root, mask_folder))))
+ self.color_to_class = create_palette(
+ os.path.join(self.root, 'class_dict.csv'))
+
+ def __getitem__(self, index):
+ img_path = os.path.join(self.root, self.img_folder, self.images[index])
+ mask_path = os.path.join(self.root, self.mask_folder,
+ self.masks[index])
+
+ img = Image.open(img_path).convert('RGB')
+ mask = Image.open(mask_path).convert('RGB') # Convert to RGB
+
+ if self.transform is not None:
+ img = self.transform(img)
+
+ # Convert the RGB values to class indices
+ mask = np.array(mask)
+ mask = mask[:, :, 0] * 65536 + mask[:, :, 1] * 256 + mask[:, :, 2]
+ labels = np.zeros_like(mask, dtype=np.int64)
+ for color, class_index in self.color_to_class.items():
+ rgb = color[0] * 65536 + color[1] * 256 + color[2]
+ labels[mask == rgb] = class_index
+
+ if self.target_transform is not None:
+ labels = self.target_transform(labels)
+ data_samples = dict(
+ labels=labels, img_path=img_path, mask_path=mask_path)
+ return img, data_samples
+
+ def __len__(self):
+ return len(self.images)
+
+```
+
+Õ¤║õ║Ä CamVid µĢ░µŹ«ń▒╗’╝īķĆēµŗ®ńøĖÕ║öńÜäµĢ░µŹ«Õó×Õ╝║µ¢╣Õ╝Å’╝īµ×äÕ╗║ train_dataloader ÕÆī val_dataloader’╝īõŠøÕÉÄń╗Ł runner õĮ┐ńö©
+
+```python
+import torch
+import torchvision.transforms as transforms
+
+norm_cfg = dict(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
+transform = transforms.Compose(
+ [transforms.ToTensor(),
+ transforms.Normalize(**norm_cfg)])
+
+target_transform = transforms.Lambda(
+ lambda x: torch.tensor(np.array(x), dtype=torch.long))
+
+train_set = CamVid(
+ 'data/CamVid',
+ img_folder='train',
+ mask_folder='train_labels',
+ transform=transform,
+ target_transform=target_transform)
+
+valid_set = CamVid(
+ 'data/CamVid',
+ img_folder='val',
+ mask_folder='val_labels',
+ transform=transform,
+ target_transform=target_transform)
+
+train_dataloader = dict(
+ batch_size=3,
+ dataset=train_set,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ collate_fn=dict(type='default_collate'))
+
+val_dataloader = dict(
+ batch_size=3,
+ dataset=valid_set,
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ collate_fn=dict(type='default_collate'))
+```
+
+## Õ«×ńÄ░Ķ»Łõ╣ēÕłåÕē▓µ©ĪÕ×ŗ
+
+Õ«Üõ╣ēõĖĆõĖ¬ÕÉŹõĖ║`MMDeeplabV3`ńÜ䵩ĪÕ×ŗń▒╗ŃĆéĶ»źń▒╗ń╗¦µē┐Ķć¬`BaseModel`’╝īÕ╣ČķøåµłÉõ║åDeepLabV3µ×ȵ×äńÜäÕłåÕē▓µ©ĪÕ×ŗŃĆé`MMDeeplabV3` ķćŹÕåÖõ║å`forward`µ¢╣µ│Ģ’╝īõ╗źÕżäńÉåĶŠōÕģźÕøŠÕāÅÕÆīµĀćńŁŠ’╝īÕ╣ȵö»µīüÕ£©Ķ«Łń╗āÕÆīķó䵥ŗµ©ĪÕ╝ÅõĖŗĶ«Īń«ŚµŹ¤Õż▒ÕÆīĶ┐öÕø×ķó䵥ŗń╗ōµ×£ŃĆé
+
+Õģ│õ║Ä`BaseModel`ńÜäµø┤ÕżÜõ┐Īµü»’╝īĶ»ĘÕÅéĶĆā[µ©ĪÕ×ŗµĢÖń©ŗ](../tutorials/model.md)ŃĆé
+
+```python
+from mmengine.model import BaseModel
+from torchvision.models.segmentation import deeplabv3_resnet50
+import torch.nn.functional as F
+
+
+class MMDeeplabV3(BaseModel):
+
+ def __init__(self, num_classes):
+ super().__init__()
+ self.deeplab = deeplabv3_resnet50()
+ self.deeplab.classifier[4] = torch.nn.Conv2d(
+ 256, num_classes, kernel_size=(1, 1), stride=(1, 1))
+
+ def forward(self, imgs, data_samples=None, mode='tensor'):
+ x = self.deeplab(imgs)['out']
+ if mode == 'loss':
+ return {'loss': F.cross_entropy(x, data_samples['labels'])}
+ elif mode == 'predict':
+ return x, data_samples
+```
+
+## õĮ┐ńö© Runner Ķ«Łń╗āµ©ĪÕ×ŗ
+
+Õ£©õĮ┐ńö© Runner Ķ┐øĶĪīĶ«Łń╗āõ╣ŗÕēŹ’╝īµłæõ╗¼ķ£ĆĶ”üÕ«×ńÄ░ IoU’╝łõ║żÕ╣ȵ»ö’╝ēµīćµĀćµØźĶ»äõ╝░µ©ĪÕ×ŗńÜäµĆ¦ĶāĮŃĆé
+
+```python
+from mmengine.evaluator import BaseMetric
+
+class IoU(BaseMetric):
+
+ def process(self, data_batch, data_samples):
+ preds, labels = data_samples[0], data_samples[1]['labels']
+ preds = torch.argmax(preds, dim=1)
+ intersect = (labels == preds).sum()
+ union = (torch.logical_or(preds, labels)).sum()
+ iou = (intersect / union).cpu()
+ self.results.append(
+ dict(batch_size=len(labels), iou=iou * len(labels)))
+
+ def compute_metrics(self, results):
+ total_iou = sum(result['iou'] for result in self.results)
+ num_samples = sum(result['batch_size'] for result in self.results)
+ return dict(iou=total_iou / num_samples)
+```
+
+Õ«×ńÄ░ÕÅ»Ķ¦åÕī¢ķÆ®ÕŁÉ’╝łHook’╝ēõ╣¤ÕŠłķćŹĶ”ü’╝īÕ«āÕÅ»õ╗źõŠ┐õ║ĵø┤ĶĮ╗µØŠÕ£░µ»öĶŠāµ©ĪÕ×ŗķó䵥ŗńÜäÕźĮÕØÅŃĆé
+
+```python
+from mmengine.hooks import Hook
+import shutil
+import cv2
+import os.path as osp
+
+
+class SegVisHook(Hook):
+
+ def __init__(self, data_root, vis_num=1) -> None:
+ super().__init__()
+ self.vis_num = vis_num
+ self.palette = create_palette(osp.join(data_root, 'class_dict.csv'))
+
+ def after_val_iter(self,
+ runner,
+ batch_idx: int,
+ data_batch=None,
+ outputs=None) -> None:
+ if batch_idx > self.vis_num:
+ return
+ preds, data_samples = outputs
+ img_paths = data_samples['img_path']
+ mask_paths = data_samples['mask_path']
+ _, C, H, W = preds.shape
+ preds = torch.argmax(preds, dim=1)
+ for idx, (pred, img_path,
+ mask_path) in enumerate(zip(preds, img_paths, mask_paths)):
+ pred_mask = np.zeros((H, W, 3), dtype=np.uint8)
+ runner.visualizer.set_image(pred_mask)
+ for color, class_id in self.palette.items():
+ runner.visualizer.draw_binary_masks(
+ pred == class_id,
+ colors=[color],
+ alphas=1.0,
+ )
+ # Convert RGB to BGR
+ pred_mask = runner.visualizer.get_image()[..., ::-1]
+ saved_dir = osp.join(runner.log_dir, 'vis_data', str(idx))
+ os.makedirs(saved_dir, exist_ok=True)
+
+ shutil.copyfile(img_path,
+ osp.join(saved_dir, osp.basename(img_path)))
+ shutil.copyfile(mask_path,
+ osp.join(saved_dir, osp.basename(mask_path)))
+ cv2.imwrite(
+ osp.join(saved_dir, f'pred_{osp.basename(img_path)}'),
+ pred_mask)
+```
+
+ÕćåÕżćÕ«īµ»Ģ’╝īĶ«®µłæõ╗¼ńö© Runner Õ╝ĆÕ¦ŗĶ«Łń╗āÕɦ’╝ü
+
+```python
+from torch.optim import AdamW
+from mmengine.optim import AmpOptimWrapper
+from mmengine.runner import Runner
+
+
+num_classes = 32 # Modify to actual number of categories.
+
+runner = Runner(
+ model=MMDeeplabV3(num_classes),
+ work_dir='./work_dir',
+ train_dataloader=train_dataloader,
+ optim_wrapper=dict(
+ type=AmpOptimWrapper, optimizer=dict(type=AdamW, lr=2e-4)),
+ train_cfg=dict(by_epoch=True, max_epochs=10, val_interval=10),
+ val_dataloader=val_dataloader,
+ val_cfg=dict(),
+ val_evaluator=dict(type=IoU),
+ custom_hooks=[SegVisHook('data/CamVid')],
+ default_hooks=dict(checkpoint=dict(type='CheckpointHook', interval=1)),
+)
+runner.train()
+```
+
+Ķ«Łń╗āÕ«īµłÉÕÉÄ’╝īõĮĀÕÅ»õ╗źÕ£© `./work_dir/{timestamp}/vis_data` µ¢ćõ╗ČÕż╣õĖŁµēŠÕł░ÕÅ»Ķ¦åÕī¢ń╗ōµ×£’╝īÕ”éõĖŗÕøŠµēĆńż║’╝Ü
+
+
+
+
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/transform.md b/internlm_langchain/knowledge_base/MMEngine/content/transform.md
new file mode 100644
index 00000000..c98ce710
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/transform.md
@@ -0,0 +1,151 @@
+# µĢ░µŹ«ÕÅśµŹóń▒╗ńÜäĶ┐üń¦╗
+
+## ń«Ćõ╗ŗ
+
+Õ£© TorchVision ńÜäµĢ░µŹ«ÕÅśµŹóń▒╗µÄźÕÅŻń║”Õ«ÜõĖŁ’╝īµĢ░µŹ«ÕÅśµŹóń▒╗ķ£ĆĶ”üÕ«×ńÄ░ `__call__` µ¢╣µ│Ģ’╝īĶĆīÕ£© OpenMMLab 1.0 ńÜäµÄźÕÅŻń║”Õ«ÜõĖŁ’╝īĶ┐øõĖƵŁźĶ”üµ▒é
+`__call__` µ¢╣µ│ĢńÜäĶŠōÕć║Õ║öÕĮōµś»õĖĆõĖ¬ÕŁŚÕģĖ’╝īÕ£©ÕÉäń¦ŹµĢ░µŹ«ÕÅśµŹóõĖŁÕ»╣Ķ┐ÖõĖ¬ÕŁŚÕģĖĶ┐øĶĪīÕó×ÕłĀµ¤źµö╣ŃĆéÕ£© OpenMMLab 2.0 õĖŁ’╝īõĖ║õ║åµÅÉÕŹćÕÉÄń╗ŁńÜäÕÅ»µē®Õ▒ĢµĆ¦’╝īµłæõ╗¼Õ░åÕĤÕģłńÜä `__call__` µ¢╣µ│ĢĶ┐üń¦╗õĖ║ `transform` µ¢╣µ│Ģ’╝īÕ╣ČĶ”üµ▒éµĢ░µŹ«ÕÅśµŹóń▒╗Õ║öÕĮōń╗¦µē┐
+[mmcv.transforms.BaseTransform](mmcv.transforms.BaseTransform)ŃĆéÕģĘõĮōÕ”éõĮĢÕ«×ńÄ░õĖĆõĖ¬µĢ░µŹ«ÕÅśµŹóń▒╗’╝īÕÅ»õ╗źÕÅéĶ¦ü[µ¢ćµĪŻ](../advanced_tutorials/data_transform.md)ŃĆé
+
+ńö▒õ║ÄÕ£©µŁżµ¼Īµø┤µ¢░õĖŁ’╝īµłæõ╗¼Õ░åķā©ÕłåÕģ▒ńö©ńÜäµĢ░µŹ«ÕÅśµŹóń▒╗ń╗¤õĖĆĶ┐üń¦╗Ķć│ MMCV õĖŁ’╝īÕøĀµŁżµ£¼µ¢ćÕ░åõ╝ÜÕ»╣µ»öĶ┐Öõ║øµĢ░µŹ«ÕÅśµŹóÕ£©µŚ¦ńēłµ£¼’╝ł[MMClassification v0.23.2](https://github.com/open-mmlab/mmclassification/tree/v0.23.2)ŃĆü[MMDetection v2.25.1](https://github.com/open-mmlab/mmdetection/tree/v2.25.1)’╝ēÕÆīµ¢░ńēłµ£¼’╝ł[MMCV v2.0.0rc0](https://github.com/open-mmlab/mmcv/tree/2.x)’╝ēõĖŁńÜäÕŖ¤ĶāĮŃĆüńö©µ│ĢÕÆīÕ«×ńÄ░õĖŖńÜäÕĘ«Õ╝éŃĆé
+
+## ÕŖ¤ĶāĮÕĘ«Õ╝é
+
+
+
+
+
+## Õ«×ńÄ░ÕĘ«Õ╝é
+
+õ╗ź `RandomFlip` õĖ║õŠŗ’╝īMMCV ńÜä [RandomFlip](https://github.com/open-mmlab/mmcv/blob/5947178e855c23eea6103b1d70e1f8027f7b2ca8/mmcv/transforms/processing.py#L985) ńøĖµ»öµŚ¦ńēł MMDetection ńÜä [RandomFlip](https://github.com/open-mmlab/mmdetection/blob/3b72b12fe9b14de906d1363982b9fba05e7d47c1/mmdet/datasets/pipelines/transforms.py#L333)’╝īķ£ĆĶ”üń╗¦µē┐ `BaseTransfrom`’╝īÕ░åÕŖ¤ĶāĮÕ«×ńÄ░µöŠÕ£© `transforms` µ¢╣µ│Ģ’╝īÕ╣ČÕ░åńö¤µłÉķÜŵ£║ń╗ōµ×£ńÜäķā©ÕłåµöŠÕ£©ÕŹĢńŗ¼ńÜäµ¢╣µ│ĢõĖŁ’╝īńö© `cache_randomness` ÕīģĶŻģŃĆéµ£ēÕģ│ķÜŵ£║µ¢╣µ│ĢńÜäÕīģĶŻģńøĖÕģ│ÕŖ¤ĶāĮ’╝īÕÅéĶ¦ü[ńøĖÕģ│µ¢ćµĪŻ](TODO)ŃĆé
+
+- MMDetection (µŚ¦’╝ē
+
+```python
+class RandomFlip:
+ def __call__(self, results):
+ """Ķ░āńö©µŚČĶ┐øĶĪīķÜŵ£║ń┐╗ĶĮ¼"""
+ ...
+ # ķÜŵ£║ķĆēµŗ®ń┐╗ĶĮ¼µ¢╣ÕÉæ
+ cur_dir = np.random.choice(direction_list, p=flip_ratio_list)
+ ...
+ return results
+```
+
+- MMCV
+
+```python
+class RandomFlip(BaseTransfrom):
+ def transform(self, results):
+ """Ķ░āńö©µŚČĶ┐øĶĪīķÜŵ£║ń┐╗ĶĮ¼"""
+ ...
+ cur_dir = self._random_direction()
+ ...
+ return results
+
+ @cache_randomness
+ def _random_direction(self):
+ """ķÜŵ£║ķĆēµŗ®ń┐╗ĶĮ¼µ¢╣ÕÉæ"""
+ ...
+ return np.random.choice(direction_list, p=flip_ratio_list)
+```
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/visualization.md b/internlm_langchain/knowledge_base/MMEngine/content/visualization.md
new file mode 100644
index 00000000..ecc8dbf1
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/visualization.md
@@ -0,0 +1,417 @@
+# ÕÅ»Ķ¦åÕī¢
+
+ÕÅ»Ķ¦åÕī¢ÕÅ»õ╗źń╗ÖµĘ▒Õ║”ÕŁ”õ╣ĀńÜ䵩ĪÕ×ŗĶ«Łń╗āÕÆīµĄŗĶ»ĢĶ┐ćń©ŗµÅÉõŠøńø┤Ķ¦éĶ¦ŻķćŖŃĆé
+
+MMEngine µÅÉõŠøõ║å `Visualizer` ÕÅ»Ķ¦åÕī¢ÕÖ©ńö©õ╗źÕÅ»Ķ¦åÕī¢ÕÆīÕŁśÕ驵©ĪÕ×ŗĶ«Łń╗āÕÆīµĄŗĶ»ĢĶ┐ćń©ŗõĖŁńÜäńŖȵĆüõ╗źÕÅŖõĖŁķŚ┤ń╗ōµ×£’╝īÕģĘÕżćÕ”éõĖŗÕŖ¤ĶāĮ’╝Ü
+
+- µö»µīüÕ¤║ńĪĆń╗śÕøŠµÄźÕÅŻõ╗źÕÅŖńē╣ÕŠüÕøŠÕÅ»Ķ¦åÕī¢
+- µö»µīüµ£¼Õ£░ŃĆüTensorBoard õ╗źÕÅŖ WandB ńŁēÕżÜń¦ŹÕÉÄń½»’╝īÕÅ»õ╗źÕ░åĶ«Łń╗āńŖȵĆüõŠŗÕ”é loss ŃĆülr µł¢ĶĆģµĆ¦ĶāĮĶ»äõ╝░µīćµĀćõ╗źÕÅŖÕÅ»Ķ¦åÕī¢ńÜäń╗ōµ×£ÕåÖÕģźµīćÕ«ÜńÜäÕŹĢõĖƵł¢ÕżÜõĖ¬ÕÉÄń½»
+- ÕģüĶ«ĖÕ£©õ╗ŻńĀüÕ║ōõ╗╗µäÅõĮŹńĮ«Ķ░āńö©’╝īÕ»╣õ╗╗µäÅõĮŹńĮ«ńÜäńē╣ÕŠüŃĆüÕøŠÕāÅÕÆīńŖȵĆüńŁēĶ┐øĶĪīÕÅ»Ķ¦åÕī¢ÕÆīÕŁśÕé©ŃĆé
+
+## Õ¤║ńĪĆń╗śÕłČµÄźÕÅŻ
+
+ÕÅ»Ķ¦åÕī¢ÕÖ©µÅÉõŠøõ║åÕĖĖńö©Õ»╣Ķ▒ĪńÜäń╗śÕłČµÄźÕÅŻ’╝īõŠŗÕ”éń╗śÕłČ**µŻĆµĄŗµĪåŃĆüńé╣ŃĆüµ¢ćµ£¼ŃĆüń║┐ŃĆüÕ£åŃĆüÕżÜĶŠ╣ÕĮóÕÆīõ║īÕĆ╝µÄ®ńĀü**ŃĆéĶ┐Öõ║øÕ¤║ńĪĆ API µö»µīüõ╗źõĖŗńē╣µĆ¦’╝Ü
+
+- ÕÅ»õ╗źÕżÜµ¼ĪĶ░āńö©’╝īÕ«×ńÄ░ÕÅĀÕŖĀń╗śÕłČķ£Ćµ▒é
+- ÕØćµö»µīüÕżÜĶŠōÕģź’╝īķÖżõ║åĶ”üµ▒éµ¢ćµ£¼ĶŠōÕģźńÜäń╗śÕłČµÄźÕÅŻÕż¢’╝īÕģČõĮֵğÕÅŻÕÉīµŚČµö»µīü Tensor õ╗źÕÅŖ Numpy array ńÜäĶŠōÕģź
+
+ÕĖĖĶ¦üńö©µ│ĢÕ”éõĖŗ’╝Ü
+
+(1) ń╗śÕłČµŻĆµĄŗµĪåŃĆüµÄ®ńĀüÕÆīµ¢ćµ£¼ńŁē
+
+```python
+import torch
+import mmcv
+from mmengine.visualization import Visualizer
+
+# https://raw.githubusercontent.com/open-mmlab/mmengine/main/docs/zh_cn/_static/image/cat_and_dog.png
+image = mmcv.imread('docs/en/_static/image/cat_and_dog.png',
+ channel_order='rgb')
+visualizer = Visualizer(image=image)
+# ń╗śÕłČÕŹĢõĖ¬µŻĆµĄŗµĪå, xyxy µĀ╝Õ╝Å
+visualizer.draw_bboxes(torch.tensor([72, 13, 179, 147]))
+# ń╗śÕłČÕżÜõĖ¬µŻĆµĄŗµĪå
+visualizer.draw_bboxes(torch.tensor([[33, 120, 209, 220], [72, 13, 179, 147]]))
+visualizer.show()
+```
+
+
+```
+
+Notes:
+1. The order of bbox labels accords with the order of entry names;
+2. In bbox location, "x_1" and "y_1" represent the upper left point coordinate of bounding box, "x_2" and "y_2" represent the lower right point coordinate of bounding box. Bounding box locations are listed in the order of [x_1, y_1, x_2, y_2].
+
+
+## LANDMARK LABELS
+
+list_landmarks_consumer2shop.txt
+
+```sh
+First Row: number of images
+Second Row: entry names
+Rest of the Rows: [ , ... ]
+```
+
+Notes:
+1. The order of landmark labels accords with the order of entry names;
+2. In clothes type, "1" represents upper-body clothes, "2" represents lower-body clothes, "3" represents full-body clothes. Upper-body clothes possess six fahsion landmarks, lower-body clothes possess four fashion landmarks, full-body clothes possess eight fashion landmarks;
+3. In variation type, "1" represents normal pose, "2" represents medium pose, "3" represents large pose, "4" represents medium zoom-in, "5" represents large zoom-in;
+4. In landmark visibility state, "0" represents visible, "1" represents invisible/occluded, "2" represents truncated/cut-off;
+5. For upper-body clothes, landmark annotations are listed in the order of ["left collar", "right collar", "left sleeve", "right sleeve", "left hem", "right hem"]; For lower-body clothes, landmark annotations are listed in the order of ["left waistline", "right waistline", "left hem", "right hem"]; For upper-body clothes, landmark annotations are listed in the order of ["left collar", "right collar", "left sleeve", "right sleeve", "left waistline", "right waistline", "left hem", "right hem"].
+
+
+## CATEGORY LABELS
+
+list_category_cloth.txt
+
+```sh
+First Row: number of categories
+Second Row: entry names
+Rest of the Rows:
+```
+
+list_category_img.txt
+
+```sh
+First Row: number of images
+Second Row: entry names
+Rest of the Rows:
+```
+
+Notes:
+1. In category type, "1" represents upper-body clothes, "2" represents lower-body clothes, "3" represents full-body clothes;
+2. The order of category labels accords with the order of category names;
+3. In category labels, the number represents the category id in category names;
+4. For the clothing categories, "Cape", "Nightdress", "Shirtdress" and "Sundress" have been merged into "Dress";
+5. Category prediction is treated as a 1-of-K classification problem.
+
+
+## ATTRIBUTE LABELS
+
+list_attr_cloth.txt
+
+```sh
+First Row: number of attributes
+Second Row: entry names
+Rest of the Rows:
+```
+
+list_attr_img.txt
+
+```sh
+First Row: number of images
+Second Row: entry names
+Rest of the Rows:
+```
+
+Notes:
+1. In attribute type, "1" represents texture-related attributes, "2" represents fabric-related attributes, "3" represents shape-related attributes, "4" represents part-related attributes, "5" represents style-related attributes;
+2. The order of attribute labels accords with the order of attribute names;
+3. In attribute labels, "1" represents positive while "-1" represents negative, '0' represents unknown;
+4. Attribute prediction is treated as a multi-label tagging problem.
+
+
+## EVALUATION PARTITIONS
+
+list_eval_partition.txt
+
+```sh
+First Row: number of images
+Second Row: entry names
+Rest of the Rows:
+```
+
+Notes:
+1. In evaluation status, "train" represents training image, "val" represents validation image, "test" represents testing image;
+2. Please refer to the paper "DeepFashion: Powering Robust Clothes Recognition and Retrieval with Rich Annotations" for more details.
diff --git a/internlm_langchain/knowledge_base/MMFashion/content/CONSUMER_TO_SHOP_DATASET.md b/internlm_langchain/knowledge_base/MMFashion/content/CONSUMER_TO_SHOP_DATASET.md
new file mode 100644
index 00000000..b59e52aa
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMFashion/content/CONSUMER_TO_SHOP_DATASET.md
@@ -0,0 +1,134 @@
+# ConsumerToShopDataset
+
+- Annotations (Anno/)
+
+ - Attribute Annotations (list_attr_cloth.txt & list_attr_type.txt & list_attr_items.txt)
+
+ clothing attribute labels. See ATTRIBUTE LABELS section below for more info.
+
+ - Bounding Box Annotations (list_bbox_consumer2shop.txt)
+
+ bounding box labels. See BBOX LABELS section below for more info.
+
+ - Item Annotations (list_item_consumer2shop.txt)
+
+ item labels. See ITEM LABELS section below for more info.
+
+ - Fashion Landmark Annotations (list_landmarks_consumer2shop.txt)
+
+ fashion landmark labels. See LANDMARK LABELS section below for more info.
+
+- Images (Img/)
+
+ consumer-to-shop clothes images. See IMAGE section below for more info.
+
+- Evaluation Partitions (Eval/list_eval_partition.txt)
+
+ image pair names for training, validation and testing set respectively. See EVALUATION PARTITIONS section below for more info.
+
+
+## IMAGE
+
+*.jpg
+
+format: JPG
+
+Notes:
+1. The long side of images are resized to 300;
+2. The aspect ratios of original images are kept unchanged.
+
+
+## BBOX LABELS
+
+list_bbox_consumer2shop.txt
+
+```sh
+First Row: number of images
+Second Row: entry names
+Rest of the Rows:
+```
+
+Notes:
+1. The order of bbox labels accords with the order of entry names;
+2. In clothes type, "1" represents upper-body clothes, "2" represents lower-body clothes, "3" represents full-body clothes;
+3. In source type, "1" represents shop image, "2" represents consumer image;
+4. In bbox location, "x_1" and "y_1" represent the upper left point coordinate of bounding box, "x_2" and "y_2" represent the lower right point coordinate of bounding box. Bounding box locations are listed in the order of [x_1, y_1, x_2, y_2].
+
+
+## LANDMARK LABELS
+
+list_landmarks_consumer2shop.txt
+
+```sh
+First Row: number of images
+Second Row: entry names
+Rest of the Rows: [ , ... ]
+```
+
+Notes:
+1. The order of landmark labels accords with the order of entry names;
+2. In clothes type, "1" represents upper-body clothes, "2" represents lower-body clothes, "3" represents full-body clothes. Upper-body clothes possess six fahsion landmarks, lower-body clothes possess four fashion landmarks, full-body clothes possess eight fashion landmarks;
+3. In variation type, "1" represents normal pose, "2" represents medium pose, "3" represents large pose, "4" represents medium zoom-in, "5" represents large zoom-in;
+4. In landmark visibility state, "0" represents visible, "1" represents invisible/occluded, "2" represents truncated/cut-off;
+5. For upper-body clothes, landmark annotations are listed in the order of ["left collar", "right collar", "left sleeve", "right sleeve", "left hem", "right hem"]; For lower-body clothes, landmark annotations are listed in the order of ["left waistline", "right waistline", "left hem", "right hem"]; For upper-body clothes, landmark annotations are listed in the order of ["left collar", "right collar", "left sleeve", "right sleeve", "left waistline", "right waistline", "left hem", "right hem"].
+
+
+## ITEM LABELS
+
+list_items_consumer2shop.txt
+
+First Row: number of items
+
+Rest of the Rows: -
+
+Notes:
+1. Please refer to the paper "DeepFashion: Powering Robust Clothes Recognition and Retrieval with Rich Annotations" for more details.
+
+
+## ATTRIBUTE LABELS
+
+list_attr_cloth.txt
+
+```sh
+First Row: number of attributes
+Second Row: entry names
+Rest of the Rows:
+```
+
+list_attr_type.txt
+
+```sh
+First Row: number of attribute types
+Second Row: entry names
+Rest of the Rows:
+```
+
+list_attr_items.txt
+
+```sh
+First Row: number of items
+Second Row: entry names
+Rest of the Rows: -
+```
+
+Notes:
+1. The order of attribute labels accords with the order of attribute names;
+2. In attribute labels, "1" represents positive while "-1" represents negative, '0' represents unknown;
+3. Attribute prediction is treated as a multi-label tagging problem.
+
+
+## EVALUATION PARTITIONS
+
+list_eval_partition.txt
+
+```sh
+First Row: number of images
+Second Row: entry names
+Rest of the Rows: -
+```
+
+Notes:
+1. In evaluation status, "train" represents training image, "val" represents validation image, "test" represents testing image;
+2. The gallery set here are all the shop images in "val + test" set;
+3. Items of clothes images are NOT overlapped within this dataset partition;
+4. Please refer to the paper "DeepFashion: Powering Robust Clothes Recognition and Retrieval with Rich Annotations" for more details.
diff --git a/internlm_langchain/knowledge_base/MMFashion/content/CONTRIBUTING.md b/internlm_langchain/knowledge_base/MMFashion/content/CONTRIBUTING.md
new file mode 100644
index 00000000..8ce4d8e0
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMFashion/content/CONTRIBUTING.md
@@ -0,0 +1,31 @@
+# Contributing to mmfashion
+
+All kinds of contributions are welcome, including but not limited to the following.
+
+- Fixes (typo, bugs)
+- New features and components
+
+## Workflow
+
+1. fork and pull the latest mmfashion
+2. checkout a new branch (do not use master branch for PRs)
+3. commit your changes
+4. create a PR
+
+Note
+- If you plan to add some new features that involve large changes, it is encouraged to open an [issue](https://github.com/open-mmlab/mmfashion/issues) for discussion first.
+
+## Code style
+
+### Python
+
+We adopt [PEP8](https://www.python.org/dev/peps/pep-0008/) as the preferred code style.
+
+We use the following tools for linting and formatting:
+- [flake8](http://flake8.pycqa.org/en/latest/): linter
+- [yapf](https://github.com/google/yapf): formatter
+- [isort](https://github.com/timothycrosley/isort): sort imports
+
+Style configurations of yapf and isort can be found in [.style.yapf](.style.yapf) and [.isort.cfg](.isort.cfg).
+
+>Before you create a PR, make sure that your code lints and is formatted by yapf.
diff --git a/internlm_langchain/knowledge_base/MMFashion/content/DATA_PREPARATION.md b/internlm_langchain/knowledge_base/MMFashion/content/DATA_PREPARATION.md
new file mode 100644
index 00000000..d718d687
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMFashion/content/DATA_PREPARATION.md
@@ -0,0 +1,227 @@
+# Data Preparation
+
+1. [DeepFashion - Category and Attribute Prediction Benchmark](http://mmlab.ie.cuhk.edu.hk/projects/DeepFashion/AttributePrediction.html)
+
+2. [DeepFashion - In-Shop Clothes Retrieval Benchmark](http://mmlab.ie.cuhk.edu.hk/projects/DeepFashion/InShopRetrieval.html)
+
+4. [DeepFashion - Consumer-to-Shop Clothes Retrieval Benchmark](http://mmlab.ie.cuhk.edu.hk/projects/DeepFashion/Consumer2ShopRetrieval.html)
+
+4. [DeepFashion - Fashion Landmark Detection Benchmark](http://mmlab.ie.cuhk.edu.hk/projects/DeepFashion/LandmarkDetection.html)
+
+5. [Polyvore Outfits](https://drive.google.com/file/d/13-J4fAPZahauaGycw3j_YvbAHO7tOTW5/view?usp=sharing)
+
+6. [VTON](https://drive.google.com/file/d/1MxCUvKxejnwWnoZ-KoCyMCXo3TLhRuTo/view)
+
+To use the DeepFashion dataset you need to first download it to 'data/' , then follow these steps to re-organize the dataset.
+
+```sh
+cd data/
+mv Category\ and\ Attribute\ Prediction\ Benchmark Attr_Predict
+mv In-shop\ Clothes\ Retrieval\ Benchmark In-shop
+mv Consumer-to-shop\ Clothes\ Retrieval\ Benchmark Consumer_to_shop
+mv Fashion\ Landmark\ Detection\ Benchmark/ Landmark_Detect
+python prepare_attr_pred.py
+python prepare_in_shop.py
+python prepare_consumer_to_shop.py
+python prepare_landmark_detect.py
+```
+
+The directory should be like this:
+
+```sh
+mmfashion
+Ōö£ŌöĆŌöĆ mmfashion
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+Ōö£ŌöĆŌöĆ data
+Ōöé Ōö£ŌöĆŌöĆ Attr_Predict
+Ōöé Ōöé Ōö£ŌöĆŌöĆ Anno_coarse
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ train.txt
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ test.txt
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ val.txt
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ train_attr.txt
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ ...
+Ōöé Ōöé Ōö£ŌöĆŌöĆ Anno_fine
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ train.txt
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ test.txt
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ val.txt
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ ...
+Ōöé Ōöé Ōö£ŌöĆŌöĆ Img
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ img
+Ōöé Ōöé Ōö£ŌöĆŌöĆ Eval
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ ...
+Ōöé Ōö£ŌöĆŌöĆ In-shop
+Ōöé Ōöé Ōö£ŌöĆŌöĆ train.txt
+Ōöé Ōöé Ōö£ŌöĆŌöĆ query.txt
+Ōöé Ōöé Ōö£ŌöĆŌöĆ gallery.txt
+Ōöé Ōöé Ōö£ŌöĆŌöĆ train_labels.txt
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ ...
+```
+
+## Prepare an AttrDataset
+
+**Updated**: We re-labeled a more accurate attribute prediction dataset, please [download](https://drive.google.com/drive/folders/19J-FY5NY7s91SiHpQQBo2ad3xjIB42iN?usp=sharing) them.
+
+The file tree should be like this:
+
+```sh
+Attr_Predict
+Ōö£ŌöĆŌöĆ Anno_fine
+Ōöé Ōö£ŌöĆŌöĆ list_attr_cloth.txt
+Ōöé Ōö£ŌöĆŌöĆ list_attr_img.txt
+Ōöé Ōö£ŌöĆŌöĆ list_bbox.txt
+Ōöé Ōö£ŌöĆŌöĆ list_category_cloth.txt
+Ōöé Ōö£ŌöĆŌöĆ list_category_img.txt
+Ōöé Ōö£ŌöĆŌöĆ list_landmarks.txt
+Ōöé Ōö£ŌöĆŌöĆ ...
+Ōö£ŌöĆŌöĆ Anno_coarse
+Ōö£ŌöĆŌöĆ Eval
+Ōöé ŌööŌöĆŌöĆ list_eval_partition.txt
+ŌööŌöĆŌöĆ Img
+ Ōö£ŌöĆŌöĆ XXX.jpg
+ ŌööŌöĆŌöĆ ...
+```
+
+Note that if you use "Anno_fine" that contains 26 better-labeled attributes, nothing else need to be done.
+
+If you use run "Anno_coarse" that contains 1000 roughly labeled attributes,
+ first run the following script to re-organize them.
+ `python prepare_attr_pred.py`
+
+Please refer to [dataset/ATTR_DATASET.md](dataset/ATTR_DATASET.md) for more info.
+
+
+## Prepare an InShopDataset
+We add segmentation annotations for "Fashion Parsing and Segmentation" task. Please download the updated data.
+The file tree should be like this:
+
+```sh
+In-shop
+Ōö£ŌöĆŌöĆ Anno
+Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ segmentation
+Ōöé┬Ā┬Ā | Ōö£ŌöĆŌöĆ DeepFashion_segmentation_train.json
+Ōöé┬Ā┬Ā | Ōö£ŌöĆŌöĆ DeepFashion_segmentation_query.json
+Ōöé┬Ā┬Ā | Ōö£ŌöĆŌöĆ DeepFashion_segmentation_gallery.json
+Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ list_bbox_inshop.txt
+Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ list_description_inshop.json
+Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ list_item_inshop.txt
+Ōöé┬Ā┬Ā ŌööŌöĆŌöĆ list_landmarks_inshop.txt
+Ōö£ŌöĆŌöĆ Eval
+Ōöé ŌööŌöĆŌöĆ list_eval_partition.txt
+ŌööŌöĆŌöĆ Img
+ Ōö£ŌöĆŌöĆ img
+ | Ōö£ŌöĆŌöĆXXX.jpg
+ Ōö£ŌöĆŌöĆ img_highres
+ ŌööŌöĆŌöĆ Ōö£ŌöĆŌöĆXXX.jpg
+
+```
+
+Then run `python prepare_in_shop.py` to re-organize the dataset.
+
+Please refer to [dataset/IN_SHOP_DATASET.md](dataset/IN_SHOP_DATASET.md) for more info.
+
+
+## Prepare a ConsumerToShopDataset
+
+The file tree should be like this:
+
+```sh
+Consumer_to_shop
+Ōö£ŌöĆŌöĆ Anno
+Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ list_attr_cloth.txt
+Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ list_attr_items.txt
+Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ list_attr_type.txt
+Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ list_bbox_consumer2shop.txt
+Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ list_item_consumer2shop.txt
+Ōöé┬Ā┬Ā ŌööŌöĆŌöĆ list_landmarks_consumer2shop.txt
+Ōö£ŌöĆŌöĆ Eval
+Ōöé ŌööŌöĆŌöĆ list_eval_partition.txt
+ŌööŌöĆŌöĆ Img
+ Ōö£ŌöĆŌöĆ XXX.jpg
+ ŌööŌöĆŌöĆ ...
+```
+
+Then run `python prepare_consumer_to_shop.py` to re-organize the dataset.
+
+Please refer to [dataset/CONSUMER_TO_SHOP_DATASET.md](dataset/CONSUMER_TO_SHOP_DATASET.md) for more info.
+
+
+## Prepare a LandmarkDetectDataset
+
+The file tree should be like this:
+
+```sh
+Landmark_Detect
+Ōö£ŌöĆŌöĆ Anno
+Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ list_bbox.txt
+Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ list_joints.txt
+Ōöé┬Ā┬Ā ŌööŌöĆŌöĆ list_landmarks.txt
+Ōö£ŌöĆŌöĆ Eval
+Ōöé ŌööŌöĆŌöĆ list_eval_partition.txt
+ŌööŌöĆŌöĆ Img
+ Ōö£ŌöĆŌöĆ XXX.jpg
+ ŌööŌöĆŌöĆ ...
+```
+
+Then run `python prepare_landmark_detect.py` to re-organize the dataset.
+
+Please refer to [dataset/LANDMARK_DETECT_DATASET.md](dataset/LANDMARK_DETECT_DATASET.md) for more info.
+
+
+## Prepare Polyvore-Outfit dataset
+Polyvore dataset is widely used for learning fashion compatibility, containing rich multimodel information like
+images and descriptions of fashion items, number of likes of the outfit, etc.
+It is firstly collected by [Maryland](https://arxiv.org/pdf/1707.05691.pdf).
+Here we use a better sorted and grouped version from [UIUC](https://arxiv.org/pdf/1803.09196.pdf).
+
+Download [Polyvore](https://drive.google.com/file/d/13-J4fAPZahauaGycw3j_YvbAHO7tOTW5/view?usp=sharing)
+and put it in the `data/`
+
+The file tree should be like this:
+
+```sh
+Polyvore
+Ōö£ŌöĆŌöĆ disjoint
+Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ compatibility_test.txt
+Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ compatibility_train.txt
+Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ fill_in_blank_test.json
+| ŌööŌöĆŌöĆ ...
+Ōö£ŌöĆŌöĆ nondisjoint
+Ōöé ŌööŌöĆŌöĆ ...
+ŌööŌöĆŌöĆ images
+Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ XXX.jpg
+Ōö£ŌöĆŌöĆ categories.csv
+Ōö£ŌöĆŌöĆ polyvore_item_metadata.json
+Ōö£ŌöĆŌöĆ polyvore_outfit_titles.json
+```
+
+
+## Prepare VTON dataset
+
+VTON dataset is used for virtual try-on task.
+It is first collected by [Han](https://arxiv.org/abs/1711.08447), containing around 19,000 front-view woman and top clothing image pairs.
+Here, we use a better sorted and grouped version from [Wang](https://arxiv.org/abs/1807.07688).
+
+Download [VTON](https://drive.google.com/file/d/1MxCUvKxejnwWnoZ-KoCyMCXo3TLhRuTo/view)
+and put it in the `data/`
+
+The file tree should be like this:
+
+```sh
+VTON
+Ōö£ŌöĆŌöĆ vton_resize
+Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ train
+Ōöé┬Ā┬Ā | Ōö£ŌöĆŌöĆ cloth
+| | Ōö£ŌöĆŌöĆ cloth-mask
+| | Ōö£ŌöĆŌöĆ image
+| | Ōö£ŌöĆŌöĆ image-parse
+| | Ōö£ŌöĆŌöĆ pose
+| | Ōö£ŌöĆŌöĆ train-pairs.txt
+ŌööŌöĆŌöĆ Ōö£ŌöĆŌöĆ test
+ ┬Ā┬Ā Ōö£ŌöĆŌöĆ cloth
+ Ōö£ŌöĆŌöĆ cloth-mask
+ Ōö£ŌöĆŌöĆ image
+ Ōö£ŌöĆŌöĆ image-parse
+ Ōö£ŌöĆŌöĆ pose
+ ŌööŌöĆŌöĆ test_pairs.txt
+```
diff --git a/internlm_langchain/knowledge_base/MMFashion/content/FASHION_COMPATIBILITY_DATASET.md b/internlm_langchain/knowledge_base/MMFashion/content/FASHION_COMPATIBILITY_DATASET.md
new file mode 100644
index 00000000..e54f1fd0
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMFashion/content/FASHION_COMPATIBILITY_DATASET.md
@@ -0,0 +1,53 @@
+#PolyvoreOutfitDataset
+
+Polyvore Dataset is widely used for learning fashion compatibility.
+There are several different split versions of this dataset. We deployed [Learning Type Aware Embeddings for Fashion Compatibility](https://arxiv.org/pdf/1803.09196.pdf) here.
+
+- Polyvore Outfits(Nondisjoint)
+
+ Outfits are split at random. The training dataset and testing dataset may have overlapped items(garments).
+
+- Polyvore Outfits(Disjoint)
+
+ The training set and testing/validation set have no overlapped items.
+
+## Annotations
+
+- train/test/valid.json
+
+ A list of outfits, their item_id and their ordering(index).
+
+- typespaces.p
+
+ A list of tuples(t1, t2), each of which identifies a type- specific embedding that compares items of type t1 to items of type t2.
+
+- train_hglmm_pca6000.txt
+
+ Each row contains 6001 comma separated values, where the first element is the label, the remaining 6000 dimensions are the PCA-reduced HGLMM fisher vectors (note: the "label" may also contain a comma).
+
+- compatibility_train/test/valid.txt
+
+ Fashion compatibility experiment data, where each row is an outfit sample. The first element of the outfit sample is the label (1/0 for positive/negative) and the remaining elements are item identifiers in that sample.
+
+- fill_in_blank_train/test/valid.json
+
+ Fill-in-the-blank experiment data, contains an array of dictionaries. These dictionaries contain the question/answer pairs, and also identifies the "index" of the item in the outfit in
+"blank_position". Since the set_id is used in the item identifiers, the correct answer can be determined by matching the set_id in the question
+elements with the set_id in the answers.
+
+
+##Images
+Images are stored by their item_id, which are organized in lists of outfits for each each version of the dataset.
+
+##Meta-Data
+- polyvore_item_metadata.json
+
+ It contains a dictionary where each key is an item_id, and the values are its associated meta-data labels.
+
+- polyvore_outfit_titles.json
+
+ It contains a dictionary where each key is a set_id and the values are its associated meta-data labels.
+
+- categories.csv
+
+ Each row contains three items: category_id, fine_grained category, semantic categroy.
diff --git a/internlm_langchain/knowledge_base/MMFashion/content/GETTING_STARTED.md b/internlm_langchain/knowledge_base/MMFashion/content/GETTING_STARTED.md
new file mode 100644
index 00000000..b830693f
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMFashion/content/GETTING_STARTED.md
@@ -0,0 +1,229 @@
+# Getting Started
+
+This page provides basic tutorials about the usage of `MMFashion`.
+
+
+## Inference with pretrained models
+
+We provide testing scripts to evaluate a whole dataset (Category and Attribute Prediction Benchmark, In-Shop Clothes Retrieval Benchmark, Fashion Landmark Detection Benchmark etc.),
+and also some high-level apis for easier integration to other projects.
+
+### Test an image
+
+You can use the following commands to test an image.
+
+```sh
+python demo/test_*.py --input ${INPUT_IMAGE_FILE}
+```
+
+Examples:
+
+Assume that you have already downloaded the checkpoints to `checkpoints/`.
+
+1. Test an attribute predictor(coarse prediction).
+
+ ```sh
+ # Prepare `Anno/list_attr_cloth.txt` which is specified in `configs/attribute_predict/global_predictor_vgg_attr.py`
+ python demo/test_attr_predictor.py \
+ --input demo/imgs/attr_pred_demo1.jpg
+ ```
+
+ Test a category and attribute predictor(**more accurate** prediction).
+
+ ```sh
+ # Prepare `Anno/list_attr_cloth.txt` which is specified in `configs/category_attribute_predict/global_predictor_vgg_attr.py`
+ python demo/test_cate_attr_predictor.py \
+ --input demo/imgs/attr_pred_demo1.jpg
+ ```
+
+2. Test an in-shop / Consumer-to_shop clothes retriever.
+
+ ```sh
+ # Prepare the gallery data which is specified in `configs/retriever_in_shop/global_retriever_vgg_loss_id.py`
+ python demo/test_retriever.py \
+ --input demo/imgs/retrieve_demo1.jpg
+ ```
+
+3. Test a landmark detector.
+
+ ```sh
+ python demo/test_landmark_detector.py \
+ --input demo/imgs/04_1_front.jpg
+ ```
+
+4. Test a fashion-compatibility predictor.
+
+ ```sh
+ python demo/test_fashion_recommender.py \
+ --input_dir demo/imgs/fashion_compatibility/set2
+ ```
+
+
+### Test a dataset
+
+You can use the following commands to test a dataset.
+
+```sh
+python tools/test_*.py --config ${CONFIG_FILE} --checkpoint ${CHECKPOINT_FILE}
+```
+
+Examples:
+
+Assume that you have already downloaded the checkpoints to `checkpoints/` and prepared the dataset in `data/`.
+
+1. Test an attribute predictor.
+
+ ```sh
+ python tools/test_predictor.py \
+ --config configs/attribute_predict/roi_predictor_vgg_attr.py \
+ --checkpoint checkpoint/Predict/vgg/roi/latest.pth
+ ```
+
+ Test a category and attribute predictor.
+
+ ```
+ python test tools/test_cate_attr_predictor.py \
+ --config configs/category_attribute_predict/roi_predictor_vgg.py \
+ --checkpoint checkpoint/CateAttrPredict/vgg/roi/latest.pth
+ ```
+
+2. Test an in-shop / Consumer-to_shop clothes retriever.
+
+ ```sh
+ python tools/test_retriever.py \
+ --config configs/retriever_in_shop/roi_retriever_vgg.py \
+ --checkpoint checkpoint/Retrieve_in_shop/vgg/latest.pth
+ ```
+
+ ```sh
+ python tools/test_retriever.py \
+ --config configs/retriever_consumer_to_shop/roi_retriever_vgg.py \
+ --checkpoint checkpoint/Retrieve_consumer_to_shop/vgg/latest.pth
+ ```
+
+3. Test a landmark detector.
+
+ ```sh
+ python tools/test_landmark_detector.py \
+ --config configs/landmark_detect/landmark_detect_vgg.py
+ --checkpoint checkpoint/LandmarkDetect/vgg/latest.pth
+ ```
+
+4. Test a fashion-compatibility predictor.
+
+ ```sh
+ python tools/test_fashion_recommender.py \
+ --config configs/fashion_recommendation/type_aware_recommendation_polyvore_disjoint.py
+ --checkpoint checkpoint/FashionRecommend/TypeAware/latest.pth
+ ```
+
+
+6. Test a virtual try-on module.
+
+ Step 1, use the geometric matching module(GMM) to generate warp-cloth and warp-mask,
+ ```sh
+ python tools/test_virtual_tryon.py \
+ --config configs/virtual_tryon/cp_vton.py \
+ --stage GMM
+ ```
+
+ Step 2, use the tryon module(TOM) to generate the results.
+ The default result directory is `data/VTON/result`, you can modify the path in config file(line 103).
+ ```sh
+ python tools/test_virtual_tryon.py \
+ --config configs/virtual_tryon/cp_vton.py \
+ --stage TOM
+ ```
+
+
+
+## Train a model
+
+You can use the following commands to train a model.
+
+```sh
+python tools/train_*.py --config ${CONFIG_FILE}
+```
+
+Examples:
+
+1. Train an attribute predictor.
+
+ ```sh
+ python tools/train_predictor.py \
+ --config configs/attribute_predict/roi_predictor_vgg_attr.py
+ ```
+
+2. Train an in-shop clothes / Consumer-to-shop retriever.
+
+ ```sh
+ python tools/train_retriever.py \
+ --config configs/retriever_in_shop/roi_retriever_vgg.py
+ ```
+
+ ```sh
+ python tools/train_retriever.py \
+ --config configs/retriever_consumer_to_shop/roi_retriever_vgg.py
+ ```
+
+3. Train a landmark detector.
+
+ ```sh
+ python tools/train_landmark_detector.py \
+ --config configs/landmark_detect/landmark_detect_vgg.py
+ ```
+
+4. Train a fashion-compatibility predictor.
+
+ ```sh
+ python tools/train_fashion_recommender.py \
+ --config configs/fashion_recommendation/type_aware_recommendation_polyvore_disjoint.py
+ ```
+
+5. Train a fashion detector.
+
+ ```sh
+ python mmdetection/tools/train.py \
+ configs/fashion_parsing_segmentation/mask_rcnn_r50_fpn_1x.py
+ ```
+
+6. Train a virtual try-on module.
+
+ Step 1, train a geometric matching module(GMM)
+ ```sh
+ python tools/train_virtual_tryon.py \
+ --config configs/virtual_tryon/cp_vton.py \
+ --stage GMM
+ ```
+
+ After training GMM, you need to generate the training images which are required by Step 2.
+
+ **Note** that you need to modify the config file `configs/virtual_tryon/cp_vton.py` as follows,
+
+ Line 87 should be `datamode='train'`,
+
+ Line 89 should be `data_list='test_pairs.txt'`,
+
+ Line 93 should be `save_dir=os.path.join(data_root, 'vton_resize', 'train')`
+
+ Then,
+ ```sh
+ python tools/test_virtual_tryon.py \
+ --config configs/virtual_tryon/cp_vton.py \
+ --stage GMM
+ ```
+
+ Step 2, train a tryon module(TOM),
+ ```sh
+ python tools/train_virtual_tryon.py \
+ --config configs/virtual_tryon/cp_vton.py \
+ --stage TOM
+ ```
+
+
+
+## Use custom datasets
+
+The simplest way is to prepare your dataset to existing dataset formats (AttrDataset, InShopDataset, ConsumerToShopDataset or LandmarkDetectDataset).
+
+Please refer to [DATA_PREPARATION.md](DATA_PREPARATION.md) for the dataset specifics.
diff --git a/internlm_langchain/knowledge_base/MMFashion/content/IN_SHOP_DATASET.md b/internlm_langchain/knowledge_base/MMFashion/content/IN_SHOP_DATASET.md
new file mode 100644
index 00000000..2c3f0583
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMFashion/content/IN_SHOP_DATASET.md
@@ -0,0 +1,167 @@
+# InShopDataset
+
+- Annotations (Anno/)
+ - segmentation/
+ clothing semgentaion and detection annotations
+
+ - Attribute Annotations (list_attr_cloth.txt & list_attr_items.txt)
+
+ clothing attribute labels. See ATTRIBUTE LABELS section below for more info.
+
+ - Bounding Box Annotations (list_bbox_inshop.txt)
+
+ bounding box labels. See BBOX LABELS section below for more info.
+
+ - Description Annotations (list_description_inshop.json)
+
+ item descriptions. See DESCRIPTION LABELS section below for more info.
+
+ - Item Annotations (list_item_inshop.txt)
+
+ item labels. See ITEM LABELS section below for more info.
+
+ - Fashion Landmark Annotations (list_landmarks_inshop.txt)
+
+ fashion landmark labels. See LANDMARK LABELS section below for more info.
+
+- Images (Img/)
+
+ in-shop clothes images. See IMAGE section below for more info.
+
+- Evaluation Partitions (Eval/list_eval_partition.txt)
+
+ image names for training, validation and testing set respectively. See EVALUATION PARTITIONS section below for more info.
+
+
+## IMAGE
+
+For Fashion Retrieval task, use "img.zip"; for fashion parsing and segmentation task, use "img_highres.zip".
+*.jpg
+
+format: JPG
+
+Notes:
+1. Images are centered and resized to 256*256;
+2. The aspect ratios of original images are kept unchanged.
+
+
+## BBOX LABELS
+
+list_bbox_inshop.txt
+
+```sh
+First Row: number of images
+Second Row: entry names
+Rest of the Rows:
+```
+
+Notes:
+1. The order of bbox labels accords with the order of entry names;
+2. In clothes type, "1" represents upper-body clothes, "2" represents lower-body clothes, "3" represents full-body clothes;
+3. In pose type, "1" represents frontal view, "2" represents side view, "3" represents back view, "4" represents zoom-out view, "5" represents zoom-in view, "6" represents stand-alone view;
+4. In bbox location, "x_1" and "y_1" represent the upper left point coordinate of bounding box, "x_2" and "y_2" represent the lower right point coordinate of bounding box. Bounding box locations are listed in the order of [x_1, y_1, x_2, y_2].
+
+
+
+## LANDMARK LABELS
+
+list_landmarks_inshop.txt
+
+```sh
+First Row: number of images
+Second Row: entry names
+Rest of the Rows: [ , ... ]
+```
+
+Notes:
+1. The order of landmark labels accords with the order of entry names;
+2. In clothes type, "1" represents upper-body clothes, "2" represents lower-body clothes, "3" represents full-body clothes. Upper-body clothes possess six fahsion landmarks, lower-body clothes possess four fashion landmarks, full-body clothes possess eight fashion landmarks;
+3. In variation type, "1" represents normal pose, "2" represents medium pose, "3" represents large pose, "4" represents medium zoom-in, "5" represents large zoom-in;
+4. In landmark visibility state, "0" represents visible, "1" represents invisible/occluded, "2" represents truncated/cut-off;
+5. For upper-body clothes, landmark annotations are listed in the order of ["left collar", "right collar", "left sleeve", "right sleeve", "left hem", "right hem"]; For lower-body clothes, landmark annotations are listed in the order of ["left waistline", "right waistline", "left hem", "right hem"]; For upper-body clothes, landmark annotations are listed in the order of ["left collar", "right collar", "left sleeve", "right sleeve", "left waistline", "right waistline", "left hem", "right hem"].
+
+
+## COLOR MAPPING LABELS
+segmentation/img_highres_seg
+
+| Color(R-G-B) | Label |
+| :-------------------: | :-------------: |
+| 0-0-0 | background |
+| 255-250-250 | top |
+| 250-235-215 | skirt |
+| 70-130-180 | leggings |
+| 16-78-139 | dress |
+| 255-250-205 | outer |
+| 255-140-0 | pants |
+| 50-205-50 | bag |
+| 220-220-220 | neckwear |
+| 255-0-0 | headwear |
+| 127-255-212 | eyeglass |
+| 0-100-0 | belt |
+| 255-255-0 | footwear |
+| 211-211-211 | hair |
+| 144-238-144 | skin |
+| 245-222-179 | face |
+
+
+
+## ITEM LABELS
+
+list_item_inshop.txt
+
+First Row: number of items
+
+Rest of the Rows: -
+
+Notes:
+1. Please refer to the paper "DeepFashion: Powering Robust Clothes Recognition and Retrieval with Rich Annotations" for more details.
+
+
+## DESCRIPTION LABELS
+
+list_description_inshop.json
+
+Each Row:
-
-
-
+
+Notes:
+1. Please refer to the paper "DeepFashion: Powering Robust Clothes Recognition and Retrieval with Rich Annotations" for more details.
+
+
+## ATTRIBUTE LABELS
+
+list_attr_cloth.txt
+
+```sh
+First Row: number of attributes
+Second Row: entry names
+Rest of the Rows:
+```
+
+list_attr_items.txt
+
+```sh
+First Row: number of items
+Second Row: entry names
+Rest of the Rows: -
+```
+
+Notes:
+1. The order of attribute labels accords with the order of attribute names;
+2. In attribute labels, "1" represents positive while "-1" represents negative, '0' represents unknown;
+3. Attribute prediction is treated as a multi-label tagging problem.
+
+
+## EVALUATION PARTITIONS
+
+list_eval_partition.txt
+
+```sh
+First Row: number of images
+Second Row: entry names
+Rest of the Rows: -
+```
+
+Notes:
+1. In evaluation status, "train" represents training image, "query" represents query image, "gallery" represents gallery image;
+2. Items of clothes images are NOT overlapped within this dataset partition;
+3. Please refer to the paper "DeepFashion: Powering Robust Clothes Recognition and Retrieval with Rich Annotations" for more details.
diff --git a/internlm_langchain/knowledge_base/MMFashion/content/LANDMARK_DETECT_DATASET.md b/internlm_langchain/knowledge_base/MMFashion/content/LANDMARK_DETECT_DATASET.md
new file mode 100644
index 00000000..87c91d9b
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMFashion/content/LANDMARK_DETECT_DATASET.md
@@ -0,0 +1,99 @@
+# LandmarkDetectDataset
+
+- Annotations (Anno/)
+
+ - Bounding Box Annotations (list_bbox.txt)
+
+ bounding box labels. See BBOX LABELS section below for more info.
+
+ - Human Joint Annotations (list_joints.txt)
+
+ human joint labels. See JOINT LABELS section below for more info.
+
+ - Fashion Landmark Annotations (list_landmarks.txt)
+
+ fashion landmark labels. See LANDMARK LABELS section below for more info.
+
+- Images (Img/)
+
+ clothes images. See IMAGE section below for more info.
+
+- Evaluation Partitions (Eval/list_eval_partition.txt)
+
+ image names for training, validation and testing set respectively. See EVALUATION PARTITIONS section below for more info.
+
+
+## IMAGE
+
+*.jpg
+
+format: JPG
+
+Notes:
+1. The long side of images are resized to 512;
+2. The aspect ratios of original images are kept unchanged.
+
+
+## BBOX LABELS
+
+list_bbox.txt
+
+```sh
+First Row: number of images
+Second Row: entry names
+Rest of the Rows:
+```
+
+Notes:
+1. The order of bbox labels accords with the order of entry names;
+2. In bbox location, "x_1" and "y_1" represent the upper left point coordinate of bounding box, "x_2" and "y_2" represent the lower right point coordinate of bounding box. Bounding box locations are listed in the order of [x_1, y_1, x_2, y_2].
+
+
+## LANDMARK LABELS
+
+list_landmarks.txt
+
+```sh
+First Row: number of images
+Second Row: entry names
+Rest of the Rows: [ , ... ]
+```
+
+Notes:
+1. The order of landmark labels accords with the order of entry names;
+2. In clothes type, "1" represents upper-body clothes, "2" represents lower-body clothes, "3" represents full-body clothes. Upper-body clothes possess six fashion landmarks, lower-body clothes possess four fashion landmarks, full-body clothes possess eight fashion landmarks;
+3. In variation type, "1" represents normal pose, "2" represents medium pose, "3" represents large pose, "4" represents medium zoom-in, "5" represents large zoom-in;
+4. In landmark visibility state, "0" represents visible, "1" represents invisible/occluded, "2" represents truncated/cut-off;
+5. For upper-body clothes, landmark annotations are listed in the order of ["left collar", "right collar", "left sleeve", "right sleeve", "left hem", "right hem"]; For lower-body clothes, landmark annotations are listed in the order of ["left waistline", "right waistline", "left hem", "right hem"]; For upper-body clothes, landmark annotations are listed in the order of ["left collar", "right collar", "left sleeve", "right sleeve", "left waistline", "right waistline", "left hem", "right hem"].
+
+
+## JOINT LABELS
+
+list_joints.txt
+
+```sh
+First Row: number of images
+Second Row: entry names
+Rest of the Rows: [ , ... ]
+```
+
+Notes:
+1. The order of joint labels accords with the order of entry names. Overall there are fourteen human joints;
+2. In clothes type, "1" represents upper-body clothes, "2" represents lower-body clothes, "3" represents full-body clothes;
+3. In variation type, "1" represents normal pose, "2" represents medium pose, "3" represents large pose, "4" represents medium zoom-in, "5" represents large zoom-in;
+4. In landmark visibility state, "0" represents visible, "1" represents invisible.
+
+
+## EVALUATION PARTITIONS
+
+list_eval_partition.txt
+
+```sh
+First Row: number of images
+Second Row: entry names
+Rest of the Rows:
+```
+
+Notes:
+1. In evaluation status, "train" represents training image, "val" represents validation image, "test" represents testing image;
+2. Please refer to the paper "Fashion Landmark Detection in the Wild" for more details.
diff --git a/internlm_langchain/knowledge_base/MMFashion/content/MODEL_ZOO.md b/internlm_langchain/knowledge_base/MMFashion/content/MODEL_ZOO.md
new file mode 100644
index 00000000..742b6bb8
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMFashion/content/MODEL_ZOO.md
@@ -0,0 +1,73 @@
+# Model Zoo
+
+More models with different backbones will be added to the model zoo.
+
+## Init models
+
+| Backbone | Download |
+| :---------: | :----------------: |
+| VGG-16 | [vgg16.pth](https://download.pytorch.org/models/vgg16-397923af.pth) |
+
+
+## Attribute Prediction(Coarse)
+
+| Backbone | Pooling | Loss | Top-5 Recall | Top-5 Acc. | Download (Google) | Download (Baidu) |
+| :---------: | :--------------: | :-----------: | :----------: | :--------: | :----------------: | :----------------: |
+| VGG-16 | Global Pooling | Cross-Entropy | 13.70 | 99.81 | [model](https://drive.google.com/open?id=1lJlUtEQUxeWCDLj1nIhUBw8QtgaYtuqe) | [model](https://pan.baidu.com/s/1QB_10Yx9hU1xqjoZSuZsaQ), passwd: j9qd |
+| VGG-16 | Landmark Pooling | Cross-Entropy | 14.79 | 99.27 | [model](https://drive.google.com/open?id=18ZWz9Tr6vsAW5Lxq81ps6GddCJPJ0gMx) | - |
+| ResNet-50 | Global Pooling | Cross-Entropy | 23.52 | 99.29 | [model](https://drive.google.com/open?id=1LmC4aKiOY3qmm9qo6RNDU5v_o-xDCAdT) | - |
+| ResNet-50 | Landmark Pooling | Cross-Entropy | 30.84 | 99.30 | [model](https://drive.google.com/open?id=1bOL4GhLyBEcXgATiVcZ-g3RD8xhKsj5f) | - |
+
+
+## Category and Attribute Prediction(Fine)
+| Backbone | Pooling | Loss | Top-5 Cate. Recall | Top-5 Attr. Recall. | Download (Google) | Download (Baidu) |
+| :---------: | :--------------: | :-----------: | :----------------: | :-----------------: | :----------------: | :----------------: |
+| VGG-16 | Global Pooling | Cross-Entropy | 35.91 | 25.44 | [model](https://drive.google.com/file/d/10SZ3Lw4U0F9OKAuHWc-tBbvLS6yfE_x8/view?usp=sharing) | - |
+| VGG-16 | Landmark Pooling | Cross-Entropy | 37.71 | 26.69 | [model](https://drive.google.com/file/d/17XlihpZS9iY__i7rPxqlzpenHHRSbLGa/view?usp=sharing) | - |
+| ResNet-50 | Global Pooling | Cross-Entropy | 42.87 | 29.37 | [model](https://drive.google.com/file/d/1zsgxJAkdumpw4uDkapb1Ulq-aG1Hwz45/view?usp=sharing) | - |
+| ResNet-50 | Landmark Pooling | Cross-Entropy | 48.25 | 32.57 | [model](https://drive.google.com/file/d/1zsgxJAkdumpw4uDkapb1Ulq-aG1Hwz45/view?usp=sharing) | - |
+
+
+## In-Shop Clothes Retrieval
+
+| Backbone | Pooling | Loss | Top-5 Acc. | Download (Google) | Download (Baidu) |
+| :---------: | :--------------: | :-----------: | :--------: | :----------------: | :----------------: |
+| VGG-16 | Global Pooling | Cross-Entropy | 38.76 | [model](https://drive.google.com/open?id=1J3FmP5iVE-arwQZKP2QVrOwDTtTvlzJZ) | [model](https://pan.baidu.com/s/1n8BnYBUm4Dug4aREFfYfpQ), passwd: wz69 |
+| VGG-16 | Landmark Pooling | Cross-Entropy | 46.29 | [model](https://drive.google.com/open?id=1BQxjEqDF4ZQV4X57SiT28qCzIttUAZc-) | - |
+| ResNet-50 | Global Pooling | Cross-Entropy | 41.81 | [model](https://drive.google.com/open?id=1UYaIaDhuCwMQiQIcOEzYlPh0M1RFfdw-) | - |
+| ResNet-50 | Landmark Pooling | Cross-Entropy | 48.82 | [model](https://drive.google.com/open?id=1HZ13jijnjXxQ4nnsiss-UZ7bxHLN0kjw) | - |
+
+
+## Consumer-to-Shop Clothes Retrieval
+
+| Backbone | Pooling | Loss | Top-5 Acc. | Download (Google) | Download (Baidu) |
+| :---------: | :--------------: | :-----------: | :--------: | :----------------: | :----------------: |
+| VGG-16 | Landmark Pooling | Cross-Entropy | 7.18 | [model](https://drive.google.com/open?id=1I5_VBDKmjqNtG0-H0e9rvGXhhrz_-lDy) | [model](https://pan.baidu.com/s/1WUOihnZzav_8vl6pfHSy1A), passwd: grfx |
+
+
+## Fashion Landmark Detection
+
+| Backbone | Loss | Normalized Error | % of Det. Landmarks | Download (Google) | Download (Baidu) |
+| :---------: | :-----: | :--------------: | :-----------------: | :----------------: | :----------------: |
+| VGG-16 | L2 Loss | 0.0813 | 55.35 | [model](https://drive.google.com/open?id=1LWhPnkT9AbbldvteFn8u_s21PCQ-h00h) | [model](https://pan.baidu.com/s/1tzVGeV5P5Sed3diXEr1UPg), passwd: 4ebx |
+| ResNet-50 | L2 Loss | 0.0758 | 56.32 | [model](https://drive.google.com/open?id=1VGbOgkqBOgs2MaZ6qvLplopqqt7vKAM1) |
+
+
+## Fashion Compatibility Predictor
+| Backbone | Dataset | Embedding Projection | Loss | Fill-in-blank Acc | Compatibility AUC | Download (Google) |
+| :---------: | :---------: | :-------------------: | :---------------------------------------------------------: | :----------------:| :----------------:| :-------------------------: |
+| ResNet-18 | Disjoint | fully-connected layer | Triplet loss, Type-specific loss, Similarity loss, VSE loss | 50.4 | 0.80 | [model](https://drive.google.com/open?id=1T-9BLWbuZhEHpX8xV6f1ZoGUpcjV3efc) |
+| ResNet-18 | Disjoint | learned metric | Triplet loss, Type-specific loss, Similarity loss, VSE loss | 55.6 | 0.84 | [model](https://drive.google.com/open?id=1sYF0vqfI2z1riBvF9O643IH6mDikER7n) |
+| ResNet-18 | Nondisjoint | fully-connected layer | Triplet loss, Type-specific loss, Similarity loss, VSE loss | 53.5 | 0.85 | [model](https://drive.google.com/open?id=177W9T7Szl7Z--mF2Zjv89q6u7nUQG2Lq) |
+
+
+## Fashion Segmentation
+| Backbone | Model type | Dataset | bbox detection Average Precision | segmentation Average Precision | Download (Google) |
+| :---------: | :----------: | :-----------------: | :--------------------------------: | :----------------------------: | :-------------------------: |
+| Resnet50 | Mask RCNN | DeepFashion-In-shop | 0.599 | 0.584 | [model](https://drive.google.com/open?id=1q6zF7J6Gb-FFgM87oIORIt6uBozaXp5r) |
+
+
+## Fashion Virual Try-on
+| Model type | Dataset | Download (Google) |
+| :-----------: | :-----------: | :-------------------------: |
+| CP-VTON | VTON | [GMM](https://drive.google.com/file/d/1-nfMaN40WOofvfv9pCbqrbq0xQT3Tnnx/view?usp=sharing) [TOM](https://drive.google.com/file/d/1zZRBQDJZbDCr5bdoAnIm0UyOiWXB5dvO/view?usp=sharing) |
diff --git a/internlm_langchain/knowledge_base/MMFashion/vector_store/index.faiss b/internlm_langchain/knowledge_base/MMFashion/vector_store/index.faiss
new file mode 100644
index 00000000..96b20ddf
Binary files /dev/null and b/internlm_langchain/knowledge_base/MMFashion/vector_store/index.faiss differ
diff --git a/internlm_langchain/knowledge_base/MMFewShot/content/customize_config.md b/internlm_langchain/knowledge_base/MMFewShot/content/customize_config.md
new file mode 100644
index 00000000..1e0586b9
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMFewShot/content/customize_config.md
@@ -0,0 +1,295 @@
+# Tutorial 1: Learn about Configs
+
+We incorporate modular and inheritance design into our config system, which is convenient to conduct various experiments.
+If you wish to inspect the config file, you may run `python tools/misc/print_config.py /PATH/TO/CONFIG` to see the complete config.
+The classification part of mmfewshot is built upon the [mmcls](https://github.com/open-mmlab/mmclassification),
+thus it is highly recommended learning the basic of mmcls.
+
+## Modify config through script arguments
+
+When submitting jobs using "tools/classification/train.py" or "tools/classification/test.py", you may specify `--cfg-options` to in-place modify the config.
+
+- Update config keys of dict chains.
+
+ The config options can be specified following the order of the dict keys in the original config.
+ For example, `--cfg-options model.backbone.norm_eval=False` changes the all BN modules in model backbones to `train` mode.
+
+- Update keys inside a list of configs.
+
+ Some config dicts are composed as a list in your config. For example, the training pipeline `data.train.pipeline` is normally a list
+ e.g. `[dict(type='LoadImageFromFile'), ...]`. If you want to change `'LoadImageFromFile'` to `'LoadImageFromWebcam'` in the pipeline,
+ you may specify `--cfg-options data.train.pipeline.0.type=LoadImageFromWebcam`.
+
+- Update values of list/tuples.
+
+ If the value to be updated is a list or a tuple. For example, the config file normally sets `workflow=[('train', 1)]`. If you want to
+ change this key, you may specify `--cfg-options workflow="[(train,1),(val,1)]"`. Note that the quotation mark " is necessary to
+ support list/tuple data types, and that **NO** white space is allowed inside the quotation marks in the specified value.
+
+## Config Name Style
+
+We follow the below style to name config files. Contributors are advised to follow the same style.
+
+```
+{algorithm}_[algorithm setting]_{backbone}_{gpu x batch_per_gpu}_[misc]_{dataset}_{meta test setting}.py
+```
+
+`{xxx}` is required field and `[yyy]` is optional.
+
+- `{algorithm}`: model type like `faster_rcnn`, `mask_rcnn`, etc.
+- `[algorithm setting]`: specific setting for some model, like `without_semantic` for `htc`, `moment` for `reppoints`, etc.
+- `{backbone}`: backbone type like `conv4`, `resnet12`.
+- `[norm_setting]`: `bn` (Batch Normalization) is used unless specified, other norm layer type could be `gn` (Group Normalization), `syncbn` (Synchronized Batch Normalization).
+ `gn-head`/`gn-neck` indicates GN is applied in head/neck only, while `gn-all` means GN is applied in the entire model, e.g. backbone, neck, head.
+- `[gpu x batch_per_gpu]`: GPUs and samples per GPU. For episodic training methods we use the total number of images in one episode, i.e. n classes x (support images+query images).
+- `[misc]`: miscellaneous setting/plugins of model.
+- `{dataset}`: dataset like `cub`, `mini-imagenet` and `tiered-imagenet`.
+- `{meta test setting}`: n way k shot setting like `5way_1shot` or `5way_5shot`.
+
+## An Example of Baseline
+
+To help the users have a basic idea of a complete config and the modules in a modern classification system,
+we make brief comments on the config of Baseline for MiniImageNet in 5 way 1 shot setting as the following.
+For more detailed usage and the corresponding alternative for each module, please refer to the API documentation.
+
+```python
+# config of model
+model = dict(
+ # classifier name
+ type='Baseline',
+ # config of backbone
+ backbone=dict(type='Conv4'),
+ # config of classifier head
+ head=dict(type='LinearHead', num_classes=64, in_channels=1600),
+ # config of classifier head used in meta test
+ meta_test_head=dict(type='LinearHead', num_classes=5, in_channels=1600))
+
+# data pipeline for training
+train_pipeline = [
+ # first pipeline to load images from file path
+ dict(type='LoadImageFromFile'),
+ # random resize crop
+ dict(type='RandomResizedCrop', size=84),
+ # random flip
+ dict(type='RandomFlip', flip_prob=0.5, direction='horizontal'),
+ # color jitter
+ dict(type='ColorJitter', brightness=0.4, contrast=0.4, saturation=0.4),
+ dict(type='Normalize', # normalization
+ # mean values used to normalization
+ mean=[123.675, 116.28, 103.53],
+ # standard variance used to normalization
+ std=[58.395, 57.12, 57.375],
+ # whether to invert the color channel, rgb2bgr or bgr2rgb
+ to_rgb=True),
+ # convert img into torch.Tensor
+ dict(type='ImageToTensor', keys=['img']),
+ # convert gt_label into torch.Tensor
+ dict(type='ToTensor', keys=['gt_label']),
+ # pipeline that decides which keys in the data should be passed to the runner
+ dict(type='Collect', keys=['img', 'gt_label'])
+]
+
+# data pipeline for testing
+test_pipeline = [
+ # first pipeline to load images from file path
+ dict(type='LoadImageFromFile'),
+ # resize image
+ dict(type='Resize', size=(96, -1)),
+ # center crop
+ dict(type='CenterCrop', crop_size=84),
+ dict(type='Normalize', # normalization
+ # mean values used to normalization
+ mean=[123.675, 116.28, 103.53],
+ # standard variance used to normalization
+ std=[58.395, 57.12, 57.375],
+ # whether to invert the color channel, rgb2bgr or bgr2rgb
+ to_rgb=True),
+ # convert img into torch.Tensor
+ dict(type='ImageToTensor', keys=['img']),
+ # pipeline that decides which keys in the data should be passed to the runner
+ dict(type='Collect', keys=['img', 'gt_label'])
+]
+
+# config of fine-tuning using support set in Meta Test
+meta_finetune_cfg = dict(
+ # number of iterations in fine-tuning
+ num_steps=150,
+ # optimizer config in fine-tuning
+ optimizer=dict(
+ type='SGD', # optimizer name
+ lr=0.01, # learning rate
+ momentum=0.9, # momentum
+ dampening=0.9, # dampening
+ weight_decay=0.001)), # weight decay
+
+data = dict(
+ # batch size of a single GPU
+ samples_per_gpu=64,
+ # worker to pre-fetch data for each single GPU
+ workers_per_gpu=4,
+ # config of training set
+ train=dict(
+ # name of dataset
+ type='MiniImageNetDataset',
+ # prefix of image
+ data_prefix='data/mini_imagenet',
+ # subset of dataset
+ subset='train',
+ # train pipeline
+ pipeline=train_pipeline),
+ # config of validation set
+ val=dict(
+ # dataset wrapper for Meta Test
+ type='MetaTestDataset',
+ # total number of test tasks
+ num_episodes=100,
+ num_ways=5, # number of class in each task
+ num_shots=1, # number of support images in each task
+ num_queries=15, # number of query images in each task
+ dataset=dict( # config of dataset
+ type='MiniImageNetDataset', # dataset name
+ subset='val', # subset of dataset
+ data_prefix='data/mini_imagenet', # prefix of images
+ pipeline=test_pipeline),
+ meta_test_cfg=dict( # config of Meta Test
+ num_episodes=100, # total number of test tasks
+ num_ways=5, # number of class in each task
+ # whether to pre-compute features from backbone for acceleration
+ fast_test=True,
+ # dataloader setting for feature extraction of fast test
+ test_set=dict(batch_size=16, num_workers=2),
+ support=dict( # support set setting in meta test
+ batch_size=4, # batch size for fine-tuning
+ num_workers=0, # number of worker set 0 since the only 5 images
+ drop_last=True, # drop last
+ train=dict( # config of fine-tuning
+ num_steps=150, # number of steps in fine-tuning
+ optimizer=dict( # optimizer config in fine-tuning
+ type='SGD', # optimizer name
+ lr=0.01, # learning rate
+ momentum=0.9, # momentum
+ dampening=0.9, # dampening
+ weight_decay=0.001))), # weight decay
+ # query set setting predict 75 images
+ query=dict(batch_size=75, num_workers=0))),
+ test=dict( # used for model validation in Meta Test fashion
+ type='MetaTestDataset', # dataset wrapper for Meta Test
+ num_episodes=2000, # total number of test tasks
+ num_ways=5, # number of class in each task
+ num_shots=1, # number of support images in each task
+ num_queries=15, # number of query images in each task
+ dataset=dict( # config of dataset
+ type='MiniImageNetDataset', # dataset name
+ subset='test', # subset of dataset
+ data_prefix='data/mini_imagenet', # prefix of images
+ pipeline=test_pipeline),
+ meta_test_cfg=dict( # config of Meta Test
+ num_episodes=2000, # total number of test tasks
+ num_ways=5, # number of class in each task
+ # whether to pre-compute features from backbone for acceleration
+ fast_test=True,
+ # dataloader setting for feature extraction of fast test
+ test_set=dict(batch_size=16, num_workers=2),
+ support=dict( # support set setting in meta test
+ batch_size=4, # batch size for fine-tuning
+ num_workers=0, # number of worker set 0 since the only 5 images
+ drop_last=True, # drop last
+ train=dict( # config of fine-tuning
+ num_steps=150, # number of steps in fine-tuning
+ optimizer=dict( # optimizer config in fine-tuning
+ type='SGD', # optimizer name
+ lr=0.01, # learning rate
+ momentum=0.9, # momentum
+ dampening=0.9, # dampening
+ weight_decay=0.001))), # weight decay
+ # query set setting predict 75 images
+ query=dict(batch_size=75, num_workers=0))))
+log_config = dict(
+ interval=50, # interval to print the log
+ hooks=[dict(type='TextLoggerHook')])
+checkpoint_config = dict(interval=20) # interval to save a checkpoint
+evaluation = dict(
+ by_epoch=True, # eval model by epoch
+ metric='accuracy', # Metrics used during evaluation
+ interval=5) # interval to eval model
+# parameters to setup distributed training, the port can also be set.
+dist_params = dict(backend='nccl')
+log_level = 'INFO' # the output level of the log.
+load_from = None # load a pre-train checkpoints
+# resume checkpoints from a given path, the training will be resumed from
+# the epoch when the checkpoint's is saved.
+resume_from = None
+# workflow for runner. [('train', 1)] means there is only one workflow and
+# the workflow named 'train' is executed once.
+workflow = [('train', 1)]
+pin_memory = True # whether to use pin memory
+# whether to use infinite sampler; infinite sampler can accelerate training efficient
+use_infinite_sampler = True
+seed = 0 # random seed
+runner = dict(type='EpochBasedRunner', max_epochs=200) # runner type and epochs of training
+optimizer = dict( # the configuration file used to build the optimizer, support all optimizers in PyTorch.
+ type='SGD', # optimizer type
+ lr=0.05, # learning rat
+ momentum=0.9, # momentum
+ weight_decay=0.0001) # weight decay of SGD
+optimizer_config = dict(grad_clip=None) # most of the methods do not use gradient clip
+lr_config = dict(
+ # the policy of scheduler, also support CosineAnnealing, Cyclic, etc. Refer to details of supported LrUpdater
+ # from https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/lr_updater.py#L9.
+ policy='step',
+ warmup='linear', # warmup type
+ warmup_iters=3000, # warmup iterations
+ warmup_ratio=0.25, # warmup ratio
+ step=[60, 120]) # Steps to decay the learning rate
+```
+
+## FAQ
+
+### Use intermediate variables in configs
+
+Some intermediate variables are used in the configuration file. The intermediate variables make the configuration file clearer and easier to modify.
+
+For example, `train_pipeline` / `test_pipeline` is the intermediate variable of the data pipeline. We first need to define `train_pipeline` / `test_pipeline`, and then pass them to `data`. If you want to modify the size of the input image during training and testing, you need to modify the intermediate variables of `train_pipeline` / `test_pipeline`.
+
+```python
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='RandomResizedCrop', size=384, backend='pillow',),
+ dict(type='RandomFlip', flip_prob=0.5, direction='horizontal'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='ToTensor', keys=['gt_label']),
+ dict(type='Collect', keys=['img', 'gt_label'])
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='Resize', size=384, backend='pillow'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img'])
+]
+data = dict(
+ train=dict(pipeline=train_pipeline),
+ val=dict(pipeline=test_pipeline),
+ test=dict(pipeline=test_pipeline))
+```
+
+### Ignore some fields in the base configs
+
+Sometimes, you need to set `_delete_=True` to ignore some domain content in the basic configuration file. You can refer to [mmcv](https://mmcv.readthedocs.io/en/latest/understand_mmcv/config.html#inherit-from-base-config-with-ignored-fields) for more instructions.
+
+The following is an example. If you want to use cosine schedule, just using inheritance and directly modify it will report `get unexcepected keyword'step'` error, because the `'step'` field of the basic config in `lr_config` domain information is reserved, and you need to add `_delete_ =True` to ignore the content of `lr_config` related fields in the basic configuration file:
+
+```python
+lr_config = dict(
+ _delete_=True,
+ policy='CosineAnnealing',
+ min_lr=0,
+ warmup='linear',
+ by_epoch=True,
+ warmup_iters=5,
+ warmup_ratio=0.1
+)
+```
diff --git a/internlm_langchain/knowledge_base/MMFewShot/content/customize_dataset.md b/internlm_langchain/knowledge_base/MMFewShot/content/customize_dataset.md
new file mode 100644
index 00000000..be00b6f2
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMFewShot/content/customize_dataset.md
@@ -0,0 +1,224 @@
+# Tutorial 2: Adding New Dataset
+
+## Customize datasets by reorganizing data
+
+### Customize loading annotations
+
+You can write a new Dataset class inherited from `BaseFewShotDataset`, and overwrite `load_annotations(self)`,
+like [CUB](https://github.com/open-mmlab/mmfewshot/blob/main/mmfewshot/classification/datasets/cub.py) and [MiniImageNet](https://github.com/open-mmlab/mmfewshot/blob/main/mmfewshot/classification/datasets/mini_imagenet.py).
+Typically, this function returns a list, where each sample is a dict, containing necessary data information, e.g., `img` and `gt_label`.
+
+Assume we are going to implement a `Filelist` dataset, which takes filelists for both training and testing. The format of annotation list is as follows:
+
+```
+000001.jpg 0
+000002.jpg 1
+```
+
+We can create a new dataset in `mmfewshot/classification/datasets/filelist.py` to load the data.
+
+```python
+import mmcv
+import numpy as np
+
+from mmcls.datasets.builder import DATASETS
+from .base import BaseFewShotDataset
+
+
+@DATASETS.register_module()
+class Filelist(BaseFewShotDataset):
+
+ def load_annotations(self):
+ assert isinstance(self.ann_file, str)
+
+ data_infos = []
+ with open(self.ann_file) as f:
+ samples = [x.strip().split(' ') for x in f.readlines()]
+ for filename, gt_label in samples:
+ info = {'img_prefix': self.data_prefix}
+ info['img_info'] = {'filename': filename}
+ info['gt_label'] = np.array(gt_label, dtype=np.int64)
+ data_infos.append(info)
+ return data_infos
+
+```
+
+And add this dataset class in `mmcls/datasets/__init__.py`
+
+```python
+from .base_dataset import BaseDataset
+...
+from .filelist import Filelist
+
+__all__ = [
+ 'BaseDataset', ... ,'Filelist'
+]
+```
+
+Then in the config, to use `Filelist` you can modify the config as the following
+
+```python
+train = dict(
+ type='Filelist',
+ ann_file = 'image_list.txt',
+ pipeline=train_pipeline
+)
+```
+
+### Customize different subsets
+
+To support different subset, we first predefine the classes of different subsets.
+Then we modify `get_classes` to handle different classes of subset.
+
+```python
+import mmcv
+import numpy as np
+
+from mmcls.datasets.builder import DATASETS
+from .base import BaseFewShotDataset
+
+@DATASETS.register_module()
+class Filelist(BaseFewShotDataset):
+
+ TRAIN_CLASSES = ['train_a', ...]
+ VAL_CLASSES = ['val_a', ...]
+ TEST_CLASSES = ['test_a', ...]
+
+ def __init__(self, subset, *args, **kwargs):
+ ...
+ self.subset = subset
+ super().__init__(*args, **kwargs)
+
+ def get_classes(self):
+ if self.subset == 'train':
+ class_names = self.TRAIN_CLASSES
+ ...
+ return class_names
+```
+
+## Customize datasets sampling
+
+### EpisodicDataset
+
+We use `EpisodicDataset` as wrapper to perform N way K shot sampling.
+For example, suppose the original dataset is Dataset_A, the config looks like the following
+
+```python
+dataset_A_train = dict(
+ type='EpisodicDataset',
+ num_episodes=100000, # number of total episodes = length of dataset wrapper
+ # each call of `__getitem__` will return
+ # {'support_data': [(num_ways * num_shots) images],
+ # 'query_data': [(num_ways * num_queries) images]}
+ num_ways=5, # number of way (different classes)
+ num_shots=5, # number of support shots of each class
+ num_queries=5, # number of query shots of each class
+ dataset=dict( # This is the original config of Dataset_A
+ type='Dataset_A',
+ ...
+ pipeline=train_pipeline
+ )
+ )
+```
+
+### Customize sampling logic
+
+An example of customizing data sampling logic for training:
+
+#### Create a new dataset wrapper
+
+We can create a new dataset wrapper in mmfewshot/classification/datasets/dataset_wrappers.py to customize sampling logic.
+
+```python
+class MyDatasetWrapper:
+ def __init__(self, dataset, args_a, args_b, ...):
+ self.dataset = dataset
+ ...
+ self.episode_idxes = self.generate_episodic_idxes()
+
+ def generate_episodic_idxes(self):
+ episode_idxes = []
+ # sampling each episode
+ for _ in range(self.num_episodes):
+ episodic_a_idx, episodic_b_idx, episodic_c_idx= [], [], []
+ # customize sampling logic
+ # select the index of data_infos from original dataset
+ ...
+ episode_idxes.append({
+ 'a': episodic_a_idx,
+ 'b': episodic_b_idx,
+ 'c': episodic_c_idx,
+ })
+ return episode_idxes
+
+ def __getitem__(self, idx):
+ # the key can be any value, but it needs to modify the code
+ # in the forward function of model.
+ return {
+ 'a_data' : [self.dataset[i] for i in self.episode_idxes[idx]['a']],
+ 'b_data' : [self.dataset[i] for i in self.episode_idxes[idx]['b']],
+ 'c_data' : [self.dataset[i] for i in self.episode_idxes[idx]['c']]
+ }
+
+```
+
+#### Update dataset builder
+
+We need to add the build code in mmfewshot/classification/datasets/builder.py
+for our customize dataset wrapper.
+
+```python
+def build_dataset(cfg, default_args=None):
+ if isinstance(cfg, (list, tuple)):
+ dataset = ConcatDataset([build_dataset(c, default_args) for c in cfg])
+ ...
+ elif cfg['type'] == 'MyDatasetWrapper':
+ dataset = MyDatasetWrapper(
+ build_dataset(cfg['dataset'], default_args),
+ # pass customize arguments
+ args_a=cfg['args_a'],
+ args_b=cfg['args_b'],
+ ...)
+ else:
+ dataset = build_from_cfg(cfg, DATASETS, default_args)
+
+ return dataset
+```
+
+#### Update the arguments in model
+
+The argument names in forward function need to be consistent with the customize dataset wrapper.
+
+```python
+class MyClassifier(BaseFewShotClassifier):
+ ...
+ def forward(self, a_data=None, b_data=None, c_data=None, ...):
+ # pass the modified arguments name.
+ if mode == 'train':
+ return self.forward_train(a_data=a_data, b_data=b_data, c_data=None, **kwargs)
+ elif mode == 'query':
+ return self.forward_query(img=img, **kwargs)
+ elif mode == 'support':
+ return self.forward_support(img=img, **kwargs)
+ elif mode == 'extract_feat':
+ return self.extract_feat(img=img)
+ else:
+ raise ValueError()
+```
+
+#### using customize dataset wrapper in config
+
+Then in the config, to use `MyDatasetWrapper` you can modify the config as the following,
+
+```python
+dataset_A_train = dict(
+ type='MyDatasetWrapper',
+ args_a=None,
+ args_b=None,
+ dataset=dict( # This is the original config of Dataset_A
+ type='Dataset_A',
+ ...
+ pipeline=train_pipeline
+ )
+ )
+```
diff --git a/internlm_langchain/knowledge_base/MMFewShot/content/customize_models.md b/internlm_langchain/knowledge_base/MMFewShot/content/customize_models.md
new file mode 100644
index 00000000..fadcd565
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMFewShot/content/customize_models.md
@@ -0,0 +1,265 @@
+# Tutorial 3: Customize Models
+
+### Add a new classifier
+
+Here we show how to develop a new classifier with an example as follows
+
+#### 1. Define a new classifier
+
+Create a new file `mmfewshot/classification/models/classifiers/my_classifier.py`.
+
+```python
+from mmcls.models.builder import CLASSIFIERS
+from .base import BaseFewShotClassifier
+
+@CLASSIFIERS.register_module()
+class MyClassifier(BaseFewShotClassifier):
+
+ def __init__(self, arg1, arg2):
+ pass
+
+ # customize input for different mode
+ # the input should keep consistent with the dataset
+ def forward(self, img, mode='train',**kwargs):
+ if mode == 'train':
+ return self.forward_train(img=img, **kwargs)
+ elif mode == 'query':
+ return self.forward_query(img=img, **kwargs)
+ elif mode == 'support':
+ return self.forward_support(img=img, **kwargs)
+ elif mode == 'extract_feat':
+ assert img is not None
+ return self.extract_feat(img=img)
+ else:
+ raise ValueError()
+
+ # customize forward function for training data
+ def forward_train(self, img, gt_label, **kwargs):
+ pass
+
+ # customize forward function for meta testing support data
+ def forward_support(self, img, gt_label, **kwargs):
+ pass
+
+ # customize forward function for meta testing query data
+ def forward_query(self, img):
+ pass
+
+ # prepare meta testing
+ def before_meta_test(self, meta_test_cfg, **kwargs):
+ pass
+
+ # prepare forward meta testing query images
+ def before_forward_support(self, **kwargs):
+ pass
+
+ # prepare forward meta testing support images
+ def before_forward_query(self, **kwargs):
+ pass
+```
+
+#### 2. Import the module
+
+You can either add the following line to `mmfewshot/classification/models/heads/__init__.py`
+
+```python
+from .my_classifier import MyClassifier
+```
+
+or alternatively add
+
+```python
+custom_imports = dict(
+ imports=['mmfewshot.classification.models.classifier.my_classifier'],
+ allow_failed_imports=False)
+```
+
+to the config file to avoid modifying the original code.
+
+#### 3. Use the classifier in your config file
+
+```python
+model = dict(
+ type="MyClassifier",
+ ...
+)
+```
+
+### Add a new backbone
+
+Here we show how to develop a new backbone with an example as follows
+
+#### 1. Define a new backbone
+
+Create a new file `mmfewshot/classification/models/backbones/mynet.py`.
+
+```python
+import torch.nn as nn
+
+from mmcls.models.builder import BACKBONES
+
+@BACKBONES.register_module()
+class MyNet(nn.Module):
+
+ def __init__(self, arg1, arg2):
+ pass
+
+ def forward(self, x): # should return a tensor
+ pass
+```
+
+#### 2. Import the module
+
+You can either add the following line to `mmfewshot/classification/models/backbones/__init__.py`
+
+```python
+from .mynet import MyNet
+```
+
+or alternatively add
+
+```python
+custom_imports = dict(
+ imports=['mmfewshot.classification.models.backbones.mynet'],
+ allow_failed_imports=False)
+```
+
+to the config file to avoid modifying the original code.
+
+#### 3. Use the backbone in your config file
+
+```python
+model = dict(
+ ...
+ backbone=dict(
+ type='MyNet',
+ arg1=xxx,
+ arg2=xxx),
+ ...
+```
+
+### Add new heads
+
+Here we show how to develop a new head with an example as follows
+
+#### 1. Define a new head
+
+Create a new file `mmfewshot/classification/models/heads/myhead.py`.
+
+```python
+from mmcls.models.builder import HEADS
+from .base_head import BaseFewShotHead
+
+@HEADS.register_module()
+class MyHead(BaseFewShotHead):
+
+ def __init__(self, arg1, arg2) -> None:
+ pass
+
+ def forward_train(self, x, gt_label, **kwargs):
+ pass
+
+ def forward_support(self, x, gt_label, **kwargs):
+ pass
+
+ def forward_query(self, x, **kwargs):
+ pass
+
+ def before_forward_support(self) -> None:
+ pass
+
+ def before_forward_query(self) -> None:
+ pass
+```
+
+#### 2. Import the module
+
+You can either add the following line to `mmfewshot/classification/models/heads/__init__.py`
+
+```python
+from .myhead import MyHead
+```
+
+or alternatively add
+
+```python
+custom_imports = dict(
+ imports=['mmfewshot.classification.models.backbones.myhead'],
+ allow_failed_imports=False)
+```
+
+to the config file to avoid modifying the original code.
+
+#### 3. Use the head in your config file
+
+```python
+model = dict(
+ ...
+ head=dict(
+ type='MyHead',
+ arg1=xxx,
+ arg2=xxx),
+ ...
+```
+
+### Add new loss
+
+To add a new loss function, the users need implement it in `mmfewshot/classification/models/losses/my_loss.py`.
+The decorator `weighted_loss` enable the loss to be weighted for each element.
+
+```python
+import torch
+import torch.nn as nn
+
+from ..builder import LOSSES
+from .utils import weighted_loss
+
+@weighted_loss
+def my_loss(pred, target):
+ assert pred.size() == target.size() and target.numel() > 0
+ loss = torch.abs(pred - target)
+ return loss
+
+@LOSSES.register_module()
+class MyLoss(nn.Module):
+
+ def __init__(self, reduction='mean', loss_weight=1.0):
+ super(MyLoss, self).__init__()
+ self.reduction = reduction
+ self.loss_weight = loss_weight
+
+ def forward(self,
+ pred,
+ target,
+ weight=None,
+ avg_factor=None,
+ reduction_override=None):
+ assert reduction_override in (None, 'none', 'mean', 'sum')
+ reduction = (
+ reduction_override if reduction_override else self.reduction)
+ loss_bbox = self.loss_weight * my_loss(
+ pred, target, weight, reduction=reduction, avg_factor=avg_factor)
+ return loss_bbox
+```
+
+Then the users need to add it in the `mmfewshot/classification/models/losses/__init__.py`.
+
+```python
+from .my_loss import MyLoss, my_loss
+```
+
+Alternatively, you can add
+
+```python
+custom_imports=dict(
+ imports=['mmfewshot.classification.models.losses.my_loss'])
+```
+
+to the config file and achieve the same goal.
+
+To use it, modify the `loss_xxx` field.
+Since MyLoss is for regression, you need to modify the `loss_bbox` field in the head.
+
+```python
+loss_bbox=dict(type='MyLoss', loss_weight=1.0))
+```
diff --git a/internlm_langchain/knowledge_base/MMFewShot/content/customize_runtime.md b/internlm_langchain/knowledge_base/MMFewShot/content/customize_runtime.md
new file mode 100644
index 00000000..035930b1
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMFewShot/content/customize_runtime.md
@@ -0,0 +1,395 @@
+# Tutorial 4: Customize Runtime Settings
+
+## Customize optimization settings
+
+### Customize optimizer supported by Pytorch
+
+We already support to use all the optimizers implemented by PyTorch, and the only modification is to change the `optimizer` field of config files.
+For example, if you want to use `ADAM` (note that the performance could drop a lot), the modification could be as the following.
+
+```python
+optimizer = dict(type='Adam', lr=0.0003, weight_decay=0.0001)
+```
+
+To modify the learning rate of the model, the users only need to modify the `lr` in the config of optimizer. The users can directly set arguments following the [API doc](https://pytorch.org/docs/stable/optim.html?highlight=optim#module-torch.optim) of PyTorch.
+
+### Customize self-implemented optimizer
+
+#### 1. Define a new optimizer
+
+A customized optimizer could be defined as following.
+
+Assume you want to add a optimizer named `MyOptimizer`, which has arguments `a`, `b`, and `c`.
+You need to create a new directory named `mmfewshot/classification/core/optimizer`.
+And then implement the new optimizer in a file, e.g., in `mmfewshot/classification/core/optimizer/my_optimizer.py`:
+
+```python
+from .registry import OPTIMIZERS
+from torch.optim import Optimizer
+
+
+@OPTIMIZERS.register_module()
+class MyOptimizer(Optimizer):
+
+ def __init__(self, a, b, c)
+
+```
+
+#### 2. Add the optimizer to registry
+
+To find the above module defined above, this module should be imported into the main namespace at first. There are two options to achieve it.
+
+- Modify `mmfewshot/classification/core/optimizer/__init__.py` to import it.
+
+ The newly defined module should be imported in `mmfewshot/classification/core/optimizer/__init__.py` so that the registry will
+ find the new module and add it:
+
+```python
+from .my_optimizer import MyOptimizer
+```
+
+- Use `custom_imports` in the config to manually import it
+
+```python
+custom_imports = dict(imports=['mmfewshot.classification.core.optimizer.my_optimizer'], allow_failed_imports=False)
+```
+
+The module `mmfewshot.classification.core.optimizer.my_optimizer` will be imported at the beginning of the program and the class `MyOptimizer` is then automatically registered.
+Note that only the package containing the class `MyOptimizer` should be imported.
+`mmfewshot.classification.core.optimizer.my_optimizer.MyOptimizer` **cannot** be imported directly.
+
+Actually users can use a totally different file directory structure using this importing method, as long as the module root can be located in `PYTHONPATH`.
+
+#### 3. Specify the optimizer in the config file
+
+Then you can use `MyOptimizer` in `optimizer` field of config files.
+In the configs, the optimizers are defined by the field `optimizer` like the following:
+
+```python
+optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
+```
+
+To use your own optimizer, the field can be changed to
+
+```python
+optimizer = dict(type='MyOptimizer', a=a_value, b=b_value, c=c_value)
+```
+
+### Customize optimizer constructor
+
+Some models may have some parameter-specific settings for optimization, e.g. weight decay for BatchNorm layers.
+The users can do those fine-grained parameter tuning through customizing optimizer constructor.
+
+```python
+from mmcv.utils import build_from_cfg
+
+from mmcv.runner.optimizer import OPTIMIZER_BUILDERS, OPTIMIZERS
+from mmfewshot.utils import get_root_logger
+from .my_optimizer import MyOptimizer
+
+
+@OPTIMIZER_BUILDERS.register_module()
+class MyOptimizerConstructor(object):
+
+ def __init__(self, optimizer_cfg, paramwise_cfg=None):
+
+ def __call__(self, model):
+
+ return my_optimizer
+
+```
+
+The default optimizer constructor is implemented [here](https://github.com/open-mmlab/mmcv/blob/9ecd6b0d5ff9d2172c49a182eaa669e9f27bb8e7/mmcv/runner/optimizer/default_constructor.py#L11), which could also serve as a template for new optimizer constructor.
+
+### Additional settings
+
+Tricks not implemented by the optimizer should be implemented through optimizer constructor (e.g., set parameter-wise learning rates) or hooks. We list some common settings that could stabilize the training or accelerate the training. Feel free to create PR, issue for more settings.
+
+- __Use gradient clip to stabilize training__:
+ Some models need gradient clip to clip the gradients to stabilize the training process. An example is as below:
+
+ ```python
+ optimizer_config = dict(grad_clip=dict(max_norm=35, norm_type=2))
+ ```
+
+- __Use momentum schedule to accelerate model convergence__:
+ We support momentum scheduler to modify model's momentum according to learning rate, which could make the model converge in a faster way.
+ Momentum scheduler is usually used with LR scheduler, for example, the following config is used in 3D detection to accelerate convergence.
+ For more details, please refer to the implementation of [CyclicLrUpdater](https://github.com/open-mmlab/mmcv/blob/f48241a65aebfe07db122e9db320c31b685dc674/mmcv/runner/hooks/lr_updater.py#L327) and [CyclicMomentumUpdater](https://github.com/open-mmlab/mmcv/blob/f48241a65aebfe07db122e9db320c31b685dc674/mmcv/runner/hooks/momentum_updater.py#L130).
+
+ ```python
+ lr_config = dict(
+ policy='cyclic',
+ target_ratio=(10, 1e-4),
+ cyclic_times=1,
+ step_ratio_up=0.4,
+ )
+ momentum_config = dict(
+ policy='cyclic',
+ target_ratio=(0.85 / 0.95, 1),
+ cyclic_times=1,
+ step_ratio_up=0.4,
+ )
+ ```
+
+## Customize training schedules
+
+By default we use step learning rate with 1x schedule, this calls [`StepLRHook`](https://github.com/open-mmlab/mmcv/blob/f48241a65aebfe07db122e9db320c31b685dc674/mmcv/runner/hooks/lr_updater.py#L153) in MMCV.
+We support many other learning rate schedule [here](https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/lr_updater.py), such as `CosineAnnealing` and `Poly` schedule. Here are some examples
+
+- Poly schedule:
+
+ ```python
+ lr_config = dict(policy='poly', power=0.9, min_lr=1e-4, by_epoch=False)
+ ```
+
+- ConsineAnnealing schedule:
+
+ ```python
+ lr_config = dict(
+ policy='CosineAnnealing',
+ warmup='linear',
+ warmup_iters=1000,
+ warmup_ratio=1.0 / 10,
+ min_lr_ratio=1e-5)
+ ```
+
+## Customize workflow
+
+Workflow is a list of (phase, epochs) to specify the running order and epochs.
+By default it is set to be
+
+```python
+workflow = [('train', 1)]
+```
+
+which means running 1 epoch for training.
+Sometimes user may want to check some metrics (e.g. loss, accuracy) about the model on the validate set.
+In such case, we can set the workflow as
+
+```python
+[('train', 1), ('val', 1)]
+```
+
+so that 1 epoch for training and 1 epoch for validation will be run iteratively.
+
+**Note**:
+
+1. The parameters of model will not be updated during val epoch.
+2. Keyword `total_epochs` in the config only controls the number of training epochs and will not affect the validation workflow.
+3. Workflows `[('train', 1), ('val', 1)]` and `[('train', 1)]` will not change the behavior of `EvalHook` because `EvalHook` is called by `after_train_epoch` and validation workflow only affect hooks that are called through `after_val_epoch`. Therefore, the only difference between `[('train', 1), ('val', 1)]` and `[('train', 1)]` is that the runner will calculate losses on validation set after each training epoch.
+
+## Customize hooks
+
+### Customize self-implemented hooks
+
+#### 1. Implement a new hook
+
+Here we give an example of creating a new hook in MMFewShot and using it in training.
+
+```python
+from mmcv.runner import HOOKS, Hook
+
+
+@HOOKS.register_module()
+class MyHook(Hook):
+
+ def __init__(self, a, b):
+ pass
+
+ def before_run(self, runner):
+ pass
+
+ def after_run(self, runner):
+ pass
+
+ def before_epoch(self, runner):
+ pass
+
+ def after_epoch(self, runner):
+ pass
+
+ def before_iter(self, runner):
+ pass
+
+ def after_iter(self, runner):
+ pass
+```
+
+Depending on the functionality of the hook, the users need to specify what the hook will do at each stage of the training in `before_run`, `after_run`, `before_epoch`, `after_epoch`, `before_iter`, and `after_iter`.
+
+#### 2. Register the new hook
+
+Then we need to make `MyHook` imported. Assuming the file is in `mmfewshot/classification/core/utils/my_hook.py` there are two ways to do that:
+
+- Modify `mmfewshot/core/utils/__init__.py` to import it.
+
+ The newly defined module should be imported in `mmfewshot/classification/core/utils/__init__.py` so that the registry will
+ find the new module and add it:
+
+```python
+from .my_hook import MyHook
+```
+
+- Use `custom_imports` in the config to manually import it
+
+```python
+custom_imports = dict(imports=['mmfewshot.classification.core.utils.my_hook'], allow_failed_imports=False)
+```
+
+#### 3. Modify the config
+
+```python
+custom_hooks = [
+ dict(type='MyHook', a=a_value, b=b_value)
+]
+```
+
+You can also set the priority of the hook by adding key `priority` to `'NORMAL'` or `'HIGHEST'` as below
+
+```python
+custom_hooks = [
+ dict(type='MyHook', a=a_value, b=b_value, priority='NORMAL')
+]
+```
+
+By default the hook's priority is set as `NORMAL` during registration.
+
+### Use hooks implemented in MMCV
+
+If the hook is already implemented in MMCV, you can directly modify the config to use the hook as below
+
+```python
+custom_hooks = [
+ dict(type='MMCVHook', a=a_value, b=b_value, priority='NORMAL')
+]
+```
+
+### Customize self-implemented eval hooks with a dataset
+
+Here we give an example of creating a new hook in MMFewShot and using it to evaluate a dataset.
+To achieve this, we can add following code in `mmfewshot/classification/apis/test.py`.
+
+```python
+if validate:
+ ...
+ # build dataset and dataloader
+ my_eval_dataset = build_dataset(cfg.data.my_eval)
+ my_eval_data_loader = build_dataloader(my_eval_dataset)
+ runner.register_hook(eval_hook(my_eval_data_loader), priority='LOW')
+```
+
+The arguments used in `test_my_single_task` can be defined in `meta_test_cfg`, for example:
+
+```python
+data = dict(
+ test=dict(
+ type='MetaTestDataset',
+ ...,
+ dataset=dict(...),
+ meta_test_cfg=dict(
+ ...,
+ test_my_single_task=dict(arg1=...)
+ )
+ )
+)
+```
+
+Then we can replace the `test_single_task` with customized `test_my_single_task` in `single_gpu_meta_test` and `multiple_gpu_meta_test`
+
+### Modify default runtime hooks
+
+There are some common hooks that are not registered through `custom_hooks`, they are
+
+- log_config
+- checkpoint_config
+- evaluation
+- lr_config
+- optimizer_config
+- momentum_config
+
+In those hooks, only the logger hook has the `VERY_LOW` priority, others' priority are `NORMAL`.
+The above-mentioned tutorials already covers how to modify `optimizer_config`, `momentum_config`, and `lr_config`.
+Here we reveals how what we can do with `log_config`, `checkpoint_config`, and `evaluation`.
+
+#### Checkpoint config
+
+The MMCV runner will use `checkpoint_config` to initialize [`CheckpointHook`](https://github.com/open-mmlab/mmcv/blob/9ecd6b0d5ff9d2172c49a182eaa669e9f27bb8e7/mmcv/runner/hooks/checkpoint.py#L9).
+
+```python
+checkpoint_config = dict(interval=1)
+```
+
+The users could set `max_keep_ckpts` to only save only small number of checkpoints or decide whether to store state dict of optimizer by `save_optimizer`. More details of the arguments are [here](https://mmcv.readthedocs.io/en/latest/api.html#mmcv.runner.CheckpointHook)
+
+#### Log config
+
+The `log_config` wraps multiple logger hooks and enables to set intervals. Now MMCV supports `WandbLoggerHook`, `MlflowLoggerHook`, and `TensorboardLoggerHook`.
+The detail usages can be found in the [doc](https://mmcv.readthedocs.io/en/latest/api.html#mmcv.runner.LoggerHook).
+
+```python
+log_config = dict(
+ interval=50,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ dict(type='TensorboardLoggerHook')
+ ])
+```
+
+#### Evaluation config
+
+The config of `evaluation` will be used to initialize the `EvalHook`.
+Except the key `interval`, other arguments such as `metric` will be passed to the `dataset.evaluate()`
+
+```python
+evaluation = dict(interval=1, metric='bbox')
+```
+
+## Customize Meta Testing
+
+We already support two ways to handle the support data, fine-tuning and straight forwarding.
+To customize the code for a meta test task, we need to add a new function `test_my_single_task`
+in the `mmfewshot/classification/apis/test.py`.
+
+```python
+def test_my_single_task(model: MetaTestParallel,
+ support_dataloader: DataLoader,
+ query_dataloader: DataLoader,
+ meta_test_cfg: Dict):
+ # use copy of model for each task
+ model = copy.deepcopy(model)
+ ...
+ # forward support set
+ model.before_forward_support()
+ # customize code for support data
+ ...
+
+ # forward query set
+ model.before_forward_query()
+ ...
+ results_list, gt_label_list = [], []
+ # customize code for query data
+ ...
+
+ # return predict results and gt labels for evaluation
+ return results_list, gt_labels
+
+```
+
+The arguments used in `test_my_single_task` can be defined in `meta_test_cfg`, for example:
+
+```python
+data = dict(
+ test=dict(
+ type='MetaTestDataset',
+ ...,
+ dataset=dict(...),
+ meta_test_cfg=dict(
+ ...,
+ test_my_single_task=dict(arg1=...)
+ )
+ )
+)
+```
+
+Then we can replace the `test_single_task` with customized `test_my_single_task` in `single_gpu_meta_test` and `multiple_gpu_meta_test`
diff --git a/internlm_langchain/knowledge_base/MMFewShot/content/faq.md b/internlm_langchain/knowledge_base/MMFewShot/content/faq.md
new file mode 100644
index 00000000..3b015f20
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMFewShot/content/faq.md
@@ -0,0 +1,95 @@
+# Frequently Asked Questions
+
+We list some common troubles faced by many users and their corresponding solutions here. Feel free to enrich the list if you find any frequent issues and have ways to help others to solve them. If the contents here do not cover your issue, please create an issue using the [provided templates](https://github.com/open-mmlab/mmdetection/blob/master/.github/ISSUE_TEMPLATE/error-report.md/) and make sure you fill in all required information in the template.
+
+## MMCV Installation
+
+- Compatibility issue between MMCV and MMDetection; "ConvWS is already registered in conv layer"; "AssertionError: MMCV==xxx is used but incompatible. Please install mmcv>=xxx, \<=xxx."
+
+ Please install the correct version of MMCV for the version of your MMDetection following the [installation instruction](https://mmdetection.readthedocs.io/en/latest/get_started.html#installation).
+
+- "No module named 'mmcv.ops'"; "No module named 'mmcv.\_ext'".
+
+ 1. Uninstall existing mmcv in the environment using `pip uninstall mmcv`.
+ 2. Install mmcv-full following the [installation instruction](https://mmcv.readthedocs.io/en/latest/#installation).
+
+## PyTorch/CUDA Environment
+
+- "RTX 30 series card fails when building MMCV or MMDet"
+
+ 1. Temporary work-around: do `MMCV_WITH_OPS=1 MMCV_CUDA_ARGS='-gencode=arch=compute_80,code=sm_80' pip install -e .`.
+ The common issue is `nvcc fatal : Unsupported gpu architecture 'compute_86'`. This means that the compiler should optimize for sm_86, i.e., nvidia 30 series card, but such optimizations have not been supported by CUDA toolkit 11.0.
+ This work-around modifies the compile flag by adding `MMCV_CUDA_ARGS='-gencode=arch=compute_80,code=sm_80'`, which tells `nvcc` to optimize for **sm_80**, i.e., Nvidia A100. Although A100 is different from the 30 series card, they use similar ampere architecture. This may hurt the performance but it works.
+ 2. PyTorch developers have updated that the default compiler flags should be fixed by [pytorch/pytorch#47585](https://github.com/pytorch/pytorch/pull/47585). So using PyTorch-nightly may also be able to solve the problem, though we have not tested it yet.
+
+- "invalid device function" or "no kernel image is available for execution".
+
+ 1. Check if your cuda runtime version (under `/usr/local/`), `nvcc --version` and `conda list cudatoolkit` version match.
+ 2. Run `python mmdet/utils/collect_env.py` to check whether PyTorch, torchvision, and MMCV are built for the correct GPU architecture.
+ You may need to set `TORCH_CUDA_ARCH_LIST` to reinstall MMCV.
+ The GPU arch table could be found [here](https://docs.nvidia.com/cuda/cuda-compiler-driver-nvcc/index.html#gpu-feature-list),
+ i.e. run `TORCH_CUDA_ARCH_LIST=7.0 pip install mmcv-full` to build MMCV for Volta GPUs.
+ The compatibility issue could happen when using old GPUS, e.g., Tesla K80 (3.7) on colab.
+ 3. Check whether the running environment is the same as that when mmcv/mmdet has compiled.
+ For example, you may compile mmcv using CUDA 10.0 but run it on CUDA 9.0 environments.
+
+- "undefined symbol" or "cannot open xxx.so".
+
+ 1. If those symbols are CUDA/C++ symbols (e.g., libcudart.so or GLIBCXX), check whether the CUDA/GCC runtimes are the same as those used for compiling mmcv,
+ i.e. run `python mmdet/utils/collect_env.py` to see if `"MMCV Compiler"`/`"MMCV CUDA Compiler"` is the same as `"GCC"`/`"CUDA_HOME"`.
+ 2. If those symbols are PyTorch symbols (e.g., symbols containing caffe, aten, and TH), check whether the PyTorch version is the same as that used for compiling mmcv.
+ 3. Run `python mmdet/utils/collect_env.py` to check whether PyTorch, torchvision, and MMCV are built by and running on the same environment.
+
+- setuptools.sandbox.UnpickleableException: DistutilsSetupError("each element of 'ext_modules' option must be an Extension instance or 2-tuple")
+
+ 1. If you are using miniconda rather than anaconda, check whether Cython is installed as indicated in [#3379](https://github.com/open-mmlab/mmdetection/issues/3379).
+ You need to manually install Cython first and then run command `pip install -r requirements.txt`.
+ 2. You may also need to check the compatibility between the `setuptools`, `Cython`, and `PyTorch` in your environment.
+
+- "Segmentation fault".
+
+ 1. Check you GCC version and use GCC 5.4. This usually caused by the incompatibility between PyTorch and the environment (e.g., GCC \< 4.9 for PyTorch). We also recommend the users to avoid using GCC 5.5 because many feedbacks report that GCC 5.5 will cause "segmentation fault" and simply changing it to GCC 5.4 could solve the problem.
+
+ 2. Check whether PyTorch is correctly installed and could use CUDA op, e.g. type the following command in your terminal.
+
+ ```shell
+ python -c 'import torch; print(torch.cuda.is_available())'
+ ```
+
+ And see whether they could correctly output results.
+
+ 3. If Pytorch is correctly installed, check whether MMCV is correctly installed.
+
+ ```shell
+ python -c 'import mmcv; import mmcv.ops'
+ ```
+
+ If MMCV is correctly installed, then there will be no issue of the above two commands.
+
+ 4. If MMCV and Pytorch is correctly installed, you man use `ipdb`, `pdb` to set breakpoints or directly add 'print' in mmdetection code and see which part leads the segmentation fault.
+
+## Training
+
+- "Loss goes Nan"
+
+ 1. Check if the dataset annotations are valid: zero-size bounding boxes will cause the regression loss to be Nan due to the commonly used transformation for box regression. Some small size (width or height are smaller than 1) boxes will also cause this problem after data augmentation (e.g., instaboost). So check the data and try to filter out those zero-size boxes and skip some risky augmentations on the small-size boxes when you face the problem.
+ 2. Reduce the learning rate: the learning rate might be too large due to some reasons, e.g., change of batch size. You can rescale them to the value that could stably train the model.
+ 3. Extend the warmup iterations: some models are sensitive to the learning rate at the start of the training. You can extend the warmup iterations, e.g., change the `warmup_iters` from 500 to 1000 or 2000.
+ 4. Add gradient clipping: some models requires gradient clipping to stabilize the training process. The default of `grad_clip` is `None`, you can add gradient clippint to avoid gradients that are too large, i.e., set `optimizer_config=dict(_delete_=True, grad_clip=dict(max_norm=35, norm_type=2))` in your config file. If your config does not inherits from any basic config that contains `optimizer_config=dict(grad_clip=None)`, you can simply add `optimizer_config=dict(grad_clip=dict(max_norm=35, norm_type=2))`.
+
+- ŌĆÖGPU out of memory"
+
+ 1. There are some scenarios when there are large amounts of ground truth boxes, which may cause OOM during target assignment. You can set `gpu_assign_thr=N` in the config of assigner thus the assigner will calculate box overlaps through CPU when there are more than N GT boxes.
+ 2. Set `with_cp=True` in the backbone. This uses the sublinear strategy in PyTorch to reduce GPU memory cost in the backbone.
+ 3. Try mixed precision training using following the examples in `config/fp16`. The `loss_scale` might need further tuning for different models.
+
+- "RuntimeError: Expected to have finished reduction in the prior iteration before starting a new one"
+
+ 1. This error indicates that your module has parameters that were not used in producing loss. This phenomenon may be caused by running different branches in your code in DDP mode.
+ 2. You can set ` find_unused_parameters = True` in the config to solve the above problems or find those unused parameters manually.
+
+## Evaluation
+
+- COCO Dataset, AP or AR = -1
+ 1. According to the definition of COCO dataset, the small and medium areas in an image are less than 1024 (32\*32), 9216 (96\*96), respectively.
+ 2. If the corresponding area has no object, the result of AP and AR will set to -1.
diff --git a/internlm_langchain/knowledge_base/MMFewShot/content/get_started.md b/internlm_langchain/knowledge_base/MMFewShot/content/get_started.md
new file mode 100644
index 00000000..231f75f4
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMFewShot/content/get_started.md
@@ -0,0 +1,143 @@
+## Test a model
+
+- single GPU
+- CPU
+- single node multiple GPU
+- multiple node
+
+You can use the following commands to infer a dataset.
+
+```shell
+# single-gpu
+python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [optional arguments]
+
+# CPU: disable GPUs and run single-gpu testing script
+export CUDA_VISIBLE_DEVICES=-1
+python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [optional arguments]
+
+# multi-gpu
+sh ./tools/dist_test.sh ${CONFIG_FILE} ${CHECKPOINT_FILE} ${GPU_NUM} [optional arguments]
+
+# multi-node in slurm environment
+python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [optional arguments] --launcher slurm
+```
+
+Examples:
+
+For classification, inference Baseline on CUB under 5way 1shot setting.
+
+```shell
+python ./tools/classification/test.py \
+ configs/classification/baseline/cub/baseline_conv4_1xb64_cub_5way-1shot.py \
+ checkpoints/SOME_CHECKPOINT.pth
+```
+
+For detection, inference TFA on VOC split1 1shot setting.
+
+```shell
+python ./tools/detection/test.py \
+ configs/detection/tfa/voc/split1/tfa_r101_fpn_voc-split1_1shot-fine-tuning.py \
+ checkpoints/SOME_CHECKPOINT.pth --eval mAP
+```
+
+## Train a model
+
+### Train with a single GPU
+
+```shell
+python tools/train.py ${CONFIG_FILE} [optional arguments]
+```
+
+If you want to specify the working directory in the command, you can add an argument `--work_dir ${YOUR_WORK_DIR}`.
+
+### Train on CPU
+
+The process of training on the CPU is consistent with single GPU training. We just need to disable GPUs before the training process.
+
+```shell
+export CUDA_VISIBLE_DEVICES=-1
+python tools/train.py ${CONFIG_FILE} [optional arguments]
+```
+
+**Note**:
+
+We do not recommend users to use CPU for training because it is too slow. We support this feature to allow users to debug on machines without GPU for convenience.
+
+### Train with multiple GPUs
+
+```shell
+sh ./tools/dist_train.sh ${CONFIG_FILE} ${GPU_NUM} [optional arguments]
+```
+
+Optional arguments are:
+
+- `--no-validate` (**not suggested**): By default, the codebase will perform evaluation during the training. To disable this behavior, use `--no-validate`.
+- `--work-dir ${WORK_DIR}`: Override the working directory specified in the config file.
+- `--resume-from ${CHECKPOINT_FILE}`: Resume from a previous checkpoint file.
+
+Difference between `resume-from` and `load-from`:
+`resume-from` loads both the model weights and optimizer status, and the epoch is also inherited from the specified checkpoint. It is usually used for resuming the training process that is interrupted accidentally.
+`load-from` only loads the model weights and the training epoch starts from 0. It is usually used for finetuning.
+
+### Train with multiple machines
+
+If you launch with multiple machines simply connected with ethernet, you can simply run following commands:
+
+On the first machine:
+
+```shell
+NNODES=2 NODE_RANK=0 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR sh tools/dist_train.sh $CONFIG $GPUS
+```
+
+On the second machine:
+
+```shell
+NNODES=2 NODE_RANK=1 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR sh tools/dist_train.sh $CONFIG $GPUS
+```
+
+Usually it is slow if you do not have high speed networking like InfiniBand.
+
+If you run MMClassification on a cluster managed with [slurm](https://slurm.schedmd.com/), you can use the script `slurm_train.sh`. (This script also supports single machine training.)
+
+```shell
+[GPUS=${GPUS}] sh ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} ${CONFIG_FILE} ${WORK_DIR}
+```
+
+You can check [slurm_train.sh](https://github.com/open-mmlab/mmclassification/blob/master/tools/slurm_train.sh) for full arguments and environment variables.
+
+If you have just multiple machines connected with ethernet, you can refer to
+PyTorch [launch utility](https://pytorch.org/docs/stable/distributed_deprecated.html#launch-utility).
+Usually it is slow if you do not have high speed networking like InfiniBand.
+
+### Launch multiple jobs on a single machine
+
+If you launch multiple jobs on a single machine, e.g., 2 jobs of 4-GPU training on a machine with 8 GPUs,
+you need to specify different ports (29500 by default) for each job to avoid communication conflict.
+
+If you use `dist_train.sh` to launch training jobs, you can set the port in commands.
+
+```shell
+CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 sh ./tools/dist_train.sh ${CONFIG_FILE} 4
+CUDA_VISIBLE_DEVICES=4,5,6,7 PORT=29501 sh ./tools/dist_train.sh ${CONFIG_FILE} 4
+```
+
+If you use launch training jobs with Slurm, you need to modify the config files (usually the 6th line from the bottom in config files) to set different communication ports.
+
+In `config1.py`,
+
+```python
+dist_params = dict(backend='nccl', port=29500)
+```
+
+In `config2.py`,
+
+```python
+dist_params = dict(backend='nccl', port=29501)
+```
+
+Then you can launch two jobs with `config1.py` ang `config2.py`.
+
+```shell
+CUDA_VISIBLE_DEVICES=0,1,2,3 GPUS=4 sh ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} config1.py ${WORK_DIR}
+CUDA_VISIBLE_DEVICES=4,5,6,7 GPUS=4 sh ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} config2.py ${WORK_DIR}
+```
diff --git a/internlm_langchain/knowledge_base/MMFewShot/content/install.md b/internlm_langchain/knowledge_base/MMFewShot/content/install.md
new file mode 100644
index 00000000..113a3fc9
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMFewShot/content/install.md
@@ -0,0 +1,157 @@
+## õŠØĶĄ¢
+
+- Linux | Windows | macOS
+- Python 3.7+
+- PyTorch 1.5+
+- CUDA 9.2+
+- GCC 5+
+- [mmcv](https://mmcv.readthedocs.io/en/latest/#installation) 1.3.12+
+- [mmdet](https://mmdetection.readthedocs.io/en/latest/#installation) 2.16.0+
+- [mmcls](https://mmclassification.readthedocs.io/en/latest/#installation) 0.15.0+
+
+MMFewShot ÕÆī MMCV, MMCls, MMDet ńēłµ£¼Õģ╝Õ«╣µĆ¦Õ”éõĖŗµēĆńż║’╝īķ£ĆĶ”üÕ«ēĶŻģµŁŻńĪ«ńÜäńēłµ£¼õ╗źķü┐ÕģŹÕ«ēĶŻģÕć║ńÄ░ķŚ«ķóśŃĆé
+
+| MMFewShot ńēłµ£¼ | MMCV ńēłµ£¼ | MMClassification ńēłµ£¼ | MMDetection ńēłµ£¼ |
+| :------------: | :---------------: | :-------------------: | :--------------: |
+| master | mmcv-full>=1.3.12 | mmdet >= 2.16.0 | mmcls >=0.15.0 |
+
+\*\*µ│©µäÅ’╝Ü\*\*Õ”éµ×£ÕĘ▓ń╗ÅÕ«ēĶŻģõ║å mmcv’╝īķ”¢Õģłķ£ĆĶ”üõĮ┐ńö© `pip uninstall mmcv` ÕŹĖĶĮĮÕĘ▓Õ«ēĶŻģńÜä mmcv’╝īÕ”éµ×£ÕÉīµŚČÕ«ēĶŻģõ║å mmcv ÕÆī mmcv-full’╝īÕ░åõ╝ܵŖź `ModuleNotFoundError` ķöÖĶ»»ŃĆé
+
+## Õ«ēĶŻģµĄüń©ŗ
+
+### õ╗ÄķøČÕ╝ĆÕ¦ŗĶ«ŠńĮ«Ķäܵ£¼
+
+ÕüćĶ«ŠÕĮōÕēŹÕĘ▓ń╗ŵłÉÕŖ¤Õ«ēĶŻģ CUDA 10.1’╝īĶ┐ÖķćīµÅÉõŠøõ║åõĖĆõĖ¬Õ«īµĢ┤ńÜäÕ¤║õ║Ä conda Õ«ēĶŻģ MMFewShot ńÜäĶäܵ£¼ŃĆéµé©ÕÅ»õ╗źÕÅéĶĆāõĖŗõĖĆĶŖéõĖŁńÜäÕłåµŁźÕ«ēĶŻģĶ»┤µśÄŃĆé
+
+```shell
+conda create -n openmmlab python=3.7 -y
+conda activate openmmlab
+
+conda install pytorch==1.7.0 torchvision==0.8.0 torchaudio==0.7.0 cudatoolkit=10.1 -c pytorch
+
+pip install openmim
+mim install mmcv-full
+
+# install mmclassification mmdetection
+mim install mmcls
+mim install mmdet
+
+# install mmfewshot
+git clone https://github.com/open-mmlab/mmfewshot.git
+cd mmfewshot
+pip install -r requirements/build.txt
+pip install -v -e . # or "python setup.py develop"
+```
+
+### ÕćåÕżćńÄ»Õóā
+
+1. õĮ┐ńö© conda µ¢░Õ╗║ĶÖܵŗ¤ńÄ»Õóā’╝īÕ╣ČĶ┐øÕģźĶ»źĶÖܵŗ¤ńÄ»Õóā’╝ø
+
+ ```shell
+ conda create -n openmmlab python=3.7 -y
+ conda activate openmmlab
+ ```
+
+2. Õ¤║õ║Ä [PyTorch Õ«śńĮæ](https://pytorch.org/)Õ«ēĶŻģ PyTorch ÕÆī torchvision’╝īõŠŗÕ”é’╝Ü
+
+ ```shell
+ conda install pytorch torchvision -c pytorch
+ ```
+
+ **µ│©µäÅ**’╝Üķ£ĆĶ”üńĪ«õ┐Ø CUDA ńÜäń╝¢Ķ»æńēłµ£¼ÕÆīĶ┐ÉĶĪīńēłµ£¼Õī╣ķģŹŃĆéÕÅ»õ╗źÕ£© [PyTorch Õ«śńĮæ](https://pytorch.org/)µ¤źń£ŗķóäń╝¢Ķ»æÕīģµēƵö»µīüńÜä CUDA ńēłµ£¼ŃĆé
+
+ `õŠŗ 1` õŠŗÕ”éÕ£© `/usr/local/cuda` õĖŗÕ«ēĶŻģõ║å CUDA 10.1’╝ī Õ╣ȵā│Õ«ēĶŻģ PyTorch 1.7’╝īÕłÖķ£ĆĶ”üÕ«ēĶŻģµö»µīü CUDA 10.1 ńÜäķóäµ×äÕ╗║ PyTorch’╝Ü
+
+ ```shell
+ conda install pytorch==1.7.0 torchvision==0.8.0 torchaudio==0.7.0 cudatoolkit=10.1 -c pytorch
+ ```
+
+### Õ«ēĶŻģ MMFewShot
+
+µłæõ╗¼Õ╗║Ķ««õĮ┐ńö© [MIM](https://github.com/open-mmlab/mim) µØźÕ«ēĶŻģ MMFewShot’╝Ü
+
+```shell
+pip install openmim
+mim install mmfewshot
+```
+
+MIM ĶāĮÕż¤Ķć¬ÕŖ©Õ£░Õ«ēĶŻģ OpenMMLab ńÜäķĪ╣ńø«õ╗źÕÅŖÕ»╣Õ║öńÜäõŠØĶĄ¢ÕīģŃĆé
+
+µł¢ĶĆģ’╝īÕÅ»õ╗źµēŗÕŖ©Õ«ēĶŻģ MMFewShot’╝Ü
+
+1. Õ«ēĶŻģ mmcv-full’╝īµłæõ╗¼Õ╗║Ķ««õĮ┐ńö©ķóäµ×äÕ╗║ÕīģµØźÕ«ēĶŻģ’╝Ü
+
+ ```shell
+ # pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/{cu_version}/{torch_version}/index.html
+ pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu102/torch1.10.0/index.html
+ ```
+
+ PyTorch Õ£© 1.x.0 ÕÆī 1.x.1 õ╣ŗķŚ┤ķĆÜÕĖĖµś»Õģ╝Õ«╣ńÜä’╝īµĢģ mmcv-full ÕŬµÅÉõŠø 1.x.0 ńÜäń╝¢Ķ»æÕīģŃĆéÕ”éµ×£õĮĀńÜä PyTorch ńēłµ£¼µś» 1.x.1’╝īõĮĀÕÅ»õ╗źµöŠÕ┐āÕ£░Õ«ēĶŻģÕ£© 1.x.0 ńēłµ£¼ń╝¢Ķ»æńÜä mmcv-fullŃĆé
+
+ ```
+ # µłæõ╗¼ÕÅ»õ╗źÕ┐ĮńĢź PyTorch ńÜäÕ░Åńēłµ£¼ÕÅĘ
+ pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu102/torch1.10/index.html
+ ```
+
+ Ķ»ĘÕÅéķśģ [MMCV](https://github.com/open-mmlab/mmcv#install-with-pip) õ║åĶ¦ŻõĖŹÕÉīńēłµ£¼ńÜä MMCV õĖÄõĖŹÕÉīńēłµ£¼ńÜä PyTorch ÕÆī CUDA ńÜäÕģ╝Õ«╣µāģÕåĄŃĆéÕÉīµŚČ’╝īµé©ÕÅ»õ╗źõĮ┐ńö©õ╗źõĖŗÕæĮõ╗żõ╗ĵ║ÉńĀüń╝¢Ķ»æ MMCV’╝Ü
+
+2. Õ«ēĶŻģ MMClassification ÕÆī MMDetection.
+
+ õĮĀÕÅ»õ╗źńø┤µÄźķĆÜĶ┐ćÕ”éõĖŗÕæĮõ╗żõ╗Ä pip Õ«ēĶŻģõĮ┐ńö© mmclassification ÕÆī mmdetection’╝Ü
+
+ ```shell
+ pip install mmcls mmdet
+ ```
+
+3. Õ«ēĶŻģ MMFewShot.
+
+ õĮĀÕÅ»õ╗źńø┤µÄźķĆÜĶ┐ćÕ”éõĖŗÕæĮõ╗żõ╗Ä pip Õ«ēĶŻģõĮ┐ńö© mmfewshot’╝Ü
+
+ ```shell
+ pip install mmfewshot
+ ```
+
+ µł¢ĶĆģõ╗Ä git õ╗ōÕ║ōń╝¢Ķ»æµ║ÉńĀü’╝Ü
+
+ ```shell
+ git clone https://github.com/open-mmlab/mmfewshot.git
+ cd mmfewshot
+ pip install -r requirements/build.txt
+ pip install -v -e . # or "python setup.py develop"
+
+ ```
+
+**Note:**
+
+(1) µīēńģ¦õĖŖĶ┐░Ķ»┤µśÄ’╝īMMDetection Õ«ēĶŻģÕ£© `dev` µ©ĪÕ╝ÅõĖŗ’╝īÕøĀµŁżÕ£©µ£¼Õ£░Õ»╣õ╗ŻńĀüÕüÜńÜäõ╗╗õĮĢõ┐«µö╣ķāĮõ╝Üńö¤µĢł’╝īµŚĀķ£Ćķ揵¢░Õ«ēĶŻģ’╝ø
+
+(2) Õ”éµ×£ÕĖīµ£øõĮ┐ńö© `opencv-python-headless` ĶĆīõĖŹµś» `opencv-python`’╝ī ÕÅ»õ╗źÕ£©Õ«ēĶŻģ MMCV õ╣ŗÕēŹÕ«ēĶŻģ’╝ø
+
+(3) õĖĆõ║øÕ«ēĶŻģõŠØĶĄ¢µś»ÕÅ»õ╗źķĆēµŗ®ńÜäŃĆéõŠŗÕ”éÕŬķ£ĆĶ”üÕ«ēĶŻģµ£ĆõĮÄĶ┐ÉĶĪīĶ”üµ▒éńÜäńēłµ£¼’╝īÕłÖÕÅ»õ╗źõĮ┐ńö© `pip install -v -e .` ÕæĮõ╗żŃĆéÕ”éµ×£ÕĖīµ£øõĮ┐ńö©ÕÅ»ķĆēµŗ®ńÜäÕāÅ `albumentations` ÕÆī `imagecorruptions` Ķ┐Öń¦ŹõŠØĶĄ¢ķĪ╣’╝īÕÅ»õ╗źõĮ┐ńö© `pip install -r requirements/optional.txt ` Ķ┐øĶĪīµēŗÕŖ©Õ«ēĶŻģ’╝īµł¢ĶĆģÕ£©õĮ┐ńö© `pip` µŚČµīćիܵēĆķ£ĆńÜäķÖäÕŖĀÕŖ¤ĶāĮ’╝łõŠŗÕ”é `pip install -v -e .[optional]`’╝ē’╝īµö»µīüķÖäÕŖĀÕŖ¤ĶāĮńÜäµ£ēµĢłķö«ÕĆ╝Õīģµŗ¼ `all`ŃĆü`tests`ŃĆü`build` õ╗źÕÅŖ `optional` ŃĆé
+
+### ÕÅ”õĖĆń¦ŹķĆēµŗ®’╝Ü Docker ķĢ£ÕāÅ
+
+µłæõ╗¼µÅÉõŠøõ║å [Dockerfile](https://github.com/open-mmlab/mmfewshot/blob/master/docker/Dockerfile) to build an image. Ensure that you are using [docker version](https://docs.docker.com/engine/install/) >=19.03.
+
+```shell
+# Õ¤║õ║Ä PyTorch 1.6, CUDA 10.1 ńö¤µłÉķĢ£ÕāÅ
+docker build -t mmfewshot docker/
+```
+
+Ķ┐ÉĶĪīÕæĮõ╗ż’╝Ü
+
+```shell
+docker run --gpus all --shm-size=8g -it -v {DATA_DIR}:/mmfewshot/data mmfewshot
+```
+
+## ķ¬īĶ»ü
+
+õĖ║õ║åķ¬īĶ»üµś»ÕÉ”µŁŻńĪ«Õ«ēĶŻģõ║å MMFewShot ÕÆīµēĆķ£ĆńÜäńÄ»Õóā’╝īµłæõ╗¼ÕÅ»õ╗źĶ┐ÉĶĪīńż║õŠŗńÜä Python õ╗ŻńĀüÕ£©ńż║õŠŗÕøŠÕāÅĶ┐øĶĪīµÄ©ńÉå’╝Ü
+
+ÕģĘõĮōńÜäń╗åĶŖéÕÅ»õ╗źÕÅéĶĆā [few shot classification demo](https://github.com/open-mmlab/mmfewshot/tree/main/demo#few-shot-classification-demo)
+õ╗źÕÅŖ [few shot detection demo](https://github.com/open-mmlab/mmfewshot/tree/main/demo#few-shot-detection-demo) ŃĆé
+Õ”éµ×£µłÉÕŖ¤Õ«ēĶŻģ MMFewShot’╝īÕłÖõĖŖķØóńÜäõ╗ŻńĀüÕÅ»õ╗źÕ«īµĢ┤Õ£░Ķ┐ÉĶĪīŃĆé
+
+## ÕćåÕżćµĢ░µŹ«ķøå
+
+ÕģĘõĮōńÜäń╗åĶŖéÕÅ»õ╗źÕÅéĶĆā [ÕćåÕżćµĢ░µŹ«](https://github.com/open-mmlab/mmfewshot/tree/main/tools/data) õĖŗĶĮĮÕ╣Čń╗äń╗ćµĢ░µŹ«ķøåŃĆé
diff --git a/internlm_langchain/knowledge_base/MMFewShot/content/model_zoo.md b/internlm_langchain/knowledge_base/MMFewShot/content/model_zoo.md
new file mode 100644
index 00000000..39745c1a
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMFewShot/content/model_zoo.md
@@ -0,0 +1,61 @@
+# Model Zoo
+
+## Few Shot Classification Model Zoo
+
+#### Baseline
+
+Please refer to [Baseline](https://github.com/open-mmlab/mmfewshot/tree/main/configs/classification/baseline) for details.
+
+#### Baseline++
+
+Please refer to [Baseline++](https://github.com/open-mmlab/mmfewshot/tree/main/configs/classification/baseline_plus) for details.
+
+#### ProtoNet
+
+Please refer to [ProtoNet](https://github.com/open-mmlab/mmfewshot/tree/main/configs/classification/proto_net) for details.
+
+#### RelationNet
+
+Please refer to [RelationNet](https://github.com/open-mmlab/mmfewshot/tree/main/configs/classification/relation_net) for details.
+
+#### MatchingNet
+
+Please refer to [MatchingNet](https://github.com/open-mmlab/mmfewshot/tree/main/configs/classification/matching_net) for details.
+
+#### MAML
+
+Please refer to [MAML](https://github.com/open-mmlab/mmfewshot/tree/main/configs/classification/maml) for details.
+
+#### NegMargin
+
+Please refer to [NegMargin](https://github.com/open-mmlab/mmfewshot/tree/main/configs/classification/neg_margin) for details.
+
+#### Meta Baseline
+
+Please refer to [Meta Baseline](https://github.com/open-mmlab/mmfewshot/tree/main/configs/classification/meta_baseline) for details.
+
+## Few Shot Detection Model Zoo
+
+#### TFA
+
+Please refer to [TFA](https://github.com/open-mmlab/mmfewshot/tree/main/configs/detection/tfa) for details.
+
+#### FSCE
+
+Please refer to [FSCE](https://github.com/open-mmlab/mmfewshot/tree/main/configs/detection/fsce) for details.
+
+#### Meta RCNN
+
+Please refer to [Meta RCNN](https://github.com/open-mmlab/mmfewshot/tree/main/configs/detection/meta_rcnn) for details.
+
+#### FSDetView
+
+Please refer to [FSDetView](https://github.com/open-mmlab/mmfewshot/tree/main/configs/detection/fsdetview) for details.
+
+#### Attention RPN
+
+Please refer to [Attention RPN](https://github.com/open-mmlab/mmfewshot/tree/main/configs/detection/attention_rpn) for details.
+
+#### MPSR
+
+Please refer to [MPSR](https://github.com/open-mmlab/mmfewshot/tree/main/configs/detection/mpsr) for details.
diff --git a/internlm_langchain/knowledge_base/MMFewShot/content/overview.md b/internlm_langchain/knowledge_base/MMFewShot/content/overview.md
new file mode 100644
index 00000000..fb95a0f9
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMFewShot/content/overview.md
@@ -0,0 +1,121 @@
+# Tutorial 0: Overview of MMFewShot Classification
+
+The main difference between general classification task and few shot classification task
+is the data usage.
+Therefore, the design of MMFewShot target at data sampling, meta test and models apis for few shot setting based on [mmcls](https://github.com/open-mmlab/mmclassification).
+Additionally, the modules in [mmcls](https://github.com/open-mmlab/mmclassification) can be imported and reused in the code or config.
+
+## Design of Data Sampling
+
+In MMFewShot, we suggest customizing the data pipeline using a dataset wrapper and modify the arguments in forward
+function when returning the dict with customize keys.
+
+```python
+class CustomizeDataset:
+
+ def __init__(self, dataset, ...):
+ self.dataset = dataset
+ self.customize_list = generate_function(dataset)
+
+ def generate_function(self, dataset):
+ pass
+
+ def __getitem__(self, idx):
+ return {
+ 'support_data': [self.dataset[i] for i in self.customize_list],
+ 'query_data': [self.dataset[i] for i in self.customize_list]
+ }
+```
+
+More details can refer to [Tutorial 2: Adding New Dataset](https://mmfewshot.readthedocs.io/en/latest/classification/customize_dataset.html)
+
+## Design of Models API
+
+Each model in MMFewShot should implement following functions to support meta testing.
+More details can refer to [Tutorial 3: Customize Models](https://mmfewshot.readthedocs.io/en/latest/classification/customize_models.html)
+
+```python
+@CLASSIFIERS.register_module()
+class BaseFewShotClassifier(BaseModule):
+
+ def forward(self, mode, ...):
+ if mode == 'train':
+ return self.forward_train(...)
+ elif mode == 'query':
+ return self.forward_query(...)
+ elif mode == 'support':
+ return self.forward_support(...)
+ ...
+
+ def forward_train(self, **kwargs):
+ pass
+
+ # --------- for meta testing ----------
+ def forward_support(self, **kwargs):
+ pass
+
+ def forward_query(self, **kwargs):
+ pass
+
+ def before_meta_test(self, meta_test_cfg, **kwargs):
+ pass
+
+ def before_forward_support(self, **kwargs):
+ pass
+
+ def before_forward_query(self, **kwargs):
+ pass
+
+```
+
+## Design of Meta Testing
+
+Meta testing performs prediction on random sampled tasks multiple times.
+Each task contains support and query data.
+More details can refer to `mmfewshot/classification/apis/test.py`.
+Here is the basic pipeline for meta testing:
+
+```text
+# the model may from training phase and may generate or fine-tine weights
+1. Copy model
+# prepare for the meta test (generate or freeze weights)
+2. Call model.before_meta_test()
+# some methods with fixed backbone can pre-compute the features for acceleration
+3. Extracting features of all images for acceleration(optional)
+# test different random sampled tasks
+4. Test tasks (loop)
+ # make sure all the task share the same initial weight
+ a. Copy model
+ # prepare model for support data
+ b. Call model.before_forward_support()
+ # fine-tune or none fine-tune models with given support data
+ c. Forward support data: model(*data, mode='support')
+ # prepare model for query data
+ d. Call model.before_forward_query()
+ # predict results of query data
+ e. Forward query data: model(*data, mode='query')
+```
+
+### meta testing on multiple gpus
+
+In MMFewShot, we also support multi-gpu meta testing during
+validation or testing phase.
+In multi-gpu meta testing, the model will be copied and wrapped with `MetaTestParallel`, which will
+send data to the device of model.
+Thus, the original model will not be affected by the operations in Meta Testing.
+More details can refer to `mmfewshot/classification/utils/meta_test_parallel.py`
+Specifically, each gpu will be assigned with (num_test_tasks / world_size) task.
+Here is the distributed logic for multi gpu meta testing:
+
+```python
+sub_num_test_tasks = num_test_tasks // world_size
+sub_num_test_tasks += 1 if num_test_tasks % world_size != 0 else 0
+for i in range(sub_num_test_tasks):
+ task_id = (i * world_size + rank)
+ if task_id >= num_test_tasks:
+ continue
+ # test task with task_id
+ ...
+```
+
+If user want to customize the way to test a task, more details can refer to [Tutorial 4: Customize Runtime Settings](https://mmfewshot.readthedocs.io/en/latest/classification/customize_runtime.html)
diff --git a/internlm_langchain/knowledge_base/MMFewShot/vector_store/index.faiss b/internlm_langchain/knowledge_base/MMFewShot/vector_store/index.faiss
new file mode 100644
index 00000000..c104c926
Binary files /dev/null and b/internlm_langchain/knowledge_base/MMFewShot/vector_store/index.faiss differ
diff --git a/internlm_langchain/knowledge_base/MMFlow/content/0_config_.md b/internlm_langchain/knowledge_base/MMFlow/content/0_config_.md
new file mode 100644
index 00000000..ae8ebb2d
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMFlow/content/0_config_.md
@@ -0,0 +1,261 @@
+# µĢÖń©ŗ0: Õ”éõĮĢõĮ┐ńö© Configs
+
+µłæõ╗¼ńÜäķģŹńĮ«µ¢ćõ╗Č (configs) õĖŁµö»µīüõ║嵩ĪÕØŚÕī¢ÕÆīń╗¦µē┐Ķ«ŠĶ«Ī’╝īĶ┐ÖõŠ┐õ║ÄĶ┐øĶĪīÕÉäń¦ŹÕ«×ķ¬īŃĆéÕ”éµ×£ķ£ĆĶ”üµŻĆµ¤źķģŹńĮ«µ¢ćõ╗Č’╝īÕÅ»õ╗źķĆÜĶ┐ćĶ┐ÉĶĪī `python tools/misc/print_config.py /PATH/TO/CONFIG` µØźµ¤źń£ŗÕ«īµĢ┤ńÜäķģŹńĮ«µ¢ćõ╗ČŃĆé
+
+## ķģŹńĮ«µ¢ćõ╗Čń╗ōµ×ä
+
+Õ£©ńø«ÕĮĢ `config/_base_` õĖŗµ£ēÕøøń¦ŹÕ¤║µ£¼µ©ĪÕØŚń▒╗Õ×ŗ’╝īÕŹ│µĢ░µŹ«ķøå (datasets) ŃĆüµ©ĪÕ×ŗ (models) ŃĆüĶ«Łń╗āĶ«ĪÕłÆ (schedules) õ╗źÕÅŖķ╗śĶ«żĶ┐ÉĶĪīķģŹńĮ« (default_runtime)ŃĆéÕŠłÕżÜµ©ĪÕ×ŗÕÅ»õ╗źÕŠłÕ«╣µśōÕ£░ÕÅéĶĆāÕģČõĖŁõĖĆń¦Źµ¢╣µ│Ģ (Õ”é PWC-Net )µØźµ×äÕ╗║ŃĆéĶ┐Öõ║øńö▒ `_base_` õĖŁńÜ䵩ĪÕØŚµ×䵳ÉńÜäķģŹńĮ«µ¢ćõ╗ČĶó½ń¦░õĖ║ *ÕĤզŗķģŹńĮ« (primitive configs)*ŃĆé
+
+Õ»╣õ║ÄÕÉīõĖƵ¢ćõ╗ČÕż╣õĖŗńÜäµēƵ£ēķģŹńĮ«’╝īÕ╗║Ķ««ÕŬµ£ē**1õĖ¬**ÕĤզŗķģŹńĮ«ŃĆéµēƵ£ēÕģČõ╗¢ķģŹńĮ«ķāĮÕ║öĶ»źõ╗ÄÕĤզŗķģŹńĮ«ń╗¦µē┐ŃĆéĶ┐ÖµĀĘ’╝īµ£ĆÕż¦ń╗¦µē┐ń║¦Õł½ (inheritance level) õĖ║ 3ŃĆé
+
+ń«ĆÕŹĢµØźĶ»┤’╝īµłæõ╗¼Õ╗║Ķ««Ķ┤Īńī«ĶĆģÕÄ╗ń╗¦µē┐ńÄ░µ£ēµ©ĪÕ×ŗńÜäķģŹńĮ«µ¢ćõ╗ČŃĆéõŠŗÕ”é’╝īÕ”éµ×£Õ£© PWC-Net ńÜäÕ¤║ńĪĆõĖŖÕüÜõ║åõĖĆõ║øµö╣ÕŖ©’╝īÕÅ»õ╗źķ”¢ÕģłķĆÜĶ┐ćÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁµīćÕ«ÜÕĤզŗķģŹńĮ« `_base_ = ../pwcnet/pwcnet_slong_8x1_flyingchairs_384x448.py` µØźń╗¦µē┐Õ¤║µ£¼ńÜä PWC-Net ń╗ōµ×ä’╝īńäČÕÉÄÕåŹµĀ╣µŹ«ķ£ĆĶ”üõ┐«µö╣ķģŹńĮ«µ¢ćõ╗ČõĖŁńÜäµīćÕ«ÜÕŁŚµ«Ą (fields)ŃĆé
+
+Õ”éµ×£ķ£ĆĶ”üµÉŁÕ╗║õĖŹĶāĮõĖÄńÄ░µ£ēµ©ĪÕ×ŗÕģ▒õ║½õ╗╗õĮĢń╗ōµ×äńÜäÕģ©µ¢░ńÜ䵩ĪÕ×ŗ’╝īµé©ÕÅ»õ╗źÕ£© `configs` õĖŗÕłøÕ╗║õĖĆõĖ¬µ¢░µ¢ćõ╗ČÕż╣ `xxx`ŃĆé
+
+µé©õ╣¤ÕÅ»õ╗źÕÅéĶĆā [mmcv](https://mmcv.readthedocs.io/en/latest/understand_mmcv/config.html) µ¢ćµĪŻõĖŁńÜäµø┤ÕżÜń╗åĶŖéŃĆé
+
+## ķģŹńĮ«µ¢ćõ╗ČÕæĮÕÉŹĶ¦äÕłÖ
+
+µłæõ╗¼µīēńģ¦õĖŗķØóńÜäķŻÄµĀ╝µØźÕæĮÕÉŹķģŹńĮ«µ¢ćõ╗ČŃĆéÕ╗║Ķ««Ķ┤Īńī«ĶĆģõĮ┐ńö©ńøĖÕÉīńÜäķŻÄµĀ╝ŃĆé
+
+```text
+{model}_{schedule}_[gpu x batch_per_gpu]_{training datasets}_[input_size].py
+```
+
+`{xxx}` ĶĪ©ńż║Õ┐ģÕĪ½ÕŁŚµ«Ą’╝īĶĆī `[yyy]` ĶĪ©ńż║ÕÅ»ķĆēÕŁŚµ«ĄŃĆé
+
+- `{model}`: µ©ĪÕ×ŗń▒╗Õ×ŗ’╝īÕ”é `pwcnet`, `flownets` ńŁēńŁēŃĆé
+- `{schedule}`: Ķ«Łń╗āĶ«ĪÕłÆŃĆéµīēńģ¦ FlowNet2 õĖŁńÜäń║”Õ«Ü’╝īµłæõ╗¼õĮ┐ńö© `slong`ŃĆü `sfine` ÕÆī `sshort`’╝īµł¢ĶĆģÕāÅ `150k` ĶĪ©ńż║150k(iterations) Ķ┐ÖµĀʵīćÕ«ÜĶ┐Łõ╗Żµ¼ĪµĢ░ŃĆé
+- `[gpu x batch_per_gpu]`: GPU µĢ░ķćÅõ╗źÕÅŖµ»ÅõĖ¬ GPUõĖŖÕłåķģŹńÜäµĀʵ£¼µĢ░’╝ī Õ”é `8x1`ŃĆé
+- `{training datasets}`: Ķ«Łń╗āµĢ░µŹ«ķøå’╝īÕ”é `flyingchairs`’╝ī `flyingthings3d_subset` µł¢ `flyingthings3d`ŃĆé
+- `[input_size]`: Ķ«Łń╗āµŚČÕøŠńēćÕż¦Õ░ÅŃĆé
+
+## ķģŹńĮ«µ¢ćõ╗Čń╗ōµ×ä
+
+õĖ║õ║åÕĖ«ÕŖ®ńö©µłĘÕ»╣Õ«īµĢ┤ńÜäķģŹńĮ«ÕÆī MMFlow õĖŁńÜ䵩ĪÕØŚµ£ēõĖĆõĖ¬Õ¤║µ£¼ńÜäõ║åĶ¦Ż’╝īµłæõ╗¼õ╗źÕ£© `flyingchairs` õĖŖõĮ┐ńö© `slong` Ķ«Łń╗āńÜä PWC-Net ńÜäķģŹńĮ«õĖ║õŠŗĶ┐øĶĪīń«ĆÕŹĢńÜäĶ«▓Ķ¦ŻŃĆéµ£ēÕģ│µ»ÅõĖ¬µ©ĪÕØŚńÜäµø┤Ķ»”ń╗åńÜäńö©µ│ĢÕÆīńøĖÕ║öńÜäµø┐õ╗Żµ¢╣µĪł’╝īĶ»ĘÕÅéķśģ API µ¢ćµĪŻÕÆī [MMDetection µĢÖń©ŗ](https://github.com/open-mmlab/mmdetection/blob/master/docs/tutorials/config.md)ŃĆé
+
+```python
+_base_ = [
+ '../_base_/models/pwcnet.py', '../_base_/datasets/flyingchairs_384x448.py',
+ '../_base_/schedules/schedule_s_long.py', '../_base_/default_runtime.py'
+]# µ¢░Õó×ķģŹńĮ«µ¢ćõ╗ČõŠØĶĄ¢ńÜäÕ¤║µ£¼ķģŹńĮ«µ¢ćõ╗Č
+```
+
+`_base_/models/pwc_net.py` µś» PWC-Net µ©ĪÕ×ŗńÜäÕ¤║µ£¼ķģŹńĮ«µ¢ćõ╗ČŃĆé
+
+```python
+model = dict(
+ type='PWCNet', # ń«Śµ│ĢÕÉŹń¦░
+ encoder=dict( # ń╝¢ńĀüÕÖ© (Encoder) µ©ĪÕØŚķģŹńĮ«
+ type='PWCNetEncoder', # PWC-Net ń╝¢ńĀüÕÖ©ÕÉŹń¦░
+ in_channels=3, # ĶŠōÕģźķĆÜķüōµĢ░
+ # ÕŁÉÕŹĘń¦»µ©ĪÕØŚńÜäń▒╗Õ×ŗ: Õ”éµ×£ net_type õĖ║ Basic’╝īÕÉäÕ░║Õ║”ńÜäÕŹĘń¦»Õ▒éµĢ░ķćÅõĖ║3’╝øÕ”éµ×£ net_type õĖ║
+ # Small’╝īÕÉäÕ░║Õ║”ńÜäÕŹĘń¦»Õ▒éµĢ░ķćÅõĖ║ 2
+ net_type='Basic',
+ pyramid_levels=[
+ 'level1', 'level2', 'level3', 'level4', 'level5', 'level6'
+ ], # ńē╣ÕŠüķćæÕŁŚÕĪöÕ░║Õ║”’╝īÕÉīµŚČõ╣¤µś»ń╝¢ńĀüÕÖ©ĶŠōÕć║ÕŁŚÕģĖ (dict) ńÜäķö«ÕĆ╝ (keys)
+ out_channels=(16, 32, 64, 96, 128, 196), # ÕÉäķćæÕŁŚÕĪöÕ░║Õ║” (pyramid level) ńÜäĶŠōÕć║ķĆÜķüōµĢ░ÕłŚĶĪ©
+ strides=(2, 2, 2, 2, 2, 2), # ÕÉäķćæÕŁŚÕĪöÕ░║Õ║” (pyramid level) ńÜ䵣źķĢ┐ (stride) ÕłŚĶĪ©
+ dilations=(1, 1, 1, 1, 1, 1), # ÕÉäķćæÕŁŚÕĪöÕ░║Õ║” (pyramid level) ńÜäĶå©ĶāĆńÄć (dilation) ÕłŚĶĪ©
+ act_cfg=dict(type='LeakyReLU', negative_slope=0.1)), # ķÆłÕ»╣ń╝¢ńĀüÕÖ©Õåģ ConvModule µ©ĪÕØŚńÜäµ┐Ƶ┤╗ÕćĮµĢ░ķģŹńĮ«
+ decoder=dict( # Ķ¦ŻńĀüÕÖ© (Decoder) µ©ĪÕØŚķģŹńĮ«
+ type='PWCNetDecoder', # ÕģēµĄüõ╝░Ķ«ĪĶ¦ŻńĀüÕÖ© (Decoder) ÕÉŹń¦░
+ in_channels=dict(
+ level6=81, level5=213, level4=181, level3=149, level2=117), # PWC-Net ńÜä basic dense block ńÜäĶŠōÕģźķĆÜķüōµĢ░
+ flow_div=20., # ńö©õ║Äń╝®µöŠń£¤Õ«×ÕĆ╝ (Ground Truth) ńÜäÕĖĖµĢ░ķÖżµĢ░
+ corr_cfg=dict(type='Correlation', max_displacement=4, padding=0),
+ warp_cfg=dict(type='Warp'),
+ act_cfg=dict(type='LeakyReLU', negative_slope=0.1),
+ scaled=False, # µś»ÕÉ”õĮ┐ńö©µīēÕÅéõĖÄńøĖÕģ│µĆ¦ (correlation) Ķ«Īń«ŚńÜäÕģāń┤ĀµĢ░ķćÅń╝®µöŠńøĖÕģ│µĆ¦Ķ«Īń«Śń╗ōµ×£
+ post_processor=dict(type='ContextNet', in_channels=565), # ÕÉÄÕżäńÉåńĮæń╗£ķģŹńĮ«
+ flow_loss=dict( # µŹ¤Õż▒ÕćĮµĢ░ķģŹńĮ«
+ type='MultiLevelEPE',
+ p=2,
+ reduction='sum',
+ weights={ # õĖŹÕÉīÕ░║Õ║”õĖŗńÜäÕģēµĄüµŹ¤Õż▒ÕŖĀµØāµØāķćŹ
+ 'level2': 0.005,
+ 'level3': 0.01,
+ 'level4': 0.02,
+ 'level5': 0.08,
+ 'level6': 0.32
+ }),
+ ),
+ # µ©ĪÕ×ŗĶ«Łń╗āµĄŗĶ»ĢķģŹńĮ«ŃĆé
+ train_cfg=dict(),
+ test_cfg=dict(),
+ init_cfg=dict(
+ type='Kaiming',
+ nonlinearity='leaky_relu',
+ layer=['Conv2d', 'ConvTranspose2d'],
+ mode='fan_in',
+ bias=0))
+```
+
+ÕĤզŗķģŹńĮ«µ¢ćõ╗Č `_base_/datasets/flyingchairs_384x448.py` õĖŁµś»:
+
+```python
+dataset_type = 'FlyingChairs' # µĢ░µŹ«ķøåÕÉŹń¦░
+data_root = 'data/FlyingChairs/data' # µĢ░µŹ«ķøåµĀ╣ńø«ÕĮĢ
+
+img_norm_cfg = dict(mean=[0., 0., 0.], std=[255., 255., 255], to_rgb=False) # ĶŠōÕģźÕøŠÕāŵĀćÕćåÕī¢µēĆķ£ĆĶ”üńÜäÕØćÕĆ╝ŃĆüµĀćÕćåÕĘ«õ┐Īµü»
+
+train_pipeline = [ # Ķ«Łń╗āÕøŠńēćÕżäńÉåń«Īķüō (Pipeline)
+ dict(type='LoadImageFromFile'), # ÕŖĀĶĮĮÕøŠńēć
+ dict(type='LoadAnnotations'), # ÕŖĀĶĮĮÕģēµĄüµĢ░µŹ«
+ dict(type='ColorJitter', # ķÜŵ£║µö╣ÕÅśĶŠōÕģźÕøŠńēćõ║«Õ║”ŃĆüÕ»╣µ»öÕ║”ŃĆüķź▒ÕÆīÕ║”õ╗źÕÅŖĶē▓Ķ░ā
+ brightness=0.5, # õ║«Õ║”Ķ░āµĢ┤ĶīāÕø┤
+ contrast=0.5, # Õ»╣µ»öÕ║”Ķ░āµĢ┤ĶīāÕø┤
+ saturation=0.5, # ķź▒ÕÆīÕ║”Ķ░āµĢ┤ĶīāÕø┤
+ hue=0.5), # Ķē▓Ķ░āĶ░āµĢ┤ĶīāÕø┤
+ dict(type='RandomGamma', gamma_range=(0.7, 1.5)), # ķÜŵ£║õ╝Įķ®¼µĀĪµŁŻķģŹńĮ«
+ dict(type='Normalize', **img_norm_cfg), # ÕøŠÕāŵĀćÕćåÕī¢ķģŹńĮ«’╝īÕģĘõĮōµĢ░ÕĆ╝µØźĶć¬ img_norm_cfg
+ dict(type='GaussianNoise', sigma_range=(0, 0.04), clamp_range=(0., 1.)), # Õó×ÕŖĀķ½śµ¢»ÕÖ¬ÕŻ░’╝īķ½śµ¢»ÕÖ¬ÕŻ░ńÜäµĀćÕćåÕĘ«ķććµĀĘĶć¬ [0, 0.04] Õī║ķŚ┤
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'), # ķÜŵ£║µ░┤Õ╣│ń┐╗ĶĮ¼ķģŹńĮ«
+ dict(type='RandomFlip', prob=0.5, direction='vertical'), # ķÜŵ£║ń½¢ńø┤ń┐╗ĶĮ¼ķģŹńĮ«
+ # ķÜŵ£║õ╗┐Õ░äÕÅśµŹóķģŹńĮ«
+ # global_transform ÕÆī relative_transform ńÜäķö«ÕĆ╝Õ║öĶ»źµś»õĖŗÕłŚÕģČõĖŁõ╣ŗõĖĆ:
+ # ('translates', 'zoom', 'shear', 'rotate')ŃĆéÕÉīµŚČ’╝īµ»ÅõĖ¬ķö«ÕĆ╝ÕÆīÕ»╣Õ║öńÜäµĢ░
+ # ÕĆ╝ķ£ĆĶ”üµ╗ĪĶČ│õĖŗķØóńÜäĶ¦äÕłÖ:
+ # - Õ╣│ń¦╗: µ▓┐ÕøŠÕāÅÕØɵĀćń│╗ x ĶĮ┤ŃĆüy ĶĮ┤ńÜäÕ╣│ń¦╗µ»öńÄćŃĆéķ╗śĶ«żõĖ║ (0., 0.)ŃĆé
+ # - ń╝®µöŠ: µ£ĆÕ░ÅŃĆüµ£ĆÕż¦ńÜäÕøŠńēćń╝®µöŠµ»öŃĆéķ╗śĶ«żõĖ║ (1.0, 1.0)ŃĆé
+ # - Õē¬Õłć: µ£ĆÕ░ÅŃĆüµ£ĆÕż¦ńÜäÕøŠńēćÕē¬Õłćµ»öŃĆé ķ╗śĶ«żõĖ║ (1.0, 1.0)ŃĆé
+ # - µŚŗĶĮ¼: µ£ĆÕ░ÅŃĆüµ£ĆÕż¦ńÜ䵌ŗĶĮ¼Ķ¦ÆÕ║”ŃĆé ķ╗śĶ«żõĖ║ (0., 0.)ŃĆé
+ dict(type='RandomAffine',
+ global_transform=dict(
+ translates=(0.05, 0.05),
+ zoom=(1.0, 1.5),
+ shear=(0.86, 1.16),
+ rotate=(-10., 10.)
+ ),
+ relative_transform=dict(
+ translates=(0.00375, 0.00375),
+ zoom=(0.985, 1.015),
+ shear=(1.0, 1.0),
+ rotate=(-1.0, 1.0)
+ )),
+ dict(type='RandomCrop', crop_size=(384, 448)), # ķÜÅÕŹ│ĶŻüÕē¬ĶŠōÕģźÕøŠÕāÅõĖÄÕģēµĄüÕł░ (384, 448) Õż¦Õ░Å
+ dict(type='DefaultFormatBundle'), # Õ«āµÅÉõŠøõ║åµĀ╝Õ╝ÅÕī¢ÕĖĖńö©ĶŠōÕģźÕŁŚµ«ĄńÜäń«ĆÕī¢µÄźÕÅŻ’╝īµö»µīü 'img1'ŃĆü'img2' ÕÆī 'flow_gt' ÕŁŚµ«Ą
+ dict(
+ type='Collect', # õ╗ÄÕŖĀĶĮĮÕÖ© (loader) µöČķøåõĖÄńē╣Õ«Üõ╗╗ÕŖĪńøĖÕģ│ńÜäµĢ░µŹ«
+ keys=['imgs', 'flow_gt'],
+ meta_keys=('img_fields', 'ann_fields', 'filename1', 'filename2',
+ 'ori_filename1', 'ori_filename2', 'filename_flow',
+ 'ori_filename_flow', 'ori_shape', 'img_shape',
+ 'img_norm_cfg')),
+]
+
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations'),
+ dict(type='InputResize', exponent=4),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='TestFormatBundle'), # Õ«āµÅÉõŠøõ║åµĀ╝Õ╝ÅÕī¢ÕĖĖńö©ĶŠōÕģźÕŁŚµ«ĄńÜäń«ĆÕī¢µÄźÕÅŻ’╝īµö»µīü 'img1'ŃĆü'img2' ÕÆī 'flow_gt' ÕŁŚµ«Ą
+ dict(
+ type='Collect',
+ keys=['imgs'], # õ╗ÄÕŖĀĶĮĮÕÖ© (loader) µöČķøåõĖÄńē╣Õ«Üõ╗╗ÕŖĪńøĖÕģ│ńÜäµĢ░µŹ«
+ meta_keys=('flow_gt', 'filename1', 'filename2', 'ori_filename1',
+ 'ori_filename2', 'ori_shape', 'img_shape', 'img_norm_cfg',
+ 'scale_factor', 'pad_shape')) # meta_keys õĖŁńÜä 'flow_gt' µś»ńö©õ║ÄÕ£©ń║┐µ©ĪÕ×ŗĶ»äõ╝░ (online evaluation) ńÜäÕŁŚµ«Ą
+]
+
+data = dict(
+ train_dataloader=dict(
+ samples_per_gpu=1, # ÕŹĢõĖĆ GPU õĖŖńÜäµĀʵ£¼µĢ░
+ workers_per_gpu=5, # µ»ÅõĖ¬ GPU õĖŖķóäÕÅ¢µĢ░µŹ«ńÜäń║┐ń©ŗµĢ░
+ drop_last=True), # µś»ÕÉ”ÕłĀķÖżµ£ĆÕÉÄõĖĆõĖ¬ķØ×Õ«īµĢ┤ńÜäµē╣µ¼Ī (batch)
+
+ val_dataloader=dict(
+ samples_per_gpu=1, # ÕŹĢõĖĆ GPU õĖŖńÜäµĀʵ£¼µĢ░
+ workers_per_gpu=2, # µ»ÅõĖ¬ GPU õĖŖķóäÕÅ¢µĢ░µŹ«ńÜäń║┐ń©ŗµĢ░
+ shuffle=False), # µś»ÕÉ”ÕłĀķÖżµ£ĆÕÉÄõĖĆõĖ¬ķØ×Õ«īµĢ┤ńÜäµē╣µ¼Ī (batch)
+
+ test_dataloader=dict(
+ samples_per_gpu=1, # ÕŹĢõĖĆ GPU õĖŖńÜäµĀʵ£¼µĢ░
+ workers_per_gpu=2, # µ»ÅõĖ¬ GPU õĖŖķóäÕÅ¢µĢ░µŹ«ńÜäń║┐ń©ŗµĢ░
+ shuffle=False), # µś»ÕÉ”µēōõ╣▒ĶŠōÕģźķĪ║Õ║Å
+
+ train=dict( # Ķ«Łń╗āµĢ░µŹ«ķøåķģŹńĮ«
+ type=dataset_type,
+ pipeline=train_pipeline,
+ data_root=data_root,
+ split_file='data/FlyingChairs_release/FlyingChairs_train_val.txt', # Ķ«Łń╗āŃĆüķ¬īĶ»üÕŁÉķøå
+ ),
+
+ val=dict(
+ type=dataset_type,
+ pipeline=test_pipeline,
+ data_root=data_root,
+ test_mode=True),
+
+ test=dict(
+ type=dataset_type,
+ pipeline=test_pipeline,
+ data_root=data_root,
+ test_mode=True)
+)
+```
+
+ÕĤզŗķģŹńĮ«µ¢ćõ╗Č `_base_/schedules/schedule_s_long.py` õĖŁµś»:
+
+```python
+# optimizer
+optimizer = dict(
+ type='Adam', lr=0.0001, weight_decay=0.0004, betas=(0.9, 0.999))
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ by_epoch=False,
+ gamma=0.5,
+ step=[400000, 600000, 800000, 1000000])
+runner = dict(type='IterBasedRunner', max_iters=1200000)
+checkpoint_config = dict(by_epoch=False, interval=100000)
+evaluation = dict(interval=100000, metric='EPE')
+```
+
+ÕĤզŗķģŹńĮ«µ¢ćõ╗Č `_base_/default_runtime.py` õĖŁµś»:
+
+```python
+log_config = dict( # ķģŹńĮ«µ│©ÕåīĶ«░ÕĮĢÕÖ©ķÆ®ÕŁÉ
+ interval=50, # µēōÕŹ░Ķ«Łń╗āµŚźÕ┐Śõ┐Īµü»ńÜäķóæńÄć
+ hooks=[
+ dict(type='TextLoggerHook'),
+ dict(type='TensorboardLoggerHook')
+ ]) # Ķ«░ÕĮĢĶ«Łń╗āĶ┐ćń©ŗńÜäĶ«░ÕĮĢÕÖ©ķģŹńĮ«
+dist_params = dict(backend='nccl') # Ķ«ŠńĮ«ÕłåÕĖāÕ╝ÅĶ«Łń╗āńÜäÕÅéµĢ░’╝īń½»ÕÅŻ (port) õ╣¤ÕÅ»õ╗źÕ£©Ķ┐ÖķćīķģŹńĮ«
+log_level = 'INFO' # µŚźÕ┐Śõ┐Īµü»ńŁēń║¦
+load_from = None # õ╗Äń╗ÖÕ«ÜĶĘ»ÕŠäÕŖĀĶĮĮµ©ĪÕ×ŗõĮ£õĖ║ķóäĶ«Łń╗āµ©ĪÕ×ŗ’╝īĶ┐ÖõĖŹÕÉīõ║ĵüóÕżŹĶ«Łń╗ā (resume training)
+workflow = [('train', 1)] # Ķ┐ÉĶĪīµ£¤ńÜäÕĘźõĮ£µĄüĶ«ŠńĮ«ŃĆé [('train', 1)] µś»µīćÕŬµ£ēõĖĆõĖ¬ÕĘźõĮ£µĄü 'train'’╝īõĖöÕ«āÕŬµē¦ĶĪīõĖƵ¼Ī
+```
+
+## ķĆÜĶ┐ćĶäܵ£¼ÕÅéµĢ░µØźõ┐«µö╣ķģŹńĮ«
+
+Õ£©õĮ┐ńö© `tools/train.py` µł¢ `tools/test.py` µŚČ’╝īÕÅ»õ╗źķĆÜĶ┐ćµīćÕ«Ü `--cfg-options` µØźÕ░▒Õ£░ (in-place) õ┐«µö╣ķģŹńĮ«ŃĆé
+
+- µø┤µ¢░ķģŹńĮ«ÕŁŚÕģĖķōŠ (dict chains) õĖŁńÜäķö« (keys)ŃĆé
+
+ ÕÅ»õ╗źµīēńģ¦ÕĤզŗķģŹńĮ«õĖŁÕŁŚÕģĖķö«ńÜäķĪ║Õ║ŵīćÕ«ÜķģŹńĮ«ķĆēķĪ╣ŃĆé
+ õŠŗÕ”é’╝ī `--cfg-option model.encoder.in_channels=6`ŃĆé
+
+- µø┤µ¢░ķģŹńĮ«ÕłŚĶĪ©õĖŁńÜäķö« (keys)ŃĆé
+
+ õĖĆõ║øķģŹńĮ«ÕŁŚÕģĖÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁń╗䵳ÉõĖĆõĖ¬ÕłŚĶĪ©ŃĆéõŠŗÕ”é’╝īĶ«Łń╗āµĢ░µŹ«ÕżäńÉåń«Īķüō (pipeline) `data.train.pipeline` ÕŠĆÕŠĆµś»õĖĆõĖ¬ÕāÅ `[dict(type='LoadImageFromFile'), ...]` õĖƵĀĘńÜäÕłŚĶĪ©ŃĆé Õ”éµ×£ÕĖīµ£øÕ░åÕģČõĖŁńÜä `'LoadImageFromFile'` µø┐µŹóõĖ║ `'LoadImageFromWebcam'`’╝īÕÅ»õ╗źķĆÜĶ┐ćµīćÕ«Ü `--cfg-option data.train.pipeline.0.type='LoadImageFromWebcam'` µØźÕ«×ńÄ░ŃĆé
+
+- µø┤µ¢░ÕłŚĶĪ©µł¢Õģāń╗äńÜäÕĆ╝ŃĆé
+
+ Õ”éµ×£ķ£ĆĶ”üµø┤µ¢░ńÜäÕĆ╝µś»õĖĆõĖ¬Õģāń╗䵳¢µś»ÕłŚĶĪ©ŃĆéõŠŗÕ”é’╝īķģŹńĮ«µ¢ćõ╗ČõĖŁķĆÜÕĖĖĶ«ŠńĮ«Ķ«Łń╗āÕĘźõĮ£µĄüõĖ║ `workflow=[('train', 1)]`ŃĆéÕ”éµ×£ÕĖīµ£øõ┐«µö╣Ķ┐ÖõĖ¬ķö«ÕĆ╝’╝īÕÅ»õ╗źķĆÜĶ┐ćµīćÕ«Ü `--cfg-options workflow="[(train,1),(val,1)]"` µØźÕ«×ńÄ░ŃĆé µ│©µäÅ’╝īÕ╝ĢÕÅĘ " Õ»╣õ║ÄÕłŚĶĪ©ŃĆüÕģāń╗äµĢ░µŹ«ń▒╗Õ×ŗµś»Õ┐ģķ£ĆńÜä’╝īõĖöÕ£©µīćÕ«ÜÕĆ╝ńÜäÕ╝ĢÕÅĘÕåģ**õĖŹÕģüĶ«Ė**µ£ēń®║µĀ╝ŃĆé
+
+## ÕĖĖĶ¦üķŚ«ķóś (FAQ)
+
+### Õ┐ĮńĢźÕĤզŗķģŹńĮ«õĖŁńÜäķā©ÕłåÕŁŚµ«Ą
+
+Õ”éµ×£ķ£ĆĶ”ü’╝īõĮĀÕÅ»õ╗źķĆÜĶ┐ćĶ«ŠńĮ« `_delete_=True` µØźÕ┐ĮńĢźÕĤզŗķģŹńĮ«µ¢ćõ╗ČõĖŁńÜäķā©ÕłåÕŁŚµ«ĄŃĆé
+ÕÅ»õ╗źÕÅéĶĆā [mmcv](https://mmcv.readthedocs.io/en/latest/utils.html#inherit-from-base-config-with-ignored-fields) õĖŁńÜäń«ĆÕŹĢĶ»┤µśÄŃĆé
+
+Ķ»Ęõ╗öń╗åķśģĶ»╗ [config µĢÖń©ŗ](https://github.com/open-mmlab/mmdetection/blob/master/docs/tutorials/config.md) õ╗źµø┤ÕźĮÕ£░õ║åĶ¦ŻĶ┐ÖõĖƵ¢╣µ│ĢŃĆé
+
+### õĮ┐ńö©ķģŹńĮ«µ¢ćõ╗ČõĖŁńÜäõĖŁķŚ┤ÕÅśķćÅ
+
+ķģŹńĮ«µ¢ćõ╗ČõĖŁõĮ┐ńö©õ║åõĖĆõ║øõĖŁķŚ┤ÕÅśķćÅ’╝īõŠŗÕ”éµĢ░µŹ«ķøåķģŹńĮ«õĖŁńÜä `train_pipeline`/`test_pipeline`ŃĆé
+ÕĆ╝ÕŠŚµ│©µäÅńÜ䵜»’╝īÕ£©õ┐«µö╣ÕŁÉķģŹńĮ«µ¢ćõ╗ČõĖŁńÜäõĖŁķŚ┤ÕÅśķćŵŚČ’╝īńö©µłĘķ£ĆĶ”üÕåŹµ¼ĪÕ░åõĖŁķŚ┤ÕÅśķćÅõ╝ĀķĆÆÕł░ńøĖÕ║öńÜäÕŁŚµ«ĄõĖŁŃĆéµø┤õĖ║ńø┤Ķ¦éńÜäõŠŗÕŁÉÕÅéĶ¦ü [config µĢÖń©ŗ](https://github.com/open-mmlab/mmdetection/blob/master/docs/tutorials/config.md)ŃĆé
diff --git a/internlm_langchain/knowledge_base/MMFlow/content/1_inference.md b/internlm_langchain/knowledge_base/MMFlow/content/1_inference.md
new file mode 100644
index 00000000..09ee328d
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMFlow/content/1_inference.md
@@ -0,0 +1,3 @@
+# µĢÖń©ŗ1 µ©ĪÕ×ŗµÄ©ńÉå
+
+µ¼óĶ┐ĵ£ēÕģ┤ĶČŻńÜäµ£ŗÕÅŗõĖĆĶĄĘń┐╗Ķ»æ MMFlow µ¢ćµĪŻŃĆéՔ鵣ēÕģ┤ĶČŻ’╝īĶ»ĘÕ£© [MMFlow issue](<>) µÅÉ issue ńĪ«Õ«Üń┐╗Ķ»æńÜäµ¢ćµĪŻŃĆé
diff --git a/internlm_langchain/knowledge_base/MMFlow/content/2_finetune.md b/internlm_langchain/knowledge_base/MMFlow/content/2_finetune.md
new file mode 100644
index 00000000..718d25f0
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMFlow/content/2_finetune.md
@@ -0,0 +1,3 @@
+# µĢÖń©ŗ2 µ©ĪÕ×ŗÕŠ«Ķ░ā
+
+µ¼óĶ┐ĵ£ēÕģ┤ĶČŻńÜäµ£ŗÕÅŗõĖĆĶĄĘń┐╗Ķ»æ MMFlow µ¢ćµĪŻŃĆéՔ鵣ēÕģ┤ĶČŻ’╝īĶ»ĘÕ£© [MMFlow issue](<>) µÅÉ issue ńĪ«Õ«Üń┐╗Ķ»æńÜäµ¢ćµĪŻŃĆé
diff --git a/internlm_langchain/knowledge_base/MMFlow/content/3_data_pipeline.md b/internlm_langchain/knowledge_base/MMFlow/content/3_data_pipeline.md
new file mode 100644
index 00000000..fec140ed
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMFlow/content/3_data_pipeline.md
@@ -0,0 +1,3 @@
+# µĢÖń©ŗ3 µĢ░µŹ«ķóäÕżäńÉå
+
+µ¼óĶ┐ĵ£ēÕģ┤ĶČŻńÜäµ£ŗÕÅŗõĖĆĶĄĘń┐╗Ķ»æ MMFlow µ¢ćµĪŻŃĆéՔ鵣ēÕģ┤ĶČŻ’╝īĶ»ĘÕ£© [MMFlow issue](<>) µÅÉ issue ńĪ«Õ«Üń┐╗Ķ»æńÜäµ¢ćµĪŻŃĆé
diff --git a/internlm_langchain/knowledge_base/MMFlow/content/4_new_modules.md b/internlm_langchain/knowledge_base/MMFlow/content/4_new_modules.md
new file mode 100644
index 00000000..6dfd2690
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMFlow/content/4_new_modules.md
@@ -0,0 +1,3 @@
+# µĢÖń©ŗ4 µĘ╗ÕŖĀµ¢░µ©ĪÕØŚ
+
+µ¼óĶ┐ĵ£ēÕģ┤ĶČŻńÜäµ£ŗÕÅŗõĖĆĶĄĘń┐╗Ķ»æ MMFlow µ¢ćµĪŻŃĆéՔ鵣ēÕģ┤ĶČŻ’╝īĶ»ĘÕ£© [MMFlow issue](<>) µÅÉ issue ńĪ«Õ«Üń┐╗Ķ»æńÜäµ¢ćµĪŻŃĆé
diff --git a/internlm_langchain/knowledge_base/MMFlow/content/5_customize_runtime.md b/internlm_langchain/knowledge_base/MMFlow/content/5_customize_runtime.md
new file mode 100644
index 00000000..a1509818
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMFlow/content/5_customize_runtime.md
@@ -0,0 +1,3 @@
+# µĢÖń©ŗ5 Ķć¬Õ«Üõ╣ēµ©ĪÕ×ŗĶ┐ÉĶĪīÕÅéµĢ░
+
+µ¼óĶ┐ĵ£ēÕģ┤ĶČŻńÜäµ£ŗÕÅŗõĖĆĶĄĘń┐╗Ķ»æ MMFlow µ¢ćµĪŻŃĆéՔ鵣ēÕģ┤ĶČŻ’╝īĶ»ĘÕ£© [MMFlow issue](<>) µÅÉ issue ńĪ«Õ«Üń┐╗Ķ»æńÜäµ¢ćµĪŻŃĆé
diff --git a/internlm_langchain/knowledge_base/MMFlow/content/README.md b/internlm_langchain/knowledge_base/MMFlow/content/README.md
new file mode 100644
index 00000000..de11dc67
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMFlow/content/README.md
@@ -0,0 +1,35 @@
+# ÕćåÕżć ChairsSDHom µĢ░µŹ«ķøå
+
+
+
+```bibtex
+@InProceedings{IMKDB17,
+ author = "E. Ilg and N. Mayer and T. Saikia and M. Keuper and A. Dosovitskiy and T. Brox",
+ title = "FlowNet 2.0: Evolution of Optical Flow Estimation with Deep Networks",
+ booktitle = "IEEE Conference on Computer Vision and Pattern Recognition (CVPR)",
+ month = "Jul",
+ year = "2017",
+ url = "http://lmb.informatik.uni-freiburg.de//Publications/2017/IMKDB17"
+}
+```
+
+```text
+ChairsSDHom
+| | Ōö£ŌöĆŌöĆ data
+| | | Ōö£ŌöĆŌöĆ train
+| | | | |ŌöĆŌöĆ flow
+| | | | | |ŌöĆŌöĆ xxxxx.pfm
+| | | | |ŌöĆŌöĆ t0
+| | | | | |ŌöĆŌöĆ xxxxx.png
+| | | | |ŌöĆŌöĆ t1
+| | | | | |ŌöĆŌöĆ xxxxx.png
+| | | Ōö£ŌöĆŌöĆ test
+| | | | |ŌöĆŌöĆ flow
+| | | | | |ŌöĆŌöĆ xxxxx.pfm
+| | | | |ŌöĆŌöĆ t0
+| | | | | |ŌöĆŌöĆ xxxxx.png
+| | | | |ŌöĆŌöĆ t1
+| | | | | |ŌöĆŌöĆ xxxxx.png
+```
+
+õ╗ĵĢ░µŹ«ķøå[Õ«śńĮæ](https://lmb.informatik.uni-freiburg.de/data/FlowNet2/ChairsSDHom/ChairsSDHom.tar.gz)õĖŗĶĮĮµ¢ćõ╗ČÕÄŗń╝®ÕīģÕÉÄ’╝īĶ¦ŻÕÄŗµ¢ćõ╗ČÕ╣ČÕ»╣ńģ¦õĖŖµ¢╣ńø«ÕĮĢµŻĆµ¤źĶ¦ŻÕÄŗÕÉÄńÜäµĢ░µŹ«ķøåńø«ÕĮĢŃĆé
diff --git a/internlm_langchain/knowledge_base/MMFlow/content/getting_started.md b/internlm_langchain/knowledge_base/MMFlow/content/getting_started.md
new file mode 100644
index 00000000..2542988f
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMFlow/content/getting_started.md
@@ -0,0 +1,145 @@
+# Õ┐½ķƤÕģźķŚ©
+
+µ£¼µ¢ćõ╗ŗń╗Ź MMFlow ńÜäÕ¤║µ£¼õĮ┐ńö©’╝īÕ«ēĶŻģµīćÕ╝ĢĶ»ĘÕÅéń£ŗ[Õ«ēĶŻģµ¢ćµĪŻ](install.md)
+
+
+
+- [Õ┐½ķƤÕģźķŚ©](#%E5%BF%AB%E9%80%9F%E5%85%A5%E9%97%A8)
+ - [ÕćåÕżćµĢ░µŹ«ķøå](#%E5%87%86%E5%A4%87%E6%95%B0%E6%8D%AE%E9%9B%86)
+ - [µ©ĪÕ×ŗµÄ©ńÉå](#%E6%A8%A1%E5%9E%8B%E6%8E%A8%E7%90%86)
+ - [µ╝öńż║µĀĘõŠŗ](#%E6%BC%94%E7%A4%BA%E6%A0%B7%E4%BE%8B)
+ - [µĢ░µŹ«ķøåõĖŖµĄŗĶ»Ģ](#%E6%95%B0%E6%8D%AE%E9%9B%86%E4%B8%8A%E6%B5%8B%E8%AF%95)
+ - [µ©ĪÕ×ŗĶ«Łń╗ā](#%E6%A8%A1%E5%9E%8B%E8%AE%AD%E7%BB%83)
+ - [ÕģČõ╗¢µĢÖń©ŗ](#%E5%85%B6%E4%BB%96%E6%95%99%E7%A8%8B)
+
+
+
+## ÕćåÕżćµĢ░µŹ«ķøå
+
+µłæõ╗¼µÄ©ĶŹÉńö©Õ░åńø«ÕĮĢ `$MMFlow/data` µīćÕÉæ’╝łsymlink’╝ēÕŁśµöŠńø«ÕĮĢńÜäÕ£░ÕØĆŃĆéĶ»ĘµĀ╣µŹ«õ╗źõĖŗµīćÕ╝ĢÕćåÕżćĶ«Łń╗āµĢ░µŹ«ķøåŃĆé
+
+- [FlyingChairs](../en/data_prepare/FlyingChairs/README.md)
+- [FlyingThings3d_subset](../en/data_prepare/FlyingThings3d_subset/README.md)
+- [FlyingThings3d](../en/data_prepare/FlyingThings3d/README.md)
+- [Sintel](../en/data_prepare/Sintel/README.md)
+- [KITTI2015](../en/data_prepare/KITTI2015/README.md)
+- [KITTI2012](../en/data_prepare/KITTI2012/README.md)
+- [FlyingChairsOcc](../en/data_prepare/FlyingChairsOcc/README.md)
+- [ChairsSDHom](../en/data_prepare/ChairsSDHom/README.md)
+- [HD1K](../en/data_prepare/hd1k/README.md)
+
+## µ©ĪÕ×ŗµÄ©ńÉå
+
+µłæõ╗¼µÅÉõŠøõ║åµĄŗĶ»ĢĶäܵ£¼’╝īÕÅ»õ╗źÕ£©µĀćÕćåńÜäµĢ░µŹ«ķøå Sintel, KITTI ńŁēõĖŖĶ┐øĶĪīµĄŗĶ»Ģ’╝īõ╣¤µÅÉõŠøÕÅ»ńø┤µÄźÕ»╣ÕøŠÕāŵł¢ĶĆģĶ¦åķóæĶ┐øĶĪīµÄ©ńÉåńÜä API ÕÆī Ķäܵ£¼ŃĆé
+
+### µ╝öńż║µĀĘõŠŗ
+
+µłæõ╗¼µÅÉõŠøõ║åµĀĘõŠŗĶäܵ£¼ÕÅ»õ╗źõ╣ŗķŚ┤µØźµÄ©ńÉåõĖżÕĖ¦õ╣ŗķŚ┤ńÜäÕģēµĄü
+
+1. [ÕøŠÕāŵĩńÉåµĀĘõŠŗ](../demo/image_demo.py)
+
+ ```shell
+ python demo/image_demo.py ${IMAGE1} ${IMAGE2} ${CONFIG_FILE} ${CHECKPOINT_FILE} ${OUTPUT_DIR} \
+ [--out_prefix] ${OUTPUT_PREFIX} [--device] ${DEVICE}
+ ```
+
+ ÕÅ»ķĆēÕÅéµĢ░’╝Ü
+
+ - `--out_prefix`: ĶŠōÕć║ń╗ōµ×£ńÜäÕēŹń╝Ć’╝īÕīģµŗ¼ÕģēµĄüµ¢ćõ╗ČÕÆīÕÅ»Ķ¦åÕī¢ÕÉÄńÜäÕģēµĄüÕøŠńēćŃĆé
+ - `--device`: ńö©õ║ĵĩńÉåńÜäĶ«ŠÕżć
+
+ õŠŗÕŁÉ’╝Ü
+
+ ÕüćĶ«Šµé©ÕĘ▓ń╗ÅÕ░å checkpoints õĖŗĶĮĮÕł░ńø«ÕĮĢõĖŁ `checkpoints/`,ŃĆĆÕ╣ČÕ░åĶŠōÕć║ńÜäń╗ōµ×£ÕŁśÕ£© `raft_demo`
+
+ ```shell
+ python demo/image_demo.py demo/frame_0001.png demo/frame_0002.png \
+ configs/raft/raft_8x2_100k_mixed_368x768.pth \
+ checkpoints/raft_8x2_100k_TSKH_368x768.pth raft_demo
+ ```
+
+2. [Ķ¦åķóæµÄ©ńÉåµĀĘõŠŗ](../demo/video_demo.py)
+
+ ```shell
+ python demo/video_demo.py ${VIDEO} ${CONFIG_FILE} ${CHECKPOINT_FILE} ${OUTPUT_FILE} \
+ [--gt] ${GROUND_TRUTH} [--device] ${DEVICE}
+ ```
+
+ ÕÅ»ķĆēÕÅéµĢ░’╝Ü
+
+ - `--gt`: ĶŠōÕģźĶ¦åķóæńÜä ground truth Ķ¦åķóæµ¢ćõ╗ČŃĆéÕ”éµ×£µīćÕ«Ü’╝īÕÅ»Ķ¦åÕī¢ń╗ōµ×£Õ░åõ╝ܵŖŖ ground truth
+ õĖÄķó䵥ŗń╗ōµ×£Ķ┐×µÄźÕ£©õĖĆĶĄĘĶŠōÕć║õĮ£õĖ║µ»öĶŠāŃĆé
+ - `--device`: ńö©õ║ĵĩńÉåńÜäĶ«ŠÕżć
+
+ õŠŗÕŁÉ’╝Ü
+
+ ÕüćĶ«Šµé©ÕĘ▓ń╗ÅÕ░å checkpoints õĖŗĶĮĮÕł░ńø«ÕĮĢõĖŁ `checkpoints/`,ŃĆĆÕ╣ČÕ░åĶŠōÕć║ńÜäń╗ōµ×£ÕŁśõĖ║ `raft_demo.mp4`
+
+ ```shell
+ python demo/video_demo.py demo/demo.mp4 \
+ configs/raft/raft_8x2_100k_mixed_368x768.py \
+ checkpoints/raft_8x2_100k_mixed_368x768.pth \
+ raft_demo.mp4 --gt demo/demo_gt.mp4
+ ```
+
+### µĢ░µŹ«ķøåõĖŖµĄŗĶ»Ģ
+
+ÕÅ»õ╗źÕł®ńö©õ╗źõĖŗÕæĮõ╗żµØźµĄŗĶ»Ģµ©ĪÕ×ŗÕ£©µĢ░µŹ«ķøåõĖŖńÜäń▓ŠÕ║”’╝īµø┤ÕżÜń╗åĶŖéÕÅ»õ╗źµ¤źń£ŗ [tutorials/1_inference](../en/tutorials/1_inference.md)ŃĆé
+
+```shell
+# single-gpu testing
+python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [optional arguments]
+```
+
+ÕÅ»ķĆēÕÅéµĢ░’╝Ü
+
+- `--out_dir`: ĶŠōÕć║µ¢ćõ╗Čõ┐ØÕŁśńø«ÕĮĢ’╝īĶó½µīćÕ«ÜÕÉÄ’╝īµ©ĪÕ×ŗĶŠōÕć║ńÜäÕģēµĄüÕ░åõ╗ź '.flo' µ¢ćõ╗ČńÜäÕĮóÕ╝Åõ╝Üõ┐ØÕŁśÕ£©Ķ»źńø«ÕĮĢŃĆé
+- `--fuse-conv-bn`: µś»ÕÉ”Õ░å conv ÕÆī bn Ķ׏ÕÉł’╝īÕ”éµ×£Õ«Üõ╣ēõĖ║ True,ŃĆĆĶ┐ÖķĪ╣µōŹõĮ£õ╝ÜÕ»╣µÄ©ńÉåĶĮ╗ÕŠ«ÕŖĀķƤŃĆé
+- `--show_dir`: ÕÅ»Ķ¦åÕī¢ÕģēµĄüÕøŠńÜäõ┐ØÕŁśńø«ÕĮĢ’╝īĶó½µīćÕ«ÜÕÉÄ’╝īµ©ĪÕ×ŗĶŠōÕć║ńÜäÕģēµĄüÕÅ»Ķ¦åÕī¢ÕÉÄÕ░åõ╗źÕøŠńēćńÜäÕĮóÕ╝Åõ┐ØÕŁśÕ£©Ķ»źńø«ÕĮĢŃĆé
+- `--eval`: Ķ»äõ╝░ńÜäµīćµĀć’╝īõŠŗÕ”é’╝ÜEPEŃĆé
+- `--cfg-option`: ķö«ÕĆ╝ xxx=yyy Õ░åĶó½ÕÉłÕ╣ČÕł░ķģŹńĮ«µ¢ćõ╗ČõĖŁŃĆéõŠŗÕ”é’╝Ü'--cfg-option model.encoder.in_channels=6'
+
+õŠŗÕŁÉ’╝Ü
+
+ÕüćĶ«Šµé©ÕĘ▓ń╗ÅÕ░å checkpoints õĖŗĶĮĮÕł░ńø«ÕĮĢõĖŁ `checkpoints/`ŃĆé
+µĄŗĶ»Ģ PWC-Net Õ£© Sintel µĢ░µŹ«ķøåńÜä clean ÕÆī final õĖżõĖ¬ÕŁÉµĢ░µŹ«ķøåõĖŖńÜä EPE µīćµĀć’╝īõĮåõĖŹõ┐ØÕŁśķó䵥ŗń╗ōµ×£ŃĆé
+
+```shell
+python tools/test.py configs/pwcnet_8x1_sfine_sintel_384x768.py \
+ checkpoints/pwcnet_8x1_sfine_sintel_384x768.pth --eval EPE
+
+```
+
+## µ©ĪÕ×ŗĶ«Łń╗ā
+
+õĮĀÕÅ»õ╗źõĮ┐ńö©[Ķ«Łń╗āĶäܵ£¼](../tools/train.py)ńø┤µÄźµØźÕÉ»ÕŖ©õĖĆõĖ¬ÕŹĢÕŹĪĶ«Łń╗āõ╗╗ÕŖĪ’╝īµø┤ÕżÜõ┐Īµü»Ķ»Ęµ¤źń£ŗ [tutorials/2_finetune](../en/tutorials/2_finetune.md)
+
+```shell
+python tools/train.py ${CONFIG_FILE} [optional arguments]
+```
+
+ÕÅ»ķĆēÕÅéµĢ░’╝Ü
+
+- `--work-dir`: ÕĘźõĮ£ńø«ÕĮĢ’╝īÕ”éµ×£µīćÕ«Üõ╝ÜĶ”åńø¢ķģŹńĮ«µ¢ćõ╗ČõĖŁńÜäÕĘźõĮ£ńø«ÕĮĢÕÅéµĢ░ŃĆé
+- `--load-from`: Õ░åĶ”üÕŖĀĶĮĮńÜä checkpoint µ¢ćõ╗ČÕÅéµĢ░ŃĆé
+- `--resume-from`: õ╗Äõ╣ŗÕēŹńÜä checkpoint µ¢ćõ╗ȵüóÕżŹĶ«Łń╗āŃĆé
+- `--no-validate`: µś»Õɔգ©Ķ«Łń╗āĶ┐ćń©ŗõĖŹÕ»╣µ©ĪÕ×ŗÕüÜĶ»äõ╝░ŃĆé
+- `--seed`: Python, Numpy ÕÆī Pytorch õĖŁńö¤µłÉķÜŵ£║µĢ░ńÜäķÜŵ£║ń¦ŹÕŁÉŃĆé
+- `--deterministic`: Õ”éµ×£µīćÕ«Ü’╝īÕ«āÕ░åõĖ║ CUDNN ÕÉÄń½»Ķ«ŠńĮ«ńĪ«Õ«ÜµĆ¦ķĆēķĪ╣ŃĆé
+- `--cfg-options`: ķö«ÕĆ╝ xxx=yyy Õ░åĶó½ÕÉłÕ╣ČÕł░ķģŹńĮ«µ¢ćõ╗ČõĖŁŃĆéõŠŗÕ”é’╝Ü'--cfg-option model.encoder.in_channels=6'
+
+`resume-from` ÕÆī `load-from` ńÜäõĖŹÕÉī’╝Ü
+
+`resume-from` ÕÉīµŚČÕŖĀĶĮĮµ©ĪÕ×ŗÕÅéµĢ░ŃĆüõ╝śÕī¢ÕÖ©ńŖȵĆüõ╗źÕÅŖÕĮōÕēŹ epoch/iterŃĆéķĆÜÕĖĖńö©õ║ĵüóÕżŹĶó½µäÅÕż¢õĖŁµ¢ŁńÜäĶ«Łń╗āĶ┐ćń©ŗŃĆé
+`load-from` ÕŬÕŖĀĶĮĮµ©ĪÕ×ŗńÜäÕÅéµĢ░,Ķ«Łń╗āÕ░åõ╝Üõ╗ÄÕż┤Õ╝ĆÕ¦ŗŃĆéķĆÜÕĖĖńö©õ║ĵ©ĪÕ×ŗÕŠ«Ķ░āŃĆé
+
+## ÕģČõ╗¢µĢÖń©ŗ
+
+µłæõ╗¼õĖ║ńö©µłĘµÅÉõŠøõ║åõĖĆõ║øµĢÖń©ŗµ¢ćµĪŻ:
+
+- [learn about configs](../en/tutorials/0_config.md)
+- [inference model](../en/tutorials/1_inference.md)
+- [finetune model](../en/tutorials/2_finetune.md)
+- [customize data pipelines](../en/tutorials/3_data_pipeline.md)
+- [add new modules](../en/tutorials/4_new_modules.md)
+- [customize runtime settings](../en/tutorials/5_customize_runtime.md).
diff --git a/internlm_langchain/knowledge_base/MMFlow/content/install.md b/internlm_langchain/knowledge_base/MMFlow/content/install.md
new file mode 100644
index 00000000..80be8ddb
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMFlow/content/install.md
@@ -0,0 +1,140 @@
+# Õ«ēĶŻģ
+
+
+
+- [Õ«ēĶŻģ](#%E5%AE%89%E8%A3%85)
+ - [õŠØĶĄ¢](#%E4%BE%9D%E8%B5%96)
+ - [ÕćåÕżćńÄ»Õóā](#%E5%87%86%E5%A4%87%E7%8E%AF%E5%A2%83)
+ - [Õ«ēĶŻģ MMFlow](#%E5%AE%89%E8%A3%85-mmflow)
+ - [õ╗ÄķøČÕ╝ĆÕ¦ŗÕ«ēĶŻģ](#%E4%BB%8E%E9%9B%B6%E5%BC%80%E5%A7%8B%E5%AE%89%E8%A3%85)
+ - [Õ«ēĶŻģķ¬īĶ»ü](#%E5%AE%89%E8%A3%85%E9%AA%8C%E8%AF%81)
+
+
+
+## õŠØĶĄ¢
+
+- Linux
+- Python 3.6+
+- PyTorch 1.5 µł¢µø┤ķ½ś
+- CUDA 9.0 µł¢µø┤ķ½ś
+- NCCL 2
+- GCC 5.4 µł¢µø┤ķ½ś
+- [mmcv](https://github.com/open-mmlab/mmcv) 1.3.15 µł¢µø┤ķ½ś
+
+## ÕćåÕżćńÄ»Õóā
+
+a. ÕłøÕ╗║Õ╣ȵ┐Ƶ┤╗ conda ĶÖܵŗ¤ńÄ»Õóā
+
+```shell
+conda create -n openmmlab python=3.7 -y
+conda activate openmmlab
+```
+
+b. µīēńģ¦ [PyTorch Õ«śµ¢╣µ¢ćµĪŻ](https://pytorch.org/) Õ«ēĶŻģ PyTorch ÕÆī torchvision
+
+µ│©’╝ÜńĪ«õ┐Ø CUDA ń╝¢Ķ»æńēłµ£¼ÕÆī CUDA Ķ┐ÉĶĪīńēłµ£¼ńøĖÕī╣ķģŹŃĆé ńö©µłĘÕÅ»õ╗źÕÅéńģ¦ [PyTorch Õ«śńĮæ](https://pytorch.org/) Õ»╣ķóäń╝¢Ķ»æÕīģµēƵö»µīüńÜä CUDA ńēłµ£¼Ķ┐øĶĪīµĀĖÕ»╣ŃĆé
+
+`õŠŗ1`’╝ÜÕ”éµ×£ `/usr/local/cuda` µ¢ćõ╗ČÕż╣õĖŗÕĘ▓Õ«ēĶŻģõ║å CUDA 10.2 ńēłµ£¼’╝īÕ╣Čķ£ĆĶ”üÕ«ēĶŻģµ£Ćµ¢░ńēłµ£¼ńÜä PyTorchŃĆé
+
+```shell
+conda install pytorch torchvision torchaudio cudatoolkit=10.2 -c pytorch
+```
+
+`õŠŗ2`’╝ÜÕ”éµ×£ `/usr/local/cuda` µ¢ćõ╗ČÕż╣õĖŗÕĘ▓Õ«ēĶŻģõ║å CUDA 9.2 ńēłµ£¼’╝īÕ╣Čķ£ĆĶ”üÕ«ēĶŻģ PyTorch 1.7.0ŃĆé
+
+```shell
+conda install pytorch==1.7.0 torchvision==0.8.0 torchaudio==0.7.0 cudatoolkit=9.2 -c pytorch
+```
+
+Õ”éµ×£õĮĀõ╗ĵ║ÉńĀüń╝¢Ķ»æ PyTorch ĶĆīõĖŹµś»Õ«ēĶŻģńÜäķóäń╝¢Ķ»æńēłµ£¼ńÜäĶ»Ø’╝īõĮĀÕÅ»õ╗źõĮ┐ńö©µø┤ÕżÜ CUDA ńēłµ£¼’╝łõŠŗÕ”é9.0’╝ēŃĆé
+
+c. Õ«ēĶŻģ MMCV’╝īµłæõ╗¼µÄ©ĶŹÉµīēńģ¦Õ”éõĖŗµ¢╣Õ╝ÅÕ«ēĶŻģķóäń╝¢Ķ»æńÜä MMCV
+
+```shell
+pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/{cu_version}/{torch_version}/index.html
+```
+
+Ķ»Ęµīēńģ¦ CUDA ÕÆī Pytorch ńÜäńēłµ£¼ µø┐µŹóķōŠµÄźõĖŁńÜä `{cu_version}` and `{torch_version}`’╝ī õŠŗÕ”é’╝īÕĮōńÄ»ÕóāõĖŁÕĘ▓Õ«ēĶŻģ CUDA 10.2 ÕÆī PyTorch 1.10.0 µŚČÕ«ēĶŻģµ£Ćµ¢░ńēłµ£¼ńÜä `mmcv-full`’╝īÕÅ»õ╗źõĮ┐ńö©õ╗źõĖŗÕæĮõ╗ż’╝Ü
+
+```shell
+pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu102/torch1.10.0/index.html
+```
+
+[Ķ┐Öķćī](https://github.com/open-mmlab/mmcv#installation) ÕÅ»õ╗źµ¤źń£ŗõĖŹÕÉī MMCV ńÜäÕ«ēĶŻģµ¢╣Õ╝ÅŃĆé
+
+µł¢ĶĆģ’╝īõ╣¤ÕÅ»õ╗źµīēõ╗źõĖŗÕæĮõ╗żõ╗ĵ║ÉńĀüń╝¢Ķ»æ MMCV
+
+```shell
+git clone https://github.com/open-mmlab/mmcv.git
+cd mmcv
+MMCV_WITH_OPS=1 pip install -e . # Ķ┐Öń¦Źµ¢╣Õ╝ÅÕÅ»õ╗źÕ«ēĶŻģÕīģÕɽ CUDA op ńÜä mmcv-full
+# pip install -e . # µł¢ĶĆģÕ«ēĶŻģõĖŹÕīģÕɽ CUDA op ńÜä mmcv
+cd ..
+```
+
+**ķćŹĶ”ü**ŃĆĆÕ”éµ×£õ╣ŗÕēŹÕ«ēĶŻģõ║å `mmcv`’╝īÕ£©Õ«ēĶŻģ `mmcv` õ╣ŗÕēŹķ£ĆĶ”üÕģłÕŹĖĶĮĮ `pip uninstall mmcv`ŃĆéÕøĀõĖ║ÕÉīµŚČÕ«ēĶŻģõ║å `mmcv` ÕÆī `mmcv-full`’╝ī
+õ╝ÜķüćÕł░ `ModuleNotFoundError` ńÜäķöÖĶ»»ŃĆé
+
+## Õ«ēĶŻģ MMFlow
+
+a. ÕģŗķÜå MMFlow õ╗ŻńĀüÕ║ō
+
+```shell
+git clone https://github.com/open-mmlab/mmflow.git
+cd mmflow
+```
+
+b. Õ«ēĶŻģńøĖÕģ│õŠØĶĄ¢ÕÆī MMFlow
+
+```shell
+pip install -r requirements/build.txt
+pip install -v -e . # or "python setup.py develop"
+```
+
+µ│©’╝Ü
+
+1. git commit ńÜä id Õ░åõ╝ÜĶó½ÕåÖÕł░ńēłµ£¼ÕÅĘõĖŁ’╝īÕ”é 0.6.0+2e7045cŃĆéĶ┐ÖõĖ¬ńēłµ£¼ÕÅĘõ╣¤õ╝ÜĶó½õ┐ØÕŁśÕł░Ķ«Łń╗āÕźĮńÜ䵩ĪÕ×ŗõĖŁŃĆé
+
+2. µĀ╣µŹ«õĖŖĶ┐░µŁźķ¬ż’╝ī MMFlow Õ░▒õ╝Üõ╗ź `dev` µ©ĪÕ╝ÅĶó½Õ«ēĶŻģ’╝īõ╗╗õĮĢµ£¼Õ£░ńÜäõ╗ŻńĀüõ┐«µö╣ķāĮõ╝Üń½ŗÕł╗ńö¤µĢł’╝īõĖŹķ£ĆĶ”üÕåŹķ揵¢░Õ«ēĶŻģõĖĆķüŹ’╝łķÖżķØ×ńö©µłĘµÅÉõ║żõ║å commits’╝īÕ╣ČõĖöµā│µø┤µ¢░ńēłµ£¼ÕÅĘ’╝ēŃĆé
+
+3. Õ”éµ×£ńö©µłĘµā│õĮ┐ńö© `opencv-python-headless` ĶĆīõĖŹµś» `opencv-python`’╝īÕŻգ©Õ«ēĶŻģ `MMCV` ÕēŹÕ«ēĶŻģ `opencv-python-headless`ŃĆé
+
+## õ╗ÄķøČÕ╝ĆÕ¦ŗÕ«ēĶŻģ
+
+ÕüćĶ«ŠÕĘ▓Õ«ēĶŻģõ║å 10.1 ńēłµ£¼ńÜä CUDA’╝īõ╗źõĖŗµś»Õ«īµĢ┤ńÜäÕ«ēĶŻģ MMFlow ńÜäÕæĮõ╗żŃĆé
+
+```shell
+conda create -n open-mmlab python=3.7 -y
+conda activate open-mmlab
+
+conda install pytorch==1.6.0 torchvision==0.7.0 cudatoolkit=10.1 -c pytorch -y
+
+# install latest mmcv
+pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu101/torch1.6.0/index.html
+
+# install mmflow
+git clone https://github.com/open-mmlab/mmflow.git
+cd mmflow
+pip install -r requirements/build.txt
+pip install -v -e .
+```
+
+## Õ«ēĶŻģķ¬īĶ»ü
+
+µłæõ╗¼ÕÅ»õ╗źÕł®ńö©õ╗źõĖŗµŁźķ¬żÕłØÕ¦ŗÕī¢µ©ĪÕ×ŗÕ╣ČÕ»╣ÕøŠÕāÅÕüܵĩńÉå’╝īµØźµŻĆµ¤ź MMFlow µś»ÕÉ”µŁŻńĪ«Õ«ēĶŻģŃĆé
+
+```python
+from mmflow.apis import inference_model, init_model
+
+config_file = 'configs/pwcnet/pwcnet_ft_4x1_300k_sintel_final_384x768.py'
+# download the checkpoint from model zoo and put it in `checkpoints/`
+# url: https://download.openmmlab.com/mmflow/pwcnet/pwcnet_ft_4x1_300k_sintel_final_384x768.pth
+checkpoint_file = 'checkpoints/pwcnet_ft_4x1_300k_sintel_final_384x768.pth'
+device = 'cuda:0'
+# init a model
+model = init_model(config_file, checkpoint_file, device=device)
+# inference the demo image
+inference_model(model, 'demo/frame_0001.png', 'demo/frame_0002.png')
+```
+
+õĖŖĶ┐░ÕæĮõ╗żÕ║öĶ»źÕ£©Õ«īµłÉÕ«ēĶŻģÕÉĵłÉÕŖ¤Ķ┐ÉĶĪīŃĆé
diff --git a/internlm_langchain/knowledge_base/MMFlow/content/model_zoo.md b/internlm_langchain/knowledge_base/MMFlow/content/model_zoo.md
new file mode 100644
index 00000000..6ecec0b3
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMFlow/content/model_zoo.md
@@ -0,0 +1,15 @@
+# µ©ĪÕ×ŗÕ║ōń╗¤Ķ«Ī
+
+- Ķ«║µ¢ćµĢ░ķćÅ: 9
+
+- µ©ĪÕ×ŗµĢ░ķćÅ: 62 ckpts
+
+ - [FlowNet: Learning Optical Flow with Convolutional Networks](../../configs/flownet) (5 ckpts)
+ - [FlowNet 2.0: Evolution of Optical Flow Estimation with Deep Networks](../../configs/flownet2) (7 ckpts)
+ - [PWC-Net: CNNs for Optical Flow Using Pyramid, Warping, and Cost Volume](../../configs/_base_/pwcnet) (6 ckpts)
+ - [LiteFlowNet: A Lightweight Convolutional Neural Network for Optical Flow Estimation](../../configs/liteflownet) (9 ckpts)
+ - [A Lightweight Optical Flow CNN-Revisiting Data Fidelity and Regularization](../../configs/liteflownet2) (8 ckpts)
+ - [Iterative Residual Refinement for Joint Optical Flow and Occlusion Estimation](../../configs/irr) (5 ckpts)
+ - [MaskFlownet: Asymmetric Feature Matching with Learnable Occlusion Mask](../../configs/maskflownet) (4 ckpts)
+ - [RAFT: Recurrent All-Pairs Field Transforms for Optical Flow](../../configs/raft) (5 ckpts)
+ - [GMA: Learning to Estimate Hidden Motions with Global Motion Aggregation](../../configs/gma) (13 ckpts)
diff --git a/internlm_langchain/knowledge_base/MMFlow/vector_store/index.faiss b/internlm_langchain/knowledge_base/MMFlow/vector_store/index.faiss
new file mode 100644
index 00000000..5114b2e3
Binary files /dev/null and b/internlm_langchain/knowledge_base/MMFlow/vector_store/index.faiss differ
diff --git a/internlm_langchain/knowledge_base/MMHuman3D/content/cameras.md b/internlm_langchain/knowledge_base/MMHuman3D/content/cameras.md
new file mode 100644
index 00000000..14504db5
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMHuman3D/content/cameras.md
@@ -0,0 +1,304 @@
+# ńøĖµ£║
+
+## ńøĖµ£║ÕłØÕ¦ŗÕī¢
+
+MMHuman3DķüĄÕŠ¬ `PyTorch3D` õĖŁńÜäńøĖµ£║Ķ¦äĶīā’╝ÜÕģČÕż¢ÕÅéń¤®ķśĄÕ«Üõ╣ēõĖ║õ╗ÄńøĖµ£║ÕØɵĀćń│╗Õł░õĖ¢ńĢīÕØɵĀćń│╗ńÜäÕÅśÕī¢ŃĆéÕż¢ÕÅéń¤®ķśĄõĮ┐ńö©ÕÅ│õ╣ś’╝īÕåģÕÅéń¤®ķśĄõĮ┐ńö©ÕĘ”õ╣śŃĆ鵳æõ╗¼Ķ┐śµÅÉõŠøõ║å`OpenCV`õĖŁńÜäńøĖµ£║Ķ¦äĶīā’╝īÕ”éµ×£µé©µø┤ń夵éē`OpenCV`’╝īµé©õ╣¤ÕÅ»õ╗źķĆēµŗ®`OpenCV`Ķ¦äĶīāµØźĶ┐øĶĪīµōŹõĮ£ŃĆé
+
+- **ńøĖµ£║Õłćńēć:**
+
+ MMHuman3DõĖŁ’╝īµÄ©ĶŹÉńÜäńøĖµ£║ÕłØÕ¦ŗÕī¢ńÜäµ¢╣Õ╝ÅõĖ║ńø┤µÄźõ╝ĀķĆÆ`K`, `R`, `T`ń¤®ķśĄŃĆé
+ ÕÅ»õ╗źµīēń┤óÕ╝ĢÕ»╣ńøĖµ£║Ķ┐øĶĪīÕłćńēć’╝īõ╣¤ÕÅ»õ╗źÕ£©batchń╗┤Õ║”Ķ┐øĶĪīµŗ╝µÄźŃĆé
+
+ ```python
+ from mmhuman3d.core.cameras import PerspectiveCameras
+ import torch
+ K = torch.eye(4, 4)[None]
+ R = torch.eye(3, 3)[None]
+ T = torch.zeros(100, 3)
+ # K, R, TńÜäBatchÕż¦Õ░ÅÕ║öĶ»źńøĖÕÉī’╝īµł¢ĶĆģõĖ║1ŃĆéÕ”éµ×£õĖŹÕÉī’╝īµ£Ćń╗łńÜäbatchÕż¦Õ░Åõ╝ܵś»õĖēĶĆģõĖŁµ£ĆÕż¦ńÜäķéŻõĖĆõĖ¬ŃĆé
+ cam = PerspectiveCameras(K=K, R=R, T=T)
+ assert cam.R.shape == (100, 3, 3)
+ assert cam.K.shape == (100, 4, 4)
+ assert cam.T.shape == (100, 3)
+ assert (cam[:10].K == cam.K[:10]).all()
+ ```
+- **µ×äÕ╗║ńøĖµ£║:**
+
+ Õ░üĶŻģÕ£©mmcv.RegistryõĖŁŃĆé
+
+ MMHuman3DõĖŁ’╝īµÄ©ĶŹÉńÜäÕłØÕ¦ŗÕī¢ńøĖµ£║ńÜäµ¢╣Õ╝ÅõĖ║ńø┤µÄźõ╝ĀķĆÆ`K`, `R`, `T`ń¤®ķśĄ, õĮåµś»õ╣¤ÕÅ»õ╗źõ╝ĀķĆÆ`focal_length` ÕÆī `principle_point` õĮ£õĖ║ĶŠōÕģźŃĆé
+
+ õ╗źÕĖĖńö©ńÜä`PerspectiveCameras`õĖ║õŠŗŃĆéÕ”éµ×£`K`, `R`, `T`µ▓Īµ£ēĶó½ńĪ«Õ«Ü’╝ī`K`Õ░åõ╝ÜõĮ┐ńö©`compute_default_projection_matrix`õĖŁķ╗śĶ«żńÜä’╝ī`principal_point` ÕÆī `R` Õ░åõ╝ÜĶó½Ķ«ŠńĮ«õĖ║ÕŹĢõĮŹń¤®ķśĄ’╝ī`T`Õ░åõ╝ÜĶó½Ķ«ŠńĮ«õĖ║ķøČń¤®ķśĄŃĆéµé©õ╣¤ÕÅ»õ╗źķĆÜĶ┐ćķćŹÕåÖ`compute_default_projection_matrix`µØźµīćÕ«ÜÕģĘõĮōńÜäµĢ░ÕĆ╝ŃĆé
+
+ ```python
+ from mmhuman3d.core.cameras import build_cameras
+
+ # õĮ┐ńö©ń╗ÖÕ«ÜńÜäK, R, Tń¤®ķśĄÕłØÕ¦ŗÕī¢ńøĖµ£║(PerspectiveCameras)ŃĆé
+ # K, R, TńÜäbatchÕż¦Õ░ÅÕ║öĶ»źńøĖÕÉī’╝īµł¢ĶĆģõĖ║1ŃĆé
+ K = torch.eye(4, 4)[None]
+ R = torch.eye(3, 3)[None]
+ T = torch.zeros(10, 3)
+
+ height, width = 1000
+ cam1 = build_cameras(
+ dict(
+ type='PerspectiveCameras',
+ K=K,
+ R=R,
+ T=T,
+ in_ndc=True,
+ image_size=(height, width),
+ convention='opencv',
+ ))
+
+ # This is the same as:
+ cam2 = PerspectiveCameras(
+ K=K,
+ R=R,
+ T=T,
+ in_ndc=True,
+ image_size=1000, # ÕøŠÕāÅÕ░║Õ║”µīćÕ«ÜõĖ║ÕŹĢµĢ░µŚČ’╝īĶĪ©ńż║µŁŻµ¢╣ÕĮóÕøŠÕāÅŃĆé
+ convention='opencv',
+ )
+ assert cam1.K.shape == cam2.K.shape == (10, 4, 4)
+ assert cam1.R.shape == cam2.R.shape == (10, 3, 3)
+ assert cam1.T.shape == cam2.T.shape == (10, 3)
+
+ # õĮ┐ńö©ń╗ÖÕ«ÜńÜä`image_size`, `principal_points`, `focal_length`ÕłØÕ¦ŗÕī¢ńøĖµ£║(PerspectiveCameras)ŃĆé
+ # `in_ndc = False` µäÅÕæ│ńØĆÕåģÕÅéń¤®ķśĄ `K` Õ£©screen spaceõĖŁĶó½Õ«Üõ╣ēŃĆé `K`õĖŁńÜä`focal_length`ÕÆī`principal_point`Ķó½Õ«Üõ╣ēõĖ║ÕāÅń┤ĀõĖ¬µĢ░ŃĆé õĖŗõŠŗõĖŁ’╝ī `principal_points` õĖ║ (500, 500) ÕāÅń┤Ā’╝ī `focal_length` õĖ║ 1000 ÕāÅń┤ĀŃĆé
+ cam = build_cameras(
+ dict(
+ type='PerspectiveCameras',
+ in_ndc=False,
+ image_size=(1000, 1000),
+ principal_points=(500, 500),
+ focal_length=1000,
+ convention='opencv',
+ ))
+
+ assert (cam.K[0] == torch.Tensor([[1000., 0., 500., 0.],
+ [0., 1000., 500., 0.],
+ [0., 0., 0., 1.],
+ [0., 0., 1., 0.]]).view(4, 4)).all()
+
+ # õĮ┐ńö©ń╗ÖÕ«ÜńÜäK, R, TÕłØÕ¦ŗÕī¢ńøĖµ£║(WeakPerspectiveCameras)ŃĆéWeakperspective Camera ÕŬµö»µīü`in_ndc = True`(ķ╗śĶ«ż)ŃĆé
+ cam = build_cameras(
+ dict(
+ type='WeakPerspectiveCameras',
+ K=K,
+ R=R,
+ T=T,
+ image_size=(1000, 1000)
+ ))
+
+ # Õ”éµ×£`K`, `R`, `T`ń¤®ķśĄµ▓Īµ£ēń╗ÖÕ«Ü’╝īÕ░åõ╝ÜõĮ┐ńö©ķ╗śĶ«żń¤®ķśĄÕłØÕ¦ŗÕī¢`in_ndc`ńÜäńøĖµ£║(PerspectiveCameras)ŃĆé
+ cam = build_cameras(
+ dict(
+ type='PerspectiveCameras',
+ in_ndc=True,
+ image_size=(1000, 1000),
+ ))
+ # Then convert it to screen. This operation requires `image_size`.
+ cam.to_screen_()
+ ```
+
+## ńøĖµ£║ķ揵ŖĢÕĮ▒ń¤®ķśĄ
+- **Perspective:**
+
+ ÕåģÕÅéń¤®ķśĄńÜäµĀ╝Õ╝Å:
+ fx, fy µś»ńä”ĶĘØ, px, py µś»ÕāÅõĖ╗ńé╣ŃĆé
+ ```python
+ K = [
+ [fx, 0, px, 0],
+ [0, fy, py, 0],
+ [0, 0, 0, 1],
+ [0, 0, 1, 0],
+ ]
+ ```
+ µø┤ÕżÜõ┐Īµü»Ķ»ĘÕÅéĶĆā[Pytorch3D](https://github.com/facebookresearch/pytorch3d/blob/main/pytorch3d/renderer/cameras.py#L895)ŃĆé
+
+- **WeakPerspective:**
+
+ ÕåģÕÅéń¤®ķśĄńÜäµĀ╝Õ╝Å:
+ ```python
+ K = [
+ [sx*r, 0, 0, tx*sx*r],
+ [0, sy, 0, ty*sy],
+ [0, 0, 1, 0],
+ [0, 0, 0, 1],
+ ]
+ ```
+ `WeakPerspectiveCameras` õ║ŗÕ«×õĖŖµś»µŁŻõ║żµŖĢÕĮ▒, õĖ╗Ķ”üńö©õ║Ä SMPL(x) µ©ĪÕ×ŗńÜäķ揵ŖĢÕĮ▒ŃĆé
+ µø┤ÕżÜõ┐Īµü»Ķ»ĘÕÅéĶĆā[mmhuman3d cameras](mmhuman3d/core/cameras/cameras.py#L40)ŃĆé
+ ÕÅ»õ╗źķĆÜĶ┐ćSMPLķó䵥ŗńÜäńøĖµ£║ÕÅéµĢ░Ķ┐øĶĪīĶĮ¼µŹó:
+ ```python
+ from mmhuman3d.core.cameras import WeakPerspectiveCameras
+ K = WeakPerspectiveCameras.convert_orig_cam_to_matrix(orig_cam)
+ ```
+ `pred_cam`µś»õĖĆõĖ¬ńö▒[scale_x, scale_y, transl_x, transl_y]ń╗䵳ÉńÜäarray/tensor, ÕģČń╗┤Õ║”õĖ║(frame, 4)ŃĆéµø┤ÕżÜõ┐Īµü»Ķ»ĘÕÅéĶĆā[VIBE](https://github.com/mkocabas/VIBE/blob/master/lib/utils/renderer.py#L40-L47).
+
+- **FoVPerspective:**
+
+ ÕåģÕÅéń¤®ķśĄńÜäµĀ╝Õ╝Å:
+ ```python
+ K = [
+ [s1, 0, w1, 0],
+ [0, s2, h1, 0],
+ [0, 0, f1, f2],
+ [0, 0, 1, 0],
+ ]
+ ```
+ s1, s2, w1, h1, f1, f2 ńö▒ FoV parameters (`fov`, `znear`, `zfar`, ńŁē)Õ«Üõ╣ē, µø┤ÕżÜõ┐Īµü»Ķ»ĘÕÅéĶĆā[Pytorch3D](https://github.com/facebookresearch/pytorch3d/blob/main/pytorch3d/renderer/cameras.py).
+
+- **Orthographics:**
+
+ ÕåģÕÅéń¤®ķśĄńÜäµĀ╝Õ╝Å:
+ ```python
+ K = [
+ [fx, 0, 0, px],
+ [0, fy, 0, py],
+ [0, 0, 1, 0],
+ [0, 0, 0, 1],
+ ]
+ ```
+ µø┤ÕżÜõ┐Īµü»Ķ»ĘÕÅéĶĆā[Pytorch3D](https://github.com/facebookresearch/pytorch3d/blob/main/pytorch3d/renderer/cameras.py).
+
+- **FoVOrthographics:**
+ ```python
+ K = [
+ [scale_x, 0, 0, -mid_x],
+ [0, scale_y, 0, -mix_y],
+ [0, 0, -scale_z, -mid_z],
+ [0, 0, 0, 1],
+ ]
+ ```
+ scale_x, scale_y, scale_z, mid_x, mid_y, mid_z ńö▒ FoV parameters(`min_x`, `min_y`, `max_x`, `max_y`, `znear`, `zfar`, ńŁē)Õ«Üõ╣ē, µø┤ÕżÜõ┐Īµü»Ķ»ĘÕÅéĶĆā[Pytorch3D](https://github.com/facebookresearch/pytorch3d/blob/main/pytorch3d/renderer/cameras.py).
+
+## ńøĖµ£║Ķ¦äĶīā
+- **Õ£©õĖŹÕÉīńøĖµ£║õ╣ŗķŚ┤Ķ┐øĶĪīĶĮ¼µŹó:**
+
+ µłæõ╗¼ÕæĮÕÉŹÕåģÕÅéń¤®ķśĄõĖ║`K`, µŚŗĶĮ¼ń¤®ķśĄõĖ║`R` Õ╣│ń¦╗ń¤®ķśĄõĖ║`T`ŃĆé
+ õĖŹÕÉīńÜäńøĖµ£║Ķ¦äĶīāµ£ēńØĆõĖŹÕÉīńÜäĶĮ┤ÕÉæ, µ£ēõ║øõĮ┐ńö©ń¤®ķśĄÕĘ”õ╣ś’╝īµ£ēõ║øõĮ┐ńö©ń¤®ķśĄÕÅ│õ╣śŃĆé ÕåģÕÅéń¤®ķśĄÕÆīÕż¢ÕÅéń¤®ķśĄÕ║öĶ»źõĮ┐ńö©ńøĖÕÉīńÜäń¤®ķśĄõ╣śµ│ĢĶ¦äĶīā’╝īõĮåµś»`PyTorch3D`Õ£©Ķ«Īń«ŚĶ┐ćń©ŗõĖŁõĮ┐ńö©ń¤®ķśĄÕÅ│õ╣ś’╝īÕ£©ńøĖµ£║ÕłØÕ¦ŗÕī¢ńÜ䵌ČÕĆÖõ╝ĀķĆÆÕĘ”õ╣śń¤®ķśĄ`K`(Ķ┐ÖõĖ╗Ķ”üµś»õĖ║õ║åõŠ┐õ║ÄńÉåĶ¦Ż)ŃĆé
+ `NDC`ÕÆī`screen`õ╣ŗķŚ┤ńÜäĶĮ¼µŹóõ╣¤õ╝ÜÕĮ▒ÕōŹÕåģÕÅéń¤®ķśĄ, Ķ┐ÖõĖÄńøĖµ£║Ķ¦äĶīāµŚĀÕģ│ŃĆé
+ Õ”éµ×£Ķ”üõĮ┐ńö©ńÄ░µ£ēńÜäĶ¦äĶīā’╝īĶ»ĘµīćÕ«Ü`['opengl', 'opencv', 'pytorch3d', 'pyrender', 'open3d']`õĖŁńÜäõĖĆõĖ¬ŃĆé
+ õŠŗÕ”é, ÕÅ»õ╗źĶ┐øĶĪīÕ”éõĖŗńÜäµōŹõĮ£’╝īÕ░åõĮ┐ńö©`OpenCV`µĀćÕ«ÜńÜäńøĖµ£║ĶĮ¼Õī¢õĖ║`PyTorch3D NDC`Õ«Üõ╣ēńÜäńøĖµ£║õ╗źĶ┐øĶĪīµĖ▓µ¤ō:
+ ```python
+ from mmhuman3d.core.conventions.cameras import convert_cameras
+ import torch
+
+ K = torch.eye(4, 4)[None]
+ R = torch.eye(3, 3)[None]
+ T = torch.zeros(10, 3)
+ height, width = 1080, 1920
+ K, R, T = convert_cameras(
+ K=K,
+ R=R,
+ T=T,
+ in_ndc_src=False,
+ in_ndc_dst=True,
+ resolution_src=(height, width),
+ convention_src='opencv',
+ convention_dst='pytorch3d')
+ ```
+ ĶŠōÕģź `K` ÕÅ»õ╗źõĖ║ None, µł¢ĶĆģń╗┤Õ║”õĖ║(batch_size, 3, 3) `array`/`tensor`’╝īń╗┤Õ║”õ╣¤ÕÅ»õ╗źõĖ║(batch_size, 4, 4)ŃĆé
+
+ ĶŠōÕģź `R` ÕÅ»õ╗źõĖ║ None, µł¢ĶĆģń╗┤Õ║”õĖ║(batch_size, 3, 3) `array`/`tensor`ŃĆé
+
+ ĶŠōÕģź `T` ÕÅ»õ╗źõĖ║ None, µł¢ĶĆģń╗┤Õ║”õĖ║(batch_size, 3) `array`/`tensor`ŃĆé
+
+ Õ”éµ×£ÕĤզŗńÜä `K` õĖ║ `None`, Õ░åõ╝ÜõĖĆńø┤õ┐صīüõĖ║ `None`ŃĆéÕ”éµ×£ÕĤզŗńÜä `R` õĖ║ `None`, Õ░åõ╝ÜĶ«ŠńĮ«õĖ║ÕŹĢõĮŹń¤®ķśĄŃĆé Õ”éµ×£ÕĤզŗńÜä `T` õĖ║ `None`, Õ░åõ╝ÜĶ«ŠńĮ«õĖ║ķøČń¤®ķśĄŃĆé
+
+ µø┤ÕżÜÕģ│õ║Ä`NDC`ÕÆī`screen`ńøĖµ£║ń®║ķŚ┤ńÜäõ┐Īµü»’╝īĶ»ĘÕÅéĶĆā[Pytorch3D](https://github.com/facebookresearch/pytorch3d/blob/main/docs/notes/cameras.md)ŃĆé
+
+- **Õ«Üõ╣ēõĖ¬õ║║ńÜäńøĖµ£║Ķ¦äĶīā:**
+
+ Õ”éµ×£õĮ┐ńö©µ¢░ńÜäńøĖµ£║Ķ¦äĶīā, Ķ»ĘÕ£©[CAMERA_CONVENTION_FACTORY](https://github.com/open-mmlab/mmhuman3d/tree/main/mmhuman3d/core/conventions/cameras/__init__.py)õĖŁ, µīēńģ¦ÕÉæÕÅ│, ÕÉæõĖŖ, ÕÆīĶ┐£ń”╗Õ▒ÅÕ╣ĢńÜäķĪ║Õ║ÅĶ┐øĶĪīÕ«Üõ╣ēŃĆéõŠŗÕ”é, õĖŗµ¢╣ń¼¼õĖĆõĖ¬`PyRender`ńÜäķĪ║Õ║ÅÕ║öĶ»źõĖ║'+x+y+z'ŃĆéń¼¼õ║īõĖ¬`OpenCV`ńÜäķĪ║Õ║ÅÕ║öĶ»źõĖ║'+x-y-z'ŃĆé ń¼¼õĖēõĖ¬`Pytorch3D`ńÜäķĪ║Õ║ÅõĖ║'-xyz'ŃĆé
+ ```
+ OpenGL(PyRender) OpenCV Pytorch3D
+ y z y
+ | / |
+ | / |
+ |_______x /________x x________ |
+ / | /
+ / | /
+ z / y | z /
+ ```
+
+## ķā©ÕłåĶĮ¼µŹóÕćĮµĢ░
+ĶĮ¼µŹóÕćĮµĢ░Õ«Üõ╣ēÕ£©`conventions.cameras`õĖŁŃĆé
+- **NDC & screen:**
+
+ ```python
+ from mmhuman3d.core.conventions.cameras import (convert_ndc_to_screen,
+ convert_screen_to_ndc)
+
+ K = convert_ndc_to_screen(K, resolution=(1080, 1920), is_perspective=True)
+ K = convert_screen_to_ndc(K, resolution=(1080, 1920), is_perspective=True)
+ ```
+
+- **3x3 & 4x4 ÕåģÕÅéń¤®ķśĄ**
+
+ ```python
+ from mmhuman3d.core.conventions.cameras import (convert_K_3x3_to_4x4,
+ convert_K_4x4_to_3x3)
+
+ K = convert_K_3x3_to_4x4(K, is_perspective=True)
+ K = convert_K_4x4_to_3x3(K, is_perspective=True)
+ ```
+
+- **world & view:**
+
+ Õ£©õĖ¢ńĢīÕØɵĀćÕÆīĶ¦åÕøŠÕØɵĀćõĖŁĶĮ¼µŹóŃĆé
+
+ ```python
+ from mmhuman3d.core.conventions.cameras import convert_world_view
+ R, T = convert_world_view(R, T)
+ ```
+- **weakperspective & perspective:**
+
+ Õ£©weakperspective ÕÆī perspectiveõĖŁĶ┐øĶĪīĶĮ¼µŹó, `zmean` ÕÅéµĢ░µś»Õ┐ģķĪ╗ńÜäŃĆé
+
+
+
+ ```python
+ from mmhuman3d.core.conventions.cameras import (
+ convert_perspective_to_weakperspective,
+ convert_weakperspective_to_perspective)
+
+ K = convert_perspective_to_weakperspective(
+ K, zmean, in_ndc=False, resolution, convention='opencv')
+ K = convert_weakperspective_to_perspective(
+ K, zmean, in_ndc=False, resolution, convention='pytorch3d')
+ ```
+
+## ķā©ÕłåĶ«Īń«ŚÕćĮµĢ░
+
+- **Õ░å3DÕØɵĀćµŖĢÕĮ▒Ķć│Õ╣│ķØó:**
+
+ ```python
+ points_xydepth = cameras.transform_points_screen(points)
+ points_xy = points_xydepth[..., :2]
+ ```
+
+- **Ķ«Īń«Śńé╣ńÜäµĘ▒Õ║”:**
+
+ ÕÅ»õ╗źń«ĆÕŹĢÕ£░Õ░åńé╣ĶĮ¼Õī¢õĖ║Ķ¦åÕøŠÕØɵĀć’╝īÕ╣ČõĖöÕŠŚÕł░µĘ▒Õ║”zŃĆé
+ µø┤ÕżÜńÜäńö©õŠŗĶ»ĘÕÅéĶĆā[DepthRenderer](https://github.com/open-mmlab/mmhuman3d/tree/main/mmhuman3d/core/renderer/torch3d_renderer/depth_renderer.py).
+ ```python
+ points_depth = cameras.compute_depth_of_points(points)
+ ```
+
+- **ĶÄĘÕÅ¢meshńÜäµ│Ģń║┐:**
+
+ õĮ┐ńö©`Pytorch3D`Ķ«Īń«ŚmeshńÜäµ│Ģń║┐ŃĆé
+ µø┤ÕżÜńÜäńö©õŠŗĶ»ĘÕÅéĶĆā[NormalRenderer](https://github.com/open-mmlab/mmhuman3d/tree/main/mmhuman3d/core/renderer/torch3d_renderer/normal_renderer.py).
+ ```python
+ normals = cameras.compute_normal_of_meshes(meshes)
+ ```
+
+- **ĶÄĘÕÅ¢ńøĖµ£║Õ╣│ķØóńÜäµ│Ģń║┐:**
+
+ ĶÄĘÕÅ¢õ╗ÄńøĖµ£║õĖŁÕ┐āµīćÕÉæńøĖµ£║Õ╣│ķØóµ│Ģń║┐ńÜäÕĮÆõĖĆÕī¢Õ╝ĀķćÅŃĆé
+ ```python
+ normals = cameras.get_camera_plane_normals()
+ ```
diff --git a/internlm_langchain/knowledge_base/MMHuman3D/content/contribute_dataset.md b/internlm_langchain/knowledge_base/MMHuman3D/content/contribute_dataset.md
new file mode 100644
index 00000000..76a90f5a
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMHuman3D/content/contribute_dataset.md
@@ -0,0 +1,153 @@
+## ÕÉæmmhuman3dõĖŁµĘ╗ÕŖĀµĢ░µŹ«ĶĮ¼µŹó
+
+### µĆ╗Ķ¦ł
+
+µēƵ£ēńÜäµĢ░µŹ«ķøåÕ£©ÕŖĀĶĮĮõ╣ŗÕēŹ’╝īķ£ĆĶ”üÕģłõĮ┐ńö©õĖŹÕÉīńÜäĶĮ¼µŹóĶäܵ£¼’╝īÕ░åÕģČķóäÕżäńÉåõĖ║ńøĖÕÉīńÜäń╗ōµ×äŃĆéĶ»źµ¢ćµĪŻµÅÅĶ┐░õ║åÕ”éõĮĢń╗Öµ¢░ńÜäµĢ░µŹ«ķøåń╝¢ÕåÖĶĮ¼µŹóÕĘźÕģĘŃĆé
+
+### 1. ķ”¢Õģłń╗ÖĶĮ¼µŹóÕĘźÕģĘÕłøÕ╗║pythonĶäܵ£¼
+
+Õ£©õĖŗķØóńÜäõŠŗÕŁÉõĖŁ, µłæõ╗¼ń╗ÖLSPµĢ░µŹ«ķøåÕłøÕ╗║ĶĮ¼µŹóĶäܵ£¼`mmhuman3d/data/data_converters/lsp.py`ŃĆé
+
+µłæõ╗¼ń╗¦µē┐õ║åõĖżń¦Źń▒╗Õ×ŗńÜäĶĮ¼µŹóÕĘźÕģĘ:
+
+(1) BaseConverter (Ķ»”µāģĶ¦ü`mmhuman3d/data/data_converters/coco.py`)
+
+CocoConverter õĮ┐ńö© `convert` ÕćĮµĢ░ĶŠōÕć║ÕżäńÉåĶ┐ćÕÉÄńÜäÕŹĢõĖ¬`.npz`µ¢ćõ╗ČŃĆé
+```
+@DATA_CONVERTERS.register_module()
+class CocoConverter(BaseConverter):
+
+ def convert(self, dataset_path: str, out_path: str) -> dict:
+ """
+ ÕÅéµĢ░:
+ dataset_path (str): ÕŁśµöŠÕĤզŗÕøŠÕāÅÕÆīµĀćµ│©ńÜäµ¢ćõ╗ČÕż╣ĶĘ»ÕŠäŃĆé
+ out_path (str): õ┐ØÕŁśÕżäńÉåĶ┐ćńÜä`.npz`µ¢ćõ╗ČńÜäĶĘ»ÕŠä
+
+ Ķ┐öÕø×ÕĆ╝:
+ dict:
+ õĖĆõĖ¬Õ¤║õ║ÄHumanData()ń╗ōµ×äńÜäÕŁŚÕģĖ’╝īÕīģÕɽõ║å
+ image_path, bbox_xywh, keypoints2d,
+ keypoints2d_maskńŁēÕģ│ķö«ÕŁŚŃĆé
+ """
+```
+
+(2) BaseModeConverter (Ķ»”µāģĶ¦ü`mmhuman3d/data/data_converters/lsp.py`)
+
+Õ”éµ×£ķ£ĆĶ”üÕ»╣Ķ«Łń╗āķøåÕÆīµĄŗĶ»ĢķøåĶ┐øĶĪīõĖŹÕÉīńÜäµōŹõĮ£’╝īµé©ÕÅ»õ╗źń╗¦µē┐`BaseModeConverter`ŃĆé õŠŗÕ”é’╝ī`LspConverter`ķĆÜĶ┐ć`convert_by_mode`ÕćĮµĢ░ĶŠōÕć║ÕżÜõĖ¬Õ«Üõ╣ēÕ£©`ACCEPTED_MODES`õĖŁ, ń╗ÅĶ┐ćÕżäńÉåńÜä`.npz`µ¢ćõ╗ČŃĆé
+```
+@DATA_CONVERTERS.register_module()
+class LspConverter(BaseModeConverter):
+
+ """
+ Args:
+ modes (list): 'test' µł¢ĶĆģ 'train'
+ """
+ ACCEPTED_MODES = ['test', 'train']
+
+ def __init__(self, modes: List = []) -> None:
+ super(LspConverter, self).__init__(modes)
+
+ def convert_by_mode(self, dataset_path: str, out_path: str,
+ mode: str) -> dict:
+
+```
+
+Ķ»ĘÕÅéĶĆā[keypoints conventions](https://github.com/open-mmlab/mmhuman3d/blob/main/docs/keypoints_convention.md)µ¤źń£ŗµé©ńÜäµĢ░µŹ«ķøåµś»ÕÉ”ÕĘ▓ń╗ŵŗźµ£ēńÄ░µłÉńÜäconventionŃĆéµ▓Īµ£ēńÜäĶ»Ø, µé©ÕÅ»õ╗źµīēńģ¦[customize_keypoints_convention](https://github.com/open-mmlab/mmhuman3d/blob/main/docs/customize_keypoints_convention.md)ńÜäµīćÕ»╝Õ«Üõ╣ēõĖĆõĖ¬µ¢░ńÜäconventionŃĆé
+
+```
+# µĀ╣µŹ«ń╗ÖÕ«ÜńÜäconventionÕé©ÕŁśÕģ│ķö«ńé╣
+keypoints2d_, mask = convert_kps(keypoints2d_, 'lsp', 'human_data')
+
+```
+
+MMHuman3DõĮ┐ńö© `HumanData` ń╗ōµ×äµØźÕé©ÕŁśÕÆīÕŖĀĶĮĮµĢ░µŹ«ŃĆé µé©ÕÅ»õ╗źÕ£©[human_data](https://github.com/open-mmlab/mmhuman3d/blob/main/docs/human_data.md)õĖŁµēŠÕł░Õ»╣ÕģČÕŖ¤ĶāĮĶ┐øõĖƵŁźńÜäµÅÅĶ┐░ŃĆé
+
+```
+ # õĮ┐ńö© HumanData Õé©ÕŁśµĢ░µŹ«
+ human_data = HumanData()
+
+ ...
+
+ # ÕŁśÕé©Õ┐ģĶ”üńÜäÕģ│ķö«ÕŁŚ’╝īõŠŗÕ”é: image path, bbox, keypoints2d, keypoints2d_mask, keypoints3d, keypoints3d_mask
+ human_data['image_path'] = image_path_
+ human_data['bbox_xywh'] = bbox_xywh_
+ human_data['keypoints2d_mask'] = mask
+ human_data['keypoints2d'] = keypoints2d_
+ human_data['config'] = 'lsp'
+ human_data.compress_keypoints_by_mask()
+
+ # Õé©ÕŁśµĢ░µŹ«ń╗ōµ×ä
+ if not os.path.isdir(out_path):
+ os.makedirs(out_path)
+
+ out_file = os.path.join(out_path, 'lsp_{}.npz'.format(mode))
+ human_data.dump(out_file)
+```
+
+### 2. Õ£©`mmhuman3d/data/data_converters/__init__.py`õĖŁÕłØÕ¦ŗÕī¢ĶĮ¼µŹóÕĘźÕģĘ
+
+Õ░åµé©ńÜäĶĮ¼µŹóÕĘźÕģʵ│©ÕåīÕ£©data_convertersõĖŁ:
+
+```python
+# Õ╝Ģńö©µé©ńÜäĶĮ¼µŹóÕĘźÕģĘ
+from .lsp import LspConverter
+
+# Õ░åµé©ńÜäĶĮ¼µŹóÕĘźÕģʵĘ╗ÕŖĀÕ£©Õ”éõĖŗÕłŚĶĪ©õĖŁ
+__all__ = [
+ 'build_data_converter', 'AgoraConverter', 'MpiiConverter', 'H36mConverter', ...
+ 'LspConverter'
+]
+```
+
+
+### 3. Õ░åµé©ńÜäµĢ░µŹ«ķøåńÜäķģŹńĮ«µ¢ćõ╗ȵĘ╗ÕŖĀÕ£©`mmhuman3d/tools/convert_datasets.py`ńÜä`DATASET-CONFIGS`õĖŁ
+
+ńÄ░µ£ēµĢ░µŹ«ķøåńÜäķģŹńĮ«µ¢ćõ╗ČńĮŚÕłŚÕ£©[convert_datasets.py](https://github.com/open-mmlab/mmhuman3d/tree/main/tools/convert_datasets.py)õĖŁŃĆé
+
+õŠŗÕ”é:
+```
+DATASET_CONFIGS = dict(
+ ...
+ lsp=dict(type='LspConverter', modes=['train', 'test'], prefix='lsp')
+)
+```
+
+ÕģČõĖŁ `lsp` µś» `dataset-name`ńÜäõĖĆõĖ¬Õ«×õŠŗŃĆé ÕÅ»õĮ┐ńö©ńÜ䵩ĪÕ╝ÅÕīģµŗ¼ `train` ÕÆī `test`, `prefix` µīćÕ«Üõ║åµĢ░µŹ«ķøåµ¢ćõ╗ČÕż╣ńÜäÕÉŹń¦░ŃĆé Õ£©Ķ»źõŠŗõĖŁ, `prefix = 'lsp'` µś»ÕŁśµöŠõ║åÕĤզŗµĀćµ│©ÕÆīÕøŠÕāÅńÜäµ¢ćõ╗ČÕż╣(µ¢ćõ╗ČÕż╣ńÜäÕģĘõĮōń╗ōµ×äÕÅ»õ╗źÕÅéĶĆā[preprocess_dataset](https://github.com/open-mmlab/mmhuman3d/blob/main/docs/preprocess_dataset.md#lsp)).
+
+
+### 4. Õ░åµé©ńÜäµĢ░µŹ«ķøåńÜälicenseÕÆīńøĖÕ║öńÜäµ¢ćõ╗ČÕż╣ń╗ōµ×äµĘ╗ÕŖĀÕł░`preprocess_dataset.md`õĖŁ
+
+`lsp.py`õĖŁÕ╝Ģńö©µĢ░µŹ«ķøåńÜäõŠŗÕŁÉ:
+- https://github.com/open-mmlab/mmhuman3d/blob/9ec38db89cb896c318ff830c12ec007f60c447ad/mmhuman3d/data/data_converters/lsp.py#L15-L22
+
+õĖŗĶĮĮķōŠµÄźÕÆīµ¢ćõ╗ČÕż╣ń╗ōµ×äµöŠńĮ«Õ£© `preprocess_dataset.md`
+- https://github.com/open-mmlab/mmhuman3d/blob/main/docs/preprocess_dataset.md#lsp
+
+
+### 5. µŻĆµ¤źĶĮ¼µŹóÕĘźÕģʵś»ÕÉ”µŁŻÕĖĖÕĘźõĮ£
+
+
+Ķ┐ÉĶĪīÕ”éõĖŗĶäܵ£¼Ķ┐øĶĪīµŻĆµ¤ź
+
+```bash
+python tools/convert_datasets.py \
+ --datasets lsp \ # Õ«Üõ╣ēÕ£©`DATASET_CONFIGS`õĖŁńÜäµĢ░µŹ«ķøåÕÉŹń¦░
+ --root_path data/datasets \
+ --output_path data/preprocessed_datasets
+```
+
+ĶÄĘÕŠŚµöŠńĮ«Õ£© `data/preprocessed_datasets` õĖŗńÜä`.npz`µ¢ćõ╗Č:
+
+```text
+mmhuman3d
+Ōö£ŌöĆŌöĆ mmhuman3d
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+ŌööŌöĆŌöĆ data
+ Ōö£ŌöĆŌöĆ datasets
+ ŌööŌöĆŌöĆ preprocessed_datasets
+ Ōö£ŌöĆŌöĆ lsp_train.npz
+ ŌööŌöĆŌöĆ lsp_test.npz
+```
diff --git a/internlm_langchain/knowledge_base/MMHuman3D/content/customize_keypoints_convention.md b/internlm_langchain/knowledge_base/MMHuman3D/content/customize_keypoints_convention.md
new file mode 100644
index 00000000..91f78afb
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMHuman3D/content/customize_keypoints_convention.md
@@ -0,0 +1,96 @@
+## Õ«óÕłČÕī¢Õģ│ķö«ńé╣ń▒╗Õ×ŗ
+
+### µĆ╗Ķ¦ł
+
+Õ”éµ×£õĮ┐ńö©ńÜäµĢ░µŹ«ķøåÕ£©MMHuman3DõĖŁõĖŹÕÅŚµö»µīü’╝īµé©ÕÅ»õ╗źµĀ╣µŹ«Ķ┐ÖõĖ¬µ¢ćµĪŻ’╝īµĘ╗ÕŖĀõĖĆõĖ¬µ¢░ńÜäÕģ│ķö«ńé╣ń▒╗Õ×ŗŃĆé
+
+õĖŗÕłŚµś»MMHuman3DõĖŁµö»µīüńÜäÕģ│ķö«ńé╣ń▒╗Õ×ŗ:
+ - agora
+ - coco
+ - coco_wholebody
+ - crowdpose
+ - h36m
+ - human_data
+ - hybrik
+ - lsp
+ - mpi_inf_3dhp
+ - mpii
+ - openpose
+ - penn_action
+ - posetrack
+ - pw3d
+ - smpl
+ - smplx
+
+
+**1. ÕłøÕ╗║µ¢░ńÜäÕģ│ķö«ńé╣ń▒╗Õ×ŗ**
+
+Ķ»ĘµĀ╣µŹ«
+[`mmhuman3d/core/conventions/keypoints_mapping/human_data.py`](https://github.com/open-mmlab/mmhuman3d/tree/main/mmhuman3d/core/conventions/keypoints_mapping/human_data.py) , ÕłøÕ╗║õĖĆõĖ¬ÕÉŹõĖ║ `NEW_CONVENTION.py` ńÜäµ¢░µ¢ćõ╗ČŃĆé
+Ķ»źµ¢ćõ╗ČõĖŁ, `NEW_KEYPOINTS` µś»õĖĆõĖ¬ÕīģÕɽÕģ│ķö«ńé╣ÕÉŹÕŁŚÕÆīÕģĘõĮōķĪ║Õ║ÅńÜäÕłŚĶĪ©ŃĆé
+
+õŠŗÕ”é, µā│Ķ”üõĖ║`AGORA`µĢ░µŹ«ķøåÕłøÕ╗║õĖĆõĖ¬µ¢░ńÜäÕģ│ķö«ńé╣ń▒╗Õ×ŗ, `agora.py` µ¢ćõ╗ČÕ║öĶ»źÕīģÕɽõ╗źõĖŗķĪ╣ńø«:
+```
+AGORA_KEYPOINTS = [
+ 'pelvis',
+ 'left_hip',
+ 'right_hip'
+ ...
+]
+```
+
+**2. Õ»╗µēŠ`human_data`õĖŁńÜäÕģ│ķö«ńé╣ÕÉŹÕŁŚ**
+
+Õ£©MMHuman3DõĖŁ’╝īõĖŹÕÉīµĢ░µŹ«ķøåõĖŁÕģʵ£ēńøĖÕÉīÕÉŹÕŁŚńÜäÕģ│ķö«ńé╣Õ║öĶ»źÕ»╣Õ║öńøĖÕÉīńÜäõ║║õĮōķā©õ╗ČŃĆé`human_data`ń▒╗Õ×ŗÕĘ▓ń╗ŵĢ┤ÕÉłõ║åµö»µīüńÜäµĢ░µŹ«ķøåõĖŁõĖŹÕÉīÕÉŹÕŁŚńÜäÕģ│ķö«ńé╣ÕÆīÕ»╣Õ║öÕģ│ń│╗ŃĆé
+
+Õ»╣õ║Ä`NEW_KEYPOINTS`õĖŁńÜäµ»ÅõĖĆõĖ¬Õģ│ķö«ńé╣, ķ£ĆĶ”üĶ┐øĶĪīÕ”éõĖŗµŻĆµ¤ź:
+
+(1)Õģ│Õüźńé╣ÕÉŹń¦░µś»ÕÉ”ÕŁśÕ£©õ║Ä[`mmhuman3d/core/conventions/keypoints_mapping/human_data.py`](https://github.com/open-mmlab/mmhuman3d/tree/main/mmhuman3d/core/conventions/keypoints_mapping/human_data.py);
+
+(2)Õģ│ķö«ńé╣µś»ÕÉ”µ£ēńøĖÕ»╣õ║Ä`human_data`õĖŁńøĖÕÉīõĮŹńĮ«Õģ│ķö«ńé╣ńÜ䵜ĀÕ░äÕģ│ń│╗ŃĆé
+
+Õ”éµ×£õĖżõĖ¬µØĪõ╗ČķāĮµ╗ĪĶČ│, Ķ»ĘÕ£©`NEW_CONVENTION.py`õĖŁõ┐ØńĢÖÕģ│ķö«ńé╣ńÜäÕÉŹÕŁŚŃĆé
+
+
+**3. Õ»╗µēŠ`human_data`õĖŁÕģ│ķö«ńé╣ńÜäÕ»╣Õ║öÕģ│ń│╗**
+
+Õ”éµ×£`NEW_KEYPOINTS`õĖŁńÜäÕģ│ķö«ńé╣õĖÄ`human_data`õĖŁõĖŹÕÉīÕÉŹÕŁŚńÜäÕģ│ķö«ńé╣µ£ēńøĖÕÉīńÜäÕ»╣Õ║öÕģ│ń│╗, õŠŗÕ”é`NEW_KEYPOINTS`õĖŁńÜä`head`Õ»╣Õ║öõ║Ä`human_data`õĖŁńÜä`head_extra`, Õ░å`NEW_KEYPOINTS`õĖŁńÜäÕģ│ķö«ńé╣µīēńģ¦`human_data`ńÜäĶ¦äĶīāķćŹÕæĮÕÉŹ, õŠŗÕ”é`head` -> `head_extra`ŃĆé
+
+**4. Õ£©`human_data`õĖŁµĘ╗ÕŖĀµ¢░ńÜäÕģ│ķö«ńé╣**
+
+Õ”éµ×£µ¢░ńÜäÕģ│ķö«ńé╣õĖÄ`human_data`õĖŁńÜäÕģ│ķö«ńé╣µ▓Īµ£ēÕ»╣Õ║öÕģ│ń│╗’╝īÕ░▒ķ£ĆĶ”üÕ░åÕģČńĮŚÕłŚÕć║µØź’╝īÕ╣ČõĖöÕ£©ÕĤզŗÕÉŹń¦░õĖŖÕŖĀõĖŖÕēŹń╝Ćõ╗źõĮ£Õī║Õłå’╝īõŠŗÕ”é`spine_3dhp`ŃĆé
+
+Ք鵣ēķ£ĆĶ”üńÜäĶ»Ø’╝īµłæõ╗¼õ╝ÜÕ»╣`human_data`Ķ┐øĶĪīµŗōÕ▒Ģõ╗źÕī╣ķģŹµ¢░ńÜäÕģ│ķö«ńé╣’╝īõĮåĶ┐ÖÕ┐ģķĪ╗Õ£©µŻĆµ¤źµ¢░ńÜäÕģ│ķö«ńé╣µ▓Īµ£ēÕ»╣Õ║öÕģ│ń│╗’╝īõĖöµ▓Īµ£ēÕæĮÕÉŹÕå▓ń¬üńÜäµāģÕåĄõĖŗÕ«īµłÉŃĆé
+
+**5. ÕłØÕ¦ŗÕī¢µ¢░ńÜäÕģ│ķö«ńé╣ń▒╗Õ×ŗķøåÕÉł**
+
+Õ£©[`mmhuman3d/core/conventions/keypoints_mapping/__init__.py`](https://github.com/open-mmlab/mmhuman3d/tree/main/mmhuman3d/core/conventions/keypoints_mapping/__init__.py#L8-25)õĖŁµĘ╗ÕŖĀ`NEW_CONVENTION.py`ńÜä`import`, Õ╣ČÕ£©[KEYPOINTS_FACTORY](https://github.com/open-mmlab/mmhuman3d/tree/main/mmhuman3d/core/conventions/keypoints_mapping/__init__.py#L27-52)ńÜäÕŁŚÕģĖõĖŁµĘ╗ÕŖĀµĀćĶ»åń¼”ŃĆé
+
+õŠŗÕ”é, µłæõ╗¼µēƵĘ╗ÕŖĀńÜäµ¢░ńÜäÕģ│ķö«ńé╣ń▒╗Õ×ŗõĖ║`agora`:
+```
+# µĘ╗ÕŖĀ import
+from mmhuman3d.core.conventions.keypoints_mapping import (
+ agora,
+ ...
+)
+
+# µĘ╗ÕŖĀÕł░ factory
+KEYPOINTS_FACTORY = {
+ 'agora': agora.AGORA_KEYPOINTS,
+ ...
+}
+```
+
+**6. Õ░åµ¢░ńÜäÕģ│ķö«ńé╣ń▒╗Õ×ŗńö©õ║ÄÕģ│ķö«ńé╣ĶĮ¼µŹó**
+
+µā│Ķ”üÕ░åńÄ░µ£ēńÜäÕģ│ķö«ńé╣ń▒╗Õ×ŗĶĮ¼µŹóõĖ║µ¢░ńÜäń▒╗Õ×ŗ’╝īÕÅ»õ╗źõĮ┐ńö©[`mmhuman3d/core/conventions/keypoints_mapping/__init__.py`](https://github.com/open-mmlab/mmhuman3d/tree/main/mmhuman3d/core/conventions/keypoints_mapping/__init__.py)õĖŁńÜä`convert_kps`ÕćĮµĢ░ŃĆéĶ»źÕćĮµĢ░õ╝Üõ║¦ńö¤õĖĆõĖ¬ńö▒0,1µ×䵳ÉńÜämask’╝īµīćńż║µś»ÕÉ”Õ║öĶ»źµ╗żķÖżµł¢ĶĆģõ┐ØńĢÖŃĆé
+
+Õ░å`coco`Õģ│ķö«ńé╣ĶĮ¼µŹóõĖ║µ¢░ńÜäÕģ│ķö«ńé╣:
+```
+ new_kps, mask = convert_kps(smplx_keypoints, src='coco', dst='NEW_CONVENTION')
+```
+
+Õ░åµ¢░ńÜäÕģ│ķö«ńé╣ĶĮ¼µŹóõĖ║`human_data`:
+```
+ new_kps, mask = convert_kps(smplx_keypoints, src='NEW_CONVENTION', dst='human_data')
+```
diff --git a/internlm_langchain/knowledge_base/MMHuman3D/content/getting_started.md b/internlm_langchain/knowledge_base/MMHuman3D/content/getting_started.md
new file mode 100644
index 00000000..c43c636a
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMHuman3D/content/getting_started.md
@@ -0,0 +1,214 @@
+# Õ╝ĆÕ¦ŗõĮ┐ńö©
+
+- [Õ╝ĆÕ¦ŗ](#getting-started)
+ - [Õ«ēĶŻģ](#Õ«ēĶŻģ)
+ - [µĢ░µŹ«ķóäÕżäńÉå](#µĢ░µŹ«ķóäÕżäńÉå)
+ - [õ║║õĮōµ©ĪÕ×ŗ](#õ║║õĮōµ©ĪÕ×ŗ)
+ - [µÄ©ńÉå / µ╝öńż║](#µÄ©ńÉå-/-µ╝öńż║)
+ - [ń”╗ń║┐Demo](#ń”╗ń║┐Demo)
+ - [Õ£©ń║┐Demo](#Õ£©ń║┐Demo)
+ - [µĄŗĶ»Ģ](#µĄŗĶ»Ģ)
+ - [õĮ┐ńö©ÕŹĢ’╝łÕżÜ’╝ēõĖ¬GPUĶ┐øĶĪīµĄŗĶ»Ģ](#õĮ┐ńö©ÕŹĢ’╝łÕżÜ’╝ēõĖ¬GPUĶ┐øĶĪīµĄŗĶ»Ģ)
+ - [õĮ┐ńö©slurmĶ┐øĶĪīµĄŗĶ»Ģ](#õĮ┐ńö©slurmĶ┐øĶĪīµĄŗĶ»Ģ)
+ - [Ķ«Łń╗ā](#Ķ«Łń╗ā)
+ - [õĮ┐ńö©ÕŹĢ’╝łÕżÜ’╝ēõĖ¬GPUĶ┐øĶĪīĶ«Łń╗ā](#õĮ┐ńö©ÕŹĢ’╝łÕżÜ’╝ēõĖ¬GPUĶ┐øĶĪīĶ«Łń╗ā)
+ - [ķĆÜĶ┐ćslurmĶ┐øĶĪīĶ«Łń╗ā](#ķĆÜĶ┐ćslurmĶ┐øĶĪīĶ«Łń╗ā)
+ - [µø┤ÕżÜµĢÖń©ŗ](#µø┤ÕżÜµĢÖń©ŗ)
+
+## Õ«ēĶŻģ
+
+Õ«ēĶŻģĶ»ĘÕÅéĶĆā [install.md](../docs_zh-CN/install.md).
+
+## µĢ░µŹ«ķóäÕżäńÉå
+
+µĢ░µŹ«ķóäÕżäńÉåĶ»ĘÕÅéĶĆā [data_preparation.md](../docs_zh-CN/preprocess_dataset.md).
+
+## õ║║õĮōµ©ĪÕ×ŗ
+
+- õĖ╗Ķ”üõĮ┐ńö©[SMPL](https://smpl.is.tue.mpg.de/) v1.0.
+ - ÕÅ»õ╗źÕ£©[SMPLify](https://smplify.is.tue.mpg.de/)õĖŗĶĮĮneutral model.
+ - µēƵ£ēńÜäõ║║õĮōµ©ĪÕ×ŗķ£ĆĶ”üķćŹÕæĮÕÉŹõĖ║ `SMPL_{GENDER}.pkl` µĀ╝Õ╝ÅŃĆé
+ õŠŗÕ”é, `SMPL_NEUTRAL.pkl` `SMPL_MALE.pkl` `SMPL_FEMALE.pkl` +- [J_regressor_extra.npy](https://openmmlab-share.oss-cn-hangzhou.aliyuncs.com/mmhuman3d/models/J_regressor_extra.npy?versionId=CAEQHhiBgIDD6c3V6xciIGIwZDEzYWI5NTBlOTRkODU4OTE1M2Y4YTI0NTVlZGM1) +- [J_regressor_h36m.npy](https://openmmlab-share.oss-cn-hangzhou.aliyuncs.com/mmhuman3d/models/J_regressor_h36m.npy?versionId=CAEQHhiBgIDE6c3V6xciIDdjYzE3MzQ4MmU4MzQyNmRiZDA5YTg2YTI5YWFkNjRi) +- [smpl_mean_params.npz](https://openmmlab-share.oss-cn-hangzhou.aliyuncs.com/mmhuman3d/models/smpl_mean_params.npz?versionId=CAEQHhiBgICN6M3V6xciIDU1MzUzNjZjZGNiOTQ3OWJiZTJmNThiZmY4NmMxMTM4) + +õĖŗĶĮĮõĖŖĶ┐░µēƵ£ēµ¢ćõ╗Č’╝īÕ╣ȵīēÕ”éõĖŗń╗ōµ×äÕ«ēµÄƵ¢ćõ╗ČÕż╣: + +```text +mmhuman3d +Ōö£ŌöĆŌöĆ mmhuman3d +Ōö£ŌöĆŌöĆ docs +Ōö£ŌöĆŌöĆ tests +Ōö£ŌöĆŌöĆ tools +Ōö£ŌöĆŌöĆ configs +ŌööŌöĆŌöĆ data + ŌööŌöĆŌöĆ body_models + Ōö£ŌöĆŌöĆ J_regressor_extra.npy + Ōö£ŌöĆŌöĆ J_regressor_h36m.npy + Ōö£ŌöĆŌöĆ smpl_mean_params.npz + ŌööŌöĆŌöĆ smpl + Ōö£ŌöĆŌöĆ SMPL_FEMALE.pkl + Ōö£ŌöĆŌöĆ SMPL_MALE.pkl + ŌööŌöĆŌöĆ SMPL_NEUTRAL.pkl +``` + +## µÄ©ńÉå / µ╝öńż║ +### ń”╗ń║┐Demo +µłæõ╗¼µÅÉõŠøõ║åńö©õ║Äõ╗ÄÕøŠÕāŵł¢Ķ¦åķóæõĖŁõ╝░Ķ«ĪÕŹĢõ║║µł¢ÕżÜõ║║`SMPL`µ©ĪÕ×ŗÕÅéµĢ░ńÜäµ╝öńż║Ķäܵ£¼’╝īĶ┐ÉĶĪīĶ»źĶäܵ£¼ÕÅ»ĶāĮõ╝Üńö©Õł░`MMDetection`ÕÆī`MMTracking`ŃĆéķĆÜĶ┐ćĶ»źĶäܵ£¼Ķ┐øĶĪīµ╝öńż║’╝īµé©ÕŬķ£ĆĶ”üõ╗ĵ©ĪÕ×ŗÕ║ōõĖŁķĆēµŗ®ńö©Õł░ńÜäķóäĶ«Łń╗āµ©ĪÕ×ŗ(µłæõ╗¼ńø«ÕēŹÕŬµö»µīü[HMR](https://github.com/open-mmlab/mmhuman3d/tree/main/configs/hmr/)ŃĆü [SPIN](https://github.com/open-mmlab/mmhuman3d/tree/main/configs/spin/)ŃĆü[VIBE](https://github.com/open-mmlab/mmhuman3d/tree/main/configs/vibe/) ÕÆī[PARE](https://github.com/open-mmlab/mmhuman3d/tree/main/configs/pare/), µ£¬µØźõ╝ÜÕŖĀÕģźµø┤ÕżÜńÜäSOTAµ¢╣µ│Ģ)’╝īÕ╣ȵīćÕ«ÜÕ░æķćÅńÜäÕÅéµĢ░ŃĆé + +õ╗źõĖŗµś»õĖĆõ║øÕÅéµĢ░ńÜäķćŖõ╣ē: + +- Õ”éµ×£µīćÕ«Ü`--output` ÕÆī `--show_path`, µ╝öńż║Ķäܵ£¼õ╝ÜÕ░åń╗ōµ×£Õé©ÕŁśÕ£©`human_data`õĖŁ’╝īÕ╣ČõĖöµĖ▓µ¤ōÕŠŚÕł░ńÜäõ║║õĮōmeshŃĆé +- Õ”éµ×£µīćÕ«Ü`--smooth_type`, µ╝öńż║Ķäܵ£¼õ╝ÜõĮ┐ńö©ńē╣Õ«ÜńÜäµ¢╣µ│ĢĶ┐øĶĪīÕ╣│µ╗æŃĆéńø«ÕēŹÕÅ»õ╗źķĆēµŗ®ńÜäÕ╣│µ╗æµ¢╣µ│ĢÕīģµŗ¼`gaus1d`ŃĆü`oneeuro`ÕÆī `savgol`ŃĆé +- Õ”éµ×£µīćÕ«Ü`--speed_up_type`, µ╝öńż║Ķäܵ£¼õ╝ÜõĮ┐ńö©ńē╣Õ«ÜńÜäµ¢╣µ│ĢĶ┐øĶĪīÕŖĀķĆ¤ÕżäńÉåŃĆéńø«ÕēŹµö»µīüÕ¤║õ║ÄÕŁ”õ╣ĀńÜäµ¢╣µ│Ģ`deciwatch`, µø┤ÕżÜńÜäõ┐Īµü»Ķ»ĘÕÅéĶĆā[DeciWatch](../configs/_base_/post_processing/README.md)ŃĆé + +Õ»╣õ║ÄÕŹĢõ║║ + +```shell +python demo/estimate_smpl.py \ + ${MMHUMAN3D_CONFIG_FILE} \ + ${MMHUMAN3D_CHECKPOINT_FILE} \ + --single_person_demo \ + --det_config ${MMDET_CONFIG_FILE} \ + --det_checkpoint ${MMDET_CHECKPOINT_FILE} \ + --input_path ${VIDEO_PATH_OR_IMG_PATH} \ + [--show_path ${VIS_OUT_PATH}] \ + [--output ${RESULT_OUT_PATH}] \ + [--smooth_type ${SMOOTH_TYPE}] \ + [--speed_up_type ${SPEED_UP_TYPE}] \ + [--draw_bbox] \ +``` + +õŠŗÕ”é: +```shell +python demo/estimate_smpl.py \ + configs/hmr/resnet50_hmr_pw3d.py \ + data/checkpoints/resnet50_hmr_pw3d.pth \ + --single_person_demo \ + --det_config demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \ + --det_checkpoint https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \ + --input_path demo/resources/single_person_demo.mp4 \ + --show_path vis_results/single_person_demo.mp4 \ + --output demo_result \ + --smooth_type savgol \ + --speed_up_type deciwatch \ + --draw_bbox +``` + +Õ»╣õ║ÄÕżÜõ║║ + + +```shell +python demo/estimate_smpl.py \ + ${MMHUMAN3D_CONFIG_FILE} \ + ${MMHUMAN3D_CHECKPOINT_FILE} \ + --multi_person_demo \ + --tracking_config ${MMTRACKING_CONFIG_FILE} \ + --input_path ${VIDEO_PATH_OR_IMG_PATH} \ + [--show_path ${VIS_OUT_PATH}] \ + [--output ${RESULT_OUT_PATH}] \ + [--smooth_type ${SMOOTH_TYPE}] \ + [--speed_up_type ${SPEED_UP_TYPE}] \ + [--draw_bbox] +``` + +õŠŗÕ”é: +```shell +python demo/estimate_smpl_image.py \ + configs/hmr/resnet50_hmr_pw3d.py \ + data/checkpoints/resnet50_hmr_pw3d.pth \ + --multi_person_demo \ + --tracking_config demo/mmtracking_cfg/deepsort_faster-rcnn_fpn_4e_mot17-private-half.py \ + --input_path demo/resources/multi_person_demo.mp4 \ + --show_path vis_results/multi_person_demo.mp4 \ + --smooth_type savgol \ + --speed_up_type deciwatch \ + [--draw_bbox] + +``` +MMHuman3DńÜächeckpointsµ¢ćõ╗ČÕÅ»õ╗źõ╗Ä[model zoo](../docs_zh-CN/model_zoo.md)õĖŗĶĮĮŃĆé +Ķ┐Öķćīµłæõ╗¼õĮ┐ńö©HMR (resnet50_hmr_pw3d.pth)õĮ£õĖ║ńż║õŠŗŃĆé + +### Õ£©ń║┐Demo +µłæõ╗¼µÅÉõŠøõĖĆõĖ¬õ╗ÄńøĖµ£║µł¢ĶĆģõĖĆõĖ¬µīćÕ«ÜńÜäĶ¦åķóæµ¢ćõ╗Čõ╝░Ķ«ĪSMPLÕÅéµĢ░ńÜäwebcamµ╝öńż║Ķäܵ£¼ŃĆéõĮĀÕÅ»õ╗źń«ĆÕŹĢńÜäĶ┐ÉĶĪīõĖŗķØóńÜäÕæĮõ╗ż’╝Ü +```shell +python demo/webcam_demo.py +``` +õ╗źõĖŗµś»õĖĆõ║øÕÅéµĢ░ńÜäķćŖõ╣ē: +- Õ”éµ×£µīćÕ«Ü`--output`, µ╝öńż║Ķäܵ£¼õ╝ÜÕ░åÕÅ»Ķ¦åÕī¢ń╗ōµ×£Õé©ÕŁśÕł░Õ»╣Õ║öńÜäµ¢ćõ╗ČõĖŁŃĆéĶ┐ÖÕÅ»ĶāĮõ╝ÜķÖŹõĮÄÕĖ¦ńÄćŃĆé +- Õ”éµ×£µīćÕ«Ü`--synchronous`, Ķ¦åķóæńÜä I/O ÕÆīµ©ĪÕ×ŗńÜäµÄ©ńÉåÕ£©µŚČÕ║ÅõĖŖÕ░åõ╝ÜÕ»╣ķĮÉ. µ│©µäÅĶ┐Öõ╝ÜķÖŹõĮÄÕĖ¦ńÄć. +- Õ”éµ×£õĮĀµā│õ╗źń”╗ń║┐ńÜäµ¢╣Õ╝ÅÕ£©Ķ¦åķóæµ¢ćõ╗ČõĖŖĶ┐ÉĶĪīwebcamµ╝öńż║, õĮĀÕ║öĶ»źµīćÕ«Ü`--cam-id=VIDEO_FILE_PATH`. µ│©µäÅ`--synchronous` Õ£©Ķ┐Öń¦ŹµāģÕĮóõĖŗÕ║öĶ»źĶó½Ķ«ŠńĮ«õĖ║ `True`. +- Ķ¦åķóæńÜäI/OÕÆīµ©ĪÕ×ŗńÜäµÄ©ńÉåµś»Õ╝鵣źńÜäĶ┐ÉĶĪī’╝īĶĆīõĖöÕÉÄĶĆģÕŠĆÕŠĆķ£ĆĶ”üµø┤ÕżÜńÜ䵌ČķŚ┤. õĖ║õ║åń╝ōĶ¦ŻÕ╗ȵŚČ’╝īõĮĀÕÅ»õ╗ź: + + - µĀ╣µŹ«µśŠńż║Õ£©ÕĘ”õĖŖĶ¦ÆńÜäµÄ©ńÉåÕ╗ȵŚČĶ«ŠńĮ«`--display-delay=MILLISECONDS` µØźÕ╗ȵŚČĶ¦åķóæµĄü. µł¢ĶĆģ, + + - Ķ«ŠńĮ« `--synchronous=True` Õ╝║ÕłČĶ¦åķóæµĄüÕÆīµÄ©ńÉåń╗ōµ×£Õ»╣ķĮÉ. Ķ┐ÖÕÅ»ĶāĮķÖŹõĮÄĶ¦åķóæńÜäÕĖ¦ńÄćŃĆé + + +## µĄŗĶ»Ģ + +µłæõ╗¼µÅÉõŠøńÜäķóäĶ«Łń╗āµ©ĪÕ×ŗÕÅ»õ╗źÕÅéĶ¦ü [config](https://github.com/open-mmlab/mmhuman3d/tree/main/configs). + +### õĮ┐ńö©ÕŹĢ’╝łÕżÜ’╝ēõĖ¬GPUĶ┐øĶĪīµĄŗĶ»Ģ + +```shell +python tools/test.py ${CONFIG} --work-dir=${WORK_DIR} ${CHECKPOINT} --metrics=${METRICS} +``` +õŠŗÕ”é: +```shell +python tools/test.py configs/hmr/resnet50_hmr_pw3d.py --work-dir=work_dirs/hmr work_dirs/hmr/latest.pth --metrics pa-mpjpe mpjpe +``` + +### õĮ┐ńö©slurmĶ┐øĶĪīµĄŗĶ»Ģ + +Õ”éµ×£ķĆÜĶ┐ć[slurm](https://slurm.schedmd.com/)Õ£©ķøåńŠżõĖŖõĮ┐ńö©MMHuman3D, µé©ÕÅ»õ╗źõĮ┐ńö©Ķäܵ£¼ `slurm_test.sh`Ķ┐øĶĪīµĄŗĶ»ĢŃĆé + +```shell +./tools/slurm_test.sh ${PARTITION} ${JOB_NAME} ${CONFIG} ${WORK_DIR} ${CHECKPOINT} --metrics ${METRICS} +``` +õŠŗÕ”é: +```shell +./tools/slurm_test.sh my_partition test_hmr configs/hmr/resnet50_hmr_pw3d.py work_dirs/hmr work_dirs/hmr/latest.pth 8 --metrics pa-mpjpe mpjpe +``` + + +## Ķ«Łń╗ā + +### õĮ┐ńö©ÕŹĢ’╝łÕżÜ’╝ēõĖ¬GPUĶ┐øĶĪīĶ«Łń╗ā + +```shell +python tools/train.py ${CONFIG_FILE} ${WORK_DIR} --no-validate +``` +õŠŗÕ”é: õĮ┐ńö©ÕŹĢõĖ¬GPUĶ«Łń╗āHMR. +```shell +python tools/train.py ${CONFIG_FILE} ${WORK_DIR} --gpus 1 --no-validate +``` + +### õĮ┐ńö©slurmĶ┐øĶĪīĶ«Łń╗ā + +Õ”éµ×£ķĆÜĶ┐ć[slurm](https://slurm.schedmd.com/)Õ£©ķøåńŠżõĖŖõĮ┐ńö©MMHuman3D, µé©ÕÅ»õ╗źõĮ┐ńö©Ķäܵ£¼ `slurm_train.sh`Ķ┐øĶĪīĶ«Łń╗āŃĆé + +```shell +./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} ${CONFIG_FILE} ${WORK_DIR} ${GPU_NUM} --no-validate +``` + +ÕÅ»ķĆēÕÅéµĢ░Õīģµŗ¼: +- `--resume-from ${CHECKPOINT_FILE}`: ń╗¦µē┐õ╣ŗÕēŹńÜäµØāķćŹń╗¦ń╗ŁĶ«Łń╗āŃĆé +- `--no-validate`: Õ£©Ķ«Łń╗āµŚČµś»ÕÉ”Ķ┐øĶĪīµĄŗĶ»ĢŃĆé + +õŠŗÕ”é: Õ£©ķøåńŠżõĖŖõĮ┐ńö©8ÕŹĪĶ«Łń╗āHMRŃĆé +```shell +./tools/slurm_train.sh my_partition my_job configs/hmr/resnet50_hmr_pw3d.py work_dirs/hmr 8 --no-validate +``` + +Ķ»”µāģĶ»ĘĶ¦ü[slurm_train.sh](https://github.com/open-mmlab/mmhuman3d/tree/main/tools/slurm_train.sh)ŃĆé + +## µø┤ÕżÜµĢÖń©ŗ + +- [Camera conventions](../docs_zh-CN/cameras.md) +- [Keypoint conventions](../docs_zh-CN/keypoints_convention.md) +- [Custom keypoint conventions](../docs_zh-CN/customize_keypoints_convention.md) +- [HumanData](../docs_zh-CN/human_data.md) +- [Keypoint visualization](../docs_zh-CN/visualize_keypoints.md) +- [Mesh visualization](../docs_zh-CN/visualize_smpl.md) diff --git a/internlm_langchain/knowledge_base/MMHuman3D/content/human_data.md b/internlm_langchain/knowledge_base/MMHuman3D/content/human_data.md new file mode 100644 index 00000000..a866f453 --- /dev/null +++ b/internlm_langchain/knowledge_base/MMHuman3D/content/human_data.md @@ -0,0 +1,287 @@ +## HumanDataµĢ░µŹ«µĀ╝Õ╝Å + +### µĆ╗Ķ¦ł + +`HumanData`µś»PythonÕåģńĮ«ÕŁŚÕģĖńÜäÕŁÉń▒╗’╝īõĖ╗Ķ”üńö©õ║ÄÕŁśµöŠÕīģÕɽõ║║õĮōńÜäÕŹĢĶ¦åĶ¦ÆÕøŠÕāÅńÜäõ┐Īµü»ŃĆéÕ«āÕģʵ£ēķĆÜńö©ńÜäÕ¤║ńĪĆń╗ōµ×ä’╝īõ╣¤Õģ╝Õ«╣Õģʵ£ēµ¢░ńē╣µĆ¦ńÜäÕ«óÕłČÕī¢µĢ░µŹ«ŃĆé +ÕĤńö¤ńÜä`HumanData`ÕīģÕɽ`numpy.ndarray`µł¢ÕģČõ╗¢ńÜäPythonÕåģńĮ«ńÜäµĢ░µŹ«ń╗ōµ×ä’╝īõĮåõĖŹÕīģÕɽ`torch.Tensor`ńÜäµĢ░µŹ«ŃĆéÕÅ»õ╗źõĮ┐ńö©`human_data.to()`Õ░åÕģČĶĮ¼µŹóõĖ║`torch.Tensor`(µö»µīüCPUÕÆīGPU)ŃĆé + +### `Key/Value`ńÜäÕ«Üõ╣ē’╝ÜÕ”éõĖŗµś»Õ»╣`HumanData`µö»µīüńÜä`Key`ÕÆī`Value`ńÜäµÅÅĶ┐░. + +#### ĶĘ»ÕŠä: + +ķĆÜÕĖĖÕīģÕɽÕøŠńēćĶĘ»ÕŠä’╝īÕ”éµ×£µĢ░µŹ«ķøåµ£ēµÅÉõŠøķóØÕż¢ńÜäµĘ▒Õ║”µł¢ĶĆģÕłåÕē▓ÕøŠ’╝īõ╣¤ÕÅ»õ╗źĶ«░ÕĮĢõĖŗµØźŃĆé +- image_path: (N, ), ÕŁŚń¼”õĖ▓ń╗䵳ÉńÜäÕłŚĶĪ©, µ»ÅõĖĆõĖ¬Õģāń┤Āµś»ÕøŠÕāÅńøĖÕ»╣õ║ĵĀ╣ńø«ÕĮĢńÜäĶĘ»ÕŠäŃĆé +- segmantation_path (ÕÅ»ķĆē): (N, ), ÕŁŚń¼”õĖ▓ń╗䵳ÉńÜäÕłŚĶĪ©, µ»ÅõĖĆõĖ¬Õģāń┤Āµś»ÕøŠÕāÅÕłåÕē▓ÕøŠńøĖÕ»╣õ║ĵĀ╣ńø«ÕĮĢńÜäĶĘ»ÕŠäŃĆé +- depth_path (ÕÅ»ķĆē): (N, ), ÕŁŚń¼”õĖ▓ń╗䵳ÉńÜäÕłŚĶĪ©, µ»ÅõĖĆõĖ¬Õģāń┤Āµś»ÕøŠÕāŵĘ▒Õ║”ÕøŠńøĖÕ»╣õ║ĵĀ╣ńø«ÕĮĢńÜäĶĘ»ÕŠäŃĆé + +#### Õģ│ķö«ńé╣’╝Ü + +õ╗źõĖŗÕģ│ķö«ńé╣keysÕ”éµ×£ķĆéńö©’╝īÕłÖÕ║öÕīģÕɽգ©HumanDataõĖŁŃĆéõ╗╗õĮĢõĖĆõĖ¬Õģ│ķö«ńé╣ńÜäkey’╝īÕ║öÕŁśÕ£©õĖĆõĖ¬mask’╝īĶĪ©ńż║ÕģČõĖŁÕō¬õ║øÕģ│ķö«ńé╣µ£ēµĢłŃĆéÕ”é`keypoints3d_original`Õ║öÕ»╣Õ║ö`keypoints3d_original_mask`ŃĆé +`HumanData` õĖŁńÜäÕģ│ķö«ńé╣ÕŁśÕ驵Ā╝Õ╝ÅõĖ║`HUMAN_DATA`, ÕīģÕɽ190õĖ¬Õģ│ķö«ńé╣ŃĆéMMHuman3dõĖŁµÅÉõŠøõ║åÕŠłÕżÜÕĖĖńö©Õģ│ķö«ńé╣µĀ╝Õ╝ÅńÜäĶĮ¼µŹó’╝ł2dÕÅŖ3dÕØćµö»µīü’╝ē, Ķ»”Ķ¦ü [keypoints_convention](../docs_zh-CN/keypoints_convention.md). +- keypoints3d_smpl / keypoints3d_smplx: (N, 190, 4), numpy array, `smplx / smplx`µ©ĪÕ×ŗńÜä3dÕģ│ĶŖéńé╣õĖÄńĮ«õ┐ĪÕ║”, µ»ÅõĖĆõĖ¬µĢ░µŹ«ķøåńÜäÕģ│ĶŖéńé╣µśĀÕ░äÕł░õ║å`HUMAN_DATA`ńÜäÕģ│ĶŖéńé╣ŃĆé +- keypoints3d_original: (N, 190, 4), numpy array, ńö▒µĢ░µŹ«ķøåµ£¼Ķ║½µÅÉõŠøńÜä3dÕģ│ĶŖéńé╣õĖÄńĮ«õ┐ĪÕ║”, µ»ÅõĖĆõĖ¬µĢ░µŹ«ķøåńÜäÕģ│ĶŖéńé╣µśĀÕ░äÕł░õ║å`HUMAN_DATA`ńÜäÕģ│ĶŖéńé╣ŃĆé +- keypoints2d_smpl / keypoints2d_smplx: (N, 190, 3), numpy array, `smpl / smplx`µ©ĪÕ×ŗńÜä2dÕģ│ĶŖéńé╣õĖÄńĮ«õ┐ĪÕ║”, µ»ÅõĖĆõĖ¬µĢ░µŹ«ķøåńÜäÕģ│ĶŖéńé╣µśĀÕ░äÕł░õ║å`HUMAN_DATA`ńÜäÕģ│ĶŖéńé╣ŃĆé +- keypoints2d_original: (N, 190, 3), numpy array, ńö▒µĢ░µŹ«ķøåµ£¼Ķ║½µÅÉõŠøńÜä2dÕģ│ĶŖéńé╣õĖÄńĮ«õ┐ĪÕ║”, µ»ÅõĖĆõĖ¬µĢ░µŹ«ķøåńÜäÕģ│ĶŖéńé╣µśĀÕ░äÕł░õ║å`HUMAN_DATA`ńÜäÕģ│ĶŖéńé╣ŃĆé +- ’╝łmaskńż║õŠŗ’╝ē keypoints2d_smpl_mask: (190, ), numpy array, ĶĪ©ńż║`keypoints2d_smpl`õĖŁÕģ│ķö«ńé╣µś»ÕÉ”µ£ēµĢłńÜäµÄ®Ķå£ŃĆé 0ĶĪ©ńż║Ķ»źõĮŹńĮ«ńÜäÕģ│ķö«ńé╣Õ£©ÕĤզŗµĢ░µŹ«ķøåõĖŁµŚĀµ│ĢµēŠÕł░ŃĆé + +#### µŻĆµĄŗµĪå’╝Ü + +Ķ║½õĮō’╝łsmpl’╝ē’╝īµēŗĶäĖ’╝łsmplx’╝ēńÜ䵯ƵĄŗµĪå’╝īµĀćµ│©õĖ║`[x_min, y_min, width, height, confidence]`’╝īõĖöõĖŹÕ║öĶČģÕć║ÕøŠńēćŃĆé +- bbox_xywh: (N, 5), numpy array, ĶŠ╣ńĢīµĪåńÜäńĮ«õ┐ĪÕ║”, ĶŠ╣ńĢīµĪåÕĘ”õĖŗĶ¦Æńé╣ńÜäÕØɵĀćxÕÆīy, ĶŠ╣ńĢīµĪåńÜäÕ«ĮwÕÆīķ½śh, ńĮ«õ┐ĪÕ║”ÕŠŚÕłåµöŠńĮ«Õ£©µ£ĆÕÉÄŃĆé +- face_bbox_xywh, lhand_bbox_xywh, rhand_bbox_xywh’╝łÕÅ»ķĆē’╝ē’╝Ü (N, 5), numpy array, Õ”éµ×£µĢ░µŹ«µĀćµ│©õĖŁÕɽµ£ē`smplx`, ÕłÖÕ║öÕīģµŗ¼Ķ┐ÖõĖēõĖ¬key’╝īńö▒smplx2dÕģ│ķö«ńé╣ÕŠŚÕć║’╝īµĀ╝Õ╝ÅÕÉīõĖŖŃĆé + +#### õ║║õĮōµ©ĪÕ×ŗÕÅéµĢ░’╝Ü + +ķĆÜÕĖĖõ╗źsmpl/smplxµĀ╝Õ╝ÅÕŁśÕé©ŃĆé +- smpl: (1, ), ÕŁŚÕģĖ, `keys` ÕłåÕł½õĖ║ ['body_pose': numpy array, (N, 23, 3), 'global_orient': numpy array, (N, 3), 'betas': numpy array, (N, 10), 'transl': numpy array, (N, 3)]. +- smplx: (1, ), ÕŁŚÕģĖ, `keys` ÕłåÕł½õĖ║ ['body_pose': numpy array, (N, 21, 3),'global_orient': numpy array, (N, 3), 'betas': numpy array, (N, 10), 'transl': numpy array, (N, 3), 'left_hand_pose': numpy array, (N, 15, 3), 'right_hand_pose': numpy array, (N, 15, 3), 'expression': numpy array (N, 10), 'leye_pose': numpy array (N, 3), 'reye_pose': (N, 3), 'jaw_pose': numpy array (N, 3)]. + +#### ÕģČÕ«ākeys + +- config: (), ÕŁŚń¼”õĖ▓, ÕŹĢõĖ¬µĢ░µŹ«ķøåńÜäķģŹńĮ«ńÜäµĀćÕ┐ŚŃĆé +- meta: (1, ), ÕŁŚÕģĖ, `keys`õĖ║µĢ░µŹ«ķøåõĖŁńÜäÕÉäń¦ŹÕģāµĢ░µŹ«ŃĆé +- misc: (1, ), ÕŁŚÕģĖ, `keys`õĖ║µĢ░µŹ«ķøåõĖŁÕÉäń¦Źńŗ¼ńē╣Ķ«ŠÕ«Ü’╝īõ╣¤ÕÅ»õ╗źńö▒ńö©µłĘĶć¬Õ«Üõ╣ēŃĆé`misc`ÕŹĀńö©ńÜäń®║ķŚ┤’╝łÕÅ»õ╗źķĆÜĶ┐ć`sys.getsizeof(misc)`ĶÄĘÕÅ¢’╝ēõĖŹĶāĮĶČģĶ┐ć6MBŃĆé + +#### `HumanData['misc']`õĖŁÕ╗║Ķ««’╝łÕÅ»ĶāĮ’╝ēÕīģÕɽńÜäÕåģÕ«╣: +Miscellaneousķā©ÕłåõĖŁÕīģÕɽõ║åµ»ÅõĖ¬µĢ░µŹ«ķøåńÜäńŗ¼ńē╣Ķ«ŠÕ«Ü’╝īÕīģµŗ¼ńøĖµ£║ń¦Źń▒╗’╝īÕģ│ķö«ńé╣µĀćµ│©µØźµ║É’╝īµŻĆµĄŗµĪåµØźµ║É’╝īµś»ÕÉ”ÕīģÕɽsmpl/smplxµĀćµ│©ńŁēńŁē’╝īńö©õ║ÄõŠ┐Õł®µĢ░µŹ«Ķ»╗ÕÅ¢ŃĆé +`HumanData['misc']`õĖŁÕīģÕɽõĖĆõĖ¬dictionary’╝īÕ╗║Ķ««ÕīģÕɽńÜäkeyÕ”éõĖŗµēĆńż║’╝Ü +- kps3d_root_aligned’╝Ü Bool µÅÅĶ┐░keypoints3dµś»ÕÉ”ń╗ÅĶ┐ćroot align’╝īÕ╗║Ķ««õĖŹĶ┐øĶĪīroot_alignment’╝īÕ”éµ×£õĖŹÕīģÕɽĶ┐ÖõĖ¬key’╝īÕłÖķ╗śĶ«żµ▓Īµ£ēĶ┐øĶĪīĶ┐ćroot_aligenment +- flat_hand_mean’╝ÜBool Õ»╣õ║ÄsmplxµĀćµ│©ńÜäµĢ░µŹ«’╝īÕ║öĶ»źÕŁśÕ£©µŁżķĪ╣’╝īÕż¦ÕżÜµĢ░µĢ░µŹ«ķøåõĖŁ`flat_hand_mean=False` +- bbox_source’╝ܵÅÅĶ┐░µŻĆµĄŗµĪåńÜäµØźµ║É’╝ī`bbox_soruce='keypoints2d_smpl' or 'keypoints2d_smplx' or 'keypoints2d_original'`’╝īµÅÅĶ┐░µŻĆµĄŗµĪåµś»ńö▒Õō¬ń¦ŹÕģ│ķö«ńé╣ÕŠŚÕć║ńÜä’╝īµł¢ĶĆģ`bbox_source='provide_by_dataset'`ĶĪ©ńż║µŻĆµĄŗµĪåńö▒µĢ░µŹ«ķøåńø┤µÄźń╗ÖÕć║’╝łµ»öÕ”éńö©ÕģČĶć¬ÕĖ”µŻĆµĄŗÕÖ©ńö¤µłÉĶĆīõĖŹµś»ńö▒Õģ│ķö«ńé╣µÄ©Õ»╝ÕŠŚÕć║’╝ē +- bbox_body_scale: Õ”éµ×£µŻĆµĄŗµĪåńö▒Õģ│ķö«ńé╣µÄ©Õ»╝ÕŠŚÕć║’╝īÕłÖÕ║öÕīģÕɽµŁżķĪ╣’╝īµÅÅĶ┐░ńö▒smpl/smplx/2d_gtÕģ│ķö«ńé╣µÄ©Õ»╝Õć║ńÜäĶ║½õĮōµŻĆµĄŗµĪåńÜäµöŠÕż¦µ»öõŠŗ’╝īÕ╗║Ķ««`bbox_body_scale=1.2` +- bbox_hand_scale, bbox_face_scale: Õ”éµ×£µŻĆµĄŗµĪåńö▒Õģ│ķö«ńé╣µÄ©Õ»╝ÕŠŚÕć║’╝īÕłÖÕ║öÕīģÕɽĶ┐ÖõĖżķĪ╣’╝īµÅÅĶ┐░ńö▒smpl/smplx/2d_gtÕģ│ķö«ńé╣µÄ©Õ»╝Õć║ńÜäĶ║½õĮōµŻĆµĄŗµĪåńÜäµöŠÕż¦µ»öõŠŗ’╝īÕ╗║Ķ««`bbox_hand_scale=1.0, bbox_face_scale=1.0` +- smpl_source / smplx_source: µÅÅĶ┐░smpl/smplxńÜäµØźµ║É’╝ī`'original', 'nerual_annot', 'eft', 'osx_annot', 'cliff_annot'`, µØźµÅÅĶ┐░smpl/smnplxµś»µØźµ║Éõ║ĵĢ░µŹ«ķøåµÅÉõŠø’╝īµł¢ĶĆģÕģČÕ«āµĀćµ│©µØźµ║É +- cam_param_type: µÅÅĶ┐░ńøĖµ£║ÕÅéµĢ░ńÜäń¦Źń▒╗’╝ī`cam_param_type='prespective' or 'predicted_camera' or 'eft_camera'` +- principal_point, focal_length: (1, 2), numpy array’╝īÕ”éµ×£µĢ░µŹ«ķøåõĖŁńøĖµ£║ÕÅéµĢ░µüÆÕ«Ü’╝īÕłÖÕ║öÕīģÕɽĶ┐ÖõĖżķĪ╣’╝īķĆÜÕĖĖķĆéńö©õ║Äńö¤µłÉµĢ░µŹ«ķøåŃĆé +- image_shape: (1, 2), numpy array’╝īÕ”éµ×£µĢ░µŹ«ķøåõĖŁÕøŠńēćÕż¦Õ░ŵüÆÕ«Ü’╝īÕłÖÕ║öÕīģÕɽµŁżķĪ╣ŃĆé + +#### `HumanData['meta']`õĖŁÕ╗║Ķ««’╝łÕÅ»ĶāĮ’╝ēÕīģÕɽńÜäÕåģÕ«╣: +- gender: (N, )’╝ī ÕŁŚń¼”õĖ▓ń╗䵳ÉńÜäÕłŚĶĪ©, µ»ÅõĖĆõĖ¬Õģāń┤Āµś»smplxµ©ĪÕ×ŗńÜäµĆ¦Õł½’╝łõĖŁµĆ¦ÕłÖõĖŹÕ┐ģµĀćµ│©’╝ē +- height’╝łwidth’╝ē’╝Ü(N, )’╝ī ÕŁŚń¼”õĖ▓ń╗䵳ÉńÜäÕłŚĶĪ©, µ»ÅõĖĆõĖ¬Õģāń┤Āµś»ÕøŠńēćńÜäķ½ś’╝łµł¢Õ«Į’╝ē’╝īĶ┐ÖķćīõĖŹµÄ©ĶŹÉõĮ┐ńö©`image_shape=(width, height): (N, 2)`’╝īÕøĀõĖ║µ£ēµŚČķ£ĆĶ”üµīēÕÅŹķĪ║Õ║ÅĶ»╗ÕÅ¢ÕøŠńēćµĀ╝Õ╝ÅŃĆé’╝łµĢ░µŹ«ķøåÕøŠńēćÕłåĶŠ©ńÄćõĖĆĶć┤ÕłÖÕ║öµĀćµ│©Õ£©`HumanData['misc']`õĖŁ’╝ē +- ÕģČÕ«āµ£ēµĀćĶ»åµĆ¦ńÜäkey’╝īĶŗźµĢ░µŹ«ķøåõĖŁĶ»źkeyõĖŹõĖĆĶć┤’╝īõĖöõ╝ÜÕĮ▒ÕōŹkeypoints or smpl/smplx’╝īÕłÖÕ╗║Ķ««µĀćµ│©’╝īÕ”éfocal_lengthõĖÄprincipal_point, focal_length = (N, 2), principal_point = (N, 2) + +#### Õģ│õ║ÄHumanDatańÜäõĖĆõ║øĶ»┤µśÄ + +- µēƵ£ēµĢ░µŹ«µĀćµ│©ÕØćÕĘ▓õ╗ÄõĖ¢ńĢīÕØɵĀćĶĮ¼ń¦╗Õł░opencvńøĖµ£║ń®║ķŚ┤’╝īĶ┐øĶĪīsmpl/smplxńÜäńøĖµ£║ń®║ķŚ┤ĶĮ¼µŹóÕÅ»õ╗źńö© + +```from mmhuman3d.models.body_models.utils import transform_to_camera_frame, batch_transform_to_camera_frame``` + +#### µŻĆµ¤ź`HumanData`õĖŁńÜä`key`. + +Õ£©ķ╗śĶ«żńÜä`HumanData`õĖŁ’╝īÕŬĶāĮÕīģÕɽõ╣ŗÕēŹµÅÅĶ┐░Ķ┐ć`key`ŃĆéÕ”éµ×£µŚĀµ│Ģķü┐ÕģŹĶ┐ÖõĖ¬ķŚ«ķóś’╝īĶ┐śµ£ēõĖĆõĖ¬µ¢╣µ│ĢŃĆé ķĆÜĶ┐ćµīćÕ«Ü`__key_strict__ == False`µ×äÕ╗║õĖĆõĖ¬`HumanData`Õ«×õŠŗŃĆé + +```python +human_data = HumanData.new(key_strict=False) +human_data['video_path'] = 'test.mp4' +``` +Ķ┐öÕø×ńÜä`HumanData`ÕģüĶ«Ėõ╗╗õĮĢÕ«óÕłČÕī¢ńÜä`key`’╝īÕ╣ČÕ£©ń¼¼õĖƵ¼ĪµÄźÕÅŚµ¢░`key`µŚČlogõĖĆõĖ¬ĶŁ”ÕæŖŃĆéÕ”éµ×£µŁŻÕ£©õĮ┐ńö©Õ«óÕłČÕī¢ńÜä`key`’╝īĶ»ĘÕ┐ĮńĢźĶ»źĶŁ”ÕæŖ’╝īÕ£©ń©ŗÕ║Åń╗ōµØ¤ÕēŹÕ«āõĖŹõ╝ÜÕåŹÕć║ńÄ░ŃĆé + +Õ”éµ×£µé©ÕĘ▓ń╗ŵ×äÕ╗║õ║åõĖĆõĖ¬`HumanData`, Õ╣ČõĖöµā│µö╣ÕÅś`strict`µ©ĪÕ╝Å, ÕÅ»õ╗źõĮ┐ńö©`set_key_strict`: + +```python +human_data = HumanData.fromfile('human_data.npz') +key_strict = human_data.get_key_strict() +human_data.set_key_strict(not key_strict) +``` + + + +#### µŻĆµ¤ź`HumanData`õĖŁńÜä`value`. + +ÕŬµ£ēµīćÕ«Ü`human_data[key] == value`µŚČ’╝īµēŹõ╝ܵŻĆµ¤źõ╣ŗÕēŹµÅÉÕł░Ķ┐ćńÜä`value`’╝īńøĖÕģ│Ķ¦äĶīāÕ£©`HumanData.SUPPORTED_KEYS`õĖŁÕ«Üõ╣ēŃĆé + +Õ»╣õ║ĵ»ÅõĖ¬`value`, Õ┐ģķĪ╗Õ£©ÕģČ`key`õĖŗµīćիܵĢ░µŹ«ń▒╗Õ×ŗ: + +```python +'smpl': { + 'type': dict, +}, +``` + +Õ»╣õ║Äń▒╗Õ×ŗõĖ║`numpy.ndarray`ńÜä`value`, ķ£ĆĶ”üµīćÕ«Ü`shape`ÕÆī`dim`ÕÅéµĢ░: + +```python +'keypoints3d': { + 'type': np.ndarray, + 'shape': (-1, -1, 4), + # value.ndim==3 value.shape[2]==4 + # value.shape[0:2] is arbitrary. + 'dim': 0 + # dimension 0 marks time(frame index, or second) +}, +``` + +Õ»╣õ║ÄõĖŹķÜÅÕĖ¦ÕÅśÕī¢ńÜä`value`’╝īµīćÕ«ÜÕģČ`dim=-1`õ╗źĶĘ│Ķ┐ćÕĖ¦µŻĆµ¤ź: + +```python +'keypoints3d_mask': { + 'type': np.ndarray, + 'shape': (-1, ), + 'dim': -1 +}, +``` + +### µĢ░µŹ«ÕÄŗń╝® + +#### ÕÄŗń╝®`mask` + +ńö▒õ║Ä`HUMAN_DATA`ńÜäÕģ│ķö«ńé╣Õ«Üõ╣ēµĢ┤ÕÉłĶć¬õĖŹÕÉīńÜäµĢ░µŹ«ķøå’╝īķā©ÕłåÕģ│ķö«ńé╣ń╝║Õż▒µś»ÕŠłÕĖĖĶ¦üńÜäŃĆéõĮ┐ńö©Õ”éõĖŗńÜäµ¢╣Õ╝Å’╝īÕÅ»õ╗źķĆÜĶ┐ć`mask`µ╗żķÖżń╝║Õż▒ńÜäÕģ│ķö«ńé╣: + +```python +# keypoints2d_agora µś»õĖĆõĖ¬ÕĮóńŖČõĖ║[frame_num, 127, 3]ńÜänumpyµĢ░ń╗ä. +# AgoraõĖŁÕ«Üõ╣ēõ║å127õĖ¬Õģ│ķö«ńé╣. +keypoints2d_human_data, mask = convert_kps(keypoints2d_agora, 'agora', 'human_data') +# keypoints2d_human_data µś»õĖĆõĖ¬ÕĮóńŖČõĖ║[frame_num, 190, 3]ńÜänumpyµĢ░ń╗ä. +# mask µś»õĖĆõĖ¬ÕĮóńŖČõĖ║[190, ]ńÜänumpyµĢ░ń╗ä, ÕåģÕɽõ║å127õĖ¬1ÕÆī63õĖ¬0. +``` + +µīćÕ«Ü`keypoints2d_mask` ÕÆī `keypoints2d`, ÕŠłµśÄµśŠ`keypoints2d`õĖŁµ£ēÕŠłÕżÜÕåŚõĮÖńÜä0: + +```python +human_data = HumanData() +human_data['keypoints2d_mask'] = mask +human_data['keypoints2d'] = keypoints2d_human_data +``` + +Ķ░āńö©`compress_keypoints_by_mask()`ÕÄ╗µÄēÕåŚõĮÖńÜä0ŃĆé Ķ»źµ¢╣µ│Ģõ╝ܵŻĆµ¤źµēƵ£ēÕīģÕɽ`keypoints`ńÜä`key`µś»ÕÉ”Õģʵ£ēńøĖÕ║öńÜä`mask`’╝īÕ”éµ×£ÕÉīµŚČÕŁśÕ£©’╝īÕ░▒Ķ┐øĶĪīÕÄŗń╝®: + +```python +human_data.compress_keypoints_by_mask() +``` + +Ķ░āńö©`get_raw_value()`ĶÄĘÕŠŚÕé©ÕŁśÕ£©`HumanData`Õ«×õŠŗõĖŁÕÄŗń╝®Ķ┐ćńÜä`value`. ÕĮōķĆÜĶ┐ć`[]`ĶÄĘÕŠŚ`item`µŚČ, Õ░åĶ┐öÕø×ńö©0ÕĪ½ÕģģÕÉÄńÜäÕģ│ķö«ńé╣: + +```python +keypoints2d_human_data = human_data.get_raw_value('keypoints2d') +print(keypoints2d_human_data.shape) # [frame_num, 127, 3] +keypoints2d_human_data = human_data['keypoints2d'] +print(keypoints2d_human_data.shape) # [frame_num, 190, 3] +``` + +Õ£©`keypoints_compressed`µ©ĪÕ╝ÅõĖŁ, ÕÅ»õ╗źÕ»╣Õģ│ķö«ńé╣Ķ┐øĶĪīń╝¢ĶŠæŃĆéµ£ēõĖżń¦ŹõĖŹÕÉīńÜäµ¢╣Õ╝Å’╝īĶ«ŠńĮ«ÕĪ½ÕģģµĢ░µŹ«µł¢ńø┤µÄźµīćÕ«ÜÕÄŗń╝®µĢ░µŹ«: + +```python +padded_keypoints2d = np.zeros(shape=[100, 190, 3]) +human_data['keypoints2d'] = padded_keypoints2d # [frame_num, 190, 3] +compressed_keypoints2d = np.zeros(shape=[100, 127, 3]) +human_data.set_raw_value('keypoints2d', compressed_keypoints2d) # [frame_num, 127, 3] +``` + +ÕĮō`HumanData`Õ«×õŠŗÕżäõ║Ä`keypoints_compressed`µ©ĪÕ╝Å, µēƵ£ēÕģ│ķö«ńé╣ńÜä`masks`õ╝ÜĶó½ķöüÕ«ÜŃĆéÕĮōµé©Õ░ØĶ»ĢĶ┐øĶĪīõ┐«µö╣µŚČ, õ╝ÜlogõĖĆõĖ¬ĶŁ”ÕæŖÕ╣ČõĖö`value`õĖŹõ╝ÜĶó½õ┐«µö╣ŃĆéÕ”éµ×£ķ£ĆĶ”üõ┐«µö╣`mask`’╝īõĮ┐ńö©`decompress_keypoints()`Ķ┐øĶĪīĶ¦ŻÕÄŗń╝®: + +```python +human_data.decompress_keypoints() +``` + +õĖŖĶ┐░ńē╣µĆ¦õ╣¤ķĆéńö©õ║ÄÕģČõ╗¢ń▒╗õ╝╝õ║Ä`keypoints*`ÕÆī`keypoints*_mask`ńÜä`key-value`Õ»╣ŃĆé + +#### ÕÄŗń╝®µ¢ćõ╗Č + +Ķ░āńö©`dump()` Õ░å`HumanData`ÕÄŗń╝®µłÉ`.npz`µ¢ćõ╗ČŃĆé + +`dump`ÕÉÄńÜä`.npz`µ¢ćõ╗ČÕÅ»õ╗źõĮ┐ńö©`load()`Ķ┐øĶĪīÕŖĀĶĮĮ: + +```python +# õ┐ØÕŁś +human_data.dump('./dumped_human_data.npz') +# ÕŖĀĶĮĮ +another_human_data = HumanData() +another_human_data.load('./dumped_human_data.npz') +``` + +µ£ēµŚČ`HumanData`Õż¬ķĢ┐õ║å’╝īńø┤µÄźĶ┐øĶĪī`dump`õ╝ܵŖźķöÖŃĆéĶ┐Öń¦ŹµāģÕåĄõĖŗ’╝īÕÅ»õ╗źĶ░āńö©`dump_by_pickle`ÕÆī`load_by_pickle`Õ░å`HumanData`ÕÄŗń╝®µłÉ`.pkl`µ¢ćõ╗ČŃĆé + +#### ÕÄŗń╝®`key` + +Õ”éµ×£`HumanData`Õ«×õŠŗõĖŹÕżäõ║Ä`key_strict`µ©ĪÕ╝Å, ÕģČÕÅ»ĶāĮõ╝ÜÕīģÕɽõĖŹÕÅŚµö»µīüńÜäķĪ╣ńø«ŃĆéĶ░āńö©`pop_unsupported_items()`µĖģķÖżĶ┐Öõ║øķĪ╣ńø«’╝īõ╗źĶŖéń£üń®║ķŚ┤: + +```python +human_data = HumanData.fromfile('human_data_not_strict.npz') +human_data.pop_unsupported_items() +human_data.set_key_strict(True) +``` + +### µĢ░µŹ«ķĆēµŗ® + +#### ķĆÜĶ┐ćÕĮóńŖČĶ┐øĶĪīķĆēµŗ® + +ÕüćÕ«Ü`keypoints2d` µś»õĖĆõĖ¬`array`’╝īÕģČÕĮóńŖČõĖ║[200, 190, 3], ÕŬķ£ĆĶ”üµ£ĆÕ╝ĆÕ¦ŗńÜä10ÕĖ¦: + +```python +first_ten_frames = human_data.get_value_in_shape('keypoints2d', shape=[10, -1, -1]) +``` + +Õ£©õĖĆõ║øµāģÕåĄõĖŗ, µłæõ╗¼ķ£ĆĶ”üÕ░å`array`µē®ÕģģµłÉńē╣Õ«ÜńÜäÕĮóńŖČ: + +```python +# ķĆÜĶ┐ćÕĪ½0Õ░åÕģČÕĮóńŖČõ╗Ä[200, 190, 3]µē®ÕģģµłÉ[200, 300, 3] +padded_keypoints2d = human_data.get_value_in_shape('keypoints2d', shape=[200, 300, -1]) +# ÕĪ½ÕģģńÜäµĢ░ÕĆ╝ÕÅ»õ╗źĶó½õ┐«µö╣ +padded_keypoints2d = human_data.get_value_in_shape('keypoints2d', shape=[200, 300, -1], padding_constant=1) +``` + +#### ķĆÜĶ┐浌ČķŚ┤ÕłćńēćĶ┐øĶĪīķĆēµŗ® + +ÕüćĶ«ŠÕ£©õĖĆõĖ¬`HumanData`Õ«×õŠŗõĖŁµ£ē200ÕĖ¦, ÕŬķ£ĆĶ”üõĖŁķŚ┤10Ķć│20ÕĖ¦: + +```python +# µēƵ£ēµö»µīüńÜä`value`ķāĮõ╝ÜĶó½Õłćńēć +sub_human_data = human_data.get_slice(10, 21) +``` + +õ╣¤ÕÅ»õ╗źĶ┐øĶĪīõĖŗķććµĀĘ,õĖŗķØóńÜäõŠŗÕŁÉµÅÅĶ┐░õ║åõĖĆń¦ŹķĆēµŗ®ÕģČ33%µĢ░µŹ«ńÜäµ¢╣µ│Ģ: + +```python +# ķĆēµŗ® [0, 3, 6, 9,..., 198] +sub_human_data = human_data.get_slice(0, 200, 3) +``` + +### ĶĮ¼µŹóõĖ║`torch.Tensor` + +õ╣ŗÕēŹµÅÉÕł░’╝īÕĤńö¤ńÜä`HumanData`õĖŁÕīģÕɽ`numpy.ndarray`µł¢pythonÕåģńĮ«ń▒╗Õ×ŗńÜä`value`’╝īõĮå`numpy.ndarray`ÕÅ»õ╗źĶĮ╗µØŠĶĮ¼µŹóõĖ║`torch.Tensor`: + +```python +# ndarrayõ╝ÜĶó½ĶĮ¼µŹóµłÉcpuõĖŖńÜäTensor. +# ÕģČõ╗¢ń▒╗Õ×ŗńÜävalueõĖŹõ╝ÜÕÅæńö¤ÕÅśÕī¢. +# Ķ┐öÕø×õĖĆõĖ¬ÕĮóÕ”éHumanDatańÜäÕŁŚÕģĖ. +dict_of_tensor = human_data.to() +# õ╣¤ÕÅ»õ╗źĶĮ¼µŹóõĖ║GPUõĖŖńÜäTensor +gpu0_device = torch.device('cuda:0') +dict_of_gpu_tensor = human_data.to(gpu0_device) +``` +## MultiHumanData + +MulitHumanData Ķó½Ķ«ŠĶ«ĪµØźµö»µīüÕżÜõ║║ķćŹÕ╗║ŃĆéÕ«āń╗¦µē┐õ║ÄHumanDataŃĆéÕ£©HumanDataõĖŁ’╝īÕøĀõĖ║ÕøŠńēćÕÆīµĢ░µŹ«µś»õĖĆõĖĆÕ»╣Õ║öńÜä’╝īµēĆõ╗źµłæõ╗¼ÕÅ»õ╗źńø┤µÄźń┤óÕ╝ĢµĢ░µŹ«ŃĆéńäČĶĆī’╝īÕ£©MultiHumanDataõĖŁµĢ░µŹ«ÕÆīÕøŠÕāŵś»ÕżÜÕ»╣õĖĆńÜäÕģ│ń│╗ŃĆé + +MultiHumanDataÕ£©HumanDatańÜäÕ¤║ńĪĆõĖŖµĘ╗ÕŖĀõĖĆõĖ¬µ¢░ńÜäkeyÕŽÕüÜ`frame_range`,Õ«āÕ«Üõ╣ēÕ”éõĖŗ’╝Ü + +```python +'frame_range': { + 'type': np.ndarray, + 'shape': (-1, 2), + 'dim': 0 + } +``` + +`frame_range`µś»ÕÆīÕøŠÕāÅõĖĆõĖĆÕ»╣Õ║öńÜäŃĆé `frame_range`õĖŁńÜäµ»ÅõĖ¬Õģāń┤Āµś»õĖżõĖ¬µīćķÆł’╝īÕ«āõ╗¼µīćÕÉæõĖĆõĖ¬µĢ░µŹ«Õī║Õ¤¤ŃĆé + +ÕüćĶ«Šµłæõ╗¼µ£ēõĖĆõĖ¬MultiHumanDatańÜäÕ«×õŠŗ’╝īµłæõ╗¼µā│ń┤óÕ╝Ģń¼¼iÕ╝ĀÕøŠÕāÅÕ»╣Õ║öńÜäµĢ░µŹ«ŃĆé ķ”¢Õģłµłæõ╗¼ńö©õĖ╗ń┤óÕ╝Ģń┤óÕ╝Ģ`frame_range`’╝īÕ«āõ╝ÜĶ┐öÕø×õĖżõĖ¬µīćķÆł’╝īńö©Ķ┐ÖõĖżõĖ¬µīćķÆłµłæõ╗¼Õ░▒ÕÅ»õ╗źń┤óÕ╝Ģń¼¼iÕ╝ĀÕøŠÕāÅÕ»╣Õ║öńÜäµēƵ£ēµĢ░µŹ«ŃĆé + +``` +image_0 ----> human_0 <--- frame_range[0][0] + - . + - . + --> human_(n-1) <--- frame_range[0][0] + (n-1) + -> human_n <--- frame_range[0][1] + . + . + . + + +image_n ----> human_0 <--- frame_range[n][0] + - . + - . + --> human_(n-1) <--- frame_range[n][0] + (n-1) + -> human_n <--- frame_range[n][1] + +``` diff --git a/internlm_langchain/knowledge_base/MMHuman3D/content/install.md b/internlm_langchain/knowledge_base/MMHuman3D/content/install.md new file mode 100644 index 00000000..4464b640 --- /dev/null +++ b/internlm_langchain/knowledge_base/MMHuman3D/content/install.md @@ -0,0 +1,227 @@ +# Õ«ēĶŻģ + +- [Õ«ēĶŻģ](#Õ«ēĶŻģ) +- [õŠØĶĄ¢](#õŠØĶĄ¢) +- [ÕćåÕżćńÄ»Õóā](#ÕćåÕżćńÄ»Õóā) +- [Õ«ēĶŻģ MMHuman3D](#Õ«ēĶŻģ-mmhuman3d) +- [õ╗ÄÕż┤Õ╝ĆÕ¦ŗÕ«ēĶŻģńÜäĶäܵ£¼](#õ╗ÄÕż┤Õ╝ĆÕ¦ŗÕ«ēĶŻģńÜäĶäܵ£¼) + +## õŠØĶĄ¢ + +- Linux +- ffmpeg +- Python 3.7+ +- PyTorch 1.6.0, 1.7.0, 1.7.1, 1.8.0, 1.8.1, 1.9.0 µł¢ 1.9.1. +- CUDA 9.2+ +- GCC 5+ +- PyTorch3D 0.4+ +- [MMCV](https://github.com/open-mmlab/mmcv) (Ķ»ĘÕ«ēĶŻģńö©õ║ÄGPUńÜämmcv-full, Ķ”üµ▒éńēłµ£¼>=1.3.17,<1.6.0) + +Optional: +- [MMPose](https://github.com/open-mmlab/mmpose) (ÕŬńö©õ║ĵ╝öńż║) +- [MMDetection](https://github.com/open-mmlab/mmdetection) (ÕŬńö©õ║ĵ╝öńż║) +- [MMTracking](https://github.com/open-mmlab/mmtracking) (ÕŬńö©õ║ÄÕżÜõ║║ńÜäµ╝öńż║ŃĆéĶ»ĘÕ«ēĶŻģ mmcls<0.23.1, mmcv-full>=1.3.17,<1.6.0) + +## ÕćåÕżćńÄ»Õóā + +a. ÕłøÕ╗║condaĶÖܵŗ¤ńÄ»ÕóāÕ╣ȵ┐Ƶ┤╗. + +```shell +conda create -n open-mmlab python=3.8 -y +conda activate open-mmlab +``` + +b. Õ«ēĶŻģ ffmpeg + +ńø┤µÄźõĮ┐ńö©condaÕ«ēĶŻģffmpeg + +```shell +conda install ffmpeg +``` + +c. µĀ╣µŹ« [Õ«śµ¢╣µīćÕ»╝](https://pytorch.org/) ’╝īÕ«ēĶŻģPyTorchÕÆītorchvision . +```shell +conda install pytorch={torch_version} torchvision cudatoolkit={cu_version} -c pytorch +``` + +õ╗źÕ«ēĶŻģ PyTorch 1.8.0 ÕÆī CUDA 10.2õĖ║õŠŗ. +```shell +conda install pytorch=1.8.0 torchvision cudatoolkit=10.2 -c pytorch +``` + +**µ│©µäÅ:** Ķ»ĘńĪ«õ┐Øcompilation CUDA versionÕÆīruntime CUDA versionńøĖÕī╣ķģŹŃĆé +ÕÅ”Õż¢’╝ī Õ»╣õ║ÄRTX 30ń│╗ÕłŚńÜ䵜ŠÕŹĪ’╝ī ķ£ĆĶ”ücudatoolkit>=11.0. + +d. Õ£©Linuxµł¢ĶĆģWindowsõĖŖÕ«ēĶŻģPyTorch3D. + +Õ»╣õ║ÄLinux’╝Ü + +```shell +conda install -c fvcore -c iopath -c conda-forge fvcore iopath -y +conda install -c bottler nvidiacub -y + +conda install pytorch3d -c pytorch3d +``` + +ńö©µłĘõ╣¤ÕÅ»õ╗źÕÅéĶĆā [PyTorch3D-install](https://github.com/facebookresearch/pytorch3d/blob/main/INSTALL.md) ńÜäµø┤ÕżÜń╗åĶŖéŃĆé +ńäČĶĆīµłæõ╗¼Ķ┐æµ£¤ńÜ䵥ŗĶ»ĢµśŠńż║õĮ┐ńö© conda Õ«ēĶŻģõ╝ÜķüćÕł░õŠØĶĄ¢Õå▓ń¬üńÜäķŚ«ķóśŃĆé +ÕøĀµŁż’╝īńö©µłĘõ╣¤ÕÅ»ķĆēµŗ®µīēńģ¦õĖŗÕłŚµŁźķ¬żõ╗ĵ║ÉńĀüÕ«ēĶŻģPytorch3DŃĆé + +```shell +git clone https://github.com/facebookresearch/pytorch3d.git +cd pytorch3d +pip install . +cd .. +``` + +Õ»╣õ║ÄWindows’╝Ü + +Ķ»ĘÕÅéĶĆā [Õ«śµ¢╣Õ«ēĶŻģµ¢ćµĪŻ](https://github.com/facebookresearch/pytorch3d/blob/main/INSTALL.md) ŃĆé Ķ┐Öķćīµłæõ╗¼µÅÉõŠøõĖĆõĖ¬ [õŠŗÕŁÉ](https://github.com/open-mmlab/mmhuman3d/pull/199#issue-1274739041) õŠøńö©µłĘÕÅéĶĆāŃĆé +**µ│©µäÅ:** Ķ┐Öķā©Õłåµś»ķÆłÕ»╣µā│Õ£©WindowsÕ╣│ÕÅ░Õ«ēĶŻģMMHuman3DńÜäńö©µłĘŃĆé + +Ķ┐ÉĶĪīÕ”éõĖŗÕæĮõ╗żµĄŗĶ»ĢPyTorch3Dµś»ÕɔիēĶŻģµłÉÕŖ¤: + +```shell +echo "import pytorch3d;print(pytorch3d.__version__); \ + from pytorch3d.renderer import MeshRenderer;print(MeshRenderer);\ + from pytorch3d.structures import Meshes;print(Meshes);\ + from pytorch3d.renderer import cameras;print(cameras);\ + from pytorch3d.transforms import Transform3d;print(Transform3d);"|python + +echo "import torch;device=torch.device('cuda');\ + from pytorch3d.utils import torus;\ + Torus = torus(r=10, R=20, sides=100, rings=100, device=device);\ + print(Torus.verts_padded());"|python +``` + +## Õ«ēĶŻģ MMHuman3D + +a. Õ«ēĶŻģ mmcv-full ŃĆü mmpose ŃĆü mmdet ÕÆī mmtrack + +- mmcv-full + +µÄ©ĶŹÉõĮ┐ńö©Õ”éõĖŗÕæĮõ╗żÕ«ēĶŻģmmcv-full. + +Õ»╣õ║Ä CPU: +```shell +pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cpu/{torch_version}/index.html +``` +õĮ┐ńö©µé©ńÜäpytorchńēłµ£¼ÕÅʵø┐µŹó`{torch_version}` + +Õ»╣õ║Ä GPU: + ```shell + pip install "mmcv-full>=1.3.17,<=1.5.3" -f https://download.openmmlab.com/mmcv/dist/{cu_version}/{torch_version}/index.html + ``` +õĮ┐ńö©µé©ńÜäcudańēłµ£¼ÕÅĘÕÆīpytorchńēłµ£¼ÕÅʵø┐µŹó`{cu_version}`ÕÆī`{torch_version}` + +õ╗źÕ£©CUDA 10.2ÕÆīPyTorch 1.8.0ńÜäńÄ»ÕóāõĖŗ, Õ«ēĶŻģmmcv-fullõĖ║õŠŗ: +```shell +pip install "mmcv-full>=1.3.17,<=1.5.3" -f https://download.openmmlab.com/mmcv/dist/cu102/torch1.8.0/index.html +``` +µé©ÕÅ»õ╗źõ╗Ä [Ķ┐Öķćī](https://mmcv.readthedocs.io/en/latest/get_started/installation.html) µ¤źń£ŗķĆéķģŹõ║ÄõĖŹÕÉīCUDAńēłµ£¼ÕÆīPyTorchńēłµ£¼ńÜäMMCV. +µø┤ÕżÜńēłµ£¼ńÜäõĖŗĶĮĮõ┐Īµü»’╝īĶ»ĘÕÅéĶĆā [openmmlab-download](https://download.openmmlab.com/mmcv/dist/index.html) ŃĆé + +µé©õ╣¤ÕÅ»õ╗źõĮ┐ńö©Õ”éõĖŗÕæĮõ╗ż’╝īõ╗ĵ║ÉńĀüń╝¢Ķ»æmmcv + +```shell +git clone https://github.com/open-mmlab/mmcv.git -b v1.5.3 +cd mmcv +MMCV_WITH_OPS=1 pip install -e . # µē¦ĶĪīµŁżµŁźķ¬żõ╝ÜÕ«ēĶŻģÕīģÕɽcudań«ŚÕŁÉńÜämmcv-full +# µł¢ĶĆģĶ┐ÉĶĪī pip install -e . # µē¦ĶĪīµŁżµŁźķ¬żõ╝ÜÕ«ēĶŻģõĖŹÕīģÕɽcudań«ŚÕŁÉńÜämmcv +cd .. +``` + +**µ│©µäÅ** Õ”éµ×£ÕĘ▓ń╗ÅÕ«ēĶŻģõ║åmmcv’╝īµé©ķ£ĆĶ”üÕģłĶ┐ÉĶĪī`pip uninstall mmcv`ŃĆé ÕÉīµŚČÕ«ēĶŻģõ║åmmcvÕÆīmmcv-full’╝īÕÅ»ĶāĮõ╝ÜÕć║ńÄ░`ModuleNotFoundError`ŃĆé + +- mmdetection (ÕÅ»ķĆē) + +```shell +pip install "mmdet<=2.25.1" +``` + +Õ”éµ×£µā│Ķ”üõ┐«µö╣mmdetńÜäõ╗ŻńĀü’╝īµé©õ╣¤ÕÅ»õ╗źõĮ┐ńö©Õ”éõĖŗÕæĮõ╗ż’╝īõ╗ĵ║ÉńĀüµ×äÕ╗║mmdet’╝Ü +```shell +git clone https://github.com/open-mmlab/mmdetection.git -b v2.25.1 +cd mmdetection +pip install -r requirements/build.txt +pip install -v -e . +``` + +- mmpose (ÕÅ»ķĆē) +```shell +pip install "mmpose<=0.28.1" +``` + +Õ”éµ×£µé©µā│Ķ”üõ┐«µö╣mmdetńÜäõ╗ŻńĀü’╝īµé©õ╣¤ÕÅ»õ╗źõĮ┐ńö©Õ”éõĖŗÕæĮõ╗ż’╝īõ╗ĵ║ÉńĀüµ×äÕ╗║mmpose’╝Ü + +```shell +git clone https://github.com/open-mmlab/mmpose.git -b v0.28.1 +cd mmpose +pip install -r requirements.txt +pip install -v -e . +``` + +- mmtracking (ÕÅ»ķĆē) + +```shell +pip install "mmcls<=0.23.2" "mmtrack<=0.13.0" +``` + +Õ”éµ×£µé©µā│Ķ”üõ┐«µö╣mmdetńÜäõ╗ŻńĀü’╝īµé©õ╣¤ÕÅ»õ╗źõĮ┐ńö©Õ”éõĖŗÕæĮõ╗ż’╝īõ╗ĵ║ÉńĀüµ×äÕ╗║mmtracking’╝Ü + +```shell +git clone https://github.com/open-mmlab/mmtracking.git -b v0.13.0 +cd mmtracking +pip install -r requirements/build.txt +pip install -v -e . # µł¢ĶĆģ "python setup.py develop" +``` +b. ÕģŗķÜåmmhuman3dõ╗ōÕ║ō. + +```shell +git clone https://github.com/open-mmlab/mmhuman3d.git +cd mmhuman3d +``` + + +c. Õ«ēĶŻģõŠØĶĄ¢ķĪ╣Õ╣ČÕ«ēĶŻģmmhuman3d. + +```shell +pip install -v -e . # µł¢ĶĆģ "python setup.py develop" +``` + +## õ╗ÄÕż┤Õ╝ĆÕ¦ŗÕ«ēĶŻģńÜäĶäܵ£¼ + +```shell +# Õ«ēĶŻģ conda ńÄ»Õóā +conda create -n open-mmlab python=3.8 -y +conda activate open-mmlab + +# Õ«ēĶŻģ ffmpeg +conda install ffmpeg + +# Õ«ēĶŻģ PyTorch +conda install pytorch==1.8.0 torchvision cudatoolkit=10.2 -c pytorch -y + +# Õ«ēĶŻģ PyTorch3D +conda install -c fvcore -c iopath -c conda-forge fvcore iopath -y +conda install -c bottler nvidiacub -y +conda install pytorch3d -c pytorch3d -y +# Õ£©ķüćÕł░õŠØĶĄ¢Õå▓ń¬üńÜäµāģÕåĄõĖŗõ╣¤ÕÅ»õĮ┐ńö©õ╗ĵ║ÉńĀüõĖŁÕ«ēĶŻģ +# git clone https://github.com/facebookresearch/pytorch3d.git +# cd pytorch3d +# pip install . +# cd .. + +# Õ«ēĶŻģ mmcv-full +pip install "mmcv-full>=1.3.17,<1.6.0" -f https://download.openmmlab.com/mmcv/dist/cu102/torch1.8.0/index.html + +# ÕÅ»ķĆē: Õ«ēĶŻģ mmdetection’╝īmmpose ÕÅŖ mmtracking +pip install "mmdet<=2.25.1" +pip install "mmpose<=0.28.1" +pip install "mmcls<=0.23.2" "mmtrack<=0.13.0" + +# Õ«ēĶŻģ mmhuman3d +git clone https://github.com/open-mmlab/mmhuman3d.git +cd mmhuman3d +pip install -v -e . +``` diff --git a/internlm_langchain/knowledge_base/MMHuman3D/content/keypoints_convention.md b/internlm_langchain/knowledge_base/MMHuman3D/content/keypoints_convention.md new file mode 100644 index 00000000..141f0fee --- /dev/null +++ b/internlm_langchain/knowledge_base/MMHuman3D/content/keypoints_convention.md @@ -0,0 +1,377 @@ +# Õģ│ķö«ńé╣ń▒╗Õ×ŗ + +## µĆ╗Ķ¦ł + +MMHuamn3DõĖŁńÜäÕģ│ķö«ńé╣ń▒╗Õ×ŗµĢ┤ÕÉłõ║åÕÉäń¦ŹÕĖĖńö©µĢ░µŹ«ķøåõĖŁõĖŹÕÉīÕģ│ķö«ńé╣ńÜäÕ«Üõ╣ēŃĆéńö▒õ║ĵĀćµ│©µĢ░µŹ«ńÜäĶ┐ćń©ŗõĖŹÕ░ĮńøĖÕÉī’╝īõĖŹÕÉīµĢ░µŹ«ķøåõĖŁÕģʵ£ēńøĖÕÉīÕÉŹÕŁŚńÜäÕģ│ķö«ńé╣ÕÅ»ĶāĮõ╝ÜÕ»╣Õ║öõĖŹÕÉīńÜäĶ║½õĮōķā©õĮŹŃĆéńøĖÕ»╣ńÜä’╝īµŗźµ£ēõĖŹÕÉīÕÉŹÕŁŚńÜäÕģ│ķö«ńé╣ÕÅ»ĶāĮÕ»╣Õ║öńøĖÕÉīńÜäĶ║½õĮōķā©õĮŹŃĆé +õĖ║õ║åń╗¤õĖĆõĖŹÕÉīµĢ░µŹ«ķøåõĖŁõĖŹÕÉīÕģ│ķö«ńé╣ńÜäÕ»╣Õ║öÕģ│ń│╗’╝īµłæõ╗¼ķććńö©`human_data`ń╗ōµ×äõĮ£õĖ║ĶĮ¼µŹóÕÆīÕŁśÕé©Õģ│ķö«ńé╣ńÜäÕ¤║µ£¼ń▒╗Õ×ŗŃĆé + +## õĮ┐ńö©µ¢╣µ│Ģ + +### õĖŹÕÉīń▒╗Õ×ŗõ╣ŗķŚ┤ńÜäĶĮ¼µŹó + +õĮ┐ńö© `convert_kps` ÕćĮµĢ░ÕÅ»õ╗źĶĮ¼µŹóõĖŹÕÉīµĢ░µŹ«ķøåõĖŁńÜäÕģ│ķö«ńé╣ŃĆé + +õĖ║õ║åÕ░å`human_data`ĶĮ¼µŹóõĖ║`coco`ńÜäµĀ╝Õ╝Å’╝īķ£ĆĶ”üµīćիܵ║Éń▒╗Õ×ŗÕÆīńø«µĀćń▒╗Õ×ŗŃĆé + + +```python +from mmhuman3d.core.conventions.keypoints_mapping import convert_kps + +keypoints_human_data = np.zeros((100, 190, 3)) +keypoints_coco, mask = convert_kps(keypoints_human_data, src='human_data', dst='coco') +assert mask.all()==1 +``` + +Õ”éµ×£ńø«µĀćń▒╗Õ×ŗµś»µ║Éń▒╗Õ×ŗńÜäÕŁÉķøåÕÉł’╝īĶŠōÕć║ńÜä`mask`Õ║öĶ»źÕģ©õĖ║1ŃĆéµ▓Īµ£ēÕ»╣Õ║öÕģ│ń│╗ńÜäÕģ│ķö«ńé╣ńÜäńĮ«õ┐ĪÕ║”õ╝ÜĶó½Ķ«ŠńĮ«õĖ║0, ÕÅ»õ╗źõĮ┐ńö©`mask`õĮ£õĖ║Õģ│ķö«ńé╣ńÜäńĮ«õ┐ĪÕ║”ŃĆé + +### ķĆÜĶ┐ćńĮ«õ┐ĪÕ║”Ķ┐øĶĪīĶĮ¼µŹó + +Õ”éµ×£ĶÄĘÕŠŚõ║åÕģ│ķö«ńé╣ńÜäńĮ«õ┐ĪÕ║”’╝īÕÅ»õ╗źõĮ┐ńö©ÕĤզŗ`mask`Õ»╣ÕģČĶ┐øĶĪīµĀćĶ«░’╝īńäČÕÉÄÕ░åõ┐Īµü»µø┤µ¢░õĖ║Ķ┐öÕø×ńÜä`mask`ŃĆéõŠŗÕ”é’╝īµā│Ķ”üÕ░å`smpl`ńÜäÕģ│ķö«ńé╣ĶĮ¼µŹóõĖ║`coco`ńÜäÕģ│ķö«ńé╣’╝īÕ╣ČõĖöÕĘ▓ń¤ź`left_shoulder`Ķó½ķü«µīĪŃĆéµā│Ķ”üÕ£©ĶĮ¼µŹóĶ┐ćń©ŗõĖŁń╗¦µē┐Ķ»źõ┐Īµü»’╝īÕÅ»õ╗źÕāÅÕ”éõĖŗĶ┐ÖµĀĘĶ«ŠńĮ«ÕĤզŗ`mask`Õ╣ČõĖöĶĮ¼µŹóõĖ║`coco`ń▒╗Õ×ŗ: + +```python +import numpy as np +from mmhuman3d.core.conventions.keypoints_mapping import KEYPOINTS_FACTORY, convert_kps + +keypoints = np.zeros((1, len(KEYPOINTS_FACTORY['smpl']), 3)) +confidence = np.ones((len(KEYPOINTS_FACTORY['smpl']))) + +# ÕüćĶ«Š 'left_shoulder' µś»µŚĀµĢłńÜä. +confidence[KEYPOINTS_FACTORY['smpl'].index('left_shoulder')] = 0 + +_, conf_coco = convert_kps( + keypoints=keypoints, confidence=confidence, src='smpl', dst='coco') +_, conf_coco_full = convert_kps( + keypoints=keypoints, src='smpl', dst='coco') + +assert conf_coco[KEYPOINTS_FACTORY['coco'].index('left_shoulder')] == 0 +conf_coco[KEYPOINTS_FACTORY['coco'].index('left_shoulder')] = 1 +assert (conf_coco == conf_coco_full).all() +``` + +`mask`ĶĪ©ńż║µ£ēµĢłõ┐Īµü»’╝īÕģČ`dtype`õĖ║`uint8`’╝īÕÉīµŚČÕģ│ķö«ńé╣ńÜäńĮ«õ┐ĪÕ║”ĶīāÕø┤õĖ║0Õł░1ŃĆé +õŠŗÕ”é’╝īµā│Ķ”üÕ░å`smpl`ńÜäÕģ│ķö«ńé╣ĶĮ¼µŹóõĖ║`coco`ńÜäÕģ│ķö«ńé╣, Õ╣ČõĖöÕĘ▓ń¤ź`left_shoulder`Ķó½ķü«µīĪŃĆé + +```python +confidence = np.ones((len(KEYPOINTS_FACTORY['smpl']))) +confidence[KEYPOINTS_FACTORY['smpl'].index('left_shoulder')] = 0.5 +kp_smpl = np.concatenate([kp_smpl, confidence], -1) +kp_smpl_converted, mask = convert_kps(kp_smpl, src='smpl', dst='coco') +new_confidence = kp_smpl_converted[..., 2:] +assert new_confidence[KEYPOINTS_FACTORY['smpl'].index('left_shoulder')] == 0.5 +``` + +## µö»µīüńÜäń¦Źń▒╗ + + +õ╗źõĖŗµś»µö»µīüńÜäÕģ│ķö«ńé╣ń¦Źń▒╗: + - [AGORA](#agora) + - [COCO](#coco) + - [COCO-WHOLEBODY](#coco-wholebody) + - [CrowdPose](#crowdpose) + - [GTA-Human](#gta-human) + - [Human3.6M](#human36m) + - human_data + - [HybrIK](#hybrik) + - [LSP](#lsp) + - [MPI-INF-3DHP](#mpi-inf-3dhp) + - [MPII](#mpii) + - openpose + - [PennAction](#pennaction) + - [PoseTrack18](#posetrack18) + - [PW3D](#pw3d) + - [SMPL](#smpl) + - [SMPL-X](#smplx) + + +### HUMANDATA + +`HumanData` õĖŁńÜäÕēŹ 144 õĖ¬Õģ│ķö«ńé╣Õ»╣Õ║öõ║Ä `SMPL-X` õĖŁńÜäÕģ│ķö«ńé╣ŃĆéÕÉÄń╝ĆõĖ║`_extra`ńÜäÕģ│ķö«ńé╣µś»µīćõ╗Ä`Jregressor_extra`ĶÄĘÕŠŚńÜäÕģ│ķö«ńé╣ŃĆé ÕÉÄń╝ĆõĖ║`_openpose`ńÜäÕģ│ķö«ńé╣µś»µīćõ╗Ä`OpenPose`ķó䵥ŗõĖŁĶÄĘÕŠŚńÜäÕģ│ķö«ńé╣ŃĆé + +`MPI-INF-3DHP`ŃĆü`Human3.6M` ÕÆī `Posetrack` õĖŁµ£ēÕćĀõĖ¬Õģ│ķö«ńé╣Õģʵ£ēńøĖÕÉīńÜäÕÉŹń¦░’╝īõĮåÕ£©Õɽõ╣ēõĖŖõĖÄ `SMPL-X` õĖŁńÜäÕģ│ķö«ńé╣õĖŹÕÉīŃĆé ÕøĀµŁż’╝īµłæõ╗¼µĘ╗ÕŖĀõ║åõĖĆõĖ¬ķóØÕż¢ńÜäÕÉÄń╝Ć`head_h36m`µØźÕī║ÕłåĶ┐Öõ║øÕģ│ķö«ńé╣ŃĆé + +### AGORA + + \
+ --root_path data/datasets \
+ --output_path data/preprocessed_datasets
+```
+
+õĮ┐ńö©µŚČ’╝īĶ»ĘµīćÕ«ÜÕģĘõĮōńÜä`dataset-name`.
+
+Ķ«Łń╗āHMRń«Śµ│Ģ’╝īķ£ĆĶ”üÕ”éõĖŗńÜäµĢ░µŹ«ķøå
+ - [COCO](#coco)
+ - [Human3.6M](#human36m)
+ - [Human3.6M Mosh](#human36m-mosh)
+ - [MPI-INF-3DHP](#mpi-inf-3dhp)
+ - [MPII](#mpii)
+ - [LSP](#lsp)
+ - [LSPET](#lspet)
+ - [PW3D](#pw3d)
+
+õĮ┐ńö©Õ”éõĖŗńÜäµĢ░µŹ«ķøåÕÉŹń¦░µø┐µŹó`dataset-names`Ķ┐øĶĪīµĢ░µŹ«ĶĮ¼µŹó:
+```
+coco, pw3d, mpii, mpi_inf_3dhp, lsp_original, lsp_extended, h36m
+```
+
+**µł¢ĶĆģ**, µé©ÕÅ»õ╗źõĖŗĶĮĮÕżäńÉåÕźĮńÜä.npzµ¢ćõ╗Č:
+- [cmu_mosh.npz](https://openmmlab-share.oss-cn-hangzhou.aliyuncs.com/mmhuman3d/datasets/cmu_mosh.npz?versionId=CAEQHhiBgIDoof_37BciIDU0OGU0MGNhMjAxMjRiZWI5YzdkMWEzMzc3YzBiZDM2)
+- [coco_2014_train.npz](https://openmmlab-share.oss-cn-hangzhou.aliyuncs.com/mmhuman3d/datasets/coco_2014_train.npz?versionId=CAEQHhiBgICUrvbS6xciIDFmZmFhMDk5OGQ3YzQ5ZDE5NzJkMGQxNzdmMmQzZDdi)
+- [h36m_train.npz](https://openmmlab-share.oss-cn-hangzhou.aliyuncs.com/mmhuman3d/datasets/h36m_train.npz?versionId=CAEQHhiBgMDrrfbS6xciIGY2NjMxMjgwMWQzNjRkNWJhYTNkZTYyYWUxNWQ4ZTE5)
+- [lsp_train.npz](https://openmmlab-share.oss-cn-hangzhou.aliyuncs.com/mmhuman3d/datasets/lsp_train.npz?versionId=CAEQHhiBgICnq_bS6xciIDU4ZTRhMDIwZTBkZjQ1YTliYTY0NGFmMDVmOGVhZjMy)
+- [lspet_train.npz](https://openmmlab-share.oss-cn-hangzhou.aliyuncs.com/mmhuman3d/datasets/lspet_train.npz?versionId=CAEQHhiBgICXrPbS6xciIDVkZGNmYWZjODlmMzQ2YjNhMjhlNmJmMzU2MjM4Yzg4)
+- [mpi_inf_3dhp_train.npz](https://openmmlab-share.oss-cn-hangzhou.aliyuncs.com/mmhuman3d/datasets/mpi_inf_3dhp_train.npz?versionId=CAEQHhiBgMD3q_bS6xciIGQwYjc4NTRjYTllMzRkODU5NTNiZDQyOTBlYmRhODg5)
+- [mpii_train.npz](https://openmmlab-share.oss-cn-hangzhou.aliyuncs.com/mmhuman3d/datasets/mpii_train.npz?versionId=CAEQHhiBgIDhq_bS6xciIDEwMmE0ZDc0NWI1NjQ2NWZhYTA5ZjEyODBiNWFmODg1)
+- [pw3d_test.npz](https://openmmlab-share.oss-cn-hangzhou.aliyuncs.com/mmhuman3d/datasets/pw3d_test.npz?versionId=CAEQHhiBgMDaq_bS6xciIGVjY2YzZGJkNjNmMjQ2NGU4OTZkYjMwMjhhYWM1Y2I0)
+
+ńö▒õ║ÄĶ«ĖÕÅ»Ķ»üńÜäķÖÉÕłČ’╝īµłæõ╗¼µŚĀµ│ĢõĖŖõ╝Ā`h36m_mosh_train.npz`ŃĆéõĮåµś»µłæõ╗¼µÅÉõŠøõ║åńøĖÕģ│ńÜäĶĮ¼µŹóÕĘźÕģĘ, Õ”éµ×£µé©µŗźµ£ēÕĤզŗńÜä`mosh`µĢ░µŹ«, µé©ÕÅ»õ╗źÕÅéĶĆā[Human3.6M Mosh](#human36m-mosh)ŃĆé
+
+ÕżäńÉåÕźĮńÜäµĢ░µŹ«ķøåÕ║öĶ»źÕģʵ£ēÕ”éõĖŗńÜäń╗ōµ×ä:
+```text
+mmhuman3d
+Ōö£ŌöĆŌöĆ mmhuman3d
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+ŌööŌöĆŌöĆ data
+ Ōö£ŌöĆŌöĆ datasets
+ ŌööŌöĆŌöĆ preprocessed_datasets
+ Ōö£ŌöĆŌöĆ coco_2014_train.npz
+ Ōö£ŌöĆŌöĆ h36m_train.npz (h36m_mosh_train.npz)
+ Ōö£ŌöĆŌöĆ lspet_train.npz
+ Ōö£ŌöĆŌöĆ lsp_train.npz
+ Ōö£ŌöĆŌöĆ mpi_inf_3dhp_train.npz
+ Ōö£ŌöĆŌöĆ mpii_train.npz
+ ŌööŌöĆŌöĆ pw3d_test.npz
+```
+
+Ķ«Łń╗āSPINń«Śµ│Ģ, ķ£ĆĶ”üÕ”éõĖŗńÜäµĢ░µŹ«ķøå:
+ - [COCO](#coco)
+ - [Human3.6M](#human36m)
+ - [Human3.6M Mosh](#human36m-mosh)
+ - [MPI-INF-3DHP](#mpi-inf-3dhp)
+ - [MPII](#mpii)
+ - [LSP](#lsp)
+ - [LSPET](#lspet)
+ - [PW3D](#pw3d)
+ - [SPIN](#spin)
+
+
+õĮ┐ńö©Õ”éõĖŗńÜäµĢ░µŹ«ķøåÕÉŹń¦░µø┐µŹó`dataset-names`Ķ┐øĶĪīµĢ░µŹ«ĶĮ¼µŹó:
+```
+spin, h36m
+```
+
+**µł¢ĶĆģ**, µé©ÕÅ»õ╗źÕģłõĖŗĶĮĮÕżäńÉåÕźĮńÜä.npzµ¢ćõ╗Č:
+- [spin_coco_2014_train.npz](https://openmmlab-share.oss-cn-hangzhou.aliyuncs.com/mmhuman3d/datasets/spin_coco_2014_train.npz?versionId=CAEQHhiBgICb6bfT6xciIGM2NmNmZDYyNDMxMDRiNTVhNDk3YzY1N2Y2ODdlMTAy)
+- [h36m_train.npz](https://openmmlab-share.oss-cn-hangzhou.aliyuncs.com/mmhuman3d/datasets/h36m_train.npz?versionId=CAEQHhiBgMDrrfbS6xciIGY2NjMxMjgwMWQzNjRkNWJhYTNkZTYyYWUxNWQ4ZTE5)
+- [spin_lsp_train.npz](https://openmmlab-share.oss-cn-hangzhou.aliyuncs.com/mmhuman3d/datasets/spin_lsp_train.npz?versionId=CAEQHhiBgIDu57fT6xciIDQ0ODAzNjUyNjJkMzQyNzQ5Y2IzNGNhOTZmZGI2NzBm)
+- [spin_lspet_train.npz](https://openmmlab-share.oss-cn-hangzhou.aliyuncs.com/mmhuman3d/datasets/spin_lspet_train.npz?versionId=CAEQHhiBgMCe6LfT6xciIDc3NzZiYzA1ZGJkYzQwNzRhYjg3ZDMwYTdjZDZmNTAw)
+- [spin_mpi_inf_3dhp_train.npz](https://openmmlab-share.oss-cn-hangzhou.aliyuncs.com/mmhuman3d/datasets/spin_mpi_inf_3dhp_train.npz?versionId=CAEQHhiBgMCV6LfT6xciIDliYTJhM2FkNDkyYjRiOWFiYTUwOTk0MGRlNThlZWRk)
+- [spin_mpii_train.npz](https://openmmlab-share.oss-cn-hangzhou.aliyuncs.com/mmhuman3d/datasets/spin_mpii_train.npz?versionId=CAEQHhiBgMDz57fT6xciIGJjMzAwMDdlYTBmMTQ0MDg4ZGE4YjhiZGNkNWQwZmM1)
+- [spin_pw3d_test.npz](https://openmmlab-share.oss-cn-hangzhou.aliyuncs.com/mmhuman3d/datasets/spin_pw3d_test.npz?versionId=CAEQHhiBgMCL6LfT6xciIGUxNjY3OTBiODU5ZDQxODliYTQ4NzU0OGVjMzJkYmRm)
+
+ńö▒õ║ÄĶ«ĖÕÅ»Ķ»üńÜäķÖÉÕłČ’╝īµłæõ╗¼µŚĀµ│ĢõĖŖõ╝Ā`h36m_mosh_train.npz`ŃĆéõĮåµś»µłæõ╗¼µÅÉõŠøõ║åńøĖÕģ│ńÜäĶĮ¼µŹóÕĘźÕģĘ, Õ”éµ×£µé©µŗźµ£ēÕĤզŗńÜä`mosh`µĢ░µŹ«, µé©ÕÅ»õ╗źÕÅéĶĆā[Human3.6M Mosh](#human36m-mosh)ŃĆé
+
+ÕżäńÉåÕźĮńÜäµĢ░µŹ«ķøåÕ║öĶ»źÕģʵ£ēÕ”éõĖŗńÜäń╗ōµ×ä:
+```text
+mmhuman3d
+Ōö£ŌöĆŌöĆ mmhuman3d
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+ŌööŌöĆŌöĆ data
+ Ōö£ŌöĆŌöĆ datasets
+ ŌööŌöĆŌöĆ preprocessed_datasets
+ Ōö£ŌöĆŌöĆ spin_coco_2014_train.npz
+ Ōö£ŌöĆŌöĆ h36m_train.npz (h36m_mosh_train.npz)
+ Ōö£ŌöĆŌöĆ spin_lsp_train.npz
+ Ōö£ŌöĆŌöĆ spin_lspet_train.npz
+ Ōö£ŌöĆŌöĆ spin_mpi_inf_3dhp_train.npz
+ Ōö£ŌöĆŌöĆ spin_mpii_train.npz
+ ŌööŌöĆŌöĆ spin_pw3d_test.npz
+```
+
+Ķ«Łń╗āVIBEń«Śµ│Ģ, ķ£ĆĶ”üÕ”éõĖŗńÜäµĢ░µŹ«ķøå:
+ - [MPI-INF-3DHP](#mpi-inf-3dhp)
+ - [PW3D](#pw3d)
+
+µĢ░µŹ«ĶĮ¼µŹóµÜ鵌ČõĖŹÕÅ»ńö©.
+
+**µł¢ĶĆģ**, µé©ÕÅ»õ╗źÕģłõĖŗĶĮĮÕżäńÉåÕźĮńÜä.npzµ¢ćõ╗Č:
+- [vibe_insta_variety.npz](https://pjlab-my.sharepoint.cn/:u:/g/personal/openmmlab_pjlab_org_cn/EYnlkp-69NBNlXDH-5ELZikBXDbSg8SZHqmdSX_3hK4EYg?e=QUl5nI)
+- [vibe_mpi_inf_3dhp_train.npz](https://openmmlab-share.oss-cn-hangzhou.aliyuncs.com/mmhuman3d/datasets/vibe_mpi_inf_3dhp_train.npz?versionId=CAEQHhiBgICTnq3U6xciIGUwMTc5YWQ2MjNhZDQ3NGE5MmYxOWJhMGQxMTcwNTll)
+- [vibe_pw3d_test.npz](https://openmmlab-share.oss-cn-hangzhou.aliyuncs.com/mmhuman3d/datasets/vibe_pw3d_test.npz?versionId=CAEQHhiBgMD5na3U6xciIGQ4MmU0MjczYTYzODQ1NDQ5M2JiNzY1N2E5MTNlOWY5)
+
+
+ÕżäńÉåÕźĮńÜäµĢ░µŹ«ķøåÕ║öĶ»źÕģʵ£ēÕ”éõĖŗńÜäń╗ōµ×ä:
+```text
+mmhuman3d
+Ōö£ŌöĆŌöĆ mmhuman3d
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+ŌööŌöĆŌöĆ data
+ Ōö£ŌöĆŌöĆ datasets
+ ŌööŌöĆŌöĆ preprocessed_datasets
+ Ōö£ŌöĆŌöĆ vibe_insta_variety.npz
+ Ōö£ŌöĆŌöĆ vibe_mpi_inf_3dhp_train.npz
+ ŌööŌöĆŌöĆ vibe_pw3d_test.npz
+```
+
+Ķ«Łń╗āHybrIKń«Śµ│Ģ, ķ£ĆĶ”üÕ”éõĖŗńÜäµĢ░µŹ«ķøå:
+ - [HybrIK](#hybrik)
+ - [COCO](#coco)
+ - [Human3.6M](#human36m)
+ - [MPI-INF-3DHP](#mpi-inf-3dhp)
+ - [PW3D](#pw3d)
+
+õĮ┐ńö©Õ”éõĖŗńÜäµĢ░µŹ«ķøåÕÉŹń¦░µø┐µŹó`dataset-names`Ķ┐øĶĪīµĢ░µŹ«ĶĮ¼µŹó:
+```
+h36m_hybrik, pw3d_hybrik, mpi_inf_3dhp_hybrik, coco_hybrik
+```
+
+**µł¢ĶĆģ**, µé©ÕÅ»õ╗źÕģłõĖŗĶĮĮÕżäńÉåÕźĮńÜä.npzµ¢ćõ╗Č:
+- [hybriK_coco_2017_train.npz](https://openmmlab-share.oss-cn-hangzhou.aliyuncs.com/mmhuman3d/datasets/hybrik_coco_2017_train.npz?versionId=CAEQHhiBgMDA6rjT6xciIDE3N2FiZDkxYTkyZDRjN2ZiYjc1ODQ2YTc5NjY0ZmFl)
+- [hybrik_h36m_train.npz](https://openmmlab-share.oss-cn-hangzhou.aliyuncs.com/mmhuman3d/datasets/hybrik_h36m_train.npz?versionId=CAEQHhiBgIC_iLjT6xciIGE4NmQ5YzUxMzY0ZjQ0Y2U5MWFkOTkwNmIwMGI4NTNm)
+- [hybrik_mpi_inf_3dhp_train.npz](https://openmmlab-share.oss-cn-hangzhou.aliyuncs.com/mmhuman3d/datasets/hybrik_mpi_inf_3dhp_train.npz?versionId=CAEQHhiBgICogLjT6xciIDQwYzRlYTVlOTE0YTQ4ZDRhYTljOGRkZDc1MDhjNDgy)
+- [hybrik_pw3d_test.npz](https://openmmlab-share.oss-cn-hangzhou.aliyuncs.com/mmhuman3d/datasets/hybrik_pw3d_test.npz?versionId=CAEQHhiBgMCO8LfT6xciIDhjMDFhOTFmZjY4MDQ4MWI4MzVmODYyYTc1NTYwNjA1)
+
+
+ÕżäńÉåÕźĮńÜäµĢ░µŹ«ķøåÕ║öĶ»źÕģʵ£ēÕ”éõĖŗńÜäń╗ōµ×ä:
+```text
+mmhuman3d
+Ōö£ŌöĆŌöĆ mmhuman3d
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+ŌööŌöĆŌöĆ data
+ Ōö£ŌöĆŌöĆ datasets
+ ŌööŌöĆŌöĆ preprocessed_datasets
+ Ōö£ŌöĆŌöĆ hybriK_coco_2017_train.npz
+ Ōö£ŌöĆŌöĆ hybrik_h36m_train.npz
+ Ōö£ŌöĆŌöĆ hybrik_mpi_inf_3dhp_train.npz
+ ŌööŌöĆŌöĆ hybrik_pw3d_test.npz
+```
+
+Ķ«Łń╗āPAREń«Śµ│Ģ, ķ£ĆĶ”üÕ”éõĖŗńÜäµĢ░µŹ«ķøå:
+ - [Human3.6M](#human36m)
+ - [Human3.6M Mosh](#human36m-mosh)
+ - [MPI-INF-3DHP](#mpi-inf-3dhp)
+ - [EFT-COCO](#EFT)
+ - [EFT-MPII](#EFT)
+ - [EFT-LSPET](#EFT)
+ - [PW3D](#pw3d)
+
+
+õĮ┐ńö©Õ”éõĖŗńÜäµĢ░µŹ«ķøåÕÉŹń¦░µø┐µŹó`dataset-names`Ķ┐øĶĪīµĢ░µŹ«ĶĮ¼µŹó:
+```
+h36m, coco, mpii, lspet, mpi-inf-3dhp, pw3d
+```
+
+**µł¢ĶĆģ**, µé©ÕÅ»õ╗źÕģłõĖŗĶĮĮÕżäńÉåÕźĮńÜä.npzµ¢ćõ╗Č:
+- [h36m_train.npz](https://openmmlab-share.oss-cn-hangzhou.aliyuncs.com/mmhuman3d/datasets/h36m_train.npz?versionId=CAEQHhiBgMDrrfbS6xciIGY2NjMxMjgwMWQzNjRkNWJhYTNkZTYyYWUxNWQ4ZTE5)
+- [mpi_inf_3dhp_train.npz](https://openmmlab-share.oss-cn-hangzhou.aliyuncs.com/mmhuman3d/datasets/mpi_inf_3dhp_train.npz?versionId=CAEQHhiBgMD3q_bS6xciIGQwYjc4NTRjYTllMzRkODU5NTNiZDQyOTBlYmRhODg5)
+- [eft_mpii.npz](https://openmmlab-share.oss-cn-hangzhou.aliyuncs.com/mmhuman3d/datasets/eft_mpii.npz?versionId=CAEQOhiBgMCXlty_gxgiIDYxNDc5YTIzZjBjMDRhMGM5ZjBiZmYzYjFjMTU1ZTRm)
+- [eft_lspet.npz](https://openmmlab-share.oss-cn-hangzhou.aliyuncs.com/mmhuman3d/datasets/eft_lspet.npz?versionId=CAEQOhiBgMC339u_gxgiIDZlNzk1YjMxMWRmMzRkNWJiNjg1OTI2Mjg5OTA1YzJh
+)
+- [eft_coco_all.npz](https://openmmlab-share.oss-cn-hangzhou.aliyuncs.com/mmhuman3d/datasets/eft_coco_all.npz?versionId=CAEQOhiBgID3iuS_gxgiIDgwYzU4NTc3ZWRkNDQyNGJiYzU4MGViYTFhYTFmMmUx)
+- [pw3d_test.npz](https://openmmlab-share.oss-cn-hangzhou.aliyuncs.com/mmhuman3d/datasets/pw3d_test.npz?versionId=CAEQHhiBgMDaq_bS6xciIGVjY2YzZGJkNjNmMjQ2NGU4OTZkYjMwMjhhYWM1Y2I0)
+
+
+ÕżäńÉåÕźĮńÜäµĢ░µŹ«ķøåÕ║öĶ»źÕģʵ£ēÕ”éõĖŗńÜäń╗ōµ×ä:
+```text
+mmhuman3d
+Ōö£ŌöĆŌöĆ mmhuman3d
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+ŌööŌöĆŌöĆ data
+ Ōö£ŌöĆŌöĆ datasets
+ ŌööŌöĆŌöĆ preprocessed_datasets
+ Ōö£ŌöĆŌöĆ h36m_mosh_train.npz
+ Ōö£ŌöĆŌöĆ h36m_train.npz
+ Ōö£ŌöĆŌöĆ mpi_inf_3dhp_train.npz
+ Ōö£ŌöĆŌöĆ eft_mpii.npz
+ Ōö£ŌöĆŌöĆ eft_lspet.npz
+ Ōö£ŌöĆŌöĆ eft_coco_all.npz
+ ŌööŌöĆŌöĆ pw3d_test.npz
+```
+
+## µ¢ćõ╗ČÕż╣ń╗ōµ×ä
+
+### AGORA
+
+
+
+ `frame_list` > `origin_frames`ŃĆé
+ Õ”éµ×£ĶāīµÖ»ÕøŠńēćĶ┐ćÕż¦’╝īÕ║öĶ»źµīćÕ«Ü`read_frames_batch` õĖ║ `True`’╝īõ╗źÕćÅĶĮ╗ĶŠōÕģźĶŠōÕć║ńÜäĶ┤¤µŗģŃĆéÕ”éµ×£Ķ¦åķóæńÜäÕĖ¦µĢ░Õż¦õ║ÄńŁēõ║Ä500’╝īõĖŖĶ┐░Ķ«ŠńĮ«õ╝ÜÕ£©õ╗ŻńĀüõĖŁĶć¬ÕŖ©Õ«īµłÉŃĆé
+
+- **smplµ©ĪÕ×ŗńÜäposeÕÆīķĪČńé╣:**
+ ÕÅ»õ╗źķććńö©õ╗źõĖŗõĖżń¦Źµ¢╣Õ╝Åõ╝ĀÕģźsmplµ©ĪÕ×ŗńÜämeshõ┐Īµü»:
+ 1). õ╝ĀÕģź`poses`ŃĆü `betas`(ÕÅ»ķĆē)ŃĆü `transl`(ÕÅ»ķĆē) ÕÆī `gender`(ÕÅ»ķĆē)ŃĆé
+ 2). õ╣¤ÕÅ»õ╗źńø┤µÄźõ╝ĀÕģź`verts`ŃĆéÕ”éµ×£ķććńö©õ╝ĀÕģź`verts`ńÜäµ¢╣Õ╝Å’╝īńö▒õ║Äķ£ĆĶ”üĶÄĘÕŠŚ`faces`’╝īµé©ķ£ĆĶ”üµīćÕ«Ü`body_model` µł¢ `model_path`ŃĆé
+ õ╝śÕģłń║¦ķĪ║Õ║ÅõĖ║`verts` > (`poses` & `betas` & `transl` & `gender`)
+ 3). Õ»╣õ║ÄÕżÜõ║║ńÜäķćŹÕ╗║’╝īµé©ķ£ĆĶ”üµīćÕ«ÜõĖĆõĖ¬ķóØÕż¢ńÜäń╗┤Õ║”`num_person`, ĶĪ©ńż║õ║║ńÜäµĢ░ķćÅŃĆéõŠŗÕ”é, smplµ©ĪÕ×ŗńÜä`verts` ńÜäÕĮóńŖČõĖ║ (num_frame, num_person, 6890, 3), smplµ©ĪÕ×ŗńÜä`poses`ÕÅéµĢ░ńÜäÕĮóńŖČõĖ║ (num_frame, num_person, 72), smplµ©ĪÕ×ŗńÜä`betas`ÕÅéµĢ░ńÜäÕĮóńŖČõĖ║ (num_frame, num_person, 10), vibeńÜä`pred_cam` ńÜäÕĮóńŖČõĖ║ (num_frame, num_person, 3)ŃĆéńö▒õ║ÄńøĖµ£║ń¤®ķśĄ`K`, `R`ÕÆī`T`µś»ķĆéńö©õ║ĵ»ÅõĖĆÕĖ¦ńÜä’╝īõĖŖĶ┐░µōŹõĮ£Õ╣ČõĖŹõ╝ÜÕ»╣Õ«āõ╗¼ķĆĀµłÉÕĮ▒ÕōŹŃĆé
+
+- **Ķ║½õĮōµ©ĪÕ×ŗ:**
+ µ£ēõĖżń¦Źõ╝ĀÕģźõ║║õĮōµ©ĪÕ×ŗńÜäµ¢╣Õ╝Å:
+ 1). õ╝ĀÕģźÕīģÕɽõĖÄ`build_body_model`ńøĖÕÉīķģŹńĮ«ńÜäÕŁŚÕģĖ`body_model_config`ŃĆé
+ 2). ńø┤µÄźõ╝ĀÕģź`body_model`ŃĆéõ╝śÕģłń║¦ķĪ║Õ║ÅõĖ║`body_model` > (`model_path` & `model_type` & `gender`)ŃĆé
+
+- **ĶŠōÕć║ĶĘ»ÕŠä:**
+ ĶŠōÕć║ĶĘ»ÕŠäÕÅ»õ╗źõĖ║Ķ¦åķóæµ¢ćõ╗Č(ń▒╗Õ×ŗõĖ║`None` µł¢ `str`)µł¢ÕøŠÕāŵ¢ćõ╗ČÕż╣ńÜäĶĘ»ÕŠä(ń▒╗Õ×ŗõĖ║`str`)ŃĆé
+ 1). Õ”éµ×£ĶŠōÕć║ĶĘ»ÕŠäµīćÕ«ÜõĖ║`None`, õĖŹõ╝ÜÕåÖÕģźĶŠōÕć║µ¢ćõ╗ČŃĆé
+ 2). Õ”éµ×£ĶŠōÕć║ĶĘ»ÕŠäµīćÕ«ÜõĖ║`xxx.mp4`, Õ░åĶ┐śõ╝ÜÕåÖÕģźõĖĆõĖ¬Ķ¦åķóæŃĆéĶ»ĘńĪ«õ┐ص£ēĶČ│Õż¤ńÜäń®║ķŚ┤ńö©õ║ÄÕŁśµöŠµŚČÕ║ÅÕøŠÕāÅ’╝īĶ┐Öõ║øÕøŠÕāÅõ╝ÜĶć¬ÕŖ©ÕłĀķÖżŃĆé
+ 3). Õ”éµ×£ĶŠōÕć║ĶĘ»ÕŠäµīćÕ«ÜõĖ║ÕøŠÕāŵ¢ćõ╗ČÕż╣`xxx/`, Õ░åõ╝ÜÕłøÕ╗║õĖĆõĖ¬µ¢ćõ╗ČÕż╣’╝īÕ╣ČÕ░åÕøŠÕāÅÕŁśµöŠÕ£©µ¢ćõ╗ČÕż╣ķćīķØóŃĆé
diff --git a/internlm_langchain/knowledge_base/MMHuman3D/vector_store/index.faiss b/internlm_langchain/knowledge_base/MMHuman3D/vector_store/index.faiss
new file mode 100644
index 00000000..4f38cfcc
Binary files /dev/null and b/internlm_langchain/knowledge_base/MMHuman3D/vector_store/index.faiss differ
diff --git a/internlm_langchain/knowledge_base/MMOCR/content/branches.md b/internlm_langchain/knowledge_base/MMOCR/content/branches.md
new file mode 100644
index 00000000..1d7f8d2f
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMOCR/content/branches.md
@@ -0,0 +1,38 @@
+# Õłåµö»Ķ┐üń¦╗
+
+Õ£©µŚ®µ£¤ķśČµ«Ą’╝īMMOCR µ£ēõĖēõĖ¬Õłåµö»’╝Ü`main`ŃĆü`1.x` ÕÆī `dev-1.x`ŃĆéķÜÅńØĆ MMOCR 1.0.0 µŁŻÕ╝ÅńēłńÜäÕÅæÕĖā’╝īµłæõ╗¼õ╣¤ķćŹÕæĮÕÉŹõ║åÕģČõĖŁõĖĆõ║øÕłåµö»’╝īõĖŗķØóµÅÉõŠøõ║åµ¢░µŚ¦Õłåµö»ńÜäÕ»╣ńģ¦ŃĆé
+
+- `main` Õłåµö»Õīģµŗ¼õ║å MMOCR 0.x’╝łõŠŗÕ”é v0.6.3’╝ēńÜäõ╗ŻńĀüŃĆéńÄ░Õ£©ÕĘ▓ń╗ÅĶó½ķćŹÕæĮÕÉŹõĖ║ `0.x`ŃĆé
+- `1.x` ÕīģÕɽõ║å MMOCR 1.x’╝łõŠŗÕ”é 1.0.0rc6’╝ēńÜäõ╗ŻńĀüŃĆéńÄ░Õ£©Õ«āµś» `main` Õłåµö»ńÜäÕł½ÕÉŹ’╝īõ╝ÜÕ£© 2023 ńÜäÕ╣┤õĖŁÕłĀķÖżŃĆé
+- `dev-1.x` µś» MMOCR 1.x ńÜäÕ╝ĆÕÅæÕłåµö»ŃĆéńÄ░Õ£©õ┐صīüõĖŹÕÅśŃĆé
+
+µ£ēÕģ│Õłåµö»ńÜäµø┤ÕżÜõ┐Īµü»’╝īĶ»Ęµ¤źń£ŗ[Õłåµö»](../notes/branches.md)ŃĆé
+
+## ÕŹćń║¦ `main` Õłåµö»µŚČĶ¦ŻÕå│Õå▓ń¬ü
+
+Õ»╣õ║ÄÕĖīµ£øõ╗ĵŚ¦ `main` Õłåµö»’╝łÕīģÕɽ MMOCR 0.x õ╗ŻńĀü’╝ēÕŹćń║¦ńÜäńö©µłĘ’╝īõ╗ŻńĀüÕÅ»ĶāĮõ╝ÜÕ»╝Ķć┤Õå▓ń¬üŃĆéĶ”üķü┐ÕģŹĶ┐Öõ║øÕå▓ń¬ü’╝īĶ»Ęµīēńģ¦õ╗źõĖŗµŁźķ¬żµōŹõĮ£’╝Ü
+
+1. Ķ»Ę commit Õ£© `main` õĖŖńÜäµēƵ£ēµø┤µö╣’╝łĶŗźµ£ē’╝ē’╝īÕ╣ČÕżćõ╗Įµé©ÕĮōÕēŹńÜä `main` Õłåµö»ŃĆé
+
+ ```bash
+ git checkout main
+ git add --all
+ git commit -m 'backup'
+ git checkout -b main_backup
+ ```
+
+2. õ╗ÄĶ┐£ń©ŗÕŁśÕé©Õ║ōĶÄĘÕÅ¢µ£Ćµ¢░µø┤µö╣ŃĆé
+
+ ```bash
+ git remote add openmmlab git@github.com:open-mmlab/mmocr.git
+ git fetch openmmlab
+ ```
+
+3. ķĆÜĶ┐ćĶ┐ÉĶĪī `git reset --hard openmmlab/main` Õ░å `main` Õłåµö»ķćŹńĮ«õĖ║Ķ┐£ń©ŗÕŁśÕé©Õ║ōõĖŖńÜäµ£Ćµ¢░ `main` Õłåµö»ŃĆé
+
+ ```bash
+ git checkout main
+ git reset --hard openmmlab/main
+ ```
+
+µīēńģ¦Ķ┐Öõ║øµŁźķ¬ż’╝īµé©ÕÅ»õ╗źµłÉÕŖ¤ÕŹćń║¦µé©ńÜä `main` Õłåµö»ŃĆé
diff --git a/internlm_langchain/knowledge_base/MMOCR/content/code.md b/internlm_langchain/knowledge_base/MMOCR/content/code.md
new file mode 100644
index 00000000..ee63dd95
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMOCR/content/code.md
@@ -0,0 +1,151 @@
+# õ╗ŻńĀüń╗ōµ×äÕÅśÕŖ©
+
+MMOCR õĖ║õ║åÕģ╝ķĪŠµ¢ćµ£¼µŻĆµĄŗŃĆüĶ»åÕł½ÕÆīÕģ│ķö«õ┐Īµü»µÅÉÕÅ¢ńŁēõ╗╗ÕŖĪ’╝īÕ£©ÕłØńēłĶ«ŠĶ«ĪµŚČÕŁśÕ£©Ķ«ĖÕżÜµ¼Āń╝║ĶĆāĶÖæńÜäÕ£░µ¢╣ŃĆéÕ£©µ£¼µ¼Ī 1.0 ńēłµ£¼ńÜäÕŹćń║¦õĖŁ’╝īMMOCR ÕÉīµŁźµÅÉÕć║õ║åµ¢░ńÜ䵩ĪÕ×ŗµ×ȵ×ä’╝īµŚ©Õ£©Õ░ĮķćÅõĖÄ OpenMMLab µĢ┤õĮōńÜäĶ«ŠĶ«ĪÕ»╣ķĮÉ’╝īõĖöÕ£©ń«Śµ│ĢÕ║ōÕåģķā©ĶŠŠµłÉń╗ōµ×äõĖŖńÜäń╗¤õĖĆŃĆéĶÖĮńäȵ£¼µ¼ĪÕŹćń║¦Õ╣ČķØ×Õ«īÕģ©ÕÉÄÕÉæÕģ╝Õ«╣’╝īõĮåµēƵ£ēńÜäÕÅśÕŖ©ķāĮµś»µ£ēĶ┐╣ÕŻՊ¬ńÜäŃĆéÕøĀµŁż’╝īµłæõ╗¼Õ£©µ£¼ń½ĀĶŖéµĆ╗ń╗ōÕć║õ║åÕ╝ĆÕÅæĶĆģÕÅ»ĶāĮõ╝ÜÕģ│Õ┐āńÜäµö╣ÕŖ©’╝īõŠøµ£ēķ£ĆĶ”üńÜäńö©µłĘÕÅéĶĆāŃĆé
+
+## µĢ┤õĮōµö╣ÕŖ©
+
+MMOCR 0.x ÕŁśÕ£©ńØĆÕ»╣µ©ĪÕØŚÕŖ¤ĶāĮĶŠ╣ńĢīÕ«Üõ╣ēõĖŹµĖģµÖ░ńÜäķŚ«ķóśŃĆéÕ£© MMOCR 1.0 õĖŁ’╝īµłæõ╗¼ķ揵×äõ║嵩ĪÕ×ŗµ©ĪÕØŚńÜäĶ«ŠĶ«Ī’╝īÕ╣ČÕ«Üõ╣ēõ║åÕ«āõ╗¼ńÜ䵩ĪÕØŚĶŠ╣ńĢīŃĆé
+
+- ĶĆāĶÖæÕł░µ¢╣ÕÉæÕĘ«Õ╝éĶ┐ćÕż¦’╝īMMOCR 1.0 õĖŁÕÅ¢µČłõ║åÕ»╣ÕæĮÕÉŹÕ«×õĮōĶ»åÕł½ńÜäµö»µīüŃĆé
+
+- µ©ĪÕ×ŗõĖŁĶ«Īń«ŚµŹ¤Õż▒’╝łloss’╝ēńÜäķā©Õłåµ©ĪÕØŚĶó½µŖĮĶ▒ĪÕī¢õĖ║ Module Loss’╝īĶĮ¼µŹóÕĤզŗµĀćµ│©õĖ║µŹ¤Õż▒ńø«µĀć’╝łloss target’╝ēńÜäÕŖ¤ĶāĮõ╣¤Ķó½Õīģµŗ¼Õ£©ÕåģŃĆéÕÅ”õĖĆõĖ¬µ©ĪÕØŚµŖĮĶ▒Ī Postprocessor ÕłÖĶ┤¤Ķ┤ŻÕ£©ķó䵥ŗµŚČĶ¦ŻńĀüµ©ĪÕ×ŗÕĤզŗĶŠōÕć║õĖ║Õ»╣Õ║öõ╗╗ÕŖĪńÜä `DataSample`ŃĆé
+
+- µēƵ£ēµ©ĪÕ×ŗńÜäĶŠōÕģźń«ĆÕī¢õĖ║ÕīģÕɽÕøŠÕāÅÕĤզŗńē╣ÕŠüńÜä `inputs` ÕÆīÕøŠńēćÕģāõ┐Īµü»ńÜä `List[DataSample]`ŃĆéĶŠōÕć║µĀ╝Õ╝Åõ╣¤ÕŠŚÕł░ń╗¤õĖĆ’╝īĶ«Łń╗āµŚČµś»ÕīģÕɽ loss ńÜäÕŁŚÕģĖ’╝īµĄŗĶ»ĢµŚČńÜäĶŠōÕć║õĖ║ÕīģÕɽķó䵥ŗń╗ōµ×£ńÜäÕ»╣Õ║öõ╗╗ÕŖĪńÜä [`DataSample`](<>)ŃĆé
+
+- Module Loss µØźµ║Éõ║Ä 0.x ńēłµ£¼õĖŁÕ«×ńÄ░õĖÄÕŹĢõĖ¬µ©ĪÕ×ŗÕ╝║ńøĖÕģ│ńÜä `XXLoss` ń▒╗’╝īÕ«āõ╗¼Õ£© 1.0 õĖŁÕØćĶó½ń╗¤õĖĆķćŹÕæĮÕÉŹõĖ║`XXModuleLoss`ńÜäÕĮóÕ╝Å’╝łÕ”é`DBLoss` Ķó½ķćŹÕæĮÕÉŹõĖ║ `DBModuleLoss`’╝ē, `head` õ╝ĀÕģźńÜä loss ķģŹńĮ«ÕÅéµĢ░ÕÉŹõ╣¤õ╗Ä `loss` µö╣õĖ║ `module_loss`ŃĆé
+
+- õĖĵ©ĪÕ×ŗÕ«×ńÄ░µŚĀÕģ│ńÜäķĆÜńö©µŹ¤Õż▒ń▒╗ÕÉŹń¦░õ┐صīü `XXLoss` ńÜäÕĮóÕ╝Å’╝īÕ╣ȵöŠńĮ«õ║Ä `mmocr/models/common/losses` õĖŗ’╝īÕ”é [`MaskedBCELoss`](mmocr.models.common.losses.MaskedBCELoss)ŃĆé
+
+- `mmocr/models/common/losses` õĖŗńÜäµö╣ÕŖ©’╝Ü0.x õĖŁ `DiceLoss` Ķó½ķćŹÕÉŹõĖ║ [`MaskedDiceLoss`](mmocr.models.common.losses.MaskedDiceLoss)ŃĆé`FocalLoss` Ķó½ń¦╗ķÖżŃĆé
+
+- Õó×ÕŖĀõ║åĶĄĘµ║Éõ║Ä label converter ńÜä Dictionary µ©ĪÕØŚ’╝īÕ«āõ╝ÜÕ£©µ¢ćµ£¼Ķ»åÕł½ÕÆīÕģ│ķö«õ┐Īµü»µÅÉÕÅ¢õ╗╗ÕŖĪõĖŁĶó½ńö©Õł░ŃĆé
+
+## µ¢ćµ£¼µŻĆµĄŗ
+
+### Õģ│ķö«µö╣ÕŖ©’╝łÕż¬ķĢ┐õĖŹń£ŗńēł’╝ē
+
+- µŚ¦ńēłńÜ䵩ĪÕ×ŗµØāķćŹõ╗ŹńäČķĆéńö©õ║ĵ¢░ńēł’╝īõĮåķ£ĆĶ”üÕ░åµØāķćŹÕŁŚÕģĖ `state_dict` õĖŁõ╗ź `bbox_head` Õ╝ĆÕż┤ńÜäÕŁŚµ«ĄķćŹÕæĮÕÉŹõĖ║ `det_head`ŃĆé
+
+- Ķ«Īń«Ś target µ£ēÕģ│ńÜäÕÅśµŹó `XXTargets` Ķó½ĶĮ¼ń¦╗Õł░õ║å `XXModuleLoss` õĖŁŃĆé
+
+### SingleStageTextDetector
+
+- ÕĤµ£¼ń╗¦µē┐ķōŠõĖ║ `mmdet.BaseDetector->SingleStageDetector->SingleStageTextDetector`’╝īńÄ░Õ£©µö╣õĖ║ńø┤µÄźń╗¦µē┐Ķć¬ `BaseDetector`, õĖŁķŚ┤ńÜä `SingleStageDetector` Ķó½ÕłĀķÖżŃĆé
+
+- `bbox_head` µö╣ÕÉŹõĖ║ `det_head`ŃĆé
+
+- `train_cfg`ŃĆü`test_cfg`ÕÆī`pretrained`ÕŁŚµ«ĄĶó½ń¦╗ķÖżŃĆé
+
+- `forward_train()` õĖÄ `simple_test()` ÕłåÕł½Ķó½ķ揵×äõĖ║ `loss()` õĖÄ `predict()` µ¢╣µ│ĢŃĆéÕģČõĖŁ `simple_test()` õĖŁĶ┤¤Ķ┤ŻÕ░嵩ĪÕ×ŗÕĤզŗĶŠōÕć║µŗåÕłåÕ╣ČĶŠōÕģź `head.get_bounary()` ńÜäķā©ÕłåĶó½µĢ┤ÕÉłĶ┐øõ║å `BaseTextDetPostProcessor` õĖŁŃĆé
+
+- `TextDetectorMixin` õĖŁÕŬի×ńÄ░õ║å `show_result()`µ¢╣µ│Ģ’╝īÕ«×ńÄ░õĖÄ `TextDetLocalVisualizer` ķćŹÕÉł’╝īÕøĀµŁżÕĘ▓ń╗ÅĶó½ń¦╗ķÖżŃĆé
+
+### Head
+
+- `HeadMixin` õĖ║`XXXHead` Õ£© 0.x ńēłµ£¼õĖŁÕ┐ģķĪ╗ń╗¦µē┐ńÜäÕ¤║ń▒╗’╝īńÄ░Õ£©Ķó½ `BaseTextDetHead` õ╗Żµø┐ŃĆéķćīķØóńÜä `get_boundary()` ÕÆī `resize_boundary()` µ¢╣µ│ĢĶó½ķćŹÕåÖõĖ║ `BaseTextDetPostProcessor` ńÜä `__call__()` ÕÆī `rescale()` µ¢╣µ│ĢŃĆé
+
+### ModuleLoss
+
+- µ¢ćµ£¼µŻĆµĄŗõĖŁńē╣µ£ēńÜäµĢ░µŹ«ÕÅśµŹó `XXXTargets` Õģ©ķā©ń¦╗ÕŖ©Õł░ `XXXModuleLoss._get_target_single` õĖŁ’╝īõĖÄńö¤µłÉ target ńøĖÕģ│ńÜäķģŹńĮ«õĖŹÕåŹÕ£©µĢ░µŹ«µĄüµ░┤ń║┐’╝łpipeline’╝ēõĖŁĶ«ŠńĮ«’╝īĶĮ¼ĶĆīÕ£© `XXXLoss` õĖŁĶó½ķģŹńĮ«ŃĆéõŠŗÕ”é’╝ī`DBNetTargets` ńÜäÕ«×ńÄ░Ķó½ń¦╗ÕŖ©Õł░ `DBModuleLoss._get_target_single()`õĖŁ’╝īĶĆīńö©µłĘÕÅ»õ╗źķĆÜĶ┐ćĶ«ŠńĮ« `DBModuleLoss` ńÜäÕłØÕ¦ŗÕī¢ÕÅéµĢ░µØźµÄ¦ÕłČµŹ¤Õż▒ńø«µĀćńÜäńö¤µłÉŃĆé
+
+### Postprocessor
+
+- ÕĤµ£¼ńÜä `XXXPostprocessor.__call__()` õĖŁńÜäķĆ╗ĶŠæĶĮ¼ń¦╗Õł░ķ揵×äÕÉÄńÜä `XXXPostprocessor.get_text_instances()` ŃĆé
+
+- `BasePostprocessor` ķ揵×äõĖ║ `BaseTextDetPostProcessor`’╝īµŁżÕ¤║ń▒╗õ╝ÜÕ░嵩ĪÕ×ŗĶŠōÕć║ńÜäķó䵥ŗń╗ōµ×£µŗåÕłåÕ╣ČķĆÉõĖ¬Ķ┐øĶĪīÕżäńÉå’╝īÕ╣ȵö»µīüµĀ╣µŹ« `scale_factor` Ķć¬ÕŖ©ń╝®µöŠĶŠōÕć║ńÜäÕżÜĶŠ╣ÕĮó’╝łpolygon’╝ēµł¢ńĢīիܵĪå’╝łbounding box’╝ēŃĆé
+
+## µ¢ćµ£¼Ķ»åÕł½
+
+### Õģ│ķö«µö╣ÕŖ©’╝łÕż¬ķĢ┐õĖŹń£ŗńēł’╝ē
+
+- ńö▒õ║ÄÕŁŚÕģĖÕ║ÅÕÅæńö¤õ║åÕÅśÕī¢’╝īõĖöÕŁśÕ£©ķā©Õłåµ©ĪÕ×ŗµ×ȵ×äõĖŖńÜä bug Ķó½õ┐«ÕżŹ’╝īµŚ¦ńēłńÜäĶ»åÕł½µ©ĪÕ×ŗµØāķćŹÕĘ▓ń╗ÅõĖŹÕåŹĶāĮńø┤µÄźÕ║öńö©õ║Ä 1.0 õĖŁ’╝īµłæõ╗¼Õ░åõ╝ÜÕ£©ÕÉÄń╗ŁõĖ║µ£ēķ£ĆĶ”üńÜäńö©µłĘµÄ©Õć║Ķ┐üń¦╗Ķäܵ£¼µĢÖń©ŗŃĆé
+
+- 0.x ńēłµ£¼õĖŁńÜä SegOCR µö»µīüµÜ鵌Čń¦╗ķÖż’╝īTPS-CRNN õ╝ÜÕ£©ÕÉÄń╗Łńēłµ£¼õĖŁĶó½µö»µīüŃĆé
+
+- µĄŗĶ»ĢµŚČÕó×Õ╝║’╝łtest time augmentation’╝ēÕ£©µŁżńēłµ£¼õĖŁµÜéµ£¬µö»µīü’╝īõĮåÕ░åõ╝ÜÕ£©ÕÉÄń╗Łńēłµ£¼õĖŁµø┤µ¢░ŃĆé
+
+- Label converter µ©ĪÕØŚĶó½ń¦╗ķÖż’╝īķćīķØóńÜäÕŖ¤ĶāĮĶó½µŗåÕłåĶć│ Dictionary, ModuleLoss ÕÆī Postprocessor µ©ĪÕØŚõĖŁŃĆé
+
+- ń╗¤õĖƵ©ĪÕ×ŗõĖŁÕ»╣ `max_seq_len` ńÜäÕ«Üõ╣ēõĖ║µ©ĪÕ×ŗńÜäÕĤզŗĶŠōÕć║ķĢ┐Õ║”ŃĆé
+
+### Label Converter
+
+- ÕĤµ£ēńÜä label converter ÕŁśÕ£©µŗ╝ÕåÖķöÖĶ»» (label convertor)’╝īµłæõ╗¼ķĆÜĶ┐ćÕłĀķÖżµÄēĶ┐ÖõĖ¬ń▒╗Ķ¦äķü┐õ║åĶ┐ÖõĖ¬ķŚ«ķóśŃĆé
+
+- Ķ┤¤Ķ┤ŻÕ»╣ÕŁŚń¼”/ÕŁŚń¼”õĖ▓õĖĵĢ░ÕŁŚń┤óÕ╝Ģõ║ÆńøĖĶĮ¼µŹóńÜäķā©ÕłåĶó½µÅÉÕÅ¢Ķć│ [`Dictionary`](mmocr.models.common.Dictionary) ń▒╗õĖŁŃĆé
+
+- Õ£©µŚ¦ńēłµ£¼õĖŁ’╝īõĖŹÕÉīńÜä label converter õ╝ܵ£ēõĖŹõĖƵĀĘńÜäńē╣µ«ŖÕŁŚń¼”ķøåÕÆīÕŁŚń¼”Õ║ÅŃĆéÕ£© 0.x ńēłµ£¼õĖŁ’╝īÕŁŚń¼”Õ║ÅÕ”éõĖŗ’╝Ü
+
+ | Converter | ÕŁŚń¼”Õ║Å |
+ | ------------------------------- | ----------------------------------------- |
+ | `AttnConvertor`, `ABIConvertor` | ``, ``, ``, characters |
+ | `CTCConvertor` | ``, ``, characters |
+
+Õ£© 1.0 õĖŁ’╝īµłæõ╗¼õĖŹÕåŹõ╗źõ╗╗ÕŖĪõĖ║ĶŠ╣ńĢīĶ«ŠĶ«ĪõĖŹÕÉīńÜäÕŁŚÕģĖÕÆīÕŁŚń¼”Õ║Å’╝īÕÅ¢ĶĆīõ╗Żõ╣ŗńÜ䵜»ń╗¤õĖĆõ║åÕŁŚń¼”Õ║ÅńÜä Dictionary’╝īÕģČÕŁŚń¼”Õ║ÅõĖ║ characters, \, \, \ŃĆé`CTCConvertor` õĖŁ \ Ķó½ńŁēõ╗ʵø┐µŹóõĖ║ \ŃĆé
+
+- `label_convertor` õĖŁÕĤµ£¼µö»µīüõĖēń¦Źµ¢╣Õ╝ÅÕłØÕ¦ŗÕī¢ÕŁŚÕģĖ’╝Ü`dict_type`ŃĆü`dict_file` ÕÆī `dict_list`’╝īńÄ░Õ£©Õ£© `Dictionary` õĖŁĶó½ń«ĆÕī¢õĖ║ `dict_file` õĖĆń¦ŹŃĆéÕÉīµŚČ’╝īµłæõ╗¼õ╣¤µŖŖÕĤµ£¼Õ£© `dict_type` õĖŁµö»µīüńÜäÕŁŚÕģĖµĀ╝Õ╝ÅĶĮ¼Õī¢õĖ║ńÄ░Õ£© `dicts/` ńø«ÕĮĢõĖŗńÜäķóäĶ«ŠÕŁŚÕģĖµ¢ćõ╗ČŃĆéÕ»╣Õ║öµśĀÕ░äÕ”éõĖŗ’╝Ü
+
+ | MMOCR 0.x: `dict_type` | MMOCR 1.0: ÕŁŚÕģĖĶĘ»ÕŠä |
+ | ---------------------- | -------------------------------------- |
+ | DICT90 | dicts/english_digits_symbols.txt |
+ | DICT91 | dicts/english_digits_symbols_space.txt |
+ | DICT36 | dicts/lower_english_digits.txt |
+ | DICT37 | dicts/lower_english_digits_space.txt |
+
+- `label_converter` õĖŁ `str2tensor()` ńÜäÕ«×ńÄ░Ķó½ĶĮ¼ń¦╗Õł░ `ModuleLoss.get_targets()` õĖŁŃĆéõĖŗķØóńÜäĶĪ©µĀ╝ÕłŚÕć║õ║åµŚ¦ńēłõĖĵ¢░ńēłµ¢╣µ│ĢÕ«×ńÄ░ńÜäÕ»╣Õ║öÕģ│ń│╗ŃĆéµ│©µäÅ’╝īµ¢░µŚ¦ńēłńÜäÕ«×ńÄ░Õ╣ČķØ×Õ«īÕģ©õĖĆĶć┤ŃĆé
+
+ | MMOCR 0.x | MMOCR 1.0 | Õżćµ│© |
+ | --------------------------------------------------------- | --------------------------------------- | -------------------------------------------- |
+ | `ABIConvertor.str2tensor()`, `AttnConvertor.str2tensor()` | `BaseTextRecogModuleLoss.get_targets()` | ÕĤµ£¼õĖżõĖ¬ń▒╗õĖŁńÜäÕ«×ńÄ░ÕŁśÕ£©ńÜäÕĘ«Õ╝éÕ£©µ¢░ńēłµ£¼õĖŁĶó½ń╗¤õĖĆ |
+ | `CTCConvertor.str2tensor()` | `CTCModuleLoss.get_targets()` | |
+
+- `label_converter` õĖŁ `tensor2idx()` ńÜäÕ«×ńÄ░Ķó½ĶĮ¼ń¦╗Õł░ `Postprocessor.get_single_prediction()` õĖŁŃĆéõĖŗķØóńÜäĶĪ©µĀ╝ÕłŚÕć║õ║åµŚ¦ńēłõĖĵ¢░ńēłµ¢╣µ│ĢÕ«×ńÄ░ńÜäÕ»╣Õ║öÕģ│ń│╗ŃĆéµ│©µäÅ’╝īµ¢░µŚ¦ńēłńÜäÕ«×ńÄ░Õ╣ČķØ×Õ«īÕģ©õĖĆĶć┤ŃĆé
+
+ | MMOCR 0.x | MMOCR 1.0 |
+ | --------------------------------------------------------- | ------------------------------------------------ |
+ | `ABIConvertor.tensor2idx()`, `AttnConvertor.tensor2idx()` | `AttentionPostprocessor.get_single_prediction()` |
+ | `CTCConvertor.tensor2idx()` | `CTCPostProcessor.get_single_prediction()` |
+
+## Õģ│ķö«õ┐Īµü»µÅÉÕÅ¢
+
+### Õģ│ķö«µö╣ÕŖ©’╝łÕż¬ķĢ┐õĖŹń£ŗńēł’╝ē
+
+- ńö▒õ║ĵ©ĪÕ×ŗńÜäĶŠōÕģźÕÅæńö¤õ║åÕÅśÕī¢’╝īµŚ¦ńēłµ©ĪÕ×ŗńÜäµØāķćŹÕĘ▓ń╗ÅõĖŹÕåŹĶāĮńø┤µÄźÕ║öńö©õ║Ä 1.0 õĖŁŃĆé
+
+### KIEDataset & OpensetKIEDataset
+
+- Ķ»╗ÕÅ¢µĢ░µŹ«ńÜäķā©ÕłåĶó½ń«ĆÕī¢Õł░ `WildReceiptDataset` õĖŁŃĆé
+
+- Õ»╣ĶŖéńé╣ÕÆīĶŠ╣õĮ£ķóØÕż¢ÕżäńÉåńÜäķā©ÕłåĶó½ĶĮ¼ń¦╗Õł░õ║å `LoadKIEAnnotation` õĖŁŃĆé
+
+- õĮ┐ńö©ÕŁŚÕģĖÕ»╣µ¢ćµ£¼Ķ┐øĶĪīĶĮ¼Õī¢ńÜäķā©ÕłåĶó½ĶĮ¼ń¦╗Õł░õ║å `SDMGRHead.convert_text()` õĖŁ’╝īõĮ┐ńö© `Dictionary` Õ«×ńÄ░ŃĆé
+
+- Ķ«Īń«Śµ¢ćµ£¼µĪåõ╣ŗķŚ┤Õģ│ń│╗ńÜäķā©Õłå`compute_relation()` Ķó½ĶĮ¼ń¦╗Õł░ `SDMGRHead.compute_relations()` õĖŁ’╝īÕ£©µ©ĪÕ×ŗÕåģĶ┐øĶĪīŃĆé
+
+- Ķ»äõ╝░µ©ĪÕ×ŗĶĪ©ńÄ░ńÜäķā©ÕłåĶó½ń«ĆÕī¢õĖ║ `F1Metric`ŃĆé
+
+- `OpensetKIEDataset` õĖŁÕżäńÉ嵩ĪÕ×ŗĶŠ╣ĶŠōÕć║ńÜäķā©ÕłåĶó½µĢ┤ńÉåÕł░ `SDMGRPostProcessor`õĖŁŃĆé
+
+### SDMGR
+
+- `show_result()` Ķó½µĢ┤ÕÉłÕł░ `KIEVisualizer` õĖŁŃĆé
+
+- `forward_test()` õĖŁÕ»╣ĶŠōÕć║Ķ┐øĶĪīÕÉÄÕżäńÉåńÜäķā©ÕłåĶó½µĢ┤ńÉåÕł░ `SDMGRPostProcessor`õĖŁŃĆé
+
+## Utils ÕÅśÕŖ©
+
+ÕĤµ£¼µĢŻÕĖāÕ£©ÕÉäÕżäńÜäÕŖ¤ĶāĮÕćĮµĢ░ńÄ░ÕĘ▓Ķó½ń╗¤õĖĆÕĮÆń▒╗Õ£© `mmocr/utils/` õĖŗŃĆéõ╗źõĖŗõĖ║Ķ»źńø«ÕĮĢõĖŗÕÉäµ¢ćõ╗ČńÜäõĮ£ńö©Õ¤¤’╝Ü
+
+- bbox_utils.py’╝ÜÕøøĶŠ╣ńĢīիܵĪå’╝łbounding box’╝ēµ£ēÕģ│ńÜäÕŖ¤ĶāĮÕćĮµĢ░ŃĆé
+- check_argument.py’╝ܵŻĆµ¤źÕÅéµĢ░ń▒╗Õ×ŗńÜäÕŖ¤ĶāĮÕćĮµĢ░ŃĆé
+- collect_env.py’╝ܵöČķøåĶ┐ÉĶĪīńÄ»ÕóāńÜäÕŖ¤ĶāĮÕćĮµĢ░ŃĆé
+- data_converter_utils.py’╝Üńö©õ║ĵĢ░µŹ«ķøåĶĮ¼µŹóńÜäÕŖ¤ĶāĮÕćĮµĢ░ŃĆé
+- fileio.py’╝ÜĶŠōÕģź/ĶŠōÕć║µ£ēÕģ│ńÜäÕŖ¤ĶāĮÕćĮµĢ░ŃĆé
+- img_utils.py’╝ÜÕżäńÉåÕøŠńēćńÜäÕŖ¤ĶāĮÕćĮµĢ░ŃĆé
+- mask_utils.py’╝ÜõĖĵĮńĀüµ£ēÕģ│ńÜäÕŖ¤ĶāĮÕćĮµĢ░ŃĆé
+- ocr.py’╝Üńö©õ║Ä MMOCR µÄ©ńÉåńÜäÕŖ¤ĶāĮÕćĮµĢ░ŃĆé
+- parsers.py’╝ÜĶ¦ŻńĀüµ¢ćõ╗ČńÜäÕŖ¤ĶāĮÕćĮµĢ░ŃĆé
+- polygon_utils.py’╝ÜÕżÜĶŠ╣ÕĮóńÜäÕŖ¤ĶāĮÕćĮµĢ░ŃĆé
+- setup_env.py’╝ÜÕŁśµöŠÕłØÕ¦ŗÕī¢ MMOCR ńÜäÕŖ¤ĶāĮÕćĮµĢ░ŃĆé
+- string_utils.py’╝ÜÕŁśµöŠÕŁŚń¼”õĖ▓ńÜäÕŖ¤ĶāĮÕćĮµĢ░ŃĆé
+- typing.py’╝ÜÕŁśµöŠ MMOCR õĖŁÕĖĖńö©µĢ░µŹ«ń▒╗Õ×ŗńÜäń╝®ÕåÖŃĆé
diff --git a/internlm_langchain/knowledge_base/MMOCR/content/config.md b/internlm_langchain/knowledge_base/MMOCR/content/config.md
new file mode 100644
index 00000000..fd16af58
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMOCR/content/config.md
@@ -0,0 +1,719 @@
+# ķģŹńĮ«µ¢ćõ╗Č
+
+MMOCR õĖ╗Ķ”üõĮ┐ńö© Python µ¢ćõ╗ČõĮ£õĖ║ķģŹńĮ«µ¢ćõ╗ČŃĆéÕģČķģŹńĮ«µ¢ćõ╗Čń│╗ń╗¤ńÜäĶ«ŠĶ«ĪµĢ┤ÕÉłõ║嵩ĪÕØŚÕī¢õĖÄń╗¦µē┐ńÜäµĆصā│’╝īµ¢╣õŠ┐ńö©µłĘĶ┐øĶĪīÕÉäń¦ŹÕ«×ķ¬īŃĆé
+
+## ÕĖĖĶ¦üńö©µ│Ģ
+
+```{note}
+µ£¼Õ░ÅĶŖéÕ╗║Ķ««ń╗ōÕÉł {external+mmengine:doc}`MMEngine: ķģŹńĮ«(Config) ` õĖŁńÜäÕłØń║¦ńö©µ│ĢÕģ▒ÕÉīķśģĶ»╗ŃĆé
+```
+
+MMOCR µ£ĆÕĖĖńö©ńÜäµōŹõĮ£õĖ║õĖēń¦Ź’╝ÜķģŹńĮ«µ¢ćõ╗ČńÜäń╗¦µē┐’╝īÕ»╣ `_base_` ÕÅśķćÅńÜäÕ╝Ģńö©õ╗źÕÅŖÕ»╣ `_base_` ÕÅśķćÅńÜäõ┐«µö╣ŃĆéÕ»╣õ║Ä `_base_` ńÜäń╗¦µē┐õĖÄõ┐«µö╣, MMEngine.Config µÅÉõŠøõ║åõĖżń¦ŹĶ»Łµ│Ģ’╝īõĖĆń¦Źµś»ķÆłÕ»╣ Python’╝īJson’╝ī Yaml ÕØćÕÅ»õĮ┐ńö©ńÜäµōŹõĮ£’╝øÕÅ”õĖĆń¦ŹÕłÖõ╗ģķĆéńö©õ║Ä Python ķģŹńĮ«µ¢ćõ╗ČŃĆéÕ£© MMOCR õĖŁ’╝īµłæõ╗¼**µø┤µÄ©ĶŹÉõĮ┐ńö©ÕŬķÆłÕ»╣PythonńÜäĶ»Łµ│Ģ**’╝īÕøĀµŁżõĖŗµ¢ćÕ░åõ╗źµŁżõĖ║Õ¤║ńĪĆõĮ£Ķ┐øõĖƵŁźõ╗ŗń╗ŹŃĆé
+
+Ķ┐Öķćīõ╗ź `configs/textdet/dbnet/dbnet_resnet18_fpnc_1200e_icdar2015.py` õĖ║õŠŗ’╝īĶ»┤µśÄÕĖĖńö©ńÜäõĖēń¦Źńö©µ│ĢŃĆé
+
+```Python
+_base_ = [
+ '_base_dbnet_resnet18_fpnc.py',
+ '../_base_/datasets/icdar2015.py',
+ '../_base_/default_runtime.py',
+ '../_base_/schedules/schedule_sgd_1200e.py',
+]
+
+# dataset settings
+icdar2015_textdet_train = _base_.icdar2015_textdet_train
+icdar2015_textdet_train.pipeline = _base_.train_pipeline
+icdar2015_textdet_test = _base_.icdar2015_textdet_test
+icdar2015_textdet_test.pipeline = _base_.test_pipeline
+
+train_dataloader = dict(
+ batch_size=16,
+ num_workers=8,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=icdar2015_textdet_train)
+
+val_dataloader = dict(
+ batch_size=1,
+ num_workers=4,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ dataset=icdar2015_textdet_test)
+```
+
+### ķģŹńĮ«µ¢ćõ╗ČńÜäń╗¦µē┐
+
+ķģŹńĮ«µ¢ćõ╗ČÕŁśÕ£©ń╗¦µē┐ńÜäµ£║ÕłČ’╝īÕŹ│õĖĆõĖ¬ķģŹńĮ«µ¢ćõ╗Č A ÕÅ»õ╗źÕ░åÕÅ”õĖĆõĖ¬ķģŹńĮ«µ¢ćõ╗Č B õĮ£õĖ║Ķć¬ÕĘ▒ńÜäÕ¤║ńĪĆÕ╣Čńø┤µÄźń╗¦µē┐ÕģČõĖŁńÜäµēƵ£ēÕŁŚµ«Ą’╝īõ╗ÄĶĆīķü┐ÕģŹõ║åÕż¦ķćÅńÜäÕżŹÕłČń▓śĶ┤┤ŃĆé
+
+Õ£© dbnet_resnet18_fpnc_1200e_icdar2015.py õĖŁÕÅ»õ╗źń£ŗÕł░’╝Ü
+
+```Python
+_base_ = [
+ '_base_dbnet_resnet18_fpnc.py',
+ '../_base_/datasets/icdar2015.py',
+ '../_base_/default_runtime.py',
+ '../_base_/schedules/schedule_sgd_1200e.py',
+]
+```
+
+õĖŖĶ┐░Ķ»ŁÕÅźõ╝ÜĶ»╗ÕÅ¢ÕłŚĶĪ©õĖŁńÜäµēƵ£ēÕ¤║ńĪĆķģŹńĮ«µ¢ćõ╗Č’╝īÕ«āõ╗¼õĖŁńÜäµēƵ£ēÕŁŚµ«ĄķāĮõ╝ÜĶó½ĶĮĮÕģźÕł░ dbnet_resnet18_fpnc_1200e_icdar2015.py õĖŁŃĆ鵳æõ╗¼ÕÅ»õ╗źķĆÜĶ┐ćÕ£© Python Ķ¦ŻķćŖõĖŁĶ┐ÉĶĪīõ╗źõĖŗĶ»ŁÕÅź’╝īõ║åĶ¦ŻķģŹńĮ«µ¢ćõ╗ČĶó½Ķ¦Żµ×ÉÕÉÄńÜäń╗ōµ×ä’╝Ü
+
+```Python
+from mmengine import Config
+db_config = Config.fromfile('configs/textdet/dbnet/dbnet_resnet18_fpnc_1200e_icdar2015.py')
+print(db_config)
+```
+
+ÕÅ»õ╗źÕÅæńÄ░’╝īĶó½Ķ¦Żµ×ÉńÜäķģŹńĮ«ÕīģÕɽõ║åµēƵ£ēbaseķģŹńĮ«õĖŁńÜäÕŁŚµ«ĄÕÆīõ┐Īµü»ŃĆé
+
+```{note}
+Ķ»Ęµ│©µäÅ’╝ÜÕÉä _base_ ķģŹńĮ«µ¢ćõ╗ČõĖŁõĖŹĶāĮÕŁśÕ£©ÕÉīÕÉŹÕÅśķćÅŃĆé
+```
+
+### `_base_` ÕÅśķćÅńÜäÕ╝Ģńö©
+
+µ£ēµŚČ’╝īµłæõ╗¼ÕÅ»ĶāĮķ£ĆĶ”üńø┤µÄźÕ╝Ģńö© `_base_` ķģŹńĮ«õĖŁńÜ䵤Éõ║øÕŁŚµ«Ą’╝īõ╗źķü┐ÕģŹķćŹÕżŹÕ«Üõ╣ēŃĆéÕüćĶ«Šµłæõ╗¼µā│Ķ”üĶÄĘÕÅ¢ `_base_` ķģŹńĮ«õĖŁńÜäÕÅśķćÅ `pseudo`’╝īÕ░▒ÕÅ»õ╗źńø┤µÄźķĆÜĶ┐ć `_base_.pseudo` ĶÄĘÕŠŚ `_base_` ķģŹńĮ«õĖŁńÜäÕÅśķćÅŃĆé
+
+Ķ»źĶ»Łµ│ĢÕĘ▓Õ╣┐µ│øńö©õ║Ä MMOCR ńÜäķģŹńĮ«õĖŁŃĆéMMOCR õĖŁÕÉäõĖ¬µ©ĪÕ×ŗńÜäµĢ░µŹ«ķøåÕÆīń«Īķüō’╝łpipeline’╝ēķģŹńĮ«ķāĮÕ╝Ģńö©õ║Ä*Õ¤║µ£¼*ķģŹńĮ«ŃĆéÕ”éÕ£©
+
+```Python
+icdar2015_textdet_train = _base_.icdar2015_textdet_train
+# ...
+train_dataloader = dict(
+ # ...
+ dataset=icdar2015_textdet_train)
+```
+
+### `_base_` ÕÅśķćÅńÜäõ┐«µö╣
+
+Õ£© MMOCR õĖŁõĖŹÕÉīń«Śµ│ĢÕ£©õĖŹÕÉīµĢ░µŹ«ķøåķĆÜÕĖĖµ£ēõĖŹÕÉīńÜäµĢ░µŹ«µĄüµ░┤ń║┐’╝łpipeline)’╝īÕøĀµŁżń╗ÅÕĖĖõ╝Üõ╝ÜÕŁśÕ£©õ┐«µö╣µĢ░µŹ«ķøåõĖŁ `pipeline` ńÜäÕ£║µÖ»ŃĆéÕÉīµŚČĶ┐śÕŁśÕ£©ÕŠłÕżÜÕ£║µÖ»ķ£ĆĶ”üõ┐«µö╣ `_base_` ķģŹńĮ«õĖŁńÜäÕÅśķćÅ’╝īõŠŗÕ”éµā│õ┐«µö╣µ¤ÉõĖ¬ń«Śµ│ĢńÜäĶ«Łń╗āńŁ¢ńĢź’╝īµ¤ÉõĖ¬µ©ĪÕ×ŗńÜ䵤Éõ║øń«Śµ│Ģµ©ĪÕØŚ’╝łµø┤µŹó backbone ńŁē’╝ēŃĆéńö©µłĘÕÅ»õ╗źńø┤µÄźÕł®ńö© Python ńÜäĶ»Łµ│Ģńø┤µÄźõ┐«µö╣Õ╝Ģńö©ńÜä `_base_` ÕÅśķćÅŃĆéķÆłÕ»╣ dict’╝īµłæõ╗¼õ╣¤µÅÉõŠøõ║åõĖÄń▒╗Õ▒׵Ʀõ┐«µö╣ń▒╗õ╝╝ńÜäµ¢╣µ│Ģ’╝īÕÅ»õ╗źńø┤µÄźõ┐«µö╣ń▒╗Õ▒׵Ʀõ┐«µö╣ÕŁŚÕģĖÕåģńÜäÕåģÕ«╣ŃĆé
+
+1. ÕŁŚÕģĖ
+
+ Ķ┐Öķćīõ╗źõ┐«µö╣µĢ░µŹ«ķøåõĖŁńÜä `pipeline` õĖ║õŠŗ’╝Ü
+
+ ÕÅ»õ╗źÕł®ńö© Python Ķ»Łµ│Ģõ┐«µö╣ÕŁŚÕģĖ’╝Ü
+
+ ```python
+ # ĶÄĘÕÅ¢ _base_ õĖŁńÜäµĢ░µŹ«ķøå
+ icdar2015_textdet_train = _base_.icdar2015_textdet_train
+ # ÕÅ»õ╗źńø┤µÄźÕł®ńö© Python ńÜä update õ┐«µö╣ÕÅśķćÅ
+ icdar2015_textdet_train.update(pipeline=_base_.train_pipeline)
+ ```
+
+ õ╣¤ÕÅ»õ╗źõĮ┐ńö©ń▒╗Õ▒׵ƦńÜäµ¢╣µ│ĢĶ┐øĶĪīõ┐«µö╣’╝Ü
+
+ ```Python
+ # ĶÄĘÕÅ¢ _base_ õĖŁńÜäµĢ░µŹ«ķøå
+ icdar2015_textdet_train = _base_.icdar2015_textdet_train
+ # ń▒╗Õ▒׵Ʀµ¢╣µ│Ģõ┐«µö╣
+ icdar2015_textdet_train.pipeline = _base_.train_pipeline
+ ```
+
+2. ÕłŚĶĪ©
+
+ ÕüćĶ«Š `_base_` ķģŹńĮ«õĖŁńÜäÕÅśķćÅ `pseudo = [1, 2, 3]`’╝ī ķ£ĆĶ”üõ┐«µö╣õĖ║ `[1, 2, 4]`:
+
+ ```Python
+ # pseudo.py
+ pseudo = [1, 2, 3]
+ ```
+
+ ÕÅ»õ╗źńø┤µÄźķćŹÕåÖ’╝Ü
+
+ ```Python
+ _base_ = ['pseudo.py']
+ pseudo = [1, 2, 4]
+ ```
+
+ µł¢ĶĆģÕł®ńö© Python Ķ»Łµ│Ģõ┐«µö╣ÕłŚĶĪ©’╝Ü
+
+ ```Python
+ _base_ = ['pseudo.py']
+ pseudo = _base_.pseudo
+ pseudo[2] = 4
+ ```
+
+### ÕæĮõ╗żĶĪīõ┐«µö╣ķģŹńĮ«
+
+µ£ēµŚČÕĆÖµłæõ╗¼ÕŬÕĖīµ£øõ┐«ķā©ÕłåķģŹńĮ«’╝īĶĆīõĖŹµā│õ┐«µö╣ķģŹńĮ«µ¢ćõ╗ȵ£¼Ķ║½ŃĆéõŠŗÕ”éÕ«×ķ¬īĶ┐ćń©ŗõĖŁµā│µø┤µŹóÕŁ”õ╣ĀńÄć’╝īõĮåµś»ÕÅłõĖŹµā│ķ揵¢░ÕåÖõĖĆõĖ¬ķģŹńĮ«µ¢ćõ╗Č’╝īÕÅ»õ╗źķĆÜĶ┐ćÕæĮõ╗żĶĪīõ╝ĀÕģźÕÅéµĢ░µØźĶ”åńø¢ńøĖÕģ│ķģŹńĮ«ŃĆé
+
+µłæõ╗¼ÕÅ»õ╗źÕ£©ÕæĮõ╗żĶĪīķćīõ╝ĀÕģź `--cfg-options`’╝īÕ╣ČÕ£©ÕģČõ╣ŗÕÉÄńÜäÕÅéµĢ░ńø┤µÄźõ┐«µö╣Õ»╣Õ║öÕŁŚµ«Ą’╝īõŠŗÕ”éµłæõ╗¼µā│Õ£©Ķ┐ÉĶĪī train ńÜ䵌ČÕĆÖõ┐«µö╣ÕŁ”õ╣ĀńÄć’╝īÕŬķ£ĆĶ”üÕ£©ÕæĮõ╗żĶĪīµē¦ĶĪī’╝Ü
+
+```Shell
+python tools/train.py example.py --cfg-options optim_wrapper.optimizer.lr=1
+```
+
+µø┤ÕżÜĶ»”ń╗åńö©µ│ĢÕÅéĶĆā {external+mmengine:ref}`MMEngine: ÕæĮõ╗żĶĪīõ┐«µö╣ķģŹńĮ« <ÕæĮõ╗żĶĪīõ┐«µö╣ķģŹńĮ«>`.
+
+## ķģŹńĮ«ÕåģÕ«╣
+
+ķĆÜĶ┐ćķģŹńĮ«µ¢ćõ╗ČõĖĵ│©ÕåīÕÖ©ńÜäķģŹÕÉł’╝īMMOCR ÕÅ»õ╗źÕ£©õĖŹõŠĄÕģźõ╗ŻńĀüńÜäÕēŹµÅÉõĖŗõ┐«µö╣Ķ«Łń╗āÕÅéµĢ░õ╗źÕÅŖµ©ĪÕ×ŗķģŹńĮ«ŃĆéÕģĘõĮōĶĆīĶ©Ć’╝īńö©µłĘÕÅ»õ╗źÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁÕ»╣Õ”éõĖŗµ©ĪÕØŚĶ┐øĶĪīĶć¬Õ«Üõ╣ēõ┐«µö╣’╝ÜńÄ»ÕóāķģŹńĮ«ŃĆüHook ķģŹńĮ«ŃĆüµŚźÕ┐ŚķģŹńĮ«ŃĆüĶ«Łń╗āńŁ¢ńĢźķģŹńĮ«ŃĆüµĢ░µŹ«ńøĖÕģ│ķģŹńĮ«ŃĆüµ©ĪÕ×ŗńøĖÕģ│ķģŹńĮ«ŃĆüĶ»äµĄŗķģŹńĮ«ŃĆüÕÅ»Ķ¦åÕī¢ķģŹńĮ«ŃĆé
+
+µ£¼µ¢ćµĪŻÕ░åõ╗źµ¢ćÕŁŚµŻĆµĄŗń«Śµ│Ģ `DBNet` ÕÆīµ¢ćÕŁŚĶ»åÕł½ń«Śµ│Ģ `CRNN` õĖ║õŠŗµØźĶ»”ń╗åõ╗ŗń╗Ź Config õĖŁńÜäÕåģÕ«╣ŃĆé
+
+
+
+### ńÄ»ÕóāķģŹńĮ«
+
+```Python
+default_scope = 'mmocr'
+env_cfg = dict(
+ cudnn_benchmark=True,
+ mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0),
+ dist_cfg=dict(backend='nccl'))
+randomness = dict(seed=None)
+```
+
+õĖ╗Ķ”üÕīģÕɽõĖēõĖ¬ķā©Õłå’╝Ü
+
+- Ķ«ŠńĮ«µēƵ£ēµ│©ÕåīÕÖ©ńÜäķ╗śĶ«ż `scope` õĖ║ `mmocr`’╝ī õ┐ØĶ»üµēƵ£ēńÜ䵩ĪÕØŚķ”¢Õģłõ╗Ä `MMOCR` õ╗ŻńĀüÕ║ōõĖŁĶ┐øĶĪīµÉ£ń┤óŃĆéĶŗźµ×£Ķ»źµ©ĪÕØŚõĖŹÕŁśÕ£©’╝īÕłÖń╗¦ń╗Łõ╗ÄõĖŖµĖĖń«Śµ│ĢÕ║ō `MMEngine` ÕÆī `MMCV` õĖŁĶ┐øĶĪīµÉ£ń┤ó’╝īĶ»”Ķ¦ü {external+mmengine:doc}`MMEngine: µ│©ÕåīÕÖ© `ŃĆé
+
+- `env_cfg` Ķ«ŠńĮ«ÕłåÕĖāÕ╝ÅńÄ»ÕóāķģŹńĮ«’╝ī µø┤ÕżÜķģŹńĮ«ÕÅ»õ╗źĶ»”Ķ¦ü {external+mmengine:doc}`MMEngine: Runner `ŃĆé
+
+- `randomness` Ķ«ŠńĮ« numpy’╝ī torch’╝īcudnn ńŁēķÜŵ£║ń¦ŹÕŁÉ’╝īµø┤ÕżÜķģŹńĮ«Ķ»”Ķ¦ü {external+mmengine:doc}`MMEngine: Runner `ŃĆé
+
+
+
+### Hook ķģŹńĮ«
+
+Hook õĖ╗Ķ”üÕłåõĖ║õĖżõĖ¬ķā©Õłå’╝īķ╗śĶ«ż hook õ╗źÕÅŖĶć¬Õ«Üõ╣ē hookŃĆéķ╗śĶ«ż hook õĖ║µēƵ£ēõ╗╗ÕŖĪµā│Ķ”üĶ┐ÉĶĪīµēĆÕ┐ģķĪ╗ńÜäķģŹńĮ«’╝īĶć¬Õ«Üõ╣ē hook õĖĆĶł¼µ£ŹÕŖĪõ║Äńē╣Õ«ÜńÜäń«Śµ│Ģµł¢µ¤Éõ║øńē╣Õ«Üõ╗╗ÕŖĪ’╝łńø«ÕēŹõĖ║µŁó MMOCR õĖŁµ▓Īµ£ēĶć¬Õ«Üõ╣ēńÜä Hook’╝ēŃĆé
+
+```Python
+default_hooks = dict(
+ timer=dict(type='IterTimerHook'), # µŚČķŚ┤Ķ«░ÕĮĢ’╝īÕīģµŗ¼µĢ░µŹ«Õó×Õ╝║µŚČķŚ┤õ╗źÕÅŖµ©ĪÕ×ŗµÄ©ńÉåµŚČķŚ┤
+ logger=dict(type='LoggerHook', interval=1), # µŚźÕ┐ŚµēōÕŹ░ķŚ┤ķÜö
+ param_scheduler=dict(type='ParamSchedulerHook'), # µø┤µ¢░ÕŁ”õ╣ĀńÄćńŁēĶČģÕÅé
+ checkpoint=dict(type='CheckpointHook', interval=1),# õ┐ØÕŁś checkpoint’╝ī intervalµÄ¦ÕłČõ┐ØÕŁśķŚ┤ķÜö
+ sampler_seed=dict(type='DistSamplerSeedHook'), # ÕżÜµ£║µāģÕåĄõĖŗĶ«ŠńĮ«ń¦ŹÕŁÉ
+ sync_buffer=dict(type='SyncBuffersHook'), # ÕżÜÕŹĪµāģÕåĄõĖŗ’╝īÕÉīµŁźbuffer
+ visualization=dict( # ÕÅ»Ķ¦åÕī¢val ÕÆī test ńÜäń╗ōµ×£
+ type='VisualizationHook',
+ interval=1,
+ enable=False,
+ show=False,
+ draw_gt=False,
+ draw_pred=False))
+ custom_hooks = []
+```
+
+Ķ┐Öķćīń«ĆÕŹĢõ╗ŗń╗ŹÕćĀõĖ¬ń╗ÅÕĖĖÕÅ»ĶāĮõ╝ÜÕÅśÕŖ©ńÜä hook’╝īķĆÜńö©ńÜäõ┐«µö╣µ¢╣µ│ĢÕÅéĶĆā[õ┐«µö╣ķģŹńĮ«](#base-ÕÅśķćÅńÜäõ┐«µö╣)ŃĆé
+
+- `LoggerHook`’╝Üńö©õ║ÄķģŹńĮ«µŚźÕ┐ŚĶ«░ÕĮĢÕÖ©ńÜäĶĪīõĖ║ŃĆéõŠŗÕ”é’╝īķĆÜĶ┐ćõ┐«µö╣ `interval` ÕÅ»õ╗źµÄ¦ÕłČµŚźÕ┐ŚµēōÕŹ░ńÜäķŚ┤ķÜö’╝īµ»Å `interval` µ¼ĪĶ┐Łõ╗Ż (iteration) µēōÕŹ░õĖƵ¼ĪµŚźÕ┐Ś’╝īµø┤ÕżÜĶ«ŠńĮ«ÕÅ»ÕÅéĶĆā [LoggerHook API](mmengine.hooks.LoggerHook)ŃĆé
+
+- `CheckpointHook`’╝Üńö©õ║ÄķģŹńĮ«µ©ĪÕ×ŗµ¢Łńé╣õ┐ØÕŁśńøĖÕģ│ńÜäĶĪīõĖ║’╝īÕ”éõ┐ØÕŁśµ£Ćõ╝śµØāķ插╝īõ┐ØÕŁśµ£Ćµ¢░µØāķćŹńŁēŃĆéÕÉīµĀĘÕÅ»õ╗źõ┐«µö╣ `interval` µÄ¦ÕłČõ┐ØÕŁś checkpoint ńÜäķŚ┤ķÜöŃĆéµø┤ÕżÜĶ«ŠńĮ«ÕÅ»ÕÅéĶĆā [CheckpointHook API](mmengine.hooks.CheckpointHook)
+
+- `VisualizationHook`’╝Üńö©õ║ÄķģŹńĮ«ÕÅ»Ķ¦åÕī¢ńøĖÕģ│ĶĪīõĖ║’╝īõŠŗÕ”éÕ£©ķ¬īĶ»üµł¢µĄŗĶ»ĢµŚČÕÅ»Ķ¦åÕī¢ķó䵥ŗń╗ōµ×£’╝ī**ķ╗śĶ«żõĖ║Õģ│**ŃĆéÕÉīµŚČĶ»ź Hook õŠØĶĄ¢[ÕÅ»Ķ¦åÕī¢ķģŹńĮ«](#ÕÅ»Ķ¦åÕī¢ķģŹńĮ«)ŃĆéµā│Ķ”üõ║åĶ¦ŻĶ»”ń╗åÕŖ¤ĶāĮÕÅ»õ╗źÕÅéĶĆā [Visualizer](visualization.md)ŃĆéµø┤ÕżÜķģŹńĮ«ÕÅ»õ╗źÕÅéĶĆā [VisualizationHook API](mmocr.engine.hooks.VisualizationHook)ŃĆé
+
+Õ”éµ×£µā│Ķ┐øõĖƵŁźõ║åĶ¦Żķ╗śĶ«ż hook ńÜäķģŹńĮ«õ╗źÕÅŖÕŖ¤ĶāĮ’╝īÕÅ»õ╗źÕÅéĶĆā {external+mmengine:doc}`MMEngine: ķÆ®ÕŁÉ(Hook) `ŃĆé
+
+
+
+### µŚźÕ┐ŚķģŹńĮ«
+
+µŁżķā©ÕłåõĖ╗Ķ”üńö©µØźķģŹńĮ«µŚźÕ┐ŚķģŹńĮ«ńŁēń║¦õ╗źÕÅŖµŚźÕ┐ŚÕżäńÉåÕÖ©ŃĆé
+
+```Python
+log_level = 'INFO' # µŚźÕ┐ŚĶ«░ÕĮĢńŁēń║¦
+log_processor = dict(type='LogProcessor',
+ window_size=10,
+ by_epoch=True)
+```
+
+- µŚźÕ┐ŚķģŹńĮ«ńŁēń║¦õĖÄ {external+python:doc}`Python: logging ` ńÜäķģŹńĮ«õĖĆĶć┤’╝ī
+
+- µŚźÕ┐ŚÕżäńÉåÕÖ©õĖ╗Ķ”üńö©µØźµÄ¦ÕłČĶŠōÕć║ńÜäµĀ╝Õ╝Å’╝īĶ»”ń╗åÕŖ¤ĶāĮÕÅ»ÕÅéĶĆā {external+mmengine:doc}`MMEngine: Ķ«░ÕĮĢµŚźÕ┐Ś `’╝Ü
+
+ - `by_epoch=True` ĶĪ©ńż║µīēńģ¦epochĶŠōÕć║µŚźÕ┐Ś’╝īµŚźÕ┐ŚµĀ╝Õ╝Åķ£ĆĶ”üÕÆī `train_cfg` õĖŁńÜä `type='EpochBasedTrainLoop'` ÕÅéµĢ░õ┐صīüõĖĆĶć┤ŃĆéõŠŗÕ”éµā│µīēĶ┐Łõ╗Żµ¼ĪµĢ░ĶŠōÕć║µŚźÕ┐Ś’╝īÕ░▒ķ£ĆĶ”üõ╗ż `log_processor` õĖŁńÜä ` by_epoch=False` ńÜäÕÉīµŚČ `train_cfg` õĖŁńÜä `type = 'IterBasedTrainLoop'`ŃĆé
+
+ - `window_size` ĶĪ©ńż║µŹ¤Õż▒ńÜäÕ╣│µ╗æń¬ŚÕÅŻ’╝īÕŹ│µ£ĆĶ┐æ `window_size` µ¼ĪĶ┐Łõ╗ŻńÜäÕÉäń¦ŹµŹ¤Õż▒ńÜäÕØćÕĆ╝ŃĆélogger õĖŁµ£Ćń╗łµēōÕŹ░ńÜä loss ÕĆ╝õĖ║ÕÉäń¦ŹµŹ¤Õż▒ńÜäÕ╣│ÕØćÕĆ╝ŃĆé
+
+
+
+### Ķ«Łń╗āńŁ¢ńĢźķģŹńĮ«
+
+µŁżķā©ÕłåõĖ╗Ķ”üÕīģÕɽõ╝śÕī¢ÕÖ©Ķ«ŠńĮ«ŃĆüÕŁ”õ╣ĀńÄćńŁ¢ńĢźÕÆī `Loop` Ķ«ŠńĮ«ŃĆé
+
+Õ»╣õĖŹÕÉīń«Śµ│Ģõ╗╗ÕŖĪ(µ¢ćÕŁŚµŻĆµĄŗ’╝īµ¢ćÕŁŚĶ»åÕł½’╝īÕģ│ķö«õ┐Īµü»µÅÉÕÅ¢)’╝īķĆÜÕĖĖµ£ēĶć¬ÕĘ▒õ╗╗ÕŖĪÕĖĖńö©ńÜäĶ░āÕÅéńŁ¢ńĢźŃĆéĶ┐ÖķćīÕłŚÕć║õ║åµ¢ćÕŁŚĶ»åÕł½õĖŁńÜä `CRNN` µēĆńö©µČēÕÅŖńÜäńøĖÕ║öķģŹńĮ«ŃĆé
+
+```Python
+# õ╝śÕī¢ÕÖ©
+optim_wrapper = dict(
+ type='OptimWrapper', optimizer=dict(type='Adadelta', lr=1.0))
+param_scheduler = [dict(type='ConstantLR', factor=1.0)]
+train_cfg = dict(type='EpochBasedTrainLoop',
+ max_epochs=5, # Ķ«Łń╗āĶĮ«µĢ░
+ val_interval=1) # Ķ»äµĄŗķŚ┤ķÜö
+val_cfg = dict(type='ValLoop')
+test_cfg = dict(type='TestLoop')
+```
+
+- `optim_wrapper` : õĖ╗Ķ”üÕīģÕɽõĖżõĖ¬ķā©Õłå’╝īõ╝śÕī¢ÕÖ©Õ░üĶŻģ (OptimWrapper) õ╗źÕÅŖõ╝śÕī¢ÕÖ© (Optimizer)ŃĆéĶ»”µāģõĮ┐ńö©õ┐Īµü»ÕÅ»Ķ¦ü {external+mmengine:doc}`MMEngine: õ╝śÕī¢ÕÖ©Õ░üĶŻģ `
+
+ - õ╝śÕī¢ÕÖ©Õ░üĶŻģµö»µīüõĖŹÕÉīńÜäĶ«Łń╗āńŁ¢ńĢź’╝īÕīģµŗ¼µĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗ā(AMP)ŃĆüµó»Õ║”ń┤»ÕŖĀÕÆīµó»Õ║”µł¬µ¢ŁŃĆé
+
+ - õ╝śÕī¢ÕÖ©Ķ«ŠńĮ«õĖŁµö»µīüõ║å PyTorch µēƵ£ēńÜäõ╝śÕī¢ÕÖ©’╝īµēƵ£ēµö»µīüńÜäõ╝śÕī¢ÕÖ©Ķ¦ü {external+torch:ref}`PyTorch õ╝śÕī¢ÕÖ©ÕłŚĶĪ© `ŃĆé
+
+- `param_scheduler` : ÕŁ”õ╣ĀńÄćĶ░āµĢ┤ńŁ¢ńĢź’╝īµö»µīüÕż¦ķā©Õłå PyTorch õĖŁńÜäÕŁ”õ╣ĀńÄćĶ░āÕ║”ÕÖ©’╝īõŠŗÕ”é `ExponentialLR`’╝ī`LinearLR`’╝ī`StepLR`’╝ī`MultiStepLR` ńŁē’╝īõĮ┐ńö©µ¢╣Õ╝Åõ╣¤Õ¤║µ£¼õĖĆĶć┤’╝īµēƵ£ēµö»µīüńÜäĶ░āÕ║”ÕÖ©Ķ¦ü[Ķ░āÕ║”ÕÖ©µÄźÕÅŻµ¢ćµĪŻ](mmengine.optim.scheduler), µø┤ÕżÜÕŖ¤ĶāĮÕÅ»õ╗źÕÅéĶĆā {external+mmengine:doc}`MMEngine: õ╝śÕī¢ÕÖ©ÕÅéµĢ░Ķ░āµĢ┤ńŁ¢ńĢź `ŃĆé
+
+- `train/test/val_cfg` : õ╗╗ÕŖĪńÜäµē¦ĶĪīµĄüń©ŗ’╝īMMEngine µÅÉõŠøõ║åÕøøń¦ŹµĄüń©ŗ’╝Ü`EpochBasedTrainLoop`, `IterBasedTrainLoop`, `ValLoop`, `TestLoop` µø┤ÕżÜÕÅ»õ╗źÕÅéĶĆā {external+mmengine:doc}`MMEngine: ÕŠ¬ńÄ»µÄ¦ÕłČÕÖ© `ŃĆé
+
+### µĢ░µŹ«ńøĖÕģ│ķģŹńĮ«
+
+
+ ’╝łõĖ║õ║åÕ»╣ńøĖÕÉīµ©ĪÕ×ŗĶ┐øĶĪīµĄŗĶ»ĢµēĆÕüÜńÜäÕģĘõĮōõ┐«µö╣ - ńé╣Õć╗Õ▒ĢÕ╝Ć’╝ē +
+ + ```diff + diff --git a/eval.py b/eval.py + index c0b2886..04921e9 100644 + --- a/eval.py + +++ b/eval.py + @@ -10,6 +10,7 @@ import os + import sys + import numpy as np + from datetime import datetime + +import time + import argparse + import importlib + import torch + @@ -28,7 +29,7 @@ parser.add_argument('--checkpoint_path', default=None, help='Model checkpoint pa + parser.add_argument('--dump_dir', default=None, help='Dump dir to save sample outputs [default: None]') + parser.add_argument('--num_point', type=int, default=20000, help='Point Number [default: 20000]') + parser.add_argument('--num_target', type=int, default=256, help='Point Number [default: 256]') + -parser.add_argument('--batch_size', type=int, default=8, help='Batch Size during training [default: 8]') + +parser.add_argument('--batch_size', type=int, default=1, help='Batch Size during training [default: 8]') + parser.add_argument('--vote_factor', type=int, default=1, help='Number of votes generated from each seed [default: 1]') + parser.add_argument('--cluster_sampling', default='vote_fps', help='Sampling strategy for vote clusters: vote_fps, seed_fps, random [default: vote_fps]') + parser.add_argument('--ap_iou_thresholds', default='0.25,0.5', help='A list of AP IoU thresholds [default: 0.25,0.5]') + @@ -132,6 +133,7 @@ CONFIG_DICT = {'remove_empty_box': (not FLAGS.faster_eval), 'use_3d_nms': FLAGS. + # ------------------------------------------------------------------------- GLOBAL CONFIG END + + def evaluate_one_epoch(): + + time_list = list() + stat_dict = {} + ap_calculator_list = [APCalculator(iou_thresh, DATASET_CONFIG.class2type) \ + for iou_thresh in AP_IOU_THRESHOLDS] + @@ -144,6 +146,8 @@ def evaluate_one_epoch(): + + # Forward pass + inputs = {'point_clouds': batch_data_label['point_clouds']} + + torch.cuda.synchronize() + + start_time = time.perf_counter() + with torch.no_grad(): + end_points = net(inputs) + + @@ -161,6 +165,12 @@ def evaluate_one_epoch(): + + batch_pred_map_cls = parse_predictions(end_points, CONFIG_DICT) + batch_gt_map_cls = parse_groundtruths(end_points, CONFIG_DICT) + + torch.cuda.synchronize() + + elapsed = time.perf_counter() - start_time + + time_list.append(elapsed) + + + + if len(time_list==200): + + print("average inference time: %4f"%(sum(time_list[5:])/len(time_list[5:]))) + for ap_calculator in ap_calculator_list: + ap_calculator.step(batch_pred_map_cls, batch_gt_map_cls) + + ``` + +### PointPillars-car + +- __MMDetection3D__’╝ÜÕ£© v0.1.0 ńēłµ£¼õĖŗ, µē¦ĶĪīÕ”éõĖŗÕæĮõ╗ż’╝Ü + + ```bash + ./tools/dist_train.sh configs/benchmark/hv_pointpillars_secfpn_3x8_100e_det3d_kitti-3d-car.py 8 --no-validate + ``` + +- __Det3D__’╝ÜÕ£© commit [519251e](https://github.com/poodarchu/Det3D/tree/519251e72a5c1fdd58972eabeac67808676b9bb7) ńēłµ£¼õĖŗ’╝īõĮ┐ńö© `kitti_point_pillars_mghead_syncbn.py` Õ╣ȵē¦ĶĪīÕ”éõĖŗÕæĮõ╗ż’╝Ü + + ```bash + ./tools/scripts/train.sh --launcher=slurm --gpus=8 + ``` + + µ│©µäÅ’╝īõĖ║õ║åĶ«Łń╗ā PointPillars’╝īµłæõ╗¼Õ»╣ `train.sh` Ķ┐øĶĪīõ║åõ┐«µö╣ŃĆé + +
+
+
+### PointPillars-3class
+
+- __MMDetection3D__’╝ÜÕ£© v0.1.0 ńēłµ£¼õĖŗ, µē¦ĶĪīÕ”éõĖŗÕæĮõ╗ż’╝Ü
+
+ ```bash
+ ./tools/dist_train.sh configs/benchmark/hv_pointpillars_secfpn_4x8_80e_pcdet_kitti-3d-3class.py 8 --no-validate
+ ```
+
+- __OpenPCDet__’╝ÜÕ£© commit [b32fbddb](https://github.com/open-mmlab/OpenPCDet/tree/b32fbddbe06183507bad433ed99b407cbc2175c2) ńēłµ£¼õĖŗ’╝īµē¦ĶĪīÕ”éõĖŗÕæĮõ╗ż’╝Ü
+
+ ```bash
+ cd tools
+ sh scripts/slurm_train.sh ${PARTITION} ${JOB_NAME} 8 --cfg_file ./cfgs/kitti_models/pointpillar.yaml --batch_size 32 --workers 32 --epochs 80
+ ```
+
+### SECOND
+
+Õ¤║ÕćåµĄŗĶ»ĢõĖŁńÜä SECOND µīćÕ£© [second.Pytorch](https://github.com/traveller59/second.pytorch) ķ”¢µ¼ĪĶó½Õ«×ńÄ░ńÜä [SECONDv1.5](https://github.com/traveller59/second.pytorch/blob/master/second/configs/all.fhd.config)ŃĆéDet3D Õ«×ńÄ░ńÜä SECOND õĖŁ’╝īõĮ┐ńö©õ║åĶć¬ÕĘ▒Õ«×ńÄ░ńÜä Multi-Group Head’╝īÕøĀµŁżµŚĀµ│ĢÕ░åÕ«āńÜäķƤÕ║”õĖÄÕģČõ╗¢õ╗ŻńĀüÕ║ōĶ┐øĶĪīÕ»╣µ»öŃĆé
+
+- __MMDetection3D__’╝ÜÕ£© v0.1.0 ńēłµ£¼õĖŗ, µē¦ĶĪīÕ”éõĖŗÕæĮõ╗ż’╝Ü
+
+ ```bash
+ ./tools/dist_train.sh configs/benchmark/hv_second_secfpn_4x8_80e_pcdet_kitti-3d-3class.py 8 --no-validate
+ ```
+
+- __OpenPCDet__’╝ÜÕ£© commit [b32fbddb](https://github.com/open-mmlab/OpenPCDet/tree/b32fbddbe06183507bad433ed99b407cbc2175c2) ńēłµ£¼õĖŗ’╝īµē¦ĶĪīÕ”éõĖŗÕæĮõ╗ż’╝Ü
+
+ ```bash
+ cd tools
+ sh ./scripts/slurm_train.sh ${PARTITION} ${JOB_NAME} 8 --cfg_file ./cfgs/kitti_models/second.yaml --batch_size 32 --workers 32 --epochs 80
+ ```
+
+### Part-A2
+
+- __MMDetection3D__’╝ÜÕ£© v0.1.0 ńēłµ£¼õĖŗ, µē¦ĶĪīÕ”éõĖŗÕæĮõ╗ż’╝Ü
+
+ ```bash
+ ./tools/dist_train.sh configs/benchmark/hv_PartA2_secfpn_4x8_cyclic_80e_pcdet_kitti-3d-3class.py 8 --no-validate
+ ```
+
+- __OpenPCDet__’╝ÜÕ£© commit [b32fbddb](https://github.com/open-mmlab/OpenPCDet/tree/b32fbddbe06183507bad433ed99b407cbc2175c2) ńēłµ£¼õĖŗ’╝īµē¦ĶĪīÕ”éõĖŗÕæĮõ╗żõ╗źĶ┐øĶĪīµ©ĪÕ×ŗĶ«Łń╗ā’╝Ü
+
+ ```bash
+ cd tools
+ sh ./scripts/slurm_train.sh ${PARTITION} ${JOB_NAME} 8 --cfg_file ./cfgs/kitti_models/PartA2.yaml --batch_size 32 --workers 32 --epochs 80
+ ```
diff --git a/internlm_langchain/knowledge_base/MMDetection3D/content/changelog.md b/internlm_langchain/knowledge_base/MMDetection3D/content/changelog.md
new file mode 100644
index 00000000..258cba0c
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection3D/content/changelog.md
@@ -0,0 +1 @@
+# v1.1 ÕÅśµø┤µŚźÕ┐Ś
diff --git a/internlm_langchain/knowledge_base/MMDetection3D/content/changelog_v1.0.x.md b/internlm_langchain/knowledge_base/MMDetection3D/content/changelog_v1.0.x.md
new file mode 100644
index 00000000..d7916ef6
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection3D/content/changelog_v1.0.x.md
@@ -0,0 +1 @@
+# v1.0.x ÕÅśµø┤µŚźÕ┐Ś
diff --git a/internlm_langchain/knowledge_base/MMDetection3D/content/compatibility.md b/internlm_langchain/knowledge_base/MMDetection3D/content/compatibility.md
new file mode 100644
index 00000000..97144d13
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection3D/content/compatibility.md
@@ -0,0 +1 @@
+# Õģ╝Õ«╣µĆ¦
diff --git a/internlm_langchain/knowledge_base/MMDetection3D/content/config.md b/internlm_langchain/knowledge_base/MMDetection3D/content/config.md
new file mode 100644
index 00000000..f971a108
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection3D/content/config.md
@@ -0,0 +1,558 @@
+# ÕŁ”õ╣ĀķģŹńĮ«µ¢ćõ╗Č
+
+MMDetection3D ÕÆīÕģČõ╗¢ OpenMMLab õ╗ōÕ║ōõĮ┐ńö© [MMEngine ńÜäķģŹńĮ«µ¢ćõ╗Čń│╗ń╗¤](https://mmengine.readthedocs.io/zh_CN/latest/advanced_tutorials/config.html)ŃĆéÕ«āÕģʵ£ēµ©ĪÕØŚÕī¢ÕÆīń╗¦µē┐µĆ¦Ķ«ŠĶ«Ī’╝īõ╗źõŠ┐õ║ÄĶ┐øĶĪīÕÉäń¦ŹÕ«×ķ¬īŃĆé
+
+## ķģŹńĮ«µ¢ćõ╗ČńÜäÕåģÕ«╣
+
+MMDetection3D ķććńö©µ©ĪÕØŚÕī¢Ķ«ŠĶ«Ī’╝īµēƵ£ēÕŖ¤ĶāĮńÜ䵩ĪÕØŚÕÅ»õ╗źķĆÜĶ┐ćķģŹńĮ«µ¢ćõ╗ČĶ┐øĶĪīķģŹńĮ«ŃĆéõ╗ź PointPillars õĖ║õŠŗ’╝īµłæõ╗¼Õ░åµĀ╣µŹ«õĖŹÕÉīńÜäÕŖ¤ĶāĮµ©ĪÕØŚõ╗ŗń╗ŹķģŹńĮ«µ¢ćõ╗ČńÜäÕÉäõĖ¬ÕŁŚµ«ĄŃĆé
+
+### µ©ĪÕ×ŗķģŹńĮ«
+
+Õ£© MMDetection3D ńÜäķģŹńĮ«õĖŁ’╝īµłæõ╗¼õĮ┐ńö© `model` ÕŁŚµ«ĄµØźķģŹńĮ«µŻĆµĄŗń«Śµ│ĢńÜäń╗äõ╗ČŃĆéķÖżõ║å `voxel_encoder`’╝ī`backbone` ńŁēńź×ń╗ÅńĮæń╗£ń╗äõ╗ČÕż¢’╝īĶ┐śķ£ĆĶ”ü `data_preprocessor`’╝ī`train_cfg` ÕÆī `test_cfg`ŃĆé`data_preprocessor` Ķ┤¤Ķ┤ŻÕ»╣µĢ░µŹ«ÕŖĀĶĮĮÕÖ©’╝łdataloader’╝ēĶŠōÕć║ńÜäµ»ÅõĖƵē╣µĢ░µŹ«Ķ┐øĶĪīķóäÕżäńÉåŃĆ鵩ĪÕ×ŗķģŹńĮ«õĖŁńÜä `train_cfg` ÕÆī `test_cfg` ńö©õ║ÄĶ«ŠńĮ«Ķ«Łń╗āÕÆīµĄŗĶ»Ģń╗äõ╗ČńÜäĶČģÕÅéµĢ░ŃĆé
+
+```python
+model = dict(
+ type='VoxelNet',
+ data_preprocessor=dict(
+ type='Det3DDataPreprocessor',
+ voxel=True,
+ voxel_layer=dict(
+ max_num_points=32,
+ point_cloud_range=[0, -39.68, -3, 69.12, 39.68, 1],
+ voxel_size=[0.16, 0.16, 4],
+ max_voxels=(16000, 40000))),
+ voxel_encoder=dict(
+ type='PillarFeatureNet',
+ in_channels=4,
+ feat_channels=[64],
+ with_distance=False,
+ voxel_size=[0.16, 0.16, 4],
+ point_cloud_range=[0, -39.68, -3, 69.12, 39.68, 1]),
+ middle_encoder=dict(
+ type='PointPillarsScatter', in_channels=64, output_shape=[496, 432]),
+ backbone=dict(
+ type='SECOND',
+ in_channels=64,
+ layer_nums=[3, 5, 5],
+ layer_strides=[2, 2, 2],
+ out_channels=[64, 128, 256]),
+ neck=dict(
+ type='SECONDFPN',
+ in_channels=[64, 128, 256],
+ upsample_strides=[1, 2, 4],
+ out_channels=[128, 128, 128]),
+ bbox_head=dict(
+ type='Anchor3DHead',
+ num_classes=3,
+ in_channels=384,
+ feat_channels=384,
+ use_direction_classifier=True,
+ assign_per_class=True,
+ anchor_generator=dict(
+ type='AlignedAnchor3DRangeGenerator',
+ ranges=[[0, -39.68, -0.6, 69.12, 39.68, -0.6],
+ [0, -39.68, -0.6, 69.12, 39.68, -0.6],
+ [0, -39.68, -1.78, 69.12, 39.68, -1.78]],
+ sizes=[[0.8, 0.6, 1.73], [1.76, 0.6, 1.73], [3.9, 1.6, 1.56]],
+ rotations=[0, 1.57],
+ reshape_out=False),
+ diff_rad_by_sin=True,
+ bbox_coder=dict(type='DeltaXYZWLHRBBoxCoder'),
+ loss_cls=dict(
+ type='mmdet.FocalLoss',
+ use_sigmoid=True,
+ gamma=2.0,
+ alpha=0.25,
+ loss_weight=1.0),
+ loss_bbox=dict(
+ type='mmdet.SmoothL1Loss',
+ beta=0.1111111111111111,
+ loss_weight=2.0),
+ loss_dir=dict(
+ type='mmdet.CrossEntropyLoss', use_sigmoid=False,
+ loss_weight=0.2)),
+ train_cfg=dict(
+ assigner=[
+ dict(
+ type='Max3DIoUAssigner',
+ iou_calculator=dict(type='BboxOverlapsNearest3D'),
+ pos_iou_thr=0.5,
+ neg_iou_thr=0.35,
+ min_pos_iou=0.35,
+ ignore_iof_thr=-1),
+ dict(
+ type='Max3DIoUAssigner',
+ iou_calculator=dict(type='BboxOverlapsNearest3D'),
+ pos_iou_thr=0.5,
+ neg_iou_thr=0.35,
+ min_pos_iou=0.35,
+ ignore_iof_thr=-1),
+ dict(
+ type='Max3DIoUAssigner',
+ iou_calculator=dict(type='BboxOverlapsNearest3D'),
+ pos_iou_thr=0.6,
+ neg_iou_thr=0.45,
+ min_pos_iou=0.45,
+ ignore_iof_thr=-1)
+ ],
+ allowed_border=0,
+ pos_weight=-1,
+ debug=False),
+ test_cfg=dict(
+ use_rotate_nms=True,
+ nms_across_levels=False,
+ nms_thr=0.01,
+ score_thr=0.1,
+ min_bbox_size=0,
+ nms_pre=100,
+ max_num=50))
+```
+
+### µĢ░µŹ«ķøåÕÆīĶ»äµĄŗÕÖ©ķģŹńĮ«
+
+Õ£©õĮ┐ńö©[µē¦ĶĪīÕÖ©’╝łRunner’╝ē](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/runner.html)Ķ┐øĶĪīĶ«Łń╗āŃĆüµĄŗĶ»ĢÕÆīķ¬īĶ»üµŚČ’╝īµłæõ╗¼ķ£ĆĶ”üķģŹńĮ«[µĢ░µŹ«ÕŖĀĶĮĮÕÖ©](https://pytorch.org/docs/stable/data.html?highlight=data%20loader#torch.utils.data.DataLoader)ŃĆéµ×äÕ╗║µĢ░µŹ«ÕŖĀĶĮĮÕÖ©ķ£ĆĶ”üĶ«ŠńĮ«µĢ░µŹ«ķøåÕÆīµĢ░µŹ«ÕżäńÉåµĄüń©ŗŃĆéńö▒õ║ÄĶ┐Öķā©ÕłåńÜäķģŹńĮ«ĶŠāõĖ║ÕżŹµØé’╝īµłæõ╗¼õĮ┐ńö©õĖŁķŚ┤ÕÅśķćÅµØźń«ĆÕī¢µĢ░µŹ«ÕŖĀĶĮĮÕÖ©ķģŹńĮ«ńÜäń╝¢ÕåÖŃĆé
+
+```python
+dataset_type = 'KittiDataset'
+data_root = 'data/kitti/'
+class_names = ['Pedestrian', 'Cyclist', 'Car']
+point_cloud_range = [0, -39.68, -3, 69.12, 39.68, 1]
+input_modality = dict(use_lidar=True, use_camera=False)
+metainfo = dict(classes=class_names)
+
+db_sampler = dict(
+ data_root=data_root,
+ info_path=data_root + 'kitti_dbinfos_train.pkl',
+ rate=1.0,
+ prepare=dict(
+ filter_by_difficulty=[-1],
+ filter_by_min_points=dict(Car=5, Pedestrian=5, Cyclist=5)),
+ classes=class_names,
+ sample_groups=dict(Car=15, Pedestrian=15, Cyclist=15),
+ points_loader=dict(
+ type='LoadPointsFromFile', coord_type='LIDAR', load_dim=4, use_dim=4))
+
+train_pipeline = [
+ dict(type='LoadPointsFromFile', coord_type='LIDAR', load_dim=4, use_dim=4),
+ dict(type='LoadAnnotations3D', with_bbox_3d=True, with_label_3d=True),
+ dict(type='ObjectSample', db_sampler=db_sampler, use_ground_plane=True),
+ dict(type='RandomFlip3D', flip_ratio_bev_horizontal=0.5),
+ dict(
+ type='GlobalRotScaleTrans',
+ rot_range=[-0.78539816, 0.78539816],
+ scale_ratio_range=[0.95, 1.05]),
+ dict(type='PointsRangeFilter', point_cloud_range=point_cloud_range),
+ dict(type='ObjectRangeFilter', point_cloud_range=point_cloud_range),
+ dict(type='PointShuffle'),
+ dict(
+ type='Pack3DDetInputs',
+ keys=['points', 'gt_labels_3d', 'gt_bboxes_3d'])
+]
+test_pipeline = [
+ dict(type='LoadPointsFromFile', coord_type='LIDAR', load_dim=4, use_dim=4),
+ dict(
+ type='MultiScaleFlipAug3D',
+ img_scale=(1333, 800),
+ pts_scale_ratio=1,
+ flip=False,
+ transforms=[
+ dict(
+ type='GlobalRotScaleTrans',
+ rot_range=[0, 0],
+ scale_ratio_range=[1., 1.],
+ translation_std=[0, 0, 0]),
+ dict(type='RandomFlip3D'),
+ dict(
+ type='PointsRangeFilter', point_cloud_range=point_cloud_range)
+ ]),
+ dict(type='Pack3DDetInputs', keys=['points'])
+]
+eval_pipeline = [
+ dict(type='LoadPointsFromFile', coord_type='LIDAR', load_dim=4, use_dim=4),
+ dict(type='Pack3DDetInputs', keys=['points'])
+]
+train_dataloader = dict(
+ batch_size=6,
+ num_workers=4,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type='RepeatDataset',
+ times=2,
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ ann_file='kitti_infos_train.pkl',
+ data_prefix=dict(pts='training/velodyne_reduced'),
+ pipeline=train_pipeline,
+ modality=input_modality,
+ test_mode=False,
+ metainfo=metainfo,
+ box_type_3d='LiDAR')))
+val_dataloader = dict(
+ batch_size=1,
+ num_workers=1,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_prefix=dict(pts='training/velodyne_reduced'),
+ ann_file='kitti_infos_val.pkl',
+ pipeline=test_pipeline,
+ modality=input_modality,
+ test_mode=True,
+ metainfo=metainfo,
+ box_type_3d='LiDAR'))
+test_dataloader = dict(
+ batch_size=1,
+ num_workers=1,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_prefix=dict(pts='training/velodyne_reduced'),
+ ann_file='kitti_infos_val.pkl',
+ pipeline=test_pipeline,
+ modality=input_modality,
+ test_mode=True,
+ metainfo=metainfo,
+ box_type_3d='LiDAR'))
+```
+
+[Ķ»äµĄŗÕÖ©](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/evaluation.html)ńö©õ║ÄĶ«Īń«ŚĶ«Łń╗āµ©ĪÕ×ŗÕ£©ķ¬īĶ»üÕÆīµĄŗĶ»ĢµĢ░µŹ«ķøåõĖŖńÜäµīćµĀćŃĆéĶ»äµĄŗÕÖ©ńÜäķģŹńĮ«ńö▒õĖĆõĖ¬µł¢õĖĆń╗äĶ»äõ╗ʵīćµĀćķģŹńĮ«ń╗䵳ɒ╝Ü
+
+```python
+val_evaluator = dict(
+ type='KittiMetric',
+ ann_file=data_root + 'kitti_infos_val.pkl',
+ metric='bbox')
+test_evaluator = val_evaluator
+```
+
+ńö▒õ║ĵĄŗĶ»ĢµĢ░µŹ«ķøåµ▓Īµ£ēµĀćµ│©µ¢ćõ╗Č’╝īÕøĀµŁż MMDetection3D õĖŁńÜä test_dataloader ÕÆī test_evaluator ķģŹńĮ«ķĆÜÕĖĖńŁēõ║Ä valŃĆéÕ”éµ×£µé©µā│Ķ”üõ┐ØÕŁśÕ£©µĄŗĶ»ĢµĢ░µŹ«ķøåõĖŖńÜ䵯ƵĄŗń╗ōµ×£’╝īÕłÖÕÅ»õ╗źÕāÅĶ┐ÖµĀĘń╝¢ÕåÖķģŹńĮ«’╝Ü
+
+```python
+# Õ£©µĄŗĶ»ĢķøåõĖŖµÄ©ńÉå’╝ī
+# Õ╣ČÕ░åµŻĆµĄŗń╗ōµ×£ĶĮ¼µŹóµĀ╝Õ╝Åõ╗źńö©õ║ĵÅÉõ║żń╗ōµ×£
+test_dataloader = dict(
+ batch_size=1,
+ num_workers=1,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_prefix=dict(pts='testing/velodyne_reduced'),
+ ann_file='kitti_infos_test.pkl',
+ load_eval_anns=False,
+ pipeline=test_pipeline,
+ modality=input_modality,
+ test_mode=True,
+ metainfo=metainfo,
+ box_type_3d='LiDAR'))
+test_evaluator = dict(
+ type='KittiMetric',
+ ann_file=data_root + 'kitti_infos_test.pkl',
+ metric='bbox',
+ format_only=True,
+ submission_prefix='results/kitti-3class/kitti_results')
+```
+
+### Ķ«Łń╗āÕÆīµĄŗĶ»ĢķģŹńĮ«
+
+MMEngine ńÜäµē¦ĶĪīÕÖ©õĮ┐ńö©ÕŠ¬ńÄ»’╝łLoop’╝ēµØźµÄ¦ÕłČĶ«Łń╗ā’╝īķ¬īĶ»üÕÆīµĄŗĶ»ĢĶ┐ćń©ŗŃĆéńö©µłĘÕÅ»õ╗źõĮ┐ńö©Ķ┐Öõ║øÕŁŚµ«ĄĶ«ŠńĮ«µ£ĆÕż¦Ķ«Łń╗āĶĮ«µ¼ĪÕÆīķ¬īĶ»üķŚ┤ķÜö’╝Ü
+
+```python
+train_cfg = dict(
+ type='EpochBasedTrainLoop',
+ max_epochs=80,
+ val_interval=2)
+val_cfg = dict(type='ValLoop')
+test_cfg = dict(type='TestLoop')
+```
+
+### õ╝śÕī¢ķģŹńĮ«
+
+`optim_wrapper` µś»ķģŹńĮ«õ╝śÕī¢ńøĖÕģ│Ķ«ŠńĮ«ńÜäÕŁŚµ«ĄŃĆéõ╝śÕī¢ÕÖ©Õ░üĶŻģõĖŹõ╗ģµÅÉõŠøõ║åõ╝śÕī¢ÕÖ©ńÜäÕŖ¤ĶāĮ’╝īĶ┐śµö»µīüµó»Õ║”ĶŻüÕē¬ŃĆüµĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗āńŁēÕŖ¤ĶāĮŃĆéµø┤ÕżÜÕåģÕ«╣Ķ»Ęń£ŗ[õ╝śÕī¢ÕÖ©Õ░üĶŻģµĢÖń©ŗ](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/optim_wrapper.html)ŃĆé
+
+```python
+optim_wrapper = dict( # õ╝śÕī¢ÕÖ©Õ░üĶŻģķģŹńĮ«
+ type='OptimWrapper', # õ╝śÕī¢ÕÖ©Õ░üĶŻģń▒╗Õ×ŗ’╝īÕłćµŹóÕł░ AmpOptimWrapper ÕÉ»ÕŖ©µĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗ā
+ optimizer=dict( # õ╝śÕī¢ÕÖ©ķģŹńĮ«ŃĆéµö»µīü PyTorch ńÜäÕÉäń¦Źõ╝śÕī¢ÕÖ©’╝īĶ»ĘÕÅéĶĆā https://pytorch.org/docs/stable/optim.html#algorithms
+ type='AdamW', lr=0.001, betas=(0.95, 0.99), weight_decay=0.01),
+ clip_grad=dict(max_norm=35, norm_type=2)) # µó»Õ║”ĶŻüÕē¬ķĆēķĪ╣ŃĆéĶ«ŠńĮ«õĖ║ None ń”üńö©µó»Õ║”ĶŻüÕē¬ŃĆéõĮ┐ńö©µ¢╣µ│ĢĶ»ĘĶ¦ü https://mmengine.readthedocs.io/zh_CN/latest/tutorials/optim_wrapper.html
+```
+
+`param_scheduler` µś»ķģŹńĮ«Ķ░āµĢ┤õ╝śÕī¢ÕÖ©ĶČģÕÅéµĢ░’╝łõŠŗÕ”éÕŁ”õ╣ĀńÄćÕÆīÕŖ©ķćÅ’╝ēńÜäÕŁŚµ«ĄŃĆéńö©µłĘÕÅ»õ╗źń╗äÕÉłÕżÜõĖ¬Ķ░āÕ║”ÕÖ©µØźÕłøÕ╗║µēĆķ£ĆĶ”üńÜäÕÅéµĢ░Ķ░āµĢ┤ńŁ¢ńĢźŃĆéµø┤ÕżÜõ┐Īµü»Ķ»ĘÕÅéĶĆā[ÕÅéµĢ░Ķ░āÕ║”ÕÖ©µĢÖń©ŗ](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/param_scheduler.html)ÕÆī[ÕÅéµĢ░Ķ░āÕ║”ÕÖ© API µ¢ćµĪŻ](https://mmengine.readthedocs.io/zh_CN/latest/api/optim.html#scheduler)ŃĆé
+
+```python
+param_scheduler = [
+ dict(
+ type='CosineAnnealingLR',
+ T_max=32,
+ eta_min=0.01,
+ begin=0,
+ end=32,
+ by_epoch=True,
+ convert_to_iter_based=True),
+ dict(
+ type='CosineAnnealingLR',
+ T_max=48,
+ eta_min=1.0000000000000001e-07,
+ begin=32,
+ end=80,
+ by_epoch=True,
+ convert_to_iter_based=True),
+ dict(
+ type='CosineAnnealingMomentum',
+ T_max=32,
+ eta_min=0.8947368421052632,
+ begin=0,
+ end=32,
+ by_epoch=True,
+ convert_to_iter_based=True),
+ dict(
+ type='CosineAnnealingMomentum',
+ T_max=48,
+ eta_min=1,
+ begin=32,
+ end=80,
+ by_epoch=True,
+ convert_to_iter_based=True),
+]
+```
+
+### ķÆ®ÕŁÉķģŹńĮ«
+
+ńö©µłĘÕÅ»õ╗źÕ£©Ķ«Łń╗āŃĆüķ¬īĶ»üÕÆīµĄŗĶ»ĢÕŠ¬ńÄ»õĖŖµĘ╗ÕŖĀķÆ®ÕŁÉ’╝īõ╗ÄĶĆīÕ£©Ķ┐ÉĶĪīµ£¤ķŚ┤µÅÆÕģźõĖĆõ║øµōŹõĮ£ŃĆéµ£ēõĖżń¦ŹõĖŹÕÉīńÜäķÆ®ÕŁÉÕŁŚµ«Ą’╝īõĖĆń¦Źµś» `default_hooks`’╝īÕÅ”õĖĆń¦Źµś» `custom_hooks`ŃĆé
+
+`default_hooks` µś»õĖĆõĖ¬ķÆ®ÕŁÉķģŹńĮ«ÕŁŚÕģĖ’╝īÕ╣ČõĖöĶ┐Öõ║øķÆ®ÕŁÉµś»Ķ┐ÉĶĪīµŚČµēĆķ£ĆĶ”üńÜäŃĆéÕ«āõ╗¼Õģʵ£ēķ╗śĶ«żõ╝śÕģłń║¦’╝īµś»õĖŹķ£ĆĶ”üõ┐«µö╣ńÜäŃĆéÕ”éµ×£µ£¬Ķ«ŠńĮ«’╝īµē¦ĶĪīÕÖ©Õ░åõĮ┐ńö©ķ╗śĶ«żÕĆ╝ŃĆéÕ”éµ×£Ķ”üń”üńö©ķ╗śĶ«żķÆ®ÕŁÉ’╝īńö©µłĘÕÅ»õ╗źÕ░åÕģČķģŹńĮ«Ķ«ŠńĮ«õĖ║ `None`ŃĆé
+
+```python
+default_hooks = dict(
+ timer=dict(type='IterTimerHook'),
+ logger=dict(type='LoggerHook', interval=50),
+ param_scheduler=dict(type='ParamSchedulerHook'),
+ checkpoint=dict(type='CheckpointHook', interval=-1),
+ sampler_seed=dict(type='DistSamplerSeedHook'),
+ visualization=dict(type='Det3DVisualizationHook'))
+```
+
+`custom_hooks` µś»õĖĆõĖ¬ńö▒ÕģČõ╗¢ķÆ®ÕŁÉķģŹńĮ«ń╗䵳ÉńÜäÕłŚĶĪ©ŃĆéńö©µłĘÕÅ»õ╗źÕ╝ĆÕÅæĶć¬ÕĘ▒ńÜäķÆ®ÕŁÉÕ╣ČÕ░åÕģȵÅÆÕģźÕł░Ķ»źÕŁŚµ«ĄõĖŁŃĆé
+
+```python
+custom_hooks = []
+```
+
+### Ķ┐ÉĶĪīķģŹńĮ«
+
+```python
+default_scope = 'mmdet3d' # Õ»╗µēŠµ©ĪÕØŚńÜäķ╗śĶ«żµ│©ÕåīÕÖ©Õ¤¤ŃĆéĶ»ĘÕÅéĶĆā https://mmengine.readthedocs.io/zh_CN/latest/advanced_tutorials/registry.html
+
+env_cfg = dict(
+ cudnn_benchmark=False, # µś»ÕÉ”ÕÉ»ńö© cudnn benchmark
+ mp_cfg=dict( # ÕżÜĶ┐øń©ŗķģŹńĮ«
+ mp_start_method='fork', # õĮ┐ńö© fork µØźÕÉ»ÕŖ©ÕżÜĶ┐øń©ŗŃĆé'fork' ķĆÜÕĖĖµ»ö 'spawn' µø┤Õ┐½’╝īõĮåÕÅ»ĶāĮõĖŹÕ«ēÕģ©ŃĆéĶ»ĘÕÅéĶĆā https://github.com/pytorch/pytorch/issues/1355
+ opencv_num_threads=0), # Õģ│ķŚŁ opencv ńÜäÕżÜĶ┐øń©ŗõ╗źķü┐ÕģŹń│╗ń╗¤ĶČģĶ┤¤ĶŹĘ
+ dist_cfg=dict(backend='nccl')) # ÕłåÕĖāÕ╝ÅķģŹńĮ«
+
+vis_backends = [dict(type='LocalVisBackend')] # ÕÅ»Ķ¦åÕī¢ÕÉÄń½»ŃĆéĶ»ĘÕÅéĶĆā https://mmengine.readthedocs.io/zh_CN/latest/advanced_tutorials/visualization.html
+visualizer = dict(
+ type='Det3DLocalVisualizer', vis_backends=vis_backends, name='visualizer')
+
+log_processor = dict(
+ type='LogProcessor', # µŚźÕ┐ŚÕżäńÉåÕÖ©ńö©õ║ÄÕżäńÉåĶ┐ÉĶĪīµŚČµŚźÕ┐Ś
+ window_size=50, # µŚźÕ┐ŚµĢ░ÕĆ╝ńÜäÕ╣│µ╗æń¬ŚÕÅŻ
+ by_epoch=True) # µś»ÕÉ”õĮ┐ńö© epoch µĀ╝Õ╝ÅńÜ䵌źÕ┐ŚŃĆéķ£ĆĶ”üõĖÄĶ«Łń╗āÕŠ¬ńÄ»ńÜäń▒╗Õ×ŗõ┐صīüõĖĆĶć┤
+
+log_level = 'INFO' # µŚźÕ┐ŚńŁēń║¦
+load_from = None # õ╗Äń╗ÖÕ«ÜĶĘ»ÕŠäÕŖĀĶĮĮµ©ĪÕ×ŗµŻĆµ¤źńé╣õĮ£õĖ║ķóäĶ«Łń╗āµ©ĪÕ×ŗŃĆéĶ┐ÖõĖŹõ╝ܵüóÕżŹĶ«Łń╗āŃĆé
+resume = False # µś»ÕÉ”õ╗Ä `load_from` õĖŁÕ«Üõ╣ēńÜ䵯Ƶ¤źńé╣µüóÕżŹŃĆéÕ”éµ×£ `load_from` õĖ║ None’╝īÕ«āÕ░åµüóÕżŹ `work_dir` õĖŁńÜäµ£ĆĶ┐æµŻĆµ¤źńé╣ŃĆé
+```
+
+## ķģŹńĮ«µ¢ćõ╗Čń╗¦µē┐
+
+Õ£© `configs/_base_` µ¢ćõ╗ČÕż╣õĖŗµ£ē 4 õĖ¬Õ¤║µ£¼ń╗äõ╗Čń▒╗Õ×ŗ’╝īÕłåÕł½µś»’╝ܵĢ░µŹ«ķøå’╝łdataset’╝ē’╝īµ©ĪÕ×ŗ’╝łmodel’╝ē’╝īĶ«Łń╗āńŁ¢ńĢź’╝łschedule’╝ēÕÆīĶ┐ÉĶĪīµŚČńÜäķ╗śĶ«żĶ«ŠńĮ«’╝łdefault runtime’╝ēŃĆéĶ«ĖÕżÜµ¢╣µ│Ģ’╝īÕ”é SECONDŃĆüPointPillarsŃĆüPartA2ŃĆüVoteNet ķāĮĶāĮÕż¤ÕŠłÕ«╣µśōÕ£░µ×äÕ╗║Õć║µØźŃĆéńö▒ `_base_` õĖŗńÜäń╗äõ╗Čń╗䵳ÉńÜäķģŹńĮ«’╝īĶó½µłæõ╗¼ń¦░õĖ║ _ÕĤզŗķģŹńĮ«’╝łprimitive’╝ē_ŃĆé
+
+Õ»╣õ║ÄÕÉīõĖĆõĖ¬µ¢ćõ╗ČÕż╣õĖŗńÜäµēƵ£ēķģŹńĮ«’╝īµÄ©ĶŹÉ**ÕŬµ£ēõĖĆõĖ¬**Õ»╣Õ║öńÜä _ÕĤզŗķģŹńĮ«_ µ¢ćõ╗ČŃĆéµēƵ£ēÕģČõ╗¢ńÜäķģŹńĮ«µ¢ćõ╗ČķāĮÕ║öĶ»źń╗¦µē┐Ķć¬Ķ┐ÖõĖ¬ _ÕĤզŗķģŹńĮ«_ µ¢ćõ╗ČŃĆéĶ┐ÖµĀĘÕ░▒ĶāĮõ┐ØĶ»üķģŹńĮ«µ¢ćõ╗ČńÜäµ£ĆÕż¦ń╗¦µē┐µĘ▒Õ║”õĖ║ 3ŃĆé
+
+õĖ║õ║åõŠ┐õ║ÄńÉåĶ¦Ż’╝īµłæõ╗¼Õ╗║Ķ««Ķ┤Īńī«ĶĆģń╗¦µē┐ńÄ░µ£ēµ¢╣µ│ĢŃĆéõŠŗÕ”é’╝īÕ”éµ×£Õ£© PointPillars ńÜäÕ¤║ńĪĆõĖŖÕüÜõ║åõĖĆõ║øõ┐«µö╣’╝īńö©µłĘÕÅ»õ╗źķ”¢ÕģłķĆÜĶ┐ćµīćÕ«Ü `_base_ = '../pointpillars/pointpillars_hv_fpn_sbn-all_8xb4-2x_nus-3d.py'` µØźń╗¦µē┐Õ¤║ńĪĆńÜä PointPillars ń╗ōµ×ä’╝īńäČÕÉÄõ┐«µö╣ķģŹńĮ«µ¢ćõ╗ČõĖŁńÜäÕ┐ģĶ”üÕÅéµĢ░õ╗źÕ«īµłÉń╗¦µē┐ŃĆé
+
+Õ”éµ×£µé©Õ£©µ×äÕ╗║õĖĆõĖ¬õĖÄõ╗╗õĮĢńÄ░µ£ēµ¢╣µ│ĢķāĮõĖŹÕģ▒õ║½ńÜäÕģ©µ¢░µ¢╣µ│Ģ’╝īķéŻõ╣łÕÅ»õ╗źÕ£© `configs` µ¢ćõ╗ČÕż╣õĖŗÕłøÕ╗║õĖĆõĖ¬µ¢░ńÜäõŠŗÕ”é `xxx_rcnn` µ¢ćõ╗ČÕż╣ŃĆé
+
+µø┤ÕżÜń╗åĶŖéĶ»ĘÕÅéĶĆā [MMEngine ķģŹńĮ«µ¢ćõ╗ȵĢÖń©ŗ](https://mmengine.readthedocs.io/zh_CN/latest/advanced_tutorials/config.html)ŃĆé
+
+ķĆÜĶ┐ćĶ«ŠńĮ« `_base_` ÕŁŚµ«Ą’╝īµłæõ╗¼ÕÅ»õ╗źĶ«ŠńĮ«ÕĮōÕēŹķģŹńĮ«µ¢ćõ╗Čń╗¦µē┐Ķć¬Õō¬õ║øµ¢ćõ╗ČŃĆé
+
+ÕĮō `_base_` õĖ║µ¢ćõ╗ČĶĘ»ÕŠäÕŁŚń¼”õĖ▓µŚČ’╝īĶĪ©ńż║ń╗¦µē┐õĖĆõĖ¬ķģŹńĮ«µ¢ćõ╗ČńÜäÕåģÕ«╣ŃĆé
+
+```python
+_base_ = './pointpillars_hv_secfpn_8xb6-160e_kitti-3d-3class.py'
+```
+
+ÕĮō `_base_` µś»ÕżÜõĖ¬µ¢ćõ╗ČĶĘ»ÕŠäń╗䵳ÉńÜäÕłŚĶĪ©Õ╝Å’╝īĶĪ©ńż║ń╗¦µē┐ÕżÜõĖ¬µ¢ćõ╗ČŃĆé
+
+```python
+_base_ = [
+ '../_base_/models/pointpillars_hv_secfpn_kitti.py',
+ '../_base_/datasets/kitti-3d-3class.py',
+ '../_base_/schedules/cyclic-40e.py', '../_base_/default_runtime.py'
+]
+```
+
+Õ”éµ×£ķ£ĆĶ”üµŻĆµĄŗķģŹńĮ«µ¢ćõ╗Č’╝īÕÅ»õ╗źķĆÜĶ┐ćĶ┐ÉĶĪī `python tools/misc/print_config.py /PATH/TO/CONFIG` µØźµ¤źń£ŗÕ«īµĢ┤ńÜäķģŹńĮ«ŃĆé
+
+### Õ┐ĮńĢźÕ¤║ńĪĆķģŹńĮ«µ¢ćõ╗ČķćīńÜäķā©ÕłåÕŁŚµ«Ą
+
+µ£ēµŚČ’╝īµé©õ╣¤Ķ«Ėõ╝ÜĶ«ŠńĮ« `_delete_=True` ÕÄ╗Õ┐ĮńĢźÕ¤║ńĪĆķģŹńĮ«µ¢ćõ╗ČķćīńÜäõĖĆõ║øÕŁŚµ«ĄŃĆéµé©ÕÅ»õ╗źÕÅéĶĆā [MMEngine ķģŹńĮ«µ¢ćõ╗ȵĢÖń©ŗ](https://mmengine.readthedocs.io/zh_CN/latest/advanced_tutorials/config.html) µØźĶÄĘÕŠŚõĖĆõ║øń«ĆÕŹĢńÜäµīćÕ»╝ŃĆé
+
+Õ£© MMDetection3D ķćī’╝īõŠŗÕ”é’╝īõ┐«µö╣õ╗źõĖŗ PointPillars ķģŹńĮ«õĖŁńÜäķółķā©ńĮæń╗£’╝Ü
+
+```python
+model = dict(
+ type='MVXFasterRCNN',
+ data_preprocessor=dict(voxel_layer=dict(...)),
+ pts_voxel_encoder=dict(...),
+ pts_middle_encoder=dict(...),
+ pts_backbone=dict(...),
+ pts_neck=dict(
+ type='FPN',
+ norm_cfg=dict(type='naiveSyncBN2d', eps=1e-3, momentum=0.01),
+ act_cfg=dict(type='ReLU'),
+ in_channels=[64, 128, 256],
+ out_channels=256,
+ start_level=0,
+ num_outs=3),
+ pts_bbox_head=dict(...))
+```
+
+`FPN` ÕÆī `SECONDFPN` õĮ┐ńö©õĖŹÕÉīńÜäÕģ│ķö«ÕŁŚµØźµ×äÕ╗║’╝Ü
+
+```python
+_base_ = '../_base_/models/pointpillars_hv_fpn_nus.py'
+model = dict(
+ pts_neck=dict(
+ _delete_=True,
+ type='SECONDFPN',
+ norm_cfg=dict(type='naiveSyncBN2d', eps=1e-3, momentum=0.01),
+ in_channels=[64, 128, 256],
+ upsample_strides=[1, 2, 4],
+ out_channels=[128, 128, 128]),
+ pts_bbox_head=dict(...))
+```
+
+`_delete_=True` Õ░åõĮ┐ńö©µ¢░ńÜäķö«ÕÄ╗µø┐µŹó `pts_neck` ÕŁŚµ«ĄÕåģµēƵ£ēµŚ¦ńÜäķö«ŃĆé
+
+### Õ£©ķģŹńĮ«µ¢ćõ╗ČķćīõĮ┐ńö©õĖŁķŚ┤ÕÅśķćÅ
+
+ķģŹńĮ«µ¢ćõ╗Čķćīõ╝ÜõĮ┐ńö©õĖĆõ║øõĖŁķŚ┤ÕÅśķćÅ’╝īõŠŗÕ”éµĢ░µŹ«ķøåķćīńÜä `train_pipeline`/`test_pipeline`ŃĆéķ£ĆĶ”üµ│©µäÅńÜ䵜»’╝īÕĮōõ┐«µö╣ÕŁÉķģŹńĮ«µ¢ćõ╗ČõĖŁńÜäõĖŁķŚ┤ÕÅśķćŵŚČ’╝īńö©µłĘķ£ĆĶ”üÕåŹµ¼ĪÕ░åõĖŁķŚ┤ÕÅśķćÅõ╝ĀķĆÆÕł░Õ»╣Õ║öńÜäÕŁŚµ«ĄõĖŁŃĆéõŠŗÕ”é’╝īµłæõ╗¼µā│õĮ┐ńö©ÕżÜÕ░║Õ║”ńŁ¢ńĢźĶ«Łń╗āÕ╣ȵĄŗĶ»Ģ PointPillars’╝ī`train_pipeline`/`test_pipeline` µś»µłæõ╗¼µā│Ķ”üõ┐«µö╣ńÜäõĖŁķŚ┤ÕÅśķćÅŃĆé
+
+```python
+_base_ = './nus-3d.py'
+train_pipeline = [
+ dict(
+ type='LoadPointsFromFile',
+ load_dim=5,
+ use_dim=5,
+ backend_args=backend_args),
+ dict(
+ type='LoadPointsFromMultiSweeps',
+ sweeps_num=10,
+ backend_args=backend_args),
+ dict(type='LoadAnnotations3D', with_bbox_3d=True, with_label_3d=True),
+ dict(
+ type='GlobalRotScaleTrans',
+ rot_range=[-0.3925, 0.3925],
+ scale_ratio_range=[0.95, 1.05],
+ translation_std=[0, 0, 0]),
+ dict(type='RandomFlip3D', flip_ratio_bev_horizontal=0.5),
+ dict(type='PointsRangeFilter', point_cloud_range=point_cloud_range),
+ dict(type='ObjectRangeFilter', point_cloud_range=point_cloud_range),
+ dict(type='ObjectNameFilter', classes=class_names),
+ dict(type='PointShuffle'),
+ dict(
+ type='Pack3DDetInputs',
+ keys=['points', 'gt_labels_3d', 'gt_bboxes_3d'])
+]
+test_pipeline = [
+ dict(
+ type='LoadPointsFromFile',
+ load_dim=5,
+ use_dim=5,
+ backend_args=backend_args),
+ dict(
+ type='LoadPointsFromMultiSweeps',
+ sweeps_num=10,
+ backend_args=backend_args),
+ dict(
+ type='MultiScaleFlipAug3D',
+ img_scale=(1333, 800),
+ pts_scale_ratio=[0.95, 1.0, 1.05],
+ flip=False,
+ transforms=[
+ dict(
+ type='GlobalRotScaleTrans',
+ rot_range=[0, 0],
+ scale_ratio_range=[1., 1.],
+ translation_std=[0, 0, 0]),
+ dict(type='RandomFlip3D'),
+ dict(
+ type='PointsRangeFilter', point_cloud_range=point_cloud_range)
+ ]),
+ dict(type='Pack3DDetInputs', keys=['points'])
+]
+train_dataloader = dict(dataset=dict(pipeline=train_pipeline))
+val_dataloader = dict(dataset=dict(pipeline=test_pipeline))
+test_dataloader = dict(dataset=dict(pipeline=test_pipeline))
+```
+
+µłæõ╗¼ķ”¢ÕģłÕ«Üõ╣ēµ¢░ńÜä `train_pipeline`/`test_pipeline`’╝īńäČÕÉÄõ╝ĀķĆÆÕł░µĢ░µŹ«ÕŖĀĶĮĮÕÖ©ÕŁŚµ«ĄõĖŁŃĆé
+
+### ÕżŹńö© \_base\_ µ¢ćõ╗ČõĖŁńÜäÕÅśķćÅ
+
+Õ”éµ×£ńö©µłĘÕĖīµ£øÕżŹńö© base µ¢ćõ╗ČõĖŁńÜäÕÅśķćÅ’╝īÕłÖÕÅ»õ╗źķĆÜĶ┐ćõĮ┐ńö© `{{_base_.xxx}}` ĶÄĘÕÅ¢Õ»╣Õ║öÕÅśķćÅńÜäµŗĘĶ┤ØŃĆéõŠŗÕ”é’╝Ü
+
+```python
+_base_ = './pointpillars_hv_secfpn_8xb6-160e_kitti-3d-3class.py'
+
+a = {{_base_.model}} # ÕÅśķćÅ `a` ńŁēõ║Ä `_base_` õĖŁÕ«Üõ╣ēńÜä `model`
+```
+
+## ķĆÜĶ┐ćĶäܵ£¼ÕÅéµĢ░õ┐«µö╣ķģŹńĮ«
+
+ÕĮōõĮ┐ńö© `tools/train.py` µł¢ĶĆģ `tools/test.py` µÅÉõ║żÕĘźõĮ£µŚČ’╝īµé©ÕÅ»õ╗źķĆÜĶ┐ćµīćÕ«Ü `--cfg-options` µØźõ┐«µö╣ķģŹńĮ«µ¢ćõ╗ČŃĆé
+
+- µø┤µ¢░ķģŹńĮ«ÕŁŚÕģĖńÜäķö«ÕĆ╝
+
+ ÕÅ»õ╗źµīēńģ¦ÕĤզŗķģŹńĮ«µ¢ćõ╗ČõĖŁÕŁŚÕģĖńÜäķö«ÕĆ╝ķĪ║Õ║ŵīćÕ«ÜķģŹńĮ«ķĆēķĪ╣ŃĆéõŠŗÕ”é’╝īõĮ┐ńö© `--cfg-options model.backbone.norm_eval=False` Õ░嵩ĪÕ×ŗõĖ╗Õ╣▓ńĮæń╗£õĖŁńÜäµēƵ£ē BN µ©ĪÕØŚķāĮµö╣õĖ║ `train` µ©ĪÕ╝ÅŃĆé
+
+- µø┤µ¢░ķģŹńĮ«ÕłŚĶĪ©õĖŁńÜäķö«ÕĆ╝
+
+ Õ£©ķģŹńĮ«µ¢ćõ╗Čķćī’╝īõĖĆõ║øķģŹńĮ«ÕŁŚÕģĖĶó½ÕīģÕɽգ©ÕłŚĶĪ©õĖŁ’╝īõŠŗÕ”é’╝īĶ«Łń╗āµĄüń©ŗ `train_dataloader.dataset.pipeline` ķĆÜÕĖĖµś»õĖĆõĖ¬ÕłŚĶĪ©’╝īõŠŗÕ”é `[dict(type='LoadPointsFromFile'), ...]`ŃĆéÕ”éµ×£µé©µā│Ķ”üÕ░åĶ«Łń╗āµĄüń©ŗõĖŁńÜä `'LoadPointsFromFile'` µö╣µłÉ `'LoadPointsFromDict'`’╝īµé©ķ£ĆĶ”üµīćÕ«Ü `--cfg-options data.train.pipeline.0.type=LoadPointsFromDict`ŃĆé
+
+- µø┤µ¢░ÕłŚĶĪ©/Õģāń╗äńÜäÕĆ╝
+
+ Õ”éµ×£Ķ”üµø┤µ¢░ńÜäÕĆ╝µś»ÕłŚĶĪ©µł¢Õģāń╗äŃĆéõŠŗÕ”é’╝īķģŹńĮ«µ¢ćõ╗ČķĆÜÕĖĖĶ«ŠńĮ« `model.data_preprocessor.mean=[123.675, 116.28, 103.53]`ŃĆéÕ”éµ×£µé©µā│Ķ”üµö╣ÕÅśĶ┐ÖõĖ¬ÕØćÕĆ╝’╝īµé©ķ£ĆĶ”üµīćÕ«Ü `--cfg-options model.data_preprocessor.mean="[127,127,127]"`ŃĆéµ│©µäÅ’╝īÕ╝ĢÕÅĘ `"` µś»µö»µīüÕłŚĶĪ©/Õģāń╗äµĢ░µŹ«ń▒╗Õ×ŗµēĆÕ┐ģķ£ĆńÜä’╝īÕ╣ČõĖöÕ£©µīćÕ«ÜÕĆ╝ńÜäÕ╝ĢÕÅĘÕåģ**õĖŹÕģüĶ«Ė**µ£ēń®║µĀ╝ŃĆé
+
+## ķģŹńĮ«µ¢ćõ╗ČÕÉŹń¦░ķŻÄµĀ╝
+
+µłæõ╗¼ķüĄÕŠ¬õ╗źõĖŗµĀĘÕ╝ÅµØźÕæĮÕÉŹķģŹńĮ«µ¢ćõ╗ČŃĆéÕ╗║Ķ««Ķ┤Īńī«ĶĆģķüĄÕŠ¬ńøĖÕÉīńÜäķŻÄµĀ╝ŃĆé
+
+```
+{algorithm name}_{model component names [component1]_[component2]_[...]}_{training settings}_{training dataset information}_{testing dataset information}.py
+```
+
+µ¢ćõ╗ČÕÉŹÕłåõĖ║õ║öõĖ¬ķā©ÕłåŃĆéµēƵ£ēķā©ÕłåÕÆīń╗äõ╗Čńö© `_` Ķ┐׵ğ’╝īµ»ÅõĖ¬ķā©Õłåµł¢ń╗äõ╗ČÕåģńÜäÕŹĢĶ»ŹÕ║öĶ»źńö© `-` Ķ┐׵ğŃĆé
+
+- `{algorithm name}`’╝Üń«Śµ│ĢńÜäÕÉŹń¦░ŃĆéÕ«āÕÅ»õ╗źµś»µŻĆµĄŗÕÖ©ńÜäÕÉŹń¦░’╝īõŠŗÕ”é `pointpillars`ŃĆü`fcos3d` ńŁēŃĆé
+- `{model component names}`’╝Üń«Śµ│ĢõĖŁõĮ┐ńö©ńÜäń╗äõ╗ČÕÉŹń¦░’╝īÕ”é voxel_encoderŃĆübackboneŃĆüneck ńŁēŃĆéõŠŗÕ”é `second_secfpn_head-dcn-circlenms` ĶĪ©ńż║õĮ┐ńö© SECOND ńÜä SparseEncoder’╝īSECONDFPN’╝īõ╗źÕÅŖÕĖ”µ£ē DCN ÕÆī circle NMS ńÜ䵯ƵĄŗÕż┤ŃĆé
+- `{training settings}`’╝ÜĶ«Łń╗āĶ«ŠńĮ«ńÜäõ┐Īµü»’╝īõŠŗÕ”éµē╣ķćÅÕż¦Õ░Å’╝īµĢ░µŹ«Õó×Õ╝║’╝īµŹ¤Õż▒ÕćĮµĢ░ńŁ¢ńĢź’╝īĶ░āÕ║”ÕÖ©õ╗źÕÅŖĶ«Łń╗āĶĮ«µ¼Ī/Ķ┐Łõ╗ŻŃĆéõŠŗÕ”é `8xb4-tta-cyclic-20e` ĶĪ©ńż║õĮ┐ńö© 8 õĖ¬ gpu’╝īµ»ÅõĖ¬ gpu µ£ē 4 õĖ¬µĢ░µŹ«µĀʵ£¼’╝īµĄŗĶ»ĢÕó×Õ╝║’╝īõĮÖÕ╝”ķĆĆńü½ÕŁ”õ╣ĀńÄć’╝īĶ«Łń╗ā 20 õĖ¬ epochŃĆéń╝®ÕåÖõ╗ŗń╗Ź’╝Ü
+ - `{gpu x batch_per_gpu}`’╝ÜGPU µĢ░ÕÆīµ»ÅõĖ¬ GPU ńÜäµĀʵ£¼µĢ░ŃĆé`bN` ĶĪ©ńż║µ»ÅõĖ¬ GPU õĖŖńÜäµē╣ķćÅÕż¦Õ░ÅõĖ║ NŃĆéõŠŗÕ”é `4xb4` µś» 4 õĖ¬ GPU’╝īµ»ÅõĖ¬ GPU µ£ē 4 õĖ¬µĀʵ£¼µĢ░ńÜäń╝®ÕåÖŃĆé
+ - `{schedule}`’╝ÜĶ«Łń╗āµ¢╣µĪł’╝īÕÅ»ķĆēķĪ╣õĖ║ `schedule-2x`ŃĆü`schedule-3x`ŃĆü`cyclic-20e` ńŁēŃĆé`schedule-2x` ÕÆī `schedule-3x` ÕłåÕł½õ╗ŻĶĪ© 24 epoch ÕÆī 36 epochŃĆé`cyclic-20e` ĶĪ©ńż║ 20 epochŃĆé
+- `{training dataset information}`’╝ÜĶ«Łń╗āµĢ░µŹ«ķøåÕÉŹ’╝īõŠŗÕ”é `kitti-3d-3class`’╝ī`nus-3d`’╝ī`s3dis-seg`’╝ī`scannet-seg`’╝ī`waymoD5-3d-car`ŃĆéĶ┐Öķćī `3d` ĶĪ©ńż║µĢ░µŹ«ķøåńö©õ║Ä 3D ńø«µĀ浯ƵĄŗ’╝ī`seg` ĶĪ©ńż║µĢ░µŹ«ķøåńö©õ║Äńé╣õ║æÕłåÕē▓ŃĆé
+- `{testing dataset information}`’╝łÕÅ»ķĆē’╝ē’╝ÜÕĮōµ©ĪÕ×ŗÕ£©õĖĆõĖ¬µĢ░µŹ«ķøåõĖŖĶ«Łń╗ā’╝īÕ£©ÕÅ”õĖĆõĖ¬µĢ░µŹ«ķøåõĖŖµĄŗĶ»ĢµŚČńÜ䵥ŗĶ»ĢµĢ░µŹ«ķøåÕÉŹŃĆéÕ”éµ×£µ▓Īµ£ēµ│©µśÄ’╝īÕłÖĶĪ©ńż║Ķ«Łń╗āÕÆīµĄŗĶ»ĢńÜäµĢ░µŹ«ķøåń▒╗Õ×ŗńøĖÕÉīŃĆé
diff --git a/internlm_langchain/knowledge_base/MMDetection3D/content/coord_sys_tutorial.md b/internlm_langchain/knowledge_base/MMDetection3D/content/coord_sys_tutorial.md
new file mode 100644
index 00000000..d666ba75
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection3D/content/coord_sys_tutorial.md
@@ -0,0 +1,245 @@
+# ÕØɵĀćń│╗
+
+## µ”éĶ┐░
+
+MMDetection3D õĮ┐ńö© 3 ń¦ŹõĖŹÕÉīńÜäÕØɵĀćń│╗ŃĆé3D ńø«µĀ浯ƵĄŗķóåÕ¤¤õĖŁõĖŹÕÉīÕØɵĀćń│╗ńÜäÕŁśÕ£©µś»ķØ×ÕĖĖµ£ēÕ┐ģĶ”üńÜä’╝īÕøĀõĖ║Õ»╣õ║ÄÕÉäń¦Ź 3D µĢ░µŹ«ķććķøåĶ«ŠÕżćµØźĶ»┤’╝īÕ”éµ┐ĆÕģēķøĘĶŠŠŃĆüµĘ▒Õ║”ńøĖµ£║ńŁē’╝īõĮ┐ńö©ńÜäÕØɵĀćń│╗µś»õĖŹõĖĆĶć┤ńÜä’╝īõĖŹÕÉīńÜä 3D µĢ░µŹ«ķøåõ╣¤ķüĄÕŠ¬õĖŹÕÉīńÜäµĢ░µŹ«µĀ╝Õ╝ÅŃĆ鵌®µ£¤ńÜäÕĘźõĮ£’╝īµ»öÕ”é SECONDŃĆüVoteNet Õ░åÕĤզŗµĢ░µŹ«ĶĮ¼µŹóõĖ║ÕÅ”õĖĆń¦ŹµĀ╝Õ╝Å’╝īÕĮóµłÉõ║åõĖĆõ║øÕÉÄń╗ŁÕĘźõĮ£õ╣¤ķüĄÕŠ¬ńÜäń║”Õ«Ü’╝īõĮ┐ÕŠŚõĖŹÕÉīÕØɵĀćń│╗õ╣ŗķŚ┤ńÜäĶĮ¼µŹóÕÅśÕŠŚµø┤ÕŖĀÕżŹµØéŃĆé
+
+Õ░Įń«ĪµĢ░µŹ«ķøåÕÆīķććķøåĶ«ŠÕżćÕżÜń¦ŹÕżÜµĀĘ’╝īõĮåµś»ķĆÜĶ┐ćµĆ╗ń╗ō 3D ńø«µĀ浯ƵĄŗńÜäÕĘźõĮ£ń║┐’╝īµłæõ╗¼ÕÅ»õ╗źÕ░åÕØɵĀćń│╗Õż¦Ķć┤ÕłåõĖ║õĖēń▒╗’╝Ü
+
+- ńøĖµ£║ÕØɵĀćń│╗ -- Õż¦ÕżÜµĢ░ńøĖµ£║ńÜäÕØɵĀćń│╗’╝īÕ£©Ķ»źÕØɵĀćń│╗õĖŁ y ĶĮ┤µŁŻµ¢╣ÕÉæµīćÕÉæÕ£░ķØó’╝īx ĶĮ┤µŁŻµ¢╣ÕÉæµīćÕÉæÕÅ│õŠ¦’╝īz ĶĮ┤µŁŻµ¢╣ÕÉæµīćÕÉæÕēŹµ¢╣ŃĆé
+
+ ```
+ õĖŖ z ÕēŹ
+ | ^
+ | /
+ | /
+ | /
+ |/
+ ÕĘ” ------ 0 ------> x ÕÅ│
+ |
+ |
+ |
+ |
+ v
+ y õĖŗ
+ ```
+
+- µ┐ĆÕģēķøĘĶŠŠÕØɵĀćń│╗ -- õ╝ŚÕżÜµ┐ĆÕģēķøĘĶŠŠńÜäÕØɵĀćń│╗’╝īÕ£©Ķ»źÕØɵĀćń│╗õĖŁ z ĶĮ┤Ķ┤¤µ¢╣ÕÉæµīćÕÉæÕ£░ķØó’╝īx ĶĮ┤µŁŻµ¢╣ÕÉæµīćÕÉæÕēŹµ¢╣’╝īy ĶĮ┤µŁŻµ¢╣ÕÉæµīćÕÉæÕĘ”õŠ¦ŃĆé
+
+ ```
+ z õĖŖ x ÕēŹ
+ ^ ^
+ | /
+ | /
+ | /
+ |/
+ y ÕĘ” <------ 0 ------ ÕÅ│
+ ```
+
+- µĘ▒Õ║”ÕØɵĀćń│╗ -- VoteNetŃĆüH3DNet ńŁēµ©ĪÕ×ŗõĮ┐ńö©ńÜäÕØɵĀćń│╗’╝īÕ£©Ķ»źÕØɵĀćń│╗õĖŁ z ĶĮ┤Ķ┤¤µ¢╣ÕÉæµīćÕÉæÕ£░ķØó’╝īx ĶĮ┤µŁŻµ¢╣ÕÉæµīćÕÉæÕÅ│õŠ¦’╝īy ĶĮ┤µŁŻµ¢╣ÕÉæµīćÕÉæÕēŹµ¢╣ŃĆé
+
+ ```
+ z õĖŖ y ÕēŹ
+ ^ ^
+ | /
+ | /
+ | /
+ |/
+ ÕĘ” ------ 0 ------> x ÕÅ│
+ ```
+
+Ķ»źµĢÖń©ŗõĖŁńÜäÕØɵĀćń│╗Õ«Üõ╣ēÕ«×ķÖģõĖŖ**õĖŹõ╗ģõ╗ģµś»Õ«Üõ╣ēõĖēõĖ¬ĶĮ┤**ŃĆéÕ»╣õ║ÄÕĮóÕ”é $(x, y, z, dx, dy, dz, r)$ ńÜäµĪåµØźĶ»┤’╝īµłæõ╗¼ńÜäÕØɵĀćń│╗õ╣¤Õ«Üõ╣ēõ║åÕ”éõĮĢĶ¦ŻķćŖµĪåńÜäÕ░║Õ»Ė $(dx, dy, dz)$ ÕÆīĶĮ¼ÕÉæĶ¦Æ (yaw) Ķ¦ÆÕ║” $r$ŃĆé
+
+õĖēõĖ¬ÕØɵĀćń│╗ńÜäÕøŠńż║Õ”éõĖŗ’╝Ü
+
+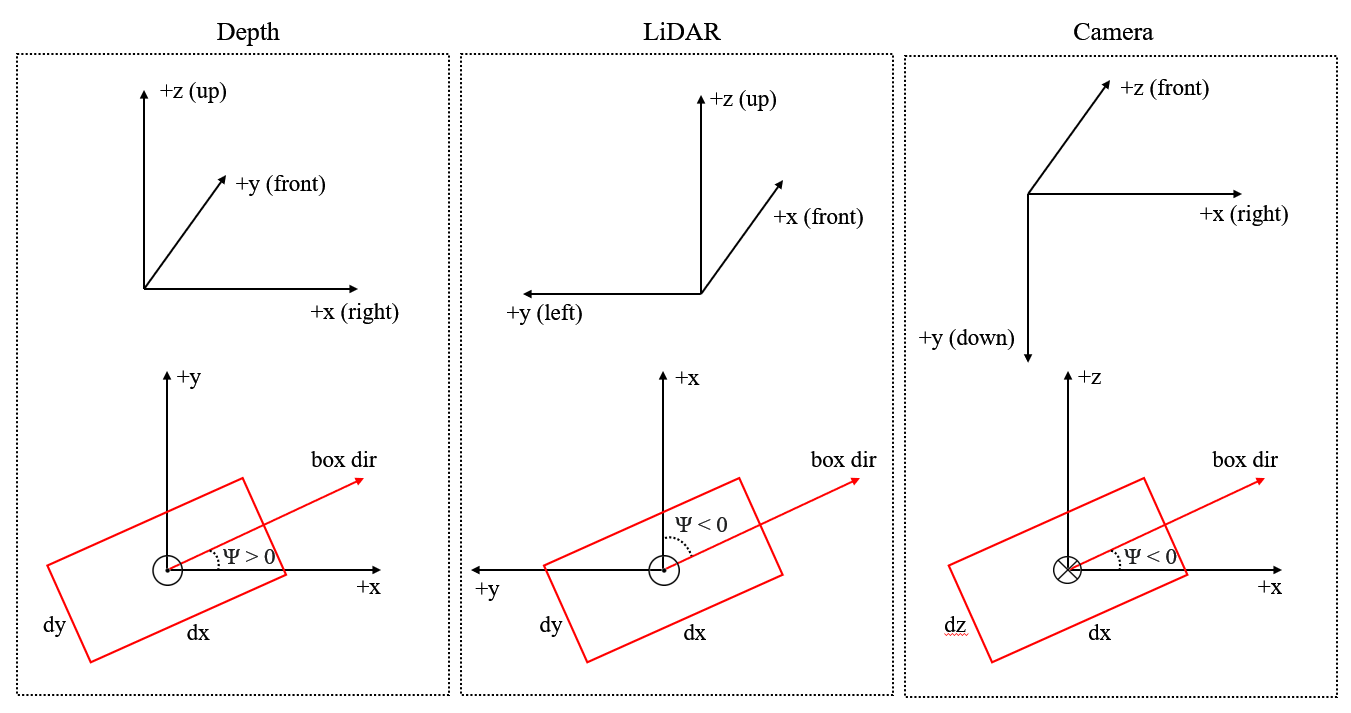
+
+õĖŖķØóõĖēÕ╝ĀÕøŠµś» 3D ÕØɵĀćń│╗’╝īõĖŗķØóõĖēÕ╝ĀÕøŠµś»ķĖ¤ń×░ÕøŠŃĆé
+
+õ╗źÕÉĵłæõ╗¼Õ░åÕØܵīüõĮ┐ńö©µ£¼µĢÖń©ŗõĖŁÕ«Üõ╣ēńÜäõĖēõĖ¬ÕØɵĀćń│╗ŃĆé
+
+## ĶĮ¼ÕÉæĶ¦Æ (yaw) ńÜäÕ«Üõ╣ē
+
+Ķ»ĘÕÅéĶĆā[ń╗┤Õ¤║ńÖŠń¦æ](https://en.wikipedia.org/wiki/Euler_angles#Tait%E2%80%93Bryan_angles)õ║åĶ¦ŻĶĮ¼ÕÉæĶ¦ÆńÜäµĀćÕćåÕ«Üõ╣ēŃĆéÕ£©ńø«µĀ浯ƵĄŗõĖŁ’╝īµłæõ╗¼ķĆēµŗ®õĖĆõĖ¬ĶĮ┤õĮ£õĖ║ķćŹÕŖøĶĮ┤’╝īÕ╣ČÕ£©Õ×éńø┤õ║ÄķćŹÕŖøĶĮ┤ńÜäÕ╣│ķØó $\\Pi$ õĖŖķĆēÕÅ¢õĖĆõĖ¬ÕÅéĶĆāµ¢╣ÕÉæ’╝īķéŻõ╣łÕÅéĶĆāµ¢╣ÕÉæńÜäĶĮ¼ÕÉæĶ¦ÆõĖ║ 0’╝īÕ£© $\\Pi$ õĖŖńÜäÕģČõ╗¢µ¢╣ÕÉæµ£ēķØ×ķøČńÜäĶĮ¼ÕÉæĶ¦Æ’╝īÕģČĶ¦ÆÕ║”ÕÅ¢Õå│õ║ÄÕģČõĖÄÕÅéĶĆāµ¢╣ÕÉæńÜäĶ¦ÆÕ║”ŃĆé
+
+ńø«ÕēŹ’╝īÕ»╣õ║ĵēƵ£ēµö»µīüńÜäµĢ░µŹ«ķøå’╝īµĀćµ│©õĖŹÕīģµŗ¼õ┐»õ╗░Ķ¦Æ (pitch) ÕÆīµ╗ÜÕŖ©Ķ¦Æ (roll)’╝īĶ┐ÖµäÅÕæ│ńØƵłæõ╗¼Õ£©ķó䵥ŗµĪåÕÆīĶ«Īń«ŚµĪåõ╣ŗķŚ┤ńÜäķćŹÕÅĀµŚČÕŬķ£ĆĶĆāĶÖæĶĮ¼ÕÉæĶ¦Æ (yaw)ŃĆé
+
+Õ£© MMDetection3D õĖŁ’╝īµēƵ£ēÕØɵĀćń│╗ķāĮµś»ÕÅ│µēŗÕØɵĀćń│╗’╝īĶ┐ÖµäÅÕæ│ńØĆÕ”éµ×£õ╗ÄķćŹÕŖøĶĮ┤ńÜäĶ┤¤µ¢╣ÕÉæ’╝łĶĮ┤ńÜ䵣Żµ¢╣ÕÉæµīćÕÉæõ║║ń£╝’╝ēń£ŗ’╝īĶĮ¼ÕÉæĶ¦Æ (yaw) µ▓┐ńØĆķĆåµŚČķÆłµ¢╣ÕÉæÕó×ÕŖĀŃĆé
+
+õĖŗÕøŠµśŠńż║’╝īÕ£©ÕÅ│µēŗÕØɵĀćń│╗õĖŁ’╝īÕ”éµ×£µłæõ╗¼Ķ«ŠÕ«Ü x ĶĮ┤µŁŻµ¢╣ÕÉæõĖ║ÕÅéĶĆāµ¢╣ÕÉæ’╝īķéŻõ╣ł y ĶĮ┤µŁŻµ¢╣ÕÉæńÜäĶĮ¼ÕÉæĶ¦Æ (yaw) õĖ║ $\\frac{\\pi}{2}$ŃĆé
+
+```
+ z õĖŖ y ÕēŹ (yaw=0.5*pi)
+ ^ ^
+ | /
+ | /
+ | /
+ |/
+ÕĘ” (yaw=pi) ------ 0 ------> x ÕÅ│ (yaw=0)
+```
+
+Õ»╣õ║ÄõĖĆõĖ¬µĪåµØźĶ»┤’╝īÕģČĶĮ¼ÕÉæĶ¦Æ (yaw) ńÜäÕĆ╝ńŁēõ║ÄÕģȵ¢╣ÕÉæÕćÅÕÄ╗õĖĆõĖ¬ÕÅéĶĆāµ¢╣ÕÉæŃĆéÕ£© MMDetection3D ńÜäµēƵ£ēõĖēõĖ¬ÕØɵĀćń│╗õĖŁ’╝īÕÅéĶĆāµ¢╣ÕÉæµĆ╗µś» x ĶĮ┤ńÜ䵣Żµ¢╣ÕÉæ’╝īĶĆīÕ”éµ×£õĖĆõĖ¬µĪåńÜäĶĮ¼ÕÉæĶ¦Æ (yaw) õĖ║ 0’╝īÕłÖÕģȵ¢╣ÕÉæĶó½Õ«Üõ╣ēõĖ║õĖÄ x ĶĮ┤Õ╣│ĶĪīŃĆéµĪåńÜäĶĮ¼ÕÉæĶ¦Æ (yaw) ńÜäÕ«Üõ╣ēÕ”éõĖŗÕøŠµēĆńż║ŃĆé
+
+```
+ y ÕēŹ
+ ^ µĪåńÜäµ¢╣ÕÉæ (yaw=0.5*pi)
+ /|\ ^
+ | /|\
+ | ____|____
+ | | | |
+ | | | |
+__|____|____|____|______\ x ÕÅ│
+ | | | | /
+ | | | |
+ | |____|____|
+ |
+```
+
+## µĪåÕ░║Õ»ĖńÜäÕ«Üõ╣ē
+
+µĪåÕ░║Õ»ĖńÜäÕ«Üõ╣ēõĖÄĶĮ¼ÕÉæĶ¦Æ (yaw) ńÜäÕ«Üõ╣ēµś»ÕłåõĖŹÕ╝ĆńÜäŃĆéÕ£©õĖŖõĖĆĶŖéõĖŁ’╝īµłæõ╗¼µÅÉÕł░Õ”éµ×£õĖĆõĖ¬µĪåńÜäĶĮ¼ÕÉæĶ¦Æ (yaw) õĖ║ 0’╝īÕ«āńÜäµ¢╣ÕÉæÕ░▒Ķó½Õ«Üõ╣ēõĖ║õĖÄ x ĶĮ┤Õ╣│ĶĪīŃĆéķéŻõ╣łĶć¬ńäČÕ£░’╝īõĖĆõĖ¬µĪåÕ»╣Õ║öõ║Ä x ĶĮ┤ńÜäÕ░║Õ»ĖÕ║öĶ»źµś» $dx$ŃĆéõĮåµś»’╝īĶ┐ÖÕ£©µ¤Éõ║øµĢ░µŹ«ķøåõĖŁÕ╣ČķØ×µĆ╗µś»Õ”鵣ż’╝łµłæõ╗¼ń©ŹÕÉÄõ╝ÜĶ¦ŻÕå│Ķ┐ÖõĖ¬ķŚ«ķóś’╝ēŃĆé
+
+õĖŗÕøŠÕ▒Ģńż║õ║å x ĶĮ┤ÕÆī $dx$’╝īy ĶĮ┤ÕÆī $dy$ Õ»╣Õ║öńÜäÕɽõ╣ēŃĆé
+
+```
+y ÕēŹ
+ ^ µĪåńÜäµ¢╣ÕÉæ (yaw=0.5*pi)
+ /|\ ^
+ | /|\
+ | ____|____
+ | | | |
+ | | | | dx
+__|____|____|____|______\ x ÕÅ│
+ | | | | /
+ | | | |
+ | |____|____|
+ | dy
+```
+
+µ│©µäŵĪåńÜäµ¢╣ÕÉæµĆ╗µś»ÕÆī $dx$ ĶŠ╣Õ╣│ĶĪīŃĆé
+
+```
+y ÕēŹ
+ ^ _________
+ /|\ | | |
+ | | | |
+ | | | | dy
+ | |____|____|____\ µĪåńÜäµ¢╣ÕÉæ (yaw=0)
+ | | | | /
+__|____|____|____|_________\ x ÕÅ│
+ | | | | /
+ | |____|____|
+ | dx
+ |
+```
+
+## õĖĵö»µīüńÜäµĢ░µŹ«ķøåńÜäÕĤզŗÕØɵĀćń│╗ńÜäÕģ│ń│╗
+
+### KITTI
+
+KITTI µĢ░µŹ«ķøåńÜäÕĤզŗµĀćµ│©µś»Õ£©ńøĖµ£║ÕØɵĀćń│╗õĖŗńÜä’╝īĶ»”Ķ¦ü [get_label_anno](https://github.com/open-mmlab/mmdetection3d/blob/master/tools/data_converter/kitti_data_utils.py)ŃĆéÕ£© MMDetection3D õĖŁ’╝īõĖ║õ║åÕ£© KITTI µĢ░µŹ«ķøåõĖŖĶ«Łń╗āÕ¤║õ║ĵ┐ĆÕģēķøĘĶŠŠńÜ䵩ĪÕ×ŗ’╝īķ”¢ÕģłÕ░åµĢ░µŹ«õ╗ÄńøĖµ£║ÕØɵĀćń│╗ĶĮ¼µŹóÕł░µ┐ĆÕģēķøĘĶŠŠÕØɵĀć’╝īĶ»”Ķ¦ü [get_ann_info](https://github.com/open-mmlab/mmdetection3d/blob/master/mmdet3d/datasets/kitti_dataset.py)ŃĆéÕ»╣õ║ÄĶ«Łń╗āÕ¤║õ║ÄĶ¦åĶ¦ēńÜ䵩ĪÕ×ŗ’╝īµĢ░µŹ«õ┐صīüÕ£©ńøĖµ£║ÕØɵĀćń│╗õĖŹÕÅśŃĆé
+
+Õ£© SECOND õĖŁ’╝īµĪåńÜäµ┐ĆÕģēķøĘĶŠŠÕØɵĀćń│╗Õ«Üõ╣ēÕ”éõĖŗ’╝łķĖ¤ń×░ÕøŠ’╝ē’╝Ü
+
+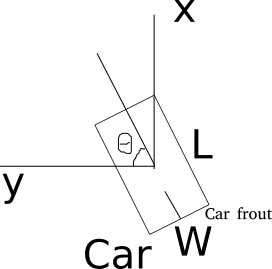
+
+Õ»╣õ║ĵ»ÅõĖ¬µĪåµØźĶ»┤’╝īÕ░║Õ»ĖõĖ║ $(w, l, h)$’╝īĶĮ¼ÕÉæĶ¦Æ (yaw) ńÜäÕÅéĶĆāµ¢╣ÕÉæõĖ║ y ĶĮ┤µŁŻµ¢╣ÕÉæŃĆéµø┤ÕżÜń╗åĶŖéĶ»ĘÕÅéĶĆā[õ╗ŻńĀüÕ║ō](https://github.com/traveller59/second.pytorch#concepts)ŃĆé
+
+µłæõ╗¼ńÜäµ┐ĆÕģēķøĘĶŠŠÕØɵĀćń│╗µ£ēõĖżÕżäµö╣ÕÅś’╝Ü
+
+- ĶĮ¼ÕÉæĶ¦Æ (yaw) Ķó½Õ«Üõ╣ēõĖ║ÕÅ│µēŗĶĆīķØ×ÕĘ”µēŗ’╝īõ╗ÄĶĆīõ┐صīüõĖĆĶć┤µĆ¦’╝ø
+- µĪåńÜäÕ░║Õ»ĖõĖ║ $(l, w, h)$ ĶĆīķØ× $(w, l, h)$’╝īńö▒õ║ÄÕ£© KITTI µĢ░µŹ«ķøåõĖŁ $w$ Õ»╣Õ║ö $dy$’╝ī$l$ Õ»╣Õ║ö $dx$ŃĆé
+
+### Waymo
+
+µłæõ╗¼õĮ┐ńö© Waymo µĢ░µŹ«ķøåńÜä KITTI µĀ╝Õ╝ŵĢ░µŹ«ŃĆéÕøĀµŁż’╝īÕ£©µłæõ╗¼ńÜäÕ«×ńÄ░õĖŁ KITTI ÕÆī Waymo õ╣¤Õģ▒ńö©ńøĖÕÉīńÜäÕØɵĀćń│╗ŃĆé
+
+### NuScenes
+
+NuScenes µÅÉõŠøõ║åõĖĆõĖ¬Ķ»äõ╝░ÕĘźÕģĘÕīģ’╝īÕģČõĖŁµ»ÅõĖ¬µĪåķāĮĶó½ÕīģĶŻģµłÉõĖĆõĖ¬ `Box` Õ«×õŠŗŃĆé`Box` ńÜäÕØɵĀćń│╗õĖŹÕÉīõ║ĵłæõ╗¼ńÜäµ┐ĆÕģēķøĘĶŠŠÕØɵĀćń│╗’╝īÕ£© `Box` ÕØɵĀćń│╗õĖŁ’╝īÕēŹõĖżõĖ¬ĶĪ©ńż║µĪåÕ░║Õ»ĖńÜäÕģāń┤ĀÕłåÕł½Õ»╣Õ║ö $(dy, dx)$ µł¢ĶĆģ $(w, l)$’╝īÕÆīµłæõ╗¼ńÜäĶĪ©ńż║µ¢╣µ│ĢńøĖÕÅŹŃĆéµø┤ÕżÜń╗åĶŖéĶ»ĘÕÅéĶĆā NuScenes [µĢÖń©ŗ](https://github.com/open-mmlab/mmdetection3d/blob/master/docs/zh_cn/datasets/nuscenes_det.md#notes)ŃĆé
+
+Ķ»╗ĶĆģÕÅ»õ╗źÕÅéĶĆā [NuScenes Õ╝ĆÕÅæÕĘźÕģĘ](https://github.com/nutonomy/nuscenes-devkit/tree/master/python-sdk/nuscenes/eval/detection)’╝īõ║åĶ¦Ż [NuScenes µĪå](https://github.com/nutonomy/nuscenes-devkit/blob/2c6a752319f23910d5f55cc995abc547a9e54142/python-sdk/nuscenes/utils/data_classes.py#L457) ńÜäÕ«Üõ╣ēÕÆī [NuScenes Ķ»äõ╝░](https://github.com/nutonomy/nuscenes-devkit/blob/master/python-sdk/nuscenes/eval/detection/evaluate.py)ńÜäĶ┐ćń©ŗŃĆé
+
+### Lyft
+
+Õ░▒µČēÕÅŖÕØɵĀćń│╗ĶĆīĶ©Ć’╝īLyft ÕÆī NuScenes Õģ▒ńö©ńøĖÕÉīńÜäµĢ░µŹ«µĀ╝Õ╝ÅŃĆé
+
+Ķ»ĘÕÅéĶĆā[Õ«śµ¢╣ńĮæń½Ö](https://www.kaggle.com/c/3d-object-detection-for-autonomous-vehicles/data)ĶÄĘÕÅ¢µø┤ÕżÜõ┐Īµü»ŃĆé
+
+### ScanNet
+
+ScanNet ńÜäÕĤզŗµĢ░µŹ«õĖŹµś»ńé╣õ║æĶĆīµś»ńĮæµĀ╝’╝īķ£ĆĶ”üÕ£©µłæõ╗¼ńÜäµĘ▒Õ║”ÕØɵĀćń│╗õĖŗĶ┐øĶĪīķććµĀĘÕŠŚÕł░ńé╣õ║æµĢ░µŹ«ŃĆéÕ»╣õ║Ä ScanNet µŻĆµĄŗõ╗╗ÕŖĪ’╝īµĪåńÜäµĀćµ│©µś»ĶĮ┤Õ»╣ķĮÉńÜä’╝īÕ╣ČõĖöĶĮ¼ÕÉæĶ¦Æ (yaw) Õ¦ŗń╗łµś» 0ŃĆéÕøĀµŁż’╝īµłæõ╗¼ńÜäµĘ▒Õ║”ÕØɵĀćń│╗õĖŁĶĮ¼ÕÉæĶ¦Æ (yaw) ńÜäµ¢╣ÕÉæÕ»╣ ScanNet µ▓Īµ£ēÕĮ▒ÕōŹŃĆé
+
+### SUN RGB-D
+
+SUN RGB-D ńÜäÕĤզŗµĢ░µŹ«õĖŹµś»ńé╣õ║æĶĆīµś» RGB-D ÕøŠÕāÅŃĆ鵳æõ╗¼ķĆÜĶ┐ćÕÅŹµŖĢÕĮ▒’╝īÕÅ»õ╗źÕŠŚÕł░µ»ÅÕ╝ĀÕøŠÕāÅÕ»╣Õ║öńÜäńé╣õ║æ’╝īÕģČÕ£©µłæõ╗¼ńÜäµĘ▒Õ║”ÕØɵĀćń│╗õĖŗŃĆéõĮåµś»’╝īµĢ░µŹ«ķøåńÜäµĀćµ│©Õ╣ČõĖŹÕ£©µłæõ╗¼ńÜäń│╗ń╗¤õĖŁ’╝īµēĆõ╗źķ£ĆĶ”üĶ┐øĶĪīĶĮ¼µŹóŃĆé
+
+Õ░åÕĤզŗµĀćµ│©ĶĮ¼µŹóõĖ║µłæõ╗¼ńÜäµĘ▒Õ║”ÕØɵĀćń│╗õĖŗńÜäµĀćµ│©ńÜäĶĮ¼µŹóĶ┐ćń©ŗĶ»ĘÕÅéĶĆā [sunrgbd_data_utils.py](https://github.com/open-mmlab/mmdetection3d/blob/master/tools/data_converter/sunrgbd_data_utils.py)ŃĆé
+
+### S3DIS
+
+Õ£©µłæõ╗¼ńÜäÕ«×ńÄ░õĖŁ’╝īS3DIS õĖÄ ScanNet Õģ▒ńö©ńøĖÕÉīńÜäÕØɵĀćń│╗ŃĆéńäČĶĆī S3DIS µś»õĖĆõĖ¬õ╗ģķÖÉõ║ÄÕłåÕē▓õ╗╗ÕŖĪńÜäµĢ░µŹ«ķøå’╝īÕøĀµŁżµ▓Īµ£ēµĀćµ│©µś»ÕØɵĀćń│╗µĢŵä¤ńÜäŃĆé
+
+## õŠŗÕŁÉ
+
+### µĪå’╝łÕ£©õĖŹÕÉīÕØɵĀćń│╗ķŚ┤’╝ēńÜäĶĮ¼µŹó
+
+õ╗źńøĖµ£║ÕØɵĀćń│╗ÕÆīµ┐ĆÕģēķøĘĶŠŠÕØɵĀćń│╗ķŚ┤ńÜäĶĮ¼µŹóõĖ║õŠŗ’╝Ü
+
+ķ”¢Õģł’╝īÕ»╣õ║Äńé╣ÕÆīµĪåńÜäõĖŁÕ┐āńé╣’╝īÕØɵĀćĶĮ¼µŹóÕēŹÕÉĵ╗ĪĶČ│õĖŗÕłŚÕģ│ń│╗’╝Ü
+
+- $x\_{LiDAR}=z\_{camera}$
+- $y\_{LiDAR}=-x\_{camera}$
+- $z\_{LiDAR}=-y\_{camera}$
+
+ńäČÕÉÄ’╝īµĪåńÜäÕ░║Õ»ĖĶĮ¼µŹóÕēŹÕÉĵ╗ĪĶČ│õĖŗÕłŚÕģ│ń│╗’╝Ü
+
+- $dx\_{LiDAR}=dx\_{camera}$
+- $dy\_{LiDAR}=dz\_{camera}$
+- $dz\_{LiDAR}=dy\_{camera}$
+
+µ£ĆÕÉÄ’╝īĶĮ¼ÕÉæĶ¦Æ (yaw) õ╣¤Õ║öĶ»źĶó½ĶĮ¼µŹó’╝Ü
+
+- $r\_{LiDAR}=-\\frac{\\pi}{2}-r\_{camera}$
+
+Ķ»”Ķ¦ü[µŁżÕżä](https://github.com/open-mmlab/mmdetection3d/blob/master/mmdet3d/core/bbox/structures/box_3d_mode.py)õ╗ŻńĀüõ║åĶ¦Żµø┤ÕżÜń╗åĶŖéŃĆé
+
+### ķĖ¤ń×░ÕøŠ
+
+Õ”éµ×£ 3D µĪåµś» $(x, y, z, dx, dy, dz, r)$’╝īńøĖµ£║ÕØɵĀćń│╗õĖŗµĪåńÜäķĖ¤ń×░ÕøŠµś» $(x, z, dx, dz, -r)$ŃĆéĶĮ¼ÕÉæĶ¦Æ (yaw) ń¼”ÕÅĘÕÅ¢ÕÅŹµś»ÕøĀõĖ║ńøĖµ£║ÕØɵĀćń│╗ķćŹÕŖøĶĮ┤ńÜ䵣Żµ¢╣ÕÉæµīćÕÉæÕ£░ķØóŃĆé
+
+Ķ»”Ķ¦ü[µŁżÕżä](https://github.com/open-mmlab/mmdetection3d/blob/master/mmdet3d/core/bbox/structures/cam_box3d.py)õ╗ŻńĀüõ║åĶ¦Żµø┤ÕżÜń╗åĶŖéŃĆé
+
+### µĪåńÜ䵌ŗĶĮ¼
+
+µłæõ╗¼Õ░åÕÉäń¦ŹµĪåńÜ䵌ŗĶĮ¼Ķ«ŠÕ«ÜõĖ║ń╗ĢńØĆķćŹÕŖøĶĮ┤ķĆåµŚČķÆłµŚŗĶĮ¼ŃĆéÕøĀµŁż’╝īõĖ║õ║åµŚŗĶĮ¼õĖĆõĖ¬ 3D µĪå’╝īµłæõ╗¼ķ”¢Õģłķ£ĆĶ”üĶ«Īń«Śµ¢░ńÜäµĪåńÜäõĖŁÕ┐ā’╝īńäČÕÉÄÕ░åµŚŗĶĮ¼Ķ¦ÆÕ║”µĘ╗ÕŖĀÕł░ĶĮ¼ÕÉæĶ¦Æ (yaw)ŃĆé
+
+Ķ»”Ķ¦ü[µŁżÕżä](https://github.com/open-mmlab/mmdetection3d/blob/master/mmdet3d/core/bbox/structures/cam_box3d.py)õ╗ŻńĀüõ║åĶ¦Żµø┤ÕżÜń╗åĶŖéŃĆé
+
+## ÕĖĖĶ¦üķŚ«ķóś
+
+#### Q1: õĖĵĪåńøĖÕģ│ńÜäń«ŚÕŁÉµś»ÕÉ”ķĆéńö©õ║ĵēƵ£ēÕØɵĀćń│╗ń▒╗Õ×ŗ’╝¤
+
+ÕÉ”ŃĆéõŠŗÕ”é’╝ī[ńö©õ║Ä RoI-Aware Pooling ńÜäń«ŚÕŁÉ](https://github.com/open-mmlab/mmcv/blob/master/mmcv/ops/roiaware_pool3d.py)ÕŬķĆéńö©õ║ĵĘ▒Õ║”ÕØɵĀćń│╗ÕÆīµ┐ĆÕģēķøĘĶŠŠÕØɵĀćń│╗õĖŗńÜäµĪåŃĆéńö▒õ║ÄÕ”éµ×£õ╗ÄõĖŖµ¢╣ń£ŗ’╝īµŚŗĶĮ¼µś»ķĪ║µŚČķÆłńÜä’╝īµēĆõ╗ź KITTI µĢ░µŹ«ķøå[Ķ┐Öķćī](https://github.com/open-mmlab/mmdetection3d/blob/master/mmdet3d/core/evaluation/kitti_utils.py)ńÜäĶ»äõ╝░ÕćĮµĢ░õ╗ģķĆéńö©õ║ÄńøĖµ£║ÕØɵĀćń│╗õĖŗńÜäµĪåŃĆé
+
+Õ»╣õ║ĵ»ÅõĖ¬ÕÆīµĪåńøĖÕģ│ńÜäń«ŚÕŁÉ’╝īµłæõ╗¼µ│©µśÄõ║åÕģȵēĆķĆéńö©ńÜäµĪåń▒╗Õ×ŗŃĆé
+
+#### Q2: Õ£©µ»ÅõĖ¬ÕØɵĀćń│╗õĖŁ’╝īõĖēõĖ¬ĶĮ┤µś»ÕÉ”ÕłåÕł½ÕćåńĪ«Õ£░µīćÕÉæÕÅ│õŠ¦ŃĆüÕēŹµ¢╣ÕÆīÕ£░ķØó’╝¤
+
+ÕÉ”ŃĆéõŠŗÕ”éÕ£© KITTI õĖŁ’╝īõ╗ÄńøĖµ£║ÕØɵĀćń│╗ĶĮ¼µŹóõĖ║µ┐ĆÕģēķøĘĶŠŠÕØɵĀćń│╗µŚČ’╝īµłæõ╗¼ķ£ĆĶ”üõĖĆõĖ¬µĀĪÕćåń¤®ķśĄŃĆé
+
+#### Q3: µĪåõĖŁĶĮ¼ÕÉæĶ¦Æ (yaw) $2\\pi$ ńÜäńøĖõĮŹÕĘ«Õ”éõĮĢÕĮ▒ÕōŹĶ»äõ╝░’╝¤
+
+Õ»╣õ║Äõ║żÕ╣ȵ»ö (IoU) Ķ«Īń«Ś’╝īĶĮ¼ÕÉæĶ¦Æ (yaw) µ£ē $2\\pi$ ńÜäńøĖõĮŹÕĘ«ńÜäõĖżõĖ¬µĪåµś»ńøĖÕÉīńÜä’╝īµēĆõ╗źõĖŹõ╝ÜÕĮ▒ÕōŹĶ»äõ╝░ŃĆé
+
+Õ»╣õ║ÄĶ¦ÆÕ║”ķó䵥ŗĶ»äõ╝░’╝īõŠŗÕ”é NuScenes õĖŁńÜä NDS µīćµĀćÕÆī KITTI õĖŁńÜä AOS µīćµĀć’╝īõ╝ÜÕģłÕ»╣ķó䵥ŗµĪåńÜäĶ¦ÆÕ║”Ķ┐øĶĪīµĀćÕćåÕī¢’╝īÕøĀµŁż $2\\pi$ ńÜäńøĖõĮŹÕĘ«õĖŹõ╝ܵö╣ÕÅśń╗ōµ×£ŃĆé
+
+#### Q4: µĪåõĖŁĶĮ¼ÕÉæĶ¦Æ (yaw) $\\pi$ ńÜäńøĖõĮŹÕĘ«Õ”éõĮĢÕĮ▒ÕōŹĶ»äõ╝░’╝¤
+
+Õ»╣õ║Äõ║żÕ╣ȵ»ö (IoU) Ķ«Īń«Ś’╝īĶĮ¼ÕÉæĶ¦Æ (yaw) µ£ē $\\pi$ ńÜäńøĖõĮŹÕĘ«ńÜäõĖżõĖ¬µĪåµś»ńøĖÕÉīńÜä’╝īµēĆõ╗źõĖŹõ╝ÜÕĮ▒ÕōŹĶ»äõ╝░ŃĆé
+
+ńäČĶĆī’╝īÕ»╣õ║ÄĶ¦ÆÕ║”ķó䵥ŗĶ»äõ╝░’╝īĶ┐Öõ╝ÜÕ»╝Ķć┤Õ«īÕģ©ńøĖÕÅŹńÜäµ¢╣ÕÉæŃĆé
+
+ĶĆāĶÖæõĖĆĶŠåµ▒ĮĶĮ”’╝īĶĮ¼ÕÉæĶ¦Æ (yaw) µś»µ▒ĮĶĮ”ÕēŹķā©µ¢╣ÕÉæõĖÄ x ĶĮ┤µŁŻµ¢╣ÕÉæõ╣ŗķŚ┤ńÜäÕż╣Ķ¦ÆŃĆéÕ”éµ×£µłæõ╗¼Õ░åĶ»źĶ¦ÆÕ║”Õó×ÕŖĀ $\\pi$’╝īĶĮ”ÕēŹķā©Õ░åÕÅśµłÉĶĮ”ÕÉÄķā©ŃĆé
+
+Õ»╣õ║ĵ¤Éõ║øń▒╗Õł½’╝īõŠŗÕ”éķÜ£ńóŹńē®’╝īÕēŹÕÉĵ▓Īµ£ēÕī║Õł½’╝īÕøĀµŁż $\\pi$ ńÜäńøĖõĮŹÕĘ«õĖŹõ╝ÜÕ»╣Ķ¦ÆÕ║”ķó䵥ŗÕłåµĢ░õ║¦ńö¤ÕĮ▒ÕōŹŃĆé
diff --git a/internlm_langchain/knowledge_base/MMDetection3D/content/customize_dataset.md b/internlm_langchain/knowledge_base/MMDetection3D/content/customize_dataset.md
new file mode 100644
index 00000000..a481fa26
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection3D/content/customize_dataset.md
@@ -0,0 +1,500 @@
+# Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøå
+
+Õ£©µ£¼ĶŖéõĖŁ’╝īµé©Õ░åõ║åĶ¦ŻÕ”éõĮĢõĮ┐ńö©Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåĶ«Łń╗āÕÆīµĄŗĶ»ĢķóäÕ«Üõ╣ēµ©ĪÕ×ŗŃĆé
+
+Õ¤║µ£¼µŁźķ¬żÕ”éõĖŗ’╝Ü
+
+1. ÕćåÕżćµĢ░µŹ«
+2. ÕćåÕżćķģŹńĮ«µ¢ćõ╗Č
+3. Õ£©Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåõĖŖĶ«Łń╗ā’╝īµĄŗĶ»ĢÕÆīµÄ©ńÉ嵩ĪÕ×ŗ
+
+## µĢ░µŹ«ÕćåÕżć
+
+ńÉåµā│µāģÕåĄõĖŗµłæõ╗¼ÕÅ»õ╗źķ揵¢░ń╗äń╗ćĶć¬Õ«Üõ╣ēńÜäÕĤզŗµĢ░µŹ«Õ╣ČÕ░åµĀćµ│©µĀ╝Õ╝ÅĶĮ¼µŹóµłÉ KITTI ķŻÄµĀ╝ŃĆéõĮåµś»’╝īĶĆāĶÖæÕł░Õ»╣õ║ÄĶć¬Õ«Üõ╣ēµĢ░µŹ«ķøåĶĆīĶ©Ć’╝īKITTI µĀ╝Õ╝ÅńÜäµĀĪÕćåµ¢ćõ╗ČÕÆī 3D µĀćµ│©ķÜŠõ╗źĶÄĘÕŠŚ’╝īÕøĀµŁżµłæõ╗¼Õ£©µ¢ćµĪŻõĖŁõ╗ŗń╗ŹÕ¤║µ£¼ńÜäµĢ░µŹ«µĀ╝Õ╝ÅŃĆé
+
+### Õ¤║µ£¼µĢ░µŹ«µĀ╝Õ╝Å
+
+#### ńé╣õ║æµĀ╝Õ╝Å
+
+ńø«ÕēŹ’╝īµłæõ╗¼ÕŬµö»µīü `.bin` µĀ╝Õ╝ÅńÜäńé╣õ║æńö©õ║ÄĶ«Łń╗āÕÆīµÄ©ńÉåŃĆéÕ£©Ķ«Łń╗āĶć¬ÕĘ▒ńÜäµĢ░µŹ«ķøåõ╣ŗÕēŹ’╝īķ£ĆĶ”üÕ░åÕģČÕ«āµĀ╝Õ╝ÅńÜäńé╣õ║æµ¢ćõ╗ČĶĮ¼µŹóµłÉ `.bin` µ¢ćõ╗ČŃĆéÕĖĖĶ¦üńÜäńé╣õ║æµĢ░µŹ«µĀ╝Õ╝ÅÕīģµŗ¼ `.pcd` ÕÆī `.las`’╝īµłæõ╗¼ÕłŚõĖŠõ║åõĖĆõ║øÕ╝Ƶ║ÉÕĘźÕģĘõĮ£õĖ║ÕÅéĶĆāŃĆé
+
+1. `.pcd` ĶĮ¼µŹóµłÉ `.bin`’╝Ühttps://github.com/DanielPollithy/pypcd
+
+- µé©ÕÅ»õ╗źķĆÜĶ┐ćõ╗źõĖŗµīćõ╗żÕ«ēĶŻģ `pypcd`’╝Ü
+
+ ```bash
+ pip install git+https://github.com/DanielPollithy/pypcd.git
+ ```
+
+- µé©ÕÅ»õ╗źõĮ┐ńö©õ╗źõĖŗĶäܵ£¼Ķ»╗ÕÅ¢ `.pcd` µ¢ćõ╗Č’╝īÕ╣ČÕ░åÕģČĶĮ¼µŹóµłÉ `.bin` µĀ╝Õ╝ÅµØźõ┐ØÕŁś’╝Ü
+
+ ```python
+ import numpy as np
+ from pypcd import pypcd
+
+ pcd_data = pypcd.PointCloud.from_path('point_cloud_data.pcd')
+ points = np.zeros([pcd_data.width, 4], dtype=np.float32)
+ points[:, 0] = pcd_data.pc_data['x'].copy()
+ points[:, 1] = pcd_data.pc_data['y'].copy()
+ points[:, 2] = pcd_data.pc_data['z'].copy()
+ points[:, 3] = pcd_data.pc_data['intensity'].copy().astype(np.float32)
+ with open('point_cloud_data.bin', 'wb') as f:
+ f.write(points.tobytes())
+ ```
+
+2. `.las` ĶĮ¼µŹóµłÉ `.bin`’╝ÜÕĖĖĶ¦üńÜäĶĮ¼µŹóµĄüń©ŗõĖ║ `.las -> .pcd -> .bin`’╝ī`.las -> .pcd` ńÜäĶĮ¼µŹóÕÅ»õ╗źńö©Ķ»ź[ÕĘźÕģĘ](https://github.com/Hitachi-Automotive-And-Industry-Lab/semantic-segmentation-editor)Õ«×ńÄ░ŃĆé
+
+#### µĀćńŁŠµĀ╝Õ╝Å
+
+µ£ĆÕ¤║µ£¼ńÜäõ┐Īµü»’╝ܵ»ÅõĖ¬Õ£║µÖ»ńÜä 3D ĶŠ╣ńĢīµĪåÕÆīń▒╗Õł½µĀćńŁŠÕ║öĶ»źÕīģÕɽգ© `.txt` µĀćµ│©µ¢ćõ╗ČõĖŁŃĆéµ»ÅõĖĆĶĪīõ╗ŻĶĪ©ńē╣Õ«ÜÕ£║µÖ»ńÜäõĖĆõĖ¬ 3D µĪå’╝īÕ”éõĖŗµēĆńż║’╝Ü
+
+```
+# µĀ╝Õ╝Å’╝Ü[x, y, z, dx, dy, dz, yaw, category_name]
+1.23 1.42 0.23 3.96 1.65 1.55 1.56 Car
+3.51 2.15 0.42 1.05 0.87 1.86 1.23 Pedestrian
+...
+```
+
+**µ│©µäÅ**’╝ÜÕ»╣õ║ÄĶć¬Õ«Üõ╣ēµĢ░µŹ«ķøåńÜäĶ»äõ╝░µłæõ╗¼ńø«ÕēŹÕŬµö»µīü KITTI Ķ»äõ╝░µ¢╣µ│ĢŃĆé
+
+3D µĪåÕ║öÕŁśÕé©Õ£©ń╗¤õĖĆńÜä 3D ÕØɵĀćń│╗õĖŁŃĆé
+
+#### µĀĪÕćåµĀ╝Õ╝Å
+
+Õ»╣õ║ĵ»ÅõĖ¬µ┐ĆÕģēķøĘĶŠŠµöČķøåńÜäńé╣õ║æµĢ░µŹ«’╝īķĆÜÕĖĖõ╝ÜĶ┐øĶĪīĶ׏ÕÉłÕ╣ČĶĮ¼µŹóÕł░ńē╣Õ«ÜńÜäµ┐ĆÕģēķøĘĶŠŠÕØɵĀćń│╗ŃĆéÕøĀµŁż’╝īµĀĪÕćåõ┐Īµü»µ¢ćõ╗ČõĖŁķĆÜÕĖĖÕ║öĶ»źÕīģÕɽµ»ÅõĖ¬ńøĖµ£║ńÜäÕåģÕÅéń¤®ķśĄÕÆīµ┐ĆÕģēķøĘĶŠŠÕł░µ»ÅõĖ¬ńøĖµ£║ńÜäÕż¢ÕÅéĶĮ¼µŹóń¤®ķśĄ’╝īÕ╣Čõ┐ØÕŁśÕ£© `.txt` µĀĪÕćåµ¢ćõ╗ČõĖŁ’╝īÕģČõĖŁ `Px` ĶĪ©ńż║ `camera_x` ńÜäÕåģÕÅéń¤®ķśĄ’╝ī`lidar2camx` ĶĪ©ńż║ `lidar` Õł░ `camera_x` ńÜäÕż¢ÕÅéĶĮ¼µŹóń¤®ķśĄŃĆé
+
+```
+P0
+P1
+P2
+P3
+P4
+...
+lidar2cam0
+lidar2cam1
+lidar2cam2
+lidar2cam3
+lidar2cam4
+...
+```
+
+### ÕĤզŗµĢ░µŹ«ń╗ōµ×ä
+
+#### Õ¤║õ║ĵ┐ĆÕģēķøĘĶŠŠńÜä 3D µŻĆµĄŗ
+
+Õ¤║õ║ĵ┐ĆÕģēķøĘĶŠŠńÜä 3D ńø«µĀ浯ƵĄŗÕĤզŗµĢ░µŹ«ķĆÜÕĖĖń╗äń╗浳ÉÕ”éõĖŗµĀ╝Õ╝Å’╝īÕģČõĖŁ `ImageSets` ÕīģÕÉ½ÕłÆÕłåµ¢ćõ╗Č’╝īµī浜ÄÕō¬õ║øµ¢ćõ╗ČÕ▒×õ║ÄĶ«Łń╗ā/ķ¬īĶ»üķøå’╝ī`points` ÕīģÕÉ½ÕŁśÕ驵łÉ `.bin` µĀ╝Õ╝ÅńÜäńé╣õ║æµĢ░µŹ«’╝ī`labels` ÕīģÕɽ 3D µŻĆµĄŗńÜäµĀćńŁŠµ¢ćõ╗ČŃĆé
+
+```
+mmdetection3d
+Ōö£ŌöĆŌöĆ mmdet3d
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+Ōö£ŌöĆŌöĆ data
+Ōöé Ōö£ŌöĆŌöĆ custom
+Ōöé Ōöé Ōö£ŌöĆŌöĆ ImageSets
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ train.txt
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ val.txt
+Ōöé Ōöé Ōö£ŌöĆŌöĆ points
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ 000000.bin
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ 000001.bin
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ ...
+Ōöé Ōöé Ōö£ŌöĆŌöĆ labels
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ 000000.txt
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ 000001.txt
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ ...
+```
+
+#### Õ¤║õ║ÄĶ¦åĶ¦ēńÜä 3D µŻĆµĄŗ
+
+Õ¤║õ║ÄĶ¦åĶ¦ēńÜä 3D ńø«µĀ浯ƵĄŗÕĤզŗµĢ░µŹ«ķĆÜÕĖĖń╗äń╗浳ÉÕ”éõĖŗµĀ╝Õ╝Å’╝īÕģČõĖŁ `ImageSets` ÕīģÕÉ½ÕłÆÕłåµ¢ćõ╗Č’╝īµī浜ÄÕō¬õ║øµ¢ćõ╗ČÕ▒×õ║ÄĶ«Łń╗ā/ķ¬īĶ»üķøå’╝ī`images` ÕīģÕɽµØźĶć¬õĖŹÕÉīńøĖµ£║ńÜäÕøŠÕāÅ’╝īõŠŗÕ”é `camera_x` ĶÄĘÕŠŚńÜäÕøŠÕāÅÕ║öµöŠÕ£© `images/images_x` õĖŗ’╝ī`calibs` ÕīģÕɽµĀĪÕćåõ┐Īµü»µ¢ćõ╗Č’╝īÕģČõĖŁÕŁśÕé©õ║åµ»ÅõĖ¬ńøĖµ£║ńÜäÕåģÕÅéń¤®ķśĄ’╝ī`labels` ÕīģÕɽ 3D µŻĆµĄŗńÜäµĀćńŁŠµ¢ćõ╗ČŃĆé
+
+```
+mmdetection3d
+Ōö£ŌöĆŌöĆ mmdet3d
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+Ōö£ŌöĆŌöĆ data
+Ōöé Ōö£ŌöĆŌöĆ custom
+Ōöé Ōöé Ōö£ŌöĆŌöĆ ImageSets
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ train.txt
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ val.txt
+Ōöé Ōöé Ōö£ŌöĆŌöĆ calibs
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ 000000.txt
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ 000001.txt
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ ...
+Ōöé Ōöé Ōö£ŌöĆŌöĆ images
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ images_0
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ 000000.png
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ 000001.png
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ ...
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ images_1
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ images_2
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ ...
+Ōöé Ōöé Ōö£ŌöĆŌöĆ labels
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ 000000.txt
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ 000001.txt
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ ...
+```
+
+#### ÕżÜµ©ĪµĆü 3D µŻĆµĄŗ
+
+ÕżÜµ©ĪµĆü 3D ńø«µĀ浯ƵĄŗÕĤզŗµĢ░µŹ«ķĆÜÕĖĖń╗äń╗浳ÉÕ”éõĖŗµĀ╝Õ╝ÅŃĆéõĖŹÕÉīõ║ÄÕ¤║õ║ÄĶ¦åĶ¦ēńÜä 3D ńø«µĀ浯ƵĄŗ’╝ī`calibs` ķćīńÜäµĀĪÕćåõ┐Īµü»µ¢ćõ╗ČÕŁśÕé©õ║åµ»ÅõĖ¬ńøĖµ£║ńÜäÕåģÕÅéń¤®ķśĄÕÆīÕż¢ÕÅéń¤®ķśĄŃĆé
+
+```
+mmdetection3d
+Ōö£ŌöĆŌöĆ mmdet3d
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+Ōö£ŌöĆŌöĆ data
+Ōöé Ōö£ŌöĆŌöĆ custom
+Ōöé Ōöé Ōö£ŌöĆŌöĆ ImageSets
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ train.txt
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ val.txt
+Ōöé Ōöé Ōö£ŌöĆŌöĆ calibs
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ 000000.txt
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ 000001.txt
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ ...
+Ōöé Ōöé Ōö£ŌöĆŌöĆ points
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ 000000.bin
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ 000001.bin
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ ...
+Ōöé Ōöé Ōö£ŌöĆŌöĆ images
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ images_0
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ 000000.png
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ 000001.png
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ ...
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ images_1
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ images_2
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ ...
+Ōöé Ōöé Ōö£ŌöĆŌöĆ labels
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ 000000.txt
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ 000001.txt
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ ...
+```
+
+#### Õ¤║õ║ĵ┐ĆÕģēķøĘĶŠŠńÜä 3D Ķ»Łõ╣ēÕłåÕē▓
+
+Õ¤║õ║ĵ┐ĆÕģēķøĘĶŠŠńÜä 3D Ķ»Łõ╣ēÕłåÕē▓ÕĤզŗµĢ░µŹ«ķĆÜÕĖĖń╗äń╗浳ÉÕ”éõĖŗµĀ╝Õ╝Å’╝īÕģČõĖŁ `ImageSets` ÕīģÕÉ½ÕłÆÕłåµ¢ćõ╗Č’╝īµī浜ÄÕō¬õ║øµ¢ćõ╗ČÕ▒×õ║ÄĶ«Łń╗ā/ķ¬īĶ»üķøå’╝ī`points` ÕīģÕɽńé╣õ║æµĢ░µŹ«’╝ī`semantic_mask` ÕīģÕɽķĆÉńé╣ń║¦µĀćńŁŠŃĆé
+
+```
+mmdetection3d
+Ōö£ŌöĆŌöĆ mmdet3d
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+Ōö£ŌöĆŌöĆ data
+Ōöé Ōö£ŌöĆŌöĆ custom
+Ōöé Ōöé Ōö£ŌöĆŌöĆ ImageSets
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ train.txt
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ val.txt
+Ōöé Ōöé Ōö£ŌöĆŌöĆ points
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ 000000.bin
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ 000001.bin
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ ...
+Ōöé Ōöé Ōö£ŌöĆŌöĆ semantic_mask
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ 000000.bin
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ 000001.bin
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ ...
+```
+
+### µĢ░µŹ«ĶĮ¼µŹó
+
+µīēńģ¦µłæõ╗¼ńÜäĶ»┤µśÄÕćåÕżćÕźĮÕĤզŗµĢ░µŹ«ÕÉÄ’╝īµé©ÕÅ»õ╗źńø┤µÄźõĮ┐ńö©õ╗źõĖŗÕæĮõ╗żńö¤µłÉĶ«Łń╗ā/ķ¬īĶ»üõ┐Īµü»µ¢ćõ╗ČŃĆé
+
+```bash
+python tools/create_data.py custom --root-path ./data/custom --out-dir ./data/custom --extra-tag custom
+```
+
+## Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåńż║õŠŗ
+
+Õ£©Õ«īµłÉµĢ░µŹ«ÕćåÕżćÕÉÄ’╝īµłæõ╗¼ÕÅ»õ╗źÕ£© `mmdet3d/datasets/my_dataset.py` õĖŁÕłøÕ╗║õĖĆõĖ¬µ¢░ńÜäµĢ░µŹ«ķøåµØźÕŖĀĶĮĮµĢ░µŹ«ŃĆé
+
+```python
+import mmengine
+
+from mmdet3d.registry import DATASETS
+from .det3d_dataset import Det3DDataset
+
+
+@DATASETS.register_module()
+class MyDataset(Det3DDataset):
+
+ # µø┐µŹóµłÉĶć¬Õ«Üõ╣ē pkl õ┐Īµü»µ¢ćõ╗ČķćīńÜäµēƵ£ēń▒╗Õł½
+ METAINFO = {
+ 'classes': ('Pedestrian', 'Cyclist', 'Car')
+ }
+
+ def parse_ann_info(self, info):
+ """Process the `instances` in data info to `ann_info`.
+
+ Args:
+ info (dict): Data information of single data sample.
+
+ Returns:
+ dict: Annotation information consists of the following keys:
+
+ - gt_bboxes_3d (:obj:`LiDARInstance3DBoxes`):
+ 3D ground truth bboxes.
+ - gt_labels_3d (np.ndarray): Labels of ground truths.
+ """
+ ann_info = super().parse_ann_info(info)
+ if ann_info is None:
+ ann_info = dict()
+ # ń®║Õ«×õŠŗ
+ ann_info['gt_bboxes_3d'] = np.zeros((0, 7), dtype=np.float32)
+ ann_info['gt_labels_3d'] = np.zeros(0, dtype=np.int64)
+
+ # Ķ┐ćµ╗żµÄēµ▓Īµ£ēÕ£©Ķ«Łń╗āõĖŁõĮ┐ńö©ńÜäń▒╗Õł½
+ ann_info = self._remove_dontcare(ann_info)
+ gt_bboxes_3d = LiDARInstance3DBoxes(ann_info['gt_bboxes_3d'])
+ ann_info['gt_bboxes_3d'] = gt_bboxes_3d
+ return ann_info
+```
+
+µĢ░µŹ«ķóäÕżäńÉåÕÉÄ’╝īńö©µłĘÕÅ»õ╗źķĆÜĶ┐ćõ╗źõĖŗõĖżõĖ¬µŁźķ¬żµØźĶ«Łń╗āĶć¬Õ«Üõ╣ēµĢ░µŹ«ķøå’╝Ü
+
+1. õ┐«µö╣ķģŹńĮ«µ¢ćõ╗ČµØźõĮ┐ńö©Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåŃĆé
+2. ķ¬īĶ»üĶć¬Õ«Üõ╣ēµĢ░µŹ«ķøåµĀćµ│©ńÜ䵣ŻńĪ«µĆ¦ŃĆé
+
+Ķ┐Öķćīµłæõ╗¼õ╗źÕ£©Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåõĖŖĶ«Łń╗ā PointPillars õĖ║õŠŗ’╝Ü
+
+### ÕćåÕżćķģŹńĮ«
+
+Ķ┐Öķćīµłæõ╗¼µ╝öńż║õĖĆõĖ¬ń║»ńé╣õ║æĶ«Łń╗āńÜäķģŹńĮ«ńż║õŠŗ’╝Ü
+
+#### ÕćåÕżćµĢ░µŹ«ķøåķģŹńĮ«
+
+Õ£© `configs/_base_/datasets/custom.py` õĖŁ’╝Ü
+
+```python
+# µĢ░µŹ«ķøåĶ«ŠńĮ«
+dataset_type = 'MyDataset'
+data_root = 'data/custom/'
+class_names = ['Pedestrian', 'Cyclist', 'Car'] # µø┐µŹóµłÉµé©ńÜäµĢ░µŹ«ķøåń▒╗Õł½
+point_cloud_range = [0, -40, -3, 70.4, 40, 1] # µĀ╣µŹ«µé©ńÜäµĢ░µŹ«ķøåĶ┐øĶĪīĶ░āµĢ┤
+input_modality = dict(use_lidar=True, use_camera=False)
+metainfo = dict(classes=class_names)
+
+train_pipeline = [
+ dict(
+ type='LoadPointsFromFile',
+ coord_type='LIDAR',
+ load_dim=4, # µø┐µŹóµłÉµé©ńÜäńé╣õ║æµĢ░µŹ«ń╗┤Õ║”
+ use_dim=4), # µø┐µŹóµłÉÕ£©Ķ«Łń╗āÕÆīµÄ©ńÉåµŚČÕ«×ķÖģõĮ┐ńö©ńÜäń╗┤Õ║”
+ dict(
+ type='LoadAnnotations3D',
+ with_bbox_3d=True,
+ with_label_3d=True),
+ dict(
+ type='ObjectNoise',
+ num_try=100,
+ translation_std=[1.0, 1.0, 0.5],
+ global_rot_range=[0.0, 0.0],
+ rot_range=[-0.78539816, 0.78539816]),
+ dict(type='RandomFlip3D', flip_ratio_bev_horizontal=0.5),
+ dict(
+ type='GlobalRotScaleTrans',
+ rot_range=[-0.78539816, 0.78539816],
+ scale_ratio_range=[0.95, 1.05]),
+ dict(type='PointsRangeFilter', point_cloud_range=point_cloud_range),
+ dict(type='ObjectRangeFilter', point_cloud_range=point_cloud_range),
+ dict(type='PointShuffle'),
+ dict(
+ type='Pack3DDetInputs',
+ keys=['points', 'gt_bboxes_3d', 'gt_labels_3d'])
+]
+test_pipeline = [
+ dict(
+ type='LoadPointsFromFile',
+ coord_type='LIDAR',
+ load_dim=4, # µø┐µŹóµłÉµé©ńÜäńé╣õ║æµĢ░µŹ«ń╗┤Õ║”
+ use_dim=4),
+ dict(type='Pack3DDetInputs', keys=['points'])
+]
+# õĖ║ÕÅ»Ķ¦åÕī¢ķśČµ«ĄńÜäµĢ░µŹ«ÕÆī GT ÕŖĀĶĮĮµ×äķĆĀµĄüµ░┤ń║┐
+eval_pipeline = [
+ dict(type='LoadPointsFromFile', coord_type='LIDAR', load_dim=4, use_dim=4),
+ dict(type='Pack3DDetInputs', keys=['points']),
+]
+train_dataloader = dict(
+ batch_size=6,
+ num_workers=4,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type='RepeatDataset',
+ times=2,
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ ann_file='custom_infos_train.pkl', # µīćիܵé©ńÜäĶ«Łń╗ā pkl õ┐Īµü»
+ data_prefix=dict(pts='points'),
+ pipeline=train_pipeline,
+ modality=input_modality,
+ test_mode=False,
+ metainfo=metainfo,
+ box_type_3d='LiDAR')))
+val_dataloader = dict(
+ batch_size=1,
+ num_workers=1,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_prefix=dict(pts='points'),
+ ann_file='custom_infos_val.pkl', # µīćիܵé©ńÜäķ¬īĶ»ü pkl õ┐Īµü»
+ pipeline=test_pipeline,
+ modality=input_modality,
+ test_mode=True,
+ metainfo=metainfo,
+ box_type_3d='LiDAR'))
+val_evaluator = dict(
+ type='KittiMetric',
+ ann_file=data_root + 'custom_infos_val.pkl', # µīćիܵé©ńÜäķ¬īĶ»ü pkl õ┐Īµü»
+ metric='bbox')
+```
+
+#### ÕćåÕżćµ©ĪÕ×ŗķģŹńĮ«
+
+Õ»╣õ║ÄÕ¤║õ║ÄõĮōń┤ĀÕī¢ńÜ䵯ƵĄŗÕÖ©Õ”é SECOND’╝īPointPillars ÕÅŖ CenterPoint’╝īńé╣õ║æĶīāÕø┤’╝łpoint cloud range’╝ēÕÆīõĮōń┤ĀÕż¦Õ░Å’╝łvoxel size’╝ēÕ║öĶ»źµĀ╣µŹ«µé©ńÜäµĢ░µŹ«ķøåÕüÜĶ░āµĢ┤ŃĆéńÉåĶ«║õĖŖ’╝ī`voxel_size` ÕÆī `point_cloud_range` ńÜäĶ«ŠńĮ«µś»ńøĖÕģ│ĶüöńÜäŃĆéĶ«ŠńĮ«ĶŠāÕ░ÅńÜä `voxel_size` Õ░åÕó×ÕŖĀõĮōń┤ĀµĢ░õ╗źÕÅŖńøĖÕ║öńÜäÕåģÕŁśµČłĶĆŚŃĆ鵣żÕż¢’╝īķ£ĆĶ”üµ│©µäÅõ╗źõĖŗķŚ«ķóś’╝Ü
+
+Õ”éµ×£Õ░å `point_cloud_range` ÕÆī `voxel_size` ÕłåÕł½Ķ«ŠńĮ«µłÉ `[0, -40, -3, 70.4, 40, 1]` ÕÆī `[0.05, 0.05, 0.1]`’╝īķéŻõ╣łõĖŁķŚ┤ńē╣ÕŠüÕøŠńÜäÕĮóńŖČÕ║öĶ»źõĖ║ `[(1-(-3))/0.1+1, (40-(-40))/0.05, (70.4-0)/0.05]=[41, 1600, 1408]`ŃĆéµø┤µö╣ `point_cloud_range` µŚČ’╝īĶ»ĘĶ«░ÕŠŚõŠØµŹ« `voxel_size` µø┤µö╣ `middle_encoder` ķćīõĖŁķŚ┤ńē╣ÕŠüÕøŠńÜäÕĮóńŖČŃĆé
+
+Õģ│õ║Ä `anchor_range` ńÜäĶ«ŠńĮ«’╝īõĖĆĶł¼ķ£ĆĶ”üµĀ╣µŹ«µĢ░µŹ«ķøåÕüÜĶ░āµĢ┤ŃĆéķ£ĆĶ”üµ│©µäÅńÜ䵜»’╝ī`z` ÕĆ╝ķ£ĆĶ”üµĀ╣µŹ«ńé╣õ║æńÜäõĮŹńĮ«ÕüÜńøĖÕ║öĶ░āµĢ┤’╝īÕģĘõĮōĶ»ĘÕÅéĶĆāµŁż [issue](https://github.com/open-mmlab/mmdetection3d/issues/986)ŃĆé
+
+Õģ│õ║Ä `anchor_size` ńÜäĶ«ŠńĮ«’╝īķĆÜÕĖĖķ£ĆĶ”üĶ«Īń«ŚµĢ┤õĖ¬Ķ«Łń╗āķøåõĖŁńø«µĀćńÜäķĢ┐ŃĆüÕ«ĮŃĆüķ½śńÜäÕ╣│ÕØćÕĆ╝õĮ£õĖ║ `anchor_size`’╝īõ╗źĶÄĘÕŠŚµ£ĆÕźĮńÜäń╗ōµ×£ŃĆé
+
+Õ£© `configs/_base_/models/pointpillars_hv_secfpn_custom.py` õĖŁ’╝Ü
+
+```python
+voxel_size = [0.16, 0.16, 4] # µĀ╣µŹ«µé©ńÜäµĢ░µŹ«ķøåÕüÜĶ░āµĢ┤
+point_cloud_range = [0, -39.68, -3, 69.12, 39.68, 1] # µĀ╣µŹ«µé©ńÜäµĢ░µŹ«ķøåÕüÜĶ░āµĢ┤
+model = dict(
+ type='VoxelNet',
+ data_preprocessor=dict(
+ type='Det3DDataPreprocessor',
+ voxel=True,
+ voxel_layer=dict(
+ max_num_points=32,
+ point_cloud_range=point_cloud_range,
+ voxel_size=voxel_size,
+ max_voxels=(16000, 40000))),
+ voxel_encoder=dict(
+ type='PillarFeatureNet',
+ in_channels=4,
+ feat_channels=[64],
+ with_distance=False,
+ voxel_size=voxel_size,
+ point_cloud_range=point_cloud_range),
+ # `output_shape` ķ£ĆĶ”üµĀ╣µŹ« `point_cloud_range` ÕÆī `voxel_size` ÕüÜńøĖÕ║öĶ░āµĢ┤
+ middle_encoder=dict(
+ type='PointPillarsScatter', in_channels=64, output_shape=[496, 432]),
+ backbone=dict(
+ type='SECOND',
+ in_channels=64,
+ layer_nums=[3, 5, 5],
+ layer_strides=[2, 2, 2],
+ out_channels=[64, 128, 256]),
+ neck=dict(
+ type='SECONDFPN',
+ in_channels=[64, 128, 256],
+ upsample_strides=[1, 2, 4],
+ out_channels=[128, 128, 128]),
+ bbox_head=dict(
+ type='Anchor3DHead',
+ num_classes=3,
+ in_channels=384,
+ feat_channels=384,
+ use_direction_classifier=True,
+ assign_per_class=True,
+ # µĀ╣µŹ«µé©ńÜäµĢ░µŹ«ķøåĶ░āµĢ┤ `ranges` ÕÆī `sizes`
+ anchor_generator=dict(
+ type='AlignedAnchor3DRangeGenerator',
+ ranges=[
+ [0, -39.68, -0.6, 69.12, 39.68, -0.6],
+ [0, -39.68, -0.6, 69.12, 39.68, -0.6],
+ [0, -39.68, -1.78, 69.12, 39.68, -1.78],
+ ],
+ sizes=[[0.8, 0.6, 1.73], [1.76, 0.6, 1.73], [3.9, 1.6, 1.56]],
+ rotations=[0, 1.57],
+ reshape_out=False),
+ diff_rad_by_sin=True,
+ bbox_coder=dict(type='DeltaXYZWLHRBBoxCoder'),
+ loss_cls=dict(
+ type='mmdet.FocalLoss',
+ use_sigmoid=True,
+ gamma=2.0,
+ alpha=0.25,
+ loss_weight=1.0),
+ loss_bbox=dict(
+ type='mmdet.SmoothL1Loss', beta=1.0 / 9.0, loss_weight=2.0),
+ loss_dir=dict(
+ type='mmdet.CrossEntropyLoss', use_sigmoid=False,
+ loss_weight=0.2)),
+ # µ©ĪÕ×ŗĶ«Łń╗āÕÆīµĄŗĶ»ĢĶ«ŠńĮ«
+ train_cfg=dict(
+ assigner=[
+ dict( # for Pedestrian
+ type='Max3DIoUAssigner',
+ iou_calculator=dict(type='BboxOverlapsNearest3D'),
+ pos_iou_thr=0.5,
+ neg_iou_thr=0.35,
+ min_pos_iou=0.35,
+ ignore_iof_thr=-1),
+ dict( # for Cyclist
+ type='Max3DIoUAssigner',
+ iou_calculator=dict(type='BboxOverlapsNearest3D'),
+ pos_iou_thr=0.5,
+ neg_iou_thr=0.35,
+ min_pos_iou=0.35,
+ ignore_iof_thr=-1),
+ dict( # for Car
+ type='Max3DIoUAssigner',
+ iou_calculator=dict(type='BboxOverlapsNearest3D'),
+ pos_iou_thr=0.6,
+ neg_iou_thr=0.45,
+ min_pos_iou=0.45,
+ ignore_iof_thr=-1),
+ ],
+ allowed_border=0,
+ pos_weight=-1,
+ debug=False),
+ test_cfg=dict(
+ use_rotate_nms=True,
+ nms_across_levels=False,
+ nms_thr=0.01,
+ score_thr=0.1,
+ min_bbox_size=0,
+ nms_pre=100,
+ max_num=50))
+```
+
+#### ÕćåÕżćµĢ┤õĮōķģŹńĮ«
+
+µłæõ╗¼Õ░åõĖŖĶ┐░ńÜäµēƵ£ēķģŹńĮ«ń╗äÕÉłÕ£© `configs/pointpillars/pointpillars_hv_secfpn_8xb6_custom.py` µ¢ćõ╗ČõĖŁ’╝Ü
+
+```python
+_base_ = [
+ '../_base_/models/pointpillars_hv_secfpn_custom.py',
+ '../_base_/datasets/custom.py',
+ '../_base_/schedules/cyclic-40e.py', '../_base_/default_runtime.py'
+]
+```
+
+#### ÕÅ»Ķ¦åÕī¢µĢ░µŹ«ķøå’╝łÕÅ»ķĆē’╝ē
+
+õĖ║õ║åķ¬īĶ»üÕćåÕżćńÜäµĢ░µŹ«ÕÆīķģŹńĮ«µś»ÕÉ”µŁŻńĪ«’╝īµłæõ╗¼Õ╗║Ķ««Õ£©Ķ«Łń╗āÕÆīķ¬īĶ»üÕēŹõĮ┐ńö© `tools/misc/browse_dataset.py` Ķäܵ£¼ÕÅ»Ķ¦åÕī¢µĢ░µŹ«ķøåÕÆīµĀćµ│©ŃĆéµø┤ÕżÜń╗åĶŖéĶ»ĘÕÅéĶĆā[ÕÅ»Ķ¦åÕī¢µ¢ćµĪŻ](https://mmdetection3d.readthedocs.io/zh_CN/dev-1.x/user_guides/visualization.html)ŃĆé
+
+## Ķ»äõ╝░
+
+ÕćåÕżćÕźĮµĢ░µŹ«ÕÆīķģŹńĮ«õ╣ŗÕÉÄ’╝īµé©ÕÅ»õ╗źķüĄÕŠ¬µłæõ╗¼ńÜäµ¢ćµĪŻńø┤µÄźĶ┐ÉĶĪīĶ«Łń╗ā/µĄŗĶ»ĢĶäܵ£¼ŃĆé
+
+**µ│©µäÅ**’╝ܵłæõ╗¼õĖ║Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåµÅÉõŠøõ║å KITTI ķŻÄµĀ╝ńÜäĶ»äõ╝░Õ«×ńÄ░µ¢╣µ│ĢŃĆéÕ£©µĢ░µŹ«ķøåķģŹńĮ«õĖŁķ£ĆĶ”üÕīģÕɽՔéõĖŗÕåģÕ«╣’╝Ü
+
+```python
+val_evaluator = dict(
+ type='KittiMetric',
+ ann_file=data_root + 'custom_infos_val.pkl', # µīćիܵé©ńÜäķ¬īĶ»ü pkl õ┐Īµü»
+ metric='bbox')
+```
diff --git a/internlm_langchain/knowledge_base/MMDetection3D/content/customize_models.md b/internlm_langchain/knowledge_base/MMDetection3D/content/customize_models.md
new file mode 100644
index 00000000..677deca3
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection3D/content/customize_models.md
@@ -0,0 +1,619 @@
+# Ķć¬Õ«Üõ╣ēµ©ĪÕ×ŗ
+
+µłæõ╗¼ķĆÜÕĖĖµŖŖµ©ĪÕ×ŗńÜäÕÉäõĖ¬ń╗䵳ɵłÉÕłåÕłåµłÉ 6 ń¦Źń▒╗Õ×ŗ’╝Ü
+
+- ń╝¢ńĀüÕÖ©’╝łencoder’╝ē’╝ÜÕīģµŗ¼ voxel encoder ÕÆī middle encoder ńŁēĶ┐øÕģź backbone ÕēŹµēĆõĮ┐ńö©ńÜäÕ¤║õ║ÄõĮōń┤ĀńÜäµ¢╣µ│Ģ’╝īÕ”é `HardVFE` ÕÆī `PointPillarsScatter`ŃĆé
+- ķ¬©Õ╣▓ńĮæń╗£’╝łbackbone’╝ē’╝ÜķĆÜÕĖĖķććńö© FCN ńĮæń╗£µØźµÅÉÕÅ¢ńē╣ÕŠüÕøŠ’╝īÕ”é `ResNet` ÕÆī `SECOND`ŃĆé
+- ķółķā©ńĮæń╗£’╝łneck’╝ē’╝ÜõĮŹõ║Ä backbones ÕÆī heads õ╣ŗķŚ┤ńÜäń╗䵳ɵ©ĪÕØŚ’╝īÕ”é `FPN` ÕÆī `SECONDFPN`ŃĆé
+- µŻĆµĄŗÕż┤’╝łhead’╝ē’╝Üńö©õ║Äńē╣Õ«Üõ╗╗ÕŖĪńÜäń╗䵳ɵ©ĪÕØŚ’╝īÕ”é`µŻĆµĄŗµĪåńÜäķó䵥ŗ`ÕÆī`µÄ®ńĀüńÜäķó䵥ŗ`ŃĆé
+- RoI µÅÉÕÅ¢ÕÖ©’╝łRoI extractor’╝ē’╝Üńö©õ║Äõ╗Äńē╣ÕŠüÕøŠõĖŁµÅÉÕÅ¢ RoI ńē╣ÕŠüńÜäń╗䵳ɵ©ĪÕØŚ’╝īÕ”é `H3DRoIHead` ÕÆī `PartAggregationROIHead`ŃĆé
+- µŹ¤Õż▒ÕćĮµĢ░’╝łloss’╝ē’╝Üheads õĖŁńö©õ║ÄĶ«Īń«ŚµŹ¤Õż▒ÕćĮµĢ░ńÜäń╗䵳ɵ©ĪÕØŚ’╝īÕ”é `FocalLoss`ŃĆü`L1Loss` ÕÆī `GHMLoss`ŃĆé
+
+## Õ╝ĆÕÅæµ¢░ńÜäń╗䵳ɵ©ĪÕØŚ
+
+### µĘ╗ÕŖĀµ¢░ńÜäń╝¢ńĀüÕÖ©
+
+µÄźõĖŗµØźµłæõ╗¼õ╗ź HardVFE õĖ║õŠŗÕ▒Ģńż║Õ”éõĮĢÕ╝ĆÕÅæµ¢░ńÜäń╗䵳ɵ©ĪÕØŚŃĆé
+
+#### 1. Õ«Üõ╣ēõĖĆõĖ¬µ¢░ńÜäõĮōń┤Āń╝¢ńĀüÕÖ©’╝łÕ”é HardVFE’╝ÜÕŹ│ HV-SECOND õĖŁõĮ┐ńö©ńÜäõĮōń┤Āńē╣ÕŠüń╝¢ńĀüÕÖ©’╝ē
+
+ÕłøÕ╗║õĖĆõĖ¬µ¢░µ¢ćõ╗Č `mmdet3d/models/voxel_encoders/voxel_encoder.py`ŃĆé
+
+```python
+import torch.nn as nn
+
+from mmdet3d.registry import MODELS
+
+
+@MODELS.register_module()
+class HardVFE(nn.Module):
+
+ def __init__(self, arg1, arg2):
+ pass
+
+ def forward(self, x): # ķ£ĆĶ”üĶ┐öÕø×õĖĆõĖ¬Õģāń╗ä
+ pass
+```
+
+#### 2. Õ»╝ÕģźĶ»źµ©ĪÕØŚ
+
+µé©ÕÅ»õ╗źÕ£© `mmdet3d/models/voxel_encoders/__init__.py` õĖŁµĘ╗ÕŖĀõ╗źõĖŗõ╗ŻńĀü’╝Ü
+
+```python
+from .voxel_encoder import HardVFE
+```
+
+µł¢ĶĆģÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁµĘ╗ÕŖĀõ╗źõĖŗõ╗ŻńĀü’╝īõ╗ÄĶĆīķü┐ÕģŹõ┐«µö╣µ║ÉńĀü’╝Ü
+
+```python
+custom_imports = dict(
+ imports=['mmdet3d.models.voxel_encoders.voxel_encoder'],
+ allow_failed_imports=False)
+```
+
+#### 3. Õ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁõĮ┐ńö©õĮōń┤Āń╝¢ńĀüÕÖ©
+
+```python
+model = dict(
+ ...
+ voxel_encoder=dict(
+ type='HardVFE',
+ arg1=xxx,
+ arg2=yyy),
+ ...
+)
+```
+
+### µĘ╗ÕŖĀµ¢░ńÜäķ¬©Õ╣▓ńĮæń╗£
+
+µÄźõĖŗµØźµłæõ╗¼õ╗ź [SECOND](https://www.mdpi.com/1424-8220/18/10/3337)’╝łSparsely Embedded Convolutional Detection’╝ēõĖ║õŠŗÕ▒Ģńż║Õ”éõĮĢÕ╝ĆÕÅæµ¢░ńÜäń╗䵳ɵ©ĪÕØŚŃĆé
+
+#### 1. Õ«Üõ╣ēõĖĆõĖ¬µ¢░ńÜäķ¬©Õ╣▓ńĮæń╗£’╝łÕ”é SECOND’╝ē
+
+ÕłøÕ╗║õĖĆõĖ¬µ¢░µ¢ćõ╗Č `mmdet3d/models/backbones/second.py`ŃĆé
+
+```python
+from mmengine.model import BaseModule
+
+from mmdet3d.registry import MODELS
+
+
+@MODELS.register_module()
+class SECOND(BaseModule):
+
+ def __init__(self, arg1, arg2):
+ pass
+
+ def forward(self, x): # ķ£ĆĶ”üĶ┐öÕø×õĖĆõĖ¬Õģāń╗ä
+ pass
+```
+
+#### 2. Õ»╝ÕģźĶ»źµ©ĪÕØŚ
+
+µé©ÕÅ»õ╗źÕ£© `mmdet3d/models/backbones/__init__.py` õĖŁµĘ╗ÕŖĀõ╗źõĖŗõ╗ŻńĀü’╝Ü
+
+```python
+from .second import SECOND
+```
+
+µł¢ĶĆģÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁµĘ╗ÕŖĀõ╗źõĖŗõ╗ŻńĀü’╝īõ╗ÄĶĆīķü┐ÕģŹõ┐«µö╣µ║ÉńĀü’╝Ü
+
+```python
+custom_imports = dict(
+ imports=['mmdet3d.models.backbones.second'],
+ allow_failed_imports=False)
+```
+
+#### 3. Õ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁõĮ┐ńö©ķ¬©Õ╣▓ńĮæń╗£
+
+```python
+model = dict(
+ ...
+ backbone=dict(
+ type='SECOND',
+ arg1=xxx,
+ arg2=yyy),
+ ...
+)
+```
+
+### µĘ╗ÕŖĀµ¢░ńÜäķółķā©ńĮæń╗£
+
+#### 1. Õ«Üõ╣ēõĖĆõĖ¬µ¢░ńÜäķółķā©ńĮæń╗£’╝łÕ”é SECONDFPN’╝ē
+
+ÕłøÕ╗║õĖĆõĖ¬µ¢░µ¢ćõ╗Č `mmdet3d/models/necks/second_fpn.py`ŃĆé
+
+```python
+from mmengine.model import BaseModule
+
+from mmdet3d.registry import MODELS
+
+
+@MODELS.register_module()
+class SECONDFPN(BaseModule):
+
+ def __init__(self,
+ in_channels=[128, 128, 256],
+ out_channels=[256, 256, 256],
+ upsample_strides=[1, 2, 4],
+ norm_cfg=dict(type='BN', eps=1e-3, momentum=0.01),
+ upsample_cfg=dict(type='deconv', bias=False),
+ conv_cfg=dict(type='Conv2d', bias=False),
+ use_conv_for_no_stride=False,
+ init_cfg=None):
+ pass
+
+ def forward(self, x):
+ # ÕģĘõĮōÕ«×ńÄ░Õ┐ĮńĢź
+ pass
+```
+
+#### 2. Õ»╝ÕģźĶ»źµ©ĪÕØŚ
+
+µé©ÕÅ»õ╗źÕ£© `mmdet3d/models/necks/__init__.py` õĖŁµĘ╗ÕŖĀõ╗źõĖŗõ╗ŻńĀü’╝Ü
+
+```python
+from .second_fpn import SECONDFPN
+```
+
+µł¢ĶĆģÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁµĘ╗ÕŖĀõ╗źõĖŗõ╗ŻńĀü’╝īõ╗ÄĶĆīķü┐ÕģŹõ┐«µö╣µ║ÉńĀü’╝Ü
+
+```python
+custom_imports = dict(
+ imports=['mmdet3d.models.necks.second_fpn'],
+ allow_failed_imports=False)
+```
+
+#### 3. Õ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁõĮ┐ńö©ķółķā©ńĮæń╗£
+
+```python
+model = dict(
+ ...
+ neck=dict(
+ type='SECONDFPN',
+ in_channels=[64, 128, 256],
+ upsample_strides=[1, 2, 4],
+ out_channels=[128, 128, 128]),
+ ...
+)
+```
+
+### µĘ╗ÕŖĀµ¢░ńÜ䵯ƵĄŗÕż┤
+
+µÄźõĖŗµØźµłæõ╗¼õ╗ź [PartA2 Head](https://arxiv.org/abs/1907.03670) õĖ║õŠŗÕ▒Ģńż║Õ”éõĮĢÕ╝ĆÕÅæµ¢░ńÜ䵯ƵĄŗÕż┤ŃĆé
+
+**µ│©µäÅ**’╝ܵŁżÕżäÕ▒Ģńż║ńÜä `PartA2 RoI Head` Õ░åńö©õ║ĵŻĆµĄŗÕÖ©ńÜäń¼¼õ║īķśČµ«ĄŃĆéÕ»╣õ║ÄÕŹĢķśČµ«ĄńÜ䵯ƵĄŗÕż┤’╝īĶ»ĘÕÅéĶĆā `mmdet3d/models/dense_heads/` õĖŁńÜäõŠŗÕŁÉŃĆéńö▒õ║ÄÕģČń«ĆÕŹĢķ½śµĢł’╝īÕ«āõ╗¼µø┤ÕĖĖńö©õ║ÄĶć¬ÕŖ©ķ®Šķ®ČÕ£║µÖ»õĖŗńÜä 3D µŻĆµĄŗõĖŁŃĆé
+
+ķ”¢Õģł’╝īÕ£© `mmdet3d/models/roi_heads/bbox_heads/parta2_bbox_head.py` õĖŁµĘ╗ÕŖĀµ¢░ńÜä bbox headŃĆé`PartA2 RoI Head` õĖ║ńø«µĀ浯ƵĄŗÕ«×ńÄ░õ║åõĖĆõĖ¬µ¢░ńÜä bbox headŃĆéõĖ║õ║åÕ«×ńÄ░õĖĆõĖ¬ bbox head’╝īµłæõ╗¼ķĆÜÕĖĖķ£ĆĶ”üÕ£©µ¢░µ©ĪÕØŚõĖŁÕ«×ńÄ░Õ”éõĖŗõĖżõĖ¬ÕćĮµĢ░ŃĆéµ£ēµŚČĶ┐śķ£ĆĶ”üÕ«×ńÄ░ÕģČõ╗¢ńøĖÕģ│ÕćĮµĢ░’╝īÕ”é `loss` ÕÆī `get_targets`ŃĆé
+
+```python
+from mmengine.model import BaseModule
+
+from mmdet3d.registry import MODELS
+
+
+@MODELS.register_module()
+class PartA2BboxHead(BaseModule):
+ """PartA2 RoI head."""
+
+ def __init__(self,
+ num_classes,
+ seg_in_channels,
+ part_in_channels,
+ seg_conv_channels=None,
+ part_conv_channels=None,
+ merge_conv_channels=None,
+ down_conv_channels=None,
+ shared_fc_channels=None,
+ cls_channels=None,
+ reg_channels=None,
+ dropout_ratio=0.1,
+ roi_feat_size=14,
+ with_corner_loss=True,
+ bbox_coder=dict(type='DeltaXYZWLHRBBoxCoder'),
+ conv_cfg=dict(type='Conv1d'),
+ norm_cfg=dict(type='BN1d', eps=1e-3, momentum=0.01),
+ loss_bbox=dict(
+ type='SmoothL1Loss', beta=1.0 / 9.0, loss_weight=2.0),
+ loss_cls=dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=True,
+ reduction='none',
+ loss_weight=1.0),
+ init_cfg=None):
+ super(PartA2BboxHead, self).__init__(init_cfg=init_cfg)
+
+ def forward(self, seg_feats, part_feats):
+ pass
+```
+
+Õģȵ¼Ī’╝īÕ”éµ×£µ£ēÕ┐ģĶ”üńÜäĶ»Øķ£ĆĶ”üÕ«×ńÄ░õĖĆõĖ¬µ¢░ńÜä RoI HeadŃĆ鵳æõ╗¼õ╗Ä `Base3DRoIHead` õĖŁń╗¦µē┐ÕŠŚÕł░µ¢░ńÜä `PartAggregationROIHead`ŃĆ鵳æõ╗¼ÕÅ»õ╗źÕÅæńÄ░ `Base3DRoIHead` ÕĘ▓ń╗ÅÕ«×ńÄ░õ║åÕ”éõĖŗÕćĮµĢ░ŃĆé
+
+```python
+from mmdet.models.roi_heads import BaseRoIHead
+
+from mmdet3d.registry import MODELS, TASK_UTILS
+
+
+class Base3DRoIHead(BaseRoIHead):
+ """Base class for 3d RoIHeads."""
+
+ def __init__(self,
+ bbox_head=None,
+ bbox_roi_extractor=None,
+ mask_head=None,
+ mask_roi_extractor=None,
+ train_cfg=None,
+ test_cfg=None,
+ init_cfg=None):
+ super(Base3DRoIHead, self).__init__(
+ bbox_head=bbox_head,
+ bbox_roi_extractor=bbox_roi_extractor,
+ mask_head=mask_head,
+ mask_roi_extractor=mask_roi_extractor,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ init_cfg=init_cfg)
+
+ def init_bbox_head(self, bbox_roi_extractor: dict,
+ bbox_head: dict) -> None:
+ """Initialize box head and box roi extractor.
+
+ Args:
+ bbox_roi_extractor (dict or ConfigDict): Config of box
+ roi extractor.
+ bbox_head (dict or ConfigDict): Config of box in box head.
+ """
+ self.bbox_roi_extractor = MODELS.build(bbox_roi_extractor)
+ self.bbox_head = MODELS.build(bbox_head)
+
+ def init_assigner_sampler(self):
+ """Initialize assigner and sampler."""
+ self.bbox_assigner = None
+ self.bbox_sampler = None
+ if self.train_cfg:
+ if isinstance(self.train_cfg.assigner, dict):
+ self.bbox_assigner = TASK_UTILS.build(self.train_cfg.assigner)
+ elif isinstance(self.train_cfg.assigner, list):
+ self.bbox_assigner = [
+ TASK_UTILS.build(res) for res in self.train_cfg.assigner
+ ]
+ self.bbox_sampler = TASK_UTILS.build(self.train_cfg.sampler)
+
+ def init_mask_head(self):
+ """Initialize mask head, skip since ``PartAggregationROIHead`` does not
+ have one."""
+ pass
+```
+
+µÄźõĖŗµØźõĖ╗Ķ”üÕ»╣ bbox_forward ńÜäķĆ╗ĶŠæĶ┐øĶĪīõ┐«µö╣’╝īÕÉīµŚČÕģČń╗¦µē┐õ║åµØźĶć¬ `Base3DRoIHead` ńÜäÕģČÕ«āķĆ╗ĶŠæŃĆéÕ£© `mmdet3d/models/roi_heads/part_aggregation_roi_head.py` õĖŁ’╝īµłæõ╗¼Õ«×ńÄ░õ║åµ¢░ńÜä RoI Head’╝īÕ”éõĖŗµēĆńż║’╝Ü
+
+```python
+from typing import Dict, List, Tuple
+
+from mmdet.models.task_modules import AssignResult, SamplingResult
+from mmengine import ConfigDict
+from torch import Tensor
+from torch.nn import functional as F
+
+from mmdet3d.registry import MODELS
+from mmdet3d.structures import bbox3d2roi
+from mmdet3d.utils import InstanceList
+from ...structures.det3d_data_sample import SampleList
+from .base_3droi_head import Base3DRoIHead
+
+
+@MODELS.register_module()
+class PartAggregationROIHead(Base3DRoIHead):
+ """Part aggregation roi head for PartA2.
+
+ Args:
+ semantic_head (ConfigDict): Config of semantic head.
+ num_classes (int): The number of classes.
+ seg_roi_extractor (ConfigDict): Config of seg_roi_extractor.
+ bbox_roi_extractor (ConfigDict): Config of part_roi_extractor.
+ bbox_head (ConfigDict): Config of bbox_head.
+ train_cfg (ConfigDict): Training config.
+ test_cfg (ConfigDict): Testing config.
+ """
+
+ def __init__(self,
+ semantic_head: dict,
+ num_classes: int = 3,
+ seg_roi_extractor: dict = None,
+ bbox_head: dict = None,
+ bbox_roi_extractor: dict = None,
+ train_cfg: dict = None,
+ test_cfg: dict = None,
+ init_cfg: dict = None) -> None:
+ super(PartAggregationROIHead, self).__init__(
+ bbox_head=bbox_head,
+ bbox_roi_extractor=bbox_roi_extractor,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ init_cfg=init_cfg)
+ self.num_classes = num_classes
+ assert semantic_head is not None
+ self.init_seg_head(seg_roi_extractor, semantic_head)
+
+ def init_seg_head(self, seg_roi_extractor: dict,
+ semantic_head: dict) -> None:
+ """Initialize semantic head and seg roi extractor.
+
+ Args:
+ seg_roi_extractor (dict): Config of seg
+ roi extractor.
+ semantic_head (dict): Config of semantic head.
+ """
+ self.semantic_head = MODELS.build(semantic_head)
+ self.seg_roi_extractor = MODELS.build(seg_roi_extractor)
+
+ @property
+ def with_semantic(self):
+ """bool: whether the head has semantic branch"""
+ return hasattr(self,
+ 'semantic_head') and self.semantic_head is not None
+
+ def predict(self,
+ feats_dict: Dict,
+ rpn_results_list: InstanceList,
+ batch_data_samples: SampleList,
+ rescale: bool = False,
+ **kwargs) -> InstanceList:
+ """Perform forward propagation of the roi head and predict detection
+ results on the features of the upstream network.
+
+ Args:
+ feats_dict (dict): Contains features from the first stage.
+ rpn_results_list (List[:obj:`InstanceData`]): Detection results
+ of rpn head.
+ batch_data_samples (List[:obj:`Det3DDataSample`]): The Data
+ samples. It usually includes information such as
+ `gt_instance_3d`, `gt_panoptic_seg_3d` and `gt_sem_seg_3d`.
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to False.
+
+ Returns:
+ list[:obj:`InstanceData`]: Detection results of each sample
+ after the post process.
+ Each item usually contains following keys.
+
+ - scores_3d (Tensor): Classification scores, has a shape
+ (num_instances, )
+ - labels_3d (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes_3d (BaseInstance3DBoxes): Prediction of bboxes,
+ contains a tensor with shape (num_instances, C), where
+ C >= 7.
+ """
+ assert self.with_bbox, 'Bbox head must be implemented in PartA2.'
+ assert self.with_semantic, 'Semantic head must be implemented' \
+ ' in PartA2.'
+
+ batch_input_metas = [
+ data_samples.metainfo for data_samples in batch_data_samples
+ ]
+ voxels_dict = feats_dict.pop('voxels_dict')
+ # TODO: Split predict semantic and bbox
+ results_list = self.predict_bbox(feats_dict, voxels_dict,
+ batch_input_metas, rpn_results_list,
+ self.test_cfg)
+ return results_list
+
+ def predict_bbox(self, feats_dict: Dict, voxel_dict: Dict,
+ batch_input_metas: List[dict],
+ rpn_results_list: InstanceList,
+ test_cfg: ConfigDict) -> InstanceList:
+ """Perform forward propagation of the bbox head and predict detection
+ results on the features of the upstream network.
+
+ Args:
+ feats_dict (dict): Contains features from the first stage.
+ voxel_dict (dict): Contains information of voxels.
+ batch_input_metas (list[dict], Optional): Batch image meta info.
+ Defaults to None.
+ rpn_results_list (List[:obj:`InstanceData`]): Detection results
+ of rpn head.
+ test_cfg (Config): Test config.
+
+ Returns:
+ list[:obj:`InstanceData`]: Detection results of each sample
+ after the post process.
+ Each item usually contains following keys.
+
+ - scores_3d (Tensor): Classification scores, has a shape
+ (num_instances, )
+ - labels_3d (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes_3d (BaseInstance3DBoxes): Prediction of bboxes,
+ contains a tensor with shape (num_instances, C), where
+ C >= 7.
+ """
+ ...
+
+ def loss(self, feats_dict: Dict, rpn_results_list: InstanceList,
+ batch_data_samples: SampleList, **kwargs) -> dict:
+ """Perform forward propagation and loss calculation of the detection
+ roi on the features of the upstream network.
+
+ Args:
+ feats_dict (dict): Contains features from the first stage.
+ rpn_results_list (List[:obj:`InstanceData`]): Detection results
+ of rpn head.
+ batch_data_samples (List[:obj:`Det3DDataSample`]): The Data
+ samples. It usually includes information such as
+ `gt_instance_3d`, `gt_panoptic_seg_3d` and `gt_sem_seg_3d`.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components
+ """
+ assert len(rpn_results_list) == len(batch_data_samples)
+ losses = dict()
+ batch_gt_instances_3d = []
+ batch_gt_instances_ignore = []
+ voxels_dict = feats_dict.pop('voxels_dict')
+ for data_sample in batch_data_samples:
+ batch_gt_instances_3d.append(data_sample.gt_instances_3d)
+ if 'ignored_instances' in data_sample:
+ batch_gt_instances_ignore.append(data_sample.ignored_instances)
+ else:
+ batch_gt_instances_ignore.append(None)
+ if self.with_semantic:
+ semantic_results = self._semantic_forward_train(
+ feats_dict, voxels_dict, batch_gt_instances_3d)
+ losses.update(semantic_results.pop('loss_semantic'))
+
+ sample_results = self._assign_and_sample(rpn_results_list,
+ batch_gt_instances_3d)
+ if self.with_bbox:
+ feats_dict.update(semantic_results)
+ bbox_results = self._bbox_forward_train(feats_dict, voxels_dict,
+ sample_results)
+ losses.update(bbox_results['loss_bbox'])
+
+ return losses
+```
+
+µŁżÕżäµłæõ╗¼ń£üńĢźõ║åńøĖÕģ│ÕćĮµĢ░ńÜäµø┤ÕżÜń╗åĶŖéŃĆéµø┤ÕżÜń╗åĶŖéĶ»ĘÕÅéĶĆā[õ╗ŻńĀü](https://github.com/open-mmlab/mmdetection3d/blob/dev-1.x/mmdet3d/models/roi_heads/part_aggregation_roi_head.py)ŃĆé
+
+µ£ĆÕÉÄ’╝īńö©µłĘķ£ĆĶ”üÕ£© `mmdet3d/models/roi_heads/bbox_heads/__init__.py` ÕÆī `mmdet3d/models/roi_heads/__init__.py` µĘ╗ÕŖĀµ©ĪÕØŚ’╝īõ╗ÄĶĆīĶāĮĶó½ńøĖÕ║öńÜäµ│©ÕåīÕÖ©µēŠÕł░Õ╣ČÕŖĀĶĮĮŃĆé
+
+µŁżÕż¢’╝īńö©µłĘõ╣¤ÕÅ»õ╗źÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁµĘ╗ÕŖĀõ╗źõĖŗõ╗ŻńĀüõ╗źĶŠŠÕł░ńøĖÕÉīńÜäńø«ńÜäŃĆé
+
+```python
+custom_imports=dict(
+ imports=['mmdet3d.models.roi_heads.part_aggregation_roi_head', 'mmdet3d.models.roi_heads.bbox_heads.parta2_bbox_head'],
+ allow_failed_imports=False)
+```
+
+`PartAggregationROIHead` ńÜäķģŹńĮ«µ¢ćõ╗ČÕ”éõĖŗµēĆńż║’╝Ü
+
+```python
+model = dict(
+ ...
+ roi_head=dict(
+ type='PartAggregationROIHead',
+ num_classes=3,
+ semantic_head=dict(
+ type='PointwiseSemanticHead',
+ in_channels=16,
+ extra_width=0.2,
+ seg_score_thr=0.3,
+ num_classes=3,
+ loss_seg=dict(
+ type='mmdet.FocalLoss',
+ use_sigmoid=True,
+ reduction='sum',
+ gamma=2.0,
+ alpha=0.25,
+ loss_weight=1.0),
+ loss_part=dict(
+ type='mmdet.CrossEntropyLoss',
+ use_sigmoid=True,
+ loss_weight=1.0)),
+ seg_roi_extractor=dict(
+ type='Single3DRoIAwareExtractor',
+ roi_layer=dict(
+ type='RoIAwarePool3d',
+ out_size=14,
+ max_pts_per_voxel=128,
+ mode='max')),
+ bbox_roi_extractor=dict(
+ type='Single3DRoIAwareExtractor',
+ roi_layer=dict(
+ type='RoIAwarePool3d',
+ out_size=14,
+ max_pts_per_voxel=128,
+ mode='avg')),
+ bbox_head=dict(
+ type='PartA2BboxHead',
+ num_classes=3,
+ seg_in_channels=16,
+ part_in_channels=4,
+ seg_conv_channels=[64, 64],
+ part_conv_channels=[64, 64],
+ merge_conv_channels=[128, 128],
+ down_conv_channels=[128, 256],
+ bbox_coder=dict(type='DeltaXYZWLHRBBoxCoder'),
+ shared_fc_channels=[256, 512, 512, 512],
+ cls_channels=[256, 256],
+ reg_channels=[256, 256],
+ dropout_ratio=0.1,
+ roi_feat_size=14,
+ with_corner_loss=True,
+ loss_bbox=dict(
+ type='mmdet.SmoothL1Loss',
+ beta=1.0 / 9.0,
+ reduction='sum',
+ loss_weight=1.0),
+ loss_cls=dict(
+ type='mmdet.CrossEntropyLoss',
+ use_sigmoid=True,
+ reduction='sum',
+ loss_weight=1.0))),
+ ...
+)
+```
+
+MMDetection 2.0 Õ╝ĆÕ¦ŗµö»µīüķģŹńĮ«µ¢ćõ╗Čõ╣ŗķŚ┤ńÜäń╗¦µē┐’╝īÕøĀµŁżńö©µłĘÕÅ»õ╗źÕģ│µ│©ķģŹńĮ«µ¢ćõ╗ČńÜäõ┐«µö╣ŃĆéPartA2 Head ńÜäń¼¼õ║īķśČµ«ĄõĖ╗Ķ”üõĮ┐ńö©õ║åµ¢░ńÜä `PartAggregationROIHead` ÕÆī `PartA2BboxHead`’╝īķ£ĆĶ”üµĀ╣µŹ«Õ»╣Õ║öµ©ĪÕØŚńÜä `__init__` ÕćĮµĢ░µØźĶ«ŠńĮ«ÕÅéµĢ░ŃĆé
+
+### µĘ╗ÕŖĀµ¢░ńÜ䵏¤Õż▒ÕćĮµĢ░
+
+ÕüćĶ«Šµé©µā│Ķ”üõĖ║µŻĆµĄŗµĪåńÜäÕø×ÕĮƵĘ╗ÕŖĀõĖĆõĖ¬µ¢░ńÜ䵏¤Õż▒ÕćĮµĢ░ `MyLoss`ŃĆéõĖ║õ║åµĘ╗ÕŖĀõĖĆõĖ¬µ¢░ńÜ䵏¤Õż▒ÕćĮµĢ░’╝īńö©µłĘķ£ĆĶ”üÕ£© `mmdet3d/models/losses/my_loss.py` õĖŁÕ«×ńÄ░Ķ»źÕćĮµĢ░ŃĆéĶŻģķź░ÕÖ© `weighted_loss` ĶāĮÕż¤õ┐ØĶ»üÕ»╣µ»ÅõĖ¬Õģāń┤ĀńÜ䵏¤Õż▒Ķ┐øĶĪīÕŖĀµØāÕ╣│ÕØćŃĆé
+
+```python
+import torch
+import torch.nn as nn
+from mmdet.models.losses.utils import weighted_loss
+
+from mmdet3d.registry import MODELS
+
+
+@weighted_loss
+def my_loss(pred, target):
+ assert pred.size() == target.size() and target.numel() > 0
+ loss = torch.abs(pred - target)
+ return loss
+
+
+@MODELS.register_module()
+class MyLoss(nn.Module):
+
+ def __init__(self, reduction='mean', loss_weight=1.0):
+ super(MyLoss, self).__init__()
+ self.reduction = reduction
+ self.loss_weight = loss_weight
+
+ def forward(self,
+ pred,
+ target,
+ weight=None,
+ avg_factor=None,
+ reduction_override=None):
+ assert reduction_override in (None, 'none', 'mean', 'sum')
+ reduction = (
+ reduction_override if reduction_override else self.reduction)
+ loss_bbox = self.loss_weight * my_loss(
+ pred, target, weight, reduction=reduction, avg_factor=avg_factor)
+ return loss_bbox
+```
+
+µÄźõĖŗµØź’╝īńö©µłĘķ£ĆĶ”üÕ£© `mmdet3d/models/losses/__init__.py` µĘ╗ÕŖĀĶ»źÕćĮµĢ░ŃĆé
+
+```python
+from .my_loss import MyLoss, my_loss
+```
+
+µł¢ĶĆģÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁµĘ╗ÕŖĀõ╗źõĖŗõ╗ŻńĀüõ╗źĶŠŠÕł░ńøĖÕÉīńÜäńø«ńÜäŃĆé
+
+```python
+custom_imports=dict(
+ imports=['mmdet3d.models.losses.my_loss'],
+ allow_failed_imports=False)
+```
+
+õĖ║õ║åõĮ┐ńö©Ķ»źÕćĮµĢ░’╝īńö©µłĘķ£ĆĶ”üõ┐«µö╣ `loss_xxx` Õ¤¤ŃĆéńö▒õ║Ä `MyLoss` µś»ńö©õ║ÄÕø×ÕĮÆńÜä’╝īµé©ķ£ĆĶ”üõ┐«µö╣ head õĖŁńÜä `loss_bbox` Õ¤¤ŃĆé
+
+```python
+loss_bbox=dict(type='MyLoss', loss_weight=1.0)
+```
diff --git a/internlm_langchain/knowledge_base/MMDetection3D/content/customize_runtime.md b/internlm_langchain/knowledge_base/MMDetection3D/content/customize_runtime.md
new file mode 100644
index 00000000..9fea0d10
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection3D/content/customize_runtime.md
@@ -0,0 +1,382 @@
+# Ķć¬Õ«Üõ╣ēĶ┐ÉĶĪīµŚČķģŹńĮ«
+
+## Ķć¬Õ«Üõ╣ēõ╝śÕī¢ÕÖ©Ķ«ŠńĮ«
+
+õ╝śÕī¢ÕÖ©ńøĖÕģ│ńÜäķģŹńĮ«µś»ńö▒ `optim_wrapper` ń«ĪńÉåńÜä’╝īÕģČķĆÜÕĖĖµ£ēõĖēõĖ¬ÕŁŚµ«Ą’╝Ü`optimizer`’╝ī`paramwise_cfg`’╝ī`clip_grad`ŃĆéµø┤ÕżÜń╗åĶŖéĶ»ĘÕÅéĶĆā [OptimWrapper](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/optim_wrapper.html)ŃĆéÕ”éõĖŗµēĆńż║’╝īõĮ┐ńö© `AdamW` õĮ£õĖ║`õ╝śÕī¢ÕÖ©`’╝īķ¬©Õ╣▓ńĮæń╗£ńÜäÕŁ”õ╣ĀńÄćķÖŹõĮÄ 10 ÕĆŹ’╝īÕ╣ȵĘ╗ÕŖĀõ║åµó»Õ║”ĶŻüÕē¬ŃĆé
+
+```python
+optim_wrapper = dict(
+ type='OptimWrapper',
+ # õ╝śÕī¢ÕÖ©
+ optimizer=dict(
+ type='AdamW',
+ lr=0.0001,
+ weight_decay=0.05,
+ eps=1e-8,
+ betas=(0.9, 0.999)),
+
+ # ÕÅéµĢ░ń║¦ÕŁ”õ╣ĀńÄćÕÅŖµØāķćŹĶĪ░ÕćÅń│╗µĢ░Ķ«ŠńĮ«
+ paramwise_cfg=dict(
+ custom_keys={
+ 'backbone': dict(lr_mult=0.1, decay_mult=1.0),
+ },
+ norm_decay_mult=0.0),
+
+ # µó»Õ║”ĶŻüÕē¬
+ clip_grad=dict(max_norm=0.01, norm_type=2))
+```
+
+### Ķć¬Õ«Üõ╣ē PyTorch µö»µīüńÜäõ╝śÕī¢ÕÖ©
+
+µłæõ╗¼ÕĘ▓ń╗ŵö»µīüõĮ┐ńö©µēƵ£ē PyTorch Õ«×ńÄ░ńÜäõ╝śÕī¢ÕÖ©’╝īõĖöÕö»õĖĆķ£ĆĶ”üõ┐«µö╣ńÜäÕ£░µ¢╣Õ░▒µś»µö╣ÕÅśķģŹńĮ«µ¢ćõ╗ČõĖŁńÜä `optim_wrapper` ÕŁŚµ«ĄõĖŁńÜä `optimizer` ÕŁŚµ«ĄŃĆéõŠŗÕ”é’╝īÕ”éµ×£µé©µā│õĮ┐ńö© `Adam`’╝łµ│©µäÅĶ┐ÖµĀĘÕÅ»ĶāĮõ╝ÜõĮ┐µĆ¦ĶāĮÕż¦Õ╣ģõĖŗķÖŹ’╝ē’╝īµé©ÕÅ»õ╗źĶ┐ÖµĀĘõ┐«µö╣’╝Ü
+
+```python
+optim_wrapper = dict(
+ type='OptimWrapper',
+ optimizer=dict(type='Adam', lr=0.0003, weight_decay=0.0001))
+```
+
+õĖ║õ║åõ┐«µö╣µ©ĪÕ×ŗńÜäÕŁ”õ╣ĀńÄć’╝īńö©µłĘÕŬķ£ĆĶ”üõ┐«µö╣ `optimizer` õĖŁńÜä `lr` ÕŁŚµ«ĄŃĆéńö©µłĘÕÅ»õ╗źµĀ╣µŹ« PyTorch ńÜä [API µ¢ćµĪŻ](https://pytorch.org/docs/stable/optim.html?highlight=optim#module-torch.optim)ńø┤µÄźĶ«ŠńĮ«ÕÅéµĢ░ŃĆé
+
+### Ķć¬Õ«Üõ╣ēÕ╣ČÕ«×ńÄ░õ╝śÕī¢ÕÖ©
+
+#### 1. Õ«Üõ╣ēµ¢░ńÜäõ╝śÕī¢ÕÖ©
+
+õĖĆõĖ¬Ķć¬Õ«Üõ╣ēõ╝śÕī¢ÕÖ©ÕÅ»õ╗źµīēńģ¦Õ”éõĖŗĶ┐ćń©ŗÕ«Üõ╣ē’╝Ü
+
+ÕüćĶ«Šµé©µā│Ķ”üµĘ╗ÕŖĀõĖĆõĖ¬ÕŽ `MyOptimizer` ńÜä’╝īµŗźµ£ēÕÅéµĢ░ `a`’╝ī`b` ÕÆī `c` ńÜäõ╝śÕī¢ÕÖ©’╝īµé©ķ£ĆĶ”üÕłøÕ╗║õĖĆõĖ¬ÕŽÕüÜ `mmdet3d/engine/optimizers` ńÜäńø«ÕĮĢŃĆéµÄźõĖŗµØź’╝īÕ║öĶ»źÕ£©ńø«ÕĮĢõĖŗµ¤ÉõĖ¬µ¢ćõ╗ČõĖŁÕ«×ńÄ░µ¢░ńÜäõ╝śÕī¢ÕÖ©’╝īµ»öÕ”é `mmdet3d/engine/optimizers/my_optimizer.py`’╝Ü
+
+```python
+from torch.optim import Optimizer
+
+from mmdet3d.registry import OPTIMIZERS
+
+
+@OPTIMIZERS.register_module()
+class MyOptimizer(Optimizer):
+
+ def __init__(self, a, b, c):
+ pass
+```
+
+#### 2. Õ░åõ╝śÕī¢ÕÖ©µĘ╗ÕŖĀÕł░µ│©ÕåīÕÖ©
+
+õĖ║õ║åµēŠÕł░õĖŖĶ┐░Õ«Üõ╣ēńÜäõ╝śÕī¢ÕÖ©µ©ĪÕØŚ’╝īĶ»źµ©ĪÕØŚķ”¢Õģłķ£ĆĶ”üĶó½Õ╝ĢÕģźõĖ╗ÕæĮÕÉŹń®║ķŚ┤ŃĆéµ£ēõĖżń¦ŹÕ«×ńÄ░µ¢╣µ│Ģ’╝Ü
+
+- õ┐«µö╣ `mmdet3d/engine/optimizers/__init__.py` Õ»╝ÕģźĶ»źµ©ĪÕØŚŃĆé
+
+ µ¢░Õ«Üõ╣ēńÜ䵩ĪÕØŚÕ║öĶ»źÕ£© `mmdet3d/engine/optimizers/__init__.py` õĖŁĶó½Õ»╝Õģź’╝īõ╗ÄĶĆīĶó½µēŠÕł░Õ╣ČõĖöĶó½µĘ╗ÕŖĀÕł░µ│©ÕåīÕÖ©õĖŁ’╝Ü
+
+ ```python
+ from .my_optimizer import MyOptimizer
+ ```
+
+- Õ£©ķģŹńĮ«õĖŁõĮ┐ńö© `custom_imports` µØźõ║║ÕĘźÕ»╝Õģźµ¢░õ╝śÕī¢ÕÖ©ŃĆé
+
+ ```python
+ custom_imports = dict(imports=['mmdet3d.engine.optimizers.my_optimizer'], allow_failed_imports=False)
+ ```
+
+ µ©ĪÕØŚ `mmdet3d.engine.optimizers.my_optimizer` õ╝ÜÕ£©ń©ŗÕ║ÅÕ╝ĆÕ¦ŗĶó½Õ»╝Õģź’╝īõĖö `MyOptimizer` ń▒╗Õ£©ķ鯵ŚČõ╝ÜĶć¬ÕŖ©Ķó½µ│©ÕåīŃĆéµ│©µäÅÕł░Õ║öĶ»źÕŬµ£ēÕīģÕɽ `MyOptimizer` ń▒╗ńÜäÕīģĶó½Õ»╝ÕģźŃĆé`mmdet3d.engine.optimizers.my_optimizer.MyOptimizer`**õĖŹĶāĮ**Ķó½ńø┤µÄźÕ»╝ÕģźŃĆé
+
+ õ║ŗÕ«×õĖŖ’╝īńö©µłĘÕÅ»õ╗źÕ£©Ķ┐Öń¦ŹÕ»╝ÕģźńÜäµ¢╣µ│ĢõĖŁõĮ┐ńö©Õ«īÕģ©õĖŹÕÉīńÜäµ¢ćõ╗Čńø«ÕĮĢń╗ōµ×ä’╝īÕŬĶ”üõ┐ØĶ»üµĀ╣ńø«ÕĮĢĶāĮÕ£© `PYTHONPATH` õĖŁĶó½Õ«ÜõĮŹŃĆé
+
+#### 3. Õ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁµīćÕ«Üõ╝śÕī¢ÕÖ©
+
+µÄźõĖŗµØźµé©ÕÅ»õ╗źÕ£©ķģŹńĮ«µ¢ćõ╗ČńÜä `optimizer` ÕŁŚµ«ĄõĖŁõĮ┐ńö© `MyOptimizer`ŃĆéÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁ’╝īõ╝śÕī¢ÕÖ©Õ£© `optimizer` ÕŁŚµ«ĄõĖŁõ╗źÕ”éõĖŗµ¢╣Õ╝ÅÕ«Üõ╣ē’╝Ü
+
+```python
+optim_wrapper = dict(
+ type='OptimWrapper',
+ optimizer=dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001))
+```
+
+õĖ║õ║åõĮ┐ńö©µé©Ķć¬ÕĘ▒ńÜäõ╝śÕī¢ÕÖ©’╝īĶ»źÕŁŚµ«ĄÕÅ»õ╗źµö╣õĖ║’╝Ü
+
+```python
+optim_wrapper = dict(
+ type='OptimWrapper',
+ optimizer=dict(type='MyOptimizer', a=a_value, b=b_value, c=c_value))
+```
+
+### Ķć¬Õ«Üõ╣ēõ╝śÕī¢ÕÖ©Õ░üĶŻģµ×äķĆĀÕÖ©
+
+ķā©Õłåµ©ĪÕ×ŗÕÅ»ĶāĮõ╝ܵŗźµ£ēõĖĆõ║øÕÅéµĢ░õĖōÕ▒×ńÜäõ╝śÕī¢ÕÖ©Ķ«ŠńĮ«’╝īµ»öÕ”é BatchNorm Õ▒éńÜäµØāķćŹĶĪ░ÕćÅ (weight decay)ŃĆéńö©µłĘÕÅ»õ╗źķĆÜĶ┐ćĶć¬Õ«Üõ╣ēõ╝śÕī¢ÕÖ©Õ░üĶŻģµ×äķĆĀÕÖ©µØźÕ»╣ķéŻõ║øń╗åń▓ÆÕ║”ńÜäÕÅéµĢ░Ķ┐øĶĪīĶ░āõ╝śŃĆé
+
+```python
+from mmengine.optim import DefaultOptimWrapperConstructor
+
+from mmdet3d.registry import OPTIM_WRAPPER_CONSTRUCTORS
+from .my_optimizer import MyOptimizer
+
+
+@OPTIM_WRAPPER_CONSTRUCTORS.register_module()
+class MyOptimizerWrapperConstructor(DefaultOptimWrapperConstructor):
+
+ def __init__(self,
+ optim_wrapper_cfg: dict,
+ paramwise_cfg: Optional[dict] = None):
+ pass
+
+ def __call__(self, model: nn.Module) -> OptimWrapper:
+
+ return optim_wrapper
+```
+
+ķ╗śĶ«żõ╝śÕī¢ÕÖ©Õ░üĶŻģµ×äķĆĀÕÖ©Õ£©[Ķ┐Öķćī](https://github.com/open-mmlab/mmengine/blob/main/mmengine/optim/optimizer/default_constructor.py#L18)Õ«×ńÄ░ŃĆéĶ┐Öķā©Õłåõ╗ŻńĀüõ╣¤ÕÅ»õ╗źńö©õĮ£µ¢░õ╝śÕī¢ÕÖ©Õ░üĶŻģµ×äķĆĀÕÖ©ńÜ䵩ĪµØ┐ŃĆé
+
+### ķóØÕż¢ńÜäĶ«ŠńĮ«
+
+µ▓Īµ£ēÕ£©õ╝śÕī¢ÕÖ©ķā©ÕłåÕ«×ńÄ░ńÜäµŖĆÕʦÕ║öĶ»źķĆÜĶ┐ćõ╝śÕī¢ÕÖ©Õ░üĶŻģµ×äķĆĀÕÖ©µł¢ĶĆģķÆ®ÕŁÉµØźÕ«×ńÄ░’╝łµ»öÕ”éķĆÉÕÅéµĢ░ńÜäÕŁ”õ╣ĀńÄćĶ«ŠńĮ«’╝ēŃĆ鵳æõ╗¼ÕłŚõĖŠõ║åõĖĆõ║øÕĖĖńö©ńÜäÕÅ»õ╗źń©│Õ«ÜĶ«Łń╗āĶ┐ćń©ŗµł¢ĶĆģÕŖĀķƤĶ«Łń╗āńÜäĶ«ŠńĮ«ŃĆ鵳æõ╗¼µ¼óĶ┐ĵÅÉõŠøµø┤ÕżÜń▒╗õ╝╝Ķ«ŠńĮ«ńÜä PR ÕÆī issueŃĆé
+
+- __õĮ┐ńö©µó»Õ║”ĶŻüÕē¬ (gradient clip) µØźń©│Õ«ÜĶ«Łń╗āĶ┐ćń©ŗ__’╝ÜõĖĆõ║øµ©ĪÕ×ŗõŠØĶĄ¢µó»Õ║”ĶŻüÕē¬µŖƵ£»µØźĶŻüÕē¬Ķ«Łń╗āõĖŁńÜäµó»Õ║”’╝īõ╗źń©│Õ«ÜĶ«Łń╗āĶ┐ćń©ŗŃĆéõĖŠõŠŗÕ”éõĖŗ’╝Ü
+
+ ```python
+ optim_wrapper = dict(
+ _delete_=True, clip_grad=dict(max_norm=35, norm_type=2))
+ ```
+
+ Õ”éµ×£µé©ńÜäķģŹńĮ«ń╗¦µē┐õ║åõĖĆõĖ¬ÕĘ▓ń╗ÅĶ«ŠńĮ«õ║å `optim_wrapper` ńÜäÕ¤║ńĪĆķģŹńĮ«’╝īķéŻõ╣łµé©ÕÅ»ĶāĮķ£ĆĶ”ü `_delete_=True` ÕŁŚµ«ĄµØźĶ”åńø¢Õ¤║ńĪĆķģŹńĮ«õĖŁµŚĀńö©ńÜäĶ«ŠńĮ«ŃĆéµø┤ÕżÜń╗åĶŖéĶ»ĘÕÅéĶĆā[ķģŹńĮ«µ¢ćµĪŻ](https://mmdetection3d.readthedocs.io/zh_CN/dev-1.x/user_guides/config.html)ŃĆé
+
+- __õĮ┐ńö©ÕŖ©ķćÅĶ░āÕ║”ÕÖ© (momentum scheduler) µØźÕŖĀķƤµ©ĪÕ×ŗµöȵĢø__’╝ܵłæõ╗¼µö»µīüńö©ÕŖ©ķćÅĶ░āÕ║”ÕÖ©µØźµĀ╣µŹ«ÕŁ”õ╣ĀńÄćµø┤µö╣µ©ĪÕ×ŗńÜäÕŖ©ķćÅ’╝īĶ┐ÖµĀĘÕÅ»õ╗źõĮ┐µ©ĪÕ×ŗµø┤Õ┐½Õ£░µöȵĢøŃĆéÕŖ©ķćÅĶ░āÕ║”ÕÖ©ķĆÜÕĖĖÕÆīÕŁ”õ╣ĀńÄćĶ░āÕ║”ÕÖ©õĖĆĶĄĘõĮ┐ńö©’╝īõŠŗÕ”é’╝īÕ”éõĖŗķģŹńĮ«µ¢ćõ╗ČÕ£© [3D µŻĆµĄŗ](https://github.com/open-mmlab/mmdetection3d/blob/dev-1.x/configs/_base_/schedules/cyclic-20e.py)õĖŁĶó½ńö©õ║ÄÕŖĀķƤµ©ĪÕ×ŗµöȵĢøŃĆéµø┤ÕżÜń╗åĶŖéĶ»ĘÕÅéĶĆā [CosineAnnealingLR](https://github.com/open-mmlab/mmengine/blob/main/mmengine/optim/scheduler/lr_scheduler.py#L43) ÕÆī [CosineAnnealingMomentum](https://github.com/open-mmlab/mmengine/blob/main/mmengine/optim/scheduler/momentum_scheduler.py#L71) ńÜäÕ«×ńÄ░µ¢╣µ│ĢŃĆé
+
+ ```python
+ param_scheduler = [
+ # ÕŁ”õ╣ĀńÄćĶ░āÕ║”ÕÖ©
+ # Õ£©ÕēŹ 8 õĖ¬ epoch’╝īÕŁ”õ╣ĀńÄćõ╗Ä 0 ÕŹćÕł░ lr * 10
+ # Õ£©µÄźõĖŗµØź 12 õĖ¬ epoch’╝īÕŁ”õ╣ĀńÄćõ╗Ä lr * 10 ķÖŹÕł░ lr * 1e-4
+ dict(
+ type='CosineAnnealingLR',
+ T_max=8,
+ eta_min=lr * 10,
+ begin=0,
+ end=8,
+ by_epoch=True,
+ convert_to_iter_based=True),
+ dict(
+ type='CosineAnnealingLR',
+ T_max=12,
+ eta_min=lr * 1e-4,
+ begin=8,
+ end=20,
+ by_epoch=True,
+ convert_to_iter_based=True),
+ # ÕŖ©ķćÅĶ░āÕ║”ÕÖ©
+ # Õ£©ÕēŹ 8 õĖ¬ epoch’╝īÕŖ©ķćÅõ╗Ä 0 ÕŹćÕł░ 0.85 / 0.95
+ # Õ£©µÄźõĖŗµØź 12 õĖ¬ epoch’╝īÕŖ©ķćÅõ╗Ä 0.85 / 0.95 ÕŹćÕł░ 1
+ dict(
+ type='CosineAnnealingMomentum',
+ T_max=8,
+ eta_min=0.85 / 0.95,
+ begin=0,
+ end=8,
+ by_epoch=True,
+ convert_to_iter_based=True),
+ dict(
+ type='CosineAnnealingMomentum',
+ T_max=12,
+ eta_min=1,
+ begin=8,
+ end=20,
+ by_epoch=True,
+ convert_to_iter_based=True)
+ ]
+ ```
+
+## Ķć¬Õ«Üõ╣ēĶ«Łń╗āĶ░āÕ║”
+
+ķ╗śĶ«żµāģÕåĄõĖŗµłæõ╗¼õĮ┐ńö©ķśČµó»Õ╝ÅÕŁ”õ╣ĀńÄćĶĪ░ÕćÅńÜä 1 ÕĆŹĶ«Łń╗āĶ░āÕ║”’╝īĶ┐Öõ╝ÜĶ░āńö© MMEngine õĖŁńÜä [`MultiStepLR`](https://github.com/open-mmlab/mmengine/blob/main/mmengine/optim/scheduler/lr_scheduler.py#L144)ŃĆ鵳æõ╗¼Õ£©[Ķ┐Öķćī](https://github.com/open-mmlab/mmengine/blob/main/mmengine/optim/scheduler/lr_scheduler.py)µö»µīüõ║åÕŠłÕżÜÕģČõ╗¢ÕŁ”õ╣ĀńÄćĶ░āÕ║”’╝īµ»öÕ”é`õĮÖÕ╝”ķĆĆńü½`ÕÆī`ÕżÜķĪ╣Õ╝ÅĶĪ░ÕćÅ`Ķ░āÕ║”ŃĆéõĖŗķØ󵜻õĖĆõ║øµĀĘõŠŗ’╝Ü
+
+- ÕżÜķĪ╣Õ╝ÅĶĪ░ÕćÅĶ░āÕ║”’╝Ü
+
+ ```python
+ param_scheduler = [
+ dict(
+ type='PolyLR',
+ power=0.9,
+ eta_min=1e-4,
+ begin=0,
+ end=8,
+ by_epoch=True)]
+ ```
+
+- õĮÖÕ╝”ķĆĆńü½Ķ░āÕ║”’╝Ü
+
+ ```python
+ param_scheduler = [
+ dict(
+ type='CosineAnnealingLR',
+ T_max=8,
+ eta_min=lr * 1e-5,
+ begin=0,
+ end=8,
+ by_epoch=True)]
+ ```
+
+## Ķć¬Õ«Üõ╣ēĶ«Łń╗āÕŠ¬ńÄ»µÄ¦ÕłČÕÖ©
+
+ķ╗śĶ«żµāģÕåĄõĖŗ’╝īµłæõ╗¼Õ£© `train_cfg` õĖŁõĮ┐ńö© `EpochBasedTrainLoop`’╝īÕ╣ČÕ£©µ»ÅõĖĆõĖ¬Ķ«Łń╗ā epoch Õ«īµłÉÕÉÄĶ┐øĶĪīõĖƵ¼Īķ¬īĶ»ü’╝īÕ”éõĖŗµēĆńż║’╝Ü
+
+```python
+train_cfg = dict(type='EpochBasedTrainLoop', max_epochs=12, val_begin=1, val_interval=1)
+```
+
+õ║ŗÕ«×õĖŖ’╝ī[`IterBasedTrainLoop`](https://github.com/open-mmlab/mmengine/blob/main/mmengine/runner/loops.py#L185) ÕÆī [`EpochBasedTrainLoop`](https://github.com/open-mmlab/mmengine/blob/main/mmengine/runner/loops.py#L18) ķāĮµö»µīüÕŖ©µĆüķŚ┤ķÜöķ¬īĶ»ü’╝īÕ”éõĖŗµēĆńż║’╝Ü
+
+```python
+# Õ£©ń¼¼ 365001 µ¼ĪĶ┐Łõ╗Żõ╣ŗÕēŹ’╝īµłæõ╗¼µ»ÅķÜö 5000 µ¼ĪĶ┐Łõ╗Żķ¬īĶ»üõĖƵ¼ĪŃĆé
+# Õ£©ń¼¼ 365000 µ¼ĪĶ┐Łõ╗Żõ╣ŗÕÉÄ’╝īµłæõ╗¼µ»ÅķÜö 368750 µ¼ĪĶ┐Łõ╗Żķ¬īĶ»üõĖƵ¼Ī’╝ī
+# Ķ┐ÖµäÅÕæ│ńØƵłæõ╗¼Õ£©Ķ«Łń╗āń╗ōµØ¤ÕÉÄĶ┐øĶĪīķ¬īĶ»üŃĆé
+
+interval = 5000
+max_iters = 368750
+dynamic_intervals = [(max_iters // interval * interval + 1, max_iters)]
+train_cfg = dict(
+ type='IterBasedTrainLoop',
+ max_iters=max_iters,
+ val_interval=interval,
+ dynamic_intervals=dynamic_intervals)
+```
+
+## Ķć¬Õ«Üõ╣ēķÆ®ÕŁÉ
+
+### Ķć¬Õ«Üõ╣ēÕ╣ČÕ«×ńÄ░ķÆ®ÕŁÉ
+
+#### 1. Õ«×ńÄ░õĖĆõĖ¬µ¢░ķÆ®ÕŁÉ
+
+MMEngine µÅÉõŠøõ║åõĖĆõ║øÕ«×ńö©ńÜä[ķÆ®ÕŁÉ](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/hook.html)’╝īõĮåµ£ēõ║øÕ£║ÕÉłńö©µłĘÕÅ»ĶāĮķ£ĆĶ”üÕ«×ńÄ░õĖĆõĖ¬µ¢░ńÜäķÆ®ÕŁÉŃĆéÕ£© v1.1.0rc0 õ╣ŗÕÉÄ’╝īMMDetection3D Õ£©Ķ«Łń╗āµŚČµö»µīüÕ¤║õ║Ä MMEngine Ķć¬Õ«Üõ╣ēķÆ®ÕŁÉŃĆéÕøĀµŁżńö©µłĘÕÅ»õ╗źńø┤µÄźÕ£© mmdet3d µł¢ĶĆģÕ¤║õ║Ä mmdet3d ńÜäõ╗ŻńĀüÕ║ōõĖŁÕ«×ńÄ░ķÆ®ÕŁÉÕ╣ČķĆÜĶ┐ćµø┤µö╣Ķ«Łń╗āķģŹńĮ«µØźõĮ┐ńö©ķÆ®ÕŁÉŃĆéĶ┐Öķćīµłæõ╗¼ń╗ÖÕć║õĖĆõĖ¬Õ£© mmdet3d õĖŁÕłøÕ╗║Õ╣ČõĮ┐ńö©µ¢░ķÆ®ÕŁÉńÜäõŠŗÕŁÉŃĆé
+
+```python
+from mmengine.hooks import Hook
+
+from mmdet3d.registry import HOOKS
+
+
+@HOOKS.register_module()
+class MyHook(Hook):
+
+ def __init__(self, a, b):
+
+ def before_run(self, runner) -> None:
+
+ def after_run(self, runner) -> None:
+
+ def before_train(self, runner) -> None:
+
+ def after_train(self, runner) -> None:
+
+ def before_train_epoch(self, runner) -> None:
+
+ def after_train_epoch(self, runner) -> None:
+
+ def before_train_iter(self,
+ runner,
+ batch_idx: int,
+ data_batch: DATA_BATCH = None) -> None:
+
+ def after_train_iter(self,
+ runner,
+ batch_idx: int,
+ data_batch: DATA_BATCH = None,
+ outputs: Optional[dict] = None) -> None:
+```
+
+ńö©µłĘķ£ĆĶ”üµĀ╣µŹ«ķÆ®ÕŁÉńÜäÕŖ¤ĶāĮµīćÕ«ÜķÆ®ÕŁÉÕ£©µ»ÅõĖ¬Ķ«Łń╗āķśČµ«ĄµŚČńÜäĶĪīõĖ║’╝īÕģĘõĮōÕīģµŗ¼Õ”éõĖŗķśČµ«Ą’╝Ü`before_run`’╝ī`after_run`’╝ī`before_train`’╝ī`after_train`’╝ī`before_train_epoch`’╝ī`after_train_epoch`’╝ī`before_train_iter`’╝īÕÆī `after_train_iter`ŃĆéµ£ēµø┤ÕżÜńÜäõĮŹńé╣ÕÅ»õ╗źµÅÆÕģźķÆ®ÕŁÉ’╝īĶ»”µāģÕÅ»ÕÅéĶĆā [base hook class](https://github.com/open-mmlab/mmengine/blob/main/mmengine/hooks/hook.py#L9)ŃĆé
+
+#### 2. µ│©Õåīµ¢░ķÆ®ÕŁÉ
+
+µÄźõĖŗµØźµłæõ╗¼ķ£ĆĶ”üÕ»╝Õģź `MyHook`ŃĆéÕüćĶ«Šµ¢░ķÆ®ÕŁÉõĮŹõ║ĵ¢ćõ╗Č `mmdet3d/engine/hooks/my_hook.py` õĖŁ’╝īµ£ēõĖżń¦ŹÕ«×ńÄ░µ¢╣µ│Ģ’╝Ü
+
+- õ┐«µö╣ `mmdet3d/engine/hooks/__init__.py` Õ»╝ÕģźĶ»źµ©ĪÕØŚŃĆé
+
+ µ¢░Õ«Üõ╣ēńÜ䵩ĪÕØŚÕ║öĶ»źÕ£© `mmdet3d/engine/hooks/__init__.py` õĖŁĶó½Õ»╝Õģź’╝īõ╗ÄĶĆīĶó½µēŠÕł░Õ╣ČõĖöĶó½µĘ╗ÕŖĀÕł░µ│©ÕåīÕÖ©õĖŁ’╝Ü
+
+ ```python
+ from .my_hook import MyHook
+ ```
+
+- Õ£©ķģŹńĮ«õĖŁõĮ┐ńö© `custom_imports` µØźõ║║õĖ║Õ£░Õ»╝Õģźµ¢░ķÆ®ÕŁÉŃĆé
+
+ ```python
+ custom_imports = dict(imports=['mmdet3d.engine.hooks.my_hook'], allow_failed_imports=False)
+ ```
+
+#### 3. µø┤µö╣ķģŹńĮ«µ¢ćõ╗Č
+
+```python
+custom_hooks = [
+ dict(type='MyHook', a=a_value, b=b_value)
+]
+```
+
+µé©ÕÅ»õ╗źÕ░åÕŁŚµ«Ą `priority` Ķ«ŠńĮ«õĖ║ `'NORMAL'` µł¢ĶĆģ `'HIGHEST'` µØźĶ«ŠńĮ«ķÆ®ÕŁÉńÜäõ╝śÕģłń║¦’╝īÕ”éõĖŗµēĆńż║’╝Ü
+
+```python
+custom_hooks = [
+ dict(type='MyHook', a=a_value, b=b_value, priority='NORMAL')
+]
+```
+
+ķ╗śĶ«żµāģÕåĄõĖŗ’╝īµ│©ÕåīķśČµ«ĄķÆ®ÕŁÉńÜäõ╝śÕģłń║¦õĖ║ `'NORMAL'`ŃĆé
+
+### õĮ┐ńö© MMDetection3D õĖŁÕ«×ńÄ░ńÜäķÆ®ÕŁÉ
+
+Õ”éµ×£ MMDetection3D õĖŁÕĘ▓ń╗ÅÕ«×ńÄ░õ║åĶ»źķÆ®ÕŁÉ’╝īµé©ÕÅ»õ╗źńø┤µÄźķĆÜĶ┐ćµø┤µö╣ķģŹńĮ«µ¢ćõ╗ČµØźõĮ┐ńö©Ķ»źķÆ®ÕŁÉŃĆé
+
+#### õŠŗÕŁÉ’╝Ü`DisableObjectSampleHook`
+
+µłæõ╗¼Õ«×ńÄ░õ║åõĖĆõĖ¬ÕÉŹõĖ║ [DisableObjectSampleHook](https://github.com/open-mmlab/mmdetection3d/blob/dev-1.x/mmdet3d/engine/hooks/disable_object_sample_hook.py) ńÜäĶć¬Õ«Üõ╣ēķÆ®ÕŁÉÕ£©Ķ«Łń╗āķśČµ«ĄĶŠŠÕł░µīćÕ«Ü epoch ÕÉÄń”üńö© `ObjectSample` Õó×Õ╝║ńŁ¢ńĢźŃĆé
+
+Õ”éµ×£µ£ēķ£ĆĶ”üńÜäĶ»Øµłæõ╗¼ÕÅ»õ╗źÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁĶ«ŠńĮ«Õ«ā’╝Ü
+
+```python
+custom_hooks = [dict(type='DisableObjectSampleHook', disable_after_epoch=15)]
+```
+
+### µø┤µö╣ķ╗śĶ«żńÜäĶ┐ÉĶĪīµŚČķÆ®ÕŁÉ
+
+µ£ēõĖĆõ║øÕĖĖńö©ńÜäķÆ®ÕŁÉķĆÜĶ┐ć `default_hooks` µ│©Õåī’╝īÕ«āõ╗¼µś»’╝Ü
+
+- `IterTimerHook`’╝ÜĶ»źķÆ®ÕŁÉńö©µØźĶ«░ÕĮĢÕŖĀĶĮĮµĢ░µŹ«ńÜ䵌ČķŚ┤ 'data_time' ÕÆīµ©ĪÕ×ŗĶ«Łń╗āõĖƵŁźńÜ䵌ČķŚ┤ 'time'ŃĆé
+- `LoggerHook`’╝ÜĶ»źķÆ®ÕŁÉńö©µØźõ╗Ä`µē¦ĶĪīÕÖ©’╝łRunner’╝ē`ńÜäõĖŹÕÉīń╗äõ╗ȵöČķøåµŚźÕ┐ŚÕ╣ČÕ░åÕģČÕåÖÕģźń╗łń½»’╝ījson µ¢ćõ╗Č’╝ītensorboard ÕÆī wandb ńŁēŃĆé
+- `ParamSchedulerHook`’╝ÜĶ»źķÆ®ÕŁÉńö©µØźµø┤µ¢░õ╝śÕī¢ÕÖ©õĖŁńÜäõĖĆõ║øĶČģÕÅéµĢ░’╝īõŠŗÕ”éÕŁ”õ╣ĀńÄćÕÆīÕŖ©ķćÅŃĆé
+- `CheckpointHook`’╝ÜĶ»źķÆ®ÕŁÉńö©µØźÕ«Üµ£¤Õ£░õ┐ØÕŁśµŻĆµ¤źńé╣ŃĆé
+- `DistSamplerSeedHook`’╝ÜĶ»źķÆ®ÕŁÉńö©µØźĶ«ŠńĮ«ķććµĀĘÕÆīµē╣ķććµĀĘńÜäń¦ŹÕŁÉŃĆé
+- `Det3DVisualizationHook`’╝ÜĶ»źķÆ®ÕŁÉńö©µØźÕÅ»Ķ¦åÕī¢ķ¬īĶ»üÕÆīµĄŗĶ»ĢĶ┐ćń©ŗńÜäķó䵥ŗń╗ōµ×£ŃĆé
+
+`IterTimerHook`’╝ī`ParamSchedulerHook` ÕÆī `DistSamplerSeedHook` ķāĮÕŠłń«ĆÕŹĢ’╝īķĆÜÕĖĖõĖŹķ£ĆĶ”üõ┐«µö╣’╝īÕøĀµŁżµŁżÕżäµłæõ╗¼Õ░åõ╗ŗń╗ŹÕ”éõĮĢõĮ┐ńö© `LoggerHook`’╝ī`CheckpointHook` ÕÆī `Det3DVisualizationHook`ŃĆé
+
+#### CheckpointHook
+
+ķÖżõ║åիܵ£¤Õ£░õ┐ØÕŁśµŻĆµ¤źńé╣’╝ī[`CheckpointHook`](https://github.com/open-mmlab/mmengine/blob/main/mmengine/hooks/checkpoint_hook.py#L18) µÅÉõŠøõ║åÕģČÕ«āńÜäÕÅ»ķĆēķĪ╣õŠŗÕ”é `max_keep_ckpts`’╝ī`save_optimizer` ńŁēŃĆéńö©µłĘÕÅ»õ╗źĶ«ŠńĮ« `max_keep_ckpts` ÕŬõ┐ØÕŁśÕ░æķćÅńÜ䵯Ƶ¤źńé╣µł¢ĶĆģķĆÜĶ┐ć `save_optimizer` Õå│իܵś»ÕÉ”õ┐ØÕŁśõ╝śÕī¢ÕÖ©ńÜäńŖȵĆüŃĆéÕÅéµĢ░ńÜäµø┤ÕżÜń╗åĶŖéĶ»ĘÕÅéĶĆā[µŁżÕżä](https://github.com/open-mmlab/mmengine/blob/main/mmengine/hooks/checkpoint_hook.py#L18)ŃĆé
+
+```python
+default_hooks = dict(
+ checkpoint=dict(
+ type='CheckpointHook',
+ interval=1,
+ max_keep_ckpts=3,
+ save_optimizer=True))
+```
+
+#### LoggerHook
+
+`LoggerHook` ÕģüĶ«ĖĶ«ŠńĮ«µŚźÕ┐ŚĶ«░ÕĮĢķŚ┤ķÜöŃĆéĶ»”ń╗åõ╗ŗń╗ŹÕÅ»ÕÅéĶĆā[µ¢ćµĪŻ](https://github.com/open-mmlab/mmengine/blob/main/mmengine/hooks/logger_hook.py#L19)ŃĆé
+
+```python
+default_hooks = dict(logger=dict(type='LoggerHook', interval=50))
+```
+
+#### Det3DVisualizationHook
+
+`Det3DVisualizationHook` õĮ┐ńö© `DetLocalVisualizer` µØźÕÅ»Ķ¦åÕī¢ķó䵥ŗń╗ōµ×£’╝ī`Det3DLocalVisualizer` µö»µīüõĖŹÕÉīńÜäÕÉÄń½»’╝īõŠŗÕ”é `TensorboardVisBackend` ÕÆī `WandbVisBackend`’╝łµø┤ÕżÜń╗åĶŖéĶ»ĘÕÅéĶĆā[µ¢ćµĪŻ](https://github.com/open-mmlab/mmengine/blob/main/mmengine/visualization/vis_backend.py)’╝ēŃĆéńö©µłĘÕÅ»õ╗źµĘ╗ÕŖĀÕżÜõĖ¬ÕÉÄń½»µØźĶ┐øĶĪīÕÅ»Ķ¦åÕī¢’╝īÕ”éõĖŗµēĆńż║ŃĆé
+
+```python
+default_hooks = dict(
+ visualization=dict(type='Det3DVisualizationHook', draw=True))
+
+vis_backends = [dict(type='LocalVisBackend'),
+ dict(type='TensorboardVisBackend')]
+visualizer = dict(
+ type='Det3DLocalVisualizer', vis_backends=vis_backends, name='visualizer')
+```
diff --git a/internlm_langchain/knowledge_base/MMDetection3D/content/data_pipeline.md b/internlm_langchain/knowledge_base/MMDetection3D/content/data_pipeline.md
new file mode 100644
index 00000000..cf50d70f
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection3D/content/data_pipeline.md
@@ -0,0 +1,191 @@
+# Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķóäÕżäńÉåµĄüń©ŗ
+
+## µĢ░µŹ«ķóäÕżäńÉåµĄüń©ŗńÜäĶ«ŠĶ«Ī
+
+ķüĄÕŠ¬õĖĆĶł¼µā»õŠŗ’╝īµłæõ╗¼õĮ┐ńö© `Dataset` ÕÆī `DataLoader` µØźĶ░āńö©ÕżÜõĖ¬Ķ┐øń©ŗĶ┐øĶĪīµĢ░µŹ«ńÜäÕŖĀĶĮĮŃĆé`Dataset` Õ░åõ╝ÜĶ┐öÕø×õĖĵ©ĪÕ×ŗÕēŹÕÉæõ╝ĀµÆŁńÜäÕÅéµĢ░µēĆÕ»╣Õ║öńÜäµĢ░µŹ«ķĪ╣µ×䵳ÉńÜäÕŁŚÕģĖŃĆéÕøĀõĖ║ńø«µĀ浯ƵĄŗõĖŁńÜäµĢ░µŹ«ńÜäÕ░║Õ»ĖÕÅ»ĶāĮµŚĀµ│Ģõ┐صīüõĖĆĶć┤’╝łÕ”éńé╣õ║æõĖŁńé╣ńÜäµĢ░ķćÅŃĆüń£¤Õ«×µĀćµ│©µĪåńÜäÕ░║Õ»ĖńŁē’╝ē’╝īµłæõ╗¼Õ£© MMCV õĖŁÕ╝ĢÕģźõĖĆõĖ¬ `DataContainer` ń▒╗Õ×ŗ’╝īµØźÕĖ«ÕŖ®µöČķøåÕÆīÕłåÕÅæõĖŹÕÉīÕ░║Õ»ĖńÜäµĢ░µŹ«ŃĆéĶ»ĘÕÅéĶĆā[µŁżÕżä](https://github.com/open-mmlab/mmcv/blob/master/mmcv/parallel/data_container.py)ĶÄĘÕÅ¢µø┤ÕżÜń╗åĶŖéŃĆé
+
+µĢ░µŹ«ķóäÕżäńÉåµĄüń©ŗÕÆīµĢ░µŹ«ķøåõ╣ŗķŚ┤µś»õ║ÆńøĖÕłåń”╗ńÜäõĖżõĖ¬ķā©Õłå’╝īķĆÜÕĖĖµĢ░µŹ«ķøåÕ«Üõ╣ēõ║åÕ”éõĮĢÕżäńÉåµĀćµ│©õ┐Īµü»’╝īĶĆīµĢ░µŹ«ķóäÕżäńÉåµĄüń©ŗÕ«Üõ╣ēõ║åÕćåÕżćµĢ░µŹ«ķĪ╣ÕŁŚÕģĖńÜäµēƵ£ēµŁźķ¬żŃĆéµĢ░µŹ«ķøåķóäÕżäńÉåµĄüń©ŗÕīģÕɽõĖĆń│╗ÕłŚńÜäµōŹõĮ£’╝īµ»ÅõĖ¬µōŹõĮ£Õ░åõĖĆõĖ¬ÕŁŚÕģĖõĮ£õĖ║ĶŠōÕģź’╝īÕ╣ČĶŠōÕć║Õ║öńö©õ║ÄõĖŗõĖĆõĖ¬ĶĮ¼µŹóńÜäõĖĆõĖ¬µ¢░ńÜäÕŁŚÕģĖŃĆé
+
+µłæõ╗¼Õ░åÕ£©õĖŗÕøŠõĖŁÕ▒Ģńż║õĖĆõĖ¬µ£Ćń╗ÅÕģĖńÜäµĢ░µŹ«ķøåķóäÕżäńÉåµĄüń©ŗ’╝īÕģČõĖŁĶōØĶē▓µĪåĶĪ©ńż║ķóäÕżäńÉåµĄüń©ŗõĖŁńÜäÕÉäķĪ╣µōŹõĮ£ŃĆéķÜÅńØĆķóäÕżäńÉåńÜäĶ┐øĶĪī’╝īµ»ÅõĖĆõĖ¬µōŹõĮ£ķāĮõ╝ܵĘ╗ÕŖĀµ¢░ńÜäķö«ÕĆ╝’╝łÕøŠõĖŁµĀćĶ«░õĖ║ń╗┐Ķē▓’╝ēÕł░ĶŠōÕć║ÕŁŚÕģĖõĖŁ’╝īµł¢ĶĆģµø┤µ¢░ÕĮōÕēŹÕŁśÕ£©ńÜäķö«ÕĆ╝’╝łÕøŠõĖŁµĀćĶ«░õĖ║µ®ÖĶē▓’╝ēŃĆé
+
+
+
+ķóäÕżäńÉåµĄüń©ŗõĖŁńÜäÕÉäķĪ╣µōŹõĮ£õĖ╗Ķ”üÕłåõĖ║µĢ░µŹ«ÕŖĀĶĮĮŃĆüķóäÕżäńÉåŃĆüµĀ╝Õ╝ÅÕī¢ŃĆüµĄŗĶ»ĢµŚČńÜäµĢ░µŹ«Õó×Õ╝║ŃĆé
+
+µÄźõĖŗµØźÕ░åÕ▒Ģńż║õĖĆõĖ¬ńö©õ║Ä PointPillars µ©ĪÕ×ŗńÜäµĢ░µŹ«ķøåķóäÕżäńÉåµĄüń©ŗńÜäõŠŗÕŁÉŃĆé
+
+```python
+train_pipeline = [
+ dict(
+ type='LoadPointsFromFile',
+ load_dim=5,
+ use_dim=5,
+ backend_args=backend_args),
+ dict(
+ type='LoadPointsFromMultiSweeps',
+ sweeps_num=10,
+ backend_args=backend_args),
+ dict(type='LoadAnnotations3D', with_bbox_3d=True, with_label_3d=True),
+ dict(
+ type='GlobalRotScaleTrans',
+ rot_range=[-0.3925, 0.3925],
+ scale_ratio_range=[0.95, 1.05],
+ translation_std=[0, 0, 0]),
+ dict(type='RandomFlip3D', flip_ratio_bev_horizontal=0.5),
+ dict(type='PointsRangeFilter', point_cloud_range=point_cloud_range),
+ dict(type='ObjectRangeFilter', point_cloud_range=point_cloud_range),
+ dict(type='ObjectNameFilter', classes=class_names),
+ dict(type='PointShuffle'),
+ dict(type='DefaultFormatBundle3D', class_names=class_names),
+ dict(type='Collect3D', keys=['points', 'gt_bboxes_3d', 'gt_labels_3d'])
+]
+test_pipeline = [
+ dict(
+ type='LoadPointsFromFile',
+ load_dim=5,
+ use_dim=5,
+ backend_args=backend_args),
+ dict(
+ type='LoadPointsFromMultiSweeps',
+ sweeps_num=10,
+ backend_args=backend_args),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(1333, 800),
+ pts_scale_ratio=1.0,
+ flip=False,
+ pcd_horizontal_flip=False,
+ pcd_vertical_flip=False,
+ transforms=[
+ dict(
+ type='GlobalRotScaleTrans',
+ rot_range=[0, 0],
+ scale_ratio_range=[1., 1.],
+ translation_std=[0, 0, 0]),
+ dict(type='RandomFlip3D'),
+ dict(
+ type='PointsRangeFilter', point_cloud_range=point_cloud_range),
+ dict(
+ type='DefaultFormatBundle3D',
+ class_names=class_names,
+ with_label=False),
+ dict(type='Collect3D', keys=['points'])
+ ])
+]
+```
+
+Õ»╣õ║ĵ»ÅķĪ╣µōŹõĮ£’╝īµłæõ╗¼Õ░åÕłŚÕć║ńøĖÕģ│ńÜäĶó½µĘ╗ÕŖĀ/µø┤µ¢░/ń¦╗ķÖżńÜäÕŁŚÕģĖķĪ╣ŃĆé
+
+### µĢ░µŹ«ÕŖĀĶĮĮ
+
+`LoadPointsFromFile`
+
+- µĘ╗ÕŖĀ’╝Üpoints
+
+`LoadPointsFromMultiSweeps`
+
+- µø┤µ¢░’╝Üpoints
+
+`LoadAnnotations3D`
+
+- µĘ╗ÕŖĀ’╝Ügt_bboxes_3d, gt_labels_3d, gt_bboxes, gt_labels, pts_instance_mask, pts_semantic_mask, bbox3d_fields, pts_mask_fields, pts_seg_fields
+
+### ķóäÕżäńÉå
+
+`GlobalRotScaleTrans`
+
+- µĘ╗ÕŖĀ’╝Üpcd_trans, pcd_rotation, pcd_scale_factor
+- µø┤µ¢░’╝Üpoints, \*bbox3d_fields
+
+`RandomFlip3D`
+
+- µĘ╗ÕŖĀ’╝Üflip, pcd_horizontal_flip, pcd_vertical_flip
+- µø┤µ¢░’╝Üpoints, \*bbox3d_fields
+
+`PointsRangeFilter`
+
+- µø┤µ¢░’╝Üpoints
+
+`ObjectRangeFilter`
+
+- µø┤µ¢░’╝Ügt_bboxes_3d, gt_labels_3d
+
+`ObjectNameFilter`
+
+- µø┤µ¢░’╝Ügt_bboxes_3d, gt_labels_3d
+
+`PointShuffle`
+
+- µø┤µ¢░’╝Üpoints
+
+`PointsRangeFilter`
+
+- µø┤µ¢░’╝Üpoints
+
+### µĀ╝Õ╝ÅÕī¢
+
+`DefaultFormatBundle3D`
+
+- µø┤µ¢░’╝Üpoints, gt_bboxes_3d, gt_labels_3d, gt_bboxes, gt_labels
+
+`Collect3D`
+
+- µĘ╗ÕŖĀ’╝Üimg_meta ’╝łńö▒ `meta_keys` µīćÕ«ÜńÜäķö«ÕĆ╝µ×䵳ÉńÜä img_meta’╝ē
+- ń¦╗ķÖż’╝ܵēƵ£ēķÖż `keys` µīćÕ«ÜńÜäķö«ÕĆ╝õ╗źÕż¢ńÜäÕģČõ╗¢ķö«ÕĆ╝
+
+### µĄŗĶ»ĢµŚČńÜäµĢ░µŹ«Õó×Õ╝║
+
+`MultiScaleFlipAug`
+
+- µø┤µ¢░: scale, pcd_scale_factor, flip, flip_direction, pcd_horizontal_flip, pcd_vertical_flip ’╝łõĖÄĶ┐Öõ║øµīćÕ«ÜńÜäÕÅéµĢ░Õ»╣Õ║öńÜäÕó×Õ╝║ÕÉÄńÜäµĢ░µŹ«ÕłŚĶĪ©’╝ē
+
+## µē®Õ▒ĢÕ╣ČõĮ┐ńö©Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåķóäÕżäńÉåµ¢╣µ│Ģ
+
+1. Õ£©õ╗╗µäŵ¢ćõ╗ČõĖŁÕåÖÕģźµ¢░ńÜäµĢ░µŹ«ķøåķóäÕżäńÉåµ¢╣µ│Ģ’╝īÕ”é `my_pipeline.py`’╝īĶ»źķóäÕżäńÉåµ¢╣µ│ĢńÜäĶŠōÕģźÕÆīĶŠōÕć║ÕØćõĖ║ÕŁŚÕģĖ
+
+ ```python
+ from mmdet.datasets import PIPELINES
+
+ @PIPELINES.register_module()
+ class MyTransform:
+
+ def __call__(self, results):
+ results['dummy'] = True
+ return results
+ ```
+
+2. Õ»╝Õģźµ¢░ńÜäķóäÕżäńÉåµ¢╣µ│Ģń▒╗
+
+ ```python
+ from .my_pipeline import MyTransform
+ ```
+
+3. Õ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁõĮ┐ńö©Ķ»źµĢ░µŹ«ķøåķóäÕżäńÉåµ¢╣µ│Ģ
+
+ ```python
+ train_pipeline = [
+ dict(
+ type='LoadPointsFromFile',
+ load_dim=5,
+ use_dim=5,
+ backend_args=backend_args),
+ dict(
+ type='LoadPointsFromMultiSweeps',
+ sweeps_num=10,
+ backend_args=backend_args),
+ dict(type='LoadAnnotations3D', with_bbox_3d=True, with_label_3d=True),
+ dict(
+ type='GlobalRotScaleTrans',
+ rot_range=[-0.3925, 0.3925],
+ scale_ratio_range=[0.95, 1.05],
+ translation_std=[0, 0, 0]),
+ dict(type='RandomFlip3D', flip_ratio_bev_horizontal=0.5),
+ dict(type='PointsRangeFilter', point_cloud_range=point_cloud_range),
+ dict(type='ObjectRangeFilter', point_cloud_range=point_cloud_range),
+ dict(type='ObjectNameFilter', classes=class_names),
+ dict(type='MyTransform'),
+ dict(type='PointShuffle'),
+ dict(type='DefaultFormatBundle3D', class_names=class_names),
+ dict(type='Collect3D', keys=['points', 'gt_bboxes_3d', 'gt_labels_3d'])
+ ]
+ ```
diff --git a/internlm_langchain/knowledge_base/MMDetection3D/content/dataset_prepare.md b/internlm_langchain/knowledge_base/MMDetection3D/content/dataset_prepare.md
new file mode 100644
index 00000000..917015dc
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMDetection3D/content/dataset_prepare.md
@@ -0,0 +1,233 @@
+# µĢ░µŹ«ķóäÕżäńÉå
+
+## Õ£©µĢ░µŹ«ķóäÕżäńÉåÕēŹ
+
+µłæõ╗¼µÄ©ĶŹÉńö©µłĘÕ░åµĢ░µŹ«ķøåńÜäĶĘ»ÕŠäĶĮ»ķōŠµÄźÕł░ `$MMDETECTION3D/data`ŃĆéÕ”éµ×£õĮĀńÜäµ¢ćõ╗ČÕż╣ń╗ōµ×äÕÆīõ╗źõĖŗµēĆÕ▒Ģńż║ńÜäń╗ōµ×äõĖŹõĖĆĶć┤’╝īõĮĀÕÅ»ĶāĮķ£ĆĶ”üµö╣ÕÅśķģŹńĮ«µ¢ćõ╗ČõĖŁńøĖÕ║öńÜäµĢ░µŹ«ĶĘ»ÕŠäŃĆé
+
+```
+mmdetection3d
+Ōö£ŌöĆŌöĆ mmdet3d
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+Ōö£ŌöĆŌöĆ data
+Ōöé Ōö£ŌöĆŌöĆ nuscenes
+Ōöé Ōöé Ōö£ŌöĆŌöĆ maps
+Ōöé Ōöé Ōö£ŌöĆŌöĆ samples
+Ōöé Ōöé Ōö£ŌöĆŌöĆ sweeps
+Ōöé Ōöé Ōö£ŌöĆŌöĆ v1.0-test
+| | Ōö£ŌöĆŌöĆ v1.0-trainval
+Ōöé Ōö£ŌöĆŌöĆ kitti
+Ōöé Ōöé Ōö£ŌöĆŌöĆ ImageSets
+Ōöé Ōöé Ōö£ŌöĆŌöĆ testing
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ calib
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ image_2
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ velodyne
+Ōöé Ōöé Ōö£ŌöĆŌöĆ training
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ calib
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ image_2
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ label_2
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ velodyne
+Ōöé Ōö£ŌöĆŌöĆ waymo
+Ōöé Ōöé Ōö£ŌöĆŌöĆ waymo_format
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ training
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ validation
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ testing
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ gt.bin
+Ōöé Ōöé Ōö£ŌöĆŌöĆ kitti_format
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ ImageSets
+Ōöé Ōö£ŌöĆŌöĆ lyft
+Ōöé Ōöé Ōö£ŌöĆŌöĆ v1.01-train
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ v1.01-train (Ķ«Łń╗āµĢ░µŹ«)
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ lidar (Ķ«Łń╗āµ┐ĆÕģēķøĘĶŠŠ)
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ images (Ķ«Łń╗āÕøŠńēć)
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ maps (Ķ«Łń╗āÕ£░ÕøŠ)
+Ōöé Ōöé Ōö£ŌöĆŌöĆ v1.01-test
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ v1.01-test (µĄŗĶ»ĢµĢ░µŹ«)
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ lidar (µĄŗĶ»Ģµ┐ĆÕģēķøĘĶŠŠ)
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ images (µĄŗĶ»ĢÕøŠńēć)
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ maps (µĄŗĶ»ĢÕ£░ÕøŠ)
+Ōöé Ōöé Ōö£ŌöĆŌöĆ train.txt
+Ōöé Ōöé Ōö£ŌöĆŌöĆ val.txt
+Ōöé Ōöé Ōö£ŌöĆŌöĆ test.txt
+Ōöé Ōöé Ōö£ŌöĆŌöĆ sample_submission.csv
+Ōöé Ōö£ŌöĆŌöĆ s3dis
+Ōöé Ōöé Ōö£ŌöĆŌöĆ meta_data
+Ōöé Ōöé Ōö£ŌöĆŌöĆ Stanford3dDataset_v1.2_Aligned_Version
+Ōöé Ōöé Ōö£ŌöĆŌöĆ collect_indoor3d_data.py
+Ōöé Ōöé Ōö£ŌöĆŌöĆ indoor3d_util.py
+Ōöé Ōöé Ōö£ŌöĆŌöĆ README.md
+Ōöé Ōö£ŌöĆŌöĆ scannet
+Ōöé Ōöé Ōö£ŌöĆŌöĆ meta_data
+Ōöé Ōöé Ōö£ŌöĆŌöĆ scans
+Ōöé Ōöé Ōö£ŌöĆŌöĆ scans_test
+Ōöé Ōöé Ōö£ŌöĆŌöĆ batch_load_scannet_data.py
+Ōöé Ōöé Ōö£ŌöĆŌöĆ load_scannet_data.py
+Ōöé Ōöé Ōö£ŌöĆŌöĆ scannet_utils.py
+Ōöé Ōöé Ōö£ŌöĆŌöĆ README.md
+Ōöé Ōö£ŌöĆŌöĆ sunrgbd
+Ōöé Ōöé Ōö£ŌöĆŌöĆ OFFICIAL_SUNRGBD
+Ōöé Ōöé Ōö£ŌöĆŌöĆ matlab
+Ōöé Ōöé Ōö£ŌöĆŌöĆ sunrgbd_data.py
+Ōöé Ōöé Ōö£ŌöĆŌöĆ sunrgbd_utils.py
+Ōöé Ōöé Ōö£ŌöĆŌöĆ README.md
+
+```
+
+## µĢ░µŹ«õĖŗĶĮĮÕÆīķóäÕżäńÉå
+
+### KITTI
+
+Õ£©[Ķ┐Öķćī](http://www.cvlibs.net/datasets/kitti/eval_object.php?obj_benchmark=3d)õĖŗĶĮĮ KITTI ńÜä 3D µŻĆµĄŗµĢ░µŹ«ŃĆéķĆÜĶ┐ćĶ┐ÉĶĪīõ╗źõĖŗµīćõ╗żÕ»╣ KITTI µĢ░µŹ«Ķ┐øĶĪīķóäÕżäńÉå’╝Ü
+
+```bash
+mkdir ./data/kitti/ && mkdir ./data/kitti/ImageSets
+
+# õĖŗĶĮĮµĢ░µŹ«ÕłÆÕłåµ¢ćõ╗Č
+wget -c https://raw.githubusercontent.com/traveller59/second.pytorch/master/second/data/ImageSets/test.txt --no-check-certificate --content-disposition -O ./data/kitti/ImageSets/test.txt
+wget -c https://raw.githubusercontent.com/traveller59/second.pytorch/master/second/data/ImageSets/train.txt --no-check-certificate --content-disposition -O ./data/kitti/ImageSets/train.txt
+wget -c https://raw.githubusercontent.com/traveller59/second.pytorch/master/second/data/ImageSets/val.txt --no-check-certificate --content-disposition -O ./data/kitti/ImageSets/val.txt
+wget -c https://raw.githubusercontent.com/traveller59/second.pytorch/master/second/data/ImageSets/trainval.txt --no-check-certificate --content-disposition -O ./data/kitti/ImageSets/trainval.txt
+```
+
+ńäČÕÉÄķĆÜĶ┐ćĶ┐ÉĶĪīõ╗źõĖŗµīćõ╗żńö¤µłÉõ┐Īµü»µ¢ćõ╗Č’╝Ü
+
+```bash
+python tools/create_data.py kitti --root-path ./data/kitti --out-dir ./data/kitti --extra-tag kitti
+```
+
+Õ£©õĮ┐ńö© slurm ńÜäńÄ»ÕóāõĖŗ’╝īńö©µłĘķ£ĆĶ”üõĮ┐ńö©õĖŗķØóńÜäµīćõ╗ż’╝Ü
+
+```bash
+sh tools/create_data.sh + ’╝łõĖ║õ║åÕ»╣ńøĖÕÉīµ©ĪÕ×ŗĶ┐øĶĪīµĄŗĶ»ĢµēĆÕüÜńÜäÕģĘõĮōõ┐«µö╣ - ńé╣Õć╗Õ▒ĢÕ╝Ć’╝ē +
+ + ```diff + diff --git a/tools/scripts/train.sh b/tools/scripts/train.sh + index 3a93f95..461e0ea 100755 + --- a/tools/scripts/train.sh + +++ b/tools/scripts/train.sh + @@ -16,9 +16,9 @@ then + fi + + # Voxelnet + -python -m torch.distributed.launch --nproc_per_node=8 ./tools/train.py examples/second/configs/ kitti_car_vfev3_spmiddlefhd_rpn1_mghead_syncbn.py --work_dir=$SECOND_WORK_DIR + +# python -m torch.distributed.launch --nproc_per_node=8 ./tools/train.py examples/second/configs/ kitti_car_vfev3_spmiddlefhd_rpn1_mghead_syncbn.py --work_dir=$SECOND_WORK_DIR + # python -m torch.distributed.launch --nproc_per_node=8 ./tools/train.py examples/cbgs/configs/ nusc_all_vfev3_spmiddleresnetfhd_rpn2_mghead_syncbn.py --work_dir=$NUSC_CBGS_WORK_DIR + # python -m torch.distributed.launch --nproc_per_node=8 ./tools/train.py examples/second/configs/ lyft_all_vfev3_spmiddleresnetfhd_rpn2_mghead_syncbn.py --work_dir=$LYFT_CBGS_WORK_DIR + + # PointPillars + -# python -m torch.distributed.launch --nproc_per_node=8 ./tools/train.py ./examples/point_pillars/configs/ original_pp_mghead_syncbn_kitti.py --work_dir=$PP_WORK_DIR + +python -m torch.distributed.launch --nproc_per_node=8 ./tools/train.py ./examples/point_pillars/configs/ kitti_point_pillars_mghead_syncbn.py + ``` + +
+  +
+
+
+1. `load metainfo`’╝ÜĶÄĘÕÅ¢µĢ░µŹ«ķøåńÜäÕģāõ┐Īµü»’╝īÕģāõ┐Īµü»µ£ēõĖēń¦ŹµØźµ║É’╝īõ╝śÕģłń║¦õ╗Äķ½śÕł░õĮÄõĖ║’╝Ü
+
+- `__init__()` µ¢╣µ│ĢõĖŁńö©µłĘõ╝ĀÕģźńÜä `metainfo` ÕŁŚÕģĖ’╝øµö╣ÕŖ©ķóæńÄćµ£Ćķ½ś’╝īÕøĀõĖ║ńö©µłĘÕÅ»õ╗źÕ£©Õ«×õŠŗÕī¢µĢ░µŹ«ķøåµŚČ’╝īõ╝ĀÕģźĶ»źÕÅéµĢ░’╝ø
+
+- ń▒╗Õ▒׵Ʀ `BaseDataset.METAINFO` ÕŁŚÕģĖ’╝øµö╣ÕŖ©ķóæńÄćõĖŁńŁē’╝īÕøĀõĖ║ńö©µłĘÕÅ»õ╗źµö╣ÕŖ©Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåń▒╗õĖŁńÜäń▒╗Õ▒׵Ʀ `BaseDataset.METAINFO`’╝ø
+
+- µĀćµ│©µ¢ćõ╗ČõĖŁÕīģÕɽńÜä `metainfo` ÕŁŚÕģĖ’╝øµö╣ÕŖ©ķóæńÄćµ£ĆõĮÄ’╝īÕøĀõĖ║µĀćµ│©µ¢ćõ╗ČõĖĆĶł¼õĖŹÕüܵö╣ÕŖ©ŃĆé
+
+ Õ”éµ×£õĖēń¦ŹµØźµ║ÉõĖŁµ£ēńøĖÕÉīńÜäÕŁŚµ«Ą’╝īõ╝śÕģłń║¦µ£Ćķ½śńÜäµØźµ║ÉÕå│Õ«ÜĶ»źÕŁŚµ«ĄńÜäÕĆ╝’╝īĶ┐Öõ║øÕŁŚµ«ĄńÜäõ╝śÕģłń║¦µ»öĶŠāµś»’╝Üńö©µłĘõ╝ĀÕģźńÜä `metainfo` ÕŁŚÕģĖķćīńÜäÕŁŚµ«Ą > `BaseDataset.METAINFO` ÕŁŚÕģĖķćīńÜäÕŁŚµ«Ą > µĀćµ│©µ¢ćõ╗ČõĖŁ `metainfo` ÕŁŚÕģĖķćīńÜäÕŁŚµ«ĄŃĆé
+
+2. `join path`’╝ÜÕżäńÉåµĢ░µŹ«õĖĵĀćµ│©µ¢ćõ╗ČńÜäĶĘ»ÕŠä’╝ø
+
+3. `build pipeline`’╝ܵ×äÕ╗║µĢ░µŹ«µĄüµ░┤ń║┐’╝łdata pipeline’╝ē’╝īńö©õ║ĵĢ░µŹ«ķóäÕżäńÉåõĖĵĢ░µŹ«ÕćåÕżć’╝ø
+
+4. `full init`’╝ÜÕ«īÕģ©ÕłØÕ¦ŗÕī¢µĢ░µŹ«ķøåń▒╗’╝īĶ»źµŁźķ¬żõĖ╗Ķ”üÕīģÕɽõ╗źõĖŗµōŹõĮ£’╝Ü
+
+- `load data list`’╝ÜĶ»╗ÕÅ¢õĖÄĶ¦Żµ×ɵ╗ĪĶČ│ OpenMMLab 2.0 µĢ░µŹ«ķøåµĀ╝Õ╝ÅĶ¦äĶīāńÜäµĀćµ│©µ¢ćõ╗Č’╝īĶ»źµŁźķ¬żõĖŁõ╝ÜĶ░āńö© `parse_data_info()` µ¢╣µ│Ģ’╝īĶ»źµ¢╣µ│ĢĶ┤¤Ķ┤ŻĶ¦Żµ×ɵĀćµ│©µ¢ćõ╗ČķćīńÜäµ»ÅõĖ¬ÕĤզŗµĢ░µŹ«’╝ø
+
+- `filter data` (ÕÅ»ķĆē)’╝ܵĀ╣µŹ« `filter_cfg` Ķ┐ćµ╗żµŚĀńö©µĢ░µŹ«’╝īµ»öÕ”éõĖŹÕīģÕɽµĀćµ│©ńÜäµĀʵ£¼ńŁē’╝øķ╗śĶ«żõĖŹÕüÜĶ┐ćµ╗żµōŹõĮ£’╝īõĖŗµĖĖÕŁÉń▒╗ÕÅ»õ╗źµīēĶć¬Ķ║½µēĆķ£ĆÕ»╣ÕģČĶ┐øĶĪīķćŹÕåÖ’╝ø
+
+- `get subset` (ÕÅ»ķĆē)’╝ܵĀ╣µŹ«ń╗ÖÕ«ÜńÜäń┤óÕ╝Ģµł¢µĢ┤µĢ░ÕĆ╝ķććµĀʵĢ░µŹ«’╝īµ»öÕ”éÕŬÕÅ¢ÕēŹ 10 õĖ¬µĀʵ£¼ÕÅéõĖÄĶ«Łń╗ā/µĄŗĶ»Ģ’╝øķ╗śĶ«żõĖŹķććµĀʵĢ░µŹ«’╝īÕŹ│õĮ┐ńö©Õģ©ķā©µĢ░µŹ«µĀʵ£¼’╝ø
+
+- `serialize data` (ÕÅ»ķĆē)’╝ÜÕ║ÅÕłŚÕī¢Õģ©ķā©µĀʵ£¼’╝īõ╗źĶŠŠÕł░ĶŖéń£üÕåģÕŁśńÜäµĢłµ×£’╝īĶ»”µāģĶ»ĘÕÅéĶĆā[ĶŖéń£üÕåģÕŁś](#ĶŖéń£üÕåģÕŁś)’╝øķ╗śĶ«żµōŹõĮ£õĖ║Õ║ÅÕłŚÕī¢Õģ©ķā©µĀʵ£¼ŃĆé
+
+µĢ░µŹ«ķøåÕ¤║ń▒╗õĖŁÕīģÕɽńÜä `parse_data_info()` µ¢╣µ│Ģńö©õ║ÄÕ░åµĀćµ│©µ¢ćõ╗ČķćīńÜäõĖĆõĖ¬ÕĤզŗµĢ░µŹ«ÕżäńÉåµłÉõĖĆõĖ¬µł¢ĶŗźÕ╣▓õĖ¬Ķ«Łń╗ā/µĄŗĶ»ĢµĀʵ£¼ńÜäµ¢╣µ│ĢŃĆéÕøĀµŁżÕ»╣õ║ÄĶć¬Õ«Üõ╣ēµĢ░µŹ«ķøåń▒╗’╝īńö©µłĘķ£ĆĶ”üÕ«×ńÄ░ `parse_data_info()` µ¢╣µ│ĢŃĆé
+
+### µĢ░µŹ«ķøåÕ¤║ń▒╗µÅÉõŠøńÜäµÄźÕÅŻ
+
+õĖÄ `torch.utils.data.Dataset` ń▒╗õ╝╝’╝īµĢ░µŹ«ķøåÕłØÕ¦ŗÕī¢ÕÉÄ’╝īµö»µīü `__getitem__` µ¢╣µ│Ģ’╝īńö©µØźń┤óÕ╝ĢµĢ░µŹ«’╝īõ╗źÕÅŖ `__len__` µōŹõĮ£ĶÄĘÕÅ¢µĢ░µŹ«ķøåÕż¦Õ░Å’╝īķÖżµŁżõ╣ŗÕż¢’╝īOpenMMLab ńÜäµĢ░µŹ«ķøåÕ¤║ń▒╗õĖ╗Ķ”üµÅÉõŠøõ║åõ╗źõĖŗµÄźÕÅŻµØźĶ«┐ķŚ«ÕģĘõĮōõ┐Īµü»’╝Ü
+
+- `metainfo`’╝ÜĶ┐öÕø×Õģāõ┐Īµü»’╝īĶ┐öÕø×ÕĆ╝õĖ║ÕŁŚÕģĖ
+
+- `get_data_info(idx)`’╝ÜĶ┐öÕø×µīćÕ«Ü `idx` ńÜäµĀʵ£¼Õģ©ķćÅõ┐Īµü»’╝īĶ┐öÕø×ÕĆ╝õĖ║ÕŁŚÕģĖ
+
+- `__getitem__(idx)`’╝ÜĶ┐öÕø×µīćÕ«Ü `idx` ńÜäµĀʵ£¼ń╗ÅĶ┐ć pipeline õ╣ŗÕÉÄńÜäń╗ōµ×£’╝łõ╣¤Õ░▒µś»ķĆüÕģźµ©ĪÕ×ŗńÜäµĢ░µŹ«’╝ē’╝īĶ┐öÕø×ÕĆ╝õĖ║ÕŁŚÕģĖ
+
+- `__len__()`’╝ÜĶ┐öÕø×µĢ░µŹ«ķøåķĢ┐Õ║”’╝īĶ┐öÕø×ÕĆ╝õĖ║µĢ┤µĢ░Õ×ŗ
+
+- `get_subset_(indices)`’╝ܵĀ╣µŹ« `indices` õ╗ź inplace ńÜäµ¢╣Õ╝Å**õ┐«µö╣ÕĤµĢ░µŹ«ķøåń▒╗**ŃĆéÕ”éµ×£ `indices` õĖ║ `int`’╝īÕłÖÕĤµĢ░µŹ«ķøåń▒╗ÕŬÕīģÕɽÕēŹĶŗźÕ╣▓õĖ¬µĢ░µŹ«µĀʵ£¼’╝øÕ”éµ×£ `indices` õĖ║ `Sequence[int]`’╝īÕłÖÕĤµĢ░µŹ«ķøåń▒╗ÕīģÕɽµĀ╣µŹ« `Sequence[int]` µīćÕ«ÜńÜäµĢ░µŹ«µĀʵ£¼ŃĆé
+
+- `get_subset(indices)`’╝ܵĀ╣µŹ« `indices` õ╗ź**ķØ×** inplace ńÜäµ¢╣Õ╝Å**Ķ┐öÕø×ÕŁÉµĢ░µŹ«ķøåń▒╗**’╝īÕŹ│ķ揵¢░ÕżŹÕłČõĖĆõ╗ĮÕŁÉµĢ░µŹ«ķøåŃĆéÕ”éµ×£ `indices` õĖ║ `int`’╝īÕłÖĶ┐öÕø×ńÜäÕŁÉµĢ░µŹ«ķøåń▒╗ÕŬÕīģÕɽÕēŹĶŗźÕ╣▓õĖ¬µĢ░µŹ«µĀʵ£¼’╝øÕ”éµ×£ `indices` õĖ║ `Sequence[int]`’╝īÕłÖĶ┐öÕø×ńÜäÕŁÉµĢ░µŹ«ķøåń▒╗ÕīģÕɽµĀ╣µŹ« `Sequence[int]` µīćÕ«ÜńÜäµĢ░µŹ«µĀʵ£¼ŃĆé
+
+## õĮ┐ńö©µĢ░µŹ«ķøåÕ¤║ń▒╗Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåń▒╗
+
+Õ£©õ║åĶ¦Żõ║åµĢ░µŹ«ķøåÕ¤║ń▒╗ńÜäÕłØÕ¦ŗÕī¢µĄüń©ŗõĖĵÅÉõŠøńÜäµÄźÕÅŻõ╣ŗÕÉÄ’╝īÕ░▒ÕÅ»õ╗źÕ¤║õ║ĵĢ░µŹ«ķøåÕ¤║ń▒╗Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåń▒╗ŃĆé
+
+### Õ»╣õ║ĵ╗ĪĶČ│ OpenMMLab 2.0 µĢ░µŹ«ķøåµĀ╝Õ╝ÅĶ¦äĶīāńÜäµĀćµ│©µ¢ćõ╗Č
+
+Õ”éõĖŖµēĆĶ┐░’╝īÕ»╣õ║ĵ╗ĪĶČ│ OpenMMLab 2.0 µĢ░µŹ«ķøåµĀ╝Õ╝ÅĶ¦äĶīāńÜäµĀćµ│©µ¢ćõ╗Č’╝īńö©µłĘÕÅ»õ╗źķćŹĶĮĮ `parse_data_info()` µØźÕŖĀĶĮĮµĀćńŁŠŃĆéõ╗źõĖŗµś»õĖĆõĖ¬õĮ┐ńö©µĢ░µŹ«ķøåÕ¤║ń▒╗µØźÕ«×ńÄ░µ¤ÉõĖĆÕģĘõĮōµĢ░µŹ«ķøåńÜäõŠŗÕŁÉŃĆé
+
+```python
+import os.path as osp
+
+from mmengine.dataset import BaseDataset
+
+
+class ToyDataset(BaseDataset):
+
+ # õ╗źõĖŖķØóµĀćµ│©µ¢ćõ╗ČõĖ║õŠŗ’╝īÕ£©Ķ┐Öķćī raw_data_info õ╗ŻĶĪ© `data_list` Õ»╣Õ║öÕłŚĶĪ©ķćīńÜ䵤ÉõĖ¬ÕŁŚÕģĖ’╝Ü
+ # {
+ # 'img_path': "xxx/xxx_0.jpg",
+ # 'img_label': 0,
+ # ...
+ # }
+ def parse_data_info(self, raw_data_info):
+ data_info = raw_data_info
+ img_prefix = self.data_prefix.get('img_path', None)
+ if img_prefix is not None:
+ data_info['img_path'] = osp.join(
+ img_prefix, data_info['img_path'])
+ return data_info
+
+```
+
+#### õĮ┐ńö©Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåń▒╗
+
+Õ£©Õ«Üõ╣ēõ║åµĢ░µŹ«ķøåń▒╗ÕÉÄ’╝īÕ░▒ÕÅ»õ╗źķĆÜĶ┐ćÕ”éõĖŗķģŹńĮ«Õ«×õŠŗÕī¢ `ToyDataset`’╝Ü
+
+```python
+
+class LoadImage:
+
+ def __call__(self, results):
+ results['img'] = cv2.imread(results['img_path'])
+ return results
+
+class ParseImage:
+
+ def __call__(self, results):
+ results['img_shape'] = results['img'].shape
+ return results
+
+pipeline = [
+ LoadImage(),
+ ParseImage(),
+]
+
+toy_dataset = ToyDataset(
+ data_root='data/',
+ data_prefix=dict(img_path='train/'),
+ ann_file='annotations/train.json',
+ pipeline=pipeline)
+```
+
+ÕÉīµŚČÕÅ»õ╗źõĮ┐ńö©µĢ░µŹ«ķøåń▒╗µÅÉõŠøńÜäÕ»╣Õż¢µÄźÕÅŻĶ«┐ķŚ«ÕģĘõĮōńÜäµĀʵ£¼õ┐Īµü»’╝Ü
+
+```python
+toy_dataset.metainfo
+# dict(classes=('cat', 'dog'))
+
+toy_dataset.get_data_info(0)
+# {
+# 'img_path': "data/train/xxx/xxx_0.jpg",
+# 'img_label': 0,
+# ...
+# }
+
+len(toy_dataset)
+# 2
+
+toy_dataset[0]
+# {
+# 'img_path': "data/train/xxx/xxx_0.jpg",
+# 'img_label': 0,
+# 'img': a ndarray with shape (H, W, 3), which denotes the value of the image,
+# 'img_shape': (H, W, 3) ,
+# ...
+# }
+
+# `get_subset` µÄźÕÅŻõĖŹÕ»╣ÕĤµĢ░µŹ«ķøåń▒╗ÕüÜõ┐«µö╣’╝īÕŹ│Õ«īÕģ©ÕżŹÕłČõĖĆõ╗Įµ¢░ńÜä
+sub_toy_dataset = toy_dataset.get_subset(1)
+len(toy_dataset), len(sub_toy_dataset)
+# 2, 1
+
+# `get_subset_` µÄźÕÅŻõ╝ÜÕ»╣ÕĤµĢ░µŹ«ķøåń▒╗ÕüÜõ┐«µö╣’╝īÕŹ│ inplace ńÜäµ¢╣Õ╝Å
+toy_dataset.get_subset_(1)
+len(toy_dataset)
+# 1
+```
+
+ń╗ÅĶ┐ćõ╗źõĖŖµŁźķ¬ż’╝īÕÅ»õ╗źõ║åĶ¦ŻÕ¤║õ║ĵĢ░µŹ«ķøåÕ¤║ń▒╗Õ”éõĮĢĶć¬Õ«Üõ╣ēµ¢░ńÜäµĢ░µŹ«ķøåń▒╗’╝īõ╗źÕÅŖÕ”éõĮĢõĮ┐ńö©Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåń▒╗ŃĆé
+
+#### Ķć¬Õ«Üõ╣ēĶ¦åķóæńÜäµĢ░µŹ«ķøåń▒╗
+
+Õ£©õĖŖķØóńÜäõŠŗÕŁÉõĖŁ’╝īµĀćµ│©µ¢ćõ╗ČńÜäµ»ÅõĖ¬ÕĤզŗµĢ░µŹ«ÕŬÕīģÕɽõĖĆõĖ¬Ķ«Łń╗ā/µĄŗĶ»ĢµĀʵ£¼’╝łķĆÜÕĖĖµś»ÕøŠÕāÅķóåÕ¤¤’╝ēŃĆéÕ”éµ×£µ»ÅõĖ¬ÕĤզŗµĢ░µŹ«ÕīģÕɽĶŗźÕ╣▓õĖ¬Ķ«Łń╗ā/µĄŗĶ»ĢµĀʵ£¼’╝łķĆÜÕĖĖµś»Ķ¦åķóæķóåÕ¤¤’╝ē’╝īÕłÖÕŬķ£Ćõ┐ØĶ»ü `parse_data_info()` ńÜäĶ┐öÕø×ÕĆ╝õĖ║ `list[dict]` ÕŹ│ÕÅ»’╝Ü
+
+```python
+from mmengine.dataset import BaseDataset
+
+
+class ToyVideoDataset(BaseDataset):
+
+ # raw_data_info õ╗ŹõĖ║õĖĆõĖ¬ÕŁŚÕģĖ’╝īõĮåÕ«āÕīģÕɽõ║åÕżÜõĖ¬µĀʵ£¼
+ def parse_data_info(self, raw_data_info):
+ data_list = []
+
+ ...
+
+ for ... :
+
+ data_info = dict()
+
+ ...
+
+ data_list.append(data_info)
+
+ return data_list
+
+```
+
+`ToyVideoDataset` õĮ┐ńö©µ¢╣µ│ĢõĖÄ `ToyDataset` ń▒╗õ╝╝’╝īÕ£©µŁżõĖŹÕüÜĶĄśĶ┐░ŃĆé
+
+### Õ»╣õ║ÄõĖŹµ╗ĪĶČ│ OpenMMLab 2.0 µĢ░µŹ«ķøåµĀ╝Õ╝ÅĶ¦äĶīāńÜäµĀćµ│©µ¢ćõ╗Č
+
+Õ»╣õ║ÄõĖŹµ╗ĪĶČ│ OpenMMLab 2.0 µĢ░µŹ«ķøåµĀ╝Õ╝ÅĶ¦äĶīāńÜäµĀćµ│©µ¢ćõ╗Č’╝īµ£ēõĖżń¦Źµ¢╣Õ╝ÅµØźõĮ┐ńö©µĢ░µŹ«ķøåÕ¤║ń▒╗’╝Ü
+
+1. Õ░åõĖŹµ╗ĪĶČ│Ķ¦äĶīāńÜäµĀćµ│©µ¢ćõ╗ČĶĮ¼µŹóµłÉµ╗ĪĶČ│Ķ¦äĶīāńÜäµĀćµ│©µ¢ćõ╗Č’╝īÕåŹķĆÜĶ┐ćõĖŖĶ┐░µ¢╣Õ╝ÅõĮ┐ńö©µĢ░µŹ«ķøåÕ¤║ń▒╗ŃĆé
+
+2. Õ«×ńÄ░õĖĆõĖ¬µ¢░ńÜäµĢ░µŹ«ķøåń▒╗’╝īń╗¦µē┐Ķ欵Ģ░µŹ«ķøåÕ¤║ń▒╗’╝īÕ╣ČõĖöķćŹĶĮĮµĢ░µŹ«ķøåÕ¤║ń▒╗ńÜä `load_data_list(self):` ÕćĮµĢ░’╝īÕżäńÉåõĖŹµ╗ĪĶČ│Ķ¦äĶīāńÜäµĀćµ│©µ¢ćõ╗Č’╝īÕ╣Čõ┐ØĶ»üĶ┐öÕø×ÕĆ╝õĖ║ `list[dict]`’╝īÕģČõĖŁµ»ÅõĖ¬ `dict` õ╗ŻĶĪ©õĖĆõĖ¬µĢ░µŹ«µĀʵ£¼ŃĆé
+
+## µĢ░µŹ«ķøåÕ¤║ń▒╗ńÜäÕģČÕ«āńē╣µĆ¦
+
+µĢ░µŹ«ķøåÕ¤║ń▒╗Ķ┐śÕīģÕɽõ╗źõĖŗńē╣µĆ¦’╝Ü
+
+### µćÆÕŖĀĶĮĮ’╝łlazy init’╝ē
+
+Õ£©µĢ░µŹ«ķøåń▒╗Õ«×õŠŗÕī¢µŚČ’╝īķ£ĆĶ”üĶ»╗ÕÅ¢Õ╣ČĶ¦Żµ×ɵĀćµ│©µ¢ćõ╗Č’╝īÕøĀµŁżõ╝ܵȳĶĆŚõĖĆիܵŚČķŚ┤ŃĆéńäČĶĆīÕ£©µ¤Éõ║øµāģÕåĄµ»öÕ”éķó䵥ŗÕÅ»Ķ¦åÕī¢µŚČ’╝īÕŠĆÕŠĆÕŬķ£ĆĶ”üµĢ░µŹ«ķøåń▒╗ńÜäÕģāõ┐Īµü»’╝īÕÅ»ĶāĮÕ╣ČõĖŹķ£ĆĶ”üĶ»╗ÕÅ¢õĖÄĶ¦Żµ×ɵĀćµ│©µ¢ćõ╗ČŃĆéõĖ║õ║åĶŖéń£üĶ┐Öń¦ŹµāģÕåĄõĖŗµĢ░µŹ«ķøåń▒╗Õ«×õŠŗÕī¢ńÜ䵌ČķŚ┤’╝īµĢ░µŹ«ķøåÕ¤║ń▒╗µö»µīüµćÆÕŖĀĶĮĮ’╝Ü
+
+```python
+pipeline = [
+ LoadImage(),
+ ParseImage(),
+]
+
+toy_dataset = ToyDataset(
+ data_root='data/',
+ data_prefix=dict(img_path='train/'),
+ ann_file='annotations/train.json',
+ pipeline=pipeline,
+ # Õ£©Ķ┐Öķćīõ╝ĀÕģź lazy_init ÕÅśķćÅ
+ lazy_init=True)
+```
+
+ÕĮō `lazy_init=True` µŚČ’╝ī`ToyDataset` ńÜäÕłØÕ¦ŗÕī¢µ¢╣µ│ĢÕŬµē¦ĶĪīõ║å[µĢ░µŹ«ķøåÕ¤║ń▒╗ńÜäÕłØÕ¦ŗÕī¢µĄüń©ŗ](#µĢ░µŹ«ķøåÕ¤║ń▒╗ńÜäÕłØÕ¦ŗÕī¢µĄüń©ŗ)õĖŁńÜä 1ŃĆü2ŃĆü3 µŁźķ¬ż’╝īµŁżµŚČ `toy_dataset` Õ╣ȵ£¬Ķó½Õ«īÕģ©ÕłØÕ¦ŗÕī¢’╝īÕøĀõĖ║ `toy_dataset` Õ╣ČõĖŹõ╝ÜĶ»╗ÕÅ¢õĖÄĶ¦Żµ×ɵĀćµ│©µ¢ćõ╗Č’╝īÕŬõ╝ÜĶ«ŠńĮ«µĢ░µŹ«ķøåń▒╗ńÜäÕģāõ┐Īµü»’╝ł`metainfo`’╝ēŃĆé
+
+Ķć¬ńäČńÜä’╝īÕ”éµ×£õ╣ŗÕÉÄķ£ĆĶ”üĶ«┐ķŚ«ÕģĘõĮōńÜäµĢ░µŹ«õ┐Īµü»’╝īÕÅ»õ╗źµēŗÕŖ©Ķ░āńö© `toy_dataset.full_init()` µÄźÕÅŻµØźµē¦ĶĪīÕ«īµĢ┤ńÜäÕłØÕ¦ŗÕī¢Ķ┐ćń©ŗ’╝īÕ£©Ķ┐ÖõĖ¬Ķ┐ćń©ŗõĖŁµĢ░µŹ«µĀćµ│©µ¢ćõ╗ČÕ░åĶó½Ķ»╗ÕÅ¢õĖÄĶ¦Żµ×ÉŃĆéĶ░āńö© `get_data_info(idx)`, `__len__()`, `__getitem__(idx)`’╝ī`get_subset_(indices)`’╝ī `get_subset(indices)` µÄźÕÅŻõ╣¤õ╝ÜĶć¬ÕŖ©Õ£░Ķ░āńö© `full_init()` µÄźÕÅŻµØźµē¦ĶĪīÕ«īµĢ┤ńÜäÕłØÕ¦ŗÕī¢Ķ┐ćń©ŗ’╝łõ╗ģÕ£©ń¼¼õĖƵ¼ĪĶ░āńö©µŚČ’╝īõ╣ŗÕÉÄĶ░āńö©õĖŹõ╝ÜķćŹÕżŹÕ£░Ķ░āńö© `full_init()` µÄźÕÅŻ’╝ē’╝Ü
+
+```python
+# Õ«īµĢ┤ÕłØÕ¦ŗÕī¢
+toy_dataset.full_init()
+
+# ÕłØÕ¦ŗÕī¢Õ«īµ»Ģ’╝īńÄ░Õ£©ÕÅ»õ╗źĶ«┐ķŚ«ÕģĘõĮōµĢ░µŹ«
+len(toy_dataset)
+# 2
+toy_dataset[0]
+# {
+# 'img_path': "data/train/xxx/xxx_0.jpg",
+# 'img_label': 0,
+# 'img': a ndarray with shape (H, W, 3), which denotes the value the image,
+# 'img_shape': (H, W, 3) ,
+# ...
+# }
+```
+
+**µ│©µäÅ’╝Ü**
+
+ķĆÜĶ┐ćńø┤µÄźĶ░āńö© `__getitem__()` µÄźÕÅŻµØźµē¦ĶĪīÕ«īµĢ┤ÕłØÕ¦ŗÕī¢õ╝ÜÕĖ”µØźõĖĆÕ«ÜķŻÄķÖ®’╝ÜÕ”éµ×£õĖĆõĖ¬µĢ░µŹ«ķøåń▒╗ķ”¢ÕģłķĆÜĶ┐ćĶ«ŠńĮ« `lazy_init=True` µ£¬Ķ┐øĶĪīÕ«īÕģ©ÕłØÕ¦ŗÕī¢’╝īńäČÕÉÄńø┤µÄźķĆüÕģźµĢ░µŹ«ÕŖĀĶĮĮÕÖ©’╝łdataloader’╝ēõĖŁ’╝īÕ£©ÕÉÄń╗ŁĶ»╗ÕÅ¢µĢ░µŹ«ńÜäĶ┐ćń©ŗõĖŁ’╝īõĖŹÕÉīńÜä worker õ╝ÜÕÉīµŚČĶ»╗ÕÅ¢õĖÄĶ¦Żµ×ɵĀćµ│©µ¢ćõ╗Č’╝īĶÖĮńäČĶ┐ÖµĀĘÕÅ»ĶāĮÕÅ»õ╗źµŁŻÕĖĖĶ┐ÉĶĪī’╝īõĮåµś»õ╝ܵȳĶĆŚÕż¦ķćÅńÜ䵌ČķŚ┤õĖÄÕåģÕŁśŃĆé**ÕøĀµŁż’╝īÕ╗║Ķ««Õ£©ķ£ĆĶ”üĶ«┐ķŚ«ÕģĘõĮōµĢ░µŹ«õ╣ŗÕēŹ’╝īµÅÉÕēŹµēŗÕŖ©Ķ░āńö© `full_init()` µÄźÕÅŻµØźµē¦ĶĪīÕ«īµĢ┤ńÜäÕłØÕ¦ŗÕī¢Ķ┐ćń©ŗŃĆé**
+
+õ╗źõĖŖķĆÜĶ┐ćĶ«ŠńĮ« `lazy_init=True` µ£¬Ķ┐øĶĪīÕ«īÕģ©ÕłØÕ¦ŗÕī¢’╝īõ╣ŗÕÉĵĀ╣µŹ«ķ£Ćµ▒éÕåŹĶ┐øĶĪīÕ«īµĢ┤ÕłØÕ¦ŗÕī¢ńÜäµ¢╣Õ╝Å’╝īń¦░õĖ║µćÆÕŖĀĶĮĮŃĆé
+
+### ĶŖéń£üÕåģÕŁś
+
+Õ£©ÕģĘõĮōńÜäĶ»╗ÕÅ¢µĢ░µŹ«Ķ┐ćń©ŗõĖŁ’╝īµĢ░µŹ«ÕŖĀĶĮĮÕÖ©’╝łdataloader’╝ēķĆÜÕĖĖõ╝ÜĶĄĘÕżÜõĖ¬ worker µØźķóäÕÅ¢µĢ░µŹ«’╝īÕżÜõĖ¬ worker ķāĮµŗźµ£ēÕ«īµĢ┤ńÜäµĢ░µŹ«ķøåń▒╗Õżćõ╗Į’╝īÕøĀµŁżÕåģÕŁśõĖŁõ╝ÜÕŁśÕ£©ÕżÜõ╗ĮńøĖÕÉīńÜä `data_list`’╝īõĖ║õ║åĶŖéń£üĶ┐Öķā©ÕłåÕåģÕŁśµČłĶĆŚ’╝īµĢ░µŹ«ķøåÕ¤║ń▒╗ÕÅ»õ╗źµÅÉÕēŹÕ░å `data_list` Õ║ÅÕłŚÕī¢ÕŁśÕģźÕåģÕŁśõĖŁ’╝īõĮ┐ÕŠŚÕżÜõĖ¬ worker ÕÅ»õ╗źÕģ▒õ║½ÕÉīõĖĆõ╗Į `data_list`’╝īõ╗źĶŠŠÕł░ĶŖéń£üÕåģÕŁśńÜäńø«ńÜäŃĆé
+
+µĢ░µŹ«ķøåÕ¤║ń▒╗ķ╗śĶ«żµś»Õ░å `data_list` Õ║ÅÕłŚÕī¢ÕŁśÕģźÕåģÕŁś’╝īõ╣¤ÕÅ»õ╗źķĆÜĶ┐ć `serialize_data` ÕÅśķćÅ’╝łķ╗śĶ«żõĖ║ `True`’╝ēµØźµÄ¦ÕłČµś»ÕÉ”µÅÉÕēŹÕ░å `data_list` Õ║ÅÕłŚÕī¢ÕŁśÕģźÕåģÕŁśõĖŁ’╝Ü
+
+```python
+pipeline = [
+ LoadImage(),
+ ParseImage(),
+]
+
+toy_dataset = ToyDataset(
+ data_root='data/',
+ data_prefix=dict(img_path='train/'),
+ ann_file='annotations/train.json',
+ pipeline=pipeline,
+ # Õ£©Ķ┐Öķćīõ╝ĀÕģź serialize_data ÕÅśķćÅ
+ serialize_data=False)
+```
+
+õĖŖķØóõŠŗÕŁÉõĖŹõ╝ܵÅÉÕēŹÕ░å `data_list` Õ║ÅÕłŚÕī¢ÕŁśÕģźÕåģÕŁśõĖŁ’╝īÕøĀµŁżõĖŹÕ╗║Ķ««Õ£©õĮ┐ńö©µĢ░µŹ«ÕŖĀĶĮĮÕÖ©Õ╝ĆÕżÜõĖ¬ worker ÕŖĀĶĮĮµĢ░µŹ«ńÜäµāģÕåĄõĖŗ’╝īõĮ┐ńö©Ķ┐Öń¦Źµ¢╣Õ╝ÅÕ«×õŠŗÕī¢µĢ░µŹ«ķøåń▒╗ŃĆé
+
+## µĢ░µŹ«ķøåÕ¤║ń▒╗ÕīģĶŻģ
+
+ķÖżõ║åµĢ░µŹ«ķøåÕ¤║ń▒╗’╝īMMEngine õ╣¤µÅÉõŠøõ║åĶŗźÕ╣▓õĖ¬µĢ░µŹ«ķøåÕ¤║ń▒╗ÕīģĶŻģ’╝Ü`ConcatDataset`, `RepeatDataset`, `ClassBalancedDataset`ŃĆéĶ┐Öõ║øµĢ░µŹ«ķøåÕ¤║ń▒╗ÕīģĶŻģÕÉīµĀĘõ╣¤µö»µīüµćÆÕŖĀĶĮĮõĖĵŗźµ£ēĶŖéń£üÕåģÕŁśńÜäńē╣µĆ¦ŃĆé
+
+### ConcatDataset
+
+MMEngine µÅÉõŠøõ║å `ConcatDataset` ÕīģĶŻģµØźµŗ╝µÄźÕżÜõĖ¬µĢ░µŹ«ķøå’╝īõĮ┐ńö©µ¢╣µ│ĢÕ”éõĖŗ’╝Ü
+
+```python
+from mmengine.dataset import ConcatDataset
+
+pipeline = [
+ LoadImage(),
+ ParseImage(),
+]
+
+toy_dataset_1 = ToyDataset(
+ data_root='data/',
+ data_prefix=dict(img_path='train/'),
+ ann_file='annotations/train.json',
+ pipeline=pipeline)
+
+toy_dataset_2 = ToyDataset(
+ data_root='data/',
+ data_prefix=dict(img_path='val/'),
+ ann_file='annotations/val.json',
+ pipeline=pipeline)
+
+toy_dataset_12 = ConcatDataset(datasets=[toy_dataset_1, toy_dataset_2])
+
+```
+
+õĖŖĶ┐░õŠŗÕŁÉÕ░åµĢ░µŹ«ķøåńÜä `train` ķā©ÕłåõĖÄ `val` ķā©ÕłåÕÉłµłÉõĖĆõĖ¬Õż¦ńÜäµĢ░µŹ«ķøåŃĆé
+
+### RepeatDataset
+
+MMEngine µÅÉõŠøõ║å `RepeatDataset` ÕīģĶŻģµØźķćŹÕżŹķććµĀʵ¤ÉõĖ¬µĢ░µŹ«ķøåĶŗźÕ╣▓µ¼Ī’╝īõĮ┐ńö©µ¢╣µ│ĢÕ”éõĖŗ’╝Ü
+
+```python
+from mmengine.dataset import RepeatDataset
+
+pipeline = [
+ LoadImage(),
+ ParseImage(),
+]
+
+toy_dataset = ToyDataset(
+ data_root='data/',
+ data_prefix=dict(img_path='train/'),
+ ann_file='annotations/train.json',
+ pipeline=pipeline)
+
+toy_dataset_repeat = RepeatDataset(dataset=toy_dataset, times=5)
+
+```
+
+õĖŖĶ┐░õŠŗÕŁÉÕ░åµĢ░µŹ«ķøåńÜä `train` ķā©ÕłåķćŹÕżŹķććµĀĘõ║å 5 µ¼ĪŃĆé
+
+### ClassBalancedDataset
+
+MMEngine µÅÉõŠøõ║å `ClassBalancedDataset` ÕīģĶŻģ’╝īµØźÕ¤║õ║ĵĢ░µŹ«ķøåõĖŁń▒╗Õł½Õć║ńÄ░ķóæńÄć’╝īķćŹÕżŹķććµĀĘńøĖÕ║öµĀʵ£¼ŃĆé
+
+**µ│©µäÅ’╝Ü**
+
+`ClassBalancedDataset` ÕīģĶŻģÕüćĶ«Šõ║åĶó½ÕīģĶŻģńÜäµĢ░µŹ«ķøåń▒╗µö»µīü `get_cat_ids(idx)` µ¢╣µ│Ģ’╝ī`get_cat_ids(idx)` µ¢╣µ│ĢĶ┐öÕø×õĖĆõĖ¬ÕłŚĶĪ©’╝īĶ»źÕłŚĶĪ©ÕīģÕɽõ║å `idx` µīćÕ«ÜńÜä `data_info` ÕīģÕɽńÜäµĀʵ£¼ń▒╗Õł½’╝īõĮ┐ńö©µ¢╣µ│ĢÕ”éõĖŗ’╝Ü
+
+```python
+from mmengine.dataset import BaseDataset, ClassBalancedDataset
+
+class ToyDataset(BaseDataset):
+
+ def parse_data_info(self, raw_data_info):
+ data_info = raw_data_info
+ img_prefix = self.data_prefix.get('img_path', None)
+ if img_prefix is not None:
+ data_info['img_path'] = osp.join(
+ img_prefix, data_info['img_path'])
+ return data_info
+
+ # Õ┐ģķĪ╗µö»µīüńÜäµ¢╣µ│Ģ’╝īķ£ĆĶ”üĶ┐öÕø×µĀʵ£¼ńÜäń▒╗Õł½
+ def get_cat_ids(self, idx):
+ data_info = self.get_data_info(idx)
+ return [int(data_info['img_label'])]
+
+pipeline = [
+ LoadImage(),
+ ParseImage(),
+]
+
+toy_dataset = ToyDataset(
+ data_root='data/',
+ data_prefix=dict(img_path='train/'),
+ ann_file='annotations/train.json',
+ pipeline=pipeline)
+
+toy_dataset_repeat = ClassBalancedDataset(dataset=toy_dataset, oversample_thr=1e-3)
+
+```
+
+õĖŖĶ┐░õŠŗÕŁÉÕ░åµĢ░µŹ«ķøåńÜä `train` ķā©Õłåõ╗ź `oversample_thr=1e-3` ķ揵¢░ķććµĀĘ’╝īÕģĘõĮōÕ£░’╝īÕ»╣õ║ĵĢ░µŹ«ķøåõĖŁÕć║ńÄ░ķóæńÄćõĮÄõ║Ä `1e-3` ńÜäń▒╗Õł½’╝īõ╝ÜķćŹÕżŹķććµĀĘĶ»źń▒╗Õł½Õ»╣Õ║öńÜäµĀʵ£¼’╝īÕÉ”ÕłÖõĖŹķćŹÕżŹķććµĀĘ’╝īÕģĘõĮōķććµĀĘńŁ¢ńĢźĶ»ĘÕÅéĶĆā `ClassBalancedDataset` API µ¢ćµĪŻŃĆé
+
+### Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåń▒╗ÕīģĶŻģ
+
+ńö▒õ║ĵĢ░µŹ«ķøåÕ¤║ń▒╗Õ«×ńÄ░õ║åµćÆÕŖĀĶĮĮńÜäÕŖ¤ĶāĮ’╝īÕøĀµŁżÕ£©Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåń▒╗ÕīģĶŻģµŚČ’╝īķ£ĆĶ”üķüĄÕŠ¬õĖĆõ║øĶ¦äÕłÖ’╝īõĖŗķØóõ╗źõĖĆõĖ¬õŠŗÕŁÉńÜäµ¢╣Õ╝ÅµØźÕ▒Ģńż║Õ”éõĮĢĶć¬Õ«Üõ╣ēµĢ░µŹ«ķøåń▒╗ÕīģĶŻģ’╝Ü
+
+```python
+from mmengine.dataset import BaseDataset
+from mmengine.registry import DATASETS
+
+
+@DATASETS.register_module()
+class ExampleDatasetWrapper:
+
+ def __init__(self, dataset, lazy_init=False, ...):
+ # µ×äÕ╗║ÕĤµĢ░µŹ«ķøå’╝łself.dataset’╝ē
+ if isinstance(dataset, dict):
+ self.dataset = DATASETS.build(dataset)
+ elif isinstance(dataset, BaseDataset):
+ self.dataset = dataset
+ else:
+ raise TypeError(
+ 'elements in datasets sequence should be config or '
+ f'`BaseDataset` instance, but got {type(dataset)}')
+ # Ķ«░ÕĮĢÕĤµĢ░µŹ«ķøåńÜäÕģāõ┐Īµü»
+ self._metainfo = self.dataset.metainfo
+
+ '''
+ 1. Õ£©Ķ┐ÖķćīÕ«×ńÄ░õĖĆõ║øõ╗ŻńĀü’╝īµØźĶ«░ÕĮĢńö©õ║ÄÕīģĶŻģµĢ░µŹ«ķøåńÜäõĖĆõ║øĶČģÕÅéŃĆé
+ '''
+
+ self._fully_initialized = False
+ if not lazy_init:
+ self.full_init()
+
+ def full_init(self):
+ if self._fully_initialized:
+ return
+
+ # Õ░åÕĤµĢ░µŹ«ķøåÕ«īÕģ©ÕłØÕ¦ŗÕī¢
+ self.dataset.full_init()
+
+ '''
+ 2. Õ£©Ķ┐ÖķćīÕ«×ńÄ░õĖĆõ║øõ╗ŻńĀü’╝īµØźÕīģĶŻģÕĤµĢ░µŹ«ķøåŃĆé
+ '''
+
+ self._fully_initialized = True
+
+ @force_full_init
+ def _get_ori_dataset_idx(self, idx: int):
+
+ '''
+ 3. Õ£©Ķ┐ÖķćīÕ«×ńÄ░õĖĆõ║øõ╗ŻńĀü’╝īµØźÕ░åÕīģĶŻģńÜäń┤óÕ╝Ģ `idx` µśĀÕ░äÕł░ÕĤµĢ░µŹ«ķøåńÜäń┤óÕ╝Ģ `ori_idx`ŃĆé
+ '''
+ ori_idx = ...
+
+ return ori_idx
+
+ # µÅÉõŠøõĖÄ `self.dataset` õĖƵĀĘńÜäÕ»╣Õż¢µÄźÕÅŻŃĆé
+ @force_full_init
+ def get_data_info(self, idx):
+ sample_idx = self._get_ori_dataset_idx(idx)
+ return self.dataset.get_data_info(sample_idx)
+
+ # µÅÉõŠøõĖÄ `self.dataset` õĖƵĀĘńÜäÕ»╣Õż¢µÄźÕÅŻŃĆé
+ def __getitem__(self, idx):
+ if not self._fully_initialized:
+ warnings.warn('Please call `full_init` method manually to '
+ 'accelerate the speed.')
+ self.full_init()
+
+ sample_idx = self._get_ori_dataset_idx(idx)
+ return self.dataset[sample_idx]
+
+ # µÅÉõŠøõĖÄ `self.dataset` õĖƵĀĘńÜäÕ»╣Õż¢µÄźÕÅŻŃĆé
+ @force_full_init
+ def __len__(self):
+
+ '''
+ 4. Õ£©Ķ┐ÖķćīÕ«×ńÄ░õĖĆõ║øõ╗ŻńĀü’╝īµØźĶ«Īń«ŚÕīģĶŻģµĢ░µŹ«ķøåõ╣ŗÕÉÄńÜäķĢ┐Õ║”ŃĆé
+ '''
+ len_wrapper = ...
+
+ return len_wrapper
+
+ # µÅÉõŠøõĖÄ `self.dataset` õĖƵĀĘńÜäÕ»╣Õż¢µÄźÕÅŻŃĆé
+ @property
+ def metainfo(self)
+ return copy.deepcopy(self._metainfo)
+```
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/better_optimizers.md b/internlm_langchain/knowledge_base/MMEngine/content/better_optimizers.md
new file mode 100644
index 00000000..a70c84b7
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/better_optimizers.md
@@ -0,0 +1,92 @@
+# µĆ¦ĶāĮµø┤õ╝śńÜäõ╝śÕī¢ÕÖ©
+
+µ£¼µ¢ćµĪŻµÅÉõŠøõ║åõĖĆõ║ø MMEngine µö»µīüńÜäń¼¼õĖēµ¢╣õ╝śÕī¢ÕÖ©’╝īÕ«āõ╗¼ÕÅ»ĶāĮõ╝ÜÕĖ”µØźµø┤Õ┐½ńÜäµöȵĢøķƤÕ║”µł¢ĶĆģµø┤ķ½śńÜäµĆ¦ĶāĮŃĆé
+
+## D-Adaptation
+
+[D-Adaptation](https://github.com/facebookresearch/dadaptation) µÅÉõŠøõ║å `DAdaptAdaGrad`ŃĆü`DAdaptAdam` ÕÆī `DAdaptSGD` õ╝śÕī¢ÕÖ©ŃĆé
+
+```{note}
+Õ”éõĮ┐ńö© D-Adaptation µÅÉõŠøńÜäõ╝śÕī¢ÕÖ©’╝īķ£ĆÕ░å mmengine ÕŹćń║¦Ķć│ `0.6.0`ŃĆé
+```
+
+- Õ«ēĶŻģ
+
+```bash
+pip install dadaptation
+```
+
+- õĮ┐ńö©
+
+õ╗źõĮ┐ńö© `DAdaptAdaGrad` õĖ║õŠŗŃĆé
+
+```python
+runner = Runner(
+ model=ResNet18(),
+ work_dir='./work_dir',
+ train_dataloader=train_dataloader_cfg,
+ # Õ”éķ£Ćµ¤źń£ŗ DAdaptAdaGrad ńÜäĶŠōÕģźÕÅéµĢ░’╝īÕÅ»µ¤źń£ŗ
+ # https://github.com/facebookresearch/dadaptation/blob/main/dadaptation/dadapt_adagrad.py
+ optim_wrapper=dict(optimizer=dict(type='DAdaptAdaGrad', lr=0.001, momentum=0.9)),
+ train_cfg=dict(by_epoch=True, max_epochs=3),
+)
+runner.train()
+```
+
+## Lion
+
+[lion-pytorch](https://github.com/lucidrains/lion-pytorch) µÅÉõŠøõ║å `Lion` õ╝śÕī¢ÕÖ©ŃĆé
+
+```{note}
+Õ”éõĮ┐ńö© Lion µÅÉõŠøńÜäõ╝śÕī¢ÕÖ©’╝īķ£ĆÕ░å mmengine ÕŹćń║¦Ķć│ `0.6.0`ŃĆé
+```
+
+- Õ«ēĶŻģ
+
+```bash
+pip install lion-pytorch
+```
+
+- õĮ┐ńö©
+
+```python
+runner = Runner(
+ model=ResNet18(),
+ work_dir='./work_dir',
+ train_dataloader=train_dataloader_cfg,
+ # Õ”éķ£Ćµ¤źń£ŗ Lion ńÜäĶŠōÕģźÕÅéµĢ░’╝īÕÅ»µ¤źń£ŗ
+ # https://github.com/lucidrains/lion-pytorch/blob/main/lion_pytorch/lion_pytorch.py
+ optim_wrapper=dict(optimizer=dict(type='Lion', lr=1e-4, weight_decay=1e-2)),
+ train_cfg=dict(by_epoch=True, max_epochs=3),
+)
+runner.train()
+```
+
+## Sophia
+
+[Sophia](https://github.com/kyegomez/Sophia) µÅÉõŠøõ║å `Sophia`ŃĆü`SophiaG`ŃĆü`DecoupledSophia` ÕÆī `Sophia2` õ╝śÕī¢ÕÖ©ŃĆé
+
+```{note}
+Õ”éõĮ┐ńö© Sophia µÅÉõŠøńÜäõ╝śÕī¢ÕÖ©’╝īķ£ĆÕ░å mmengine ÕŹćń║¦Ķć│ `0.7.4`ŃĆé
+```
+
+- Õ«ēĶŻģ
+
+```bash
+pip install Sophia-Optimizer
+```
+
+- õĮ┐ńö©
+
+```python
+runner = Runner(
+ model=ResNet18(),
+ work_dir='./work_dir',
+ train_dataloader=train_dataloader_cfg,
+ # Õ”éķ£Ćµ¤źń£ŗ SophiaG ńÜäĶŠōÕģźÕÅéµĢ░’╝īÕÅ»µ¤źń£ŗ
+ # https://github.com/kyegomez/Sophia/blob/main/Sophia/Sophia.py
+ optim_wrapper=dict(optimizer=dict(type='SophiaG', lr=2e-4, betas=(0.965, 0.99), rho = 0.01, weight_decay=1e-1)),
+ train_cfg=dict(by_epoch=True, max_epochs=3),
+)
+runner.train()
+```
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/code_style.md b/internlm_langchain/knowledge_base/MMEngine/content/code_style.md
new file mode 100644
index 00000000..b294cde3
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/code_style.md
@@ -0,0 +1,609 @@
+# õ╗ŻńĀüĶ¦äĶīā
+
+## õ╗ŻńĀüĶ¦äĶīāµĀćÕćå
+
+### PEP 8 ŌĆöŌĆö Python Õ«śµ¢╣õ╗ŻńĀüĶ¦äĶīā
+
+[Python Õ«śµ¢╣ńÜäõ╗ŻńĀüķŻÄµĀ╝µīćÕŹŚ](https://www.python.org/dev/peps/pep-0008/)’╝īÕīģÕɽõ║åõ╗źõĖŗÕćĀõĖ¬µ¢╣ķØóńÜäÕåģÕ«╣’╝Ü
+
+- õ╗ŻńĀüÕĖāÕ▒Ć’╝īõ╗ŗń╗Źõ║å Python õĖŁń®║ĶĪīŃĆüµ¢ŁĶĪīõ╗źÕÅŖÕ»╝ÕģźńøĖÕģ│ńÜäõ╗ŻńĀüķŻÄµĀ╝Ķ¦äĶīāŃĆéµ»öÕ”éõĖĆõĖ¬ÕĖĖĶ¦üńÜäķŚ«ķóś’╝ÜÕĮōµłæńÜäõ╗ŻńĀüĶŠāķĢ┐’╝īµŚĀµ│ĢÕ£©õĖĆĶĪīÕåÖõĖŗµŚČ’╝īõĮĢÕżäÕÅ»õ╗źµ¢ŁĶĪī’╝¤
+
+- ĶĪ©ĶŠŠÕ╝Å’╝īõ╗ŗń╗Źõ║å Python õĖŁĶĪ©ĶŠŠÕ╝Åń®║µĀ╝ńøĖÕģ│ńÜäõĖĆõ║øķŻÄµĀ╝Ķ¦äĶīāŃĆé
+
+- Õ░ŠķÜÅķĆŚÕÅĘńøĖÕģ│ńÜäĶ¦äĶīāŃĆéÕĮōÕłŚĶĪ©ĶŠāķĢ┐’╝īµŚĀµ│ĢõĖĆĶĪīÕåÖõĖŗĶĆīÕåÖµłÉÕ”éõĖŗķĆÉĶĪīÕłŚĶĪ©µŚČ’╝īµÄ©ĶŹÉÕ£©µ£½ķĪ╣ÕÉÄÕŖĀķĆŚÕÅĘ’╝īõ╗ÄĶĆīõŠ┐õ║ÄĶ┐ĮÕŖĀķĆēķĪ╣ŃĆüńēłµ£¼µÄ¦ÕłČńŁēŃĆé
+
+ ```python
+ # Correct:
+ FILES = ['setup.cfg', 'tox.ini']
+ # Correct:
+ FILES = [
+ 'setup.cfg',
+ 'tox.ini',
+ ]
+ # Wrong:
+ FILES = ['setup.cfg', 'tox.ini',]
+ # Wrong:
+ FILES = [
+ 'setup.cfg',
+ 'tox.ini'
+ ]
+ ```
+
+- ÕæĮÕÉŹńøĖÕģ│Ķ¦äĶīāŃĆüµ│©ķćŖńøĖÕģ│Ķ¦äĶīāŃĆüń▒╗Õ×ŗµ│©Ķ¦ŻńøĖÕģ│Ķ¦äĶīā’╝īµłæõ╗¼Õ░åÕ£©ÕÉÄń╗Łń½ĀĶŖéõĖŁÕüÜĶ»”ń╗åõ╗ŗń╗ŹŃĆé
+
+ "A style guide is about consistency. Consistency with this style guide is important. Consistency within a project is more important. Consistency within one module or function is the most important." PEP 8 -- Style Guide for Python Code
+
+:::{note}
+PEP 8 ńÜäõ╗ŻńĀüĶ¦äĶīāÕ╣ČõĖŹµś»ń╗ØÕ»╣ńÜä’╝īķĪ╣ńø«ÕåģńÜäõĖĆĶć┤µĆ¦Ķ”üõ╝śÕģłõ║Ä PEP 8 ńÜäĶ¦äĶīāŃĆéOpenMMLab ÕÉäõĖ¬ķĪ╣ńø«ķāĮÕ£© setup.cfg Ķ«ŠÕ«Üõ║åõĖĆõ║øõ╗ŻńĀüĶ¦äĶīāńÜäĶ«ŠńĮ«’╝īĶ»ĘķüĄńģ¦Ķ┐Öõ║øĶ«ŠńĮ«ŃĆéõĖĆõĖ¬õŠŗÕŁÉµś»Õ£© PEP 8 õĖŁµ£ēÕ”éõĖŗõĖĆõĖ¬õŠŗÕŁÉ’╝Ü
+
+```python
+# Correct:
+hypot2 = x*x + y*y
+# Wrong:
+hypot2 = x * x + y * y
+```
+
+Ķ┐ÖõĖĆĶ¦äĶīāµś»õĖ║õ║åµīćńż║õĖŹÕÉīõ╝śÕģłń║¦’╝īõĮå OpenMMLab ńÜäĶ«ŠńĮ«õĖŁķĆÜÕĖĖµ▓Īµ£ēÕÉ»ńö© yapf ńÜä `ARITHMETIC_PRECEDENCE_INDICATION` ķĆēķĪ╣’╝īÕøĀĶĆīµĀ╝Õ╝ÅĶ¦äĶīāÕĘźÕģĘõĖŹõ╝ܵīēńģ¦µÄ©ĶŹÉµĀĘÕ╝ŵĀ╝Õ╝ÅÕī¢’╝īõ╗źĶ«ŠńĮ«õĖ║ÕćåŃĆé
+:::
+
+### Google Õ╝Ƶ║ÉķĪ╣ńø«ķŻÄµĀ╝µīćÕŹŚ
+
+[Google õĮ┐ńö©ńÜäń╝¢ń©ŗķŻÄµĀ╝µīćÕŹŚ](https://google.github.io/styleguide/pyguide.html)’╝īÕīģµŗ¼õ║å Python ńøĖÕģ│ńÜäń½ĀĶŖéŃĆéńøĖĶŠāõ║Ä PEP 8’╝īĶ»źµīćÕŹŚµÅÉõŠøõ║åµø┤õĖ║Ķ»”Õ░ĮńÜäõ╗ŻńĀüµīćÕŹŚŃĆéĶ»źµīćÕŹŚÕīģµŗ¼õ║åĶ»ŁĶ©ĆĶ¦äĶīāÕÆīķŻÄµĀ╝Ķ¦äĶīāõĖżõĖ¬ķā©ÕłåŃĆé
+
+ÕģČõĖŁ’╝īĶ»ŁĶ©ĆĶ¦äĶīāÕ»╣ Python õĖŁÕŠłÕżÜĶ»ŁĶ©Ćńē╣µĆ¦Ķ┐øĶĪīõ║åõ╝śń╝║ńé╣ńÜäÕłåµ×É’╝īÕ╣Čń╗ÖÕć║õ║åõĮ┐ńö©µīćÕ»╝µäÅĶ¦ü’╝īÕ”éÕ╝éÕĖĖŃĆüLambda ĶĪ©ĶŠŠÕ╝ÅŃĆüÕłŚĶĪ©µÄ©Õ»╝Õ╝ÅŃĆümetaclass ńŁēŃĆé
+
+ķŻÄµĀ╝Ķ¦äĶīāńÜäÕåģÕ«╣õĖÄ PEP 8 ĶŠāõĖ║µÄźĶ┐æ’╝īÕż¦ķā©Õłåń║”Õ«ÜÕ╗║ń½ŗÕ£© PEP 8 ńÜäÕ¤║ńĪĆõĖŖ’╝īõ╣¤µ£ēõĖĆõ║øµø┤õĖ║Ķ»”ń╗åńÜäń║”Õ«Ü’╝īÕ”éÕćĮµĢ░ķĢ┐Õ║”ŃĆüTODO µ│©ķćŖŃĆüµ¢ćõ╗ČõĖÄ socket Õ»╣Ķ▒ĪńÜäĶ«┐ķŚ«ńŁēŃĆé
+
+µÄ©ĶŹÉÕ░åĶ»źµīćÕŹŚõĮ£õĖ║ÕÅéĶĆāĶ┐øĶĪīÕ╝ĆÕÅæ’╝īõĮåõĖŹÕ┐ģõĖźµĀ╝ķüĄńģ¦’╝īõĖĆµØźĶ»źµīćÕŹŚÕŁśÕ£©õĖĆõ║ø Python 2 Õģ╝Õ«╣ķ£Ćµ▒é’╝īõŠŗÕ”éµīćÕŹŚõĖŁĶ”üµ▒éµēƵ£ēµŚĀÕ¤║ń▒╗ńÜäń▒╗Õ║öÕĮōµśŠÕ╝ÅÕ£░ń╗¦µē┐ Object, ĶĆīÕ£©õ╗ģõĮ┐ńö© Python 3 ńÜäńÄ»ÕóāõĖŁ’╝īĶ┐ÖõĖĆĶ”üµ▒鵜»õĖŹÕ┐ģĶ”üńÜä’╝īõŠØµ£¼ķĪ╣ńø«õĖŁńÜäµā»õŠŗÕŹ│ÕÅ»ŃĆéõ║īµØź OpenMMLab ńÜäķĪ╣ńø«õĮ£õĖ║µĪåµ×Čń║¦ńÜäÕ╝Ƶ║ÉĶĮ»õ╗Č’╝īõĖŹÕ┐ģÕ»╣õĖĆõ║øķ½śń║¦µŖĆÕʦĶ┐ćõ║Äķü┐Ķ«│’╝īÕ░żÕģȵś» MMCVŃĆéõĮåÕ░ØĶ»ĢõĮ┐ńö©Ķ┐Öõ║øµŖĆÕʦÕēŹÕ║öÕĮōĶ«żń£¤ĶĆāĶÖæµś»ÕÉ”ń£¤ńÜäµ£ēÕ┐ģĶ”ü’╝īÕ╣ČÕ»╗µ▒éÕģČõ╗¢Õ╝ĆÕÅæõ║║ÕæśńÜäÕ╣┐µ│øĶ»äõ╝░ŃĆé
+
+ÕÅ”Õż¢ķ£ĆĶ”üµ│©µäÅńÜäõĖĆÕżäĶ¦äĶīāµś»Õģ│õ║ÄÕīģńÜäÕ»╝Õģź’╝īÕ£©Ķ»źµīćÕŹŚõĖŁ’╝īĶ”üµ▒éÕ»╝Õģźµ£¼Õ£░ÕīģµŚČÕ┐ģķĪ╗õĮ┐ńö©ĶĘ»ÕŠäÕģ©ń¦░’╝īõĖöÕ»╝ÕģźńÜäµ»ÅõĖĆõĖ¬µ©ĪÕØŚķāĮÕ║öÕĮōÕŹĢńŗ¼µłÉĶĪī’╝īķĆÜÕĖĖĶ┐Öµś»õĖŹÕ┐ģĶ”üńÜä’╝īĶĆīõĖöõ╣¤õĖŹń¼”ÕÉłńø«ÕēŹķĪ╣ńø«ńÜäÕ╝ĆÕÅæµā»õŠŗ’╝īµŁżÕżäĶ┐øĶĪīÕ”éõĖŗń║”Õ«Ü’╝Ü
+
+```python
+# Correct
+from mmcv.cnn.bricks import (Conv2d, build_norm_layer, DropPath, MaxPool2d,
+ Linear)
+from ..utils import ext_loader
+
+# Wrong
+from mmcv.cnn.bricks import Conv2d, build_norm_layer, DropPath, MaxPool2d, \
+ Linear # õĮ┐ńö©µŗ¼ÕÅĘĶ┐øĶĪīĶ┐׵ğ’╝īĶĆīõĖŹµś»ÕÅŹµ¢£µØĀ
+from ...utils import is_str # µ£ĆÕżÜÕÉæõĖŖÕø×µ║»õĖĆÕ▒é’╝īĶ┐ćÕżÜńÜäÕø×µ║»Õ«╣µśōÕ»╝Ķć┤ń╗ōµ×äµĘĘõ╣▒
+```
+
+OpenMMLab ķĪ╣ńø«õĮ┐ńö© pre-commit ÕĘźÕģĘĶć¬ÕŖ©µĀ╝Õ╝ÅÕī¢õ╗ŻńĀü’╝īĶ»”µāģĶ¦ü[Ķ┤Īńī«õ╗ŻńĀü](./contributing.md#python-õ╗ŻńĀüķŻÄµĀ╝)ŃĆé
+
+## ÕæĮÕÉŹĶ¦äĶīā
+
+### ÕæĮÕÉŹĶ¦äĶīāńÜäķćŹĶ”üµĆ¦
+
+õ╝śń¦ĆńÜäÕæĮÕÉŹµś»Ķē»ÕźĮõ╗ŻńĀüÕÅ»Ķ»╗ńÜäÕ¤║ńĪĆŃĆéÕ¤║ńĪĆńÜäÕæĮÕÉŹĶ¦äĶīāÕ»╣ÕÉäń▒╗ÕÅśķćÅńÜäÕæĮÕÉŹÕüÜõ║åĶ”üµ▒é’╝īõĮ┐Ķ»╗ĶĆģÕÅ»õ╗źµ¢╣õŠ┐Õ£░µĀ╣µŹ«õ╗ŻńĀüÕÉŹõ║åĶ¦ŻÕÅśķćŵś»õĖĆõĖ¬ń▒╗ / Õ▒Ćķā©ÕÅśķćÅ / Õģ©Õ▒ĆÕÅśķćÅńŁēŃĆéĶĆīõ╝śń¦ĆńÜäÕæĮÕÉŹÕłÖķ£ĆĶ”üõ╗ŻńĀüõĮ£ĶĆģÕ»╣õ║ÄÕÅśķćÅńÜäÕŖ¤ĶāĮµ£ēµĖģµÖ░ńÜäĶ«żĶ»å’╝īõ╗źÕÅŖĶē»ÕźĮńÜäĶĪ©ĶŠŠĶāĮÕŖø’╝īõ╗ÄĶĆīõĮ┐Ķ»╗ĶĆģµĀ╣µŹ«ÕÉŹń¦░Õ░▒ĶāĮõ║åĶ¦ŻÕģČÕɽõ╣ē’╝īńöÜĶć│ÕĖ«ÕŖ®õ║åĶ¦ŻĶ»źµ«Ąõ╗ŻńĀüńÜäÕŖ¤ĶāĮŃĆé
+
+### Õ¤║ńĪĆÕæĮÕÉŹĶ¦äĶīā
+
+| ń▒╗Õ×ŗ | Õģ¼µ£ē | ń¦üµ£ē |
+| --------------- | ---------------- | ------------------ |
+| µ©ĪÕØŚ | lower_with_under | \_lower_with_under |
+| Õīģ | lower_with_under | |
+| ń▒╗ | CapWords | \_CapWords |
+| Õ╝éÕĖĖ | CapWordsError | |
+| ÕćĮµĢ░’╝łµ¢╣µ│Ģ’╝ē | lower_with_under | \_lower_with_under |
+| ÕćĮµĢ░ / µ¢╣µ│ĢÕÅéµĢ░ | lower_with_under | |
+| Õģ©Õ▒Ć / ń▒╗ÕåģÕĖĖķćÅ | CAPS_WITH_UNDER | \_CAPS_WITH_UNDER |
+| Õģ©Õ▒Ć / ń▒╗ÕåģÕÅśķćÅ | lower_with_under | \_lower_with_under |
+| ÕÅśķćÅ | lower_with_under | \_lower_with_under |
+| Õ▒Ćķā©ÕÅśķćÅ | lower_with_under | |
+
+µ│©µäÅ’╝Ü
+
+- Õ░ĮķćÅķü┐ÕģŹÕÅśķćÅÕÉŹõĖÄõ┐ØńĢÖÕŁŚÕå▓ń¬ü’╝īńē╣µ«ŖµāģÕåĄõĖŗÕ”éõĖŹÕÅ»ķü┐ÕģŹ’╝īÕÅ»õĮ┐ńö©õĖĆõĖ¬ÕÉÄńĮ«õĖŗÕłÆń║┐’╝īÕ”é class\_
+- Õ░ĮķćÅõĖŹĶ”üõĮ┐ńö©Ķ┐ćõ║Äń«ĆÕŹĢńÜäÕæĮÕÉŹ’╝īķÖżõ║åń║”Õ«Üõ┐ŚµłÉńÜäÕŠ¬ńÄ»ÕÅśķćÅ i’╝īµ¢ćõ╗ČÕÅśķćÅ f’╝īķöÖĶ»»ÕÅśķćÅ e ńŁēŃĆé
+- õĖŹõ╝ÜĶó½ńö©Õł░ńÜäÕÅśķćÅÕÅ»õ╗źÕæĮÕÉŹõĖ║ \_’╝īķĆ╗ĶŠæµŻĆµ¤źÕÖ©õ╝ÜÕ░åÕģČÕ┐ĮńĢźŃĆé
+
+### ÕæĮÕÉŹµŖĆÕʦ
+
+Ķē»ÕźĮńÜäÕÅśķćÅÕæĮÕÉŹķ£ĆĶ”üõ┐ØĶ»üõĖēńé╣’╝Ü
+
+1. Õɽõ╣ēÕćåńĪ«’╝īµ▓Īµ£ēµŁ¦õ╣ē
+2. ķĢ┐ń¤ŁķĆéõĖŁ
+3. ÕēŹÕÉÄń╗¤õĖĆ
+
+```python
+# Wrong
+class Masks(metaclass=ABCMeta): # ÕæĮÕÉŹµŚĀµ│ĢĶĪ©ńÄ░Õ¤║ń▒╗’╝øInstance or Semantic’╝¤
+ pass
+
+# Correct
+class BaseInstanceMasks(metaclass=ABCMeta):
+ pass
+
+# Wrong’╝īõĖŹÕÉīÕ£░µ¢╣Õɽõ╣ēńøĖÕÉīńÜäÕÅśķćÅÕ░ĮķćÅńö©ń╗¤õĖĆńÜäÕæĮÕÉŹ
+def __init__(self, inplanes, planes):
+ pass
+
+def __init__(self, in_channels, out_channels):
+ pass
+```
+
+ÕĖĖĶ¦üńÜäÕćĮµĢ░ÕæĮÕÉŹµ¢╣µ│Ģ’╝Ü
+
+- ÕŖ©Õ«ŠÕæĮÕÉŹµ│Ģ’╝Ücrop_img, init_weights
+- ÕŖ©Õ«ŠÕĆÆńĮ«ÕæĮÕÉŹµ│Ģ’╝Üimread, bbox_flip
+
+µ│©µäÅÕćĮµĢ░ÕæĮÕÉŹõĖÄÕÅéµĢ░ńÜäķĪ║Õ║Å’╝īõ┐ØĶ»üõĖ╗Ķ»ŁÕ£©ÕēŹ’╝īń¼”ÕÉłĶ»ŁĶ©Ćõ╣Āµā»’╝Ü
+
+- check_keys_exist(key, container)
+- check_keys_contain(container, key)
+
+µ│©µäÅķü┐ÕģŹķØ×ÕĖĖĶ¦äµł¢ń╗¤õĖĆń║”Õ«ÜńÜäń╝®ÕåÖ’╝īÕ”é nb -> num_blocks’╝īin_nc -> in_channels
+
+## docstring Ķ¦äĶīā
+
+### õĖ║õ╗Ćõ╣łĶ”üÕåÖ docstring
+
+docstring µś»Õ»╣õĖĆõĖ¬ń▒╗ŃĆüõĖĆõĖ¬ÕćĮµĢ░ÕŖ¤ĶāĮõĖÄ API µÄźÕÅŻńÜäĶ»”ń╗åµÅÅĶ┐░’╝īµ£ēõĖżõĖ¬ÕŖ¤ĶāĮ’╝īõĖƵś»ÕĖ«ÕŖ®ÕģČõ╗¢Õ╝ĆÕÅæĶĆģõ║åĶ¦Żõ╗ŻńĀüÕŖ¤ĶāĮ’╝īµ¢╣õŠ┐ debug ÕÆīÕżŹńö©õ╗ŻńĀü’╝øõ║īµś»Õ£© Readthedocs µ¢ćµĪŻõĖŁĶć¬ÕŖ©ńö¤µłÉńøĖÕģ│ńÜä API reference µ¢ćµĪŻ’╝īÕĖ«ÕŖ®õĖŹõ║åĶ¦Żµ║Éõ╗ŻńĀüńÜäńżŠÕī║ńö©µłĘõĮ┐ńö©ńøĖÕģ│ÕŖ¤ĶāĮŃĆé
+
+### Õ”éõĮĢÕåÖ docstring
+
+õĖĵ│©ķćŖõĖŹÕÉī’╝īõĖĆõ╗ĮĶ¦äĶīāńÜä docstring µ£ēńØĆõĖźµĀ╝ńÜäµĀ╝Õ╝ÅĶ”üµ▒é’╝īõ╗źõŠ┐õ║Ä Python Ķ¦ŻķćŖÕÖ©õ╗źÕÅŖ sphinx Ķ┐øĶĪīµ¢ćµĪŻĶ¦Żµ×É’╝īĶ»”ń╗åńÜä docstring ń║”Õ«ÜÕÅéĶ¦ü [PEP 257](https://www.python.org/dev/peps/pep-0257/)ŃĆ鵣żÕżäõ╗źõŠŗÕŁÉńÜäÕĮóÕ╝Åõ╗ŗń╗ŹÕÉäń¦Źµ¢ćµĪŻńÜäµĀćÕćåµĀ╝Õ╝Å’╝īÕÅéĶĆāµĀ╝Õ╝ÅõĖ║ [Google ķŻÄµĀ╝](https://zh-google-styleguide.readthedocs.io/en/latest/google-python-styleguide/python_style_rules/#comments)ŃĆé
+
+1. µ©ĪÕØŚµ¢ćµĪŻ
+
+ õ╗ŻńĀüķŻÄµĀ╝Ķ¦äĶīāµÄ©ĶŹÉõĖ║µ»ÅõĖĆõĖ¬µ©ĪÕØŚ’╝łÕŹ│ Python µ¢ćõ╗Č’╝ēń╝¢ÕåÖõĖĆõĖ¬ docstring’╝īõĮåńø«ÕēŹ OpenMMLab ķĪ╣ńø«Õż¦ķā©Õłåµ▓Īµ£ēµŁżń▒╗ docstring’╝īÕøĀµŁżõĖŹÕüÜńĪ¼µĆ¦Ķ”üµ▒éŃĆé
+
+ ```python
+ """A one line summary of the module or program, terminated by a period.
+
+ Leave one blank line. The rest of this docstring should contain an
+ overall description of the module or program. Optionally, it may also
+ contain a brief description of exported classes and functions and/or usage
+ examples.
+
+ Typical usage example:
+
+ foo = ClassFoo()
+ bar = foo.FunctionBar()
+ """
+ ```
+
+2. ń▒╗µ¢ćµĪŻ
+
+ ń▒╗µ¢ćµĪŻµś»µłæõ╗¼µ£ĆÕĖĖķ£ĆĶ”üń╝¢ÕåÖńÜä’╝īµŁżÕżä’╝īµīēńģ¦ OpenMMLab ńÜäµā»õŠŗ’╝īµłæõ╗¼õĮ┐ńö©õ║åõĖÄ Google ķŻÄµĀ╝õĖŹÕÉīńÜäÕåÖµ│ĢŃĆéÕ”éõĖŗõŠŗµēĆńż║’╝īµ¢ćµĪŻõĖŁµ▓Īµ£ēõĮ┐ńö© Attributes µÅÅĶ┐░ń▒╗Õ▒׵Ʀ’╝īĶĆīµś»õĮ┐ńö© Args µÅÅĶ┐░ __init__ ÕćĮµĢ░ńÜäÕÅéµĢ░ŃĆé
+
+ Õ£© Args õĖŁ’╝īķüĄńģ¦ `parameter (type): Description.` ńÜäµĀ╝Õ╝Å’╝īµÅÅĶ┐░µ»ÅõĖĆõĖ¬ÕÅéµĢ░ń▒╗Õ×ŗÕÆīÕŖ¤ĶāĮŃĆéÕģČõĖŁ’╝īÕżÜń¦Źń▒╗Õ×ŗÕÅ»õĮ┐ńö© `(float or str)` ńÜäÕåÖµ│Ģ’╝īÕÅ»õ╗źõĖ║ None ńÜäÕÅéµĢ░ÕÅ»õ╗źÕåÖõĖ║ `(int, optional)`ŃĆé
+
+ ```python
+ class BaseRunner(metaclass=ABCMeta):
+ """The base class of Runner, a training helper for PyTorch.
+
+ All subclasses should implement the following APIs:
+
+ - ``run()``
+ - ``train()``
+ - ``val()``
+ - ``save_checkpoint()``
+
+ Args:
+ model (:obj:`torch.nn.Module`): The model to be run.
+ batch_processor (callable, optional): A callable method that process
+ a data batch. The interface of this method should be
+ ``batch_processor(model, data, train_mode) -> dict``.
+ Defaults to None.
+ optimizer (dict or :obj:`torch.optim.Optimizer`, optional): It can be
+ either an optimizer (in most cases) or a dict of optimizers
+ (in models that requires more than one optimizer, e.g., GAN).
+ Defaults to None.
+ work_dir (str, optional): The working directory to save checkpoints
+ and logs. Defaults to None.
+ logger (:obj:`logging.Logger`): Logger used during training.
+ Defaults to None. (The default value is just for backward
+ compatibility)
+ meta (dict, optional): A dict records some import information such as
+ environment info and seed, which will be logged in logger hook.
+ Defaults to None.
+ max_epochs (int, optional): Total training epochs. Defaults to None.
+ max_iters (int, optional): Total training iterations. Defaults to None.
+ """
+
+ def __init__(self,
+ model,
+ batch_processor=None,
+ optimizer=None,
+ work_dir=None,
+ logger=None,
+ meta=None,
+ max_iters=None,
+ max_epochs=None):
+ ...
+ ```
+
+ ÕÅ”Õż¢’╝īÕ£©õĖĆõ║øń«Śµ│ĢÕ«×ńÄ░ńÜäõĖ╗õĮōń▒╗õĖŁ’╝īÕ╗║Ķ««ÕŖĀÕģźÕĤĶ«║µ¢ćńÜäķōŠµÄź’╝øÕ”éµ×£ÕÅéĶĆāõ║åÕģČõ╗¢Õ╝Ƶ║Éõ╗ŻńĀüńÜäÕ«×ńÄ░’╝īÕłÖÕ║öÕŖĀÕģź modified from’╝īĶĆīÕ”éµ×£µś»ńø┤µÄźÕżŹÕłČõ║åÕģČõ╗¢õ╗ŻńĀüÕ║ōńÜäÕ«×ńÄ░’╝īÕłÖÕ║öÕŖĀÕģź copied from ’╝īÕ╣ȵ│©µäŵ║ÉńĀüńÜä LicenseŃĆéՔ鵣ēÕ┐ģĶ”ü’╝īõ╣¤ÕÅ»õ╗źķĆÜĶ┐ć .. math:: µØźÕŖĀÕģźµĢ░ÕŁ”Õģ¼Õ╝Å
+
+ ```python
+ # ÕÅéĶĆāÕ«×ńÄ░
+ # This func is modified from `detectron2
+ #
+| µ©ĪÕØŚ | +Õł½ÕÉŹ | +µ│©µäÅõ║ŗķĪ╣ | + +
|---|---|---|
| nearest | +torch.nn.modules.upsampling.Upsample | +Õ░å type µø┐µŹóµłÉ Upsample ÕÉÄ’╝īķ£ĆĶ”üķóØÕż¢Õ░å mode ÕÅéµĢ░µīćÕ«ÜõĖ║ 'nearest' | +
| bilinear | +torch.nn.modules.upsampling.Upsample | +Õ░å type µø┐µŹóµłÉ Upsample ÕÉÄ’╝īķ£ĆĶ”üķóØÕż¢Õ░å mode ÕÅéµĢ░µīćÕ«ÜõĖ║ 'bilinear' | +
| Clip | +mmcv.cnn.bricks.activation.Clamp | +µŚĀ | +
| Conv | +mmcv.cnn.bricks.wrappers.Conv2d | +µŚĀ | +
| BN | +torch.nn.modules.batchnorm.BatchNorm2d | +µŚĀ | +
| BN1d | +torch.nn.modules.batchnorm.BatchNorm1d | +µŚĀ | +
| BN2d | +torch.nn.modules.batchnorm.BatchNorm2d | +µŚĀ | +
| BN3d | +torch.nn.modules.batchnorm.BatchNorm3d | +µŚĀ | +
| SyncBN | +torch.nn.SyncBatchNorm | +µŚĀ | +
| GN | +torch.nn.modules.normalization.GroupNorm | +µŚĀ | +
| LN | +torch.nn.modules.normalization.LayerNorm | +µŚĀ | +
| IN | +torch.nn.modules.instancenorm.InstanceNorm2d | +µŚĀ | +
| IN1d | +torch.nn.modules.instancenorm.InstanceNorm1d | +µŚĀ | +
| IN2d | +torch.nn.modules.instancenorm.InstanceNorm2d | +µŚĀ | +
| IN3d | +torch.nn.modules.instancenorm.InstanceNorm3d | +µŚĀ | +
| zero | +torch.nn.modules.padding.ZeroPad2d | +µŚĀ | +
| reflect | +torch.nn.modules.padding.ReflectionPad2d | +µŚĀ | +
| replicate | +torch.nn.modules.padding.ReplicationPad2d | +µŚĀ | +
| ConvWS | +mmcv.cnn.bricks.conv_ws.ConvWS2d | +µŚĀ | +
| ConvAWS | +mmcv.cnn.bricks.conv_ws.ConvAWS2d | +µŚĀ | +
| HSwish | +torch.nn.modules.activation.Hardswish | +µŚĀ | +
| pixel_shuffle | +mmcv.cnn.bricks.upsample.PixelShufflePack | +µŚĀ | +
| deconv | +mmcv.cnn.bricks.wrappers.ConvTranspose2d | +µŚĀ | +
| deconv3d | +mmcv.cnn.bricks.wrappers.ConvTranspose3d | +µŚĀ | +
| Constant | +mmengine.model.weight_init.ConstantInit | +µŚĀ | +
| Xavier | +mmengine.model.weight_init.XavierInit | +µŚĀ | +
| Normal | +mmengine.model.weight_init.NormalInit | +µŚĀ | +
| TruncNormal | +mmengine.model.weight_init.TruncNormalInit | +µŚĀ | +
| Uniform | +mmengine.model.weight_init.UniformInit | +µŚĀ | +
| Kaiming | +mmengine.model.weight_init.KaimingInit | +µŚĀ | +
| Caffe2Xavier | +mmengine.model.weight_init.Caffe2XavierInit | +µŚĀ | +
| Pretrained | +mmengine.model.weight_init.PretrainedInit | +µŚĀ | +
+
+Õ░åõ╗ŻńĀüÕģŗķÜåÕł░µ£¼Õ£░
+
+```shell
+git clone git@github.com:{username}/mmengine.git
+```
+
+µĘ╗ÕŖĀÕĤõ╗ŻńĀüÕ║ōõĖ║õĖŖµĖĖõ╗ŻńĀüÕ║ō
+
+```bash
+git remote add upstream git@github.com:open-mmlab/mmengine
+```
+
+µŻĆµ¤ź remote µś»ÕÉ”µĘ╗ÕŖĀµłÉÕŖ¤’╝īÕ£©ń╗łń½»ĶŠōÕģź `git remote -v`
+
+```bash
+origin git@github.com:{username}/mmengine.git (fetch)
+origin git@github.com:{username}/mmengine.git (push)
+upstream git@github.com:open-mmlab/mmengine (fetch)
+upstream git@github.com:open-mmlab/mmengine (push)
+```
+
+```{note}
+Ķ┐ÖķćīÕ»╣ origin ÕÆī upstream Ķ┐øĶĪīõĖĆõĖ¬ń«ĆÕŹĢńÜäõ╗ŗń╗Ź’╝īÕĮōµłæõ╗¼õĮ┐ńö© git clone µØźÕģŗķÜåõ╗ŻńĀüµŚČ’╝īõ╝Üķ╗śĶ«żÕłøÕ╗║õĖĆõĖ¬ origin ńÜä remote’╝īÕ«āµīćÕÉæµłæõ╗¼ÕģŗķÜåńÜäõ╗ŻńĀüÕ║ōÕ£░ÕØĆ’╝īĶĆī upstream ÕłÖµś»µłæõ╗¼Ķć¬ÕĘ▒µĘ╗ÕŖĀńÜä’╝īńö©µØźµīćÕÉæÕĤզŗõ╗ŻńĀüÕ║ōÕ£░ÕØĆŃĆéÕĮōńäČÕ”éµ×£õĮĀõĖŹÕ¢£µ¼óõ╗¢ÕŽ upstream’╝īõ╣¤ÕÅ»õ╗źĶć¬ÕĘ▒õ┐«µö╣’╝īµ»öÕ”éÕŽ open-mmlabŃĆ鵳æõ╗¼ķĆÜÕĖĖÕÉæ origin µÅÉõ║żõ╗ŻńĀü’╝łÕŹ│ fork õĖŗµØźńÜäĶ┐£ń©ŗõ╗ōÕ║ō’╝ē’╝īńäČÕÉÄÕÉæ upstream µÅÉõ║żõĖĆõĖ¬ pull requestŃĆéÕ”éµ×£µÅÉõ║żńÜäõ╗ŻńĀüÕÆīµ£Ćµ¢░ńÜäõ╗ŻńĀüÕÅæńö¤Õå▓ń¬ü’╝īÕåŹõ╗Ä upstream µŗēÕÅ¢µ£Ćµ¢░ńÜäõ╗ŻńĀü’╝īÕÆīµ£¼Õ£░Õłåµö»Ķ¦ŻÕå│Õå▓ń¬ü’╝īÕåŹµÅÉõ║żÕł░ originŃĆé
+```
+
+### 2. ķģŹńĮ« pre-commit
+
+Õ£©µ£¼Õ£░Õ╝ĆÕÅæńÄ»ÕóāõĖŁ’╝īµłæõ╗¼õĮ┐ńö© [pre-commit](https://pre-commit.com/#intro) µØźµŻĆµ¤źõ╗ŻńĀüķŻÄµĀ╝’╝īõ╗źńĪ«õ┐Øõ╗ŻńĀüķŻÄµĀ╝ńÜäń╗¤õĖĆŃĆéÕ£©µÅÉõ║żõ╗ŻńĀü’╝īķ£ĆĶ”üÕģłÕ«ēĶŻģ pre-commit’╝łķ£ĆĶ”üÕ£© mmengine ńø«ÕĮĢõĖŗµē¦ĶĪī’╝ē:
+
+```shell
+pip install -U pre-commit
+pre-commit install
+```
+
+µŻĆµ¤ź pre-commit µś»ÕÉ”ķģŹńĮ«µłÉÕŖ¤’╝īÕ╣ČÕ«ēĶŻģ `.pre-commit-config.yaml` õĖŁńÜäķÆ®ÕŁÉ’╝Ü
+
+```shell
+pre-commit run --all-files
+```
+
+
+
+
+
+```{note}
+Õ”éµ×£õĮĀµś»õĖŁÕøĮńö©µłĘ’╝īńö▒õ║ÄńĮæń╗£ÕĤÕøĀ’╝īÕÅ»ĶāĮõ╝ÜÕć║ńÄ░Õ«ēĶŻģÕż▒Ķ┤źńÜäµāģÕåĄ’╝īĶ┐ÖµŚČÕÅ»õ╗źõĮ┐ńö©ÕøĮÕåģµ║É
+pre-commit install -c .pre-commit-config-zh-cn.yaml
+pre-commit run --all-files -c .pre-commit-config-zh-cn.yaml
+```
+
+Õ”éµ×£Õ«ēĶŻģĶ┐ćń©ŗĶó½õĖŁµ¢Ł’╝īÕÅ»õ╗źķćŹÕżŹµē¦ĶĪī `pre-commit run ...` ń╗¦ń╗ŁÕ«ēĶŻģŃĆé
+
+Õ”éµ×£µÅÉõ║żńÜäõ╗ŻńĀüõĖŹń¼”ÕÉłõ╗ŻńĀüķŻÄµĀ╝Ķ¦äĶīā’╝īpre-commit õ╝ÜÕÅæÕć║ĶŁ”ÕæŖ’╝īÕ╣ČĶć¬ÕŖ©õ┐«ÕżŹķā©ÕłåķöÖĶ»»ŃĆé
+
+
+
+Õ”éµ×£µłæõ╗¼µā│õĖ┤µŚČń╗ĢÕ╝Ć pre-commit ńÜ䵯Ƶ¤źµÅÉõ║żõĖƵ¼Īõ╗ŻńĀü’╝īÕÅ»õ╗źÕ£© `git commit` µŚČÕŖĀõĖŖ `--no-verify`’╝łķ£ĆĶ”üõ┐ØĶ»üµ£ĆÕÉĵĩķĆüĶć│Ķ┐£ń©ŗõ╗ōÕ║ōńÜäõ╗ŻńĀüĶāĮÕż¤ķĆÜĶ┐ć pre-commit µŻĆµ¤ź’╝ēŃĆé
+
+```shell
+git commit -m "xxx" --no-verify
+```
+
+### 3. ÕłøÕ╗║Õ╝ĆÕÅæÕłåµö»
+
+Õ«ēĶŻģÕ«ī pre-commit õ╣ŗÕÉÄ’╝īµłæõ╗¼ķ£ĆĶ”üÕ¤║õ║Ä master ÕłøÕ╗║Õ╝ĆÕÅæÕłåµö»’╝īÕ╗║Ķ««ńÜäÕłåµö»ÕæĮÕÉŹĶ¦äÕłÖõĖ║ `username/pr_name`ŃĆé
+
+```shell
+git checkout -b yhc/refactor_contributing_doc
+```
+
+Õ£©ÕÉÄń╗ŁńÜäÕ╝ĆÕÅæõĖŁ’╝īÕ”éµ×£µ£¼Õ£░õ╗ōÕ║ōńÜä master Õłåµö»ĶÉĮÕÉÄõ║Ä upstream ńÜä master Õłåµö»’╝īµłæõ╗¼ķ£ĆĶ”üÕģłµŗēÕÅ¢ upstream ńÜäõ╗ŻńĀüĶ┐øĶĪīÕÉīµŁź’╝īÕåŹµē¦ĶĪīõĖŖķØóńÜäÕæĮõ╗ż
+
+```shell
+git pull upstream master
+```
+
+### 4. µÅÉõ║żõ╗ŻńĀüÕ╣ČÕ£©µ£¼Õ£░ķĆÜĶ┐ćÕŹĢÕģāµĄŗĶ»Ģ
+
+- MMEngine Õ╝ĢÕģźõ║å mypy µØźÕüÜķØÖµĆüń▒╗Õ×ŗµŻĆµ¤ź’╝īõ╗źÕó×ÕŖĀõ╗ŻńĀüńÜäķ▓üµŻÆµĆ¦ŃĆéÕøĀµŁżµłæõ╗¼Õ£©µÅÉõ║żõ╗ŻńĀüµŚČ’╝īķ£ĆĶ”üĶĪźÕģģ Type HintsŃĆéÕģĘõĮōĶ¦äÕłÖÕÅ»õ╗źÕÅéĶĆā[µĢÖń©ŗ](https://zhuanlan.zhihu.com/p/519335398)ŃĆé
+
+- µÅÉõ║żńÜäõ╗ŻńĀüÕÉīµĀĘķ£ĆĶ”üķĆÜĶ┐ćÕŹĢÕģāµĄŗĶ»Ģ
+
+ ```shell
+ # ķĆÜĶ┐ćÕģ©ķćÅÕŹĢÕģāµĄŗĶ»Ģ
+ pytest tests
+
+ # µłæõ╗¼ķ£ĆĶ”üõ┐ØĶ»üµÅÉõ║żńÜäõ╗ŻńĀüĶāĮÕż¤ķĆÜĶ┐ćõ┐«µö╣µ©ĪÕØŚńÜäÕŹĢÕģāµĄŗĶ»Ģ’╝īõ╗ź runner õĖ║õŠŗ
+ pytest tests/test_runner/test_runner.py
+ ```
+
+ Õ”éµ×£õĮĀńö▒õ║Äń╝║Õ░æõŠØĶĄ¢µŚĀµ│ĢĶ┐ÉĶĪīõ┐«µö╣µ©ĪÕØŚńÜäÕŹĢÕģāµĄŗĶ»Ģ’╝īÕÅ»õ╗źÕÅéĶĆā[µīćÕ╝Ģ-ÕŹĢÕģāµĄŗĶ»Ģ](#ÕŹĢÕģāµĄŗĶ»Ģ)
+
+- Õ”éµ×£õ┐«µö╣/µĘ╗ÕŖĀõ║åµ¢ćµĪŻ’╝īÕÅéĶĆā[µīćÕ╝Ģ](#µ¢ćµĪŻµĖ▓µ¤ō)ńĪ«Ķ«żµ¢ćµĪŻµĖ▓µ¤ōµŁŻÕĖĖŃĆé
+
+### 5. µÄ©ķĆüõ╗ŻńĀüÕł░Ķ┐£ń©ŗ
+
+õ╗ŻńĀüķĆÜĶ┐ćÕŹĢÕģāµĄŗĶ»ĢÕÆī pre-commit µŻĆµ¤źÕÉÄ’╝īÕ░åõ╗ŻńĀüµÄ©ķĆüÕł░Ķ┐£ń©ŗõ╗ōÕ║ō’╝īÕ”éµ×£µś»ń¼¼õĖƵ¼ĪµÄ©ķĆü’╝īÕÅ»õ╗źÕ£© `git push` ÕÉÄÕŖĀõĖŖ `-u` ÕÅéµĢ░õ╗źÕģ│ĶüöĶ┐£ń©ŗÕłåµö»
+
+```shell
+git push -u origin {branch_name}
+```
+
+Ķ┐ÖµĀĘõĖŗµ¼ĪÕ░▒ÕÅ»õ╗źńø┤µÄźõĮ┐ńö© `git push` ÕæĮõ╗żµÄ©ķĆüõ╗ŻńĀüõ║å’╝īĶĆīµŚĀķ£ĆµīćÕ«ÜÕłåµö»ÕÆīĶ┐£ń©ŗõ╗ōÕ║ōŃĆé
+
+### 6. µÅÉõ║żµŗēÕÅ¢Ķ»Ęµ▒é’╝łPR’╝ē
+
+(1) Õ£© GitHub ńÜä Pull request ńĢīķØóÕłøÕ╗║µŗēÕÅ¢Ķ»Ęµ▒é
+
+
+(2) µĀ╣µŹ«µīćÕ╝Ģõ┐«µö╣ PR µÅÅĶ┐░’╝īõ╗źõŠ┐õ║ÄÕģČõ╗¢Õ╝ĆÕÅæĶĆģµø┤ÕźĮÕ£░ńÉåĶ¦ŻõĮĀńÜäõ┐«µö╣
+
+
+
+µÅÅĶ┐░Ķ¦äĶīāĶ»”Ķ¦ü[µŗēÕÅ¢Ķ»Ęµ▒éĶ¦äĶīā](#µŗēÕÅ¢Ķ»Ęµ▒éĶ¦äĶīā)
+
+
+
+**µ│©µäÅõ║ŗķĪ╣**
+
+(a) PR µÅÅĶ┐░Õ║öĶ»źÕīģÕɽõ┐«µö╣ńÉåńö▒ŃĆüõ┐«µö╣ÕåģÕ«╣õ╗źÕÅŖõ┐«µö╣ÕÉÄÕĖ”µØźńÜäÕĮ▒ÕōŹ’╝īÕ╣ČÕģ│ĶüöńøĖÕģ│ Issue’╝łÕģĘõĮōµ¢╣Õ╝ÅĶ¦ü[µ¢ćµĪŻ](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue)’╝ē
+
+(b) Õ”éµ×£µś»ń¼¼õĖƵ¼ĪõĖ║ OpenMMLab ÕüÜĶ┤Īńī«’╝īķ£ĆĶ”üńŁŠńĮ▓ CLA
+
+
+
+(c) µŻĆµ¤źµÅÉõ║żńÜä PR µś»ÕÉ”ķĆÜĶ┐ć CI’╝łķøåµłÉµĄŗĶ»Ģ’╝ē
+
+
+
+MMEngine õ╝ÜÕ£©õĖŹÕÉīńÜäÕ╣│ÕÅ░’╝łLinuxŃĆüWindowŃĆüMac’╝ē’╝īÕ¤║õ║ÄõĖŹÕÉīńēłµ£¼ńÜä PythonŃĆüPyTorchŃĆüCUDA Õ»╣µÅÉõ║żńÜäõ╗ŻńĀüĶ┐øĶĪīÕŹĢÕģāµĄŗĶ»Ģ’╝īõ╗źõ┐ØĶ»üõ╗ŻńĀüńÜ䵣ŻńĪ«µĆ¦’╝īÕ”éµ×£µ£ēõ╗╗õĮĢõĖĆõĖ¬µ▓Īµ£ēķĆÜĶ┐ć’╝īµłæõ╗¼ÕÅ»ńé╣Õć╗õĖŖÕøŠõĖŁńÜä `Details` µØźµ¤źń£ŗÕģĘõĮōńÜ䵥ŗĶ»Ģõ┐Īµü»’╝īõ╗źõŠ┐õ║ĵłæõ╗¼õ┐«µö╣õ╗ŻńĀüŃĆé
+
+(3) Õ”éµ×£ PR ķĆÜĶ┐ćõ║å CI’╝īķéŻõ╣łÕ░▒ÕÅ»õ╗źńŁēÕŠģÕģČõ╗¢Õ╝ĆÕÅæĶĆģńÜä review’╝īÕ╣ȵĀ╣µŹ« reviewer ńÜäµäÅĶ¦ü’╝īõ┐«µö╣õ╗ŻńĀü’╝īÕ╣ČķćŹÕżŹ [4](#4-µÅÉõ║żõ╗ŻńĀüÕ╣ČÕ£©µ£¼Õ£░ķĆÜĶ┐ćÕŹĢÕģāµĄŗĶ»Ģ)-[5](#5-µÄ©ķĆüõ╗ŻńĀüÕł░Ķ┐£ń©ŗ) µŁźķ¬ż’╝īńø┤Õł░ reviewer ÕÉīµäÅÕÉłÕģź PRŃĆé
+
+
+
+µēƵ£ē reviewer ÕÉīµäÅÕÉłÕģź PR ÕÉÄ’╝īµłæõ╗¼õ╝ÜÕ░ĮÕ┐½Õ░å PR ÕÉłÕ╣ČÕł░õĖ╗Õłåµö»ŃĆé
+
+### 7. Ķ¦ŻÕå│Õå▓ń¬ü
+
+ķÜÅńØƵŚČķŚ┤ńÜäµÄ©ń¦╗’╝īµłæõ╗¼ńÜäõ╗ŻńĀüÕ║ōõ╝ÜõĖŹµ¢Łµø┤µ¢░’╝īĶ┐ÖµŚČÕĆÖ’╝īÕ”éµ×£õĮĀńÜä PR õĖÄõĖ╗Õłåµö»ÕŁśÕ£©Õå▓ń¬ü’╝īõĮĀķ£ĆĶ”üĶ¦ŻÕå│Õå▓ń¬ü’╝īĶ¦ŻÕå│Õå▓ń¬üńÜäµ¢╣Õ╝ŵ£ēõĖżń¦Ź’╝Ü
+
+```shell
+git fetch --all --prune
+git rebase upstream/master
+```
+
+µł¢ĶĆģ
+
+```shell
+git fetch --all --prune
+git merge upstream/master
+```
+
+Õ”éµ×£õĮĀķØ×ÕĖĖÕ¢äõ║ÄÕżäńÉåÕå▓ń¬ü’╝īķéŻõ╣łÕÅ»õ╗źõĮ┐ńö© rebase ńÜäµ¢╣Õ╝ÅµØźĶ¦ŻÕå│Õå▓ń¬ü’╝īÕøĀõĖ║Ķ┐ÖĶāĮÕż¤õ┐ØĶ»üõĮĀńÜä commit log ńÜäµĢ┤µ┤üŃĆéÕ”éµ×£õĮĀõĖŹÕż¬ń夵éē `rebase` ńÜäõĮ┐ńö©’╝īķéŻõ╣łÕÅ»õ╗źõĮ┐ńö© `merge` ńÜäµ¢╣Õ╝ÅµØźĶ¦ŻÕå│Õå▓ń¬üŃĆé
+
+## µīćÕ╝Ģ
+
+### ÕŹĢÕģāµĄŗĶ»Ģ
+
+Õ£©µÅÉõ║żõ┐«ÕżŹõ╗ŻńĀüķöÖĶ»»µł¢µ¢░Õó×ńē╣µĆ¦ńÜäµŗēÕÅ¢Ķ»Ęµ▒鵌Ȓ╝īµłæõ╗¼Õ║öĶ»źÕ░ĮÕÅ»ĶāĮńÜäĶ«®ÕŹĢÕģāµĄŗĶ»ĢĶ”åńø¢µēƵ£ēµÅÉõ║żńÜäõ╗ŻńĀü’╝īĶ«Īń«ŚÕŹĢÕģāµĄŗĶ»ĢĶ”åńø¢ńÄćńÜäµ¢╣µ│ĢÕ”éõĖŗ
+
+```shell
+python -m coverage run -m pytest /path/to/test_file
+python -m coverage html
+# check file in htmlcov/index.html
+```
+
+### µ¢ćµĪŻµĖ▓µ¤ō
+
+Õ£©µÅÉõ║żõ┐«ÕżŹõ╗ŻńĀüķöÖĶ»»µł¢µ¢░Õó×ńē╣µĆ¦ńÜäµŗēÕÅ¢Ķ»Ęµ▒鵌Ȓ╝īÕÅ»ĶāĮõ╝Üķ£ĆĶ”üõ┐«µö╣/µ¢░Õó×µ©ĪÕØŚńÜä docstringŃĆ鵳æõ╗¼ķ£ĆĶ”üńĪ«Ķ«żµĖ▓µ¤ōÕÉÄńÜäµ¢ćµĪŻµĀĘÕ╝ŵś»µŁŻńĪ«ńÜäŃĆé
+µ£¼Õ£░ńö¤µłÉµĖ▓µ¤ōÕÉÄńÜäµ¢ćµĪŻńÜäµ¢╣µ│ĢÕ”éõĖŗ
+
+```shell
+pip install -r requirements/docs.txt
+cd docs/zh_cn/
+# or docs/en
+make html
+# check file in ./docs/zh_cn/_build/html/index.html
+```
+
+## Python õ╗ŻńĀüķŻÄµĀ╝
+
+[PEP8](https://www.python.org/dev/peps/pep-0008/) õĮ£õĖ║ OpenMMLab ń«Śµ│ĢÕ║ōķ”¢ķĆēńÜäõ╗ŻńĀüĶ¦äĶīā’╝īµłæõ╗¼õĮ┐ńö©õ╗źõĖŗÕĘźÕģʵŻĆµ¤źÕÆīµĀ╝Õ╝ÅÕī¢õ╗ŻńĀü
+
+- [flake8](https://github.com/PyCQA/flake8): Python Õ«śµ¢╣ÕÅæÕĖāńÜäõ╗ŻńĀüĶ¦äĶīāµŻĆµ¤źÕĘźÕģĘ’╝īµś»ÕżÜõĖ¬µŻĆµ¤źÕĘźÕģĘńÜäÕ░üĶŻģ
+- [isort](https://github.com/timothycrosley/isort): Ķć¬ÕŖ©Ķ░āµĢ┤µ©ĪÕØŚÕ»╝ÕģźķĪ║Õ║ÅńÜäÕĘźÕģĘ
+- [yapf](https://github.com/google/yapf): Google ÕÅæÕĖāńÜäõ╗ŻńĀüĶ¦äĶīāµŻĆµ¤źÕĘźÕģĘ
+- [codespell](https://github.com/codespell-project/codespell): µŻĆµ¤źÕŹĢĶ»Źµŗ╝ÕåÖµś»ÕÉ”µ£ēĶ»»
+- [mdformat](https://github.com/executablebooks/mdformat): µŻĆµ¤ź markdown µ¢ćõ╗ČńÜäÕĘźÕģĘ
+- [docformatter](https://github.com/myint/docformatter): µĀ╝Õ╝ÅÕī¢ docstring ńÜäÕĘźÕģĘ
+
+yapf ÕÆī isort ńÜäķģŹńĮ«ÕÅ»õ╗źÕ£© [setup.cfg](https://github.com/open-mmlab/mmengine/blob/main/setup.cfg) µēŠÕł░
+
+ķĆÜĶ┐ćķģŹńĮ« [pre-commit hook](https://pre-commit.com/) ’╝īµłæõ╗¼ÕÅ»õ╗źÕ£©µÅÉõ║żõ╗ŻńĀüµŚČĶć¬ÕŖ©µŻĆµ¤źÕÆīµĀ╝Õ╝ÅÕī¢ `flake8`ŃĆü`yapf`ŃĆü`isort`ŃĆü`trailing whitespaces`ŃĆü`markdown files`’╝īõ┐«ÕżŹ `end-of-files`ŃĆü`double-quoted-strings`ŃĆü`python-encoding-pragma`ŃĆü`mixed-line-ending`’╝īĶ░āµĢ┤ `requirments.txt` ńÜäÕīģķĪ║Õ║ÅŃĆé
+pre-commit ķÆ®ÕŁÉńÜäķģŹńĮ«ÕÅ»õ╗źÕ£© [.pre-commit-config](https://github.com/open-mmlab/mmengine/blob/main/.pre-commit-config-zh-cn.yaml) µēŠÕł░ŃĆé
+
+pre-commit ÕģĘõĮōńÜäÕ«ēĶŻģõĮ┐ńö©µ¢╣Õ╝ÅĶ¦ü[µŗēÕÅ¢Ķ»Ęµ▒é](#2-ķģŹńĮ«-pre-commit)ŃĆé
+
+µø┤ÕģĘõĮōńÜäĶ¦äĶīāĶ»ĘÕÅéĶĆā [OpenMMLab õ╗ŻńĀüĶ¦äĶīā](code_style.md)ŃĆé
+
+## µŗēÕÅ¢Ķ»Ęµ▒éĶ¦äĶīā
+
+1. õĮ┐ńö© [pre-commit hook](https://pre-commit.com)’╝īÕ░ĮķćÅÕćÅÕ░æõ╗ŻńĀüķŻÄµĀ╝ńøĖÕģ│ķŚ«ķóś
+
+2. õĖĆõĖ¬`µŗēÕÅ¢Ķ»Ęµ▒é`Õ»╣Õ║öõĖĆõĖ¬ń¤Łµ£¤Õłåµö»
+
+3. ń▓ÆÕ║”Ķ”üń╗å’╝īõĖĆõĖ¬`µŗēÕÅ¢Ķ»Ęµ▒é`ÕŬÕüÜõĖĆõ╗Čõ║ŗµāģ’╝īķü┐ÕģŹĶČģÕż¦ńÜä`µŗēÕÅ¢Ķ»Ęµ▒é`
+
+ - Bad’╝ÜÕ«×ńÄ░ Faster R-CNN
+ - Acceptable’╝Üń╗Ö Faster R-CNN µĘ╗ÕŖĀõĖĆõĖ¬ box head
+ - Good’╝Üń╗Ö box head Õó×ÕŖĀõĖĆõĖ¬ÕÅéµĢ░µØźµö»µīüĶć¬Õ«Üõ╣ēńÜä conv Õ▒éµĢ░
+
+4. µ»Åµ¼Ī Commit µŚČķ£ĆĶ”üµÅÉõŠøµĖģµÖ░õĖöµ£ēµäÅõ╣ē commit õ┐Īµü»
+
+5. µÅÉõŠøµĖģµÖ░õĖöµ£ēµäÅõ╣ēńÜä`µŗēÕÅ¢Ķ»Ęµ▒é`µÅÅĶ┐░
+
+ - µĀćķóśÕåÖµśÄńÖĮõ╗╗ÕŖĪÕÉŹń¦░’╝īõĖĆĶł¼µĀ╝Õ╝Å:\[Prefix\] Short description of the pull request (Suffix)
+ - prefix: µ¢░Õó×ÕŖ¤ĶāĮ \[Feature\], õ┐« bug \[Fix\], µ¢ćµĪŻńøĖÕģ│ \[Docs\], Õ╝ĆÕÅæõĖŁ \[WIP\] (µÜ鵌ČõĖŹõ╝ÜĶó½review)
+ - µÅÅĶ┐░ķćīõ╗ŗń╗Ź`µŗēÕÅ¢Ķ»Ęµ▒é`ńÜäõĖ╗Ķ”üõ┐«µö╣ÕåģÕ«╣’╝īń╗ōµ×£’╝īõ╗źÕÅŖÕ»╣ÕģČõ╗¢ķā©ÕłåńÜäÕĮ▒ÕōŹ, ÕÅéĶĆā`µŗēÕÅ¢Ķ»Ęµ▒é`µ©ĪµØ┐
+ - Õģ│ĶüöńøĖÕģ│ńÜä`Ķ««ķóś` (issue) ÕÆīÕģČõ╗¢`µŗēÕÅ¢Ķ»Ęµ▒é`
+
+6. Õ”éµ×£Õ╝ĢÕģźõ║åÕģČõ╗¢õĖēµ¢╣Õ║ō’╝īµł¢ÕƤķē┤õ║åõĖēµ¢╣Õ║ōńÜäõ╗ŻńĀü’╝īĶ»ĘńĪ«Ķ«żõ╗¢õ╗¼ńÜäĶ«ĖÕÅ»Ķ»üÕÆī MMEngine Õģ╝Õ«╣’╝īÕ╣ČÕ£©ÕƤķē┤ńÜäõ╗ŻńĀüõĖŖĶĪźÕģģ `This code is inspired from http://`
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/cross_library.md b/internlm_langchain/knowledge_base/MMEngine/content/cross_library.md
new file mode 100644
index 00000000..a70dc728
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/cross_library.md
@@ -0,0 +1,94 @@
+# ĶĘ©Õ║ōĶ░āńö©µ©ĪÕØŚ
+
+ķĆÜĶ┐ćõĮ┐ńö© MMEngine ńÜä[µ│©ÕåīÕÖ©’╝łRegistry’╝ē](registry.md)ÕÆī[ķģŹńĮ«µ¢ćõ╗Č’╝łConfig’╝ē](config.md)’╝īńö©µłĘÕÅ»õ╗źÕ«×ńÄ░ĶĘ©ĶĮ»õ╗ČÕīģńÜ䵩ĪÕØŚµ×äÕ╗║ŃĆé
+õŠŗÕ”é’╝īÕ£© [MMDetection](https://github.com/open-mmlab/mmdetection) õĖŁõĮ┐ńö© [MMPretrain](https://github.com/open-mmlab/mmpretrain) ńÜä Backbone’╝īµł¢ĶĆģÕ£© [MMRotate](https://github.com/open-mmlab/mmrotate) õĖŁõĮ┐ńö© [MMDetection](https://github.com/open-mmlab/mmdetection) ńÜä Transform’╝īµł¢ĶĆģÕ£© [MMTracking](https://github.com/open-mmlab/mmtracking) õĖŁõĮ┐ńö© [MMDetection](https://github.com/open-mmlab/mmdetection) ńÜä DetectorŃĆé
+õĖĆĶł¼µØźĶ»┤’╝īÕÉīń▒╗µ©ĪÕØŚķāĮÕÅ»õ╗źĶ┐øĶĪīĶĘ©Õ║ōĶ░āńö©’╝īÕŬķ£ĆĶ”üÕ£©ķģŹńĮ«µ¢ćõ╗ČńÜ䵩ĪÕØŚń▒╗Õ×ŗÕēŹÕŖĀõĖŖĶĮ»õ╗ČÕīģÕÉŹńÜäÕēŹń╝ĆÕŹ│ÕÅ»ŃĆéõĖŗķØóõĖŠÕćĀõĖ¬ÕĖĖĶ¦üńÜäõŠŗÕŁÉ’╝Ü
+
+## ĶĘ©Õ║ōĶ░āńö© Backbone:
+
+õ╗źÕ£© MMDetection õĖŁĶ░āńö© MMPretrain ńÜä ConvNeXt õĖ║õŠŗ’╝īķ”¢Õģłķ£ĆĶ”üÕ£©ķģŹńĮ«õĖŁÕŖĀÕģź `custom_imports` ÕŁŚµ«ĄÕ░å MMPretrain ńÜä Backbone µĘ╗ÕŖĀĶ┐øµ│©ÕåīÕÖ©’╝īńäČÕÉÄÕŬķ£ĆĶ”üÕ£© Backbone ńÜäķģŹńĮ«õĖŁńÜä `type` ÕŖĀõĖŖ MMPretrain ńÜäĶĮ»õ╗ČÕīģÕÉŹ `mmpretrain` õĮ£õĖ║ÕēŹń╝Ć’╝īÕŹ│ `mmpretrain.ConvNeXt` ÕŹ│ÕÅ»’╝Ü
+
+```python
+# õĮ┐ńö© custom_imports Õ░å mmpretrain ńÜä models µĘ╗ÕŖĀĶ┐øµ│©ÕåīÕÖ©
+custom_imports = dict(imports=['mmpretrain.models'], allow_failed_imports=False)
+
+model = dict(
+ type='MaskRCNN',
+ data_preprocessor=dict(...),
+ backbone=dict(
+ type='mmpretrain.ConvNeXt', # µĘ╗ÕŖĀ mmpretrain ÕēŹń╝ĆÕ«īµłÉĶĘ©Õ║ōĶ░āńö©
+ arch='tiny',
+ out_indices=[0, 1, 2, 3],
+ drop_path_rate=0.4,
+ layer_scale_init_value=1.0,
+ gap_before_final_norm=False,
+ init_cfg=dict(
+ type='Pretrained',
+ checkpoint=
+ 'https://download.openmmlab.com/mmclassification/v0/convnext/downstream/convnext-tiny_3rdparty_32xb128-noema_in1k_20220301-795e9634.pth',
+ prefix='backbone.')),
+ neck=dict(...),
+ rpn_head=dict(...))
+```
+
+## ĶĘ©Õ║ōĶ░āńö© Transform:
+
+õĖÄõĖŖµ¢ćńÜäĶĘ©Õ║ōĶ░āńö© Backbone õĖƵĀĘ’╝īõĮ┐ńö© custom_imports ÕÆīµĘ╗ÕŖĀÕēŹń╝ĆÕŹ│ÕŻի×ńÄ░ĶĘ©Õ║ōĶ░āńö©’╝Ü
+
+```python
+# õĮ┐ńö© custom_imports Õ░å mmdet ńÜä transforms µĘ╗ÕŖĀĶ┐øµ│©ÕåīÕÖ©
+custom_imports = dict(imports=['mmdet.datasets.transforms'], allow_failed_imports=False)
+
+# µĘ╗ÕŖĀ mmdet ÕēŹń╝ĆÕ«īµłÉĶĘ©Õ║ōĶ░āńö©
+train_pipeline=[
+ dict(type='mmdet.LoadImageFromFile'),
+ dict(type='mmdet.LoadAnnotations', with_bbox=True, box_type='qbox'),
+ dict(type='ConvertBoxType', box_type_mapping=dict(gt_bboxes='rbox')),
+ dict(type='mmdet.Resize', scale=(1024, 2014), keep_ratio=True),
+ dict(type='mmdet.RandomFlip', prob=0.5),
+ dict(type='mmdet.PackDetInputs')
+]
+```
+
+## ĶĘ©Õ║ōĶ░āńö© Detector:
+
+ĶĘ©Õ║ōĶ░āńö©ń«Śµ│Ģµś»õĖĆõĖ¬µ»öĶŠāÕżŹµØéńÜäõŠŗÕŁÉ’╝īõĖĆõĖ¬ń«Śµ│Ģõ╝ÜÕīģÕÉ½ÕżÜõĖ¬ÕŁÉµ©ĪÕØŚ’╝īÕøĀµŁżµ»ÅõĖ¬ÕŁÉµ©ĪÕØŚõ╣¤ķ£ĆĶ”üÕ£©`type`õĖŁÕó×ÕŖĀÕēŹń╝Ć’╝īõ╗źÕ£© MMTracking õĖŁĶ░āńö© MMDetection ńÜä YOLOX õĖ║õŠŗ’╝Ü
+
+```python
+# õĮ┐ńö© custom_imports Õ░å mmdet ńÜä models µĘ╗ÕŖĀĶ┐øµ│©ÕåīÕÖ©
+custom_imports = dict(imports=['mmdet.models'], allow_failed_imports=False)
+model = dict(
+ type='mmdet.YOLOX',
+ backbone=dict(type='mmdet.CSPDarknet', deepen_factor=1.33, widen_factor=1.25),
+ neck=dict(
+ type='mmdet.YOLOXPAFPN',
+ in_channels=[320, 640, 1280],
+ out_channels=320,
+ num_csp_blocks=4),
+ bbox_head=dict(
+ type='mmdet.YOLOXHead', num_classes=1, in_channels=320, feat_channels=320),
+ train_cfg=dict(assigner=dict(type='mmdet.SimOTAAssigner', center_radius=2.5)))
+```
+
+õĖ║õ║åķü┐ÕģŹń╗Öµ»ÅõĖ¬ÕŁÉµ©ĪÕØŚµēŗÕŖ©Õó×ÕŖĀÕēŹń╝Ć’╝īķģŹńĮ«µ¢ćõ╗ČõĖŁÕ╝ĢÕģźõ║å `_scope_` Õģ│ķö«ÕŁŚ’╝īÕĮōµ¤ÉõĖƵ©ĪÕØŚńÜäķģŹńĮ«õĖŁµĘ╗ÕŖĀõ║å `_scope_` Õģ│ķö«ÕŁŚÕÉÄ’╝īĶ»źµ©ĪÕØŚķģŹńĮ«µ¢ćõ╗ČõĖŗķØóńÜäµēƵ£ēÕŁÉµ©ĪÕØŚķģŹńĮ«ķāĮõ╝Üõ╗ÄĶ»źÕģ│ķö«ÕŁŚµēĆÕ»╣Õ║öńÜäĶĮ»õ╗ČÕīģÕåģÕÄ╗µ×äÕ╗║’╝Ü
+
+```python
+# õĮ┐ńö© custom_imports Õ░å mmdet ńÜä models µĘ╗ÕŖĀĶ┐øµ│©ÕåīÕÖ©
+custom_imports = dict(imports=['mmdet.models'], allow_failed_imports=False)
+model = dict(
+ _scope_='mmdet', # õĮ┐ńö© _scope_ Õģ│ķö«ÕŁŚ’╝īķü┐ÕģŹń╗ÖµēƵ£ēÕŁÉµ©ĪÕØŚµĘ╗ÕŖĀÕēŹń╝Ć
+ type='YOLOX',
+ backbone=dict(type='CSPDarknet', deepen_factor=1.33, widen_factor=1.25),
+ neck=dict(
+ type='YOLOXPAFPN',
+ in_channels=[320, 640, 1280],
+ out_channels=320,
+ num_csp_blocks=4),
+ bbox_head=dict(
+ type='YOLOXHead', num_classes=1, in_channels=320, feat_channels=320),
+ train_cfg=dict(assigner=dict(type='SimOTAAssigner', center_radius=2.5)))
+```
+
+õ╗źõĖŖĶ┐ÖõĖżń¦ŹÕåÖµ│Ģõ║ÆńøĖńŁēõ╗ĘŃĆé
+
+ĶŗźÕĖīµ£øõ║åĶ¦Żµø┤ÕżÜÕģ│õ║ĵ│©ÕåīÕÖ©ÕÆīķģŹńĮ«µ¢ćõ╗ČńÜäÕåģÕ«╣’╝īĶ»ĘÕÅéĶĆā[ķģŹńĮ«µ¢ćõ╗ȵĢÖń©ŗ](config.md)ÕÆī[µ│©ÕåīÕÖ©µĢÖń©ŗ](registry.md)
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/data_element.md b/internlm_langchain/knowledge_base/MMEngine/content/data_element.md
new file mode 100644
index 00000000..7574a925
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/data_element.md
@@ -0,0 +1,1098 @@
+# µŖĮĶ▒ĪµĢ░µŹ«µÄźÕÅŻ
+
+Õ£©µ©ĪÕ×ŗńÜäĶ«Łń╗ā/µĄŗĶ»ĢĶ┐ćń©ŗõĖŁ’╝īń╗äõ╗Čõ╣ŗķŚ┤ÕŠĆÕŠĆµ£ēÕż¦ķćÅńÜäµĢ░µŹ«ķ£ĆĶ”üõ╝ĀķĆÆ’╝īõĖŹÕÉīńÜäń«Śµ│Ģķ£ĆĶ”üõ╝ĀķĆÆńÜäµĢ░µŹ«ń╗ÅÕĖĖµś»õĖŹõĖƵĀĘńÜä’╝īõŠŗÕ”é’╝īĶ«Łń╗āÕŹĢķśČµ«ĄµŻĆµĄŗÕÖ©ķ£ĆĶ”üĶÄĘÕŠŚµĢ░µŹ«ķøåńÜäµĀćµ│©µĪå’╝łground truth bounding boxes’╝ēÕÆīµĀćńŁŠ’╝łground truth box labels’╝ē’╝īĶ«Łń╗ā Mask R-CNN µŚČĶ┐śķ£ĆĶ”üÕ«×õŠŗµÄ®ńĀü’╝łinstance masks’╝ēŃĆé
+Ķ«Łń╗āĶ┐Öõ║øµ©ĪÕ×ŗµŚČńÜäõ╗ŻńĀüÕ”éõĖŗµēĆńż║
+
+```python
+for img, img_metas, gt_bboxes, gt_labels in data_loader:
+ loss = retinanet(img, img_metas, gt_bboxes, gt_labels)
+```
+
+```python
+for img, img_metas, gt_bboxes, gt_masks, gt_labels in data_loader:
+ loss = mask_rcnn(img, img_metas, gt_bboxes, gt_masks, gt_labels)
+```
+
+ÕÅ»õ╗źÕÅæńÄ░’╝īÕ£©õĖŹÕŖĀÕ░üĶŻģńÜäµāģÕåĄõĖŗ’╝īõĖŹÕÉīń«Śµ│ĢµēĆķ£ĆµĢ░µŹ«ńÜäõĖŹõĖĆĶć┤Õ»╝Ķć┤õ║åõĖŹÕÉīń«Śµ│Ģµ©ĪÕØŚõ╣ŗķŚ┤µÄźÕÅŻńÜäõĖŹõĖĆĶć┤’╝īÕĮ▒ÕōŹõ║åń«Śµ│ĢÕ║ōńÜäµŗōÕ▒ĢµĆ¦’╝īÕÉīµŚČõĖĆõĖ¬ń«Śµ│ĢÕ║ōÕåģńÜ䵩ĪÕØŚõĖ║õ║åõ┐صīüÕģ╝Õ«╣µĆ¦ÕŠĆÕŠĆÕ£©µÄźÕÅŻõĖŖÕŁśÕ£©ÕåŚõĮÖŃĆé
+õĖŖĶ┐░Õ╝Ŗń½»Õ£©ń«Śµ│ĢÕ║ōõ╣ŗķŚ┤õ╝ÜõĮōńÄ░Õ£░µø┤ÕŖĀµśÄµśŠ’╝īÕ»╝Ķć┤Õ£©Õ«×ńÄ░ÕżÜõ╗╗ÕŖĪ’╝łÕÉīµŚČĶ┐øĶĪīÕ”éĶ»Łõ╣ēÕłåÕē▓ŃĆüµŻĆµĄŗŃĆüÕģ│ķö«ńé╣µŻĆµĄŗńŁēÕżÜõĖ¬õ╗╗ÕŖĪ’╝ēµä¤ń¤źµ©ĪÕ×ŗµŚČµ©ĪÕØŚķÜŠõ╗źÕżŹńö©’╝īµÄźÕÅŻķÜŠõ╗źµŗōÕ▒ĢŃĆé
+
+õĖ║õ║åĶ¦ŻÕå│õĖŖĶ┐░ķŚ«ķóś’╝īMMEngine Õ«Üõ╣ēõ║åõĖĆÕźŚµŖĮĶ▒ĪńÜäµĢ░µŹ«µÄźÕÅŻµØźÕ░üĶŻģµ©ĪÕ×ŗĶ┐ÉĶĪīĶ┐ćń©ŗõĖŁńÜäÕÉäń¦ŹµĢ░µŹ«ŃĆéÕüćĶ«ŠÕ░åõĖŖĶ┐░õĖŹÕÉīńÜäµĢ░µŹ«Õ░üĶŻģĶ┐ø `data_sample` ’╝īõĖŹÕÉīń«Śµ│ĢńÜäĶ«Łń╗āķāĮÕÅ»õ╗źĶó½µŖĮĶ▒ĪÕÆīń╗¤õĖƵłÉÕ”éõĖŗõ╗ŻńĀü
+
+```python
+for img, data_sample in dataloader:
+ loss = model(img, data_sample)
+```
+
+ķĆÜĶ┐ćÕ»╣ÕÉäń¦ŹµĢ░µŹ«µÅÉõŠøń╗¤õĖĆńÜäÕ░üĶŻģ’╝īµŖĮĶ▒ĪµĢ░µŹ«µÄźÕÅŻń╗¤õĖĆÕ╣Čń«ĆÕī¢õ║åń«Śµ│ĢÕ║ōõĖŁÕÉäõĖ¬µ©ĪÕØŚńÜäµÄźÕÅŻ’╝īÕÅ»õ╗źĶó½ńö©õ║Äń«Śµ│ĢÕ║ōõĖŁ dataset’╝īmodel’╝īvisualizer’╝īÕÆī evaluator ń╗äõ╗Čõ╣ŗķŚ┤’╝īµł¢ĶĆģ model ÕåģÕÉäõĖ¬µ©ĪÕØŚõ╣ŗķŚ┤ńÜäµĢ░µŹ«õ╝ĀķĆÆŃĆé
+µŖĮĶ▒ĪµĢ░µŹ«µÄźÕÅŻÕ«×ńÄ░õ║åÕ¤║µ£¼ńÜäÕó×/ÕłĀ/µö╣/µ¤źÕŖ¤ĶāĮ’╝īÕÉīµŚČµö»µīüõĖŹÕÉīĶ«ŠÕżćõ╣ŗķŚ┤ńÜäĶ┐üń¦╗’╝īµö»µīüń▒╗ÕŁŚÕģĖÕÆīÕ╝ĀķćÅńÜäµōŹõĮ£’╝īÕÅ»õ╗źÕģģÕłåµ╗ĪĶČ│ń«Śµ│ĢÕ║ōÕ»╣õ║ÄĶ┐Öõ║øµĢ░µŹ«ńÜäõĮ┐ńö©Ķ”üµ▒éŃĆé
+Õ¤║õ║Ä MMEngine ńÜäń«Śµ│ĢÕ║ōÕÅ»õ╗źń╗¦µē┐Ķ┐ÖÕźŚµŖĮĶ▒ĪµĢ░µŹ«µÄźÕÅŻÕ╣ČÕ«×ńÄ░Ķć¬ÕĘ▒ńÜäµŖĮĶ▒ĪµĢ░µŹ«µÄźÕÅŻµØźķĆéÕ║öõĖŹÕÉīń«Śµ│ĢõĖŁµĢ░µŹ«ńÜäńē╣ńé╣õĖÄÕ«×ķÖģķ£ĆĶ”ü’╝īÕ£©õ┐صīüń╗¤õĖƵğÕÅŻńÜäÕÉīµŚČµÅÉķ½śõ║åń«Śµ│Ģµ©ĪÕØŚńÜäµŗōÕ▒ĢµĆ¦ŃĆé
+
+Õ£©Õ«×ķÖģÕ«×ńÄ░Ķ┐ćń©ŗõĖŁ’╝īń«Śµ│ĢÕ║ōõĖŁńÜäÕÉäõĖ¬ń╗äõ╗ȵēĆÕģĘÕżćńÜäµĢ░µŹ«µÄźÕÅŻ’╝īõĖĆĶł¼õĖ║õ╗źõĖŗõĖżń¦Ź’╝Ü
+
+- õĖĆõĖ¬Ķ«Łń╗āµł¢µĄŗĶ»ĢµĀʵ£¼’╝łõŠŗÕ”éõĖĆÕ╝ĀÕøŠÕāÅ’╝ēńÜäµēƵ£ēńÜäµĀćµ│©õ┐Īµü»ÕÆīķó䵥ŗõ┐Īµü»ńÜäķøåÕÉł’╝īõŠŗÕ”éµĢ░µŹ«ķøåńÜäĶŠōÕć║ŃĆüµ©ĪÕ×ŗõ╗źÕÅŖÕÅ»Ķ¦åÕī¢ÕÖ©ńÜäĶŠōÕģźõĖĆĶł¼õĖ║ÕŹĢõĖ¬Ķ«Łń╗āµł¢µĄŗĶ»ĢµĀʵ£¼ńÜäµēƵ£ēõ┐Īµü»ŃĆéMMEngine Õ░åÕģČÕ«Üõ╣ēõĖ║µĢ░µŹ«µĀʵ£¼’╝łDataSample’╝ē
+- ÕŹĢõĖĆń▒╗Õ×ŗńÜäķó䵥ŗµł¢µĀćµ│©’╝īõĖĆĶł¼µś»ń«Śµ│Ģµ©ĪÕ×ŗõĖŁµ¤ÉõĖ¬ÕŁÉµ©ĪÕØŚńÜäĶŠōÕć║, õŠŗÕ”éõ║īķśČµ«ĄµŻĆµĄŗõĖŁRPNńÜäĶŠōÕć║ŃĆüĶ»Łõ╣ēÕłåÕē▓µ©ĪÕ×ŗńÜäĶŠōÕć║ŃĆüÕģ│ķö«ńé╣Õłåµö»ńÜäĶŠōÕć║’╝īGANõĖŁńö¤µłÉÕÖ©ńÜäĶŠōÕć║ńŁēŃĆéMMEngine Õ░åÕģČÕ«Üõ╣ēõĖ║µĢ░µŹ«Õģāń┤Ā’╝łXXXData’╝ē
+
+õĖŗĶŠ╣ķ”¢Õģłõ╗ŗń╗ŹõĖĆõĖŗµĢ░µŹ«µĀʵ£¼õĖĵĢ░µŹ«Õģāń┤ĀńÜäÕ¤║ń▒╗ [BaseDataElement](mmengine.structures.BaseDataElement)ŃĆé
+
+## µĢ░µŹ«Õ¤║ń▒╗(BaseDataElement)
+
+`BaseDataElement` õĖŁÕŁśÕ£©õĖżń¦Źń▒╗Õ×ŗńÜäµĢ░µŹ«’╝īõĖĆń¦Źµś» `data` ń▒╗Õ×ŗ’╝īÕ”éµĀćµ│©µĪåŃĆüµĪåńÜäµĀćńŁŠŃĆüÕÆīÕ«×õŠŗµÄ®ńĀüńŁē’╝øÕÅ”õĖĆń¦Źµś» `metainfo` ń▒╗Õ×ŗ’╝īÕīģÕɽµĢ░µŹ«ńÜäÕģāõ┐Īµü»õ╗źńĪ«õ┐صĢ░µŹ«ńÜäÕ«īµĢ┤µĆ¦’╝īÕ”é `img_shape`, `img_id` ńŁēµĢ░µŹ«µēĆÕ£©ÕøŠńēćńÜäõĖĆõ║øÕ¤║µ£¼õ┐Īµü»’╝īµ¢╣õŠ┐ÕÅ»Ķ¦åÕī¢ńŁēµāģÕåĄõĖŗÕ»╣µĢ░µŹ«Ķ┐øĶĪīµüóÕżŹÕÆīõĮ┐ńö©ŃĆéńö©µłĘÕ£©ÕłøÕ╗║ `BaseDataElement` ńÜäĶ┐ćń©ŗõĖŁķ£ĆĶ”üÕ»╣Ķ┐ÖõĖżń▒╗Õ▒׵ƦńÜäµĢ░µŹ«Ķ┐øĶĪīµśŠÕ╝ÅÕ£░Õī║ÕłåÕÆīÕŻ░µśÄŃĆé
+
+õĖ║õ║åĶāĮÕż¤µø┤ÕŖĀµ¢╣õŠ┐Õ£░õĮ┐ńö© `BaseDataElement`’╝ī`data` ÕÆī `metainfo` õĖŁńÜäµĢ░µŹ«ÕØćõĖ║ `BaseDataElement` ńÜäÕ▒׵ƦŃĆ鵳æõ╗¼ÕÅ»õ╗źķĆÜĶ┐ćĶ«┐ķŚ«ń▒╗Õ▒׵ƦńÜäµ¢╣Õ╝Åńø┤µÄźĶ«┐ķŚ« `data` ÕÆī `metainfo` õĖŁńÜäµĢ░µŹ«ŃĆ鵣żÕż¢’╝ī`BaseDataElement` Ķ┐śµÅÉõŠøõ║åÕŠłÕżÜµ¢╣µ│Ģ’╝īµ¢╣õŠ┐µłæõ╗¼µōŹõĮ£ `data` ÕåģńÜäµĢ░µŹ«’╝Ü
+
+- Õó×/ÕłĀ/µö╣/µ¤ź `data` õĖŁõĖŹÕÉīÕŁŚµ«ĄńÜäµĢ░µŹ«
+- Õ░å `data` Ķ┐üń¦╗Ķć│ńø«µĀćĶ«ŠÕżć
+- µö»µīüÕāÅĶ«┐ķŚ«ÕŁŚÕģĖ/Õ╝ĀķćÅõĖƵĀĘĶ«┐ķŚ« data ÕåģńÜäµĢ░µŹ«õ╗źÕģģÕłåµ╗ĪĶČ│ń«Śµ│ĢÕ║ōÕ»╣õ║ÄĶ┐Öõ║øµĢ░µŹ«ńÜäõĮ┐ńö©Ķ”üµ▒éŃĆé
+
+### 1. µĢ░µŹ«Õģāń┤ĀńÜäÕłøÕ╗║
+
+`BaseDataElement` ńÜä data ÕÅéµĢ░ÕÅ»õ╗źńø┤µÄźķĆÜĶ┐ć `key=value` ńÜäµ¢╣Õ╝ÅĶć¬ńö▒µĘ╗ÕŖĀ’╝īmetainfo ńÜäÕŁŚµ«Ąķ£ĆĶ”üµśŠÕ╝ÅķĆÜĶ┐ćÕģ│ķö«ÕŁŚ `metainfo` µīćÕ«ÜŃĆé
+
+```python
+import torch
+from mmengine.structures import BaseDataElement
+# ÕÅ»õ╗źÕŻ░µśÄõĖĆõĖ¬ń®║ńÜä object
+data_element = BaseDataElement()
+
+bboxes = torch.rand((5, 4)) # ÕüćÕ«Ü bboxes µś»õĖĆõĖ¬ Nx4 ń╗┤ńÜä tensor’╝īN õ╗ŻĶĪ©µĪåńÜäõĖ¬µĢ░
+scores = torch.rand((5,)) # ÕüćիܵĪåńÜäÕłåµĢ░µś»õĖĆõĖ¬ N ń╗┤ńÜä tensor’╝īN õ╗ŻĶĪ©µĪåńÜäõĖ¬µĢ░
+img_id = 0 # ÕøŠÕāÅńÜä ID
+H = 800 # ÕøŠÕāÅńÜäķ½śÕ║”
+W = 1333 # ÕøŠÕāÅńÜäÕ«ĮÕ║”
+
+# ńø┤µÄźĶ«ŠńĮ« BaseDataElement ńÜä data ÕÅéµĢ░
+data_element = BaseDataElement(bboxes=bboxes, scores=scores)
+
+# µśŠÕ╝ÅÕŻ░µśÄµØźĶ«ŠńĮ« BaseDataElement ńÜäÕÅéµĢ░ metainfo
+data_element = BaseDataElement(
+ bboxes=bboxes,
+ scores=scores,
+ metainfo=dict(img_id=img_id, img_shape=(H, W)))
+```
+
+### 2. `new` õĖÄ `clone` ÕćĮµĢ░
+
+ńö©µłĘÕÅ»õ╗źõĮ┐ńö© `new()` µ¢╣µ│ĢÕ¤║õ║ÄÕĘ▓µ£ēńÜä `BaseDataElement` ÕłøÕ╗║õĖĆõĖ¬Õģʵ£ēńøĖÕÉī `data` ÕÆī `metainfo` ńÜä `BaseDataElement`ŃĆéńö©µłĘõ╣¤ÕÅ»õ╗źÕ£©Ķ░āńö© `new` µ¢╣µ│ĢµŚČõ╝ĀÕģźµ¢░ńÜä `data` ÕÆī `metainfo`’╝īõŠŗÕ”é `new(metainfo=xx)` ’╝īµŁżµŚČÕłøÕ╗║ńÜä `BaseDataElement` ńøĖĶŠāõ║ÄÕĘ▓µ£ēńÜä `BaseDataElement`’╝ī`data` Õ«īÕģ©õĖĆĶć┤ ’╝īĶĆī `metainfo` ÕłÖõĖ║µ¢░Ķ«ŠńĮ«ńÜäÕåģÕ«╣ŃĆé
+õ╣¤ÕÅ»õ╗źńø┤µÄźõĮ┐ńö© `clone()` µØźĶÄĘÕŠŚõĖĆõ╗ĮµĘ▒µŗĘĶ┤Ø’╝ī`clone()` ÕćĮµĢ░ńÜäĶĪīõĖ║õĖÄ PyTorch õĖŁ Tensor ńÜä `clone()` ÕÅéµĢ░õ┐صīüõĖĆĶć┤ŃĆé
+
+```python
+data_element = BaseDataElement(
+ bboxes=torch.rand((5, 4)),
+ scores=torch.rand((5,)),
+ metainfo=dict(img_id=1, img_shape=(640, 640)))
+
+# ÕÅ»õ╗źÕ£©ÕłøÕ╗║µ¢░ `BaseDataElement` µŚČĶ«ŠńĮ« metainfo ÕÆī data’╝īõĮ┐ÕŠŚµ¢░ńÜä BaseDataElement µ£ēńøĖÕÉīµ£¬Ķó½Ķ«ŠńĮ«ńÜäµĢ░µŹ«
+data_element1 = data_element.new(metainfo=dict(img_id=2, img_shape=(320, 320)))
+print('bboxes is in data_element1:', 'bboxes' in data_element1) # True
+print('bboxes in data_element1 is same as bbox in data_element', (data_element1.bboxes == data_element.bboxes).all())
+print('img_id in data_element1 is', data_element1.img_id == 2) # True
+
+data_element2 = data_element.new(label=torch.rand(5,))
+print('bboxes is not in data_element2', 'bboxes' not in data_element2) # True
+print('img_id in data_element2 is same as img_id in data_element', data_element2.img_id == data_element.img_id)
+print('label in data_element2 is', 'label' in data_element2)
+
+# õ╣¤ÕÅ»õ╗źķĆÜĶ┐ć `clone` µ×äÕ╗║õĖĆõĖ¬µ¢░ńÜä object’╝īµ¢░ńÜä object õ╝ܵŗźµ£ēÕÆī data_element ńøĖÕÉīńÜä data ÕÆī metainfo ÕåģÕ«╣õ╗źÕÅŖńŖȵĆüŃĆé
+data_element2 = data_element1.clone()
+```
+
+```
+bboxes is in data_element1: True
+bboxes in data_element1 is same as bbox in data_element tensor(True)
+img_id in data_element1 is True
+bboxes is not in data_element2 True
+img_id in data_element2 is same as img_id in data_element True
+label in data_element2 is True
+```
+
+### 3. Õ▒׵ƦńÜäÕó×ÕŖĀõĖĵ¤źĶ»ó
+
+Õ»╣Õó×ÕŖĀÕ▒׵ƦĶĆīĶ©Ć’╝īńö©µłĘÕÅ»õ╗źÕāÅÕó×ÕŖĀń▒╗Õ▒׵Ʀķ鯵ĀĘÕó×ÕŖĀ `data` ÕåģńÜäÕ▒׵Ʀ’╝øÕ»╣ `metainfo` ĶĆīĶ©Ć’╝īõĖĆĶł¼Õé©ÕŁśńÜäõĖ║õĖĆõ║øÕøŠÕāÅńÜäÕģāõ┐Īµü»’╝īõĖĆĶł¼µāģÕåĄõĖŗõĖŹõ╝Üõ┐«µö╣’╝īÕ”éµ×£ķ£ĆĶ”üÕó×ÕŖĀ’╝īńö©µłĘÕ║öÕĮōõĮ┐ńö© `set_metainfo` µÄźÕÅŻµśŠńż║Õ£░õ┐«µö╣ŃĆé
+
+Õ»╣µ¤źĶ»óĶĆīĶ©Ć’╝īńö©µłĘÕÅ»õ╗źÕÅ»õ╗źķĆÜĶ┐ć `keys`’╝ī`values`’╝īÕÆī `items` µØźĶ«┐ķŚ«ÕÅ¬ÕŁśÕ£©õ║Ä data õĖŁńÜäķö«ÕĆ╝’╝īõ╣¤ÕÅ»õ╗źķĆÜĶ┐ć `metainfo_keys`’╝ī`metainfo_values`’╝īÕÆī`metainfo_items` µØźĶ«┐ķŚ«ÕÅ¬ÕŁśÕ£©õ║Ä metainfo õĖŁńÜäķö«ÕĆ╝ŃĆé
+ńö©µłĘĶ┐śĶāĮķĆÜĶ┐ć `all_keys`’╝ī`all_values`’╝ī `all_items` µØźĶ«┐ķŚ« `BaseDataElement` ńÜäµēƵ£ēńÜäÕ▒׵ƦÕ╣ČõĖöõĖŹÕī║Õłåõ╗¢õ╗¼ńÜäń▒╗Õ×ŗŃĆé
+
+ÕÉīµŚČõĖ║õ║åµ¢╣õŠ┐õĮ┐ńö©’╝īńö©µłĘÕÅ»õ╗źÕāÅĶ«┐ķŚ«ń▒╗Õ▒׵ƦõĖƵĀĘĶ«┐ķŚ« data õĖÄ metainfo ÕåģńÜäµĢ░µŹ«’╝īµł¢ńØĆń▒╗ÕŁŚÕģĖµ¢╣Õ╝ÅķĆÜĶ┐ć `get()` µÄźÕÅŻĶ«┐ķŚ«µĢ░µŹ«ŃĆé
+
+**µ│©µäÅ’╝Ü**
+
+1. `BaseDataElement` õĖŹµö»µīü metainfo ÕÆī data Õ▒׵ƦõĖŁµ£ēÕÉīÕÉŹńÜäÕŁŚµ«Ą’╝īµēĆõ╗źńö©µłĘÕ║öÕĮōķü┐ÕģŹ metainfo ÕÆī data Õ▒׵ƦõĖŁĶ«ŠńĮ«ńøĖÕÉīńÜäÕŁŚµ«Ą’╝īÕÉ”ÕłÖ `BaseDataElement` õ╝ܵŖźķöÖŃĆé
+2. ĶĆāĶÖæÕł░ `InstanceData` ÕÆī `PixelData` µö»µīüÕ»╣µĢ░µŹ«Ķ┐øĶĪīÕłćńēćµōŹõĮ£’╝īõĖ║õ║åķü┐ÕģŹ `[]` ńö©µ│ĢńÜäõĖŹõĖĆĶć┤’╝īÕÉīµŚČÕćÅÕ░æÕÉīń¦Źķ£Ćµ▒éńÜäõĖŹÕÉīµ¢╣µ│Ģ’╝ī`BaseDataElement` õĖŹµö»µīüÕāÅÕŁŚÕģĖķ鯵ĀĘĶ«┐ķŚ«ÕÆīĶ«ŠńĮ«Õ«āńÜäÕ▒׵Ʀ’╝īµēĆõ╗źń▒╗õ╝╝ `BaseDataElement[name]` ńÜäÕÅ¢ÕĆ╝ĶĄŗÕĆ╝µōŹõĮ£µś»õĖŹĶó½µö»µīüńÜäŃĆé
+
+```python
+data_element = BaseDataElement()
+# ķĆÜĶ┐ć `set_metainfo`Ķ«ŠńĮ« data_element ńÜä metainfo ÕŁŚµ«Ą’╝ī
+# ÕÉīµŚČ img_id ÕÆī img_shape µłÉõĖ║ data_element ńÜäÕ▒׵Ʀ
+data_element.set_metainfo(dict(img_id=9, img_shape=(100, 100)))
+# µ¤źń£ŗ metainfo ńÜä key, value ÕÆī item
+print("metainfo'keys are", data_element.metainfo_keys())
+print("metainfo'values are", data_element.metainfo_values())
+for k, v in data_element.metainfo_items():
+ print(f'{k}: {v}')
+
+print("ķĆÜĶ┐ćń▒╗Õ▒׵Ʀµ¤źń£ŗ img_id ÕÆī img_shape")
+print('img_id:', data_element.img_id)
+print('img_shape:', data_element.img_shape)
+```
+
+```
+metainfo'keys are ['img_id', 'img_shape']
+metainfo'values are [9, (100, 100)]
+img_id: 9
+img_shape: (100, 100)
+ķĆÜĶ┐ćń▒╗Õ▒׵Ʀµ¤źń£ŗ img_id ÕÆī img_shape
+img_id: 9
+img_shape: (100, 100)
+```
+
+```python
+
+# ķĆÜĶ┐ćń▒╗Õ▒׵Ʀńø┤µÄźĶ«ŠńĮ« BaseDataElement õĖŁńÜä data ÕŁŚµ«Ą
+data_element.scores = torch.rand((5,))
+data_element.bboxes = torch.rand((5, 4))
+
+print("data's key is:", data_element.keys())
+print("data's value is:", data_element.values())
+for k, v in data_element.items():
+ print(f'{k}: {v}')
+
+print("ķĆÜĶ┐ćń▒╗Õ▒׵Ʀµ¤źń£ŗ scores ÕÆī bboxes")
+print('scores:', data_element.scores)
+print('bboxes:', data_element.bboxes)
+
+print("ķĆÜĶ┐ć get() µ¤źń£ŗ scores ÕÆī bboxes")
+print('scores:', data_element.get('scores', None))
+print('bboxes:', data_element.get('bboxes', None))
+print('fake:', data_element.get('fake', 'not exist'))
+```
+
+```
+data's key is: ['scores', 'bboxes']
+data's value is: [tensor([0.7937, 0.6307, 0.3682, 0.4425, 0.8515]), tensor([[0.9204, 0.2110, 0.2886, 0.7925],
+ [0.7993, 0.8982, 0.5698, 0.4120],
+ [0.7085, 0.7016, 0.3069, 0.3216],
+ [0.0206, 0.5253, 0.1376, 0.9322],
+ [0.2512, 0.7683, 0.3010, 0.2672]])]
+scores: tensor([0.7937, 0.6307, 0.3682, 0.4425, 0.8515])
+bboxes: tensor([[0.9204, 0.2110, 0.2886, 0.7925],
+ [0.7993, 0.8982, 0.5698, 0.4120],
+ [0.7085, 0.7016, 0.3069, 0.3216],
+ [0.0206, 0.5253, 0.1376, 0.9322],
+ [0.2512, 0.7683, 0.3010, 0.2672]])
+ķĆÜĶ┐ćń▒╗Õ▒׵Ʀµ¤źń£ŗ scores ÕÆī bboxes
+scores: tensor([0.7937, 0.6307, 0.3682, 0.4425, 0.8515])
+bboxes: tensor([[0.9204, 0.2110, 0.2886, 0.7925],
+ [0.7993, 0.8982, 0.5698, 0.4120],
+ [0.7085, 0.7016, 0.3069, 0.3216],
+ [0.0206, 0.5253, 0.1376, 0.9322],
+ [0.2512, 0.7683, 0.3010, 0.2672]])
+ķĆÜĶ┐ć get() µ¤źń£ŗ scores ÕÆī bboxes
+scores: tensor([0.7937, 0.6307, 0.3682, 0.4425, 0.8515])
+bboxes: tensor([[0.9204, 0.2110, 0.2886, 0.7925],
+ [0.7993, 0.8982, 0.5698, 0.4120],
+ [0.7085, 0.7016, 0.3069, 0.3216],
+ [0.0206, 0.5253, 0.1376, 0.9322],
+ [0.2512, 0.7683, 0.3010, 0.2672]])
+fake: not exist
+```
+
+```python
+
+print("All key in data_element is:", data_element.all_keys())
+print("The length of values in data_element is", len(data_element.all_values()))
+for k, v in data_element.all_items():
+ print(f'{k}: {v}')
+```
+
+```
+All key in data_element is: ['img_id', 'img_shape', 'scores', 'bboxes']
+The length of values in data_element is 4
+img_id: 9
+img_shape: (100, 100)
+scores: tensor([0.7937, 0.6307, 0.3682, 0.4425, 0.8515])
+bboxes: tensor([[0.9204, 0.2110, 0.2886, 0.7925],
+ [0.7993, 0.8982, 0.5698, 0.4120],
+ [0.7085, 0.7016, 0.3069, 0.3216],
+ [0.0206, 0.5253, 0.1376, 0.9322],
+ [0.2512, 0.7683, 0.3010, 0.2672]])
+```
+
+### 4. Õ▒׵ƦńÜäÕłĀµö╣
+
+ńö©µłĘÕÅ»õ╗źÕāÅõ┐«µö╣Õ«×õŠŗÕ▒׵ƦõĖƵĀĘõ┐«µö╣ `BaseDataElement` ńÜä `data`, Õ»╣`metainfo` ĶĆīĶ©Ć’╝īõĖĆĶł¼Õé©ÕŁśńÜäõĖ║õĖĆõ║øÕøŠÕāÅńÜäÕģāõ┐Īµü»’╝īõĖĆĶł¼µāģÕåĄõĖŗõĖŹõ╝Üõ┐«µö╣’╝īÕ”éµ×£ķ£ĆĶ”üõ┐«µö╣’╝īńö©µłĘÕ║öÕĮōõĮ┐ńö© `set_metainfo` µÄźÕÅŻµśŠńż║ńÜäõ┐«µö╣ŃĆé
+
+ÕÉīµŚČõĖ║õ║åµōŹõĮ£ńÜäõŠ┐µŹĘµĆ¦’╝īÕ»╣ `data` ÕÆī `metainfo` õĖŁńÜäµĢ░µŹ«ÕÅ»õ╗źķĆÜĶ┐ć `del` ńø┤µÄźÕłĀķÖż’╝īõ╣¤µö»µīü `pop` Õ£©Ķ«┐ķŚ«Õ▒׵ƦÕÉÄÕłĀķÖżÕ▒׵ƦŃĆé
+
+```python
+data_element = BaseDataElement(
+ bboxes=torch.rand((6, 4)), scores=torch.rand((6,)),
+ metainfo=dict(img_id=0, img_shape=(640, 640))
+)
+for k, v in data_element.all_items():
+ print(f'{k}: {v}')
+```
+
+```
+img_id: 0
+img_shape: (640, 640)
+scores: tensor([0.8445, 0.6678, 0.8172, 0.9125, 0.7186, 0.5462])
+bboxes: tensor([[0.5773, 0.0289, 0.4793, 0.7573],
+ [0.8187, 0.8176, 0.3455, 0.3368],
+ [0.6947, 0.5592, 0.7285, 0.0281],
+ [0.7710, 0.9867, 0.7172, 0.5815],
+ [0.3999, 0.9192, 0.7817, 0.2535],
+ [0.2433, 0.0132, 0.1757, 0.6196]])
+```
+
+```python
+# Õ»╣ data Ķ┐øĶĪīõ┐«µö╣
+data_element.bboxes = data_element.bboxes * 2
+data_element.scores = data_element.scores * -1
+for k, v in data_element.items():
+ print(f'{k}: {v}')
+
+# ÕłĀķÖż data õĖŁńÜäÕ▒׵Ʀ
+del data_element.bboxes
+for k, v in data_element.items():
+ print(f'{k}: {v}')
+
+data_element.pop('scores', None)
+print('The keys in data is', data_element.keys())
+```
+
+```
+scores: tensor([-0.8445, -0.6678, -0.8172, -0.9125, -0.7186, -0.5462])
+bboxes: tensor([[1.1546, 0.0578, 0.9586, 1.5146],
+ [1.6374, 1.6352, 0.6911, 0.6735],
+ [1.3893, 1.1185, 1.4569, 0.0562],
+ [1.5420, 1.9734, 1.4344, 1.1630],
+ [0.7999, 1.8384, 1.5635, 0.5070],
+ [0.4867, 0.0264, 0.3514, 1.2392]])
+scores: tensor([-0.8445, -0.6678, -0.8172, -0.9125, -0.7186, -0.5462])
+The keys in data is []
+```
+
+```python
+# Õ»╣ metainfo Ķ┐øĶĪīõ┐«µö╣
+data_element.set_metainfo(dict(img_shape = (1280, 1280), img_id=10))
+print(data_element.img_shape) # (1280, 1280)
+for k, v in data_element.metainfo_items():
+ print(f'{k}: {v}')
+
+# µÅÉõŠøõ║åõŠ┐µŹĘńÜäÕ▒×µĆ¦ÕłĀķÖżÕÆīĶ«┐ķŚ«µōŹõĮ£ pop
+del data_element.img_shape
+for k, v in data_element.metainfo_items():
+ print(f'{k}: {v}')
+
+data_element.pop('img_id')
+print('The keys in metainfo is', data_element.metainfo_keys())
+```
+
+```
+(1280, 1280)
+img_id: 10
+img_shape: (1280, 1280)
+img_id: 10
+The keys in metainfo is []
+```
+
+### 5. ń▒╗Õ╝ĀķćŵōŹõĮ£
+
+ńö©µłĘÕÅ»õ╗źÕāÅ torch.Tensor ķ鯵ĀĘÕ»╣ `BaseDataElement` ńÜä data Ķ┐øĶĪīńŖȵĆüĶĮ¼µŹó’╝īńø«ÕēŹµö»µīü `cuda`’╝ī `cpu`’╝ī `to`’╝ī `numpy` ńŁēµōŹõĮ£ŃĆé
+ÕģČõĖŁ’╝ī`to` ÕćĮµĢ░µŗźµ£ēÕÆī `torch.Tensor.to()` ńøĖÕÉīńÜäµÄźÕÅŻ’╝īõĮ┐ÕŠŚńö©µłĘÕÅ»õ╗źńüĄµ┤╗Õ£░Õ░åĶó½Õ░üĶŻģńÜä tensor Ķ┐øĶĪīńŖȵĆüĶĮ¼µŹóŃĆé
+**µ│©µäÅ’╝Ü** Ķ┐Öõ║øµÄźÕÅŻÕŬõ╝ÜÕżäńÉåń▒╗Õ×ŗõĖ║ np.array’╝ītorch.Tensor’╝īµł¢ĶĆģµĢ░ÕŁŚńÜäÕ║ÅÕłŚ’╝īÕģČõ╗¢Õ▒׵ƦńÜäµĢ░µŹ«’╝łÕ”éÕŁŚń¼”õĖ▓’╝ēõ╝ÜĶó½ĶĘ│Ķ┐ćÕżäńÉåŃĆé
+
+```python
+data_element = BaseDataElement(
+ bboxes=torch.rand((6, 4)), scores=torch.rand((6,)),
+ metainfo=dict(img_id=0, img_shape=(640, 640))
+)
+# Õ░åµēƵ£ē data ĶĮ¼ń¦╗Õł░ GPU õĖŖ
+cuda_element_1 = data_element.cuda()
+print('cuda_element_1 is on the device of', cuda_element_1.bboxes.device) # cuda:0
+cuda_element_2 = data_element.to('cuda:0')
+print('cuda_element_1 is on the device of', cuda_element_2.bboxes.device) # cuda:0
+
+# Õ░åµēƵ£ē data ĶĮ¼ń¦╗Õł░ cpu õĖŖ
+cpu_element_1 = cuda_element_1.cpu()
+print('cpu_element_1 is on the device of', cpu_element_1.bboxes.device) # cpu
+cpu_element_2 = cuda_element_2.to('cpu')
+print('cpu_element_2 is on the device of', cpu_element_2.bboxes.device) # cpu
+
+# Õ░åµēƵ£ē data ÕÅśµłÉ FP16
+fp16_instances = cuda_element_1.to(
+ device=None, dtype=torch.float16, non_blocking=False, copy=False,
+ memory_format=torch.preserve_format)
+print('The type of bboxes in fp16_instances is', fp16_instances.bboxes.dtype) # torch.float16
+
+# ķś╗µ¢ŁµēƵ£ē data ńÜäµó»Õ║”
+cuda_element_3 = cuda_element_2.detach()
+print('The data in cuda_element_3 requires grad: ', cuda_element_3.bboxes.requires_grad)
+# ĶĮ¼ń¦╗ data Õł░ numpy array
+np_instances = cpu_element_1.numpy()
+print('The type of cpu_element_1 is convert to', type(np_instances.bboxes))
+```
+
+```
+cuda_element_1 is on the device of cuda:0
+cuda_element_1 is on the device of cuda:0
+cpu_element_1 is on the device of cpu
+cpu_element_2 is on the device of cpu
+The type of bboxes in fp16_instances is torch.float16
+The data in cuda_element_3 requires grad: False
+The type of cpu_element_1 is convert to
+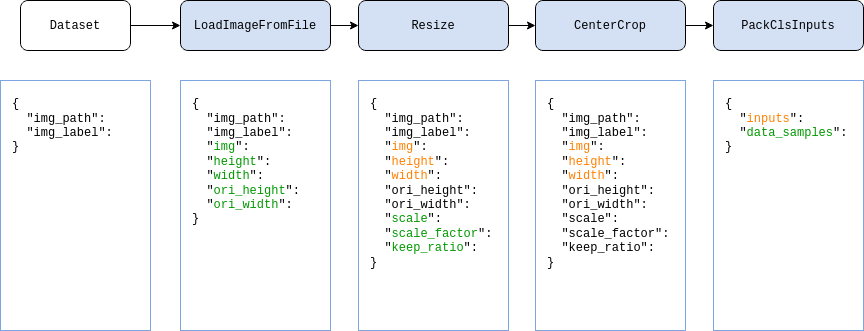 +
+
+
+Õ”éµ×£µłæõ╗¼ÕĖīµ£øÕ£©µĄŗĶ»ĢõĖŁõĮ┐ńö©õĖŖĶ┐░µĢ░µŹ«µĄüµ░┤ń║┐’╝īÕłÖķģŹńĮ«µ¢ćõ╗ČÕ”éõĖŗµēĆńż║’╝Ü
+
+```python
+test_dataloader = dict(
+ batch_size=32,
+ dataset=dict(
+ type='ImageNet',
+ data_root='data/imagenet',
+ pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='Resize', size=256, keep_ratio=True),
+ dict(type='CenterCrop', crop_size=224),
+ dict(type='PackClsInputs'),
+ ]
+ )
+)
+```
+
+## ÕĖĖńö©ńÜäµĢ░µŹ«ÕÅśµŹóń▒╗
+
+µīēńģ¦ÕŖ¤ĶāĮ’╝īÕĖĖńö©ńÜäµĢ░µŹ«ÕÅśµŹóń▒╗ÕÅ»õ╗źÕż¦Ķć┤ÕłåõĖ║µĢ░µŹ«ÕŖĀĶĮĮŃĆüµĢ░µŹ«ķóäÕżäńÉåõĖÄÕó×Õ╝║ŃĆüµĢ░µŹ«µĀ╝Õ╝ÅÕī¢ŃĆ鵳æõ╗¼Õ£© MMCV õĖŁµÅÉõŠøõ║åõĖĆń│╗ÕłŚÕĖĖńö©ńÜäµĢ░µŹ«ÕÅśµŹóń▒╗’╝Ü
+
+### µĢ░µŹ«ÕŖĀĶĮĮ
+
+õĖ║õ║åµö»µīüÕż¦Ķ¦äµ©ĪµĢ░µŹ«ķøåńÜäÕŖĀĶĮĮ’╝īķĆÜÕĖĖÕ£©µĢ░µŹ«ķøåÕłØÕ¦ŗÕī¢µŚČõĖŹÕŖĀĶĮĮµĢ░µŹ«’╝īÕŬÕŖĀĶĮĮńøĖÕ║öńÜäĶĘ»ÕŠäŃĆéÕøĀµŁżķ£ĆĶ”üÕ£©µĢ░µŹ«µĄüµ░┤ń║┐õĖŁĶ┐øĶĪīÕģĘõĮōµĢ░µŹ«ńÜäÕŖĀĶĮĮŃĆé
+
+| µĢ░µŹ«ÕÅśµŹóń▒╗ | ÕŖ¤ĶāĮ |
+| :------------------------------------------------------: | :---------------------------------------: |
+| [`LoadImageFromFile`](mmcv.transforms.LoadImageFromFile) | µĀ╣µŹ«ĶĘ»ÕŠäÕŖĀĶĮĮÕøŠÕāÅ |
+| [`LoadAnnotations`](mmcv.transforms.LoadAnnotations) | ÕŖĀĶĮĮÕÆīń╗äń╗ćµĀćµ│©õ┐Īµü»’╝īÕ”é bboxŃĆüĶ»Łõ╣ēÕłåÕē▓ÕøŠńŁē |
+
+### µĢ░µŹ«ķóäÕżäńÉåÕÅŖÕó×Õ╝║
+
+µĢ░µŹ«ķóäÕżäńÉåÕÆīÕó×Õ╝║ķĆÜÕĖĖµś»Õ»╣ÕøŠÕāŵ£¼Ķ║½Ķ┐øĶĪīÕÅśµŹó’╝īÕ”éĶŻüÕē¬ŃĆüÕĪ½ÕģģŃĆüń╝®µöŠńŁēŃĆé
+
+| µĢ░µŹ«ÕÅśµŹóń▒╗ | ÕŖ¤ĶāĮ |
+| :--------------------------------------------------------: | :--------------------------------: |
+| [`Pad`](mmcv.transforms.Pad) | ÕĪ½ÕģģÕøŠÕāÅĶŠ╣ń╝ś |
+| [`CenterCrop`](mmcv.transforms.CenterCrop) | Õ▒ģõĖŁĶŻüÕē¬ |
+| [`Normalize`](mmcv.transforms.Normalize) | Õ»╣ÕøŠÕāÅĶ┐øĶĪīÕĮÆõĖĆÕī¢ |
+| [`Resize`](mmcv.transforms.Resize) | µīēńģ¦µīćÕ«ÜÕ░║Õ»Ėµł¢µ»öõŠŗń╝®µöŠÕøŠÕāÅ |
+| [`RandomResize`](mmcv.transforms.RandomResize) | ń╝®µöŠÕøŠÕāÅĶć│µīćÕ«ÜĶīāÕø┤ńÜäķÜŵ£║Õ░║Õ»Ė |
+| [`RandomChoiceResize`](mmcv.transforms.RandomChoiceResize) | ń╝®µöŠÕøŠÕāÅĶć│ÕżÜõĖ¬Õ░║Õ»ĖõĖŁńÜäķÜŵ£║õĖĆõĖ¬Õ░║Õ»Ė |
+| [`RandomGrayscale`](mmcv.transforms.RandomGrayscale) | ķÜŵ£║ńü░Õ║”Õī¢ |
+| [`RandomFlip`](mmcv.transforms.RandomFlip) | ÕøŠÕāÅķÜŵ£║ń┐╗ĶĮ¼ |
+
+### µĢ░µŹ«µĀ╝Õ╝ÅÕī¢
+
+µĢ░µŹ«µĀ╝Õ╝ÅÕī¢µōŹõĮ£ķĆÜÕĖĖµś»Õ»╣µĢ░µŹ«Ķ┐øĶĪīńÜäń▒╗Õ×ŗĶĮ¼µŹóŃĆé
+
+| µĢ░µŹ«ÕÅśµŹóń▒╗ | ÕŖ¤ĶāĮ |
+| :----------------------------------------------: | :-------------------------------: |
+| [`ToTensor`](mmcv.transforms.ToTensor) | Õ░åµīćÕ«ÜńÜäµĢ░µŹ«ĶĮ¼µŹóõĖ║ `torch.Tensor` |
+| [`ImageToTensor`](mmcv.transforms.ImageToTensor) | Õ░åÕøŠÕāÅĶĮ¼µŹóõĖ║ `torch.Tensor` |
+
+## Ķć¬Õ«Üõ╣ēµĢ░µŹ«ÕÅśµŹóń▒╗
+
+Ķ”üÕ«×ńÄ░õĖĆõĖ¬µ¢░ńÜäµĢ░µŹ«ÕÅśµŹóń▒╗’╝īķ£ĆĶ”üń╗¦µē┐ `BaseTransform`’╝īÕ╣ČÕ«×ńÄ░ `transform` µ¢╣µ│ĢŃĆéĶ┐Öķćī’╝īµłæõ╗¼õĮ┐ńö©õĖĆõĖ¬ń«ĆÕŹĢńÜäń┐╗ĶĮ¼ÕÅśµŹó’╝ł`MyFlip`’╝ēõĮ£õĖ║ńż║õŠŗ’╝Ü
+
+```python
+import random
+import mmcv
+from mmcv.transforms import BaseTransform, TRANSFORMS
+
+@TRANSFORMS.register_module()
+class MyFlip(BaseTransform):
+ def __init__(self, direction: str):
+ super().__init__()
+ self.direction = direction
+
+ def transform(self, results: dict) -> dict:
+ img = results['img']
+ results['img'] = mmcv.imflip(img, direction=self.direction)
+ return results
+```
+
+õ╗ÄĶĆī’╝īµłæõ╗¼ÕÅ»õ╗źÕ«×õŠŗÕī¢õĖĆõĖ¬ `MyFlip` Õ»╣Ķ▒Ī’╝īÕ╣ČÕ░åõ╣ŗõĮ£õĖ║õĖĆõĖ¬ÕÅ»Ķ░āńö©Õ»╣Ķ▒Ī’╝īµØźÕżäńÉåµłæõ╗¼ńÜäµĢ░µŹ«ÕŁŚÕģĖŃĆé
+
+```python
+import numpy as np
+
+transform = MyFlip(direction='horizontal')
+data_dict = {'img': np.random.rand(224, 224, 3)}
+data_dict = transform(data_dict)
+processed_img = data_dict['img']
+```
+
+ÕÅłµł¢ĶĆģ’╝īÕ£©ķģŹńĮ«µ¢ćõ╗ČńÜä pipeline õĖŁõĮ┐ńö© `MyFlip` ÕÅśµŹó
+
+```python
+pipeline = [
+ ...
+ dict(type='MyFlip', direction='horizontal'),
+ ...
+]
+```
+
+ķ£ĆĶ”üµ│©µäÅńÜ䵜»’╝īÕ”éķ£ĆÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁõĮ┐ńö©’╝īķ£ĆĶ”üõ┐ØĶ»ü `MyFlip` ń▒╗µēĆÕ£©ńÜäµ¢ćõ╗ČÕ£©Ķ┐ÉĶĪīµŚČĶāĮÕż¤Ķó½Õ»╝ÕģźŃĆé
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/dataset.md b/internlm_langchain/knowledge_base/MMEngine/content/dataset.md
new file mode 100644
index 00000000..a7fd09a1
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/dataset.md
@@ -0,0 +1,198 @@
+# µĢ░µŹ«ķøå’╝łDataset’╝ēõĖĵĢ░µŹ«ÕŖĀĶĮĮÕÖ©’╝łDataLoader’╝ē
+
+```{hint}
+Õ”éµ×£õĮĀµ▓Īµ£ēµÄźĶ¦”Ķ┐ć PyTorch ńÜäµĢ░µŹ«ķøåõĖĵĢ░µŹ«ÕŖĀĶĮĮÕÖ©’╝īµłæõ╗¼µÄ©ĶŹÉÕģłµĄÅĶ¦ł [PyTorch Õ«śµ¢╣µĢÖń©ŗ](https://pytorch.org/tutorials/beginner/basics/data_tutorial.html)õ╗źõ║åĶ¦ŻõĖĆõ║øÕ¤║µ£¼µ”éÕ┐Ą
+```
+
+µĢ░µŹ«ķøåõĖĵĢ░µŹ«ÕŖĀĶĮĮÕÖ©µś» MMEngine õĖŁĶ«Łń╗āµĄüń©ŗńÜäÕ┐ģĶ”üń╗äõ╗Č’╝īÕ«āõ╗¼ńÜäµ”éÕ┐ĄµØźµ║Éõ║Ä PyTorch’╝īÕ╣ČõĖöÕ£©Õɽõ╣ēõĖŖõĖÄ PyTorch õ┐صīüõĖĆĶć┤ŃĆéķĆÜÕĖĖµØźĶ»┤’╝īµĢ░µŹ«ķøåÕ«Üõ╣ēõ║åµĢ░µŹ«ńÜäµĆ╗õĮōµĢ░ķćÅŃĆüĶ»╗ÕÅ¢µ¢╣Õ╝Åõ╗źÕÅŖķóäÕżäńÉå’╝īĶĆīµĢ░µŹ«ÕŖĀĶĮĮÕÖ©ÕłÖÕ£©õĖŹÕÉīńÜäĶ«ŠńĮ«õĖŗĶ┐Łõ╗ŻÕ£░ÕŖĀĶĮĮµĢ░µŹ«’╝īÕ”éµē╣µ¼ĪÕż¦Õ░Å’╝ł`batch_size`’╝ēŃĆüķÜŵ£║õ╣▒Õ║Å’╝ł`shuffle`’╝ēŃĆüÕ╣ČĶĪī’╝ł`num_workers`’╝ēńŁēŃĆéµĢ░µŹ«ķøåń╗ÅĶ┐ćµĢ░µŹ«ÕŖĀĶĮĮÕÖ©Õ░üĶŻģÕÉĵ×䵳Éõ║åµĢ░µŹ«µ║ÉŃĆéÕ£©µ£¼ń»ćµĢÖń©ŗõĖŁ’╝īµłæõ╗¼Õ░åµīēńģ¦õ╗ÄÕż¢’╝łµĢ░µŹ«ÕŖĀĶĮĮÕÖ©’╝ēÕł░Õåģ’╝łµĢ░µŹ«ķøå’╝ēńÜäķĪ║Õ║Å’╝īķĆɵŁźõ╗ŗń╗ŹÕ«āõ╗¼Õ£© MMEngine µē¦ĶĪīÕÖ©õĖŁńÜäńö©µ│Ģ’╝īÕ╣Čń╗ÖÕć║õĖĆõ║øÕĖĖńö©ńż║õŠŗŃĆéĶ»╗Õ«īµ£¼ń»ćµĢÖń©ŗ’╝īõĮĀÕ░åõ╝Ü’╝Ü
+
+- µÄīµÅĪÕ”éõĮĢÕ£© MMEngine ńÜäµē¦ĶĪīÕÖ©õĖŁķģŹńĮ«µĢ░µŹ«ÕŖĀĶĮĮÕÖ©
+- ÕŁ”õ╝ÜÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁõĮ┐ńö©ÕĘ▓µ£ē’╝łÕ”é `torchvision`’╝ēµĢ░µŹ«ķøå
+- õ║åĶ¦ŻÕ”éõĮĢõĮ┐ńö©Ķć¬ÕĘ▒ńÜäµĢ░µŹ«ķøå
+
+## µĢ░µŹ«ÕŖĀĶĮĮÕÖ©Ķ»”Ķ¦Ż
+
+Õ£©µē¦ĶĪīÕÖ©’╝ł`Runner`’╝ēõĖŁ’╝īõĮĀÕÅ»õ╗źÕłåÕł½ķģŹńĮ«õ╗źõĖŗ 3 õĖ¬ÕÅéµĢ░µØźµīćÕ«ÜÕ»╣Õ║öńÜäµĢ░µŹ«ÕŖĀĶĮĮÕÖ©
+
+- `train_dataloader`’╝ÜÕ£© `Runner.train()` õĖŁĶó½õĮ┐ńö©’╝īõĖ║µ©ĪÕ×ŗµÅÉõŠøĶ«Łń╗āµĢ░µŹ«
+- `val_dataloader`’╝ÜÕ£© `Runner.val()` õĖŁĶó½õĮ┐ńö©’╝īõ╣¤õ╝ÜÕ£© `Runner.train()` õĖŁµ»ÅķŚ┤ķÜöõĖƵ«ĄµŚČķŚ┤Ķó½õĮ┐ńö©’╝īńö©õ║ĵ©ĪÕ×ŗńÜäķ¬īĶ»üĶ»äµĄŗ
+- `test_dataloader`’╝ÜÕ£© `Runner.test()` õĖŁĶó½õĮ┐ńö©’╝īńö©õ║ĵ©ĪÕ×ŗńÜ䵥ŗĶ»Ģ
+
+MMEngine Õ«īÕģ©µö»µīü PyTorch ńÜäÕĤńö¤ `DataLoader`’╝īÕøĀµŁżõĖŖĶ┐░ 3 õĖ¬ÕÅéµĢ░ÕØćÕÅ»õ╗źńø┤µÄźõ╝ĀÕģźµ×äÕ╗║ÕźĮńÜä `DataLoader`’╝īÕ”é[15ÕłåķƤõĖŖµēŗ](../get_started/15_minutes.md)õĖŁńÜäõŠŗÕŁÉµēĆńż║ŃĆéÕÉīµŚČ’╝īÕƤÕŖ® MMEngine ńÜä[µ│©Õåīµ£║ÕłČ](../advanced_tutorials/registry.md)’╝īõ╗źõĖŖÕÅéµĢ░õ╣¤ÕÅ»õ╗źõ╝ĀÕģź `dict`’╝īÕ”éõĖŗķØóõ╗ŻńĀü’╝łõ╗źõĖŗń«Ćń¦░õŠŗ 1’╝ēµēĆńż║ŃĆéÕŁŚÕģĖõĖŁńÜäķö«ÕĆ╝õĖÄ `DataLoader` ńÜäµ×äķĆĀÕÅéµĢ░õĖĆõĖĆÕ»╣Õ║öŃĆé
+
+```python
+runner = Runner(
+ train_dataloader=dict(
+ batch_size=32,
+ sampler=dict(
+ type='DefaultSampler',
+ shuffle=True),
+ dataset=torchvision.datasets.CIFAR10(...),
+ collate_fn=dict(type='default_collate')
+ )
+)
+```
+
+Õ£©Ķ┐Öń¦ŹµāģÕåĄõĖŗ’╝īµĢ░µŹ«ÕŖĀĶĮĮÕÖ©õ╝ÜÕ£©Õ«×ķÖģĶó½ńö©Õł░µŚČ’╝īÕ£©µē¦ĶĪīÕÖ©Õåģķā©Ķó½µ×äÕ╗║ŃĆé
+
+```{note}
+Õģ│õ║Ä `DataLoader` ńÜäµø┤ÕżÜÕÅ»ķģŹńĮ«ÕÅéµĢ░’╝īõĮĀÕÅ»õ╗źÕÅéĶĆā [PyTorch API µ¢ćµĪŻ](https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader)
+```
+
+```{note}
+Õ”éµ×£õĮĀÕ»╣õ║ĵ×äÕ╗║ńÜäÕģĘõĮōń╗åĶŖéµä¤Õģ┤ĶČŻ’╝īõĮĀÕÅ»õ╗źÕÅéĶĆā [build_dataloader](mmengine.runner.Runner.build_dataloader)
+```
+
+ń╗åÕ┐āńÜäõĮĀÕÅ»ĶāĮõ╝ÜÕÅæńÄ░’╝īõŠŗ 1 **Õ╣ČķØ×**ńø┤µÄźńö▒[15ÕłåķƤõĖŖµēŗ](../get_started/15_minutes.md)õĖŁńÜäńż║õŠŗõ╗ŻńĀüń«ĆÕŹĢõ┐«µö╣ĶĆīµØźŃĆéõĮĀÕÅ»ĶāĮµ£¼õ╗źõĖ║Õ░å `DataLoader` ń«ĆÕŹĢµø┐µŹóõĖ║ `dict` Õ░▒ÕÅ»õ╗źµŚĀń╝ØÕłćµŹó’╝īõĮåķüŚµåŠńÜ䵜»’╝īÕ¤║õ║ĵ│©Õåīµ£║ÕłČµ×äÕ╗║µŚČ MMEngine õ╝ܵ£ēõĖĆõ║øķÜÉÕ╝ÅńÜäĶĮ¼µŹóÕÆīń║”Õ«ÜŃĆ鵳æõ╗¼Õ░åõ╗ŗń╗ŹÕģČõĖŁńÜäõĖŹÕÉīńé╣’╝īõ╗źķü┐ÕģŹõĮĀõĮ┐ńö©ķģŹńĮ«µ¢ćõ╗ȵŚČõ║¦ńö¤õĖŹÕ┐ģĶ”üńÜäń¢æµāæŃĆé
+
+### sampler õĖÄ shuffle
+
+õĖÄ 15 ÕłåķƤõĖŖµēŗµśÄµśŠõĖŹÕÉī’╝īõŠŗ 1 õĖŁµłæõ╗¼µĘ╗ÕŖĀõ║å `sampler` ÕÅéµĢ░’╝īĶ┐Öµś»ńö▒õ║ÄÕ£© MMEngine õĖŁµłæõ╗¼Ķ”üµ▒éķĆÜĶ┐ć `dict` õ╝ĀÕģźńÜäµĢ░µŹ«ÕŖĀĶĮĮÕÖ©ńÜäķģŹńĮ«**Õ┐ģķĪ╗ÕīģÕɽ `sampler` ÕÅéµĢ░**ŃĆéÕÉīµŚČ’╝ī`shuffle` ÕÅéµĢ░õ╣¤õ╗Ä `DataLoader` õĖŁń¦╗ķÖż’╝īĶ┐Öµś»ńö▒õ║ÄÕ£© PyTorch õĖŁ **`sampler` õĖÄ `shuffle` ÕÅéµĢ░µś»õ║Ƶ¢źńÜä**’╝īĶ¦ü [PyTorch API µ¢ćµĪŻ](https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader)ŃĆé
+
+```{note}
+õ║ŗÕ«×õĖŖ’╝īÕ£© PyTorch ńÜäÕ«×ńÄ░õĖŁ’╝ī`shuffle` ÕŬµś»õĖĆõĖ¬õŠ┐Õł®Ķ«░ÕÅĘŃĆéÕĮōĶ«ŠńĮ«õĖ║ `True` µŚČ `DataLoader` õ╝ÜĶć¬ÕŖ©Õ£©Õåģķā©õĮ┐ńö© `RandomSampler`
+```
+
+ÕĮōĶĆāĶÖæ `sampler` µŚČ’╝īõŠŗ 1 õ╗ŻńĀü**Õ¤║µ£¼**ÕÅ»õ╗źĶ«żõĖ║ńŁēõ╗Ęõ║ÄõĖŗķØóńÜäõ╗ŻńĀüÕØŚ
+
+```python
+from mmengine.dataset import DefaultSampler
+
+dataset = torchvision.datasets.CIFAR10(...)
+sampler = DefaultSampler(dataset, shuffle=True)
+
+runner = Runner(
+ train_dataloader=DataLoader(
+ batch_size=32,
+ sampler=sampler,
+ dataset=dataset,
+ collate_fn=default_collate
+ )
+)
+```
+
+```{warning}
+õĖŖĶ┐░õ╗ŻńĀüńÜäńŁēõ╗ʵƦÕŬµ£ēÕ£©’╝Ü1’╝ēõĮ┐ńö©ÕŹĢĶ┐øń©ŗĶ«Łń╗ā’╝īõ╗źÕÅŖ 2’╝ēµ▓Īµ£ēķģŹńĮ«µē¦ĶĪīÕÖ©ńÜä `randomness` ÕÅéµĢ░µŚČµłÉń½ŗŃĆéĶ┐Öµś»ńö▒õ║ÄõĮ┐ńö© `dict` õ╝ĀÕģź `sampler` µŚČ’╝īµē¦ĶĪīÕÖ©õ╝Üõ┐ØĶ»üÕ«āÕ£©ÕłåÕĖāÕ╝ÅĶ«Łń╗āńÄ»ÕóāĶ«ŠńĮ«Õ«īµłÉÕÉĵēŹĶó½µā░µĆ¦µ×äķĆĀ’╝īÕ╣ȵğµöČÕł░µŁŻńĪ«ńÜäķÜŵ£║ń¦ŹÕŁÉŃĆéĶ┐ÖõĖżńé╣Õ£©µēŗÕŖ©µ×äķĆĀµŚČķ£ĆĶ”üķóØÕż¢ÕĘźõĮ£õĖöµ×üµśōÕć║ķöÖŃĆéÕøĀµŁż’╝īõĖŖĶ┐░ńÜäÕåÖµ│ĢÕŬµś»õĖĆõĖ¬ńż║µäÅĶĆīķØ׵ĩĶŹÉÕåÖµ│ĢŃĆ鵳æõ╗¼**Õ╝║ńāłÕ╗║Ķ«« `sampler` õ╗ź `dict` ńÜäÕĮóÕ╝Åõ╝ĀÕģź**’╝īĶ«®µē¦ĶĪīÕÖ©ÕżäńÉåµ×äķĆĀķĪ║Õ║Å’╝īõ╗źķü┐ÕģŹÕć║ńÄ░ķŚ«ķóśŃĆé
+```
+
+### DefaultSampler
+
+õĖŖķØóõŠŗÕŁÉÕÅ»ĶāĮõ╝ÜĶ«®õĮĀÕźĮÕźć’╝Ü`DefaultSampler` µś»õ╗Ćõ╣ł’╝īõĖ║õ╗Ćõ╣łĶ”üõĮ┐ńö©Õ«ā’╝īµś»ÕÉ”µ£ēÕģČõ╗¢ķĆēķĪ╣’╝¤õ║ŗÕ«×õĖŖ’╝ī`DefaultSampler` µś» MMEngine ÕåģńĮ«ńÜäõĖĆń¦ŹķććµĀĘÕÖ©’╝īÕ«āÕ▒ÅĶöĮõ║åÕŹĢĶ┐øń©ŗĶ«Łń╗āõĖÄÕżÜĶ┐øń©ŗĶ«Łń╗āńÜäń╗åĶŖéÕĘ«Õ╝é’╝īõĮ┐ÕŠŚÕŹĢÕŹĪõĖÄÕżÜÕŹĪĶ«Łń╗āÕÅ»õ╗źµŚĀń╝ØÕłćµŹóŃĆéÕ”éµ×£õĮĀµ£ēĶ┐ćõĮ┐ńö© PyTorch `DistributedDataParallel` ńÜäń╗Åķ¬ī’╝īõĮĀõĖĆÕ«Üõ╝ÜÕ»╣ÕģČõĖŁµø┤µŹóµĢ░µŹ«ÕŖĀĶĮĮÕÖ©ńÜä `sampler` ÕÅéµĢ░µ£ēµēĆÕŹ░Ķ▒ĪŃĆéõĮåÕ£© MMEngine õĖŁ’╝īĶ┐ÖõĖĆń╗åĶŖéķĆÜĶ┐ć `DefaultSampler` ĶĆīĶó½Õ▒ÅĶöĮŃĆé
+
+ķÖżõ║å `Dataset` µ£¼Ķ║½õ╣ŗÕż¢’╝ī`DefaultSampler` Ķ┐śµö»µīüõ╗źõĖŗÕÅéµĢ░ķģŹńĮ«’╝Ü
+
+- `shuffle` Ķ«ŠńĮ«õĖ║ `True` µŚČõ╝ܵēōõ╣▒µĢ░µŹ«ķøåńÜäĶ»╗ÕÅ¢ķĪ║Õ║Å
+- `seed` µēōõ╣▒µĢ░µŹ«ķøåµēĆńö©ńÜäķÜŵ£║ń¦ŹÕŁÉ’╝īķĆÜÕĖĖõĖŹķ£ĆĶ”üÕ£©µŁżµēŗÕŖ©Ķ«ŠńĮ«’╝īõ╝Üõ╗Ä `Runner` ńÜä `randomness` ÕģźÕÅéõĖŁĶ»╗ÕÅ¢
+- `round_up` Ķ«ŠńĮ«õĖ║ `True` µŚČ’╝īõĖÄ PyTorch `DataLoader` õĖŁĶ«ŠńĮ« `drop_last=False` ĶĪīõĖ║õĖĆĶć┤ŃĆéÕ”éµ×£õĮĀÕ£©Ķ┐üń¦╗ PyTorch ńÜäķĪ╣ńø«’╝īõĮĀÕÅ»ĶāĮķ£ĆĶ”üµ│©µäÅĶ┐ÖõĖĆńé╣ŃĆé
+
+```{note}
+µø┤ÕżÜÕģ│õ║Ä `DefaultSampler` ńÜäÕåģÕ«╣ÕÅ»õ╗źÕÅéĶĆā [API µ¢ćµĪŻ](mmengine.dataset.DefaultSampler)
+```
+
+`DefaultSampler` ķĆéńö©õ║Äń╗ØÕż¦ķā©ÕłåµāģÕåĄ’╝īÕ╣ČõĖöµłæõ╗¼õ┐ØĶ»üÕ£©µē¦ĶĪīÕÖ©õĖŁõĮ┐ńö©Õ«āµŚČ’╝īķÜŵ£║µĢ░ńŁēÕ«╣µśōÕć║ķöÖńÜäń╗åĶŖéķāĮĶó½µŁŻńĪ«Õ£░ÕżäńÉå’╝īķś▓µŁóõĮĀķÖĘÕģźÕżÜĶ┐øń©ŗĶ«Łń╗āńÜäÕĖĖĶ¦üķÖĘķś▒ŃĆéÕ”éµ×£õĮĀµā│Ķ”üõĮ┐ńö©Õ¤║õ║ÄĶ┐Łõ╗Żµ¼ĪµĢ░ (iteration-based) ńÜäĶ«Łń╗āµĄüń©ŗ’╝īõĮĀõ╣¤Ķ«Ėõ╝ÜÕ»╣ [InfiniteSampler](mmengine.dataset.InfiniteSampler) µä¤Õģ┤ĶČŻŃĆéÕ”éµ×£õĮĀµ£ēµø┤ÕżÜńÜäĶ┐øķśČķ£Ćµ▒é’╝īõĮĀÕÅ»ĶāĮõ╝ܵā│Ķ”üÕÅéĶĆāõĖŖĶ┐░õĖżõĖ¬ÕåģńĮ« `sampler` ńÜäõ╗ŻńĀü’╝īÕ«×ńÄ░õĖĆõĖ¬Ķć¬Õ«Üõ╣ēńÜä `sampler` Õ╣ȵ│©ÕåīÕł░ `DATA_SAMPLERS` µĀ╣µ│©ÕåīÕÖ©õĖŁŃĆé
+
+```python
+@DATA_SAMPLERS.register_module()
+class MySampler(Sampler):
+ pass
+
+runner = Runner(
+ train_dataloader=dict(
+ sampler=dict(type='MySampler'),
+ ...
+ )
+)
+```
+
+### õĖŹĶĄĘń£╝ńÜä collate_fn
+
+PyTorch ńÜä `DataLoader` õĖŁ’╝ī`collate_fn` Ķ┐ÖõĖĆÕÅéµĢ░ÕĖĖÕĖĖĶó½õĮ┐ńö©ĶĆģÕ┐ĮńĢź’╝īõĮåÕ£© MMEngine õĖŁõĮĀķ£ĆĶ”üķóØÕż¢µ│©µäÅ’╝ÜÕĮōõĮĀõ╝ĀÕģź `dict` µØźµ×äķĆĀµĢ░µŹ«ÕŖĀĶĮĮÕÖ©µŚČ’╝īMMEngine õ╝Üķ╗śĶ«żõĮ┐ńö©ÕåģńĮ«ńÜä [pseudo_collate](mmengine.dataset.pseudo_collate)’╝īĶ┐ÖõĖĆńé╣µśÄµśŠÕī║Õł½õ║Ä PyTorch ķ╗śĶ«żńÜä [default_collate](https://pytorch.org/docs/stable/data.html#torch.utils.data.default_collate)ŃĆéÕøĀµŁż’╝īÕĮōõĮĀĶ┐üń¦╗ PyTorch ķĪ╣ńø«µŚČ’╝īķ£ĆĶ”üÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁµēŗÕŖ©µīćµśÄ `collate_fn` õ╗źõ┐صīüĶĪīõĖ║õĖĆĶć┤ŃĆé
+
+```{note}
+MMEngine õĖŁõĮ┐ńö© `pseudo_collate` õĮ£õĖ║ķ╗śĶ«żÕĆ╝’╝īõĖ╗Ķ”üµś»ńö▒õ║ÄÕÄåÕÅ▓Õģ╝Õ«╣µĆ¦ÕĤÕøĀ’╝īõĮĀÕÅ»õ╗źõĖŹÕ┐ģĶ┐ćõ║ĵĘ▒ń®Č’╝īÕŬķ£Ćõ║åĶ¦ŻÕ╣Čķü┐ÕģŹķöÖĶ»»õĮ┐ńö©ÕŹ│ÕÅ»ŃĆé
+```
+
+MMengine õĖŁµÅÉõŠøõ║å 2 ń¦ŹÕåģńĮ«ńÜä `collate_fn`’╝Ü
+
+- `pseudo_collate`’╝īń╝║ń£üµŚČńÜäķ╗śĶ«żÕÅéµĢ░ŃĆéÕ«āõĖŹõ╝ÜÕ░åµĢ░µŹ«µ▓┐ńØĆ `batch` ńÜäń╗┤Õ║”ÕÉłÕ╣ČŃĆéĶ»”ń╗åĶ»┤µśÄÕÅ»õ╗źÕÅéĶĆā [pseudo_collate](mmengine.dataset.pseudo_collate)
+- `default_collate`’╝īõĖÄ PyTorch õĖŁńÜä `default_collate` ĶĪīõĖ║ÕćĀõ╣ÄÕ«īÕģ©õĖĆĶć┤’╝īõ╝ÜÕ░åµĢ░µŹ«ĶĮ¼Õī¢õĖ║ `Tensor` Õ╣ȵ▓┐ńØĆ `batch` ń╗┤Õ║”ÕÉłÕ╣ČŃĆéõĖĆõ║øń╗åÕŠ«õĖŹÕÉīÕÆīĶ»”ń╗åĶ»┤µśÄÕÅ»õ╗źÕÅéĶĆā [default_collate](mmengine.dataset.default_collate)
+
+Õ”éµ×£õĮĀµā│Ķ”üõĮ┐ńö©Ķć¬Õ«Üõ╣ēńÜä `collate_fn`’╝īõĮĀõ╣¤ÕÅ»õ╗źÕ░åÕ«āµ│©ÕåīÕł░ `FUNCTIONS` µĀ╣µ│©ÕåīÕÖ©õĖŁµØźõĮ┐ńö©
+
+```python
+@FUNCTIONS.register_module()
+def my_collate_func(data_batch: Sequence) -> Any:
+ pass
+
+runner = Runner(
+ train_dataloader=dict(
+ ...
+ collate_fn=dict(type='my_collate_func')
+ )
+)
+```
+
+## µĢ░µŹ«ķøåĶ»”Ķ¦Ż
+
+µĢ░µŹ«ķøåķĆÜÕĖĖÕ«Üõ╣ēõ║åµĢ░µŹ«ńÜäµĢ░ķćÅŃĆüĶ»╗ÕÅ¢µ¢╣Õ╝ÅõĖÄķóäÕżäńÉå’╝īÕ╣ČõĮ£õĖ║ÕÅéµĢ░õ╝ĀķĆÆń╗ÖµĢ░µŹ«ÕŖĀĶĮĮÕÖ©õŠøÕÉÄĶĆģÕłåµē╣µ¼ĪÕŖĀĶĮĮŃĆéńö▒õ║ĵłæõ╗¼õĮ┐ńö©õ║å PyTorch ńÜä `DataLoader`’╝īÕøĀµŁżµĢ░µŹ«ķøåõ╣¤Ķć¬ńäČõĖÄ PyTorch `Dataset` Õ«īÕģ©Õģ╝Õ«╣ŃĆéÕÉīµŚČÕŠŚńøŖõ║ĵ│©Õåīµ£║ÕłČ’╝īÕĮōµĢ░µŹ«ÕŖĀĶĮĮÕÖ©õĮ┐ńö© `dict` Õ£©µē¦ĶĪīÕÖ©Õåģķā©µ×äÕ╗║µŚČ’╝ī`dataset` ÕÅéµĢ░õ╣¤ÕÅ»õ╗źõĮ┐ńö© `dict` õ╝ĀÕģźÕ╣ČÕ£©Õåģķā©Ķó½µ×äÕ╗║ŃĆéĶ┐ÖõĖĆńé╣õĮ┐ÕŠŚń╝¢ÕåÖķģŹńĮ«µ¢ćõ╗ȵłÉõĖ║ÕÅ»ĶāĮŃĆé
+
+### õĮ┐ńö© torchvision µĢ░µŹ«ķøå
+
+`torchvision` õĖŁµÅÉõŠøõ║åõĖ░Õ»īńÜäÕģ¼Õ╝ƵĢ░µŹ«ķøå’╝īÕ«āõ╗¼ķāĮÕÅ»õ╗źÕ£© MMEngine õĖŁńø┤µÄźõĮ┐ńö©’╝īõŠŗÕ”é [15 ÕłåķƤõĖŖµēŗ](../get_started/15_minutes.md)õĖŁńÜäńż║õŠŗõ╗ŻńĀüÕ░▒õĮ┐ńö©õ║åÕģČõĖŁńÜä `Cifar10` µĢ░µŹ«ķøå’╝īÕ╣ČõĖöõĮ┐ńö©õ║å `torchvision` õĖŁÕåģńĮ«ńÜäµĢ░µŹ«ķóäÕżäńÉ嵩ĪÕØŚŃĆé
+
+õĮåµś»’╝īÕĮōķ£ĆĶ”üÕ░åõĖŖĶ┐░ńż║õŠŗĶĮ¼µŹóõĖ║ķģŹńĮ«µ¢ćõ╗ȵŚČ’╝īõĮĀķ£ĆĶ”üÕ»╣ `torchvision` õĖŁńÜäµĢ░µŹ«ķøåĶ┐øĶĪīķóØÕż¢ńÜäµ│©ÕåīŃĆéÕ”éµ×£õĮĀÕÉīµŚČńö©Õł░õ║å `torchvision` õĖŁńÜäµĢ░µŹ«ķóäÕżäńÉ嵩ĪÕØŚ’╝īķéŻõ╣łõĮĀõ╣¤ķ£ĆĶ”üń╝¢ÕåÖķóØÕż¢õ╗ŻńĀüµØźÕ»╣Õ«āõ╗¼Ķ┐øĶĪīµ│©ÕåīÕÆīµ×äÕ╗║ŃĆéõĖŗķØóµłæõ╗¼Õ░åń╗ÖÕć║õĖĆõĖ¬ńŁēµĢłńÜäõŠŗÕŁÉµØźÕ▒Ģńż║Õ”éõĮĢÕüÜÕł░Ķ┐ÖõĖĆńé╣ŃĆé
+
+```python
+import torchvision.transforms as tvt
+from mmengine.registry import DATASETS, TRANSFORMS
+from mmengine.dataset.base_dataset import Compose
+
+# µ│©Õåī torchvision ńÜä CIFAR10 µĢ░µŹ«ķøå
+# µĢ░µŹ«ķóäÕżäńÉåõ╣¤ķ£ĆĶ”üÕ£©µŁżõĖĆĶĄĘµ×äÕ╗║
+@DATASETS.register_module(name='Cifar10', force=False)
+def build_torchvision_cifar10(transform=None, **kwargs):
+ if isinstance(transform, dict):
+ transform = [transform]
+ if isinstance(transform, (list, tuple)):
+ transform = Compose(transform)
+ return torchvision.datasets.CIFAR10(**kwargs, transform=transform)
+
+# µ│©Õåī torchvision õĖŁńö©Õł░ńÜäµĢ░µŹ«ķóäÕżäńÉ嵩ĪÕØŚ
+DATA_TRANSFORMS.register_module('RandomCrop', module=tvt.RandomCrop)
+DATA_TRANSFORMS.register_module('RandomHorizontalFlip', module=tvt.RandomHorizontalFlip)
+DATA_TRANSFORMS.register_module('ToTensor', module=tvt.ToTensor)
+DATA_TRANSFORMS.register_module('Normalize', module=tvt.Normalize)
+
+# Õ£© Runner õĖŁõĮ┐ńö©
+runner = Runner(
+ train_dataloader=dict(
+ batch_size=32,
+ sampler=dict(
+ type='DefaultSampler',
+ shuffle=True),
+ dataset=dict(type='Cifar10',
+ root='data/cifar10',
+ train=True,
+ download=True,
+ transform=[
+ dict(type='RandomCrop', size=32, padding=4),
+ dict(type='RandomHorizontalFlip'),
+ dict(type='ToTensor'),
+ dict(type='Normalize', **norm_cfg)])
+ )
+)
+```
+
+```{note}
+õĖŖĶ┐░õŠŗÕŁÉõĖŁÕż¦ķćÅõĮ┐ńö©õ║å[µ│©Õåīµ£║ÕłČ](../advanced_tutorials/registry.md)’╝īÕ╣ČõĖöńö©Õł░õ║å MMEngine õĖŁńÜä [Compose](mmengine.dataset.Compose)ŃĆéÕ”éµ×£õĮĀµĆźķ£ĆÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁõĮ┐ńö© `torchvision` µĢ░µŹ«ķøå’╝īõĮĀÕÅ»õ╗źÕÅéĶĆāõĖŖĶ┐░õ╗ŻńĀüÕ╣ČńĢźõĮ£õ┐«µö╣ŃĆéõĮåµłæõ╗¼µø┤ÕŖĀµÄ©ĶŹÉõĮĀµ£ēķ£ĆĶ”üµŚČÕ£©õĖŗµĖĖÕ║ō’╝łÕ”é [MMDet](https://github.com/open-mmlab/mmdetection) ÕÆī [MMPretrain](https://github.com/open-mmlab/mmpretrain) ńŁē’╝ēõĖŁÕ»╗µēŠÕ»╣Õ║öńÜäµĢ░µŹ«ķøåÕ«×ńÄ░’╝īõ╗ÄĶĆīĶÄĘÕŠŚµø┤ÕźĮńÜäõĮ┐ńö©õĮōķ¬īŃĆé
+```
+
+### Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøå
+
+õĮĀÕÅ»õ╗źÕāÅõĮ┐ńö© PyTorch õĖƵĀĘ’╝īĶć¬ńö▒Õ£░Õ«Üõ╣ēĶć¬ÕĘ▒ńÜäµĢ░µŹ«ķøå’╝īµł¢Õ░åõ╣ŗÕēŹ PyTorch ķĪ╣ńø«õĖŁńÜäµĢ░µŹ«ķøåµŗĘĶ┤ØĶ┐ćµØźŃĆéÕ”éµ×£õĮĀµā│Ķ”üõ║åĶ¦ŻÕ”éõĮĢĶć¬Õ«Üõ╣ēµĢ░µŹ«ķøå’╝īÕÅ»õ╗źÕÅéĶĆā [PyTorch Õ«śµ¢╣µĢÖń©ŗ](https://pytorch.org/tutorials/beginner/basics/data_tutorial.html#creating-a-custom-dataset-for-your-files)
+
+### õĮ┐ńö© MMEngine ńÜäµĢ░µŹ«ķøåÕ¤║ń▒╗
+
+ķÖżõ║åńø┤µÄźõĮ┐ńö© PyTorch ńÜä `Dataset` µØźĶć¬Õ«Üõ╣ēµĢ░µŹ«ķøåõ╣ŗÕż¢’╝īõĮĀõ╣¤ÕÅ»õ╗źõĮ┐ńö© MMEngine ÕåģńĮ«ńÜä `BaseDataset`’╝īÕÅéĶĆā[µĢ░µŹ«ķøåÕ¤║ń▒╗](../advanced_tutorials/basedataset.md)µ¢ćµĪŻŃĆéÕ«āÕ»╣µĀćµ│©µ¢ćõ╗ČńÜäµĀ╝Õ╝ÅÕüÜõ║åõĖĆõ║øń║”Õ«Ü’╝īõĮ┐ÕŠŚµĢ░µŹ«µÄźÕÅŻµø┤ÕŖĀń╗¤õĖĆŃĆüÕżÜõ╗╗ÕŖĪĶ«Łń╗āµø┤ÕŖĀõŠ┐µŹĘŃĆéÕÉīµŚČ’╝īµĢ░µŹ«ķøåÕ¤║ń▒╗õ╣¤ÕÅ»õ╗źĶĮ╗µØŠÕ£░µÉŁķģŹÕåģńĮ«ńÜä[µĢ░µŹ«ÕÅśµŹó](../advanced_tutorials/data_transform.md)õĮ┐ńö©’╝īÕćÅĶĮ╗õĮĀõ╗ÄÕż┤µÉŁÕ╗║Ķ«Łń╗āµĄüń©ŗńÜäÕĘźõĮ£ķćÅŃĆé
+
+ńø«ÕēŹ’╝ī`BaseDataset` ÕĘ▓ń╗ÅÕ£© OpenMMLab 2.0 ń│╗ÕłŚńÜäõĖŗµĖĖõ╗ōÕ║ōõĖŁĶó½Õ╣┐µ│øõĮ┐ńö©ŃĆé
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/debug_tricks.md b/internlm_langchain/knowledge_base/MMEngine/content/debug_tricks.md
new file mode 100644
index 00000000..734e967c
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/debug_tricks.md
@@ -0,0 +1,153 @@
+# Ķ░āĶ»ĢµŖĆÕʦ
+
+## Ķ«ŠńĮ«µĢ░µŹ«ķøåńÜäķĢ┐Õ║”
+
+Õ£©Ķ░āĶ»Ģõ╗ŻńĀüńÜäĶ┐ćń©ŗõĖŁ’╝īµ£ēµŚČķ£ĆĶ”üĶ«Łń╗āÕćĀõĖ¬ epoch’╝īõŠŗÕ”éĶ░āĶ»Ģķ¬īĶ»üĶ┐ćń©ŗµł¢ĶĆģµØāķćŹńÜäõ┐ØÕŁśµś»ÕÉ”ń¼”ÕÉłµ£¤µ£øŃĆéńäČĶĆīÕ”éµ×£µĢ░µŹ«ķøåÕż¬Õż¦’╝īķ£ĆĶ”üĶŖ▒Ķ┤╣ĶŠāķĢ┐µŚČķŚ┤µēŹĶāĮĶ«ŁÕ«īõĖĆõĖ¬ epoch’╝īĶ┐Öń¦ŹµāģÕåĄõĖŗÕÅ»õ╗źĶ«ŠńĮ«µĢ░µŹ«ķøåńÜäķĢ┐Õ║”ŃĆéµ│©µäÅ’╝īÕŬµ£ēń╗¦µē┐Ķć¬ [BaseDataset](mmengine.dataset.BaseDataset) ńÜä Dataset µēŹµö»µīüĶ┐ÖõĖ¬ÕŖ¤ĶāĮ’╝ī`BaseDataset` ńÜäńö©µ│ĢÕÅ»ķśģĶ»╗ [µĢ░µŹ«ķøåÕ¤║ń▒╗’╝łBASEDATASET’╝ē](../advanced_tutorials/basedataset.md)ŃĆé
+
+õ╗ź `MMPretrain` õĖ║õŠŗ’╝łÕÅéĶĆā[µ¢ćµĪŻ](https://mmpretrain.readthedocs.io/zh_CN/latest/get_started.html)Õ«ēĶŻģ MMPretrain’╝ēŃĆé
+
+ÕÉ»ÕŖ©Ķ«Łń╗āÕæĮõ╗ż
+
+```bash
+python tools/train.py configs/resnet/resnet18_8xb16_cifar10.py
+```
+
+õĖŗķØ󵜻Ķ«Łń╗āńÜäķā©ÕłåµŚźÕ┐Ś’╝īÕģČõĖŁ `3125` ĶĪ©ńż║ķ£ĆĶ”üĶ┐Łõ╗ŻńÜäµ¼ĪµĢ░ŃĆé
+
+```
+02/20 14:43:11 - mmengine - INFO - Epoch(train) [1][ 100/3125] lr: 1.0000e-01 eta: 6:12:01 time: 0.0149 data_time: 0.0003 memory: 214 loss: 2.0611
+02/20 14:43:13 - mmengine - INFO - Epoch(train) [1][ 200/3125] lr: 1.0000e-01 eta: 4:23:08 time: 0.0154 data_time: 0.0003 memory: 214 loss: 2.0963
+02/20 14:43:14 - mmengine - INFO - Epoch(train) [1][ 300/3125] lr: 1.0000e-01 eta: 3:46:27 time: 0.0146 data_time: 0.0003 memory: 214 loss: 1.9858
+```
+
+Õģ│µÄēĶ«Łń╗ā’╝īńäČÕÉÄõ┐«µö╣ [configs/_base_/datasets/cifar10_bs16.py](https://github.com/open-mmlab/mmpretrain/blob/main/configs/_base_/datasets/cifar100_bs16.py) õĖŁńÜä `dataset` ÕŁŚµ«Ą’╝īĶ«ŠńĮ« `indices=5000`ŃĆé
+
+```python
+train_dataloader = dict(
+ batch_size=16,
+ num_workers=2,
+ dataset=dict(
+ type=dataset_type,
+ data_prefix='data/cifar10',
+ test_mode=False,
+ indices=5000, # Ķ«ŠńĮ« indices=5000’╝īĶĪ©ńż║µ»ÅõĖ¬ epoch ÕŬĶ┐Łõ╗Ż 5000 õĖ¬µĀʵ£¼
+ pipeline=train_pipeline),
+ sampler=dict(type='DefaultSampler', shuffle=True),
+)
+```
+
+ķ揵¢░ÕÉ»ÕŖ©Ķ«Łń╗ā
+
+```bash
+python tools/train.py configs/resnet/resnet18_8xb16_cifar10.py
+```
+
+ÕÅ»õ╗źń£ŗÕł░’╝īĶ┐Łõ╗Żµ¼ĪµĢ░ÕÅśµłÉõ║å `313`’╝īńøĖµ»öÕĤÕģł’╝īĶ┐ÖµĀĘĶāĮÕż¤µø┤Õ┐½ĶĘæÕ«īõĖĆõĖ¬ epochŃĆé
+
+```
+02/20 14:44:58 - mmengine - INFO - Epoch(train) [1][100/313] lr: 1.0000e-01 eta: 0:31:09 time: 0.0154 data_time: 0.0004 memory: 214 loss: 2.1852
+02/20 14:44:59 - mmengine - INFO - Epoch(train) [1][200/313] lr: 1.0000e-01 eta: 0:23:18 time: 0.0143 data_time: 0.0002 memory: 214 loss: 2.0424
+02/20 14:45:01 - mmengine - INFO - Epoch(train) [1][300/313] lr: 1.0000e-01 eta: 0:20:39 time: 0.0143 data_time: 0.0003 memory: 214 loss: 1.814
+```
+
+## µŻĆµ¤źõĖŹÕÅéõĖÄ loss Ķ«Īń«ŚńÜäÕÅéµĢ░
+
+õĮ┐ńö©ÕżÜÕŹĪĶ«Łń╗āµŚČ’╝īÕĮōµ©ĪÕ×ŗńÜäÕÅéµĢ░ÕÅéõĖÄõ║åÕēŹÕÉæĶ«Īń«Ś’╝īõĮåµ▓Īµ£ēÕÅéõĖÄ loss ńÜäĶ«Īń«Ś’╝īń©ŗÕ║Åõ╝ܵŖøÕć║õĖŗķØóńÜäķöÖĶ»»’╝Ü
+
+```
+RuntimeError: Expected to have finished reduction in the prior iteration before starting a new one. This error indicates that your module has parameters that were not used in producing loss. You can enable unused parameter detection by passing the keyword argument `find_unused_parameters=True` to `torch.nn.parallel.DistributedDataParallel`, and by
+making sure all `forward` function outputs participate in calculating loss.
+```
+
+µłæõ╗¼õ╗ź[15 ÕłåķƤõĖŖµēŗ MMEngine](../get_started/15_minutes.md) õĖŁÕ«Üõ╣ēńÜ䵩ĪÕ×ŗõĖ║õŠŗ’╝Ü
+
+```python
+class MMResNet50(BaseModel):
+ def __init__(self):
+ super().__init__()
+ self.resnet = torchvision.models.resnet50()
+
+ def forward(self, imgs, labels, mode):
+ x = self.resnet(imgs)
+ if mode == 'loss':
+ return {'loss': F.cross_entropy(x, labels)}
+ elif mode == 'predict':
+ return x, labels
+```
+
+Õ░åÕģČõ┐«µö╣õĖ║õĖŗķØóńÜäõ╗ŻńĀü’╝Ü
+
+```python
+class MMResNet50(BaseModel):
+
+ def __init__(self):
+ super().__init__()
+ self.resnet = torchvision.models.resnet50()
+ self.param = nn.Parameter(torch.ones(1))
+
+ def forward(self, imgs, labels, mode):
+ x = self.resnet(imgs)
+ # self.param ÕÅéõĖÄõ║åÕēŹÕÉæĶ«Īń«Ś’╝īõĮå y µ▓Īµ£ēÕÅéõĖÄ loss ńÜäĶ«Īń«Ś
+ y = self.param + x
+ if mode == 'loss':
+ return {'loss': F.cross_entropy(x, labels)}
+ elif mode == 'predict':
+ return x, labels
+```
+
+õĮ┐ńö©õĖżÕ╝ĀÕŹĪÕÉ»ÕŖ©Ķ«Łń╗ā
+
+```bash
+torchrun --nproc-per-node 2 examples/distributed_training.py --launcher pytorch
+```
+
+ń©ŗÕ║Åõ╝ܵŖøÕć║õĖŖķØóµÅÉÕł░ńÜäķöÖĶ»»ŃĆé
+
+µłæõ╗¼ÕÅ»õ╗źķĆÜĶ┐ćĶ«ŠńĮ« `find_unused_parameters=True` µØźĶ¦ŻÕå│Ķ┐ÖõĖ¬ķŚ«ķóś’╝ī
+
+```python
+cfg = dict(
+ model_wrapper_cfg=dict(
+ type='MMDistributedDataParallel', find_unused_parameters=True)
+)
+runner = Runner(
+ model=MMResNet50(),
+ work_dir='./work_dir',
+ train_dataloader=train_dataloader,
+ optim_wrapper=dict(optimizer=dict(type=SGD, lr=0.001, momentum=0.9)),
+ train_cfg=dict(by_epoch=True, max_epochs=2, val_interval=1),
+ val_dataloader=val_dataloader,
+ val_cfg=dict(),
+ val_evaluator=dict(type=Accuracy),
+ launcher=args.launcher,
+ cfg=cfg,
+)
+runner.train()
+```
+
+ķ揵¢░ÕÉ»ÕŖ©Ķ«Łń╗ā’╝īÕÅ»õ╗źń£ŗÕł░ń©ŗÕ║ÅÕÅ»õ╗źµŁŻÕĖĖĶ«Łń╗āÕ╣ȵēōÕŹ░µŚźÕ┐ŚŃĆé
+
+õĮåµś»’╝īĶ«ŠńĮ« `find_unused_parameters=True` õ╝ÜĶ«®ń©ŗÕ║ÅÕÅśµģó’╝īÕøĀµŁż’╝īµłæõ╗¼ÕĖīµ£øµēŠÕć║Ķ┐Öõ║øÕÅéµĢ░Õ╣ČÕłåµ×ÉÕ«āõ╗¼µ▓Īµ£ēÕÅéõĖÄ loss Ķ«Īń«ŚńÜäÕĤÕøĀŃĆé
+
+ÕÅ»õ╗źķĆÜĶ┐ćĶ«ŠńĮ« `detect_anomalous_params=True` µØźµēōÕŹ░µ£¬Ķó½õĮ┐ńö©ńÜäÕÅéµĢ░ŃĆé
+
+```python
+cfg = dict(
+ model_wrapper_cfg=dict(
+ type='MMDistributedDataParallel',
+ find_unused_parameters=True,
+ detect_anomalous_params=True),
+)
+```
+
+ķ揵¢░ÕÉ»ÕŖ©Ķ«Łń╗ā’╝īÕÅ»õ╗źń£ŗÕł░µŚźÕ┐ŚõĖŁµēōÕŹ░õ║åµ£¬ÕÅéõĖÄ loss Ķ«Īń«ŚńÜäÕÅéµĢ░ŃĆé
+
+```
+08/03 15:04:42 - mmengine - ERROR - mmengine/logging/logger.py - print_log - 323 - module.param with shape torch.Size([1]) is not in the computational graph
+```
+
+Õ£©µēŠÕł░Ķ┐Öõ║øÕÅéµĢ░ÕÉÄ’╝īµłæõ╗¼ÕÅ»õ╗źÕłåµ×ÉõĖ║õ╗Ćõ╣łĶ┐Öõ║øÕÅéµĢ░µ▓Īµ£ēÕÅéõĖÄ loss ńÜäĶ«Īń«ŚŃĆé
+
+```{important}
+ÕŬÕ║öÕ£©Ķ░āĶ»ĢµŚČĶ«ŠńĮ« `find_unused_parameters=True` ÕÆī `detect_anomalous_params=True`ŃĆé
+```
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/debug_with_vscode.md b/internlm_langchain/knowledge_base/MMEngine/content/debug_with_vscode.md
new file mode 100644
index 00000000..121d8e4e
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/debug_with_vscode.md
@@ -0,0 +1,75 @@
+# VS Code Ķ░āĶ»Ģń©ŗÕ║Å
+
+## Ķ░āĶ»ĢÕżÜÕŹĪń©ŗÕ║Å
+
+ÕżÜĶ┐øń©ŗ’╝łÕżÜÕŹĪ’╝ēń©ŗÕ║ÅÕć║ńÄ░ķöÖĶ»»µŚČ’╝īÕģłÕłżµ¢Łµś»ÕÉ”ÕÆīÕżÜĶ┐øń©ŗńøĖÕģ│’╝īÕ”éõĖŹńøĖÕģ│’╝īÕ╗║Ķ««õĮ┐ńö©ÕŹĢÕŹĪĶ░āĶ»ĢŃĆé
+
+µ£¼µ¢ćÕ░åÕ¤║õ║Ä MMEngine õĖŁńÜä [example](https://github.com/open-mmlab/mmengine/blob/main/examples/distributed_training.py) Ķäܵ£¼µØźõ╗ŗń╗ŹÕ”éõĮĢõĮ┐ńö© VS Code Ķ░āĶ»ĢÕżÜÕŹĪń©ŗÕ║ÅŃĆé
+
+### Õ«ēĶŻģ MMEngine
+
+ÕøĀõĖ║ķ£ĆĶ”üõĮ┐ńö© MMEngine õĖŁńÜä example Ķäܵ£¼’╝īõĖ║õ║åµ¢╣õŠ┐’╝īÕÅ»õ╗źµ║ÉńĀüÕ«ēĶŻģ MMEngineŃĆé
+
+```bash
+# Õ”éµ×£ÕģŗķÜåõ╗ŻńĀüõ╗ōÕ║ōńÜäķƤÕ║”Ķ┐ćµģó’╝īÕÅ»õ╗źõ╗Ä https://gitee.com/open-mmlab/mmengine.git ÕģŗķÜå
+git clone https://github.com/open-mmlab/mmengine.git
+cd mmengine
+pip install -e . -v
+```
+
+### Ķ┐ÉĶĪīÕżÜÕŹĪń©ŗÕ║Å
+
+```bash
+torchrun --nproc_per_node=2 examples/distributed_training.py --launcher pytorch
+```
+
+Ķ┐ÉĶĪīõĖŖķØóńÜäÕæĮõ╗ż’╝īÕÅ»õ╗źń£ŗÕł░Ķäܵ£¼µŁŻÕĖĖĶ┐ÉĶĪīÕ╣ȵēōÕŹ░Ķ«Łń╗āµŚźÕ┐ŚŃĆé
+
+
+
+Ķäܵ£¼µŁŻÕĖĖĶ┐ÉĶĪīÕÉÄ’╝īÕÅ»õ╗źÕü£µÄēń©ŗÕ║ÅŃĆé
+
+### Ķ░āĶ»ĢÕżÜÕŹĪń©ŗÕ║Å
+
+õĮ┐ńö© VS Code Ķ░āĶ»Ģķ£ĆÕģłķģŹńĮ« `~/.vscode/launch.json`ŃĆé
+
+```json
+{
+ "version": "0.2.0",
+ "configurations": [
+ {
+ "name": "Python: torchrun",
+ "type": "python",
+ "request": "launch",
+ // Ķ«ŠńĮ« program ńÜäĶĘ»ÕŠäõĖ║ torchrun Ķäܵ£¼Õ»╣Õ║öńÜäń╗ØÕ»╣ĶĘ»ÕŠä
+ // ÕÅ»õĮ┐ńö© pip show torch µ¤źń£ŗ torch ńÜäÕ«ēĶŻģĶĘ»ÕŠä
+ "program": "/home/username/miniconda3/envs/py39pt20cu117/lib/python3.9/site-packages/torch/distributed/run.py",
+ // Ķ«ŠńĮ« torchrun ÕæĮõ╗żńÜäÕÅéµĢ░
+ "args":[
+ "--nproc_per_node=2",
+ // examples/distributed_training.py ńÜäń╗ØÕ»╣ĶĘ»ÕŠä
+ "/home/username/codebases/mmengine/examples/distributed_training.py",
+ "--launcher=pytorch"
+ ],
+ "console": "integratedTerminal",
+ "justMyCode": true
+ }
+ ]
+}
+```
+
+```{note}
+Õ”éµ×£õĮĀõĮ┐ńö©ńÜäÕÉ»ÕŖ©ÕæĮõ╗żµś» `python -m torch.distributed.launch --nproc_per_node=2 examples/distributed_training.py --launcher pytorch`’╝īÕłÖÕŬķ£ĆÕ░åõĖŖķØóķģŹńĮ«ńÜä program ńÜä `run.py` µø┐µŹóõĖ║ `launcher.py` ÕŹ│ÕÅ»ŃĆé
+```
+
+µÄźõĖŗµØźÕ£© VS Code õĖŁĶ«ŠńĮ«µ¢Łńé╣’╝īõŠŗÕ”éµłæõ╗¼ÕĖīµ£øń£ŗõĖĆõĖŗ MMEngine Runner ńÜä train Ķ┐ćń©ŗ’╝īµłæõ╗¼ÕÅ»õ╗źÕ£© `runner.train()` ÕżäĶ«ŠńĮ«µ¢Łńé╣ŃĆé
+
+
+
+µ£ĆÕÉÄńé╣Õć╗ `Python: Current File` µīēķÆ«ÕŹ│ÕÅ»Õ╝ĆÕ¦ŗĶ░āĶ»ĢŃĆé
+
+
+
+ńé╣Õć╗ F11 ÕÅ»ĶĘ│Õģź `runner.train()` µ¤źń£ŗÕ«āńÜäÕ«×ńÄ░ŃĆé
+
+
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/distributed.md b/internlm_langchain/knowledge_base/MMEngine/content/distributed.md
new file mode 100644
index 00000000..ffa2e5ee
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/distributed.md
@@ -0,0 +1,47 @@
+# ÕłåÕĖāÕ╝ÅķĆÜõ┐ĪÕĤĶ»Ł
+
+Õ£©ÕłåÕĖāÕ╝ÅĶ«Łń╗āµł¢µĄŗĶ»ĢńÜäĶ┐ćń©ŗõĖŁ’╝īõĖŹÕÉīĶ┐øń©ŗµ£ēµŚČķ£ĆĶ”üµĀ╣µŹ«ÕłåÕĖāÕ╝ÅńÜäńÄ»Õóāõ┐Īµü»µē¦ĶĪīõĖŹÕÉīńÜäõ╗ŻńĀüķĆ╗ĶŠæ’╝īÕÉīµŚČõĖŹÕÉīĶ┐øń©ŗõ╣ŗķŚ┤õ╣¤ń╗ÅÕĖĖõ╝ܵ£ēńøĖõ║ÆķĆÜõ┐ĪńÜäķ£Ćµ▒é’╝īÕ»╣õĖĆõ║øµĢ░µŹ«Ķ┐øĶĪīÕÉīµŁźńŁēµōŹõĮ£ŃĆé
+PyTorch µÅÉõŠøõ║åõĖĆÕźŚÕ¤║ńĪĆńÜäķĆÜõ┐ĪÕĤĶ»Łńö©õ║ÄÕżÜĶ┐øń©ŗõ╣ŗķŚ┤Õ╝ĀķćÅńÜäķĆÜõ┐Ī’╝īÕ¤║õ║ÄĶ┐ÖÕźŚÕĤĶ»Ł’╝īMMEngine Õ«×ńÄ░õ║åµø┤ķ½śÕ▒éµ¼ĪńÜäķĆÜõ┐ĪÕĤĶ»ŁÕ░üĶŻģõ╗źµ╗ĪĶČ│µø┤ÕŖĀõĖ░Õ»īńÜäķ£Ćµ▒éŃĆéÕ¤║õ║Ä MMEngine ńÜäķĆÜõ┐ĪÕĤĶ»Ł’╝īń«Śµ│ĢÕ║ōõĖŁńÜ䵩ĪÕØŚÕÅ»õ╗ź
+
+1. Õ£©õĮ┐ńö©ķĆÜõ┐ĪÕĤĶ»ŁÕ░üĶŻģµŚČõĖŹµśŠÕ╝ÅÕī║ÕłåÕłåÕĖāÕ╝Å/ķØ×ÕłåÕĖāÕ╝ÅńÄ»Õóā
+2. Ķ┐øĶĪīķÖż Tensor õ╗źÕż¢ń▒╗Õ×ŗµĢ░µŹ«ńÜäÕżÜĶ┐øń©ŗķĆÜõ┐Ī
+3. µŚĀķ£Ćõ║åĶ¦ŻÕ║ĢÕ▒éķĆÜõ┐ĪÕÉÄń½»µł¢µĪåµ×Č
+
+Ķ┐Öõ║øķĆÜõ┐ĪÕĤĶ»ŁÕ░üĶŻģńÜäµÄźÕÅŻÕÆīÕŖ¤ĶāĮÕÅ»õ╗źÕż¦Ķć┤ÕĮÆń▒╗õĖ║Õ”éõĖŗõĖēń¦Ź’╝īµłæõ╗¼Õ£©ÕÉÄń╗Łń½ĀĶŖéõĖŁķĆÉõĖ¬õ╗ŗń╗Ź
+
+1. ÕłåÕĖāÕ╝ÅÕłØÕ¦ŗÕī¢’╝Ü`init_dist` Ķ┤¤Ķ┤ŻÕłØÕ¦ŗÕī¢µē¦ĶĪīÕÖ©ńÜäÕłåÕĖāÕ╝ÅńÄ»Õóā
+2. ÕłåÕĖāÕ╝Åõ┐Īµü»ĶÄĘÕÅ¢õĖÄµÄ¦ÕłČ’╝ÜÕīģµŗ¼ `get_world_size` ńŁēÕćĮµĢ░ĶÄĘÕÅ¢ÕĮōÕēŹńÜä `rank` ÕÆī `world_size` ńŁēõ┐Īµü»
+3. ÕłåÕĖāÕ╝ÅķĆÜõ┐ĪµÄźÕÅŻ’╝ÜÕīģµŗ¼Õ”é `all_reduce` ńŁēķĆÜõ┐ĪÕćĮµĢ░’╝łcollective functions’╝ē
+
+## ÕłåÕĖāÕ╝ÅÕłØÕ¦ŗÕī¢
+
+- [init_dist](mmengine.dist.init_dist)’╝Ü µś»ÕłåÕĖāÕ╝ÅĶ«Łń╗āńÜäÕÉ»ÕŖ©ÕćĮµĢ░’╝īńø«ÕēŹµö»µīü pytorch’╝īslurm’╝īMPI 3 ń¦ŹÕłåÕĖāÕ╝ÅÕÉ»ÕŖ©µ¢╣Õ╝Å’╝īÕÉīµŚČÕģüĶ«ĖĶ«ŠńĮ«ķĆÜõ┐ĪńÜäÕÉÄń½»’╝īķ╗śĶ«żõĮ┐ńö© NCCLŃĆé
+
+## ÕłåÕĖāÕ╝Åõ┐Īµü»ĶÄĘÕÅ¢õĖÄµÄ¦ÕłČ
+
+ÕłåÕĖāÕ╝Åõ┐Īµü»ńÜäĶÄĘÕÅ¢õĖÄµÄ¦ÕłČÕćĮµĢ░µ▓Īµ£ēÕÅéµĢ░’╝īĶ┐Öõ║øÕćĮµĢ░Õģ╝Õ«╣ķØ×ÕłåÕĖāÕ╝ÅĶ«Łń╗āńÜäµāģÕåĄ’╝īÕŖ¤ĶāĮÕ”éõĖŗ
+
+- [get_world_size](mmengine.dist.get_world_size)’╝ÜĶÄĘÕÅ¢ÕĮōÕēŹĶ┐øń©ŗń╗äńÜäĶ┐øń©ŗµĆ╗µĢ░’╝īķØ×ÕłåÕĖāÕ╝ŵāģÕåĄõĖŗĶ┐öÕø× 1
+- [get_rank](mmengine.dist.get_rank)’╝ÜĶÄĘÕÅ¢ÕĮōÕēŹĶ┐øń©ŗÕ»╣Õ║öńÜäÕģ©Õ▒Ć rank µĢ░’╝īķØ×ÕłåÕĖāÕ╝ŵāģÕåĄõĖŗĶ┐öÕø× 0
+- [get_backend](mmengine.dist.get_backend)’╝ÜĶÄĘÕÅ¢ÕĮōÕēŹķĆÜõ┐ĪõĮ┐ńö©ńÜäÕÉÄń½»’╝īķØ×ÕłåÕĖāÕ╝ŵāģÕåĄõĖŗĶ┐öÕø× None
+- [get_local_rank](mmengine.dist.get_local_rank)’╝ÜĶÄĘÕÅ¢ÕĮōÕēŹĶ┐øń©ŗÕ»╣Õ║öÕł░ÕĮōÕēŹµ£║ÕÖ©ńÜä rank µĢ░’╝īķØ×ÕłåÕĖāÕ╝ŵāģÕåĄõĖŗĶ┐öÕø× 0
+- [get_local_size](mmengine.dist.get_local_size)’╝ÜĶÄĘÕÅ¢ÕĮōÕēŹĶ┐øń©ŗµēĆÕ£©µ£║ÕÖ©ńÜäµĆ╗Ķ┐øń©ŗµĢ░’╝īķØ×ÕłåÕĖāÕ╝ŵāģÕåĄõĖŗĶ┐öÕø× 0
+- [get_dist_info](mmengine.dist.get_dist_info)’╝ÜĶÄĘÕÅ¢ÕĮōÕēŹõ╗╗ÕŖĪńÜäĶ┐øń©ŗµĆ╗µĢ░ÕÆīÕĮōÕēŹĶ┐øń©ŗÕ»╣Õ║öÕł░Õģ©Õ▒ĆńÜä rank µĢ░’╝īķØ×ÕłåÕĖāÕ╝ŵāģÕåĄõĖŗ word_size = 1’╝īrank = 0
+- [is_main_process](mmengine.dist.is_main_process)’╝ÜÕłżµ¢Łµś»ÕÉ”õĖ║ 0 ÕÅĘõĖ╗Ķ┐øń©ŗ’╝īķØ×ÕłåÕĖāÕ╝ŵāģÕåĄõĖŗĶ┐öÕø× True
+- [master_only](mmengine.dist.master_only)’╝ÜÕćĮµĢ░ĶŻģķź░ÕÖ©’╝īńö©õ║Äõ┐«ķź░ÕŬķ£ĆĶ”üÕģ©Õ▒Ć 0 ÕÅĘĶ┐øń©ŗ’╝łrank 0 ĶĆīõĖŹµś» local rank 0’╝ēµē¦ĶĪīńÜäÕćĮµĢ░
+- [barrier](mmengine.dist.barrier)’╝ÜÕÉīµŁźµēƵ£ēĶ┐øń©ŗÕł░ĶŠŠńøĖÕÉīõĮŹńĮ«
+
+## ÕłåÕĖāÕ╝ÅķĆÜõ┐ĪÕćĮµĢ░
+
+ķĆÜõ┐ĪÕćĮµĢ░ ’╝łCollective functions’╝ē’╝īõĖ╗Ķ”üńö©õ║ÄĶ┐øń©ŗķŚ┤µĢ░µŹ«ńÜäķĆÜõ┐Ī’╝īÕ¤║õ║Ä PyTorch ÕĤńö¤ńÜä all_reduce’╝īall_gather’╝īgather’╝ībroadcast µÄźÕÅŻ’╝īMMEngine µÅÉõŠøõ║åÕ”éõĖŗµÄźÕÅŻ’╝īÕģ╝Õ«╣ķØ×ÕłåÕĖāÕ╝ÅĶ«Łń╗āńÜäµāģÕåĄ’╝īÕ╣ȵö»µīüµø┤õĖ░Õ»īµĢ░µŹ«ń▒╗Õ×ŗńÜäķĆÜõ┐ĪŃĆé
+
+- [all_reduce](mmengine.dist.all_reduce): Õ»╣Ķ┐øń©ŗķŚ┤ tensor Ķ┐øĶĪī AllReduce µōŹõĮ£
+- [all_gather](mmengine.dist.all_gather)’╝ÜÕ»╣Ķ┐øń©ŗķŚ┤ tensor Ķ┐øĶĪī AllGather µōŹõĮ£
+- [gather](mmengine.dist.gather)’╝ÜÕ░åĶ┐øń©ŗńÜä tensor µöČķøåÕł░õĖĆõĖ¬ńø«µĀć rank
+- [broadcast](mmengine.dist.broadcast)’╝ÜÕ»╣µ¤ÉõĖ¬Ķ┐øń©ŗńÜä tensor Ķ┐øĶĪīÕ╣┐µÆŁ
+- [sync_random_seed](mmengine.dist.sync_random_seed)’╝ÜÕÉīµŁźĶ┐øń©ŗõ╣ŗķŚ┤ńÜäķÜŵ£║ń¦ŹÕŁÉ
+- [broadcast_object_list](mmengine.dist.broadcast_object_list)’╝ܵö»µīüÕ»╣õ╗╗µäÅÕÅ»Ķó½ Pickle Õ║ÅÕłŚÕī¢ńÜä Python Õ»╣Ķ▒ĪÕłŚĶĪ©Ķ┐øĶĪīÕ╣┐µÆŁ’╝īÕ¤║õ║Ä broadcast µÄźÕÅŻÕ«×ńÄ░
+- [all_reduce_dict](mmengine.dist.all_reduce_dict)’╝ÜÕ»╣ dict õĖŁńÜäÕåģÕ«╣Ķ┐øĶĪī all_reduce µōŹõĮ£’╝īÕ¤║õ║Ä broadcast ÕÆī all_reduce µÄźÕÅŻÕ«×ńÄ░
+- [all_gather_object](mmengine.dist.all_gather_object)’╝ÜÕ¤║õ║Ä all_gather Õ«×ńÄ░Õ»╣õ╗╗µäÅÕÅ»õ╗źĶó½ Pickle Õ║ÅÕłŚÕī¢ńÜä Python Õ»╣Ķ▒ĪĶ┐øĶĪī all_gather µōŹõĮ£
+- [gather_object](mmengine.dist.gather_object)’╝ÜÕ░å group ķćīµ»ÅõĖ¬ rank õĖŁõ╗╗µäÅÕÅ»Ķó½ Pickle Õ║ÅÕłŚÕī¢ńÜä Python Õ»╣Ķ▒Ī gather Õł░µīćÕ«ÜńÜäńø«µĀć rank
+- [collect_results](mmengine.dist.collect_results)’╝ܵö»µīüÕ¤║õ║Ä CPU ķĆÜõ┐Īµł¢ĶĆģ GPU ķĆÜõ┐ĪÕ»╣õĖŹÕÉīĶ┐øń©ŗķŚ┤ńÜäÕłŚĶĪ©µĢ░µŹ«Ķ┐øĶĪīµöČķøå
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/distributed_training.md b/internlm_langchain/knowledge_base/MMEngine/content/distributed_training.md
new file mode 100644
index 00000000..8afedc96
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/distributed_training.md
@@ -0,0 +1,107 @@
+# ÕłåÕĖāÕ╝ÅĶ«Łń╗ā
+
+MMEngine µö»µīü CPUŃĆüÕŹĢÕŹĪŃĆüÕŹĢµ£║ÕżÜÕŹĪõ╗źÕÅŖÕżÜµ£║ÕżÜÕŹĪńÜäĶ«Łń╗āŃĆéÕĮōńÄ»ÕóāõĖŁµ£ēÕżÜÕ╝ĀµśŠÕŹĪµŚČ’╝īµłæõ╗¼ÕÅ»õ╗źõĮ┐ńö©õ╗źõĖŗÕæĮõ╗żÕ╝ĆÕÉ»ÕŹĢµ£║ÕżÜÕŹĪµł¢ĶĆģÕżÜµ£║ÕżÜÕŹĪńÜäµ¢╣Õ╝Åõ╗ÄĶĆīń╝®ń¤Łµ©ĪÕ×ŗńÜäĶ«Łń╗āµŚČķŚ┤ŃĆé
+
+## ÕÉ»ÕŖ©Ķ«Łń╗ā
+
+### ÕŹĢµ£║ÕżÜÕŹĪ
+
+ÕüćĶ«ŠÕĮōÕēŹµ£║ÕÖ©µ£ē 8 Õ╝ĀµśŠÕŹĪ’╝īÕÅ»õ╗źõĮ┐ńö©õ╗źõĖŗÕæĮõ╗żÕ╝ĆÕÉ»ÕżÜÕŹĪĶ«Łń╗ā
+
+```bash
+python -m torch.distributed.launch --nproc_per_node=8 examples/distributed_training.py --launcher pytorch
+```
+
+Õ”éµ×£ķ£ĆĶ”üµīćիܵśŠÕŹĪńÜäń╝¢ÕÅĘ’╝īÕÅ»õ╗źĶ«ŠńĮ« `CUDA_VISIBLE_DEVICES` ńÄ»ÕóāÕÅśķćÅ’╝īõŠŗÕ”éõĮ┐ńö©ń¼¼ 0 ÕÆīń¼¼ 3 Õ╝ĀÕŹĪ
+
+```bash
+CUDA_VISIBLE_DEVICES=0,3 python -m torch.distributed.launch --nproc_per_node=2 examples/distributed_training.py --launcher pytorch
+```
+
+### ÕżÜµ£║ÕżÜÕŹĪ
+
+ÕüćĶ«Šµ£ē 2 ÕÅ░µ£║ÕÖ©’╝īµ»ÅÕÅ░µ£║ÕÖ©µ£ē 8 Õ╝ĀÕŹĪŃĆé
+
+ń¼¼õĖĆÕÅ░µ£║ÕÖ©Ķ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗ż
+
+```bash
+python -m torch.distributed.launch \
+ --nnodes 8 \
+ --node_rank 0 \
+ --master_addr 127.0.0.1 \
+ --master_port 29500 \
+ --nproc_per_node=8 \
+ examples/distributed_training.py --launcher pytorch
+```
+
+ń¼¼ 2 ÕÅ░µ£║ÕÖ©Ķ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗ż
+
+```bash
+python -m torch.distributed.launch \
+ --nnodes 8 \
+ --node_rank 1 \
+ --master_addr 127.0.0.1 \
+ --master_port 29500 \
+ --nproc_per_node=8 \
+ examples/distributed_training.py --launcher pytorch
+```
+
+Õ”éµ×£Õ£© slurm ķøåńŠżĶ┐ÉĶĪī MMEngine’╝īÕŬķ£ĆĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗żÕŹ│ÕÅ»Õ╝ĆÕÉ» 2 µ£║ 16 ÕŹĪńÜäĶ«Łń╗ā
+
+```bash
+srun -p mm_dev \
+ --job-name=test \
+ --gres=gpu:8 \
+ --ntasks=16 \
+ --ntasks-per-node=8 \
+ --cpus-per-task=5 \
+ --kill-on-bad-exit=1 \
+ python examples/distributed_training.py --launcher="slurm"
+```
+
+## Õ«ÜÕłČÕī¢ÕłåÕĖāÕ╝ÅĶ«Łń╗ā
+
+ÕĮōńö©µłĘõ╗ÄÕŹĢÕŹĪĶ«Łń╗āÕłćµŹóÕł░ÕżÜÕŹĪĶ«Łń╗āµŚČ’╝īµŚĀķ£ĆÕüÜõ╗╗õĮĢµö╣ÕŖ©’╝ī[Runner](mmengine.runner.Runner.wrap_model) õ╝Üķ╗śĶ«żõĮ┐ńö© [MMDistributedDataParallel](mmengine.model.MMDistributedDataParallel) Õ░üĶŻģ model’╝īõ╗ÄĶĆīµö»µīüÕżÜÕŹĪĶ«Łń╗āŃĆé
+Õ”éµ×£õĮĀÕĖīµ£øń╗Ö `MMDistributedDataParallel` õ╝ĀÕģźµø┤ÕżÜńÜäÕÅéµĢ░µł¢ĶĆģõĮ┐ńö©Ķć¬Õ«Üõ╣ēńÜä `CustomDistributedDataParallel`’╝īõĮĀÕÅ»õ╗źĶ«ŠńĮ« `model_wrapper_cfg`ŃĆé
+
+### ÕŠĆ MMDistributedDataParallel õ╝ĀÕģźµø┤ÕżÜńÜäÕÅéµĢ░
+
+õŠŗÕ”éĶ«ŠńĮ« `find_unused_parameters` õĖ║ `True`’╝Ü
+
+```python
+cfg = dict(
+ model_wrapper_cfg=dict(
+ type='MMDistributedDataParallel', find_unused_parameters=True)
+)
+runner = Runner(
+ model=ResNet18(),
+ work_dir='./work_dir',
+ train_dataloader=train_dataloader_cfg,
+ optim_wrapper=dict(optimizer=dict(type='SGD', lr=0.001, momentum=0.9)),
+ train_cfg=dict(by_epoch=True, max_epochs=3),
+ cfg=cfg,
+)
+runner.train()
+```
+
+### õĮ┐ńö©Ķć¬Õ«Üõ╣ēńÜä CustomDistributedDataParallel
+
+```python
+from mmengine.registry import MODEL_WRAPPERS
+
+@MODEL_WRAPPERS.register_module()
+class CustomDistributedDataParallel(DistributedDataParallel):
+ pass
+
+
+cfg = dict(model_wrapper_cfg=dict(type='CustomDistributedDataParallel'))
+runner = Runner(
+ model=ResNet18(),
+ work_dir='./work_dir',
+ train_dataloader=train_dataloader_cfg,
+ optim_wrapper=dict(optimizer=dict(type='SGD', lr=0.001, momentum=0.9)),
+ train_cfg=dict(by_epoch=True, max_epochs=3),
+ cfg=cfg,
+)
+runner.train()
+```
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/epoch_to_iter.md b/internlm_langchain/knowledge_base/MMEngine/content/epoch_to_iter.md
new file mode 100644
index 00000000..5f844b3f
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/epoch_to_iter.md
@@ -0,0 +1,342 @@
+# õ╗Ä EpochBased ÕłćµŹóĶć│ IterBased
+
+MMEngine µö»µīüõĖżń¦ŹĶ«Łń╗āµ©ĪÕ╝Å’╝īÕ¤║õ║ÄĶĮ«µ¼ĪńÜä EpochBased µ¢╣Õ╝ÅÕÆīÕ¤║õ║ÄĶ┐Łõ╗Żµ¼ĪµĢ░ńÜä IterBased µ¢╣Õ╝Å’╝īĶ┐ÖõĖżń¦Źµ¢╣Õ╝ÅÕ£©õĖŗµĖĖń«Śµ│ĢÕ║ōÕØćµ£ēõĮ┐ńö©’╝īõŠŗÕ”é [MMDetection](https://github.com/open-mmlab/mmdetection) ķ╗śĶ«żõĮ┐ńö© EpochBased µ¢╣Õ╝Å’╝ī[MMSegmentation](https://github.com/open-mmlab/mmsegmentation) ķ╗śĶ«żõĮ┐ńö© IterBased µ¢╣Õ╝ÅŃĆé
+
+MMEngine ÕŠłÕżÜµ©ĪÕØŚķ╗śĶ«żõ╗ź EpochBased ńÜ䵩ĪÕ╝ŵē¦ĶĪī’╝īõŠŗÕ”é `ParamScheduler`, `LoggerHook`, `CheckpointHook` ńŁē’╝īÕĖĖĶ¦üńÜä EpochBased ķģŹńĮ«ÕåÖµ│ĢÕ”éõĖŗ’╝Ü
+
+```python
+param_scheduler = dict(
+ type='MultiStepLR',
+ milestones=[6, 8]
+ by_epoch=True # by_epoch ķ╗śĶ«żõĖ║ True’╝īĶ┐ÖĶŠ╣µśŠÕ╝ÅńÜäÕåÖÕć║µØźÕŬµś»õĖ║õ║åµ¢╣õŠ┐Õ»╣µ»ö
+)
+
+default_hooks = dict(
+ logger=dict(type='LoggerHook'),
+ checkpoint=dict(type='CheckpointHook', interval=2),
+)
+
+train_cfg = dict(
+ by_epoch=True, # by_epoch ķ╗śĶ«żõĖ║ True’╝īĶ┐ÖĶŠ╣µśŠÕ╝ÅńÜäÕåÖÕć║µØźÕŬµś»õĖ║õ║åµ¢╣õŠ┐Õ»╣µ»ö
+ max_epochs=10,
+ val_interval=2
+)
+
+log_processor = dict(
+ by_epoch=True
+) # log_processor ńÜä by_epoch ķ╗śĶ«żõĖ║ True’╝īĶ┐ÖĶŠ╣µśŠÕ╝ÅńÜäÕåÖÕć║µØźÕŬµś»õĖ║õ║åµ¢╣õŠ┐Õ»╣µ»ö’╝ī Õ«×ķÖģõĖŖõĖŹķ£ĆĶ”üĶ«ŠńĮ«
+
+runner = Runner(
+ model=ResNet18(),
+ work_dir='./work_dir',
+ train_dataloader=train_dataloader_cfg,
+ optim_wrapper=dict(optimizer=dict(type='SGD', lr=0.001, momentum=0.9)),
+ param_scheduler=param_scheduler
+ default_hooks=default_hooks,
+ log_processor=log_processor,
+ train_cfg=train_cfg,
+ resume=True,
+)
+```
+
+Õ”éµ×£µā│µīēńģ¦ iter Ķ«Łń╗āµ©ĪÕ×ŗ’╝īķ£ĆĶ”üÕüÜõ╗źõĖŗµö╣ÕŖ©’╝Ü
+
+1. Õ░å `train_cfg` õĖŁńÜä `by_epoch` Ķ«ŠńĮ«õĖ║ `False`’╝īÕÉīµŚČÕ░å `max_iters` Ķ«ŠńĮ«õĖ║Ķ«Łń╗āńÜäµĆ╗ iter µĢ░’╝ī`val_iterval` Ķ«ŠńĮ«õĖ║ķ¬īĶ»üķŚ┤ķÜöńÜä iter µĢ░ŃĆé
+
+ ```python
+ train_cfg = dict(
+ by_epoch=False,
+ max_iters=10000,
+ val_interval=2000
+ )
+ ```
+
+2. Õ░å `default_hooks` õĖŁńÜä `logger` ńÜä `log_metric_by_epoch` Ķ«ŠńĮ«õĖ║ False’╝ī `checkpoint` ńÜä `by_epoch` Ķ«ŠńĮ«õĖ║ `False`ŃĆé
+
+ ```python
+ default_hooks = dict(
+ logger=dict(type='LoggerHook', log_metric_by_epoch=False),
+ checkpoint=dict(type='CheckpointHook', by_epoch=False, interval=2000),
+ )
+ ```
+
+3. Õ░å `param_scheduler` õĖŁńÜä `by_epoch` Ķ«ŠńĮ«õĖ║ `False`’╝īÕ╣ČÕ░ć `epoch` ńøĖÕģ│ńÜäÕÅéµĢ░µŹóń«ŚµłÉ `iter`
+
+ ```python
+ param_scheduler = dict(
+ type='MultiStepLR',
+ milestones=[6000, 8000],
+ by_epoch=False,
+ )
+ ```
+
+ ķÖżõ║åĶ┐Öń¦Źµ¢╣Õ╝Å’╝īÕ”éµ×£õĮĀĶāĮõ┐ØĶ»ü IterBasedTraining ÕÆī EpochBasedTraining µĆ╗ iter µĢ░õĖĆĶć┤’╝īńø┤µÄźĶ«ŠńĮ« `convert_to_iter_based` õĖ║ `True` ÕŹ│ÕÅ»ŃĆé
+
+ ```python
+ param_scheduler = dict(
+ type='MultiStepLR',
+ milestones=[6, 8]
+ convert_to_iter_based=True
+ )
+ ```
+
+4. Õ░å `log_processor` ńÜä `by_epoch` Ķ«ŠńĮ«õĖ║ `False`ŃĆé
+
+ ```python
+ log_processor = dict(
+ by_epoch=False
+ )
+ ```
+
+õ╗ź [15 ÕłåķƤµĢÖń©ŗĶ«Łń╗ā CIFAR10 µĢ░µŹ«ķøå](../get_started/15_minutes.md)õĖ║õŠŗ’╝Ü
+
+
+| Step | +Training by epoch | +Training by iteration | +
|---|---|---|
| Build model | +
+
+```python
+import torch.nn.functional as F
+import torchvision
+from mmengine.model import BaseModel
+
+
+class MMResNet50(BaseModel):
+ def __init__(self):
+ super().__init__()
+ self.resnet = torchvision.models.resnet50()
+
+ def forward(self, imgs, labels, mode):
+ x = self.resnet(imgs)
+ if mode == 'loss':
+ return {'loss': F.cross_entropy(x, labels)}
+ elif mode == 'predict':
+ return x, labels
+```
+
+ |
+
+|
| Build dataloader | + ++ +```python +import torchvision.transforms as transforms +from torch.utils.data import DataLoader + +norm_cfg = dict(mean=[0.491, 0.482, 0.447], std=[0.202, 0.199, 0.201]) +train_dataloader = DataLoader( + batch_size=32, + shuffle=True, + dataset=torchvision.datasets.CIFAR10( + 'data/cifar10', + train=True, + download=True, + transform=transforms.Compose([ + transforms.RandomCrop(32, padding=4), + transforms.RandomHorizontalFlip(), + transforms.ToTensor(), + transforms.Normalize(**norm_cfg)]))) + +val_dataloader = DataLoader( + batch_size=32, + shuffle=False, + dataset=torchvision.datasets.CIFAR10( + 'data/cifar10', + train=False, + download=True, + transform=transforms.Compose([ + transforms.ToTensor(), + transforms.Normalize(**norm_cfg)]))) +``` + + | +|
| Prepare metric | ++ +```python +from mmengine.evaluator import BaseMetric + +class Accuracy(BaseMetric): + def process(self, data_batch, data_samples): + score, gt = data_samples + # save the middle result of a batch to `self.results` + self.results.append({ + 'batch_size': len(gt), + 'correct': (score.argmax(dim=1) == gt).sum().cpu(), + }) + + def compute_metrics(self, results): + total_correct = sum(item['correct'] for item in results) + total_size = sum(item['batch_size'] for item in results) + # return the dict containing the eval results + # the key is the name of the metric name + return dict(accuracy=100 * total_correct / total_size) +``` + + | +|
| Configure default hooks | +
+
+
+```python
+default_hooks = dict(
+ logger=dict(type='LoggerHook', log_metric_by_epoch=True),
+ checkpoint=dict(type='CheckpointHook', interval=2, by_epoch=True),
+)
+```
+
+
+ |
+
+
+
+
+```python
+default_hooks = dict(
+ logger=dict(type='LoggerHook', log_metric_by_epoch=False),
+ checkpoint=dict(type='CheckpointHook', by_epoch=False, interval=2000),
+)
+```
+
+
+ |
+
| Configure parameter scheduler | +
+
+
+```python
+param_scheduler = dict(
+ type='MultiStepLR',
+ milestones=[6, 8],
+ by_epoch=True,
+)
+```
+
+
+ |
+
+
+
+
+```python
+param_scheduler = dict(
+ type='MultiStepLR',
+ milestones=[6000, 8000],
+ by_epoch=False,
+)
+```
+
+
+ |
+
| Configure log_processor | +
+
+
+```python
+# The default configuration of log_processor is used for epoch based training.
+# Defining it here additionally is for building runner with the same way.
+log_processor = dict(by_epoch=True)
+```
+
+
+ |
+
+
+
+
+```python
+log_processor = dict(by_epoch=False)
+```
+
+
+ |
+
| Configure train_cfg | +
+
+
+```python
+train_cfg = dict(
+ by_epoch=True,
+ max_epochs=10,
+ val_interval=2
+)
+```
+
+
+ |
+
+
+
+
+```python
+train_cfg = dict(
+ by_epoch=False,
+ max_iters=10000,
+ val_interval=2000
+)
+```
+
+
+ |
+
| Build Runner | ++ +```python +from torch.optim import SGD +from mmengine.runner import Runner +runner = Runner( + model=MMResNet50(), + work_dir='./work_dir', + train_dataloader=train_dataloader, + optim_wrapper=dict(optimizer=dict(type=SGD, lr=0.001, momentum=0.9)), + train_cfg=train_cfg, + log_processor=log_processor, + default_hooks=default_hooks, + val_dataloader=val_dataloader, + val_cfg=dict(), + val_evaluator=dict(type=Accuracy), +) +runner.train() +``` + + | +|
+ 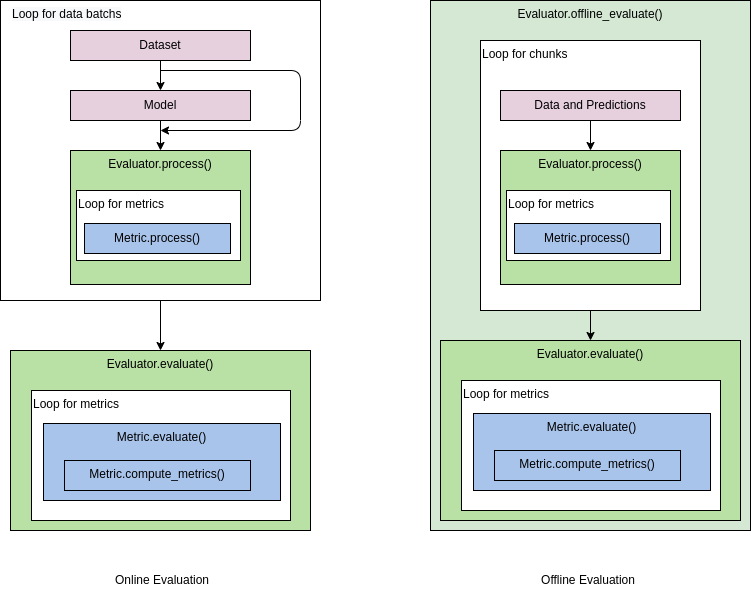 +
+
+
+## Õó×ÕŖĀĶć¬Õ«Üõ╣ēĶ»äµĄŗµīćµĀć
+
+Õ£© OpenMMLab ńÜäÕÉäõĖ¬ń«Śµ│ĢÕ║ōõĖŁ’╝īÕĘ▓ń╗ÅÕ«×ńÄ░õ║åÕ»╣Õ║öµ¢╣ÕÉæńÜäÕĖĖńö©Ķ»äµĄŗµīćµĀćŃĆéÕ”é MMDetection õĖŁµÅÉõŠøõ║å COCO Ķ»äµĄŗµīćµĀć’╝īMMPretrain õĖŁµÅÉõŠøõ║å AccuracyŃĆüF1Score ńŁēĶ»äµĄŗµīćµĀćńŁēŃĆé
+
+ńö©µłĘõ╣¤ÕÅ»õ╗źÕó×ÕŖĀĶć¬Õ«Üõ╣ēńÜäĶ»äµĄŗµīćµĀćŃĆéÕģĘõĮōµ¢╣µ│ĢÕÅ»õ╗źÕÅéĶĆā[µĢÖń©ŗµ¢ćµĪŻ](../tutorials/evaluation.md#Ķć¬Õ«Üõ╣ēĶ»äµĄŗµīćµĀć)õĖŁń╗ÖÕć║ńÜäńż║õŠŗŃĆé
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/fileio.md b/internlm_langchain/knowledge_base/MMEngine/content/fileio.md
new file mode 100644
index 00000000..10a58734
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/fileio.md
@@ -0,0 +1,213 @@
+# µ¢ćõ╗ČĶ»╗ÕåÖ
+
+`MMEngine` Õ£© `fileio` µ©ĪÕØŚõĖŁÕ«×ńÄ░õ║åõĖĆÕźŚń╗¤õĖĆńÜäµ¢ćõ╗ČĶ»╗ÕåֵğÕÅŻŃĆéķĆÜĶ┐ć `fileio` µ©ĪÕØŚ’╝īµłæõ╗¼ÕÅ»õ╗źńö©ÕÉīõĖĆõĖ¬ÕćĮµĢ░µØźÕżäńÉåõĖŹÕÉīńÜäµ¢ćõ╗ȵĀ╝Õ╝Å’╝īÕ”é `json`ŃĆü`yaml` ÕÆī `pickle`’╝īÕ╣ČõĖöÕÅ»õ╗źµ¢╣õŠ┐Õ£░µŗōÕ▒ĢÕģČÕ«āńÜäµ¢ćõ╗ȵĀ╝Õ╝ÅŃĆé
+
+`fileio` µ©ĪÕØŚõ╣¤µö»µīüõ╗ÄÕżÜń¦Źµ¢ćõ╗ČÕŁśÕé©ÕÉÄń½»Ķ»╗ÕåÖµ¢ćõ╗Č’╝īÕīģµŗ¼µ£¼Õ£░ńŻüńøśŃĆüPetrel’╝łÕåģķā©õĮ┐ńö©’╝ēŃĆüMemcachedŃĆüLMDB ÕÆī HTTPŃĆé
+
+## Ķ»╗ÕÅ¢ÕÆīõ┐ØÕŁśµĢ░µŹ«
+
+`MMEngine` õĖ║Ķ»╗ÕÅ¢ÕÆīõ┐ØÕŁśµĢ░µŹ«µÅÉõŠøõ║åń╗¤õĖĆńÜä API µÄźÕÅŻ’╝īńø«ÕēŹµö»µīüńÜäµĀ╝Õ╝ŵ£ē `json`ŃĆü`yaml` ÕÆī `pickle`ŃĆé
+
+### õ╗ÄńĪ¼ńøśõĖŁĶ»╗ÕåÖµ¢ćõ╗Č
+
+```python
+from mmengine import load, dump
+
+# õ╗ĵ¢ćõ╗ČõĖŁĶ»╗ÕÅ¢µĢ░µŹ«
+data = load('test.json')
+data = load('test.yaml')
+data = load('test.pkl')
+# õ╗ĵ¢ćõ╗ČÕ»╣Ķ▒ĪõĖŁĶ»╗ÕÅ¢µĢ░µŹ«
+with open('test.json', 'r') as f:
+ data = load(f, file_format='json')
+
+# Õ░åµĢ░µŹ«Õ║ÅÕłŚÕī¢õĖ║ÕŁŚń¼”õĖ▓
+json_str = dump(data, file_format='json')
+
+# Õ░åµĢ░µŹ«õ┐ØÕŁśĶć│µ¢ćõ╗Č (µĀ╣µŹ«µ¢ćõ╗ČÕÉŹÕÉÄń╝ĆÕÅŹµÄ©µ¢ćõ╗Čń▒╗Õ×ŗ)
+dump(data, 'out.pkl')
+
+# Õ░åµĢ░µŹ«õ┐ØÕŁśĶć│µ¢ćõ╗ČÕ»╣Ķ▒Ī
+with open('test.yaml', 'w') as f:
+ data = dump(data, f, file_format='yaml')
+```
+
+### õ╗ÄÕģČÕ«āµ¢ćõ╗ČÕŁśÕé©ÕÉÄń½»Ķ»╗ÕåÖµ¢ćõ╗Č
+
+```python
+from mmengine import load, dump
+
+# õ╗Ä s3 µ¢ćõ╗ČõĖŁĶ»╗ÕÅ¢µĢ░µŹ«
+data = load('s3://bucket-name/test.json')
+data = load('s3://bucket-name/test.yaml')
+data = load('s3://bucket-name/test.pkl')
+
+# Õ░åµĢ░µŹ«õ┐ØÕŁśĶć│ s3 µ¢ćõ╗Č’╝łµĀ╣µŹ«µ¢ćõ╗ČÕÉŹÕÉÄń╝ĆÕÅŹµÄ©µ¢ćõ╗Čń▒╗Õ×ŗ’╝ē
+dump(data, 's3://bucket-name/out.pkl')
+```
+
+µŗōÕ▒Ģ API õ╗źµö»µīüµø┤ÕżÜńÜäµ¢ćõ╗ȵĀ╝Õ╝ŵś»ÕŠłµ¢╣õŠ┐ńÜäŃĆéõĮĀµēĆķ£ĆĶ”üÕüÜńÜ䵜»ÕåÖõĖĆõĖ¬ń╗¦µē┐Ķć¬ `BaseFileHandler` ńÜäµ¢ćõ╗ČÕÅźµ¤ä’╝īÕ╣ČõĮ┐ńö©õĖĆõĖ¬µł¢ĶĆģÕżÜõĖ¬µ¢ćõ╗ȵĀ╝Õ╝ÅµØźµ│©ÕåīÕ«āŃĆé
+
+```python
+from mmengine import register_handler, BaseFileHandler
+
+# õĖ║õ║åµ│©ÕåīÕżÜõĖ¬µ¢ćõ╗ȵĀ╝Õ╝Å’╝īÕÅ»õ╗źõĮ┐ńö©ÕłŚĶĪ©õĮ£õĖ║ÕÅéµĢ░ŃĆé
+# @register_handler(['txt', 'log'])
+@register_handler('txt')
+class TxtHandler1(BaseFileHandler):
+
+ def load_from_fileobj(self, file):
+ return file.read()
+
+ def dump_to_fileobj(self, obj, file):
+ file.write(str(obj))
+
+ def dump_to_str(self, obj, **kwargs):
+ return str(obj)
+```
+
+õ╗ź `PickleHandler` õĖ║õŠŗ’╝Ü
+
+```python
+from mmengine import BaseFileHandler
+import pickle
+
+class PickleHandler(BaseFileHandler):
+
+ def load_from_fileobj(self, file, **kwargs):
+ return pickle.load(file, **kwargs)
+
+ def load_from_path(self, filepath, **kwargs):
+ return super(PickleHandler, self).load_from_path(
+ filepath, mode='rb', **kwargs)
+
+ def dump_to_str(self, obj, **kwargs):
+ kwargs.setdefault('protocol', 2)
+ return pickle.dumps(obj, **kwargs)
+
+ def dump_to_fileobj(self, obj, file, **kwargs):
+ kwargs.setdefault('protocol', 2)
+ pickle.dump(obj, file, **kwargs)
+
+ def dump_to_path(self, obj, filepath, **kwargs):
+ super(PickleHandler, self).dump_to_path(
+ obj, filepath, mode='wb', **kwargs)
+```
+
+## Ķ»╗ÕÅ¢µ¢ćõ╗ČÕ╣ČĶ┐öÕø×ÕłŚĶĪ©µł¢ÕŁŚÕģĖ
+
+õŠŗÕ”é’╝ī`a.txt` µś»µ¢ćµ£¼µ¢ćõ╗Č’╝īõĖĆÕģ▒µ£ē 5 ĶĪīÕåģÕ«╣ŃĆé
+
+```
+a
+b
+c
+d
+e
+```
+
+### õ╗ÄńĪ¼ńøśĶ»╗ÕÅ¢
+
+õĮ┐ńö© `list_from_file` õ╗Ä `a.txt` õĖŁĶ»╗ÕÅ¢ÕłŚĶĪ©’╝Ü
+
+```python
+from mmengine import list_from_file
+
+print(list_from_file('a.txt'))
+# ['a', 'b', 'c', 'd', 'e']
+print(list_from_file('a.txt', offset=2))
+# ['c', 'd', 'e']
+print(list_from_file('a.txt', max_num=2))
+# ['a', 'b']
+print(list_from_file('a.txt', prefix='/mnt/'))
+# ['/mnt/a', '/mnt/b', '/mnt/c', '/mnt/d', '/mnt/e']
+```
+
+õŠŗÕ”é’╝ī`b.txt` µś»µ¢ćµ£¼µ¢ćõ╗Č’╝īõĖĆÕģ▒µ£ē 3 ĶĪīÕåģÕ«╣ŃĆé
+
+```
+1 cat
+2 dog cow
+3 panda
+```
+
+õĮ┐ńö© `dict_from_file` õ╗Ä `b.txt` õĖŁĶ»╗ÕÅ¢ÕŁŚÕģĖ’╝Ü
+
+```python
+from mmengine import dict_from_file
+
+print(dict_from_file('b.txt'))
+# {'1': 'cat', '2': ['dog', 'cow'], '3': 'panda'}
+print(dict_from_file('b.txt', key_type=int))
+# {1: 'cat', 2: ['dog', 'cow'], 3: 'panda'}
+```
+
+### õ╗ÄÕģČõ╗¢ÕŁśÕé©ÕÉÄń½»Ķ»╗ÕÅ¢
+
+õĮ┐ńö© `list_from_file` õ╗Ä `s3://bucket-name/a.txt` õĖŁĶ»╗ÕÅ¢ÕłŚĶĪ©’╝Ü
+
+```python
+from mmengine import list_from_file
+
+print(list_from_file('s3://bucket-name/a.txt'))
+# ['a', 'b', 'c', 'd', 'e']
+print(list_from_file('s3://bucket-name/a.txt', offset=2))
+# ['c', 'd', 'e']
+print(list_from_file('s3://bucket-name/a.txt', max_num=2))
+# ['a', 'b']
+print(list_from_file('s3://bucket-name/a.txt', prefix='/mnt/'))
+# ['/mnt/a', '/mnt/b', '/mnt/c', '/mnt/d', '/mnt/e']
+```
+
+õĮ┐ńö© `dict_from_file` õ╗Ä `s3://bucket-name/b.txt` õĖŁĶ»╗ÕÅ¢ÕŁŚÕģĖ’╝Ü
+
+```python
+from mmengine import dict_from_file
+
+print(dict_from_file('s3://bucket-name/b.txt'))
+# {'1': 'cat', '2': ['dog', 'cow'], '3': 'panda'}
+print(dict_from_file('s3://bucket-name/b.txt', key_type=int))
+# {1: 'cat', 2: ['dog', 'cow'], 3: 'panda'}
+```
+
+## Ķ»╗ÕÅ¢ÕÆīõ┐ØÕŁśµØāķ揵¢ćõ╗Č
+
+ķĆÜÕĖĖµāģÕåĄõĖŗ’╝īµłæõ╗¼ÕÅ»õ╗źķĆÜĶ┐ćõĖŗķØóńÜäµ¢╣Õ╝Åõ╗ÄńŻüńøśµł¢ńĮæń╗£Ķ┐£ń½»Ķ»╗ÕÅ¢µØāķ揵¢ćõ╗Č’╝Ü
+
+```python
+import torch
+
+filepath1 = '/path/of/your/checkpoint1.pth'
+filepath2 = 'http://path/of/your/checkpoint3.pth'
+
+# õ╗ĵ£¼Õ£░ńŻüńøśĶ»╗ÕÅ¢µØāķ揵¢ćõ╗Č
+checkpoint = torch.load(filepath1)
+# õ┐ØÕŁśµØāķ揵¢ćõ╗ČÕł░µ£¼Õ£░ńŻüńøś
+torch.save(checkpoint, filepath1)
+
+# õ╗ÄńĮæń╗£Ķ┐£ń½»Ķ»╗ÕÅ¢µØāķ揵¢ćõ╗Č
+checkpoint = torch.utils.model_zoo.load_url(filepath2)
+```
+
+Õ£© `MMEngine` õĖŁ’╝īÕ£©õĖŹÕÉīÕŁśÕ驵Ā╝Õ╝ÅõĖŁĶ»╗ÕÅ¢µØāķ揵¢ćõ╗ČÕÅ»õ╗źķĆÜĶ┐ć `load_checkpoint` ÕÆī `save_checkpoint` µØźń╗¤õĖĆÕ«×ńÄ░’╝Ü
+
+```python
+from mmengine import load_checkpoint, save_checkpoint
+
+filepath1 = '/path/of/your/checkpoint1.pth'
+filepath2 = 's3://bucket-name/path/of/your/checkpoint1.pth'
+filepath3 = 'http://path/of/your/checkpoint3.pth'
+
+# õ╗ĵ£¼Õ£░ńŻüńøśĶ»╗ÕÅ¢µØāķ揵¢ćõ╗Č
+checkpoint = load_checkpoint(filepath1)
+# õ┐ØÕŁśµØāķ揵¢ćõ╗ČÕł░µ£¼Õ£░ńŻüńøś
+save_checkpoint(checkpoint, filepath1)
+
+# õ╗Ä s3 Ķ»╗ÕÅ¢µØāķ揵¢ćõ╗Č
+checkpoint = load_checkpoint(filepath2)
+# õ┐ØÕŁśµØāķ揵¢ćõ╗ČÕł░ s3
+save_checkpoint(checkpoint, filepath2)
+
+# õ╗ÄńĮæń╗£Ķ┐£ń½»Ķ»╗ÕÅ¢µØāķ揵¢ćõ╗Č
+checkpoint = load_checkpoint(filepath3)
+```
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/hook.md b/internlm_langchain/knowledge_base/MMEngine/content/hook.md
new file mode 100644
index 00000000..98756b37
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/hook.md
@@ -0,0 +1,204 @@
+# ķÆ®ÕŁÉ
+
+ķÆ®ÕŁÉń╝¢ń©ŗµś»õĖĆń¦Źń╝¢ń©ŗµ©ĪÕ╝Å’╝īµś»µīćÕ£©ń©ŗÕ║ÅńÜäõĖĆõĖ¬µł¢ĶĆģÕżÜõĖ¬õĮŹńĮ«Ķ«ŠńĮ«õĮŹńé╣’╝łµīéĶĮĮńé╣’╝ē’╝īÕĮōń©ŗÕ║ÅĶ┐ÉĶĪīĶć│µ¤ÉõĖ¬õĮŹńé╣µŚČ’╝īõ╝ÜĶć¬ÕŖ©Ķ░āńö©Ķ┐ÉĶĪīµŚČµ│©ÕåīÕł░õĮŹńé╣ńÜäµēƵ£ēµ¢╣µ│ĢŃĆéķÆ®ÕŁÉń╝¢ń©ŗÕÅ»õ╗źµÅÉķ½śń©ŗÕ║ÅńÜäńüĄµ┤╗µĆ¦ÕÆīµŗōÕ▒ĢµĆ¦’╝īńö©µłĘÕ░åĶć¬Õ«Üõ╣ēńÜäµ¢╣µ│Ģµ│©ÕåīÕł░õĮŹńé╣õŠ┐ÕÅ»Ķó½Ķ░āńö©ĶĆīµŚĀķ£Ćõ┐«µö╣ń©ŗÕ║ÅõĖŁńÜäõ╗ŻńĀüŃĆé
+
+## ķÆ®ÕŁÉńż║õŠŗ
+
+õĖŗķØ󵜻ķÆ®ÕŁÉńÜäń«ĆÕŹĢńż║õŠŗŃĆé
+
+```python
+pre_hooks = [(print, 'hello')]
+post_hooks = [(print, 'goodbye')]
+
+def main():
+ for func, arg in pre_hooks:
+ func(arg)
+ print('do something here')
+ for func, arg in post_hooks:
+ func(arg)
+
+main()
+```
+
+õĖŗķØ󵜻ń©ŗÕ║ÅńÜäĶŠōÕć║’╝Ü
+
+```
+hello
+do something here
+goodbye
+```
+
+ÕÅ»õ╗źń£ŗÕł░’╝ī`main` ÕćĮµĢ░Õ£©õĖżõĖ¬õĮŹńĮ«Ķ░āńö©ķÆ®ÕŁÉõĖŁńÜäÕćĮµĢ░ĶĆīµŚĀķ£ĆÕüÜõ╗╗õĮĢµö╣ÕŖ©ŃĆé
+
+Õ£© PyTorch õĖŁ’╝īķÆ®ÕŁÉńÜäÕ║öńö©õ╣¤ķÜÅÕżäÕÅ»Ķ¦ü’╝īõŠŗÕ”éńź×ń╗ÅńĮæń╗£µ©ĪÕØŚ’╝łnn.Module’╝ēõĖŁńÜäķÆ®ÕŁÉÕÅ»õ╗źĶÄĘÕŠŚµ©ĪÕØŚńÜäÕēŹÕÉæĶŠōÕģźĶŠōÕć║õ╗źÕÅŖÕÅŹÕÉæńÜäĶŠōÕģźĶŠōÕć║ŃĆéõ╗ź [`register_forward_hook`](https://pytorch.org/docs/stable/generated/torch.nn.Module.html#torch.nn.Module.register_forward_hook) µ¢╣µ│ĢõĖ║õŠŗ’╝īĶ»źµ¢╣µ│ĢÕŠĆµ©ĪÕØŚµ│©ÕåīõĖĆõĖ¬ÕēŹÕÉæķÆ®ÕŁÉ’╝īķÆ®ÕŁÉÕÅ»õ╗źĶÄĘÕŠŚµ©ĪÕØŚńÜäÕēŹÕÉæĶŠōÕģźÕÆīĶŠōÕć║ŃĆé
+
+õĖŗķØ󵜻 `register_forward_hook` ńö©µ│ĢńÜäń«ĆÕŹĢńż║õŠŗ’╝Ü
+
+```python
+import torch
+import torch.nn as nn
+
+def forward_hook_fn(
+ module, # Ķó½µ│©ÕåīķÆ®ÕŁÉńÜäÕ»╣Ķ▒Ī
+ input, # module ÕēŹÕÉæĶ«Īń«ŚńÜäĶŠōÕģź
+ output, # module ÕēŹÕÉæĶ«Īń«ŚńÜäĶŠōÕć║
+):
+ print(f'"forward_hook_fn" is invoked by {module.name}')
+ print('weight:', module.weight.data)
+ print('bias:', module.bias.data)
+ print('input:', input)
+ print('output:', output)
+
+class Model(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.fc = nn.Linear(3, 1)
+
+ def forward(self, x):
+ y = self.fc(x)
+ return y
+
+model = Model()
+# Õ░å forward_hook_fn µ│©ÕåīÕł░ model µ»ÅõĖ¬ÕŁÉµ©ĪÕØŚ
+for module in model.children():
+ module.register_forward_hook(forward_hook_fn)
+
+x = torch.Tensor([[0.0, 1.0, 2.0]])
+y = model(x)
+```
+
+õĖŗķØ󵜻ń©ŗÕ║ÅńÜäĶŠōÕć║’╝Ü
+
+```python
+"forward_hook_fn" is invoked by Linear(in_features=3, out_features=1, bias=True)
+weight: tensor([[-0.4077, 0.0119, -0.3606]])
+bias: tensor([-0.2943])
+input: (tensor([[0., 1., 2.]]),)
+output: tensor([[-1.0036]], grad_fn=
+| Initializer | +Registered name | +Function | +
|---|---|---|
| ConstantInit | +Constant | +Õ░å weight ÕÆī bias ÕłØÕ¦ŗÕī¢õĖ║µīćÕ«ÜÕĖĖķćÅ’╝īķĆÜÕĖĖńö©õ║ÄÕłØÕ¦ŗÕī¢ÕŹĘń¦» | +
| XavierInit | +Xavier | +Õ░å weight Xavier µ¢╣Õ╝ÅÕłØÕ¦ŗÕī¢’╝īÕ░å bias ÕłØÕ¦ŗÕī¢µłÉµīćÕ«ÜÕĖĖķćÅ’╝īķĆÜÕĖĖńö©õ║ÄÕłØÕ¦ŗÕī¢ÕŹĘń¦» | +
| NormalInit | +Normal | +Õ░å weight õ╗źµŁŻµĆüÕłåÕĖāńÜäµ¢╣Õ╝ÅÕłØÕ¦ŗÕī¢’╝īÕ░å bias ÕłØÕ¦ŗÕī¢µłÉµīćÕ«ÜÕĖĖķćÅ’╝īķĆÜÕĖĖńö©õ║ÄÕłØÕ¦ŗÕī¢ÕŹĘń¦» | +
| TruncNormalInit | +TruncNormal | +Õ░å weight õ╗źĶó½µł¬µ¢ŁńÜ䵣ŻµĆüÕłåÕĖāńÜäµ¢╣Õ╝ÅÕłØÕ¦ŗÕī¢’╝īÕÅéµĢ░ a ÕÆī b õĖ║µŁŻµĆüÕłåÕĖāńÜäµ£ēµĢłÕī║Õ¤¤’╝øÕ░å bias ÕłØÕ¦ŗÕī¢µłÉµīćÕ«ÜÕĖĖķćÅ’╝īķĆÜÕĖĖńö©õ║ÄÕłØÕ¦ŗÕī¢ Transformer | +
| UniformInit | +Uniform | +Õ░å weight õ╗źÕØćÕīĆÕłåÕĖāńÜäµ¢╣Õ╝ÅÕłØÕ¦ŗÕī¢’╝īÕÅéµĢ░ a ÕÆī b õĖ║ÕØćÕīĆÕłåÕĖāńÜäĶīāÕø┤’╝øÕ░å bias ÕłØÕ¦ŗÕī¢õĖ║µīćÕ«ÜÕĖĖķćÅ’╝īķĆÜÕĖĖńö©õ║ÄÕłØÕ¦ŗÕī¢ÕŹĘń¦» | +
| KaimingInit | +Kaiming | +Õ░å weight õ╗ź Kaiming ńÜäµ¢╣Õ╝ÅÕłØÕ¦ŗÕī¢’╝īÕ░å bias ÕłØÕ¦ŗÕī¢µłÉµīćÕ«ÜÕĖĖķćÅ’╝īķĆÜÕĖĖńö©õ║ÄÕłØÕ¦ŗÕī¢ÕŹĘń¦» | +
| Caffe2XavierInit | +Caffe2Xavier | +Caffe2 õĖŁ Xavier ÕłØÕ¦ŗÕī¢µ¢╣Õ╝Å’╝īÕ£© Pytorch õĖŁÕ»╣Õ║ö "fan_in", "normal" µ©ĪÕ╝ÅńÜä Kaiming ÕłØÕ¦ŗÕī¢’╝ī’╝īķĆÜÕĖĖńö©õ║ÄÕłØÕ¦ŗÕī¢ÕŹĘ | +
| Pretrained | +PretrainedInit | +ÕŖĀĶĮĮķóäĶ«Łń╗āµØāķćŹ | +
| ÕłØÕ¦ŗÕī¢ÕćĮµĢ░ | +ÕŖ¤ĶāĮ | +
|---|---|
| constant_init | +Õ░å weight ÕÆī bias ÕłØÕ¦ŗÕī¢õĖ║µīćÕ«ÜÕĖĖķćÅ’╝īķĆÜÕĖĖńö©õ║ÄÕłØÕ¦ŗÕī¢ÕŹĘń¦» | +
| xavier_init | +Õ░å weight õ╗ź Xavier µ¢╣Õ╝ÅÕłØÕ¦ŗÕī¢’╝īÕ░å bias ÕłØÕ¦ŗÕī¢µłÉµīćÕ«ÜÕĖĖķćÅ’╝īķĆÜÕĖĖńö©õ║ÄÕłØÕ¦ŗÕī¢ÕŹĘń¦» | +
| normal_init | +Õ░å weight õ╗źµŁŻµĆüÕłåÕĖāńÜäµ¢╣Õ╝ÅÕłØÕ¦ŗÕī¢’╝īÕ░å bias ÕłØÕ¦ŗÕī¢µłÉµīćÕ«ÜÕĖĖķćÅ’╝īķĆÜÕĖĖńö©õ║ÄÕłØÕ¦ŗÕī¢ÕŹĘń¦» | +
| trunc_normal_init | +Õ░å weight õ╗źĶó½µł¬µ¢ŁńÜ䵣ŻµĆüÕłåÕĖāńÜäµ¢╣Õ╝ÅÕłØÕ¦ŗÕī¢’╝īÕÅéµĢ░ a ÕÆī b õĖ║µŁŻµĆüÕłåÕĖāńÜäµ£ēµĢłÕī║Õ¤¤’╝øÕ░å bias ÕłØÕ¦ŗÕī¢µłÉµīćÕ«ÜÕĖĖķćÅ’╝īķĆÜÕĖĖńö©õ║ÄÕłØÕ¦ŗÕī¢ Transformer | +
| uniform_init | +Õ░å weight õ╗źÕØćÕīĆÕłåÕĖāńÜäµ¢╣Õ╝ÅÕłØÕ¦ŗÕī¢’╝īÕÅéµĢ░ a ÕÆī b õĖ║ÕØćÕīĆÕłåÕĖāńÜäĶīāÕø┤’╝øÕ░å bias ÕłØÕ¦ŗÕī¢õĖ║µīćÕ«ÜÕĖĖķćÅ’╝īķĆÜÕĖĖńö©õ║ÄÕłØÕ¦ŗÕī¢ÕŹĘń¦» | +
| kaiming_init | +Õ░å weight õ╗ź Kaiming µ¢╣Õ╝ÅÕłØÕ¦ŗÕī¢’╝īÕ░å bias ÕłØÕ¦ŗÕī¢µłÉµīćÕ«ÜÕĖĖķćÅ’╝īķĆÜÕĖĖńö©õ║ÄÕłØÕ¦ŗÕī¢ÕŹĘń¦» | +
| caffe2_xavier_init | +Caffe2 õĖŁ Xavier ÕłØÕ¦ŗÕī¢µ¢╣Õ╝Å’╝īÕ£© Pytorch õĖŁÕ»╣Õ║ö "fan_in", "normal" µ©ĪÕ╝ÅńÜä Kaiming ÕłØÕ¦ŗÕī¢’╝īķĆÜÕĖĖńö©õ║ÄÕłØÕ¦ŗÕī¢ÕŹĘń¦» | +
| bias_init_with_prob | +õ╗źµ”éńÄćÕĆ╝ńÜäÕĮóÕ╝ÅÕłØÕ¦ŗÕī¢ bias | +
+
+MMEngine Õ░åĶ«Łń╗āĶ┐ćń©ŗõĖŁµČēÕÅŖńÜäń╗äõ╗ČÕÆīÕ«āõ╗¼ńÜäÕģ│ń│╗Ķ┐øĶĪīõ║åµŖĮĶ▒Ī’╝īÕ”éõĖŖÕøŠµēĆńż║ŃĆéõĖŹÕÉīń«Śµ│ĢÕ║ōõĖŁńÜäÕÉīń▒╗Õ×ŗń╗äõ╗ČÕģʵ£ēńøĖÕÉīńÜäµÄźÕÅŻÕ«Üõ╣ēŃĆé
+
+### µĀĖÕ┐āµ©ĪÕØŚõĖÄńøĖÕģ│ń╗äõ╗Č
+
+Ķ«Łń╗āÕ╝ĢµōÄńÜäµĀĖÕ┐āµ©ĪÕØŚµś»[µē¦ĶĪīÕÖ©’╝łRunner’╝ē](../tutorials/runner.md)ŃĆéµē¦ĶĪīÕÖ©Ķ┤¤Ķ┤Żµē¦ĶĪīĶ«Łń╗āŃĆüµĄŗĶ»ĢÕÆīµÄ©ńÉåõ╗╗ÕŖĪÕ╣Čń«ĪńÉåĶ┐Öõ║øĶ┐ćń©ŗõĖŁµēĆķ£ĆĶ”üńÜäÕÉäõĖ¬ń╗äõ╗ČŃĆéÕ£©Ķ«Łń╗āŃĆüµĄŗĶ»ĢŃĆüµÄ©ńÉåõ╗╗ÕŖĪµē¦ĶĪīĶ┐ćń©ŗõĖŁńÜäńē╣Õ«ÜõĮŹńĮ«’╝īµē¦ĶĪīÕÖ©Ķ«ŠńĮ«õ║å[ķÆ®ÕŁÉ’╝łHook’╝ē](../tutorials/hook.md)µØźÕģüĶ«Ėńö©µłĘµŗōÕ▒ĢŃĆüµÅÆÕģźÕÆīµē¦ĶĪīĶć¬Õ«Üõ╣ēķĆ╗ĶŠæŃĆéµē¦ĶĪīÕÖ©õĖ╗Ķ”üĶ░āńö©Õ”éõĖŗń╗äõ╗ČµØźÕ«īµłÉĶ«Łń╗āÕÆīµÄ©ńÉåĶ┐ćń©ŗõĖŁńÜäÕŠ¬ńÄ»’╝Ü
+
+- [µĢ░µŹ«ķøå’╝łDataset’╝ē](../tutorials/dataset.md)’╝ÜĶ┤¤Ķ┤ŻÕ£©Ķ«Łń╗āŃĆüµĄŗĶ»ĢŃĆüµÄ©ńÉåõ╗╗ÕŖĪõĖŁµ×äÕ╗║µĢ░µŹ«ķøå’╝īÕ╣ČÕ░åµĢ░µŹ«ķĆüń╗Öµ©ĪÕ×ŗŃĆéÕ«×ķÖģõĮ┐ńö©Ķ┐ćń©ŗõĖŁõ╝ÜĶó½µĢ░µŹ«ÕŖĀĶĮĮÕÖ©’╝łDataLoader’╝ēÕ░üĶŻģõĖĆÕ▒é’╝īµĢ░µŹ«ÕŖĀĶĮĮÕÖ©õ╝ÜÕÉ»ÕŖ©ÕżÜõĖ¬ÕŁÉĶ┐øń©ŗµØźÕŖĀĶĮĮµĢ░µŹ«ŃĆé
+- [µ©ĪÕ×ŗ’╝łModel’╝ē](../tutorials/model.md)’╝ÜÕ£©Ķ«Łń╗āĶ┐ćń©ŗõĖŁµÄźÕÅŚµĢ░µŹ«Õ╣ČĶŠōÕć║ loss’╝øÕ£©µĄŗĶ»ĢŃĆüµÄ©ńÉåõ╗╗ÕŖĪõĖŁµÄźÕÅŚµĢ░µŹ«’╝īÕ╣ČĶ┐øĶĪīķó䵥ŗŃĆéÕłåÕĖāÕ╝ÅĶ«Łń╗āńŁēµāģÕåĄõĖŗõ╝ÜĶ󽵩ĪÕ×ŗńÜäÕ░üĶŻģÕÖ©’╝łModel Wrapper’╝īÕ”é `MMDistributedDataParallel`’╝ēÕ░üĶŻģõĖĆÕ▒éŃĆé
+- [õ╝śÕī¢ÕÖ©Õ░üĶŻģ’╝łOptimizer’╝ē](../tutorials/optim_wrapper.md)’╝Üõ╝śÕī¢ÕÖ©Õ░üĶŻģĶ┤¤Ķ┤ŻÕ£©Ķ«Łń╗āĶ┐ćń©ŗõĖŁµē¦ĶĪīÕÅŹÕÉæõ╝ĀµÆŁõ╝śÕī¢µ©ĪÕ×ŗ’╝īÕ╣ČõĖöõ╗źń╗¤õĖĆńÜäµÄźÕÅŻµö»µīüõ║åµĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗āÕÆīµó»Õ║”ń┤»ÕŖĀŃĆé
+- [ÕÅéµĢ░Ķ░āÕ║”ÕÖ©’╝łParameter Scheduler’╝ē](../tutorials/param_scheduler.md)’╝ÜĶ«Łń╗āĶ┐ćń©ŗõĖŁ’╝īÕ»╣ÕŁ”õ╣ĀńÄćŃĆüÕŖ©ķćÅńŁēõ╝śÕī¢ÕÖ©ĶČģÕÅéµĢ░Ķ┐øĶĪīÕŖ©µĆüĶ░āµĢ┤ŃĆé
+
+Õ£©Ķ«Łń╗āķŚ┤ķÜÖµł¢ĶĆģµĄŗĶ»ĢķśČµ«Ą’╝ī[Ķ»äµĄŗµīćµĀćõĖÄĶ»äµĄŗÕÖ©’╝łMetrics & Evaluator’╝ē](../tutorials/evaluation.md)õ╝ÜĶ┤¤Ķ┤ŻÕ»╣µ©ĪÕ×ŗµĆ¦ĶāĮĶ┐øĶĪīĶ»äµĄŗŃĆéÕģČõĖŁĶ»äµĄŗÕÖ©Ķ┤¤Ķ┤ŻÕ¤║õ║ĵĢ░µŹ«ķøåÕ»╣µ©ĪÕ×ŗńÜäķó䵥ŗĶ┐øĶĪīĶ»äõ╝░ŃĆéĶ»äµĄŗÕÖ©ÕåģĶ┐śµ£ēõĖĆÕ▒éµŖĮĶ▒Īµś»Ķ»äµĄŗµīćµĀć’╝īĶ┤¤Ķ┤ŻĶ«Īń«ŚÕģĘõĮōńÜäõĖĆõĖ¬µł¢ÕżÜõĖ¬Ķ»äµĄŗµīćµĀć’╝łÕ”éÕżÕø×ńÄćŃĆüµŁŻńĪ«ńÄćńŁē’╝ēŃĆé
+
+õĖ║õ║åń╗¤õĖƵğÕÅŻ’╝īOpenMMLab 2.0 õĖŁÕÉäõĖ¬ń«Śµ│ĢÕ║ōńÜäĶ»äµĄŗÕÖ©’╝īµ©ĪÕ×ŗÕÆīµĢ░µŹ«õ╣ŗķŚ┤õ║żµĄüńÜäµÄźÕÅŻķāĮõĮ┐ńö©õ║å[µĢ░µŹ«Õģāń┤Ā’╝łData Element’╝ē](../advanced_tutorials/data_element.md)µØźĶ┐øĶĪīÕ░üĶŻģŃĆé
+
+Õ£©Ķ«Łń╗āŃĆüµÄ©ńÉåµē¦ĶĪīĶ┐ćń©ŗõĖŁ’╝īõĖŖĶ┐░ÕÉäõĖ¬ń╗äõ╗ČķāĮÕÅ»õ╗źĶ░āńö©µŚźÕ┐Śń«ĪńÉ嵩ĪÕØŚÕÆīÕÅ»Ķ¦åÕī¢ÕÖ©Ķ┐øĶĪīń╗ōµ×äÕī¢ÕÆīķØ×ń╗ōµ×äÕī¢µŚźÕ┐ŚńÜäÕŁśÕé©õĖÄÕ▒Ģńż║ŃĆé[µŚźÕ┐Śń«ĪńÉå’╝łLogging Modules’╝ē](../advanced_tutorials/logging.md)’╝ÜĶ┤¤Ķ┤Żń«ĪńÉåµē¦ĶĪīÕÖ©Ķ┐ÉĶĪīĶ┐ćń©ŗõĖŁõ║¦ńö¤ńÜäÕÉäń¦ŹµŚźÕ┐Śõ┐Īµü»ŃĆéÕģČõĖŁµČłµü»µ×óń║Į’╝łMessageHub’╝ēĶ┤¤Ķ┤ŻÕ«×ńÄ░ń╗äõ╗ČõĖÄń╗äõ╗ČŃĆüµē¦ĶĪīÕÖ©õĖĵē¦ĶĪīÕÖ©õ╣ŗķŚ┤ńÜäµĢ░µŹ«Õģ▒õ║½’╝īµŚźÕ┐ŚÕżäńÉåÕÖ©’╝łLog Processor’╝ēĶ┤¤Ķ┤ŻÕ»╣µŚźÕ┐Śõ┐Īµü»Ķ┐øĶĪīÕżäńÉå’╝īÕżäńÉåÕÉÄńÜ䵌źÕ┐Śõ╝ÜÕłåÕł½ÕÅæķĆüń╗Öµē¦ĶĪīÕÖ©ńÜ䵌źÕ┐ŚÕÖ©’╝łLogger’╝ēÕÆīÕÅ»Ķ¦åÕī¢ÕÖ©’╝łVisualizer’╝ēĶ┐øĶĪīµŚźÕ┐ŚńÜäń«ĪńÉåõĖÄÕ▒Ģńż║ŃĆé[ÕÅ»Ķ¦åÕī¢ÕÖ©’╝łVisualizer’╝ē](../advanced_tutorials/visualization.md)’╝ÜÕÅ»Ķ¦åÕī¢ÕÖ©Ķ┤¤Ķ┤ŻÕ»╣µ©ĪÕ×ŗńÜäńē╣ÕŠüÕøŠŃĆüķó䵥ŗń╗ōµ×£ÕÆīĶ«Łń╗āĶ┐ćń©ŗõĖŁõ║¦ńö¤ńÜäń╗ōµ×äÕī¢µŚźÕ┐ŚĶ┐øĶĪīÕÅ»Ķ¦åÕī¢’╝īµö»µīü Tensorboard ÕÆī WanDB ńŁēÕżÜń¦ŹÕÅ»Ķ¦åÕī¢ÕÉÄń½»ŃĆé
+
+### Õģ¼Õģ▒Õ¤║ńĪƵ©ĪÕØŚ
+
+MMEngine õĖŁĶ┐śÕ«×ńÄ░õ║åÕÉäń¦Źń«Śµ│Ģµ©ĪÕ×ŗµē¦ĶĪīĶ┐ćń©ŗõĖŁķ£ĆĶ”üńö©Õł░ńÜäÕģ¼Õģ▒Õ¤║ńĪƵ©ĪÕØŚ’╝īÕīģµŗ¼
+
+- [ķģŹńĮ«ń▒╗’╝łConfig’╝ē](../advanced_tutorials/config.md)’╝ÜÕ£© OpenMMLab ń«Śµ│ĢÕ║ōõĖŁ’╝īńö©µłĘÕÅ»õ╗źķĆÜĶ┐ćń╝¢ÕåÖ config µØźķģŹńĮ«Ķ«Łń╗āŃĆüµĄŗĶ»ĢĶ┐ćń©ŗõ╗źÕÅŖńøĖÕģ│ńÜäń╗äõ╗ČŃĆé
+- [µ│©ÕåīÕÖ©’╝łRegistry’╝ē](../advanced_tutorials/registry.md)’╝ÜĶ┤¤Ķ┤Żń«ĪńÉåń«Śµ│ĢÕ║ōõĖŁÕģʵ£ēńøĖÕÉīÕŖ¤ĶāĮńÜ䵩ĪÕØŚŃĆéMMEngine µĀ╣µŹ«Õ»╣ń«Śµ│ĢÕ║ōµ©ĪÕØŚńÜäµŖĮĶ▒Ī’╝īÕ«Üõ╣ēõ║åõĖĆÕźŚµĀ╣µ│©ÕåīÕÖ©’╝īń«Śµ│ĢÕ║ōõĖŁńÜäµ│©ÕåīÕÖ©ÕÅ»õ╗źń╗¦µē┐Ķć¬Ķ┐ÖÕźŚµĀ╣µ│©ÕåīÕÖ©’╝īÕ«×ńÄ░µ©ĪÕØŚńÜäĶĘ©ń«Śµ│ĢÕ║ōĶ░āńö©ŃĆé
+- [µ¢ćõ╗ČĶ»╗ÕåÖ’╝łFile I/O’╝ē](../advanced_tutorials/fileio.md)’╝ÜõĖ║ÕÉäõĖ¬µ©ĪÕØŚńÜäµ¢ćõ╗ČĶ»╗ÕåÖµÅÉõŠøõ║åń╗¤õĖĆńÜäµÄźÕÅŻ’╝īõ╗źń╗¤õĖĆńÜäÕĮóÕ╝ŵö»µīüõ║åÕżÜń¦Źµ¢ćõ╗ČĶ»╗ÕåÖÕÉÄń½»ÕÆīÕżÜń¦Źµ¢ćõ╗ȵĀ╝Õ╝Å’╝īÕ╣ČÕģĘÕżćµē®Õ▒ĢµĆ¦ŃĆé
+- [ÕłåÕĖāÕ╝ÅķĆÜõ┐ĪÕĤĶ»Ł’╝łDistributed Communication Primitives’╝ē](../advanced_tutorials/distributed.md)’╝ÜĶ┤¤Ķ┤ŻÕ£©ń©ŗÕ║ÅÕłåÕĖāÕ╝ÅĶ┐ÉĶĪīĶ┐ćń©ŗõĖŁõĖŹÕÉīĶ┐øń©ŗķŚ┤ńÜäķĆÜõ┐ĪŃĆéĶ┐ÖÕźŚµÄźÕÅŻÕ▒ÅĶöĮõ║åÕłåÕĖāÕ╝ÅÕÆīķØ×ÕłåÕĖāÕ╝ÅńÄ»ÕóāńÜäÕī║Õł½’╝īÕÉīµŚČõ╣¤Ķć¬ÕŖ©ÕżäńÉåõ║åµĢ░µŹ«ńÜäĶ«ŠÕżćÕÆīķĆÜõ┐ĪÕÉÄń½»ŃĆé
+- [ÕģČõ╗¢ÕĘźÕģĘ’╝łUtils’╝ē](../advanced_tutorials/manager_mixin.md)’╝ÜĶ┐śµ£ēõĖĆõ║øÕĘźÕģʵƦńÜ䵩ĪÕØŚ’╝īÕ”é ManagerMixin’╝īÕ«āÕ«×ńÄ░õ║åõĖĆń¦ŹÕģ©Õ▒ĆÕÅśķćÅńÜäÕłøÕ╗║ÕÆīĶÄĘÕÅ¢µ¢╣Õ╝Å’╝īµē¦ĶĪīÕÖ©ÕåģÕŠłÕżÜÕģ©Õ▒ĆÕÅ»Ķ¦üÕ»╣Ķ▒ĪńÜäÕ¤║ń▒╗Õ░▒µś» ManagerMixinŃĆé
+
+ńö©µłĘÕÅ»õ╗źĶ┐øõĖƵŁźķśģĶ»╗[µĢÖń©ŗ](../tutorials/runner.md)µØźõ║åĶ¦ŻĶ┐Öõ║øµ©ĪÕØŚńÜäķ½śń║¦ńö©µ│Ģ’╝īõ╣¤ÕÅ»õ╗źÕÅéĶĆā[Ķ«ŠĶ«Īµ¢ćµĪŻ](../design/hook.md) õ║åĶ¦ŻÕ«āõ╗¼ńÜäĶ«ŠĶ«ĪµĆØĶĘ»õĖÄń╗åĶŖéŃĆé
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/large_model_training.md b/internlm_langchain/knowledge_base/MMEngine/content/large_model_training.md
new file mode 100644
index 00000000..6539d1a2
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/large_model_training.md
@@ -0,0 +1,265 @@
+# Õż¦µ©ĪÕ×ŗĶ«Łń╗ā
+
+Õ£©Ķ«Łń╗āÕż¦µ©ĪÕ×ŗµŚČ’╝īķ£ĆĶ”üÕ║×Õż¦ńÜäĶĄäµ║ÉŃĆéÕŹĢÕŹĪµśŠÕŁśķĆÜÕĖĖõĖŹĶāĮµ╗ĪĶČ│Ķ«Łń╗āńÜäķ£ĆĶ”ü’╝īÕøĀµŁżÕć║ńÄ░õ║åÕż¦µ©ĪÕ×ŗĶ«Łń╗āµŖƵ£»’╝īÕģČõĖŁÕģĖÕ×ŗńÜäõĖĆń¦Źµś» [DeepSpeed ZeRO](https://www.deepspeed.ai/tutorials/zero/#zero-overview)ŃĆéDeepSpedd ZeRO µö»µīüÕłćÕłåõ╝śÕī¢ÕÖ©ŃĆüµó»Õ║”õ╗źÕÅŖÕÅéµĢ░ŃĆé
+
+õĖ║õ║åµø┤ÕŖĀńüĄµ┤╗Õ£░µö»µīüÕż¦µ©ĪÕ×ŗĶ«Łń╗āµŖƵ£»’╝īõ╗Ä MMEngine v0.8.0 Õ╝ĆÕ¦ŗ’╝īµłæõ╗¼µÅÉõŠøõ║åµ¢░ńÜäµē¦ĶĪīÕÖ© [FlexibleRunner](mmengine.runner.FlexibleRunner) ÕÆīÕżÜõĖ¬µŖĮĶ▒ĪńŁ¢ńĢź [Strategy](../api/strategy)ŃĆé
+
+```{warning}
+µ¢░ńÜäµē¦ĶĪīÕÖ© FlexibleRunner ÕÆī Strategy Ķ┐śÕżäõ║ÄÕ«×ķ¬īµĆ¦ķśČµ«Ą’╝īÕ£©Õ░åµØźńÜäńēłµ£¼õĖŁ’╝īÕ«āõ╗¼ńÜäµÄźÕÅŻµ£ēÕÅ»ĶāĮõ╝ÜÕÅæńö¤ÕÅśÕī¢ŃĆé
+```
+
+õĖŗķØóńÜäńż║õŠŗõ╗ŻńĀüµæśĶć¬ [examples/distributed_training_with_flexible_runner.py](https://github.com/open-mmlab/mmengine/blob/main/examples/distributed_training_with_flexible_runner.py)ŃĆé
+
+## DeepSpeed
+
+[DeepSpeed](https://github.com/microsoft/DeepSpeed/tree/master) µś»ÕŠ«ĶĮ»Õ╝Ƶ║ÉńÜäÕ¤║õ║Ä PyTorch ńÜäÕłåÕĖāÕ╝ŵĪåµ×Č’╝īÕģȵö»µīüõ║å `ZeRO`, `3D-Parallelism`, `DeepSpeed-MoE`, `ZeRO-Infinity` ńŁēĶ«Łń╗āńŁ¢ńĢźŃĆé
+MMEngine Ķć¬ v0.8.0 Õ╝ĆÕ¦ŗµö»µīüõĮ┐ńö© DeepSpeed Ķ┐øĶĪīµ©ĪÕ×ŗńÜäĶ«Łń╗āŃĆé
+
+õĮ┐ńö© DeepSpeed ÕēŹķ£ĆÕ«ēĶŻģ deepspeed’╝Ü
+
+```bash
+pip install deepspeed
+```
+
+Õ«ēĶŻģÕźĮ deepspeed ÕÉÄ’╝īķ£ĆķģŹńĮ« FlexibleRunner ńÜä strategy ÕÆī optim_wrapper ÕÅéµĢ░’╝Ü
+
+- strategy’╝ܵīćÕ«Ü `type='DeepSpeedStrategy'` Õ╣ČķģŹńĮ«ÕÅéµĢ░ŃĆéÕÅéµĢ░ńÜäĶ»”ń╗åõ╗ŗń╗ŹÕÅ»ķśģĶ»╗ [DeepSpeedStrategy](mmengine._strategy.DeepSpeedStrategy)ŃĆé
+- optim_wrapper’╝ܵīćÕ«Ü `type='DeepSpeedOptimWrapper'` Õ╣ČķģŹńĮ«ÕÅéµĢ░ŃĆéÕÅéµĢ░ńÜäĶ»”ń╗åõ╗ŗń╗ŹÕÅ»ķśģĶ»╗ [DeepSpeedOptimWrapper](mmengine._strategy.deepspeed.DeepSpeedOptimWrapper)ŃĆé
+
+õĖŗķØ󵜻 DeepSpeed ńøĖÕģ│ńÜäķģŹńĮ«’╝Ü
+
+```python
+from mmengine.runner._flexible_runner import FlexibleRunner
+
+# µīćÕ«Ü DeepSpeedStrategy Õ╣ČķģŹńĮ«ÕÅéµĢ░
+strategy = dict(
+ type='DeepSpeedStrategy',
+ fp16=dict(
+ enabled=True,
+ fp16_master_weights_and_grads=False,
+ loss_scale=0,
+ loss_scale_window=500,
+ hysteresis=2,
+ min_loss_scale=1,
+ initial_scale_power=15,
+ ),
+ inputs_to_half=[0],
+ zero_optimization=dict(
+ stage=3,
+ allgather_partitions=True,
+ reduce_scatter=True,
+ allgather_bucket_size=50000000,
+ reduce_bucket_size=50000000,
+ overlap_comm=True,
+ contiguous_gradients=True,
+ cpu_offload=False),
+)
+
+# µīćÕ«Ü DeepSpeedOptimWrapper Õ╣ČķģŹńĮ«ÕÅéµĢ░
+optim_wrapper = dict(
+ type='DeepSpeedOptimWrapper',
+ optimizer=dict(type='AdamW', lr=1e-3))
+
+# ÕłØÕ¦ŗÕī¢ FlexibleRunner
+runner = FlexibleRunner(
+ model=MMResNet50(),
+ work_dir='./work_dirs',
+ strategy=strategy,
+ train_dataloader=train_dataloader,
+ optim_wrapper=optim_wrapper,
+ param_scheduler=dict(type='LinearLR'),
+ train_cfg=dict(by_epoch=True, max_epochs=10, val_interval=1),
+ val_dataloader=val_dataloader,
+ val_cfg=dict(),
+ val_evaluator=dict(type=Accuracy))
+
+# Õ╝ĆÕ¦ŗĶ«Łń╗ā
+runner.train()
+```
+
+õĮ┐ńö©õĖżÕ╝ĀÕŹĪÕÉ»ÕŖ©ÕłåÕĖāÕ╝ÅĶ«Łń╗ā’╝Ü
+
+```bash
+torchrun --nproc-per-node 2 examples/distributed_training_with_flexible_runner.py --use-deepspeed
+```
+
+
+
+
+## FullyShardedDataParallel (FSDP)
+
+PyTorch õ╗Ä v1.11 ńēłµ£¼Õ╝ĆÕ¦ŗµö»µīü [FullyShardedDataParallel](https://pytorch.org/docs/stable/fsdp.html) Ķ«Łń╗ā’╝īõĮåńö▒õ║ÄÕģȵğÕÅŻõĖĆńø┤Õżäõ║ÄÕÅśÕŖ©õĖŁ’╝īµłæõ╗¼ÕŬµö»µīü PyTorch v2.0.0 ÕÅŖõ╗źõĖŖńÜäńēłµ£¼ŃĆé
+
+õĮ┐ńö© FSDP ķ£ĆķģŹńĮ« FlexibleRunner ńÜä strategy ÕÅéµĢ░’╝ܵīćÕ«Ü `type='FSDPStrategy'` Õ╣ČķģŹńĮ«ÕÅéµĢ░ŃĆéÕÅéµĢ░ńÜäĶ»”ń╗åõ╗ŗń╗ŹÕÅ»ķśģĶ»╗ [FSDPStrategy](mmengine._strategy.FSDPStrategy)ŃĆé
+
+õĖŗķØ󵜻 FSDP ńøĖÕģ│ńÜäķģŹńĮ«’╝Ü
+
+```python
+from torch.distributed.fsdp.wrap import size_based_auto_wrap_policy
+size_based_auto_wrap_policy = partial(
+ size_based_auto_wrap_policy, min_num_params=1e7)
+
+# µīćÕ«Ü FSDPStrategy Õ╣ČķģŹńĮ«ÕÅéµĢ░
+strategy = dict(
+ type='FSDPStrategy',
+ model_wrapper=dict(auto_wrap_policy=size_based_auto_wrap_policy))
+
+# µīćÕ«Ü AmpOptimWrapper Õ╣ČķģŹńĮ«ÕÅéµĢ░
+optim_wrapper = dict(
+ type='AmpOptimWrapper', optimizer=dict(type='AdamW', lr=1e-3))
+
+# ÕłØÕ¦ŗÕī¢ FlexibleRunner
+runner = FlexibleRunner(
+ model=MMResNet50(),
+ work_dir='./work_dirs',
+ strategy=strategy,
+ train_dataloader=train_dataloader,
+ optim_wrapper=optim_wrapper,
+ param_scheduler=dict(type='LinearLR'),
+ train_cfg=dict(by_epoch=True, max_epochs=10, val_interval=1),
+ val_dataloader=val_dataloader,
+ val_cfg=dict(),
+ val_evaluator=dict(type=Accuracy))
+
+# Õ╝ĆÕ¦ŗĶ«Łń╗ā
+runner.train()
+```
+
+õĮ┐ńö©õĖżÕ╝ĀÕŹĪÕÉ»ÕŖ©ÕłåÕĖāÕ╝ÅĶ«Łń╗ā’╝Ü
+
+```bash
+torchrun --nproc-per-node 2 examples/distributed_training_with_flexible_runner.py --use-fsdp
+```
+
+Ķ«Łń╗āµŚźÕ┐Ś
+ +``` +07/03 13:04:17 - mmengine - INFO - Epoch(train) [1][ 10/196] lr: 3.3333e-04 eta: 0:13:14 time: 0.4073 data_time: 0.0335 memory: 970 loss: 6.1887 +07/03 13:04:19 - mmengine - INFO - Epoch(train) [1][ 20/196] lr: 3.3333e-04 eta: 0:09:39 time: 0.1904 data_time: 0.0327 memory: 970 loss: 2.5746 +07/03 13:04:21 - mmengine - INFO - Epoch(train) [1][ 30/196] lr: 3.3333e-04 eta: 0:08:32 time: 0.1993 data_time: 0.0342 memory: 970 loss: 2.4180 +07/03 13:04:23 - mmengine - INFO - Epoch(train) [1][ 40/196] lr: 3.3333e-04 eta: 0:08:01 time: 0.2052 data_time: 0.0368 memory: 970 loss: 2.3682 +07/03 13:04:25 - mmengine - INFO - Epoch(train) [1][ 50/196] lr: 3.3333e-04 eta: 0:07:39 time: 0.2013 data_time: 0.0356 memory: 970 loss: 2.3025 +07/03 13:04:27 - mmengine - INFO - Epoch(train) [1][ 60/196] lr: 3.3333e-04 eta: 0:07:25 time: 0.2025 data_time: 0.0353 memory: 970 loss: 2.2078 +07/03 13:04:29 - mmengine - INFO - Epoch(train) [1][ 70/196] lr: 3.3333e-04 eta: 0:07:13 time: 0.1999 data_time: 0.0352 memory: 970 loss: 2.2045 +07/03 13:04:31 - mmengine - INFO - Epoch(train) [1][ 80/196] lr: 3.3333e-04 eta: 0:07:04 time: 0.2013 data_time: 0.0350 memory: 970 loss: 2.1709 +07/03 13:04:33 - mmengine - INFO - Epoch(train) [1][ 90/196] lr: 3.3333e-04 eta: 0:06:56 time: 0.1975 data_time: 0.0341 memory: 970 loss: 2.2070 +07/03 13:04:35 - mmengine - INFO - Epoch(train) [1][100/196] lr: 3.3333e-04 eta: 0:06:49 time: 0.1993 data_time: 0.0347 memory: 970 loss: 2.0891 +07/03 13:04:37 - mmengine - INFO - Epoch(train) [1][110/196] lr: 3.3333e-04 eta: 0:06:44 time: 0.1995 data_time: 0.0357 memory: 970 loss: 2.0700 +07/03 13:04:39 - mmengine - INFO - Epoch(train) [1][120/196] lr: 3.3333e-04 eta: 0:06:38 time: 0.1966 data_time: 0.0342 memory: 970 loss: 1.9983 +07/03 13:04:41 - mmengine - INFO - Epoch(train) [1][130/196] lr: 3.3333e-04 eta: 0:06:37 time: 0.2216 data_time: 0.0341 memory: 970 loss: 1.9409 +07/03 13:04:43 - mmengine - INFO - Epoch(train) [1][140/196] lr: 3.3333e-04 eta: 0:06:32 time: 0.1944 data_time: 0.0336 memory: 970 loss: 1.9800 +07/03 13:04:45 - mmengine - INFO - Epoch(train) [1][150/196] lr: 3.3333e-04 eta: 0:06:27 time: 0.1946 data_time: 0.0338 memory: 970 loss: 1.9356 +07/03 13:04:47 - mmengine - INFO - Epoch(train) [1][160/196] lr: 3.3333e-04 eta: 0:06:22 time: 0.1937 data_time: 0.0333 memory: 970 loss: 1.8145 +07/03 13:04:49 - mmengine - INFO - Epoch(train) [1][170/196] lr: 3.3333e-04 eta: 0:06:18 time: 0.1941 data_time: 0.0335 memory: 970 loss: 1.8525 +07/03 13:04:51 - mmengine - INFO - Epoch(train) [1][180/196] lr: 3.3333e-04 eta: 0:06:17 time: 0.2204 data_time: 0.0341 memory: 970 loss: 1.7637 +07/03 13:04:53 - mmengine - INFO - Epoch(train) [1][190/196] lr: 3.3333e-04 eta: 0:06:14 time: 0.1998 data_time: 0.0345 memory: 970 loss: 1.7523 +``` + +
+
+
+## ColossalAI
+
+[ColossalAI](https://colossalai.org/) µś»õĖĆõĖ¬Õģʵ£ēķ½śµĢłÕ╣ČĶĪīÕī¢µŖƵ£»ńÜäń╗╝ÕÉłÕż¦Ķ¦äµ©Īµ©ĪÕ×ŗĶ«Łń╗āń│╗ń╗¤ŃĆéMMEngine Ķć¬ v0.8.5 Õ╝ĆÕ¦ŗ’╝īµö»µīüõĮ┐ńö© ColossalAI õĖŁńÜä ZeRO ń│╗ÕłŚõ╝śÕī¢ńŁ¢ńĢźĶ«Łń╗āµ©ĪÕ×ŗŃĆé
+
+Õ«ēĶŻģńēłµ£¼Õż¦õ║Ä v0.3.1 ńÜä ColossalAIŃĆéĶ┐ÖõĖ¬ńēłµ£¼ķÖÉÕłČµś»ńö▒õ║Ä v0.3.1 ÕŁśÕ£©õĖĆõ║øń©ŗÕ║Åķś╗ÕĪ×ńÜä [Bug](https://github.com/hpcaitech/ColossalAI/issues/4393)’╝īĶĆīĶ»ź Bug Õ£©õ╣ŗÕÉÄńÜäńēłµ£¼õĖŁÕĘ▓ń╗Åõ┐«ÕżŹŃĆéÕ”éµ×£ńø«ÕēŹ ColossalAI ńÜäµ£Ćķ½śńēłµ£¼õ╗ŹõĖ║ v0.3.1’╝īÕ╗║Ķ««õ╗ĵ║ÉńĀüÕ«ēĶŻģõĖ╗Õłåµö»ńÜä ColossalAIŃĆé
+
+```{note}
+ķ£ĆĶ”üµ│©µäÅńÜ䵜»’╝īÕ”éµ×£õĮĀńÜä PyTorch ńēłµ£¼ķ½śõ║Ä 2.0’╝īÕ╣ČķüćÕł░õ║å `nvcc fatal : Unsupported gpu architecture 'compute_90'` ń▒╗õ╝╝ńÜäń╝¢Ķ»æķöÖĶ»»’╝īÕłÖķ£ĆĶ”ü git clone µ║ÉńĀü’╝īÕÅéĶĆāĶ»ź [PR](https://github.com/hpcaitech/ColossalAI/pull/4357) Ķ┐øĶĪīõ┐«µö╣µ║ÉńĀü’╝īÕåŹĶ┐øĶĪīÕ«ēĶŻģ
+```
+
+```bash
+pip install git+https://github.com/hpcaitech/ColossalAI
+```
+
+Õ”éµ×£ ColossalAI ńÜäµ£Ćµ¢░ńēłµ£¼Õż¦õ║Ä v0.3.1’╝īÕÅ»õ╗źńø┤µÄźõĮ┐ńö© pip Õ«ēĶŻģ’╝Ü
+
+```bash
+pip install colossalai
+```
+
+Õ«ēĶŻģÕźĮ ColossalAI ÕÉÄ’╝īķ£ĆķģŹńĮ« FlexibleRunner ńÜä strategy ÕÆī optim_wrapper ÕÅéµĢ░’╝Ü
+
+- strategy’╝ܵīćÕ«Ü `type='ColossalAIStrategy'` Õ╣ČķģŹńĮ«ÕÅéµĢ░ŃĆéÕÅéµĢ░ńÜäĶ»”ń╗åõ╗ŗń╗ŹÕÅ»ķśģĶ»╗ [ColossalAIStrategy](mmengine._strategy.ColossalAIStrategy)ŃĆé
+- optim_wrapper’╝Üń╝║ń£ü `type` ÕÅéµĢ░’╝īµł¢µīćÕ«Ü `type=ColossalAIOptimWrapper`’╝īõ╝śÕī¢ÕÖ©ń▒╗Õ×ŗÕ╗║Ķ««ķĆēµŗ® `HybridAdam`ŃĆéÕģČõ╗¢ÕÅ»ķģŹńĮ«ń▒╗Õ×ŗÕÅ»ķśģĶ»╗ [ColossalAIOptimWrapper](mmengine._strategy.ColossalAIOptimWrapper)ŃĆé
+
+õĖŗķØ󵜻 ColossalAI ńøĖÕģ│ńÜäķģŹńĮ«’╝Ü
+
+```python
+from mmengine.runner._flexible_runner import FlexibleRunner
+
+strategy = dict(type='ColossalAIStrategy')
+optim_wrapper = dict(optimizer=dict(type='HybridAdam', lr=1e-3))
+
+# ÕłØÕ¦ŗÕī¢ FlexibleRunner
+runner = FlexibleRunner(
+ model=MMResNet50(),
+ work_dir='./work_dirs',
+ strategy=strategy,
+ train_dataloader=train_dataloader,
+ optim_wrapper=optim_wrapper,
+ param_scheduler=dict(type='LinearLR'),
+ train_cfg=dict(by_epoch=True, max_epochs=10, val_interval=1),
+ val_dataloader=val_dataloader,
+ val_cfg=dict(),
+ val_evaluator=dict(type=Accuracy))
+
+# Õ╝ĆÕ¦ŗĶ«Łń╗ā
+runner.train()
+```
+
+õĮ┐ńö©õĖżÕ╝ĀÕŹĪÕÉ»ÕŖ©ÕłåÕĖāÕ╝ÅĶ«Łń╗ā’╝Ü
+
+```bash
+torchrun --nproc-per-node 2 examples/distributed_training_with_flexible_runner.py --use-colossalai
+```
+
+Ķ«Łń╗āµŚźÕ┐Ś
+ +``` +07/03 13:05:37 - mmengine - INFO - Epoch(train) [1][ 10/196] lr: 3.3333e-04 eta: 0:08:28 time: 0.2606 data_time: 0.0330 memory: 954 loss: 6.1265 +07/03 13:05:38 - mmengine - INFO - Epoch(train) [1][ 20/196] lr: 3.3333e-04 eta: 0:05:18 time: 0.0673 data_time: 0.0325 memory: 954 loss: 2.5584 +07/03 13:05:39 - mmengine - INFO - Epoch(train) [1][ 30/196] lr: 3.3333e-04 eta: 0:04:13 time: 0.0666 data_time: 0.0320 memory: 954 loss: 2.4816 +07/03 13:05:39 - mmengine - INFO - Epoch(train) [1][ 40/196] lr: 3.3333e-04 eta: 0:03:41 time: 0.0666 data_time: 0.0321 memory: 954 loss: 2.3695 +07/03 13:05:40 - mmengine - INFO - Epoch(train) [1][ 50/196] lr: 3.3333e-04 eta: 0:03:21 time: 0.0671 data_time: 0.0324 memory: 954 loss: 2.3208 +07/03 13:05:41 - mmengine - INFO - Epoch(train) [1][ 60/196] lr: 3.3333e-04 eta: 0:03:08 time: 0.0667 data_time: 0.0320 memory: 954 loss: 2.2431 +07/03 13:05:41 - mmengine - INFO - Epoch(train) [1][ 70/196] lr: 3.3333e-04 eta: 0:02:58 time: 0.0667 data_time: 0.0320 memory: 954 loss: 2.1873 +07/03 13:05:42 - mmengine - INFO - Epoch(train) [1][ 80/196] lr: 3.3333e-04 eta: 0:02:51 time: 0.0669 data_time: 0.0320 memory: 954 loss: 2.2006 +07/03 13:05:43 - mmengine - INFO - Epoch(train) [1][ 90/196] lr: 3.3333e-04 eta: 0:02:45 time: 0.0671 data_time: 0.0324 memory: 954 loss: 2.1547 +07/03 13:05:43 - mmengine - INFO - Epoch(train) [1][100/196] lr: 3.3333e-04 eta: 0:02:40 time: 0.0667 data_time: 0.0321 memory: 954 loss: 2.1361 +07/03 13:05:44 - mmengine - INFO - Epoch(train) [1][110/196] lr: 3.3333e-04 eta: 0:02:36 time: 0.0668 data_time: 0.0320 memory: 954 loss: 2.0405 +07/03 13:05:45 - mmengine - INFO - Epoch(train) [1][120/196] lr: 3.3333e-04 eta: 0:02:32 time: 0.0669 data_time: 0.0320 memory: 954 loss: 2.0228 +07/03 13:05:45 - mmengine - INFO - Epoch(train) [1][130/196] lr: 3.3333e-04 eta: 0:02:29 time: 0.0670 data_time: 0.0324 memory: 954 loss: 2.0375 +07/03 13:05:46 - mmengine - INFO - Epoch(train) [1][140/196] lr: 3.3333e-04 eta: 0:02:26 time: 0.0664 data_time: 0.0320 memory: 954 loss: 1.9926 +07/03 13:05:47 - mmengine - INFO - Epoch(train) [1][150/196] lr: 3.3333e-04 eta: 0:02:24 time: 0.0668 data_time: 0.0320 memory: 954 loss: 1.9820 +07/03 13:05:47 - mmengine - INFO - Epoch(train) [1][160/196] lr: 3.3333e-04 eta: 0:02:22 time: 0.0674 data_time: 0.0325 memory: 954 loss: 1.9728 +07/03 13:05:48 - mmengine - INFO - Epoch(train) [1][170/196] lr: 3.3333e-04 eta: 0:02:20 time: 0.0666 data_time: 0.0320 memory: 954 loss: 1.9359 +07/03 13:05:49 - mmengine - INFO - Epoch(train) [1][180/196] lr: 3.3333e-04 eta: 0:02:18 time: 0.0667 data_time: 0.0321 memory: 954 loss: 1.9488 +07/03 13:05:49 - mmengine - INFO - Epoch(train) [1][190/196] lr: 3.3333e-04 eta: 0:02:16 time: 0.0671 data_time: 0.0323 memory: 954 loss: 1.9023\ +``` + +
+
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/logging.md b/internlm_langchain/knowledge_base/MMEngine/content/logging.md
new file mode 100644
index 00000000..451ba04e
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/logging.md
@@ -0,0 +1,312 @@
+# Ķ«░ÕĮĢµŚźÕ┐Ś
+
+[µē¦ĶĪīÕÖ©’╝łRunner’╝ē](../tutorials/runner.md)Õ£©Ķ┐ÉĶĪīĶ┐ćń©ŗõĖŁõ╝Üõ║¦ńö¤ÕŠłÕżÜµŚźÕ┐Ś’╝īõŠŗÕ”éµŹ¤Õż▒ŃĆüĶ┐Łõ╗ŻµŚČķŚ┤ŃĆüÕŁ”õ╣ĀńÄćńŁēŃĆéMMEngine Õ«×ńÄ░õ║åõĖĆÕźŚńüĄµ┤╗ńÜ䵌źÕ┐Śń│╗ń╗¤Ķ«®µłæõ╗¼ĶāĮÕż¤Õ£©ķģŹńĮ«µē¦ĶĪīÕÖ©µŚČ’╝īķĆēµŗ®õĖŹÕÉīń▒╗Õ×ŗµŚźÕ┐ŚńÜäń╗¤Ķ«Īµ¢╣Õ╝Å’╝øÕ£©õ╗ŻńĀüńÜäõ╗╗µäÅõĮŹńĮ«’╝īµ¢░Õó×ķ£ĆĶ”üĶó½ń╗¤Ķ«ĪńÜ䵌źÕ┐ŚŃĆé
+
+## ńüĄµ┤╗ńÜ䵌źÕ┐Śń╗¤Ķ«Īµ¢╣Õ╝Å
+
+µłæõ╗¼ÕÅ»õ╗źķĆÜĶ┐ćÕ£©µ×äÕ╗║µē¦ĶĪīÕÖ©µŚČÕĆÖķģŹńĮ«[µŚźÕ┐ŚÕżäńÉåÕÖ©](mmengine.runner.LogProcessor)’╝īµØźńüĄµ┤╗Õ£░ķĆēµŗ®µŚźÕ┐Śń╗¤Ķ«Īµ¢╣Õ╝ÅŃĆéÕ”éµ×£õĖŹõĖ║µē¦ĶĪīÕÖ©ķģŹńĮ«µŚźÕ┐ŚÕżäńÉåÕÖ©’╝īÕłÖõ╝ܵīēńģ¦µŚźÕ┐ŚÕżäńÉåÕÖ©ńÜäķ╗śĶ«żÕÅéµĢ░µ×äÕ╗║Õ«×õŠŗ’╝īµĢłµ×£ńŁēõ╗Ęõ║Ä’╝Ü
+
+```python
+log_processor = dict(window_size=10, by_epoch=True, custom_cfg=None, num_digits=4)
+```
+
+ÕģČĶŠōÕć║ńÜ䵌źÕ┐ŚµĀ╝Õ╝ÅÕ”éõĖŗ’╝Ü
+
+```python
+import torch
+import torch.nn as nn
+from torch.utils.data import DataLoader
+
+from mmengine.runner import Runner
+from mmengine.model import BaseModel
+
+train_dataset = [(torch.ones(1, 1), torch.ones(1, 1))] * 50
+train_dataloader = DataLoader(train_dataset, batch_size=2)
+
+
+class ToyModel(BaseModel):
+ def __init__(self) -> None:
+ super().__init__()
+ self.linear = nn.Linear(1, 1)
+
+ def forward(self, img, label, mode):
+ feat = self.linear(img)
+ loss1 = (feat - label).pow(2)
+ loss2 = (feat - label).abs()
+ return dict(loss1=loss1, loss2=loss2)
+
+runner = Runner(
+ model=ToyModel(),
+ work_dir='tmp_dir',
+ train_dataloader=train_dataloader,
+ train_cfg=dict(by_epoch=True, max_epochs=1),
+ optim_wrapper=dict(optimizer=dict(type='SGD', lr=0.01))
+)
+runner.train()
+```
+
+```
+08/21 02:58:41 - mmengine - INFO - Epoch(train) [1][10/25] lr: 1.0000e-02 eta: 0:00:00 time: 0.0019 data_time: 0.0004 loss1: 0.8381 loss2: 0.9007 loss: 1.7388
+08/21 02:58:41 - mmengine - INFO - Epoch(train) [1][20/25] lr: 1.0000e-02 eta: 0:00:00 time: 0.0029 data_time: 0.0010 loss1: 0.1978 loss2: 0.4312 loss: 0.6290
+```
+
+õ╗źĶ«Łń╗āķśČµ«ĄõĖ║õŠŗ’╝īµŚźÕ┐ŚÕżäńÉåÕÖ©ķ╗śĶ«żõ╝ܵīēńģ¦õ╗źõĖŗµ¢╣Õ╝Åń╗¤Ķ«Īµē¦ĶĪīÕÖ©ĶŠōÕć║ńÜ䵌źÕ┐Ś’╝Ü
+
+- µŚźÕ┐ŚÕēŹń╝Ć’╝Ü
+ - Epoch µ©ĪÕ╝Å’╝ł`by_epoch=True`’╝ē’╝Ü`Epoch(train) [{ÕĮōÕēŹepochµ¼ĪµĢ░}][{ÕĮōÕēŹĶ┐Łõ╗Żµ¼ĪµĢ░}/{Dataloader µĆ╗ķĢ┐Õ║”}]`
+ - Iter µ©ĪÕ╝Å’╝ł`by_epoch=False`’╝ē’╝Ü `Iter(train) [{ÕĮōÕēŹĶ┐Łõ╗Żµ¼ĪµĢ░}/{µĆ╗Ķ┐Łõ╗Żµ¼ĪµĢ░}]`
+- ÕŁ”õ╣ĀńÄć’╝ł`lr`’╝ē’╝Üń╗¤Ķ«Īµ£ĆĶ┐æõĖƵ¼ĪĶ┐Łõ╗Ż’╝īÕÅéµĢ░µø┤µ¢░ńÜäÕŁ”õ╣ĀńÄć
+- µŚČķŚ┤
+ - Ķ┐Łõ╗ŻµŚČķŚ┤’╝ł`time`’╝ē’╝ܵ£ĆĶ┐æ `window_size`’╝łµŚźÕ┐ŚÕżäńÉåÕÖ©ÕÅéµĢ░’╝ē µ¼ĪĶ┐Łõ╗Ż’╝īÕżäńÉåõĖĆõĖ¬ batch µĢ░µŹ«’╝łÕīģµŗ¼µĢ░µŹ«ÕŖĀĶĮĮÕÆīµ©ĪÕ×ŗÕēŹÕÉæµÄ©ńÉå’╝ēńÜäÕ╣│ÕØ浌ČķŚ┤
+ - µĢ░µŹ«µŚČķŚ┤’╝ł`data_time`’╝ē’╝ܵ£ĆĶ┐æ `window_size` µ¼ĪĶ┐Łõ╗Ż’╝īÕŖĀĶĮĮõĖĆõĖ¬ batch µĢ░µŹ«ńÜäÕ╣│ÕØ浌ČķŚ┤
+ - Õē®õĮÖµŚČķŚ┤’╝ł`eta`’╝ē’╝ܵĀ╣µŹ«µĆ╗Ķ┐Łõ╗Żµ¼ĪµĢ░ÕÆīÕÄåµ¼ĪĶ┐Łõ╗ŻµŚČķŚ┤Ķ«Īń«ŚÕć║µØźńÜäµĆ╗Õē®õĮÖµŚČķŚ┤’╝īÕē®õĮÖµŚČķŚ┤ķÜÅńØĆĶ┐Łõ╗Żµ¼ĪµĢ░Õó×ÕŖĀķĆɵĖÉĶČŗõ║Äń©│Õ«Ü
+- µŹ¤Õż▒’╝ܵ©ĪÕ×ŗÕēŹÕÉæµÄ©ńÉåÕŠŚÕł░ńÜäÕÉäń¦ŹÕŁŚµ«ĄńÜ䵏¤Õż▒’╝īķ╗śĶ«żń╗¤Ķ«Īµ£ĆĶ┐æ `window_size` µ¼ĪĶ┐Łõ╗ŻńÜäÕ╣│ÕØ浏¤Õż▒ŃĆé
+
+ķ╗śĶ«żµāģÕåĄõĖŗ’╝ī`window_size=10`’╝īµŚźÕ┐ŚÕżäńÉåÕÖ©õ╝Üń╗¤Ķ«Īµ£ĆĶ┐æ 10 µ¼ĪĶ┐Łõ╗Ż’╝īµŹ¤Õż▒ŃĆüĶ┐Łõ╗ŻµŚČķŚ┤ŃĆüµĢ░µŹ«µŚČķŚ┤ńÜäÕØćÕĆ╝ŃĆé
+
+ķ╗śĶ«żµāģÕåĄõĖŗ’╝īµēƵ£ēµŚźÕ┐ŚńÜäµ£ēµĢłõĮŹµĢ░’╝ł`num_digits` ÕÅéµĢ░’╝ēõĖ║ 4ŃĆé
+
+ķ╗śĶ«żµāģÕåĄõĖŗ’╝īĶŠōÕć║µēƵ£ēĶć¬Õ«Üõ╣ēµŚźÕ┐Śµ£ĆĶ┐æõĖƵ¼ĪĶ┐Łõ╗ŻńÜäÕĆ╝ŃĆé
+
+Õ¤║õ║ÄõĖŖĶ┐░Ķ¦äÕłÖ’╝īõ╗ŻńĀüńż║õŠŗõĖŁńÜ䵌źÕ┐ŚÕżäńÉåÕÖ©õ╝ÜĶŠōÕć║ `loss1` ÕÆī `loss2` µ»Å 10 µ¼ĪĶ┐Łõ╗ŻńÜäÕØćÕĆ╝ŃĆéÕ”éµ×£µłæõ╗¼µā│ń╗¤Ķ«Ī `loss1` õ╗Äń¼¼õĖƵ¼ĪĶ┐Łõ╗ŻÕ╝ĆÕ¦ŗĶć│õ╗ŖńÜäÕģ©Õ▒ĆÕØćÕĆ╝’╝īÕÅ»õ╗źĶ┐ÖµĀĘķģŹńĮ«’╝Ü
+
+```python
+runner = Runner(
+ model=ToyModel(),
+ work_dir='tmp_dir',
+ train_dataloader=train_dataloader,
+ train_cfg=dict(by_epoch=True, max_epochs=1),
+ optim_wrapper=dict(optimizer=dict(type='SGD', lr=0.01)),
+ log_processor=dict( # ķģŹńĮ«µŚźÕ┐ŚÕżäńÉåÕÖ©
+ custom_cfg=[
+ dict(data_src='loss1', # ÕĤµŚźÕ┐ŚÕÉŹ’╝Üloss1
+ method_name='mean', # ń╗¤Ķ«Īµ¢╣µ│Ģ’╝ÜÕØćÕĆ╝ń╗¤Ķ«Ī
+ window_size='global')]) # ń╗¤Ķ«Īń¬ŚÕÅŻ’╝ÜÕģ©Õ▒Ć
+)
+runner.train()
+```
+
+```
+08/21 02:58:49 - mmengine - INFO - Epoch(train) [1][10/25] lr: 1.0000e-02 eta: 0:00:00 time: 0.0026 data_time: 0.0007 loss1: 0.7381 loss2: 0.8446 loss: 1.5827
+08/21 02:58:49 - mmengine - INFO - Epoch(train) [1][20/25] lr: 1.0000e-02 eta: 0:00:00 time: 0.0030 data_time: 0.0012 loss1: 0.4521 loss2: 0.3939 loss: 0.5600
+```
+
+```{note}
+log_processor ķ╗śĶ«żĶŠōÕć║ `by_epoch=True` µĀ╝Õ╝ÅńÜ䵌źÕ┐ŚŃĆ鵌źÕ┐ŚµĀ╝Õ╝Åķ£ĆĶ”üÕÆī `train_cfg` õĖŁńÜä `by_epoch` ÕÅéµĢ░õ┐صīüõĖĆĶć┤’╝īõŠŗÕ”éµłæõ╗¼µā│µīēĶ┐Łõ╗Żµ¼ĪµĢ░ĶŠōÕć║µŚźÕ┐Ś’╝īÕ░▒ķ£ĆĶ”üÕÅ” `log_processor` ÕÆī `train_cfg` ńÜä `by_epoch=False`ŃĆé
+```
+
+ÕģČõĖŁ `data_src` õĖ║ÕĤµŚźÕ┐ŚÕÉŹ’╝ī`mean` õĖ║ń╗¤Ķ«Īµ¢╣µ│Ģ’╝ī`global` õĖ║ń╗¤Ķ«Īµ¢╣µ│ĢńÜäÕÅéµĢ░ŃĆéĶ┐ÖµĀĘńÜäĶ»Ø’╝īµŚźÕ┐ŚõĖŁń╗¤Ķ«ĪńÜä `loss1` Õ░▒µś»Õģ©Õ▒ĆÕØćÕĆ╝ŃĆ鵳æõ╗¼ÕÅ»õ╗źÕ£©µŚźÕ┐ŚÕżäńÉåÕÖ©õĖŁķģŹńĮ«õ╗źõĖŗń╗¤Ķ«Īµ¢╣µ│Ģ’╝Ü
+
+Ķ«Łń╗āµŚźÕ┐Ś
+ +``` +08/18 11:56:34 - mmengine - INFO - Epoch(train) [1][ 10/196] lr: 3.3333e-04 eta: 0:10:31 time: 0.3238 data_time: 0.0344 memory: 597 loss: 3.8766 +08/18 11:56:35 - mmengine - INFO - Epoch(train) [1][ 20/196] lr: 3.3333e-04 eta: 0:06:56 time: 0.1057 data_time: 0.0338 memory: 597 loss: 2.3797 +08/18 11:56:36 - mmengine - INFO - Epoch(train) [1][ 30/196] lr: 3.3333e-04 eta: 0:05:45 time: 0.1068 data_time: 0.0342 memory: 597 loss: 2.3219 +08/18 11:56:37 - mmengine - INFO - Epoch(train) [1][ 40/196] lr: 3.3333e-04 eta: 0:05:08 time: 0.1059 data_time: 0.0337 memory: 597 loss: 2.2641 +08/18 11:56:38 - mmengine - INFO - Epoch(train) [1][ 50/196] lr: 3.3333e-04 eta: 0:04:45 time: 0.1062 data_time: 0.0338 memory: 597 loss: 2.2250 +08/18 11:56:40 - mmengine - INFO - Epoch(train) [1][ 60/196] lr: 3.3333e-04 eta: 0:04:31 time: 0.1097 data_time: 0.0339 memory: 597 loss: 2.1672 +08/18 11:56:41 - mmengine - INFO - Epoch(train) [1][ 70/196] lr: 3.3333e-04 eta: 0:04:21 time: 0.1096 data_time: 0.0340 memory: 597 loss: 2.1688 +08/18 11:56:42 - mmengine - INFO - Epoch(train) [1][ 80/196] lr: 3.3333e-04 eta: 0:04:13 time: 0.1098 data_time: 0.0338 memory: 597 loss: 2.1781 +08/18 11:56:43 - mmengine - INFO - Epoch(train) [1][ 90/196] lr: 3.3333e-04 eta: 0:04:06 time: 0.1097 data_time: 0.0338 memory: 597 loss: 2.0938 +08/18 11:56:44 - mmengine - INFO - Epoch(train) [1][100/196] lr: 3.3333e-04 eta: 0:04:01 time: 0.1097 data_time: 0.0339 memory: 597 loss: 2.1078 +08/18 11:56:45 - mmengine - INFO - Epoch(train) [1][110/196] lr: 3.3333e-04 eta: 0:04:01 time: 0.1395 data_time: 0.0340 memory: 597 loss: 2.0141 +08/18 11:56:46 - mmengine - INFO - Epoch(train) [1][120/196] lr: 3.3333e-04 eta: 0:03:56 time: 0.1090 data_time: 0.0338 memory: 597 loss: 2.0273 +08/18 11:56:48 - mmengine - INFO - Epoch(train) [1][130/196] lr: 3.3333e-04 eta: 0:03:52 time: 0.1096 data_time: 0.0339 memory: 597 loss: 2.0086 +08/18 11:56:49 - mmengine - INFO - Epoch(train) [1][140/196] lr: 3.3333e-04 eta: 0:03:49 time: 0.1096 data_time: 0.0339 memory: 597 loss: 1.9180 +08/18 11:56:50 - mmengine - INFO - Epoch(train) [1][150/196] lr: 3.3333e-04 eta: 0:03:46 time: 0.1092 data_time: 0.0339 memory: 597 loss: 1.9578 +08/18 11:56:51 - mmengine - INFO - Epoch(train) [1][160/196] lr: 3.3333e-04 eta: 0:03:43 time: 0.1097 data_time: 0.0339 memory: 597 loss: 1.9375 +08/18 11:56:52 - mmengine - INFO - Epoch(train) [1][170/196] lr: 3.3333e-04 eta: 0:03:40 time: 0.1092 data_time: 0.0339 memory: 597 loss: 1.9312 +08/18 11:56:53 - mmengine - INFO - Epoch(train) [1][180/196] lr: 3.3333e-04 eta: 0:03:37 time: 0.1070 data_time: 0.0339 memory: 597 loss: 1.9078 +``` + +| ń╗¤Ķ«Īµ¢╣µ│Ģ | +ÕÅéµĢ░ | +ÕŖ¤ĶāĮ | +
|---|---|---|
| mean | +window_size | +ń╗¤Ķ«Īń¬ŚÕÅŻÕåģµŚźÕ┐ŚńÜäÕØćÕĆ╝ | +
| min | +window_size | +ń╗¤Ķ«Īń¬ŚÕÅŻÕåģµŚźÕ┐ŚńÜäµ£ĆÕ░ÅÕĆ╝ | +
| max | +window_size | +ń╗¤Ķ«Īń¬ŚÕÅŻÕåģµŚźÕ┐ŚńÜäµ£ĆÕż¦ÕĆ╝ | +
| current | +/ | +Ķ┐öÕø×µ£ĆĶ┐æõĖƵ¼Īµø┤µ¢░ńÜ䵌źÕ┐Ś | +
| MMCV µ©ĪÕ×ŗ | +MMEngine µ©ĪÕ×ŗ | +
|---|---|
+
+```python
+class MMCVToyModel(nn.Module):
+
+ def __init__(self) -> None:
+ super().__init__()
+ self.linear = nn.Linear(1, 1)
+
+ def forward(self, img, label, return_loss=False):
+ feat = self.linear(img)
+ loss1 = (feat - label).pow(2)
+ loss2 = (feat - label).abs()
+ loss = (loss1 + loss2).sum()
+ return dict(loss=loss,
+ num_samples=len(img),
+ log_vars=dict(
+ loss1=loss1.sum().item(),
+ loss2=loss2.sum().item()))
+
+ def train_step(self, data, optimizer=None):
+ return self(*data, return_loss=True)
+
+ def val_step(self, data, optimizer=None):
+ return self(*data, return_loss=False)
+```
+
+
+ |
+
+
+```python
+class MMEngineToyModel(BaseModel):
+
+ def __init__(self) -> None:
+ super().__init__()
+ self.linear = nn.Linear(1, 1)
+
+ def forward(self, img, label, mode):
+ if mode == 'loss':
+ feat = self.linear(img)
+ loss1 = (feat - label).pow(2)
+ loss2 = (feat - label).abs()
+ return dict(loss1=loss1, loss2=loss2)
+ elif mode == 'predict':
+ return [_feat for _feat in feat]
+ else:
+ pass
+
+ # µ©ĪÕ×ŗÕ¤║ń▒╗ `train_step` ńŁēµĢłõ╗ŻńĀü
+ # def train_step(self, data, optim_wrapper):
+ # data = self.data_preprocessor(data)
+ # loss_dict = self(*data, mode='loss')
+ # loss_dict['loss1'] = loss_dict['loss1'].sum()
+ # loss_dict['loss2'] = loss_dict['loss2'].sum()
+ # loss = (loss_dict['loss1'] + loss_dict['loss2']).sum()
+ # Ķ░āńö©õ╝śÕī¢ÕÖ©Õ░üĶŻģµø┤µ¢░µ©ĪÕ×ŗÕÅéµĢ░
+ # optim_wrapper.update_params(loss)
+ # return loss_dict
+```
+
+
+ |
+
| Training gan in MMCV | +Training gan in MMEngine | +
|---|---|
+
+```python
+ def train_discriminator(self, inputs, optimizer):
+ real_imgs = inputs['inputs']
+ z = torch.randn(
+ (real_imgs.shape[0], self.noise_size)).type_as(real_imgs)
+ with torch.no_grad():
+ fake_imgs = self.generator(z)
+
+ disc_pred_fake = self.discriminator(fake_imgs)
+ disc_pred_real = self.discriminator(real_imgs)
+
+ parsed_losses, log_vars = self.disc_loss(disc_pred_fake,
+ disc_pred_real)
+ parsed_losses.backward()
+ optimizer.step()
+ optimizer.zero_grad()
+ return log_vars
+
+ def train_generator(self, inputs, optimizer_wrapper):
+ real_imgs = inputs['inputs']
+ z = torch.randn(inputs['inputs'].shape[0], self.noise_size).type_as(
+ real_imgs)
+
+ fake_imgs = self.generator(z)
+
+ disc_pred_fake = self.discriminator(fake_imgs)
+ parsed_loss, log_vars = self.gen_loss(disc_pred_fake)
+
+ parsed_losses.backward()
+ optimizer.step()
+ optimizer.zero_grad()
+ return log_vars
+```
+
+ |
+
+
+
+```python
+ def train_discriminator(self, inputs, optimizer_wrapper):
+ real_imgs = inputs['inputs']
+ z = torch.randn(
+ (real_imgs.shape[0], self.noise_size)).type_as(real_imgs)
+ with torch.no_grad():
+ fake_imgs = self.generator(z)
+
+ disc_pred_fake = self.discriminator(fake_imgs)
+ disc_pred_real = self.discriminator(real_imgs)
+
+ parsed_losses, log_vars = self.disc_loss(disc_pred_fake,
+ disc_pred_real)
+ optimizer_wrapper.update_params(parsed_losses)
+ return log_vars
+
+
+
+ def train_generator(self, inputs, optimizer_wrapper):
+ real_imgs = inputs['inputs']
+ z = torch.randn(real_imgs.shape[0], self.noise_size).type_as(real_imgs)
+
+ fake_imgs = self.generator(z)
+
+ disc_pred_fake = self.discriminator(fake_imgs)
+ parsed_loss, log_vars = self.gen_loss(disc_pred_fake)
+
+ optimizer_wrapper.update_params(parsed_loss)
+ return log_vars
+```
+
+ |
+
+
| MMCV ÕłåÕĖāÕ╝ÅĶ«Łń╗āµ×äÕ╗║µ©ĪÕ×ŗ | +MMEngine ÕłåÕĖāÕ╝ÅĶ«Łń╗ā | +
|---|---|
+
+```python
+model = MMDistributedDataParallel(
+ model,
+ device_ids=[int(os.environ['LOCAL_RANK'])],
+ broadcast_buffers=False,
+ find_unused_parameters=find_unused_parameters)
+...
+runner = Runner(model=model, ...)
+```
+
+
+ |
+
+
+```python
+runner = Runner(
+ model=model,
+ launcher='pytorch', #Õ╝ĆÕÉ»ÕłåÕĖāÕ╝ÅĶ«Łń╗ā
+ ..., # ÕģČõ╗¢ÕÅéµĢ░
+)
+```
+
+
+ |
+
| MMCV-1.x | +MMEngine | +
|---|---|
| + +```python +lr_config = dict( + warmup='constant', + warmup_ratio=0.1, + warmup_iters=500, + warmup_by_epoch=False +) +``` + + | ++ +```python +param_scheduler = [ + dict(type='ConstantLR', + factor=0.1, + begin=0, + end=500, + by_epoch=False), + dict(...) # õĖ╗ÕŁ”õ╣ĀńÄćĶ░āÕ║”ÕÖ©ķģŹńĮ« +] +``` + + | +
| MMCV-1.x | +MMEngine | +
|---|---|
| + +```python +lr_config = dict( + warmup='linear', + warmup_ratio=0.1, + warmup_iters=500, + warmup_by_epoch=False +) +``` + + | ++ +```python +param_scheduler = [ + dict(type='LinearLR', + start_factor=0.1, + begin=0, + end=500, + by_epoch=False), + dict(...) # õĖ╗ÕŁ”õ╣ĀńÄćĶ░āÕ║”ÕÖ©ķģŹńĮ« +] +``` + + | +
| MMCV-1.x | +MMEngine | +
|---|---|
| + +```python +lr_config = dict( + warmup='exp', + warmup_ratio=0.1, + warmup_iters=500, + warmup_by_epoch=False +) +``` + + | ++ +```python +param_scheduler = [ + dict(type='ExponentialLR', + gamma=0.1, + begin=0, + end=500, + by_epoch=False), + dict(...) # õĖ╗ÕŁ”õ╣ĀńÄćĶ░āÕ║”ÕÖ©ķģŹńĮ« +] +``` + + | +
| MMCV-1.x | +MMEngine | +
|---|---|
| + +```python +lr_config = dict(policy='fixed') +``` + + | ++ +```python +param_scheduler = [ + dict(type='ConstantLR', factor=1) +] +``` + + | +
| MMCV-1.x | +MMEngine | +
|---|---|
| + +```python +lr_config = dict( + policy='step', + step=[8, 11], + gamma=0.1, + by_epoch=True +) +``` + + | ++ +```python +param_scheduler = [ + dict(type='MultiStepLR', + milestones=[8, 11], + gamma=0.1, + by_epoch=True) +] +``` + + | +
| MMCV-1.x | +MMEngine | +
|---|---|
| + +```python +lr_config = dict( + policy='poly', + power=0.7, + min_lr=0.001, + by_epoch=True +) +``` + + | ++ +```python +param_scheduler = [ + dict(type='PolyLR', + power=0.7, + eta_min=0.001, + begin=0, + end=num_epochs, + by_epoch=True) +] +``` + + | +
| MMCV-1.x | +MMEngine | +
|---|---|
| + +```python +lr_config = dict( + policy='exp', + power=0.5, + by_epoch=True +) +``` + + | ++ +```python +param_scheduler = [ + dict(type='ExponentialLR', + gamma=0.5, + begin=0, + end=num_epochs, + by_epoch=True) +] +``` + + | +
| MMCV-1.x | +MMEngine | +
|---|---|
| + +```python +lr_config = dict( + policy='CosineAnnealing', + min_lr=0.5, + by_epoch=True +) +``` + + | ++ +```python +param_scheduler = [ + dict(type='CosineAnnealingLR', + eta_min=0.5, + T_max=num_epochs, + begin=0, + end=num_epochs, + by_epoch=True) +] +``` + + | +
| MMCV-1.x | +MMEngine | +
|---|---|
| + +```python +lr_config = dict( + policy='FlatCosineAnnealing', + start_percent=0.5, + min_lr=0.005, + by_epoch=True +) +``` + + | ++ +```python +param_scheduler = [ + dict(type='ConstantLR', factor=1, begin=0, end=num_epochs * 0.75) + dict(type='CosineAnnealingLR', + eta_min=0.005, + begin=num_epochs * 0.75, + end=num_epochs, + T_max=num_epochs * 0.25, + by_epoch=True) +] +``` + + | +
| MMCV-1.x | +MMEngine | +
|---|---|
| + +```python +lr_config = dict(policy='CosineRestart', + periods=[5, 10, 15], + restart_weights=[1, 0.7, 0.3], + min_lr=0.001, + by_epoch=True) +``` + + | ++ +```python +param_scheduler = [ + dict(type='CosineRestartLR', + periods=[5, 10, 15], + restart_weights=[1, 0.7, 0.3], + eta_min=0.001, + by_epoch=True) +] +``` + + | +
| MMCV-1.x | +MMEngine | +
|---|---|
| + +```python +lr_config = dict(policy='OneCycle', + max_lr=0.02, + total_steps=90000, + pct_start=0.3, + anneal_strategy='cos', + div_factor=25, + final_div_factor=1e4, + three_phase=True, + by_epoch=False) +``` + + | ++ +```python +param_scheduler = [ + dict(type='OneCycleLR', + eta_max=0.02, + total_steps=90000, + pct_start=0.3, + anneal_strategy='cos', + div_factor=25, + final_div_factor=1e4, + three_phase=True, + by_epoch=False) +] +``` + + | +
| MMCV-1.x | +MMEngine | +
|---|---|
| + +```python +lr_config = dict( + policy='LinearAnnealing', + min_lr_ratio=0.01, + by_epoch=True +) +``` + + | ++ +```python +param_scheduler = [ + dict(type='LinearLR', + start_factor=1, + end_factor=0.01, + begin=0, + end=num_epochs, + by_epoch=True) +] +``` + + | +
| MMCV-1.x | +MMEngine | +
|---|---|
| + +```python +lr_config = dict(...) +momentum_config = dict( + policy='CosineAnnealing', + min_momentum=0.1, + by_epoch=True +) +``` + + | ++ +```python +param_scheduler = [ + # ÕŁ”õ╣ĀńÄćĶ░āÕ║”ÕÖ©ķģŹńĮ« + dict(...), + # ÕŖ©ķćÅĶ░āÕ║”ÕÖ©ķģŹńĮ« + dict(type='CosineAnnealingMomentum', + eta_min=0.1, + T_max=num_epochs, + begin=0, + end=num_epochs, + by_epoch=True) +] +``` + + | +
| MMCV-1.x | +MMEngine | +
|---|---|
| + +```python +lr_config = dict( + policy='CosineAnnealing', + min_lr=0.5, + by_epoch=False +) +``` + + | ++ +```python +param_scheduler = [ + dict( + type='CosineAnnealingLR', + eta_min=0.5, + T_max=num_epochs, + by_epoch=True, # µ│©µäÅ’╝īby_epoch ķ£ĆĶ”üĶ«ŠńĮ«õĖ║ True + convert_to_iter_based=True # ĶĮ¼µŹóõĖ║µīē iter µø┤µ¢░ÕÅéµĢ░ + ) +] +``` + + | +
+  +
+
+
+ÕÅ»õ╗źĶ░āńö© [count_registered_modules](mmengine.registry.count_registered_modules) ÕćĮµĢ░µēōÕŹ░ÕĘ▓µ│©ÕåīÕł░ MMEngine ńÜ䵩ĪÕØŚõ╗źÕÅŖÕ▒éń║¦ń╗ōµ×äŃĆé
+
+```python
+from mmengine.registry import count_registered_modules
+
+count_registered_modules()
+```
+
+Õ£© `MMAlpha` õĖŁÕ«Üõ╣ēµ©ĪÕØŚ `LogSoftmax`’╝īÕ╣ČÕŠĆ `MMAlpha` ńÜä `MODELS` µ│©ÕåīŃĆé
+
+```python
+@MODELS.register_module()
+class LogSoftmax(nn.Module):
+ def __init__(self, dim=None):
+ super().__init__()
+
+ def forward(self, x):
+ print('call LogSoftmax.forward')
+ return x
+```
+
+Õ£© `MMAlpha` õĖŁõĮ┐ńö©ķģŹńĮ«Ķ░āńö© `LogSoftmax`
+
+```python
+model = MODELS.build(cfg=dict(type='LogSoftmax'))
+```
+
+õ╣¤ÕÅ»õ╗źÕ£© `MMAlpha` õĖŁĶ░āńö©ńłČĶŖéńé╣ `MMEngine` ńÜ䵩ĪÕØŚŃĆé
+
+```python
+model = MODELS.build(cfg=dict(type='RReLU', lower=0.2))
+# õ╣¤ÕÅ»õ╗źÕŖĀ scope
+model = MODELS.build(cfg=dict(type='mmengine.RReLU'))
+```
+
+Õ”éµ×£õĖŹÕŖĀÕēŹń╝Ć’╝ī`build` µ¢╣µ│Ģķ”¢Õģłµ¤źµēŠÕĮōÕēŹĶŖéńé╣µś»ÕÉ”ÕŁśÕ£©Ķ»źµ©ĪÕØŚ’╝īÕ”éµ×£ÕŁśÕ£©ÕłÖĶ┐öÕø×Ķ»źµ©ĪÕØŚ’╝īÕÉ”ÕłÖõ╝Üń╗¦ń╗ŁÕÉæõĖŖµ¤źµēŠńłČĶŖéńé╣ńöÜĶć│ńź¢ÕģłĶŖéńé╣ńø┤Õł░µēŠÕł░Ķ»źµ©ĪÕØŚ’╝īÕøĀµŁż’╝īÕ”éµ×£ÕĮōÕēŹĶŖéńé╣ÕÆīńłČĶŖéńé╣ÕŁśÕ£©ÕÉīõĖƵ©ĪÕØŚÕ╣ČõĖöÕĖīµ£øĶ░āńö©ńłČĶŖéńé╣ńÜ䵩ĪÕØŚ’╝īµłæõ╗¼ķ£ĆĶ”üµīćÕ«Ü `scope` ÕēŹń╝ĆŃĆé
+
+```python
+import torch
+
+input = torch.randn(2)
+output = model(input)
+# call RReLU.forward
+print(output)
+```
+
+### Ķ░āńö©ÕģäÕ╝¤ĶŖéńé╣ńÜ䵩ĪÕØŚ
+
+ķÖżõ║åÕÅ»õ╗źĶ░āńö©ńłČĶŖéńé╣ńÜ䵩ĪÕØŚ’╝īõ╣¤ÕÅ»õ╗źĶ░āńö©ÕģäÕ╝¤ĶŖéńé╣ńÜ䵩ĪÕØŚŃĆé
+
+ÕüćĶ«Šµ£ēÕÅ”õĖĆõĖ¬ķĪ╣ńø«ÕŽ `MMBeta`’╝īÕ«āÕÆī `MMAlpha` õĖƵĀĘ’╝īÕ«Üõ╣ēõ║å `MODELS` õ╗źÕÅŖĶ«ŠńĮ«ÕģČńłČĶŖéńé╣õĖ║ `MMEngine` ńÜä `MODELS`ŃĆé
+
+```python
+from mmengine import Registry, MODELS as MMENGINE_MODELS
+
+MODELS = Registry('model', parent=MMENGINE_MODELS, scope='mmbeta')
+```
+
+õĖŗÕøŠµś» MMEngine’╝īMMAlpha ÕÆī MMBeta ńÜäµ│©ÕåīÕÖ©Õ▒éń║¦ń╗ōµ×äŃĆé
+
+
+
+  +
+
+
+Õ£© `MMBeta` õĖŁĶ░āńö©ÕģäÕ╝¤ĶŖéńé╣ `MMAlpha` ńÜ䵩ĪÕØŚ’╝ī
+
+```python
+model = MODELS.build(cfg=dict(type='mmalpha.LogSoftmax'))
+output = model(input)
+# call LogSoftmax.forward
+print(output)
+```
+
+Ķ░āńö©ÕģäÕ╝¤ĶŖéńé╣ńÜ䵩ĪÕØŚķ£ĆĶ”üÕ£© `type` õĖŁµīćÕ«Ü `scope` ÕēŹń╝Ć’╝īµēĆõ╗źõĖŖķØóńÜäķģŹńĮ«ķ£ĆĶ”üÕŖĀÕēŹń╝Ć `mmalpha`ŃĆé
+
+Õ”éµ×£ķ£ĆĶ”üĶ░āńö©ÕģäÕ╝¤ĶŖéńé╣ńÜäµĢ░õĖ¬µ©ĪÕØŚ’╝īµ»ÅõĖ¬µ©ĪÕØŚķāĮÕŖĀÕēŹń╝Ć’╝īĶ┐Öķ£ĆĶ”üÕüÜÕż¦ķćÅńÜäõ┐«µö╣ŃĆéõ║ĵś» `MMEngine` Õ╝ĢÕģźõ║å [DefaultScope](mmengine.registry.DefaultScope)’╝ī`Registry` ÕƤÕŖ®Õ«āÕÅ»õ╗źÕŠłµ¢╣õŠ┐Õ£░µö»µīüõĖ┤µŚČÕłćµŹóÕĮōÕēŹĶŖéńé╣õĖ║µīćÕ«ÜńÜäĶŖéńé╣ŃĆé
+
+Õ”éµ×£ķ£ĆĶ”üõĖ┤µŚČÕłćµŹóÕĮōÕēŹĶŖéńé╣õĖ║µīćÕ«ÜńÜäĶŖéńé╣’╝īÕŬķ£ĆÕ£© `cfg` Ķ«ŠńĮ« `_scope_` õĖ║µīćÕ«ÜĶŖéńé╣ńÜäõĮ£ńö©Õ¤¤ŃĆé
+
+```python
+model = MODELS.build(cfg=dict(type='LogSoftmax', _scope_='mmalpha'))
+output = model(input)
+# call LogSoftmax.forward
+print(output)
+```
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/resume_training.md b/internlm_langchain/knowledge_base/MMEngine/content/resume_training.md
new file mode 100644
index 00000000..a7382597
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/resume_training.md
@@ -0,0 +1,36 @@
+# µüóÕżŹĶ«Łń╗ā
+
+µüóÕżŹĶ«Łń╗āµś»µīćõ╗Äõ╣ŗÕēŹµ¤Éµ¼ĪĶ«Łń╗āõ┐ØÕŁśõĖŗµØźńÜäńŖȵĆüÕ╝ĆÕ¦ŗń╗¦ń╗ŁĶ«Łń╗ā’╝īĶ┐ÖķćīńÜäńŖȵĆüÕīģµŗ¼µ©ĪÕ×ŗńÜäµØāķćŹŃĆüõ╝śÕī¢ÕÖ©ÕÆīõ╝śÕī¢ÕÖ©ÕÅéµĢ░Ķ░āµĢ┤ńŁ¢ńĢźńÜäńŖȵĆüŃĆé
+
+## Ķć¬ÕŖ©µüóÕżŹĶ«Łń╗ā
+
+ńö©µłĘÕÅ»õ╗źĶ«ŠńĮ« `Runner` ńÜä `resume` ÕÅéµĢ░Õ╝ĆÕÉ»Ķć¬ÕŖ©µüóÕżŹĶ«Łń╗āńÜäÕŖ¤ĶāĮŃĆéÕ£©ÕÉ»ÕŖ©Ķ«Łń╗āµŚČ’╝īĶ«ŠńĮ« `Runner` ńÜä `resume` ńŁēõ║Ä `True`’╝ī`Runner` õ╝Üõ╗Ä `work_dir` õĖŁÕŖĀĶĮĮµ£Ćµ¢░ńÜä checkpointŃĆéÕ”éµ×£ `work_dir` õĖŁµ£ēµ£Ćµ¢░ńÜä checkpoint’╝łõŠŗÕ”éĶ»źĶ«Łń╗āÕ£©õĖŖõĖƵ¼ĪĶ«Łń╗āµŚČĶó½õĖŁµ¢Ł’╝ē’╝īÕłÖõ╝Üõ╗ÄĶ»ź checkpoint µüóÕżŹĶ«Łń╗ā’╝īÕÉ”ÕłÖ’╝łõŠŗÕ”éõĖŖõĖƵ¼ĪĶ«Łń╗āĶ┐śµ▓ĪµØźÕŠŚÕÅŖõ┐ØÕŁś checkpoint µł¢ĶĆģÕÉ»ÕŖ©õ║åµ¢░ńÜäĶ«Łń╗āõ╗╗ÕŖĪ’╝ēõ╝Üķ揵¢░Õ╝ĆÕ¦ŗĶ«Łń╗āŃĆéõĖŗķØ󵜻õĖĆõĖ¬Õ╝ĆÕÉ»Ķć¬ÕŖ©µüóÕżŹĶ«Łń╗āńÜäńż║õŠŗ
+
+```python
+runner = Runner(
+ model=ResNet18(),
+ work_dir='./work_dir',
+ train_dataloader=train_dataloader_cfg,
+ optim_wrapper=dict(optimizer=dict(type='SGD', lr=0.001, momentum=0.9)),
+ train_cfg=dict(by_epoch=True, max_epochs=3),
+ resume=True,
+)
+runner.train()
+```
+
+## µīćÕ«Ü checkpoint ĶĘ»ÕŠä
+
+Õ”éµ×£ÕĖīµ£øµīćիܵüóÕżŹĶ«Łń╗āńÜäĶĘ»ÕŠä’╝īķÖżõ║åĶ«ŠńĮ« `resume=True`’╝īĶ┐śķ£ĆĶ”üĶ«ŠńĮ« `load_from` ÕÅéµĢ░ŃĆéķ£ĆĶ”üµ│©µäÅńÜ䵜»’╝īÕ”éµ×£ÕŬĶ«ŠńĮ«õ║å `load_from` ĶĆīµ▓Īµ£ēĶ«ŠńĮ« `resume=True`’╝īÕłÖÕŬõ╝ÜÕŖĀĶĮĮ checkpoint õĖŁńÜäµØāķćŹÕ╣Čķ揵¢░Õ╝ĆÕ¦ŗĶ«Łń╗ā’╝īĶĆīõĖŹµś»µÄźńØĆõ╣ŗÕēŹńÜäńŖȵĆüń╗¦ń╗ŁĶ«Łń╗āŃĆé
+
+```python
+runner = Runner(
+ model=ResNet18(),
+ work_dir='./work_dir',
+ train_dataloader=train_dataloader_cfg,
+ optim_wrapper=dict(optimizer=dict(type='SGD', lr=0.001, momentum=0.9)),
+ train_cfg=dict(by_epoch=True, max_epochs=3),
+ load_from='./work_dir/epoch_2.pth',
+ resume=True,
+)
+runner.train()
+```
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/runner.md b/internlm_langchain/knowledge_base/MMEngine/content/runner.md
new file mode 100644
index 00000000..474d7bdc
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/runner.md
@@ -0,0 +1,157 @@
+# µē¦ĶĪīÕÖ©
+
+µĘ▒Õ║”ÕŁ”õ╣Āń«Śµ│ĢńÜäĶ«Łń╗āŃĆüķ¬īĶ»üÕÆīµĄŗĶ»ĢķĆÜÕĖĖķāĮµŗźµ£ēńøĖõ╝╝ńÜ䵥üń©ŗ’╝īÕøĀµŁż’╝ī MMEngine µŖĮĶ▒ĪÕć║õ║åµē¦ĶĪīÕÖ©µØźĶ┤¤Ķ┤ŻķĆÜńö©ńÜäń«Śµ│Ģµ©ĪÕ×ŗńÜäĶ«Łń╗āŃĆüµĄŗĶ»ĢŃĆüµÄ©ńÉåõ╗╗ÕŖĪŃĆéńö©µłĘõĖĆĶł¼ÕÅ»õ╗źńø┤µÄźõĮ┐ńö© MMEngine õĖŁńÜäķ╗śĶ«żµē¦ĶĪīÕÖ©’╝īõ╣¤ÕÅ»õ╗źÕ»╣µē¦ĶĪīÕÖ©Ķ┐øĶĪīõ┐«µö╣õ╗źµ╗ĪĶČ│Õ«ÜÕłČÕī¢ķ£Ćµ▒éŃĆé
+
+Õ£©õ╗ŗń╗Źµē¦ĶĪīÕÖ©ńÜäĶ«ŠĶ«Īõ╣ŗÕēŹ’╝īµłæõ╗¼ÕģłõĖŠÕćĀõĖ¬õŠŗÕŁÉµØźÕĖ«ÕŖ®ńö©µłĘńÉåĶ¦ŻõĖ║õ╗Ćõ╣łķ£ĆĶ”üµē¦ĶĪīÕÖ©ŃĆéõĖŗķØ󵜻õĖƵ«ĄõĮ┐ńö© PyTorch Ķ┐øĶĪīµ©ĪÕ×ŗĶ«Łń╗āńÜäõ╝¬õ╗ŻńĀü’╝Ü
+
+```python
+model = ResNet()
+optimizer = SGD(model.parameters(), lr=0.01, momentum=0.9)
+train_dataset = ImageNetDataset(...)
+train_dataloader = DataLoader(train_dataset, ...)
+
+for i in range(max_epochs):
+ for data_batch in train_dataloader:
+ optimizer.zero_grad()
+ outputs = model(data_batch)
+ loss = loss_func(outputs, data_batch)
+ loss.backward()
+ optimizer.step()
+```
+
+õĖŗķØ󵜻õĖƵ«ĄõĮ┐ńö© PyTorch Ķ┐øĶĪīµ©ĪÕ×ŗµĄŗĶ»ĢńÜäõ╝¬õ╗ŻńĀü’╝Ü
+
+```python
+model = ResNet()
+model.load_state_dict(torch.load(CKPT_PATH))
+model.eval()
+
+test_dataset = ImageNetDataset(...)
+test_dataloader = DataLoader(test_dataset, ...)
+
+for data_batch in test_dataloader:
+ outputs = model(data_batch)
+ acc = calculate_acc(outputs, data_batch)
+```
+
+õĖŗķØ󵜻õĖƵ«ĄõĮ┐ńö© PyTorch Ķ┐øĶĪīµ©ĪÕ×ŗµÄ©ńÉåńÜäõ╝¬õ╗ŻńĀü’╝Ü
+
+```python
+model = ResNet()
+model.load_state_dict(torch.load(CKPT_PATH))
+model.eval()
+
+for img in imgs:
+ prediction = model(img)
+```
+
+ÕÅ»õ╗źõ╗ÄõĖŖķØóńÜäõĖēµ«Ąõ╗ŻńĀüń£ŗÕć║’╝īĶ┐ÖõĖēõĖ¬õ╗╗ÕŖĪńÜäµē¦ĶĪīµĄüń©ŗķāĮÕÅ»õ╗źÕĮÆń║│õĖ║µ×äÕ╗║µ©ĪÕ×ŗŃĆüĶ»╗ÕÅ¢µĢ░µŹ«ŃĆüÕŠ¬ńÄ»Ķ┐Łõ╗ŻńŁēµŁźķ¬żŃĆéõĖŖĶ┐░õ╗ŻńĀüķāĮµś»õ╗źÕøŠÕāÅÕłåń▒╗õĖ║õŠŗ’╝īõĮåõĖŹĶ«║µś»ÕøŠÕāÅÕłåń▒╗Ķ┐śµś»ńø«µĀ浯ƵĄŗµł¢µś»ÕøŠÕāÅÕłåÕē▓’╝īķāĮĶä▒ń”╗õĖŹõ║åĶ┐ÖÕźŚĶīāÕ╝ÅŃĆé
+ÕøĀµŁż’╝īµłæõ╗¼Õ░嵩ĪÕ×ŗńÜäĶ«Łń╗āŃĆüķ¬īĶ»üŃĆüµĄŗĶ»ĢńÜ䵥üń©ŗµĢ┤ÕÉłĶĄĘµØź’╝īÕĮóµłÉõ║åµē¦ĶĪīÕÖ©ŃĆéÕ£©µē¦ĶĪīÕÖ©õĖŁ’╝īµłæõ╗¼ÕŬķ£ĆĶ”üÕćåÕżćÕźĮµ©ĪÕ×ŗŃĆüµĢ░µŹ«ńŁēõ╗╗ÕŖĪÕ┐ģķĪ╗ńÜ䵩ĪÕØŚµł¢µś»Ķ┐Öõ║øµ©ĪÕØŚńÜäķģŹńĮ«µ¢ćõ╗Č’╝īµē¦ĶĪīÕÖ©õ╝ÜĶć¬ÕŖ©Õ«īµłÉõ╗╗ÕŖĪµĄüń©ŗńÜäÕćåÕżćÕÆīµē¦ĶĪīŃĆé
+ķĆÜĶ┐ćõĮ┐ńö©µē¦ĶĪīÕÖ©õ╗źÕÅŖ MMEngine õĖŁõĖ░Õ»īńÜäÕŖ¤ĶāĮµ©ĪÕØŚ’╝īńö©µłĘõĖŹÕåŹķ£ĆĶ”üµēŗÕŖ©µÉŁÕ╗║Ķ«Łń╗āµĄŗĶ»ĢńÜ䵥üń©ŗ’╝īõ╣¤õĖŹÕåŹķ£ĆĶ”üÕÄ╗ÕżäńÉåÕłåÕĖāÕ╝ÅõĖÄķØ×ÕłåÕĖāÕ╝ÅĶ«Łń╗āńÜäÕī║Õł½’╝īÕÅ»õ╗źõĖōµ│©õ║Äń«Śµ│ĢÕÆīµ©ĪÕ×ŗµ£¼Ķ║½ŃĆé
+
+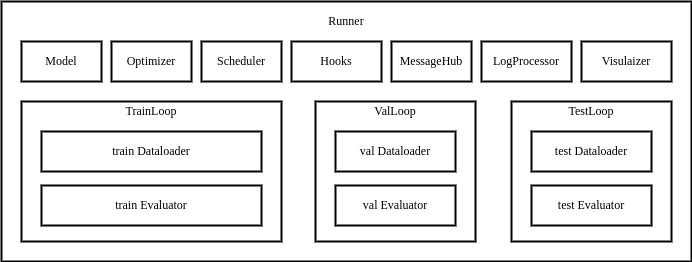
+
+MMEngine ńÜäµē¦ĶĪīÕÖ©ÕåģÕīģÕɽĶ«Łń╗āŃĆüµĄŗĶ»ĢŃĆüķ¬īĶ»üµēĆķ£ĆńÜäÕÉäõĖ¬µ©ĪÕØŚ’╝īõ╗źÕÅŖÕŠ¬ńÄ»µÄ¦ÕłČÕÖ©’╝łLoop’╝ēÕÆī[ķÆ®ÕŁÉ’╝łHook’╝ē](../tutorials/hook.md)ŃĆéńö©µłĘķĆÜĶ┐ćµÅÉõŠøķģŹńĮ«µ¢ćõ╗ȵł¢ÕĘ▓µ×äÕ╗║Õ«īµłÉńÜ䵩ĪÕØŚ’╝īµē¦ĶĪīÕÖ©Õ░åĶć¬ÕŖ©Õ«īµłÉĶ┐ÉĶĪīńÄ»ÕóāńÜäķģŹńĮ«’╝īµ©ĪÕØŚńÜäµ×äÕ╗║ÕÆīń╗äÕÉł’╝īµ£Ćń╗łķĆÜĶ┐ćÕŠ¬ńÄ»µÄ¦ÕłČÕÖ©µē¦ĶĪīõ╗╗ÕŖĪÕŠ¬ńÄ»ŃĆéµē¦ĶĪīÕÖ©Õ»╣Õż¢µÅÉõŠøõĖēõĖ¬µÄźÕÅŻ’╝Ü`train`’╝ī `val`’╝ī `test`’╝īÕĮōĶ░āńö©Ķ┐ÖõĖēõĖ¬µÄźÕÅŻµŚČ’╝īõŠ┐õ╝ÜĶ┐ÉĶĪīÕ»╣Õ║öńÜäÕŠ¬ńÄ»µÄ¦ÕłČÕÖ©’╝īÕ╣ČÕ£©ÕŠ¬ńÄ»ńÜäĶ┐ÉĶĪīĶ┐ćń©ŗõĖŁĶ░āńö©ķÆ®ÕŁÉµ©ĪÕØŚÕÉäõĖ¬õĮŹńé╣ńÜäķÆ®ÕŁÉÕćĮµĢ░ŃĆé
+
+ÕĮōńö©µłĘµ×äÕ╗║õĖĆõĖ¬µē¦ĶĪīÕÖ©Õ╣ČĶ░āńö©Ķ«Łń╗āŃĆüķ¬īĶ»üŃĆüµĄŗĶ»ĢńÜäµÄźÕÅŻµŚČ’╝īµē¦ĶĪīÕÖ©ńÜäµē¦ĶĪīµĄüń©ŗÕ”éõĖŗ’╝ÜÕłøÕ╗║ÕĘźõĮ£ńø«ÕĮĢ -> ķģŹńĮ«Ķ┐ÉĶĪīńÄ»Õóā -> ÕćåÕżćõ╗╗ÕŖĪµēĆķ£Ćµ©ĪÕØŚ -> µ│©ÕåīķÆ®ÕŁÉ -> Ķ┐ÉĶĪīÕŠ¬ńÄ»
+
+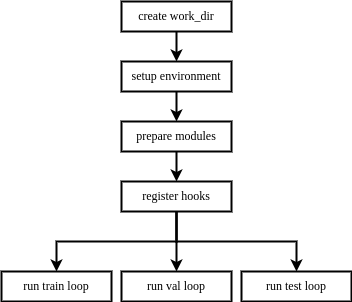
+
+µē¦ĶĪīÕÖ©Õģʵ£ēÕ╗ČĶ┐¤ÕłØÕ¦ŗÕī¢’╝łLazy Initialization’╝ēńÜäńē╣µĆ¦’╝īÕ£©ÕłØÕ¦ŗÕī¢µē¦ĶĪīÕÖ©µŚČ’╝īÕ╣ČõĖŹķ£ĆĶ”üõŠØĶĄ¢Ķ«Łń╗āŃĆüķ¬īĶ»üÕÆīµĄŗĶ»ĢńÜäÕģ©ķćŵ©ĪÕØŚ’╝īÕŬµ£ēÕĮōĶ┐ÉĶĪīµ¤ÉõĖ¬ÕŠ¬ńÄ»µÄ¦ÕłČÕÖ©µŚČ’╝īµēŹõ╝ܵŻĆµ¤źµēĆķ£Ćµ©ĪÕØŚµś»ÕÉ”µ×äÕ╗║ŃĆéÕøĀµŁż’╝īĶŗźńö©µłĘÕŬķ£ĆĶ”üµē¦ĶĪīĶ«Łń╗āŃĆüķ¬īĶ»üµł¢µĄŗĶ»ĢõĖŁńÜ䵤ÉõĖĆķĪ╣ÕŖ¤ĶāĮ’╝īÕŬķ£ĆµÅÉõŠøÕ»╣Õ║öńÜ䵩ĪÕØŚµł¢µ©ĪÕØŚńÜäķģŹńĮ«ÕŹ│ÕÅ»ŃĆé
+
+## ÕŠ¬ńÄ»µÄ¦ÕłČÕÖ©
+
+Õ£© MMEngine õĖŁ’╝īµłæõ╗¼Õ░åõ╗╗ÕŖĪńÜäµē¦ĶĪīµĄüń©ŗµŖĮĶ▒ĪµłÉÕŠ¬ńÄ»µÄ¦ÕłČÕÖ©’╝łLoop’╝ē’╝īÕøĀõĖ║Õż¦ķā©ÕłåńÜäµĘ▒Õ║”ÕŁ”õ╣Āõ╗╗ÕŖĪµē¦ĶĪīµĄüń©ŗķāĮÕÅ»õ╗źÕĮÆń║│õĖ║µ©ĪÕ×ŗÕ£©õĖĆń╗䵳¢ÕżÜń╗äµĢ░µŹ«õĖŖĶ┐øĶĪīÕŠ¬ńÄ»Ķ┐Łõ╗ŻŃĆé
+MMEngine ÕåģµÅÉõŠøõ║åÕøøń¦Źķ╗śĶ«żńÜäÕŠ¬ńÄ»µÄ¦ÕłČÕÖ©’╝Ü
+
+- EpochBasedTrainLoop Õ¤║õ║ÄĶĮ«µ¼ĪńÜäĶ«Łń╗āÕŠ¬ńÄ»
+- IterBasedTrainLoop Õ¤║õ║ÄĶ┐Łõ╗Żµ¼ĪµĢ░ńÜäĶ«Łń╗āÕŠ¬ńÄ»
+- ValLoop µĀćÕćåńÜäķ¬īĶ»üÕŠ¬ńÄ»
+- TestLoop µĀćÕćåńÜ䵥ŗĶ»ĢÕŠ¬ńÄ»
+
+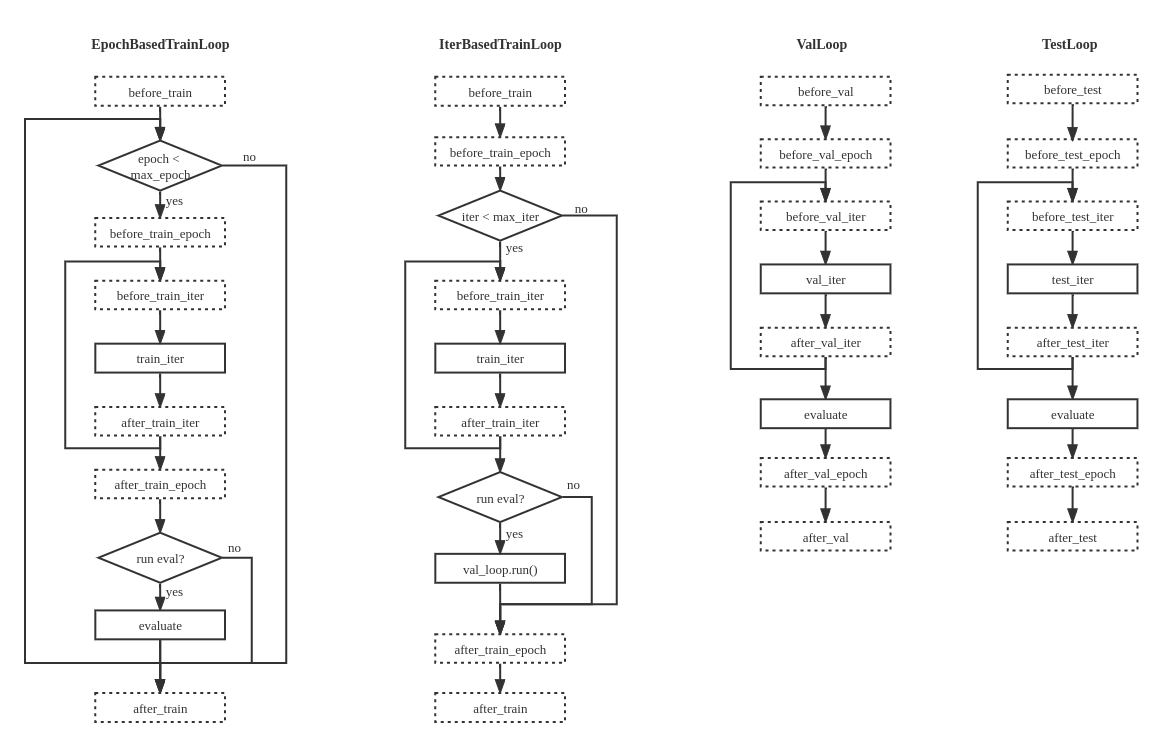
+
+MMEngine õĖŁńÜäķ╗śĶ«żµē¦ĶĪīÕÖ©ÕÆīÕŠ¬ńÄ»µÄ¦ÕłČÕÖ©ĶāĮÕż¤Õ«īµłÉÕż¦ķā©ÕłåńÜäµĘ▒Õ║”ÕŁ”õ╣Āõ╗╗ÕŖĪ’╝īõĮåõĖŹÕÅ»ķü┐ÕģŹõ╝ÜÕŁśÕ£©µŚĀµ│Ģµ╗ĪĶČ│ńÜäµāģÕåĄŃĆéµ£ēńÜäńö©µłĘÕĖīµ£øĶāĮÕż¤Õ»╣µē¦ĶĪīÕÖ©Ķ┐øĶĪīµø┤ÕżÜĶć¬Õ«Üõ╣ēõ┐«µö╣’╝īÕøĀµŁż’╝īMMEngine µö»µīüĶć¬Õ«Üõ╣ēµ©ĪÕ×ŗńÜäĶ«Łń╗āŃĆüķ¬īĶ»üõ╗źÕÅŖµĄŗĶ»ĢńÜ䵥üń©ŗŃĆé
+
+ńö©µłĘÕÅ»õ╗źķĆÜĶ┐ćń╗¦µē┐ÕŠ¬ńĻդ║ń▒╗µØźÕ«×ńÄ░Ķć¬ÕĘ▒ńÜäĶ«Łń╗āµĄüń©ŗŃĆéÕŠ¬ńĻդ║ń▒╗ķ£ĆĶ”üµÅÉõŠøõĖżõĖ¬ĶŠōÕģź’╝Ü`runner` µē¦ĶĪīÕÖ©ńÜäÕ«×õŠŗÕÆī `dataloader` ÕŠ¬ńÄ»µēĆķ£ĆĶ”üĶ┐Łõ╗ŻńÜäĶ┐Łõ╗ŻÕÖ©ŃĆé
+ńö©µłĘÕ”éµ×£µ£ēĶć¬Õ«Üõ╣ēńÜäķ£Ćµ▒é’╝īõ╣¤ÕÅ»õ╗źÕó×ÕŖĀµø┤ÕżÜńÜäĶŠōÕģźÕÅéµĢ░ŃĆéMMEngine õĖŁÕÉīµĀʵÅÉõŠøõ║å LOOPS µ│©ÕåīÕÖ©Õ»╣ÕŠ¬ńÄ»ń▒╗Ķ┐øĶĪīń«ĪńÉå’╝īńö©µłĘÕÅ»õ╗źÕÉæµ│©ÕåīÕÖ©Õåģµ│©ÕåīĶć¬Õ«Üõ╣ēńÜäÕŠ¬ńÄ»µ©ĪÕØŚ’╝īńäČÕÉÄÕ£©ķģŹńĮ«µ¢ćõ╗ČńÜä `train_cfg`ŃĆü`val_cfg`ŃĆü`test_cfg` õĖŁÕó×ÕŖĀ `type` ÕŁŚµ«ĄµØźµīćÕ«ÜõĮ┐ńö©õĮĢń¦ŹÕŠ¬ńÄ»ŃĆé
+ńö©µłĘÕÅ»õ╗źÕ£©Ķć¬Õ«Üõ╣ēńÜäÕŠ¬ńÄ»õĖŁÕ«×ńÄ░õ╗╗µäÅńÜäµē¦ĶĪīķĆ╗ĶŠæ’╝īõ╣¤ÕÅ»õ╗źÕó×ÕŖĀµł¢ÕłĀÕćÅķÆ®ÕŁÉ’╝łhook’╝ēńé╣õĮŹ’╝īõĮåķ£ĆĶ”üµ│©µäÅńÜ䵜»õĖƵŚ”ķÆ®ÕŁÉńé╣õĮŹĶó½õ┐«µö╣’╝īķ╗śĶ«żńÜäķÆ®ÕŁÉÕćĮµĢ░ÕÅ»ĶāĮõĖŹõ╝ÜĶó½µē¦ĶĪī’╝īÕ»╝Ķć┤õĖĆõ║øĶ«Łń╗āĶ┐ćń©ŗõĖŁķ╗śĶ«żÕÅæńö¤ńÜäĶĪīõĖ║ÕÅæńö¤ÕÅśÕī¢ŃĆé
+ÕøĀµŁż’╝īµłæõ╗¼Õ╝║ńāłÕ╗║Ķ««ńö©µłĘµīēńģ¦µ£¼µ¢ćµĪŻõĖŁÕ«Üõ╣ēńÜäÕŠ¬ńÄ»µē¦ĶĪīµĄüń©ŗÕøŠõ╗źÕÅŖ[ķÆ®ÕŁÉĶ«ŠĶ«Ī](../tutorials/hook.md) ÕÄ╗ķćŹĶĮĮÕŠ¬ńĻդ║ń▒╗ŃĆé
+
+```python
+from mmengine.registry import LOOPS, HOOKS
+from mmengine.runner import BaseLoop
+from mmengine.hooks import Hook
+
+
+# Ķć¬Õ«Üõ╣ēķ¬īĶ»üÕŠ¬ńÄ»
+@LOOPS.register_module()
+class CustomValLoop(BaseLoop):
+ def __init__(self, runner, dataloader, evaluator, dataloader2):
+ super().__init__(runner, dataloader, evaluator)
+ self.dataloader2 = runner.build_dataloader(dataloader2)
+
+ def run(self):
+ self.runner.call_hooks('before_val_epoch')
+ for idx, data_batch in enumerate(self.dataloader):
+ self.runner.call_hooks(
+ 'before_val_iter', batch_idx=idx, data_batch=data_batch)
+ outputs = self.run_iter(idx, data_batch)
+ self.runner.call_hooks(
+ 'after_val_iter', batch_idx=idx, data_batch=data_batch, outputs=outputs)
+ metric = self.evaluator.evaluate()
+
+ # Õó×ÕŖĀķóØÕż¢ńÜäķ¬īĶ»üÕŠ¬ńÄ»
+ for idx, data_batch in enumerate(self.dataloader2):
+ # Õó×ÕŖĀķóØÕż¢ńÜäķÆ®ÕŁÉńé╣õĮŹ
+ self.runner.call_hooks(
+ 'before_valloader2_iter', batch_idx=idx, data_batch=data_batch)
+ self.run_iter(idx, data_batch)
+ # Õó×ÕŖĀķóØÕż¢ńÜäķÆ®ÕŁÉńé╣õĮŹ
+ self.runner.call_hooks(
+ 'after_valloader2_iter', batch_idx=idx, data_batch=data_batch, outputs=outputs)
+ metric2 = self.evaluator.evaluate()
+
+ ...
+
+ self.runner.call_hooks('after_val_epoch')
+
+
+# Õ«Üõ╣ēķóØÕż¢ńé╣õĮŹńÜäķÆ®ÕŁÉń▒╗
+@HOOKS.register_module()
+class CustomValHook(Hook):
+ def before_valloader2_iter(self, batch_idx, data_batch):
+ ...
+
+ def after_valloader2_iter(self, batch_idx, data_batch, outputs):
+ ...
+
+```
+
+õĖŖķØóńÜäõŠŗÕŁÉõĖŁÕ«×ńÄ░õ║åõĖĆõĖ¬õĖÄķ╗śĶ«żķ¬īĶ»üÕŠ¬ńÄ»õĖŹõĖƵĀĘńÜäĶć¬Õ«Üõ╣ēķ¬īĶ»üÕŠ¬ńÄ»’╝īÕ«āÕ£©õĖżõĖ¬õĖŹÕÉīńÜäķ¬īĶ»üķøåõĖŖĶ┐øĶĪīķ¬īĶ»ü’╝īÕÉīµŚČÕ»╣ń¼¼õ║īµ¼Īķ¬īĶ»üÕó×ÕŖĀõ║åķóØÕż¢ńÜäķÆ®ÕŁÉńé╣õĮŹ’╝īÕ╣ČÕ£©µ£ĆÕÉÄÕ»╣õĖżõĖ¬ķ¬īĶ»üń╗ōµ×£Ķ┐øĶĪīĶ┐øõĖƵŁźńÜäÕżäńÉåŃĆéÕ£©Õ«×ńÄ░õ║åĶć¬Õ«Üõ╣ēńÜäÕŠ¬ńÄ»ń▒╗õ╣ŗÕÉÄ’╝īÕŬķ£ĆĶ”üÕ£©ķģŹńĮ«µ¢ćõ╗ČńÜä `val_cfg` ÕåģĶ«ŠńĮ« `type='CustomValLoop'`’╝īÕ╣ȵĘ╗ÕŖĀķóØÕż¢ńÜäķģŹńĮ«ÕŹ│ÕÅ»ŃĆé
+
+```python
+# Ķć¬Õ«Üõ╣ēķ¬īĶ»üÕŠ¬ńÄ»
+val_cfg = dict(type='CustomValLoop', dataloader2=dict(dataset=dict(type='ValDataset2'), ...))
+# ķóØÕż¢ńé╣õĮŹńÜäķÆ®ÕŁÉ
+custom_hooks = [dict(type='CustomValHook')]
+```
+
+## Ķć¬Õ«Üõ╣ēµē¦ĶĪīÕÖ©
+
+µø┤Ķ┐øõĖƵŁź’╝īÕ”éµ×£ķ╗śĶ«żµē¦ĶĪīÕÖ©õĖŁõŠØńäȵ£ēÕģČõ╗¢µŚĀµ│Ģµ╗ĪĶČ│ķ£Ćµ▒éńÜäķā©Õłå’╝īńö©µłĘÕÅ»õ╗źÕāÅĶć¬Õ«Üõ╣ēÕģČõ╗¢µ©ĪÕØŚõĖƵĀĘ’╝īķĆÜĶ┐ćń╗¦µē┐ķćŹÕåÖńÜäµ¢╣Õ╝Å’╝īÕ«×ńÄ░Ķć¬Õ«Üõ╣ēńÜäµē¦ĶĪīÕÖ©ŃĆéµē¦ĶĪīÕÖ©ÕÉīµĀĘõ╣¤ÕÅ»õ╗źķĆÜĶ┐ćµ│©ÕåīÕÖ©Ķ┐øĶĪīń«ĪńÉåŃĆéÕģĘõĮōÕ«×ńÄ░µĄüń©ŗõĖÄÕģČõ╗¢µ©ĪÕØŚµŚĀÕ╝é’╝Üń╗¦µē┐ MMEngine õĖŁńÜä Runner’╝īķćŹÕåÖķ£ĆĶ”üõ┐«µö╣ńÜäÕćĮµĢ░’╝īµĘ╗ÕŖĀĶ┐ø RUNNERS µ│©ÕåīÕÖ©õĖŁ’╝īµ£ĆÕÉÄÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁµīćÕ«Ü `runner_type` ÕŹ│ÕÅ»ŃĆé
+
+```python
+from mmengine.registry import RUNNERS
+from mmengine.runner import Runner
+
+@RUNNERS.register_module()
+class CustomRunner(Runner):
+
+ def setup_env(self):
+ ...
+```
+
+õĖŖĶ┐░õŠŗÕŁÉÕ«×ńÄ░õ║åõĖĆõĖ¬Ķć¬Õ«Üõ╣ēńÜäµē¦ĶĪīÕÖ©’╝īÕ╣ČķćŹÕåÖõ║å `setup_env` ÕćĮµĢ░’╝īńäČÕÉĵĘ╗ÕŖĀĶ┐øõ║å RUNNERS µ│©ÕåīÕÖ©õĖŁ’╝īÕ«īµłÉõ║åĶ┐Öõ║øµŁźķ¬żõ╣ŗÕÉÄ’╝īõŠ┐ÕÅ»õ╗źÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁĶ«ŠńĮ« `runner_type='CustomRunner'` µØźµ×äÕ╗║Ķć¬Õ«Üõ╣ēńÜäµē¦ĶĪīÕÖ©ŃĆé
+
+õĮĀÕÅ»ĶāĮĶ┐śµā│ķśģĶ»╗[µē¦ĶĪīÕÖ©ńÜäµĢÖń©ŗ](../tutorials/runner.md)µł¢ĶĆģ[µē¦ĶĪīÕÖ©ńÜä API µ¢ćµĪŻ](mmengine.runner.Runner)ŃĆé
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/save_gpu_memory.md b/internlm_langchain/knowledge_base/MMEngine/content/save_gpu_memory.md
new file mode 100644
index 00000000..efa95264
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/save_gpu_memory.md
@@ -0,0 +1,120 @@
+# ĶŖéń£üµśŠÕŁś
+
+Õ£©µĘ▒Õ║”ÕŁ”õ╣ĀĶ«Łń╗āµÄ©ńÉåĶ┐ćń©ŗõĖŁµśŠÕŁśÕ«╣ķćÅĶć│Õģ│ķćŹĶ”ü’╝īÕģČÕå│Õ«Üõ║嵩ĪÕ×ŗµś»ÕÉ”ĶāĮµłÉÕŖ¤Ķ┐ÉĶĪīŃĆéÕĖĖĶ¦üńÜäĶŖéń£üµśŠÕŁśÕŖ×µ│ĢÕīģµŗ¼’╝Ü
+
+- ÕÉ»ńö©ķ½śµĢłÕŹĘń¦»BNĶ»äõ╝░ÕŖ¤ĶāĮ’╝łÕ«×ķ¬īµĆ¦’╝ē
+
+ Õ¤║õ║ÄÕ£©[Ķ┐Öń»ćĶ«║µ¢ć](https://arxiv.org/abs/2305.11624)õĖŁĶ«©Ķ«║ńÜäµ”éÕ┐Ą’╝īµłæõ╗¼µ£ĆĶ┐æÕ£©MMCVõĖŁ[Õ╝ĢÕģź](https://github.com/open-mmlab/mmcv/pull/2807)õ║åõĖĆõĖ¬Õ«×ķ¬īµĆ¦ÕŖ¤ĶāĮ’╝Üķ½śµĢłÕŹĘń¦»BNĶ»äõ╝░ŃĆéĶ┐ÖõĖ¬ÕŖ¤ĶāĮńÜäĶ«ŠĶ«Īńø«µĀ浜»Õ£©õĖŹµŹ¤Õ«│µĆ¦ĶāĮńÜäµāģÕåĄõĖŗÕćÅÕ░æńĮæń╗£Ķ«Łń╗āĶ┐ćń©ŗõĖŁńÜ䵜ŠÕŁśÕŹĀńö©ŃĆéÕ”éµ×£õĮĀńÜäńĮæń╗£µ×ȵ×äÕīģÕɽõ║åõĖĆń│╗ÕłŚĶ┐×ń╗ŁńÜäConv+BNµ©ĪÕØŚ’╝īĶĆīõĖöĶ┐Öõ║øBNÕ▒éÕ£©Ķ«Łń╗āĶ┐ćń©ŗõĖŁõ┐صīüÕ£© `eval` µ©ĪÕ╝Å’╝łÕ£©õĮ┐ńö© [MMDetection](https://github.com/open-mmlab/mmdetection)Ķ«Łń╗āÕ»╣Ķ▒ĪµŻĆµĄŗÕÖ©µŚČÕŠłÕĖĖĶ¦ü’╝ē’╝īĶ┐ÖõĖ¬ÕŖ¤ĶāĮÕÅ»õ╗źÕ░åµśŠÕŁśµČłĶĆŚÕćÅÕ░æĶČģĶ┐ć $20%$ŃĆéĶ”üÕÉ»ńö©ķ½śµĢłÕŹĘń¦»BNĶ»äõ╝░ÕŖ¤ĶāĮ’╝īÕŬķ£ĆµĘ╗ÕŖĀõ╗źõĖŗÕæĮõ╗żĶĪīÕÅéµĢ░’╝Ü`--cfg-options efficient_conv_bn_eval="[backbone]"`ŃĆéÕĮōõĮĀÕ£©ĶŠōÕć║µŚźÕ┐ŚõĖŁń£ŗÕł░ `Enabling the "efficient_conv_bn_eval" feature for these modules ...`µŚČ’╝īµäÅÕæ│ńØĆÕŖ¤ĶāĮÕĘ▓µłÉÕŖ¤ÕÉ»ńö©ŃĆéńö▒õ║ÄĶ┐Öõ╗ŹÕżäõ║ÄÕ«×ķ¬īķśČµ«Ą’╝īµłæõ╗¼ķØ×ÕĖĖµ£¤ÕŠģÕÉ¼Õł░õĮĀÕ»╣Õ«āńÜäõĮ┐ńö©õĮōķ¬īŃĆéĶ»ĘÕ£©[Ķ┐ÖõĖ¬Ķ«©Ķ«║ń║┐ń©ŗ](https://github.com/open-mmlab/mmengine/discussions/1252)Õłåõ║½õĮĀńÜäõĮ┐ńö©µŖźÕæŖŃĆüĶ¦éÕ»¤ÕÆīÕ╗║Ķ««ŃĆéõĮĀńÜäÕÅŹķ”łÕ»╣õ║ÄĶ┐øõĖƵŁźńÜäÕ╝ĆÕÅæÕÆīńĪ«Õ«Üµś»ÕÉ”Õ║öÕ░åµŁżÕŖ¤ĶāĮķøåµłÉÕł░ń©│Õ«ÜńēłõĖŁĶć│Õģ│ķćŹĶ”üŃĆé
+
+- µó»Õ║”ń┤»ÕŖĀ
+
+ µó»Õ║”ń┤»ÕŖĀµś»µīćÕ£©µ»ÅĶ«Īń«ŚõĖĆõĖ¬µē╣µ¼ĪńÜäµó»Õ║”ÕÉÄ’╝īõĖŹĶ┐øĶĪīµĖģķøČĶĆīµś»Ķ┐øĶĪīµó»Õ║”ń┤»ÕŖĀ’╝īÕĮōń┤»ÕŖĀÕł░õĖĆÕ«ÜńÜäµ¼ĪµĢ░õ╣ŗÕÉÄ’╝īÕåŹµø┤µ¢░ńĮæń╗£ÕÅéµĢ░ÕÆīµó»Õ║”µĖģķøČŃĆé ķĆÜĶ┐ćĶ┐Öń¦ŹÕÅéµĢ░Õ╗ČĶ┐¤µø┤µ¢░ńÜäµēŗµ«Ą’╝īÕ«×ńÄ░õĖÄķććńö©Õż¦ batch Õ░║Õ»ĖńøĖĶ┐æńÜäµĢłµ×£’╝īĶŠŠÕł░ĶŖéń£üµśŠÕŁśńÜäńø«ńÜäŃĆéõĮåµś»ķ£ĆĶ”üµ│©µäÅÕ”éµ×£µ©ĪÕ×ŗõĖŁÕīģÕɽ batch normalization Õ▒é’╝īõĮ┐ńö©µó»Õ║”ń┤»ÕŖĀõ╝ÜÕ»╣µĆ¦ĶāĮµ£ēõĖĆÕ«ÜÕĮ▒ÕōŹŃĆé
+
+- µó»Õ║”µŻĆµ¤źńé╣
+
+ µó»Õ║”µŻĆµ¤źńé╣µś»õĖĆń¦Źõ╗źµŚČķŚ┤µŹóń®║ķŚ┤ńÜäµ¢╣µ│Ģ’╝īķĆÜĶ┐ćÕćÅÕ░æõ┐ØÕŁśńÜäµ┐Ƶ┤╗ÕĆ╝µØźÕÄŗń╝®µ©ĪÕ×ŗÕŹĀńö©ń®║ķŚ┤’╝īõĮåµś»Õ£©Ķ«Īń«Śµó»Õ║”µŚČÕ┐ģķĪ╗ķ揵¢░Ķ«Īń«Śµ▓Īµ£ēÕŁśÕé©ńÜäµ┐Ƶ┤╗ÕĆ╝ŃĆéÕ£© torch.utils.checkpoint ÕīģõĖŁÕĘ▓ń╗ÅÕ«×ńÄ░õ║åÕ»╣Õ║öÕŖ¤ĶāĮŃĆéń«ĆĶ”üÕ«×ńÄ░Ķ┐ćń©ŗµś»’╝ÜÕ£©ÕēŹÕÉæķśČµ«Ąõ╝ĀķĆÆÕł░ checkpoint õĖŁńÜä forward ÕćĮµĢ░õ╝Üõ╗ź `torch.no_grad` µ©ĪÕ╝ÅĶ┐ÉĶĪī’╝īÕ╣ČõĖöõ╗ģõ╗ģõ┐ØÕŁś forward ÕćĮµĢ░ńÜäĶŠōÕģźÕÆīĶŠōÕć║’╝īńäČÕÉÄÕ£©ÕÅŹÕÉæķśČµ«Ąķ揵¢░Ķ«Īń«ŚõĖŁķŚ┤Õ▒éńÜäµ┐Ƶ┤╗ÕĆ╝ ’╝łintermediate activations’╝ēŃĆé
+
+- Õż¦µ©ĪÕ×ŗĶ«Łń╗āµŖƵ£»
+
+ µ£ĆĶ┐æńÜäńĀöń®ČĶĪ©µśÄÕż¦Õ×ŗµ©ĪÕ×ŗĶ«Łń╗āÕ░åµ£ēÕł®õ║ĵÅÉķ½śµ©ĪÕ×ŗĶ┤©ķćÅ’╝īõĮåµś»Ķ«Łń╗āÕ”éµŁżÕż¦ńÜ䵩ĪÕ×ŗķ£ĆĶ”üÕĘ©Õż¦ńÜäĶĄäµ║É’╝īÕŹĢÕŹĪµśŠÕŁśÕĘ▓ń╗ÅĶČŖµØźĶČŖķÜŠõ╗źµ╗ĪĶČ│ÕŁśµöŠµĢ┤õĖ¬µ©ĪÕ×ŗ’╝īÕøĀµŁżĶ»×ńö¤õ║åÕż¦µ©ĪÕ×ŗĶ«Łń╗āµŖƵ£»’╝īÕģĖÕ×ŗńÜäÕ”é [DeepSpeed ZeRO](https://www.deepspeed.ai/tutorials/zero/#zero-overview) ÕÆī FairScale ńÜä[Õ«īÕģ©ÕłåńēćµĢ░µŹ«Õ╣ČĶĪī](https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/)’╝łFully Sharded Data Parallel, FSDP’╝ēµŖƵ£»’╝īÕģČÕģüĶ«ĖÕ£©µĢ░µŹ«Õ╣ČĶĪīĶ┐øń©ŗõ╣ŗķŚ┤Õłåńē浩ĪÕ×ŗńÜäÕÅéµĢ░ŃĆüµó»Õ║”ÕÆīõ╝śÕī¢ÕÖ©ńŖȵĆü’╝īÕ╣ČÕÉīµŚČõ╗ŹńäČõ┐صīüµĢ░µŹ«Õ╣ČĶĪīńÜäń«ĆÕŹĢµĆ¦ŃĆé
+
+MMEngine ńø«ÕēŹµö»µīü`µó»Õ║”ń┤»ÕŖĀ`ÕÆī`Õż¦µ©ĪÕ×ŗĶ«Łń╗ā FSDP µŖƵ£» `ŃĆéõĖŗķØóĶ»┤µśÄÕģČńö©µ│ĢŃĆé
+
+## µó»Õ║”ń┤»ÕŖĀ
+
+ķģŹńĮ«ÕåÖµ│ĢÕ”éõĖŗµēĆńż║’╝Ü
+
+```python
+optim_wrapper_cfg = dict(
+ type='OptimWrapper',
+ optimizer=dict(type='SGD', lr=0.001, momentum=0.9),
+ # ń┤»ÕŖĀ 4 µ¼ĪÕÅéµĢ░µø┤µ¢░õĖƵ¼Ī
+ accumulative_counts=4)
+```
+
+ķģŹÕÉł Runner õĮ┐ńö©ńÜäÕ«īµĢ┤õŠŗÕŁÉÕ”éõĖŗ’╝Ü
+
+```python
+import torch
+import torch.nn as nn
+from torch.utils.data import DataLoader
+from mmengine.runner import Runner
+from mmengine.model import BaseModel
+
+train_dataset = [(torch.ones(1, 1), torch.ones(1, 1))] * 50
+train_dataloader = DataLoader(train_dataset, batch_size=2)
+
+
+class ToyModel(BaseModel):
+ def __init__(self) -> None:
+ super().__init__()
+ self.linear = nn.Linear(1, 1)
+
+ def forward(self, img, label, mode):
+ feat = self.linear(img)
+ loss1 = (feat - label).pow(2)
+ loss2 = (feat - label).abs()
+ return dict(loss1=loss1, loss2=loss2)
+
+
+runner = Runner(
+ model=ToyModel(),
+ work_dir='tmp_dir',
+ train_dataloader=train_dataloader,
+ train_cfg=dict(by_epoch=True, max_epochs=1),
+ optim_wrapper=dict(optimizer=dict(type='SGD', lr=0.01),
+ accumulative_counts=4)
+)
+runner.train()
+```
+
+## Õż¦µ©ĪÕ×ŗĶ«Łń╗ā
+
+```{warning}
+Õ”éµ×£õĮĀµ£ēĶ«Łń╗āÕż¦µ©ĪÕ×ŗńÜäķ£Ćµ▒é’╝īµÄ©ĶŹÉķśģĶ»╗[Õż¦µ©ĪÕ×ŗĶ«Łń╗ā](./large_model_training.md)ŃĆé
+```
+
+PyTorch 1.11 õĖŁÕĘ▓ń╗ÅÕĤńö¤µö»µīüõ║å FSDP µŖƵ£»ŃĆéķģŹńĮ«ÕåÖµ│ĢÕ”éõĖŗµēĆńż║’╝Ü
+
+```python
+# õĮŹõ║Ä cfg ķģŹńĮ«µ¢ćõ╗ČõĖŁ
+model_wrapper_cfg=dict(type='MMFullyShardedDataParallel', cpu_offload=True)
+```
+
+ķģŹÕÉł Runner õĮ┐ńö©ńÜäÕ«īµĢ┤õŠŗÕŁÉÕ”éõĖŗ’╝Ü
+
+```python
+import torch
+import torch.nn as nn
+from torch.utils.data import DataLoader
+from mmengine.runner import Runner
+from mmengine.model import BaseModel
+
+train_dataset = [(torch.ones(1, 1), torch.ones(1, 1))] * 50
+train_dataloader = DataLoader(train_dataset, batch_size=2)
+
+
+class ToyModel(BaseModel):
+ def __init__(self) -> None:
+ super().__init__()
+ self.linear = nn.Linear(1, 1)
+
+ def forward(self, img, label, mode):
+ feat = self.linear(img)
+ loss1 = (feat - label).pow(2)
+ loss2 = (feat - label).abs()
+ return dict(loss1=loss1, loss2=loss2)
+
+
+runner = Runner(
+ model=ToyModel(),
+ work_dir='tmp_dir',
+ train_dataloader=train_dataloader,
+ train_cfg=dict(by_epoch=True, max_epochs=1),
+ optim_wrapper=dict(optimizer=dict(type='SGD', lr=0.01)),
+ cfg=dict(model_wrapper_cfg=dict(type='MMFullyShardedDataParallel', cpu_offload=True))
+)
+runner.train()
+```
+
+µ│©µäÅÕ┐ģķĪ╗Õ£©ÕłåÕĖāÕ╝ÅĶ«Łń╗āńÄ»ÕóāõĖŁ FSDP µēŹĶāĮńö¤µĢłŃĆé
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/set_interval.md b/internlm_langchain/knowledge_base/MMEngine/content/set_interval.md
new file mode 100644
index 00000000..38073760
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/set_interval.md
@@ -0,0 +1,116 @@
+# Ķ«ŠńĮ«µŚźÕ┐ŚŃĆüµØāķćŹõ┐ØÕŁśŃĆüķ¬īĶ»üńÜäķóæńÄć
+
+MMEngine µö»µīüõĖżń¦ŹĶ«Łń╗āµ©ĪÕ╝Å’╝īÕ¤║õ║ÄĶĮ«µ¼ĪńÜä `EpochBased` µ¢╣Õ╝ÅÕÆīÕ¤║õ║ÄĶ┐Łõ╗Żµ¼ĪµĢ░ńÜä `IterBased` µ¢╣Õ╝Å’╝īĶ┐ÖõĖżń¦Źµ¢╣Õ╝ÅÕ£©õĖŗµĖĖń«Śµ│ĢÕ║ōÕØćµ£ēõĮ┐ńö©’╝īõŠŗÕ”é [MMDetection](https://github.com/open-mmlab/mmdetection) ķ╗śĶ«żõĮ┐ńö© EpochBased µ¢╣Õ╝Å’╝ī[MMSegmentation](https://github.com/open-mmlab/mmsegmentation) ķ╗śĶ«żõĮ┐ńö© IterBased µ¢╣Õ╝ÅŃĆé
+
+Õ£©õĖŹÕÉīńÜäĶ«Łń╗āµ©ĪÕ╝ÅõĖŗ’╝īMMEngine ķŚ┤ķÜö’╝łinterval’╝ēńÜäĶ»Łõ╣ēõ╝ܵ£ēÕī║Õł½’╝ī`EpochBased` ńÜäķŚ┤ķÜöõ╗ź `Epoch` õĖ║ÕŹĢõĮŹ’╝ī`IterBased` õ╗ź `Iteration` õĖ║ÕŹĢõĮŹŃĆé
+
+## Ķ«ŠńĮ«Ķ«Łń╗āÕÆīķ¬īĶ»üńÜäķŚ┤ķÜö
+
+Ķ«ŠńĮ« [Runner](mmengine.runner.Runner) ÕłØÕ¦ŗÕī¢ÕÅéµĢ░ `train_cfg` õĖŁńÜä `val_interval` ÕĆ╝ÕŹ│ÕŻիÜÕłČĶ«Łń╗āÕÆīķ¬īĶ»üńÜäķŚ┤ķÜöŃĆé
+
+- EpochBased
+
+Õ£© `EpochBased` µ©ĪÕ╝ÅõĖŗ’╝ī`val_interval` ńÜäķ╗śĶ«żÕĆ╝õĖ║ 1’╝īĶĪ©ńż║Ķ«Łń╗āõĖĆõĖ¬ Epoch’╝īķ¬īĶ»üõĖƵ¼ĪŃĆé
+
+```python
+runner = Runner(
+ model=MMResNet50(),
+ work_dir='./work_dir',
+ train_dataloader=train_dataloader,
+ optim_wrapper=dict(optimizer=dict(type=SGD, lr=0.001, momentum=0.9)),
+ train_cfg=dict(by_epoch=True, max_epochs=5, val_interval=1),
+ val_dataloader=val_dataloader,
+ val_cfg=dict(),
+ val_evaluator=dict(type=Accuracy),
+)
+runner.train()
+```
+
+- IterBased
+
+Õ£© `IterBased` µ©ĪÕ╝ÅõĖŗ’╝ī`val_interval` ńÜäķ╗śĶ«żÕĆ╝õĖ║ 1000’╝īĶĪ©ńż║Ķ«Łń╗āĶ┐Łõ╗Ż 1000 µ¼Ī’╝īķ¬īĶ»üõĖƵ¼ĪŃĆé
+
+```python
+runner = Runner(
+ model=MMResNet50(),
+ work_dir='./work_dir',
+ train_dataloader=train_dataloader,
+ optim_wrapper=dict(optimizer=dict(type=SGD, lr=0.001, momentum=0.9)),
+ train_cfg=dict(by_epoch=False, max_iters=10000, val_interval=2000),
+ val_dataloader=val_dataloader,
+ val_cfg=dict(),
+ val_evaluator=dict(type=Accuracy),
+)
+runner.train()
+```
+
+## Ķ«ŠńĮ«õ┐ØÕŁśµØāķćŹńÜäķŚ┤ķÜö
+
+Ķ«ŠńĮ« [CheckpointHook](mmengine.hooks.CheckpointHook) ńÜä `interval` ÕĆ╝ÕŹ│ÕŻիÜÕłČõ┐ØÕŁśµØāķćŹńÜäķŚ┤ķÜöŃĆé
+
+- EpochBased
+
+Õ£© `EpochBased` µ©ĪÕ╝ÅõĖŗ’╝ī`interval` ńÜäķ╗śĶ«żÕĆ╝õĖ║ 1’╝īĶĪ©ńż║Ķ«Łń╗āõĖĆõĖ¬ Epoch’╝īõ┐ØÕŁśõĖƵ¼ĪµØāķćŹŃĆé
+
+```python
+# Õ░å interval Ķ«ŠńĮ«õĖ║ 2’╝īĶĪ©ńż║µ»Å 2 õĖ¬ epoch õ┐ØÕŁśõĖƵ¼ĪµØāķćŹ
+default_hooks = dict(checkpoint=dict(type='CheckpointHook', interval=2))
+runner = Runner(
+ model=MMResNet50(),
+ work_dir='./work_dir',
+ train_dataloader=train_dataloader,
+ optim_wrapper=dict(optimizer=dict(type=SGD, lr=0.001, momentum=0.9)),
+ train_cfg=dict(by_epoch=True, max_epochs=5, val_interval=1),
+ val_dataloader=val_dataloader,
+ val_cfg=dict(),
+ val_evaluator=dict(type=Accuracy),
+ default_hooks=default_hooks,
+)
+runner.train()
+```
+
+- IterBased
+
+ķ╗śĶ«żõ╗ź Epoch õĖ║ÕŹĢõĮŹõ┐ØÕŁśµØāķ插╝īÕ”éµ×£ÕĖīµ£øõ╗ź Iteration õĖ║ÕŹĢõĮŹ’╝īķ£ĆĶ«ŠńĮ« `by_epoch=False`ŃĆé
+
+```python
+# Ķ«ŠńĮ« by_epoch=False õ╗źÕÅŖ interval = 500’╝īĶĪ©ńż║µ»Å 500 õĖ¬ iteration õ┐ØÕŁśõĖƵ¼ĪµØāķćŹ
+default_hooks = dict(checkpoint=dict(type='CheckpointHook', by_epoch=False, interval=500))
+runner = Runner(
+ model=MMResNet50(),
+ work_dir='./work_dir',
+ train_dataloader=train_dataloader,
+ optim_wrapper=dict(optimizer=dict(type=SGD, lr=0.001, momentum=0.9)),
+ train_cfg=dict(by_epoch=False, max_iters=10000, val_interval=1000),
+ val_dataloader=val_dataloader,
+ val_cfg=dict(),
+ val_evaluator=dict(type=Accuracy),
+ default_hooks=default_hooks,
+)
+runner.train()
+```
+
+`CheckpointHook` ńÜäµø┤ÕżÜńö©µ│ĢÕÅ»µ¤źń£ŗ [CheckpointHook µĢÖń©ŗ](../tutorials/hook.md#checkpointhook)ŃĆé
+
+## Ķ«ŠńĮ«µēōÕŹ░µŚźÕ┐ŚńÜäķŚ┤ķÜö
+
+ķ╗śĶ«żµāģÕåĄõĖŗ’╝īµ»ÅĶ┐Łõ╗Ż 10 µ¼ĪÕŠĆń╗łń½»µēōÕŹ░ 1 µ¼ĪµŚźÕ┐Ś’╝īÕÅ»õ╗źķĆÜĶ┐ćĶ«ŠńĮ« [LoggerHook](mmengine.hooks.LoggerHook) ńÜä `interval` ÕÅéµĢ░Ķ┐øĶĪīĶ«ŠńĮ«ŃĆé
+
+```python
+# Ķ«ŠńĮ«µ»Å 20 µ¼ĪµēōÕŹ░õĖƵ¼Ī
+default_hooks = dict(logger=dict(type='LoggerHook', interval=20))
+runner = Runner(
+ model=MMResNet50(),
+ work_dir='./work_dir',
+ train_dataloader=train_dataloader,
+ optim_wrapper=dict(optimizer=dict(type=SGD, lr=0.001, momentum=0.9)),
+ train_cfg=dict(by_epoch=True, max_epochs=5, val_interval=1),
+ val_dataloader=val_dataloader,
+ val_cfg=dict(),
+ val_evaluator=dict(type=Accuracy),
+ default_hooks=default_hooks,
+)
+runner.train()
+```
+
+`LoggerHook` ńÜäµø┤ÕżÜńö©µ│ĢÕÅ»µ¤źń£ŗ [LoggerHook µĢÖń©ŗ](../tutorials/hook.md#loggerhook)ŃĆé
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/set_random_seed.md b/internlm_langchain/knowledge_base/MMEngine/content/set_random_seed.md
new file mode 100644
index 00000000..7b0ce555
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/set_random_seed.md
@@ -0,0 +1,29 @@
+# Ķ«ŠńĮ«ķÜŵ£║ń¦ŹÕŁÉ
+
+Õ£© [PyTorch REPRODUCIBILITY](https://pytorch.org/docs/stable/notes/randomness.html) õĖŁõ╗ŗń╗Źõ║åÕĮ▒ÕōŹÕ«×ķ¬īµś»ÕÉ”ÕÅ»ÕżŹńÄ░ńÜäõĖżõĖ¬ÕøĀń┤Ā’╝īõĖĆõĖ¬µś»ķÜŵ£║µĢ░’╝īÕÅ”õĖĆõĖ¬µś»µ¤Éõ║øń«ŚÕŁÉńÜäÕ«×ńÄ░ń«Śµ│ĢÕģʵ£ēõĖŹńĪ«Õ«ÜµĆ¦ŃĆé
+
+MMEngine µÅÉõŠøõ║åĶ«ŠńĮ«ķÜŵ£║µĢ░õ╗źÕÅŖµś»ÕÉ”ķĆēµŗ®ńĪ«Õ«ÜµĆ¦ń«Śµ│ĢńÜäÕŖ¤ĶāĮ’╝īńö©µłĘÕŬķ£ĆĶ«ŠńĮ« `Runner` ńÜä `randomness` ÕÅéµĢ░’╝łµ£Ćń╗łĶ░āńö© [set_random_seed](mmengine.runner.set_random_seed)’╝ēÕŹ│ÕÅ»’╝īÕ«āµ£ēõ╗źõĖŗõĖēõĖ¬ÕÅ»Ķ«ŠńĮ«ńÜäÕŁŚµ«Ą’╝Ü
+
+- seed: ķÜŵ£║ń¦ŹÕŁÉ’╝īÕ”éµ×£õĖŹĶ«ŠńĮ« seed’╝īÕłÖõ╝ÜõĮ┐ńö©ķÜŵ£║µĢ░õĮ£õĖ║ń¦ŹÕŁÉ
+- diff_rank_seed: µś»ÕÉ”õĖ║õĖŹÕÉīńÜäĶ┐øń©ŗĶ«ŠńĮ«õĖŹÕÉīńÜäń¦ŹÕŁÉ’╝īÕ£© seed ńÜäÕ¤║ńĪĆõĖŖÕŖĀõĖŖĶ┐øń©ŗń┤óÕ╝ĢµĢ░
+- deterministic: µś»ÕÉ”õĖ║ CUDNN ÕÉÄń½»Ķ«ŠńĮ«ńĪ«Õ«ÜµĆ¦ķĆēķĪ╣
+
+õ╗ź[15 ÕłåķƤõĖŖµēŗ MMEngine](../get_started/15_minutes.md) ńÜä Runner ÕłØÕ¦ŗÕī¢ÕÅéµĢ░õĖŁµĘ╗ÕŖĀ `randomness` õĖ║õŠŗŃĆé
+
+```python
+runner = Runner(
+ model=MMResNet50(),
+ work_dir='./work_dir',
+ train_dataloader=train_dataloader,
+ optim_wrapper=dict(optimizer=dict(type=SGD, lr=0.001, momentum=0.9)),
+ train_cfg=dict(by_epoch=True, max_epochs=5, val_interval=1),
+ val_dataloader=val_dataloader,
+ val_cfg=dict(),
+ val_evaluator=dict(type=Accuracy),
+ # µ¢░Õó× randomness Ķ«ŠńĮ«
+ randomness=dict(seed=0),
+)
+runner.train()
+```
+
+ķ£ĆĶ”üµ│©µäÅńÜ䵜»’╝īÕŹ│õĮ┐Ķ«ŠńĮ«õ║åķÜŵ£║µĢ░õ╗źÕÅŖķĆēµŗ®õ║åńĪ«Õ«ÜµĆ¦ń«Śµ│Ģ’╝īõŠØńäČÕÅ»ĶāĮÕć║ńÄ░õĖżµ¼ĪÕ«×ķ¬īµ£ēµ│óÕŖ©’╝īÕģĘõĮōÕłåµ×ÉĶ¦ü[Õ¤║õ║ÄPyTorchńÜäMMDetectionõĖŁĶ«Łń╗āńÜäķÜŵ£║µĆ¦µØźĶć¬õĮĢÕżä’╝¤](https://www.zhihu.com/question/453511684/answer/1839683634)
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/speed_up_training.md b/internlm_langchain/knowledge_base/MMEngine/content/speed_up_training.md
new file mode 100644
index 00000000..2c5d0919
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/speed_up_training.md
@@ -0,0 +1,79 @@
+# ÕŖĀķƤĶ«Łń╗ā
+
+## ÕłåÕĖāÕ╝ÅĶ«Łń╗ā
+
+```{warning}
+ÕåģÕ«╣ÕĘ▓Ķó½Ķ┐üń¦╗Ķć│ [ÕłåÕĖāÕ╝ÅĶ«Łń╗ā](./distributed_training.md)ŃĆé
+```
+
+## µĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗ā
+
+Nvidia Õ£© Volta ÕÆī Turing µ×ȵ×äõĖŁÕ╝ĢÕģź Tensor Core ÕŹĢÕģā’╝īµØźµö»µīü FP32 ÕÆī FP16 µĘĘÕÉłń▓ŠÕ║”Ķ«Īń«ŚŃĆéÕ£© Ampere µ×ȵ×äõĖŁ’╝īõ╗¢õ╗¼Ķ┐øõĖƵŁźµö»µīüõ║å BF16 Ķ«Īń«ŚŃĆéÕ╝ĆÕÉ»Ķć¬ÕŖ©µĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗āÕÉÄ’╝īķā©Õłåń«ŚÕŁÉńÜäµōŹõĮ£ń▓ŠÕ║”µś» FP16/BF16’╝īÕģČõĮÖń«ŚÕŁÉńÜäµōŹõĮ£ń▓ŠÕ║”µś» FP32ŃĆéĶ┐ÖµĀĘÕ£©õĖŹµö╣ÕÅśµ©ĪÕ×ŗŃĆüõĖŹķÖŹõĮĵ©ĪÕ×ŗĶ«Łń╗āń▓ŠÕ║”ńÜäÕēŹµÅÉõĖŗ’╝īÕÅ»õ╗źń╝®ń¤ŁĶ«Łń╗āµŚČķŚ┤’╝īķÖŹõĮÄÕŁśÕé©ķ£Ćµ▒é’╝īÕøĀĶĆīĶāĮµö»µīüµø┤Õż¦ńÜä batch sizeŃĆüµø┤Õż¦µ©ĪÕ×ŗÕÆīÕ░║Õ»Ėµø┤Õż¦ńÜäĶŠōÕģźńÜäĶ«Łń╗āŃĆé
+
+[PyTorch õ╗Ä 1.6 Õ╝ĆÕ¦ŗÕ«śµ¢╣µö»µīü amp](https://pytorch.org/blog/accelerating-training-on-nvidia-gpus-with-pytorch-automatic-mixed-precision/)ŃĆéÕ”éµ×£õĮĀÕ»╣Ķć¬ÕŖ©µĘĘÕÉłń▓ŠÕ║”ńÜäÕ«×ńÄ░µä¤Õģ┤ĶČŻ’╝īÕÅ»õ╗źķśģĶ»╗ [torch.cuda.amp: Ķć¬ÕŖ©µĘĘÕÉłń▓ŠÕ║”Ķ»”Ķ¦Ż](https://zhuanlan.zhihu.com/p/348554267)ŃĆé
+
+MMEngine µÅÉõŠøĶć¬ÕŖ©µĘĘÕÉłń▓ŠÕ║”ńÜäÕ░üĶŻģ [AmpOptimWrapper](mmengine.optim.AmpOptimWrapper) ’╝īÕŬķ£ĆÕ£© `optim_wrapper` Ķ«ŠńĮ« `type='AmpOptimWrapper'` ÕŹ│ÕÅ»Õ╝ĆÕÉ»Ķć¬ÕŖ©µĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗ā’╝īµŚĀķ£ĆÕ»╣õ╗ŻńĀüÕüÜÕģČõ╗¢õ┐«µö╣ŃĆé
+
+```python
+runner = Runner(
+ model=ResNet18(),
+ work_dir='./work_dir',
+ train_dataloader=train_dataloader_cfg,
+ optim_wrapper=dict(
+ type='AmpOptimWrapper',
+ # Õ”éµ×£õĮĀµā│Ķ”üõĮ┐ńö© BF16’╝īĶ»ĘÕÅ¢µČłõĖŗķØóõĖĆĶĪīńÜäõ╗ŻńĀüµ│©ķćŖ
+ # dtype='bfloat16', # ÕÅ»ńö©ÕĆ╝’╝Ü ('float16', 'bfloat16', None)
+ optimizer=dict(type='SGD', lr=0.001, momentum=0.9)),
+ train_cfg=dict(by_epoch=True, max_epochs=3),
+)
+runner.train()
+```
+
+```{warning}
+µł¬µŁóÕł░ PyTorch 1.13 ńēłµ£¼’╝īÕ£© `Convolution` õĖŁńø┤µÄźõĮ┐ńö© `torch.bfloat16` µĆ¦ĶāĮõĮÄõĖŗ’╝īÕ┐ģķĪ╗µēŗÕŖ©Ķ«ŠńĮ«ńÄ»ÕóāÕÅśķćÅ `TORCH_CUDNN_V8_API_ENABLED=1` õ╗źÕÉ»ńö© CuDNN ńēłµ£¼ńÜä BF16 ConvolutionŃĆéńøĖÕģ│Ķ«©Ķ«║Ķ¦ü [PyTorch Issue](https://github.com/pytorch/pytorch/issues/57707#issuecomment-1166656767)
+```
+
+## µ©ĪÕ×ŗń╝¢Ķ»æ
+
+PyTorch 2.0 ńēłµ£¼Õ╝ĢÕģźõ║å [torch.compile](https://pytorch.org/docs/2.0/dynamo/get-started.html) µ¢░ńē╣µĆ¦’╝īķĆÜĶ┐ćÕ»╣µ©ĪÕ×ŗĶ┐øĶĪīń╝¢Ķ»æµØźÕŖĀķƤĶ«Łń╗āŃĆüķ¬īĶ»üŃĆéMMEngine õ╗Ä v0.7.0 ńēłµ£¼Õ╝ĆÕ¦ŗµö»µīüĶ┐ÖõĖĆńē╣µĆ¦’╝īõĮĀÕÅ»õ╗źķĆÜĶ┐ćÕÉæ `Runner` ńÜä `cfg` ÕÅéµĢ░õ╝ĀÕģźõĖĆõĖ¬ÕĖ”µ£ē `compile` Õģ│ķö«Ķ»ŹńÜäÕŁŚÕģĖµØźÕ╝ĆÕÉ»µ©ĪÕ×ŗń╝¢Ķ»æ’╝Ü
+
+```python
+runner = Runner(
+ model=ResNet18(),
+ ... # õĮĀńÜäÕģČõ╗¢ Runner ķģŹńĮ«ÕÅéµĢ░
+ cfg=dict(compile=True)
+)
+```
+
+µŁżÕż¢’╝īõĮĀõ╣¤ÕÅ»õ╗źõ╝ĀÕģźµø┤ÕżÜńÜäń╝¢Ķ»æķģŹńĮ«ķĆēķĪ╣’╝īµēƵ£ēń╝¢Ķ»æķģŹńĮ«ķĆēķĪ╣ÕÅ»õ╗źÕÅéĶĆā [torch.compile API µ¢ćµĪŻ](https://pytorch.org/docs/2.0/generated/torch.compile.html#torch-compile)
+
+```python
+compile_options = dict(backend='inductor', mode='max-autotune')
+runner = Runner(
+ model=ResNet18(),
+ ... # õĮĀńÜäÕģČõ╗¢ Runner ķģŹńĮ«ÕÅéµĢ░
+ cfg=dict(compile=compile_options)
+)
+```
+
+Ķ┐ÖõĖĆńē╣µĆ¦ÕŬµ£ēÕ£©õĮĀÕ«ēĶŻģ PyTorch >= 2.0.0 ńēłµ£¼µŚČµēŹÕÅ»ńö©ŃĆé
+
+```{warning}
+`torch.compile` ńø«ÕēŹõ╗ŹńäČńö▒ PyTorch Õøóķś¤µīüń╗ŁÕ╝ĆÕÅæõĖŁ’╝īõĖĆõ║øµ©ĪÕ×ŗÕÅ»ĶāĮõ╝Üń╝¢Ķ»æÕż▒Ķ┤źŃĆéÕ”éµ×£ķüćÕł░õ║åń▒╗õ╝╝ķŚ«ķóś’╝īõĮĀÕÅ»õ╗źµ¤źķśģ [PyTorch Dynamo FAQ](https://pytorch.org/docs/2.0/dynamo/faq.html) Ķ¦ŻÕå│ÕĖĖĶ¦üķŚ«ķóś’╝īµł¢ÕÅéĶĆā [TorchDynamo Troubleshooting](https://pytorch.org/docs/2.0/dynamo/troubleshooting.html) ÕÉæ PyTorch µÅÉ issue.
+```
+
+## õĮ┐ńö©µø┤Õ┐½ńÜäõ╝śÕī¢ÕÖ©
+
+Õ”éµ×£õĮ┐ńö©õ║åµśćĶģŠńÜäĶ«ŠÕżć’╝īÕÅ»õ╗źõĮ┐ńö©µśćĶģŠńÜäõ╝śÕī¢ÕÖ©õ╗ÄĶĆīń╝®ń¤Łµ©ĪÕ×ŗńÜäĶ«Łń╗āµŚČķŚ┤ŃĆ鵜ćĶģŠĶ«ŠÕżćµö»µīüńÜäõ╝śÕī¢ÕÖ©Õ”éõĖŗ
+
+- NpuFusedAdadelta
+- NpuFusedAdam
+- NpuFusedAdamP
+- NpuFusedAdamW
+- NpuFusedBertAdam
+- NpuFusedLamb
+- NpuFusedRMSprop
+- NpuFusedRMSpropTF
+- NpuFusedSGD
+
+õĮ┐ńö©µ¢╣Õ╝ÅÕÉīÕĤńö¤õ╝śÕī¢ÕÖ©õĖƵĀĘ’╝īÕÅ»ÕÅéĶĆā[õ╝śÕī¢ÕÖ©ńÜäõĮ┐ńö©](../tutorials/optim_wrapper.md#Õ£©µē¦ĶĪīÕÖ©õĖŁķģŹńĮ«õ╝śÕī¢ÕÖ©Õ░üĶŻģ)ŃĆé
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/test_time_augmentation.md b/internlm_langchain/knowledge_base/MMEngine/content/test_time_augmentation.md
new file mode 100644
index 00000000..77b85b51
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/test_time_augmentation.md
@@ -0,0 +1,159 @@
+# µĄŗĶ»ĢµŚČÕó×Õ╝║’╝łTest time augmentation’╝ē
+
+µĄŗĶ»ĢµŚČÕó×Õ╝║’╝łTest time augmentation’╝īÕÉĵ¢ćń«Ćń¦░ TTA’╝ēµś»õĖĆń¦ŹµĄŗĶ»ĢķśČµ«ĄńÜäµĢ░µŹ«Õó×Õ╝║ńŁ¢ńĢź’╝īµŚ©Õ£©µĄŗĶ»ĢĶ┐ćń©ŗõĖŁ’╝īÕ»╣ÕÉīõĖĆÕ╝ĀÕøŠńēćÕüÜń┐╗ĶĮ¼ŃĆüń╝®µöŠńŁēÕÉäń¦ŹµĢ░µŹ«Õó×Õ╝║’╝īÕ░åÕó×Õ╝║ÕÉĵ»ÅÕ╝ĀÕøŠńēćķó䵥ŗńÜäń╗ōµ×£Ķ┐śÕÄ¤Õł░ÕĤզŗÕ░║Õ»ĖÕ╣ČÕüÜĶ׏ÕÉł’╝īõ╗źĶÄĘÕŠŚµø┤ÕŖĀÕćåńĪ«ńÜäķó䵥ŗń╗ōµ×£ŃĆéõĖ║õ║åĶ«®ńö©µłĘµø┤ÕŖĀµ¢╣õŠ┐Õ£░õĮ┐ńö© TTA’╝īMMEngine µÅÉõŠøõ║å [BaseTTAModel](mmengine.model.BaseTTAModel) ń▒╗’╝īńö©µłĘÕŬķ£Ćµīēńģ¦õ╗╗ÕŖĪķ£Ćµ▒é’╝īń╗¦µē┐ BaseTTAModel ń▒╗’╝īÕ«×ńÄ░õĖŹÕÉīńÜä TTA ńŁ¢ńĢźÕŹ│ÕÅ»ŃĆé
+
+TTA ńÜäµĀĖÕ┐āÕ«×ńÄ░ķĆÜÕĖĖÕłåõĖ║õĖżõĖ¬ķā©Õłå’╝Ü
+
+1. µĄŗĶ»ĢµŚČńÜäµĢ░µŹ«Õó×Õ╝║’╝ܵĄŗĶ»ĢµŚČµĢ░µŹ«Õó×Õ╝║õĖ╗Ķ”üÕ£© MMCV õĖŁÕ«×ńÄ░’╝īÕÅ»õ╗źÕÅéĶĆā [TestTimeAug ńÜä API µ¢ćµĪŻ](mmcv.transforms.TestTimeAug)’╝īµ£¼µ¢ćµĪŻõĖŹÕåŹĶĄśĶ┐░ŃĆé
+2. µ©ĪÕ×ŗµÄ©ńÉåõ╗źÕÅŖń╗ōµ×£Ķ׏ÕÉł’╝Ü`BaseTTAModel` ńÜäõĖ╗Ķ”üÕŖ¤ĶāĮÕ░▒µś»Õ«×ńÄ░Ķ┐ÖõĖĆķā©Õłå’╝ī`BaseTTAModel.test_step` õ╝ÜĶ¦Żµ×ɵĄŗĶ»ĢµŚČÕó×Õ╝║ÕÉÄńÜäµĢ░µŹ«Õ╣ČĶ┐øĶĪīµÄ©ńÉåŃĆéńö©µłĘń╗¦µē┐ `BaseTTAModel` ÕÉÄÕŬķ£ĆÕ«×ńÄ░ńøĖÕ║öńÜäĶ׏ÕÉłńŁ¢ńĢźÕŹ│ÕÅ»ŃĆé
+
+## Õ┐½ķƤõĖŖµēŗ
+
+õĖĆõĖ¬ń«ĆÕŹĢńÜäµö»µīü TTA ńÜäńż║õŠŗÕÅ»õ╗źÕÅéĶĆā [examples/test_time_augmentation.py](https://github.com/open-mmlab/mmengine/blob/main/examples/test_time_augmentation.py)
+
+### ÕćåÕżć TTA µĢ░µŹ«Õó×Õ╝║
+
+`BaseTTAModel` ķ£ĆĶ”üķģŹÕÉł MMCV õĖŁÕ«×ńÄ░ńÜä `TestTimeAug` õĮ┐ńö©’╝īĶ┐ÖĶŠ╣ń«ĆÕŹĢń╗ÖÕć║õĖĆõĖ¬µĀĘõŠŗķģŹńĮ«’╝Ü
+
+```python
+tta_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='TestTimeAug',
+ transforms=[
+ [dict(type='Resize', img_scale=(1333, 800), keep_ratio=True)],
+ [dict(type='RandomFlip', flip_ratio=0.),
+ dict(type='RandomFlip', flip_ratio=1.)],
+ [dict(type='PackXXXInputs', keys=['img'])],
+ ])
+]
+```
+
+Ķ»źķģŹńĮ«ĶĪ©ńż║Õ£©µĄŗĶ»ĢµŚČ’╝īµ»ÅÕ╝ĀÕøŠńēćń╝®µöŠ’╝łResize’╝ēÕÉÄķāĮõ╝ÜĶ┐øĶĪīń┐╗ĶĮ¼Õó×Õ╝║’╝īÕÅśµłÉõĖżÕ╝ĀÕøŠńēćŃĆé
+
+### Õ«Üõ╣ē TTA µ©ĪÕ×ŗĶ׏ÕÉłńŁ¢ńĢź
+
+`BaseTTAModel` ķ£ĆĶ”üÕ»╣ń┐╗ĶĮ¼ÕēŹÕÉÄńÜäÕøŠńēćĶ┐øĶĪīµÄ©ńÉå’╝īÕ╣ČÕ░åń╗ōµ×£Ķ׏ÕÉłŃĆé`merge_preds` µ¢╣µ│ĢµÄźÕÅŚõĖĆÕłŚĶĪ©’╝īÕłŚĶĪ©õĖŁµ»ÅõĖĆõĖ¬Õģāń┤ĀĶĪ©ńż║ batch õĖŁńÜ䵤ÉõĖ¬µĢ░µŹ«ÕÅŹÕżŹÕó×Õ╝║ÕÉÄńÜäń╗ōµ×£ŃĆéõŠŗÕ”é batch_size=3’╝īµłæõ╗¼Õ»╣ batch õĖŁńÜäµ»ÅÕ╝ĀÕøŠńēćÕüÜń┐╗ĶĮ¼Õó×Õ╝║’╝ī`merge_preds` µÄźÕÅŚńÜäÕÅéµĢ░õĖ║’╝Ü
+
+```python
+# data_{i}_{j} ĶĪ©ńż║Õ»╣ń¼¼ i Õ╝ĀÕøŠńēćÕüÜń¼¼ j ń¦ŹÕó×Õ╝║ÕÉÄńÜäń╗ōµ×£’╝ī
+# õŠŗÕ”é batch_size=3’╝īķéŻõ╣ł i ńÜä ÕÅ¢ÕĆ╝ĶīāÕø┤õĖ║ 0’╝ī1’╝ī2’╝ī
+# Õó×Õ╝║µ¢╣Õ╝ŵ£ē 2 ń¦Ź’╝łń┐╗ĶĮ¼’╝ē’╝īķéŻõ╣ł j ńÜäÕÅ¢ÕĆ╝ĶīāÕø┤õĖ║ 0’╝ī1
+
+demo_results = [
+ [data_0_0, data_0_1],
+ [data_1_0, data_1_1],
+ [data_2_0, data_2_1],
+]
+```
+
+merge_preds ķ£ĆĶ”üÕ░å demo_results Ķ׏ÕÉłµłÉµĢ┤õĖ¬ batch ńÜäµÄ©ńÉåń╗ōµ×£ŃĆéõ╗źĶ׏ÕÉłÕłåń▒╗ń╗ōµ×£õĖ║õŠŗ’╝Ü
+
+```python
+class AverageClsScoreTTA(BaseTTAModel):
+ def merge_preds(
+ self,
+ data_samples_list: List[List[ClsDataSample]],
+ ) -> List[ClsDataSample]:
+
+ merged_data_samples = []
+ for data_samples in data_samples_list:
+ merged_data_sample: ClsDataSample = data_samples[0].new()
+ merged_score = sum(data_sample.pred_label.score
+ for data_sample in data_samples) / len(data_samples)
+ merged_data_sample.set_pred_score(merged_score)
+ merged_data_samples.append(merged_data_sample)
+ return merged_data_samples
+```
+
+ńøĖÕ║öńÜäķģŹńĮ«µ¢ćõ╗ČõĖ║’╝Ü
+
+```python
+tta_model = dict(type='AverageClsScoreTTA')
+```
+
+### µö╣ÕåÖµĄŗĶ»ĢĶäܵ£¼
+
+```python
+cfg.model = ConfigDict(**cfg.tta_model, module=cfg.model)
+cfg.test_dataloader.dataset.pipeline = cfg.tta_pipeline
+```
+
+## Ķ┐øķśČõĮ┐ńö©
+
+õĖĆĶł¼µāģÕåĄõĖŗ’╝īńö©µłĘń╗¦µē┐ `BaseTTAModel` ÕÉÄ’╝īÕŬķ£ĆĶ”üÕ«×ńÄ░ `merge_preds` µ¢╣µ│Ģ’╝īÕŹ│ÕŻիīµłÉń╗ōµ×£Ķ׏ÕÉłŃĆéõĮåµś»Õ»╣õ║ÄÕżŹµØéµāģÕåĄ’╝īõŠŗÕ”éĶ׏ÕÉłÕżÜķśČµ«ĄµŻĆµĄŗÕÖ©ńÜäµÄ©ńÉåń╗ōµ×£’╝īÕłÖÕÅ»ĶāĮõ╝Üķ£ĆĶ”üķćŹÕåÖ `test_step` µ¢╣µ│ĢŃĆéĶ┐ÖÕ░▒Ķ”üµ▒鵳æõ╗¼ÕÄ╗Ķ┐øõĖƵŁźõ║åĶ¦Ż `BaseTTAModel` ńÜäµĢ░µŹ«µĄüõ╗źÕÅŖÕ«āÕÆīÕÉäń╗äõ╗Čõ╣ŗķŚ┤ńÜäÕģ│ń│╗ŃĆé
+
+### BaseTTAModel ÕÆīÕÉäń╗äõ╗ČńÜäÕģ│ń│╗
+
+`BaseTTAModel` µś» `DDPWrapper` ÕÆī `Model` ńÜäõĖŁķŚ┤Õ▒éŃĆéÕ£©µē¦ĶĪī `Runner.test()` ńÜäĶ┐ćń©ŗõĖŁ’╝īõ╝ÜÕģłµē¦ĶĪī `DDPWrapper.test_step()`’╝īńäČÕÉĵē¦ĶĪī `TTAModel.test_step()`’╝īµ£ĆÕÉÄÕåŹµē¦ĶĪī `model.test_step()`’╝Ü
+
+
+| ÕĤÕøŠ | +ķó䵥ŗń╗ōµ×£ | +µĀćńŁŠ | +
|---|---|---|
| + | MMClassification (µŚ¦) | +MMDetection (µŚ¦) | +MMCV (µ¢░) | +
|---|---|---|---|
LoadImageFromFile |
+ õ╗Ä 'img_prefix' ÕÆī 'img_info.filename' ÕŁŚµ«Ąń╗äÕÉłĶÄĘÕŠŚµ¢ćõ╗ČĶĘ»ÕŠäÕ╣ČĶ»╗ÕÅ¢ | +õ╗Ä 'img_prefix' ÕÆī 'img_info.filename' ÕŁŚµ«Ąń╗äÕÉłĶÄĘÕŠŚµ¢ćõ╗ČĶĘ»ÕŠäÕ╣ČĶ»╗ÕÅ¢’╝īµö»µīüµīćÕ«ÜķĆÜķüōķĪ║Õ║Å | +õ╗Ä 'img_path' ĶÄĘÕŠŚµ¢ćõ╗ČĶĘ»ÕŠäÕ╣ČĶ»╗ÕÅ¢’╝īµö»µīüµīćÕ«ÜÕŖĀĶĮĮÕż▒Ķ┤źõĖŹµŖźķöÖ’╝īµö»µīüµīćÕ«ÜĶ¦ŻńĀüÕÉÄń½» | +
LoadAnnotations |
+ µŚĀ | +µö»µīüĶ»╗ÕÅ¢ bbox’╝īlabel’╝īmask’╝łÕīģµŗ¼ÕżÜĶŠ╣ÕĮóµĀĘÕ╝Å’╝ē’╝īseg map’╝īĶĮ¼µŹó bbox ÕØɵĀćń│╗ | +µö»µīüĶ»╗ÕÅ¢ bbox’╝īlabel’╝īmask’╝łõĖŹÕīģµŗ¼ÕżÜĶŠ╣ÕĮóµĀĘÕ╝Å’╝ē’╝īseg map | +
Pad |
+ ÕĪ½Õģģ "img_fields" õĖŁµēƵ£ēÕŁŚµ«Ą’╝īõĖŹµö»µīüµīćÕ«ÜÕĪ½ÕģģĶć│µĢ┤µĢ░ÕĆŹ | +ÕĪ½Õģģ "img_fields" õĖŁµēƵ£ēÕŁŚµ«Ą’╝īµö»µīüµīćÕ«ÜÕĪ½ÕģģĶć│µĢ┤µĢ░ÕĆŹ | +ÕĪ½Õģģ "img" ÕŁŚµ«Ą’╝īµö»µīüµīćÕ«ÜÕĪ½ÕģģĶć│µĢ┤µĢ░ÕĆŹ | +
CenterCrop |
+ ĶŻüÕłć "img_fields" õĖŁµēƵ£ēÕŁŚµ«Ą’╝īµö»µīüõ╗ź EfficientNet µ¢╣Õ╝ÅĶ┐øĶĪīĶŻüÕłć | +µŚĀ | +ĶŻüÕłć "img" ÕŁŚµ«ĄńÜäÕøŠÕāÅ’╝ī"gt_bboxes" ÕŁŚµ«ĄńÜä bbox’╝ī"gt_seg_map" ÕŁŚµ«ĄńÜäÕłåÕē▓ÕøŠ’╝ī"gt_keypoints" ÕŁŚµ«ĄńÜäÕģ│ķö«ńé╣’╝īµö»µīüĶć¬ÕŖ©ÕĪ½ÕģģĶŻüÕłćĶŠ╣ń╝ś | +
Normalize |
+ ÕøŠÕāÅÕĮÆõĖĆÕī¢ | +µŚĀÕĘ«Õ╝é | +µŚĀÕĘ«Õ╝é’╝īõĮå MMEngine µÄ©ĶŹÉÕ£©µĢ░µŹ«ķóäÕżäńÉåÕÖ©õĖŁĶ┐øĶĪīÕĮÆõĖĆÕī¢ | +
Resize |
+ ń╝®µöŠ "img_fields" õĖŁµēƵ£ēÕŁŚµ«Ą’╝īÕģüĶ«ĖµīćիܵĀ╣µŹ«µ¤ÉĶŠ╣ķĢ┐ńŁēµ»öõŠŗń╝®µöŠ | +ÕŖ¤ĶāĮńö▒ Resize Õ«×ńÄ░ŃĆéķ£ĆĶ”ü ratio_range õĖ║ None’╝īimg_scale õ╗ģµīćÕ«ÜõĖĆõĖ¬Õ░║Õ»Ė’╝īõĖö multiscale_mode õĖ║ "value" ŃĆé |
+ ń╝®µöŠ "img" ÕŁŚµ«ĄńÜäÕøŠÕāÅ’╝ī"gt_bboxes" ÕŁŚµ«ĄńÜä bbox’╝ī"gt_seg_map" ÕŁŚµ«ĄńÜäÕłåÕē▓ÕøŠ’╝ī"gt_keypoints" ÕŁŚµ«ĄńÜäÕģ│ķö«ńé╣’╝īµö»µīüµīćÕ«Üń╝®µöŠµ»öõŠŗ’╝īµö»µīüńŁēµ»öõŠŗń╝®µöŠÕøŠÕāÅĶć│µīćÕ«ÜÕ░║Õ»ĖÕåģ | +
RandomResize |
+ µŚĀ | +ÕŖ¤ĶāĮńö▒ Resize Õ«×ńÄ░ŃĆéķ£ĆĶ”ü ratio_range õĖ║ None’╝īimg_scaleµīćÕ«ÜõĖżõĖ¬Õ░║Õ»Ė’╝īõĖö multiscale_mode õĖ║ "range"’╝īµł¢ ratio_range õĖŹõĖ║ NoneŃĆé
+ Resize( + img_sacle=[(640, 480), (960, 720)], + mode="range", +)+ |
+ ń╝®µöŠÕŖ¤ĶāĮÕÉī Resize’╝īµö»µīüõ╗ĵīćÕ«ÜÕ░║Õ»ĖĶīāÕø┤µł¢µīćիܵ»öõŠŗĶīāÕø┤ķÜŵ£║ķććµĀĘń╝®µöŠÕ░║Õ»ĖŃĆé
+ RandomResize(scale=[(640, 480), (960, 720)])+ |
+
RandomChoiceResize |
+ µŚĀ | +ÕŖ¤ĶāĮńö▒ Resize Õ«×ńÄ░ŃĆéķ£ĆĶ”ü ratio_range õĖ║ None’╝īimg_scale µīćÕ«ÜÕżÜõĖ¬Õ░║Õ»Ė’╝īõĖö multiscale_mode õĖ║ "value"ŃĆé
+ Resize( + img_sacle=[(640, 480), (960, 720)], + mode="value", +)+ |
+ ń╝®µöŠÕŖ¤ĶāĮÕÉī Resize’╝īµö»µīüõ╗ÄĶŗźÕ╣▓µīćÕ«ÜÕ░║Õ»ĖõĖŁķÜŵ£║ķĆēµŗ®ń╝®µöŠÕ░║Õ»ĖŃĆé
+ RandomChoiceResize(scales=[(640, 480), (960, 720)])+ |
+
RandomGrayscale |
+ ńü░Õ║”Õī¢ "img_fields" õĖŁµēƵ£ēÕŁŚµ«Ą’╝īńü░Õ║”Õī¢ÕÉÄõ┐صīüķĆÜķüōµĢ░ŃĆé | +µŚĀ | +ńü░Õ║”Õī¢ "img" ÕŁŚµ«Ą’╝īµö»µīüµīćÕ«Üńü░Õ║”Õī¢µØāķ插╝īµö»µīüµīćիܵś»Õɔգ©ńü░Õ║”Õī¢ÕÉÄõ┐صīüķĆÜķüōµĢ░’╝łķ╗śĶ«żõĖŹõ┐صīü’╝ēŃĆé | +
RandomFlip |
+ ń┐╗ĶĮ¼ "img_fields" õĖŁµēƵ£ēÕŁŚµ«Ą’╝īµö»µīüµīćիܵ░┤Õ╣│µł¢Õ×éńø┤ń┐╗ĶĮ¼ŃĆé | +ń┐╗ĶĮ¼ "img_fields", "bbox_fields", "mask_fields", "seg_fields" õĖŁµēƵ£ēÕŁŚµ«Ą’╝īµö»µīüµīćիܵ░┤Õ╣│ŃĆüÕ×éńø┤µł¢Õ»╣Ķ¦Æń┐╗ĶĮ¼’╝īµö»µīüµīćÕ«ÜÕÉäń▒╗ń┐╗ĶĮ¼µ”éńÄćŃĆé | +ń┐╗ĶĮ¼ "img", "gt_bboxes", "gt_seg_map", "gt_keypoints" ÕŁŚµ«Ą’╝īµö»µīüµīćիܵ░┤Õ╣│ŃĆüÕ×éńø┤µł¢Õ»╣Ķ¦Æń┐╗ĶĮ¼’╝īµö»µīüµīćÕ«ÜÕÉäń▒╗ń┐╗ĶĮ¼µ”éńÄćŃĆé | +
MultiScaleFlipAug |
+ µŚĀ | +ńö©õ║ĵĄŗĶ»ĢµŚČÕó×Õ╝║ | +õĮ┐ńö© TestTimeAug |
+
ToTensor |
+ Õ░åµīćÕ«ÜÕŁŚµ«ĄĶĮ¼µŹóõĖ║ torch.Tensor |
+ µŚĀÕĘ«Õ╝é | +µŚĀÕĘ«Õ╝é | +
ImageToTensor |
+ Õ░åµīćÕ«ÜÕŁŚµ«ĄĶĮ¼µŹóõĖ║ torch.Tensor’╝īÕ╣ČĶ░āµĢ┤ķĆÜķüōķĪ║Õ║ÅĶć│ CHWŃĆé |
+ µŚĀÕĘ«Õ╝é | +µŚĀÕĘ«Õ╝é | +
+ +
+
+
+```python
+visualizer.set_image(image=image)
+visualizer.draw_texts("cat and dog", torch.tensor([10, 20]))
+visualizer.show()
+```
+
+
+
+ +
+
+
+õĮĀõ╣¤ÕÅ»õ╗źķĆÜĶ┐ćÕÉäõĖ¬ń╗śÕłČµÄźÕÅŻõĖŁµÅÉõŠøńÜäÕÅéµĢ░µØźÕ«ÜÕłČń╗śÕłČÕ»╣Ķ▒ĪńÜäķó£Ķē▓ÕÆīÕ«ĮÕ║”ńŁēńŁē
+
+```python
+visualizer.set_image(image=image)
+visualizer.draw_bboxes(torch.tensor([72, 13, 179, 147]),
+ edge_colors='r',
+ line_widths=3)
+visualizer.draw_bboxes(torch.tensor([[33, 120, 209, 220]]),line_styles='--')
+visualizer.show()
+```
+
+
+
+ +
+
+
+(2) ÕÅĀÕŖĀµśŠńż║
+
+õĖŖĶ┐░ń╗śÕłČµÄźÕÅŻÕÅ»õ╗źÕżÜµ¼ĪĶ░āńö©’╝īõ╗ÄĶĆīÕ«×ńÄ░ÕÅĀÕŖĀµśŠńż║ķ£Ćµ▒é
+
+```python
+visualizer.set_image(image=image)
+visualizer.draw_bboxes(torch.tensor([[33, 120, 209, 220], [72, 13, 179, 147]]))
+visualizer.draw_texts("cat and dog",
+ torch.tensor([10, 20])).draw_circles(torch.tensor([40, 50]),
+ torch.tensor([20]))
+visualizer.show()
+```
+
+
+
+ +
+
+
+## ńē╣ÕŠüÕøŠń╗śÕłČ
+
+ńē╣ÕŠüÕøŠÕÅ»Ķ¦åÕī¢ÕŖ¤ĶāĮĶŠāÕżÜ’╝īńø«ÕēŹÕŬµö»µīüÕŹĢÕ╝Āńē╣ÕŠüÕøŠńÜäÕÅ»Ķ¦åÕī¢’╝īõĖ║õ║åµ¢╣õŠ┐ńÉåĶ¦Ż’╝īÕ░åÕģČÕ»╣Õż¢µÄźÕÅŻµó│ńÉåÕ”éõĖŗ’╝Ü
+
+```python
+@staticmethod
+def draw_featmap(
+ # ĶŠōÕģźµĀ╝Õ╝ÅĶ”üµ▒éõĖ║ CHW
+ featmap: torch.Tensor,
+ # Õ”éµ×£ÕÉīµŚČĶŠōÕģźõ║å image µĢ░µŹ«’╝īÕłÖńē╣ÕŠüÕøŠõ╝ÜÕÅĀÕŖĀÕł░ image õĖŖń╗śÕłČ
+ overlaid_image: Optional[np.ndarray] = None,
+ # ÕżÜõĖ¬ķĆÜķüōÕÄŗń╝®õĖ║ÕŹĢķĆÜķüōńÜäńŁ¢ńĢź
+ channel_reduction: Optional[str] = 'squeeze_mean',
+ # ÕÅ»ķĆēµŗ®µ┐Ƶ┤╗Õ║”µ£Ćķ½śńÜä topk õĖ¬ńē╣ÕŠüÕøŠµśŠńż║
+ topk: int = 10,
+ # ÕżÜķĆÜķüōÕ▒ĢÕ╝ĆõĖ║ÕżÜÕ╝ĀÕøŠµŚČÕĆÖÕĖāÕ▒Ć
+ arrangement: Tuple[int, int] = (5, 2),
+ # ÕÅ»õ╗źµīćÕ«Ü resize_shape ÕÅéµĢ░µØźń╝®µöŠńē╣ÕŠüÕøŠ
+ resize_shape: Optional[tuple] = None,
+ # ÕøŠńēćÕÆīńē╣ÕŠüÕøŠń╗śÕłČńÜäÕÅĀÕŖĀµ»öõŠŗ
+ alpha: float = 0.5,
+) -> np.ndarray:
+```
+
+ÕģČÕŖ¤ĶāĮÕÅ»õ╗źÕĮÆń║│Õ”éõĖŗ
+
+- ĶŠōÕģźńÜä Tensor õĖĆĶł¼µś»Õīģµŗ¼ÕżÜõĖ¬ķĆÜķüōńÜä’╝īchannel_reduction ÕÅéµĢ░ÕÅ»õ╗źÕ░åÕżÜõĖ¬ķĆÜķüōÕÄŗń╝®õĖ║ÕŹĢķĆÜķüō’╝īńäČÕÉÄÕÆīÕøŠńēćĶ┐øĶĪīÕÅĀÕŖĀµśŠńż║
+
+ - `squeeze_mean` Õ░åĶŠōÕģźńÜä C ń╗┤Õ║”ķććńö© mean ÕćĮµĢ░ÕÄŗń╝®õĖ║õĖĆõĖ¬ķĆÜķüō’╝īĶŠōÕć║ń╗┤Õ║”ÕÅśµłÉ (1, H, W)
+ - `select_max` õ╗ÄĶŠōÕģźńÜä C ń╗┤Õ║”õĖŁÕģłÕ£©ń®║ķŚ┤ń╗┤Õ║” sum’╝īń╗┤Õ║”ÕÅśµłÉ (C, )’╝īńäČÕÉÄķĆēµŗ®ÕĆ╝µ£ĆÕż¦ńÜäķĆÜķüō
+ - `None` ĶĪ©ńż║õĖŹķ£ĆĶ”üÕÄŗń╝®’╝īµŁżµŚČÕÅ»õ╗źķĆÜĶ┐ć topk ÕÅéµĢ░ÕÅ»ķĆēµŗ®µ┐Ƶ┤╗Õ║”µ£Ćķ½śńÜä topk õĖ¬ńē╣ÕŠüÕøŠµśŠńż║
+
+- Õ£© channel_reduction ÕÅéµĢ░õĖ║ None ńÜäµāģÕåĄõĖŗ’╝ītopk ÕÅéµĢ░ńö¤µĢł’╝īÕģČõ╝ܵīēńģ¦µ┐Ƶ┤╗Õ║”µÄÆÕ║ÅķĆēµŗ® topk õĖ¬ķĆÜķüō’╝īńäČÕÉÄÕÆīÕøŠńēćĶ┐øĶĪīÕÅĀÕŖĀµśŠńż║’╝īÕ╣ČõĖöµŁżµŚČõ╝ÜķĆÜĶ┐ć arrangement ÕÅéµĢ░µīćիܵśŠńż║ńÜäÕĖāÕ▒Ć
+
+ - Õ”éµ×£ topk õĖŹµś» -1’╝īÕłÖõ╝ܵīēńģ¦µ┐Ƶ┤╗Õ║”µÄÆÕ║ÅķĆēµŗ® topk õĖ¬ķĆÜķüōµśŠńż║
+ - Õ”éµ×£ topk = -1’╝īµŁżµŚČķĆÜķüō C Õ┐ģķĪ╗µś» 1 µł¢ĶĆģ 3 ĶĪ©ńż║ĶŠōÕģźµĢ░µŹ«µś»ÕøŠńēć’╝īÕÉ”ÕłÖµŖźķöÖµÅÉńż║ńö©µłĘÕ║öĶ»źĶ«ŠńĮ« `channel_reduction`µØźÕÄŗń╝®ķĆÜķüōŃĆé
+
+- ĶĆāĶÖæÕł░ĶŠōÕģźńÜäńē╣ÕŠüÕøŠķĆÜÕĖĖķØ×ÕĖĖÕ░Å’╝īÕćĮµĢ░µö»µīüĶŠōÕģź `resize_shape` ÕÅéµĢ░’╝īµ¢╣õŠ┐Õ░åńē╣ÕŠüÕøŠĶ┐øĶĪīõĖŖķććµĀĘÕÉÄĶ┐øĶĪīÕÅ»Ķ¦åÕī¢ŃĆé
+
+ÕĖĖĶ¦üńö©µ│ĢÕ”éõĖŗ’╝Üõ╗źķóäĶ«Łń╗āÕźĮńÜä ResNet18 µ©ĪÕ×ŗõĖ║õŠŗ’╝īķĆÜĶ┐ćµÅÉÕÅ¢ layer4 Õ▒éĶŠōÕć║Ķ┐øĶĪīńē╣ÕŠüÕøŠÕÅ»Ķ¦åÕī¢
+
+(1) Õ░åÕżÜķĆÜķüōńē╣ÕŠüÕøŠķććńö© `select_max` ÕÅéµĢ░ÕÄŗń╝®õĖ║ÕŹĢķĆÜķüōÕ╣ȵśŠńż║
+
+```python
+import numpy as np
+from torchvision.models import resnet18
+from torchvision.transforms import Compose, Normalize, ToTensor
+
+def preprocess_image(img, mean, std):
+ preprocessing = Compose([
+ ToTensor(),
+ Normalize(mean=mean, std=std)
+ ])
+ return preprocessing(img.copy()).unsqueeze(0)
+
+model = resnet18(pretrained=True)
+
+def _forward(x):
+ x = model.conv1(x)
+ x = model.bn1(x)
+ x = model.relu(x)
+ x = model.maxpool(x)
+
+ x1 = model.layer1(x)
+ x2 = model.layer2(x1)
+ x3 = model.layer3(x2)
+ x4 = model.layer4(x3)
+ return x4
+
+model.forward = _forward
+
+image_norm = np.float32(image) / 255
+input_tensor = preprocess_image(image_norm,
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225])
+feat = model(input_tensor)[0]
+
+visualizer = Visualizer()
+drawn_img = visualizer.draw_featmap(feat, channel_reduction='select_max')
+visualizer.show(drawn_img)
+```
+
+
+
+ +
+
+
+ńö▒õ║ÄĶŠōÕć║ńÜä feat ńē╣ÕŠüÕøŠÕ░║Õ»ĖõĖ║ 7x7’╝īńø┤µÄźÕÅ»Ķ¦åÕī¢µĢłµ×£õĖŹõĮ│’╝īńö©µłĘÕÅ»õ╗źķĆÜĶ┐ćÕÅĀÕŖĀĶŠōÕģźÕøŠńē浳¢ĶĆģ `resize_shape` ÕÅéµĢ░µØźń╝®µöŠńē╣ÕŠüÕøŠŃĆéÕ”éµ×£õ╝ĀÕģźÕøŠńēćÕ░║Õ»ĖÕÆīńē╣ÕŠüÕøŠÕż¦Õ░ÅõĖŹõĖĆĶć┤’╝īõ╝ÜÕ╝║ÕłČÕ░åńē╣ÕŠüÕøŠķććµĀĘÕł░ÕÆīĶŠōÕģźÕøŠńēćńøĖÕÉīń®║ķŚ┤Õ░║Õ»Ė
+
+```python
+drawn_img = visualizer.draw_featmap(feat, image, channel_reduction='select_max')
+visualizer.show(drawn_img)
+```
+
+
+
+ +
+
+
+(2) Õł®ńö© `topk=5` ÕÅéµĢ░ķĆēµŗ®ÕżÜķĆÜķüōńē╣ÕŠüÕøŠõĖŁµ┐Ƶ┤╗Õ║”µ£Ćķ½śńÜä 5 õĖ¬ķĆÜķüōÕ╣Čķććńö© 2x3 ÕĖāÕ▒ƵśŠńż║
+
+```python
+drawn_img = visualizer.draw_featmap(feat, image, channel_reduction=None,
+ topk=5, arrangement=(2, 3))
+visualizer.show(drawn_img)
+```
+
+
+
+ +
+
+
+ńö©µłĘÕÅ»õ╗źķĆÜĶ┐ć `arrangement` ÕÅéµĢ░ķĆēµŗ®Ķć¬ÕĘ▒µā│Ķ”üńÜäÕĖāÕ▒Ć
+
+```python
+drawn_img = visualizer.draw_featmap(feat, image, channel_reduction=None,
+ topk=5, arrangement=(4, 2))
+visualizer.show(drawn_img)
+```
+
+
+
+ +
+
+
+## Õ¤║ńĪĆÕŁśÕ驵ğÕÅŻ
+
+Õ£©ń╗śÕłČÕ«īµłÉÕÉÄ’╝īÕÅ»õ╗źķĆēµŗ®µ£¼Õ£░ń¬ŚÕÅŻµśŠńż║’╝īõ╣¤ÕÅ»õ╗źÕŁśÕé©Õł░õĖŹÕÉīÕÉÄń½»õĖŁ’╝īńø«ÕēŹ MMEngine ÕåģńĮ«õ║åµ£¼Õ£░ÕŁśÕé©ŃĆüTensorboard ÕŁśÕé©ÕÆī WandB ÕŁśÕé© 3 õĖ¬ÕÉÄń½»’╝īõĖöµö»µīüÕŁśÕé©ń╗śÕłČÕÉÄńÜäÕøŠńēćŃĆüloss ńŁēµĀćķćŵĢ░µŹ«ÕÆīķģŹńĮ«µ¢ćõ╗ČŃĆé
+
+**(1) ÕŁśÕé©ń╗śÕłČÕÉÄńÜäÕøŠńēć**
+
+ÕüćĶ«ŠÕŁśÕé©ÕÉÄń½»õĖ║µ£¼Õ£░ÕŁśÕé©
+
+```python
+visualizer = Visualizer(image=image,
+ vis_backends=[dict(type='LocalVisBackend')],
+ save_dir='temp_dir')
+visualizer.draw_bboxes(torch.tensor([[33, 120, 209, 220], [72, 13, 179, 147]]))
+visualizer.draw_texts("cat and dog", torch.tensor([10, 20]))
+visualizer.draw_circles(torch.tensor([40, 50]), torch.tensor([20]))
+
+# õ╝Üńö¤µłÉ temp_dir/vis_data/vis_image/demo_0.png
+visualizer.add_image('demo', visualizer.get_image())
+```
+
+ÕģČõĖŁńö¤µłÉńÜäÕÉÄń╝Ć 0 µś»ńö©µØźÕī║ÕłåõĖŹÕÉī step Õ£║µÖ»
+
+```python
+# õ╝Üńö¤µłÉ temp_dir/vis_data/vis_image/demo_1.png
+visualizer.add_image('demo', visualizer.get_image(), step=1)
+# õ╝Üńö¤µłÉ temp_dir/vis_data/vis_image/demo_3.png
+visualizer.add_image('demo', visualizer.get_image(), step=3)
+```
+
+Õ”éµ×£µā│õĮ┐ńö©ÕģČõ╗¢ÕÉÄń½»’╝īÕłÖÕŬķ£ĆĶ”üõ┐«µö╣ķģŹńĮ«µ¢ćõ╗ČÕŹ│ÕÅ»
+
+```python
+# TensorboardVisBackend
+visualizer = Visualizer(image=image,
+ vis_backends=[dict(type='TensorboardVisBackend')],
+ save_dir='temp_dir')
+# µł¢ĶĆģ WandbVisBackend
+visualizer = Visualizer(image=image,
+ vis_backends=[dict(type='WandbVisBackend')],
+ save_dir='temp_dir')
+```
+
+**(2) ÕŁśÕé©ńē╣ÕŠüÕøŠ**
+
+```python
+visualizer = Visualizer(vis_backends=[dict(type='LocalVisBackend')],
+ save_dir='temp_dir')
+drawn_img = visualizer.draw_featmap(feat, image, channel_reduction=None,
+ topk=5, arrangement=(2, 3))
+# õ╝Üńö¤µłÉ temp_dir/vis_data/vis_image/feat_0.png
+visualizer.add_image('feat', drawn_img)
+```
+
+**(3) ÕŁśÕé© loss ńŁēµĀćķćŵĢ░µŹ«**
+
+```python
+# õ╝Üńö¤µłÉ temp_dir/vis_data/scalars.json
+# õ┐ØÕŁś loss
+visualizer.add_scalar('loss', 0.2, step=0)
+visualizer.add_scalar('loss', 0.1, step=1)
+# õ┐ØÕŁś acc
+visualizer.add_scalar('acc', 0.7, step=0)
+visualizer.add_scalar('acc', 0.8, step=1)
+```
+
+õ╣¤ÕÅ»õ╗źõĖƵ¼ĪµĆ¦õ┐ØÕŁśÕżÜõĖ¬µĀćķćŵĢ░µŹ«
+
+```python
+# õ╝ÜÕ░åÕåģÕ«╣Ķ┐ĮÕŖĀÕł░ temp_dir/vis_data/scalars.json
+visualizer.add_scalars({'loss': 0.3, 'acc': 0.8}, step=3)
+```
+
+**(4) õ┐ØÕŁśķģŹńĮ«µ¢ćõ╗Č**
+
+```python
+from mmengine import Config
+cfg=Config.fromfile('tests/data/config/py_config/config.py')
+# õ╝Üńö¤µłÉ temp_dir/vis_data/config.py
+visualizer.add_config(cfg)
+```
+
+## ÕżÜÕÉÄń½»ÕŁśÕé©
+
+Õ«×ķÖģõĖŖ’╝īõ╗╗õĮĢõĖĆõĖ¬ÕÅ»Ķ¦åÕī¢ÕÖ©ķāĮÕÅ»õ╗źķģŹńĮ«õ╗╗µäÅÕżÜõĖ¬ÕŁśÕé©ÕÉÄń½»’╝īÕÅ»Ķ¦åÕī¢ÕÖ©õ╝ÜÕŠ¬ńÄ»Ķ░āńö©ķģŹńĮ«ÕźĮńÜäÕżÜõĖ¬ÕŁśÕé©ÕÉÄń½»’╝īõ╗ÄĶĆīÕ░åń╗ōµ×£õ┐ØÕŁśÕł░ÕżÜÕÉÄń½»õĖŁŃĆé
+
+```python
+visualizer = Visualizer(image=image,
+ vis_backends=[dict(type='TensorboardVisBackend'),
+ dict(type='LocalVisBackend')],
+ save_dir='temp_dir')
+# õ╝Üńö¤µłÉ temp_dir/vis_data/events.out.tfevents.xxx µ¢ćõ╗Č
+visualizer.draw_bboxes(torch.tensor([[33, 120, 209, 220], [72, 13, 179, 147]]))
+visualizer.draw_texts("cat and dog", torch.tensor([10, 20]))
+visualizer.draw_circles(torch.tensor([40, 50]), torch.tensor([20]))
+
+visualizer.add_image('demo', visualizer.get_image())
+```
+
+µ│©µäÅ’╝ÜÕ”éµ×£ÕżÜõĖ¬ÕŁśÕé©ÕÉÄń½»õĖŁÕŁśÕ£©ÕÉīõĖĆõĖ¬ń▒╗ńÜäÕżÜõĖ¬ÕÉÄń½»’╝īķéŻõ╣łÕ┐ģķĪ╗µīćÕ«Ü name ÕŁŚµ«Ą’╝īÕÉ”ÕłÖµŚĀµ│ĢÕī║Õłåµś»Õō¬õĖ¬ÕŁśÕé©ÕÉÄń½»
+
+```python
+visualizer = Visualizer(
+ image=image,
+ vis_backends=[
+ dict(type='TensorboardVisBackend', name='tb_1', save_dir='temp_dir_1'),
+ dict(type='TensorboardVisBackend', name='tb_2', save_dir='temp_dir_2'),
+ dict(type='LocalVisBackend', name='local')
+ ],
+ save_dir='temp_dir')
+```
+
+## õ╗╗µäÅńé╣õĮŹĶ┐øĶĪīÕÅ»Ķ¦åÕī¢
+
+Õ£©µĘ▒Õ║”ÕŁ”õ╣ĀĶ┐ćń©ŗõĖŁ’╝īõ╝ÜÕŁśÕ£©Õ£©µ¤Éõ║øõ╗ŻńĀüõĮŹńĮ«µÅÆÕģźÕÅ»Ķ¦åÕī¢ÕćĮµĢ░’╝īÕ╣ČÕ░åÕģČõ┐ØÕŁśÕł░õĖŹÕÉīÕÉÄń½»ńÜäķ£Ćµ▒é’╝īĶ┐Öń▒╗ķ£Ćµ▒éõĖ╗Ķ”üńö©õ║ÄÕÅ»Ķ¦åÕī¢Õłåµ×ÉÕÆīĶ░āĶ»ĢķśČµ«ĄŃĆéMMEngine Ķ«ŠĶ«ĪńÜäÕÅ»Ķ¦åÕī¢ÕÖ©µö»µīüÕ£©õ╗╗µäÅńé╣õĮŹĶÄĘÕÅ¢ÕÉīõĖĆõĖ¬ÕÅ»Ķ¦åÕī¢ÕÖ©ńäČÕÉÄĶ┐øĶĪīÕÅ»Ķ¦åÕī¢ńÜäÕŖ¤ĶāĮŃĆé
+ńö©µłĘÕŬķ£ĆĶ”üÕ£©ÕłØÕ¦ŗÕī¢µŚČÕĆÖķĆÜĶ┐ć `get_instance` µÄźÕÅŻÕ«×õŠŗÕī¢ÕÅ»Ķ¦åÕī¢Õ»╣Ķ▒Ī’╝īµŁżµŚČĶ»źÕÅ»Ķ¦åÕī¢Õ»╣Ķ▒ĪÕŹ│õĖ║Õģ©Õ▒ĆÕÅ»ĶÄĘÕÅ¢Õö»õĖĆÕ»╣Ķ▒Ī’╝īÕÉÄń╗ŁķĆÜĶ┐ć `Visualizer.get_current_instance()` ÕŹ│ÕŻգ©õ╗ŻńĀüõ╗╗µäÅõĮŹńĮ«ĶÄĘÕÅ¢ŃĆé
+
+```python
+# Õ£©ń©ŗÕ║ÅÕłØÕ¦ŗÕī¢µŚČÕĆÖĶ░āńö©
+visualizer1 = Visualizer.get_instance(
+ name='vis',
+ vis_backends=[dict(type='LocalVisBackend')]
+)
+
+# Õ£©õ╗╗õĮĢõ╗ŻńĀüõĮŹńĮ«ķāĮÕÅ»Ķ░āńö©
+visualizer2 = Visualizer.get_current_instance()
+visualizer2.add_scalar('map', 0.7, step=0)
+
+assert id(visualizer1) == id(visualizer2)
+```
+
+õ╣¤ÕÅ»õ╗źķĆÜĶ┐ćÕŁŚµ«ĄķģŹńĮ«µ¢╣Õ╝ÅÕģ©Õ▒ĆÕłØÕ¦ŗÕī¢
+
+```python
+from mmengine.registry import VISUALIZERS
+
+visualizer_cfg = dict(type='Visualizer',
+ name='vis_new',
+ vis_backends=[dict(type='LocalVisBackend')])
+VISUALIZERS.build(visualizer_cfg)
+```
+
+## µē®Õ▒ĢÕŁśÕé©ÕÉÄń½»ÕÆīÕÅ»Ķ¦åÕī¢ÕÖ©
+
+**(1) Ķ░āńö©ńē╣Õ«ÜÕŁśÕé©ÕÉÄń½»**
+
+ńø«ÕēŹÕŁśÕé©ÕÉÄń½»õ╗ģõ╗ģµÅÉõŠøõ║åõ┐ØÕŁśķģŹńĮ«ŃĆüõ┐ØÕŁśµĀćķćÅńŁēÕ¤║µ£¼ÕŖ¤ĶāĮ’╝īõĮåµś»ńö▒õ║Ä WandB ÕÆī Tensorboard Ķ┐Öń▒╗ÕŁśÕé©ÕÉÄń½»ÕŖ¤ĶāĮķØ×ÕĖĖÕ╝║Õż¦’╝ī ńö©µłĘÕÅ»ĶāĮõ╝ÜÕĖīµ£øÕł®ńö©Õł░Ķ┐Öń▒╗ÕŁśÕé©ÕÉÄń½»ńÜäÕģČõ╗¢ÕŖ¤ĶāĮŃĆéÕøĀµŁż’╝īÕŁśÕé©ÕÉÄń½»µÅÉõŠøõ║å `experiment` Õ▒׵ƦµØźµ¢╣õŠ┐ńö©µłĘĶÄĘÕÅ¢ÕÉÄń½»Õ»╣Ķ▒Ī’╝īµ╗ĪĶČ│ÕÉäń▒╗Õ«ÜÕłČÕī¢ÕŖ¤ĶāĮŃĆé
+õŠŗÕ”é WandB µÅÉõŠøõ║åĶĪ©µĀ╝µśŠńż║ńÜä API µÄźÕÅŻ’╝īńö©µłĘÕÅ»õ╗źķĆÜĶ┐ć `experiment`Õ▒׵ƦĶÄĘÕÅ¢ WandB Õ»╣Ķ▒Ī’╝īńäČÕÉÄĶ░āńö©ńē╣Õ«ÜńÜä API µØźÕ░åĶć¬Õ«Üõ╣ēµĢ░µŹ«õ┐ØÕŁśõĖ║ĶĪ©µĀ╝µśŠńż║
+
+```python
+visualizer = Visualizer(image=image,
+ vis_backends=[dict(type='WandbVisBackend')],
+ save_dir='temp_dir')
+
+# ĶÄĘÕÅ¢ WandB Õ»╣Ķ▒Ī
+wandb = visualizer.get_backend('WandbVisBackend').experiment
+# Ķ┐ĮÕŖĀĶĪ©µĀ╝µĢ░µŹ«
+table = wandb.Table(columns=["step", "mAP"])
+table.add_data(1, 0.2)
+table.add_data(2, 0.5)
+table.add_data(3, 0.9)
+# õ┐ØÕŁś
+wandb.log({"table": table})
+```
+
+**(2) µē®Õ▒ĢÕŁśÕé©ÕÉÄń½»**
+
+ńö©µłĘÕÅ»õ╗źµ¢╣õŠ┐Õ┐½µŹĘńÜäµē®Õ▒ĢÕŁśÕé©ÕÉÄń½»ŃĆéÕŬķ£ĆĶ”üń╗¦µē┐Ķć¬ `BaseVisBackend` Õ╣ČÕ«×ńÄ░ÕÉäń▒╗ `add_xx` µ¢╣µ│ĢÕŹ│ÕÅ»
+
+```python
+from mmengine.registry import VISBACKENDS
+from mmengine.visualization import BaseVisBackend
+
+@VISBACKENDS.register_module()
+class DemoVisBackend(BaseVisBackend):
+ def add_image(self, **kwargs):
+ pass
+
+visualizer = Visualizer(vis_backends=[dict(type='DemoVisBackend')],
+ save_dir='temp_dir')
+visualizer.add_image('demo',image)
+```
+
+**(3) µē®Õ▒ĢÕÅ»Ķ¦åÕī¢ÕÖ©**
+
+ÕÉīµĀĘńÜä’╝īńö©µłĘÕÅ»õ╗źķĆÜĶ┐ćń╗¦µē┐ Visualizer Õ╣ČÕ«×ńÄ░µā│Ķ”åÕåÖńÜäÕćĮµĢ░µØźµ¢╣õŠ┐Õ┐½µŹĘńÜäµē®Õ▒ĢÕÅ»Ķ¦åÕī¢ÕÖ©ŃĆéÕż¦ķā©ÕłåµāģÕåĄõĖŗ’╝īńö©µłĘķ£ĆĶ”üĶ”åÕåÖ `add_datasample`µØźĶ┐øĶĪīµŗōÕ▒ĢŃĆéµĢ░µŹ«õĖŁķĆÜÕĖĖÕīģµŗ¼µĀćµ│©µł¢µ©ĪÕ×ŗķó䵥ŗńÜ䵯ƵĄŗµĪåÕÆīÕ«×õŠŗµÄ®ńĀü’╝īĶ»źµÄźÕÅŻõĖ║ÕÉäõĖ¬õĖŗµĖĖÕ║ōń╗śÕłČ datasample µĢ░µŹ«ńÜäµŖĮĶ▒ĪµÄźÕÅŻŃĆéõ╗ź MMDetection õĖ║õŠŗ’╝īdatasample µĢ░µŹ«õĖŁķĆÜÕĖĖÕīģµŗ¼µĀćµ│© bboxŃĆüµĀćµ│© mask ŃĆüķó䵥ŗ bbox µł¢ĶĆģķó䵥ŗ mask ńŁēµĢ░µŹ«’╝īMMDetection õ╝Üń╗¦µē┐ Visualizer Õ╣ČÕ«×ńÄ░ `add_datasample` µÄźÕÅŻ’╝īÕ£©Ķ»źµÄźÕÅŻÕåģķā©õ╝ÜķÆłÕ»╣µŻĆµĄŗõ╗╗ÕŖĪńøĖÕģ│µĢ░µŹ«Ķ┐øĶĪīÕÅ»Ķ¦åÕī¢ń╗śÕłČ’╝īõ╗ÄĶĆīń«ĆÕī¢µŻĆµĄŗõ╗╗ÕŖĪÕÅ»Ķ¦åÕī¢ķ£Ćµ▒éŃĆé
+
+```python
+from mmengine.registry import VISUALIZERS
+
+@VISUALIZERS.register_module()
+class DetLocalVisualizer(Visualizer):
+ def add_datasample(self,
+ name,
+ image: np.ndarray,
+ data_sample: Optional['BaseDataElement'] = None,
+ draw_gt: bool = True,
+ draw_pred: bool = True,
+ show: bool = False,
+ wait_time: int = 0,
+ step: int = 0) -> None:
+ pass
+
+visualizer_cfg = dict(type='DetLocalVisualizer',
+ vis_backends=[dict(type='WandbVisBackend')],
+ name='visualizer')
+
+# Õģ©Õ▒ĆÕłØÕ¦ŗÕī¢
+VISUALIZERS.build(visualizer_cfg)
+
+# õ╗╗µäÅõ╗ŻńĀüõĮŹńĮ«
+det_local_visualizer = Visualizer.get_current_instance()
+det_local_visualizer.add_datasample('det', image, data_sample)
+```
diff --git a/internlm_langchain/knowledge_base/MMEngine/content/visualize_training_log.md b/internlm_langchain/knowledge_base/MMEngine/content/visualize_training_log.md
new file mode 100644
index 00000000..36830df9
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMEngine/content/visualize_training_log.md
@@ -0,0 +1,151 @@
+# ÕÅ»Ķ¦åÕī¢Ķ«Łń╗āµŚźÕ┐Ś
+
+MMEngine ķøåµłÉõ║å [TensorBoard](https://www.tensorflow.org/tensorboard?hl=zh-cn)ŃĆü[Weights & Biases (WandB)](https://docs.wandb.ai/)ŃĆü[MLflow](https://mlflow.org/docs/latest/index.html) ŃĆü[ClearML](https://clear.ml/docs/latest/docs) ÕÆī [Neptune](https://docs.neptune.ai/) Õ«×ķ¬īń«ĪńÉåÕĘźÕģĘ’╝īõĮĀÕÅ»õ╗źÕŠłµ¢╣õŠ┐Õ£░ĶʤĶĖ¬ÕÆīÕÅ»Ķ¦åÕī¢µŹ¤Õż▒ÕÅŖÕćåńĪ«ńÄćńŁēµīćµĀćŃĆé
+
+õĖŗķØóÕ¤║õ║Ä[15 ÕłåķƤõĖŖµēŗ MMENGINE](../get_started/15_minutes.md)õĖŁńÜäõŠŗÕŁÉõ╗ŗń╗ŹÕ”éõĮĢõĖĆĶĪīķģŹńĮ«Õ«×ķ¬īń«ĪńÉåÕĘźÕģĘŃĆé
+
+## TensorBoard
+
+Ķ«ŠńĮ« `Runner` ÕłØÕ¦ŗÕī¢ÕÅéµĢ░õĖŁńÜä `visualizer`’╝īÕ╣ČÕ░å `vis_backends` Ķ«ŠńĮ«õĖ║ [TensorboardVisBackend](mmengine.visualization.TensorboardVisBackend)ŃĆé
+
+```python
+runner = Runner(
+ model=MMResNet50(),
+ work_dir='./work_dir',
+ train_dataloader=train_dataloader,
+ optim_wrapper=dict(optimizer=dict(type=SGD, lr=0.001, momentum=0.9)),
+ train_cfg=dict(by_epoch=True, max_epochs=5, val_interval=1),
+ val_dataloader=val_dataloader,
+ val_cfg=dict(),
+ val_evaluator=dict(type=Accuracy),
+ visualizer=dict(type='Visualizer', vis_backends=[dict(type='TensorboardVisBackend')]),
+)
+runner.train()
+```
+
+## WandB
+
+õĮ┐ńö© WandB ÕēŹķ£ĆÕ«ēĶŻģõŠØĶĄ¢Õ║ō `wandb` Õ╣ČńÖ╗ÕĮĢĶć│ wandbŃĆé
+
+```bash
+pip install wandb
+wandb login
+```
+
+Ķ«ŠńĮ« `Runner` ÕłØÕ¦ŗÕī¢ÕÅéµĢ░õĖŁńÜä `visualizer`’╝īÕ╣ČÕ░å `vis_backends` Ķ«ŠńĮ«õĖ║ [WandbVisBackend](mmengine.visualization.WandbVisBackend)ŃĆé
+
+```python
+runner = Runner(
+ model=MMResNet50(),
+ work_dir='./work_dir',
+ train_dataloader=train_dataloader,
+ optim_wrapper=dict(optimizer=dict(type=SGD, lr=0.001, momentum=0.9)),
+ train_cfg=dict(by_epoch=True, max_epochs=5, val_interval=1),
+ val_dataloader=val_dataloader,
+ val_cfg=dict(),
+ val_evaluator=dict(type=Accuracy),
+ visualizer=dict(type='Visualizer', vis_backends=[dict(type='WandbVisBackend')]),
+)
+runner.train()
+```
+
+
+
+ÕÅ»õ╗źńé╣Õć╗ [WandbVisBackend API](mmengine.visualization.WandbVisBackend) µ¤źń£ŗ `WandbVisBackend` ÕÅ»ķģŹńĮ«ńÜäÕÅéµĢ░ŃĆéõŠŗÕ”é `init_kwargs`’╝īĶ»źÕÅéµĢ░õ╝Üõ╝Āń╗Ö [wandb.init](https://docs.wandb.ai/ref/python/init) µ¢╣µ│ĢŃĆé
+
+```python
+runner = Runner(
+ ...
+ visualizer=dict(
+ type='Visualizer',
+ vis_backends=[
+ dict(
+ type='WandbVisBackend',
+ init_kwargs=dict(project='toy-example')
+ ),
+ ],
+ ),
+ ...
+)
+runner.train()
+```
+
+## MLflow (WIP)
+
+## ClearML
+
+õĮ┐ńö© ClearML ÕēŹķ£ĆÕ«ēĶŻģõŠØĶĄ¢Õ║ō `clearml` Õ╣ČÕÅéĶĆā [Connect ClearML SDK to the Server](https://clear.ml/docs/latest/docs/getting_started/ds/ds_first_steps#connect-clearml-sdk-to-the-server) Ķ┐øĶĪīķģŹńĮ«ŃĆé
+
+```bash
+pip install clearml
+clearml-init
+```
+
+Ķ«ŠńĮ« `Runner` ÕłØÕ¦ŗÕī¢ÕÅéµĢ░õĖŁńÜä `visualizer`’╝īÕ╣ČÕ░å `vis_backends` Ķ«ŠńĮ«õĖ║ [ClearMLVisBackend](mmengine.visualization.ClearMLVisBackend)ŃĆé
+
+```python
+runner = Runner(
+ model=MMResNet50(),
+ work_dir='./work_dir',
+ train_dataloader=train_dataloader,
+ optim_wrapper=dict(optimizer=dict(type=SGD, lr=0.001, momentum=0.9)),
+ train_cfg=dict(by_epoch=True, max_epochs=5, val_interval=1),
+ val_dataloader=val_dataloader,
+ val_cfg=dict(),
+ val_evaluator=dict(type=Accuracy),
+ visualizer=dict(type='Visualizer', vis_backends=[dict(type='ClearMLVisBackend')]),
+)
+runner.train()
+```
+
+
+
+## Neptune
+
+õĮ┐ńö© Neptune ÕēŹķ£ĆÕģłÕ«ēĶŻģõŠØĶĄ¢Õ║ō `neptune` Õ╣ČńÖ╗ÕĮĢ [Neptune.AI](https://docs.neptune.ai/) Ķ┐øĶĪīķģŹńĮ«ŃĆé
+
+```bash
+pip install neptune
+```
+
+Ķ«ŠńĮ« `Runner` ÕłØÕ¦ŗÕī¢ÕÅéµĢ░õĖŁńÜä `visualizer`’╝īÕ╣ČÕ░å `vis_backends` Ķ«ŠńĮ«õĖ║ [NeptuneVisBackend](mmengine.visualization.NeptuneVisBackend)ŃĆé
+
+```python
+runner = Runner(
+ model=MMResNet50(),
+ work_dir='./work_dir',
+ train_dataloader=train_dataloader,
+ optim_wrapper=dict(optimizer=dict(type=SGD, lr=0.001, momentum=0.9)),
+ train_cfg=dict(by_epoch=True, max_epochs=5, val_interval=1),
+ val_dataloader=val_dataloader,
+ val_cfg=dict(),
+ val_evaluator=dict(type=Accuracy),
+ visualizer=dict(type='Visualizer', vis_backends=[dict(type='NeptuneVisBackend')]),
+)
+runner.train()
+```
+
+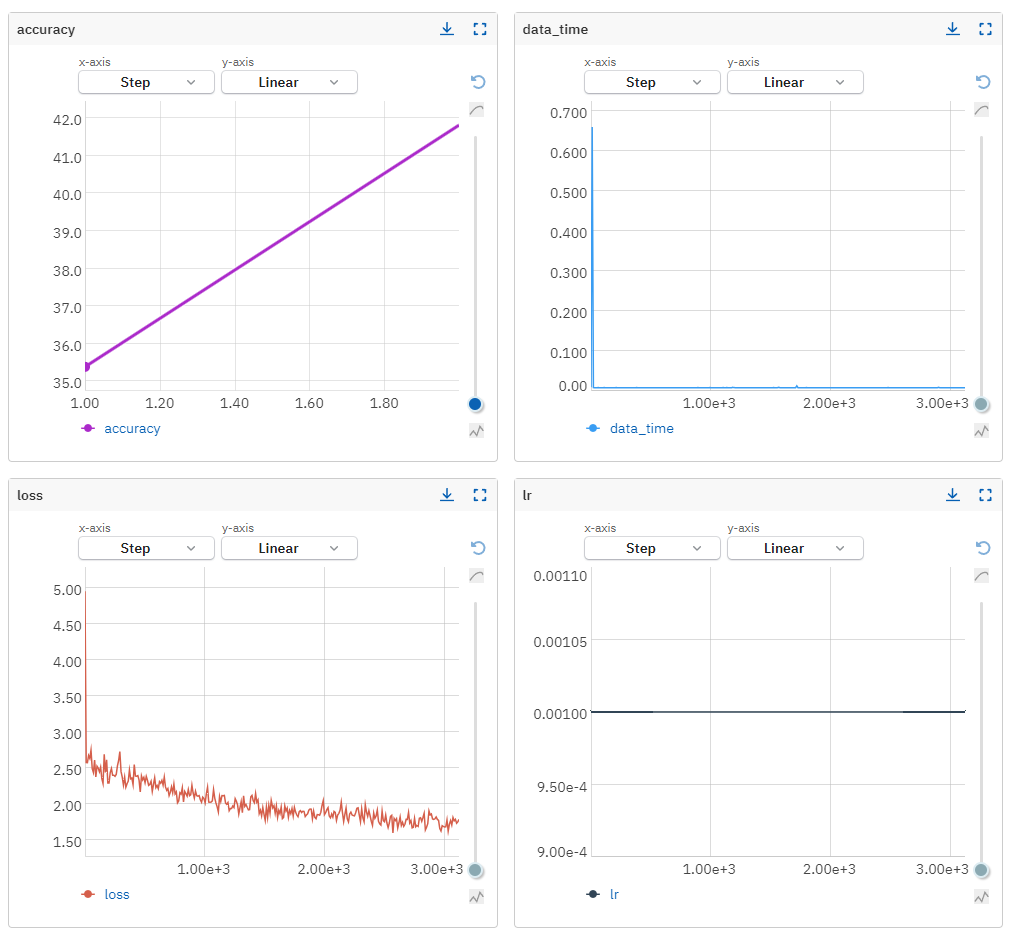
+
+Ķ»Ęµ│©µäÅ’╝ÜĶŗźµ£¬µÅÉõŠø `project` ÕÆī `api_token` ’╝īneptune Õ░åĶó½Ķ«ŠńĮ«µłÉń”╗ń║┐µ©ĪÕ╝Å’╝īõ║¦ńö¤ńÜäµ¢ćõ╗ČÕ░åõ┐ØÕŁśÕł░µ£¼Õ£░ `.neptune` µ¢ćõ╗ČõĖŗŃĆé
+µÄ©ĶŹÉÕ£©ÕłØÕ¦ŗÕī¢µŚČµÅÉõŠø `project` ÕÆī `api_token` ’╝īÕģĘõĮōµ¢╣µ│ĢÕ”éõĖŗµēĆńż║’╝Ü
+
+```python
+runner = Runner(
+ ...
+ visualizer=dict(
+ type='Visualizer',
+ vis_backends=[
+ dict(
+ type='NeptuneVisBackend',
+ init_kwargs=dict(project='workspace-name/project-name',
+ api_token='your api token')
+ ),
+ ],
+ ),
+ ...
+)
+runner.train()
+```
+
+µø┤ÕżÜÕłØÕ¦ŗÕī¢ķģŹńĮ«ÕÅéµĢ░ÕÅ»ńé╣Õć╗ [neptune.init_run API](https://docs.neptune.ai/api/neptune/#init_run) µ¤źĶ»óŃĆé
diff --git a/internlm_langchain/knowledge_base/MMEngine/vector_store/index.faiss b/internlm_langchain/knowledge_base/MMEngine/vector_store/index.faiss
new file mode 100644
index 00000000..cedca32f
Binary files /dev/null and b/internlm_langchain/knowledge_base/MMEngine/vector_store/index.faiss differ
diff --git a/internlm_langchain/knowledge_base/MMFashion/content/ATTR_DATASET.md b/internlm_langchain/knowledge_base/MMFashion/content/ATTR_DATASET.md
new file mode 100644
index 00000000..cc46d1ff
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMFashion/content/ATTR_DATASET.md
@@ -0,0 +1,137 @@
+# AttrDataset
+
+- Annotations (Anno_fine/ Anno_coarse/)
+
+ - Attribute Annotations (list_attr_cloth.txt & list_attr_img.txt)
+
+ clothing attribute labels. See ATTRIBUTE LABELS section below for more info.
+
+ - Bounding Box Annotations (list_bbox.txt)
+
+ bounding box labels. See BBOX LABELS section below for more info.
+
+ - Category Annotations (list_category_cloth.txt & list_category_img.txt)
+
+ clothing category labels. See CATEGORY LABELS section below for more info.
+
+ - Fashion Landmark Annotations (list_landmarks.txt)
+
+ fashion landmark labels. See LANDMARK LABELS section below for more info.
+
+- Images (Img/)
+
+ clothes images. See IMAGE section below for more info.
+
+- Evaluation Partitions (Eval/list_eval_partition.txt)
+
+ image names for training, validation and testing set respectively. See EVALUATION PARTITIONS section below for more info.
+
+
+## IMAGE
+
+*.jpg
+
+format: JPG
+
+Notes:
+1. The long side of images are resized to 300;
+2. The aspect ratios of original images are kept unchanged.
+
+
+## BBOX LABELS
+
+list_bbox.txt
+
+```sh
+First Row: number of images
+Second Row: entry names
+Rest of the Rows:
++ õŠŗÕ”é, `SMPL_NEUTRAL.pkl` `SMPL_MALE.pkl` `SMPL_FEMALE.pkl` +- [J_regressor_extra.npy](https://openmmlab-share.oss-cn-hangzhou.aliyuncs.com/mmhuman3d/models/J_regressor_extra.npy?versionId=CAEQHhiBgIDD6c3V6xciIGIwZDEzYWI5NTBlOTRkODU4OTE1M2Y4YTI0NTVlZGM1) +- [J_regressor_h36m.npy](https://openmmlab-share.oss-cn-hangzhou.aliyuncs.com/mmhuman3d/models/J_regressor_h36m.npy?versionId=CAEQHhiBgIDE6c3V6xciIDdjYzE3MzQ4MmU4MzQyNmRiZDA5YTg2YTI5YWFkNjRi) +- [smpl_mean_params.npz](https://openmmlab-share.oss-cn-hangzhou.aliyuncs.com/mmhuman3d/models/smpl_mean_params.npz?versionId=CAEQHhiBgICN6M3V6xciIDU1MzUzNjZjZGNiOTQ3OWJiZTJmNThiZmY4NmMxMTM4) + +õĖŗĶĮĮõĖŖĶ┐░µēƵ£ēµ¢ćõ╗Č’╝īÕ╣ȵīēÕ”éõĖŗń╗ōµ×äÕ«ēµÄƵ¢ćõ╗ČÕż╣: + +```text +mmhuman3d +Ōö£ŌöĆŌöĆ mmhuman3d +Ōö£ŌöĆŌöĆ docs +Ōö£ŌöĆŌöĆ tests +Ōö£ŌöĆŌöĆ tools +Ōö£ŌöĆŌöĆ configs +ŌööŌöĆŌöĆ data + ŌööŌöĆŌöĆ body_models + Ōö£ŌöĆŌöĆ J_regressor_extra.npy + Ōö£ŌöĆŌöĆ J_regressor_h36m.npy + Ōö£ŌöĆŌöĆ smpl_mean_params.npz + ŌööŌöĆŌöĆ smpl + Ōö£ŌöĆŌöĆ SMPL_FEMALE.pkl + Ōö£ŌöĆŌöĆ SMPL_MALE.pkl + ŌööŌöĆŌöĆ SMPL_NEUTRAL.pkl +``` + +## µÄ©ńÉå / µ╝öńż║ +### ń”╗ń║┐Demo +µłæõ╗¼µÅÉõŠøõ║åńö©õ║Äõ╗ÄÕøŠÕāŵł¢Ķ¦åķóæõĖŁõ╝░Ķ«ĪÕŹĢõ║║µł¢ÕżÜõ║║`SMPL`µ©ĪÕ×ŗÕÅéµĢ░ńÜäµ╝öńż║Ķäܵ£¼’╝īĶ┐ÉĶĪīĶ»źĶäܵ£¼ÕÅ»ĶāĮõ╝Üńö©Õł░`MMDetection`ÕÆī`MMTracking`ŃĆéķĆÜĶ┐ćĶ»źĶäܵ£¼Ķ┐øĶĪīµ╝öńż║’╝īµé©ÕŬķ£ĆĶ”üõ╗ĵ©ĪÕ×ŗÕ║ōõĖŁķĆēµŗ®ńö©Õł░ńÜäķóäĶ«Łń╗āµ©ĪÕ×ŗ(µłæõ╗¼ńø«ÕēŹÕŬµö»µīü[HMR](https://github.com/open-mmlab/mmhuman3d/tree/main/configs/hmr/)ŃĆü [SPIN](https://github.com/open-mmlab/mmhuman3d/tree/main/configs/spin/)ŃĆü[VIBE](https://github.com/open-mmlab/mmhuman3d/tree/main/configs/vibe/) ÕÆī[PARE](https://github.com/open-mmlab/mmhuman3d/tree/main/configs/pare/), µ£¬µØźõ╝ÜÕŖĀÕģźµø┤ÕżÜńÜäSOTAµ¢╣µ│Ģ)’╝īÕ╣ȵīćÕ«ÜÕ░æķćÅńÜäÕÅéµĢ░ŃĆé + +õ╗źõĖŗµś»õĖĆõ║øÕÅéµĢ░ńÜäķćŖõ╣ē: + +- Õ”éµ×£µīćÕ«Ü`--output` ÕÆī `--show_path`, µ╝öńż║Ķäܵ£¼õ╝ÜÕ░åń╗ōµ×£Õé©ÕŁśÕ£©`human_data`õĖŁ’╝īÕ╣ČõĖöµĖ▓µ¤ōÕŠŚÕł░ńÜäõ║║õĮōmeshŃĆé +- Õ”éµ×£µīćÕ«Ü`--smooth_type`, µ╝öńż║Ķäܵ£¼õ╝ÜõĮ┐ńö©ńē╣Õ«ÜńÜäµ¢╣µ│ĢĶ┐øĶĪīÕ╣│µ╗æŃĆéńø«ÕēŹÕÅ»õ╗źķĆēµŗ®ńÜäÕ╣│µ╗æµ¢╣µ│ĢÕīģµŗ¼`gaus1d`ŃĆü`oneeuro`ÕÆī `savgol`ŃĆé +- Õ”éµ×£µīćÕ«Ü`--speed_up_type`, µ╝öńż║Ķäܵ£¼õ╝ÜõĮ┐ńö©ńē╣Õ«ÜńÜäµ¢╣µ│ĢĶ┐øĶĪīÕŖĀķĆ¤ÕżäńÉåŃĆéńø«ÕēŹµö»µīüÕ¤║õ║ÄÕŁ”õ╣ĀńÜäµ¢╣µ│Ģ`deciwatch`, µø┤ÕżÜńÜäõ┐Īµü»Ķ»ĘÕÅéĶĆā[DeciWatch](../configs/_base_/post_processing/README.md)ŃĆé + +Õ»╣õ║ÄÕŹĢõ║║ + +```shell +python demo/estimate_smpl.py \ + ${MMHUMAN3D_CONFIG_FILE} \ + ${MMHUMAN3D_CHECKPOINT_FILE} \ + --single_person_demo \ + --det_config ${MMDET_CONFIG_FILE} \ + --det_checkpoint ${MMDET_CHECKPOINT_FILE} \ + --input_path ${VIDEO_PATH_OR_IMG_PATH} \ + [--show_path ${VIS_OUT_PATH}] \ + [--output ${RESULT_OUT_PATH}] \ + [--smooth_type ${SMOOTH_TYPE}] \ + [--speed_up_type ${SPEED_UP_TYPE}] \ + [--draw_bbox] \ +``` + +õŠŗÕ”é: +```shell +python demo/estimate_smpl.py \ + configs/hmr/resnet50_hmr_pw3d.py \ + data/checkpoints/resnet50_hmr_pw3d.pth \ + --single_person_demo \ + --det_config demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \ + --det_checkpoint https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \ + --input_path demo/resources/single_person_demo.mp4 \ + --show_path vis_results/single_person_demo.mp4 \ + --output demo_result \ + --smooth_type savgol \ + --speed_up_type deciwatch \ + --draw_bbox +``` + +Õ»╣õ║ÄÕżÜõ║║ + + +```shell +python demo/estimate_smpl.py \ + ${MMHUMAN3D_CONFIG_FILE} \ + ${MMHUMAN3D_CHECKPOINT_FILE} \ + --multi_person_demo \ + --tracking_config ${MMTRACKING_CONFIG_FILE} \ + --input_path ${VIDEO_PATH_OR_IMG_PATH} \ + [--show_path ${VIS_OUT_PATH}] \ + [--output ${RESULT_OUT_PATH}] \ + [--smooth_type ${SMOOTH_TYPE}] \ + [--speed_up_type ${SPEED_UP_TYPE}] \ + [--draw_bbox] +``` + +õŠŗÕ”é: +```shell +python demo/estimate_smpl_image.py \ + configs/hmr/resnet50_hmr_pw3d.py \ + data/checkpoints/resnet50_hmr_pw3d.pth \ + --multi_person_demo \ + --tracking_config demo/mmtracking_cfg/deepsort_faster-rcnn_fpn_4e_mot17-private-half.py \ + --input_path demo/resources/multi_person_demo.mp4 \ + --show_path vis_results/multi_person_demo.mp4 \ + --smooth_type savgol \ + --speed_up_type deciwatch \ + [--draw_bbox] + +``` +MMHuman3DńÜächeckpointsµ¢ćõ╗ČÕÅ»õ╗źõ╗Ä[model zoo](../docs_zh-CN/model_zoo.md)õĖŗĶĮĮŃĆé +Ķ┐Öķćīµłæõ╗¼õĮ┐ńö©HMR (resnet50_hmr_pw3d.pth)õĮ£õĖ║ńż║õŠŗŃĆé + +### Õ£©ń║┐Demo +µłæõ╗¼µÅÉõŠøõĖĆõĖ¬õ╗ÄńøĖµ£║µł¢ĶĆģõĖĆõĖ¬µīćÕ«ÜńÜäĶ¦åķóæµ¢ćõ╗Čõ╝░Ķ«ĪSMPLÕÅéµĢ░ńÜäwebcamµ╝öńż║Ķäܵ£¼ŃĆéõĮĀÕÅ»õ╗źń«ĆÕŹĢńÜäĶ┐ÉĶĪīõĖŗķØóńÜäÕæĮõ╗ż’╝Ü +```shell +python demo/webcam_demo.py +``` +õ╗źõĖŗµś»õĖĆõ║øÕÅéµĢ░ńÜäķćŖõ╣ē: +- Õ”éµ×£µīćÕ«Ü`--output`, µ╝öńż║Ķäܵ£¼õ╝ÜÕ░åÕÅ»Ķ¦åÕī¢ń╗ōµ×£Õé©ÕŁśÕł░Õ»╣Õ║öńÜäµ¢ćõ╗ČõĖŁŃĆéĶ┐ÖÕÅ»ĶāĮõ╝ÜķÖŹõĮÄÕĖ¦ńÄćŃĆé +- Õ”éµ×£µīćÕ«Ü`--synchronous`, Ķ¦åķóæńÜä I/O ÕÆīµ©ĪÕ×ŗńÜäµÄ©ńÉåÕ£©µŚČÕ║ÅõĖŖÕ░åõ╝ÜÕ»╣ķĮÉ. µ│©µäÅĶ┐Öõ╝ÜķÖŹõĮÄÕĖ¦ńÄć. +- Õ”éµ×£õĮĀµā│õ╗źń”╗ń║┐ńÜäµ¢╣Õ╝ÅÕ£©Ķ¦åķóæµ¢ćõ╗ČõĖŖĶ┐ÉĶĪīwebcamµ╝öńż║, õĮĀÕ║öĶ»źµīćÕ«Ü`--cam-id=VIDEO_FILE_PATH`. µ│©µäÅ`--synchronous` Õ£©Ķ┐Öń¦ŹµāģÕĮóõĖŗÕ║öĶ»źĶó½Ķ«ŠńĮ«õĖ║ `True`. +- Ķ¦åķóæńÜäI/OÕÆīµ©ĪÕ×ŗńÜäµÄ©ńÉåµś»Õ╝鵣źńÜäĶ┐ÉĶĪī’╝īĶĆīõĖöÕÉÄĶĆģÕŠĆÕŠĆķ£ĆĶ”üµø┤ÕżÜńÜ䵌ČķŚ┤. õĖ║õ║åń╝ōĶ¦ŻÕ╗ȵŚČ’╝īõĮĀÕÅ»õ╗ź: + + - µĀ╣µŹ«µśŠńż║Õ£©ÕĘ”õĖŖĶ¦ÆńÜäµÄ©ńÉåÕ╗ȵŚČĶ«ŠńĮ«`--display-delay=MILLISECONDS` µØźÕ╗ȵŚČĶ¦åķóæµĄü. µł¢ĶĆģ, + + - Ķ«ŠńĮ« `--synchronous=True` Õ╝║ÕłČĶ¦åķóæµĄüÕÆīµÄ©ńÉåń╗ōµ×£Õ»╣ķĮÉ. Ķ┐ÖÕÅ»ĶāĮķÖŹõĮÄĶ¦åķóæńÜäÕĖ¦ńÄćŃĆé + + +## µĄŗĶ»Ģ + +µłæõ╗¼µÅÉõŠøńÜäķóäĶ«Łń╗āµ©ĪÕ×ŗÕÅ»õ╗źÕÅéĶ¦ü [config](https://github.com/open-mmlab/mmhuman3d/tree/main/configs). + +### õĮ┐ńö©ÕŹĢ’╝łÕżÜ’╝ēõĖ¬GPUĶ┐øĶĪīµĄŗĶ»Ģ + +```shell +python tools/test.py ${CONFIG} --work-dir=${WORK_DIR} ${CHECKPOINT} --metrics=${METRICS} +``` +õŠŗÕ”é: +```shell +python tools/test.py configs/hmr/resnet50_hmr_pw3d.py --work-dir=work_dirs/hmr work_dirs/hmr/latest.pth --metrics pa-mpjpe mpjpe +``` + +### õĮ┐ńö©slurmĶ┐øĶĪīµĄŗĶ»Ģ + +Õ”éµ×£ķĆÜĶ┐ć[slurm](https://slurm.schedmd.com/)Õ£©ķøåńŠżõĖŖõĮ┐ńö©MMHuman3D, µé©ÕÅ»õ╗źõĮ┐ńö©Ķäܵ£¼ `slurm_test.sh`Ķ┐øĶĪīµĄŗĶ»ĢŃĆé + +```shell +./tools/slurm_test.sh ${PARTITION} ${JOB_NAME} ${CONFIG} ${WORK_DIR} ${CHECKPOINT} --metrics ${METRICS} +``` +õŠŗÕ”é: +```shell +./tools/slurm_test.sh my_partition test_hmr configs/hmr/resnet50_hmr_pw3d.py work_dirs/hmr work_dirs/hmr/latest.pth 8 --metrics pa-mpjpe mpjpe +``` + + +## Ķ«Łń╗ā + +### õĮ┐ńö©ÕŹĢ’╝łÕżÜ’╝ēõĖ¬GPUĶ┐øĶĪīĶ«Łń╗ā + +```shell +python tools/train.py ${CONFIG_FILE} ${WORK_DIR} --no-validate +``` +õŠŗÕ”é: õĮ┐ńö©ÕŹĢõĖ¬GPUĶ«Łń╗āHMR. +```shell +python tools/train.py ${CONFIG_FILE} ${WORK_DIR} --gpus 1 --no-validate +``` + +### õĮ┐ńö©slurmĶ┐øĶĪīĶ«Łń╗ā + +Õ”éµ×£ķĆÜĶ┐ć[slurm](https://slurm.schedmd.com/)Õ£©ķøåńŠżõĖŖõĮ┐ńö©MMHuman3D, µé©ÕÅ»õ╗źõĮ┐ńö©Ķäܵ£¼ `slurm_train.sh`Ķ┐øĶĪīĶ«Łń╗āŃĆé + +```shell +./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} ${CONFIG_FILE} ${WORK_DIR} ${GPU_NUM} --no-validate +``` + +ÕÅ»ķĆēÕÅéµĢ░Õīģµŗ¼: +- `--resume-from ${CHECKPOINT_FILE}`: ń╗¦µē┐õ╣ŗÕēŹńÜäµØāķćŹń╗¦ń╗ŁĶ«Łń╗āŃĆé +- `--no-validate`: Õ£©Ķ«Łń╗āµŚČµś»ÕÉ”Ķ┐øĶĪīµĄŗĶ»ĢŃĆé + +õŠŗÕ”é: Õ£©ķøåńŠżõĖŖõĮ┐ńö©8ÕŹĪĶ«Łń╗āHMRŃĆé +```shell +./tools/slurm_train.sh my_partition my_job configs/hmr/resnet50_hmr_pw3d.py work_dirs/hmr 8 --no-validate +``` + +Ķ»”µāģĶ»ĘĶ¦ü[slurm_train.sh](https://github.com/open-mmlab/mmhuman3d/tree/main/tools/slurm_train.sh)ŃĆé + +## µø┤ÕżÜµĢÖń©ŗ + +- [Camera conventions](../docs_zh-CN/cameras.md) +- [Keypoint conventions](../docs_zh-CN/keypoints_convention.md) +- [Custom keypoint conventions](../docs_zh-CN/customize_keypoints_convention.md) +- [HumanData](../docs_zh-CN/human_data.md) +- [Keypoint visualization](../docs_zh-CN/visualize_keypoints.md) +- [Mesh visualization](../docs_zh-CN/visualize_smpl.md) diff --git a/internlm_langchain/knowledge_base/MMHuman3D/content/human_data.md b/internlm_langchain/knowledge_base/MMHuman3D/content/human_data.md new file mode 100644 index 00000000..a866f453 --- /dev/null +++ b/internlm_langchain/knowledge_base/MMHuman3D/content/human_data.md @@ -0,0 +1,287 @@ +## HumanDataµĢ░µŹ«µĀ╝Õ╝Å + +### µĆ╗Ķ¦ł + +`HumanData`µś»PythonÕåģńĮ«ÕŁŚÕģĖńÜäÕŁÉń▒╗’╝īõĖ╗Ķ”üńö©õ║ÄÕŁśµöŠÕīģÕɽõ║║õĮōńÜäÕŹĢĶ¦åĶ¦ÆÕøŠÕāÅńÜäõ┐Īµü»ŃĆéÕ«āÕģʵ£ēķĆÜńö©ńÜäÕ¤║ńĪĆń╗ōµ×ä’╝īõ╣¤Õģ╝Õ«╣Õģʵ£ēµ¢░ńē╣µĆ¦ńÜäÕ«óÕłČÕī¢µĢ░µŹ«ŃĆé +ÕĤńö¤ńÜä`HumanData`ÕīģÕɽ`numpy.ndarray`µł¢ÕģČõ╗¢ńÜäPythonÕåģńĮ«ńÜäµĢ░µŹ«ń╗ōµ×ä’╝īõĮåõĖŹÕīģÕɽ`torch.Tensor`ńÜäµĢ░µŹ«ŃĆéÕÅ»õ╗źõĮ┐ńö©`human_data.to()`Õ░åÕģČĶĮ¼µŹóõĖ║`torch.Tensor`(µö»µīüCPUÕÆīGPU)ŃĆé + +### `Key/Value`ńÜäÕ«Üõ╣ē’╝ÜÕ”éõĖŗµś»Õ»╣`HumanData`µö»µīüńÜä`Key`ÕÆī`Value`ńÜäµÅÅĶ┐░. + +#### ĶĘ»ÕŠä: + +ķĆÜÕĖĖÕīģÕɽÕøŠńēćĶĘ»ÕŠä’╝īÕ”éµ×£µĢ░µŹ«ķøåµ£ēµÅÉõŠøķóØÕż¢ńÜäµĘ▒Õ║”µł¢ĶĆģÕłåÕē▓ÕøŠ’╝īõ╣¤ÕÅ»õ╗źĶ«░ÕĮĢõĖŗµØźŃĆé +- image_path: (N, ), ÕŁŚń¼”õĖ▓ń╗䵳ÉńÜäÕłŚĶĪ©, µ»ÅõĖĆõĖ¬Õģāń┤Āµś»ÕøŠÕāÅńøĖÕ»╣õ║ĵĀ╣ńø«ÕĮĢńÜäĶĘ»ÕŠäŃĆé +- segmantation_path (ÕÅ»ķĆē): (N, ), ÕŁŚń¼”õĖ▓ń╗䵳ÉńÜäÕłŚĶĪ©, µ»ÅõĖĆõĖ¬Õģāń┤Āµś»ÕøŠÕāÅÕłåÕē▓ÕøŠńøĖÕ»╣õ║ĵĀ╣ńø«ÕĮĢńÜäĶĘ»ÕŠäŃĆé +- depth_path (ÕÅ»ķĆē): (N, ), ÕŁŚń¼”õĖ▓ń╗䵳ÉńÜäÕłŚĶĪ©, µ»ÅõĖĆõĖ¬Õģāń┤Āµś»ÕøŠÕāŵĘ▒Õ║”ÕøŠńøĖÕ»╣õ║ĵĀ╣ńø«ÕĮĢńÜäĶĘ»ÕŠäŃĆé + +#### Õģ│ķö«ńé╣’╝Ü + +õ╗źõĖŗÕģ│ķö«ńé╣keysÕ”éµ×£ķĆéńö©’╝īÕłÖÕ║öÕīģÕɽգ©HumanDataõĖŁŃĆéõ╗╗õĮĢõĖĆõĖ¬Õģ│ķö«ńé╣ńÜäkey’╝īÕ║öÕŁśÕ£©õĖĆõĖ¬mask’╝īĶĪ©ńż║ÕģČõĖŁÕō¬õ║øÕģ│ķö«ńé╣µ£ēµĢłŃĆéÕ”é`keypoints3d_original`Õ║öÕ»╣Õ║ö`keypoints3d_original_mask`ŃĆé +`HumanData` õĖŁńÜäÕģ│ķö«ńé╣ÕŁśÕ驵Ā╝Õ╝ÅõĖ║`HUMAN_DATA`, ÕīģÕɽ190õĖ¬Õģ│ķö«ńé╣ŃĆéMMHuman3dõĖŁµÅÉõŠøõ║åÕŠłÕżÜÕĖĖńö©Õģ│ķö«ńé╣µĀ╝Õ╝ÅńÜäĶĮ¼µŹó’╝ł2dÕÅŖ3dÕØćµö»µīü’╝ē, Ķ»”Ķ¦ü [keypoints_convention](../docs_zh-CN/keypoints_convention.md). +- keypoints3d_smpl / keypoints3d_smplx: (N, 190, 4), numpy array, `smplx / smplx`µ©ĪÕ×ŗńÜä3dÕģ│ĶŖéńé╣õĖÄńĮ«õ┐ĪÕ║”, µ»ÅõĖĆõĖ¬µĢ░µŹ«ķøåńÜäÕģ│ĶŖéńé╣µśĀÕ░äÕł░õ║å`HUMAN_DATA`ńÜäÕģ│ĶŖéńé╣ŃĆé +- keypoints3d_original: (N, 190, 4), numpy array, ńö▒µĢ░µŹ«ķøåµ£¼Ķ║½µÅÉõŠøńÜä3dÕģ│ĶŖéńé╣õĖÄńĮ«õ┐ĪÕ║”, µ»ÅõĖĆõĖ¬µĢ░µŹ«ķøåńÜäÕģ│ĶŖéńé╣µśĀÕ░äÕł░õ║å`HUMAN_DATA`ńÜäÕģ│ĶŖéńé╣ŃĆé +- keypoints2d_smpl / keypoints2d_smplx: (N, 190, 3), numpy array, `smpl / smplx`µ©ĪÕ×ŗńÜä2dÕģ│ĶŖéńé╣õĖÄńĮ«õ┐ĪÕ║”, µ»ÅõĖĆõĖ¬µĢ░µŹ«ķøåńÜäÕģ│ĶŖéńé╣µśĀÕ░äÕł░õ║å`HUMAN_DATA`ńÜäÕģ│ĶŖéńé╣ŃĆé +- keypoints2d_original: (N, 190, 3), numpy array, ńö▒µĢ░µŹ«ķøåµ£¼Ķ║½µÅÉõŠøńÜä2dÕģ│ĶŖéńé╣õĖÄńĮ«õ┐ĪÕ║”, µ»ÅõĖĆõĖ¬µĢ░µŹ«ķøåńÜäÕģ│ĶŖéńé╣µśĀÕ░äÕł░õ║å`HUMAN_DATA`ńÜäÕģ│ĶŖéńé╣ŃĆé +- ’╝łmaskńż║õŠŗ’╝ē keypoints2d_smpl_mask: (190, ), numpy array, ĶĪ©ńż║`keypoints2d_smpl`õĖŁÕģ│ķö«ńé╣µś»ÕÉ”µ£ēµĢłńÜäµÄ®Ķå£ŃĆé 0ĶĪ©ńż║Ķ»źõĮŹńĮ«ńÜäÕģ│ķö«ńé╣Õ£©ÕĤզŗµĢ░µŹ«ķøåõĖŁµŚĀµ│ĢµēŠÕł░ŃĆé + +#### µŻĆµĄŗµĪå’╝Ü + +Ķ║½õĮō’╝łsmpl’╝ē’╝īµēŗĶäĖ’╝łsmplx’╝ēńÜ䵯ƵĄŗµĪå’╝īµĀćµ│©õĖ║`[x_min, y_min, width, height, confidence]`’╝īõĖöõĖŹÕ║öĶČģÕć║ÕøŠńēćŃĆé +- bbox_xywh: (N, 5), numpy array, ĶŠ╣ńĢīµĪåńÜäńĮ«õ┐ĪÕ║”, ĶŠ╣ńĢīµĪåÕĘ”õĖŗĶ¦Æńé╣ńÜäÕØɵĀćxÕÆīy, ĶŠ╣ńĢīµĪåńÜäÕ«ĮwÕÆīķ½śh, ńĮ«õ┐ĪÕ║”ÕŠŚÕłåµöŠńĮ«Õ£©µ£ĆÕÉÄŃĆé +- face_bbox_xywh, lhand_bbox_xywh, rhand_bbox_xywh’╝łÕÅ»ķĆē’╝ē’╝Ü (N, 5), numpy array, Õ”éµ×£µĢ░µŹ«µĀćµ│©õĖŁÕɽµ£ē`smplx`, ÕłÖÕ║öÕīģµŗ¼Ķ┐ÖõĖēõĖ¬key’╝īńö▒smplx2dÕģ│ķö«ńé╣ÕŠŚÕć║’╝īµĀ╝Õ╝ÅÕÉīõĖŖŃĆé + +#### õ║║õĮōµ©ĪÕ×ŗÕÅéµĢ░’╝Ü + +ķĆÜÕĖĖõ╗źsmpl/smplxµĀ╝Õ╝ÅÕŁśÕé©ŃĆé +- smpl: (1, ), ÕŁŚÕģĖ, `keys` ÕłåÕł½õĖ║ ['body_pose': numpy array, (N, 23, 3), 'global_orient': numpy array, (N, 3), 'betas': numpy array, (N, 10), 'transl': numpy array, (N, 3)]. +- smplx: (1, ), ÕŁŚÕģĖ, `keys` ÕłåÕł½õĖ║ ['body_pose': numpy array, (N, 21, 3),'global_orient': numpy array, (N, 3), 'betas': numpy array, (N, 10), 'transl': numpy array, (N, 3), 'left_hand_pose': numpy array, (N, 15, 3), 'right_hand_pose': numpy array, (N, 15, 3), 'expression': numpy array (N, 10), 'leye_pose': numpy array (N, 3), 'reye_pose': (N, 3), 'jaw_pose': numpy array (N, 3)]. + +#### ÕģČÕ«ākeys + +- config: (), ÕŁŚń¼”õĖ▓, ÕŹĢõĖ¬µĢ░µŹ«ķøåńÜäķģŹńĮ«ńÜäµĀćÕ┐ŚŃĆé +- meta: (1, ), ÕŁŚÕģĖ, `keys`õĖ║µĢ░µŹ«ķøåõĖŁńÜäÕÉäń¦ŹÕģāµĢ░µŹ«ŃĆé +- misc: (1, ), ÕŁŚÕģĖ, `keys`õĖ║µĢ░µŹ«ķøåõĖŁÕÉäń¦Źńŗ¼ńē╣Ķ«ŠÕ«Ü’╝īõ╣¤ÕÅ»õ╗źńö▒ńö©µłĘĶć¬Õ«Üõ╣ēŃĆé`misc`ÕŹĀńö©ńÜäń®║ķŚ┤’╝łÕÅ»õ╗źķĆÜĶ┐ć`sys.getsizeof(misc)`ĶÄĘÕÅ¢’╝ēõĖŹĶāĮĶČģĶ┐ć6MBŃĆé + +#### `HumanData['misc']`õĖŁÕ╗║Ķ««’╝łÕÅ»ĶāĮ’╝ēÕīģÕɽńÜäÕåģÕ«╣: +Miscellaneousķā©ÕłåõĖŁÕīģÕɽõ║åµ»ÅõĖ¬µĢ░µŹ«ķøåńÜäńŗ¼ńē╣Ķ«ŠÕ«Ü’╝īÕīģµŗ¼ńøĖµ£║ń¦Źń▒╗’╝īÕģ│ķö«ńé╣µĀćµ│©µØźµ║É’╝īµŻĆµĄŗµĪåµØźµ║É’╝īµś»ÕÉ”ÕīģÕɽsmpl/smplxµĀćµ│©ńŁēńŁē’╝īńö©õ║ÄõŠ┐Õł®µĢ░µŹ«Ķ»╗ÕÅ¢ŃĆé +`HumanData['misc']`õĖŁÕīģÕɽõĖĆõĖ¬dictionary’╝īÕ╗║Ķ««ÕīģÕɽńÜäkeyÕ”éõĖŗµēĆńż║’╝Ü +- kps3d_root_aligned’╝Ü Bool µÅÅĶ┐░keypoints3dµś»ÕÉ”ń╗ÅĶ┐ćroot align’╝īÕ╗║Ķ««õĖŹĶ┐øĶĪīroot_alignment’╝īÕ”éµ×£õĖŹÕīģÕɽĶ┐ÖõĖ¬key’╝īÕłÖķ╗śĶ«żµ▓Īµ£ēĶ┐øĶĪīĶ┐ćroot_aligenment +- flat_hand_mean’╝ÜBool Õ»╣õ║ÄsmplxµĀćµ│©ńÜäµĢ░µŹ«’╝īÕ║öĶ»źÕŁśÕ£©µŁżķĪ╣’╝īÕż¦ÕżÜµĢ░µĢ░µŹ«ķøåõĖŁ`flat_hand_mean=False` +- bbox_source’╝ܵÅÅĶ┐░µŻĆµĄŗµĪåńÜäµØźµ║É’╝ī`bbox_soruce='keypoints2d_smpl' or 'keypoints2d_smplx' or 'keypoints2d_original'`’╝īµÅÅĶ┐░µŻĆµĄŗµĪåµś»ńö▒Õō¬ń¦ŹÕģ│ķö«ńé╣ÕŠŚÕć║ńÜä’╝īµł¢ĶĆģ`bbox_source='provide_by_dataset'`ĶĪ©ńż║µŻĆµĄŗµĪåńö▒µĢ░µŹ«ķøåńø┤µÄźń╗ÖÕć║’╝łµ»öÕ”éńö©ÕģČĶć¬ÕĖ”µŻĆµĄŗÕÖ©ńö¤µłÉĶĆīõĖŹµś»ńö▒Õģ│ķö«ńé╣µÄ©Õ»╝ÕŠŚÕć║’╝ē +- bbox_body_scale: Õ”éµ×£µŻĆµĄŗµĪåńö▒Õģ│ķö«ńé╣µÄ©Õ»╝ÕŠŚÕć║’╝īÕłÖÕ║öÕīģÕɽµŁżķĪ╣’╝īµÅÅĶ┐░ńö▒smpl/smplx/2d_gtÕģ│ķö«ńé╣µÄ©Õ»╝Õć║ńÜäĶ║½õĮōµŻĆµĄŗµĪåńÜäµöŠÕż¦µ»öõŠŗ’╝īÕ╗║Ķ««`bbox_body_scale=1.2` +- bbox_hand_scale, bbox_face_scale: Õ”éµ×£µŻĆµĄŗµĪåńö▒Õģ│ķö«ńé╣µÄ©Õ»╝ÕŠŚÕć║’╝īÕłÖÕ║öÕīģÕɽĶ┐ÖõĖżķĪ╣’╝īµÅÅĶ┐░ńö▒smpl/smplx/2d_gtÕģ│ķö«ńé╣µÄ©Õ»╝Õć║ńÜäĶ║½õĮōµŻĆµĄŗµĪåńÜäµöŠÕż¦µ»öõŠŗ’╝īÕ╗║Ķ««`bbox_hand_scale=1.0, bbox_face_scale=1.0` +- smpl_source / smplx_source: µÅÅĶ┐░smpl/smplxńÜäµØźµ║É’╝ī`'original', 'nerual_annot', 'eft', 'osx_annot', 'cliff_annot'`, µØźµÅÅĶ┐░smpl/smnplxµś»µØźµ║Éõ║ĵĢ░µŹ«ķøåµÅÉõŠø’╝īµł¢ĶĆģÕģČÕ«āµĀćµ│©µØźµ║É +- cam_param_type: µÅÅĶ┐░ńøĖµ£║ÕÅéµĢ░ńÜäń¦Źń▒╗’╝ī`cam_param_type='prespective' or 'predicted_camera' or 'eft_camera'` +- principal_point, focal_length: (1, 2), numpy array’╝īÕ”éµ×£µĢ░µŹ«ķøåõĖŁńøĖµ£║ÕÅéµĢ░µüÆÕ«Ü’╝īÕłÖÕ║öÕīģÕɽĶ┐ÖõĖżķĪ╣’╝īķĆÜÕĖĖķĆéńö©õ║Äńö¤µłÉµĢ░µŹ«ķøåŃĆé +- image_shape: (1, 2), numpy array’╝īÕ”éµ×£µĢ░µŹ«ķøåõĖŁÕøŠńēćÕż¦Õ░ŵüÆÕ«Ü’╝īÕłÖÕ║öÕīģÕɽµŁżķĪ╣ŃĆé + +#### `HumanData['meta']`õĖŁÕ╗║Ķ««’╝łÕÅ»ĶāĮ’╝ēÕīģÕɽńÜäÕåģÕ«╣: +- gender: (N, )’╝ī ÕŁŚń¼”õĖ▓ń╗䵳ÉńÜäÕłŚĶĪ©, µ»ÅõĖĆõĖ¬Õģāń┤Āµś»smplxµ©ĪÕ×ŗńÜäµĆ¦Õł½’╝łõĖŁµĆ¦ÕłÖõĖŹÕ┐ģµĀćµ│©’╝ē +- height’╝łwidth’╝ē’╝Ü(N, )’╝ī ÕŁŚń¼”õĖ▓ń╗䵳ÉńÜäÕłŚĶĪ©, µ»ÅõĖĆõĖ¬Õģāń┤Āµś»ÕøŠńēćńÜäķ½ś’╝łµł¢Õ«Į’╝ē’╝īĶ┐ÖķćīõĖŹµÄ©ĶŹÉõĮ┐ńö©`image_shape=(width, height): (N, 2)`’╝īÕøĀõĖ║µ£ēµŚČķ£ĆĶ”üµīēÕÅŹķĪ║Õ║ÅĶ»╗ÕÅ¢ÕøŠńēćµĀ╝Õ╝ÅŃĆé’╝łµĢ░µŹ«ķøåÕøŠńēćÕłåĶŠ©ńÄćõĖĆĶć┤ÕłÖÕ║öµĀćµ│©Õ£©`HumanData['misc']`õĖŁ’╝ē +- ÕģČÕ«āµ£ēµĀćĶ»åµĆ¦ńÜäkey’╝īĶŗźµĢ░µŹ«ķøåõĖŁĶ»źkeyõĖŹõĖĆĶć┤’╝īõĖöõ╝ÜÕĮ▒ÕōŹkeypoints or smpl/smplx’╝īÕłÖÕ╗║Ķ««µĀćµ│©’╝īÕ”éfocal_lengthõĖÄprincipal_point, focal_length = (N, 2), principal_point = (N, 2) + +#### Õģ│õ║ÄHumanDatańÜäõĖĆõ║øĶ»┤µśÄ + +- µēƵ£ēµĢ░µŹ«µĀćµ│©ÕØćÕĘ▓õ╗ÄõĖ¢ńĢīÕØɵĀćĶĮ¼ń¦╗Õł░opencvńøĖµ£║ń®║ķŚ┤’╝īĶ┐øĶĪīsmpl/smplxńÜäńøĖµ£║ń®║ķŚ┤ĶĮ¼µŹóÕÅ»õ╗źńö© + +```from mmhuman3d.models.body_models.utils import transform_to_camera_frame, batch_transform_to_camera_frame``` + +#### µŻĆµ¤ź`HumanData`õĖŁńÜä`key`. + +Õ£©ķ╗śĶ«żńÜä`HumanData`õĖŁ’╝īÕŬĶāĮÕīģÕɽõ╣ŗÕēŹµÅÅĶ┐░Ķ┐ć`key`ŃĆéÕ”éµ×£µŚĀµ│Ģķü┐ÕģŹĶ┐ÖõĖ¬ķŚ«ķóś’╝īĶ┐śµ£ēõĖĆõĖ¬µ¢╣µ│ĢŃĆé ķĆÜĶ┐ćµīćÕ«Ü`__key_strict__ == False`µ×äÕ╗║õĖĆõĖ¬`HumanData`Õ«×õŠŗŃĆé + +```python +human_data = HumanData.new(key_strict=False) +human_data['video_path'] = 'test.mp4' +``` +Ķ┐öÕø×ńÜä`HumanData`ÕģüĶ«Ėõ╗╗õĮĢÕ«óÕłČÕī¢ńÜä`key`’╝īÕ╣ČÕ£©ń¼¼õĖƵ¼ĪµÄźÕÅŚµ¢░`key`µŚČlogõĖĆõĖ¬ĶŁ”ÕæŖŃĆéÕ”éµ×£µŁŻÕ£©õĮ┐ńö©Õ«óÕłČÕī¢ńÜä`key`’╝īĶ»ĘÕ┐ĮńĢźĶ»źĶŁ”ÕæŖ’╝īÕ£©ń©ŗÕ║Åń╗ōµØ¤ÕēŹÕ«āõĖŹõ╝ÜÕåŹÕć║ńÄ░ŃĆé + +Õ”éµ×£µé©ÕĘ▓ń╗ŵ×äÕ╗║õ║åõĖĆõĖ¬`HumanData`, Õ╣ČõĖöµā│µö╣ÕÅś`strict`µ©ĪÕ╝Å, ÕÅ»õ╗źõĮ┐ńö©`set_key_strict`: + +```python +human_data = HumanData.fromfile('human_data.npz') +key_strict = human_data.get_key_strict() +human_data.set_key_strict(not key_strict) +``` + + + +#### µŻĆµ¤ź`HumanData`õĖŁńÜä`value`. + +ÕŬµ£ēµīćÕ«Ü`human_data[key] == value`µŚČ’╝īµēŹõ╝ܵŻĆµ¤źõ╣ŗÕēŹµÅÉÕł░Ķ┐ćńÜä`value`’╝īńøĖÕģ│Ķ¦äĶīāÕ£©`HumanData.SUPPORTED_KEYS`õĖŁÕ«Üõ╣ēŃĆé + +Õ»╣õ║ĵ»ÅõĖ¬`value`, Õ┐ģķĪ╗Õ£©ÕģČ`key`õĖŗµīćիܵĢ░µŹ«ń▒╗Õ×ŗ: + +```python +'smpl': { + 'type': dict, +}, +``` + +Õ»╣õ║Äń▒╗Õ×ŗõĖ║`numpy.ndarray`ńÜä`value`, ķ£ĆĶ”üµīćÕ«Ü`shape`ÕÆī`dim`ÕÅéµĢ░: + +```python +'keypoints3d': { + 'type': np.ndarray, + 'shape': (-1, -1, 4), + # value.ndim==3 value.shape[2]==4 + # value.shape[0:2] is arbitrary. + 'dim': 0 + # dimension 0 marks time(frame index, or second) +}, +``` + +Õ»╣õ║ÄõĖŹķÜÅÕĖ¦ÕÅśÕī¢ńÜä`value`’╝īµīćÕ«ÜÕģČ`dim=-1`õ╗źĶĘ│Ķ┐ćÕĖ¦µŻĆµ¤ź: + +```python +'keypoints3d_mask': { + 'type': np.ndarray, + 'shape': (-1, ), + 'dim': -1 +}, +``` + +### µĢ░µŹ«ÕÄŗń╝® + +#### ÕÄŗń╝®`mask` + +ńö▒õ║Ä`HUMAN_DATA`ńÜäÕģ│ķö«ńé╣Õ«Üõ╣ēµĢ┤ÕÉłĶć¬õĖŹÕÉīńÜäµĢ░µŹ«ķøå’╝īķā©ÕłåÕģ│ķö«ńé╣ń╝║Õż▒µś»ÕŠłÕĖĖĶ¦üńÜäŃĆéõĮ┐ńö©Õ”éõĖŗńÜäµ¢╣Õ╝Å’╝īÕÅ»õ╗źķĆÜĶ┐ć`mask`µ╗żķÖżń╝║Õż▒ńÜäÕģ│ķö«ńé╣: + +```python +# keypoints2d_agora µś»õĖĆõĖ¬ÕĮóńŖČõĖ║[frame_num, 127, 3]ńÜänumpyµĢ░ń╗ä. +# AgoraõĖŁÕ«Üõ╣ēõ║å127õĖ¬Õģ│ķö«ńé╣. +keypoints2d_human_data, mask = convert_kps(keypoints2d_agora, 'agora', 'human_data') +# keypoints2d_human_data µś»õĖĆõĖ¬ÕĮóńŖČõĖ║[frame_num, 190, 3]ńÜänumpyµĢ░ń╗ä. +# mask µś»õĖĆõĖ¬ÕĮóńŖČõĖ║[190, ]ńÜänumpyµĢ░ń╗ä, ÕåģÕɽõ║å127õĖ¬1ÕÆī63õĖ¬0. +``` + +µīćÕ«Ü`keypoints2d_mask` ÕÆī `keypoints2d`, ÕŠłµśÄµśŠ`keypoints2d`õĖŁµ£ēÕŠłÕżÜÕåŚõĮÖńÜä0: + +```python +human_data = HumanData() +human_data['keypoints2d_mask'] = mask +human_data['keypoints2d'] = keypoints2d_human_data +``` + +Ķ░āńö©`compress_keypoints_by_mask()`ÕÄ╗µÄēÕåŚõĮÖńÜä0ŃĆé Ķ»źµ¢╣µ│Ģõ╝ܵŻĆµ¤źµēƵ£ēÕīģÕɽ`keypoints`ńÜä`key`µś»ÕÉ”Õģʵ£ēńøĖÕ║öńÜä`mask`’╝īÕ”éµ×£ÕÉīµŚČÕŁśÕ£©’╝īÕ░▒Ķ┐øĶĪīÕÄŗń╝®: + +```python +human_data.compress_keypoints_by_mask() +``` + +Ķ░āńö©`get_raw_value()`ĶÄĘÕŠŚÕé©ÕŁśÕ£©`HumanData`Õ«×õŠŗõĖŁÕÄŗń╝®Ķ┐ćńÜä`value`. ÕĮōķĆÜĶ┐ć`[]`ĶÄĘÕŠŚ`item`µŚČ, Õ░åĶ┐öÕø×ńö©0ÕĪ½ÕģģÕÉÄńÜäÕģ│ķö«ńé╣: + +```python +keypoints2d_human_data = human_data.get_raw_value('keypoints2d') +print(keypoints2d_human_data.shape) # [frame_num, 127, 3] +keypoints2d_human_data = human_data['keypoints2d'] +print(keypoints2d_human_data.shape) # [frame_num, 190, 3] +``` + +Õ£©`keypoints_compressed`µ©ĪÕ╝ÅõĖŁ, ÕÅ»õ╗źÕ»╣Õģ│ķö«ńé╣Ķ┐øĶĪīń╝¢ĶŠæŃĆéµ£ēõĖżń¦ŹõĖŹÕÉīńÜäµ¢╣Õ╝Å’╝īĶ«ŠńĮ«ÕĪ½ÕģģµĢ░µŹ«µł¢ńø┤µÄźµīćÕ«ÜÕÄŗń╝®µĢ░µŹ«: + +```python +padded_keypoints2d = np.zeros(shape=[100, 190, 3]) +human_data['keypoints2d'] = padded_keypoints2d # [frame_num, 190, 3] +compressed_keypoints2d = np.zeros(shape=[100, 127, 3]) +human_data.set_raw_value('keypoints2d', compressed_keypoints2d) # [frame_num, 127, 3] +``` + +ÕĮō`HumanData`Õ«×õŠŗÕżäõ║Ä`keypoints_compressed`µ©ĪÕ╝Å, µēƵ£ēÕģ│ķö«ńé╣ńÜä`masks`õ╝ÜĶó½ķöüÕ«ÜŃĆéÕĮōµé©Õ░ØĶ»ĢĶ┐øĶĪīõ┐«µö╣µŚČ, õ╝ÜlogõĖĆõĖ¬ĶŁ”ÕæŖÕ╣ČõĖö`value`õĖŹõ╝ÜĶó½õ┐«µö╣ŃĆéÕ”éµ×£ķ£ĆĶ”üõ┐«µö╣`mask`’╝īõĮ┐ńö©`decompress_keypoints()`Ķ┐øĶĪīĶ¦ŻÕÄŗń╝®: + +```python +human_data.decompress_keypoints() +``` + +õĖŖĶ┐░ńē╣µĆ¦õ╣¤ķĆéńö©õ║ÄÕģČõ╗¢ń▒╗õ╝╝õ║Ä`keypoints*`ÕÆī`keypoints*_mask`ńÜä`key-value`Õ»╣ŃĆé + +#### ÕÄŗń╝®µ¢ćõ╗Č + +Ķ░āńö©`dump()` Õ░å`HumanData`ÕÄŗń╝®µłÉ`.npz`µ¢ćõ╗ČŃĆé + +`dump`ÕÉÄńÜä`.npz`µ¢ćõ╗ČÕÅ»õ╗źõĮ┐ńö©`load()`Ķ┐øĶĪīÕŖĀĶĮĮ: + +```python +# õ┐ØÕŁś +human_data.dump('./dumped_human_data.npz') +# ÕŖĀĶĮĮ +another_human_data = HumanData() +another_human_data.load('./dumped_human_data.npz') +``` + +µ£ēµŚČ`HumanData`Õż¬ķĢ┐õ║å’╝īńø┤µÄźĶ┐øĶĪī`dump`õ╝ܵŖźķöÖŃĆéĶ┐Öń¦ŹµāģÕåĄõĖŗ’╝īÕÅ»õ╗źĶ░āńö©`dump_by_pickle`ÕÆī`load_by_pickle`Õ░å`HumanData`ÕÄŗń╝®µłÉ`.pkl`µ¢ćõ╗ČŃĆé + +#### ÕÄŗń╝®`key` + +Õ”éµ×£`HumanData`Õ«×õŠŗõĖŹÕżäõ║Ä`key_strict`µ©ĪÕ╝Å, ÕģČÕÅ»ĶāĮõ╝ÜÕīģÕɽõĖŹÕÅŚµö»µīüńÜäķĪ╣ńø«ŃĆéĶ░āńö©`pop_unsupported_items()`µĖģķÖżĶ┐Öõ║øķĪ╣ńø«’╝īõ╗źĶŖéń£üń®║ķŚ┤: + +```python +human_data = HumanData.fromfile('human_data_not_strict.npz') +human_data.pop_unsupported_items() +human_data.set_key_strict(True) +``` + +### µĢ░µŹ«ķĆēµŗ® + +#### ķĆÜĶ┐ćÕĮóńŖČĶ┐øĶĪīķĆēµŗ® + +ÕüćÕ«Ü`keypoints2d` µś»õĖĆõĖ¬`array`’╝īÕģČÕĮóńŖČõĖ║[200, 190, 3], ÕŬķ£ĆĶ”üµ£ĆÕ╝ĆÕ¦ŗńÜä10ÕĖ¦: + +```python +first_ten_frames = human_data.get_value_in_shape('keypoints2d', shape=[10, -1, -1]) +``` + +Õ£©õĖĆõ║øµāģÕåĄõĖŗ, µłæõ╗¼ķ£ĆĶ”üÕ░å`array`µē®ÕģģµłÉńē╣Õ«ÜńÜäÕĮóńŖČ: + +```python +# ķĆÜĶ┐ćÕĪ½0Õ░åÕģČÕĮóńŖČõ╗Ä[200, 190, 3]µē®ÕģģµłÉ[200, 300, 3] +padded_keypoints2d = human_data.get_value_in_shape('keypoints2d', shape=[200, 300, -1]) +# ÕĪ½ÕģģńÜäµĢ░ÕĆ╝ÕÅ»õ╗źĶó½õ┐«µö╣ +padded_keypoints2d = human_data.get_value_in_shape('keypoints2d', shape=[200, 300, -1], padding_constant=1) +``` + +#### ķĆÜĶ┐浌ČķŚ┤ÕłćńēćĶ┐øĶĪīķĆēµŗ® + +ÕüćĶ«ŠÕ£©õĖĆõĖ¬`HumanData`Õ«×õŠŗõĖŁµ£ē200ÕĖ¦, ÕŬķ£ĆĶ”üõĖŁķŚ┤10Ķć│20ÕĖ¦: + +```python +# µēƵ£ēµö»µīüńÜä`value`ķāĮõ╝ÜĶó½Õłćńēć +sub_human_data = human_data.get_slice(10, 21) +``` + +õ╣¤ÕÅ»õ╗źĶ┐øĶĪīõĖŗķććµĀĘ,õĖŗķØóńÜäõŠŗÕŁÉµÅÅĶ┐░õ║åõĖĆń¦ŹķĆēµŗ®ÕģČ33%µĢ░µŹ«ńÜäµ¢╣µ│Ģ: + +```python +# ķĆēµŗ® [0, 3, 6, 9,..., 198] +sub_human_data = human_data.get_slice(0, 200, 3) +``` + +### ĶĮ¼µŹóõĖ║`torch.Tensor` + +õ╣ŗÕēŹµÅÉÕł░’╝īÕĤńö¤ńÜä`HumanData`õĖŁÕīģÕɽ`numpy.ndarray`µł¢pythonÕåģńĮ«ń▒╗Õ×ŗńÜä`value`’╝īõĮå`numpy.ndarray`ÕÅ»õ╗źĶĮ╗µØŠĶĮ¼µŹóõĖ║`torch.Tensor`: + +```python +# ndarrayõ╝ÜĶó½ĶĮ¼µŹóµłÉcpuõĖŖńÜäTensor. +# ÕģČõ╗¢ń▒╗Õ×ŗńÜävalueõĖŹõ╝ÜÕÅæńö¤ÕÅśÕī¢. +# Ķ┐öÕø×õĖĆõĖ¬ÕĮóÕ”éHumanDatańÜäÕŁŚÕģĖ. +dict_of_tensor = human_data.to() +# õ╣¤ÕÅ»õ╗źĶĮ¼µŹóõĖ║GPUõĖŖńÜäTensor +gpu0_device = torch.device('cuda:0') +dict_of_gpu_tensor = human_data.to(gpu0_device) +``` +## MultiHumanData + +MulitHumanData Ķó½Ķ«ŠĶ«ĪµØźµö»µīüÕżÜõ║║ķćŹÕ╗║ŃĆéÕ«āń╗¦µē┐õ║ÄHumanDataŃĆéÕ£©HumanDataõĖŁ’╝īÕøĀõĖ║ÕøŠńēćÕÆīµĢ░µŹ«µś»õĖĆõĖĆÕ»╣Õ║öńÜä’╝īµēĆõ╗źµłæõ╗¼ÕÅ»õ╗źńø┤µÄźń┤óÕ╝ĢµĢ░µŹ«ŃĆéńäČĶĆī’╝īÕ£©MultiHumanDataõĖŁµĢ░µŹ«ÕÆīÕøŠÕāŵś»ÕżÜÕ»╣õĖĆńÜäÕģ│ń│╗ŃĆé + +MultiHumanDataÕ£©HumanDatańÜäÕ¤║ńĪĆõĖŖµĘ╗ÕŖĀõĖĆõĖ¬µ¢░ńÜäkeyÕŽÕüÜ`frame_range`,Õ«āÕ«Üõ╣ēÕ”éõĖŗ’╝Ü + +```python +'frame_range': { + 'type': np.ndarray, + 'shape': (-1, 2), + 'dim': 0 + } +``` + +`frame_range`µś»ÕÆīÕøŠÕāÅõĖĆõĖĆÕ»╣Õ║öńÜäŃĆé `frame_range`õĖŁńÜäµ»ÅõĖ¬Õģāń┤Āµś»õĖżõĖ¬µīćķÆł’╝īÕ«āõ╗¼µīćÕÉæõĖĆõĖ¬µĢ░µŹ«Õī║Õ¤¤ŃĆé + +ÕüćĶ«Šµłæõ╗¼µ£ēõĖĆõĖ¬MultiHumanDatańÜäÕ«×õŠŗ’╝īµłæõ╗¼µā│ń┤óÕ╝Ģń¼¼iÕ╝ĀÕøŠÕāÅÕ»╣Õ║öńÜäµĢ░µŹ«ŃĆé ķ”¢Õģłµłæõ╗¼ńö©õĖ╗ń┤óÕ╝Ģń┤óÕ╝Ģ`frame_range`’╝īÕ«āõ╝ÜĶ┐öÕø×õĖżõĖ¬µīćķÆł’╝īńö©Ķ┐ÖõĖżõĖ¬µīćķÆłµłæõ╗¼Õ░▒ÕÅ»õ╗źń┤óÕ╝Ģń¼¼iÕ╝ĀÕøŠÕāÅÕ»╣Õ║öńÜäµēƵ£ēµĢ░µŹ«ŃĆé + +``` +image_0 ----> human_0 <--- frame_range[0][0] + - . + - . + --> human_(n-1) <--- frame_range[0][0] + (n-1) + -> human_n <--- frame_range[0][1] + . + . + . + + +image_n ----> human_0 <--- frame_range[n][0] + - . + - . + --> human_(n-1) <--- frame_range[n][0] + (n-1) + -> human_n <--- frame_range[n][1] + +``` diff --git a/internlm_langchain/knowledge_base/MMHuman3D/content/install.md b/internlm_langchain/knowledge_base/MMHuman3D/content/install.md new file mode 100644 index 00000000..4464b640 --- /dev/null +++ b/internlm_langchain/knowledge_base/MMHuman3D/content/install.md @@ -0,0 +1,227 @@ +# Õ«ēĶŻģ + +- [Õ«ēĶŻģ](#Õ«ēĶŻģ) +- [õŠØĶĄ¢](#õŠØĶĄ¢) +- [ÕćåÕżćńÄ»Õóā](#ÕćåÕżćńÄ»Õóā) +- [Õ«ēĶŻģ MMHuman3D](#Õ«ēĶŻģ-mmhuman3d) +- [õ╗ÄÕż┤Õ╝ĆÕ¦ŗÕ«ēĶŻģńÜäĶäܵ£¼](#õ╗ÄÕż┤Õ╝ĆÕ¦ŗÕ«ēĶŻģńÜäĶäܵ£¼) + +## õŠØĶĄ¢ + +- Linux +- ffmpeg +- Python 3.7+ +- PyTorch 1.6.0, 1.7.0, 1.7.1, 1.8.0, 1.8.1, 1.9.0 µł¢ 1.9.1. +- CUDA 9.2+ +- GCC 5+ +- PyTorch3D 0.4+ +- [MMCV](https://github.com/open-mmlab/mmcv) (Ķ»ĘÕ«ēĶŻģńö©õ║ÄGPUńÜämmcv-full, Ķ”üµ▒éńēłµ£¼>=1.3.17,<1.6.0) + +Optional: +- [MMPose](https://github.com/open-mmlab/mmpose) (ÕŬńö©õ║ĵ╝öńż║) +- [MMDetection](https://github.com/open-mmlab/mmdetection) (ÕŬńö©õ║ĵ╝öńż║) +- [MMTracking](https://github.com/open-mmlab/mmtracking) (ÕŬńö©õ║ÄÕżÜõ║║ńÜäµ╝öńż║ŃĆéĶ»ĘÕ«ēĶŻģ mmcls<0.23.1, mmcv-full>=1.3.17,<1.6.0) + +## ÕćåÕżćńÄ»Õóā + +a. ÕłøÕ╗║condaĶÖܵŗ¤ńÄ»ÕóāÕ╣ȵ┐Ƶ┤╗. + +```shell +conda create -n open-mmlab python=3.8 -y +conda activate open-mmlab +``` + +b. Õ«ēĶŻģ ffmpeg + +ńø┤µÄźõĮ┐ńö©condaÕ«ēĶŻģffmpeg + +```shell +conda install ffmpeg +``` + +c. µĀ╣µŹ« [Õ«śµ¢╣µīćÕ»╝](https://pytorch.org/) ’╝īÕ«ēĶŻģPyTorchÕÆītorchvision . +```shell +conda install pytorch={torch_version} torchvision cudatoolkit={cu_version} -c pytorch +``` + +õ╗źÕ«ēĶŻģ PyTorch 1.8.0 ÕÆī CUDA 10.2õĖ║õŠŗ. +```shell +conda install pytorch=1.8.0 torchvision cudatoolkit=10.2 -c pytorch +``` + +**µ│©µäÅ:** Ķ»ĘńĪ«õ┐Øcompilation CUDA versionÕÆīruntime CUDA versionńøĖÕī╣ķģŹŃĆé +ÕÅ”Õż¢’╝ī Õ»╣õ║ÄRTX 30ń│╗ÕłŚńÜ䵜ŠÕŹĪ’╝ī ķ£ĆĶ”ücudatoolkit>=11.0. + +d. Õ£©Linuxµł¢ĶĆģWindowsõĖŖÕ«ēĶŻģPyTorch3D. + +Õ»╣õ║ÄLinux’╝Ü + +```shell +conda install -c fvcore -c iopath -c conda-forge fvcore iopath -y +conda install -c bottler nvidiacub -y + +conda install pytorch3d -c pytorch3d +``` + +ńö©µłĘõ╣¤ÕÅ»õ╗źÕÅéĶĆā [PyTorch3D-install](https://github.com/facebookresearch/pytorch3d/blob/main/INSTALL.md) ńÜäµø┤ÕżÜń╗åĶŖéŃĆé +ńäČĶĆīµłæõ╗¼Ķ┐æµ£¤ńÜ䵥ŗĶ»ĢµśŠńż║õĮ┐ńö© conda Õ«ēĶŻģõ╝ÜķüćÕł░õŠØĶĄ¢Õå▓ń¬üńÜäķŚ«ķóśŃĆé +ÕøĀµŁż’╝īńö©µłĘõ╣¤ÕÅ»ķĆēµŗ®µīēńģ¦õĖŗÕłŚµŁźķ¬żõ╗ĵ║ÉńĀüÕ«ēĶŻģPytorch3DŃĆé + +```shell +git clone https://github.com/facebookresearch/pytorch3d.git +cd pytorch3d +pip install . +cd .. +``` + +Õ»╣õ║ÄWindows’╝Ü + +Ķ»ĘÕÅéĶĆā [Õ«śµ¢╣Õ«ēĶŻģµ¢ćµĪŻ](https://github.com/facebookresearch/pytorch3d/blob/main/INSTALL.md) ŃĆé Ķ┐Öķćīµłæõ╗¼µÅÉõŠøõĖĆõĖ¬ [õŠŗÕŁÉ](https://github.com/open-mmlab/mmhuman3d/pull/199#issue-1274739041) õŠøńö©µłĘÕÅéĶĆāŃĆé +**µ│©µäÅ:** Ķ┐Öķā©Õłåµś»ķÆłÕ»╣µā│Õ£©WindowsÕ╣│ÕÅ░Õ«ēĶŻģMMHuman3DńÜäńö©µłĘŃĆé + +Ķ┐ÉĶĪīÕ”éõĖŗÕæĮõ╗żµĄŗĶ»ĢPyTorch3Dµś»ÕɔիēĶŻģµłÉÕŖ¤: + +```shell +echo "import pytorch3d;print(pytorch3d.__version__); \ + from pytorch3d.renderer import MeshRenderer;print(MeshRenderer);\ + from pytorch3d.structures import Meshes;print(Meshes);\ + from pytorch3d.renderer import cameras;print(cameras);\ + from pytorch3d.transforms import Transform3d;print(Transform3d);"|python + +echo "import torch;device=torch.device('cuda');\ + from pytorch3d.utils import torus;\ + Torus = torus(r=10, R=20, sides=100, rings=100, device=device);\ + print(Torus.verts_padded());"|python +``` + +## Õ«ēĶŻģ MMHuman3D + +a. Õ«ēĶŻģ mmcv-full ŃĆü mmpose ŃĆü mmdet ÕÆī mmtrack + +- mmcv-full + +µÄ©ĶŹÉõĮ┐ńö©Õ”éõĖŗÕæĮõ╗żÕ«ēĶŻģmmcv-full. + +Õ»╣õ║Ä CPU: +```shell +pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cpu/{torch_version}/index.html +``` +õĮ┐ńö©µé©ńÜäpytorchńēłµ£¼ÕÅʵø┐µŹó`{torch_version}` + +Õ»╣õ║Ä GPU: + ```shell + pip install "mmcv-full>=1.3.17,<=1.5.3" -f https://download.openmmlab.com/mmcv/dist/{cu_version}/{torch_version}/index.html + ``` +õĮ┐ńö©µé©ńÜäcudańēłµ£¼ÕÅĘÕÆīpytorchńēłµ£¼ÕÅʵø┐µŹó`{cu_version}`ÕÆī`{torch_version}` + +õ╗źÕ£©CUDA 10.2ÕÆīPyTorch 1.8.0ńÜäńÄ»ÕóāõĖŗ, Õ«ēĶŻģmmcv-fullõĖ║õŠŗ: +```shell +pip install "mmcv-full>=1.3.17,<=1.5.3" -f https://download.openmmlab.com/mmcv/dist/cu102/torch1.8.0/index.html +``` +µé©ÕÅ»õ╗źõ╗Ä [Ķ┐Öķćī](https://mmcv.readthedocs.io/en/latest/get_started/installation.html) µ¤źń£ŗķĆéķģŹõ║ÄõĖŹÕÉīCUDAńēłµ£¼ÕÆīPyTorchńēłµ£¼ńÜäMMCV. +µø┤ÕżÜńēłµ£¼ńÜäõĖŗĶĮĮõ┐Īµü»’╝īĶ»ĘÕÅéĶĆā [openmmlab-download](https://download.openmmlab.com/mmcv/dist/index.html) ŃĆé + +µé©õ╣¤ÕÅ»õ╗źõĮ┐ńö©Õ”éõĖŗÕæĮõ╗ż’╝īõ╗ĵ║ÉńĀüń╝¢Ķ»æmmcv + +```shell +git clone https://github.com/open-mmlab/mmcv.git -b v1.5.3 +cd mmcv +MMCV_WITH_OPS=1 pip install -e . # µē¦ĶĪīµŁżµŁźķ¬żõ╝ÜÕ«ēĶŻģÕīģÕɽcudań«ŚÕŁÉńÜämmcv-full +# µł¢ĶĆģĶ┐ÉĶĪī pip install -e . # µē¦ĶĪīµŁżµŁźķ¬żõ╝ÜÕ«ēĶŻģõĖŹÕīģÕɽcudań«ŚÕŁÉńÜämmcv +cd .. +``` + +**µ│©µäÅ** Õ”éµ×£ÕĘ▓ń╗ÅÕ«ēĶŻģõ║åmmcv’╝īµé©ķ£ĆĶ”üÕģłĶ┐ÉĶĪī`pip uninstall mmcv`ŃĆé ÕÉīµŚČÕ«ēĶŻģõ║åmmcvÕÆīmmcv-full’╝īÕÅ»ĶāĮõ╝ÜÕć║ńÄ░`ModuleNotFoundError`ŃĆé + +- mmdetection (ÕÅ»ķĆē) + +```shell +pip install "mmdet<=2.25.1" +``` + +Õ”éµ×£µā│Ķ”üõ┐«µö╣mmdetńÜäõ╗ŻńĀü’╝īµé©õ╣¤ÕÅ»õ╗źõĮ┐ńö©Õ”éõĖŗÕæĮõ╗ż’╝īõ╗ĵ║ÉńĀüµ×äÕ╗║mmdet’╝Ü +```shell +git clone https://github.com/open-mmlab/mmdetection.git -b v2.25.1 +cd mmdetection +pip install -r requirements/build.txt +pip install -v -e . +``` + +- mmpose (ÕÅ»ķĆē) +```shell +pip install "mmpose<=0.28.1" +``` + +Õ”éµ×£µé©µā│Ķ”üõ┐«µö╣mmdetńÜäõ╗ŻńĀü’╝īµé©õ╣¤ÕÅ»õ╗źõĮ┐ńö©Õ”éõĖŗÕæĮõ╗ż’╝īõ╗ĵ║ÉńĀüµ×äÕ╗║mmpose’╝Ü + +```shell +git clone https://github.com/open-mmlab/mmpose.git -b v0.28.1 +cd mmpose +pip install -r requirements.txt +pip install -v -e . +``` + +- mmtracking (ÕÅ»ķĆē) + +```shell +pip install "mmcls<=0.23.2" "mmtrack<=0.13.0" +``` + +Õ”éµ×£µé©µā│Ķ”üõ┐«µö╣mmdetńÜäõ╗ŻńĀü’╝īµé©õ╣¤ÕÅ»õ╗źõĮ┐ńö©Õ”éõĖŗÕæĮõ╗ż’╝īõ╗ĵ║ÉńĀüµ×äÕ╗║mmtracking’╝Ü + +```shell +git clone https://github.com/open-mmlab/mmtracking.git -b v0.13.0 +cd mmtracking +pip install -r requirements/build.txt +pip install -v -e . # µł¢ĶĆģ "python setup.py develop" +``` +b. ÕģŗķÜåmmhuman3dõ╗ōÕ║ō. + +```shell +git clone https://github.com/open-mmlab/mmhuman3d.git +cd mmhuman3d +``` + + +c. Õ«ēĶŻģõŠØĶĄ¢ķĪ╣Õ╣ČÕ«ēĶŻģmmhuman3d. + +```shell +pip install -v -e . # µł¢ĶĆģ "python setup.py develop" +``` + +## õ╗ÄÕż┤Õ╝ĆÕ¦ŗÕ«ēĶŻģńÜäĶäܵ£¼ + +```shell +# Õ«ēĶŻģ conda ńÄ»Õóā +conda create -n open-mmlab python=3.8 -y +conda activate open-mmlab + +# Õ«ēĶŻģ ffmpeg +conda install ffmpeg + +# Õ«ēĶŻģ PyTorch +conda install pytorch==1.8.0 torchvision cudatoolkit=10.2 -c pytorch -y + +# Õ«ēĶŻģ PyTorch3D +conda install -c fvcore -c iopath -c conda-forge fvcore iopath -y +conda install -c bottler nvidiacub -y +conda install pytorch3d -c pytorch3d -y +# Õ£©ķüćÕł░õŠØĶĄ¢Õå▓ń¬üńÜäµāģÕåĄõĖŗõ╣¤ÕÅ»õĮ┐ńö©õ╗ĵ║ÉńĀüõĖŁÕ«ēĶŻģ +# git clone https://github.com/facebookresearch/pytorch3d.git +# cd pytorch3d +# pip install . +# cd .. + +# Õ«ēĶŻģ mmcv-full +pip install "mmcv-full>=1.3.17,<1.6.0" -f https://download.openmmlab.com/mmcv/dist/cu102/torch1.8.0/index.html + +# ÕÅ»ķĆē: Õ«ēĶŻģ mmdetection’╝īmmpose ÕÅŖ mmtracking +pip install "mmdet<=2.25.1" +pip install "mmpose<=0.28.1" +pip install "mmcls<=0.23.2" "mmtrack<=0.13.0" + +# Õ«ēĶŻģ mmhuman3d +git clone https://github.com/open-mmlab/mmhuman3d.git +cd mmhuman3d +pip install -v -e . +``` diff --git a/internlm_langchain/knowledge_base/MMHuman3D/content/keypoints_convention.md b/internlm_langchain/knowledge_base/MMHuman3D/content/keypoints_convention.md new file mode 100644 index 00000000..141f0fee --- /dev/null +++ b/internlm_langchain/knowledge_base/MMHuman3D/content/keypoints_convention.md @@ -0,0 +1,377 @@ +# Õģ│ķö«ńé╣ń▒╗Õ×ŗ + +## µĆ╗Ķ¦ł + +MMHuamn3DõĖŁńÜäÕģ│ķö«ńé╣ń▒╗Õ×ŗµĢ┤ÕÉłõ║åÕÉäń¦ŹÕĖĖńö©µĢ░µŹ«ķøåõĖŁõĖŹÕÉīÕģ│ķö«ńé╣ńÜäÕ«Üõ╣ēŃĆéńö▒õ║ĵĀćµ│©µĢ░µŹ«ńÜäĶ┐ćń©ŗõĖŹÕ░ĮńøĖÕÉī’╝īõĖŹÕÉīµĢ░µŹ«ķøåõĖŁÕģʵ£ēńøĖÕÉīÕÉŹÕŁŚńÜäÕģ│ķö«ńé╣ÕÅ»ĶāĮõ╝ÜÕ»╣Õ║öõĖŹÕÉīńÜäĶ║½õĮōķā©õĮŹŃĆéńøĖÕ»╣ńÜä’╝īµŗźµ£ēõĖŹÕÉīÕÉŹÕŁŚńÜäÕģ│ķö«ńé╣ÕÅ»ĶāĮÕ»╣Õ║öńøĖÕÉīńÜäĶ║½õĮōķā©õĮŹŃĆé +õĖ║õ║åń╗¤õĖĆõĖŹÕÉīµĢ░µŹ«ķøåõĖŁõĖŹÕÉīÕģ│ķö«ńé╣ńÜäÕ»╣Õ║öÕģ│ń│╗’╝īµłæõ╗¼ķććńö©`human_data`ń╗ōµ×äõĮ£õĖ║ĶĮ¼µŹóÕÆīÕŁśÕé©Õģ│ķö«ńé╣ńÜäÕ¤║µ£¼ń▒╗Õ×ŗŃĆé + +## õĮ┐ńö©µ¢╣µ│Ģ + +### õĖŹÕÉīń▒╗Õ×ŗõ╣ŗķŚ┤ńÜäĶĮ¼µŹó + +õĮ┐ńö© `convert_kps` ÕćĮµĢ░ÕÅ»õ╗źĶĮ¼µŹóõĖŹÕÉīµĢ░µŹ«ķøåõĖŁńÜäÕģ│ķö«ńé╣ŃĆé + +õĖ║õ║åÕ░å`human_data`ĶĮ¼µŹóõĖ║`coco`ńÜäµĀ╝Õ╝Å’╝īķ£ĆĶ”üµīćիܵ║Éń▒╗Õ×ŗÕÆīńø«µĀćń▒╗Õ×ŗŃĆé + + +```python +from mmhuman3d.core.conventions.keypoints_mapping import convert_kps + +keypoints_human_data = np.zeros((100, 190, 3)) +keypoints_coco, mask = convert_kps(keypoints_human_data, src='human_data', dst='coco') +assert mask.all()==1 +``` + +Õ”éµ×£ńø«µĀćń▒╗Õ×ŗµś»µ║Éń▒╗Õ×ŗńÜäÕŁÉķøåÕÉł’╝īĶŠōÕć║ńÜä`mask`Õ║öĶ»źÕģ©õĖ║1ŃĆéµ▓Īµ£ēÕ»╣Õ║öÕģ│ń│╗ńÜäÕģ│ķö«ńé╣ńÜäńĮ«õ┐ĪÕ║”õ╝ÜĶó½Ķ«ŠńĮ«õĖ║0, ÕÅ»õ╗źõĮ┐ńö©`mask`õĮ£õĖ║Õģ│ķö«ńé╣ńÜäńĮ«õ┐ĪÕ║”ŃĆé + +### ķĆÜĶ┐ćńĮ«õ┐ĪÕ║”Ķ┐øĶĪīĶĮ¼µŹó + +Õ”éµ×£ĶÄĘÕŠŚõ║åÕģ│ķö«ńé╣ńÜäńĮ«õ┐ĪÕ║”’╝īÕÅ»õ╗źõĮ┐ńö©ÕĤզŗ`mask`Õ»╣ÕģČĶ┐øĶĪīµĀćĶ«░’╝īńäČÕÉÄÕ░åõ┐Īµü»µø┤µ¢░õĖ║Ķ┐öÕø×ńÜä`mask`ŃĆéõŠŗÕ”é’╝īµā│Ķ”üÕ░å`smpl`ńÜäÕģ│ķö«ńé╣ĶĮ¼µŹóõĖ║`coco`ńÜäÕģ│ķö«ńé╣’╝īÕ╣ČõĖöÕĘ▓ń¤ź`left_shoulder`Ķó½ķü«µīĪŃĆéµā│Ķ”üÕ£©ĶĮ¼µŹóĶ┐ćń©ŗõĖŁń╗¦µē┐Ķ»źõ┐Īµü»’╝īÕÅ»õ╗źÕāÅÕ”éõĖŗĶ┐ÖµĀĘĶ«ŠńĮ«ÕĤզŗ`mask`Õ╣ČõĖöĶĮ¼µŹóõĖ║`coco`ń▒╗Õ×ŗ: + +```python +import numpy as np +from mmhuman3d.core.conventions.keypoints_mapping import KEYPOINTS_FACTORY, convert_kps + +keypoints = np.zeros((1, len(KEYPOINTS_FACTORY['smpl']), 3)) +confidence = np.ones((len(KEYPOINTS_FACTORY['smpl']))) + +# ÕüćĶ«Š 'left_shoulder' µś»µŚĀµĢłńÜä. +confidence[KEYPOINTS_FACTORY['smpl'].index('left_shoulder')] = 0 + +_, conf_coco = convert_kps( + keypoints=keypoints, confidence=confidence, src='smpl', dst='coco') +_, conf_coco_full = convert_kps( + keypoints=keypoints, src='smpl', dst='coco') + +assert conf_coco[KEYPOINTS_FACTORY['coco'].index('left_shoulder')] == 0 +conf_coco[KEYPOINTS_FACTORY['coco'].index('left_shoulder')] = 1 +assert (conf_coco == conf_coco_full).all() +``` + +`mask`ĶĪ©ńż║µ£ēµĢłõ┐Īµü»’╝īÕģČ`dtype`õĖ║`uint8`’╝īÕÉīµŚČÕģ│ķö«ńé╣ńÜäńĮ«õ┐ĪÕ║”ĶīāÕø┤õĖ║0Õł░1ŃĆé +õŠŗÕ”é’╝īµā│Ķ”üÕ░å`smpl`ńÜäÕģ│ķö«ńé╣ĶĮ¼µŹóõĖ║`coco`ńÜäÕģ│ķö«ńé╣, Õ╣ČõĖöÕĘ▓ń¤ź`left_shoulder`Ķó½ķü«µīĪŃĆé + +```python +confidence = np.ones((len(KEYPOINTS_FACTORY['smpl']))) +confidence[KEYPOINTS_FACTORY['smpl'].index('left_shoulder')] = 0.5 +kp_smpl = np.concatenate([kp_smpl, confidence], -1) +kp_smpl_converted, mask = convert_kps(kp_smpl, src='smpl', dst='coco') +new_confidence = kp_smpl_converted[..., 2:] +assert new_confidence[KEYPOINTS_FACTORY['smpl'].index('left_shoulder')] == 0.5 +``` + +## µö»µīüńÜäń¦Źń▒╗ + + +õ╗źõĖŗµś»µö»µīüńÜäÕģ│ķö«ńé╣ń¦Źń▒╗: + - [AGORA](#agora) + - [COCO](#coco) + - [COCO-WHOLEBODY](#coco-wholebody) + - [CrowdPose](#crowdpose) + - [GTA-Human](#gta-human) + - [Human3.6M](#human36m) + - human_data + - [HybrIK](#hybrik) + - [LSP](#lsp) + - [MPI-INF-3DHP](#mpi-inf-3dhp) + - [MPII](#mpii) + - openpose + - [PennAction](#pennaction) + - [PoseTrack18](#posetrack18) + - [PW3D](#pw3d) + - [SMPL](#smpl) + - [SMPL-X](#smplx) + + +### HUMANDATA + +`HumanData` õĖŁńÜäÕēŹ 144 õĖ¬Õģ│ķö«ńé╣Õ»╣Õ║öõ║Ä `SMPL-X` õĖŁńÜäÕģ│ķö«ńé╣ŃĆéÕÉÄń╝ĆõĖ║`_extra`ńÜäÕģ│ķö«ńé╣µś»µīćõ╗Ä`Jregressor_extra`ĶÄĘÕŠŚńÜäÕģ│ķö«ńé╣ŃĆé ÕÉÄń╝ĆõĖ║`_openpose`ńÜäÕģ│ķö«ńé╣µś»µīćõ╗Ä`OpenPose`ķó䵥ŗõĖŁĶÄĘÕŠŚńÜäÕģ│ķö«ńé╣ŃĆé + +`MPI-INF-3DHP`ŃĆü`Human3.6M` ÕÆī `Posetrack` õĖŁµ£ēÕćĀõĖ¬Õģ│ķö«ńé╣Õģʵ£ēńøĖÕÉīńÜäÕÉŹń¦░’╝īõĮåÕ£©Õɽõ╣ēõĖŖõĖÄ `SMPL-X` õĖŁńÜäÕģ│ķö«ńé╣õĖŹÕÉīŃĆé ÕøĀµŁż’╝īµłæõ╗¼µĘ╗ÕŖĀõ║åõĖĆõĖ¬ķóØÕż¢ńÜäÕÉÄń╝Ć`head_h36m`µØźÕī║ÕłåĶ┐Öõ║øÕģ│ķö«ńé╣ŃĆé + +### AGORA + +
+
+
+### COCO
+
+AGORA (CVPR'2021)
+ +```bibtex +@inproceedings{Patel:CVPR:2021, + title = {{AGORA}: Avatars in Geography Optimized for Regression Analysis}, + author = {Patel, Priyanka and Huang, Chun-Hao P. and Tesch, Joachim and Hoffmann, David T. and Tripathi, Shashank and Black, Michael J.}, + booktitle = {Proceedings IEEE/CVF Conf.~on Computer Vision and Pattern Recognition ({CVPR})}, + month = jun, + year = {2021}, + month_numeric = {6} +} +``` + +
+
+
+
+### COCO-WHOLEBODY
+
+COCO (ECCV'2014)
+ +```bibtex +@inproceedings{lin2014microsoft, + title={Microsoft coco: Common objects in context}, + author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence}, + booktitle={European conference on computer vision}, + pages={740--755}, + year={2014}, + organization={Springer} +} +``` + +
+
+
+
+### CrowdPose
+
+COCO-Wholebody (ECCV'2020)
+ +```bibtex +@inproceedings{jin2020whole, + title={Whole-Body Human Pose Estimation in the Wild}, + author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping}, + booktitle={Proceedings of the European Conference on Computer Vision (ECCV)}, + year={2020} +} +``` + +
+
+
+### Human3.6M
+
+
+CrowdPose (CVPR'2019)
+ +```bibtex +@article{li2018crowdpose, + title={CrowdPose: Efficient Crowded Scenes Pose Estimation and A New Benchmark}, + author={Li, Jiefeng and Wang, Can and Zhu, Hao and Mao, Yihuan and Fang, Hao-Shu and Lu, Cewu}, + journal={Proceedings IEEE/CVF Conf.~on Computer Vision and Pattern Recognition ({CVPR})}, + year={2019} +} +``` + +
+
+
+
+### GTA-Human
+
+Human3.6M (TPAMI'2014)
+ +```bibtex +@article{h36m_pami, + author = {Ionescu, Catalin and Papava, Dragos and Olaru, Vlad and Sminchisescu, Cristian}, + title = {Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments}, + journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence}, + publisher = {IEEE Computer Society}, + volume = {36}, + number = {7}, + pages = {1325-1339}, + month = {jul}, + year = {2014} +} +``` + +
+
+
+
+### HybrIK
+
+GTA-Human (arXiv'2021)
+ +```bibtex +@article{cai2021playing, + title={Playing for 3D Human Recovery}, + author={Cai, Zhongang and Zhang, Mingyuan and Ren, Jiawei and Wei, Chen and Ren, Daxuan and Li, Jiatong and Lin, Zhengyu and Zhao, Haiyu and Yi, Shuai and Yang, Lei and others}, + journal={arXiv preprint arXiv:2110.07588}, + year={2021} +} +``` + +
+
+
+### LSP
+
+
+HybrIK (CVPR'2021)
+ +```bibtex +@inproceedings{li2020hybrikg, + author = {Li, Jiefeng and Xu, Chao and Chen, Zhicun and Bian, Siyuan and Yang, Lixin and Lu, Cewu}, + title = {HybrIK: A Hybrid Analytical-Neural Inverse Kinematics Solution for 3D Human Pose and Shape Estimation}, + booktitle={CVPR 2021}, + pages={3383--3393}, + year={2021}, + organization={IEEE} +} +``` + +
+
+
+### MPI-INF-3DHP
+
+LSP (BMVC'2010)
+ +```bibtex +@inproceedings{johnson2010clustered, + title={Clustered Pose and Nonlinear Appearance Models for Human Pose Estimation.}, + author={Johnson, Sam and Everingham, Mark}, + booktitle={bmvc}, + volume={2}, + number={4}, + pages={5}, + year={2010}, + organization={Citeseer} +} +``` +
+
+
+
+### MPII
+
+
+MPI_INF_3DHP (3DV'2017)
+ +```bibtex +@inproceedings{mono-3dhp2017, + author = {Mehta, Dushyant and Rhodin, Helge and Casas, Dan and Fua, Pascal and Sotnychenko, Oleksandr and Xu, Weipeng and Theobalt, Christian}, + title = {Monocular 3D Human Pose Estimation In The Wild Using Improved CNN Supervision}, + booktitle = {3D Vision (3DV), 2017 Fifth International Conference on}, + url = {http://gvv.mpi-inf.mpg.de/3dhp_dataset}, + year = {2017}, + organization={IEEE}, + doi={10.1109/3dv.2017.00064}, +} +``` + +
+
+
+### PoseTrack18
+
+
+MPII (CVPR'2014)
+ +```bibtex +@inproceedings{andriluka14cvpr, + author = {Mykhaylo Andriluka and Leonid Pishchulin and Peter Gehler and Schiele, Bernt}, + title = {2D Human Pose Estimation: New Benchmark and State of the Art Analysis}, + booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, + year = {2014}, + month = {June} +} +``` + +
+
+
+### OpenPose
+
+
+PoseTrack18 (CVPR'2018)
+ +```bibtex +@inproceedings{andriluka2018posetrack, + title={Posetrack: A benchmark for human pose estimation and tracking}, + author={Andriluka, Mykhaylo and Iqbal, Umar and Insafutdinov, Eldar and Pishchulin, Leonid and Milan, Anton and Gall, Juergen and Schiele, Bernt}, + booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition}, + pages={5167--5176}, + year={2018} +} +``` + +
+
+
+### PennAction
+
+
+OpenPose(TPMAI'2019)
+ +```bibtex +@article{8765346, + author = {Z. {Cao} and G. {Hidalgo Martinez} and T. {Simon} and S. {Wei} and Y. A. {Sheikh}}, + journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence}, + title = {OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields}, + year = {2019} +} +``` + +
+
+
+
+### SMPL
+
+
+PennAction(ICCV'2013)
+ +```bibtex +@inproceedings{zhang2013, + title={From Actemes to Action: A Strongly-supervised Representation for Detailed Action Understanding}, + author={Zhang, Weiyu and Zhu, Menglong and Derpanis, Konstantinos}, + booktitle={Proceedings of the International Conference on Computer Vision}, + year={2013} +} +``` + +
+
+
+
+### SMPL-X
+
+
+SMPL(ACM'2015)
+ +```bibtex +@article{SMPL:2015, + author = {Loper, Matthew and Mahmood, Naureen and Romero, Javier and Pons-Moll, Gerard and Black, Michael J.}, + title = {{SMPL}: A Skinned Multi-Person Linear Model}, + journal = {ACM Trans. Graphics (Proc. SIGGRAPH Asia)}, + month = oct, + number = {6}, + pages = {248:1--248:16}, + publisher = {ACM}, + volume = {34}, + year = {2015} + } +``` + +
+
+
+
+### Õ«óÕłČÕī¢Õģ│ķö«ńé╣ń¦Źń▒╗
+
+Ķ»ĘÕÅéĶĆā[customize_keypoints_convention](../docs_zh-CN/customize_keypoints_convention.md).
diff --git a/internlm_langchain/knowledge_base/MMHuman3D/content/model_zoo.md b/internlm_langchain/knowledge_base/MMHuman3D/content/model_zoo.md
new file mode 100644
index 00000000..0c093834
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMHuman3D/content/model_zoo.md
@@ -0,0 +1,34 @@
+# µ©ĪÕ×ŗÕ║ō
+
+µłæõ╗¼õĖ║µēƵ£ēµö»µīüńÜäń«Śµ│ĢµÅÉõŠøķģŹńĮ«µ¢ćõ╗Č’╝īlogµ¢ćõ╗ČÕÆīķóäĶ«Łń╗āµ©ĪÕ×ŗŃĆé
+µēƵ£ēńÜäķóäĶ«Łń╗āµ©ĪÕ×ŗÕ£©õĖēõĖ¬benchmarkõĖŖĶ┐øĶĪīĶ»äõ╝░’╝Ü`3DPW`, `Human3.6M`, ÕÆī `MPI-INF-3DHP`ŃĆé
+
+## Õ¤║Õćåń«Śµ│Ģ
+
+### HMR
+
+Ķ»”µāģĶ»ĘÕÅéĶĆā[HMR](https://github.com/open-mmlab/mmhuman3d/tree/main/configs/hmr/)ŃĆé
+
+### SPIN
+
+Ķ»”µāģĶ»ĘÕÅéĶĆā[SPIN](https://github.com/open-mmlab/mmhuman3d/tree/main/configs/spin/)ŃĆé
+
+### VIBE
+
+Ķ»”µāģĶ»ĘÕÅéĶĆā[VIBE](https://github.com/open-mmlab/mmhuman3d/tree/main/configs/vibe/)ŃĆé
+
+### HybrIK
+
+Ķ»”µāģĶ»ĘÕÅéĶĆā[HybrIK](https://github.com/open-mmlab/mmhuman3d/tree/main/configs/hybrik/)ŃĆé
+
+### PARE
+
+Ķ»”µāģĶ»ĘÕÅéĶĆā[PARE](https://github.com/open-mmlab/mmhuman3d/tree/main/configs/pare/)ŃĆé
+
+### ExPose
+
+Ķ»”µāģĶ»ĘÕÅéĶĆā[ExPose](https://github.com/open-mmlab/mmhuman3d/tree/main/configs/expose/)ŃĆé
+
+### PyMAF-X
+
+Ķ»”µāģĶ»ĘÕÅéĶĆā[PyMAF-X](https://github.com/open-mmlab/mmhuman3d/tree/main/configs/pymafx/)ŃĆé
diff --git a/internlm_langchain/knowledge_base/MMHuman3D/content/preprocess_dataset.md b/internlm_langchain/knowledge_base/MMHuman3D/content/preprocess_dataset.md
new file mode 100644
index 00000000..3ec7ff87
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMHuman3D/content/preprocess_dataset.md
@@ -0,0 +1,1306 @@
+# µĢ░µŹ«ķóäÕżäńÉå
+
+
+
+- [õĖŹÕÉīń«Śµ│ĢõĮ┐ńö©ńÜäµĢ░µŹ«ķøå](#datasets-for-supported-algorithms)
+- [µ¢ćõ╗ČÕż╣ń╗ōµ×ä](#folder-structure)
+ * [AGORA](#agora)
+ * [COCO](#coco)
+ * [COCO-WholeBody](#coco-wholebody)
+ * [CrowdPose](#crowdpose)
+ * [EFT](#eft)
+ * [GTA-Human](#gta-human)
+ * [Human3.6M](#human36m)
+ * [Human3.6M Mosh](#human36m-mosh)
+ * [HybrIK](#hybrik)
+ * [LSP](#lsp)
+ * [LSPET](#lspet)
+ * [MPI-INF-3DHP](#mpi-inf-3dhp)
+ * [MPII](#mpii)
+ * [PoseTrack18](#posetrack18)
+ * [Penn Action](#penn-action)
+ * [PW3D](#pw3d)
+ * [SPIN](#spin)
+ * [SURREAL](#surreal)
+
+
+## µĆ╗Ķ¦ł
+
+µłæõ╗¼õĮ┐ńö© [HumanData](./human_data.md) ń╗ōµ×äńö©õ║ÄÕŁśÕé©ÕÆīÕŖĀĶĮĮµĢ░µŹ«ŃĆéń╗ÅĶ┐ćÕżäńÉåńÜä.npzÕÅ»õ╗źõĮ┐ńö©µłæõ╗¼µÅÉõŠøńÜäµĢ░µŹ«ĶĮ¼µŹóĶäܵ£¼õ╗ÄÕĤզŗµĢ░µŹ«µĀ╝Õ╝ÅĶÄĘÕÅ¢’╝īĶ»”µāģĶ»ĘÕÅéĶĆā[convert_datasets.py](https://github.com/open-mmlab/mmhuman3d/tree/main/tools/convert_datasets.py).
+
+Õ”éõĖŗµś»µłæõ╗¼µö»µīüńÜäµĀ╝Õ╝ÅĶĮ¼µŹóµ¢╣Õ╝ÅÕÆīÕģĘõĮōńÜä `µĢ░µŹ«ķøåÕÉŹń¦░`:
+- AgoraConverter (`agora`)
+- AmassConverter (`amass`)
+- CocoConverter (`coco`)
+- CocoHybrIKConverter (`coco_hybrik`)
+- CocoWholebodyConverter (`coco_wholebody`)
+- CrowdposeConverter (`crowdpose`)
+- EftConverter (`eft`)
+- GTAHumanConverter (`gta_human`)
+- H36mConverter (`h36m_p1`, `h36m_p2`)
+- H36mHybrIKConverter (`h36m_hybrik`)
+- H36mSpinConverter (`h36m_spin`)
+- InstaVibeConverter (`instavariety_vibe`)
+- LspExtendedConverter (`lsp_extended`)
+- LspConverter (`lsp_original`, `lsp_dataset`)
+- MpiiConverter (`mpii`)
+- MpiInf3dhpConverter (`mpi_inf_3dhp`)
+- MpiInf3dhpHybrIKConverter (`mpi_inf_3dhp_hybrik`)
+- PennActionConverter (`penn_action`)
+- PosetrackConverter (`posetrack`)
+- Pw3dConverter (`pw3d`)
+- Pw3dHybrIKConverter (`pw3d_hybrik`)
+- SurrealConverter (`surreal`)
+- SpinConverter (`spin`)
+- Up3dConverter (`up3d`)
+
+
+
+## õĖŹÕÉīń«Śµ│ĢõĮ┐ńö©ńÜäµĢ░µŹ«ķøå
+
+µēƵ£ēń«Śµ│ĢõĮ┐ńö©ńÜäµĢ░µŹ«ķøåĶĘ»ÕŠäÕÆīń╗ÅĶ┐ćÕżäńÉåńÜä.npzµ¢ćõ╗ČĶĘ»ÕŠäõĖ║`data/datasets` ÕÆī `data/preprocessed_datasets`ŃĆéõĮ┐ńö©Õ”éõĖŗÕæĮõ╗żĶ┐øĶĪīµĢ░µŹ«µĀ╝Õ╝ÅĶĮ¼µŹó’╝Ü
+
+```bash
+python tools/convert_datasets.py \
+ --datasets SMPL-X(CVPR'2019)
+ +```bibtex +@inproceedings{SMPL-X:2019, + title = {Expressive Body Capture: {3D} Hands, Face, and Body from a Single Image}, + author = {Pavlakos, Georgios and Choutas, Vasileios and Ghorbani, Nima and Bolkart, Timo and Osman, Ahmed A. A. and Tzionas, Dimitrios and Black, Michael J.}, + booktitle = {Proceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR)}, + pages = {10975--10985}, + year = {2019} +} +``` + +
+
+
+Ķ»Ęõ╗Ä[Ķ┐Öķćī](https://agora.is.tue.mpg.de/index.html)õĖŗĶĮĮAGORAµĢ░µŹ«ķøå’╝īÕ╣ȵīēńģ¦Õ”éõĖŗń╗ōµ×äµöŠńĮ«µ¢ćõ╗ČÕż╣:
+
+```text
+mmhuman3d
+Ōö£ŌöĆŌöĆ mmhuman3d
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+ŌööŌöĆŌöĆ data
+ ŌööŌöĆŌöĆ datasets
+ ŌööŌöĆŌöĆ agora
+ Ōö£ŌöĆŌöĆ camera_dataframe # smplx annotations
+ Ōöé Ōö£ŌöĆŌöĆ train_0_withjv.pkl
+ Ōöé Ōö£ŌöĆŌöĆ validation_0_withjv.pkl
+ Ōöé ŌööŌöĆŌöĆ ...
+ Ōö£ŌöĆŌöĆ camera_dataframe_smpl # smpl annotations
+ Ōöé Ōö£ŌöĆŌöĆ train_0_withjv.pkl
+ Ōöé Ōö£ŌöĆŌöĆ validation_0_withjv.pkl
+ Ōöé ŌööŌöĆŌöĆ ...
+ Ōö£ŌöĆŌöĆ images
+ Ōöé Ōö£ŌöĆŌöĆ train
+ Ōöé Ōöé Ōö£ŌöĆŌöĆ ag_trainset_3dpeople_bfh_archviz_5_10_cam00_00000_1280x720.png
+ Ōöé Ōöé Ōö£ŌöĆŌöĆ ag_trainset_3dpeople_bfh_archviz_5_10_cam00_00001_1280x720.png
+ Ōöé Ōöé ŌööŌöĆŌöĆ ...
+ Ōöé Ōö£ŌöĆŌöĆ validation
+ Ōöé ŌööŌöĆŌöĆ test
+ Ōö£ŌöĆŌöĆ smpl_gt
+ Ōöé Ōö£ŌöĆŌöĆ trainset_3dpeople_adults_bfh
+ Ōöé Ōöé Ōö£ŌöĆŌöĆ 10004_w_Amaya_0_0.mtl
+ Ōöé Ōöé Ōö£ŌöĆŌöĆ 10004_w_Amaya_0_0.obj
+ Ōöé Ōöé Ōö£ŌöĆŌöĆ 10004_w_Amaya_0_0.pkl
+ Ōöé Ōöé ŌööŌöĆŌöĆ ...
+ Ōöé ŌööŌöĆŌöĆ ...
+ ŌööŌöĆŌöĆ smplx_gt
+ Ōö£ŌöĆŌöĆ 10004_w_Amaya_0_0.obj
+ Ōö£ŌöĆŌöĆ 10004_w_Amaya_0_0.pkl
+ ŌööŌöĆŌöĆ ...
+```
+
+### AMASS
+
+
+
+AGORA (CVPR'2021)
+ +```bibtex +@inproceedings{Patel:CVPR:2021, + title = {{AGORA}: Avatars in Geography Optimized for Regression Analysis}, + author = {Patel, Priyanka and Huang, Chun-Hao P. and Tesch, Joachim and Hoffmann, David T. and Tripathi, Shashank and Black, Michael J.}, + booktitle = {Proceedings IEEE/CVF Conf.~on Computer Vision and Pattern Recognition ({CVPR})}, + month = jun, + year = {2021}, + month_numeric = {6} +} +``` + +
+
+
+µ£¬µØźõ╝ܵĘ╗ÕŖĀµø┤ÕżÜÕģ│õ║ÄÕżäńÉåAMASSµĢ░µŹ«ķøåńÜäń╗åĶŖéŃĆé
+
+**µł¢ĶĆģ**, µé©ÕÅ»õ╗źńø┤µÄźõĖŗĶĮĮÕżäńÉåÕźĮńÜä.npzµ¢ćõ╗Č:
+- [amass_smplh.npz](https://openmmlab-share.oss-cn-hangzhou.aliyuncs.com/mmhuman3d/datasets/amass_smplh.npz?versionId=CAEQIhiBgICS4Mrt7xciIGU5MDBmZmE4Y2I0NjRiYTc4ZWY2NzY2MzU1ZmIwZTQ2)
+- [amass_smplx.npz](https://openmmlab-share.oss-cn-hangzhou.aliyuncs.com/mmhuman3d/datasets/amass_smplx.npz?versionId=CAEQIhiBgIDh387t7xciIGRlN2JlZjA0ZGM0YzRkNmM5OWJhNmVjMmZlN2RiN2E1)
+
+### COCO
+
+
+
+AMASS (ICCV'2019)
+ +```bibtex +@inproceedings{AMASS:2019, + title={AMASS: Archive of Motion Capture as Surface Shapes}, + author={Mahmood, Naureen and Ghorbani, Nima and F. Troje, Nikolaus and Pons-Moll, Gerard and Black, Michael J.}, + booktitle = {The IEEE International Conference on Computer Vision (ICCV)}, + year={2019}, + month = {Oct}, + url = {https://amass.is.tue.mpg.de}, + month_numeric = {10} +} +``` + +
+
+
+Ķ»Ęõ╗Ä[Ķ┐Öķćī](http://cocodataset.org/#download)õĖŗĶĮĮ`COCO`µĢ░µŹ«ķøåŃĆéÕģČõĖŁ’╝īĶ«Łń╗āHMRķ£ĆĶ”ü`COCO2014`’╝īĶ«Łń╗āHybrIKķ£ĆĶ”ü`COCO2017`ŃĆé
+õĖŗĶĮĮÕ╣ČĶ¦ŻÕÄŗĶć│ `$MMHUMAN3D/data/datasets`, õĮ┐Õ«āõ╗¼Õģʵ£ēÕ”éõĖŗńÜäń╗ōµ×ä:
+
+```text
+mmhuman3d
+Ōö£ŌöĆŌöĆ mmhuman3d
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+ŌööŌöĆŌöĆ data
+ ŌööŌöĆŌöĆ datasets
+ ŌööŌöĆŌöĆ coco
+ Ōö£ŌöĆŌöĆ annotations
+ | Ōö£ŌöĆŌöĆ person_keypoints_train2014.json
+ | Ōö£ŌöĆŌöĆ person_keypoints_val2014.json
+ Ōö£ŌöĆŌöĆ train2014
+ Ōöé Ōö£ŌöĆŌöĆ COCO_train2014_000000000009.jpg
+ Ōöé Ōö£ŌöĆŌöĆ COCO_train2014_000000000025.jpg
+ Ōöé Ōö£ŌöĆŌöĆ COCO_train2014_000000000030.jpg
+ | ŌööŌöĆŌöĆ ...
+ ŌööŌöĆŌöĆ train_2017
+ ŌöéŌöĆŌöĆ annotations
+ Ōöé Ōö£ŌöĆŌöĆ person_keypoints_train2017.json
+ Ōöé ŌööŌöĆŌöĆ person_keypoints_val2017.json
+ ŌöéŌöĆŌöĆ train2017
+ Ōöé Ōö£ŌöĆŌöĆ 000000000009.jpg
+ Ōöé Ōö£ŌöĆŌöĆ 000000000025.jpg
+ Ōöé Ōö£ŌöĆŌöĆ 000000000030.jpg
+ Ōöé ŌööŌöĆŌöĆ ...
+ ŌööŌöĆŌöĆ val2017
+ Ōö£ŌöĆŌöĆ 000000000139.jpg
+ Ōö£ŌöĆŌöĆ 000000000285.jpg
+ Ōö£ŌöĆŌöĆ 000000000632.jpg
+ ŌööŌöĆŌöĆ ...
+```
+
+
+### COCO-WholeBody
+
+
+
+COCO (ECCV'2014)
+ +```bibtex +@inproceedings{lin2014microsoft, + title={Microsoft coco: Common objects in context}, + author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence}, + booktitle={European conference on computer vision}, + pages={740--755}, + year={2014}, + organization={Springer} +} +``` + +
+
+
+Ķ»Ęõ╗Ä[Ķ┐Öķćī](http://cocodataset.org/#download)õĖŗĶĮĮ[COCO-WholeBody](https://github.com/jin-s13/COCO-WholeBody/)µĢ░µŹ«ķøå(2017 train/val)õĖŁńÜäÕøŠÕāÅ’╝īõ╗Ä[Ķ┐Öķćī](https://github.com/jin-s13/COCO-WholeBody/)õĖŗĶĮĮµĀćµ│©µ¢ćõ╗ČŃĆé
+Ķ¦ŻÕÄŗĶć│`$MMHUMAN3D/data/datasets`µ¢ćõ╗ČÕż╣’╝īÕ╣ČõĮ┐ÕģČÕģʵ£ēÕ”éõĖŗńÜäń╗ōµ×ä:
+
+```text
+mmhuman3d
+Ōö£ŌöĆŌöĆ mmhuman3d
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+ŌööŌöĆŌöĆ data
+ ŌööŌöĆŌöĆ datasets
+ ŌööŌöĆŌöĆ coco
+ Ōö£ŌöĆŌöĆ annotations
+ | Ōö£ŌöĆŌöĆ coco_wholebody_train_v1.0.json
+ | ŌööŌöĆŌöĆ coco_wholebody_val_v1.0.json
+ ŌööŌöĆŌöĆ train_2017
+ ŌöéŌöĆŌöĆ train2017
+ Ōöé Ōö£ŌöĆŌöĆ 000000000009.jpg
+ Ōöé Ōö£ŌöĆŌöĆ 000000000025.jpg
+ Ōöé Ōö£ŌöĆŌöĆ 000000000030.jpg
+ Ōöé ŌööŌöĆŌöĆ ...
+ ŌööŌöĆŌöĆ val2017
+ Ōö£ŌöĆŌöĆ 000000000139.jpg
+ Ōö£ŌöĆŌöĆ 000000000285.jpg
+ Ōö£ŌöĆŌöĆ 000000000632.jpg
+ ŌööŌöĆŌöĆ ...
+
+```
+
+
+
+
+### CrowdPose
+
+
+
+COCO-WholeBody (ECCV'2020)
+ +```bibtex +@inproceedings{jin2020whole, + title={Whole-Body Human Pose Estimation in the Wild}, + author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping}, + booktitle={Proceedings of the European Conference on Computer Vision (ECCV)}, + year={2020} +} +``` + +
+
+
+õĖŗĶĮĮ[CrowdPose](https://github.com/Jeff-sjtu/CrowdPose)µĢ░µŹ«ķøå’╝īÕ╣ČĶ¦ŻÕÄŗĶć│µ¢ćõ╗ČÕż╣`$MMHUMAN3D/data/datasets`’╝īõĮ┐ÕģČÕģʵ£ēÕ”éõĖŗń╗ōµ×ä’╝Ü
+
+```text
+mmhuman3d
+Ōö£ŌöĆŌöĆ mmhuman3d
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+ŌööŌöĆŌöĆ data
+ ŌööŌöĆŌöĆ datasets
+ ŌööŌöĆŌöĆ crowdpose
+ Ōö£ŌöĆŌöĆ crowdpose_train.json
+ Ōö£ŌöĆŌöĆ crowdpose_val.json
+ Ōö£ŌöĆŌöĆ crowdpose_trainval.json
+ Ōö£ŌöĆŌöĆ crowdpose_test.json
+ ŌööŌöĆŌöĆ images
+ Ōö£ŌöĆŌöĆ 100000.jpg
+ Ōö£ŌöĆŌöĆ 100001.jpg
+ Ōö£ŌöĆŌöĆ 100002.jpg
+ ŌööŌöĆŌöĆ ...
+```
+
+### EFT
+
+
+
+CrowdPose (CVPR'2019)
+ +```bibtex +@article{li2018crowdpose, + title={CrowdPose: Efficient Crowded Scenes Pose Estimation and A New Benchmark}, + author={Li, Jiefeng and Wang, Can and Zhu, Hao and Mao, Yihuan and Fang, Hao-Shu and Lu, Cewu}, + journal={arXiv preprint arXiv:1812.00324}, + year={2018} +} +``` + +
+
+
+õĖŗĶĮĮ[EFT](https://github.com/facebookresearch/eft)µĢ░µŹ«ķøå’╝īĶ¦ŻÕÄŗĶć│`$MMHUMAN3D/data/datasets`’╝īÕ╣ČõĮ┐ÕģČÕģʵ£ēÕ”éõĖŗń╗ōµ×ä:
+
+```text
+mmhuman3d
+Ōö£ŌöĆŌöĆ mmhuman3d
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+ŌööŌöĆŌöĆ data
+ ŌööŌöĆŌöĆ datasets
+ ŌööŌöĆŌöĆ eft
+ Ōö£ŌöĆŌöĆ coco_2014_train_fit
+ | Ōö£ŌöĆŌöĆ COCO2014-All-ver01.json
+ | ŌööŌöĆŌöĆ COCO2014-Part-ver01.json
+ |ŌöĆŌöĆ LSPet_fit
+ | ŌööŌöĆŌöĆ LSPet_ver01.json
+ ŌööŌöĆŌöĆ MPII_fit
+ ŌööŌöĆŌöĆ MPII_ver01.json
+```
+
+### GTA-Human
+
+
+
+EFT (3DV'2021)
+ +```bibtex +@inproceedings{joo2020eft, + title={Exemplar Fine-Tuning for 3D Human Pose Fitting Towards In-the-Wild 3D Human Pose Estimation}, + author={Joo, Hanbyul and Neverova, Natalia and Vedaldi, Andrea}, + booktitle={3DV}, + year={2020} +} +``` + +
+
+
+### Human3.6M
+
+
+
+GTA-Human (arXiv'2021)
+ +```bibtex +@article{cai2021playing, + title={Playing for 3D Human Recovery}, + author={Cai, Zhongang and Zhang, Mingyuan and Ren, Jiawei and Wei, Chen and Ren, Daxuan and Li, Jiatong and Lin, Zhengyu and Zhao, Haiyu and Yi, Shuai and Yang, Lei and others}, + journal={arXiv preprint arXiv:2110.07588}, + year={2021} +} +``` + +More details are coming soon! + + +
+
+
+õ╗ÄÕ«śńĮæõĖŗĶĮĮ[Human3.6M](http://vision.imar.ro/human3.6m/description.php)µĢ░µŹ«ķøå’╝īÕ╣ČõĮ┐ńö©[Ķäܵ£¼](https://github.com/open-mmlab/mmhuman3d/tree/main/mmhuman3d/data/data_converters/h36m.py)Ķ┐øĶĪīķóäÕżäńÉå’╝īķŚ┤ķÜö5ÕĖ¦µÅÉÕÅ¢µĀćµ│©ŃĆé
+ÕżäńÉåĶ┐ćńÜäµĢ░µŹ«ķøåÕģʵ£ēÕ”éõĖŗńÜäń╗ōµ×ä:
+
+```text
+mmhuman3d
+Ōö£ŌöĆŌöĆ mmhuman3d
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+ŌööŌöĆŌöĆ data
+ ŌööŌöĆŌöĆ datasets
+ ŌööŌöĆŌöĆ h36m
+ Ōö£ŌöĆŌöĆ annot
+ Ōö£ŌöĆŌöĆ S1
+ | Ōö£ŌöĆŌöĆ images
+ | | |ŌöĆŌöĆ S1_Directions_1.54138969
+ | | | Ōö£ŌöĆŌöĆ S1_Directions_1.54138969_00001.jpg
+ | | | Ōö£ŌöĆŌöĆ S1_Directions_1.54138969_00002.jpg
+ | | | ŌööŌöĆŌöĆ ...
+ | | ŌööŌöĆŌöĆ ...
+ | Ōö£ŌöĆŌöĆ MyPoseFeatures
+ | | |ŌöĆŌöĆ D2Positions
+ | | ŌööŌöĆŌöĆ D3_Positions_Mono
+ | Ōö£ŌöĆŌöĆ MySegmentsMat
+ | | ŌööŌöĆŌöĆ ground_truth_bs
+ | ŌööŌöĆŌöĆ Videos
+ | |ŌöĆŌöĆ Directions 1.54138969.mp4
+ | |ŌöĆŌöĆ Directions 1.55011271.mp4
+ | ŌööŌöĆŌöĆ ...
+ Ōö£ŌöĆŌöĆ S5
+ Ōö£ŌöĆŌöĆ S6
+ Ōö£ŌöĆŌöĆ S7
+ Ōö£ŌöĆŌöĆ S8
+ Ōö£ŌöĆŌöĆ S9
+ Ōö£ŌöĆŌöĆ S11
+ ŌööŌöĆŌöĆ metadata.xml
+```
+
+õ┐«µö╣[ķģŹńĮ«µ¢ćõ╗Č](https://github.com/open-mmlab/mmhuman3d/blob/main/tools/convert_datasets.py)õĖŁńÜä`h36m_p1`’╝īõ╗ÄÕĤզŗńÜä[Human3.6M](http://vision.imar.ro/human3.6m/description.php)µĢ░µŹ«ķøåõĖŁńÜäĶ¦åķóæµÅÉÕÅ¢ÕøŠÕāÅŃĆé
+
+```python
+h36m_p1=dict(
+ type='H36mConverter',
+ modes=['train', 'valid'],
+ protocol=1,
+ extract_img=True, # õ╗ÄÕĤĶ¦åķóæõĖŁµÅÉÕÅ¢ÕøŠÕāÅ’╝īĶ«ŠńĮ«õĖ║True
+ prefix='h36m'),
+```
+
+### Human3.6M Mosh
+
+
+
+µłæõ╗¼õĮ┐ńö©[HMR](https://github.com/akanazawa/hmr)µÅÉõŠøńÜä[MoShed](https://mosh.is.tue.mpg.de/)µĢ░µŹ«ķøåĶ«Łń╗ā`HMR`ŃĆü`SPIN`ÕÆī`PARE`ŃĆéńö▒õ║ÄńēłµØāńÜäķÖÉÕłČ’╝īµłæõ╗¼µŚĀµ│ĢõĖŖõ╝ĀĶ»źµĢ░µŹ«ķøåŃĆéÕŹ│õĮ┐µ▓Īµ£ēõĮ┐ńö©moshÕÅéµĢ░ńÜäĶ«ĖÕÅ»’╝īõ╗ŹÕÅ»õĮ┐ńö©µłæõ╗¼µÅÉõŠøńÜä[ĶĮ¼µŹóĶäܵ£¼](https://github.com/open-mmlab/mmhuman3d/tree/main/mmhuman3d/data/data_converters/h36m.py)ńö¤µłÉh36mńÜä.npzµ¢ćõ╗ČŃĆé
+
+õ┐«µö╣[ķģŹńĮ«µ¢ćõ╗Č](https://github.com/open-mmlab/mmhuman3d/blob/main/tools/convert_datasets.py)õĖŁńÜä`h36m_p1`’╝īõ╗ÄÕĤզŗńÜä[Human3.6M](http://vision.imar.ro/human3.6m/description.php)µĢ░µŹ«ķøåõĖŁńÜäĶ¦åķóæµÅÉÕÅ¢ÕøŠÕāÅŃĆé
+
+õĖŹÕģʵ£ēmoshµĢ░µŹ«ńÜäķģŹńĮ«µ¢ćõ╗Č:
+```python
+h36m_p1=dict(
+ type='H36mConverter',
+ modes=['train', 'valid'],
+ protocol=1,
+ extract_img=True, # õ╗ÄÕĤĶ¦åķóæõĖŁµÅÉÕÅ¢ÕøŠÕāÅ’╝īĶ«ŠńĮ«õĖ║True
+ prefix='h36m'),
+```
+
+Õģʵ£ēmoshµĢ░µŹ«ńÜäķģŹńĮ«µ¢ćõ╗Č:
+```python
+h36m_p1=dict(
+ type='H36mConverter',
+ modes=['train', 'valid'],
+ protocol=1,
+ extract_img=True, # õ╗ÄÕĤĶ¦åķóæõĖŁµÅÉÕÅ¢ÕøŠÕāÅ’╝īĶ«ŠńĮ«õĖ║True
+ mosh_dir='data/datasets/h36m_mosh', # Õ”éµ×£µŗźµ£ēmoshµĢ░µŹ«’╝īµīćÕ«ÜÕģČńÜäĶĘ»ÕŠä
+ prefix='h36m'),
+```
+
+Õ”éµ×£µé©ÕÅ»õ╗źĶÄĘÕÅ¢Õł░Human3.6mńÜäMoshµĢ░µŹ«’╝īµĢ┤õĖ¬µ¢ćõ╗ČÕż╣Õ║öĶ»źÕģʵ£ēÕ”éõĖŗńÜäµ×ȵ×ä’╝Ü
+
+```text
+mmhuman3d
+Ōö£ŌöĆŌöĆ mmhuman3d
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+ŌööŌöĆŌöĆ data
+ ŌööŌöĆŌöĆ datasets
+ ŌööŌöĆŌöĆ h36m_mosh
+ Ōö£ŌöĆŌöĆ annot
+ Ōö£ŌöĆŌöĆ S1
+ | Ōö£ŌöĆŌöĆ images
+ | | Ōö£ŌöĆŌöĆ Directions 1_cam0_aligned.pkl
+ | | Ōö£ŌöĆŌöĆ Directions 1_cam1_aligned.pkl
+ | | ŌööŌöĆŌöĆ ...
+ Ōö£ŌöĆŌöĆ S5
+ Ōö£ŌöĆŌöĆ S6
+ Ōö£ŌöĆŌöĆ S7
+ Ōö£ŌöĆŌöĆ S8
+ Ōö£ŌöĆŌöĆ S9
+ ŌööŌöĆŌöĆ S11
+```
+
+### HybrIK
+
+
+
+Human3.6M (TPAMI'2014)
+ +```bibtex +@article{h36m_pami, + author = {Ionescu, Catalin and Papava, Dragos and Olaru, Vlad and Sminchisescu, Cristian}, + title = {Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments}, + journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence}, + publisher = {IEEE Computer Society}, + volume = {36}, + number = {7}, + pages = {1325-1339}, + month = {jul}, + year = {2014} +} +``` + +
+
+
+õĖŗĶĮĮ[HybrIK](https://github.com/Jeff-sjtu/HybrIK)µĢ░µŹ«ķøåńÜä[µĀćµ│©](https://github.com/Jeff-sjtu/HybrIK#fetch-data), Õ╣ČõĮ┐Õģȵ¢ćõ╗ČÕż╣Õģʵ£ēÕ”éõĖŗńÜäń╗ōµ×ä:
+
+```text
+mmhuman3d
+Ōö£ŌöĆŌöĆ mmhuman3d
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+ŌööŌöĆŌöĆ data
+ ŌööŌöĆŌöĆ datasets
+ ŌööŌöĆŌöĆ hybrik_data
+ Ōö£ŌöĆŌöĆ Sample_5_train_Human36M_smpl_leaf_twist_protocol_2.json
+ Ōö£ŌöĆŌöĆ Sample_20_test_Human36M_smpl_protocol_2.json
+ Ōö£ŌöĆŌöĆ 3DPW_test_new.json
+ Ōö£ŌöĆŌöĆ annotation_mpi_inf_3dhp_train_v2.json
+ ŌööŌöĆŌöĆ annotation_mpi_inf_3dhp_test.json
+```
+
+Ķ┐ÉĶĪīÕ”éõĖŗĶäܵ£¼’╝īÕ░å.jsonµ¢ćõ╗ČÕżäńÉåµłÉmmhuman3dõĖŁõĮ┐ńö©ńÜä.npzµ¢ćõ╗Č’╝Ü
+
+ - [Human3.6M](https://github.com/open-mmlab/mmhuman3d/tree/main/mmhuman3d/data/data_converters/h36m_hybrik.py)
+ - [PW3D](https://github.com/open-mmlab/mmhuman3d/tree/main/mmhuman3d/data/data_converters/pw3d_hybrik.py)
+ - [Mpi-Inf-3dhp](https://github.com/open-mmlab/mmhuman3d/tree/main/mmhuman3d/data/data_converters/mpi_inf_3dhp_hybrik.py)
+ - [COCO](https://github.com/open-mmlab/mmhuman3d/tree/main/mmhuman3d/data/data_converters/coco_hybrik.py)
+
+
+### LSP
+
+
+
+HybrIK (CVPR'2021)
+ +```bibtex +@inproceedings{li2020hybrikg, + author = {Li, Jiefeng and Xu, Chao and Chen, Zhicun and Bian, Siyuan and Yang, Lixin and Lu, Cewu}, + title = {HybrIK: A Hybrid Analytical-Neural Inverse Kinematics Solution for 3D Human Pose and Shape Estimation}, + booktitle={CVPR 2021}, + pages={3383--3393}, + year={2021}, + organization={IEEE} +} +``` + +
+
+
+õĖŗĶĮĮÕģʵ£ēķ½śÕłåĶŠ©ńÄćńÜäLSPµĢ░µŹ«ķøå[LSP dataset original](http://sam.johnson.io/research/lsp_dataset_original.zip)’╝īĶ¦ŻÕÄŗĶć│µ¢ćõ╗ČÕż╣`$MMHUMAN3D/data/datasets`’╝īÕ╣ČõĮ┐ÕģČÕģʵ£ēÕ”éõĖŗńÜäń╗ōµ×ä:
+
+```text
+mmhuman3d
+Ōö£ŌöĆŌöĆ mmhuman3d
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+ŌööŌöĆŌöĆ data
+ ŌööŌöĆŌöĆ datasets
+ ŌööŌöĆŌöĆ lsp
+ Ōö£ŌöĆŌöĆ images
+ | Ōö£ŌöĆŌöĆ im0001.jpg
+ | Ōö£ŌöĆŌöĆ im0002.jpg
+ | ŌööŌöĆŌöĆ ...
+ ŌööŌöĆŌöĆ joints.mat
+```
+
+### LSPET
+
+
+
+LSP (BMVC'2010)
+ +```bibtex +@inproceedings{johnson2010clustered, + title={Clustered Pose and Nonlinear Appearance Models for Human Pose Estimation.}, + author={Johnson, Sam and Everingham, Mark}, + booktitle={bmvc}, + volume={2}, + number={4}, + pages={5}, + year={2010}, + organization={Citeseer} +} +``` +
+
+
+õĖŗĶĮĮÕģʵ£ēķ½śÕłåĶŠ©ńÄćńÜäLSPETµĢ░µŹ«ķøå[HR-LSPET](http://datasets.d2.mpi-inf.mpg.de/hr-lspet/hr-lspet.zip)’╝īĶ¦ŻÕÄŗĶć│µ¢ćõ╗ČÕż╣`$MMHUMAN3D/data/datasets`’╝īÕ╣ČõĮ┐ÕģČÕģʵ£ēÕ”éõĖŗńÜäń╗ōµ×ä:
+
+```text
+mmhuman3d
+Ōö£ŌöĆŌöĆ mmhuman3d
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+ŌööŌöĆŌöĆ data
+ ŌööŌöĆŌöĆ datasets
+ ŌööŌöĆŌöĆ lspet
+ Ōö£ŌöĆŌöĆ im00001.jpg
+ Ōö£ŌöĆŌöĆ im00002.jpg
+ Ōö£ŌöĆŌöĆ im00003.jpg
+ Ōö£ŌöĆŌöĆ ...
+ ŌööŌöĆŌöĆ joints.mat
+```
+
+
+
+### MPI-INF-3DHP
+
+LSP-Extended (CVPR'2011)
+ +```bibtex +@inproceedings{johnson2011learning, + title={Learning effective human pose estimation from inaccurate annotation}, + author={Johnson, Sam and Everingham, Mark}, + booktitle={CVPR 2011}, + pages={1465--1472}, + year={2011}, + organization={IEEE} +} +``` + +
+
+
+õ┐«µö╣[ķģŹńĮ«µ¢ćõ╗Č](https://github.com/open-mmlab/mmhuman3d/blob/main/tools/convert_datasets.py)õĖŁńÜä`mpi_inf_3dhp`’╝īõ╗ÄÕĤզŗĶ¦åķóæõĖŁµÅÉÕÅ¢ÕøŠÕāÅŃĆé
+Ķ»Ęµ│©µäÅ’╝īĶ┐Öõ╝ÜĶŖ▒Ķ┤╣ĶŠāķĢ┐ńÜ䵌ČķŚ┤ŃĆé
+
+Config:
+```python
+mpi_inf_3dhp=dict(
+ type='MpiInf3dhpConverter',
+ modes=['train', 'test'],
+ extract_img=True), # õ╗ÄÕĤĶ¦åķóæõĖŁµÅÉÕÅ¢ÕøŠÕāÅ’╝īĶ«ŠńĮ«õĖ║True
+```
+
+õĖŗĶĮĮ[MPI-INF-3DHP](http://gvv.mpi-inf.mpg.de/3dhp-dataset/)µĢ░µŹ«ķøå, Ķ¦ŻÕÄŗĶć│µ¢ćõ╗ČÕż╣`$MMHUMAN3D/data/datasets`, õĮ┐ÕģČÕģʵ£ēÕ”éõĖŗńÜäń╗ōµ×ä:
+
+```text
+mmhuman3d
+Ōö£ŌöĆŌöĆ mmhuman3d
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+ŌööŌöĆŌöĆ data
+ ŌööŌöĆŌöĆ datasets
+ ŌööŌöĆŌöĆ mpi_inf_3dhp
+ Ōö£ŌöĆŌöĆ mpi_inf_3dhp_test_set
+ Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ TS1
+ Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ TS2
+ Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ TS3
+ Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ TS4
+ Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ TS5
+ Ōöé┬Ā┬Ā ŌööŌöĆŌöĆ TS6
+ Ōö£ŌöĆŌöĆ S1
+ Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ Seq1
+ Ōöé┬Ā┬Ā ŌööŌöĆŌöĆ Seq2
+ Ōö£ŌöĆŌöĆ S2
+ Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ Seq1
+ Ōöé┬Ā┬Ā ŌööŌöĆŌöĆ Seq2
+ Ōö£ŌöĆŌöĆ S3
+ Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ Seq1
+ Ōöé┬Ā┬Ā ŌööŌöĆŌöĆ Seq2
+ Ōö£ŌöĆŌöĆ S4
+ Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ Seq1
+ Ōöé┬Ā┬Ā ŌööŌöĆŌöĆ Seq2
+ Ōö£ŌöĆŌöĆ S5
+ Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ Seq1
+ Ōöé┬Ā┬Ā ŌööŌöĆŌöĆ Seq2
+ Ōö£ŌöĆŌöĆ S6
+ Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ Seq1
+ Ōöé┬Ā┬Ā ŌööŌöĆŌöĆ Seq2
+ Ōö£ŌöĆŌöĆ S7
+ Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ Seq1
+ Ōöé┬Ā┬Ā ŌööŌöĆŌöĆ Seq2
+ ŌööŌöĆŌöĆ S8
+ Ōö£ŌöĆŌöĆ Seq1
+ ŌööŌöĆŌöĆ Seq2
+```
+
+
+
+### MPII
+
+
+
+MPI_INF_3DHP (3DV'2017)
+ +```bibtex +@inproceedings{mono-3dhp2017, + author = {Mehta, Dushyant and Rhodin, Helge and Casas, Dan and Fua, Pascal and Sotnychenko, Oleksandr and Xu, Weipeng and Theobalt, Christian}, + title = {Monocular 3D Human Pose Estimation In The Wild Using Improved CNN Supervision}, + booktitle = {3D Vision (3DV), 2017 Fifth International Conference on}, + url = {http://gvv.mpi-inf.mpg.de/3dhp_dataset}, + year = {2017}, + organization={IEEE}, + doi={10.1109/3dv.2017.00064}, +} +``` +
+
+
+õĖŗĶĮĮ[MPII](http://human-pose.mpi-inf.mpg.de/#download)µĢ░µŹ«ķøå’╝īÕ╣Čõ╗Ä[Ķ┐Öķćī](https://github.com/princeton-vl/pose-hg-train/tree/master/data/mpii/annot?rgh-link-date=2020-07-05T04%3A14%3A02Z)õĖŗĶĮĮµĀćµ│©ŃĆé
+Ķ¦ŻÕÄŗĶć│µ¢ćõ╗ČÕż╣`$MMHUMAN3D/data/datasets`, õĮ┐ÕģČÕģʵ£ēÕ”éõĖŗńÜäń╗ōµ×ä:
+
+```text
+mmhuman3d
+Ōö£ŌöĆŌöĆ mmhuman3d
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+ŌööŌöĆŌöĆ data
+ ŌööŌöĆŌöĆ datasets
+ ŌööŌöĆŌöĆ mpii
+ |ŌöĆŌöĆ train.h5
+ ŌööŌöĆŌöĆ images
+ |ŌöĆŌöĆ 000001163.jpg
+ |ŌöĆŌöĆ 000003072.jpg
+ ŌööŌöĆŌöĆ ...
+```
+
+
+### PoseTrack18
+
+
+
+MPII (CVPR'2014)
+ +```bibtex +@inproceedings{andriluka14cvpr, + author = {Mykhaylo Andriluka and Leonid Pishchulin and Peter Gehler and Schiele, Bernt}, + title = {2D Human Pose Estimation: New Benchmark and State of the Art Analysis}, + booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, + year = {2014}, + month = {June} +} +``` + +
+
+
+õĖŗĶĮĮ[PoseTrack18](https://posetrack.net/users/download.php)µĢ░µŹ«ķøå’╝īĶ¦ŻÕÄŗĶć│µ¢ćõ╗ČÕż╣`$MMHUMAN3D/data/datasets`’╝īõĮ┐ÕģČÕģʵ£ēÕ”éõĖŗńÜäń╗ōµ×ä:
+
+```text
+mmhuman3d
+Ōö£ŌöĆŌöĆ mmhuman3d
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+ŌööŌöĆŌöĆ data
+ ŌööŌöĆŌöĆ datasets
+ ŌööŌöĆŌöĆ posetrack
+ Ōö£ŌöĆŌöĆ images
+ Ōöé Ōö£ŌöĆŌöĆ train
+ Ōöé Ōöé Ōö£ŌöĆŌöĆ 000001_bonn_train
+ Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ 000000.jpg
+ Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ 000001.jpg
+ Ōöé Ōöé Ōöé ŌööŌöĆŌöĆ ...
+ Ōöé Ōöé ŌööŌöĆŌöĆ ...
+ Ōöé Ōö£ŌöĆŌöĆ val
+ Ōöé Ōöé Ōö£ŌöĆŌöĆ 000342_mpii_test
+ Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ 000000.jpg
+ Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ 000001.jpg
+ Ōöé Ōöé Ōöé ŌööŌöĆŌöĆ ...
+ Ōöé Ōöé ŌööŌöĆŌöĆ ...
+ Ōöé ŌööŌöĆŌöĆ test
+ Ōöé Ōö£ŌöĆŌöĆ 000001_mpiinew_test
+ Ōöé Ōöé Ōö£ŌöĆŌöĆ 000000.jpg
+ Ōöé Ōöé Ōö£ŌöĆŌöĆ 000001.jpg
+ Ōöé Ōöé ŌööŌöĆŌöĆ ...
+ Ōöé ŌööŌöĆŌöĆ ...
+ ŌööŌöĆŌöĆ posetrack_data
+ ŌööŌöĆŌöĆ annotations
+ Ōö£ŌöĆŌöĆ train
+ Ōöé Ōö£ŌöĆŌöĆ 000001_bonn_train.json
+ Ōöé Ōö£ŌöĆŌöĆ 000002_bonn_train.json
+ Ōöé ŌööŌöĆŌöĆ ...
+ Ōö£ŌöĆŌöĆ val
+ Ōöé Ōö£ŌöĆŌöĆ 000342_mpii_test.json
+ Ōöé Ōö£ŌöĆŌöĆ 000522_mpii_test.json
+ Ōöé ŌööŌöĆŌöĆ ...
+ ŌööŌöĆŌöĆ test
+ Ōö£ŌöĆŌöĆ 000001_mpiinew_test.json
+ Ōö£ŌöĆŌöĆ 000002_mpiinew_test.json
+ ŌööŌöĆŌöĆ ...
+```
+
+### Penn Action
+
+
+
+PoseTrack18 (CVPR'2018)
+ +```bibtex +@inproceedings{andriluka2018posetrack, + title={Posetrack: A benchmark for human pose estimation and tracking}, + author={Andriluka, Mykhaylo and Iqbal, Umar and Insafutdinov, Eldar and Pishchulin, Leonid and Milan, Anton and Gall, Juergen and Schiele, Bernt}, + booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition}, + pages={5167--5176}, + year={2018} +} +``` + +
+
+
+õĖŗĶĮĮ[Penn Action](https://upenn.box.com/PennAction)µĢ░µŹ«ķøå’╝īĶ¦ŻÕÄŗĶć│µ¢ćõ╗ČÕż╣`$MMHUMAN3D/data/datasets`’╝īõĮ┐ÕģČÕģʵ£ēÕ”éõĖŗńÜäń╗ōµ×ä:
+
+```text
+mmhuman3d
+Ōö£ŌöĆŌöĆ mmhuman3d
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+ŌööŌöĆŌöĆ data
+ ŌööŌöĆŌöĆ datasets
+ ŌööŌöĆŌöĆ penn_action
+ Ōö£ŌöĆŌöĆ frames
+ Ōöé Ōö£ŌöĆŌöĆ 0001
+ Ōöé Ōöé Ōö£ŌöĆŌöĆ 000001.jpg
+ Ōöé Ōöé Ōö£ŌöĆŌöĆ 000002.jpg
+ Ōöé Ōöé ŌööŌöĆŌöĆ ...
+ Ōöé ŌööŌöĆŌöĆ ...
+ ŌööŌöĆŌöĆ labels
+ Ōö£ŌöĆŌöĆ 0001.mat
+ Ōö£ŌöĆŌöĆ 0002.mat
+ ŌööŌöĆŌöĆ ...
+```
+
+### PW3D
+
+
+
+Penn Action (ICCV'2013)
+ +```bibtex +@inproceedings{zhang2013pennaction, + title={From Actemes to Action: A Strongly-supervised Representation for Detailed Action Understanding}, + author={Zhang, Weiyu and Zhu, Menglong and Derpanis, Konstantinos}, + booktitle={ICCV}, + year={2013} +} +``` + +
+
+
+õĖŗĶĮĮ[PW3D](https://virtualhumans.mpi-inf.mpg.de/3DPW/)µĢ░µŹ«ķøå’╝īĶ¦ŻÕÄŗĶć│µ¢ćõ╗ČÕż╣`$MMHUMAN3D/data/datasets`’╝īÕ╣ČõĮ┐ÕģČÕģʵ£ēÕ”éõĖŗńÜäń╗ōµ×ä:
+
+```text
+mmhuman3d
+Ōö£ŌöĆŌöĆ mmhuman3d
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+ŌööŌöĆŌöĆ data
+ ŌööŌöĆŌöĆ datasets
+ ŌööŌöĆŌöĆ pw3d
+ |ŌöĆŌöĆ imageFiles
+ | | ŌööŌöĆŌöĆ courtyard_arguing_00
+ | | Ōö£ŌöĆŌöĆ image_00000.jpg
+ | | Ōö£ŌöĆŌöĆ image_00001.jpg
+ | | ŌööŌöĆŌöĆ ...
+ ŌööŌöĆŌöĆ sequenceFiles
+ Ōö£ŌöĆŌöĆ train
+ Ōöé Ōö£ŌöĆŌöĆ downtown_arguing_00.pkl
+ Ōöé ŌööŌöĆŌöĆ ...
+ Ōö£ŌöĆŌöĆ val
+ Ōöé Ōö£ŌöĆŌöĆ courtyard_arguing_00.pkl
+ Ōöé ŌööŌöĆŌöĆ ...
+ ŌööŌöĆŌöĆ test
+ Ōö£ŌöĆŌöĆ courtyard_basketball_00.pkl
+ ŌööŌöĆŌöĆ ...
+
+```
+
+
+
+### SPIN
+
+
+
+PW3D (ECCV'2018)
+ +```bibtex +@inproceedings{vonMarcard2018, +title = {Recovering Accurate 3D Human Pose in The Wild Using IMUs and a Moving Camera}, +author = {von Marcard, Timo and Henschel, Roberto and Black, Michael and Rosenhahn, Bodo and Pons-Moll, Gerard}, +booktitle = {European Conference on Computer Vision (ECCV)}, +year = {2018}, +month = {sep} +} +``` + +
+
+
+õĖŗĶĮĮń╗ÅĶ┐ćÕżäńÉåńÜä[.npz µ¢ćõ╗Č](https://github.com/nkolot/SPIN/blob/master/fetch_data.sh)’╝īõĮ┐µ¢ćõ╗ČÕż╣Õģʵ£ēÕ”éõĖŗńÜäń╗ōµ×ä:
+
+```text
+mmhuman3d
+Ōö£ŌöĆŌöĆ mmhuman3d
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+ŌööŌöĆŌöĆ data
+ ŌööŌöĆŌöĆ datasets
+ ŌööŌöĆŌöĆ spin_data
+ Ōö£ŌöĆŌöĆ coco_2014_train.npz
+ Ōö£ŌöĆŌöĆ hr-lspet_train.npz
+ Ōö£ŌöĆŌöĆ lsp_dataset_original_train.npz
+ Ōö£ŌöĆŌöĆ mpi_inf_3dhp_train.npz
+ ŌööŌöĆŌöĆ mpii_train.npz
+```
+
+
+
+### SURREAL
+
+
+
+SPIN (ICCV'2019)
+ +```bibtex +@inproceedings{kolotouros2019spin, + author = {Kolotouros, Nikos and Pavlakos, Georgios and Black, Michael J and Daniilidis, Kostas}, + title = {Learning to Reconstruct 3D Human Pose and Shape via Model-fitting in the Loop}, + booktitle={ICCV}, + year={2019} +} +``` + +
+
+
+õĖŗĶĮĮ[SURREAL](https://www.di.ens.fr/willow/research/surreal/data/)µĢ░µŹ«ķøå’╝īÕ╣ČõĮ┐ÕģČÕģʵ£ēÕ”éõĖŗńÜäń╗ōµ×ä:
+
+```text
+mmhuman3d
+Ōö£ŌöĆŌöĆ mmhuman3d
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+ŌööŌöĆŌöĆ data
+ ŌööŌöĆŌöĆ datasets
+ ŌööŌöĆŌöĆ surreal
+ Ōö£ŌöĆŌöĆ train
+ Ōöé Ōö£ŌöĆŌöĆ run0
+ | | Ōö£ŌöĆŌöĆ 03_01
+ | | Ōöé Ōö£ŌöĆŌöĆ 03_01_c0001_depth.mat
+ | | Ōöé Ōö£ŌöĆŌöĆ 03_01_c0001_info.mat
+ | | Ōöé Ōö£ŌöĆŌöĆ 03_01_c0001_segm.mat
+ | | Ōöé Ōö£ŌöĆŌöĆ 03_01_c0001.mp4
+ | | Ōöé ŌööŌöĆŌöĆ ...
+ | | ŌööŌöĆŌöĆ ...
+ Ōöé Ōö£ŌöĆŌöĆ run1
+ Ōöé ŌööŌöĆŌöĆ run2
+ Ōö£ŌöĆŌöĆ val
+ Ōöé Ōö£ŌöĆŌöĆ run0
+ Ōöé Ōö£ŌöĆŌöĆ run1
+ Ōöé ŌööŌöĆŌöĆ run2
+ ŌööŌöĆŌöĆ test
+ Ōö£ŌöĆŌöĆ run0
+ Ōö£ŌöĆŌöĆ run1
+ ŌööŌöĆŌöĆ run2
+```
+
+
+### VIBE
+
+
+
+SURREAL (CVPR'2017)
+ +```bibtex +@inproceedings{varol17_surreal, + title = {Learning from Synthetic Humans}, + author = {Varol, G{\"u}l and Romero, Javier and Martin, Xavier and Mahmood, Naureen and Black, Michael J. and Laptev, Ivan and Schmid, Cordelia}, + booktitle = {CVPR}, + year = {2017} +} +``` + +
+
+
+Ķ»ĘõĖŗĶĮĮń╗ÅĶ┐ćÕżäńÉåńÜä`mpi_inf_3dhp`õĖÄ`pw3d`ńÜä[.npz µ¢ćõ╗Č](https://github.com/nkolot/SPIN/blob/master/fetch_data.sh)’╝īõ╗źÕÅŖķóäĶ«Łń╗āõ╣ŗÕÉÄńÜäńē╣ÕŠüµÅÉÕÅ¢µØāķćŹ [spin.pth](https://openmmlab-share.oss-cn-hangzhou.aliyuncs.com/mmhuman3d/models/vibe/spin.pth?versionId=CAEQHhiBgIDrxqbU6xciIGIzOWFkMWYyNzMwMjRhMzBiYzM3NDFiMmVkY2JkZTVh)ŃĆé Õ░åµ¢ćõ╗ČÕż╣µĢ┤ńÉåµłÉÕ”éõĖŗńÜäń╗ōµ×ä:
+
+```text
+mmhuman3d
+Ōö£ŌöĆŌöĆ mmhuman3d
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+ŌööŌöĆŌöĆ data
+ Ōö£ŌöĆŌöĆ checkpoints
+ | ŌööŌöĆŌöĆ spin.pth
+ ŌööŌöĆŌöĆ datasets
+ ŌööŌöĆŌöĆ vibe_data
+ Ōö£ŌöĆŌöĆ mpi_inf_3dhp_train.npz
+ ŌööŌöĆŌöĆ pw3d_test.npz
+```
diff --git a/internlm_langchain/knowledge_base/MMHuman3D/content/render.md b/internlm_langchain/knowledge_base/MMHuman3D/content/render.md
new file mode 100644
index 00000000..2cb0b852
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMHuman3D/content/render.md
@@ -0,0 +1,148 @@
+# µĖ▓µ¤ō Meshes
+
+## µĖ▓µ¤ōÕÖ©ÕłØÕ¦ŗÕī¢
+
+µłæõ╗¼õĮ┐ńö© `Pytorch3D` µĖ▓µ¤ōÕÖ©ŃĆéķĆÜĶ┐ćÕģēµĀģÕī¢ÕÖ©ŃĆüńØĆĶē▓ÕÖ©ÕÆīÕģČõ╗¢Ķ«ŠÕ«ÜÕłØÕ¦ŗÕī¢µĖ▓µ¤ōÕÖ©ŃĆé `MMHuman3D`õĖŁńÜäµĖ▓µ¤ōÕÖ©Õģ╝Õ«╣`Pytorch3D`ńÜäµĖ▓µ¤ōÕÖ©’╝īõĮåÕŖ¤ĶāĮµø┤ÕŖĀõĖ░Õ»īõĖöµø┤µśōńö©ŃĆé õŠŗÕ”é’╝īµé©ÕÅ»õ╗źÕāÅ`Pytorch3D`ķ鯵ĀĘ’╝īķĆÜĶ┐ćõ╝ĀÕģźÕģēµĀģÕī¢ÕÖ©ÕÆīńØĆĶē▓ÕÖ©ÕłØÕ¦ŗÕī¢µĖ▓µ¤ōÕÖ©’╝īõ╣¤ÕÅ»õ╗źõ╝ĀÕģźÕīģÕɽńøĖÕģ│Ķ«ŠńĮ«ńÜäÕŁŚÕģĖµł¢õĮ┐ńö©ķ╗śĶ«żńÜäĶ«ŠńĮ«ŃĆé
+Õ£©`mmhuman3d`õĖŁ, µłæõ╗¼µÅÉõŠøõ║åõĖŹÕÉīńÜäµĖ▓µ¤ōÕÖ©’╝īÕīģµŗ¼ `MeshRenderer`, `DepthRenderer`, `NormalRenderer`, `PointCloudRenderer`, `SegmentationRenderer`, `SilhouetteRenderer` ÕÆī `UVRenderer`ŃĆéÕģČõĖŁ, `UVRenderer` µ»öĶŠāńē╣Õł½’╝īĶ»ĘÕÅéĶĆā[UVRenderer](#uvrenderer)ŃĆé
+
+õĖŖĶ┐░µēƵ£ēńÜäµĖ▓µ¤ōÕÖ©ÕÅ»õ╗źķĆÜĶ┐ć`MMCV.Registry`Ķ┐øĶĪīÕłØÕ¦ŗÕī¢ŃĆéķĆÜĶ┐ćÕŁŚÕģĖÕé©ÕŁśµĖ▓µ¤ōÕÖ©ńÜäķģŹńĮ«õ╝ÜÕŠłµ¢╣õŠ┐ŃĆé
+
+- **`pytorch3d`ÕÆī`mmhuman3d`ńÜäµ»öĶŠā:**
+```python
+### ķĆÜĶ┐ćPytorch3DÕłØÕ¦ŗÕī¢
+import torch
+from pytorch3d.renderer import MeshRenderer, RasterizationSettings
+from pytorch3d.renderer.lighting import PointLights
+from pytorch3d.renderer.cameras import FoVPerspectiveCameras
+
+device = torch.device('cuda')
+R, T = look_at_view_transform(dist=2.7, elev=0, azim=0)
+cameras = FoVPerspectiveCameras(device=device, R=R, T=T)
+
+lights = PointLights(
+ device=device,
+ ambient_color=((0.5, 0.5, 0.5), ),
+ diffuse_color=((0.3, 0.3, 0.3), ),
+ specular_color=((0.2, 0.2, 0.2), ),
+ direction=((0, 1, 0), ),
+)
+raster_settings = RasterizationSettings(
+ image_size=128,
+ blur_radius=0.0,
+ faces_per_pixel=1,
+)
+renderer = MeshRenderer(
+ rasterizer=MeshRasterizer(
+ cameras=cameras, raster_settings=raster_settings),
+ shader=SoftPhongShader(device=device, cameras=cameras, lights=lights))
+
+### ķĆÜĶ┐ćmmhuman3dÕłØÕ¦ŗÕī¢
+from mmhuman3d.core.visualization.renderer import MeshRenderer
+# ÕÅ»õ╗źķĆÜĶ┐ćnn.ModuleÕÆīdictÕłØÕ¦ŗÕī¢ÕģēµĀģÕī¢ÕÖ©
+rasterizer = dict(
+ image_size=128,
+ blur_radius=0.0,
+ faces_per_pixel=1,
+)
+# ÕÅ»õ╗źķĆÜĶ┐ćnn.ModuleÕÆīdictÕłØÕ¦ŗÕī¢Õģēń║┐
+lights = dict(type='point', ambient_color=((0.5, 0.5, 0.5), ),
+ diffuse_color=((0.3, 0.3, 0.3), ),
+ specular_color=((0.2, 0.2, 0.2), ),
+ direction=((0, 1, 0), ),)
+
+# ÕÅ»õ╗źķĆÜĶ┐ćcameraÕÆīÕŁŚÕģĖÕłØÕ¦ŗÕī¢ÕģēµĀģÕī¢ÕÖ©
+cameras = dict(type='fovperspective', R=R, T=T, device=device)
+
+# ÕÅ»õ╗źķĆÜĶ┐ćnn.ModuleÕÆīdictÕłØÕ¦ŗÕī¢ńØĆĶē▓ÕÖ©
+shader = dict(type='SoftPhongShader')
+```
+
+Ķ┐ÖõĖżń¦Źµ¢╣Õ╝ŵś»ńŁēõ╗ĘńÜäŃĆé
+```python
+import torch.nn as nn
+from mmhuman3d.core.visualization.renderer import MeshRenderer, build_renderer
+
+renderer = MeshRenderer(shader=shader, device=device, rasterizer=rasterizer, resolution=resolution)
+renderer = build_renderer(dict(type='mesh', device=device, shader=shader, rasterizer=rasterizer, resolution=resolution))
+
+# õĮ┐ńö©ķ╗śĶ«żńÜäÕģēµĀģÕī¢ÕÖ©ÕÆīńØĆĶē▓ÕÖ©ńÜäķģŹńĮ«
+renderer = build_renderer(dict(type='mesh', device=device, resolution=resolution))
+assert isinstance(renderer.rasterizer, nn.Module)
+assert isinstance(renderer.shader, nn.Module)
+```
+
+µłæõ╗¼µÅÉõŠøõ║åńö©õ║ÄÕÅ»Ķ¦åÕī¢ńÜä`tensor2rgba`ÕćĮµĢ░’╝īÕģČĶ┐öÕø×ńÜ䵜»ÕÅ»Ķ¦åÕī¢ÕĮ®Ķē▓ÕøŠÕāÅńÜäÕ╝ĀķćÅŃĆé
+Õ»╣õ║ÄõĖŹÕÉīńÜäµĖ▓µ¤ōÕÖ©’╝īĶ»źÕćĮµĢ░µś»õĖŹÕÉīńÜäŃĆéõŠŗÕ”é’╝ī`DepthRenderer`µĖ▓µ¤ōÕć║ńÜ䵜»õĖĆõĖ¬ÕĮóńŖČõĖ║(N, H, W, 1)ńÜäÕ╝ĀķćÅ’╝īµłæõ╗¼Õ░åÕģČÕżŹÕłČµłÉÕĮóńŖČõĖ║(N, H, W, 4)ńÜäÕøŠÕāÅÕ╝ĀķćÅŃĆé`SegmentationRenderer`µĖ▓µ¤ōÕć║ńÜ䵜»õĖĆõĖ¬ÕĮóńŖČõĖ║(N, H, W, C)ńÜäÕ╝ĀķćÅ’╝īµłæõ╗¼µĀ╣µŹ«Ķē▓ÕĮ®Õī╣ķģŹÕģ│ń│╗Õ░åÕģČĶĮ¼µŹóµłÉ(N, H, W, 4)ńÜäÕøŠÕāÅÕ╝ĀķćÅŃĆé`NormalRenderer`µĖ▓µ¤ōÕć║ńÜ䵜»õĖĆõĖ¬ÕĮóńŖČõĖ║(N, H, W, 4)ńÜäÕ╝ĀķćÅ’╝īÕģČÕÅ¢ÕĆ╝ĶīāÕø┤õĖ║[-1, 1]’╝ī`tensor2rgba`õ╝ÜÕ░åÕģČÕĮÆõĖĆÕī¢Õł░[0, 1]ŃĆé
+
+```python
+import torch
+from mmhuman3d.core.visualization.renderer import build_renderer
+
+renderer = build_renderer(dict(type='mesh', device=device, resolution=resolution))
+rendered_tensor = renderer(meshes=meshes, cameras=cameras, lights=lights)
+rendered_rgba = renderer.tensor2rgba(rendered_tensor)
+```
+
+`MMHuman3D`õĖŁńÜäµĖ▓µ¤ōÕÖ©ÕÅ»õ╗źµø┤µö╣ĶŠōÕć║Ķ«ŠńĮ«’╝īÕ╣ČõĖöµÅÉõŠøõ║åµ¢ćõ╗ČńÜäĶŠōÕģźĶŠōÕć║µōŹõĮ£’╝ī`tensor2rgba`ÕćĮµĢ░õ╝ÜÕ»╣ÕåÖÕģźńÜäÕøŠÕāÅÕÆīĶ¦åķóæĶ┐øĶĪīĶĮ¼µŹóŃĆé
+
+```python
+# ÕåÖÕģźĶ¦åķóæ
+renderer = build_renderer(dict(type='mesh', device=device, resolution=resolution, output_path='test.mp4'))
+backgrounds = torch.Tensor(N, H, W, 3)
+rendered_tensor = renderer(meshes=meshes, cameras=cameras, lights=lights, backgrounds=backgrounds)
+renderer.export() #Ķ┐ÖõĖƵŁźÕ»╣õ║ÄĶ¦åķóæµś»Õ┐ģĶ”üńÜä
+
+# Õ£©µ¢ćõ╗ČÕż╣õĖŁÕåÖÕģźÕøŠÕāÅ
+renderer = build_renderer(dict(type='mesh', device=device, resolution=resolution, output_path='test_folder', out_img_format='%06d.png'))
+backgrounds = torch.Tensor(N, H, W, 3)
+rendered_tensor = renderer(meshes=meshes, cameras=cameras, lights=lights, backgrounds=backgrounds)
+```
+
+
+## õĮ┐ńö© render_runner
+
+µé©ÕÅ»õ╗źķĆÜĶ┐ć`render_runner`õ╝ĀÕģźńö©õ║ĵĖ▓µ¤ōńÜäµĢ░µŹ«ŃĆéÕ«āõ╝ÜõĮ┐ńö©forÕŠ¬ńÄ»µē╣ķćŵĖ▓µ¤ōÕ╝ĀķćÅ’╝īÕøĀµŁżÕÅ»õ╗źÕ»╣õĖĆķĢ┐õĖ▓Ķ¦åķóæÕ║ÅÕłŚĶ┐øĶĪīµĖ▓µ¤ō’╝īĶĆīõĖŹõ╝ÜÕć║ńÄ░`CUDA out of memory`ńÜäµŖźķöÖŃĆé
+
+```python
+import torch
+from mmhuman3d.core.visualization.renderer import render_runner
+
+render_data = dict(cameras=cameras, lights=lights, meshes=meshes, backgrounds=backgrounds)
+# Õ»╣õ║ÄõĖŹÕŻՊ«ńÜäµĖ▓µ¤ō’╝īµīćÕ«Üno_grad=True
+rendered_tensor = render_runner.render(renderer=renderer, output_path=output_path, resolution=resolution, batch_size=batch_size, device=device, no_grad=True, return_tensor=True, **render_data)
+```
+
+## UVRenderer
+
+`UVRenderer` õĖŹÕÉīõ║ÄÕģČõ╗¢ńÜäµĖ▓µ¤ōÕÖ©’╝īÕ«āµś»õĖĆõĖ¬smpl uvµŗōµēæÕ«Üõ╣ēńÜäÕīģĶŻģÕÖ©ÕÆīķććµĀĘÕÖ©ŃĆéÕģČÕīģÕɽµ£ēõĖżõĖ¬ÕŖ¤ĶāĮ: Õ░åķĪČńé╣ńÜäÕ▒׵ƦÕīģĶŻģõĖ║map, õ╗ÄmapõĖŖķććµĀĘķĪČńé╣Õ▒׵ƦŃĆé
+
+### ÕłØÕ¦ŗÕī¢
+UV õ┐Īµü»Õé©ÕŁśÕ£©`smpl_uv.npz`µ¢ćõ╗ČõĖŁŃĆé
+```python
+uv_renderer = build_renderer(dict(type='uv', resolution=resolution, device=device, model_type='smpl', uv_param_path='data/body_models/smpl/smpl_uv.npz'))
+```
+### ÕīģĶŻģ
+Õ░åńü░Ķē▓ńÜäń║╣ńÉåÕøŠÕāÅÕÅśÕĮóõĖ║smplńÜämeshŃĆé
+
+```python
+import torch
+from mmhuman3d.models import build_body_model
+from pytorch3d.structures import meshes
+from mmhuman3d.core.visualization.renderer import build_renderer
+body_model = build_body_model(dict(type='smpl', model_path=model_path)).to(device)
+pose_dict = body_model.tensor2dict(torch.zeros(1, 72))
+verts = body_model(**pose_dict)['vertices']
+faces = body_model.faces_tensor[None]
+smpl_mesh = Meshes(verts=verts, faces=faces)
+texture_image = torch.ones(1, 512, 512, 3) * 0.5
+smpl_mesh.textures = uv_renderer.warp_texture(texture_image=texture_image)
+```
+### ķććµĀĘ
+õ╗ÄmapķććµĀĘķĪČńé╣ŃĆé
+
+```python
+normal_map = torch.ones(1, 512, 512, 3)
+vertex_normals = uv_renderer.vertex_resample(normal_map)
+assert vertex_normals.shape == (1 ,6890, 3)
+assert (vertex_normals == 1).all()
+```
diff --git a/internlm_langchain/knowledge_base/MMHuman3D/content/smc.md b/internlm_langchain/knowledge_base/MMHuman3D/content/smc.md
new file mode 100644
index 00000000..63aa629c
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMHuman3D/content/smc.md
@@ -0,0 +1,159 @@
+# SMC(SenseMoCap) µ¢ćõ╗ȵĀ╝Õ╝ŵÅÅĶ┐░
+
+SMC (SenseMoCap) µś»õĖĆõĖ¬Ķ«ŠĶ«Īńö©µØźÕŁśÕé©ÕżÜńø«ÕżÜµ©ĪµĆüńÜäµ¢ćõ╗ȵĀ╝Õ╝ÅŃĆéµ»ÅõĖĆõĖ¬SMCµ£¼Ķ┤©õĖŖµś»õĖĆõĖ¬HDF5ńÜäµĢ░µŹ«Õ║ō’╝īµö»µīüõĖŹÕÉīÕ╣│ÕÅ░’╝īõĖŹÕÉīń╝¢ń©ŗĶ»ŁĶ©ĆńÜäĶ»╗ÕåÖŃĆé
+
+µ»ÅõĖ¬SMCńÜäµ£║µ×äń║”Õ«ÜÕ”éõĖŗ:
+
+- ### *.smc (File)
+
+ - Attributes
+
+ - actor_id: µ╝öÕæśń╝¢ÕÅĘ, int32 ÕŁŚń¼”
+ - action_id: ÕŖ©õĮ£ń╝¢ÕÅĘ, int32 ÕŁŚń¼”
+ - datetime_str: µĢ░µŹ«ķććķøåµŚČķŚ┤µł│, ÕŁŚń¼”õĖ▓ (YYYY-MM-DD-hh-mm-ss)
+
+ - ### Extrinsics (Dataset):
+
+ - õĖĆõĖ¬ÕŁśÕé©NõĖ¬KinectÕÆīMõĖ¬iPhoneµĀćիܵĢ░µŹ«ńÜäJSONÕŁŚń¼”õĖ▓
+ - Indexing cameras:
+ - Kinect RGBńøĖµ£║ń╝¢ÕÅʵś»ÕüȵĢ░: i*2, 0<=iVIBE (CVPR'2020)
+ +```BibTeX +@inproceedings{VIBE, + author = {Muhammed Kocabas and + Nikos Athanasiou and + Michael J. Black}, + title = {{VIBE}: Video Inference for Human Body Pose and Shape Estimation}, + booktitle = {CVPR}, + year = {2020} +} +``` + +
+
+#### µĢ░µŹ«ķøåķģŹńĮ«
+
+õĖ╗Ķ”üńö©õ║ÄķģŹńĮ«õĖżõĖ¬µ¢╣ÕÉæ’╝Ü
+
+- µĢ░µŹ«ķøåńÜäÕøŠÕāÅõĖĵĀćµ│©µ¢ćõ╗ČńÜäõĮŹńĮ«ŃĆé
+
+- µĢ░µŹ«Õó×Õ╝║ńøĖÕģ│ńÜäķģŹńĮ«ŃĆéÕ£© OCR ķóåÕ¤¤õĖŁ’╝īµĢ░µŹ«Õó×Õ╝║ķĆÜÕĖĖõĖĵ©ĪÕ×ŗÕ╝║ńøĖÕģ│ŃĆé
+
+µø┤ÕżÜÕÅéµĢ░ķģŹńĮ«ÕÅ»õ╗źÕÅéĶĆā[µĢ░µŹ«Õ¤║ń▒╗](#TODO)ŃĆé
+
+µĢ░µŹ«ķøåÕŁŚµ«ĄńÜäÕæĮÕÉŹĶ¦äÕłÖÕ£© MMOCR õĖŁõĖ║’╝Ü
+
+```Python
+{µĢ░µŹ«ķøåÕÉŹń¦░ń╝®ÕåÖ}_{ń«Śµ│Ģõ╗╗ÕŖĪ}_{Ķ«Łń╗ā/µĄŗĶ»Ģ/ķ¬īĶ»ü} = dict(...)
+```
+
+- µĢ░µŹ«ķøåń╝®ÕåÖ’╝ÜĶ¦ü [µĢ░µŹ«ķøåÕÉŹń¦░Õ»╣Õ║öĶĪ©](#TODO)
+
+- ń«Śµ│Ģõ╗╗ÕŖĪ’╝ܵ¢ćµ£¼µŻĆµĄŗ-det’╝īµ¢ćÕŁŚĶ»åÕł½-rec’╝īÕģ│ķö«õ┐Īµü»µÅÉÕÅ¢-kie
+
+- Ķ«Łń╗ā/µĄŗĶ»Ģ/ķ¬īĶ»ü’╝ܵĢ░µŹ«ķøåńö©õ║ÄĶ«Łń╗ā’╝īµĄŗĶ»ĢĶ┐śµś»ķ¬īĶ»ü
+
+õ╗źĶ»åÕł½õĖ║õŠŗ’╝īõĮ┐ńö© Syn90k õĮ£õĖ║Ķ«Łń╗āķøå’╝īõ╗ź icdar2013 ÕÆī icdar2015 õĮ£õĖ║µĄŗĶ»ĢķøåķģŹńĮ«Õ”éõĖŗ’╝Ü
+
+```Python
+# Ķ»åÕł½µĢ░µŹ«ķøåķģŹńĮ«
+mjsynth_textrecog_train = dict(
+ type='OCRDataset',
+ data_root='data/rec/Syn90k/',
+ data_prefix=dict(img_path='mnt/ramdisk/max/90kDICT32px'),
+ ann_file='train_labels.json',
+ test_mode=False,
+ pipeline=None)
+
+icdar2013_textrecog_test = dict(
+ type='OCRDataset',
+ data_root='data/rec/icdar_2013/',
+ data_prefix=dict(img_path='Challenge2_Test_Task3_Images/'),
+ ann_file='test_labels.json',
+ test_mode=True,
+ pipeline=None)
+
+icdar2015_textrecog_test = dict(
+ type='OCRDataset',
+ data_root='data/rec/icdar_2015/',
+ data_prefix=dict(img_path='ch4_test_word_images_gt/'),
+ ann_file='test_labels.json',
+ test_mode=True,
+ pipeline=None)
+```
+
+
+
+#### µĢ░µŹ«µĄüµ░┤ń║┐ķģŹńĮ«
+
+MMOCR õĖŁ’╝īµĢ░µŹ«ķøåńÜäµ×äÕ╗║õĖĵĢ░µŹ«ÕćåÕżćµś»ńøĖõ║ÆĶ¦ŻĶĆ”ńÜäŃĆéõ╣¤Õ░▒µś»Ķ»┤’╝ī`OCRDataset` ńŁēµĢ░µŹ«ķøåµ×äÕ╗║ń▒╗Ķ┤¤Ķ┤ŻÕ«īµłÉµĀćµ│©µ¢ćõ╗ČńÜäĶ»╗ÕÅ¢õĖÄĶ¦Żµ×ÉÕŖ¤ĶāĮ’╝øĶĆīµĢ░µŹ«ÕÅśµŹóµ¢╣µ│Ģ’╝łData Transforms’╝ēÕłÖĶ┐øõĖƵŁźÕ«×ńÄ░õ║åµĢ░µŹ«Ķ»╗ÕÅ¢ŃĆüµĢ░µŹ«Õó×Õ╝║ŃĆüµĢ░µŹ«µĀ╝Õ╝ÅÕī¢ńŁēńøĖÕģ│ÕŖ¤ĶāĮŃĆé
+
+ÕÉīµŚČõĖĆĶł¼µāģÕåĄõĖŗĶ«Łń╗āÕÆīµĄŗĶ»Ģõ╝ÜÕŁśÕ£©õĖŹÕÉīńÜäÕó×Õ╝║ńŁ¢ńĢź’╝īÕøĀµŁżõĖĆĶł¼õ╝ÜÕŁśÕ£©Ķ«Łń╗āµĄüµ░┤ń║┐’╝łtrain_pipeline’╝ēÕÆīµĄŗĶ»ĢµĄüµ░┤ń║┐’╝łtest_pipeline’╝ēŃĆéµø┤ÕżÜõ┐Īµü»ÕÅ»õ╗źÕÅéĶĆā[µĢ░µŹ«µĄüµ░┤ń║┐](../basic_concepts/transforms.md)
+
+- Ķ«Łń╗āµĄüµ░┤ń║┐ńÜäµĢ░µŹ«Õó×Õ╝║µĄüń©ŗķĆÜÕĖĖõĖ║’╝ܵĢ░µŹ«Ķ»╗ÕÅ¢(LoadImageFromFile)->µĀćµ│©õ┐Īµü»Ķ»╗ÕÅ¢(LoadXXXAnntation)->µĢ░µŹ«Õó×Õ╝║->µĢ░µŹ«µĀ╝Õ╝ÅÕī¢(PackXXXInputs)ŃĆé
+
+- µĄŗĶ»ĢµĄüµ░┤ń║┐ńÜäµĢ░µŹ«Õó×Õ╝║µĄüń©ŗķĆÜÕĖĖõĖ║’╝ܵĢ░µŹ«Ķ»╗ÕÅ¢(LoadImageFromFile)->µĢ░µŹ«Õó×Õ╝║->µĀćµ│©õ┐Īµü»Ķ»╗ÕÅ¢(LoadXXXAnntation)->µĢ░µŹ«µĀ╝Õ╝ÅÕī¢(PackXXXInputs)ŃĆé
+
+ńö▒õ║Ä OCR õ╗╗ÕŖĪńÜäńē╣µ«ŖµĆ¦’╝īõĖĆĶł¼µāģÕåĄõĖŗõĖŹÕÉīµ©ĪÕ×ŗµ£ēõĖŹÕÉīµĢ░µŹ«Õó×Õ╝║ńÜäµ¢╣Õ╝Å’╝īńøĖÕÉīµ©ĪÕ×ŗÕ£©õĖŹÕÉīµĢ░µŹ«ķøåõĖĆĶł¼õ╣¤õ╝ܵ£ēõĖŹÕÉīńÜäµĢ░µŹ«Õó×Õ╝║µ¢╣Õ╝ÅŃĆéõ╗ź CRNN õĖ║õŠŗ’╝Ü
+
+```Python
+# µĢ░µŹ«Õó×Õ╝║
+train_pipeline = [
+ dict(
+ type='LoadImageFromFile',
+ color_type='grayscale',
+ ignore_empty=True,
+ min_size=5),
+ dict(type='LoadOCRAnnotations', with_text=True),
+ dict(type='Resize', scale=(100, 32), keep_ratio=False),
+ dict(
+ type='PackTextRecogInputs',
+ meta_keys=('img_path', 'ori_shape', 'img_shape', 'valid_ratio'))
+]
+test_pipeline = [
+ dict(
+ type='LoadImageFromFile',
+ color_type='grayscale'),
+ dict(
+ type='RescaleToHeight',
+ height=32,
+ min_width=32,
+ max_width=None,
+ width_divisor=16),
+ dict(type='LoadOCRAnnotations', with_text=True),
+ dict(
+ type='PackTextRecogInputs',
+ meta_keys=('img_path', 'ori_shape', 'img_shape', 'valid_ratio'))
+]
+```
+
+
+
+#### Dataloader ķģŹńĮ«
+
+õĖ╗Ķ”üõĖ║µ×äķĆĀµĢ░µŹ«ķøåÕŖĀĶĮĮÕÖ©(dataloader)µēĆķ£ĆńÜäķģŹńĮ«õ┐Īµü»’╝īµø┤ÕżÜµĢÖń©ŗń£ŗÕÅéĶĆā {external+torch:doc}`PyTorch µĢ░µŹ«ÕŖĀĶĮĮÕÖ© `ŃĆé
+
+```Python
+# Dataloader ķā©Õłå
+train_dataloader = dict(
+ batch_size=64,
+ num_workers=8,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type='ConcatDataset',
+ datasets=[mjsynth_textrecog_train],
+ pipeline=train_pipeline))
+val_dataloader = dict(
+ batch_size=1,
+ num_workers=4,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ dataset=dict(
+ type='ConcatDataset',
+ datasets=[icdar2013_textrecog_test, icdar2015_textrecog_test],
+ pipeline=test_pipeline))
+test_dataloader = val_dataloader
+```
+
+### µ©ĪÕ×ŗńøĖÕģ│ķģŹńĮ«
+
+
+
+#### ńĮæń╗£ķģŹńĮ«
+
+ńö©õ║ÄķģŹńĮ«µ©ĪÕ×ŗńÜäńĮæń╗£ń╗ōµ×ä’╝īõĖŹÕÉīńÜäń«Śµ│Ģõ╗╗ÕŖĪµ£ēõĖŹÕÉīńÜäńĮæń╗£ń╗ōµ×äŃĆéµø┤ÕżÜõ┐Īµü»ÕÅ»õ╗źÕÅéĶĆā[ńĮæń╗£ń╗ōµ×ä](../basic_concepts/structures.md)
+
+##### µ¢ćµ£¼µŻĆµĄŗ
+
+µ¢ćµ£¼µŻĆµĄŗõĖ╗Ķ”üÕīģÕɽÕćĀõĖ¬ķā©Õłå:
+
+- `data_preprocessor`: [µĢ░µŹ«ÕżäńÉåÕÖ©](mmocr.models.textdet.data_preprocessors.TextDetDataPreprocessor)
+- `backbone`: ńē╣ÕŠüµÅÉÕÅ¢ńĮæń╗£
+- `neck`: ķółńĮæń╗£ķģŹńĮ«
+- `det_head`: µŻĆµĄŗÕż┤ńĮæń╗£ķģŹńĮ«
+ - `module_loss`: µ©ĪÕ×ŗµŹ¤Õż▒ÕćĮµĢ░ķģŹńĮ«
+ - `postprocessor`: µ©ĪÕ×ŗķó䵥ŗń╗ōµ×£ÕÉÄÕżäńÉåķģŹńĮ«
+
+µłæõ╗¼õ╗ź DBNet õĖ║õŠŗ’╝īõ╗ŗń╗Źµ¢ćÕŁŚµŻĆµĄŗõĖŁµ©ĪÕ×ŗķģŹńĮ«’╝Ü
+
+```Python
+model = dict(
+ type='DBNet',
+ data_preprocessor=dict(
+ type='TextDetDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True,
+ pad_size_divisor=32)
+ backbone=dict(
+ type='mmdet.ResNet',
+ depth=18,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ frozen_stages=-1,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet18'),
+ norm_eval=False,
+ style='caffe'),
+ neck=dict(
+ type='FPNC', in_channels=[64, 128, 256, 512], lateral_channels=256),
+ det_head=dict(
+ type='DBHead',
+ in_channels=256,
+ module_loss=dict(type='DBModuleLoss'),
+ postprocessor=dict(type='DBPostprocessor', text_repr_type='quad')))
+```
+
+##### µ¢ćµ£¼Ķ»åÕł½
+
+µ¢ćµ£¼Ķ»åÕł½õĖ╗Ķ”üÕīģÕɽ’╝Ü
+
+- `data_processor`: [µĢ░µŹ«ķóäÕżäńÉåķģŹńĮ«](mmocr.models.textrec.data_processors.TextRecDataPreprocessor)
+- `preprocessor`: ńĮæń╗£ķóäÕżäńÉåķģŹńĮ«’╝īÕ”éTPSńŁē
+- `backbone`:ńē╣ÕŠüµÅÉÕÅ¢ķģŹńĮ«
+- `encoder`: ń╝¢ńĀüÕÖ©ķģŹńĮ«
+- `decoder`: Ķ¦ŻńĀüÕÖ©ķģŹńĮ«
+ - `module_loss`: Ķ¦ŻńĀüÕÖ©µŹ¤Õż▒
+ - `postprocessor`: Ķ¦ŻńĀüÕÖ©ÕÉÄÕżäńÉå
+ - `dictionary`: ÕŁŚÕģĖķģŹńĮ«
+
+õ╗ź CRNN õĖ║õŠŗ’╝Ü
+
+```Python
+# µ©ĪÕ×ŗķā©Õłå
+model = dict(
+ type='CRNN',
+ data_preprocessor=dict(
+ type='TextRecogDataPreprocessor', mean=[127], std=[127])
+ preprocessor=None,
+ backbone=dict(type='VeryDeepVgg', leaky_relu=False, input_channels=1),
+ encoder=None,
+ decoder=dict(
+ type='CRNNDecoder',
+ in_channels=512,
+ rnn_flag=True,
+ module_loss=dict(type='CTCModuleLoss', letter_case='lower'),
+ postprocessor=dict(type='CTCPostProcessor'),
+ dictionary=dict(
+ type='Dictionary',
+ dict_file='dicts/lower_english_digits.txt',
+ with_padding=True)))
+```
+
+
+
+#### µØāķćŹÕŖĀĶĮĮķģŹńĮ«
+
+ÕÅ»õ╗źķĆÜĶ┐ć `load_from` ÕÅéµĢ░ÕŖĀĶĮĮµŻĆµ¤źńé╣’╝łcheckpoint’╝ēµ¢ćõ╗ČõĖŁńÜ䵩ĪÕ×ŗµØāķ插╝īÕŬķ£ĆĶ”üÕ░å `load_from` ÕÅéµĢ░Ķ«ŠńĮ«õĖ║µŻĆµ¤źńé╣µ¢ćõ╗ČńÜäĶĘ»ÕŠäÕŹ│ÕÅ»ŃĆé
+
+ńö©µłĘõ╣¤ÕÅ»ķĆÜĶ┐ćĶ«ŠńĮ« `resume=True` ’╝īÕŖĀĶĮĮµŻĆµ¤źńé╣õĖŁńÜäĶ«Łń╗āńŖȵĆüõ┐Īµü»µØźµüóÕżŹĶ«Łń╗āŃĆéÕĮō `load_from` ÕÆī `resume=True` ÕÉīµŚČĶó½Ķ«ŠńĮ«µŚČ’╝īµē¦ĶĪīÕÖ©Õ░åÕŖĀĶĮĮ `load_from` ĶĘ»ÕŠäÕ»╣Õ║öńÜ䵯Ƶ¤źńé╣µ¢ćõ╗ČõĖŁńÜäĶ«Łń╗āńŖȵĆüŃĆé
+
+Õ”éµ×£õ╗ģĶ«ŠńĮ« `resume=True`’╝īµē¦ĶĪīÕÖ©Õ░åõ╝ÜÕ░ØĶ»Ģõ╗Ä `work_dir` µ¢ćõ╗ČÕż╣õĖŁÕ»╗µēŠÕ╣ČĶ»╗ÕÅ¢µ£Ćµ¢░ńÜ䵯Ƶ¤źńé╣µ¢ćõ╗Č
+
+```Python
+load_from = None # ÕŖĀĶĮĮcheckpointńÜäĶĘ»ÕŠä
+resume = False # µś»ÕÉ” resume
+```
+
+µø┤ÕżÜÕÅ»õ╗źÕÅéĶĆā {external+mmengine:ref}`MMEngine: ÕŖĀĶĮĮµØāķ揵ł¢µüóÕżŹĶ«Łń╗ā <ÕŖĀĶĮĮµØāķ揵ł¢µüóÕżŹĶ«Łń╗ā>` õĖÄ [OCR Ķ┐øķśČµŖĆÕʦ-µ¢Łńé╣µüóÕżŹĶ«Łń╗ā](train_test.md#õ╗ĵ¢Łńé╣µüóÕżŹĶ«Łń╗ā)ŃĆé
+
+
+
+### Ķ»äµĄŗķģŹńĮ«
+
+Õ£©µ©ĪÕ×ŗķ¬īĶ»üÕÆīµ©ĪÕ×ŗµĄŗĶ»ĢõĖŁ’╝īķĆÜÕĖĖķ£ĆĶ”üÕ»╣µ©ĪÕ×ŗń▓ŠÕ║”ÕüÜÕ«ÜķćÅĶ»äµĄŗŃĆéMMOCR ķĆÜĶ┐ćĶ»äµĄŗµīćµĀć(Metric)ÕÆīĶ»äµĄŗÕÖ©(Evaluator)µØźÕ«īµłÉĶ┐ÖõĖĆÕŖ¤ĶāĮŃĆéµø┤ÕżÜÕÅ»õ╗źÕÅéĶĆā{external+mmengine:doc}`MMEngine: Ķ»äµĄŗµīćµĀć(Metric)ÕÆīĶ»äµĄŗÕÖ©(Evaluator) ` ÕÆī [Ķ»äµĄŗÕÖ©](../basic_concepts/evaluation.md)
+
+Ķ»äµĄŗķā©ÕłåÕīģÕɽõĖżõĖ¬ķā©Õłå’╝īĶ»äµĄŗÕÖ©ÕÆīĶ»äµĄŗµīćµĀćŃĆéµÄźõĖŗµØźµłæõ╗¼Õłåķā©ÕłåÕ▒ĢÕ╝ĆĶ«▓Ķ¦ŻŃĆé
+
+#### Ķ»äµĄŗÕÖ©
+
+Ķ»äµĄŗÕÖ©õĖ╗Ķ”üńö©µØźń«ĪńÉåÕżÜõĖ¬µĢ░µŹ«ķøåõ╗źÕÅŖÕżÜõĖ¬ `Metric`ŃĆéķÆłÕ»╣ÕŹĢµĢ░µŹ«ķøåõĖÄÕżÜµĢ░µŹ«ķøåµāģÕåĄ’╝īĶ»äµĄŗÕÖ©ÕłåõĖ║õ║åÕŹĢµĢ░µŹ«ķøåĶ»äµĄŗÕÖ©õĖÄÕżÜµĢ░µŹ«ķøåĶ»äµĄŗÕÖ©’╝īĶ┐ÖõĖżń¦ŹĶ»äµĄŗÕÖ©ÕØćÕÅ»ń«ĪńÉåÕżÜõĖ¬ `Metric`.
+
+ÕŹĢµĢ░µŹ«ķøåĶ»äµĄŗÕÖ©ķģŹńĮ«Õ”éõĖŗ’╝Ü
+
+```Python
+# ÕŹĢõĖ¬µĢ░µŹ«ķøå ÕŹĢõĖ¬ Metric µāģÕåĄ
+val_evaluator = dict(
+ type='Evaluator',
+ metrics=dict())
+
+# ÕŹĢõĖ¬µĢ░µŹ«ķøå ÕżÜõĖ¬ Metric µāģÕåĄ
+val_evaluator = dict(
+ type='Evaluator',
+ metrics=[...])
+```
+
+Õ£©Õ«×ńÄ░õĖŁķ╗śĶ«żõĖ║ÕŹĢµĢ░µŹ«ķøåĶ»äµĄŗÕÖ©’╝īÕøĀµŁżÕ»╣ÕŹĢµĢ░µŹ«ķøåĶ»äµĄŗµāģÕåĄõĖŗ’╝īõĖĆĶł¼µāģÕåĄõĖŗÕŬķ£ĆķģŹńĮ«Ķ»äµĄŗÕÖ©’╝īÕŹ│õĖ║
+
+```Python
+# ÕŹĢõĖ¬µĢ░µŹ«ķøå ÕŹĢõĖ¬ Metric µāģÕåĄ
+val_evaluator = dict()
+
+# ÕŹĢõĖ¬µĢ░µŹ«ķøå ÕżÜõĖ¬ Metric µāģÕåĄ
+val_evaluator = [...]
+```
+
+ÕżÜµĢ░µŹ«ķøåĶ»äµĄŗõĖÄÕŹĢµĢ░µŹ«ķøåĶ»äµĄŗÕŁśÕ£©õĖżõĖ¬õĮŹńĮ«õĖŖńÜäõĖŹÕÉī’╝ÜĶ»äµĄŗÕÖ©ń▒╗Õł½õĖÄÕēŹń╝ĆŃĆéĶ»äµĄŗÕÖ©ń▒╗Õł½Õ┐ģķĪ╗õĖ║`MultiDatasetsEvaluator`õĖöõĖŹĶāĮń£üńĢź’╝īÕēŹń╝ĆõĖ╗Ķ”üńö©µØźÕī║ÕłåõĖŹÕÉīµĢ░µŹ«ķøåÕ£©ńøĖÕÉīĶ»äµĄŗµīćµĀćõĖŗńÜäń╗ōµ×£’╝īĶ»ĘÕÅéĶĆā[ÕżÜµĢ░µŹ«ķøåĶ»äµĄŗ](../basic_concepts/evaluation.md)ŃĆé
+
+ÕüćĶ«Šµłæõ╗¼ķ£ĆĶ”üÕ£© IC13 ÕÆī IC15 µāģÕåĄõĖŗµĄŗĶ»Ģń▓ŠÕ║”’╝īÕłÖķģŹńĮ«Õ”éõĖŗ’╝Ü
+
+```Python
+# ÕżÜõĖ¬µĢ░µŹ«ķøå’╝īÕŹĢõĖ¬ Metric µāģÕåĄ
+val_evaluator = dict(
+ type='MultiDatasetsEvaluator',
+ metrics=dict(),
+ dataset_prefixes=['IC13', 'IC15'])
+
+# ÕżÜõĖ¬µĢ░µŹ«ķøå’╝īÕżÜõĖ¬ Metric µāģÕåĄ
+val_evaluator = dict(
+ type='MultiDatasetsEvaluator',
+ metrics=[...],
+ dataset_prefixes=['IC13', 'IC15'])
+```
+
+#### Ķ»äµĄŗµīćµĀć
+
+Ķ»äµĄŗµīćµĀćµīćõĖŹÕÉīÕ║”ķćÅń▓ŠÕ║”ńÜäµ¢╣µ│Ģ’╝īÕÉīµŚČÕÅ»õ╗źÕżÜõĖ¬Ķ»äµĄŗµīćµĀćÕģ▒ÕÉīõĮ┐ńö©’╝īµø┤ÕżÜĶ»äµĄŗµīćµĀćÕĤńÉåÕÅéĶĆā {external+mmengine:doc}`MMEngine: Ķ»äµĄŗµīćµĀć `’╝īÕ£© MMOCR õĖŁõĖŹÕÉīń«Śµ│Ģõ╗╗ÕŖĪµ£ēõĖŹÕÉīńÜäĶ»äµĄŗµīćµĀćŃĆé µø┤ÕżÜ OCR ńøĖÕģ│ńÜäĶ»äµĄŗµīćµĀćÕÅ»õ╗źÕÅéĶĆā [Ķ»äµĄŗµīćµĀć](../basic_concepts/evaluation.md)ŃĆé
+
+µ¢ćÕŁŚµŻĆµĄŗ: [`HmeanIOUMetric`](mmocr.evaluation.metrics.HmeanIOUMetric)
+
+µ¢ćÕŁŚĶ»åÕł½: [`WordMetric`](mmocr.evaluation.metrics.WordMetric)’╝ī[`CharMetric`](mmocr.evaluation.metrics.CharMetric)’╝ī [`OneMinusNEDMetric`](mmocr.evaluation.metrics.OneMinusNEDMetric)
+
+Õģ│ķö«õ┐Īµü»µÅÉÕÅ¢: [`F1Metric`](mmocr.evaluation.metrics.F1Metric)
+
+õ╗źµ¢ćµ£¼µŻĆµĄŗõĖ║õŠŗĶ»┤µśÄ’╝īÕ£©ÕŹĢµĢ░µŹ«ķøåĶ»äµĄŗµāģÕåĄõĖŗ’╝īõĮ┐ńö©ÕŹĢõĖ¬ `Metric`’╝Ü
+
+```Python
+val_evaluator = dict(type='HmeanIOUMetric')
+```
+
+õ╗źµ¢ćµ£¼Ķ»åÕł½õĖ║õŠŗ’╝īÕ»╣ÕżÜõĖ¬µĢ░µŹ«ķøå(IC13 ÕÆī IC15)ńö©ÕżÜõĖ¬ `Metric` (`WordMetric` ÕÆī `CharMetric`)Ķ┐øĶĪīĶ»äµĄŗ’╝Ü
+
+```Python
+# Ķ»äµĄŗķā©Õłå
+val_evaluator = dict(
+ type='MultiDatasetsEvaluator',
+ metrics=[
+ dict(
+ type='WordMetric',
+ mode=['exact', 'ignore_case', 'ignore_case_symbol']),
+ dict(type='CharMetric')
+ ],
+ dataset_prefixes=['IC13', 'IC15'])
+test_evaluator = val_evaluator
+```
+
+
+
+### ÕÅ»Ķ¦åÕī¢ķģŹńĮ«
+
+µ»ÅõĖ¬õ╗╗ÕŖĪķģŹńĮ«Ķ»źõ╗╗ÕŖĪÕ»╣Õ║öńÜäÕÅ»Ķ¦åÕī¢ÕÖ©ŃĆéÕÅ»Ķ¦åÕī¢ÕÖ©õĖ╗Ķ”üńö©õ║Äńö©µłĘµ©ĪÕ×ŗõĖŁķŚ┤ń╗ōµ×£ńÜäÕÅ»Ķ¦åÕī¢µł¢ÕŁśÕé©’╝īÕÅŖ val ÕÆī test ķó䵥ŗń╗ōµ×£ńÜäÕÅ»Ķ¦åÕī¢ŃĆéÕÉīµŚČÕÅ»Ķ¦åÕī¢ńÜäń╗ōµ×£ÕÅ»õ╗źķĆÜĶ┐ćÕÅ»Ķ¦åÕī¢ÕÉÄń½»Õé©ÕŁśÕł░õĖŹÕÉīńÜäÕÉÄń½»’╝īµ»öÕ”é WandB’╝īTensorBoard ńŁēŃĆéÕĖĖńö©õ┐«µö╣µōŹõĮ£ÕÅ»Ķ¦ü[ÕÅ»Ķ¦åÕī¢](visualization.md)ŃĆé
+
+µ¢ćµ£¼µŻĆµĄŗńÜäÕÅ»Ķ¦åÕī¢ķ╗śĶ«żķģŹńĮ«Õ”éõĖŗ’╝Ü
+
+```Python
+vis_backends = [dict(type='LocalVisBackend')]
+visualizer = dict(
+ type='TextDetLocalVisualizer', # õĖŹÕÉīõ╗╗ÕŖĪµ£ēõĖŹÕÉīńÜäÕÅ»Ķ¦åÕī¢ÕÖ©
+ vis_backends=vis_backends,
+ name='visualizer')
+```
+
+## ńø«ÕĮĢń╗ōµ×ä
+
+`MMOCR` µēƵ£ēķģŹńĮ«µ¢ćõ╗ČķāĮµöŠńĮ«Õ£© `configs` µ¢ćõ╗ČÕż╣õĖŗŃĆéõĖ║õ║åķü┐ÕģŹķģŹńĮ«µ¢ćõ╗ČĶ┐ćķĢ┐’╝īÕÉīµŚČµÅÉķ½śķģŹńĮ«µ¢ćõ╗ČńÜäÕÅ»ÕżŹńö©µĆ¦õ╗źÕÅŖµĖģµÖ░µĆ¦’╝īMMOCR Õł®ńö© Config µ¢ćõ╗ČńÜäń╗¦µē┐ńē╣µĆ¦’╝īÕ░åķģŹńĮ«ÕåģÕ«╣ńÜäÕģ½õĖ¬ķā©ÕłåÕüÜõ║åµŗåÕłåŃĆéÕøĀõĖ║µ»Åķā©ÕłåÕØćõĖÄń«Śµ│Ģõ╗╗ÕŖĪńøĖÕģ│’╝īÕøĀµŁż MMOCR Õ»╣µ»ÅõĖ¬õ╗╗ÕŖĪÕ£© Config õĖŁµÅÉõŠøõ║åõĖĆõĖ¬õ╗╗ÕŖĪµ¢ćõ╗ČÕż╣’╝īÕŹ│ `textdet` (µ¢ćÕŁŚµŻĆµĄŗõ╗╗ÕŖĪ)ŃĆü`textrecog` (µ¢ćÕŁŚĶ»åÕł½õ╗╗ÕŖĪ)ŃĆü`kie` (Õģ│ķö«õ┐Īµü»µÅÉÕÅ¢)ŃĆéÕÉīµŚČÕÉäõĖ¬õ╗╗ÕŖĪń«Śµ│ĢķģŹńĮ«µ¢ćõ╗ČÕż╣õĖŗĶ┐øõĖƵŁźÕłÆÕłåõĖ║õĖżõĖ¬ķā©Õłå’╝Ü`_base_` µ¢ćõ╗ČÕż╣õĖÄĶ»ĖÕżÜń«Śµ│Ģµ¢ćõ╗ČÕż╣’╝Ü
+
+1. `_base_` µ¢ćõ╗ČÕż╣õĖŗõĖ╗Ķ”üÕŁśµöŠõĖÄÕģĘõĮōń«Śµ│ĢµŚĀÕģ│ńÜäõĖĆõ║øķĆÜńö©ķģŹńĮ«µ¢ćõ╗Č’╝īÕÉäķā©ÕłåõŠØńø«ÕĮĢÕłåõĖ║ÕĖĖńö©ńÜäµĢ░µŹ«ķøåŃĆüÕĖĖńö©ńÜäĶ«Łń╗āńŁ¢ńĢźõ╗źÕÅŖķĆÜńö©ńÜäĶ┐ÉĶĪīķģŹńĮ«ŃĆé
+
+2. ń«Śµ│ĢķģŹńĮ«µ¢ćõ╗ČÕż╣õĖŁÕŁśµöŠõĖÄń«Śµ│ĢÕ╝║ńøĖÕģ│ńÜäķģŹńĮ«ķĪ╣ŃĆéń«Śµ│ĢķģŹńĮ«µ¢ćõ╗ČÕż╣õĖ╗Ķ”üÕłåõĖ║õĖżķā©Õłå’╝Ü
+
+ 1. ń«Śµ│ĢńÜ䵩ĪÕ×ŗõĖĵĢ░µŹ«µĄüµ░┤ń║┐’╝ÜOCR ķóåÕ¤¤õĖŁõĖĆĶł¼µāģÕåĄõĖŗµĢ░µŹ«Õó×Õ╝║ńŁ¢ńĢźõĖÄń«Śµ│ĢÕ╝║ńøĖÕģ│’╝īÕøĀµŁżµ©ĪÕ×ŗõĖĵĢ░µŹ«µĄüµ░┤ń║┐ķĆÜÕĖĖńĮ«õ║Äń╗¤õĖĆõĮŹńĮ«ŃĆé
+
+ 2. ń«Śµ│ĢÕ£©ÕłČիܵĢ░µŹ«ķøåõĖŖńÜäńē╣Õ«ÜķģŹńĮ«’╝Üńö©õ║ÄĶ«Łń╗āÕÆīµĄŗĶ»ĢńÜäķģŹńĮ«’╝īÕ░åÕłåµĢŻÕ£©õĖŹÕÉīõĮŹńĮ«ńÜä *base* ķģŹńĮ«µ▒ćµĆ╗ŃĆéÕÉīµŚČÕÅ»ĶāĮõ╝Üõ┐«µö╣õĖĆõ║ø`_base_`õĖŁńÜäÕÅśķćÅ’╝īÕ”ébatch size, µĢ░µŹ«µĄüµ░┤ń║┐’╝īĶ«Łń╗āńŁ¢ńĢźńŁē
+
+µ£ĆÕÉÄńÜäÕ░åķģŹńĮ«ÕåģÕ«╣õĖŁńÜäÕÉäõĖ¬µ©ĪÕØŚÕłåÕĖāÕ£©õĖŹÕÉīķģŹńĮ«µ¢ćõ╗ČõĖŁ’╝īµ£Ćń╗łÕÉäķģŹńĮ«µ¢ćõ╗ČÕåģÕ«╣Õ”éõĖŗ:
+
+
+
+
+
+
+
+µ£Ćń╗łńø«ÕĮĢń╗ōµ×äÕ”éõĖŗ’╝Ü
+
+```Python
+configs
+Ōö£ŌöĆŌöĆ textdet
+Ōöé Ōö£ŌöĆŌöĆ _base_
+Ōöé Ōöé Ōö£ŌöĆŌöĆ datasets
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ icdar2015.py
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ icdar2017.py
+Ōöé Ōöé Ōöé ŌööŌöĆŌöĆ totaltext.py
+Ōöé Ōöé Ōö£ŌöĆŌöĆ schedules
+Ōöé Ōöé Ōöé ŌööŌöĆŌöĆ schedule_adam_600e.py
+Ōöé Ōöé ŌööŌöĆŌöĆ default_runtime.py
+Ōöé ŌööŌöĆŌöĆ dbnet
+Ōöé Ōö£ŌöĆŌöĆ _base_dbnet_resnet18_fpnc.py
+Ōöé ŌööŌöĆŌöĆ dbnet_resnet18_fpnc_1200e_icdar2015.py
+Ōö£ŌöĆŌöĆ textrecog
+Ōöé Ōö£ŌöĆŌöĆ _base_
+Ōöé Ōöé Ōö£ŌöĆŌöĆ datasets
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ icdar2015.py
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ icdar2017.py
+Ōöé Ōöé Ōöé ŌööŌöĆŌöĆ totaltext.py
+Ōöé Ōöé Ōö£ŌöĆŌöĆ schedules
+Ōöé Ōöé Ōöé ŌööŌöĆŌöĆ schedule_adam_base.py
+Ōöé Ōöé ŌööŌöĆŌöĆ default_runtime.py
+Ōöé ŌööŌöĆŌöĆ crnn
+Ōöé Ōö£ŌöĆŌöĆ _base_crnn_mini-vgg.py
+Ōöé ŌööŌöĆŌöĆ crnn_mini-vgg_5e_mj.py
+ŌööŌöĆŌöĆ kie
+ Ōö£ŌöĆŌöĆ _base_
+ Ōöé Ōö£ŌöĆŌöĆdatasets
+ Ōöé ŌööŌöĆŌöĆ default_runtime.py
+ ŌööŌöĆŌöĆ sgdmr
+ ŌööŌöĆŌöĆ sdmgr_novisual_60e_wildreceipt_openset.py
+```
+
+## ķģŹńĮ«µ¢ćõ╗Čõ╗źÕÅŖµØāķćŹÕæĮÕÉŹĶ¦äÕłÖ
+
+MMOCR µīēńģ¦õ╗źõĖŗķŻÄµĀ╝Ķ┐øĶĪīķģŹńĮ«µ¢ćõ╗ČÕæĮÕÉŹ’╝īõ╗ŻńĀüÕ║ōńÜäĶ┤Īńī«ĶĆģķ£ĆĶ”üķüĄÕŠ¬ńøĖÕÉīńÜäÕæĮÕÉŹĶ¦äÕłÖŃĆéµ¢ćõ╗ČÕÉŹµĆ╗õĮōÕłåõĖ║Õøøķā©Õłå’╝Üń«Śµ│Ģõ┐Īµü»’╝īµ©ĪÕØŚõ┐Īµü»’╝īĶ«Łń╗āõ┐Īµü»ÕÆīµĢ░µŹ«õ┐Īµü»ŃĆéķĆ╗ĶŠæõĖŖÕ▒×õ║ÄõĖŹÕÉīķā©ÕłåńÜäÕŹĢĶ»Źõ╣ŗķŚ┤ńö©õĖŗÕłÆń║┐ `'_'` Ķ┐׵ğ’╝īÕÉīõĖĆķā©Õłåµ£ēÕżÜõĖ¬ÕŹĢĶ»Źńö©ń¤Łµ©¬ń║┐ `'-'` Ķ┐׵ğŃĆé
+
+```Python
+{{ń«Śµ│Ģõ┐Īµü»}}_{{µ©ĪÕØŚõ┐Īµü»}}_{{Ķ«Łń╗āõ┐Īµü»}}_{{µĢ░µŹ«õ┐Īµü»}}.py
+```
+
+- ń«Śµ│Ģõ┐Īµü»(algorithm info)’╝Üń«Śµ│ĢÕÉŹń¦░’╝īÕ”é dbnet, crnn ńŁē
+
+- µ©ĪÕØŚõ┐Īµü»(module info)’╝ܵīēńģ¦µĢ░µŹ«µĄüńÜäķĪ║Õ║ÅÕłŚõĖŠõĖĆõ║øõĖŁķŚ┤ńÜ䵩ĪÕØŚ’╝īÕģČÕåģÕ«╣õŠØĶĄ¢õ║Äń«Śµ│Ģõ╗╗ÕŖĪ’╝īÕÉīµŚČõĖ║õ║åķü┐ÕģŹConfigĶ┐ćķĢ┐’╝īõ╝Üń£üńĢźõĖĆõ║øõĖĵ©ĪÕ×ŗÕ╝║ńøĖÕģ│ńÜ䵩ĪÕØŚŃĆéõĖŗķØóõĖŠõŠŗĶ»┤µśÄ’╝Ü
+
+ - Õ»╣õ║ĵ¢ćÕŁŚµŻĆµĄŗõ╗╗ÕŖĪÕÆīÕģ│ķö«õ┐Īµü»µÅÉÕÅ¢õ╗╗ÕŖĪ:
+
+ ```Python
+ {{ń«Śµ│Ģõ┐Īµü»}}_{{backbone}}_{{neck}}_{{head}}_{{Ķ«Łń╗āõ┐Īµü»}}_{{µĢ░µŹ«õ┐Īµü»}}.py
+ ```
+
+ õĖĆĶł¼µāģÕåĄõĖŗ head õĮŹńĮ«õĖĆĶł¼õĖ║ń«Śµ│ĢõĖōµ£ēńÜä head’╝īÕøĀµŁżõĖĆĶł¼ń£üńĢźŃĆé
+
+ - Õ»╣õ║ĵ¢ćµ£¼Ķ»åÕł½õ╗╗ÕŖĪ’╝Ü
+
+ ```Python
+ {{ń«Śµ│Ģõ┐Īµü»}}_{{backbone}}_{{encoder}}_{{decoder}}_{{Ķ«Łń╗āõ┐Īµü»}}_{{µĢ░µŹ«õ┐Īµü»}}.py
+ ```
+
+ õĖĆĶł¼µāģÕåĄõĖŗ encoder ÕÆī decoder õĮŹńĮ«õĖĆĶł¼õĖ║ń«Śµ│ĢõĖōµ£ē’╝īÕøĀµŁżõĖĆĶł¼ń£üńĢźŃĆé
+
+- Ķ«Łń╗āõ┐Īµü»(training info)’╝ÜĶ«Łń╗āńŁ¢ńĢźńÜäõĖĆõ║øĶ«ŠńĮ«’╝īÕīģµŗ¼ batch size’╝īschedule ńŁē
+
+- µĢ░µŹ«õ┐Īµü»(data info)’╝ܵĢ░µŹ«ķøåÕÉŹń¦░ŃĆüµ©ĪµĆüŃĆüĶŠōÕģźÕ░║Õ»ĖńŁē’╝īÕ”é icdar2015’╝īsynthtext ńŁē
diff --git a/internlm_langchain/knowledge_base/MMOCR/content/contribution_guide.md b/internlm_langchain/knowledge_base/MMOCR/content/contribution_guide.md
new file mode 100644
index 00000000..90611e8a
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMOCR/content/contribution_guide.md
@@ -0,0 +1,135 @@
+# Ķ┤Īńī«µīćÕŹŚ
+
+OpenMMLab µ¼óĶ┐ĵēƵ£ēõ║║ÕÅéõĖĵłæõ╗¼ķĪ╣ńø«ńÜäÕģ▒Õ╗║ŃĆéµ£¼µ¢ćµĪŻÕ░åµīćÕ»╝µé©Õ”éõĮĢķĆÜĶ┐ćµŗēÕÅ¢Ķ»Ęµ▒éõĖ║ OpenMMLab ķĪ╣ńø«õĮ£Õć║Ķ┤Īńī«ŃĆé
+
+## õ╗Ćõ╣łµś»µŗēÕÅ¢Ķ»Ęµ▒é’╝¤
+
+`µŗēÕÅ¢Ķ»Ęµ▒é` (Pull Request), [GitHub Õ«śµ¢╣µ¢ćµĪŻ](https://docs.github.com/en/github/collaborating-with-pull-requests/proposing-changes-to-your-work-with-pull-requests/about-pull-requests)Õ«Üõ╣ēÕ”éõĖŗŃĆé
+
+```
+µŗēÕÅ¢Ķ»Ęµ▒鵜»õĖĆń¦ŹķĆÜń¤źµ£║ÕłČŃĆéõĮĀõ┐«µö╣õ║åõ╗¢õ║║ńÜäõ╗ŻńĀü’╝īÕ░åõĮĀńÜäõ┐«µö╣ķĆÜń¤źÕĤµØźõĮ£ĶĆģ’╝īÕĖīµ£øõ╗¢ÕÉłÕ╣ČõĮĀńÜäõ┐«µö╣ŃĆé
+```
+
+## Õ¤║µ£¼ńÜäÕĘźõĮ£µĄü’╝Ü
+
+1. ĶÄĘÕÅ¢µ£Ćµ¢░ńÜäõ╗ŻńĀüÕ║ō
+2. õ╗ĵ£Ćµ¢░ńÜä `dev-1.x` Õłåµö»ÕłøÕ╗║Õłåµö»Ķ┐øĶĪīÕ╝ĆÕÅæ
+3. µÅÉõ║żõ┐«µö╣ ([õĖŹĶ”üÕ┐śĶ«░õĮ┐ńö© pre-commit hooks!](#3-µÅÉõ║żõĮĀńÜäõ┐«µö╣))
+4. µÄ©ķĆüõĮĀńÜäõ┐«µö╣Õ╣ČÕłøÕ╗║õĖĆõĖ¬ `µŗēÕÅ¢Ķ»Ęµ▒é`
+5. Ķ«©Ķ«║ŃĆüÕ«ĪµĀĖõ╗ŻńĀü
+6. Õ░åÕ╝ĆÕÅæÕłåµö»ÕÉłÕ╣ČÕł░ `dev-1.x` Õłåµö»
+
+## ÕģĘõĮōµŁźķ¬ż
+
+### 1. ĶÄĘÕÅ¢µ£Ćµ¢░ńÜäõ╗ŻńĀüÕ║ō
+
+- ÕĮōõĮĀń¼¼õĖƵ¼ĪµÅÉ PR µŚČ
+
+ ÕżŹÕł╗ OpenMMLab ÕĤõ╗ŻńĀüÕ║ō’╝īńé╣Õć╗ GitHub ķĪĄķØóÕÅ│õĖŖĶ¦ÆńÜä **Fork** µīēķÆ«ÕŹ│ÕÅ»
+ 
+
+ ÕģŗķÜåÕżŹÕł╗ńÜäõ╗ŻńĀüÕ║ōÕł░µ£¼Õ£░
+
+ ```bash
+ git clone git@github.com:XXX/mmocr.git
+ ```
+
+ µĘ╗ÕŖĀÕĤõ╗ŻńĀüÕ║ōõĖ║õĖŖµĖĖõ╗ŻńĀüÕ║ō
+
+ ```bash
+ git remote add upstream git@github.com:open-mmlab/mmocr
+ ```
+
+- õ╗Äń¼¼õ║īõĖ¬ PR ĶĄĘ
+
+ µŻĆÕć║µ£¼Õ£░õ╗ŻńĀüÕ║ōńÜäõĖ╗Õłåµö»’╝īńäČÕÉÄõ╗ĵ£Ćµ¢░ńÜäÕĤõ╗ŻńĀüÕ║ōńÜäõĖ╗Õłåµö»µŗēÕÅ¢µø┤µ¢░ŃĆéĶ┐ÖķćīÕüćĶ«ŠõĮĀµŁŻÕ¤║õ║Ä `dev-1.x` Õ╝ĆÕÅæŃĆé
+
+ ```bash
+ git checkout dev-1.x
+ git pull upstream dev-1.x
+ ```
+
+### 2. õ╗Ä `dev-1.x` Õłåµö»ÕłøÕ╗║õĖĆõĖ¬µ¢░ńÜäÕ╝ĆÕÅæÕłåµö»
+
+```bash
+git checkout -b branchname
+```
+
+```{tip}
+õĖ║õ║åõ┐ØĶ»üµÅÉõ║żÕÄåÕÅ▓µĖģµÖ░ÕÅ»Ķ»╗’╝īµłæõ╗¼Õ╝║ńāłµÄ©ĶŹÉµé©ÕģłÕłćµŹóÕł░ `dev-1.x` Õłåµö»’╝īÕåŹÕłøÕ╗║µ¢░ńÜäÕłåµö»ŃĆé
+```
+
+### 3. µÅÉõ║żõĮĀńÜäõ┐«µö╣
+
+- Õ”éµ×£õĮĀµś»ń¼¼õĖƵ¼ĪÕ░ØĶ»ĢĶ┤Īńī«’╝īĶ»ĘÕ£© MMOCR ńÜäńø«ÕĮĢõĖŗÕ«ēĶŻģÕ╣ČÕłØÕ¦ŗÕī¢ pre-commit hooksŃĆé
+
+ ```bash
+ pip install -U pre-commit
+ pre-commit install
+ ```
+
+- µÅÉõ║żõ┐«µö╣ŃĆéÕ£©µ»Åµ¼ĪµÅÉõ║żÕēŹ’╝īpre-commit hooks ķāĮõ╝ÜĶó½Ķ¦”ÕÅæÕ╣ČĶ¦äĶīāÕī¢õĮĀńÜäõ╗ŻńĀüµĀ╝Õ╝ÅŃĆé
+
+ ```bash
+ # coding
+ git add [files]
+ git commit -m 'messages'
+ ```
+
+ ```{note}
+ µ£ēµŚČõĮĀńÜäµ¢ćõ╗ČÕÅ»ĶāĮõ╝ÜÕ£©µÅÉõ║żµŚČĶó½ pre-commit hooks Ķć¬ÕŖ©õ┐«µö╣ŃĆéĶ┐ÖµŚČĶ»Ęķ揵¢░µĘ╗ÕŖĀÕ╣ȵÅÉõ║żõ┐«µö╣ÕÉÄńÜäµ¢ćõ╗ČŃĆé
+ ```
+
+### 4. µÄ©ķĆüõĮĀńÜäõ┐«µö╣Õł░ÕżŹÕł╗ńÜäõ╗ŻńĀüÕ║ō’╝īÕ╣ČÕłøÕ╗║õĖĆõĖ¬µŗēÕÅ¢Ķ»Ęµ▒é
+
+- µÄ©ķĆüÕĮōÕēŹÕłåµö»Õł░Ķ┐£ń½»ÕżŹÕł╗ńÜäõ╗ŻńĀüÕ║ō
+
+ ```bash
+ git push origin branchname
+ ```
+
+- ÕłøÕ╗║õĖĆõĖ¬µŗēÕÅ¢Ķ»Ęµ▒é
+
+ 
+
+- õ┐«µö╣µŗēÕÅ¢Ķ»Ęµ▒éõ┐Īµü»µ©ĪµØ┐’╝īµÅÅĶ┐░õ┐«µö╣ÕĤÕøĀÕÆīõ┐«µö╣ÕåģÕ«╣ŃĆéĶ┐śÕÅ»õ╗źÕ£© PR µÅÅĶ┐░õĖŁ’╝īµēŗÕŖ©Õģ│ĶüöÕł░ńøĖÕģ│ńÜäĶ««ķóś (issue),’╝łµø┤ÕżÜń╗åĶŖé’╝īĶ»ĘÕÅéĶĆā[Õ«śµ¢╣µ¢ćµĪŻ](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue)’╝ēŃĆé
+
+- ÕÅ”Õż¢’╝īÕ”éµ×£õĮĀµŁŻÕ£©ÕŠĆ `dev-1.x` Õłåµö»µÅÉõ║żõ╗ŻńĀü’╝īõĮĀĶ┐śķ£ĆĶ”üÕ£©ÕłøÕ╗║ PR ńÜäńĢīķØóõĖŁÕ░åÕ¤║ńĪĆÕłåµö»µö╣õĖ║ `dev-1.x`’╝īÕøĀõĖ║ńÄ░Õ£©ķ╗śĶ«żńÜäÕ¤║ńĪĆÕłåµö»µś» `main`ŃĆé
+
+ 
+
+- õĮĀÕÉīµĀĘÕÅ»õ╗źµŖŖ PR Õģ│Ķüöń╗ÖńøĖÕģ│õ║║ÕæśĶ┐øĶĪīĶ»äÕ«ĪŃĆé
+
+### 5. Ķ«©Ķ«║Õ╣ČĶ»äÕ«ĪõĮĀńÜäõ╗ŻńĀü
+
+- µĀ╣µŹ«Ķ»äÕ«Īõ║║ÕæśńÜäµäÅĶ¦üõ┐«µö╣õ╗ŻńĀü’╝īÕ╣ȵĩķĆüõ┐«µö╣
+
+### 6. `µŗēÕÅ¢Ķ»Ęµ▒é`ÕÉłÕ╣Čõ╣ŗÕÉÄÕłĀķÖżĶ»źÕłåµö»
+
+- Õ£© PR ÕÉłÕ╣Čõ╣ŗÕÉÄ’╝īõĮĀÕ░▒ÕÅ»õ╗źÕłĀķÖżĶ»źÕłåµö»õ║åŃĆé
+
+ ```bash
+ git branch -d branchname # ÕłĀķÖżµ£¼Õ£░Õłåµö»
+ git push origin --delete branchname # ÕłĀķÖżĶ┐£ń©ŗÕłåµö»
+ ```
+
+## PR Ķ¦äĶīā
+
+1. õĮ┐ńö© [pre-commit hook](https://pre-commit.com)’╝īÕ░ĮķćÅÕćÅÕ░æõ╗ŻńĀüķŻÄµĀ╝ńøĖÕģ│ķŚ«ķóś
+
+2. õĖĆõĖ¬ PR Õ»╣Õ║öõĖĆõĖ¬ń¤Łµ£¤Õłåµö»
+
+3. ń▓ÆÕ║”Ķ”üń╗å’╝īõĖĆõĖ¬PRÕŬÕüÜõĖĆõ╗Čõ║ŗµāģ’╝īķü┐ÕģŹĶČģÕż¦ńÜäPR
+
+ - Bad’╝ÜÕ«×ńÄ░ Faster R-CNN
+ - Acceptable’╝Üń╗Ö Faster R-CNN µĘ╗ÕŖĀõĖĆõĖ¬ box head
+ - Good’╝Üń╗Ö box head Õó×ÕŖĀõĖĆõĖ¬ÕÅéµĢ░µØźµö»µīüĶć¬Õ«Üõ╣ēńÜä conv Õ▒éµĢ░
+
+4. µ»Åµ¼Ī Commit µŚČķ£ĆĶ”üµÅÉõŠøµĖģµÖ░õĖöµ£ēµäÅõ╣ē commit õ┐Īµü»
+
+5. µÅÉõŠøµĖģµÖ░õĖöµ£ēµäÅõ╣ēńÜä`µŗēÕÅ¢Ķ»Ęµ▒é`µÅÅĶ┐░
+
+ - µĀćķóśÕåÖµśÄńÖĮõ╗╗ÕŖĪÕÉŹń¦░’╝īõĖĆĶł¼µĀ╝Õ╝Å:\[Prefix\] Short description of the pull request (Suffix)
+ - prefix: µ¢░Õó×ÕŖ¤ĶāĮ \[Feature\], õ┐« bug \[Fix\], µ¢ćµĪŻńøĖÕģ│ \[Docs\], Õ╝ĆÕÅæõĖŁ \[WIP\] (µÜ鵌ČõĖŹõ╝ÜĶó½review)
+ - µÅÅĶ┐░ķćīõ╗ŗń╗Ź`µŗēÕÅ¢Ķ»Ęµ▒é`ńÜäõĖ╗Ķ”üõ┐«µö╣ÕåģÕ«╣’╝īń╗ōµ×£’╝īõ╗źÕÅŖÕ»╣ÕģČõ╗¢ķā©ÕłåńÜäÕĮ▒ÕōŹ, ÕÅéĶĆā`µŗēÕÅ¢Ķ»Ęµ▒é`µ©ĪµØ┐
+ - Õģ│ĶüöńøĖÕģ│ńÜä`Ķ««ķóś` (issue) ÕÆīÕģČõ╗¢`µŗēÕÅ¢Ķ»Ęµ▒é`
diff --git a/internlm_langchain/knowledge_base/MMOCR/content/convention.md b/internlm_langchain/knowledge_base/MMOCR/content/convention.md
new file mode 100644
index 00000000..a094becc
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMOCR/content/convention.md
@@ -0,0 +1,3 @@
+# Õ╝ĆÕÅæķ╗śĶ«żń║”Õ«Ü\[ÕŠģµø┤µ¢░\]
+
+ÕŠģµø┤µ¢░
diff --git a/internlm_langchain/knowledge_base/MMOCR/content/data_flow.md b/internlm_langchain/knowledge_base/MMOCR/content/data_flow.md
new file mode 100644
index 00000000..a07a158b
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMOCR/content/data_flow.md
@@ -0,0 +1,3 @@
+# µĢ░µŹ«µĄü\[ÕŠģµø┤µ¢░\]
+
+ÕŠģµø┤µ¢░
diff --git a/internlm_langchain/knowledge_base/MMOCR/content/dataset.md b/internlm_langchain/knowledge_base/MMOCR/content/dataset.md
new file mode 100644
index 00000000..ac69703b
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMOCR/content/dataset.md
@@ -0,0 +1,254 @@
+# µĢ░µŹ«ķøåĶ┐üń¦╗
+
+Õ£© OpenMMLab 2.0 ń│╗ÕłŚń«Śµ│ĢÕ║ōÕ¤║õ║Ä [MMEngine](https://github.com/open-mmlab/mmengine) Ķ«ŠĶ«Īõ║åń╗¤õĖĆńÜäµĢ░µŹ«ķøåÕ¤║ń▒╗ [BaseDataset](mmengine.dataset.BaseDataset)’╝īÕ╣ČÕłČÕ«Üõ║åµĢ░µŹ«ķøåµĀćµ│©µ¢ćõ╗ČĶ¦äĶīāŃĆéÕ¤║õ║ĵŁż’╝īµłæõ╗¼Õ£© MMOCR 1.0 ńēłµ£¼õĖŁķ揵×äõ║å OCR õ╗╗ÕŖĪµĢ░µŹ«ķøåÕ¤║ń▒╗ [`OCRDataset`](mmocr.datasets.OCRDataset)ŃĆéõ╗źõĖŗµ¢ćµĪŻÕ░åõ╗ŗń╗Ź MMOCR õĖŁµ¢░µŚ¦µĢ░µŹ«ķøåµĀ╝Õ╝ÅńÜäÕī║Õł½’╝īõ╗źÕÅŖÕ”éõĮĢÕ░åµŚ¦µĢ░µŹ«ķøåĶ┐üń¦╗Ķć│µ¢░ńēłµ£¼õĖŁŃĆéÕ»╣õ║ĵÜéõĖŹµ¢╣õŠ┐Ķ┐øĶĪīµĢ░µŹ«Ķ┐üń¦╗ńÜäńö©µłĘ’╝īµłæõ╗¼õ╣¤Õ£©[ń¼¼õĖēĶŖé](#Õģ╝Õ«╣µĆ¦)µÅÉõŠøõ║åõĖ┤µŚČńÜäõ╗ŻńĀüÕģ╝Õ«╣µ¢╣µĪłŃĆé
+
+```{note}
+Õģ│ķö«õ┐Īµü»µŖĮÕÅ¢õ╗╗ÕŖĪõ╗Źķććńö©ÕĤµ£ēńÜä WildReceipt µĢ░µŹ«ķøåµĀćµ│©µĀ╝Õ╝ÅŃĆé
+```
+
+## µŚ¦ńēłµĢ░µŹ«µĀ╝Õ╝ÅÕø×ķĪŠ
+
+ķÆłÕ»╣õĖŹÕÉīõ╗╗ÕŖĪ’╝īMMOCR 0.x ńēłµ£¼Õ«×ńÄ░õ║åÕżÜń¦ŹõĖŹÕÉīńÜäµĢ░µŹ«ķøåń▒╗Õ×ŗ’╝īÕ”éµ¢ćµ£¼µŻĆµĄŗõ╗╗ÕŖĪńÜä `IcdarDataset`’╝ī`TextDetDataset`’╝øµ¢ćµ£¼Ķ»åÕł½õ╗╗ÕŖĪńÜä `OCRDataset`’╝ī`OCRSegDataset` ńŁēŃĆéĶĆīõĖŹÕÉīńÜäµĢ░µŹ«ķøåń▒╗Õ×ŗÕÉīµŚČĶ┐śÕÅ»ĶāĮÕŁśÕ£©ÕżÜń¦ŹõĖŹÕÉīńÜäµĀćµ│©ÕÅŖµ¢ćõ╗ČÕŁśÕé©ÕÉÄń½»’╝īÕ”é `.txt`ŃĆü`.json`ŃĆü`.jsonl` ńŁē’╝īõĮ┐ÕŠŚńö©µłĘÕ£©Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåµŚČķ£ĆĶ”üķģŹńĮ«ÕÉäń▒╗µĢ░µŹ«ÕŖĀĶĮĮÕÖ© (`Loader`) õ╗źÕÅŖµĢ░µŹ«Ķ¦Żµ×ÉÕÖ© (`Parser`)ŃĆéĶ┐ÖõĖŹõ╗ģÕó×ÕŖĀõ║åńö©µłĘńÜäõĮ┐ńö©ķÜŠÕ║”’╝īõ╣¤ÕĖ”µØźõ║åĶ«ĖÕżÜķŚ«ķóśÕÆīķÜɵéŻŃĆéõŠŗÕ”é’╝īõ╗ź `.txt` µĀ╝Õ╝ÅÕŁśÕé©ńÜäń«ĆÕŹĢ `OCDDataset` Õ£©ķüćÕł░ÕīģÕɽń®║µĀ╝ńÜäµ¢ćµ£¼µĀćµ│©µŚČÕ░åõ╝ܵŖźķöÖŃĆé
+
+### µ¢ćµ£¼µŻĆµĄŗ
+
+µ¢ćµ£¼µŻĆµĄŗõ╗╗ÕŖĪõĖŁ’╝ī`IcdarDataset` ķććńö©õ║åõĖÄķĆÜńö©ńø«µĀ浯ƵĄŗ COCO µĢ░µŹ«ķøåõĖĆĶć┤ńÜäµĀćµ│©µĀ╝Õ╝ÅŃĆé
+
+```json
+{
+ "images": [
+ {
+ "id": 1,
+ "width": 800,
+ "height": 600,
+ "file_name": "test.jpg"
+ }
+ ],
+ "annotations": [
+ {
+ "id": 1,
+ "image_id": 1,
+ "category_id": 1,
+ "bbox": [0,0,10,10],
+ "segmentation": [
+ [0,0,10,0,10,10,0,10]
+ ],
+ "area": 100,
+ "iscrowd": 0
+ }
+ ]
+}
+```
+
+ĶĆī `TextDetDataset` ÕłÖķććńö©õ║å JSON Line ńÜäÕŁśÕ驵Ā╝Õ╝Å’╝īÕ░åń▒╗õ╝╝ COCO µĀ╝Õ╝ÅńÜäµĀćńŁŠĶĮ¼µŹóµłÉµ¢ćµ£¼ÕŁśµöŠÕ£© `.txt` µł¢ `.jsonl` µĀ╝Õ╝ŵ¢ćõ╗ČõĖŁŃĆé
+
+```text
+{"file_name": "test/img_2.jpg", "height": 720, "width": 1280, "annotations": [{"iscrowd": 0, "category_id": 1, "bbox": [602.0, 173.0, 33.0, 24.0], "segmentation": [[602, 173, 635, 175, 634, 197, 602, 196]]}, {"iscrowd": 0, "category_id": 1, "bbox": [734.0, 310.0, 58.0, 54.0], "segmentation": [[734, 310, 792, 320, 792, 364, 738, 361]]}]}
+{"file_name": "test/img_5.jpg", "height": 720, "width": 1280, "annotations": [{"iscrowd": 1, "category_id": 1, "bbox": [405.0, 409.0, 32.0, 52.0], "segmentation": [[408, 409, 437, 436, 434, 461, 405, 433]]}, {"iscrowd": 1, "category_id": 1, "bbox": [435.0, 434.0, 8.0, 33.0], "segmentation": [[437, 434, 443, 440, 441, 467, 435, 462]]}]}
+```
+
+### µ¢ćµ£¼Ķ»åÕł½
+
+Õ»╣õ║ĵ¢ćµ£¼Ķ»åÕł½õ╗╗ÕŖĪ’╝īMMOCR 0.x ńēłµ£¼õĖŁÕŁśÕ£©õĖżń¦ŹµĢ░µŹ«µĀćµ│©µĀ╝Õ╝ÅŃĆéÕģČõĖŁ `.txt` µĀ╝Õ╝ÅńÜäµĀćµ│©µ¢ćõ╗ȵ»ÅõĖĆĶĪīÕģ▒µ£ēõĖżõĖ¬ÕŁŚµ«Ą’╝īÕłåÕł½ÕŁśµöŠõ║åÕøŠńēćÕÉŹõ╗źÕÅŖµĀćµ│©ńÜäµ¢ćµ£¼ÕåģÕ«╣’╝īÕ╣Čõ╗źń®║µĀ╝ÕłåķÜöŃĆé
+
+```text
+img1.jpg OpenMMLab
+img2.jpg MMOCR
+```
+
+ĶĆī JSON Line µĀ╝Õ╝ÅÕłÖõĮ┐ńö© `json.dumps` Õ░å JSON µĀ╝Õ╝ÅńÜäµĀćµ│©ĶĮ¼µŹóõĖ║µ¢ćµ£¼ÕåģÕ«╣ÕÉÄÕŁśµöŠÕ£© .jsonl µ¢ćõ╗ČõĖŁ’╝īÕģČÕåģÕ«╣ÕĮóõ╝╝õĖĆõĖ¬ÕŁŚÕģĖ’╝īÕ░åµ¢ćõ╗ČÕÉŹÕÆīµ¢ćµ£¼µĀćµ│©õ┐Īµü»ÕłåÕł½ÕŁśµöŠÕ£© `filename` ÕÆī `text` ÕŁŚµ«ĄõĖŁŃĆé
+
+```json
+{"filename": "img1.jpg", "text": "OpenMMLab"}
+{"filename": "img2.jpg", "text": "MMOCR"}
+```
+
+## µ¢░ńēłµĢ░µŹ«µĀ╝Õ╝Å
+
+õĖ║Ķ¦ŻÕå│ 0.x ńēłµ£¼õĖŁµĢ░µŹ«ķøåµĀ╝Õ╝ÅĶ┐ćõ║ĵĘʵØéńÜäµāģÕåĄ’╝īMMOCR 1.x ķććńö©õ║åÕ¤║õ║Ä MMEngine Ķ«ŠĶ«ĪńÜäń╗¤õĖƵĢ░µŹ«µĀćÕćåŃĆéµ»ÅõĖĆõĖ¬µĢ░µŹ«µĀćµ│©µ¢ćõ╗ČÕŁśµöŠÕ£© `.json` µ¢ćõ╗ČõĖŁ’╝īÕ╣ČõĮ┐ńö©ń▒╗õ╝╝ÕŁŚÕģĖńÜäµĀ╝Õ╝ÅÕłåÕł½ÕŁśµöŠõ║åµĢ░µŹ«ķøåńÜäÕģāõ┐Īµü»’╝ł`metainfo`’╝ēõĖÄÕģĘõĮōńÜäµĀćµ│©ÕåģÕ«╣’╝ł`data_list`’╝ēŃĆé
+
+```json
+{
+ "metainfo":
+ {
+ "classes": ("cat", "dog"),
+ // ...
+ },
+ "data_list":
+ [
+ {
+ "img_path": "xxx/xxx_0.jpg",
+ "img_label": 0,
+ // ...
+ },
+ // ...
+ ]
+}
+```
+
+Õ¤║õ║ĵŁż’╝īµłæõ╗¼ķÆłÕ»╣ MMOCR ńē╣µ£ēńÜäõ╗╗ÕŖĪĶ«ŠĶ«Īõ║å `TextDetDataset`ŃĆü`TextRecogDataset`ŃĆé
+
+### µ¢ćµ£¼µŻĆµĄŗ
+
+#### µ¢░ńēłµĀ╝Õ╝Åõ╗ŗń╗Ź
+
+`TextDetDataset` õĖŁÕŁśµöŠõ║åµ¢ćµ£¼µŻĆµĄŗõ╗╗ÕŖĪµēĆķ£ĆńÜäĶŠ╣ńĢīńøƵĀćµ│©ŃĆüµ¢ćõ╗ČÕÉŹńŁēõ┐Īµü»ŃĆéńö▒õ║ĵ¢ćµ£¼µŻĆµĄŗõ╗╗ÕŖĪõĖŁÕŬµ£ē 1 õĖ¬ń▒╗Õł½’╝īÕøĀµŁżµłæõ╗¼Õ░åÕģČń▒╗Õł½ id ķ╗śĶ«żĶ«ŠńĮ«õĖ║ 0’╝īĶĆīĶāīµÖ»ń▒╗ÕłÖõĖ║ 1ŃĆé`tests/data/det_toy_dataset/instances_test.json` õĖŁÕŁśµöŠõ║åõĖĆõĖ¬µ¢ćµ£¼µŻĆµĄŗõ╗╗ÕŖĪńÜäµĢ░µŹ«µĀćµ│©ńż║õŠŗ’╝īńö©µłĘÕÅ»õ╗źÕÅéĶĆāĶ»źµ¢ćõ╗ČµØźÕ░åĶć¬ÕĘ▒ńÜäµĢ░µŹ«ķøåĶĮ¼µŹóõĖ║µłæõ╗¼µö»µīüńÜäµĀ╝Õ╝ÅŃĆé
+
+```json
+{
+ "metainfo":
+ {
+ "dataset_type": "TextDetDataset",
+ "task_name": "textdet",
+ "category": [{"id": 0, "name": "text"}]
+ },
+ "data_list":
+ [
+ {
+ "img_path": "test_img.jpg",
+ "height": 640,
+ "width": 640,
+ "instances":
+ [
+ {
+ "polygon": [0, 0, 0, 10, 10, 20, 20, 0],
+ "bbox": [0, 0, 10, 20],
+ "bbox_label": 0,
+ "ignore": False
+ },
+ // ...
+ ]
+ }
+ ]
+}
+```
+
+ÕģČõĖŁ’╝ī`bbox` ÕŁŚµ«ĄńÜäµĀ╝Õ╝ÅõĖ║ `[min_x, min_y, max_x, max_y]`ŃĆé
+
+#### Ķ┐üń¦╗Ķäܵ£¼
+
+õĖ║ÕĖ«ÕŖ®ńö©µłĘÕ░åµŚ¦ńēłµ£¼µĀćµ│©µ¢ćõ╗ČĶ┐üń¦╗Ķć│µ¢░µĀ╝Õ╝Å’╝īµłæõ╗¼µÅÉõŠøõ║åĶ┐üń¦╗Ķäܵ£¼ŃĆéõĮ┐ńö©µ¢╣µ│ĢÕ”éõĖŗ’╝Ü
+
+```bash
+python tools/dataset_converters/textdet/data_migrator.py ${IN_PATH} ${OUT_PATH}
+```
+
+| ÕÅéµĢ░ | ń▒╗Õ×ŗ | Ķ»┤µśÄ |
+| -------- | -------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------- |
+| in_path | str | ’╝łÕ┐ģķĪ╗’╝ēµŚ¦ńēłµĀćµ│©ńÜäĶĘ»ÕŠä |
+| out_path | str | ’╝łÕ┐ģķĪ╗’╝ēµ¢░ńēłµĀćµ│©ńÜäĶĘ»ÕŠä |
+| --task | 'auto', 'textdet', 'textspotter' | µīćÕ«ÜĶŠōÕć║µĢ░µŹ«ķøåµĀćµ│©ńÜäµēĆÕģ╝Õ«╣ńÜäõ╗╗ÕŖĪŃĆéĶŗźµīćÕ«ÜõĖ║ textdet ’╝īÕłÖõĖŹõ╝ÜĶĮ¼ÕŁś coco µĀ╝Õ╝ÅõĖŁńÜä text ÕŁŚµ«ĄŃĆéķ╗śĶ«żõĖ║ auto’╝īÕŹ│µĀ╣µŹ«µŚ¦ńēłµĀćµ│©ńÜäµĀ╝Õ╝ÅĶć¬ÕŖ©Õå│Õ«ÜĶŠōÕć║ńÜäµĀćµ│©µĀ╝Õ╝ÅŃĆé |
+
+### µ¢ćµ£¼Ķ»åÕł½
+
+#### µ¢░ńēłµĀ╝Õ╝Åõ╗ŗń╗Ź
+
+`TextRecogDataset` õĖŁÕŁśµöŠõ║åµ¢ćµ£¼Ķ»åÕł½õ╗╗ÕŖĪµēĆķ£ĆńÜäµ¢ćµ£¼ÕåģÕ«╣’╝īķĆÜÕĖĖĶĆīĶ©Ć’╝īµ¢ćµ£¼Ķ»åÕł½µĢ░µŹ«ķøåõĖŁńÜäµ»ÅõĖĆÕ╝ĀÕøŠńēćķāĮõ╗ģÕīģÕɽõĖĆõĖ¬µ¢ćµ£¼Õ«×õŠŗŃĆ鵳æõ╗¼Õ£© `tests/data/rec_toy_dataset/labels.json` µÅÉõŠøõ║åõĖĆõĖ¬ń«ĆÕŹĢńÜäĶ»åÕł½µĢ░µŹ«µĀ╝Õ╝Åńż║õŠŗ’╝īńö©µłĘÕÅ»õ╗źÕÅéĶĆāĶ»źµ¢ćõ╗Čõ╗źĶ┐øõĖƵŁźõ║åĶ¦ŻÕģČõĖŁńÜäń╗åĶŖéŃĆé
+
+```json
+{
+ "metainfo":
+ {
+ "dataset_type": "TextRecogDataset",
+ "task_name": "textrecog",
+ },
+ "data_list":
+ [
+ {
+ "img_path": "test_img.jpg",
+ "instances":
+ [
+ {
+ "text": "GRAND"
+ }
+ ]
+ }
+ ]
+}
+```
+
+#### Ķ┐üń¦╗Ķäܵ£¼
+
+õĖ║ÕĖ«ÕŖ®ńö©µłĘÕ░åµŚ¦ńēłµ£¼µĀćµ│©µ¢ćõ╗ČĶ┐üń¦╗Ķć│µ¢░µĀ╝Õ╝Å’╝īµłæõ╗¼µÅÉõŠøõ║åĶ┐üń¦╗Ķäܵ£¼ŃĆéõĮ┐ńö©µ¢╣µ│ĢÕ”éõĖŗ’╝Ü
+
+```bash
+python tools/dataset_converters/textrecog/data_migrator.py ${IN_PATH} ${OUT_PATH} --format ${txt, jsonl, lmdb}
+```
+
+| ÕÅéµĢ░ | ń▒╗Õ×ŗ | Ķ»┤µśÄ |
+| -------- | ---------------------- | -------------------------- |
+| in_path | str | ’╝łÕ┐ģķĪ╗’╝ēµŚ¦ńēłµĀćµ│©ńÜäĶĘ»ÕŠä |
+| out_path | str | ’╝łÕ┐ģķĪ╗’╝ēµ¢░ńēłµĀćµ│©ńÜäĶĘ»ÕŠä |
+| --format | 'txt', 'jsonl', 'lmdb' | µīćիܵŚ¦ńēłµĢ░µŹ«ķøåµĀćµ│©ńÜäµĀ╝Õ╝ÅŃĆé |
+
+## Õģ╝Õ«╣µĆ¦
+
+ĶĆāĶÖæÕł░ńö©µłĘÕ»╣µĢ░µŹ«Ķ┐üń¦╗µēĆķ£ĆńÜ䵳ɵ£¼’╝īµłæõ╗¼Õ£© MMOCR 1.x ńēłµ£¼õĖŁµÜ鵌ČÕ»╣ MMOCR 0.x µŚ¦ńēłµ£¼µĀ╝Õ╝ÅĶ┐øĶĪīõ║åÕģ╝Õ«╣ŃĆé
+
+```{note}
+ńö©õ║ÄÕģ╝Õ«╣µŚ¦µĢ░µŹ«µĀ╝Õ╝ÅńÜäõ╗ŻńĀüÕÆīń╗äõ╗ČÕÅ»ĶāĮÕ£©µ£¬µØźńÜäńēłµ£¼õĖŁĶó½Õ«īÕģ©ń¦╗ķÖżŃĆéÕøĀµŁż’╝īµłæõ╗¼Õ╝║ńāłÕ╗║Ķ««ńö©µłĘÕ░åµĢ░µŹ«ķøåĶ┐üń¦╗Ķć│µ¢░ńÜäµĢ░µŹ«µĀ╝Õ╝ŵĀćÕćåŃĆé
+```
+
+ÕģĘõĮōĶĆīĶ©Ć’╝īµłæõ╗¼µÅÉõŠøõ║åõĖēõĖ¬õĖ┤µŚČńÜäµĢ░µŹ«ķøåń▒╗ [IcdarDataset](mmocr.datasets.IcdarDataset), [RecogTextDataset](mmocr.datasets.RecogTextDataset), [RecogLMDBDataset](mmocr.datasets.RecogLMDBDataset) µØźÕģ╝Õ«╣µŚ¦µĀ╝Õ╝ÅńÜäµĀćµ│©µ¢ćõ╗ČŃĆéÕłåÕł½Õ»╣Õ║öõ║å MMOCR 0.x ńēłµ£¼õĖŁńÜäµ¢ćµ£¼µŻĆµĄŗµĢ░µŹ«ķøå `IcdarDataset`’╝ī`.txt`ŃĆü`.jsonl` ÕÆī `LMDB` µĀ╝Õ╝ÅńÜäµ¢ćµ£¼Ķ»åÕł½µĢ░µŹ«µĀćµ│©ŃĆéÕģČõĮ┐ńö©µ¢╣Õ╝ÅõĖÄ 0.x ńēłµ£¼õĖĆĶć┤ŃĆé
+
+1. [IcdarDataset](mmocr.datasets.IcdarDataset) µö»µīü 0.x ńēłµ£¼µ¢ćµ£¼µŻĆµĄŗõ╗╗ÕŖĪńÜä COCO µĀćµ│©µĀ╝Õ╝ÅŃĆéÕŬķ£ĆĶ”üÕ£© `configs/textdet/_base_/datasets` õĖŁµĘ╗ÕŖĀµ¢░ńÜäµĢ░µŹ«ķøåķģŹńĮ«µ¢ćõ╗Č’╝īÕ╣ȵīćÕ«ÜÕģȵĢ░µŹ«ķøåń▒╗Õ×ŗõĖ║ `IcdarDataset` ÕŹ│ÕÅ»ŃĆé
+
+ ```python
+ data_root = 'data/det/icdar2015'
+
+ train_dataset = dict(
+ type='IcdarDataset',
+ data_root=data_root,
+ ann_file='instances_training.json',
+ data_prefix=dict(img_path='imgs/'),
+ filter_cfg=dict(filter_empty_gt=True, min_size=32),
+ pipeline=None)
+ ```
+
+2. [RecogTextDataset](mmocr.datasets.RecogTextDataset) µö»µīü 0.x ńēłµ£¼µ¢ćµ£¼Ķ»åÕł½õ╗╗ÕŖĪńÜä `txt` ÕÆī `jsonl` µĀćµ│©µĀ╝Õ╝ÅŃĆéÕŬķ£ĆĶ”üÕ£© `configs/textrecog/_base_/datasets` õĖŁµĘ╗ÕŖĀµ¢░ńÜäµĢ░µŹ«ķøåķģŹńĮ«µ¢ćõ╗Č’╝īÕ╣ȵīćÕ«ÜÕģȵĢ░µŹ«ķøåń▒╗Õ×ŗõĖ║ `RecogTextDataset` ÕŹ│ÕÅ»ŃĆéõŠŗÕ”é’╝īõ╗źõĖŗńż║õŠŗÕ▒Ģńż║õ║åÕ”éõĮĢķģŹńĮ«Õ╣ČĶ»╗ÕÅ¢ toy dataset õĖŁńÜ䵌¦µĀ╝Õ╝ŵĀćńŁŠ `old_label.txt` õ╗źÕÅŖ `old_label.jsonl`ŃĆé
+
+ ```python
+ data_root = 'tests/data/rec_toy_dataset/'
+
+ # Ķ»╗ÕÅ¢µŚ¦ńēł txt µĀ╝Õ╝ÅĶ»åÕł½µĢ░µŹ«µĀćńŁŠ
+ txt_dataset = dict(
+ type='RecogTextDataset',
+ data_root=data_root,
+ ann_file='old_label.txt',
+ data_prefix=dict(img_path='imgs'),
+ parser_cfg=dict(
+ type='LineStrParser',
+ keys=['filename', 'text'],
+ keys_idx=[0, 1]),
+ pipeline=[])
+
+ # Ķ»╗ÕÅ¢µŚ¦ńēł json line µĀ╝Õ╝ÅĶ»åÕł½µĢ░µŹ«µĀćńŁŠ
+ jsonl_dataset = dict(
+ type='RecogTextDataset',
+ data_root=data_root,
+ ann_file='old_label.jsonl',
+ data_prefix=dict(img_path='imgs'),
+ parser_cfg=dict(
+ type='LineJsonParser',
+ keys=['filename', 'text'],
+ pipeline=[])
+ ```
+
+3. [RecogLMDBDataset](mmocr.datasets.RecogLMDBDataset) µö»µīü 0.x ńēłµ£¼µ¢ćµ£¼Ķ»åÕł½õ╗╗ÕŖĪ**ÕøŠÕāÅ+µ¢ćÕŁŚ**ńÜä `LMDB` µĀćµ│©µĀ╝Õ╝ÅŃĆéÕŬķ£ĆĶ”üÕ£© `configs/textrecog/_base_/datasets` õĖŁµĘ╗ÕŖĀµ¢░ńÜäµĢ░µŹ«ķøåķģŹńĮ«µ¢ćõ╗Č’╝īÕ╣ȵīćÕ«ÜÕģȵĢ░µŹ«ķøåń▒╗Õ×ŗõĖ║ `RecogLMDBDataset` ÕŹ│ÕÅ»ŃĆéõŠŗÕ”é’╝īõ╗źõĖŗńż║õŠŗÕ▒Ģńż║õ║åÕ”éõĮĢķģŹńĮ«Õ╣ČĶ»╗ÕÅ¢ toy dataset õĖŁńÜä `imgs.lmdb`’╝īĶ»ź `lmdb` µ¢ćõ╗Č**ÕīģÕɽµĀćńŁŠÕÆīÕøŠÕāÅ**ŃĆé
+
+ ```python
+ # Õ░åµĢ░µŹ«ķøåń▒╗Õ×ŗĶ«ŠÕ«ÜõĖ║ RecogLMDBDataset
+ data_root = 'tests/data/rec_toy_dataset/'
+
+ lmdb_dataset = dict(
+ type='RecogLMDBDataset',
+ data_root=data_root,
+ ann_file='imgs.lmdb',
+ pipeline=None)
+ ```
+
+ Ķ┐śķ£ĆµŖŖ `train_pipeline` ÕÅŖ `test_pipeline` õĖŁńÜäµĢ░µŹ«Ķ»╗ÕÅ¢µ¢╣µ│ĢÕ”é [`LoadImageFromFile`](mmocr.datasets.transforms.LoadImageFromFile) µø┐µŹóõĖ║ [`LoadImageFromNDArray`](mmocr.datasets.transforms.LoadImageFromNDArray)’╝Ü
+
+ ```python
+ train_pipeline = [dict(type='LoadImageFromNDArray')]
+ ```
diff --git a/internlm_langchain/knowledge_base/MMOCR/content/dataset_prepare.md b/internlm_langchain/knowledge_base/MMOCR/content/dataset_prepare.md
new file mode 100644
index 00000000..a0e3d0ba
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMOCR/content/dataset_prepare.md
@@ -0,0 +1,153 @@
+# µĢ░µŹ«ķøåÕćåÕżć
+
+## ÕēŹĶ©Ć
+
+ń╗ÅĶ┐ćµĢ░ÕŹüÕ╣┤ńÜäÕÅæÕ▒Ģ’╝īOCR ķóåÕ¤¤µČīńÄ░Õć║õ║åõĖĆń│╗ÕłŚńÜäńøĖÕģ│µĢ░µŹ«ķøå’╝īĶ┐Öõ║øµĢ░µŹ«ķøåÕŠĆÕŠĆķććńö©ķŻÄµĀ╝ÕÉäÕ╝éńÜäµĀ╝Õ╝ÅµØźµÅÉõŠøµ¢ćµ£¼ńÜäµĀćµ│©µ¢ćõ╗Č’╝īõĮ┐ÕŠŚńö©µłĘÕ£©õĮ┐ńö©Ķ┐Öõ║øµĢ░µŹ«ķøåµŚČõĖŹÕŠŚõĖŹĶ┐øĶĪīµĀ╝Õ╝ÅĶĮ¼µŹóŃĆéÕøĀµŁż’╝īõĖ║õ║åµ¢╣õŠ┐ńö©µłĘĶ┐øĶĪīµĢ░µŹ«ķøåÕćåÕżć’╝īµłæõ╗¼µÅÉõŠøõ║å[õĖĆķö«Õ╝ÅńÜäµĢ░µŹ«ÕćåÕżćĶäܵ£¼](./data_prepare/dataset_preparer.md)’╝īõĮ┐ÕŠŚńö©µłĘõ╗ģķ£ĆõĮ┐ńö©õĖĆĶĪīÕæĮõ╗żÕŹ│ÕŻիīµłÉµĢ░µŹ«ķøåÕćåÕżćńÜäÕģ©ķā©µŁźķ¬żŃĆé
+
+Õ£©Ķ┐ÖõĖĆĶŖé’╝īµłæõ╗¼Õ░åõ╗ŗń╗ŹõĖĆõĖ¬ÕģĖÕ×ŗńÜäµĢ░µŹ«ķøåÕćåÕżćµĄüń©ŗ’╝Ü
+
+1. [õĖŗĶĮĮµĢ░µŹ«ķøåÕ╣ČÕ░åÕģȵĀ╝Õ╝ÅĶĮ¼µŹóõĖ║ MMOCR µö»µīüńÜäµĀ╝Õ╝Å](#µĢ░µŹ«ķøåõĖŗĶĮĮÕÅŖµĀ╝Õ╝ÅĶĮ¼µŹó)
+2. [õ┐«µö╣ķģŹńĮ«µ¢ćõ╗Č](#õ┐«µö╣ķģŹńĮ«µ¢ćõ╗Č)
+
+ńäČĶĆī’╝īÕ”éµ×£õĮĀÕĘ▓ń╗ŵ£ēõ║å MMOCR µö»µīüńÜäµĀ╝Õ╝ÅńÜäµĢ░µŹ«ķøå’╝īķéŻõ╣łń¼¼õĖƵŁźÕ░▒õĖŹµś»Õ┐ģķĪ╗ńÜäŃĆéõĮĀÕÅ»õ╗źķśģĶ»╗[µĢ░µŹ«ķøåń▒╗ÕÅŖµĀćµ│©µĀ╝Õ╝Å](../basic_concepts/datasets.md#µĢ░µŹ«ķøåń▒╗ÕÅŖµĀćµ│©µĀ╝Õ╝Å)µØźõ║åĶ¦Żµø┤ÕżÜń╗åĶŖéŃĆé
+
+## µĢ░µŹ«ķøåõĖŗĶĮĮÕÅŖµĀ╝Õ╝ÅĶĮ¼µŹó
+
+õ╗ź ICDAR 2015 µĢ░µŹ«ķøåńÜäµ¢ćµ£¼µŻĆµĄŗõ╗╗ÕŖĪÕćåÕżćµŁźķ¬żõĖ║õŠŗ’╝īõĮĀÕÅ»õ╗źµē¦ĶĪīõ╗źõĖŗÕæĮõ╗żµØźÕ«īµłÉµĢ░µŹ«ķøåÕćåÕżć’╝Ü
+
+```shell
+python tools/dataset_converters/prepare_dataset.py icdar2015 --task textdet
+```
+
+ÕæĮõ╗żµē¦ĶĪīÕ«īµłÉÕÉÄ’╝īµĢ░µŹ«ķøåÕ░åĶó½õĖŗĶĮĮÕ╣ČĶĮ¼µŹóĶć│ MMOCR µĀ╝Õ╝Å’╝īµ¢ćõ╗Čńø«ÕĮĢń╗ōµ×äÕ”éõĖŗ’╝Ü
+
+```text
+data/icdar2015
+Ōö£ŌöĆŌöĆ textdet_imgs
+Ōöé Ōö£ŌöĆŌöĆ test
+Ōöé ŌööŌöĆŌöĆ train
+Ōö£ŌöĆŌöĆ textdet_test.json
+ŌööŌöĆŌöĆ textdet_train.json
+```
+
+µĢ░µŹ«ÕćåÕżćÕ«īµ»Ģõ╗źÕÉÄ’╝īõĮĀõ╣¤ÕÅ»õ╗źķĆÜĶ┐ćõĮ┐ńö©µłæõ╗¼µÅÉõŠøńÜäµĢ░µŹ«ķøåµĄÅĶ¦łÕĘźÕģĘ [browse_dataset.py](./useful_tools.md#µĢ░µŹ«ķøåÕÅ»Ķ¦åÕī¢ÕĘźÕģĘ) µØźÕÅ»Ķ¦åÕī¢µĢ░µŹ«ķøåńÜäµĀćńŁŠµś»ÕÉ”Ķó½µŁŻńĪ«ńö¤µłÉ’╝īõŠŗÕ”é’╝Ü
+
+```bash
+python tools/analysis_tools/browse_dataset.py configs/textdet/_base_/datasets/icdar2015.py
+```
+
+## õ┐«µö╣ķģŹńĮ«µ¢ćõ╗Č
+
+### ÕŹĢµĢ░µŹ«ķøåĶ«Łń╗ā
+
+Õ£©õĮ┐ńö©µ¢░ńÜäµĢ░µŹ«ķøåµŚČ’╝īµłæõ╗¼ķ£ĆĶ”üÕ»╣ÕģČÕøŠÕāÅŃĆüµĀćµ│©µ¢ćõ╗ČńÜäĶĘ»ÕŠäńŁēÕ¤║ńĪĆõ┐Īµü»Ķ┐øĶĪīķģŹńĮ«ŃĆé`configs/xxx/_base_/datasets/` ĶĘ»ÕŠäõĖŗÕĘ▓ķóäÕģłķģŹńĮ«õ║å MMOCR õĖŁÕĖĖńö©ńÜäµĢ░µŹ«ķøå’╝łÕĮōõĮĀõĮ┐ńö© `prepare_dataset.py` µØźÕćåÕżćµĢ░µŹ«ķøåµŚČ’╝īĶ┐ÖõĖ¬ķģŹńĮ«µ¢ćõ╗ČķĆÜÕĖĖõ╝ÜÕ£©µĢ░µŹ«ķøåÕćåÕżćÕ░▒ń╗¬ÕÉÄĶć¬ÕŖ©ńö¤µłÉ’╝ē’╝īĶ┐Öķćīµłæõ╗¼õ╗ź ICDAR 2015 µĢ░µŹ«ķøåõĖ║õŠŗ’╝łĶ¦ü `configs/textdet/_base_/datasets/icdar2015.py`’╝ē’╝Ü
+
+```Python
+icdar2015_textdet_data_root = 'data/icdar2015' # µĢ░µŹ«ķøåµĀ╣ńø«ÕĮĢ
+
+# Ķ«Łń╗āķøåķģŹńĮ«
+icdar2015_textdet_train = dict(
+ type='OCRDataset',
+ data_root=icdar2015_textdet_data_root, # µĢ░µŹ«µĀ╣ńø«ÕĮĢ
+ ann_file='textdet_train.json', # µĀćµ│©µ¢ćõ╗ČÕÉŹń¦░
+ filter_cfg=dict(filter_empty_gt=True, min_size=32), # µĢ░µŹ«Ķ┐ćµ╗ż
+ pipeline=None)
+# µĄŗĶ»ĢķøåķģŹńĮ«
+icdar2015_textdet_test = dict(
+ type='OCRDataset',
+ data_root=icdar2015_textdet_data_root,
+ ann_file='textdet_test.json',
+ test_mode=True,
+ pipeline=None)
+```
+
+Õ£©ķģŹńĮ«ÕźĮµĢ░µŹ«ķøåÕÉÄ’╝īµłæõ╗¼Ķ┐śķ£ĆĶ”üÕ£©ńøĖÕ║öńÜäń«Śµ│Ģµ©ĪÕ×ŗķģŹńĮ«µ¢ćõ╗ČõĖŁÕ»╝Õģźµā│Ķ”üõĮ┐ńö©ńÜäµĢ░µŹ«ķøåŃĆéõŠŗÕ”é’╝īÕ£© ICDAR 2015 µĢ░µŹ«ķøåõĖŖĶ«Łń╗ā "DBNet_R18" µ©ĪÕ×ŗ’╝Ü
+
+```Python
+_base_ = [
+ '_base_dbnet_r18_fpnc.py',
+ '../_base_/datasets/icdar2015.py', # Õ»╝ÕģźµĢ░µŹ«ķøåķģŹńĮ«µ¢ćõ╗Č
+ '../_base_/default_runtime.py',
+ '../_base_/schedules/schedule_sgd_1200e.py',
+]
+
+icdar2015_textdet_train = _base_.icdar2015_textdet_train # µīćÕ«ÜĶ«Łń╗āķøå
+icdar2015_textdet_train.pipeline = _base_.train_pipeline # µīćÕ«ÜĶ«Łń╗āķøåõĮ┐ńö©ńÜäµĢ░µŹ«µĄüµ░┤ń║┐
+icdar2015_textdet_test = _base_.icdar2015_textdet_test # µīćիܵĄŗĶ»Ģķøå
+icdar2015_textdet_test.pipeline = _base_.test_pipeline # µīćիܵĄŗĶ»ĢķøåõĮ┐ńö©ńÜäµĢ░µŹ«µĄüµ░┤ń║┐
+
+train_dataloader = dict(
+ batch_size=16,
+ num_workers=8,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=icdar2015_textdet_train) # Õ£© train_dataloader õĖŁµīćÕ«ÜõĮ┐ńö©ńÜäĶ«Łń╗āµĢ░µŹ«ķøå
+
+val_dataloader = dict(
+ batch_size=1,
+ num_workers=4,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ dataset=icdar2015_textdet_test) # Õ£© val_dataloader õĖŁµīćÕ«ÜõĮ┐ńö©ńÜäķ¬īĶ»üµĢ░µŹ«ķøå
+
+test_dataloader = val_dataloader
+```
+
+### ÕżÜµĢ░µŹ«ķøåĶ«Łń╗ā
+
+µŁżÕż¢’╝īÕ¤║õ║Ä [`ConcatDataset`](mmocr.datasets.ConcatDataset)’╝īńö©µłĘĶ┐śÕÅ»õ╗źõĮ┐ńö©ÕżÜõĖ¬µĢ░µŹ«ķøåń╗äÕÉłµØźĶ«Łń╗āµł¢µĄŗĶ»Ģµ©ĪÕ×ŗŃĆéńö©µłĘÕŬķ£ĆÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁÕ░å dataloader õĖŁńÜä dataset ń▒╗Õ×ŗĶ«ŠńĮ«õĖ║ `ConcatDataset`’╝īÕ╣ȵīćÕ«ÜÕ»╣Õ║öńÜäµĢ░µŹ«ķøåÕłŚĶĪ©ÕŹ│ÕÅ»ŃĆé
+
+```Python
+train_list = [ic11, ic13, ic15]
+train_dataloader = dict(
+ dataset=dict(
+ type='ConcatDataset', datasets=train_list, pipeline=train_pipeline))
+```
+
+õŠŗÕ”é’╝īõ╗źõĖŗķģŹńĮ«õĮ┐ńö©õ║å MJSynth µĢ░µŹ«ķøåĶ┐øĶĪīĶ«Łń╗ā’╝īÕ╣ČõĮ┐ńö© 6 õĖ¬ÕŁ”µ£»µĢ░µŹ«ķøå’╝łCUTE80, IIIT5K, SVT, SVTP, ICDAR2013, ICDAR2015’╝ēĶ┐øĶĪīµĄŗĶ»ĢŃĆé
+
+```Python
+_base_ = [ # Õ»╝ÕģźµēƵ£ēķ£ĆĶ”üõĮ┐ńö©ńÜäµĢ░µŹ«ķøåķģŹńĮ«
+ '../_base_/datasets/mjsynth.py',
+ '../_base_/datasets/cute80.py',
+ '../_base_/datasets/iiit5k.py',
+ '../_base_/datasets/svt.py',
+ '../_base_/datasets/svtp.py',
+ '../_base_/datasets/icdar2013.py',
+ '../_base_/datasets/icdar2015.py',
+ '../_base_/default_runtime.py',
+ '../_base_/schedules/schedule_adadelta_5e.py',
+ '_base_crnn_mini-vgg.py',
+]
+
+# Ķ«Łń╗āķøåÕłŚĶĪ©
+train_list = [_base_.mjsynth_textrecog_train]
+# µĄŗĶ»ĢķøåÕłŚĶĪ©
+test_list = [
+ _base_.cute80_textrecog_test, _base_.iiit5k_textrecog_test, _base_.svt_textrecog_test,
+ _base_.svtp_textrecog_test, _base_.icdar2013_textrecog_test, _base_.icdar2015_textrecog_test
+]
+
+# õĮ┐ńö© ConcatDataset µØźń║¦ĶüöÕłŚĶĪ©õĖŁńÜäÕżÜõĖ¬µĢ░µŹ«ķøå
+train_dataset = dict(
+ type='ConcatDataset', datasets=train_list, pipeline=_base_.train_pipeline)
+test_dataset = dict(
+ type='ConcatDataset', datasets=test_list, pipeline=_base_.test_pipeline)
+
+train_dataloader = dict(
+ batch_size=192 * 4,
+ num_workers=32,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=train_dataset)
+
+test_dataloader = dict(
+ batch_size=1,
+ num_workers=4,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ dataset=test_dataset)
+
+val_dataloader = test_dataloader
+```
diff --git a/internlm_langchain/knowledge_base/MMOCR/content/dataset_preparer.md b/internlm_langchain/knowledge_base/MMOCR/content/dataset_preparer.md
new file mode 100644
index 00000000..f7558336
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMOCR/content/dataset_preparer.md
@@ -0,0 +1,780 @@
+# µĢ░µŹ«ÕćåÕżć (Beta)
+
+```{note}
+Dataset Preparer ńø«ÕēŹõ╗ŹÕżäÕ£©Õģ¼µĄŗķśČµ«Ą’╝īµ¼óĶ┐ÄÕ░Øķ▓£Ķ»Ģńö©’╝üÕ”éķüćÕł░õ╗╗õĮĢķŚ«ķóś’╝īĶ»ĘÕÅŖµŚČÕÉæµłæõ╗¼ÕÅŹķ”łŃĆé
+```
+
+## õĖĆķö«Õ╝ŵĢ░µŹ«ÕćåÕżćĶäܵ£¼
+
+MMOCR µÅÉõŠøõ║åń╗¤õĖĆńÜäõĖĆń½ÖÕ╝ŵĢ░µŹ«ķøåÕćåÕżćĶäܵ£¼ `prepare_dataset.py`ŃĆé
+
+õ╗ģķ£ĆõĖĆĶĪīÕæĮõ╗żÕŹ│ÕŻիīµłÉµĢ░µŹ«ńÜäõĖŗĶĮĮŃĆüĶ¦ŻÕÄŗŃĆüµĀ╝Õ╝ÅĶĮ¼µŹó’╝īÕÅŖÕ¤║ńĪĆķģŹńĮ«ńÜäńö¤µłÉŃĆé
+
+```bash
+python tools/dataset_converters/prepare_dataset.py [-h] [--nproc NPROC] [--task {textdet,textrecog,textspotting,kie}] [--splits SPLITS [SPLITS ...]] [--lmdb] [--overwrite-cfg] [--dataset-zoo-path DATASET_ZOO_PATH] datasets [datasets ...]
+```
+
+| ÕÅéµĢ░ | ń▒╗Õ×ŗ | Ķ»┤µśÄ |
+| ------------------ | -------------------------- | ----------------------------------------------------------------------------------------------------- |
+| dataset_name | str | ’╝łÕ┐ģķĪ╗’╝ēķ£ĆĶ”üÕćåÕżćńÜäµĢ░µŹ«ķøåÕÉŹń¦░ŃĆé |
+| --nproc | str | õĮ┐ńö©ńÜäĶ┐øń©ŗµĢ░’╝īķ╗śĶ«żõĖ║ 4ŃĆé |
+| --task | str | Õ░åµĢ░µŹ«ķøåµĀ╝Õ╝ÅĶĮ¼µŹóõĖ║µīćÕ«Üõ╗╗ÕŖĪńÜä MMOCR µĀ╝Õ╝ÅŃĆéÕÅ»ķĆēķĪ╣õĖ║’╝Ü 'textdet', 'textrecog', 'textspotting' ÕÆī 'kie'ŃĆé |
+| --splits | \['train', 'val', 'test'\] | ÕĖīµ£øÕćåÕżćńÜäµĢ░µŹ«ķøåÕłåÕē▓’╝īÕÅ»õ╗źµÄźÕÅŚÕżÜõĖ¬ÕÅéµĢ░ŃĆéķ╗śĶ«żõĖ║ `train val test`ŃĆé |
+| --lmdb | str | µŖŖµĢ░µŹ«Õé©ÕŁśõĖ║ LMDB µĀ╝Õ╝Å’╝īõ╗ģÕĮōõ╗╗ÕŖĪõĖ║ `textrecog` µŚČńö¤µĢłŃĆé |
+| --overwrite-cfg | str | ĶŗźµĢ░µŹ«ķøåńÜäÕ¤║ńĪĆķģŹńĮ«ÕĘ▓ń╗ÅÕ£© `configs/{task}/_base_/datasets` õĖŁÕŁśÕ£©’╝īõŠØńäČķćŹÕåÖĶ»źķģŹńĮ« |
+| --dataset-zoo-path | str | ÕŁśµöŠµĢ░µŹ«Õ║ōķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠäŃĆéĶŗźõĖŹµīćÕ«Ü’╝īÕłÖķ╗śĶ«żõĖ║ `./dataset_zoo` |
+
+õŠŗÕ”é’╝īõ╗źõĖŗÕæĮõ╗żÕ▒Ģńż║õ║åÕ”éõĮĢõĮ┐ńö©Ķ»źĶäܵ£¼õĖ║ ICDAR2015 µĢ░µŹ«ķøåÕćåÕżćµ¢ćµ£¼µŻĆµĄŗõ╗╗ÕŖĪµēĆķ£ĆńÜäµĢ░µŹ«ŃĆé
+
+```bash
+python tools/dataset_converters/prepare_dataset.py icdar2015 --task textdet --overwrite-cfg
+```
+
+Ķ»źĶäܵ£¼õ╣¤µö»µīüÕÉīµŚČÕćåÕżćÕżÜõĖ¬µĢ░µŹ«ķøå’╝īõŠŗÕ”é’╝īõ╗źõĖŗÕæĮõ╗żÕ▒Ģńż║õ║åÕ”éõĮĢõĮ┐ńö©Ķ»źĶäܵ£¼ÕÉīµŚČõĖ║ ICDAR2015 ÕÆī TotalText µĢ░µŹ«ķøåÕćåÕżćµ¢ćµ£¼Ķ»åÕł½õ╗╗ÕŖĪµēĆķ£ĆńÜäµĢ░µŹ«ŃĆé
+
+```bash
+python tools/dataset_converters/prepare_dataset.py icdar2015 totaltext --task textrecog --overwrite-cfg
+```
+
+Ķ┐øõĖƵŁźõ║åĶ¦Ż Dataset Preparer µö»µīüńÜäµĢ░µŹ«ķøå’╝īµé©ÕÅ»õ╗źµĄÅĶ¦ł[µö»µīüńÜäµĢ░µŹ«ķøåµ¢ćµĪŻ](./datasetzoo.md)ŃĆéõĖĆõ║øķ£ĆĶ”üµēŗÕŖ©ÕćåÕżćńÜäµĢ░µŹ«ķøåõ╣¤ÕłŚÕ£©õ║å [µ¢ćÕŁŚµŻĆµĄŗ](./det.md) ÕÆī [µ¢ćÕŁŚĶ»åÕł½](./recog.md) ÕåģŃĆé
+
+Õ»╣õ║ÄõĖŁÕøĮÕóāÕåģńÜäńö©µłĘ’╝īµłæõ╗¼õ╣¤µÄ©ĶŹÉķĆÜĶ┐ćÕ╝Ƶ║ɵĢ░µŹ«Õ╣│ÕÅ░[OpenDataLab](https://opendatalab.com/)µØźõĖŗĶĮĮµĢ░µŹ«’╝īõ╗źĶÄĘÕŠŚµø┤ÕźĮńÜäõĖŗĶĮĮõĮōķ¬īŃĆéµĢ░µŹ«õĖŗĶĮĮÕÉÄ’╝īÕÅéĶĆāĶäܵ£¼õĖŁ `data_obtainer` ńÜä `save_name` ÕŁŚµ«Ą’╝īÕ░åµ¢ćõ╗ȵöŠÕ£© `data/cache/` õĖŗÕ╣Čķ揵¢░Ķ┐ÉĶĪīĶäܵ£¼ÕŹ│ÕÅ»ŃĆé
+
+## Ķ┐øķśČńö©µ│Ģ
+
+### LMDB µĀ╝Õ╝Å
+
+Õ£©µ¢ćµ£¼Ķ»åÕł½õ╗╗ÕŖĪõĖŁ’╝īķĆÜÕĖĖõĮ┐ńö© LMDB µĀ╝Õ╝ÅµØźÕŁśÕ驵Ģ░µŹ«’╝īõ╗źÕŖĀÕ┐½µĢ░µŹ«ńÜäĶ»╗ÕÅ¢ķƤÕ║”ŃĆéÕ£©õĮ┐ńö© `prepare_dataset.py` Ķäܵ£¼ÕćåÕżćµĢ░µŹ«µŚČ’╝īÕÅ»õ╗źķĆÜĶ┐ć `--lmdb` ÕÅéµĢ░µØźµīćÕ«ÜÕ░åµĢ░µŹ«ĶĮ¼µŹóõĖ║ LMDB µĀ╝Õ╝ÅŃĆéõŠŗÕ”é’╝Ü
+
+```bash
+python tools/dataset_converters/prepare_dataset.py icdar2015 --task textrecog --lmdb
+```
+
+µĢ░µŹ«ķøåÕćåÕżćÕ«īµłÉÕÉÄ’╝īDataset Preparer õ╝ÜÕ£© `configs/textrecog/_base_/datasets/` õĖŁńö¤µłÉ `icdar2015_lmdb.py` ķģŹńĮ«ŃĆéõĮĀÕÅ»õ╗źń╗¦µē┐Ķ»źķģŹńĮ«’╝īÕ╣ČÕ░å `dataloader` µīćÕÉæ LMDB µĢ░µŹ«ķøåŃĆéńäČĶĆī’╝īLMDB µĢ░µŹ«ķøåńÜäĶ»╗ÕÅ¢ķ£ĆĶ”üķģŹÕÉł [`LoadImageFromNDArray`](mmocr.datasets.transforms.LoadImageFromNDArray)’╝īÕøĀµŁżõĮĀõ╣¤ÕÉīµĀĘķ£ĆĶ”üõ┐«µö╣ `pipeline`ŃĆé
+
+õŠŗÕ”é’╝īµā│Ķ”üÕ░å `configs/textrecog/crnn/crnn_mini-vgg_5e_mj.py` ńÜäĶ«Łń╗āķøåµö╣õĖ║ÕłÜÕłÜńö¤µłÉńÜä icdar2015’╝īÕłÖķ£ĆĶ”üõĮ£Õ”éõĖŗõ┐«µö╣’╝Ü
+
+1. õ┐«µö╣ `configs/textrecog/crnn/crnn_mini-vgg_5e_mj.py`:
+
+ ```python
+ _base_ = [
+ '../_base_/datasets/icdar2015_lmdb.py', # µīćÕÉæ icdar2015 lmdb µĢ░µŹ«ķøå
+ ... # ń£üńĢź
+ ]
+
+ train_list = [_base_.icdar2015_lmdb_textrecog_train]
+ ...
+ ```
+
+2. õ┐«µö╣ `configs/textrecog/crnn/_base_crnn_mini-vgg.py` õĖŁńÜä `train_pipeline`, Õ░å `LoadImageFromFile` µö╣õĖ║ `LoadImageFromNDArray`’╝Ü
+
+ ```python
+ train_pipeline = [
+ dict(
+ type='LoadImageFromNDArray',
+ color_type='grayscale',
+ file_client_args=file_client_args,
+ ignore_empty=True,
+ min_size=2),
+ ...
+ ]
+ ```
+
+## Ķ«ŠĶ«Ī
+
+OCR µĢ░µŹ«ķøåµĢ░ķćÅõ╝ŚÕżÜ’╝īõĖŹÕÉīńÜäµĢ░µŹ«ķøåµ£ēńØĆõĖŹÕÉīńÜäĶ»ŁĶ©Ć’╝īõĖŹÕÉīńÜäµĀćµ│©µĀ╝Õ╝Å’╝īõĖŹÕÉīńÜäÕ£║µÖ»ńŁēŃĆé µĢ░µŹ«ķøåńÜäõĮ┐ńö©µāģÕåĄõĖĆĶł¼µ£ēõĖżń¦Ź’╝īõĖĆń¦Źµś»Õ┐½ķƤńÜäõ║åĶ¦ŻµĢ░µŹ«ķøåńÜäńøĖÕģ│õ┐Īµü»’╝īÕÅ”õĖĆń¦Źµś»Õ£©õĮ┐ńö©µĢ░µŹ«ķøåĶ«Łń╗āµ©ĪÕ×ŗŃĆéõĖ║õ║åµ╗ĪĶČ│Ķ┐ÖõĖżń¦ŹõĮ┐ńö©Õ£║µÖ»MMOCR µÅÉõŠøµĢ░µŹ«ķøåĶć¬ÕŖ©Õī¢ÕćåÕżćĶäܵ£¼’╝īµĢ░µŹ«ķøåĶć¬ÕŖ©Õī¢ÕćåÕżćĶäܵ£¼õĮ┐ńö©õ║嵩ĪÕØŚÕī¢ńÜäĶ«ŠĶ«Ī’╝īµ×üÕż¦Õ£░Õó×Õ╝║õ║åµē®Õ▒ĢµĆ¦’╝īńö©µłĘĶāĮÕż¤ÕŠłµ¢╣õŠ┐Õ£░ķģŹńĮ«ÕģČõ╗¢Õģ¼Õ╝ƵĢ░µŹ«ķøåµł¢ń¦üµ£ēµĢ░µŹ«ķøåŃĆéµĢ░µŹ«ķøåĶć¬ÕŖ©Õī¢ÕćåÕżćĶäܵ£¼ńÜäķģŹńĮ«µ¢ćõ╗ČĶó½ń╗¤õĖĆÕŁśÕé©Õ£© `dataset_zoo/` ńø«ÕĮĢõĖŗ’╝īńö©µłĘÕÅ»õ╗źÕ£©Ķ»źńø«ÕĮĢõĖŗµēŠÕł░µēƵ£ēÕĘ▓ńö▒ MMOCR Õ«śµ¢╣µö»µīüńÜäµĢ░µŹ«ķøåÕćåÕżćĶäܵ£¼ķģŹńĮ«µ¢ćõ╗ČŃĆéĶ»źµ¢ćõ╗ČÕż╣ńÜäńø«ÕĮĢń╗ōµ×äÕ”éõĖŗ’╝Ü
+
+```text
+dataset_zoo/
+Ōö£ŌöĆŌöĆ icdar2015
+Ōöé Ōö£ŌöĆŌöĆ metafile.yml
+Ōöé Ōö£ŌöĆŌöĆ sample_anno.md
+Ōöé Ōö£ŌöĆŌöĆ textdet.py
+Ōöé Ōö£ŌöĆŌöĆ textrecog.py
+Ōöé ŌööŌöĆŌöĆ textspotting.py
+ŌööŌöĆŌöĆ wildreceipt
+ Ōö£ŌöĆŌöĆ metafile.yml
+ Ōö£ŌöĆŌöĆ sample_anno.md
+ Ōö£ŌöĆŌöĆ kie.py
+ Ōö£ŌöĆŌöĆ textdet.py
+ Ōö£ŌöĆŌöĆ textrecog.py
+ ŌööŌöĆŌöĆ textspotting.py
+```
+
+### µĢ░µŹ«ķøåńøĖÕģ│õ┐Īµü»
+
+µĢ░µŹ«ķøåńÜäńøĖÕģ│õ┐Īµü»Õīģµŗ¼µĢ░µŹ«ķøåńÜäµĀćµ│©µĀ╝Õ╝ÅŃĆüµĢ░µŹ«ķøåńÜäµĀćµ│©ńż║õŠŗŃĆüµĢ░µŹ«ķøåńÜäÕ¤║µ£¼ń╗¤Ķ«Īõ┐Īµü»ńŁēŃĆéĶÖĮńäČÕ£©µ»ÅõĖ¬µĢ░µŹ«ķøåńÜäÕ«śńĮæõĖŁķāĮµ£ēĶ┐Öõ║øõ┐Īµü»’╝īõĮåµś»Ķ┐Öõ║øõ┐Īµü»ÕłåµĢŻÕ£©ÕÉäõĖ¬µĢ░µŹ«ķøåńÜäÕ«śńĮæõĖŁ’╝īńö©µłĘķ£ĆĶ”üĶŖ▒Ķ┤╣Õż¦ķćÅńÜ䵌ČķŚ┤µØźµī¢µÄśµĢ░µŹ«ķøåńÜäÕ¤║µ£¼õ┐Īµü»ŃĆéÕøĀµŁż’╝īMMOCR Ķ«ŠĶ«Īõ║åõĖĆõ║øĶīāÕ╝Å’╝īÕ«āÕÅ»õ╗źÕĖ«ÕŖ®ńö©µłĘÕ┐½ķƤõ║åĶ¦ŻµĢ░µŹ«ķøåńÜäÕ¤║µ£¼õ┐Īµü»ŃĆé MMOCR Õ░åµĢ░µŹ«ķøåńÜäńøĖÕģ│õ┐Īµü»ÕłåõĖ║õĖżõĖ¬ķā©Õłå’╝īõĖĆķā©Õłåµś»µĢ░µŹ«ķøåńÜäÕ¤║µ£¼õ┐Īµü»Õīģµŗ¼Õīģµŗ¼ÕÅæÕĖāÕ╣┤õ╗Į’╝īĶ«║µ¢ćõĮ£ĶĆģ’╝īõ╗źÕÅŖńēłµØāńŁēÕģČõ╗¢õ┐Īµü»’╝īÕÅ”õĖĆķā©Õłåµś»µĢ░µŹ«ķøåńÜäµĀćµ│©õ┐Īµü»’╝īÕīģµŗ¼µĢ░µŹ«ķøåńÜäµĀćµ│©µĀ╝Õ╝ÅŃĆüµĢ░µŹ«ķøåńÜäµĀćµ│©ńż║õŠŗŃĆéµ»ÅõĖĆķā©Õłå MMOCR ķāĮõ╝ܵÅÉõŠøõĖĆõĖ¬ĶīāÕ╝Å’╝īĶ┤Īńī«ĶĆģÕÅ»õ╗źµĀ╣µŹ«ĶīāÕ╝ÅµØźÕĪ½ÕåÖµĢ░µŹ«ķøåńÜäÕ¤║µ£¼õ┐Īµü»’╝īõĮ┐ńö©ńö©µłĘÕ░▒ÕÅ»õ╗źÕ┐½ķƤõ║åĶ¦ŻµĢ░µŹ«ķøåńÜäÕ¤║µ£¼õ┐Īµü»ŃĆé µĀ╣µŹ«µĢ░µŹ«ķøåńÜäÕ¤║µ£¼õ┐Īµü» MMOCR µÅÉõŠøõ║åõĖĆõĖ¬ `metafile.yml` µ¢ćõ╗Č’╝īÕģČõĖŁÕŁśµöŠõ║åÕ»╣Õ║öµĢ░µŹ«ķøåńÜäÕ¤║µ£¼õ┐Īµü»’╝īÕīģµŗ¼ÕÅæÕĖāÕ╣┤õ╗Į’╝īĶ«║µ¢ćõĮ£ĶĆģ’╝īõ╗źÕÅŖńēłµØāńŁēÕģČõ╗¢õ┐Īµü»’╝īĶ┐ÖµĀĘńö©µłĘÕ░▒ÕÅ»õ╗źÕ┐½ķƤõ║åĶ¦ŻµĢ░µŹ«ķøåńÜäÕ¤║µ£¼õ┐Īµü»ŃĆéĶ»źµ¢ćõ╗ČÕ£©µĢ░µŹ«ķøåÕćåÕżćĶ┐ćń©ŗõĖŁÕ╣ČõĖŹµś»Õ╝║ÕłČĶ”üµ▒éńÜä’╝łÕøĀµŁżńö©µłĘÕ£©õĮ┐ńö©µĘ╗ÕŖĀĶć¬ÕĘ▒ńÜäń¦üµ£ēµĢ░µŹ«ķøåµŚČÕÅ»õ╗źÕ┐ĮńĢźĶ»źµ¢ćõ╗Č’╝ē’╝īõĮåõĖ║õ║åńö©µłĘµø┤ÕźĮÕ£░õ║åĶ¦ŻÕÉäõĖ¬Õģ¼Õ╝ƵĢ░µŹ«ķøåńÜäõ┐Īµü»’╝īMMOCR Õ╗║Ķ««ńö©µłĘÕ£©õĮ┐ńö©µĢ░µŹ«ķøåÕćåÕżćĶäܵ£¼ÕēŹķśģĶ»╗Õ»╣Õ║öńÜäÕģāµ¢ćõ╗Čõ┐Īµü»’╝īõ╗źõ║åĶ¦ŻĶ»źµĢ░µŹ«ķøåńÜäńē╣ÕŠüµś»ÕÉ”ń¼”ÕÉłńö©µłĘķ£Ćµ▒éŃĆéMMOCR õ╗ź ICDAR2015 õĮ£õĖ║ńż║õŠŗ’╝ī ÕģČńż║õŠŗÕåģÕ«╣Õ”éõĖŗµēĆńż║’╝Ü
+
+```yaml
+Name: 'Incidental Scene Text IC15'
+Paper:
+ Title: ICDAR 2015 Competition on Robust Reading
+ URL: https://rrc.cvc.uab.es/files/short_rrc_2015.pdf
+ Venue: ICDAR
+ Year: '2015'
+ BibTeX: '@inproceedings{karatzas2015icdar,
+ title={ICDAR 2015 competition on robust reading},
+ author={Karatzas, Dimosthenis and Gomez-Bigorda, Lluis and Nicolaou, Anguelos and Ghosh, Suman and Bagdanov, Andrew and Iwamura, Masakazu and Matas, Jiri and Neumann, Lukas and Chandrasekhar, Vijay Ramaseshan and Lu, Shijian and others},
+ booktitle={2015 13th international conference on document analysis and recognition (ICDAR)},
+ pages={1156--1160},
+ year={2015},
+ organization={IEEE}}'
+Data:
+ Website: https://rrc.cvc.uab.es/?ch=4
+ Language:
+ - English
+ Scene:
+ - Natural Scene
+ Granularity:
+ - Word
+ Tasks:
+ - textdet
+ - textrecog
+ - textspotting
+ License:
+ Type: CC BY 4.0
+ Link: https://creativecommons.org/licenses/by/4.0/
+```
+
+ÕģĘõĮōÕ£░’╝īMMOCR Õ£©õĖŗĶĪ©õĖŁÕłŚÕć║µ»ÅõĖ¬ÕŁŚµ«ĄÕ»╣Õ║öńÜäÕɽõ╣ē’╝Ü
+
+| ÕŁŚµ«ĄÕÉŹ | Õɽõ╣ē |
+| :--------------- | :-------------------------------------------------------------------- |
+| Name | µĢ░µŹ«ķøåńÜäÕÉŹń¦░ |
+| Paper.Title | µĢ░µŹ«ķøåĶ«║µ¢ćńÜäµĀćķóś |
+| Paper.URL | µĢ░µŹ«ķøåĶ«║µ¢ćńÜäķōŠµÄź |
+| Paper.Venue | µĢ░µŹ«ķøåĶ«║µ¢ćÕÅæĶĪ©ńÜäõ╝ÜĶ««/µ£¤ÕłŖÕÉŹń¦░ |
+| Paper.Year | µĢ░µŹ«ķøåĶ«║µ¢ćÕÅæĶĪ©ńÜäÕ╣┤õ╗Į |
+| Paper.BibTeX | µĢ░µŹ«ķøåĶ«║µ¢ćńÜäÕ╝Ģńö©ńÜä BibTex |
+| Data.Website | µĢ░µŹ«ķøåńÜäÕ«śµ¢╣ńĮæń½Ö |
+| Data.Language | µĢ░µŹ«ķøåµö»µīüńÜäĶ»ŁĶ©Ć |
+| Data.Scene | µĢ░µŹ«ķøåµö»µīüńÜäÕ£║µÖ»’╝īÕ”é `Natural Scene`, `Document`, `Handwritten` ńŁē |
+| Data.Granularity | µĢ░µŹ«ķøåµö»µīüńÜäń▓ÆÕ║”’╝īÕ”é `Character`, `Word`, `Line` ńŁē |
+| Data.Tasks | µĢ░µŹ«ķøåµö»µīüńÜäõ╗╗ÕŖĪ’╝īÕ”é `textdet`, `textrecog`, `textspotting`, `kie` ńŁē |
+| Data.License | µĢ░µŹ«ķøåńÜäĶ«ĖÕÅ»Ķ»üõ┐Īµü»’╝īÕ”éµ×£õĖŹÕŁśÕ£©Ķ«ĖÕÅ»Ķ»ü’╝īÕłÖõĮ┐ńö© `N/A` ÕĪ½Õģģ |
+| Data.Format | µĢ░µŹ«ķøåµĀćµ│©µ¢ćõ╗ČńÜäµĀ╝Õ╝Å’╝īÕ”é `.txt`, `.xml`, `.json` ńŁē |
+| Data.Keywords | µĢ░µŹ«ķøåńÜäńē╣µĆ¦Õģ│ķö«Ķ»Ź’╝īÕ”é `Horizontal`, `Vertical`, `Curved` ńŁē |
+
+Õ»╣õ║ĵĢ░µŹ«ķøåńÜäµĀćµ│©õ┐Īµü»’╝īMMOCR µÅÉõŠøõ║åõĖĆõĖ¬ `sample_anno.md` µ¢ćõ╗Č’╝īńö©µłĘÕÅ»õ╗źµĀ╣µŹ«ĶīāÕ╝ÅµØźÕĪ½ÕåÖµĢ░µŹ«ķøåńÜäµĀćµ│©õ┐Īµü»’╝īĶ┐ÖµĀĘńö©µłĘÕ░▒ÕÅ»õ╗źÕ┐½ķƤõ║åĶ¦ŻµĢ░µŹ«ķøåńÜäµĀćµ│©õ┐Īµü»ŃĆéMMOCR õ╗ź ICDAR2015 õĮ£õĖ║ńż║õŠŗ’╝ī ÕģČńż║õŠŗÕåģÕ«╣Õ”éõĖŗµēĆńż║’╝Ü
+
+````markdown
+ **Text Detection**
+
+ ```text
+ # x1,y1,x2,y2,x3,y3,x4,y4,trans
+
+ 377,117,463,117,465,130,378,130,Genaxis Theatre
+ 493,115,519,115,519,131,493,131,[06]
+ 374,155,409,155,409,170,374,170,###
+ ```
+````
+
+`sample_anno.md` õĖŁÕīģÕɽµĢ░µŹ«ķøåķÆłÕ»╣õĖŹÕÉīõ╗╗ÕŖĪńÜäµĀćµ│©õ┐Īµü»’╝īÕīģÕɽµĀćµ│©µ¢ćõ╗ČńÜäµĀ╝Õ╝Å(text Õ»╣Õ║öńÜ䵜» txt µ¢ćõ╗Č’╝īµĀćµ│©µ¢ćõ╗ČńÜäµĀ╝Õ╝Åõ╣¤ÕÅ»õ╗źÕ£© meta.yml õĖŁµēŠÕł░)’╝īµĀćµ│©ńÜäńż║õŠŗŃĆé
+
+ķĆÜĶ┐ćõĖŖĶ┐░õĖżõĖ¬µ¢ćõ╗ČńÜäõ┐Īµü»’╝īńö©µłĘÕ░▒ÕÅ»õ╗źÕ┐½ķƤõ║åĶ¦ŻµĢ░µŹ«ķøåńÜäÕ¤║µ£¼õ┐Īµü»’╝īÕÉīµŚČ MMOCR µ▒ćµĆ╗õ║åµēƵ£ēµĢ░µŹ«ķøåńÜäÕ¤║µ£¼õ┐Īµü»’╝īńö©µłĘÕÅ»õ╗źÕ£© [Overview](.overview.md) õĖŁµ¤źń£ŗµēƵ£ēµĢ░µŹ«ķøåńÜäÕ¤║µ£¼õ┐Īµü»ŃĆé
+
+### µĢ░µŹ«ķøåõĮ┐ńö©
+
+ń╗ÅĶ┐ćµĢ░ÕŹüÕ╣┤ńÜäÕÅæÕ▒Ģ’╝īOCR ķóåÕ¤¤µČīńÄ░Õć║õ║åõĖĆń│╗ÕłŚńÜäńøĖÕģ│µĢ░µŹ«ķøå’╝īĶ┐Öõ║øµĢ░µŹ«ķøåÕŠĆÕŠĆķććńö©ķŻÄµĀ╝ÕÉäÕ╝éńÜäµĀ╝Õ╝ÅµØźµÅÉõŠøµ¢ćµ£¼ńÜäµĀćµ│©µ¢ćõ╗Č’╝īõĮ┐ÕŠŚńö©µłĘÕ£©õĮ┐ńö©Ķ┐Öõ║øµĢ░µŹ«ķøåµŚČõĖŹÕŠŚõĖŹĶ┐øĶĪīµĀ╝Õ╝ÅĶĮ¼µŹóŃĆéÕøĀµŁż’╝īõĖ║õ║åµ¢╣õŠ┐ńö©µłĘĶ┐øĶĪīµĢ░µŹ«ķøåÕćåÕżć’╝īµłæõ╗¼Ķ«ŠĶ«Īõ║å Dataset Preaprer’╝īÕĖ«ÕŖ®ńö©µłĘÕ┐½ķƤÕ░åµĢ░µŹ«ķøåÕćåÕżćõĖ║ MMOCR µö»µīüńÜäµĀ╝Õ╝Å, Ķ»”Ķ¦ü[µĢ░µŹ«µĀ╝Õ╝ŵ¢ćµĪŻ](../../basic_concepts/datasets.md)ŃĆéõĖŗÕøŠÕ▒Ģńż║õ║å Dataset Preparer ńÜäÕģĖÕ×ŗĶ┐ÉĶĪīµĄüń©ŗŃĆé
+
+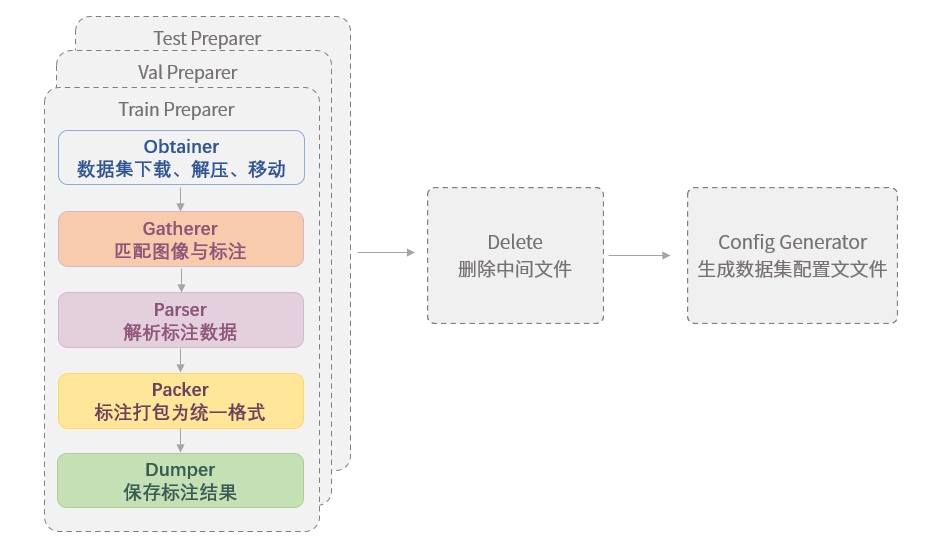
+
+ńö▒ÕøŠÕÅ»Ķ¦ü’╝īDataset Preparer Õ£©Ķ┐ÉĶĪīµŚČ’╝īõ╝ÜõŠØµ¼Īµē¦ĶĪīõ╗źõĖŗµōŹõĮ£’╝Ü
+
+1. Õ»╣Ķ«Łń╗āķøåŃĆüķ¬īĶ»üķøåÕÆīµĄŗĶ»Ģķøå’╝īńö▒ÕÉä preparer Ķ┐øĶĪī’╝Ü
+
+ 1. [µĢ░µŹ«ķøåńÜäõĖŗĶĮĮŃĆüĶ¦ŻÕÄŗŃĆüń¦╗ÕŖ©’╝łObtainer’╝ē](#µĢ░µŹ«ķøåõĖŗĶĮĮĶ¦ŻÕÄŗń¦╗ÕŖ©-obtainer)
+ 2. [Õī╣ķģŹµĀćµ│©õĖÄÕøŠÕāÅ’╝łGatherer’╝ē](#µĢ░µŹ«ķøåµöČķøå-gatherer)
+ 3. [Ķ¦Żµ×ÉÕĤµĀćµ│©’╝łParser’╝ē](#µĢ░µŹ«ķøåĶ¦Żµ×É-parser)
+ 4. [µēōÕīģµĀćµ│©õĖ║ń╗¤õĖƵĀ╝Õ╝Å’╝łPacker’╝ē](#µĢ░µŹ«ķøåĶĮ¼µŹó-packer)
+ 5. [õ┐ØÕŁśµĀćµ│©’╝łDumper’╝ē](#µĀćµ│©õ┐ØÕŁś-dumper)
+
+2. ÕłĀķÖżµ¢ćõ╗Č’╝łDelete’╝ē
+
+3. ńö¤µłÉµĢ░µŹ«ķøåńÜäķģŹńĮ«µ¢ćõ╗Č’╝łConfig Generator’╝ē
+
+õĖ║õ║åõŠ┐õ║ÄÕ║öÕ»╣ÕÉäń¦ŹµĢ░µŹ«ķøåńÜäµāģÕåĄ’╝īMMOCR Õ░åµ»ÅõĖ¬ķā©ÕłåÕØćĶ«ŠĶ«ĪõĖ║ÕÅ»µÅƵŗöńÜ䵩ĪÕØŚ’╝īÕ╣ČÕģüĶ«Ėńö©µłĘķĆÜĶ┐ć dataset_zoo/ õĖŗńÜäķģŹńĮ«µ¢ćõ╗ČÕ»╣µĢ░µŹ«ķøåÕćåÕżćµĄüń©ŗĶ┐øĶĪīķģŹńĮ«ŃĆéĶ┐Öõ║øķģŹńĮ«µ¢ćõ╗Čķććńö©õ║å Python µĀ╝Õ╝Å’╝īÕģČõĮ┐ńö©µ¢╣µ│ĢõĖÄ MMOCR ń«Śµ│ĢÕ║ōńÜäÕģČõ╗¢ķģŹńĮ«µ¢ćõ╗ČÕ«īÕģ©õĖĆĶć┤’╝īĶ»”Ķ¦ü[ķģŹńĮ«µ¢ćõ╗ȵ¢ćµĪŻ](../config.md)ŃĆé
+
+Õ£© `dataset_zoo/` õĖŗ’╝īµ»ÅõĖ¬µĢ░µŹ«ķøåÕØćÕŹĀµ£ēõĖĆõĖ¬µ¢ćõ╗ČÕż╣’╝īµ¢ćõ╗ČÕż╣õĖŗõ╝Üõ╗źõ╗╗ÕŖĪÕÉŹÕæĮÕÉŹķģŹńĮ«µ¢ćõ╗Č’╝īõ╗źÕī║ÕłåõĖŹÕÉīõ╗╗ÕŖĪõĖŗńÜäķģŹńĮ«ŃĆéõ╗ź ICDAR2015 µ¢ćÕŁŚµŻĆµĄŗķā©ÕłåõĖ║õŠŗ’╝īńż║õŠŗķģŹńĮ« `dataset_zoo/icdar2015/textdet.py` Õ”éõĖŗµēĆńż║’╝Ü
+
+```python
+data_root = 'data/icdar2015'
+cache_path = 'data/cache'
+train_preparer = dict(
+ obtainer=dict(
+ type='NaiveDataObtainer',
+ cache_path=cache_path,
+ files=[
+ dict(
+ url='https://rrc.cvc.uab.es/downloads/ch4_training_images.zip',
+ save_name='ic15_textdet_train_img.zip',
+ md5='c51cbace155dcc4d98c8dd19d378f30d',
+ content=['image'],
+ mapping=[['ic15_textdet_train_img', 'textdet_imgs/train']]),
+ dict(
+ url='https://rrc.cvc.uab.es/downloads/'
+ 'ch4_training_localization_transcription_gt.zip',
+ save_name='ic15_textdet_train_gt.zip',
+ md5='3bfaf1988960909014f7987d2343060b',
+ content=['annotation'],
+ mapping=[['ic15_textdet_train_gt', 'annotations/train']]),
+ ]),
+ gatherer=dict(
+ type='PairGatherer',
+ img_suffixes=['.jpg', '.JPG'],
+ rule=[r'img_(\d+)\.([jJ][pP][gG])', r'gt_img_\1.txt']),
+ parser=dict(type='ICDARTxtTextDetAnnParser', encoding='utf-8-sig'),
+ packer=dict(type='TextDetPacker'),
+ dumper=dict(type='JsonDumper'),
+)
+
+test_preparer = dict(
+ obtainer=dict(
+ type='NaiveDataObtainer',
+ cache_path=cache_path,
+ files=[
+ dict(
+ url='https://rrc.cvc.uab.es/downloads/ch4_test_images.zip',
+ save_name='ic15_textdet_test_img.zip',
+ md5='97e4c1ddcf074ffcc75feff2b63c35dd',
+ content=['image'],
+ mapping=[['ic15_textdet_test_img', 'textdet_imgs/test']]),
+ dict(
+ url='https://rrc.cvc.uab.es/downloads/'
+ 'Challenge4_Test_Task4_GT.zip',
+ save_name='ic15_textdet_test_gt.zip',
+ md5='8bce173b06d164b98c357b0eb96ef430',
+ content=['annotation'],
+ mapping=[['ic15_textdet_test_gt', 'annotations/test']]),
+ ]),
+ gatherer=dict(
+ type='PairGatherer',
+ img_suffixes=['.jpg', '.JPG'],
+ rule=[r'img_(\d+)\.([jJ][pP][gG])', r'gt_img_\1.txt']),
+ parser=dict(type='ICDARTxtTextDetAnnParser', encoding='utf-8-sig'),
+ packer=dict(type='TextDetPacker'),
+ dumper=dict(type='JsonDumper'),
+)
+
+delete = ['annotations', 'ic15_textdet_test_img', 'ic15_textdet_train_img']
+config_generator = dict(type='TextDetConfigGenerator')
+```
+
+#### µĢ░µŹ«ķøåõĖŗĶĮĮŃĆüĶ¦ŻÕÄŗŃĆüń¦╗ÕŖ© (Obtainer)
+
+Dataset Preparer õĖŁ’╝ī`obtainer` µ©ĪÕØŚĶ┤¤Ķ┤Żõ║åµĢ░µŹ«ķøåńÜäõĖŗĶĮĮŃĆüĶ¦ŻÕÄŗÕÆīń¦╗ÕŖ©ŃĆéÕ”éõ╗Ŗ’╝īMMOCR µÜ鵌ČÕŬµÅÉõŠøõ║å `NaiveDataObtainer`ŃĆéķĆÜÕĖĖµØźĶ»┤’╝īÕåģńĮ«ńÜä `NaiveDataObtainer` ÕŹ│ÕŻիīµłÉń╗ØÕż¦ķā©ÕłåÕÅ»õ╗źķĆÜĶ┐ćńø┤ķōŠĶ«┐ķŚ«ńÜäµĢ░µŹ«ķøåńÜäõĖŗĶĮĮ’╝īÕ╣ȵö»µīüĶ¦ŻÕÄŗŃĆüń¦╗ÕŖ©µ¢ćõ╗ČÕÆīķćŹÕæĮÕÉŹńŁēµōŹõĮ£ŃĆéńäČĶĆī’╝īMMOCR µÜ鵌ČõĖŹµö»µīüĶć¬ÕŖ©õĖŗĶĮĮÕŁśÕé©Õ£©ńÖŠÕ║”µł¢Ķ░ʵŁīńĮæńøśńŁēķ£ĆĶ”üńÖ╗ķÖåµēŹĶāĮĶ«┐ķŚ«ĶĄäµ║ÉńÜäµĢ░µŹ«ķøåŃĆé Ķ┐Öķćīń«ĆĶ”üõ╗ŗń╗ŹõĖĆõĖŗ `NaiveDataObtainer`.
+
+| ÕŁŚµ«ĄÕÉŹ | Õɽõ╣ē |
+| ---------- | ---------------------------------------------------------- |
+| cache_path | µĢ░µŹ«ķøåń╝ōÕŁśĶĘ»ÕŠä’╝īńö©õ║ÄÕŁśÕ驵Ģ░µŹ«ķøåÕćåÕżćĶ┐ćń©ŗõĖŁõĖŗĶĮĮńÜäÕÄŗń╝®ÕīģńŁēµ¢ćõ╗Č |
+| data_root | µĢ░µŹ«ķøåÕŁśÕé©ńÜäµĀ╣ńø«ÕĮĢ |
+| files | µĢ░µŹ«ķøåµ¢ćõ╗ČÕłŚĶĪ©’╝īńö©õ║ĵÅÅĶ┐░µĢ░µŹ«ķøåńÜäõĖŗĶĮĮõ┐Īµü» |
+
+`files` ÕŁŚµ«Ąµś»õĖĆõĖ¬ÕłŚĶĪ©’╝īÕłŚĶĪ©õĖŁńÜäµ»ÅõĖ¬Õģāń┤ĀķāĮµś»õĖĆõĖ¬ÕŁŚÕģĖ’╝īńö©õ║ĵÅÅĶ┐░õĖĆõĖ¬µĢ░µŹ«ķøåµ¢ćõ╗ČńÜäõĖŗĶĮĮõ┐Īµü»ŃĆéÕ”éõĖŗĶĪ©µēĆńż║’╝Ü
+
+| ÕŁŚµ«ĄÕÉŹ | Õɽõ╣ē |
+| ----------------- | -------------------------------------------------------------------- |
+| url | µĢ░µŹ«ķøåµ¢ćõ╗ČńÜäõĖŗĶĮĮķōŠµÄź |
+| save_name | µĢ░µŹ«ķøåµ¢ćõ╗ČńÜäõ┐ØÕŁśÕÉŹń¦░ |
+| md5 (ÕÅ»ķĆē) | µĢ░µŹ«ķøåµ¢ćõ╗ČńÜä md5 ÕĆ╝’╝īńö©õ║ĵĀĪķ¬īõĖŗĶĮĮńÜäµ¢ćõ╗ȵś»ÕɔիīµĢ┤ |
+| split ’╝łÕÅ»ķĆē’╝ē | µĢ░µŹ«ķøåµ¢ćõ╗ȵēĆÕ▒×ńÜäµĢ░µŹ«ķøåÕłÆÕłå’╝īÕ”é `train`’╝ī`test` ńŁē’╝īĶ»źÕŁŚµ«ĄÕÅ»õ╗źń®║ń╝║ |
+| content ’╝łÕÅ»ķĆē’╝ē | µĢ░µŹ«ķøåµ¢ćõ╗ČńÜäÕåģÕ«╣’╝īÕ”é `image`’╝ī`annotation` ńŁē’╝īĶ»źÕŁŚµ«ĄÕÅ»õ╗źń®║ń╝║ |
+| mapping ’╝łÕÅ»ķĆē’╝ē | µĢ░µŹ«ķøåµ¢ćõ╗ČńÜäĶ¦ŻÕÄŗµśĀÕ░ä’╝īńö©õ║ĵīćÕ«ÜĶ¦ŻÕÄŗÕÉÄńÜäµ¢ćõ╗ČÕŁśÕé©ńÜäõĮŹńĮ«’╝īĶ»źÕŁŚµ«ĄÕÅ»õ╗źń®║ń╝║ |
+
+ÕÉīµŚČ’╝īDataset Preparer ÕŁśÕ£©õ╗źõĖŗń║”Õ«Ü’╝Ü
+
+- õĖŹÕÉīń▒╗Õ×ŗńÜäµĢ░µŹ«ķøåńÜäÕøŠńēćń╗¤õĖĆń¦╗ÕŖ©Õł░Õ»╣Õ║öń▒╗Õł½ `{taskname}_imgs/{split}/`µ¢ćõ╗ČÕż╣õĖŗ’╝īÕ”é `textdet_imgs/train/`ŃĆé
+- Õ»╣õ║ÄõĖĆõĖ¬µĀćµ│©µ¢ćõ╗ČÕīģÕɽµēƵ£ēÕøŠÕāÅńÜäµĀćµ│©õ┐Īµü»ńÜäµāģÕåĄ’╝īµĀćµ│©ń¦╗Õł░Õł░`annotations/{split}.*`µ¢ćõ╗ČõĖŁŃĆé Õ”é `annotations/train.json`ŃĆé
+- Õ»╣õ║ÄõĖĆõĖ¬µĀćµ│©µ¢ćõ╗ČÕīģÕɽõĖĆõĖ¬ÕøŠÕāÅńÜäµĀćµ│©õ┐Īµü»ńÜäµāģÕåĄ’╝īµēƵ£ēńÜäµĀćµ│©µ¢ćõ╗Čń¦╗ÕŖ©Õł░`annotations/{split}/`µ¢ćõ╗ČõĖŁŃĆé Õ”é `annotations/train/`ŃĆé
+- Õ»╣õ║ÄõĖĆõ║øÕģČõ╗¢ńÜäńē╣µ«ŖµāģÕåĄ’╝īµ»öÕ”éµēƵ£ēĶ«Łń╗āŃĆüµĄŗĶ»ĢŃĆüķ¬īĶ»üńÜäÕøŠÕāÅķāĮÕ£©õĖĆõĖ¬µ¢ćõ╗ČÕż╣õĖŗ’╝īÕÅ»õ╗źÕ░åÕøŠÕāÅń¦╗ÕŖ©Õł░Ķć¬ÕĘ▒Ķ«ŠÕ«ÜńÜäµ¢ćõ╗ČÕż╣õĖŗ’╝īµ»öÕ”é `{taskname}_imgs/imgs/`’╝īÕÉīµŚČĶ”üÕ£©ÕÉÄń╗ŁńÜä `gatherer` µ©ĪÕØŚõĖŁµīćÕ«ÜÕøŠÕāÅńÜäÕŁśÕé©õĮŹńĮ«ŃĆé
+
+ńż║õŠŗķģŹńĮ«Õ”éõĖŗ’╝Ü
+
+```python
+ obtainer=dict(
+ type='NaiveDataObtainer',
+ cache_path=cache_path,
+ files=[
+ dict(
+ url='https://rrc.cvc.uab.es/downloads/ch4_training_images.zip',
+ save_name='ic15_textdet_train_img.zip',
+ md5='c51cbace155dcc4d98c8dd19d378f30d',
+ content=['image'],
+ mapping=[['ic15_textdet_train_img', 'textdet_imgs/train']]),
+ dict(
+ url='https://rrc.cvc.uab.es/downloads/'
+ 'ch4_training_localization_transcription_gt.zip',
+ save_name='ic15_textdet_train_gt.zip',
+ md5='3bfaf1988960909014f7987d2343060b',
+ content=['annotation'],
+ mapping=[['ic15_textdet_train_gt', 'annotations/train']]),
+ ]),
+```
+
+#### µĢ░µŹ«ķøåµöČķøå (Gatherer)
+
+`gatherer` ķüŹÕÄåµĢ░µŹ«ķøåńø«ÕĮĢõĖŗńÜäµ¢ćõ╗Č’╝īÕ░åÕøŠÕāÅõĖĵĀćµ│©µ¢ćõ╗ČõĖĆõĖĆÕ»╣Õ║ö’╝īÕ╣ȵĢ┤ńÉåÕć║õĖĆõ╗Įµ¢ćõ╗ČÕłŚĶĪ©õŠø `parser` Ķ»╗ÕÅ¢ŃĆéÕøĀµŁż’╝īķ”¢Õģłķ£ĆĶ”üń¤źķüōÕĮōÕēŹµĢ░µŹ«ķøåõĖŗ’╝īÕøŠńēćµ¢ćõ╗ČõĖĵĀćµ│©µ¢ćõ╗ČÕī╣ķģŹńÜäĶ¦äÕłÖŃĆéOCR µĢ░µŹ«ķøåµ£ēõĖżń¦ŹÕĖĖńö©µĀćµ│©õ┐ØÕŁśÕĮóÕ╝Å’╝īõĖĆń¦ŹõĖ║ÕżÜõĖ¬µĀćµ│©µ¢ćõ╗ČÕ»╣Õ║öÕżÜÕ╝ĀÕøŠńēć’╝īõĖĆń¦ŹÕłÖõĖ║ÕŹĢõĖ¬µĀćµ│©µ¢ćõ╗ČÕ»╣Õ║öÕżÜÕ╝ĀÕøŠńēć’╝īÕ”é’╝Ü
+
+```text
+ÕżÜÕ»╣ÕżÜ
+Ōö£ŌöĆŌöĆ {taskname}_imgs/{split}/img_img_1.jpg
+Ōö£ŌöĆŌöĆ annotations/{split}/gt_img_1.txt
+Ōö£ŌöĆŌöĆ {taskname}_imgs/{split}/img_2.jpg
+Ōö£ŌöĆŌöĆ annotations/{split}/gt_img_2.txt
+Ōö£ŌöĆŌöĆ {taskname}_imgs/{split}/img_3.JPG
+Ōö£ŌöĆŌöĆ annotations/{split}/gt_img_3.txt
+
+ÕŹĢÕ»╣ÕżÜ
+Ōö£ŌöĆŌöĆ {taskname}/{split}/img_1.jpg
+Ōö£ŌöĆŌöĆ {taskname}/{split}/img_2.jpg
+Ōö£ŌöĆŌöĆ {taskname}/{split}/img_3.JPG
+Ōö£ŌöĆŌöĆ annotations/gt.txt
+```
+
+ÕģĘõĮōĶ«ŠĶ«ĪÕ”éõĖŗµēĆńż║
+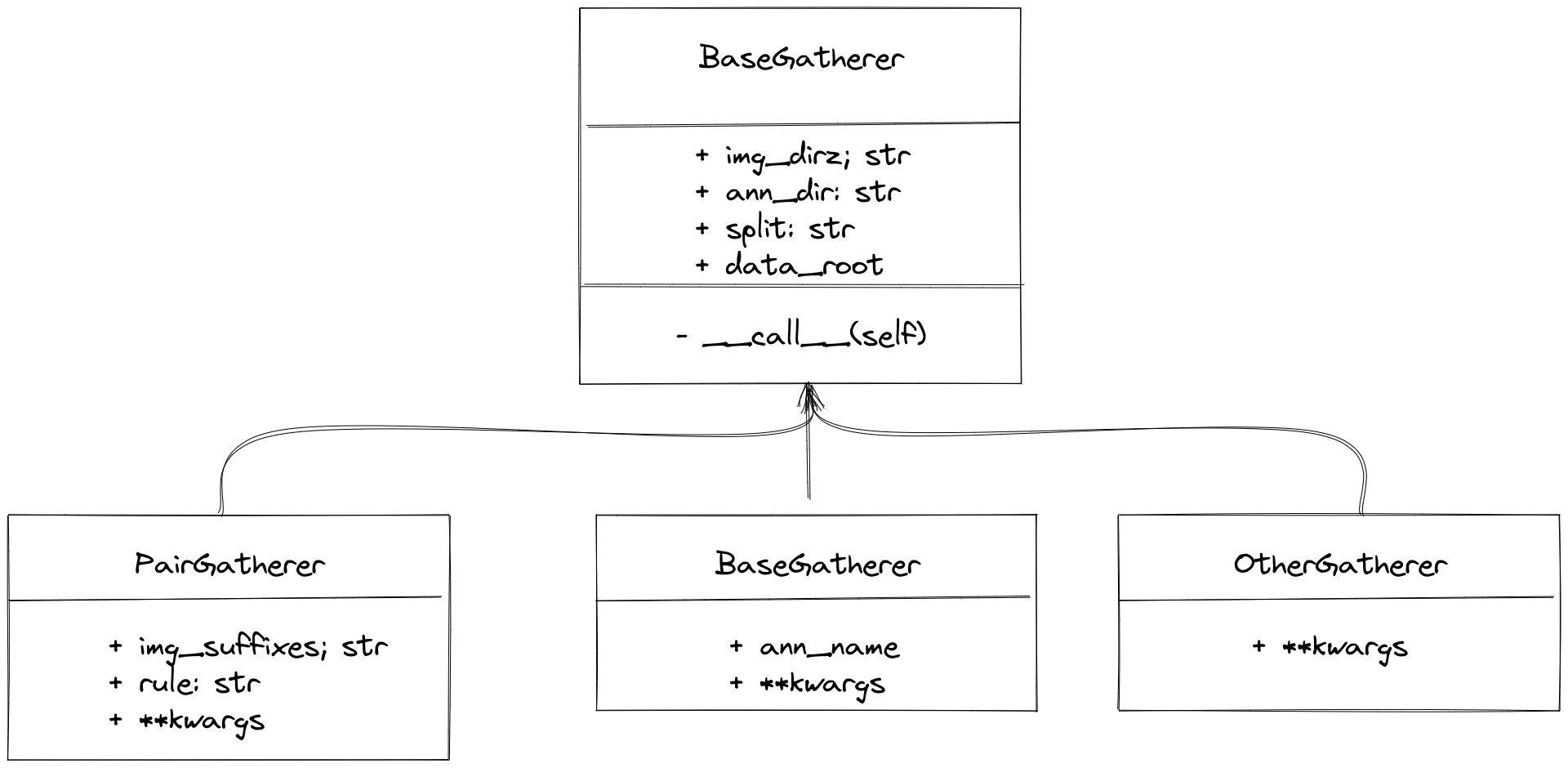
+
+MMOCR ÕåģńĮ«õ║å `PairGatherer` õĖÄ `MonoGatherer` µØźÕżäńÉåõ╗źõĖŖĶ┐ÖõĖżń¦ŹÕĖĖńö©µāģÕåĄŃĆéÕģČõĖŁ `PairGatherer` ńö©õ║ÄÕżÜÕ»╣ÕżÜńÜäµāģÕåĄ’╝ī`MonoGatherer` ńö©õ║ÄÕŹĢÕ»╣ÕżÜńÜäµāģÕåĄŃĆé
+
+```{note}
+õĖ║õ║åń«ĆÕī¢ÕżäńÉå’╝īgatherer ń║”իܵĢ░µŹ«ķøåńÜäÕøŠńēćÕÆīµĀćµ│©ķ£ĆĶ”üÕłåÕł½Õé©ÕŁśÕ£© `{taskname}_imgs/{split}/` ÕÆī `annotations/` õĖŗŃĆéńē╣Õł½Õ£░’╝īÕ»╣õ║ÄÕżÜÕ»╣ÕżÜńÜäµāģÕåĄ’╝īµĀćµ│©µ¢ćõ╗Čķ£ĆĶ”üµöŠńĮ«õ║Ä `annotations/{split}`ŃĆé
+```
+
+- Õ£©ÕżÜÕ»╣ÕżÜńÜäµāģÕåĄõĖŗ’╝ī`PairGatherer` ķ£ĆĶ”üµīēńģ¦õĖĆÕ«ÜńÜäÕæĮÕÉŹĶ¦äÕłÖµēŠÕł░ÕøŠńēćµ¢ćõ╗ČÕÆīÕ»╣Õ║öńÜäµĀćµ│©µ¢ćõ╗ČŃĆéķ”¢Õģł’╝īķ£ĆĶ”üķĆÜĶ┐ć `img_suffixes` ÕÅéµĢ░µīćÕ«ÜÕøŠńēćńÜäÕÉÄń╝ĆÕÉŹ’╝īÕ”éõĖŖĶ┐░õŠŗÕŁÉõĖŁńÜä `img_suffixes=[.jpg,.JPG]`ŃĆ鵣żÕż¢’╝īĶ┐śķ£ĆĶ”üķĆÜĶ┐ć[µŁŻÕłÖĶĪ©ĶŠŠÕ╝Å](https://docs.python.org/3/library/re.html) `rule`, µØźµīćÕ«ÜÕøŠńēćõĖĵĀćµ│©µ¢ćõ╗ČńÜäÕ»╣Õ║öÕģ│ń│╗’╝īÕģČõĖŁ’╝īĶ¦äÕłÖ `rule` µś»õĖĆõĖ¬**µŁŻÕłÖĶĪ©ĶŠŠÕ╝ÅÕ»╣**’╝īõŠŗÕ”é `rule=[r'img_(\d+)\.([jJ][pP][gG])'’╝īr'gt_img_\1.txt']`ŃĆé ń¼¼õĖĆõĖ¬µŁŻÕłÖĶĪ©ĶŠŠÕ╝Åńö©õ║ÄÕī╣ķģŹÕøŠńēćµ¢ćõ╗ČÕÉŹ’╝ī`\d+` ńö©õ║ÄÕī╣ķģŹÕøŠńēćńÜäÕ║ÅÕÅĘ’╝ī`([jJ][pP][gG])` ńö©õ║ÄÕī╣ķģŹÕøŠńēćńÜäÕÉÄń╝ĆÕÉŹŃĆé ń¼¼õ║īõĖ¬µŁŻÕłÖĶĪ©ĶŠŠÕ╝Åńö©õ║ÄÕī╣ķģŹµĀćµ│©µ¢ćõ╗ČÕÉŹ’╝īÕģČõĖŁ `\1` ÕłÖÕ░åÕī╣ķģŹÕł░ńÜäÕøŠńēćÕ║ÅÕÅĘõĖĵĀćµ│©µ¢ćõ╗ČÕ║ÅÕÅĘÕ»╣Õ║öĶĄĘµØźŃĆéńż║õŠŗķģŹńĮ«õĖ║
+
+```python
+ gatherer=dict(
+ type='PairGatherer',
+ img_suffixes=['.jpg', '.JPG'],
+ rule=[r'img_(\d+)\.([jJ][pP][gG])', r'gt_img_\1.txt']),
+```
+
+- ÕŹĢÕ»╣ÕżÜńÜäµāģÕåĄķĆÜÕĖĖµ»öĶŠāń«ĆÕŹĢ’╝īńö©µłĘÕŬķ£ĆĶ”üµīćիܵĀćµ│©µ¢ćõ╗ČÕÉŹÕŹ│ÕÅ»ŃĆéÕ»╣õ║ÄĶ«Łń╗āķøåńż║õŠŗķģŹńĮ«õĖ║
+
+```python
+ gatherer=dict(type='MonoGatherer', ann_name='train.txt'),
+```
+
+MMOCR ÕÉīµĀĘÕ»╣ `Gatherer` ńÜäĶ┐öÕø×ÕĆ╝ÕüÜõ║åń║”Õ«Ü’╝ī`Gatherer` õ╝ÜĶ┐öÕø×õĖżõĖ¬Õģāń┤ĀńÜäÕģāń╗ä’╝īń¼¼õĖĆõĖ¬Õģāń┤ĀõĖ║ÕøŠÕāÅĶĘ»ÕŠäÕłŚĶĪ©(ÕīģÕɽµēƵ£ēÕøŠÕāÅĶĘ»ÕŠä) µł¢ĶĆģµēƵ£ēÕøŠÕāŵēĆÕ£©ńÜäµ¢ćõ╗ČÕż╣’╝ī ń¼¼õ║īõĖ¬Õģāń┤ĀõĖ║µĀćµ│©µ¢ćõ╗ČĶĘ»ÕŠäÕłŚĶĪ©(ÕīģÕɽµēƵ£ēµĀćµ│©µ¢ćõ╗ČĶĘ»ÕŠä)µł¢ĶĆģµĀćµ│©µ¢ćõ╗ČńÜäĶĘ»ÕŠä(Ķ»źµĀćµ│©µ¢ćõ╗ČÕīģÕɽµēƵ£ēÕøŠÕāŵĀćµ│©õ┐Īµü»)ŃĆé
+ÕģĘõĮōĶĆīĶ©Ć’╝ī`PairGatherer` ńÜäĶ┐öÕø×ÕĆ╝õĖ║(ÕøŠÕāÅĶĘ»ÕŠäÕłŚĶĪ©’╝ī µĀćµ│©µ¢ćõ╗ČĶĘ»ÕŠäÕłŚĶĪ©)’╝īńż║õŠŗÕ”éõĖŗ’╝Ü
+
+```python
+ (['{taskname}_imgs/{split}/img_1.jpg', '{taskname}_imgs/{split}/img_2.jpg', '{taskname}_imgs/{split}/img_3.JPG'],
+ ['annotations/{split}/gt_img_1.txt', 'annotations/{split}/gt_img_2.txt', 'annotations/{split}/gt_img_3.txt'])
+```
+
+`MonoGatherer` ńÜäĶ┐öÕø×ÕĆ╝õĖ║(ÕøŠÕāŵ¢ćõ╗ČÕż╣ĶĘ»ÕŠä’╝ī µĀćµ│©µ¢ćõ╗ČĶĘ»ÕŠä)’╝ī ńż║õŠŗõĖ║’╝Ü
+
+```python
+ ('{taskname}/{split}', 'annotations/gt.txt')
+```
+
+#### µĢ░µŹ«ķøåĶ¦Żµ×É (Parser)
+
+`Parser` õĖ╗Ķ”üńö©õ║ÄĶ¦Żµ×ÉÕĤզŗńÜäµĀćµ│©µ¢ćõ╗Č’╝īÕøĀõĖ║ÕĤզŗµĀćµ│©µāģÕåĄÕżÜń¦ŹÕżÜµĀĘ’╝īÕøĀµŁż MMOCR µÅÉõŠøõ║å `BaseParser` õĮ£õĖ║Õ¤║ń▒╗’╝īńö©µłĘÕÅ»õ╗źń╗¦µē┐Ķ»źń▒╗µØźÕ«×ńÄ░Ķć¬ÕĘ▒ńÜä `Parser`ŃĆéÕ£© `BaseParser` õĖŁ’╝īMMOCR Ķ«ŠĶ«Īõ║åõĖżõĖ¬µÄźÕÅŻ’╝Ü`parse_files` ÕÆī `parse_file`’╝īń║”Õ«ÜÕ£©ÕģČõĖŁĶ┐øĶĪīµĀćµ│©ńÜäĶ¦Żµ×ÉŃĆéĶĆīÕ»╣õ║Ä `Gatherer` ńÜäõĖżń¦ŹõĖŹÕÉīĶŠōÕģźµāģÕåĄ’╝łÕżÜÕ»╣ÕżÜŃĆüÕŹĢÕ»╣ÕżÜ’╝ē’╝īĶ┐ÖõĖżõĖ¬µÄźÕÅŻńÜäÕ«×ńÄ░ÕłÖÕ║öµ£ēµēĆõĖŹÕÉīŃĆé
+
+- `BaseParser` ķ╗śĶ«żÕżäńÉå**ÕżÜÕ»╣ÕżÜ**ńÜäµāģÕåĄŃĆéÕģČõĖŁ’╝īńö▒ `parer_files` Õ░åµĢ░µŹ«Õ╣ČĶĪīÕłåÕÅæĶć│ÕżÜõĖ¬ `parse_file` Ķ┐øń©ŗ’╝īÕ╣Čńö▒µ»ÅõĖ¬ `parse_file` ÕłåÕł½Ķ┐øĶĪīÕŹĢõĖ¬ÕøŠÕāŵĀćµ│©ńÜäĶ¦Żµ×ÉŃĆé
+- Õ»╣õ║Ä**ÕŹĢÕ»╣ÕżÜ**ńÜäµāģÕåĄ’╝īńö©µłĘÕłÖķ£ĆĶ”üķćŹÕåÖ `parse_files`’╝īõ╗źÕ«×ńÄ░ÕŖĀĶĮĮµĀćµ│©’╝īÕ╣ČĶ┐öÕø×Ķ¦äĶīāńÜäń╗ōµ×£ŃĆé
+
+`BaseParser` ńÜäµÄźÕÅŻÕ«Üõ╣ēÕ”éõĖŗµēĆńż║’╝Ü
+
+```python
+class BaseParser:
+
+ def __call__(self, img_paths, ann_paths):
+ return self.parse_files(img_paths, ann_paths)
+
+ def parse_files(self, img_paths: Union[List[str], str],
+ ann_paths: Union[List[str], str]) -> List[Tuple]:
+ samples = track_parallel_progress_multi_args(
+ self.parse_file, (img_paths, ann_paths), nproc=self.nproc)
+ return samples
+
+ @abstractmethod
+ def parse_file(self, img_path: str, ann_path: str) -> Tuple:
+
+ raise NotImplementedError
+```
+
+õĖ║õ║åõ┐ØĶ»üÕÉÄń╗Łµ©ĪÕØŚńÜäń╗¤õĖƵƦ’╝īMMOCR Õ»╣ `parse_files` õĖÄ `parse_file` ńÜäĶ┐öÕø×ÕĆ╝ÕüÜõ║åń║”Õ«ÜŃĆé `parse_file` ńÜäĶ┐öÕø×ÕĆ╝õĖ║õĖĆõĖ¬Õģāń╗ä’╝īÕģāń╗äõĖŁńÜäń¼¼õĖĆõĖ¬Õģāń┤ĀõĖ║ÕøŠÕāÅĶĘ»ÕŠä’╝īń¼¼õ║īõĖ¬Õģāń┤ĀõĖ║µĀćµ│©õ┐Īµü»ŃĆéµĀćµ│©õ┐Īµü»õĖ║õĖĆõĖ¬ÕłŚĶĪ©’╝īÕłŚĶĪ©õĖŁńÜäµ»ÅõĖ¬Õģāń┤ĀõĖ║õĖĆõĖ¬ÕŁŚÕģĖ’╝īÕŁŚÕģĖõĖŁńÜäÕŁŚµ«ĄõĖ║`poly`, `text`, `ignore`’╝īÕ”éõĖŗµēĆńż║’╝Ü
+
+```python
+# An example of returned values:
+(
+ 'imgs/train/xxx.jpg',
+ [
+ dict(
+ poly=[0, 1, 1, 1, 1, 0, 0, 0],
+ text='hello',
+ ignore=False),
+ ...
+ ]
+)
+```
+
+`parse_files` ńÜäĶŠōÕć║õĖ║õĖĆõĖ¬ÕłŚĶĪ©’╝īÕłŚĶĪ©õĖŁńÜäµ»ÅõĖ¬Õģāń┤ĀõĖ║ `parse_file` ńÜäĶ┐öÕø×ÕĆ╝ŃĆé ńż║õŠŗõĖ║’╝Ü
+
+```python
+[
+ (
+ 'imgs/train/xxx.jpg',
+ [
+ dict(
+ poly=[0, 1, 1, 1, 1, 0, 0, 0],
+ text='hello',
+ ignore=False),
+ ...
+ ]
+ ),
+ ...
+]
+```
+
+#### µĢ░µŹ«ķøåĶĮ¼µŹó (Packer)
+
+`packer` õĖ╗Ķ”üµś»Õ░åµĢ░µŹ«ĶĮ¼Õī¢Õł░ń╗¤õĖĆńÜäµĀćµ│©µĀ╝Õ╝Å, ÕøĀõĖ║ĶŠōÕģźńÜäµĢ░µŹ«õĖ║ Parsers ńÜäĶŠōÕć║’╝īµĀ╝Õ╝ÅÕĘ▓ń╗ÅÕø║Õ«Ü’╝ī ÕøĀµŁż Packer ÕŬķ£ĆĶ”üÕ░åĶŠōÕģźńÜäµĀ╝Õ╝ÅĶĮ¼Õī¢õĖ║µ»Åń¦Źõ╗╗ÕŖĪń╗¤õĖĆńÜäµĀćµ│©µĀ╝Õ╝ÅÕŹ│ÕÅ»ŃĆéÕ”éõ╗Ŗ MMOCR µö»µīüńÜäõ╗╗ÕŖĪµ£ēµ¢ćµ£¼µŻĆµĄŗŃĆüµ¢ćµ£¼Ķ»åÕł½ŃĆüń½»Õ»╣ń½»OCR õ╗źÕÅŖÕģ│ķö«õ┐Īµü»µÅÉÕÅ¢’╝īMMOCR ķÆłÕ»╣µ»ÅõĖ¬õ╗╗ÕŖĪÕØćµ£ēÕ»╣Õ║öńÜä Packer’╝īÕ”éõĖŗµēĆńż║’╝Ü
+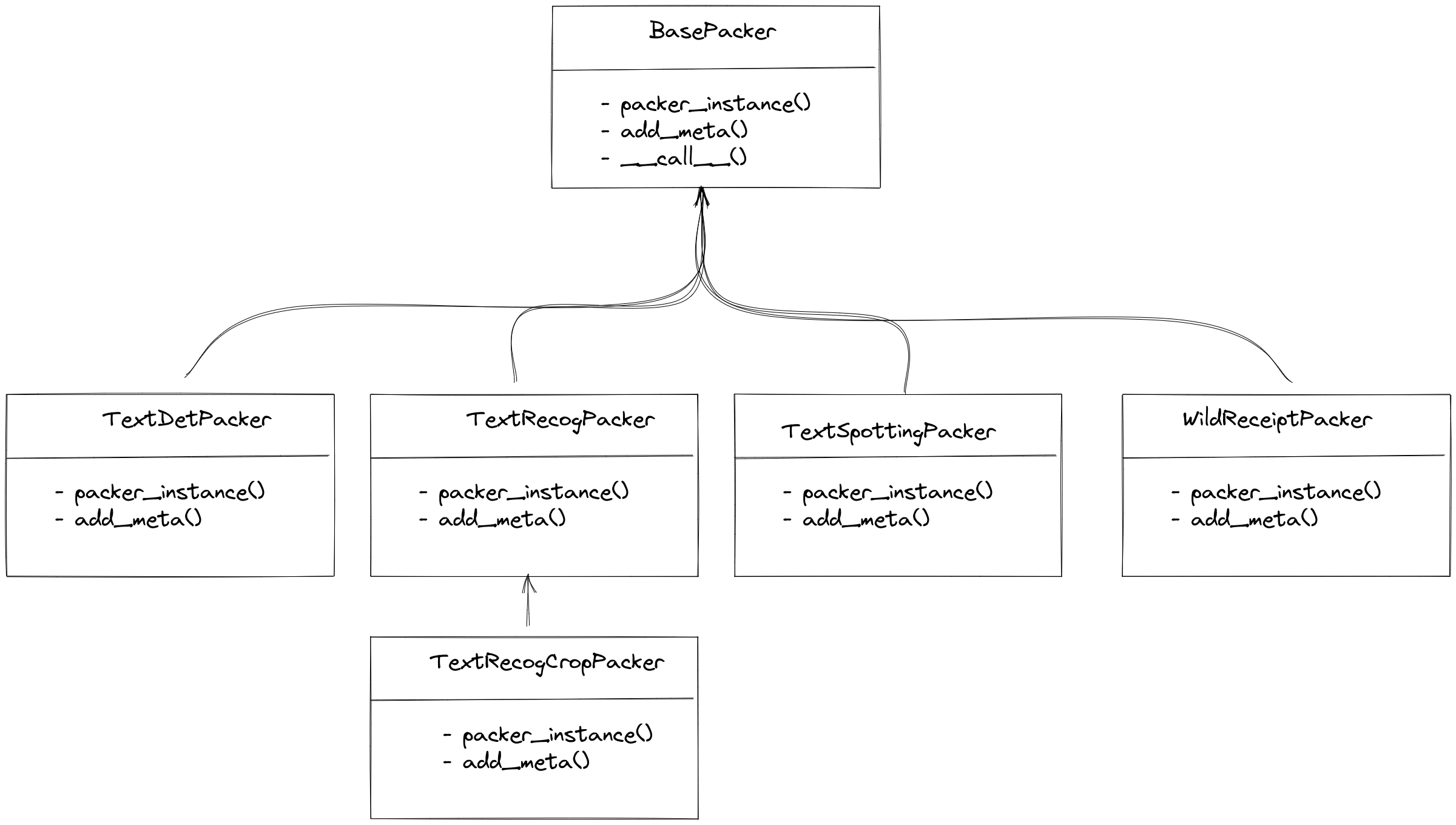
+
+Õ»╣õ║ĵ¢ćÕŁŚµŻĆµĄŗŃĆüń½»Õ»╣ń½»OCRÕÅŖÕģ│ķö«õ┐Īµü»µÅÉÕÅ¢’╝īMMOCR ÕØćµ£ēÕö»õĖĆÕ»╣Õ║öńÜä `Packer`ŃĆéĶĆīÕ£©µ¢ćÕŁŚĶ»åÕł½ķóåÕ¤¤’╝ī MMOCR ÕłÖµÅÉõŠøõ║åõĖżń¦Ź `Packer`’╝īÕłåÕł½õĖ║ `TextRecogPacker` ÕÆī `TextRecogCropPacker`’╝īÕģČÕĤÕøĀÕ£©õĖĵ¢ćÕŁŚĶ»åÕł½ńÜäµĢ░µŹ«ķøåÕŁśÕ£©õĖżń¦ŹµāģÕåĄ’╝Ü
+
+- µ»ÅõĖ¬ÕøŠÕāÅÕØćõĖ║õĖĆõĖ¬Ķ»åÕł½µĀʵ£¼’╝ī`parser` Ķ┐öÕø×ńÜäµĀćµ│©õ┐Īµü»õ╗ģõĖ║õĖĆõĖ¬`dict(text='xxx')`’╝īµŁżµŚČõĮ┐ńö© `TextRecogPacker` ÕŹ│ÕÅ»ŃĆé
+- µĢ░µŹ«ķøåµ▓Īµ£ēÕ░åµ¢ćÕŁŚõ╗ÄÕøŠÕāÅõĖŁĶŻüÕē¬Õć║µØź’╝īµ£¼Ķ┤©µś»õĖĆõĖ¬ń½»Õ»╣ń½»OCRńÜäµĀćµ│©’╝īÕīģÕɽõ║åµ¢ćÕŁŚńÜäõĮŹńĮ«õ┐Īµü»õ╗źÕÅŖÕ»╣Õ║öńÜäµ¢ćµ£¼õ┐Īµü»’╝ī`TextRecogCropPacker` õ╝ÜÕ░åµ¢ćÕŁŚõ╗ÄÕøŠÕāÅõĖŁĶŻüÕē¬Õć║µØź’╝īńäČÕÉÄÕåŹĶĮ¼Õī¢µłÉµ¢ćÕŁŚĶ»åÕł½ńÜäń╗¤õĖƵĀ╝Õ╝ÅŃĆé
+
+#### µĀćµ│©õ┐ØÕŁś (Dumper)
+
+`dumper` µØźÕå│Õ«ÜĶ”üÕ░åµĢ░µŹ«õ┐ØÕŁśõĖ║õĮĢń¦ŹµĀ╝Õ╝ÅŃĆéńø«ÕēŹ’╝īMMOCR µö»µīü `JsonDumper`’╝ī `WildreceiptOpensetDumper`’╝īÕÅŖ `TextRecogLMDBDumper`ŃĆéõ╗¢õ╗¼ÕłåÕł½ńö©õ║ÄÕ░åµĢ░µŹ«õ┐ØÕŁśõĖ║µĀćÕćåńÜä MMOCR Json µĀ╝Õ╝ÅŃĆüWildreceipt µĀ╝Õ╝Å’╝īÕÅŖµ¢ćµ£¼Ķ»åÕł½ķóåÕ¤¤ÕŁ”µ£»ńĢīÕĖĖńö©ńÜä LMDB µĀ╝Õ╝ÅŃĆé
+
+#### õĖ┤µŚČµ¢ćõ╗ȵĖģńÉå (Delete)
+
+Õ£©ÕżäńÉåµĢ░µŹ«ķøåµŚČ’╝īÕŠĆÕŠĆõ╝Üõ║¦ńö¤õĖĆõ║øõĖŹķ£ĆĶ”üńÜäõĖ┤µŚČµ¢ćõ╗ČŃĆéĶ┐ÖķćīÕÅ»õ╗źõ╗źÕłŚĶĪ©ńÜäÕĮóÕ╝Åõ╝ĀÕģźĶ┐Öõ║øµ¢ćõ╗ȵł¢µ¢ćõ╗ČÕż╣’╝īÕ£©ń╗ōµØ¤ĶĮ¼µŹóµŚČÕŹ│õ╝ÜÕłĀķÖżŃĆé
+
+#### ńö¤µłÉÕ¤║ńĪĆķģŹńĮ« (ConfigGenerator)
+
+õĖ║õ║åÕ£©µĢ░µŹ«ķøåÕćåÕżćÕ«īµ»ĢÕÉÄÕÅ»õ╗źĶć¬ÕŖ©ńö¤µłÉÕ¤║ńĪĆķģŹńĮ«’╝īńø«ÕēŹ’╝īMMOCR µīēõ╗╗ÕŖĪÕ«×ńÄ░õ║å `TextDetConfigGenerator`ŃĆü`TextRecogConfigGenerator` ÕÆī `TextSpottingConfigGenerator`ŃĆéÕ«āõ╗¼µö»µīüńÜäõĖ╗Ķ”üÕÅéµĢ░Õ”éõĖŗ’╝Ü
+
+| ÕŁŚµ«ĄÕÉŹ | Õɽõ╣ē |
+| ----------- | --------------------------------------------------------------------------------------------------------------------------------------------------- |
+| data_root | µĢ░µŹ«ķøåÕŁśÕé©ńÜäµĀ╣ńø«ÕĮĢ |
+| train_anns | ķģŹńĮ«µ¢ćõ╗ČÕåģĶ«Łń╗āķøåµĀćµ│©ńÜäĶĘ»ÕŠäŃĆéĶŗźõĖŹµīćÕ«Ü’╝īÕłÖķ╗śĶ«żõĖ║ `[dict(ann_file='{taskname}_train.json', dataset_postfix='']`ŃĆé |
+| val_anns | ķģŹńĮ«µ¢ćõ╗ČÕåģķ¬īĶ»üķøåµĀćµ│©ńÜäĶĘ»ÕŠäŃĆéĶŗźõĖŹµīćÕ«Ü’╝īÕłÖķ╗śĶ«żõĖ║ń®║ŃĆé |
+| test_anns | ķģŹńĮ«µ¢ćõ╗ČÕåģµĄŗĶ»ĢķøåµĀćµ│©ńÜäĶĘ»ÕŠäŃĆéĶŗźõĖŹµīćÕ«Ü’╝īÕłÖķ╗śĶ«żµīćÕÉæ `[dict(ann_file='{taskname}_test.json', dataset_postfix='']`ŃĆé |
+| config_path | ń«Śµ│ĢÕ║ōÕŁśµöŠķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠä’╝īķģŹńĮ«ńö¤µłÉÕÖ©õ╝ÜÕ░åķ╗śĶ«żķģŹńĮ«ÕåÖÕģź `{config_path}/{taskname}/_base_/datasets/{dataset_name}.py` õĖŗŃĆéĶŗźõĖŹµīćÕ«Ü’╝īÕłÖķ╗śĶ«żõĖ║ `configs/` |
+
+Õ£©ÕćåÕżćÕźĮµĢ░µŹ«ķøåńÜäµēƵ£ēµ¢ćõ╗ČÕÉÄ’╝īķģŹńĮ«ńö¤µłÉÕÖ©Õ░▒õ╝ÜĶć¬ÕŖ©ńö¤µłÉĶ░āńö©Ķ»źµĢ░µŹ«ķøåµēĆķ£ĆĶ”üńÜäÕ¤║ńĪĆķģŹńĮ«µ¢ćõ╗ČŃĆéõĖŗķØóń╗ÖÕć║õ║åõĖĆõĖ¬µ£ĆÕ░ÅÕī¢ńÜä `TextDetConfigGenerator` ķģŹńĮ«ńż║õŠŗ’╝Ü
+
+```python
+config_generator = dict(type='TextDetConfigGenerator')
+```
+
+ńö¤µłÉÕÉÄńÜäµ¢ćõ╗Čķ╗śĶ«żõ╝ÜĶó½ńĮ«õ║Ä `configs/{task}/_base_/datasets/` õĖŗŃĆéõŠŗÕ”é’╝īµ£¼õŠŗõĖŁ’╝īicdar 2015 ńÜäÕ¤║ńĪĆķģŹńĮ«µ¢ćõ╗ČÕ░▒õ╝ÜĶó½ńö¤µłÉÕ£© `configs/textdet/_base_/datasets/icdar2015.py` õĖŗ’╝Ü
+
+```python
+icdar2015_textdet_data_root = 'data/icdar2015'
+
+icdar2015_textdet_train = dict(
+ type='OCRDataset',
+ data_root=icdar2015_textdet_data_root,
+ ann_file='textdet_train.json',
+ filter_cfg=dict(filter_empty_gt=True, min_size=32),
+ pipeline=None)
+
+icdar2015_textdet_test = dict(
+ type='OCRDataset',
+ data_root=icdar2015_textdet_data_root,
+ ann_file='textdet_test.json',
+ test_mode=True,
+ pipeline=None)
+```
+
+ÕüćÕ”éµĢ░µŹ«ķøåµ»öĶŠāńē╣µ«Ŗ’╝īµĀćµ│©ÕŁśÕ£©ńØĆÕćĀõĖ¬ÕÅśõĮō’╝īķģŹńĮ«ńö¤µłÉÕÖ©õ╣¤µö»µīüÕ£©Õ¤║ńĪĆķģŹńĮ«õĖŁńö¤µłÉµīćÕÉæÕÉäĶć¬ÕÅśõĮōńÜäÕÅśķćÅ’╝īõĮåĶ┐Öķ£ĆĶ”üńö©µłĘÕ£©Ķ«ŠńĮ«µŚČńö©õĖŹÕÉīńÜä `dataset_postfix` Õī║ÕłåŃĆéõŠŗÕ”é’╝īICDAR 2015 µ¢ćÕŁŚĶ»åÕł½µĢ░µŹ«ńÜ䵥ŗĶ»ĢķøåÕ░▒ÕŁśÕ£©ńØĆÕĤńēłÕÆī 1811 õĖżń¦ŹµĀćµ│©ńēłµ£¼’╝īÕÅ»õ╗źÕ£© `test_anns` õĖŁµīćÕ«ÜÕ«āõ╗¼’╝īÕ”éõĖŗµēĆńż║’╝Ü
+
+```python
+config_generator = dict(
+ type='TextRecogConfigGenerator',
+ test_anns=[
+ dict(ann_file='textrecog_test.json'),
+ dict(dataset_postfix='857', ann_file='textrecog_test_857.json')
+ ])
+```
+
+ķģŹńĮ«ńö¤µłÉÕÖ©õ╝Üńö¤µłÉõ╗źõĖŗķģŹńĮ«’╝Ü
+
+```python
+icdar2015_textrecog_data_root = 'data/icdar2015'
+
+icdar2015_textrecog_train = dict(
+ type='OCRDataset',
+ data_root=icdar2015_textrecog_data_root,
+ ann_file='textrecog_train.json',
+ pipeline=None)
+
+icdar2015_textrecog_test = dict(
+ type='OCRDataset',
+ data_root=icdar2015_textrecog_data_root,
+ ann_file='textrecog_test.json',
+ test_mode=True,
+ pipeline=None)
+
+icdar2015_1811_textrecog_test = dict(
+ type='OCRDataset',
+ data_root=icdar2015_textrecog_data_root,
+ ann_file='textrecog_test_1811.json',
+ test_mode=True,
+ pipeline=None)
+```
+
+µ£ēõ║åĶ»źµ¢ćõ╗ČÕÉÄ’╝īMMOCR Õ░▒ĶāĮõ╗ĵ©ĪÕ×ŗńÜäķģŹńĮ«µ¢ćõ╗ČõĖŁńø┤µÄźÕ»╝ÕģźĶ»źµĢ░µŹ«ķøåÕł░ `dataloader` õĖŁõĮ┐ńö©’╝łõ╗źõĖŗµĀĘõŠŗĶŖéķĆēĶć¬ [`configs/textdet/dbnet/dbnet_resnet18_fpnc_1200e_icdar2015.py`](/configs/textdet/dbnet/dbnet_resnet18_fpnc_1200e_icdar2015.py)’╝ē’╝Ü
+
+```python
+_base_ = [
+ '../_base_/datasets/icdar2015.py',
+ # ...
+]
+
+# dataset settings
+icdar2015_textdet_train = _base_.icdar2015_textdet_train
+icdar2015_textdet_test = _base_.icdar2015_textdet_test
+# ...
+
+train_dataloader = dict(
+ dataset=icdar2015_textdet_train)
+
+val_dataloader = dict(
+ dataset=icdar2015_textdet_test)
+
+test_dataloader = val_dataloader
+```
+
+```{note}
+ķÖżķØ×ńö©µłĘÕ£©Ķ┐ÉĶĪīĶäܵ£¼ńÜ䵌ČÕĆÖµēŗÕŖ©µīćÕ«Üõ║å `overwrite-cfg`’╝īķģŹńĮ«ńö¤µłÉÕÖ©ķ╗śĶ«żõĖŹõ╝ÜĶć¬ÕŖ©Ķ”åńø¢ÕĘ▓ń╗ÅÕŁśÕ£©ńÜäÕ¤║ńĪĆķģŹńĮ«µ¢ćõ╗ČŃĆé
+```
+
+## ÕÉæ Dataset Preparer µĘ╗ÕŖĀµ¢░ńÜäµĢ░µŹ«ķøå
+
+### µĘ╗ÕŖĀÕģ¼Õ╝ƵĢ░µŹ«ķøå
+
+MMOCR ÕĘ▓ń╗ŵö»µīüõ║åĶ«ĖÕżÜ[ÕĖĖńö©ńÜäÕģ¼Õ╝ƵĢ░µŹ«ķøå](./datasetzoo.md)ŃĆéÕ”éµ×£õĮĀµā│ńö©ńÜäµĢ░µŹ«ķøåĶ┐śµ▓Īµ£ēĶó½µö»µīü’╝īÕ╣ČõĖöõĮĀõ╣¤µä┐µäÅõĖ║ MMOCR Õ╝Ƶ║ÉńżŠÕī║[Ķ┤Īńī«õ╗ŻńĀü](../../notes/contribution_guide.md)’╝īõĮĀÕÅ»õ╗źµīēńģ¦õ╗źõĖŗµŁźķ¬żµØźµĘ╗ÕŖĀõĖĆõĖ¬µ¢░ńÜäµĢ░µŹ«ķøåŃĆé
+
+µÄźõĖŗµØźõ╗źµĘ╗ÕŖĀ **ICDAR2013** µĢ░µŹ«ķøåõĖ║õŠŗ’╝īÕ▒Ģńż║Õ”éõĮĢõĖƵŁźõĖƵŁźÕ£░µĘ╗ÕŖĀõĖĆõĖ¬µ¢░ńÜäÕģ¼Õ╝ƵĢ░µŹ«ķøåŃĆé
+
+#### µĘ╗ÕŖĀ `metafile.yml`
+
+ķ”¢Õģł’╝īńĪ«Ķ«ż `dataset_zoo/` õĖŁõĖŹÕŁśÕ£©ÕćåÕżćµĘ╗ÕŖĀńÜäµĢ░µŹ«ķøåŃĆéńäČÕÉĵłæõ╗¼Õģłµ¢░Õ╗║õ╗źÕŠģµĘ╗ÕŖĀµĢ░µŹ«ķøåÕæĮÕÉŹńÜäµ¢ćõ╗ČÕż╣’╝īÕ”é `icdar2013/`’╝łķĆÜÕĖĖ’╝īõĮ┐ńö©õĖŹÕīģÕɽń¼”ÕÅĘńÜäÕ░ÅÕåÖĶŗ▒µ¢ćÕŁŚµ»ŹÕÅŖµĢ░ÕŁŚµØźÕæĮÕÉŹµĢ░µŹ«ķøå’╝ēŃĆéÕ£© `icdar2013/` µ¢ćõ╗ČÕż╣õĖŁ’╝īµ¢░Õ╗║ `metafile.yml` µ¢ćõ╗Č’╝īÕ╣ȵīēńģ¦õ╗źõĖŗµ©ĪµØ┐µØźÕĪ½ÕģģµĢ░µŹ«ķøåńÜäÕ¤║µ£¼õ┐Īµü»’╝Ü
+
+```yaml
+Name: 'Incidental Scene Text IC13'
+Paper:
+ Title: ICDAR 2013 Robust Reading Competition
+ URL: https://www.imlab.jp/publication_data/1352/icdar_competition_report.pdf
+ Venue: ICDAR
+ Year: '2013'
+ BibTeX: '@inproceedings{karatzas2013icdar,
+ title={ICDAR 2013 robust reading competition},
+ author={Karatzas, Dimosthenis and Shafait, Faisal and Uchida, Seiichi and Iwamura, Masakazu and i Bigorda, Lluis Gomez and Mestre, Sergi Robles and Mas, Joan and Mota, David Fernandez and Almazan, Jon Almazan and De Las Heras, Lluis Pere},
+ booktitle={2013 12th international conference on document analysis and recognition},
+ pages={1484--1493},
+ year={2013},
+ organization={IEEE}}'
+Data:
+ Website: https://rrc.cvc.uab.es/?ch=2
+ Language:
+ - English
+ Scene:
+ - Natural Scene
+ Granularity:
+ - Word
+ Tasks:
+ - textdet
+ - textrecog
+ - textspotting
+ License:
+ Type: N/A
+ Link: N/A
+ Format: .txt
+ Keywords:
+ - Horizontal
+```
+
+#### µĘ╗ÕŖĀµĀćµ│©ńż║õŠŗ
+
+µ£ĆÕÉÄ’╝īÕÅ»õ╗źÕ£© `dataset_zoo/icdar2013/` ńø«ÕĮĢõĖŗµĘ╗ÕŖĀµĀćµ│©ńż║õŠŗµ¢ćõ╗Č `sample_anno.md` õ╗źÕĖ«ÕŖ®µ¢ćµĪŻĶäܵ£¼Õ£©ńö¤µłÉµ¢ćµĪŻµŚČµĘ╗ÕŖĀµĀćµ│©ńż║õŠŗ’╝īµĀćµ│©ńż║õŠŗµ¢ćõ╗ȵś»õĖĆõĖ¬ Markdown µ¢ćõ╗Č’╝īÕģČÕåģÕ«╣ķĆÜÕĖĖÕīģÕɽõ║åÕŹĢõĖ¬µĀʵ£¼ńÜäÕĤզŗµĢ░µŹ«µĀ╝Õ╝ÅŃĆéõŠŗÕ”é’╝īõ╗źõĖŗõ╗ŻńĀüÕØŚÕ▒Ģńż║õ║å ICDAR2013 µĢ░µŹ«ķøåńÜäµĢ░µŹ«µĀĘõŠŗµ¢ćõ╗Č’╝Ü
+
+````markdown
+ **Text Detection**
+
+ ```text
+ # train split
+ # x1 y1 x2 y2 "transcript"
+
+ 158 128 411 181 "Footpath"
+ 443 128 501 169 "To"
+ 64 200 363 243 "Colchester"
+
+ # test split
+ # x1, y1, x2, y2, "transcript"
+
+ 38, 43, 920, 215, "Tiredness"
+ 275, 264, 665, 450, "kills"
+ 0, 699, 77, 830, "A"
+ ```
+````
+
+#### µĘ╗ÕŖĀÕ»╣Õ║öõ╗╗ÕŖĪńÜäķģŹńĮ«µ¢ćõ╗Č
+
+Õ£© `dataset_zoo/icdar2013` õĖŁ’╝īµÄźńØƵĘ╗ÕŖĀõ╗źõ╗╗ÕŖĪÕÉŹń¦░ÕæĮÕÉŹńÜä `.py` ķģŹńĮ«µ¢ćõ╗ČŃĆéÕ”é `textdet.py`’╝ī`textrecog.py`’╝ī`textspotting.py`’╝ī`kie.py` ńŁēŃĆéķģŹńĮ«µ©ĪµØ┐Õ”éõĖŗµēĆńż║’╝Ü
+
+```python
+data_root = ''
+data_cache = 'data/cache'
+train_prepare = dict(
+ obtainer=dict(
+ type='NaiveObtainer',
+ data_cache=data_cache,
+ files=[
+ dict(
+ url='xx',
+ md5='',
+ save_name='xxx',
+ mapping=list())
+ ]),
+ gatherer=dict(type='xxxGatherer', **kwargs),
+ parser=dict(type='xxxParser', **kwargs),
+ packer=dict(type='TextxxxPacker'), # Õ»╣Õ║öõ╗╗ÕŖĪńÜä Packer
+ dumper=dict(type='JsonDumper'),
+)
+test_prepare = dict(
+ obtainer=dict(
+ type='NaiveObtainer',
+ data_cache=data_cache,
+ files=[
+ dict(
+ url='xx',
+ md5='',
+ save_name='xxx',
+ mapping=list())
+ ]),
+ gatherer=dict(type='xxxGatherer', **kwargs),
+ parser=dict(type='xxxParser', **kwargs),
+ packer=dict(type='TextxxxPacker'), # Õ»╣Õ║öõ╗╗ÕŖĪńÜä Packer
+ dumper=dict(type='JsonDumper'),
+)
+```
+
+õ╗źµ¢ćõ╗ȵŻĆµĄŗõ╗╗ÕŖĪõĖ║õŠŗ’╝īµØźõ╗ŗń╗ŹķģŹńĮ«µ¢ćõ╗ČńÜäÕģĘõĮōÕåģÕ«╣ŃĆé
+õĖĆĶł¼µāģÕåĄõĖŗńö©µłĘµŚĀķ£Ćķ揵¢░Õ«×ńÄ░µ¢░ńÜä `obtainer`, `gatherer`, `packer` µł¢ `dumper`’╝īõĮåµś»ķĆÜÕĖĖķ£ĆĶ”üµĀ╣µŹ«µĢ░µŹ«ķøåńÜäµĀćµ│©µĀ╝Õ╝ÅÕ«×ńÄ░µ¢░ńÜä `parser`ŃĆé
+Õ»╣õ║Ä `obtainer` ńÜäķģŹńĮ«Ķ┐ÖķćīõĖŹÕ£©ÕüÜĶ┐ćńÜäõ╗ŗń╗Ź’╝īÕÅ»õ╗źÕÅéĶĆā [µĢ░µŹ«ķøåõĖŗĶĮĮŃĆüĶ¦ŻÕÄŗŃĆüń¦╗ÕŖ©](#µĢ░µŹ«ķøåõĖŗĶĮĮĶ¦ŻÕÄŗń¦╗ÕŖ©-obtainer)ŃĆé
+ķÆłÕ»╣ `gatherer`’╝īķĆÜĶ┐ćĶ¦éÕ»¤ĶÄĘÕÅ¢ńÜä ICDAR2013 µĢ░µŹ«ķøåµ¢ćõ╗ČÕÅæńÄ░’╝īÕģȵ»ÅõĖĆÕ╝ĀÕøŠńēćķāĮµ£ēõĖĆõĖ¬Õ»╣Õ║öńÜä `.txt` µĀ╝Õ╝ÅńÜäµĀćµ│©µ¢ćõ╗Č’╝Ü
+
+```text
+data_root
+Ōö£ŌöĆŌöĆ textdet_imgs/train/
+Ōöé Ōö£ŌöĆŌöĆ img_1.jpg
+Ōöé Ōö£ŌöĆŌöĆ img_2.jpg
+Ōöé ŌööŌöĆŌöĆ ...
+Ōö£ŌöĆŌöĆ annotations/train/
+Ōöé Ōö£ŌöĆŌöĆ gt_img_1.txt
+Ōöé Ōö£ŌöĆŌöĆ gt_img_2.txt
+Ōöé ŌööŌöĆŌöĆ ...
+```
+
+õĖöµ»ÅõĖ¬µĀćµ│©µ¢ćõ╗ČÕÉŹõĖÄÕøŠńēćńÜäÕ»╣Õ║öÕģ│ń│╗õĖ║’╝Ü`gt_img_1.txt` Õ»╣Õ║ö `img_1.jpg`’╝īõ╗źµŁżń▒╗µÄ©ŃĆéÕøĀµŁżÕÅ»õ╗źõĮ┐ńö© `PairGatherer` µØźĶ┐øĶĪīÕī╣ķģŹŃĆé
+
+```python
+gatherer=dict(
+ type='PairGatherer',
+ img_suffixes=['.jpg'],
+ rule=[r'(\w+)\.jpg', r'gt_\1.txt'])
+```
+
+Ķ¦äÕłÖ `rule` ń¼¼õĖĆõĖ¬µŁŻÕłÖĶĪ©ĶŠŠÕ╝Åńö©õ║ÄÕī╣ķģŹÕøŠńēćµ¢ćõ╗ČÕÉŹ’╝īń¼¼õ║īõĖ¬µŁŻÕłÖĶĪ©ĶŠŠÕ╝Åńö©õ║ÄÕī╣ķģŹµĀćµ│©µ¢ćõ╗ČÕÉŹŃĆéÕ£©Ķ┐Öķćī’╝īõĮ┐ńö© `(\w+)` µØźÕī╣ķģŹÕøŠńēćµ¢ćõ╗ČÕÉŹ’╝īõĮ┐ńö© `gt_\1.txt` µØźÕī╣ķģŹµĀćµ│©µ¢ćõ╗ČÕÉŹ’╝īÕģČõĖŁ `\1` ĶĪ©ńż║ń¼¼õĖĆõĖ¬µŁŻÕłÖĶĪ©ĶŠŠÕ╝ÅÕī╣ķģŹÕł░ńÜäÕåģÕ«╣ŃĆéÕŹ│’╝īÕ«×ńÄ░õ║åÕ░å `img_xx.jpg` µø┐µŹóõĖ║ `gt_img_xx.txt` ńÜäÕŖ¤ĶāĮŃĆé
+
+µÄźõĖŗµØź’╝īķ£ĆĶ”üÕ«×ńÄ░ `parser`’╝īÕŹ│Õ░åÕĤզŗµĀćµ│©µ¢ćõ╗ČĶ¦Żµ×ÉõĖ║µĀćÕćåµĀ╝Õ╝ÅŃĆéķĆÜÕĖĖµØźĶ»┤’╝īńö©µłĘÕ£©µĘ╗ÕŖĀµ¢░ńÜäµĢ░µŹ«ķøåÕēŹ’╝īÕÅ»õ╗źµĄÅĶ¦łÕĘ▓µö»µīüµĢ░µŹ«ķøåńÜä[Ķ»”µāģķĪĄ](./datasetzoo.md)’╝īÕ╣ȵ¤źń£ŗµś»ÕÉ”ÕĘ▓µ£ēńøĖÕÉīµĀ╝Õ╝ÅńÜäµĢ░µŹ«ķøåŃĆéÕ”éµ×£ÕĘ▓µ£ēńøĖÕÉīµĀ╝Õ╝ÅńÜäµĢ░µŹ«ķøå’╝īÕłÖÕÅ»õ╗źńø┤µÄźõĮ┐ńö©Ķ»źµĢ░µŹ«ķøåńÜä `parser`ŃĆéÕÉ”ÕłÖ’╝īÕłÖķ£ĆĶ”üÕ«×ńÄ░µ¢░ńÜäµĀ╝Õ╝ÅĶ¦Żµ×ÉÕÖ©ŃĆé
+
+µĢ░µŹ«µĀ╝Õ╝ÅĶ¦Żµ×ÉÕÖ©Ķó½ń╗¤õĖĆÕŁśÕé©Õ£© `mmocr/datasets/preparers/parsers` ńø«ÕĮĢõĖŗŃĆéµēƵ£ēńÜä `parser` ķāĮķ£ĆĶ”üń╗¦µē┐ `BaseParser`’╝īÕ╣ČÕ«×ńÄ░ `parse_file` µł¢ `parse_files` µ¢╣µ│ĢŃĆéÕģĘõĮōÕÅ»õ╗źÕÅéĶĆā[µĢ░µŹ«ķøåĶ¦Żµ×É](#µĢ░µŹ«ķøåĶ¦Żµ×É)
+
+ķĆÜĶ┐ćĶ¦éÕ»¤ ICDAR2013 µĢ░µŹ«ķøåńÜäµĀćµ│©µ¢ćõ╗Č’╝Ü
+
+```text
+158 128 411 181 "Footpath"
+443 128 501 169 "To"
+64 200 363 243 "Colchester"
+542, 710, 938, 841, "break"
+87, 884, 457, 1021, "could"
+517, 919, 831, 1024, "save"
+```
+
+µłæõ╗¼ÕÅæńÄ░ÕåģńĮ«ńÜä `ICDARTxtTextDetAnnParser` ÕĘ▓ń╗ÅÕÅ»õ╗źµ╗ĪĶČ│ķ£Ćµ▒é’╝īÕøĀµŁżÕÅ»õ╗źńø┤µÄźõĮ┐ńö©Ķ»ź `parser`’╝īÕ╣ČÕ░åÕģČķģŹńĮ«Õł░ `preparer` õĖŁŃĆé
+
+```python
+parser=dict(
+ type='ICDARTxtTextDetAnnParser',
+ remove_strs=[',', '"'],
+ encoding='utf-8',
+ format='x1 y1 x2 y2 trans',
+ separator=' ',
+ mode='xyxy')
+```
+
+ÕģČõĖŁ’╝īńö▒õ║ĵĀćµ│©µ¢ćõ╗ČõĖŁµĘʵØéõ║åÕżÜõĮÖńÜäÕ╝ĢÕÅĘ `ŌĆ£ŌĆØ` ÕÆīķĆŚÕÅĘ `,`’╝īÕÅ»õ╗źķĆÜĶ┐ćµīćÕ«Ü `remove_strs=[',', '"']` µØźĶ┐øĶĪīń¦╗ķÖżŃĆéÕÅ”Õż¢Õ£© `format` õĖŁµīćÕ«Üõ║åµĀćµ│©µ¢ćõ╗ČńÜäµĀ╝Õ╝Å’╝īÕģČõĖŁ `x1 y1 x2 y2 trans` ĶĪ©ńż║µĀćµ│©µ¢ćõ╗ČõĖŁńÜäµ»ÅõĖĆĶĪīÕīģÕɽõ║åÕøøõĖ¬ÕØɵĀćÕÆīõĖĆõĖ¬µ¢ćµ£¼ÕåģÕ«╣’╝īõĖöÕØɵĀćÕÆīµ¢ćµ£¼ÕåģÕ«╣õ╣ŗķŚ┤õĮ┐ńö©ń®║µĀ╝ÕłåķÜö’╝ł`separator`=' '’╝ēŃĆéÕÅ”Õż¢’╝īķ£ĆĶ”üµīćÕ«Ü `mode` õĖ║ `xyxy`’╝īĶĪ©ńż║µĀćµ│©µ¢ćõ╗ČõĖŁńÜäÕØɵĀ浜»ÕĘ”õĖŖĶ¦ÆÕÆīÕÅ│õĖŗĶ¦ÆńÜäÕØɵĀć’╝īĶ┐ÖµĀĘõ╗źµØź’╝ī`ICDARTxtTextDetAnnParser` ÕŹ│ÕÅ»Õ░åĶ»źµĀ╝Õ╝ÅńÜäµĀćµ│©Ķ¦Żµ×ÉõĖ║ń╗¤õĖƵĀ╝Õ╝ÅŃĆé
+
+Õ»╣õ║Ä `packer`’╝īõ╗źµ¢ćõ╗ȵŻĆµĄŗõ╗╗ÕŖĪõĖ║õŠŗ’╝īÕģČ `packer` õĖ║ `TextDetPacker`’╝īÕģČķģŹńĮ«Õ”éõĖŗ’╝Ü
+
+```python
+packer=dict(type='TextDetPacker')
+```
+
+µ£ĆÕÉÄ’╝īµīćÕ«Ü `dumper`’╝īĶ┐ÖķćīõĖĆĶł¼µāģÕåĄõĖŗõ┐ØÕŁśõĖ║jsonµĀ╝Õ╝Å’╝īÕģČķģŹńĮ«Õ”éõĖŗ’╝Ü
+
+```python
+dumper=dict(type='JsonDumper')
+```
+
+ń╗ÅĶ┐ćõĖŖĶ┐░ķģŹńĮ«ÕÉÄ’╝īķÆłÕ»╣ ICDAR2013 Ķ«Łń╗āķøåńÜäķģŹńĮ«µ¢ćõ╗ČÕ”éõĖŗ’╝Ü
+
+```python
+train_preparer = dict(
+ obtainer=dict(
+ type='NaiveDataObtainer',
+ cache_path=cache_path,
+ files=[
+ dict(
+ url='https://rrc.cvc.uab.es/downloads/'
+ 'Challenge2_Training_Task12_Images.zip',
+ save_name='ic13_textdet_train_img.zip',
+ md5='a443b9649fda4229c9bc52751bad08fb',
+ content=['image'],
+ mapping=[['ic13_textdet_train_img', 'textdet_imgs/train']]),
+ dict(
+ url='https://rrc.cvc.uab.es/downloads/'
+ 'Challenge2_Training_Task1_GT.zip',
+ save_name='ic13_textdet_train_gt.zip',
+ md5='f3a425284a66cd67f455d389c972cce4',
+ content=['annotation'],
+ mapping=[['ic13_textdet_train_gt', 'annotations/train']]),
+ ]),
+ gatherer=dict(
+ type='PairGatherer',
+ img_suffixes=['.jpg'],
+ rule=[r'(\w+)\.jpg', r'gt_\1.txt']),
+ parser=dict(
+ type='ICDARTxtTextDetAnnParser',
+ remove_strs=[',', '"'],
+ format='x1 y1 x2 y2 trans',
+ separator=' ',
+ mode='xyxy'),
+ packer=dict(type='TextDetPacker'),
+ dumper=dict(type='JsonDumper'),
+)
+```
+
+õĖ║õ║åÕ£©µĢ░µŹ«ķøåÕćåÕżćÕ«īµ»ĢÕÉÄÕÅ»õ╗źĶć¬ÕŖ©ńö¤µłÉÕ¤║ńĪĆķģŹńĮ«’╝ī Ķ┐śķ£ĆĶ”üķģŹńĮ«õĖĆõĖŗÕ»╣Õ║öõ╗╗ÕŖĪńÜä `config_generator`ŃĆé
+
+Õ£©µ£¼õŠŗõĖŁ’╝īÕøĀõĖ║õĖ║µ¢ćÕŁŚµŻĆµĄŗõ╗╗ÕŖĪ’╝īõ╗ģķ£ĆĶ”üĶ«ŠńĮ« Generator õĖ║ `TextDetConfigGenerator`ÕŹ│ÕÅ»
+
+```python
+config_generator = dict(type='TextDetConfigGenerator', )
+```
+
+### µĘ╗ÕŖĀń¦üµ£ēµĢ░µŹ«ķøå
+
+ÕŠģµø┤µ¢░...
diff --git a/internlm_langchain/knowledge_base/MMOCR/content/datasets.md b/internlm_langchain/knowledge_base/MMOCR/content/datasets.md
new file mode 100644
index 00000000..16e6162d
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMOCR/content/datasets.md
@@ -0,0 +1,489 @@
+# µĢ░µŹ«ķøåń▒╗
+
+## µ”éĶ¦ł
+
+Õ£© MMOCR õĖŁ’╝īµēƵ£ēńÜäµĢ░µŹ«ķøåķāĮķĆÜĶ┐ćõĖŹÕÉīńÜäÕ¤║õ║Ä [mmengine.BaseDataset](mmengine.dataset.BaseDataset) ńÜä Dataset ń▒╗Ķ┐øĶĪīÕżäńÉåŃĆé Dataset ń▒╗Ķ┤¤Ķ┤ŻÕŖĀĶĮĮµĢ░µŹ«Õ╣ČĶ┐øĶĪīÕłØÕ¦ŗĶ¦Żµ×É’╝īńäČÕÉÄÕ░åÕģČķ”łķĆüÕł░ [µĢ░µŹ«µĄüµ░┤ń║┐](./transforms.md) Ķ┐øĶĪīµĢ░µŹ«ķóäÕżäńÉåŃĆüÕó×Õ╝║ŃĆüµĀ╝Õ╝ÅÕī¢ńŁēµōŹõĮ£ŃĆé
+
+` õ║åĶ¦Żµø┤ÕżÜĶ»”ń╗åõ┐Īµü»ŃĆé
+```
+
+## ÕĖĖĶ¦üµÄźÕÅŻ
+
+ńÄ░Õ£©’╝īĶ«®µłæõ╗¼ń£ŗõĖĆõĖ¬ÕģĘõĮōńÜäńż║õŠŗÕ╣ČÕŁ”õ╣Ā Dataset ń▒╗ńÜäõĖĆõ║øÕģĖÕ×ŗµÄźÕÅŻŃĆé`OCRDataset` µś» MMOCR õĖŁķ╗śĶ«żõĮ┐ńö©ńÜä Dataset Õ«×ńÄ░’╝īÕøĀõĖ║Õ«āńÜäµĀćµ│©µĀ╝Õ╝ÅĶČ│Õż¤ńüĄµ┤╗’╝īµö»µīü *µēƵ£ē* OCR õ╗╗ÕŖĪ’╝łĶ»”Ķ¦ü [OCRDataset](#ocrdataset)’╝ēŃĆéńÄ░Õ£©µłæõ╗¼Õ░åÕ«×õŠŗÕī¢õĖĆõĖ¬ `OCRDataset` Õ»╣Ķ▒Ī’╝īÕģČõĖŁÕ░åÕŖĀĶĮĮ `tests/data/det_toy_dataset` õĖŁńÜäńÄ®ÕģʵĢ░µŹ«ķøåŃĆé
+
+```python
+from mmocr.datasets import OCRDataset
+from mmengine.registry import init_default_scope
+init_default_scope('mmocr')
+
+train_pipeline = [
+ dict(
+ type='LoadImageFromFile'),
+ dict(
+ type='LoadOCRAnnotations',
+ with_polygon=True,
+ with_bbox=True,
+ with_label=True,
+ ),
+ dict(type='RandomCrop', min_side_ratio=0.1),
+ dict(type='Resize', scale=(640, 640), keep_ratio=True),
+ dict(type='Pad', size=(640, 640)),
+ dict(
+ type='PackTextDetInputs',
+ meta_keys=('img_path', 'ori_shape', 'img_shape'))
+]
+dataset = OCRDataset(
+ data_root='tests/data/det_toy_dataset',
+ ann_file='textdet_test.json',
+ test_mode=False,
+ pipeline=train_pipeline)
+
+```
+
+Ķ«®µłæõ╗¼µ¤źń£ŗõĖĆõĖŗĶ┐ÖõĖ¬µĢ░µŹ«ķøåńÜäÕż¦Õ░Å’╝Ü
+
+```python
+>>> print(len(dataset))
+
+10
+```
+
+ķĆÜÕĖĖ’╝īDataset ń▒╗ÕŖĀĶĮĮÕ╣ČÕŁśÕé©õĖżń¦Źń▒╗Õ×ŗńÜäõ┐Īµü»’╝Ü’╝ł1’╝ē**Õģāõ┐Īµü»**’╝ÜÕé©ÕŁśµĢ░µŹ«ķøåńÜäÕ▒׵Ʀ’╝īõŠŗÕ”éµŁżµĢ░µŹ«ķøåõĖŁÕÅ»ńö©ńÜäÕ»╣Ķ▒Īń▒╗Õł½ŃĆé ’╝ł2’╝ē**µĀćµ│©**’╝ÜÕøŠÕāÅńÜäĶĘ»ÕŠäÕÅŖÕģȵĀćńŁŠŃĆ鵳æõ╗¼ÕÅ»õ╗źķĆÜĶ┐ć `dataset.metainfo` Ķ«┐ķŚ«Õģāõ┐Īµü»’╝Ü
+
+```python
+>>> from pprint import pprint
+>>> pprint(dataset.metainfo)
+
+{'category': [{'id': 0, 'name': 'text'}],
+ 'dataset_type': 'TextDetDataset',
+ 'task_name': 'textdet'}
+```
+
+Õ»╣õ║ĵĀćµ│©’╝īµłæõ╗¼ÕÅ»õ╗źķĆÜĶ┐ć `dataset.get_data_info(idx)` Ķ«┐ķŚ«Õ«āŃĆéĶ»źµ¢╣µ│ĢĶ┐öÕø×õĖĆõĖ¬ÕŁŚÕģĖ’╝īÕģČõĖŁÕīģÕɽµĢ░µŹ«ķøåõĖŁń¼¼ `idx` õĖ¬µĀʵ£¼ńÜäõ┐Īµü»ŃĆéĶ»źµĀʵ£¼ÕĘ▓ń╗Åń╗ÅĶ┐ćÕłØµŁźĶ¦Żµ×É’╝īõĮåÕ░ܵ£¬ńö▒ [µĢ░µŹ«µĄüµ░┤ń║┐](./transforms.md) ÕżäńÉåŃĆé
+
+```python
+>>> from pprint import pprint
+>>> pprint(dataset.get_data_info(0))
+
+{'height': 720,
+ 'img_path': 'tests/data/det_toy_dataset/test/img_10.jpg',
+ 'instances': [{'bbox': [260.0, 138.0, 284.0, 158.0],
+ 'bbox_label': 0,
+ 'ignore': True,
+ 'polygon': [261, 138, 284, 140, 279, 158, 260, 158]},
+ ...,
+ {'bbox': [1011.0, 157.0, 1079.0, 173.0],
+ 'bbox_label': 0,
+ 'ignore': True,
+ 'polygon': [1011, 157, 1079, 160, 1076, 173, 1011, 170]}],
+ 'sample_idx': 0,
+ 'seg_map': 'test/gt_img_10.txt',
+ 'width': 1280}
+```
+
+ÕÅ”õĖƵ¢╣ķØó’╝īµłæõ╗¼ÕÅ»õ╗źķĆÜĶ┐ć `dataset[idx]` µł¢ `dataset.__getitem__(idx)` ĶÄĘÕÅ¢ńö▒µĢ░µŹ«µĄüµ░┤ń║┐Õ«īµĢ┤ÕżäńÉåĶ┐ćÕÉÄńÜäµĀʵ£¼’╝īĶ»źµĀʵ£¼ÕÅ»õ╗źńø┤µÄźķ”łÕģźµ©ĪÕ×ŗÕ╣ȵē¦ĶĪīÕ«īµĢ┤ńÜäĶ«Łń╗ā/µĄŗĶ»ĢÕŠ¬ńÄ»ŃĆéÕ«āµ£ēõĖżõĖ¬ÕŁŚµ«Ą’╝Ü
+
+- `inputs`’╝Üń╗ÅĶ┐ćµĢ░µŹ«Õó×Õ╝║ÕÉÄńÜäÕøŠÕāÅ’╝ø
+- `data_samples`’╝ÜÕīģÕɽń╗ÅĶ┐ćµĢ░µŹ«Õó×Õ╝║ÕÉÄńÜäµĀćµ│©ÕÆīÕģāõ┐Īµü»ńÜä [DataSample](./structures.md)’╝īĶ┐Öõ║øÕģāõ┐Īµü»ÕÅ»ĶāĮńö▒õĖĆõ║øµĢ░µŹ«ÕÅśµŹóõ║¦ńö¤’╝īÕ╣Čńö©õ╗źĶ«░ÕĮĢĶ»źµĀʵ£¼ńÜ䵤Éõ║øÕģ│ķö«Õ▒׵ƦŃĆé
+
+```python
+>>> pprint(dataset[0])
+
+{'data_samples':
+) at 0x7f735a0508e0>,
+ 'inputs': tensor([[[129, 111, 131, ..., 0, 0, 0], ...
+ [ 19, 18, 15, ..., 0, 0, 0]]], dtype=torch.uint8)}
+```
+
+## µĢ░µŹ«ķøåń▒╗ÕÅŖµĀćµ│©µĀ╝Õ╝Å
+
+µ»ÅõĖ¬µĢ░µŹ«ķøåÕ«×ńÄ░ÕŬĶāĮÕŖĀĶĮĮńē╣իܵĀ╝Õ╝ÅńÜäµĢ░µŹ«ķøåŃĆéĶ┐ÖķćīÕłŚÕć║õ║åµēƵ£ēµö»µīüńÜäµĢ░µŹ«ķøåń▒╗ÕÅŖÕģČÕģ╝Õ«╣ńÜäµĀ╝Õ╝Å’╝īõ╗źÕÅŖõĖĆõĖ¬ńż║õŠŗķģŹńĮ«’╝īõ╗źµ╝öńż║Õ”éõĮĢÕ£©Õ«×ĶĘĄõĖŁõĮ┐ńö©Õ«āõ╗¼ŃĆé
+
+```{note}
+Õ”éµ×£µé©õĖŹń夵éēķģŹńĮ«ń│╗ń╗¤’╝īÕÅ»õ╗źķśģĶ»╗ [µĢ░µŹ«ķøåķģŹńĮ«µ¢ćõ╗Č](../user_guides/dataset_prepare.md#µĢ░µŹ«ķøåķģŹńĮ«µ¢ćõ╗Č)ŃĆé
+```
+
+### OCRDataset
+
+ķĆÜÕĖĖ’╝īOCR µĢ░µŹ«ķøåõĖŁµ£ēĶ«ĖÕżÜõĖŹÕÉīń▒╗Õ×ŗńÜäµĀćµ│©’╝īÕ£©õĖŹÕÉīńÜäÕŁÉõ╗╗ÕŖĪ’╝łÕ”éµ¢ćµ£¼µŻĆµĄŗÕÆīµ¢ćµ£¼Ķ»åÕł½’╝ēõĖŁ’╝īµĀ╝Õ╝Åõ╣¤ń╗ÅÕĖĖõ╝ܵ£ēµēĆõĖŹÕÉīŃĆéĶ┐Öõ║øÕĘ«Õ╝éÕÅ»ĶāĮõ╝ÜÕ»╝Ķć┤Õ£©õĮ┐ńö©õĖŹÕÉīµĢ░µŹ«ķøåµŚČķ£ĆĶ”üõĖŹÕÉīńÜäµĢ░µŹ«ÕŖĀĶĮĮõ╗ŻńĀü’╝īÕó×ÕŖĀõ║åńö©µłĘńÜäÕŁ”õ╣ĀÕÆīń╗┤µŖżµłÉµ£¼ŃĆé
+
+Õ£© MMOCR õĖŁ’╝īµłæõ╗¼µÅÉÕć║õ║åõĖĆń¦Źń╗¤õĖĆńÜäµĢ░µŹ«ķøåµĀ╝Õ╝Å’╝īÕÅ»õ╗źķĆéÕ║ö OCR ńÜäµēƵ£ēõĖēõĖ¬ÕŁÉõ╗╗ÕŖĪ’╝ܵ¢ćµ£¼µŻĆµĄŗŃĆüµ¢ćµ£¼Ķ»åÕł½ÕÆīń½»Õł░ń½» OCRŃĆéĶ┐Öń¦ŹĶ«ŠĶ«Īµ£ĆÕż¦ń©ŗÕ║”Õ£░µÅÉķ½śõ║åµĢ░µŹ«ķøåńÜäõĖĆĶć┤µĆ¦’╝īÕģüĶ«ĖÕ£©õĖŹÕÉīõ╗╗ÕŖĪõ╣ŗķŚ┤ķćŹÕżŹõĮ┐ńö©µĢ░µŹ«µĀćµ│©’╝īõ╣¤õĮ┐ÕŠŚµĢ░µŹ«ķøåń«ĪńÉåµø┤ÕŖĀµ¢╣õŠ┐ŃĆéĶĆāĶÖæÕł░µĄüĶĪīńÜäµĢ░µŹ«ķøåµĀ╝Õ╝ÅÕ╣ČõĖŹõĖĆĶć┤’╝īMMOCR µÅÉõŠøõ║å [Dataset Preparer](../user_guides/data_prepare/dataset_preparer.md) µØźÕĖ«ÕŖ®ńö©µłĘÕ░åÕģȵĢ░µŹ«ķøåĶĮ¼µŹóõĖ║ MMOCR µĀ╝Õ╝ÅŃĆ鵳æõ╗¼õ╣¤ÕŹüÕłåķ╝ōÕŖ▒ńĀöń®Čõ║║ÕæśÕ¤║õ║ĵŁżµĢ░µŹ«µĀ╝Õ╝ÅÕ╝ĆÕÅæĶć¬ÕĘ▒ńÜäµĢ░µŹ«ķøåŃĆé
+
+#### µĀćµ│©µĀ╝Õ╝Å
+
+µŁżµĀćµ│©µ¢ćõ╗ȵś»õĖĆõĖ¬ `.json` µ¢ćõ╗Č’╝īÕŁśÕé©õĖĆõĖ¬ÕīģÕɽ `metainfo` ÕÆī `data_list` ńÜä `dict`’╝īÕēŹĶĆģÕīģµŗ¼µ£ēÕģ│µĢ░µŹ«ķøåńÜäÕ¤║µ£¼õ┐Īµü»’╝īÕÉÄĶĆģńö▒µ»ÅõĖ¬ÕøŠńēćńÜäµĀćµ│©ń╗䵳ÉŃĆéĶ┐ÖķćīÕæłńÄ░õ║åµĀćµ│©µ¢ćõ╗ČõĖŁńÜäµēƵ£ēÕŁŚµ«ĄńÜäÕłŚĶĪ©’╝īõĮåÕģČõĖŁµ¤Éõ║øÕŁŚµ«Ąõ╗ģõ╝ÜÕ£©ńē╣Õ«Üõ╗╗ÕŖĪõĖŁĶó½ńö©Õł░ŃĆé
+
+```python
+{
+ "metainfo":
+ {
+ "dataset_type": "TextDetDataset", # ÕÅ»ķĆēķĪ╣: TextDetDataset/TextRecogDataset/TextSpotterDataset
+ "task_name": "textdet", # ÕÅ»ķĆēķĪ╣: textdet/textspotter/textrecog
+ "category": [{"id": 0, "name": "text"}] # Õ£© textdet/textspotter ķćīńö©Õł░
+ },
+ "data_list":
+ [
+ {
+ "img_path": "test_img.jpg",
+ "height": 604,
+ "width": 640,
+ "instances": # õĖĆÕøŠÕåģńÜäÕżÜõĖ¬Õ«×õŠŗ
+ [
+ {
+ "bbox": [0, 0, 10, 20], # textdet/textspotter Õåģńö©Õł░, [x1, y1, x2, y2]ŃĆé
+ "bbox_label": 0, # Õ»╣Ķ▒Īń▒╗Õł½, Õ£© MMOCR õĖŁµüÆõĖ║ 0 (µ¢ćµ£¼)
+ "polygon": [0, 0, 0, 10, 10, 20, 20, 0], # textdet/textspotter Õåģńö©Õł░ŃĆé [x1, y1, x2, y2, ....]
+ "text": "mmocr", # textspotter/textrecog Õåģńö©Õł░
+ "ignore": False # textspotter/textdet Õåģńö©Õł░’╝īÕå│իܵś»Õɔգ©Ķ«Łń╗āµŚČÕ┐ĮńĢźĶ»źÕ«×õŠŗ
+ },
+ #...
+ ],
+ }
+ #... ÕżÜÕøŠńēć
+ ]
+}
+```
+
+#### ńż║õŠŗķģŹńĮ«
+
+õ╗źõĖŗµś»ķģŹńĮ«ńÜäõĖĆķā©Õłå’╝īµłæõ╗¼Õ£© `train_dataloader` õĖŁõĮ┐ńö© `OCRDataset` ÕŖĀĶĮĮńö©õ║ĵ¢ćµ£¼µŻĆµĄŗµ©ĪÕ×ŗńÜä ICDAR2015 µĢ░µŹ«ķøåŃĆéĶ»Ęµ│©µäÅ’╝ī`OCRDataset` ÕÅ»õ╗źÕŖĀĶĮĮńö▒ Dataset Preparer ÕćåÕżćńÜäõ╗╗õĮĢ OCR µĢ░µŹ«ķøåŃĆéõ╣¤Õ░▒µś»Ķ»┤’╝īµé©ÕÅ»õ╗źÕ░åÕģČńö©õ║ĵ¢ćµ£¼Ķ»åÕł½ÕÆīµ¢ćµ£¼µŻĆµĄŗ’╝īõĮåµé©õ╗ŹńäČķ£ĆĶ”üµĀ╣µŹ«õĖŹÕÉīõ╗╗ÕŖĪńÜäķ£Ćµ▒éõ┐«µö╣ `pipeline` õĖŁńÜäµĢ░µŹ«ÕÅśµŹóŃĆé
+
+```python
+pipeline = [
+ dict(
+ type='LoadImageFromFile'),
+ dict(
+ type='LoadOCRAnnotations',
+ with_polygon=True,
+ with_bbox=True,
+ with_label=True,
+ ),
+ dict(
+ type='PackTextDetInputs',
+ meta_keys=('img_path', 'ori_shape', 'img_shape'))
+]
+
+icdar2015_textdet_train = dict(
+ type='OCRDataset',
+ data_root='data/icdar2015',
+ ann_file='textdet_train.json',
+ filter_cfg=dict(filter_empty_gt=True, min_size=32),
+ pipeline=pipeline)
+
+train_dataloader = dict(
+ batch_size=16,
+ num_workers=8,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=icdar2015_textdet_train)
+```
+
+### RecogLMDBDataset
+
+ÕĮōµĢ░µŹ«ķćÅķØ×ÕĖĖÕż¦µŚČ’╝īõ╗ĵ¢ćõ╗ČõĖŁĶ»╗ÕÅ¢ÕøŠÕāŵł¢µĀćńŁŠÕÅ»ĶāĮõ╝ÜÕŠłµģóŃĆ鵣żÕż¢’╝īÕ£©ÕŁ”µ£»ńĢī’╝īÕż¦ÕżÜµĢ░Õ£║µÖ»µ¢ćµ£¼Ķ»åÕł½µĢ░µŹ«ķøåńÜäÕøŠÕāÅÕÆīµĀćńŁŠķāĮõ╗ź lmdb µĀ╝Õ╝ÅÕŁśÕé©ŃĆé’╝ł[ńż║õŠŗ](https://github.com/clovaai/deep-text-recognition-benchmark)’╝ē
+
+õĖ║õ║åµø┤µÄźĶ┐æõĖ╗µĄüÕ«×ĶĘĄÕ╣ȵÅÉķ½śµĢ░µŹ«ÕŁśÕ驵ĢłńÄć’╝īMMOCRµö»µīüķĆÜĶ┐ć `RecogLMDBDataset` õ╗Ä lmdb µĢ░µŹ«ķøåÕŖĀĶĮĮÕøŠÕāÅÕÆīµĀćńŁŠŃĆé
+
+#### µĀćµ│©µĀ╝Õ╝Å
+
+MMOCR õ╝ÜĶ»╗ÕÅ¢ lmdb µĢ░µŹ«ķøåõĖŁńÜäõ╗źõĖŗķö«’╝Ü
+
+- `num_samples`’╝ܵÅÅĶ┐░µĢ░µŹ«ķøåńÜäµĢ░µŹ«ķćÅńÜäÕÅéµĢ░ŃĆé
+- ÕøŠÕāÅÕÆīµĀćńŁŠńÜäķö«ÕłåÕł½õ╗ź `image-000000001` ÕÆī `label-000000001` ńÜäµĀ╝Õ╝ÅÕæĮÕÉŹ’╝īń┤óÕ╝Ģõ╗Ä1Õ╝ĆÕ¦ŗŃĆé
+
+MMOCR Õ£© `tests/data/rec_toy_dataset/imgs.lmdb` õĖŁµÅÉõŠøõ║åõĖĆõĖ¬ toy lmdb µĢ░µŹ«ķøåŃĆéµé©ÕÅ»õ╗źõĮ┐ńö©õ╗źõĖŗõ╗ŻńĀüńē浫Ąõ║åĶ¦ŻÕģȵĀ╝Õ╝ÅŃĆé
+
+```python
+>>> import lmdb
+>>>
+>>> env = lmdb.open('tests/data/rec_toy_dataset/imgs.lmdb')
+>>> txn = env.begin()
+>>> for k, v in txn.cursor():
+>>> print(k, v)
+
+b'image-000000001' b'\xff...'
+b'image-000000002' b'\xff...'
+b'image-000000003' b'\xff...'
+b'image-000000004' b'\xff...'
+b'image-000000005' b'\xff...'
+b'image-000000006' b'\xff...'
+b'image-000000007' b'\xff...'
+b'image-000000008' b'\xff...'
+b'image-000000009' b'\xff...'
+b'image-000000010' b'\xff...'
+b'label-000000001' b'GRAND'
+b'label-000000002' b'HOTEL'
+b'label-000000003' b'HOTEL'
+b'label-000000004' b'PACIFIC'
+b'label-000000005' b'03/09/2009'
+b'label-000000006' b'ANING'
+b'label-000000007' b'Virgin'
+b'label-000000008' b'america'
+b'label-000000009' b'ATTACK'
+b'label-000000010' b'DAVIDSON'
+b'num-samples' b'10'
+
+```
+
+#### ńż║õŠŗķģŹńĮ«
+
+õ╗źõĖŗµś»ńż║õŠŗķģŹńĮ«ńÜäõĖĆķā©Õłå’╝īµłæõ╗¼Õ£©ÕģČõĖŁõĮ┐ńö© `RecogLMDBDataset` ÕŖĀĶĮĮ toy µĢ░µŹ«ķøåŃĆéńö▒õ║Ä `RecogLMDBDataset` õ╝ÜÕ░åÕøŠÕāÅÕŖĀĶĮĮõĖ║ numpy µĢ░ń╗ä’╝īÕøĀµŁżÕ”éµ×£Ķ”üÕ£©µĢ░µŹ«ń«ĪķüōõĖŁµłÉÕŖ¤ÕŖĀĶĮĮÕøŠÕāÅ’╝īÕ║öĶ»źĶ«░ÕŠŚµŖŖ`LoadImageFromFile` µø┐µŹóµłÉ `LoadImageFromNDArray` ŃĆé
+
+```python
+pipeline = [
+ dict(
+ type='LoadImageFromNDArray'),
+ dict(
+ type='LoadOCRAnnotations',
+ with_text=True,
+ ),
+ dict(
+ type='PackTextRecogInputs',
+ meta_keys=('img_path', 'ori_shape', 'img_shape'))
+]
+
+toy_textrecog_train = dict(
+ type='RecogLMDBDataset',
+ data_root='tests/data/rec_toy_dataset/',
+ ann_file='imgs.lmdb',
+ pipeline=pipeline)
+
+train_dataloader = dict(
+ batch_size=16,
+ num_workers=8,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=toy_textrecog_train)
+```
+
+### RecogTextDataset
+
+Õ£© MMOCR 1.0 õ╣ŗÕēŹ’╝īMMOCR 0.x ńÜäµ¢ćµ£¼Ķ»åÕł½õ╗╗ÕŖĪńÜäĶŠōÕģźµś»µ¢ćµ£¼µ¢ćõ╗ČŃĆéĶ┐Öõ║øµĀ╝Õ╝ÅÕĘ▓Õ£© MMOCR 1.0 õĖŁÕ╝āńö©’╝īĶ┐ÖõĖ¬ń▒╗ķÜŵŚČÕÅ»ĶāĮĶó½ÕłĀķÖżŃĆé[µø┤ÕżÜõ┐Īµü»](../migration/dataset.md)
+
+#### µĀćµ│©µĀ╝Õ╝Å
+
+µ¢ćµ£¼µ¢ćõ╗ČÕÅ»õ╗źµś» `txt` µĀ╝Õ╝ŵł¢ `jsonl` µĀ╝Õ╝ÅŃĆéń«ĆÕŹĢńÜä `.txt` µĀćµ│©ķĆÜĶ┐ćń®║µĀ╝Õ░åÕøŠÕāÅÕÉŹń¦░ÕÆīĶ»ŹĶ»ŁµĀćµ│©ÕłåķÜöÕ╝Ć’╝īÕøĀµŁżĶ┐Öń¦ŹµĀ╝Õ╝ÅÕ╣ȵŚĀµ│ĢÕżäńÉåµ¢ćµ£¼Õ«×õŠŗõĖŁÕīģÕɽń®║µĀ╝ńÜäµāģÕåĄŃĆé
+
+```text
+img1.jpg OpenMMLab
+img2.jpg MMOCR
+```
+
+`jsonl` µĀ╝Õ╝ÅõĮ┐ńö©ń▒╗õ╝╝ÕŁŚÕģĖńÜäń╗ōµ×äµØźĶĪ©ńż║µĀćµ│©’╝īÕģČõĖŁķö« `filename` ÕÆī `text` ÕŁśÕé©ÕøŠÕāÅÕÉŹń¦░ÕÆīÕŹĢĶ»ŹµĀćńŁŠŃĆé
+
+```json
+{"filename": "img1.jpg", "text": "OpenMMLab"}
+{"filename": "img2.jpg", "text": "MMOCR"}
+```
+
+#### ńż║õŠŗķģŹńĮ«
+
+õ╗źõĖŗµś»õĖĆõĖ¬ńż║õŠŗķģŹńĮ«’╝īµłæõ╗¼Õ£©Ķ«Łń╗āõĖŁõĮ┐ńö© `RecogTextDataset` ÕŖĀĶĮĮ txt µĀćńŁŠ’╝īĶĆīÕ£©µĄŗĶ»ĢõĖŁõĮ┐ńö© jsonl µĀćńŁŠŃĆé
+
+```python
+pipeline = [
+ dict(
+ type='LoadImageFromFile'),
+ dict(
+ type='LoadOCRAnnotations',
+ with_polygon=True,
+ with_bbox=True,
+ with_label=True,
+ ),
+ dict(
+ type='PackTextDetInputs',
+ meta_keys=('img_path', 'ori_shape', 'img_shape'))
+]
+
+ # loading 0.x txt format annos
+ txt_dataset = dict(
+ type='RecogTextDataset',
+ data_root=data_root,
+ ann_file='old_label.txt',
+ data_prefix=dict(img_path='imgs'),
+ parser_cfg=dict(
+ type='LineStrParser',
+ keys=['filename', 'text'],
+ keys_idx=[0, 1]),
+ pipeline=pipeline)
+
+
+train_dataloader = dict(
+ batch_size=16,
+ num_workers=8,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=txt_dataset)
+
+ # loading 0.x json line format annos
+ jsonl_dataset = dict(
+ type='RecogTextDataset',
+ data_root=data_root,
+ ann_file='old_label.jsonl',
+ data_prefix=dict(img_path='imgs'),
+ parser_cfg=dict(
+ type='LineJsonParser',
+ keys=['filename', 'text'],
+ pipeline=pipeline))
+
+test_dataloader = dict(
+ batch_size=16,
+ num_workers=8,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ dataset=jsonl_dataset)
+```
+
+### IcdarDataset
+
+Õ£© MMOCR 1.0 õ╣ŗÕēŹ’╝īMMOCR 0.x ńÜäµ¢ćµ£¼µŻĆµĄŗĶŠōÕģźķććńö©õ║åń▒╗õ╝╝ COCO µĀ╝Õ╝ÅńÜäµ│©ķćŖŃĆéĶ┐Öõ║øµĀ╝Õ╝ÅÕĘ▓Õ£© MMOCR 1.0 õĖŁÕ╝āńö©’╝īĶ┐ÖõĖ¬ń▒╗Õ£©Õ░åµØźńÜäõ╗╗õĮĢµŚČÕĆÖķāĮÕÅ»ĶāĮĶó½ÕłĀķÖżŃĆé[µø┤ÕżÜõ┐Īµü»](../migration/dataset.md)
+
+#### µĀćµ│©µĀ╝Õ╝Å
+
+```json
+{
+ "images": [
+ {
+ "id": 1,
+ "width": 800,
+ "height": 600,
+ "file_name": "test.jpg"
+ }
+ ],
+ "annotations": [
+ {
+ "id": 1,
+ "image_id": 1,
+ "category_id": 1,
+ "bbox": [0,0,10,10],
+ "segmentation": [
+ [0,0,10,0,10,10,0,10]
+ ],
+ "area": 100,
+ "iscrowd": 0
+ }
+ ]
+}
+
+```
+
+#### ķģŹńĮ«ńż║õŠŗ
+
+Ķ┐Öµś»ķģŹńĮ«ńż║õŠŗńÜäõĖĆķā©Õłå’╝īÕģČõĖŁµłæõ╗¼õ╗ż `train_dataloader` õĮ┐ńö© `IcdarDataset` µØźÕŖĀĶĮĮµŚ¦µĀćńŁŠŃĆé
+
+```python
+pipeline = [
+ dict(
+ type='LoadImageFromFile'),
+ dict(
+ type='LoadOCRAnnotations',
+ with_polygon=True,
+ with_bbox=True,
+ with_label=True,
+ ),
+ dict(
+ type='PackTextDetInputs',
+ meta_keys=('img_path', 'ori_shape', 'img_shape'))
+]
+
+icdar2015_textdet_train = dict(
+ type='IcdarDatasetDataset',
+ data_root='data/det/icdar2015',
+ ann_file='instances_training.json',
+ filter_cfg=dict(filter_empty_gt=True, min_size=32),
+ pipeline=pipeline)
+
+train_dataloader = dict(
+ batch_size=16,
+ num_workers=8,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=icdar2015_textdet_train)
+```
+
+### WildReceiptDataset
+
+Ķ»źń▒╗õĖ║ [WildReceipt](https://mmocr.readthedocs.io/en/dev-1.x/user_guides/data_prepare/datasetzoo.html#wildreceipt) µĢ░µŹ«ķøåÕ«ÜÕłČŃĆé
+
+#### µĀćµ│©µĀ╝Õ╝Å
+
+```json
+// Close Set
+{
+ "file_name": "image_files/Image_16/11/d5de7f2a20751e50b84c747c17a24cd98bed3554.jpeg",
+ "height": 1200,
+ "width": 1600,
+ "annotations":
+ [
+ {
+ "box": [550.0, 190.0, 937.0, 190.0, 937.0, 104.0, 550.0, 104.0],
+ "text": "SAFEWAY",
+ "label": 1
+ },
+ {
+ "box": [1048.0, 211.0, 1074.0, 211.0, 1074.0, 196.0, 1048.0, 196.0],
+ "text": "TM",
+ "label": 25
+ }
+ ], //...
+}
+
+// Open Set
+{
+ "file_name": "image_files/Image_12/10/845be0dd6f5b04866a2042abd28d558032ef2576.jpeg",
+ "height": 348,
+ "width": 348,
+ "annotations":
+ [
+ {
+ "box": [114.0, 19.0, 230.0, 19.0, 230.0, 1.0, 114.0, 1.0],
+ "text": "CHOEUN",
+ "label": 2,
+ "edge": 1
+ },
+ {
+ "box": [97.0, 35.0, 236.0, 35.0, 236.0, 19.0, 97.0, 19.0],
+ "text": "KOREANRESTAURANT",
+ "label": 2,
+ "edge": 1
+ }
+ ]
+}
+```
+
+#### ķģŹńĮ«ńż║õŠŗ
+
+Ķ»ĘÕÅéĶĆā [SDMGR ńÜäķģŹńĮ«](https://github.com/open-mmlab/mmocr/blob/f30c16ce96bd2393570c04eeb9cf48a7916315cc/configs/kie/sdmgr/sdmgr_novisual_60e_wildreceipt.py)ŃĆé
diff --git a/internlm_langchain/knowledge_base/MMOCR/content/engine.md b/internlm_langchain/knowledge_base/MMOCR/content/engine.md
new file mode 100644
index 00000000..57cb62ae
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMOCR/content/engine.md
@@ -0,0 +1,3 @@
+# Õ╝ĢµōÄ\[ÕŠģµø┤µ¢░\]
+
+ÕŠģµø┤µ¢░
diff --git a/internlm_langchain/knowledge_base/MMOCR/content/evaluation.md b/internlm_langchain/knowledge_base/MMOCR/content/evaluation.md
new file mode 100644
index 00000000..15eab4da
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMOCR/content/evaluation.md
@@ -0,0 +1,198 @@
+# µ©ĪÕ×ŗĶ»äµĄŗ
+
+```{note}
+ķśģĶ»╗µŁżµ¢ćµĪŻÕēŹ’╝īÕ╗║Ķ««µé©Õģłõ║åĶ¦Ż {external+mmengine:doc}`MMEngine: µ©ĪÕ×ŗń▓ŠÕ║”Ķ»äµĄŗÕ¤║µ£¼µ”éÕ┐Ą `ŃĆé
+```
+
+## Ķ»äµĄŗµīćµĀć
+
+MMOCR Õ¤║õ║Ä {external+mmengine:doc}`MMEngine: BaseMetric ` Õ¤║ń▒╗Õ«×ńÄ░õ║åÕĖĖńö©ńÜäµ¢ćµ£¼µŻĆµĄŗŃĆüµ¢ćµ£¼Ķ»åÕł½õ╗źÕÅŖÕģ│ķö«õ┐Īµü»µŖĮÕÅ¢õ╗╗ÕŖĪńÜäĶ»äµĄŗµīćµĀć’╝īńö©µłĘÕÅ»õ╗źķĆÜĶ┐ćõ┐«µö╣ķģŹńĮ«µ¢ćõ╗ČõĖŁńÜä `val_evaluator` õĖÄ `test_evaluator` ÕŁŚµ«ĄµØźõŠ┐µŹĘÕ£░µīćÕ«Üķ¬īĶ»üõĖĵĄŗĶ»ĢķśČµ«Ąķććńö©ńÜäĶ»äµĄŗµ¢╣µ│ĢŃĆéõŠŗÕ”é’╝īõ╗źõĖŗķģŹńĮ«Õ▒Ģńż║õ║åÕ”éõĮĢÕ£©µ¢ćµ£¼µŻĆµĄŗń«Śµ│ĢõĖŁõĮ┐ńö© `HmeanIOUMetric` µØźĶ»äµĄŗµ©ĪÕ×ŗµĆ¦ĶāĮŃĆé
+
+```python
+# µ¢ćµ£¼µŻĆµĄŗõ╗╗ÕŖĪõĖŁķĆÜÕĖĖõĮ┐ńö© HmeanIOUMetric µØźĶ»äµĄŗµ©ĪÕ×ŗµĆ¦ĶāĮ
+val_evaluator = [dict(type='HmeanIOUMetric')]
+
+# µŁżÕż¢’╝īMMOCR õ╣¤µö»µīüńøĖÕÉīõ╗╗ÕŖĪõĖŗńÜäÕżÜń¦ŹµīćµĀćń╗äÕÉłĶ»äµĄŗ’╝īÕ”éÕÉīµŚČõĮ┐ńö© WordMetric ÕÅŖ CharMetric
+val_evaluator = [
+ dict(type='WordMetric', mode=['exact', 'ignore_case', 'ignore_case_symbol']),
+ dict(type='CharMetric')
+]
+```
+
+```{tip}
+µø┤ÕżÜĶ»äµĄŗńøĖÕģ│ķģŹńĮ«Ķ»ĘÕÅéĶĆā[Ķ»äµĄŗķģŹńĮ«µĢÖń©ŗ](../user_guides/config.md#Ķ»äµĄŗķģŹńĮ«)ŃĆé
+```
+
+Õ”éõĖŗĶĪ©µēĆńż║’╝īMMOCR ńø«ÕēŹķÆłÕ»╣µ¢ćµ£¼µŻĆµĄŗŃĆüĶ»åÕł½ŃĆüÕÅŖÕģ│ķö«õ┐Īµü»µŖĮÕÅ¢ńŁēõ╗╗ÕŖĪÕģ▒ÕåģńĮ«õ║å 5 ń¦ŹĶ»äµĄŗµīćµĀć’╝īÕłåÕł½õĖ║ `HmeanIOUMetric`’╝ī`WordMetric`’╝ī`CharMetric`’╝ī`OneMinusNEDMetric`’╝īÕÆī `F1Metric`ŃĆé
+
+| | | | |
+| --------------------------------------- | ------------ | ------------------------------------------------- | --------------------------------------------------------------------- |
+| Ķ»äµĄŗµīćµĀć | õ╗╗ÕŖĪń▒╗Õ×ŗ | ĶŠōÕģźÕŁŚµ«Ą | ĶŠōÕć║ÕŁŚµ«Ą |
+| [HmeanIOUMetric](#hmeanioumetric) | µ¢ćµ£¼µŻĆµĄŗ | `pred_polygons`
`pred_scores`
`gt_polygons` | `recall`
`precision`
`hmean` | +| [WordMetric](#wordmetric) | µ¢ćµ£¼Ķ»åÕł½ | `pred_text`
`gt_text` | `word_acc`
`word_acc_ignore_case`
`word_acc_ignore_case_symbol` | +| [CharMetric](#charmetric) | µ¢ćµ£¼Ķ»åÕł½ | `pred_text`
`gt_text` | `char_recall`
`char_precision` | +| [OneMinusNEDMetric](#oneminusnedmetric) | µ¢ćµ£¼Ķ»åÕł½ | `pred_text`
`gt_text` | `1-N.E.D` | +| [F1Metric](#f1metric) | Õģ│ķö«õ┐Īµü»µŖĮÕÅ¢ | `pred_labels`
`gt_labels` | `macro_f1`
`micro_f1` | + +ķĆÜÕĖĖµØźĶ»┤’╝īµ»ÅõĖĆń▒╗õ╗╗ÕŖĪµēĆķććńö©ńÜäĶ»äµĄŗµĀćÕćåµś»ń║”Õ«Üõ┐ŚµłÉńÜä’╝īńö©µłĘõĖĆĶł¼µŚĀķĪ╗µĘ▒Õģźõ║åĶ¦Żµł¢µēŗÕŖ©õ┐«µö╣Ķ»äµĄŗµ¢╣µ│ĢńÜäÕåģķā©Õ«×ńÄ░ŃĆéńäČĶĆī’╝īõĖ║õ║åµ¢╣õŠ┐ńö©µłĘÕ«×ńÄ░µø┤ÕŖĀÕ«ÜÕłČÕī¢ńÜäķ£Ćµ▒é’╝īµ£¼µ¢ćµĪŻÕ░åĶ┐øõĖƵŁźõ╗ŗń╗Źõ║å MMOCR ÕåģńĮ«Ķ»äµĄŗń«Śµ│ĢńÜäÕģĘõĮōÕ«×ńÄ░ńŁ¢ńĢź’╝īõ╗źÕÅŖÕÅ»ķģŹńĮ«ÕÅéµĢ░ŃĆé + +### HmeanIOUMetric + +[HmeanIOUMetric](mmocr.evaluation.metrics.hmean_iou_metric.HmeanIOUMetric) µś»µ¢ćµ£¼µŻĆµĄŗõ╗╗ÕŖĪõĖŁÕ║öńö©µ£ĆÕ╣┐µ│øńÜäĶ»äµĄŗµīćµĀćõ╣ŗõĖĆ’╝īÕøĀÕģČĶ«Īń«Śõ║åµŻĆµĄŗń▓ŠÕ║”’╝łPrecision’╝ēõĖÄÕżÕø×ńÄć’╝łRecall’╝ēõ╣ŗķŚ┤ńÜäĶ░āÕÆīÕ╣│ÕØćµĢ░’╝łHarmonic mean, H-mean’╝ē’╝īµĢģÕŠŚÕÉŹ `HmeanIOUMetric`ŃĆéĶ«░ń▓ŠÕ║”õĖ║ *P*’╝īÕżÕø×ńÄćõĖ║ *R*’╝īÕłÖ `HmeanIOUMetric` ÕÅ»ńö▒õĖŗÕ╝ÅĶ«Īń«ŚÕŠŚÕł░’╝Ü + +```{math} +H = \frac{2}{\frac{1}{P} + \frac{1}{R}} = \frac{2PR}{P+R} +``` + +ÕÅ”Õż¢’╝īńö▒õ║ÄÕģČńŁēõ╗Ęõ║Ä {math}`\beta = 1` µŚČńÜä F-score (ÕÅłń¦░ F-measure µł¢ F-metric)’╝ī`HmeanIOUMetric` µ£ēµŚČõ╣¤Ķó½ÕåÖõĮ£ `F1Metric` µł¢ `f1-score` ńŁē’╝Ü + +```{math} +F_1=(1+\beta^2)\cdot\frac{PR}{\beta^2\cdot P+R} = \frac{2PR}{P+R} +``` + +Õ£© MMOCR ńÜäĶ«ŠĶ«ĪõĖŁ’╝ī`HmeanIOUMetric` ńÜäĶ«Īń«ŚÕÅ»õ╗źµ”éµŗ¼õĖ║õ╗źõĖŗÕćĀõĖ¬µŁźķ¬ż’╝Ü + +1. Ķ┐ćµ╗żµŚĀµĢłńÜäķó䵥ŗĶŠ╣ńĢīńøÆ + + - õŠØµŹ«ńĮ«õ┐ĪÕ║”ķśłÕĆ╝ `pred_score_thrs` Ķ┐ćµ╗żµÄēÕŠŚÕłåĶŠāõĮÄńÜäķó䵥ŗĶŠ╣ńĢīńøÆ + - õŠØµŹ« `ignore_precision_thr` ķśłÕĆ╝Ķ┐ćµ╗żµÄēõĖÄ `ignored` µĀʵ£¼ķćŹÕÉłÕ║”Ķ┐ćķ½śńÜäķó䵥ŗĶŠ╣ńĢīńøÆ + + ÕĆ╝ÕŠŚµ│©µäÅńÜ䵜»’╝ī`pred_score_thrs` ķ╗śĶ«żÕ░å**Ķć¬ÕŖ©µÉ£ń┤ó**õĖĆÕ«ÜĶīāÕø┤ÕåģńÜä**µ£ĆõĮ│ķśłÕĆ╝**’╝īńö©µłĘõ╣¤ÕÅ»õ╗źķĆÜĶ┐ćµēŗÕŖ©õ┐«µö╣ķģŹńĮ«µ¢ćõ╗ČµØźĶć¬Õ«Üõ╣ēµÉ£ń┤óĶīāÕø┤’╝Ü + + ```python + # HmeanIOUMetric ķ╗śĶ«żõ╗ź 0.1 õĖ║µŁźķĢ┐µÉ£ń┤ó [0.3, 0.9] ĶīāÕø┤ÕåģńÜäµ£ĆõĮ│ÕŠŚÕłåķśłÕĆ╝ + val_evaluator = dict(type='HmeanIOUMetric', pred_score_thrs=dict(start=0.3, stop=0.9, step=0.1)) + ``` + +2. Ķ«Īń«Ś IoU ń¤®ķśĄ + + - Õ£©µĢ░µŹ«ÕżäńÉåķśČµ«Ą’╝ī`HmeanIOUMetric` õ╝ÜĶ«Īń«ŚÕ╣Čń╗┤µŖżõĖĆõĖ¬ {math}`M \times N` ńÜä IoU ń¤®ķśĄ `iou_metric`’╝īõ╗źµ¢╣õŠ┐ÕÉÄń╗ŁńÜäĶŠ╣ńĢīńøÆķģŹÕ»╣µŁźķ¬żŃĆéÕģČõĖŁ’╝īM ÕÆī N ÕłåÕł½õĖ║µĀćńŁŠĶŠ╣ńĢīńøÆõĖÄĶ┐ćµ╗żÕÉÄķó䵥ŗĶŠ╣ńĢīńøÆńÜäµĢ░ķćÅŃĆéńö▒µŁż’╝īĶ»źń¤®ķśĄńÜäµ»ÅõĖ¬Õģāń┤ĀķāĮÕŁśµöŠõ║åń¼¼ m õĖ¬µĀćńŁŠĶŠ╣ńĢīńøÆõĖÄń¼¼ n õĖ¬ķó䵥ŗĶŠ╣ńĢīńøÆõ╣ŗķŚ┤ńÜäõ║żÕ╣ȵ»ö’╝łIoU’╝ēŃĆé + +3. Õ¤║õ║ÄńøĖÕ║öńÜäķģŹÕ»╣ńŁ¢ńĢźń╗¤Ķ«ĪĶāĮĶó½ÕćåńĪ«Õī╣ķģŹńÜä GT µĀʵ£¼µĢ░ + + Õ░Įń«Ī `HmeanIOUMetric` ÕÅ»õ╗źńö▒Õø║Õ«ÜńÜäÕģ¼Õ╝ÅĶ«Īń«ŚÕÅ¢ÕŠŚ’╝īõĖŹÕÉīńÜäõ╗╗ÕŖĪµł¢ń«Śµ│ĢÕ║ōÕåģķā©ńÜäÕģĘõĮōÕ«×ńÄ░õ╗ŹÕÅ»ĶāĮÕŁśÕ£©õĖĆõ║øń╗åÕŠ«ÕĘ«Õł½ŃĆéĶ┐Öõ║øÕĘ«Õ╝éõĖ╗Ķ”üõĮōńÄ░Õ£©ķććńö©õĖŹÕÉīńÜäńŁ¢ńĢźµØźÕī╣ķģŹń£¤Õ«×õĖÄķó䵥ŗĶŠ╣ńĢīńøÆ’╝īõ╗ÄĶĆīÕ»╝Ķć┤µ£Ćń╗łÕŠŚÕłåńÜäÕĘ«ĶĘØŃĆéńø«ÕēŹ’╝īMMOCR Õåģķā©ńÜä `HmeanIOUMetric` Õģ▒µö»µīüõĖżń¦ŹõĖŹÕÉīńÜäÕī╣ķģŹńŁ¢ńĢź’╝īÕŹ│ `vanilla` õĖÄ `max_matching`ŃĆéÕ”éõĖŗµēĆńż║’╝īńö©µłĘÕÅ»õ╗źķĆÜĶ┐ćõ┐«µö╣ķģŹńĮ«µ¢ćõ╗ČµØźµīćÕ«ÜõĖŹÕÉīńÜäÕī╣ķģŹńŁ¢ńĢźŃĆé + + - `vanilla` Õī╣ķģŹńŁ¢ńĢź + + `HmeanIOUMetric` ķ╗śĶ«żķććńö© `vanilla` Õī╣ķģŹńŁ¢ńĢź’╝īĶ»źÕ«×ńÄ░õĖÄ MMOCR 0.x ńēłµ£¼õĖŁńÜä `hmean-iou` ÕÅŖ ICDAR ń│╗ÕłŚ**Õ«śµ¢╣µ¢ćµ£¼µŻĆµĄŗń½×ĶĄøńÜäĶ»äµĄŗµĀćÕćåõ┐صīüõĖĆĶć┤**’╝īķććńö©ÕģłÕł░ÕģłÕŠŚńÜäÕī╣ķģŹµ¢╣Õ╝ÅÕ»╣µĀćńŁŠĶŠ╣ńĢīńøÆ’╝łGround-truth bbox’╝ēõĖÄķó䵥ŗĶŠ╣ńĢīńøÆ’╝łPredicted bbox’╝ēĶ┐øĶĪīķģŹÕ»╣ŃĆé + + ```python + # õĖŹµīćÕ«Ü strategy µŚČ’╝īHmeanIOUMetric ķ╗śĶ«żķććńö© 'vanilla' Õī╣ķģŹńŁ¢ńĢź + val_evaluator = dict(type='HmeanIOUMetric') + ``` + + - `max_matching` Õī╣ķģŹńŁ¢ńĢź + + ķÆłÕ»╣ńÄ░µ£ēÕī╣ķģŹµ£║ÕłČõĖŁńÜäõĖŹÕ«īÕ¢äõ╣ŗÕżä’╝īMMOCR ń«Śµ│ĢÕ║ōÕ«×ńÄ░õ║åõĖĆÕźŚµø┤ķ½śµĢłńÜäÕī╣ķģŹńŁ¢ńĢź’╝īńö©õ╗źµ£ĆÕż¦Õī¢Õī╣ķģŹµĢ░ńø«ŃĆé + + ```python + # µīćÕ«Üķććńö© 'max_matching' Õī╣ķģŹńŁ¢ńĢź + val_evaluator = dict(type='HmeanIOUMetric', strategy='max_matching') + ``` + + ```{note} + µłæõ╗¼Õ╗║Ķ««ķØóÕÉæÕŁ”µ£»ńĀöń®ČńÜäÕ╝ĆÕÅæńö©µłĘķććńö©ķ╗śĶ«żńÜä `vanilla` Õī╣ķģŹńŁ¢ńĢź’╝īõ╗źõ┐ØĶ»üõĖÄÕģČõ╗¢Ķ«║µ¢ćńÜäÕ»╣µ»öń╗ōµ×£õ┐صīüõĖĆĶć┤ŃĆéĶĆīķØóÕÉæÕĘźõĖÜÕ║öńö©ńÜäÕ╝ĆÕÅæńö©µłĘÕłÖÕÅ»õ╗źķććńö© `max_matching` Õī╣ķģŹńŁ¢ńĢź’╝īõ╗źĶÄĘÕŠŚń▓ŠÕćåńÜäń╗ōµ×£ŃĆé + ``` + +4. µĀ╣µŹ«õĖŖµ¢ćõ╗ŗń╗ŹńÜä `HmeanIOUMetric` Õģ¼Õ╝ÅĶ«Īń«Śµ£Ćń╗łńÜäĶ»äµĄŗÕŠŚÕłå + +### WordMetric + +[WordMetric](mmocr.evaluation.metrics.recog_metric.WordMetric) Õ«×ńÄ░õ║å**ÕŹĢĶ»Źń║¦Õł½**ńÜäµ¢ćµ£¼Ķ»åÕł½Ķ»äµĄŗµīćµĀć’╝īÕ╣ČÕåģńĮ«õ║å `exact`’╝ī`ignore_case`’╝īÕÅŖ `ignore_case_symbol` õĖēń¦Źµ¢ćµ£¼Õī╣ķģŹµ©ĪÕ╝Å’╝īńö©µłĘÕÅ»õ╗źÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁõ┐«µö╣ `mode` ÕŁŚµ«ĄµØźĶć¬ńö▒ń╗äÕÉłĶŠōÕć║õĖĆń¦Źµł¢ÕżÜń¦Źµ¢ćµ£¼Õī╣ķģŹµ©ĪÕ╝ÅõĖŗńÜä `WordMetric` ÕŠŚÕłåŃĆé + +```python +# Õ£©µ¢ćµ£¼Ķ»åÕł½õ╗╗ÕŖĪõĖŁõĮ┐ńö© WordMetric Ķ»äµĄŗ +val_evaluator = [ + dict(type='WordMetric', mode=['exact', 'ignore_case', 'ignore_case_symbol']) +] +``` + +- `exact`’╝ÜÕģ©Õī╣ķģŹµ©ĪÕ╝Å’╝īÕŹ│’╝īķó䵥ŗõĖĵĀćńŁŠÕ«īÕģ©õĖĆĶć┤µēŹĶāĮĶó½Ķ«░ÕĮĢõĖ║µŁŻńĪ«µĀʵ£¼ŃĆé +- `ignore_case`’╝ÜÕ┐ĮńĢźÕż¦Õ░ÅÕåÖńÜäÕī╣ķģŹµ©ĪÕ╝ÅŃĆé +- `ignore_case_symbol`’╝ÜÕ┐ĮńĢźÕż¦Õ░ÅÕåÖÕÅŖń¼”ÕÅĘńÜäÕī╣ķģŹµ©ĪÕ╝Å’╝īĶ┐Öõ╣¤µś»Õż¦ķā©ÕłåÕŁ”µ£»Ķ«║µ¢ćõĖŁµŖźÕæŖńÜäµ¢ćµ£¼Ķ»åÕł½ÕćåńĪ«ńÄć’╝øMMOCR µŖźÕæŖńÜäĶ»åÕł½µ©ĪÕ×ŗµĆ¦ĶāĮķ╗śĶ«żķććńö©Ķ»źÕī╣ķģŹµ©ĪÕ╝ÅŃĆé + +ÕüćĶ«Šń£¤Õ«×µĀćńŁŠõĖ║ `MMOCR!`’╝īµ©ĪÕ×ŗńÜäĶŠōÕć║ń╗ōµ×£õĖ║ `mmocr`’╝īÕłÖõĖēń¦ŹÕī╣ķģŹµ©ĪÕ╝ÅõĖŗńÜä `WordMetric` ÕŠŚÕłåÕłåÕł½õĖ║’╝Ü`{'exact': 0, 'ignore_case': 0, 'ignore_case_symbol': 1}`ŃĆé + +### CharMetric + +[CharMetric](mmocr.evaluation.metrics.recog_metric.CharMetric) Õ«×ńÄ░õ║å**õĖŹÕī║ÕłåÕż¦Õ░ÅÕåÖ**ńÜä**ÕŁŚń¼”ń║¦Õł½**ńÜäµ¢ćµ£¼Ķ»åÕł½Ķ»äµĄŗµīćµĀćŃĆé + +```python +# Õ£©µ¢ćµ£¼Ķ»åÕł½õ╗╗ÕŖĪõĖŁõĮ┐ńö© CharMetric Ķ»äµĄŗ +val_evaluator = [dict(type='CharMetric')] +``` + +ÕģĘõĮōĶĆīĶ©Ć’╝ī`CharMetric` õ╝ÜĶŠōÕć║õĖżõĖ¬Ķ»äµĄŗĶ»äµĄŗµīćµĀć’╝īÕŹ│ÕŁŚń¼”ń▓ŠÕ║” `char_precision` ÕÆīÕŁŚń¼”ÕżÕø×ńÄć `char_recall`ŃĆéĶ«ŠµŁŻńĪ«ķó䵥ŗńÜäÕŁŚń¼”’╝łTrue Positive’╝ēµĢ░ķćÅõĖ║ {math}`\sigma_{tp}`’╝īÕłÖń▓ŠÕ║” *P* ÕÆīÕżÕø×ńÄć *R* ÕÅ»ńö▒õĖŗÕ╝ÅĶ«Īń«ŚÕÅ¢ÕŠŚ’╝Ü + +```{math} +P=\frac{\sigma_{tp}}{\sigma_{pred}}, R = \frac{\sigma_{tp}}{\sigma_{gt}} +``` + +ÕģČõĖŁ’╝ī{math}`\sigma_{gt}` õĖÄ {math}`\sigma_{pred}` ÕłåÕł½õĖ║µĀćńŁŠµ¢ćµ£¼õĖÄķó䵥ŗµ¢ćµ£¼µēĆÕīģÕɽńÜäÕŁŚń¼”µĆ╗µĢ░ŃĆé + +õŠŗÕ”é’╝īÕüćĶ«ŠµĀćńŁŠµ¢ćµ£¼õĖ║ "MM**O**CR"’╝īķó䵥ŗµ¢ćµ£¼õĖ║ "mm**0**cR**1**"’╝īÕłÖõĮ┐ńö© `CharMetric` Ķ»äµĄŗµīćµĀćńÜäÕŠŚÕłåõĖ║’╝Ü + +```{math} +P=\frac{4}{6}, R=\frac{4}{5} +``` + +### OneMinusNEDMetric + +[`OneMinusNEDMetric(1-N.E.D)`](mmocr.evaluation.metrics.recog_metric.OneMinusNEDMetric) ÕĖĖńö©õ║ÄõĖŁµ¢ćµł¢Ķŗ▒µ¢ć**µ¢ćµ£¼ĶĪīń║¦Õł½**µĀćµ│©ńÜäµ¢ćµ£¼Ķ»åÕł½Ķ»äµĄŗ’╝īõĖŹÕÉīõ║ÄÕģ©Õī╣ķģŹńÜäĶ»äµĄŗµĀćÕćåĶ”üµ▒éķó䵥ŗõĖÄń£¤Õ«×µĀʵ£¼Õ«īÕģ©õĖĆĶć┤’╝īĶ»źĶ»äµĄŗµīćµĀćõĮ┐ńö©ÕĮÆõĖĆÕī¢ńÜä[ń╝¢ĶŠæĶĘØń”╗](https://en.wikipedia.org/wiki/Edit_distance)’╝łEdit Distance’╝īÕÅłÕÉŹĶÄ▒µĖ®µ¢»ÕØ”ĶĘØń”╗ Levenshtein Distance’╝ēµØźµĄŗķćÅķó䵥ŗµ¢ćµ£¼õĖÄń£¤Õ«×µ¢ćµ£¼õ╣ŗķŚ┤ńÜäÕĘ«Õ╝éµĆ¦’╝īõ╗ÄĶĆīÕ£©Ķ»äµĄŗķĢ┐µ¢ćµ£¼µĀʵ£¼µŚČĶāĮÕż¤µø┤ÕźĮÕ£░Õī║ÕłåÕć║µ©ĪÕ×ŗńÜäµĆ¦ĶāĮÕĘ«Õ╝éŃĆéÕüćĶ«Šń£¤Õ«×ÕÆīķó䵥ŗµ¢ćµ£¼ÕłåÕł½õĖ║ {math}`s_i` ÕÆī {math}`\hat{s_i}`’╝īÕģČķĢ┐Õ║”ÕłåÕł½õĖ║ {math}`l_{i}` ÕÆī {math}`\hat{l_i}`’╝īÕłÖ `OneMinusNEDMetric` ÕŠŚÕłåÕÅ»ńö▒õĖŗÕ╝ÅĶ«Īń«ŚÕŠŚÕł░’╝Ü + +```{math} +score = 1 - \frac{1}{N}\sum_{i=1}^{N}\frac{D(s_i, \hat{s_{i}})}{max(l_{i},\hat{l_{i}})} +``` + +ÕģČõĖŁ’╝ī*N* µś»µĀʵ£¼µĆ╗µĢ░’╝ī{math}`D(s_1, s_2)` õĖ║õĖżõĖ¬ÕŁŚń¼”õĖ▓õ╣ŗķŚ┤ńÜäń╝¢ĶŠæĶĘØń”╗ŃĆé + +õŠŗÕ”é’╝īÕüćĶ«Šń£¤Õ«×µĀćńŁŠõĖ║ "OpenMMLabMMOCR"’╝īµ©ĪÕ×ŗ A ńÜäķó䵥ŗń╗ōµ×£õĖ║ "0penMMLabMMOCR", µ©ĪÕ×ŗ B ńÜäķó䵥ŗń╗ōµ×£õĖ║ "uvwxyz"’╝īÕłÖķććńö©Õģ©Õī╣ķģŹÕÆī `OneMinusNEDMetric` Ķ»äµĄŗµīćµĀćńÜäń╗ōµ×£ÕłåÕł½õĖ║: + +| | | | +| ------ | ------ | ---------- | +| | Õģ©Õī╣ķģŹ | 1 - N.E.D. | +| µ©ĪÕ×ŗ A | 0 | 0.92857 | +| µ©ĪÕ×ŗ B | 0 | 0 | + +ńö▒õĖŖĶĪ©ÕÅ»õ╗źÕÅæńÄ░’╝īÕ░Įń«Īµ©ĪÕ×ŗ A õ╗ģķó䵥ŗķöÖõ║åõĖĆõĖ¬ÕŁŚµ»Ź’╝īĶĆīµ©ĪÕ×ŗ B Õģ©ķā©ķó䵥ŗķöÖĶ»»’╝īÕ£©õĮ┐ńö©Õģ©Õī╣ķģŹńÜäĶ»äµĄŗµīćµĀ浌Ȓ╝īĶ┐ÖõĖżõĖ¬µ©ĪÕ×ŗńÜäÕŠŚÕłåķāĮõĖ║0’╝øĶĆīõĮ┐ńö© `OneMinuesNEDMetric` ńÜäĶ»äµĄŗµīćµĀćÕłÖĶāĮÕż¤µø┤ÕźĮÕ£░Õī║Õłåµ©ĪÕ×ŗÕ£©**ķĢ┐µ¢ćµ£¼**õĖŖńÜäµĆ¦ĶāĮÕĘ«Õ╝éŃĆé + +### F1Metric + +[F1Metric](mmocr.evaluation.metrics.f_metric.F1Metric) Õ«×ńÄ░õ║åķÆłÕ»╣ KIE õ╗╗ÕŖĪńÜä F1-Metric Ķ»äµĄŗµīćµĀć’╝īÕ╣ȵÅÉõŠøõ║å `micro` ÕÆī `macro` õĖżń¦ŹĶ»äµĄŗµ©ĪÕ╝ÅŃĆé + +```python +val_evaluator = [ + dict(type='F1Metric', mode=['micro', 'macro'], +] +``` + +- `micro` µ©ĪÕ╝Å’╝ÜõŠØµŹ« True Positive’╝īFalse Negative’╝īÕÅŖ False Positive µĆ╗µĢ░µØźĶ«Īń«ŚÕģ©Õ▒Ć F1-Metric ÕŠŚÕłåŃĆé + +- `macro` µ©ĪÕ╝Å’╝ÜõŠØµŹ«ń▒╗Õł½µĀćńŁŠĶ«Īń«Śµ»ÅõĖĆń▒╗ńÜä F1-Metric’╝īÕ╣ȵ▒éÕ╣│ÕØćÕĆ╝ŃĆé + +### Ķć¬Õ«Üõ╣ēĶ»äµĄŗµīćµĀć + +Õ»╣õ║ÄĶ┐Įµ▒éµø┤ķ½śÕ«ÜÕłČÕī¢ÕŖ¤ĶāĮńÜäńö©µłĘ’╝īMMOCR õ╣¤µö»µīüĶć¬Õ«Üõ╣ēÕ«×ńÄ░õĖŹÕÉīń▒╗Õ×ŗńÜäĶ»äµĄŗµīćµĀćŃĆéõĖĆĶł¼µØźĶ»┤’╝īńö©µłĘÕŬķ£ĆĶ”üµ¢░Õ╗║Ķć¬Õ«Üõ╣ēĶ»äµĄŗµīćµĀćń▒╗ `CustomizedMetric` Õ╣Čń╗¦µē┐ {external+mmengine:doc}`MMEngine: BaseMetric`’╝īńäČÕÉÄÕłåÕł½ķćŹÕåÖµĢ░µŹ«µĀ╝Õ╝ÅÕżäńÉåµ¢╣µ│Ģ `process` õ╗źÕÅŖµīćµĀćĶ«Īń«Śµ¢╣µ│Ģ `compute_metrics`ŃĆéµ£ĆÕÉÄ’╝īÕ░åÕģČÕŖĀÕģź `METRICS` µ│©ÕåīÕÖ©ÕŹ│ÕŻի×ńÄ░õ╗╗µäÅÕ«ÜÕłČÕī¢ńÜäĶ»äµĄŗµīćµĀćŃĆé
+
+```python
+from mmengine.evaluator import BaseMetric
+from mmocr.registry import METRICS
+
+@METRICS.register_module()
+class CustomizedMetric(BaseMetric):
+
+ def process(self, data_batch: Sequence[Dict], predictions: Sequence[Dict]):
+ """ process µÄźµöČõĖżõĖ¬ÕÅéµĢ░’╝īÕłåÕł½õĖ║ data_batch ÕŁśµöŠń£¤Õ«×µĀćńŁŠõ┐Īµü»’╝īõ╗źÕÅŖ predictions
+ ÕŁśµöŠķó䵥ŗń╗ōµ×£ŃĆéprocess µ¢╣µ│ĢĶ┤¤Ķ┤ŻÕ░åµĀćńŁŠõ┐Īµü»ĶĮ¼µŹóÕ╣ČÕŁśµöŠĶć│ self.results ÕÅśķćÅõĖŁ
+ """
+ pass
+
+ def compute_metrics(self, results: List):
+ """ compute_metric õĮ┐ńö©ń╗ÅĶ┐ć process µ¢╣µ│ĢÕżäńÉåĶ┐ćńÜäµĀćńŁŠµĢ░µŹ«Ķ«Īń«Śµ£Ćń╗łĶ»äµĄŗÕŠŚÕłå
+ """
+ pass
+```
+
+```{note}
+µø┤ÕżÜÕåģÕ«╣ÕÅ»ÕÅéĶ¦ü {external+mmengine:doc}`MMEngine µ¢ćµĪŻ: BaseMetric `ŃĆé
+```
diff --git a/internlm_langchain/knowledge_base/MMOCR/content/inference.md b/internlm_langchain/knowledge_base/MMOCR/content/inference.md
new file mode 100644
index 00000000..7b69dcee
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMOCR/content/inference.md
@@ -0,0 +1,534 @@
+# µÄ©ńÉå
+
+Õ£© OpenMMLab õĖŁ’╝īµēƵ£ēńÜäµÄ©ńÉåµōŹõĮ£ķāĮĶó½ń╗¤õĖĆÕł░õ║åµÄ©ńÉåÕÖ© `Inferencer` õĖŁŃĆéµÄ©ńÉåÕÖ©Ķó½Ķ«ŠĶ«ĪµłÉõĖ║õĖĆõĖ¬ń«Ćµ┤üµśōńö©ńÜä API’╝īÕ«āÕ£©õĖŹÕÉīńÜä OpenMMLab Õ║ōõĖŁķāĮµ£ēńØĆķØ×ÕĖĖńøĖõ╝╝ńÜäµÄźÕÅŻŃĆé
+
+MMOCR õĖŁÕŁśÕ£©õĖżń¦ŹõĖŹÕÉīńÜäµÄ©ńÉåÕÖ©’╝Ü
+
+- **µĀćÕćåµÄ©ńÉåÕÖ©**’╝ÜMMOCR õĖŁńÜäµ»ÅõĖ¬Õ¤║µ£¼õ╗╗ÕŖĪķāĮµ£ēõĖĆõĖ¬µĀćÕćåµÄ©ńÉåÕÖ©’╝īÕŹ│ `TextDetInferencer`’╝łµ¢ćµ£¼µŻĆµĄŗ’╝ē’╝ī`TextRecInferencer`’╝łµ¢ćµ£¼Ķ»åÕł½’╝ē’╝ī`TextSpottingInferencer`’╝łń½»Õł░ń½» OCR’╝ē ÕÆī `KIEInferencer`’╝łÕģ│ķö«õ┐Īµü»µÅÉÕÅ¢’╝ēŃĆéÕ«āõ╗¼Õģʵ£ēķØ×ÕĖĖńøĖõ╝╝ńÜäµÄźÕÅŻ’╝īÕģʵ£ēµĀćÕćåńÜäĶŠōÕģź/ĶŠōÕć║ÕŹÅĶ««’╝īÕ╣ČõĖöµĆ╗õĮōķüĄÕŠ¬ OpenMMLab ńÜäĶ«ŠĶ«ĪŃĆéĶ┐Öõ║øµÄ©ńÉåÕÖ©õ╣¤ÕÅ»õ╗źĶó½õĖ▓ĶüöÕ£©õĖĆĶĄĘ’╝īõ╗źõŠ┐Õ»╣õĖĆń│╗ÕłŚõ╗╗ÕŖĪĶ┐øĶĪīµÄ©ńÉåŃĆé
+- **MMOCRInferencer**’╝ܵłæõ╗¼Ķ┐śµÅÉõŠøõ║å `MMOCRInferencer`’╝īõĖĆõĖ¬õĖōķŚ©õĖ║ MMOCR Ķ«ŠĶ«ĪńÜäõŠ┐µŹĘµÄ©ńÉåµÄźÕÅŻŃĆéÕ«āÕ░üĶŻģÕÆīķōŠµÄźõ║å MMOCR õĖŁńÜäµēƵ£ēµÄ©ńÉåÕÖ©’╝īÕøĀµŁżńö©µłĘÕÅ»õ╗źõĮ┐ńö©µŁżµÄ©ńÉåÕÖ©Õ»╣ÕøŠÕāŵē¦ĶĪīõĖĆń│╗ÕłŚõ╗╗ÕŖĪ’╝īÕ╣Čńø┤µÄźĶÄĘÕŠŚµ£Ćń╗łń╗ōµ×£ŃĆé*õĮåµś»’╝īÕ«āńÜäµÄźÕÅŻõĖĵĀćÕćåµÄ©ńÉåÕÖ©µ£ēõĖĆõ║øõĖŹÕÉī’╝īÕ╣ČõĖöõĖ║õ║åń«ĆÕŹĢĶĄĘĶ¦ü’╝īÕÅ»ĶāĮõ╝Üńē║ńē▓õĖĆõ║øµĀćÕćåńÜäµÄ©ńÉåÕÖ©ÕŖ¤ĶāĮŃĆé*
+
+Õ»╣õ║ĵ¢░ńö©µłĘ’╝īµłæõ╗¼Õ╗║Ķ««õĮ┐ńö© **MMOCRInferencer** µØźµĄŗĶ»ĢõĖŹÕÉīµ©ĪÕ×ŗńÜäń╗äÕÉłŃĆé
+
+Õ”éµ×£õĮĀµś»Õ╝ĆÕÅæõ║║ÕæśÕ╣ČÕĖīµ£øÕ░嵩ĪÕ×ŗķøåµłÉÕł░Ķć¬ÕĘ▒ńÜäķĪ╣ńø«õĖŁ’╝īµłæõ╗¼Õ╗║Ķ««õĮ┐ńö©**µĀćÕćåµÄ©ńÉåÕÖ©**’╝īÕøĀõĖ║Õ«āõ╗¼µø┤ńüĄµ┤╗õĖöµĀćÕćåÕī¢’╝īÕ╣ČÕģʵ£ēÕ«īµĢ┤ńÜäÕŖ¤ĶāĮŃĆé
+
+## Õ¤║ńĪĆńö©µ│Ģ
+
+`````{tabs}
+
+````{group-tab} MMOCRInferencer
+
+ńø«ÕēŹ’╝ī`MMOCRInferencer` ÕÅ»õ╗źÕ»╣õ╗źõĖŗõ╗╗ÕŖĪĶ┐øĶĪīµÄ©ńÉå’╝Ü
+
+- µ¢ćµ£¼µŻĆµĄŗ
+- µ¢ćµ£¼Ķ»åÕł½
+- OCR’╝łµ¢ćµ£¼µŻĆµĄŗ + µ¢ćµ£¼Ķ»åÕł½’╝ē
+- Õģ│ķö«õ┐Īµü»µÅÉÕÅ¢’╝łµ¢ćµ£¼µŻĆµĄŗ + µ¢ćµ£¼Ķ»åÕł½ + Õģ│ķö«õ┐Īµü»µÅÉÕÅ¢’╝ē
+- *OCR’╝łtext spotting’╝ē*’╝łÕŹ│Õ░åµÄ©Õć║’╝ē
+
+õĖ║õ║åõŠ┐õ║ÄõĮ┐ńö©’╝ī`MMOCRInferencer` ÕÉæńö©µłĘµÅÉõŠøõ║å Python µÄźÕÅŻÕÆīÕæĮõ╗żĶĪīµÄźÕÅŻŃĆéõŠŗÕ”é’╝īÕ”éµ×£õĮĀµā│Ķ”üÕ»╣ demo/demo_text_ocr.jpg Ķ┐øĶĪī OCR µÄ©ńÉå’╝īõĮ┐ńö© `DBNet` õĮ£õĖ║µ¢ćµ£¼µŻĆµĄŗµ©ĪÕ×ŗ’╝ī`CRNN` õĮ£õĖ║µ¢ćµ£¼Ķ»åÕł½µ©ĪÕ×ŗ’╝īÕŬķ£Ćµē¦ĶĪīõ╗źõĖŗÕæĮõ╗ż:
+
+::::{tabs}
+
+:::{code-tab} python
+>>> from mmocr.apis import MMOCRInferencer
+>>> # Ķ»╗ÕÅ¢µ©ĪÕ×ŗ
+>>> ocr = MMOCRInferencer(det='DBNet', rec='SAR')
+>>> # Ķ┐øĶĪīµÄ©ńÉåÕ╣ČÕÅ»Ķ¦åÕī¢ń╗ōµ×£
+>>> ocr('demo/demo_text_ocr.jpg', show=True)
+:::
+
+:::{code-tab} bash ÕæĮõ╗żĶĪī
+python tools/infer.py demo/demo_text_ocr.jpg --det DBNet --rec SAR --show
+:::
+::::
+
+ÕÅ»Ķ¦åÕī¢ń╗ōµ×£Õ░åĶó½µśŠńż║Õ£©õĖĆõĖ¬µ¢░ń¬ŚÕÅŻõĖŁ’╝Ü
+
+
+ +ÕÅ»õ╗źĶ¦üÕł░’╝īMMOCRInferencer ńÜä Python µÄźÕÅŻõĖÄÕæĮõ╗żĶĪīµÄźÕÅŻńÜäõĮ┐ńö©µ¢╣µ│ĢķØ×ÕĖĖńøĖõ╝╝ŃĆéõĖŗµ¢ćÕ░åõ╗ź Python µÄźÕÅŻõĖ║õŠŗ’╝īõ╗ŗń╗Ź MMOCRInferencer ńÜäÕģĘõĮōńö©µ│ĢŃĆéÕģ│õ║ÄÕæĮõ╗żĶĪīµÄźÕÅŻńÜäµø┤ÕżÜõ┐Īµü»’╝īĶ»ĘÕÅéĶĆā [ÕæĮõ╗żĶĪīµÄźÕÅŻ](#ÕæĮõ╗żĶĪīµÄźÕÅŻ)ŃĆé + + +```` + +````{group-tab} µĀćÕćåµÄ©ńÉåÕÖ© + +ķĆÜÕĖĖ’╝īOpenMMLab õĖŁńÜäµēƵ£ēµĀćÕćåµÄ©ńÉåÕÖ©ķāĮÕģʵ£ēķØ×ÕĖĖńøĖõ╝╝ńÜäµÄźÕÅŻŃĆéõĖŗķØóńÜäõŠŗÕŁÉÕ▒Ģńż║õ║åÕ”éõĮĢõĮ┐ńö© `TextDetInferencer` Õ»╣ÕŹĢõĖ¬ÕøŠÕāÅĶ┐øĶĪīµÄ©ńÉåŃĆé + +```python +>>> from mmocr.apis import TextDetInferencer +>>> # Ķ»╗ÕÅ¢µ©ĪÕ×ŗ +>>> inferencer = TextDetInferencer(model='DBNet') +>>> # µÄ©ńÉå +>>> inferencer('demo/demo_text_ocr.jpg', show=True) +``` + +ÕÅ»Ķ¦åÕī¢ń╗ōµ×£Õ”éÕøŠ’╝Ü + +
+ +µŁżÕżäÕłŚõĖŠõ║åõĖĆõ║øÕĖĖĶ¦üńÜäÕłØÕ¦ŗÕī¢µ©ĪÕ×ŗńÜäµ¢╣µ│ĢŃĆé + +- õĮĀÕÅ»õ╗źķĆÜĶ┐ćõ╝ĀķĆƵ©ĪÕ×ŗńÜäÕÉŹń¦░ń╗Ö `model` µØźµÄ©ńÉå MMOCR ńÜäķóäĶ«Łń╗āµ©ĪÕ×ŗŃĆéµØāķćŹÕ░åõ╝ÜĶć¬ÕŖ©õ╗Ä OpenMMLab ńÜ䵩ĪÕ×ŗÕ║ōõĖŁõĖŗĶĮĮÕ╣ČÕŖĀĶĮĮŃĆé + + ```python + >>> from mmocr.apis import TextDetInferencer + >>> inferencer = TextDetInferencer(model='DBNet') + ``` + + ```{note} + µ©ĪÕ×ŗõĖĵĩńÉåÕÖ©ńÜäõ╗╗ÕŖĪń¦Źń▒╗Õ┐ģķĪ╗Õī╣ķģŹŃĆé + ``` + + õĮĀÕÅ»õ╗źķĆÜĶ┐ćÕ░åµØāķćŹńÜäĶĘ»ÕŠäµł¢ URL õ╝ĀķĆÆń╗Ö `weights` µØźĶ«®µÄ©ńÉåÕÖ©ÕŖĀĶĮĮĶć¬Õ«Üõ╣ēńÜäµØāķćŹŃĆé + + ```python + >>> inferencer = TextDetInferencer(model='DBNet', weights='path/to/dbnet.pth') + ``` + +- Õ”éµ×£µ£ēĶć¬Õ«Üõ╣ēńÜäķģŹńĮ«ÕÆīµØāķ插╝īõĮĀÕÅ»õ╗źÕ░åķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠäõ╝ĀķĆÆń╗Ö `model`’╝īÕ░åµØāķćŹńÜäĶĘ»ÕŠäõ╝ĀķĆÆń╗Ö `weights`ŃĆé + + ```python + >>> inferencer = TextDetInferencer(model='path/to/dbnet_config.py', weights='path/to/dbnet.pth') + ``` + +- ķ╗śĶ«żµāģÕåĄõĖŗ’╝ī[MMEngine](https://github.com/open-mmlab/mmengine/) õ╝ÜÕ£©Ķ«Łń╗āµ©ĪÕ×ŗµŚČĶć¬ÕŖ©Õ░åķģŹńĮ«µ¢ćõ╗ČĶĮ¼Õé©Õł░µØāķ揵¢ćõ╗ČõĖŁŃĆéÕ”éµ×£õĮĀµ£ēõĖĆõĖ¬Õ£© MMEngine õĖŖĶ«Łń╗āńÜäµØāķ插╝īõĮĀõ╣¤ÕÅ»õ╗źÕ░åµØāķ揵¢ćõ╗ČńÜäĶĘ»ÕŠäõ╝ĀķĆÆń╗Ö `weights`’╝īĶĆīõĖŹķ£ĆĶ”üµīćÕ«Ü `model`’╝Ü + + ```python + >>> # Õ”éµ×£µŚĀµ│ĢÕ£©µØāķćŹõĖŁµēŠÕł░ķģŹńĮ«µ¢ćõ╗Č’╝īÕłÖõ╝ÜÕ╝ĢÕÅæķöÖĶ»» + >>> inferencer = TextDetInferencer(weights='path/to/dbnet.pth') + ``` + +- õ╝ĀķĆÆķģŹńĮ«µ¢ćõ╗ČÕł░ `model` ĶĆīõĖŹµīćÕ«Ü `weight` ÕłÖõ╝Üõ║¦ńö¤õĖĆõĖ¬ķÜŵ£║ÕłØÕ¦ŗÕī¢ńÜ䵩ĪÕ×ŗŃĆé + +```` +````` + +### µÄ©ńÉåĶ«ŠÕżć + +µ»ÅõĖ¬µÄ©ńÉåÕÖ©Õ«×õŠŗķāĮõ╝ÜĶʤõĖĆõĖ¬Ķ«ŠÕżćń╗æÕ«ÜŃĆéķ╗śĶ«żµāģÕåĄõĖŗ’╝īµ£ĆõĮ│Ķ«ŠÕżćµś»ńö▒ [MMEngine](https://github.com/open-mmlab/mmengine/) Ķć¬ÕŖ©Õå│Õ«ÜńÜäŃĆéõĮĀõ╣¤ÕÅ»õ╗źķĆÜĶ┐ćµīćÕ«Ü `device` ÕÅéµĢ░µØźµö╣ÕÅśĶ«ŠÕżćŃĆéõŠŗÕ”é’╝īõĮĀÕÅ»õ╗źõĮ┐ńö©õ╗źõĖŗõ╗ŻńĀüÕ£© GPU 1õĖŖÕłøÕ╗║õĖĆõĖ¬µÄ©ńÉåÕÖ©ŃĆé + +`````{tabs} + +````{group-tab} MMOCRInferencer + +```python +>>> inferencer = MMOCRInferencer(det='DBNet', device='cuda:1') +``` + +```` + +````{group-tab} µĀćÕćåµÄ©ńÉåÕÖ© + +```python +>>> inferencer = TextDetInferencer(model='DBNet', device='cuda:1') +``` + +```` + +````` + +Õ”éĶ”üÕ£© CPU õĖŖÕłøÕ╗║õĖĆõĖ¬µÄ©ńÉåÕÖ©’╝Ü + +`````{tabs} + +````{group-tab} MMOCRInferencer + +```python +>>> inferencer = MMOCRInferencer(det='DBNet', device='cpu') +``` + +```` + +````{group-tab} µĀćÕćåµÄ©ńÉåÕÖ© + +```python +>>> inferencer = TextDetInferencer(model='DBNet', device='cpu') +``` + +```` + +````` + +Ķ»ĘÕÅéĶĆā [torch.device](torch.device) õ║åĶ¦Ż `device` ÕÅéµĢ░µö»µīüńÜäµēƵ£ēÕĮóÕ╝ÅŃĆé + +## µÄ©ńÉå + +ÕĮōµÄ©ńÉåÕÖ©ÕłØÕ¦ŗÕī¢ÕÉÄ’╝īõĮĀÕÅ»õ╗źńø┤µÄźõ╝ĀÕģźĶ”üµÄ©ńÉåńÜäÕĤզŗµĢ░µŹ«’╝īõ╗ÄĶ┐öÕø×ÕĆ╝õĖŁĶÄĘÕÅ¢µÄ©ńÉåń╗ōµ×£ŃĆé + +### ĶŠōÕģź + +`````{tabs} + +````{tab} MMOCRInferencer / TextDetInferencer / TextRecInferencer / TextSpottingInferencer + +ĶŠōÕģźÕÅ»õ╗źµś»õ╗źõĖŗõ╗╗µäÅõĖĆń¦ŹµĀ╝Õ╝Å’╝Ü + +- str: ÕøŠÕāÅńÜäĶĘ»ÕŠä/URLŃĆé + + ```python + >>> inferencer('demo/demo_text_ocr.jpg') + ``` + +- array: ÕøŠÕāÅńÜä numpy µĢ░ń╗äŃĆéÕ«āÕ║öĶ»źµś» BGR µĀ╝Õ╝ÅŃĆé + + ```python + >>> import mmcv + >>> array = mmcv.imread('demo/demo_text_ocr.jpg') + >>> inferencer(array) + ``` + +- list: Õ¤║µ£¼ń▒╗Õ×ŗńÜäÕłŚĶĪ©ŃĆéÕłŚĶĪ©õĖŁńÜäµ»ÅõĖ¬Õģāń┤ĀķāĮÕ░åÕŹĢńŗ¼ÕżäńÉåŃĆé + + ```python + >>> inferencer(['img_1.jpg', 'img_2.jpg]) + >>> # ÕłŚĶĪ©ÕåģµĘĘÕÉłń▒╗Õ×ŗõ╣¤µś»ÕģüĶ«ĖńÜä + >>> inferencer(['img_1.jpg', array]) + ``` + +- str: ńø«ÕĮĢńÜäĶĘ»ÕŠäŃĆéńø«ÕĮĢõĖŁńÜäµēƵ£ēÕøŠÕāÅķāĮÕ░åĶó½ÕżäńÉåŃĆé + + ```python + >>> inferencer('tests/data/det_toy_dataset/imgs/test/') + ``` + +```` + +````{tab} KIEInferencer + +ĶŠōÕģźÕÅ»õ╗źµś»õĖĆõĖ¬ÕŁŚÕģĖµł¢ĶĆģõĖĆõĖ¬ÕŁŚÕģĖÕłŚĶĪ©’╝īÕģČõĖŁµ»ÅõĖ¬ÕŁŚÕģĖÕīģÕɽõ╗źõĖŗķö«’╝Ü + +- `img` (str µł¢ĶĆģ ndarray): ÕøŠÕāÅńÜäĶĘ»ÕŠäµł¢ÕøŠÕāŵ£¼Ķ║½ŃĆéÕ”éµ×£ KIE µÄ©ńÉåÕÖ©Õ£©µŚĀÕÅ»Ķ¦åµ©ĪÕ╝ÅõĖŗõĮ┐ńö©’╝īÕłÖõĖŹķ£ĆĶ”üµŁżķö«ŃĆéÕ”éµ×£Õ«āµś»õĖĆõĖ¬ numpy µĢ░ń╗ä’╝īÕłÖÕ║öĶ»źµś» BGR ķĪ║Õ║Åń╝¢ńĀüńÜäÕøŠńēćŃĆé +- `img_shape` (tuple(int, int)): ÕøŠÕāÅńÜäÕĮóńŖČ (H, W)ŃĆéõ╗ģÕ£© KIE µÄ©ńÉåÕÖ©Õ£©µŚĀÕÅ»Ķ¦åµ©ĪÕ╝ÅõĖŗõĮ┐ńö©õĖöµ▓Īµ£ēµÅÉõŠø `img` µŚČµēŹķ£ĆĶ”üŃĆé +- `instances` (list[dict]): Õ«×õŠŗÕłŚĶĪ©ŃĆé + +µ»ÅõĖ¬ `instance` ķāĮÕ║öĶ»źÕīģÕɽõ╗źõĖŗķö«’╝Ü + +```python +{ + # õĖĆõĖ¬ÕĄīÕźŚÕłŚĶĪ©’╝īÕģČõĖŁÕīģÕɽ 4 õĖ¬µĢ░ÕŁŚ’╝īĶĪ©ńż║Õ«×õŠŗńÜäĶŠ╣ńĢīµĪå’╝īķĪ║Õ║ÅõĖ║ (x1, y1, x2, y2) + "bbox": np.array([[x1, y1, x2, y2], [x1, y1, x2, y2], ...], + dtype=np.int32), + + # µ¢ćµ£¼ÕłŚĶĪ© + "texts": ['text1', 'text2', ...], +} +``` + +```` +````` + +### ĶŠōÕć║ + +ķ╗śĶ«żµāģÕåĄõĖŗ’╝īµ»ÅõĖ¬µÄ©ńÉåÕÖ©ķāĮõ╗źÕŁŚÕģĖµĀ╝Õ╝ÅĶ┐öÕø×ķó䵥ŗń╗ōµ×£ŃĆé + +- `visualization` ÕīģÕɽÕÅ»Ķ¦åÕī¢ńÜäķó䵥ŗń╗ōµ×£ŃĆéõĮåķ╗śĶ«żµāģÕåĄõĖŗ’╝īÕ«āµś»õĖĆõĖ¬ń®║ÕłŚĶĪ©’╝īķÖżķØ× `return_vis=True`ŃĆé + +- `predictions` ÕīģÕɽõ╗ź json-ÕÅ»Õ║ÅÕłŚÕī¢µĀ╝Õ╝ÅĶ┐öÕø×ńÜäķó䵥ŗń╗ōµ×£ŃĆéÕ”éõĖŗµēĆńż║’╝īÕåģÕ«╣ÕøĀõ╗╗ÕŖĪń▒╗Õ×ŗĶĆīÕ╝éŃĆé + + `````{tabs} + + :::{group-tab} MMOCRInferencer + + ```python + { + 'predictions' : [ + # µ»ÅõĖ¬Õ«×õŠŗķāĮÕ»╣Õ║öõ║ÄõĖĆõĖ¬ĶŠōÕģźÕøŠÕāÅ + { + 'det_polygons': [...], # 2d ÕłŚĶĪ©’╝īķĢ┐Õ║”õĖ║ (N,)’╝īµĀ╝Õ╝ÅõĖ║ [x1, y1, x2, y2, ...] + 'det_scores': [...], # µĄ«ńé╣ÕłŚĶĪ©’╝īķĢ┐Õ║”õĖ║’╝łN, ’╝ē + 'det_bboxes': [...], # 2d ÕłŚĶĪ©’╝īÕĮóńŖČõĖ║ (N, 4)’╝īµĀ╝Õ╝ÅõĖ║ [min_x, min_y, max_x, max_y] + 'rec_texts': [...], # ÕŁŚń¼”õĖ▓ÕłŚĶĪ©’╝īķĢ┐Õ║”õĖ║’╝łN, ’╝ē + 'rec_scores': [...], # µĄ«ńé╣ÕłŚĶĪ©’╝īķĢ┐Õ║”õĖ║’╝łN, ’╝ē + 'kie_labels': [...], # ĶŖéńé╣µĀćńŁŠ’╝īķĢ┐Õ║”õĖ║ (N, ) + 'kie_scores': [...], # ĶŖéńé╣ńĮ«õ┐ĪÕ║”’╝īķĢ┐Õ║”õĖ║ (N, ) + 'kie_edge_scores': [...], # ĶŠ╣ķó䵥ŗńĮ«õ┐ĪÕ║”, ÕĮóńŖČõĖ║ (N, N) + 'kie_edge_labels': [...] # ĶŠ╣µĀćńŁŠ, ÕĮóńŖČõĖ║ (N, N) + }, + ... + ], + 'visualization' : [ + array(..., dtype=uint8), + ] + } + ``` + + ::: + + ````{group-tab} µĀćÕćåµÄ©ńÉåÕÖ© + + ::::{tabs} + :::{code-tab} python TextDetInferencer + + { + 'predictions' : [ + # µ»ÅõĖ¬Õ«×õŠŗķāĮÕ»╣Õ║öõ║ÄõĖĆõĖ¬ĶŠōÕģźÕøŠÕāÅ + { + 'polygons': [...], # 2d ÕłŚĶĪ©’╝īķĢ┐Õ║”õĖ║ (N,)’╝īµĀ╝Õ╝ÅõĖ║ [x1, y1, x2, y2, ...] + 'bboxes': [...], # 2d ÕłŚĶĪ©’╝īÕĮóńŖČõĖ║ (N, 4)’╝īµĀ╝Õ╝ÅõĖ║ [min_x, min_y, max_x, max_y] + 'scores': [...] # µĄ«ńé╣ÕłŚĶĪ©’╝īķĢ┐Õ║”õĖ║’╝łN, ’╝ē + }, + ... + ] + 'visualization' : [ + array(..., dtype=uint8), + ] + } + ::: + + :::{code-tab} python TextRecInferencer + { + 'predictions' : [ + # µ»ÅõĖ¬Õ«×õŠŗķāĮÕ»╣Õ║öõ║ÄõĖĆõĖ¬ĶŠōÕģźÕøŠÕāÅ + { + 'text': '...', # ÕŁŚń¼”õĖ▓ + 'scores': 0.1, # µĄ«ńé╣ + }, + ... + ] + 'visualization' : [ + array(..., dtype=uint8), + ] + } + ::: + + :::{code-tab} python TextSpottingInferencer + { + 'predictions' : [ + # µ»ÅõĖ¬Õ«×õŠŗķāĮÕ»╣Õ║öõ║ÄõĖĆõĖ¬ĶŠōÕģźÕøŠÕāÅ + { + 'polygons': [...], # 2d ÕłŚĶĪ©’╝īķĢ┐Õ║”õĖ║ (N,)’╝īµĀ╝Õ╝ÅõĖ║ [x1, y1, x2, y2, ...] + 'bboxes': [...], # 2d ÕłŚĶĪ©’╝īÕĮóńŖČõĖ║ (N, 4)’╝īµĀ╝Õ╝ÅõĖ║ [min_x, min_y, max_x, max_y] + 'scores': [...] # µĄ«ńé╣ÕłŚĶĪ©’╝īķĢ┐Õ║”õĖ║’╝łN, ’╝ē + 'texts': ['...',] # ÕŁŚń¼”õĖ▓ÕłŚĶĪ©’╝īķĢ┐Õ║”õĖ║’╝łN, ’╝ē + }, + ] + 'visualization' : [ + array(..., dtype=uint8), + ] + } + ::: + + :::{code-tab} python KIEInferencer + { + 'predictions' : [ + # µ»ÅõĖ¬Õ«×õŠŗķāĮÕ»╣Õ║öõ║ÄõĖĆõĖ¬ĶŠōÕģźÕøŠÕāÅ + { + 'labels': [...], # ĶŖéńé╣µĀćńŁŠ’╝īķĢ┐Õ║”õĖ║ (N, ) + 'scores': [...], # ĶŖéńé╣ńĮ«õ┐ĪÕ║”’╝īķĢ┐Õ║”õĖ║ (N, ) + 'edge_scores': [...], # ĶŠ╣ķó䵥ŗńĮ«õ┐ĪÕ║”, ÕĮóńŖČõĖ║ (N, N) + 'edge_labels': [...], # ĶŠ╣µĀćńŁŠ, ÕĮóńŖČõĖ║ (N, N) + }, + ] + 'visualization' : [ + array(..., dtype=uint8), + ] + } + ::: + :::: + ```` + + ````` + +Õ”éµ×£õĮĀµā│Ķ”üõ╗ĵ©ĪÕ×ŗõĖŁĶÄĘÕÅ¢ÕĤզŗĶŠōÕć║’╝īÕÅ»õ╗źÕ░å `return_datasamples` Ķ«ŠńĮ«õĖ║ `True` µØźĶÄĘÕÅ¢ÕĤզŗńÜä [DataSample](structures.md)’╝īÕ«āÕ░åÕŁśÕé©Õ£© `predictions` õĖŁŃĆé + +### Õé©ÕŁśń╗ōµ×£ + +ķÖżõ║åõ╗ÄĶ┐öÕø×ÕĆ╝õĖŁĶÄĘÕÅ¢ķó䵥ŗń╗ōµ×£’╝īõĮĀĶ┐śÕÅ»õ╗źķĆÜĶ┐ćĶ«ŠńĮ« `out_dir` ÕÆī `save_pred`/`save_vis` ÕÅéµĢ░Õ░åķó䵥ŗń╗ōµ×£ÕÆīÕÅ»Ķ¦åÕī¢ń╗ōµ×£Õ»╝Õć║Õł░µ¢ćõ╗ČõĖŁŃĆé + +```python +>>> inferencer('img_1.jpg', out_dir='outputs/', save_pred=True, save_vis=True) +``` + +ń╗ōµ×£ńø«ÕĮĢń╗ōµ×äÕ”éõĖŗ’╝Ü + +```text +outputs +Ōö£ŌöĆŌöĆ preds +Ōöé ŌööŌöĆŌöĆ img_1.json +ŌööŌöĆŌöĆ vis + ŌööŌöĆŌöĆ img_1.jpg +``` + +µ¢ćõ╗ČÕÉŹõĖÄÕ»╣Õ║öńÜäĶŠōÕģźÕøŠÕāŵ¢ćõ╗ČÕÉŹńøĖÕÉīŃĆé Õ”éµ×£ĶŠōÕģźÕøŠÕāŵś»µĢ░ń╗ä’╝īÕłÖµ¢ćõ╗ČÕÉŹÕ░åµś»õ╗Ä0Õ╝ĆÕ¦ŗńÜäµĢ░ÕŁŚŃĆé + +### µē╣ķćŵĩńÉå + +õĮĀÕÅ»õ╗źķĆÜĶ┐ćĶ«ŠńĮ« `batch_size` µØźĶć¬Õ«Üõ╣ēµē╣ķćŵĩńÉåńÜäµē╣Õż¦Õ░ÅŃĆé ķ╗śĶ«żµē╣Õż¦Õ░ÅõĖ║ 1ŃĆé + +## API + +Ķ┐ÖķćīÕłŚÕć║õ║åµÄ©ńÉåÕÖ©Ķ»”Õ░ĮńÜäÕÅéµĢ░ÕłŚĶĪ©ŃĆé + +````{tabs} + +```{group-tab} MMOCRInferencer + +**MMOCRInferencer.\_\_init\_\_():** + +| ÕÅéµĢ░ | ń▒╗Õ×ŗ | ķ╗śĶ«żÕĆ╝ | µÅÅĶ┐░ | +| ------------- | ----------------------------------------- | ------ | ------------------------------------------------------------------------------------------------------------------------------ | +| `det` | str µł¢ [µØāķćŹ](../modelzoo.html#id2), ÕÅ»ķĆē | None | ķóäĶ«Łń╗āńÜäµ¢ćµ£¼µŻĆµĄŗń«Śµ│ĢŃĆéÕ«āµś»ķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠäµł¢ĶĆģµś» metafile õĖŁÕ«Üõ╣ēńÜ䵩ĪÕ×ŗÕÉŹń¦░ŃĆé | +| `det_weights` | str, ÕÅ»ķĆē | None | det µ©ĪÕ×ŗńÜäµØāķ揵¢ćõ╗ČńÜäĶĘ»ÕŠäŃĆé | +| `rec` | str µł¢ [µØāķćŹ](../modelzoo.html#id2), ÕÅ»ķĆē | None | ķóäĶ«Łń╗āńÜäµ¢ćµ£¼Ķ»åÕł½ń«Śµ│ĢŃĆéÕ«āµś»ķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠäµł¢ĶĆģµś» metafile õĖŁÕ«Üõ╣ēńÜ䵩ĪÕ×ŗÕÉŹń¦░ŃĆé | +| `rec_weights` | str, ÕÅ»ķĆē | None | rec µ©ĪÕ×ŗńÜäµØāķ揵¢ćõ╗ČńÜäĶĘ»ÕŠäŃĆé | +| `kie` \[1\] | str µł¢ [µØāķćŹ](../modelzoo.html#id2), ÕÅ»ķĆē | None | ķóäĶ«Łń╗āńÜäÕģ│ķö«õ┐Īµü»µÅÉÕÅ¢ń«Śµ│ĢŃĆéÕ«āµś»ķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠäµł¢ĶĆģµś» metafile õĖŁÕ«Üõ╣ēńÜ䵩ĪÕ×ŗÕÉŹń¦░ŃĆé | +| `kie_weights` | str, ÕÅ»ķĆē | None | kie µ©ĪÕ×ŗńÜäµØāķ揵¢ćõ╗ČńÜäĶĘ»ÕŠäŃĆé | +| `device` | str, ÕÅ»ķĆē | None | µÄ©ńÉåõĮ┐ńö©ńÜäĶ«ŠÕżć’╝īµÄźÕÅŚ `torch.device` ÕģüĶ«ĖńÜäµēƵ£ēÕŁŚń¼”õĖ▓ŃĆéõŠŗÕ”é’╝ī'cuda:0' µł¢ 'cpu'ŃĆéÕ”éµ×£õĖ║ None’╝īÕ░åĶć¬ÕŖ©õĮ┐ńö©ÕÅ»ńö©Ķ«ŠÕżćŃĆé ķ╗śĶ«żõĖ║ NoneŃĆé | + +\[1\]: ÕĮōÕÉīµŚČµīćÕ«Üõ║åµ¢ćµ£¼µŻĆµĄŗÕÆīĶ»åÕł½µ©ĪÕ×ŗµŚČ’╝ī`kie` µēŹõ╝Üńö¤µĢłŃĆé + +**MMOCRInferencer.\_\_call\_\_()** + +| ÕÅéµĢ░ | ń▒╗Õ×ŗ | ķ╗śĶ«żÕĆ╝ | µÅÅĶ┐░ | +| -------------------- | ----------------------- | ---------- | ---------------------------------------------------------------------------------------------- | +| `inputs` | str/list/tuple/np.array | **Õ┐ģķ£Ć** | Õ«āÕÅ»õ╗źµś»õĖĆõĖ¬ÕøŠńēć/µ¢ćõ╗ČÕż╣ńÜäĶĘ»ÕŠä’╝īõĖĆõĖ¬ numpy µĢ░ń╗ä’╝īµł¢ĶĆģµś»õĖĆõĖ¬ÕīģÕɽÕøŠńēćĶĘ»ÕŠäµł¢ numpy µĢ░ń╗äńÜäÕłŚĶĪ©/Õģāń╗ä | +| `return_datasamples` | bool | False | µś»ÕÉ”Õ░åń╗ōµ×£õĮ£õĖ║ DataSample Ķ┐öÕø×ŃĆéÕ”éµ×£õĖ║ False’╝īń╗ōµ×£Õ░åĶó½µēōÕīģµłÉõĖĆõĖ¬ÕŁŚÕģĖŃĆé | +| `batch_size` | int | 1 | µÄ©ńÉåńÜäµē╣Õż¦Õ░ÅŃĆé | +| `det_batch_size` | int, ÕÅ»ķĆē | None | µÄ©ńÉåńÜäµē╣Õż¦Õ░Å (µ¢ćµ£¼µŻĆµĄŗµ©ĪÕ×ŗ)ŃĆéÕ”éµ×£õĖŹõĖ║ None’╝īÕłÖĶ”åńø¢ batch_sizeŃĆé | +| `rec_batch_size` | int, ÕÅ»ķĆē | None | µÄ©ńÉåńÜäµē╣Õż¦Õ░Å (µ¢ćµ£¼Ķ»åÕł½µ©ĪÕ×ŗ)ŃĆéÕ”éµ×£õĖŹõĖ║ None’╝īÕłÖĶ”åńø¢ batch_sizeŃĆé | +| `kie_batch_size` | int, ÕÅ»ķĆē | None | µÄ©ńÉåńÜäµē╣Õż¦Õ░Å (Õģ│ķö«õ┐Īµü»µÅÉÕÅ¢µ©ĪÕ×ŗ)ŃĆéÕ”éµ×£õĖŹõĖ║ None’╝īÕłÖĶ”åńø¢ batch_sizeŃĆé | +| `return_vis` | bool | False | µś»ÕÉ”Ķ┐öÕø×ÕÅ»Ķ¦åÕī¢ń╗ōµ×£ŃĆé | +| `print_result` | bool | False | µś»ÕÉ”Õ░åµÄ©ńÉåń╗ōµ×£µēōÕŹ░Õł░µÄ¦ÕłČÕÅ░ŃĆé | +| `show` | bool | False | µś»Õɔգ©Õ╝╣Õć║ń¬ŚÕÅŻõĖŁµśŠńż║ÕÅ»Ķ¦åÕī¢ń╗ōµ×£ŃĆé | +| `wait_time` | float | 0 | Õ╝╣ń¬ŚÕ▒Ģńż║ÕÅ»Ķ¦åÕī¢ń╗ōµ×£ńÜ䵌ČķŚ┤ķŚ┤ķÜöŃĆé | +| `out_dir` | str | `results/` | ń╗ōµ×£ńÜäĶŠōÕć║ńø«ÕĮĢŃĆé | +| `save_vis` | bool | False | µś»ÕÉ”Õ░åÕÅ»Ķ¦åÕī¢ń╗ōµ×£õ┐ØÕŁśÕł░ `out_dir`ŃĆé | +| `save_pred` | bool | False | µś»ÕÉ”Õ░åµÄ©ńÉåń╗ōµ×£õ┐ØÕŁśÕł░ `out_dir`ŃĆé | + +``` + +```{group-tab} µĀćÕćåµÄ©ńÉåÕÖ© + +**Inferencer.\_\_init\_\_():** + +| ÕÅéµĢ░ | ń▒╗Õ×ŗ | ķ╗śĶ«żÕĆ╝ | µÅÅĶ┐░ | +| --------- | ----------------------------------------- | ------ | ---------------------------------------------------------------------------------------------------------------------------------- | +| `model` | str µł¢ [µØāķćŹ](../modelzoo.html#id2), ÕÅ»ķĆē | None | ĶĘ»ÕŠäÕł░ķģŹńĮ«µ¢ćõ╗ȵł¢ĶĆģÕ£© metafile õĖŁÕ«Üõ╣ēńÜ䵩ĪÕ×ŗÕÉŹń¦░ŃĆé | +| `weights` | str, ÕÅ»ķĆē | None | µØāķ揵¢ćõ╗ČńÜäĶĘ»ÕŠäŃĆé | +| `device` | str, ÕÅ»ķĆē | None | µÄ©ńÉåõĮ┐ńö©ńÜäĶ«ŠÕżć’╝īµÄźÕÅŚ `torch.device` ÕģüĶ«ĖńÜäµēƵ£ēÕŁŚń¼”õĖ▓ŃĆé õŠŗÕ”é’╝ī'cuda:0' µł¢ 'cpu'ŃĆé Õ”éµ×£õĖ║ None’╝īÕłÖÕ░åĶć¬ÕŖ©õĮ┐ńö©ÕÅ»ńö©Ķ«ŠÕżćŃĆé ķ╗śĶ«żõĖ║ NoneŃĆé | + +**Inferencer.\_\_call\_\_()** + +| ÕÅéµĢ░ | ń▒╗Õ×ŗ | ķ╗śĶ«żÕĆ╝ | µÅÅĶ┐░ | +| -------------------- | ----------------------- | ---------- | ----------------------------------------------------------------------------------- | +| `inputs` | str/list/tuple/np.array | **Õ┐ģķ£Ć** | ÕÅ»õ╗źµś»ÕøŠÕāÅńÜäĶĘ»ÕŠä/µ¢ćõ╗ČÕż╣’╝īnp µĢ░ń╗䵳¢ÕłŚĶĪ©/Õģāń╗ä’╝łÕĖ”µ£ēÕøŠÕāÅĶĘ»ÕŠäµł¢ np µĢ░ń╗ä’╝ē | +| `return_datasamples` | bool | False | µś»ÕÉ”Õ░åń╗ōµ×£õĮ£õĖ║ DataSamples Ķ┐öÕø×ŃĆé Õ”éµ×£õĖ║ False’╝īÕłÖń╗ōµ×£Õ░åĶó½µēōÕīģÕł░õĖĆõĖ¬ dict õĖŁŃĆé | +| `batch_size` | int | 1 | µÄ©ńÉåµē╣Õż¦Õ░ÅŃĆé | +| `progress_bar` | bool | True | µś»ÕÉ”µśŠńż║Ķ┐øÕ║”µØĪŃĆé | +| `return_vis` | bool | False | µś»ÕÉ”Ķ┐öÕø×ÕÅ»Ķ¦åÕī¢ń╗ōµ×£ŃĆé | +| `print_result` | bool | False | µś»ÕÉ”Õ░åµÄ©ńÉåń╗ōµ×£µēōÕŹ░Õł░µÄ¦ÕłČÕÅ░ŃĆé | +| `show` | bool | False | µś»Õɔգ©Õ╝╣Õć║ń¬ŚÕÅŻõĖŁµśŠńż║ÕÅ»Ķ¦åÕī¢ń╗ōµ×£ŃĆé | +| `wait_time` | float | 0 | Õ╝╣ń¬ŚÕ▒Ģńż║ÕÅ»Ķ¦åÕī¢ń╗ōµ×£ńÜ䵌ČķŚ┤ķŚ┤ķÜöŃĆé | +| `draw_pred` | bool | True | µś»ÕÉ”ń╗śÕłČķó䵥ŗńÜäĶŠ╣ńĢīµĪåŃĆé *õ╗ģķĆéńö©õ║Ä `TextDetInferencer` ÕÆī `TextSpottingInferencer`ŃĆé* | +| `out_dir` | str | `results/` | ń╗ōµ×£ńÜäĶŠōÕć║ńø«ÕĮĢŃĆé | +| `save_vis` | bool | False | µś»ÕÉ”Õ░åÕÅ»Ķ¦åÕī¢ń╗ōµ×£õ┐ØÕŁśÕł░ `out_dir`ŃĆé | +| `save_pred` | bool | False | µś»ÕÉ”Õ░åµÄ©ńÉåń╗ōµ×£õ┐ØÕŁśÕł░ `out_dir`ŃĆé | + +``` +```` + +## ÕæĮõ╗żĶĪīµÄźÕÅŻ + +```{note} +Ķ»źĶŖéõ╗ģķĆéńö©õ║Ä `MMOCRInferencer`. +``` + +`MMOCRInferencer` ńÜäÕæĮõ╗żĶĪīÕĮóÕ╝ÅÕÅ»õ╗źķĆÜĶ┐ć `tools/infer.py` Ķ░āńö©’╝īÕż¦Ķć┤ÕĮóÕ╝ÅÕ”éõĖŗ’╝Ü + +```bash +python tools/infer.py INPUT_PATH [--det DET] [--det-weights ...] ... +``` + +ÕģČõĖŁ’╝ī`INPUT_PATH` õĖ║Õ┐ģķĪ╗ÕŁŚµ«Ą’╝īÕåģÕ«╣Õ║öÕĮōõĖ║µīćÕÉæÕøŠńē浳¢µ¢ćõ╗Čńø«ÕĮĢńÜäĶĘ»ÕŠäŃĆéÕģČõ╗¢ÕÅéµĢ░õĖÄ Python µÄźÕÅŻķüĄÕŠ¬ńÜ䵜ĀÕ░äÕģ│ń│╗Õ”éõĖŗ’╝Ü + +- Õ£©ÕæĮõ╗żĶĪīõĖŁĶ░āńö©ÕÅéµĢ░µŚČ’╝īķ£ĆĶ”üÕ£© Python µÄźÕÅŻńÜäÕÅéµĢ░ÕēŹķØóÕŖĀõĖŖõĖżõĖ¬`-`’╝īńäČÕÉĵŖŖõĖŗÕłÆń║┐`_`µø┐µŹóµłÉĶ┐×ÕŁŚń¼”`-`ŃĆéõŠŗÕ”é’╝ī `out_dir` õ╝ÜÕÅśµłÉ `--out-dir`ŃĆé +- Õ»╣õ║ÄÕĖāÕ░öń▒╗Õ×ŗńÜäÕÅéµĢ░’╝īÕ░åÕÅéµĢ░µöŠÕ£©ÕæĮõ╗żõĖŁÕ░▒ńøĖÕĮōõ║ÄÕ░åÕģȵīćÕ«ÜõĖ║ TrueŃĆéõŠŗÕ”é’╝ī `--show` õ╝ÜÕ░å `show` ÕÅéµĢ░µīćÕ«ÜõĖ║ TrueŃĆé + +µŁżÕż¢’╝īÕæĮõ╗żĶĪīõĖŁķ╗śĶ«żõĖŹõ╝ÜÕø×µśŠµÄ©ńÉåń╗ōµ×£’╝īõĮĀÕÅ»õ╗źķĆÜĶ┐ć `--print-result` ÕÅéµĢ░µØźµ¤źń£ŗµÄ©ńÉåń╗ōµ×£ŃĆé + +õĖŗķØ󵜻õĖĆõĖ¬õŠŗÕŁÉ’╝Ü + +```bash +python tools/infer.py demo/demo_text_ocr.jpg --det DBNet --rec SAR --show --print-result +``` + +Ķ┐ÉĶĪīĶ»źÕæĮõ╗ż’╝īÕÅ»õ╗źÕŠŚÕł░Õ”éõĖŗń╗ōµ×£’╝Ü + +```bash +{'predictions': [{'rec_texts': ['CBank', 'Docbcba', 'GROUP', 'MAUN', 'CROBINSONS', 'AOCOC', '916M3', 'BOO9', 'Oven', 'BRANDS', 'ARETAIL', '14', '70S', 'ROUND', 'SALE', 'YEAR', 'ALLY', 'SALE', 'SALE'],
+'rec_scores': [0.9753464579582214, ...], 'det_polygons': [[551.9930285844646, 411.9138765335083, 553.6153911653112,
+383.53195309638977, 620.2410061195247, 387.33785033226013, 618.6186435386782, 415.71977376937866], ...], 'det_scores': [0.8230461478233337, ...]}]}
+```
diff --git a/internlm_langchain/knowledge_base/MMOCR/content/install.md b/internlm_langchain/knowledge_base/MMOCR/content/install.md
new file mode 100644
index 00000000..47e2da19
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMOCR/content/install.md
@@ -0,0 +1,244 @@
+# Õ«ēĶŻģ
+
+## ńÄ»ÕóāõŠØĶĄ¢
+
+- Linux | Windows | macOS
+- Python 3.7
+- PyTorch 1.6 µł¢µø┤ķ½śńēłµ£¼
+- torchvision 0.7.0
+- CUDA 10.1
+- NCCL 2
+- GCC 5.4.0 µł¢µø┤ķ½śńēłµ£¼
+
+## ÕćåÕżćńÄ»Õóā
+
+```{note}
+Õ”éµ×£õĮĀÕĘ▓ń╗ÅÕ£©µ£¼Õ£░Õ«ēĶŻģõ║å PyTorch’╝īĶ»Ęńø┤µÄźĶĘ│ĶĮ¼Õł░[Õ«ēĶŻģµŁźķ¬ż](#Õ«ēĶŻģµŁźķ¬ż)ŃĆé
+```
+
+**ń¼¼õĖƵŁź** õĖŗĶĮĮÕ╣ČÕ«ēĶŻģ [Miniconda](https://docs.conda.io/en/latest/miniconda.html).
+
+**ń¼¼õ║īµŁź** ÕłøÕ╗║Õ╣ȵ┐Ƶ┤╗õĖĆõĖ¬ conda ńÄ»Õóā’╝Ü
+
+```shell
+conda create --name openmmlab python=3.8 -y
+conda activate openmmlab
+```
+
+**ń¼¼õĖēµŁź** õŠØńģ¦[Õ«śµ¢╣µīćÕŹŚ](https://pytorch.org/get-started/locally/)’╝īÕ«ēĶŻģ PyTorchŃĆé
+
+````{tabs}
+
+```{code-tab} shell GPU Õ╣│ÕÅ░
+conda install pytorch torchvision -c pytorch
+```
+
+```{code-tab} shell CPU Õ╣│ÕÅ░
+conda install pytorch torchvision cpuonly -c pytorch
+```
+
+````
+
+## Õ«ēĶŻģµŁźķ¬ż
+
+µłæõ╗¼Õ╗║Ķ««Õż¦ÕżÜµĢ░ńö©µłĘķććńö©µłæõ╗¼ńÜäµÄ©ĶŹÉµ¢╣Õ╝ÅÕ«ēĶŻģ MMOCRŃĆéÕĆśĶŗźõĮĀķ£ĆĶ”üµø┤ńüĄµ┤╗ńÜäÕ«ēĶŻģĶ┐ćń©ŗ’╝īÕłÖÕÅ»õ╗źÕÅéĶĆā[Ķć¬Õ«Üõ╣ēÕ«ēĶŻģ](#Ķć¬Õ«Üõ╣ēÕ«ēĶŻģ)õĖĆĶŖéŃĆé
+
+### µÄ©ĶŹÉµŁźķ¬ż
+
+**ń¼¼õĖƵŁź** õĮ┐ńö© [MIM](https://github.com/open-mmlab/mim) Õ«ēĶŻģ [MMEngine](https://github.com/open-mmlab/mmengine)’╝ī [MMCV](https://github.com/open-mmlab/mmcv) ÕÆī [MMDetection](https://github.com/open-mmlab/mmdetection)ŃĆé
+
+```shell
+pip install -U openmim
+mim install mmengine
+mim install mmcv
+mim install mmdet
+```
+
+**ń¼¼õ║īµŁź** Õ«ēĶŻģ MMOCR.
+
+ĶŗźõĮĀķ£ĆĶ”üńø┤µÄźĶ┐ÉĶĪī MMOCR µł¢Õ£©ÕģČÕ¤║ńĪĆõĖŖĶ┐øĶĪīÕ╝ĆÕÅæ’╝īÕłÖķĆÜĶ┐ćµ║ÉńĀüÕ«ēĶŻģ’╝łµÄ©ĶŹÉ’╝ēŃĆé
+
+Õ”éµ×£õĮĀÕ░å MMOCR õĮ£õĖ║õĖĆõĖ¬Õż¢ńĮ«õŠØĶĄ¢Õ║ōõĮ┐ńö©’╝īÕłÖÕÅ»õ╗źķĆÜĶ┐ć MIM Õ«ēĶŻģŃĆé
+
+`````{tabs}
+
+````{group-tab} µ║ÉńĀüÕ«ēĶŻģ
+
+```shell
+git clone https://github.com/open-mmlab/mmocr.git
+cd mmocr
+pip install -v -e .
+# "-v" õ╝ÜĶ«®Õ«ēĶŻģĶ┐ćń©ŗõ║¦ńö¤µø┤Ķ»”ń╗åńÜäĶŠōÕć║
+# "-e" õ╝Üõ╗źÕÅ»ń╝¢ĶŠæńÜäµ¢╣Õ╝ÅÕ«ēĶŻģĶ»źõ╗ŻńĀüÕ║ō’╝īõĮĀÕ»╣Ķ»źõ╗ŻńĀüÕ║ōµēĆõĮ£ńÜäõ╗╗õĮĢµø┤µö╣ķāĮõ╝Üń½ŗÕŹ│ńö¤µĢł
+```
+
+````
+
+````{group-tab} MIM Õ«ēĶŻģ
+
+```shell
+
+mim install mmocr
+
+```
+
+````
+
+`````
+
+**ń¼¼õĖēµŁź’╝łÕÅ»ķĆē’╝ē** Õ”éµ×£õĮĀķ£ĆĶ”üõĮ┐ńö©õĖÄ `albumentations` µ£ēÕģ│ńÜäÕÅśµŹó’╝łÕ”é ABINet µĢ░µŹ«µĄüµ░┤ń║┐õĖŁńÜä `Albu`’╝ē’╝īµł¢ķ£ĆĶ”üµ×äÕ╗║µ¢ćµĪŻŃĆüĶ┐ÉĶĪīÕŹĢÕģāµĄŗĶ»ĢńÜäõŠØĶĄ¢’╝īĶ»ĘõĮ┐ńö©õ╗źõĖŗÕæĮõ╗żÕ«ēĶŻģõŠØĶĄ¢’╝Ü
+
+`````{tabs}
+
+````{group-tab} µ║ÉńĀüÕ«ēĶŻģ
+
+```shell
+# Õ«ēĶŻģ albu
+pip install -r requirements/albu.txt
+# Õ«ēĶŻģµ¢ćµĪŻŃĆüµĄŗĶ»ĢńŁēõŠØĶĄ¢
+pip install -r requirements.txt
+```
+
+````
+
+````{group-tab} MIM Õ«ēĶŻģ
+
+```shell
+pip install albumentations>=1.1.0 --no-binary qudida,albumentations
+```
+
+````
+
+`````
+
+```{note}
+
+µłæõ╗¼Õ╗║Ķ««Õ£©Õ«ēĶŻģ `albumentations` õ╣ŗÕÉĵŻĆµ¤źÕĮōÕēŹńÄ»Õóā’╝īńĪ«õ┐Ø `opencv-python` ÕÆī `opencv-python-headless` µ▓Īµ£ēÕÉīµŚČĶó½Õ«ēĶŻģ’╝īÕÉ”ÕłÖµ£ēÕÅ»ĶāĮõ╝Üõ║¦ńö¤õĖĆõ║øµŚĀµ│Ģķóäń¤źńÜäķöÖĶ»»ŃĆéÕ”éµ×£Õ«āõ╗¼õĖŹÕʦÕÉīµŚČÕŁśÕ£©õ║ÄńÄ»ÕóāÕĮōõĖŁ’╝īĶ»ĘÕŹĖĶĮĮ `opencv-python-headless` õ╗źńĪ«õ┐Ø MMOCR ńÜäÕÅ»Ķ¦åÕī¢ÕĘźÕģĘÕÅ»õ╗źµŁŻÕĖĖĶ┐ÉĶĪīŃĆé
+
+µ¤źń£ŗ [`albumentations` ńÜäÕ«śµ¢╣µ¢ćµĪŻ](https://albumentations.ai/docs/getting_started/installation/#note-on-opencv-dependencies)õ╗źĶÄĘń¤źĶ»”µāģŃĆé
+
+```
+
+### µŻĆķ¬ī
+
+õĮĀÕÅ»õ╗źķĆÜĶ┐ćĶ┐ÉĶĪīõĖĆõĖ¬ń«ĆÕŹĢńÜäµÄ©ńÉåõ╗╗ÕŖĪµØźµŻĆķ¬ī MMOCR ńÜäÕ«ēĶŻģµś»ÕÉ”µłÉÕŖ¤ŃĆé
+
+`````{tabs}
+
+````{tab} Python
+
+Õ£© Python õĖŁĶ┐ÉĶĪīõ╗źõĖŗõ╗ŻńĀü’╝Ü
+
+```python
+>>> from mmocr.apis import MMOCRInferencer
+>>> ocr = MMOCRInferencer(det='DBNet', rec='CRNN')
+>>> ocr('demo/demo_text_ocr.jpg', show=True, print_result=True)
+```
+````
+
+````{tab} Shell
+
+Õ”éµ×£õĮĀµś»ķĆÜĶ┐ćµ║ÉńĀüÕ«ēĶŻģńÜä MMOCR’╝īõĮĀÕÅ»õ╗źÕ£© MMOCR ńÜäµĀ╣ńø«ÕĮĢõĖŗĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗ż’╝Ü
+
+```shell
+python tools/infer.py demo/demo_text_ocr.jpg --det DBNet --rec CRNN --show --print-result
+```
+````
+
+`````
+
+Ķŗź MMOCR ńÜäÕ«ēĶŻģµŚĀĶ»»’╝īõĮĀÕ£©Ķ┐ÖõĖĆĶŖéÕ«īµłÉÕÉÄÕ║öÕĮōĶāĮń£ŗÕł░õ╗źÕøŠńēćÕÆīµ¢ćÕŁŚÕĮóÕ╝ÅĶĪ©ńż║ńÜäĶ»åÕł½ń╗ōµ×£’╝Ü
+
+
+ +```bash +# Ķ»åÕł½ń╗ōµ×£ +{'predictions': [{'rec_texts': ['cbanks', 'docecea', 'grouf', 'pwate', 'chobnsonsg', 'soxee', 'oeioh', 'c', 'sones', 'lbrandec', 'sretalg', '11', 'to8', 'round', 'sale', 'year', +'ally', 'sie', 'sall'], 'rec_scores': [...], 'det_polygons': [...], 'det_scores': +[...]}]} +``` + +```{note} +Õ”éµ×£õĮĀÕ£©µ▓Īµ£ē GUI ńÜäµ£ŹÕŖĪÕÖ©õĖŖĶ┐ÉĶĪī MMOCR’╝īµł¢ĶĆģķĆÜĶ┐ćµ▓Īµ£ēÕ╝ĆÕÉ» X11 ĶĮ¼ÕÅæńÜä SSH ķܦķüōĶ┐ÉĶĪī MMOCR’╝īõĮĀÕÅ»ĶāĮµŚĀµ│Ģń£ŗÕł░Õ╝╣Õć║ńÜäń¬ŚÕÅŻŃĆé +``` + +## Ķć¬Õ«Üõ╣ēÕ«ēĶŻģ + +### CUDA ńēłµ£¼ + +Õ«ēĶŻģ PyTorch µŚČ’╝īķ£ĆĶ”üµīćÕ«Ü CUDA ńēłµ£¼ŃĆéÕ”éµ×£µé©õĖŹµĖģµźÜķĆēµŗ®Õō¬õĖ¬’╝īĶ»ĘķüĄÕŠ¬µłæõ╗¼ńÜäÕ╗║Ķ««’╝Ü + +- Õ»╣õ║Ä Ampere µ×ȵ×äńÜä NVIDIA GPU’╝īõŠŗÕ”é GeForce 30 series õ╗źÕÅŖ NVIDIA A100’╝īCUDA 11 µś»Õ┐ģķ£ĆńÜäŃĆé +- Õ»╣õ║ĵø┤µŚ®ńÜä NVIDIA GPU’╝īCUDA 11 µś»ÕÉæÕēŹÕģ╝Õ«╣ńÜä’╝īõĮå CUDA 10.2 ĶāĮÕż¤µÅÉõŠøµø┤ÕźĮńÜäÕģ╝Õ«╣µĆ¦’╝īõ╣¤µø┤ÕŖĀĶĮ╗ķćÅŃĆé + +Ķ»ĘńĪ«õ┐ØõĮĀńÜä GPU ķ®▒ÕŖ©ńēłµ£¼µ╗ĪĶČ│µ£ĆõĮÄńÜäńēłµ£¼ķ£Ćµ▒é’╝īÕÅéķśģ[Ķ┐ÖÕ╝ĀĶĪ©](https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html#cuda-major-component-versions__table-cuda-toolkit-driver-versions)ŃĆé + +```{note} +Õ”éµ×£µīēńģ¦µłæõ╗¼ńÜäµ£ĆõĮ│Õ«×ĶĘĄĶ┐øĶĪīÕ«ēĶŻģ’╝īCUDA Ķ┐ÉĶĪīµŚČÕ║ōÕ░▒ĶČ│Õż¤õ║å’╝īÕøĀõĖ║µłæõ╗¼µÅÉõŠøńøĖÕģ│ CUDA õ╗ŻńĀüńÜäķóäń╝¢Ķ»æ’╝īõĮĀõĖŹķ£ĆĶ”üĶ┐øĶĪīµ£¼Õ£░ń╝¢Ķ»æŃĆé +õĮåÕ”éµ×£õĮĀÕĖīµ£øõ╗ĵ║ÉńĀüĶ┐øĶĪī MMCV ńÜäń╝¢Ķ»æ’╝īµł¢µś»Ķ┐øĶĪīÕģČõ╗¢ CUDA ń«ŚÕŁÉńÜäÕ╝ĆÕÅæ’╝īķéŻõ╣łÕ░▒Õ┐ģķĪ╗Õ«ēĶŻģÕ«īµĢ┤ńÜä CUDA ÕĘźÕģĘķōŠ’╝īÕÅéĶ¦ü +[NVIDIA Õ«śńĮæ](https://developer.nvidia.com/cuda-downloads)’╝īÕÅ”Õż¢Ķ┐śķ£ĆĶ”üńĪ«õ┐ØĶ»ź CUDA ÕĘźÕģĘķōŠńÜäńēłµ£¼õĖÄ PyTorch Õ«ēĶŻģµŚČ +ńÜäķģŹńĮ«ńøĖÕī╣ķģŹ’╝łÕ”éńö© `conda install` Õ«ēĶŻģ PyTorch µŚČµīćÕ«ÜńÜä cudatoolkit ńēłµ£¼’╝ēŃĆé +``` + +### õĖŹõĮ┐ńö© MIM Õ«ēĶŻģ MMCV + +MMCV ÕīģÕɽ C++ ÕÆī CUDA µē®Õ▒Ģ’╝īÕøĀµŁżÕģČÕ»╣ PyTorch ńÜäõŠØĶĄ¢µ»öĶŠāÕżŹµØéŃĆéMIM õ╝ÜĶć¬ÕŖ©Ķ¦Żµ×ÉĶ┐Öõ║ø +õŠØĶĄ¢’╝īķĆēµŗ®ÕÉłķĆéńÜä MMCV ķóäń╝¢Ķ»æÕīģ’╝īõĮ┐Õ«ēĶŻģµø┤ń«ĆÕŹĢ’╝īõĮåÕ«āÕ╣ČõĖŹµś»Õ┐ģķ£ĆńÜäŃĆé + +Ķ”üõĮ┐ńö© pip ĶĆīõĖŹµś» MIM µØźÕ«ēĶŻģ MMCV’╝īĶ»ĘķüĄńģ¦ [MMCV Õ«ēĶŻģµīćÕŹŚ](https://mmcv.readthedocs.io/zh_CN/latest/get_started/installation.html)ŃĆé +Õ«āķ£ĆĶ”üõĮĀńö©µīćÕ«Ü url ńÜäÕĮóÕ╝ŵēŗÕŖ©µīćÕ«ÜÕ»╣Õ║öńÜä PyTorch ÕÆī CUDA ńēłµ£¼ŃĆé + +õĖŠõĖ¬õŠŗÕŁÉ’╝īÕ”éõĖŗÕæĮõ╗żÕ░åõ╝ÜÕ«ēĶŻģÕ¤║õ║Ä PyTorch 1.10.x ÕÆī CUDA 11.3 ń╝¢Ķ»æńÜä mmcv-fullŃĆé + +```shell +pip install 'mmcv>=2.0.0rc1' -f https://download.openmmlab.com/mmcv/dist/cu113/torch1.10/index.html +``` + +### Õ£© CPU ńÄ»ÕóāõĖŁÕ«ēĶŻģ + +MMOCR ÕÅ»õ╗źõ╗ģÕ£© CPU ńÄ»ÕóāõĖŁÕ«ēĶŻģ’╝īÕ£© CPU µ©ĪÕ╝ÅõĖŗ’╝īõĮĀÕÅ»õ╗źÕ«īµłÉĶ«Łń╗ā’╝łķ£ĆĶ”ü MMCV ńēłµ£¼ >= 1.4.4’╝ēŃĆüµĄŗĶ»ĢÕÆīµ©ĪÕ×ŗµÄ©ńÉåńŁēµēƵ£ēµōŹõĮ£ŃĆé + +Õ£© CPU µ©ĪÕ╝ÅõĖŗ’╝īMMCV õĖŁńÜäõ╗źõĖŗń«ŚÕŁÉÕ░åõĖŹÕÅ»ńö©’╝Ü + +- Deformable Convolution +- Modulated Deformable Convolution +- ROI pooling +- SyncBatchNorm + +Õ”éµ×£õĮĀÕ░ØĶ»ĢõĮ┐ńö©ńö©Õł░õ║åõ╗źõĖŖń«ŚÕŁÉńÜ䵩ĪÕ×ŗĶ┐øĶĪīĶ«Łń╗āŃĆüµĄŗĶ»Ģµł¢µÄ©ńÉå’╝īń©ŗÕ║ÅÕ░åõ╝ܵŖźķöÖŃĆéõ╗źõĖŗõĖ║ÕÅ»ĶāĮÕÅŚÕł░ÕĮ▒ÕōŹńÜ䵩ĪÕ×ŗÕłŚĶĪ©’╝Ü + +| ń«ŚÕŁÉ | µ©ĪÕ×ŗ | +| :-----------------------------------------------------: | :-----------------------------------------------------: | +| Deformable Convolution/Modulated Deformable Convolution | DBNet (r50dcnv2), DBNet++ (r50dcnv2), FCENet (r50dcnv2) | +| SyncBatchNorm | PANet, PSENet | + +### ķĆÜĶ┐ć Docker õĮ┐ńö© MMOCR + +µłæõ╗¼µÅÉõŠøõ║åõĖĆõĖ¬ [Dockerfile](https://github.com/open-mmlab/mmocr/blob/master/docker/Dockerfile) µ¢ćõ╗Čõ╗źÕ╗║ń½ŗ docker ķĢ£ÕāÅ ŃĆé + +```shell +# build an image with PyTorch 1.6, CUDA 10.1 +docker build -t mmocr docker/ +``` + +õĮ┐ńö©õ╗źõĖŗÕæĮõ╗żĶ┐ÉĶĪīŃĆé + +```shell +docker run --gpus all --shm-size=8g -it -v {Õ«×ķÖģµĢ░µŹ«ńø«ÕĮĢ}:/mmocr/data mmocr +``` + +## Õ»╣ MMEngineŃĆüMMCV ÕÆī MMDetection ńÜäńēłµ£¼õŠØĶĄ¢ + +õĖ║õ║åńĪ«õ┐Øõ╗ŻńĀüÕ«×ńÄ░ńÜ䵣ŻńĪ«µĆ¦’╝īMMOCR µ»ÅõĖ¬ńēłµ£¼ķāĮµ£ēÕÅ»ĶāĮµö╣ÕÅśÕ»╣ MMEngineŃĆüMMCV ÕÆī MMDetection ńēłµ£¼ńÜäõŠØĶĄ¢ŃĆéĶ»ĘµĀ╣µŹ«õ╗źõĖŗĶĪ©µĀ╝ńĪ«õ┐Øńēłµ£¼õ╣ŗķŚ┤ńÜäńøĖõ║ÆÕī╣ķģŹŃĆé + +| MMOCR | MMEngine | MMCV | MMDetection | +| -------------- | --------------------------- | -------------------------- | --------------------------- | +| dev-1.x | 0.7.1 \<= mmengine \< 1.1.0 | 2.0.0rc4 \<= mmcv \< 2.1.0 | 3.0.0rc5 \<= mmdet \< 3.2.0 | +| 1.0.1 | 0.7.1 \<= mmengine \< 1.1.0 | 2.0.0rc4 \<= mmcv \< 2.1.0 | 3.0.0rc5 \<= mmdet \< 3.2.0 | +| 1.0.0 | 0.7.1 \<= mmengine \< 1.0.0 | 2.0.0rc4 \<= mmcv \< 2.1.0 | 3.0.0rc5 \<= mmdet \< 3.1.0 | +| 1.0.0rc6 | 0.6.0 \<= mmengine \< 1.0.0 | 2.0.0rc4 \<= mmcv \< 2.1.0 | 3.0.0rc5 \<= mmdet \< 3.1.0 | +| 1.0.0rc\[4-5\] | 0.1.0 \<= mmengine \< 1.0.0 | 2.0.0rc1 \<= mmcv \< 2.1.0 | 3.0.0rc0 \<= mmdet \< 3.1.0 | +| 1.0.0rc\[0-3\] | 0.0.0 \<= mmengine \< 0.2.0 | 2.0.0rc1 \<= mmcv \< 2.1.0 | 3.0.0rc0 \<= mmdet \< 3.1.0 | diff --git a/internlm_langchain/knowledge_base/MMOCR/content/kie.md b/internlm_langchain/knowledge_base/MMOCR/content/kie.md new file mode 100644 index 00000000..ce8d1462 --- /dev/null +++ b/internlm_langchain/knowledge_base/MMOCR/content/kie.md @@ -0,0 +1,40 @@ +# Õģ│ķö«õ┐Īµü»µÅÉÕÅ¢ + +```{note} +µłæõ╗¼µŁŻÕŖ¬ÕŖøÕŠĆ [Dataset Preparer](./dataset_preparer.md) õĖŁÕó×ÕŖĀµø┤ÕżÜµĢ░µŹ«ķøåŃĆéÕ»╣õ║Ä [Dataset Preparer](./dataset_preparer.md) µÜéµ£¬ĶāĮÕ«īµĢ┤µö»µīüńÜäµĢ░µŹ«ķøå’╝īµ£¼ķĪĄµÅÉõŠøõ║åõĖĆń│╗ÕłŚµēŗÕŖ©õĖŗĶĮĮńÜ䵣źķ¬ż’╝īõŠøµ£ēķ£ĆĶ”üńÜäńö©µłĘõĮ┐ńö©ŃĆé +``` + +## µ”éĶ¦ł + +Õģ│ķö«õ┐Īµü»µÅÉÕÅ¢õ╗╗ÕŖĪńÜäµĢ░µŹ«ķøå’╝īµ¢ćõ╗Čńø«ÕĮĢÕ║öµīēÕ”éõĖŗķģŹńĮ«’╝Ü + +```text +ŌööŌöĆŌöĆ wildreceipt + Ōö£ŌöĆŌöĆ class_list.txt + Ōö£ŌöĆŌöĆ dict.txt + Ōö£ŌöĆŌöĆ image_files + Ōö£ŌöĆŌöĆ test.txt + ŌööŌöĆŌöĆ train.txt +``` + +## ÕćåÕżćµŁźķ¬ż + +### WildReceipt + +- õĖŗĶĮĮÕ╣ČĶ¦ŻÕÄŗ [wildreceipt.tar](https://download.openmmlab.com/mmocr/data/wildreceipt.tar) + +### WildReceiptOpenset + +- ÕćåÕżćÕźĮ [WildReceipt](#WildReceipt)ŃĆé +- ĶĮ¼µŹó WildReceipt µłÉ OpenSet µĀ╝Õ╝Å: + +```bash +# õĮĀÕÅ»õ╗źĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗żõ╗źĶÄĘÕÅ¢µø┤ÕżÜÕÅ»ńö©ÕÅéµĢ░’╝Ü +# python tools/data/kie/closeset_to_openset.py -h +python tools/data/kie/closeset_to_openset.py data/wildreceipt/train.txt data/wildreceipt/openset_train.txt +python tools/data/kie/closeset_to_openset.py data/wildreceipt/test.txt data/wildreceipt/openset_test.txt +``` + +```{note} +[Ķ┐Öń»ćµĢÖń©ŗ](../tutorials/kie_closeset_openset.md)ķćīĶ«▓Ķ┐░õ║åµø┤ÕżÜ CloseSet ÕÆī OpenSet µĢ░µŹ«µĀ╝Õ╝Åõ╣ŗķŚ┤ńÜäÕī║Õł½ŃĆé +``` diff --git a/internlm_langchain/knowledge_base/MMOCR/content/model.md b/internlm_langchain/knowledge_base/MMOCR/content/model.md new file mode 100644 index 00000000..0e276513 --- /dev/null +++ b/internlm_langchain/knowledge_base/MMOCR/content/model.md @@ -0,0 +1,5 @@ +# ķóäĶ«Łń╗āµ©ĪÕ×ŗĶ┐üń¦╗µīćÕŹŚ + +ńö▒õ║ÄÕ£©µ¢░ńēłµ£¼õĖŁµłæõ╗¼Õ»╣µ©ĪÕ×ŗńÜäń╗ōµ×äĶ┐øĶĪīõ║åÕż¦ķćÅńÜäķ揵×äÕÆīõ┐«ÕżŹ’╝īMMOCR 1.x Õ╣ČõĖŹĶāĮńø┤µÄźĶ»╗ÕģźµŚ¦ńēłńÜäķóäĶ«Łń╗āµØāķćŹŃĆ鵳æõ╗¼Õ£©ńĮæń½ÖõĖŖÕÉīµŁźµø┤µ¢░õ║åµēƵ£ēµ©ĪÕ×ŗńÜäķóäĶ«Łń╗āµØāķćŹÕÆīlog’╝īõŠøµ£ēķ£ĆĶ”üńÜäńö©µłĘõĮ┐ńö©ŃĆé + +µŁżÕż¢’╝īµłæõ╗¼µŁŻÕ£©Ķ┐øĶĪīķÆłÕ»╣µ¢ćµ£¼µŻĆµĄŗõ╗╗ÕŖĪńÜäµØāķćŹĶ┐üń¦╗ÕĘźÕģĘńÜäÕ╝ĆÕÅæ’╝īÕ╣ČĶ«ĪÕłÆõ║ÄĶ┐æµ£¤ńēłµ£¼ÕåģÕÅæÕĖāŃĆéńö▒õ║ĵ¢ćµ£¼Ķ»åÕł½ÕÆīÕģ│ķö«õ┐Īµü»µÅÉÕÅ¢µ©ĪÕ×ŗµö╣ÕŖ©Ķ┐ćÕż¦’╝īõĖöĶ┐üń¦╗µś»µ£ēµŹ¤ńÜä’╝īµłæõ╗¼µÜ鵌ČõĖŹĶ«ĪÕłÆõĮ£ńøĖÕ║öµö»µīüŃĆéÕ”éµ×£µé©µ£ēÕģĘõĮōńÜäķ£Ćµ▒é’╝īµ¼óĶ┐ÄķĆÜĶ┐ć [Issue](https://github.com/open-mmlab/mmocr/issues) ÕÉæµłæõ╗¼µÅÉķŚ«ŃĆé diff --git a/internlm_langchain/knowledge_base/MMOCR/content/models.md b/internlm_langchain/knowledge_base/MMOCR/content/models.md new file mode 100644 index 00000000..7ec449d5 --- /dev/null +++ b/internlm_langchain/knowledge_base/MMOCR/content/models.md @@ -0,0 +1,3 @@ +# µ©ĪÕ×ŗ\[ÕŠģµø┤µ¢░\] + +ÕŠģµø┤µ¢░ diff --git a/internlm_langchain/knowledge_base/MMOCR/content/news.md b/internlm_langchain/knowledge_base/MMOCR/content/news.md new file mode 100644 index 00000000..e1ca6f91 --- /dev/null +++ b/internlm_langchain/knowledge_base/MMOCR/content/news.md @@ -0,0 +1,19 @@ +# MMOCR 1.x µø┤µ¢░µ▒ćµĆ╗ + +µŁżÕżäÕłŚÕć║õ║å MMOCR 1.x ńøĖÕ»╣õ║Ä 0.x ńēłµ£¼ńÜäķćŹÕż¦µø┤µ¢░ŃĆé + +1. µ×ȵ×äÕŹćń║¦’╝ÜMMOCR 1.x µś»Õ¤║õ║Ä [MMEngine](https://github.com/open-mmlab/mmengine)’╝īµÅÉõŠøõ║åõĖĆõĖ¬ķĆÜńö©ńÜäŃĆüÕ╝║Õż¦ńÜäµē¦ĶĪīÕÖ©’╝īÕģüĶ«Ėµø┤ńüĄµ┤╗ńÜäÕ«ÜÕłČ’╝īµÅÉõŠøõ║åń╗¤õĖĆńÜäĶ«Łń╗āÕÆīµĄŗĶ»ĢÕģźÕÅŻŃĆé + +2. ń╗¤õĖƵğÕÅŻ’╝ÜMMOCR 1.x ń╗¤õĖĆõ║åµĢ░µŹ«ķøåŃĆüµ©ĪÕ×ŗŃĆüĶ»äõ╝░ÕÆīÕÅ»Ķ¦åÕī¢ńÜäµÄźÕÅŻÕÆīÕåģķā©ķĆ╗ĶŠæŃĆéµö»µīüµø┤Õ╝║ńÜäµē®Õ▒ĢµĆ¦ŃĆé + +3. ĶĘ©ķĪ╣ńø«Ķ░āńö©’╝ÜÕÅŚńøŖõ║Äń╗¤õĖĆńÜäĶ«ŠĶ«Ī’╝īõĮĀÕÅ»õ╗źõĮ┐ńö©ÕģČõ╗¢OpenMMLabķĪ╣ńø«õĖŁÕ«×ńÄ░ńÜ䵩ĪÕ×ŗ’╝īÕ”éMMDetŃĆé µłæõ╗¼µÅÉõŠøõ║åõĖĆõĖ¬õŠŗÕŁÉ’╝īĶ»┤µśÄÕ”éõĮĢķĆÜĶ┐ćMMDetWrapperõĮ┐ńö©MMDetectionńÜäMask R-CNNŃĆ鵤źń£ŗµłæõ╗¼ńÜäµ¢ćµĪŻõ╗źõ║åĶ¦Żµø┤ÕżÜń╗åĶŖéŃĆéµø┤ÕżÜńÜäÕīģĶŻģÕÖ©Õ░åÕ£©µ£¬µØźÕÅæÕĖāŃĆé + +4. µø┤Õ╝║ńÜäÕÅ»Ķ¦åÕī¢’╝ܵłæõ╗¼µÅÉõŠøõ║åõĖĆń│╗ÕłŚÕÅ»Ķ¦åÕī¢ÕĘźÕģĘ’╝ī ńö©µłĘńÄ░Õ£©ÕÅ»õ╗źµø┤µ¢╣õŠ┐ÕÅ»Ķ¦åÕī¢µĢ░µŹ«ŃĆé + +5. µø┤ÕżÜńÜäµ¢ćµĪŻÕÆīµĢÖń©ŗ’╝ܵłæõ╗¼Õó×ÕŖĀõ║åµø┤ÕżÜńÜäµĢÖń©ŗ’╝īķÖŹõĮÄńö©µłĘńÜäÕŁ”õ╣ĀķŚ©µ¦øŃĆé + +6. õĖĆń½ÖÕ╝ŵĢ░µŹ«ÕćåÕżć’╝ÜÕćåÕżćµĢ░µŹ«ķøåÕĘ▓ń╗ÅõĖŹÕåŹµś»ķÜŠõ║ŗŃĆéõĮ┐ńö©µłæõ╗¼ńÜä [Dataset Preparer](https://mmocr.readthedocs.io/zh_CN/dev-1.x/user_guides/data_prepare/dataset_preparer.html)’╝īõĖĆĶĪīÕæĮõ╗żÕŹ│ÕÅ»Ķ«®ÕżÜõĖ¬µĢ░µŹ«ķøåÕćåÕżćÕ░▒ń╗¬ŃĆé + +7. µŗźµŖ▒µø┤ÕżÜ `projects/`: µłæõ╗¼µÄ©Õć║õ║å `projects/` µ¢ćõ╗ČÕż╣’╝īńö©õ║ÄÕŁśµöŠõĖĆõ║øÕ«×ķ¬īµĆ¦ńÜäµ¢░ńē╣µĆ¦ŃĆüµĪåµ×ČÕÆīµ©ĪÕ×ŗŃĆ鵳æõ╗¼Õ»╣Ķ┐ÖõĖ¬µ¢ćõ╗ČÕż╣õĖŗńÜäõ╗ŻńĀüĶ¦äĶīāõĖŹõĮ£Ķ┐ćÕżÜĶ”üµ▒é’╝īÕŖøµ▒éĶ«®ńżŠÕī║ńÜäµēƵ£ēµā│µ│Ģń¼¼õĖƵŚČķŚ┤ÕŠŚÕł░Õ«×ńÄ░ÕÆīÕ▒Ģńż║ŃĆéĶ»Ęµ¤źń£ŗµłæõ╗¼ńÜä[µĀĘõŠŗ project](https://github.com/open-mmlab/mmocr/blob/dev-1.x/projects/example_project/) õ╗źõ║åĶ¦Żµø┤ÕżÜŃĆé + +8. µø┤ÕżÜµ¢░µ©ĪÕ×ŗ’╝ÜMMOCR 1.0 µö»µīüõ║åµø┤ÕżÜµ©ĪÕ×ŗÕÆīµ©ĪÕ×ŗń¦Źń▒╗ŃĆé diff --git a/internlm_langchain/knowledge_base/MMOCR/content/overview.md b/internlm_langchain/knowledge_base/MMOCR/content/overview.md new file mode 100644 index 00000000..bbd72139 --- /dev/null +++ b/internlm_langchain/knowledge_base/MMOCR/content/overview.md @@ -0,0 +1,3 @@ +# Ķ«ŠĶ«ĪńÉåÕ┐ĄõĖÄńē╣µĆ¦\[ÕŠģµø┤µ¢░\] + +ÕŠģµø┤µ¢░ diff --git a/internlm_langchain/knowledge_base/MMOCR/content/quick_run.md b/internlm_langchain/knowledge_base/MMOCR/content/quick_run.md new file mode 100644 index 00000000..bcca7370 --- /dev/null +++ b/internlm_langchain/knowledge_base/MMOCR/content/quick_run.md @@ -0,0 +1,201 @@ +# Õ┐½ķƤĶ┐ÉĶĪī + +Ķ┐ÖõĖ¬ń½ĀĶŖéõ╝Üõ╗ŗń╗Ź MMOCR ńÜäõĖĆõ║øÕ¤║µ£¼ÕŖ¤ĶāĮŃĆ鵳æõ╗¼ÕüćĶ«ŠõĮĀÕĘ▓ń╗Å[õ╗ĵ║ÉńĀüÕ«ēĶŻģõ║å MMOCR](install.md#best-practices)ŃĆ鵣żÕż¢’╝īõĮĀõ╣¤ÕÅ»õ╗źķĆÜĶ┐ć[µĢÖń©ŗ Notebook](https://colab.research.google.com/github/open-mmlab/mmocr/blob/dev-1.x/demo/tutorial.ipynb)µØźõ║åĶ¦ŻÕ”éõĮĢÕ£©õ║żõ║ÆÕ╝ÅńÄ»ÕóāõĖŗÕ«×ńÄ░µÄ©ńÉåŃĆüĶ«Łń╗āÕÆīµĄŗĶ»ĢŃĆé + +## µÄ©ńÉå + +Õ£© MMOCR ńÜäµĀ╣ńø«ÕĮĢõĖŗĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗ż’╝Ü + +```shell +python tools/infer.py demo/demo_text_ocr.jpg --det DBNet --rec CRNN --show --print-result +``` + +õĮĀÕÅ»õ╗źń£ŗÕł░Õ╝╣Õć║ńÜäķó䵥ŗń╗ōµ×£’╝īõ╗źÕÅŖÕ£©µÄ¦ÕłČÕÅ░õĖŁµēōÕŹ░Õć║ńÜäµÄ©ńÉåń╗ōµ×£ŃĆé + +
+ +```bash +# Ķ»åÕł½ń╗ōµ×£ +{'predictions': [{'rec_texts': ['cbanks', 'docecea', 'grouf', 'pwate', 'chobnsonsg', 'soxee', 'oeioh', 'c', 'sones', 'lbrandec', 'sretalg', '11', 'to8', 'round', 'sale', 'year', +'ally', 'sie', 'sall'], 'rec_scores': [...], 'det_polygons': [...], 'det_scores': +[...]}]} +``` + +```{note} +Õ”éµ×£õĮĀÕ£©µ▓Īµ£ē GUI ńÜäµ£ŹÕŖĪÕÖ©õĖŖĶ┐ÉĶĪī MMOCR’╝īµł¢ĶĆģķĆÜĶ┐ćµ▓Īµ£ēÕ╝ĆÕÉ» X11 ĶĮ¼ÕÅæńÜä SSH ķܦķüōĶ┐ÉĶĪī MMOCR’╝īõĮĀÕÅ»ĶāĮµŚĀµ│Ģń£ŗÕł░Õ╝╣Õć║ńÜäń¬ŚÕÅŻŃĆé +``` + +Õ»╣ MMOCR õĖŁµÄ©ńÉåµÄźÕÅŻµø┤õĖ║Ķ»”ń╗åńÜäĶ»┤µśÄ’╝īÕÅ»õ╗źÕ£©[Ķ┐Öķćī](../user_guides/inference.md)µēŠÕł░ŃĆé + +ķÖżõ║åõĮ┐ńö©µłæõ╗¼µÅÉõŠøÕźĮńÜäķóäĶ«Łń╗āµ©ĪÕ×ŗ’╝īńö©µłĘõ╣¤ÕÅ»õ╗źÕ£©Ķć¬ÕĘ▒ńÜäµĢ░µŹ«ķøåõĖŖĶ«Łń╗āµĄüĶĪīµ©ĪÕ×ŗŃĆéµÄźõĖŗµØźµłæõ╗¼õ╗źÕ£©Ķ┐ĘõĮĀńÜä [ICDAR 2015](https://rrc.cvc.uab.es/?ch=4&com=downloads) µĢ░µŹ«ķøåõĖŖĶ«Łń╗ā DBNet õĖ║õŠŗ’╝īÕĖ”Õż¦Õ«Čń夵éē MMOCR ńÜäÕ¤║µ£¼ÕŖ¤ĶāĮŃĆé + +## ÕćåÕżćµĢ░µŹ«ķøå + +ńö▒õ║Ä OCR õ╗╗ÕŖĪńÜäµĢ░µŹ«ķøåń¦Źń▒╗ÕżÜµĀĘ’╝īµĀ╝Õ╝ÅõĖŹõĖĆ’╝īõĖŹÕł®õ║ÄÕżÜµĢ░µŹ«ķøåńÜäÕłćµŹóÕÆīĶüöÕÉłĶ«Łń╗ā’╝īÕøĀµŁż MMOCR ń║”Õ«Üõ║åõĖĆń¦Ź[ń╗¤õĖĆńÜäµĢ░µŹ«µĀ╝Õ╝Å](../user_guides/dataset_prepare.md)’╝īÕ╣ČķÆłÕ»╣ÕĖĖńö©ńÜä OCR µĢ░µŹ«ķøåµÅÉõŠøõ║å[õĖĆķö«Õ╝ŵĢ░µŹ«ÕćåÕżćĶäܵ£¼](../user_guides/data_prepare/dataset_preparer.md)ŃĆéķĆÜÕĖĖ’╝īĶ”üÕ£© MMOCR õĖŁõĮ┐ńö©µĢ░µŹ«ķøå’╝īõĮĀÕŬķ£ĆĶ”üµīēńģ¦Õ»╣Õ║öµŁźķ¬żĶ┐ÉĶĪīµīćõ╗żÕŹ│ÕÅ»ŃĆé + +```{note} +õĮåµłæõ╗¼õ║”µĘ▒ń¤ź’╝īµĢłńÄćÕ░▒µś»ńö¤ÕæĮŌĆöŌĆöÕ░żÕģČÕ»╣µā│Ķ”üÕ┐½ķƤõĖŖµēŗ MMOCR ńÜäõĮĀµØźĶ»┤ŃĆé +``` + +Õ£©Ķ┐Öķćī’╝īµłæõ╗¼ÕćåÕżćõ║åõĖĆõĖ¬ńö©õ║ĵ╝öńż║ńÜäń▓Šń«Ćńēł ICDAR 2015 µĢ░µŹ«ķøåŃĆéõĖŗĶĮĮµłæõ╗¼ķóäÕģłÕćåÕżćÕźĮńÜä[ÕÄŗń╝®Õīģ](https://download.openmmlab.com/mmocr/data/icdar2015/mini_icdar2015.tar.gz)’╝īĶ¦ŻÕÄŗÕł░ mmocr ńÜä `data/` ńø«ÕĮĢõĖŗ’╝īÕ░▒ĶāĮÕŠŚÕł░µłæõ╗¼ÕćåÕżćÕźĮńÜäÕøŠńēćÕÆīµĀćµ│©µ¢ćõ╗ČŃĆé + +```Bash +wget https://download.openmmlab.com/mmocr/data/icdar2015/mini_icdar2015.tar.gz +mkdir -p data/ +tar xzvf mini_icdar2015.tar.gz -C data/ +``` + +## õ┐«µö╣ķģŹńĮ« + +ÕćåÕżćÕźĮµĢ░µŹ«ķøåÕÉÄ’╝īµłæõ╗¼µÄźõĖŗµØźÕ░▒ķ£ĆĶ”üķĆÜĶ┐ćõ┐«µö╣ķģŹńĮ«ńÜäµ¢╣Õ╝ŵīćÕ«ÜĶ«Łń╗āķøåńÜäõĮŹńĮ«ÕÆīĶ«Łń╗āÕÅéµĢ░ŃĆé + +Õ£©Ķ┐ÖõĖ¬õŠŗÕŁÉõĖŁ’╝īµłæõ╗¼Õ░åõ╝ÜĶ«Łń╗āõĖĆõĖ¬õ╗ź resnet18 õĮ£õĖ║ķ¬©Õ╣▓ńĮæń╗£’╝łbackbone’╝ēńÜä DBNetŃĆéńö▒õ║Ä MMOCR ÕĘ▓ń╗ŵ£ēķÆłÕ»╣Õ«īµĢ┤ ICDAR 2015 µĢ░µŹ«ķøåńÜäķģŹńĮ« ’╝ł`configs/textdet/dbnet/dbnet_resnet18_fpnc_1200e_icdar2015.py`’╝ē’╝īµłæõ╗¼ÕŬķ£ĆĶ”üÕ£©Õ«āńÜäÕ¤║ńĪĆõĖŖõĮ£Õć║õĖĆńé╣õ┐«µö╣ŃĆé + +µłæõ╗¼ķ”¢Õģłķ£ĆĶ”üõ┐«µö╣µĢ░µŹ«ķøåńÜäĶĘ»ÕŠäŃĆéÕ£©Ķ┐ÖõĖ¬ķģŹńĮ«õĖŁ’╝īÕż¦ķā©ÕłåÕģ│ķö«ńÜäķģŹńĮ«µ¢ćõ╗ČķāĮÕ£© `_base_` õĖŁĶó½Õ»╝Õģź’╝īÕ”éµĢ░µŹ«Õ║ōńÜäķģŹńĮ«Õ░▒µØźĶć¬ `configs/textdet/_base_/datasets/icdar2015.py`ŃĆéµēōÕ╝ĆĶ»źµ¢ćõ╗Č’╝īµŖŖń¼¼õĖĆĶĪī `icdar2015_textdet_data_root` µīćÕÉæńÜäĶĘ»ÕŠäµø┐µŹó’╝Ü + +```Python +icdar2015_textdet_data_root = 'data/mini_icdar2015' +``` + +ÕÅ”Õż¢’╝īÕøĀõĖ║µĢ░µŹ«ķøåÕ░║Õ»Ėń╝®Õ░Åõ║å’╝īµłæõ╗¼õ╣¤Ķ”üńøĖÕ║öÕ£░ÕćÅÕ░æĶ«Łń╗āńÜäĶĮ«µ¼ĪÕł░ 400’╝īń╝®ń¤Łķ¬īĶ»üÕÆīÕé©ÕŁśµØāķćŹńÜäķŚ┤ķÜöÕł░10ĶĮ«’╝īÕ╣ȵöŠÕ╝āÕŁ”õ╣ĀńÄćĶĪ░ÕćÅńŁ¢ńĢźŃĆéńø┤µÄźµŖŖõ╗źõĖŗÕćĀĶĪīķģŹńĮ«µöŠÕģź `configs/textdet/dbnet/dbnet_resnet18_fpnc_1200e_icdar2015.py`ÕŹ│ÕÅ»ńö¤µĢł’╝Ü + +```Python +# µ»Å 10 õĖ¬ epoch Õé©ÕŁśõĖƵ¼ĪµØāķ插╝īõĖöÕŬõ┐ØńĢÖµ£ĆÕÉÄõĖĆõĖ¬µØāķćŹ +default_hooks = dict( + checkpoint=dict( + type='CheckpointHook', + interval=10, + max_keep_ckpts=1, + )) +# Ķ«ŠńĮ«µ£ĆÕż¦ epoch µĢ░õĖ║ 400’╝īµ»Å 10 õĖ¬ epoch Ķ┐ÉĶĪīõĖƵ¼Īķ¬īĶ»ü +train_cfg = dict(type='EpochBasedTrainLoop', max_epochs=400, val_interval=10) +# õ╗żÕŁ”õ╣ĀńÄćõĖ║ÕĖĖķćÅ’╝īÕŹ│õĖŹĶ┐øĶĪīÕŁ”õ╣ĀńÄćĶĪ░ÕćÅ +param_scheduler = [dict(type='ConstantLR', factor=1.0),] +``` + +Ķ┐Öķćī’╝īµłæõ╗¼ķĆÜĶ┐ćķģŹńĮ«ńÜäń╗¦µē┐ ({external+mmengine:doc}`MMEngine: Config`) µ£║ÕłČÕ░åÕ¤║ńĪĆķģŹńĮ«õĖŁńÜäńøĖÕ║öÕÅéµĢ░ńø┤µÄźĶ┐øĶĪīõ║åµö╣ÕåÖŃĆéÕĤµ£¼ńÜäÕŁŚµ«ĄÕłåÕĖāÕ£© `configs/textdet/_base_/schedules/schedule_sgd_1200e.py` ÕÆī `configs/textdet/_base_/default_runtime.py` õĖŁ’╝īµä¤Õģ┤ĶČŻńÜäĶ»╗ĶĆģÕÅ»õ╗źĶć¬ĶĪīµ¤źń£ŗŃĆé
+
+```{note}
+Õģ│õ║ÄķģŹńĮ«µ¢ćõ╗ȵø┤ÕŖĀĶ»”Õ░ĮńÜäĶ»┤µśÄ’╝īĶ»ĘÕÅéĶĆā[µŁżÕżä](../user_guides/config.md)ŃĆé
+```
+
+## ÕÅ»Ķ¦åÕī¢µĢ░µŹ«ķøå
+
+Õ£©µŁŻÕ╝ÅÕ╝ĆÕ¦ŗĶ«Łń╗āÕēŹ’╝īµłæõ╗¼Ķ┐śÕÅ»õ╗źÕÅ»Ķ¦åÕī¢õĖĆõĖŗń╗ÅĶ┐ćĶ«Łń╗āĶ┐ćń©ŗõĖŁ[µĢ░µŹ«ÕÅśµŹó’╝łtransforms’╝ē](../basic_concepts/transforms.md)ÕÉÄńÜäÕøŠÕāÅŃĆéµ¢╣µ│Ģõ╣¤ÕŠłń«ĆÕŹĢ’╝īµŖŖµłæõ╗¼ķ£ĆĶ”üÕÅ»Ķ¦åÕī¢ńÜäķģŹńĮ«õ╝ĀÕģź [browse_dataset.py](/tools/analysis_tools/browse_dataset.py) Ķäܵ£¼ÕŹ│ÕÅ»’╝Ü
+
+```Bash
+python tools/analysis_tools/browse_dataset.py configs/textdet/dbnet/dbnet_resnet18_fpnc_1200e_icdar2015.py
+```
+
+µĢ░µŹ«ÕÅśµŹóÕÉÄńÜäÕøŠńēćÕÆīµĀćńŁŠõ╝ÜÕ£©Õ╝╣ń¬ŚõĖŁķĆÉÕ╝ĀĶó½Õ▒Ģńż║Õć║µØźŃĆé
+
+
+ 

 +
+
+
+```{note}
+µ£ēÕģ│Ķ»źĶäܵ£¼µø┤Ķ»”ń╗åńÜäµīćÕŹŚ’╝īĶ»ĘÕÅéĶĆā[µŁżÕżä](../user_guides/useful_tools.md).
+```
+
+```{tip}
+ķÖżõ║åµ╗ĪĶČ│ÕźĮÕźćÕ┐āõ╣ŗÕż¢’╝īÕÅ»Ķ¦åÕī¢Ķ┐śÕÅ»õ╗źÕĖ«ÕŖ®µłæõ╗¼Õ£©Ķ«Łń╗āÕēŹµŻĆµ¤źÕÅ»ĶāĮÕĮ▒ÕōŹÕł░µ©ĪÕ×ŗĶĪ©ńÄ░ńÜäķā©Õłå’╝īÕ”éķģŹńĮ«µ¢ćõ╗ČŃĆüµĢ░µŹ«ķøåÕÅŖµĢ░µŹ«ÕÅśµŹóõĖŁńÜäķŚ«ķóśŃĆé
+```
+
+## Ķ«Łń╗ā
+
+õĖćõ║ŗõ┐▒Õżć’╝īÕŬµ¼ĀõĖ£ķŻÄŃĆéĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗żÕÉ»ÕŖ©Ķ«Łń╗ā’╝Ü
+
+```Bash
+python tools/train.py configs/textdet/dbnet/dbnet_resnet18_fpnc_1200e_icdar2015.py
+```
+
+µĀ╣µŹ«ń│╗ń╗¤µāģÕåĄ’╝īMMOCR õ╝ÜĶć¬ÕŖ©õĮ┐ńö©µ£ĆõĮ│ńÜäĶ«ŠÕżćĶ┐øĶĪīĶ«Łń╗āŃĆéÕ”éµ×£µ£ē GPU’╝īÕłÖõ╝Üķ╗śĶ«żÕ£©ń¼¼õĖĆÕ╝ĀÕŹĪÕÉ»ÕŖ©ÕŹĢÕŹĪĶ«Łń╗āŃĆéÕĮōÕ╝ĆÕ¦ŗń£ŗÕł░ loss ńÜäĶŠōÕć║’╝īÕ░▒Ķ»┤µśÄõĮĀÕĘ▓ń╗ŵłÉÕŖ¤ÕÉ»ÕŖ©õ║åĶ«Łń╗āŃĆé
+
+```Bash
+2022/08/22 18:42:22 - mmengine - INFO - Epoch(train) [1][5/7] lr: 7.0000e-03 memory: 7730 data_time: 0.4496 loss_prob: 14.6061 loss_thr: 2.2904 loss_db: 0.9879 loss: 17.8843 time: 1.8666
+2022/08/22 18:42:24 - mmengine - INFO - Exp name: dbnet_resnet18_fpnc_1200e_icdar2015
+2022/08/22 18:42:28 - mmengine - INFO - Epoch(train) [2][5/7] lr: 7.0000e-03 memory: 6695 data_time: 0.2052 loss_prob: 6.7840 loss_thr: 1.4114 loss_db: 0.9855 loss: 9.1809 time: 0.7506
+2022/08/22 18:42:29 - mmengine - INFO - Exp name: dbnet_resnet18_fpnc_1200e_icdar2015
+2022/08/22 18:42:33 - mmengine - INFO - Epoch(train) [3][5/7] lr: 7.0000e-03 memory: 6690 data_time: 0.2101 loss_prob: 3.0700 loss_thr: 1.1800 loss_db: 0.9967 loss: 5.2468 time: 0.6244
+2022/08/22 18:42:33 - mmengine - INFO - Exp name: dbnet_resnet18_fpnc_1200e_icdar2015
+```
+
+Õ£©õĖŹµīćÕ«ÜķóØÕż¢ÕÅéµĢ░µŚČ’╝īĶ«Łń╗āńÜäµØāķćŹķ╗śĶ«żõ╝ÜĶó½õ┐ØÕŁśÕł░ `work_dirs/dbnet_resnet18_fpnc_1200e_icdar2015/` õĖŗķØó’╝īĶĆīµŚźÕ┐ŚÕłÖõ╝Üõ┐ØÕŁśÕ£©`work_dirs/dbnet_resnet18_fpnc_1200e_icdar2015/Õ╝ĆÕ¦ŗĶ«Łń╗āńÜ䵌ČķŚ┤µł│/`ķćīŃĆéµÄźõĖŗµØź’╝īµłæõ╗¼ÕŬķ£ĆĶ”üĶĆÉÕ┐āńŁēÕŠģµ©ĪÕ×ŗĶ«Łń╗āÕ«īµłÉÕŹ│ÕÅ»ŃĆé
+
+```{note}
+Ķŗźķ£ĆĶ”üõ║åĶ¦ŻĶ«Łń╗āńÜäķ½śń║¦ńö©µ│Ģ’╝īÕ”é CPU Ķ«Łń╗āŃĆüÕżÜÕŹĪĶ«Łń╗āÕÅŖķøåńŠżĶ«Łń╗āńŁē’╝īĶ»Ęµ¤źķśģ[Ķ«Łń╗āõĖĵĄŗĶ»Ģ](../user_guides/train_test.md)ŃĆé
+```
+
+## µĄŗĶ»Ģ
+
+ń╗ÅĶ┐ćµĢ░ÕŹüÕłåķƤńÜäńŁēÕŠģ’╝īµ©ĪÕ×ŗķĪ║Õł®Õ«īµłÉõ║å400 epochsńÜäĶ«Łń╗āŃĆ鵳æõ╗¼ķĆÜĶ┐ćµÄ¦ÕłČÕÅ░ńÜäĶŠōÕć║’╝īĶ¦éÕ»¤Õł░ DBNet Õ£©µ£ĆÕÉÄõĖĆõĖ¬ epoch ńÜäĶĪ©ńÄ░µ£ĆÕźĮ’╝ī`hmean` ĶŠŠÕł░õ║å 60.86’╝łõĮĀÕÅ»ĶāĮõ╝ÜÕŠŚÕł░õĖĆõĖ¬õĖŹÕż¬õĖƵĀĘńÜäń╗ōµ×£’╝ē’╝Ü
+
+```Bash
+08/22 19:24:52 - mmengine - INFO - Epoch(val) [400][100/100] icdar/precision: 0.7285 icdar/recall: 0.5226 icdar/hmean: 0.6086
+```
+
+```{note}
+Õ«āµł¢Ķ«ĖĶ┐śµ▓ĪĶó½Ķ«Łń╗āÕł░µ£Ćõ╝śńŖȵĆü’╝īõĮåÕ»╣õ║ÄõĖĆõĖ¬µ╝öńż║ĶĆīĶ©ĆÕĘ▓ń╗ÅĶČ│Õż¤õ║åŃĆé
+```
+
+ńäČĶĆī’╝īĶ┐ÖõĖ¬µĢ░ÕĆ╝ÕŬÕÅŹµśĀõ║å DBNet Õ£©Ķ┐ĘõĮĀ ICDAR 2015 µĢ░µŹ«ķøåõĖŖńÜäµĆ¦ĶāĮŃĆéĶ”üµā│µø┤ÕŖĀÕ«óĶ¦éÕ£░Ķ»äÕłżÕ«āńÜ䵯ƵĄŗĶāĮÕŖø’╝īµłæõ╗¼Ķ┐śĶ”üń£ŗń£ŗÕ«āÕ£©ÕłåÕĖāÕż¢µĢ░µŹ«ķøåõĖŖńÜäĶĪ©ńÄ░ŃĆéõŠŗÕ”é’╝ī`tests/data/det_toy_dataset` Õ░▒µś»õĖĆõĖ¬ÕŠłÕ░ÅńÜäń£¤Õ«×µĢ░µŹ«ķøå’╝īµłæõ╗¼ÕÅ»õ╗źńö©Õ«āµØźķ¬īĶ»üõĖĆõĖŗ DBNet ńÜäÕ«×ķÖģµĆ¦ĶāĮŃĆé
+
+Õ£©µĄŗĶ»ĢÕēŹ’╝īµłæõ╗¼ÕÉīµĀĘķ£ĆĶ”üÕ»╣µĢ░µŹ«ķøåńÜäõĮŹńĮ«ÕüÜõĖĆõĖŗõ┐«µö╣ŃĆéµēōÕ╝Ć `configs/textdet/_base_/datasets/icdar2015.py`’╝īõ┐«µö╣ `icdar2015_textdet_test` ńÜä `data_root` õĖ║ `tests/data/det_toy_dataset`:
+
+```Python
+# ...
+icdar2015_textdet_test = dict(
+ type='OCRDataset',
+ data_root='tests/data/det_toy_dataset',
+ # ...
+ )
+```
+
+õ┐«µö╣Õ«īµ»Ģ’╝īĶ┐ÉĶĪīÕæĮõ╗żÕÉ»ÕŖ©µĄŗĶ»ĢŃĆé
+
+```Bash
+python tools/test.py configs/textdet/dbnet/dbnet_resnet18_fpnc_1200e_icdar2015.py work_dirs/dbnet_resnet18_fpnc_1200e_icdar2015/epoch_400.pth
+```
+
+ÕŠŚÕł░ĶŠōÕć║’╝Ü
+
+```Bash
+08/21 21:45:59 - mmengine - INFO - Epoch(test) [5/10] memory: 8562
+08/21 21:45:59 - mmengine - INFO - Epoch(test) [10/10] eta: 0:00:00 time: 0.4893 data_time: 0.0191 memory: 283
+08/21 21:45:59 - mmengine - INFO - Evaluating hmean-iou...
+08/21 21:45:59 - mmengine - INFO - prediction score threshold: 0.30, recall: 0.6190, precision: 0.4815, hmean: 0.5417
+08/21 21:45:59 - mmengine - INFO - prediction score threshold: 0.40, recall: 0.6190, precision: 0.5909, hmean: 0.6047
+08/21 21:45:59 - mmengine - INFO - prediction score threshold: 0.50, recall: 0.6190, precision: 0.6842, hmean: 0.6500
+08/21 21:45:59 - mmengine - INFO - prediction score threshold: 0.60, recall: 0.6190, precision: 0.7222, hmean: 0.6667
+08/21 21:45:59 - mmengine - INFO - prediction score threshold: 0.70, recall: 0.3810, precision: 0.8889, hmean: 0.5333
+08/21 21:45:59 - mmengine - INFO - prediction score threshold: 0.80, recall: 0.0000, precision: 0.0000, hmean: 0.0000
+08/21 21:45:59 - mmengine - INFO - prediction score threshold: 0.90, recall: 0.0000, precision: 0.0000, hmean: 0.0000
+08/21 21:45:59 - mmengine - INFO - Epoch(test) [10/10] icdar/precision: 0.7222 icdar/recall: 0.6190 icdar/hmean: 0.6667
+```
+
+ÕÅ»õ╗źÕÅæńÄ░’╝īµ©ĪÕ×ŗÕ£©Ķ┐ÖõĖ¬µĢ░µŹ«ķøåõĖŖĶāĮĶŠŠÕł░ńÜä hmean õĖ║ 0.6667’╝īµĢłµ×£Ķ┐śµś»õĖŹķöÖńÜäŃĆé
+
+```{note}
+Ķŗźķ£ĆĶ”üõ║åĶ¦ŻµĄŗĶ»ĢńÜäķ½śń║¦ńö©µ│Ģ’╝īÕ”é CPU µĄŗĶ»ĢŃĆüÕżÜÕŹĪµĄŗĶ»ĢÕÅŖķøåńŠżµĄŗĶ»ĢńŁē’╝īĶ»Ęµ¤źķśģ[Ķ«Łń╗āõĖĵĄŗĶ»Ģ](../user_guides/train_test.md)ŃĆé
+```
+
+## ÕÅ»Ķ¦åÕī¢ĶŠōÕć║
+
+õĖ║õ║åÕ»╣µ©ĪÕ×ŗńÜäĶŠōÕć║µ£ēõĖĆõĖ¬µø┤ńø┤Ķ¦éńÜäµä¤ÕÅŚ’╝īµłæõ╗¼Ķ┐śÕÅ»õ╗źńø┤µÄźÕÅ»Ķ¦åÕī¢Õ«āńÜäķó䵥ŗĶŠōÕć║ŃĆéÕ£© `test.py` õĖŁ’╝īńö©µłĘÕÅ»õ╗źķĆÜĶ┐ć `show` ÕÅéµĢ░µēōÕ╝ĆÕ╝╣ń¬ŚÕÅ»Ķ¦åÕī¢’╝øõ╣¤ÕÅ»õ╗źķĆÜĶ┐ć `show-dir` ÕÅéµĢ░µīćÕ«Üķó䵥ŗń╗ōµ×£ÕøŠÕ»╝Õć║ńÜäńø«ÕĮĢŃĆé
+
+```Bash
+python tools/test.py configs/textdet/dbnet/dbnet_resnet18_fpnc_1200e_icdar2015.py work_dirs/dbnet_resnet18_fpnc_1200e_icdar2015/epoch_400.pth --show-dir imgs/
+```
+
+ń£¤Õ«×µĀćńŁŠÕÆīķó䵥ŗÕĆ╝õ╝ÜÕ£©ÕÅ»Ķ¦åÕī¢ń╗ōµ×£õĖŁõ╗źÕ╣│ķō║ńÜäµ¢╣Õ╝ÅÕ▒Ģńż║ŃĆéÕĘ”ÕøŠńÜäń╗┐µĪåĶĪ©ńż║ń£¤Õ«×µĀćńŁŠ’╝īÕÅ│ÕøŠńÜäń║óµĪåĶĪ©ńż║ķó䵥ŗÕĆ╝ŃĆé
+
+` Õ░åÕÉäõ╗╗ÕŖĪµēĆķ£ĆńÜäµĢ░µŹ«ń╗¤õĖĆÕ░üĶŻģÕģź `data_sample` õĖŁŃĆéMMEngine ńÜäµŖĮĶ▒ĪµĢ░µŹ«µÄźÕÅŻÕ«×ńÄ░õ║åÕ¤║ńĪĆńÜäÕó×/ÕłĀ/µö╣/µ¤źÕŖ¤ĶāĮ’╝īõĖöµö»µīüõĖŹÕÉīĶ«ŠÕżćķŚ┤ńÜäµĢ░µŹ«Ķ┐üń¦╗’╝īõ╣¤µö»µīüõ║åń▒╗ÕŁŚÕģĖÕÆīÕ╝ĀķćÅńÜäµōŹõĮ£’╝īÕģģÕłåµ╗ĪĶČ│õ║åµĢ░µŹ«ńÜ䵌źÕĖĖõĮ┐ńö©ķ£Ćµ▒é’╝īĶ┐Öõ╣¤õĮ┐ÕŠŚõĖŹÕÉīń«Śµ│ĢńÜäµĢ░µŹ«µÄźÕÅŻÕÅ»õ╗źÕŠŚÕł░ń╗¤õĖĆŃĆé
+
+ÕŠŚńøŖõ║Äń╗¤õĖĆńÜäµĢ░µŹ«Õ░üĶŻģ’╝īń«Śµ│ĢÕ║ōÕåģńÜä [`visualizer`](./visualizers.md)’╝ī[`evaluator`](./evaluation.md)’╝ī[`dataset`](./datasets.md) ńŁēÕÉäõĖ¬µ©ĪÕØŚķŚ┤ńÜäµĢ░µŹ«µĄüķĆÜķāĮÕŠŚÕł░õ║åµ×üÕż¦ńÜäń«ĆÕī¢ŃĆéÕ£© MMOCR õĖŁ’╝īµłæõ╗¼Õ»╣µĢ░µŹ«µÄźÕÅŻń▒╗Õ×ŗõĮ£Õć║õ╗źõĖŗń║”Õ«Ü’╝Ü
+
+- **xxxData**: ÕŹĢõĖĆń▓ÆÕ║”ńÜäµĢ░µŹ«µĀćµ│©µł¢µ©ĪÕ×ŗĶŠōÕć║ŃĆéńø«ÕēŹ MMEngine ÕåģńĮ«õ║åõĖēń¦Źń▓ÆÕ║”ńÜä{external+mmengine:doc}`µĢ░µŹ«Õģāń┤Ā `’╝īÕīģµŗ¼Õ«×õŠŗń║¦µĢ░µŹ«’╝ł`InstanceData`’╝ē’╝īÕāÅń┤Āń║¦µĢ░µŹ«’╝ł`PixelData`’╝ēõ╗źÕÅŖÕøŠÕāÅń║¦ńÜäµĀćńŁŠµĢ░µŹ«’╝ł`LabelData`’╝ēŃĆéÕ£© MMOCR ńø«ÕēŹµö»µīüńÜäõ╗╗ÕŖĪõĖŁ’╝īµ¢ćµ£¼µŻĆµĄŗõ╗źÕÅŖÕģ│ķö«õ┐Īµü»µŖĮÕÅ¢õ╗╗ÕŖĪõĮ┐ńö© `InstanceData` µØźÕ░üĶŻģµ¢ćµ£¼Õ«×õŠŗńÜ䵯ƵĄŗµĪåÕÅŖÕ»╣Õ║öµĀćńŁŠ’╝īĶĆīµ¢ćµ£¼Ķ»åÕł½õ╗╗ÕŖĪÕłÖõĮ┐ńö©õ║å `LabelData` µØźÕ░üĶŻģµ¢ćµ£¼ÕåģÕ«╣ŃĆé
+- **xxxDataSample**: ń╗¦µē┐Ķć¬ {external+mmengine:doc}`MMEngine: µĢ░µŹ«Õ¤║ń▒╗ ` `BaseDataElement`’╝īńö©õ║Äõ┐ØÕŁśÕŹĢõĖ¬õ╗╗ÕŖĪńÜäĶ«Łń╗āµł¢µĄŗĶ»ĢµĀʵ£¼ńÜä**µēƵ£ē**µĀćµ│©ÕÅŖķó䵥ŗõ┐Īµü»ŃĆéÕ”éµ¢ćµ£¼µŻĆµĄŗõ╗╗ÕŖĪńÜäµĢ░µŹ«µĀʵ£¼ń▒╗ [`TextDetDataSample`](mmocr.structures.textdet_data_sample.TextDetDataSample)’╝īµ¢ćµ£¼Ķ»åÕł½õ╗╗ÕŖĪńÜäµĢ░µŹ«µĀʵ£¼ń▒╗ [`TextRecogDataSample`](mmocr.structures.textrecog_data_sample.TextRecogDataSample)’╝īõ╗źÕÅŖÕģ│ķö«õ┐Īµü»µŖĮõ╗╗ÕŖĪńÜäµĢ░µŹ«µĀʵ£¼ń▒╗ [`KIEDataSample`](mmocr.structures.kie_data_sample.KIEDataSample)ŃĆé
+
+õĖŗķØó’╝īµłæõ╗¼Õ░åÕłåÕł½õ╗ŗń╗ŹµĢ░µŹ«Õģāń┤Ā **xxxData** õĖĵĢ░µŹ«µĀʵ£¼ **xxxDataSample** Õ£© MMOCR õĖŁńÜäÕ«×ķÖģÕ║öńö©ŃĆé
+
+## µĢ░µŹ«Õģāń┤Ā xxxData
+
+`InstanceData` ÕÆī `LabelData` µś» `MMEngine`õĖŁÕ«Üõ╣ēńÜäÕ¤║ńĪƵĢ░µŹ«Õģāń┤Ā’╝īńö©õ║ÄÕ░üĶŻģõĖŹÕÉīń▓ÆÕ║”ńÜäµĀćµ│©µĢ░µŹ«µł¢µ©ĪÕ×ŗĶŠōÕć║ŃĆéÕ£© MMOCR õĖŁ’╝īµłæõ╗¼ķÆłÕ»╣õĖŹÕÉīõ╗╗ÕŖĪõĖŁÕ«×ķÖģõĮ┐ńö©ńÜäµĢ░µŹ«ń▒╗Õ×ŗ’╝īÕłåÕł½ķććńö©õ║å `InstanceData` õĖÄ `LabelData` Ķ┐øĶĪīõ║åÕ░üĶŻģŃĆé
+
+### InstanceData
+
+Õ£©**µ¢ćµ£¼µŻĆµĄŗ**õ╗╗ÕŖĪõĖŁ’╝īµŻĆµĄŗÕÖ©Õģ│µ│©ńÜ䵜»Õ«×õŠŗń║¦Õł½ńÜäµ¢ćÕŁŚµĀʵ£¼’╝īÕøĀµŁżµłæõ╗¼õĮ┐ńö© `InstanceData` µØźÕ░üĶŻģĶ»źõ╗╗ÕŖĪµēĆķ£ĆńÜäµĢ░µŹ«ŃĆéÕģȵēĆķ£ĆńÜäĶ«Łń╗āµĀćµ│©ÕÆīķó䵥ŗĶŠōÕć║ķĆÜÕĖĖÕīģÕɽõ║åń¤®ÕĮóµł¢ÕżÜĶŠ╣ÕĮóĶŠ╣ńĢīńøÆ’╝īõ╗źÕÅŖĶŠ╣ńĢīńøƵĀćńŁŠŃĆéńö▒õ║ĵ¢ćµ£¼µŻĆµĄŗõ╗╗ÕŖĪÕŬµ£ēõĖĆń¦ŹµŁŻµĀʵ£¼ń▒╗’╝īÕŹ│ ŌĆ£textŌĆØ’╝īÕ£© MMOCR õĖŁµłæõ╗¼ķ╗śĶ«żõĮ┐ńö© `0` µØźń╝¢ÕÅĘĶ»źń▒╗Õł½ŃĆéõ╗źõĖŗõ╗ŻńĀüńż║õŠŗÕ▒Ģńż║õ║åÕ”éõĮĢõĮ┐ńö© `InstanceData` µĢ░µŹ«µŖĮĶ▒ĪµÄźÕÅŻµØźÕ░üĶŻģµ¢ćµ£¼µŻĆµĄŗõ╗╗ÕŖĪõĖŁõĮ┐ńö©ńÜäµĢ░µŹ«ń▒╗Õ×ŗŃĆé
+
+```python
+import torch
+from mmengine.structures import InstanceData
+
+# Õ«Üõ╣ē gt_instance ńö©õ║ÄÕ░üĶŻģĶŠ╣ńĢīńøÆńÜäµĀćµ│©õ┐Īµü»
+gt_instance = InstanceData()
+gt_instance.bbox = torch.Tensor([[0, 0, 10, 10], [10, 10, 20, 20]])
+gt_instance.polygons = torch.Tensor([[[0, 0], [10, 0], [10, 10], [0, 10]],
+ [[10, 10], [20, 10], [20, 20], [10, 20]]])
+gt_instance.label = torch.Tensor([0, 0])
+
+# Õ«Üõ╣ē pred_instance ńö©õ║ÄÕ░üĶŻģµ©ĪÕ×ŗńÜäĶŠōÕć║õ┐Īµü»
+pred_instances = InstanceData()
+pred_polygons, scores = model(input)
+pred_instances.polygons = pred_polygons
+pred_instances.scores = scores
+```
+
+MMOCR õĖŁÕ»╣ `InstanceData` ÕŁŚµ«ĄńÜäń║”Õ«ÜÕ”éõĖŗĶĪ©µēĆńż║ŃĆéÕĆ╝ÕŠŚµ│©µäÅńÜ䵜»’╝ī`InstanceData` õĖŁńÜäÕÉäÕŁŚµ«ĄńÜäķĢ┐Õ║”Õ┐ģķĪ╗õĖ║õĖĵĀʵ£¼õĖŁńÜäÕ«×õŠŗõĖ¬µĢ░ `N` ńøĖńŁēŃĆé
+
+| | | |
+| ----------- | ---------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------ |
+| ÕŁŚµ«Ą | ń▒╗Õ×ŗ | Ķ»┤µśÄ |
+| bboxes | `torch.FloatTensor` | µ¢ćµ£¼ĶŠ╣ńĢīµĪå `[x1, y1, x2, y2]`’╝īÕĮóńŖČõĖ║ `(N, 4)`ŃĆé |
+| labels | `torch.LongTensor` | Õ«×õŠŗńÜäń▒╗Õł½’╝īķĢ┐Õ║”õĖ║ `(N, )`ŃĆéMMOCR õĖŁķ╗śĶ«żõĮ┐ńö© `0` µØźĶĪ©ńż║µŁŻµĀʵ£¼ń▒╗’╝īÕŹ│ ŌĆ£textŌĆØ ń▒╗ŃĆé |
+| polygons | `list[np.array(dtype=np.float32)]` | ĶĪ©ńż║µ¢ćµ£¼Õ«×õŠŗńÜäÕżÜĶŠ╣ÕĮó’╝īÕłŚĶĪ©ķĢ┐Õ║”õĖ║ `(N, )`ŃĆé |
+| scores | `torch.Tensor` | µ¢ćµ£¼Õ«×õŠŗµŻĆµĄŗµĪåńÜäńĮ«õ┐ĪÕ║”’╝īķĢ┐Õ║”õĖ║ `(N, )`ŃĆé |
+| ignored | `torch.BoolTensor` | µś»Õɔգ©Ķ«Łń╗āõĖŁÕ┐ĮńĢźÕĮōÕēŹµ¢ćµ£¼Õ«×õŠŗ’╝īķĢ┐Õ║”õĖ║ `(N, )`ŃĆé |
+| texts | `list[str]` | Õ«×õŠŗÕ»╣Õ║öńÜäµ¢ćµ£¼’╝īķĢ┐Õ║”õĖ║ `(N, )`’╝īńö©õ║Äń½»Õł░ń½» OCR õ╗╗ÕŖĪÕÆī KIEŃĆé |
+| text_scores | `torch.FloatTensor` | µ¢ćµ£¼ķó䵥ŗńÜäńĮ«õ┐ĪÕ║”’╝īķĢ┐Õ║”õĖ║`(N, )`’╝īńö©õ║Äń½»Õł░ń½» OCR õ╗╗ÕŖĪŃĆé |
+| edge_labels | `torch.IntTensor` | ĶŖéńé╣ńÜäķé╗µÄźń¤®ķśĄ’╝īÕĮóńŖČõĖ║ `(N, N)`ŃĆéÕ£© KIE õ╗╗ÕŖĪõĖŁ’╝īĶŖéńé╣õ╣ŗķŚ┤ńŖȵĆüńÜäÕÅ»ķĆēÕĆ╝õĖ║ `-1` ’╝łÕ┐ĮńĢź’╝īõĖŹÕÅéõĖÄ loss Ķ«Īń«Ś’╝ē’╝ī`0` ’╝łµ¢ŁÕ╝Ć’╝ēÕÆī `1`’╝łĶ┐׵ğ’╝ēŃĆé |
+| edge_scores | `torch.FloatTensor` | ńö©õ║Ä KIE õ╗╗ÕŖĪõĖŁµ»ÅµØĪĶŠ╣ńÜäķó䵥ŗńĮ«õ┐ĪÕ║”’╝īÕĮóńŖČõĖ║ `(N, N)`ŃĆé |
+
+### LabelData
+
+Õ»╣õ║Ä**µ¢ćÕŁŚĶ»åÕł½**õ╗╗ÕŖĪ’╝īµĀćµ│©ÕåģÕ«╣ÕÆīķó䵥ŗÕåģÕ«╣ķāĮõ╝ÜõĮ┐ńö© `LabelData` Ķ┐øĶĪīÕ░üĶŻģŃĆé
+
+```python
+import torch
+from mmengine.data import LabelData
+
+# Õ«Üõ╣ēõĖĆõĖ¬ gt_text ńö©õ║ÄÕ░üĶŻģµĀćńŁŠµ¢ćµ£¼ÕåģÕ«╣
+gt_text = LabelData()
+gt_text.item = 'MMOCR'
+
+# Õ«Üõ╣ēõĖĆõĖ¬ pred_text Õ»╣Ķ▒Īńö©õ║ÄÕ░üĶŻģķó䵥ŗµ¢ćµ£¼õ╗źÕÅŖńĮ«õ┐ĪÕ║”
+pred_text = LabelData()
+index, score = model(input)
+text = dictionary.idx2str(index)
+pred_text.score = score
+pred_text.item = text
+```
+
+MMOCR õĖŁÕ»╣ `LabelData` ÕŁŚµ«ĄńÜäń║”Õ«ÜÕ”éõĖŗĶĪ©µēĆńż║’╝Ü
+
+| | | |
+| -------------- | ------------------ | -------------------------------------------------------------------------------------------------------------------------- |
+| ÕŁŚµ«Ą | ń▒╗Õ×ŗ | Ķ»┤µśÄ |
+| item | `str` | µ¢ćµ£¼ÕåģÕ«╣ŃĆé |
+| score | `list[float]` | ķó䵥ŗńÜäµ¢ćµ£¼ÕåģÕ«╣ńÜäńĮ«õ┐ĪÕ║”ŃĆé |
+| indexes | `torch.LongTensor` | µ¢ćµ£¼ÕŁŚń¼”ń╗ÅĶ┐ć[ÕŁŚÕģĖ](../basic_concepts/models.md#dictionary)ń╝¢ńĀüÕÉÄńÜäÕ║ÅÕłŚ’╝īõĖöÕīģÕɽõ║åķÖż `` õ╗źÕż¢ńÜäµēƵ£ēńē╣µ«ŖÕŁŚń¼”ŃĆé |
+| padded_indexes | `torch.LongTensor` | Õ”éµ×£ indexes ńÜäķĢ┐Õ║”Õ░Åõ║ĵ£ĆÕż¦Õ║ÅÕłŚķĢ┐Õ║”’╝īõĖö `pad_idx` ÕŁśÕ£©µŚČ’╝īĶ»źÕŁŚµ«Ąõ┐ØÕŁśõ║åÕĪ½ÕģģĶć│µ£ĆÕż¦Õ║ÅÕłŚķĢ┐Õ║” `max_seq_len`ńÜäń╝¢ńĀüÕÉÄńÜäµ¢ćµ£¼Õ║ÅÕłŚŃĆé |
+
+## µĢ░µŹ«µĀʵ£¼ xxxDataSample
+
+ķĆÜĶ┐ćÕ«Üõ╣ēń╗¤õĖĆńÜäµĢ░µŹ«ń╗ōµ×ä’╝īµłæõ╗¼ÕÅ»õ╗źµ¢╣õŠ┐Õ£░Õ░åµĀćµ│©µĢ░µŹ«ÕÆīķó䵥ŗń╗ōµ×£Ķ┐øĶĪīń╗¤õĖĆÕ░üĶŻģ’╝īõĮ┐õ╗ŻńĀüÕ║ōõĖŹÕÉīµ©ĪÕØŚķŚ┤ńÜäµĢ░µŹ«õ╝ĀķĆƵø┤ÕŖĀõŠ┐µŹĘŃĆéÕ£© MMOCR õĖŁ’╝īµłæõ╗¼Õ¤║õ║ÄńÄ░Õ£©µö»µīüńÜäõĖēõĖ¬õ╗╗ÕŖĪÕÅŖÕģȵēĆķ£ĆĶ”üńÜäµĢ░µŹ«ÕłåÕł½Õ░üĶŻģõ║åõĖēń¦ŹµĢ░µŹ«µŖĮĶ▒Ī’╝īÕīģµŗ¼µ¢ćµ£¼µŻĆµĄŗõ╗╗ÕŖĪµĢ░µŹ«µŖĮĶ▒Ī [`TextDetDataSample`](mmocr.structures.textdet_data_sample.TextDetDataSample)’╝īµ¢ćµ£¼Ķ»åÕł½õ╗╗ÕŖĪµĢ░µŹ«µŖĮĶ▒Ī [`TextRecogDataSample`](mmocr.structures.textrecog_data_sample.TextRecogDataSample)’╝īõ╗źÕÅŖÕģ│ķö«õ┐Īµü»µŖĮÕÅ¢õ╗╗ÕŖĪµĢ░µŹ«µŖĮĶ▒Ī [`KIEDataSample`](mmocr.structures.kie_data_sample.KIEDataSample)ŃĆéĶ┐Öõ║øµĢ░µŹ«µŖĮĶ▒ĪÕØćń╗¦µē┐Ķć¬ {external+mmengine:doc}`MMEngine: µĢ░µŹ«Õ¤║ń▒╗ ` `BaseDataElement`’╝īńö©õ║Äõ┐ØÕŁśÕŹĢõĖ¬õ╗╗ÕŖĪńÜäĶ«Łń╗āµł¢µĄŗĶ»ĢµĀʵ£¼ńÜäµēƵ£ēµĀćµ│©ÕÅŖķó䵥ŗõ┐Īµü»ŃĆé
+
+### µ¢ćµ£¼µŻĆµĄŗõ╗╗ÕŖĪµĢ░µŹ«µŖĮĶ▒Ī TextDetDataSample
+
+[TextDetDataSample](mmocr.structures.textdet_data_sample.TextDetDataSample) ńö©õ║ÄÕ░üĶŻģµ¢ćÕŁŚµŻĆµĄŗõ╗╗ÕŖĪµēĆķ£ĆńÜäµĢ░µŹ«’╝īÕģČõĖ╗Ķ”üÕīģÕɽõ║åõĖżõĖ¬ÕŁŚµ«Ą `gt_instances` õĖÄ `pred_instances`’╝īÕłåÕł½ńö©õ║ÄÕŁśµöŠµĀćµ│©õ┐Īµü»õĖÄķó䵥ŗń╗ōµ×£ŃĆé
+
+| | | |
+| -------------- | ------------------------------- | ---------- |
+| ÕŁŚµ«Ą | ń▒╗Õ×ŗ | Ķ»┤µśÄ |
+| gt_instances | [`InstanceData`](#instancedata) | µĀćµ│©õ┐Īµü»ŃĆé |
+| pred_instances | [`InstanceData`](#instancedata) | ķó䵥ŗń╗ōµ×£ŃĆé |
+
+ÕģČõĖŁõ╝Üńö©Õł░ńÜä [`InstanceData`](#instancedata) ń║”Õ«ÜÕŁŚµ«Ąµ£ē’╝Ü
+
+| | | |
+| -------- | ---------------------------------- | -------------------------------------------------------------------------------- |
+| ÕŁŚµ«Ą | ń▒╗Õ×ŗ | Ķ»┤µśÄ |
+| bboxes | `torch.FloatTensor` | µ¢ćµ£¼ĶŠ╣ńĢīµĪå `[x1, y1, x2, y2]`’╝īÕĮóńŖČõĖ║ `(N, 4)`ŃĆé |
+| labels | `torch.LongTensor` | Õ«×õŠŗńÜäń▒╗Õł½’╝īķĢ┐Õ║”õĖ║ `(N, )`ŃĆéÕ£© MMOCR õĖŁķĆÜÕĖĖõĮ┐ńö© `0` µØźĶĪ©ńż║µŁŻµĀʵ£¼ń▒╗’╝īÕŹ│ ŌĆ£textŌĆØ ń▒╗ |
+| polygons | `list[np.array(dtype=np.float32)]` | ĶĪ©ńż║µ¢ćµ£¼Õ«×õŠŗńÜäÕżÜĶŠ╣ÕĮó’╝īÕłŚĶĪ©ķĢ┐Õ║”õĖ║ `(N, )`ŃĆé |
+| scores | `torch.Tensor` | µ¢ćµ£¼Õ«×õŠŗõ╗╗ÕŖĪķó䵥ŗńÜ䵯ƵĄŗµĪåńÜäńĮ«õ┐ĪÕ║”’╝īķĢ┐Õ║”õĖ║ `(N, )`ŃĆé |
+| ignored | `torch.BoolTensor` | µś»Õɔգ©Ķ«Łń╗āõĖŁÕ┐ĮńĢźÕĮōÕēŹµ¢ćµ£¼Õ«×õŠŗ’╝īķĢ┐Õ║”õĖ║ `(N, )`ŃĆé |
+
+ńö▒õ║ĵ¢ćµ£¼µŻĆµĄŗµ©ĪÕ×ŗķĆÜÕĖĖÕŬõ╝ÜĶŠōÕć║ bboxes/polygons õĖŁńÜäõĖĆķĪ╣’╝īÕøĀµŁżµłæõ╗¼ÕŬķ£ĆńĪ«õ┐ØĶ┐ÖõĖżķĪ╣õĖŁńÜäõĖĆõĖ¬Ķó½ĶĄŗÕĆ╝ÕŹ│ÕÅ»ŃĆé
+
+õ╗źõĖŗńż║õŠŗõ╗ŻńĀüÕ▒Ģńż║õ║å `TextDetDataSample` ńÜäõĮ┐ńö©µ¢╣µ│Ģ’╝Ü
+
+```python
+import torch
+from mmengine.data import TextDetDataSample
+
+data_sample = TextDetDataSample()
+# µīćÕ«ÜÕĮōÕēŹÕøŠńēćńÜäµĀćµ│©õ┐Īµü»
+img_meta = dict(img_shape=(800, 1196, 3), pad_shape=(800, 1216, 3))
+gt_instances = InstanceData(metainfo=img_meta)
+gt_instances.bboxes = torch.rand((5, 4))
+gt_instances.labels = torch.zeros((5,), dtype=torch.long)
+data_sample.gt_instances = gt_instances
+
+# µīćÕ«ÜÕĮōÕēŹÕøŠńēćńÜäķó䵥ŗõ┐Īµü»
+pred_instances = InstanceData()
+pred_instances.bboxes = torch.rand((5, 4))
+pred_instances.labels = torch.zeros((5,), dtype=torch.long)
+data_sample.pred_instances = pred_instances
+```
+
+### µ¢ćµ£¼Ķ»åÕł½õ╗╗ÕŖĪµĢ░µŹ«µŖĮĶ▒Ī TextRecogDataSample
+
+[`TextRecogDataSample`](mmocr.structures.textrecog_data_sample.TextRecogDataSample) ńö©õ║ÄÕ░üĶŻģµ¢ćÕŁŚĶ»åÕł½õ╗╗ÕŖĪńÜäµĢ░µŹ«ŃĆéÕ«āµ£ēõĖżõĖ¬Õ▒׵Ʀ’╝ī`gt_text` ÕÆī `pred_text` , ÕłåÕł½ńö©õ║ÄÕŁśµöŠµĀćµ│©õ┐Īµü»ÕÆīķó䵥ŗń╗ōµ×£ŃĆé
+
+| | | |
+| --------- | ------------------------- | ---------- |
+| ÕŁŚµ«Ą | ń▒╗Õ×ŗ | Ķ»┤µśÄ |
+| gt_text | [`LabelData`](#labeldata) | µĀćµ│©õ┐Īµü»ŃĆé |
+| pred_text | [`LabelData`](#labeldata) | ķó䵥ŗń╗ōµ×£ŃĆé |
+
+õ╗źõĖŗńż║õŠŗõ╗ŻńĀüÕ▒Ģńż║õ║å [`TextRecogDataSample`](mmocr.structures.textrecog_data_sample.TextRecogDataSample) ńÜäõĮ┐ńö©µ¢╣µ│Ģ’╝Ü
+
+```python
+import torch
+from mmengine.data import TextRecogDataSample
+
+data_sample = TextRecogDataSample()
+# µīćÕ«ÜÕĮōÕēŹÕøŠńēćńÜäµĀćµ│©õ┐Īµü»
+img_meta = dict(img_shape=(800, 1196, 3), pad_shape=(800, 1216, 3))
+gt_text = LabelData(metainfo=img_meta)
+gt_text.item = 'mmocr'
+data_sample.gt_text = gt_text
+
+# µīćÕ«ÜÕĮōÕēŹÕøŠńēćńÜäķó䵥ŗń╗ōµ×£
+pred_text = LabelData(metainfo=img_meta)
+pred_text.item = 'mmocr'
+data_sample.pred_text = pred_text
+```
+
+ÕģČõĖŁõ╝Üńö©Õł░ńÜä `LabelData` ÕŁŚµ«Ąµ£ē’╝Ü
+
+| | | |
+| -------------- | ------------------- | -------------------------------------------------------------------------------------------------------------------------- |
+| ÕŁŚµ«Ą | ń▒╗Õ×ŗ | Ķ»┤µśÄ |
+| item | `list[str]` | Õ«×õŠŗÕ»╣Õ║öńÜäµ¢ćµ£¼’╝īķĢ┐Õ║”õĖ║ (N, ) ’╝īńö©õ║Äń½»Õł░ń½» OCR õ╗╗ÕŖĪÕÆī KIE |
+| score | `torch.FloatTensor` | µ¢ćµ£¼ķó䵥ŗńÜäńĮ«õ┐ĪÕ║”’╝īķĢ┐Õ║”õĖ║ (N, )’╝īńö©õ║Äń½»Õł░ń½» OCR õ╗╗ÕŖĪ |
+| indexes | `torch.LongTensor` | µ¢ćµ£¼ÕŁŚń¼”ń╗ÅĶ┐ć[ÕŁŚÕģĖ](../basic_concepts/models.md#dictionary)ń╝¢ńĀüÕÉÄńÜäÕ║ÅÕłŚ’╝īõĖöÕīģÕɽõ║åķÖż `` õ╗źÕż¢ńÜäµēƵ£ēńē╣µ«ŖÕŁŚń¼”ŃĆé |
+| padded_indexes | `torch.LongTensor` | Õ”éµ×£ indexes ńÜäķĢ┐Õ║”Õ░Åõ║ĵ£ĆÕż¦Õ║ÅÕłŚķĢ┐Õ║”’╝īõĖö `pad_idx` ÕŁśÕ£©µŚČ’╝īĶ»źÕŁŚµ«Ąõ┐ØÕŁśõ║åÕĪ½ÕģģĶć│µ£ĆÕż¦Õ║ÅÕłŚķĢ┐Õ║” `max_seq_len`ńÜäń╝¢ńĀüÕÉÄńÜäµ¢ćµ£¼Õ║ÅÕłŚŃĆé |
+
+### Õģ│ķö«õ┐Īµü»µŖĮÕÅ¢õ╗╗ÕŖĪµĢ░µŹ«µŖĮĶ▒Ī KIEDataSample
+
+[`KIEDataSample`](mmocr.structures.kie_data_sample.KIEDataSample) ńö©õ║ÄÕ░üĶŻģ KIE õ╗╗ÕŖĪµēĆķ£ĆńÜäµĢ░µŹ«’╝īÕģČÕÉīµĀĘń║”Õ«Üõ║åõĖżõĖ¬Õ▒׵Ʀ’╝īÕŹ│ `gt_instances` õĖÄ `pred_instances`’╝īÕłåÕł½ńö©õ║ÄÕŁśµöŠµĀćµ│©õ┐Īµü»õĖÄķó䵥ŗń╗ōµ×£ŃĆé
+
+| | | |
+| -------------- | ------------------------------- | ---------- |
+| ÕŁŚµ«Ą | ń▒╗Õ×ŗ | Ķ»┤µśÄ |
+| gt_instances | [`InstanceData`](#instancedata) | µĀćµ│©õ┐Īµü»ŃĆé |
+| pred_instances | [`InstanceData`](#instancedata) | ķó䵥ŗń╗ōµ×£ŃĆé |
+
+Ķ»źõ╗╗ÕŖĪõ╝Üńö©Õł░ńÜä [`InstanceData`](#instancedata) ÕŁŚµ«ĄÕ”éõĖŗĶĪ©µēĆńż║’╝Ü
+
+| | | |
+| ----------- | ------------------- | --------------------------------------------------------------------------------------------------------------------------------------------- |
+| ÕŁŚµ«Ą | ń▒╗Õ×ŗ | Ķ»┤µśÄ |
+| bboxes | `torch.Tensor` | µ¢ćµ£¼ĶŠ╣ńĢīµĪå `[x1, y1, x2, y2]`’╝īÕĮóńŖČõĖ║ `(N, 4)`ŃĆé |
+| labels | `torch.LongTensor` | Õ«×õŠŗńÜäń▒╗Õł½’╝īķĢ┐Õ║”õĖ║ `(N, )`ŃĆéÕ£© MMOCR õĖŁķĆÜÕĖĖõĖ║ 0’╝īÕŹ│ ŌĆ£textŌĆØ ń▒╗ŃĆé |
+| texts | `list[str]` | Õ«×õŠŗÕ»╣Õ║öńÜäµ¢ćµ£¼’╝īķĢ┐Õ║”õĖ║ `(N, )` ’╝īńö©õ║Äń½»Õł░ń½» OCR õ╗╗ÕŖĪÕÆī KIE õ╗╗ÕŖĪŃĆé |
+| edge_labels | `torch.IntTensor` | ĶŖéńé╣õ╣ŗķŚ┤ńÜäķé╗µÄźń¤®ķśĄ’╝īÕĮóńŖČõĖ║ `(N, N)`ŃĆéÕ£© KIE õ╗╗ÕŖĪõĖŁ’╝īĶŖéńé╣õ╣ŗķŚ┤ńŖȵĆüńÜäÕÅ»ķĆēÕĆ╝õĖ║ `-1` ’╝łõĖŹÕģ│Õ┐ā’╝īõĖöõĖŹÕÅéõĖÄ loss Ķ«Īń«Ś’╝ē’╝ī`0` ’╝łµ¢ŁÕ╝Ć’╝ēÕÆī `1` ’╝łĶ┐׵ğ’╝ēŃĆé |
+| edge_scores | `torch.FloatTensor` | µ»ÅµØĪĶŠ╣ńÜäķó䵥ŗńĮ«õ┐ĪÕ║”’╝īÕĮóńŖČõĖ║ `(N, N)`ŃĆé |
+| scores | `torch.FloatTensor` | ĶŖéńé╣µĀćńŁŠńÜäķó䵥ŗńĮ«õ┐ĪÕ║”, ÕĮóńŖČõĖ║ `(N,)`ŃĆé |
+
+```{warning}
+ńö▒õ║Ä KIE õ╗╗ÕŖĪńÜ䵩ĪÕ×ŗÕ«×ńÄ░Õ░ܵ£¬µ£ēń╗¤õĖƵĀćÕćå’╝īĶ»źĶ«ŠĶ«Īńø«ÕēŹõ╗ģĶĆāĶÖæõ║å [SDMGR](../../../configs/kie/sdmgr/README.md) µ©ĪÕ×ŗńÜäõĮ┐ńö©Õ£║µÖ»ŃĆéÕøĀµŁż’╝īĶ»źĶ«ŠĶ«Īµ£ēÕÅ»ĶāĮÕ£©µłæõ╗¼µö»µīüµø┤ÕżÜ KIE µ©ĪÕ×ŗÕÉÄõ║¦ńö¤ÕÅśÕŖ©ŃĆé
+```
+
+õ╗źõĖŗńż║õŠŗõ╗ŻńĀüÕ▒Ģńż║õ║å [`KIEDataSample`](mmocr.structures.kie_data_sample.KIEDataSample) ńÜäõĮ┐ńö©µ¢╣µ│ĢŃĆé
+
+```python
+import torch
+from mmengine.data import KIEDataSample
+
+data_sample = KIEDataSample()
+# µīćÕ«ÜÕĮōÕēŹÕøŠńēćńÜäµĀćµ│©õ┐Īµü»
+img_meta = dict(img_shape=(800, 1196, 3),pad_shape=(800, 1216, 3))
+gt_instances = InstanceData(metainfo=img_meta)
+gt_instances.bboxes = torch.rand((5, 4))
+gt_instances.labels = torch.zeros((5,), dtype=torch.long)
+gt_instances.texts = ['text1', 'text2', 'text3', 'text4', 'text5']
+gt_instances.edge_lebels = torch.randint(-1, 2, (5, 5))
+data_sample.gt_instances = gt_instances
+
+# µīćÕ«ÜÕĮōÕēŹÕøŠńēćńÜäķó䵥ŗõ┐Īµü»
+pred_instances = InstanceData()
+pred_instances.bboxes = torch.rand((5, 4))
+pred_instances.labels = torch.rand((5,))
+pred_instances.edge_labels = torch.randint(-1, 2, (10, 10))
+pred_instances.edge_scores = torch.rand((10, 10))
+data_sample.pred_instances = pred_instances
+```
diff --git a/internlm_langchain/knowledge_base/MMOCR/content/train_test.md b/internlm_langchain/knowledge_base/MMOCR/content/train_test.md
new file mode 100644
index 00000000..7ab634f8
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMOCR/content/train_test.md
@@ -0,0 +1,324 @@
+# Ķ«Łń╗āõĖĵĄŗĶ»Ģ
+
+õĖ║õ║åķĆéķģŹÕżÜµĀĘÕī¢ńÜäńö©µłĘķ£Ćµ▒é’╝īMMOCR Õ«×ńÄ░õ║åÕżÜń¦ŹõĖŹÕÉīµōŹõĮ£ń│╗ń╗¤ÕÅŖĶ«ŠÕżćõĖŖńÜ䵩ĪÕ×ŗĶ«Łń╗āÕÅŖµĄŗĶ»ĢŃĆ鵌ĀĶ«║µś»õĮ┐ńö©µ£¼Õ£░µ£║ÕÖ©Ķ┐øĶĪīÕŹĢµ£║ÕŹĢÕŹĪĶ«Łń╗āµĄŗĶ»Ģ’╝īĶ┐śµś»Õ£©ķā©ńĮ▓õ║å slurm ń│╗ń╗¤ńÜäÕż¦Ķ¦äµ©ĪķøåńŠżõĖŖĶ┐øĶĪīĶ«Łń╗āµĄŗĶ»Ģ’╝īMMOCR ķāĮµÅÉõŠøõ║åõŠ┐µŹĘńÜäĶ¦ŻÕå│µ¢╣µĪłŃĆé
+
+## ÕŹĢÕŹĪµ£║ÕÖ©Ķ«Łń╗āÕÅŖµĄŗĶ»Ģ
+
+### Ķ«Łń╗ā
+
+`tools/train.py` Õ«×ńÄ░õ║åÕ¤║ńĪĆńÜäĶ«Łń╗āµ£ŹÕŖĪŃĆéMMOCR µÄ©ĶŹÉńö©µłĘõĮ┐ńö© GPU Ķ┐øĶĪīµ©ĪÕ×ŗĶ«Łń╗āÕÆīµĄŗĶ»Ģ’╝īõĮåµś»’╝īńö©µłĘõ╣¤ÕÅ»õ╗źķĆÜĶ┐ćµīćÕ«Ü `CUDA_VISIBLE_DEVICES=-1` µØźõĮ┐ńö© CPU Ķ«ŠÕżćĶ┐øĶĪīµ©ĪÕ×ŗĶ«Łń╗āÕÅŖµĄŗĶ»ĢŃĆéõŠŗÕ”é’╝īõ╗źõĖŗÕæĮõ╗żµ╝öńż║õ║åÕ”éõĮĢõĮ┐ńö© CPU µł¢ÕŹĢÕŹĪ GPU µØźĶ«Łń╗ā DBNet µ¢ćµ£¼µŻĆµĄŗÕÖ©ŃĆé
+
+```bash
+# ķĆÜĶ┐ćĶ░āńö© tools/train.py µØźĶ«Łń╗āµīćÕ«ÜńÜä MMOCR µ©ĪÕ×ŗ
+CUDA_VISIBLE_DEVICES= python tools/train.py ${CONFIG_FILE} [PY_ARGS]
+
+# Ķ«Łń╗ā
+# ńż║õŠŗ 1’╝ÜõĮ┐ńö© CPU Ķ«Łń╗ā DBNet
+CUDA_VISIBLE_DEVICES=-1 python tools/train.py configs/textdet/dbnet/dbnet_resnet50-dcnv2_fpnc_1200e_icdar2015.py
+
+# ńż║õŠŗ 2’╝ܵīćÕ«ÜõĮ┐ńö© gpu:0 Ķ«Łń╗ā DBNet’╝īµīćÕ«ÜÕĘźõĮ£ńø«ÕĮĢõĖ║ dbnet/’╝īÕ╣ȵēōÕ╝ƵĘĘÕÉłń▓ŠÕ║”’╝łamp’╝ēĶ«Łń╗ā
+CUDA_VISIBLE_DEVICES=0 python tools/train.py configs/textdet/dbnet/dbnet_resnet50-dcnv2_fpnc_1200e_icdar2015.py --work-dir dbnet/ --amp
+```
+
+```{note}
+µŁżÕż¢’╝īÕ”éķ£ĆõĮ┐ńö©µīćÕ«Üń╝¢ÕÅĘńÜä GPU Ķ┐øĶĪīĶ«Łń╗āµł¢µĄŗĶ»Ģ’╝īõŠŗÕ”éõĮ┐ńö©3ÕÅĘ GPU’╝īÕłÖÕÅ»õ╗źķĆÜĶ┐ćĶ«ŠÕ«Ü CUDA_VISIBLE_DEVICES=3 µØźÕ«×ńÄ░ŃĆé
+```
+
+õĖŗĶĪ©ÕłŚÕć║õ║å `train.py` µö»µīüńÜäµēƵ£ēÕÅéµĢ░ŃĆéÕģČõĖŁ’╝īõĖŹÕĖ” `--` ÕēŹń╝ĆńÜäÕÅéµĢ░õĖ║Õ┐ģķĪ╗ńÜäõĮŹńĮ«ÕÅéµĢ░’╝īÕĖ” `--` ÕēŹń╝ĆńÜäÕÅéµĢ░õĖ║ÕÅ»ķĆēÕÅéµĢ░ŃĆé
+
+| ÕÅéµĢ░ | ń▒╗Õ×ŗ | Ķ»┤µśÄ |
+| --------------- | ---- | -------------------------------------------------------------- |
+| config | str | ’╝łÕ┐ģķĪ╗’╝ēķģŹńĮ«µ¢ćõ╗ČĶĘ»ÕŠäŃĆé |
+| --work-dir | str | µīćÕ«ÜÕĘźõĮ£ńø«ÕĮĢ’╝īńö©õ║ÄÕŁśµöŠĶ«Łń╗āµŚźÕ┐Śõ╗źÕÅŖµ©ĪÕ×ŗ checkpointsŃĆé |
+| --resume | bool | µś»ÕÉ”õ╗ĵ¢Łńé╣ÕżäµüóÕżŹĶ«Łń╗āŃĆé |
+| --amp | bool | µś»ÕÉ”õĮ┐ńö©µĘĘÕÉłń▓ŠÕ║”ŃĆé |
+| --auto-scale-lr | bool | µś»ÕÉ”õĮ┐ńö©ÕŁ”õ╣ĀńÄćĶć¬ÕŖ©ń╝®µöŠŃĆé |
+| --cfg-options | str | ńö©õ║ÄĶ”åÕåÖķģŹńĮ«µ¢ćõ╗ČõĖŁńÜäµīćÕ«ÜÕÅéµĢ░ŃĆé[ńż║õŠŗ](#µĘ╗ÕŖĀńż║õŠŗ) |
+| --launcher | str | ÕÉ»ÕŖ©ÕÖ©ķĆēķĪ╣’╝īÕÅ»ķĆēķĪ╣ńø«õĖ║ \['none', 'pytorch', 'slurm', 'mpi'\]ŃĆé |
+| --local_rank | int | µ£¼Õ£░µ£║ÕÖ©ń╝¢ÕÅĘ’╝īńö©õ║ÄÕżÜµ£║ÕżÜÕŹĪÕłåÕĖāÕ╝ÅĶ«Łń╗ā’╝īķ╗śĶ«żõĖ║ 0ŃĆé |
+
+### µĄŗĶ»Ģ
+
+`tools/test.py` µÅÉõŠøõ║åÕ¤║ńĪĆńÜ䵥ŗĶ»Ģµ£ŹÕŖĪ’╝īÕģČõĮ┐ńö©ÕĤńÉåÕÆīĶ«Łń╗āĶäܵ£¼ń▒╗õ╝╝ŃĆéõŠŗÕ”é’╝īõ╗źõĖŗÕæĮõ╗żµ╝öńż║õ║å CPU µł¢ GPU ÕŹĢÕŹĪµĄŗĶ»Ģ DBNet µ©ĪÕ×ŗŃĆé
+
+```bash
+# ķĆÜĶ┐ćĶ░āńö© tools/test.py µØźµĄŗĶ»ĢµīćÕ«ÜńÜä MMOCR µ©ĪÕ×ŗ
+CUDA_VISIBLE_DEVICES= python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [PY_ARGS]
+
+# µĄŗĶ»Ģ
+# ńż║õŠŗ 1’╝ÜõĮ┐ńö© CPU µĄŗĶ»Ģ DBNet
+CUDA_VISIBLE_DEVICES=-1 python tools/test.py configs/textdet/dbnet/dbnet_resnet50-dcnv2_fpnc_1200e_icdar2015.py dbnet_r50.pth
+# ńż║õŠŗ 2’╝ÜõĮ┐ńö© gpu:0 µĄŗĶ»Ģ DBNet
+CUDA_VISIBLE_DEVICES=0 python tools/test.py configs/textdet/dbnet/dbnet_resnet50-dcnv2_fpnc_1200e_icdar2015.py dbnet_r50.pth
+```
+
+õĖŗĶĪ©ÕłŚÕć║õ║å `test.py` µö»µīüńÜäµēƵ£ēÕÅéµĢ░ŃĆéÕģČõĖŁ’╝īõĖŹÕĖ” `--` ÕēŹń╝ĆńÜäÕÅéµĢ░õĖ║Õ┐ģķĪ╗ńÜäõĮŹńĮ«ÕÅéµĢ░’╝īÕĖ” `--` ÕēŹń╝ĆńÜäÕÅéµĢ░õĖ║ÕÅ»ķĆēÕÅéµĢ░ŃĆé
+
+| ÕÅéµĢ░ | ń▒╗Õ×ŗ | Ķ»┤µśÄ |
+| ------------- | ----- | -------------------------------------------------------------- |
+| config | str | ’╝łÕ┐ģķĪ╗’╝ēķģŹńĮ«µ¢ćõ╗ČĶĘ»ÕŠäŃĆé |
+| checkpoint | str | ’╝łÕ┐ģķĪ╗’╝ēÕŠģµĄŗĶ»Ģµ©ĪÕ×ŗĶĘ»ÕŠäŃĆé |
+| --work-dir | str | ÕĘźõĮ£ńø«ÕĮĢ’╝īńö©õ║ÄÕŁśµöŠĶ«Łń╗āµŚźÕ┐Śõ╗źÕÅŖµ©ĪÕ×ŗ checkpointsŃĆé |
+| --save-preds | bool | µś»ÕÉ”Õ░åķó䵥ŗń╗ōµ×£ÕåÖÕģź pkl µ¢ćõ╗ČÕ╣Čõ┐ØÕŁśŃĆé |
+| --show | bool | µś»ÕÉ”ÕÅ»Ķ¦åÕī¢ķó䵥ŗń╗ōµ×£ŃĆé |
+| --show-dir | str | Õ░åÕÅ»Ķ¦åÕī¢ńÜäķó䵥ŗń╗ōµ×£õ┐ØÕŁśĶć│µīćÕ«ÜĶĘ»ÕŠäŃĆé |
+| --wait-time | float | ÕÅ»Ķ¦åÕī¢ķŚ┤ķÜöµŚČķŚ┤’╝łń¦Æ’╝ē’╝īķ╗śĶ«żõĖ║ 2 ń¦ÆŃĆé |
+| --cfg-options | str | ńö©õ║ÄĶ”åÕåÖķģŹńĮ«µ¢ćõ╗ČõĖŁńÜäµīćÕ«ÜÕÅéµĢ░ŃĆé[ńż║õŠŗ](#µĘ╗ÕŖĀńż║õŠŗ) |
+| --launcher | str | ÕÉ»ÕŖ©ÕÖ©ķĆēķĪ╣’╝īÕÅ»ķĆēķĪ╣ńø«õĖ║ \['none', 'pytorch', 'slurm', 'mpi'\]ŃĆé |
+| --local_rank | int | µ£¼Õ£░µ£║ÕÖ©ń╝¢ÕÅĘ’╝īńö©õ║ÄÕżÜµ£║ÕżÜÕŹĪÕłåÕĖāÕ╝ÅĶ«Łń╗ā’╝īķ╗śĶ«żõĖ║ 0ŃĆé |
+| --tta | bool | µś»ÕÉ”õĮ┐ńö©µĄŗĶ»ĢµŚČµĢ░µŹ«Õó×Õ╝║ |
+
+## ÕżÜÕŹĪµ£║ÕÖ©Ķ«Łń╗āÕÅŖµĄŗĶ»Ģ
+
+Õ»╣õ║ÄÕż¦Ķ¦äµ©Īµ©ĪÕ×ŗ’╝īķććńö©ÕżÜ GPU Ķ«Łń╗āÕÆīµĄŗĶ»ĢÕÅ»õ╗źµ×üÕż¦Õ£░µÅÉÕŹćµōŹõĮ£ńÜäµĢłńÄćŃĆéõĖ║µŁż’╝īMMOCR µÅÉõŠøõ║åÕ¤║õ║Ä [MMDistributedDataParallel](mmengine.model.wrappers.MMDistributedDataParallel) Õ«×ńÄ░ńÜäÕłåÕĖāÕ╝ÅĶäܵ£¼ `tools/dist_train.sh` ÕÆī `tools/dist_test.sh`ŃĆé
+
+```bash
+# Ķ«Łń╗ā
+NNODES=${NNODES} NODE_RANK=${NODE_RANK} PORT=${MASTER_PORT} MASTER_ADDR=${MASTER_ADDR} ./tools/dist_train.sh ${CONFIG_FILE} ${GPU_NUM} [PY_ARGS]
+# µĄŗĶ»Ģ
+NNODES=${NNODES} NODE_RANK=${NODE_RANK} PORT=${MASTER_PORT} MASTER_ADDR=${MASTER_ADDR} ./tools/dist_test.sh ${CONFIG_FILE} ${CHECKPOINT_FILE} ${GPU_NUM} [PY_ARGS]
+```
+
+õĖŗĶĪ©ÕłŚÕć║õ║å `dist_*.sh` µö»µīüńÜäÕÅéµĢ░’╝Ü
+
+| ÕÅéµĢ░ | ń▒╗Õ×ŗ | Ķ»┤µśÄ |
+| --------------- | ---- | ---------------------------------------------------------------------------------- |
+| NNODES | int | µĆ╗Õģ▒õĮ┐ńö©ńÜäµ£║ÕÖ©ĶŖéńé╣õĖ¬µĢ░’╝īķ╗śĶ«żõĖ║ 1ŃĆé |
+| NODE_RANK | int | ĶŖéńé╣ń╝¢ÕÅĘ’╝īķ╗śĶ«żõĖ║ 0ŃĆé |
+| PORT | int | Õ£© RANK 0 µ£║ÕÖ©õĖŖõĮ┐ńö©ńÜä MASTER_PORT ń½»ÕÅŻÕÅĘ’╝īÕÅ¢ÕĆ╝ĶīāÕø┤µś» 0 Ķć│ 65535’╝īķ╗śĶ«żÕĆ╝õĖ║ 29500ŃĆé |
+| MASTER_ADDR | str | RANK 0 µ£║ÕÖ©ńÜä IP Õ£░ÕØĆ’╝īķ╗śĶ«żÕĆ╝õĖ║ 127.0.0.1ŃĆé |
+| CONFIG_FILE | str | ’╝łÕ┐ģķĪ╗’╝ēµīćÕ«ÜķģŹńĮ«µ¢ćõ╗ČńÜäÕ£░ÕØĆŃĆé |
+| CHECKPOINT_FILE | str | ’╝łÕ┐ģķĪ╗’╝īõ╗ģÕ£© dist_test.sh õĖŁķĆéńö©’╝ēµīćիܵ©ĪÕ×ŗµØāķćŹńÜäÕ£░ÕØĆŃĆé |
+| GPU_NUM | int | ’╝łÕ┐ģķĪ╗’╝ēµīćÕ«Ü GPU ńÜäµĢ░ķćÅŃĆé |
+| \[PY_ARGS\] | str | Ķ»źķā©ÕłåõĖĆÕłćńÜäÕÅéµĢ░ķāĮõ╝ÜĶó½ńø┤µÄźõ╝ĀÕģź tools/train.py µł¢ tools/test.py õĖŁŃĆé |
+
+Ķ┐ÖõĖżõĖ¬Ķäܵ£¼ÕÅ»õ╗źÕ«×ńÄ░**ÕŹĢµ£║ÕżÜÕŹĪ**µł¢**ÕżÜµ£║ÕżÜÕŹĪ**ńÜäĶ«Łń╗āÕÆīµĄŗĶ»Ģ’╝īõĖŗķØóµ╝öńż║õ║åÕ«āõ╗¼Õ£©õĖŹÕÉīÕ£║µÖ»õĖŗńÜäńö©µ│ĢŃĆé
+
+### ÕŹĢµ£║ÕżÜÕŹĪ
+
+õ╗źõĖŗÕæĮõ╗żµ╝öńż║õ║åÕ”éõĮĢÕ£©µÉŁĶĮĮÕżÜÕØŚ GPU ńÜä**ÕŹĢÕÅ░µ£║ÕÖ©**õĖŖõĮ┐ńö©µīćիܵĢ░ńø«ńÜä GPU Ķ┐øĶĪīĶ«Łń╗āÕÅŖµĄŗĶ»Ģ’╝Ü
+
+1. **Ķ«Łń╗ā**
+
+ õĮ┐ńö©ÕŹĢÕÅ░µ£║ÕÖ©õĖŖńÜä 4 ÕØŚ GPU Ķ«Łń╗ā DBNetŃĆé
+
+ ```bash
+ # ÕŹĢµ£║ 4 ÕŹĪĶ«Łń╗ā DBNet
+ tools/dist_train.sh configs/textdet/dbnet/dbnet_r50dcnv2_fpnc_1200e_icdar2015.py 4
+ ```
+
+2. **µĄŗĶ»Ģ**
+
+ õĮ┐ńö©ÕŹĢÕÅ░µ£║ÕÖ©õĖŖńÜä 4 ÕØŚ GPU µĄŗĶ»Ģ DBNetŃĆé
+
+ ```bash
+ # ÕŹĢµ£║ 4 ÕŹĪµĄŗĶ»Ģ DBNet
+ tools/dist_test.sh configs/textdet/dbnet/dbnet_r50dcnv2_fpnc_1200e_icdar2015.py dbnet_r50.pth 4
+ ```
+
+### ÕŹĢµ£║ÕżÜõ╗╗ÕŖĪĶ«Łń╗āÕÅŖµĄŗĶ»Ģ
+
+Õ»╣õ║ĵɣĶĮĮÕżÜÕØŚ GPU ńÜäÕŹĢÕÅ░µ£ŹÕŖĪÕÖ©ĶĆīĶ©Ć’╝īńö©µłĘÕÅ»õ╗źķĆÜĶ┐ćµīćÕ«Ü GPU ńÜäÕĮóÕ╝ÅµØźÕÉīµŚČµē¦ĶĪīõĖŹÕÉīńÜäĶ«Łń╗āõ╗╗ÕŖĪŃĆéõŠŗÕ”é’╝īõ╗źõĖŗÕæĮõ╗żµ╝öńż║õ║åÕ”éõĮĢÕ£©õĖĆÕÅ░ 8 ÕŹĪ GPU µ£ŹÕŖĪÕÖ©õĖŖÕłåÕł½õĮ┐ńö© `[0, 1, 2, 3]` ÕŹĪµĄŗĶ»Ģ DBNet ÕÅŖ `[4, 5, 6, 7]` ÕŹĪĶ«Łń╗ā CRNN’╝Ü
+
+```bash
+# µīćÕ«ÜõĮ┐ńö© gpu:0,1,2,3 µĄŗĶ»Ģ DBNet’╝īÕ╣ČÕłåķģŹń½»ÕÅŻÕÅĘ 29500
+CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 ./tools/dist_test.sh configs/textdet/dbnet/dbnet_r50dcnv2_fpnc_1200e_icdar2015.py dbnet_r50.pth 4
+# µīćÕ«ÜõĮ┐ńö© gpu:4,5,6,7 Ķ«Łń╗ā CRNN’╝īÕ╣ČÕłåķģŹń½»ÕÅŻÕÅĘ 29501
+CUDA_VISIBLE_DEVICES=4,5,6,7 PORT=29501 ./tools/dist_train.sh configs/textrecog/crnn/crnn_academic_dataset.py 4
+```
+
+```{note}
+`dist_train.sh` ķ╗śĶ«żÕ░å `MASTER_PORT` Ķ«ŠńĮ«õĖ║ `29500`’╝īÕĮōÕŹĢÕÅ░µ£║ÕÖ©õĖŖµ£ēÕģČÕ«āĶ┐øń©ŗÕĘ▓ÕŹĀńö©Ķ»źń½»ÕÅŻµŚČ’╝īń©ŗÕ║ÅÕłÖõ╝ÜÕć║ńÄ░Ķ┐ÉĶĪīµŚČķöÖĶ»» `RuntimeError: Address already in use`ŃĆ鵣żµŚČ’╝īńö©µłĘķ£ĆĶ”üÕ░å `MASTER_PORT` Ķ«ŠńĮ«õĖ║ `(0~65535)` ĶīāÕø┤ÕåģńÜäÕģČÕ«āń®║ķŚ▓ń½»ÕÅŻÕÅĘŃĆé
+```
+
+### ÕżÜµ£║ÕżÜÕŹĪĶ«Łń╗āÕÅŖµĄŗĶ»Ģ
+
+MMOCR Õ¤║õ║Ä[torch.distributed](https://pytorch.org/docs/stable/distributed.html#launch-utility) µÅÉõŠøõ║åńøĖÕÉīÕ▒ĆÕ¤¤ńĮæõĖŗńÜäÕżÜÕÅ░µ£║ÕÖ©ķŚ┤ńÜäÕżÜÕŹĪÕłåÕĖāÕ╝ÅĶ«Łń╗āŃĆé
+
+1. **Ķ«Łń╗ā**
+
+ õ╗źõĖŗÕæĮõ╗żµ╝öńż║õ║åÕ”éõĮĢÕ£©õĖżÕÅ░µ£║ÕÖ©õĖŖÕłåÕł½õĮ┐ńö© 2 Õ╝Ā GPU ÕÉłĶ«Ī 4 ÕŹĪĶ«Łń╗ā DBNet’╝Ü
+
+ ```bash
+ # ńż║õŠŗ’╝ÜÕ£©õĖżÕÅ░µ£║ÕÖ©õĖŖÕłåÕł½õĮ┐ńö© 2 Õ╝Ā GPU ÕÉłĶ«Ī 4 ÕŹĪĶ«Łń╗ā DBNet
+ # Õ£© ŌĆ£µ£║ÕÖ©1ŌĆØ õĖŖĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗ż
+ NNODES=2 NODE_RANK=0 PORT=29501 MASTER_ADDR=10.140.0.169 tools/dist_train.sh configs/textdet/dbnet/dbnet_r50dcnv2_fpnc_1200e_icdar2015.py 2
+ # Õ£© ŌĆ£µ£║ÕÖ©2ŌĆØ õĖŖĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗ż
+ NNODES=2 NODE_RANK=1 PORT=29501 MASTER_ADDR=10.140.0.169 tools/dist_train.sh configs/textdet/dbnet/dbnet_r50dcnv2_fpnc_1200e_icdar2015.py 2
+ ```
+
+2. **µĄŗĶ»Ģ**
+
+ õ╗źõĖŗÕæĮõ╗żµ╝öńż║õ║åÕ”éõĮĢÕ£©õĖżÕÅ░µ£║ÕÖ©õĖŖÕłåÕł½õĮ┐ńö© 2 Õ╝Ā GPU ÕÉłĶ«Ī 4 ÕŹĪµĄŗĶ»Ģ’╝Ü
+
+ ```bash
+ # ńż║õŠŗ’╝ÜÕ£©õĖżÕÅ░µ£║ÕÖ©õĖŖÕłåÕł½õĮ┐ńö© 2 Õ╝Ā GPU ÕÉłĶ«Ī 4 ÕŹĪµĄŗĶ»Ģ
+ # Õ£© ŌĆ£µ£║ÕÖ©1ŌĆØ õĖŖĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗ż
+ NNODES=2 NODE_RANK=0 PORT=29500 MASTER_ADDR=10.140.0.169 tools/dist_test.sh configs/textdet/dbnet/dbnet_r50dcnv2_fpnc_1200e_icdar2015.py dbnet_r50.pth 2
+ # Õ£© ŌĆ£µ£║ÕÖ©2ŌĆØ õĖŖĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗ż
+ NNODES=2 NODE_RANK=1 PORT=29501 MASTER_ADDR=10.140.0.169 tools/dist_test.sh configs/textdet/dbnet/dbnet_r50dcnv2_fpnc_1200e_icdar2015.py dbnet_r50.pth 2
+ ```
+
+ ```{note}
+ ķ£ĆĶ”üµ│©µäÅńÜ䵜»’╝īķććńö©ÕżÜµ£║ÕżÜÕŹĪĶ«Łń╗āµŚČ’╝īµ£║ÕÖ©ķŚ┤ńÜäńĮæń╗£õ╝ĀĶŠōķƤÕ║”ÕÅ»ĶāĮµłÉõĖ║Ķ«Łń╗āķƤÕ║”ńÜäńōČķółŃĆé
+ ```
+
+## ķøåńŠżĶ«Łń╗āÕÅŖµĄŗĶ»Ģ
+
+ķÆłÕ»╣ [Slurm](https://slurm.schedmd.com/) Ķ░āÕ║”ń│╗ń╗¤ń«ĪńÉåńÜäĶ«Īń«ŚķøåńŠż’╝īMMOCR µÅÉõŠøõ║åÕ»╣Õ║öńÜäĶ«Łń╗āÕÆīµĄŗĶ»Ģõ╗╗ÕŖĪµÅÉõ║żĶäܵ£¼ `tools/slurm_train.sh` ÕÅŖ `tools/slurm_test.sh`ŃĆé
+
+```bash
+# tools/slurm_train.sh µÅÉõŠøÕ¤║õ║Ä slurm Ķ░āÕ║”ń│╗ń╗¤ń«ĪńÉåńÜäĶ«Īń«ŚķøåńŠżõĖŖµÅÉõ║żĶ«Łń╗āõ╗╗ÕŖĪńÜäĶäܵ£¼
+GPUS=${GPUS} GPUS_PER_NODE=${GPUS_PER_NODE} CPUS_PER_TASK=${CPUS_PER_TASK} SRUN_ARGS=${SRUN_ARGS} ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} ${CONFIG_FILE} ${WORK_DIR} [PY_ARGS]
+
+# tools/slurm_test.sh µÅÉõŠøÕ¤║õ║Ä slurm Ķ░āÕ║”ń│╗ń╗¤ń«ĪńÉåńÜäĶ«Īń«ŚķøåńŠżõĖŖµÅÉõ║żµĄŗĶ»Ģõ╗╗ÕŖĪńÜäĶäܵ£¼
+GPUS=${GPUS} GPUS_PER_NODE=${GPUS_PER_NODE} CPUS_PER_TASK=${CPUS_PER_TASK} SRUN_ARGS=${SRUN_ARGS} ./tools/slurm_test.sh ${PARTITION} ${JOB_NAME} ${CONFIG_FILE} ${CHECKPOINT_FILE} ${WORK_DIR} [PY_ARGS]
+```
+
+| ÕÅéµĢ░ | ń▒╗Õ×ŗ | Ķ»┤µśÄ |
+| --------------- | ---- | ------------------------------------------------------------------------- |
+| GPUS | int | õĮ┐ńö©ńÜä GPU µĢ░ńø«’╝īķ╗śĶ«żõĖ║8ŃĆé |
+| GPUS_PER_NODE | int | µ»ÅÕÅ░ĶŖéńé╣µ£║ÕÖ©õĖŖµÉŁĶĮĮńÜä GPU µĢ░ńø«’╝īķ╗śĶ«żõĖ║8ŃĆé |
+| CPUS_PER_TASK | int | õ╗╗ÕŖĪõĮ┐ńö©ńÜä CPU õĖ¬µĢ░’╝īķ╗śĶ«żõĖ║5ŃĆé |
+| SRUN_ARGS | str | ÕģČõ╗¢ srun µö»µīüńÜäÕÅéµĢ░ŃĆéĶ»”Ķ¦ü[Ķ┐Öķćī](https://slurm.schedmd.com/srun.html) |
+| PARTITION | str | ’╝łÕ┐ģķĪ╗’╝ēµīćÕ«ÜõĮ┐ńö©ńÜäķøåńŠżÕłåÕī║ŃĆé |
+| JOB_NAME | str | ’╝łÕ┐ģķĪ╗’╝ēµÅÉõ║żõ╗╗ÕŖĪńÜäÕÉŹń¦░ŃĆé |
+| WORK_DIR | str | ’╝łÕ┐ģķĪ╗’╝ēõ╗╗ÕŖĪńÜäÕĘźõĮ£ńø«ÕĮĢ’╝īĶ«Łń╗āµŚźÕ┐Śõ╗źÕÅŖµ©ĪÕ×ŗńÜä checkpoints Õ░åĶó½õ┐ØÕŁśĶć│Ķ»źńø«ÕĮĢŃĆé |
+| CHECKPOINT_FILE | str | ’╝łÕ┐ģķĪ╗’╝īõ╗ģÕ£© slurm_test.sh õĖŁķĆéńö©’╝ēµīćÕÉ浩ĪÕ×ŗµØāķćŹńÜäÕ£░ÕØĆŃĆé |
+| \[PY_ARGS\] | str | tools/train.py õ╗źÕÅŖ tools/test.py µö»µīüńÜäÕÅéµĢ░ŃĆé |
+
+Ķ┐ÖõĖżõĖ¬Ķäܵ£¼ÕÅ»õ╗źÕ«×ńÄ░ slurm ķøåńŠżõĖŖńÜäĶ«Łń╗āÕÆīµĄŗĶ»Ģ’╝īõĖŗķØóµ╝öńż║õ║åÕ«āõ╗¼Õ£©õĖŹÕÉīÕ£║µÖ»õĖŗńÜäńö©µ│ĢŃĆé
+
+1. Ķ«Łń╗ā
+
+ õ╗źõĖŗńż║õŠŗõĖ║Õ£© slurm ķøåńŠż dev ÕłåÕī║ńö│Ķ»Ę 1 ÕØŚ GPU Ķ┐øĶĪī DBNet Ķ«Łń╗āŃĆé
+
+```bash
+# ńż║õŠŗ’╝ÜÕ£© slurm ķøåńŠż dev ÕłåÕī║ńö│Ķ»Ę 1ÕØŚ GPU ĶĄäµ║ÉĶ┐øĶĪī DBNet Ķ«Łń╗āõ╗╗ÕŖĪ
+GPUS=1 GPUS_PER_NODE=1 CPUS_PER_TASK=5 tools/slurm_train.sh dev db_r50 configs/textdet/dbnet/dbnet_r50dcnv2_fpnc_1200e_icdar2015.py work_dir
+```
+
+2. µĄŗĶ»Ģ
+
+ ÕÉīńÉå’╝ī ÕłÖµÅÉõŠøõ║åµĄŗĶ»Ģõ╗╗ÕŖĪµÅÉõ║żĶäܵ£¼ŃĆéõ╗źõĖŗńż║õŠŗõĖ║Õ£© slurm ķøåńŠż dev ÕłåÕī║ńö│Ķ»Ę 1 ÕØŚ GPU ĶĄäµ║ÉĶ┐øĶĪī DBNet µĄŗĶ»ĢŃĆé
+
+```bash
+# ńż║õŠŗ’╝ÜÕ£© slurm ķøåńŠż dev ÕłåÕī║ńö│Ķ»Ę 1ÕØŚ GPU ĶĄäµ║ÉĶ┐øĶĪī DBNet µĄŗĶ»Ģõ╗╗ÕŖĪ
+GPUS=1 GPUS_PER_NODE=1 CPUS_PER_TASK=5 tools/slurm_test.sh dev db_r50 configs/textdet/dbnet/dbnet_r50dcnv2_fpnc_1200e_icdar2015.py dbnet_r50.pth work_dir
+```
+
+## Ķ┐øķśČµŖĆÕʦ
+
+### õ╗ĵ¢Łńé╣µüóÕżŹĶ«Łń╗ā
+
+`tools/train.py` µÅÉõŠøõ║åõ╗ĵ¢Łńé╣µüóÕżŹĶ«Łń╗āńÜäÕŖ¤ĶāĮ’╝īńö©µłĘõ╗ģķ£ĆÕ£©ÕæĮõ╗żõĖŁµīćÕ«Ü `--resume` ÕÅéµĢ░’╝īÕŹ│ÕÅ»Ķć¬ÕŖ©õ╗ĵ¢Łńé╣µüóÕżŹĶ«Łń╗āŃĆé
+
+```bash
+# ńż║õŠŗ’╝Üõ╗ĵ¢Łńé╣µüóÕżŹĶ«Łń╗ā
+python tools/train.py configs/textdet/dbnet/dbnet_r50dcnv2_fpnc_1200e_icdar2015.py 4 --resume
+```
+
+ķ╗śĶ«żÕ£░’╝īń©ŗÕ║ÅÕ░åĶć¬ÕŖ©õ╗ÄõĖŖµ¼ĪĶ«Łń╗āĶ┐ćń©ŗõĖŁµ£ĆÕÉĵłÉÕŖ¤õ┐ØÕŁśńÜäµ¢Łńé╣’╝īÕŹ│ `latest.pth` ÕżäÕ╝ĆÕ¦ŗń╗¦ń╗ŁĶ«Łń╗āŃĆéÕ”éµ×£ńö©µłĘÕĖīµ£øµīćÕ«Üõ╗Äńē╣Õ«ÜńÜäµ¢Łńé╣ÕżäÕ╝ĆÕ¦ŗµüóÕżŹĶ«Łń╗ā’╝īÕłÖÕÅ»õ╗źµīēÕ”éõĖŗµĀ╝Õ╝ÅÕ£©µ©ĪÕ×ŗńÜäķģŹńĮ«µ¢ćõ╗ČõĖŁĶ«ŠÕ«ÜĶ»źµ¢Łńé╣ńÜäĶĘ»ÕŠäŃĆé
+
+```python
+# ńż║õŠŗ’╝ÜÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁĶ«ŠńĮ«µā│Ķ”üÕŖĀĶĮĮńÜäµ¢Łńé╣ĶĘ»ÕŠä
+load_from = 'work_dir/dbnet/models/epoch_10000.pth'
+```
+
+### µĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗ā
+
+µĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗āÕÅ»õ╗źÕ£©ń╝®ÕćÅÕåģÕŁśÕŹĀńö©ńÜäÕÉīµŚČµÅÉÕŹćĶ«Łń╗āķƤÕ║”’╝īõĖ║µŁż’╝īMMOCR µÅÉõŠøõ║åõĖĆķö«Õ╝ÅńÜäµĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗āµ¢╣µĪł’╝īõ╗ģķ£ĆÕ£©Ķ«Łń╗āµŚČµĘ╗ÕŖĀ `--amp` ÕÅéµĢ░ÕŹ│ÕÅ»ŃĆé
+
+```bash
+# ńż║õŠŗ’╝ÜõĮ┐ńö©Ķć¬ÕŖ©µĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗ā
+python tools/train.py configs/textdet/dbnet/dbnet_r50dcnv2_fpnc_1200e_icdar2015.py 4 --amp
+```
+
+õĖŗĶĪ©ÕłŚÕć║õ║å MMOCR õĖŁÕÉäń«Śµ│ĢÕ»╣Ķć¬ÕŖ©µĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗āńÜäµö»µīüµāģÕåĄ’╝Ü
+
+| | µś»ÕÉ”µö»µīüµĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗ā | Õżćµ│© |
+| ------------- | :------------------: | :---------------------------: |
+| | µ¢ćµ£¼µŻĆµĄŗ | |
+| DBNet | µś» | |
+| DBNetpp | µś» | |
+| DRRG | ÕÉ” | roi_align_rotated õĖŹµö»µīü fp16 |
+| FCENet | ÕÉ” | BCELoss õĖŹµö»µīü fp16 |
+| Mask R-CNN | µś» | |
+| PANet | µś» | |
+| PSENet | µś» | |
+| TextSnake | ÕÉ” | |
+| | µ¢ćµ£¼Ķ»åÕł½ | |
+| ABINet | µś» | |
+| ASTER | µś» | |
+| CRNN | µś» | |
+| MASTER | µś» | |
+| NRTR | µś» | |
+| RobustScanner | µś» | |
+| SAR | µś» | |
+| SATRN | µś» | |
+
+### Ķć¬ÕŖ©ÕŁ”õ╣ĀńÄćń╝®µöŠ
+
+MMOCR Õ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁõĖ║µ»ÅõĖĆõĖ¬µ©ĪÕ×ŗĶ«ŠńĮ«õ║åķ╗śĶ«żńÜäÕłØÕ¦ŗÕŁ”õ╣ĀńÄć’╝īńäČĶĆī’╝īÕĮōńö©µłĘõĮ┐ńö©ńÜä `batch_size` õĖŹÕÉīõ║ĵłæõ╗¼ķóäĶ«ŠńÜä `base_batch_size` µŚČ’╝īĶ┐Öõ║øÕłØÕ¦ŗÕŁ”õ╣ĀńÄćÕÅ»ĶāĮõĖŹÕåŹÕ«īÕģ©ķĆéńö©ŃĆéÕøĀµŁż’╝īµłæõ╗¼µÅÉõŠøõ║åĶć¬ÕŖ©ÕŁ”õ╣ĀńÄćń╝®µöŠÕĘźÕģĘŃĆéÕĮōõĮ┐ńö©õĖŹÕÉīõ║Ä MMOCR ķóäĶ«ŠńÜä `base_batch_size` Ķ┐øĶĪīĶ«Łń╗āµŚČ’╝īńö©µłĘõ╗ģķ£ĆµĘ╗ÕŖĀ `--auto-scale-lr` ÕÅéµĢ░ÕŹ│ÕÅ»Ķć¬ÕŖ©õŠØµŹ«µ¢░ńÜä `batch_size` Õ░åÕŁ”õ╣ĀńÄćń╝®µöŠĶć│Õ»╣Õ║öÕ░║Õ║”ŃĆé
+
+```bash
+# ńż║õŠŗ’╝ÜõĮ┐ńö©Ķć¬ÕŖ©ÕŁ”õ╣ĀńÄćń╝®µöŠ
+python tools/train.py configs/textdet/dbnet/dbnet_r50dcnv2_fpnc_1200e_icdar2015.py 4 --auto-scale-lr
+```
+
+### ÕÅ»Ķ¦åÕī¢µ©ĪÕ×ŗµĄŗĶ»Ģń╗ōµ×£
+
+`tools/test.py` µÅÉõŠøõ║åÕÅ»Ķ¦åÕī¢µÄźÕÅŻ’╝īõ╗źµ¢╣õŠ┐ńö©µłĘÕ»╣µ©ĪÕ×ŗĶ┐øĶĪīÕ«ÜµĆ¦Õłåµ×ÉŃĆé
+
+
textdet_transforms.py
textrecog_transforms.py | Õ«×ńÄ░õ║åõĖŹÕÉīõ╗╗ÕŖĪõĖŗńÜäÕÉäń▒╗µĢ░µŹ«Õó×Õ╝║µ¢╣µ│ĢŃĆé | +| ÕīģĶŻģń▒╗ | wrappers.py | Õ«×ńÄ░õ║åÕ»╣ ImgAug ńŁēÕĖĖńö©ń«Śµ│ĢÕ║ōńÜäÕīģĶŻģ’╝īõĮ┐ÕģČķĆéķģŹ MMOCR ńÜäÕåģķā©µĢ░µŹ«µĀ╝Õ╝ÅŃĆé | + +ńö▒õ║ĵ»ÅõĖĆõĖ¬µĢ░µŹ«ÕÅśµŹóń▒╗õ╣ŗķŚ┤ķāĮµś»ńøĖõ║Æńŗ¼ń½ŗńÜä’╝īÕøĀµŁż’╝īÕ£©ń║”Õ«ÜÕźĮÕø║Õ«ÜńÜäµĢ░µŹ«ÕŁśÕé©ÕŁŚµ«ĄÕÉÄ’╝īµłæõ╗¼ÕÅ»õ╗źõŠ┐µŹĘÕ£░ķććńö©õ╗╗µäÅńÜäµĢ░µŹ«ÕÅśµŹóń╗äÕÉłµØźµ×äÕ╗║µĢ░µŹ«µĄüµ░┤ń║┐’╝łPipeline’╝ēŃĆéÕ”éõĖŗÕøŠµēĆńż║’╝īÕ£© MMOCR õĖŁ’╝īõĖĆõĖ¬ÕģĖÕ×ŗńÜäĶ«Łń╗āµĢ░µŹ«µĄüµ░┤ń║┐õĖ╗Ķ”üńö▒**µĢ░µŹ«Ķ»╗ÕÅ¢**ŃĆü**ÕøŠÕāÅÕó×Õ╝║**õ╗źÕÅŖ**µĢ░µŹ«µĀ╝Õ╝ÅÕī¢**õĖēķā©Õłåµ×䵳ɒ╝īńö©µłĘÕŬķ£ĆĶ”üÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁÕ«Üõ╣ēńøĖÕģ│ńÜäµĢ░µŹ«µĄüµ░┤ń║┐ÕłŚĶĪ©’╝īÕ╣ȵīćÕ«ÜÕģĘõĮōµēĆķ£ĆńÜäµĢ░µŹ«ÕÅśµŹóń▒╗ÕÅŖÕģČÕÅéµĢ░ÕŹ│ÕÅ»’╝Ü + +
`img_shape`
`ori_shape` | õ╗ÄÕøŠńēćĶĘ»ÕŠäĶ»╗ÕÅ¢ÕøŠńēć’╝īµö»µīüÕżÜń¦Źµ¢ćõ╗ČÕŁśÕé©ÕÉÄń½»’╝łÕ”é `disk`, `http`, `petrel` ńŁē’╝ēÕÅŖÕøŠńēćĶ¦ŻńĀüÕÉÄń½»’╝łÕ”é `cv2`, `turbojpeg`, `pillow`, `tifffile`ńŁē’╝ēŃĆé | +| LoadOCRAnnotations | `bbox`
`bbox_label`
`polygon`
`ignore`
`text` | `gt_bboxes`
`gt_bboxes_labels`
`gt_polygons`
`gt_ignored`
`gt_texts` | Ķ¦Żµ×É OCR õ╗╗ÕŖĪµēĆķ£ĆńÜäµĀćµ│©õ┐Īµü»ŃĆé | +| LoadKIEAnnotations | `bboxes` `bbox_labels` `edge_labels`
`texts` | `gt_bboxes`
`gt_bboxes_labels`
`gt_edge_labels`
`gt_texts`
`ori_shape` | Ķ¦Żµ×É KIE õ╗╗ÕŖĪµēĆķ£ĆńÜäµĀćµ│©õ┐Īµü»ŃĆé | + +## µĢ░µŹ«Õó×Õ╝║ - xxx_transforms.py + +µĢ░µŹ«Õó×Õ╝║µś»µ¢ćµ£¼µŻĆµĄŗŃĆüĶ»åÕł½ńŁēõ╗╗ÕŖĪõĖŁÕ┐ģõĖŹÕÅ»Õ░æńÜ䵥üń©ŗõ╣ŗõĖĆŃĆéńø«ÕēŹ’╝īMMOCR õĖŁÕģ▒Õ«×ńÄ░õ║åµĢ░ÕŹüń¦Źµ¢ćµ£¼ķóåÕ¤¤ÕåģÕĖĖńö©ńÜäµĢ░µŹ«Õó×Õ╝║µ©ĪÕØŚ’╝īõŠØµŹ«ÕģČõ╗╗ÕŖĪń▒╗Õ×ŗ’╝īÕłåÕł½õĖ║ķĆÜńö© OCR µĢ░µŹ«Õó×Õ╝║µ©ĪÕØŚ [ocr_transforms.py](/mmocr/datasets/transforms/ocr_transforms.py)’╝īµ¢ćµ£¼µŻĆµĄŗµĢ░µŹ«Õó×Õ╝║µ©ĪÕØŚ [textdet_transforms.py](/mmocr/datasets/transforms/textdet_transforms.py)’╝īõ╗źÕÅŖµ¢ćµ£¼Ķ»åÕł½µĢ░µŹ«Õó×Õ╝║µ©ĪÕØŚ [textrecog_transforms.py](/mmocr/datasets/transforms/textrecog_transforms.py)ŃĆé + +ÕģĘõĮōĶĆīĶ©Ć’╝ī`ocr_transforms.py` õĖŁÕ«×ńÄ░õ║åķÜŵ£║Õē¬ĶŻüŃĆüķÜŵ£║µŚŗĶĮ¼ńŁēÕÉäõ╗╗ÕŖĪķĆÜńö©ńÜäµĢ░µŹ«Õó×Õ╝║µ©ĪÕØŚ’╝Ü + +| | | | | +| -------------- | -------------------------------------------------------------- | -------------------------------------------------------------- | -------------------------------------------------------------- | +| µĢ░µŹ«ĶĮ¼µŹóń▒╗ÕÉŹń¦░ | ķ£Ćµ▒éÕŁŚµ«Ą | õ┐«µö╣/µĘ╗ÕŖĀÕŁŚµ«Ą | Ķ»┤µśÄ | +| RandomCrop | `img`
`gt_bboxes`
`gt_bboxes_labels`
`gt_polygons`
`gt_ignored`
`gt_texts` (optional) | `img`
`img_shape`
`gt_bboxes`
`gt_bboxes_labels`
`gt_polygons`
`gt_ignored`
`gt_texts` (optional) | ķÜŵ£║ĶŻüÕē¬’╝īÕ╣ČńĪ«õ┐ØĶŻüÕē¬ÕÉÄńÜäÕøŠńēćĶć│Õ░æÕīģÕɽõĖĆõĖ¬µ¢ćµ£¼Õ«×õŠŗŃĆéÕÅ»ķĆēÕÅéµĢ░õĖ║ `min_side_ratio`’╝īńö©õ╗źµÄ¦ÕłČĶŻüÕē¬ÕøŠńēćńÜäń¤ŁĶŠ╣ÕŹĀÕĤզŗÕøŠńēćńÜäµ»öõŠŗ’╝īķ╗śĶ«żÕĆ╝õĖ║ `0.4`ŃĆé | +| RandomRotate | `img`
`img_shape`
`gt_bboxes` (optional)
`gt_polygons` (optional) | `img`
`img_shape`
`gt_bboxes` (optional)
`gt_polygons` (optional)
`rotated_angle` | ķÜŵ£║µŚŗĶĮ¼’╝īÕ╣ČÕÅ»ķĆēµŗ®Õ»╣µŚŗĶĮ¼ÕÉÄÕøŠÕāÅńÜäķ╗æĶŠ╣Ķ┐øĶĪīÕĪ½ÕģģŃĆé | +| | | | | + +`textdet_transforms.py` ÕłÖÕ«×ńÄ░õ║åµ¢ćµ£¼µŻĆµĄŗõ╗╗ÕŖĪõĖŁÕĖĖńö©ńÜäµĢ░µŹ«Õó×Õ╝║µ©ĪÕØŚ’╝Ü + +| | | | | +| ----------------- | ------------------------------------- | ------------------------------------------------------------------- | -------------------------------------------------------------------- | +| µĢ░µŹ«ĶĮ¼µŹóń▒╗ÕÉŹń¦░ | ķ£Ćµ▒éÕŁŚµ«Ą | õ┐«µö╣/µĘ╗ÕŖĀÕŁŚµ«Ą | Ķ»┤µśÄ | +| RandomFlip | `img`
`gt_bboxes`
`gt_polygons` | `img`
`gt_bboxes`
`gt_polygons`
`flip`
`flip_direction` | ķÜŵ£║ń┐╗ĶĮ¼’╝īµö»µīüµ░┤Õ╣│ŃĆüÕ×éńø┤ÕÆīÕ»╣Ķ¦ÆõĖēń¦Źµ¢╣ÕÉæńÜäÕøŠÕāÅń┐╗ĶĮ¼ŃĆéķ╗śĶ«żõĮ┐ńö©µ░┤Õ╣│ń┐╗ĶĮ¼ŃĆé | +| FixInvalidPolygon | `gt_polygons`
`gt_ignored` | `gt_polygons`
`gt_ignored` | Ķć¬ÕŖ©õ┐«ÕżŹµł¢Õ┐ĮńĢźķØ×µ│ĢÕżÜĶŠ╣ÕĮóµĀćµ│©ŃĆé | + +`textrecog_transforms.py` õĖŁÕ«×ńÄ░õ║åµ¢ćµ£¼Ķ»åÕł½õ╗╗ÕŖĪõĖŁÕĖĖńö©ńÜäµĢ░µŹ«Õó×Õ╝║µ©ĪÕØŚ’╝Ü + +| | | | | +| --------------- | -------- | ----------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------- | +| µĢ░µŹ«ĶĮ¼µŹóń▒╗ÕÉŹń¦░ | ķ£Ćµ▒éÕŁŚµ«Ą | õ┐«µö╣/µĘ╗ÕŖĀÕŁŚµ«Ą | Ķ»┤µśÄ | +| RescaleToHeight | `img` | `img`
`img_shape`
`scale`
`scale_factor`
`keep_ratio` | ń╝®µöŠÕøŠÕāÅĶć│µīćÕ«Üķ½śÕ║”’╝īÕ╣ČÕ░ĮÕÅ»ĶāĮõ┐صīüķĢ┐Õ«Įµ»öõĖŹÕÅśŃĆéÕĮō `min_width` ÕÅŖ `max_width` Ķó½µīćիܵŚČ’╝īķĢ┐Õ«Įµ»öÕłÖÕÅ»ĶāĮõ╝ÜĶó½µö╣ÕÅśŃĆé | +| | | | | + +```{warning} +õ╗źõĖŖĶĪ©µĀ╝õ╗ģķĆēµŗ®µĆ¦Õ£░Õ»╣ķā©ÕłåµĢ░µŹ«Õó×Õ╝║µ¢╣µ│ĢõĮ£ń«ĆĶ”üõ╗ŗń╗Ź’╝īµø┤ÕżÜµĢ░µŹ«Õó×Õ╝║µ¢╣µ│Ģõ╗ŗń╗ŹĶ»ĘÕÅéĶĆā[API µ¢ćµĪŻ](../api.rst)µł¢ķśģĶ»╗õ╗ŻńĀüÕåģńÜäµ¢ćµĪŻµ│©ķćŖŃĆé +``` + +## µĢ░µŹ«µĀ╝Õ╝ÅÕī¢ - formatting.py + +µĢ░µŹ«µĀ╝Õ╝ÅÕī¢Ķ┤¤Ķ┤ŻÕ░åÕøŠÕāÅŃĆüń£¤Õ«×µĀćńŁŠõ╗źÕÅŖÕģČÕ«āÕĖĖńö©õ┐Īµü»ńŁēµēōÕīģµłÉõĖĆõĖ¬ÕŁŚÕģĖŃĆéõĖŹÕÉīńÜäõ╗╗ÕŖĪķĆÜÕĖĖõŠØĶĄ¢õ║ÄõĖŹÕÉīńÜäµĢ░µŹ«µĀ╝Õ╝ÅÕī¢µĢ░µŹ«ÕÅśµŹóń▒╗ŃĆéõŠŗÕ”é’╝Ü + +| | | | | +| ------------------- | -------- | ------------- | ------------------------------------------ | +| µĢ░µŹ«ĶĮ¼µŹóń▒╗ÕÉŹń¦░ | ķ£Ćµ▒éÕŁŚµ«Ą | õ┐«µö╣/µĘ╗ÕŖĀÕŁŚµ«Ą | Ķ»┤µśÄ | +| PackTextDetInputs | - | - | ńö©õ║ĵēōÕīģµ¢ćµ£¼µŻĆµĄŗõ╗╗ÕŖĪµēĆķ£ĆĶ”üńÜäĶŠōÕģźõ┐Īµü»ŃĆé | +| PackTextRecogInputs | - | - | ńö©õ║ĵēōÕīģµ¢ćµ£¼Ķ»åÕł½õ╗╗ÕŖĪµēĆķ£ĆĶ”üńÜäĶŠōÕģźõ┐Īµü»ŃĆé | +| PackKIEInputs | - | - | ńö©õ║ĵēōÕīģÕģ│ķö«õ┐Īµü»µŖĮÕÅ¢õ╗╗ÕŖĪµēĆķ£ĆĶ”üńÜäĶŠōÕģźõ┐Īµü»ŃĆé | + +## ĶĘ©Õ║ōµĢ░µŹ«ķĆéķģŹÕÖ© - adapters.py + +ĶĘ©Õ║ōµĢ░µŹ«ķĆéķģŹÕÖ©µēōķĆÜõ║å MMOCR õĖÄÕģČõ╗¢ OpenMMLab ń│╗ÕłŚń«Śµ│ĢÕ║ōÕ”é [MMDetection](https://github.com/open-mmlab/mmdetection) õ╣ŗķŚ┤ńÜäµĢ░µŹ«µĀ╝Õ╝Å’╝īõĮ┐ÕŠŚĶĘ©ķĪ╣ńø«Ķ░āńö©ÕģČÕ«āÕ╝Ƶ║Éń«Śµ│ĢÕ║ōńÜäķģŹńĮ«µ¢ćõ╗ČÕÅŖń«Śµ│ĢµłÉõĖ║õ║åÕÅ»ĶāĮŃĆéńø«ÕēŹ’╝īMMOCR Õ«×ńÄ░õ║å `MMDet2MMOCR` õ╗źÕÅŖ `MMOCR2MMDet`’╝īõĮ┐ÕŠŚµĢ░µŹ«ÕÅ»õ╗źÕ£© MMDetection õĖÄ MMOCR ńÜäµĀ╝Õ╝Åõ╣ŗķŚ┤Ķć¬ńö▒ĶĮ¼µŹó’╝øÕƤÕŖ®Ķ┐Öõ║øķĆéķģŹĶĮ¼µŹóÕÖ©’╝īńö©µłĘÕÅ»õ╗źÕ£© MMOCR ń«Śµ│ĢÕ║ōÕåģķā©ĶĮ╗µØŠĶ░āńö©õ╗╗õĮĢ MMDetection ÕĘ▓µö»µīüńÜ䵯ƵĄŗń«Śµ│Ģ’╝īÕ╣ČÕ£© OCR ńøĖÕģ│µĢ░µŹ«ķøåõĖŖĶ┐øĶĪīĶ«Łń╗āŃĆéõŠŗÕ”é’╝īµłæõ╗¼õ╗ź Mask R-CNN õĖ║õŠŗµÅÉõŠøõ║å[µĢÖń©ŗ](#todo)’╝īÕ▒Ģńż║õ║åÕ”éõĮĢÕ£© MMOCR õĖŁõĮ┐ńö© MMDetection ńÜ䵯ƵĄŗń«Śµ│ĢĶ«Łń╗āµ¢ćµ£¼µŻĆµĄŗÕÖ©ŃĆé + +| | | | | +| -------------- | -------------------------------------------- | ----------------------------- | ---------------------------------------------- | +| µĢ░µŹ«ĶĮ¼µŹóń▒╗ÕÉŹń¦░ | ķ£Ćµ▒éÕŁŚµ«Ą | õ┐«µö╣/µĘ╗ÕŖĀÕŁŚµ«Ą | Ķ»┤µśÄ | +| MMDet2MMOCR | `gt_masks` `gt_ignore_flags` | `gt_polygons`
`gt_ignored` | Õ░å MMDet õĖŁķććńö©ńÜäÕŁŚµ«ĄĶĮ¼µŹóõĖ║Õ»╣Õ║öńÜä MMOCR ÕŁŚµ«ĄŃĆé | +| MMOCR2MMDet | `img_shape`
`gt_polygons`
`gt_ignored` | `gt_masks` `gt_ignore_flags` | Õ░å MMOCR õĖŁķććńö©ńÜäÕŁŚµ«ĄĶĮ¼µŹóõĖ║Õ»╣Õ║öńÜä MMDet ÕŁŚµ«ĄŃĆé | + +## ÕīģĶŻģń▒╗ - wrappers.py + +õĖ║õ║åµ¢╣õŠ┐ńö©µłĘÕ£© MMOCR Õåģķā©µŚĀń╝ØĶ░āńö©ÕĖĖńö©ńÜä CV ń«Śµ│ĢÕ║ō’╝īµłæõ╗¼Õ£© wrappers.py õĖŁµÅÉõŠøõ║åńøĖÕ║öńÜäÕīģĶŻģń▒╗ŃĆéÕģČõĖ╗Ķ”üµēōķĆÜõ║å MMOCR õĖÄÕģČÕ«āń¼¼õĖēµ¢╣ń«Śµ│ĢÕ║ōõ╣ŗķŚ┤ńÜäµĢ░µŹ«µĀ╝Õ╝ÅÕÆīĶĮ¼µŹóµĀćÕćå’╝īõĮ┐ÕŠŚńö©µłĘÕÅ»õ╗źÕ£© MMOCR ńÜäķģŹńĮ«µ¢ćõ╗ČÕåģńø┤µÄźķģŹńĮ«õĮ┐ńö©Ķ┐Öõ║øń¼¼õĖēµ¢╣Õ║ōµÅÉõŠøńÜäµĢ░µŹ«ÕÅśµŹóµ¢╣µ│ĢŃĆéńø«ÕēŹµö»µīüńÜäÕīģĶŻģń▒╗µ£ē’╝Ü + +| | | | | +| ------------------ | ------------------------------------------------------------ | ------------------------------------------------------------- | ------------------------------------------------------------- | +| µĢ░µŹ«ĶĮ¼µŹóń▒╗ÕÉŹń¦░ | ķ£Ćµ▒éÕŁŚµ«Ą | õ┐«µö╣/µĘ╗ÕŖĀÕŁŚµ«Ą | Ķ»┤µśÄ | +| ImgAugWrapper | `img`
`gt_polygons` (optional for text recognition)
`gt_bboxes` (optional for text recognition)
`gt_bboxes_labels` (optional for text recognition)
`gt_ignored` (optional for text recognition)
`gt_texts` (optional) | `img`
`gt_polygons` (optional for text recognition)
`gt_bboxes` (optional for text recognition)
`gt_bboxes_labels` (optional for text recognition)
`gt_ignored` (optional for text recognition)
`img_shape` (optional)
`gt_texts` (optional) | [ImgAug](https://github.com/aleju/imgaug) ÕīģĶŻģń▒╗’╝īńö©õ║ĵēōķĆÜ ImgAug õĖÄ MMOCR ńÜäµĢ░µŹ«µĀ╝Õ╝ÅÕÅŖķģŹńĮ«’╝īµ¢╣õŠ┐ńö©µłĘĶ░āńö© ImgAug Õ«×ńÄ░ńÜäõĖĆń│╗ÕłŚµĢ░µŹ«Õó×Õ╝║µ¢╣µ│ĢŃĆé | +| TorchVisionWrapper | `img` | `img`
`img_shape` | [TorchVision](https://github.com/pytorch/vision) ÕīģĶŻģń▒╗’╝īńö©õ║ĵēōķĆÜ TorchVision õĖÄ MMOCR ńÜäµĢ░µŹ«µĀ╝Õ╝ÅÕÅŖķģŹńĮ«’╝īµ¢╣õŠ┐ńö©µłĘĶ░āńö© `torchvision.transforms` õĖŁÕ«×ńÄ░ńÜäõĖĆń│╗ÕłŚµĢ░µŹ«ÕÅśµŹóµ¢╣µ│ĢŃĆé | + +### `ImgAugWrapper` ńż║õŠŗ + +õŠŗÕ”é’╝īÕ£©ÕĤńö¤ńÜä ImgAug õĖŁ’╝īµłæõ╗¼ÕÅ»õ╗źµīēńģ¦Õ”éõĖŗõ╗ŻńĀüÕ«Üõ╣ēõĖĆõĖ¬ `Sequential` ń▒╗Õ×ŗńÜäµĢ░µŹ«Õó×Õ╝║µĄüń©ŗ’╝īÕ»╣ÕøŠÕāÅÕłåÕł½Ķ┐øĶĪīķÜŵ£║ń┐╗ĶĮ¼ŃĆüķÜŵ£║µŚŗĶĮ¼ÕÆīķÜŵ£║ń╝®µöŠ’╝Ü + +```python +import imgaug.augmenters as iaa + +aug = iaa.Sequential( + iaa.Fliplr(0.5), # õ╗źµ”éńÄć 0.5 Ķ┐øĶĪīµ░┤Õ╣│ń┐╗ĶĮ¼ + iaa.Affine(rotate=(-10, 10)), # ķÜŵ£║µŚŗĶĮ¼ -10 Õł░ 10 Õ║” + iaa.Resize((0.5, 3.0)) # ķÜŵ£║ń╝®µöŠÕł░ 50% Õł░ 300% ńÜäÕ░║Õ»Ė +) +``` + +ĶĆīÕ£© MMOCR õĖŁ’╝īµłæõ╗¼ÕÅ»õ╗źķĆÜĶ┐ć `ImgAugWrapper` ÕīģĶŻģń▒╗’╝īÕ░åõĖŖĶ┐░µĢ░µŹ«Õó×Õ╝║µĄüń©ŗńø┤µÄźķģŹńĮ«Õł░ `train_pipeline` õĖŁ’╝Ü + +```python +dict( + type='ImgAugWrapper', + args=[ + ['Fliplr', 0.5], + dict(cls='Affine', rotate=[-10, 10]), + ['Resize', [0.5, 3.0]], + ] +) +``` + +ÕģČõĖŁ’╝ī`args` ÕÅéµĢ░µÄźµöČõĖĆõĖ¬ÕłŚĶĪ©’╝īÕłŚĶĪ©õĖŁńÜäµ»ÅõĖ¬Õģāń┤ĀÕÅ»õ╗źµś»õĖĆõĖ¬ÕłŚĶĪ©’╝īõ╣¤ÕÅ»õ╗źµś»õĖĆõĖ¬ÕŁŚÕģĖŃĆéÕ”éµ×£µś»ÕłŚĶĪ©’╝īÕłÖÕłŚĶĪ©ńÜäń¼¼õĖĆõĖ¬Õģāń┤ĀõĖ║ `imgaug.augmenters` õĖŁńÜäń▒╗ÕÉŹ’╝īÕÉÄķØóńÜäÕģāń┤ĀõĖ║Ķ»źń▒╗ńÜäÕłØÕ¦ŗÕī¢ÕÅéµĢ░’╝øÕ”éµ×£µś»ÕŁŚÕģĖ’╝īÕłÖÕŁŚÕģĖńÜä `cls` ķö«Õ»╣Õ║ö `imgaug.augmenters` õĖŁńÜäń▒╗ÕÉŹ’╝īÕģČõ╗¢ķö«ÕĆ╝Õ»╣ÕłÖÕ»╣Õ║öĶ»źń▒╗ńÜäÕłØÕ¦ŗÕī¢ÕÅéµĢ░ŃĆé + +### `TorchVisionWrapper` ńż║õŠŗ + +õŠŗÕ”é’╝īÕ£©ÕĤńö¤ńÜä TorchVision õĖŁ’╝īµłæõ╗¼ÕÅ»õ╗źµīēńģ¦Õ”éõĖŗõ╗ŻńĀüÕ«Üõ╣ēõĖĆõĖ¬ `Compose` ń▒╗Õ×ŗńÜäµĢ░µŹ«ÕÅśµŹóµĄüń©ŗ’╝īÕ»╣ÕøŠÕāÅĶ┐øĶĪīĶē▓ÕĮ®µŖ¢ÕŖ©’╝Ü + +```python +import torchvision.transforms as transforms + +aug = transforms.Compose([ + transforms.ColorJitter( + brightness=32.0 / 255, # õ║«Õ║”µŖ¢ÕŖ©ĶīāÕø┤ + saturation=0.5) # ķź▒ÕÆīÕ║”µŖ¢ÕŖ©ĶīāÕø┤ +]) +``` + +ĶĆīÕ£© MMOCR õĖŁ’╝īµłæõ╗¼ÕÅ»õ╗źķĆÜĶ┐ć `TorchVisionWrapper` ÕīģĶŻģń▒╗’╝īÕ░åõĖŖĶ┐░µĢ░µŹ«ÕÅśµŹóµĄüń©ŗńø┤µÄźķģŹńĮ«Õł░ `train_pipeline` õĖŁ’╝Ü + +```python +dict( + type='TorchVisionWrapper', + op='ColorJitter', + brightness=32.0 / 255, + saturation=0.5 +) +``` + +ÕģČõĖŁ’╝ī`op` ÕÅéµĢ░õĖ║ `torchvision.transforms` õĖŁńÜäń▒╗ÕÉŹ’╝īÕÉÄķØóńÜäÕÅéµĢ░ÕłÖÕ»╣Õ║öĶ»źń▒╗ńÜäÕłØÕ¦ŗÕī¢ÕÅéµĢ░ŃĆé diff --git a/internlm_langchain/knowledge_base/MMOCR/content/useful_tools.md b/internlm_langchain/knowledge_base/MMOCR/content/useful_tools.md new file mode 100644 index 00000000..2a607245 --- /dev/null +++ b/internlm_langchain/knowledge_base/MMOCR/content/useful_tools.md @@ -0,0 +1,241 @@ +# ÕĖĖńö©ÕĘźÕģĘ + +## ÕÅ»Ķ¦åÕī¢ÕĘźÕģĘ + +### µĢ░µŹ«ķøåÕÅ»Ķ¦åÕī¢ÕĘźÕģĘ + +MMOCR µÅÉõŠøõ║åµĢ░µŹ«ķøåÕÅ»Ķ¦åÕī¢ÕĘźÕģĘ `tools/visualizations/browse_datasets.py` õ╗źĶŠģÕŖ®ńö©µłĘµÄƵ¤źÕÅ»ĶāĮķüćÕł░ńÜäµĢ░µŹ«ķøåńøĖÕģ│ńÜäķŚ«ķóśŃĆéńö©µłĘÕŬķ£ĆĶ”üµīćիܵēĆõĮ┐ńö©ńÜäĶ«Łń╗āķģŹńĮ«µ¢ćõ╗Č’╝łķĆÜÕĖĖÕŁśµöŠÕ£©Õ”é `configs/textdet/dbnet/xxx.py` µ¢ćõ╗ČõĖŁ’╝ēµł¢µĢ░µŹ«ķøåķģŹńĮ«’╝łķĆÜÕĖĖÕŁśµöŠÕ£© `configs/textdet/_base_/datasets/xxx.py` µ¢ćõ╗ČõĖŁ’╝ēĶĘ»ÕŠäŃĆéĶ»źÕĘźÕģĘÕ░åõŠØµŹ«ĶŠōÕģźńÜäķģŹńĮ«µ¢ćõ╗Čń▒╗Õ×ŗĶć¬ÕŖ©Õ░åń╗ÅĶ┐ćµĢ░µŹ«µĄüµ░┤ń║┐’╝łdata pipeline’╝ēÕżäńÉåĶ┐ćńÜäÕøŠÕāÅÕÅŖÕģČÕ»╣Õ║öńÜäµĀćńŁŠ’╝īµł¢ÕĤզŗÕøŠńēćÕÅŖÕģČÕ»╣Õ║öńÜäµĀćńŁŠń╗śÕłČÕć║µØźŃĆé + +#### µö»µīüÕÅéµĢ░ + +```bash +python tools/visualizations/browse_dataset.py \ + ${CONFIG_FILE} \ + [-o, --output-dir ${OUTPUT_DIR}] \ + [-p, --phase ${DATASET_PHASE}] \ + [-m, --mode ${DISPLAY_MODE}] \ + [-t, --task ${DATASET_TASK}] \ + [-n, --show-number ${NUMBER_IMAGES_DISPLAY}] \ + [-i, --show-interval ${SHOW_INTERRVAL}] \ + [--cfg-options ${CFG_OPTIONS}] +``` + +| ÕÅéµĢ░ÕÉŹ | ń▒╗Õ×ŗ | µÅÅĶ┐░ | +| ------------------- | ------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------ | +| config | str | (Õ┐ģķĪ╗) ķģŹńĮ«µ¢ćõ╗ČĶĘ»ÕŠäŃĆé | +| -o, --output-dir | str | Õ”éµ×£ÕøŠÕĮóÕī¢ńĢīķØóõĖŹÕÅ»ńö©’╝īĶ»ĘµīćÕ«ÜõĖĆõĖ¬ĶŠōÕć║ĶĘ»ÕŠäµØźõ┐ØÕŁśÕÅ»Ķ¦åÕī¢ń╗ōµ×£ŃĆé | +| -p, --phase | str | ńö©õ║ĵīćÕ«Üķ£ĆĶ”üÕÅ»Ķ¦åÕī¢ńÜäµĢ░µŹ«ķøåÕłćńēć’╝īÕ”é "train", "test", "val"ŃĆéÕĮōµĢ░µŹ«ķøåÕŁśÕ£©ÕżÜõĖ¬ÕÅśń¦ŹµŚČ’╝īõ╣¤ÕÅ»õ╗źķĆÜĶ┐ćĶ»źÕÅéµĢ░µØźµīćÕ«ÜÕŠģÕÅ»Ķ¦åÕī¢ńÜäÕłćńēćŃĆé | +| -m, --mode | `original`, `transformed`, `pipeline` | ńö©õ║ĵīćիܵĢ░µŹ«ÕÅ»Ķ¦åÕī¢ńÜ䵩ĪÕ╝ÅŃĆé`original`’╝ÜÕĤզŗµ©ĪÕ╝Å’╝īõ╗ģÕÅ»Ķ¦åÕī¢µĢ░µŹ«ķøåńÜäÕĤզŗµĀćµ│©’╝ø`transformed`’╝ÜÕÅśµŹóµ©ĪÕ╝Å’╝īÕ▒Ģńż║ń╗ÅĶ┐ćµēƵ£ēµĢ░µŹ«ÕÅśµŹóµŁźķ¬żńÜäµ£Ćń╗łÕøŠÕāÅ’╝ø`pipeline`’╝ܵĄüµ░┤ń║┐µ©ĪÕ╝Å’╝īÕ▒Ģńż║µĢ░µŹ«ÕÅśµŹóĶ┐ćń©ŗõĖŁµ»ÅõĖĆõĖ¬õĖŁķŚ┤µŁźķ¬żńÜäÕÅśµŹóÕøŠÕāÅŃĆéķ╗śĶ«żõĮ┐ńö© `transformed` ÕÅśµŹóµ©ĪÕ╝ÅŃĆé | +| -t, --task | `auto`, `textdet`, `textrecog` | ńö©õ║ĵīćÕ«ÜÕÅ»Ķ¦åÕī¢µĢ░µŹ«ķøåńÜäõ╗╗ÕŖĪń▒╗Õ×ŗŃĆé`auto`’╝ÜĶć¬ÕŖ©µ©ĪÕ╝Å’╝īÕ░åõŠØµŹ«ń╗ÖÕ«ÜńÜäķģŹńĮ«µ¢ćõ╗ČĶć¬ÕŖ©ķĆēµŗ®ÕÉłķĆéńÜäõ╗╗ÕŖĪń▒╗Õ×ŗ’╝īÕ”éµ×£µŚĀµ│ĢĶć¬ÕŖ©ĶÄĘÕÅ¢õ╗╗ÕŖĪń▒╗Õ×ŗ’╝īÕłÖķ£ĆĶ”üńö©µłĘµēŗÕŖ©µīćÕ«ÜõĖ║ `textdet` µ¢ćµ£¼µŻĆµĄŗõ╗╗ÕŖĪ µł¢ `textrecog` µ¢ćµ£¼Ķ»åÕł½õ╗╗ÕŖĪŃĆéķ╗śĶ«żķććńö© `auto` Ķć¬ÕŖ©µ©ĪÕ╝ÅŃĆé | +| -n, --show-number | int | µīćÕ«Üķ£ĆĶ”üÕÅ»Ķ¦åÕī¢ńÜäµĀʵ£¼µĢ░ķćÅŃĆéĶŗźĶ»źÕÅéµĢ░ń╝║ń£üÕłÖķ╗śĶ«żÕ░åÕÅ»Ķ¦åÕī¢Õģ©ķā©ÕøŠńēćŃĆé | +| -i, --show-interval | float | ÕÅ»Ķ¦åÕī¢ÕøŠÕāÅķŚ┤ķÜöµŚČķŚ┤’╝īķ╗śĶ«żõĖ║ 2 ń¦ÆŃĆé | +| --cfg-options | float | ńö©õ║ÄĶ”åńø¢ķģŹńĮ«µ¢ćõ╗ČõĖŁńÜäÕÅéµĢ░’╝īĶ»”Ķ¦ü[ńż║õŠŗ](./config.md#command-line-modification)ŃĆé | + +#### ńö©µ│Ģńż║õŠŗ + +õ╗źõĖŗńż║õŠŗµ╝öńż║õ║åÕ”éõĮĢõĮ┐ńö©Ķ»źÕĘźÕģĘÕÅ»Ķ¦åÕī¢ "DBNet_R50_icdar2015" µ©ĪÕ×ŗõĮ┐ńö©ńÜäĶ«Łń╗āµĢ░µŹ«ŃĆé + +```Bash +# õĮ┐ńö©ķ╗śĶ«żÕÅéµĢ░ÕÅ»Ķ¦åÕī¢ "dbnet_r50dcn_v2_fpnc_1200e_icadr2015" µ©ĪÕ×ŗńÜäĶ«Łń╗āµĢ░µŹ« +python tools/visualizations/browse_dataset.py configs/textdet/dbnet/dbnet_resnet50-dcnv2_fpnc_1200e_icdar2015.py +``` + +ķ╗śĶ«żµāģÕåĄõĖŗ’╝īÕÅ»Ķ¦åÕī¢µ©ĪÕ╝ÅõĖ║ "transformed"’╝īµé©Õ░åń£ŗÕł░ń╗Åńö▒µĢ░µŹ«µĄüµ░┤ń║┐ÕÅśµŹóĶ┐ćÕÉÄńÜäÕøŠÕāÅÕÆīµĀćµ│©’╝Ü + +
+
+
+
+Õ”éµ×£µé©ÕŬµā│ÕÅ»Ķ¦åÕī¢ÕĤզŗµĢ░µŹ«ķøå’╝īÕŬķ£ĆÕ░嵩ĪÕ╝ÅĶ«ŠńĮ«õĖ║ "original"’╝Ü
+
+```Bash
+python tools/visualizations/browse_dataset.py configs/textdet/dbnet/dbnet_resnet50-dcnv2_fpnc_1200e_icdar2015.py -m original
+```
+
+ +
+µł¢ĶĆģ’╝īµé©õ╣¤ÕÅ»õ╗źõĮ┐ńö© "pipeline" µ©ĪÕ╝ÅµØźÕÅ»Ķ¦åÕī¢µĢ┤õĖ¬µĢ░µŹ«µĄüµ░┤ń║┐ńÜäõĖŁķŚ┤ń╗ōµ×£’╝Ü
+
+```Bash
+python tools/visualizations/browse_dataset.py configs/textdet/dbnet/dbnet_resnet50-dcnv2_fpnc_1200e_icdar2015.py -m pipeline
+```
+
+
+
+µł¢ĶĆģ’╝īµé©õ╣¤ÕÅ»õ╗źõĮ┐ńö© "pipeline" µ©ĪÕ╝ÅµØźÕÅ»Ķ¦åÕī¢µĢ┤õĖ¬µĢ░µŹ«µĄüµ░┤ń║┐ńÜäõĖŁķŚ┤ń╗ōµ×£’╝Ü
+
+```Bash
+python tools/visualizations/browse_dataset.py configs/textdet/dbnet/dbnet_resnet50-dcnv2_fpnc_1200e_icdar2015.py -m pipeline
+```
+
+ +
+ÕÅ”Õż¢’╝īńö©µłĘĶ┐śÕÅ»õ╗źķĆÜĶ┐ćµīćիܵĢ░µŹ«ķøåķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠäµØźÕÅ»Ķ¦åÕī¢µĢ░µŹ«ķøåńÜäÕĤզŗÕøŠÕāÅÕÅŖÕģČÕ»╣Õ║öńÜäµĀćµ│©’╝īõŠŗÕ”é’╝Ü
+
+```Bash
+python tools/visualizations/browse_dataset.py configs/textrecog/_base_/datasets/icdar2015.py
+```
+
+ķā©ÕłåµĢ░µŹ«ķøåÕÅ»ĶāĮµ£ēÕżÜõĖ¬ÕÅśõĮōŃĆéõŠŗÕ”é’╝ī`icdar2015` µ¢ćµ£¼Ķ»åÕł½µĢ░µŹ«ķøåńÜä[ķģŹńĮ«µ¢ćõ╗Č](/configs/textrecog/_base_/datasets/icdar2015.py)õĖŁÕīģÕɽõĖżõĖ¬µĄŗĶ»ĢķøåÕÅśõĮō’╝īÕłåÕł½õĖ║ `icdar2015_textrecog_test` ÕÆī `icdar2015_1811_textrecog_test`’╝īÕ”éõĖŗµēĆńż║’╝Ü
+
+```python
+icdar2015_textrecog_test = dict(
+ ann_file='textrecog_test.json',
+ # ...
+ )
+
+icdar2015_1811_textrecog_test = dict(
+ ann_file='textrecog_test_1811.json',
+ # ...
+)
+```
+
+Õ£©Ķ┐Öń¦ŹµāģÕåĄõĖŗ’╝īńö©µłĘÕÅ»õ╗źķĆÜĶ┐ćµīćÕ«Ü `-p` ÕÅéµĢ░µØźÕÅ»Ķ¦åÕī¢õĖŹÕÉīńÜäÕÅśõĮō’╝īõŠŗÕ”é’╝īõĮ┐ńö©õ╗źõĖŗÕæĮõ╗żÕÅ»Ķ¦åÕī¢ `icdar2015_1811_textrecog_test` ÕÅśõĮō’╝Ü
+
+```Bash
+python tools/visualizations/browse_dataset.py configs/textrecog/_base_/datasets/icdar2015.py -p icdar2015_1811_textrecog_test
+```
+
+Õ¤║õ║ÄĶ»źÕĘźÕģĘ’╝īńö©µłĘÕÅ»õ╗źĶĮ╗µØŠÕ£░µ¤źń£ŗµĢ░µŹ«ķøåńÜäÕĤզŗÕøŠÕāÅÕÅŖÕģČÕ»╣Õ║öńÜäµĀćµ│©’╝īõ╗źõŠ┐õ║ĵŻĆµ¤źµĢ░µŹ«ķøåńÜäµĀćµ│©µś»ÕÉ”µŁŻńĪ«ŃĆé
+
+### õ╝śÕī¢ÕÖ©ÕÅéµĢ░ńŁ¢ńĢźÕÅ»Ķ¦åÕī¢ÕĘźÕģĘ
+
+MMOCRµÅÉõŠøõ║åõ╝śÕī¢ÕÖ©ÕÅéµĢ░ÕÅ»Ķ¦åÕī¢ÕĘźÕģĘ `tools/visualizations/vis_scheduler.py` õ╗źĶŠģÕŖ®ńö©µłĘµÄƵ¤źõ╝śÕī¢ÕÖ©ńÜäĶČģÕÅéµĢ░Ķ░āÕ║”ÕÖ©’╝łµŚĀķ£ĆĶ«Łń╗ā’╝ē’╝īµö»µīüÕŁ”õ╣ĀńÄć’╝łlearning rate’╝ēÕÆīÕŖ©ķćÅ’╝łmomentum’╝ēŃĆé
+
+#### ÕĘźÕģĘń«Ćõ╗ŗ
+
+```bash
+python tools/visualizations/vis_scheduler.py \
+ ${CONFIG_FILE} \
+ [-p, --parameter ${PARAMETER_NAME}] \
+ [-d, --dataset-size ${DATASET_SIZE}] \
+ [-n, --ngpus ${NUM_GPUs}] \
+ [-s, --save-path ${SAVE_PATH}] \
+ [--title ${TITLE}] \
+ [--style ${STYLE}] \
+ [--window-size ${WINDOW_SIZE}] \
+ [--cfg-options]
+```
+
+**µēƵ£ēÕÅéµĢ░ńÜäĶ»┤µśÄ**’╝Ü
+
+- `config` : µ©ĪÕ×ŗķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠäŃĆé
+- **`-p, parameter`**: ÕÅ»Ķ¦åÕī¢ÕÅéµĢ░ÕÉŹ’╝īÕŬĶāĮõĖ║ `["lr", "momentum"]` õ╣ŗõĖĆ’╝ī ķ╗śĶ«żõĖ║ `"lr"`.
+- **`-d, --dataset-size`**: µĢ░µŹ«ķøåńÜäÕż¦Õ░ÅŃĆéÕ”éµ×£µīćÕ«Ü’╝ī`build_dataset` Õ░åĶó½ĶĘ│Ķ┐ćÕ╣ČõĮ┐ńö©Ķ┐ÖõĖ¬Õż¦Õ░ÅõĮ£õĖ║µĢ░µŹ«ķøåÕż¦Õ░Å’╝īķ╗śĶ«żõĮ┐ńö© `build_dataset` µēĆÕŠŚµĢ░µŹ«ķøåńÜäÕż¦Õ░ÅŃĆé
+- **`-n, --ngpus`**: õĮ┐ńö© GPU ńÜäµĢ░ķćÅ, ķ╗śĶ«żõĖ║1ŃĆé
+- **`-s, --save-path`**: õ┐ØÕŁśńÜäÕÅ»Ķ¦åÕī¢ÕøŠńēćńÜäĶĘ»ÕŠä’╝īķ╗śĶ«żõĖŹõ┐ØÕŁśŃĆé
+- `--title`: ÕÅ»Ķ¦åÕī¢ÕøŠńēćńÜäµĀćķóś’╝īķ╗śĶ«żõĖ║ķģŹńĮ«µ¢ćõ╗ČÕÉŹŃĆé
+- `--style`: ÕÅ»Ķ¦åÕī¢ÕøŠńēćńÜäķŻÄµĀ╝’╝īķ╗śĶ«żõĖ║ `whitegrid`ŃĆé
+- `--window-size`: ÕÅ»Ķ¦åÕī¢ń¬ŚÕÅŻÕż¦Õ░Å’╝īÕ”éµ×£µ▓Īµ£ēµīćÕ«Ü’╝īķ╗śĶ«żõĖ║ `12*7`ŃĆéÕ”éµ×£ķ£ĆĶ”üµīćÕ«Ü’╝īµīēńģ¦µĀ╝Õ╝Å \`W\*H'ŃĆé
+- `--cfg-options`: Õ»╣ķģŹńĮ«µ¢ćõ╗ČńÜäõ┐«µö╣’╝īÕÅéĶĆā[ÕŁ”õ╣ĀķģŹńĮ«µ¢ćõ╗Č](../user_guides/config.md)ŃĆé
+
+```{note}
+ķā©ÕłåµĢ░µŹ«ķøåÕ£©Ķ¦Żµ×ɵĀćµ│©ķśČµ«Ąµ»öĶŠāĶĆŚµŚČ’╝īÕÅ»ńø┤µÄźÕ░å `-d, dataset-size` µīćիܵĢ░µŹ«ķøåńÜäÕż¦Õ░Å’╝īõ╗źĶŖéń║”µŚČķŚ┤ŃĆé
+```
+
+#### Õ”éõĮĢÕ£©Õ╝ĆÕ¦ŗĶ«Łń╗āÕēŹÕÅ»Ķ¦åÕī¢ÕŁ”õ╣ĀńÄćµø▓ń║┐
+
+õĮĀÕÅ»õ╗źõĮ┐ńö©Õ”éõĖŗÕæĮõ╗żµØźń╗śÕłČķģŹńĮ«µ¢ćõ╗Č `configs/textdet/dbnet/dbnet_resnet50-dcnv2_fpnc_1200e_icdar2015.py` Õ░åõ╝ÜõĮ┐ńö©ńÜäÕÅśÕī¢ńÄćµø▓ń║┐’╝Ü
+
+```bash
+python tools/visualizations/vis_scheduler.py configs/textdet/dbnet/dbnet_resnet50-dcnv2_fpnc_1200e_icdar2015.py -d 100
+```
+
+
+
+ÕÅ”Õż¢’╝īńö©µłĘĶ┐śÕÅ»õ╗źķĆÜĶ┐ćµīćիܵĢ░µŹ«ķøåķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠäµØźÕÅ»Ķ¦åÕī¢µĢ░µŹ«ķøåńÜäÕĤզŗÕøŠÕāÅÕÅŖÕģČÕ»╣Õ║öńÜäµĀćµ│©’╝īõŠŗÕ”é’╝Ü
+
+```Bash
+python tools/visualizations/browse_dataset.py configs/textrecog/_base_/datasets/icdar2015.py
+```
+
+ķā©ÕłåµĢ░µŹ«ķøåÕÅ»ĶāĮµ£ēÕżÜõĖ¬ÕÅśõĮōŃĆéõŠŗÕ”é’╝ī`icdar2015` µ¢ćµ£¼Ķ»åÕł½µĢ░µŹ«ķøåńÜä[ķģŹńĮ«µ¢ćõ╗Č](/configs/textrecog/_base_/datasets/icdar2015.py)õĖŁÕīģÕɽõĖżõĖ¬µĄŗĶ»ĢķøåÕÅśõĮō’╝īÕłåÕł½õĖ║ `icdar2015_textrecog_test` ÕÆī `icdar2015_1811_textrecog_test`’╝īÕ”éõĖŗµēĆńż║’╝Ü
+
+```python
+icdar2015_textrecog_test = dict(
+ ann_file='textrecog_test.json',
+ # ...
+ )
+
+icdar2015_1811_textrecog_test = dict(
+ ann_file='textrecog_test_1811.json',
+ # ...
+)
+```
+
+Õ£©Ķ┐Öń¦ŹµāģÕåĄõĖŗ’╝īńö©µłĘÕÅ»õ╗źķĆÜĶ┐ćµīćÕ«Ü `-p` ÕÅéµĢ░µØźÕÅ»Ķ¦åÕī¢õĖŹÕÉīńÜäÕÅśõĮō’╝īõŠŗÕ”é’╝īõĮ┐ńö©õ╗źõĖŗÕæĮõ╗żÕÅ»Ķ¦åÕī¢ `icdar2015_1811_textrecog_test` ÕÅśõĮō’╝Ü
+
+```Bash
+python tools/visualizations/browse_dataset.py configs/textrecog/_base_/datasets/icdar2015.py -p icdar2015_1811_textrecog_test
+```
+
+Õ¤║õ║ÄĶ»źÕĘźÕģĘ’╝īńö©µłĘÕÅ»õ╗źĶĮ╗µØŠÕ£░µ¤źń£ŗµĢ░µŹ«ķøåńÜäÕĤզŗÕøŠÕāÅÕÅŖÕģČÕ»╣Õ║öńÜäµĀćµ│©’╝īõ╗źõŠ┐õ║ĵŻĆµ¤źµĢ░µŹ«ķøåńÜäµĀćµ│©µś»ÕÉ”µŁŻńĪ«ŃĆé
+
+### õ╝śÕī¢ÕÖ©ÕÅéµĢ░ńŁ¢ńĢźÕÅ»Ķ¦åÕī¢ÕĘźÕģĘ
+
+MMOCRµÅÉõŠøõ║åõ╝śÕī¢ÕÖ©ÕÅéµĢ░ÕÅ»Ķ¦åÕī¢ÕĘźÕģĘ `tools/visualizations/vis_scheduler.py` õ╗źĶŠģÕŖ®ńö©µłĘµÄƵ¤źõ╝śÕī¢ÕÖ©ńÜäĶČģÕÅéµĢ░Ķ░āÕ║”ÕÖ©’╝łµŚĀķ£ĆĶ«Łń╗ā’╝ē’╝īµö»µīüÕŁ”õ╣ĀńÄć’╝łlearning rate’╝ēÕÆīÕŖ©ķćÅ’╝łmomentum’╝ēŃĆé
+
+#### ÕĘźÕģĘń«Ćõ╗ŗ
+
+```bash
+python tools/visualizations/vis_scheduler.py \
+ ${CONFIG_FILE} \
+ [-p, --parameter ${PARAMETER_NAME}] \
+ [-d, --dataset-size ${DATASET_SIZE}] \
+ [-n, --ngpus ${NUM_GPUs}] \
+ [-s, --save-path ${SAVE_PATH}] \
+ [--title ${TITLE}] \
+ [--style ${STYLE}] \
+ [--window-size ${WINDOW_SIZE}] \
+ [--cfg-options]
+```
+
+**µēƵ£ēÕÅéµĢ░ńÜäĶ»┤µśÄ**’╝Ü
+
+- `config` : µ©ĪÕ×ŗķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠäŃĆé
+- **`-p, parameter`**: ÕÅ»Ķ¦åÕī¢ÕÅéµĢ░ÕÉŹ’╝īÕŬĶāĮõĖ║ `["lr", "momentum"]` õ╣ŗõĖĆ’╝ī ķ╗śĶ«żõĖ║ `"lr"`.
+- **`-d, --dataset-size`**: µĢ░µŹ«ķøåńÜäÕż¦Õ░ÅŃĆéÕ”éµ×£µīćÕ«Ü’╝ī`build_dataset` Õ░åĶó½ĶĘ│Ķ┐ćÕ╣ČõĮ┐ńö©Ķ┐ÖõĖ¬Õż¦Õ░ÅõĮ£õĖ║µĢ░µŹ«ķøåÕż¦Õ░Å’╝īķ╗śĶ«żõĮ┐ńö© `build_dataset` µēĆÕŠŚµĢ░µŹ«ķøåńÜäÕż¦Õ░ÅŃĆé
+- **`-n, --ngpus`**: õĮ┐ńö© GPU ńÜäµĢ░ķćÅ, ķ╗śĶ«żõĖ║1ŃĆé
+- **`-s, --save-path`**: õ┐ØÕŁśńÜäÕÅ»Ķ¦åÕī¢ÕøŠńēćńÜäĶĘ»ÕŠä’╝īķ╗śĶ«żõĖŹõ┐ØÕŁśŃĆé
+- `--title`: ÕÅ»Ķ¦åÕī¢ÕøŠńēćńÜäµĀćķóś’╝īķ╗śĶ«żõĖ║ķģŹńĮ«µ¢ćõ╗ČÕÉŹŃĆé
+- `--style`: ÕÅ»Ķ¦åÕī¢ÕøŠńēćńÜäķŻÄµĀ╝’╝īķ╗śĶ«żõĖ║ `whitegrid`ŃĆé
+- `--window-size`: ÕÅ»Ķ¦åÕī¢ń¬ŚÕÅŻÕż¦Õ░Å’╝īÕ”éµ×£µ▓Īµ£ēµīćÕ«Ü’╝īķ╗śĶ«żõĖ║ `12*7`ŃĆéÕ”éµ×£ķ£ĆĶ”üµīćÕ«Ü’╝īµīēńģ¦µĀ╝Õ╝Å \`W\*H'ŃĆé
+- `--cfg-options`: Õ»╣ķģŹńĮ«µ¢ćõ╗ČńÜäõ┐«µö╣’╝īÕÅéĶĆā[ÕŁ”õ╣ĀķģŹńĮ«µ¢ćõ╗Č](../user_guides/config.md)ŃĆé
+
+```{note}
+ķā©ÕłåµĢ░µŹ«ķøåÕ£©Ķ¦Żµ×ɵĀćµ│©ķśČµ«Ąµ»öĶŠāĶĆŚµŚČ’╝īÕÅ»ńø┤µÄźÕ░å `-d, dataset-size` µīćիܵĢ░µŹ«ķøåńÜäÕż¦Õ░Å’╝īõ╗źĶŖéń║”µŚČķŚ┤ŃĆé
+```
+
+#### Õ”éõĮĢÕ£©Õ╝ĆÕ¦ŗĶ«Łń╗āÕēŹÕÅ»Ķ¦åÕī¢ÕŁ”õ╣ĀńÄćµø▓ń║┐
+
+õĮĀÕÅ»õ╗źõĮ┐ńö©Õ”éõĖŗÕæĮõ╗żµØźń╗śÕłČķģŹńĮ«µ¢ćõ╗Č `configs/textdet/dbnet/dbnet_resnet50-dcnv2_fpnc_1200e_icdar2015.py` Õ░åõ╝ÜõĮ┐ńö©ńÜäÕÅśÕī¢ńÄćµø▓ń║┐’╝Ü
+
+```bash
+python tools/visualizations/vis_scheduler.py configs/textdet/dbnet/dbnet_resnet50-dcnv2_fpnc_1200e_icdar2015.py -d 100
+```
+
+ +
+## Õłåµ×ÉÕĘźÕģĘ
+
+### ń”╗ń║┐Ķ»äµĄŗÕĘźÕģĘ
+
+Õ»╣õ║ÄÕĘ▓õ┐ØÕŁśńÜäķó䵥ŗń╗ōµ×£’╝īµłæõ╗¼µÅÉõŠøõ║åń”╗ń║┐Ķ»äµĄŗĶäܵ£¼ `tools/analysis_tools/offline_eval.py`ŃĆéõŠŗÕ”é’╝īõ╗źõĖŗõ╗ŻńĀüµ╝öńż║õ║åÕ”éõĮĢõĮ┐ńö©Ķ»źÕĘźÕģĘÕ»╣ "PSENet" µ©ĪÕ×ŗńÜäĶŠōÕć║ń╗ōµ×£Ķ┐øĶĪīń”╗ń║┐Ķ»äõ╝░’╝Ü
+
+```Bash
+# ÕłØµ¼ĪĶ┐ÉĶĪīµĄŗĶ»ĢĶäܵ£¼µŚČ’╝īńö©µłĘÕÅ»õ╗źķĆÜĶ┐ćµīćÕ«Ü --save-preds ÕÅéµĢ░µØźõ┐ØÕŁśµ©ĪÕ×ŗńÜäĶŠōÕć║ń╗ōµ×£
+python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} --save-preds
+# ńż║õŠŗ’╝ÜÕ»╣ PSENet Ķ┐øĶĪīµĄŗĶ»Ģ
+python tools/test.py configs/textdet/psenet/psenet_r50_fpnf_600e_icdar2015.py epoch_600.pth --save-preds
+
+# õ╣ŗÕÉÄÕŹ│ÕÅ»õĮ┐ńö©ÕĘ▓õ┐ØÕŁśńÜäĶŠōÕć║µ¢ćõ╗ČĶ┐øĶĪīń”╗ń║┐Ķ»äõ╝░
+python tools/analysis_tool/offline_eval.py ${CONFIG_FILE} ${PRED_FILE}
+# ńż║õŠŗ’╝ÜÕ»╣ÕĘ▓õ┐ØÕŁśńÜä PSENet ń╗ōµ×£Ķ┐øĶĪīń”╗ń║┐Ķ»äõ╝░
+python tools/analysis_tools/offline_eval.py configs/textdet/psenet/psenet_r50_fpnf_600e_icdar2015.py work_dirs/psenet_r50_fpnf_600e_icdar2015/epoch_600.pth_predictions.pkl
+```
+
+`--save-preds` ķ╗śĶ«żÕ░åĶŠōÕć║ń╗ōµ×£õ┐ØÕŁśĶć│ `work_dir/CONFIG_NAME/MODEL_NAME_predictions.pkl`
+
+µŁżÕż¢’╝īÕ¤║õ║ĵŁżÕĘźÕģĘ’╝īńö©µłĘõ╣¤ÕÅ»õ╗źÕ░åÕģČõ╗¢ń«Śµ│ĢÕ║ōĶÄĘÕÅ¢ńÜäķó䵥ŗń╗ōµ×£ĶĮ¼µŹóµłÉ MMOCR µö»µīüńÜäµĀ╝Õ╝Å’╝īõ╗ÄĶĆīõĮ┐ńö© MMOCR ÕåģńĮ«ńÜäĶ»äõ╝░µīćµĀćµØźÕ»╣ÕģČõ╗¢ń«Śµ│ĢÕ║ōńÜ䵩ĪÕ×ŗĶ┐øĶĪīĶ»äµĄŗŃĆé
+
+| ÕÅéµĢ░ | ń▒╗Õ×ŗ | Ķ»┤µśÄ |
+| ------------- | ----- | ---------------------------------------------------------------- |
+| config | str | ’╝łÕ┐ģķĪ╗’╝ēķģŹńĮ«µ¢ćõ╗ČĶĘ»ÕŠäŃĆé |
+| pkl_results | str | ’╝łÕ┐ģķĪ╗’╝ēķóäÕģłõ┐ØÕŁśńÜäķó䵥ŗń╗ōµ×£µ¢ćõ╗ČŃĆé |
+| --cfg-options | float | ńö©õ║ÄĶ”åÕåÖķģŹńĮ«µ¢ćõ╗ČõĖŁńÜäµīćÕ«ÜÕÅéµĢ░ŃĆé[ńż║õŠŗ](./config.md#ÕæĮõ╗żĶĪīõ┐«µö╣ķģŹńĮ«) |
+
+### Ķ«Īń«Ś FLOPs ÕÆīÕÅéµĢ░ķćÅ
+
+µłæõ╗¼µÅÉõŠøõĖĆõĖ¬Ķ«Īń«Ś FLOPs ÕÆīÕÅéµĢ░ķćÅńÜäµ¢╣µ│Ģ’╝īķ”¢Õģłµłæõ╗¼õĮ┐ńö©õ╗źõĖŗÕæĮõ╗żÕ«ēĶŻģõŠØĶĄ¢ŃĆé
+
+```shell
+pip install fvcore
+```
+
+Ķ«Īń«Ś FLOPs ÕÆīÕÅéµĢ░ķćÅńÜäĶäܵ£¼õĮ┐ńö©µ¢╣µ│ĢÕ”éõĖŗ’╝Ü
+
+```shell
+python tools/analysis_tools/get_flops.py ${config} --shape ${IMAGE_SHAPE}
+```
+
+| ÕÅéµĢ░ | ń▒╗Õ×ŗ | Ķ»┤µśÄ |
+| ------- | ------ | ------------------------------------------------------------------ |
+| config | str | ’╝łÕ┐ģķĪ╗) ķģŹńĮ«µ¢ćõ╗ČĶĘ»ÕŠäŃĆé |
+| --shape | int\*2 | Ķ«Īń«Ś FLOPs õĮ┐ńö©ńÜäÕøŠńēćÕ░║Õ»Ė’╝īÕ”é `--shape 320 320`ŃĆé ķ╗śĶ«żõĖ║ `640 640` |
+
+ĶÄĘÕÅ¢ `dbnet_resnet18_fpnc_100k_synthtext.py` FLOPs ÕÆīÕÅéµĢ░ķćÅńÜäńż║õŠŗÕæĮõ╗żÕ”éõĖŗŃĆé
+
+```shell
+python tools/analysis_tools/get_flops.py configs/textdet/dbnet/dbnet_resnet18_fpnc_100k_synthtext.py --shape 1024 1024
+```
+
+ĶŠōÕć║Õ”éõĖŗ’╝Ü
+
+```shell
+input shape is (1, 3, 1024, 1024)
+| module | #parameters or shape | #flops |
+| :------------------------ | :------------------- | :------ |
+| model | 12.341M | 63.955G |
+| backbone | 11.177M | 38.159G |
+| backbone.conv1 | 9.408K | 2.466G |
+| backbone.conv1.weight | (64, 3, 7, 7) | |
+| backbone.bn1 | 0.128K | 83.886M |
+| backbone.bn1.weight | (64,) | |
+| backbone.bn1.bias | (64,) | |
+| backbone.layer1 | 0.148M | 9.748G |
+| backbone.layer1.0 | 73.984K | 4.874G |
+| backbone.layer1.1 | 73.984K | 4.874G |
+| backbone.layer2 | 0.526M | 8.642G |
+| backbone.layer2.0 | 0.23M | 3.79G |
+| backbone.layer2.1 | 0.295M | 4.853G |
+| backbone.layer3 | 2.1M | 8.616G |
+| backbone.layer3.0 | 0.919M | 3.774G |
+| backbone.layer3.1 | 1.181M | 4.842G |
+| backbone.layer4 | 8.394M | 8.603G |
+| backbone.layer4.0 | 3.673M | 3.766G |
+| backbone.layer4.1 | 4.721M | 4.837G |
+| neck | 0.836M | 14.887G |
+| neck.lateral_convs | 0.246M | 2.013G |
+| neck.lateral_convs.0.conv | 16.384K | 1.074G |
+| neck.lateral_convs.1.conv | 32.768K | 0.537G |
+| neck.lateral_convs.2.conv | 65.536K | 0.268G |
+| neck.lateral_convs.3.conv | 0.131M | 0.134G |
+| neck.smooth_convs | 0.59M | 12.835G |
+| neck.smooth_convs.0.conv | 0.147M | 9.664G |
+| neck.smooth_convs.1.conv | 0.147M | 2.416G |
+| neck.smooth_convs.2.conv | 0.147M | 0.604G |
+| neck.smooth_convs.3.conv | 0.147M | 0.151G |
+| det_head | 0.329M | 10.909G |
+| det_head.binarize | 0.164M | 10.909G |
+| det_head.binarize.0 | 0.147M | 9.664G |
+| det_head.binarize.1 | 0.128K | 20.972M |
+| det_head.binarize.3 | 16.448K | 1.074G |
+| det_head.binarize.4 | 0.128K | 83.886M |
+| det_head.binarize.6 | 0.257K | 67.109M |
+| det_head.threshold | 0.164M | |
+| det_head.threshold.0 | 0.147M | |
+| det_head.threshold.1 | 0.128K | |
+| det_head.threshold.3 | 16.448K | |
+| det_head.threshold.4 | 0.128K | |
+| det_head.threshold.6 | 0.257K | |
+!!!Please be cautious if you use the results in papers. You may need to check if all ops are supported and verify that the flops computation is correct.
+```
diff --git a/internlm_langchain/knowledge_base/MMOCR/content/visualization.md b/internlm_langchain/knowledge_base/MMOCR/content/visualization.md
new file mode 100644
index 00000000..79a9d7e3
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMOCR/content/visualization.md
@@ -0,0 +1,107 @@
+# ÕÅ»Ķ¦åÕī¢
+
+ķśģĶ»╗µ£¼µ¢ćÕēŹÕ╗║Ķ««ÕģłķśģĶ»╗ {external+mmengine:doc}`MMEngine: ÕÅ»Ķ¦åÕī¢
+
+## Õłåµ×ÉÕĘźÕģĘ
+
+### ń”╗ń║┐Ķ»äµĄŗÕĘźÕģĘ
+
+Õ»╣õ║ÄÕĘ▓õ┐ØÕŁśńÜäķó䵥ŗń╗ōµ×£’╝īµłæõ╗¼µÅÉõŠøõ║åń”╗ń║┐Ķ»äµĄŗĶäܵ£¼ `tools/analysis_tools/offline_eval.py`ŃĆéõŠŗÕ”é’╝īõ╗źõĖŗõ╗ŻńĀüµ╝öńż║õ║åÕ”éõĮĢõĮ┐ńö©Ķ»źÕĘźÕģĘÕ»╣ "PSENet" µ©ĪÕ×ŗńÜäĶŠōÕć║ń╗ōµ×£Ķ┐øĶĪīń”╗ń║┐Ķ»äõ╝░’╝Ü
+
+```Bash
+# ÕłØµ¼ĪĶ┐ÉĶĪīµĄŗĶ»ĢĶäܵ£¼µŚČ’╝īńö©µłĘÕÅ»õ╗źķĆÜĶ┐ćµīćÕ«Ü --save-preds ÕÅéµĢ░µØźõ┐ØÕŁśµ©ĪÕ×ŗńÜäĶŠōÕć║ń╗ōµ×£
+python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} --save-preds
+# ńż║õŠŗ’╝ÜÕ»╣ PSENet Ķ┐øĶĪīµĄŗĶ»Ģ
+python tools/test.py configs/textdet/psenet/psenet_r50_fpnf_600e_icdar2015.py epoch_600.pth --save-preds
+
+# õ╣ŗÕÉÄÕŹ│ÕÅ»õĮ┐ńö©ÕĘ▓õ┐ØÕŁśńÜäĶŠōÕć║µ¢ćõ╗ČĶ┐øĶĪīń”╗ń║┐Ķ»äõ╝░
+python tools/analysis_tool/offline_eval.py ${CONFIG_FILE} ${PRED_FILE}
+# ńż║õŠŗ’╝ÜÕ»╣ÕĘ▓õ┐ØÕŁśńÜä PSENet ń╗ōµ×£Ķ┐øĶĪīń”╗ń║┐Ķ»äõ╝░
+python tools/analysis_tools/offline_eval.py configs/textdet/psenet/psenet_r50_fpnf_600e_icdar2015.py work_dirs/psenet_r50_fpnf_600e_icdar2015/epoch_600.pth_predictions.pkl
+```
+
+`--save-preds` ķ╗śĶ«żÕ░åĶŠōÕć║ń╗ōµ×£õ┐ØÕŁśĶć│ `work_dir/CONFIG_NAME/MODEL_NAME_predictions.pkl`
+
+µŁżÕż¢’╝īÕ¤║õ║ĵŁżÕĘźÕģĘ’╝īńö©µłĘõ╣¤ÕÅ»õ╗źÕ░åÕģČõ╗¢ń«Śµ│ĢÕ║ōĶÄĘÕÅ¢ńÜäķó䵥ŗń╗ōµ×£ĶĮ¼µŹóµłÉ MMOCR µö»µīüńÜäµĀ╝Õ╝Å’╝īõ╗ÄĶĆīõĮ┐ńö© MMOCR ÕåģńĮ«ńÜäĶ»äõ╝░µīćµĀćµØźÕ»╣ÕģČõ╗¢ń«Śµ│ĢÕ║ōńÜ䵩ĪÕ×ŗĶ┐øĶĪīĶ»äµĄŗŃĆé
+
+| ÕÅéµĢ░ | ń▒╗Õ×ŗ | Ķ»┤µśÄ |
+| ------------- | ----- | ---------------------------------------------------------------- |
+| config | str | ’╝łÕ┐ģķĪ╗’╝ēķģŹńĮ«µ¢ćõ╗ČĶĘ»ÕŠäŃĆé |
+| pkl_results | str | ’╝łÕ┐ģķĪ╗’╝ēķóäÕģłõ┐ØÕŁśńÜäķó䵥ŗń╗ōµ×£µ¢ćõ╗ČŃĆé |
+| --cfg-options | float | ńö©õ║ÄĶ”åÕåÖķģŹńĮ«µ¢ćõ╗ČõĖŁńÜäµīćÕ«ÜÕÅéµĢ░ŃĆé[ńż║õŠŗ](./config.md#ÕæĮõ╗żĶĪīõ┐«µö╣ķģŹńĮ«) |
+
+### Ķ«Īń«Ś FLOPs ÕÆīÕÅéµĢ░ķćÅ
+
+µłæõ╗¼µÅÉõŠøõĖĆõĖ¬Ķ«Īń«Ś FLOPs ÕÆīÕÅéµĢ░ķćÅńÜäµ¢╣µ│Ģ’╝īķ”¢Õģłµłæõ╗¼õĮ┐ńö©õ╗źõĖŗÕæĮõ╗żÕ«ēĶŻģõŠØĶĄ¢ŃĆé
+
+```shell
+pip install fvcore
+```
+
+Ķ«Īń«Ś FLOPs ÕÆīÕÅéµĢ░ķćÅńÜäĶäܵ£¼õĮ┐ńö©µ¢╣µ│ĢÕ”éõĖŗ’╝Ü
+
+```shell
+python tools/analysis_tools/get_flops.py ${config} --shape ${IMAGE_SHAPE}
+```
+
+| ÕÅéµĢ░ | ń▒╗Õ×ŗ | Ķ»┤µśÄ |
+| ------- | ------ | ------------------------------------------------------------------ |
+| config | str | ’╝łÕ┐ģķĪ╗) ķģŹńĮ«µ¢ćõ╗ČĶĘ»ÕŠäŃĆé |
+| --shape | int\*2 | Ķ«Īń«Ś FLOPs õĮ┐ńö©ńÜäÕøŠńēćÕ░║Õ»Ė’╝īÕ”é `--shape 320 320`ŃĆé ķ╗śĶ«żõĖ║ `640 640` |
+
+ĶÄĘÕÅ¢ `dbnet_resnet18_fpnc_100k_synthtext.py` FLOPs ÕÆīÕÅéµĢ░ķćÅńÜäńż║õŠŗÕæĮõ╗żÕ”éõĖŗŃĆé
+
+```shell
+python tools/analysis_tools/get_flops.py configs/textdet/dbnet/dbnet_resnet18_fpnc_100k_synthtext.py --shape 1024 1024
+```
+
+ĶŠōÕć║Õ”éõĖŗ’╝Ü
+
+```shell
+input shape is (1, 3, 1024, 1024)
+| module | #parameters or shape | #flops |
+| :------------------------ | :------------------- | :------ |
+| model | 12.341M | 63.955G |
+| backbone | 11.177M | 38.159G |
+| backbone.conv1 | 9.408K | 2.466G |
+| backbone.conv1.weight | (64, 3, 7, 7) | |
+| backbone.bn1 | 0.128K | 83.886M |
+| backbone.bn1.weight | (64,) | |
+| backbone.bn1.bias | (64,) | |
+| backbone.layer1 | 0.148M | 9.748G |
+| backbone.layer1.0 | 73.984K | 4.874G |
+| backbone.layer1.1 | 73.984K | 4.874G |
+| backbone.layer2 | 0.526M | 8.642G |
+| backbone.layer2.0 | 0.23M | 3.79G |
+| backbone.layer2.1 | 0.295M | 4.853G |
+| backbone.layer3 | 2.1M | 8.616G |
+| backbone.layer3.0 | 0.919M | 3.774G |
+| backbone.layer3.1 | 1.181M | 4.842G |
+| backbone.layer4 | 8.394M | 8.603G |
+| backbone.layer4.0 | 3.673M | 3.766G |
+| backbone.layer4.1 | 4.721M | 4.837G |
+| neck | 0.836M | 14.887G |
+| neck.lateral_convs | 0.246M | 2.013G |
+| neck.lateral_convs.0.conv | 16.384K | 1.074G |
+| neck.lateral_convs.1.conv | 32.768K | 0.537G |
+| neck.lateral_convs.2.conv | 65.536K | 0.268G |
+| neck.lateral_convs.3.conv | 0.131M | 0.134G |
+| neck.smooth_convs | 0.59M | 12.835G |
+| neck.smooth_convs.0.conv | 0.147M | 9.664G |
+| neck.smooth_convs.1.conv | 0.147M | 2.416G |
+| neck.smooth_convs.2.conv | 0.147M | 0.604G |
+| neck.smooth_convs.3.conv | 0.147M | 0.151G |
+| det_head | 0.329M | 10.909G |
+| det_head.binarize | 0.164M | 10.909G |
+| det_head.binarize.0 | 0.147M | 9.664G |
+| det_head.binarize.1 | 0.128K | 20.972M |
+| det_head.binarize.3 | 16.448K | 1.074G |
+| det_head.binarize.4 | 0.128K | 83.886M |
+| det_head.binarize.6 | 0.257K | 67.109M |
+| det_head.threshold | 0.164M | |
+| det_head.threshold.0 | 0.147M | |
+| det_head.threshold.1 | 0.128K | |
+| det_head.threshold.3 | 16.448K | |
+| det_head.threshold.4 | 0.128K | |
+| det_head.threshold.6 | 0.257K | |
+!!!Please be cautious if you use the results in papers. You may need to check if all ops are supported and verify that the flops computation is correct.
+```
diff --git a/internlm_langchain/knowledge_base/MMOCR/content/visualization.md b/internlm_langchain/knowledge_base/MMOCR/content/visualization.md
new file mode 100644
index 00000000..79a9d7e3
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMOCR/content/visualization.md
@@ -0,0 +1,107 @@
+# ÕÅ»Ķ¦åÕī¢
+
+ķśģĶ»╗µ£¼µ¢ćÕēŹÕ╗║Ķ««ÕģłķśģĶ»╗ {external+mmengine:doc}`MMEngine: ÕÅ»Ķ¦åÕī¢ ` õ╗źÕłØµŁźõ║åĶ¦Ż Visualizer ńÜäÕ«Üõ╣ēÕÅŖńøĖÕģ│ńö©µ│ĢŃĆé
+
+ń«ĆÕŹĢµØźĶ»┤’╝īMMEngine õĖŁÕ«×ńÄ░õ║åńö©õ║ĵ╗ĪĶČ│µŚźÕĖĖÕÅ»Ķ¦åÕī¢ķ£Ćµ▒éńÜäÕÅ»Ķ¦åÕī¢ÕÖ©õ╗Č [`Visualizer`](mmengine.visualization.Visualizer)’╝īÕģČõĖ╗Ķ”üÕīģÕɽõĖēõĖ¬ÕŖ¤ĶāĮ’╝Ü
+
+- Õ«×ńÄ░õ║åÕĖĖńö©ńÜäń╗śÕøŠ API’╝īõŠŗÕ”é [`draw_bboxes`](mmengine.visualization.Visualizer.draw_bboxes) Õ«×ńÄ░õ║åĶŠ╣ńĢīńøÆńÜäń╗śÕłČÕŖ¤ĶāĮ’╝ī[`draw_lines`](mmengine.visualization.Visualizer.draw_lines) Õ«×ńÄ░õ║åń║┐µØĪńÜäń╗śÕłČÕŖ¤ĶāĮŃĆé
+- µö»µīüÕ░åÕÅ»Ķ¦åÕī¢ń╗ōµ×£ŃĆüÕŁ”õ╣ĀńÄćµø▓ń║┐ŃĆüµŹ¤Õż▒ÕćĮµĢ░µø▓ń║┐õ╗źÕÅŖķ¬īĶ»üń▓ŠÕ║”µø▓ń║┐ńŁēÕåÖÕģźÕżÜń¦ŹÕÉÄń½»õĖŁ’╝īÕīģµŗ¼µ£¼Õ£░ńŻüńøśõ╗źÕÅŖÕĖĖńö©ńÜäµĘ▒Õ║”ÕŁ”õ╣ĀĶ«Łń╗āµŚźÕ┐ŚĶ«░ÕĮĢÕĘźÕģĘ’╝īÕ”é [TensorBoard](https://www.tensorflow.org/tensorboard) ÕÆī [WandB](https://wandb.ai/site)ŃĆé
+- µö»µīüÕ£©õ╗ŻńĀüõĖŁńÜäõ╗╗µäÅõĮŹńĮ«Ķ┐øĶĪīĶ░āńö©’╝īõŠŗÕ”éÕ£©Ķ«Łń╗āµł¢µĄŗĶ»ĢĶ┐ćń©ŗõĖŁÕÅ»Ķ¦åÕī¢µł¢Ķ«░ÕĮĢµ©ĪÕ×ŗńÜäõĖŁķŚ┤ńŖȵĆü’╝īÕ”éńē╣ÕŠüÕøŠÕÅŖķ¬īĶ»üń╗ōµ×£ńŁēŃĆé
+
+Õ¤║õ║Ä MMEngine ńÜä Visualizer’╝īMMOCR ÕåģķóäńĮ«õ║åÕżÜń¦ŹÕÅ»Ķ¦åÕī¢ÕĘźÕģĘ’╝īńö©µłĘõ╗ģķ£Ćń«ĆÕŹĢõ┐«µö╣ķģŹńĮ«µ¢ćõ╗ČÕŹ│ÕÅ»õĮ┐ńö©’╝Ü
+
+- `tools/analysis_tools/browse_dataset.py` Ķäܵ£¼µÅÉõŠøõ║åµĢ░µŹ«ķøåÕÅ»Ķ¦åÕī¢ÕŖ¤ĶāĮ’╝īÕģČÕÅ»õ╗źń╗śÕłČń╗ÅĶ┐ćµĢ░µŹ«ÕÅśµŹó’╝łData Transforms’╝ēõ╣ŗÕÉÄńÜäÕøŠÕāÅÕÅŖÕ»╣Õ║öńÜäµĀćµ│©ÕåģÕ«╣’╝īĶ»”Ķ¦ü [`browse_dataset.py`](useful_tools.md)ŃĆé
+- MMEngine õĖŁÕ«×ńÄ░õ║å `LoggerHook`’╝īĶ»ź Hook Õł®ńö© `Visualizer` Õ░åÕŁ”õ╣ĀńÄćŃĆüµŹ¤Õż▒õ╗źÕÅŖĶ»äõ╝░ń╗ōµ×£ńŁēµĢ░µŹ«ÕåÖÕģź `Visualizer` Ķ«ŠńĮ«ńÜäÕÉÄń½»õĖŁ’╝īÕøĀµŁżķĆÜĶ┐ćõ┐«µö╣ķģŹńĮ«µ¢ćõ╗ČõĖŁńÜä `Visualizer` ÕÉÄń½»’╝īµ»öÕ”éõ┐«µö╣õĖ║`TensorBoardVISBackend` µł¢ `WandbVISBackend`’╝īÕÅ»õ╗źÕ«×ńÄ░Õ░åµŚźÕ┐ŚÕł░ `TensorBoard` µł¢ `WandB` ńŁēÕĖĖĶ¦üńÜäĶ«Łń╗āµŚźÕ┐ŚĶ«░ÕĮĢÕĘźÕģĘõĖŁ’╝īõ╗ÄĶĆīµ¢╣õŠ┐ńö©µłĘõĮ┐ńö©Ķ┐Öõ║øÕÅ»Ķ¦åÕī¢ÕĘźÕģĘµØźÕłåµ×ÉÕÆīńøæµÄ¦Ķ«Łń╗āµĄüń©ŗŃĆé
+- MMOCR õĖŁÕ«×ńÄ░õ║å`VisualizerHook`’╝īĶ»ź Hook Õł®ńö© `Visualizer` Õ░åķ¬īĶ»üķśČµ«Ąµł¢ķó䵥ŗķśČµ«ĄńÜäķó䵥ŗń╗ōµ×£Ķ┐øĶĪīÕÅ»Ķ¦åÕī¢µł¢Õé©ÕŁśĶć│ `Visualizer` Ķ«ŠńĮ«ńÜäÕÉÄń½»õĖŁ’╝īÕøĀµŁżķĆÜĶ┐ćõ┐«µö╣ķģŹńĮ«µ¢ćõ╗ČõĖŁńÜä `Visualizer` ÕÉÄń½»’╝īµ»öÕ”éõ┐«µö╣õĖ║`TensorBoardVISBackend` µł¢ `WandbVISBackend`’╝īÕÅ»õ╗źÕ«×ńÄ░Õ░åķó䵥ŗńÜäÕøŠÕāÅÕŁśÕé©Õł░ `TensorBoard` µł¢ `Wandb`õĖŁŃĆé
+
+## ķģŹńĮ«
+
+ÕŠŚńøŖõ║ĵ│©Õåīµ£║ÕłČńÜäõĮ┐ńö©’╝īÕ£© MMOCR õĖŁ’╝īµłæõ╗¼ÕÅ»õ╗źķĆÜĶ┐ćõ┐«µö╣ķģŹńĮ«µ¢ćõ╗ČµØźĶ«ŠńĮ«ÕÅ»Ķ¦åÕī¢ÕÖ©õ╗Č `Visualizer` ńÜäĶĪīõĖ║ŃĆéķĆÜÕĖĖ’╝īµłæõ╗¼Õ£© `task/_base_/default_runtime.py` õĖŁÕ«Üõ╣ēÕÅ»Ķ¦åÕī¢ńøĖÕģ│ńÜäķ╗śĶ«żķģŹńĮ«’╝ī Ķ»”Ķ¦ü[ķģŹńĮ«µĢÖń©ŗ](config.md)ŃĆé
+
+```Python
+vis_backends = [dict(type='LocalVisBackend')]
+visualizer = dict(
+ type='TextxxxLocalVisualizer', # õĖŹÕÉīõ╗╗ÕŖĪõĮ┐ńö©õĖŹÕÉīńÜäÕÅ»Ķ¦åÕī¢ÕÖ©
+ vis_backends=vis_backends,
+ name='visualizer')
+```
+
+õŠØµŹ«õ╗źõĖŖńż║õŠŗ’╝īµłæõ╗¼ÕÅ»õ╗źń£ŗÕć║ `Visualizer` ńÜäķģŹńĮ«õĖ╗Ķ”üńö▒õĖżõĖ¬ķā©Õłåń╗䵳ɒ╝īÕŹ│’╝ī`Visualizer`ńÜäń▒╗Õ×ŗõ╗źÕÅŖÕģČķććńö©ńÜäÕÅ»Ķ¦åÕī¢ÕÉÄń½» `vis_backends`ŃĆé
+
+- ķÆłÕ»╣õĖŹÕÉīńÜä OCR õ╗╗ÕŖĪ’╝īMMOCR õĖŁķóäńĮ«õ║åÕżÜń¦ŹÕÅ»Ķ¦åÕī¢ÕÖ©õ╗Č’╝īÕīģµŗ¼ [`TextDetLocalVisualizer`](mmocr.visualization.TextDetLocalVisualizer)’╝ī[`TextRecogLocalVisualizer`](mmocr.visualization.TextRecogLocalVisualizer)’╝ī[`TextSpottingLocalVisualizer`](mmocr.visualization.TextSpottingLocalVisualizer) õ╗źÕÅŖ[`KIELocalVisualizer`](mmocr.visualization.KIELocalVisualizer)ŃĆéĶ┐Öõ║øÕÅ»Ķ¦åÕī¢ÕÖ©õ╗ČõŠØńģ¦Ķć¬Ķ║½õ╗╗ÕŖĪńÜäńē╣ńé╣Õ»╣Õ¤║ńĪĆńÜä Visulizer API Ķ┐øĶĪīõ║åµŗōÕ▒Ģ’╝īÕ╣ČÕ«×ńÄ░õ║åńøĖÕ║öńÜäµĀćńŁŠõ┐Īµü»µÄźÕÅŻ `add_datasamples`ŃĆéõŠŗÕ”é’╝īńö©µłĘÕÅ»õ╗źńø┤µÄźõĮ┐ńö© `TextDetLocalVisualizer` µØźÕÅ»Ķ¦åÕī¢µ¢ćµ£¼µŻĆµĄŗõ╗╗ÕŖĪńÜäµĀćńŁŠµł¢ķó䵥ŗń╗ōµ×£ŃĆé
+- MMOCR ķ╗śĶ«żÕ░åÕÅ»Ķ¦åÕī¢ÕÉÄń½» `vis_backend` Ķ«ŠńĮ«õĖ║µ£¼Õ£░ÕÅ»Ķ¦åÕī¢ÕÉÄń½» `LocalVisBackend`’╝īÕ░åµēƵ£ēÕÅ»Ķ¦åÕī¢ń╗ōµ×£ÕÅŖÕģČõ╗¢Ķ«Łń╗āõ┐Īµü»õ┐ØÕŁśÕ£©µ£¼Õ£░µ¢ćõ╗ČÕż╣õĖŁŃĆé
+
+## ÕŁśÕé©
+
+MMOCR ķ╗śĶ«żõĮ┐ńö©µ£¼Õ£░ÕÅ»Ķ¦åÕī¢ÕÉÄń½» [`LocalVisBackend`](mmengine.visualization.LocalVisBackend)’╝ī`VisualizerHook` ÕÆī`LoggerHook` õĖŁÕŁśÕé©ńÜ䵩ĪÕ×ŗµŹ¤Õż▒ŃĆüÕŁ”õ╣ĀńÄćŃĆüµ©ĪÕ×ŗĶ»äõ╝░ń▓ŠÕ║”õ╗źÕÅŖÕÅ»Ķ¦åÕī¢ń╗ōµ×£ńŁēõ┐Īµü»Õ░åĶó½ķ╗śĶ«żõ┐ØÕŁśĶć│`{work_dir}/{config_name}/{time}/{vis_data}` µ¢ćõ╗ČÕż╣ŃĆ鵣żÕż¢’╝īMMOCR õ╣¤µö»µīüÕģČÕ«āÕĖĖńö©ńÜäÕÅ»Ķ¦åÕī¢ÕÉÄń½»’╝īÕ”é `TensorboardVisBackend` õ╗źÕÅŖ `WandbVisBackend`ńö©µłĘÕŬķ£ĆĶ”üÕ░åķģŹńĮ«µ¢ćõ╗ČõĖŁńÜä `vis_backends` ń▒╗Õ×ŗõ┐«µö╣õĖ║Õ»╣Õ║öńÜäÕÅ»Ķ¦åÕī¢ÕÉÄń½»ÕŹ│ÕÅ»ŃĆéõŠŗÕ”é’╝īńö©µłĘÕŬķ£ĆĶ”üÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁµÅÆÕģźõ╗źõĖŗõ╗ŻńĀüÕØŚ’╝īÕŹ│ÕÅ»Õ░åµĢ░µŹ«ÕŁśÕé©Ķć│ `TensorBoard` õ╗źÕÅŖ `WandB`õĖŁŃĆé
+
+```Python
+_base_.visualizer.vis_backends = [
+ dict(type='LocalVisBackend'),
+ dict(type='TensorboardVisBackend'),
+ dict(type='WandbVisBackend'),]
+```
+
+## ń╗śÕłČ
+
+### ń╗śÕłČķó䵥ŗń╗ōµ×£õ┐Īµü»
+
+MMOCR õĖ╗Ķ”üÕł®ńö© [`VisualizationHook`](mmocr.engine.hooks.VisualizationHook)validation ÕÆī test ńÜäķó䵥ŗń╗ōµ×£, ķ╗śĶ«żµāģÕåĄõĖŗ `VisualizationHook`õĖ║Õģ│ķŚŁńŖȵĆü’╝īķ╗śĶ«żķģŹńĮ«Õ”éõĖŗ’╝Ü
+
+```Python
+visualization=dict( # ńö©µłĘÕÅ»Ķ¦åÕī¢ validation ÕÆī test ńÜäń╗ōµ×£
+ type='VisualizationHook',
+ enable=False,
+ interval=1,
+ show=False,
+ draw_gt=False,
+ draw_pred=False)
+```
+
+õĖŗĶĪ©õĖ║ `VisualizationHook` µö»µīüńÜäÕÅéµĢ░’╝Ü
+
+| ÕÅéµĢ░ | Ķ»┤µśÄ |
+| :-------: | :---------------------------------------------------------------------------------: |
+| enable | VisualizationHook ńÜäÕ╝ĆÕÉ»ÕÆīÕģ│ķŚŁńö▒ÕÅéµĢ░enableµÄ¦ÕłČķ╗śĶ«żµś»Õģ│ķŚŁńÜäńŖȵĆü’╝ī |
+| interval | Õ£©VisualizationHookÕ╝ĆÕÉ»ńÜäµāģÕåĄõĖŗ,ńö©õ╗źµÄ¦ÕłČÕżÜÕ░æiteration ÕŁśÕ驵ł¢Õ▒Ģńż║ val µł¢ test ńÜäń╗ōµ×£ |
+| show | µÄ¦ÕłČµś»ÕÉ”ÕÅ»Ķ¦åÕī¢ val µł¢ test ńÜäń╗ōµ×£ |
+| draw_gt | val µł¢ test ńÜäń╗ōµ×£µś»ÕÉ”ń╗śÕłČµĀćµ│©õ┐Īµü» |
+| draw_pred | val µł¢ test ńÜäń╗ōµ×£µś»ÕÉ”ń╗śÕłČķó䵥ŗń╗ōµ×£ |
+
+Õ”éµ×£Õ£©Ķ«Łń╗āµł¢ĶĆģµĄŗĶ»ĢĶ┐ćń©ŗõĖŁµā│Õ╝ĆÕÉ» `VisualizationHook` ńøĖÕģ│ÕŖ¤ĶāĮÕÆīķģŹńĮ«’╝īõ╗ģķ£Ćõ┐«µö╣ķģŹńĮ«ÕŹ│ÕÅ»’╝īõ╗ź `dbnet_resnet18_fpnc_1200e_icdar2015.py`õĖ║õŠŗ’╝ī ÕÉīµŚČń╗śÕłČµĀćµ│©ÕÆīķó䵥ŗ’╝īÕ╣ČõĖöÕ░åÕøŠÕāÅÕ▒Ģńż║’╝īķģŹńĮ«ÕÅ»Ķ┐øĶĪīÕ”éõĖŗõ┐«µö╣
+
+```Python
+visualization = _base_.default_hooks.visualization
+visualization.update(
+ dict(enable=True, show=True, draw_gt=True, draw_pred=True))
+```
+
+
+
+... # Convert bbox from xywh to center-scale center, scale = self.\_xywh2cs(\*obj\['clean_bbox'\]\[:4\]) # Data sample contains center and scale rec.append({ 'bbox': obj\['clean_bbox\]\[:4\], 'center': center, 'scale': scale, ... })
+
+
+
+
+
+
+
+Pipeline Config
+
+(e.g. [HRNet+COCO](https://github.com/open-mmlab/mmpose/blob/master/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w32_coco_256x192.py))
+
+
+
+... train_pipeline = \[ dict(type='LoadImageFromFile'), # Convert bbox from xywh to center-scale dict(type='TopDownGetBboxCenterScale', padding=1.25), # Randomly shift bbox center dict(type='TopDownRandomShiftBboxCenter', shift_factor=0.16, prob=0.3), ... \]
+
+
+
+
+
+... train_pipeline = \[ dict(type='LoadImageFromFile'), ... \]
+
+
+
+
+
+
+
+Advantage
+
+
+
+Simpler data sample content
+
+Flexible bbox format conversion and augmentation
+
+Apply bbox random translation every epoch (instead of only applying once at the annotation loading)
+
+
+
+-
+
+
+
+
+
+BC Breaking
+
+The method `_xywh2cs` of dataset base classes (e.g. [Kpt2dSviewRgbImgTopDownDataset](https://github.com/open-mmlab/mmpose/blob/master/mmpose/datasets/datasets/base/kpt_2d_sview_rgb_img_top_down_dataset.py)) will be deprecated in the future. Custom datasets will need modifications to move the bbox format conversion to pipelines.
+
+-
+
+
+
+
+
+
+
+## **v0.25.0 (02/04/2022)**
+
+**Highlights**
+
+- Support Shelf and Campus datasets with pre-trained VoxelPose models, ["3D Pictorial Structures for Multiple Human Pose Estimation"](http://campar.in.tum.de/pub/belagiannis2014cvpr/belagiannis2014cvpr.pdf), CVPR'2014 ([#1225](https://github.com/open-mmlab/mmpose/pull/1225)) @liqikai9, @wusize
+
+- Add `Smoother` module for temporal smoothing of the pose estimation with configurable filters ([#1127](https://github.com/open-mmlab/mmpose/pull/1127)) @ailingzengzzz, @ly015
+
+- Support SmoothNet for pose smoothing, ["SmoothNet: A Plug-and-Play Network for Refining Human Poses in Videos"](https://arxiv.org/abs/2112.13715), arXiv'2021 ([#1279](https://github.com/open-mmlab/mmpose/pull/1279)) @ailingzengzzz, @ly015
+
+- Add multiview 3D pose estimation demo ([#1270](https://github.com/open-mmlab/mmpose/pull/1270)) @wusize
+
+**New Features**
+
+- Support Shelf and Campus datasets with pre-trained VoxelPose models, ["3D Pictorial Structures for Multiple Human Pose Estimation"](http://campar.in.tum.de/pub/belagiannis2014cvpr/belagiannis2014cvpr.pdf), CVPR'2014 ([#1225](https://github.com/open-mmlab/mmpose/pull/1225)) @liqikai9, @wusize
+
+- Add `Smoother` module for temporal smoothing of the pose estimation with configurable filters ([#1127](https://github.com/open-mmlab/mmpose/pull/1127)) @ailingzengzzz, @ly015
+
+- Support SmoothNet for pose smoothing, ["SmoothNet: A Plug-and-Play Network for Refining Human Poses in Videos"](https://arxiv.org/abs/2112.13715), arXiv'2021 ([#1279](https://github.com/open-mmlab/mmpose/pull/1279)) @ailingzengzzz, @ly015
+
+- Add multiview 3D pose estimation demo ([#1270](https://github.com/open-mmlab/mmpose/pull/1270)) @wusize
+
+- Support multi-machine distributed training ([#1248](https://github.com/open-mmlab/mmpose/pull/1248)) @ly015
+
+**Improvements**
+
+- Update HRFormer configs and checkpoints with relative position bias ([#1245](https://github.com/open-mmlab/mmpose/pull/1245)) @zengwang430521
+
+- Support using different random seed for each distributed node ([#1257](https://github.com/open-mmlab/mmpose/pull/1257), [#1229](https://github.com/open-mmlab/mmpose/pull/1229)) @ly015
+
+- Improve documentation quality ([#1275](https://github.com/open-mmlab/mmpose/pull/1275), [#1255](https://github.com/open-mmlab/mmpose/pull/1255), [#1258](https://github.com/open-mmlab/mmpose/pull/1258), [#1249](https://github.com/open-mmlab/mmpose/pull/1249), [#1247](https://github.com/open-mmlab/mmpose/pull/1247), [#1240](https://github.com/open-mmlab/mmpose/pull/1240), [#1235](https://github.com/open-mmlab/mmpose/pull/1235)) @ly015, @jin-s13, @YoniChechik
+
+**Bug Fixes**
+
+- Fix keypoint index in RHD dataset meta information ([#1265](https://github.com/open-mmlab/mmpose/pull/1265)) @liqikai9
+
+- Fix pre-commit hook unexpected behavior on Windows ([#1282](https://github.com/open-mmlab/mmpose/pull/1282)) @liqikai9
+
+- Remove python-dev installation in CI ([#1276](https://github.com/open-mmlab/mmpose/pull/1276)) @ly015
+
+- Unify hyphens in argument names in tools and demos ([#1271](https://github.com/open-mmlab/mmpose/pull/1271)) @ly015
+
+- Fix ambiguous channel size in `channel_shuffle` that may cause exporting failure (#1242) @PINTO0309
+
+- Fix a bug in Webcam API that causes single-class detectors fail ([#1239](https://github.com/open-mmlab/mmpose/pull/1239)) @674106399
+
+- Fix the issue that `custom_hook` can not be set in configs ([#1236](https://github.com/open-mmlab/mmpose/pull/1236)) @bladrome
+
+- Fix incompatible MMCV version in DockerFile ([#raykindle](https://github.com/open-mmlab/mmpose/pull/raykindle))
+
+- Skip invisible joints in visualization ([#1228](https://github.com/open-mmlab/mmpose/pull/1228)) @womeier
+
+## **v0.24.0 (07/03/2022)**
+
+**Highlights**
+
+- Support HRFormer ["HRFormer: High-Resolution Vision Transformer for Dense Predict"](https://proceedings.neurips.cc/paper/2021/hash/3bbfdde8842a5c44a0323518eec97cbe-Abstract.html), NeurIPS'2021 ([#1203](https://github.com/open-mmlab/mmpose/pull/1203)) @zengwang430521
+
+- Support Windows installation with pip ([#1213](https://github.com/open-mmlab/mmpose/pull/1213)) @jin-s13, @ly015
+
+- Add WebcamAPI documents ([#1187](https://github.com/open-mmlab/mmpose/pull/1187)) @ly015
+
+**New Features**
+
+- Support HRFormer ["HRFormer: High-Resolution Vision Transformer for Dense Predict"](https://proceedings.neurips.cc/paper/2021/hash/3bbfdde8842a5c44a0323518eec97cbe-Abstract.html), NeurIPS'2021 ([#1203](https://github.com/open-mmlab/mmpose/pull/1203)) @zengwang430521
+
+- Support Windows installation with pip ([#1213](https://github.com/open-mmlab/mmpose/pull/1213)) @jin-s13, @ly015
+
+- Support CPU training with mmcv \< v1.4.4 ([#1161](https://github.com/open-mmlab/mmpose/pull/1161)) @EasonQYS, @ly015
+
+- Add "Valentine Magic" demo with WebcamAPI ([#1189](https://github.com/open-mmlab/mmpose/pull/1189), [#1191](https://github.com/open-mmlab/mmpose/pull/1191)) @liqikai9
+
+**Improvements**
+
+- Refactor multi-view 3D pose estimation framework towards better modularization and expansibility ([#1196](https://github.com/open-mmlab/mmpose/pull/1196)) @wusize
+
+- Add WebcamAPI documents and tutorials ([#1187](https://github.com/open-mmlab/mmpose/pull/1187)) @ly015
+
+- Refactor dataset evaluation interface to align with other OpenMMLab codebases ([#1209](https://github.com/open-mmlab/mmpose/pull/1209)) @ly015
+
+- Add deprecation message for deploy tools since [MMDeploy](https://github.com/open-mmlab/mmdeploy) has supported MMPose ([#1207](https://github.com/open-mmlab/mmpose/pull/1207)) @QwQ2000
+
+- Improve documentation quality ([#1206](https://github.com/open-mmlab/mmpose/pull/1206), [#1161](https://github.com/open-mmlab/mmpose/pull/1161)) @ly015
+
+- Switch to OpenMMLab official pre-commit-hook for copyright check ([#1214](https://github.com/open-mmlab/mmpose/pull/1214)) @ly015
+
+**Bug Fixes**
+
+- Fix hard-coded data collating and scattering in inference ([#1175](https://github.com/open-mmlab/mmpose/pull/1175)) @ly015
+
+- Fix model configs on JHMDB dataset ([#1188](https://github.com/open-mmlab/mmpose/pull/1188)) @jin-s13
+
+- Fix area calculation in pose tracking inference ([#1197](https://github.com/open-mmlab/mmpose/pull/1197)) @pallgeuer
+
+- Fix registry scope conflict of module wrapper ([#1204](https://github.com/open-mmlab/mmpose/pull/1204)) @ly015
+
+- Update MMCV installation in CI and documents ([#1205](https://github.com/open-mmlab/mmpose/pull/1205))
+
+- Fix incorrect color channel order in visualization functions ([#1212](https://github.com/open-mmlab/mmpose/pull/1212)) @ly015
+
+## **v0.23.0 (11/02/2022)**
+
+**Highlights**
+
+- Add [MMPose Webcam API](https://github.com/open-mmlab/mmpose/tree/master/tools/webcam): A simple yet powerful tools to develop interactive webcam applications with MMPose functions. ([#1178](https://github.com/open-mmlab/mmpose/pull/1178), [#1173](https://github.com/open-mmlab/mmpose/pull/1173), [#1173](https://github.com/open-mmlab/mmpose/pull/1173), [#1143](https://github.com/open-mmlab/mmpose/pull/1143), [#1094](https://github.com/open-mmlab/mmpose/pull/1094), [#1133](https://github.com/open-mmlab/mmpose/pull/1133), [#1098](https://github.com/open-mmlab/mmpose/pull/1098), [#1160](https://github.com/open-mmlab/mmpose/pull/1160)) @ly015, @jin-s13, @liqikai9, @wusize, @luminxu, @zengwang430521 @mzr1996
+
+**New Features**
+
+- Add [MMPose Webcam API](https://github.com/open-mmlab/mmpose/tree/master/tools/webcam): A simple yet powerful tools to develop interactive webcam applications with MMPose functions. ([#1178](https://github.com/open-mmlab/mmpose/pull/1178), [#1173](https://github.com/open-mmlab/mmpose/pull/1173), [#1173](https://github.com/open-mmlab/mmpose/pull/1173), [#1143](https://github.com/open-mmlab/mmpose/pull/1143), [#1094](https://github.com/open-mmlab/mmpose/pull/1094), [#1133](https://github.com/open-mmlab/mmpose/pull/1133), [#1098](https://github.com/open-mmlab/mmpose/pull/1098), [#1160](https://github.com/open-mmlab/mmpose/pull/1160)) @ly015, @jin-s13, @liqikai9, @wusize, @luminxu, @zengwang430521 @mzr1996
+
+- Support ConcatDataset ([#1139](https://github.com/open-mmlab/mmpose/pull/1139)) @Canwang-sjtu
+
+- Support CPU training and testing ([#1157](https://github.com/open-mmlab/mmpose/pull/1157)) @ly015
+
+**Improvements**
+
+- Add multi-processing configurations to speed up distributed training and testing ([#1146](https://github.com/open-mmlab/mmpose/pull/1146)) @ly015
+
+- Add default runtime config ([#1145](https://github.com/open-mmlab/mmpose/pull/1145))
+
+- Upgrade isort in pre-commit hook ([#1179](https://github.com/open-mmlab/mmpose/pull/1179)) @liqikai9
+
+- Update README and documents ([#1171](https://github.com/open-mmlab/mmpose/pull/1171), [#1167](https://github.com/open-mmlab/mmpose/pull/1167), [#1153](https://github.com/open-mmlab/mmpose/pull/1153), [#1149](https://github.com/open-mmlab/mmpose/pull/1149), [#1148](https://github.com/open-mmlab/mmpose/pull/1148), [#1147](https://github.com/open-mmlab/mmpose/pull/1147), [#1140](https://github.com/open-mmlab/mmpose/pull/1140)) @jin-s13, @wusize, @TommyZihao, @ly015
+
+**Bug Fixes**
+
+- Fix undeterministic behavior in pre-commit hooks ([#1136](https://github.com/open-mmlab/mmpose/pull/1136)) @jin-s13
+
+- Deprecate the support for "python setup.py test" ([#1179](https://github.com/open-mmlab/mmpose/pull/1179)) @ly015
+
+- Fix incompatible settings with MMCV on HSigmoid default parameters ([#1132](https://github.com/open-mmlab/mmpose/pull/1132)) @ly015
+
+- Fix albumentation installation ([#1184](https://github.com/open-mmlab/mmpose/pull/1184)) @BIGWangYuDong
+
+## **v0.22.0 (04/01/2022)**
+
+**Highlights**
+
+- Support VoxelPose ["VoxelPose: Towards Multi-Camera 3D Human Pose Estimation in Wild Environment"](https://arxiv.org/abs/2004.06239), ECCV'2020 ([#1050](https://github.com/open-mmlab/mmpose/pull/1050)) @wusize
+
+- Support Soft Wing loss ["Structure-Coherent Deep Feature Learning for Robust Face Alignment"](https://linchunze.github.io/papers/TIP21_Structure_coherent_FA.pdf), TIP'2021 ([#1077](https://github.com/open-mmlab/mmpose/pull/1077)) @jin-s13
+
+- Support Adaptive Wing loss ["Adaptive Wing Loss for Robust Face Alignment via Heatmap Regression"](https://arxiv.org/abs/1904.07399), ICCV'2019 ([#1072](https://github.com/open-mmlab/mmpose/pull/1072)) @jin-s13
+
+**New Features**
+
+- Support VoxelPose ["VoxelPose: Towards Multi-Camera 3D Human Pose Estimation in Wild Environment"](https://arxiv.org/abs/2004.06239), ECCV'2020 ([#1050](https://github.com/open-mmlab/mmpose/pull/1050)) @wusize
+
+- Support Soft Wing loss ["Structure-Coherent Deep Feature Learning for Robust Face Alignment"](https://linchunze.github.io/papers/TIP21_Structure_coherent_FA.pdf), TIP'2021 ([#1077](https://github.com/open-mmlab/mmpose/pull/1077)) @jin-s13
+
+- Support Adaptive Wing loss ["Adaptive Wing Loss for Robust Face Alignment via Heatmap Regression"](https://arxiv.org/abs/1904.07399), ICCV'2019 ([#1072](https://github.com/open-mmlab/mmpose/pull/1072)) @jin-s13
+
+- Add LiteHRNet-18 Checkpoints trained on COCO. ([#1120](https://github.com/open-mmlab/mmpose/pull/1120)) @jin-s13
+
+**Improvements**
+
+- Improve documentation quality ([#1115](https://github.com/open-mmlab/mmpose/pull/1115), [#1111](https://github.com/open-mmlab/mmpose/pull/1111), [#1105](https://github.com/open-mmlab/mmpose/pull/1105), [#1087](https://github.com/open-mmlab/mmpose/pull/1087), [#1086](https://github.com/open-mmlab/mmpose/pull/1086), [#1085](https://github.com/open-mmlab/mmpose/pull/1085), [#1084](https://github.com/open-mmlab/mmpose/pull/1084), [#1083](https://github.com/open-mmlab/mmpose/pull/1083), [#1124](https://github.com/open-mmlab/mmpose/pull/1124), [#1070](https://github.com/open-mmlab/mmpose/pull/1070), [#1068](https://github.com/open-mmlab/mmpose/pull/1068)) @jin-s13, @liqikai9, @ly015
+
+- Support CircleCI ([#1074](https://github.com/open-mmlab/mmpose/pull/1074)) @ly015
+
+- Skip unit tests in CI when only document files were changed ([#1074](https://github.com/open-mmlab/mmpose/pull/1074), [#1041](https://github.com/open-mmlab/mmpose/pull/1041)) @QwQ2000, @ly015
+
+- Support file_client_args in LoadImageFromFile ([#1076](https://github.com/open-mmlab/mmpose/pull/1076)) @jin-s13
+
+**Bug Fixes**
+
+- Fix a bug in Dark UDP postprocessing that causes error when the channel number is large. ([#1079](https://github.com/open-mmlab/mmpose/pull/1079), [#1116](https://github.com/open-mmlab/mmpose/pull/1116)) @X00123, @jin-s13
+
+- Fix hard-coded `sigmas` in bottom-up image demo ([#1107](https://github.com/open-mmlab/mmpose/pull/1107), [#1101](https://github.com/open-mmlab/mmpose/pull/1101)) @chenxinfeng4, @liqikai9
+
+- Fix unstable checks in unit tests ([#1112](https://github.com/open-mmlab/mmpose/pull/1112)) @ly015
+
+- Do not destroy NULL windows if `args.show==False` in demo scripts ([#1104](https://github.com/open-mmlab/mmpose/pull/1104)) @bladrome
+
+## **v0.21.0 (06/12/2021)**
+
+**Highlights**
+
+- Support ["Learning Temporal Pose Estimation from Sparsely-Labeled Videos"](https://arxiv.org/abs/1906.04016), NeurIPS'2019 ([#932](https://github.com/open-mmlab/mmpose/pull/932), [#1006](https://github.com/open-mmlab/mmpose/pull/1006), [#1036](https://github.com/open-mmlab/mmpose/pull/1036), [#1060](https://github.com/open-mmlab/mmpose/pull/1060)) @liqikai9
+
+- Add ViPNAS-MobileNetV3 models ([#1025](https://github.com/open-mmlab/mmpose/pull/1025)) @luminxu, @jin-s13
+
+- Add inference speed benchmark ([#1028](https://github.com/open-mmlab/mmpose/pull/1028), [#1034](https://github.com/open-mmlab/mmpose/pull/1034), [#1044](https://github.com/open-mmlab/mmpose/pull/1044)) @liqikai9
+
+**New Features**
+
+- Support ["Learning Temporal Pose Estimation from Sparsely-Labeled Videos"](https://arxiv.org/abs/1906.04016), NeurIPS'2019 ([#932](https://github.com/open-mmlab/mmpose/pull/932), [#1006](https://github.com/open-mmlab/mmpose/pull/1006), [#1036](https://github.com/open-mmlab/mmpose/pull/1036)) @liqikai9
+
+- Add ViPNAS-MobileNetV3 models ([#1025](https://github.com/open-mmlab/mmpose/pull/1025)) @luminxu, @jin-s13
+
+- Add light-weight top-down models for whole-body keypoint detection ([#1009](https://github.com/open-mmlab/mmpose/pull/1009), [#1020](https://github.com/open-mmlab/mmpose/pull/1020), [#1055](https://github.com/open-mmlab/mmpose/pull/1055)) @luminxu, @ly015
+
+- Add HRNet checkpoints with various settings on PoseTrack18 ([#1035](https://github.com/open-mmlab/mmpose/pull/1035)) @liqikai9
+
+**Improvements**
+
+- Add inference speed benchmark ([#1028](https://github.com/open-mmlab/mmpose/pull/1028), [#1034](https://github.com/open-mmlab/mmpose/pull/1034), [#1044](https://github.com/open-mmlab/mmpose/pull/1044)) @liqikai9
+
+- Update model metafile format ([#1001](https://github.com/open-mmlab/mmpose/pull/1001)) @ly015
+
+- Support minus output feature index in mobilenet_v3 ([#1005](https://github.com/open-mmlab/mmpose/pull/1005)) @luminxu
+
+- Improve documentation quality ([#1018](https://github.com/open-mmlab/mmpose/pull/1018), [#1026](https://github.com/open-mmlab/mmpose/pull/1026), [#1027](https://github.com/open-mmlab/mmpose/pull/1027), [#1031](https://github.com/open-mmlab/mmpose/pull/1031), [#1038](https://github.com/open-mmlab/mmpose/pull/1038), [#1046](https://github.com/open-mmlab/mmpose/pull/1046), [#1056](https://github.com/open-mmlab/mmpose/pull/1056), [#1057](https://github.com/open-mmlab/mmpose/pull/1057)) @edybk, @luminxu, @ly015, @jin-s13
+
+- Set default random seed in training initialization ([#1030](https://github.com/open-mmlab/mmpose/pull/1030)) @ly015
+
+- Skip CI when only specific files changed ([#1041](https://github.com/open-mmlab/mmpose/pull/1041), [#1059](https://github.com/open-mmlab/mmpose/pull/1059)) @QwQ2000, @ly015
+
+- Automatically cancel uncompleted action runs when new commit arrives ([#1053](https://github.com/open-mmlab/mmpose/pull/1053)) @ly015
+
+**Bug Fixes**
+
+- Update pose tracking demo to be compatible with latest mmtracking ([#1014](https://github.com/open-mmlab/mmpose/pull/1014)) @jin-s13
+
+- Fix symlink creation failure when installed in Windows environments ([#1039](https://github.com/open-mmlab/mmpose/pull/1039)) @QwQ2000
+
+- Fix AP-10K dataset sigmas ([#1040](https://github.com/open-mmlab/mmpose/pull/1040)) @jin-s13
+
+## **v0.20.0 (01/11/2021)**
+
+**Highlights**
+
+- Add AP-10K dataset for animal pose estimation ([#987](https://github.com/open-mmlab/mmpose/pull/987)) @Annbless, @AlexTheBad, @jin-s13, @ly015
+
+- Support TorchServe ([#979](https://github.com/open-mmlab/mmpose/pull/979)) @ly015
+
+**New Features**
+
+- Add AP-10K dataset for animal pose estimation ([#987](https://github.com/open-mmlab/mmpose/pull/987)) @Annbless, @AlexTheBad, @jin-s13, @ly015
+
+- Add HRNetv2 checkpoints on 300W and COFW datasets ([#980](https://github.com/open-mmlab/mmpose/pull/980)) @jin-s13
+
+- Support TorchServe ([#979](https://github.com/open-mmlab/mmpose/pull/979)) @ly015
+
+**Bug Fixes**
+
+- Fix some deprecated or risky settings in configs ([#963](https://github.com/open-mmlab/mmpose/pull/963), [#976](https://github.com/open-mmlab/mmpose/pull/976), [#992](https://github.com/open-mmlab/mmpose/pull/992)) @jin-s13, @wusize
+
+- Fix issues of default arguments of training and testing scripts ([#970](https://github.com/open-mmlab/mmpose/pull/970), [#985](https://github.com/open-mmlab/mmpose/pull/985)) @liqikai9, @wusize
+
+- Fix heatmap and tag size mismatch in bottom-up with UDP ([#994](https://github.com/open-mmlab/mmpose/pull/994)) @wusize
+
+- Fix python3.9 installation in CI ([#983](https://github.com/open-mmlab/mmpose/pull/983)) @ly015
+
+- Fix model zoo document integrity issue ([#990](https://github.com/open-mmlab/mmpose/pull/990)) @jin-s13
+
+**Improvements**
+
+- Support non-square input shape for bottom-up ([#991](https://github.com/open-mmlab/mmpose/pull/991)) @wusize
+
+- Add image and video resources for demo ([#971](https://github.com/open-mmlab/mmpose/pull/971)) @liqikai9
+
+- Use CUDA docker images to accelerate CI ([#973](https://github.com/open-mmlab/mmpose/pull/973)) @ly015
+
+- Add codespell hook and fix detected typos ([#977](https://github.com/open-mmlab/mmpose/pull/977)) @ly015
+
+## **v0.19.0 (08/10/2021)**
+
+**Highlights**
+
+- Add models for Associative Embedding with Hourglass network backbone ([#906](https://github.com/open-mmlab/mmpose/pull/906), [#955](https://github.com/open-mmlab/mmpose/pull/955)) @jin-s13, @luminxu
+
+- Support COCO-Wholebody-Face and COCO-Wholebody-Hand datasets ([#813](https://github.com/open-mmlab/mmpose/pull/813)) @jin-s13, @innerlee, @luminxu
+
+- Upgrade dataset interface ([#901](https://github.com/open-mmlab/mmpose/pull/901), [#924](https://github.com/open-mmlab/mmpose/pull/924)) @jin-s13, @innerlee, @ly015, @liqikai9
+
+- New style of documentation ([#945](https://github.com/open-mmlab/mmpose/pull/945)) @ly015
+
+**New Features**
+
+- Add models for Associative Embedding with Hourglass network backbone ([#906](https://github.com/open-mmlab/mmpose/pull/906), [#955](https://github.com/open-mmlab/mmpose/pull/955)) @jin-s13, @luminxu
+
+- Support COCO-Wholebody-Face and COCO-Wholebody-Hand datasets ([#813](https://github.com/open-mmlab/mmpose/pull/813)) @jin-s13, @innerlee, @luminxu
+
+- Add pseudo-labeling tool to generate COCO style keypoint annotations with given bounding boxes ([#928](https://github.com/open-mmlab/mmpose/pull/928)) @soltkreig
+
+- New style of documentation ([#945](https://github.com/open-mmlab/mmpose/pull/945)) @ly015
+
+**Bug Fixes**
+
+- Fix segmentation parsing in Macaque dataset preprocessing ([#948](https://github.com/open-mmlab/mmpose/pull/948)) @jin-s13
+
+- Fix dependencies that may lead to CI failure in downstream projects ([#936](https://github.com/open-mmlab/mmpose/pull/936), [#953](https://github.com/open-mmlab/mmpose/pull/953)) @RangiLyu, @ly015
+
+- Fix keypoint order in Human3.6M dataset ([#940](https://github.com/open-mmlab/mmpose/pull/940)) @ttxskk
+
+- Fix unstable image loading for Interhand2.6M ([#913](https://github.com/open-mmlab/mmpose/pull/913)) @zengwang430521
+
+**Improvements**
+
+- Upgrade dataset interface ([#901](https://github.com/open-mmlab/mmpose/pull/901), [#924](https://github.com/open-mmlab/mmpose/pull/924)) @jin-s13, @innerlee, @ly015, @liqikai9
+
+- Improve demo usability and stability ([#908](https://github.com/open-mmlab/mmpose/pull/908), [#934](https://github.com/open-mmlab/mmpose/pull/934)) @ly015
+
+- Standardize model metafile format ([#941](https://github.com/open-mmlab/mmpose/pull/941)) @ly015
+
+- Support `persistent_worker` and several other arguments in configs ([#946](https://github.com/open-mmlab/mmpose/pull/946)) @jin-s13
+
+- Use MMCV root model registry to enable cross-project module building ([#935](https://github.com/open-mmlab/mmpose/pull/935)) @RangiLyu
+
+- Improve the document quality ([#916](https://github.com/open-mmlab/mmpose/pull/916), [#909](https://github.com/open-mmlab/mmpose/pull/909), [#942](https://github.com/open-mmlab/mmpose/pull/942), [#913](https://github.com/open-mmlab/mmpose/pull/913), [#956](https://github.com/open-mmlab/mmpose/pull/956)) @jin-s13, @ly015, @bit-scientist, @zengwang430521
+
+- Improve pull request template ([#952](https://github.com/open-mmlab/mmpose/pull/952), [#954](https://github.com/open-mmlab/mmpose/pull/954)) @ly015
+
+**Breaking Changes**
+
+- Upgrade dataset interface ([#901](https://github.com/open-mmlab/mmpose/pull/901)) @jin-s13, @innerlee, @ly015
+
+## **v0.18.0 (01/09/2021)**
+
+**Bug Fixes**
+
+- Fix redundant model weight loading in pytorch-to-onnx conversion ([#850](https://github.com/open-mmlab/mmpose/pull/850)) @ly015
+
+- Fix a bug in update_model_index.py that may cause pre-commit hook failure([#866](https://github.com/open-mmlab/mmpose/pull/866)) @ly015
+
+- Fix a bug in interhand_3d_head ([#890](https://github.com/open-mmlab/mmpose/pull/890)) @zengwang430521
+
+- Fix pose tracking demo failure caused by out-of-date configs ([#891](https://github.com/open-mmlab/mmpose/pull/891))
+
+**Improvements**
+
+- Add automatic benchmark regression tools ([#849](https://github.com/open-mmlab/mmpose/pull/849), [#880](https://github.com/open-mmlab/mmpose/pull/880), [#885](https://github.com/open-mmlab/mmpose/pull/885)) @liqikai9, @ly015
+
+- Add copyright information and checking hook ([#872](https://github.com/open-mmlab/mmpose/pull/872))
+
+- Add PR template ([#875](https://github.com/open-mmlab/mmpose/pull/875)) @ly015
+
+- Add citation information ([#876](https://github.com/open-mmlab/mmpose/pull/876)) @ly015
+
+- Add python3.9 in CI ([#877](https://github.com/open-mmlab/mmpose/pull/877), [#883](https://github.com/open-mmlab/mmpose/pull/883)) @ly015
+
+- Improve the quality of the documents ([#845](https://github.com/open-mmlab/mmpose/pull/845), [#845](https://github.com/open-mmlab/mmpose/pull/845), [#848](https://github.com/open-mmlab/mmpose/pull/848), [#867](https://github.com/open-mmlab/mmpose/pull/867), [#870](https://github.com/open-mmlab/mmpose/pull/870), [#873](https://github.com/open-mmlab/mmpose/pull/873), [#896](https://github.com/open-mmlab/mmpose/pull/896)) @jin-s13, @ly015, @zhiqwang
+
+## **v0.17.0 (06/08/2021)**
+
+**Highlights**
+
+1. Support ["Lite-HRNet: A Lightweight High-Resolution Network"](https://arxiv.org/abs/2104.06403) CVPR'2021 ([#733](https://github.com/open-mmlab/mmpose/pull/733),[#800](https://github.com/open-mmlab/mmpose/pull/800)) @jin-s13
+
+2. Add 3d body mesh demo ([#771](https://github.com/open-mmlab/mmpose/pull/771)) @zengwang430521
+
+3. Add Chinese documentation ([#787](https://github.com/open-mmlab/mmpose/pull/787), [#798](https://github.com/open-mmlab/mmpose/pull/798), [#799](https://github.com/open-mmlab/mmpose/pull/799), [#802](https://github.com/open-mmlab/mmpose/pull/802), [#804](https://github.com/open-mmlab/mmpose/pull/804), [#805](https://github.com/open-mmlab/mmpose/pull/805), [#815](https://github.com/open-mmlab/mmpose/pull/815), [#816](https://github.com/open-mmlab/mmpose/pull/816), [#817](https://github.com/open-mmlab/mmpose/pull/817), [#819](https://github.com/open-mmlab/mmpose/pull/819), [#839](https://github.com/open-mmlab/mmpose/pull/839)) @ly015, @luminxu, @jin-s13, @liqikai9, @zengwang430521
+
+4. Add Colab Tutorial ([#834](https://github.com/open-mmlab/mmpose/pull/834)) @ly015
+
+**New Features**
+
+- Support ["Lite-HRNet: A Lightweight High-Resolution Network"](https://arxiv.org/abs/2104.06403) CVPR'2021 ([#733](https://github.com/open-mmlab/mmpose/pull/733),[#800](https://github.com/open-mmlab/mmpose/pull/800)) @jin-s13
+
+- Add 3d body mesh demo ([#771](https://github.com/open-mmlab/mmpose/pull/771)) @zengwang430521
+
+- Add Chinese documentation ([#787](https://github.com/open-mmlab/mmpose/pull/787), [#798](https://github.com/open-mmlab/mmpose/pull/798), [#799](https://github.com/open-mmlab/mmpose/pull/799), [#802](https://github.com/open-mmlab/mmpose/pull/802), [#804](https://github.com/open-mmlab/mmpose/pull/804), [#805](https://github.com/open-mmlab/mmpose/pull/805), [#815](https://github.com/open-mmlab/mmpose/pull/815), [#816](https://github.com/open-mmlab/mmpose/pull/816), [#817](https://github.com/open-mmlab/mmpose/pull/817), [#819](https://github.com/open-mmlab/mmpose/pull/819), [#839](https://github.com/open-mmlab/mmpose/pull/839)) @ly015, @luminxu, @jin-s13, @liqikai9, @zengwang430521
+
+- Add Colab Tutorial ([#834](https://github.com/open-mmlab/mmpose/pull/834)) @ly015
+
+- Support training for InterHand v1.0 dataset ([#761](https://github.com/open-mmlab/mmpose/pull/761)) @zengwang430521
+
+**Bug Fixes**
+
+- Fix mpii pckh@0.1 index ([#773](https://github.com/open-mmlab/mmpose/pull/773)) @jin-s13
+
+- Fix multi-node distributed test ([#818](https://github.com/open-mmlab/mmpose/pull/818)) @ly015
+
+- Fix docstring and init_weights error of ShuffleNetV1 ([#814](https://github.com/open-mmlab/mmpose/pull/814)) @Junjun2016
+
+- Fix imshow_bbox error when input bboxes is empty ([#796](https://github.com/open-mmlab/mmpose/pull/796)) @ly015
+
+- Fix model zoo doc generation ([#778](https://github.com/open-mmlab/mmpose/pull/778)) @ly015
+
+- Fix typo ([#767](https://github.com/open-mmlab/mmpose/pull/767)), ([#780](https://github.com/open-mmlab/mmpose/pull/780), [#782](https://github.com/open-mmlab/mmpose/pull/782)) @ly015, @jin-s13
+
+**Breaking Changes**
+
+- Use MMCV EvalHook ([#686](https://github.com/open-mmlab/mmpose/pull/686)) @ly015
+
+**Improvements**
+
+- Add pytest.ini and fix docstring ([#812](https://github.com/open-mmlab/mmpose/pull/812)) @jin-s13
+
+- Update MSELoss ([#829](https://github.com/open-mmlab/mmpose/pull/829)) @Ezra-Yu
+
+- Move process_mmdet_results into inference.py ([#831](https://github.com/open-mmlab/mmpose/pull/831)) @ly015
+
+- Update resource limit ([#783](https://github.com/open-mmlab/mmpose/pull/783)) @jin-s13
+
+- Use COCO 2D pose model in 3D demo examples ([#785](https://github.com/open-mmlab/mmpose/pull/785)) @ly015
+
+- Change model zoo titles in the doc from center-aligned to left-aligned ([#792](https://github.com/open-mmlab/mmpose/pull/792), [#797](https://github.com/open-mmlab/mmpose/pull/797)) @ly015
+
+- Support MIM ([#706](https://github.com/open-mmlab/mmpose/pull/706), [#794](https://github.com/open-mmlab/mmpose/pull/794)) @ly015
+
+- Update out-of-date configs ([#827](https://github.com/open-mmlab/mmpose/pull/827)) @jin-s13
+
+- Remove opencv-python-headless dependency by albumentations ([#833](https://github.com/open-mmlab/mmpose/pull/833)) @ly015
+
+- Update QQ QR code in README_CN.md ([#832](https://github.com/open-mmlab/mmpose/pull/832)) @ly015
+
+## **v0.16.0 (02/07/2021)**
+
+**Highlights**
+
+1. Support ["ViPNAS: Efficient Video Pose Estimation via Neural Architecture Search"](https://arxiv.org/abs/2105.10154) CVPR'2021 ([#742](https://github.com/open-mmlab/mmpose/pull/742),[#755](https://github.com/open-mmlab/mmpose/pull/755)).
+
+2. Support MPI-INF-3DHP dataset ([#683](https://github.com/open-mmlab/mmpose/pull/683),[#746](https://github.com/open-mmlab/mmpose/pull/746),[#751](https://github.com/open-mmlab/mmpose/pull/751)).
+
+3. Add webcam demo tool ([#729](https://github.com/open-mmlab/mmpose/pull/729))
+
+4. Add 3d body and hand pose estimation demo ([#704](https://github.com/open-mmlab/mmpose/pull/704), [#727](https://github.com/open-mmlab/mmpose/pull/727)).
+
+**New Features**
+
+- Support ["ViPNAS: Efficient Video Pose Estimation via Neural Architecture Search"](https://arxiv.org/abs/2105.10154) CVPR'2021 ([#742](https://github.com/open-mmlab/mmpose/pull/742),[#755](https://github.com/open-mmlab/mmpose/pull/755))
+
+- Support MPI-INF-3DHP dataset ([#683](https://github.com/open-mmlab/mmpose/pull/683),[#746](https://github.com/open-mmlab/mmpose/pull/746),[#751](https://github.com/open-mmlab/mmpose/pull/751))
+
+- Support Webcam demo ([#729](https://github.com/open-mmlab/mmpose/pull/729))
+
+- Support Interhand 3d demo ([#704](https://github.com/open-mmlab/mmpose/pull/704))
+
+- Support 3d pose video demo ([#727](https://github.com/open-mmlab/mmpose/pull/727))
+
+- Support H36m dataset for 2d pose estimation ([#709](https://github.com/open-mmlab/mmpose/pull/709), [#735](https://github.com/open-mmlab/mmpose/pull/735))
+
+- Add scripts to generate mim metafile ([#749](https://github.com/open-mmlab/mmpose/pull/749))
+
+**Bug Fixes**
+
+- Fix typos ([#692](https://github.com/open-mmlab/mmpose/pull/692),[#696](https://github.com/open-mmlab/mmpose/pull/696),[#697](https://github.com/open-mmlab/mmpose/pull/697),[#698](https://github.com/open-mmlab/mmpose/pull/698),[#712](https://github.com/open-mmlab/mmpose/pull/712),[#718](https://github.com/open-mmlab/mmpose/pull/718),[#728](https://github.com/open-mmlab/mmpose/pull/728))
+
+- Change model download links from `http` to `https` ([#716](https://github.com/open-mmlab/mmpose/pull/716))
+
+**Breaking Changes**
+
+- Switch to MMCV MODEL_REGISTRY ([#669](https://github.com/open-mmlab/mmpose/pull/669))
+
+**Improvements**
+
+- Refactor MeshMixDataset ([#752](https://github.com/open-mmlab/mmpose/pull/752))
+
+- Rename 'GaussianHeatMap' to 'GaussianHeatmap' ([#745](https://github.com/open-mmlab/mmpose/pull/745))
+
+- Update out-of-date configs ([#734](https://github.com/open-mmlab/mmpose/pull/734))
+
+- Improve compatibility for breaking changes ([#731](https://github.com/open-mmlab/mmpose/pull/731))
+
+- Enable to control radius and thickness in visualization ([#722](https://github.com/open-mmlab/mmpose/pull/722))
+
+- Add regex dependency ([#720](https://github.com/open-mmlab/mmpose/pull/720))
+
+## **v0.15.0 (02/06/2021)**
+
+**Highlights**
+
+1. Support 3d video pose estimation (VideoPose3D).
+
+2. Support 3d hand pose estimation (InterNet).
+
+3. Improve presentation of modelzoo.
+
+**New Features**
+
+- Support "InterHand2.6M: A Dataset and Baseline for 3D Interacting Hand Pose Estimation from a Single RGB Image" (ECCVŌĆś20) ([#624](https://github.com/open-mmlab/mmpose/pull/624))
+
+- Support "3D human pose estimation in video with temporal convolutions and semi-supervised training" (CVPR'19) ([#602](https://github.com/open-mmlab/mmpose/pull/602), [#681](https://github.com/open-mmlab/mmpose/pull/681))
+
+- Support 3d pose estimation demo ([#653](https://github.com/open-mmlab/mmpose/pull/653), [#670](https://github.com/open-mmlab/mmpose/pull/670))
+
+- Support bottom-up whole-body pose estimation ([#689](https://github.com/open-mmlab/mmpose/pull/689))
+
+- Support mmcli ([#634](https://github.com/open-mmlab/mmpose/pull/634))
+
+**Bug Fixes**
+
+- Fix opencv compatibility ([#635](https://github.com/open-mmlab/mmpose/pull/635))
+
+- Fix demo with UDP ([#637](https://github.com/open-mmlab/mmpose/pull/637))
+
+- Fix bottom-up model onnx conversion ([#680](https://github.com/open-mmlab/mmpose/pull/680))
+
+- Fix `GPU_IDS` in distributed training ([#668](https://github.com/open-mmlab/mmpose/pull/668))
+
+- Fix MANIFEST.in ([#641](https://github.com/open-mmlab/mmpose/pull/641), [#657](https://github.com/open-mmlab/mmpose/pull/657))
+
+- Fix docs ([#643](https://github.com/open-mmlab/mmpose/pull/643),[#684](https://github.com/open-mmlab/mmpose/pull/684),[#688](https://github.com/open-mmlab/mmpose/pull/688),[#690](https://github.com/open-mmlab/mmpose/pull/690),[#692](https://github.com/open-mmlab/mmpose/pull/692))
+
+**Breaking Changes**
+
+- Reorganize configs by tasks, algorithms, datasets, and techniques ([#647](https://github.com/open-mmlab/mmpose/pull/647))
+
+- Rename heads and detectors ([#667](https://github.com/open-mmlab/mmpose/pull/667))
+
+**Improvements**
+
+- Add `radius` and `thickness` parameters in visualization ([#638](https://github.com/open-mmlab/mmpose/pull/638))
+
+- Add `trans_prob` parameter in `TopDownRandomTranslation` ([#650](https://github.com/open-mmlab/mmpose/pull/650))
+
+- Switch to `MMCV MODEL_REGISTRY` ([#669](https://github.com/open-mmlab/mmpose/pull/669))
+
+- Update dependencies ([#674](https://github.com/open-mmlab/mmpose/pull/674), [#676](https://github.com/open-mmlab/mmpose/pull/676))
+
+## **v0.14.0 (06/05/2021)**
+
+**Highlights**
+
+1. Support animal pose estimation with 7 popular datasets.
+
+2. Support "A simple yet effective baseline for 3d human pose estimation" (ICCV'17).
+
+**New Features**
+
+- Support "A simple yet effective baseline for 3d human pose estimation" (ICCV'17) ([#554](https://github.com/open-mmlab/mmpose/pull/554),[#558](https://github.com/open-mmlab/mmpose/pull/558),[#566](https://github.com/open-mmlab/mmpose/pull/566),[#570](https://github.com/open-mmlab/mmpose/pull/570),[#589](https://github.com/open-mmlab/mmpose/pull/589))
+
+- Support animal pose estimation ([#559](https://github.com/open-mmlab/mmpose/pull/559),[#561](https://github.com/open-mmlab/mmpose/pull/561),[#563](https://github.com/open-mmlab/mmpose/pull/563),[#571](https://github.com/open-mmlab/mmpose/pull/571),[#603](https://github.com/open-mmlab/mmpose/pull/603),[#605](https://github.com/open-mmlab/mmpose/pull/605))
+
+- Support Horse-10 dataset ([#561](https://github.com/open-mmlab/mmpose/pull/561)), MacaquePose dataset ([#561](https://github.com/open-mmlab/mmpose/pull/561)), Vinegar Fly dataset ([#561](https://github.com/open-mmlab/mmpose/pull/561)), Desert Locust dataset ([#561](https://github.com/open-mmlab/mmpose/pull/561)), Grevy's Zebra dataset ([#561](https://github.com/open-mmlab/mmpose/pull/561)), ATRW dataset ([#571](https://github.com/open-mmlab/mmpose/pull/571)), and Animal-Pose dataset ([#603](https://github.com/open-mmlab/mmpose/pull/603))
+
+- Support bottom-up pose tracking demo ([#574](https://github.com/open-mmlab/mmpose/pull/574))
+
+- Support FP16 training ([#584](https://github.com/open-mmlab/mmpose/pull/584),[#616](https://github.com/open-mmlab/mmpose/pull/616),[#626](https://github.com/open-mmlab/mmpose/pull/626))
+
+- Support NMS for bottom-up ([#609](https://github.com/open-mmlab/mmpose/pull/609))
+
+**Bug Fixes**
+
+- Fix bugs in the top-down demo, when there are no people in the images ([#569](https://github.com/open-mmlab/mmpose/pull/569)).
+
+- Fix the links in the doc ([#612](https://github.com/open-mmlab/mmpose/pull/612))
+
+**Improvements**
+
+- Speed up top-down inference ([#560](https://github.com/open-mmlab/mmpose/pull/560))
+
+- Update github CI ([#562](https://github.com/open-mmlab/mmpose/pull/562), [#564](https://github.com/open-mmlab/mmpose/pull/564))
+
+- Update Readme ([#578](https://github.com/open-mmlab/mmpose/pull/578),[#579](https://github.com/open-mmlab/mmpose/pull/579),[#580](https://github.com/open-mmlab/mmpose/pull/580),[#592](https://github.com/open-mmlab/mmpose/pull/592),[#599](https://github.com/open-mmlab/mmpose/pull/599),[#600](https://github.com/open-mmlab/mmpose/pull/600),[#607](https://github.com/open-mmlab/mmpose/pull/607))
+
+- Update Faq ([#587](https://github.com/open-mmlab/mmpose/pull/587), [#610](https://github.com/open-mmlab/mmpose/pull/610))
+
+## **v0.13.0 (31/03/2021)**
+
+**Highlights**
+
+1. Support Wingloss.
+
+2. Support RHD hand dataset.
+
+**New Features**
+
+- Support Wingloss ([#482](https://github.com/open-mmlab/mmpose/pull/482))
+
+- Support RHD hand dataset ([#523](https://github.com/open-mmlab/mmpose/pull/523), [#551](https://github.com/open-mmlab/mmpose/pull/551))
+
+- Support Human3.6m dataset for 3d keypoint detection ([#518](https://github.com/open-mmlab/mmpose/pull/518), [#527](https://github.com/open-mmlab/mmpose/pull/527))
+
+- Support TCN model for 3d keypoint detection ([#521](https://github.com/open-mmlab/mmpose/pull/521), [#522](https://github.com/open-mmlab/mmpose/pull/522))
+
+- Support Interhand3D model for 3d hand detection ([#536](https://github.com/open-mmlab/mmpose/pull/536))
+
+- Support Multi-task detector ([#480](https://github.com/open-mmlab/mmpose/pull/480))
+
+**Bug Fixes**
+
+- Fix PCKh@0.1 calculation ([#516](https://github.com/open-mmlab/mmpose/pull/516))
+
+- Fix unittest ([#529](https://github.com/open-mmlab/mmpose/pull/529))
+
+- Fix circular importing ([#542](https://github.com/open-mmlab/mmpose/pull/542))
+
+- Fix bugs in bottom-up keypoint score ([#548](https://github.com/open-mmlab/mmpose/pull/548))
+
+**Improvements**
+
+- Update config & checkpoints ([#525](https://github.com/open-mmlab/mmpose/pull/525), [#546](https://github.com/open-mmlab/mmpose/pull/546))
+
+- Fix typos ([#514](https://github.com/open-mmlab/mmpose/pull/514), [#519](https://github.com/open-mmlab/mmpose/pull/519), [#532](https://github.com/open-mmlab/mmpose/pull/532), [#537](https://github.com/open-mmlab/mmpose/pull/537), )
+
+- Speed up post processing ([#535](https://github.com/open-mmlab/mmpose/pull/535))
+
+- Update mmcv version dependency ([#544](https://github.com/open-mmlab/mmpose/pull/544))
+
+## **v0.12.0 (28/02/2021)**
+
+**Highlights**
+
+1. Support DeepPose algorithm.
+
+**New Features**
+
+- Support DeepPose algorithm ([#446](https://github.com/open-mmlab/mmpose/pull/446), [#461](https://github.com/open-mmlab/mmpose/pull/461))
+
+- Support interhand3d dataset ([#468](https://github.com/open-mmlab/mmpose/pull/468))
+
+- Support Albumentation pipeline ([#469](https://github.com/open-mmlab/mmpose/pull/469))
+
+- Support PhotometricDistortion pipeline ([#485](https://github.com/open-mmlab/mmpose/pull/485))
+
+- Set seed option for training ([#493](https://github.com/open-mmlab/mmpose/pull/493))
+
+- Add demos for face keypoint detection ([#502](https://github.com/open-mmlab/mmpose/pull/502))
+
+**Bug Fixes**
+
+- Change channel order according to configs ([#504](https://github.com/open-mmlab/mmpose/pull/504))
+
+- Fix `num_factors` in UDP encoding ([#495](https://github.com/open-mmlab/mmpose/pull/495))
+
+- Fix configs ([#456](https://github.com/open-mmlab/mmpose/pull/456))
+
+**Breaking Changes**
+
+- Refactor configs for wholebody pose estimation ([#487](https://github.com/open-mmlab/mmpose/pull/487), [#491](https://github.com/open-mmlab/mmpose/pull/491))
+
+- Rename `decode` function for heads ([#481](https://github.com/open-mmlab/mmpose/pull/481))
+
+**Improvements**
+
+- Update config & checkpoints ([#453](https://github.com/open-mmlab/mmpose/pull/453),[#484](https://github.com/open-mmlab/mmpose/pull/484),[#487](https://github.com/open-mmlab/mmpose/pull/487))
+
+- Add README in Chinese ([#462](https://github.com/open-mmlab/mmpose/pull/462))
+
+- Add tutorials about configs ([#465](https://github.com/open-mmlab/mmpose/pull/465))
+
+- Add demo videos for various tasks ([#499](https://github.com/open-mmlab/mmpose/pull/499), [#503](https://github.com/open-mmlab/mmpose/pull/503))
+
+- Update docs about MMPose installation ([#467](https://github.com/open-mmlab/mmpose/pull/467), [#505](https://github.com/open-mmlab/mmpose/pull/505))
+
+- Rename `stat.py` to `stats.py` ([#483](https://github.com/open-mmlab/mmpose/pull/483))
+
+- Fix typos ([#463](https://github.com/open-mmlab/mmpose/pull/463), [#464](https://github.com/open-mmlab/mmpose/pull/464), [#477](https://github.com/open-mmlab/mmpose/pull/477), [#481](https://github.com/open-mmlab/mmpose/pull/481))
+
+- latex to bibtex ([#471](https://github.com/open-mmlab/mmpose/pull/471))
+
+- Update FAQ ([#466](https://github.com/open-mmlab/mmpose/pull/466))
+
+## **v0.11.0 (31/01/2021)**
+
+**Highlights**
+
+1. Support fashion landmark detection.
+
+2. Support face keypoint detection.
+
+3. Support pose tracking with MMTracking.
+
+**New Features**
+
+- Support fashion landmark detection (DeepFashion) ([#413](https://github.com/open-mmlab/mmpose/pull/413))
+
+- Support face keypoint detection (300W, AFLW, COFW, WFLW) ([#367](https://github.com/open-mmlab/mmpose/pull/367))
+
+- Support pose tracking demo with MMTracking ([#427](https://github.com/open-mmlab/mmpose/pull/427))
+
+- Support face demo ([#443](https://github.com/open-mmlab/mmpose/pull/443))
+
+- Support AIC dataset for bottom-up methods ([#438](https://github.com/open-mmlab/mmpose/pull/438), [#449](https://github.com/open-mmlab/mmpose/pull/449))
+
+**Bug Fixes**
+
+- Fix multi-batch training ([#434](https://github.com/open-mmlab/mmpose/pull/434))
+
+- Fix sigmas in AIC dataset ([#441](https://github.com/open-mmlab/mmpose/pull/441))
+
+- Fix config file ([#420](https://github.com/open-mmlab/mmpose/pull/420))
+
+**Breaking Changes**
+
+- Refactor Heads ([#382](https://github.com/open-mmlab/mmpose/pull/382))
+
+**Improvements**
+
+- Update readme ([#409](https://github.com/open-mmlab/mmpose/pull/409), [#412](https://github.com/open-mmlab/mmpose/pull/412), [#415](https://github.com/open-mmlab/mmpose/pull/415), [#416](https://github.com/open-mmlab/mmpose/pull/416), [#419](https://github.com/open-mmlab/mmpose/pull/419), [#421](https://github.com/open-mmlab/mmpose/pull/421), [#422](https://github.com/open-mmlab/mmpose/pull/422), [#424](https://github.com/open-mmlab/mmpose/pull/424), [#425](https://github.com/open-mmlab/mmpose/pull/425), [#435](https://github.com/open-mmlab/mmpose/pull/435), [#436](https://github.com/open-mmlab/mmpose/pull/436), [#437](https://github.com/open-mmlab/mmpose/pull/437), [#444](https://github.com/open-mmlab/mmpose/pull/444), [#445](https://github.com/open-mmlab/mmpose/pull/445))
+
+- Add GAP (global average pooling) neck ([#414](https://github.com/open-mmlab/mmpose/pull/414))
+
+- Speed up ([#411](https://github.com/open-mmlab/mmpose/pull/411), [#423](https://github.com/open-mmlab/mmpose/pull/423))
+
+- Support COCO test-dev test ([#433](https://github.com/open-mmlab/mmpose/pull/433))
+
+## **v0.10.0 (31/12/2020)**
+
+**Highlights**
+
+1. Support more human pose estimation methods.
+
+ 1. [UDP](https://arxiv.org/abs/1911.07524)
+
+2. Support pose tracking.
+
+3. Support multi-batch inference.
+
+4. Add some useful tools, including `analyze_logs`, `get_flops`, `print_config`.
+
+5. Support more backbone networks.
+
+ 1. [ResNest](https://arxiv.org/pdf/2004.08955.pdf)
+ 2. [VGG](https://arxiv.org/abs/1409.1556)
+
+**New Features**
+
+- Support UDP ([#353](https://github.com/open-mmlab/mmpose/pull/353), [#371](https://github.com/open-mmlab/mmpose/pull/371), [#402](https://github.com/open-mmlab/mmpose/pull/402))
+
+- Support multi-batch inference ([#390](https://github.com/open-mmlab/mmpose/pull/390))
+
+- Support MHP dataset ([#386](https://github.com/open-mmlab/mmpose/pull/386))
+
+- Support pose tracking demo ([#380](https://github.com/open-mmlab/mmpose/pull/380))
+
+- Support mpii-trb demo ([#372](https://github.com/open-mmlab/mmpose/pull/372))
+
+- Support mobilenet for hand pose estimation ([#377](https://github.com/open-mmlab/mmpose/pull/377))
+
+- Support ResNest backbone ([#370](https://github.com/open-mmlab/mmpose/pull/370))
+
+- Support VGG backbone ([#370](https://github.com/open-mmlab/mmpose/pull/370))
+
+- Add some useful tools, including `analyze_logs`, `get_flops`, `print_config` ([#324](https://github.com/open-mmlab/mmpose/pull/324))
+
+**Bug Fixes**
+
+- Fix bugs in pck evaluation ([#328](https://github.com/open-mmlab/mmpose/pull/328))
+
+- Fix model download links in README ([#396](https://github.com/open-mmlab/mmpose/pull/396), [#397](https://github.com/open-mmlab/mmpose/pull/397))
+
+- Fix CrowdPose annotations and update benchmarks ([#384](https://github.com/open-mmlab/mmpose/pull/384))
+
+- Fix modelzoo stat ([#354](https://github.com/open-mmlab/mmpose/pull/354), [#360](https://github.com/open-mmlab/mmpose/pull/360), [#362](https://github.com/open-mmlab/mmpose/pull/362))
+
+- Fix config files for aic datasets ([#340](https://github.com/open-mmlab/mmpose/pull/340))
+
+**Breaking Changes**
+
+- Rename `image_thr` to `det_bbox_thr` for top-down methods.
+
+**Improvements**
+
+- Organize the readme files ([#398](https://github.com/open-mmlab/mmpose/pull/398), [#399](https://github.com/open-mmlab/mmpose/pull/399), [#400](https://github.com/open-mmlab/mmpose/pull/400))
+
+- Check linting for markdown ([#379](https://github.com/open-mmlab/mmpose/pull/379))
+
+- Add faq.md ([#350](https://github.com/open-mmlab/mmpose/pull/350))
+
+- Remove PyTorch 1.4 in CI ([#338](https://github.com/open-mmlab/mmpose/pull/338))
+
+- Add pypi badge in readme ([#329](https://github.com/open-mmlab/mmpose/pull/329))
+
+## **v0.9.0 (30/11/2020)**
+
+**Highlights**
+
+1. Support more human pose estimation methods.
+
+ 1. [MSPN](https://arxiv.org/abs/1901.00148)
+ 2. [RSN](https://arxiv.org/abs/2003.04030)
+
+2. Support video pose estimation datasets.
+
+ 1. [sub-JHMDB](http://jhmdb.is.tue.mpg.de/dataset)
+
+3. Support Onnx model conversion.
+
+**New Features**
+
+- Support MSPN ([#278](https://github.com/open-mmlab/mmpose/pull/278))
+
+- Support RSN ([#221](https://github.com/open-mmlab/mmpose/pull/221), [#318](https://github.com/open-mmlab/mmpose/pull/318))
+
+- Support new post-processing method for MSPN & RSN ([#288](https://github.com/open-mmlab/mmpose/pull/288))
+
+- Support sub-JHMDB dataset ([#292](https://github.com/open-mmlab/mmpose/pull/292))
+
+- Support urls for pre-trained models in config files ([#232](https://github.com/open-mmlab/mmpose/pull/232))
+
+- Support Onnx ([#305](https://github.com/open-mmlab/mmpose/pull/305))
+
+**Bug Fixes**
+
+- Fix model download links in README ([#255](https://github.com/open-mmlab/mmpose/pull/255), [#315](https://github.com/open-mmlab/mmpose/pull/315))
+
+**Breaking Changes**
+
+- `post_process=True|False` and `unbiased_decoding=True|False` are deprecated, use `post_process=None|default|unbiased` etc. instead ([#288](https://github.com/open-mmlab/mmpose/pull/288))
+
+**Improvements**
+
+- Enrich the model zoo ([#256](https://github.com/open-mmlab/mmpose/pull/256), [#320](https://github.com/open-mmlab/mmpose/pull/320))
+
+- Set the default map_location as 'cpu' to reduce gpu memory cost ([#227](https://github.com/open-mmlab/mmpose/pull/227))
+
+- Support return heatmaps and backbone features for bottom-up models ([#229](https://github.com/open-mmlab/mmpose/pull/229))
+
+- Upgrade mmcv maximum & minimum version ([#269](https://github.com/open-mmlab/mmpose/pull/269), [#313](https://github.com/open-mmlab/mmpose/pull/313))
+
+- Automatically add modelzoo statistics to readthedocs ([#252](https://github.com/open-mmlab/mmpose/pull/252))
+
+- Fix Pylint issues ([#258](https://github.com/open-mmlab/mmpose/pull/258), [#259](https://github.com/open-mmlab/mmpose/pull/259), [#260](https://github.com/open-mmlab/mmpose/pull/260), [#262](https://github.com/open-mmlab/mmpose/pull/262), [#265](https://github.com/open-mmlab/mmpose/pull/265), [#267](https://github.com/open-mmlab/mmpose/pull/267), [#268](https://github.com/open-mmlab/mmpose/pull/268), [#270](https://github.com/open-mmlab/mmpose/pull/270), [#271](https://github.com/open-mmlab/mmpose/pull/271), [#272](https://github.com/open-mmlab/mmpose/pull/272), [#273](https://github.com/open-mmlab/mmpose/pull/273), [#275](https://github.com/open-mmlab/mmpose/pull/275), [#276](https://github.com/open-mmlab/mmpose/pull/276), [#283](https://github.com/open-mmlab/mmpose/pull/283), [#285](https://github.com/open-mmlab/mmpose/pull/285), [#293](https://github.com/open-mmlab/mmpose/pull/293), [#294](https://github.com/open-mmlab/mmpose/pull/294), [#295](https://github.com/open-mmlab/mmpose/pull/295))
+
+- Improve README ([#226](https://github.com/open-mmlab/mmpose/pull/226), [#257](https://github.com/open-mmlab/mmpose/pull/257), [#264](https://github.com/open-mmlab/mmpose/pull/264), [#280](https://github.com/open-mmlab/mmpose/pull/280), [#296](https://github.com/open-mmlab/mmpose/pull/296))
+
+- Support PyTorch 1.7 in CI ([#274](https://github.com/open-mmlab/mmpose/pull/274))
+
+- Add docs/tutorials for running demos ([#263](https://github.com/open-mmlab/mmpose/pull/263))
+
+## **v0.8.0 (31/10/2020)**
+
+**Highlights**
+
+1. Support more human pose estimation datasets.
+
+ 1. [CrowdPose](https://github.com/Jeff-sjtu/CrowdPose)
+ 2. [PoseTrack18](https://posetrack.net/)
+
+2. Support more 2D hand keypoint estimation datasets.
+
+ 1. [InterHand2.6](https://github.com/facebookresearch/InterHand2.6M)
+
+3. Support adversarial training for 3D human shape recovery.
+
+4. Support multi-stage losses.
+
+5. Support mpii demo.
+
+**New Features**
+
+- Support [CrowdPose](https://github.com/Jeff-sjtu/CrowdPose) dataset ([#195](https://github.com/open-mmlab/mmpose/pull/195))
+
+- Support [PoseTrack18](https://posetrack.net/) dataset ([#220](https://github.com/open-mmlab/mmpose/pull/220))
+
+- Support [InterHand2.6](https://github.com/facebookresearch/InterHand2.6M) dataset ([#202](https://github.com/open-mmlab/mmpose/pull/202))
+
+- Support adversarial training for 3D human shape recovery ([#192](https://github.com/open-mmlab/mmpose/pull/192))
+
+- Support multi-stage losses ([#204](https://github.com/open-mmlab/mmpose/pull/204))
+
+**Bug Fixes**
+
+- Fix config files ([#190](https://github.com/open-mmlab/mmpose/pull/190))
+
+**Improvements**
+
+- Add mpii demo ([#216](https://github.com/open-mmlab/mmpose/pull/216))
+
+- Improve README ([#181](https://github.com/open-mmlab/mmpose/pull/181), [#183](https://github.com/open-mmlab/mmpose/pull/183), [#208](https://github.com/open-mmlab/mmpose/pull/208))
+
+- Support return heatmaps and backbone features ([#196](https://github.com/open-mmlab/mmpose/pull/196), [#212](https://github.com/open-mmlab/mmpose/pull/212))
+
+- Support different return formats of mmdetection models ([#217](https://github.com/open-mmlab/mmpose/pull/217))
+
+## **v0.7.0 (30/9/2020)**
+
+**Highlights**
+
+1. Support HMR for 3D human shape recovery.
+
+2. Support WholeBody human pose estimation.
+
+ 1. [COCO-WholeBody](https://github.com/jin-s13/COCO-WholeBody)
+
+3. Support more 2D hand keypoint estimation datasets.
+
+ 1. [Frei-hand](https://lmb.informatik.uni-freiburg.de/projects/freihand/)
+ 2. [CMU Panoptic HandDB](http://domedb.perception.cs.cmu.edu/handdb.html)
+
+4. Add more popular backbones & enrich the [modelzoo](https://mmpose.readthedocs.io/en/latest/model_zoo.html)
+
+ 1. ShuffleNetv2
+
+5. Support hand demo and whole-body demo.
+
+**New Features**
+
+- Support HMR for 3D human shape recovery ([#157](https://github.com/open-mmlab/mmpose/pull/157), [#160](https://github.com/open-mmlab/mmpose/pull/160), [#161](https://github.com/open-mmlab/mmpose/pull/161), [#162](https://github.com/open-mmlab/mmpose/pull/162))
+
+- Support [COCO-WholeBody](https://github.com/jin-s13/COCO-WholeBody) dataset ([#133](https://github.com/open-mmlab/mmpose/pull/133))
+
+- Support [Frei-hand](https://lmb.informatik.uni-freiburg.de/projects/freihand/) dataset ([#125](https://github.com/open-mmlab/mmpose/pull/125))
+
+- Support [CMU Panoptic HandDB](http://domedb.perception.cs.cmu.edu/handdb.html) dataset ([#144](https://github.com/open-mmlab/mmpose/pull/144))
+
+- Support H36M dataset ([#159](https://github.com/open-mmlab/mmpose/pull/159))
+
+- Support ShuffleNetv2 ([#139](https://github.com/open-mmlab/mmpose/pull/139))
+
+- Support saving best models based on key indicator ([#127](https://github.com/open-mmlab/mmpose/pull/127))
+
+**Bug Fixes**
+
+- Fix typos in docs ([#121](https://github.com/open-mmlab/mmpose/pull/121))
+
+- Fix assertion ([#142](https://github.com/open-mmlab/mmpose/pull/142))
+
+**Improvements**
+
+- Add tools to transform .mat format to .json format ([#126](https://github.com/open-mmlab/mmpose/pull/126))
+
+- Add hand demo ([#115](https://github.com/open-mmlab/mmpose/pull/115))
+
+- Add whole-body demo ([#163](https://github.com/open-mmlab/mmpose/pull/163))
+
+- Reuse mmcv utility function and update version files ([#135](https://github.com/open-mmlab/mmpose/pull/135), [#137](https://github.com/open-mmlab/mmpose/pull/137))
+
+- Enrich the modelzoo ([#147](https://github.com/open-mmlab/mmpose/pull/147), [#169](https://github.com/open-mmlab/mmpose/pull/169))
+
+- Improve docs ([#174](https://github.com/open-mmlab/mmpose/pull/174), [#175](https://github.com/open-mmlab/mmpose/pull/175), [#178](https://github.com/open-mmlab/mmpose/pull/178))
+
+- Improve README ([#176](https://github.com/open-mmlab/mmpose/pull/176))
+
+- Improve version.py ([#173](https://github.com/open-mmlab/mmpose/pull/173))
+
+## **v0.6.0 (31/8/2020)**
+
+**Highlights**
+
+1. Add more popular backbones & enrich the [modelzoo](https://mmpose.readthedocs.io/en/latest/model_zoo.html)
+
+ 1. ResNext
+ 2. SEResNet
+ 3. ResNetV1D
+ 4. MobileNetv2
+ 5. ShuffleNetv1
+ 6. CPM (Convolutional Pose Machine)
+
+2. Add more popular datasets:
+
+ 1. [AIChallenger](https://arxiv.org/abs/1711.06475?context=cs.CV)
+ 2. [MPII](http://human-pose.mpi-inf.mpg.de/)
+ 3. [MPII-TRB](https://github.com/kennymckormick/Triplet-Representation-of-human-Body)
+ 4. [OCHuman](http://www.liruilong.cn/projects/pose2seg/index.html)
+
+3. Support 2d hand keypoint estimation.
+
+ 1. [OneHand10K](https://www.yangangwang.com/papers/WANG-MCC-2018-10.html)
+
+4. Support bottom-up inference.
+
+**New Features**
+
+- Support [OneHand10K](https://www.yangangwang.com/papers/WANG-MCC-2018-10.html) dataset ([#52](https://github.com/open-mmlab/mmpose/pull/52))
+
+- Support [MPII](http://human-pose.mpi-inf.mpg.de/) dataset ([#55](https://github.com/open-mmlab/mmpose/pull/55))
+
+- Support [MPII-TRB](https://github.com/kennymckormick/Triplet-Representation-of-human-Body) dataset ([#19](https://github.com/open-mmlab/mmpose/pull/19), [#47](https://github.com/open-mmlab/mmpose/pull/47), [#48](https://github.com/open-mmlab/mmpose/pull/48))
+
+- Support [OCHuman](http://www.liruilong.cn/projects/pose2seg/index.html) dataset ([#70](https://github.com/open-mmlab/mmpose/pull/70))
+
+- Support [AIChallenger](https://arxiv.org/abs/1711.06475?context=cs.CV) dataset ([#87](https://github.com/open-mmlab/mmpose/pull/87))
+
+- Support multiple backbones ([#26](https://github.com/open-mmlab/mmpose/pull/26))
+
+- Support CPM model ([#56](https://github.com/open-mmlab/mmpose/pull/56))
+
+**Bug Fixes**
+
+- Fix configs for MPII & MPII-TRB datasets ([#93](https://github.com/open-mmlab/mmpose/pull/93))
+
+- Fix the bug of missing `test_pipeline` in configs ([#14](https://github.com/open-mmlab/mmpose/pull/14))
+
+- Fix typos ([#27](https://github.com/open-mmlab/mmpose/pull/27), [#28](https://github.com/open-mmlab/mmpose/pull/28), [#50](https://github.com/open-mmlab/mmpose/pull/50), [#53](https://github.com/open-mmlab/mmpose/pull/53), [#63](https://github.com/open-mmlab/mmpose/pull/63))
+
+**Improvements**
+
+- Update benchmark ([#93](https://github.com/open-mmlab/mmpose/pull/93))
+
+- Add Dockerfile ([#44](https://github.com/open-mmlab/mmpose/pull/44))
+
+- Improve unittest coverage and minor fix ([#18](https://github.com/open-mmlab/mmpose/pull/18))
+
+- Support CPUs for train/val/demo ([#34](https://github.com/open-mmlab/mmpose/pull/34))
+
+- Support bottom-up demo ([#69](https://github.com/open-mmlab/mmpose/pull/69))
+
+- Add tools to publish model ([#62](https://github.com/open-mmlab/mmpose/pull/62))
+
+- Enrich the modelzoo ([#64](https://github.com/open-mmlab/mmpose/pull/64), [#68](https://github.com/open-mmlab/mmpose/pull/68), [#82](https://github.com/open-mmlab/mmpose/pull/82))
+
+## **v0.5.0 (21/7/2020)**
+
+**Highlights**
+
+- MMPose is released.
+
+**Main Features**
+
+- Support both top-down and bottom-up pose estimation approaches.
+
+- Achieve higher training efficiency and higher accuracy than other popular codebases (e.g. AlphaPose, HRNet)
+
+- Support various backbone models: ResNet, HRNet, SCNet, Houglass and HigherHRNet.
diff --git a/internlm_langchain/knowledge_base/MMPose/content/codecs.md b/internlm_langchain/knowledge_base/MMPose/content/codecs.md
new file mode 100644
index 00000000..85d4d2e5
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPose/content/codecs.md
@@ -0,0 +1,227 @@
+# ń╝¢Ķ¦ŻńĀüÕÖ©
+
+Õ£©Õģ│ķö«ńé╣µŻĆµĄŗõ╗╗ÕŖĪõĖŁ’╝īµĀ╣µŹ«ń«Śµ│ĢńÜäõĖŹÕÉī’╝īķ£ĆĶ”üÕł®ńö©µĀćµ│©õ┐Īµü»’╝īńö¤µłÉõĖŹÕÉīµĀ╝Õ╝ÅńÜäĶ«Łń╗āńø«µĀć’╝īµ»öÕ”éÕĮÆõĖĆÕī¢ńÜäÕØɵĀćÕĆ╝ŃĆüõĖĆń╗┤ÕÉæķćÅŃĆüķ½śµ¢»ńāŁÕøŠńŁēŃĆéÕÉīµĀĘńÜä’╝īÕ»╣õ║ĵ©ĪÕ×ŗĶŠōÕć║ńÜäń╗ōµ×£’╝īõ╣¤ķ£ĆĶ”üń╗ÅĶ┐ćÕżäńÉåĶĮ¼µŹóµłÉµĀćµ│©õ┐Īµü»µĀ╝Õ╝ÅŃĆ鵳æõ╗¼õĖĆĶł¼Õ░åµĀćµ│©õ┐Īµü»Õł░Ķ«Łń╗āńø«µĀćńÜäÕżäńÉåĶ┐ćń©ŗń¦░õĖ║ń╝¢ńĀü’╝īµ©ĪÕ×ŗĶŠōÕć║Õł░µĀćµ│©õ┐Īµü»ńÜäÕżäńÉåĶ┐ćń©ŗń¦░õĖ║Ķ¦ŻńĀüŃĆé
+
+ń╝¢ńĀüÕÆīĶ¦ŻńĀüµś»õĖĆÕ»╣ń┤¦Õ»åńøĖÕģ│ńÜäõ║ÆķĆåÕżäńÉåĶ┐ćń©ŗŃĆéÕ£© MMPose µŚ®µ£¤ńēłµ£¼õĖŁ’╝īń╝¢ńĀüÕÆīĶ¦ŻńĀüĶ┐ćń©ŗÕŠĆÕŠĆÕłåµĢŻÕ£©õĖŹÕÉīµ©ĪÕØŚķćī’╝īõĮ┐ÕģČõĖŹÕż¤ńø┤Ķ¦éÕÆīń╗¤õĖĆ’╝īÕó×ÕŖĀõ║åÕŁ”õ╣ĀÕÆīń╗┤µŖżµłÉµ£¼ŃĆé
+
+MMPose 1.0 õĖŁÕ╝ĢÕģźõ║åµ¢░µ©ĪÕØŚ **ń╝¢Ķ¦ŻńĀüÕÖ©’╝łCodec’╝ē** ’╝īÕ░åÕģ│ķö«ńé╣µĢ░µŹ«ńÜäń╝¢ńĀüÕÆīĶ¦ŻńĀüĶ┐ćń©ŗĶ┐øĶĪīķøåµłÉ’╝īõ╗źÕó×ÕŖĀõ╗ŻńĀüńÜäÕÅŗÕźĮÕ║”ÕÆīÕżŹńö©µĆ¦ŃĆé
+
+ń╝¢Ķ¦ŻńĀüÕÖ©Õ£©ÕĘźõĮ£µĄüń©ŗõĖŁµēĆÕżäńÜäõĮŹńĮ«Õ”éõĖŗµēĆńż║’╝Ü
+
+
+
+õĖĆõĖ¬ń╝¢Ķ¦ŻńĀüÕÖ©õĖ╗Ķ”üÕīģÕɽõĖżõĖ¬ķā©Õłå’╝Ü
+
+- ń╝¢ńĀüÕÖ©
+- Ķ¦ŻńĀüÕÖ©
+
+### ń╝¢ńĀüÕÖ©
+
+ń╝¢ńĀüÕÖ©õĖ╗Ķ”üĶ┤¤Ķ┤ŻÕ░åÕżäõ║ÄĶŠōÕģźÕøŠńēćÕ░║Õ║”ńÜäÕØɵĀćÕĆ╝’╝īń╝¢ńĀüõĖ║µ©ĪÕ×ŗĶ«Łń╗āµēĆķ£ĆĶ”üńÜäńø«µĀćµĀ╝Õ╝Å’╝īõĖ╗Ķ”üÕīģµŗ¼’╝Ü
+
+- ÕĮÆõĖĆÕī¢ńÜäÕØɵĀćÕĆ╝’╝Üńö©õ║Ä Regression-based µ¢╣µ│Ģ
+- õĖĆń╗┤ÕÉæķćÅ’╝Üńö©õ║Ä SimCC-based µ¢╣µ│Ģ
+- ķ½śµ¢»ńāŁÕøŠ’╝Üńö©õ║Ä Heatmap-based µ¢╣µ│Ģ
+
+õ╗ź Regression-based µ¢╣µ│ĢńÜäń╝¢ńĀüÕÖ©õĖ║õŠŗ’╝Ü
+
+```Python
+def encode(self,
+ keypoints: np.ndarray,
+ keypoints_visible: Optional[np.ndarray] = None) -> dict:
+ """Encoding keypoints from input image space to normalized space.
+
+ Args:
+ keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D)
+ keypoints_visible (np.ndarray): Keypoint visibilities in shape
+ (N, K)
+
+ Returns:
+ dict:
+ - keypoint_labels (np.ndarray): The normalized regression labels in
+ shape (N, K, D) where D is 2 for 2d coordinates
+ - keypoint_weights (np.ndarray): The target weights in shape
+ (N, K)
+ """
+ if keypoints_visible is None:
+ keypoints_visible = np.ones(keypoints.shape[:2], dtype=np.float32)
+
+ w, h = self.input_size
+ valid = ((keypoints >= 0) &
+ (keypoints <= [w - 1, h - 1])).all(axis=-1) & (
+ keypoints_visible > 0.5)
+
+ keypoint_labels = (keypoints / np.array([w, h])).astype(np.float32)
+ keypoint_weights = np.where(valid, 1., 0.).astype(np.float32)
+
+ encoded = dict(
+ keypoint_labels=keypoint_labels, keypoint_weights=keypoint_weights)
+
+ return encoded
+```
+
+ń╝¢ńĀüÕÉÄńÜäµĢ░µŹ«õ╝ÜÕ£© `PackPoseInputs` õĖŁĶó½ĶĮ¼µŹóõĖ║ Tensor µĀ╝Õ╝Å’╝īÕ╣ČÕ░üĶŻģÕł░ `data_sample.gt_instance_labels` õĖŁõŠøµ©ĪÕ×ŗĶ░āńö©’╝īõĖĆĶł¼õĖ╗Ķ”üńö©õ║Ä loss Ķ«Īń«Ś’╝īõĖŗķØóõ╗ź `RegressionHead` õĖŁńÜä `loss()` õĖ║õŠŗ’╝Ü
+
+```Python
+def loss(self,
+ inputs: Tuple[Tensor],
+ batch_data_samples: OptSampleList,
+ train_cfg: ConfigType = {}) -> dict:
+ """Calculate losses from a batch of inputs and data samples."""
+
+ pred_outputs = self.forward(inputs)
+
+ keypoint_labels = torch.cat(
+ [d.gt_instance_labels.keypoint_labels for d in batch_data_samples])
+ keypoint_weights = torch.cat([
+ d.gt_instance_labels.keypoint_weights for d in batch_data_samples
+ ])
+
+ # calculate losses
+ losses = dict()
+ loss = self.loss_module(pred_outputs, keypoint_labels,
+ keypoint_weights.unsqueeze(-1))
+
+ losses.update(loss_kpt=loss)
+ ### ÕÉÄń╗ŁÕåģÕ«╣ń£üńĢź ###
+```
+
+### Ķ¦ŻńĀüÕÖ©
+
+Ķ¦ŻńĀüÕÖ©õĖ╗Ķ”üĶ┤¤Ķ┤ŻÕ░嵩ĪÕ×ŗńÜäĶŠōÕć║Ķ¦ŻńĀüõĖ║ĶŠōÕģźÕøŠńēćÕ░║Õ║”ńÜäÕØɵĀćÕĆ╝’╝īÕżäńÉåĶ┐ćń©ŗõĖÄń╝¢ńĀüÕÖ©ńøĖÕÅŹŃĆé
+
+õ╗ź Regression-based µ¢╣µ│ĢńÜäĶ¦ŻńĀüÕÖ©õĖ║õŠŗ’╝Ü
+
+```Python
+def decode(self, encoded: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
+ """Decode keypoint coordinates from normalized space to input image
+ space.
+
+ Args:
+ encoded (np.ndarray): Coordinates in shape (N, K, D)
+
+ Returns:
+ tuple:
+ - keypoints (np.ndarray): Decoded coordinates in shape (N, K, D)
+ - scores (np.ndarray): The keypoint scores in shape (N, K).
+ It usually represents the confidence of the keypoint prediction
+
+ """
+
+ if encoded.shape[-1] == 2:
+ N, K, _ = encoded.shape
+ normalized_coords = encoded.copy()
+ scores = np.ones((N, K), dtype=np.float32)
+ elif encoded.shape[-1] == 4:
+ # split coords and sigma if outputs contain output_sigma
+ normalized_coords = encoded[..., :2].copy()
+ output_sigma = encoded[..., 2:4].copy()
+ scores = (1 - output_sigma).mean(axis=-1)
+ else:
+ raise ValueError(
+ 'Keypoint dimension should be 2 or 4 (with sigma), '
+ f'but got {encoded.shape[-1]}')
+
+ w, h = self.input_size
+ keypoints = normalized_coords * np.array([w, h])
+
+ return keypoints, scores
+```
+
+ķ╗śĶ«żµāģÕåĄõĖŗ’╝ī`decode()` µ¢╣µ│ĢÕŬµÅÉõŠøÕŹĢõĖ¬ńø«µĀćµĢ░µŹ«ńÜäĶ¦ŻńĀüĶ┐ćń©ŗ’╝īõĮĀõ╣¤ÕÅ»õ╗źķĆÜĶ┐ć `batch_decode()` µØźÕ«×ńÄ░µē╣ķćÅĶ¦ŻńĀüµÅÉÕŹćµē¦ĶĪīµĢłńÄćŃĆé
+
+## ÕĖĖĶ¦üńö©µ│Ģ
+
+Õ£© MMPose ķģŹńĮ«µ¢ćõ╗ČõĖŁ’╝īõĖ╗Ķ”üµ£ēõĖēÕżäµČēÕÅŖń╝¢Ķ¦ŻńĀüÕÖ©’╝Ü
+
+- Õ«Üõ╣ēń╝¢Ķ¦ŻńĀüÕÖ©
+- ńö¤µłÉĶ«Łń╗āńø«µĀć
+- µ©ĪÕ×ŗÕż┤ķā©
+
+### Õ«Üõ╣ēń╝¢Ķ¦ŻńĀüÕÖ©
+
+õ╗źÕø×ÕĮƵ¢╣µ│Ģńö¤µłÉÕĮÆõĖĆÕī¢ńÜäÕØɵĀćÕĆ╝õĖ║õŠŗ’╝īÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁ’╝īµłæõ╗¼ķĆÜĶ┐ćÕ”éõĖŗµ¢╣Õ╝ÅÕ«Üõ╣ēń╝¢Ķ¦ŻńĀüÕÖ©’╝Ü
+
+```Python
+codec = dict(type='RegressionLabel', input_size=(192, 256))
+```
+
+### ńö¤µłÉĶ«Łń╗āńø«µĀć
+
+Õ£©µĢ░µŹ«ÕżäńÉåķśČµ«Ąńö¤µłÉĶ«Łń╗āńø«µĀ浌Ȓ╝īķ£ĆĶ”üõ╝ĀÕģźń╝¢Ķ¦ŻńĀüÕÖ©ńö©õ║Äń╝¢ńĀü’╝Ü
+
+```Python
+dict(type='GenerateTarget', encoder=codec)
+```
+
+### µ©ĪÕ×ŗÕż┤ķā©
+
+Õ£© MMPose õĖŁ’╝īµłæõ╗¼Õ£©µ©ĪÕ×ŗÕż┤ķā©Õ»╣µ©ĪÕ×ŗńÜäĶŠōÕć║Ķ┐øĶĪīĶ¦ŻńĀü’╝īķ£ĆĶ”üõ╝ĀÕģźń╝¢Ķ¦ŻńĀüÕÖ©ńö©õ║ÄĶ¦ŻńĀü’╝Ü
+
+```Python
+head=dict(
+ type='RLEHead',
+ in_channels=2048,
+ num_joints=17,
+ loss=dict(type='RLELoss', use_target_weight=True),
+ decoder=codec
+)
+```
+
+Õ«āõ╗¼Õ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁńÜäÕģĘõĮōõĮŹńĮ«Õ”éõĖŗ:
+
+```Python
+
+# codec settings
+codec = dict(type='RegressionLabel', input_size=(192, 256)) ## Õ«Üõ╣ē ##
+
+# model settings
+model = dict(
+ type='TopdownPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ type='ResNet',
+ depth=50,
+ init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50'),
+ ),
+ neck=dict(type='GlobalAveragePooling'),
+ head=dict(
+ type='RLEHead',
+ in_channels=2048,
+ num_joints=17,
+ loss=dict(type='RLELoss', use_target_weight=True),
+ decoder=codec), ## µ©ĪÕ×ŗÕż┤ķā© ##
+ test_cfg=dict(
+ flip_test=True,
+ shift_coords=True,
+ ))
+
+# base dataset settings
+dataset_type = 'CocoDataset'
+data_mode = 'topdown'
+data_root = 'data/coco/'
+
+backend_args = dict(backend='local')
+
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(type='RandomBBoxTransform'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='GenerateTarget', encoder=codec), ## ńö¤µłÉĶ«Łń╗āńø«µĀć ##
+ dict(type='PackPoseInputs')
+]
+test_pipeline = [
+ dict(type='LoadImage', backend_args=backend_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='PackPoseInputs')
+]
+```
diff --git a/internlm_langchain/knowledge_base/MMPose/content/configs.md b/internlm_langchain/knowledge_base/MMPose/content/configs.md
new file mode 100644
index 00000000..0bcb7aa1
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPose/content/configs.md
@@ -0,0 +1,466 @@
+# ķģŹńĮ«µ¢ćõ╗Č
+
+MMPose õĮ┐ńö© Python µ¢ćõ╗ČõĮ£õĖ║ķģŹńĮ«µ¢ćõ╗Č’╝īÕ░嵩ĪÕØŚÕī¢Ķ«ŠĶ«ĪÕÆīń╗¦µē┐Ķ«ŠĶ«Īń╗ōÕÉłÕł░ķģŹńĮ«ń│╗ń╗¤õĖŁ’╝īõŠ┐õ║ÄĶ┐øĶĪīÕÉäń¦ŹÕ«×ķ¬īŃĆé
+
+## ń«Ćõ╗ŗ
+
+MMPose µŗźµ£ēõĖĆÕźŚÕ╝║Õż¦ńÜäķģŹńĮ«ń│╗ń╗¤’╝īÕ£©µ│©ÕåīÕÖ©ńÜäķģŹÕÉłõĖŗ’╝īńö©µłĘÕÅ»õ╗źķĆÜĶ┐ćõĖĆõĖ¬ķģŹńĮ«µ¢ćõ╗ČµØźÕ«Üõ╣ēµĢ┤õĖ¬ķĪ╣ńø«ķ£ĆĶ”üńö©Õł░ńÜäµēƵ£ēÕåģÕ«╣’╝īõ╗ź Python ÕŁŚÕģĖÕĮóÕ╝Åń╗äń╗ćķģŹńĮ«õ┐Īµü»’╝īõ╝ĀķĆÆń╗Öµ│©ÕåīÕÖ©Õ«īµłÉÕ»╣Õ║öµ©ĪÕØŚńÜäÕ«×õŠŗÕī¢ŃĆé
+
+õĖŗķØ󵜻õĖĆõĖ¬ÕĖĖĶ¦üńÜä Pytorch µ©ĪÕØŚÕ«Üõ╣ēńÜäõŠŗÕŁÉ’╝Ü
+
+```Python
+# Õ£©loss_a.pyõĖŁÕ«Üõ╣ēLoss_Ań▒╗
+Class Loss_A(nn.Module):
+ def __init__(self, param1, param2):
+ self.param1 = param1
+ self.param2 = param2
+ def forward(self, x):
+ return x
+
+# Õ£©ķ£ĆĶ”üńÜäÕ£░µ¢╣Ķ┐øĶĪīÕ«×õŠŗÕī¢
+loss = Loss_A(param1=1.0, param2=True)
+```
+
+ÕŬķ£ĆĶ”üķĆÜĶ┐ćõĖĆĶĪīõ╗ŻńĀüÕ»╣Ķ┐ÖõĖ¬ń▒╗Ķ┐øĶĪīµ│©Õåī’╝Ü
+
+```Python
+# Õ£©loss_a.pyõĖŁÕ«Üõ╣ēLoss_Ań▒╗
+from mmpose.registry import MODELS
+
+@MODELS.register_module() # µ│©ÕåīĶ»źń▒╗Õł░ MODELS õĖŗ
+Class Loss_A(nn.Module):
+ def __init__(self, param1, param2):
+ self.param1 = param1
+ self.param2 = param2
+ def forward(self, x):
+ return x
+```
+
+Õ╣ČÕ£©Õ»╣Õ║öńø«ÕĮĢõĖŗńÜä `__init__.py` õĖŁĶ┐øĶĪī `import`’╝Ü
+
+```Python
+# __init__.py of mmpose/models/losses
+from .loss_a.py import Loss_A
+
+__all__ = ['Loss_A']
+```
+
+µłæõ╗¼Õ░▒ÕÅ»õ╗źķĆÜĶ┐ćÕ”éõĖŗµ¢╣Õ╝ÅµØźõ╗ÄķģŹńĮ«µ¢ćõ╗ČÕ«Üõ╣ēÕ╣ČĶ┐øĶĪīÕ«×õŠŗÕī¢’╝Ü
+
+```Python
+# Õ£©config_file.pyõĖŁÕ«Üõ╣ē
+loss_cfg = dict(
+ type='Loss_A', # ķĆÜĶ┐ćtypeµīćÕ«Üń▒╗ÕÉŹ
+ param1=1.0, # õ╝ĀķĆÆ__init__µēĆķ£ĆńÜäÕÅéµĢ░
+ param2=True
+)
+
+# Õ£©ķ£ĆĶ”üńÜäÕ£░µ¢╣Ķ┐øĶĪīÕ«×õŠŗÕī¢
+loss = MODELS.build(loss_cfg) # ńŁēõ╗Ęõ║Ä loss = Loss_A(param1=1.0, param2=True)
+```
+
+MMPose ķóäÕ«Üõ╣ēńÜä Registry Õ£© `$MMPOSE/mmpose/registry.py` õĖŁ’╝īńø«ÕēŹµö»µīüńÜäµ£ē’╝Ü
+
+- `DATASETS`’╝ܵĢ░µŹ«ķøå
+
+- `TRANSFORMS`’╝ܵĢ░µŹ«ÕÅśµŹó
+
+- `MODELS`’╝ܵ©ĪÕ×ŗµ©ĪÕØŚ’╝łBackboneŃĆüNeckŃĆüHeadŃĆüLossńŁē’╝ē
+
+- `VISUALIZERS`’╝ÜÕÅ»Ķ¦åÕī¢ÕĘźÕģĘ
+
+- `VISBACKENDS`’╝ÜÕÅ»Ķ¦åÕī¢ÕÉÄń½»
+
+- `METRICS`’╝ÜĶ»äµĄŗµīćµĀć
+
+- `KEYPOINT_CODECS`’╝Üń╝¢Ķ¦ŻńĀüÕÖ©
+
+- `HOOKS`’╝ÜķÆ®ÕŁÉń▒╗
+
+```{note}
+ķ£ĆĶ”üµ│©µäÅńÜ䵜»’╝īµēƵ£ēµ¢░Õó×ńÜ䵩ĪÕØŚķāĮķ£ĆĶ”üõĮ┐ńö©µ│©ÕåīÕÖ©’╝łRegistry’╝ēĶ┐øĶĪīµ│©Õåī’╝īÕ╣ČÕ£©Õ»╣Õ║öńø«ÕĮĢńÜä `__init__.py` õĖŁĶ┐øĶĪī `import`’╝īõ╗źõŠ┐ĶāĮÕż¤õĮ┐ńö©ķģŹńĮ«µ¢ćõ╗ȵ×äÕ╗║ÕģČÕ«×õŠŗŃĆé
+```
+
+## ķģŹńĮ«ń│╗ń╗¤
+
+ÕģĘõĮōĶĆīĶ©Ć’╝īõĖĆõĖ¬ķģŹńĮ«µ¢ćõ╗ČõĖ╗Ķ”üÕīģÕɽՔéõĖŗõ║öõĖ¬ķā©Õłå’╝Ü
+
+- ķĆÜńö©ķģŹńĮ«’╝ÜõĖÄĶ«Łń╗āµł¢µĄŗĶ»ĢµŚĀÕģ│ńÜäķĆÜńö©ķģŹńĮ«’╝īÕ”éµŚČķŚ┤ń╗¤Ķ«Ī’╝īµ©ĪÕ×ŗÕŁśÕé©õĖÄÕŖĀĶĮĮ’╝īÕÅ»Ķ¦åÕī¢ńŁēńøĖÕģ│ Hook’╝īõ╗źÕÅŖõĖĆõ║øÕłåÕĖāÕ╝ÅńøĖÕģ│ńÜäńÄ»ÕóāķģŹńĮ«
+
+- µĢ░µŹ«ķģŹńĮ«’╝ܵĢ░µŹ«Õó×Õ╝║ńŁ¢ńĢź’╝īDatasetÕÆīDataloaderńøĖÕģ│ķģŹńĮ«
+
+- Ķ«Łń╗āķģŹńĮ«’╝ܵ¢Łńé╣µüóÕżŹŃĆüµ©ĪÕ×ŗµØāķćŹÕŖĀĶĮĮŃĆüõ╝śÕī¢ÕÖ©ŃĆüÕŁ”õ╣ĀńÄćĶ░āµĢ┤ŃĆüĶ«Łń╗āĶĮ«µĢ░ÕÆīµĄŗĶ»ĢķŚ┤ķÜöńŁē
+
+- µ©ĪÕ×ŗķģŹńĮ«’╝ܵ©ĪÕ×ŗµ©ĪÕØŚŃĆüÕÅéµĢ░ŃĆüµŹ¤Õż▒ÕćĮµĢ░ńŁē
+
+- Ķ»äµĄŗķģŹńĮ«’╝ܵ©ĪÕ×ŗµĆ¦ĶāĮĶ»äµĄŗµīćµĀć
+
+õĮĀÕÅ»õ╗źÕ£© `$MMPOSE/configs` õĖŗµēŠÕł░µłæõ╗¼µÅÉõŠøńÜäķģŹńĮ«µ¢ćõ╗Č’╝īķģŹńĮ«µ¢ćõ╗Čõ╣ŗķŚ┤ķĆÜĶ┐ćń╗¦µē┐µØźķü┐ÕģŹÕåŚõĮÖŃĆéõĖ║õ║åõ┐صīüķģŹńĮ«µ¢ćõ╗Čń«Ćµ┤üµśōĶ»╗’╝īµłæõ╗¼Õ░åõĖĆõ║øÕ┐ģĶ”üõĮåõĖŹÕĖĖµö╣ÕŖ©ńÜäķģŹńĮ«ÕŁśµöŠÕł░õ║å `$MMPOSE/configs/_base_` ńø«ÕĮĢõĖŗ’╝īÕ”éµ×£ÕĖīµ£øµ¤źķśģÕ«īµĢ┤ńÜäķģŹńĮ«õ┐Īµü»’╝īõĮĀÕÅ»õ╗źĶ┐ÉĶĪīÕ”éõĖŗµīćõ╗ż’╝Ü
+
+```Bash
+python tools/analysis/print_config.py /PATH/TO/CONFIG
+```
+
+### ķĆÜńö©ķģŹńĮ«
+
+ķĆÜńö©ķģŹńĮ«µīćõĖÄĶ«Łń╗āµł¢µĄŗĶ»ĢµŚĀÕģ│ńÜäÕ┐ģĶ”üķģŹńĮ«’╝īõĖ╗Ķ”üÕīģµŗ¼’╝Ü
+
+- **ķ╗śĶ«żHook**’╝ÜĶ┐Łõ╗ŻµŚČķŚ┤ń╗¤Ķ«Ī’╝īĶ«Łń╗āµŚźÕ┐Ś’╝īÕÅéµĢ░µø┤µ¢░’╝īcheckpoint ńŁē
+
+- **ńÄ»ÕóāķģŹńĮ«**’╝ÜÕłåÕĖāÕ╝ÅÕÉÄń½»’╝īcudnn’╝īÕżÜĶ┐øń©ŗķģŹńĮ«ńŁē
+
+- **ÕÅ»Ķ¦åÕī¢ÕÖ©**’╝ÜÕÅ»Ķ¦åÕī¢ÕÉÄń½»ÕÆīńŁ¢ńĢźĶ«ŠńĮ«
+
+- **µŚźÕ┐ŚķģŹńĮ«**’╝ܵŚźÕ┐ŚńŁēń║¦’╝īµĀ╝Õ╝Å’╝īµēōÕŹ░ÕÆīĶ«░ÕĮĢķŚ┤ķÜöńŁē
+
+õĖŗķØ󵜻ķĆÜńö©ķģŹńĮ«ńÜäµĀĘõŠŗĶ»┤µśÄ’╝Ü
+
+```Python
+# ķĆÜńö©ķģŹńĮ«
+default_scope = 'mmpose'
+default_hooks = dict(
+ timer=dict(type='IterTimerHook'), # Ķ┐Łõ╗ŻµŚČķŚ┤ń╗¤Ķ«Ī’╝īÕīģµŗ¼µĢ░µŹ«ĶĆŚµŚČÕÆīµ©ĪÕ×ŗĶĆŚµŚČ
+ logger=dict(type='LoggerHook', interval=50), # µŚźÕ┐ŚµēōÕŹ░ķŚ┤ķÜö
+ param_scheduler=dict(type='ParamSchedulerHook'), # ńö©õ║ÄĶ░āÕ║”ÕŁ”õ╣ĀńÄćµø┤µ¢░
+ checkpoint=dict(
+ type='CheckpointHook', interval=1, save_best='coco/AP', # ckptõ┐ØÕŁśķŚ┤ķÜö’╝īµ£Ćõ╝śckptÕÅéĶĆāµīćµĀć
+ rule='greater'), # µ£Ćõ╝śckptµīćµĀćĶ»äõ╗ĘĶ¦äÕłÖ
+ sampler_seed=dict(type='DistSamplerSeedHook')) # ÕłåÕĖāÕ╝ÅķÜŵ£║ń¦ŹÕŁÉĶ«ŠńĮ«
+env_cfg = dict(
+ cudnn_benchmark=False, # cudnn benchmarkÕ╝ĆÕģ│
+ mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0), # opencvÕżÜń║┐ń©ŗķģŹńĮ«
+ dist_cfg=dict(backend='nccl')) # ÕłåÕĖāÕ╝ÅĶ«Łń╗āÕÉÄń½»Ķ«ŠńĮ«
+vis_backends = [dict(type='LocalVisBackend')] # ÕÅ»Ķ¦åÕī¢ÕÖ©ÕÉÄń½»Ķ«ŠńĮ«
+visualizer = dict( # ÕÅ»Ķ¦åÕī¢ÕÖ©Ķ«ŠńĮ«
+ type='PoseLocalVisualizer',
+ vis_backends=[dict(type='LocalVisBackend')],
+ name='visualizer')
+log_processor = dict( # Ķ«Łń╗āµŚźÕ┐ŚµĀ╝Õ╝ÅŃĆüķŚ┤ķÜö
+ type='LogProcessor', window_size=50, by_epoch=True, num_digits=6)
+log_level = 'INFO' # µŚźÕ┐ŚĶ«░ÕĮĢńŁēń║¦
+```
+
+ķĆÜńö©ķģŹńĮ«õĖĆĶł¼ÕŹĢńŗ¼ÕŁśµöŠÕł░`$MMPOSE/configs/_base_`ńø«ÕĮĢõĖŗ’╝īķĆÜĶ┐ćÕ”éõĖŗµ¢╣Õ╝ÅĶ┐øĶĪīń╗¦µē┐’╝Ü
+
+```Python
+_base_ = ['../../../_base_/default_runtime.py'] # õ╗źĶ┐ÉĶĪīµŚČńÜäconfigµ¢ćõ╗ČõĮŹńĮ«õĖ║ńøĖÕ»╣ĶĘ»ÕŠäĶĄĘńé╣
+```
+
+```{note}
+CheckpointHook:
+
+- save_best: `'coco/AP'` ńö©õ║Ä `CocoMetric`, `'PCK'` ńö©õ║Ä `PCKAccuracy`
+- max_keep_ckpts: µ£ĆÕż¦õ┐ØńĢÖckptµĢ░ķćÅ’╝īķ╗śĶ«żõĖ║-1’╝īõ╗ŻĶĪ©õĖŹķÖÉÕłČ
+
+µĀĘõŠŗ:
+
+`default_hooks = dict(checkpoint=dict(save_best='PCK', rule='greater', max_keep_ckpts=1))`
+```
+
+### µĢ░µŹ«ķģŹńĮ«
+
+µĢ░µŹ«ķģŹńĮ«µīćµĢ░µŹ«ÕżäńÉåńøĖÕģ│ńÜäķģŹńĮ«’╝īõĖ╗Ķ”üÕīģµŗ¼’╝Ü
+
+- **µĢ░µŹ«ÕÉÄń½»**’╝ܵĢ░µŹ«õŠøń╗ÖÕÉÄń½»Ķ«ŠńĮ«’╝īķ╗śĶ«żõĖ║µ£¼Õ£░ńĪ¼ńøś’╝īµłæõ╗¼õ╣¤µö»µīüõ╗Ä LMDB’╝īS3 Bucket ńŁēÕŖĀĶĮĮ
+
+- **µĢ░µŹ«ķøå**’╝ÜÕøŠÕāÅõĖĵĀćµ│©µ¢ćõ╗ČĶĘ»ÕŠä
+
+- **ÕŖĀĶĮĮ**’╝ÜÕŖĀĶĮĮńŁ¢ńĢź’╝īµē╣ķćÅÕż¦Õ░ÅńŁē
+
+- **µĄüµ░┤ń║┐**’╝ܵĢ░µŹ«Õó×Õ╝║ńŁ¢ńĢź
+
+- **ń╝¢ńĀüÕÖ©**’╝ܵĀ╣µŹ«µĀćµ│©ńö¤µłÉńē╣իܵĀ╝Õ╝ÅńÜäńøæńØŻõ┐Īµü»
+
+õĖŗķØ󵜻µĢ░µŹ«ķģŹńĮ«ńÜäµĀĘõŠŗĶ»┤µśÄ’╝Ü
+
+```Python
+backend_args = dict(backend='local') # µĢ░µŹ«ÕŖĀĶĮĮÕÉÄń½»Ķ«ŠńĮ«’╝īķ╗śĶ«żõ╗ĵ£¼Õ£░ńĪ¼ńøśÕŖĀĶĮĮ
+dataset_type = 'CocoDataset' # µĢ░µŹ«ķøåń▒╗ÕÉŹ
+data_mode = 'topdown' # ń«Śµ│Ģń╗ōµ×äń▒╗Õ×ŗ’╝īńö©õ║ĵīćիܵĀćµ│©õ┐Īµü»ÕŖĀĶĮĮńŁ¢ńĢź
+data_root = 'data/coco/' # µĢ░µŹ«ÕŁśµöŠĶĘ»ÕŠä
+ # Õ«Üõ╣ēµĢ░µŹ«ń╝¢Ķ¦ŻńĀüÕÖ©’╝īńö©õ║Äńö¤µłÉtargetÕÆīÕ»╣predĶ┐øĶĪīĶ¦ŻńĀü’╝īÕÉīµŚČÕīģÕɽõ║åĶŠōÕģźÕøŠńēćÕÆīĶŠōÕć║heatmapÕ░║Õ»ĖńŁēõ┐Īµü»
+codec = dict(
+ type='MSRAHeatmap', input_size=(192, 256), heatmap_size=(48, 64), sigma=2)
+train_pipeline = [ # Ķ«Łń╗āµŚČµĢ░µŹ«Õó×Õ╝║
+ dict(type='LoadImage', backend_args=backend_args, # ÕŖĀĶĮĮÕøŠńēć
+ dict(type='GetBBoxCenterScale'), # µĀ╣µŹ«bboxĶÄĘÕÅ¢centerÕÆīscale
+ dict(type='RandomBBoxTransform'), # ńö¤µłÉķÜŵ£║õĮŹń¦╗ŃĆüń╝®µöŠŃĆüµŚŗĶĮ¼ÕÅśµŹóń¤®ķśĄ
+ dict(type='RandomFlip', direction='horizontal'), # ńö¤µłÉķÜŵ£║ń┐╗ĶĮ¼ÕÅśµŹóń¤®ķśĄ
+ dict(type='RandomHalfBody'), # ķÜŵ£║ÕŹŖĶ║½Õó×Õ╝║
+ dict(type='TopdownAffine', input_size=codec['input_size']), # µĀ╣µŹ«ÕÅśµŹóń¤®ķśĄµø┤µ¢░ńø«µĀćµĢ░µŹ«
+ dict(
+ type='GenerateTarget', # µĀ╣µŹ«ńø«µĀćµĢ░µŹ«ńö¤µłÉńøæńØŻõ┐Īµü»
+ # ńøæńØŻõ┐Īµü»ń▒╗Õ×ŗ
+ encoder=codec, # õ╝ĀÕģźń╝¢Ķ¦ŻńĀüÕÖ©’╝īńö©õ║ĵĢ░µŹ«ń╝¢ńĀü’╝īńö¤µłÉńē╣իܵĀ╝Õ╝ÅńÜäńøæńØŻõ┐Īµü»
+ dict(type='PackPoseInputs') # Õ»╣targetĶ┐øĶĪīµēōÕīģńö©õ║ÄĶ«Łń╗ā
+]
+test_pipeline = [ # µĄŗĶ»ĢµŚČµĢ░µŹ«Õó×Õ╝║
+ dict(type='LoadImage', backend_args=backend_args), # ÕŖĀĶĮĮÕøŠńēć
+ dict(type='GetBBoxCenterScale'), # µĀ╣µŹ«bboxĶÄĘÕÅ¢centerÕÆīscale
+ dict(type='TopdownAffine', input_size=codec['input_size']), # µĀ╣µŹ«ÕÅśµŹóń¤®ķśĄµø┤µ¢░ńø«µĀćµĢ░µŹ«
+ dict(type='PackPoseInputs') # Õ»╣targetĶ┐øĶĪīµēōÕīģńö©õ║ÄĶ«Łń╗ā
+]
+train_dataloader = dict( # Ķ«Łń╗āµĢ░µŹ«ÕŖĀĶĮĮ
+ batch_size=64, # µē╣µ¼ĪÕż¦Õ░Å
+ num_workers=2, # µĢ░µŹ«ÕŖĀĶĮĮĶ┐øń©ŗµĢ░
+ persistent_workers=True, # Õ£©õĖŹµ┤╗ĶĘāµŚČń╗┤µīüĶ┐øń©ŗõĖŹń╗łµŁó’╝īķü┐ÕģŹÕÅŹÕżŹÕÉ»ÕŖ©Ķ┐øń©ŗńÜäÕ╝ĆķöĆ
+ sampler=dict(type='DefaultSampler', shuffle=True), # ķććµĀĘńŁ¢ńĢź’╝īµēōõ╣▒µĢ░µŹ«
+ dataset=dict(
+ type=dataset_type , # µĢ░µŹ«ķøåń▒╗ÕÉŹ
+ data_root=data_root, # µĢ░µŹ«ķøåĶĘ»ÕŠä
+ data_mode=data_mode, # ń«Śµ│Ģń▒╗Õ×ŗ
+ ann_file='annotations/person_keypoints_train2017.json', # µĀćµ│©µ¢ćõ╗ČĶĘ»ÕŠä
+ data_prefix=dict(img='train2017/'), # ÕøŠÕāÅĶĘ»ÕŠä
+ pipeline=train_pipeline # µĢ░µŹ«µĄüµ░┤ń║┐
+ ))
+val_dataloader = dict(
+ batch_size=32,
+ num_workers=2,
+ persistent_workers=True, # Õ£©õĖŹµ┤╗ĶĘāµŚČń╗┤µīüĶ┐øń©ŗõĖŹń╗łµŁó’╝īķü┐ÕģŹÕÅŹÕżŹÕÉ»ÕŖ©Ķ┐øń©ŗńÜäÕ╝ĆķöĆ
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False), # ķććµĀĘńŁ¢ńĢź’╝īõĖŹĶ┐øĶĪīµēōõ╣▒
+ dataset=dict(
+ type=dataset_type , # µĢ░µŹ«ķøåń▒╗ÕÉŹ
+ data_root=data_root, # µĢ░µŹ«ķøåĶĘ»ÕŠä
+ data_mode=data_mode, # ń«Śµ│Ģń▒╗Õ×ŗ
+ ann_file='annotations/person_keypoints_val2017.json', # µĀćµ│©µ¢ćõ╗ČĶĘ»ÕŠä
+ bbox_file=
+ 'data/coco/person_detection_results/COCO_val2017_detections_AP_H_56_person.json', # µŻĆµĄŗµĪåµĀćµ│©µ¢ćõ╗Č’╝ītopdownµ¢╣µ│ĢõĖōńö©
+ data_prefix=dict(img='val2017/'), # ÕøŠÕāÅĶĘ»ÕŠä
+ test_mode=True, # µĄŗĶ»Ģµ©ĪÕ╝ÅÕ╝ĆÕģ│
+ pipeline=test_pipeline # µĢ░µŹ«µĄüµ░┤ń║┐
+ ))
+test_dataloader = val_dataloader # ķ╗śĶ«żµāģÕåĄõĖŗõĖŹÕī║Õłåķ¬īĶ»üķøåÕÆīµĄŗĶ»Ģķøå’╝īńö©µłĘµĀ╣µŹ«ķ£ĆĶ”üµØźĶć¬ĶĪīÕ«Üõ╣ē
+```
+
+```{note}
+
+ÕĖĖńö©ÕŖ¤ĶāĮÕÅ»õ╗źÕÅéĶĆāõ╗źõĖŗµĢÖń©ŗ:
+- [µüóÕżŹĶ«Łń╗ā](../common_usages/resume_training.md)
+- [Ķć¬ÕŖ©µĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗ā](../common_usages/amp_training.md)
+- [Ķ«ŠńĮ«ķÜŵ£║ń¦ŹÕŁÉ](../common_usages/set_random_seed.md)
+
+```
+
+### Ķ«Łń╗āķģŹńĮ«
+
+Ķ«Łń╗āķģŹńĮ«µīćĶ«Łń╗āńŁ¢ńĢźńøĖÕģ│ńÜäķģŹńĮ«’╝īõĖ╗Ķ”üÕīģµŗ¼’╝Ü
+
+- õ╗ĵ¢Łńé╣µüóÕżŹĶ«Łń╗ā
+
+- µ©ĪÕ×ŗµØāķćŹÕŖĀĶĮĮ
+
+- Ķ«Łń╗āĶĮ«µĢ░ÕÆīµĄŗĶ»ĢķŚ┤ķÜö
+
+- ÕŁ”õ╣ĀńÄćĶ░āµĢ┤ńŁ¢ńĢź’╝īÕ”é warmup’╝īscheduler
+
+- õ╝śÕī¢ÕÖ©ÕÆīÕŁ”õ╣ĀńÄć
+
+- ķ½śń║¦Ķ«Łń╗āńŁ¢ńĢźĶ«ŠńĮ«’╝īÕ”éĶć¬ÕŖ©ÕŁ”õ╣ĀńÄćń╝®µöŠ
+
+õĖŗķØ󵜻Ķ«Łń╗āķģŹńĮ«ńÜäµĀĘõŠŗĶ»┤µśÄ’╝Ü
+
+```Python
+resume = False # µ¢Łńé╣µüóÕżŹ
+load_from = None # µ©ĪÕ×ŗµØāķćŹÕŖĀĶĮĮ
+train_cfg = dict(by_epoch=True, max_epochs=210, val_interval=10) # Ķ«Łń╗āĶĮ«µĢ░’╝īµĄŗĶ»ĢķŚ┤ķÜö
+param_scheduler = [
+ dict( # warmupńŁ¢ńĢź
+ type='LinearLR', begin=0, end=500, start_factor=0.001, by_epoch=False),
+ dict( # scheduler
+ type='MultiStepLR',
+ begin=0,
+ end=210,
+ milestones=[170, 200],
+ gamma=0.1,
+ by_epoch=True)
+]
+optim_wrapper = dict(optimizer=dict(type='Adam', lr=0.0005)) # õ╝śÕī¢ÕÖ©ÕÆīÕŁ”õ╣ĀńÄć
+auto_scale_lr = dict(base_batch_size=512) # µĀ╣µŹ«batch_sizeĶć¬ÕŖ©ń╝®µöŠÕŁ”õ╣ĀńÄć
+```
+
+### µ©ĪÕ×ŗķģŹńĮ«
+
+µ©ĪÕ×ŗķģŹńĮ«µī浩ĪÕ×ŗĶ«Łń╗āÕÆīµÄ©ńÉåńøĖÕģ│ńÜäķģŹńĮ«’╝īõĖ╗Ķ”üÕīģµŗ¼’╝Ü
+
+- µ©ĪÕ×ŗń╗ōµ×ä
+
+- µŹ¤Õż▒ÕćĮµĢ░
+
+- µĢ░µŹ«Ķ¦ŻńĀüńŁ¢ńĢź
+
+- µĄŗĶ»ĢµŚČÕó×Õ╝║ńŁ¢ńĢź
+
+õĖŗķØ󵜻µ©ĪÕ×ŗķģŹńĮ«ńÜäµĀĘõŠŗĶ»┤µśÄ’╝īÕ«Üõ╣ēõ║åõĖĆõĖ¬Õ¤║õ║Ä HRNetw32 ńÜä Top-down Heatmap-based µ©ĪÕ×ŗ’╝Ü
+
+```Python
+# Õ«Üõ╣ēµĢ░µŹ«ń╝¢Ķ¦ŻńĀüÕÖ©’╝īÕ”éµ×£Õ£©µĢ░µŹ«ķģŹńĮ«ķā©ÕłåÕĘ▓ń╗ÅÕ«Üõ╣ēĶ┐ćÕłÖµŚĀķ£ĆķćŹÕżŹÕ«Üõ╣ē
+codec = dict(
+ type='MSRAHeatmap', input_size=(192, 256), heatmap_size=(48, 64), sigma=2)
+# µ©ĪÕ×ŗķģŹńĮ«
+model = dict(
+ type='TopdownPoseEstimator', # µ©ĪÕ×ŗń╗ōµ×äÕå│Õ«Üõ║åń«Śµ│ĢµĄüń©ŗ
+ data_preprocessor=dict( # µĢ░µŹ«ÕĮÆõĖĆÕī¢ÕÆīķĆÜķüōķĪ║Õ║ÅĶ░āµĢ┤’╝īõĮ£õĖ║µ©ĪÕ×ŗńÜäõĖĆķā©Õłå
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict( # ķ¬©Õ╣▓ńĮæń╗£Õ«Üõ╣ē
+ type='HRNet',
+ in_channels=3,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256))),
+ init_cfg=dict(
+ type='Pretrained', # ķóäĶ«Łń╗āÕÅéµĢ░’╝īÕŬÕŖĀĶĮĮbackboneµØāķćŹńö©õ║ÄĶ┐üń¦╗ÕŁ”õ╣Ā
+ checkpoint='https://download.openmmlab.com/mmpose'
+ '/pretrain_models/hrnet_w32-36af842e.pth'),
+ ),
+ head=dict( # µ©ĪÕ×ŗÕż┤ķā©
+ type='HeatmapHead',
+ in_channels=32,
+ out_channels=17,
+ deconv_out_channels=None,
+ loss=dict(type='KeypointMSELoss', use_target_weight=True), # µŹ¤Õż▒ÕćĮµĢ░
+ decoder=codec), # Ķ¦ŻńĀüÕÖ©’╝īÕ░åheatmapĶ¦ŻńĀüµłÉÕØɵĀćÕĆ╝
+ test_cfg=dict(
+ flip_test=True, # Õ╝ĆÕÉ»µĄŗĶ»ĢµŚČµ░┤Õ╣│ń┐╗ĶĮ¼ķøåµłÉ
+ flip_mode='heatmap', # Õ»╣heatmapĶ┐øĶĪīń┐╗ĶĮ¼
+ shift_heatmap=True, # Õ»╣ń┐╗ĶĮ¼ÕÉÄńÜäń╗ōµ×£Ķ┐øĶĪīÕ╣│ń¦╗µÅÉķ½śń▓ŠÕ║”
+ ))
+```
+
+### Ķ»äµĄŗķģŹńĮ«
+
+Ķ»äµĄŗķģŹńĮ«µīćÕģ¼Õ╝ƵĢ░µŹ«ķøåõĖŁÕģ│ķö«ńé╣µŻĆµĄŗõ╗╗ÕŖĪÕĖĖńö©ńÜäĶ»äµĄŗµīćµĀć’╝īõĖ╗Ķ”üÕīģµŗ¼’╝Ü
+
+- AR, AP and mAP
+
+- PCK, PCKh, tPCK
+
+- AUC
+
+- EPE
+
+- NME
+
+õĖŗķØ󵜻Ķ»äµĄŗķģŹńĮ«ńÜäµĀĘõŠŗĶ»┤µśÄ’╝īÕ«Üõ╣ēõ║åõĖĆõĖ¬COCOµīćµĀćĶ»äµĄŗÕÖ©’╝Ü
+
+```Python
+val_evaluator = dict(
+ type='CocoMetric', # coco Ķ»äµĄŗµīćµĀć
+ ann_file=data_root + 'annotations/person_keypoints_val2017.json') # ÕŖĀĶĮĮĶ»äµĄŗµĀćµ│©µĢ░µŹ«
+test_evaluator = val_evaluator # ķ╗śĶ«żµāģÕåĄõĖŗõĖŹÕī║Õłåķ¬īĶ»üķøåÕÆīµĄŗĶ»Ģķøå’╝īńö©µłĘµĀ╣µŹ«ķ£ĆĶ”üµØźĶć¬ĶĪīÕ«Üõ╣ē
+```
+
+## ķģŹńĮ«µ¢ćõ╗ČÕæĮÕÉŹĶ¦äÕłÖ
+
+MMPose ķģŹńĮ«µ¢ćõ╗ČÕæĮÕÉŹķŻÄµĀ╝Õ”éõĖŗ’╝Ü
+
+```Python
+{{ń«Śµ│Ģõ┐Īµü»}}_{{µ©ĪÕØŚõ┐Īµü»}}_{{Ķ«Łń╗āõ┐Īµü»}}_{{µĢ░µŹ«õ┐Īµü»}}.py
+```
+
+µ¢ćõ╗ČÕÉŹµĆ╗õĮōÕłåõĖ║Õøøķā©Õłå’╝Üń«Śµ│Ģõ┐Īµü»’╝īµ©ĪÕØŚõ┐Īµü»’╝īĶ«Łń╗āõ┐Īµü»ÕÆīµĢ░µŹ«õ┐Īµü»ŃĆéõĖŹÕÉīķā©ÕłåńÜäÕŹĢĶ»Źõ╣ŗķŚ┤ńö©õĖŗÕłÆń║┐ `'_'` Ķ┐׵ğ’╝īÕÉīõĖĆķā©Õłåµ£ēÕżÜõĖ¬ÕŹĢĶ»Źńö©ń¤Łµ©¬ń║┐ `'-'` Ķ┐׵ğŃĆé
+
+- **ń«Śµ│Ģõ┐Īµü»**’╝Üń«Śµ│ĢÕÉŹń¦░’╝īÕ”é `topdown-heatmap`’╝ī`topdown-rle` ńŁē
+
+- **µ©ĪÕØŚõ┐Īµü»**’╝ܵīēńģ¦µĢ░µŹ«µĄüńÜäķĪ║Õ║ÅÕłŚõĖŠõĖĆõ║øõĖŁķŚ┤ńÜ䵩ĪÕØŚ’╝īÕģČÕåģÕ«╣õŠØĶĄ¢õ║Äń«Śµ│Ģõ╗╗ÕŖĪ’╝īÕ”é `res101`’╝ī`hrnet-w48`ńŁē
+
+- **Ķ«Łń╗āõ┐Īµü»**’╝ÜĶ«Łń╗āńŁ¢ńĢźńÜäõĖĆõ║øĶ«ŠńĮ«’╝īÕīģµŗ¼ `batch size`’╝ī`schedule` ńŁē’╝īÕ”é `8xb64-210e`
+
+- **µĢ░µŹ«õ┐Īµü»**’╝ܵĢ░µŹ«ķøåÕÉŹń¦░ŃĆüµ©ĪµĆüŃĆüĶŠōÕģźÕ░║Õ»ĖńŁē’╝īÕ”é `ap10k-256x256`’╝ī`zebra-160x160` ńŁē
+
+µ£ēµŚČõĖ║õ║åķü┐ÕģŹµ¢ćõ╗ČÕÉŹĶ┐ćķĢ┐’╝īõ╝Üń£üńĢźµ©ĪÕ×ŗõ┐Īµü»õĖŁõĖĆõ║øÕ╝║ńøĖÕģ│ńÜ䵩ĪÕØŚ’╝īÕŬõ┐ØńĢÖÕģ│ķö«õ┐Īµü»’╝īÕ”éRLE-basedń«Śµ│ĢõĖŁńÜä`GAP`’╝īHeatmap-basedń«Śµ│ĢõĖŁńÜä `deconv` ńŁēŃĆé
+
+Õ”éµ×£õĮĀÕĖīµ£øÕÉæMMPoseµĘ╗ÕŖĀµ¢░ńÜäµ¢╣µ│Ģ’╝īõĮĀńÜäķģŹńĮ«µ¢ćõ╗ČÕÉīµĀĘķ£ĆĶ”üķüĄÕ«łĶ»źÕæĮÕÉŹĶ¦äÕłÖŃĆé
+
+## ÕĖĖĶ¦üńö©µ│Ģ
+
+### ķģŹńĮ«µ¢ćõ╗ČńÜäń╗¦µē┐
+
+Ķ»źńö©µ│ĢÕĖĖńö©õ║ÄķÜÉĶŚÅõĖĆõ║øÕ┐ģĶ”üõĮåõĖŹķ£ĆĶ”üõ┐«µö╣ńÜäķģŹńĮ«’╝īõ╗źµÅÉķ½śķģŹńĮ«µ¢ćõ╗ČńÜäÕÅ»Ķ»╗µĆ¦ŃĆéÕüćՔ鵣ēÕ”éõĖŗõĖżõĖ¬ķģŹńĮ«µ¢ćõ╗Č’╝Ü
+
+`optimizer_cfg.py`:
+
+```Python
+optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
+```
+
+`resnet50.py`:
+
+```Python
+_base_ = ['optimizer_cfg.py']
+model = dict(type='ResNet', depth=50)
+```
+
+ĶÖĮńäȵłæõ╗¼Õ£© `resnet50.py` õĖŁµ▓Īµ£ēÕ«Üõ╣ē optimizer ÕŁŚµ«Ą’╝īõĮåńö▒õ║ĵłæõ╗¼ÕåÖõ║å `_base_ = ['optimizer_cfg.py']`’╝īõ╝ÜõĮ┐Ķ┐ÖõĖ¬ķģŹńĮ«µ¢ćõ╗ČĶÄĘÕŠŚ `optimizer_cfg.py` õĖŁńÜäµēƵ£ēÕŁŚµ«Ą’╝Ü
+
+```Python
+cfg = Config.fromfile('resnet50.py')
+cfg.optimizer # ConfigDict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
+```
+
+### ń╗¦µē┐ÕŁŚµ«ĄńÜäõ┐«µö╣
+
+Õ»╣õ║Äń╗¦µē┐Ķ┐ćµØźńÜäÕĘ▓ń╗ÅÕ«Üõ╣ēÕźĮńÜäÕŁŚÕģĖ’╝īÕÅ»õ╗źńø┤µÄźµīćÕ«ÜÕ»╣Õ║öÕŁŚµ«ĄĶ┐øĶĪīõ┐«µö╣’╝īĶĆīõĖŹķ£ĆĶ”üķ揵¢░Õ«Üõ╣ēÕ«īµĢ┤ńÜäÕŁŚÕģĖ’╝Ü
+
+`resnet50_lr0.01.py`:
+
+```Python
+_base_ = ['optimizer_cfg.py']
+model = dict(type='ResNet', depth=50)
+optimizer = dict(lr=0.01) # ńø┤µÄźõ┐«µö╣Õ»╣Õ║öÕŁŚµ«Ą
+```
+
+Ķ┐ÖõĖ¬ķģŹńĮ«µ¢ćõ╗ČÕŬõ┐«µö╣õ║åÕ»╣Õ║öÕŁŚµ«Ą`lr`ńÜäõ┐Īµü»’╝Ü
+
+```Python
+cfg = Config.fromfile('resnet50_lr0.01.py')
+cfg.optimizer # ConfigDict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0001)
+```
+
+### ÕłĀķÖżÕŁŚÕģĖõĖŁńÜäÕŁŚµ«Ą
+
+Õ”éµ×£õĖŹõ╗ģµś»ķ£ĆĶ”üõ┐«µö╣µ¤Éõ║øÕŁŚµ«Ą’╝īĶ┐śķ£ĆĶ”üÕłĀķÖżÕĘ▓Õ«Üõ╣ēńÜäõĖĆõ║øÕŁŚµ«Ą’╝īķ£ĆĶ”üÕ£©ķ揵¢░Õ«Üõ╣ēĶ┐ÖõĖ¬ÕŁŚÕģĖµŚČµīćÕ«Ü`_delete_=True`’╝īĶĪ©ńż║Õ░åµ▓Īµ£ēÕ£©µ¢░Õ«Üõ╣ēõĖŁÕć║ńÄ░ńÜäÕŁŚµ«ĄÕģ©ķā©ÕłĀķÖż’╝Ü
+
+`resnet50.py`:
+
+```Python
+_base_ = ['optimizer_cfg.py', 'runtime_cfg.py']
+model = dict(type='ResNet', depth=50)
+optimizer = dict(_delete_=True, type='SGD', lr=0.01) # ķ揵¢░Õ«Üõ╣ēÕŁŚÕģĖ
+```
+
+µŁżµŚČÕŁŚÕģĖõĖŁķÖżõ║å `type` ÕÆī `lr` õ╗źÕż¢ńÜäÕåģÕ«╣’╝ł`momentum`ÕÆī`weight_decay`’╝ēÕ░åĶó½Õģ©ķā©ÕłĀķÖż’╝Ü
+
+```Python
+cfg = Config.fromfile('resnet50_lr0.01.py')
+cfg.optimizer # ConfigDict(type='SGD', lr=0.01)
+```
+
+```{note}
+Õ”éµ×£õĮĀÕĖīµ£øµø┤µĘ▒ÕģźÕ£░õ║åĶ¦ŻķģŹńĮ«ń│╗ń╗¤ńÜäķ½śń║¦ńö©µ│Ģ’╝īÕÅ»õ╗źµ¤źń£ŗ [MMEngine µĢÖń©ŗ](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/config.html)ŃĆé
+```
diff --git a/internlm_langchain/knowledge_base/MMPose/content/contribution_guide.md b/internlm_langchain/knowledge_base/MMPose/content/contribution_guide.md
new file mode 100644
index 00000000..96be7d17
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPose/content/contribution_guide.md
@@ -0,0 +1,207 @@
+# Õ”éõĮĢń╗Ö MMPose Ķ┤Īńī«õ╗ŻńĀü
+
+µ¼óĶ┐ÄÕŖĀÕģź MMPose ńżŠÕī║’╝īµłæõ╗¼Ķć┤ÕŖøõ║ĵēōķĆĀµ£ĆÕēŹµ▓┐ńÜäĶ«Īń«Śµ£║Ķ¦åĶ¦ēÕ¤║ńĪĆÕ║ō’╝īµłæõ╗¼µ¼óĶ┐Äõ╗╗õĮĢÕĮóÕ╝ÅńÜäĶ┤Īńī«’╝īÕīģµŗ¼õĮåõĖŹķÖÉõ║Ä’╝Ü
+
+- **õ┐«ÕżŹķöÖĶ»»**
+ 1. Õ”éµ×£µÅÉõ║żńÜäõ╗ŻńĀüµö╣ÕŖ©ĶŠāÕż¦’╝īµłæõ╗¼ķ╝ōÕŖ▒õĮĀÕģłÕ╝ĆõĖĆõĖ¬ issue Õ╣ȵŁŻńĪ«µÅÅĶ┐░ńÄ░Ķ▒ĪŃĆüÕĤÕøĀÕÆīÕżŹńÄ░µ¢╣Õ╝Å’╝īĶ«©Ķ«║ÕÉÄńĪ«Ķ«żõ┐«ÕżŹµ¢╣µĪłŃĆé
+ 2. õ┐«ÕżŹķöÖĶ»»Õ╣ČĶĪźÕģģńøĖÕ║öńÜäÕŹĢÕģāµĄŗĶ»Ģ’╝īµÅÉõ║ż PR ŃĆé
+- **µ¢░Õó×ÕŖ¤ĶāĮµł¢ń╗äõ╗Č**
+ 1. Õ”éµ×£µ¢░ÕŖ¤ĶāĮµł¢µ©ĪÕØŚµČēÕÅŖĶŠāÕż¦ńÜäõ╗ŻńĀüµö╣ÕŖ©’╝īµłæõ╗¼Õ╗║Ķ««ÕģłµÅÉõ║ż issue’╝īõĖĵłæõ╗¼ńĪ«Ķ«żÕŖ¤ĶāĮńÜäÕ┐ģĶ”üµĆ¦ŃĆé
+ 2. Õ«×ńÄ░µ¢░Õó×ÕŖ¤ĶāĮÕ╣ȵĘ╗ÕŖĀÕŹĢÕģāµĄŗĶ»Ģ’╝īµÅÉõ║ż PR ŃĆé
+- **µ¢ćµĪŻĶĪźÕģģµł¢ń┐╗Ķ»æ**
+ - Õ”éµ×£ÕÅæńÄ░µ¢ćµĪŻµ£ēķöÖĶ»»µł¢õĖŹÕ«īÕ¢äńÜäÕ£░µ¢╣’╝īµ¼óĶ┐Äńø┤µÄźµÅÉõ║ż PR ŃĆé
+
+```{note}
+- Õ”éµ×£õĮĀÕĖīµ£øÕÉæ MMPose 1.0 Ķ┤Īńī«õ╗ŻńĀü’╝īĶ»Ęõ╗Ä dev-1.x õĖŖÕłøÕ╗║µ¢░Õłåµö»’╝īÕ╣ȵÅÉõ║ż PR Õł░ dev-1.x Õłåµö»õĖŖŃĆé
+- Õ”éµ×£õĮĀµś»Ķ«║µ¢ćõĮ£ĶĆģ’╝īÕ╣ČÕĖīµ£øÕ░åõĮĀńÜäµ¢╣µ│ĢÕŖĀÕģźÕł░ MMPose õĖŁ’╝īµ¼óĶ┐ÄĶüöń│╗µłæõ╗¼’╝īµłæõ╗¼Õ░åķØ×ÕĖĖµä¤Ķ░óõĮĀńÜäĶ┤Īńī«ŃĆé
+- Õ”éµ×£õĮĀÕĖīµ£øÕ░ĮÕ┐½Õ░åõĮĀńÜäķĪ╣ńø«Õłåõ║½Õł░ MMPose Õ╝Ƶ║ÉńżŠÕī║’╝īµ¼óĶ┐ÄÕ░å PR µÅÉÕł░ Projects ńø«ÕĮĢõĖŗ’╝īĶ»źńø«ÕĮĢõĖŗńÜäķĪ╣ńø«Õ░åń«ĆÕī¢ Review µĄüń©ŗÕ╣ČÕ░ĮÕ┐½ÕÉłÕģźŃĆé
+- Õ”éµ×£õĮĀÕĖīµ£øÕŖĀÕģź MMPose ńÜäń╗┤µŖżĶĆģ’╝īµ¼óĶ┐ÄĶüöń│╗µłæõ╗¼’╝īµłæõ╗¼Õ░åķéĆĶ»ĘõĮĀÕŖĀÕģź MMPose ńÜäń╗┤µŖżĶĆģńŠżŃĆé
+```
+
+## ÕćåÕżćÕĘźõĮ£
+
+PR µōŹõĮ£µēĆõĮ┐ńö©ńÜäÕæĮõ╗żķāĮµś»ńö© Git ÕÄ╗Õ«×ńÄ░ńÜä’╝īĶ»źń½ĀĶŖéÕ░åõ╗ŗń╗ŹÕ”éõĮĢĶ┐øĶĪī Git ķģŹńĮ«õĖÄ GitHub ń╗æÕ«ÜŃĆé
+
+### Git ķģŹńĮ«
+
+ķ”¢Õģł’╝īõĮĀķ£ĆĶ”üÕ£©µ£¼Õ£░Õ«ēĶŻģ Git’╝īńäČÕÉÄķģŹńĮ«õĮĀńÜä Git ńö©µłĘÕÉŹÕÆīķé«ń«▒’╝Ü
+
+```Shell
+# Õ£©ÕæĮõ╗żµÅÉńż║ń¼”’╝łcmd’╝ēµł¢ń╗łń½»’╝łterminal’╝ēõĖŁĶŠōÕģźõ╗źõĖŗÕæĮõ╗ż’╝īµ¤źń£ŗ Git ńēłµ£¼
+git --version
+```
+
+ńäČÕÉÄ’╝īõĮĀķ£ĆĶ”üµŻĆµ¤źĶć¬ÕĘ▒ńÜä Git Config µś»ÕÉ”µŁŻńĪ«ķģŹńĮ«’╝īÕ”éµ×£ `user.name` ÕÆī `user.email` õĖ║ń®║’╝īõĮĀķ£ĆĶ”üķģŹńĮ«õĮĀńÜä Git ńö©µłĘÕÉŹÕÆīķé«ń«▒’╝Ü
+
+```Shell
+# Õ£©ÕæĮõ╗żµÅÉńż║ń¼”’╝łcmd’╝ēµł¢ń╗łń½»’╝łterminal’╝ēõĖŁĶŠōÕģźõ╗źõĖŗÕæĮõ╗ż’╝īµ¤źń£ŗ Git ķģŹńĮ«
+git config --global --list
+# Ķ«ŠńĮ« Git ńö©µłĘÕÉŹÕÆīķé«ń«▒
+git config --global user.name "Ķ┐ÖķćīÕĪ½ÕģźõĮĀńÜäńö©µłĘÕÉŹ"
+git config --global user.email "Ķ┐ÖķćīÕĪ½ÕģźõĮĀńÜäķé«ń«▒"
+```
+
+## PR µĄüń©ŗ
+
+Õ”éµ×£õĮĀÕ»╣ PR µĄüń©ŗõĖŹń夵éē’╝īµÄźõĖŗµØźÕ░åõ╝Üõ╗ÄķøČÕ╝ĆÕ¦ŗ’╝īõĖƵŁźõĖƵŁźÕ£░µĢÖõĮĀÕ”éõĮĢµÅÉõ║ż PRŃĆéÕ”éµ×£õĮĀµā│µĘ▒Õģźõ║åĶ¦Ż PR Õ╝ĆÕÅ浩ĪÕ╝Å’╝īÕÅ»õ╗źÕÅéĶĆā [GitHub Õ«śµ¢╣µ¢ćµĪŻ](https://docs.github.com/cn/github/collaborating-with-issues-and-pull-requests/about-pull-requests)ŃĆé
+
+### 1. Fork ķĪ╣ńø«
+
+ÕĮōõĮĀń¼¼õĖƵ¼ĪµÅÉõ║ż PR µŚČ’╝īķ£ĆĶ”üÕģł Fork ķĪ╣ńø«Õł░Ķć¬ÕĘ▒ńÜä GitHub Ķ┤”ÕÅĘõĖŗŃĆéńé╣Õć╗ķĪ╣ńø«ÕÅ│õĖŖĶ¦ÆńÜä Fork µīēķÆ«’╝īÕ░åķĪ╣ńø« Fork Õł░Ķć¬ÕĘ▒ńÜä GitHub Ķ┤”ÕÅĘõĖŗŃĆé
+
+
+
+µÄźńØĆ’╝īõĮĀķ£ĆĶ”üÕ░åõĮĀńÜä Fork õ╗ōÕ║ō Clone Õł░µ£¼Õ£░’╝īńäČÕÉĵĘ╗ÕŖĀÕ«śµ¢╣õ╗ōÕ║ōõĮ£õĖ║Ķ┐£ń©ŗõ╗ōÕ║ō’╝Ü
+
+```Shell
+
+# Clone õĮĀńÜä Fork õ╗ōÕ║ōÕł░µ£¼Õ£░
+git clone https://github.com/username/mmpose.git
+
+# µĘ╗ÕŖĀÕ«śµ¢╣õ╗ōÕ║ōõĮ£õĖ║Ķ┐£ń©ŗõ╗ōÕ║ō
+cd mmpose
+git remote add upstream https://github.com/open-mmlab/mmpose.git
+```
+
+Õ£©ń╗łń½»õĖŁĶŠōÕģźõ╗źõĖŗÕæĮõ╗ż’╝īµ¤źń£ŗĶ┐£ń©ŗõ╗ōÕ║ōµś»ÕÉ”µłÉÕŖ¤µĘ╗ÕŖĀ’╝Ü
+
+```Shell
+git remote -v
+```
+
+Õ”éµ×£Õć║ńÄ░õ╗źõĖŗõ┐Īµü»’╝īĶ»┤µśÄõĮĀÕĘ▓ń╗ŵłÉÕŖ¤µĘ╗ÕŖĀõ║åĶ┐£ń©ŗõ╗ōÕ║ō’╝Ü
+
+```Shell
+origin https://github.com/{username}/mmpose.git (fetch)
+origin https://github.com/{username}/mmpose.git (push)
+upstream https://github.com/open-mmlab/mmpose.git (fetch)
+upstream https://github.com/open-mmlab/mmpose.git (push)
+```
+
+```{note}
+Ķ┐ÖķćīÕ»╣ origin ÕÆī upstream Ķ┐øĶĪīõĖĆõĖ¬ń«ĆÕŹĢńÜäõ╗ŗń╗Ź’╝īÕĮōµłæõ╗¼õĮ┐ńö© git clone µØźÕģŗķÜåõ╗ŻńĀüµŚČ’╝īõ╝Üķ╗śĶ«żÕłøÕ╗║õĖĆõĖ¬ origin ńÜä remote’╝īÕ«āµīćÕÉæµłæõ╗¼ÕģŗķÜåńÜäõ╗ŻńĀüÕ║ōÕ£░ÕØĆ’╝īĶĆī upstream ÕłÖµś»µłæõ╗¼Ķć¬ÕĘ▒µĘ╗ÕŖĀńÜä’╝īńö©µØźµīćÕÉæÕĤզŗõ╗ŻńĀüÕ║ōÕ£░ÕØĆŃĆéÕĮōńäČÕ”éµ×£õĮĀõĖŹÕ¢£µ¼óõ╗¢ÕŽ upstream’╝īõ╣¤ÕÅ»õ╗źĶć¬ÕĘ▒õ┐«µö╣’╝īµ»öÕ”éÕŽ open-mmlabŃĆ鵳æõ╗¼ķĆÜÕĖĖÕÉæ origin µÅÉõ║żõ╗ŻńĀü’╝łÕŹ│ fork õĖŗµØźńÜäĶ┐£ń©ŗõ╗ōÕ║ō’╝ē’╝īńäČÕÉÄÕÉæ upstream µÅÉõ║żõĖĆõĖ¬ pull requestŃĆéÕ”éµ×£µÅÉõ║żńÜäõ╗ŻńĀüÕÆīµ£Ćµ¢░ńÜäõ╗ŻńĀüÕÅæńö¤Õå▓ń¬ü’╝īÕåŹõ╗Ä upstream µŗēÕÅ¢µ£Ćµ¢░ńÜäõ╗ŻńĀü’╝īÕÆīµ£¼Õ£░Õłåµö»Ķ¦ŻÕå│Õå▓ń¬ü’╝īÕåŹµÅÉõ║żÕł░ originŃĆé
+```
+
+### 2. ķģŹńĮ« pre-commit
+
+Õ£©µ£¼Õ£░Õ╝ĆÕÅæńÄ»ÕóāõĖŁ’╝īµłæõ╗¼õĮ┐ńö© pre-commit µØźµŻĆµ¤źõ╗ŻńĀüķŻÄµĀ╝’╝īõ╗źńĪ«õ┐Øõ╗ŻńĀüķŻÄµĀ╝ńÜäń╗¤õĖĆŃĆéÕ£©µÅÉõ║żõ╗ŻńĀüÕēŹ’╝īõĮĀķ£ĆĶ”üÕģłÕ«ēĶŻģ pre-commit’╝Ü
+
+```Shell
+pip install -U pre-commit
+
+# Õ£© mmpose µĀ╣ńø«ÕĮĢõĖŗÕ«ēĶŻģ pre-commit
+pre-commit install
+```
+
+µŻĆµ¤ź pre-commit µś»ÕÉ”ķģŹńĮ«µłÉÕŖ¤’╝īÕ╣ČÕ«ēĶŻģ `.pre-commit-config.yaml` õĖŁńÜäķÆ®ÕŁÉ’╝Ü
+
+```Shell
+pre-commit run --all-files
+```
+
+
+
+```{note}
+Õ”éµ×£õĮĀµś»õĖŁÕøĮÕż¦ķÖåńö©µłĘ’╝īńö▒õ║ÄńĮæń╗£ÕĤÕøĀ’╝īÕÅ»ĶāĮõ╝ÜÕć║ńÄ░ pre-commit Õ«ēĶŻģÕż▒Ķ┤źńÜäµāģÕåĄŃĆé
+
+Ķ┐ÖµŚČõĮĀÕÅ»õ╗źõĮ┐ńö©µĖģÕŹÄµ║ÉµØźÕ«ēĶŻģ pre-commit’╝Ü
+pip install -U pre-commit -i https://pypi.tuna.tsinghua.edu.cn/simple
+
+µł¢ĶĆģõĮ┐ńö©ÕøĮÕåģķĢ£ÕāÅµØźÕ«ēĶŻģ pre-commit’╝Ü
+pip install -U pre-commit -i https://pypi.mirrors.ustc.edu.cn/simple
+```
+
+Õ”éµ×£Õ«ēĶŻģĶ┐ćń©ŗĶó½õĖŁµ¢Ł’╝īÕÅ»õ╗źķćŹÕżŹµē¦ĶĪīõĖŖĶ┐░ÕæĮõ╗ż’╝īńø┤Õł░Õ«ēĶŻģµłÉÕŖ¤ŃĆé
+
+Õ”éµ×£õĮĀµÅÉõ║żńÜäõ╗ŻńĀüõĖŁµ£ēõĖŹń¼”ÕÉłĶ¦äĶīāńÜäÕ£░µ¢╣’╝īpre-commit õ╝ÜÕÅæÕć║ĶŁ”ÕæŖ’╝īÕ╣ČĶć¬ÕŖ©õ┐«ÕżŹķā©ÕłåķöÖĶ»»ŃĆé
+
+
+
+### 3. ÕłøÕ╗║Õ╝ĆÕÅæÕłåµö»
+
+Õ«ēĶŻģÕ«ī pre-commit õ╣ŗÕÉÄ’╝īµłæõ╗¼ķ£ĆĶ”üÕ¤║õ║Ä dev Õłåµö»ÕłøÕ╗║õĖĆõĖ¬µ¢░ńÜäÕ╝ĆÕÅæÕłåµö»’╝īÕ╗║Ķ««õ╗ź `username/pr_name` ńÜäÕĮóÕ╝ÅÕæĮÕÉŹ’╝īõŠŗÕ”é’╝Ü
+
+```Shell
+git checkout -b username/refactor_contributing_doc
+```
+
+Õ£©ÕÉÄń╗ŁńÜäÕ╝ĆÕÅæõĖŁ’╝īÕ”éµ×£µ£¼Õ£░õ╗ōÕ║ōńÜä dev Õłåµö»ĶÉĮÕÉÄõ║ÄÕ«śµ¢╣õ╗ōÕ║ōńÜä dev Õłåµö»’╝īķ£ĆĶ”üÕģłµŗēÕÅ¢ upstream ńÜä dev Õłåµö»’╝īńäČÕÉÄ rebase Õł░µ£¼Õ£░ńÜäÕ╝ĆÕÅæÕłåµö»õĖŖ’╝Ü
+
+```Shell
+git checkout username/refactor_contributing_doc
+git fetch upstream
+git rebase upstream/dev-1.x
+```
+
+Õ£© rebase µŚČ’╝īÕ”éµ×£Õć║ńÄ░Õå▓ń¬ü’╝īķ£ĆĶ”üµēŗÕŖ©Ķ¦ŻÕå│Õå▓ń¬ü’╝īńäČÕÉĵē¦ĶĪī `git add` ÕæĮõ╗ż’╝īÕåŹµē¦ĶĪī `git rebase --continue` ÕæĮõ╗ż’╝īńø┤Õł░ rebase Õ«īµłÉŃĆé
+
+### 4. µÅÉõ║żõ╗ŻńĀüÕ╣ČÕ£©µ£¼Õ£░ķĆÜĶ┐ćÕŹĢÕģāµĄŗĶ»Ģ
+
+Õ£©µ£¼Õ£░Õ╝ĆÕÅæÕ«īµłÉÕÉÄ’╝īµłæõ╗¼ķ£ĆĶ”üÕ£©µ£¼Õ£░ķĆÜĶ┐ćÕŹĢÕģāµĄŗĶ»Ģ’╝īńäČÕÉĵÅÉõ║żõ╗ŻńĀüŃĆé
+
+```shell
+# Ķ┐ÉĶĪīÕŹĢÕģāµĄŗĶ»Ģ
+pytest tests/
+
+# µÅÉõ║żõ╗ŻńĀü
+git add .
+git commit -m "commit message"
+```
+
+### 5. µÄ©ķĆüõ╗ŻńĀüÕł░Ķ┐£ń©ŗõ╗ōÕ║ō
+
+Õ£©µ£¼Õ£░Õ╝ĆÕÅæÕ«īµłÉÕÉÄ’╝īµłæõ╗¼ķ£ĆĶ”üÕ░åõ╗ŻńĀüµÄ©ķĆüÕł░Ķ┐£ń©ŗõ╗ōÕ║ōŃĆé
+
+```Shell
+git push origin username/refactor_contributing_doc
+```
+
+### 6. µÅÉõ║ż Pull Request (PR)
+
+#### (1) Õ£© GitHub õĖŖÕłøÕ╗║ PR
+
+
+
+#### (2) Õ£© PR õĖŁµĀ╣µŹ«µīćÕ╝Ģõ┐«µö╣µÅÅĶ┐░’╝īµĘ╗ÕŖĀÕ┐ģĶ”üńÜäõ┐Īµü»
+
+
+
+```{note}
+- Õ£© PR branch ÕĘ”õŠ¦ķĆēµŗ® `dev` Õłåµö»’╝īÕÉ”ÕłÖ PR õ╝ÜĶó½µŗÆń╗ØŃĆé
+- Õ”éµ×£õĮĀµś»ń¼¼õĖƵ¼ĪÕÉæ OpenMMLab µÅÉõ║ż PR’╝īķ£ĆĶ”üńŁŠńĮ▓ CLAŃĆé
+```
+
+
+
+## õ╗ŻńĀüķŻÄµĀ╝
+
+### Python
+
+µłæõ╗¼ķććńö©[PEP8](https://www.python.org/dev/peps/pep-0008/)õĮ£õĖ║õ╗ŻńĀüķŻÄµĀ╝ŃĆé
+
+õĮ┐ńö©õĖŗķØóńÜäÕĘźÕģĘµØźÕ»╣õ╗ŻńĀüĶ┐øĶĪīµĢ┤ńÉåÕÆīµĀ╝Õ╝ÅÕī¢’╝Ü
+
+- [flake8](http://flake8.pycqa.org/en/latest/)’╝Üõ╗ŻńĀüµÅÉńż║
+- [isort](https://github.com/timothycrosley/isort)’╝Üimport µÄÆÕ║Å
+- [yapf](https://github.com/google/yapf)’╝ܵĀ╝Õ╝ÅÕī¢ÕĘźÕģĘ
+- [codespell](https://github.com/codespell-project/codespell)’╝Ü ÕŹĢĶ»Źµŗ╝ÕåÖµŻĆµ¤ź
+- [mdformat](https://github.com/executablebooks/mdformat): markdown µ¢ćõ╗ȵĀ╝Õ╝ÅÕī¢ÕĘźÕģĘ
+- [docformatter](https://github.com/myint/docformatter): docstring µĀ╝Õ╝ÅÕī¢ÕĘźÕģĘ
+
+`yapf`ÕÆī`isort`ńÜäµĀĘÕ╝ÅķģŹńĮ«ÕÅ»õ╗źÕ£©[setup.cfg](/setup.cfg)õĖŁµēŠÕł░ŃĆé
+
+µłæõ╗¼õĮ┐ńö©[pre-commit hook](https://pre-commit.com/)µØź’╝Ü
+
+- µŻĆµ¤źÕÆīµĀ╝Õ╝ÅÕī¢ `flake8`ŃĆü`yapf`ŃĆü`isort`ŃĆü`trailing whitespaces`
+- õ┐«ÕżŹ `end-of-files`
+- Õ£©µ»Åµ¼ĪµÅÉõ║żµŚČĶć¬ÕŖ©µÄÆÕ║Å `requirments.txt`
+
+`pre-commit`ńÜäķģŹńĮ«ÕŁśÕé©Õ£©[.pre-commit-config](/.pre-commit-config.yaml)õĖŁŃĆé
+
+```{note}
+Õ£©õĮĀÕłøÕ╗║PRõ╣ŗÕēŹ’╝īĶ»ĘńĪ«õ┐ØõĮĀńÜäõ╗ŻńĀüµĀ╝Õ╝Åń¼”ÕÉłĶ¦äĶīā’╝īõĖöń╗ÅĶ┐ćõ║å yapf µĀ╝Õ╝ÅÕī¢ŃĆé
+```
+
+### C++õĖÄCUDA
+
+ķüĄÕŠ¬[Google C++ķŻÄµĀ╝µīćÕŹŚ](https://google.github.io/styleguide/cppguide.html)
diff --git a/internlm_langchain/knowledge_base/MMPose/content/customize_datasets.md b/internlm_langchain/knowledge_base/MMPose/content/customize_datasets.md
new file mode 100644
index 00000000..61b58dc9
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPose/content/customize_datasets.md
@@ -0,0 +1,264 @@
+# Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøå
+
+MMPose ńø«ÕēŹÕĘ▓µö»µīüõ║åÕżÜõĖ¬õ╗╗ÕŖĪÕÆīńøĖÕ║öńÜäµĢ░µŹ«ķøåŃĆéµé©ÕÅ»õ╗źÕ£© [µĢ░µŹ«ķøå](https://mmpose.readthedocs.io/zh_CN/latest/dataset_zoo.html) µēŠÕł░Õ«āõ╗¼ŃĆéĶ»Ęµīēńģ¦ńøĖÕ║öńÜäµīćÕŹŚÕćåÕżćµĢ░µŹ«ŃĆé
+
+
+
+- [Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøå-Õ░åµĢ░µŹ«ń╗äń╗ćõĖ║ COCO µĀ╝Õ╝Å](#Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøå-Õ░åµĢ░µŹ«ń╗äń╗ćõĖ║-coco-µĀ╝Õ╝Å)
+- [ÕłøÕ╗║Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåńÜäÕģāõ┐Īµü»µ¢ćõ╗Č](#ÕłøÕ╗║Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåńÜäÕģāõ┐Īµü»µ¢ćõ╗Č)
+- [ÕłøÕ╗║Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåń▒╗](#ÕłøÕ╗║Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåń▒╗)
+- [ÕłøÕ╗║Ķć¬Õ«Üõ╣ēķģŹńĮ«µ¢ćõ╗Č](#ÕłøÕ╗║Ķć¬Õ«Üõ╣ēķģŹńĮ«µ¢ćõ╗Č)
+- [µĢ░µŹ«ķøåÕ░üĶŻģ](#µĢ░µŹ«ķøåÕ░üĶŻģ)
+
+
+
+## Õ░åµĢ░µŹ«ń╗äń╗ćõĖ║ COCO µĀ╝Õ╝Å
+
+µ£Ćń«ĆÕŹĢńÜäõĮ┐ńö©Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåńÜäµ¢╣µ│Ģµś»Õ░åµé©ńÜäµ│©ķćŖµĀ╝Õ╝ÅĶĮ¼µŹóõĖ║ COCO µĢ░µŹ«ķøåµĀ╝Õ╝ÅŃĆé
+
+COCO µĀ╝Õ╝ÅńÜäµ│©ķćŖ JSON µ¢ćõ╗ČÕģʵ£ēõ╗źõĖŗÕ┐ģĶ”üķö«’╝Ü
+
+```python
+'images': [
+ {
+ 'file_name': '000000001268.jpg',
+ 'height': 427,
+ 'width': 640,
+ 'id': 1268
+ },
+ ...
+],
+'annotations': [
+ {
+ 'segmentation': [[426.36,
+ ...
+ 424.34,
+ 223.3]],
+ 'keypoints': [0,0,0,
+ 0,0,0,
+ 0,0,0,
+ 427,220,2,
+ 443,222,2,
+ 414,228,2,
+ 449,232,2,
+ 408,248,1,
+ 454,261,2,
+ 0,0,0,
+ 0,0,0,
+ 411,287,2,
+ 431,287,2,
+ 0,0,0,
+ 458,265,2,
+ 0,0,0,
+ 466,300,1],
+ 'num_keypoints': 10,
+ 'area': 3894.5826,
+ 'iscrowd': 0,
+ 'image_id': 1268,
+ 'bbox': [402.34, 205.02, 65.26, 88.45],
+ 'category_id': 1,
+ 'id': 215218
+ },
+ ...
+],
+'categories': [
+ {'id': 1, 'name': 'person'},
+ ]
+```
+
+JSON µĀćµ│©µ¢ćõ╗ČõĖŁµ£ēõĖēõĖ¬Õģ│ķö«Ķ»Źµś»Õ┐ģķ£ĆńÜä’╝Ü
+
+- `images`’╝ÜÕīģÕɽµēƵ£ēÕøŠÕāÅõ┐Īµü»ńÜäÕłŚĶĪ©’╝īµ»ÅõĖ¬ÕøŠÕāÅķāĮµ£ēõĖĆõĖ¬ `file_name`ŃĆü`height`ŃĆü`width` ÕÆī `id` ķö«ŃĆé
+- `annotations`’╝ÜÕīģÕɽµēƵ£ēÕ«×õŠŗµĀćµ│©õ┐Īµü»ńÜäÕłŚĶĪ©’╝īµ»ÅõĖ¬Õ«×õŠŗķāĮµ£ēõĖĆõĖ¬ `segmentation`ŃĆü`keypoints`ŃĆü`num_keypoints`ŃĆü`area`ŃĆü`iscrowd`ŃĆü`image_id`ŃĆü`bbox`ŃĆü`category_id` ÕÆī `id` ķö«ŃĆé
+- `categories`’╝ÜÕīģÕɽµēƵ£ēń▒╗Õł½õ┐Īµü»ńÜäÕłŚĶĪ©’╝īµ»ÅõĖ¬ń▒╗Õł½ķāĮµ£ēõĖĆõĖ¬ `id` ÕÆī `name` ķö«ŃĆéõ╗źõ║║õĮōÕ¦┐µĆüõ╝░Ķ«ĪõĖ║õŠŗ’╝ī`id` õĖ║ 1’╝ī`name` õĖ║ `person`ŃĆé
+
+Õ”éµ×£µé©ńÜäµĢ░µŹ«ķøåÕĘ▓ń╗ŵś» COCO µĀ╝Õ╝ÅńÜä’╝īķéŻõ╣łµé©ÕÅ»õ╗źńø┤µÄźõĮ┐ńö© `CocoDataset` ń▒╗µØźĶ»╗ÕÅ¢Ķ»źµĢ░µŹ«ķøåŃĆé
+
+## ÕłøÕ╗║Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåńÜäÕģāõ┐Īµü»µ¢ćõ╗Č
+
+Õ»╣õ║ÄõĖĆõĖ¬µ¢░ńÜäµĢ░µŹ«ķøåĶĆīĶ©Ć’╝īµé©ķ£ĆĶ”üÕłøÕ╗║õĖĆõĖ¬µ¢░ńÜäµĢ░µŹ«ķøåÕģāõ┐Īµü»µ¢ćõ╗ČŃĆéĶ»źµ¢ćõ╗ČÕīģÕɽõ║åµĢ░µŹ«ķøåńÜäÕ¤║µ£¼õ┐Īµü»’╝īÕ”éÕģ│ķö«ńé╣õĖ¬µĢ░ŃĆüµÄÆÕłŚķĪ║Õ║ÅŃĆüÕÅ»Ķ¦åÕī¢ķó£Ķē▓ŃĆüķ¬©µ×ČĶ┐׵ğÕģ│ń│╗ńŁēŃĆéÕģāõ┐Īµü»µ¢ćõ╗ČķĆÜÕĖĖÕŁśµöŠÕ£© `config/_base_/datasets/` ńø«ÕĮĢõĖŗ’╝īõŠŗÕ”é’╝Ü
+
+```
+config/_base_/datasets/custom.py
+```
+
+Õģāõ┐Īµü»µ¢ćõ╗ČõĖŁķ£ĆĶ”üÕīģÕɽõ╗źõĖŗõ┐Īµü»’╝Ü
+
+- `keypoint_info`’╝ܵ»ÅõĖ¬Õģ│ķö«ńé╣ńÜäõ┐Īµü»’╝Ü
+ 1. `name`: Õģ│ķö«ńé╣ÕÉŹń¦░’╝īÕ┐ģķĪ╗µś»Õö»õĖĆńÜä’╝īõŠŗÕ”é `nose`ŃĆü`left_eye` ńŁēŃĆé
+ 2. `id`: Õģ│ķö«ńé╣ ID’╝īÕ┐ģķĪ╗µś»Õö»õĖĆńÜä’╝īõ╗Ä 0 Õ╝ĆÕ¦ŗŃĆé
+ 3. `color`: Õģ│ķö«ńé╣ÕÅ»Ķ¦åÕī¢µŚČńÜäķó£Ķē▓’╝īõ╗ź (\[B, G, R\]) µĀ╝Õ╝Åń╗äń╗ćĶĄĘµØź’╝īńö©õ║ÄÕÅ»Ķ¦åÕī¢ŃĆé
+ 4. `type`: Õģ│ķö«ńé╣ń▒╗Õ×ŗ’╝īÕÅ»õ╗źµś» `upper`ŃĆü`lower` µł¢ \`\`’╝īńö©õ║ĵĢ░µŹ«Õó×Õ╝║ŃĆé
+ 5. `swap`: Õģ│ķö«ńé╣õ║żµŹóÕģ│ń│╗’╝īńö©õ║ĵ░┤Õ╣│ń┐╗ĶĮ¼µĢ░µŹ«Õó×Õ╝║ŃĆé
+- `skeleton_info`’╝Üķ¬©µ×ČĶ┐׵ğÕģ│ń│╗’╝īńö©õ║ÄÕÅ»Ķ¦åÕī¢ŃĆé
+- `joint_weights`’╝ܵ»ÅõĖ¬Õģ│ķö«ńé╣ńÜäµØāķ插╝īńö©õ║ĵŹ¤Õż▒ÕćĮµĢ░Ķ«Īń«ŚŃĆé
+- `sigma`’╝ܵĀćÕćåÕĘ«’╝īńö©õ║ÄĶ«Īń«Ś OKS ÕłåµĢ░’╝īĶ»”ń╗åõ┐Īµü»Ķ»ĘÕÅéĶĆā [keypoints-eval](https://cocodataset.org/#keypoints-eval)ŃĆé
+
+õĖŗķØ󵜻õĖĆõĖ¬ń«ĆÕī¢ńēłµ£¼ńÜäÕģāõ┐Īµü»µ¢ćõ╗Č’╝ł[Õ«īµĢ┤ńēł](/configs/_base_/datasets/coco.py)’╝ē’╝Ü
+
+```python
+dataset_info = dict(
+ dataset_name='coco',
+ paper_info=dict(
+ author='Lin, Tsung-Yi and Maire, Michael and '
+ 'Belongie, Serge and Hays, James and '
+ 'Perona, Pietro and Ramanan, Deva and '
+ r'Doll{\'a}r, Piotr and Zitnick, C Lawrence',
+ title='Microsoft coco: Common objects in context',
+ container='European conference on computer vision',
+ year='2014',
+ homepage='http://cocodataset.org/',
+ ),
+ keypoint_info={
+ 0:
+ dict(name='nose', id=0, color=[51, 153, 255], type='upper', swap=''),
+ 1:
+ dict(
+ name='left_eye',
+ id=1,
+ color=[51, 153, 255],
+ type='upper',
+ swap='right_eye'),
+ ...
+ 16:
+ dict(
+ name='right_ankle',
+ id=16,
+ color=[255, 128, 0],
+ type='lower',
+ swap='left_ankle')
+ },
+ skeleton_info={
+ 0:
+ dict(link=('left_ankle', 'left_knee'), id=0, color=[0, 255, 0]),
+ ...
+ 18:
+ dict(
+ link=('right_ear', 'right_shoulder'), id=18, color=[51, 153, 255])
+ },
+ joint_weights=[
+ 1., 1., 1., 1., 1., 1., 1., 1.2, 1.2, 1.5, 1.5, 1., 1., 1.2, 1.2, 1.5,
+ 1.5
+ ],
+ sigmas=[
+ 0.026, 0.025, 0.025, 0.035, 0.035, 0.079, 0.079, 0.072, 0.072, 0.062,
+ 0.062, 0.107, 0.107, 0.087, 0.087, 0.089, 0.089
+ ])
+```
+
+## ÕłøÕ╗║Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåń▒╗
+
+Õ”éµ×£µĀćµ│©õ┐Īµü»õĖŹµś»ńö© COCO µĀ╝Õ╝ÅÕŁśÕé©ńÜä’╝īķéŻõ╣łµé©ķ£ĆĶ”üÕłøÕ╗║õĖĆõĖ¬µ¢░ńÜäµĢ░µŹ«ķøåń▒╗ŃĆéµĢ░µŹ«ķøåń▒╗ķ£ĆĶ”üń╗¦µē┐Ķć¬ `BaseDataset` ń▒╗’╝īÕ╣ČõĖöķ£ĆĶ”üµīēńģ¦õ╗źõĖŗµŁźķ¬żÕ«×ńÄ░’╝Ü
+
+1. Õ£© `mmpose/datasets/datasets` ńø«ÕĮĢõĖŗµēŠÕł░Ķ»źµĢ░µŹ«ķøåń¼”ÕÉłńÜä package’╝īÕ”éµ×£µ▓Īµ£ēń¼”ÕÉłńÜä’╝īÕłÖÕłøÕ╗║õĖĆõĖ¬µ¢░ńÜä packageŃĆé
+
+2. Õ£©Ķ»ź package õĖŗÕłøÕ╗║õĖĆõĖ¬µ¢░ńÜäµĢ░µŹ«ķøåń▒╗’╝īÕ£©Õ»╣Õ║öńÜäµ│©ÕåīÕÖ©õĖŁĶ┐øĶĪīµ│©Õåī’╝Ü
+
+ ```python
+ from mmengine.dataset import BaseDataset
+ from mmpose.registry import DATASETS
+
+ @DATASETS.register_module(name='MyCustomDataset')
+ class MyCustomDataset(BaseDataset):
+ ```
+
+ Õ”éµ×£µ£¬µ│©Õåī’╝īõĮĀõ╝ÜÕ£©Ķ┐ÉĶĪīµŚČķüćÕł░ `KeyError: 'XXXXX is not in the dataset registry'`ŃĆé
+ Õģ│õ║Ä `mmengine.BaseDataset` ńÜäµø┤ÕżÜõ┐Īµü»’╝īĶ»ĘÕÅéĶĆā [Ķ┐ÖõĖ¬µ¢ćµĪŻ](https://mmengine.readthedocs.io/en/latest/advanced_tutorials/basedataset.html)ŃĆé
+
+3. ńĪ«õ┐ØõĮĀÕ£© package ńÜä `__init__.py` õĖŁÕ»╝Õģźõ║åĶ»źµĢ░µŹ«ķøåń▒╗ŃĆé
+
+4. ńĪ«õ┐ØõĮĀÕ£© `mmpose/datasets/__init__.py` õĖŁÕ»╝Õģźõ║åĶ»ź packageŃĆé
+
+## ÕłøÕ╗║Ķć¬Õ«Üõ╣ēķģŹńĮ«µ¢ćõ╗Č
+
+Õ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁ’╝īõĮĀķ£ĆĶ”üõ┐«µö╣ĶʤµĢ░µŹ«ķøåµ£ēÕģ│ńÜäķā©Õłå’╝īõŠŗÕ”é’╝Ü
+
+```python
+...
+# Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåń▒╗
+dataset_type = 'MyCustomDataset' # or 'CocoDataset'
+
+train_dataloader = dict(
+ batch_size=2,
+ dataset=dict(
+ type=dataset_type,
+ data_root='root/of/your/train/data',
+ ann_file='path/to/your/train/json',
+ data_prefix=dict(img='path/to/your/train/img'),
+ metainfo=dict(from_file='configs/_base_/datasets/custom.py'),
+ ...),
+ )
+
+val_dataloader = dict(
+ batch_size=2,
+ dataset=dict(
+ type=dataset_type,
+ data_root='root/of/your/val/data',
+ ann_file='path/to/your/val/json',
+ data_prefix=dict(img='path/to/your/val/img'),
+ metainfo=dict(from_file='configs/_base_/datasets/custom.py'),
+ ...),
+ )
+
+test_dataloader = dict(
+ batch_size=2,
+ dataset=dict(
+ type=dataset_type,
+ data_root='root/of/your/test/data',
+ ann_file='path/to/your/test/json',
+ data_prefix=dict(img='path/to/your/test/img'),
+ metainfo=dict(from_file='configs/_base_/datasets/custom.py'),
+ ...),
+ )
+...
+```
+
+Ķ»ĘńĪ«õ┐صēƵ£ēńÜäĶĘ»ÕŠäķāĮµś»µŁŻńĪ«ńÜäŃĆé
+
+## µĢ░µŹ«ķøåÕ░üĶŻģ
+
+ńø«ÕēŹ [MMEngine](https://github.com/open-mmlab/mmengine) µö»µīüõ╗źõĖŗµĢ░µŹ«ķøåÕ░üĶŻģ’╝Ü
+
+- [ConcatDataset](https://mmengine.readthedocs.io/zh_CN/latest/advanced_tutorials/basedataset.html#concatdataset)
+- [RepeatDataset](https://mmengine.readthedocs.io/zh_CN/latest/advanced_tutorials/basedataset.html#repeatdataset)
+
+### CombinedDataset
+
+MMPose µÅÉõŠøõ║åõĖĆõĖ¬ `CombinedDataset` ń▒╗’╝īÕ«āÕÅ»õ╗źÕ░åÕżÜõĖ¬µĢ░µŹ«ķøåÕ░üĶŻģµłÉõĖĆõĖ¬µĢ░µŹ«ķøåŃĆéÕ«āńÜäõĮ┐ńö©µ¢╣µ│ĢÕ”éõĖŗ’╝Ü
+
+```python
+dataset_1 = dict(
+ type='dataset_type_1',
+ data_root='root/of/your/dataset1',
+ data_prefix=dict(img_path='path/to/your/img'),
+ ann_file='annotations/train.json',
+ pipeline=[
+ # õĮ┐ńö©ĶĮ¼µŹóÕÖ©Õ░åµĀćµ│©õ┐Īµü»ń╗¤õĖĆõĖ║ķ£ĆĶ”üńÜäµĀ╝Õ╝Å
+ converter_transform_1
+ ])
+
+dataset_2 = dict(
+ type='dataset_type_2',
+ data_root='root/of/your/dataset2',
+ data_prefix=dict(img_path='path/to/your/img'),
+ ann_file='annotations/train.json',
+ pipeline=[
+ converter_transform_2
+ ])
+
+shared_pipeline = [
+ LoadImage(),
+ ParseImage(),
+]
+
+combined_dataset = dict(
+ type='CombinedDataset',
+ metainfo=dict(from_file='path/to/your/metainfo'),
+ datasets=[dataset_1, dataset_2],
+ pipeline=shared_pipeline,
+)
+```
+
+- **ÕÉłÕ╣ȵĢ░µŹ«ķøåńÜäÕģāõ┐Īµü»** Õå│Õ«Üõ║åµĀćµ│©µĀ╝Õ╝Å’╝īÕÅ»õ╗źµś»ÕŁÉµĢ░µŹ«ķøåńÜäÕģāõ┐Īµü»’╝īõ╣¤ÕÅ»õ╗źµś»Ķć¬Õ«Üõ╣ēńÜäÕģāõ┐Īµü»ŃĆéÕ”éµ×£Ķ”üĶć¬Õ«Üõ╣ēÕģāõ┐Īµü»’╝īÕÅ»õ╗źÕÅéĶĆā [ÕłøÕ╗║Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåńÜäÕģāõ┐Īµü»µ¢ćõ╗Č](#ÕłøÕ╗║Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåńÜäÕģāõ┐Īµü»µ¢ćõ╗Č)ŃĆé
+- **KeypointConverter** ńö©õ║ÄÕ░åõĖŹÕÉīńÜäµĀćµ│©µĀ╝Õ╝ÅĶĮ¼µŹóµłÉń╗¤õĖĆńÜäµĀ╝Õ╝ÅŃĆéµ»öÕ”éÕ░åÕģ│ķö«ńé╣õĖ¬µĢ░õĖŹÕÉīŃĆüÕģ│ķö«ńé╣µÄÆÕłŚķĪ║Õ║ÅõĖŹÕÉīńÜäµĢ░µŹ«ķøåĶ┐øĶĪīÕÉłÕ╣ČŃĆé
+- µø┤Ķ»”ń╗åńÜäĶ»┤µśÄĶ»ĘÕēŹÕŠĆ[µĘĘÕÉłµĢ░µŹ«ķøåĶ«Łń╗ā](../user_guides/mixed_datasets.md)ŃĆé
diff --git a/internlm_langchain/knowledge_base/MMPose/content/customize_logging.md b/internlm_langchain/knowledge_base/MMPose/content/customize_logging.md
new file mode 100644
index 00000000..093a530d
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPose/content/customize_logging.md
@@ -0,0 +1,3 @@
+# Customize Logging
+
+Coming soon.
diff --git a/internlm_langchain/knowledge_base/MMPose/content/customize_optimizer.md b/internlm_langchain/knowledge_base/MMPose/content/customize_optimizer.md
new file mode 100644
index 00000000..fd6a2829
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPose/content/customize_optimizer.md
@@ -0,0 +1,3 @@
+# Customize Optimizer and Scheduler
+
+Coming soon.
diff --git a/internlm_langchain/knowledge_base/MMPose/content/customize_transforms.md b/internlm_langchain/knowledge_base/MMPose/content/customize_transforms.md
new file mode 100644
index 00000000..15441399
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPose/content/customize_transforms.md
@@ -0,0 +1,3 @@
+# Customize Data Transformation and Augmentation
+
+Coming soon.
diff --git a/internlm_langchain/knowledge_base/MMPose/content/dataflow.md b/internlm_langchain/knowledge_base/MMPose/content/dataflow.md
new file mode 100644
index 00000000..9f098b02
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPose/content/dataflow.md
@@ -0,0 +1,3 @@
+# Dataflow in MMPose
+
+Coming soon.
diff --git a/internlm_langchain/knowledge_base/MMPose/content/dataset_tools.md b/internlm_langchain/knowledge_base/MMPose/content/dataset_tools.md
new file mode 100644
index 00000000..a2e6d01d
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPose/content/dataset_tools.md
@@ -0,0 +1,413 @@
+# µĢ░µŹ«ķøåµĀ╝Õ╝ÅĶĮ¼µŹóĶäܵ£¼
+
+MMPose µÅÉõŠøõ║åõĖĆõ║øÕĘźÕģĘµØźÕĖ«ÕŖ®ńö©µłĘÕżäńÉåµĢ░µŹ«ķøåŃĆé
+
+## Animal Pose µĢ░µŹ«ķøå
+
+
+ + - µŗ╝µÄźµōŹõĮ£ + + ```python + neck=dict(type='FeatureMapProcessor', concat=True) + ``` + +
+ + µŗ╝µÄźõ╣ŗÕēŹ’╝īÕģČÕ«āńē╣ÕŠüÕøŠõ╝ÜĶó½ń╝®µöŠÕł░ÕÆīÕ║ÅÕÅĘõĖ║ 0 ńÜäńē╣ÕŠüÕøŠńøĖÕÉīńÜäÕ░║Õ»ĖŃĆé + + - ń╝®µöŠµōŹõĮ£ + + ```python + neck=dict(type='FeatureMapProcessor', scale_factor=2.0) + ``` + +
+ +### ķó䵥ŗÕż┤’╝łHead’╝ē + +ķĆÜÕĖĖµØźĶ»┤’╝īķó䵥ŗÕż┤µś»µ©ĪÕ×ŗń«Śµ│ĢÕ«×ńÄ░ńÜäµĀĖÕ┐ā’╝īńö©õ║ÄµÄ¦ÕłČµ©ĪÕ×ŗńÜäĶŠōÕć║’╝īÕ╣ČĶ┐øĶĪīµŹ¤Õż▒ÕćĮµĢ░Ķ«Īń«ŚŃĆé + +MMPose õĖŁ Head ńøĖÕģ│ńÜ䵩ĪÕØŚÕ«Üõ╣ēÕ£© `$MMPOSE/mmpose/models/heads` ńø«ÕĮĢõĖŗ’╝īÕ╝ĆÕÅæĶĆģÕ£©Ķć¬Õ«Üõ╣ēķó䵥ŗÕż┤µŚČķ£ĆĶ”üń╗¦µē┐µłæõ╗¼µÅÉõŠøńÜäÕ¤║ń▒╗ `BaseHead`’╝īÕ╣ČķćŹĶĮĮõ╗źõĖŗõĖēõĖ¬µ¢╣µ│ĢÕ»╣Õ║öµ©ĪÕ×ŗµÄ©ńÉåńÜäõĖēń¦Źµ©ĪÕ╝Å’╝Ü + +- forward() + +- predict() + +- loss() + +ÕģĘõĮōĶĆīĶ©Ć’╝ī`predict()` Ķ┐öÕø×ńÜäÕ║öµś»ĶŠōÕģźÕøŠńēćÕ░║Õ║”õĖŗńÜäń╗ōµ×£’╝īÕøĀµŁżķ£ĆĶ”üĶ░āńö© `self.decode()` Õ»╣ńĮæń╗£ĶŠōÕć║Ķ┐øĶĪīĶ¦ŻńĀü’╝īĶ┐ÖõĖĆĶ┐ćń©ŗÕ«×ńÄ░Õ£© `BaseHead` õĖŁÕĘ▓ń╗ÅÕ«×ńÄ░’╝īÕ«āõ╝ÜĶ░āńö©ń╝¢Ķ¦ŻńĀüÕÖ©µÅÉõŠøńÜä `decode()` µ¢╣µ│ĢµØźÕ«īµłÉĶ¦ŻńĀüŃĆé + +ÕÅ”õĖƵ¢╣ķØó’╝īµłæõ╗¼õ╝ÜÕ£© `predict()` õĖŁĶ┐øĶĪīµĄŗĶ»ĢµŚČÕó×Õ╝║ŃĆéÕ£©Ķ┐øĶĪīķó䵥ŗµŚČ’╝īõĖĆõĖ¬ÕĖĖĶ¦üńÜ䵥ŗĶ»ĢµŚČÕó×Õ╝║µŖĆÕʦµś»Ķ┐øĶĪīń┐╗ĶĮ¼ķøåµłÉŃĆéÕŹ│’╝īÕ░åõĖĆÕ╝ĀÕøŠńēćÕģłĶ┐øĶĪīõĖƵ¼ĪµÄ©ńÉå’╝īÕåŹÕ░åÕøŠńēćµ░┤Õ╣│ń┐╗ĶĮ¼Ķ┐øĶĪīõĖƵ¼ĪµÄ©ńÉå’╝īµÄ©ńÉåńÜäń╗ōµ×£ÕåŹµ¼Īµ░┤Õ╣│ń┐╗ĶĮ¼Õø×ÕÄ╗’╝īÕ»╣õĖżµ¼ĪµÄ©ńÉåńÜäń╗ōµ×£Ķ┐øĶĪīÕ╣│ÕØćŃĆéĶ┐ÖõĖ¬µŖĆÕʦĶāĮµ£ēµĢłµÅÉÕŹćµ©ĪÕ×ŗńÜäķó䵥ŗń©│Õ«ÜµĆ¦ŃĆé + +õĖŗķØóµś»Õ£© `RegressionHead` õĖŁÕ«Üõ╣ē `predict()` ńÜäõŠŗÕŁÉ’╝Ü + +```Python +def predict(self, + feats: Tuple[Tensor], + batch_data_samples: OptSampleList, + test_cfg: ConfigType = {}) -> Predictions: + """Predict results from outputs.""" + + if test_cfg.get('flip_test', False): + # TTA: flip test -> feats = [orig, flipped] + assert isinstance(feats, list) and len(feats) == 2 + flip_indices = batch_data_samples[0].metainfo['flip_indices'] + input_size = batch_data_samples[0].metainfo['input_size'] + _feats, _feats_flip = feats + _batch_coords = self.forward(_feats) + _batch_coords_flip = flip_coordinates( + self.forward(_feats_flip), + flip_indices=flip_indices, + shift_coords=test_cfg.get('shift_coords', True), + input_size=input_size) + batch_coords = (_batch_coords + _batch_coords_flip) * 0.5 + else: + batch_coords = self.forward(feats) # (B, K, D) + + batch_coords.unsqueeze_(dim=1) # (B, N, K, D) + preds = self.decode(batch_coords) +``` + +`loss()`ķÖżõ║åĶ┐øĶĪīµŹ¤Õż▒ÕćĮµĢ░ńÜäĶ«Īń«Ś’╝īĶ┐śõ╝ÜĶ┐øĶĪī accuracy ńŁēĶ«Łń╗āµŚČµīćµĀćńÜäĶ«Īń«Ś’╝īÕ╣ČķĆÜĶ┐ćõĖĆõĖ¬ÕŁŚÕģĖ `losses` µØźõ╝ĀķĆÆ: + +```Python + # calculate accuracy +_, avg_acc, _ = keypoint_pck_accuracy( + pred=to_numpy(pred_coords), + gt=to_numpy(keypoint_labels), + mask=to_numpy(keypoint_weights) > 0, + thr=0.05, + norm_factor=np.ones((pred_coords.size(0), 2), dtype=np.float32)) + +acc_pose = torch.tensor(avg_acc, device=keypoint_labels.device) +losses.update(acc_pose=acc_pose) +``` + +µ»ÅõĖ¬ batch ńÜäµĢ░µŹ«ķāĮµēōÕīģµłÉõ║å `batch_data_samples`ŃĆéõ╗ź Regression-based µ¢╣µ│ĢõĖ║õŠŗ’╝īĶ«Łń╗āµēĆķ£ĆńÜäÕĮÆõĖĆÕī¢ńÜäÕØɵĀćÕĆ╝ÕÆīÕģ│ķö«ńé╣µØāķćŹÕÅ»õ╗źńö©Õ”éõĖŗµ¢╣Õ╝ÅĶÄĘÕÅ¢’╝Ü + +```Python +keypoint_labels = torch.cat( + [d.gt_instance_labels.keypoint_labels for d in batch_data_samples]) +keypoint_weights = torch.cat([ + d.gt_instance_labels.keypoint_weights for d in batch_data_samples +]) +``` + +õ╗źõĖŗõĖ║ `RegressionHead` õĖŁÕ«īµĢ┤ńÜä `loss()` Õ«×ńÄ░’╝Ü + +```Python +def loss(self, + inputs: Tuple[Tensor], + batch_data_samples: OptSampleList, + train_cfg: ConfigType = {}) -> dict: + """Calculate losses from a batch of inputs and data samples.""" + + pred_outputs = self.forward(inputs) + + keypoint_labels = torch.cat( + [d.gt_instance_labels.keypoint_labels for d in batch_data_samples]) + keypoint_weights = torch.cat([ + d.gt_instance_labels.keypoint_weights for d in batch_data_samples + ]) + + # calculate losses + losses = dict() + loss = self.loss_module(pred_outputs, keypoint_labels, + keypoint_weights.unsqueeze(-1)) + + if isinstance(loss, dict): + losses.update(loss) + else: + losses.update(loss_kpt=loss) + + # calculate accuracy + _, avg_acc, _ = keypoint_pck_accuracy( + pred=to_numpy(pred_outputs), + gt=to_numpy(keypoint_labels), + mask=to_numpy(keypoint_weights) > 0, + thr=0.05, + norm_factor=np.ones((pred_outputs.size(0), 2), dtype=np.float32)) + acc_pose = torch.tensor(avg_acc, device=keypoint_labels.device) + losses.update(acc_pose=acc_pose) + + return losses +``` diff --git a/internlm_langchain/knowledge_base/MMPose/content/how_to_deploy.md b/internlm_langchain/knowledge_base/MMPose/content/how_to_deploy.md new file mode 100644 index 00000000..b4fead87 --- /dev/null +++ b/internlm_langchain/knowledge_base/MMPose/content/how_to_deploy.md @@ -0,0 +1,3 @@ +# How to Deploy MMPose Models + +Coming soon. diff --git a/internlm_langchain/knowledge_base/MMPose/content/implement_new_models.md b/internlm_langchain/knowledge_base/MMPose/content/implement_new_models.md new file mode 100644 index 00000000..4a10b0c3 --- /dev/null +++ b/internlm_langchain/knowledge_base/MMPose/content/implement_new_models.md @@ -0,0 +1,3 @@ +# Implement New Models + +Coming soon. diff --git a/internlm_langchain/knowledge_base/MMPose/content/inference.md b/internlm_langchain/knowledge_base/MMPose/content/inference.md new file mode 100644 index 00000000..0844bc61 --- /dev/null +++ b/internlm_langchain/knowledge_base/MMPose/content/inference.md @@ -0,0 +1,267 @@ +# õĮ┐ńö©ńÄ░µ£ēµ©ĪÕ×ŗĶ┐øĶĪīµÄ©ńÉå + +MMPoseõĖ║Õ¦┐µĆüõ╝░Ķ«ĪµÅÉõŠøõ║åÕż¦ķćÅÕÅ»õ╗źõ╗Ä[µ©ĪÕ×ŗÕ║ō](https://mmpose.readthedocs.io/en/latest/model_zoo.html)õĖŁµēŠÕł░ńÜäķó䵥ŗĶ«Łń╗āµ©ĪÕ×ŗŃĆéµ£¼µīćÕŹŚÕ░åµ╝öńż║**Õ”éõĮĢµē¦ĶĪīµÄ©ńÉå**’╝īµł¢õĮ┐ńö©Ķ«Łń╗āĶ┐ćńÜ䵩ĪÕ×ŗÕ»╣µÅÉõŠøńÜäÕøŠÕāŵł¢Ķ¦åķóæĶ┐ÉĶĪīÕ¦┐µĆüõ╝░Ķ«ĪŃĆé + +µ£ēÕģ│Õ£©µĀćÕćåµĢ░µŹ«ķøåõĖŖµĄŗĶ»ĢńÄ░µ£ēµ©ĪÕ×ŗńÜäĶ»┤µśÄ’╝īĶ»ĘÕÅéķśģµ£¼µīćÕŹŚŃĆé + +Õ£©MMPose’╝īµ©ĪÕ×ŗńö▒ķģŹńĮ«µ¢ćõ╗ČÕ«Üõ╣ē’╝īĶĆīÕģČÕĘ▓Ķ«Īń«ŚÕźĮńÜäÕÅéµĢ░ÕŁśÕé©Õ£©µØāķ揵¢ćõ╗Č’╝łcheckpoint file’╝ēõĖŁŃĆéµé©ÕÅ»õ╗źÕ£©[µ©ĪÕ×ŗÕ║ō](https://mmpose.readthedocs.io/en/latest/model_zoo.html)õĖŁµēŠÕł░µ©ĪÕ×ŗķģŹńĮ«µ¢ćõ╗ČÕÆīńøĖÕ║öńÜäµØāķ揵¢ćõ╗ČńÜäURLŃĆ鵳æõ╗¼Õ╗║Ķ««õ╗ÄõĮ┐ńö©HRNetµ©ĪÕ×ŗńÜä[ķģŹńĮ«µ¢ćõ╗Č](https://github.com/open-mmlab/mmpose/blob/main/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192.py)ÕÆī[µØāķ揵¢ćõ╗Č](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192-81c58e40_20220909.pth)Õ╝ĆÕ¦ŗŃĆé + +## µÄ©ńÉåÕÖ©’╝Üń╗¤õĖĆńÜäµÄ©ńÉåµÄźÕÅŻ + +MMPoseµÅÉõŠøõ║åõĖĆõĖ¬Ķó½ń¦░õĖ║`MMPoseInferencer`ńÜäŃĆüÕģ©ķØóńÜäµÄ©ńÉåAPIŃĆéĶ┐ÖõĖ¬APIõĮ┐ÕŠŚńö©µłĘÕŠŚõ╗źõĮ┐ńö©µēƵ£ēMMPoseµö»µīüńÜ䵩ĪÕ×ŗµØźÕ»╣ÕøŠÕāÅÕÆīĶ¦åķóæĶ┐øĶĪīµ©ĪÕ×ŗµÄ©ńÉåŃĆ鵣żÕż¢’╝īĶ»źAPIÕÅ»õ╗źÕ«īµłÉµÄ©ńÉåń╗ōµ×£Ķć¬ÕŖ©Õī¢’╝īÕ╣ȵ¢╣õŠ┐ńö©µłĘõ┐ØÕŁśķó䵥ŗń╗ōµ×£ŃĆé + +### Õ¤║µ£¼ńö©µ│Ģ + +`MMPoseInferencer`ÕÅ»õ╗źÕ£©õ╗╗õĮĢPythonń©ŗÕ║ÅõĖŁĶó½ńö©µØźµē¦ĶĪīÕ¦┐µĆüõ╝░Ķ«Īõ╗╗ÕŖĪŃĆéõ╗źõĖŗµś»Õ£©õĖĆõĖ¬Õ£©Python ShellõĖŁõĮ┐ńö©ķóäĶ«Łń╗āńÜäõ║║õĮōÕ¦┐µĆüµ©ĪÕ×ŗÕ»╣ń╗ÖÕ«ÜÕøŠÕāÅĶ┐øĶĪīµÄ©ńÉåńÜäńż║õŠŗŃĆé + +```python +from mmpose.apis import MMPoseInferencer + +img_path = 'tests/data/coco/000000000785.jpg' # Õ░åimg_pathµø┐µŹóń╗ÖõĮĀĶć¬ÕĘ▒ńÜäĶĘ»ÕŠä + +# õĮ┐ńö©µ©ĪÕ×ŗÕł½ÕÉŹÕłøÕ╗║µÄ©µ¢ŁÕÖ© +inferencer = MMPoseInferencer('human') + +# MMPoseInferencerķććńö©õ║åµā░µĆ¦µÄ©µ¢Łµ¢╣µ│Ģ’╝īÕ£©ń╗ÖÕ«ÜĶŠōÕģźµŚČÕłøÕ╗║õĖĆõĖ¬ķó䵥ŗńö¤µłÉÕÖ© +result_generator = inferencer(img_path, show=True) +result = next(result_generator) +``` + +Õ”éµ×£õĖĆÕłćµŁŻÕĖĖ’╝īõĮĀÕ░åÕ£©õĖĆõĖ¬µ¢░ń¬ŚÕÅŻõĖŁń£ŗÕł░õĖŗÕøŠ’╝Ü + + + +`result` ÕÅśķćŵś»õĖĆõĖ¬ÕīģÕɽõĖżõĖ¬ķö«ÕĆ╝ `'visualization'` ÕÆī `'predictions'` ńÜäÕŁŚÕģĖŃĆé + +- `'visualization'` ķö«Õ»╣Õ║öńÜäÕĆ╝µś»õĖĆõĖ¬ÕłŚĶĪ©’╝īĶ»źÕłŚĶĪ©’╝Ü + - ÕīģÕɽÕÅ»Ķ¦åÕī¢ń╗ōµ×£’╝īõŠŗÕ”éĶŠōÕģźÕøŠÕāÅŃĆüõ╝░Ķ«ĪÕ¦┐µĆüńÜäµĀćĶ«░’╝īõ╗źÕÅŖÕÅ»ķĆēńÜäķó䵥ŗńāŁÕøŠŃĆé + - Õ”éµ×£µ▓Īµ£ēµīćÕ«Ü `return_vis` ÕÅéµĢ░’╝īĶ»źÕłŚĶĪ©Õ░åõ┐صīüõĖ║ń®║ŃĆé +- `'predictions'` ķö«Õ»╣Õ║öńÜäÕĆ╝µś»’╝Ü + - õĖĆõĖ¬ÕīģÕɽµ»ÅõĖ¬µŻĆµĄŗÕ«×õŠŗńÜäķóäõ╝░Õģ│ķö«ńé╣ńÜäÕłŚĶĪ©ŃĆé + +`result` ÕŁŚÕģĖńÜäń╗ōµ×äÕ”éõĖŗµēĆńż║’╝Ü + +```python +result = { + 'visualization': [ + # Õģāń┤ĀµĢ░ķćÅ’╝Übatch_size’╝łķ╗śĶ«żõĖ║1’╝ē + vis_image_1, + ... + ], + 'predictions': [ + # µ»ÅÕ╝ĀÕøŠÕāÅńÜäÕ¦┐µĆüõ╝░Ķ«Īń╗ōµ×£ + # Õģāń┤ĀµĢ░ķćÅ’╝Übatch_size’╝łķ╗śĶ«żõĖ║1’╝ē + [ + # µ»ÅõĖ¬µŻĆµĄŗÕł░ńÜäÕ«×õŠŗńÜäÕ¦┐µĆüõ┐Īµü» + # Õģāń┤ĀµĢ░ķćÅ’╝ܵŻĆµĄŗÕł░ńÜäÕ«×õŠŗµĢ░ + {'keypoints': ..., # Õ«×õŠŗ 1 + 'keypoint_scores': ..., + ... + }, + {'keypoints': ..., # Õ«×õŠŗ 2 + 'keypoint_scores': ..., + ... + }, + ] + ... + ] +} +``` + +Ķ┐śÕÅ»õ╗źõĮ┐ńö©ńö©õ║Äńö©õ║ĵĩµ¢ŁńÜä**ÕæĮõ╗żĶĪīńĢīķØóÕĘźÕģĘ**’╝łCLI, command-line interface’╝ē: `demo/inferencer_demo.py`ŃĆéĶ┐ÖõĖ¬ÕĘźÕģĘÕģüĶ«Ėńö©µłĘõĮ┐ńö©õ╗źõĖŗÕæĮõ╗żõĮ┐ńö©ńøĖÕÉīńÜ䵩ĪÕ×ŗÕÆīĶŠōÕģźµē¦ĶĪīµÄ©ńÉå’╝Ü + +```python +python demo/inferencer_demo.py 'tests/data/coco/000000000785.jpg' \ + --pose2d 'human' --show --pred-out-dir 'predictions' +``` + +ķó䵥ŗń╗ōµ×£Õ░åĶó½õ┐ØÕŁśÕ£©ĶĘ»ÕŠä`predictions/000000000785.json`ŃĆéõĮ£õĖ║õĖĆõĖ¬API’╝ī`inferencer_demo.py`ńÜäĶŠōÕģźÕÅéµĢ░õĖÄ`MMPoseInferencer`ńÜäńøĖÕÉīŃĆéÕēŹĶĆģĶāĮÕż¤ÕżäńÉåõĖĆń│╗ÕłŚĶŠōÕģźń▒╗Õ×ŗ’╝īÕīģµŗ¼õ╗źõĖŗÕåģÕ«╣’╝Ü + +- ÕøŠÕāÅĶĘ»ÕŠä + +- Ķ¦åķóæĶĘ»ÕŠä + +- µ¢ćõ╗ČÕż╣ĶĘ»ÕŠä’╝łĶ┐Öõ╝ÜÕ»╝Ķć┤Ķ»źµ¢ćõ╗ČÕż╣õĖŁńÜäµēƵ£ēÕøŠÕāÅķāĮĶó½µÄ©µ¢ŁÕć║µØź’╝ē + +- ĶĪ©ńż║ÕøŠÕāÅńÜä numpy array (Õ£©ÕæĮõ╗żĶĪīńĢīķØóÕĘźÕģĘõĖŁµ£¬µö»µīü) + +- ĶĪ©ńż║ÕøŠÕāÅńÜä numpy array ÕłŚĶĪ© (Õ£©ÕæĮõ╗żĶĪīńĢīķØóÕĘźÕģĘõĖŁµ£¬µö»µīü) + +- µæäÕāÅÕż┤’╝łÕ£©Ķ┐Öń¦ŹµāģÕåĄõĖŗ’╝īĶŠōÕģźÕÅéµĢ░Õ║öĶ»źĶ«ŠńĮ«õĖ║`webcam`µł¢`webcam:{CAMERA_ID}`’╝ē + +ÕĮōĶŠōÕģźÕ»╣Õ║öõ║ÄÕżÜõĖ¬ÕøŠÕāŵŚČ’╝īõŠŗÕ”éĶŠōÕģźõĖ║**Ķ¦åķóæ**µł¢**µ¢ćõ╗ČÕż╣**ĶĘ»ÕŠäµŚČ’╝īµÄ©ńÉåńö¤µłÉÕÖ©Õ┐ģķĪ╗Ķó½ķüŹÕÄå’╝īõ╗źõŠ┐µÄ©ńÉåÕÖ©Õ»╣Ķ¦åķóæ/µ¢ćõ╗ČÕż╣õĖŁńÜäµēƵ£ēÕĖ¦/ÕøŠÕāÅĶ┐øĶĪīµÄ©ńÉåŃĆéõ╗źõĖŗµś»õĖĆõĖ¬ńż║õŠŗ’╝Ü + +```python +folder_path = 'tests/data/coco' + +result_generator = inferencer(folder_path, show=True) +results = [result for result in result_generator] +``` + +Õ£©Ķ┐ÖõĖ¬ńż║õŠŗõĖŁ’╝ī`inferencer` µÄźÕÅŚ `folder_path` õĮ£õĖ║ĶŠōÕģź’╝īÕ╣ČĶ┐öÕø×õĖĆõĖ¬ńö¤µłÉÕÖ©Õ»╣Ķ▒Ī’╝ł`result_generator`’╝ē’╝īńö©õ║Äńö¤µłÉµÄ©ńÉåń╗ōµ×£ŃĆéķĆÜĶ┐ćķüŹÕÄå `result_generator` Õ╣ČÕ░åµ»ÅõĖ¬ń╗ōµ×£ÕŁśÕé©Õ£© `results` ÕłŚĶĪ©õĖŁ’╝īµé©ÕÅ»õ╗źĶÄĘÕŠŚĶ¦åķóæ/µ¢ćõ╗ČÕż╣õĖŁµēƵ£ēÕĖ¦/ÕøŠÕāÅńÜäµÄ©ńÉåń╗ōµ×£ŃĆé + +### Ķć¬Õ«Üõ╣ēÕ¦┐µĆüõ╝░Ķ«Īµ©ĪÕ×ŗ + +`MMPoseInferencer`µÅÉõŠøõ║åÕćĀń¦ŹÕÅ»ńö©õ║ÄĶć¬Õ«Üõ╣ēµēĆõĮ┐ńö©ńÜ䵩ĪÕ×ŗńÜäµ¢╣µ│Ģ’╝Ü + +```python +# õĮ┐ńö©µ©ĪÕ×ŗÕł½ÕÉŹµ×äÕ╗║µÄ©µ¢ŁÕÖ© +inferencer = MMPoseInferencer('human') + +# õĮ┐ńö©µ©ĪÕ×ŗķģŹńĮ«ÕÉŹµ×äÕ╗║µÄ©µ¢ŁÕÖ© +inferencer = MMPoseInferencer('td-hm_hrnet-w32_8xb64-210e_coco-256x192') + +# õĮ┐ńö©µ©ĪÕ×ŗķģŹńĮ«µ¢ćõ╗ČÕÆīµØāķ揵¢ćõ╗ČńÜäĶĘ»ÕŠäµł¢ URL µ×äÕ╗║µÄ©µ¢ŁÕÖ© +inferencer = MMPoseInferencer( + pose2d='configs/body_2d_keypoint/topdown_heatmap/coco/' \ + 'td-hm_hrnet-w32_8xb64-210e_coco-256x192.py', + pose2d_weights='https://download.openmmlab.com/mmpose/top_down/' \ + 'hrnet/hrnet_w32_coco_256x192-c78dce93_20200708.pth' +) +``` + +µ©ĪÕ×ŗÕł½ÕÉŹńÜäÕ«īµĢ┤ÕłŚĶĪ©ÕÅ»õ╗źÕ£©µ©ĪÕ×ŗÕł½ÕÉŹķā©ÕłåõĖŁµēŠÕł░ŃĆé + +µŁżÕż¢’╝īĶć¬ķĪČÕÉæõĖŗńÜäÕ¦┐µĆüõ╝░Ķ«ĪÕÖ©Ķ┐śķ£ĆĶ”üõĖĆõĖ¬Õ»╣Ķ▒ĪµŻĆµĄŗµ©ĪÕ×ŗŃĆé`MMPoseInferencer`ĶāĮÕż¤µÄ©µ¢Łńö©MMPoseµö»µīüńÜäµĢ░µŹ«ķøåĶ«Łń╗āńÜ䵩ĪÕ×ŗńÜäÕ«×õŠŗń▒╗Õ×ŗ’╝īńäČÕÉĵ×äÕ╗║Õ┐ģĶ”üńÜäÕ»╣Ķ▒ĪµŻĆµĄŗµ©ĪÕ×ŗŃĆéńö©µłĘõ╣¤ÕÅ»õ╗źķĆÜĶ┐ćõ╗źõĖŗµ¢╣Õ╝ŵēŗÕŖ©µīćիܵŻĆµĄŗµ©ĪÕ×ŗ: + +```python +# ķĆÜĶ┐ćÕł½ÕÉŹµīćիܵŻĆµĄŗµ©ĪÕ×ŗ +# ÕÅ»ńö©ńÜäÕł½ÕÉŹÕīģµŗ¼ŌĆ£humanŌĆØŃĆüŌĆ£handŌĆØŃĆüŌĆ£faceŌĆØŃĆüŌĆ£animalŌĆØŃĆü +# õ╗źÕÅŖmmdetõĖŁÕ«Üõ╣ēńÜäõ╗╗õĮĢÕģČõ╗¢Õł½ÕÉŹ +inferencer = MMPoseInferencer( + # ÕüćĶ«ŠÕ¦┐µĆüõ╝░Ķ«ĪÕÖ©µś»Õ£©Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåõĖŖĶ«Łń╗āńÜä + pose2d='custom_human_pose_estimator.py', + pose2d_weights='custom_human_pose_estimator.pth', + det_model='human' +) + +# õĮ┐ńö©µ©ĪÕ×ŗķģŹńĮ«ÕÉŹń¦░µīćիܵŻĆµĄŗµ©ĪÕ×ŗ +inferencer = MMPoseInferencer( + pose2d='human', + det_model='yolox_l_8x8_300e_coco', + det_cat_ids=[0], # µīćÕ«Ü'human'ń▒╗ńÜäń▒╗Õł½id +) + +# õĮ┐ńö©µ©ĪÕ×ŗķģŹńĮ«µ¢ćõ╗ČÕÆīµØāķ揵¢ćõ╗ČńÜäĶĘ»ÕŠäµł¢URLµ×äÕ╗║µÄ©µ¢ŁÕÖ© +inferencer = MMPoseInferencer( + pose2d='human', + det_model=f'{PATH_TO_MMDET}/configs/yolox/yolox_l_8x8_300e_coco.py', + det_weights='https://download.openmmlab.com/mmdetection/v2.0/' \ + 'yolox/yolox_l_8x8_300e_coco/' \ + 'yolox_l_8x8_300e_coco_20211126_140236-d3bd2b23.pth', + det_cat_ids=[0], # µīćÕ«Ü'human'ń▒╗ńÜäń▒╗Õł½id +) +``` + +### ĶĮ¼Õé©ń╗ōµ×£ + +Õ£©µē¦ĶĪīÕ¦┐µĆüõ╝░Ķ«ĪµÄ©ńÉåõ╗╗ÕŖĪõ╣ŗÕÉÄ’╝īµé©ÕÅ»ĶāĮÕĖīµ£øõ┐ØÕŁśń╗ōµ×£õ╗źõŠøĶ┐øõĖƵŁźÕłåµ×ɵł¢ÕżäńÉåŃĆéµ£¼ĶŖéÕ░åµīćÕ»╝µé©Õ░åķó䵥ŗńÜäÕģ│ķö«ńé╣ÕÆīÕÅ»Ķ¦åÕī¢ń╗ōµ×£õ┐ØÕŁśÕł░µ£¼Õ£░ŃĆé + +Ķ”üÕ░åķó䵥ŗõ┐ØÕŁśÕ£©JSONµ¢ćõ╗ČõĖŁ’╝īÕ£©Ķ┐ÉĶĪī`MMPoseInferencer`ńÜäÕ«×õŠŗ`inferencer`µŚČõĮ┐ńö©`pred_out_dir`ÕÅéµĢ░: + +```python +result_generator = inferencer(img_path, pred_out_dir='predictions') +result = next(result_generator) +``` + +ķó䵥ŗń╗ōµ×£Õ░åõ╗źJSONµĀ╝Õ╝Åõ┐ØÕŁśÕ£©`predictions/`µ¢ćõ╗ČÕż╣õĖŁ’╝īµ»ÅõĖ¬µ¢ćõ╗Čõ╗źńøĖÕ║öńÜäĶŠōÕģźÕøŠÕāŵł¢Ķ¦åķóæńÜäÕÉŹń¦░ÕæĮÕÉŹŃĆé + +Õ»╣õ║ĵø┤ķ½śń║¦ńÜäÕ£║µÖ»’╝īĶ┐śÕÅ»õ╗źńø┤µÄźõ╗Ä`inferencer`Ķ┐öÕø×ńÜä`result`ÕŁŚÕģĖõĖŁĶ«┐ķŚ«ķó䵥ŗń╗ōµ×£ŃĆéÕģČõĖŁ’╝ī`predictions`ÕīģÕɽĶŠōÕģźÕøŠÕāŵł¢Ķ¦åķóæõĖŁµ»ÅõĖ¬ÕŹĢńŗ¼Õ«×õŠŗńÜäķó䵥ŗÕģ│ķö«ńé╣ÕłŚĶĪ©ŃĆéńäČÕÉÄ’╝īµé©ÕÅ»õ╗źõĮ┐ńö©µé©Õ¢£µ¼óńÜäµ¢╣µ│ĢµōŹõĮ£µł¢ÕŁśÕé©Ķ┐Öõ║øń╗ōµ×£ŃĆé + +Ķ»ĘĶ«░õĮÅ’╝īÕ”éµ×£õĮĀµā│Õ░åÕÅ»Ķ¦åÕī¢ÕøŠÕāÅÕÆīķó䵥ŗµ¢ćõ╗Čõ┐ØÕŁśÕ£©õĖĆõĖ¬µ¢ćõ╗ČÕż╣õĖŁ’╝īõĮĀÕÅ»õ╗źõĮ┐ńö©`out_dir`ÕÅéµĢ░’╝Ü + +```python +result_generator = inferencer(img_path, out_dir='output') +result = next(result_generator) +``` + +Õ£©Ķ┐Öń¦ŹµāģÕåĄõĖŗ’╝īÕÅ»Ķ¦åÕī¢ÕøŠÕāÅÕ░åõ┐ØÕŁśÕ£©`output/visualization/`µ¢ćõ╗ČÕż╣õĖŁ’╝īĶĆīķó䵥ŗÕ░åÕŁśÕé©Õ£©`output/forecasts/`µ¢ćõ╗ČÕż╣õĖŁŃĆé + +### ÕÅ»Ķ¦åÕī¢ + +µÄ©ńÉåÕÖ©`inferencer`ÕÅ»õ╗źĶć¬ÕŖ©Õ»╣ĶŠōÕģźńÜäÕøŠÕāŵł¢Ķ¦åķóæĶ┐øĶĪīķó䵥ŗŃĆéÕÅ»Ķ¦åÕī¢ń╗ōµ×£ÕÅ»õ╗źµśŠńż║Õ£©õĖĆõĖ¬µ¢░ńÜäń¬ŚÕÅŻõĖŁ’╝īÕ╣Čõ┐ØÕŁśÕ£©µ£¼Õ£░ŃĆé + +Ķ”üÕ£©µ¢░ń¬ŚÕÅŻõĖŁµ¤źń£ŗÕÅ»Ķ¦åÕī¢ń╗ōµ×£’╝īĶ»ĘõĮ┐ńö©õ╗źõĖŗõ╗ŻńĀü’╝Ü + +Ķ»Ęµ│©µäÅ’╝Ü + +- Õ”éµ×£ĶŠōÕģźĶ¦åķóæµØźĶć¬ńĮæń╗£µæäÕāÅÕż┤’╝īķ╗śĶ«żµāģÕåĄõĖŗÕ░åÕ£©µ¢░ń¬ŚÕÅŻõĖŁµśŠńż║ÕÅ»Ķ¦åÕī¢ń╗ōµ×£’╝īõ╗źµŁżĶ«®ńö©µłĘń£ŗÕł░ĶŠōÕģź + +- Õ”éµ×£Õ╣│ÕÅ░õĖŖµ▓Īµ£ēGUI’╝īĶ┐ÖõĖ¬µŁźķ¬żÕÅ»ĶāĮõ╝ÜÕŹĪõĮÅ + +Ķ”üÕ░åÕÅ»Ķ¦åÕī¢ń╗ōµ×£õ┐ØÕŁśÕ£©µ£¼Õ£░’╝īÕÅ»õ╗źÕāÅĶ┐ÖµĀʵīćÕ«Ü`vis_out_dir`ÕÅéµĢ░: + +```python +result_generator = inferencer(img_path, vis_out_dir='vis_results') +result = next(result_generator) +``` + +ĶŠōÕģźÕøŠńē浳¢Ķ¦åķóæńÜäÕÅ»Ķ¦åÕī¢ķó䵥ŗń╗ōµ×£Õ░åõ┐ØÕŁśÕ£©`vis_results/`µ¢ćõ╗ČÕż╣õĖŁ + +Õ£©Õ╝ĆÕż┤Õ▒Ģńż║ńÜäµ╗æķø¬ÕøŠõĖŁ’╝īÕ¦┐µĆüńÜäÕÅ»Ķ¦åÕī¢õ╝░Ķ«Īń╗ōµ×£ńö▒Õģ│ķö«ńé╣’╝łńö©Õ«×Õ┐āÕ£åµÅÅń╗ś’╝ēÕÆīķ¬©µ×Č’╝łńö©ń║┐µØĪĶĪ©ńż║’╝ēń╗䵳ÉŃĆéĶ┐Öõ║øĶ¦åĶ¦ēÕģāń┤ĀńÜäķ╗śĶ«żÕż¦Õ░ÅÕÅ»ĶāĮõĖŹõ╝Üõ║¦ńö¤õ╗żõ║║µ╗ĪµäÅńÜäń╗ōµ×£ŃĆéńö©µłĘÕÅ»õ╗źõĮ┐ńö©`radius`ÕÆī`thickness`ÕÅéµĢ░µØźĶ░āµĢ┤Õ£åńÜäÕż¦Õ░ÅÕÆīń║┐ńÜäń▓Śń╗å’╝īÕ”éõĖŗµēĆńż║’╝Ü + +```python +result_generator = inferencer(img_path, show=True, radius=4, thickness=2) +result = next(result_generator) +``` + +### µÄ©ńÉåÕÖ©ÕÅéµĢ░ + +`MMPoseInferencer`µÅÉõŠøõ║åÕÉäń¦ŹĶć¬Õ«Üõ╣ēÕ¦┐µĆüõ╝░Ķ«ĪŃĆüÕÅ»Ķ¦åÕī¢ÕÆīõ┐ØÕŁśķó䵥ŗń╗ōµ×£ńÜäÕÅéµĢ░ŃĆéõĖŗķØóµś»ÕłØÕ¦ŗÕī¢µÄ©µ¢ŁÕÖ©µŚČÕÅ»ńö©ńÜäÕÅéµĢ░ÕłŚĶĪ©ÕÅŖÕ»╣Ķ┐Öõ║øÕÅéµĢ░ńÜäµÅÅĶ┐░’╝Ü + +| Argument | Description | +| ---------------- | ------------------------------------------------------------ | +| `pose2d` | µīćÕ«Ü 2D Õ¦┐µĆüõ╝░Ķ«Īµ©ĪÕ×ŗńÜ䵩ĪÕ×ŗÕł½ÕÉŹŃĆüķģŹńĮ«µ¢ćõ╗ČÕÉŹń¦░µł¢ķģŹńĮ«µ¢ćõ╗ČĶĘ»ÕŠäŃĆé | +| `pose2d_weights` | µīćÕ«Ü 2D Õ¦┐µĆüõ╝░Ķ«Īµ©ĪÕ×ŗµØāķ揵¢ćõ╗ČńÜäURLµł¢µ£¼Õ£░ĶĘ»ÕŠäŃĆé | +| `pose3d` | µīćÕ«Ü 3D Õ¦┐µĆüõ╝░Ķ«Īµ©ĪÕ×ŗńÜ䵩ĪÕ×ŗÕł½ÕÉŹŃĆüķģŹńĮ«µ¢ćõ╗ČÕÉŹń¦░µł¢ķģŹńĮ«µ¢ćõ╗ČĶĘ»ÕŠäŃĆé | +| `pose3d_weights` | µīćÕ«Ü 3D Õ¦┐µĆüõ╝░Ķ«Īµ©ĪÕ×ŗµØāķ揵¢ćõ╗ČńÜäURLµł¢µ£¼Õ£░ĶĘ»ÕŠäŃĆé | +| `det_model` | µīćÕ«ÜÕ»╣Ķ▒ĪµŻĆµĄŗµ©ĪÕ×ŗńÜ䵩ĪÕ×ŗÕł½ÕÉŹŃĆüķģŹńĮ«µ¢ćõ╗ČÕÉŹµł¢ķģŹńĮ«µ¢ćõ╗ČĶĘ»ÕŠäŃĆé | +| `det_weights` | µīćÕ«ÜÕ»╣Ķ▒ĪµŻĆµĄŗµ©ĪÕ×ŗµØāķ揵¢ćõ╗ČńÜä URL µł¢µ£¼Õ£░ĶĘ»ÕŠäŃĆé | +| `det_cat_ids` | µīćÕ«ÜõĖÄĶ”üµŻĆµĄŗńÜäÕ»╣Ķ▒Īń▒╗Õ»╣Õ║öńÜäń▒╗Õł½ id ÕłŚĶĪ©ŃĆé | +| `device` | µē¦ĶĪīµÄ©ńÉåńÜäĶ«ŠÕżćŃĆéÕ”éµ×£õĖ║ `None`’╝īµÄ©ńÉåÕÖ©Õ░åķĆēµŗ®µ£ĆÕÉłķĆéńÜäõĖĆõĖ¬ŃĆé | +| `scope` | Õ«Üõ╣ēµ©ĪÕ×ŗµ©ĪÕØŚńÜäÕÉŹń¦░ń®║ķŚ┤ | + +µÄ©ńÉåÕÖ©Ķó½Ķ«ŠĶ«Īńö©õ║ÄÕÅ»Ķ¦åÕī¢ÕÆīõ┐ØÕŁśķó䵥ŗŃĆéõ╗źõĖŗĶĪ©µĀ╝ÕłŚÕć║õ║åÕ£©õĮ┐ńö© `MMPoseInferencer` Ķ┐øĶĪīµÄ©µ¢ŁµŚČÕÅ»ńö©ńÜäÕÅéµĢ░ÕłŚĶĪ©’╝īõ╗źÕÅŖÕ«āõ╗¼õĖÄ 2D ÕÆī 3D µÄ©ńÉåÕÖ©ńÜäÕģ╝Õ«╣µĆ¦’╝Ü + +| ÕÅéµĢ░ | µÅÅĶ┐░ | 2D | 3D | +| ------------------------ | -------------------------------------------------------------------------------------------------------------------------- | --- | --- | +| `show` | µÄ¦ÕłČµś»Õɔգ©Õ╝╣Õć║ń¬ŚÕÅŻõĖŁµśŠńż║ÕøŠÕāŵł¢Ķ¦åķóæŃĆé | Ō£ö’ĖÅ | Ō£ö’ĖÅ | +| `radius` | Ķ«ŠńĮ«ÕÅ»Ķ¦åÕī¢Õģ│ķö«ńé╣ńÜäÕŹŖÕŠäŃĆé | Ō£ö’ĖÅ | Ō£ö’ĖÅ | +| `thickness` | ńĪ«Õ«ÜÕÅ»Ķ¦åÕī¢ķōŠµÄźńÜäÕÄÜÕ║”ŃĆé | Ō£ö’ĖÅ | Ō£ö’ĖÅ | +| `kpt_thr` | Ķ«ŠńĮ«Õģ│ķö«ńé╣ÕłåµĢ░ķśłÕĆ╝ŃĆéÕłåµĢ░ĶČģĶ┐浣żķśłÕĆ╝ńÜäÕģ│ķö«ńé╣Õ░åĶó½µśŠńż║ŃĆé | Ō£ö’ĖÅ | Ō£ö’ĖÅ | +| `draw_bbox` | Õå│իܵś»ÕÉ”µśŠńż║Õ«×õŠŗńÜäĶŠ╣ńĢīµĪåŃĆé | Ō£ö’ĖÅ | Ō£ö’ĖÅ | +| `draw_heatmap` | Õå│իܵś»ÕÉ”ń╗śÕłČķó䵥ŗńÜäńāŁÕøŠŃĆé | Ō£ö’ĖÅ | ŌØī | +| `black_background` | Õå│իܵś»Õɔգ©ķ╗æĶē▓ĶāīµÖ»õĖŖµśŠńż║ķóäõ╝░ńÜäÕ¦┐ÕŖ┐ŃĆé | Ō£ö’ĖÅ | ŌØī | +| `skeleton_style` | Ķ«ŠńĮ«ķ¬©µ×ȵĀĘÕ╝ÅŃĆéÕÅ»ķĆēķĪ╣Õīģµŗ¼ 'mmpose'’╝łķ╗śĶ«ż’╝ēÕÆī 'openpose'ŃĆé | Ō£ö’ĖÅ | ŌØī | +| `use_oks_tracking` | Õå│իܵś»Õɔգ©Ķ┐ĮĶĖ¬õĖŁõĮ┐ńö©OKSõĮ£õĖ║ńøĖõ╝╝Õ║”µĄŗķćÅŃĆé | ŌØī | Ō£ö’ĖÅ | +| `tracking_thr` | Ķ«ŠńĮ«Ķ┐ĮĶĖ¬ńÜäńøĖõ╝╝Õ║”ķśłÕĆ╝ŃĆé | ŌØī | Ō£ö’ĖÅ | +| `norm_pose_2d` | Õå│իܵś»ÕÉ”Õ░åĶŠ╣ńĢīµĪåń╝®µöŠĶć│µĢ░µŹ«ķøåńÜäÕ╣│ÕØćĶŠ╣ńĢīµĪåÕ░║Õ»Ė’╝īÕ╣ČÕ░åĶŠ╣ńĢīµĪåń¦╗Ķć│µĢ░µŹ«ķøåńÜäÕ╣│ÕØćĶŠ╣ńĢīµĪåõĖŁÕ┐āŃĆé | ŌØī | Ō£ö’ĖÅ | +| `rebase_keypoint_height` | Õå│իܵś»ÕÉ”Õ░åµ£ĆõĮÄÕģ│ķö«ńé╣ńÜäķ½śÕ║”ńĮ«õĖ║ 0ŃĆé | ŌØī | Ō£ö’ĖÅ | +| `return_vis` | Õå│իܵś»Õɔգ©ń╗ōµ×£õĖŁÕīģÕɽÕÅ»Ķ¦åÕī¢ÕøŠÕāÅŃĆé | Ō£ö’ĖÅ | Ō£ö’ĖÅ | +| `vis_out_dir` | Õ«Üõ╣ēõ┐ØÕŁśÕÅ»Ķ¦åÕī¢ÕøŠÕāÅńÜäµ¢ćõ╗ČÕż╣ĶĘ»ÕŠäŃĆéÕ”éµ×£µ£¬Ķ«ŠńĮ«’╝īÕ░åõĖŹõ┐ØÕŁśÕÅ»Ķ¦åÕī¢ÕøŠÕāÅŃĆé | Ō£ö’ĖÅ | Ō£ö’ĖÅ | +| `return_datasample` | Õå│իܵś»ÕÉ”õ╗ź `PoseDataSample` µĀ╝Õ╝ÅĶ┐öÕø×ķó䵥ŗŃĆé | Ō£ö’ĖÅ | Ō£ö’ĖÅ | +| `pred_out_dir` | µīćÕ«Üõ┐ØÕŁśķó䵥ŗńÜäµ¢ćõ╗ČÕż╣ĶĘ»ÕŠäŃĆéÕ”éµ×£µ£¬Ķ«ŠńĮ«’╝īÕ░åõĖŹõ┐ØÕŁśķó䵥ŗŃĆé | Ō£ö’ĖÅ | Ō£ö’ĖÅ | +| `out_dir` | Õ”éµ×£ `vis_out_dir` µł¢ `pred_out_dir` µ£¬Ķ«ŠńĮ«’╝īÕ«āõ╗¼Õ░åÕłåÕł½Ķ«ŠńĮ«õĖ║ `f'{out_dir}/visualization'` µł¢ `f'{out_dir}/predictions'`ŃĆé | Ō£ö’ĖÅ | Ō£ö’ĖÅ | + +### µ©ĪÕ×ŗÕł½ÕÉŹ + +MMPoseõĖ║ÕĖĖńö©µ©ĪÕ×ŗµÅÉõŠøõ║åõĖĆń╗äķóäÕ«Üõ╣ēńÜäÕł½ÕÉŹŃĆéÕ£©ÕłØÕ¦ŗÕī¢ `MMPoseInferencer` µŚČ’╝īĶ┐Öõ║øÕł½ÕÉŹÕÅ»õ╗źńö©õĮ£ń«ĆńĢźńÜäĶĪ©ĶŠŠµ¢╣Õ╝Å’╝īĶĆīõĖŹµś»µīćÕ«ÜÕ«īµĢ┤ńÜ䵩ĪÕ×ŗķģŹńĮ«ÕÉŹń¦░ŃĆéõĖŗķØ󵜻ÕÅ»ńö©ńÜ䵩ĪÕ×ŗÕł½ÕÉŹÕÅŖÕģČÕ»╣Õ║öńÜäķģŹńĮ«ÕÉŹń¦░ńÜäÕłŚĶĪ©’╝Ü + +| Õł½ÕÉŹ | ķģŹńĮ«µ¢ćõ╗ČÕÉŹń¦░ | Õ»╣Õ║öõ╗╗ÕŖĪ | Õ¦┐µĆüõ╝░Ķ«Īµ©ĪÕ×ŗ | µŻĆµĄŗµ©ĪÕ×ŗ | +| --------- | -------------------------------------------------- | ------------------------------- | ------------- | ------------------- | +| animal | rtmpose-m_8xb64-210e_ap10k-256x256 | Animal pose estimation | RTMPose-m | RTMDet-m | +| human | rtmpose-m_8xb256-420e_aic-coco-256x192 | Human pose estimation | RTMPose-m | RTMDet-m | +| face | rtmpose-m_8xb64-60e_wflw-256x256 | Face keypoint detection | RTMPose-m | yolox-s | +| hand | rtmpose-m_8xb32-210e_coco-wholebody-hand-256x256 | Hand keypoint detection | RTMPose-m | ssdlite_mobilenetv2 | +| wholebody | rtmpose-m_8xb64-270e_coco-wholebody-256x192 | Human wholebody pose estimation | RTMPose-m | RTMDet-m | +| vitpose | td-hm_ViTPose-base-simple_8xb64-210e_coco-256x192 | Human pose estimation | ViTPose-base | RTMDet-m | +| vitpose-s | td-hm_ViTPose-small-simple_8xb64-210e_coco-256x192 | Human pose estimation | ViTPose-small | RTMDet-m | +| vitpose-b | td-hm_ViTPose-base-simple_8xb64-210e_coco-256x192 | Human pose estimation | ViTPose-base | RTMDet-m | +| vitpose-l | td-hm_ViTPose-large-simple_8xb64-210e_coco-256x192 | Human pose estimation | ViTPose-large | RTMDet-m | +| vitpose-h | td-hm_ViTPose-huge-simple_8xb64-210e_coco-256x192 | Human pose estimation | ViTPose-huge | RTMDet-m | + +µŁżÕż¢’╝īńö©µłĘÕÅ»õ╗źõĮ┐ńö©ÕæĮõ╗żĶĪīńĢīķØóÕĘźÕģʵśŠńż║µēƵ£ēÕÅ»ńö©ńÜäÕł½ÕÉŹ’╝īõĮ┐ńö©õ╗źõĖŗÕæĮõ╗ż: + +```shell +python demo/inferencer_demo.py --show-alias +``` diff --git a/internlm_langchain/knowledge_base/MMPose/content/installation.md b/internlm_langchain/knowledge_base/MMPose/content/installation.md new file mode 100644 index 00000000..ef515c80 --- /dev/null +++ b/internlm_langchain/knowledge_base/MMPose/content/installation.md @@ -0,0 +1,248 @@ +# Õ«ēĶŻģ + +µłæõ╗¼µÄ©ĶŹÉńö©µłĘµīēńģ¦µłæõ╗¼ńÜäµ£ĆõĮ│Õ«×ĶĘĄµØźÕ«ēĶŻģ MMPoseŃĆéõĮåķÖżµŁżõ╣ŗÕż¢’╝īÕ”éµ×£µé©µā│µĀ╣µŹ« +µé©ńÜäõ╣Āµā»Õ«īµłÉÕ«ēĶŻģµĄüń©ŗ’╝īõ╣¤ÕÅ»õ╗źÕÅéĶ¦ü [Ķć¬Õ«Üõ╣ēÕ«ēĶŻģ](#Ķć¬Õ«Üõ╣ēÕ«ēĶŻģ) õĖĆĶŖéµØźĶÄĘÕÅ¢µø┤ÕżÜõ┐Īµü»ŃĆé + +- [Õ«ēĶŻģ](#Õ«ēĶŻģ) + - [õŠØĶĄ¢ńÄ»Õóā](#õŠØĶĄ¢ńÄ»Õóā) + - [µ£ĆõĮ│Õ«×ĶĘĄ](#µ£ĆõĮ│Õ«×ĶĘĄ) + - [õ╗ĵ║ÉńĀüÕ«ēĶŻģ MMPose](#õ╗ĵ║ÉńĀüÕ«ēĶŻģ-mmpose) + - [õĮ£õĖ║ Python ÕīģÕ«ēĶŻģ](#õĮ£õĖ║-python-ÕīģÕ«ēĶŻģ) + - [ķ¬īĶ»üÕ«ēĶŻģ](#ķ¬īĶ»üÕ«ēĶŻģ) + - [Ķć¬Õ«Üõ╣ēÕ«ēĶŻģ](#Ķć¬Õ«Üõ╣ēÕ«ēĶŻģ) + - [CUDA ńēłµ£¼](#cuda-ńēłµ£¼) + - [õĖŹõĮ┐ńö© MIM Õ«ēĶŻģ MMEngine](#õĖŹõĮ┐ńö©-mim-Õ«ēĶŻģ-mmengine) + - [Õ£© CPU ńÄ»ÕóāõĖŁÕ«ēĶŻģ](#Õ£©-cpu-ńÄ»ÕóāõĖŁÕ«ēĶŻģ) + - [Õ£© Google Colab õĖŁÕ«ēĶŻģ](#Õ£©-google-colab-õĖŁÕ«ēĶŻģ) + - [ķĆÜĶ┐ć Docker õĮ┐ńö© MMPose](#ķĆÜĶ┐ć-docker-õĮ┐ńö©-mmpose) + - [µĢģķÜ£Ķ¦ŻÕå│](#µĢģķÜ£Ķ¦ŻÕå│) + +## õŠØĶĄ¢ńÄ»Õóā + +Õ£©µ£¼ĶŖéõĖŁ’╝īµłæõ╗¼Õ░åµ╝öńż║Õ”éõĮĢÕćåÕżć PyTorch ńøĖÕģ│ńÜäõŠØĶĄ¢ńÄ»ÕóāŃĆé + +MMPose ķĆéńö©õ║Ä LinuxŃĆüWindows ÕÆī macOSŃĆéÕ«āķ£ĆĶ”ü Python 3.7+ŃĆüCUDA 9.2+ ÕÆī PyTorch 1.8+ŃĆé + +Õ”éµ×£µé©Õ»╣ķģŹńĮ« PyTorch ńÄ»ÕóāÕĘ▓ń╗ÅÕŠłń夵éē’╝īÕ╣ČõĖöÕĘ▓ń╗ÅÕ«īµłÉõ║åķģŹńĮ«’╝īÕÅ»õ╗źńø┤µÄźĶ┐øÕģźõĖŗõĖĆĶŖé’╝Ü[Õ«ēĶŻģ](#Õ«ēĶŻģ-mmpose)ŃĆéÕÉ”ÕłÖ’╝īĶ»ĘõŠØńģ¦õ╗źõĖŗµŁźķ¬żÕ«īµłÉķģŹńĮ«ŃĆé + +**ń¼¼ 1 µŁź** õ╗Ä[Õ«śńĮæ](https://docs.conda.io/en/latest/miniconda.html) õĖŗĶĮĮÕ╣ČÕ«ēĶŻģ MinicondaŃĆé + +**ń¼¼ 2 µŁź** ÕłøÕ╗║õĖĆõĖ¬ conda ĶÖܵŗ¤ńÄ»ÕóāÕ╣ȵ┐Ƶ┤╗Õ«āŃĆé + +```shell +conda create --name openmmlab python=3.8 -y +conda activate openmmlab +``` + +**ń¼¼ 3 µŁź** µīēńģ¦[Õ«śµ¢╣µīćÕŹŚ](https://pytorch.org/get-started/locally/) Õ«ēĶŻģ PyTorchŃĆéõŠŗÕ”é’╝Ü + +Õ£© GPU Õ╣│ÕÅ░’╝Ü + +```shell +conda install pytorch torchvision -c pytorch +``` + +```{warning} +õ╗źõĖŖÕæĮõ╗żõ╝ÜĶć¬ÕŖ©Õ«ēĶŻģµ£Ćµ¢░ńēłńÜä PyTorch õĖÄÕ»╣Õ║öńÜä cudatoolkit’╝īĶ»ĘµŻĆµ¤źÕ«āõ╗¼µś»ÕÉ”õĖĵé©ńÜäńÄ»ÕóāÕī╣ķģŹŃĆé +``` + +Õ£© CPU Õ╣│ÕÅ░’╝Ü + +```shell +conda install pytorch torchvision cpuonly -c pytorch +``` + +**ń¼¼ 4 µŁź** õĮ┐ńö© [MIM](https://github.com/open-mmlab/mim) Õ«ēĶŻģ [MMEngine](https://github.com/open-mmlab/mmengine) ÕÆī [MMCV](https://github.com/open-mmlab/mmcv/tree/2.x) + +```shell +pip install -U openmim +mim install mmengine +mim install "mmcv>=2.0.1" +``` + +Ķ»Ęµ│©µäÅ’╝īMMPose õĖŁńÜäõĖĆõ║øµÄ©ńÉåńż║õŠŗĶäܵ£¼ķ£ĆĶ”üõĮ┐ńö© [MMDetection](https://github.com/open-mmlab/mmdetection) (mmdet) µŻĆµĄŗõ║║õĮōŃĆéÕ”éµ×£µé©µā│Ķ┐ÉĶĪīĶ┐Öõ║øńż║õŠŗĶäܵ£¼’╝īÕÅ»õ╗źķĆÜĶ┐ćĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗żÕ«ēĶŻģ mmdet: + +```shell +mim install "mmdet>=3.1.0" +``` + +## µ£ĆõĮ│Õ«×ĶĘĄ + +µĀ╣µŹ«ÕģĘõĮōķ£Ćµ▒é’╝īµłæõ╗¼µö»µīüõĖżń¦ŹÕ«ēĶŻģµ©ĪÕ╝Å: õ╗ĵ║ÉńĀüÕ«ēĶŻģ’╝łµÄ©ĶŹÉ’╝ēÕÆīõĮ£õĖ║ Python ÕīģÕ«ēĶŻģ + +### õ╗ĵ║ÉńĀüÕ«ēĶŻģ’╝łµÄ©ĶŹÉ’╝ē + +Õ”éµ×£Õ¤║õ║Ä MMPose µĪåµ×ČÕ╝ĆÕÅæĶć¬ÕĘ▒ńÜäõ╗╗ÕŖĪ’╝īķ£ĆĶ”üµĘ╗ÕŖĀµ¢░ńÜäÕŖ¤ĶāĮ’╝īµ»öՔ鵢░ńÜ䵩ĪÕ×ŗµł¢µś»µĢ░µŹ«ķøå’╝īµł¢ĶĆģõĮ┐ńö©µłæõ╗¼µÅÉõŠøńÜäÕÉäń¦ŹÕĘźÕģĘŃĆéõ╗ĵ║ÉńĀüµīēÕ”éõĖŗµ¢╣Õ╝ÅÕ«ēĶŻģ mmpose’╝Ü + +```shell +git clone https://github.com/open-mmlab/mmpose.git +cd mmpose +pip install -r requirements.txt +pip install -v -e . +# "-v" ĶĪ©ńż║ĶŠōÕć║µø┤ÕżÜÕ«ēĶŻģńøĖÕģ│ńÜäõ┐Īµü» +# "-e" ĶĪ©ńż║õ╗źÕÅ»ń╝¢ĶŠæÕĮóÕ╝ÅÕ«ēĶŻģ’╝īĶ┐ÖµĀĘÕÅ»õ╗źÕ£©õĖŹķ揵¢░Õ«ēĶŻģńÜäµāģÕåĄõĖŗ’╝īĶ«®µ£¼Õ£░õ┐«µö╣ńø┤µÄźńö¤µĢł +``` + +### õĮ£õĖ║ Python ÕīģÕ«ēĶŻģ + +Õ”éµ×£ÕŬµś»ÕĖīµ£øĶ░āńö© MMPose ńÜäµÄźÕÅŻ’╝īµł¢ĶĆģÕ£©Ķć¬ÕĘ▒ńÜäķĪ╣ńø«õĖŁÕ»╝Õģź MMPose õĖŁńÜ䵩ĪÕØŚŃĆéńø┤µÄźõĮ┐ńö© mim Õ«ēĶŻģÕŹ│ÕÅ»ŃĆé + +```shell +mim install "mmpose>=1.1.0" +``` + +## ķ¬īĶ»üÕ«ēĶŻģ + +õĖ║õ║åķ¬īĶ»ü MMPose µś»ÕɔիēĶŻģµŁŻńĪ«’╝īµé©ÕÅ»õ╗źķĆÜĶ┐ćõ╗źõĖŗµŁźķ¬żĶ┐ÉĶĪīµ©ĪÕ×ŗµÄ©ńÉåŃĆé + +**ń¼¼ 1 µŁź** µłæõ╗¼ķ£ĆĶ”üõĖŗĶĮĮķģŹńĮ«µ¢ćõ╗ČÕÆīµ©ĪÕ×ŗµØāķ揵¢ćõ╗Č + +```shell +mim download mmpose --config td-hm_hrnet-w48_8xb32-210e_coco-256x192 --dest . +``` + +õĖŗĶĮĮĶ┐ćń©ŗÕŠĆÕŠĆķ£ĆĶ”üÕćĀń¦Æµł¢µø┤ÕżÜńÜ䵌ČķŚ┤’╝īĶ┐ÖÕÅ¢Õå│õ║ĵé©ńÜäńĮæń╗£ńÄ»ÕóāŃĆéÕ«īµłÉõ╣ŗÕÉÄ’╝īµé©õ╝ÜÕ£©ÕĮōÕēŹńø«ÕĮĢõĖŗµēŠÕł░Ķ┐ÖõĖżõĖ¬µ¢ćõ╗Č’╝Ü`td-hm_hrnet-w48_8xb32-210e_coco-256x192.py` ÕÆī `hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth`, ÕłåÕł½µś»ķģŹńĮ«µ¢ćõ╗ČÕÆīÕ»╣Õ║öńÜ䵩ĪÕ×ŗµØāķ揵¢ćõ╗ČŃĆé + +**ń¼¼ 2 µŁź** ķ¬īĶ»üµÄ©ńÉåńż║õŠŗ + +Õ”éµ×£µé©µś»**õ╗ĵ║ÉńĀüÕ«ēĶŻģ**ńÜä mmpose’╝īÕÅ»õ╗źńø┤µÄźĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗żĶ┐øĶĪīķ¬īĶ»ü’╝Ü + +```shell +python demo/image_demo.py \ + tests/data/coco/000000000785.jpg \ + td-hm_hrnet-w48_8xb32-210e_coco-256x192.py \ + hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth \ + --out-file vis_results.jpg \ + --draw-heatmap +``` + +Õ”éµ×£õĖĆÕłćķĪ║Õł®’╝īµé©Õ░åõ╝ÜÕŠŚÕł░Ķ┐ÖµĀĘńÜäÕÅ»Ķ¦åÕī¢ń╗ōµ×£’╝Ü + + + +õ╗ŻńĀüõ╝ÜÕ░åķó䵥ŗńÜäÕģ│ķö«ńé╣ÕÆīńāŁÕøŠń╗śÕłČÕ£©ÕøŠÕāÅõĖŁńÜäõ║║õĮōõĖŖ’╝īÕ╣Čõ┐ØÕŁśÕł░ÕĮōÕēŹµ¢ćõ╗ČÕż╣õĖŗńÜä `vis_results.jpg`ŃĆé + +Õ”éµ×£µé©µś»**õĮ£õĖ║ Python ÕīģÕ«ēĶŻģ**’╝īÕÅ»õ╗źµēōÕ╝Ƶé©ńÜä Python Ķ¦ŻķćŖÕÖ©’╝īÕżŹÕłČÕ╣Čń▓śĶ┤┤Õ”éõĖŗõ╗ŻńĀü’╝Ü + +```python +from mmpose.apis import inference_topdown, init_model +from mmpose.utils import register_all_modules + +register_all_modules() + +config_file = 'td-hm_hrnet-w48_8xb32-210e_coco-256x192.py' +checkpoint_file = 'hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth' +model = init_model(config_file, checkpoint_file, device='cpu') # or device='cuda:0' + +# Ķ»ĘÕćåÕżćÕźĮõĖĆÕ╝ĀÕĖ”µ£ēõ║║õĮōńÜäÕøŠńēć +results = inference_topdown(model, 'demo.jpg') +``` + +ńż║õŠŗÕøŠńēć `demo.jpg` ÕÅ»õ╗źõ╗Ä [Github](https://raw.githubusercontent.com/open-mmlab/mmpose/main/tests/data/coco/000000000785.jpg) õĖŗĶĮĮŃĆé +µÄ©ńÉåń╗ōµ×£µś»õĖĆõĖ¬ `PoseDataSample` ÕłŚĶĪ©’╝īķó䵥ŗń╗ōµ×£Õ░åõ╝Üõ┐ØÕŁśÕ£© `pred_instances` õĖŁ’╝īÕīģµŗ¼µŻĆµĄŗÕł░ńÜäÕģ│ķö«ńé╣õĮŹńĮ«ÕÆīńĮ«õ┐ĪÕ║”ŃĆé + +## Ķć¬Õ«Üõ╣ēÕ«ēĶŻģ + +### CUDA ńēłµ£¼ + +Õ«ēĶŻģ PyTorch µŚČ’╝īķ£ĆĶ”üµīćÕ«Ü CUDA ńēłµ£¼ŃĆéÕ”éµ×£µé©õĖŹµĖģµźÜķĆēµŗ®Õō¬õĖ¬’╝īĶ»ĘķüĄÕŠ¬µłæõ╗¼ńÜäÕ╗║Ķ««’╝Ü + +- Õ»╣õ║Ä Ampere µ×ȵ×äńÜä NVIDIA GPU’╝īõŠŗÕ”é GeForce 30 ń│╗ÕłŚ õ╗źÕÅŖ NVIDIA A100’╝īCUDA 11 µś»Õ┐ģķ£ĆńÜäŃĆé +- Õ»╣õ║ĵø┤µŚ®ńÜä NVIDIA GPU’╝īCUDA 11 µś»ÕÉæÕÉÄÕģ╝Õ«╣ (backward compatible) ńÜä’╝īõĮå CUDA 10.2 ĶāĮÕż¤µÅÉõŠøµø┤ÕźĮńÜäÕģ╝Õ«╣µĆ¦’╝īõ╣¤µø┤ÕŖĀĶĮ╗ķćÅŃĆé + +Ķ»ĘńĪ«õ┐صé©ńÜä GPU ķ®▒ÕŖ©ńēłµ£¼µ╗ĪĶČ│µ£ĆõĮÄńÜäńēłµ£¼ķ£Ćµ▒é’╝īÕÅéķśģ[Ķ┐ÖÕ╝ĀĶĪ©](https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html#cuda-major-component-versions__table-cuda-toolkit-driver-versions)ŃĆé + +```{note} +Õ”éµ×£µīēńģ¦µłæõ╗¼ńÜäµ£ĆõĮ│Õ«×ĶĘĄĶ┐øĶĪīÕ«ēĶŻģ’╝īCUDA Ķ┐ÉĶĪīµŚČÕ║ōÕ░▒ĶČ│Õż¤õ║å’╝īÕøĀõĖ║µłæõ╗¼µÅÉõŠøńøĖÕģ│ CUDA õ╗ŻńĀüńÜäķóäń╝¢Ķ»æ’╝īµé©õĖŹķ£ĆĶ”üĶ┐øĶĪīµ£¼Õ£░ń╝¢Ķ»æŃĆé +õĮåÕ”éµ×£µé©ÕĖīµ£øõ╗ĵ║ÉńĀüĶ┐øĶĪī MMCV ńÜäń╝¢Ķ»æ’╝īµł¢µś»Ķ┐øĶĪīÕģČõ╗¢ CUDA ń«ŚÕŁÉńÜäÕ╝ĆÕÅæ’╝īķéŻõ╣łÕ░▒Õ┐ģķĪ╗Õ«ēĶŻģÕ«īµĢ┤ńÜä CUDA ÕĘźÕģĘķōŠ’╝īÕÅéĶ¦ü +[NVIDIA Õ«śńĮæ](https://developer.nvidia.com/cuda-downloads)’╝īÕÅ”Õż¢Ķ┐śķ£ĆĶ”üńĪ«õ┐ØĶ»ź CUDA ÕĘźÕģĘķōŠńÜäńēłµ£¼õĖÄ PyTorch Õ«ēĶŻģµŚČ +ńÜäķģŹńĮ«ńøĖÕī╣ķģŹ’╝łÕ”éńö© `conda install` Õ«ēĶŻģ PyTorch µŚČµīćÕ«ÜńÜä cudatoolkit ńēłµ£¼’╝ēŃĆé +``` + +### õĖŹõĮ┐ńö© MIM Õ«ēĶŻģ MMEngine + +ĶŗźõĖŹõĮ┐ńö© mim Õ«ēĶŻģ MMEngine’╝īĶ»ĘķüĄÕŠ¬ [ MMEngine Õ«ēĶŻģµīćÕŹŚ](https://mmengine.readthedocs.io/zh_CN/latest/get_started/installation.html). + +õŠŗÕ”é’╝īµé©ÕÅ»õ╗źķĆÜĶ┐ćõ╗źõĖŗÕæĮõ╗żÕ«ēĶŻģ MMEngine: + +```shell +pip install mmengine +``` + +### õĖŹõĮ┐ńö© MIM Õ«ēĶŻģ MMCV + +MMCV ÕīģÕɽ C++ ÕÆī CUDA µē®Õ▒Ģ’╝īÕøĀµŁżÕģČÕ»╣ PyTorch ńÜäõŠØĶĄ¢µ»öĶŠāÕżŹµØéŃĆéMIM õ╝ÜĶć¬ÕŖ©Ķ¦Żµ×ÉĶ┐Öõ║ø +õŠØĶĄ¢’╝īķĆēµŗ®ÕÉłķĆéńÜä MMCV ķóäń╝¢Ķ»æÕīģ’╝īõĮ┐Õ«ēĶŻģµø┤ń«ĆÕŹĢ’╝īõĮåÕ«āÕ╣ČõĖŹµś»Õ┐ģķ£ĆńÜäŃĆé + +ĶŗźõĖŹõĮ┐ńö© mim µØźÕ«ēĶŻģ MMCV’╝īĶ»ĘķüĄńģ¦ [MMCV Õ«ēĶŻģµīćÕŹŚ](https://mmcv.readthedocs.io/zh_CN/2.x/get_started/installation.html)ŃĆé +Õ«āķ£ĆĶ”üµé©ńö©µīćÕ«Ü url ńÜäÕĮóÕ╝ŵēŗÕŖ©µīćÕ«ÜÕ»╣Õ║öńÜä PyTorch ÕÆī CUDA ńēłµ£¼ŃĆé + +õĖŠõĖ¬õŠŗÕŁÉ’╝īÕ”éõĖŗÕæĮõ╗żÕ░åõ╝ÜÕ«ēĶŻģÕ¤║õ║Ä PyTorch 1.10.x ÕÆī CUDA 11.3 ń╝¢Ķ»æńÜä mmcvŃĆé + +```shell +pip install 'mmcv>=2.0.1' -f https://download.openmmlab.com/mmcv/dist/cu113/torch1.10/index.html +``` + +### Õ£© CPU ńÄ»ÕóāõĖŁÕ«ēĶŻģ + +MMPose ÕÅ»õ╗źõ╗ģÕ£© CPU ńÄ»ÕóāõĖŁÕ«ēĶŻģ’╝īÕ£© CPU µ©ĪÕ╝ÅõĖŗ’╝īµé©ÕÅ»õ╗źÕ«īµłÉĶ«Łń╗āŃĆüµĄŗĶ»ĢÕÆīµ©ĪÕ×ŗµÄ©ńÉåńŁēµēƵ£ēµōŹõĮ£ŃĆé + +Õ£© CPU µ©ĪÕ╝ÅõĖŗ’╝īMMCV ńÜäķā©ÕłåÕŖ¤ĶāĮÕ░åõĖŹÕÅ»ńö©’╝īķĆÜÕĖĖµś»õĖĆõ║ø GPU ń╝¢Ķ»æńÜäń«ŚÕŁÉ’╝īÕ”é `Deformable Convolution`ŃĆéMMPose õĖŁÕż¦ķā©ÕłåńÜ䵩ĪÕ×ŗķāĮõĖŹõ╝ÜõŠØĶĄ¢Ķ┐Öõ║øń«ŚÕŁÉ’╝īõĮåµś»Õ”éµ×£µé©Õ░ØĶ»ĢõĮ┐ńö©ÕīģÕɽĶ┐Öõ║øń«ŚÕŁÉńÜ䵩ĪÕ×ŗµØźĶ┐ÉĶĪīĶ«Łń╗āŃĆüµĄŗĶ»Ģµł¢µÄ©ńÉå’╝īÕ░åõ╝ܵŖźķöÖŃĆé + +### Õ£© Google Colab õĖŁÕ«ēĶŻģ + +[Google Colab](https://colab.research.google.com/) ķĆÜÕĖĖÕĘ▓ń╗ÅÕīģÕɽõ║å PyTorch ńÄ»Õóā’╝īÕøĀµŁżµłæõ╗¼ÕŬķ£ĆĶ”üÕ«ēĶŻģ MMEngine, MMCV ÕÆī MMPose ÕŹ│ÕÅ»’╝īÕæĮõ╗żÕ”éõĖŗ’╝Ü + +**ń¼¼ 1 µŁź** õĮ┐ńö© [MIM](https://github.com/open-mmlab/mim) Õ«ēĶŻģ [MMEngine](https://github.com/open-mmlab/mmengine) ÕÆī [MMCV](https://github.com/open-mmlab/mmcv/tree/2.x) + +```shell +!pip3 install openmim +!mim install mmengine +!mim install "mmcv>=2.0.1" +``` + +**ń¼¼ 2 µŁź** õ╗ĵ║ÉńĀüÕ«ēĶŻģ mmpose + +```shell +!git clone https://github.com/open-mmlab/mmpose.git +%cd mmpose +!pip install -e . +``` + +**ń¼¼ 3 µŁź** ķ¬īĶ»ü + +```python +import mmpose +print(mmpose.__version__) +# ķóäµ£¤ĶŠōÕć║’╝Ü 1.1.0 +``` + +```{note} +Õ£© Jupyter õĖŁ’╝īµä¤ÕÅ╣ÕÅĘ `!` ńö©õ║ĵē¦ĶĪīÕż¢ķā©ÕæĮõ╗ż’╝īĶĆī `%cd` µś»õĖĆõĖ¬[ķŁöµ£»ÕæĮõ╗ż](https://ipython.readthedocs.io/en/stable/interactive/magics.html#magic-cd)’╝īńö©õ║ÄÕłćµŹó Python ńÜäÕĘźõĮ£ĶĘ»ÕŠäŃĆé +``` + +### ķĆÜĶ┐ć Docker õĮ┐ńö© MMPose + +MMPose µÅÉõŠø [Dockerfile](https://github.com/open-mmlab/mmpose/blob/master/docker/Dockerfile) +ńö©õ║ĵ×äÕ╗║ķĢ£ÕāÅŃĆéĶ»ĘńĪ«õ┐صé©ńÜä [Docker ńēłµ£¼](https://docs.docker.com/engine/install/) >=19.03ŃĆé + +```shell +# µ×äÕ╗║ķ╗śĶ«żńÜä PyTorch 1.8.0’╝īCUDA 10.1 ńēłµ£¼ķĢ£ÕāÅ +# Õ”éµ×£µé©ÕĖīµ£øõĮ┐ńö©ÕģČõ╗¢ńēłµ£¼’╝īĶ»Ęõ┐«µö╣ Dockerfile +docker build -t mmpose docker/ +``` + +**µ│©µäÅ**’╝ÜĶ»ĘńĪ«õ┐صé©ÕĘ▓ń╗ÅÕ«ēĶŻģõ║å [nvidia-container-toolkit](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html#docker)ŃĆé + +ńö©õ╗źõĖŗÕæĮõ╗żĶ┐ÉĶĪī Docker ķĢ£ÕāÅ’╝Ü + +```shell +docker run --gpus all --shm-size=8g -it -v {DATA_DIR}:/mmpose/data mmpose +``` + +`{DATA_DIR}` µś»µé©µ£¼Õ£░ÕŁśµöŠńö©õ║Ä MMPose Ķ«Łń╗āŃĆüµĄŗĶ»ĢŃĆüµÄ©ńÉåńŁēµĄüń©ŗńÜäµĢ░µŹ«ńø«ÕĮĢŃĆé + +## µĢģķÜ£Ķ¦ŻÕå│ + +Õ”éµ×£µé©Õ£©Õ«ēĶŻģĶ┐ćń©ŗõĖŁķüćÕł░õ║åõ╗Ćõ╣łķŚ«ķóś’╝īĶ»ĘÕģłµ¤źķśģ[ÕĖĖĶ¦üķŚ«ķóś](faq.md)ŃĆéÕ”éµ×£µ▓Īµ£ēµēŠÕł░Ķ¦ŻÕå│µ¢╣µ│Ģ’╝īÕÅ»õ╗źÕ£© GitHub +õĖŖ[µÅÉÕć║ issue](https://github.com/open-mmlab/mmpose/issues/new/choose)ŃĆé diff --git a/internlm_langchain/knowledge_base/MMPose/content/label_studio.md b/internlm_langchain/knowledge_base/MMPose/content/label_studio.md new file mode 100644 index 00000000..94cbd641 --- /dev/null +++ b/internlm_langchain/knowledge_base/MMPose/content/label_studio.md @@ -0,0 +1,76 @@ +# Label Studio µĀćµ│©ÕĘźÕģĘĶĮ¼COCOĶäܵ£¼ + +[Label Studio](https://labelstud.io/) µś»õĖƵ¼ŠÕ╣┐ÕÅŚµ¼óĶ┐ÄńÜäµĘ▒Õ║”ÕŁ”õ╣ĀµĀćµ│©ÕĘźÕģĘ’╝īÕÅ»õ╗źÕ»╣ÕżÜń¦Źõ╗╗ÕŖĪĶ┐øĶĪīµĀćµ│©’╝īńäČĶĆīÕ»╣õ║ÄÕģ│ķö«ńé╣µĀćµ│©’╝īLabel Studio µŚĀµ│Ģńø┤µÄźÕ»╝Õć║µłÉ MMPose µēĆķ£ĆĶ”üńÜä COCO µĀ╝Õ╝ÅŃĆéµ£¼µ¢ćÕ░åõ╗ŗń╗ŹÕ”éõĮĢõĮ┐ńö©Label Studio µĀćµ│©Õģ│ķö«ńé╣µĢ░µŹ«’╝īÕ╣ČÕł®ńö© [labelstudio2coco.py](../../../tools/dataset_converters/labelstudio2coco.py) ÕĘźÕģĘÕ░åÕģČĶĮ¼µŹóõĖ║Ķ«Łń╗āµēĆķ£ĆńÜäµĀ╝Õ╝ÅŃĆé + +## Label Studio µĀćµ│©Ķ”üµ▒é + +µĀ╣µŹ« COCO µĀ╝Õ╝ÅńÜäĶ”üµ▒é’╝īµ»ÅõĖ¬µĀćµ│©ńÜäÕ«×õŠŗõĖŁķāĮķ£ĆĶ”üÕīģÕɽÕģ│ķö«ńé╣ŃĆüÕłåÕē▓ÕÆī bbox ńÜäõ┐Īµü»’╝īńäČĶĆī Label Studio Õ£©µĀćµ│©µŚČõ╝ÜÕ░åĶ┐Öõ║øõ┐Īµü»ÕłåµĢŻÕ£©õĖŹÕÉīńÜäÕ«×õŠŗõĖŁ’╝īÕøĀµŁżķ£ĆĶ”üµīēõĖĆÕ«ÜĶ¦äÕłÖĶ┐øĶĪīµĀćµ│©’╝īµēŹĶāĮµŁŻÕĖĖõĮ┐ńö©ÕÉÄń╗ŁńÜäĶäܵ£¼ŃĆé + +1. µĀćńŁŠµÄźÕÅŻĶ«ŠńĮ« + +Õ»╣õ║ÄõĖĆõĖ¬µ¢░Õ╗║ńÜä Label Studio ķĪ╣ńø«’╝īķ”¢ÕģłĶ”üĶ«ŠńĮ«Õ«āńÜäµĀćńŁŠµÄźÕÅŻŃĆéĶ┐Öķćīķ£ĆĶ”üµ£ēõĖēń¦Źń▒╗Õ×ŗńÜäµĀćµ│©’╝Ü`KeyPointLabels`ŃĆü`PolygonLabels`ŃĆü`RectangleLabels`’╝īÕłåÕł½Õ»╣Õ║ö COCO µĀ╝Õ╝ÅõĖŁńÜä`keypoints`ŃĆü`segmentation`ŃĆü`bbox`ŃĆéõ╗źõĖŗµś»õĖĆõĖ¬µĀćńŁŠµÄźÕÅŻńÜäńż║õŠŗ’╝īÕÅ»õ╗źÕ£©ķĪ╣ńø«ńÜä`Settings`õĖŁµēŠÕł░`Labeling Interface`’╝īńé╣Õć╗`Code`’╝īń▓śĶ┤┤õĮ┐ńö©Ķ»źńż║õŠŗŃĆé + +```xml +
+
+
+
+
+
+
+
+
+
+
+```
+
+2. µĀćµ│©ķĪ║Õ║Å
+
+ńö▒õ║Äķ£ĆĶ”üÕ░åÕżÜõĖ¬µĀćµ│©Õ«×õŠŗõĖŁńÜäõĖŹÕÉīń▒╗Õ×ŗµĀćµ│©ń╗äÕÉłÕł░õĖĆõĖ¬Õ«×õŠŗõĖŁ’╝īÕøĀµŁżķććÕÅ¢õ║åµīēńē╣Õ«ÜķĪ║Õ║ŵĀćµ│©ńÜäµ¢╣Õ╝Å’╝īõ╗źµŁżµØźÕłżµ¢ŁÕÉäµĀćµ│©µś»ÕÉ”õĮŹõ║ÄÕÉīõĖĆõĖ¬Õ«×õŠŗŃĆéµĀćµ│©µŚČķĪ╗µīēńģ¦ **KeyPointLabels -> PolygonLabels/RectangleLabels** ńÜäķĪ║Õ║ŵĀćµ│©’╝īÕģČõĖŁ KeyPointLabels ńÜäķĪ║Õ║ÅÕÆīµĢ░ķćÅĶ”üõĖÄ MMPose ķģŹńĮ«µ¢ćõ╗ČõĖŁńÜä`dataset_info`ńÜäÕģ│ķö«ńé╣ķĪ║Õ║ÅÕÆīµĢ░ķćÅõĖĆĶć┤’╝ī PolygonLabels ÕÆī RectangleLabels ńÜäµĀćµ│©ķĪ║Õ║ÅÕÅ»õ╗źõ║ƵŹó’╝īõĖöÕÅ»õ╗źÕŬµĀćµ│©ÕģČõĖŁõĖĆõĖ¬’╝īÕŬĶ”üõ┐ØĶ»üõĖĆõĖ¬Õ«×õŠŗńÜäµĀćµ│©õĖŁ’╝īõ╗źÕģ│ķö«ńé╣Õ╝ĆÕ¦ŗ’╝īõ╗źķØ×Õģ│ķö«ńé╣ń╗ōµØ¤ÕŹ│ÕÅ»ŃĆéõĖŗÕøŠõĖ║µĀćµ│©ńÜäńż║õŠŗ’╝Ü
+
+*µ│©’╝Übbox ÕÆī area õ╝ܵĀ╣µŹ«ķØĀÕÉÄńÜä PolygonLabels/RectangleLabels µØźĶ«Īń«Ś’╝īÕ”éĶŗźÕģłµĀć PolygonLabels’╝īķéŻõ╣łbboxõ╝ܵś»ķØĀÕÉÄńÜä RectangleLabels ńÜäĶīāÕø┤’╝īķØóń¦»õĖ║ń¤®ÕĮóńÜäķØóń¦»’╝īÕÅŹõ╣ŗÕłÖµś»ÕżÜĶŠ╣ÕĮóÕż¢µÄźń¤®ÕĮóÕÆīÕżÜĶŠ╣ÕĮóńÜäķØóń¦»*
+
+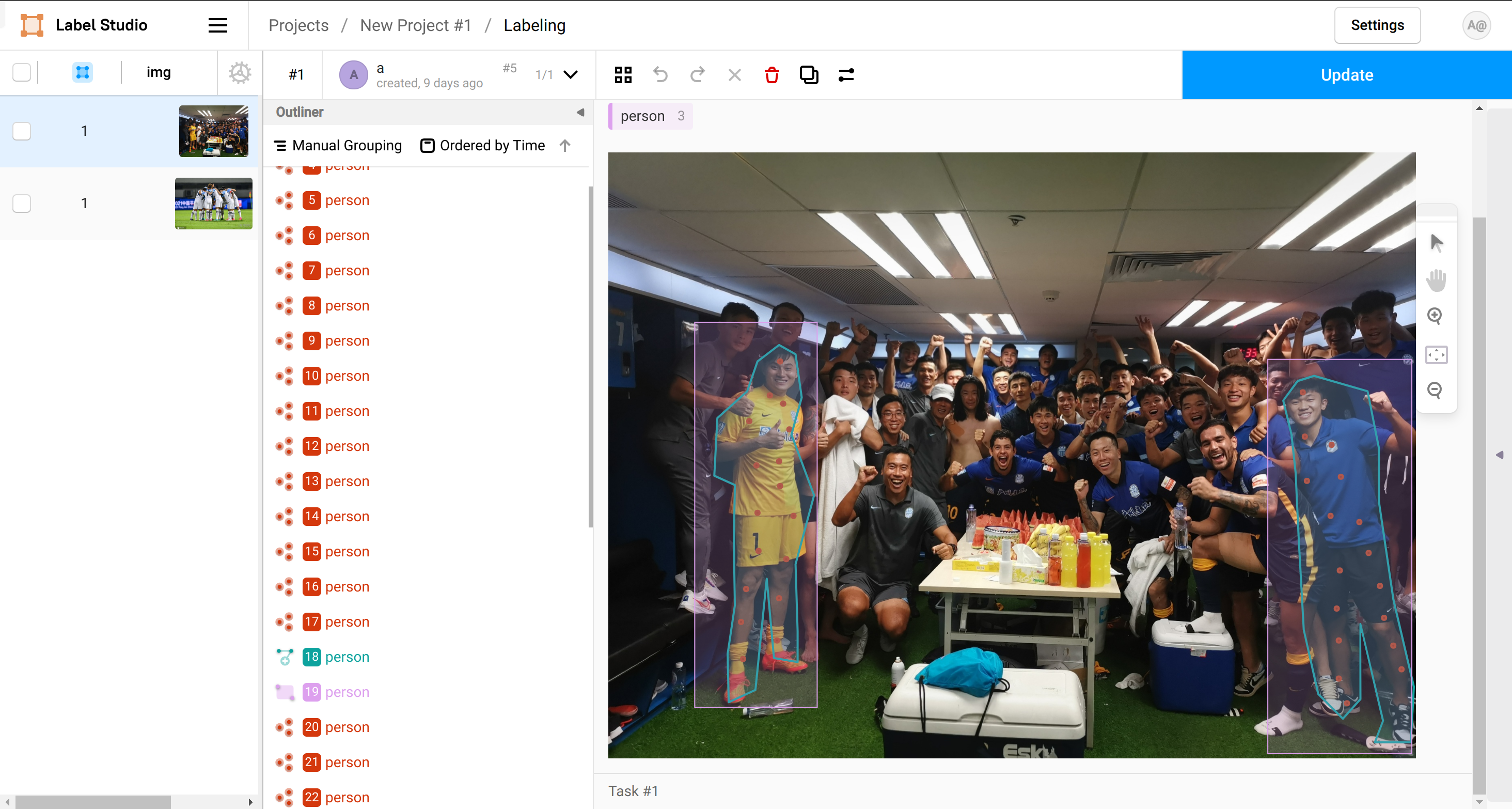
+
+3. Õ»╝Õć║µĀćµ│©
+
+õĖŖĶ┐░µĀćµ│©Õ«īµłÉÕÉÄ’╝īķ£ĆĶ”üÕ░åµĀćµ│©Ķ┐øĶĪīÕ»╝Õć║ŃĆéķĆēµŗ®ķĪ╣ńø«ńĢīķØóńÜä`Export`µīēķÆ«’╝īķĆēµŗ®`JSON`µĀ╝Õ╝Å’╝īÕåŹńé╣Õć╗`Export`ÕŹ│ÕÅ»õĖŗĶĮĮÕīģÕɽµĀćńŁŠńÜä JSON µĀ╝Õ╝ŵ¢ćõ╗ČŃĆé
+
+*µ│©’╝ÜõĖŖĶ┐░µ¢ćõ╗ČõĖŁõ╗ģõ╗ģÕīģÕɽµĀćńŁŠ’╝īõĖŹÕīģÕɽÕĤզŗÕøŠńēć’╝īÕøĀµŁżķ£ĆĶ”üķóØÕż¢µÅÉõŠøµĀćµ│©Õ»╣Õ║öńÜäÕøŠńēćŃĆéńö▒õ║Ä Label Studio õ╝ÜÕ»╣Ķ┐ćķĢ┐ńÜäµ¢ćõ╗ČÕÉŹĶ┐øĶĪīµł¬µ¢Ł’╝īÕøĀµŁżõĖŹÕ╗║Ķ««ńø┤µÄźõĮ┐ńö©õĖŖõ╝ĀńÜäµ¢ćõ╗Č’╝īĶĆīµś»õĮ┐ńö©`Export`ÕŖ¤ĶāĮõĖŁńÜäÕ»╝Õć║ COCO µĀ╝Õ╝ÅÕĘźÕģĘ’╝īõĮ┐ńö©ÕÄŗń╝®ÕīģÕåģńÜäÕøŠńēćµ¢ćõ╗ČÕż╣ŃĆé*
+
+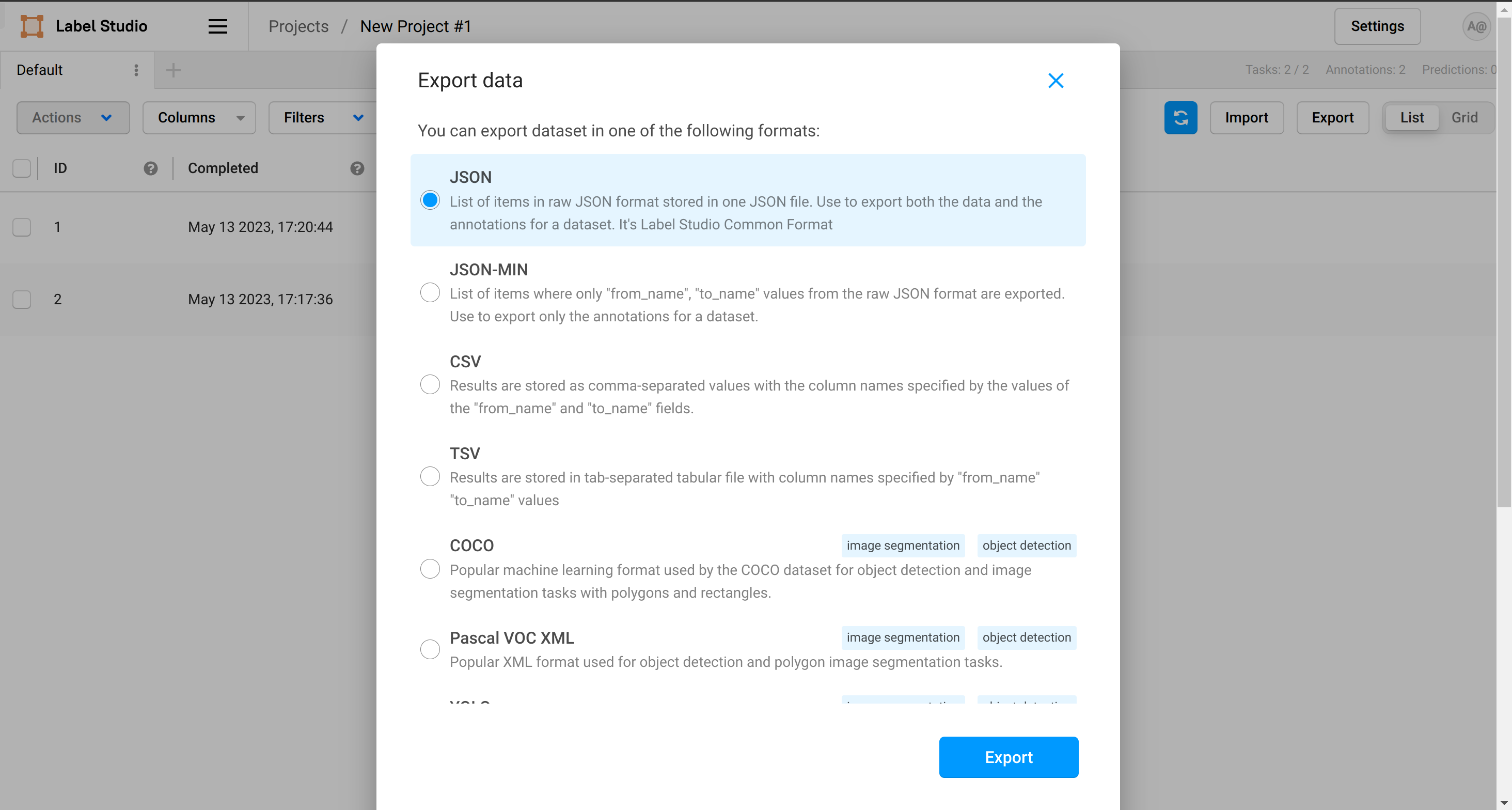
+
+## ĶĮ¼µŹóÕĘźÕģĘĶäܵ£¼ńÜäõĮ┐ńö©
+
+ĶĮ¼µŹóÕĘźÕģĘĶäܵ£¼õĮŹõ║Ä`tools/dataset_converters/labelstudio2coco.py`’╝īõĮ┐ńö©µ¢╣Õ╝ÅÕ”éõĖŗ’╝Ü
+
+```bash
+python tools/dataset_converters/labelstudio2coco.py config.xml project-1-at-2023-05-13-09-22-91b53efa.json output/result.json
+```
+
+ÕģČõĖŁ`config.xml`ńÜäÕåģÕ«╣õĖ║µĀćńŁŠµÄźÕÅŻĶ«ŠńĮ«õĖŁµÅÉÕł░ńÜä`Labeling Interface`õĖŁńÜä`Code`’╝ī`project-1-at-2023-05-13-09-22-91b53efa.json`ÕŹ│õĖ║Õ»╝Õć║µĀćµ│©µŚČÕ»╝Õć║ńÜä Label Studio µĀ╝Õ╝ÅńÜä JSON µ¢ćõ╗Č’╝ī`output/result.json`õĖ║ĶĮ¼µŹóÕÉÄÕŠŚÕł░ńÜä COCO µĀ╝Õ╝ÅńÜä JSON µ¢ćõ╗ČĶĘ»ÕŠä’╝īĶŗźĶĘ»ÕŠäõĖŹÕŁśÕ£©’╝īĶ»źĶäܵ£¼õ╝ÜĶć¬ÕŖ©ÕłøÕ╗║ĶĘ»ÕŠäŃĆé
+
+ķÜÅÕÉÄ’╝īÕ░åÕøŠńēćńÜäµ¢ćõ╗ČÕż╣µöŠńĮ«Õ£©ĶŠōÕć║ńø«ÕĮĢõĖŗ’╝īÕŹ│ÕŻիīµłÉ COCO µĢ░µŹ«ķøåńÜäĶĮ¼µŹóŃĆéńø«ÕĮĢń╗ōµ×äńż║õŠŗÕ”éõĖŗ’╝Ü
+
+```bash
+.
+Ōö£ŌöĆŌöĆ images
+Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ 38b480f2.jpg
+Ōöé┬Ā┬Ā ŌööŌöĆŌöĆ aeb26f04.jpg
+ŌööŌöĆŌöĆ result.json
+
+```
+
+Ķŗźµā│Õ£© MMPose õĖŁõĮ┐ńö©Ķ»źµĢ░µŹ«ķøå’╝īÕÅ»õ╗źĶ┐øĶĪīń▒╗õ╝╝Õ”éõĖŗńÜäõ┐«µö╣’╝Ü
+
+```python
+dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='result.json',
+ data_prefix=dict(img='images/'),
+ pipeline=train_pipeline,
+)
+```
diff --git a/internlm_langchain/knowledge_base/MMPose/content/migration.md b/internlm_langchain/knowledge_base/MMPose/content/migration.md
new file mode 100644
index 00000000..9a591dfc
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPose/content/migration.md
@@ -0,0 +1,201 @@
+# MMPose 0.X Õģ╝Õ«╣µĆ¦Ķ»┤µśÄ
+
+MMPose 1.0 ń╗ÅĶ┐ćõ║åÕż¦Ķ¦äµ©Īķ揵×äÕ╣ČĶ¦ŻÕå│õ║åĶ«ĖÕżÜķüŚńĢÖķŚ«ķóś’╝īÕ»╣õ║Ä 0.x ńēłµ£¼ńÜäÕż¦ķā©Õłåõ╗ŻńĀü MMPose 1.0 Õ░åõĖŹÕģ╝Õ«╣ŃĆé
+
+## µĢ░µŹ«ÕÅśµŹó
+
+### Õ╣│ń¦╗ŃĆüµŚŗĶĮ¼ÕÆīń╝®µöŠ
+
+µŚ¦ńēłńÜäµĢ░µŹ«ÕÅśµŹóµ¢╣µ│Ģ `TopDownRandomShiftBboxCenter` ÕÆī `TopDownGetRandomScaleRotation`’╝īÕ░åĶó½ÕÉłÕ╣ČõĖ║ `RandomBBoxTransform`’╝Ü
+
+```Python
+@TRANSFORMS.register_module()
+class RandomBBoxTransform(BaseTransform):
+ r"""Rnadomly shift, resize and rotate the bounding boxes.
+
+ Required Keys:
+
+ - bbox_center
+ - bbox_scale
+
+ Modified Keys:
+
+ - bbox_center
+ - bbox_scale
+
+ Added Keys:
+ - bbox_rotation
+
+ Args:
+ shift_factor (float): Randomly shift the bbox in range
+ :math:`[-dx, dx]` and :math:`[-dy, dy]` in X and Y directions,
+ where :math:`dx(y) = x(y)_scale \cdot shift_factor` in pixels.
+ Defaults to 0.16
+ shift_prob (float): Probability of applying random shift. Defaults to
+ 0.3
+ scale_factor (Tuple[float, float]): Randomly resize the bbox in range
+ :math:`[scale_factor[0], scale_factor[1]]`. Defaults to (0.5, 1.5)
+ scale_prob (float): Probability of applying random resizing. Defaults
+ to 1.0
+ rotate_factor (float): Randomly rotate the bbox in
+ :math:`[-rotate_factor, rotate_factor]` in degrees. Defaults
+ to 80.0
+ rotate_prob (float): Probability of applying random rotation. Defaults
+ to 0.6
+ """
+
+ def __init__(self,
+ shift_factor: float = 0.16,
+ shift_prob: float = 0.3,
+ scale_factor: Tuple[float, float] = (0.5, 1.5),
+ scale_prob: float = 1.0,
+ rotate_factor: float = 80.0,
+ rotate_prob: float = 0.6) -> None:
+```
+
+### µĀćńŁŠńö¤µłÉ
+
+µŚ¦ńēłńö©õ║ÄĶ«Łń╗āµĀćńŁŠńö¤µłÉńÜäµ¢╣µ│Ģ `TopDownGenerateTarget` ŃĆü`TopDownGenerateTargetRegression`ŃĆü`BottomUpGenerateHeatmapTarget`ŃĆü`BottomUpGenerateTarget` ńŁēÕ░åĶó½ÕÉłÕ╣ČõĖ║ `GenerateTarget`’╝īĶĆīÕ«×ķÖģńÜäńö¤µłÉµ¢╣µ│Ģńö▒[ń╝¢Ķ¦ŻńĀüÕÖ©](./user_guides/codecs.md) µÅÉõŠø’╝Ü
+
+```Python
+@TRANSFORMS.register_module()
+class GenerateTarget(BaseTransform):
+ """Encode keypoints into Target.
+
+ The generated target is usually the supervision signal of the model
+ learning, e.g. heatmaps or regression labels.
+
+ Required Keys:
+
+ - keypoints
+ - keypoints_visible
+ - dataset_keypoint_weights
+
+ Added Keys:
+
+ - The keys of the encoded items from the codec will be updated into
+ the results, e.g. ``'heatmaps'`` or ``'keypoint_weights'``. See
+ the specific codec for more details.
+
+ Args:
+ encoder (dict | list[dict]): The codec config for keypoint encoding.
+ Both single encoder and multiple encoders (given as a list) are
+ supported
+ multilevel (bool): Determine the method to handle multiple encoders.
+ If ``multilevel==True``, generate multilevel targets from a group
+ of encoders of the same type (e.g. multiple :class:`MSRAHeatmap`
+ encoders with different sigma values); If ``multilevel==False``,
+ generate combined targets from a group of different encoders. This
+ argument will have no effect in case of single encoder. Defaults
+ to ``False``
+ use_dataset_keypoint_weights (bool): Whether use the keypoint weights
+ from the dataset meta information. Defaults to ``False``
+ """
+
+ def __init__(self,
+ encoder: MultiConfig,
+ multilevel: bool = False,
+ use_dataset_keypoint_weights: bool = False) -> None:
+```
+
+### µĢ░µŹ«ÕĮÆõĖĆÕī¢
+
+µŚ¦ńēłńÜäµĢ░µŹ«ÕĮÆõĖĆÕī¢µōŹõĮ£ `NormalizeTensor` ÕÆī `ToTensor` µ¢╣µ│ĢÕ░åńö▒ **DataPreprocessor** µ©ĪÕØŚµø┐õ╗Ż’╝īõĖŹÕåŹõĮ£õĖ║µĄüµ░┤ń║┐ńÜäõĖĆķā©Õłå’╝īĶĆīµś»õĮ£õĖ║µ©ĪÕØŚÕŖĀÕģźÕł░µ©ĪÕ×ŗÕēŹÕÉæõ╝ĀµÆŁõĖŁŃĆé
+
+## µ©ĪÕ×ŗÕģ╝Õ«╣
+
+µłæõ╗¼Õ»╣ model zoo µÅÉõŠøńÜ䵩ĪÕ×ŗµØāķćŹĶ┐øĶĪīõ║åÕģ╝Õ«╣µĆ¦ÕżäńÉå’╝īńĪ«õ┐ØńøĖÕÉīńÜ䵩ĪÕ×ŗµØāķ揵ĄŗĶ»Ģń▓ŠÕ║”ĶāĮÕż¤õĖÄ 0.x ńēłµ£¼õ┐صīüÕÉīńŁēµ░┤Õ╣│’╝īõĮåńö▒õ║ÄÕ£©Ķ┐ÖõĖżõĖ¬ńēłµ£¼õĖŁÕŁśÕ£©Õż¦ķćÅÕżäńÉåń╗åĶŖéńÜäÕĘ«Õ╝é’╝īµÄ©ńÉåń╗ōµ×£ÕÅ»ĶāĮõ╝Üõ║¦ńö¤ĶĮ╗ÕŠ«ńÜäõĖŹÕÉī’╝łń▓ŠÕ║”Ķ»»ÕĘ«Õ░Åõ║Ä 0.05%’╝ēŃĆé
+
+Õ»╣õ║ÄõĮ┐ńö© 0.x ńēłµ£¼Ķ«Łń╗āõ┐ØÕŁśńÜ䵩ĪÕ×ŗµØāķ插╝īµłæõ╗¼Õ£©ķó䵥ŗÕż┤õĖŁµÅÉõŠøõ║å `_load_state_dict_pre_hook()` µ¢╣µ│ĢµØźÕ░åµŚ¦ńēłńÜäµØāķćŹÕŁŚÕģĖµø┐µŹóõĖ║µ¢░ńēł’╝īÕ”éµ×£õĮĀÕĖīµ£øÕ░åÕ£©µŚ¦ńēłõĖŖÕ╝ĆÕÅæńÜ䵩ĪÕ×ŗÕģ╝Õ«╣Õł░µ¢░ńēł’╝īÕÅ»õ╗źÕÅéĶĆāµłæõ╗¼ńÜäÕ«×ńÄ░ŃĆé
+
+```Python
+@MODELS.register_module()
+class YourHead(BaseHead):
+def __init__(self):
+
+ ## omitted
+
+ # Register the hook to automatically convert old version state dicts
+ self._register_load_state_dict_pre_hook(self._load_state_dict_pre_hook)
+```
+
+### Heatmap-based µ¢╣µ│Ģ
+
+Õ»╣õ║ÄÕ¤║õ║ÄSimpleBaselineµ¢╣µ│ĢńÜ䵩ĪÕ×ŗ’╝īõĖ╗Ķ”üķ£ĆĶ”üµ│©µäŵ£ĆÕÉÄõĖĆÕ▒éÕŹĘń¦»Õ▒éńÜäÕģ╝Õ«╣’╝Ü
+
+```Python
+def _load_state_dict_pre_hook(self, state_dict, prefix, local_meta, *args,
+ **kwargs):
+ version = local_meta.get('version', None)
+
+ if version and version >= self._version:
+ return
+
+ # convert old-version state dict
+ keys = list(state_dict.keys())
+ for _k in keys:
+ if not _k.startswith(prefix):
+ continue
+ v = state_dict.pop(_k)
+ k = _k[len(prefix):]
+ # In old version, "final_layer" includes both intermediate
+ # conv layers (new "conv_layers") and final conv layers (new
+ # "final_layer").
+ #
+ # If there is no intermediate conv layer, old "final_layer" will
+ # have keys like "final_layer.xxx", which should be still
+ # named "final_layer.xxx";
+ #
+ # If there are intermediate conv layers, old "final_layer" will
+ # have keys like "final_layer.n.xxx", where the weights of the last
+ # one should be renamed "final_layer.xxx", and others should be
+ # renamed "conv_layers.n.xxx"
+ k_parts = k.split('.')
+ if k_parts[0] == 'final_layer':
+ if len(k_parts) == 3:
+ assert isinstance(self.conv_layers, nn.Sequential)
+ idx = int(k_parts[1])
+ if idx < len(self.conv_layers):
+ # final_layer.n.xxx -> conv_layers.n.xxx
+ k_new = 'conv_layers.' + '.'.join(k_parts[1:])
+ else:
+ # final_layer.n.xxx -> final_layer.xxx
+ k_new = 'final_layer.' + k_parts[2]
+ else:
+ # final_layer.xxx remains final_layer.xxx
+ k_new = k
+ else:
+ k_new = k
+
+ state_dict[prefix + k_new] = v
+```
+
+### RLE-based µ¢╣µ│Ģ
+
+Õ»╣õ║ÄÕ¤║õ║Ä RLE ńÜ䵩ĪÕ×ŗ’╝īńö▒õ║ĵ¢░ńēłńÜä `loss` µ©ĪÕØŚµø┤ÕÉŹõĖ║ `loss_module`’╝īõĖö flow µ©ĪÕ×ŗÕĮÆÕ▒×Õ£© `loss` µ©ĪÕØŚõĖŗ’╝īÕøĀµŁżķ£ĆĶ”üÕ»╣µØāķćŹÕŁŚÕģĖõĖŁ `loss` ÕŁŚµ«ĄĶ┐øĶĪīµø┤µö╣’╝Ü
+
+```Python
+def _load_state_dict_pre_hook(self, state_dict, prefix, local_meta, *args,
+ **kwargs):
+
+ version = local_meta.get('version', None)
+
+ if version and version >= self._version:
+ return
+
+ # convert old-version state dict
+ keys = list(state_dict.keys())
+ for _k in keys:
+ v = state_dict.pop(_k)
+ k = _k.lstrip(prefix)
+ # In old version, "loss" includes the instances of loss,
+ # now it should be renamed "loss_module"
+ k_parts = k.split('.')
+ if k_parts[0] == 'loss':
+ # loss.xxx -> loss_module.xxx
+ k_new = prefix + 'loss_module.' + '.'.join(k_parts[1:])
+ else:
+ k_new = _k
+
+ state_dict[k_new] = v
+```
diff --git a/internlm_langchain/knowledge_base/MMPose/content/mixed_datasets.md b/internlm_langchain/knowledge_base/MMPose/content/mixed_datasets.md
new file mode 100644
index 00000000..fac38e33
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPose/content/mixed_datasets.md
@@ -0,0 +1,159 @@
+# µĘĘÕÉłµĢ░µŹ«ķøåĶ«Łń╗ā
+
+MMPose µÅÉõŠøõ║åõĖĆõĖ¬ńüĄµ┤╗ŃĆüõŠ┐µŹĘńÜäÕĘźÕģĘ `CombinedDataset` µØźĶ┐øĶĪīµĘĘÕÉłµĢ░µŹ«ķøåĶ«Łń╗āŃĆéÕ«āõĮ£õĖ║õĖĆõĖ¬Õ░üĶŻģÕÖ©’╝īÕÅ»õ╗źÕīģÕÉ½ÕżÜõĖ¬ÕŁÉµĢ░µŹ«ķøå’╝īÕ╣ČÕ░åµØźĶć¬õĖŹÕÉīÕŁÉµĢ░µŹ«ķøåńÜäµĢ░µŹ«ĶĮ¼µŹóµłÉõĖĆõĖ¬ń╗¤õĖĆńÜäµĀ╝Õ╝Å’╝īõ╗źńö©õ║ĵ©ĪÕ×ŗĶ«Łń╗āŃĆéõĮ┐ńö© `CombinedDataset` ńÜäµĢ░µŹ«ÕżäńÉåµĄüń©ŗÕ”éõĖŗÕøŠµēĆńż║ŃĆé
+
+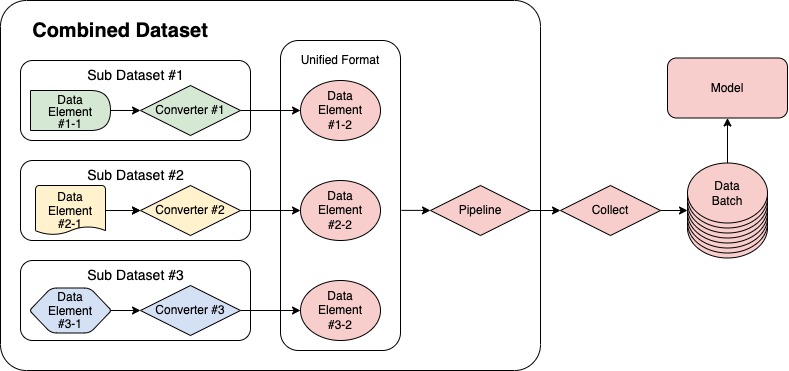
+
+µ£¼ń»ćµĢÖń©ŗńÜäÕÉÄń╗Łķā©ÕłåÕ░åķĆÜĶ┐ćõĖĆõĖ¬ń╗ōÕÉł COCO ÕÆī AI Challenger (AIC) µĢ░µŹ«ķøåńÜäõŠŗÕŁÉĶ»”ń╗åõ╗ŗń╗ŹÕ”éõĮĢķģŹńĮ« `CombinedDataset`ŃĆé
+
+## COCO & AIC µĢ░µŹ«ķøåµĘĘÕÉłµĪłõŠŗ
+
+COCO ÕÆī AIC ķāĮµś» 2D õ║║õĮōÕ¦┐µĆüµĢ░µŹ«ķøåŃĆéõĮåµś»’╝īĶ┐ÖõĖżõĖ¬µĢ░µŹ«ķøåÕ£©Õģ│ķö«ńé╣ńÜäµĢ░ķćÅÕÆīµÄÆÕłŚķĪ║Õ║ÅõĖŖµ£ēµēĆõĖŹÕÉīŃĆéõĖŗķØóµś»ÕłåÕł½µØźĶć¬Ķ┐ÖõĖżõĖ¬µĢ░µŹ«ķøåńÜäÕøŠńēćÕÅŖÕģ│ķö«ńé╣’╝Ü
+
+
+ +µ£ēõ║øÕģ│ķö«ńé╣’╝łõŠŗÕ”éŌĆ£ÕĘ”µēŗŌĆØ’╝ēÕ£©õĖżõĖ¬µĢ░µŹ«ķøåõĖŁķāĮµ£ēÕ«Üõ╣ē’╝īõĮåÕ«āõ╗¼Õģʵ£ēõĖŹÕÉīńÜäÕ║ÅÕÅĘŃĆéÕģĘõĮōµØźĶ»┤’╝īŌĆ£ÕĘ”µēŗŌĆØÕģ│ķö«ńé╣Õ£© COCO µĢ░µŹ«ķøåõĖŁńÜäÕ║ÅÕÅĘõĖ║ 9’╝īÕ£©AICµĢ░µŹ«ķøåõĖŁńÜäÕ║ÅÕÅĘõĖ║ 5ŃĆ鵣żÕż¢’╝īµ»ÅõĖ¬µĢ░µŹ«ķøåķāĮÕīģÕɽńŗ¼ńē╣ńÜäÕģ│ķö«ńé╣’╝īÕÅ”õĖĆõĖ¬µĢ░µŹ«ķøåõĖŁõĖŹÕŁśÕ£©ŃĆéõŠŗÕ”é’╝īķØóķā©Õģ│ķö«ńé╣’╝łÕ║ÅÕÅĘõĖ║0ŃĆ£4’╝ēõ╗ģÕ£© COCO µĢ░µŹ«ķøåõĖŁÕ«Üõ╣ē’╝īĶĆīŌĆ£Õż┤ķĪČŌĆØ’╝łÕ║ÅÕÅĘõĖ║ 12’╝ēÕÆīŌĆ£ķółķā©ŌĆØ’╝łÕ║ÅÕÅĘõĖ║ 13’╝ēÕģ│ķö«ńé╣õ╗ģÕ£© AIC µĢ░µŹ«ķøåõĖŁÕŁśÕ£©ŃĆéõ╗źõĖŗńÜäń╗┤µü®ÕøŠµśŠńż║õ║åõĖżõĖ¬µĢ░µŹ«ķøåõĖŁÕģ│ķö«ńé╣õ╣ŗķŚ┤ńÜäÕģ│ń│╗ŃĆé + +
+ +µÄźõĖŗµØź’╝īµłæõ╗¼õ╝Üõ╗ŗń╗ŹõĖżń¦ŹµĘĘÕÉłµĢ░µŹ«ķøåńÜäµ¢╣Õ╝Å’╝Ü + +- [Õ░å AIC ÕÉłÕģź COCO µĢ░µŹ«ķøå](#Õ░å-aic-ÕÉłÕģź-coco-µĢ░µŹ«ķøå) +- [ÕÉłÕ╣Č AIC ÕÆī COCO µĢ░µŹ«ķøå](#ÕÉłÕ╣Č-aic-ÕÆī-coco-µĢ░µŹ«ķøå) + +### Õ░å AIC ÕÉłÕģź COCO µĢ░µŹ«ķøå + +Õ”éµ×£ńö©µłĘµā│µÅÉķ½śÕģȵ©ĪÕ×ŗÕ£© COCO µł¢ń▒╗õ╝╝µĢ░µŹ«ķøåõĖŖńÜäµĆ¦ĶāĮ’╝īÕÅ»õ╗źÕ░å AIC µĢ░µŹ«ķøåõĮ£õĖ║ĶŠģÕŖ®µĢ░µŹ«ŃĆ鵣żµŚČÕ║öĶ»źõ╗ģķĆēµŗ® AIC µĢ░µŹ«ķøåõĖŁõĖÄ COCO µĢ░µŹ«ķøåÕģ▒õ║½ńÜäÕģ│ķö«ńé╣’╝īÕ┐ĮńĢźÕģČõĮÖÕģ│ķö«ńé╣ŃĆ鵣żÕż¢’╝īĶ┐śķ£ĆĶ”üÕ░åĶ┐Öõ║øĶó½ķĆēµŗ®ńÜäÕģ│ķö«ńé╣Õ£© AIC µĢ░µŹ«ķøåõĖŁńÜäÕ║ÅÕÅĘĶ┐øĶĪīĶĮ¼µŹó’╝īõ╗źÕī╣ķģŹÕ£© COCO µĢ░µŹ«ķøåõĖŁÕ»╣Õ║öÕģ│ķö«ńé╣ńÜäÕ║ÅÕÅĘŃĆé + +
+ +Õ£©Ķ┐Öń¦ŹµāģÕåĄõĖŗ’╝īµØźĶć¬ COCO ńÜäµĢ░µŹ«õĖŹķ£ĆĶ”üĶ┐øĶĪīĶĮ¼µŹóŃĆ鵣żµŚČ COCO µĢ░µŹ«ķøåÕÅ»ķĆÜĶ┐ćÕ”éõĖŗµ¢╣Õ╝ÅķģŹńĮ«’╝Ü + +```python +dataset_coco = dict( + type='CocoDataset', + data_root='data/coco/', + ann_file='annotations/person_keypoints_train2017.json', + data_prefix=dict(img='train2017/'), + pipeline=[], # `pipeline` Õ║öõĖ║ń®║ÕłŚĶĪ©’╝īÕøĀõĖ║ COCO µĢ░µŹ«õĖŹķ£ĆĶ”üĶĮ¼µŹó +) +``` + +Õ»╣õ║Ä AIC µĢ░µŹ«ķøå’╝īķ£ĆĶ”üĶĮ¼µŹóÕģ│ķö«ńé╣ńÜäķĪ║Õ║ÅŃĆéMMPose µÅÉõŠøõ║åõĖĆõĖ¬ `KeypointConverter` ĶĮ¼µŹóÕÖ©µØźÕ«×ńÄ░Ķ┐ÖõĖĆńé╣ŃĆéõ╗źõĖŗµś»ķģŹńĮ« AIC ÕŁÉµĢ░µŹ«ķøåńÜäńż║õŠŗ’╝Ü + +```python +dataset_aic = dict( + type='AicDataset', + data_root='data/aic/', + ann_file='annotations/aic_train.json', + data_prefix=dict(img='ai_challenger_keypoint_train_20170902/' + 'keypoint_train_images_20170902/'), + pipeline=[ + dict( + type='KeypointConverter', + num_keypoints=17, # õĖÄ COCO µĢ░µŹ«ķøåÕģ│ķö«ńé╣µĢ░õĖĆĶć┤ + mapping=[ # ķ£ĆĶ”üÕłŚÕć║µēƵ£ēÕĖ”ĶĮ¼µŹóÕģ│ķö«ńé╣ńÜäÕ║ÅÕÅĘ + (0, 6), # 0 (AIC õĖŁńÜäÕ║ÅÕÅĘ) -> 6 (COCO õĖŁńÜäÕ║ÅÕÅĘ) + (1, 8), + (2, 10), + (3, 5), + (4, 7), + (5, 9), + (6, 12), + (7, 14), + (8, 16), + (9, 11), + (10, 13), + (11, 15), + ]) + ], +) +``` + +`KeypointConverter` õ╝ÜÕ░åÕĤÕ║ÅÕÅĘÕ£© 0 Õł░ 11 õ╣ŗķŚ┤ńÜäÕģ│ķö«ńé╣ńÜäÕ║ÅÕÅĘĶĮ¼µŹóõĖ║Õ£© 5 Õł░ 16 õ╣ŗķŚ┤ńÜäÕ»╣Õ║öÕ║ÅÕÅĘŃĆéÕÉīµŚČ’╝īÕ£© AIC õĖŁÕ║ÅÕÅĘõĖ║õĖ║ 12 ÕÆī 13 ńÜäÕģ│ķö«ńé╣Õ░åĶó½ÕłĀķÖżŃĆéÕÅ”Õż¢’╝īńø«µĀćÕ║ÅÕÅĘÕ£© 0 Õł░ 4 õ╣ŗķŚ┤ńÜäÕģ│ķö«ńé╣Õ£© `mapping` ÕÅéµĢ░õĖŁµ▓Īµ£ēÕ«Üõ╣ē’╝īĶ┐Öõ║øńé╣Õ░åĶó½Ķ«ŠõĖ║õĖŹÕÅ»Ķ¦ü’╝īÕ╣ČõĖöõĖŹõ╝ÜÕ£©Ķ«Łń╗āõĖŁõĮ┐ńö©ŃĆé + +ÕŁÉµĢ░µŹ«ķøåķāĮÕ«īµłÉķģŹńĮ«ÕÉÄ, µĘĘÕÉłµĢ░µŹ«ķøå `CombinedDataset` ÕÅ»õ╗źķĆÜĶ┐ćÕ”éõĖŗµ¢╣Õ╝ÅķģŹńĮ«: + +```python +dataset = dict( + type='CombinedDataset', + # µĘĘÕÉłµĢ░µŹ«ķøåÕģ│ķö«ńé╣ķĪ║Õ║ÅÕÆī COCO µĢ░µŹ«ķøåńøĖÕÉī’╝ī + # µēĆõ╗źõĮ┐ńö© COCO µĢ░µŹ«ķøåńÜäµÅÅĶ┐░õ┐Īµü» + metainfo=dict(from_file='configs/_base_/datasets/coco.py'), + datasets=[dataset_coco, dataset_aic], + # `train_pipeline` ÕīģÕɽõ║åÕĖĖńö©ńÜäµĢ░µŹ«ķóäÕżäńÉå’╝ī + # µ»öÕ”éÕøŠńēćĶ»╗ÕÅ¢ŃĆüµĢ░µŹ«Õó×Õ╣┐ńŁē + pipeline=train_pipeline, +) +``` + +MMPose µÅÉõŠøõ║åõĖĆõ╗ĮÕ«īµĢ┤ńÜä [ķģŹńĮ«µ¢ćõ╗Č](https://github.com/open-mmlab/mmpose/blob/dev-1.x/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-aic-256x192-merge.py) µØźÕ░å AIC ÕÉłÕģź COCO µĢ░µŹ«ķøåÕ╣Čńö©õ║ÄĶ«Łń╗āńĮæń╗£ŃĆéńö©µłĘÕÅ»õ╗źµ¤źķśģĶ┐ÖõĖ¬µ¢ćõ╗Čõ╗źĶÄĘÕÅ¢µø┤ÕżÜń╗åĶŖé’╝īµł¢ĶĆģÕÅéĶĆāĶ┐ÖõĖ¬µ¢ćõ╗ČµØźµ×äÕ╗║µ¢░ńÜäµĘĘÕÉłµĢ░µŹ«ķøåŃĆé + +### ÕÉłÕ╣Č AIC ÕÆī COCO µĢ░µŹ«ķøå + +Õ░å AIC ÕÉłÕģź COCO µĢ░µŹ«ķøåńÜäĶ┐ćń©ŗõĖŁõĖóÕ╝āõ║åķā©Õłå AIC µĢ░µŹ«ķøåõĖŁńÜäµĀćµ│©õ┐Īµü»ŃĆéÕ”éµ×£ńö©µłĘµā│Ķ”üõĮ┐ńö©õĖżõĖ¬µĢ░µŹ«ķøåõĖŁńÜäµēƵ£ēõ┐Īµü»’╝īÕÅ»õ╗źÕ░åõĖżõĖ¬µĢ░µŹ«ķøåÕÉłÕ╣Č’╝īÕŹ│Õ£©õĖżõĖ¬µĢ░µŹ«ķøåõĖŁÕÅ¢Õģ│ķö«ńé╣ńÜäÕ╣ČķøåŃĆé + +
+ +Õ£©Ķ┐Öń¦ŹµāģÕåĄõĖŗ’╝īCOCO ÕÆī AIC µĢ░µŹ«ķøåķāĮķ£ĆĶ”üõĮ┐ńö© `KeypointConverter` µØźĶ░āµĢ┤Õ«āõ╗¼Õģ│ķö«ńé╣ńÜäķĪ║Õ║Å’╝Ü + +```python +dataset_coco = dict( + type='CocoDataset', + data_root='data/coco/', + ann_file='annotations/person_keypoints_train2017.json', + data_prefix=dict(img='train2017/'), + pipeline=[ + dict( + type='KeypointConverter', + num_keypoints=19, # Õ╣ČķøåõĖŁµ£ē 19 õĖ¬Õģ│ķö«ńé╣ + mapping=[ + (0, 0), + (1, 1), + # ń£üńĢź + (16, 16), + ]) + ]) + +dataset_aic = dict( + type='AicDataset', + data_root='data/aic/', + ann_file='annotations/aic_train.json', + data_prefix=dict(img='ai_challenger_keypoint_train_20170902/' + 'keypoint_train_images_20170902/'), + pipeline=[ + dict( + type='KeypointConverter', + num_keypoints=19, # Õ╣ČķøåõĖŁµ£ē 19 õĖ¬Õģ│ķö«ńé╣ + mapping=[ + (0, 6), + # ń£üńĢź + (12, 17), + (13, 18), + ]) + ], +) +``` + +ÕÉłÕ╣ČÕÉÄńÜäµĢ░µŹ«ķøåµ£ē 19 õĖ¬Õģ│ķö«ńé╣’╝īĶ┐ÖõĖÄ COCO µł¢ AIC µĢ░µŹ«ķøåķāĮõĖŹÕÉī’╝īÕøĀµŁżķ£ĆĶ”üõĖĆõĖ¬µ¢░ńÜäµĢ░µŹ«ķøåµÅÅĶ┐░õ┐Īµü»µ¢ćõ╗ČŃĆé[coco_aic.py](https://github.com/open-mmlab/mmpose/blob/dev-1.x/configs/_base_/datasets/coco_aic.py) µś»õĖĆõĖ¬µÅÅĶ┐░õ┐Īµü»µ¢ćõ╗ČńÜäńż║õŠŗ’╝īÕ«āÕ¤║õ║Ä [coco.py](https://github.com/open-mmlab/mmpose/blob/dev-1.x/configs/_base_/datasets/coco.py) Õ╣ČĶ┐øĶĪīõ║åõ╗źõĖŗÕćĀńé╣õ┐«µö╣: + +- µĘ╗ÕŖĀõ║å AIC µĢ░µŹ«ķøåńÜäµ¢ćń½Āõ┐Īµü»’╝ø +- Õ£© `keypoint_info` õĖŁµĘ╗ÕŖĀõ║åŌĆ£Õż┤ķĪČŌĆØÕÆīŌĆ£ķółķā©ŌĆØĶ┐ÖõĖżõĖ¬ÕŬգ© AIC õĖŁÕ«Üõ╣ēńÜäÕģ│ķö«ńé╣’╝ø +- Õ£© `skeleton_info` õĖŁµĘ╗ÕŖĀõ║åŌĆ£Õż┤ķĪČŌĆØÕÆīŌĆ£ķółķā©ŌĆØķŚ┤ńÜäĶ┐×ń║┐’╝ø +- µŗōÕ▒Ģ `joint_weights` ÕÆī `sigmas` õ╗źµĘ╗ÕŖĀµ¢░Õó×Õģ│ķö«ńé╣ńÜäõ┐Īµü»ŃĆé + +Õ«īµłÉõ╗źõĖŖµŁźķ¬żÕÉÄ’╝īÕÉłÕ╣ȵĢ░µŹ«ķøå `CombinedDataset` ÕÅ»õ╗źķĆÜĶ┐ćõ╗źõĖŗµ¢╣Õ╝ÅķģŹńĮ«’╝Ü + +```python +dataset = dict( + type='CombinedDataset', + # õĮ┐ńö©µ¢░ńÜäµÅÅĶ┐░õ┐Īµü»µ¢ćõ╗Č + metainfo=dict(from_file='configs/_base_/datasets/coco_aic.py'), + datasets=[dataset_coco, dataset_aic], + # `train_pipeline` ÕīģÕɽõ║åÕĖĖńö©ńÜäµĢ░µŹ«ķóäÕżäńÉå’╝ī + # µ»öÕ”éÕøŠńēćĶ»╗ÕÅ¢ŃĆüµĢ░µŹ«Õó×Õ╣┐ńŁē + pipeline=train_pipeline, +) +``` + +µŁżÕż¢’╝īÕ£©õĮ┐ńö©µĘĘÕÉłµĢ░µŹ«ķøåµŚČ’╝īńö▒õ║ÄÕģ│ķö«ńé╣µĢ░ķćÅńÜäÕÅśÕī¢’╝īµ©ĪÕ×ŗńÜäĶŠōÕć║ķĆÜķüōµĢ░õ╣¤Ķ”üÕüÜńøĖÕ║öĶ░āµĢ┤ŃĆéÕ”éµ×£ńö©µłĘńö©µĘĘÕÉłµĢ░µŹ«ķøåĶ«Łń╗āõ║嵩ĪÕ×ŗ’╝īõĮåµś»Ķ”üÕ£© COCO µĢ░µŹ«ķøåõĖŖĶ»äõ╝░µ©ĪÕ×ŗ’╝īÕ░▒ķ£ĆĶ”üõ╗ĵ©ĪÕ×ŗĶŠōÕć║ńÜäÕģ│ķö«ńé╣õĖŁÕÅ¢Õć║õĖĆõĖ¬ÕŁÉķøåµØźÕī╣ķģŹ COCO õĖŁńÜäÕģ│ķö«ńé╣µĀ╝Õ╝ÅŃĆéÕÅ»õ╗źķĆÜĶ┐ć `test_cfg` õĖŁńÜä `output_keypoint_indices` ÕÅéµĢ░Ķć¬Õ«Üõ╣ēµŁżÕŁÉķøåŃĆéĶ┐ÖõĖ¬ [ķģŹńĮ«µ¢ćõ╗Č](https://github.com/open-mmlab/mmpose/blob/dev-1.x/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-aic-256x192-combine.py) Õ▒Ģńż║õ║åÕ”éõĮĢńö© AIC ÕÆī COCO ÕÉłÕ╣ČÕÉÄńÜäµĢ░µŹ«ķøåĶ«Łń╗āµ©ĪÕ×ŗÕ╣ČÕ£© COCO µĢ░µŹ«ķøåõĖŖĶ┐øĶĪīµĄŗĶ»ĢŃĆéńö©µłĘÕÅ»õ╗źµ¤źķśģĶ┐ÖõĖ¬µ¢ćõ╗Čõ╗źĶÄĘÕÅ¢µø┤ÕżÜń╗åĶŖé’╝īµł¢ĶĆģÕÅéĶĆāĶ┐ÖõĖ¬µ¢ćõ╗ČµØźµ×äÕ╗║µ¢░ńÜäµĘĘÕÉłµĢ░µŹ«ķøåŃĆé diff --git a/internlm_langchain/knowledge_base/MMPose/content/model_analysis.md b/internlm_langchain/knowledge_base/MMPose/content/model_analysis.md new file mode 100644 index 00000000..234dc5be --- /dev/null +++ b/internlm_langchain/knowledge_base/MMPose/content/model_analysis.md @@ -0,0 +1,100 @@ +# Model Analysis + +## ń╗¤Ķ«Īµ©ĪÕ×ŗÕÅéµĢ░ķćÅõĖÄĶ«Īń«ŚķćÅ + +MMPose µÅÉõŠøõ║å `tools/analysis_tools/get_flops.py` µØźń╗¤Ķ«Īµ©ĪÕ×ŗńÜäÕÅéµĢ░ķćÅõĖÄĶ«Īń«ŚķćÅŃĆé + +```shell +python tools/analysis_tools/get_flops.py ${CONFIG_FILE} [--shape ${INPUT_SHAPE}] [--cfg-options ${CFG_OPTIONS}] +``` + +ÕÅéµĢ░Ķ»┤µśÄ’╝Ü + +`CONFIG_FILE` : µ©ĪÕ×ŗķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠäŃĆé + +`--shape`: µ©ĪÕ×ŗńÜäĶŠōÕģźÕ╝ĀķćÅÕĮóńŖČŃĆé + +`--input-constructor`: Õ”éµ×£µīćÕ«ÜõĖ║ `batch`’╝īÕ░åõ╝Üńö¤µłÉõĖĆõĖ¬ `batch tensor` µØźĶ«Īń«Ś FLOPsŃĆé + +`--batch-size`’╝ÜÕ”éµ×£ `--input-constructor` µīćÕ«ÜõĖ║ `batch`’╝īÕ░åõ╝Üńö¤µłÉõĖĆõĖ¬ķÜŵ£║ `tensor`’╝īÕĮóńŖČõĖ║ `(batch_size, 3, **input_shape)` µØźĶ«Īń«Ś FLOPsŃĆé + +`--cfg-options`: Õ”éµ×£µīćÕ«Ü’╝īÕÅ»ķĆēńÜä `cfg` ńÜäķö«ÕĆ╝Õ»╣Õ░åõ╝ÜĶó½ÕÉłÕ╣ČÕł░ķģŹńĮ«µ¢ćõ╗ČõĖŁŃĆé + +ńż║õŠŗ’╝Ü + +```shell +python tools/analysis_tools/get_flops.py configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192.py +``` + +ń╗ōµ×£Õ”éõĖŗ’╝Ü + +```text +============================== +Input shape: (1, 3, 256, 192) +Flops: 7.7 GFLOPs +Params: 28.54 M +============================== +``` + +```{note} +ńø«ÕēŹĶ»źÕĘźÕģĘõ╗ŹÕżäõ║ÄÕ«×ķ¬īķśČµ«Ą’╝īµłæõ╗¼õĖŹĶāĮõ┐ØĶ»üń╗¤Ķ«Īń╗ōµ×£ń╗ØÕ»╣µŁŻńĪ«’╝īõĖĆõ║øń«ŚÕŁÉ’╝łµ»öÕ”é GN µł¢Ķć¬Õ«Üõ╣ēń«ŚÕŁÉ’╝ēµ▓Īµ£ēĶó½ń╗¤Ķ«ĪÕł░ FLOPs õĖŁŃĆé +``` + +## Õłåµ×ÉĶ«Łń╗āµŚźÕ┐Ś + +MMPose µÅÉõŠøõ║å `tools/analysis_tools/analyze_logs.py` µØźÕ»╣Ķ«Łń╗āµŚźÕ┐ŚĶ┐øĶĪīń«ĆÕŹĢńÜäÕłåµ×É’╝īÕīģµŗ¼’╝Ü + +- Õ░åµŚźÕ┐Śń╗śÕłČµłÉµŹ¤Õż▒ÕÆīń▓ŠÕ║”µø▓ń║┐ÕøŠ +- ń╗¤Ķ«ĪĶ«Łń╗āķƤÕ║” + +### ń╗śÕłČµŹ¤Õż▒ÕÆīń▓ŠÕ║”µø▓ń║┐ÕøŠ + +Ķ»źÕŖ¤ĶāĮõŠØĶĄ¢õ║Ä `seaborn`’╝īĶ»ĘÕģłĶ┐ÉĶĪī `pip install seaborn` Õ«ēĶŻģõŠØĶĄ¢ÕīģŃĆé + + + +```shell +python tools/analysis_tools/analyze_logs.py plot_curve ${JSON_LOGS} [--keys ${KEYS}] [--title ${TITLE}] [--legend ${LEGEND}] [--backend ${BACKEND}] [--style ${STYLE}] [--out ${OUT_FILE}] +``` + +ńż║õŠŗ’╝Ü + +- ń╗śÕłČµŹ¤Õż▒µø▓ń║┐ + + ```shell + python tools/analysis_tools/analyze_logs.py plot_curve log.json --keys loss_kpt --legend loss_kpt + ``` + +- ń╗śÕłČń▓ŠÕ║”µø▓ń║┐Õ╣ČÕ»╝Õć║õĖ║ PDF µ¢ćõ╗Č + + ```shell + python tools/analysis_tools/analyze_logs.py plot_curve log.json --keys acc_pose --out results.pdf + ``` + +- Õ░åÕżÜõĖ¬µŚźÕ┐Śµ¢ćõ╗Čń╗śÕłČÕ£©ÕÉīõĖĆÕ╝ĀÕøŠõĖŖ + + ```shell + python tools/analysis_tools/analyze_logs.py plot_curve log1.json log2.json --keys loss_kpt --legend run1 run2 --title loss_kpt --out loss_kpt.png + ``` + +### ń╗¤Ķ«ĪĶ«Łń╗āķƤÕ║” + +```shell +python tools/analysis_tools/analyze_logs.py cal_train_time ${JSON_LOGS} [--include-outliers] +``` + +ńż║õŠŗ’╝Ü + +```shell +python tools/analysis_tools/analyze_logs.py cal_train_time log.json +``` + +ń╗ōµ×£Õ”éõĖŗ’╝Ü + +```text +-----Analyze train time of hrnet_w32_256x192.json----- +slowest epoch 56, average time is 0.6924 +fastest epoch 1, average time is 0.6502 +time std over epochs is 0.0085 +average iter time: 0.6688 s/iter +``` diff --git a/internlm_langchain/knowledge_base/MMPose/content/overview.md b/internlm_langchain/knowledge_base/MMPose/content/overview.md new file mode 100644 index 00000000..a790cd3b --- /dev/null +++ b/internlm_langchain/knowledge_base/MMPose/content/overview.md @@ -0,0 +1,76 @@ +# µ”éĶ┐░ + +µ£¼ń½ĀÕ░åÕÉæõĮĀõ╗ŗń╗Ź MMPose ńÜäµĢ┤õĮōµĪåµ×Č’╝īÕ╣ȵÅÉõŠøĶ»”ń╗åńÜäµĢÖń©ŗķōŠµÄźŃĆé + +## õ╗Ćõ╣łµś» MMPose + + + +MMPose µś»õĖƵ¼ŠÕ¤║õ║Ä Pytorch ńÜäÕ¦┐µĆüõ╝░Ķ«ĪÕ╝Ƶ║ÉÕĘźÕģĘń«▒’╝īµś» OpenMMLab ķĪ╣ńø«ńÜ䵳ÉÕæśõ╣ŗõĖĆ’╝īÕīģÕɽõ║åõĖ░Õ»īńÜä 2D ÕżÜõ║║Õ¦┐µĆüõ╝░Ķ«ĪŃĆü2D µēŗķā©Õ¦┐µĆüõ╝░Ķ«ĪŃĆü2D õ║║ĶäĖÕģ│ķö«ńé╣µŻĆµĄŗŃĆü133Õģ│ķö«ńé╣Õģ©Ķ║½õ║║õĮōÕ¦┐µĆüõ╝░Ķ«ĪŃĆüÕŖ©ńē®Õģ│ķö«ńé╣µŻĆµĄŗŃĆüµ£Źķź░Õģ│ķö«ńé╣µŻĆµĄŗńŁēń«Śµ│Ģõ╗źÕÅŖńøĖÕģ│ńÜäń╗äõ╗ČÕÆīµ©ĪÕØŚ’╝īõĖŗķØóµś»Õ«āńÜäµĢ┤õĮōµĪåµ×Č’╝Ü + +MMPose ńö▒ **8** õĖ¬õĖ╗Ķ”üķā©Õłåń╗䵳ɒ╝īapisŃĆüstructuresŃĆüdatasetsŃĆücodecsŃĆümodelsŃĆüengineŃĆüevaluation ÕÆī visualizationŃĆé + +- **apis** µÅÉõŠøńö©õ║ĵ©ĪÕ×ŗµÄ©ńÉåńÜäķ½śń║¦ API + +- **structures** µÅÉõŠø bboxŃĆükeypoint ÕÆī PoseDataSample ńŁēµĢ░µŹ«ń╗ōµ×ä + +- **datasets** µö»µīüńö©õ║ÄÕ¦┐µĆüõ╝░Ķ«ĪńÜäÕÉäń¦ŹµĢ░µŹ«ķøå + + - **transforms** ÕīģÕɽÕÉäń¦ŹµĢ░µŹ«Õó×Õ╝║ÕÅśµŹó + +- **codecs** µÅÉõŠøÕ¦┐µĆüń╝¢Ķ¦ŻńĀüÕÖ©’╝Üń╝¢ńĀüÕÖ©ńö©õ║ÄÕ░åÕ¦┐µĆüõ┐Īµü»’╝łķĆÜÕĖĖõĖ║Õģ│ķö«ńé╣ÕØɵĀć’╝ēń╝¢ńĀüõĖ║µ©ĪÕ×ŗÕŁ”õ╣Āńø«µĀć’╝łÕ”éńāŁÕŖøÕøŠ’╝ē’╝īĶ¦ŻńĀüÕÖ©ÕłÖńö©õ║ÄÕ░嵩ĪÕ×ŗĶŠōÕć║Ķ¦ŻńĀüõĖ║Õ¦┐µĆüõ╝░Ķ«Īń╗ōµ×£ + +- **models** õ╗źµ©ĪÕØŚÕī¢ń╗ōµ×äµÅÉõŠøõ║åÕ¦┐µĆüõ╝░Ķ«Īµ©ĪÕ×ŗńÜäÕÉäń▒╗ń╗äõ╗Č + + - **pose_estimators** Õ«Üõ╣ēõ║åµēƵ£ēÕ¦┐µĆüõ╝░Ķ«Īµ©ĪÕ×ŗń▒╗ + - **data_preprocessors** ńö©õ║ÄķóäÕżäńÉ嵩ĪÕ×ŗńÜäĶŠōÕģźµĢ░µŹ« + - **backbones** ÕīģÕɽÕÉäń¦Źķ¬©Õ╣▓ńĮæń╗£ + - **necks** ÕīģÕɽÕÉäń¦Źµ©ĪÕ×ŗķółķā©ń╗äõ╗Č + - **heads** ÕīģÕɽÕÉäń¦Źµ©ĪÕ×ŗÕż┤ķā© + - **losses** ÕīģÕɽÕÉäń¦ŹµŹ¤Õż▒ÕćĮµĢ░ + +- **engine** ÕīģÕɽõĖÄÕ¦┐µĆüõ╝░Ķ«Īõ╗╗ÕŖĪńøĖÕģ│ńÜäĶ┐ÉĶĪīµŚČń╗äõ╗Č + + - **hooks** µÅÉõŠøĶ┐ÉĶĪīµŚČńÜäÕÉäń¦ŹķÆ®ÕŁÉ + +- **evaluation** µÅÉõŠøÕÉäń¦ŹĶ»äõ╝░µ©ĪÕ×ŗµĆ¦ĶāĮńÜäµīćµĀć + +- **visualization** ńö©õ║ÄÕÅ»Ķ¦åÕī¢Õģ│ķö«ńé╣ķ¬©µ×ČÕÆīńāŁÕŖøÕøŠńŁēõ┐Īµü» + +## Õ”éõĮĢõĮ┐ńö©µ£¼µīćÕŹŚ + +ķÆłÕ»╣õĖŹÕÉīń▒╗Õ×ŗńÜäńö©µłĘ’╝īµłæõ╗¼ÕćåÕżćõ║åĶ»”ń╗åńÜäµīćÕŹŚ’╝Ü + +1. Õ«ēĶŻģĶ»┤µśÄ’╝Ü + + - [Õ«ēĶŻģ](./installation.md) + +2. MMPose ńÜäÕ¤║µ£¼õĮ┐ńö©µ¢╣µ│Ģ’╝Ü + + - [20 ÕłåķƤõĖŖµēŗµĢÖń©ŗ](./guide_to_framework.md) + - [Demos](./demos.md) + - [µ©ĪÕ×ŗµÄ©ńÉå](./user_guides/inference.md) + - [ķģŹńĮ«µ¢ćõ╗Č](./user_guides/configs.md) + - [ÕćåÕżćµĢ░µŹ«ķøå](./user_guides/prepare_datasets.md) + - [Ķ«Łń╗āõĖĵĄŗĶ»Ģ](./user_guides/train_and_test.md) + +3. Õ»╣õ║ÄÕĖīµ£øÕ¤║õ║Ä MMPose Ķ┐øĶĪīÕ╝ĆÕÅæńÜäńĀöń®ČĶĆģÕÆīÕ╝ĆÕÅæĶĆģ’╝Ü + + - [ń╝¢Ķ¦ŻńĀüÕÖ©](./advanced_guides/codecs.md) + - [µĢ░µŹ«µĄü](./advanced_guides/dataflow.md) + - [Õ«×ńÄ░µ¢░µ©ĪÕ×ŗ](./advanced_guides/implement_new_models.md) + - [Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøå](./advanced_guides/customize_datasets.md) + - [Ķć¬Õ«Üõ╣ēµĢ░µŹ«ÕÅśµŹó](./advanced_guides/customize_transforms.md) + - [Ķć¬Õ«Üõ╣ēõ╝śÕī¢ÕÖ©](./advanced_guides/customize_optimizer.md) + - [Ķć¬Õ«Üõ╣ēµŚźÕ┐Ś](./advanced_guides/customize_logging.md) + - [µ©ĪÕ×ŗķā©ńĮ▓](./advanced_guides/how_to_deploy.md) + - [µ©ĪÕ×ŗÕłåµ×ÉÕĘźÕģĘ](./advanced_guides/model_analysis.md) + - [Ķ┐üń¦╗µīćÕŹŚ](./migration.md) + +4. Õ»╣õ║ÄÕĖīµ£øÕŖĀÕģźÕ╝Ƶ║ÉńżŠÕī║’╝īÕÉæ MMPose Ķ┤Īńī«õ╗ŻńĀüńÜäńĀöń®ČĶĆģÕÆīÕ╝ĆÕÅæĶĆģ’╝Ü + + - [ÕÅéõĖÄĶ┤Īńī«õ╗ŻńĀü](./contribution_guide.md) + +5. Õ»╣õ║ÄõĮ┐ńö©Ķ┐ćń©ŗõĖŁńÜäÕĖĖĶ¦üķŚ«ķóś’╝Ü + + - [FAQ](./faq.md) diff --git a/internlm_langchain/knowledge_base/MMPose/content/prepare_datasets.md b/internlm_langchain/knowledge_base/MMPose/content/prepare_datasets.md new file mode 100644 index 00000000..8b7d651e --- /dev/null +++ b/internlm_langchain/knowledge_base/MMPose/content/prepare_datasets.md @@ -0,0 +1,221 @@ +# ÕćåÕżćµĢ░µŹ«ķøå + +Õ£©Ķ┐Öõ╗Įµ¢ćµĪŻÕ░åµīćÕ»╝Õ”éõĮĢõĖ║ MMPose ÕćåÕżćµĢ░µŹ«ķøå’╝īÕīģµŗ¼õĮ┐ńö©ÕåģńĮ«µĢ░µŹ«ķøåŃĆüÕłøÕ╗║Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåŃĆüń╗ōÕÉłµĢ░µŹ«ķøåĶ┐øĶĪīĶ«Łń╗āŃĆüµĄÅĶ¦łÕÆīõĖŗĶĮĮµĢ░µŹ«ķøåŃĆé + +## õĮ┐ńö©ÕåģńĮ«µĢ░µŹ«ķøå + +**µŁźķ¬żõĖĆ**: ÕćåÕżćµĢ░µŹ« + +MMPose µö»µīüÕżÜń¦Źõ╗╗ÕŖĪÕÆīńøĖÕ║öńÜäµĢ░µŹ«ķøåŃĆéõĮĀÕÅ»õ╗źÕ£© [µĢ░µŹ«ķøåõ╗ōÕ║ō](https://mmpose.readthedocs.io/en/latest/dataset_zoo.html) õĖŁµēŠÕł░Õ«āõ╗¼ŃĆéõĖ║õ║åµŁŻńĪ«ÕćåÕżćõĮĀńÜäµĢ░µŹ«’╝īĶ»Ęµīēńģ¦õĮĀķĆēµŗ®ńÜäµĢ░µŹ«ķøåńÜäµīćÕŹŚĶ┐øĶĪīµōŹõĮ£ŃĆé + +**µŁźķ¬żõ║ī**: Õ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁĶ┐øĶĪīµĢ░µŹ«ķøåĶ«ŠńĮ« + +Õ£©Õ╝ĆÕ¦ŗĶ«Łń╗āµł¢Ķ»äõ╝░µ©ĪÕ×ŗõ╣ŗÕēŹ’╝īõĮĀÕ┐ģķĪ╗ķģŹńĮ«µĢ░µŹ«ķøåĶ«ŠńĮ«ŃĆéõ╗ź [`td-hm_hrnet-w32_8xb64-210e_coco-256x192.py`](/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192.py) õĖ║õŠŗ’╝īÕ«āÕÅ»õ╗źńö©õ║ÄÕ£© COCO µĢ░µŹ«ķøåõĖŖĶ«Łń╗āµł¢Ķ»äõ╝░ HRNet Õ¦┐µĆüõ╝░Ķ«ĪÕÖ©ŃĆéõĖŗķØóµłæõ╗¼µĄÅĶ¦łõĖĆõĖŗµĢ░µŹ«ķøåķģŹńĮ«’╝Ü + +- Õ¤║ńĪƵĢ░µŹ«ķøåÕÅéµĢ░ + + ```python + # base dataset settings + dataset_type = 'CocoDataset' + data_mode = 'topdown' + data_root = 'data/coco/' + ``` + + - `dataset_type` µīćիܵĢ░µŹ«ķøåńÜäń▒╗ÕÉŹŃĆéńö©µłĘÕÅ»õ╗źÕÅéĶĆā [µĢ░µŹ«ķøå API](https://mmpose.readthedocs.io/en/latest/api.html#datasets) µØźµēŠÕł░õ╗¢õ╗¼µā│Ķ”üńÜäµĢ░µŹ«ķøåńÜäń▒╗ÕÉŹŃĆé + - `data_mode` Õå│Õ«Üõ║åµĢ░µŹ«ķøåńÜäĶŠōÕć║µĀ╝Õ╝Å’╝īµ£ēõĖżõĖ¬ķĆēķĪ╣ÕÅ»ńö©’╝Ü`'topdown'` ÕÆī `'bottomup'`ŃĆéÕ”éµ×£ `data_mode='topdown'`’╝īµĢ░µŹ«Õģāń┤ĀĶĪ©ńż║õĖĆõĖ¬Õ«×õŠŗÕÅŖÕģČÕ¦┐µĆü’╝øÕÉ”ÕłÖ’╝īõĖĆõĖ¬µĢ░µŹ«Õģāń┤Āõ╗ŻĶĪ©õĖĆÕ╝ĀÕøŠÕāÅ’╝īÕīģÕÉ½ÕżÜõĖ¬Õ«×õŠŗÕÆīÕ¦┐µĆüŃĆé + - `data_root` µīćիܵĢ░µŹ«ķøåńÜäµĀ╣ńø«ÕĮĢŃĆé + +- µĢ░µŹ«ÕżäńÉåµĄüń©ŗ + + ```python + # pipelines + train_pipeline = [ + dict(type='LoadImage'), + dict(type='GetBBoxCenterScale'), + dict(type='RandomFlip', direction='horizontal'), + dict(type='RandomHalfBody'), + dict(type='RandomBBoxTransform'), + dict(type='TopdownAffine', input_size=codec['input_size']), + dict(type='GenerateTarget', encoder=codec), + dict(type='PackPoseInputs') + ] + val_pipeline = [ + dict(type='LoadImage'), + dict(type='GetBBoxCenterScale'), + dict(type='TopdownAffine', input_size=codec['input_size']), + dict(type='PackPoseInputs') + ] + ``` + + `train_pipeline` ÕÆī `val_pipeline` ÕłåÕł½Õ«Üõ╣ēõ║åĶ«Łń╗āÕÆīĶ»äõ╝░ķśČµ«ĄÕżäńÉåµĢ░µŹ«Õģāń┤ĀńÜ䵣źķ¬żŃĆéķÖżõ║åÕŖĀĶĮĮÕøŠÕāÅÕÆīµēōÕīģĶŠōÕģźõ╣ŗÕż¢’╝ī`train_pipeline` õĖ╗Ķ”üÕīģÕɽµĢ░µŹ«Õó×Õ╝║µŖƵ£»ÕÆīńø«µĀćńö¤µłÉÕÖ©’╝īĶĆī `val_pipeline` ÕłÖõĖōµ│©õ║ÄÕ░åµĢ░µŹ«Õģāń┤ĀĶĮ¼µŹóõĖ║ń╗¤õĖĆńÜäµĀ╝Õ╝ÅŃĆé + +- µĢ░µŹ«ÕŖĀĶĮĮÕÖ© + + ```python + # data loaders + train_dataloader = dict( + batch_size=64, + num_workers=2, + persistent_workers=True, + sampler=dict(type='DefaultSampler', shuffle=True), + dataset=dict( + type=dataset_type, + data_root=data_root, + data_mode=data_mode, + ann_file='annotations/person_keypoints_train2017.json', + data_prefix=dict(img='train2017/'), + pipeline=train_pipeline, + )) + val_dataloader = dict( + batch_size=32, + num_workers=2, + persistent_workers=True, + drop_last=False, + sampler=dict(type='DefaultSampler', shuffle=False, round_up=False), + dataset=dict( + type=dataset_type, + data_root=data_root, + data_mode=data_mode, + ann_file='annotations/person_keypoints_val2017.json', + bbox_file='data/coco/person_detection_results/' + 'COCO_val2017_detections_AP_H_56_person.json', + data_prefix=dict(img='val2017/'), + test_mode=True, + pipeline=val_pipeline, + )) + test_dataloader = val_dataloader + ``` + + Ķ┐ÖõĖ¬ķā©Õłåµś»ķģŹńĮ«µĢ░µŹ«ķøåńÜäÕģ│ķö«ŃĆéķÖżõ║åÕēŹķØóĶ«©Ķ«║Ķ┐ćńÜäÕ¤║ńĪƵĢ░µŹ«ķøåÕÅéµĢ░ÕÆīµĢ░µŹ«ÕżäńÉåµĄüń©ŗõ╣ŗÕż¢’╝īĶ┐ÖķćīĶ┐śÕ«Üõ╣ēõ║åÕģČõ╗¢ķćŹĶ”üńÜäÕÅéµĢ░ŃĆé`batch_size` Õå│Õ«Üõ║åµ»ÅõĖ¬ GPU ńÜä batch size’╝ø`ann_file` µīćÕ«Üõ║åµĢ░µŹ«ķøåńÜäµ│©ķćŖµ¢ćõ╗Č’╝ø`data_prefix` µīćÕ«Üõ║åÕøŠÕāŵ¢ćõ╗ČÕż╣ŃĆé`bbox_file` õ╗ģÕ£© top-down µĢ░µŹ«ķøåńÜä val/test µĢ░µŹ«ÕŖĀĶĮĮÕÖ©õĖŁõĮ┐ńö©’╝īńö©õ║ĵÅÉõŠøµŻĆµĄŗÕł░ńÜäĶŠ╣ńĢīµĪåõ┐Īµü»ŃĆé + +µłæõ╗¼µÄ©ĶŹÉõ╗ÄõĮ┐ńö©ńøĖÕÉīµĢ░µŹ«ķøåńÜäķģŹńĮ«µ¢ćõ╗ČõĖŁÕżŹÕłČµĢ░µŹ«ķøåķģŹńĮ«’╝īĶĆīõĖŹµś»õ╗ÄÕż┤Õ╝ĆÕ¦ŗń╝¢ÕåÖ’╝īõ╗źµ£ĆÕ░ÅÕī¢µĮ£Õ£©ńÜäķöÖĶ»»ŃĆéķĆÜĶ┐ćĶ┐ÖµĀĘÕüÜ’╝īńö©µłĘÕÅ»õ╗źµĀ╣µŹ«ķ£ĆĶ”üĶ┐øĶĪīÕ┐ģĶ”üńÜäõ┐«µö╣’╝īõ╗ÄĶĆīńĪ«õ┐صø┤ÕÅ»ķØĀÕÆīķ½śµĢłńÜäĶ«ŠńĮ«Ķ┐ćń©ŗŃĆé + +## õĮ┐ńö©Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøå + +[Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøå](../advanced_guides/customize_datasets.md) µīćÕŹŚµÅÉõŠøõ║åÕ”éõĮĢµ×äÕ╗║Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåńÜäĶ»”ń╗åõ┐Īµü»ŃĆéÕ£©µ£¼ĶŖéõĖŁ’╝īµłæõ╗¼Õ░åÕ╝║Ķ░āõĖĆõ║øõĮ┐ńö©ÕÆīķģŹńĮ«Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåńÜäÕģ│ķö«µŖĆÕʦŃĆé + +- ńĪ«Õ«ÜµĢ░µŹ«ķøåń▒╗ÕÉŹŃĆéÕ”éµ×£õĮĀÕ░åµĢ░µŹ«ķøåķćŹń╗äõĖ║ COCO µĀ╝Õ╝Å’╝īõĮĀÕÅ»õ╗źń«ĆÕŹĢÕ£░õĮ┐ńö© `CocoDataset` õĮ£õĖ║ `dataset_type` ńÜäÕĆ╝ŃĆéÕÉ”ÕłÖ’╝īõĮĀÕ░åķ£ĆĶ”üõĮ┐ńö©õĮĀµĘ╗ÕŖĀńÜäĶć¬Õ«Üõ╣ēµĢ░µŹ«ķøåń▒╗ńÜäÕÉŹń¦░ŃĆé + +- µīćÕ«ÜÕģāõ┐Īµü»ķģŹńĮ«µ¢ćõ╗ČŃĆéMMPose 1.x ķććńö©õ║åõĖÄ MMPose 0.x õĖŹÕÉīńÜäńŁ¢ńĢźµØźµīćÕ«ÜÕģāõ┐Īµü»ŃĆéÕ£© MMPose 1.x õĖŁ’╝īńö©µłĘÕÅ»õ╗źµīēńģ¦õ╗źõĖŗµ¢╣Õ╝ŵīćÕ«ÜÕģāõ┐Īµü»ķģŹńĮ«µ¢ćõ╗Č’╝Ü + + ```python + train_dataloader = dict( + ... + dataset=dict( + type=dataset_type, + data_root='root/of/your/train/data', + ann_file='path/to/your/train/json', + data_prefix=dict(img='path/to/your/train/img'), + # specify dataset meta information + metainfo=dict(from_file='configs/_base_/datasets/custom.py'), + ...), + ) + ``` + + µ│©µäÅ’╝ī`metainfo` ÕÅéµĢ░Õ┐ģķĪ╗Õ£© val/test µĢ░µŹ«ÕŖĀĶĮĮÕÖ©õĖŁµīćÕ«ÜŃĆé + +## õĮ┐ńö©µĘĘÕÉłµĢ░µŹ«ķøåĶ┐øĶĪīĶ«Łń╗ā + +MMPose µÅÉõŠøõ║åõĖĆõĖ¬µ¢╣õŠ┐õĖöÕżÜÕŖ¤ĶāĮńÜäĶ¦ŻÕå│µ¢╣µĪł’╝īńö©õ║ÄĶ«Łń╗āµĘĘÕÉłµĢ░µŹ«ķøåŃĆéĶ»ĘÕÅéĶĆā[µĘĘÕÉłµĢ░µŹ«ķøåĶ«Łń╗ā](./mixed_datasets.md)ŃĆé + +## µĄÅĶ¦łµĢ░µŹ«ķøå + +`tools/analysis_tools/browse_dataset.py` ÕĖ«ÕŖ®ńö©µłĘÕÅ»Ķ¦åÕī¢Õ£░µĄÅĶ¦łÕ¦┐µĆüµĢ░µŹ«ķøå’╝īµł¢Õ░åÕøŠÕāÅõ┐ØÕŁśÕł░µīćÕ«ÜńÜäńø«ÕĮĢŃĆé + +```shell +python tools/misc/browse_dataset.py ${CONFIG} [-h] [--output-dir ${OUTPUT_DIR}] [--not-show] [--phase ${PHASE}] [--mode ${MODE}] [--show-interval ${SHOW_INTERVAL}] +``` + +| ARGS | Description | +| -------------------------------- | ---------------------------------------------------------------------------------------------------------- | +| `CONFIG` | ķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠä | +| `--output-dir OUTPUT_DIR` | õ┐ØÕŁśÕÅ»Ķ¦åÕī¢ń╗ōµ×£ńÜäńø«µĀćµ¢ćõ╗ČÕż╣ŃĆéÕ”éµ×£õĖŹµīćÕ«Ü’╝īÕÅ»Ķ¦åÕī¢ńÜäń╗ōµ×£Õ░åõĖŹõ╝ÜĶó½õ┐ØÕŁś | +| `--not-show` | õĖŹķĆéńö©Õż¢ķā©ń¬ŚÕÅŻµśŠńż║ÕÅ»Ķ¦åÕī¢ńÜäń╗ōµ×£ | +| `--phase {train, val, test}` | µĢ░µŹ«ķøåķĆēķĪ╣ | +| `--mode {original, transformed}` | µīćÕ«ÜÕÅ»Ķ¦åÕī¢ÕøŠńēćń▒╗Õ×ŗŃĆé `original` õĖ║õĖŹõĮ┐ńö©µĢ░µŹ«Õó×Õ╝║ńÜäÕĤզŗÕøŠńēćÕÅŖµĀćµ│©ÕÅ»Ķ¦åÕī¢; `transformed` õĖ║ń╗ÅĶ┐ćÕó×Õ╝║ÕÉÄńÜäÕÅ»Ķ¦åÕī¢ | +| `--show-interval SHOW_INTERVAL` | µśŠńż║ÕøŠńēćńÜ䵌ČķŚ┤ķŚ┤ķÜö | + +õŠŗÕ”é’╝īńö©µłĘµā│Ķ”üÕÅ»Ķ¦åÕī¢ COCO µĢ░µŹ«ķøåõĖŁńÜäÕøŠÕāÅÕÆīµĀćµ│©’╝īÕÅ»õ╗źõĮ┐ńö©’╝Ü + +```shell +python tools/misc/browse_dataset.py configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-e210_coco-256x192.py --mode original +``` + +µŻĆµĄŗµĪåÕÆīÕģ│ķö«ńé╣Õ░åĶó½ń╗śÕłČÕ£©ÕĤզŗÕøŠÕāÅõĖŖŃĆéõĖŗķØ󵜻õĖĆõĖ¬õŠŗÕŁÉ’╝Ü + + +ÕĤզŗÕøŠÕāÅÕ£©Ķó½ĶŠōÕģźµ©ĪÕ×ŗõ╣ŗÕēŹķ£ĆĶ”üĶó½ÕżäńÉåŃĆéõĖ║õ║åÕÅ»Ķ¦åÕī¢ķóäÕżäńÉåÕÉÄńÜäÕøŠÕāÅÕÆīµĀćµ│©’╝īńö©µłĘķ£ĆĶ”üÕ░åÕÅéµĢ░ `mode` õ┐«µö╣õĖ║ `transformed`ŃĆéõŠŗÕ”é’╝Ü + +```shell +python tools/misc/browse_dataset.py configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-e210_coco-256x192.py --mode transformed +``` + +Ķ┐Öµś»õĖĆõĖ¬ÕżäńÉåÕÉÄńÜäµĀʵ£¼’╝Ü + + + +ńāŁÕøŠńø«µĀćÕ░åõĖÄõ╣ŗõĖĆĶĄĘÕÅ»Ķ¦åÕī¢’╝īÕ”éµ×£Õ«āµś»Õ£© pipeline õĖŁńö¤µłÉńÜäŃĆé + +## ńö© MIM õĖŗĶĮĮµĢ░µŹ«ķøå + +ķĆÜĶ┐ćõĮ┐ńö© [OpenDataLab](https://opendatalab.com/)’╝īµé©ÕÅ»õ╗źńø┤µÄźõĖŗĶĮĮÕ╝Ƶ║ɵĢ░µŹ«ķøåŃĆéķĆÜĶ┐ćÕ╣│ÕÅ░ńÜäµÉ£ń┤óÕŖ¤ĶāĮ’╝īµé©ÕÅ»õ╗źÕ┐½ķƤĶĮ╗µØŠÕ£░µēŠÕł░õ╗¢õ╗¼µŁŻÕ£©Õ»╗µēŠńÜäµĢ░µŹ«ķøåŃĆéõĮ┐ńö©Õ╣│ÕÅ░õĖŖńÜäµĀ╝Õ╝ÅÕī¢µĢ░µŹ«ķøå’╝īµé©ÕÅ»õ╗źķ½śµĢłÕ£░ĶĘ©µĢ░µŹ«ķøåµē¦ĶĪīõ╗╗ÕŖĪŃĆé + +Õ”éµ×£µé©õĮ┐ńö© MIM õĖŗĶĮĮ’╝īĶ»ĘńĪ«õ┐Øńēłµ£¼Õż¦õ║Ä v0.3.8ŃĆéµé©ÕÅ»õ╗źõĮ┐ńö©õ╗źõĖŗÕæĮõ╗żĶ┐øĶĪīµø┤µ¢░ŃĆüÕ«ēĶŻģŃĆüńÖ╗ÕĮĢÕÆīµĢ░µŹ«ķøåõĖŗĶĮĮ’╝Ü + +```shell +# upgrade your MIM +pip install -U openmim + +# install OpenDataLab CLI tools +pip install -U opendatalab +# log in OpenDataLab, registry +odl login + +# download coco2017 and preprocess by MIM +mim download mmpose --dataset coco2017 +``` + +### ÕĘ▓µö»µīüńÜäµĢ░µŹ«ķøå + +õĖŗķØ󵜻µö»µīüńÜäµĢ░µŹ«ķøåÕłŚĶĪ©’╝īµø┤ÕżÜµĢ░µŹ«ķøåÕ░åÕ£©õ╣ŗÕÉĵīüń╗Łµø┤µ¢░’╝Ü + +#### õ║║õĮōµĢ░µŹ«ķøå + +| Dataset name | Download command | +| ------------- | ----------------------------------------- | +| COCO 2017 | `mim download mmpose --dataset coco2017` | +| MPII | `mim download mmpose --dataset mpii` | +| AI Challenger | `mim download mmpose --dataset aic` | +| CrowdPose | `mim download mmpose --dataset crowdpose` | + +#### õ║║ĶäĖµĢ░µŹ«ķøå + +| Dataset name | Download command | +| ------------ | ------------------------------------ | +| LaPa | `mim download mmpose --dataset lapa` | +| 300W | `mim download mmpose --dataset 300w` | +| WFLW | `mim download mmpose --dataset wflw` | + +#### µēŗķā©µĢ░µŹ«ķøå + +| Dataset name | Download command | +| ------------ | ------------------------------------------ | +| OneHand10K | `mim download mmpose --dataset onehand10k` | +| FreiHand | `mim download mmpose --dataset freihand` | +| HaGRID | `mim download mmpose --dataset hagrid` | + +#### Õģ©Ķ║½µĢ░µŹ«ķøå + +| Dataset name | Download command | +| ------------ | ------------------------------------- | +| Halpe | `mim download mmpose --dataset halpe` | + +#### ÕŖ©ńē®µĢ░µŹ«ķøå + +| Dataset name | Download command | +| ------------ | ------------------------------------- | +| AP-10K | `mim download mmpose --dataset ap10k` | + +#### µ£ŹĶŻģµĢ░µŹ«ķøå + +Coming Soon diff --git a/internlm_langchain/knowledge_base/MMPose/content/projects.md b/internlm_langchain/knowledge_base/MMPose/content/projects.md new file mode 100644 index 00000000..460d8583 --- /dev/null +++ b/internlm_langchain/knowledge_base/MMPose/content/projects.md @@ -0,0 +1,20 @@ +# Projects based on MMPose + +There are many projects built upon MMPose. We list some of them as examples of how to extend MMPose for your own projects. As the page might not be completed, please feel free to create a PR to update this page. + +## Projects as an extension + +Some projects extend the boundary of MMPose for deployment or other research fields. They reveal the potential of what MMPose can do. We list several of them as below. + +- [Anime Face Detector](https://github.com/hysts/anime-face-detector): An anime face landmark detection toolbox. +- [PosePipeline](https://github.com/peabody124/PosePipeline): Open-Source Human Pose Estimation Pipeline for Clinical Research + +## Projects of papers + +There are also projects released with papers. Some of the papers are published in top-tier conferences (CVPR, ICCV, and ECCV), the others are also highly influential. We list some of these works as a reference for the community to develop and compare new pose estimation algorithms. Methods already supported and maintained by MMPose are not listed. + +- Pose for Everything: Towards Category-Agnostic Pose Estimation, ECCV 2022. [\[paper\]](https://arxiv.org/abs/2207.10387)[\[github\]](https://github.com/luminxu/Pose-for-Everything) +- UniFormer: Unified Transformer for Efficient Spatiotemporal Representation Learning, ICLR 2022. [\[paper\]](https://arxiv.org/abs/2201.04676)[\[github\]](https://github.com/Sense-X/UniFormer) +- Poseur:Direct Human Pose Regression with Transformers, ECCV 2022. [\[paper\]](https://arxiv.org/abs/2201.07412)[\[github\]](https://github.com/aim-uofa/Poseur) +- ViTAEv2: Vision Transformer Advanced by Exploring Inductive Bias for Image Recognition and Beyond, NeurIPS 2022. [\[paper\]](https://arxiv.org/abs/2106.03348)[\[github\]](https://github.com/ViTAE-Transformer/ViTAE-Transformer) +- Dite-HRNet:Dynamic Lightweight High-Resolution Network for Human Pose Estimation, IJCAI-ECAI 2021. [\[paper\]](https://arxiv.org/abs/2204.10762)[\[github\]](https://github.com/ZiyiZhang27/Dite-HRNet) diff --git a/internlm_langchain/knowledge_base/MMPose/content/pytorch_2.md b/internlm_langchain/knowledge_base/MMPose/content/pytorch_2.md new file mode 100644 index 00000000..4892e554 --- /dev/null +++ b/internlm_langchain/knowledge_base/MMPose/content/pytorch_2.md @@ -0,0 +1,14 @@ +# PyTorch 2.0 Compatibility and Benchmarks + +MMPose 1.0.0 is now compatible with PyTorch 2.0, ensuring that users can leverage the latest features and performance improvements offered by the PyTorch 2.0 framework when using MMPose. With the integration of inductor, users can expect faster model speeds. The table below shows several example models: + +| Model | Training Speed | Memory | +| :-------- | :---------------------: | :-----------: | +| ViTPose-B | 29.6% Ōåæ (0.931 ŌåÆ 0.655) | 10586 ŌåÆ 10663 | +| ViTPose-S | 33.7% Ōåæ (0.563 ŌåÆ 0.373) | 6091 ŌåÆ 6170 | +| HRNet-w32 | 12.8% Ōåæ (0.553 ŌåÆ 0.482) | 9849 ŌåÆ 10145 | +| HRNet-w48 | 37.1% Ōåæ (0.437 ŌåÆ 0.275) | 7319 ŌåÆ 7394 | +| RTMPose-t | 6.3% Ōåæ (1.533 ŌåÆ 1.437) | 6292 ŌåÆ 6489 | +| RTMPose-s | 13.1% Ōåæ (1.645 ŌåÆ 1.430) | 9013 ŌåÆ 9208 | + +- Pytorch 2.0 test, add projects doc and refactor by @LareinaM in [PR#2136](https://github.com/open-mmlab/mmpose/pull/2136) diff --git a/internlm_langchain/knowledge_base/MMPose/content/quick_run.md b/internlm_langchain/knowledge_base/MMPose/content/quick_run.md new file mode 100644 index 00000000..55c2d63b --- /dev/null +++ b/internlm_langchain/knowledge_base/MMPose/content/quick_run.md @@ -0,0 +1,188 @@ +# Õ┐½ķƤõĖŖµēŗ + +Õ£©Ķ┐ÖõĖĆń½Āķćī’╝īµłæõ╗¼Õ░åÕĖ”ķóåõĮĀĶĄ░Ķ┐ćMMPoseÕĘźõĮ£µĄüń©ŗõĖŁÕģ│ķö«ńÜäõĖāõĖ¬µŁźķ¬ż’╝īÕĖ«ÕŖ®õĮĀÕ┐½ķƤõĖŖµēŗ’╝Ü + +1. õĮ┐ńö©ķóäĶ«Łń╗āµ©ĪÕ×ŗĶ┐øĶĪīµÄ©ńÉå +2. ÕćåÕżćµĢ░µŹ«ķøå +3. ÕćåÕżćķģŹńĮ«µ¢ćõ╗Č +4. ÕÅ»Ķ¦åÕī¢Ķ«Łń╗āÕøŠńēć +5. Ķ«Łń╗ā +6. µĄŗĶ»Ģ +7. ÕÅ»Ķ¦åÕī¢ + +## Õ«ēĶŻģ + +Ķ»Ęµ¤źń£ŗ[Õ«ēĶŻģµīćÕŹŚ](./installation.md)’╝īõ╗źõ║åĶ¦ŻÕ«īµĢ┤µŁźķ¬żŃĆé + +## Õ┐½ķƤÕ╝ĆÕ¦ŗ + +### õĮ┐ńö©ķóäĶ«Łń╗āµ©ĪÕ×ŗĶ┐øĶĪīµÄ©ńÉå + +õĮĀÕÅ»õ╗źķĆÜĶ┐ćõ╗źõĖŗÕæĮõ╗żµØźõĮ┐ńö©ķóäĶ«Łń╗āµ©ĪÕ×ŗÕ»╣ÕŹĢÕ╝ĀÕøŠńēćĶ┐øĶĪīĶ»åÕł½’╝Ü + +```Bash +python demo/image_demo.py \ + tests/data/coco/000000000785.jpg \ + configs/body_2d_keypoint/topdown_regression/coco/td-reg_res50_rle-8xb64-210e_coco-256x192.py\ + https://download.openmmlab.com/mmpose/top_down/deeppose/deeppose_res50_coco_256x192_rle-2ea9bb4a_20220616.pth +``` + +Ķ»źÕæĮõ╗żõĖŁńö©Õł░õ║åµĄŗĶ»ĢÕøŠńēćŃĆüÕ«īµĢ┤ńÜäķģŹńĮ«µ¢ćõ╗ČŃĆüķóäĶ«Łń╗āµ©ĪÕ×ŗ’╝īÕ”éµ×£MMPoseÕ«ēĶŻģµŚĀĶ»»’╝īÕ░åõ╝ÜÕ╝╣Õć║õĖĆõĖ¬µ¢░ń¬ŚÕÅŻ’╝īÕ»╣µŻĆµĄŗń╗ōµ×£Ķ┐øĶĪīÕÅ»Ķ¦åÕī¢µśŠńż║’╝Ü + + + +µø┤ÕżÜµ╝öńż║Ķäܵ£¼ńÜäĶ»”ń╗åÕÅéµĢ░Ķ»┤µśÄÕÅ»õ╗źÕ£© [µ©ĪÕ×ŗµÄ©ńÉå](./user_guides/inference.md) õĖŁµēŠÕł░ŃĆé + +### ÕćåÕżćµĢ░µŹ«ķøå + +MMPoseµö»µīüÕÉäń¦ŹõĖŹÕÉīńÜäõ╗╗ÕŖĪ’╝īµłæõ╗¼µÅÉõŠøõ║åÕ»╣Õ║öńÜäµĢ░µŹ«ķøåÕćåÕżćµĢÖń©ŗŃĆé + +- [2Dõ║║õĮōÕģ│ķö«ńé╣](./dataset_zoo/2d_body_keypoint.md) + +- [3Dõ║║õĮōÕģ│ķö«ńé╣](./dataset_zoo/3d_body_keypoint.md) + +- [2Dõ║║µēŗÕģ│ķö«ńé╣](./dataset_zoo/2d_hand_keypoint.md) + +- [3Dõ║║µēŗÕģ│ķö«ńé╣](./dataset_zoo/3d_hand_keypoint.md) + +- [2Dõ║║ĶäĖÕģ│ķö«ńé╣](./dataset_zoo/2d_face_keypoint.md) + +- [2DÕģ©Ķ║½õ║║õĮōÕģ│ķö«ńé╣](./dataset_zoo/2d_wholebody_keypoint.md) + +- [2Dµ£Źķź░Õģ│ķö«ńé╣](./dataset_zoo/2d_fashion_landmark.md) + +- [2DÕŖ©ńē®Õģ│ķö«ńé╣](./dataset_zoo/2d_animal_keypoint.md) + +õĮĀÕÅ»õ╗źÕ£©ŃĆÉ2Dõ║║õĮōÕģ│ķö«ńé╣µĢ░µŹ«ķøåŃĆæ>ŃĆÉCOCOŃĆæõĖŗµēŠÕł░COCOµĢ░µŹ«ķøåńÜäÕćåÕżćµĢÖń©ŗ’╝īÕ╣ȵīēńģ¦µĢÖń©ŗÕ«īµłÉµĢ░µŹ«ķøåńÜäõĖŗĶĮĮÕÆīµĢ┤ńÉåŃĆé + +```{note} +Õ£©MMPoseõĖŁ’╝īµłæõ╗¼Õ╗║Ķ««Õ░åCOCOµĢ░µŹ«ķøåÕŁśµöŠÕł░µ¢░Õ╗║ńÜä `$MMPOSE/data` ńø«ÕĮĢõĖŗŃĆé +``` + +### ÕćåÕżćķģŹńĮ«µ¢ćõ╗Č + +MMPoseµŗźµ£ēõĖĆÕźŚÕ╝║Õż¦ńÜäķģŹńĮ«ń│╗ń╗¤’╝īńö©õ║Äń«ĪńÉåĶ«Łń╗āµēĆķ£ĆńÜäõĖĆń│╗ÕłŚÕ┐ģĶ”üÕÅéµĢ░’╝Ü + +- **ķĆÜńö©**’╝ÜńÄ»ÕóāŃĆüHookŃĆüCheckpointŃĆüLoggerŃĆüTimerńŁē + +- **µĢ░µŹ«**’╝ÜDatasetŃĆüDataloaderŃĆüµĢ░µŹ«Õó×Õ╝║ńŁē + +- **Ķ«Łń╗ā**’╝Üõ╝śÕī¢ÕÖ©ŃĆüÕŁ”õ╣ĀńÄćĶ░āµĢ┤ńŁē + +- **µ©ĪÕ×ŗ**’╝ÜBackboneŃĆüNeckŃĆüHeadŃĆüµŹ¤Õż▒ÕćĮµĢ░ńŁē + +- **Ķ»äµĄŗ**’╝ÜMetrics + +Õ£©`$MMPOSE/configs`ńø«ÕĮĢõĖŗ’╝īµłæõ╗¼µÅÉõŠøõ║åÕż¦ķćÅÕēŹµ▓┐Ķ«║µ¢ćµ¢╣µ│ĢńÜäķģŹńĮ«µ¢ćõ╗Č’╝īÕÅ»õŠøńø┤µÄźõĮ┐ńö©ÕÆīÕÅéĶĆāŃĆé + +Ķ”üÕ£©COCOµĢ░µŹ«ķøåõĖŖĶ«Łń╗āÕ¤║õ║ÄResNet50ńÜäRLEµ©ĪÕ×ŗµŚČ’╝īµēĆķ£ĆńÜäķģŹńĮ«µ¢ćõ╗ČõĖ║’╝Ü + +```Bash +$MMPOSE/configs/body_2d_keypoint/topdown_regression/coco/td-reg_res50_rle-8xb64-210e_coco-256x192.py +``` + +µłæõ╗¼ķ£ĆĶ”üÕ░åķģŹńĮ«µ¢ćõ╗ČõĖŁńÜä data_root ÕÅśķćÅõ┐«µö╣õĖ║COCOµĢ░µŹ«ķøåÕŁśµöŠĶĘ»ÕŠä’╝Ü + +```Python +data_root = 'data/coco' +``` + +```{note} +µä¤Õģ┤ĶČŻńÜäĶ»╗ĶĆģõ╣¤ÕÅ»õ╗źµ¤źķśģ [ķģŹńĮ«µ¢ćõ╗Č](./user_guides/configs.md) µØźĶ┐øõĖƵŁźÕŁ”õ╣ĀMMPoseµēĆõĮ┐ńö©ńÜäķģŹńĮ«ń│╗ń╗¤ŃĆé +``` + +### ÕÅ»Ķ¦åÕī¢Ķ«Łń╗āÕøŠńēć + +Õ£©Õ╝ĆÕ¦ŗĶ«Łń╗āõ╣ŗÕēŹ’╝īµłæõ╗¼Ķ┐śÕÅ»õ╗źÕ»╣Ķ«Łń╗āÕøŠńēćĶ┐øĶĪīÕÅ»Ķ¦åÕī¢’╝īµŻĆµ¤źĶ«Łń╗āÕøŠńē浜»ÕÉ”µŁŻńĪ«Ķ┐øĶĪīõ║åµĢ░µŹ«Õó×Õ╝║ŃĆé + +µłæõ╗¼µÅÉõŠøõ║åńøĖÕ║öńÜäÕÅ»Ķ¦åÕī¢Ķäܵ£¼’╝Ü + +```Bash +python tools/misc/browse_dastaset.py \ + configs/body_2d_keypoint/topdown_regression/coco/td-reg_res50_rle-8xb64-210e_coco-256x192.py \ + --mode transformed +``` + + + +### Ķ«Łń╗ā + +ńĪ«Õ«ÜµĢ░µŹ«µŚĀĶ»»ÕÉÄ’╝īĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗żÕÉ»ÕŖ©Ķ«Łń╗ā’╝Ü + +```Bash +python tools/train.py configs/body_2d_keypoint/topdown_regression/coco/td-reg_res50_rle-8xb64-210e_coco-256x192.py +``` + +```{note} +MMPoseõĖŁķøåµłÉõ║åÕż¦ķćÅÕ«×ńö©Ķ«Łń╗ātrickÕÆīÕŖ¤ĶāĮ’╝Ü + +- ÕŁ”õ╣ĀńÄćwarmupÕÆīscheduling + +- ImageNetķóäĶ«Łń╗āµØāķćŹ + +- Ķć¬ÕŖ©ÕŁ”õ╣ĀńÄćń╝®µöŠŃĆüĶć¬ÕŖ©batch sizeń╝®µöŠ + +- CPUĶ«Łń╗āŃĆüÕżÜµ£║ÕżÜÕŹĪĶ«Łń╗āŃĆüķøåńŠżĶ«Łń╗ā + +- HardDiskŃĆüLMDBŃĆüPetrelŃĆüHTTPńŁēõĖŹÕÉīµĢ░µŹ«ÕÉÄń½» + +- µĘĘÕÉłń▓ŠÕ║”µĄ«ńé╣Ķ«Łń╗ā + +- TensorBoard +``` + +### µĄŗĶ»Ģ + +Õ£©õĖŹµīćÕ«ÜķóØÕż¢ÕÅéµĢ░µŚČ’╝īĶ«Łń╗āńÜäµØāķćŹÕÆīµŚźÕ┐Śõ┐Īµü»õ╝Üķ╗śĶ«żÕŁśÕé©Õł░`$MMPOSE/work_dirs`ńø«ÕĮĢõĖŗ’╝īµ£Ćõ╝śńÜ䵩ĪÕ×ŗµØāķćŹÕŁśµöŠÕ£©`$MMPOSE/work_dir/best_coco`ńø«ÕĮĢõĖŗŃĆé + +µłæõ╗¼ÕÅ»õ╗źķĆÜĶ┐ćÕ”éõĖŗµīćõ╗żµĄŗĶ»Ģµ©ĪÕ×ŗÕ£©COCOķ¬īĶ»üķøåõĖŖńÜäń▓ŠÕ║”’╝Ü + +```Bash +python tools/test.py \ + configs/body_2d_keypoint/topdown_regression/coco/td-reg_res50_rle-8xb64-210e_coco-256x192.py \ + work_dir/best_coco/AP_epoch_20.pth +``` + +Õ£©COCOķ¬īĶ»üķøåõĖŖĶ»äµĄŗń╗ōµ×£µĀĘõŠŗÕ”éõĖŗ’╝Ü + +```Bash + Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets= 20 ] = 0.704 + Average Precision (AP) @[ IoU=0.50 | area= all | maxDets= 20 ] = 0.883 + Average Precision (AP) @[ IoU=0.75 | area= all | maxDets= 20 ] = 0.777 + Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets= 20 ] = 0.667 + Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets= 20 ] = 0.769 + Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 20 ] = 0.751 + Average Recall (AR) @[ IoU=0.50 | area= all | maxDets= 20 ] = 0.920 + Average Recall (AR) @[ IoU=0.75 | area= all | maxDets= 20 ] = 0.815 + Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets= 20 ] = 0.709 + Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets= 20 ] = 0.811 +08/23 12:04:42 - mmengine - INFO - Epoch(test) [3254/3254] coco/AP: 0.704168 coco/AP .5: 0.883134 coco/AP .75: 0.777015 coco/AP (M): 0.667207 coco/AP (L): 0.768644 coco/AR: 0.750913 coco/AR .5: 0.919710 coco/AR .75: 0.815334 coco/AR (M): 0.709232 coco/AR (L): 0.811334 +``` + +```{note} +Õ”éµ×£ķ£ĆĶ”üµĄŗĶ»Ģµ©ĪÕ×ŗÕ£©ÕģČõ╗¢µĢ░µŹ«ķøåõĖŖńÜäĶĪ©ńÄ░’╝īÕÅ»õ╗źÕēŹÕŠĆ [Ķ«Łń╗āõĖĵĄŗĶ»Ģ](./user_guides/train_and_test.md) µ¤źń£ŗŃĆé +``` + +### ÕÅ»Ķ¦åÕī¢ + +ķÖżõ║åÕ»╣Õģ│ķö«ńé╣ķ¬©µ×ČńÜäÕÅ»Ķ¦åÕī¢õ╗źÕż¢’╝īµłæõ╗¼Ķ┐śµö»µīüÕ»╣ńāŁÕ║”ÕøŠĶ┐øĶĪīÕÅ»Ķ¦åÕī¢’╝īõĮĀÕŬķ£ĆĶ”üÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁĶ«ŠńĮ«`output_heatmap=True`’╝Ü + +```Python +model = dict( + ## ÕåģÕ«╣ń£üńĢź + test_cfg = dict( + ## ÕåģÕ«╣ń£üńĢź + output_heatmaps=True + ) +) +``` + +µł¢Õ£©ÕæĮõ╗żĶĪīõĖŁµĘ╗ÕŖĀ`--cfg-options='model.test_cfg.output_heatmaps=True'`ŃĆé + +ÕÅ»Ķ¦åÕī¢µĢłµ×£Õ”éõĖŗ’╝Ü + + + +```{note} +Õ”éµ×£õĮĀÕĖīµ£øµĘ▒ÕģźÕ£░ÕŁ”õ╣ĀMMPose’╝īÕ░åÕģČÕ║öńö©Õł░Ķć¬ÕĘ▒ńÜäķĪ╣ńø«ÕĮōõĖŁ’╝īµłæõ╗¼ÕćåÕżćõ║åõĖĆõ╗ĮĶ»”ń╗åńÜä [Ķ┐üń¦╗µīćÕŹŚ](./migration.md) ŃĆé +``` diff --git a/internlm_langchain/knowledge_base/MMPose/content/train_and_test.md b/internlm_langchain/knowledge_base/MMPose/content/train_and_test.md new file mode 100644 index 00000000..452eddc9 --- /dev/null +++ b/internlm_langchain/knowledge_base/MMPose/content/train_and_test.md @@ -0,0 +1,5 @@ +# Ķ«Łń╗āõĖĵĄŗĶ»Ģ + +õĖŁµ¢ćÕåģÕ«╣Õ╗║Ķ«ŠõĖŁ’╝īµÜ鵌ČĶ»Ęµ¤źķśģ[Ķŗ▒µ¢ćńēłµ¢ćµĪŻ](../../en/user_guides/train_and_test.md) + +Õ”éµ×£µé©µä┐µäÅÕÅéõĖÄõĖŁµ¢ćµ¢ćµĪŻńÜäń┐╗Ķ»æõĖÄń╗┤µŖż’╝īµłæõ╗¼Õøóķś¤Õ░åÕŹüÕłåµä¤Ķ░óµé©ńÜäĶ┤Īńī«’╝üµ¼óĶ┐ÄÕŖĀÕģźµłæõ╗¼ńÜäńżŠÕī║ńŠżõĖĵłæõ╗¼ÕÅ¢ÕŠŚĶüöń│╗’╝īµł¢ńø┤µÄźµīēńģ¦ [Õ”éõĮĢń╗Ö MMPose Ķ┤Īńī«õ╗ŻńĀü](../contribution_guide.md) Õ£© GitHub õĖŖµÅÉõ║ż Pull RequestŃĆé diff --git a/internlm_langchain/knowledge_base/MMPose/content/useful_tools.md b/internlm_langchain/knowledge_base/MMPose/content/useful_tools.md new file mode 100644 index 00000000..f2ceb771 --- /dev/null +++ b/internlm_langchain/knowledge_base/MMPose/content/useful_tools.md @@ -0,0 +1,5 @@ +# ÕĖĖńö©ÕĘźÕģĘ + +õĖŁµ¢ćÕåģÕ«╣Õ╗║Ķ«ŠõĖŁ’╝īµÜ鵌ČĶ»Ęµ¤źķśģ[Ķŗ▒µ¢ćńēłµ¢ćµĪŻ](../../en/user_guides/useful_tools.md) + +Õ”éµ×£µé©µä┐µäÅÕÅéõĖÄõĖŁµ¢ćµ¢ćµĪŻńÜäń┐╗Ķ»æõĖÄń╗┤µŖż’╝īµłæõ╗¼Õøóķś¤Õ░åÕŹüÕłåµä¤Ķ░óµé©ńÜäĶ┤Īńī«’╝üµ¼óĶ┐ÄÕŖĀÕģźµłæõ╗¼ńÜäńżŠÕī║ńŠżõĖĵłæõ╗¼ÕÅ¢ÕŠŚĶüöń│╗’╝īµł¢ńø┤µÄźµīēńģ¦ [Õ”éõĮĢń╗Ö MMPose Ķ┤Īńī«õ╗ŻńĀü](../contribution_guide.md) Õ£© GitHub õĖŖµÅÉõ║ż Pull RequestŃĆé diff --git a/internlm_langchain/knowledge_base/MMPose/content/visualization.md b/internlm_langchain/knowledge_base/MMPose/content/visualization.md new file mode 100644 index 00000000..a584eb45 --- /dev/null +++ b/internlm_langchain/knowledge_base/MMPose/content/visualization.md @@ -0,0 +1,5 @@ +# ÕÅ»Ķ¦åÕī¢ + +õĖŁµ¢ćÕåģÕ«╣Õ╗║Ķ«ŠõĖŁ’╝īµÜ鵌ČĶ»Ęµ¤źķśģ[Ķŗ▒µ¢ćńēłµ¢ćµĪŻ](../../en/user_guides/visualization.md) + +Õ”éµ×£µé©µä┐µäÅÕÅéõĖÄõĖŁµ¢ćµ¢ćµĪŻńÜäń┐╗Ķ»æõĖÄń╗┤µŖż’╝īµłæõ╗¼Õøóķś¤Õ░åÕŹüÕłåµä¤Ķ░óµé©ńÜäĶ┤Īńī«’╝üµ¼óĶ┐ÄÕŖĀÕģźµłæõ╗¼ńÜäńżŠÕī║ńŠżõĖĵłæõ╗¼ÕÅ¢ÕŠŚĶüöń│╗’╝īµł¢ńø┤µÄźµīēńģ¦ [Õ”éõĮĢń╗Ö MMPose Ķ┤Īńī«õ╗ŻńĀü](../contribution_guide.md) Õ£© GitHub õĖŖµÅÉõ║ż Pull RequestŃĆé diff --git a/internlm_langchain/knowledge_base/MMPose/vector_store/index.faiss b/internlm_langchain/knowledge_base/MMPose/vector_store/index.faiss new file mode 100644 index 00000000..844a8a0b Binary files /dev/null and b/internlm_langchain/knowledge_base/MMPose/vector_store/index.faiss differ diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/cam_visualization.md b/internlm_langchain/knowledge_base/MMPreTrain/content/cam_visualization.md new file mode 100644 index 00000000..94d5ed17 --- /dev/null +++ b/internlm_langchain/knowledge_base/MMPreTrain/content/cam_visualization.md @@ -0,0 +1,164 @@ +# ń▒╗Õł½µ┐Ƶ┤╗ÕøŠ’╝łCAM’╝ēÕÅ»Ķ¦åÕī¢ + +## ń▒╗Õł½µ┐Ƶ┤╗ÕøŠÕÅ»Ķ¦åÕī¢ÕĘźÕģĘõ╗ŗń╗Ź + +MMPretrain µÅÉõŠø `tools/visualization/vis_cam.py` ÕĘźÕģĘµØźÕÅ»Ķ¦åÕī¢ń▒╗Õł½µ┐Ƶ┤╗ÕøŠŃĆéĶ»ĘõĮ┐ńö© `pip install "grad-cam>=1.3.6"` Õ«ēĶŻģõŠØĶĄ¢ńÜä [pytorch-grad-cam](https://github.com/jacobgil/pytorch-grad-cam)ŃĆé + +ńø«ÕēŹµö»µīüńÜäµ¢╣µ│Ģµ£ē’╝Ü + +| Method | What it does | +| :----------: | :-----------------------------------------------------------------------------------------------: | +| GradCAM | õĮ┐ńö©Õ╣│ÕØćµó»Õ║”Õ»╣ 2D µ┐Ƶ┤╗Ķ┐øĶĪīÕŖĀµØā | +| GradCAM++ | ń▒╗õ╝╝ GradCAM’╝īõĮåõĮ┐ńö©õ║åõ║īķśČµó»Õ║” | +| XGradCAM | ń▒╗õ╝╝ GradCAM’╝īõĮåķĆÜĶ┐ćÕĮÆõĖĆÕī¢ńÜäµ┐Ƶ┤╗Õ»╣µó»Õ║”Ķ┐øĶĪīõ║åÕŖĀµØā | +| EigenCAM | õĮ┐ńö© 2D µ┐Ƶ┤╗ńÜäń¼¼õĖĆõĖ╗µłÉÕłå’╝łµŚĀµ│ĢÕī║Õłåń▒╗Õł½’╝īõĮåµĢłµ×£õ╝╝õ╣ÄõĖŹķöÖ’╝ē | +| EigenGradCAM | ń▒╗õ╝╝ EigenCAM’╝īõĮåµö»µīüń▒╗Õł½Õī║Õłå’╝īõĮ┐ńö©õ║åµ┐Ƶ┤╗ * µó»Õ║”ńÜäń¼¼õĖĆõĖ╗µłÉÕłå’╝īń£ŗĶĄĘµØźÕÆī GradCAM ÕĘ«õĖŹÕżÜ’╝īõĮåµś»µø┤Õ╣▓ÕćĆ | +| LayerCAM | õĮ┐ńö©µŁŻµó»Õ║”Õ»╣µ┐Ƶ┤╗Ķ┐øĶĪīń®║ķŚ┤ÕŖĀµØā’╝īÕ»╣õ║ĵĄģÕ▒éµ£ēµø┤ÕźĮńÜäµĢłµ×£ | + +õ╣¤ÕÅ»õ╗źõĮ┐ńö©µ¢░ńēłµ£¼ `pytorch-grad-cam` µö»µīüńÜäµø┤ÕżÜ CAM µ¢╣µ│Ģ’╝īõĮåµłæõ╗¼Õ░ܵ£¬ķ¬īĶ»üÕÅ»ńö©µĆ¦ŃĆé + +**ÕæĮõ╗żĶĪī**’╝Ü + +```bash +python tools/visualization/vis_cam.py \ + ${IMG} \ + ${CONFIG_FILE} \ + ${CHECKPOINT} \ + [--target-layers ${TARGET-LAYERS}] \ + [--preview-model] \ + [--method ${METHOD}] \ + [--target-category ${TARGET-CATEGORY}] \ + [--save-path ${SAVE_PATH}] \ + [--vit-like] \ + [--num-extra-tokens ${NUM-EXTRA-TOKENS}] + [--aug_smooth] \ + [--eigen_smooth] \ + [--device ${DEVICE}] \ + [--cfg-options ${CFG-OPTIONS}] +``` + +**µēƵ£ēÕÅéµĢ░ńÜäĶ»┤µśÄ**’╝Ü + +- `img`’╝Üńø«µĀćÕøŠńēćĶĘ»ÕŠäŃĆé +- `config`’╝ܵ©ĪÕ×ŗķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠäŃĆé +- `checkpoint`’╝ܵØāķćŹĶĘ»ÕŠäŃĆé +- `--target-layers`’╝ܵēƵ¤źń£ŗńÜäńĮæń╗£Õ▒éÕÉŹń¦░’╝īÕÅ»ĶŠōÕģźõĖĆõĖ¬µł¢ĶĆģÕżÜõĖ¬ńĮæń╗£Õ▒é’╝īÕ”éµ×£õĖŹĶ«ŠńĮ«’╝īÕ░åõĮ┐ńö©µ£ĆÕÉÄõĖĆõĖ¬`block`õĖŁńÜä`norm`Õ▒éŃĆé +- `--preview-model`’╝ܵś»ÕÉ”µ¤źń£ŗµ©ĪÕ×ŗµēƵ£ēńĮæń╗£Õ▒éŃĆé +- `--method`’╝Üń▒╗Õł½µ┐Ƶ┤╗ÕøŠÕøŠÕÅ»Ķ¦åÕī¢ńÜäµ¢╣µ│Ģ’╝īńø«ÕēŹµö»µīü `GradCAM`, `GradCAM++`, `XGradCAM`, `EigenCAM`, `EigenGradCAM`, `LayerCAM`’╝īõĖŹÕī║ÕłåÕż¦Õ░ÅÕåÖŃĆéÕ”éµ×£õĖŹĶ«ŠńĮ«’╝īķ╗śĶ«żõĖ║ `GradCAM`ŃĆé +- `--target-category`’╝ܵ¤źń£ŗńÜäńø«µĀćń▒╗Õł½’╝īÕ”éµ×£õĖŹĶ«ŠńĮ«’╝īõĮ┐ńö©µ©ĪÕ×ŗµŻĆµĄŗÕć║µØźńÜäń▒╗Õł½ÕüÜõĖ║ńø«µĀćń▒╗Õł½ŃĆé +- `--save-path`’╝Üõ┐ØÕŁśńÜäÕÅ»Ķ¦åÕī¢ÕøŠńēćńÜäĶĘ»ÕŠä’╝īķ╗śĶ«żõĖŹõ┐ØÕŁśŃĆé +- `--eigen-smooth`’╝ܵś»ÕÉ”õĮ┐ńö©õĖ╗µłÉÕłåķÖŹõĮÄÕÖ¬ķ¤│’╝īķ╗śĶ«żõĖŹÕ╝ĆÕÉ»ŃĆé +- `--vit-like`: µś»ÕÉ”õĖ║ `ViT` ń▒╗õ╝╝ńÜä Transformer-based ńĮæń╗£ +- `--num-extra-tokens`: `ViT` ń▒╗ńĮæń╗£ńÜäķóØÕż¢ńÜä tokens ķĆÜķüōµĢ░’╝īķ╗śĶ«żõĮ┐ńö©õĖ╗Õ╣▓ńĮæń╗£ńÜä `num_extra_tokens`ŃĆé +- `--aug-smooth`’╝ܵś»ÕÉ”õĮ┐ńö©µĄŗĶ»ĢµŚČÕó×Õ╝║ +- `--device`’╝ÜõĮ┐ńö©ńÜäĶ«Īń«ŚĶ«ŠÕżć’╝īÕ”éµ×£õĖŹĶ«ŠńĮ«’╝īķ╗śĶ«żõĖ║'cpu'ŃĆé +- `--cfg-options`’╝ÜÕ»╣ķģŹńĮ«µ¢ćõ╗ČńÜäõ┐«µö╣’╝īÕÅéĶĆā[ÕŁ”õ╣ĀķģŹńĮ«µ¢ćõ╗Č](../user_guides/config.md)ŃĆé + +```{note} +Õ£©µīćÕ«Ü `--target-layers` µŚČ’╝īÕ”éµ×£õĖŹń¤źķüōµ©ĪÕ×ŗµ£ēÕō¬õ║øńĮæń╗£Õ▒é’╝īÕÅ»õĮ┐ńö©ÕæĮõ╗żĶĪīµĘ╗ÕŖĀ `--preview-model` µ¤źń£ŗµēƵ£ēńĮæń╗£Õ▒éÕÉŹń¦░’╝ø +``` + +## Õ”éõĮĢÕÅ»Ķ¦åÕī¢ CNN ńĮæń╗£ńÜäń▒╗Õł½µ┐Ƶ┤╗ÕøŠ’╝łÕ”é ResNet-50’╝ē + +`--target-layers` Õ£© `Resnet-50` õĖŁńÜäõĖĆõ║øńż║õŠŗÕ”éõĖŗ’╝Ü + +- `'backbone.layer4'`’╝īĶĪ©ńż║ń¼¼ÕøøõĖ¬ `ResLayer` Õ▒éńÜäĶŠōÕć║ŃĆé +- `'backbone.layer4.2'` ĶĪ©ńż║ń¼¼ÕøøõĖ¬ `ResLayer` Õ▒éõĖŁń¼¼õĖēõĖ¬ `BottleNeck` ÕØŚńÜäĶŠōÕć║ŃĆé +- `'backbone.layer4.2.conv1'` ĶĪ©ńż║õĖŖĶ┐░ `BottleNeck` ÕØŚõĖŁ `conv1` Õ▒éńÜäĶŠōÕć║ŃĆé + +1. õĮ┐ńö©õĖŹÕÉīµ¢╣µ│ĢÕÅ»Ķ¦åÕī¢ `ResNet50`’╝īķ╗śĶ«ż `target-category` õĖ║µ©ĪÕ×ŗµŻĆµĄŗńÜäń╗ōµ×£’╝īõĮ┐ńö©ķ╗śĶ«żµÄ©Õ»╝ńÜä `target-layers`ŃĆé + + ```shell + python tools/visualization/vis_cam.py \ + demo/bird.JPEG \ + configs/resnet/resnet50_8xb32_in1k.py \ + https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_batch256_imagenet_20200708-cfb998bf.pth \ + --method GradCAM + # GradCAM++, XGradCAM, EigenCAM, EigenGradCAM, LayerCAM + ``` + + | Image | GradCAM | GradCAM++ | EigenGradCAM | LayerCAM | + | ------------------------------------ | --------------------------------------- | ----------------------------------------- | -------------------------------------------- | ---------------------------------------- | + | |
|  |
|  |
|  |
|  |
+
+2. ÕÉīõĖĆÕ╝ĀÕøŠõĖŹÕÉīń▒╗Õł½ńÜäµ┐Ƶ┤╗ÕøŠµĢłµ×£ÕøŠ’╝īÕ£© `ImageNet` µĢ░µŹ«ķøåõĖŁ’╝īń▒╗Õł½ 238 õĖ║ 'Greater Swiss Mountain dog'’╝īń▒╗Õł½ 281 õĖ║ 'tabby, tabby cat'ŃĆé
+
+ ```shell
+ python tools/visualization/vis_cam.py \
+ demo/cat-dog.png configs/resnet/resnet50_8xb32_in1k.py \
+ https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_batch256_imagenet_20200708-cfb998bf.pth \
+ --target-layers 'backbone.layer4.2' \
+ --method GradCAM \
+ --target-category 238
+ # --target-category 281
+ ```
+
+ | Category | Image | GradCAM | XGradCAM | LayerCAM |
+ | -------- | ---------------------------------------------- | ------------------------------------------------ | ------------------------------------------------- | ------------------------------------------------- |
+ | Dog |
|
+
+2. ÕÉīõĖĆÕ╝ĀÕøŠõĖŹÕÉīń▒╗Õł½ńÜäµ┐Ƶ┤╗ÕøŠµĢłµ×£ÕøŠ’╝īÕ£© `ImageNet` µĢ░µŹ«ķøåõĖŁ’╝īń▒╗Õł½ 238 õĖ║ 'Greater Swiss Mountain dog'’╝īń▒╗Õł½ 281 õĖ║ 'tabby, tabby cat'ŃĆé
+
+ ```shell
+ python tools/visualization/vis_cam.py \
+ demo/cat-dog.png configs/resnet/resnet50_8xb32_in1k.py \
+ https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_batch256_imagenet_20200708-cfb998bf.pth \
+ --target-layers 'backbone.layer4.2' \
+ --method GradCAM \
+ --target-category 238
+ # --target-category 281
+ ```
+
+ | Category | Image | GradCAM | XGradCAM | LayerCAM |
+ | -------- | ---------------------------------------------- | ------------------------------------------------ | ------------------------------------------------- | ------------------------------------------------- |
+ | Dog |  |
|  |
|  |
|  |
+ | Cat | |
|
+ | Cat | |  |
|  |
|  |
+
+3. õĮ┐ńö© `--eigen-smooth` õ╗źÕÅŖ `--aug-smooth` ĶÄĘÕÅ¢µø┤ÕźĮńÜäÕÅ»Ķ¦åÕī¢µĢłµ×£ŃĆé
+
+ ```shell
+ python tools/visualization/vis_cam.py \
+ demo/dog.jpg \
+ configs/mobilenet_v3/mobilenet-v3-large_8xb128_in1k.py \
+ https://download.openmmlab.com/mmclassification/v0/mobilenet_v3/convert/mobilenet_v3_large-3ea3c186.pth \
+ --target-layers 'backbone.layer16' \
+ --method LayerCAM \
+ --eigen-smooth --aug-smooth
+ ```
+
+ | Image | LayerCAM | eigen-smooth | aug-smooth | eigen&aug |
+ | ------------------------------------ | --------------------------------------- | ------------------------------------------- | ----------------------------------------- | ----------------------------------------- |
+ |
|
+
+3. õĮ┐ńö© `--eigen-smooth` õ╗źÕÅŖ `--aug-smooth` ĶÄĘÕÅ¢µø┤ÕźĮńÜäÕÅ»Ķ¦åÕī¢µĢłµ×£ŃĆé
+
+ ```shell
+ python tools/visualization/vis_cam.py \
+ demo/dog.jpg \
+ configs/mobilenet_v3/mobilenet-v3-large_8xb128_in1k.py \
+ https://download.openmmlab.com/mmclassification/v0/mobilenet_v3/convert/mobilenet_v3_large-3ea3c186.pth \
+ --target-layers 'backbone.layer16' \
+ --method LayerCAM \
+ --eigen-smooth --aug-smooth
+ ```
+
+ | Image | LayerCAM | eigen-smooth | aug-smooth | eigen&aug |
+ | ------------------------------------ | --------------------------------------- | ------------------------------------------- | ----------------------------------------- | ----------------------------------------- |
+ |  |
|  |
|  |
|  |
|  |
+
+## Õ”éõĮĢÕÅ»Ķ¦åÕī¢ Transformer ń▒╗Õ×ŗńĮæń╗£ńÜäń▒╗Õł½µ┐Ƶ┤╗ÕøŠ
+
+`--target-layers` Õ£© Transformer-based ńĮæń╗£õĖŁńÜäõĖĆõ║øńż║õŠŗÕ”éõĖŗ’╝Ü
+
+- Swin-Transformer õĖŁ’╝Ü`'backbone.norm3'`
+- ViT õĖŁ’╝Ü`'backbone.layers.11.ln1'`
+
+Õ»╣õ║Ä Transformer-based ńÜäńĮæń╗£’╝īµ»öÕ”é ViTŃĆüT2T-ViT ÕÆī Swin-Transformer’╝īńē╣ÕŠüµś»Ķó½Õ▒ĢÕ╣│ńÜäŃĆéõĖ║õ║åń╗śÕłČ CAM ÕøŠ’╝īµłæõ╗¼ķ£ĆĶ”üµīćÕ«Ü `--vit-like` ķĆēķĪ╣’╝īõ╗ÄĶĆīĶ«®Ķó½Õ▒ĢÕ╣│ńÜäńē╣ÕŠüµüóÕżŹµ¢╣ÕĮóńÜäńē╣ÕŠüÕøŠŃĆé
+
+ķÖżõ║åńē╣ÕŠüĶó½Õ▒ĢÕ╣│õ╣ŗÕż¢’╝īõĖĆõ║øń▒╗ ViT ńÜäńĮæń╗£Ķ┐śõ╝ܵĘ╗ÕŖĀķóØÕż¢ńÜä tokensŃĆéµ»öÕ”é ViT ÕÆī T2T-ViT õĖŁµĘ╗ÕŖĀõ║åÕłåń▒╗ token’╝īDeiT õĖŁĶ┐śµĘ╗ÕŖĀõ║åĶÆĖķ”Å tokenŃĆéÕ£©Ķ┐Öõ║øńĮæń╗£õĖŁ’╝īÕłåń▒╗Ķ«Īń«ŚÕ£©µ£ĆÕÉÄõĖĆõĖ¬µ│©µäÅÕŖøµ©ĪÕØŚõ╣ŗÕÉÄÕ░▒ÕĘ▓ń╗ÅÕ«īµłÉõ║å’╝īÕłåń▒╗ÕŠŚÕłåõ╣¤ÕŬÕÆīĶ┐Öõ║øķóØÕż¢ńÜä tokens µ£ēÕģ│’╝īõĖÄńē╣ÕŠüÕøŠµŚĀÕģ│’╝īõ╣¤Õ░▒µś»Ķ»┤’╝īÕłåń▒╗ÕŠŚÕłåÕ»╣Ķ┐Öõ║øńē╣ÕŠüÕøŠńÜäÕ»╝µĢ░õĖ║ 0ŃĆéÕøĀµŁż’╝īµłæõ╗¼õĖŹĶāĮõĮ┐ńö©µ£ĆÕÉÄõĖĆõĖ¬µ│©µäÅÕŖøµ©ĪÕØŚńÜäĶŠōÕć║õĮ£õĖ║ CAM ń╗śÕłČńÜäńø«µĀćÕ▒éŃĆé
+
+ÕÅ”Õż¢’╝īõĖ║õ║åÕÄ╗ķÖżĶ┐Öõ║øķóØÕż¢ńÜä toekns õ╗źĶÄĘÕŠŚńē╣ÕŠüÕøŠ’╝īµłæõ╗¼ķ£ĆĶ”üń¤źķüōĶ┐Öõ║øķóØÕż¢ tokens ńÜäµĢ░ķćÅŃĆéMMPretrain õĖŁÕćĀõ╣ĵēƵ£ē Transformer-based ńÜäńĮæń╗£ķāĮµŗźµ£ē `num_extra_tokens` Õ▒׵ƦŃĆéĶĆīÕ”éµ×£õĮĀÕĖīµ£øÕ░åµŁżÕĘźÕģĘÕ║öńö©õ║ĵ¢░ńÜä’╝īµł¢ĶĆģń¼¼õĖēµ¢╣ńÜäńĮæń╗£’╝īĶĆīõĖöĶ»źńĮæń╗£µ▓Īµ£ēµīćÕ«Ü `num_extra_tokens` Õ▒׵Ʀ’╝īķéŻõ╣łÕÅ»õ╗źõĮ┐ńö© `--num-extra-tokens` ÕÅéµĢ░µēŗÕŖ©µīćÕ«ÜÕģȵĢ░ķćÅŃĆé
+
+1. Õ»╣ `Swin Transformer` õĮ┐ńö©ķ╗śĶ«ż `target-layers` Ķ┐øĶĪī CAM ÕÅ»Ķ¦åÕī¢’╝Ü
+
+ ```shell
+ python tools/visualization/vis_cam.py \
+ demo/bird.JPEG \
+ configs/swin_transformer/swin-tiny_16xb64_in1k.py \
+ https://download.openmmlab.com/mmclassification/v0/swin-transformer/swin_tiny_224_b16x64_300e_imagenet_20210616_090925-66df6be6.pth \
+ --vit-like
+ ```
+
+2. Õ»╣ `Vision Transformer(ViT)` Ķ┐øĶĪī CAM ÕÅ»Ķ¦åÕī¢’╝Ü
+
+ ```shell
+ python tools/visualization/vis_cam.py \
+ demo/bird.JPEG \
+ configs/vision_transformer/vit-base-p16_64xb64_in1k-384px.py \
+ https://download.openmmlab.com/mmclassification/v0/vit/finetune/vit-base-p16_in21k-pre-3rdparty_ft-64xb64_in1k-384_20210928-98e8652b.pth \
+ --vit-like \
+ --target-layers 'backbone.layers.11.ln1'
+ ```
+
+3. Õ»╣ `T2T-ViT` Ķ┐øĶĪī CAM ÕÅ»Ķ¦åÕī¢’╝Ü
+
+ ```shell
+ python tools/visualization/vis_cam.py \
+ demo/bird.JPEG \
+ configs/t2t_vit/t2t-vit-t-14_8xb64_in1k.py \
+ https://download.openmmlab.com/mmclassification/v0/t2t-vit/t2t-vit-t-14_3rdparty_8xb64_in1k_20210928-b7c09b62.pth \
+ --vit-like \
+ --target-layers 'backbone.encoder.12.ln1'
+ ```
+
+| Image | ResNet50 | ViT | Swin | T2T-ViT |
+| --------------------------------------- | ------------------------------------------ | -------------------------------------- | --------------------------------------- | ------------------------------------------ |
+| |
|
+
+## Õ”éõĮĢÕÅ»Ķ¦åÕī¢ Transformer ń▒╗Õ×ŗńĮæń╗£ńÜäń▒╗Õł½µ┐Ƶ┤╗ÕøŠ
+
+`--target-layers` Õ£© Transformer-based ńĮæń╗£õĖŁńÜäõĖĆõ║øńż║õŠŗÕ”éõĖŗ’╝Ü
+
+- Swin-Transformer õĖŁ’╝Ü`'backbone.norm3'`
+- ViT õĖŁ’╝Ü`'backbone.layers.11.ln1'`
+
+Õ»╣õ║Ä Transformer-based ńÜäńĮæń╗£’╝īµ»öÕ”é ViTŃĆüT2T-ViT ÕÆī Swin-Transformer’╝īńē╣ÕŠüµś»Ķó½Õ▒ĢÕ╣│ńÜäŃĆéõĖ║õ║åń╗śÕłČ CAM ÕøŠ’╝īµłæõ╗¼ķ£ĆĶ”üµīćÕ«Ü `--vit-like` ķĆēķĪ╣’╝īõ╗ÄĶĆīĶ«®Ķó½Õ▒ĢÕ╣│ńÜäńē╣ÕŠüµüóÕżŹµ¢╣ÕĮóńÜäńē╣ÕŠüÕøŠŃĆé
+
+ķÖżõ║åńē╣ÕŠüĶó½Õ▒ĢÕ╣│õ╣ŗÕż¢’╝īõĖĆõ║øń▒╗ ViT ńÜäńĮæń╗£Ķ┐śõ╝ܵĘ╗ÕŖĀķóØÕż¢ńÜä tokensŃĆéµ»öÕ”é ViT ÕÆī T2T-ViT õĖŁµĘ╗ÕŖĀõ║åÕłåń▒╗ token’╝īDeiT õĖŁĶ┐śµĘ╗ÕŖĀõ║åĶÆĖķ”Å tokenŃĆéÕ£©Ķ┐Öõ║øńĮæń╗£õĖŁ’╝īÕłåń▒╗Ķ«Īń«ŚÕ£©µ£ĆÕÉÄõĖĆõĖ¬µ│©µäÅÕŖøµ©ĪÕØŚõ╣ŗÕÉÄÕ░▒ÕĘ▓ń╗ÅÕ«īµłÉõ║å’╝īÕłåń▒╗ÕŠŚÕłåõ╣¤ÕŬÕÆīĶ┐Öõ║øķóØÕż¢ńÜä tokens µ£ēÕģ│’╝īõĖÄńē╣ÕŠüÕøŠµŚĀÕģ│’╝īõ╣¤Õ░▒µś»Ķ»┤’╝īÕłåń▒╗ÕŠŚÕłåÕ»╣Ķ┐Öõ║øńē╣ÕŠüÕøŠńÜäÕ»╝µĢ░õĖ║ 0ŃĆéÕøĀµŁż’╝īµłæõ╗¼õĖŹĶāĮõĮ┐ńö©µ£ĆÕÉÄõĖĆõĖ¬µ│©µäÅÕŖøµ©ĪÕØŚńÜäĶŠōÕć║õĮ£õĖ║ CAM ń╗śÕłČńÜäńø«µĀćÕ▒éŃĆé
+
+ÕÅ”Õż¢’╝īõĖ║õ║åÕÄ╗ķÖżĶ┐Öõ║øķóØÕż¢ńÜä toekns õ╗źĶÄĘÕŠŚńē╣ÕŠüÕøŠ’╝īµłæõ╗¼ķ£ĆĶ”üń¤źķüōĶ┐Öõ║øķóØÕż¢ tokens ńÜäµĢ░ķćÅŃĆéMMPretrain õĖŁÕćĀõ╣ĵēƵ£ē Transformer-based ńÜäńĮæń╗£ķāĮµŗźµ£ē `num_extra_tokens` Õ▒׵ƦŃĆéĶĆīÕ”éµ×£õĮĀÕĖīµ£øÕ░åµŁżÕĘźÕģĘÕ║öńö©õ║ĵ¢░ńÜä’╝īµł¢ĶĆģń¼¼õĖēµ¢╣ńÜäńĮæń╗£’╝īĶĆīõĖöĶ»źńĮæń╗£µ▓Īµ£ēµīćÕ«Ü `num_extra_tokens` Õ▒׵Ʀ’╝īķéŻõ╣łÕÅ»õ╗źõĮ┐ńö© `--num-extra-tokens` ÕÅéµĢ░µēŗÕŖ©µīćÕ«ÜÕģȵĢ░ķćÅŃĆé
+
+1. Õ»╣ `Swin Transformer` õĮ┐ńö©ķ╗śĶ«ż `target-layers` Ķ┐øĶĪī CAM ÕÅ»Ķ¦åÕī¢’╝Ü
+
+ ```shell
+ python tools/visualization/vis_cam.py \
+ demo/bird.JPEG \
+ configs/swin_transformer/swin-tiny_16xb64_in1k.py \
+ https://download.openmmlab.com/mmclassification/v0/swin-transformer/swin_tiny_224_b16x64_300e_imagenet_20210616_090925-66df6be6.pth \
+ --vit-like
+ ```
+
+2. Õ»╣ `Vision Transformer(ViT)` Ķ┐øĶĪī CAM ÕÅ»Ķ¦åÕī¢’╝Ü
+
+ ```shell
+ python tools/visualization/vis_cam.py \
+ demo/bird.JPEG \
+ configs/vision_transformer/vit-base-p16_64xb64_in1k-384px.py \
+ https://download.openmmlab.com/mmclassification/v0/vit/finetune/vit-base-p16_in21k-pre-3rdparty_ft-64xb64_in1k-384_20210928-98e8652b.pth \
+ --vit-like \
+ --target-layers 'backbone.layers.11.ln1'
+ ```
+
+3. Õ»╣ `T2T-ViT` Ķ┐øĶĪī CAM ÕÅ»Ķ¦åÕī¢’╝Ü
+
+ ```shell
+ python tools/visualization/vis_cam.py \
+ demo/bird.JPEG \
+ configs/t2t_vit/t2t-vit-t-14_8xb64_in1k.py \
+ https://download.openmmlab.com/mmclassification/v0/t2t-vit/t2t-vit-t-14_3rdparty_8xb64_in1k_20210928-b7c09b62.pth \
+ --vit-like \
+ --target-layers 'backbone.encoder.12.ln1'
+ ```
+
+| Image | ResNet50 | ViT | Swin | T2T-ViT |
+| --------------------------------------- | ------------------------------------------ | -------------------------------------- | --------------------------------------- | ------------------------------------------ |
+| |  |
|  |
|  |
|  |
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/changelog.md b/internlm_langchain/knowledge_base/MMPreTrain/content/changelog.md
new file mode 100644
index 00000000..a0dabe10
Binary files /dev/null and b/internlm_langchain/knowledge_base/MMPreTrain/content/changelog.md differ
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/complexity_analysis.md b/internlm_langchain/knowledge_base/MMPreTrain/content/complexity_analysis.md
new file mode 100644
index 00000000..83e76325
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/complexity_analysis.md
@@ -0,0 +1,80 @@
+# µ©ĪÕ×ŗÕżŹµØéÕ║”Õłåµ×É
+
+## Ķ«Īń«Ś FLOPs ÕÆīÕÅéµĢ░µĢ░ķćÅ’╝łÕ«×ķ¬īµĆ¦ńÜä’╝ē
+
+µłæõ╗¼µĀ╣µŹ« [MMEngine](https://github.com/open-mmlab/mmengine/blob/main/mmengine/analysis/complexity_analysis.py) µÅÉõŠøõ║åõĖĆõĖ¬Ķäܵ£¼ńö©õ║ÄĶ«Īń«Śń╗Öիܵ©ĪÕ×ŗńÜä FLOPs ÕÆīÕÅéµĢ░ķćÅŃĆé
+
+```shell
+python tools/analysis_tools/get_flops.py ${CONFIG_FILE} [--shape ${INPUT_SHAPE}]
+```
+
+µēƵ£ēÕÅéµĢ░Ķ»┤µśÄ’╝Ü
+
+- `config` : ķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠäŃĆé
+- `--shape`: ĶŠōÕģźÕ░║Õ»Ė’╝īµö»µīüÕŹĢÕĆ╝µł¢ĶĆģÕÅīÕĆ╝’╝ī Õ”é’╝Ü `--shape 256`ŃĆü`--shape 224 256`ŃĆéķ╗śĶ«żõĖ║`224 224`ŃĆé
+
+ńż║õŠŗ’╝Ü
+
+```shell
+python tools/analysis_tools/get_flops.py configs/resnet/resnet50_8xb32_in1k.py
+```
+
+õĮĀÕ░åĶÄĘÕŠŚÕ”éõĖŗń╗ōµ×£’╝Ü
+
+```text
+==============================
+Input shape: (3, 224, 224)
+Flops: 4.109G
+Params: 25.557M
+Activation: 11.114M
+==============================
+```
+
+ÕÉīµŚČ’╝īõĮĀõ╝ÜÕŠŚÕł░µ»ÅÕ▒éńÜäĶ»”ń╗åÕżŹµØéÕ║”õ┐Īµü»’╝īÕ”éõĖŗµēĆńż║’╝Ü
+
+```text
++--------------------------+----------------------+-----------+--------------+
+| module | #parameters or shape | #flops | #activations |
++--------------------------+----------------------+-----------+--------------+
+| model | 25.557M | 4.109G | 11.114M |
+| backbone | 23.508M | 4.109G | 11.114M |
+| backbone.conv1 | 9.408K | 0.118G | 0.803M |
+| backbone.conv1.weight | (64, 3, 7, 7) | | |
+| backbone.bn1 | 0.128K | 1.606M | 0 |
+| backbone.bn1.weight | (64,) | | |
+| backbone.bn1.bias | (64,) | | |
+| backbone.layer1 | 0.216M | 0.677G | 4.415M |
+| backbone.layer1.0 | 75.008K | 0.235G | 2.007M |
+| backbone.layer1.1 | 70.4K | 0.221G | 1.204M |
+| backbone.layer1.2 | 70.4K | 0.221G | 1.204M |
+| backbone.layer2 | 1.22M | 1.034G | 3.111M |
+| backbone.layer2.0 | 0.379M | 0.375G | 1.305M |
+| backbone.layer2.1 | 0.28M | 0.22G | 0.602M |
+| backbone.layer2.2 | 0.28M | 0.22G | 0.602M |
+| backbone.layer2.3 | 0.28M | 0.22G | 0.602M |
+| backbone.layer3 | 7.098M | 1.469G | 2.158M |
+| backbone.layer3.0 | 1.512M | 0.374G | 0.652M |
+| backbone.layer3.1 | 1.117M | 0.219G | 0.301M |
+| backbone.layer3.2 | 1.117M | 0.219G | 0.301M |
+| backbone.layer3.3 | 1.117M | 0.219G | 0.301M |
+| backbone.layer3.4 | 1.117M | 0.219G | 0.301M |
+| backbone.layer3.5 | 1.117M | 0.219G | 0.301M |
+| backbone.layer4 | 14.965M | 0.81G | 0.627M |
+| backbone.layer4.0 | 6.04M | 0.373G | 0.326M |
+| backbone.layer4.1 | 4.463M | 0.219G | 0.151M |
+| backbone.layer4.2 | 4.463M | 0.219G | 0.151M |
+| head.fc | 2.049M | | |
+| head.fc.weight | (1000, 2048) | | |
+| head.fc.bias | (1000,) | | |
+| neck.gap | | 0.1M | 0 |
++--------------------------+----------------------+-----------+--------------+
+```
+
+```{warning}
+ĶŁ”ÕæŖ
+
+µŁżÕĘźÕģĘõ╗ŹÕżäõ║ÄĶ»Ģķ¬īķśČµ«Ą’╝īµłæõ╗¼õĖŹõ┐ØĶ»üĶ»źµĢ░ÕŁŚµŁŻńĪ«µŚĀĶ»»ŃĆéµé©µ£ĆÕźĮÕ░åń╗ōµ×£ńö©õ║Äń«ĆÕŹĢµ»öĶŠā’╝īõĮåÕ£©µŖƵ£»µŖźÕæŖµł¢Ķ«║µ¢ćõĖŁķććńö©Ķ»źń╗ōµ×£õ╣ŗÕēŹ’╝īĶ»Ęõ╗öń╗åµŻĆµ¤źŃĆé
+
+- FLOPs õĖÄĶŠōÕģźńÜäÕ░║Õ»Ėµ£ēÕģ│’╝īĶĆīÕÅéµĢ░ķćÅõĖÄĶŠōÕģźÕ░║Õ»ĖµŚĀÕģ│ŃĆéķ╗śĶ«żĶŠōÕģźÕ░║Õ»ĖõĖ║ (1, 3, 224, 224)
+- õĖĆõ║øĶ┐Éń«ŚõĖŹõ╝ÜĶó½Ķ«ĪÕģź FLOPs ńÜäń╗¤Ķ«ĪõĖŁ’╝īõŠŗՔ鵤Éõ║øĶć¬Õ«Üõ╣ēĶ┐Éń«ŚŃĆéĶ»”ń╗åõ┐Īµü»Ķ»ĘÕÅéĶĆā [`mmengine.analysis.complexity_analysis._DEFAULT_SUPPORTED_FLOP_OPS`](https://github.com/open-mmlab/mmengine/blob/main/mmengine/analysis/complexity_analysis.py)ŃĆé
+```
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/config.md b/internlm_langchain/knowledge_base/MMPreTrain/content/config.md
new file mode 100644
index 00000000..c6013f28
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/config.md
@@ -0,0 +1,412 @@
+# ÕŁ”õ╣ĀķģŹńĮ«µ¢ćõ╗Č
+
+õĖ║õ║åń«ĪńÉåµĘ▒Õ║”ÕŁ”õ╣ĀÕ«×ķ¬īńÜäÕÉäń¦ŹĶ«ŠńĮ«’╝īµłæõ╗¼õĮ┐ńö©ķģŹńĮ«µ¢ćõ╗ČµØźĶ«░ÕĮĢµēƵ£ēĶ┐Öõ║øķģŹńĮ«ŃĆéĶ┐Öń¦ŹķģŹńĮ«µ¢ćõ╗Čń│╗ń╗¤Õģʵ£ēµ©ĪÕØŚÕī¢ÕÆīń╗¦µē┐ńē╣µĆ¦’╝īµø┤ÕżÜń╗åĶŖéÕÅ»õ╗źÕ£©{external+mmengine:doc}`MMEngine õĖŁńÜäµĢÖń©ŗ
|
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/changelog.md b/internlm_langchain/knowledge_base/MMPreTrain/content/changelog.md
new file mode 100644
index 00000000..a0dabe10
Binary files /dev/null and b/internlm_langchain/knowledge_base/MMPreTrain/content/changelog.md differ
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/complexity_analysis.md b/internlm_langchain/knowledge_base/MMPreTrain/content/complexity_analysis.md
new file mode 100644
index 00000000..83e76325
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/complexity_analysis.md
@@ -0,0 +1,80 @@
+# µ©ĪÕ×ŗÕżŹµØéÕ║”Õłåµ×É
+
+## Ķ«Īń«Ś FLOPs ÕÆīÕÅéµĢ░µĢ░ķćÅ’╝łÕ«×ķ¬īµĆ¦ńÜä’╝ē
+
+µłæõ╗¼µĀ╣µŹ« [MMEngine](https://github.com/open-mmlab/mmengine/blob/main/mmengine/analysis/complexity_analysis.py) µÅÉõŠøõ║åõĖĆõĖ¬Ķäܵ£¼ńö©õ║ÄĶ«Īń«Śń╗Öիܵ©ĪÕ×ŗńÜä FLOPs ÕÆīÕÅéµĢ░ķćÅŃĆé
+
+```shell
+python tools/analysis_tools/get_flops.py ${CONFIG_FILE} [--shape ${INPUT_SHAPE}]
+```
+
+µēƵ£ēÕÅéµĢ░Ķ»┤µśÄ’╝Ü
+
+- `config` : ķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠäŃĆé
+- `--shape`: ĶŠōÕģźÕ░║Õ»Ė’╝īµö»µīüÕŹĢÕĆ╝µł¢ĶĆģÕÅīÕĆ╝’╝ī Õ”é’╝Ü `--shape 256`ŃĆü`--shape 224 256`ŃĆéķ╗śĶ«żõĖ║`224 224`ŃĆé
+
+ńż║õŠŗ’╝Ü
+
+```shell
+python tools/analysis_tools/get_flops.py configs/resnet/resnet50_8xb32_in1k.py
+```
+
+õĮĀÕ░åĶÄĘÕŠŚÕ”éõĖŗń╗ōµ×£’╝Ü
+
+```text
+==============================
+Input shape: (3, 224, 224)
+Flops: 4.109G
+Params: 25.557M
+Activation: 11.114M
+==============================
+```
+
+ÕÉīµŚČ’╝īõĮĀõ╝ÜÕŠŚÕł░µ»ÅÕ▒éńÜäĶ»”ń╗åÕżŹµØéÕ║”õ┐Īµü»’╝īÕ”éõĖŗµēĆńż║’╝Ü
+
+```text
++--------------------------+----------------------+-----------+--------------+
+| module | #parameters or shape | #flops | #activations |
++--------------------------+----------------------+-----------+--------------+
+| model | 25.557M | 4.109G | 11.114M |
+| backbone | 23.508M | 4.109G | 11.114M |
+| backbone.conv1 | 9.408K | 0.118G | 0.803M |
+| backbone.conv1.weight | (64, 3, 7, 7) | | |
+| backbone.bn1 | 0.128K | 1.606M | 0 |
+| backbone.bn1.weight | (64,) | | |
+| backbone.bn1.bias | (64,) | | |
+| backbone.layer1 | 0.216M | 0.677G | 4.415M |
+| backbone.layer1.0 | 75.008K | 0.235G | 2.007M |
+| backbone.layer1.1 | 70.4K | 0.221G | 1.204M |
+| backbone.layer1.2 | 70.4K | 0.221G | 1.204M |
+| backbone.layer2 | 1.22M | 1.034G | 3.111M |
+| backbone.layer2.0 | 0.379M | 0.375G | 1.305M |
+| backbone.layer2.1 | 0.28M | 0.22G | 0.602M |
+| backbone.layer2.2 | 0.28M | 0.22G | 0.602M |
+| backbone.layer2.3 | 0.28M | 0.22G | 0.602M |
+| backbone.layer3 | 7.098M | 1.469G | 2.158M |
+| backbone.layer3.0 | 1.512M | 0.374G | 0.652M |
+| backbone.layer3.1 | 1.117M | 0.219G | 0.301M |
+| backbone.layer3.2 | 1.117M | 0.219G | 0.301M |
+| backbone.layer3.3 | 1.117M | 0.219G | 0.301M |
+| backbone.layer3.4 | 1.117M | 0.219G | 0.301M |
+| backbone.layer3.5 | 1.117M | 0.219G | 0.301M |
+| backbone.layer4 | 14.965M | 0.81G | 0.627M |
+| backbone.layer4.0 | 6.04M | 0.373G | 0.326M |
+| backbone.layer4.1 | 4.463M | 0.219G | 0.151M |
+| backbone.layer4.2 | 4.463M | 0.219G | 0.151M |
+| head.fc | 2.049M | | |
+| head.fc.weight | (1000, 2048) | | |
+| head.fc.bias | (1000,) | | |
+| neck.gap | | 0.1M | 0 |
++--------------------------+----------------------+-----------+--------------+
+```
+
+```{warning}
+ĶŁ”ÕæŖ
+
+µŁżÕĘźÕģĘõ╗ŹÕżäõ║ÄĶ»Ģķ¬īķśČµ«Ą’╝īµłæõ╗¼õĖŹõ┐ØĶ»üĶ»źµĢ░ÕŁŚµŁŻńĪ«µŚĀĶ»»ŃĆéµé©µ£ĆÕźĮÕ░åń╗ōµ×£ńö©õ║Äń«ĆÕŹĢµ»öĶŠā’╝īõĮåÕ£©µŖƵ£»µŖźÕæŖµł¢Ķ«║µ¢ćõĖŁķććńö©Ķ»źń╗ōµ×£õ╣ŗÕēŹ’╝īĶ»Ęõ╗öń╗åµŻĆµ¤źŃĆé
+
+- FLOPs õĖÄĶŠōÕģźńÜäÕ░║Õ»Ėµ£ēÕģ│’╝īĶĆīÕÅéµĢ░ķćÅõĖÄĶŠōÕģźÕ░║Õ»ĖµŚĀÕģ│ŃĆéķ╗śĶ«żĶŠōÕģźÕ░║Õ»ĖõĖ║ (1, 3, 224, 224)
+- õĖĆõ║øĶ┐Éń«ŚõĖŹõ╝ÜĶó½Ķ«ĪÕģź FLOPs ńÜäń╗¤Ķ«ĪõĖŁ’╝īõŠŗՔ鵤Éõ║øĶć¬Õ«Üõ╣ēĶ┐Éń«ŚŃĆéĶ»”ń╗åõ┐Īµü»Ķ»ĘÕÅéĶĆā [`mmengine.analysis.complexity_analysis._DEFAULT_SUPPORTED_FLOP_OPS`](https://github.com/open-mmlab/mmengine/blob/main/mmengine/analysis/complexity_analysis.py)ŃĆé
+```
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/config.md b/internlm_langchain/knowledge_base/MMPreTrain/content/config.md
new file mode 100644
index 00000000..c6013f28
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/config.md
@@ -0,0 +1,412 @@
+# ÕŁ”õ╣ĀķģŹńĮ«µ¢ćõ╗Č
+
+õĖ║õ║åń«ĪńÉåµĘ▒Õ║”ÕŁ”õ╣ĀÕ«×ķ¬īńÜäÕÉäń¦ŹĶ«ŠńĮ«’╝īµłæõ╗¼õĮ┐ńö©ķģŹńĮ«µ¢ćõ╗ČµØźĶ«░ÕĮĢµēƵ£ēĶ┐Öõ║øķģŹńĮ«ŃĆéĶ┐Öń¦ŹķģŹńĮ«µ¢ćõ╗Čń│╗ń╗¤Õģʵ£ēµ©ĪÕØŚÕī¢ÕÆīń╗¦µē┐ńē╣µĆ¦’╝īµø┤ÕżÜń╗åĶŖéÕÅ»õ╗źÕ£©{external+mmengine:doc}`MMEngine õĖŁńÜäµĢÖń©ŗ `ŃĆé
+
+MMPretrain õĖ╗Ķ”üõĮ┐ńö© python µ¢ćõ╗ČõĮ£õĖ║ķģŹńĮ«µ¢ćõ╗Č’╝īµēƵ£ēķģŹńĮ«µ¢ćõ╗ČķāĮµöŠńĮ«Õ£© [`configs`](https://github.com/open-mmlab/mmpretrain/tree/main/configs) µ¢ćõ╗ČÕż╣õĖŗ’╝īńø«ÕĮĢń╗ōµ×äÕ”éõĖŗµēĆńż║’╝Ü
+
+```text
+MMPretrain/
+ Ōö£ŌöĆŌöĆ configs/
+ Ōöé Ōö£ŌöĆŌöĆ _base_/ # primitive configuration folder
+ Ōöé Ōöé Ōö£ŌöĆŌöĆ datasets/ # primitive datasets
+ Ōöé Ōöé Ōö£ŌöĆŌöĆ models/ # primitive models
+ Ōöé Ōöé Ōö£ŌöĆŌöĆ schedules/ # primitive schedules
+ Ōöé Ōöé ŌööŌöĆŌöĆ default_runtime.py # primitive runtime setting
+ Ōöé Ōö£ŌöĆŌöĆ beit/ # BEiT Algorithms Folder
+ Ōöé Ōö£ŌöĆŌöĆ mae/ # MAE Algorithms Folder
+ Ōöé Ōö£ŌöĆŌöĆ mocov2/ # MoCoV2 Algorithms Folder
+ Ōöé Ōö£ŌöĆŌöĆ resnet/ # ResNet Algorithms Folder
+ Ōöé Ōö£ŌöĆŌöĆ swin_transformer/ # Swin Algorithms Folder
+ Ōöé Ōö£ŌöĆŌöĆ vision_transformer/ # ViT Algorithms Folder
+ Ōöé Ōö£ŌöĆŌöĆ ...
+ ŌööŌöĆŌöĆ ...
+```
+
+ÕÅ»õ╗źõĮ┐ńö© `python tools/misc/print_config.py /PATH/TO/CONFIG` ÕæĮõ╗żµØźµ¤źń£ŗÕ«īµĢ┤ńÜäķģŹńĮ«õ┐Īµü»’╝īõ╗ÄĶĆīµ¢╣õŠ┐µŻĆµ¤źµēĆÕ»╣Õ║öńÜäķģŹńĮ«µ¢ćõ╗ČŃĆé
+
+µ£¼µ¢ćõĖ╗Ķ”üĶ«▓Ķ¦Ż MMPretrain ķģŹńĮ«µ¢ćõ╗ČńÜäÕæĮÕÉŹÕÆīń╗ōµ×ä’╝īõ╗źÕÅŖÕ”éõĮĢÕ¤║õ║ÄÕĘ▓µ£ēńÜäķģŹńĮ«µ¢ćõ╗Čõ┐«µö╣’╝īÕ╣Čõ╗ź [ResNet50 ķģŹńĮ«µ¢ćõ╗Č](https://github.com/open-mmlab/mmpretrain/blob/main/configs/resnet/resnet50_8xb32_in1k.py) ķĆÉĶĪīĶ¦ŻķćŖŃĆé
+
+## ķģŹńĮ«µ¢ćõ╗Čń╗ōµ×ä
+
+Õ£© `configs/_base_` µ¢ćõ╗ČÕż╣õĖŗµ£ē 4 õĖ¬Õ¤║µ£¼ń╗äõ╗Čń▒╗Õ×ŗ’╝īÕłåÕł½µś»’╝Ü
+
+- [µ©ĪÕ×ŗ(model)](https://github.com/open-mmlab/mmpretrain/tree/main/configs/_base_/models)
+- [µĢ░µŹ«(data)](https://github.com/open-mmlab/mmpretrain/tree/main/configs/_base_/datasets)
+- [Ķ«Łń╗āńŁ¢ńĢź(schedule)](https://github.com/open-mmlab/mmpretrain/tree/main/configs/_base_/schedules)
+- [Ķ┐ÉĶĪīĶ«ŠńĮ«(runtime)](https://github.com/open-mmlab/mmpretrain/blob/main/configs/_base_/default_runtime.py)
+
+õĮĀÕÅ»õ╗źķĆÜĶ┐ćń╗¦µē┐õĖĆõ║øÕ¤║µ£¼ķģŹńĮ«µ¢ćõ╗ČĶĮ╗µØŠµ×äÕ╗║Ķć¬ÕĘ▒ńÜäĶ«Łń╗āķģŹńĮ«µ¢ćõ╗ČŃĆ鵳æõ╗¼ń¦░Ķ┐Öõ║øĶó½ń╗¦µē┐ńÜäķģŹńĮ«µ¢ćõ╗ČõĖ║ _ÕĤզŗķģŹńĮ«µ¢ćõ╗Č_’╝īÕ”é `_base_` µ¢ćõ╗ČÕż╣õĖŁńÜäµ¢ćõ╗ČõĖĆĶł¼õ╗ģõĮ£õĖ║ÕĤզŗķģŹńĮ«µ¢ćõ╗ČŃĆé
+
+õĖŗķØóõĮ┐ńö© [ResNet50 ķģŹńĮ«µ¢ćõ╗Č](https://github.com/open-mmlab/mmpretrain/blob/main/configs/resnet/resnet50_8xb32_in1k.py) õĮ£õĖ║µĪłõŠŗĶ┐øĶĪīĶ»┤µśÄÕ╣ȵ│©ķćŖµ»ÅõĖĆĶĪīÕɽõ╣ēŃĆé
+
+```python
+_base_ = [ # µŁżķģŹńĮ«µ¢ćõ╗ČÕ░åń╗¦µē┐µēƵ£ē `_base_` õĖŁńÜäķģŹńĮ«
+ '../_base_/models/resnet50.py', # µ©ĪÕ×ŗķģŹńĮ«
+ '../_base_/datasets/imagenet_bs32.py', # µĢ░µŹ«ķģŹńĮ«
+ '../_base_/schedules/imagenet_bs256.py', # Ķ«Łń╗āńŁ¢ńĢźķģŹńĮ«
+ '../_base_/default_runtime.py' # ķ╗śĶ«żĶ┐ÉĶĪīĶ«ŠńĮ«
+]
+```
+
+µłæõ╗¼Õ░åÕ£©õĖŗķØóÕłåÕł½Ķ¦ŻķćŖĶ┐ÖÕøøõĖ¬ÕĤզŗķģŹńĮ«µ¢ćõ╗ČŃĆé
+
+### µ©ĪÕ×ŗķģŹńĮ«
+
+µ©ĪÕ×ŗÕĤզŗķģŹńĮ«µ¢ćõ╗ČÕīģÕɽõĖĆõĖ¬ `model` ÕŁŚÕģĖµĢ░µŹ«ń╗ōµ×ä’╝īõĖ╗Ķ”üÕīģµŗ¼ńĮæń╗£ń╗ōµ×äŃĆüµŹ¤Õż▒ÕćĮµĢ░ńŁēõ┐Īµü»’╝Ü
+
+- `type`’╝Üń«Śµ│Ģń▒╗Õ×ŗ’╝īµłæõ╗¼µö»µīüõ║åÕżÜń¦Źõ╗╗ÕŖĪ
+ - Õ»╣õ║ÄÕøŠÕāÅÕłåń▒╗õ╗╗ÕŖĪ’╝īķĆÜÕĖĖõĖ║ `ImageClassifier`’╝īµø┤ÕżÜń╗åĶŖéĶ»ĘÕÅéĶĆā [API µ¢ćµĪŻ](mmpretrain.models.classifiers)ŃĆé
+ - Õ»╣õ║ÄĶć¬ńøæńØŻõ╗╗ÕŖĪ’╝īµ£ēÕżÜń¦Źń▒╗Õ×ŗńÜäń«Śµ│Ģ’╝īõŠŗÕ”é `MoCoV2`, `BEiT`, `MAE` ńŁēŃĆéµø┤ÕżÜń╗åĶŖéĶ»ĘÕÅéĶĆā [API µ¢ćµĪŻ](mmpretrain.models.selfsup)ŃĆé
+ - Õ»╣õ║ÄÕøŠÕāŵŻĆń┤óõ╗╗ÕŖĪ’╝īķĆÜÕĖĖõĖ║ `ImageToImageRetriever`’╝īµø┤ÕżÜń╗åĶŖéĶ»ĘÕÅéĶĆā [API µ¢ćµĪŻ](mmpretrain.models.retrievers).
+
+ķĆÜÕĖĖ’╝īµłæõ╗¼õĮ┐ńö© **`type`ÕŁŚµ«Ą** µØźµīćÕ«Üń╗äõ╗ČńÜäń▒╗’╝īÕ╣ČõĮ┐ńö©ÕģČõ╗¢ÕŁŚµ«ĄµØźõ╝ĀķĆÆń▒╗ńÜäÕłØÕ¦ŗÕī¢ÕÅéµĢ░ŃĆé{external+mmengine:doc}`µ│©ÕåīÕÖ©µĢÖń©ŗ ` Õ»╣ÕģČĶ┐øĶĪīõ║åĶ»”ń╗åµÅÅĶ┐░ŃĆé
+
+Ķ┐Öķćīµłæõ╗¼õ╗ź [`ImageClassifier`](mmpretrain.models.classifiers.ImageClassifier) ńÜäķģŹńĮ«ÕŁŚµ«ĄõĖ║õŠŗ’╝īÕ»╣ÕłØÕ¦ŗÕī¢ÕÅéµĢ░Ķ┐øĶĪīĶ»┤µśÄ’╝Ü
+
+- `backbone`’╝Ü õĖ╗Õ╣▓ńĮæń╗£Ķ«ŠńĮ«’╝īõĖ╗Õ╣▓ńĮæń╗£õĖ║õĖ╗Ķ”üńÜäńē╣ÕŠüµÅÉÕÅ¢ńĮæń╗£’╝īµ»öÕ”é `ResNet`, `Swin Transformer`, `Vision Transformer` ńŁēńŁēŃĆéµø┤ÕżÜÕÅ»ńö©ķĆēķĪ╣Ķ»ĘÕÅéĶĆā [API µ¢ćµĪŻ](mmpretrain.models.backbones)ŃĆé
+ - Õ»╣õ║ÄĶć¬ńøæńØŻÕŁ”õ╣Ā’╝īµ£ēõ║øõĖ╗Õ╣▓ńĮæń╗£ķ£ĆĶ”üķ揵¢░Õ«×ńÄ░’╝īµé©ÕÅ»õ╗źÕ£© [API µ¢ćµĪŻ](mmpretrain.models.selfsup) õĖŁĶÄĘÕÅ¢µø┤ÕżÜń╗åĶŖéŃĆé
+- `neck`’╝Ü ķółńĮæń╗£Ķ«ŠńĮ«’╝īķółńĮæń╗£õĖ╗Ķ”üµś»Ķ┐׵ğõĖ╗Õ╣▓ńĮæÕÆīÕż┤ńĮæń╗£ńÜäõĖŁķŚ┤ķā©Õłå’╝īµ»öÕ”é `GlobalAveragePooling` ńŁē’╝īµø┤ÕżÜÕÅ»ńö©ķĆēķĪ╣Ķ»ĘÕÅéĶĆā [API µ¢ćµĪŻ](mmpretrain.models.necks)ŃĆé
+- `head`’╝Ü Õż┤ńĮæń╗£Ķ«ŠńĮ«’╝īÕż┤ńĮæń╗£õĖ╗Ķ”üµś»õĖÄÕģĘõĮōõ╗╗ÕŖĪÕģ│ĶüöńÜäķā©õ╗Č’╝īÕ”éÕøŠÕāÅÕłåń▒╗ŃĆüĶć¬ńøæńØŻĶ«Łń╗āńŁē’╝īµø┤ÕżÜÕÅ»ńö©ķĆēķĪ╣Ķ»ĘÕÅéĶĆā [API µ¢ćµĪŻ](mmpretrain.models.heads)ŃĆé
+ - `loss`’╝Ü µŹ¤Õż▒ÕćĮµĢ░Ķ«ŠńĮ«’╝ī µö»µīü `CrossEntropyLoss`, `LabelSmoothLoss`, `PixelReconstructionLoss` ńŁē’╝īµø┤ÕżÜÕÅ»ńö©ķĆēķĪ╣ÕÅéĶĆā [API µ¢ćµĪŻ](mmpretrain.models.losses)ŃĆé
+- `data_preprocessor`: ÕøŠÕāÅĶŠōÕģźńÜäķóäÕżäńÉ嵩ĪÕØŚ’╝īĶŠōÕģźÕ£©Ķ┐øÕģźµ©ĪÕ×ŗÕēŹńÜäķóäÕżäńÉåµōŹõĮ£’╝īõŠŗÕ”é `ClsDataPreprocessor`, µ£ēÕģ│Ķ»”ń╗åõ┐Īµü»’╝īĶ»ĘÕÅéķśģ [API µ¢ćµĪŻ](mmpretrain.models.utils.data_preprocessor)ŃĆé
+- `train_cfg`: `ImageClassifier` ńÜäķóØÕż¢Ķ«Łń╗āķģŹńĮ«ŃĆéÕ£© `ImageClassifier` õĖŁ’╝īµłæõ╗¼õĮ┐ńö©Ķ┐ÖõĖĆÕÅéµĢ░µīćիܵē╣µĢ░µŹ«Õó×Õ╝║Ķ«ŠńĮ«’╝īµ»öÕ”é `Mixup` ÕÆī `CutMix`ŃĆéĶ»”Ķ¦ü[µ¢ćµĪŻ](mmpretrain.models.utils.batch_augments)ŃĆé
+
+õ╗źõĖŗµś» ResNet50 ńÜ䵩ĪÕ×ŗķģŹńĮ«['configs/_base_/models/resnet50.py'](https://github.com/open-mmlab/mmpretrain/blob/main/configs/_base_/models/resnet50.py)’╝Ü
+
+```python
+model = dict(
+ type='ImageClassifier', # õĖ╗µ©ĪÕ×ŗń▒╗Õ×ŗ’╝łÕ»╣õ║ÄÕøŠÕāÅÕłåń▒╗õ╗╗ÕŖĪ’╝īõĮ┐ńö© `ImageClassifier`’╝ē
+ backbone=dict(
+ type='ResNet', # õĖ╗Õ╣▓ńĮæń╗£ń▒╗Õ×ŗ
+ # ķÖżõ║å `type` õ╣ŗÕż¢ńÜäµēƵ£ēÕŁŚµ«ĄķāĮµØźĶć¬ `ResNet` ń▒╗ńÜä __init__ µ¢╣µ│Ģ
+ # ÕÅ»µ¤źķśģ https://mmpretrain.readthedocs.io/zh_CN/latest/api/generated/mmpretrain.models.backbones.ResNet.html
+ depth=50,
+ num_stages=4, # õĖ╗Õ╣▓ńĮæń╗£ńŖȵĆü(stages)ńÜäµĢ░ńø«’╝īĶ┐Öõ║øńŖȵĆüõ║¦ńö¤ńÜäńē╣ÕŠüÕøŠõĮ£õĖ║ÕÉÄń╗ŁńÜä head ńÜäĶŠōÕģźŃĆé
+ out_indices=(3, ), # ĶŠōÕć║ńÜäńē╣ÕŠüÕøŠĶŠōÕć║ń┤óÕ╝ĢŃĆé
+ frozen_stages=-1, # Õå╗ń╗ōõĖ╗Õ╣▓ńĮæńÜäÕ▒éµĢ░
+ style='pytorch'),
+ neck=dict(type='GlobalAveragePooling'), # ķółńĮæń╗£ń▒╗Õ×ŗ
+ head=dict(
+ type='LinearClsHead', # Õłåń▒╗ķółńĮæń╗£ń▒╗Õ×ŗ
+ # ķÖżõ║å `type` õ╣ŗÕż¢ńÜäµēƵ£ēÕŁŚµ«ĄķāĮµØźĶć¬ `LinearClsHead` ń▒╗ńÜä __init__ µ¢╣µ│Ģ
+ # ÕÅ»µ¤źķśģ https://mmpretrain.readthedocs.io/zh_CN/latest/api/generated/mmpretrain.models.heads.LinearClsHead.html
+ num_classes=1000,
+ in_channels=2048,
+ loss=dict(type='CrossEntropyLoss', loss_weight=1.0), # µŹ¤Õż▒ÕćĮµĢ░ķģŹńĮ«õ┐Īµü»
+ topk=(1, 5), # Ķ»äõ╝░µīćµĀć’╝īTop-k ÕćåńĪ«ńÄć’╝ī Ķ┐ÖķćīõĖ║ top1 õĖÄ top5 ÕćåńĪ«ńÄć
+ ))
+```
+
+### µĢ░µŹ«
+
+µĢ░µŹ«ÕĤզŗķģŹńĮ«µ¢ćõ╗ČõĖ╗Ķ”üÕīģµŗ¼ķóäÕżäńÉåĶ«ŠńĮ«ŃĆüdataloader õ╗źÕÅŖ Ķ»äõ╝░ÕÖ©ńŁēĶ«ŠńĮ«’╝Ü
+
+- `data_preprocessor`: µ©ĪÕ×ŗĶŠōÕģźķóäÕżäńÉåķģŹńĮ«’╝īõĖÄ `model.data_preprocessor` ńøĖÕÉī’╝īõĮåõ╝śÕģłń║¦µø┤õĮÄŃĆé
+- `train_evaluator | val_evaluator | test_evaluator`: µ×äÕ╗║Ķ»äõ╝░ÕÖ©’╝īÕÅéĶĆā [API µ¢ćµĪŻ](mmpretrain.evaluation)ŃĆé
+- `train_dataloader | val_dataloader | test_dataloader`: µ×äÕ╗║ dataloader
+ - `batch_size`: µ»ÅõĖ¬ GPU ńÜä batch size
+ - `num_workers`: µ»ÅõĖ¬ GPU ńÜäń║┐ń©ŗµĢ░
+ - `sampler`: ķććµĀĘÕÖ©ķģŹńĮ«
+ - `dataset`: µĢ░µŹ«ķøåķģŹńĮ«
+ - `type`: µĢ░µŹ«ķøåń▒╗Õ×ŗ’╝ī MMPretrain µö»µīü `ImageNet`ŃĆü `Cifar` ńŁēµĢ░µŹ«ķøå ’╝īÕÅéĶĆā [API µ¢ćµĪŻ](mmpretrain.datasets)
+ - `pipeline`: µĢ░µŹ«ÕżäńÉåµĄüµ░┤ń║┐’╝īÕÅéĶĆāńøĖÕģ│µĢÖń©ŗµ¢ćµĪŻ [Õ”éõĮĢĶ«ŠĶ«ĪµĢ░µŹ«ÕżäńÉåµĄüµ░┤ń║┐](../advanced_guides/pipeline.md)
+
+õ╗źõĖŗµś» ResNet50 ńÜäµĢ░µŹ«ķģŹńĮ« ['configs/_base_/datasets/imagenet_bs32.py'](https://github.com/open-mmlab/mmpretrain/blob/main/configs/_base_/datasets/imagenet_bs32.py)’╝Ü
+
+```python
+dataset_type = 'ImageNet'
+# ķóäÕżäńÉåķģŹńĮ«
+data_preprocessor = dict(
+ # ĶŠōÕģźńÜäÕøŠńēćµĢ░µŹ«ķĆÜķüōõ╗ź 'RGB' ķĪ║Õ║Å
+ mean=[123.675, 116.28, 103.53], # ĶŠōÕģźÕøŠÕāÅÕĮÆõĖĆÕī¢ńÜä RGB ķĆÜķüōÕØćÕĆ╝
+ std=[58.395, 57.12, 57.375], # ĶŠōÕģźÕøŠÕāÅÕĮÆõĖĆÕī¢ńÜä RGB ķĆÜķüōµĀćÕćåÕĘ«
+ to_rgb=True, # µś»ÕÉ”Õ░åķĆÜķüōń┐╗ĶĮ¼’╝īõ╗Ä BGR ĶĮ¼õĖ║ RGB µł¢ĶĆģ RGB ĶĮ¼õĖ║ BGR
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'), # Ķ»╗ÕÅ¢ÕøŠÕāÅ
+ dict(type='RandomResizedCrop', scale=224), # ķÜŵ£║µöŠń╝®ĶŻüÕē¬
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'), # ķÜŵ£║µ░┤Õ╣│ń┐╗ĶĮ¼
+ dict(type='PackInputs'), # ÕćåÕżćÕøŠÕāÅõ╗źÕÅŖµĀćńŁŠ
+]
+
+test_pipeline = [
+ dict(type='LoadImageFromFile'), # Ķ»╗ÕÅ¢ÕøŠÕāÅ
+ dict(type='ResizeEdge', scale=256, edge='short'), # ń╝®µöŠń¤ŁĶŠ╣Õ░║Õ»ĖĶć│ 256px
+ dict(type='CenterCrop', crop_size=224), # õĖŁÕ┐āĶŻüÕē¬
+ dict(type='PackInputs'), # ÕćåÕżćÕøŠÕāÅõ╗źÕÅŖµĀćńŁŠ
+]
+
+# µ×äķĆĀĶ«Łń╗āķøå dataloader
+train_dataloader = dict(
+ batch_size=32, # µ»ÅÕ╝Ā GPU ńÜä batchsize
+ num_workers=5, # µ»ÅõĖ¬ GPU ńÜäń║┐ń©ŗµĢ░
+ dataset=dict( # Ķ«Łń╗āµĢ░µŹ«ķøå
+ type=dataset_type,
+ data_root='data/imagenet',
+ ann_file='meta/train.txt',
+ data_prefix='train',
+ pipeline=train_pipeline),
+ sampler=dict(type='DefaultSampler', shuffle=True), # ķ╗śĶ«żķććµĀĘÕÖ©
+ persistent_workers=True, # µś»ÕÉ”õ┐صīüĶ┐øń©ŗ’╝īÕÅ»õ╗źń╝®ń¤Łµ»ÅõĖ¬ epoch ńÜäÕćåÕżćµŚČķŚ┤
+)
+
+# µ×äķĆĀķ¬īĶ»üķøå dataloader
+val_dataloader = dict(
+ batch_size=32,
+ num_workers=5,
+ dataset=dict(
+ type=dataset_type,
+ data_root='data/imagenet',
+ ann_file='meta/val.txt',
+ data_prefix='val',
+ pipeline=test_pipeline),
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ persistent_workers=True,
+)
+# ķ¬īĶ»üķøåĶ»äõ╝░Ķ«ŠńĮ«’╝īõĮ┐ńö©ÕćåńĪ«ńÄćõĖ║µīćµĀć’╝ī Ķ┐ÖķćīõĮ┐ńö© topk1 õ╗źÕÅŖ top5 ÕćåńĪ«ńÄć
+val_evaluator = dict(type='Accuracy', topk=(1, 5))
+
+test_dataloader = val_dataloader # test dataloader ķģŹńĮ«’╝īĶ┐Öķćīńø┤µÄźõĖÄ val_dataloader ńøĖÕÉī
+test_evaluator = val_evaluator # µĄŗĶ»ĢķøåńÜäĶ»äõ╝░ķģŹńĮ«’╝īĶ┐Öķćīńø┤µÄźõĖÄ val_evaluator ńøĖÕÉī
+```
+
+```{note}
+ķóäÕżäńÉåķģŹńĮ«’╝ł`data_preprocessor`’╝ēµŚóÕÅ»õ╗źõĮ£õĖ║ `model` ńÜäõĖĆõĖ¬ÕŁÉÕŁŚµ«Ą’╝īõ╣¤ÕÅ»õ╗źÕ«Üõ╣ēÕ£©Õż¢ķā©ńÜä `data_preprocessor` ÕŁŚµ«Ą’╝ī
+ÕÉīµŚČķģŹńĮ«µŚČ’╝īõ╝śÕģłõĮ┐ńö© `model.data_preprocessor` ńÜäķģŹńĮ«ŃĆé
+```
+
+### Ķ«Łń╗āńŁ¢ńĢź
+
+Ķ«Łń╗āńŁ¢ńĢźÕĤզŗķģŹńĮ«µ¢ćõ╗ČõĖ╗Ķ”üÕīģµŗ¼ķóäõ╝śÕī¢ÕÖ©Ķ«ŠńĮ«ÕÆīĶ«Łń╗āŃĆüķ¬īĶ»üÕÅŖµĄŗĶ»ĢńÜäÕŠ¬ńÄ»µÄ¦ÕłČÕÖ©(LOOP)’╝Ü
+
+- `optim_wrapper`: õ╝śÕī¢ÕÖ©ĶŻģķź░ÕÖ©ķģŹńĮ«õ┐Īµü»’╝īµłæõ╗¼õĮ┐ńö©õ╝śÕī¢ÕÖ©ĶŻģķź░ķģŹńĮ«õ╝śÕī¢Ķ┐øń©ŗŃĆé
+ - `optimizer`: µö»µīü `pytorch` µēƵ£ēńÜäõ╝śÕī¢ÕÖ©’╝īÕÅéĶĆāńøĖÕģ│ {external+mmengine:doc}`MMEngine ` µ¢ćµĪŻŃĆé
+ - `paramwise_cfg`: µĀ╣µŹ«ÕÅéµĢ░ńÜäń▒╗Õ×ŗµł¢ÕÉŹń¦░Ķ«ŠńĮ«õĖŹÕÉīńÜäõ╝śÕī¢ÕÅéµĢ░’╝īÕÅéĶĆāńøĖÕģ│ [ÕŁ”õ╣ĀńŁ¢ńĢźµ¢ćµĪŻ](../advanced_guides/schedule.md) µ¢ćµĪŻŃĆé
+ - `accumulative_counts`: ń¦»ń┤»ÕćĀõĖ¬ÕÅŹÕÉæõ╝ĀµÆŁÕÉÄÕåŹõ╝śÕī¢ÕÅéµĢ░’╝īõĮĀÕÅ»õ╗źńö©Õ«āķĆÜĶ┐ćÕ░ŵē╣ķćÅµØźµ©Īµŗ¤Õż¦µē╣ķćÅŃĆé
+- `param_scheduler` : ÕŁ”õ╣ĀńÄćńŁ¢ńĢź’╝īõĮĀÕÅ»õ╗źµīćÕ«ÜĶ«Łń╗āµ£¤ķŚ┤ńÜäÕŁ”õ╣ĀńÄćÕÆīÕŖ©ķćŵø▓ń║┐ŃĆéµ£ēÕģ│Ķ»”ń╗åõ┐Īµü»’╝īĶ»ĘÕÅéķśģ MMEngine õĖŁńÜä {external+mmengine:doc}`µ¢ćµĪŻ `ŃĆé
+- `train_cfg | val_cfg | test_cfg`: Ķ«Łń╗āŃĆüķ¬īĶ»üõ╗źÕÅŖµĄŗĶ»ĢńÜäÕŠ¬ńÄ»µē¦ĶĪīÕÖ©ķģŹńĮ«’╝īĶ»ĘÕÅéĶĆāńøĖÕģ│ńÜä{external+mmengine:doc}`MMEngine µ¢ćµĪŻ `ŃĆé
+
+õ╗źõĖŗµś» ResNet50 ńÜäĶ«Łń╗āńŁ¢ńĢźķģŹńĮ«['configs/_base_/schedules/imagenet_bs256.py'](https://github.com/open-mmlab/mmpretrain/blob/main/configs/_base_/schedules/imagenet_bs256.py)’╝Ü
+
+```python
+optim_wrapper = dict(
+ # õĮ┐ńö© SGD õ╝śÕī¢ÕÖ©µØźõ╝śÕī¢ÕÅéµĢ░
+ optimizer=dict(type='SGD', lr=0.1, momentum=0.9, weight_decay=0.0001))
+
+# ÕŁ”õ╣ĀńÄćÕÅéµĢ░ńÜäĶ░āµĢ┤ńŁ¢ńĢź
+# 'MultiStepLR' ĶĪ©ńż║õĮ┐ńö©ÕżÜµŁźńŁ¢ńĢźµØźĶ░āÕ║”ÕŁ”õ╣ĀńÄć’╝łLR’╝ēŃĆé
+param_scheduler = dict(
+ type='MultiStepLR', by_epoch=True, milestones=[30, 60, 90], gamma=0.1)
+
+# Ķ«Łń╗āńÜäķģŹńĮ«’╝īĶ┐Łõ╗Ż 100 õĖ¬ epoch’╝īµ»ÅõĖĆõĖ¬Ķ«Łń╗ā epoch ÕÉÄķāĮÕüÜķ¬īĶ»üķøåĶ»äõ╝░
+# 'by_epoch=True' ķ╗śĶ«żõĮ┐ńö© `EpochBaseLoop`, 'by_epoch=False' ķ╗śĶ«żõĮ┐ńö© `IterBaseLoop`
+train_cfg = dict(by_epoch=True, max_epochs=100, val_interval=1)
+# õĮ┐ńö©ķ╗śĶ«żńÜäķ¬īĶ»üÕŠ¬ńÄ»µÄ¦ÕłČÕÖ©
+val_cfg = dict()
+# õĮ┐ńö©ķ╗śĶ«żńÜ䵥ŗĶ»ĢÕŠ¬ńÄ»µÄ¦ÕłČÕÖ©
+test_cfg = dict()
+
+# ķĆÜĶ┐ćķ╗śĶ«żńŁ¢ńĢźĶć¬ÕŖ©ń╝®µöŠÕŁ”õ╣ĀńÄć’╝īµŁżńŁ¢ńĢźķĆéńö©õ║ĵĆ╗µē╣µ¼ĪÕż¦Õ░Å 256
+# Õ”éµ×£õĮĀõĮ┐ńö©õĖŹÕÉīńÜäµĆ╗µē╣ķćÅÕż¦Õ░Å’╝īµ»öÕ”é 512 Õ╣ČÕÉ»ńö©Ķć¬ÕŖ©ÕŁ”õ╣ĀńÄćń╝®µöŠ
+# µłæõ╗¼Õ░åÕŁ”õ╣ĀńÄćµē®Õż¦Õł░ 2 ÕĆŹ
+auto_scale_lr = dict(base_batch_size=256)
+```
+
+### Ķ┐ÉĶĪīĶ«ŠńĮ«
+
+µ£¼ķā©ÕłåõĖ╗Ķ”üÕīģµŗ¼õ┐ØÕŁśµØāķćŹńŁ¢ńĢźŃĆüµŚźÕ┐ŚķģŹńĮ«ŃĆüĶ«Łń╗āÕÅéµĢ░ŃĆüµ¢Łńé╣µØāķćŹĶĘ»ÕŠäÕÆīÕĘźõĮ£ńø«ÕĮĢńŁēńŁēŃĆé
+
+õ╗źõĖŗµś»ÕćĀõ╣ĵēƵ£ēń«Śµ│ĢķāĮõĮ┐ńö©ńÜäĶ┐ÉĶĪīķģŹńĮ«['configs/_base_/default_runtime.py'](https://github.com/open-mmlab/mmpretrain/blob/main//configs/_base_/default_runtime.py)’╝Ü
+
+```python
+# ķ╗śĶ«żµēƵ£ēµ│©ÕåīÕÖ©õĮ┐ńö©ńÜäÕ¤¤
+default_scope = 'mmpretrain'
+
+# ķģŹńĮ«ķ╗śĶ«żńÜä hook
+default_hooks = dict(
+ # Ķ«░ÕĮĢµ»Åµ¼ĪĶ┐Łõ╗ŻńÜ䵌ČķŚ┤ŃĆé
+ timer=dict(type='IterTimerHook'),
+
+ # µ»Å 100 µ¼ĪĶ┐Łõ╗ŻµēōÕŹ░õĖƵ¼ĪµŚźÕ┐ŚŃĆé
+ logger=dict(type='LoggerHook', interval=100),
+
+ # ÕÉ»ńö©ķ╗śĶ«żÕÅéµĢ░Ķ░āÕ║” hookŃĆé
+ param_scheduler=dict(type='ParamSchedulerHook'),
+
+ # µ»ÅõĖ¬ epoch õ┐ØÕŁśµŻĆµ¤źńé╣ŃĆé
+ checkpoint=dict(type='CheckpointHook', interval=1),
+
+ # Õ£©ÕłåÕĖāÕ╝ÅńÄ»ÕóāõĖŁĶ«ŠńĮ«ķććµĀĘÕÖ©ń¦ŹÕŁÉŃĆé
+ sampler_seed=dict(type='DistSamplerSeedHook'),
+
+ # ķ¬īĶ»üń╗ōµ×£ÕÅ»Ķ¦åÕī¢’╝īķ╗śĶ«żõĖŹÕÉ»ńö©’╝īĶ«ŠńĮ« True µŚČÕÉ»ńö©ŃĆé
+ visualization=dict(type='VisualizationHook', enable=False),
+)
+
+# ķģŹńĮ«ńÄ»Õóā
+env_cfg = dict(
+ # µś»ÕÉ”Õ╝ĆÕÉ» cudnn benchmark
+ cudnn_benchmark=False,
+
+ # Ķ«ŠńĮ«ÕżÜĶ┐øń©ŗÕÅéµĢ░
+ mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0),
+
+ # Ķ«ŠńĮ«ÕłåÕĖāÕ╝ÅÕÅéµĢ░
+ dist_cfg=dict(backend='nccl'),
+)
+
+# Ķ«ŠńĮ«ÕÅ»Ķ¦åÕī¢ÕĘźÕģĘ
+vis_backends = [dict(type='LocalVisBackend')] # õĮ┐ńö©ńŻüńøś(HDD)ÕÉÄń½»
+visualizer = dict(
+ type='UniversalVisualizer', vis_backends=vis_backends, name='visualizer')
+
+# Ķ«ŠńĮ«µŚźÕ┐Śń║¦Õł½
+log_level = 'INFO'
+
+# õ╗ÄÕō¬õĖ¬µŻĆµ¤źńé╣ÕŖĀĶĮĮ
+load_from = None
+
+# µś»ÕÉ”õ╗ÄÕŖĀĶĮĮńÜ䵯Ƶ¤źńé╣µüóÕżŹĶ«Łń╗ā
+resume = False
+```
+
+## ń╗¦µē┐Õ╣Čõ┐«µö╣ķģŹńĮ«µ¢ćõ╗Č
+
+õĖ║õ║åń▓Šń«Ćõ╗ŻńĀüŃĆüµø┤Õ┐½ńÜäõ┐«µö╣ķģŹńĮ«µ¢ćõ╗Čõ╗źÕÅŖõŠ┐õ║ÄńÉåĶ¦Ż’╝īµłæõ╗¼Õ╗║Ķ««ń╗¦µē┐ńÄ░µ£ēµ¢╣µ│ĢŃĆé
+
+Õ»╣õ║ÄÕ£©ÕÉīõĖĆń«Śµ│Ģµ¢ćõ╗ČÕż╣õĖŗńÜäµēƵ£ēķģŹńĮ«µ¢ćõ╗Č’╝īMMPretrain µÄ©ĶŹÉÕÅ¬ÕŁśÕ£© **õĖĆõĖ¬** Õ»╣Õ║öńÜä _ÕĤզŗķģŹńĮ«_ µ¢ćõ╗ČŃĆé
+µēƵ£ēÕģČõ╗¢ńÜäķģŹńĮ«µ¢ćõ╗ČķāĮÕ║öĶ»źń╗¦µē┐ _ÕĤզŗķģŹńĮ«_ µ¢ćõ╗Č’╝īĶ┐ÖµĀĘÕ░▒ĶāĮõ┐ØĶ»üķģŹńĮ«µ¢ćõ╗ČńÜäµ£ĆÕż¦ń╗¦µē┐µĘ▒Õ║”õĖ║ 3ŃĆé
+
+õŠŗÕ”é’╝īÕ”éµ×£Õ£© ResNet ńÜäÕ¤║ńĪĆõĖŖÕüÜõ║åõĖĆõ║øõ┐«µö╣’╝īńö©µłĘķ”¢ÕģłÕÅ»õ╗źķĆÜĶ┐ćµīćÕ«Ü `_base_ = './resnet50_8xb32_in1k.py'`’╝łńøĖÕ»╣õ║ÄõĮĀńÜäķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠä’╝ē’╝īµØźń╗¦µē┐Õ¤║ńĪĆńÜä ResNet ń╗ōµ×äŃĆüµĢ░µŹ«ķøåõ╗źÕÅŖÕģČõ╗¢Ķ«Łń╗āķģŹńĮ«õ┐Īµü»’╝īńäČÕÉÄõ┐«µö╣ķģŹńĮ«µ¢ćõ╗ČõĖŁńÜäÕ┐ģĶ”üÕÅéµĢ░õ╗źÕ«īµłÉń╗¦µē┐ŃĆéÕ”éµā│Õ£©Õ¤║ńĪĆ resnet50 ńÜäÕ¤║ńĪĆõĖŖõĮ┐ńö© `CutMix` Ķ«Łń╗āÕó×Õ╝║’╝īÕ░åĶ«Łń╗āĶĮ«µĢ░ńö▒ 100 µö╣õĖ║ 300 ÕÆīõ┐«µö╣ÕŁ”õ╣ĀńÄćĶĪ░ÕćÅĶĮ«µĢ░’╝īÕÉīµŚČõ┐«µö╣µĢ░µŹ«ķøåĶĘ»ÕŠä’╝īÕÅ»õ╗źÕ╗║ń½ŗµ¢░ńÜäķģŹńĮ«µ¢ćõ╗Č `configs/resnet/resnet50_8xb32-300e_in1k.py`’╝ī µ¢ćõ╗ČõĖŁÕåÖÕģźõ╗źõĖŗÕåģÕ«╣’╝Ü
+
+```python
+# Õ£© 'configs/resnet/' ÕłøÕ╗║µŁżµ¢ćõ╗Č
+_base_ = './resnet50_8xb32_in1k.py'
+
+# µ©ĪÕ×ŗÕ£©õ╣ŗÕēŹńÜäÕ¤║ńĪĆõĖŖõĮ┐ńö© CutMix Ķ«Łń╗āÕó×Õ╝║
+model = dict(
+ train_cfg=dict(
+ augments=dict(type='CutMix', alpha=1.0)
+ )
+)
+
+# õ╝śÕī¢ńŁ¢ńĢźÕ£©õ╣ŗÕēŹÕ¤║ńĪĆõĖŖĶ«Łń╗āµø┤ÕżÜõĖ¬ epoch
+train_cfg = dict(max_epochs=300, val_interval=10) # Ķ«Łń╗ā 300 õĖ¬ epoch’╝īµ»Å 10 õĖ¬ epoch Ķ»äõ╝░õĖƵ¼Ī
+param_scheduler = dict(step=[150, 200, 250]) # ÕŁ”õ╣ĀńÄćĶ░āµĢ┤õ╣¤µ£ēµēĆÕÅśÕŖ©
+
+# õĮ┐ńö©Ķć¬ÕĘ▒ńÜäµĢ░µŹ«ķøåńø«ÕĮĢ
+train_dataloader = dict(
+ dataset=dict(data_root='mydata/imagenet/train'),
+)
+val_dataloader = dict(
+ batch_size=64, # ķ¬īĶ»üµŚČµ▓Īµ£ēÕÅŹÕÉæõ╝ĀµÆŁ’╝īÕÅ»õ╗źõĮ┐ńö©µø┤Õż¦ńÜä batchsize
+ dataset=dict(data_root='mydata/imagenet/val'),
+)
+test_dataloader = dict(
+ batch_size=64, # µĄŗĶ»ĢµŚČµ▓Īµ£ēÕÅŹÕÉæõ╝ĀµÆŁ’╝īÕÅ»õ╗źõĮ┐ńö©µø┤Õż¦ńÜä batchsize
+ dataset=dict(data_root='mydata/imagenet/val'),
+)
+```
+
+### õĮ┐ńö©ķģŹńĮ«µ¢ćõ╗ČķćīńÜäõĖŁķŚ┤ÕÅśķćÅ
+
+ńö©õĖĆõ║øõĖŁķŚ┤ÕÅśķćÅ’╝īõĖŁķŚ┤ÕÅśķćÅĶ«®ķģŹńĮ«µ¢ćõ╗ȵø┤ÕŖĀµĖģµÖ░’╝īõ╣¤µø┤Õ«╣µśōõ┐«µö╣ŃĆé
+
+õŠŗÕ”éµĢ░µŹ«ķøåķćīńÜä `train_pipeline` / `test_pipeline` µś»õĮ£õĖ║µĢ░µŹ«µĄüµ░┤ń║┐ńÜäõĖŁķŚ┤ÕÅśķćÅŃĆ鵳æõ╗¼ķ”¢ÕģłĶ”üÕ«Üõ╣ēÕ«āõ╗¼’╝īńäČÕÉÄÕ░åÕ«āõ╗¼õ╝ĀķĆÆÕł░ `train_dataloader` / `test_dataloader` õĖŁŃĆéÕ”éµ×£µā│õ┐«µö╣Ķ«Łń╗āµł¢µĄŗĶ»ĢµŚČĶŠōÕģźÕøŠńēćńÜäÕż¦Õ░Å’╝īÕ░▒ķ£ĆĶ”üõ┐«µö╣ `train_pipeline` / `test_pipeline` Ķ┐Öõ║øõĖŁķŚ┤ÕÅśķćÅŃĆé
+
+```python
+bgr_mean = [103.53, 116.28, 123.675]
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='RandomResizedCrop', scale=224, backend='pillow', interpolation='bicubic'),
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'),
+ dict(
+ type='RandAugment',
+ policies='timm_increasing',
+ num_policies=2,
+ total_level=10,
+ magnitude_level=6,
+ magnitude_std=0.5,
+ hparams=dict(pad_val=[round(x) for x in bgr_mean], interpolation='bicubic')),
+ dict(type='PackInputs'),
+]
+
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='ResizeEdge', scale=236, edge='short', backend='pillow', interpolation='bicubic'),
+ dict(type='CenterCrop', crop_size=224),
+ dict(type='PackInputs')
+]
+
+train_dataloader = dict(dataset=dict(pipeline=train_pipeline))
+val_dataloader = dict(dataset=dict(pipeline=val_pipeline))
+test_dataloader = dict(dataset=dict(pipeline=val_pipeline))
+```
+
+### Õ┐ĮńĢźÕ¤║ńĪĆķģŹńĮ«µ¢ćõ╗ČķćīńÜäķā©ÕłåÕåģÕ«╣
+
+µ£ēµŚČ’╝īµé©ķ£ĆĶ”üĶ«ŠńĮ« `_delete_=True` ÕÄ╗Õ┐ĮńĢźÕ¤║ńĪĆķģŹńĮ«µ¢ćõ╗ČķćīńÜäõĖĆõ║øÕ¤¤ÕåģÕ«╣ŃĆéÕÅ»õ╗źµ¤źń£ŗ {external+mmengine:doc}`MMEngine µ¢ćµĪŻ ` Ķ┐øõĖƵŁźõ║åĶ¦ŻĶ»źĶ«ŠĶ«ĪŃĆé
+
+õ╗źõĖŗµś»õĖĆõĖ¬ń«ĆÕŹĢÕ║öńö©µĪłõŠŗŃĆé Õ”éµ×£Õ£©õĖŖĶ┐░ ResNet50 µĪłõŠŗõĖŁ õĮ┐ńö©õĮÖÕ╝”Ķ░āÕ║” ,õĮ┐ńö©ń╗¦µē┐Õ╣Čńø┤µÄźõ┐«µö╣õ╝ܵŖź `get unexcepected keyword 'step'` ķöÖ’╝īÕøĀõĖ║Õ¤║ńĪĆķģŹńĮ«µ¢ćõ╗Č `param_scheduler` Õ¤¤õ┐Īµü»ńÜä `'step'` ÕŁŚµ«ĄĶó½õ┐ØńĢÖõĖŗµØźõ║å’╝īķ£ĆĶ”üÕŖĀÕģź `_delete_=True` ÕÄ╗Õ┐ĮńĢźÕ¤║ńĪĆķģŹńĮ«µ¢ćõ╗ČķćīńÜä `param_scheduler` ńøĖÕģ│Õ¤¤ÕåģÕ«╣’╝Ü
+
+```python
+_base_ = '../../configs/resnet/resnet50_8xb32_in1k.py'
+
+# ÕŁ”õ╣ĀńÄćĶ░āµĢ┤ńŁ¢ńĢź
+param_scheduler = dict(type='CosineAnnealingLR', by_epoch=True, _delete_=True)
+```
+
+### Õ╝Ģńö©Õ¤║ńĪĆķģŹńĮ«µ¢ćõ╗ČķćīńÜäÕÅśķćÅ
+
+µ£ēµŚČ’╝īµé©ÕÅ»õ╗źÕ╝Ģńö© `_base_` ķģŹńĮ«õ┐Īµü»ńÜäõĖĆõ║øÕ¤¤ÕåģÕ«╣’╝īĶ┐ÖµĀĘÕÅ»õ╗źķü┐ÕģŹķćŹÕżŹÕ«Üõ╣ēŃĆéÕÅ»õ╗źµ¤źń£ŗ {external+mmengine:doc}`MMEngine µ¢ćµĪŻ ` Ķ┐øõĖƵŁźõ║åĶ¦ŻĶ»źĶ«ŠĶ«ĪŃĆé
+
+õ╗źõĖŗµś»õĖĆõĖ¬ń«ĆÕŹĢÕ║öńö©µĪłõŠŗ’╝īÕ£©Ķ«Łń╗āµĢ░µŹ«ķóäÕżäńÉåµĄüµ░┤ń║┐õĖŁõĮ┐ńö© `auto augment` µĢ░µŹ«Õó×Õ╝║’╝īÕÅéĶĆāķģŹńĮ«µ¢ćõ╗Č [`configs/resnest/resnest50_32xb64_in1k.py`](https://github.com/open-mmlab/mmpretrain/blob/main/configs/resnest/resnest50_32xb64_in1k.py)ŃĆé Õ£©Õ«Üõ╣ē `train_pipeline` µŚČ’╝īÕÅ»õ╗źńø┤µÄźÕ£© `_base_` õĖŁÕŖĀÕģźÕ«Üõ╣ē auto augment µĢ░µŹ«Õó×Õ╝║ńÜäµ¢ćõ╗ČÕæĮÕÉŹ’╝īÕåŹķĆÜĶ┐ć `{{_base_.auto_increasing_policies}}` Õ╝Ģńö©ÕÅśķćÅ’╝Ü
+
+```python
+_base_ = [
+ '../_base_/models/resnest50.py', '../_base_/datasets/imagenet_bs64.py',
+ '../_base_/default_runtime.py', './_randaug_policies.py',
+]
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='RandAugment',
+ policies={{_base_.policies}}, # Ķ┐ÖķćīõĮ┐ńö©õ║å _base_ ķćīńÜä `policies` ÕÅéµĢ░ŃĆé
+ num_policies=2,
+ magnitude_level=12),
+ dict(type='EfficientNetRandomCrop', scale=224, backend='pillow'),
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'),
+ dict(type='ColorJitter', brightness=0.4, contrast=0.4, saturation=0.4),
+ dict(
+ type='Lighting',
+ eigval=EIGVAL,
+ eigvec=EIGVEC,
+ alphastd=0.1,
+ to_rgb=False),
+ dict(type='PackInputs'),
+]
+
+train_dataloader = dict(dataset=dict(pipeline=train_pipeline))
+```
+
+## ķĆÜĶ┐ćÕæĮõ╗żĶĪīÕÅéµĢ░õ┐«µö╣ķģŹńĮ«õ┐Īµü»
+
+ÕĮōńö©µłĘõĮ┐ńö©Ķäܵ£¼ "tools/train.py" µł¢ĶĆģ "tools/test.py" µÅÉõ║żõ╗╗ÕŖĪ’╝īõ╗źÕÅŖõĮ┐ńö©õĖĆõ║øÕĘźÕģĘĶäܵ£¼µŚČ’╝īÕÅ»õ╗źķĆÜĶ┐ćµīćÕ«Ü `--cfg-options` ÕÅéµĢ░µØźńø┤µÄźõ┐«µö╣µēĆõĮ┐ńö©ńÜäķģŹńĮ«µ¢ćõ╗ČÕåģÕ«╣ŃĆé
+
+- µø┤µ¢░ķģŹńĮ«µ¢ćõ╗ČÕåģńÜäÕŁŚÕģĖ
+
+ ÕÅ»õ╗źµīēńģ¦ÕĤզŗķģŹńĮ«µ¢ćõ╗ČõĖŁÕŁŚÕģĖńÜäķö«ńÜäķĪ║Õ║ŵīćÕ«ÜķģŹńĮ«ķĆēķĪ╣ŃĆé
+ õŠŗÕ”é’╝ī`--cfg-options model.backbone.norm_eval=False` Õ░åõĖ╗Õ╣▓ńĮæń╗£õĖŁńÜäµēƵ£ē BN µ©ĪÕØŚµø┤µö╣õĖ║ `train` µ©ĪÕ╝ÅŃĆé
+
+- µø┤µ¢░ķģŹńĮ«µ¢ćõ╗ČÕåģÕłŚĶĪ©ńÜäķö«
+
+ õĖĆõ║øķģŹńĮ«ÕŁŚÕģĖÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁõ╝ÜÕĮóµłÉõĖĆõĖ¬ÕłŚĶĪ©ŃĆéõŠŗÕ”é’╝īĶ«Łń╗āµĄüµ░┤ń║┐ `data.train.pipeline` ķĆÜÕĖĖµś»õĖĆõĖ¬ÕłŚĶĪ©ŃĆé
+ õŠŗÕ”é’╝ī`[dict(type='LoadImageFromFile'), dict(type='TopDownRandomFlip', flip_prob=0.5), ...]` ŃĆéÕ”éµ×£Ķ”üÕ░åµĄüµ░┤ń║┐õĖŁńÜä `'flip_prob=0.5'` µø┤µö╣õĖ║ `'flip_prob=0.0'`’╝īµé©ÕÅ»õ╗źĶ┐ÖµĀʵīćÕ«Ü `--cfg-options data.train.pipeline.1.flip_prob=0.0` ŃĆé
+
+- µø┤µ¢░ÕłŚĶĪ©/Õģāń╗äńÜäÕĆ╝ŃĆé
+
+ ÕĮōķģŹńĮ«µ¢ćõ╗ČõĖŁķ£ĆĶ”üµø┤µ¢░ńÜ䵜»õĖĆõĖ¬ÕłŚĶĪ©µł¢ĶĆģÕģāń╗ä’╝īõŠŗÕ”é’╝īķģŹńĮ«µ¢ćõ╗ČķĆÜÕĖĖõ╝ÜĶ«ŠńĮ« `val_evaluator = dict(type='Accuracy', topk=(1, 5))`’╝īńö©µłĘÕ”éµ×£µā│µø┤µö╣ `topk`’╝ī
+ ķ£ĆĶ”üµīćÕ«Ü `--cfg-options val_evaluator.topk="(1,3)"`ŃĆéµ│©µäÅĶ┐ÖķćīńÜäÕ╝ĢÕÅĘ " Õ»╣õ║ÄÕłŚĶĪ©õ╗źÕÅŖÕģāń╗äµĢ░µŹ«ń▒╗Õ×ŗńÜäõ┐«µö╣µś»Õ┐ģĶ”üńÜä’╝ī
+ Õ╣ČõĖö **õĖŹÕģüĶ«Ė** Õ╝ĢÕÅĘÕåģµēƵīćÕ«ÜńÜäÕĆ╝ńÜäõ╣”ÕåÖÕŁśÕ£©ń®║µĀ╝ŃĆé
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/confusion_matrix.md b/internlm_langchain/knowledge_base/MMPreTrain/content/confusion_matrix.md
new file mode 100644
index 00000000..98c039c6
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/confusion_matrix.md
@@ -0,0 +1,83 @@
+# µĘʵĘåń¤®ķśĄ
+
+MMPretrain µÅÉõŠø `tools/analysis_tools/confusion_matrix.py` ÕĘźÕģĘµØźÕłåµ×Éķó䵥ŗń╗ōµ×£ńÜäµĘʵĘåń¤®ķśĄŃĆéÕģ│õ║ĵĘʵĘåń¤®ķśĄńÜäõ╗ŗń╗Ź’╝īÕÅ»ÕÅéĶĆā[ķōŠµÄź](https://zh.wikipedia.org/zh-cn/%E6%B7%B7%E6%B7%86%E7%9F%A9%E9%98%B5)ŃĆé
+
+## ÕæĮõ╗żĶĪīõĮ┐ńö©
+
+**ÕæĮõ╗żĶĪī**’╝Ü
+
+```shell
+python tools/analysis_tools/confusion_matrix.py \
+ ${CONFIG_FILE} \
+ ${CHECKPOINT} \
+ [--show] \
+ [--show-path] \
+ [--include-values] \
+ [--cmap ${CMAP}] \
+ [--cfg-options ${CFG-OPTIONS}]
+```
+
+**µēƵ£ēÕÅéµĢ░ńÜäĶ»┤µśÄ**’╝Ü
+
+- `config`’╝ܵ©ĪÕ×ŗķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠäŃĆé
+- `checkpoint`’╝ܵØāķćŹĶĘ»ÕŠäŃĆé
+- `--show`’╝ܵś»ÕÉ”Õ▒Ģńż║µĘʵĘåń¤®ķśĄńÜä matplotlib ÕÅ»Ķ¦åÕī¢ń╗ōµ×£’╝īķ╗śĶ«żõĖŹÕ▒Ģńż║ŃĆé
+- `--show-path`’╝ÜÕ”éµ×£ `show` õĖ║ True’╝īÕÅ»Ķ¦åÕī¢ń╗ōµ×£ńÜäõ┐ØÕŁśĶĘ»ÕŠäŃĆé
+- `--include-values`’╝ܵś»Õɔգ©ÕÅ»Ķ¦åÕī¢ń╗ōµ×£õĖŖµĘ╗ÕŖĀµĢ░ÕĆ╝ŃĆé
+- `--cmap`’╝ÜÕÅ»Ķ¦åÕī¢ń╗ōµ×£õĮ┐ńö©ńÜäķó£Ķē▓µśĀÕ░äÕøŠ’╝īÕŹ│ `cmap`’╝īķ╗śĶ«żõĖ║ `viridis`ŃĆé
+- `--cfg-options`’╝ÜÕ»╣ķģŹńĮ«µ¢ćõ╗ČńÜäõ┐«µö╣’╝īÕÅéĶĆā[ÕŁ”õ╣ĀķģŹńĮ«µ¢ćõ╗Č](../user_guides/config.md)ŃĆé
+
+**õĮ┐ńö©ńż║õŠŗ**’╝Ü
+
+```shell
+python tools/analysis_tools/confusion_matrix.py \
+ configs/resnet/resnet50_8xb16_cifar10.py \
+ https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_b16x8_cifar10_20210528-f54bfad9.pth \
+ --show
+```
+
+**ĶŠōÕć║ÕøŠńēć**’╝Ü
+
+ +
+## Õ¤║ńĪĆńö©µ│Ģ
+
+```python
+>>> import torch
+>>> from mmpretrain.evaluation import ConfusionMatrix
+>>> y_pred = [0, 1, 1, 3]
+>>> y_true = [0, 2, 1, 3]
+>>> ConfusionMatrix.calculate(y_pred, y_true, num_classes=4)
+tensor([[1, 0, 0, 0],
+ [0, 1, 0, 0],
+ [0, 1, 0, 0],
+ [0, 0, 0, 1]])
+>>> # plot the confusion matrix
+>>> import matplotlib.pyplot as plt
+>>> y_score = torch.rand((1000, 10))
+>>> y_true = torch.randint(10, (1000, ))
+>>> matrix = ConfusionMatrix.calculate(y_score, y_true)
+>>> ConfusionMatrix().plot(matrix)
+>>> plt.show()
+```
+
+## ń╗ōÕÉłĶ»äõ╝░ÕÖ©õĮ┐ńö©
+
+```python
+>>> import torch
+>>> from mmpretrain.evaluation import ConfusionMatrix
+>>> from mmpretrain.structures import DataSample
+>>> from mmengine.evaluator import Evaluator
+>>> data_samples = [
+... DataSample().set_gt_label(i%5).set_pred_score(torch.rand(5))
+... for i in range(1000)
+... ]
+>>> evaluator = Evaluator(metrics=ConfusionMatrix())
+>>> evaluator.process(data_samples)
+>>> evaluator.evaluate(1000)
+{'confusion_matrix/result': tensor([[37, 37, 48, 43, 35],
+ [35, 51, 32, 46, 36],
+ [45, 28, 39, 42, 46],
+ [42, 40, 40, 35, 43],
+ [40, 39, 41, 37, 43]])}
+```
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/contribution_guide.md b/internlm_langchain/knowledge_base/MMPreTrain/content/contribution_guide.md
new file mode 100644
index 00000000..2549cc28
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/contribution_guide.md
@@ -0,0 +1,62 @@
+# ÕÅéõĖÄĶ┤Īńī« OpenMMLab
+
+µ¼óĶ┐Äõ╗╗õĮĢń▒╗Õ×ŗńÜäĶ┤Īńī«’╝īÕīģµŗ¼õĮåõĖŹķÖÉõ║Ä
+
+- õ┐«µö╣µŗ╝ÕåÖķöÖĶ»»µł¢õ╗ŻńĀüķöÖĶ»»
+- µĘ╗ÕŖĀµ¢ćµĪŻµł¢Õ░åµ¢ćµĪŻń┐╗Ķ»æµłÉÕģČõ╗¢Ķ»ŁĶ©Ć
+- µĘ╗ÕŖĀµ¢░ÕŖ¤ĶāĮÕÆīµ¢░ń╗äõ╗Č
+
+## ÕĘźõĮ£µĄüń©ŗ
+
+1. fork Õ╣Č pull µ£Ćµ¢░ńÜä OpenMMLab õ╗ōÕ║ō (MMPreTrain)
+2. ńŁŠÕć║Õł░õĖĆõĖ¬µ¢░Õłåµö»’╝łõĖŹĶ”üõĮ┐ńö© master Õłåµö»µÅÉõ║ż PR’╝ē
+3. Ķ┐øĶĪīõ┐«µö╣Õ╣ȵÅÉõ║żĶć│ fork Õć║ńÜäĶć¬ÕĘ▒ńÜäĶ┐£ń©ŗõ╗ōÕ║ō
+4. Õ£©µłæõ╗¼ńÜäõ╗ōÕ║ōõĖŁÕłøÕ╗║õĖĆõĖ¬ PR
+
+```{note}
+Õ”éµ×£õĮĀĶ«ĪÕłÆµĘ╗ÕŖĀõĖĆõ║øµ¢░ńÜäÕŖ¤ĶāĮ’╝īÕ╣ČÕ╝ĢÕģźÕż¦ķćŵö╣ÕŖ©’╝īĶ»ĘÕ░ĮķćÅķ”¢ÕģłÕłøÕ╗║õĖĆõĖ¬ issue µØźĶ┐øĶĪīĶ«©Ķ«║ŃĆé
+```
+
+## õ╗ŻńĀüķŻÄµĀ╝
+
+### Python
+
+µłæõ╗¼ķććńö© [PEP8](https://www.python.org/dev/peps/pep-0008/) õĮ£õĖ║ń╗¤õĖĆńÜäõ╗ŻńĀüķŻÄµĀ╝ŃĆé
+
+µłæõ╗¼õĮ┐ńö©õĖŗÕłŚÕĘźÕģĘµØźĶ┐øĶĪīõ╗ŻńĀüķŻÄµĀ╝µŻĆµ¤źõĖĵĀ╝Õ╝ÅÕī¢’╝Ü
+
+- [flake8](https://github.com/PyCQA/flake8): Python Õ«śµ¢╣ÕÅæÕĖāńÜäõ╗ŻńĀüĶ¦äĶīāµŻĆµ¤źÕĘźÕģĘ’╝īµś»ÕżÜõĖ¬µŻĆµ¤źÕĘźÕģĘńÜäÕ░üĶŻģ
+- [isort](https://github.com/timothycrosley/isort): Ķć¬ÕŖ©Ķ░āµĢ┤µ©ĪÕØŚÕ»╝ÕģźķĪ║Õ║ÅńÜäÕĘźÕģĘ
+- [yapf](https://github.com/google/yapf): õĖĆõĖ¬ Python µ¢ćõ╗ČńÜäµĀ╝Õ╝ÅÕī¢ÕĘźÕģĘŃĆé
+- [codespell](https://github.com/codespell-project/codespell): µŻĆµ¤źÕŹĢĶ»Źµŗ╝ÕåÖµś»ÕÉ”µ£ēĶ»»
+- [mdformat](https://github.com/executablebooks/mdformat): µŻĆµ¤ź markdown µ¢ćõ╗ČńÜäÕĘźÕģĘ
+- [docformatter](https://github.com/myint/docformatter): õĖĆõĖ¬ docstring µĀ╝Õ╝ÅÕī¢ÕĘźÕģĘŃĆé
+
+yapf ÕÆī isort ńÜäµĀ╝Õ╝ÅĶ«ŠńĮ«õĮŹõ║Ä [setup.cfg](https://github.com/open-mmlab/mmpretrain/blob/main/setup.cfg)
+
+µłæõ╗¼õĮ┐ńö© [pre-commit hook](https://pre-commit.com/) µØźõ┐ØĶ»üµ»Åµ¼ĪµÅÉõ║żµŚČĶć¬ÕŖ©Ķ┐øĶĪīõ╗Ż
+ńĀüµŻĆµ¤źÕÆīµĀ╝Õ╝ÅÕī¢’╝īÕÉ»ńö©ńÜäÕŖ¤ĶāĮÕīģµŗ¼ `flake8`, `yapf`, `isort`, `trailing whitespaces`, `markdown files`, õ┐«ÕżŹ `end-of-files`, `double-quoted-strings`,
+`python-encoding-pragma`, `mixed-line-ending`, Õ»╣ `requirments.txt`ńÜäµÄÆÕ║ÅńŁēŃĆé
+pre-commit hook ńÜäķģŹńĮ«µ¢ćõ╗ČõĮŹõ║Ä [.pre-commit-config](https://github.com/open-mmlab/mmpretrain/blob/main/.pre-commit-config.yaml)
+
+Õ£©õĮĀÕģŗķÜåõ╗ōÕ║ōÕÉÄ’╝īõĮĀķ£ĆĶ”üµīēńģ¦Õ”éõĖŗµŁźķ¬żÕ«ēĶŻģÕ╣ČÕłØÕ¦ŗÕī¢ pre-commit hookŃĆé
+
+```shell
+pip install -U pre-commit
+```
+
+Õ£©õ╗ōÕ║ōµ¢ćõ╗ČÕż╣õĖŁµē¦ĶĪī
+
+```shell
+pre-commit install
+```
+
+Õ£©µŁżõ╣ŗÕÉÄ’╝īµ»Åµ¼ĪµÅÉõ║ż’╝īõ╗ŻńĀüĶ¦äĶīāµŻĆµ¤źÕÆīµĀ╝Õ╝ÅÕī¢ÕĘźÕģĘķāĮÕ░åĶó½Õ╝║ÕłČµē¦ĶĪīŃĆé
+
+```{important}
+Õ£©ÕłøÕ╗║ PR õ╣ŗÕēŹ’╝īĶ»ĘńĪ«õ┐ØõĮĀńÜäõ╗ŻńĀüÕ«īµłÉõ║åõ╗ŻńĀüĶ¦äĶīāµŻĆµ¤ź’╝īÕ╣Čń╗ÅĶ┐ćõ║å yapf ńÜäµĀ╝Õ╝ÅÕī¢ŃĆé
+```
+
+### C++ ÕÆī CUDA
+
+C++ ÕÆī CUDA ńÜäõ╗ŻńĀüĶ¦äĶīāķüĄõ╗Ä [Google C++ Style Guide](https://google.github.io/styleguide/cppguide.html)
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/convention.md b/internlm_langchain/knowledge_base/MMPreTrain/content/convention.md
new file mode 100644
index 00000000..941236b6
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/convention.md
@@ -0,0 +1,114 @@
+# MMPretrain õĖŁńÜäń║”Õ«Ü
+
+## µ©ĪÕ×ŗÕæĮÕÉŹĶ¦äÕłÖ
+
+MMPretrain µīēńģ¦õ╗źõĖŗķŻÄµĀ╝Ķ┐øĶĪīµ©ĪÕ×ŗÕæĮÕÉŹ’╝īõ╗ŻńĀüÕ║ōńÜäĶ┤Īńī«ĶĆģķ£ĆĶ”üķüĄÕŠ¬ńøĖÕÉīńÜäÕæĮÕÉŹĶ¦äÕłÖŃĆ鵩ĪÕ×ŗÕÉŹµĆ╗õĮōÕłåõĖ║õ║öõĖ¬ķā©Õłå’╝Üń«Śµ│Ģõ┐Īµü»’╝īµ©ĪÕØŚõ┐Īµü»’╝īķóäĶ«Łń╗āõ┐Īµü»’╝īĶ«Łń╗āõ┐Īµü»ÕÆīµĢ░µŹ«õ┐Īµü»ŃĆéķĆ╗ĶŠæõĖŖÕ▒×õ║ÄõĖŹÕÉīķā©ÕłåńÜäÕŹĢĶ»Źõ╣ŗķŚ┤ńö©õĖŗÕłÆń║┐ `'_'` Ķ┐׵ğ’╝īÕÉīõĖĆķā©Õłåµ£ēÕżÜõĖ¬ÕŹĢĶ»Źńö©ń¤Łµ©¬ń║┐ `'-'` Ķ┐׵ğŃĆé
+
+```text
+{algorithm info}_{module info}_{pretrain info}_{training info}_{data info}
+```
+
+- `algorithm info`’╝łÕÅ»ķĆē’╝ē’╝Üń«Śµ│Ģõ┐Īµü»’╝īĶĪ©ńż║ńö©õ╗źĶ«Łń╗āĶ»źµ©ĪÕ×ŗńÜäõĖ╗Ķ”üń«Śµ│Ģ’╝īÕ”é MAEŃĆüBEiT ńŁē
+- `module info`’╝ܵ©ĪÕØŚõ┐Īµü»’╝īõĖ╗Ķ”üÕīģÕɽµ©ĪÕ×ŗńÜäõĖ╗Õ╣▓ńĮæń╗£ÕÉŹń¦░’╝īÕ”é resnetŃĆüvit ńŁē
+- `pretrain info`’╝łÕÅ»ķĆē’╝ē’╝ÜķóäĶ«Łń╗āõ┐Īµü»’╝īµ»öÕ”éķóäĶ«Łń╗āµ©ĪÕ×ŗµś»Õ£© ImageNet-21k µĢ░µŹ«ķøåõĖŖĶ«Łń╗āńÜäńŁē
+- `training info`’╝ÜĶ«Łń╗āõ┐Īµü»’╝īĶ«Łń╗āńŁ¢ńĢźĶ«ŠńĮ«’╝īÕīģµŗ¼ batch size’╝īschedule õ╗źÕÅŖµĢ░µŹ«Õó×Õ╝║ńŁē’╝ø
+- `data info`’╝ܵĢ░µŹ«õ┐Īµü»’╝īµĢ░µŹ«ķøåÕÉŹń¦░ŃĆüµ©ĪµĆüŃĆüĶŠōÕģźÕ░║Õ»ĖńŁē’╝īÕ”é imagenet, cifar ńŁē’╝ø
+
+### ń«Śµ│Ģõ┐Īµü»
+
+µīćńö©õ╗źĶ«Łń╗āĶ»źµ©ĪÕ×ŗńÜäń«Śµ│ĢÕÉŹń¦░’╝īõŠŗÕ”é’╝Ü
+
+- `simclr`
+- `mocov2`
+- `eva-mae-style`
+
+õĮ┐ńö©ńøæńØŻÕøŠÕāÅÕłåń▒╗õ╗╗ÕŖĪĶ«Łń╗āńÜ䵩ĪÕ×ŗÕÅ»õ╗źń£üńĢźĶ┐ÖõĖ¬ÕŁŚµ«ĄŃĆé
+
+### µ©ĪÕØŚõ┐Īµü»
+
+µī浩ĪÕ×ŗńÜäń╗ōµ×äõ┐Īµü»’╝īõĖĆĶł¼õĖ╗Ķ”üÕīģÕɽµ©ĪÕ×ŗńÜäõĖ╗Õ╣▓ńĮæń╗£ń╗ōµ×ä’╝ī`neck` ÕÆī `head` õ┐Īµü»õĖĆĶł¼Ķó½ń£üńĢźŃĆéõŠŗÕ”é’╝Ü
+
+- `resnet50`
+- `vit-base-p16`
+- `swin-base`
+
+### ķóäĶ«Łń╗āõ┐Īµü»
+
+Õ”éµ×£Ķ»źµ©ĪÕ×ŗµś»Õ£©ķóäĶ«Łń╗āµ©ĪÕ×ŗÕ¤║ńĪĆõĖŖ’╝īķĆÜĶ┐ćÕŠ«Ķ░āĶÄĘÕŠŚńÜä’╝īµłæõ╗¼ķ£ĆĶ”üĶ«░ÕĮĢķóäĶ«Łń╗āµ©ĪÕ×ŗńÜäõĖĆõ║øõ┐Īµü»ŃĆéõŠŗÕ”é’╝Ü
+
+- ķóäĶ«Łń╗āµ©ĪÕ×ŗńÜäµØźµ║É’╝Ü`fb`ŃĆü`openai`ńŁēŃĆé
+- Ķ«Łń╗āķóäĶ«Łń╗āµ©ĪÕ×ŗńÜäµ¢╣µ│Ģ’╝Ü`clip`ŃĆü`mae`ŃĆü`distill` ńŁēŃĆé
+- ńö©õ║ÄķóäĶ«Łń╗āńÜäµĢ░µŹ«ķøå’╝Ü`in21k`ŃĆü`laion2b`ńŁē’╝ł`in1k`ÕÅ»õ╗źń£üńĢź’╝ē
+- Ķ«Łń╗āµŚČķĢ┐’╝Ü`300e`ŃĆü`1600e` ńŁēŃĆé
+
+Õ╣ČķØ×µēƵ£ēõ┐Īµü»ķāĮµś»Õ┐ģĶ”üńÜä’╝īÕŬķ£ĆĶ”üķĆēµŗ®ńö©õ╗źÕī║ÕłåõĖŹÕÉīńÜäķóäĶ«Łń╗āµ©ĪÕ×ŗńÜäõ┐Īµü»ÕŹ│ÕÅ»ŃĆé
+
+Õ£©µŁżÕŁŚµ«ĄńÜäµ£½Õ░Š’╝īõĮ┐ńö© `-pre` õĮ£õĖ║µĀćĶ»åń¼”’╝īõŠŗÕ”é `mae-in21k-pre`ŃĆé
+
+### Ķ«Łń╗āõ┐Īµü»
+
+Ķ«Łń╗āńŁ¢ńĢźńÜäõĖĆõ║øĶ«ŠńĮ«’╝īÕīģµŗ¼Ķ«Łń╗āń▒╗Õ×ŗŃĆü `batch size`ŃĆü `lr schedule`ŃĆü µĢ░µŹ«Õó×Õ╝║õ╗źÕÅŖńē╣µ«ŖńÜ䵏¤Õż▒ÕćĮµĢ░ńŁēńŁē,µ»öÕ”é:
+Batch size õ┐Īµü»’╝Ü
+
+- µĀ╝Õ╝ÅõĖ║`{gpu x batch_per_gpu}`, Õ”é `8xb32`
+
+Ķ«Łń╗āń▒╗Õ×ŗ(õĖ╗Ķ”üĶ¦üõ║Ä transformer ńĮæń╗£’╝īÕ”é `ViT` ń«Śµ│Ģ’╝īĶ┐Öń▒╗ń«Śµ│ĢķĆÜÕĖĖÕłåõĖ║ķóäĶ«Łń╗āÕÆīÕŠ«Ķ░āõĖżń¦Źµ©ĪÕ╝Å):
+
+- `ft` : Finetune config’╝īńö©õ║ÄÕŠ«Ķ░āńÜäķģŹńĮ«µ¢ćõ╗Č
+- `pt` : Pretrain config’╝īńö©õ║ÄķóäĶ«Łń╗āńÜäķģŹńĮ«µ¢ćõ╗Č
+
+Ķ«Łń╗āńŁ¢ńĢźõ┐Īµü»’╝īĶ«Łń╗āńŁ¢ńĢźõ╗źÕżŹńÄ░ķģŹńĮ«µ¢ćõ╗ČõĖ║Õ¤║ńĪĆ’╝īµŁżÕ¤║ńĪĆõĖŹÕ┐ģµĀćµ│©Ķ«Łń╗āńŁ¢ńĢźŃĆéõĮåÕ”éµ×£Õ£©µŁżÕ¤║ńĪĆõĖŖĶ┐øĶĪīµö╣Ķ┐ø’╝īÕłÖķ£Ćµ│©µśÄĶ«Łń╗āńŁ¢ńĢź’╝īµīēńģ¦Õ║öńö©ńé╣õĮŹķĪ║Õ║ŵÄÆÕłŚ’╝īÕ”é’╝Ü`{pipeline aug}-{train aug}-{loss trick}-{scheduler}-{epochs}`
+
+- `coslr-200e` : õĮ┐ńö© cosine scheduler, Ķ«Łń╗ā 200 õĖ¬ epoch
+- `autoaug-mixup-lbs-coslr-50e` : õĮ┐ńö©õ║å `autoaug`ŃĆü`mixup`ŃĆü`label smooth`ŃĆü`cosine scheduler`, Ķ«Łń╗āõ║å 50 õĖ¬ĶĮ«µ¼Ī
+
+Õ”éµ×£µ©ĪÕ×ŗµś»õ╗ÄÕ«śµ¢╣õ╗ōÕ║ōńŁēń¼¼õĖēµ¢╣õ╗ōÕ║ōĶĮ¼µŹóĶ┐ćµØźńÜä’╝īĶ«Łń╗āõ┐Īµü»ÕÅ»õ╗źń£üńĢź’╝īõĮ┐ńö© `3rdparty` õĮ£õĖ║µĀćĶ»åń¼”ŃĆé
+
+### µĢ░µŹ«õ┐Īµü»
+
+- `in1k` : `ImageNet1k` µĢ░µŹ«ķøå’╝īķ╗śĶ«żõĮ┐ńö© `224x224` Õż¦Õ░ÅńÜäÕøŠńēć
+- `in21k` : `ImageNet21k` µĢ░µŹ«ķøå’╝īµ£ēõ║øÕ£░µ¢╣õ╣¤ń¦░õĖ║ `ImageNet22k` µĢ░µŹ«ķøå’╝īķ╗śĶ«żõĮ┐ńö© `224x224` Õż¦Õ░ÅńÜäÕøŠńēć
+- `in1k-384px` : ĶĪ©ńż║Ķ«Łń╗āńÜäĶŠōÕć║ÕøŠńēćÕż¦Õ░ÅõĖ║ `384x384`
+- `cifar100`
+
+### µ©ĪÕ×ŗÕæĮÕÉŹµĪłõŠŗ
+
+```text
+vit-base-p32_clip-openai-pre_3rdparty_in1k
+```
+
+- `vit-base-p32`: µ©ĪÕØŚõ┐Īµü»
+- `clip-openai-pre`’╝ÜķóäĶ«Łń╗āõ┐Īµü»
+ - `clip`’╝ÜķóäĶ«Łń╗āµ¢╣µ│Ģµś» clip
+ - `openai`’╝ÜķóäĶ«Łń╗āµ©ĪÕ×ŗµØźĶć¬ OpenAI
+ - `pre`’╝ÜķóäĶ«Łń╗āµĀćĶ»åń¼”
+- `3rdparty`’╝ܵ©ĪÕ×ŗµś»õ╗Äń¼¼õĖēµ¢╣õ╗ōÕ║ōĶĮ¼µŹóĶĆīµØźńÜä
+- `in1k`’╝ܵĢ░µŹ«ķøåõ┐Īµü»ŃĆéĶ»źµ©ĪÕ×ŗµś»õ╗Ä ImageNet-1k µĢ░µŹ«ķøåĶ«Łń╗āĶĆīµØźńÜä’╝īĶŠōÕģźÕż¦Õ░ÅõĖ║ `224x224`
+
+```text
+beit_beit-base-p16_8xb256-amp-coslr-300e_in1k
+```
+
+- `beit`: ń«Śµ│Ģõ┐Īµü»
+- `beit-base`’╝ܵ©ĪÕØŚõ┐Īµü»’╝īńö▒õ║ÄõĖ╗Õ╣▓ńĮæń╗£µØźĶć¬ BEiT õĖŁµÅÉÕć║ńÜäõ┐«µö╣ńēł ViT’╝īõĖ╗Õ╣▓ńĮæń╗£ÕÉŹń¦░õ╣¤µś» `beit`
+- `8xb256-amp-coslr-300e`’╝ÜĶ«Łń╗āõ┐Īµü»
+ - `8xb256`’╝ÜõĮ┐ńö© 8 õĖ¬ GPU’╝īµ»ÅõĖ¬ GPU ńÜäµē╣ķćÅÕż¦Õ░ÅõĖ║ 256
+ - `amp`’╝ÜõĮ┐ńö©Ķć¬ÕŖ©µĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗ā
+ - `coslr`’╝ÜõĮ┐ńö©õĮÖÕ╝”ķĆĆńü½ÕŁ”õ╣ĀńÄćĶ░āÕ║”ÕÖ©
+ - `300e`’╝ÜĶ«Łń╗ā 300 õĖ¬ epoch
+- `in1k`’╝ܵĢ░µŹ«ķøåõ┐Īµü»ŃĆéĶ»źµ©ĪÕ×ŗµś»õ╗Ä ImageNet-1k µĢ░µŹ«ķøåĶ«Łń╗āĶĆīµØźńÜä’╝īĶŠōÕģźÕż¦Õ░ÅõĖ║ `224x224`
+
+## ķģŹńĮ«µ¢ćõ╗ČÕæĮÕÉŹĶ¦äÕłÖ
+
+ķģŹńĮ«µ¢ćõ╗ČńÜäÕæĮÕÉŹõĖĵ©ĪÕ×ŗÕÉŹń¦░ÕćĀõ╣ÄńøĖÕÉī’╝īµ£ēÕćĀńé╣õĖŹÕÉī’╝Ü
+
+- Ķ«Łń╗āõ┐Īµü»µś»Õ┐ģĶ”üńÜä’╝īõĖŹĶāĮµś» `3rdparty`
+- Õ”éµ×£ķģŹńĮ«µ¢ćõ╗ČÕŬÕīģÕɽõĖ╗Õ╣▓ńĮæń╗£Ķ«ŠńĮ«’╝īµŚóµ▓Īµ£ēÕż┤ķā©Ķ«ŠńĮ«õ╣¤µ▓Īµ£ēµĢ░µŹ«ķøåĶ«ŠńĮ«’╝īµłæõ╗¼Õ░åÕģČÕæĮÕÉŹõĖ║`{module info}_headless.py`ŃĆéĶ┐Öń¦ŹķģŹńĮ«µ¢ćõ╗ČķĆÜÕĖĖńö©õ║ÄÕż¦Õ×ŗµĢ░µŹ«ķøåõĖŖńÜäń¼¼õĖēµ¢╣ķóäĶ«Łń╗āµ©ĪÕ×ŗŃĆé
+
+### µØāķćŹÕæĮÕÉŹĶ¦äÕłÖ
+
+µØāķćŹńÜäÕæĮÕÉŹõĖ╗Ķ”üÕīģµŗ¼µ©ĪÕ×ŗÕÉŹń¦░’╝īµŚźµ£¤ÕÆīÕōłÕĖīÕĆ╝ŃĆé
+
+```text
+{model_name}_{date}-{hash}.pth
+```
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/dataset_prepare.md b/internlm_langchain/knowledge_base/MMPreTrain/content/dataset_prepare.md
new file mode 100644
index 00000000..59a0d0af
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/dataset_prepare.md
@@ -0,0 +1,351 @@
+# ÕćåÕżćµĢ░µŹ«ķøå
+
+## CustomDataset
+
+[`CustomDataset`](mmpretrain.datasets.CustomDataset) µś»õĖĆõĖ¬ķĆÜńö©ńÜäµĢ░µŹ«ķøåń▒╗’╝īõŠøµé©õĮ┐ńö©Ķć¬ÕĘ▒ńÜäµĢ░µŹ«ķøåŃĆéńø«ÕēŹ `CustomDataset` µö»µīüõ╗źõĖŗõĖżń¦Źµ¢╣Õ╝Åń╗äń╗ćõĮĀńÜäµĢ░µŹ«ķøåµ¢ćõ╗Č’╝Ü
+
+### ÕŁÉµ¢ćõ╗ČÕż╣µ¢╣Õ╝Å
+
+Õ£©Ķ┐Öń¦ŹµĀ╝Õ╝ÅõĖŗ’╝īµé©ÕŬķ£ĆĶ”üķ揵¢░ń╗äń╗ćµé©ńÜäµĢ░µŹ«ķøåµ¢ćõ╗ČÕż╣Õ╣ČÕ░åµēƵ£ēµĀʵ£¼µöŠÕ£©õĖĆõĖ¬µ¢ćõ╗ČÕż╣õĖŁ’╝īĶĆīµŚĀķ£ĆÕłøÕ╗║õ╗╗õĮĢµĀćµ│©µ¢ćõ╗ČŃĆé
+
+Õ»╣õ║ÄńøæńØŻõ╗╗ÕŖĪ’╝łõĮ┐ńö© `with_label=true`’╝ē’╝īµłæõ╗¼õĮ┐ńö©ÕŁÉµ¢ćõ╗ČÕż╣ńÜäÕÉŹń¦░õĮ£õĖ║ń▒╗Õł½ÕÉŹń¦░’╝īÕ”éõĖŗõŠŗµēĆńż║’╝ī`class_x` ÕÆī `class_y` Õ░åĶó½Ķ»åÕł½õĖ║ń▒╗Õł½ÕÉŹń¦░ŃĆé
+
+```text
+data_prefix/
+Ōö£ŌöĆŌöĆ class_x
+Ōöé Ōö£ŌöĆŌöĆ xxx.png
+Ōöé Ōö£ŌöĆŌöĆ xxy.png
+Ōöé ŌööŌöĆŌöĆ ...
+Ōöé ŌööŌöĆŌöĆ xxz.png
+ŌööŌöĆŌöĆ class_y
+ Ōö£ŌöĆŌöĆ 123.png
+ Ōö£ŌöĆŌöĆ nsdf3.png
+ Ōö£ŌöĆŌöĆ ...
+ ŌööŌöĆŌöĆ asd932_.png
+```
+
+Õ»╣õ║ĵŚĀńøæńØŻõ╗╗ÕŖĪ’╝łõĮ┐ńö© `with_label=false`’╝ē’╝īµłæõ╗¼ńø┤µÄźÕŖĀĶĮĮµīćիܵ¢ćõ╗ČÕż╣õĖŗńÜäµēƵ£ēµĀʵ£¼µ¢ćõ╗Č’╝Ü
+
+```
+data_prefix/
+Ōö£ŌöĆŌöĆ folder_1
+Ōöé Ōö£ŌöĆŌöĆ xxx.png
+Ōöé Ōö£ŌöĆŌöĆ xxy.png
+Ōöé ŌööŌöĆŌöĆ ...
+Ōö£ŌöĆŌöĆ 123.png
+Ōö£ŌöĆŌöĆ nsdf3.png
+ŌööŌöĆŌöĆ ...
+```
+
+ÕüćÕ”éõĮĀÕĖīµ£øÕ░åõ╣ŗńö©õ║ÄĶ«Łń╗ā’╝īķéŻõ╣łķģŹńĮ«µ¢ćõ╗ČõĖŁķ£ĆĶ”üµĘ╗ÕŖĀõ╗źõĖŗķģŹńĮ«’╝Ü
+
+```python
+train_dataloader = dict(
+ ...
+ # Ķ«Łń╗āµĢ░µŹ«ķøåķģŹńĮ«
+ dataset=dict(
+ type='CustomDataset',
+ data_prefix='path/to/data_prefix',
+ with_label=True, # Õ»╣õ║ĵŚĀńøæńØŻõ╗╗ÕŖĪ’╝īõĮ┐ńö© False
+ pipeline=...
+ )
+)
+```
+
+```{note}
+Õ”éµ×£Ķ”üõĮ┐ńö©µŁżµĀ╝Õ╝Å’╝īĶ»ĘõĖŹĶ”üµīćÕ«Ü `ann_file`’╝īµł¢µīćÕ«Ü `ann_file=''`ŃĆé
+
+Ķ»Ęµ│©µäÅ’╝īÕŁÉµ¢ćõ╗ČÕż╣µĀ╝Õ╝Åķ£ĆĶ”üÕ»╣µ¢ćõ╗ČÕż╣Ķ┐øĶĪīµē½µÅÅ’╝īĶ┐ÖÕÅ»ĶāĮõ╝ÜÕ»╝Ķć┤ÕłØÕ¦ŗÕī¢ķƤÕ║”ÕÅśµģó’╝īÕ░żÕģȵś»Õ»╣õ║ÄÕż¦Õ×ŗµĢ░µŹ«ķøåµł¢µģóķƤµ¢ćõ╗Č IOŃĆé
+```
+
+### µĀćµ│©µ¢ćõ╗ȵ¢╣Õ╝Å
+
+µĀćµ│©µ¢ćõ╗ȵĀ╝Õ╝ÅõĖ╗Ķ”üõĮ┐ńö©µ¢ćµ£¼µ¢ćõ╗ČµØźõ┐ØÕŁśń▒╗Õł½õ┐Īµü»’╝ī`data_prefix` ÕŁśµöŠÕøŠńēć’╝ī`ann_file` ÕŁśµöŠµĀćµ│©ń▒╗Õł½õ┐Īµü»ŃĆé
+
+Õ”éõĖŗµĪłõŠŗ’╝īdataset ńø«ÕĮĢÕ”éõĖŗ’╝Ü
+
+Õ£©Ķ┐Öń¦ŹµĀ╝Õ╝ÅõĖŁ’╝īµłæõ╗¼õĮ┐ńö©µ¢ćµ£¼µĀćµ│©µ¢ćõ╗ČµØźÕŁśÕé©ÕøŠÕāŵ¢ćõ╗ČĶĘ»ÕŠäÕÆīÕ»╣Õ║öńÜäń▒╗Õł½ń┤óÕ╝ĢŃĆé
+
+Õ»╣õ║ÄńøæńØŻõ╗╗ÕŖĪ’╝ł`with_label=true`’╝ē’╝īµ│©ķćŖµ¢ćõ╗ČÕ║öÕ£©õĖĆĶĪīõĖŁÕīģÕɽõĖĆõĖ¬µĀʵ£¼ńÜäµ¢ćõ╗ČĶĘ»ÕŠäÕÆīń▒╗Õł½ń┤óÕ╝Ģ’╝īÕ╣Čńö©ń®║µĀ╝ÕłåķÜö’╝īÕ”éõĖŗµēĆńż║’╝Ü
+
+µēƵ£ēĶ┐Öõ║øµ¢ćõ╗ČĶĘ»ÕŠäķāĮÕÅ»õ╗źµś»ń╗ØÕ»╣ĶĘ»ÕŠä’╝īõ╣¤ÕÅ»õ╗źµś»ńøĖÕ»╣õ║Ä `data_prefix` ńÜäńøĖÕ»╣ĶĘ»ÕŠäŃĆé
+
+```text
+folder_1/xxx.png 0
+folder_1/xxy.png 1
+123.png 4
+nsdf3.png 3
+...
+```
+
+```{note}
+ń▒╗Õł½ńÜäń┤óÕ╝ĢÕÅĘõ╗Ä 0 Õ╝ĆÕ¦ŗŃĆéń£¤Õ«×µĀćńŁŠńÜäÕĆ╝Õ║öÕ£©`[0, num_classes - 1]`ĶīāÕø┤ÕåģŃĆé
+
+µŁżÕż¢’╝īĶ»ĘõĮ┐ńö©µĢ░µŹ«ķøåĶ«ŠńĮ«õĖŁńÜä `classes` ÕŁŚµ«ĄµØźµīćիܵ»ÅõĖ¬ń▒╗Õł½ńÜäÕÉŹń¦░
+```
+
+Õ»╣õ║ĵŚĀńøæńØŻõ╗╗ÕŖĪ’╝ł`with_label=false`’╝ē’╝īµĀćµ│©µ¢ćõ╗ČÕŬķ£ĆĶ”üÕ£©õĖĆĶĪīõĖŁÕīģÕɽõĖĆõĖ¬µĀʵ£¼ńÜäµ¢ćõ╗ČĶĘ»ÕŠä’╝īÕ”éõĖŗ’╝Ü
+
+```text
+folder_1/xxx.png
+folder_1/xxy.png
+123.png
+nsdf3.png
+...
+```
+
+ÕüćĶ«ŠµĢ┤õĖ¬µĢ░µŹ«ķøåµ¢ćõ╗ČÕż╣Õ”éõĖŗ’╝Ü
+
+```text
+data_root
+Ōö£ŌöĆŌöĆ meta
+Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ test.txt # µĄŗĶ»ĢµĢ░µŹ«ķøåńÜäµĀćµ│©µ¢ćõ╗Č
+Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ train.txt # Ķ«Łń╗āµĢ░µŹ«ķøåńÜäµĀćµ│©µ¢ćõ╗Č
+Ōöé┬Ā┬Ā ŌööŌöĆŌöĆ val.txt # ķ¬īĶ»üµĢ░µŹ«ķøåńÜäµĀćµ│©µ¢ćõ╗Č
+
+Ōö£ŌöĆŌöĆ train
+Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ 123.png
+Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ folder_1
+Ōöé┬Ā┬Ā Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ xxx.png
+Ōöé┬Ā┬Ā Ōöé┬Ā┬Ā ŌööŌöĆŌöĆ xxy.png
+Ōöé┬Ā┬Ā ŌööŌöĆŌöĆ nsdf3.png
+Ōö£ŌöĆŌöĆ test
+ŌööŌöĆŌöĆ val
+```
+
+Ķ┐Öµś»ķģŹńĮ«µ¢ćõ╗ČõĖŁńÜäµĢ░µŹ«ķøåĶ«ŠńĮ«ńÜäńż║õŠŗ’╝Ü
+
+```python
+# Ķ«Łń╗āµĢ░µŹ«Ķ«ŠńĮ«
+train_dataloader = dict(
+ dataset=dict(
+ type='CustomDataset',
+ data_root='path/to/data_root', # `ann_flie` ÕÆī `data_prefix` Õģ▒ÕÉīńÜäµ¢ćõ╗ČĶĘ»ÕŠäÕēŹń╝Ć
+ ann_file='meta/train.txt', # ńøĖÕ»╣õ║Ä `data_root` ńÜäµĀćµ│©µ¢ćõ╗ČĶĘ»ÕŠä
+ data_prefix='train', # `ann_file` õĖŁµ¢ćõ╗ČĶĘ»ÕŠäńÜäÕēŹń╝Ć’╝īńøĖÕ»╣õ║Ä `data_root`
+ classes=['A', 'B', 'C', 'D', ...], # µ»ÅõĖ¬ń▒╗Õł½ńÜäÕÉŹń¦░
+ pipeline=..., # ÕżäńÉåµĢ░µŹ«ķøåµĀʵ£¼ńÜäõĖĆń│╗ÕłŚÕÅśµŹóµōŹõĮ£
+ )
+ ...
+)
+```
+
+```{note}
+µ£ēÕģ│Õ”éõĮĢõĮ┐ńö© `CustomDataset` ńÜäÕ«īµĢ┤ńż║õŠŗ’╝īĶ»ĘÕÅéķśģ[Õ”éõĮĢõĮ┐ńö©Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåĶ┐øĶĪīķóäĶ«Łń╗ā](../notes/pretrain_custom_dataset.md)
+```
+
+## ImageNet
+
+ImageNet µ£ēÕżÜõĖ¬ńēłµ£¼’╝īõĮåµ£ĆÕĖĖńö©ńÜäõĖĆõĖ¬µś» [ILSVRC 2012](http://www.image-net.org/challenges/LSVRC/2012/)ŃĆé ÕÅ»õ╗źķĆÜĶ┐ćõ╗źõĖŗµŁźķ¬żõĮ┐ńö©Õ«āŃĆé
+
+`````{tabs}
+
+````{group-tab} MIM õĖŗĶĮĮ
+
+MIMµö»µīüõĮ┐ńö©õĖƵØĪÕæĮõ╗żĶĪīõ╗Ä [OpenDataLab](https://opendatalab.com/) õĖŗĶĮĮÕ╣ČķóäÕżäńÉå ImageNet µĢ░µŹ«ķøåŃĆé
+
+_ķ£ĆĶ”üÕ£© [OpenDataLab Õ«śńĮæ](https://opendatalab.com/) µ│©ÕåīĶ┤”ÕÅĘÕ╣ČÕæĮõ╗żĶĪīńÖ╗ÕĮĢ_ŃĆé
+
+```Bash
+# Õ«ēĶŻģopendatalabÕ║ō
+pip install -U opendatalab
+# ńÖ╗ÕĮĢÕł░ OpenDataLab, Õ”éµ×£Ķ┐śµ▓Īµ£ēµ│©Õåī’╝īĶ»ĘÕł░Õ«śńĮæµ│©ÕåīõĖĆõĖ¬
+odl login
+# õĮ┐ńö© MIM õĖŗĶĮĮµĢ░µŹ«ķøå, µ£ĆÕźĮÕ£© $MMPreTrain ńø«ÕĮĢµē¦ĶĪī
+mim download mmpretrain --dataset imagenet1k
+```
+
+````
+
+````{group-tab} õ╗ÄÕ«śńĮæõĖŗĶĮĮ
+
+
+1. µ│©ÕåīõĖĆõĖ¬ÕĖɵłĘÕ╣ČńÖ╗ÕĮĢÕł░[õĖŗĶĮĮķĪĄķØó](http://www.image-net.org/download-images)ŃĆé
+2. µēŠÕł░ ILSVRC2012 ńÜäõĖŗĶĮĮķōŠµÄź’╝īõĖŗĶĮĮõ╗źõĖŗõĖżõĖ¬µ¢ćõ╗Č’╝Ü
+ - ILSVRC2012_img_train.tar (~138GB)
+ - ILSVRC2012_img_val.tar (~6.3GB)
+3. Ķ¦ŻÕÄŗÕĘ▓õĖŗĶĮĮńÜäÕøŠńēćŃĆé
+
+````
+`````
+
+### ImageNetµĢ░µŹ«ķøåńø«ÕĮĢń╗ōµ×ä
+
+µłæõ╗¼µö»µīüõĖżń¦Źµ¢╣Õ╝Åń╗äń╗ćImageNetµĢ░µŹ«ķøå’╝īÕŁÉńø«ÕĮĢµĀ╝Õ╝ÅÕÆīµ¢ćµ£¼µ│©ķćŖµ¢ćõ╗ȵĀ╝Õ╝ÅŃĆé
+
+#### ÕŁÉµ¢ćõ╗ČÕż╣µĀ╝Õ╝Å
+
+µłæõ╗¼µÅÉõŠøõ║åõĖĆõĖ¬µĀĘõŠŗ’╝īµé©ÕÅ»õ╗źõ╗ÄĶ┐ÖõĖ¬[ķōŠµÄź](https://download.openmmlab.com/mmpretrain/datasets/imagenet_1k.zip)õĖŗĶĮĮÕÆīĶ¦ŻÕÄŗŃĆéµĢ░µŹ«ķøåńÜäńø«ÕĮĢń╗ōµ×äÕ║öÕ”éõĖŗµēĆńż║’╝Ü
+
+```text
+data/imagenet/
+Ōö£ŌöĆŌöĆ train/
+Ōöé Ōö£ŌöĆŌöĆ n01440764
+Ōöé Ōöé Ōö£ŌöĆŌöĆ n01440764_10026.JPEG
+Ōöé Ōöé Ōö£ŌöĆŌöĆ n01440764_10027.JPEG
+Ōöé Ōöé Ōö£ŌöĆŌöĆ n01440764_10029.JPEG
+Ōöé Ōöé Ōö£ŌöĆŌöĆ n01440764_10040.JPEG
+Ōöé Ōöé Ōö£ŌöĆŌöĆ n01440764_10042.JPEG
+Ōöé Ōöé Ōö£ŌöĆŌöĆ n01440764_10043.JPEG
+Ōöé Ōöé ŌööŌöĆŌöĆ n01440764_10048.JPEG
+Ōöé Ōö£ŌöĆŌöĆ ...
+Ōö£ŌöĆŌöĆ val/
+Ōöé Ōö£ŌöĆŌöĆ n01440764
+Ōöé Ōöé Ōö£ŌöĆŌöĆ ILSVRC2012_val_00000293.JPEG
+Ōöé Ōöé Ōö£ŌöĆŌöĆ ILSVRC2012_val_00002138.JPEG
+Ōöé Ōöé Ōö£ŌöĆŌöĆ ILSVRC2012_val_00003014.JPEG
+Ōöé Ōöé ŌööŌöĆŌöĆ ...
+Ōöé Ōö£ŌöĆŌöĆ ...
+```
+
+#### µ¢ćµ£¼µĀćµ│©µ¢ćõ╗ȵĀ╝Õ╝Å
+
+µé©ÕÅ»õ╗źõ╗Ä[µŁżķōŠµÄź](https://download.openmmlab.com/mmclassification/datasets/imagenet/meta/caffe_ilsvrc12.tar.gz)õĖŗĶĮĮÕ╣ČĶ¦ŻÕÄŗÕģāµĢ░µŹ«’╝īńäČÕÉÄń╗äń╗ćµ¢ćõ╗ČÕż╣Õ”éõĖŗ’╝Ü
+
+```text
+data/imagenet/
+Ōö£ŌöĆŌöĆ meta/
+Ōöé Ōö£ŌöĆŌöĆ train.txt
+Ōöé Ōö£ŌöĆŌöĆ test.txt
+Ōöé ŌööŌöĆŌöĆ val.txt
+Ōö£ŌöĆŌöĆ train/
+Ōöé Ōö£ŌöĆŌöĆ n01440764
+Ōöé Ōöé Ōö£ŌöĆŌöĆ n01440764_10026.JPEG
+Ōöé Ōöé Ōö£ŌöĆŌöĆ n01440764_10027.JPEG
+Ōöé Ōöé Ōö£ŌöĆŌöĆ n01440764_10029.JPEG
+Ōöé Ōöé Ōö£ŌöĆŌöĆ n01440764_10040.JPEG
+Ōöé Ōöé Ōö£ŌöĆŌöĆ n01440764_10042.JPEG
+Ōöé Ōöé Ōö£ŌöĆŌöĆ n01440764_10043.JPEG
+Ōöé Ōöé ŌööŌöĆŌöĆ n01440764_10048.JPEG
+Ōöé Ōö£ŌöĆŌöĆ ...
+Ōö£ŌöĆŌöĆ val/
+Ōöé Ōö£ŌöĆŌöĆ ILSVRC2012_val_00000001.JPEG
+Ōöé Ōö£ŌöĆŌöĆ ILSVRC2012_val_00000002.JPEG
+Ōöé Ōö£ŌöĆŌöĆ ILSVRC2012_val_00000003.JPEG
+Ōöé Ōö£ŌöĆŌöĆ ILSVRC2012_val_00000004.JPEG
+Ōöé Ōö£ŌöĆŌöĆ ...
+```
+
+### ķģŹńĮ«
+
+ÕĮōµé©ńÜäµĢ░µŹ«ķøåõ╗źõĖŖĶ┐░µ¢╣Õ╝Åń╗äń╗浌Ȓ╝īµé©ÕÅ»õ╗źõĮ┐ńö©Õģʵ£ēõ╗źõĖŗķģŹńĮ«ńÜä [`ImageNet`](mmpretrain.datasets.ImageNet) µĢ░µŹ«ķøå’╝Ü
+
+```python
+train_dataloader = dict(
+ ...
+ # Ķ«Łń╗āµĢ░µŹ«ķøåķģŹńĮ«
+ dataset=dict(
+ type='ImageNet',
+ data_root='data/imagenet/',
+ split='train',
+ pipeline=...,
+ )
+)
+
+val_dataloader = dict(
+ ...
+ # ķ¬īĶ»üµĢ░µŹ«ķøåķģŹńĮ«
+ dataset=dict(
+ type='ImageNet',
+ data_root='data/imagenet/',
+ split='val',
+ pipeline=...,
+ )
+)
+
+test_dataloader = val_dataloader
+```
+
+## µö»µīüńÜäÕøŠÕāÅÕłåń▒╗µĢ░µŹ«ķøå
+
+| µĢ░µŹ«ķøå | split | õĖ╗ķĪĄ |
+| ----------------------------------------------------------------------------------- | ----------------------------------- | ---------------------------------------------------------------------------------- |
+| [`Calthch101`](mmpretrain.datasets.Caltech101)(data_root[, split, pipeline, ...]) | ["train", "test"] | [Caltech 101](https://data.caltech.edu/records/mzrjq-6wc02) µĢ░µŹ«ķøå |
+| [`CIFAR10`](mmpretrain.datasets.CIFAR10)(data_root[, split, pipeline, ...]) | ["train", "test"] | [CIFAR10](https://www.cs.toronto.edu/~kriz/cifar.html) µĢ░µŹ«ķøå |
+| [`CIFAR100`](mmpretrain.datasets.CIFAR100)(data_root[, split, pipeline, ...]) | ["train", "test"] | [CIFAR100](https://www.cs.toronto.edu/~kriz/cifar.html) µĢ░µŹ«ķøå |
+| [`CUB`](mmpretrain.datasets.CUB)(data_root[, split, pipeline, ...]) | ["train", "test"] | [CUB-200-2011](http://www.vision.caltech.edu/datasets/cub_200_2011/) µĢ░µŹ«ķøå |
+| [`DTD`](mmpretrain.datasets.DTD)(data_root[, split, pipeline, ...]) | ["train", "val", "tranval", "test"] | [Describable Texture Dataset (DTD)](https://www.robots.ox.ac.uk/~vgg/data/dtd/) µĢ░µŹ«ķøå |
+| [`FashionMNIST`](mmpretrain.datasets.FashionMNIST) (data_root[, split, pipeline, ...]) | ["train", "test"] | [Fashion-MNIST](https://github.com/zalandoresearch/fashion-mnist) µĢ░µŹ«ķøå |
+| [`FGVCAircraft`](mmpretrain.datasets.FGVCAircraft)(data_root[, split, pipeline, ...]) | ["train", "val", "tranval", "test"] | [FGVC Aircraft](https://www.robots.ox.ac.uk/~vgg/data/fgvc-aircraft/) µĢ░µŹ«ķøå |
+| [`Flowers102`](mmpretrain.datasets.Flowers102)(data_root[, split, pipeline, ...]) | ["train", "val", "tranval", "test"] | [Oxford 102 Flower](https://www.robots.ox.ac.uk/~vgg/data/flowers/102/) µĢ░µŹ«ķøå |
+| [`Food101`](mmpretrain.datasets.Food101)(data_root[, split, pipeline, ...]) | ["train", "test"] | [Food101](https://data.vision.ee.ethz.ch/cvl/datasets_extra/food-101/) µĢ░µŹ«ķøå |
+| [`MNIST`](mmpretrain.datasets.MNIST) (data_root[, split, pipeline, ...]) | ["train", "test"] | [MNIST](http://yann.lecun.com/exdb/mnist/) µĢ░µŹ«ķøå |
+| [`OxfordIIITPet`](mmpretrain.datasets.OxfordIIITPet)(data_root[, split, pipeline, ...]) | ["tranval", test"] | [Oxford-IIIT Pets](https://www.robots.ox.ac.uk/~vgg/data/pets/) µĢ░µŹ«ķøå |
+| [`Places205`](mmpretrain.datasets.Places205)(data_root[, pipeline, ...]) | - | [Places205](http://places.csail.mit.edu/downloadData.html) µĢ░µŹ«ķøå |
+| [`StanfordCars`](mmpretrain.datasets.StanfordCars)(data_root[, split, pipeline, ...]) | ["train", "test"] | [StanfordCars](https://ai.stanford.edu/~jkrause/cars/car_dataset.html) µĢ░µŹ«ķøå |
+| [`SUN397`](mmpretrain.datasets.SUN397)(data_root[, split, pipeline, ...]) | ["train", "test"] | [SUN397](https://vision.princeton.edu/projects/2010/SUN/) µĢ░µŹ«ķøå |
+| [`VOC`](mmpretrain.datasets.VOC)(data_root[, image_set_path, pipeline, ...]) | ["train", "val", "tranval", "test"] | [Pascal VOC](http://host.robots.ox.ac.uk/pascal/VOC/) µĢ░µŹ«ķøå |
+
+µ£ēõ║øµĢ░µŹ«ķøåõĖ╗ķĪĄķōŠµÄźÕÅ»ĶāĮÕĘ▓ń╗ÅÕż▒µĢł’╝īµé©ÕÅ»õ╗źķĆÜĶ┐ć[OpenDataLab](https://opendatalab.com/)õĖŗĶĮĮµĢ░µŹ«ķøå’╝īõŠŗÕ”é [Stanford Cars](https://opendatalab.com/Stanford_Cars/download)µĢ░µŹ«ķøåŃĆé
+
+## OpenMMLab 2.0 µĀćÕćåµĢ░µŹ«ķøå
+
+õĖ║õ║åń╗¤õĖĆõĖŹÕÉīõ╗╗ÕŖĪńÜäµĢ░µŹ«ķøåµÄźÕÅŻ’╝īõŠ┐õ║ÄÕżÜõ╗╗ÕŖĪńÜäń«Śµ│Ģµ©ĪÕ×ŗĶ«Łń╗ā’╝īOpenMMLab ÕłČÕ«Üõ║å **OpenMMLab 2.0 µĢ░µŹ«ķøåµĀ╝Õ╝ÅĶ¦äĶīā**’╝ī µĢ░µŹ«ķøåµĀćµ│©µ¢ćõ╗Čķ£Ćń¼”ÕÉłĶ»źĶ¦äĶīā’╝īµĢ░µŹ«ķøåÕ¤║ń▒╗Õ¤║õ║ÄĶ»źĶ¦äĶīāÕÄ╗Ķ»╗ÕÅ¢õĖÄĶ¦Żµ×ɵĢ░µŹ«µĀćµ│©µ¢ćõ╗ČŃĆéÕ”éµ×£ńö©µłĘµÅÉõŠøńÜäµĢ░µŹ«µĀćµ│©µ¢ćõ╗ČõĖŹń¼”ÕÉłĶ¦äիܵĀ╝Õ╝Å’╝īńö©µłĘÕÅ»õ╗źķĆēµŗ®Õ░åÕģČĶĮ¼Õī¢õĖ║Ķ¦äիܵĀ╝Õ╝Å’╝īÕ╣ČõĮ┐ńö© OpenMMLab ńÜäń«Śµ│ĢÕ║ōÕ¤║õ║ÄĶ»źµĢ░µŹ«µĀćµ│©µ¢ćõ╗ČĶ┐øĶĪīń«Śµ│ĢĶ«Łń╗āÕÆīµĄŗĶ»ĢŃĆé
+
+OpenMMLab 2.0 µĢ░µŹ«ķøåµĀ╝Õ╝ÅĶ¦äĶīāĶ¦äÕ«Ü’╝īµĀćµ│©µ¢ćõ╗ČÕ┐ģķĪ╗õĖ║ `json` µł¢ `yaml`’╝ī`yml` µł¢ `pickle`’╝ī`pkl` µĀ╝Õ╝Å’╝øµĀćµ│©µ¢ćõ╗ČõĖŁÕŁśÕé©ńÜäÕŁŚÕģĖÕ┐ģķĪ╗ÕīģÕɽ `metainfo` ÕÆī `data_list` õĖżõĖ¬ÕŁŚµ«ĄŃĆéÕģČõĖŁ `metainfo` µś»õĖĆõĖ¬ÕŁŚÕģĖ’╝īķćīķØóÕīģÕɽµĢ░µŹ«ķøåńÜäÕģāõ┐Īµü»’╝ø`data_list` µś»õĖĆõĖ¬ÕłŚĶĪ©’╝īÕłŚĶĪ©õĖŁµ»ÅõĖ¬Õģāń┤Āµś»õĖĆõĖ¬ÕŁŚÕģĖ’╝īĶ»źÕŁŚÕģĖÕ«Üõ╣ēõ║åõĖĆõĖ¬ÕĤզŗµĢ░µŹ«’╝łraw data’╝ē’╝īµ»ÅõĖ¬ÕĤզŗµĢ░µŹ«ÕīģÕɽõĖĆõĖ¬µł¢ĶŗźÕ╣▓õĖ¬Ķ«Łń╗ā/µĄŗĶ»ĢµĀʵ£¼ŃĆé
+
+ÕüćĶ«Šµé©Ķ”üõĮ┐ńö©Ķ«Łń╗āµĢ░µŹ«ķøå’╝īķéŻõ╣łķģŹńĮ«µ¢ćõ╗ČÕ”éõĖŗµēĆńż║’╝Ü
+
+```
+
+{
+ 'metainfo':
+ {
+ 'classes': ('cat', 'dog'), # 'cat' ńÜäń▒╗Õł½Õ║ÅÕÅĘõĖ║ 0’╝ī'dog' õĖ║ 1ŃĆé
+ ...
+ },
+ 'data_list':
+ [
+ {
+ 'img_path': "xxx/xxx_0.jpg",
+ 'gt_label': 0,
+ ...
+ },
+ {
+ 'img_path': "xxx/xxx_1.jpg",
+ 'gt_label': 1,
+ ...
+ },
+ ...
+ ]
+}
+```
+
+ÕÉīµŚČÕüćĶ«ŠµĢ░µŹ«ķøåÕŁśµöŠĶĘ»ÕŠäÕ”éõĖŗ’╝Ü
+
+```text
+data
+Ōö£ŌöĆŌöĆ annotations
+Ōöé Ōö£ŌöĆŌöĆ train.json
+Ōöé ŌööŌöĆŌöĆ ...
+Ōö£ŌöĆŌöĆ train
+Ōöé Ōö£ŌöĆŌöĆ xxx/xxx_0.jpg
+Ōöé Ōö£ŌöĆŌöĆ xxx/xxx_1.jpg
+Ōöé Ōö£ŌöĆŌöĆ ...
+```
+
+ķĆÜĶ┐ćõ╗źõĖŗÕŁŚÕģĖµ×äÕ╗║’╝Ü
+
+```python
+dataset_cfg=dict(
+ type='CustomDataset',
+ ann_file='path/to/ann_file_path',
+ data_prefix='path/to/images_folder',
+ pipeline=transfrom_list)
+```
+
+## ÕģČõ╗¢µĢ░µŹ«ķøå
+
+MMPretrain Ķ┐śµö»µīüµø┤ÕżÜÕģČõ╗¢ńÜäµĢ░µŹ«ķøå’╝īÕÅ»õ╗źķĆÜĶ┐浤źķśģ[µĢ░µŹ«ķøåµ¢ćµĪŻ](mmpretrain.datasets)ĶÄĘÕÅ¢Õ«āõ╗¼ńÜäķģŹńĮ«õ┐Īµü»ŃĆé
+
+Õ”éµ×£ķ£ĆĶ”üõĮ┐ńö©õĖĆõ║øńē╣µ«ŖµĀ╝Õ╝ÅńÜäµĢ░µŹ«ķøå’╝īµé©ķ£ĆĶ”üÕ«×ńÄ░µé©Ķć¬ÕĘ▒ńÜäµĢ░µŹ«ķøåń▒╗’╝īĶ»ĘÕÅéķśģ[µĘ╗ÕŖĀµ¢░µĢ░µŹ«ķøå](../advanced_guides/datasets.md)ŃĆé
+
+## µĢ░µŹ«ķøåÕīģĶŻģ
+
+MMEngine õĖŁµö»µīüõ╗źõĖŗµĢ░µŹ«ÕīģĶŻģÕÖ©’╝īµé©ÕÅ»õ╗źÕÅéĶĆā {external+mmengine:doc}`MMEngine µĢÖń©ŗ
+
+## Õ¤║ńĪĆńö©µ│Ģ
+
+```python
+>>> import torch
+>>> from mmpretrain.evaluation import ConfusionMatrix
+>>> y_pred = [0, 1, 1, 3]
+>>> y_true = [0, 2, 1, 3]
+>>> ConfusionMatrix.calculate(y_pred, y_true, num_classes=4)
+tensor([[1, 0, 0, 0],
+ [0, 1, 0, 0],
+ [0, 1, 0, 0],
+ [0, 0, 0, 1]])
+>>> # plot the confusion matrix
+>>> import matplotlib.pyplot as plt
+>>> y_score = torch.rand((1000, 10))
+>>> y_true = torch.randint(10, (1000, ))
+>>> matrix = ConfusionMatrix.calculate(y_score, y_true)
+>>> ConfusionMatrix().plot(matrix)
+>>> plt.show()
+```
+
+## ń╗ōÕÉłĶ»äõ╝░ÕÖ©õĮ┐ńö©
+
+```python
+>>> import torch
+>>> from mmpretrain.evaluation import ConfusionMatrix
+>>> from mmpretrain.structures import DataSample
+>>> from mmengine.evaluator import Evaluator
+>>> data_samples = [
+... DataSample().set_gt_label(i%5).set_pred_score(torch.rand(5))
+... for i in range(1000)
+... ]
+>>> evaluator = Evaluator(metrics=ConfusionMatrix())
+>>> evaluator.process(data_samples)
+>>> evaluator.evaluate(1000)
+{'confusion_matrix/result': tensor([[37, 37, 48, 43, 35],
+ [35, 51, 32, 46, 36],
+ [45, 28, 39, 42, 46],
+ [42, 40, 40, 35, 43],
+ [40, 39, 41, 37, 43]])}
+```
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/contribution_guide.md b/internlm_langchain/knowledge_base/MMPreTrain/content/contribution_guide.md
new file mode 100644
index 00000000..2549cc28
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/contribution_guide.md
@@ -0,0 +1,62 @@
+# ÕÅéõĖÄĶ┤Īńī« OpenMMLab
+
+µ¼óĶ┐Äõ╗╗õĮĢń▒╗Õ×ŗńÜäĶ┤Īńī«’╝īÕīģµŗ¼õĮåõĖŹķÖÉõ║Ä
+
+- õ┐«µö╣µŗ╝ÕåÖķöÖĶ»»µł¢õ╗ŻńĀüķöÖĶ»»
+- µĘ╗ÕŖĀµ¢ćµĪŻµł¢Õ░åµ¢ćµĪŻń┐╗Ķ»æµłÉÕģČõ╗¢Ķ»ŁĶ©Ć
+- µĘ╗ÕŖĀµ¢░ÕŖ¤ĶāĮÕÆīµ¢░ń╗äõ╗Č
+
+## ÕĘźõĮ£µĄüń©ŗ
+
+1. fork Õ╣Č pull µ£Ćµ¢░ńÜä OpenMMLab õ╗ōÕ║ō (MMPreTrain)
+2. ńŁŠÕć║Õł░õĖĆõĖ¬µ¢░Õłåµö»’╝łõĖŹĶ”üõĮ┐ńö© master Õłåµö»µÅÉõ║ż PR’╝ē
+3. Ķ┐øĶĪīõ┐«µö╣Õ╣ȵÅÉõ║żĶć│ fork Õć║ńÜäĶć¬ÕĘ▒ńÜäĶ┐£ń©ŗõ╗ōÕ║ō
+4. Õ£©µłæõ╗¼ńÜäõ╗ōÕ║ōõĖŁÕłøÕ╗║õĖĆõĖ¬ PR
+
+```{note}
+Õ”éµ×£õĮĀĶ«ĪÕłÆµĘ╗ÕŖĀõĖĆõ║øµ¢░ńÜäÕŖ¤ĶāĮ’╝īÕ╣ČÕ╝ĢÕģźÕż¦ķćŵö╣ÕŖ©’╝īĶ»ĘÕ░ĮķćÅķ”¢ÕģłÕłøÕ╗║õĖĆõĖ¬ issue µØźĶ┐øĶĪīĶ«©Ķ«║ŃĆé
+```
+
+## õ╗ŻńĀüķŻÄµĀ╝
+
+### Python
+
+µłæõ╗¼ķććńö© [PEP8](https://www.python.org/dev/peps/pep-0008/) õĮ£õĖ║ń╗¤õĖĆńÜäõ╗ŻńĀüķŻÄµĀ╝ŃĆé
+
+µłæõ╗¼õĮ┐ńö©õĖŗÕłŚÕĘźÕģĘµØźĶ┐øĶĪīõ╗ŻńĀüķŻÄµĀ╝µŻĆµ¤źõĖĵĀ╝Õ╝ÅÕī¢’╝Ü
+
+- [flake8](https://github.com/PyCQA/flake8): Python Õ«śµ¢╣ÕÅæÕĖāńÜäõ╗ŻńĀüĶ¦äĶīāµŻĆµ¤źÕĘźÕģĘ’╝īµś»ÕżÜõĖ¬µŻĆµ¤źÕĘźÕģĘńÜäÕ░üĶŻģ
+- [isort](https://github.com/timothycrosley/isort): Ķć¬ÕŖ©Ķ░āµĢ┤µ©ĪÕØŚÕ»╝ÕģźķĪ║Õ║ÅńÜäÕĘźÕģĘ
+- [yapf](https://github.com/google/yapf): õĖĆõĖ¬ Python µ¢ćõ╗ČńÜäµĀ╝Õ╝ÅÕī¢ÕĘźÕģĘŃĆé
+- [codespell](https://github.com/codespell-project/codespell): µŻĆµ¤źÕŹĢĶ»Źµŗ╝ÕåÖµś»ÕÉ”µ£ēĶ»»
+- [mdformat](https://github.com/executablebooks/mdformat): µŻĆµ¤ź markdown µ¢ćõ╗ČńÜäÕĘźÕģĘ
+- [docformatter](https://github.com/myint/docformatter): õĖĆõĖ¬ docstring µĀ╝Õ╝ÅÕī¢ÕĘźÕģĘŃĆé
+
+yapf ÕÆī isort ńÜäµĀ╝Õ╝ÅĶ«ŠńĮ«õĮŹõ║Ä [setup.cfg](https://github.com/open-mmlab/mmpretrain/blob/main/setup.cfg)
+
+µłæõ╗¼õĮ┐ńö© [pre-commit hook](https://pre-commit.com/) µØźõ┐ØĶ»üµ»Åµ¼ĪµÅÉõ║żµŚČĶć¬ÕŖ©Ķ┐øĶĪīõ╗Ż
+ńĀüµŻĆµ¤źÕÆīµĀ╝Õ╝ÅÕī¢’╝īÕÉ»ńö©ńÜäÕŖ¤ĶāĮÕīģµŗ¼ `flake8`, `yapf`, `isort`, `trailing whitespaces`, `markdown files`, õ┐«ÕżŹ `end-of-files`, `double-quoted-strings`,
+`python-encoding-pragma`, `mixed-line-ending`, Õ»╣ `requirments.txt`ńÜäµÄÆÕ║ÅńŁēŃĆé
+pre-commit hook ńÜäķģŹńĮ«µ¢ćõ╗ČõĮŹõ║Ä [.pre-commit-config](https://github.com/open-mmlab/mmpretrain/blob/main/.pre-commit-config.yaml)
+
+Õ£©õĮĀÕģŗķÜåõ╗ōÕ║ōÕÉÄ’╝īõĮĀķ£ĆĶ”üµīēńģ¦Õ”éõĖŗµŁźķ¬żÕ«ēĶŻģÕ╣ČÕłØÕ¦ŗÕī¢ pre-commit hookŃĆé
+
+```shell
+pip install -U pre-commit
+```
+
+Õ£©õ╗ōÕ║ōµ¢ćõ╗ČÕż╣õĖŁµē¦ĶĪī
+
+```shell
+pre-commit install
+```
+
+Õ£©µŁżõ╣ŗÕÉÄ’╝īµ»Åµ¼ĪµÅÉõ║ż’╝īõ╗ŻńĀüĶ¦äĶīāµŻĆµ¤źÕÆīµĀ╝Õ╝ÅÕī¢ÕĘźÕģĘķāĮÕ░åĶó½Õ╝║ÕłČµē¦ĶĪīŃĆé
+
+```{important}
+Õ£©ÕłøÕ╗║ PR õ╣ŗÕēŹ’╝īĶ»ĘńĪ«õ┐ØõĮĀńÜäõ╗ŻńĀüÕ«īµłÉõ║åõ╗ŻńĀüĶ¦äĶīāµŻĆµ¤ź’╝īÕ╣Čń╗ÅĶ┐ćõ║å yapf ńÜäµĀ╝Õ╝ÅÕī¢ŃĆé
+```
+
+### C++ ÕÆī CUDA
+
+C++ ÕÆī CUDA ńÜäõ╗ŻńĀüĶ¦äĶīāķüĄõ╗Ä [Google C++ Style Guide](https://google.github.io/styleguide/cppguide.html)
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/convention.md b/internlm_langchain/knowledge_base/MMPreTrain/content/convention.md
new file mode 100644
index 00000000..941236b6
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/convention.md
@@ -0,0 +1,114 @@
+# MMPretrain õĖŁńÜäń║”Õ«Ü
+
+## µ©ĪÕ×ŗÕæĮÕÉŹĶ¦äÕłÖ
+
+MMPretrain µīēńģ¦õ╗źõĖŗķŻÄµĀ╝Ķ┐øĶĪīµ©ĪÕ×ŗÕæĮÕÉŹ’╝īõ╗ŻńĀüÕ║ōńÜäĶ┤Īńī«ĶĆģķ£ĆĶ”üķüĄÕŠ¬ńøĖÕÉīńÜäÕæĮÕÉŹĶ¦äÕłÖŃĆ鵩ĪÕ×ŗÕÉŹµĆ╗õĮōÕłåõĖ║õ║öõĖ¬ķā©Õłå’╝Üń«Śµ│Ģõ┐Īµü»’╝īµ©ĪÕØŚõ┐Īµü»’╝īķóäĶ«Łń╗āõ┐Īµü»’╝īĶ«Łń╗āõ┐Īµü»ÕÆīµĢ░µŹ«õ┐Īµü»ŃĆéķĆ╗ĶŠæõĖŖÕ▒×õ║ÄõĖŹÕÉīķā©ÕłåńÜäÕŹĢĶ»Źõ╣ŗķŚ┤ńö©õĖŗÕłÆń║┐ `'_'` Ķ┐׵ğ’╝īÕÉīõĖĆķā©Õłåµ£ēÕżÜõĖ¬ÕŹĢĶ»Źńö©ń¤Łµ©¬ń║┐ `'-'` Ķ┐׵ğŃĆé
+
+```text
+{algorithm info}_{module info}_{pretrain info}_{training info}_{data info}
+```
+
+- `algorithm info`’╝łÕÅ»ķĆē’╝ē’╝Üń«Śµ│Ģõ┐Īµü»’╝īĶĪ©ńż║ńö©õ╗źĶ«Łń╗āĶ»źµ©ĪÕ×ŗńÜäõĖ╗Ķ”üń«Śµ│Ģ’╝īÕ”é MAEŃĆüBEiT ńŁē
+- `module info`’╝ܵ©ĪÕØŚõ┐Īµü»’╝īõĖ╗Ķ”üÕīģÕɽµ©ĪÕ×ŗńÜäõĖ╗Õ╣▓ńĮæń╗£ÕÉŹń¦░’╝īÕ”é resnetŃĆüvit ńŁē
+- `pretrain info`’╝łÕÅ»ķĆē’╝ē’╝ÜķóäĶ«Łń╗āõ┐Īµü»’╝īµ»öÕ”éķóäĶ«Łń╗āµ©ĪÕ×ŗµś»Õ£© ImageNet-21k µĢ░µŹ«ķøåõĖŖĶ«Łń╗āńÜäńŁē
+- `training info`’╝ÜĶ«Łń╗āõ┐Īµü»’╝īĶ«Łń╗āńŁ¢ńĢźĶ«ŠńĮ«’╝īÕīģµŗ¼ batch size’╝īschedule õ╗źÕÅŖµĢ░µŹ«Õó×Õ╝║ńŁē’╝ø
+- `data info`’╝ܵĢ░µŹ«õ┐Īµü»’╝īµĢ░µŹ«ķøåÕÉŹń¦░ŃĆüµ©ĪµĆüŃĆüĶŠōÕģźÕ░║Õ»ĖńŁē’╝īÕ”é imagenet, cifar ńŁē’╝ø
+
+### ń«Śµ│Ģõ┐Īµü»
+
+µīćńö©õ╗źĶ«Łń╗āĶ»źµ©ĪÕ×ŗńÜäń«Śµ│ĢÕÉŹń¦░’╝īõŠŗÕ”é’╝Ü
+
+- `simclr`
+- `mocov2`
+- `eva-mae-style`
+
+õĮ┐ńö©ńøæńØŻÕøŠÕāÅÕłåń▒╗õ╗╗ÕŖĪĶ«Łń╗āńÜ䵩ĪÕ×ŗÕÅ»õ╗źń£üńĢźĶ┐ÖõĖ¬ÕŁŚµ«ĄŃĆé
+
+### µ©ĪÕØŚõ┐Īµü»
+
+µī浩ĪÕ×ŗńÜäń╗ōµ×äõ┐Īµü»’╝īõĖĆĶł¼õĖ╗Ķ”üÕīģÕɽµ©ĪÕ×ŗńÜäõĖ╗Õ╣▓ńĮæń╗£ń╗ōµ×ä’╝ī`neck` ÕÆī `head` õ┐Īµü»õĖĆĶł¼Ķó½ń£üńĢźŃĆéõŠŗÕ”é’╝Ü
+
+- `resnet50`
+- `vit-base-p16`
+- `swin-base`
+
+### ķóäĶ«Łń╗āõ┐Īµü»
+
+Õ”éµ×£Ķ»źµ©ĪÕ×ŗµś»Õ£©ķóäĶ«Łń╗āµ©ĪÕ×ŗÕ¤║ńĪĆõĖŖ’╝īķĆÜĶ┐ćÕŠ«Ķ░āĶÄĘÕŠŚńÜä’╝īµłæõ╗¼ķ£ĆĶ”üĶ«░ÕĮĢķóäĶ«Łń╗āµ©ĪÕ×ŗńÜäõĖĆõ║øõ┐Īµü»ŃĆéõŠŗÕ”é’╝Ü
+
+- ķóäĶ«Łń╗āµ©ĪÕ×ŗńÜäµØźµ║É’╝Ü`fb`ŃĆü`openai`ńŁēŃĆé
+- Ķ«Łń╗āķóäĶ«Łń╗āµ©ĪÕ×ŗńÜäµ¢╣µ│Ģ’╝Ü`clip`ŃĆü`mae`ŃĆü`distill` ńŁēŃĆé
+- ńö©õ║ÄķóäĶ«Łń╗āńÜäµĢ░µŹ«ķøå’╝Ü`in21k`ŃĆü`laion2b`ńŁē’╝ł`in1k`ÕÅ»õ╗źń£üńĢź’╝ē
+- Ķ«Łń╗āµŚČķĢ┐’╝Ü`300e`ŃĆü`1600e` ńŁēŃĆé
+
+Õ╣ČķØ×µēƵ£ēõ┐Īµü»ķāĮµś»Õ┐ģĶ”üńÜä’╝īÕŬķ£ĆĶ”üķĆēµŗ®ńö©õ╗źÕī║ÕłåõĖŹÕÉīńÜäķóäĶ«Łń╗āµ©ĪÕ×ŗńÜäõ┐Īµü»ÕŹ│ÕÅ»ŃĆé
+
+Õ£©µŁżÕŁŚµ«ĄńÜäµ£½Õ░Š’╝īõĮ┐ńö© `-pre` õĮ£õĖ║µĀćĶ»åń¼”’╝īõŠŗÕ”é `mae-in21k-pre`ŃĆé
+
+### Ķ«Łń╗āõ┐Īµü»
+
+Ķ«Łń╗āńŁ¢ńĢźńÜäõĖĆõ║øĶ«ŠńĮ«’╝īÕīģµŗ¼Ķ«Łń╗āń▒╗Õ×ŗŃĆü `batch size`ŃĆü `lr schedule`ŃĆü µĢ░µŹ«Õó×Õ╝║õ╗źÕÅŖńē╣µ«ŖńÜ䵏¤Õż▒ÕćĮµĢ░ńŁēńŁē,µ»öÕ”é:
+Batch size õ┐Īµü»’╝Ü
+
+- µĀ╝Õ╝ÅõĖ║`{gpu x batch_per_gpu}`, Õ”é `8xb32`
+
+Ķ«Łń╗āń▒╗Õ×ŗ(õĖ╗Ķ”üĶ¦üõ║Ä transformer ńĮæń╗£’╝īÕ”é `ViT` ń«Śµ│Ģ’╝īĶ┐Öń▒╗ń«Śµ│ĢķĆÜÕĖĖÕłåõĖ║ķóäĶ«Łń╗āÕÆīÕŠ«Ķ░āõĖżń¦Źµ©ĪÕ╝Å):
+
+- `ft` : Finetune config’╝īńö©õ║ÄÕŠ«Ķ░āńÜäķģŹńĮ«µ¢ćõ╗Č
+- `pt` : Pretrain config’╝īńö©õ║ÄķóäĶ«Łń╗āńÜäķģŹńĮ«µ¢ćõ╗Č
+
+Ķ«Łń╗āńŁ¢ńĢźõ┐Īµü»’╝īĶ«Łń╗āńŁ¢ńĢźõ╗źÕżŹńÄ░ķģŹńĮ«µ¢ćõ╗ČõĖ║Õ¤║ńĪĆ’╝īµŁżÕ¤║ńĪĆõĖŹÕ┐ģµĀćµ│©Ķ«Łń╗āńŁ¢ńĢźŃĆéõĮåÕ”éµ×£Õ£©µŁżÕ¤║ńĪĆõĖŖĶ┐øĶĪīµö╣Ķ┐ø’╝īÕłÖķ£Ćµ│©µśÄĶ«Łń╗āńŁ¢ńĢź’╝īµīēńģ¦Õ║öńö©ńé╣õĮŹķĪ║Õ║ŵÄÆÕłŚ’╝īÕ”é’╝Ü`{pipeline aug}-{train aug}-{loss trick}-{scheduler}-{epochs}`
+
+- `coslr-200e` : õĮ┐ńö© cosine scheduler, Ķ«Łń╗ā 200 õĖ¬ epoch
+- `autoaug-mixup-lbs-coslr-50e` : õĮ┐ńö©õ║å `autoaug`ŃĆü`mixup`ŃĆü`label smooth`ŃĆü`cosine scheduler`, Ķ«Łń╗āõ║å 50 õĖ¬ĶĮ«µ¼Ī
+
+Õ”éµ×£µ©ĪÕ×ŗµś»õ╗ÄÕ«śµ¢╣õ╗ōÕ║ōńŁēń¼¼õĖēµ¢╣õ╗ōÕ║ōĶĮ¼µŹóĶ┐ćµØźńÜä’╝īĶ«Łń╗āõ┐Īµü»ÕÅ»õ╗źń£üńĢź’╝īõĮ┐ńö© `3rdparty` õĮ£õĖ║µĀćĶ»åń¼”ŃĆé
+
+### µĢ░µŹ«õ┐Īµü»
+
+- `in1k` : `ImageNet1k` µĢ░µŹ«ķøå’╝īķ╗śĶ«żõĮ┐ńö© `224x224` Õż¦Õ░ÅńÜäÕøŠńēć
+- `in21k` : `ImageNet21k` µĢ░µŹ«ķøå’╝īµ£ēõ║øÕ£░µ¢╣õ╣¤ń¦░õĖ║ `ImageNet22k` µĢ░µŹ«ķøå’╝īķ╗śĶ«żõĮ┐ńö© `224x224` Õż¦Õ░ÅńÜäÕøŠńēć
+- `in1k-384px` : ĶĪ©ńż║Ķ«Łń╗āńÜäĶŠōÕć║ÕøŠńēćÕż¦Õ░ÅõĖ║ `384x384`
+- `cifar100`
+
+### µ©ĪÕ×ŗÕæĮÕÉŹµĪłõŠŗ
+
+```text
+vit-base-p32_clip-openai-pre_3rdparty_in1k
+```
+
+- `vit-base-p32`: µ©ĪÕØŚõ┐Īµü»
+- `clip-openai-pre`’╝ÜķóäĶ«Łń╗āõ┐Īµü»
+ - `clip`’╝ÜķóäĶ«Łń╗āµ¢╣µ│Ģµś» clip
+ - `openai`’╝ÜķóäĶ«Łń╗āµ©ĪÕ×ŗµØźĶć¬ OpenAI
+ - `pre`’╝ÜķóäĶ«Łń╗āµĀćĶ»åń¼”
+- `3rdparty`’╝ܵ©ĪÕ×ŗµś»õ╗Äń¼¼õĖēµ¢╣õ╗ōÕ║ōĶĮ¼µŹóĶĆīµØźńÜä
+- `in1k`’╝ܵĢ░µŹ«ķøåõ┐Īµü»ŃĆéĶ»źµ©ĪÕ×ŗµś»õ╗Ä ImageNet-1k µĢ░µŹ«ķøåĶ«Łń╗āĶĆīµØźńÜä’╝īĶŠōÕģźÕż¦Õ░ÅõĖ║ `224x224`
+
+```text
+beit_beit-base-p16_8xb256-amp-coslr-300e_in1k
+```
+
+- `beit`: ń«Śµ│Ģõ┐Īµü»
+- `beit-base`’╝ܵ©ĪÕØŚõ┐Īµü»’╝īńö▒õ║ÄõĖ╗Õ╣▓ńĮæń╗£µØźĶć¬ BEiT õĖŁµÅÉÕć║ńÜäõ┐«µö╣ńēł ViT’╝īõĖ╗Õ╣▓ńĮæń╗£ÕÉŹń¦░õ╣¤µś» `beit`
+- `8xb256-amp-coslr-300e`’╝ÜĶ«Łń╗āõ┐Īµü»
+ - `8xb256`’╝ÜõĮ┐ńö© 8 õĖ¬ GPU’╝īµ»ÅõĖ¬ GPU ńÜäµē╣ķćÅÕż¦Õ░ÅõĖ║ 256
+ - `amp`’╝ÜõĮ┐ńö©Ķć¬ÕŖ©µĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗ā
+ - `coslr`’╝ÜõĮ┐ńö©õĮÖÕ╝”ķĆĆńü½ÕŁ”õ╣ĀńÄćĶ░āÕ║”ÕÖ©
+ - `300e`’╝ÜĶ«Łń╗ā 300 õĖ¬ epoch
+- `in1k`’╝ܵĢ░µŹ«ķøåõ┐Īµü»ŃĆéĶ»źµ©ĪÕ×ŗµś»õ╗Ä ImageNet-1k µĢ░µŹ«ķøåĶ«Łń╗āĶĆīµØźńÜä’╝īĶŠōÕģźÕż¦Õ░ÅõĖ║ `224x224`
+
+## ķģŹńĮ«µ¢ćõ╗ČÕæĮÕÉŹĶ¦äÕłÖ
+
+ķģŹńĮ«µ¢ćõ╗ČńÜäÕæĮÕÉŹõĖĵ©ĪÕ×ŗÕÉŹń¦░ÕćĀõ╣ÄńøĖÕÉī’╝īµ£ēÕćĀńé╣õĖŹÕÉī’╝Ü
+
+- Ķ«Łń╗āõ┐Īµü»µś»Õ┐ģĶ”üńÜä’╝īõĖŹĶāĮµś» `3rdparty`
+- Õ”éµ×£ķģŹńĮ«µ¢ćõ╗ČÕŬÕīģÕɽõĖ╗Õ╣▓ńĮæń╗£Ķ«ŠńĮ«’╝īµŚóµ▓Īµ£ēÕż┤ķā©Ķ«ŠńĮ«õ╣¤µ▓Īµ£ēµĢ░µŹ«ķøåĶ«ŠńĮ«’╝īµłæõ╗¼Õ░åÕģČÕæĮÕÉŹõĖ║`{module info}_headless.py`ŃĆéĶ┐Öń¦ŹķģŹńĮ«µ¢ćõ╗ČķĆÜÕĖĖńö©õ║ÄÕż¦Õ×ŗµĢ░µŹ«ķøåõĖŖńÜäń¼¼õĖēµ¢╣ķóäĶ«Łń╗āµ©ĪÕ×ŗŃĆé
+
+### µØāķćŹÕæĮÕÉŹĶ¦äÕłÖ
+
+µØāķćŹńÜäÕæĮÕÉŹõĖ╗Ķ”üÕīģµŗ¼µ©ĪÕ×ŗÕÉŹń¦░’╝īµŚźµ£¤ÕÆīÕōłÕĖīÕĆ╝ŃĆé
+
+```text
+{model_name}_{date}-{hash}.pth
+```
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/dataset_prepare.md b/internlm_langchain/knowledge_base/MMPreTrain/content/dataset_prepare.md
new file mode 100644
index 00000000..59a0d0af
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/dataset_prepare.md
@@ -0,0 +1,351 @@
+# ÕćåÕżćµĢ░µŹ«ķøå
+
+## CustomDataset
+
+[`CustomDataset`](mmpretrain.datasets.CustomDataset) µś»õĖĆõĖ¬ķĆÜńö©ńÜäµĢ░µŹ«ķøåń▒╗’╝īõŠøµé©õĮ┐ńö©Ķć¬ÕĘ▒ńÜäµĢ░µŹ«ķøåŃĆéńø«ÕēŹ `CustomDataset` µö»µīüõ╗źõĖŗõĖżń¦Źµ¢╣Õ╝Åń╗äń╗ćõĮĀńÜäµĢ░µŹ«ķøåµ¢ćõ╗Č’╝Ü
+
+### ÕŁÉµ¢ćõ╗ČÕż╣µ¢╣Õ╝Å
+
+Õ£©Ķ┐Öń¦ŹµĀ╝Õ╝ÅõĖŗ’╝īµé©ÕŬķ£ĆĶ”üķ揵¢░ń╗äń╗ćµé©ńÜäµĢ░µŹ«ķøåµ¢ćõ╗ČÕż╣Õ╣ČÕ░åµēƵ£ēµĀʵ£¼µöŠÕ£©õĖĆõĖ¬µ¢ćõ╗ČÕż╣õĖŁ’╝īĶĆīµŚĀķ£ĆÕłøÕ╗║õ╗╗õĮĢµĀćµ│©µ¢ćõ╗ČŃĆé
+
+Õ»╣õ║ÄńøæńØŻõ╗╗ÕŖĪ’╝łõĮ┐ńö© `with_label=true`’╝ē’╝īµłæõ╗¼õĮ┐ńö©ÕŁÉµ¢ćõ╗ČÕż╣ńÜäÕÉŹń¦░õĮ£õĖ║ń▒╗Õł½ÕÉŹń¦░’╝īÕ”éõĖŗõŠŗµēĆńż║’╝ī`class_x` ÕÆī `class_y` Õ░åĶó½Ķ»åÕł½õĖ║ń▒╗Õł½ÕÉŹń¦░ŃĆé
+
+```text
+data_prefix/
+Ōö£ŌöĆŌöĆ class_x
+Ōöé Ōö£ŌöĆŌöĆ xxx.png
+Ōöé Ōö£ŌöĆŌöĆ xxy.png
+Ōöé ŌööŌöĆŌöĆ ...
+Ōöé ŌööŌöĆŌöĆ xxz.png
+ŌööŌöĆŌöĆ class_y
+ Ōö£ŌöĆŌöĆ 123.png
+ Ōö£ŌöĆŌöĆ nsdf3.png
+ Ōö£ŌöĆŌöĆ ...
+ ŌööŌöĆŌöĆ asd932_.png
+```
+
+Õ»╣õ║ĵŚĀńøæńØŻõ╗╗ÕŖĪ’╝łõĮ┐ńö© `with_label=false`’╝ē’╝īµłæõ╗¼ńø┤µÄźÕŖĀĶĮĮµīćիܵ¢ćõ╗ČÕż╣õĖŗńÜäµēƵ£ēµĀʵ£¼µ¢ćõ╗Č’╝Ü
+
+```
+data_prefix/
+Ōö£ŌöĆŌöĆ folder_1
+Ōöé Ōö£ŌöĆŌöĆ xxx.png
+Ōöé Ōö£ŌöĆŌöĆ xxy.png
+Ōöé ŌööŌöĆŌöĆ ...
+Ōö£ŌöĆŌöĆ 123.png
+Ōö£ŌöĆŌöĆ nsdf3.png
+ŌööŌöĆŌöĆ ...
+```
+
+ÕüćÕ”éõĮĀÕĖīµ£øÕ░åõ╣ŗńö©õ║ÄĶ«Łń╗ā’╝īķéŻõ╣łķģŹńĮ«µ¢ćõ╗ČõĖŁķ£ĆĶ”üµĘ╗ÕŖĀõ╗źõĖŗķģŹńĮ«’╝Ü
+
+```python
+train_dataloader = dict(
+ ...
+ # Ķ«Łń╗āµĢ░µŹ«ķøåķģŹńĮ«
+ dataset=dict(
+ type='CustomDataset',
+ data_prefix='path/to/data_prefix',
+ with_label=True, # Õ»╣õ║ĵŚĀńøæńØŻõ╗╗ÕŖĪ’╝īõĮ┐ńö© False
+ pipeline=...
+ )
+)
+```
+
+```{note}
+Õ”éµ×£Ķ”üõĮ┐ńö©µŁżµĀ╝Õ╝Å’╝īĶ»ĘõĖŹĶ”üµīćÕ«Ü `ann_file`’╝īµł¢µīćÕ«Ü `ann_file=''`ŃĆé
+
+Ķ»Ęµ│©µäÅ’╝īÕŁÉµ¢ćõ╗ČÕż╣µĀ╝Õ╝Åķ£ĆĶ”üÕ»╣µ¢ćõ╗ČÕż╣Ķ┐øĶĪīµē½µÅÅ’╝īĶ┐ÖÕÅ»ĶāĮõ╝ÜÕ»╝Ķć┤ÕłØÕ¦ŗÕī¢ķƤÕ║”ÕÅśµģó’╝īÕ░żÕģȵś»Õ»╣õ║ÄÕż¦Õ×ŗµĢ░µŹ«ķøåµł¢µģóķƤµ¢ćõ╗Č IOŃĆé
+```
+
+### µĀćµ│©µ¢ćõ╗ȵ¢╣Õ╝Å
+
+µĀćµ│©µ¢ćõ╗ȵĀ╝Õ╝ÅõĖ╗Ķ”üõĮ┐ńö©µ¢ćµ£¼µ¢ćõ╗ČµØźõ┐ØÕŁśń▒╗Õł½õ┐Īµü»’╝ī`data_prefix` ÕŁśµöŠÕøŠńēć’╝ī`ann_file` ÕŁśµöŠµĀćµ│©ń▒╗Õł½õ┐Īµü»ŃĆé
+
+Õ”éõĖŗµĪłõŠŗ’╝īdataset ńø«ÕĮĢÕ”éõĖŗ’╝Ü
+
+Õ£©Ķ┐Öń¦ŹµĀ╝Õ╝ÅõĖŁ’╝īµłæõ╗¼õĮ┐ńö©µ¢ćµ£¼µĀćµ│©µ¢ćõ╗ČµØźÕŁśÕé©ÕøŠÕāŵ¢ćõ╗ČĶĘ»ÕŠäÕÆīÕ»╣Õ║öńÜäń▒╗Õł½ń┤óÕ╝ĢŃĆé
+
+Õ»╣õ║ÄńøæńØŻõ╗╗ÕŖĪ’╝ł`with_label=true`’╝ē’╝īµ│©ķćŖµ¢ćõ╗ČÕ║öÕ£©õĖĆĶĪīõĖŁÕīģÕɽõĖĆõĖ¬µĀʵ£¼ńÜäµ¢ćõ╗ČĶĘ»ÕŠäÕÆīń▒╗Õł½ń┤óÕ╝Ģ’╝īÕ╣Čńö©ń®║µĀ╝ÕłåķÜö’╝īÕ”éõĖŗµēĆńż║’╝Ü
+
+µēƵ£ēĶ┐Öõ║øµ¢ćõ╗ČĶĘ»ÕŠäķāĮÕÅ»õ╗źµś»ń╗ØÕ»╣ĶĘ»ÕŠä’╝īõ╣¤ÕÅ»õ╗źµś»ńøĖÕ»╣õ║Ä `data_prefix` ńÜäńøĖÕ»╣ĶĘ»ÕŠäŃĆé
+
+```text
+folder_1/xxx.png 0
+folder_1/xxy.png 1
+123.png 4
+nsdf3.png 3
+...
+```
+
+```{note}
+ń▒╗Õł½ńÜäń┤óÕ╝ĢÕÅĘõ╗Ä 0 Õ╝ĆÕ¦ŗŃĆéń£¤Õ«×µĀćńŁŠńÜäÕĆ╝Õ║öÕ£©`[0, num_classes - 1]`ĶīāÕø┤ÕåģŃĆé
+
+µŁżÕż¢’╝īĶ»ĘõĮ┐ńö©µĢ░µŹ«ķøåĶ«ŠńĮ«õĖŁńÜä `classes` ÕŁŚµ«ĄµØźµīćիܵ»ÅõĖ¬ń▒╗Õł½ńÜäÕÉŹń¦░
+```
+
+Õ»╣õ║ĵŚĀńøæńØŻõ╗╗ÕŖĪ’╝ł`with_label=false`’╝ē’╝īµĀćµ│©µ¢ćõ╗ČÕŬķ£ĆĶ”üÕ£©õĖĆĶĪīõĖŁÕīģÕɽõĖĆõĖ¬µĀʵ£¼ńÜäµ¢ćõ╗ČĶĘ»ÕŠä’╝īÕ”éõĖŗ’╝Ü
+
+```text
+folder_1/xxx.png
+folder_1/xxy.png
+123.png
+nsdf3.png
+...
+```
+
+ÕüćĶ«ŠµĢ┤õĖ¬µĢ░µŹ«ķøåµ¢ćõ╗ČÕż╣Õ”éõĖŗ’╝Ü
+
+```text
+data_root
+Ōö£ŌöĆŌöĆ meta
+Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ test.txt # µĄŗĶ»ĢµĢ░µŹ«ķøåńÜäµĀćµ│©µ¢ćõ╗Č
+Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ train.txt # Ķ«Łń╗āµĢ░µŹ«ķøåńÜäµĀćµ│©µ¢ćõ╗Č
+Ōöé┬Ā┬Ā ŌööŌöĆŌöĆ val.txt # ķ¬īĶ»üµĢ░µŹ«ķøåńÜäµĀćµ│©µ¢ćõ╗Č
+
+Ōö£ŌöĆŌöĆ train
+Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ 123.png
+Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ folder_1
+Ōöé┬Ā┬Ā Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ xxx.png
+Ōöé┬Ā┬Ā Ōöé┬Ā┬Ā ŌööŌöĆŌöĆ xxy.png
+Ōöé┬Ā┬Ā ŌööŌöĆŌöĆ nsdf3.png
+Ōö£ŌöĆŌöĆ test
+ŌööŌöĆŌöĆ val
+```
+
+Ķ┐Öµś»ķģŹńĮ«µ¢ćõ╗ČõĖŁńÜäµĢ░µŹ«ķøåĶ«ŠńĮ«ńÜäńż║õŠŗ’╝Ü
+
+```python
+# Ķ«Łń╗āµĢ░µŹ«Ķ«ŠńĮ«
+train_dataloader = dict(
+ dataset=dict(
+ type='CustomDataset',
+ data_root='path/to/data_root', # `ann_flie` ÕÆī `data_prefix` Õģ▒ÕÉīńÜäµ¢ćõ╗ČĶĘ»ÕŠäÕēŹń╝Ć
+ ann_file='meta/train.txt', # ńøĖÕ»╣õ║Ä `data_root` ńÜäµĀćµ│©µ¢ćõ╗ČĶĘ»ÕŠä
+ data_prefix='train', # `ann_file` õĖŁµ¢ćõ╗ČĶĘ»ÕŠäńÜäÕēŹń╝Ć’╝īńøĖÕ»╣õ║Ä `data_root`
+ classes=['A', 'B', 'C', 'D', ...], # µ»ÅõĖ¬ń▒╗Õł½ńÜäÕÉŹń¦░
+ pipeline=..., # ÕżäńÉåµĢ░µŹ«ķøåµĀʵ£¼ńÜäõĖĆń│╗ÕłŚÕÅśµŹóµōŹõĮ£
+ )
+ ...
+)
+```
+
+```{note}
+µ£ēÕģ│Õ”éõĮĢõĮ┐ńö© `CustomDataset` ńÜäÕ«īµĢ┤ńż║õŠŗ’╝īĶ»ĘÕÅéķśģ[Õ”éõĮĢõĮ┐ńö©Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåĶ┐øĶĪīķóäĶ«Łń╗ā](../notes/pretrain_custom_dataset.md)
+```
+
+## ImageNet
+
+ImageNet µ£ēÕżÜõĖ¬ńēłµ£¼’╝īõĮåµ£ĆÕĖĖńö©ńÜäõĖĆõĖ¬µś» [ILSVRC 2012](http://www.image-net.org/challenges/LSVRC/2012/)ŃĆé ÕÅ»õ╗źķĆÜĶ┐ćõ╗źõĖŗµŁźķ¬żõĮ┐ńö©Õ«āŃĆé
+
+`````{tabs}
+
+````{group-tab} MIM õĖŗĶĮĮ
+
+MIMµö»µīüõĮ┐ńö©õĖƵØĪÕæĮõ╗żĶĪīõ╗Ä [OpenDataLab](https://opendatalab.com/) õĖŗĶĮĮÕ╣ČķóäÕżäńÉå ImageNet µĢ░µŹ«ķøåŃĆé
+
+_ķ£ĆĶ”üÕ£© [OpenDataLab Õ«śńĮæ](https://opendatalab.com/) µ│©ÕåīĶ┤”ÕÅĘÕ╣ČÕæĮõ╗żĶĪīńÖ╗ÕĮĢ_ŃĆé
+
+```Bash
+# Õ«ēĶŻģopendatalabÕ║ō
+pip install -U opendatalab
+# ńÖ╗ÕĮĢÕł░ OpenDataLab, Õ”éµ×£Ķ┐śµ▓Īµ£ēµ│©Õåī’╝īĶ»ĘÕł░Õ«śńĮæµ│©ÕåīõĖĆõĖ¬
+odl login
+# õĮ┐ńö© MIM õĖŗĶĮĮµĢ░µŹ«ķøå, µ£ĆÕźĮÕ£© $MMPreTrain ńø«ÕĮĢµē¦ĶĪī
+mim download mmpretrain --dataset imagenet1k
+```
+
+````
+
+````{group-tab} õ╗ÄÕ«śńĮæõĖŗĶĮĮ
+
+
+1. µ│©ÕåīõĖĆõĖ¬ÕĖɵłĘÕ╣ČńÖ╗ÕĮĢÕł░[õĖŗĶĮĮķĪĄķØó](http://www.image-net.org/download-images)ŃĆé
+2. µēŠÕł░ ILSVRC2012 ńÜäõĖŗĶĮĮķōŠµÄź’╝īõĖŗĶĮĮõ╗źõĖŗõĖżõĖ¬µ¢ćõ╗Č’╝Ü
+ - ILSVRC2012_img_train.tar (~138GB)
+ - ILSVRC2012_img_val.tar (~6.3GB)
+3. Ķ¦ŻÕÄŗÕĘ▓õĖŗĶĮĮńÜäÕøŠńēćŃĆé
+
+````
+`````
+
+### ImageNetµĢ░µŹ«ķøåńø«ÕĮĢń╗ōµ×ä
+
+µłæõ╗¼µö»µīüõĖżń¦Źµ¢╣Õ╝Åń╗äń╗ćImageNetµĢ░µŹ«ķøå’╝īÕŁÉńø«ÕĮĢµĀ╝Õ╝ÅÕÆīµ¢ćµ£¼µ│©ķćŖµ¢ćõ╗ȵĀ╝Õ╝ÅŃĆé
+
+#### ÕŁÉµ¢ćõ╗ČÕż╣µĀ╝Õ╝Å
+
+µłæõ╗¼µÅÉõŠøõ║åõĖĆõĖ¬µĀĘõŠŗ’╝īµé©ÕÅ»õ╗źõ╗ÄĶ┐ÖõĖ¬[ķōŠµÄź](https://download.openmmlab.com/mmpretrain/datasets/imagenet_1k.zip)õĖŗĶĮĮÕÆīĶ¦ŻÕÄŗŃĆéµĢ░µŹ«ķøåńÜäńø«ÕĮĢń╗ōµ×äÕ║öÕ”éõĖŗµēĆńż║’╝Ü
+
+```text
+data/imagenet/
+Ōö£ŌöĆŌöĆ train/
+Ōöé Ōö£ŌöĆŌöĆ n01440764
+Ōöé Ōöé Ōö£ŌöĆŌöĆ n01440764_10026.JPEG
+Ōöé Ōöé Ōö£ŌöĆŌöĆ n01440764_10027.JPEG
+Ōöé Ōöé Ōö£ŌöĆŌöĆ n01440764_10029.JPEG
+Ōöé Ōöé Ōö£ŌöĆŌöĆ n01440764_10040.JPEG
+Ōöé Ōöé Ōö£ŌöĆŌöĆ n01440764_10042.JPEG
+Ōöé Ōöé Ōö£ŌöĆŌöĆ n01440764_10043.JPEG
+Ōöé Ōöé ŌööŌöĆŌöĆ n01440764_10048.JPEG
+Ōöé Ōö£ŌöĆŌöĆ ...
+Ōö£ŌöĆŌöĆ val/
+Ōöé Ōö£ŌöĆŌöĆ n01440764
+Ōöé Ōöé Ōö£ŌöĆŌöĆ ILSVRC2012_val_00000293.JPEG
+Ōöé Ōöé Ōö£ŌöĆŌöĆ ILSVRC2012_val_00002138.JPEG
+Ōöé Ōöé Ōö£ŌöĆŌöĆ ILSVRC2012_val_00003014.JPEG
+Ōöé Ōöé ŌööŌöĆŌöĆ ...
+Ōöé Ōö£ŌöĆŌöĆ ...
+```
+
+#### µ¢ćµ£¼µĀćµ│©µ¢ćõ╗ȵĀ╝Õ╝Å
+
+µé©ÕÅ»õ╗źõ╗Ä[µŁżķōŠµÄź](https://download.openmmlab.com/mmclassification/datasets/imagenet/meta/caffe_ilsvrc12.tar.gz)õĖŗĶĮĮÕ╣ČĶ¦ŻÕÄŗÕģāµĢ░µŹ«’╝īńäČÕÉÄń╗äń╗ćµ¢ćõ╗ČÕż╣Õ”éõĖŗ’╝Ü
+
+```text
+data/imagenet/
+Ōö£ŌöĆŌöĆ meta/
+Ōöé Ōö£ŌöĆŌöĆ train.txt
+Ōöé Ōö£ŌöĆŌöĆ test.txt
+Ōöé ŌööŌöĆŌöĆ val.txt
+Ōö£ŌöĆŌöĆ train/
+Ōöé Ōö£ŌöĆŌöĆ n01440764
+Ōöé Ōöé Ōö£ŌöĆŌöĆ n01440764_10026.JPEG
+Ōöé Ōöé Ōö£ŌöĆŌöĆ n01440764_10027.JPEG
+Ōöé Ōöé Ōö£ŌöĆŌöĆ n01440764_10029.JPEG
+Ōöé Ōöé Ōö£ŌöĆŌöĆ n01440764_10040.JPEG
+Ōöé Ōöé Ōö£ŌöĆŌöĆ n01440764_10042.JPEG
+Ōöé Ōöé Ōö£ŌöĆŌöĆ n01440764_10043.JPEG
+Ōöé Ōöé ŌööŌöĆŌöĆ n01440764_10048.JPEG
+Ōöé Ōö£ŌöĆŌöĆ ...
+Ōö£ŌöĆŌöĆ val/
+Ōöé Ōö£ŌöĆŌöĆ ILSVRC2012_val_00000001.JPEG
+Ōöé Ōö£ŌöĆŌöĆ ILSVRC2012_val_00000002.JPEG
+Ōöé Ōö£ŌöĆŌöĆ ILSVRC2012_val_00000003.JPEG
+Ōöé Ōö£ŌöĆŌöĆ ILSVRC2012_val_00000004.JPEG
+Ōöé Ōö£ŌöĆŌöĆ ...
+```
+
+### ķģŹńĮ«
+
+ÕĮōµé©ńÜäµĢ░µŹ«ķøåõ╗źõĖŖĶ┐░µ¢╣Õ╝Åń╗äń╗浌Ȓ╝īµé©ÕÅ»õ╗źõĮ┐ńö©Õģʵ£ēõ╗źõĖŗķģŹńĮ«ńÜä [`ImageNet`](mmpretrain.datasets.ImageNet) µĢ░µŹ«ķøå’╝Ü
+
+```python
+train_dataloader = dict(
+ ...
+ # Ķ«Łń╗āµĢ░µŹ«ķøåķģŹńĮ«
+ dataset=dict(
+ type='ImageNet',
+ data_root='data/imagenet/',
+ split='train',
+ pipeline=...,
+ )
+)
+
+val_dataloader = dict(
+ ...
+ # ķ¬īĶ»üµĢ░µŹ«ķøåķģŹńĮ«
+ dataset=dict(
+ type='ImageNet',
+ data_root='data/imagenet/',
+ split='val',
+ pipeline=...,
+ )
+)
+
+test_dataloader = val_dataloader
+```
+
+## µö»µīüńÜäÕøŠÕāÅÕłåń▒╗µĢ░µŹ«ķøå
+
+| µĢ░µŹ«ķøå | split | õĖ╗ķĪĄ |
+| ----------------------------------------------------------------------------------- | ----------------------------------- | ---------------------------------------------------------------------------------- |
+| [`Calthch101`](mmpretrain.datasets.Caltech101)(data_root[, split, pipeline, ...]) | ["train", "test"] | [Caltech 101](https://data.caltech.edu/records/mzrjq-6wc02) µĢ░µŹ«ķøå |
+| [`CIFAR10`](mmpretrain.datasets.CIFAR10)(data_root[, split, pipeline, ...]) | ["train", "test"] | [CIFAR10](https://www.cs.toronto.edu/~kriz/cifar.html) µĢ░µŹ«ķøå |
+| [`CIFAR100`](mmpretrain.datasets.CIFAR100)(data_root[, split, pipeline, ...]) | ["train", "test"] | [CIFAR100](https://www.cs.toronto.edu/~kriz/cifar.html) µĢ░µŹ«ķøå |
+| [`CUB`](mmpretrain.datasets.CUB)(data_root[, split, pipeline, ...]) | ["train", "test"] | [CUB-200-2011](http://www.vision.caltech.edu/datasets/cub_200_2011/) µĢ░µŹ«ķøå |
+| [`DTD`](mmpretrain.datasets.DTD)(data_root[, split, pipeline, ...]) | ["train", "val", "tranval", "test"] | [Describable Texture Dataset (DTD)](https://www.robots.ox.ac.uk/~vgg/data/dtd/) µĢ░µŹ«ķøå |
+| [`FashionMNIST`](mmpretrain.datasets.FashionMNIST) (data_root[, split, pipeline, ...]) | ["train", "test"] | [Fashion-MNIST](https://github.com/zalandoresearch/fashion-mnist) µĢ░µŹ«ķøå |
+| [`FGVCAircraft`](mmpretrain.datasets.FGVCAircraft)(data_root[, split, pipeline, ...]) | ["train", "val", "tranval", "test"] | [FGVC Aircraft](https://www.robots.ox.ac.uk/~vgg/data/fgvc-aircraft/) µĢ░µŹ«ķøå |
+| [`Flowers102`](mmpretrain.datasets.Flowers102)(data_root[, split, pipeline, ...]) | ["train", "val", "tranval", "test"] | [Oxford 102 Flower](https://www.robots.ox.ac.uk/~vgg/data/flowers/102/) µĢ░µŹ«ķøå |
+| [`Food101`](mmpretrain.datasets.Food101)(data_root[, split, pipeline, ...]) | ["train", "test"] | [Food101](https://data.vision.ee.ethz.ch/cvl/datasets_extra/food-101/) µĢ░µŹ«ķøå |
+| [`MNIST`](mmpretrain.datasets.MNIST) (data_root[, split, pipeline, ...]) | ["train", "test"] | [MNIST](http://yann.lecun.com/exdb/mnist/) µĢ░µŹ«ķøå |
+| [`OxfordIIITPet`](mmpretrain.datasets.OxfordIIITPet)(data_root[, split, pipeline, ...]) | ["tranval", test"] | [Oxford-IIIT Pets](https://www.robots.ox.ac.uk/~vgg/data/pets/) µĢ░µŹ«ķøå |
+| [`Places205`](mmpretrain.datasets.Places205)(data_root[, pipeline, ...]) | - | [Places205](http://places.csail.mit.edu/downloadData.html) µĢ░µŹ«ķøå |
+| [`StanfordCars`](mmpretrain.datasets.StanfordCars)(data_root[, split, pipeline, ...]) | ["train", "test"] | [StanfordCars](https://ai.stanford.edu/~jkrause/cars/car_dataset.html) µĢ░µŹ«ķøå |
+| [`SUN397`](mmpretrain.datasets.SUN397)(data_root[, split, pipeline, ...]) | ["train", "test"] | [SUN397](https://vision.princeton.edu/projects/2010/SUN/) µĢ░µŹ«ķøå |
+| [`VOC`](mmpretrain.datasets.VOC)(data_root[, image_set_path, pipeline, ...]) | ["train", "val", "tranval", "test"] | [Pascal VOC](http://host.robots.ox.ac.uk/pascal/VOC/) µĢ░µŹ«ķøå |
+
+µ£ēõ║øµĢ░µŹ«ķøåõĖ╗ķĪĄķōŠµÄźÕÅ»ĶāĮÕĘ▓ń╗ÅÕż▒µĢł’╝īµé©ÕÅ»õ╗źķĆÜĶ┐ć[OpenDataLab](https://opendatalab.com/)õĖŗĶĮĮµĢ░µŹ«ķøå’╝īõŠŗÕ”é [Stanford Cars](https://opendatalab.com/Stanford_Cars/download)µĢ░µŹ«ķøåŃĆé
+
+## OpenMMLab 2.0 µĀćÕćåµĢ░µŹ«ķøå
+
+õĖ║õ║åń╗¤õĖĆõĖŹÕÉīõ╗╗ÕŖĪńÜäµĢ░µŹ«ķøåµÄźÕÅŻ’╝īõŠ┐õ║ÄÕżÜõ╗╗ÕŖĪńÜäń«Śµ│Ģµ©ĪÕ×ŗĶ«Łń╗ā’╝īOpenMMLab ÕłČÕ«Üõ║å **OpenMMLab 2.0 µĢ░µŹ«ķøåµĀ╝Õ╝ÅĶ¦äĶīā**’╝ī µĢ░µŹ«ķøåµĀćµ│©µ¢ćõ╗Čķ£Ćń¼”ÕÉłĶ»źĶ¦äĶīā’╝īµĢ░µŹ«ķøåÕ¤║ń▒╗Õ¤║õ║ÄĶ»źĶ¦äĶīāÕÄ╗Ķ»╗ÕÅ¢õĖÄĶ¦Żµ×ɵĢ░µŹ«µĀćµ│©µ¢ćõ╗ČŃĆéÕ”éµ×£ńö©µłĘµÅÉõŠøńÜäµĢ░µŹ«µĀćµ│©µ¢ćõ╗ČõĖŹń¼”ÕÉłĶ¦äիܵĀ╝Õ╝Å’╝īńö©µłĘÕÅ»õ╗źķĆēµŗ®Õ░åÕģČĶĮ¼Õī¢õĖ║Ķ¦äիܵĀ╝Õ╝Å’╝īÕ╣ČõĮ┐ńö© OpenMMLab ńÜäń«Śµ│ĢÕ║ōÕ¤║õ║ÄĶ»źµĢ░µŹ«µĀćµ│©µ¢ćõ╗ČĶ┐øĶĪīń«Śµ│ĢĶ«Łń╗āÕÆīµĄŗĶ»ĢŃĆé
+
+OpenMMLab 2.0 µĢ░µŹ«ķøåµĀ╝Õ╝ÅĶ¦äĶīāĶ¦äÕ«Ü’╝īµĀćµ│©µ¢ćõ╗ČÕ┐ģķĪ╗õĖ║ `json` µł¢ `yaml`’╝ī`yml` µł¢ `pickle`’╝ī`pkl` µĀ╝Õ╝Å’╝øµĀćµ│©µ¢ćõ╗ČõĖŁÕŁśÕé©ńÜäÕŁŚÕģĖÕ┐ģķĪ╗ÕīģÕɽ `metainfo` ÕÆī `data_list` õĖżõĖ¬ÕŁŚµ«ĄŃĆéÕģČõĖŁ `metainfo` µś»õĖĆõĖ¬ÕŁŚÕģĖ’╝īķćīķØóÕīģÕɽµĢ░µŹ«ķøåńÜäÕģāõ┐Īµü»’╝ø`data_list` µś»õĖĆõĖ¬ÕłŚĶĪ©’╝īÕłŚĶĪ©õĖŁµ»ÅõĖ¬Õģāń┤Āµś»õĖĆõĖ¬ÕŁŚÕģĖ’╝īĶ»źÕŁŚÕģĖÕ«Üõ╣ēõ║åõĖĆõĖ¬ÕĤզŗµĢ░µŹ«’╝łraw data’╝ē’╝īµ»ÅõĖ¬ÕĤզŗµĢ░µŹ«ÕīģÕɽõĖĆõĖ¬µł¢ĶŗźÕ╣▓õĖ¬Ķ«Łń╗ā/µĄŗĶ»ĢµĀʵ£¼ŃĆé
+
+ÕüćĶ«Šµé©Ķ”üõĮ┐ńö©Ķ«Łń╗āµĢ░µŹ«ķøå’╝īķéŻõ╣łķģŹńĮ«µ¢ćõ╗ČÕ”éõĖŗµēĆńż║’╝Ü
+
+```
+
+{
+ 'metainfo':
+ {
+ 'classes': ('cat', 'dog'), # 'cat' ńÜäń▒╗Õł½Õ║ÅÕÅĘõĖ║ 0’╝ī'dog' õĖ║ 1ŃĆé
+ ...
+ },
+ 'data_list':
+ [
+ {
+ 'img_path': "xxx/xxx_0.jpg",
+ 'gt_label': 0,
+ ...
+ },
+ {
+ 'img_path': "xxx/xxx_1.jpg",
+ 'gt_label': 1,
+ ...
+ },
+ ...
+ ]
+}
+```
+
+ÕÉīµŚČÕüćĶ«ŠµĢ░µŹ«ķøåÕŁśµöŠĶĘ»ÕŠäÕ”éõĖŗ’╝Ü
+
+```text
+data
+Ōö£ŌöĆŌöĆ annotations
+Ōöé Ōö£ŌöĆŌöĆ train.json
+Ōöé ŌööŌöĆŌöĆ ...
+Ōö£ŌöĆŌöĆ train
+Ōöé Ōö£ŌöĆŌöĆ xxx/xxx_0.jpg
+Ōöé Ōö£ŌöĆŌöĆ xxx/xxx_1.jpg
+Ōöé Ōö£ŌöĆŌöĆ ...
+```
+
+ķĆÜĶ┐ćõ╗źõĖŗÕŁŚÕģĖµ×äÕ╗║’╝Ü
+
+```python
+dataset_cfg=dict(
+ type='CustomDataset',
+ ann_file='path/to/ann_file_path',
+ data_prefix='path/to/images_folder',
+ pipeline=transfrom_list)
+```
+
+## ÕģČõ╗¢µĢ░µŹ«ķøå
+
+MMPretrain Ķ┐śµö»µīüµø┤ÕżÜÕģČõ╗¢ńÜäµĢ░µŹ«ķøå’╝īÕÅ»õ╗źķĆÜĶ┐浤źķśģ[µĢ░µŹ«ķøåµ¢ćµĪŻ](mmpretrain.datasets)ĶÄĘÕÅ¢Õ«āõ╗¼ńÜäķģŹńĮ«õ┐Īµü»ŃĆé
+
+Õ”éµ×£ķ£ĆĶ”üõĮ┐ńö©õĖĆõ║øńē╣µ«ŖµĀ╝Õ╝ÅńÜäµĢ░µŹ«ķøå’╝īµé©ķ£ĆĶ”üÕ«×ńÄ░µé©Ķć¬ÕĘ▒ńÜäµĢ░µŹ«ķøåń▒╗’╝īĶ»ĘÕÅéķśģ[µĘ╗ÕŖĀµ¢░µĢ░µŹ«ķøå](../advanced_guides/datasets.md)ŃĆé
+
+## µĢ░µŹ«ķøåÕīģĶŻģ
+
+MMEngine õĖŁµö»µīüõ╗źõĖŗµĢ░µŹ«ÕīģĶŻģÕÖ©’╝īµé©ÕÅ»õ╗źÕÅéĶĆā {external+mmengine:doc}`MMEngine µĢÖń©ŗ ` õ║åĶ¦ŻÕ”éõĮĢõĮ┐ńö©Õ«āŃĆé
+
+- {external:py:class}`~mmengine.dataset.ConcatDataset`
+- {external:py:class}`~mmengine.dataset.RepeatDataset`
+- {external:py:class}`~mmengine.dataset.ClassBalancedDataset`
+
+ķÖżõĖŖĶ┐░õ╣ŗÕż¢’╝īMMPretrain Ķ┐śµö»µīüõ║å[KFoldDataset](mmpretrain.datasets.KFoldDataset)’╝īķ£Ćńö©ķĆÜĶ┐ćõĮ┐ńö© `tools/kfold-cross-valid.py` µØźõĮ┐ńö©Õ«āŃĆé
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/dataset_visualization.md b/internlm_langchain/knowledge_base/MMPreTrain/content/dataset_visualization.md
new file mode 100644
index 00000000..aa20251d
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/dataset_visualization.md
@@ -0,0 +1,90 @@
+# µĢ░µŹ«ķøåÕÅ»Ķ¦åÕī¢
+
+## µĢ░µŹ«ķøåÕÅ»Ķ¦åÕī¢ÕĘźÕģĘń«Ćõ╗ŗ
+
+```bash
+python tools/visualization/browse_dataset.py \
+ ${CONFIG_FILE} \
+ [-o, --output-dir ${OUTPUT_DIR}] \
+ [-p, --phase ${DATASET_PHASE}] \
+ [-n, --show-number ${NUMBER_IMAGES_DISPLAY}] \
+ [-i, --show-interval ${SHOW_INTERRVAL}] \
+ [-m, --mode ${DISPLAY_MODE}] \
+ [-r, --rescale-factor ${RESCALE_FACTOR}] \
+ [-c, --channel-order ${CHANNEL_ORDER}] \
+ [--cfg-options ${CFG_OPTIONS}]
+```
+
+**µēƵ£ēÕÅéµĢ░ńÜäĶ»┤µśÄ**’╝Ü
+
+- `config` : µ©ĪÕ×ŗķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠäŃĆé
+- `-o, --output-dir`: õ┐ØÕŁśÕøŠńēćµ¢ćõ╗ČÕż╣’╝īÕ”éµ×£µ▓Īµ£ēµīćÕ«Ü’╝īķ╗śĶ«żõĖ║ `''`,ĶĪ©ńż║õĖŹõ┐ØÕŁśŃĆé
+- **`-p, --phase`**: ÕÅ»Ķ¦åÕī¢µĢ░µŹ«ķøåńÜäķśČµ«Ą’╝īÕŬĶāĮõĖ║ `['train', 'val', 'test']` õ╣ŗõĖĆ’╝īķ╗śĶ«żõĖ║ `'train'`ŃĆé
+- **`-n, --show-number`**: ÕÅ»Ķ¦åÕī¢µĀʵ£¼µĢ░ķćÅŃĆéÕ”éµ×£µ▓Īµ£ēµīćÕ«Ü’╝īķ╗śĶ«żÕ▒Ģńż║µĢ░µŹ«ķøåńÜäµēƵ£ēÕøŠńēćŃĆé
+- `-i, --show-interval`: µĄÅĶ¦łµŚČ’╝īµ»ÅÕ╝ĀÕøŠńēćńÜäÕü£ńĢÖķŚ┤ķÜö’╝īÕŹĢõĮŹõĖ║ń¦ÆŃĆé
+- **`-m, --mode`**: ÕÅ»Ķ¦åÕī¢ńÜ䵩ĪÕ╝Å’╝īÕŬĶāĮõĖ║ `['original', 'transformed', 'concat', 'pipeline']` õ╣ŗõĖĆŃĆé ķ╗śĶ«żõĖ║`'transformed'`.
+- `-r, --rescale-factor`: Õ£© `mode='original'` õĖŗ’╝īÕÅ»Ķ¦åÕī¢ÕøŠńēćńÜäµöŠń╝®ÕĆŹµĢ░’╝īÕ£©ÕøŠńēćĶ┐ćÕż¦µł¢Ķ┐ćÕ░ŵŚČĶ«ŠńĮ«ŃĆé
+- `-c, --channel-order`: ÕøŠńēćńÜäķĆÜķüōķĪ║Õ║Å’╝īõĖ║ `['BGR', 'RGB']` õ╣ŗõĖĆ’╝īķ╗śĶ«żõĖ║ `'BGR'`ŃĆé
+- `--cfg-options` : Õ»╣ķģŹńĮ«µ¢ćõ╗ČńÜäõ┐«µö╣’╝īÕÅéĶĆā[ÕŁ”õ╣ĀķģŹńĮ«µ¢ćõ╗Č](../user_guides/config.md)ŃĆé
+
+```{note}
+
+1. `-m, --mode` ńö©õ║ÄĶ«ŠńĮ«ÕÅ»Ķ¦åÕī¢ńÜ䵩ĪÕ╝Å’╝īķ╗śĶ«żĶ«ŠńĮ«õĖ║ 'transformed'ŃĆé
+- Õ”éµ×£ `--mode` Ķ«ŠńĮ«õĖ║ 'original'’╝īÕłÖĶÄĘÕÅ¢ÕĤզŗÕøŠńēć’╝ø
+- Õ”éµ×£ `--mode` Ķ«ŠńĮ«õĖ║ 'transformed'’╝īÕłÖĶÄĘÕÅ¢ķóäÕżäńÉåÕÉÄńÜäÕøŠńēć’╝ø
+- Õ”éµ×£ `--mode` Ķ«ŠńĮ«õĖ║ 'concat'’╝īĶÄĘÕÅ¢ÕĤզŗÕøŠńēćÕÆīķóäÕżäńÉåÕÉÄÕøŠńēćµŗ╝µÄźńÜäÕøŠńēć’╝ø
+- Õ”éµ×£ `--mode` Ķ«ŠńĮ«õĖ║ 'pipeline'’╝īÕłÖĶÄĘÕŠŚµĢ░µŹ«µĄüµ░┤ń║┐µēƵ£ēõĖŁķŚ┤Ķ┐ćń©ŗÕøŠńēćŃĆé
+
+2. `-r, --rescale-factor` Õ£©µĢ░µŹ«ķøåõĖŁÕøŠńēćńÜäÕłåĶŠ©ńÄćĶ┐ćÕż¦µł¢ĶĆģĶ┐ćÕ░ŵŚČĶ«ŠńĮ«ŃĆéµ»öÕ”éÕ£©ÕÅ»Ķ¦åÕī¢ CIFAR µĢ░µŹ«ķøåµŚČ’╝īńö▒õ║ÄÕøŠńēćńÜäÕłåĶŠ©ńÄćķØ×ÕĖĖÕ░Å’╝īÕÅ»Õ░å `-r, --rescale-factor` Ķ«ŠńĮ«õĖ║ 10ŃĆé
+```
+
+## Õ”éõĮĢÕÅ»Ķ¦åÕī¢ÕĤզŗÕøŠÕāÅ
+
+õĮ┐ńö© **'original'** µ©ĪÕ╝Å ’╝Ü
+
+```shell
+python ./tools/visualization/browse_dataset.py ./configs/resnet/resnet101_8xb16_cifar10.py --phase val --output-dir tmp --mode original --show-number 100 --rescale-factor 10 --channel-order RGB
+```
+
+- `--phase val`: ÕÅ»Ķ¦åÕī¢ķ¬īĶ»üķøå’╝īÕÅ»ń«ĆÕī¢õĖ║ `-p val`;
+- `--output-dir tmp`: ÕÅ»Ķ¦åÕī¢ń╗ōµ×£õ┐ØÕŁśÕ£© "tmp" µ¢ćõ╗ČÕż╣’╝īÕÅ»ń«ĆÕī¢õĖ║ `-o tmp`;
+- `--mode original`: ÕÅ»Ķ¦åÕī¢ÕĤÕøŠ’╝īÕÅ»ń«ĆÕī¢õĖ║ `-m original`;
+- `--show-number 100`: ÕÅ»Ķ¦åÕī¢ 100 Õ╝ĀÕøŠ’╝īÕÅ»ń«ĆÕī¢õĖ║ `-n 100`;
+- `--rescale-factor`: ÕøŠÕāŵöŠÕż¦ 10 ÕĆŹ’╝īÕÅ»ń«ĆÕī¢õĖ║ `-r 10`;
+- `--channel-order RGB`: ÕÅ»Ķ¦åÕī¢ÕøŠÕāÅńÜäķĆÜķüōķĪ║Õ║ÅõĖ║ "RGB", ÕÅ»ń«ĆÕī¢õĖ║ `-c RGB`ŃĆé
+
+ +
+## Õ”éõĮĢÕÅ»Ķ¦åÕī¢ÕżäńÉåÕÉÄÕøŠÕāÅ
+
+õĮ┐ńö© **'transformed'** µ©ĪÕ╝Å’╝Ü
+
+```shell
+python ./tools/visualization/browse_dataset.py ./configs/resnet/resnet50_8xb32_in1k.py -n 100
+```
+
+
+
+## Õ”éõĮĢÕÅ»Ķ¦åÕī¢ÕżäńÉåÕÉÄÕøŠÕāÅ
+
+õĮ┐ńö© **'transformed'** µ©ĪÕ╝Å’╝Ü
+
+```shell
+python ./tools/visualization/browse_dataset.py ./configs/resnet/resnet50_8xb32_in1k.py -n 100
+```
+
+ +
+## Õ”éõĮĢÕÉīµŚČÕÅ»Ķ¦åÕī¢ÕĤզŗÕøŠÕāÅõĖÄÕżäńÉåÕÉÄÕøŠÕāÅ
+
+õĮ┐ńö© **'concat'** µ©ĪÕ╝Å’╝Ü
+
+```shell
+python ./tools/visualization/browse_dataset.py configs/swin_transformer/swin-small_16xb64_in1k.py -n 10 -m concat
+```
+
+
+
+## Õ”éõĮĢÕÉīµŚČÕÅ»Ķ¦åÕī¢ÕĤզŗÕøŠÕāÅõĖÄÕżäńÉåÕÉÄÕøŠÕāÅ
+
+õĮ┐ńö© **'concat'** µ©ĪÕ╝Å’╝Ü
+
+```shell
+python ./tools/visualization/browse_dataset.py configs/swin_transformer/swin-small_16xb64_in1k.py -n 10 -m concat
+```
+
+ +
+õĮ┐ńö© **'pipeline'** µ©ĪÕ╝Å’╝Ü
+
+```shell
+python ./tools/visualization/browse_dataset.py configs/swin_transformer/swin-small_16xb64_in1k.py -m pipeline
+```
+
+
+
+õĮ┐ńö© **'pipeline'** µ©ĪÕ╝Å’╝Ü
+
+```shell
+python ./tools/visualization/browse_dataset.py configs/swin_transformer/swin-small_16xb64_in1k.py -m pipeline
+```
+
+ +
+```shell
+python ./tools/visualization/browse_dataset.py configs/beit/beit_beit-base-p16_8xb256-amp-coslr-300e_in1k.py -m pipeline
+```
+
+
+
+```shell
+python ./tools/visualization/browse_dataset.py configs/beit/beit_beit-base-p16_8xb256-amp-coslr-300e_in1k.py -m pipeline
+```
+
+ diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/datasets.md b/internlm_langchain/knowledge_base/MMPreTrain/content/datasets.md
new file mode 100644
index 00000000..83b7959b
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/datasets.md
@@ -0,0 +1,73 @@
+# µĘ╗ÕŖĀµ¢░µĢ░µŹ«ķøå
+
+ńö©µłĘÕÅ»õ╗źń╝¢ÕåÖõĖĆõĖ¬ń╗¦µē┐Ķć¬ [BasesDataset](https://mmpretrain.readthedocs.io/zh_CN/latest/_modules/mmpretrain/datasets/base_dataset.html#BaseDataset) ńÜäµ¢░µĢ░µŹ«ķøåń▒╗’╝īÕ╣ČķćŹĶĮĮ `load_data_list(self)` µ¢╣µ│Ģ’╝īń▒╗õ╝╝ [CIFAR10](https://github.com/open-mmlab/mmpretrain/blob/main/mmpretrain/datasets/cifar.py) ÕÆī [ImageNet](https://github.com/open-mmlab/mmpretrain/blob/main/mmpretrain/datasets/imagenet.py)ŃĆé
+
+ķĆÜÕĖĖ’╝īµŁżµ¢╣µ│ĢĶ┐öÕø×õĖĆõĖ¬ÕīģÕɽµēƵ£ēµĀʵ£¼ńÜäÕłŚĶĪ©’╝īÕģČõĖŁńÜäµ»ÅõĖ¬µĀʵ£¼ķāĮµś»õĖĆõĖ¬ÕŁŚÕģĖŃĆéÕŁŚÕģĖõĖŁÕīģÕɽõ║åÕ┐ģĶ”üńÜäµĢ░µŹ«õ┐Īµü»’╝īõŠŗÕ”é `img` ÕÆī `gt_label`ŃĆé
+
+ÕüćĶ«Šµłæõ╗¼Õ░åĶ”üÕ«×ńÄ░õĖĆõĖ¬ `Filelist` µĢ░µŹ«ķøå’╝īĶ»źµĢ░µŹ«ķøåÕ░åõĮ┐ńö©µ¢ćõ╗ČÕłŚĶĪ©Ķ┐øĶĪīĶ«Łń╗āÕÆīµĄŗĶ»ĢŃĆéµ│©ķćŖÕłŚĶĪ©ńÜäµĀ╝Õ╝ÅÕ”éõĖŗ’╝Ü
+
+```text
+000001.jpg 0
+000002.jpg 1
+...
+```
+
+## 1. ÕłøÕ╗║µĢ░µŹ«ķøåń▒╗
+
+µłæõ╗¼ÕÅ»õ╗źÕ£© `mmpretrain/datasets/filelist.py` õĖŁÕłøÕ╗║õĖĆõĖ¬µ¢░ńÜäµĢ░µŹ«ķøåń▒╗õ╗źÕŖĀĶĮĮµĢ░µŹ«ŃĆé
+
+```python
+from mmpretrain.registry import DATASETS
+from .base_dataset import BaseDataset
+
+
+@DATASETS.register_module()
+class Filelist(BaseDataset):
+
+ def load_data_list(self):
+ assert isinstance(self.ann_file, str)
+
+ data_list = []
+ with open(self.ann_file) as f:
+ samples = [x.strip().split(' ') for x in f.readlines()]
+ for filename, gt_label in samples:
+ img_path = add_prefix(filename, self.img_prefix)
+ info = {'img_path': img_path, 'gt_label': int(gt_label)}
+ data_list.append(info)
+ return data_list
+```
+
+## 2. µĘ╗ÕŖĀÕł░Õ║ō
+
+Õ░åµ¢░ńÜäµĢ░µŹ«ķøåń▒╗ÕŖĀÕģźÕł░ `mmpretrain/datasets/__init__.py` õĖŁ’╝Ü
+
+```python
+from .base_dataset import BaseDataset
+...
+from .filelist import Filelist
+
+__all__ = [
+ 'BaseDataset', ... ,'Filelist'
+]
+```
+
+### 3. õ┐«µö╣ńøĖÕģ│ķģŹńĮ«µ¢ćõ╗Č
+
+ńäČÕÉÄÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁ’╝īõĖ║õ║åõĮ┐ńö© `Filelist`’╝īńö©µłĘÕÅ»õ╗źµīēõ╗źõĖŗµ¢╣Õ╝Åõ┐«µö╣ķģŹńĮ«
+
+```python
+train_dataloader = dict(
+ ...
+ dataset=dict(
+ type='Filelist',
+ ann_file='image_list.txt',
+ pipeline=train_pipeline,
+ )
+)
+```
+
+µēƵ£ēń╗¦µē┐ [`BaseDataset`](https://github.com/open-mmlab/mmpretrain/blob/main/mmpretrain/datasets/base_dataset.py) ńÜäµĢ░µŹ«ķøåń▒╗ķāĮÕģʵ£ē**µćÆÕŖĀĶĮĮ**õ╗źÕÅŖ**ĶŖéń£üÕåģÕŁś**ńÜäńē╣µĆ¦’╝īÕÅ»õ╗źÕÅéĶĆāńøĖÕģ│µ¢ćµĪŻ {external+mmengine:doc}`BaseDataset
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/datasets.md b/internlm_langchain/knowledge_base/MMPreTrain/content/datasets.md
new file mode 100644
index 00000000..83b7959b
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/datasets.md
@@ -0,0 +1,73 @@
+# µĘ╗ÕŖĀµ¢░µĢ░µŹ«ķøå
+
+ńö©µłĘÕÅ»õ╗źń╝¢ÕåÖõĖĆõĖ¬ń╗¦µē┐Ķć¬ [BasesDataset](https://mmpretrain.readthedocs.io/zh_CN/latest/_modules/mmpretrain/datasets/base_dataset.html#BaseDataset) ńÜäµ¢░µĢ░µŹ«ķøåń▒╗’╝īÕ╣ČķćŹĶĮĮ `load_data_list(self)` µ¢╣µ│Ģ’╝īń▒╗õ╝╝ [CIFAR10](https://github.com/open-mmlab/mmpretrain/blob/main/mmpretrain/datasets/cifar.py) ÕÆī [ImageNet](https://github.com/open-mmlab/mmpretrain/blob/main/mmpretrain/datasets/imagenet.py)ŃĆé
+
+ķĆÜÕĖĖ’╝īµŁżµ¢╣µ│ĢĶ┐öÕø×õĖĆõĖ¬ÕīģÕɽµēƵ£ēµĀʵ£¼ńÜäÕłŚĶĪ©’╝īÕģČõĖŁńÜäµ»ÅõĖ¬µĀʵ£¼ķāĮµś»õĖĆõĖ¬ÕŁŚÕģĖŃĆéÕŁŚÕģĖõĖŁÕīģÕɽõ║åÕ┐ģĶ”üńÜäµĢ░µŹ«õ┐Īµü»’╝īõŠŗÕ”é `img` ÕÆī `gt_label`ŃĆé
+
+ÕüćĶ«Šµłæõ╗¼Õ░åĶ”üÕ«×ńÄ░õĖĆõĖ¬ `Filelist` µĢ░µŹ«ķøå’╝īĶ»źµĢ░µŹ«ķøåÕ░åõĮ┐ńö©µ¢ćõ╗ČÕłŚĶĪ©Ķ┐øĶĪīĶ«Łń╗āÕÆīµĄŗĶ»ĢŃĆéµ│©ķćŖÕłŚĶĪ©ńÜäµĀ╝Õ╝ÅÕ”éõĖŗ’╝Ü
+
+```text
+000001.jpg 0
+000002.jpg 1
+...
+```
+
+## 1. ÕłøÕ╗║µĢ░µŹ«ķøåń▒╗
+
+µłæõ╗¼ÕÅ»õ╗źÕ£© `mmpretrain/datasets/filelist.py` õĖŁÕłøÕ╗║õĖĆõĖ¬µ¢░ńÜäµĢ░µŹ«ķøåń▒╗õ╗źÕŖĀĶĮĮµĢ░µŹ«ŃĆé
+
+```python
+from mmpretrain.registry import DATASETS
+from .base_dataset import BaseDataset
+
+
+@DATASETS.register_module()
+class Filelist(BaseDataset):
+
+ def load_data_list(self):
+ assert isinstance(self.ann_file, str)
+
+ data_list = []
+ with open(self.ann_file) as f:
+ samples = [x.strip().split(' ') for x in f.readlines()]
+ for filename, gt_label in samples:
+ img_path = add_prefix(filename, self.img_prefix)
+ info = {'img_path': img_path, 'gt_label': int(gt_label)}
+ data_list.append(info)
+ return data_list
+```
+
+## 2. µĘ╗ÕŖĀÕł░Õ║ō
+
+Õ░åµ¢░ńÜäµĢ░µŹ«ķøåń▒╗ÕŖĀÕģźÕł░ `mmpretrain/datasets/__init__.py` õĖŁ’╝Ü
+
+```python
+from .base_dataset import BaseDataset
+...
+from .filelist import Filelist
+
+__all__ = [
+ 'BaseDataset', ... ,'Filelist'
+]
+```
+
+### 3. õ┐«µö╣ńøĖÕģ│ķģŹńĮ«µ¢ćõ╗Č
+
+ńäČÕÉÄÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁ’╝īõĖ║õ║åõĮ┐ńö© `Filelist`’╝īńö©µłĘÕÅ»õ╗źµīēõ╗źõĖŗµ¢╣Õ╝Åõ┐«µö╣ķģŹńĮ«
+
+```python
+train_dataloader = dict(
+ ...
+ dataset=dict(
+ type='Filelist',
+ ann_file='image_list.txt',
+ pipeline=train_pipeline,
+ )
+)
+```
+
+µēƵ£ēń╗¦µē┐ [`BaseDataset`](https://github.com/open-mmlab/mmpretrain/blob/main/mmpretrain/datasets/base_dataset.py) ńÜäµĢ░µŹ«ķøåń▒╗ķāĮÕģʵ£ē**µćÆÕŖĀĶĮĮ**õ╗źÕÅŖ**ĶŖéń£üÕåģÕŁś**ńÜäńē╣µĆ¦’╝īÕÅ»õ╗źÕÅéĶĆāńøĖÕģ│µ¢ćµĪŻ {external+mmengine:doc}`BaseDataset `ŃĆé
+
+```{note}
+Õ”éµ×£µĢ░µŹ«µĀʵ£¼µŚČĶÄĘÕÅ¢ńÜäÕŁŚÕģĖõĖŁ’╝īÕŬÕīģÕɽõ║å 'img_path' õĖŹÕīģÕɽ 'img'’╝ī ÕłÖÕ£© pipeline õĖŁÕ┐ģķĪ╗ÕīģÕɽ 'LoadImgFromFile'ŃĆé
+```
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/downstream.md b/internlm_langchain/knowledge_base/MMPreTrain/content/downstream.md
new file mode 100644
index 00000000..0744f1e3
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/downstream.md
@@ -0,0 +1,125 @@
+# õĖŗµĖĖõ╗╗ÕŖĪ
+
+## µŻĆµĄŗ
+
+µłæõ╗¼õĮ┐ńö© MMDetection Ķ┐øĶĪīÕøŠÕāŵŻĆµĄŗŃĆéķ”¢ÕģłńĪ«õ┐صé©ÕĘ▓ń╗ÅÕ«ēĶŻģõ║å [MIM](https://github.com/open-mmlab/mim)’╝īĶ┐Öõ╣¤µś» OpenMMLab ńÜäõĖĆõĖ¬ķĪ╣ńø«ŃĆé
+
+```shell
+pip install openmim
+mim install 'mmdet>=3.0.0rc0'
+```
+
+µŁżÕż¢’╝īĶ»ĘÕÅéĶĆā MMDetection ńÜä[Õ«ēĶŻģ](https://mmdetection.readthedocs.io/en/dev-3.x/get_started.html)ÕÆī[µĢ░µŹ«ÕćåÕżć](https://mmdetection.readthedocs.io/en/dev-3.x/user_guides/dataset_prepare.html)
+
+### Ķ«Łń╗ā
+
+Õ«ēĶŻģÕ«īÕÉÄ’╝īµé©ÕÅ»õ╗źõĮ┐ńö©Õ”éõĖŗńÜäń«ĆÕŹĢÕæĮõ╗żĶ┐ÉĶĪī MMDetectionŃĆé
+
+```shell
+# distributed version
+bash tools/benchmarks/mmdetection/mim_dist_train_c4.sh ${CONFIG} ${PRETRAIN} ${GPUS}
+bash tools/benchmarks/mmdetection/mim_dist_train_fpn.sh ${CONFIG} ${PRETRAIN} ${GPUS}
+
+# slurm version
+bash tools/benchmarks/mmdetection/mim_slurm_train_c4.sh ${PARTITION} ${CONFIG} ${PRETRAIN}
+bash tools/benchmarks/mmdetection/mim_slurm_train_fpn.sh ${PARTITION} ${CONFIG} ${PRETRAIN}
+```
+
+- `${CONFIG}`’╝Üńø┤µÄźńö© MMDetection õĖŁńÜäķģŹńĮ«µ¢ćõ╗ČĶĘ»ÕŠäÕŹ│ÕÅ»ŃĆéÕ»╣õ║ÄõĖĆõ║øń«Śµ│Ģ’╝īµłæõ╗¼µ£ēõĖĆõ║øõ┐«µö╣Ķ┐ćńÜäķģŹńĮ«µ¢ćõ╗Č’╝ī
+ ÕÅ»õ╗źÕ£©ńøĖÕ║öń«Śµ│Ģµ¢ćõ╗ČÕż╣õĖŗńÜä `benchmarks` µ¢ćõ╗ČÕż╣õĖŁµēŠÕł░ŃĆéÕÅ”Õż¢’╝īµé©õ╣¤ÕÅ»õ╗źõ╗ÄÕż┤Õ╝ĆÕ¦ŗń╝¢ÕåÖķģŹńĮ«µ¢ćõ╗ČŃĆé
+- `${PRETRAIN}`’╝ÜķóäĶ«Łń╗āµ©ĪÕ×ŗµ¢ćõ╗Č
+- `${GPUS}`’╝ÜõĮ┐ńö©ÕżÜÕ░æ GPU Ķ┐øĶĪīĶ«Łń╗ā’╝īÕ»╣õ║ĵŻĆµĄŗõ╗╗ÕŖĪ’╝īµłæõ╗¼ķ╗śĶ«żõĮ┐ńö© 8 õĖ¬ GPUŃĆé
+
+õŠŗÕŁÉ’╝Ü
+
+```shell
+bash ./tools/benchmarks/mmdetection/mim_dist_train_c4.sh \
+ configs/byol/benchmarks/mask-rcnn_r50-c4_ms-1x_coco.py \
+ https://download.openmmlab.com/mmselfsup/1.x/byol/byol_resnet50_16xb256-coslr-200e_in1k/byol_resnet50_16xb256-coslr-200e_in1k_20220825-de817331.pth 8
+```
+
+### µĄŗĶ»Ģ
+
+Õ£©Ķ«Łń╗āõ╣ŗÕÉÄ’╝īµé©ÕÅ»õ╗źĶ┐ÉĶĪīÕ”éõĖŗÕæĮõ╗żµĄŗĶ»Ģµé©ńÜ䵩ĪÕ×ŗŃĆé
+
+```shell
+# distributed version
+bash tools/benchmarks/mmdetection/mim_dist_test.sh ${CONFIG} ${CHECKPOINT} ${GPUS}
+
+# slurm version
+bash tools/benchmarks/mmdetection/mim_slurm_test.sh ${PARTITION} ${CONFIG} ${CHECKPOINT}
+```
+
+Õżćµ│©’╝Ü
+
+- `${CHECKPOINT}`’╝ܵ驵ā│µĄŗĶ»ĢńÜäĶ«Łń╗āÕźĮńÜ䵯ƵĄŗµ©ĪÕ×ŗŃĆé
+
+õŠŗÕŁÉ’╝Ü
+
+```shell
+bash ./tools/benchmarks/mmdetection/mim_dist_test.sh \
+configs/benchmarks/mmdetection/coco/mask-rcnn_r50_fpn_ms-1x_coco.py \
+https://download.openmmlab.com/mmselfsup/1.x/byol/byol_resnet50_16xb256-coslr-200e_in1k/byol_resnet50_16xb256-coslr-200e_in1k_20220825-de817331.pth 8
+```
+
+## ÕłåÕē▓
+
+µłæõ╗¼õĮ┐ńö© MMSegmentation Ķ┐øĶĪīÕøŠÕāÅÕłåÕē▓ŃĆéķ”¢ÕģłńĪ«õ┐صé©ÕĘ▓ń╗ÅÕ«ēĶŻģõ║å [MIM](https://github.com/open-mmlab/mim)’╝īĶ┐Öõ╣¤µś» OpenMMLab ńÜäõĖĆõĖ¬ķĪ╣ńø«ŃĆé
+
+```shell
+pip install openmim
+mim install 'mmsegmentation>=1.0.0rc0'
+```
+
+µŁżÕż¢’╝īĶ»ĘÕÅéĶĆā MMSegmentation ńÜä[Õ«ēĶŻģ](https://mmsegmentation.readthedocs.io/en/dev-1.x/get_started.html)ÕÆī[µĢ░µŹ«ÕćåÕżć](https://mmsegmentation.readthedocs.io/en/dev-1.x/user_guides/2_dataset_prepare.html)ŃĆé
+
+### Ķ«Łń╗ā
+
+Õ£©Õ«ēĶŻģÕ«īÕÉÄ’╝īÕÅ»õ╗źõĮ┐ńö©Õ”éõĖŗń«ĆÕŹĢÕæĮõ╗żĶ┐ÉĶĪī MMSegmentationŃĆé
+
+```shell
+# distributed version
+bash tools/benchmarks/mmsegmentation/mim_dist_train.sh ${CONFIG} ${PRETRAIN} ${GPUS}
+
+# slurm version
+bash tools/benchmarks/mmsegmentation/mim_slurm_train.sh ${PARTITION} ${CONFIG} ${PRETRAIN}
+```
+
+Õżćµ│©’╝Ü
+
+- `${CONFIG}`’╝Üńø┤µÄźńö© MMSegmentation õĖŁńÜäķģŹńĮ«µ¢ćõ╗ČĶĘ»ÕŠäÕŹ│ÕÅ»ŃĆéÕ»╣õ║ÄõĖĆõ║øń«Śµ│Ģ’╝īµłæõ╗¼µ£ēõĖĆõ║øõ┐«µö╣Ķ┐ćńÜäķģŹńĮ«µ¢ćõ╗Č’╝ī
+ ÕÅ»õ╗źÕ£©ńøĖÕ║öń«Śµ│Ģµ¢ćõ╗ČÕż╣õĖŗńÜä `benchmarks` µ¢ćõ╗ČÕż╣õĖŁµēŠÕł░ŃĆéÕÅ”Õż¢’╝īµé©õ╣¤ÕÅ»õ╗źõ╗ÄÕż┤Õ╝ĆÕ¦ŗń╝¢ÕåÖķģŹńĮ«µ¢ćõ╗ČŃĆé
+- `${PRETRAIN}`’╝ÜķóäĶ«Łń╗āµ©ĪÕ×ŗµ¢ćõ╗Č
+- `${GPUS}`’╝ÜõĮ┐ńö©ÕżÜÕ░æ GPU Ķ┐øĶĪīĶ«Łń╗ā’╝īÕ»╣õ║ĵŻĆµĄŗõ╗╗ÕŖĪ’╝īµłæõ╗¼ķ╗śĶ«żõĮ┐ńö© 8 õĖ¬ GPUŃĆé
+
+õŠŗÕŁÉ’╝Ü
+
+```shell
+bash ./tools/benchmarks/mmsegmentation/mim_dist_train.sh \
+configs/benchmarks/mmsegmentation/voc12aug/fcn_r50-d8_4xb4-20k_voc12aug-512x512.py \
+https://download.openmmlab.com/mmselfsup/1.x/byol/byol_resnet50_16xb256-coslr-200e_in1k/byol_resnet50_16xb256-coslr-200e_in1k_20220825-de817331.pth 4
+```
+
+### µĄŗĶ»Ģ
+
+Õ£©Ķ«Łń╗āõ╣ŗÕÉÄ’╝īµé©ÕÅ»õ╗źĶ┐ÉĶĪīÕ”éõĖŗÕæĮõ╗żµĄŗĶ»Ģµé©ńÜ䵩ĪÕ×ŗŃĆé
+
+```shell
+# distributed version
+bash tools/benchmarks/mmsegmentation/mim_dist_test.sh ${CONFIG} ${CHECKPOINT} ${GPUS}
+
+# slurm version
+bash tools/benchmarks/mmsegmentation/mim_slurm_test.sh ${PARTITION} ${CONFIG} ${CHECKPOINT}
+```
+
+Õżćµ│©’╝Ü
+
+- `${CHECKPOINT}`’╝ܵ驵ā│µĄŗĶ»ĢńÜäĶ«Łń╗āÕźĮńÜäÕłåÕē▓µ©ĪÕ×ŗŃĆé
+
+õŠŗÕŁÉ’╝Ü
+
+```shell
+bash ./tools/benchmarks/mmsegmentation/mim_dist_test.sh \
+configs/benchmarks/mmsegmentation/voc12aug/fcn_r50-d8_4xb4-20k_voc12aug-512x512.py \
+https://download.openmmlab.com/mmselfsup/1.x/byol/byol_resnet50_16xb256-coslr-200e_in1k/byol_resnet50_16xb256-coslr-200e_in1k_20220825-de817331.pth 4
+```
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/evaluation.md b/internlm_langchain/knowledge_base/MMPreTrain/content/evaluation.md
new file mode 100644
index 00000000..32db1975
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/evaluation.md
@@ -0,0 +1,97 @@
+# Ķć¬Õ«Üõ╣ēĶ»äõ╝░µīćµĀć
+
+## õĮ┐ńö© MMPretrain õĖŁńÜäµīćµĀć
+
+Õ£© MMPretrain õĖŁ’╝īµłæõ╗¼õĖ║ÕŹĢµĀćńŁŠÕłåń▒╗ÕÆīÕżÜµĀćńŁŠÕłåń▒╗µÅÉõŠøõ║åÕżÜń¦ŹµīćµĀć’╝Ü
+
+**ÕŹĢµĀćńŁŠÕłåń▒╗**:
+
+- [`Accuracy`](mmpretrain.evaluation.Accuracy)
+- [`SingleLabelMetric`](mmpretrain.evaluation.SingleLabelMetric)’╝īÕīģµŗ¼ń▓ŠÕ║”ŃĆüÕżÕø×ńÄćŃĆüf1-score ÕÆīµö»µīüÕ║”ŃĆé
+
+**ÕżÜµĀćńŁŠÕłåń▒╗**:
+
+- [`AveragePrecision`](mmpretrain.evaluation.AveragePrecision)’╝ī µł¢ AP (mAP)ŃĆé
+- [`MultiLabelMetric`](mmpretrain.evaluation.MultiLabelMetric)’╝īÕīģµŗ¼ń▓ŠÕ║”ŃĆüÕżÕø×ńÄćŃĆüf1-score ÕÆīµö»µīüÕ║”ŃĆé
+
+Ķ”üÕ£©ķ¬īĶ»üÕÆīµĄŗĶ»Ģµ£¤ķŚ┤õĮ┐ńö©Ķ┐Öõ║øµīćµĀć’╝īµłæõ╗¼ķ£ĆĶ”üõ┐«µö╣ķģŹńĮ«µ¢ćõ╗ČõĖŁńÜä `val_evaluator` ÕÆī `test_evaluator` ÕŁŚµ«ĄŃĆé
+
+õ╗źõĖŗõĖ║ÕćĀõĖ¬õŠŗÕŁÉ’╝Ü
+
+1. Õ£©ķ¬īĶ»üÕÆīµĄŗĶ»Ģµ£¤ķŚ┤Ķ«Īń«Ś top-1 ÕÆī top-5 ÕćåńĪ«ńÄćŃĆé
+
+ ```python
+ val_evaluator = dict(type='Accuracy', topk=(1, 5))
+ test_evaluator = val_evaluator
+ ```
+
+2. Õ£©ķ¬īĶ»üÕÆīµĄŗĶ»Ģµ£¤ķŚ┤Ķ«Īń«Ś top-1 ÕćåńĪ«ńÄćŃĆütop-5 ÕćåńĪ«Õ║”ŃĆüń▓ŠńĪ«Õ║”ÕÆīÕżÕø×ńÄćŃĆé
+
+ ```python
+ val_evaluator = [
+ dict(type='Accuracy', topk=(1, 5)),
+ dict(type='SingleLabelMetric', items=['precision', 'recall']),
+ ]
+ test_evaluator = val_evaluator
+ ```
+
+3. Ķ«Īń«Ś mAP’╝łÕ╣│ÕØćÕ╣│ÕØćń▓ŠÕ║”’╝ēŃĆüCP’╝łń▒╗Õł½Õ╣│ÕØćń▓ŠÕ║”’╝ēŃĆüCR’╝łń▒╗Õł½Õ╣│ÕØćÕżÕø×ńÄć’╝ēŃĆüCF’╝łń▒╗Õł½Õ╣│ÕØć F1 ÕłåµĢ░’╝ēŃĆüOP’╝łµĆ╗õĮōÕ╣│ÕØćń▓ŠÕ║”’╝ēŃĆüOR’╝łµĆ╗õĮōÕ╣│ÕØćÕżÕø×ńÄć’╝ēÕÆī OF1’╝łµĆ╗õĮōÕ╣│ÕØć F1 ÕłåµĢ░’╝ēŃĆé
+
+ ```python
+ val_evaluator = [
+ dict(type='AveragePrecision'),
+ dict(type='MultiLabelMetric', average='macro'), # class-wise mean
+ dict(type='MultiLabelMetric', average='micro'), # overall mean
+ ]
+ test_evaluator = val_evaluator
+ ```
+
+## µĘ╗ÕŖĀµ¢░ńÜäµīćµĀć
+
+MMPretrain µö»µīüõĖ║Ķ┐Įµ▒éµø┤ķ½śÕ«ÜÕłČÕī¢ńÜäńö©µłĘÕ«×ńÄ░Õ«ÜÕłČÕī¢ńÜäĶ»äõ╝░µīćµĀćŃĆé
+
+µé©ķ£ĆĶ”üÕ£© `mmpretrain/evaluation/metrics` õĖŗÕłøÕ╗║õĖĆõĖ¬µ¢░µ¢ćõ╗Č’╝īÕ╣ČÕ£©Ķ»źµ¢ćõ╗ČõĖŁÕ«×ńÄ░µ¢░ńÜäµīćµĀć’╝īõŠŗÕ”é’╝īÕ£© `mmpretrain/evaluation/metrics/my_metric.py` õĖŁŃĆéÕ╣ČÕłøÕ╗║õĖĆõĖ¬Ķć¬Õ«Üõ╣ēńÜäĶ»äõ╝░µīćµĀćń▒╗ `MyMetric` ń╗¦µē┐ [MMEngine õĖŁńÜä BaseMetric](mmengine.evaluator.BaseMetric)ŃĆé
+
+ķ£ĆĶ”üÕłåÕł½Ķ”åńø¢µĢ░µŹ«µĀ╝Õ╝ÅÕżäńÉåµ¢╣µ│Ģ`process`ÕÆīÕ║”ķćÅĶ«Īń«Śµ¢╣µ│Ģ`compute_metrics`ŃĆé Õ░åÕģȵĘ╗ÕŖĀÕł░ŌĆ£METRICSŌĆص│©ÕåīĶĪ©õ╗źÕ«×µ¢Įõ╗╗õĮĢĶć¬Õ«Üõ╣ēĶ»äõ╝░µīćµĀćŃĆé
+
+```python
+from mmengine.evaluator import BaseMetric
+from mmpretrain.registry import METRICS
+
+@METRICS.register_module()
+class MyMetric(BaseMetric):
+
+ def process(self, data_batch: Sequence[Dict], data_samples: Sequence[Dict]):
+ """ The processed results should be stored in ``self.results``, which will
+ be used to computed the metrics when all batches have been processed.
+ `data_batch` stores the batch data from dataloader,
+ and `data_samples` stores the batch outputs from model.
+ """
+ ...
+
+ def compute_metrics(self, results: List):
+ """ Compute the metrics from processed results and returns the evaluation results.
+ """
+ ...
+```
+
+ńäČÕÉÄ’╝īÕ░åÕģČÕ»╝Õģź `mmpretrain/evaluation/metrics/__init__.py` õ╗źÕ░åÕģȵĘ╗ÕŖĀÕł░ `mmpretrain.evaluation` ÕīģõĖŁŃĆé
+
+```python
+# In mmpretrain/evaluation/metrics/__init__.py
+...
+from .my_metric import MyMetric
+
+__all__ = [..., 'MyMetric']
+```
+
+µ£ĆÕÉÄ’╝īÕ£©ķģŹńĮ«µ¢ćõ╗ČńÜä `val_evaluator` ÕÆī `test_evaluator` ÕŁŚµ«ĄõĖŁõĮ┐ńö© `MyMetric`ŃĆé
+
+```python
+val_evaluator = dict(type='MyMetric', ...)
+test_evaluator = val_evaluator
+```
+
+```{note}
+µø┤ÕżÜńÜäń╗åĶŖéÕÅ»õ╗źÕÅéĶĆā {external+mmengine:doc}`MMEngine µ¢ćµĪŻ: Evaluation `.
+```
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/faq.md b/internlm_langchain/knowledge_base/MMPreTrain/content/faq.md
new file mode 100644
index 00000000..efd2ff5e
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/faq.md
@@ -0,0 +1,100 @@
+# ÕĖĖĶ¦üķŚ«ķóś
+
+µłæõ╗¼Õ£©Ķ┐ÖķćīÕłŚÕć║õ║åõĖĆõ║øÕĖĖĶ¦üķŚ«ķóśÕÅŖÕģČńøĖÕ║öńÜäĶ¦ŻÕå│µ¢╣µĪłŃĆéÕ”éµ×£µé©ÕÅæńÄ░õ╗╗õĮĢÕĖĖĶ¦üķŚ«ķóśÕ╣ȵ£ēµ¢╣µ│Ģ
+ÕĖ«ÕŖ®Ķ¦ŻÕå│’╝īµ¼óĶ┐ÄķÜŵŚČõĖ░Õ»īÕłŚĶĪ©ŃĆéÕ”éµ×£Ķ┐ÖķćīńÜäÕåģÕ«╣µ▓Īµ£ēµČĄńø¢µé©ńÜäķŚ«ķóś’╝īĶ»Ęµīēńģ¦
+[µÅÉķŚ«µ©ĪµØ┐](https://github.com/open-mmlab/mmpretrain/issues/new/choose)
+Õ£© GitHub õĖŖµÅÉÕć║ķŚ«ķóś’╝īÕ╣ČĶĪźÕģģµ©ĪµØ┐õĖŁķ£ĆĶ”üńÜäõ┐Īµü»ŃĆé
+
+## Õ«ēĶŻģ
+
+- MMEngine, MMCV õĖÄ MMPretrain ńÜäÕģ╝Õ«╣ķŚ«ķóś
+
+ Ķ┐Öķćīµłæõ╗¼ÕłŚõĖŠõ║åÕÉäńēłµ£¼ MMPretrain Õ»╣ MMEngine ÕÆī MMCV ńēłµ£¼ńÜäõŠØĶĄ¢’╝īĶ»ĘķĆēµŗ®ÕÉłķĆéńÜä MMEngine ÕÆī MMCV ńēłµ£¼µØźķü┐ÕģŹÕ«ēĶŻģÕÆīõĮ┐ńö©õĖŁńÜäķŚ«ķóśŃĆé
+
+ | MMPretrain ńēłµ£¼ | MMEngine ńēłµ£¼ | MMCV ńēłµ£¼ |
+ | :-------------: | :---------------: | :--------------: |
+ | 1.0.2 (main) | mmengine >= 0.8.3 | mmcv >= 2.0.0 |
+ | 1.0.0 | mmengine >= 0.8.0 | mmcv >= 2.0.0 |
+ | 1.0.0rc8 | mmengine >= 0.7.1 | mmcv >= 2.0.0rc4 |
+ | 1.0.0rc7 | mmengine >= 0.5.0 | mmcv >= 2.0.0rc4 |
+
+ ```{note}
+ ńö▒õ║Ä `dev` Õłåµö»Õżäõ║Äķóæń╣üÕ╝ĆÕÅæõĖŁ’╝īMMEngine ÕÆī MMCV ńēłµ£¼õŠØĶĄ¢ÕÅ»ĶāĮõĖŹÕćåńĪ«ŃĆéÕ”éµ×£µé©Õ£©õĮ┐ńö©
+ `dev` Õłåµö»µŚČķüćÕł░ķŚ«ķóś’╝īĶ»ĘÕ░ØĶ»Ģµø┤µ¢░ MMEngine ÕÆī MMCV Õł░µ£Ćµ¢░ńēłŃĆé
+ ```
+
+- õĮ┐ńö© Albumentations
+
+ Õ”éµ×£õĮĀÕĖīµ£øõĮ┐ńö© `albumentations` ńøĖÕģ│ńÜäÕŖ¤ĶāĮ’╝īµłæõ╗¼Õ╗║Ķ««õĮ┐ńö© `pip install -r requirements/optional.txt` µł¢ĶĆģ
+ `pip install -U albumentations>=0.3.2 --no-binary qudida,albumentations` ÕæĮõ╗żĶ┐øĶĪīÕ«ēĶŻģŃĆé
+
+ Õ”éµ×£õĮĀńø┤µÄźõĮ┐ńö© `pip install albumentations>=0.3.2` µØźÕ«ēĶŻģ’╝īÕ«āõ╝ÜÕÉīµŚČÕ«ēĶŻģ `opencv-python-headless`
+ ’╝łÕŹ│õĮ┐õĮĀÕĘ▓ń╗ÅÕ«ēĶŻģõ║å `opencv-python`’╝ēŃĆéÕģĘõĮōń╗åĶŖéÕÅ»ÕÅéķśģ
+ [Õ«śµ¢╣µ¢ćµĪŻ](https://albumentations.ai/docs/getting_started/installation/#note-on-opencv-dependencies)ŃĆé
+
+## ķĆÜńö©ķŚ«ķóś
+
+### Õ”éµ×£µłæÕ»╣µ║ÉńĀüĶ┐øĶĪīõ║åµö╣ÕŖ©’╝īķ£ĆĶ”üķ揵¢░Õ«ēĶŻģõ╗źõĮ┐µö╣ÕŖ©ńö¤µĢłÕÉŚ’╝¤
+
+Õ”éµ×£õĮĀķüĄńģ¦[µ£ĆõĮ│Õ«×ĶĘĄ](../get_started.md#µ£ĆõĮ│Õ«×ĶĘĄ)ńÜäµīćÕ╝Ģ’╝īõ╗ĵ║ÉńĀüÕ«ēĶŻģ mmpretrain’╝īķéŻõ╣łõ╗╗õĮĢµ£¼Õ£░õ┐«µö╣ķāĮõĖŹķ£ĆĶ”üķ揵¢░Õ«ēĶŻģÕŹ│ÕÅ»ńö¤µĢłŃĆé
+
+### Õ”éõĮĢÕ£©ÕżÜõĖ¬ MMPretrain ńēłµ£¼õĖŗĶ┐øĶĪīÕ╝ĆÕÅæ’╝¤
+
+ķĆÜÕĖĖµØźĶ»┤’╝īµłæõ╗¼µÄ©ĶŹÉķĆÜĶ┐ćõĖŹÕÉīĶÖܵŗ¤ńÄ»ÕóāµØźń«ĪńÉåÕżÜõĖ¬Õ╝ĆÕÅæńø«ÕĮĢõĖŗńÜä MMPretrainŃĆé
+õĮåÕ”éµ×£õĮĀÕĖīµ£øÕ£©õĖŹÕÉīńø«ÕĮĢ’╝łÕ”é mmpretrain-0.21, mmpretrain-0.23 ńŁē’╝ēõĮ┐ńö©ÕÉīõĖĆõĖ¬ńÄ»ÕóāĶ┐øĶĪīÕ╝ĆÕÅæ’╝ī
+µłæõ╗¼µÅÉõŠøńÜäĶ«Łń╗āÕÆīµĄŗĶ»Ģ shell Ķäܵ£¼õ╝ÜĶć¬ÕŖ©õĮ┐ńö©ÕĮōÕēŹńø«ÕĮĢńÜä mmpretrain’╝īÕģČõ╗¢ Python Ķäܵ£¼
+ÕłÖÕÅ»õ╗źÕ£©ÕæĮõ╗żÕēŹµĘ╗ÕŖĀ `` PYTHONPATH=`pwd` `` µØźõĮ┐ńö©ÕĮōÕēŹńø«ÕĮĢńÜäõ╗ŻńĀüŃĆé
+
+ÕÅŹĶ┐ćµØź’╝īÕ”éµ×£õĮĀÕĖīµ£ø shell Ķäܵ£¼õĮ┐ńö©ńÄ»ÕóāõĖŁÕ«ēĶŻģńÜä MMPretrain’╝īĶĆīõĖŹµś»ÕĮōÕēŹńø«ÕĮĢńÜä’╝ī
+ÕłÖÕÅ»õ╗źÕÄ╗µÄē shell Ķäܵ£¼õĖŁÕ”éõĖŗõĖĆĶĪīõ╗ŻńĀü’╝Ü
+
+```shell
+PYTHONPATH="$(dirname $0)/..":$PYTHONPATH
+```
+
+### `load_from` ÕÆī `init_cfg` õ╣ŗķŚ┤ńÜäÕģ│ń│╗µś»õ╗Ćõ╣ł’╝¤
+
+- `load_from`: Õ”éµ×£`resume=False`’╝īÕŬջ╝Õģźµ©ĪÕ×ŗµØāķ插╝īõĖ╗Ķ”üńö©õ║ÄÕŖĀĶĮĮĶ«Łń╗āĶ┐ćńÜ䵩ĪÕ×ŗ’╝ø
+ Õ”éµ×£ `resume=True` ’╝īÕŖĀĶĮĮµēƵ£ēńÜ䵩ĪÕ×ŗµØāķćŹŃĆüõ╝śÕī¢ÕÖ©ńŖȵĆüÕÆīÕģČõ╗¢Ķ«Łń╗āõ┐Īµü»’╝īõĖ╗Ķ”üńö©õ║ĵüóÕżŹõĖŁµ¢ŁńÜäĶ«Łń╗āŃĆé
+
+- `init_cfg`: õĮĀõ╣¤ÕÅ»õ╗źµīćÕ«Ü`init=dict(type="Pretrained", checkpoint=xxx)`µØźÕŖĀĶĮĮµØāķ插╝ī
+ ĶĪ©ńż║Õ£©µ©ĪÕ×ŗµØāķćŹÕłØÕ¦ŗÕī¢µŚČÕŖĀĶĮĮµØāķ插╝īķĆÜÕĖĖÕ£©Ķ«Łń╗āńÜäÕ╝ĆÕ¦ŗķśČµ«Ąµē¦ĶĪīŃĆé
+ õĖ╗Ķ”üńö©õ║ÄÕŠ«Ķ░āķóäĶ«Łń╗āµ©ĪÕ×ŗ’╝īõĮĀÕÅ»õ╗źÕ£©ķ¬©Õ╣▓ńĮæń╗£ńÜäķģŹńĮ«õĖŁķģŹńĮ«Õ«ā’╝īĶ┐śÕÅ»õ╗źõĮ┐ńö© `prefix` ÕŁŚµ«ĄµØźÕŬÕŖĀĶĮĮÕ»╣Õ║öńÜäµØāķ插╝īõŠŗÕ”é’╝Ü
+
+ ```python
+ model = dict(
+ backbone=dict(
+ type='ResNet',
+ depth=50,
+ init_cfg=dict(type='Pretrained', checkpoints=xxx, prefix='backbone'),
+ )
+ ...
+ )
+ ```
+
+ÕÅéĶ¦ü [ÕŠ«Ķ░āµ©ĪÕ×ŗ](./finetune_custom_dataset.md) õ╗źõ║åĶ¦Żµø┤ÕżÜÕģ│õ║ĵ©ĪÕ×ŗÕŠ«Ķ░āńÜäń╗åĶŖéŃĆé
+
+### `default_hooks` ÕÆī `custom_hooks` õ╣ŗķŚ┤µ£ēõ╗Ćõ╣łÕī║Õł½’╝¤
+
+ÕćĀõ╣ĵ▓Īµ£ēÕī║Õł½ŃĆéķĆÜÕĖĖ’╝ī`default_hooks` ÕŁŚµ«Ąńö©õ║ĵīćÕ«ÜÕćĀõ╣ĵēƵ£ēÕ«×ķ¬īķāĮõ╝ÜõĮ┐ńö©ńÜäķÆ®ÕŁÉ’╝ī
+ĶĆī `custom_hooks` ÕŁŚµ«Ąµīćķā©ÕłåÕ«×ķ¬īńē╣µ£ēńÜäķÆ®ÕŁÉŃĆé
+
+ÕÅ”õĖĆõĖ¬Õī║Õł½µś» `default_hooks` µś»õĖĆõĖ¬ÕŁŚÕģĖ’╝īĶĆī `custom_hooks` µś»õĖĆõĖ¬ÕłŚĶĪ©’╝īĶ»ĘõĖŹĶ”üµĘʵĘåŃĆé
+
+### Õ£©Ķ«Łń╗āµ£¤ķŚ┤’╝īµłæµ▓Īµ£ēµöČÕł░Ķ«Łń╗āµŚźÕ┐Ś’╝īĶ┐Öµś»õ╗Ćõ╣łÕĤÕøĀ’╝¤
+
+Õ”éµ×£õĮĀńÜäĶ«Łń╗āµĢ░µŹ«ķøåÕŠłÕ░Å’╝īĶĆīµē╣ÕżäńÉåķćÅÕŹ┤ÕŠłÕż¦’╝īµłæõ╗¼ķ╗śĶ«żńÜ䵌źÕ┐ŚķŚ┤ķÜöÕÅ»ĶāĮÕż¬Õż¦’╝īµŚĀµ│ĢĶ«░ÕĮĢõĮĀńÜäĶ«Łń╗āµŚźÕ┐ŚŃĆé
+
+õĮĀÕÅ»õ╗źń╝®ÕćŵŚźÕ┐ŚķŚ┤ķÜö’╝īÕåŹĶ»ĢõĖƵ¼Ī’╝īµ»öÕ”é:
+
+```python
+default_hooks = dict(
+ ...
+ logger=dict(type='LoggerHook', interval=10),
+ ...
+)
+```
+
+### Õ”éõĮĢÕ¤║õ║ÄÕģČÕ«āµĢ░µŹ«ķøåĶ«Łń╗ā’╝īõŠŗÕ”éµłæĶć¬ÕĘ▒ńÜäµĢ░µŹ«ķøåµł¢ĶĆģµś» COCO µĢ░µŹ«ķøå’╝¤
+
+µłæõ╗¼µÅÉõŠøõ║å [ÕģĘõĮōńż║õŠŗ](./pretrain_custom_dataset.md) µØźÕ▒Ģńż║Õ”éõĮĢÕ£©ÕģČÕ«āµĢ░µŹ«ķøåõĖŖĶ┐øĶĪīĶ«Łń╗āŃĆé
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/finetune_custom_dataset.md b/internlm_langchain/knowledge_base/MMPreTrain/content/finetune_custom_dataset.md
new file mode 100644
index 00000000..2b8cbd68
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/finetune_custom_dataset.md
@@ -0,0 +1,328 @@
+# Õ”éõĮĢÕ£©Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåõĖŖÕŠ«Ķ░āµ©ĪÕ×ŗ
+
+Õ£©ÕŠłÕżÜÕ£║µÖ»õĖŗ’╝īµłæõ╗¼ķ£ĆĶ”üÕ┐½ķĆ¤Õ£░Õ░嵩ĪÕ×ŗÕ║öńö©Õł░µ¢░ńÜäµĢ░µŹ«ķøåõĖŖ’╝īõĮåõ╗ÄÕż┤Ķ«Łń╗āµ©ĪÕ×ŗķĆÜÕĖĖÕŠłķÜŠÕ┐½ķƤµöȵĢø’╝īĶ┐Öń¦ŹõĖŹńĪ«Õ«ÜµĆ¦õ╝ܵĄ¬Ķ┤╣ķóØÕż¢ńÜ䵌ČķŚ┤ŃĆé
+ķĆÜÕĖĖ’╝īÕĘ▓µ£ēńÜäŃĆüÕ£©Õż¦µĢ░µŹ«ķøåõĖŖĶ«Łń╗āÕźĮńÜ䵩ĪÕ×ŗõ╝ܵ»öķÜŵ£║ÕłØÕ¦ŗÕī¢µÅÉõŠøµø┤õĖ║µ£ēµĢłńÜäÕģłķ¬īõ┐Īµü»’╝īń▓ŚńĢźµØźĶ«▓’╝īÕ£©µŁżÕ¤║ńĪĆõĖŖńÜäÕŁ”õ╣Āµłæõ╗¼ń¦░õ╣ŗõĖ║µ©ĪÕ×ŗÕŠ«Ķ░āŃĆé
+
+ÕĘ▓ń╗ÅĶ»üµśÄ’╝īÕ£© ImageNet µĢ░µŹ«ķøåõĖŖķóäĶ«Łń╗āńÜ䵩ĪÕ×ŗÕ»╣õ║ÄÕģČõ╗¢µĢ░µŹ«ķøåÕÆīÕģČõ╗¢õĖŗµĖĖõ╗╗ÕŖĪµ£ēÕŠłÕźĮńÜäµĢłµ×£ŃĆé
+ÕøĀµŁż’╝īĶ»źµĢÖń©ŗµÅÉõŠøõ║åÕ”éõĮĢÕ░å [Model Zoo](../modelzoo_statistics.md) õĖŁµÅÉõŠøńÜäķóäĶ«Łń╗āµ©ĪÕ×ŗńö©õ║ÄÕģČõ╗¢µĢ░µŹ«ķøå’╝īÕĘ▓ĶÄĘÕŠŚµø┤ÕźĮńÜäµĢłµ×£ŃĆé
+
+Õ£©µ£¼µĢÖń©ŗõĖŁ’╝īµłæõ╗¼µÅÉõŠøõ║åõĖĆõĖ¬Õ«×ĶĘĄńż║õŠŗÕÆīõĖĆõ║øÕģ│õ║ÄÕ”éõĮĢÕ£©Ķć¬ÕĘ▒ńÜäµĢ░µŹ«ķøåõĖŖÕŠ«Ķ░āµ©ĪÕ×ŗńÜäµŖĆÕʦŃĆé
+
+## ń¼¼õĖƵŁź’╝ÜÕćåÕżćõĮĀńÜäµĢ░µŹ«ķøå
+
+µīēńģ¦ [ÕćåÕżćµĢ░µŹ«ķøå](../user_guides/dataset_prepare.md) ÕćåÕżćõĮĀńÜäµĢ░µŹ«ķøåŃĆé
+ÕüćĶ«Šµłæõ╗¼ńÜäµĢ░µŹ«ķøåµĀ╣µ¢ćõ╗ČÕż╣ĶĘ»ÕŠäõĖ║ `data/custom_dataset/`
+
+ÕüćĶ«Šµłæõ╗¼µā│Ķ┐øĶĪīµ£ēńøæńØŻÕøŠÕāÅÕłåń▒╗Ķ«Łń╗ā’╝īÕ╣ČõĮ┐ńö©ÕŁÉµ¢ćõ╗ČÕż╣µĀ╝Õ╝ÅńÜä `CustomDataset` µØźń╗äń╗ćµĢ░µŹ«ķøå’╝Ü
+
+```text
+data/custom_dataset/
+Ōö£ŌöĆŌöĆ train
+Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ class_x
+Ōöé┬Ā┬Ā Ōöé Ōö£ŌöĆŌöĆ x_1.png
+Ōöé Ōöé Ōö£ŌöĆŌöĆ x_2.png
+Ōöé Ōöé Ōö£ŌöĆŌöĆ x_3.png
+Ōöé Ōöé ŌööŌöĆŌöĆ ...
+Ōöé Ōö£ŌöĆŌöĆ class_y
+Ōöé┬Ā┬Ā ŌööŌöĆŌöĆ ...
+ŌööŌöĆŌöĆ test
+ ┬Ā┬Ā Ōö£ŌöĆŌöĆ class_x
+ ┬Ā┬Ā Ōöé Ōö£ŌöĆŌöĆ test_x_1.png
+ Ōöé Ōö£ŌöĆŌöĆ test_x_2.png
+ Ōöé Ōö£ŌöĆŌöĆ test_x_3.png
+ Ōöé ŌööŌöĆŌöĆ ...
+ Ōö£ŌöĆŌöĆ class_y
+ ┬Ā┬Ā ŌööŌöĆŌöĆ ...
+```
+
+## ń¼¼õ║īµŁź’╝ÜķĆēµŗ®õĖĆõĖ¬ķģŹńĮ«µ¢ćõ╗ČõĮ£õĖ║µ©ĪµØ┐
+
+Õ£©Ķ┐Öķćī’╝īµłæõ╗¼õĮ┐ńö© `configs/resnet/resnet50_8xb32_in1k.py` õĮ£õĖ║ńż║õŠŗŃĆé
+ķ”¢ÕģłÕ£©ÕÉīõĖƵ¢ćõ╗ČÕż╣õĖŗÕżŹÕłČõĖĆõ╗ĮķģŹńĮ«µ¢ćõ╗Č’╝īÕ╣ČÕ░åÕģČķćŹÕæĮÕÉŹõĖ║ `resnet50_8xb32-ft_custom.py`ŃĆé
+
+```{tip}
+µīēńģ¦µā»õŠŗ’╝īķģŹńĮ«ÕÉŹń¦░ńÜäµ£ĆÕÉÄõĖĆõĖ¬ÕŁŚµ«Ąµś»µĢ░µŹ«ķøå’╝īõŠŗÕ”é’╝ī`in1k` ĶĪ©ńż║ ImageNet-1k’╝ī`coco` ĶĪ©ńż║ coco µĢ░µŹ«ķøå
+```
+
+Ķ┐ÖõĖ¬ķģŹńĮ«ńÜäÕåģÕ«╣µś»’╝Ü
+
+```python
+_base_ = [
+ '../_base_/models/resnet50.py', # µ©ĪÕ×ŗĶ«ŠńĮ«
+ '../_base_/datasets/imagenet_bs32.py', # µĢ░µŹ«Ķ«ŠńĮ«
+ '../_base_/schedules/imagenet_bs256.py', # Ķ«Łń╗āńŁ¢ńĢźĶ«ŠńĮ«
+ '../_base_/default_runtime.py', # Ķ┐ÉĶĪīĶ«ŠńĮ«
+]
+```
+
+## ń¼¼õĖēµŁź’╝Üõ┐«µö╣µ©ĪÕ×ŗĶ«ŠńĮ«
+
+Õ£©Ķ┐øĶĪīµ©ĪÕ×ŗÕŠ«Ķ░āµŚČ’╝īµłæõ╗¼ķĆÜÕĖĖÕĖīµ£øÕ£©õĖ╗Õ╣▓ńĮæń╗£’╝łbackbone’╝ēÕŖĀĶĮĮķóäĶ«Łń╗āµ©ĪÕ×ŗ’╝īÕåŹńö©µłæõ╗¼ńÜäµĢ░µŹ«ķøåĶ«Łń╗āõĖĆõĖ¬µ¢░ńÜäÕłåń▒╗Õż┤’╝łhead’╝ēŃĆé
+
+õĖ║õ║åÕ£©õĖ╗Õ╣▓ńĮæń╗£ÕŖĀĶĮĮķóäĶ«Łń╗āµ©ĪÕ×ŗ’╝īµłæõ╗¼ķ£ĆĶ”üõ┐«µö╣õĖ╗Õ╣▓ńĮæń╗£ńÜäÕłØÕ¦ŗÕī¢Ķ«ŠńĮ«’╝īõĮ┐ńö©
+`Pretrained` ń▒╗Õ×ŗńÜäÕłØÕ¦ŗÕī¢ÕćĮµĢ░ŃĆéÕÅ”Õż¢’╝īÕ£©ÕłØÕ¦ŗÕī¢Ķ«ŠńĮ«õĖŁ’╝īµłæõ╗¼õĮ┐ńö© `prefix='backbone'`
+µØźÕæŖĶ»ēÕłØÕ¦ŗÕī¢ÕćĮµĢ░ķ£ĆĶ”üÕŖĀĶĮĮńÜäÕŁÉµ©ĪÕØŚńÜäÕēŹń╝Ć’╝ī`backbone`ÕŹ│µīćÕŖĀĶĮĮµ©ĪÕ×ŗõĖŁńÜäõĖ╗Õ╣▓ńĮæń╗£ŃĆé
+µ¢╣õŠ┐ĶĄĘĶ¦ü’╝īµłæõ╗¼Ķ┐ÖķćīõĮ┐ńö©õĖĆõĖ¬Õ£©ń║┐ńÜäµØāķ揵¢ćõ╗ČķōŠµÄź’╝īÕ«ā
+õ╝ÜÕ£©Ķ«Łń╗āÕēŹĶć¬ÕŖ©õĖŗĶĮĮÕ»╣Õ║öńÜäµ¢ćõ╗Č’╝īõĮĀõ╣¤ÕÅ»õ╗źµÅÉÕēŹõĖŗĶĮĮĶ┐ÖõĖ¬µ©ĪÕ×ŗ’╝īńäČÕÉÄõĮ┐ńö©µ£¼Õ£░ĶĘ»ÕŠäŃĆé
+
+µÄźõĖŗµØź’╝īµ¢░ńÜäķģŹńĮ«µ¢ćõ╗Čķ£ĆĶ”üµīēńģ¦µ¢░µĢ░µŹ«ķøåńÜäń▒╗Õł½µĢ░ńø«µØźõ┐«µö╣Õłåń▒╗Õż┤ńÜäķģŹńĮ«ŃĆéÕŬķ£ĆĶ”üõ┐«µö╣Õłå
+ń▒╗Õż┤õĖŁńÜä `num_classes` Ķ«ŠńĮ«ÕŹ│ÕÅ»ŃĆé
+
+ÕÅ”Õż¢’╝īÕĮōµ¢░ńÜäÕ░ŵĢ░µŹ«ķøåÕÆīÕĤµ£¼ķóäĶ«Łń╗āńÜäÕż¦µĢ░µŹ«ķøåõĖŁńÜäµĢ░µŹ«ÕłåÕĖāĶŠāõĖ║ń▒╗õ╝╝ńÜäĶ»Ø’╝īµłæõ╗¼Õ£©Ķ┐øĶĪīÕŠ«Ķ░āµŚČõ╝ÜÕĖīµ£ø
+Õå╗ń╗ōõĖ╗Õ╣▓ńĮæń╗£ÕēŹķØóÕćĀÕ▒éńÜäÕÅéµĢ░’╝īÕŬĶ«Łń╗āÕÉÄķØóÕ▒éõ╗źÕÅŖÕłåń▒╗Õż┤ńÜäÕÅéµĢ░’╝īĶ┐Öõ╣łÕüܵ£ēÕŖ®õ║ÄÕ£©ÕÉÄń╗ŁĶ«Łń╗āõĖŁ’╝ī
+õ┐صīüńĮæń╗£õ╗ÄķóäĶ«Łń╗āµØāķćŹõĖŁĶÄĘÕŠŚńÜäµÅÉÕÅ¢õĮÄķśČńē╣ÕŠüńÜäĶāĮÕŖøŃĆéÕ£© MMPretrain õĖŁ’╝ī
+Ķ┐ÖõĖĆÕŖ¤ĶāĮÕÅ»õ╗źķĆÜĶ┐ćń«ĆÕŹĢńÜäõĖĆõĖ¬ `frozen_stages` ÕÅéµĢ░µØźÕ«×ńÄ░ŃĆéµ»öÕ”éµłæõ╗¼ķ£ĆĶ”üÕå╗ń╗ōÕēŹõĖżÕ▒éńĮæ
+ń╗£ńÜäÕÅéµĢ░’╝īÕŬķ£ĆĶ”üÕ£©õĖŖķØóńÜäķģŹńĮ«õĖŁµĘ╗ÕŖĀõĖĆĶĪī’╝Ü
+
+```{note}
+µ│©µäÅ’╝īńø«ÕēŹÕ╣ČķØ×µēƵ£ēńÜäõĖ╗Õ╣▓ńĮæń╗£ķāĮµö»µīü `frozen_stages` ÕÅéµĢ░ŃĆéĶ»ĘµŻĆµ¤ź[µ¢ćµĪŻ](https://mmpretrain.readthedocs.io/en/latest/api.html#module-mmpretrain.models.backbones)
+ńĪ«Ķ«żõĮ┐ńö©ńÜäõĖ╗Õ╣▓ńĮæń╗£µś»ÕÉ”µö»µīüĶ┐ÖõĖĆÕÅéµĢ░ŃĆé
+```
+
+```python
+_base_ = [
+ '../_base_/models/resnet50.py', # µ©ĪÕ×ŗĶ«ŠńĮ«
+ '../_base_/datasets/imagenet_bs32.py', # µĢ░µŹ«Ķ«ŠńĮ«
+ '../_base_/schedules/imagenet_bs256.py', # Ķ«Łń╗āńŁ¢ńĢźĶ«ŠńĮ«
+ '../_base_/default_runtime.py', # Ķ┐ÉĶĪīĶ«ŠńĮ«
+]
+
+# >>>>>>>>>>>>>>> Õ£©Ķ┐ÖķćīķćŹĶĮĮµ©ĪÕ×ŗńøĖÕģ│ķģŹńĮ« >>>>>>>>>>>>>>>>>>>
+model = dict(
+ backbone=dict(
+ frozen_stages=2,
+ init_cfg=dict(
+ type='Pretrained',
+ checkpoint='https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_8xb32_in1k_20210831-ea4938fc.pth',
+ prefix='backbone',
+ )),
+ head=dict(num_classes=10),
+)
+# <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
+```
+
+```{tip}
+Ķ┐Öķćīµłæõ╗¼ÕŬķ£ĆĶ”üĶ«ŠÕ«Üµłæõ╗¼µā│Ķ”üõ┐«µö╣ńÜäķā©ÕłåķģŹńĮ«’╝īÕģČõ╗¢ķģŹńĮ«Õ░åõ╝ÜĶć¬ÕŖ©õ╗ĵłæõ╗¼ńÜäÕ¤║ķģŹńĮ«µ¢ćõ╗ČõĖŁĶÄĘÕÅ¢ŃĆé
+```
+
+## ń¼¼ÕøøµŁź’╝Üõ┐«µö╣µĢ░µŹ«ķøåĶ«ŠńĮ«
+
+õĖ║õ║åÕ£©µ¢░µĢ░µŹ«ķøåõĖŖĶ┐øĶĪīÕŠ«Ķ░ā’╝īµłæõ╗¼ķ£ĆĶ”üĶ”åńø¢õĖĆõ║øµĢ░µŹ«ķøåĶ«ŠńĮ«’╝īõŠŗÕ”éµĢ░µŹ«ķøåń▒╗Õ×ŗŃĆüµĢ░µŹ«µĄüµ░┤ń║┐ńŁēŃĆé
+
+```python
+_base_ = [
+ '../_base_/models/resnet50.py', # µ©ĪÕ×ŗĶ«ŠńĮ«
+ '../_base_/datasets/imagenet_bs32.py', # µĢ░µŹ«Ķ«ŠńĮ«
+ '../_base_/schedules/imagenet_bs256.py', # Ķ«Łń╗āńŁ¢ńĢźĶ«ŠńĮ«
+ '../_base_/default_runtime.py', # Ķ┐ÉĶĪīĶ«ŠńĮ«
+]
+
+# µ©ĪÕ×ŗĶ«ŠńĮ«
+model = dict(
+ backbone=dict(
+ frozen_stages=2,
+ init_cfg=dict(
+ type='Pretrained',
+ checkpoint='https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_8xb32_in1k_20210831-ea4938fc.pth',
+ prefix='backbone',
+ )),
+ head=dict(num_classes=10),
+)
+
+# >>>>>>>>>>>>>>> Õ£©Ķ┐ÖķćīķćŹĶĮĮµĢ░µŹ«ķģŹńĮ« >>>>>>>>>>>>>>>>>>>
+data_root = 'data/custom_dataset'
+train_dataloader = dict(
+ dataset=dict(
+ type='CustomDataset',
+ data_root=data_root,
+ ann_file='', # µłæõ╗¼ÕüćÕ«ÜõĮ┐ńö©ÕŁÉµ¢ćõ╗ČÕż╣µĀ╝Õ╝Å’╝īÕøĀµŁżķ£ĆĶ”üÕ░åµĀćµ│©µ¢ćõ╗ČńĮ«ń®║
+ data_prefix='train',
+ ))
+val_dataloader = dict(
+ dataset=dict(
+ type='CustomDataset',
+ data_root=data_root,
+ ann_file='', # µłæõ╗¼ÕüćÕ«ÜõĮ┐ńö©ÕŁÉµ¢ćõ╗ČÕż╣µĀ╝Õ╝Å’╝īÕøĀµŁżķ£ĆĶ”üÕ░åµĀćµ│©µ¢ćõ╗ČńĮ«ń®║
+ data_prefix='test',
+ ))
+test_dataloader = val_dataloader
+# <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
+```
+
+## ń¼¼õ║öµŁź’╝Üõ┐«µö╣Ķ«Łń╗āńŁ¢ńĢźĶ«ŠńĮ«’╝łÕÅ»ķĆē’╝ē
+
+ÕŠ«Ķ░āµēĆõĮ┐ńö©ńÜäĶ«Łń╗āĶČģÕÅéµĢ░õĖĆĶł¼õĖÄķ╗śĶ«żńÜäĶČģÕÅéµĢ░õĖŹÕÉī’╝īÕ«āķĆÜÕĖĖķ£ĆĶ”üµø┤Õ░ÅńÜäÕŁ”õ╣ĀńÄćÕÆīµø┤Õ┐½ńÜäÕŁ”õ╣ĀńÄćĶĪ░ÕćÅŃĆé
+
+```python
+_base_ = [
+ '../_base_/models/resnet50.py', # µ©ĪÕ×ŗĶ«ŠńĮ«
+ '../_base_/datasets/imagenet_bs32.py', # µĢ░µŹ«Ķ«ŠńĮ«
+ '../_base_/schedules/imagenet_bs256.py', # Ķ«Łń╗āńŁ¢ńĢźĶ«ŠńĮ«
+ '../_base_/default_runtime.py', # Ķ┐ÉĶĪīĶ«ŠńĮ«
+]
+
+# µ©ĪÕ×ŗĶ«ŠńĮ«
+model = dict(
+ backbone=dict(
+ frozen_stages=2,
+ init_cfg=dict(
+ type='Pretrained',
+ checkpoint='https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_8xb32_in1k_20210831-ea4938fc.pth',
+ prefix='backbone',
+ )),
+ head=dict(num_classes=10),
+)
+
+# µĢ░µŹ«Ķ«ŠńĮ«
+data_root = 'data/custom_dataset'
+train_dataloader = dict(
+ dataset=dict(
+ type='CustomDataset',
+ data_root=data_root,
+ ann_file='',
+ data_prefix='train',
+ ))
+val_dataloader = dict(
+ dataset=dict(
+ type='CustomDataset',
+ data_root=data_root,
+ ann_file='',
+ data_prefix='test',
+ ))
+test_dataloader = val_dataloader
+
+# >>>>>>>>>>>>>>> Õ£©Ķ┐ÖķćīķćŹĶĮĮĶ«Łń╗āńŁ¢ńĢźĶ«ŠńĮ« >>>>>>>>>>>>>>>>>>>
+# õ╝śÕī¢ÕÖ©ĶČģÕÅéµĢ░
+optim_wrapper = dict(
+ optimizer=dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0001))
+# ÕŁ”õ╣ĀńÄćńŁ¢ńĢź
+param_scheduler = dict(
+ type='MultiStepLR', by_epoch=True, milestones=[15], gamma=0.1)
+# <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
+```
+
+```{tip}
+µø┤ÕżÜÕģ│õ║ÄķģŹńĮ«µ¢ćõ╗ČńÜäõ┐Īµü»’╝īĶ»ĘÕÅéķśģ[ÕŁ”õ╣ĀķģŹńĮ«µ¢ćõ╗Č](../user_guides/config.md)
+```
+
+## Õ╝ĆÕ¦ŗĶ«Łń╗ā
+
+ńÄ░Õ£©’╝īµłæõ╗¼Õ«īµłÉõ║åńö©õ║ÄÕŠ«Ķ░āńÜäķģŹńĮ«µ¢ćõ╗Č’╝īÕ«īµĢ┤ńÜäµ¢ćõ╗ČÕ”éõĖŗ’╝Ü
+
+```python
+_base_ = [
+ '../_base_/models/resnet50.py', # µ©ĪÕ×ŗĶ«ŠńĮ«
+ '../_base_/datasets/imagenet_bs32.py', # µĢ░µŹ«Ķ«ŠńĮ«
+ '../_base_/schedules/imagenet_bs256.py', # Ķ«Łń╗āńŁ¢ńĢźĶ«ŠńĮ«
+ '../_base_/default_runtime.py', # Ķ┐ÉĶĪīĶ«ŠńĮ«
+]
+
+# µ©ĪÕ×ŗĶ«ŠńĮ«
+model = dict(
+ backbone=dict(
+ frozen_stages=2,
+ init_cfg=dict(
+ type='Pretrained',
+ checkpoint='https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_8xb32_in1k_20210831-ea4938fc.pth',
+ prefix='backbone',
+ )),
+ head=dict(num_classes=10),
+)
+
+# µĢ░µŹ«Ķ«ŠńĮ«
+data_root = 'data/custom_dataset'
+train_dataloader = dict(
+ dataset=dict(
+ type='CustomDataset',
+ data_root=data_root,
+ ann_file='',
+ data_prefix='train',
+ ))
+val_dataloader = dict(
+ dataset=dict(
+ type='CustomDataset',
+ data_root=data_root,
+ ann_file='',
+ data_prefix='test',
+ ))
+test_dataloader = val_dataloader
+
+# Ķ«Łń╗āńŁ¢ńĢźĶ«ŠńĮ«
+optim_wrapper = dict(
+ optimizer=dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0001))
+param_scheduler = dict(
+ type='MultiStepLR', by_epoch=True, milestones=[15], gamma=0.1)
+```
+
+µÄźõĖŗµØź’╝īµłæõ╗¼õĮ┐ńö©õĖĆÕÅ░ 8 Õ╝Ā GPU ńÜäńöĄĶäæµØźĶ«Łń╗āµłæõ╗¼ńÜ䵩ĪÕ×ŗ’╝īµīćõ╗żÕ”éõĖŗ’╝Ü
+
+```shell
+bash tools/dist_train.sh configs/resnet/resnet50_8xb32-ft_custom.py 8
+```
+
+ÕĮōńäČ’╝īµłæõ╗¼õ╣¤ÕÅ»õ╗źõĮ┐ńö©ÕŹĢÕ╝Ā GPU µØźĶ┐øĶĪīĶ«Łń╗ā’╝īõĮ┐ńö©Õ”éõĖŗÕæĮõ╗ż’╝Ü
+
+```shell
+python tools/train.py configs/resnet/resnet50_8xb32-ft_custom.py
+```
+
+õĮåµś»Õ”éµ×£µłæõ╗¼õĮ┐ńö©ÕŹĢÕ╝Ā GPU Ķ┐øĶĪīĶ«Łń╗āńÜäĶ»Ø’╝īķ£ĆĶ”üÕ£©µĢ░µŹ«ķøåĶ«ŠńĮ«ķā©ÕłåõĮ£Õ”éõĖŗõ┐«µö╣’╝Ü
+
+```python
+data_root = 'data/custom_dataset'
+train_dataloader = dict(
+ batch_size=256,
+ dataset=dict(
+ type='CustomDataset',
+ data_root=data_root,
+ ann_file='',
+ data_prefix='train',
+ ))
+val_dataloader = dict(
+ dataset=dict(
+ type='CustomDataset',
+ data_root=data_root,
+ ann_file='',
+ data_prefix='test',
+ ))
+test_dataloader = val_dataloader
+```
+
+Ķ┐Öµś»ÕøĀõĖ║µłæõ╗¼ńÜäĶ«Łń╗āńŁ¢ńĢźµś»ķÆłÕ»╣µē╣µ¼ĪÕż¦Õ░Å’╝łbatch size’╝ēõĖ║ 256 Ķ«ŠńĮ«ńÜäŃĆéÕ£©ńłČķģŹńĮ«µ¢ćõ╗ČõĖŁ’╝ī
+Ķ«ŠńĮ«õ║åÕŹĢÕ╝Ā `batch_size=32`’╝īÕ”éµ×£õĮ┐ńö© 8 Õ╝Ā GPU’╝īµĆ╗ńÜäµē╣µ¼ĪÕż¦Õ░ÅÕ░▒µś» 256ŃĆéĶĆīÕ”éµ×£õĮ┐
+ńö©ÕŹĢÕ╝Ā GPU’╝īÕ░▒Õ┐ģķĪ╗µēŗÕŖ©õ┐«µö╣ `batch_size=256` µØźÕī╣ķģŹĶ«Łń╗āńŁ¢ńĢźŃĆé
+
+ńäČĶĆī’╝īµø┤Õż¦ńÜäµē╣µ¼ĪÕż¦Õ░Åķ£ĆĶ”üµø┤Õż¦ńÜä GPU µśŠÕŁś’╝īĶ┐Öķćīµ£ēÕćĀõĖ¬ń«ĆÕŹĢńÜäµŖĆÕʦµØźĶŖéń£üµśŠÕŁś’╝Ü
+
+1. ÕÉ»ńö©Ķć¬ÕŖ©µĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗ā
+
+ ```shell
+ python tools/train.py configs/resnet/resnet50_8xb32-ft_custom.py --amp
+ ```
+
+2. õĮ┐ńö©ĶŠāÕ░ÅńÜäµē╣µ¼ĪÕż¦Õ░Å’╝īõŠŗÕ”éõ╗ŹńäČõĮ┐ńö© `batch_size=32`’╝īĶĆīõĖŹµś» 256’╝īÕ╣ČÕÉ»ńö©ÕŁ”õ╣ĀńÄćĶć¬ÕŖ©ń╝®µöŠ
+
+ ```shell
+ python tools/train.py configs/resnet/resnet50_8xb32-ft_custom.py --auto-scale-lr
+ ```
+
+ ÕŁ”õ╣ĀńÄćĶć¬ÕŖ©ń╝®µöŠÕŖ¤ĶāĮõ╝ܵĀ╣µŹ«Õ«×ķÖģńÜä batch size ÕÆīķģŹńĮ«µ¢ćõ╗ČõĖŁńÜä `auto_scale_lr.base_batch_size`
+ ÕŁŚµ«ĄÕ»╣ÕŁ”õ╣ĀńÄćĶ┐øĶĪīń║┐µĆ¦Ķ░āµĢ┤’╝łõĮĀÕÅ»õ╗źÕ£©Õ¤║ķģŹńĮ«µ¢ćõ╗Č `configs/_base_/schedules/imagenet_bs256.py`
+ õĖŁµēŠÕł░Ķ┐ÖõĖĆÕŁŚµ«Ą’╝ē
+
+```{note}
+õ╗źõĖŖµŖĆÕʦķāĮµ£ēÕÅ»ĶāĮÕ»╣Ķ«Łń╗āµĢłµ×£ķĆĀµłÉĶĮ╗ÕŠ«ÕĮ▒ÕōŹŃĆé
+```
+
+### Õ£©ÕæĮõ╗żĶĪīµīćÕ«ÜķóäĶ«Łń╗āµ©ĪÕ×ŗ
+
+Õ”éµ×£µé©õĖŹµā│õ┐«µö╣ķģŹńĮ«µ¢ćõ╗Č’╝īµé©ÕÅ»õ╗źõĮ┐ńö© `--cfg-options` Õ░åµé©ńÜäķóäĶ«Łń╗āµ©ĪÕ×ŗµ¢ćõ╗ȵĘ╗ÕŖĀÕł░ `init_cfg`.
+
+õŠŗÕ”é’╝īõ╗źõĖŗÕæĮõ╗żõ╣¤õ╝ÜÕŖĀĶĮĮķóäĶ«Łń╗āµ©ĪÕ×ŗ’╝Ü
+
+```shell
+bash tools/dist_train.sh configs/tutorial/resnet50_finetune_cifar.py 8 \
+ --cfg-options model.backbone.init_cfg.type='Pretrained' \
+ model.backbone.init_cfg.checkpoint='https://download.openmmlab.com/mmselfsup/1.x/mocov3/mocov3_resnet50_8xb512-amp-coslr-100e_in1k/mocov3_resnet50_8xb512-amp-coslr-100e_in1k_20220927-f1144efa.pth' \
+ model.backbone.init_cfg.prefix='backbone' \
+```
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/get_started.md b/internlm_langchain/knowledge_base/MMPreTrain/content/get_started.md
new file mode 100644
index 00000000..0cf252f1
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/get_started.md
@@ -0,0 +1,163 @@
+# õŠØĶĄ¢ńÄ»Õóā
+
+Õ£©µ£¼ĶŖéõĖŁ’╝īµłæõ╗¼Õ░åµ╝öńż║Õ”éõĮĢÕćåÕżć PyTorch ńøĖÕģ│ńÜäõŠØĶĄ¢ńÄ»ÕóāŃĆé
+
+MMPretrain ķĆéńö©õ║Ä LinuxŃĆüWindows ÕÆī macOSŃĆéÕ«āķ£ĆĶ”ü Python 3.7+ŃĆüCUDA 10.2+ ÕÆī PyTorch 1.8+ŃĆé
+
+```{note}
+Õ”éµ×£õĮĀÕ»╣ķģŹńĮ« PyTorch ńÄ»ÕóāÕĘ▓ń╗ÅÕŠłń夵éē’╝īÕ╣ČõĖöÕĘ▓ń╗ÅÕ«īµłÉõ║åķģŹńĮ«’╝īÕÅ»õ╗źńø┤µÄźĶ┐øÕģź[õĖŗõĖĆĶŖé](#Õ«ēĶŻģ)ŃĆé
+ÕÉ”ÕłÖńÜäĶ»Ø’╝īĶ»ĘõŠØńģ¦õ╗źõĖŗµŁźķ¬żÕ«īµłÉķģŹńĮ«ŃĆé
+```
+
+**ń¼¼ 1 µŁź** õ╗Ä[Õ«śńĮæ](https://docs.conda.io/en/latest/miniconda.html)õĖŗĶĮĮÕ╣ČÕ«ēĶŻģ MinicondaŃĆé
+
+**ń¼¼ 2 µŁź** ÕłøÕ╗║õĖĆõĖ¬ conda ĶÖܵŗ¤ńÄ»ÕóāÕ╣ȵ┐Ƶ┤╗Õ«āŃĆé
+
+```shell
+conda create --name openmmlab python=3.8 -y
+conda activate openmmlab
+```
+
+**ń¼¼ 3 µŁź** µīēńģ¦[Õ«śµ¢╣µīćÕŹŚ](https://pytorch.org/get-started/locally/)Õ«ēĶŻģ PyTorchŃĆéõŠŗÕ”é’╝Ü
+
+Õ£© GPU Õ╣│ÕÅ░’╝Ü
+
+```shell
+conda install pytorch torchvision -c pytorch
+```
+
+```{warning}
+õ╗źõĖŖÕæĮõ╗żõ╝ÜĶć¬ÕŖ©Õ«ēĶŻģµ£Ćµ¢░ńēłńÜä PyTorch õĖÄÕ»╣Õ║öńÜä cudatoolkit’╝īĶ»ĘµŻĆµ¤źÕ«āõ╗¼µś»ÕÉ”õĖÄõĮĀńÜäńÄ»ÕóāÕī╣ķģŹŃĆé
+```
+
+Õ£© CPU Õ╣│ÕÅ░’╝Ü
+
+```shell
+conda install pytorch torchvision cpuonly -c pytorch
+```
+
+# Õ«ēĶŻģ
+
+µłæõ╗¼µÄ©ĶŹÉńö©µłĘµīēńģ¦µłæõ╗¼ńÜäµ£ĆõĮ│Õ«×ĶĘĄµØźÕ«ēĶŻģ MMPretrainŃĆéõĮåķÖżµŁżõ╣ŗÕż¢’╝īÕ”éµ×£õĮĀµā│µĀ╣µŹ«
+õĮĀńÜäõ╣Āµā»Õ«īµłÉÕ«ēĶŻģµĄüń©ŗ’╝īõ╣¤ÕÅ»õ╗źÕÅéĶ¦ü[Ķć¬Õ«Üõ╣ēÕ«ēĶŻģ](#Ķć¬Õ«Üõ╣ēÕ«ēĶŻģ)õĖĆĶŖéµØźĶÄĘÕÅ¢µø┤ÕżÜõ┐Īµü»ŃĆé
+
+## µ£ĆõĮ│Õ«×ĶĘĄ
+
+µĀ╣µŹ«ÕģĘõĮōķ£Ćµ▒é’╝īµłæõ╗¼µö»µīüõĖżń¦ŹÕ«ēĶŻģµ©ĪÕ╝Å’╝Ü
+
+- [õ╗ĵ║ÉńĀüÕ«ēĶŻģ’╝łµÄ©ĶŹÉ’╝ē](#õ╗ĵ║ÉńĀüÕ«ēĶŻģ)’╝ÜÕĖīµ£øÕ¤║õ║Ä MMPretrain µĪåµ×ČÕ╝ĆÕÅæĶć¬ÕĘ▒ńÜäķóäĶ«Łń╗āõ╗╗ÕŖĪ’╝īķ£ĆĶ”üµĘ╗ÕŖĀµ¢░ńÜäÕŖ¤ĶāĮ’╝īµ»öՔ鵢░ńÜ䵩ĪÕ×ŗµł¢µś»µĢ░µŹ«ķøå’╝īµł¢ĶĆģõĮ┐ńö©µłæõ╗¼µÅÉõŠøńÜäÕÉäń¦ŹÕĘźÕģĘŃĆé
+- [õĮ£õĖ║ Python ÕīģÕ«ēĶŻģ](#õĮ£õĖ║-python-ÕīģÕ«ēĶŻģ)’╝ÜÕŬµś»ÕĖīµ£øĶ░āńö© MMPretrain ńÜä API µÄźÕÅŻ’╝īµł¢ĶĆģÕ£©Ķć¬ÕĘ▒ńÜäķĪ╣ńø«õĖŁÕ»╝Õģź MMPretrain õĖŁńÜ䵩ĪÕØŚŃĆé
+
+### õ╗ĵ║ÉńĀüÕ«ēĶŻģ
+
+Ķ┐Öń¦ŹµāģÕåĄõĖŗ’╝īõ╗ĵ║ÉńĀüµīēÕ”éõĖŗµ¢╣Õ╝ÅÕ«ēĶŻģ mmpretrain’╝Ü
+
+```shell
+git clone https://github.com/open-mmlab/mmpretrain.git
+cd mmpretrain
+pip install -U openmim && mim install -e .
+```
+
+```{note}
+`"-e"` ĶĪ©ńż║õ╗źÕÅ»ń╝¢ĶŠæÕĮóÕ╝ÅÕ«ēĶŻģ’╝īĶ┐ÖµĀĘÕÅ»õ╗źÕ£©õĖŹķ揵¢░Õ«ēĶŻģńÜäµāģÕåĄõĖŗ’╝īĶ«®µ£¼Õ£░õ┐«µö╣ńø┤µÄźńö¤µĢł
+```
+
+### õĮ£õĖ║ Python ÕīģÕ«ēĶŻģ
+
+ńø┤µÄźõĮ┐ńö© mim Õ«ēĶŻģÕŹ│ÕÅ»ŃĆé
+
+```shell
+pip install -U openmim && mim install "mmpretrain>=1.0.0rc8"
+```
+
+```{note}
+`mim` µś»õĖĆõĖ¬ĶĮ╗ķćÅń║¦ńÜäÕæĮõ╗żĶĪīÕĘźÕģĘ’╝īÕÅ»õ╗źµĀ╣µŹ« PyTorch ÕÆī CUDA ńēłµ£¼õĖ║ OpenMMLab ń«Śµ│ĢÕ║ōķģŹńĮ«ÕÉłķĆéńÜäńÄ»ÕóāŃĆéÕÉīµŚČÕ«āõ╣¤µÅÉõŠøõ║åõĖĆõ║øÕ»╣õ║ĵĘ▒Õ║”ÕŁ”õ╣ĀÕ«×ķ¬īÕŠłµ£ēÕĖ«ÕŖ®ńÜäÕŖ¤ĶāĮŃĆé
+```
+
+## Õ«ēĶŻģÕżÜµ©ĪµĆüµö»µīü (ÕÅ»ķĆē)
+
+MMPretrain õĖŁńÜäÕżÜµ©ĪµĆüµ©ĪÕ×ŗķ£ĆĶ”üķóØÕż¢ńÜäõŠØĶĄ¢ķĪ╣’╝īĶ”üÕ«ēĶŻģĶ┐Öõ║øõŠØĶĄ¢ķĪ╣’╝īĶ»ĘÕ£©Õ«ēĶŻģĶ┐ćń©ŗõĖŁµĘ╗ÕŖĀ `[multimodal]` ÕÅéµĢ░’╝īÕ”éõĖŗµēĆńż║’╝Ü
+
+```shell
+# õ╗ĵ║ÉńĀüÕ«ēĶŻģ
+mim install -e ".[multimodal]"
+
+# õĮ£õĖ║ Python ÕīģÕ«ēĶŻģ
+mim install "mmpretrain[multimodal]>=1.0.0rc8"
+```
+
+## ķ¬īĶ»üÕ«ēĶŻģ
+
+õĖ║õ║åķ¬īĶ»ü MMPretrain ńÜäÕ«ēĶŻģµś»ÕÉ”µŁŻńĪ«’╝īµłæõ╗¼µÅÉõŠøõ║åõĖĆõ║øńż║õŠŗõ╗ŻńĀüµØźµē¦ĶĪīµ©ĪÕ×ŗµÄ©ńÉåŃĆé
+
+Õ”éµ×£õĮĀµś»**õ╗ĵ║ÉńĀüÕ«ēĶŻģ**ńÜä mmpretrain’╝īķéŻõ╣łńø┤µÄźĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗żĶ┐øĶĪīķ¬īĶ»ü’╝Ü
+
+```shell
+python demo/image_demo.py demo/demo.JPEG resnet18_8xb32_in1k --device cpu
+```
+
+õĮĀÕÅ»õ╗źń£ŗÕł░ÕæĮõ╗żĶĪīõĖŁĶŠōÕć║õ║åń╗ōµ×£ÕŁŚÕģĖ’╝īÕīģµŗ¼ `pred_label`’╝ī`pred_score` ÕÆī `pred_class` õĖēõĖ¬ÕŁŚµ«ĄŃĆé
+
+Õ”éµ×£õĮĀµś»**õĮ£õĖ║ Python ÕīģÕ«ēĶŻģ**’╝īķéŻõ╣łÕÅ»õ╗źµēōÕ╝ĆõĮĀńÜä Python Ķ¦ŻķćŖÕÖ©’╝īÕ╣Čń▓śĶ┤┤Õ”éõĖŗõ╗ŻńĀü’╝Ü
+
+```python
+from mmpretrain import get_model, inference_model
+
+model = get_model('resnet18_8xb32_in1k', device='cpu') # µł¢ĶĆģ device='cuda:0'
+inference_model(model, 'demo/demo.JPEG')
+```
+
+õĮĀõ╝Üń£ŗÕł░ĶŠōÕć║õĖĆõĖ¬ÕŁŚÕģĖ’╝īÕīģÕɽķó䵥ŗńÜäµĀćńŁŠŃĆüÕŠŚÕłåÕÅŖń▒╗Õł½ÕÉŹŃĆé
+
+```{note}
+õ╗źõĖŖńż║õŠŗõĖŁ’╝ī`resnet18_8xb32_in1k` µś»µ©ĪÕ×ŗÕÉŹń¦░ŃĆéõĮĀÕÅ»õ╗źõĮ┐ńö© [`mmpretrain.list_models`](mmpretrain.apis.list_models) µÄźÕÅŻµØź
+µĄÅĶ¦łµēƵ£ēńÜ䵩ĪÕ×ŗ’╝īµł¢ĶĆģÕ£©[µ©ĪÕ×ŗµ▒ćµĆ╗](./modelzoo_statistics.md)ķĪĄķØóĶ┐øĶĪīµ¤źµēŠŃĆé
+```
+
+## Ķć¬Õ«Üõ╣ēÕ«ēĶŻģ
+
+### CUDA ńēłµ£¼
+
+Õ«ēĶŻģ PyTorch µŚČ’╝īķ£ĆĶ”üµīćÕ«Ü CUDA ńēłµ£¼ŃĆéÕ”éµ×£µé©õĖŹµĖģµźÜķĆēµŗ®Õō¬õĖ¬’╝īĶ»ĘķüĄÕŠ¬µłæõ╗¼ńÜäÕ╗║Ķ««’╝Ü
+
+- Õ»╣õ║Ä Ampere µ×ȵ×äńÜä NVIDIA GPU’╝īõŠŗÕ”é GeForce 30 series õ╗źÕÅŖ NVIDIA A100’╝īCUDA 11 µś»Õ┐ģķ£ĆńÜäŃĆé
+- Õ»╣õ║ĵø┤µŚ®ńÜä NVIDIA GPU’╝īCUDA 11 µś»ÕÉæÕēŹÕģ╝Õ«╣ńÜä’╝īõĮå CUDA 10.2 ĶāĮÕż¤µÅÉõŠøµø┤ÕźĮńÜäÕģ╝Õ«╣µĆ¦’╝īõ╣¤µø┤ÕŖĀĶĮ╗ķćÅŃĆé
+
+Ķ»ĘńĪ«õ┐ØõĮĀńÜä GPU ķ®▒ÕŖ©ńēłµ£¼µ╗ĪĶČ│µ£ĆõĮÄńÜäńēłµ£¼ķ£Ćµ▒é’╝īÕÅéķśģ[Ķ┐ÖÕ╝ĀĶĪ©](https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html#cuda-major-component-versions__table-cuda-toolkit-driver-versions)ŃĆé
+
+```{note}
+Õ”éµ×£µīēńģ¦µłæõ╗¼ńÜäµ£ĆõĮ│Õ«×ĶĘĄĶ┐øĶĪīÕ«ēĶŻģ’╝īCUDA Ķ┐ÉĶĪīµŚČÕ║ōÕ░▒ĶČ│Õż¤õ║å’╝īÕøĀõĖ║µłæõ╗¼µÅÉõŠøńøĖÕģ│ CUDA õ╗ŻńĀüńÜäķóäń╝¢Ķ»æ’╝īõĮĀõĖŹķ£ĆĶ”üĶ┐øĶĪīµ£¼Õ£░ń╝¢Ķ»æŃĆé
+õĮåÕ”éµ×£õĮĀÕĖīµ£øõ╗ĵ║ÉńĀüĶ┐øĶĪī MMCV ńÜäń╝¢Ķ»æ’╝īµł¢µś»Ķ┐øĶĪīÕģČõ╗¢ CUDA ń«ŚÕŁÉńÜäÕ╝ĆÕÅæ’╝īķéŻõ╣łÕ░▒Õ┐ģķĪ╗Õ«ēĶŻģÕ«īµĢ┤ńÜä CUDA ÕĘźÕģĘķōŠ’╝īÕÅéĶ¦ü
+[NVIDIA Õ«śńĮæ](https://developer.nvidia.com/cuda-downloads)’╝īÕÅ”Õż¢Ķ┐śķ£ĆĶ”üńĪ«õ┐ØĶ»ź CUDA ÕĘźÕģĘķōŠńÜäńēłµ£¼õĖÄ PyTorch Õ«ēĶŻģµŚČ
+ńÜäķģŹńĮ«ńøĖÕī╣ķģŹ’╝łÕ”éńö© `conda install` Õ«ēĶŻģ PyTorch µŚČµīćÕ«ÜńÜä cudatoolkit ńēłµ£¼’╝ēŃĆé
+```
+
+### Õ£© CPU ńÄ»ÕóāõĖŁÕ«ēĶŻģ
+
+MMPretrain ÕÅ»õ╗źõ╗ģÕ£© CPU ńÄ»ÕóāõĖŁÕ«ēĶŻģ’╝īÕ£© CPU µ©ĪÕ╝ÅõĖŗ’╝īõĮĀÕÅ»õ╗źÕ«īµłÉĶ«Łń╗āŃĆüµĄŗĶ»ĢÕÆīµ©ĪÕ×ŗµÄ©ńÉåńŁēµēƵ£ēµōŹõĮ£ŃĆé
+
+### Õ£© Google Colab õĖŁÕ«ēĶŻģ
+
+ÕÅéĶĆā [Colab µĢÖń©ŗ](https://colab.research.google.com/github/mzr1996/mmclassification-tutorial/blob/master/1.x/MMClassification_tools.ipynb) Õ«ēĶŻģÕŹ│ÕÅ»ŃĆé
+
+### ķĆÜĶ┐ć Docker õĮ┐ńö© MMPretrain
+
+MMPretrain µÅÉõŠø [Dockerfile](https://github.com/open-mmlab/mmpretrain/blob/main/docker/Dockerfile)
+ńö©õ║ĵ×äÕ╗║ķĢ£ÕāÅŃĆéĶ»ĘńĪ«õ┐ØõĮĀńÜä [Docker ńēłµ£¼](https://docs.docker.com/engine/install/) >=19.03ŃĆé
+
+```shell
+# µ×äÕ╗║ķ╗śĶ«żńÜä PyTorch 1.12.1’╝īCUDA 11.3 ńēłµ£¼ķĢ£ÕāÅ
+# Õ”éµ×£õĮĀÕĖīµ£øõĮ┐ńö©ÕģČõ╗¢ńēłµ£¼’╝īĶ»Ęõ┐«µö╣ Dockerfile
+docker build -t mmpretrain docker/
+```
+
+ńö©õ╗źõĖŗÕæĮõ╗żĶ┐ÉĶĪī Docker ķĢ£ÕāÅ’╝Ü
+
+```shell
+docker run --gpus all --shm-size=8g -it -v {DATA_DIR}:/mmpretrain/data mmpretrain
+```
+
+## µĢģķÜ£Ķ¦ŻÕå│
+
+Õ”éµ×£õĮĀÕ£©Õ«ēĶŻģĶ┐ćń©ŗõĖŁķüćÕł░õ║åõ╗Ćõ╣łķŚ«ķóś’╝īĶ»ĘÕģłµ¤źķśģ[ÕĖĖĶ¦üķŚ«ķóś](./notes/faq.md)ŃĆéÕ”éµ×£µ▓Īµ£ēµēŠÕł░Ķ¦ŻÕå│µ¢╣µ│Ģ’╝īÕÅ»õ╗źÕ£© GitHub
+õĖŖ[µÅÉÕć║ issue](https://github.com/open-mmlab/mmpretrain/issues/new/choose)ŃĆé
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/inference.md b/internlm_langchain/knowledge_base/MMPreTrain/content/inference.md
new file mode 100644
index 00000000..068e42e1
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/inference.md
@@ -0,0 +1,176 @@
+# õĮ┐ńö©ńÄ░µ£ēµ©ĪÕ×ŗĶ┐øĶĪīµÄ©ńÉå
+
+µ£¼µ¢ćÕ░åÕ▒Ģńż║Õ”éõĮĢõĮ┐ńö©õ╗źõĖŗAPI’╝Ü
+
+- [**`list_models`**](mmpretrain.apis.list_models): ÕłŚõĖŠ MMPretrain õĖŁµēƵ£ēÕÅ»ńö©µ©ĪÕ×ŗÕÉŹń¦░
+- [**`get_model`**](mmpretrain.apis.get_model): ķĆÜĶ┐浩ĪÕ×ŗÕÉŹń¦░µł¢µ©ĪÕ×ŗķģŹńĮ«µ¢ćõ╗ČĶÄĘÕÅ¢µ©ĪÕ×ŗ
+- [**`inference_model`**](mmpretrain.apis.inference_model): õĮ┐ńö©õĖĵ©ĪÕ×ŗńøĖÕ»╣Õ║öõ╗╗ÕŖĪńÜäµÄ©ńÉåÕÖ©Ķ┐øĶĪīµÄ©ńÉåŃĆéõĖ╗Ķ”üńö©õĮ£Õ┐½ķƤ
+ Õ▒Ģńż║ŃĆéÕ”éķ£ĆķģŹńĮ«Ķ┐øķśČńö©µ│Ģ’╝īĶ┐śķ£ĆĶ”üńø┤µÄźõĮ┐ńö©õĖŗÕłŚµÄ©ńÉåÕÖ©ŃĆé
+- µÄ©ńÉåÕÖ©:
+ 1. [**`ImageClassificationInferencer`**](mmpretrain.apis.ImageClassificationInferencer):
+ Õ»╣ń╗ÖÕ«ÜÕøŠÕāŵē¦ĶĪīÕøŠÕāÅÕłåń▒╗ŃĆé
+ 2. [**`ImageRetrievalInferencer`**](mmpretrain.apis.ImageRetrievalInferencer):
+ õ╗Äń╗ÖÕ«ÜńÜäõĖĆń│╗ÕłŚÕøŠÕāÅõĖŁ’╝īµŻĆń┤óõĖÄń╗ÖÕ«ÜÕøŠÕāŵ£ĆńøĖõ╝╝ńÜäÕøŠÕāÅŃĆé
+ 3. [**`ImageCaptionInferencer`**](mmpretrain.apis.ImageCaptionInferencer):
+ ńö¤µłÉń╗ÖÕ«ÜÕøŠÕāÅńÜäõĖƵ«ĄµÅÅĶ┐░ŃĆé
+ 4. [**`VisualQuestionAnsweringInferencer`**](mmpretrain.apis.VisualQuestionAnsweringInferencer):
+ µĀ╣µŹ«ń╗ÖÕ«ÜńÜäÕøŠÕāÅÕø×ńŁöķŚ«ķóśŃĆé
+ 5. [**`VisualGroundingInferencer`**](mmpretrain.apis.VisualGroundingInferencer):
+ µĀ╣µŹ«õĖƵ«ĄµÅÅĶ┐░’╝īõ╗Äń╗ÖÕ«ÜÕøŠÕāÅõĖŁµēŠÕł░õĖĆõĖ¬õĖĵÅÅĶ┐░Õ»╣Õ║öńÜäÕ»╣Ķ▒ĪŃĆé
+ 6. [**`TextToImageRetrievalInferencer`**](mmpretrain.apis.TextToImageRetrievalInferencer):
+ õ╗Äń╗ÖÕ«ÜńÜäõĖĆń│╗ÕłŚÕøŠÕāÅõĖŁ’╝īµŻĆń┤óõĖÄń╗Öիܵ¢ćµ£¼µ£ĆńøĖõ╝╝ńÜäÕøŠÕāÅŃĆé
+ 7. [**`ImageToTextRetrievalInferencer`**](mmpretrain.apis.ImageToTextRetrievalInferencer):
+ õ╗Äń╗ÖÕ«ÜńÜäõĖĆń│╗ÕłŚµ¢ćµ£¼õĖŁ’╝īµŻĆń┤óõĖÄń╗ÖÕ«ÜÕøŠÕāŵ£ĆńøĖõ╝╝ńÜäµ¢ćµ£¼ŃĆé
+ 8. [**`NLVRInferencer`**](mmpretrain.apis.NLVRInferencer):
+ Õ»╣ń╗ÖÕ«ÜńÜäõĖĆÕ»╣ÕøŠÕāÅÕÆīõĖƵ«Ąµ¢ćµ£¼Ķ┐øĶĪīĶć¬ńäČĶ»ŁĶ©ĆĶ¦åĶ¦ēµÄ©ńÉå’╝łNLVR õ╗╗ÕŖĪ’╝ēŃĆé
+ 9. [**`FeatureExtractor`**](mmpretrain.apis.FeatureExtractor):
+ ķĆÜĶ┐ćĶ¦åĶ¦ēõĖ╗Õ╣▓ńĮæń╗£õ╗ÄÕøŠÕāŵ¢ćõ╗ȵÅÉÕÅ¢ńē╣ÕŠüŃĆé
+
+## ÕłŚõĖŠÕÅ»ńö©µ©ĪÕ×ŗ
+
+ÕłŚÕć║ MMPreTrain õĖŁńÜäµēƵ£ēÕĘ▓µö»µīüńÜ䵩ĪÕ×ŗŃĆé
+
+```python
+>>> from mmpretrain import list_models
+>>> list_models()
+['barlowtwins_resnet50_8xb256-coslr-300e_in1k',
+ 'beit-base-p16_beit-in21k-pre_3rdparty_in1k',
+ ...]
+```
+
+`list_models` µö»µīü Unix µ¢ćõ╗ČÕÉŹķŻÄµĀ╝ńÜ䵩ĪÕ╝ÅÕī╣ķģŹ’╝īõĮĀÕÅ»õ╗źõĮ┐ńö© \*\* * \*\* Õī╣ķģŹõ╗╗µäÅÕŁŚń¼”ŃĆé
+
+```python
+>>> from mmpretrain import list_models
+>>> list_models("*convnext-b*21k")
+['convnext-base_3rdparty_in21k',
+ 'convnext-base_in21k-pre-3rdparty_in1k-384px',
+ 'convnext-base_in21k-pre_3rdparty_in1k']
+```
+
+õĮĀĶ┐śÕÅ»õ╗źõĮ┐ńö©µÄ©ńÉåÕÖ©ńÜä `list_models` µ¢╣µ│ĢĶÄĘÕÅ¢Õ»╣Õ║öõ╗╗ÕŖĪÕÅ»ńö©ńÜäµēƵ£ēµ©ĪÕ×ŗŃĆé
+
+```python
+>>> from mmpretrain import ImageCaptionInferencer
+>>> ImageCaptionInferencer.list_models()
+['blip-base_3rdparty_caption',
+ 'blip2-opt2.7b_3rdparty-zeroshot_caption',
+ 'flamingo_3rdparty-zeroshot_caption',
+ 'ofa-base_3rdparty-finetuned_caption']
+```
+
+## ĶÄĘÕÅ¢µ©ĪÕ×ŗ
+
+ķĆēÕ«Üķ£ĆĶ”üńÜ䵩ĪÕ×ŗÕÉÄ’╝īõĮĀÕÅ»õ╗źõĮ┐ńö© `get_model` ĶÄĘÕÅ¢ńē╣իܵ©ĪÕ×ŗŃĆé
+
+```python
+>>> from mmpretrain import get_model
+
+# õĖŹÕŖĀĶĮĮķóäĶ«Łń╗āµØāķćŹńÜ䵩ĪÕ×ŗ
+>>> model = get_model("convnext-base_in21k-pre_3rdparty_in1k")
+
+# ÕŖĀĶĮĮķ╗śĶ«żńÜäµØāķ揵¢ćõ╗Č
+>>> model = get_model("convnext-base_in21k-pre_3rdparty_in1k", pretrained=True)
+
+# ÕŖĀĶĮĮÕłČÕ«ÜńÜäµØāķ揵¢ćõ╗Č
+>>> model = get_model("convnext-base_in21k-pre_3rdparty_in1k", pretrained="your_local_checkpoint_path")
+
+# µīćÕ«ÜķóØÕż¢ńÜ䵩ĪÕ×ŗÕłØÕ¦ŗÕī¢ÕÅéµĢ░’╝īõŠŗÕ”éõ┐«µö╣ head õĖŁńÜä num_classesŃĆé
+>>> model = get_model("convnext-base_in21k-pre_3rdparty_in1k", head=dict(num_classes=10))
+
+# ÕÅ”Õż¢õĖĆõĖ¬õŠŗÕŁÉ’╝Üń¦╗ķÖżµ©ĪÕ×ŗńÜä neck’╝īhead µ©ĪÕØŚ’╝īńø┤µÄźõ╗Ä backbone õĖŁńÜä stage 1, 2, 3 ĶŠōÕć║
+>>> model_headless = get_model("resnet18_8xb32_in1k", head=None, neck=None, backbone=dict(out_indices=(1, 2, 3)))
+```
+
+ĶÄĘÕŠŚńÜ䵩ĪÕ×ŗµś»õĖĆõĖ¬ķĆÜÕĖĖńÜä PyTorch Module
+
+```python
+>>> import torch
+>>> from mmpretrain import get_model
+>>> model = get_model('convnext-base_in21k-pre_3rdparty_in1k', pretrained=True)
+>>> x = torch.rand((1, 3, 224, 224))
+>>> y = model(x)
+>>> print(type(y), y.shape)
+ torch.Size([1, 1000])
+```
+
+## Õ£©ń╗ÖÕ«ÜÕøŠÕāÅõĖŖĶ┐øĶĪīµÄ©ńÉå
+
+Ķ┐Öķćīµś»õĖĆõĖ¬õŠŗÕŁÉ’╝īµłæõ╗¼Õ░åõĮ┐ńö© ResNet-50 ķóäĶ«Łń╗āµ©ĪÕ×ŗÕ»╣ń╗ÖÕ«ÜńÜä [ÕøŠÕāÅ](https://github.com/open-mmlab/mmpretrain/raw/main/demo/demo.JPEG) Ķ┐øĶĪīÕłåń▒╗ŃĆé
+
+```python
+>>> from mmpretrain import inference_model
+>>> image = 'https://github.com/open-mmlab/mmpretrain/raw/main/demo/demo.JPEG'
+>>> # Õ”éµ×£õĮĀµ▓Īµ£ēÕøŠÕĮóńĢīķØó’╝īĶ»ĘĶ«ŠńĮ« `show=False`
+>>> result = inference_model('resnet50_8xb32_in1k', image, show=True)
+>>> print(result['pred_class'])
+sea snake
+```
+
+õĖŖĶ┐░ `inference_model` µÄźÕÅŻÕÅ»õ╗źÕ┐½ķƤĶ┐øĶĪīµ©ĪÕ×ŗµÄ©ńÉå’╝īõĮåÕ«āµ»Åµ¼ĪĶ░āńö©ķāĮķ£ĆĶ”üķ揵¢░ÕłØÕ¦ŗÕī¢µ©ĪÕ×ŗ’╝īõ╣¤µŚĀµ│ĢĶ┐øĶĪīÕżÜõĖ¬µĀʵ£¼ńÜäµÄ©ńÉåŃĆé
+ÕøĀµŁżµłæõ╗¼ķ£ĆĶ”üõĮ┐ńö©µÄ©ńÉåÕÖ©µØźĶ┐øĶĪīÕżÜµ¼ĪĶ░āńö©ŃĆé
+
+```python
+>>> from mmpretrain import ImageClassificationInferencer
+>>> image = 'https://github.com/open-mmlab/mmpretrain/raw/main/demo/demo.JPEG'
+>>> inferencer = ImageClassificationInferencer('resnet50_8xb32_in1k')
+>>> # µ│©µäŵĩńÉåÕÖ©ńÜäĶŠōÕć║Õ¦ŗń╗łõĖ║õĖĆõĖ¬ń╗ōµ×£ÕłŚĶĪ©’╝īÕŹ│õĮ┐ĶŠōÕģźÕŬµ£ēõĖĆõĖ¬µĀʵ£¼
+>>> result = inferencer('https://github.com/open-mmlab/mmpretrain/raw/main/demo/demo.JPEG')[0]
+>>> print(result['pred_class'])
+sea snake
+>>>
+>>> # õĮĀÕÅ»õ╗źÕ»╣ÕżÜÕ╝ĀÕøŠÕāÅĶ┐øĶĪīµē╣ķćŵĩńÉå
+>>> image_list = ['demo/demo.JPEG', 'demo/bird.JPEG'] * 16
+>>> results = inferencer(image_list, batch_size=8)
+>>> print(len(results))
+32
+>>> print(results[1]['pred_class'])
+house finch, linnet, Carpodacus mexicanus
+```
+
+ķĆÜÕĖĖ’╝īµ»ÅõĖ¬µĀʵ£¼ńÜäń╗ōµ×£ķāĮµś»õĖĆõĖ¬ÕŁŚÕģĖŃĆéµ»öÕ”éÕøŠÕāÅÕłåń▒╗ńÜäń╗ōµ×£µś»õĖĆõĖ¬ÕīģÕɽõ║å `pred_label`ŃĆü`pred_score`ŃĆü`pred_scores`ŃĆü`pred_class` ńŁēÕŁŚµ«ĄńÜäÕŁŚÕģĖ’╝Ü
+
+```python
+{
+ "pred_label": 65,
+ "pred_score": 0.6649366617202759,
+ "pred_class":"sea snake",
+ "pred_scores": array([..., 0.6649366617202759, ...], dtype=float32)
+}
+```
+
+õĮĀÕÅ»õ╗źõĖ║µÄ©ńÉåÕÖ©ķģŹńĮ«ķóØÕż¢ńÜäÕÅéµĢ░’╝īµ»öÕ”éõĮ┐ńö©õĮĀĶć¬ÕĘ▒ńÜäķģŹńĮ«µ¢ćõ╗ČÕÆīµØāķ揵¢ćõ╗Č’╝īÕ£© CUDA õĖŖĶ┐øĶĪīµÄ©ńÉå’╝Ü
+
+```python
+>>> from mmpretrain import ImageClassificationInferencer
+>>> image = 'https://github.com/open-mmlab/mmpretrain/raw/main/demo/demo.JPEG'
+>>> config = 'configs/resnet/resnet50_8xb32_in1k.py'
+>>> checkpoint = 'https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_8xb32_in1k_20210831-ea4938fc.pth'
+>>> inferencer = ImageClassificationInferencer(model=config, pretrained=checkpoint, device='cuda')
+>>> result = inferencer(image)[0]
+>>> print(result['pred_class'])
+sea snake
+```
+
+## õĮ┐ńö© Gradio µÄ©ńÉåńż║õŠŗ
+
+µłæõ╗¼Ķ┐śµÅÉõŠøõ║åõĖĆõĖ¬Õ¤║õ║Ä gradio ńÜäµÄ©ńÉåńż║õŠŗ’╝īµÅÉõŠøõ║å MMPretrain µēƵö»µīüńÜäµēƵ£ēõ╗╗ÕŖĪńÜäµÄ©ńÉåÕ▒Ģńż║ÕŖ¤ĶāĮ’╝īõĮĀÕÅ»õ╗źÕ£© [projects/gradio_demo/launch.py](https://github.com/open-mmlab/mmpretrain/blob/main/projects/gradio_demo/launch.py) µēŠÕł░Ķ┐ÖõĖĆõŠŗń©ŗŃĆé
+
+Ķ»Ęķ”¢ÕģłõĮ┐ńö© `pip install -U gradio` Õ«ēĶŻģ `gradio` Õ║ōŃĆé
+
+Ķ┐Öķćīµś»ńĢīķØóµĢłµ×£ķóäĶ¦ł’╝Ü
+
+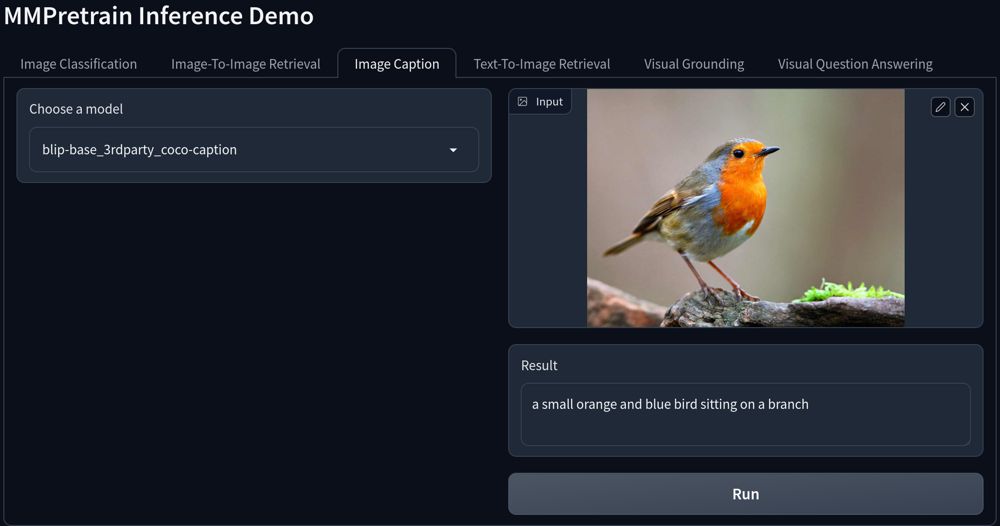 +
+## õ╗ÄÕøŠÕāÅõĖŁµÅÉÕÅ¢ńē╣ÕŠü
+
+õĖÄ `model.extract_feat` ńøĖµ»ö’╝ī`FeatureExtractor` ńö©õ║Äńø┤µÄźõ╗ÄÕøŠÕāŵ¢ćõ╗ČõĖŁµÅÉÕÅ¢ńē╣ÕŠü’╝īĶĆīõĖŹµś»õ╗ÄõĖƵē╣Õ╝ĀķćÅõĖŁµÅÉÕÅ¢ńē╣ÕŠüŃĆéń«ĆÕŹĢĶ»┤’╝ī`model.extract_feat` ńÜäĶŠōÕģźµś» `torch.Tensor`’╝ī`FeatureExtractor` ńÜäĶŠōÕģźµś»ÕøŠÕāÅŃĆé
+
+```
+>>> from mmpretrain import FeatureExtractor, get_model
+>>> model = get_model('resnet50_8xb32_in1k', backbone=dict(out_indices=(0, 1, 2, 3)))
+>>> extractor = FeatureExtractor(model)
+>>> features = extractor('https://github.com/open-mmlab/mmpretrain/raw/main/demo/demo.JPEG')[0]
+>>> features[0].shape, features[1].shape, features[2].shape, features[3].shape
+(torch.Size([256]), torch.Size([512]), torch.Size([1024]), torch.Size([2048]))
+```
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/log_result_analysis.md b/internlm_langchain/knowledge_base/MMPreTrain/content/log_result_analysis.md
new file mode 100644
index 00000000..748a9076
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/log_result_analysis.md
@@ -0,0 +1,223 @@
+# µŚźÕ┐ŚÕłåµ×ÉÕĘźÕģĘ
+
+## µŚźÕ┐ŚÕłåµ×É
+
+### µŚźÕ┐ŚÕłåµ×ÉÕĘźÕģĘõ╗ŗń╗Ź
+
+`tools/analysis_tools/analyze_logs.py` Ķäܵ£¼ń╗śÕłČµīćÕ«Üķö«ÕĆ╝ńÜäÕÅśÕī¢µø▓ń║┐ŃĆé
+
+
+
+## õ╗ÄÕøŠÕāÅõĖŁµÅÉÕÅ¢ńē╣ÕŠü
+
+õĖÄ `model.extract_feat` ńøĖµ»ö’╝ī`FeatureExtractor` ńö©õ║Äńø┤µÄźõ╗ÄÕøŠÕāŵ¢ćõ╗ČõĖŁµÅÉÕÅ¢ńē╣ÕŠü’╝īĶĆīõĖŹµś»õ╗ÄõĖƵē╣Õ╝ĀķćÅõĖŁµÅÉÕÅ¢ńē╣ÕŠüŃĆéń«ĆÕŹĢĶ»┤’╝ī`model.extract_feat` ńÜäĶŠōÕģźµś» `torch.Tensor`’╝ī`FeatureExtractor` ńÜäĶŠōÕģźµś»ÕøŠÕāÅŃĆé
+
+```
+>>> from mmpretrain import FeatureExtractor, get_model
+>>> model = get_model('resnet50_8xb32_in1k', backbone=dict(out_indices=(0, 1, 2, 3)))
+>>> extractor = FeatureExtractor(model)
+>>> features = extractor('https://github.com/open-mmlab/mmpretrain/raw/main/demo/demo.JPEG')[0]
+>>> features[0].shape, features[1].shape, features[2].shape, features[3].shape
+(torch.Size([256]), torch.Size([512]), torch.Size([1024]), torch.Size([2048]))
+```
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/log_result_analysis.md b/internlm_langchain/knowledge_base/MMPreTrain/content/log_result_analysis.md
new file mode 100644
index 00000000..748a9076
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/log_result_analysis.md
@@ -0,0 +1,223 @@
+# µŚźÕ┐ŚÕłåµ×ÉÕĘźÕģĘ
+
+## µŚźÕ┐ŚÕłåµ×É
+
+### µŚźÕ┐ŚÕłåµ×ÉÕĘźÕģĘõ╗ŗń╗Ź
+
+`tools/analysis_tools/analyze_logs.py` Ķäܵ£¼ń╗śÕłČµīćÕ«Üķö«ÕĆ╝ńÜäÕÅśÕī¢µø▓ń║┐ŃĆé
+
+ +
+```shell
+python tools/analysis_tools/analyze_logs.py plot_curve \
+ ${JSON_LOGS} \
+ [--keys ${KEYS}] \
+ [--title ${TITLE}] \
+ [--legend ${LEGEND}] \
+ [--backend ${BACKEND}] \
+ [--style ${STYLE}] \
+ [--out ${OUT_FILE}] \
+ [--window-size ${WINDOW_SIZE}]
+```
+
+**µēƵ£ēÕÅéµĢ░ńÜäĶ»┤µśÄ’╝Ü**
+
+- `json_logs` : µ©ĪÕ×ŗķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠä’╝łÕÅ»ÕÉīµŚČõ╝ĀÕģźÕżÜõĖ¬’╝īõĮ┐ńö©ń®║µĀ╝ÕłåÕ╝Ć’╝ēŃĆé
+- `--keys` : Õłåµ×ɵŚźÕ┐ŚńÜäÕģ│ķö«ÕŁŚµ«Ą’╝īµĢ░ķćÅõĖ║ `len(${JSON_LOGS}) * len(${KEYS})` ķ╗śĶ«żõĖ║ ŌĆślossŌĆÖŃĆé
+- `--title` : Õłåµ×ɵŚźÕ┐ŚńÜäÕøŠńēćÕÉŹń¦░’╝īķ╗śĶ«żõĮ┐ńö©ķģŹńĮ«µ¢ćõ╗ČÕÉŹ’╝ī ķ╗śĶ«żõĖ║ń®║ŃĆé
+- `--legend` : ÕøŠõŠŗńÜäÕÉŹń¦░’╝īÕģȵĢ░ńø«Õ┐ģķĪ╗õĖÄńøĖńŁē`len(${JSON_LOGS}) * len(${KEYS})`ŃĆé ķ╗śĶ«żõĮ┐ńö© `"${JSON_LOG}-${KEYS}"`.
+- `--backend` : matplotlib ńÜäń╗śÕøŠÕÉÄń½»’╝īķ╗śĶ«żńö▒ matplotlib Ķć¬ÕŖ©ķĆēµŗ®ŃĆé
+- `--style` : ń╗śÕøŠķģŹĶē▓ķŻÄµĀ╝’╝īķ╗śĶ«żõĖ║ `whitegrid`ŃĆé
+- `--out` : õ┐ØÕŁśÕłåµ×ÉÕøŠńēćńÜäĶĘ»ÕŠä’╝īÕ”éõĖŹµīćÕ«ÜÕłÖõĖŹõ┐ØÕŁśŃĆé
+- `--window-size`: ÕÅ»Ķ¦åÕī¢ń¬ŚÕÅŻÕż¦Õ░Å’╝īÕ”éµ×£µ▓Īµ£ēµīćÕ«Ü’╝īķ╗śĶ«żõĖ║ `'12*7'`ŃĆéÕ”éµ×£ķ£ĆĶ”üµīćÕ«Ü’╝īķ£Ćµīēńģ¦µĀ╝Õ╝Å `'W*H'`ŃĆé
+
+```{note}
+The `--style` option depends on `seaborn` package, please install it before setting it.
+```
+
+### Õ”éõĮĢµł¢ń╗śÕłČµŹ¤Õż▒/ń▓ŠÕ║”µø▓ń║┐
+
+µłæõ╗¼Õ░åń╗ÖÕć║õĖĆõ║øńż║õŠŗ’╝īµØźÕ▒Ģńż║Õ”éõĮĢõĮ┐ńö© `tools/analysis_tools/analyze_logs.py`Ķäܵ£¼ń╗śÕłČń▓ŠÕ║”µø▓ń║┐ńÜ䵏¤Õż▒µø▓ń║┐
+
+#### ń╗śÕłČµ¤ÉµŚźÕ┐Śµ¢ćõ╗ČÕ»╣Õ║öńÜ䵏¤Õż▒µø▓ń║┐ÕøŠ
+
+```shell
+python tools/analysis_tools/analyze_logs.py plot_curve your_log_json --keys loss --legend loss
+```
+
+#### ń╗śÕłČµ¤ÉµŚźÕ┐Śµ¢ćõ╗ČÕ»╣Õ║öńÜä top-1 ÕÆī top-5 ÕćåńĪ«ńÄćµø▓ń║┐ÕøŠ’╝īÕ╣ČÕ░åµø▓ń║┐ÕøŠÕ»╝Õć║õĖ║ results.jpg µ¢ćõ╗ČŃĆé
+
+```shell
+python tools/analysis_tools/analyze_logs.py plot_curve your_log_json --keys accuracy/top1 accuracy/top5 --legend top1 top5 --out results.jpg
+```
+
+#### Õ£©ÕÉīõĖĆÕøŠÕāÅÕåģń╗śÕłČõĖżõ╗ĮµŚźÕ┐Śµ¢ćõ╗ČÕ»╣Õ║öńÜä top-1 ÕćåńĪ«ńÄćµø▓ń║┐ÕøŠŃĆé
+
+```shell
+python tools/analysis_tools/analyze_logs.py plot_curve log1.json log2.json --keys accuracy/top1 --legend exp1 exp2
+```
+
+### Õ”éõĮĢń╗¤Ķ«ĪĶ«Łń╗āµŚČķŚ┤
+
+`tools/analysis_tools/analyze_logs.py` õ╣¤ÕÅ»õ╗źµĀ╣µŹ«µŚźÕ┐Śµ¢ćõ╗Čń╗¤Ķ«ĪĶ«Łń╗āĶĆŚµŚČŃĆé
+
+```shell
+python tools/analysis_tools/analyze_logs.py cal_train_time \
+ ${JSON_LOGS}
+ [--include-outliers]
+```
+
+**µēƵ£ēÕÅéµĢ░ńÜäĶ»┤µśÄ’╝Ü**
+
+- `json_logs`’╝ܵ©ĪÕ×ŗķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠä’╝łÕÅ»ÕÉīµŚČõ╝ĀÕģźÕżÜõĖ¬’╝īõĮ┐ńö©ń®║µĀ╝ÕłåÕ╝Ć’╝ēŃĆé
+- `--include-outliers`’╝ÜÕ”éµ×£µīćÕ«Ü’╝īÕ░åõĖŹõ╝ܵÄÆķÖżµ»ÅõĖ¬ĶĮ«µ¼ĪõĖŁń¼¼õĖĆõĖ¬µŚČķŚ┤Ķ«░ÕĮĢ’╝łµ£ēµŚČń¼¼õĖĆĶĮ«Ķ┐Łõ╗Żõ╝ÜĶĆŚµŚČĶŠāķĢ┐’╝ēŃĆé
+
+**ńż║õŠŗ’╝Ü**
+
+```shell
+python tools/analysis_tools/analyze_logs.py cal_train_time work_dirs/your_exp/20230206_181002/vis_data/scalars.json
+```
+
+ķóäĶ«ĪĶŠōÕć║ń╗ōµ×£Õ”éõĖŗµēĆńż║’╝Ü
+
+```text
+-----Analyze train time of work_dirs/your_exp/20230206_181002/vis_data/scalars.json-----
+slowest epoch 68, average time is 0.3818
+fastest epoch 1, average time is 0.3694
+time std over epochs is 0.0020
+average iter time: 0.3777 s/iter
+```
+
+## ń╗ōµ×£Õłåµ×É
+
+Õł®ńö© `tools/test.py` ńÜä`--out`’╝īµłæõ╗¼ÕÅ»õ╗źÕ░åµēƵ£ēńÜäµĀʵ£¼ńÜäµÄ©ńÉåń╗ōµ×£õ┐ØÕŁśÕł░ĶŠōÕć║µ¢ćõ╗ČõĖŁŃĆéÕł®ńö©Ķ┐ÖõĖƵ¢ćõ╗Č’╝īµłæõ╗¼ÕÅ»õ╗źĶ┐øĶĪīĶ┐øõĖƵŁźńÜäÕłåµ×ÉŃĆé
+
+### Õ”éõĮĢĶ┐øĶĪīń”╗ń║┐Õ║”ķćÅĶ»äõ╝░
+
+µłæõ╗¼µÅÉõŠøõ║å `tools/analysis_tools/eval_metric.py` Ķäܵ£¼’╝īõĮ┐ńö©µłĘĶāĮÕż¤µĀ╣µŹ«ķó䵥ŗµ¢ćõ╗ČĶ»äõ╝░µ©ĪÕ×ŗŃĆé
+
+```shell
+python tools/analysis_tools/eval_metric.py \
+ ${RESULT} \
+ [--metric ${METRIC_OPTIONS} ...]
+```
+
+**µēƵ£ēÕÅéµĢ░Ķ»┤µśÄ**’╝Ü
+
+- `result`’╝Ü`tools/test.py` ĶŠōÕć║ńÜäń╗ōµ×£µ¢ćõ╗ČŃĆé
+- `--metric`’╝Üńö©õ║ÄĶ»äõ╝░ń╗ōµ×£ńÜäµīćµĀć’╝īĶ»ĘĶć│Õ░æµīćÕ«ÜõĖĆõĖ¬µīćµĀć’╝īÕ╣ČõĖöõĮĀÕÅ»õ╗źķĆÜĶ┐ćµīćÕ«ÜÕżÜõĖ¬ `--metric` µØźÕÉīµŚČĶ«Īń«ŚÕżÜõĖ¬µīćµĀćŃĆé
+
+Ķ»ĘÕÅéĶĆā[Ķ»äõ╝░µ¢ćµĪŻ](mmpretrain.evaluation)ķĆēµŗ®ÕÅ»ńö©ńÜäĶ»äõ╝░µīćµĀćÕÆīÕ»╣Õ║öńÜäķĆēķĪ╣ŃĆé
+
+```{note}
+Õ£© `tools/test.py` õĖŁ’╝īµłæõ╗¼µö»µīüõĮ┐ńö© `--out-item` ķĆēķĪ╣µØźķĆēµŗ®õ┐ØÕŁśõĮĢń¦Źń╗ōµ×£Ķć│ĶŠōÕć║µ¢ćõ╗ČŃĆé
+Ķ»ĘńĪ«õ┐ص▓Īµ£ēķóØÕż¢µīćÕ«Ü `--out-item`’╝īµł¢µīćÕ«Üõ║å `--out-item=pred`ŃĆé
+```
+
+**ńż║õŠŗ**:
+
+```shell
+# ĶÄĘÕÅ¢ń╗ōµ×£µ¢ćõ╗Č
+python tools/test.py configs/resnet/resnet18_8xb16_cifar10.py \
+ https://download.openmmlab.com/mmclassification/v0/resnet/resnet18_b16x8_cifar10_20210528-bd6371c8.pth \
+ --out results.pkl
+
+# Ķ«Īń«Ś top-1 ÕÆī top-5 ÕćåńĪ«ńÄć
+python tools/analysis_tools/eval_metric.py results.pkl --metric type=Accuracy topk=1,5
+
+# Ķ«Īń«ŚµĆ╗õĮōÕćåńĪ«ńÄć’╝īÕÉäõĖ¬ń▒╗Õł½õĖŖńÜäń▓ŠńĪ«Õ║”ŃĆüÕżÕø×ńÄćŃĆüF1-score
+python tools/analysis_tools/eval_metric.py results.pkl --metric type=Accuracy \
+ --metric type=SingleLabelMetric items=precision,recall,f1-score average=None
+```
+
+### Õ”éõĮĢń╗śÕłČµĄŗĶ»Ģń╗ōµ×£ńÜäµĘʵĘåń¤®ķśĄ
+
+µłæõ╗¼µÅÉõŠø `tools/analysis_tools/confusion_matrix.py`’╝īÕĖ«ÕŖ®ńö©µłĘĶāĮÕż¤õ╗ĵĄŗĶ»ĢĶŠōÕć║µ¢ćõ╗ČõĖŁń╗śÕłČµĘʵĘåń¤®ķśĄŃĆé
+
+```shell
+python tools/analysis_tools/confusion_matrix.py \
+ ${CONFIG} \
+ ${RESULT} \
+ [--out ${OUT}] \
+ [--show] \
+ [--show-path ${SHOW_PATH}] \
+ [--include-values] \
+ [--cmap] \
+ [--cfg-options ${CFG_OPTIONS} ...] \
+```
+
+**µēƵ£ēÕÅéµĢ░Ķ»┤µśÄ**’╝Ü
+
+- `config`’╝ÜķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠäŃĆé
+- `result`’╝Ü`tools/test.py`ńÜäĶŠōÕć║ń╗ōµ×£µ¢ćõ╗Č’╝īµł¢µś»µ©ĪÕ×ŗµØāķ揵¢ćõ╗ČŃĆé
+- `--out`’╝ÜÕ░åµĘʵĘåń¤®ķśĄõ┐ØÕŁśÕł░µīćÕ«ÜĶĘ»ÕŠäõĖŗńÜä pickle µ¢ćõ╗ČõĖŁŃĆé
+- `--show`’╝ܵś»ÕÉ”ÕÅ»Ķ¦åÕī¢µĘʵĘåń¤®ķśĄÕøŠŃĆé
+- `--show-path`’╝ÜÕ░åÕÅ»Ķ¦åÕī¢µĘʵĘåń¤®ķśĄÕøŠõ┐ØÕŁśÕł░µīćÕ«ÜĶĘ»ÕŠäõĖŗŃĆé
+- `--include-values`’╝ܵś»Õɔգ©ÕÅ»Ķ¦åÕī¢µĘʵĘåń¤®ķśĄÕøŠõĖŁµśŠńż║ÕģĘõĮōÕĆ╝ŃĆé
+- `--cmap`’╝Üńö©õ╗źÕÅ»Ķ¦åÕī¢µĘʵĘåń¤®ķśĄńÜäķó£Ķē▓ķģŹńĮ«ŃĆé
+- `--cfg-options`’╝ÜķóØÕż¢ńÜäķģŹńĮ«ķĆēķĪ╣’╝īõ╝ÜĶó½ÕÉłÕģźķģŹńĮ«µ¢ćõ╗Č’╝īÕÅéĶĆā[ÕŁ”õ╣ĀķģŹńĮ«µ¢ćõ╗Č](../user_guides/config.md)ŃĆé
+
+```{note}
+Õ£© `tools/test.py` õĖŁ’╝īµłæõ╗¼µö»µīüõĮ┐ńö© `--out-item` ķĆēķĪ╣µØźķĆēµŗ®õ┐ØÕŁśõĮĢń¦Źń╗ōµ×£Ķć│ĶŠōÕć║µ¢ćõ╗ČŃĆé
+Ķ»ĘńĪ«õ┐ص▓Īµ£ēķóØÕż¢µīćÕ«Ü `--out-item`’╝īµł¢µīćÕ«Üõ║å `--out-item=pred`ŃĆé
+```
+
+**Examples**:
+
+```shell
+# ĶÄĘÕÅ¢ń╗ōµ×£µ¢ćõ╗Č
+python tools/test.py configs/resnet/resnet18_8xb16_cifar10.py \
+ https://download.openmmlab.com/mmclassification/v0/resnet/resnet18_b16x8_cifar10_20210528-bd6371c8.pth \
+ --out results.pkl
+
+# Õ░åµĘʵĘåń¤®ķśĄĶ«Īń«Śń╗ōµ×£õ┐ØÕŁśĶć│ cm.pkl õĖŁ
+python tools/analysis_tools/confusion_matrix.py configs/resnet/resnet18_8xb16_cifar10.py results.pkl --out cm.pkl
+
+# ÕÅ»Ķ¦åÕī¢µĘʵĘåń¤®ķśĄÕøŠ’╝īÕ╣ČÕ£©ÕøŠÕĮóń¬ŚÕÅŻµśŠńż║
+python tools/analysis_tools/confusion_matrix.py configs/resnet/resnet18_8xb16_cifar10.py results.pkl --show
+```
+
+### Õ”éõĮĢÕ░åķó䵥ŗń╗ōµ×£ÕÅ»Ķ¦åÕī¢
+
+µłæõ╗¼ÕÅ»õ╗źõĮ┐ńö©Ķäܵ£¼ `tools/analysis_tools/analyze_results.py` µØźõ┐ØÕŁśķó䵥ŗµłÉÕŖ¤µł¢Õż▒Ķ┤źµŚČÕŠŚÕłåµ£Ćķ½śńÜäÕøŠÕāÅŃĆé
+
+```shell
+python tools/analysis_tools/analyze_results.py \
+ ${CONFIG} \
+ ${RESULT} \
+ [--out-dir ${OUT_DIR}] \
+ [--topk ${TOPK}] \
+ [--rescale-factor ${RESCALE_FACTOR}] \
+ [--cfg-options ${CFG_OPTIONS}]
+```
+
+**µēƵ£ēÕÅéµĢ░Ķ»┤µśÄ’╝Ü**:
+
+- `config`’╝ÜķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠäŃĆé
+- `result`’╝Ü`tools/test.py`ńÜäĶŠōÕć║ń╗ōµ×£µ¢ćõ╗ČŃĆé
+- `--out_dir`’╝Üõ┐ØÕŁśń╗ōµ×£Õłåµ×ÉńÜäµ¢ćõ╗ČÕż╣ĶĘ»ÕŠäŃĆé
+- `--topk`’╝ÜÕłåÕł½õ┐ØÕŁśÕżÜÕ░æÕ╝Āķó䵥ŗµłÉÕŖ¤/Õż▒Ķ┤źńÜäÕøŠÕāÅŃĆéÕ”éµ×£õĖŹµīćÕ«Ü’╝īķ╗śĶ«żõĖ║ `20`ŃĆé
+- `--rescale-factor`’╝ÜÕøŠÕāÅńÜäń╝®µöŠń│╗µĢ░’╝īÕ”éµ×£µĀʵ£¼ÕøŠÕāÅĶ┐ćÕż¦µł¢Ķ┐ćÕ░ŵŚČÕÅ»õ╗źõĮ┐ńö©’╝łĶ┐ćÕ░ÅńÜäÕøŠÕāÅÕÅ»ĶāĮÕ»╝Ķć┤ń╗ōµ×£µĀćńŁŠķØ×ÕĖĖµ©Īń│Ŗ’╝ēŃĆé
+- `--cfg-options`’╝ÜķóØÕż¢ńÜäķģŹńĮ«ķĆēķĪ╣’╝īõ╝ÜĶó½ÕÉłÕģźķģŹńĮ«µ¢ćõ╗Č’╝īÕÅéĶĆā[ÕŁ”õ╣ĀķģŹńĮ«µ¢ćõ╗Č](../user_guides/config.md)ŃĆé
+
+```{note}
+Õ£© `tools/test.py` õĖŁ’╝īµłæõ╗¼µö»µīüõĮ┐ńö© `--out-item` ķĆēķĪ╣µØźķĆēµŗ®õ┐ØÕŁśõĮĢń¦Źń╗ōµ×£Ķć│ĶŠōÕć║µ¢ćõ╗ČŃĆé
+Ķ»ĘńĪ«õ┐ص▓Īµ£ēķóØÕż¢µīćÕ«Ü `--out-item`’╝īµł¢µīćÕ«Üõ║å `--out-item=pred`ŃĆé
+```
+
+**ńż║õŠŗ**:
+
+```shell
+# ĶÄĘÕÅ¢ķó䵥ŗń╗ōµ×£µ¢ćõ╗Č
+python tools/test.py configs/resnet/resnet18_8xb16_cifar10.py \
+ https://download.openmmlab.com/mmclassification/v0/resnet/resnet18_b16x8_cifar10_20210528-bd6371c8.pth \
+ --out results.pkl
+
+# õ┐ØÕŁśķó䵥ŗµłÉÕŖ¤/Õż▒Ķ┤źńÜäÕøŠÕāÅõĖŁ’╝īÕŠŚÕłåµ£Ćķ½śńÜäÕēŹ 10 Õ╝Ā’╝īÕ╣ČÕ£©ÕÅ»Ķ¦åÕī¢µŚČÕ░åĶŠōÕć║ÕøŠÕāŵöŠÕż¦ 10 ÕĆŹŃĆé
+python tools/analysis_tools/analyze_results.py \
+ configs/resnet/resnet18_8xb16_cifar10.py \
+ results.pkl \
+ --out-dir output \
+ --topk 10 \
+ --rescale-factor 10
+```
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/model_serving.md b/internlm_langchain/knowledge_base/MMPreTrain/content/model_serving.md
new file mode 100644
index 00000000..12f67797
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/model_serving.md
@@ -0,0 +1,88 @@
+# TorchServe ķā©ńĮ▓
+
+õĖ║õ║åõĮ┐ńö© [`TorchServe`](https://pytorch.org/serve/) ķā©ńĮ▓õĖĆõĖ¬ `MMPretrain` µ©ĪÕ×ŗ’╝īķ£ĆĶ”üĶ┐øĶĪīõ╗źõĖŗÕćĀµŁź’╝Ü
+
+## 1. ĶĮ¼µŹó MMPretrain µ©ĪÕ×ŗĶć│ TorchServe
+
+```shell
+python tools/torchserve/mmpretrain2torchserve.py ${CONFIG_FILE} ${CHECKPOINT_FILE} \
+--output-folder ${MODEL_STORE} \
+--model-name ${MODEL_NAME}
+```
+
+```{note}
+${MODEL_STORE} ķ£ĆĶ”üµś»õĖĆõĖ¬µ¢ćõ╗ČÕż╣ńÜäń╗ØÕ»╣ĶĘ»ÕŠäŃĆé
+```
+
+ńż║õŠŗ’╝Ü
+
+```shell
+python tools/torchserve/mmpretrain2torchserve.py \
+ configs/resnet/resnet18_8xb32_in1k.py \
+ checkpoints/resnet18_8xb32_in1k_20210831-fbbb1da6.pth \
+ --output-folder ./checkpoints \
+ --model-name resnet18_in1k
+```
+
+## 2. µ×äÕ╗║ `mmpretrain-serve` docker ķĢ£ÕāÅ
+
+```shell
+docker build -t mmpretrain-serve:latest docker/serve/
+```
+
+## 3. Ķ┐ÉĶĪī `mmpretrain-serve` ķĢ£ÕāÅ
+
+Ķ»ĘÕÅéĶĆāÕ«śµ¢╣µ¢ćµĪŻ [Õ¤║õ║Ä docker Ķ┐ÉĶĪī TorchServe](https://github.com/pytorch/serve/blob/master/docker/README.md#running-torchserve-in-a-production-docker-environment).
+
+õĖ║õ║åõĮ┐ķĢ£ÕāÅĶāĮÕż¤õĮ┐ńö© GPU ĶĄäµ║É’╝īķ£ĆĶ”üÕ«ēĶŻģ [nvidia-docker](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html)ŃĆéõ╣ŗÕÉÄÕÅ»õ╗źõ╝ĀķĆÆ `--gpus` ÕÅéµĢ░õ╗źÕ£© GPU õĖŖĶ┐ÉŃĆé
+
+ńż║õŠŗ’╝Ü
+
+```shell
+docker run --rm \
+--name mar \
+--cpus 8 \
+--gpus device=0 \
+-p8080:8080 -p8081:8081 -p8082:8082 \
+--mount type=bind,source=`realpath ./checkpoints`,target=/home/model-server/model-store \
+mmpretrain-serve:latest
+```
+
+```{note}
+`realpath ./checkpoints` µś» "./checkpoints" ńÜäń╗ØÕ»╣ĶĘ»ÕŠä’╝īõĮĀÕÅ»õ╗źÕ░åÕģȵø┐µŹóõĖ║õĮĀõ┐ØÕŁś TorchServe µ©ĪÕ×ŗńÜäńø«ÕĮĢńÜäń╗ØÕ»╣ĶĘ»ÕŠäŃĆé
+```
+
+ÕÅéĶĆā [Ķ»źµ¢ćµĪŻ](https://github.com/pytorch/serve/blob/master/docs/rest_api.md) õ║åĶ¦ŻÕģ│õ║ĵĩńÉå (8080)’╝īń«ĪńÉå (8081) ÕÆīµīćµĀć (8082) ńŁē API ńÜäõ┐Īµü»ŃĆé
+
+## 4. µĄŗĶ»Ģķā©ńĮ▓
+
+```shell
+curl http://127.0.0.1:8080/predictions/${MODEL_NAME} -T demo/demo.JPEG
+```
+
+µé©Õ║öĶ»źĶÄĘÕŠŚń▒╗õ╝╝õ║Äõ╗źõĖŗÕåģÕ«╣ńÜäÕōŹÕ║ö’╝Ü
+
+```json
+{
+ "pred_label": 58,
+ "pred_score": 0.38102269172668457,
+ "pred_class": "water snake"
+}
+```
+
+ÕÅ”Õż¢’╝īõĮĀõ╣¤ÕÅ»õ╗źõĮ┐ńö© `test_torchserver.py` µØźµ»öĶŠā TorchServe ÕÆī PyTorch ńÜäń╗ōµ×£’╝īÕ╣ČĶ┐øĶĪīÕÅ»Ķ¦åÕī¢ŃĆé
+
+```shell
+python tools/torchserve/test_torchserver.py ${IMAGE_FILE} ${CONFIG_FILE} ${CHECKPOINT_FILE} ${MODEL_NAME}
+[--inference-addr ${INFERENCE_ADDR}] [--device ${DEVICE}]
+```
+
+ńż║õŠŗ’╝Ü
+
+```shell
+python tools/torchserve/test_torchserver.py \
+ demo/demo.JPEG \
+ configs/resnet/resnet18_8xb32_in1k.py \
+ checkpoints/resnet18_8xb32_in1k_20210831-fbbb1da6.pth \
+ resnet18_in1k
+```
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/modules.md b/internlm_langchain/knowledge_base/MMPreTrain/content/modules.md
new file mode 100644
index 00000000..cb0fac6a
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/modules.md
@@ -0,0 +1,512 @@
+# Ķć¬Õ«Üõ╣ēµ©ĪÕ×ŗ
+
+Õ£©µłæõ╗¼ńÜäĶ«ŠĶ«ĪõĖŁ’╝īµłæõ╗¼Õ«Üõ╣ēõĖĆõĖ¬Õ«īµĢ┤ńÜ䵩ĪÕ×ŗõĖ║ķĪČÕ▒鵩ĪÕØŚ’╝īµĀ╣µŹ«ÕŖ¤ĶāĮńÜäõĖŹÕÉī’╝īÕ¤║µ£¼ÕćĀń¦ŹõĖŹÕÉīń▒╗Õ×ŗńÜ䵩ĪÕ×ŗń╗äõ╗Čń╗䵳ÉŃĆé
+
+- µ©ĪÕ×ŗ’╝ÜķĪČÕ▒鵩ĪÕØŚÕ«Üõ╣ēõ║åÕģĘõĮōńÜäõ╗╗ÕŖĪń▒╗Õ×ŗ’╝īõŠŗÕ”é `ImageClassifier` ńö©Õ£©ÕøŠÕāÅÕłåń▒╗õ╗╗ÕŖĪõĖŁ’╝ī `MAE` ńö©Õ£©Ķć¬ńøæńØŻÕŁ”õ╣ĀõĖŁ’╝ī `ImageToImageRetriever` ńö©Õ£©ÕøŠÕāŵŻĆń┤óõĖŁŃĆé
+- õĖ╗Õ╣▓ńĮæń╗£’╝ÜķĆÜÕĖĖµś»õĖĆõĖ¬ńē╣ÕŠüµÅÉÕÅ¢ńĮæń╗£’╝īµČĄńø¢õ║嵩ĪÕ×ŗõ╣ŗķŚ┤ń╗ØÕż¦ÕżÜµĢ░ńÜäÕĘ«Õ╝é’╝īõŠŗÕ”é `ResNet`ŃĆü`MobileNet`ŃĆé
+- ķółķā©’╝Üńö©õ║ÄĶ┐׵ğõĖ╗Õ╣▓ńĮæń╗£ÕÆīÕż┤ķā©ńÜäń╗äõ╗Č’╝īõŠŗÕ”é `GlobalAveragePooling`ŃĆé
+- Õż┤ķā©’╝Üńö©õ║ĵē¦ĶĪīńē╣Õ«Üõ╗╗ÕŖĪńÜäń╗äõ╗Č’╝īõŠŗÕ”é `ClsHead`ŃĆü `ContrastiveHead`ŃĆé
+- µŹ¤Õż▒ÕćĮµĢ░’╝ÜÕ£©Õż┤ķā©ńö©õ║ÄĶ«Īń«ŚµŹ¤Õż▒ÕćĮµĢ░ńÜäń╗äõ╗Č’╝īõŠŗÕ”é `CrossEntropyLoss`ŃĆü`LabelSmoothLoss`ŃĆé
+- ńø«µĀćńö¤µłÉÕÖ©: ńö©õ║ÄĶć¬ńøæńØŻÕŁ”õ╣Āõ╗╗ÕŖĪńÜäń╗äõ╗Č’╝īõŠŗÕ”é `VQKD`ŃĆü `HOGGenerator`ŃĆé
+
+## µĘ╗ÕŖĀµ¢░ńÜäķĪČÕ▒鵩ĪÕ×ŗ
+
+ķĆÜÕĖĖµØźĶ»┤’╝īÕ»╣õ║ÄÕøŠÕāÅÕłåń▒╗ÕÆīÕøŠÕāŵŻĆń┤óõ╗╗ÕŖĪµØźĶ»┤’╝īµ©ĪÕ×ŗķĪČÕ▒鵩ĪÕ×ŗµĄüń©ŗÕ¤║µ£¼õĖĆĶć┤ŃĆéõĮåµś»õĖŹÕÉīńÜäĶć¬ńøæńØŻÕŁ”õ╣Āń«Śµ│ĢÕŹ┤ńö©õĖŹÕÉīńÜäĶ«Īń«ŚµĄüń©ŗ’╝īÕāÅ `MAE` ÕÆī `BEiT` Õ░▒Õż¦õĖŹńøĖÕÉīŃĆé µēĆõ╗źÕ£©Ķ┐ÖõĖ¬ķā©Õłå’╝īµłæõ╗¼Õ░åń«ĆÕŹĢõ╗ŗń╗ŹÕ”éõĮĢµĘ╗ÕŖĀõĖĆõĖ¬µ¢░ńÜäĶć¬ńøæńØŻÕŁ”õ╣Āń«Śµ│ĢŃĆé
+
+### µĘ╗ÕŖĀµ¢░ńÜäĶć¬ńøæńØŻÕŁ”õ╣Āń«Śµ│Ģ
+
+1. ÕłøÕ╗║µ¢░µ¢ćõ╗Č `mmpretrain/models/selfsup/new_algorithm.py` õ╗źÕÅŖÕ«×ńÄ░ `NewAlgorithm`
+
+ ```python
+ from mmpretrain.registry import MODELS
+ from .base import BaseSelfSupvisor
+
+
+ @MODELS.register_module()
+ class NewAlgorithm(BaseSelfSupvisor):
+
+ def __init__(self, backbone, neck=None, head=None, init_cfg=None):
+ super().__init__(init_cfg)
+ pass
+
+ # ``extract_feat`` function is defined in BaseSelfSupvisor, you could
+ # overwrite it if needed
+ def extract_feat(self, inputs, **kwargs):
+ pass
+
+ # the core function to compute the loss
+ def loss(self, inputs, data_samples, **kwargs):
+ pass
+
+ ```
+
+2. Õ£© `mmpretrain/models/selfsup/__init__.py` õĖŁÕ»╝ÕģźÕ»╣Õ║öńÜäµ¢░ń«Śµ│Ģ
+
+ ```python
+ ...
+ from .new_algorithm import NewAlgorithm
+
+ __all__ = [
+ ...,
+ 'NewAlgorithm',
+ ...
+ ]
+ ```
+
+3. Õ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁõĮ┐ńö©µ¢░ń«Śµ│Ģ
+
+ ```python
+ model = dict(
+ type='NewAlgorithm',
+ backbone=...,
+ neck=...,
+ head=...,
+ ...
+ )
+ ```
+
+## µĘ╗ÕŖĀµ¢░ńÜäõĖ╗Õ╣▓ńĮæń╗£
+
+Ķ┐Öķćī’╝īµłæõ╗¼õ╗ź `ResNet_CIFAR` õĖ║õŠŗ’╝īÕ▒Ģńż║õ║åÕ”éõĮĢÕ╝ĆÕÅæõĖĆõĖ¬µ¢░ńÜäõĖ╗Õ╣▓ńĮæń╗£ń╗äõ╗ČŃĆé
+
+`ResNet_CIFAR` ķÆłÕ»╣ CIFAR 32x32 ńÜäÕøŠÕāÅĶŠōÕģź’╝īĶ┐£Õ░Åõ║ÄÕż¦ÕżÜµĢ░µ©ĪÕ×ŗõĮ┐ńö©ńÜäImageNetķ╗śĶ«żńÜä224x224ĶŠōÕģźķģŹńĮ«’╝īµēĆõ╗źµłæõ╗¼Õ░åķ¬©Õ╣▓ńĮæń╗£õĖŁ `kernel_size=7,stride=2`
+ńÜäĶ«ŠńĮ«µø┐µŹóõĖ║ `kernel_size=3, stride=1`’╝īÕ╣Čń¦╗ķÖżõ║å stem Õ▒éõ╣ŗÕÉÄńÜä
+`MaxPooling`’╝īõ╗źķü┐ÕģŹõ╝ĀķĆÆĶ┐ćÕ░ÅńÜäńē╣ÕŠüÕøŠÕł░µ«ŗÕĘ«ÕØŚõĖŁŃĆé
+
+µ£Ćń«ĆÕŹĢńÜäµ¢╣Õ╝ÅÕ░▒µś»ń╗¦µē┐Ķć¬ `ResNet` Õ╣ČÕŬõ┐«µö╣ stem Õ▒éŃĆé
+
+1. ÕłøÕ╗║õĖĆõĖ¬µ¢░µ¢ćõ╗Č `mmpretrain/models/backbones/resnet_cifar.py`ŃĆé
+
+ ```python
+ import torch.nn as nn
+
+ from mmpretrain.registry import MODELS
+ from .resnet import ResNet
+
+
+ @MODELS.register_module()
+ class ResNet_CIFAR(ResNet):
+
+ """ResNet backbone for CIFAR.
+
+ ’╝łÕ»╣Ķ┐ÖõĖ¬õĖ╗Õ╣▓ńĮæń╗£ńÜäń«Ćń¤ŁµÅÅĶ┐░’╝ē
+
+ Args:
+ depth(int): Network depth, from {18, 34, 50, 101, 152}.
+ ...
+ ’╝łÕÅéµĢ░µ¢ćµĪŻ’╝ē
+ """
+
+ def __init__(self, depth, deep_stem=False, **kwargs):
+ # Ķ░āńö©Õ¤║ń▒╗ ResNet ńÜäÕłØÕ¦ŗÕī¢ÕćĮµĢ░
+ super(ResNet_CIFAR, self).__init__(depth, deep_stem=deep_stem **kwargs)
+ # ÕģČõ╗¢ńē╣µ«ŖńÜäÕłØÕ¦ŗÕī¢µĄüń©ŗ
+ assert not self.deep_stem, 'ResNet_CIFAR do not support deep_stem'
+
+ def _make_stem_layer(self, in_channels, base_channels):
+ # ķćŹĶĮĮÕ¤║ń▒╗ńÜäµ¢╣µ│Ģ’╝īõ╗źÕ«×ńÄ░Õ»╣ńĮæń╗£ń╗ōµ×äńÜäõ┐«µö╣
+ self.conv1 = build_conv_layer(
+ self.conv_cfg,
+ in_channels,
+ base_channels,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=False)
+ self.norm1_name, norm1 = build_norm_layer(
+ self.norm_cfg, base_channels, postfix=1)
+ self.add_module(self.norm1_name, norm1)
+ self.relu = nn.ReLU(inplace=True)
+
+ def forward(self, x):
+ # Õ”éµ×£ķ£ĆĶ”üńÜäĶ»Ø’╝īÕÅ»õ╗źĶć¬Õ«Üõ╣ēforwardµ¢╣µ│Ģ
+ x = self.conv1(x)
+ x = self.norm1(x)
+ x = self.relu(x)
+ outs = []
+ for i, layer_name in enumerate(self.res_layers):
+ res_layer = getattr(self, layer_name)
+ x = res_layer(x)
+ if i in self.out_indices:
+ outs.append(x)
+ # ĶŠōÕć║ÕĆ╝ķ£ĆĶ”üµś»õĖĆõĖ¬ÕīģÕɽõĖŹÕÉīÕ▒éÕżÜÕ░║Õ║”ĶŠōÕć║ńÜäÕģāń╗ä
+ # Õ”éµ×£õĖŹķ£ĆĶ”üÕżÜÕ░║Õ║”ńē╣ÕŠü’╝īÕÅ»õ╗źńø┤µÄźÕ£©µ£Ćń╗łĶŠōÕć║õĖŖÕīģõĖĆÕ▒éÕģāń╗ä
+ return tuple(outs)
+
+ def init_weights(self):
+ # Õ”éµ×£ķ£ĆĶ”üńÜäĶ»Ø’╝īÕÅ»õ╗źĶć¬Õ«Üõ╣ēµØāķćŹÕłØÕ¦ŗÕī¢ńÜäµ¢╣µ│Ģ
+ super().init_weights()
+
+ # Õ”éµ×£µ£ēķóäĶ«Łń╗āµ©ĪÕ×ŗ’╝īÕłÖõĖŹķ£ĆĶ”üĶ┐øĶĪīµØāķćŹÕłØÕ¦ŗÕī¢
+ if self.init_cfg is not None and self.init_cfg['type'] == 'Pretrained':
+ return
+
+ # ķĆÜÕĖĖµØźĶ»┤’╝īµłæõ╗¼Õ╗║Ķ««ńö©`init_cfg`ÕÄ╗ÕłŚõĖŠõĖŹÕÉīÕ▒éµØāķćŹÕłØÕ¦ŗÕī¢µ¢╣µ│Ģ
+ # Õīģµŗ¼ÕŹĘń¦»Õ▒é’╝īń║┐µĆ¦Õ▒é’╝īÕĮÆõĖĆÕī¢Õ▒éńŁēńŁē
+ # Õ”éµ×£µ£ēńē╣µ«Ŗķ£ĆĶ”ü’╝īÕÅ»õ╗źÕ£©Ķ┐ÖķćīĶ┐øĶĪīķóØÕż¢ńÜäÕłØÕ¦ŗÕī¢µōŹõĮ£
+ ...
+ ```
+
+```{note}
+Õ£© OpenMMLab 2.0 ńÜäĶ«ŠĶ«ĪõĖŁ’╝īÕ░åÕĤµ£ēńÜä`BACKBONES`ŃĆü`NECKS`ŃĆü`HEADS`ŃĆü`LOSSES`ńŁēµ│©ÕåīÕÉŹń╗¤õĖĆõĖ║`MODELS`.
+```
+
+2. Õ£© `mmpretrain/models/backbones/__init__.py` õĖŁÕ»╝Õģźµ¢░µ©ĪÕØŚ
+
+ ```python
+ ...
+ from .resnet_cifar import ResNet_CIFAR
+
+ __all__ = [
+ ..., 'ResNet_CIFAR'
+ ]
+ ```
+
+3. Õ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁõĮ┐ńö©µ¢░ńÜäõĖ╗Õ╣▓ńĮæń╗£
+
+ ```python
+ model = dict(
+ ...
+ backbone=dict(
+ type='ResNet_CIFAR',
+ depth=18,
+ other_arg=xxx),
+ ...
+ ```
+
+### õĖ║Ķć¬ńøæńØŻÕŁ”õ╣ĀµĘ╗ÕŖĀµ¢░ńÜäõĖ╗Õ╣▓ńĮæń╗£
+
+Õ»╣õ║ÄõĖĆķā©ÕłåĶć¬ńøæńØŻÕŁ”õ╣Āń«Śµ│Ģ’╝īõĖ╗Õ╣▓ńĮæń╗£ÕüÜõ║åõĖĆÕ«Üõ┐«µö╣’╝īõŠŗÕ”é `MAE`ŃĆü`BEiT` ńŁēŃĆé Ķ┐Öõ║øõĖ╗Õ╣▓ńĮæń╗£ķ£ĆĶ”üÕżäńÉå `mask` ńøĖÕģ│ńÜäķĆ╗ĶŠæ’╝īõ╗źµŁżõ╗ÄÕÅ»Ķ¦üńÜäÕøŠÕāÅÕØŚõĖŁµÅÉÕÅ¢Õ»╣Õ║öńÜäńē╣ÕŠüõ┐Īµü»ŃĆé
+
+õ╗ź [MAEViT](mmpretrain.models.selfsup.MAEViT) õĮ£õĖ║õŠŗÕŁÉ’╝īµłæõ╗¼ķ£ĆĶ”üķćŹÕåÖ `forward` ÕćĮµĢ░’╝īĶ┐øĶĪīÕ¤║õ║Ä `mask` ńÜäĶ«Īń«ŚŃĆ鵳æõ╗¼Õ«×ńÄ░õ║å `init_weights` Ķ┐øĶĪīńē╣իܵØāķćŹńÜäÕłØÕ¦ŗÕī¢ÕÆī `random_masking` ÕćĮµĢ░µØźńö¤µłÉ `MAE` ķóäĶ«Łń╗āµēĆķ£ĆĶ”üńÜä `mask`ŃĆé
+
+```python
+class MAEViT(VisionTransformer):
+ """Vision Transformer for MAE pre-training"""
+
+ def __init__(mask_ratio, **kwargs) -> None:
+ super().__init__(**kwargs)
+ # position embedding is not learnable during pretraining
+ self.pos_embed.requires_grad = False
+ self.mask_ratio = mask_ratio
+ self.num_patches = self.patch_resolution[0] * self.patch_resolution[1]
+
+ def init_weights(self) -> None:
+ """Initialize position embedding, patch embedding and cls token."""
+ super().init_weights()
+ # define what if needed
+ pass
+
+ def random_masking(
+ self,
+ x: torch.Tensor,
+ mask_ratio: float = 0.75
+ ) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
+ """Generate the mask for MAE Pre-training."""
+ pass
+
+ def forward(
+ self,
+ x: torch.Tensor,
+ mask: Optional[bool] = True
+ ) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
+ """Generate features for masked images.
+
+ The function supports two kind of forward behaviors. If the ``mask`` is
+ ``True``, the function will generate mask to masking some patches
+ randomly and get the hidden features for visible patches, which means
+ the function will be executed as masked imagemodeling pre-training;
+ if the ``mask`` is ``None`` or ``False``, the forward function will
+ call ``super().forward()``, which extract features from images without
+ mask.
+ """
+ if mask is None or False:
+ return super().forward(x)
+
+ else:
+ B = x.shape[0]
+ x = self.patch_embed(x)[0]
+ # add pos embed w/o cls token
+ x = x + self.pos_embed[:, 1:, :]
+
+ # masking: length -> length * mask_ratio
+ x, mask, ids_restore = self.random_masking(x, self.mask_ratio)
+
+ # append cls token
+ cls_token = self.cls_token + self.pos_embed[:, :1, :]
+ cls_tokens = cls_token.expand(B, -1, -1)
+ x = torch.cat((cls_tokens, x), dim=1)
+
+ for _, layer in enumerate(self.layers):
+ x = layer(x)
+ # Use final norm
+ x = self.norm1(x)
+
+ return (x, mask, ids_restore)
+
+```
+
+## µĘ╗ÕŖĀµ¢░ńÜäķółķā©ń╗äõ╗Č
+
+Ķ┐Öķćīµłæõ╗¼õ╗ź `GlobalAveragePooling` õĖ║õŠŗŃĆéĶ┐Öµś»õĖĆõĖ¬ķØ×ÕĖĖń«ĆÕŹĢńÜäķółķā©ń╗äõ╗Č’╝īµ▓Īµ£ēõ╗╗õĮĢÕÅéµĢ░ŃĆé
+
+Ķ”üµĘ╗ÕŖĀµ¢░ńÜäķółķā©ń╗äõ╗Č’╝īµłæõ╗¼õĖ╗Ķ”üķ£ĆĶ”üÕ«×ńÄ░ `forward` ÕćĮµĢ░’╝īĶ»źÕćĮµĢ░Õ»╣õĖ╗Õ╣▓ńĮæń╗£ńÜäĶŠōÕć║Ķ┐øĶĪī
+õĖĆõ║øµōŹõĮ£Õ╣ČÕ░åń╗ōµ×£õ╝ĀķĆÆÕł░Õż┤ķā©ŃĆé
+
+1. ÕłøÕ╗║õĖĆõĖ¬µ¢░µ¢ćõ╗Č `mmpretrain/models/necks/gap.py`
+
+ ```python
+ import torch.nn as nn
+
+ from mmpretrain.registry import MODELS
+
+ @MODELS.register_module()
+ class GlobalAveragePooling(nn.Module):
+
+ def __init__(self):
+ self.gap = nn.AdaptiveAvgPool2d((1, 1))
+
+ def forward(self, inputs):
+ # ń«ĆÕŹĢĶĄĘĶ¦ü’╝īµłæõ╗¼ķ╗śĶ«żĶŠōÕģźµś»õĖĆõĖ¬Õ╝ĀķćÅ
+ outs = self.gap(inputs)
+ outs = outs.view(inputs.size(0), -1)
+ return outs
+ ```
+
+2. Õ£© `mmpretrain/models/necks/__init__.py` õĖŁÕ»╝Õģźµ¢░µ©ĪÕØŚ
+
+ ```python
+ ...
+ from .gap import GlobalAveragePooling
+
+ __all__ = [
+ ..., 'GlobalAveragePooling'
+ ]
+ ```
+
+3. õ┐«µö╣ķģŹńĮ«µ¢ćõ╗Čõ╗źõĮ┐ńö©µ¢░ńÜäķółķā©ń╗äõ╗Č
+
+ ```python
+ model = dict(
+ neck=dict(type='GlobalAveragePooling'),
+ )
+ ```
+
+## µĘ╗ÕŖĀµ¢░ńÜäÕż┤ķā©ń╗äõ╗Č
+
+### Õ¤║õ║ÄÕłåń▒╗Õż┤
+
+Õ£©µŁż’╝īµłæõ╗¼õ╗źõĖĆõĖ¬ń«ĆÕī¢ńÜä `VisionTransformerClsHead` õĖ║õŠŗ’╝īĶ»┤µśÄÕ”éõĮĢÕ╝ĆÕÅæµ¢░ńÜäÕż┤ķā©ń╗äõ╗ČŃĆé
+
+Ķ”üµĘ╗ÕŖĀõĖĆõĖ¬µ¢░ńÜäÕż┤ķā©ń╗äõ╗Č’╝īÕ¤║µ£¼õĖŖµłæõ╗¼ķ£ĆĶ”üÕ«×ńÄ░ `pre_logits` ÕćĮµĢ░ńö©õ║ÄĶ┐øÕģźµ£ĆÕÉÄńÜäÕłåń▒╗Õż┤õ╣ŗÕēŹķ£ĆĶ”üńÜäÕżäńÉå’╝ī
+õ╗źÕÅŖ `forward` ÕćĮµĢ░ŃĆé
+
+1. ÕłøÕ╗║õĖĆõĖ¬µ¢ćõ╗Č `mmpretrain/models/heads/vit_head.py`.
+
+ ```python
+ import torch.nn as nn
+
+ from mmpretrain.registry import MODELS
+ from .cls_head import ClsHead
+
+
+ @MODELS.register_module()
+ class LinearClsHead(ClsHead):
+
+ def __init__(self, num_classes, in_channels, hidden_dim, **kwargs):
+ super().__init__(**kwargs)
+ self.in_channels = in_channels
+ self.num_classes = num_classes
+ self.hidden_dim = hidden_dim
+
+ self.fc1 = nn.Linear(in_channels, hidden_dim)
+ self.act = nn.Tanh()
+ self.fc2 = nn.Linear(hidden_dim, num_classes)
+
+ def pre_logits(self, feats):
+ # ķ¬©Õ╣▓ńĮæń╗£ńÜäĶŠōÕć║ķĆÜÕĖĖÕīģÕÉ½ÕżÜÕ░║Õ║”õ┐Īµü»ńÜäÕģāń╗ä
+ # Õ»╣õ║ÄÕłåń▒╗õ╗╗ÕŖĪµØźĶ»┤’╝īµłæõ╗¼ÕŬķ£ĆĶ”üÕģ│µ│©µ£ĆÕÉÄńÜäĶŠōÕć║
+ feat = feats[-1]
+
+ # VisionTransformerńÜäµ£Ćń╗łĶŠōÕć║µś»õĖĆõĖ¬ÕīģÕɽpatch tokensÕÆīcls tokensńÜäÕģāń╗ä
+ # Ķ┐Öķćīµłæõ╗¼ÕŬķ£ĆĶ”ücls tokens
+ _, cls_token = feat
+
+ # Õ«īµłÉķÖżõ║åµ£ĆÕÉÄńÜäń║┐µĆ¦Õłåń▒╗Õż┤õ╗źÕż¢ńÜäµōŹõĮ£
+ return self.act(self.fc1(cls_token))
+
+ def forward(self, feats):
+ pre_logits = self.pre_logits(feats)
+
+ # Õ«īµłÉµ£ĆÕÉÄńÜäÕłåń▒╗Õż┤
+ cls_score = self.fc(pre_logits)
+ return cls_score
+ ```
+
+2. Õ£© `mmpretrain/models/heads/__init__.py` õĖŁÕ»╝ÕģźĶ┐ÖõĖ¬µ©ĪÕØŚ
+
+ ```python
+ ...
+ from .vit_head import VisionTransformerClsHead
+
+ __all__ = [
+ ..., 'VisionTransformerClsHead'
+ ]
+ ```
+
+3. õ┐«µö╣ķģŹńĮ«µ¢ćõ╗Čõ╗źõĮ┐ńö©µ¢░ńÜäÕż┤ķā©ń╗äõ╗ČŃĆé
+
+ ```python
+ model = dict(
+ head=dict(
+ type='VisionTransformerClsHead',
+ ...,
+ ))
+ ```
+
+### Õ¤║õ║Ä BaseModule ń▒╗
+
+Ķ┐Öµś»õĖĆõĖ¬Õ¤║õ║Ä MMEngine õĖŁńÜä `BaseModule` Ķ┐øĶĪīÕ╝ĆÕÅæõŠŗÕŁÉ’╝ī`MAEPretrainHead`’╝īõĖ╗Ķ”üµś»õĖ║õ║å `MAE` µÄ®ńĀüÕŁ”õ╣ĀŃĆ鵳æõ╗¼ķ£ĆĶ”üÕ«×ńÄ░ `loss` ÕćĮµĢ░µØźĶ«Īń«ŚµŹ¤Õż▒ÕÉŚ’╝īõĖŹĶ┐ćÕģČÕ«āńÜäÕćĮµĢ░ÕØćõĖ║ÕÅ»ķĆēķĪ╣ŃĆé
+
+```python
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+from mmengine.model import BaseModule
+
+from mmpretrain.registry import MODELS
+
+
+@MODELS.register_module()
+class MAEPretrainHead(BaseModule):
+ """Head for MAE Pre-training."""
+
+ def __init__(self,
+ loss: dict,
+ norm_pix: bool = False,
+ patch_size: int = 16) -> None:
+ super().__init__()
+ self.norm_pix = norm_pix
+ self.patch_size = patch_size
+ self.loss_module = MODELS.build(loss)
+
+ def patchify(self, imgs: torch.Tensor) -> torch.Tensor:
+ """Split images into non-overlapped patches."""
+ p = self.patch_size
+ assert imgs.shape[2] == imgs.shape[3] and imgs.shape[2] % p == 0
+
+ h = w = imgs.shape[2] // p
+ x = imgs.reshape(shape=(imgs.shape[0], 3, h, p, w, p))
+ x = torch.einsum('nchpwq->nhwpqc', x)
+ x = x.reshape(shape=(imgs.shape[0], h * w, p**2 * 3))
+ return x
+
+ def construct_target(self, target: torch.Tensor) -> torch.Tensor:
+ """Construct the reconstruction target."""
+ target = self.patchify(target)
+ if self.norm_pix:
+ # normalize the target image
+ mean = target.mean(dim=-1, keepdim=True)
+ var = target.var(dim=-1, keepdim=True)
+ target = (target - mean) / (var + 1.e-6)**.5
+
+ return target
+
+ def loss(self, pred: torch.Tensor, target: torch.Tensor,
+ mask: torch.Tensor) -> torch.Tensor:
+ """Generate loss."""
+ target = self.construct_target(target)
+ loss = self.loss_module(pred, target, mask)
+
+ return loss
+```
+
+Õ«īµłÉÕ«×ńÄ░ÕÉÄ’╝īõ╣ŗÕÉÄńÜ䵣źķ¬żÕÆī [Õ¤║õ║ÄÕłåń▒╗Õż┤](#Õ¤║õ║ÄÕłåń▒╗Õż┤) õĖŁńÜ䵣źķ¬ż 2 ÕÆīµŁźķ¬ż 3 õĖĆĶć┤ŃĆé
+
+## µĘ╗ÕŖĀµ¢░ńÜ䵏¤Õż▒ÕćĮµĢ░
+
+Ķ”üµĘ╗ÕŖĀµ¢░ńÜ䵏¤Õż▒ÕćĮµĢ░’╝īµłæõ╗¼õĖ╗Ķ”üķ£ĆĶ”üÕ£©µŹ¤Õż▒ÕćĮµĢ░µ©ĪÕØŚõĖŁ `forward` ÕćĮµĢ░ŃĆéĶ┐Öķćīķ£ĆĶ”üµ│©µäÅńÜ䵜»’╝īµŹ¤Õż▒µ©ĪÕØŚõ╣¤Õ║öĶ»źµ│©ÕåīÕł░`MODELS`õĖŁŃĆéÕÅ”Õż¢’╝īÕł®ńö©ĶŻģķź░ÕÖ© `weighted_loss` ÕÅ»õ╗źµ¢╣õŠ┐ńÜäÕ«×ńÄ░Õ»╣µ»ÅõĖ¬Õģāń┤ĀńÜ䵏¤Õż▒Ķ┐øĶĪīÕŖĀµØāÕ╣│ÕØćŃĆé
+
+ÕüćĶ«Šµłæõ╗¼Ķ”üµ©Īµŗ¤õ╗ÄÕÅ”õĖĆõĖ¬Õłåń▒╗µ©ĪÕ×ŗńö¤µłÉńÜäµ”éńÄćÕłåÕĖā’╝īķ£ĆĶ”üµĘ╗ÕŖĀ `L1loss` µØźÕ«×ńÄ░Ķ»źńø«ńÜäŃĆé
+
+1. ÕłøÕ╗║õĖĆõĖ¬µ¢░µ¢ćõ╗Č `mmpretrain/models/losses/l1_loss.py`
+
+ ```python
+ import torch
+ import torch.nn as nn
+
+ from mmpretrain.registry import MODELS
+ from .utils import weighted_loss
+
+ @weighted_loss
+ def l1_loss(pred, target):
+ assert pred.size() == target.size() and target.numel() > 0
+ loss = torch.abs(pred - target)
+ return loss
+
+ @MODELS.register_module()
+ class L1Loss(nn.Module):
+
+ def __init__(self, reduction='mean', loss_weight=1.0):
+ super(L1Loss, self).__init__()
+ self.reduction = reduction
+ self.loss_weight = loss_weight
+
+ def forward(self,
+ pred,
+ target,
+ weight=None,
+ avg_factor=None,
+ reduction_override=None):
+ assert reduction_override in (None, 'none', 'mean', 'sum')
+ reduction = (
+ reduction_override if reduction_override else self.reduction)
+ loss = self.loss_weight * l1_loss(
+ pred, target, weight, reduction=reduction, avg_factor=avg_factor)
+ return loss
+ ```
+
+2. Õ£©µ¢ćõ╗Č `mmpretrain/models/losses/__init__.py` õĖŁÕ»╝ÕģźĶ┐ÖõĖ¬µ©ĪÕØŚ
+
+ ```python
+ ...
+ from .l1_loss import L1Loss
+
+ __all__ = [
+ ..., 'L1Loss'
+ ]
+ ```
+
+3. õ┐«µö╣ķģŹńĮ«µ¢ćõ╗ČõĖŁńÜä `loss` ÕŁŚµ«Ąõ╗źõĮ┐ńö©µ¢░ńÜ䵏¤Õż▒ÕćĮµĢ░
+
+ ```python
+ model = dict(
+ head=dict(
+ loss=dict(type='L1Loss', loss_weight=1.0),
+ ))
+ ```
+
+µ£ĆÕÉĵłæõ╗¼ÕÅ»õ╗źÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁń╗ōÕÉłµēƵ£ēµ¢░Õó×ńÜ䵩ĪÕ×ŗń╗äõ╗ČµØźõĮ┐ńö©µ¢░ńÜ䵩ĪÕ×ŗŃĆéńö▒õ║Ä`ResNet_CIFAR` õĖŹµś»õĖĆõĖ¬Õ¤║õ║ÄViTńÜäķ¬©Õ╣▓ńĮæń╗£’╝īĶ┐Öķćīµłæõ╗¼õĖŹńö©`VisionTransformerClsHead`ńÜäķģŹńĮ«ŃĆé
+
+```python
+model = dict(
+ type='ImageClassifier',
+ backbone=dict(
+ type='ResNet_CIFAR',
+ depth=18,
+ num_stages=4,
+ out_indices=(3, ),
+ style='pytorch'),
+ neck=dict(type='GlobalAveragePooling'),
+ head=dict(
+ type='LinearClsHead',
+ num_classes=10,
+ in_channels=512,
+ loss=dict(type='L1Loss', loss_weight=1.0),
+ topk=(1, 5),
+ ))
+
+```
+
+```{tip}
+õĖ║õ║åµ¢╣õŠ┐’╝īńøĖÕÉīńÜ䵩ĪÕ×ŗń╗äõ╗ČÕÅ»õ╗źńø┤µÄźõ╗ÄÕĘ▓µ£ēńÜäconfigµ¢ćõ╗Čķćīń╗¦µē┐’╝īµø┤ÕżÜń╗åĶŖéÕÅ»õ╗źÕÅéĶĆā[ÕŁ”õ╣ĀķģŹńĮ«µ¢ćõ╗Č](../user_guides/config.md)ŃĆé
+```
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/npu.md b/internlm_langchain/knowledge_base/MMPreTrain/content/npu.md
new file mode 100644
index 00000000..b81c1751
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/npu.md
@@ -0,0 +1,41 @@
+# NPU (ÕŹÄõĖ║µśćĶģŠ)
+
+## õĮ┐ńö©µ¢╣µ│Ģ
+
+ķ”¢Õģł’╝īĶ»ĘÕÅéĶĆā[ķōŠµÄź](https://mmcv.readthedocs.io/zh_CN/latest/get_started/build.html#npu-mmcv-full)Õ«ēĶŻģÕĖ”µ£ē NPU µö»µīüńÜä MMCV ÕÆī[ķōŠµÄź](https://mmengine.readthedocs.io/en/latest/get_started/installation.html#build-from-source)Õ«ēĶŻģ MMEngineŃĆé
+
+õĮ┐ńö©Õ”éõĖŗÕæĮõ╗ż’╝īÕÅ»õ╗źÕł®ńö© 8 õĖ¬ NPU Õ£©µ£║ÕÖ©õĖŖĶ«Łń╗āµ©ĪÕ×ŗ’╝łõ╗ź ResNet õĖ║õŠŗ’╝ē’╝Ü
+
+```shell
+bash tools/dist_train.sh configs/cspnet/resnet50_8xb32_in1k.py 8
+```
+
+µł¢ĶĆģ’╝īõĮ┐ńö©Õ”éõĖŗÕæĮõ╗ż’╝īÕ£©õĖĆõĖ¬ NPU õĖŖĶ«Łń╗āµ©ĪÕ×ŗ’╝łõ╗ź ResNet õĖ║õŠŗ’╝ē’╝Ü
+
+```shell
+python tools/train.py configs/cspnet/resnet50_8xb32_in1k.py
+```
+
+## ń╗ÅĶ┐ćķ¬īĶ»üńÜ䵩ĪÕ×ŗ
+
+| Model | Top-1 (%) | Top-5 (%) | Config | Download |
+| :---------------------------------------------------------: | :-------: | :-------: | :----------------------------------------------------------: | :-------------------------------------------------------------: |
+| [ResNet-50](https://github.com/open-mmlab/mmclassification/blob/1.x/configs/resnet/README.md) | 76.40 | 93.21 | [config](https://github.com/open-mmlab/mmclassification/blob/1.x/configs/resnet/resnet50_8xb32_in1k.py) | [model](<>) \| [log](https://download.openmmlab.com/mmclassification/v1/device/npu/resnet50_8xb32_in1k.log) |
+| [ResNetXt-32x4d-50](https://github.com/open-mmlab/mmclassification/blob/1.x/configs/resnext/README.md) | 77.48 | 93.75 | [config](https://github.com/open-mmlab/mmclassification/blob/1.x/configs/resnext/resnext50-32x4d_8xb32_in1k.py) | [model](<>) \| [log](https://download.openmmlab.com/mmclassification/v1/device/npu/resnext50-32x4d_8xb32_in1k.log) |
+| [HRNet-W18](https://github.com/open-mmlab/mmclassification/blob/master/configs/hrnet/README.md) | 77.06 | 93.57 | [config](https://github.com/open-mmlab/mmclassification/blob/1.x/configs/hrnet/hrnet-w18_4xb32_in1k.py) | [model](<>) \| [log](https://download.openmmlab.com/mmclassification/v1/device/npu/hrnet-w18_4xb32_in1k.log) |
+| [ResNetV1D-152](https://github.com/open-mmlab/mmclassification/blob/1.x/configs/resnet/README.md) | 79.41 | 94.48 | [config](https://github.com/open-mmlab/mmclassification/blob/1.x/configs/resnet/resnetv1d152_8xb32_in1k.py) | [model](<>) \| [log](https://download.openmmlab.com/mmclassification/v1/device/npu/resnetv1d152_8xb32_in1k.log) |
+| [SE-ResNet-50](https://github.com/open-mmlab/mmclassification/blob/1.x/configs/seresnet/README.md) | 77.65 | 93.74 | [config](https://github.com/open-mmlab/mmclassification/blob/1.x/configs/seresnet/seresnet50_8xb32_in1k.py) | [model](<>) \|[log](https://download.openmmlab.com/mmclassification/v1/device/npu/seresnet50_8xb32_in1k.log) |
+| [ShuffleNetV2 1.0x](https://github.com/open-mmlab/mmclassification/blob/1.x/configs/shufflenet_v2/README.md) | 69.52 | 88.79 | [config](https://github.com/open-mmlab/mmclassification/blob/1.x/configs/shufflenet_v2/shufflenet-v2-1x_16xb64_in1k.py) | [model](<>) \| [log](https://download.openmmlab.com/mmclassification/v1/device/npu/shufflenet-v2-1x_16xb64_in1k.log) |
+| [MobileNetV2](https://github.com/open-mmlab/mmclassification/tree/1.x/configs/mobilenet_v2) | 71.74 | 90.28 | [config](https://github.com/open-mmlab/mmclassification/blob/1.x/configs/mobilenet_v2/mobilenet-v2_8xb32_in1k.py) | [model](<>) \| [log](https://download.openmmlab.com/mmclassification/v1/device/npu/mobilenet-v2_8xb32_in1k.log) |
+| [MobileNetV3-Small](https://github.com/open-mmlab/mmclassification/blob/1.x/configs/mobilenet_v3/README.md) | 67.09 | 87.17 | [config](https://github.com/open-mmlab/mmclassification/blob/1.x/configs/mobilenet_v3/mobilenet-v3-small_8xb128_in1k.py) | [model](<>) \| [log](https://download.openmmlab.com/mmclassification/v1/device/npu/mobilenet-v3-small.log) |
+| [\*CSPResNeXt50](https://github.com/open-mmlab/mmclassification/blob/1.x/configs/cspnet/README.md) | 77.25 | 93.46 | [config](https://github.com/open-mmlab/mmclassification/blob/1.x/configs/cspnet/cspresnext50_8xb32_in1k.py) | [model](<>) \| [log](https://download.openmmlab.com/mmclassification/v1/device/npu/cspresnext50_8xb32_in1k.log) |
+| [\*EfficientNet-B4](https://github.com/open-mmlab/mmclassification/blob/1.x/configs/efficientnet/README.md) | 75.73 | 92.9100 | [config](https://github.com/open-mmlab/mmclassification/blob/1.x/configs/efficientnet/efficientnet-b4_8xb32_in1k.py) | [model](<>) \|[log](https://download.openmmlab.com/mmclassification/v1/device/npu/efficientnet-b4_8xb32_in1k.log) |
+| [\*\*DenseNet121](https://github.com/open-mmlab/mmclassification/blob/1.x/configs/densenet/README.md) | 72.53 | 90.85 | [config](https://github.com/open-mmlab/mmclassification/blob/1.x/configs/densenet/densenet121_4xb256_in1k.py) | [model](<>) \| [log](https://download.openmmlab.com/mmclassification/v1/device/npu/densenet121_4xb256_in1k.log) |
+
+**µ│©µäÅ:**
+
+- Õ”éµ×£µ▓Īµ£ēńē╣Õł½µĀćĶ«░’╝īNPU õĖŖńÜäń╗ōµ×£õĖÄõĮ┐ńö© FP32 ńÜä GPU õĖŖńÜäń╗ōµ×£ń╗ōµ×£ńøĖÕÉīŃĆé
+- (\*) Ķ┐Öõ║øµ©ĪÕ×ŗńÜäĶ«Łń╗āń╗ōµ×£õĮÄõ║ÄńøĖÕ║öµ©ĪÕ×ŗõĖŁĶć¬Ķ┐░µ¢ćõ╗ČõĖŖńÜäń╗ōµ×£’╝īõĖ╗Ķ”üµś»ÕøĀõĖ║Ķć¬Ķ┐░µ¢ćõ╗ČõĖŖńÜäń╗ōµ×£ńø┤µÄźµś» timm Ķ«Łń╗āÕŠŚÕć║ńÜäµØāķ插╝īĶĆīĶ┐ÖĶŠ╣ńÜäń╗ōµ×£µś»µĀ╣µŹ« mmcls ńÜäķģŹńĮ«ķ揵¢░Ķ«Łń╗āÕŠŚÕł░ńÜäń╗ōµ×£ŃĆéGPU õĖŖńÜäķģŹńĮ«Ķ«Łń╗āń╗ōµ×£õĖÄ NPU ńÜäń╗ōµ×£ńøĖÕÉīŃĆé
+- (\*\*)Ķ┐ÖõĖ¬µ©ĪÕ×ŗńÜäń▓ŠÕ║”ńĢźõĮÄ’╝īÕøĀõĖ║ config µś» 4 Õ╝ĀÕŹĪńÜäķģŹńĮ«’╝īµłæõ╗¼õĮ┐ńö© 8 Õ╝ĀÕŹĪµØźĶ┐ÉĶĪī’╝īńö©µłĘÕÅ»õ╗źĶ░āµĢ┤ĶČģÕÅéµĢ░õ╗źĶÄĘÕŠŚµ£ĆõĮ│ń▓ŠÕ║”ń╗ōµ×£ŃĆé
+
+**õ╗źõĖŖµēƵ£ēµ©ĪÕ×ŗµØāķćŹÕÅŖĶ«Łń╗āµŚźÕ┐ŚÕØćńö▒ÕŹÄõĖ║µśćĶģŠÕøóķś¤µÅÉõŠø**
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/pipeline.md b/internlm_langchain/knowledge_base/MMPreTrain/content/pipeline.md
new file mode 100644
index 00000000..99506b08
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/pipeline.md
@@ -0,0 +1,148 @@
+# Ķć¬Õ«Üõ╣ēµĢ░µŹ«ÕżäńÉåµĄüń©ŗ
+
+## µĢ░µŹ«µĄüńÜäĶ«ŠĶ«Ī
+
+Õ£©[µ¢░µĢ░µŹ«ķøåµĢÖń©ŗ](./datasets.md)õĖŁ’╝īµłæõ╗¼ń¤źķüōµĢ░µŹ«ķøåń▒╗õĮ┐ńö© `load_data_list` µ¢╣µ│ĢµØźÕłØÕ¦ŗÕī¢µĢ┤õĖ¬µĢ░µŹ«ķøå’╝īµłæõ╗¼Õ░åµ»ÅõĖ¬µĀʵ£¼ńÜäõ┐Īµü»õ┐ØÕŁśÕł░õĖĆõĖ¬ dict õĖŁŃĆé
+
+ķĆÜÕĖĖ’╝īõĖ║õ║åĶŖéń£üÕåģÕŁś’╝īµłæõ╗¼ÕŬÕŖĀĶĮĮ `load_data_list` õĖŁńÜäÕøŠńēćĶĘ»ÕŠäÕÆīµĀćńŁŠ’╝īõĮ┐ńö©µŚČÕŖĀĶĮĮÕ«īµĢ┤ńÜäÕøŠńēćÕåģÕ«╣ŃĆ鵣żÕż¢’╝īµłæõ╗¼ÕÅ»ĶāĮÕĖīµ£øÕ£©Ķ«Łń╗āµŚČķĆēµŗ®µĀʵ£¼µŚČĶ┐øĶĪīõĖĆõ║øķÜŵ£║µĢ░µŹ«µē®ÕģģŃĆéÕćĀõ╣ĵēƵ£ēńÜäµĢ░µŹ«ÕŖĀĶĮĮŃĆüķóäÕżäńÉåÕÆīµĀ╝Õ╝ÅÕī¢µōŹõĮ£ķāĮÕÅ»õ╗źķĆÜĶ┐ć**µĢ░µŹ«ń«Īķüō**Õ£© MMPretrain õĖŁĶ┐øĶĪīķģŹńĮ«ŃĆé
+
+µĢ░µŹ«ń«ĪķüōµäÅÕæ│ńØĆÕ£©õ╗ĵĢ░µŹ«ķøåõĖŁń┤óÕ╝ĢµĀʵ£¼µŚČÕ”éõĮĢÕżäńÉåµĀʵ£¼ÕŁŚÕģĖ’╝īÕ«āńö▒õĖĆń│╗ÕłŚµĢ░µŹ«ÕÅśµŹóń╗䵳ÉŃĆéµ»ÅõĖ¬µĢ░µŹ«ÕÅśµŹóķāĮÕ░åõĖĆõĖ¬ÕŁŚÕģĖõĮ£õĖ║ĶŠōÕģź’╝īÕ»╣ÕģČĶ┐øĶĪīÕżäńÉå’╝īÕ╣ČõĖ║õĖŗõĖĆõĖ¬µĢ░µŹ«ÕÅśµŹóĶŠōÕć║õĖĆõĖ¬ÕŁŚÕģĖŃĆé
+
+Ķ┐Öµś» ImageNet õĖŖ ResNet-50 Ķ«Łń╗āńÜäµĢ░µŹ«ń«Īķüōńż║õŠŗŃĆé
+
+```python
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='RandomResizedCrop', scale=224),
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'),
+ dict(type='PackInputs'),
+]
+```
+
+MMPretrain õĖŁµēƵ£ēÕÅ»ńö©ńÜäµĢ░µŹ«ÕÅśµŹóķāĮÕÅ»õ╗źÕ£© [µĢ░µŹ«ÕÅśµŹóµ¢ćµĪŻ](mmpretrain.datasets.transforms) õĖŁµēŠÕł░ŃĆé
+
+## õ┐«µö╣Ķ«Łń╗ā/µĄŗĶ»Ģń«Īķüō
+
+MMPretrain õĖŁńÜäµĢ░µŹ«ń«ĪķüōķØ×ÕĖĖńüĄµ┤╗ŃĆéµé©ÕćĀõ╣ÄÕÅ»õ╗źõ╗ÄķģŹńĮ«µ¢ćõ╗ČõĖŁµÄ¦ÕłČµĢ░µŹ«ķóäÕżäńÉåńÜäµ»ÅõĖƵŁź’╝īõĮåÕÅ”õĖƵ¢╣ķØó’╝īķØóÕ»╣Õ”éµŁżÕżÜńÜäķĆēķĪ╣’╝īµé©ÕÅ»ĶāĮõ╝ܵä¤Õł░Õø░µāæŃĆé
+
+Ķ┐Öµś»ÕøŠÕāÅÕłåń▒╗õ╗╗ÕŖĪńÜäÕĖĖĶ¦üÕüܵ│ĢÕÆīµīćÕŹŚŃĆé
+
+### Ķ»╗ÕÅ¢
+
+Õ£©µĢ░µŹ«ń«ĪķüōńÜäÕ╝ĆÕ¦ŗ’╝īµłæõ╗¼ķĆÜÕĖĖķ£ĆĶ”üõ╗ĵ¢ćõ╗ČĶĘ»ÕŠäÕŖĀĶĮĮÕøŠÕāŵĢ░µŹ«ŃĆé
+[`LoadImageFromFile`](mmcv.transforms.LoadImageFromFile) ķĆÜÕĖĖńö©õ║ĵē¦ĶĪīµŁżõ╗╗ÕŖĪŃĆé
+
+```python
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ ...
+]
+```
+
+Õ”éµ×£µé©µā│õ╗ÄÕģʵ£ēńē╣µ«ŖµĀ╝Õ╝ŵł¢ńē╣µ«ŖõĮŹńĮ«ńÜäµ¢ćõ╗ČõĖŁÕŖĀĶĮĮµĢ░µŹ«’╝īµé©ÕÅ»õ╗ź [Õ«×µ¢Įµ¢░ńÜäÕŖĀĶĮĮÕÅśµŹó](#µĘ╗ÕŖĀµ¢░ńÜäµĢ░µŹ«ÕÅśµŹó) Õ╣ČÕ░åÕģȵĘ╗ÕŖĀÕł░µĢ░µŹ«ń«ĪķüōńÜäÕ╝ĆÕż┤ŃĆé
+
+### Õó×Õ╝║ÕÆīÕģČÕ«āÕżäńÉå
+
+Õ£©Ķ«Łń╗āĶ┐ćń©ŗõĖŁ’╝īµłæõ╗¼ķĆÜÕĖĖķ£ĆĶ”üÕüܵĢ░µŹ«Õó×Õ╝║µØźķü┐ÕģŹĶ┐ćµŗ¤ÕÉłŃĆéÕ£©µĄŗĶ»ĢĶ┐ćń©ŗõĖŁ’╝īµłæõ╗¼Ķ┐śķ£ĆĶ”üÕüÜõĖĆõ║øµĢ░µŹ«ÕżäńÉå’╝īµ»öÕ”éĶ░āµĢ┤Õż¦Õ░ÅÕÆīĶŻüÕē¬ŃĆéĶ┐Öõ║øµĢ░µŹ«ÕÅśµŹóÕ░åµöŠńĮ«Õ£©ÕŖĀĶĮĮĶ┐ćń©ŗõ╣ŗÕÉÄŃĆé
+
+Ķ┐Öµś»õĖĆõĖ¬ń«ĆÕŹĢńÜäµĢ░µŹ«µē®Õģģµ¢╣µĪłńż║õŠŗŃĆéÕ«āõ╝ÜÕ░åĶŠōÕģźÕøŠÕāÅķÜŵ£║Ķ░āµĢ┤Õż¦Õ░ÅÕ╣ČĶŻüÕē¬Õł░µīćիܵ»öõŠŗ’╝īÕ╣ČķÜŵ£║µ░┤Õ╣│ń┐╗ĶĮ¼ÕøŠÕāÅŃĆé
+
+```python
+train_pipeline = [
+ ...
+ dict(type='RandomResizedCrop', scale=224),
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'),
+ ...
+]
+```
+
+Ķ┐Öµś» [Swin-Transformer](../papers/swin_transformer.md) Ķ«Łń╗āõĖŁõĮ┐ńö©ńÜäÕż¦ķćŵĢ░µŹ«Õó×Õ╝║ķģŹµ¢╣ńż║õŠŗŃĆé õĖ║õ║åõĖÄÕ«śµ¢╣Õ«×µ¢Įõ┐صīüõĖĆĶć┤’╝īÕ«āµīćÕ«Ü `pillow` õĮ£õĖ║Ķ░āµĢ┤Õż¦Õ░ÅÕÉÄń½»’╝ī`bicubic` õĮ£õĖ║Ķ░āµĢ┤Õż¦Õ░Åń«Śµ│ĢŃĆé µŁżÕż¢’╝īÕ«āµĘ╗ÕŖĀõ║å [`RandAugment`](mmpretrain.datasets.transforms.RandAugment) ÕÆī [`RandomErasing`](mmpretrain.datasets.transforms.RandomErasing) õĮ£õĖ║ķóØÕż¢ńÜäµĢ░µŹ«Õó×Õ╝║µ¢╣µ│ĢŃĆé
+
+µŁżķģŹńĮ«µīćÕ«Üõ║åµĢ░µŹ«µē®ÕģģńÜäµ»ÅõĖ¬ń╗åĶŖé’╝īµé©ÕŬķ£ĆÕ░åÕģČÕżŹÕłČÕł░µé©Ķć¬ÕĘ▒ńÜäķģŹńĮ«µ¢ćõ╗ČõĖŁÕŹ│ÕÅ»Õ║öńö© Swin-Transformer ńÜäµĢ░µŹ«µē®ÕģģŃĆé
+
+```python
+bgr_mean = [103.53, 116.28, 123.675]
+bgr_std = [57.375, 57.12, 58.395]
+
+train_pipeline = [
+ ...
+ dict(type='RandomResizedCrop', scale=224, backend='pillow', interpolation='bicubic'),
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'),
+ dict(
+ type='RandAugment',
+ policies='timm_increasing',
+ num_policies=2,
+ total_level=10,
+ magnitude_level=9,
+ magnitude_std=0.5,
+ hparams=dict(
+ pad_val=[round(x) for x in bgr_mean], interpolation='bicubic')),
+ dict(
+ type='RandomErasing',
+ erase_prob=0.25,
+ mode='rand',
+ min_area_ratio=0.02,
+ max_area_ratio=1 / 3,
+ fill_color=bgr_mean,
+ fill_std=bgr_std),
+ ...
+]
+```
+
+```{note}
+ķĆÜÕĖĖ’╝īµĢ░µŹ«ń«ĪķüōõĖŁńÜäµĢ░µŹ«Õó×Õ╝║ķā©Õłåõ╗ģÕżäńÉåÕøŠÕāŵ¢╣ķØóńÜäÕÅśµŹó’╝īĶĆīõĖŹÕżäńÉåÕøŠÕāÅÕĮÆõĖĆÕī¢µł¢µĘĘÕÉł/Õē¬ÕłćµĘĘÕÉłńŁēÕÅśµŹóŃĆé ÕøĀõĖ║µłæõ╗¼ÕÅ»õ╗źÕ»╣ batch data ÕüÜ image normalization ÕÆī mixup/cutmix µØźÕŖĀķƤŃĆéĶ”üķģŹńĮ«ÕøŠÕāÅÕĮÆõĖĆÕī¢ÕÆī mixup/cutmix’╝īĶ»ĘõĮ┐ńö© [µĢ░µŹ«ķóäÕżäńÉåÕÖ©](mmpretrain.models.utils.data_preprocessor)ŃĆé
+```
+
+### µĀ╝Õ╝ÅÕī¢
+
+µĀ╝Õ╝ÅÕī¢µś»õ╗ĵĢ░µŹ«õ┐Īµü»ÕŁŚÕģĖõĖŁµöČķøåĶ«Łń╗āµĢ░µŹ«’╝īÕ╣ČÕ░åĶ┐Öõ║øµĢ░µŹ«ĶĮ¼µŹóõĖ║µ©ĪÕ×ŗÕÅŗÕźĮńÜäµĀ╝Õ╝ÅŃĆé
+
+Õ£©Õż¦ÕżÜµĢ░µāģÕåĄõĖŗ’╝īµé©ÕÅ»õ╗źń«ĆÕŹĢÕ£░õĮ┐ńö© [`PackInputs`](mmpretrain.datasets.transforms.PackInputs)’╝īÕ«āÕ░å NumPy µĢ░ń╗äµĀ╝Õ╝ÅńÜäÕøŠÕāÅĶĮ¼µŹóõĖ║ PyTorch Õ╝ĀķćÅ’╝īÕ╣ČÕ░å ground truth ń▒╗Õł½õ┐Īµü»ÕÆīÕģČõ╗¢Õģāõ┐Īµü»µēōÕīģõĖ║ [`DataSample`](mmpretrain.structures.DataSample)ŃĆé
+
+```python
+train_pipeline = [
+ ...
+ dict(type='PackInputs'),
+]
+```
+
+## µĘ╗ÕŖĀµ¢░ńÜäµĢ░µŹ«ÕÅśµŹó
+
+1. Õ£©õ╗╗õĮĢµ¢ćõ╗ČõĖŁÕåÖÕģźõĖĆõĖ¬µ¢░ńÜäµĢ░µŹ«ĶĮ¼µŹó’╝īõŠŗÕ”é `my_transform.py`’╝īÕ╣ČÕ░åÕģȵöŠÕ£©µ¢ćõ╗ČÕż╣ `mmpretrain/datasets/transforms/` õĖŁŃĆé µĢ░µŹ«ÕÅśµŹóń▒╗ķ£ĆĶ”üń╗¦µē┐ [`mmcv.transforms.BaseTransform`](mmcv.transforms.BaseTransform) ń▒╗Õ╣ČĶ”åńø¢õ╗źÕŁŚÕģĖõĮ£õĖ║ĶŠōÕģźÕ╣ČĶ┐öÕø×ÕŁŚÕģĖńÜä `transform` µ¢╣µ│ĢŃĆé
+
+ ```python
+ from mmcv.transforms import BaseTransform
+ from mmpretrain.registry import TRANSFORMS
+
+ @TRANSFORMS.register_module()
+ class MyTransform(BaseTransform):
+
+ def transform(self, results):
+ # Modify the data information dict `results`.
+ return results
+ ```
+
+2. Õ£© `mmpretrain/datasets/transforms/__init__.py` õĖŁÕ»╝Õģźµ¢░ńÜäÕÅśµŹó
+
+ ```python
+ ...
+ from .my_transform import MyTransform
+
+ __all__ = [
+ ..., 'MyTransform'
+ ]
+ ```
+
+3. Õ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁõĮ┐ńö©
+
+ ```python
+ train_pipeline = [
+ ...
+ dict(type='MyTransform'),
+ ...
+ ]
+ ```
+
+## µĢ░µŹ«ń«ĪķüōÕÅ»Ķ¦åÕī¢
+
+µĢ░µŹ«µĄüµ░┤ń║┐Ķ«ŠĶ«ĪÕ«īµłÉÕÉÄ’╝īÕÅ»õ╗źõĮ┐ńö© [ÕÅ»Ķ¦åÕī¢ÕĘźÕģĘ](../useful_tools/dataset_visualization.md) µ¤źń£ŗµĢłµ×£ŃĆé
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/pretrain_custom_dataset.md b/internlm_langchain/knowledge_base/MMPreTrain/content/pretrain_custom_dataset.md
new file mode 100644
index 00000000..786ecba8
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/pretrain_custom_dataset.md
@@ -0,0 +1,247 @@
+# Õ”éõĮĢÕ£©Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåõĖŖĶ┐øĶĪīµ©ĪÕ×ŗķóäĶ«Łń╗ā
+
+Õ£©µ£¼µĢÖń©ŗõĖŁ’╝īµłæõ╗¼µÅÉõŠøõ║åõĖĆõĖ¬Õ«×ĶĘĄńż║õŠŗÕÆīõĖĆõ║øµ£ēÕģ│Õ”éõĮĢÕ£©µé©Ķć¬ÕĘ▒ńÜäµĢ░µŹ«ķøåõĖŖĶ┐øĶĪīĶ«Łń╗āńÜäµŖĆÕʦŃĆé
+
+Õ£© MMPretrain õĖŁ’╝īµłæõ╗¼µö»µīüńö©µłĘńø┤µÄźĶ░āńö© MMPretrain ńÜä `CustomDataset` ’╝łń▒╗õ╝╝õ║Ä `torchvision` ńÜä `ImageFolder`’╝ē, Ķ»źµĢ░µŹ«ķøåĶāĮĶć¬ÕŖ©ńÜäĶ»╗ÕÅ¢ń╗ÖńÜäĶĘ»ÕŠäõĖŗńÜäÕøŠńēćŃĆéõĮĀÕŬķ£ĆĶ”üÕćåÕżćõĮĀńÜäµĢ░µŹ«ķøåĶĘ»ÕŠä’╝īÕ╣Čõ┐«µö╣ķģŹńĮ«µ¢ćõ╗Č’╝īÕŹ│ÕÅ»ĶĮ╗µØŠõĮ┐ńö© MMPretrain Ķ┐øĶĪīķóäĶ«Łń╗āŃĆé
+
+## ń¼¼õĖƵŁź’╝ÜÕćåÕżćõĮĀńÜäµĢ░µŹ«ķøå
+
+µīēńģ¦ [ÕćåÕżćµĢ░µŹ«ķøå](../user_guides/dataset_prepare.md) ÕćåÕżćõĮĀńÜäµĢ░µŹ«ķøåŃĆé
+ÕüćĶ«Šµłæõ╗¼ńÜäµĢ░µŹ«ķøåµĀ╣µ¢ćõ╗ČÕż╣ĶĘ»ÕŠäõĖ║ `data/custom_dataset/`
+
+ÕüćĶ«Šµłæõ╗¼µā│õĮ┐ńö© MAE ń«Śµ│ĢĶ┐øĶĪīÕøŠÕāÅĶć¬ńøæńØŻĶ«Łń╗ā’╝īÕ╣ČõĮ┐ńö©ÕŁÉµ¢ćõ╗ČÕż╣µĀ╝Õ╝ÅńÜä `CustomDataset` µØźń╗äń╗ćµĢ░µŹ«ķøå’╝Ü
+
+```text
+data/custom_dataset/
+Ōö£ŌöĆŌöĆ sample1.png
+Ōö£ŌöĆŌöĆ sample2.png
+Ōö£ŌöĆŌöĆ sample3.png
+Ōö£ŌöĆŌöĆ sample4.png
+ŌööŌöĆŌöĆ ...
+```
+
+## ń¼¼õ║īµŁź’╝ÜķĆēµŗ®õĖĆõĖ¬ķģŹńĮ«µ¢ćõ╗ČõĮ£õĖ║µ©ĪµØ┐
+
+Õ£©µ£¼µĢÖń©ŗõĖŁ’╝īµłæõ╗¼õĮ┐ńö© `configs/mae/mae_vit-base-p16_8xb512-amp-coslr-300e_in1k.py` õĮ£õĖ║õĖĆõĖ¬ńż║õŠŗĶ┐øĶĪīõ╗ŗń╗ŹŃĆé
+ķ”¢ÕģłÕ£©ÕÉīõĖƵ¢ćõ╗ČÕż╣õĖŗÕżŹÕłČõĖĆõ╗ĮķģŹńĮ«µ¢ćõ╗Č’╝īÕ╣ČÕ░åÕģČķćŹÕæĮÕÉŹõĖ║ `mae_vit-base-p16_8xb512-amp-coslr-300e_custom.py`ŃĆé
+
+```{tip}
+µīēńģ¦µā»õŠŗ’╝īķģŹńĮ«ÕÉŹń¦░ńÜäµ£ĆÕÉÄõĖĆõĖ¬ÕŁŚµ«Ąµś»µĢ░µŹ«ķøå’╝īõŠŗÕ”é’╝ī`in1k` ĶĪ©ńż║ ImageNet-1k’╝ī`coco` ĶĪ©ńż║ coco µĢ░µŹ«ķøå
+```
+
+Ķ┐ÖõĖ¬ķģŹńĮ«µ¢ćõ╗ČńÜäÕåģÕ«╣Õ”éõĖŗ’╝Ü
+
+```python
+_base_ = [
+ '../_base_/models/mae_vit-base-p16.py',
+ '../_base_/datasets/imagenet_bs512_mae.py',
+ '../_base_/default_runtime.py',
+]
+
+# optimizer wrapper
+optim_wrapper = dict(
+ type='AmpOptimWrapper',
+ loss_scale='dynamic',
+ optimizer=dict(
+ type='AdamW',
+ lr=1.5e-4 * 4096 / 256,
+ betas=(0.9, 0.95),
+ weight_decay=0.05),
+ paramwise_cfg=dict(
+ custom_keys={
+ 'ln': dict(decay_mult=0.0),
+ 'bias': dict(decay_mult=0.0),
+ 'pos_embed': dict(decay_mult=0.),
+ 'mask_token': dict(decay_mult=0.),
+ 'cls_token': dict(decay_mult=0.)
+ }))
+
+# learning rate scheduler
+param_scheduler = [
+ dict(
+ type='LinearLR',
+ start_factor=0.0001,
+ by_epoch=True,
+ begin=0,
+ end=40,
+ convert_to_iter_based=True),
+ dict(
+ type='CosineAnnealingLR',
+ T_max=260,
+ by_epoch=True,
+ begin=40,
+ end=300,
+ convert_to_iter_based=True)
+]
+
+# runtime settings
+train_cfg = dict(type='EpochBasedTrainLoop', max_epochs=300)
+default_hooks = dict(
+ # only keeps the latest 3 checkpoints
+ checkpoint=dict(type='CheckpointHook', interval=1, max_keep_ckpts=3))
+
+randomness = dict(seed=0, diff_rank_seed=True)
+
+# auto resume
+resume = True
+
+# NOTE: `auto_scale_lr` is for automatically scaling LR
+# based on the actual training batch size.
+auto_scale_lr = dict(base_batch_size=4096)
+```
+
+## ń¼¼õĖēµŁź’╝Üõ┐«µö╣µĢ░µŹ«ķøåĶ«ŠńĮ«
+
+- ķćŹĶĮĮµĢ░µŹ«ķøåĶ«ŠńĮ«õĖŁńÜä `type` õĖ║ `'CustomDataset'`
+- ķćŹĶĮĮµĢ░µŹ«ķøåĶ«ŠńĮ«õĖŁńÜä `data_root` õĖ║ `data/custom_dataset`
+- ķćŹĶĮĮµĢ░µŹ«ķøåĶ«ŠńĮ«õĖŁńÜä `ann_file` õĖ║ń®║ÕŁŚń¼”õĖ▓’╝īĶ┐Öµś»ÕøĀõĖ║µłæõ╗¼õĮ┐ńö©ÕŁÉµ¢ćõ╗ȵĀ╝Õ╝ÅńÜä `CustomDataset`’╝īķ£ĆĶ”üÕ░åķģŹńĮ«µ¢ćõ╗ČńĮ«ń®║
+- ķćŹĶĮĮµĢ░µŹ«ķøåĶ«ŠńĮ«õĖŁńÜä `data_prefix` õĖ║ń®║ÕŁŚń¼”õĖ▓’╝īĶ┐Öµś»ÕøĀõĖ║µłæõ╗¼ÕĖīµ£øõĮ┐ńö©µĢ░µŹ«ķøåµĀ╣ńø«ÕĮĢõĖŗńÜäµēƵ£ēµĢ░µŹ«Ķ┐øĶĪīĶ«Łń╗ā’╝īÕ╣ČõĖŹķ£ĆĶ”üÕ░åÕģȵŗåÕłåõĖ║õĖŹÕÉīÕŁÉķøåŃĆé
+
+õ┐«µö╣ÕÉÄńÜäµ¢ćõ╗ČÕ║öÕ”éõĖŗ’╝Ü
+
+```python
+_base_ = [
+ '../_base_/models/mae_vit-base-p16.py',
+ '../_base_/datasets/imagenet_bs512_mae.py',
+ '../_base_/default_runtime.py',
+]
+
+# >>>>>>>>>>>>>>> Õ£©µŁżķćŹĶĮĮµĢ░µŹ«Ķ«ŠńĮ« >>>>>>>>>>>>>>>>>>>
+train_dataloader = dict(
+ dataset=dict(
+ type='CustomDataset',
+ data_root='data/custom_dataset/',
+ ann_file='', # µłæõ╗¼ÕüćÕ«ÜõĮ┐ńö©ÕŁÉµ¢ćõ╗ČÕż╣µĀ╝Õ╝Å’╝īÕøĀµŁżķ£ĆĶ”üÕ░åµĀćµ│©µ¢ćõ╗ČńĮ«ń®║
+ data_prefix='', # õĮ┐ńö© `data_root` ĶĘ»ÕŠäõĖŗµēƵ£ēµĢ░µŹ«
+ with_label=False,
+ )
+)
+# <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
+
+# optimizer wrapper
+optim_wrapper = dict(
+ type='AmpOptimWrapper',
+ loss_scale='dynamic',
+ optimizer=dict(
+ type='AdamW',
+ lr=1.5e-4 * 4096 / 256,
+ betas=(0.9, 0.95),
+ weight_decay=0.05),
+ paramwise_cfg=dict(
+ custom_keys={
+ 'ln': dict(decay_mult=0.0),
+ 'bias': dict(decay_mult=0.0),
+ 'pos_embed': dict(decay_mult=0.),
+ 'mask_token': dict(decay_mult=0.),
+ 'cls_token': dict(decay_mult=0.)
+ }))
+
+# learning rate scheduler
+param_scheduler = [
+ dict(
+ type='LinearLR',
+ start_factor=0.0001,
+ by_epoch=True,
+ begin=0,
+ end=40,
+ convert_to_iter_based=True),
+ dict(
+ type='CosineAnnealingLR',
+ T_max=260,
+ by_epoch=True,
+ begin=40,
+ end=300,
+ convert_to_iter_based=True)
+]
+
+# runtime settings
+train_cfg = dict(type='EpochBasedTrainLoop', max_epochs=300)
+default_hooks = dict(
+ # only keeps the latest 3 checkpoints
+ checkpoint=dict(type='CheckpointHook', interval=1, max_keep_ckpts=3))
+
+randomness = dict(seed=0, diff_rank_seed=True)
+
+# auto resume
+resume = True
+
+# NOTE: `auto_scale_lr` is for automatically scaling LR
+# based on the actual training batch size.
+auto_scale_lr = dict(base_batch_size=4096)
+```
+
+õĮ┐ńö©õĖŖĶ┐░ķģŹńĮ«µ¢ćõ╗Č’╝īõĮĀÕ░▒ĶāĮÕż¤ĶĮ╗µØŠńÜäÕ£©Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåõĖŖõĮ┐ńö© `MAE` ń«Śµ│ĢµØźĶ┐øĶĪīķóäĶ«Łń╗āõ║åŃĆé
+
+## ÕÅ”õĖĆõĖ¬õŠŗÕŁÉ’╝ÜÕ£© COCO µĢ░µŹ«ķøåõĖŖĶ«Łń╗ā MAE
+
+```{note}
+õĮĀÕÅ»ĶāĮķ£ĆĶ”üÕÅéĶĆā[µ¢ćµĪŻ](https://github.com/open-mmlab/mmdetection/blob/3.x/docs/en/get_started.md)Õ«ēĶŻģ MMDetection µØźõĮ┐ńö© `mmdet.CocoDataset`ŃĆé
+```
+
+õĖÄÕ£©Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåõĖŖĶ┐øĶĪīķóäĶ«Łń╗āń▒╗õ╝╝’╝īµłæõ╗¼Õ£©µ£¼µĢÖń©ŗõĖŁõ╣¤µÅÉõŠøõ║åõĖĆõĖ¬õĮ┐ńö© COCO µĢ░µŹ«ķøåĶ┐øĶĪīķóäĶ«Łń╗āńÜäńż║õŠŗŃĆéõ┐«µö╣ÕÉÄńÜäµ¢ćõ╗ČÕ”éõĖŗ’╝Ü
+
+```python
+# >>>>>>>>>>>>>>>>>>>>> Start of Changed >>>>>>>>>>>>>>>>>>>>>>>>>
+_base_ = [
+ '../_base_/models/mae_vit-base-p16.py',
+ '../_base_/datasets/imagenet_mae.py',
+ '../_base_/default_runtime.py',
+]
+
+# >>>>>>>>>>>>>>> Õ£©Ķ┐ÖķćīķćŹĶĮĮµĢ░µŹ«ķģŹńĮ« >>>>>>>>>>>>>>>>>>>
+train_dataloader = dict(
+ dataset=dict(
+ type='mmdet.CocoDataset',
+ data_root='data/coco/',
+ ann_file='annotations/instances_train2017.json', # õ╗ģńö©õ║ÄÕŖĀĶĮĮÕøŠńēć’╝īõĖŹõ╝ÜõĮ┐ńö©µĀćńŁŠ
+ data_prefix=dict(img='train2017/'),
+ )
+)
+# <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
+
+# optimizer wrapper
+optim_wrapper = dict(
+ type='AmpOptimWrapper',
+ loss_scale='dynamic',
+ optimizer=dict(
+ type='AdamW',
+ lr=1.5e-4 * 4096 / 256,
+ betas=(0.9, 0.95),
+ weight_decay=0.05),
+ paramwise_cfg=dict(
+ custom_keys={
+ 'ln': dict(decay_mult=0.0),
+ 'bias': dict(decay_mult=0.0),
+ 'pos_embed': dict(decay_mult=0.),
+ 'mask_token': dict(decay_mult=0.),
+ 'cls_token': dict(decay_mult=0.)
+ }))
+# learning rate scheduler
+param_scheduler = [
+ dict(
+ type='LinearLR',
+ start_factor=0.0001,
+ by_epoch=True,
+ begin=0,
+ end=40,
+ convert_to_iter_based=True),
+ dict(
+ type='CosineAnnealingLR',
+ T_max=260,
+ by_epoch=True,
+ begin=40,
+ end=300,
+ convert_to_iter_based=True)
+]
+# runtime settings
+train_cfg = dict(type='EpochBasedTrainLoop', max_epochs=300)
+default_hooks = dict(
+ # only keeps the latest 3 checkpoints
+ checkpoint=dict(type='CheckpointHook', interval=1, max_keep_ckpts=3))
+randomness = dict(seed=0, diff_rank_seed=True)
+# auto resume
+resume = True
+# NOTE: `auto_scale_lr` is for automatically scaling LR
+# based on the actual training batch size.
+auto_scale_lr = dict(base_batch_size=4096)
+```
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/print_config.md b/internlm_langchain/knowledge_base/MMPreTrain/content/print_config.md
new file mode 100644
index 00000000..3ec0d303
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/print_config.md
@@ -0,0 +1,28 @@
+# µēōÕŹ░Õ«īµĢ┤ķģŹńĮ«µ¢ćõ╗Č
+
+`print_config.py`Ķäܵ£¼Ķäܵ£¼õ╝ÜĶ¦Żµ×ɵēƵ£ēĶŠōÕģźÕÅśķćÅ’╝īÕ╣ȵēōÕŹ░Õ«īµĢ┤ķģŹńĮ«õ┐Īµü»ŃĆé
+
+## Ķ»┤µśÄ’╝Ü
+
+`tools/misc/print_config.py` Ķäܵ£¼õ╝ÜķĆÉÕŁŚµēōÕŹ░µĢ┤õĖ¬ķģŹńĮ«µ¢ćõ╗Č’╝īÕ╣ČÕ▒Ģńż║µēƵ£ēÕ»╝ÕģźńÜäµ¢ćõ╗ČŃĆé
+
+```shell
+python tools/misc/print_config.py ${CONFIG} [--cfg-options ${CFG_OPTIONS}]
+```
+
+µēƵ£ēÕÅéµĢ░ńÜäĶ»┤µśÄ’╝Ü
+
+- `config`’╝ܵ©ĪÕ×ŗķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠäŃĆé
+- `--cfg-options`’╝ÜķóØÕż¢ńÜäķģŹńĮ«ķĆēķĪ╣’╝īõ╝ÜĶó½ÕÉłÕģźķģŹńĮ«µ¢ćõ╗Č’╝īÕÅéĶĆā[ÕŁ”õ╣ĀķģŹńĮ«µ¢ćõ╗Č](../user_guides/config.md)ŃĆé
+
+## ńż║õŠŗ’╝Ü
+
+µēōÕŹ░`configs/t2t_vit/t2t-vit-t-14_8xb64_in1k.py`µ¢ćõ╗ČńÜäÕ«īµĢ┤ķģŹńĮ«
+
+```shell
+# µēōÕŹ░Õ«īµłÉńÜäķģŹńĮ«µ¢ćõ╗Č
+python tools/misc/print_config.py configs/t2t_vit/t2t-vit-t-14_8xb64_in1k.py
+
+# Õ░åÕ«īµĢ┤ńÜäķģŹńĮ«µ¢ćõ╗Čõ┐ØÕŁśõĖ║õĖĆõĖ¬ńŗ¼ń½ŗńÜäķģŹńĮ«µ¢ćõ╗Č
+python tools/misc/print_config.py configs/t2t_vit/t2t-vit-t-14_8xb64_in1k.py > final_config.py
+```
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/projects.md b/internlm_langchain/knowledge_base/MMPreTrain/content/projects.md
new file mode 100644
index 00000000..0843dc4d
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/projects.md
@@ -0,0 +1 @@
+# Õ¤║õ║Ä MMPretrain ńÜäķĪ╣ńø«ÕłŚĶĪ©’╝łÕŠģµø┤µ¢░’╝ē
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/runtime.md b/internlm_langchain/knowledge_base/MMPreTrain/content/runtime.md
new file mode 100644
index 00000000..e5fa3864
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/runtime.md
@@ -0,0 +1,213 @@
+# Ķć¬Õ«Üõ╣ēĶ┐ÉĶĪīÕÅéµĢ░
+
+Ķ┐ÉĶĪīÕÅéµĢ░ķģŹńĮ«Õīģµŗ¼Ķ«ĖÕżÜµ£ēńö©ńÜäÕŖ¤ĶāĮ’╝īÕ”éµØāķ揵¢ćõ╗Čõ┐ØÕŁśŃĆüµŚźÕ┐ŚķģŹńĮ«ńŁēńŁē’╝īÕ£©µ£¼µĢÖń©ŗõĖŁ’╝īµłæõ╗¼Õ░åõ╗ŗń╗ŹÕ”éõĮĢķģŹńĮ«Ķ┐Öõ║øÕŖ¤ĶāĮŃĆé
+
+## õ┐ØÕŁśµØāķ揵¢ćõ╗Č
+
+µØāķ揵¢ćõ╗Čõ┐ØÕŁśÕŖ¤ĶāĮµś»õĖĆõĖ¬Õ£©Ķ«Łń╗āķśČµ«Ąķ╗śĶ«żµ│©ÕåīńÜäķÆ®ÕŁÉ’╝ī õĮĀÕÅ»õ╗źķĆÜĶ┐ćķģŹńĮ«µ¢ćõ╗ČõĖŁńÜä `default_hooks.checkpoint` ÕŁŚµ«ĄķģŹńĮ«Õ«āŃĆé
+
+```{note}
+ķÆ®ÕŁÉµ£║ÕłČÕ£© OpenMMLab Õ╝Ƶ║Éń«Śµ│ĢÕ║ōõĖŁÕ║öńö©ķØ×ÕĖĖÕ╣┐µ│øŃĆéķĆÜĶ┐ćķÆ®ÕŁÉ’╝īõĮĀÕÅ»õ╗źÕ£©õĖŹõ┐«µö╣Ķ┐ÉĶĪīÕÖ©ńÜäõĖ╗Ķ”üµē¦ĶĪīķĆ╗ĶŠæńÜäµāģÕåĄõĖŗµÅÆÕģźĶ«ĖÕżÜÕŖ¤ĶāĮŃĆé
+
+ÕÅ»õ╗źķĆÜĶ┐ć{external+mmengine:doc}`ńøĖÕģ│µ¢ćń½Ā
+
+```shell
+python tools/analysis_tools/analyze_logs.py plot_curve \
+ ${JSON_LOGS} \
+ [--keys ${KEYS}] \
+ [--title ${TITLE}] \
+ [--legend ${LEGEND}] \
+ [--backend ${BACKEND}] \
+ [--style ${STYLE}] \
+ [--out ${OUT_FILE}] \
+ [--window-size ${WINDOW_SIZE}]
+```
+
+**µēƵ£ēÕÅéµĢ░ńÜäĶ»┤µśÄ’╝Ü**
+
+- `json_logs` : µ©ĪÕ×ŗķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠä’╝łÕÅ»ÕÉīµŚČõ╝ĀÕģźÕżÜõĖ¬’╝īõĮ┐ńö©ń®║µĀ╝ÕłåÕ╝Ć’╝ēŃĆé
+- `--keys` : Õłåµ×ɵŚźÕ┐ŚńÜäÕģ│ķö«ÕŁŚµ«Ą’╝īµĢ░ķćÅõĖ║ `len(${JSON_LOGS}) * len(${KEYS})` ķ╗śĶ«żõĖ║ ŌĆślossŌĆÖŃĆé
+- `--title` : Õłåµ×ɵŚźÕ┐ŚńÜäÕøŠńēćÕÉŹń¦░’╝īķ╗śĶ«żõĮ┐ńö©ķģŹńĮ«µ¢ćõ╗ČÕÉŹ’╝ī ķ╗śĶ«żõĖ║ń®║ŃĆé
+- `--legend` : ÕøŠõŠŗńÜäÕÉŹń¦░’╝īÕģȵĢ░ńø«Õ┐ģķĪ╗õĖÄńøĖńŁē`len(${JSON_LOGS}) * len(${KEYS})`ŃĆé ķ╗śĶ«żõĮ┐ńö© `"${JSON_LOG}-${KEYS}"`.
+- `--backend` : matplotlib ńÜäń╗śÕøŠÕÉÄń½»’╝īķ╗śĶ«żńö▒ matplotlib Ķć¬ÕŖ©ķĆēµŗ®ŃĆé
+- `--style` : ń╗śÕøŠķģŹĶē▓ķŻÄµĀ╝’╝īķ╗śĶ«żõĖ║ `whitegrid`ŃĆé
+- `--out` : õ┐ØÕŁśÕłåµ×ÉÕøŠńēćńÜäĶĘ»ÕŠä’╝īÕ”éõĖŹµīćÕ«ÜÕłÖõĖŹõ┐ØÕŁśŃĆé
+- `--window-size`: ÕÅ»Ķ¦åÕī¢ń¬ŚÕÅŻÕż¦Õ░Å’╝īÕ”éµ×£µ▓Īµ£ēµīćÕ«Ü’╝īķ╗śĶ«żõĖ║ `'12*7'`ŃĆéÕ”éµ×£ķ£ĆĶ”üµīćÕ«Ü’╝īķ£Ćµīēńģ¦µĀ╝Õ╝Å `'W*H'`ŃĆé
+
+```{note}
+The `--style` option depends on `seaborn` package, please install it before setting it.
+```
+
+### Õ”éõĮĢµł¢ń╗śÕłČµŹ¤Õż▒/ń▓ŠÕ║”µø▓ń║┐
+
+µłæõ╗¼Õ░åń╗ÖÕć║õĖĆõ║øńż║õŠŗ’╝īµØźÕ▒Ģńż║Õ”éõĮĢõĮ┐ńö© `tools/analysis_tools/analyze_logs.py`Ķäܵ£¼ń╗śÕłČń▓ŠÕ║”µø▓ń║┐ńÜ䵏¤Õż▒µø▓ń║┐
+
+#### ń╗śÕłČµ¤ÉµŚźÕ┐Śµ¢ćõ╗ČÕ»╣Õ║öńÜ䵏¤Õż▒µø▓ń║┐ÕøŠ
+
+```shell
+python tools/analysis_tools/analyze_logs.py plot_curve your_log_json --keys loss --legend loss
+```
+
+#### ń╗śÕłČµ¤ÉµŚźÕ┐Śµ¢ćõ╗ČÕ»╣Õ║öńÜä top-1 ÕÆī top-5 ÕćåńĪ«ńÄćµø▓ń║┐ÕøŠ’╝īÕ╣ČÕ░åµø▓ń║┐ÕøŠÕ»╝Õć║õĖ║ results.jpg µ¢ćõ╗ČŃĆé
+
+```shell
+python tools/analysis_tools/analyze_logs.py plot_curve your_log_json --keys accuracy/top1 accuracy/top5 --legend top1 top5 --out results.jpg
+```
+
+#### Õ£©ÕÉīõĖĆÕøŠÕāÅÕåģń╗śÕłČõĖżõ╗ĮµŚźÕ┐Śµ¢ćõ╗ČÕ»╣Õ║öńÜä top-1 ÕćåńĪ«ńÄćµø▓ń║┐ÕøŠŃĆé
+
+```shell
+python tools/analysis_tools/analyze_logs.py plot_curve log1.json log2.json --keys accuracy/top1 --legend exp1 exp2
+```
+
+### Õ”éõĮĢń╗¤Ķ«ĪĶ«Łń╗āµŚČķŚ┤
+
+`tools/analysis_tools/analyze_logs.py` õ╣¤ÕÅ»õ╗źµĀ╣µŹ«µŚźÕ┐Śµ¢ćõ╗Čń╗¤Ķ«ĪĶ«Łń╗āĶĆŚµŚČŃĆé
+
+```shell
+python tools/analysis_tools/analyze_logs.py cal_train_time \
+ ${JSON_LOGS}
+ [--include-outliers]
+```
+
+**µēƵ£ēÕÅéµĢ░ńÜäĶ»┤µśÄ’╝Ü**
+
+- `json_logs`’╝ܵ©ĪÕ×ŗķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠä’╝łÕÅ»ÕÉīµŚČõ╝ĀÕģźÕżÜõĖ¬’╝īõĮ┐ńö©ń®║µĀ╝ÕłåÕ╝Ć’╝ēŃĆé
+- `--include-outliers`’╝ÜÕ”éµ×£µīćÕ«Ü’╝īÕ░åõĖŹõ╝ܵÄÆķÖżµ»ÅõĖ¬ĶĮ«µ¼ĪõĖŁń¼¼õĖĆõĖ¬µŚČķŚ┤Ķ«░ÕĮĢ’╝łµ£ēµŚČń¼¼õĖĆĶĮ«Ķ┐Łõ╗Żõ╝ÜĶĆŚµŚČĶŠāķĢ┐’╝ēŃĆé
+
+**ńż║õŠŗ’╝Ü**
+
+```shell
+python tools/analysis_tools/analyze_logs.py cal_train_time work_dirs/your_exp/20230206_181002/vis_data/scalars.json
+```
+
+ķóäĶ«ĪĶŠōÕć║ń╗ōµ×£Õ”éõĖŗµēĆńż║’╝Ü
+
+```text
+-----Analyze train time of work_dirs/your_exp/20230206_181002/vis_data/scalars.json-----
+slowest epoch 68, average time is 0.3818
+fastest epoch 1, average time is 0.3694
+time std over epochs is 0.0020
+average iter time: 0.3777 s/iter
+```
+
+## ń╗ōµ×£Õłåµ×É
+
+Õł®ńö© `tools/test.py` ńÜä`--out`’╝īµłæõ╗¼ÕÅ»õ╗źÕ░åµēƵ£ēńÜäµĀʵ£¼ńÜäµÄ©ńÉåń╗ōµ×£õ┐ØÕŁśÕł░ĶŠōÕć║µ¢ćõ╗ČõĖŁŃĆéÕł®ńö©Ķ┐ÖõĖƵ¢ćõ╗Č’╝īµłæõ╗¼ÕÅ»õ╗źĶ┐øĶĪīĶ┐øõĖƵŁźńÜäÕłåµ×ÉŃĆé
+
+### Õ”éõĮĢĶ┐øĶĪīń”╗ń║┐Õ║”ķćÅĶ»äõ╝░
+
+µłæõ╗¼µÅÉõŠøõ║å `tools/analysis_tools/eval_metric.py` Ķäܵ£¼’╝īõĮ┐ńö©µłĘĶāĮÕż¤µĀ╣µŹ«ķó䵥ŗµ¢ćõ╗ČĶ»äõ╝░µ©ĪÕ×ŗŃĆé
+
+```shell
+python tools/analysis_tools/eval_metric.py \
+ ${RESULT} \
+ [--metric ${METRIC_OPTIONS} ...]
+```
+
+**µēƵ£ēÕÅéµĢ░Ķ»┤µśÄ**’╝Ü
+
+- `result`’╝Ü`tools/test.py` ĶŠōÕć║ńÜäń╗ōµ×£µ¢ćõ╗ČŃĆé
+- `--metric`’╝Üńö©õ║ÄĶ»äõ╝░ń╗ōµ×£ńÜäµīćµĀć’╝īĶ»ĘĶć│Õ░æµīćÕ«ÜõĖĆõĖ¬µīćµĀć’╝īÕ╣ČõĖöõĮĀÕÅ»õ╗źķĆÜĶ┐ćµīćÕ«ÜÕżÜõĖ¬ `--metric` µØźÕÉīµŚČĶ«Īń«ŚÕżÜõĖ¬µīćµĀćŃĆé
+
+Ķ»ĘÕÅéĶĆā[Ķ»äõ╝░µ¢ćµĪŻ](mmpretrain.evaluation)ķĆēµŗ®ÕÅ»ńö©ńÜäĶ»äõ╝░µīćµĀćÕÆīÕ»╣Õ║öńÜäķĆēķĪ╣ŃĆé
+
+```{note}
+Õ£© `tools/test.py` õĖŁ’╝īµłæõ╗¼µö»µīüõĮ┐ńö© `--out-item` ķĆēķĪ╣µØźķĆēµŗ®õ┐ØÕŁśõĮĢń¦Źń╗ōµ×£Ķć│ĶŠōÕć║µ¢ćõ╗ČŃĆé
+Ķ»ĘńĪ«õ┐ص▓Īµ£ēķóØÕż¢µīćÕ«Ü `--out-item`’╝īµł¢µīćÕ«Üõ║å `--out-item=pred`ŃĆé
+```
+
+**ńż║õŠŗ**:
+
+```shell
+# ĶÄĘÕÅ¢ń╗ōµ×£µ¢ćõ╗Č
+python tools/test.py configs/resnet/resnet18_8xb16_cifar10.py \
+ https://download.openmmlab.com/mmclassification/v0/resnet/resnet18_b16x8_cifar10_20210528-bd6371c8.pth \
+ --out results.pkl
+
+# Ķ«Īń«Ś top-1 ÕÆī top-5 ÕćåńĪ«ńÄć
+python tools/analysis_tools/eval_metric.py results.pkl --metric type=Accuracy topk=1,5
+
+# Ķ«Īń«ŚµĆ╗õĮōÕćåńĪ«ńÄć’╝īÕÉäõĖ¬ń▒╗Õł½õĖŖńÜäń▓ŠńĪ«Õ║”ŃĆüÕżÕø×ńÄćŃĆüF1-score
+python tools/analysis_tools/eval_metric.py results.pkl --metric type=Accuracy \
+ --metric type=SingleLabelMetric items=precision,recall,f1-score average=None
+```
+
+### Õ”éõĮĢń╗śÕłČµĄŗĶ»Ģń╗ōµ×£ńÜäµĘʵĘåń¤®ķśĄ
+
+µłæõ╗¼µÅÉõŠø `tools/analysis_tools/confusion_matrix.py`’╝īÕĖ«ÕŖ®ńö©µłĘĶāĮÕż¤õ╗ĵĄŗĶ»ĢĶŠōÕć║µ¢ćõ╗ČõĖŁń╗śÕłČµĘʵĘåń¤®ķśĄŃĆé
+
+```shell
+python tools/analysis_tools/confusion_matrix.py \
+ ${CONFIG} \
+ ${RESULT} \
+ [--out ${OUT}] \
+ [--show] \
+ [--show-path ${SHOW_PATH}] \
+ [--include-values] \
+ [--cmap] \
+ [--cfg-options ${CFG_OPTIONS} ...] \
+```
+
+**µēƵ£ēÕÅéµĢ░Ķ»┤µśÄ**’╝Ü
+
+- `config`’╝ÜķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠäŃĆé
+- `result`’╝Ü`tools/test.py`ńÜäĶŠōÕć║ń╗ōµ×£µ¢ćõ╗Č’╝īµł¢µś»µ©ĪÕ×ŗµØāķ揵¢ćõ╗ČŃĆé
+- `--out`’╝ÜÕ░åµĘʵĘåń¤®ķśĄõ┐ØÕŁśÕł░µīćÕ«ÜĶĘ»ÕŠäõĖŗńÜä pickle µ¢ćõ╗ČõĖŁŃĆé
+- `--show`’╝ܵś»ÕÉ”ÕÅ»Ķ¦åÕī¢µĘʵĘåń¤®ķśĄÕøŠŃĆé
+- `--show-path`’╝ÜÕ░åÕÅ»Ķ¦åÕī¢µĘʵĘåń¤®ķśĄÕøŠõ┐ØÕŁśÕł░µīćÕ«ÜĶĘ»ÕŠäõĖŗŃĆé
+- `--include-values`’╝ܵś»Õɔգ©ÕÅ»Ķ¦åÕī¢µĘʵĘåń¤®ķśĄÕøŠõĖŁµśŠńż║ÕģĘõĮōÕĆ╝ŃĆé
+- `--cmap`’╝Üńö©õ╗źÕÅ»Ķ¦åÕī¢µĘʵĘåń¤®ķśĄńÜäķó£Ķē▓ķģŹńĮ«ŃĆé
+- `--cfg-options`’╝ÜķóØÕż¢ńÜäķģŹńĮ«ķĆēķĪ╣’╝īõ╝ÜĶó½ÕÉłÕģźķģŹńĮ«µ¢ćõ╗Č’╝īÕÅéĶĆā[ÕŁ”õ╣ĀķģŹńĮ«µ¢ćõ╗Č](../user_guides/config.md)ŃĆé
+
+```{note}
+Õ£© `tools/test.py` õĖŁ’╝īµłæõ╗¼µö»µīüõĮ┐ńö© `--out-item` ķĆēķĪ╣µØźķĆēµŗ®õ┐ØÕŁśõĮĢń¦Źń╗ōµ×£Ķć│ĶŠōÕć║µ¢ćõ╗ČŃĆé
+Ķ»ĘńĪ«õ┐ص▓Īµ£ēķóØÕż¢µīćÕ«Ü `--out-item`’╝īµł¢µīćÕ«Üõ║å `--out-item=pred`ŃĆé
+```
+
+**Examples**:
+
+```shell
+# ĶÄĘÕÅ¢ń╗ōµ×£µ¢ćõ╗Č
+python tools/test.py configs/resnet/resnet18_8xb16_cifar10.py \
+ https://download.openmmlab.com/mmclassification/v0/resnet/resnet18_b16x8_cifar10_20210528-bd6371c8.pth \
+ --out results.pkl
+
+# Õ░åµĘʵĘåń¤®ķśĄĶ«Īń«Śń╗ōµ×£õ┐ØÕŁśĶć│ cm.pkl õĖŁ
+python tools/analysis_tools/confusion_matrix.py configs/resnet/resnet18_8xb16_cifar10.py results.pkl --out cm.pkl
+
+# ÕÅ»Ķ¦åÕī¢µĘʵĘåń¤®ķśĄÕøŠ’╝īÕ╣ČÕ£©ÕøŠÕĮóń¬ŚÕÅŻµśŠńż║
+python tools/analysis_tools/confusion_matrix.py configs/resnet/resnet18_8xb16_cifar10.py results.pkl --show
+```
+
+### Õ”éõĮĢÕ░åķó䵥ŗń╗ōµ×£ÕÅ»Ķ¦åÕī¢
+
+µłæõ╗¼ÕÅ»õ╗źõĮ┐ńö©Ķäܵ£¼ `tools/analysis_tools/analyze_results.py` µØźõ┐ØÕŁśķó䵥ŗµłÉÕŖ¤µł¢Õż▒Ķ┤źµŚČÕŠŚÕłåµ£Ćķ½śńÜäÕøŠÕāÅŃĆé
+
+```shell
+python tools/analysis_tools/analyze_results.py \
+ ${CONFIG} \
+ ${RESULT} \
+ [--out-dir ${OUT_DIR}] \
+ [--topk ${TOPK}] \
+ [--rescale-factor ${RESCALE_FACTOR}] \
+ [--cfg-options ${CFG_OPTIONS}]
+```
+
+**µēƵ£ēÕÅéµĢ░Ķ»┤µśÄ’╝Ü**:
+
+- `config`’╝ÜķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠäŃĆé
+- `result`’╝Ü`tools/test.py`ńÜäĶŠōÕć║ń╗ōµ×£µ¢ćõ╗ČŃĆé
+- `--out_dir`’╝Üõ┐ØÕŁśń╗ōµ×£Õłåµ×ÉńÜäµ¢ćõ╗ČÕż╣ĶĘ»ÕŠäŃĆé
+- `--topk`’╝ÜÕłåÕł½õ┐ØÕŁśÕżÜÕ░æÕ╝Āķó䵥ŗµłÉÕŖ¤/Õż▒Ķ┤źńÜäÕøŠÕāÅŃĆéÕ”éµ×£õĖŹµīćÕ«Ü’╝īķ╗śĶ«żõĖ║ `20`ŃĆé
+- `--rescale-factor`’╝ÜÕøŠÕāÅńÜäń╝®µöŠń│╗µĢ░’╝īÕ”éµ×£µĀʵ£¼ÕøŠÕāÅĶ┐ćÕż¦µł¢Ķ┐ćÕ░ŵŚČÕÅ»õ╗źõĮ┐ńö©’╝łĶ┐ćÕ░ÅńÜäÕøŠÕāÅÕÅ»ĶāĮÕ»╝Ķć┤ń╗ōµ×£µĀćńŁŠķØ×ÕĖĖµ©Īń│Ŗ’╝ēŃĆé
+- `--cfg-options`’╝ÜķóØÕż¢ńÜäķģŹńĮ«ķĆēķĪ╣’╝īõ╝ÜĶó½ÕÉłÕģźķģŹńĮ«µ¢ćõ╗Č’╝īÕÅéĶĆā[ÕŁ”õ╣ĀķģŹńĮ«µ¢ćõ╗Č](../user_guides/config.md)ŃĆé
+
+```{note}
+Õ£© `tools/test.py` õĖŁ’╝īµłæõ╗¼µö»µīüõĮ┐ńö© `--out-item` ķĆēķĪ╣µØźķĆēµŗ®õ┐ØÕŁśõĮĢń¦Źń╗ōµ×£Ķć│ĶŠōÕć║µ¢ćõ╗ČŃĆé
+Ķ»ĘńĪ«õ┐ص▓Īµ£ēķóØÕż¢µīćÕ«Ü `--out-item`’╝īµł¢µīćÕ«Üõ║å `--out-item=pred`ŃĆé
+```
+
+**ńż║õŠŗ**:
+
+```shell
+# ĶÄĘÕÅ¢ķó䵥ŗń╗ōµ×£µ¢ćõ╗Č
+python tools/test.py configs/resnet/resnet18_8xb16_cifar10.py \
+ https://download.openmmlab.com/mmclassification/v0/resnet/resnet18_b16x8_cifar10_20210528-bd6371c8.pth \
+ --out results.pkl
+
+# õ┐ØÕŁśķó䵥ŗµłÉÕŖ¤/Õż▒Ķ┤źńÜäÕøŠÕāÅõĖŁ’╝īÕŠŚÕłåµ£Ćķ½śńÜäÕēŹ 10 Õ╝Ā’╝īÕ╣ČÕ£©ÕÅ»Ķ¦åÕī¢µŚČÕ░åĶŠōÕć║ÕøŠÕāŵöŠÕż¦ 10 ÕĆŹŃĆé
+python tools/analysis_tools/analyze_results.py \
+ configs/resnet/resnet18_8xb16_cifar10.py \
+ results.pkl \
+ --out-dir output \
+ --topk 10 \
+ --rescale-factor 10
+```
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/model_serving.md b/internlm_langchain/knowledge_base/MMPreTrain/content/model_serving.md
new file mode 100644
index 00000000..12f67797
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/model_serving.md
@@ -0,0 +1,88 @@
+# TorchServe ķā©ńĮ▓
+
+õĖ║õ║åõĮ┐ńö© [`TorchServe`](https://pytorch.org/serve/) ķā©ńĮ▓õĖĆõĖ¬ `MMPretrain` µ©ĪÕ×ŗ’╝īķ£ĆĶ”üĶ┐øĶĪīõ╗źõĖŗÕćĀµŁź’╝Ü
+
+## 1. ĶĮ¼µŹó MMPretrain µ©ĪÕ×ŗĶć│ TorchServe
+
+```shell
+python tools/torchserve/mmpretrain2torchserve.py ${CONFIG_FILE} ${CHECKPOINT_FILE} \
+--output-folder ${MODEL_STORE} \
+--model-name ${MODEL_NAME}
+```
+
+```{note}
+${MODEL_STORE} ķ£ĆĶ”üµś»õĖĆõĖ¬µ¢ćõ╗ČÕż╣ńÜäń╗ØÕ»╣ĶĘ»ÕŠäŃĆé
+```
+
+ńż║õŠŗ’╝Ü
+
+```shell
+python tools/torchserve/mmpretrain2torchserve.py \
+ configs/resnet/resnet18_8xb32_in1k.py \
+ checkpoints/resnet18_8xb32_in1k_20210831-fbbb1da6.pth \
+ --output-folder ./checkpoints \
+ --model-name resnet18_in1k
+```
+
+## 2. µ×äÕ╗║ `mmpretrain-serve` docker ķĢ£ÕāÅ
+
+```shell
+docker build -t mmpretrain-serve:latest docker/serve/
+```
+
+## 3. Ķ┐ÉĶĪī `mmpretrain-serve` ķĢ£ÕāÅ
+
+Ķ»ĘÕÅéĶĆāÕ«śµ¢╣µ¢ćµĪŻ [Õ¤║õ║Ä docker Ķ┐ÉĶĪī TorchServe](https://github.com/pytorch/serve/blob/master/docker/README.md#running-torchserve-in-a-production-docker-environment).
+
+õĖ║õ║åõĮ┐ķĢ£ÕāÅĶāĮÕż¤õĮ┐ńö© GPU ĶĄäµ║É’╝īķ£ĆĶ”üÕ«ēĶŻģ [nvidia-docker](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html)ŃĆéõ╣ŗÕÉÄÕÅ»õ╗źõ╝ĀķĆÆ `--gpus` ÕÅéµĢ░õ╗źÕ£© GPU õĖŖĶ┐ÉŃĆé
+
+ńż║õŠŗ’╝Ü
+
+```shell
+docker run --rm \
+--name mar \
+--cpus 8 \
+--gpus device=0 \
+-p8080:8080 -p8081:8081 -p8082:8082 \
+--mount type=bind,source=`realpath ./checkpoints`,target=/home/model-server/model-store \
+mmpretrain-serve:latest
+```
+
+```{note}
+`realpath ./checkpoints` µś» "./checkpoints" ńÜäń╗ØÕ»╣ĶĘ»ÕŠä’╝īõĮĀÕÅ»õ╗źÕ░åÕģȵø┐µŹóõĖ║õĮĀõ┐ØÕŁś TorchServe µ©ĪÕ×ŗńÜäńø«ÕĮĢńÜäń╗ØÕ»╣ĶĘ»ÕŠäŃĆé
+```
+
+ÕÅéĶĆā [Ķ»źµ¢ćµĪŻ](https://github.com/pytorch/serve/blob/master/docs/rest_api.md) õ║åĶ¦ŻÕģ│õ║ĵĩńÉå (8080)’╝īń«ĪńÉå (8081) ÕÆīµīćµĀć (8082) ńŁē API ńÜäõ┐Īµü»ŃĆé
+
+## 4. µĄŗĶ»Ģķā©ńĮ▓
+
+```shell
+curl http://127.0.0.1:8080/predictions/${MODEL_NAME} -T demo/demo.JPEG
+```
+
+µé©Õ║öĶ»źĶÄĘÕŠŚń▒╗õ╝╝õ║Äõ╗źõĖŗÕåģÕ«╣ńÜäÕōŹÕ║ö’╝Ü
+
+```json
+{
+ "pred_label": 58,
+ "pred_score": 0.38102269172668457,
+ "pred_class": "water snake"
+}
+```
+
+ÕÅ”Õż¢’╝īõĮĀõ╣¤ÕÅ»õ╗źõĮ┐ńö© `test_torchserver.py` µØźµ»öĶŠā TorchServe ÕÆī PyTorch ńÜäń╗ōµ×£’╝īÕ╣ČĶ┐øĶĪīÕÅ»Ķ¦åÕī¢ŃĆé
+
+```shell
+python tools/torchserve/test_torchserver.py ${IMAGE_FILE} ${CONFIG_FILE} ${CHECKPOINT_FILE} ${MODEL_NAME}
+[--inference-addr ${INFERENCE_ADDR}] [--device ${DEVICE}]
+```
+
+ńż║õŠŗ’╝Ü
+
+```shell
+python tools/torchserve/test_torchserver.py \
+ demo/demo.JPEG \
+ configs/resnet/resnet18_8xb32_in1k.py \
+ checkpoints/resnet18_8xb32_in1k_20210831-fbbb1da6.pth \
+ resnet18_in1k
+```
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/modules.md b/internlm_langchain/knowledge_base/MMPreTrain/content/modules.md
new file mode 100644
index 00000000..cb0fac6a
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/modules.md
@@ -0,0 +1,512 @@
+# Ķć¬Õ«Üõ╣ēµ©ĪÕ×ŗ
+
+Õ£©µłæõ╗¼ńÜäĶ«ŠĶ«ĪõĖŁ’╝īµłæõ╗¼Õ«Üõ╣ēõĖĆõĖ¬Õ«īµĢ┤ńÜ䵩ĪÕ×ŗõĖ║ķĪČÕ▒鵩ĪÕØŚ’╝īµĀ╣µŹ«ÕŖ¤ĶāĮńÜäõĖŹÕÉī’╝īÕ¤║µ£¼ÕćĀń¦ŹõĖŹÕÉīń▒╗Õ×ŗńÜ䵩ĪÕ×ŗń╗äõ╗Čń╗䵳ÉŃĆé
+
+- µ©ĪÕ×ŗ’╝ÜķĪČÕ▒鵩ĪÕØŚÕ«Üõ╣ēõ║åÕģĘõĮōńÜäõ╗╗ÕŖĪń▒╗Õ×ŗ’╝īõŠŗÕ”é `ImageClassifier` ńö©Õ£©ÕøŠÕāÅÕłåń▒╗õ╗╗ÕŖĪõĖŁ’╝ī `MAE` ńö©Õ£©Ķć¬ńøæńØŻÕŁ”õ╣ĀõĖŁ’╝ī `ImageToImageRetriever` ńö©Õ£©ÕøŠÕāŵŻĆń┤óõĖŁŃĆé
+- õĖ╗Õ╣▓ńĮæń╗£’╝ÜķĆÜÕĖĖµś»õĖĆõĖ¬ńē╣ÕŠüµÅÉÕÅ¢ńĮæń╗£’╝īµČĄńø¢õ║嵩ĪÕ×ŗõ╣ŗķŚ┤ń╗ØÕż¦ÕżÜµĢ░ńÜäÕĘ«Õ╝é’╝īõŠŗÕ”é `ResNet`ŃĆü`MobileNet`ŃĆé
+- ķółķā©’╝Üńö©õ║ÄĶ┐׵ğõĖ╗Õ╣▓ńĮæń╗£ÕÆīÕż┤ķā©ńÜäń╗äõ╗Č’╝īõŠŗÕ”é `GlobalAveragePooling`ŃĆé
+- Õż┤ķā©’╝Üńö©õ║ĵē¦ĶĪīńē╣Õ«Üõ╗╗ÕŖĪńÜäń╗äõ╗Č’╝īõŠŗÕ”é `ClsHead`ŃĆü `ContrastiveHead`ŃĆé
+- µŹ¤Õż▒ÕćĮµĢ░’╝ÜÕ£©Õż┤ķā©ńö©õ║ÄĶ«Īń«ŚµŹ¤Õż▒ÕćĮµĢ░ńÜäń╗äõ╗Č’╝īõŠŗÕ”é `CrossEntropyLoss`ŃĆü`LabelSmoothLoss`ŃĆé
+- ńø«µĀćńö¤µłÉÕÖ©: ńö©õ║ÄĶć¬ńøæńØŻÕŁ”õ╣Āõ╗╗ÕŖĪńÜäń╗äõ╗Č’╝īõŠŗÕ”é `VQKD`ŃĆü `HOGGenerator`ŃĆé
+
+## µĘ╗ÕŖĀµ¢░ńÜäķĪČÕ▒鵩ĪÕ×ŗ
+
+ķĆÜÕĖĖµØźĶ»┤’╝īÕ»╣õ║ÄÕøŠÕāÅÕłåń▒╗ÕÆīÕøŠÕāŵŻĆń┤óõ╗╗ÕŖĪµØźĶ»┤’╝īµ©ĪÕ×ŗķĪČÕ▒鵩ĪÕ×ŗµĄüń©ŗÕ¤║µ£¼õĖĆĶć┤ŃĆéõĮåµś»õĖŹÕÉīńÜäĶć¬ńøæńØŻÕŁ”õ╣Āń«Śµ│ĢÕŹ┤ńö©õĖŹÕÉīńÜäĶ«Īń«ŚµĄüń©ŗ’╝īÕāÅ `MAE` ÕÆī `BEiT` Õ░▒Õż¦õĖŹńøĖÕÉīŃĆé µēĆõ╗źÕ£©Ķ┐ÖõĖ¬ķā©Õłå’╝īµłæõ╗¼Õ░åń«ĆÕŹĢõ╗ŗń╗ŹÕ”éõĮĢµĘ╗ÕŖĀõĖĆõĖ¬µ¢░ńÜäĶć¬ńøæńØŻÕŁ”õ╣Āń«Śµ│ĢŃĆé
+
+### µĘ╗ÕŖĀµ¢░ńÜäĶć¬ńøæńØŻÕŁ”õ╣Āń«Śµ│Ģ
+
+1. ÕłøÕ╗║µ¢░µ¢ćõ╗Č `mmpretrain/models/selfsup/new_algorithm.py` õ╗źÕÅŖÕ«×ńÄ░ `NewAlgorithm`
+
+ ```python
+ from mmpretrain.registry import MODELS
+ from .base import BaseSelfSupvisor
+
+
+ @MODELS.register_module()
+ class NewAlgorithm(BaseSelfSupvisor):
+
+ def __init__(self, backbone, neck=None, head=None, init_cfg=None):
+ super().__init__(init_cfg)
+ pass
+
+ # ``extract_feat`` function is defined in BaseSelfSupvisor, you could
+ # overwrite it if needed
+ def extract_feat(self, inputs, **kwargs):
+ pass
+
+ # the core function to compute the loss
+ def loss(self, inputs, data_samples, **kwargs):
+ pass
+
+ ```
+
+2. Õ£© `mmpretrain/models/selfsup/__init__.py` õĖŁÕ»╝ÕģźÕ»╣Õ║öńÜäµ¢░ń«Śµ│Ģ
+
+ ```python
+ ...
+ from .new_algorithm import NewAlgorithm
+
+ __all__ = [
+ ...,
+ 'NewAlgorithm',
+ ...
+ ]
+ ```
+
+3. Õ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁõĮ┐ńö©µ¢░ń«Śµ│Ģ
+
+ ```python
+ model = dict(
+ type='NewAlgorithm',
+ backbone=...,
+ neck=...,
+ head=...,
+ ...
+ )
+ ```
+
+## µĘ╗ÕŖĀµ¢░ńÜäõĖ╗Õ╣▓ńĮæń╗£
+
+Ķ┐Öķćī’╝īµłæõ╗¼õ╗ź `ResNet_CIFAR` õĖ║õŠŗ’╝īÕ▒Ģńż║õ║åÕ”éõĮĢÕ╝ĆÕÅæõĖĆõĖ¬µ¢░ńÜäõĖ╗Õ╣▓ńĮæń╗£ń╗äõ╗ČŃĆé
+
+`ResNet_CIFAR` ķÆłÕ»╣ CIFAR 32x32 ńÜäÕøŠÕāÅĶŠōÕģź’╝īĶ┐£Õ░Åõ║ÄÕż¦ÕżÜµĢ░µ©ĪÕ×ŗõĮ┐ńö©ńÜäImageNetķ╗śĶ«żńÜä224x224ĶŠōÕģźķģŹńĮ«’╝īµēĆõ╗źµłæõ╗¼Õ░åķ¬©Õ╣▓ńĮæń╗£õĖŁ `kernel_size=7,stride=2`
+ńÜäĶ«ŠńĮ«µø┐µŹóõĖ║ `kernel_size=3, stride=1`’╝īÕ╣Čń¦╗ķÖżõ║å stem Õ▒éõ╣ŗÕÉÄńÜä
+`MaxPooling`’╝īõ╗źķü┐ÕģŹõ╝ĀķĆÆĶ┐ćÕ░ÅńÜäńē╣ÕŠüÕøŠÕł░µ«ŗÕĘ«ÕØŚõĖŁŃĆé
+
+µ£Ćń«ĆÕŹĢńÜäµ¢╣Õ╝ÅÕ░▒µś»ń╗¦µē┐Ķć¬ `ResNet` Õ╣ČÕŬõ┐«µö╣ stem Õ▒éŃĆé
+
+1. ÕłøÕ╗║õĖĆõĖ¬µ¢░µ¢ćõ╗Č `mmpretrain/models/backbones/resnet_cifar.py`ŃĆé
+
+ ```python
+ import torch.nn as nn
+
+ from mmpretrain.registry import MODELS
+ from .resnet import ResNet
+
+
+ @MODELS.register_module()
+ class ResNet_CIFAR(ResNet):
+
+ """ResNet backbone for CIFAR.
+
+ ’╝łÕ»╣Ķ┐ÖõĖ¬õĖ╗Õ╣▓ńĮæń╗£ńÜäń«Ćń¤ŁµÅÅĶ┐░’╝ē
+
+ Args:
+ depth(int): Network depth, from {18, 34, 50, 101, 152}.
+ ...
+ ’╝łÕÅéµĢ░µ¢ćµĪŻ’╝ē
+ """
+
+ def __init__(self, depth, deep_stem=False, **kwargs):
+ # Ķ░āńö©Õ¤║ń▒╗ ResNet ńÜäÕłØÕ¦ŗÕī¢ÕćĮµĢ░
+ super(ResNet_CIFAR, self).__init__(depth, deep_stem=deep_stem **kwargs)
+ # ÕģČõ╗¢ńē╣µ«ŖńÜäÕłØÕ¦ŗÕī¢µĄüń©ŗ
+ assert not self.deep_stem, 'ResNet_CIFAR do not support deep_stem'
+
+ def _make_stem_layer(self, in_channels, base_channels):
+ # ķćŹĶĮĮÕ¤║ń▒╗ńÜäµ¢╣µ│Ģ’╝īõ╗źÕ«×ńÄ░Õ»╣ńĮæń╗£ń╗ōµ×äńÜäõ┐«µö╣
+ self.conv1 = build_conv_layer(
+ self.conv_cfg,
+ in_channels,
+ base_channels,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=False)
+ self.norm1_name, norm1 = build_norm_layer(
+ self.norm_cfg, base_channels, postfix=1)
+ self.add_module(self.norm1_name, norm1)
+ self.relu = nn.ReLU(inplace=True)
+
+ def forward(self, x):
+ # Õ”éµ×£ķ£ĆĶ”üńÜäĶ»Ø’╝īÕÅ»õ╗źĶć¬Õ«Üõ╣ēforwardµ¢╣µ│Ģ
+ x = self.conv1(x)
+ x = self.norm1(x)
+ x = self.relu(x)
+ outs = []
+ for i, layer_name in enumerate(self.res_layers):
+ res_layer = getattr(self, layer_name)
+ x = res_layer(x)
+ if i in self.out_indices:
+ outs.append(x)
+ # ĶŠōÕć║ÕĆ╝ķ£ĆĶ”üµś»õĖĆõĖ¬ÕīģÕɽõĖŹÕÉīÕ▒éÕżÜÕ░║Õ║”ĶŠōÕć║ńÜäÕģāń╗ä
+ # Õ”éµ×£õĖŹķ£ĆĶ”üÕżÜÕ░║Õ║”ńē╣ÕŠü’╝īÕÅ»õ╗źńø┤µÄźÕ£©µ£Ćń╗łĶŠōÕć║õĖŖÕīģõĖĆÕ▒éÕģāń╗ä
+ return tuple(outs)
+
+ def init_weights(self):
+ # Õ”éµ×£ķ£ĆĶ”üńÜäĶ»Ø’╝īÕÅ»õ╗źĶć¬Õ«Üõ╣ēµØāķćŹÕłØÕ¦ŗÕī¢ńÜäµ¢╣µ│Ģ
+ super().init_weights()
+
+ # Õ”éµ×£µ£ēķóäĶ«Łń╗āµ©ĪÕ×ŗ’╝īÕłÖõĖŹķ£ĆĶ”üĶ┐øĶĪīµØāķćŹÕłØÕ¦ŗÕī¢
+ if self.init_cfg is not None and self.init_cfg['type'] == 'Pretrained':
+ return
+
+ # ķĆÜÕĖĖµØźĶ»┤’╝īµłæõ╗¼Õ╗║Ķ««ńö©`init_cfg`ÕÄ╗ÕłŚõĖŠõĖŹÕÉīÕ▒éµØāķćŹÕłØÕ¦ŗÕī¢µ¢╣µ│Ģ
+ # Õīģµŗ¼ÕŹĘń¦»Õ▒é’╝īń║┐µĆ¦Õ▒é’╝īÕĮÆõĖĆÕī¢Õ▒éńŁēńŁē
+ # Õ”éµ×£µ£ēńē╣µ«Ŗķ£ĆĶ”ü’╝īÕÅ»õ╗źÕ£©Ķ┐ÖķćīĶ┐øĶĪīķóØÕż¢ńÜäÕłØÕ¦ŗÕī¢µōŹõĮ£
+ ...
+ ```
+
+```{note}
+Õ£© OpenMMLab 2.0 ńÜäĶ«ŠĶ«ĪõĖŁ’╝īÕ░åÕĤµ£ēńÜä`BACKBONES`ŃĆü`NECKS`ŃĆü`HEADS`ŃĆü`LOSSES`ńŁēµ│©ÕåīÕÉŹń╗¤õĖĆõĖ║`MODELS`.
+```
+
+2. Õ£© `mmpretrain/models/backbones/__init__.py` õĖŁÕ»╝Õģźµ¢░µ©ĪÕØŚ
+
+ ```python
+ ...
+ from .resnet_cifar import ResNet_CIFAR
+
+ __all__ = [
+ ..., 'ResNet_CIFAR'
+ ]
+ ```
+
+3. Õ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁõĮ┐ńö©µ¢░ńÜäõĖ╗Õ╣▓ńĮæń╗£
+
+ ```python
+ model = dict(
+ ...
+ backbone=dict(
+ type='ResNet_CIFAR',
+ depth=18,
+ other_arg=xxx),
+ ...
+ ```
+
+### õĖ║Ķć¬ńøæńØŻÕŁ”õ╣ĀµĘ╗ÕŖĀµ¢░ńÜäõĖ╗Õ╣▓ńĮæń╗£
+
+Õ»╣õ║ÄõĖĆķā©ÕłåĶć¬ńøæńØŻÕŁ”õ╣Āń«Śµ│Ģ’╝īõĖ╗Õ╣▓ńĮæń╗£ÕüÜõ║åõĖĆÕ«Üõ┐«µö╣’╝īõŠŗÕ”é `MAE`ŃĆü`BEiT` ńŁēŃĆé Ķ┐Öõ║øõĖ╗Õ╣▓ńĮæń╗£ķ£ĆĶ”üÕżäńÉå `mask` ńøĖÕģ│ńÜäķĆ╗ĶŠæ’╝īõ╗źµŁżõ╗ÄÕÅ»Ķ¦üńÜäÕøŠÕāÅÕØŚõĖŁµÅÉÕÅ¢Õ»╣Õ║öńÜäńē╣ÕŠüõ┐Īµü»ŃĆé
+
+õ╗ź [MAEViT](mmpretrain.models.selfsup.MAEViT) õĮ£õĖ║õŠŗÕŁÉ’╝īµłæõ╗¼ķ£ĆĶ”üķćŹÕåÖ `forward` ÕćĮµĢ░’╝īĶ┐øĶĪīÕ¤║õ║Ä `mask` ńÜäĶ«Īń«ŚŃĆ鵳æõ╗¼Õ«×ńÄ░õ║å `init_weights` Ķ┐øĶĪīńē╣իܵØāķćŹńÜäÕłØÕ¦ŗÕī¢ÕÆī `random_masking` ÕćĮµĢ░µØźńö¤µłÉ `MAE` ķóäĶ«Łń╗āµēĆķ£ĆĶ”üńÜä `mask`ŃĆé
+
+```python
+class MAEViT(VisionTransformer):
+ """Vision Transformer for MAE pre-training"""
+
+ def __init__(mask_ratio, **kwargs) -> None:
+ super().__init__(**kwargs)
+ # position embedding is not learnable during pretraining
+ self.pos_embed.requires_grad = False
+ self.mask_ratio = mask_ratio
+ self.num_patches = self.patch_resolution[0] * self.patch_resolution[1]
+
+ def init_weights(self) -> None:
+ """Initialize position embedding, patch embedding and cls token."""
+ super().init_weights()
+ # define what if needed
+ pass
+
+ def random_masking(
+ self,
+ x: torch.Tensor,
+ mask_ratio: float = 0.75
+ ) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
+ """Generate the mask for MAE Pre-training."""
+ pass
+
+ def forward(
+ self,
+ x: torch.Tensor,
+ mask: Optional[bool] = True
+ ) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
+ """Generate features for masked images.
+
+ The function supports two kind of forward behaviors. If the ``mask`` is
+ ``True``, the function will generate mask to masking some patches
+ randomly and get the hidden features for visible patches, which means
+ the function will be executed as masked imagemodeling pre-training;
+ if the ``mask`` is ``None`` or ``False``, the forward function will
+ call ``super().forward()``, which extract features from images without
+ mask.
+ """
+ if mask is None or False:
+ return super().forward(x)
+
+ else:
+ B = x.shape[0]
+ x = self.patch_embed(x)[0]
+ # add pos embed w/o cls token
+ x = x + self.pos_embed[:, 1:, :]
+
+ # masking: length -> length * mask_ratio
+ x, mask, ids_restore = self.random_masking(x, self.mask_ratio)
+
+ # append cls token
+ cls_token = self.cls_token + self.pos_embed[:, :1, :]
+ cls_tokens = cls_token.expand(B, -1, -1)
+ x = torch.cat((cls_tokens, x), dim=1)
+
+ for _, layer in enumerate(self.layers):
+ x = layer(x)
+ # Use final norm
+ x = self.norm1(x)
+
+ return (x, mask, ids_restore)
+
+```
+
+## µĘ╗ÕŖĀµ¢░ńÜäķółķā©ń╗äõ╗Č
+
+Ķ┐Öķćīµłæõ╗¼õ╗ź `GlobalAveragePooling` õĖ║õŠŗŃĆéĶ┐Öµś»õĖĆõĖ¬ķØ×ÕĖĖń«ĆÕŹĢńÜäķółķā©ń╗äõ╗Č’╝īµ▓Īµ£ēõ╗╗õĮĢÕÅéµĢ░ŃĆé
+
+Ķ”üµĘ╗ÕŖĀµ¢░ńÜäķółķā©ń╗äõ╗Č’╝īµłæõ╗¼õĖ╗Ķ”üķ£ĆĶ”üÕ«×ńÄ░ `forward` ÕćĮµĢ░’╝īĶ»źÕćĮµĢ░Õ»╣õĖ╗Õ╣▓ńĮæń╗£ńÜäĶŠōÕć║Ķ┐øĶĪī
+õĖĆõ║øµōŹõĮ£Õ╣ČÕ░åń╗ōµ×£õ╝ĀķĆÆÕł░Õż┤ķā©ŃĆé
+
+1. ÕłøÕ╗║õĖĆõĖ¬µ¢░µ¢ćõ╗Č `mmpretrain/models/necks/gap.py`
+
+ ```python
+ import torch.nn as nn
+
+ from mmpretrain.registry import MODELS
+
+ @MODELS.register_module()
+ class GlobalAveragePooling(nn.Module):
+
+ def __init__(self):
+ self.gap = nn.AdaptiveAvgPool2d((1, 1))
+
+ def forward(self, inputs):
+ # ń«ĆÕŹĢĶĄĘĶ¦ü’╝īµłæõ╗¼ķ╗śĶ«żĶŠōÕģźµś»õĖĆõĖ¬Õ╝ĀķćÅ
+ outs = self.gap(inputs)
+ outs = outs.view(inputs.size(0), -1)
+ return outs
+ ```
+
+2. Õ£© `mmpretrain/models/necks/__init__.py` õĖŁÕ»╝Õģźµ¢░µ©ĪÕØŚ
+
+ ```python
+ ...
+ from .gap import GlobalAveragePooling
+
+ __all__ = [
+ ..., 'GlobalAveragePooling'
+ ]
+ ```
+
+3. õ┐«µö╣ķģŹńĮ«µ¢ćõ╗Čõ╗źõĮ┐ńö©µ¢░ńÜäķółķā©ń╗äõ╗Č
+
+ ```python
+ model = dict(
+ neck=dict(type='GlobalAveragePooling'),
+ )
+ ```
+
+## µĘ╗ÕŖĀµ¢░ńÜäÕż┤ķā©ń╗äõ╗Č
+
+### Õ¤║õ║ÄÕłåń▒╗Õż┤
+
+Õ£©µŁż’╝īµłæõ╗¼õ╗źõĖĆõĖ¬ń«ĆÕī¢ńÜä `VisionTransformerClsHead` õĖ║õŠŗ’╝īĶ»┤µśÄÕ”éõĮĢÕ╝ĆÕÅæµ¢░ńÜäÕż┤ķā©ń╗äõ╗ČŃĆé
+
+Ķ”üµĘ╗ÕŖĀõĖĆõĖ¬µ¢░ńÜäÕż┤ķā©ń╗äõ╗Č’╝īÕ¤║µ£¼õĖŖµłæõ╗¼ķ£ĆĶ”üÕ«×ńÄ░ `pre_logits` ÕćĮµĢ░ńö©õ║ÄĶ┐øÕģźµ£ĆÕÉÄńÜäÕłåń▒╗Õż┤õ╣ŗÕēŹķ£ĆĶ”üńÜäÕżäńÉå’╝ī
+õ╗źÕÅŖ `forward` ÕćĮµĢ░ŃĆé
+
+1. ÕłøÕ╗║õĖĆõĖ¬µ¢ćõ╗Č `mmpretrain/models/heads/vit_head.py`.
+
+ ```python
+ import torch.nn as nn
+
+ from mmpretrain.registry import MODELS
+ from .cls_head import ClsHead
+
+
+ @MODELS.register_module()
+ class LinearClsHead(ClsHead):
+
+ def __init__(self, num_classes, in_channels, hidden_dim, **kwargs):
+ super().__init__(**kwargs)
+ self.in_channels = in_channels
+ self.num_classes = num_classes
+ self.hidden_dim = hidden_dim
+
+ self.fc1 = nn.Linear(in_channels, hidden_dim)
+ self.act = nn.Tanh()
+ self.fc2 = nn.Linear(hidden_dim, num_classes)
+
+ def pre_logits(self, feats):
+ # ķ¬©Õ╣▓ńĮæń╗£ńÜäĶŠōÕć║ķĆÜÕĖĖÕīģÕÉ½ÕżÜÕ░║Õ║”õ┐Īµü»ńÜäÕģāń╗ä
+ # Õ»╣õ║ÄÕłåń▒╗õ╗╗ÕŖĪµØźĶ»┤’╝īµłæõ╗¼ÕŬķ£ĆĶ”üÕģ│µ│©µ£ĆÕÉÄńÜäĶŠōÕć║
+ feat = feats[-1]
+
+ # VisionTransformerńÜäµ£Ćń╗łĶŠōÕć║µś»õĖĆõĖ¬ÕīģÕɽpatch tokensÕÆīcls tokensńÜäÕģāń╗ä
+ # Ķ┐Öķćīµłæõ╗¼ÕŬķ£ĆĶ”ücls tokens
+ _, cls_token = feat
+
+ # Õ«īµłÉķÖżõ║åµ£ĆÕÉÄńÜäń║┐µĆ¦Õłåń▒╗Õż┤õ╗źÕż¢ńÜäµōŹõĮ£
+ return self.act(self.fc1(cls_token))
+
+ def forward(self, feats):
+ pre_logits = self.pre_logits(feats)
+
+ # Õ«īµłÉµ£ĆÕÉÄńÜäÕłåń▒╗Õż┤
+ cls_score = self.fc(pre_logits)
+ return cls_score
+ ```
+
+2. Õ£© `mmpretrain/models/heads/__init__.py` õĖŁÕ»╝ÕģźĶ┐ÖõĖ¬µ©ĪÕØŚ
+
+ ```python
+ ...
+ from .vit_head import VisionTransformerClsHead
+
+ __all__ = [
+ ..., 'VisionTransformerClsHead'
+ ]
+ ```
+
+3. õ┐«µö╣ķģŹńĮ«µ¢ćõ╗Čõ╗źõĮ┐ńö©µ¢░ńÜäÕż┤ķā©ń╗äõ╗ČŃĆé
+
+ ```python
+ model = dict(
+ head=dict(
+ type='VisionTransformerClsHead',
+ ...,
+ ))
+ ```
+
+### Õ¤║õ║Ä BaseModule ń▒╗
+
+Ķ┐Öµś»õĖĆõĖ¬Õ¤║õ║Ä MMEngine õĖŁńÜä `BaseModule` Ķ┐øĶĪīÕ╝ĆÕÅæõŠŗÕŁÉ’╝ī`MAEPretrainHead`’╝īõĖ╗Ķ”üµś»õĖ║õ║å `MAE` µÄ®ńĀüÕŁ”õ╣ĀŃĆ鵳æõ╗¼ķ£ĆĶ”üÕ«×ńÄ░ `loss` ÕćĮµĢ░µØźĶ«Īń«ŚµŹ¤Õż▒ÕÉŚ’╝īõĖŹĶ┐ćÕģČÕ«āńÜäÕćĮµĢ░ÕØćõĖ║ÕÅ»ķĆēķĪ╣ŃĆé
+
+```python
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+from mmengine.model import BaseModule
+
+from mmpretrain.registry import MODELS
+
+
+@MODELS.register_module()
+class MAEPretrainHead(BaseModule):
+ """Head for MAE Pre-training."""
+
+ def __init__(self,
+ loss: dict,
+ norm_pix: bool = False,
+ patch_size: int = 16) -> None:
+ super().__init__()
+ self.norm_pix = norm_pix
+ self.patch_size = patch_size
+ self.loss_module = MODELS.build(loss)
+
+ def patchify(self, imgs: torch.Tensor) -> torch.Tensor:
+ """Split images into non-overlapped patches."""
+ p = self.patch_size
+ assert imgs.shape[2] == imgs.shape[3] and imgs.shape[2] % p == 0
+
+ h = w = imgs.shape[2] // p
+ x = imgs.reshape(shape=(imgs.shape[0], 3, h, p, w, p))
+ x = torch.einsum('nchpwq->nhwpqc', x)
+ x = x.reshape(shape=(imgs.shape[0], h * w, p**2 * 3))
+ return x
+
+ def construct_target(self, target: torch.Tensor) -> torch.Tensor:
+ """Construct the reconstruction target."""
+ target = self.patchify(target)
+ if self.norm_pix:
+ # normalize the target image
+ mean = target.mean(dim=-1, keepdim=True)
+ var = target.var(dim=-1, keepdim=True)
+ target = (target - mean) / (var + 1.e-6)**.5
+
+ return target
+
+ def loss(self, pred: torch.Tensor, target: torch.Tensor,
+ mask: torch.Tensor) -> torch.Tensor:
+ """Generate loss."""
+ target = self.construct_target(target)
+ loss = self.loss_module(pred, target, mask)
+
+ return loss
+```
+
+Õ«īµłÉÕ«×ńÄ░ÕÉÄ’╝īõ╣ŗÕÉÄńÜ䵣źķ¬żÕÆī [Õ¤║õ║ÄÕłåń▒╗Õż┤](#Õ¤║õ║ÄÕłåń▒╗Õż┤) õĖŁńÜ䵣źķ¬ż 2 ÕÆīµŁźķ¬ż 3 õĖĆĶć┤ŃĆé
+
+## µĘ╗ÕŖĀµ¢░ńÜ䵏¤Õż▒ÕćĮµĢ░
+
+Ķ”üµĘ╗ÕŖĀµ¢░ńÜ䵏¤Õż▒ÕćĮµĢ░’╝īµłæõ╗¼õĖ╗Ķ”üķ£ĆĶ”üÕ£©µŹ¤Õż▒ÕćĮµĢ░µ©ĪÕØŚõĖŁ `forward` ÕćĮµĢ░ŃĆéĶ┐Öķćīķ£ĆĶ”üµ│©µäÅńÜ䵜»’╝īµŹ¤Õż▒µ©ĪÕØŚõ╣¤Õ║öĶ»źµ│©ÕåīÕł░`MODELS`õĖŁŃĆéÕÅ”Õż¢’╝īÕł®ńö©ĶŻģķź░ÕÖ© `weighted_loss` ÕÅ»õ╗źµ¢╣õŠ┐ńÜäÕ«×ńÄ░Õ»╣µ»ÅõĖ¬Õģāń┤ĀńÜ䵏¤Õż▒Ķ┐øĶĪīÕŖĀµØāÕ╣│ÕØćŃĆé
+
+ÕüćĶ«Šµłæõ╗¼Ķ”üµ©Īµŗ¤õ╗ÄÕÅ”õĖĆõĖ¬Õłåń▒╗µ©ĪÕ×ŗńö¤µłÉńÜäµ”éńÄćÕłåÕĖā’╝īķ£ĆĶ”üµĘ╗ÕŖĀ `L1loss` µØźÕ«×ńÄ░Ķ»źńø«ńÜäŃĆé
+
+1. ÕłøÕ╗║õĖĆõĖ¬µ¢░µ¢ćõ╗Č `mmpretrain/models/losses/l1_loss.py`
+
+ ```python
+ import torch
+ import torch.nn as nn
+
+ from mmpretrain.registry import MODELS
+ from .utils import weighted_loss
+
+ @weighted_loss
+ def l1_loss(pred, target):
+ assert pred.size() == target.size() and target.numel() > 0
+ loss = torch.abs(pred - target)
+ return loss
+
+ @MODELS.register_module()
+ class L1Loss(nn.Module):
+
+ def __init__(self, reduction='mean', loss_weight=1.0):
+ super(L1Loss, self).__init__()
+ self.reduction = reduction
+ self.loss_weight = loss_weight
+
+ def forward(self,
+ pred,
+ target,
+ weight=None,
+ avg_factor=None,
+ reduction_override=None):
+ assert reduction_override in (None, 'none', 'mean', 'sum')
+ reduction = (
+ reduction_override if reduction_override else self.reduction)
+ loss = self.loss_weight * l1_loss(
+ pred, target, weight, reduction=reduction, avg_factor=avg_factor)
+ return loss
+ ```
+
+2. Õ£©µ¢ćõ╗Č `mmpretrain/models/losses/__init__.py` õĖŁÕ»╝ÕģźĶ┐ÖõĖ¬µ©ĪÕØŚ
+
+ ```python
+ ...
+ from .l1_loss import L1Loss
+
+ __all__ = [
+ ..., 'L1Loss'
+ ]
+ ```
+
+3. õ┐«µö╣ķģŹńĮ«µ¢ćõ╗ČõĖŁńÜä `loss` ÕŁŚµ«Ąõ╗źõĮ┐ńö©µ¢░ńÜ䵏¤Õż▒ÕćĮµĢ░
+
+ ```python
+ model = dict(
+ head=dict(
+ loss=dict(type='L1Loss', loss_weight=1.0),
+ ))
+ ```
+
+µ£ĆÕÉĵłæõ╗¼ÕÅ»õ╗źÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁń╗ōÕÉłµēƵ£ēµ¢░Õó×ńÜ䵩ĪÕ×ŗń╗äõ╗ČµØźõĮ┐ńö©µ¢░ńÜ䵩ĪÕ×ŗŃĆéńö▒õ║Ä`ResNet_CIFAR` õĖŹµś»õĖĆõĖ¬Õ¤║õ║ÄViTńÜäķ¬©Õ╣▓ńĮæń╗£’╝īĶ┐Öķćīµłæõ╗¼õĖŹńö©`VisionTransformerClsHead`ńÜäķģŹńĮ«ŃĆé
+
+```python
+model = dict(
+ type='ImageClassifier',
+ backbone=dict(
+ type='ResNet_CIFAR',
+ depth=18,
+ num_stages=4,
+ out_indices=(3, ),
+ style='pytorch'),
+ neck=dict(type='GlobalAveragePooling'),
+ head=dict(
+ type='LinearClsHead',
+ num_classes=10,
+ in_channels=512,
+ loss=dict(type='L1Loss', loss_weight=1.0),
+ topk=(1, 5),
+ ))
+
+```
+
+```{tip}
+õĖ║õ║åµ¢╣õŠ┐’╝īńøĖÕÉīńÜ䵩ĪÕ×ŗń╗äõ╗ČÕÅ»õ╗źńø┤µÄźõ╗ÄÕĘ▓µ£ēńÜäconfigµ¢ćõ╗Čķćīń╗¦µē┐’╝īµø┤ÕżÜń╗åĶŖéÕÅ»õ╗źÕÅéĶĆā[ÕŁ”õ╣ĀķģŹńĮ«µ¢ćõ╗Č](../user_guides/config.md)ŃĆé
+```
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/npu.md b/internlm_langchain/knowledge_base/MMPreTrain/content/npu.md
new file mode 100644
index 00000000..b81c1751
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/npu.md
@@ -0,0 +1,41 @@
+# NPU (ÕŹÄõĖ║µśćĶģŠ)
+
+## õĮ┐ńö©µ¢╣µ│Ģ
+
+ķ”¢Õģł’╝īĶ»ĘÕÅéĶĆā[ķōŠµÄź](https://mmcv.readthedocs.io/zh_CN/latest/get_started/build.html#npu-mmcv-full)Õ«ēĶŻģÕĖ”µ£ē NPU µö»µīüńÜä MMCV ÕÆī[ķōŠµÄź](https://mmengine.readthedocs.io/en/latest/get_started/installation.html#build-from-source)Õ«ēĶŻģ MMEngineŃĆé
+
+õĮ┐ńö©Õ”éõĖŗÕæĮõ╗ż’╝īÕÅ»õ╗źÕł®ńö© 8 õĖ¬ NPU Õ£©µ£║ÕÖ©õĖŖĶ«Łń╗āµ©ĪÕ×ŗ’╝łõ╗ź ResNet õĖ║õŠŗ’╝ē’╝Ü
+
+```shell
+bash tools/dist_train.sh configs/cspnet/resnet50_8xb32_in1k.py 8
+```
+
+µł¢ĶĆģ’╝īõĮ┐ńö©Õ”éõĖŗÕæĮõ╗ż’╝īÕ£©õĖĆõĖ¬ NPU õĖŖĶ«Łń╗āµ©ĪÕ×ŗ’╝łõ╗ź ResNet õĖ║õŠŗ’╝ē’╝Ü
+
+```shell
+python tools/train.py configs/cspnet/resnet50_8xb32_in1k.py
+```
+
+## ń╗ÅĶ┐ćķ¬īĶ»üńÜ䵩ĪÕ×ŗ
+
+| Model | Top-1 (%) | Top-5 (%) | Config | Download |
+| :---------------------------------------------------------: | :-------: | :-------: | :----------------------------------------------------------: | :-------------------------------------------------------------: |
+| [ResNet-50](https://github.com/open-mmlab/mmclassification/blob/1.x/configs/resnet/README.md) | 76.40 | 93.21 | [config](https://github.com/open-mmlab/mmclassification/blob/1.x/configs/resnet/resnet50_8xb32_in1k.py) | [model](<>) \| [log](https://download.openmmlab.com/mmclassification/v1/device/npu/resnet50_8xb32_in1k.log) |
+| [ResNetXt-32x4d-50](https://github.com/open-mmlab/mmclassification/blob/1.x/configs/resnext/README.md) | 77.48 | 93.75 | [config](https://github.com/open-mmlab/mmclassification/blob/1.x/configs/resnext/resnext50-32x4d_8xb32_in1k.py) | [model](<>) \| [log](https://download.openmmlab.com/mmclassification/v1/device/npu/resnext50-32x4d_8xb32_in1k.log) |
+| [HRNet-W18](https://github.com/open-mmlab/mmclassification/blob/master/configs/hrnet/README.md) | 77.06 | 93.57 | [config](https://github.com/open-mmlab/mmclassification/blob/1.x/configs/hrnet/hrnet-w18_4xb32_in1k.py) | [model](<>) \| [log](https://download.openmmlab.com/mmclassification/v1/device/npu/hrnet-w18_4xb32_in1k.log) |
+| [ResNetV1D-152](https://github.com/open-mmlab/mmclassification/blob/1.x/configs/resnet/README.md) | 79.41 | 94.48 | [config](https://github.com/open-mmlab/mmclassification/blob/1.x/configs/resnet/resnetv1d152_8xb32_in1k.py) | [model](<>) \| [log](https://download.openmmlab.com/mmclassification/v1/device/npu/resnetv1d152_8xb32_in1k.log) |
+| [SE-ResNet-50](https://github.com/open-mmlab/mmclassification/blob/1.x/configs/seresnet/README.md) | 77.65 | 93.74 | [config](https://github.com/open-mmlab/mmclassification/blob/1.x/configs/seresnet/seresnet50_8xb32_in1k.py) | [model](<>) \|[log](https://download.openmmlab.com/mmclassification/v1/device/npu/seresnet50_8xb32_in1k.log) |
+| [ShuffleNetV2 1.0x](https://github.com/open-mmlab/mmclassification/blob/1.x/configs/shufflenet_v2/README.md) | 69.52 | 88.79 | [config](https://github.com/open-mmlab/mmclassification/blob/1.x/configs/shufflenet_v2/shufflenet-v2-1x_16xb64_in1k.py) | [model](<>) \| [log](https://download.openmmlab.com/mmclassification/v1/device/npu/shufflenet-v2-1x_16xb64_in1k.log) |
+| [MobileNetV2](https://github.com/open-mmlab/mmclassification/tree/1.x/configs/mobilenet_v2) | 71.74 | 90.28 | [config](https://github.com/open-mmlab/mmclassification/blob/1.x/configs/mobilenet_v2/mobilenet-v2_8xb32_in1k.py) | [model](<>) \| [log](https://download.openmmlab.com/mmclassification/v1/device/npu/mobilenet-v2_8xb32_in1k.log) |
+| [MobileNetV3-Small](https://github.com/open-mmlab/mmclassification/blob/1.x/configs/mobilenet_v3/README.md) | 67.09 | 87.17 | [config](https://github.com/open-mmlab/mmclassification/blob/1.x/configs/mobilenet_v3/mobilenet-v3-small_8xb128_in1k.py) | [model](<>) \| [log](https://download.openmmlab.com/mmclassification/v1/device/npu/mobilenet-v3-small.log) |
+| [\*CSPResNeXt50](https://github.com/open-mmlab/mmclassification/blob/1.x/configs/cspnet/README.md) | 77.25 | 93.46 | [config](https://github.com/open-mmlab/mmclassification/blob/1.x/configs/cspnet/cspresnext50_8xb32_in1k.py) | [model](<>) \| [log](https://download.openmmlab.com/mmclassification/v1/device/npu/cspresnext50_8xb32_in1k.log) |
+| [\*EfficientNet-B4](https://github.com/open-mmlab/mmclassification/blob/1.x/configs/efficientnet/README.md) | 75.73 | 92.9100 | [config](https://github.com/open-mmlab/mmclassification/blob/1.x/configs/efficientnet/efficientnet-b4_8xb32_in1k.py) | [model](<>) \|[log](https://download.openmmlab.com/mmclassification/v1/device/npu/efficientnet-b4_8xb32_in1k.log) |
+| [\*\*DenseNet121](https://github.com/open-mmlab/mmclassification/blob/1.x/configs/densenet/README.md) | 72.53 | 90.85 | [config](https://github.com/open-mmlab/mmclassification/blob/1.x/configs/densenet/densenet121_4xb256_in1k.py) | [model](<>) \| [log](https://download.openmmlab.com/mmclassification/v1/device/npu/densenet121_4xb256_in1k.log) |
+
+**µ│©µäÅ:**
+
+- Õ”éµ×£µ▓Īµ£ēńē╣Õł½µĀćĶ«░’╝īNPU õĖŖńÜäń╗ōµ×£õĖÄõĮ┐ńö© FP32 ńÜä GPU õĖŖńÜäń╗ōµ×£ń╗ōµ×£ńøĖÕÉīŃĆé
+- (\*) Ķ┐Öõ║øµ©ĪÕ×ŗńÜäĶ«Łń╗āń╗ōµ×£õĮÄõ║ÄńøĖÕ║öµ©ĪÕ×ŗõĖŁĶć¬Ķ┐░µ¢ćõ╗ČõĖŖńÜäń╗ōµ×£’╝īõĖ╗Ķ”üµś»ÕøĀõĖ║Ķć¬Ķ┐░µ¢ćõ╗ČõĖŖńÜäń╗ōµ×£ńø┤µÄźµś» timm Ķ«Łń╗āÕŠŚÕć║ńÜäµØāķ插╝īĶĆīĶ┐ÖĶŠ╣ńÜäń╗ōµ×£µś»µĀ╣µŹ« mmcls ńÜäķģŹńĮ«ķ揵¢░Ķ«Łń╗āÕŠŚÕł░ńÜäń╗ōµ×£ŃĆéGPU õĖŖńÜäķģŹńĮ«Ķ«Łń╗āń╗ōµ×£õĖÄ NPU ńÜäń╗ōµ×£ńøĖÕÉīŃĆé
+- (\*\*)Ķ┐ÖõĖ¬µ©ĪÕ×ŗńÜäń▓ŠÕ║”ńĢźõĮÄ’╝īÕøĀõĖ║ config µś» 4 Õ╝ĀÕŹĪńÜäķģŹńĮ«’╝īµłæõ╗¼õĮ┐ńö© 8 Õ╝ĀÕŹĪµØźĶ┐ÉĶĪī’╝īńö©µłĘÕÅ»õ╗źĶ░āµĢ┤ĶČģÕÅéµĢ░õ╗źĶÄĘÕŠŚµ£ĆõĮ│ń▓ŠÕ║”ń╗ōµ×£ŃĆé
+
+**õ╗źõĖŖµēƵ£ēµ©ĪÕ×ŗµØāķćŹÕÅŖĶ«Łń╗āµŚźÕ┐ŚÕØćńö▒ÕŹÄõĖ║µśćĶģŠÕøóķś¤µÅÉõŠø**
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/pipeline.md b/internlm_langchain/knowledge_base/MMPreTrain/content/pipeline.md
new file mode 100644
index 00000000..99506b08
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/pipeline.md
@@ -0,0 +1,148 @@
+# Ķć¬Õ«Üõ╣ēµĢ░µŹ«ÕżäńÉåµĄüń©ŗ
+
+## µĢ░µŹ«µĄüńÜäĶ«ŠĶ«Ī
+
+Õ£©[µ¢░µĢ░µŹ«ķøåµĢÖń©ŗ](./datasets.md)õĖŁ’╝īµłæõ╗¼ń¤źķüōµĢ░µŹ«ķøåń▒╗õĮ┐ńö© `load_data_list` µ¢╣µ│ĢµØźÕłØÕ¦ŗÕī¢µĢ┤õĖ¬µĢ░µŹ«ķøå’╝īµłæõ╗¼Õ░åµ»ÅõĖ¬µĀʵ£¼ńÜäõ┐Īµü»õ┐ØÕŁśÕł░õĖĆõĖ¬ dict õĖŁŃĆé
+
+ķĆÜÕĖĖ’╝īõĖ║õ║åĶŖéń£üÕåģÕŁś’╝īµłæõ╗¼ÕŬÕŖĀĶĮĮ `load_data_list` õĖŁńÜäÕøŠńēćĶĘ»ÕŠäÕÆīµĀćńŁŠ’╝īõĮ┐ńö©µŚČÕŖĀĶĮĮÕ«īµĢ┤ńÜäÕøŠńēćÕåģÕ«╣ŃĆ鵣żÕż¢’╝īµłæõ╗¼ÕÅ»ĶāĮÕĖīµ£øÕ£©Ķ«Łń╗āµŚČķĆēµŗ®µĀʵ£¼µŚČĶ┐øĶĪīõĖĆõ║øķÜŵ£║µĢ░µŹ«µē®ÕģģŃĆéÕćĀõ╣ĵēƵ£ēńÜäµĢ░µŹ«ÕŖĀĶĮĮŃĆüķóäÕżäńÉåÕÆīµĀ╝Õ╝ÅÕī¢µōŹõĮ£ķāĮÕÅ»õ╗źķĆÜĶ┐ć**µĢ░µŹ«ń«Īķüō**Õ£© MMPretrain õĖŁĶ┐øĶĪīķģŹńĮ«ŃĆé
+
+µĢ░µŹ«ń«ĪķüōµäÅÕæ│ńØĆÕ£©õ╗ĵĢ░µŹ«ķøåõĖŁń┤óÕ╝ĢµĀʵ£¼µŚČÕ”éõĮĢÕżäńÉåµĀʵ£¼ÕŁŚÕģĖ’╝īÕ«āńö▒õĖĆń│╗ÕłŚµĢ░µŹ«ÕÅśµŹóń╗䵳ÉŃĆéµ»ÅõĖ¬µĢ░µŹ«ÕÅśµŹóķāĮÕ░åõĖĆõĖ¬ÕŁŚÕģĖõĮ£õĖ║ĶŠōÕģź’╝īÕ»╣ÕģČĶ┐øĶĪīÕżäńÉå’╝īÕ╣ČõĖ║õĖŗõĖĆõĖ¬µĢ░µŹ«ÕÅśµŹóĶŠōÕć║õĖĆõĖ¬ÕŁŚÕģĖŃĆé
+
+Ķ┐Öµś» ImageNet õĖŖ ResNet-50 Ķ«Łń╗āńÜäµĢ░µŹ«ń«Īķüōńż║õŠŗŃĆé
+
+```python
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='RandomResizedCrop', scale=224),
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'),
+ dict(type='PackInputs'),
+]
+```
+
+MMPretrain õĖŁµēƵ£ēÕÅ»ńö©ńÜäµĢ░µŹ«ÕÅśµŹóķāĮÕÅ»õ╗źÕ£© [µĢ░µŹ«ÕÅśµŹóµ¢ćµĪŻ](mmpretrain.datasets.transforms) õĖŁµēŠÕł░ŃĆé
+
+## õ┐«µö╣Ķ«Łń╗ā/µĄŗĶ»Ģń«Īķüō
+
+MMPretrain õĖŁńÜäµĢ░µŹ«ń«ĪķüōķØ×ÕĖĖńüĄµ┤╗ŃĆéµé©ÕćĀõ╣ÄÕÅ»õ╗źõ╗ÄķģŹńĮ«µ¢ćõ╗ČõĖŁµÄ¦ÕłČµĢ░µŹ«ķóäÕżäńÉåńÜäµ»ÅõĖƵŁź’╝īõĮåÕÅ”õĖƵ¢╣ķØó’╝īķØóÕ»╣Õ”éµŁżÕżÜńÜäķĆēķĪ╣’╝īµé©ÕÅ»ĶāĮõ╝ܵä¤Õł░Õø░µāæŃĆé
+
+Ķ┐Öµś»ÕøŠÕāÅÕłåń▒╗õ╗╗ÕŖĪńÜäÕĖĖĶ¦üÕüܵ│ĢÕÆīµīćÕŹŚŃĆé
+
+### Ķ»╗ÕÅ¢
+
+Õ£©µĢ░µŹ«ń«ĪķüōńÜäÕ╝ĆÕ¦ŗ’╝īµłæõ╗¼ķĆÜÕĖĖķ£ĆĶ”üõ╗ĵ¢ćõ╗ČĶĘ»ÕŠäÕŖĀĶĮĮÕøŠÕāŵĢ░µŹ«ŃĆé
+[`LoadImageFromFile`](mmcv.transforms.LoadImageFromFile) ķĆÜÕĖĖńö©õ║ĵē¦ĶĪīµŁżõ╗╗ÕŖĪŃĆé
+
+```python
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ ...
+]
+```
+
+Õ”éµ×£µé©µā│õ╗ÄÕģʵ£ēńē╣µ«ŖµĀ╝Õ╝ŵł¢ńē╣µ«ŖõĮŹńĮ«ńÜäµ¢ćõ╗ČõĖŁÕŖĀĶĮĮµĢ░µŹ«’╝īµé©ÕÅ»õ╗ź [Õ«×µ¢Įµ¢░ńÜäÕŖĀĶĮĮÕÅśµŹó](#µĘ╗ÕŖĀµ¢░ńÜäµĢ░µŹ«ÕÅśµŹó) Õ╣ČÕ░åÕģȵĘ╗ÕŖĀÕł░µĢ░µŹ«ń«ĪķüōńÜäÕ╝ĆÕż┤ŃĆé
+
+### Õó×Õ╝║ÕÆīÕģČÕ«āÕżäńÉå
+
+Õ£©Ķ«Łń╗āĶ┐ćń©ŗõĖŁ’╝īµłæõ╗¼ķĆÜÕĖĖķ£ĆĶ”üÕüܵĢ░µŹ«Õó×Õ╝║µØźķü┐ÕģŹĶ┐ćµŗ¤ÕÉłŃĆéÕ£©µĄŗĶ»ĢĶ┐ćń©ŗõĖŁ’╝īµłæõ╗¼Ķ┐śķ£ĆĶ”üÕüÜõĖĆõ║øµĢ░µŹ«ÕżäńÉå’╝īµ»öÕ”éĶ░āµĢ┤Õż¦Õ░ÅÕÆīĶŻüÕē¬ŃĆéĶ┐Öõ║øµĢ░µŹ«ÕÅśµŹóÕ░åµöŠńĮ«Õ£©ÕŖĀĶĮĮĶ┐ćń©ŗõ╣ŗÕÉÄŃĆé
+
+Ķ┐Öµś»õĖĆõĖ¬ń«ĆÕŹĢńÜäµĢ░µŹ«µē®Õģģµ¢╣µĪłńż║õŠŗŃĆéÕ«āõ╝ÜÕ░åĶŠōÕģźÕøŠÕāÅķÜŵ£║Ķ░āµĢ┤Õż¦Õ░ÅÕ╣ČĶŻüÕē¬Õł░µīćիܵ»öõŠŗ’╝īÕ╣ČķÜŵ£║µ░┤Õ╣│ń┐╗ĶĮ¼ÕøŠÕāÅŃĆé
+
+```python
+train_pipeline = [
+ ...
+ dict(type='RandomResizedCrop', scale=224),
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'),
+ ...
+]
+```
+
+Ķ┐Öµś» [Swin-Transformer](../papers/swin_transformer.md) Ķ«Łń╗āõĖŁõĮ┐ńö©ńÜäÕż¦ķćŵĢ░µŹ«Õó×Õ╝║ķģŹµ¢╣ńż║õŠŗŃĆé õĖ║õ║åõĖÄÕ«śµ¢╣Õ«×µ¢Įõ┐صīüõĖĆĶć┤’╝īÕ«āµīćÕ«Ü `pillow` õĮ£õĖ║Ķ░āµĢ┤Õż¦Õ░ÅÕÉÄń½»’╝ī`bicubic` õĮ£õĖ║Ķ░āµĢ┤Õż¦Õ░Åń«Śµ│ĢŃĆé µŁżÕż¢’╝īÕ«āµĘ╗ÕŖĀõ║å [`RandAugment`](mmpretrain.datasets.transforms.RandAugment) ÕÆī [`RandomErasing`](mmpretrain.datasets.transforms.RandomErasing) õĮ£õĖ║ķóØÕż¢ńÜäµĢ░µŹ«Õó×Õ╝║µ¢╣µ│ĢŃĆé
+
+µŁżķģŹńĮ«µīćÕ«Üõ║åµĢ░µŹ«µē®ÕģģńÜäµ»ÅõĖ¬ń╗åĶŖé’╝īµé©ÕŬķ£ĆÕ░åÕģČÕżŹÕłČÕł░µé©Ķć¬ÕĘ▒ńÜäķģŹńĮ«µ¢ćõ╗ČõĖŁÕŹ│ÕÅ»Õ║öńö© Swin-Transformer ńÜäµĢ░µŹ«µē®ÕģģŃĆé
+
+```python
+bgr_mean = [103.53, 116.28, 123.675]
+bgr_std = [57.375, 57.12, 58.395]
+
+train_pipeline = [
+ ...
+ dict(type='RandomResizedCrop', scale=224, backend='pillow', interpolation='bicubic'),
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'),
+ dict(
+ type='RandAugment',
+ policies='timm_increasing',
+ num_policies=2,
+ total_level=10,
+ magnitude_level=9,
+ magnitude_std=0.5,
+ hparams=dict(
+ pad_val=[round(x) for x in bgr_mean], interpolation='bicubic')),
+ dict(
+ type='RandomErasing',
+ erase_prob=0.25,
+ mode='rand',
+ min_area_ratio=0.02,
+ max_area_ratio=1 / 3,
+ fill_color=bgr_mean,
+ fill_std=bgr_std),
+ ...
+]
+```
+
+```{note}
+ķĆÜÕĖĖ’╝īµĢ░µŹ«ń«ĪķüōõĖŁńÜäµĢ░µŹ«Õó×Õ╝║ķā©Õłåõ╗ģÕżäńÉåÕøŠÕāŵ¢╣ķØóńÜäÕÅśµŹó’╝īĶĆīõĖŹÕżäńÉåÕøŠÕāÅÕĮÆõĖĆÕī¢µł¢µĘĘÕÉł/Õē¬ÕłćµĘĘÕÉłńŁēÕÅśµŹóŃĆé ÕøĀõĖ║µłæõ╗¼ÕÅ»õ╗źÕ»╣ batch data ÕüÜ image normalization ÕÆī mixup/cutmix µØźÕŖĀķƤŃĆéĶ”üķģŹńĮ«ÕøŠÕāÅÕĮÆõĖĆÕī¢ÕÆī mixup/cutmix’╝īĶ»ĘõĮ┐ńö© [µĢ░µŹ«ķóäÕżäńÉåÕÖ©](mmpretrain.models.utils.data_preprocessor)ŃĆé
+```
+
+### µĀ╝Õ╝ÅÕī¢
+
+µĀ╝Õ╝ÅÕī¢µś»õ╗ĵĢ░µŹ«õ┐Īµü»ÕŁŚÕģĖõĖŁµöČķøåĶ«Łń╗āµĢ░µŹ«’╝īÕ╣ČÕ░åĶ┐Öõ║øµĢ░µŹ«ĶĮ¼µŹóõĖ║µ©ĪÕ×ŗÕÅŗÕźĮńÜäµĀ╝Õ╝ÅŃĆé
+
+Õ£©Õż¦ÕżÜµĢ░µāģÕåĄõĖŗ’╝īµé©ÕÅ»õ╗źń«ĆÕŹĢÕ£░õĮ┐ńö© [`PackInputs`](mmpretrain.datasets.transforms.PackInputs)’╝īÕ«āÕ░å NumPy µĢ░ń╗äµĀ╝Õ╝ÅńÜäÕøŠÕāÅĶĮ¼µŹóõĖ║ PyTorch Õ╝ĀķćÅ’╝īÕ╣ČÕ░å ground truth ń▒╗Õł½õ┐Īµü»ÕÆīÕģČõ╗¢Õģāõ┐Īµü»µēōÕīģõĖ║ [`DataSample`](mmpretrain.structures.DataSample)ŃĆé
+
+```python
+train_pipeline = [
+ ...
+ dict(type='PackInputs'),
+]
+```
+
+## µĘ╗ÕŖĀµ¢░ńÜäµĢ░µŹ«ÕÅśµŹó
+
+1. Õ£©õ╗╗õĮĢµ¢ćõ╗ČõĖŁÕåÖÕģźõĖĆõĖ¬µ¢░ńÜäµĢ░µŹ«ĶĮ¼µŹó’╝īõŠŗÕ”é `my_transform.py`’╝īÕ╣ČÕ░åÕģȵöŠÕ£©µ¢ćõ╗ČÕż╣ `mmpretrain/datasets/transforms/` õĖŁŃĆé µĢ░µŹ«ÕÅśµŹóń▒╗ķ£ĆĶ”üń╗¦µē┐ [`mmcv.transforms.BaseTransform`](mmcv.transforms.BaseTransform) ń▒╗Õ╣ČĶ”åńø¢õ╗źÕŁŚÕģĖõĮ£õĖ║ĶŠōÕģźÕ╣ČĶ┐öÕø×ÕŁŚÕģĖńÜä `transform` µ¢╣µ│ĢŃĆé
+
+ ```python
+ from mmcv.transforms import BaseTransform
+ from mmpretrain.registry import TRANSFORMS
+
+ @TRANSFORMS.register_module()
+ class MyTransform(BaseTransform):
+
+ def transform(self, results):
+ # Modify the data information dict `results`.
+ return results
+ ```
+
+2. Õ£© `mmpretrain/datasets/transforms/__init__.py` õĖŁÕ»╝Õģźµ¢░ńÜäÕÅśµŹó
+
+ ```python
+ ...
+ from .my_transform import MyTransform
+
+ __all__ = [
+ ..., 'MyTransform'
+ ]
+ ```
+
+3. Õ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁõĮ┐ńö©
+
+ ```python
+ train_pipeline = [
+ ...
+ dict(type='MyTransform'),
+ ...
+ ]
+ ```
+
+## µĢ░µŹ«ń«ĪķüōÕÅ»Ķ¦åÕī¢
+
+µĢ░µŹ«µĄüµ░┤ń║┐Ķ«ŠĶ«ĪÕ«īµłÉÕÉÄ’╝īÕÅ»õ╗źõĮ┐ńö© [ÕÅ»Ķ¦åÕī¢ÕĘźÕģĘ](../useful_tools/dataset_visualization.md) µ¤źń£ŗµĢłµ×£ŃĆé
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/pretrain_custom_dataset.md b/internlm_langchain/knowledge_base/MMPreTrain/content/pretrain_custom_dataset.md
new file mode 100644
index 00000000..786ecba8
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/pretrain_custom_dataset.md
@@ -0,0 +1,247 @@
+# Õ”éõĮĢÕ£©Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåõĖŖĶ┐øĶĪīµ©ĪÕ×ŗķóäĶ«Łń╗ā
+
+Õ£©µ£¼µĢÖń©ŗõĖŁ’╝īµłæõ╗¼µÅÉõŠøõ║åõĖĆõĖ¬Õ«×ĶĘĄńż║õŠŗÕÆīõĖĆõ║øµ£ēÕģ│Õ”éõĮĢÕ£©µé©Ķć¬ÕĘ▒ńÜäµĢ░µŹ«ķøåõĖŖĶ┐øĶĪīĶ«Łń╗āńÜäµŖĆÕʦŃĆé
+
+Õ£© MMPretrain õĖŁ’╝īµłæõ╗¼µö»µīüńö©µłĘńø┤µÄźĶ░āńö© MMPretrain ńÜä `CustomDataset` ’╝łń▒╗õ╝╝õ║Ä `torchvision` ńÜä `ImageFolder`’╝ē, Ķ»źµĢ░µŹ«ķøåĶāĮĶć¬ÕŖ©ńÜäĶ»╗ÕÅ¢ń╗ÖńÜäĶĘ»ÕŠäõĖŗńÜäÕøŠńēćŃĆéõĮĀÕŬķ£ĆĶ”üÕćåÕżćõĮĀńÜäµĢ░µŹ«ķøåĶĘ»ÕŠä’╝īÕ╣Čõ┐«µö╣ķģŹńĮ«µ¢ćõ╗Č’╝īÕŹ│ÕÅ»ĶĮ╗µØŠõĮ┐ńö© MMPretrain Ķ┐øĶĪīķóäĶ«Łń╗āŃĆé
+
+## ń¼¼õĖƵŁź’╝ÜÕćåÕżćõĮĀńÜäµĢ░µŹ«ķøå
+
+µīēńģ¦ [ÕćåÕżćµĢ░µŹ«ķøå](../user_guides/dataset_prepare.md) ÕćåÕżćõĮĀńÜäµĢ░µŹ«ķøåŃĆé
+ÕüćĶ«Šµłæõ╗¼ńÜäµĢ░µŹ«ķøåµĀ╣µ¢ćõ╗ČÕż╣ĶĘ»ÕŠäõĖ║ `data/custom_dataset/`
+
+ÕüćĶ«Šµłæõ╗¼µā│õĮ┐ńö© MAE ń«Śµ│ĢĶ┐øĶĪīÕøŠÕāÅĶć¬ńøæńØŻĶ«Łń╗ā’╝īÕ╣ČõĮ┐ńö©ÕŁÉµ¢ćõ╗ČÕż╣µĀ╝Õ╝ÅńÜä `CustomDataset` µØźń╗äń╗ćµĢ░µŹ«ķøå’╝Ü
+
+```text
+data/custom_dataset/
+Ōö£ŌöĆŌöĆ sample1.png
+Ōö£ŌöĆŌöĆ sample2.png
+Ōö£ŌöĆŌöĆ sample3.png
+Ōö£ŌöĆŌöĆ sample4.png
+ŌööŌöĆŌöĆ ...
+```
+
+## ń¼¼õ║īµŁź’╝ÜķĆēµŗ®õĖĆõĖ¬ķģŹńĮ«µ¢ćõ╗ČõĮ£õĖ║µ©ĪµØ┐
+
+Õ£©µ£¼µĢÖń©ŗõĖŁ’╝īµłæõ╗¼õĮ┐ńö© `configs/mae/mae_vit-base-p16_8xb512-amp-coslr-300e_in1k.py` õĮ£õĖ║õĖĆõĖ¬ńż║õŠŗĶ┐øĶĪīõ╗ŗń╗ŹŃĆé
+ķ”¢ÕģłÕ£©ÕÉīõĖƵ¢ćõ╗ČÕż╣õĖŗÕżŹÕłČõĖĆõ╗ĮķģŹńĮ«µ¢ćõ╗Č’╝īÕ╣ČÕ░åÕģČķćŹÕæĮÕÉŹõĖ║ `mae_vit-base-p16_8xb512-amp-coslr-300e_custom.py`ŃĆé
+
+```{tip}
+µīēńģ¦µā»õŠŗ’╝īķģŹńĮ«ÕÉŹń¦░ńÜäµ£ĆÕÉÄõĖĆõĖ¬ÕŁŚµ«Ąµś»µĢ░µŹ«ķøå’╝īõŠŗÕ”é’╝ī`in1k` ĶĪ©ńż║ ImageNet-1k’╝ī`coco` ĶĪ©ńż║ coco µĢ░µŹ«ķøå
+```
+
+Ķ┐ÖõĖ¬ķģŹńĮ«µ¢ćõ╗ČńÜäÕåģÕ«╣Õ”éõĖŗ’╝Ü
+
+```python
+_base_ = [
+ '../_base_/models/mae_vit-base-p16.py',
+ '../_base_/datasets/imagenet_bs512_mae.py',
+ '../_base_/default_runtime.py',
+]
+
+# optimizer wrapper
+optim_wrapper = dict(
+ type='AmpOptimWrapper',
+ loss_scale='dynamic',
+ optimizer=dict(
+ type='AdamW',
+ lr=1.5e-4 * 4096 / 256,
+ betas=(0.9, 0.95),
+ weight_decay=0.05),
+ paramwise_cfg=dict(
+ custom_keys={
+ 'ln': dict(decay_mult=0.0),
+ 'bias': dict(decay_mult=0.0),
+ 'pos_embed': dict(decay_mult=0.),
+ 'mask_token': dict(decay_mult=0.),
+ 'cls_token': dict(decay_mult=0.)
+ }))
+
+# learning rate scheduler
+param_scheduler = [
+ dict(
+ type='LinearLR',
+ start_factor=0.0001,
+ by_epoch=True,
+ begin=0,
+ end=40,
+ convert_to_iter_based=True),
+ dict(
+ type='CosineAnnealingLR',
+ T_max=260,
+ by_epoch=True,
+ begin=40,
+ end=300,
+ convert_to_iter_based=True)
+]
+
+# runtime settings
+train_cfg = dict(type='EpochBasedTrainLoop', max_epochs=300)
+default_hooks = dict(
+ # only keeps the latest 3 checkpoints
+ checkpoint=dict(type='CheckpointHook', interval=1, max_keep_ckpts=3))
+
+randomness = dict(seed=0, diff_rank_seed=True)
+
+# auto resume
+resume = True
+
+# NOTE: `auto_scale_lr` is for automatically scaling LR
+# based on the actual training batch size.
+auto_scale_lr = dict(base_batch_size=4096)
+```
+
+## ń¼¼õĖēµŁź’╝Üõ┐«µö╣µĢ░µŹ«ķøåĶ«ŠńĮ«
+
+- ķćŹĶĮĮµĢ░µŹ«ķøåĶ«ŠńĮ«õĖŁńÜä `type` õĖ║ `'CustomDataset'`
+- ķćŹĶĮĮµĢ░µŹ«ķøåĶ«ŠńĮ«õĖŁńÜä `data_root` õĖ║ `data/custom_dataset`
+- ķćŹĶĮĮµĢ░µŹ«ķøåĶ«ŠńĮ«õĖŁńÜä `ann_file` õĖ║ń®║ÕŁŚń¼”õĖ▓’╝īĶ┐Öµś»ÕøĀõĖ║µłæõ╗¼õĮ┐ńö©ÕŁÉµ¢ćõ╗ȵĀ╝Õ╝ÅńÜä `CustomDataset`’╝īķ£ĆĶ”üÕ░åķģŹńĮ«µ¢ćõ╗ČńĮ«ń®║
+- ķćŹĶĮĮµĢ░µŹ«ķøåĶ«ŠńĮ«õĖŁńÜä `data_prefix` õĖ║ń®║ÕŁŚń¼”õĖ▓’╝īĶ┐Öµś»ÕøĀõĖ║µłæõ╗¼ÕĖīµ£øõĮ┐ńö©µĢ░µŹ«ķøåµĀ╣ńø«ÕĮĢõĖŗńÜäµēƵ£ēµĢ░µŹ«Ķ┐øĶĪīĶ«Łń╗ā’╝īÕ╣ČõĖŹķ£ĆĶ”üÕ░åÕģȵŗåÕłåõĖ║õĖŹÕÉīÕŁÉķøåŃĆé
+
+õ┐«µö╣ÕÉÄńÜäµ¢ćõ╗ČÕ║öÕ”éõĖŗ’╝Ü
+
+```python
+_base_ = [
+ '../_base_/models/mae_vit-base-p16.py',
+ '../_base_/datasets/imagenet_bs512_mae.py',
+ '../_base_/default_runtime.py',
+]
+
+# >>>>>>>>>>>>>>> Õ£©µŁżķćŹĶĮĮµĢ░µŹ«Ķ«ŠńĮ« >>>>>>>>>>>>>>>>>>>
+train_dataloader = dict(
+ dataset=dict(
+ type='CustomDataset',
+ data_root='data/custom_dataset/',
+ ann_file='', # µłæõ╗¼ÕüćÕ«ÜõĮ┐ńö©ÕŁÉµ¢ćõ╗ČÕż╣µĀ╝Õ╝Å’╝īÕøĀµŁżķ£ĆĶ”üÕ░åµĀćµ│©µ¢ćõ╗ČńĮ«ń®║
+ data_prefix='', # õĮ┐ńö© `data_root` ĶĘ»ÕŠäõĖŗµēƵ£ēµĢ░µŹ«
+ with_label=False,
+ )
+)
+# <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
+
+# optimizer wrapper
+optim_wrapper = dict(
+ type='AmpOptimWrapper',
+ loss_scale='dynamic',
+ optimizer=dict(
+ type='AdamW',
+ lr=1.5e-4 * 4096 / 256,
+ betas=(0.9, 0.95),
+ weight_decay=0.05),
+ paramwise_cfg=dict(
+ custom_keys={
+ 'ln': dict(decay_mult=0.0),
+ 'bias': dict(decay_mult=0.0),
+ 'pos_embed': dict(decay_mult=0.),
+ 'mask_token': dict(decay_mult=0.),
+ 'cls_token': dict(decay_mult=0.)
+ }))
+
+# learning rate scheduler
+param_scheduler = [
+ dict(
+ type='LinearLR',
+ start_factor=0.0001,
+ by_epoch=True,
+ begin=0,
+ end=40,
+ convert_to_iter_based=True),
+ dict(
+ type='CosineAnnealingLR',
+ T_max=260,
+ by_epoch=True,
+ begin=40,
+ end=300,
+ convert_to_iter_based=True)
+]
+
+# runtime settings
+train_cfg = dict(type='EpochBasedTrainLoop', max_epochs=300)
+default_hooks = dict(
+ # only keeps the latest 3 checkpoints
+ checkpoint=dict(type='CheckpointHook', interval=1, max_keep_ckpts=3))
+
+randomness = dict(seed=0, diff_rank_seed=True)
+
+# auto resume
+resume = True
+
+# NOTE: `auto_scale_lr` is for automatically scaling LR
+# based on the actual training batch size.
+auto_scale_lr = dict(base_batch_size=4096)
+```
+
+õĮ┐ńö©õĖŖĶ┐░ķģŹńĮ«µ¢ćõ╗Č’╝īõĮĀÕ░▒ĶāĮÕż¤ĶĮ╗µØŠńÜäÕ£©Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåõĖŖõĮ┐ńö© `MAE` ń«Śµ│ĢµØźĶ┐øĶĪīķóäĶ«Łń╗āõ║åŃĆé
+
+## ÕÅ”õĖĆõĖ¬õŠŗÕŁÉ’╝ÜÕ£© COCO µĢ░µŹ«ķøåõĖŖĶ«Łń╗ā MAE
+
+```{note}
+õĮĀÕÅ»ĶāĮķ£ĆĶ”üÕÅéĶĆā[µ¢ćµĪŻ](https://github.com/open-mmlab/mmdetection/blob/3.x/docs/en/get_started.md)Õ«ēĶŻģ MMDetection µØźõĮ┐ńö© `mmdet.CocoDataset`ŃĆé
+```
+
+õĖÄÕ£©Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåõĖŖĶ┐øĶĪīķóäĶ«Łń╗āń▒╗õ╝╝’╝īµłæõ╗¼Õ£©µ£¼µĢÖń©ŗõĖŁõ╣¤µÅÉõŠøõ║åõĖĆõĖ¬õĮ┐ńö© COCO µĢ░µŹ«ķøåĶ┐øĶĪīķóäĶ«Łń╗āńÜäńż║õŠŗŃĆéõ┐«µö╣ÕÉÄńÜäµ¢ćõ╗ČÕ”éõĖŗ’╝Ü
+
+```python
+# >>>>>>>>>>>>>>>>>>>>> Start of Changed >>>>>>>>>>>>>>>>>>>>>>>>>
+_base_ = [
+ '../_base_/models/mae_vit-base-p16.py',
+ '../_base_/datasets/imagenet_mae.py',
+ '../_base_/default_runtime.py',
+]
+
+# >>>>>>>>>>>>>>> Õ£©Ķ┐ÖķćīķćŹĶĮĮµĢ░µŹ«ķģŹńĮ« >>>>>>>>>>>>>>>>>>>
+train_dataloader = dict(
+ dataset=dict(
+ type='mmdet.CocoDataset',
+ data_root='data/coco/',
+ ann_file='annotations/instances_train2017.json', # õ╗ģńö©õ║ÄÕŖĀĶĮĮÕøŠńēć’╝īõĖŹõ╝ÜõĮ┐ńö©µĀćńŁŠ
+ data_prefix=dict(img='train2017/'),
+ )
+)
+# <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
+
+# optimizer wrapper
+optim_wrapper = dict(
+ type='AmpOptimWrapper',
+ loss_scale='dynamic',
+ optimizer=dict(
+ type='AdamW',
+ lr=1.5e-4 * 4096 / 256,
+ betas=(0.9, 0.95),
+ weight_decay=0.05),
+ paramwise_cfg=dict(
+ custom_keys={
+ 'ln': dict(decay_mult=0.0),
+ 'bias': dict(decay_mult=0.0),
+ 'pos_embed': dict(decay_mult=0.),
+ 'mask_token': dict(decay_mult=0.),
+ 'cls_token': dict(decay_mult=0.)
+ }))
+# learning rate scheduler
+param_scheduler = [
+ dict(
+ type='LinearLR',
+ start_factor=0.0001,
+ by_epoch=True,
+ begin=0,
+ end=40,
+ convert_to_iter_based=True),
+ dict(
+ type='CosineAnnealingLR',
+ T_max=260,
+ by_epoch=True,
+ begin=40,
+ end=300,
+ convert_to_iter_based=True)
+]
+# runtime settings
+train_cfg = dict(type='EpochBasedTrainLoop', max_epochs=300)
+default_hooks = dict(
+ # only keeps the latest 3 checkpoints
+ checkpoint=dict(type='CheckpointHook', interval=1, max_keep_ckpts=3))
+randomness = dict(seed=0, diff_rank_seed=True)
+# auto resume
+resume = True
+# NOTE: `auto_scale_lr` is for automatically scaling LR
+# based on the actual training batch size.
+auto_scale_lr = dict(base_batch_size=4096)
+```
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/print_config.md b/internlm_langchain/knowledge_base/MMPreTrain/content/print_config.md
new file mode 100644
index 00000000..3ec0d303
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/print_config.md
@@ -0,0 +1,28 @@
+# µēōÕŹ░Õ«īµĢ┤ķģŹńĮ«µ¢ćõ╗Č
+
+`print_config.py`Ķäܵ£¼Ķäܵ£¼õ╝ÜĶ¦Żµ×ɵēƵ£ēĶŠōÕģźÕÅśķćÅ’╝īÕ╣ȵēōÕŹ░Õ«īµĢ┤ķģŹńĮ«õ┐Īµü»ŃĆé
+
+## Ķ»┤µśÄ’╝Ü
+
+`tools/misc/print_config.py` Ķäܵ£¼õ╝ÜķĆÉÕŁŚµēōÕŹ░µĢ┤õĖ¬ķģŹńĮ«µ¢ćõ╗Č’╝īÕ╣ČÕ▒Ģńż║µēƵ£ēÕ»╝ÕģźńÜäµ¢ćõ╗ČŃĆé
+
+```shell
+python tools/misc/print_config.py ${CONFIG} [--cfg-options ${CFG_OPTIONS}]
+```
+
+µēƵ£ēÕÅéµĢ░ńÜäĶ»┤µśÄ’╝Ü
+
+- `config`’╝ܵ©ĪÕ×ŗķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠäŃĆé
+- `--cfg-options`’╝ÜķóØÕż¢ńÜäķģŹńĮ«ķĆēķĪ╣’╝īõ╝ÜĶó½ÕÉłÕģźķģŹńĮ«µ¢ćõ╗Č’╝īÕÅéĶĆā[ÕŁ”õ╣ĀķģŹńĮ«µ¢ćõ╗Č](../user_guides/config.md)ŃĆé
+
+## ńż║õŠŗ’╝Ü
+
+µēōÕŹ░`configs/t2t_vit/t2t-vit-t-14_8xb64_in1k.py`µ¢ćõ╗ČńÜäÕ«īµĢ┤ķģŹńĮ«
+
+```shell
+# µēōÕŹ░Õ«īµłÉńÜäķģŹńĮ«µ¢ćõ╗Č
+python tools/misc/print_config.py configs/t2t_vit/t2t-vit-t-14_8xb64_in1k.py
+
+# Õ░åÕ«īµĢ┤ńÜäķģŹńĮ«µ¢ćõ╗Čõ┐ØÕŁśõĖ║õĖĆõĖ¬ńŗ¼ń½ŗńÜäķģŹńĮ«µ¢ćõ╗Č
+python tools/misc/print_config.py configs/t2t_vit/t2t-vit-t-14_8xb64_in1k.py > final_config.py
+```
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/projects.md b/internlm_langchain/knowledge_base/MMPreTrain/content/projects.md
new file mode 100644
index 00000000..0843dc4d
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/projects.md
@@ -0,0 +1 @@
+# Õ¤║õ║Ä MMPretrain ńÜäķĪ╣ńø«ÕłŚĶĪ©’╝łÕŠģµø┤µ¢░’╝ē
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/runtime.md b/internlm_langchain/knowledge_base/MMPreTrain/content/runtime.md
new file mode 100644
index 00000000..e5fa3864
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/runtime.md
@@ -0,0 +1,213 @@
+# Ķć¬Õ«Üõ╣ēĶ┐ÉĶĪīÕÅéµĢ░
+
+Ķ┐ÉĶĪīÕÅéµĢ░ķģŹńĮ«Õīģµŗ¼Ķ«ĖÕżÜµ£ēńö©ńÜäÕŖ¤ĶāĮ’╝īÕ”éµØāķ揵¢ćõ╗Čõ┐ØÕŁśŃĆüµŚźÕ┐ŚķģŹńĮ«ńŁēńŁē’╝īÕ£©µ£¼µĢÖń©ŗõĖŁ’╝īµłæõ╗¼Õ░åõ╗ŗń╗ŹÕ”éõĮĢķģŹńĮ«Ķ┐Öõ║øÕŖ¤ĶāĮŃĆé
+
+## õ┐ØÕŁśµØāķ揵¢ćõ╗Č
+
+µØāķ揵¢ćõ╗Čõ┐ØÕŁśÕŖ¤ĶāĮµś»õĖĆõĖ¬Õ£©Ķ«Łń╗āķśČµ«Ąķ╗śĶ«żµ│©ÕåīńÜäķÆ®ÕŁÉ’╝ī õĮĀÕÅ»õ╗źķĆÜĶ┐ćķģŹńĮ«µ¢ćõ╗ČõĖŁńÜä `default_hooks.checkpoint` ÕŁŚµ«ĄķģŹńĮ«Õ«āŃĆé
+
+```{note}
+ķÆ®ÕŁÉµ£║ÕłČÕ£© OpenMMLab Õ╝Ƶ║Éń«Śµ│ĢÕ║ōõĖŁÕ║öńö©ķØ×ÕĖĖÕ╣┐µ│øŃĆéķĆÜĶ┐ćķÆ®ÕŁÉ’╝īõĮĀÕÅ»õ╗źÕ£©õĖŹõ┐«µö╣Ķ┐ÉĶĪīÕÖ©ńÜäõĖ╗Ķ”üµē¦ĶĪīķĆ╗ĶŠæńÜäµāģÕåĄõĖŗµÅÆÕģźĶ«ĖÕżÜÕŖ¤ĶāĮŃĆé
+
+ÕÅ»õ╗źķĆÜĶ┐ć{external+mmengine:doc}`ńøĖÕģ│µ¢ćń½Ā `Ķ┐øõĖƵŁźńÉåĶ¦ŻķÆ®ÕŁÉŃĆé
+```
+
+**ķ╗śĶ«żķģŹńĮ«:**
+
+```python
+default_hooks = dict(
+ ...
+ checkpoint = dict(type='CheckpointHook', interval=1)
+ ...
+)
+```
+
+õĖŗķØ󵜻õĖĆõ║ø[µØāķ揵¢ćõ╗ČķÆ®ÕŁÉ(CheckpointHook)](mmengine.hooks.CheckpointHook)ńÜäÕĖĖńö©ÕÅ»ķģŹńĮ«ÕÅéµĢ░ŃĆé
+
+- **`interval`** (int): µ¢ćõ╗Čõ┐ØÕŁśÕ橵£¤ŃĆéÕ”éµ×£õĮ┐ńö©-1’╝īÕ«āÕ░åµ░ĖĶ┐£õĖŹõ╝Üõ┐ØÕŁśµØāķćŹŃĆé
+- **`by_epoch`** (bool): ķĆēµŗ® **`interval`** µś»Õ¤║õ║ÄepochĶ┐śµś»Õ¤║õ║Äiteration’╝ī ķ╗śĶ«żõĖ║ `True`.
+- **`out_dir`** (str): õ┐ØÕŁśµØāķ揵¢ćõ╗ČńÜäµĀ╣ńø«ÕĮĢŃĆéÕ”éµ×£õĖŹµīćÕ«Ü’╝īµŻĆµ¤źńé╣Õ░åĶó½õ┐ØÕŁśÕ£©ÕĘźõĮ£ńø«ÕĮĢõĖŁŃĆéÕ”éµ×£µīćÕ«Ü’╝īµŻĆµ¤źńé╣Õ░åĶó½õ┐ØÕŁśÕ£© **`out_dir`** ńÜäÕŁÉµ¢ćõ╗ČÕż╣õĖŁŃĆé
+- **`max_keep_ckpts`** (int): Ķ”üõ┐ØńĢÖńÜäµØāķ揵¢ćõ╗ȵĢ░ķćÅŃĆéÕ£©µ¤Éõ║øµāģÕåĄõĖŗ’╝īõĖ║õ║åĶŖéń£üńŻüńøśń®║ķŚ┤’╝īµłæõ╗¼ÕĖīµ£øÕŬõ┐ØńĢÖµ£ĆĶ┐æńÜäÕćĀõĖ¬µØāķ揵¢ćõ╗ČŃĆéķ╗śĶ«żõĖ║ -1’╝īõ╣¤Õ░▒µś»µŚĀķÖÉÕłČŃĆé
+- **`save_best`** (str, List[str]): Õ”éµ×£µīćÕ«Ü’╝īÕ«āÕ░åõ┐ØÕŁśÕģʵ£ēµ£ĆõĮ│Ķ»äõ╝░ń╗ōµ×£ńÜäµØāķćŹŃĆé
+ ķĆÜÕĖĖµāģÕåĄõĖŗ’╝īõĮĀÕÅ»õ╗źńø┤µÄźõĮ┐ńö©`save_best="auto"`µØźĶć¬ÕŖ©ķĆēµŗ®Ķ»äõ╝░µīćµĀćŃĆé
+
+ĶĆīÕ”éµ×£õĮĀµā│Ķ”üµø┤ķ½śń║¦ńÜäķģŹńĮ«’╝īĶ»ĘÕÅéĶĆā[µØāķ揵¢ćõ╗ČķÆ®ÕŁÉ(CheckpointHook)](tutorials/hook.md#checkpointhook)ŃĆé
+
+## µØāķćŹÕŖĀĶĮĮ / µ¢Łńé╣Ķ«Łń╗ā
+
+Õ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁ’╝īõĮĀÕÅ»õ╗źÕŖĀĶĮĮµīćիܵ©ĪÕ×ŗµØāķ揵ł¢ĶĆģµ¢Łńé╣ń╗¦ń╗ŁĶ«Łń╗ā’╝īÕ”éõĖŗµēĆńż║:
+
+```python
+# õ╗ĵīćիܵØāķ揵¢ćõ╗ČÕŖĀĶĮĮ
+load_from = "Your checkpoint path"
+
+# µś»ÕÉ”õ╗ÄÕŖĀĶĮĮńÜäµ¢Łńé╣ń╗¦ń╗ŁĶ«Łń╗ā
+resume = False
+```
+
+`load_from` ÕŁŚµ«ĄÕÅ»õ╗źµś»µ£¼Õ£░ĶĘ»ÕŠä’╝īõ╣¤ÕÅ»õ╗źµś»HTTPĶĘ»ÕŠäŃĆéõĮĀÕÅ»õ╗źõ╗ĵŻĆµ¤źńé╣µüóÕżŹĶ«Łń╗ā’╝īµ¢╣µ│Ģµś»µīćÕ«Ü `resume=True`ŃĆé
+
+```{tip}
+õĮĀõ╣¤ÕÅ»õ╗źķĆÜĶ┐ćµīćÕ«Ü `load_from=None` ÕÆī `resume=True` ÕÉ»ńö©õ╗ĵ£Ćµ¢░ńÜäµ¢Łńé╣Ķć¬ÕŖ©µüóÕżŹŃĆé
+Runnerµē¦ĶĪīÕÖ©Õ░åĶć¬ÕŖ©õ╗ÄÕĘźõĮ£ńø«ÕĮĢõĖŁµēŠÕł░µ£Ćµ¢░ńÜäµØāķ揵¢ćõ╗ČŃĆé
+```
+
+Õ”éµ×£õĮĀńö©µłæõ╗¼ńÜä `tools/train.py` Ķäܵ£¼µØźĶ«Łń╗āµ©ĪÕ×ŗ’╝īõĮĀÕŬķ£ĆõĮ┐ńö© `--resume` ÕÅéµĢ░µØźµüóÕżŹĶ«Łń╗ā’╝īÕ░▒õĖŹńö©µēŗÕŖ©õ┐«µö╣ķģŹńĮ«µ¢ćõ╗Čõ║åŃĆéÕ”éõĖŗµēĆńż║:
+
+```bash
+# Ķć¬ÕŖ©õ╗ĵ£Ćµ¢░ńÜäµ¢Łńé╣µüóÕżŹ
+python tools/train.py configs/resnet/resnet50_8xb32_in1k.py --resume
+
+# õ╗ĵīćÕ«ÜńÜäµ¢Łńé╣µüóÕżŹ
+python tools/train.py configs/resnet/resnet50_8xb32_in1k.py --resume checkpoints/resnet.pth
+```
+
+## ķÜŵ£║µĆ¦(Randomness)ķģŹńĮ«
+
+õĖ║õ║åĶ«®Õ«×ķ¬īÕ░ĮÕÅ»ĶāĮµś»ÕÅ»ÕżŹńÄ░ńÜä’╝ī µłæõ╗¼Õ£© `randomness` ÕŁŚµ«ĄõĖŁµÅÉõŠøõ║åõĖĆõ║øµÄ¦ÕłČķÜŵ£║µĆ¦ńÜäķĆēķĪ╣ŃĆé
+
+ķ╗śĶ«żµāģÕåĄõĖŗ’╝īµłæõ╗¼õĖŹõ╝ÜÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁµīćÕ«ÜķÜŵ£║µĢ░ń¦ŹÕŁÉ’╝īÕ£©µ»Åµ¼ĪÕ«×ķ¬īõĖŁ’╝īń©ŗÕ║Åõ╝Üńö¤µłÉõĖĆõĖ¬õĖŹÕÉīńÜäķÜŵ£║µĢ░ń¦ŹÕŁÉŃĆé
+
+**ķ╗śĶ«żķģŹńĮ«:**
+
+```python
+randomness = dict(seed=None, deterministic=False)
+```
+
+õĖ║õ║åõĮ┐Õ«×ķ¬īµø┤ÕģĘÕÅ»ÕżŹńÄ░µĆ¦’╝īõĮĀÕÅ»õ╗źµīćÕ«ÜõĖĆõĖ¬ń¦ŹÕŁÉÕ╣ČĶ«ŠńĮ« `deterministic=True`ŃĆé
+`deterministic` ķĆēķĪ╣ńÜäõĮ┐ńö©µĢłµ×£ÕÅ»õ╗źÕ£©[Ķ┐Öķćī](https://pytorch.org/docs/stable/notes/randomness.html#cuda-convolution-benchmarking)µēŠÕł░ŃĆé
+
+## µŚźÕ┐ŚķģŹńĮ«
+
+µŚźÕ┐ŚńÜäķģŹńĮ«õĖÄÕżÜõĖ¬ÕŁŚµ«Ąµ£ēÕģ│ŃĆé
+
+Õ£©`log_level`ÕŁŚµ«ĄõĖŁ’╝īõĮĀÕÅ»õ╗źµīćÕ«ÜÕģ©Õ▒ƵŚźÕ┐Śń║¦Õł½ŃĆéÕÅéĶ¦ü {external+python:ref}`Logging Levels` õ╗źĶÄĘÕŠŚµŚźÕ┐Śń║¦Õł½ÕłŚĶĪ©ŃĆé
+
+```python
+log_level = 'INFO'
+```
+
+Õ£© `default_hooks.logger` ÕŁŚµ«ĄõĖŁ’╝īõĮĀÕÅ»õ╗źµīćÕ«ÜĶ«Łń╗āÕÆīµĄŗĶ»Ģµ£¤ķŚ┤ńÜ䵌źÕ┐ŚķŚ┤ķÜöŃĆé
+ĶĆīµēƵ£ēÕÅ»ńö©ńÜäÕÅéµĢ░ÕÅ»õ╗źÕ£©[µŚźÕ┐ŚķÆ®ÕŁÉµ¢ćµĪŻ](tutorials/hook.md#loggerhook)õĖŁµēŠÕł░ŃĆé
+
+```python
+default_hooks = dict(
+ ...
+ # µ»Å100µ¼ĪĶ┐Łõ╗ŻÕ░▒µēōÕŹ░õĖƵ¼ĪµŚźÕ┐Ś
+ logger=dict(type='LoggerHook', interval=100),
+ ...
+)
+```
+
+Õ£© `log_processor` ÕŁŚµ«ĄõĖŁ’╝īõĮĀÕÅ»õ╗źµīćիܵŚźÕ┐Śõ┐Īµü»ńÜäÕ╣│µ╗æµ¢╣µ│ĢŃĆé
+ķĆÜÕĖĖ’╝īµłæõ╗¼õĮ┐ńö©õĖĆõĖ¬ķĢ┐Õ║”õĖ║10ńÜäń¬ŚÕÅŻµØźÕ╣│µ╗æµŚźÕ┐ŚõĖŁńÜäÕĆ╝’╝īÕ╣ČĶŠōÕć║µēƵ£ēõ┐Īµü»ńÜäÕ╣│ÕØćÕĆ╝ŃĆé
+Õ”éµ×£õĮĀµā│ńē╣Õł½µīćիܵ¤Éõ║øõ┐Īµü»ńÜäÕ╣│µ╗æµ¢╣µ│Ģ’╝īĶ»ĘÕÅéķśģ{external+mmengine:doc}`µŚźÕ┐ŚÕżäńÉåÕÖ©µ¢ćµĪŻ `ŃĆé
+
+```python
+# ķ╗śĶ«żĶ«ŠńĮ«’╝īÕ«āÕ░åķĆÜĶ┐ćõĖĆõĖ¬10ķĢ┐Õ║”ńÜäń¬ŚÕÅŻÕ╣│µ╗æĶ«Łń╗āµŚźÕ┐ŚõĖŁńÜäÕĆ╝
+log_processor = dict(window_size=10)
+```
+
+Õ£© `visualizer` ÕŁŚµ«ĄõĖŁ’╝īõĮĀÕÅ»õ╗źµīćÕ«ÜÕżÜõĖ¬ÕÉÄń½»µØźõ┐ØÕŁśµŚźÕ┐Śõ┐Īµü»’╝īÕ”éTensorBoardÕÆīWandBŃĆé
+µø┤ÕżÜńÜäń╗åĶŖéÕÅ»õ╗źÕ£©[ÕÅ»Ķ¦åÕī¢ÕĘźÕģĘ](#visualizer)µēŠÕł░ŃĆé
+
+## Ķć¬Õ«Üõ╣ēķÆ®ÕŁÉ
+
+õĖŖĶ┐░Ķ«ĖÕżÜÕŖ¤ĶāĮµś»ńö▒ķÆ®ÕŁÉÕ«×ńÄ░ńÜä’╝īõĮĀõ╣¤ÕÅ»õ╗źķĆÜĶ┐ćõ┐«µö╣ `custom_hooks` ÕŁŚµ«ĄµØźµÅÆÕģźÕģČõ╗¢ńÜäĶć¬Õ«Üõ╣ēķÆ®ÕŁÉŃĆé
+õĖŗķØ󵜻 MMEngine ÕÆī MMPretrain õĖŁńÜäõĖĆõ║øķÆ®ÕŁÉ’╝īõĮĀÕÅ»õ╗źńø┤µÄźõĮ┐ńö©’╝īõŠŗÕ”é’╝Ü
+
+- [EMAHook](mmpretrain.engine.hooks.EMAHook)
+- [SyncBuffersHook](mmengine.hooks.SyncBuffersHook)
+- [EmptyCacheHook](mmengine.hooks.EmptyCacheHook)
+- [ClassNumCheckHook](mmpretrain.engine.hooks.ClassNumCheckHook)
+- ......
+
+õŠŗÕ”é’╝īEMA’╝łExponential Moving Average’╝ēÕ£©µ©ĪÕ×ŗĶ«Łń╗āõĖŁĶó½Õ╣┐µ│øõĮ┐ńö©’╝īõĮĀÕÅ»õ╗źõ╗źõĖŗµ¢╣Õ╝ÅÕÉ»ńö©Õ«ā’╝Ü
+
+```python
+custom_hooks = [
+ dict(type='EMAHook', momentum=4e-5, priority='ABOVE_NORMAL'),
+]
+```
+
+## ķ¬īĶ»üÕÅ»Ķ¦åÕī¢
+
+ķ¬īĶ»üÕÅ»Ķ¦åÕī¢ķÆ®ÕŁÉµś»õĖĆõĖ¬ķ¬īĶ»üĶ┐ćń©ŗõĖŁķ╗śĶ«żµ│©ÕåīńÜäķÆ®ÕŁÉŃĆé
+õĮĀÕÅ»õ╗źÕ£© `default_hooks.visualization` ÕŁŚµ«ĄõĖŁµØźķģŹńĮ«Õ«āŃĆé
+
+ķ╗śĶ«żµāģÕåĄõĖŗ’╝īµłæõ╗¼ń”üńö©Ķ┐ÖõĖ¬ķÆ®ÕŁÉ’╝īõĮĀÕÅ»õ╗źķĆÜĶ┐ćµīćÕ«Ü `enable=True` µØźÕÉ»ńö©Õ«āŃĆéĶĆīµø┤ÕżÜńÜäÕÅéµĢ░ÕÅ»õ╗źÕ£©
+[ÕÅ»Ķ¦åÕī¢ķÆ®ÕŁÉµ¢ćµĪŻ](mmpretrain.engine.hooks.VisualizationHook)õĖŁµēŠÕł░ŃĆé
+
+```python
+default_hooks = dict(
+ ...
+ visualization=dict(type='VisualizationHook', enable=False),
+ ...
+)
+```
+
+Ķ┐ÖõĖ¬ķÆ®ÕŁÉÕ░åÕ£©ķ¬īĶ»üµĢ░µŹ«ķøåõĖŁķĆēµŗ®õĖĆķā©ÕłåÕøŠÕāÅ’╝īÕ£©µ»Åµ¼Īķ¬īĶ»üĶ┐ćń©ŗõĖŁĶ«░ÕĮĢÕ╣ČÕÅ»Ķ¦åÕī¢Õ«āõ╗¼ńÜäķó䵥ŗń╗ōµ×£ŃĆé
+õĮĀÕÅ»õ╗źńö©Õ«āµØźĶ¦éÕ»¤Ķ«Łń╗āµ£¤ķŚ┤µ©ĪÕ×ŗÕ£©Õ«×ķÖģÕøŠÕāÅõĖŖńÜäµĆ¦ĶāĮÕÅśÕī¢ŃĆé
+
+µŁżÕż¢’╝īÕ”éµ×£õĮĀńÜäķ¬īĶ»üµĢ░µŹ«ķøåõĖŁńÜäÕøŠÕāÅÕŠłÕ░Å’╝ł\<100’╝ī Õ”éCifraµĢ░µŹ«ķøå’╝ē’╝ī
+õĮĀÕÅ»õ╗źµīćÕ«Ü `rescale_factor` µØźń╝®µöŠÕ«āõ╗¼’╝īÕ”é `rescale_factor=2.`, Õ░åÕÅ»Ķ¦åÕī¢ńÜäÕøŠÕāŵöŠÕż¦õĖżÕĆŹŃĆé
+
+## Visualizer
+
+`Visualizer` ńö©õ║ÄĶ«░ÕĮĢĶ«Łń╗āÕÆīµĄŗĶ»ĢĶ┐ćń©ŗõĖŁńÜäÕÉäń¦Źõ┐Īµü»’╝īÕīģµŗ¼µŚźÕ┐ŚŃĆüÕøŠÕāÅÕÆīµĀćķćÅŃĆé
+ķ╗śĶ«żµāģÕåĄõĖŗ’╝īĶ«░ÕĮĢńÜäõ┐Īµü»Õ░åĶó½õ┐ØÕŁśÕ£©ÕĘźõĮ£ńø«ÕĮĢõĖŗńÜä `vis_data` µ¢ćõ╗ČÕż╣õĖŁŃĆé
+
+**ķ╗śĶ«żķģŹńĮ«:**
+
+```python
+visualizer = dict(
+ type='UniversalVisualizer',
+ vis_backends=[
+ dict(type='LocalVisBackend'),
+ ]
+)
+```
+
+ķĆÜÕĖĖ’╝īµ£Ćµ£ēńö©ńÜäÕŖ¤ĶāĮµś»Õ░åµŚźÕ┐ŚÕÆīµĀćķćÅÕ”é `loss` õ┐ØÕŁśÕł░õĖŹÕÉīńÜäÕÉÄń½»ŃĆé
+õŠŗÕ”é’╝īĶ”üµŖŖÕ«āõ╗¼õ┐ØÕŁśÕł░ TensorBoard’╝īÕŬķ£ĆÕāÅõĖŗķØóĶ┐ÖµĀĘĶ«ŠńĮ«’╝Ü
+
+```python
+visualizer = dict(
+ type='UniversalVisualizer',
+ vis_backends=[
+ dict(type='LocalVisBackend'),
+ dict(type='TensorboardVisBackend'),
+ ]
+)
+```
+
+µł¢ĶĆģÕāÅõĖŗķØóĶ┐ÖµĀʵŖŖÕ«āõ╗¼õ┐ØÕŁśÕł░ WandB’╝Ü
+
+```python
+visualizer = dict(
+ type='UniversalVisualizer',
+ vis_backends=[
+ dict(type='LocalVisBackend'),
+ dict(type='WandbVisBackend'),
+ ]
+)
+```
+
+## ńÄ»ÕóāķģŹńĮ«
+
+Õ£© `env_cfg` ÕŁŚµ«ĄõĖŁ’╝īõĮĀÕÅ»õ╗źķģŹńĮ«õĖĆõ║øÕ║ĢÕ▒éńÜäÕÅéµĢ░’╝īÕ”é cuDNNŃĆüÕżÜĶ┐øń©ŗÕÆīÕłåÕĖāÕ╝ÅķĆÜõ┐ĪŃĆé
+
+**Õ£©õ┐«µö╣Ķ┐Öõ║øÕÅéµĢ░õ╣ŗÕēŹ’╝īĶ»ĘńĪ«õ┐ØõĮĀńÉåĶ¦ŻĶ┐Öõ║øÕÅéµĢ░ńÜäÕɽõ╣ēŃĆé**
+
+```python
+env_cfg = dict(
+ # µś»ÕÉ”ÕÉ»ńö©cudnnÕ¤║ÕćåµĄŗĶ»Ģ
+ cudnn_benchmark=False,
+
+ # Ķ«ŠńĮ«ÕżÜĶ┐øń©ŗÕÅéµĢ░
+ mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0),
+
+ # Ķ«ŠńĮ«ÕłåÕĖāÕ╝ÅÕÅéµĢ░
+ dist_cfg=dict(backend='nccl'),
+)
+```
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/schedule.md b/internlm_langchain/knowledge_base/MMPreTrain/content/schedule.md
new file mode 100644
index 00000000..d1c347d1
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/schedule.md
@@ -0,0 +1,359 @@
+# Ķć¬Õ«Üõ╣ēĶ«Łń╗āõ╝śÕī¢ńŁ¢ńĢź
+
+Õ£©µłæõ╗¼ńÜäń«Śµ│ĢÕ║ōõĖŁ’╝īÕĘ▓ń╗ŵÅÉõŠøõ║åķĆÜńö©µĢ░µŹ«ķøå’╝łÕ”éImageNet’╝īCIFAR’╝ēńÜä[ķ╗śĶ«żĶ«Łń╗āńŁ¢ńĢźķģŹńĮ«](https://github.com/open-mmlab/mmpretrain/blob/main/configs/_base_/schedules)ŃĆéÕ”éµ×£µā│Ķ”üÕ£©Ķ┐Öõ║øµĢ░µŹ«ķøåõĖŖń╗¦ń╗ŁµÅÉÕŹćµ©ĪÕ×ŗµĆ¦ĶāĮ’╝īµł¢ĶĆģÕ£©õĖŹÕÉīµĢ░µŹ«ķøåÕÆīµ¢╣µ│ĢõĖŖĶ┐øĶĪīµ¢░ńÜäÕ░ØĶ»Ģ’╝īµłæõ╗¼ķĆÜÕĖĖķ£ĆĶ”üõ┐«µö╣Ķ┐Öõ║øķ╗śĶ«żńÜäńŁ¢ńĢźŃĆé
+
+Õ£©µ£¼µĢÖń©ŗõĖŁ’╝īµłæõ╗¼Õ░åõ╗ŗń╗ŹÕ”éõĮĢÕ£©Ķ┐ÉĶĪīĶć¬Õ«Üõ╣ēĶ«Łń╗āµŚČ’╝īķĆÜĶ┐ćõ┐«µö╣ķģŹńĮ«µ¢ćõ╗ČĶ┐øĶĪīµ×äķĆĀõ╝śÕī¢ÕÖ©ŃĆüÕÅéµĢ░Õī¢ń▓Šń╗åķģŹńĮ«ŃĆüµó»Õ║”ĶŻüÕē¬ŃĆüµó»Õ║”ń┤»Ķ«Īõ╗źÕÅŖÕ«ÜÕłČÕŖ©ķćÅĶ░āµĢ┤ńŁ¢ńĢźńŁēŃĆéÕÉīµŚČõ╣¤õ╝ÜķĆÜĶ┐浩ĪµØ┐ń«ĆÕŹĢõ╗ŗń╗ŹÕ”éõĮĢĶć¬Õ«Üõ╣ēÕ╝ĆÕÅæõ╝śÕī¢ÕÖ©ÕÆīµ×äķĆĀÕÖ©ŃĆé
+
+## ķģŹńĮ«Ķ«Łń╗āõ╝śÕī¢ńŁ¢ńĢź
+
+µłæõ╗¼ķĆÜĶ┐ć `optim_wrapper` µØźķģŹńĮ«õĖ╗Ķ”üńÜäõ╝śÕī¢ńŁ¢ńĢź’╝īÕīģµŗ¼õ╝śÕī¢ÕÖ©ńÜäķĆēµŗ®’╝īµĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗āńÜäķĆēµŗ®’╝īÕÅéµĢ░Õī¢ń▓Šń╗åķģŹńĮ«’╝īµó»Õ║”ĶŻüÕē¬õ╗źÕÅŖµó»Õ║”ń┤»Ķ«ĪŃĆéµÄźõĖŗµØźÕ░åÕłåÕł½õ╗ŗń╗ŹĶ┐Öõ║øÕåģÕ«╣ŃĆé
+
+### µ×äķĆĀ PyTorch ÕåģńĮ«õ╝śÕī¢ÕÖ©
+
+MMPretrain µö»µīü PyTorch Õ«×ńÄ░ńÜäµēƵ£ēõ╝śÕī¢ÕÖ©’╝īõ╗ģķ£ĆÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁ’╝īµīćÕ«Üõ╝śÕī¢ÕÖ©Õ░üĶŻģķ£ĆĶ”üńÜä `optimizer` ÕŁŚµ«ĄŃĆé
+
+Õ”éµ×£Ķ”üõĮ┐ńö© [`SGD`](torch.optim.SGD)’╝īÕłÖõ┐«µö╣Õ”éõĖŗŃĆéĶ┐ÖķćīĶ”üµ│©µäŵēƵ£ēõ╝śÕī¢ńøĖÕģ│ńÜäķģŹńĮ«ķāĮķ£ĆĶ”üÕ░üĶŻģÕ£© `optim_wrapper` ķģŹńĮ«ķćīŃĆé
+
+```python
+optim_wrapper = dict(
+ type='OptimWrapper',
+ optimizer=dict(type='SGD', lr=0.0003, weight_decay=0.0001)
+)
+```
+
+```{note}
+ķģŹńĮ«µ¢ćõ╗ČõĖŁńÜä 'type' õĖŹµś»µ×äķĆĀµŚČńÜäÕÅéµĢ░’╝īĶĆīµś» PyTorch ÕåģńĮ«õ╝śÕī¢ÕÖ©ńÜäń▒╗ÕÉŹŃĆé
+µø┤ÕżÜõ╝śÕī¢ÕÖ©ķĆēµŗ®ÕÅ»õ╗źÕÅéĶĆā{external+torch:ref}`PyTorch µö»µīüńÜäõ╝śÕī¢ÕÖ©ÕłŚĶĪ©`ŃĆé
+```
+
+Ķ”üõ┐«µö╣µ©ĪÕ×ŗńÜäÕŁ”õ╣ĀńÄć’╝īÕŬķ£ĆĶ”üÕ£©õ╝śÕī¢ÕÖ©ńÜäķģŹńĮ«õĖŁõ┐«µö╣ `lr` ÕŹ│ÕÅ»ŃĆé
+Ķ”üķģŹńĮ«ÕģČõ╗¢ÕÅéµĢ░’╝īÕÅ»ńø┤µÄźµĀ╣µŹ« [PyTorch API µ¢ćµĪŻ](torch.optim) Ķ┐øĶĪīŃĆé
+
+õŠŗÕ”é’╝īÕ”éµ×£µā│õĮ┐ńö© [`Adam`](torch.optim.Adam) Õ╣ČĶ«ŠńĮ«ÕÅéµĢ░õĖ║ `torch.optim.Adam(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0, amsgrad=False)`ŃĆé
+ÕłÖķ£ĆĶ”üĶ┐øĶĪīÕ”éõĖŗõ┐«µö╣’╝Ü
+
+```python
+optim_wrapper = dict(
+ type='OptimWrapper',
+ optimizer = dict(
+ type='Adam',
+ lr=0.001,
+ betas=(0.9, 0.999),
+ eps=1e-08,
+ weight_decay=0,
+ amsgrad=False),
+)
+```
+
+````{note}
+ĶĆāĶÖæÕł░Õ»╣õ║ÄÕŹĢń▓ŠÕ║”Ķ«Łń╗āµØźĶ»┤’╝īõ╝śÕī¢ÕÖ©Õ░üĶŻģńÜäķ╗śĶ«żń▒╗Õ×ŗÕ░▒µś» `OptimWrapper`’╝īµłæõ╗¼Õ£©Ķ┐ÖķćīÕÅ»õ╗źńø┤µÄźń£üńĢź’╝īÕøĀµŁżķģŹńĮ«µ¢ćõ╗ČÕÅ»õ╗źĶ┐øõĖƵŁźń«ĆÕī¢õĖ║’╝Ü
+
+```python
+optim_wrapper = dict(
+ optimizer=dict(
+ type='Adam',
+ lr=0.001,
+ betas=(0.9, 0.999),
+ eps=1e-08,
+ weight_decay=0,
+ amsgrad=False))
+```
+````
+
+### µĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗ā
+
+Õ”éµ×£µłæõ╗¼µā│Ķ”üõĮ┐ńö©µĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗ā’╝łAutomactic Mixed Precision’╝ē’╝īµłæõ╗¼ÕŬķ£Ćń«ĆÕŹĢÕ£░Õ░å `optim_wrapper` ńÜäń▒╗Õ×ŗµö╣õĖ║ `AmpOptimWrapper`ŃĆé
+
+```python
+optim_wrapper = dict(type='AmpOptimWrapper', optimizer=...)
+```
+
+ÕÅ”Õż¢’╝īõĖ║õ║åµ¢╣õŠ┐’╝īµłæõ╗¼ÕÉīµŚČÕ£©ÕÉ»ÕŖ©Ķ«Łń╗āĶäܵ£¼ `tools/train.py` õĖŁµÅÉõŠøõ║å `--amp` ÕÅéµĢ░õĮ£õĖ║Õ╝ĆÕÉ»µĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗āńÜäÕ╝ĆÕģ│’╝īµø┤ÕżÜń╗åĶŖéÕÅ»õ╗źÕÅéĶĆā[Ķ«Łń╗āµĢÖń©ŗ](../user_guides/train.md)ŃĆé
+
+### ÕÅéµĢ░Õī¢ń▓Šń╗åķģŹńĮ«
+
+Õ£©õĖĆõ║øµ©ĪÕ×ŗõĖŁ’╝īõĖŹÕÉīńÜäõ╝śÕī¢ńŁ¢ńĢźķ£ĆĶ”üķĆéÕ║öńē╣Õ«ÜńÜäÕÅéµĢ░’╝īõŠŗÕ”éõĖŹÕ£© BatchNorm Õ▒éõĮ┐ńö©µØāķćŹĶĪ░ÕćÅ’╝īµł¢ĶĆģÕ£©õĖŹÕÉīÕ▒éõĮ┐ńö©õĖŹÕÉīńÜäÕŁ”õ╣ĀńÄćńŁēńŁēŃĆé
+µłæõ╗¼ķ£ĆĶ”üńö©Õł░ `optim_wrapper` õĖŁńÜä `paramwise_cfg` ÕÅéµĢ░µØźĶ┐øĶĪīń▓Šń╗åÕī¢ķģŹńĮ«ŃĆé
+
+- **õĖ║õĖŹÕÉīń▒╗Õ×ŗńÜäÕÅéµĢ░Ķ«ŠńĮ«ĶČģÕÅéõ╣śÕŁÉ**
+
+ õŠŗÕ”é’╝īµłæõ╗¼ÕÅ»õ╗źÕ£© `paramwise_cfg` ķģŹńĮ«õĖŁĶ«ŠńĮ« `norm_decay_mult=0.` µØźµö╣ÕÅśÕĮÆõĖĆÕī¢Õ▒éµØāķćŹÕÆīÕüÅń¦╗ńÜäĶĪ░ÕćÅõĖ║0ŃĆé
+
+ ```python
+ optim_wrapper = dict(
+ optimizer=dict(type='SGD', lr=0.8, weight_decay=1e-4),
+ paramwise_cfg=dict(norm_decay_mult=0.))
+ ```
+
+ µö»µīüµø┤ÕżÜń▒╗Õ×ŗńÜäÕÅéµĢ░ķģŹńĮ«’╝īÕÅéĶĆāõ╗źõĖŗÕłŚĶĪ©’╝Ü
+
+ - `bias_lr_mult`’╝ÜÕüÅńĮ«ńÜäÕŁ”õ╣ĀńÄćń│╗µĢ░’╝łõĖŹÕīģµŗ¼µŁŻÕłÖÕī¢Õ▒éńÜäÕüÅńĮ«õ╗źÕÅŖÕÅ»ÕÅśÕĮóÕŹĘń¦»ńÜä offset’╝ē’╝īķ╗śĶ«żÕĆ╝õĖ║ 1
+ - `bias_decay_mult`’╝ÜÕüÅńĮ«ńÜäµØāÕĆ╝ĶĪ░ÕćÅń│╗µĢ░’╝łõĖŹÕīģµŗ¼µŁŻÕłÖÕī¢Õ▒éńÜäÕüÅńĮ«õ╗źÕÅŖÕÅ»ÕÅśÕĮóÕŹĘń¦»ńÜä offset’╝ē’╝īķ╗śĶ«żÕĆ╝õĖ║ 1
+ - `norm_decay_mult`’╝ܵŁŻÕłÖÕī¢Õ▒éµØāķćŹÕÆīÕüÅńĮ«ńÜäµØāÕĆ╝ĶĪ░ÕćÅń│╗µĢ░’╝īķ╗śĶ«żÕĆ╝õĖ║ 1
+ - `flat_decay_mult`: õĖĆń╗┤ÕÅéµĢ░ńÜäµØāÕĆ╝ĶĪ░ÕćÅń│╗µĢ░’╝īķ╗śĶ«żÕĆ╝õĖ║ 1
+ - `dwconv_decay_mult`’╝ÜDepth-wise ÕŹĘń¦»ńÜäµØāÕĆ╝ĶĪ░ÕćÅń│╗µĢ░’╝īķ╗śĶ«żÕĆ╝õĖ║ 1
+ - `bypass_duplicate`’╝ܵś»ÕÉ”ĶĘ│Ķ┐ćķćŹÕżŹńÜäÕÅéµĢ░’╝īķ╗śĶ«żõĖ║ `False`
+ - `dcn_offset_lr_mult`’╝ÜÕÅ»ÕÅśÕĮóÕŹĘń¦»’╝łDeformable Convolution’╝ēńÜäÕŁ”õ╣ĀńÄćń│╗µĢ░’╝īķ╗śĶ«żÕĆ╝õĖ║ 1
+
+- **õĖ║ńē╣Õ«ÜÕÅéµĢ░Ķ«ŠńĮ«ĶČģÕÅéõ╣śÕŁÉ**
+
+ MMPretrain ķĆÜĶ┐ć `paramwise_cfg` ńÜä `custom_keys` ÕÅéµĢ░µØźķģŹńĮ«ńē╣Õ«ÜÕÅéµĢ░ńÜäĶČģÕÅéõ╣śÕŁÉŃĆé
+
+ õŠŗÕ”é’╝īµłæõ╗¼ÕÅ»õ╗źķĆÜĶ┐ćõ╗źõĖŗķģŹńĮ«µØźĶ«ŠńĮ«µēƵ£ē `backbone.layer0` Õ▒éńÜäÕŁ”õ╣ĀńÄćÕÆīµØāķćŹĶĪ░ÕćÅõĖ║0’╝ī `backbone` ńÜäÕģČõĮÖÕ▒éÕÆīõ╝śÕī¢ÕÖ©õ┐صīüõĖĆĶć┤’╝īÕÅ”Õż¢ `head` Õ▒éńÜäÕŁ”õ╣ĀńÄćõĖ║0.001.
+
+ ```python
+ optim_wrapper = dict(
+ optimizer=dict(type='SGD', lr=0.01, weight_decay=0.0001),
+ paramwise_cfg=dict(
+ custom_keys={
+ 'backbone.layer0': dict(lr_mult=0, decay_mult=0),
+ 'backbone': dict(lr_mult=1),
+ 'head': dict(lr_mult=0.1)
+ }))
+ ```
+
+### µó»Õ║”ĶŻüÕē¬
+
+Õ£©Ķ«Łń╗āĶ┐ćń©ŗõĖŁ’╝īµŹ¤Õż▒ÕćĮµĢ░ÕÅ»ĶāĮµÄźĶ┐æõ║ÄõĖĆõ║øÕ╝éÕĖĖķÖĪÕ│ŁńÜäÕī║Õ¤¤’╝īõ╗ÄĶĆīÕ»╝Ķć┤µó»Õ║”ńłåńéĖŃĆéĶĆīµó»Õ║”ĶŻüÕē¬ÕÅ»õ╗źÕĖ«ÕŖ®ń©│Õ«ÜĶ«Łń╗āĶ┐ćń©ŗ’╝īµø┤ÕżÜõ╗ŗń╗ŹÕÅ»õ╗źÕÅéĶ¦ü[Ķ»źķĪĄķØó](https://paperswithcode.com/method/gradient-clipping)ŃĆé
+
+ńø«ÕēŹµłæõ╗¼µö»µīüÕ£© `optim_wrapper` ÕŁŚµ«ĄõĖŁµĘ╗ÕŖĀ `clip_grad` ÕÅéµĢ░µØźĶ┐øĶĪīµó»Õ║”ĶŻüÕē¬’╝īµø┤Ķ»”ń╗åńÜäÕÅéµĢ░ÕÅ»ÕÅéĶĆā [PyTorch µ¢ćµĪŻ](torch.nn.utils.clip_grad_norm_)ŃĆé
+
+ńö©õŠŗÕ”éõĖŗ’╝Ü
+
+```python
+optim_wrapper = dict(
+ optimizer=dict(type='SGD', lr=0.01, weight_decay=0.0001),
+ # norm_type: õĮ┐ńö©ńÜäĶīāµĢ░ń▒╗Õ×ŗ’╝īµŁżÕżäõĮ┐ńö©ĶīāµĢ░2ŃĆé
+ clip_grad=dict(max_norm=35, norm_type=2))
+```
+
+### µó»Õ║”ń┤»Ķ«Ī
+
+Ķ«Īń«ŚĶĄäµ║Éń╝║õ╣Åń╝║õ╣ŵŚČ’╝īµ»ÅõĖ¬Ķ«Łń╗āµē╣µ¼ĪńÜäÕż¦Õ░Å’╝łbatch size’╝ēÕŬĶāĮĶ«ŠńĮ«õĖ║ĶŠāÕ░ÅńÜäÕĆ╝’╝īĶ┐ÖÕÅ»ĶāĮõ╝ÜÕĮ▒ÕōŹµ©ĪÕ×ŗńÜäµĆ¦ĶāĮŃĆé
+
+ÕÅ»õ╗źõĮ┐ńö©µó»Õ║”ń┤»Ķ«ĪµØźĶ¦äķü┐Ķ┐ÖõĖĆķŚ«ķóśŃĆ鵳æõ╗¼µö»µīüÕ£© `optim_wrapper` ÕŁŚµ«ĄõĖŁµĘ╗ÕŖĀ `accumulative_counts` ÕÅéµĢ░µØźĶ┐øĶĪīµó»Õ║”ń┤»Ķ«ĪŃĆé
+
+ńö©õŠŗÕ”éõĖŗ’╝Ü
+
+```python
+train_dataloader = dict(batch_size=64)
+optim_wrapper = dict(
+ optimizer=dict(type='SGD', lr=0.01, weight_decay=0.0001),
+ accumulative_counts=4)
+```
+
+ĶĪ©ńż║Ķ«Łń╗āµŚČ’╝īµ»Å 4 õĖ¬ iter µē¦ĶĪīõĖƵ¼ĪÕÅŹÕÉæõ╝ĀµÆŁŃĆéńö▒õ║ĵŁżµŚČÕŹĢÕ╝Ā GPU õĖŖńÜäµē╣µ¼ĪÕż¦Õ░ÅõĖ║ 64’╝īõ╣¤Õ░▒ńŁēõ╗Ęõ║ÄÕŹĢÕ╝Ā GPU õĖŖõĖƵ¼ĪĶ┐Łõ╗ŻńÜäµē╣µ¼ĪÕż¦Õ░ÅõĖ║ 256’╝īõ╣¤ÕŹ│’╝Ü
+
+```python
+train_dataloader = dict(batch_size=256)
+optim_wrapper = dict(
+ optimizer=dict(type='SGD', lr=0.01, weight_decay=0.0001))
+```
+
+## ķģŹńĮ«ÕÅéµĢ░õ╝śÕī¢ńŁ¢ńĢź
+
+Õ£©Ķ«Łń╗āĶ┐ćń©ŗõĖŁ’╝īõ╝śÕī¢ÕÅéµĢ░õŠŗÕ”éÕŁ”õ╣ĀńÄćŃĆüÕŖ©ķćÅ’╝īķĆÜÕĖĖõĖŹõ╝ܵś»Õø║Õ«ÜõĖŹÕÅś’╝īĶĆīµś»ķÜÅńØĆĶ«Łń╗āĶ┐øń©ŗńÜäÕÅśÕī¢ĶĆīĶ░āµĢ┤ŃĆéPyTorch µö»µīüõĖĆõ║øÕŁ”õ╣ĀńÄćĶ░āµĢ┤ńÜäĶ░āÕ║”ÕÖ©’╝īõĮåµś»õĖŹĶČ│õ╗źÕ«īµłÉÕżŹµØéńÜäńŁ¢ńĢźŃĆéÕ£© MMPretrain õĖŁ’╝īµłæõ╗¼µÅÉõŠø `param_scheduler` µØźµø┤ÕźĮÕ£░µÄ¦ÕłČõĖŹÕÉīõ╝śÕī¢ÕÅéµĢ░ńÜäńŁ¢ńĢźŃĆé
+
+### ķģŹńĮ«ÕŁ”õ╣ĀńÄćĶ░āµĢ┤ńŁ¢ńĢź
+
+µĘ▒Õ║”ÕŁ”õ╣ĀńĀöń®ČõĖŁ’╝īÕ╣┐µ│øÕ║öńö©ÕŁ”õ╣ĀńÄćĶĪ░ÕćÅµØźµÅÉķ½śńĮæń╗£ńÜäµĆ¦ĶāĮŃĆ鵳æõ╗¼µö»µīüÕż¦ÕżÜµĢ░ PyTorch ÕŁ”õ╣ĀńÄćĶ░āÕ║”ÕÖ©’╝ī ÕģČõĖŁÕīģµŗ¼ `ExponentialLR`, `LinearLR`, `StepLR`, `MultiStepLR` ńŁēńŁēŃĆé
+
+- **ÕŹĢõĖ¬ÕŁ”õ╣ĀńÄćńŁ¢ńĢź**
+
+ ÕżÜµĢ░µāģÕåĄõĖŗ’╝īµłæõ╗¼õĮ┐ńö©ÕŹĢõĖĆÕŁ”õ╣ĀńÄćńŁ¢ńĢź’╝īĶ┐Öķćī `param_scheduler` õ╝ܵś»õĖĆõĖ¬ÕŁŚÕģĖŃĆéµ»öÕ”éÕ£©ķ╗śĶ«żńÜä ResNet ńĮæń╗£Ķ«Łń╗āõĖŁ’╝īµłæõ╗¼õĮ┐ńö©ķśČµó»Õ╝ÅńÜäÕŁ”õ╣ĀńÄćĶĪ░ÕćÅńŁ¢ńĢź [`MultiStepLR`](mmengine.optim.MultiStepLR)’╝īķģŹńĮ«µ¢ćõ╗ČõĖ║’╝Ü
+
+ ```python
+ param_scheduler = dict(
+ type='MultiStepLR',
+ by_epoch=True,
+ milestones=[100, 150],
+ gamma=0.1)
+ ```
+
+ µł¢ĶĆģµłæõ╗¼µā│õĮ┐ńö© [`CosineAnnealingLR`](mmengine.optim.CosineAnnealingLR) µØźĶ┐øĶĪīÕŁ”õ╣ĀńÄćĶĪ░ÕćÅ’╝Ü
+
+ ```python
+ param_scheduler = dict(
+ type='CosineAnnealingLR',
+ by_epoch=True,
+ T_max=num_epochs)
+ ```
+
+- **ÕżÜõĖ¬ÕŁ”õ╣ĀńÄćńŁ¢ńĢź**
+
+ ńäČĶĆīÕ£©õĖĆõ║øÕģČõ╗¢µāģÕåĄõĖŗ’╝īõĖ║õ║åµÅÉķ½śµ©ĪÕ×ŗńÜäń▓ŠÕ║”’╝īķĆÜÕĖĖõ╝ÜõĮ┐ńö©ÕżÜń¦ŹÕŁ”õ╣ĀńÄćńŁ¢ńĢźŃĆéõŠŗÕ”é’╝īÕ£©Ķ«Łń╗āńÜ䵌®µ£¤ķśČµ«Ą’╝īńĮæń╗£Õ«╣µśōõĖŹń©│Õ«Ü’╝īĶĆīÕŁ”õ╣ĀńÄćńÜäķóäńāŁÕ░▒µś»õĖ║õ║åÕćÅÕ░æĶ┐Öń¦ŹõĖŹń©│Õ«ÜµĆ¦ŃĆé
+
+ µĢ┤õĖ¬ÕŁ”õ╣ĀĶ┐ćń©ŗõĖŁ’╝īÕŁ”õ╣ĀńÄćÕ░åõ╝ÜķĆÜĶ┐ćķóäńāŁõ╗ÄõĖĆõĖ¬ÕŠłÕ░ÅńÜäÕĆ╝ķĆɵŁźµÅÉķ½śÕł░ķóäÕ«ÜÕĆ╝’╝īÕåŹõ╝ÜķĆÜĶ┐ćÕģČõ╗¢ńÜäńŁ¢ńĢźĶ┐øõĖƵŁźĶ░āµĢ┤ŃĆé
+
+ Õ£© MMPretrain õĖŁ’╝īµłæõ╗¼ÕÉīµĀĘõĮ┐ńö© `param_scheduler` ’╝īÕ░åÕżÜń¦ŹÕŁ”õ╣ĀńŁ¢ńĢźÕåÖµłÉÕłŚĶĪ©Õ░▒ÕÅ»õ╗źÕ«īµłÉõĖŖĶ┐░ķóäńāŁńŁ¢ńĢźńÜäń╗äÕÉłŃĆé
+
+ õŠŗÕ”é’╝Ü
+
+ 1. Õ£©ÕēŹ50µ¼ĪĶ┐Łõ╗ŻõĖŁķĆÉ**Ķ┐Łõ╗Żµ¼ĪµĢ░**Õ£░**ń║┐µĆ¦**ķóäńāŁ
+
+ ```python
+ param_scheduler = [
+ # ķĆÉĶ┐Łõ╗Żµ¼ĪµĢ░’╝īń║┐µĆ¦ķóäńāŁ
+ dict(type='LinearLR',
+ start_factor=0.001,
+ by_epoch=False, # ķĆÉĶ┐Łõ╗Żµ¼ĪµĢ░
+ end=50), # ÕŬķóäńāŁ50µ¼ĪĶ┐Łõ╗Żµ¼ĪµĢ░
+ # õĖ╗Ķ”üńÜäÕŁ”õ╣ĀńÄćńŁ¢ńĢź
+ dict(type='MultiStepLR',
+ by_epoch=True,
+ milestones=[8, 11],
+ gamma=0.1)
+ ]
+ ```
+
+ 2. Õ£©ÕēŹ10ĶĮ«Ķ┐Łõ╗ŻõĖŁķĆÉ**Ķ┐Łõ╗Żµ¼ĪµĢ░**Õ£░**ń║┐µĆ¦**ķóäńāŁ
+
+ ```python
+ param_scheduler = [
+ # Õ£©ÕēŹ10ĶĮ«Ķ┐Łõ╗ŻõĖŁ’╝īķĆÉĶ┐Łõ╗Żµ¼ĪµĢ░’╝īń║┐µĆ¦ķóäńāŁ
+ dict(type='LinearLR',
+ start_factor=0.001,
+ by_epoch=True,
+ end=10,
+ convert_to_iter_based=True, # ķĆÉĶ┐Łõ╗Żµ¼ĪµĢ░µø┤µ¢░ÕŁ”õ╣ĀńÄć.
+ ),
+ # Õ£© 10 ĶĮ«µ¼ĪÕÉÄ’╝īķĆÜĶ┐ćõĮÖÕ╝”ķĆĆńü½ĶĪ░ÕćÅ
+ dict(type='CosineAnnealingLR', by_epoch=True, begin=10)
+ ]
+ ```
+
+ µ│©µäÅĶ┐ÖķćīÕó×ÕŖĀõ║å `begin` ÕÆī `end` ÕÅéµĢ░’╝īĶ┐ÖõĖżõĖ¬ÕÅéµĢ░µīćÕ«Üõ║åĶ░āÕ║”ÕÖ©ńÜä**ńö¤µĢłÕī║ķŚ┤**ŃĆéńö¤µĢłÕī║ķŚ┤ķĆÜÕĖĖÕŬգ©ÕżÜõĖ¬Ķ░āÕ║”ÕÖ©ń╗äÕÉłµŚČµēŹķ£ĆĶ”üÕÄ╗Ķ«ŠńĮ«’╝īõĮ┐ńö©ÕŹĢõĖ¬Ķ░āÕ║”ÕÖ©µŚČÕÅ»õ╗źÕ┐ĮńĢźŃĆéÕĮōµīćÕ«Üõ║å `begin` ÕÆī `end` ÕÅéµĢ░µŚČ’╝īĶĪ©ńż║Ķ»źĶ░āÕ║”ÕÖ©ÕŬգ© [begin, end) Õī║ķŚ┤Õåģńö¤µĢł’╝īÕģČÕŹĢõĮŹµś»ńö▒ `by_epoch` ÕÅéµĢ░Õå│Õ«ÜŃĆéÕ£©ń╗äÕÉłõĖŹÕÉīĶ░āÕ║”ÕÖ©µŚČ’╝īÕÉäĶ░āÕ║”ÕÖ©ńÜä `by_epoch` ÕÅéµĢ░õĖŹÕ┐ģńøĖÕÉīŃĆéÕ”éµ×£µ▓Īµ£ēµīćÕ«ÜńÜäµāģÕåĄõĖŗ’╝ī`begin` õĖ║ 0’╝ī `end` õĖ║µ£ĆÕż¦Ķ┐Łõ╗ŻĶĮ«µ¼Īµł¢ĶĆģµ£ĆÕż¦Ķ┐Łõ╗Żµ¼ĪµĢ░ŃĆé
+
+ Õ”éµ×£ńøĖķé╗õĖżõĖ¬Ķ░āÕ║”ÕÖ©ńÜäńö¤µĢłÕī║ķŚ┤µ▓Īµ£ēń┤¦ķé╗’╝īĶĆīµś»µ£ēõĖƵ«ĄÕī║ķŚ┤µ▓Īµ£ēĶó½Ķ”åńø¢’╝īķéŻõ╣łĶ┐Öµ«ĄÕī║ķŚ┤ńÜäÕŁ”õ╣ĀńÄćń╗┤µīüõĖŹÕÅśŃĆéĶĆīÕ”éµ×£õĖżõĖ¬Ķ░āÕ║”ÕÖ©ńÜäńö¤µĢłÕī║ķŚ┤ÕÅæńö¤õ║åķćŹÕÅĀ’╝īÕłÖÕ»╣ÕżÜń╗äĶ░āÕ║”ÕÖ©ÕÅĀÕŖĀõĮ┐ńö©’╝īÕŁ”õ╣ĀńÄćńÜäĶ░āµĢ┤õ╝ܵīēńģ¦Ķ░āÕ║”ÕÖ©ķģŹńĮ«µ¢ćõ╗ČõĖŁńÜäķĪ║Õ║ÅĶ¦”ÕÅæ’╝łĶĪīõĖ║õĖÄ PyTorch õĖŁ [`ChainedScheduler`](torch.optim.lr_scheduler.ChainedScheduler) õĖĆĶć┤’╝ēŃĆé
+
+ ```{tip}
+ õĖ║õ║åķü┐ÕģŹÕŁ”õ╣ĀńÄćµø▓ń║┐õĖÄķóäµ£¤õĖŹń¼”’╝ī ķģŹńĮ«Õ«īµłÉÕÉÄ’╝īÕÅ»õ╗źõĮ┐ńö© MMPretrain µÅÉõŠøńÜä [ÕŁ”õ╣ĀńÄćÕÅ»Ķ¦åÕī¢ÕĘźÕģĘ](../useful_tools/scheduler_visualization.md) ńö╗Õć║Õ»╣Õ║öÕŁ”õ╣ĀńÄćĶ░āµĢ┤µø▓ń║┐ŃĆé
+ ```
+
+### ķģŹńĮ«ÕŖ©ķćÅĶ░āµĢ┤ńŁ¢ńĢź
+
+MMPretrain µö»µīüÕŖ©ķćÅĶ░āÕ║”ÕÖ©µĀ╣µŹ«ÕŁ”õ╣ĀńÄćõ┐«µö╣õ╝śÕī¢ÕÖ©ńÜäÕŖ©ķćÅ’╝īõ╗ÄĶĆīõĮ┐µŹ¤Õż▒ÕćĮµĢ░µöȵĢøµø┤Õ┐½ŃĆéńö©µ│ĢÕÆīÕŁ”õ╣ĀńÄćĶ░āÕ║”ÕÖ©õĖĆĶć┤ŃĆé
+
+µłæõ╗¼µö»µīüńÜäÕŖ©ķćÅńŁ¢ńĢźÕÆīĶ»”ń╗åńÜäõĮ┐ńö©ń╗åĶŖéÕÅ»õ╗źÕÅéĶĆā[Ķ┐Öķćī](https://github.com/open-mmlab/mmengine/blob/main/mmengine/optim/scheduler/momentum_scheduler.py)ŃĆ鵳æõ╗¼ÕŬÕ░åĶ░āÕ║”ÕÖ©õĖŁńÜä `LR` µø┐µŹóõĖ║õ║å `Momentum`’╝īÕŖ©ķćÅńŁ¢ńĢźÕÅ»õ╗źńø┤µÄźĶ┐ĮÕŖĀ `param_scheduler` ÕłŚĶĪ©õĖŁŃĆé
+
+Ķ┐Öķćīµś»õĖĆõĖ¬ńö©õŠŗ’╝Ü
+
+```python
+param_scheduler = [
+ # ÕŁ”õ╣ĀńÄćńŁ¢ńĢź
+ dict(type='LinearLR', ...),
+ # ÕŖ©ķćÅńŁ¢ńĢź
+ dict(type='LinearMomentum',
+ start_factor=0.001,
+ by_epoch=False,
+ begin=0,
+ end=1000)
+]
+```
+
+## µ¢░Õó×õ╝śÕī¢ÕÖ©µł¢ĶĆģõ╝śÕī¢ÕÖ©µ×äķĆĀÕÖ©
+
+```{note}
+µ£¼ķā©ÕłåÕ░åõ┐«µö╣ MMPretrain µ║ÉńĀüµł¢ĶĆģÕÉæ MMPretrain µĪåµ×ȵĘ╗ÕŖĀõ╗ŻńĀü’╝īÕłØÕŁ”ĶĆģÕÅ»ĶĘ│Ķ┐ćŃĆé
+```
+
+### µ¢░Õó×õ╝śÕī¢ÕÖ©
+
+Õ£©ÕŁ”µ£»ńĀöń®ČÕÆīÕĘźõĖÜÕ«×ĶĘĄõĖŁ’╝īÕÅ»ĶāĮķ£ĆĶ”üõĮ┐ńö© MMPretrain µ£¬Õ«×ńÄ░ńÜäõ╝śÕī¢µ¢╣µ│Ģ’╝īÕÅ»õ╗źķĆÜĶ┐ćõ╗źõĖŗµ¢╣µ│ĢµĘ╗ÕŖĀŃĆé
+
+1. Õ«Üõ╣ēõĖĆõĖ¬µ¢░ńÜäõ╝śÕī¢ÕÖ©
+
+ õĖĆõĖ¬Ķć¬Õ«Üõ╣ēńÜäõ╝śÕī¢ÕÖ©ÕÅ»µĀ╣µŹ«Õ”éõĖŗĶ¦äÕłÖĶ┐øĶĪīÕ«ÜÕłČ’╝Ü
+
+ ÕüćĶ«Šµłæõ╗¼µā│µĘ╗ÕŖĀõĖĆõĖ¬ÕÉŹõĖ║ `MyOptimzer` ńÜäõ╝śÕī¢ÕÖ©’╝īÕģȵŗźµ£ēÕÅéµĢ░ `a`, `b` ÕÆī `c`ŃĆé
+ ÕÅ»õ╗źÕłøÕ╗║õĖĆõĖ¬ÕÉŹõĖ║ `mmpretrain/engine/optimizer` ńÜäµ¢ćõ╗ČÕż╣’╝īÕ╣ČÕ£©ńø«ÕĮĢõĖŗńÜäõĖĆõĖ¬µ¢ćõ╗Č’╝īÕ”é `mmpretrain/engine/optimizer/my_optimizer.py` õĖŁÕ«×ńÄ░Ķ»źĶć¬Õ«Üõ╣ēõ╝śÕī¢ÕÖ©’╝Ü
+
+ ```python
+ from mmpretrain.registry import OPTIMIZERS
+ from torch.optim import Optimizer
+
+
+ @OPTIMIZERS.register_module()
+ class MyOptimizer(Optimizer):
+
+ def __init__(self, a, b, c):
+ ...
+
+ def step(self, closure=None):
+ ...
+ ```
+
+2. µ│©Õåīõ╝śÕī¢ÕÖ©
+
+ Ķ”üµ│©ÕåīõĖŖķØóÕ«Üõ╣ēńÜäõĖŖĶ┐░µ©ĪÕØŚ’╝īķ”¢Õģłķ£ĆĶ”üÕ░åµŁżµ©ĪÕØŚÕ»╝ÕģźÕł░õĖ╗ÕæĮÕÉŹń®║ķŚ┤õĖŁŃĆéµ£ēõĖżń¦Źµ¢╣µ│ĢÕÅ»õ╗źÕ«×ńÄ░Õ«āŃĆé
+
+ õ┐«µö╣ `mmpretrain/engine/optimizers/__init__.py`’╝īÕ░åÕģČÕ»╝ÕģźĶć│ `mmpretrain.engine` ÕīģŃĆé
+
+ ```python
+ # Õ£© mmpretrain/engine/optimizers/__init__.py õĖŁ
+ ...
+ from .my_optimizer import MyOptimizer # MyOptimizer µś»µłæõ╗¼Ķć¬Õ«Üõ╣ēńÜäõ╝śÕī¢ÕÖ©ńÜäÕÉŹÕŁŚ
+
+ __all__ = [..., 'MyOptimizer']
+ ```
+
+ Õ£©Ķ┐ÉĶĪīĶ┐ćń©ŗõĖŁ’╝īµłæõ╗¼õ╝ÜĶć¬ÕŖ©Õ»╝Õģź `mmpretrain.engine` ÕīģÕ╣ČÕÉīµŚČµ│©Õåī `MyOptimizer`ŃĆé
+
+3. Õ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁµīćÕ«Üõ╝śÕī¢ÕÖ©
+
+ õ╣ŗÕÉÄ’╝īńö©µłĘõŠ┐ÕŻգ©ķģŹńĮ«µ¢ćõ╗ČńÜä `optim_wrapper.optimizer` Õ¤¤õĖŁõĮ┐ńö© `MyOptimizer`’╝Ü
+
+ ```python
+ optim_wrapper = dict(
+ optimizer=dict(type='MyOptimizer', a=a_value, b=b_value, c=c_value))
+ ```
+
+### µ¢░Õó×õ╝śÕī¢ÕÖ©µ×äķĆĀÕÖ©
+
+µ¤Éõ║øµ©ĪÕ×ŗÕÅ»ĶāĮÕģʵ£ēõĖĆõ║øńē╣Õ«Üõ║ÄÕÅéµĢ░ńÜäĶ«ŠńĮ«õ╗źĶ┐øĶĪīõ╝śÕī¢’╝īõŠŗÕ”éõĖ║µēƵ£ē BatchNorm Õ▒éĶ«ŠńĮ«õĖŹÕÉīńÜäµØāķćŹĶĪ░ÕćÅŃĆé
+
+Õ░Įń«Īµłæõ╗¼ÕĘ▓ń╗ÅÕÅ»õ╗źõĮ┐ńö© [`optim_wrapper.paramwise_cfg` ÕŁŚµ«Ą](#ÕÅéµĢ░Õī¢ń▓Šń╗åķģŹńĮ«)µØźķģŹńĮ«ńē╣Õ«ÜÕÅéµĢ░ńÜäõ╝śÕī¢Ķ«ŠńĮ«’╝īõĮåÕÅ»ĶāĮõ╗ŹńäȵŚĀµ│ĢĶ”åńø¢õĮĀńÜäķ£Ćµ▒éŃĆé
+
+ÕĮōńäČõĮĀÕÅ»õ╗źÕ£©µŁżÕ¤║ńĪĆõĖŖĶ┐øĶĪīõ┐«µö╣ŃĆ鵳æõ╗¼ķ╗śĶ«żõĮ┐ńö© [`DefaultOptimWrapperConstructor`](mmengine.optim.DefaultOptimWrapperConstructor) µØźµ×äķĆĀõ╝śÕī¢ÕÖ©ŃĆéÕ£©µ×äķĆĀĶ┐ćń©ŗõĖŁ’╝īķĆÜĶ┐ć `paramwise_cfg` µØźń▓Šń╗åÕī¢ķģŹńĮ«õĖŹÕÉīĶ«ŠńĮ«ŃĆéĶ┐ÖõĖ¬ķ╗śĶ«żµ×äķĆĀÕÖ©ÕÅ»õ╗źõĮ£õĖ║µ¢░õ╝śÕī¢ÕÖ©µ×äķĆĀÕÖ©Õ«×ńÄ░ńÜ䵩ĪµØ┐ŃĆé
+
+µłæõ╗¼ÕÅ»õ╗źµ¢░Õó×õĖĆõĖ¬õ╝śÕī¢ÕÖ©µ×äķĆĀÕÖ©µØźĶ”åńø¢Ķ┐Öõ║øĶĪīõĖ║ŃĆé
+
+```python
+# Õ£© mmpretrain/engine/optimizers/my_optim_constructor.py õĖŁ
+from mmengine.optim import DefaultOptimWrapperConstructor
+from mmpretrain.registry import OPTIM_WRAPPER_CONSTRUCTORS
+
+
+@OPTIM_WRAPPER_CONSTRUCTORS.register_module()
+class MyOptimWrapperConstructor:
+
+ def __init__(self, optim_wrapper_cfg, paramwise_cfg=None):
+ ...
+
+ def __call__(self, model):
+ ...
+```
+
+Ķ┐Öµś»õĖĆõĖ¬ÕĘ▓Õ«×ńÄ░ńÜä [OptimWrapperConstructor](mmpretrain.engine.optimizers.LearningRateDecayOptimWrapperConstructor) ÕģĘõĮōõŠŗÕŁÉŃĆé
+
+µÄźõĖŗµØźń▒╗õ╝╝ [µ¢░Õó×õ╝śÕī¢ÕÖ©µĢÖń©ŗ](#µ¢░Õó×õ╝śÕī¢ÕÖ©) µØźÕ»╝ÕģźÕ╣ČõĮ┐ńö©µ¢░ńÜäõ╝śÕī¢ÕÖ©µ×äķĆĀÕÖ©ŃĆé
+
+1. õ┐«µö╣ `mmpretrain/engine/optimizers/__init__.py`’╝īÕ░åÕģČÕ»╝ÕģźĶć│ `mmpretrain.engine` ÕīģŃĆé
+
+ ```python
+ # Õ£© mmpretrain/engine/optimizers/__init__.py õĖŁ
+ ...
+ from .my_optim_constructor import MyOptimWrapperConstructor
+
+ __all__ = [..., 'MyOptimWrapperConstructor']
+ ```
+
+2. Õ£©ķģŹńĮ«µ¢ćõ╗ČńÜä `optim_wrapper.constructor` ÕŁŚµ«ĄõĖŁõĮ┐ńö© `MyOptimWrapperConstructor` ŃĆé
+
+ ```python
+ optim_wrapper = dict(
+ constructor=dict(type='MyOptimWrapperConstructor'),
+ optimizer=...,
+ paramwise_cfg=...,
+ )
+ ```
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/scheduler_visualization.md b/internlm_langchain/knowledge_base/MMPreTrain/content/scheduler_visualization.md
new file mode 100644
index 00000000..8ac903ac
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/scheduler_visualization.md
@@ -0,0 +1,44 @@
+# õ╝śÕī¢ÕÖ©ÕÅéµĢ░ńŁ¢ńĢźÕÅ»Ķ¦åÕī¢
+
+Ķ»źÕĘźÕģʵŚ©Õ£©ÕĖ«ÕŖ®ńö©µłĘµŻĆµ¤źõ╝śÕī¢ÕÖ©ńÜäĶČģÕÅéµĢ░Ķ░āÕ║”ÕÖ©’╝łµŚĀķ£ĆĶ«Łń╗ā’╝ē’╝īµö»µīüÕŁ”õ╣ĀńÄć’╝łlearning rate’╝ēÕÆīÕŖ©ķćÅ’╝łmomentum’╝ēŃĆé
+
+## ÕĘźÕģĘń«Ćõ╗ŗ
+
+```bash
+python tools/visualization/vis_scheduler.py \
+ ${CONFIG_FILE} \
+ [-p, --parameter ${PARAMETER_NAME}] \
+ [-d, --dataset-size ${DATASET_SIZE}] \
+ [-n, --ngpus ${NUM_GPUs}] \
+ [-s, --save-path ${SAVE_PATH}] \
+ [--title ${TITLE}] \
+ [--style ${STYLE}] \
+ [--window-size ${WINDOW_SIZE}] \
+ [--cfg-options]
+```
+
+**µēƵ£ēÕÅéµĢ░ńÜäĶ»┤µśÄ**’╝Ü
+
+- `config` : µ©ĪÕ×ŗķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠäŃĆé
+- **`-p, parameter`**: ÕÅ»Ķ¦åÕī¢ÕÅéµĢ░ÕÉŹ’╝īÕŬĶāĮõĖ║ `["lr", "momentum"]` õ╣ŗõĖĆ’╝ī ķ╗śĶ«żõĖ║ `"lr"`.
+- **`-d, --dataset-size`**: µĢ░µŹ«ķøåńÜäÕż¦Õ░ÅŃĆéÕ”éµ×£µīćÕ«Ü’╝ī`build_dataset` Õ░åĶó½ĶĘ│Ķ┐ćÕ╣ČõĮ┐ńö©Ķ┐ÖõĖ¬Õż¦Õ░ÅõĮ£õĖ║µĢ░µŹ«ķøåÕż¦Õ░Å’╝īķ╗śĶ«żõĮ┐ńö© `build_dataset` µēĆÕŠŚµĢ░µŹ«ķøåńÜäÕż¦Õ░ÅŃĆé
+- **`-n, --ngpus`**: õĮ┐ńö© GPU ńÜäµĢ░ķćÅ’╝īķ╗śĶ«żõĖ║ 1ŃĆé
+- **`-s, --save-path`**: õ┐ØÕŁśńÜäÕÅ»Ķ¦åÕī¢ÕøŠńēćńÜäĶĘ»ÕŠä’╝īķ╗śĶ«żõĖŹõ┐ØÕŁśŃĆé
+- `--title`: ÕÅ»Ķ¦åÕī¢ÕøŠńēćńÜäµĀćķóś’╝īķ╗śĶ«żõĖ║ķģŹńĮ«µ¢ćõ╗ČÕÉŹŃĆé
+- `--style`: ÕÅ»Ķ¦åÕī¢ÕøŠńēćńÜäķŻÄµĀ╝’╝īķ╗śĶ«żõĖ║ `whitegrid`ŃĆé
+- `--window-size`: ÕÅ»Ķ¦åÕī¢ń¬ŚÕÅŻÕż¦Õ░Å’╝īÕ”éµ×£µ▓Īµ£ēµīćÕ«Ü’╝īķ╗śĶ«żõĖ║ `12*7`ŃĆéÕ”éµ×£ķ£ĆĶ”üµīćÕ«Ü’╝īµīēńģ¦µĀ╝Õ╝Å `'W*H'`ŃĆé
+- `--cfg-options`: Õ»╣ķģŹńĮ«µ¢ćõ╗ČńÜäõ┐«µö╣’╝īÕÅéĶĆā[ÕŁ”õ╣ĀķģŹńĮ«µ¢ćõ╗Č](../user_guides/config.md)ŃĆé
+
+```{note}
+ķā©ÕłåµĢ░µŹ«ķøåÕ£©Ķ¦Żµ×ɵĀćµ│©ķśČµ«Ąµ»öĶŠāĶĆŚµŚČ’╝īÕÅ»ńø┤µÄźÕ░å `-d, dataset-size` µīćիܵĢ░µŹ«ķøåńÜäÕż¦Õ░Å’╝īõ╗źĶŖéń║”µŚČķŚ┤ŃĆé
+```
+
+## Õ”éõĮĢÕ£©Õ╝ĆÕ¦ŗĶ«Łń╗āÕēŹÕÅ»Ķ¦åÕī¢ÕŁ”õ╣ĀńÄćµø▓ń║┐
+
+õĮĀÕÅ»õ╗źõĮ┐ńö©Õ”éõĖŗÕæĮõ╗żµØźń╗śÕłČķģŹńĮ«µ¢ćõ╗Č `configs/swin_transformer/swin-base_16xb64_in1k.py` Õ░åõ╝ÜõĮ┐ńö©ńÜäÕÅśÕī¢ńÄćµø▓ń║┐’╝Ü
+
+```bash
+python tools/visualization/vis_scheduler.py configs/swin_transformer/swin-base_16xb64_in1k.py --dataset-size 1281167 --ngpus 16
+```
+
+ diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/shape_bias.md b/internlm_langchain/knowledge_base/MMPreTrain/content/shape_bias.md
new file mode 100644
index 00000000..f557197d
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/shape_bias.md
@@ -0,0 +1,96 @@
+## ÕĮóńŖČÕüÅÕĘ«(Shape Bias)ÕĘźÕģĘńö©µ│Ģ
+
+ÕĮóńŖČÕüÅÕĘ«(shape bias)ĶĪĪķćŵ©ĪÕ×ŗõĖÄń║╣ńÉåńøĖµ»ö’╝īÕ”éõĮĢõŠØĶĄ¢ÕĮóńŖČµØźµä¤ń¤źÕøŠÕāÅõĖŁńÜäĶ»Łõ╣ēŃĆéÕģ│õ║ĵø┤ÕżÜń╗åĶŖé’╝īµłæõ╗¼ÕÉæµä¤Õģ┤ĶČŻńÜäĶ»╗ĶĆģµÄ©ĶŹÉĶ┐Öń»ć[Ķ«║µ¢ć](https://arxiv.org/abs/2106.07411) ŃĆéMMPretrainµÅÉõŠøńÄ░µłÉńÜäÕĘźÕģĘń«▒µØźĶÄĘÕŠŚÕłåń▒╗µ©ĪÕ×ŗńÜäÕĮóńŖČÕüÅÕĘ«ŃĆéµé©ÕÅ»õ╗źµīēńģ¦õ╗źõĖŗµŁźķ¬żµōŹõĮ£’╝Ü
+
+### ÕćåÕżćµĢ░µŹ«ķøå
+
+ķ”¢ÕģłõĮĀÕ║öĶ»źõĖŗĶĮĮ[cue-conflict](https://github.com/bethgelab/model-vs-human/releases/download/v0.1/cue-conflict.tar.gz) Õł░`data`µ¢ćõ╗ČÕż╣’╝īńäČÕÉÄĶ¦ŻÕÄŗń╝®Ķ┐ÖõĖ¬µĢ░µŹ«ķøåŃĆéõ╣ŗÕÉÄ’╝īõĮĀńÜä`data`µ¢ćõ╗ČÕż╣Õ║öÕģʵ£ēõĖĆõĖŗń╗ōµ×ä’╝Ü
+
+```text
+data
+Ōö£ŌöĆŌöĆcue-conflict
+| |ŌöĆŌöĆairplane
+| |ŌöĆŌöĆbear
+| ...
+| |ŌöĆŌöĆ truck
+```
+
+### õ┐«µö╣Õłåń▒╗ķģŹńĮ«
+
+µłæõ╗¼Õ£©õĮ┐ńö©MAEķóäĶ«Łń╗āńÜäViT-baseµ©ĪÕ×ŗõĖŖĶ┐ÉĶĪīÕĮóńŖČÕüÅń¦╗ÕĘźÕģĘŃĆéÕ«āńÜäķģŹńĮ«µ¢ćõ╗ČõĖ║`configs/mae/benchmarks/vit-base-p16_8xb128-coslr-100e_in1k.py`’╝īÕ«āńÜ䵯Ƶ¤źńé╣ÕÅ»õ╗Ä[µŁżķōŠµÄź](https://download.openmmlab.com/mmselfsup/1.x/mae/mae_vit-base-p16_8xb512-fp16-coslr-1600e_in1k/vit-base-p16_ft-8xb128-coslr-100e_in1k/vit-base-p16_ft-8xb128-coslr-100e_in1k_20220825-cf70aa21.pth) õĖŗĶĮĮŃĆéÕ░åÕĤզŗķģŹńĮ«õĖŁńÜätest_pipeline, test_dataloaderÕÆītest_evaluationµø┐µŹóõĖ║õ╗źõĖŗķģŹńĮ«’╝Ü
+
+```python
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='ResizeEdge',
+ scale=256,
+ edge='short',
+ backend='pillow'),
+ dict(type='CenterCrop', crop_size=224),
+ dict(type='PackInputs')
+]
+test_dataloader = dict(
+ pin_memory=True,
+ collate_fn=dict(type='default_collate'),
+ batch_size=32,
+ num_workers=4,
+ dataset=dict(
+ type='CustomDataset',
+ data_root='data/cue-conflict',
+ pipeline=test_pipeline,
+ _delete_=True),
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ persistent_workers=True,
+ drop_last=False)
+test_evaluator = dict(
+ type='mmpretrain.ShapeBiasMetric',
+ _delete_=True,
+ csv_dir='work_dirs/shape_bias',
+ model_name='mae')
+```
+
+Ķ»Ęµ│©µäÅ’╝īõĮĀÕ║öĶ»źÕ»╣õĖŖķØóńÜä`csv_dir`ÕÆī`model_name`Ķ┐øĶĪīĶć¬Õ«Üõ╣ēõ┐«µö╣ŃĆ鵳æµŖŖõ┐«µö╣ÕÉÄńÜäńż║õŠŗķģŹńĮ«µ¢ćõ╗ČķćŹÕæĮÕÉŹõĖ║`configs/mae/benchmarks/`µ¢ćõ╗ČÕż╣õĖŁńÜä`vit-base-p16_8xb128-coslr-100e_in1k_shape-bias.py`µ¢ćõ╗ČŃĆé
+
+### ńö©õĖŖķØóõ┐«µö╣ÕÉÄńÜäķģŹńĮ«µ¢ćõ╗ČÕ£©õĮĀńÜ䵩ĪÕ×ŗõĖŖÕüܵĩµ¢Ł
+
+ńäČÕÉÄ’╝īõĮĀÕ║öĶ»źõĮ┐ńö©õ┐«µö╣ÕÉÄńÜäķģŹńĮ«µ¢ćõ╗ČÕ£©`cue-conflict`µĢ░µŹ«ķøåõĖŖµÄ©µ¢ŁõĮĀńÜ䵩ĪÕ×ŗŃĆé
+
+```shell
+# For PyTorch
+bash tools/dist_test.sh $CONFIG $CHECKPOINT
+```
+
+**µēƵ£ēÕÅéµĢ░ńÜäĶ»┤µśÄ**’╝Ü
+
+- `$CONFIG`: õ┐«µö╣ÕÉÄńÜäķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠäŃĆé
+- `$CHECKPOINT`: µŻĆµ¤źńé╣µ¢ćõ╗ČńÜäĶĘ»ÕŠäµł¢ķōŠµÄźŃĆé
+
+```shell
+# Example
+bash tools/dist_test.sh configs/mae/benchmarks/vit-base-p16_8xb128-coslr-100e_in1k_shape-bias.py https://download.openmmlab.com/mmselfsup/1.x/mae/mae_vit-base-p16_8xb512-fp16-coslr-1600e_in1k/vit-base-p16_ft-8xb128-coslr-100e_in1k/vit-base-p16_ft-8xb128-coslr-100e_in1k_20220825-cf70aa21.pth 1
+```
+
+õ╣ŗÕÉÄ’╝īõĮĀÕ║öĶ»źÕ£©`csv_dir`µ¢ćõ╗ČÕż╣õĖŁĶÄĘÕŠŚõĖĆõĖ¬ÕÉŹõĖ║`cue-conflict_model-name_session-1.csv`ńÜäcsvµ¢ćõ╗ČŃĆéķÖżõ║åĶ┐ÖõĖ¬µ¢ćõ╗Čõ╗źÕż¢’╝īõĮĀĶ┐śÕ║öĶ»źõĖŗĶĮĮĶ┐Öõ║ø[csvµ¢ćõ╗Č](https://github.com/bethgelab/model-vs-human/tree/master/raw-data/cue-conflict) Õł░`csv_dir`ŃĆé
+
+### ń╗śÕłČÕĮóńŖČÕüÅÕĘ«ÕøŠ
+
+ńäČÕÉĵłæõ╗¼ÕÅ»õ╗źÕ╝ĆÕ¦ŗń╗śÕłČÕĮóńŖČÕüÅÕĘ«ÕøŠ’╝Ü
+
+```shell
+python tools/analysis_tools/shape_bias.py --csv-dir $CSV_DIR --result-dir $RESULT_DIR --colors $RGB --markers o --plotting-names $YOUR_MODEL_NAME --model-names $YOUR_MODEL_NAME
+```
+
+**µēƵ£ēÕÅéµĢ░ńÜäĶ»┤µśÄ**:
+
+- `--csv-dir $CSV_DIR`, õĖÄõ┐ØÕŁśĶ┐Öõ║øcsvµ¢ćõ╗ČńÜäńø«ÕĮĢńøĖÕÉīŃĆé
+- `--result-dir $RESULT_DIR`, ĶŠōÕć║ÕÉŹõĖ║`cue-conflict_shape-bias_matrixplot.pdf`ńÜäń╗ōµ×£ńÜäńø«ÕĮĢŃĆé
+- `--colors $RGB`, Õ║öĶ»źµś»RGBÕĆ╝’╝īµĀ╝Õ╝ÅõĖ║R G B’╝īõŠŗÕ”é100 100 100’╝īÕ”éµ×£õĮĀµā│ń╗śÕłČÕćĀõĖ¬µ©ĪÕ×ŗńÜäÕĮóńŖČÕüÅÕĘ«’╝īÕÅ»õ╗źµś»ÕżÜõĖ¬RGBÕĆ╝ŃĆé
+- `--plotting-names $YOUR_MODEL_NAME`, ÕĮóńŖČÕüÅń¦╗ÕøŠõĖŁÕøŠõŠŗńÜäÕÉŹń¦░’╝īµé©ÕÅ»õ╗źÕ░åÕģČĶ«ŠńĮ«õĖ║µ©ĪÕ×ŗÕÉŹń¦░ŃĆéÕ”éµ×£Ķ”üń╗śÕłČÕżÜõĖ¬µ©ĪÕ×ŗ’╝īplotting_namesÕÅ»õ╗źµś»ÕżÜõĖ¬ÕĆ╝ŃĆé
+- `model-names $YOUR_MODEL_NAME`, Õ║öõĖÄķģŹńĮ«õĖŁµīćÕ«ÜńÜäÕÉŹń¦░ńøĖÕÉī’╝īÕ”éµ×£Ķ”üń╗śÕłČÕżÜõĖ¬µ©ĪÕ×ŗńÜäÕĮóńŖČÕüÅÕĘ«’╝īÕłÖÕÅ»õ╗źµś»ÕżÜõĖ¬ÕÉŹń¦░ŃĆé
+
+Ķ»Ęµ│©µäÅ’╝ī`--colors`ńÜäµ»ÅõĖēõĖ¬ÕĆ╝Õ»╣Õ║öõ║Ä`--model-names`ńÜäõĖĆõĖ¬ÕĆ╝ŃĆéÕ«īµłÉõ╗źõĖŖµēƵ£ēµŁźķ¬żÕÉÄ’╝īõĮĀÕ░åĶÄĘÕŠŚõĖŗÕøŠŃĆé
+
+
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/shape_bias.md b/internlm_langchain/knowledge_base/MMPreTrain/content/shape_bias.md
new file mode 100644
index 00000000..f557197d
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/shape_bias.md
@@ -0,0 +1,96 @@
+## ÕĮóńŖČÕüÅÕĘ«(Shape Bias)ÕĘźÕģĘńö©µ│Ģ
+
+ÕĮóńŖČÕüÅÕĘ«(shape bias)ĶĪĪķćŵ©ĪÕ×ŗõĖÄń║╣ńÉåńøĖµ»ö’╝īÕ”éõĮĢõŠØĶĄ¢ÕĮóńŖČµØźµä¤ń¤źÕøŠÕāÅõĖŁńÜäĶ»Łõ╣ēŃĆéÕģ│õ║ĵø┤ÕżÜń╗åĶŖé’╝īµłæõ╗¼ÕÉæµä¤Õģ┤ĶČŻńÜäĶ»╗ĶĆģµÄ©ĶŹÉĶ┐Öń»ć[Ķ«║µ¢ć](https://arxiv.org/abs/2106.07411) ŃĆéMMPretrainµÅÉõŠøńÄ░µłÉńÜäÕĘźÕģĘń«▒µØźĶÄĘÕŠŚÕłåń▒╗µ©ĪÕ×ŗńÜäÕĮóńŖČÕüÅÕĘ«ŃĆéµé©ÕÅ»õ╗źµīēńģ¦õ╗źõĖŗµŁźķ¬żµōŹõĮ£’╝Ü
+
+### ÕćåÕżćµĢ░µŹ«ķøå
+
+ķ”¢ÕģłõĮĀÕ║öĶ»źõĖŗĶĮĮ[cue-conflict](https://github.com/bethgelab/model-vs-human/releases/download/v0.1/cue-conflict.tar.gz) Õł░`data`µ¢ćõ╗ČÕż╣’╝īńäČÕÉÄĶ¦ŻÕÄŗń╝®Ķ┐ÖõĖ¬µĢ░µŹ«ķøåŃĆéõ╣ŗÕÉÄ’╝īõĮĀńÜä`data`µ¢ćõ╗ČÕż╣Õ║öÕģʵ£ēõĖĆõĖŗń╗ōµ×ä’╝Ü
+
+```text
+data
+Ōö£ŌöĆŌöĆcue-conflict
+| |ŌöĆŌöĆairplane
+| |ŌöĆŌöĆbear
+| ...
+| |ŌöĆŌöĆ truck
+```
+
+### õ┐«µö╣Õłåń▒╗ķģŹńĮ«
+
+µłæõ╗¼Õ£©õĮ┐ńö©MAEķóäĶ«Łń╗āńÜäViT-baseµ©ĪÕ×ŗõĖŖĶ┐ÉĶĪīÕĮóńŖČÕüÅń¦╗ÕĘźÕģĘŃĆéÕ«āńÜäķģŹńĮ«µ¢ćõ╗ČõĖ║`configs/mae/benchmarks/vit-base-p16_8xb128-coslr-100e_in1k.py`’╝īÕ«āńÜ䵯Ƶ¤źńé╣ÕÅ»õ╗Ä[µŁżķōŠµÄź](https://download.openmmlab.com/mmselfsup/1.x/mae/mae_vit-base-p16_8xb512-fp16-coslr-1600e_in1k/vit-base-p16_ft-8xb128-coslr-100e_in1k/vit-base-p16_ft-8xb128-coslr-100e_in1k_20220825-cf70aa21.pth) õĖŗĶĮĮŃĆéÕ░åÕĤզŗķģŹńĮ«õĖŁńÜätest_pipeline, test_dataloaderÕÆītest_evaluationµø┐µŹóõĖ║õ╗źõĖŗķģŹńĮ«’╝Ü
+
+```python
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='ResizeEdge',
+ scale=256,
+ edge='short',
+ backend='pillow'),
+ dict(type='CenterCrop', crop_size=224),
+ dict(type='PackInputs')
+]
+test_dataloader = dict(
+ pin_memory=True,
+ collate_fn=dict(type='default_collate'),
+ batch_size=32,
+ num_workers=4,
+ dataset=dict(
+ type='CustomDataset',
+ data_root='data/cue-conflict',
+ pipeline=test_pipeline,
+ _delete_=True),
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ persistent_workers=True,
+ drop_last=False)
+test_evaluator = dict(
+ type='mmpretrain.ShapeBiasMetric',
+ _delete_=True,
+ csv_dir='work_dirs/shape_bias',
+ model_name='mae')
+```
+
+Ķ»Ęµ│©µäÅ’╝īõĮĀÕ║öĶ»źÕ»╣õĖŖķØóńÜä`csv_dir`ÕÆī`model_name`Ķ┐øĶĪīĶć¬Õ«Üõ╣ēõ┐«µö╣ŃĆ鵳æµŖŖõ┐«µö╣ÕÉÄńÜäńż║õŠŗķģŹńĮ«µ¢ćõ╗ČķćŹÕæĮÕÉŹõĖ║`configs/mae/benchmarks/`µ¢ćõ╗ČÕż╣õĖŁńÜä`vit-base-p16_8xb128-coslr-100e_in1k_shape-bias.py`µ¢ćõ╗ČŃĆé
+
+### ńö©õĖŖķØóõ┐«µö╣ÕÉÄńÜäķģŹńĮ«µ¢ćõ╗ČÕ£©õĮĀńÜ䵩ĪÕ×ŗõĖŖÕüܵĩµ¢Ł
+
+ńäČÕÉÄ’╝īõĮĀÕ║öĶ»źõĮ┐ńö©õ┐«µö╣ÕÉÄńÜäķģŹńĮ«µ¢ćõ╗ČÕ£©`cue-conflict`µĢ░µŹ«ķøåõĖŖµÄ©µ¢ŁõĮĀńÜ䵩ĪÕ×ŗŃĆé
+
+```shell
+# For PyTorch
+bash tools/dist_test.sh $CONFIG $CHECKPOINT
+```
+
+**µēƵ£ēÕÅéµĢ░ńÜäĶ»┤µśÄ**’╝Ü
+
+- `$CONFIG`: õ┐«µö╣ÕÉÄńÜäķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠäŃĆé
+- `$CHECKPOINT`: µŻĆµ¤źńé╣µ¢ćõ╗ČńÜäĶĘ»ÕŠäµł¢ķōŠµÄźŃĆé
+
+```shell
+# Example
+bash tools/dist_test.sh configs/mae/benchmarks/vit-base-p16_8xb128-coslr-100e_in1k_shape-bias.py https://download.openmmlab.com/mmselfsup/1.x/mae/mae_vit-base-p16_8xb512-fp16-coslr-1600e_in1k/vit-base-p16_ft-8xb128-coslr-100e_in1k/vit-base-p16_ft-8xb128-coslr-100e_in1k_20220825-cf70aa21.pth 1
+```
+
+õ╣ŗÕÉÄ’╝īõĮĀÕ║öĶ»źÕ£©`csv_dir`µ¢ćõ╗ČÕż╣õĖŁĶÄĘÕŠŚõĖĆõĖ¬ÕÉŹõĖ║`cue-conflict_model-name_session-1.csv`ńÜäcsvµ¢ćõ╗ČŃĆéķÖżõ║åĶ┐ÖõĖ¬µ¢ćõ╗Čõ╗źÕż¢’╝īõĮĀĶ┐śÕ║öĶ»źõĖŗĶĮĮĶ┐Öõ║ø[csvµ¢ćõ╗Č](https://github.com/bethgelab/model-vs-human/tree/master/raw-data/cue-conflict) Õł░`csv_dir`ŃĆé
+
+### ń╗śÕłČÕĮóńŖČÕüÅÕĘ«ÕøŠ
+
+ńäČÕÉĵłæõ╗¼ÕÅ»õ╗źÕ╝ĆÕ¦ŗń╗śÕłČÕĮóńŖČÕüÅÕĘ«ÕøŠ’╝Ü
+
+```shell
+python tools/analysis_tools/shape_bias.py --csv-dir $CSV_DIR --result-dir $RESULT_DIR --colors $RGB --markers o --plotting-names $YOUR_MODEL_NAME --model-names $YOUR_MODEL_NAME
+```
+
+**µēƵ£ēÕÅéµĢ░ńÜäĶ»┤µśÄ**:
+
+- `--csv-dir $CSV_DIR`, õĖÄõ┐ØÕŁśĶ┐Öõ║øcsvµ¢ćõ╗ČńÜäńø«ÕĮĢńøĖÕÉīŃĆé
+- `--result-dir $RESULT_DIR`, ĶŠōÕć║ÕÉŹõĖ║`cue-conflict_shape-bias_matrixplot.pdf`ńÜäń╗ōµ×£ńÜäńø«ÕĮĢŃĆé
+- `--colors $RGB`, Õ║öĶ»źµś»RGBÕĆ╝’╝īµĀ╝Õ╝ÅõĖ║R G B’╝īõŠŗÕ”é100 100 100’╝īÕ”éµ×£õĮĀµā│ń╗śÕłČÕćĀõĖ¬µ©ĪÕ×ŗńÜäÕĮóńŖČÕüÅÕĘ«’╝īÕÅ»õ╗źµś»ÕżÜõĖ¬RGBÕĆ╝ŃĆé
+- `--plotting-names $YOUR_MODEL_NAME`, ÕĮóńŖČÕüÅń¦╗ÕøŠõĖŁÕøŠõŠŗńÜäÕÉŹń¦░’╝īµé©ÕÅ»õ╗źÕ░åÕģČĶ«ŠńĮ«õĖ║µ©ĪÕ×ŗÕÉŹń¦░ŃĆéÕ”éµ×£Ķ”üń╗śÕłČÕżÜõĖ¬µ©ĪÕ×ŗ’╝īplotting_namesÕÅ»õ╗źµś»ÕżÜõĖ¬ÕĆ╝ŃĆé
+- `model-names $YOUR_MODEL_NAME`, Õ║öõĖÄķģŹńĮ«õĖŁµīćÕ«ÜńÜäÕÉŹń¦░ńøĖÕÉī’╝īÕ”éµ×£Ķ”üń╗śÕłČÕżÜõĖ¬µ©ĪÕ×ŗńÜäÕĮóńŖČÕüÅÕĘ«’╝īÕłÖÕÅ»õ╗źµś»ÕżÜõĖ¬ÕÉŹń¦░ŃĆé
+
+Ķ»Ęµ│©µäÅ’╝ī`--colors`ńÜäµ»ÅõĖēõĖ¬ÕĆ╝Õ»╣Õ║öõ║Ä`--model-names`ńÜäõĖĆõĖ¬ÕĆ╝ŃĆéÕ«īµłÉõ╗źõĖŖµēƵ£ēµŁźķ¬żÕÉÄ’╝īõĮĀÕ░åĶÄĘÕŠŚõĖŗÕøŠŃĆé
+
+ |
|  |
+
+## Õ”éõĮĢÕÅ»Ķ¦åÕī¢Ķć¬ńøæńØŻµ©ĪÕ×ŗńÜät-SNE’╝łÕ”é MAE’╝ē
+
+õ╗źõĖŗµś»Õ£©ImageNetµĢ░µŹ«ķøåõĖŖĶ«Łń╗āńÜä MAE-ViT-base µ©ĪÕ×ŗõĖŖĶ┐ÉĶĪī t-SNE ÕÅ»Ķ¦åÕī¢ńÜäõĖĆõĖ¬µĀĘõŠŗŃĆéĶŠōÕģźµĢ░µŹ«µØźĶć¬ ImageNet ķ¬īĶ»üķøåŃĆéMAEÕÆīõĖĆõ║øĶć¬ńøæńØŻķóäĶ«Łń╗āń«Śµ│ĢķģŹńĮ«õĖŁµ▓Īµ£ē test_dataloader õ┐Īµü»ŃĆéÕ£©Õłåµ×ÉĶ┐Öõ║øĶć¬ńøæńØŻń«Śµ│ĢµŚČ’╝īõĮĀķ£ĆĶ”üÕ£©ķģŹńĮ«õĖŁµĘ╗ÕŖĀ test_dataloader õ┐Īµü»’╝īµł¢ĶĆģõĮ┐ńö© `--test-cfg` ÕŁŚµ«ĄµØźµīćÕ«ÜõĖĆõĖ¬ķģŹńĮ«µ¢ćõ╗ČŃĆé
+
+```shell
+python tools/visualization/vis_tsne.py \
+ configs/mae/mae_vit-base-p16_8xb512-amp-coslr-800e_in1k.py \
+ --checkpoint https://download.openmmlab.com/mmselfsup/1.x/mae/mae_vit-base-p16_8xb512-fp16-coslr-800e_in1k/mae_vit-base-p16_8xb512-coslr-800e-fp16_in1k_20220825-5d81fbc4.pth \
+ --test-cfg configs/_base_/datasets/imagenet_bs32.py
+```
+
+| MAE-ViT-base |
+| ------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+|
|
+
+## Õ”éõĮĢÕÅ»Ķ¦åÕī¢Ķć¬ńøæńØŻµ©ĪÕ×ŗńÜät-SNE’╝łÕ”é MAE’╝ē
+
+õ╗źõĖŗµś»Õ£©ImageNetµĢ░µŹ«ķøåõĖŖĶ«Łń╗āńÜä MAE-ViT-base µ©ĪÕ×ŗõĖŖĶ┐ÉĶĪī t-SNE ÕÅ»Ķ¦åÕī¢ńÜäõĖĆõĖ¬µĀĘõŠŗŃĆéĶŠōÕģźµĢ░µŹ«µØźĶć¬ ImageNet ķ¬īĶ»üķøåŃĆéMAEÕÆīõĖĆõ║øĶć¬ńøæńØŻķóäĶ«Łń╗āń«Śµ│ĢķģŹńĮ«õĖŁµ▓Īµ£ē test_dataloader õ┐Īµü»ŃĆéÕ£©Õłåµ×ÉĶ┐Öõ║øĶć¬ńøæńØŻń«Śµ│ĢµŚČ’╝īõĮĀķ£ĆĶ”üÕ£©ķģŹńĮ«õĖŁµĘ╗ÕŖĀ test_dataloader õ┐Īµü»’╝īµł¢ĶĆģõĮ┐ńö© `--test-cfg` ÕŁŚµ«ĄµØźµīćÕ«ÜõĖĆõĖ¬ķģŹńĮ«µ¢ćõ╗ČŃĆé
+
+```shell
+python tools/visualization/vis_tsne.py \
+ configs/mae/mae_vit-base-p16_8xb512-amp-coslr-800e_in1k.py \
+ --checkpoint https://download.openmmlab.com/mmselfsup/1.x/mae/mae_vit-base-p16_8xb512-fp16-coslr-800e_in1k/mae_vit-base-p16_8xb512-coslr-800e-fp16_in1k_20220825-5d81fbc4.pth \
+ --test-cfg configs/_base_/datasets/imagenet_bs32.py
+```
+
+| MAE-ViT-base |
+| ------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+|  |
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/test.md b/internlm_langchain/knowledge_base/MMPreTrain/content/test.md
new file mode 100644
index 00000000..054e1e41
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/test.md
@@ -0,0 +1,117 @@
+# µĄŗĶ»Ģ
+
+## ÕŹĢµ£║ÕŹĢÕŹĪµĄŗĶ»Ģ
+
+õĮĀÕÅ»õ╗źõĮ┐ńö© `tools/test.py` Õ£©ńöĄĶäæõĖŖńö© CPU µł¢µś» GPU Ķ┐øĶĪīµ©ĪÕ×ŗńÜ䵥ŗĶ»ĢŃĆé
+
+õ╗źõĖŗµś»µĄŗĶ»ĢĶäܵ£¼ńÜäÕ«īµĢ┤ńö©µ│Ģ’╝Ü
+
+```shell
+python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [ARGS]
+```
+
+````{note}
+ķ╗śĶ«żµāģÕåĄõĖŗ’╝īMMPretrain õ╝ÜĶć¬ÕŖ©Ķ░āńö©õĮĀńÜä GPU Ķ┐øĶĪīµĄŗĶ»ĢŃĆéÕ”éµ×£õĮĀµ£ē GPU õĮåõ╗Źµā│õĮ┐ńö© CPU Ķ┐øĶĪīµĄŗĶ»Ģ’╝īĶ»ĘĶ«ŠńĮ«ńÄ»ÕóāÕÅśķćÅ `CUDA_VISIBLE_DEVICES` õĖ║ń®║µł¢ĶĆģ -1 µØźÕ»╣ń”üńö© GPUŃĆé
+
+```bash
+CUDA_VISIBLE_DEVICES=-1 python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [ARGS]
+```
+````
+
+| ÕÅéµĢ░ | µÅÅĶ┐░ |
+| ------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| `CONFIG_FILE` | ķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠäŃĆé |
+| `CHECKPOINT_FILE` | µØāķ揵¢ćõ╗ČĶĘ»ÕŠä’╝łµö»µīü http ķōŠµÄź’╝īõĮĀÕÅ»õ╗źÕ£©[Ķ┐Öķćī](https://mmpretrain.readthedocs.io/en/latest/modelzoo_statistics.html)Õ»╗µēŠķ£ĆĶ”üńÜäµØāķ揵¢ćõ╗Č’╝ēŃĆé |
+| `--work-dir WORK_DIR` | ńö©µØźõ┐ØÕŁśµĄŗĶ»ĢµīćµĀćń╗ōµ×£ńÜäµ¢ćõ╗ČÕż╣ŃĆé |
+| `--out OUT` | ńö©µØźõ┐ØÕŁśµĄŗĶ»ĢĶŠōÕć║ńÜäµ¢ćõ╗ČŃĆé |
+| `--out-item OUT_ITEM` | µīćիܵĄŗĶ»ĢĶŠōÕć║µ¢ćõ╗ČńÜäÕåģÕ«╣’╝īÕÅ»õ╗źõĖ║ "pred" µł¢ "metrics"’╝īÕģČõĖŁ "pred" ĶĪ©ńż║õ┐ØÕŁśµēƵ£ēµ©ĪÕ×ŗĶŠōÕć║’╝īĶ┐Öõ║øµĢ░µŹ«ÕÅ»õ╗źńö©õ║Äń”╗ń║┐µĄŗĶ»ä’╝ø"metrics" ĶĪ©ńż║ĶŠōÕć║µĄŗĶ»ĢµīćµĀćŃĆéķ╗śĶ«żõĖ║ "pred"ŃĆé |
+| `--cfg-options CFG_OPTIONS` | ķćŹĶĮĮķģŹńĮ«µ¢ćõ╗ČõĖŁńÜäõĖĆõ║øĶ«ŠńĮ«ŃĆéõĮ┐ńö©ń▒╗õ╝╝ `xxx=yyy` ńÜäķö«ÕĆ╝Õ»╣ÕĮóÕ╝ŵīćÕ«Ü’╝īĶ┐Öõ║øĶ«ŠńĮ«õ╝ÜĶó½Ķ׏ÕÉłÕģźõ╗ÄķģŹńĮ«µ¢ćõ╗ČĶ»╗ÕÅ¢ńÜäķģŹńĮ«ŃĆéõĮĀÕÅ»õ╗źõĮ┐ńö© `key="[a,b]"` µł¢ĶĆģ `key=a,b` ńÜäµĀ╝Õ╝ÅµØźµīćÕ«ÜÕłŚĶĪ©µĀ╝Õ╝ÅńÜäÕĆ╝’╝īõĖöµö»µīüÕĄīÕźŚ’╝īõŠŗÕ”é \`key="[(a,b),(c,d)]"’╝īĶ┐ÖķćīńÜäÕ╝ĢÕÅʵś»õĖŹÕÅ»ń£üńĢźńÜäŃĆéÕÅ”Õż¢µ»ÅõĖ¬ķćŹĶĮĮķĪ╣Õåģķā©õĖŹÕÅ»Õć║ńÄ░ń®║µĀ╝ŃĆé |
+| `--show-dir SHOW_DIR` | ńö©õ║Äõ┐ØÕŁśÕÅ»Ķ¦åÕī¢ķó䵥ŗń╗ōµ×£ÕøŠÕāÅńÜäµ¢ćõ╗ČÕż╣ŃĆé |
+| `--show` | Õ£©ń¬ŚÕÅŻõĖŁµśŠńż║ķó䵥ŗń╗ōµ×£ÕøŠÕāÅŃĆé |
+| `--interval INTERVAL` | µ»ÅķÜöÕżÜÕ░æµĀʵ£¼Ķ┐øĶĪīõĖƵ¼Īķó䵥ŗń╗ōµ×£ÕÅ»Ķ¦åÕī¢ŃĆé |
+| `--wait-time WAIT_TIME` | µ»ÅõĖ¬ń¬ŚÕÅŻńÜ䵜Šńż║µŚČķŚ┤’╝łÕŹĢõĮŹõĖ║ń¦Æ’╝ēŃĆé |
+| `--no-pin-memory` | µś»Õɔգ© dataloaders õĖŁÕģ│ķŚŁ `pin_memory` ķĆēķĪ╣ |
+| `--tta` | µś»ÕÉ”Õ╝ĆÕÉ» Test-Time-Aug (TTA). Õ”éµ×£ķģŹńĮ«µ¢ćõ╗ȵ£ē `tta_pipeline` ÕÆī `tta_model`’╝īÕ░åõĮ┐ńö©Ķ┐Öõ║øķģŹńĮ«µīćÕ«Ü TTA transforms’╝īÕ╣ČõĖöÕå│Õ«ÜÕ”éõĮĢĶ׏ÕÉł TTA ńÜäń╗ōµ×£ŃĆé ÕÉ”ÕłÖ’╝īķĆÜĶ┐ćÕ╣│ÕØćÕłåń▒╗ÕłåµĢ░õĮ┐ńö© flip TTAŃĆé |
+| `--launcher {none,pytorch,slurm,mpi}` | ÕÉ»ÕŖ©ÕÖ©’╝īķ╗śĶ«żõĖ║ "none"ŃĆé |
+
+## ÕŹĢµ£║ÕżÜÕŹĪµĄŗĶ»Ģ
+
+µłæõ╗¼µÅÉõŠøõ║åõĖĆõĖ¬ shell Ķäܵ£¼’╝īÕÅ»õ╗źõĮ┐ńö© `torch.distributed.launch` ÕÉ»ÕŖ©ÕżÜ GPU õ╗╗ÕŖĪŃĆé
+
+```shell
+bash ./tools/dist_test.sh ${CONFIG_FILE} ${CHECKPOINT_FILE} ${GPU_NUM} [PY_ARGS]
+```
+
+| ÕÅéµĢ░ | µÅÅĶ┐░ |
+| ----------------- | ---------------------------------------------------------------------------------------------------------------------------------------- |
+| `CONFIG_FILE` | ķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠäŃĆé |
+| `CHECKPOINT_FILE` | µØāķ揵¢ćõ╗ČĶĘ»ÕŠä’╝łµö»µīü http ķōŠµÄź’╝īõĮĀÕÅ»õ╗źÕ£©[Ķ┐Öķćī](https://mmpretrain.readthedocs.io/en/latest/modelzoo_statistics.html)Õ»╗µēŠķ£ĆĶ”üńÜäµØāķ揵¢ćõ╗Č’╝ēŃĆé |
+| `GPU_NUM` | õĮ┐ńö©ńÜä GPU µĢ░ķćÅŃĆé |
+| `[PY_ARGS]` | `tools/test.py` µö»µīüńÜäÕģČõ╗¢ÕÅ»ķĆēÕÅéµĢ░’╝īÕÅéĶ¦ü[õĖŖµ¢ć](#ÕŹĢµ£║ÕŹĢÕŹĪµĄŗĶ»Ģ)ŃĆé |
+
+õĮĀĶ┐śÕÅ»õ╗źõĮ┐ńö©ńÄ»ÕóāÕÅśķćÅµØźµīćÕ«ÜÕÉ»ÕŖ©ÕÖ©ńÜäķóØÕż¢ÕÅéµĢ░’╝īµ»öÕ”éńö©Õ”éõĖŗÕæĮõ╗żÕ░åÕÉ»ÕŖ©ÕÖ©ńÜäķĆÜĶ«»ń½»ÕÅŻÕÅśµø┤õĖ║ 29666’╝Ü
+
+```shell
+PORT=29666 bash ./tools/dist_test.sh ${CONFIG_FILE} ${CHECKPOINT_FILE} ${GPU_NUM} [PY_ARGS]
+```
+
+Õ”éµ×£õĮĀÕĖīµ£øõĮ┐ńö©õĖŹÕÉīńÜä GPU Ķ┐øĶĪīÕżÜķĪ╣µĄŗĶ»Ģõ╗╗ÕŖĪ’╝īÕÅ»õ╗źÕ£©ÕÉ»ÕŖ©µŚČµīćÕ«ÜõĖŹÕÉīńÜäķĆÜĶ«»ń½»ÕÅŻÕÆīõĖŹÕÉīńÜäÕÅ»ńö©Ķ«ŠÕżćŃĆé
+
+```shell
+CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 bash ./tools/dist_test.sh ${CONFIG_FILE1} ${CHECKPOINT_FILE} 4 [PY_ARGS]
+CUDA_VISIBLE_DEVICES=4,5,6,7 PORT=29501 bash ./tools/dist_test.sh ${CONFIG_FILE2} ${CHECKPOINT_FILE} 4 [PY_ARGS]
+```
+
+## ÕżÜµ£║µĄŗĶ»Ģ
+
+### ÕÉīõĖĆńĮæń╗£õĖŗńÜäÕżÜµ£║
+
+Õ”éµ×£õĮĀÕĖīµ£øõĮ┐ńö©ÕÉīõĖĆÕ▒ĆÕ¤¤ńĮæõĖŗĶ┐׵ğńÜäÕżÜÕÅ░ńöĄĶäæĶ┐øĶĪīõĖĆõĖ¬µĄŗĶ»Ģõ╗╗ÕŖĪ’╝īÕÅ»õ╗źõĮ┐ńö©Õ”éõĖŗÕæĮõ╗ż’╝Ü
+
+Õ£©ń¼¼õĖĆÕÅ░µ£║ÕÖ©õĖŖ’╝Ü
+
+```shell
+NNODES=2 NODE_RANK=0 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR bash tools/dist_test.sh $CONFIG $CHECKPOINT_FILE $GPUS
+```
+
+Õ£©ń¼¼õ║īÕÅ░µ£║ÕÖ©õĖŖ’╝Ü
+
+```shell
+NNODES=2 NODE_RANK=1 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR bash tools/dist_test.sh $CONFIG $CHECKPOINT_FILE $GPUS
+```
+
+ÕÆīÕŹĢµ£║ÕżÜÕŹĪńøĖµ»ö’╝īõĮĀķ£ĆĶ”üµīćÕ«ÜõĖĆõ║øķóØÕż¢ńÜäńÄ»ÕóāÕÅśķćÅ’╝Ü
+
+| ńÄ»ÕóāÕÅśķćÅ | µÅÅĶ┐░ |
+| ------------- | ---------------------------------------------- |
+| `NNODES` | µ£║ÕÖ©µĆ╗µĢ░ŃĆé |
+| `NODE_RANK` | µ£¼µ£║ńÜäÕ║ÅÕÅĘ |
+| `PORT` | ķĆÜĶ«»ń½»ÕÅŻ’╝īÕ«āÕ£©µēƵ£ēµ£║ÕÖ©õĖŖķāĮÕ║öÕĮōµś»õĖĆĶć┤ńÜäŃĆé |
+| `MASTER_ADDR` | õĖ╗µ£║ńÜä IP Õ£░ÕØĆ’╝īÕ«āÕ£©µēƵ£ēµ£║ÕÖ©õĖŖķāĮÕ║öÕĮōµś»õĖĆĶć┤ńÜäŃĆé |
+
+### Slurm ń«ĪńÉåõĖŗńÜäÕżÜµ£║ķøåńŠż
+
+Õ”éµ×£õĮĀÕ£© [slurm](https://slurm.schedmd.com/) ķøåńŠżõĖŖ’╝īÕÅ»õ╗źõĮ┐ńö© `tools/slurm_test.sh` Ķäܵ£¼ÕÉ»ÕŖ©õ╗╗ÕŖĪŃĆé
+
+```shell
+[ENV_VARS] ./tools/slurm_test.sh ${PARTITION} ${JOB_NAME} ${CONFIG_FILE} ${CHECKPOINT_FILE} [PY_ARGS]
+```
+
+Ķ┐Öķćīµś»Ķ»źĶäܵ£¼ńÜäõĖĆõ║øÕÅéµĢ░’╝Ü
+
+| ÕÅéµĢ░ | µÅÅĶ┐░ |
+| ----------------- | ---------------------------------------------------------------------------------------------------------------------------------------- |
+| `PARTITION` | õĮ┐ńö©ńÜäķøåńŠżÕłåÕī║ŃĆé |
+| `JOB_NAME` | õ╗╗ÕŖĪńÜäÕÉŹń¦░’╝īõĮĀÕÅ»õ╗źķÜŵäÅĶĄĘõĖĆõĖ¬ÕÉŹÕŁŚŃĆé |
+| `CONFIG_FILE` | ķģŹńĮ«µ¢ćõ╗ČĶĘ»ÕŠäŃĆé |
+| `CHECKPOINT_FILE` | µØāķ揵¢ćõ╗ČĶĘ»ÕŠä’╝łµö»µīü http ķōŠµÄź’╝īõĮĀÕÅ»õ╗źÕ£©[Ķ┐Öķćī](https://mmpretrain.readthedocs.io/en/latest/modelzoo_statistics.html)Õ»╗µēŠķ£ĆĶ”üńÜäµØāķ揵¢ćõ╗Č’╝ēŃĆé |
+| `[PY_ARGS]` | `tools/test.py` µö»µīüńÜäÕģČõ╗¢ÕÅ»ķĆēÕÅéµĢ░’╝īÕÅéĶ¦ü[õĖŖµ¢ć](#ÕŹĢµ£║ÕŹĢÕŹĪµĄŗĶ»Ģ)ŃĆé |
+
+Ķ┐Öķćīµś»õĖĆõ║øõĮĀÕÅ»õ╗źńö©µØźķģŹńĮ« slurm õ╗╗ÕŖĪńÜäńÄ»ÕóāÕÅśķćÅ’╝Ü
+
+| ńÄ»ÕóāÕÅśķćÅ | µÅÅĶ┐░ |
+| --------------- | ------------------------------------------------------------------------------------------ |
+| `GPUS` | õĮ┐ńö©ńÜä GPU µĆ╗µĢ░’╝īķ╗śĶ«żõĖ║ 8ŃĆé |
+| `GPUS_PER_NODE` | µ»ÅõĖ¬ĶŖéńé╣ÕłåķģŹńÜä GPU µĢ░’╝īõĮĀÕÅ»õ╗źµĀ╣µŹ«ĶŖéńé╣µāģÕåĄµīćÕ«ÜŃĆéķ╗śĶ«żõĖ║ 8ŃĆé |
+| `CPUS_PER_TASK` | µ»ÅõĖ¬õ╗╗ÕŖĪÕłåķģŹńÜä CPU µĢ░’╝łķĆÜÕĖĖõĖĆõĖ¬ GPU Õ»╣Õ║öõĖĆõĖ¬õ╗╗ÕŖĪ’╝ēŃĆéķ╗śĶ«żõĖ║ 5ŃĆé |
+| `SRUN_ARGS` | `srun` ÕæĮõ╗żµö»µīüńÜäÕģČõ╗¢ÕÅéµĢ░ŃĆéÕÅ»ńö©ńÜäķĆēķĪ╣ÕÅéĶ¦ü[Õ«śµ¢╣µ¢ćµĪŻ](https://slurm.schedmd.com/srun.html)ŃĆé |
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/train.md b/internlm_langchain/knowledge_base/MMPreTrain/content/train.md
new file mode 100644
index 00000000..841edabb
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/train.md
@@ -0,0 +1,118 @@
+# Ķ«Łń╗ā
+
+Õ£©µ£¼µĢÖń©ŗõĖŁ’╝īµłæõ╗¼Õ░åõ╗ŗń╗ŹÕ”éõĮĢõĮ┐ńö© MMPretrain õĖŁµÅÉõŠøńÜäĶäܵ£¼ÕÉ»ÕŖ©Ķ«Łń╗āõ╗╗ÕŖĪŃĆé
+Õ”éµ×£õĮĀķ£ĆĶ”üõ║åĶ¦ŻõĖĆõ║øÕģĘõĮōńÜäĶ«Łń╗āõŠŗÕŁÉ’╝īÕÅ»õ╗źµ¤źķśģ [Õ”éõĮĢÕ£©Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåõĖŖĶ┐øĶĪīµ©ĪÕ×ŗķóäĶ«Łń╗ā](../notes/pretrain_custom_dataset.md) ÕÆī [Õ”éõĮĢÕ£©Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåõĖŖÕŠ«Ķ░āµ©ĪÕ×ŗ](../notes/finetune_custom_dataset.md).
+
+## ÕŹĢµ£║ÕŹĢÕŹĪĶ«Łń╗ā
+
+õĮĀÕÅ»õ╗źõĮ┐ńö© `tools/train.py` Õ£©ńöĄĶäæõĖŖńö© CPU µł¢µś» GPU Ķ┐øĶĪīµ©ĪÕ×ŗńÜäĶ«Łń╗āŃĆé
+
+õ╗źõĖŗµś»Ķ«Łń╗āĶäܵ£¼ńÜäÕ«īµĢ┤ńö©µ│Ģ’╝Ü
+
+```shell
+python tools/train.py ${CONFIG_FILE} [ARGS]
+```
+
+````{note}
+ķ╗śĶ«żµāģÕåĄõĖŗ’╝īMMPretrain õ╝ÜĶć¬ÕŖ©Ķ░āńö©õĮĀńÜä GPU Ķ┐øĶĪīĶ«Łń╗āŃĆéÕ”éµ×£õĮĀµ£ē GPU õĮåõ╗Źµā│õĮ┐ńö© CPU Ķ┐øĶĪīĶ«Łń╗ā’╝īĶ»ĘĶ«ŠńĮ«ńÄ»ÕóāÕÅśķćÅ `CUDA_VISIBLE_DEVICES` õĖ║ń®║µł¢ĶĆģ -1 µØźÕ»╣ń”üńö© GPUŃĆé
+
+```bash
+CUDA_VISIBLE_DEVICES=-1 python tools/train.py ${CONFIG_FILE} [ARGS]
+```
+````
+
+| ÕÅéµĢ░ | µÅÅĶ┐░ |
+| ------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| `CONFIG_FILE` | ķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠäŃĆé |
+| `--work-dir WORK_DIR` | ńö©µØźõ┐ØÕŁśĶ«Łń╗āµŚźÕ┐ŚÕÆīµØāķ揵¢ćõ╗ČńÜäµ¢ćõ╗ČÕż╣’╝īķ╗śĶ«żµś» `./work_dirs` ńø«ÕĮĢõĖŗ’╝īõĖÄķģŹńĮ«µ¢ćõ╗ČÕÉīÕÉŹńÜäµ¢ćõ╗ČÕż╣ŃĆé |
+| `--resume [RESUME]` | µüóÕżŹĶ«Łń╗āŃĆéÕ”éµ×£µīćÕ«Üõ║åµØāķ揵¢ćõ╗ČĶĘ»ÕŠä’╝īÕłÖõ╗ĵīćÕ«ÜńÜäµØāķ揵¢ćõ╗ȵüóÕżŹ’╝øÕ”éµ×£µ▓Īµ£ēµīćÕ«Ü’╝īÕłÖÕ░ØĶ»Ģõ╗ĵ£Ćµ¢░ńÜäµØāķ揵¢ćõ╗ČĶ┐øĶĪīµüóÕżŹŃĆé |
+| `--amp` | ÕÉ»ńö©µĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗āŃĆé |
+| `--no-validate` | **õĖŹÕ╗║Ķ««** Õ£©Ķ«Łń╗āĶ┐ćń©ŗõĖŁõĖŹĶ┐øĶĪīķ¬īĶ»üķøåõĖŖńÜäń▓ŠÕ║”ķ¬īĶ»üŃĆé |
+| `--auto-scale-lr` | Ķć¬ÕŖ©µĀ╣µŹ«Õ«×ķÖģńÜäµē╣µ¼ĪÕż¦Õ░Å’╝łbatch size’╝ēÕÆīķóäĶ«ŠńÜäµē╣µ¼ĪÕż¦Õ░ÅÕ»╣ÕŁ”õ╣ĀńÄćĶ┐øĶĪīń╝®µöŠŃĆé |
+| `--no-pin-memory` | µś»Õɔգ© dataloaders õĖŁÕģ│ķŚŁ `pin_memory` ķĆēķĪ╣ |
+| `--no-persistent-workers` | µś»Õɔգ© dataloaders õĖŁÕģ│ķŚŁ `persistent_workers` ķĆēķĪ╣ |
+| `--cfg-options CFG_OPTIONS` | ķćŹĶĮĮķģŹńĮ«µ¢ćõ╗ČõĖŁńÜäõĖĆõ║øĶ«ŠńĮ«ŃĆéõĮ┐ńö©ń▒╗õ╝╝ `xxx=yyy` ńÜäķö«ÕĆ╝Õ»╣ÕĮóÕ╝ŵīćÕ«Ü’╝īĶ┐Öõ║øĶ«ŠńĮ«õ╝ÜĶó½Ķ׏ÕÉłÕģźõ╗ÄķģŹńĮ«µ¢ćõ╗ČĶ»╗ÕÅ¢ńÜäķģŹńĮ«ŃĆéõĮĀÕÅ»õ╗źõĮ┐ńö© `key="[a,b]"` µł¢ĶĆģ `key=a,b` ńÜäµĀ╝Õ╝ÅµØźµīćÕ«ÜÕłŚĶĪ©µĀ╝Õ╝ÅńÜäÕĆ╝’╝īõĖöµö»µīüÕĄīÕźŚ’╝īõŠŗÕ”é \`key="[(a,b),(c,d)]"’╝īĶ┐ÖķćīńÜäÕ╝ĢÕÅʵś»õĖŹÕÅ»ń£üńĢźńÜäŃĆéÕÅ”Õż¢µ»ÅõĖ¬ķćŹĶĮĮķĪ╣Õåģķā©õĖŹÕÅ»Õć║ńÄ░ń®║µĀ╝ŃĆé |
+| `--launcher {none,pytorch,slurm,mpi}` | ÕÉ»ÕŖ©ÕÖ©’╝īķ╗śĶ«żõĖ║ "none"ŃĆé |
+
+## ÕŹĢµ£║ÕżÜÕŹĪĶ«Łń╗ā
+
+µłæõ╗¼µÅÉõŠøõ║åõĖĆõĖ¬ shell Ķäܵ£¼’╝īÕÅ»õ╗źõĮ┐ńö© `torch.distributed.launch` ÕÉ»ÕŖ©ÕżÜ GPU õ╗╗ÕŖĪŃĆé
+
+```shell
+bash ./tools/dist_train.sh ${CONFIG_FILE} ${GPU_NUM} [PY_ARGS]
+```
+
+| ÕÅéµĢ░ | µÅÅĶ┐░ |
+| ------------- | ---------------------------------------------------------------- |
+| `CONFIG_FILE` | ķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠäŃĆé |
+| `GPU_NUM` | õĮ┐ńö©ńÜä GPU µĢ░ķćÅŃĆé |
+| `[PY_ARGS]` | `tools/train.py` µö»µīüńÜäÕģČõ╗¢ÕÅ»ķĆēÕÅéµĢ░’╝īÕÅéĶ¦ü[õĖŖµ¢ć](#ÕŹĢµ£║ÕŹĢÕŹĪĶ«Łń╗ā)ŃĆé |
+
+õĮĀĶ┐śÕÅ»õ╗źõĮ┐ńö©ńÄ»ÕóāÕÅśķćÅµØźµīćÕ«ÜÕÉ»ÕŖ©ÕÖ©ńÜäķóØÕż¢ÕÅéµĢ░’╝īµ»öÕ”éńö©Õ”éõĖŗÕæĮõ╗żÕ░åÕÉ»ÕŖ©ÕÖ©ńÜäķĆÜĶ«»ń½»ÕÅŻÕÅśµø┤õĖ║ 29666’╝Ü
+
+```shell
+PORT=29666 bash ./tools/dist_train.sh ${CONFIG_FILE} ${GPU_NUM} [PY_ARGS]
+```
+
+Õ”éµ×£õĮĀÕĖīµ£øõĮ┐ńö©õĖŹÕÉīńÜä GPU Ķ┐øĶĪīÕżÜķĪ╣Ķ«Łń╗āõ╗╗ÕŖĪ’╝īÕÅ»õ╗źÕ£©ÕÉ»ÕŖ©µŚČµīćÕ«ÜõĖŹÕÉīńÜäķĆÜĶ«»ń½»ÕÅŻÕÆīõĖŹÕÉīńÜäÕÅ»ńö©Ķ«ŠÕżćŃĆé
+
+```shell
+CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 bash ./tools/dist_train.sh ${CONFIG_FILE1} 4 [PY_ARGS]
+CUDA_VISIBLE_DEVICES=4,5,6,7 PORT=29501 bash ./tools/dist_train.sh ${CONFIG_FILE2} 4 [PY_ARGS]
+```
+
+## ÕżÜµ£║Ķ«Łń╗ā
+
+### ÕÉīõĖĆńĮæń╗£õĖŗńÜäÕżÜµ£║
+
+Õ”éµ×£õĮĀÕĖīµ£øõĮ┐ńö©ÕÉīõĖĆÕ▒ĆÕ¤¤ńĮæõĖŗĶ┐׵ğńÜäÕżÜÕÅ░ńöĄĶäæĶ┐øĶĪīõĖĆõĖ¬Ķ«Łń╗āõ╗╗ÕŖĪ’╝īÕÅ»õ╗źõĮ┐ńö©Õ”éõĖŗÕæĮõ╗ż’╝Ü
+
+Õ£©ń¼¼õĖĆÕÅ░µ£║ÕÖ©õĖŖ’╝Ü
+
+```shell
+NNODES=2 NODE_RANK=0 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR bash tools/dist_train.sh $CONFIG $GPUS
+```
+
+Õ£©ń¼¼õ║īÕÅ░µ£║ÕÖ©õĖŖ’╝Ü
+
+```shell
+NNODES=2 NODE_RANK=1 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR bash tools/dist_train.sh $CONFIG $GPUS
+```
+
+ÕÆīÕŹĢµ£║ÕżÜÕŹĪńøĖµ»ö’╝īõĮĀķ£ĆĶ”üµīćÕ«ÜõĖĆõ║øķóØÕż¢ńÜäńÄ»ÕóāÕÅśķćÅ’╝Ü
+
+| ńÄ»ÕóāÕÅśķćÅ | µÅÅĶ┐░ |
+| ------------- | ---------------------------------------------- |
+| `NNODES` | µ£║ÕÖ©µĆ╗µĢ░ŃĆé |
+| `NODE_RANK` | µ£¼µ£║ńÜäÕ║ÅÕÅĘ |
+| `PORT` | ķĆÜĶ«»ń½»ÕÅŻ’╝īÕ«āÕ£©µēƵ£ēµ£║ÕÖ©õĖŖķāĮÕ║öÕĮōµś»õĖĆĶć┤ńÜäŃĆé |
+| `MASTER_ADDR` | õĖ╗µ£║ńÜä IP Õ£░ÕØĆ’╝īÕ«āÕ£©µēƵ£ēµ£║ÕÖ©õĖŖķāĮÕ║öÕĮōµś»õĖĆĶć┤ńÜäŃĆé |
+
+ķĆÜÕĖĖµØźĶ»┤’╝īÕ”éµ×£Ķ┐ÖÕćĀÕÅ░µ£║ÕÖ©õ╣ŗķŚ┤õĖŹµś»ķ½śķƤńĮæń╗£Ķ┐׵ğ’╝īĶ«Łń╗āķƤÕ║”õ╝ÜķØ×ÕĖĖµģóŃĆé
+
+### Slurm ń«ĪńÉåõĖŗńÜäÕżÜµ£║ķøåńŠż
+
+Õ”éµ×£õĮĀÕ£© [slurm](https://slurm.schedmd.com/) ķøåńŠżõĖŖ’╝īÕÅ»õ╗źõĮ┐ńö© `tools/slurm_train.sh` Ķäܵ£¼ÕÉ»ÕŖ©õ╗╗ÕŖĪŃĆé
+
+```shell
+[ENV_VARS] ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} ${CONFIG_FILE} ${WORK_DIR} [PY_ARGS]
+```
+
+Ķ┐Öķćīµś»Ķ»źĶäܵ£¼ńÜäõĖĆõ║øÕÅéµĢ░’╝Ü
+
+| ÕÅéµĢ░ | µÅÅĶ┐░ |
+| ------------- | ---------------------------------------------------------------- |
+| `PARTITION` | õĮ┐ńö©ńÜäķøåńŠżÕłåÕī║ŃĆé |
+| `JOB_NAME` | õ╗╗ÕŖĪńÜäÕÉŹń¦░’╝īõĮĀÕÅ»õ╗źķÜŵäÅĶĄĘõĖĆõĖ¬ÕÉŹÕŁŚŃĆé |
+| `CONFIG_FILE` | ķģŹńĮ«µ¢ćõ╗ČĶĘ»ÕŠäŃĆé |
+| `WORK_DIR` | ńö©õ╗źõ┐ØÕŁśµŚźÕ┐ŚÕÆīµØāķ揵¢ćõ╗ČńÜäµ¢ćõ╗ČÕż╣ŃĆé |
+| `[PY_ARGS]` | `tools/train.py` µö»µīüńÜäÕģČõ╗¢ÕÅ»ķĆēÕÅéµĢ░’╝īÕÅéĶ¦ü[õĖŖµ¢ć](#ÕŹĢµ£║ÕŹĢÕŹĪĶ«Łń╗ā)ŃĆé |
+
+Ķ┐Öķćīµś»õĖĆõ║øõĮĀÕÅ»õ╗źńö©µØźķģŹńĮ« slurm õ╗╗ÕŖĪńÜäńÄ»ÕóāÕÅśķćÅ’╝Ü
+
+| ńÄ»ÕóāÕÅśķćÅ | µÅÅĶ┐░ |
+| --------------- | ------------------------------------------------------------------------------------------ |
+| `GPUS` | õĮ┐ńö©ńÜä GPU µĆ╗µĢ░’╝īķ╗śĶ«żõĖ║ 8ŃĆé |
+| `GPUS_PER_NODE` | µ»ÅõĖ¬ĶŖéńé╣ÕłåķģŹńÜä GPU µĢ░’╝īõĮĀÕÅ»õ╗źµĀ╣µŹ«ĶŖéńé╣µāģÕåĄµīćÕ«ÜŃĆéķ╗śĶ«żõĖ║ 8ŃĆé |
+| `CPUS_PER_TASK` | µ»ÅõĖ¬õ╗╗ÕŖĪÕłåķģŹńÜä CPU µĢ░’╝łķĆÜÕĖĖõĖĆõĖ¬ GPU Õ»╣Õ║öõĖĆõĖ¬õ╗╗ÕŖĪ’╝ēŃĆéķ╗śĶ«żõĖ║ 5ŃĆé |
+| `SRUN_ARGS` | `srun` ÕæĮõ╗żµö»µīüńÜäÕģČõ╗¢ÕÅéµĢ░ŃĆéÕÅ»ńö©ńÜäķĆēķĪ╣ÕÅéĶ¦ü[Õ«śµ¢╣µ¢ćµĪŻ](https://slurm.schedmd.com/srun.html)ŃĆé |
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/verify_dataset.md b/internlm_langchain/knowledge_base/MMPreTrain/content/verify_dataset.md
new file mode 100644
index 00000000..655ce977
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/verify_dataset.md
@@ -0,0 +1,28 @@
+# µĢ░µŹ«ķøåķ¬īĶ»ü
+
+Õ£© MMPretrain õĖŁ’╝ī`tools/misc/verify_dataset.py` Ķäܵ£¼õ╝ܵŻĆµ¤źµĢ░µŹ«ķøåńÜäµēƵ£ēÕøŠńēć’╝īµ¤źń£ŗµś»ÕÉ”µ£ē**ÕĘ▓ń╗ŵŹ¤ÕØÅ**ńÜäÕøŠńēćŃĆé
+
+## ÕĘźÕģĘõ╗ŗń╗Ź
+
+```shell
+python tools/print_config.py \
+ ${CONFIG} \
+ [--out-path ${OUT-PATH}] \
+ [--phase ${PHASE}] \
+ [--num-process ${NUM-PROCESS}]
+ [--cfg-options ${CFG_OPTIONS}]
+```
+
+**µēƵ£ēÕÅéµĢ░Ķ»┤µśÄ**:
+
+- `config` : ķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠäŃĆé
+- `--out-path` : ĶŠōÕć║ń╗ōµ×£ĶĘ»ÕŠä’╝īķ╗śĶ«żõĖ║ ŌĆśbrokenfiles.logŌĆÖŃĆé
+- `--phase` : µŻĆµ¤źÕō¬õĖ¬ķśČµ«ĄńÜäµĢ░µŹ«ķøå’╝īÕÅ»ńö©ÕĆ╝õĖ║ ŌĆ£trainŌĆØ ŃĆüŌĆØtestŌĆØ µł¢ĶĆģ ŌĆ£valŌĆØ’╝ī ķ╗śĶ«żõĖ║ ŌĆ£trainŌĆØŃĆé
+- `--num-process` : µīćÕ«ÜńÜäĶ┐øń©ŗµĢ░’╝īķ╗śĶ«żõĖ║ 1ŃĆé
+- `--cfg-options`: ķóØÕż¢ńÜäķģŹńĮ«ķĆēķĪ╣’╝īõ╝ÜĶó½ÕÉłÕģźķģŹńĮ«µ¢ćõ╗Č’╝īÕÅéĶĆā[µĢÖń©ŗ 1’╝ÜÕ”éõĮĢń╝¢ÕåÖķģŹńĮ«µ¢ćõ╗Č](https://mmpretrain.readthedocs.io/zh_CN/latest/tutorials/config.html)ŃĆé
+
+## ńż║õŠŗ’╝Ü
+
+```shell
+python tools/misc/verify_dataset.py configs/t2t_vit/t2t-vit-t-14_8xb64_in1k.py --out-path broken_imgs.log --phase val --num-process 8
+```
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/vector_store/index.faiss b/internlm_langchain/knowledge_base/MMPreTrain/vector_store/index.faiss
new file mode 100644
index 00000000..3c0ec00c
Binary files /dev/null and b/internlm_langchain/knowledge_base/MMPreTrain/vector_store/index.faiss differ
diff --git a/internlm_langchain/knowledge_base/MMRazor/content/1_learn_about_config.md b/internlm_langchain/knowledge_base/MMRazor/content/1_learn_about_config.md
new file mode 100644
index 00000000..05cfd254
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMRazor/content/1_learn_about_config.md
@@ -0,0 +1,17 @@
+# Learn about Configs
+
+## Directory structure of configs in mmrazor
+
+
+
+`mmxxx`: means some task repositories of OpenMMLab, such mmcls, mmdet, mmseg and so on.
+
+`_base_`: includes configures of datasets, experiment settings and model architectures.
+
+`distill`/`nas`/`pruning`: model compression algorithms.
+
+`vanilla`: task models owned by mmrazor.
+
+## More about config
+
+Please refer to [config](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/tutorials/config.md) in mmengine.
diff --git a/internlm_langchain/knowledge_base/MMRazor/content/2_train_different_types_algorithms.md b/internlm_langchain/knowledge_base/MMRazor/content/2_train_different_types_algorithms.md
new file mode 100644
index 00000000..06c68970
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMRazor/content/2_train_different_types_algorithms.md
@@ -0,0 +1,107 @@
+# Train different types algorithms
+
+**Before running our algorithms, you may need to prepare the datasets according to the instructions in the corresponding document.**
+
+**Note**:
+
+- With the help of mmengine, mmrazor unified entered interfaces for various tasks, thus our algorithms will adapt all OpenMMLab upstream repos in theory.
+
+- We dynamically pass arguments `cfg-options` (e.g., `mutable_cfg` in nas algorithm or `channel_cfg` in pruning algorithm) to **avoid the need for a config for each subnet or checkpoint**. If you want to specify different subnets for retraining or testing, you just need to change this argument.
+
+### NAS
+
+Here we take SPOS(Single Path One Shot) as an example. There are three steps to start neural network search(NAS), including **supernet pre-training**, **search for subnet on the trained supernet** and **subnet retraining**.
+
+#### Supernet Pre-training
+
+```Python
+python tools/train.py ${CONFIG_FILE} [optional arguments]
+```
+
+The usage of optional arguments are the same as corresponding tasks like mmclassification, mmdetection and mmsegmentation.
+
+For example,
+
+```Python
+python ./tools/train.py \
+ configs/nas/mmcls/spos/spos_shufflenet_supernet_8xb128_in1k.py
+ --work-dir $WORK_DIR
+```
+
+#### Search for Subnet on The Trained Supernet
+
+```Python
+python tools/train.py ${CONFIG_FILE} --cfg-options load_from=${CHECKPOINT_PATH} [optional arguments]
+```
+
+For example,
+
+```Python
+python ./tools/train.py \
+ configs/nas/mmcls/spos/spos_shufflenet_search_8xb128_in1k.py \
+ --cfg-options load_from=$STEP1_CKPT \
+ --work-dir $WORK_DIR
+```
+
+#### Subnet Retraining
+
+```Python
+python tools/train.py ${CONFIG_FILE} \
+ --cfg-options algorithm.fix_subnet=${MUTABLE_CFG_PATH} [optional arguments]
+```
+
+- `MUTABLE_CFG_PATH`: Path of `fix_subnet`. `fix_subnet` represents **config for mutable of the subnet searched out**, used to specify different subnets for retraining. An example for `fix_subnet` can be found [here](https://github.com/open-mmlab/mmrazor/blob/master/configs/nas/spos/SPOS_SHUFFLENETV2_330M_IN1k_PAPER.yaml), and the usage can be found [here](https://github.com/open-mmlab/mmrazor/blob/master/configs/nas/spos/README.md#subnet-retraining-on-imagenet).
+
+For example,
+
+```Python
+python ./tools/train.py \
+ configs/nas/mmcls/spos/spos_shufflenet_subnet_8xb128_in1k.py \
+ --work-dir $WORK_DIR \
+ --cfg-options algorithm.fix_subnet=$YAML_FILE_BY_STEP2
+```
+
+We note that instead of using `--cfg-options`, you can also directly modify ``` configs/nas/mmcls/spos/``spos_shufflenet_subnet_8xb128_in1k``.py ``` like this:
+
+```Python
+fix_subnet = 'configs/nas/mmcls/spos/SPOS_SHUFFLENETV2_330M_IN1k_PAPER.yaml'
+model = dict(fix_subnet=fix_subnet)
+```
+
+### Pruning
+
+Pruning has three steps, including **supernet pre-training**, **search for subnet on the trained supernet** and **subnet retraining**. The commands of the first two steps are similar to NAS, except that we need to use `CONFIG_FILE` of Pruning here. The commands of the **subnet retraining** are as follows.
+
+#### Subnet Retraining
+
+```Python
+python tools/train.py ${CONFIG_FILE} --cfg-options model._channel_cfg_paths=${CHANNEL_CFG_PATH} [optional arguments]
+```
+
+Different from NAS, the argument that needs to be specified here is `channel_cfg_paths` .
+
+- `CHANNEL_CFG_PATH`: Path of `_channel_cfg_path`. `channel_cfg` represents **config for channel of the subnet searched out**, used to specify different subnets for testing.
+
+For example, the default `_channel_cfg_paths` is set in the config below.
+
+```Python
+python ./tools/train.py \
+ configs/pruning/mmcls/autoslim/autoslim_mbv2_1.5x_subnet_8xb256_in1k_flops-530M.py \
+ --work-dir your_work_dir
+```
+
+### Distillation
+
+There is only one step to start knowledge distillation.
+
+```Python
+python tools/train.py ${CONFIG_FILE} [optional arguments]
+```
+
+For example,
+
+```Python
+python ./tools/train.py \
+ configs/distill/mmcls/kd/kd_logits_r34_r18_8xb32_in1k.py \
+ --work-dir your_work_dir
+```
diff --git a/internlm_langchain/knowledge_base/MMRazor/content/3_train_with_different_devices.md b/internlm_langchain/knowledge_base/MMRazor/content/3_train_with_different_devices.md
new file mode 100644
index 00000000..aa24654e
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMRazor/content/3_train_with_different_devices.md
@@ -0,0 +1,93 @@
+# Train with different devices
+
+**Note**: The default learning rate in config files is for 8 GPUs. If using different number GPUs, the total batch size will change in proportion, you have to scale the learning rate following `new_lr = old_lr * new_ngpus / old_ngpus`. We recommend to use `tools/dist_train.sh` even with 1 gpu, since some methods do not support non-distributed training.
+
+### Training with CPU
+
+```Python
+export CUDA_VISIBLE_DEVICES=-1
+python tools/train.py ${CONFIG_FILE}
+```
+
+**Note**: We do not recommend users to use CPU for training because it is too slow and some algorithms are using `SyncBN` which is based on distributed training. We support this feature to allow users to debug on machines without GPU for convenience.
+
+### Train with single/multiple GPUs
+
+```Python
+sh tools/dist_train.sh ${CONFIG_FILE} ${GPUS} --work_dir ${YOUR_WORK_DIR} [optional arguments]
+```
+
+**Note**: During training, checkpoints and logs are saved in the same folder structure as the config file under `work_dirs/`. Custom work directory is not recommended since evaluation scripts infer work directories from the config file name. If you want to save your weights somewhere else, please use symlink, for example:
+
+```Python
+ln -s ${YOUR_WORK_DIRS} ${MMRAZOR}/work_dirs
+```
+
+Alternatively, if you run MMRazor on a cluster managed with [slurm](https://slurm.schedmd.com/):
+
+```Python
+GPUS_PER_NODE=${GPUS_PER_NODE} GPUS=${GPUS} SRUN_ARGS=${SRUN_ARGS} sh tools/xxx/slurm_train.sh ${PARTITION} ${JOB_NAME} ${CONFIG_FILE} ${YOUR_WORK_DIR} [optional arguments]
+```
+
+### Train with multiple machines
+
+If you launch with multiple machines simply connected with ethernet, you can simply run the following commands:
+
+On the first machine:
+
+```Python
+NNODES=2 NODE_RANK=0 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR sh tools/dist_train.sh $CONFIG $GPUS
+```
+
+On the second machine:
+
+```Python
+NNODES=2 NODE_RANK=1 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR sh tools/dist_train.sh $CONFIG $GPUS
+```
+
+Usually it is slow if you do not have high speed networking like InfiniBand.
+
+If you launch with slurm, the command is the same as that on single machine described above, but you need refer to [slurm_train.sh](https://github.com/open-mmlab/mmselfsup/blob/master/tools/slurm_train.sh) to set appropriate parameters and environment variables.
+
+### Launch multiple jobs on a single machine
+
+If you launch multiple jobs on a single machine, e.g., 2 jobs of 4-GPU training on a machine with 8 GPUs, you need to specify different ports (29500 by default) for each job to avoid communication conflict.
+
+If you use `dist_train.sh` to launch training jobs:
+
+```Python
+CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 sh tools/xxx/dist_train.sh ${CONFIG_FILE} 4 --work_dir tmp_work_dir_1
+CUDA_VISIBLE_DEVICES=4,5,6,7 PORT=29501 sh tools/xxx/dist_train.sh ${CONFIG_FILE} 4 --work_dir tmp_work_dir_2
+```
+
+If you use launch training jobs with slurm, you have two options to set different communication ports:
+
+Option 1:
+
+In `config1.py`:
+
+```Python
+dist_params = dict(backend='nccl', port=29500)
+```
+
+In `config2.py`:
+
+```Python
+dist_params = dict(backend='nccl', port=29501)
+```
+
+Then you can launch two jobs with config1.py and config2.py.
+
+```Python
+CUDA_VISIBLE_DEVICES=0,1,2,3 GPUS=4 sh tools/slurm_train.sh ${PARTITION} ${JOB_NAME} config1.py tmp_work_dir_1
+CUDA_VISIBLE_DEVICES=4,5,6,7 GPUS=4 sh tools/slurm_train.sh ${PARTITION} ${JOB_NAME} config2.py tmp_work_dir_2
+```
+
+Option 2:
+
+You can set different communication ports without the need to modify the configuration file, but have to set the `cfg-options` to overwrite the default port in configuration file.
+
+```Python
+CUDA_VISIBLE_DEVICES=0,1,2,3 GPUS=4 sh tools/slurm_train.sh ${PARTITION} ${JOB_NAME} config1.py tmp_work_dir_1 --cfg-options dist_params.port=29500
+CUDA_VISIBLE_DEVICES=4,5,6,7 GPUS=4 sh tools/slurm_train.sh ${PARTITION} ${JOB_NAME} config2.py tmp_work_dir_2 --cfg-options dist_params.port=29501
+```
diff --git a/internlm_langchain/knowledge_base/MMRazor/content/4_test_a_model.md b/internlm_langchain/knowledge_base/MMRazor/content/4_test_a_model.md
new file mode 100644
index 00000000..152b5dc4
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMRazor/content/4_test_a_model.md
@@ -0,0 +1,79 @@
+# Test a model
+
+### NAS
+
+To test nas method, you can use the following command.
+
+```Python
+python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_PATH} --cfg-options algorithm.fix_subnet=${FIX_SUBNET_PATH} [optional arguments]
+```
+
+- `FIX_SUBNET_PATH`: Path of `fix_subnet`. `fix_subnet` represents **config for mutable of the subnet searched out**, used to specify different subnets for testing. An example for `fix_subnet` can be found [here](https://github.com/open-mmlab/mmrazor/blob/master/configs/nas/spos/SPOS_SHUFFLENETV2_330M_IN1k_PAPER.yaml).
+
+The usage of optional arguments are the same as corresponding tasks like mmclassification, mmdetection and mmsegmentation.
+
+For example,
+
+```Python
+python tools/test.py \
+ configs/nas/mmcls/spos/spos_subnet_shufflenetv2_8xb128_in1k.py \
+ your_subnet_checkpoint_path \
+ --cfg-options algorithm.fix_subnet=configs/nas/mmcls/spos/SPOS_SHUFFLENETV2_330M_IN1k_PAPER.yaml
+```
+
+### Pruning
+
+#### Split Checkpoint(Optional)
+
+If you train a slimmable model during retraining, checkpoints of different subnets are actually fused in only one checkpoint. You can split this checkpoint to multiple independent checkpoints by using the following command
+
+```Python
+python tools/model_converters/split_checkpoint.py ${CONFIG_FILE} ${CHECKPOINT_PATH} --channel-cfgs ${CHANNEL_CFG_PATH} [optional arguments]
+```
+
+- `CHANNEL_CFG_PATH`: A list of paths of `channel_cfg`. For example, when you retrain a slimmable model, your command will be like `--cfg-options algorithm.channel_cfg=cfg1,cfg2,cfg3`. And your command here should be `--channel-cfgs cfg1 cfg2 cfg3`. The order of them should be the same.
+
+For example,
+
+```Python
+python tools/model_converters/split_checkpoint.py \
+ configs/pruning/autoslim/autoslim_mbv2_subnet_8xb256_in1k.py \
+ your_retraining_checkpoint_path \
+ --channel-cfgs configs/pruning/autoslim/AUTOSLIM_MBV2_530M_OFFICIAL.yaml configs/pruning/autoslim/AUTOSLIM_MBV2_320M_OFFICIAL.yaml configs/pruning/autoslim/AUTOSLIM_MBV2_220M_OFFICIAL.yaml
+```
+
+#### Test
+
+To test pruning method, you can use following command
+
+```Python
+python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_PATH} --cfg-options model._channel_cfg_paths=${CHANNEL_CFG_PATH} [optional arguments]
+```
+
+- `task`: one of `mmcls`ŃĆü`mmdet` and `mmseg`
+
+- `CHANNEL_CFG_PATH`: Path of `channel_cfg`. `channel_cfg` represents **config for channel of the subnet searched out**, used to specify different subnets for testing. An example for `channel_cfg` can be found [here](https://github.com/open-mmlab/mmrazor/blob/master/configs/pruning/autoslim/AUTOSLIM_MBV2_220M_OFFICIAL.yaml), and the usage can be found [here](https://github.com/open-mmlab/mmrazor/blob/master/configs/pruning/autoslim/README.md#test-a-subnet).
+
+For example,
+
+```Python
+python ./tools/test.py \
+ configs/pruning/mmcls/autoslim/autoslim_mbv2__1.5x_subnet_8xb256_in1k-530M.py \
+ your_splitted_checkpoint_path --metrics accuracy
+```
+
+### Distillation
+
+To test the distillation method, you can use the following command
+
+```Python
+python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_PATH} [optional arguments]
+```
+
+For example,
+
+```Python
+python ./tools/test.py \
+ configs/distill/mmseg/cwd/cwd_logits_pspnet_r101_d8_pspnet_r18_d8_512x1024_cityscapes_80k.py \
+ your_splitted_checkpoint_path --show
+```
diff --git a/internlm_langchain/knowledge_base/MMRazor/content/algorithm.md b/internlm_langchain/knowledge_base/MMRazor/content/algorithm.md
new file mode 100644
index 00000000..ae632db6
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMRazor/content/algorithm.md
@@ -0,0 +1,273 @@
+# Algorithm
+
+## Introduction
+
+### What is algorithm in MMRazor
+
+MMRazor is a model compression toolkit, which includes 4 mianstream technologies:
+
+- Neural Architecture Search (NAS)
+- Pruning
+- Knowledge Distillation (KD)
+- Quantization (come soon)
+
+And in MMRazor, `algorithm` is a general item for these technologies. For example, in NAS,
+
+[SPOS](https://github.com/open-mmlab/mmrazor/blob/master/configs/nas/spos)[ ](https://arxiv.org/abs/1904.00420)is an `algorithm`, [CWD](https://github.com/open-mmlab/mmrazor/blob/master/configs/distill/cwd) is also an `algorithm` of knowledge distillation.
+
+`algorithm` is the entrance of `mmrazor/models` . Its role in MMRazor is the same as both `classifier` in [MMClassification](https://github.com/open-mmlab/mmclassification) and `detector` in [MMDetection](https://github.com/open-mmlab/mmdetection).
+
+### About base algorithm
+
+In the directory of `models/algorithms`, all model compression algorithms are divided into 4 subdirectories: nas / pruning / distill / quantization. These algorithms must inherit from `BaseAlgorithm`, whose definition is as below.
+
+```Python
+from typing import Dict, List, Optional, Tuple, Union
+from mmengine.model import BaseModel
+from mmrazor.registry import MODELS
+
+LossResults = Dict[str, torch.Tensor]
+TensorResults = Union[Tuple[torch.Tensor], torch.Tensor]
+PredictResults = List[BaseDataElement]
+ForwardResults = Union[LossResults, TensorResults, PredictResults]
+
+@MODELS.register_module()
+class BaseAlgorithm(BaseModel):
+
+ def __init__(self,
+ architecture: Union[BaseModel, Dict],
+ data_preprocessor: Optional[Union[Dict, nn.Module]] = None,
+ init_cfg: Optional[Dict] = None):
+
+ ......
+
+ super().__init__(data_preprocessor, init_cfg)
+ self.architecture = architecture
+
+ def forward(self,
+ batch_inputs: torch.Tensor,
+ data_samples: Optional[List[BaseDataElement]] = None,
+ mode: str = 'tensor') -> ForwardResults:
+
+ if mode == 'loss':
+ return self.loss(batch_inputs, data_samples)
+ elif mode == 'tensor':
+ return self._forward(batch_inputs, data_samples)
+ elif mode == 'predict':
+ return self._predict(batch_inputs, data_samples)
+ else:
+ raise RuntimeError(f'Invalid mode "{mode}". '
+ 'Only supports loss, predict and tensor mode')
+
+ def loss(
+ self,
+ batch_inputs: torch.Tensor,
+ data_samples: Optional[List[BaseDataElement]] = None,
+ ) -> LossResults:
+ """Calculate losses from a batch of inputs and data samples."""
+ return self.architecture(batch_inputs, data_samples, mode='loss')
+
+ def _forward(
+ self,
+ batch_inputs: torch.Tensor,
+ data_samples: Optional[List[BaseDataElement]] = None,
+ ) -> TensorResults:
+ """Network forward process."""
+ return self.architecture(batch_inputs, data_samples, mode='tensor')
+
+ def _predict(
+ self,
+ batch_inputs: torch.Tensor,
+ data_samples: Optional[List[BaseDataElement]] = None,
+ ) -> PredictResults:
+ """Predict results from a batch of inputs and data samples with post-
+ processing."""
+ return self.architecture(batch_inputs, data_samples, mode='predict')
+```
+
+As you can see from above, `BaseAlgorithm` is inherited from `BaseModel` of MMEngine. `BaseModel` implements the basic functions of the algorithmic model, such as weights initialize,
+
+batch inputs preprocess (see more information in `BaseDataPreprocessor` class of MMEngine), parse losses, and update model parameters. For more details of `BaseModel` , you can see docs for `BaseModel`.
+
+`BaseAlgorithm`'s forward is just a wrapper of `BaseModel`'s forward. Sub-classes inherited from BaseAlgorithm only need to override the `loss` method, which implements the logic to calculate loss, thus various algorithms can be trained in the runner.
+
+## How to use existing algorithms in MMRazor
+
+1. Configure your architecture that will be slimmed
+
+- Use the model config of other repos of OpenMMLab directly as below, which is an example of setting Faster-RCNN as our architecture.
+
+```Python
+_base_ = [
+ 'mmdet::_base_/models/faster_rcnn_r50_fpn.py',
+]
+
+architecture = _base_.model
+```
+
+- Use your customized model as below, which is an example of defining a VGG model as our architecture.
+
+```{note}
+How to customize architectures can refer to our tutorial: [Customize Architectures](https://mmrazor.readthedocs.io/en/main/advanced_guides/customize_architectures.html).
+```
+
+```Python
+default_scope='mmcls'
+architecture = dict(
+ type='ImageClassifier',
+ backbone=dict(type='VGG', depth=11, num_classes=1000),
+ neck=None,
+ head=dict(
+ type='ClsHead',
+ loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
+ topk=(1, 5),
+ ))
+```
+
+2. Apply the registered algorithm to your architecture.
+
+```{note}
+The arg name of `algorithm` in config is **model** rather than **algorithm** in order to get better supports of MMCV and MMEngine.
+```
+
+Maybe more args in model need to set according to the used algorithm.
+
+```Python
+model = dict(
+ type='BaseAlgorithm',
+ architecture=architecture)
+```
+
+```{note}
+About the usage of `Config`, refer to [config.md](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/tutorials/config.md) please.
+```
+
+3. Apply some custom hooks or loops to your algorithm. (optional)
+
+- Custom hooks
+
+```Python
+custom_hooks = [
+ dict(type='NaiveVisualizationHook', priority='LOWEST'),
+]
+```
+
+- Custom loops
+
+```Python
+_base_ = ['./spos_shufflenet_supernet_8xb128_in1k.py']
+
+# To chose from ['train_cfg', 'val_cfg', 'test_cfg'] based on your loop type
+train_cfg = dict(
+ _delete_=True,
+ type='mmrazor.EvolutionSearchLoop',
+ dataloader=_base_.val_dataloader,
+ evaluator=_base_.val_evaluator)
+
+val_cfg = dict()
+test_cfg = dict()
+```
+
+## How to customize your algorithm
+
+### Common pipeline
+
+1. Register a new algorithm
+
+Create a new file `mmrazor/models/algorithms/{subdirectory}/xxx.py`
+
+```Python
+from mmrazor.models.algorithms import BaseAlgorithm
+from mmrazor.registry import MODELS
+
+@MODELS.register_module()
+class XXX(BaseAlgorithm):
+ def __init__(self, architecture):
+ super().__init__(architecture)
+ pass
+
+ def loss(self, batch_inputs):
+ pass
+```
+
+2. Rewrite its `loss` method.
+
+```Python
+from mmrazor.models.algorithms import BaseAlgorithm
+from mmrazor.registry import MODELS
+
+@MODELS.register_module()
+class XXX(BaseAlgorithm):
+ def __init__(self, architecture):
+ super().__init__(architecture)
+ ......
+
+ def loss(self, batch_inputs):
+ ......
+ return LossResults
+```
+
+3. Add the remaining functions of the algorithm
+
+```{note}
+This step is special because of the diversity of algorithms. Some functions of the algorithm may also be implemented in other files.
+```
+
+```Python
+from mmrazor.models.algorithms import BaseAlgorithm
+from mmrazor.registry import MODELS
+
+@MODELS.register_module()
+class XXX(BaseAlgorithm):
+ def __init__(self, architecture):
+ super().__init__(architecture)
+ ......
+
+ def loss(self, batch_inputs):
+ ......
+ return LossResults
+
+ def aaa(self):
+ ......
+
+ def bbb(self):
+ ......
+```
+
+4. Import the class
+
+You can add the following line to `mmrazor/models/algorithms/{subdirectory}/__init__.py`
+
+```CoffeeScript
+from .xxx import XXX
+
+__all__ = ['XXX']
+```
+
+In addition, import XXX in `mmrazor/models/algorithms/__init__.py`
+
+5. Use the algorithm in your config file.
+
+Please refer to the previous section about how to use existing algorithms in MMRazor
+
+```Python
+model = dict(
+ type='XXX',
+ architecture=architecture)
+```
+
+### Pipelines for different algorithms
+
+Please refer to our tutorials about how to customize different algorithms for more details as below.
+
+1. NAS
+
+[Customize NAS algorithms](https://mmrazor.readthedocs.io/en/main/advanced_guides/customize_nas_algorithms.html)
+
+2. Pruning
+
+[Customize Pruning algorithms](https://mmrazor.readthedocs.io/en/main/advanced_guides/customize_pruning_algorithms.html)
+
+3. Distill
+
+[Customize KD algorithms](https://mmrazor.readthedocs.io/en/main/advanced_guides/customize_kd_algorithms.html)
diff --git a/internlm_langchain/knowledge_base/MMRazor/content/apply_existing_algorithms_to_new_tasks.md b/internlm_langchain/knowledge_base/MMRazor/content/apply_existing_algorithms_to_new_tasks.md
new file mode 100644
index 00000000..119d7a6c
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMRazor/content/apply_existing_algorithms_to_new_tasks.md
@@ -0,0 +1,83 @@
+# Apply existing algorithms to new tasks
+
+Here we show how to apply existing algorithms to other tasks with an example of [SPOS ](https://github.com/open-mmlab/mmrazor/tree/main/configs/nas/mmcls/spos)& [DetNAS](https://github.com/open-mmlab/mmrazor/tree/main/configs/nas/mmdet/detnas).
+
+> SPOS: Single Path One-Shot NAS for classification
+>
+> DetNAS: Single Path One-Shot NAS for detection
+
+**You just need to configure the existing algorithms in your config only by replacing** **the architecture of** **mmcls** **with** **mmdet** **'s**
+
+You can implement a new algorithm by inheriting from the existing algorithm quickly if the new task's specificity leads to the failure of applying directly.
+
+SPOS config VS DetNAS config
+
+- SPOS
+
+```Python
+_base_ = [
+ 'mmrazor::_base_/settings/imagenet_bs1024_spos.py',
+ 'mmrazor::_base_/nas_backbones/spos_shufflenet_supernet.py',
+ 'mmcls::_base_/default_runtime.py',
+]
+
+# model
+supernet = dict(
+ type='ImageClassifier',
+ data_preprocessor=_base_.preprocess_cfg,
+ backbone=_base_.nas_backbone,
+ neck=dict(type='GlobalAveragePooling'),
+ head=dict(
+ type='LinearClsHead',
+ num_classes=1000,
+ in_channels=1024,
+ loss=dict(
+ type='LabelSmoothLoss',
+ num_classes=1000,
+ label_smooth_val=0.1,
+ mode='original',
+ loss_weight=1.0),
+ topk=(1, 5)))
+
+model = dict(
+ type='mmrazor.SPOS',
+ architecture=supernet,
+ mutator=dict(type='mmrazor.OneShotModuleMutator'))
+
+find_unused_parameters = True
+```
+
+- DetNAS
+
+```Python
+_base_ = [
+ 'mmdet::_base_/models/faster-rcnn_r50_fpn.py',
+ 'mmdet::_base_/datasets/coco_detection.py',
+ 'mmdet::_base_/schedules/schedule_1x.py',
+ 'mmdet::_base_/default_runtime.py',
+ 'mmrazor::_base_/nas_backbones/spos_shufflenet_supernet.py'
+]
+
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+
+supernet = _base_.model
+
+supernet.backbone = _base_.nas_backbone
+supernet.backbone.norm_cfg = norm_cfg
+supernet.backbone.out_indices = (0, 1, 2, 3)
+supernet.backbone.with_last_layer = False
+
+supernet.neck.norm_cfg = norm_cfg
+supernet.neck.in_channels = [64, 160, 320, 640]
+
+supernet.roi_head.bbox_head.norm_cfg = norm_cfg
+supernet.roi_head.bbox_head.type = 'Shared4Conv1FCBBoxHead'
+
+model = dict(
+ _delete_=True,
+ type='mmrazor.SPOS',
+ architecture=supernet,
+ mutator=dict(type='mmrazor.OneShotModuleMutator'))
+
+find_unused_parameters = True
+```
diff --git a/internlm_langchain/knowledge_base/MMRazor/content/changelog.md b/internlm_langchain/knowledge_base/MMRazor/content/changelog.md
new file mode 100644
index 00000000..338c9425
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMRazor/content/changelog.md
@@ -0,0 +1,278 @@
+# Changelog of v1.x
+
+## v1.0.0 (24/04/2023)
+
+We are excited to announce the first official release of MMRazor 1.0.
+
+### Highlights
+
+- MMRazor quantization is released, which has got through task models and model deployment. With its help, we can quantize and deploy pre-trained models in OpenMMLab to specified backend quickly.
+
+### New Features & Improvements
+
+#### NAS
+
+- Update searchable model. (https://github.com/open-mmlab/mmrazor/pull/438)
+- Update NasMutator to build search_space in NAS. (https://github.com/open-mmlab/mmrazor/pull/426)
+
+#### Pruning
+
+- Add a new pruning algorithm named GroupFisher. We support the full pipeline for GroupFisher, including pruning, finetuning and deployment.(https://github.com/open-mmlab/mmrazor/pull/459)
+
+#### KD
+
+- Support stopping distillation after a certain epoch. (https://github.com/open-mmlab/mmrazor/pull/455)
+- Support distilling rtmdet with mmrazor, refer to here. (https://github.com/open-mmlab/mmyolo/pull/544)
+- Add mask channel in MGD Loss. (https://github.com/open-mmlab/mmrazor/pull/461)
+
+#### Quantization
+
+- Support two quantization types: QAT and PTQ (https://github.com/open-mmlab/mmrazor/pull/513)
+- Support various quantization bits. (https://github.com/open-mmlab/mmrazor/pull/513)
+- Support various quantization methods, such as per_tensor / per_channel, symmetry / asymmetry and so on. (https://github.com/open-mmlab/mmrazor/pull/513)
+- Support deploy quantized models to multiple backends, such as OpenVINO, TensorRT and so on. (https://github.com/open-mmlab/mmrazor/pull/513)
+- Support applying quantization algorithms to multiple task repos directly, such as mmcls, mmdet and so on. (https://github.com/open-mmlab/mmrazor/pull/513)
+
+### Bug Fixes
+
+- Fix split in Darts config. (https://github.com/open-mmlab/mmrazor/pull/451)
+- Fix a bug in Recorders. (https://github.com/open-mmlab/mmrazor/pull/446)
+- Fix a bug when using get_channel_unit.py. (https://github.com/open-mmlab/mmrazor/pull/432)
+- Fix a bug when deploying a pruned model to cuda. (https://github.com/open-mmlab/mmrazor/pull/495)
+
+### Contributors
+
+A total of 10 developers contributed to this release.
+Thanks @415905716 @gaoyang07 @humu789 @LKJacky @HIT-cwh @aptsunny @cape-zck @vansin @twmht @wm901115nwpu
+
+## v1.0.0rc2 (06/01/2023)
+
+We are excited to announce the release of MMRazor 1.0.0rc2.
+
+### New Features
+
+#### NAS
+
+- Add Performance Predictor: Support 4 performance predictors with 4 basic machine learning algorithms, which can be used to directly predict model accuracy without evaluation.(https://github.com/open-mmlab/mmrazor/pull/306)
+
+- Support [Autoformer](https://arxiv.org/pdf/2107.00651.pdf), a one-shot architecture search algorithm dedicated to vision transformer search.(https://github.com/open-mmlab/mmrazor/pull/315 )
+
+- Support [BigNAS](https://arxiv.org/pdf/2003.11142), a NAS algorithm which searches the following items in MobileNetV3 with the one-shot paradigm: kernel_sizes, out_channels, expand_ratios, block_depth and input sizes. (https://github.com/open-mmlab/mmrazor/pull/219 )
+
+#### Pruning
+
+- Support [DCFF](https://arxiv.org/abs/2107.06916), a filter channel pruning algorithm dedicated to efficient image classification.(https://github.com/open-mmlab/mmrazor/pull/295)
+
+- We release a powerful tool to automatically analyze channel dependency, named ChannelAnalyzer. Here is an example as shown below.(https://github.com/open-mmlab/mmrazor/pull/371)
+
+Now, ChannelAnalyzer supports most of CNN models in torchvision, mmcls, mmseg and mmdet. We will continue to support more models.
+
+```python
+from mmrazor.models.task_modules import ChannelAnalyzer
+from mmengine.hub import get_model
+import json
+
+model = get_model('mmdet::retinanet/retinanet_r18_fpn_1x_coco.py')
+unit_configs: dict = ChannelAnalyzer().analyze(model)
+unit_config0 = list(unit_configs.values())[0]
+print(json.dumps(unit_config0, indent=4))
+# # short version of the config
+# {
+# "channels": {
+# "input_related": [
+# {"name": "backbone.layer2.0.bn1"},
+# {ŌĆ£name": "backbone.layer2.0.conv2"}
+# ],
+# "output_related": [
+# {"name": "backbone.layer2.0.conv1"},
+# {"name": "backbone.layer2.0.bn1"}
+# ]
+# },
+#}
+```
+
+#### KD
+
+- Support [MGD](https://arxiv.org/abs/2205.01529), a detection distillation algorithm.(https://github.com/open-mmlab/mmrazor/pull/381)
+
+### Bug Fixes
+
+- Fix `FpnTeacherDistll` techer forward from `backbone + neck + head` to `backbone + neck`(#387 )
+- Fix some expire configs and checkpoints(#373 #372 #422 )
+
+### Ongoing Changes
+
+We will release Quantization in next version(1.0.0rc3)!
+
+### Contributors
+
+A total of 11 developers contributed to this release: @wutongshenqiu @sunnyxiaohu @aptsunny @humu789 @TinyTigerPan @FreakieHuang @LKJacky @wilxy @gaoyang07 @spynccat @yivona08.
+
+## v1.0.0rc1 (27/10/2022)
+
+We are excited to announce the release of MMRazor 1.0.0rc1.
+
+### Highlights
+
+- **New Pruning Framework**’╝ÜWe have systematically refactored the Pruning module. The new Pruning module can more automatically resolve the dependencies between channels and cover more corner cases.
+
+### New Features
+
+#### Pruning
+
+- A new pruning framework is released in this release. (#311, #313)
+ It consists of five core modules, including Algorithm, `ChannelMutator`, `MutableChannelUnit`, `MutableChannel` and `DynamicOp`.
+
+- MutableChannelUnit is introduced for the first time. Each MutableChannelUnit manages all channels with channel dependency.
+
+ ```python
+ from mmrazor.registry import MODELS
+
+ ARCHITECTURE_CFG = dict(
+ _scope_='mmcls',
+ type='ImageClassifier',
+ backbone=dict(type='MobileNetV2', widen_factor=1.5),
+ neck=dict(type='GlobalAveragePooling'),
+ head=dict(type='mmcls.LinearClsHead', num_classes=1000, in_channels=1920))
+ model = MODELS.build(ARCHITECTURE_CFG)
+ from mmrazor.models.mutators import ChannelMutator
+
+ channel_mutator = ChannelMutator()
+ channel_mutator.prepare_from_supernet(model)
+ units = channel_mutator.mutable_units
+ print(units[0])
+ # SequentialMutableChannelUnit(
+ # name=backbone.conv1.conv_(0, 48)_48
+ # (output_related): ModuleList(
+ # (0): Channel(backbone.conv1.conv, index=(0, 48), is_output_channel=true, expand_ratio=1)
+ # (1): Channel(backbone.conv1.bn, index=(0, 48), is_output_channel=true, expand_ratio=1)
+ # (2): Channel(backbone.layer1.0.conv.0.conv, index=(0, 48), is_output_channel=true, expand_ratio=1)
+ # (3): Channel(backbone.layer1.0.conv.0.bn, index=(0, 48), is_output_channel=true, expand_ratio=1)
+ # )
+ # (input_related): ModuleList(
+ # (0): Channel(backbone.conv1.bn, index=(0, 48), is_output_channel=false, expand_ratio=1)
+ # (1): Channel(backbone.layer1.0.conv.0.conv, index=(0, 48), is_output_channel=false, expand_ratio=1)
+ # (2): Channel(backbone.layer1.0.conv.0.bn, index=(0, 48), is_output_channel=false, expand_ratio=1)
+ # (3): Channel(backbone.layer1.0.conv.1.conv, index=(0, 48), is_output_channel=false, expand_ratio=1)
+ # )
+ # (mutable_channel): SquentialMutableChannel(num_channels=48, activated_channels=48)
+ # )
+ ```
+
+Our new pruning algorithm can help you develop pruning algorithm more fluently. Pelease refer to our documents [PruningUserGuide](<./docs/en/user_guides/../../pruning/%5Bpruning_user_guide.md%5D(http://pruning_user_guide.md/)>) for model detail.
+
+#### Distillation
+
+- Support [CRD](https://arxiv.org/abs/1910.10699), a distillation algorithm based on contrastive representation learning. (#281)
+
+- Support [PKD](https://arxiv.org/abs/2207.02039), a distillation algorithm that can be used in `MMDetection` and `MMDetection3D`. #304
+
+- Support [DEIT](https://arxiv.org/abs/2012.12877), a classic **Transformer** distillation algorithm.(#332)
+
+- Add a more powerful baseline setting for [KD](https://arxiv.org/abs/1503.02531). (#305)
+
+- Add `MethodInputsRecorder` and `FuncInputsRecorder` to record the input of a class method or a function.(#320)
+
+#### NAS
+
+- Support [DSNAS](https://arxiv.org/pdf/2002.09128.pdf), a nas algorithm that does not require retraining. (#226 )
+
+#### Tools
+
+- Support configurable immediate feature map visualization. (#293 )
+ A useful tool is supported in this release to visualize the immediate features of a neural network. Please refer to our documents [VisualizationUserGuide](http://./docs/zh_cn/user_guides/visualization.md) for more details.
+
+### Bug Fixes
+
+- Fix the bug that `FunctionXXRecorder` and `FunctionXXDelivery` can not be pickled. (#320)
+
+### Ongoing changes
+
+- Quantization: We are developing the basic interface of PTQ and QAT. RFC(Request for Comments) will be released soon.
+- AutoSlim: AutoSlim is not yet available and is being refactored.
+- Fx Pruning Tracer: Currently, the model topology can only be resolved through the backward tracer. In the future, both backward tracer and fx tracer will be supported.
+- More Algorithms: BigNASŃĆüAutoFormerŃĆüGreedyNAS and Resrep will be released in the next few versions.
+- Documentation: we will add more design docs, tutorials, and migration guidance so that the community can deep dive into our new design, participate the future development, and smoothly migrate downstream libraries to MMRazor 1.x.
+
+### Contributors
+
+A total of 12 developers contributed to this release.
+Thanks @FreakieHuang @gaoyang07 @HIT-cwh @humu789 @LKJacky @pppppM @pprp @spynccat @sunnyxiaohu @wilxy @kitecats @SheffieldCao
+
+## v1.0.0rc0 (31/8/2022)
+
+We are excited to announce the release of MMRazor 1.0.0rc0.
+MMRazor 1.0.0rc0 is the first version of MMRazor 1.x, a part of the OpenMMLab 2.0 projects.
+Built upon the new [training engine](https://github.com/open-mmlab/mmengine),
+MMRazor 1.x simplified the interaction with other OpenMMLab repos, and upgraded the basic APIs of KD / Pruning / NAS.
+It also provides a series of knowledge distillation algorithms.
+
+### Highlights
+
+- **New engines**. MMRazor 1.x is based on [MMEngine](https://github.com/open-mmlab/mmengine), which provides a general and powerful runner that allows more flexible customizations and significantly simplifies the entrypoints of high-level interfaces.
+
+- **Unified interfaces**. As a part of the OpenMMLab 2.0 projects, MMRazor 1.x unifies and refactors the interfaces and internal logic of train, testing, datasets, models, evaluation, and visualization. All the OpenMMLab 2.0 projects share the same design in those interfaces and logic to allow the emergence of multi-task/modality algorithms.
+
+- **More configurable KD**. MMRazor 1.x add [Recorder](../advanced_guides/recorder.md) to get the data needed for KD more automatically’╝ī[Delivery ](../advanced_guides/delivery.md) to automatically pass the teacher's intermediate results to the student’╝ī and connector to handle feature dimension mismatches between teacher and student.
+
+- **More kinds of KD algorithms**. Benefitting from the powerful APIs of KD’╝ī we have added several categories of KD algorithms, data-free distillation, self-distillation, and zero-shot distillation.
+
+- **Unify the basic interface of NAS and Pruning**. We refactored [Mutable](../advanced_guides/mutable.md), adding mutable value and mutable channel. Both NAS and Pruning can be developed based on mutables.
+
+- **More documentation and tutorials**. We add a bunch of documentation and tutorials to help users get started more smoothly. Read it [here](https://mmrazor.readthedocs.io/en/1.0.0rc0/).
+
+### Breaking Changes
+
+#### Training and testing
+
+- MMRazor 1.x runs on PyTorch>=1.6. We have deprecated the support of PyTorch 1.5 to embrace the mixed precision training and other new features since PyTorch 1.6. Some models can still run on PyTorch 1.5, but the full functionality of MMRazor 1.x is not guaranteed.
+- MMRazor 1.x uses Runner in [MMEngine](https://github.com/open-mmlab/mmengine) rather than that in MMCV. The new Runner implements and unifies the building logic of dataset, model, evaluation, and visualizer. Therefore, MMRazor 1.x no longer maintains the building logics of those modules in `mmdet.train.apis` and `tools/train.py`. Those code have been migrated into [MMEngine](https://github.com/open-mmlab/mmengine/blob/main/mmengine/runner/runner.py).
+- The Runner in MMEngine also supports testing and validation. The testing scripts are also simplified, which has similar logic as that in training scripts to build the runner.
+
+#### Configs
+
+- The [Runner in MMEngine](https://github.com/open-mmlab/mmengine/blob/main/mmengine/runner/runner.py) uses a different config structures
+- Config and model names
+
+#### Components
+
+- Algorithms
+- Distillers
+- Mutators
+- Mutables
+- Hooks
+
+### Improvements
+
+- Support mixed precision training of all the models. However, some models may got Nan results due to some numerical issues. We will update the documentation and list their results (accuracy of failure) of mixed precision training.
+
+### Bug Fixes
+
+- AutoSlim: Models of different sizes will no longer have the same size checkpoint
+
+### New Features
+
+- Support [Activation Boundaries Loss](https://arxiv.org/pdf/1811.03233.pdf)
+- Support [Be Your Own Teacher](https://arxiv.org/abs/1905.08094)
+- Support [Data-Free Learning of Student Networks](https://doi.org/10.1109/ICCV.2019.00361)
+- Support [Data-Free Adversarial Distillation](https://arxiv.org/pdf/1912.11006.pdf)
+- Support [Decoupled Knowledge Distillation](https://arxiv.org/pdf/2203.08679.pdf)
+- Support [Factor Transfer](https://arxiv.org/abs/1802.04977)
+- Support [FitNets](https://arxiv.org/abs/1412.6550)
+- Support [Distilling the Knowledge in a Neural Network](https://arxiv.org/abs/1503.02531)
+- Support [Overhaul](https://arxiv.org/abs/1904.01866)
+- Support [Zero-shot Knowledge Transfer via Adversarial Belief Matching](https://arxiv.org/abs/1905.09768)
+
+### Ongoing changes
+
+- Quantization: We are developing the basic interface of PTQ and QAT. RFC(Request for Comments) will be released soon.
+- AutoSlim: AutoSlim is not yet available and is being refactored.
+- Fx Pruning Tracer: Currently, the model topology can only be resolved through the backward tracer. In the future, both backward tracer and fx tracer will be supported.
+- More Algorithms: BigNASŃĆüAutoFormerŃĆüGreedyNAS and Resrep will be released in the next few versions.
+- Documentation: we will add more design docs, tutorials, and migration guidance so that the community can deep dive into our new design, participate the future development, and smoothly migrate downstream libraries to MMRazor 1.x.
+
+### Contributors
+
+A total of 13 developers contributed to this release.
+Thanks @FreakieHuang @gaoyang07 @HIT-cwh @humu789 @LKJacky @pppppM @pprp @spynccat @sunnyxiaohu @wilxy @wutongshenqiu @NickYangMin @Hiwyl
+Special thanks to @Davidgzx for his contribution to the data-free distillation algorithms
diff --git a/internlm_langchain/knowledge_base/MMRazor/content/contribution_guide.md b/internlm_langchain/knowledge_base/MMRazor/content/contribution_guide.md
new file mode 100644
index 00000000..1ca3a9af
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMRazor/content/contribution_guide.md
@@ -0,0 +1,59 @@
+# Contribute Guide
+
+All kinds of contributions are welcome, including but not limited to the following.
+
+- Fix typo or bugs
+- Add documentation or translate the documentation into other languages
+- Add new features and components
+
+### Workflow
+
+1. fork and pull the latest OpenMMLab repository
+2. checkout a new branch (do not use master branch for PRs)
+3. commit your changes
+4. create a PR
+
+```{note}
+If you plan to add some new features that involve large changes, it is encouraged to open an issue for discussion first.
+```
+
+### Code style
+
+#### Python
+
+We adopt [PEP8](https://www.python.org/dev/peps/pep-0008/) as the preferred code style.
+
+We use the following tools for linting and formatting:
+
+- [flake8](https://github.com/PyCQA/flake8): A wrapper around some linter tools.
+- [isort](https://github.com/timothycrosley/isort): A Python utility to sort imports.
+- [yapf](https://github.com/google/yapf): A formatter for Python files.
+- [codespell](https://github.com/codespell-project/codespell): A Python utility to fix common misspellings in text files.
+- [mdformat](https://github.com/executablebooks/mdformat): Mdformat is an opinionated Markdown formatter that can be used to enforce a consistent style in Markdown files.
+- [docformatter](https://github.com/myint/docformatter): A formatter to format docstring.
+
+Style configurations of yapf and isort can be found in [setup.cfg](./setup.cfg).
+
+We use [pre-commit hook](https://pre-commit.com/) that checks and formats for `flake8`, `yapf`, `isort`, `trailing whitespaces`, `markdown files`,
+fixes `end-of-files`, `double-quoted-strings`, `python-encoding-pragma`, `mixed-line-ending`, sorts `requirments.txt` automatically on every commit.
+The config for a pre-commit hook is stored in [.pre-commit-config](./.pre-commit-config.yaml).
+
+After you clone the repository, you will need to install initialize pre-commit hook.
+
+```shell
+pip install -U pre-commit
+```
+
+From the repository folder
+
+```shell
+pre-commit install
+```
+
+After this on every commit check code linters and formatter will be enforced.
+
+> Before you create a PR, make sure that your code lints and is formatted by yapf.
+
+#### C++ and CUDA
+
+We follow the [Google C++ Style Guide](https://google.github.io/styleguide/cppguide.html).
diff --git a/internlm_langchain/knowledge_base/MMRazor/content/customize_architectures.md b/internlm_langchain/knowledge_base/MMRazor/content/customize_architectures.md
new file mode 100644
index 00000000..d815eb79
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMRazor/content/customize_architectures.md
@@ -0,0 +1,255 @@
+# Customize Architectures
+
+Different from other tasks, architectures in MMRazor may consist of some special model components, such as **searchable backbones, connectors, dynamic ops**. In MMRazor, you can not only develop some common model components like other codebases of OpenMMLab, but also develop some special model components. Here is how to develop searchable model components and common model components.
+
+## Develop searchable model components
+
+1. Define a new backbone
+
+Create a new file `mmrazor/models/architectures/backbones/searchable_shufflenet_v2.py`, class `SearchableShuffleNetV2` inherits from `BaseBackBone` of mmcls, which is the codebase that you will use to build the model.
+
+```Python
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+from typing import Dict, List, Optional, Sequence, Tuple, Union
+
+import torch.nn as nn
+from mmcls.models.backbones.base_backbone import BaseBackbone
+from mmcv.cnn import ConvModule, constant_init, normal_init
+from mmcv.runner import ModuleList, Sequential
+from torch import Tensor
+from torch.nn.modules.batchnorm import _BatchNorm
+
+from mmrazor.registry import MODELS
+
+@MODELS.register_module()
+class SearchableShuffleNetV2(BaseBackbone):
+
+ def __init__(self, ):
+ pass
+
+ def _make_layer(self, out_channels, num_blocks, stage_idx):
+ pass
+
+ def _freeze_stages(self):
+ pass
+
+ def init_weights(self):
+ pass
+
+ def forward(self, x):
+ pass
+
+ def train(self, mode=True):
+ pass
+```
+
+2. Build the architecture of the new backbone based on `arch_setting`
+
+```Python
+@MODELS.register_module()
+class SearchableShuffleNetV2(BaseBackbone):
+ def __init__(self,
+ arch_setting: List[List],
+ stem_multiplier: int = 1,
+ widen_factor: float = 1.0,
+ out_indices: Sequence[int] = (4, ),
+ frozen_stages: int = -1,
+ with_last_layer: bool = True,
+ conv_cfg: Optional[Dict] = None,
+ norm_cfg: Dict = dict(type='BN'),
+ act_cfg: Dict = dict(type='ReLU'),
+ norm_eval: bool = False,
+ with_cp: bool = False,
+ init_cfg: Optional[Union[Dict, List[Dict]]] = None) -> None:
+ layers_nums = 5 if with_last_layer else 4
+ for index in out_indices:
+ if index not in range(0, layers_nums):
+ raise ValueError('the item in out_indices must in '
+ f'range(0, 5). But received {index}')
+
+ self.frozen_stages = frozen_stages
+ if frozen_stages not in range(-1, layers_nums):
+ raise ValueError('frozen_stages must be in range(-1, 5). '
+ f'But received {frozen_stages}')
+
+ super().__init__(init_cfg)
+
+ self.arch_setting = arch_setting
+ self.widen_factor = widen_factor
+ self.out_indices = out_indices
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+ self.norm_eval = norm_eval
+ self.with_cp = with_cp
+
+ last_channels = 1024
+ self.in_channels = 16 * stem_multiplier
+
+ # build the first layer
+ self.conv1 = ConvModule(
+ in_channels=3,
+ out_channels=self.in_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ # build the middle layers
+ self.layers = ModuleList()
+ for channel, num_blocks, mutable_cfg in arch_setting:
+ out_channels = round(channel * widen_factor)
+ layer = self._make_layer(out_channels, num_blocks,
+ copy.deepcopy(mutable_cfg))
+ self.layers.append(layer)
+
+ # build the last layer
+ if with_last_layer:
+ self.layers.append(
+ ConvModule(
+ in_channels=self.in_channels,
+ out_channels=last_channels,
+ kernel_size=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+```
+
+3. Implement`_make_layer` with `mutable_cfg`
+
+```Python
+@MODELS.register_module()
+class SearchableShuffleNetV2(BaseBackbone):
+
+ ...
+
+ def _make_layer(self, out_channels: int, num_blocks: int,
+ mutable_cfg: Dict) -> Sequential:
+ """Stack mutable blocks to build a layer for ShuffleNet V2.
+ Note:
+ Here we use ``module_kwargs`` to pass dynamic parameters such as
+ ``in_channels``, ``out_channels`` and ``stride``
+ to build the mutable.
+ Args:
+ out_channels (int): out_channels of the block.
+ num_blocks (int): number of blocks.
+ mutable_cfg (dict): Config of mutable.
+ Returns:
+ mmcv.runner.Sequential: The layer made.
+ """
+ layers = []
+ for i in range(num_blocks):
+ stride = 2 if i == 0 else 1
+
+ mutable_cfg.update(
+ module_kwargs=dict(
+ in_channels=self.in_channels,
+ out_channels=out_channels,
+ stride=stride))
+ layers.append(MODELS.build(mutable_cfg))
+ self.in_channels = out_channels
+
+ return Sequential(*layers)
+
+ ...
+```
+
+4. Implement other common methods
+
+You can refer to the implementation of `ShuffleNetV2` in mmcls for finishing other common methods.
+
+5. Import the module
+
+You can either add the following line to `mmrazor/models/architectures/backbones/__init__.py`
+
+```Python
+from .searchable_shufflenet_v2 import SearchableShuffleNetV2
+
+__all__ = ['SearchableShuffleNetV2']
+```
+
+or alternatively add
+
+```Python
+custom_imports = dict(
+ imports=['mmrazor.models.architectures.backbones.searchable_shufflenet_v2'],
+ allow_failed_imports=False)
+```
+
+to the config file to avoid modifying the original code.
+
+6. Use the backbone in your config file
+
+```Python
+architecture = dict(
+ type=xxx,
+ model=dict(
+ ...
+ backbone=dict(
+ type='mmrazor.SearchableShuffleNetV2',
+ arg1=xxx,
+ arg2=xxx),
+ ...
+```
+
+## Develop common model components
+
+Here we show how to add a new backbone with an example of `xxxNet`.
+
+1. Define a new backbone
+
+Create a new file `mmrazor/models/architectures/backbones/xxxnet.py`, then implement the class `xxxNet`.
+
+```Python
+from mmengine.model import BaseModule
+from mmrazor.registry import MODELS
+
+@MODELS.register_module()
+class xxxNet(BaseModule):
+
+ def __init__(self, arg1, arg2, init_cfg=None):
+ super().__init__(init_cfg=init_cfg)
+ pass
+
+ def forward(self, x):
+ pass
+```
+
+2. Import the module
+
+You can either add the following line to `mmrazor/models/architectures/backbones/__init__.py`
+
+```Python
+from .xxxnet import xxxNet
+
+__all__ = ['xxxNet']
+```
+
+or alternatively add
+
+```Python
+custom_imports = dict(
+ imports=['mmrazor.models.architectures.backbones.xxxnet'],
+ allow_failed_imports=False)
+```
+
+to the config file to avoid modifying the original code.
+
+3. Use the backbone in your config file
+
+```Python
+architecture = dict(
+ type=xxx,
+ model=dict(
+ ...
+ backbone=dict(
+ type='xxxNet',
+ arg1=xxx,
+ arg2=xxx),
+ ...
+```
+
+How to add other model components is similar to backbone's. For more details, please refer to other codebases' docs.
diff --git a/internlm_langchain/knowledge_base/MMRazor/content/customize_kd_algorithms.md b/internlm_langchain/knowledge_base/MMRazor/content/customize_kd_algorithms.md
new file mode 100644
index 00000000..dee759c5
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMRazor/content/customize_kd_algorithms.md
@@ -0,0 +1,124 @@
+# Customize KD algorithms
+
+Here we show how to develop new KD algorithms with an example of `SingleTeacherDistill`.
+
+1. Register a new algorithm
+
+Create a new file `mmrazor/models/algorithms/distill/configurable/single_teacher_distill.py`, class `SingleTeacherDistill` inherits from class `BaseAlgorithm`
+
+```Python
+from mmrazor.registry import MODELS
+from ..base import BaseAlgorithm
+
+@ALGORITHMS.register_module()
+class SingleTeacherDistill(BaseAlgorithm):
+ def __init__(self, use_gt, **kwargs):
+ super(Distillation, self).__init__(**kwargs)
+ pass
+
+ def train_step(self, data, optimizer):
+ pass
+```
+
+2. Develop connectors (Optional) .
+
+Take ConvModuleConnector as an example.
+
+```python
+from mmrazor.registry import MODELS
+from .base_connector import BaseConnector
+
+@MODELS.register_module()
+class ConvModuleConnector(BaseConnector):
+ def __init__(self, in_channel, out_channel, kernel_size = 1, stride = 1):
+ ...
+
+ def forward_train(self, feature):
+ ...
+```
+
+3. Develop distiller.
+
+Take `ConfigurableDistiller` as an example.
+
+```python
+from .base_distiller import BaseDistiller
+from mmrazor.registry import MODELS
+
+
+@MODELS.register_module()
+class ConfigurableDistiller(BaseDistiller):
+ def __init__(self,
+ student_recorders = None,
+ teacher_recorders = None,
+ distill_deliveries = None,
+ connectors = None,
+ distill_losses = None,
+ loss_forward_mappings = None):
+ ...
+
+ def build_connectors(self, connectors):
+ ...
+
+ def build_distill_losses(self, losses):
+ ...
+
+ def compute_distill_losses(self):
+ ...
+```
+
+4. Develop custom loss (Optional).
+
+Here we take `L1Loss` as an example. Create a new file in `mmrazor/models/losses/l1_loss.py`.
+
+```python
+from mmrazor.registry import MODELS
+
+@MODELS.register_module()
+class L1Loss(nn.Module):
+ def __init__(
+ self,
+ loss_weight: float = 1.0,
+ size_average: Optional[bool] = None,
+ reduce: Optional[bool] = None,
+ reduction: str = 'mean',
+ ) -> None:
+ super().__init__()
+ ...
+
+ def forward(self, s_feature, t_feature):
+ loss = F.l1_loss(s_feature, t_feature, self.size_average, self.reduce,
+ self.reduction)
+ return self.loss_weight * loss
+```
+
+5. Import the class
+
+You can either add the following line to `mmrazor/models/algorithms/__init__.py`
+
+```Python
+from .single_teacher_distill import SingleTeacherDistill
+
+__all__ = [..., 'SingleTeacherDistill']
+```
+
+or alternatively add
+
+```Python
+custom_imports = dict(
+ imports=['mmrazor.models.algorithms.distill.configurable.single_teacher_distill'],
+ allow_failed_imports=False)
+```
+
+to the config file to avoid modifying the original code.
+
+6. Use the algorithm in your config file
+
+```Python
+algorithm = dict(
+ type='Distill',
+ distiller=dict(type='SingleTeacherDistill', ...),
+ # you can also use your new algorithm components here
+ ...
+)
+```
diff --git a/internlm_langchain/knowledge_base/MMRazor/content/customize_mixed_algorithms.md b/internlm_langchain/knowledge_base/MMRazor/content/customize_mixed_algorithms.md
new file mode 100644
index 00000000..17b928d1
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMRazor/content/customize_mixed_algorithms.md
@@ -0,0 +1,164 @@
+# Customize mixed algorithms
+
+Here we show how to customize mixed algorithms with our algorithm components. We take [AutoSlim ](https://github.com/open-mmlab/mmrazor/tree/main/configs/pruning/mmcls/autoslim)as an example.
+
+```{note}
+**Why is AutoSlim a mixed algorithm?**
+
+In [AutoSlim](https://github.com/open-mmlab/mmrazor/tree/main/configs/pruning/mmcls/autoslim), the sandwich rule and the inplace distillation will be introduced to enhance the training process, which is called as the slimmable training. The sandwich rule means that we train the model at smallest width, largest width and (n ŌłÆ 2) random widths, instead of n random widths. And the inplace distillation means that we use the predicted label of the model at the largest width as the training label for other widths, while for the largest width we use ground truth. So both the KD algorithm and the pruning algorithm are used in [AutoSlim](https://github.com/open-mmlab/mmrazor/tree/main/configs/pruning/mmcls/autoslim).
+```
+
+1. Register a new algorithm
+
+Create a new file `mmrazor/models/algorithms/nas/autoslim.py`, class `AutoSlim` inherits from class `BaseAlgorithm`. You need to build the KD algorithm component (distiller) and the pruning algorithm component (mutator) because AutoSlim is a mixed algorithm.
+
+```{note}
+You can also inherit from the existing algorithm instead of `BaseAlgorithm` if your algorithm is similar to the existing algorithm.
+```
+
+```{note}
+You can choose existing algorithm components in MMRazor, such as `OneShotChannelMutator` and `ConfigurableDistiller` in AutoSlim.
+
+If these in MMRazor don't meet your needs, you can customize new algorithm components for your algorithm. Reference is as follows:
+
+[Customize NAS algorithms](https://mmrazor.readthedocs.io/en/main/advanced_guides/customize_nas_algorithms.html)
+[Customize Pruning algorithms](https://mmrazor.readthedocs.io/en/main/advanced_guides/customize_pruning_algorithms.html)
+[Customize KD algorithms](https://mmrazor.readthedocs.io/en/main/advanced_guides/customize_kd_algorithms.html)
+```
+
+```Python
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Optional, Union
+import torch
+from torch import nn
+
+from mmrazor.models.distillers import ConfigurableDistiller
+from mmrazor.models.mutators import OneShotChannelMutator
+from mmrazor.registry import MODELS
+from ..base import BaseAlgorithm
+
+VALID_MUTATOR_TYPE = Union[OneShotChannelMutator, Dict]
+VALID_DISTILLER_TYPE = Union[ConfigurableDistiller, Dict]
+
+@MODELS.register_module()
+class AutoSlim(BaseAlgorithm):
+ def __init__(self,
+ mutator: VALID_MUTATOR_TYPE,
+ distiller: VALID_DISTILLER_TYPE,
+ architecture: Union[BaseModel, Dict],
+ data_preprocessor: Optional[Union[Dict, nn.Module]] = None,
+ num_random_samples: int = 2,
+ init_cfg: Optional[Dict] = None) -> None:
+ super().__init__(architecture, data_preprocessor, init_cfg)
+ self.mutator = self._build_mutator(mutator)
+ # `prepare_from_supernet` must be called before distiller initialized
+ self.mutator.prepare_from_supernet(self.architecture)
+
+ self.distiller = self._build_distiller(distiller)
+ self.distiller.prepare_from_teacher(self.architecture)
+ self.distiller.prepare_from_student(self.architecture)
+
+ ......
+
+ def _build_mutator(self,
+ mutator: VALID_MUTATOR_TYPE) -> OneShotChannelMutator:
+ """build mutator."""
+ if isinstance(mutator, dict):
+ mutator = MODELS.build(mutator)
+ if not isinstance(mutator, OneShotChannelMutator):
+ raise TypeError('mutator should be a `dict` or '
+ '`OneShotModuleMutator` instance, but got '
+ f'{type(mutator)}')
+
+ return mutator
+
+ def _build_distiller(
+ self, distiller: VALID_DISTILLER_TYPE) -> ConfigurableDistiller:
+ if isinstance(distiller, dict):
+ distiller = MODELS.build(distiller)
+ if not isinstance(distiller, ConfigurableDistiller):
+ raise TypeError('distiller should be a `dict` or '
+ '`ConfigurableDistiller` instance, but got '
+ f'{type(distiller)}')
+
+ return distiller
+```
+
+2. Implement the core logic in `train_step`
+
+In `train_step`, both the `mutator` and the `distiller` play an important role. For example, `sample_subnet`, `set_max_subnet` and `set_min_subnet` are supported by the `mutator`, and the function of`distill_step` is mainly implemented by the `distiller`.
+
+```Python
+@MODELS.register_module()
+class AutoSlim(BaseAlgorithm):
+
+ ......
+
+ def train_step(self, data: List[dict],
+ optim_wrapper: OptimWrapper) -> Dict[str, torch.Tensor]:
+
+ def distill_step(
+ batch_inputs: torch.Tensor, data_samples: List[BaseDataElement]
+ ) -> Dict[str, torch.Tensor]:
+ ......
+
+ ......
+
+ batch_inputs, data_samples = self.data_preprocessor(data, True)
+
+ total_losses = dict()
+ for kind in self.sample_kinds:
+ # update the max subnet loss.
+ if kind == 'max':
+ self.set_max_subnet()
+ ......
+ total_losses.update(add_prefix(max_subnet_losses, 'max_subnet'))
+ # update the min subnet loss.
+ elif kind == 'min':
+ self.set_min_subnet()
+ min_subnet_losses = distill_step(batch_inputs, data_samples)
+ total_losses.update(add_prefix(min_subnet_losses, 'min_subnet'))
+ # update the random subnets loss.
+ elif 'random' in kind:
+ self.set_subnet(self.sample_subnet())
+ random_subnet_losses = distill_step(batch_inputs, data_samples)
+ total_losses.update(
+ add_prefix(random_subnet_losses, f'{kind}_subnet'))
+
+ return total_losses
+```
+
+3. Import the class
+
+You can either add the following line to `mmrazor/models/algorithms/nas/__init__.py`
+
+```Python
+from .autoslim import AutoSlim
+
+__all__ = ['AutoSlim']
+```
+
+or alternatively add
+
+```Python
+custom_imports = dict(
+ imports=['mmrazor.models.algorithms.nas.autoslim'],
+ allow_failed_imports=False)
+```
+
+to the config file to avoid modifying the original code.
+
+4. Use the algorithm in your config file
+
+```Python
+model= dict(
+ type='mmrazor.AutoSlim',
+ architecture=...,
+ mutator=dict(
+ type='OneShotChannelMutator',
+ ...),
+ distiller=dict(
+ type='ConfigurableDistiller',
+ ...),
+ ...)
+```
diff --git a/internlm_langchain/knowledge_base/MMRazor/content/customize_nas_algorithms.md b/internlm_langchain/knowledge_base/MMRazor/content/customize_nas_algorithms.md
new file mode 100644
index 00000000..b8f180c0
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMRazor/content/customize_nas_algorithms.md
@@ -0,0 +1,136 @@
+# Customize NAS algorithms
+
+Here we show how to develop new NAS algorithms with an example of SPOS.
+
+1. Register a new algorithm
+
+Create a new file `mmrazor/models/algorithms/nas/spos.py`, class `SPOS` inherits from class `BaseAlgorithm`
+
+```Python
+from mmrazor.registry import MODELS
+from ..base import BaseAlgorithm
+
+@MODELS.register_module()
+class SPOS(BaseAlgorithm):
+ def __init__(self, **kwargs):
+ super(SPOS, self).__init__(**kwargs)
+ pass
+
+ def loss(self, batch_inputs, data_samples):
+ pass
+```
+
+2. Develop new algorithm components (optional)
+
+SPOS can directly use class `OneShotModuleMutator` as core functions provider. If mutators provided in MMRazor donŌĆÖt meet your needs, you can develop new algorithm components for your algorithm like `OneShotModuleMutator`, we will take `OneShotModuleMutator` as an example to introduce how to develop a new algorithm component:
+
+a. Create a new file `mmrazor/models/mutators/module_mutator/one_shot_module_mutator.py`, class `OneShotModuleMutator` inherits from class `ModuleMutator`
+
+b. Finish the functions you need in `OneShotModuleMutator`, eg: `sample_choices`, `set_choices` and so on.
+
+```Python
+from mmrazor.registry import MODELS
+from .module_mutator import ModuleMutator
+
+
+@MODELS.register_module()
+class OneShotModuleMutator(ModuleMutator):
+
+ def __init__(self, **kwargs):
+ super().__init__(**kwargs)
+
+ def sample_choices(self) -> Dict[int, Any]:
+ pass
+
+ def set_choices(self, choices: Dict[int, Any]) -> None:
+ pass
+
+ @property
+ def mutable_class_type(self):
+ return OneShotMutableModule
+```
+
+c. Import the new mutator
+
+You can either add the following line to `mmrazor/models/mutators/__init__.py`
+
+```Python
+from .module_mutator import OneShotModuleMutator
+```
+
+or alternatively add
+
+```Python
+custom_imports = dict(
+ imports=['mmrazor.models.mutators.module_mutator.one_shot_module_mutator'],
+ allow_failed_imports=False)
+```
+
+to the config file to avoid modifying the original code.
+
+d. Use the algorithm component in your config file
+
+```Python
+mutator=dict(type='mmrazor.OneShotModuleMutator')
+```
+
+For further information, please refer to [Mutator ](https://mmrazor.readthedocs.io/en/main/advanced_guides/mutator.html)for more details.
+
+3. Rewrite its `loss` function.
+
+Develop key logic of your algorithm in function`loss`. When having special steps to optimize, you should rewrite the function `train_step`.
+
+```Python
+@MODELS.register_module()
+class SPOS(BaseAlgorithm):
+ def __init__(self, **kwargs):
+ super(SPOS, self).__init__(**kwargs)
+ pass
+
+ def sample_subnet(self):
+ pass
+
+ def set_subnet(self, subnet):
+ pass
+
+ def loss(self, batch_inputs, data_samples):
+ if self.is_supernet:
+ random_subnet = self.sample_subnet()
+ self.set_subnet(random_subnet)
+ return self.architecture(batch_inputs, data_samples, mode='loss')
+ else:
+ return self.architecture(batch_inputs, data_samples, mode='loss')
+```
+
+4. Add your custom functions (optional)
+
+After finishing your key logic in function `loss`, if you also need other custom functions, you can add them in class `SPOS` as follows.
+
+5. Import the class
+
+You can either add the following line to `mmrazor/models/algorithms/nas/__init__.py`
+
+```Python
+from .spos import SPOS
+
+__all__ = ['SPOS']
+```
+
+or alternatively add
+
+```Python
+custom_imports = dict(
+ imports=['mmrazor.models.algorithms.nas.spos'],
+ allow_failed_imports=False)
+```
+
+to the config file to avoid modifying the original code.
+
+6. Use the algorithm in your config file
+
+```Python
+model = dict(
+ type='mmrazor.SPOS',
+ architecture=supernet,
+ mutator=dict(type='mmrazor.OneShotModuleMutator'))
+```
diff --git a/internlm_langchain/knowledge_base/MMRazor/content/customize_pruning_algorithms.md b/internlm_langchain/knowledge_base/MMRazor/content/customize_pruning_algorithms.md
new file mode 100644
index 00000000..3980dfbd
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMRazor/content/customize_pruning_algorithms.md
@@ -0,0 +1,155 @@
+# Customize pruning algorithms
+
+Here we show how to develop new Pruning algorithms with an example of AutoSlim.
+
+1. Register a new algorithm
+
+Create a new file `mmrazor/models/algorithms/prunning/autoslim.py`, class `AutoSlim` inherits from class `BaseAlgorithm`.
+
+```Python
+from mmrazor.registry import MODELS
+from .base import BaseAlgorithm
+
+@MODELS.register_module()
+class AutoSlim(BaseAlgorithm):
+ def __init__(self,
+ mutator,
+ distiller,
+ architecture,
+ data_preprocessor,
+ num_random_samples = 2,
+ init_cfg = None) -> None:
+ super().__init__(**kwargs)
+ pass
+
+ def train_step(self, data, optimizer):
+ pass
+```
+
+2. Develop new algorithm components (optional)
+
+AutoSlim can directly use class `OneShotChannelMutator` as core functions provider. If it can not meet your needs, you can develop new algorithm components for your algorithm like `OneShotChannalMutator`. We will take `OneShotChannelMutator` as an example to introduce how to develop a new algorithm component:
+
+a. Create a new file `mmrazor/models/mutators/channel_mutator/one_shot_channel_mutator.py`, class `OneShotChannelMutator` can inherits from `ChannelMutator`.
+
+b. Finish the functions you need, eg: `build_search_groups`, `set_choices` , `sample_choices` and so on
+
+```Python
+from mmrazor.registry import MODELS
+from .channel_mutator import ChannelMutator
+
+
+@MODELS.register_module()
+class OneShotChannelMutator(ChannelMutator):
+ def __init__(self, **kwargs):
+ super().__init__(**kwargs)
+
+ def sample_choices(self):
+ pass
+
+ def set_choices(self, choice_dict):
+ pass
+
+ # supernet is a kind of architecture in `mmrazor/models/architectures/`
+ def build_search_groups(self, supernet):
+ pass
+```
+
+c. Import the module in `mmrazor/models/mutators/channel_mutator/__init__.py`
+
+```Python
+from .one_shot_channel_mutator import OneShotChannelMutator
+
+ __all__ = [..., 'OneShotChannelMutator']
+```
+
+3. Rewrite its train_step
+
+Develop key logic of your algorithm in function`train_step`
+
+```Python
+from mmrazor.registry import MODELS
+from ..base import BaseAlgorithm
+
+@ALGORITHMS.register_module()
+class AutoSlim(BaseAlgorithm):
+ def __init__(self,
+ mutator,
+ distiller,
+ architecture,
+ data_preprocessor,
+ num_random_samples = 2,
+ init_cfg = None) -> None:
+ super(AutoSlim, self).__init__(**kwargs)
+ pass
+
+ def train_step(self, data: List[dict],
+ optim_wrapper: OptimWrapper) -> Dict[str, torch.Tensor]:
+
+ def distill_step(
+ batch_inputs: torch.Tensor, data_samples: List[BaseDataElement]
+ ) -> Dict[str, torch.Tensor]:
+ ...
+ return subnet_losses
+
+ batch_inputs, data_samples = self.data_preprocessor(data, True)
+
+ total_losses = dict()
+ for kind in self.sample_kinds:
+ # update the max subnet loss.
+ if kind == 'max':
+ self.set_max_subnet()
+ with optim_wrapper.optim_context(
+ self), self.distiller.teacher_recorders: # type: ignore
+ max_subnet_losses = self(batch_inputs, data_samples, mode='loss')
+ parsed_max_subnet_losses, _ = self.parse_losses(max_subnet_losses)
+ optim_wrapper.update_params(parsed_max_subnet_losses)
+ total_losses.update(add_prefix(max_subnet_losses, 'max_subnet'))
+ # update the min subnet loss.
+ elif kind == 'min':
+ self.set_min_subnet()
+ min_subnet_losses = distill_step(batch_inputs, data_samples)
+ total_losses.update(add_prefix(min_subnet_losses, 'min_subnet'))
+ # update the random subnets loss.
+ elif 'random' in kind:
+ self.set_subnet(self.sample_subnet())
+ random_subnet_losses = distill_step(batch_inputs, data_samples)
+ total_losses.update(
+ add_prefix(random_subnet_losses, f'{kind}_subnet'))
+
+ return total_losses
+```
+
+4. Add your custom functions (optional)
+
+After finishing your key logic in function `train_step`, if you also need other custom functions, you can add them in class `AutoSlim`.
+
+5. Import the class
+
+You can either add the following line to `mmrazor/models/algorithms/__init__.py`
+
+```Python
+from .pruning import AutoSlim
+
+__all__ = [..., 'AutoSlim']
+```
+
+Or alternatively add
+
+```Python
+custom_imports = dict(
+ imports=['mmrazor.models.algorithms.pruning.autoslim'],
+ allow_failed_imports=False)
+```
+
+to the config file to avoid modifying the original code.
+
+6. Use the algorithm in your config file
+
+```Python
+model = dict(
+ type='AutoSlim',
+ architecture=...,
+ mutator=dict(type='OneShotChannelMutator', ...),
+ )
+```
diff --git a/internlm_langchain/knowledge_base/MMRazor/content/customize_quantization_algorithms.md b/internlm_langchain/knowledge_base/MMRazor/content/customize_quantization_algorithms.md
new file mode 100644
index 00000000..e1dd25ea
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMRazor/content/customize_quantization_algorithms.md
@@ -0,0 +1,283 @@
+# Customize Quantization algorithms
+
+Here we show how to develop new QAT algorithms with an example of LSQ on OpenVINO backend.
+
+This document is mainly aimed at QAT because the ptq process is relatively fixed and the components we provide can meet most of the needs. We will first give an overview of the overall required development components, and then introduce the specific implementation step by step.
+
+## Overall
+
+In the mmrazor quantization pipeline, in order to better support the openmmlab environment, we have configured most of the code modules for users. You can configure all the components directly in the config file. How to configure them can be found in our [file](https://github.com/open-mmlab/mmrazor/blob/quantize/configs/quantization/qat/minmax_openvino_resnet18_8xb32_in1k.py).
+
+```Python
+global_qconfig = dict(
+ w_observer=dict(),
+ a_observer=dict(),
+ w_fake_quant=dict(),
+ a_fake_quant=dict(),
+ w_qscheme=dict(),
+ a_qscheme=dict(),
+)
+model = dict(
+ type='mmrazor.MMArchitectureQuant',
+ architecture=resnet,
+ quantizer=dict(
+ type='mmrazor.OpenvinoQuantizer',
+ global_qconfig=global_qconfig,
+ tracer=dict()))
+train_cfg = dict(type='mmrazor.LSQEpochBasedLoop')
+```
+
+For `algorithm` and `tracer`, we recommend that you use the default configurations `MMArchitectureQuant` and `CustomTracer` provided by us. These two module operators are specially built for the openmmlab environment, while other modules can refer to the following steps and choose or develop new operators according to your needs.
+
+To adapt to different backends, you need to select a different `quantizer`.
+
+To develop new quantization algorithms, you need to define new `observer` and `fakequant`.
+
+If the existing `loop` does not meet your needs, you may need to make some changes to the existing `loop` based on your algorithm.
+
+## Detailed steps
+
+1. Select a quantization algorithm
+
+We recommend that you directly use the`MMArchitectureQuant` in `mmrazor/models/algorithms/quantization/mm_architecture.py`.The class `MMArchitectureQuant` inherits from class `BaseAlgorithm`.
+
+This structure is built for the model in openmmlab. If you have other requirements, you can also refer to this [document](https://mmrazor.readthedocs.io/en/main/advanced_guides/customize_architectures.html#develop-common-model-components) to design the overall framework.
+
+2. Select quantizer
+
+At present, the quantizers we support are `NativeQuantizer`, `OpenVINOQuantizer`, `TensorRTQuantizer` and `AcademicQuantizer` in `mmrazor/models/quantizers/`. `AcademicQuantizer` and `NativeQuantizer` inherit from class `BaseQuantizer` in `mmrazor/models/quantizers/base.py`:
+
+```Python
+class BaseQuantizer(BaseModule):
+ def __init__(self, tracer):
+ super().__init__()
+ self.tracer = TASK_UTILS.build(tracer)
+ @abstractmethod
+ def prepare(self, model, graph_module):
+ """tmp."""
+ pass
+ def swap_ff_with_fxff(self, model):
+ pass
+```
+
+`NativeQuantizer` is the operator we developed to adapt to the environment of mmrazor according to pytorch's official quantization logic. `AcademicQuantizer` is an operator designed for academic research to give users more space to operate.
+
+The class `OpenVINOQuantizer` and `TensorRTQuantizer` inherits from class `NativeQuantize`. They adapted `OpenVINO` and `TensorRT`backend respectively. You can also try to develop a quantizer based on other backends according to your own needs.
+
+3. Select tracer
+
+Tracer we use `CustomTracer` in `mmrazor/models/task_modules/tracer/fx/custom_tracer.py`. You can inherit this class and customize your own tracer.
+
+4. Develop new fakequant method(optional)
+
+You can use fakequants provided by pytorch in `mmrazor/models/fake_quants/torch_fake_quants.py` as core functions provider. If you want to use the fakequant methods from other papers, you can also define them yourself. Let's take lsq as an example as follows:
+
+a.Create a new file `mmrazor/models/fake_quants/lsq.py`, class `LearnableFakeQuantize` inherits from class `FakeQuantizeBase`.
+
+b. Finish the functions you need, eg: `observe_quant_params`, `calculate_qparams` and so on.
+
+```Python
+from mmrazor.registry import MODELS
+from torch.ao.quantization import FakeQuantizeBase
+
+@MODELS.register_module()
+class LearnableFakeQuantize(FakeQuantizeBase):
+ def __init__(self,
+ observer,
+ quant_min=0,
+ quant_max=255,
+ scale=1.,
+ zero_point=0.,
+ use_grad_scaling=True,
+ zero_point_trainable=False,
+ **observer_kwargs):
+ super(LearnableFakeQuantize, self).__init__()
+ pass
+
+ def observe_quant_params(self):
+ pass
+
+ def calculate_qparams(self):
+ pass
+
+ def forward(self, X):
+ pass
+```
+
+c.Import the module in `mmrazor/models/fake_quants/__init__.py`.
+
+```Python
+from .lsq import LearnableFakeQuantize
+
+__all__ = ['LearnableFakeQuantize']
+```
+
+5. Develop new observer(optional)
+
+You can directly use observers provided by pytorch in `mmrazor/models/observers/torch_observers.py` or use observers customized by yourself. Let's take `LSQObserver` as follows:
+
+a.Create a new observer file `mmrazor/models/observers/lsq.py`, class `LSQObserver` inherits from class `MinMaxObserver` and `LSQObserverMixIn`. These two observers can calculate `zero_point` and `scale`, respectively.
+
+b.Finish the functions you need, eg: `calculate_qparams` and so on.
+
+```Python
+from mmrazor.registry import MODELS
+from torch.ao.quantization.observer import MinMaxObserver
+
+class LSQObserverMixIn:
+ def __init__(self):
+ self.tensor_norm = None
+
+ @torch.jit.export
+ def _calculate_scale(self):
+ scale = 2 * self.tensor_norm / math.sqrt(self.quant_max)
+ sync_tensor(scale)
+ return scale
+
+@MODELS.register_module()
+class LSQObserver(MinMaxObserver, LSQObserverMixIn):
+ """LSQ observer.
+ Paper: Learned Step Size Quantization.
|
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/test.md b/internlm_langchain/knowledge_base/MMPreTrain/content/test.md
new file mode 100644
index 00000000..054e1e41
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/test.md
@@ -0,0 +1,117 @@
+# µĄŗĶ»Ģ
+
+## ÕŹĢµ£║ÕŹĢÕŹĪµĄŗĶ»Ģ
+
+õĮĀÕÅ»õ╗źõĮ┐ńö© `tools/test.py` Õ£©ńöĄĶäæõĖŖńö© CPU µł¢µś» GPU Ķ┐øĶĪīµ©ĪÕ×ŗńÜ䵥ŗĶ»ĢŃĆé
+
+õ╗źõĖŗµś»µĄŗĶ»ĢĶäܵ£¼ńÜäÕ«īµĢ┤ńö©µ│Ģ’╝Ü
+
+```shell
+python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [ARGS]
+```
+
+````{note}
+ķ╗śĶ«żµāģÕåĄõĖŗ’╝īMMPretrain õ╝ÜĶć¬ÕŖ©Ķ░āńö©õĮĀńÜä GPU Ķ┐øĶĪīµĄŗĶ»ĢŃĆéÕ”éµ×£õĮĀµ£ē GPU õĮåõ╗Źµā│õĮ┐ńö© CPU Ķ┐øĶĪīµĄŗĶ»Ģ’╝īĶ»ĘĶ«ŠńĮ«ńÄ»ÕóāÕÅśķćÅ `CUDA_VISIBLE_DEVICES` õĖ║ń®║µł¢ĶĆģ -1 µØźÕ»╣ń”üńö© GPUŃĆé
+
+```bash
+CUDA_VISIBLE_DEVICES=-1 python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [ARGS]
+```
+````
+
+| ÕÅéµĢ░ | µÅÅĶ┐░ |
+| ------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| `CONFIG_FILE` | ķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠäŃĆé |
+| `CHECKPOINT_FILE` | µØāķ揵¢ćõ╗ČĶĘ»ÕŠä’╝łµö»µīü http ķōŠµÄź’╝īõĮĀÕÅ»õ╗źÕ£©[Ķ┐Öķćī](https://mmpretrain.readthedocs.io/en/latest/modelzoo_statistics.html)Õ»╗µēŠķ£ĆĶ”üńÜäµØāķ揵¢ćõ╗Č’╝ēŃĆé |
+| `--work-dir WORK_DIR` | ńö©µØźõ┐ØÕŁśµĄŗĶ»ĢµīćµĀćń╗ōµ×£ńÜäµ¢ćõ╗ČÕż╣ŃĆé |
+| `--out OUT` | ńö©µØźõ┐ØÕŁśµĄŗĶ»ĢĶŠōÕć║ńÜäµ¢ćõ╗ČŃĆé |
+| `--out-item OUT_ITEM` | µīćիܵĄŗĶ»ĢĶŠōÕć║µ¢ćõ╗ČńÜäÕåģÕ«╣’╝īÕÅ»õ╗źõĖ║ "pred" µł¢ "metrics"’╝īÕģČõĖŁ "pred" ĶĪ©ńż║õ┐ØÕŁśµēƵ£ēµ©ĪÕ×ŗĶŠōÕć║’╝īĶ┐Öõ║øµĢ░µŹ«ÕÅ»õ╗źńö©õ║Äń”╗ń║┐µĄŗĶ»ä’╝ø"metrics" ĶĪ©ńż║ĶŠōÕć║µĄŗĶ»ĢµīćµĀćŃĆéķ╗śĶ«żõĖ║ "pred"ŃĆé |
+| `--cfg-options CFG_OPTIONS` | ķćŹĶĮĮķģŹńĮ«µ¢ćõ╗ČõĖŁńÜäõĖĆõ║øĶ«ŠńĮ«ŃĆéõĮ┐ńö©ń▒╗õ╝╝ `xxx=yyy` ńÜäķö«ÕĆ╝Õ»╣ÕĮóÕ╝ŵīćÕ«Ü’╝īĶ┐Öõ║øĶ«ŠńĮ«õ╝ÜĶó½Ķ׏ÕÉłÕģźõ╗ÄķģŹńĮ«µ¢ćõ╗ČĶ»╗ÕÅ¢ńÜäķģŹńĮ«ŃĆéõĮĀÕÅ»õ╗źõĮ┐ńö© `key="[a,b]"` µł¢ĶĆģ `key=a,b` ńÜäµĀ╝Õ╝ÅµØźµīćÕ«ÜÕłŚĶĪ©µĀ╝Õ╝ÅńÜäÕĆ╝’╝īõĖöµö»µīüÕĄīÕźŚ’╝īõŠŗÕ”é \`key="[(a,b),(c,d)]"’╝īĶ┐ÖķćīńÜäÕ╝ĢÕÅʵś»õĖŹÕÅ»ń£üńĢźńÜäŃĆéÕÅ”Õż¢µ»ÅõĖ¬ķćŹĶĮĮķĪ╣Õåģķā©õĖŹÕÅ»Õć║ńÄ░ń®║µĀ╝ŃĆé |
+| `--show-dir SHOW_DIR` | ńö©õ║Äõ┐ØÕŁśÕÅ»Ķ¦åÕī¢ķó䵥ŗń╗ōµ×£ÕøŠÕāÅńÜäµ¢ćõ╗ČÕż╣ŃĆé |
+| `--show` | Õ£©ń¬ŚÕÅŻõĖŁµśŠńż║ķó䵥ŗń╗ōµ×£ÕøŠÕāÅŃĆé |
+| `--interval INTERVAL` | µ»ÅķÜöÕżÜÕ░æµĀʵ£¼Ķ┐øĶĪīõĖƵ¼Īķó䵥ŗń╗ōµ×£ÕÅ»Ķ¦åÕī¢ŃĆé |
+| `--wait-time WAIT_TIME` | µ»ÅõĖ¬ń¬ŚÕÅŻńÜ䵜Šńż║µŚČķŚ┤’╝łÕŹĢõĮŹõĖ║ń¦Æ’╝ēŃĆé |
+| `--no-pin-memory` | µś»Õɔգ© dataloaders õĖŁÕģ│ķŚŁ `pin_memory` ķĆēķĪ╣ |
+| `--tta` | µś»ÕÉ”Õ╝ĆÕÉ» Test-Time-Aug (TTA). Õ”éµ×£ķģŹńĮ«µ¢ćõ╗ȵ£ē `tta_pipeline` ÕÆī `tta_model`’╝īÕ░åõĮ┐ńö©Ķ┐Öõ║øķģŹńĮ«µīćÕ«Ü TTA transforms’╝īÕ╣ČõĖöÕå│Õ«ÜÕ”éõĮĢĶ׏ÕÉł TTA ńÜäń╗ōµ×£ŃĆé ÕÉ”ÕłÖ’╝īķĆÜĶ┐ćÕ╣│ÕØćÕłåń▒╗ÕłåµĢ░õĮ┐ńö© flip TTAŃĆé |
+| `--launcher {none,pytorch,slurm,mpi}` | ÕÉ»ÕŖ©ÕÖ©’╝īķ╗śĶ«żõĖ║ "none"ŃĆé |
+
+## ÕŹĢµ£║ÕżÜÕŹĪµĄŗĶ»Ģ
+
+µłæõ╗¼µÅÉõŠøõ║åõĖĆõĖ¬ shell Ķäܵ£¼’╝īÕÅ»õ╗źõĮ┐ńö© `torch.distributed.launch` ÕÉ»ÕŖ©ÕżÜ GPU õ╗╗ÕŖĪŃĆé
+
+```shell
+bash ./tools/dist_test.sh ${CONFIG_FILE} ${CHECKPOINT_FILE} ${GPU_NUM} [PY_ARGS]
+```
+
+| ÕÅéµĢ░ | µÅÅĶ┐░ |
+| ----------------- | ---------------------------------------------------------------------------------------------------------------------------------------- |
+| `CONFIG_FILE` | ķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠäŃĆé |
+| `CHECKPOINT_FILE` | µØāķ揵¢ćõ╗ČĶĘ»ÕŠä’╝łµö»µīü http ķōŠµÄź’╝īõĮĀÕÅ»õ╗źÕ£©[Ķ┐Öķćī](https://mmpretrain.readthedocs.io/en/latest/modelzoo_statistics.html)Õ»╗µēŠķ£ĆĶ”üńÜäµØāķ揵¢ćõ╗Č’╝ēŃĆé |
+| `GPU_NUM` | õĮ┐ńö©ńÜä GPU µĢ░ķćÅŃĆé |
+| `[PY_ARGS]` | `tools/test.py` µö»µīüńÜäÕģČõ╗¢ÕÅ»ķĆēÕÅéµĢ░’╝īÕÅéĶ¦ü[õĖŖµ¢ć](#ÕŹĢµ£║ÕŹĢÕŹĪµĄŗĶ»Ģ)ŃĆé |
+
+õĮĀĶ┐śÕÅ»õ╗źõĮ┐ńö©ńÄ»ÕóāÕÅśķćÅµØźµīćÕ«ÜÕÉ»ÕŖ©ÕÖ©ńÜäķóØÕż¢ÕÅéµĢ░’╝īµ»öÕ”éńö©Õ”éõĖŗÕæĮõ╗żÕ░åÕÉ»ÕŖ©ÕÖ©ńÜäķĆÜĶ«»ń½»ÕÅŻÕÅśµø┤õĖ║ 29666’╝Ü
+
+```shell
+PORT=29666 bash ./tools/dist_test.sh ${CONFIG_FILE} ${CHECKPOINT_FILE} ${GPU_NUM} [PY_ARGS]
+```
+
+Õ”éµ×£õĮĀÕĖīµ£øõĮ┐ńö©õĖŹÕÉīńÜä GPU Ķ┐øĶĪīÕżÜķĪ╣µĄŗĶ»Ģõ╗╗ÕŖĪ’╝īÕÅ»õ╗źÕ£©ÕÉ»ÕŖ©µŚČµīćÕ«ÜõĖŹÕÉīńÜäķĆÜĶ«»ń½»ÕÅŻÕÆīõĖŹÕÉīńÜäÕÅ»ńö©Ķ«ŠÕżćŃĆé
+
+```shell
+CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 bash ./tools/dist_test.sh ${CONFIG_FILE1} ${CHECKPOINT_FILE} 4 [PY_ARGS]
+CUDA_VISIBLE_DEVICES=4,5,6,7 PORT=29501 bash ./tools/dist_test.sh ${CONFIG_FILE2} ${CHECKPOINT_FILE} 4 [PY_ARGS]
+```
+
+## ÕżÜµ£║µĄŗĶ»Ģ
+
+### ÕÉīõĖĆńĮæń╗£õĖŗńÜäÕżÜµ£║
+
+Õ”éµ×£õĮĀÕĖīµ£øõĮ┐ńö©ÕÉīõĖĆÕ▒ĆÕ¤¤ńĮæõĖŗĶ┐׵ğńÜäÕżÜÕÅ░ńöĄĶäæĶ┐øĶĪīõĖĆõĖ¬µĄŗĶ»Ģõ╗╗ÕŖĪ’╝īÕÅ»õ╗źõĮ┐ńö©Õ”éõĖŗÕæĮõ╗ż’╝Ü
+
+Õ£©ń¼¼õĖĆÕÅ░µ£║ÕÖ©õĖŖ’╝Ü
+
+```shell
+NNODES=2 NODE_RANK=0 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR bash tools/dist_test.sh $CONFIG $CHECKPOINT_FILE $GPUS
+```
+
+Õ£©ń¼¼õ║īÕÅ░µ£║ÕÖ©õĖŖ’╝Ü
+
+```shell
+NNODES=2 NODE_RANK=1 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR bash tools/dist_test.sh $CONFIG $CHECKPOINT_FILE $GPUS
+```
+
+ÕÆīÕŹĢµ£║ÕżÜÕŹĪńøĖµ»ö’╝īõĮĀķ£ĆĶ”üµīćÕ«ÜõĖĆõ║øķóØÕż¢ńÜäńÄ»ÕóāÕÅśķćÅ’╝Ü
+
+| ńÄ»ÕóāÕÅśķćÅ | µÅÅĶ┐░ |
+| ------------- | ---------------------------------------------- |
+| `NNODES` | µ£║ÕÖ©µĆ╗µĢ░ŃĆé |
+| `NODE_RANK` | µ£¼µ£║ńÜäÕ║ÅÕÅĘ |
+| `PORT` | ķĆÜĶ«»ń½»ÕÅŻ’╝īÕ«āÕ£©µēƵ£ēµ£║ÕÖ©õĖŖķāĮÕ║öÕĮōµś»õĖĆĶć┤ńÜäŃĆé |
+| `MASTER_ADDR` | õĖ╗µ£║ńÜä IP Õ£░ÕØĆ’╝īÕ«āÕ£©µēƵ£ēµ£║ÕÖ©õĖŖķāĮÕ║öÕĮōµś»õĖĆĶć┤ńÜäŃĆé |
+
+### Slurm ń«ĪńÉåõĖŗńÜäÕżÜµ£║ķøåńŠż
+
+Õ”éµ×£õĮĀÕ£© [slurm](https://slurm.schedmd.com/) ķøåńŠżõĖŖ’╝īÕÅ»õ╗źõĮ┐ńö© `tools/slurm_test.sh` Ķäܵ£¼ÕÉ»ÕŖ©õ╗╗ÕŖĪŃĆé
+
+```shell
+[ENV_VARS] ./tools/slurm_test.sh ${PARTITION} ${JOB_NAME} ${CONFIG_FILE} ${CHECKPOINT_FILE} [PY_ARGS]
+```
+
+Ķ┐Öķćīµś»Ķ»źĶäܵ£¼ńÜäõĖĆõ║øÕÅéµĢ░’╝Ü
+
+| ÕÅéµĢ░ | µÅÅĶ┐░ |
+| ----------------- | ---------------------------------------------------------------------------------------------------------------------------------------- |
+| `PARTITION` | õĮ┐ńö©ńÜäķøåńŠżÕłåÕī║ŃĆé |
+| `JOB_NAME` | õ╗╗ÕŖĪńÜäÕÉŹń¦░’╝īõĮĀÕÅ»õ╗źķÜŵäÅĶĄĘõĖĆõĖ¬ÕÉŹÕŁŚŃĆé |
+| `CONFIG_FILE` | ķģŹńĮ«µ¢ćõ╗ČĶĘ»ÕŠäŃĆé |
+| `CHECKPOINT_FILE` | µØāķ揵¢ćõ╗ČĶĘ»ÕŠä’╝łµö»µīü http ķōŠµÄź’╝īõĮĀÕÅ»õ╗źÕ£©[Ķ┐Öķćī](https://mmpretrain.readthedocs.io/en/latest/modelzoo_statistics.html)Õ»╗µēŠķ£ĆĶ”üńÜäµØāķ揵¢ćõ╗Č’╝ēŃĆé |
+| `[PY_ARGS]` | `tools/test.py` µö»µīüńÜäÕģČõ╗¢ÕÅ»ķĆēÕÅéµĢ░’╝īÕÅéĶ¦ü[õĖŖµ¢ć](#ÕŹĢµ£║ÕŹĢÕŹĪµĄŗĶ»Ģ)ŃĆé |
+
+Ķ┐Öķćīµś»õĖĆõ║øõĮĀÕÅ»õ╗źńö©µØźķģŹńĮ« slurm õ╗╗ÕŖĪńÜäńÄ»ÕóāÕÅśķćÅ’╝Ü
+
+| ńÄ»ÕóāÕÅśķćÅ | µÅÅĶ┐░ |
+| --------------- | ------------------------------------------------------------------------------------------ |
+| `GPUS` | õĮ┐ńö©ńÜä GPU µĆ╗µĢ░’╝īķ╗śĶ«żõĖ║ 8ŃĆé |
+| `GPUS_PER_NODE` | µ»ÅõĖ¬ĶŖéńé╣ÕłåķģŹńÜä GPU µĢ░’╝īõĮĀÕÅ»õ╗źµĀ╣µŹ«ĶŖéńé╣µāģÕåĄµīćÕ«ÜŃĆéķ╗śĶ«żõĖ║ 8ŃĆé |
+| `CPUS_PER_TASK` | µ»ÅõĖ¬õ╗╗ÕŖĪÕłåķģŹńÜä CPU µĢ░’╝łķĆÜÕĖĖõĖĆõĖ¬ GPU Õ»╣Õ║öõĖĆõĖ¬õ╗╗ÕŖĪ’╝ēŃĆéķ╗śĶ«żõĖ║ 5ŃĆé |
+| `SRUN_ARGS` | `srun` ÕæĮõ╗żµö»µīüńÜäÕģČõ╗¢ÕÅéµĢ░ŃĆéÕÅ»ńö©ńÜäķĆēķĪ╣ÕÅéĶ¦ü[Õ«śµ¢╣µ¢ćµĪŻ](https://slurm.schedmd.com/srun.html)ŃĆé |
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/train.md b/internlm_langchain/knowledge_base/MMPreTrain/content/train.md
new file mode 100644
index 00000000..841edabb
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/train.md
@@ -0,0 +1,118 @@
+# Ķ«Łń╗ā
+
+Õ£©µ£¼µĢÖń©ŗõĖŁ’╝īµłæõ╗¼Õ░åõ╗ŗń╗ŹÕ”éõĮĢõĮ┐ńö© MMPretrain õĖŁµÅÉõŠøńÜäĶäܵ£¼ÕÉ»ÕŖ©Ķ«Łń╗āõ╗╗ÕŖĪŃĆé
+Õ”éµ×£õĮĀķ£ĆĶ”üõ║åĶ¦ŻõĖĆõ║øÕģĘõĮōńÜäĶ«Łń╗āõŠŗÕŁÉ’╝īÕÅ»õ╗źµ¤źķśģ [Õ”éõĮĢÕ£©Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåõĖŖĶ┐øĶĪīµ©ĪÕ×ŗķóäĶ«Łń╗ā](../notes/pretrain_custom_dataset.md) ÕÆī [Õ”éõĮĢÕ£©Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåõĖŖÕŠ«Ķ░āµ©ĪÕ×ŗ](../notes/finetune_custom_dataset.md).
+
+## ÕŹĢµ£║ÕŹĢÕŹĪĶ«Łń╗ā
+
+õĮĀÕÅ»õ╗źõĮ┐ńö© `tools/train.py` Õ£©ńöĄĶäæõĖŖńö© CPU µł¢µś» GPU Ķ┐øĶĪīµ©ĪÕ×ŗńÜäĶ«Łń╗āŃĆé
+
+õ╗źõĖŗµś»Ķ«Łń╗āĶäܵ£¼ńÜäÕ«īµĢ┤ńö©µ│Ģ’╝Ü
+
+```shell
+python tools/train.py ${CONFIG_FILE} [ARGS]
+```
+
+````{note}
+ķ╗śĶ«żµāģÕåĄõĖŗ’╝īMMPretrain õ╝ÜĶć¬ÕŖ©Ķ░āńö©õĮĀńÜä GPU Ķ┐øĶĪīĶ«Łń╗āŃĆéÕ”éµ×£õĮĀµ£ē GPU õĮåõ╗Źµā│õĮ┐ńö© CPU Ķ┐øĶĪīĶ«Łń╗ā’╝īĶ»ĘĶ«ŠńĮ«ńÄ»ÕóāÕÅśķćÅ `CUDA_VISIBLE_DEVICES` õĖ║ń®║µł¢ĶĆģ -1 µØźÕ»╣ń”üńö© GPUŃĆé
+
+```bash
+CUDA_VISIBLE_DEVICES=-1 python tools/train.py ${CONFIG_FILE} [ARGS]
+```
+````
+
+| ÕÅéµĢ░ | µÅÅĶ┐░ |
+| ------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| `CONFIG_FILE` | ķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠäŃĆé |
+| `--work-dir WORK_DIR` | ńö©µØźõ┐ØÕŁśĶ«Łń╗āµŚźÕ┐ŚÕÆīµØāķ揵¢ćõ╗ČńÜäµ¢ćõ╗ČÕż╣’╝īķ╗śĶ«żµś» `./work_dirs` ńø«ÕĮĢõĖŗ’╝īõĖÄķģŹńĮ«µ¢ćõ╗ČÕÉīÕÉŹńÜäµ¢ćõ╗ČÕż╣ŃĆé |
+| `--resume [RESUME]` | µüóÕżŹĶ«Łń╗āŃĆéÕ”éµ×£µīćÕ«Üõ║åµØāķ揵¢ćõ╗ČĶĘ»ÕŠä’╝īÕłÖõ╗ĵīćÕ«ÜńÜäµØāķ揵¢ćõ╗ȵüóÕżŹ’╝øÕ”éµ×£µ▓Īµ£ēµīćÕ«Ü’╝īÕłÖÕ░ØĶ»Ģõ╗ĵ£Ćµ¢░ńÜäµØāķ揵¢ćõ╗ČĶ┐øĶĪīµüóÕżŹŃĆé |
+| `--amp` | ÕÉ»ńö©µĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗āŃĆé |
+| `--no-validate` | **õĖŹÕ╗║Ķ««** Õ£©Ķ«Łń╗āĶ┐ćń©ŗõĖŁõĖŹĶ┐øĶĪīķ¬īĶ»üķøåõĖŖńÜäń▓ŠÕ║”ķ¬īĶ»üŃĆé |
+| `--auto-scale-lr` | Ķć¬ÕŖ©µĀ╣µŹ«Õ«×ķÖģńÜäµē╣µ¼ĪÕż¦Õ░Å’╝łbatch size’╝ēÕÆīķóäĶ«ŠńÜäµē╣µ¼ĪÕż¦Õ░ÅÕ»╣ÕŁ”õ╣ĀńÄćĶ┐øĶĪīń╝®µöŠŃĆé |
+| `--no-pin-memory` | µś»Õɔգ© dataloaders õĖŁÕģ│ķŚŁ `pin_memory` ķĆēķĪ╣ |
+| `--no-persistent-workers` | µś»Õɔգ© dataloaders õĖŁÕģ│ķŚŁ `persistent_workers` ķĆēķĪ╣ |
+| `--cfg-options CFG_OPTIONS` | ķćŹĶĮĮķģŹńĮ«µ¢ćõ╗ČõĖŁńÜäõĖĆõ║øĶ«ŠńĮ«ŃĆéõĮ┐ńö©ń▒╗õ╝╝ `xxx=yyy` ńÜäķö«ÕĆ╝Õ»╣ÕĮóÕ╝ŵīćÕ«Ü’╝īĶ┐Öõ║øĶ«ŠńĮ«õ╝ÜĶó½Ķ׏ÕÉłÕģźõ╗ÄķģŹńĮ«µ¢ćõ╗ČĶ»╗ÕÅ¢ńÜäķģŹńĮ«ŃĆéõĮĀÕÅ»õ╗źõĮ┐ńö© `key="[a,b]"` µł¢ĶĆģ `key=a,b` ńÜäµĀ╝Õ╝ÅµØźµīćÕ«ÜÕłŚĶĪ©µĀ╝Õ╝ÅńÜäÕĆ╝’╝īõĖöµö»µīüÕĄīÕźŚ’╝īõŠŗÕ”é \`key="[(a,b),(c,d)]"’╝īĶ┐ÖķćīńÜäÕ╝ĢÕÅʵś»õĖŹÕÅ»ń£üńĢźńÜäŃĆéÕÅ”Õż¢µ»ÅõĖ¬ķćŹĶĮĮķĪ╣Õåģķā©õĖŹÕÅ»Õć║ńÄ░ń®║µĀ╝ŃĆé |
+| `--launcher {none,pytorch,slurm,mpi}` | ÕÉ»ÕŖ©ÕÖ©’╝īķ╗śĶ«żõĖ║ "none"ŃĆé |
+
+## ÕŹĢµ£║ÕżÜÕŹĪĶ«Łń╗ā
+
+µłæõ╗¼µÅÉõŠøõ║åõĖĆõĖ¬ shell Ķäܵ£¼’╝īÕÅ»õ╗źõĮ┐ńö© `torch.distributed.launch` ÕÉ»ÕŖ©ÕżÜ GPU õ╗╗ÕŖĪŃĆé
+
+```shell
+bash ./tools/dist_train.sh ${CONFIG_FILE} ${GPU_NUM} [PY_ARGS]
+```
+
+| ÕÅéµĢ░ | µÅÅĶ┐░ |
+| ------------- | ---------------------------------------------------------------- |
+| `CONFIG_FILE` | ķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠäŃĆé |
+| `GPU_NUM` | õĮ┐ńö©ńÜä GPU µĢ░ķćÅŃĆé |
+| `[PY_ARGS]` | `tools/train.py` µö»µīüńÜäÕģČõ╗¢ÕÅ»ķĆēÕÅéµĢ░’╝īÕÅéĶ¦ü[õĖŖµ¢ć](#ÕŹĢµ£║ÕŹĢÕŹĪĶ«Łń╗ā)ŃĆé |
+
+õĮĀĶ┐śÕÅ»õ╗źõĮ┐ńö©ńÄ»ÕóāÕÅśķćÅµØźµīćÕ«ÜÕÉ»ÕŖ©ÕÖ©ńÜäķóØÕż¢ÕÅéµĢ░’╝īµ»öÕ”éńö©Õ”éõĖŗÕæĮõ╗żÕ░åÕÉ»ÕŖ©ÕÖ©ńÜäķĆÜĶ«»ń½»ÕÅŻÕÅśµø┤õĖ║ 29666’╝Ü
+
+```shell
+PORT=29666 bash ./tools/dist_train.sh ${CONFIG_FILE} ${GPU_NUM} [PY_ARGS]
+```
+
+Õ”éµ×£õĮĀÕĖīµ£øõĮ┐ńö©õĖŹÕÉīńÜä GPU Ķ┐øĶĪīÕżÜķĪ╣Ķ«Łń╗āõ╗╗ÕŖĪ’╝īÕÅ»õ╗źÕ£©ÕÉ»ÕŖ©µŚČµīćÕ«ÜõĖŹÕÉīńÜäķĆÜĶ«»ń½»ÕÅŻÕÆīõĖŹÕÉīńÜäÕÅ»ńö©Ķ«ŠÕżćŃĆé
+
+```shell
+CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 bash ./tools/dist_train.sh ${CONFIG_FILE1} 4 [PY_ARGS]
+CUDA_VISIBLE_DEVICES=4,5,6,7 PORT=29501 bash ./tools/dist_train.sh ${CONFIG_FILE2} 4 [PY_ARGS]
+```
+
+## ÕżÜµ£║Ķ«Łń╗ā
+
+### ÕÉīõĖĆńĮæń╗£õĖŗńÜäÕżÜµ£║
+
+Õ”éµ×£õĮĀÕĖīµ£øõĮ┐ńö©ÕÉīõĖĆÕ▒ĆÕ¤¤ńĮæõĖŗĶ┐׵ğńÜäÕżÜÕÅ░ńöĄĶäæĶ┐øĶĪīõĖĆõĖ¬Ķ«Łń╗āõ╗╗ÕŖĪ’╝īÕÅ»õ╗źõĮ┐ńö©Õ”éõĖŗÕæĮõ╗ż’╝Ü
+
+Õ£©ń¼¼õĖĆÕÅ░µ£║ÕÖ©õĖŖ’╝Ü
+
+```shell
+NNODES=2 NODE_RANK=0 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR bash tools/dist_train.sh $CONFIG $GPUS
+```
+
+Õ£©ń¼¼õ║īÕÅ░µ£║ÕÖ©õĖŖ’╝Ü
+
+```shell
+NNODES=2 NODE_RANK=1 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR bash tools/dist_train.sh $CONFIG $GPUS
+```
+
+ÕÆīÕŹĢµ£║ÕżÜÕŹĪńøĖµ»ö’╝īõĮĀķ£ĆĶ”üµīćÕ«ÜõĖĆõ║øķóØÕż¢ńÜäńÄ»ÕóāÕÅśķćÅ’╝Ü
+
+| ńÄ»ÕóāÕÅśķćÅ | µÅÅĶ┐░ |
+| ------------- | ---------------------------------------------- |
+| `NNODES` | µ£║ÕÖ©µĆ╗µĢ░ŃĆé |
+| `NODE_RANK` | µ£¼µ£║ńÜäÕ║ÅÕÅĘ |
+| `PORT` | ķĆÜĶ«»ń½»ÕÅŻ’╝īÕ«āÕ£©µēƵ£ēµ£║ÕÖ©õĖŖķāĮÕ║öÕĮōµś»õĖĆĶć┤ńÜäŃĆé |
+| `MASTER_ADDR` | õĖ╗µ£║ńÜä IP Õ£░ÕØĆ’╝īÕ«āÕ£©µēƵ£ēµ£║ÕÖ©õĖŖķāĮÕ║öÕĮōµś»õĖĆĶć┤ńÜäŃĆé |
+
+ķĆÜÕĖĖµØźĶ»┤’╝īÕ”éµ×£Ķ┐ÖÕćĀÕÅ░µ£║ÕÖ©õ╣ŗķŚ┤õĖŹµś»ķ½śķƤńĮæń╗£Ķ┐׵ğ’╝īĶ«Łń╗āķƤÕ║”õ╝ÜķØ×ÕĖĖµģóŃĆé
+
+### Slurm ń«ĪńÉåõĖŗńÜäÕżÜµ£║ķøåńŠż
+
+Õ”éµ×£õĮĀÕ£© [slurm](https://slurm.schedmd.com/) ķøåńŠżõĖŖ’╝īÕÅ»õ╗źõĮ┐ńö© `tools/slurm_train.sh` Ķäܵ£¼ÕÉ»ÕŖ©õ╗╗ÕŖĪŃĆé
+
+```shell
+[ENV_VARS] ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} ${CONFIG_FILE} ${WORK_DIR} [PY_ARGS]
+```
+
+Ķ┐Öķćīµś»Ķ»źĶäܵ£¼ńÜäõĖĆõ║øÕÅéµĢ░’╝Ü
+
+| ÕÅéµĢ░ | µÅÅĶ┐░ |
+| ------------- | ---------------------------------------------------------------- |
+| `PARTITION` | õĮ┐ńö©ńÜäķøåńŠżÕłåÕī║ŃĆé |
+| `JOB_NAME` | õ╗╗ÕŖĪńÜäÕÉŹń¦░’╝īõĮĀÕÅ»õ╗źķÜŵäÅĶĄĘõĖĆõĖ¬ÕÉŹÕŁŚŃĆé |
+| `CONFIG_FILE` | ķģŹńĮ«µ¢ćõ╗ČĶĘ»ÕŠäŃĆé |
+| `WORK_DIR` | ńö©õ╗źõ┐ØÕŁśµŚźÕ┐ŚÕÆīµØāķ揵¢ćõ╗ČńÜäµ¢ćõ╗ČÕż╣ŃĆé |
+| `[PY_ARGS]` | `tools/train.py` µö»µīüńÜäÕģČõ╗¢ÕÅ»ķĆēÕÅéµĢ░’╝īÕÅéĶ¦ü[õĖŖµ¢ć](#ÕŹĢµ£║ÕŹĢÕŹĪĶ«Łń╗ā)ŃĆé |
+
+Ķ┐Öķćīµś»õĖĆõ║øõĮĀÕÅ»õ╗źńö©µØźķģŹńĮ« slurm õ╗╗ÕŖĪńÜäńÄ»ÕóāÕÅśķćÅ’╝Ü
+
+| ńÄ»ÕóāÕÅśķćÅ | µÅÅĶ┐░ |
+| --------------- | ------------------------------------------------------------------------------------------ |
+| `GPUS` | õĮ┐ńö©ńÜä GPU µĆ╗µĢ░’╝īķ╗śĶ«żõĖ║ 8ŃĆé |
+| `GPUS_PER_NODE` | µ»ÅõĖ¬ĶŖéńé╣ÕłåķģŹńÜä GPU µĢ░’╝īõĮĀÕÅ»õ╗źµĀ╣µŹ«ĶŖéńé╣µāģÕåĄµīćÕ«ÜŃĆéķ╗śĶ«żõĖ║ 8ŃĆé |
+| `CPUS_PER_TASK` | µ»ÅõĖ¬õ╗╗ÕŖĪÕłåķģŹńÜä CPU µĢ░’╝łķĆÜÕĖĖõĖĆõĖ¬ GPU Õ»╣Õ║öõĖĆõĖ¬õ╗╗ÕŖĪ’╝ēŃĆéķ╗śĶ«żõĖ║ 5ŃĆé |
+| `SRUN_ARGS` | `srun` ÕæĮõ╗żµö»µīüńÜäÕģČõ╗¢ÕÅéµĢ░ŃĆéÕÅ»ńö©ńÜäķĆēķĪ╣ÕÅéĶ¦ü[Õ«śµ¢╣µ¢ćµĪŻ](https://slurm.schedmd.com/srun.html)ŃĆé |
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/verify_dataset.md b/internlm_langchain/knowledge_base/MMPreTrain/content/verify_dataset.md
new file mode 100644
index 00000000..655ce977
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/verify_dataset.md
@@ -0,0 +1,28 @@
+# µĢ░µŹ«ķøåķ¬īĶ»ü
+
+Õ£© MMPretrain õĖŁ’╝ī`tools/misc/verify_dataset.py` Ķäܵ£¼õ╝ܵŻĆµ¤źµĢ░µŹ«ķøåńÜäµēƵ£ēÕøŠńēć’╝īµ¤źń£ŗµś»ÕÉ”µ£ē**ÕĘ▓ń╗ŵŹ¤ÕØÅ**ńÜäÕøŠńēćŃĆé
+
+## ÕĘźÕģĘõ╗ŗń╗Ź
+
+```shell
+python tools/print_config.py \
+ ${CONFIG} \
+ [--out-path ${OUT-PATH}] \
+ [--phase ${PHASE}] \
+ [--num-process ${NUM-PROCESS}]
+ [--cfg-options ${CFG_OPTIONS}]
+```
+
+**µēƵ£ēÕÅéµĢ░Ķ»┤µśÄ**:
+
+- `config` : ķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠäŃĆé
+- `--out-path` : ĶŠōÕć║ń╗ōµ×£ĶĘ»ÕŠä’╝īķ╗śĶ«żõĖ║ ŌĆśbrokenfiles.logŌĆÖŃĆé
+- `--phase` : µŻĆµ¤źÕō¬õĖ¬ķśČµ«ĄńÜäµĢ░µŹ«ķøå’╝īÕÅ»ńö©ÕĆ╝õĖ║ ŌĆ£trainŌĆØ ŃĆüŌĆØtestŌĆØ µł¢ĶĆģ ŌĆ£valŌĆØ’╝ī ķ╗śĶ«żõĖ║ ŌĆ£trainŌĆØŃĆé
+- `--num-process` : µīćÕ«ÜńÜäĶ┐øń©ŗµĢ░’╝īķ╗śĶ«żõĖ║ 1ŃĆé
+- `--cfg-options`: ķóØÕż¢ńÜäķģŹńĮ«ķĆēķĪ╣’╝īõ╝ÜĶó½ÕÉłÕģźķģŹńĮ«µ¢ćõ╗Č’╝īÕÅéĶĆā[µĢÖń©ŗ 1’╝ÜÕ”éõĮĢń╝¢ÕåÖķģŹńĮ«µ¢ćõ╗Č](https://mmpretrain.readthedocs.io/zh_CN/latest/tutorials/config.html)ŃĆé
+
+## ńż║õŠŗ’╝Ü
+
+```shell
+python tools/misc/verify_dataset.py configs/t2t_vit/t2t-vit-t-14_8xb64_in1k.py --out-path broken_imgs.log --phase val --num-process 8
+```
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/vector_store/index.faiss b/internlm_langchain/knowledge_base/MMPreTrain/vector_store/index.faiss
new file mode 100644
index 00000000..3c0ec00c
Binary files /dev/null and b/internlm_langchain/knowledge_base/MMPreTrain/vector_store/index.faiss differ
diff --git a/internlm_langchain/knowledge_base/MMRazor/content/1_learn_about_config.md b/internlm_langchain/knowledge_base/MMRazor/content/1_learn_about_config.md
new file mode 100644
index 00000000..05cfd254
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMRazor/content/1_learn_about_config.md
@@ -0,0 +1,17 @@
+# Learn about Configs
+
+## Directory structure of configs in mmrazor
+
+
+
+`mmxxx`: means some task repositories of OpenMMLab, such mmcls, mmdet, mmseg and so on.
+
+`_base_`: includes configures of datasets, experiment settings and model architectures.
+
+`distill`/`nas`/`pruning`: model compression algorithms.
+
+`vanilla`: task models owned by mmrazor.
+
+## More about config
+
+Please refer to [config](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/tutorials/config.md) in mmengine.
diff --git a/internlm_langchain/knowledge_base/MMRazor/content/2_train_different_types_algorithms.md b/internlm_langchain/knowledge_base/MMRazor/content/2_train_different_types_algorithms.md
new file mode 100644
index 00000000..06c68970
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMRazor/content/2_train_different_types_algorithms.md
@@ -0,0 +1,107 @@
+# Train different types algorithms
+
+**Before running our algorithms, you may need to prepare the datasets according to the instructions in the corresponding document.**
+
+**Note**:
+
+- With the help of mmengine, mmrazor unified entered interfaces for various tasks, thus our algorithms will adapt all OpenMMLab upstream repos in theory.
+
+- We dynamically pass arguments `cfg-options` (e.g., `mutable_cfg` in nas algorithm or `channel_cfg` in pruning algorithm) to **avoid the need for a config for each subnet or checkpoint**. If you want to specify different subnets for retraining or testing, you just need to change this argument.
+
+### NAS
+
+Here we take SPOS(Single Path One Shot) as an example. There are three steps to start neural network search(NAS), including **supernet pre-training**, **search for subnet on the trained supernet** and **subnet retraining**.
+
+#### Supernet Pre-training
+
+```Python
+python tools/train.py ${CONFIG_FILE} [optional arguments]
+```
+
+The usage of optional arguments are the same as corresponding tasks like mmclassification, mmdetection and mmsegmentation.
+
+For example,
+
+```Python
+python ./tools/train.py \
+ configs/nas/mmcls/spos/spos_shufflenet_supernet_8xb128_in1k.py
+ --work-dir $WORK_DIR
+```
+
+#### Search for Subnet on The Trained Supernet
+
+```Python
+python tools/train.py ${CONFIG_FILE} --cfg-options load_from=${CHECKPOINT_PATH} [optional arguments]
+```
+
+For example,
+
+```Python
+python ./tools/train.py \
+ configs/nas/mmcls/spos/spos_shufflenet_search_8xb128_in1k.py \
+ --cfg-options load_from=$STEP1_CKPT \
+ --work-dir $WORK_DIR
+```
+
+#### Subnet Retraining
+
+```Python
+python tools/train.py ${CONFIG_FILE} \
+ --cfg-options algorithm.fix_subnet=${MUTABLE_CFG_PATH} [optional arguments]
+```
+
+- `MUTABLE_CFG_PATH`: Path of `fix_subnet`. `fix_subnet` represents **config for mutable of the subnet searched out**, used to specify different subnets for retraining. An example for `fix_subnet` can be found [here](https://github.com/open-mmlab/mmrazor/blob/master/configs/nas/spos/SPOS_SHUFFLENETV2_330M_IN1k_PAPER.yaml), and the usage can be found [here](https://github.com/open-mmlab/mmrazor/blob/master/configs/nas/spos/README.md#subnet-retraining-on-imagenet).
+
+For example,
+
+```Python
+python ./tools/train.py \
+ configs/nas/mmcls/spos/spos_shufflenet_subnet_8xb128_in1k.py \
+ --work-dir $WORK_DIR \
+ --cfg-options algorithm.fix_subnet=$YAML_FILE_BY_STEP2
+```
+
+We note that instead of using `--cfg-options`, you can also directly modify ``` configs/nas/mmcls/spos/``spos_shufflenet_subnet_8xb128_in1k``.py ``` like this:
+
+```Python
+fix_subnet = 'configs/nas/mmcls/spos/SPOS_SHUFFLENETV2_330M_IN1k_PAPER.yaml'
+model = dict(fix_subnet=fix_subnet)
+```
+
+### Pruning
+
+Pruning has three steps, including **supernet pre-training**, **search for subnet on the trained supernet** and **subnet retraining**. The commands of the first two steps are similar to NAS, except that we need to use `CONFIG_FILE` of Pruning here. The commands of the **subnet retraining** are as follows.
+
+#### Subnet Retraining
+
+```Python
+python tools/train.py ${CONFIG_FILE} --cfg-options model._channel_cfg_paths=${CHANNEL_CFG_PATH} [optional arguments]
+```
+
+Different from NAS, the argument that needs to be specified here is `channel_cfg_paths` .
+
+- `CHANNEL_CFG_PATH`: Path of `_channel_cfg_path`. `channel_cfg` represents **config for channel of the subnet searched out**, used to specify different subnets for testing.
+
+For example, the default `_channel_cfg_paths` is set in the config below.
+
+```Python
+python ./tools/train.py \
+ configs/pruning/mmcls/autoslim/autoslim_mbv2_1.5x_subnet_8xb256_in1k_flops-530M.py \
+ --work-dir your_work_dir
+```
+
+### Distillation
+
+There is only one step to start knowledge distillation.
+
+```Python
+python tools/train.py ${CONFIG_FILE} [optional arguments]
+```
+
+For example,
+
+```Python
+python ./tools/train.py \
+ configs/distill/mmcls/kd/kd_logits_r34_r18_8xb32_in1k.py \
+ --work-dir your_work_dir
+```
diff --git a/internlm_langchain/knowledge_base/MMRazor/content/3_train_with_different_devices.md b/internlm_langchain/knowledge_base/MMRazor/content/3_train_with_different_devices.md
new file mode 100644
index 00000000..aa24654e
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMRazor/content/3_train_with_different_devices.md
@@ -0,0 +1,93 @@
+# Train with different devices
+
+**Note**: The default learning rate in config files is for 8 GPUs. If using different number GPUs, the total batch size will change in proportion, you have to scale the learning rate following `new_lr = old_lr * new_ngpus / old_ngpus`. We recommend to use `tools/dist_train.sh` even with 1 gpu, since some methods do not support non-distributed training.
+
+### Training with CPU
+
+```Python
+export CUDA_VISIBLE_DEVICES=-1
+python tools/train.py ${CONFIG_FILE}
+```
+
+**Note**: We do not recommend users to use CPU for training because it is too slow and some algorithms are using `SyncBN` which is based on distributed training. We support this feature to allow users to debug on machines without GPU for convenience.
+
+### Train with single/multiple GPUs
+
+```Python
+sh tools/dist_train.sh ${CONFIG_FILE} ${GPUS} --work_dir ${YOUR_WORK_DIR} [optional arguments]
+```
+
+**Note**: During training, checkpoints and logs are saved in the same folder structure as the config file under `work_dirs/`. Custom work directory is not recommended since evaluation scripts infer work directories from the config file name. If you want to save your weights somewhere else, please use symlink, for example:
+
+```Python
+ln -s ${YOUR_WORK_DIRS} ${MMRAZOR}/work_dirs
+```
+
+Alternatively, if you run MMRazor on a cluster managed with [slurm](https://slurm.schedmd.com/):
+
+```Python
+GPUS_PER_NODE=${GPUS_PER_NODE} GPUS=${GPUS} SRUN_ARGS=${SRUN_ARGS} sh tools/xxx/slurm_train.sh ${PARTITION} ${JOB_NAME} ${CONFIG_FILE} ${YOUR_WORK_DIR} [optional arguments]
+```
+
+### Train with multiple machines
+
+If you launch with multiple machines simply connected with ethernet, you can simply run the following commands:
+
+On the first machine:
+
+```Python
+NNODES=2 NODE_RANK=0 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR sh tools/dist_train.sh $CONFIG $GPUS
+```
+
+On the second machine:
+
+```Python
+NNODES=2 NODE_RANK=1 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR sh tools/dist_train.sh $CONFIG $GPUS
+```
+
+Usually it is slow if you do not have high speed networking like InfiniBand.
+
+If you launch with slurm, the command is the same as that on single machine described above, but you need refer to [slurm_train.sh](https://github.com/open-mmlab/mmselfsup/blob/master/tools/slurm_train.sh) to set appropriate parameters and environment variables.
+
+### Launch multiple jobs on a single machine
+
+If you launch multiple jobs on a single machine, e.g., 2 jobs of 4-GPU training on a machine with 8 GPUs, you need to specify different ports (29500 by default) for each job to avoid communication conflict.
+
+If you use `dist_train.sh` to launch training jobs:
+
+```Python
+CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 sh tools/xxx/dist_train.sh ${CONFIG_FILE} 4 --work_dir tmp_work_dir_1
+CUDA_VISIBLE_DEVICES=4,5,6,7 PORT=29501 sh tools/xxx/dist_train.sh ${CONFIG_FILE} 4 --work_dir tmp_work_dir_2
+```
+
+If you use launch training jobs with slurm, you have two options to set different communication ports:
+
+Option 1:
+
+In `config1.py`:
+
+```Python
+dist_params = dict(backend='nccl', port=29500)
+```
+
+In `config2.py`:
+
+```Python
+dist_params = dict(backend='nccl', port=29501)
+```
+
+Then you can launch two jobs with config1.py and config2.py.
+
+```Python
+CUDA_VISIBLE_DEVICES=0,1,2,3 GPUS=4 sh tools/slurm_train.sh ${PARTITION} ${JOB_NAME} config1.py tmp_work_dir_1
+CUDA_VISIBLE_DEVICES=4,5,6,7 GPUS=4 sh tools/slurm_train.sh ${PARTITION} ${JOB_NAME} config2.py tmp_work_dir_2
+```
+
+Option 2:
+
+You can set different communication ports without the need to modify the configuration file, but have to set the `cfg-options` to overwrite the default port in configuration file.
+
+```Python
+CUDA_VISIBLE_DEVICES=0,1,2,3 GPUS=4 sh tools/slurm_train.sh ${PARTITION} ${JOB_NAME} config1.py tmp_work_dir_1 --cfg-options dist_params.port=29500
+CUDA_VISIBLE_DEVICES=4,5,6,7 GPUS=4 sh tools/slurm_train.sh ${PARTITION} ${JOB_NAME} config2.py tmp_work_dir_2 --cfg-options dist_params.port=29501
+```
diff --git a/internlm_langchain/knowledge_base/MMRazor/content/4_test_a_model.md b/internlm_langchain/knowledge_base/MMRazor/content/4_test_a_model.md
new file mode 100644
index 00000000..152b5dc4
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMRazor/content/4_test_a_model.md
@@ -0,0 +1,79 @@
+# Test a model
+
+### NAS
+
+To test nas method, you can use the following command.
+
+```Python
+python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_PATH} --cfg-options algorithm.fix_subnet=${FIX_SUBNET_PATH} [optional arguments]
+```
+
+- `FIX_SUBNET_PATH`: Path of `fix_subnet`. `fix_subnet` represents **config for mutable of the subnet searched out**, used to specify different subnets for testing. An example for `fix_subnet` can be found [here](https://github.com/open-mmlab/mmrazor/blob/master/configs/nas/spos/SPOS_SHUFFLENETV2_330M_IN1k_PAPER.yaml).
+
+The usage of optional arguments are the same as corresponding tasks like mmclassification, mmdetection and mmsegmentation.
+
+For example,
+
+```Python
+python tools/test.py \
+ configs/nas/mmcls/spos/spos_subnet_shufflenetv2_8xb128_in1k.py \
+ your_subnet_checkpoint_path \
+ --cfg-options algorithm.fix_subnet=configs/nas/mmcls/spos/SPOS_SHUFFLENETV2_330M_IN1k_PAPER.yaml
+```
+
+### Pruning
+
+#### Split Checkpoint(Optional)
+
+If you train a slimmable model during retraining, checkpoints of different subnets are actually fused in only one checkpoint. You can split this checkpoint to multiple independent checkpoints by using the following command
+
+```Python
+python tools/model_converters/split_checkpoint.py ${CONFIG_FILE} ${CHECKPOINT_PATH} --channel-cfgs ${CHANNEL_CFG_PATH} [optional arguments]
+```
+
+- `CHANNEL_CFG_PATH`: A list of paths of `channel_cfg`. For example, when you retrain a slimmable model, your command will be like `--cfg-options algorithm.channel_cfg=cfg1,cfg2,cfg3`. And your command here should be `--channel-cfgs cfg1 cfg2 cfg3`. The order of them should be the same.
+
+For example,
+
+```Python
+python tools/model_converters/split_checkpoint.py \
+ configs/pruning/autoslim/autoslim_mbv2_subnet_8xb256_in1k.py \
+ your_retraining_checkpoint_path \
+ --channel-cfgs configs/pruning/autoslim/AUTOSLIM_MBV2_530M_OFFICIAL.yaml configs/pruning/autoslim/AUTOSLIM_MBV2_320M_OFFICIAL.yaml configs/pruning/autoslim/AUTOSLIM_MBV2_220M_OFFICIAL.yaml
+```
+
+#### Test
+
+To test pruning method, you can use following command
+
+```Python
+python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_PATH} --cfg-options model._channel_cfg_paths=${CHANNEL_CFG_PATH} [optional arguments]
+```
+
+- `task`: one of `mmcls`ŃĆü`mmdet` and `mmseg`
+
+- `CHANNEL_CFG_PATH`: Path of `channel_cfg`. `channel_cfg` represents **config for channel of the subnet searched out**, used to specify different subnets for testing. An example for `channel_cfg` can be found [here](https://github.com/open-mmlab/mmrazor/blob/master/configs/pruning/autoslim/AUTOSLIM_MBV2_220M_OFFICIAL.yaml), and the usage can be found [here](https://github.com/open-mmlab/mmrazor/blob/master/configs/pruning/autoslim/README.md#test-a-subnet).
+
+For example,
+
+```Python
+python ./tools/test.py \
+ configs/pruning/mmcls/autoslim/autoslim_mbv2__1.5x_subnet_8xb256_in1k-530M.py \
+ your_splitted_checkpoint_path --metrics accuracy
+```
+
+### Distillation
+
+To test the distillation method, you can use the following command
+
+```Python
+python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_PATH} [optional arguments]
+```
+
+For example,
+
+```Python
+python ./tools/test.py \
+ configs/distill/mmseg/cwd/cwd_logits_pspnet_r101_d8_pspnet_r18_d8_512x1024_cityscapes_80k.py \
+ your_splitted_checkpoint_path --show
+```
diff --git a/internlm_langchain/knowledge_base/MMRazor/content/algorithm.md b/internlm_langchain/knowledge_base/MMRazor/content/algorithm.md
new file mode 100644
index 00000000..ae632db6
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMRazor/content/algorithm.md
@@ -0,0 +1,273 @@
+# Algorithm
+
+## Introduction
+
+### What is algorithm in MMRazor
+
+MMRazor is a model compression toolkit, which includes 4 mianstream technologies:
+
+- Neural Architecture Search (NAS)
+- Pruning
+- Knowledge Distillation (KD)
+- Quantization (come soon)
+
+And in MMRazor, `algorithm` is a general item for these technologies. For example, in NAS,
+
+[SPOS](https://github.com/open-mmlab/mmrazor/blob/master/configs/nas/spos)[ ](https://arxiv.org/abs/1904.00420)is an `algorithm`, [CWD](https://github.com/open-mmlab/mmrazor/blob/master/configs/distill/cwd) is also an `algorithm` of knowledge distillation.
+
+`algorithm` is the entrance of `mmrazor/models` . Its role in MMRazor is the same as both `classifier` in [MMClassification](https://github.com/open-mmlab/mmclassification) and `detector` in [MMDetection](https://github.com/open-mmlab/mmdetection).
+
+### About base algorithm
+
+In the directory of `models/algorithms`, all model compression algorithms are divided into 4 subdirectories: nas / pruning / distill / quantization. These algorithms must inherit from `BaseAlgorithm`, whose definition is as below.
+
+```Python
+from typing import Dict, List, Optional, Tuple, Union
+from mmengine.model import BaseModel
+from mmrazor.registry import MODELS
+
+LossResults = Dict[str, torch.Tensor]
+TensorResults = Union[Tuple[torch.Tensor], torch.Tensor]
+PredictResults = List[BaseDataElement]
+ForwardResults = Union[LossResults, TensorResults, PredictResults]
+
+@MODELS.register_module()
+class BaseAlgorithm(BaseModel):
+
+ def __init__(self,
+ architecture: Union[BaseModel, Dict],
+ data_preprocessor: Optional[Union[Dict, nn.Module]] = None,
+ init_cfg: Optional[Dict] = None):
+
+ ......
+
+ super().__init__(data_preprocessor, init_cfg)
+ self.architecture = architecture
+
+ def forward(self,
+ batch_inputs: torch.Tensor,
+ data_samples: Optional[List[BaseDataElement]] = None,
+ mode: str = 'tensor') -> ForwardResults:
+
+ if mode == 'loss':
+ return self.loss(batch_inputs, data_samples)
+ elif mode == 'tensor':
+ return self._forward(batch_inputs, data_samples)
+ elif mode == 'predict':
+ return self._predict(batch_inputs, data_samples)
+ else:
+ raise RuntimeError(f'Invalid mode "{mode}". '
+ 'Only supports loss, predict and tensor mode')
+
+ def loss(
+ self,
+ batch_inputs: torch.Tensor,
+ data_samples: Optional[List[BaseDataElement]] = None,
+ ) -> LossResults:
+ """Calculate losses from a batch of inputs and data samples."""
+ return self.architecture(batch_inputs, data_samples, mode='loss')
+
+ def _forward(
+ self,
+ batch_inputs: torch.Tensor,
+ data_samples: Optional[List[BaseDataElement]] = None,
+ ) -> TensorResults:
+ """Network forward process."""
+ return self.architecture(batch_inputs, data_samples, mode='tensor')
+
+ def _predict(
+ self,
+ batch_inputs: torch.Tensor,
+ data_samples: Optional[List[BaseDataElement]] = None,
+ ) -> PredictResults:
+ """Predict results from a batch of inputs and data samples with post-
+ processing."""
+ return self.architecture(batch_inputs, data_samples, mode='predict')
+```
+
+As you can see from above, `BaseAlgorithm` is inherited from `BaseModel` of MMEngine. `BaseModel` implements the basic functions of the algorithmic model, such as weights initialize,
+
+batch inputs preprocess (see more information in `BaseDataPreprocessor` class of MMEngine), parse losses, and update model parameters. For more details of `BaseModel` , you can see docs for `BaseModel`.
+
+`BaseAlgorithm`'s forward is just a wrapper of `BaseModel`'s forward. Sub-classes inherited from BaseAlgorithm only need to override the `loss` method, which implements the logic to calculate loss, thus various algorithms can be trained in the runner.
+
+## How to use existing algorithms in MMRazor
+
+1. Configure your architecture that will be slimmed
+
+- Use the model config of other repos of OpenMMLab directly as below, which is an example of setting Faster-RCNN as our architecture.
+
+```Python
+_base_ = [
+ 'mmdet::_base_/models/faster_rcnn_r50_fpn.py',
+]
+
+architecture = _base_.model
+```
+
+- Use your customized model as below, which is an example of defining a VGG model as our architecture.
+
+```{note}
+How to customize architectures can refer to our tutorial: [Customize Architectures](https://mmrazor.readthedocs.io/en/main/advanced_guides/customize_architectures.html).
+```
+
+```Python
+default_scope='mmcls'
+architecture = dict(
+ type='ImageClassifier',
+ backbone=dict(type='VGG', depth=11, num_classes=1000),
+ neck=None,
+ head=dict(
+ type='ClsHead',
+ loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
+ topk=(1, 5),
+ ))
+```
+
+2. Apply the registered algorithm to your architecture.
+
+```{note}
+The arg name of `algorithm` in config is **model** rather than **algorithm** in order to get better supports of MMCV and MMEngine.
+```
+
+Maybe more args in model need to set according to the used algorithm.
+
+```Python
+model = dict(
+ type='BaseAlgorithm',
+ architecture=architecture)
+```
+
+```{note}
+About the usage of `Config`, refer to [config.md](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/tutorials/config.md) please.
+```
+
+3. Apply some custom hooks or loops to your algorithm. (optional)
+
+- Custom hooks
+
+```Python
+custom_hooks = [
+ dict(type='NaiveVisualizationHook', priority='LOWEST'),
+]
+```
+
+- Custom loops
+
+```Python
+_base_ = ['./spos_shufflenet_supernet_8xb128_in1k.py']
+
+# To chose from ['train_cfg', 'val_cfg', 'test_cfg'] based on your loop type
+train_cfg = dict(
+ _delete_=True,
+ type='mmrazor.EvolutionSearchLoop',
+ dataloader=_base_.val_dataloader,
+ evaluator=_base_.val_evaluator)
+
+val_cfg = dict()
+test_cfg = dict()
+```
+
+## How to customize your algorithm
+
+### Common pipeline
+
+1. Register a new algorithm
+
+Create a new file `mmrazor/models/algorithms/{subdirectory}/xxx.py`
+
+```Python
+from mmrazor.models.algorithms import BaseAlgorithm
+from mmrazor.registry import MODELS
+
+@MODELS.register_module()
+class XXX(BaseAlgorithm):
+ def __init__(self, architecture):
+ super().__init__(architecture)
+ pass
+
+ def loss(self, batch_inputs):
+ pass
+```
+
+2. Rewrite its `loss` method.
+
+```Python
+from mmrazor.models.algorithms import BaseAlgorithm
+from mmrazor.registry import MODELS
+
+@MODELS.register_module()
+class XXX(BaseAlgorithm):
+ def __init__(self, architecture):
+ super().__init__(architecture)
+ ......
+
+ def loss(self, batch_inputs):
+ ......
+ return LossResults
+```
+
+3. Add the remaining functions of the algorithm
+
+```{note}
+This step is special because of the diversity of algorithms. Some functions of the algorithm may also be implemented in other files.
+```
+
+```Python
+from mmrazor.models.algorithms import BaseAlgorithm
+from mmrazor.registry import MODELS
+
+@MODELS.register_module()
+class XXX(BaseAlgorithm):
+ def __init__(self, architecture):
+ super().__init__(architecture)
+ ......
+
+ def loss(self, batch_inputs):
+ ......
+ return LossResults
+
+ def aaa(self):
+ ......
+
+ def bbb(self):
+ ......
+```
+
+4. Import the class
+
+You can add the following line to `mmrazor/models/algorithms/{subdirectory}/__init__.py`
+
+```CoffeeScript
+from .xxx import XXX
+
+__all__ = ['XXX']
+```
+
+In addition, import XXX in `mmrazor/models/algorithms/__init__.py`
+
+5. Use the algorithm in your config file.
+
+Please refer to the previous section about how to use existing algorithms in MMRazor
+
+```Python
+model = dict(
+ type='XXX',
+ architecture=architecture)
+```
+
+### Pipelines for different algorithms
+
+Please refer to our tutorials about how to customize different algorithms for more details as below.
+
+1. NAS
+
+[Customize NAS algorithms](https://mmrazor.readthedocs.io/en/main/advanced_guides/customize_nas_algorithms.html)
+
+2. Pruning
+
+[Customize Pruning algorithms](https://mmrazor.readthedocs.io/en/main/advanced_guides/customize_pruning_algorithms.html)
+
+3. Distill
+
+[Customize KD algorithms](https://mmrazor.readthedocs.io/en/main/advanced_guides/customize_kd_algorithms.html)
diff --git a/internlm_langchain/knowledge_base/MMRazor/content/apply_existing_algorithms_to_new_tasks.md b/internlm_langchain/knowledge_base/MMRazor/content/apply_existing_algorithms_to_new_tasks.md
new file mode 100644
index 00000000..119d7a6c
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMRazor/content/apply_existing_algorithms_to_new_tasks.md
@@ -0,0 +1,83 @@
+# Apply existing algorithms to new tasks
+
+Here we show how to apply existing algorithms to other tasks with an example of [SPOS ](https://github.com/open-mmlab/mmrazor/tree/main/configs/nas/mmcls/spos)& [DetNAS](https://github.com/open-mmlab/mmrazor/tree/main/configs/nas/mmdet/detnas).
+
+> SPOS: Single Path One-Shot NAS for classification
+>
+> DetNAS: Single Path One-Shot NAS for detection
+
+**You just need to configure the existing algorithms in your config only by replacing** **the architecture of** **mmcls** **with** **mmdet** **'s**
+
+You can implement a new algorithm by inheriting from the existing algorithm quickly if the new task's specificity leads to the failure of applying directly.
+
+SPOS config VS DetNAS config
+
+- SPOS
+
+```Python
+_base_ = [
+ 'mmrazor::_base_/settings/imagenet_bs1024_spos.py',
+ 'mmrazor::_base_/nas_backbones/spos_shufflenet_supernet.py',
+ 'mmcls::_base_/default_runtime.py',
+]
+
+# model
+supernet = dict(
+ type='ImageClassifier',
+ data_preprocessor=_base_.preprocess_cfg,
+ backbone=_base_.nas_backbone,
+ neck=dict(type='GlobalAveragePooling'),
+ head=dict(
+ type='LinearClsHead',
+ num_classes=1000,
+ in_channels=1024,
+ loss=dict(
+ type='LabelSmoothLoss',
+ num_classes=1000,
+ label_smooth_val=0.1,
+ mode='original',
+ loss_weight=1.0),
+ topk=(1, 5)))
+
+model = dict(
+ type='mmrazor.SPOS',
+ architecture=supernet,
+ mutator=dict(type='mmrazor.OneShotModuleMutator'))
+
+find_unused_parameters = True
+```
+
+- DetNAS
+
+```Python
+_base_ = [
+ 'mmdet::_base_/models/faster-rcnn_r50_fpn.py',
+ 'mmdet::_base_/datasets/coco_detection.py',
+ 'mmdet::_base_/schedules/schedule_1x.py',
+ 'mmdet::_base_/default_runtime.py',
+ 'mmrazor::_base_/nas_backbones/spos_shufflenet_supernet.py'
+]
+
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+
+supernet = _base_.model
+
+supernet.backbone = _base_.nas_backbone
+supernet.backbone.norm_cfg = norm_cfg
+supernet.backbone.out_indices = (0, 1, 2, 3)
+supernet.backbone.with_last_layer = False
+
+supernet.neck.norm_cfg = norm_cfg
+supernet.neck.in_channels = [64, 160, 320, 640]
+
+supernet.roi_head.bbox_head.norm_cfg = norm_cfg
+supernet.roi_head.bbox_head.type = 'Shared4Conv1FCBBoxHead'
+
+model = dict(
+ _delete_=True,
+ type='mmrazor.SPOS',
+ architecture=supernet,
+ mutator=dict(type='mmrazor.OneShotModuleMutator'))
+
+find_unused_parameters = True
+```
diff --git a/internlm_langchain/knowledge_base/MMRazor/content/changelog.md b/internlm_langchain/knowledge_base/MMRazor/content/changelog.md
new file mode 100644
index 00000000..338c9425
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMRazor/content/changelog.md
@@ -0,0 +1,278 @@
+# Changelog of v1.x
+
+## v1.0.0 (24/04/2023)
+
+We are excited to announce the first official release of MMRazor 1.0.
+
+### Highlights
+
+- MMRazor quantization is released, which has got through task models and model deployment. With its help, we can quantize and deploy pre-trained models in OpenMMLab to specified backend quickly.
+
+### New Features & Improvements
+
+#### NAS
+
+- Update searchable model. (https://github.com/open-mmlab/mmrazor/pull/438)
+- Update NasMutator to build search_space in NAS. (https://github.com/open-mmlab/mmrazor/pull/426)
+
+#### Pruning
+
+- Add a new pruning algorithm named GroupFisher. We support the full pipeline for GroupFisher, including pruning, finetuning and deployment.(https://github.com/open-mmlab/mmrazor/pull/459)
+
+#### KD
+
+- Support stopping distillation after a certain epoch. (https://github.com/open-mmlab/mmrazor/pull/455)
+- Support distilling rtmdet with mmrazor, refer to here. (https://github.com/open-mmlab/mmyolo/pull/544)
+- Add mask channel in MGD Loss. (https://github.com/open-mmlab/mmrazor/pull/461)
+
+#### Quantization
+
+- Support two quantization types: QAT and PTQ (https://github.com/open-mmlab/mmrazor/pull/513)
+- Support various quantization bits. (https://github.com/open-mmlab/mmrazor/pull/513)
+- Support various quantization methods, such as per_tensor / per_channel, symmetry / asymmetry and so on. (https://github.com/open-mmlab/mmrazor/pull/513)
+- Support deploy quantized models to multiple backends, such as OpenVINO, TensorRT and so on. (https://github.com/open-mmlab/mmrazor/pull/513)
+- Support applying quantization algorithms to multiple task repos directly, such as mmcls, mmdet and so on. (https://github.com/open-mmlab/mmrazor/pull/513)
+
+### Bug Fixes
+
+- Fix split in Darts config. (https://github.com/open-mmlab/mmrazor/pull/451)
+- Fix a bug in Recorders. (https://github.com/open-mmlab/mmrazor/pull/446)
+- Fix a bug when using get_channel_unit.py. (https://github.com/open-mmlab/mmrazor/pull/432)
+- Fix a bug when deploying a pruned model to cuda. (https://github.com/open-mmlab/mmrazor/pull/495)
+
+### Contributors
+
+A total of 10 developers contributed to this release.
+Thanks @415905716 @gaoyang07 @humu789 @LKJacky @HIT-cwh @aptsunny @cape-zck @vansin @twmht @wm901115nwpu
+
+## v1.0.0rc2 (06/01/2023)
+
+We are excited to announce the release of MMRazor 1.0.0rc2.
+
+### New Features
+
+#### NAS
+
+- Add Performance Predictor: Support 4 performance predictors with 4 basic machine learning algorithms, which can be used to directly predict model accuracy without evaluation.(https://github.com/open-mmlab/mmrazor/pull/306)
+
+- Support [Autoformer](https://arxiv.org/pdf/2107.00651.pdf), a one-shot architecture search algorithm dedicated to vision transformer search.(https://github.com/open-mmlab/mmrazor/pull/315 )
+
+- Support [BigNAS](https://arxiv.org/pdf/2003.11142), a NAS algorithm which searches the following items in MobileNetV3 with the one-shot paradigm: kernel_sizes, out_channels, expand_ratios, block_depth and input sizes. (https://github.com/open-mmlab/mmrazor/pull/219 )
+
+#### Pruning
+
+- Support [DCFF](https://arxiv.org/abs/2107.06916), a filter channel pruning algorithm dedicated to efficient image classification.(https://github.com/open-mmlab/mmrazor/pull/295)
+
+- We release a powerful tool to automatically analyze channel dependency, named ChannelAnalyzer. Here is an example as shown below.(https://github.com/open-mmlab/mmrazor/pull/371)
+
+Now, ChannelAnalyzer supports most of CNN models in torchvision, mmcls, mmseg and mmdet. We will continue to support more models.
+
+```python
+from mmrazor.models.task_modules import ChannelAnalyzer
+from mmengine.hub import get_model
+import json
+
+model = get_model('mmdet::retinanet/retinanet_r18_fpn_1x_coco.py')
+unit_configs: dict = ChannelAnalyzer().analyze(model)
+unit_config0 = list(unit_configs.values())[0]
+print(json.dumps(unit_config0, indent=4))
+# # short version of the config
+# {
+# "channels": {
+# "input_related": [
+# {"name": "backbone.layer2.0.bn1"},
+# {ŌĆ£name": "backbone.layer2.0.conv2"}
+# ],
+# "output_related": [
+# {"name": "backbone.layer2.0.conv1"},
+# {"name": "backbone.layer2.0.bn1"}
+# ]
+# },
+#}
+```
+
+#### KD
+
+- Support [MGD](https://arxiv.org/abs/2205.01529), a detection distillation algorithm.(https://github.com/open-mmlab/mmrazor/pull/381)
+
+### Bug Fixes
+
+- Fix `FpnTeacherDistll` techer forward from `backbone + neck + head` to `backbone + neck`(#387 )
+- Fix some expire configs and checkpoints(#373 #372 #422 )
+
+### Ongoing Changes
+
+We will release Quantization in next version(1.0.0rc3)!
+
+### Contributors
+
+A total of 11 developers contributed to this release: @wutongshenqiu @sunnyxiaohu @aptsunny @humu789 @TinyTigerPan @FreakieHuang @LKJacky @wilxy @gaoyang07 @spynccat @yivona08.
+
+## v1.0.0rc1 (27/10/2022)
+
+We are excited to announce the release of MMRazor 1.0.0rc1.
+
+### Highlights
+
+- **New Pruning Framework**’╝ÜWe have systematically refactored the Pruning module. The new Pruning module can more automatically resolve the dependencies between channels and cover more corner cases.
+
+### New Features
+
+#### Pruning
+
+- A new pruning framework is released in this release. (#311, #313)
+ It consists of five core modules, including Algorithm, `ChannelMutator`, `MutableChannelUnit`, `MutableChannel` and `DynamicOp`.
+
+- MutableChannelUnit is introduced for the first time. Each MutableChannelUnit manages all channels with channel dependency.
+
+ ```python
+ from mmrazor.registry import MODELS
+
+ ARCHITECTURE_CFG = dict(
+ _scope_='mmcls',
+ type='ImageClassifier',
+ backbone=dict(type='MobileNetV2', widen_factor=1.5),
+ neck=dict(type='GlobalAveragePooling'),
+ head=dict(type='mmcls.LinearClsHead', num_classes=1000, in_channels=1920))
+ model = MODELS.build(ARCHITECTURE_CFG)
+ from mmrazor.models.mutators import ChannelMutator
+
+ channel_mutator = ChannelMutator()
+ channel_mutator.prepare_from_supernet(model)
+ units = channel_mutator.mutable_units
+ print(units[0])
+ # SequentialMutableChannelUnit(
+ # name=backbone.conv1.conv_(0, 48)_48
+ # (output_related): ModuleList(
+ # (0): Channel(backbone.conv1.conv, index=(0, 48), is_output_channel=true, expand_ratio=1)
+ # (1): Channel(backbone.conv1.bn, index=(0, 48), is_output_channel=true, expand_ratio=1)
+ # (2): Channel(backbone.layer1.0.conv.0.conv, index=(0, 48), is_output_channel=true, expand_ratio=1)
+ # (3): Channel(backbone.layer1.0.conv.0.bn, index=(0, 48), is_output_channel=true, expand_ratio=1)
+ # )
+ # (input_related): ModuleList(
+ # (0): Channel(backbone.conv1.bn, index=(0, 48), is_output_channel=false, expand_ratio=1)
+ # (1): Channel(backbone.layer1.0.conv.0.conv, index=(0, 48), is_output_channel=false, expand_ratio=1)
+ # (2): Channel(backbone.layer1.0.conv.0.bn, index=(0, 48), is_output_channel=false, expand_ratio=1)
+ # (3): Channel(backbone.layer1.0.conv.1.conv, index=(0, 48), is_output_channel=false, expand_ratio=1)
+ # )
+ # (mutable_channel): SquentialMutableChannel(num_channels=48, activated_channels=48)
+ # )
+ ```
+
+Our new pruning algorithm can help you develop pruning algorithm more fluently. Pelease refer to our documents [PruningUserGuide](<./docs/en/user_guides/../../pruning/%5Bpruning_user_guide.md%5D(http://pruning_user_guide.md/)>) for model detail.
+
+#### Distillation
+
+- Support [CRD](https://arxiv.org/abs/1910.10699), a distillation algorithm based on contrastive representation learning. (#281)
+
+- Support [PKD](https://arxiv.org/abs/2207.02039), a distillation algorithm that can be used in `MMDetection` and `MMDetection3D`. #304
+
+- Support [DEIT](https://arxiv.org/abs/2012.12877), a classic **Transformer** distillation algorithm.(#332)
+
+- Add a more powerful baseline setting for [KD](https://arxiv.org/abs/1503.02531). (#305)
+
+- Add `MethodInputsRecorder` and `FuncInputsRecorder` to record the input of a class method or a function.(#320)
+
+#### NAS
+
+- Support [DSNAS](https://arxiv.org/pdf/2002.09128.pdf), a nas algorithm that does not require retraining. (#226 )
+
+#### Tools
+
+- Support configurable immediate feature map visualization. (#293 )
+ A useful tool is supported in this release to visualize the immediate features of a neural network. Please refer to our documents [VisualizationUserGuide](http://./docs/zh_cn/user_guides/visualization.md) for more details.
+
+### Bug Fixes
+
+- Fix the bug that `FunctionXXRecorder` and `FunctionXXDelivery` can not be pickled. (#320)
+
+### Ongoing changes
+
+- Quantization: We are developing the basic interface of PTQ and QAT. RFC(Request for Comments) will be released soon.
+- AutoSlim: AutoSlim is not yet available and is being refactored.
+- Fx Pruning Tracer: Currently, the model topology can only be resolved through the backward tracer. In the future, both backward tracer and fx tracer will be supported.
+- More Algorithms: BigNASŃĆüAutoFormerŃĆüGreedyNAS and Resrep will be released in the next few versions.
+- Documentation: we will add more design docs, tutorials, and migration guidance so that the community can deep dive into our new design, participate the future development, and smoothly migrate downstream libraries to MMRazor 1.x.
+
+### Contributors
+
+A total of 12 developers contributed to this release.
+Thanks @FreakieHuang @gaoyang07 @HIT-cwh @humu789 @LKJacky @pppppM @pprp @spynccat @sunnyxiaohu @wilxy @kitecats @SheffieldCao
+
+## v1.0.0rc0 (31/8/2022)
+
+We are excited to announce the release of MMRazor 1.0.0rc0.
+MMRazor 1.0.0rc0 is the first version of MMRazor 1.x, a part of the OpenMMLab 2.0 projects.
+Built upon the new [training engine](https://github.com/open-mmlab/mmengine),
+MMRazor 1.x simplified the interaction with other OpenMMLab repos, and upgraded the basic APIs of KD / Pruning / NAS.
+It also provides a series of knowledge distillation algorithms.
+
+### Highlights
+
+- **New engines**. MMRazor 1.x is based on [MMEngine](https://github.com/open-mmlab/mmengine), which provides a general and powerful runner that allows more flexible customizations and significantly simplifies the entrypoints of high-level interfaces.
+
+- **Unified interfaces**. As a part of the OpenMMLab 2.0 projects, MMRazor 1.x unifies and refactors the interfaces and internal logic of train, testing, datasets, models, evaluation, and visualization. All the OpenMMLab 2.0 projects share the same design in those interfaces and logic to allow the emergence of multi-task/modality algorithms.
+
+- **More configurable KD**. MMRazor 1.x add [Recorder](../advanced_guides/recorder.md) to get the data needed for KD more automatically’╝ī[Delivery ](../advanced_guides/delivery.md) to automatically pass the teacher's intermediate results to the student’╝ī and connector to handle feature dimension mismatches between teacher and student.
+
+- **More kinds of KD algorithms**. Benefitting from the powerful APIs of KD’╝ī we have added several categories of KD algorithms, data-free distillation, self-distillation, and zero-shot distillation.
+
+- **Unify the basic interface of NAS and Pruning**. We refactored [Mutable](../advanced_guides/mutable.md), adding mutable value and mutable channel. Both NAS and Pruning can be developed based on mutables.
+
+- **More documentation and tutorials**. We add a bunch of documentation and tutorials to help users get started more smoothly. Read it [here](https://mmrazor.readthedocs.io/en/1.0.0rc0/).
+
+### Breaking Changes
+
+#### Training and testing
+
+- MMRazor 1.x runs on PyTorch>=1.6. We have deprecated the support of PyTorch 1.5 to embrace the mixed precision training and other new features since PyTorch 1.6. Some models can still run on PyTorch 1.5, but the full functionality of MMRazor 1.x is not guaranteed.
+- MMRazor 1.x uses Runner in [MMEngine](https://github.com/open-mmlab/mmengine) rather than that in MMCV. The new Runner implements and unifies the building logic of dataset, model, evaluation, and visualizer. Therefore, MMRazor 1.x no longer maintains the building logics of those modules in `mmdet.train.apis` and `tools/train.py`. Those code have been migrated into [MMEngine](https://github.com/open-mmlab/mmengine/blob/main/mmengine/runner/runner.py).
+- The Runner in MMEngine also supports testing and validation. The testing scripts are also simplified, which has similar logic as that in training scripts to build the runner.
+
+#### Configs
+
+- The [Runner in MMEngine](https://github.com/open-mmlab/mmengine/blob/main/mmengine/runner/runner.py) uses a different config structures
+- Config and model names
+
+#### Components
+
+- Algorithms
+- Distillers
+- Mutators
+- Mutables
+- Hooks
+
+### Improvements
+
+- Support mixed precision training of all the models. However, some models may got Nan results due to some numerical issues. We will update the documentation and list their results (accuracy of failure) of mixed precision training.
+
+### Bug Fixes
+
+- AutoSlim: Models of different sizes will no longer have the same size checkpoint
+
+### New Features
+
+- Support [Activation Boundaries Loss](https://arxiv.org/pdf/1811.03233.pdf)
+- Support [Be Your Own Teacher](https://arxiv.org/abs/1905.08094)
+- Support [Data-Free Learning of Student Networks](https://doi.org/10.1109/ICCV.2019.00361)
+- Support [Data-Free Adversarial Distillation](https://arxiv.org/pdf/1912.11006.pdf)
+- Support [Decoupled Knowledge Distillation](https://arxiv.org/pdf/2203.08679.pdf)
+- Support [Factor Transfer](https://arxiv.org/abs/1802.04977)
+- Support [FitNets](https://arxiv.org/abs/1412.6550)
+- Support [Distilling the Knowledge in a Neural Network](https://arxiv.org/abs/1503.02531)
+- Support [Overhaul](https://arxiv.org/abs/1904.01866)
+- Support [Zero-shot Knowledge Transfer via Adversarial Belief Matching](https://arxiv.org/abs/1905.09768)
+
+### Ongoing changes
+
+- Quantization: We are developing the basic interface of PTQ and QAT. RFC(Request for Comments) will be released soon.
+- AutoSlim: AutoSlim is not yet available and is being refactored.
+- Fx Pruning Tracer: Currently, the model topology can only be resolved through the backward tracer. In the future, both backward tracer and fx tracer will be supported.
+- More Algorithms: BigNASŃĆüAutoFormerŃĆüGreedyNAS and Resrep will be released in the next few versions.
+- Documentation: we will add more design docs, tutorials, and migration guidance so that the community can deep dive into our new design, participate the future development, and smoothly migrate downstream libraries to MMRazor 1.x.
+
+### Contributors
+
+A total of 13 developers contributed to this release.
+Thanks @FreakieHuang @gaoyang07 @HIT-cwh @humu789 @LKJacky @pppppM @pprp @spynccat @sunnyxiaohu @wilxy @wutongshenqiu @NickYangMin @Hiwyl
+Special thanks to @Davidgzx for his contribution to the data-free distillation algorithms
diff --git a/internlm_langchain/knowledge_base/MMRazor/content/contribution_guide.md b/internlm_langchain/knowledge_base/MMRazor/content/contribution_guide.md
new file mode 100644
index 00000000..1ca3a9af
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMRazor/content/contribution_guide.md
@@ -0,0 +1,59 @@
+# Contribute Guide
+
+All kinds of contributions are welcome, including but not limited to the following.
+
+- Fix typo or bugs
+- Add documentation or translate the documentation into other languages
+- Add new features and components
+
+### Workflow
+
+1. fork and pull the latest OpenMMLab repository
+2. checkout a new branch (do not use master branch for PRs)
+3. commit your changes
+4. create a PR
+
+```{note}
+If you plan to add some new features that involve large changes, it is encouraged to open an issue for discussion first.
+```
+
+### Code style
+
+#### Python
+
+We adopt [PEP8](https://www.python.org/dev/peps/pep-0008/) as the preferred code style.
+
+We use the following tools for linting and formatting:
+
+- [flake8](https://github.com/PyCQA/flake8): A wrapper around some linter tools.
+- [isort](https://github.com/timothycrosley/isort): A Python utility to sort imports.
+- [yapf](https://github.com/google/yapf): A formatter for Python files.
+- [codespell](https://github.com/codespell-project/codespell): A Python utility to fix common misspellings in text files.
+- [mdformat](https://github.com/executablebooks/mdformat): Mdformat is an opinionated Markdown formatter that can be used to enforce a consistent style in Markdown files.
+- [docformatter](https://github.com/myint/docformatter): A formatter to format docstring.
+
+Style configurations of yapf and isort can be found in [setup.cfg](./setup.cfg).
+
+We use [pre-commit hook](https://pre-commit.com/) that checks and formats for `flake8`, `yapf`, `isort`, `trailing whitespaces`, `markdown files`,
+fixes `end-of-files`, `double-quoted-strings`, `python-encoding-pragma`, `mixed-line-ending`, sorts `requirments.txt` automatically on every commit.
+The config for a pre-commit hook is stored in [.pre-commit-config](./.pre-commit-config.yaml).
+
+After you clone the repository, you will need to install initialize pre-commit hook.
+
+```shell
+pip install -U pre-commit
+```
+
+From the repository folder
+
+```shell
+pre-commit install
+```
+
+After this on every commit check code linters and formatter will be enforced.
+
+> Before you create a PR, make sure that your code lints and is formatted by yapf.
+
+#### C++ and CUDA
+
+We follow the [Google C++ Style Guide](https://google.github.io/styleguide/cppguide.html).
diff --git a/internlm_langchain/knowledge_base/MMRazor/content/customize_architectures.md b/internlm_langchain/knowledge_base/MMRazor/content/customize_architectures.md
new file mode 100644
index 00000000..d815eb79
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMRazor/content/customize_architectures.md
@@ -0,0 +1,255 @@
+# Customize Architectures
+
+Different from other tasks, architectures in MMRazor may consist of some special model components, such as **searchable backbones, connectors, dynamic ops**. In MMRazor, you can not only develop some common model components like other codebases of OpenMMLab, but also develop some special model components. Here is how to develop searchable model components and common model components.
+
+## Develop searchable model components
+
+1. Define a new backbone
+
+Create a new file `mmrazor/models/architectures/backbones/searchable_shufflenet_v2.py`, class `SearchableShuffleNetV2` inherits from `BaseBackBone` of mmcls, which is the codebase that you will use to build the model.
+
+```Python
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+from typing import Dict, List, Optional, Sequence, Tuple, Union
+
+import torch.nn as nn
+from mmcls.models.backbones.base_backbone import BaseBackbone
+from mmcv.cnn import ConvModule, constant_init, normal_init
+from mmcv.runner import ModuleList, Sequential
+from torch import Tensor
+from torch.nn.modules.batchnorm import _BatchNorm
+
+from mmrazor.registry import MODELS
+
+@MODELS.register_module()
+class SearchableShuffleNetV2(BaseBackbone):
+
+ def __init__(self, ):
+ pass
+
+ def _make_layer(self, out_channels, num_blocks, stage_idx):
+ pass
+
+ def _freeze_stages(self):
+ pass
+
+ def init_weights(self):
+ pass
+
+ def forward(self, x):
+ pass
+
+ def train(self, mode=True):
+ pass
+```
+
+2. Build the architecture of the new backbone based on `arch_setting`
+
+```Python
+@MODELS.register_module()
+class SearchableShuffleNetV2(BaseBackbone):
+ def __init__(self,
+ arch_setting: List[List],
+ stem_multiplier: int = 1,
+ widen_factor: float = 1.0,
+ out_indices: Sequence[int] = (4, ),
+ frozen_stages: int = -1,
+ with_last_layer: bool = True,
+ conv_cfg: Optional[Dict] = None,
+ norm_cfg: Dict = dict(type='BN'),
+ act_cfg: Dict = dict(type='ReLU'),
+ norm_eval: bool = False,
+ with_cp: bool = False,
+ init_cfg: Optional[Union[Dict, List[Dict]]] = None) -> None:
+ layers_nums = 5 if with_last_layer else 4
+ for index in out_indices:
+ if index not in range(0, layers_nums):
+ raise ValueError('the item in out_indices must in '
+ f'range(0, 5). But received {index}')
+
+ self.frozen_stages = frozen_stages
+ if frozen_stages not in range(-1, layers_nums):
+ raise ValueError('frozen_stages must be in range(-1, 5). '
+ f'But received {frozen_stages}')
+
+ super().__init__(init_cfg)
+
+ self.arch_setting = arch_setting
+ self.widen_factor = widen_factor
+ self.out_indices = out_indices
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+ self.norm_eval = norm_eval
+ self.with_cp = with_cp
+
+ last_channels = 1024
+ self.in_channels = 16 * stem_multiplier
+
+ # build the first layer
+ self.conv1 = ConvModule(
+ in_channels=3,
+ out_channels=self.in_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ # build the middle layers
+ self.layers = ModuleList()
+ for channel, num_blocks, mutable_cfg in arch_setting:
+ out_channels = round(channel * widen_factor)
+ layer = self._make_layer(out_channels, num_blocks,
+ copy.deepcopy(mutable_cfg))
+ self.layers.append(layer)
+
+ # build the last layer
+ if with_last_layer:
+ self.layers.append(
+ ConvModule(
+ in_channels=self.in_channels,
+ out_channels=last_channels,
+ kernel_size=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+```
+
+3. Implement`_make_layer` with `mutable_cfg`
+
+```Python
+@MODELS.register_module()
+class SearchableShuffleNetV2(BaseBackbone):
+
+ ...
+
+ def _make_layer(self, out_channels: int, num_blocks: int,
+ mutable_cfg: Dict) -> Sequential:
+ """Stack mutable blocks to build a layer for ShuffleNet V2.
+ Note:
+ Here we use ``module_kwargs`` to pass dynamic parameters such as
+ ``in_channels``, ``out_channels`` and ``stride``
+ to build the mutable.
+ Args:
+ out_channels (int): out_channels of the block.
+ num_blocks (int): number of blocks.
+ mutable_cfg (dict): Config of mutable.
+ Returns:
+ mmcv.runner.Sequential: The layer made.
+ """
+ layers = []
+ for i in range(num_blocks):
+ stride = 2 if i == 0 else 1
+
+ mutable_cfg.update(
+ module_kwargs=dict(
+ in_channels=self.in_channels,
+ out_channels=out_channels,
+ stride=stride))
+ layers.append(MODELS.build(mutable_cfg))
+ self.in_channels = out_channels
+
+ return Sequential(*layers)
+
+ ...
+```
+
+4. Implement other common methods
+
+You can refer to the implementation of `ShuffleNetV2` in mmcls for finishing other common methods.
+
+5. Import the module
+
+You can either add the following line to `mmrazor/models/architectures/backbones/__init__.py`
+
+```Python
+from .searchable_shufflenet_v2 import SearchableShuffleNetV2
+
+__all__ = ['SearchableShuffleNetV2']
+```
+
+or alternatively add
+
+```Python
+custom_imports = dict(
+ imports=['mmrazor.models.architectures.backbones.searchable_shufflenet_v2'],
+ allow_failed_imports=False)
+```
+
+to the config file to avoid modifying the original code.
+
+6. Use the backbone in your config file
+
+```Python
+architecture = dict(
+ type=xxx,
+ model=dict(
+ ...
+ backbone=dict(
+ type='mmrazor.SearchableShuffleNetV2',
+ arg1=xxx,
+ arg2=xxx),
+ ...
+```
+
+## Develop common model components
+
+Here we show how to add a new backbone with an example of `xxxNet`.
+
+1. Define a new backbone
+
+Create a new file `mmrazor/models/architectures/backbones/xxxnet.py`, then implement the class `xxxNet`.
+
+```Python
+from mmengine.model import BaseModule
+from mmrazor.registry import MODELS
+
+@MODELS.register_module()
+class xxxNet(BaseModule):
+
+ def __init__(self, arg1, arg2, init_cfg=None):
+ super().__init__(init_cfg=init_cfg)
+ pass
+
+ def forward(self, x):
+ pass
+```
+
+2. Import the module
+
+You can either add the following line to `mmrazor/models/architectures/backbones/__init__.py`
+
+```Python
+from .xxxnet import xxxNet
+
+__all__ = ['xxxNet']
+```
+
+or alternatively add
+
+```Python
+custom_imports = dict(
+ imports=['mmrazor.models.architectures.backbones.xxxnet'],
+ allow_failed_imports=False)
+```
+
+to the config file to avoid modifying the original code.
+
+3. Use the backbone in your config file
+
+```Python
+architecture = dict(
+ type=xxx,
+ model=dict(
+ ...
+ backbone=dict(
+ type='xxxNet',
+ arg1=xxx,
+ arg2=xxx),
+ ...
+```
+
+How to add other model components is similar to backbone's. For more details, please refer to other codebases' docs.
diff --git a/internlm_langchain/knowledge_base/MMRazor/content/customize_kd_algorithms.md b/internlm_langchain/knowledge_base/MMRazor/content/customize_kd_algorithms.md
new file mode 100644
index 00000000..dee759c5
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMRazor/content/customize_kd_algorithms.md
@@ -0,0 +1,124 @@
+# Customize KD algorithms
+
+Here we show how to develop new KD algorithms with an example of `SingleTeacherDistill`.
+
+1. Register a new algorithm
+
+Create a new file `mmrazor/models/algorithms/distill/configurable/single_teacher_distill.py`, class `SingleTeacherDistill` inherits from class `BaseAlgorithm`
+
+```Python
+from mmrazor.registry import MODELS
+from ..base import BaseAlgorithm
+
+@ALGORITHMS.register_module()
+class SingleTeacherDistill(BaseAlgorithm):
+ def __init__(self, use_gt, **kwargs):
+ super(Distillation, self).__init__(**kwargs)
+ pass
+
+ def train_step(self, data, optimizer):
+ pass
+```
+
+2. Develop connectors (Optional) .
+
+Take ConvModuleConnector as an example.
+
+```python
+from mmrazor.registry import MODELS
+from .base_connector import BaseConnector
+
+@MODELS.register_module()
+class ConvModuleConnector(BaseConnector):
+ def __init__(self, in_channel, out_channel, kernel_size = 1, stride = 1):
+ ...
+
+ def forward_train(self, feature):
+ ...
+```
+
+3. Develop distiller.
+
+Take `ConfigurableDistiller` as an example.
+
+```python
+from .base_distiller import BaseDistiller
+from mmrazor.registry import MODELS
+
+
+@MODELS.register_module()
+class ConfigurableDistiller(BaseDistiller):
+ def __init__(self,
+ student_recorders = None,
+ teacher_recorders = None,
+ distill_deliveries = None,
+ connectors = None,
+ distill_losses = None,
+ loss_forward_mappings = None):
+ ...
+
+ def build_connectors(self, connectors):
+ ...
+
+ def build_distill_losses(self, losses):
+ ...
+
+ def compute_distill_losses(self):
+ ...
+```
+
+4. Develop custom loss (Optional).
+
+Here we take `L1Loss` as an example. Create a new file in `mmrazor/models/losses/l1_loss.py`.
+
+```python
+from mmrazor.registry import MODELS
+
+@MODELS.register_module()
+class L1Loss(nn.Module):
+ def __init__(
+ self,
+ loss_weight: float = 1.0,
+ size_average: Optional[bool] = None,
+ reduce: Optional[bool] = None,
+ reduction: str = 'mean',
+ ) -> None:
+ super().__init__()
+ ...
+
+ def forward(self, s_feature, t_feature):
+ loss = F.l1_loss(s_feature, t_feature, self.size_average, self.reduce,
+ self.reduction)
+ return self.loss_weight * loss
+```
+
+5. Import the class
+
+You can either add the following line to `mmrazor/models/algorithms/__init__.py`
+
+```Python
+from .single_teacher_distill import SingleTeacherDistill
+
+__all__ = [..., 'SingleTeacherDistill']
+```
+
+or alternatively add
+
+```Python
+custom_imports = dict(
+ imports=['mmrazor.models.algorithms.distill.configurable.single_teacher_distill'],
+ allow_failed_imports=False)
+```
+
+to the config file to avoid modifying the original code.
+
+6. Use the algorithm in your config file
+
+```Python
+algorithm = dict(
+ type='Distill',
+ distiller=dict(type='SingleTeacherDistill', ...),
+ # you can also use your new algorithm components here
+ ...
+)
+```
diff --git a/internlm_langchain/knowledge_base/MMRazor/content/customize_mixed_algorithms.md b/internlm_langchain/knowledge_base/MMRazor/content/customize_mixed_algorithms.md
new file mode 100644
index 00000000..17b928d1
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMRazor/content/customize_mixed_algorithms.md
@@ -0,0 +1,164 @@
+# Customize mixed algorithms
+
+Here we show how to customize mixed algorithms with our algorithm components. We take [AutoSlim ](https://github.com/open-mmlab/mmrazor/tree/main/configs/pruning/mmcls/autoslim)as an example.
+
+```{note}
+**Why is AutoSlim a mixed algorithm?**
+
+In [AutoSlim](https://github.com/open-mmlab/mmrazor/tree/main/configs/pruning/mmcls/autoslim), the sandwich rule and the inplace distillation will be introduced to enhance the training process, which is called as the slimmable training. The sandwich rule means that we train the model at smallest width, largest width and (n ŌłÆ 2) random widths, instead of n random widths. And the inplace distillation means that we use the predicted label of the model at the largest width as the training label for other widths, while for the largest width we use ground truth. So both the KD algorithm and the pruning algorithm are used in [AutoSlim](https://github.com/open-mmlab/mmrazor/tree/main/configs/pruning/mmcls/autoslim).
+```
+
+1. Register a new algorithm
+
+Create a new file `mmrazor/models/algorithms/nas/autoslim.py`, class `AutoSlim` inherits from class `BaseAlgorithm`. You need to build the KD algorithm component (distiller) and the pruning algorithm component (mutator) because AutoSlim is a mixed algorithm.
+
+```{note}
+You can also inherit from the existing algorithm instead of `BaseAlgorithm` if your algorithm is similar to the existing algorithm.
+```
+
+```{note}
+You can choose existing algorithm components in MMRazor, such as `OneShotChannelMutator` and `ConfigurableDistiller` in AutoSlim.
+
+If these in MMRazor don't meet your needs, you can customize new algorithm components for your algorithm. Reference is as follows:
+
+[Customize NAS algorithms](https://mmrazor.readthedocs.io/en/main/advanced_guides/customize_nas_algorithms.html)
+[Customize Pruning algorithms](https://mmrazor.readthedocs.io/en/main/advanced_guides/customize_pruning_algorithms.html)
+[Customize KD algorithms](https://mmrazor.readthedocs.io/en/main/advanced_guides/customize_kd_algorithms.html)
+```
+
+```Python
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Optional, Union
+import torch
+from torch import nn
+
+from mmrazor.models.distillers import ConfigurableDistiller
+from mmrazor.models.mutators import OneShotChannelMutator
+from mmrazor.registry import MODELS
+from ..base import BaseAlgorithm
+
+VALID_MUTATOR_TYPE = Union[OneShotChannelMutator, Dict]
+VALID_DISTILLER_TYPE = Union[ConfigurableDistiller, Dict]
+
+@MODELS.register_module()
+class AutoSlim(BaseAlgorithm):
+ def __init__(self,
+ mutator: VALID_MUTATOR_TYPE,
+ distiller: VALID_DISTILLER_TYPE,
+ architecture: Union[BaseModel, Dict],
+ data_preprocessor: Optional[Union[Dict, nn.Module]] = None,
+ num_random_samples: int = 2,
+ init_cfg: Optional[Dict] = None) -> None:
+ super().__init__(architecture, data_preprocessor, init_cfg)
+ self.mutator = self._build_mutator(mutator)
+ # `prepare_from_supernet` must be called before distiller initialized
+ self.mutator.prepare_from_supernet(self.architecture)
+
+ self.distiller = self._build_distiller(distiller)
+ self.distiller.prepare_from_teacher(self.architecture)
+ self.distiller.prepare_from_student(self.architecture)
+
+ ......
+
+ def _build_mutator(self,
+ mutator: VALID_MUTATOR_TYPE) -> OneShotChannelMutator:
+ """build mutator."""
+ if isinstance(mutator, dict):
+ mutator = MODELS.build(mutator)
+ if not isinstance(mutator, OneShotChannelMutator):
+ raise TypeError('mutator should be a `dict` or '
+ '`OneShotModuleMutator` instance, but got '
+ f'{type(mutator)}')
+
+ return mutator
+
+ def _build_distiller(
+ self, distiller: VALID_DISTILLER_TYPE) -> ConfigurableDistiller:
+ if isinstance(distiller, dict):
+ distiller = MODELS.build(distiller)
+ if not isinstance(distiller, ConfigurableDistiller):
+ raise TypeError('distiller should be a `dict` or '
+ '`ConfigurableDistiller` instance, but got '
+ f'{type(distiller)}')
+
+ return distiller
+```
+
+2. Implement the core logic in `train_step`
+
+In `train_step`, both the `mutator` and the `distiller` play an important role. For example, `sample_subnet`, `set_max_subnet` and `set_min_subnet` are supported by the `mutator`, and the function of`distill_step` is mainly implemented by the `distiller`.
+
+```Python
+@MODELS.register_module()
+class AutoSlim(BaseAlgorithm):
+
+ ......
+
+ def train_step(self, data: List[dict],
+ optim_wrapper: OptimWrapper) -> Dict[str, torch.Tensor]:
+
+ def distill_step(
+ batch_inputs: torch.Tensor, data_samples: List[BaseDataElement]
+ ) -> Dict[str, torch.Tensor]:
+ ......
+
+ ......
+
+ batch_inputs, data_samples = self.data_preprocessor(data, True)
+
+ total_losses = dict()
+ for kind in self.sample_kinds:
+ # update the max subnet loss.
+ if kind == 'max':
+ self.set_max_subnet()
+ ......
+ total_losses.update(add_prefix(max_subnet_losses, 'max_subnet'))
+ # update the min subnet loss.
+ elif kind == 'min':
+ self.set_min_subnet()
+ min_subnet_losses = distill_step(batch_inputs, data_samples)
+ total_losses.update(add_prefix(min_subnet_losses, 'min_subnet'))
+ # update the random subnets loss.
+ elif 'random' in kind:
+ self.set_subnet(self.sample_subnet())
+ random_subnet_losses = distill_step(batch_inputs, data_samples)
+ total_losses.update(
+ add_prefix(random_subnet_losses, f'{kind}_subnet'))
+
+ return total_losses
+```
+
+3. Import the class
+
+You can either add the following line to `mmrazor/models/algorithms/nas/__init__.py`
+
+```Python
+from .autoslim import AutoSlim
+
+__all__ = ['AutoSlim']
+```
+
+or alternatively add
+
+```Python
+custom_imports = dict(
+ imports=['mmrazor.models.algorithms.nas.autoslim'],
+ allow_failed_imports=False)
+```
+
+to the config file to avoid modifying the original code.
+
+4. Use the algorithm in your config file
+
+```Python
+model= dict(
+ type='mmrazor.AutoSlim',
+ architecture=...,
+ mutator=dict(
+ type='OneShotChannelMutator',
+ ...),
+ distiller=dict(
+ type='ConfigurableDistiller',
+ ...),
+ ...)
+```
diff --git a/internlm_langchain/knowledge_base/MMRazor/content/customize_nas_algorithms.md b/internlm_langchain/knowledge_base/MMRazor/content/customize_nas_algorithms.md
new file mode 100644
index 00000000..b8f180c0
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMRazor/content/customize_nas_algorithms.md
@@ -0,0 +1,136 @@
+# Customize NAS algorithms
+
+Here we show how to develop new NAS algorithms with an example of SPOS.
+
+1. Register a new algorithm
+
+Create a new file `mmrazor/models/algorithms/nas/spos.py`, class `SPOS` inherits from class `BaseAlgorithm`
+
+```Python
+from mmrazor.registry import MODELS
+from ..base import BaseAlgorithm
+
+@MODELS.register_module()
+class SPOS(BaseAlgorithm):
+ def __init__(self, **kwargs):
+ super(SPOS, self).__init__(**kwargs)
+ pass
+
+ def loss(self, batch_inputs, data_samples):
+ pass
+```
+
+2. Develop new algorithm components (optional)
+
+SPOS can directly use class `OneShotModuleMutator` as core functions provider. If mutators provided in MMRazor donŌĆÖt meet your needs, you can develop new algorithm components for your algorithm like `OneShotModuleMutator`, we will take `OneShotModuleMutator` as an example to introduce how to develop a new algorithm component:
+
+a. Create a new file `mmrazor/models/mutators/module_mutator/one_shot_module_mutator.py`, class `OneShotModuleMutator` inherits from class `ModuleMutator`
+
+b. Finish the functions you need in `OneShotModuleMutator`, eg: `sample_choices`, `set_choices` and so on.
+
+```Python
+from mmrazor.registry import MODELS
+from .module_mutator import ModuleMutator
+
+
+@MODELS.register_module()
+class OneShotModuleMutator(ModuleMutator):
+
+ def __init__(self, **kwargs):
+ super().__init__(**kwargs)
+
+ def sample_choices(self) -> Dict[int, Any]:
+ pass
+
+ def set_choices(self, choices: Dict[int, Any]) -> None:
+ pass
+
+ @property
+ def mutable_class_type(self):
+ return OneShotMutableModule
+```
+
+c. Import the new mutator
+
+You can either add the following line to `mmrazor/models/mutators/__init__.py`
+
+```Python
+from .module_mutator import OneShotModuleMutator
+```
+
+or alternatively add
+
+```Python
+custom_imports = dict(
+ imports=['mmrazor.models.mutators.module_mutator.one_shot_module_mutator'],
+ allow_failed_imports=False)
+```
+
+to the config file to avoid modifying the original code.
+
+d. Use the algorithm component in your config file
+
+```Python
+mutator=dict(type='mmrazor.OneShotModuleMutator')
+```
+
+For further information, please refer to [Mutator ](https://mmrazor.readthedocs.io/en/main/advanced_guides/mutator.html)for more details.
+
+3. Rewrite its `loss` function.
+
+Develop key logic of your algorithm in function`loss`. When having special steps to optimize, you should rewrite the function `train_step`.
+
+```Python
+@MODELS.register_module()
+class SPOS(BaseAlgorithm):
+ def __init__(self, **kwargs):
+ super(SPOS, self).__init__(**kwargs)
+ pass
+
+ def sample_subnet(self):
+ pass
+
+ def set_subnet(self, subnet):
+ pass
+
+ def loss(self, batch_inputs, data_samples):
+ if self.is_supernet:
+ random_subnet = self.sample_subnet()
+ self.set_subnet(random_subnet)
+ return self.architecture(batch_inputs, data_samples, mode='loss')
+ else:
+ return self.architecture(batch_inputs, data_samples, mode='loss')
+```
+
+4. Add your custom functions (optional)
+
+After finishing your key logic in function `loss`, if you also need other custom functions, you can add them in class `SPOS` as follows.
+
+5. Import the class
+
+You can either add the following line to `mmrazor/models/algorithms/nas/__init__.py`
+
+```Python
+from .spos import SPOS
+
+__all__ = ['SPOS']
+```
+
+or alternatively add
+
+```Python
+custom_imports = dict(
+ imports=['mmrazor.models.algorithms.nas.spos'],
+ allow_failed_imports=False)
+```
+
+to the config file to avoid modifying the original code.
+
+6. Use the algorithm in your config file
+
+```Python
+model = dict(
+ type='mmrazor.SPOS',
+ architecture=supernet,
+ mutator=dict(type='mmrazor.OneShotModuleMutator'))
+```
diff --git a/internlm_langchain/knowledge_base/MMRazor/content/customize_pruning_algorithms.md b/internlm_langchain/knowledge_base/MMRazor/content/customize_pruning_algorithms.md
new file mode 100644
index 00000000..3980dfbd
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMRazor/content/customize_pruning_algorithms.md
@@ -0,0 +1,155 @@
+# Customize pruning algorithms
+
+Here we show how to develop new Pruning algorithms with an example of AutoSlim.
+
+1. Register a new algorithm
+
+Create a new file `mmrazor/models/algorithms/prunning/autoslim.py`, class `AutoSlim` inherits from class `BaseAlgorithm`.
+
+```Python
+from mmrazor.registry import MODELS
+from .base import BaseAlgorithm
+
+@MODELS.register_module()
+class AutoSlim(BaseAlgorithm):
+ def __init__(self,
+ mutator,
+ distiller,
+ architecture,
+ data_preprocessor,
+ num_random_samples = 2,
+ init_cfg = None) -> None:
+ super().__init__(**kwargs)
+ pass
+
+ def train_step(self, data, optimizer):
+ pass
+```
+
+2. Develop new algorithm components (optional)
+
+AutoSlim can directly use class `OneShotChannelMutator` as core functions provider. If it can not meet your needs, you can develop new algorithm components for your algorithm like `OneShotChannalMutator`. We will take `OneShotChannelMutator` as an example to introduce how to develop a new algorithm component:
+
+a. Create a new file `mmrazor/models/mutators/channel_mutator/one_shot_channel_mutator.py`, class `OneShotChannelMutator` can inherits from `ChannelMutator`.
+
+b. Finish the functions you need, eg: `build_search_groups`, `set_choices` , `sample_choices` and so on
+
+```Python
+from mmrazor.registry import MODELS
+from .channel_mutator import ChannelMutator
+
+
+@MODELS.register_module()
+class OneShotChannelMutator(ChannelMutator):
+ def __init__(self, **kwargs):
+ super().__init__(**kwargs)
+
+ def sample_choices(self):
+ pass
+
+ def set_choices(self, choice_dict):
+ pass
+
+ # supernet is a kind of architecture in `mmrazor/models/architectures/`
+ def build_search_groups(self, supernet):
+ pass
+```
+
+c. Import the module in `mmrazor/models/mutators/channel_mutator/__init__.py`
+
+```Python
+from .one_shot_channel_mutator import OneShotChannelMutator
+
+ __all__ = [..., 'OneShotChannelMutator']
+```
+
+3. Rewrite its train_step
+
+Develop key logic of your algorithm in function`train_step`
+
+```Python
+from mmrazor.registry import MODELS
+from ..base import BaseAlgorithm
+
+@ALGORITHMS.register_module()
+class AutoSlim(BaseAlgorithm):
+ def __init__(self,
+ mutator,
+ distiller,
+ architecture,
+ data_preprocessor,
+ num_random_samples = 2,
+ init_cfg = None) -> None:
+ super(AutoSlim, self).__init__(**kwargs)
+ pass
+
+ def train_step(self, data: List[dict],
+ optim_wrapper: OptimWrapper) -> Dict[str, torch.Tensor]:
+
+ def distill_step(
+ batch_inputs: torch.Tensor, data_samples: List[BaseDataElement]
+ ) -> Dict[str, torch.Tensor]:
+ ...
+ return subnet_losses
+
+ batch_inputs, data_samples = self.data_preprocessor(data, True)
+
+ total_losses = dict()
+ for kind in self.sample_kinds:
+ # update the max subnet loss.
+ if kind == 'max':
+ self.set_max_subnet()
+ with optim_wrapper.optim_context(
+ self), self.distiller.teacher_recorders: # type: ignore
+ max_subnet_losses = self(batch_inputs, data_samples, mode='loss')
+ parsed_max_subnet_losses, _ = self.parse_losses(max_subnet_losses)
+ optim_wrapper.update_params(parsed_max_subnet_losses)
+ total_losses.update(add_prefix(max_subnet_losses, 'max_subnet'))
+ # update the min subnet loss.
+ elif kind == 'min':
+ self.set_min_subnet()
+ min_subnet_losses = distill_step(batch_inputs, data_samples)
+ total_losses.update(add_prefix(min_subnet_losses, 'min_subnet'))
+ # update the random subnets loss.
+ elif 'random' in kind:
+ self.set_subnet(self.sample_subnet())
+ random_subnet_losses = distill_step(batch_inputs, data_samples)
+ total_losses.update(
+ add_prefix(random_subnet_losses, f'{kind}_subnet'))
+
+ return total_losses
+```
+
+4. Add your custom functions (optional)
+
+After finishing your key logic in function `train_step`, if you also need other custom functions, you can add them in class `AutoSlim`.
+
+5. Import the class
+
+You can either add the following line to `mmrazor/models/algorithms/__init__.py`
+
+```Python
+from .pruning import AutoSlim
+
+__all__ = [..., 'AutoSlim']
+```
+
+Or alternatively add
+
+```Python
+custom_imports = dict(
+ imports=['mmrazor.models.algorithms.pruning.autoslim'],
+ allow_failed_imports=False)
+```
+
+to the config file to avoid modifying the original code.
+
+6. Use the algorithm in your config file
+
+```Python
+model = dict(
+ type='AutoSlim',
+ architecture=...,
+ mutator=dict(type='OneShotChannelMutator', ...),
+ )
+```
diff --git a/internlm_langchain/knowledge_base/MMRazor/content/customize_quantization_algorithms.md b/internlm_langchain/knowledge_base/MMRazor/content/customize_quantization_algorithms.md
new file mode 100644
index 00000000..e1dd25ea
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMRazor/content/customize_quantization_algorithms.md
@@ -0,0 +1,283 @@
+# Customize Quantization algorithms
+
+Here we show how to develop new QAT algorithms with an example of LSQ on OpenVINO backend.
+
+This document is mainly aimed at QAT because the ptq process is relatively fixed and the components we provide can meet most of the needs. We will first give an overview of the overall required development components, and then introduce the specific implementation step by step.
+
+## Overall
+
+In the mmrazor quantization pipeline, in order to better support the openmmlab environment, we have configured most of the code modules for users. You can configure all the components directly in the config file. How to configure them can be found in our [file](https://github.com/open-mmlab/mmrazor/blob/quantize/configs/quantization/qat/minmax_openvino_resnet18_8xb32_in1k.py).
+
+```Python
+global_qconfig = dict(
+ w_observer=dict(),
+ a_observer=dict(),
+ w_fake_quant=dict(),
+ a_fake_quant=dict(),
+ w_qscheme=dict(),
+ a_qscheme=dict(),
+)
+model = dict(
+ type='mmrazor.MMArchitectureQuant',
+ architecture=resnet,
+ quantizer=dict(
+ type='mmrazor.OpenvinoQuantizer',
+ global_qconfig=global_qconfig,
+ tracer=dict()))
+train_cfg = dict(type='mmrazor.LSQEpochBasedLoop')
+```
+
+For `algorithm` and `tracer`, we recommend that you use the default configurations `MMArchitectureQuant` and `CustomTracer` provided by us. These two module operators are specially built for the openmmlab environment, while other modules can refer to the following steps and choose or develop new operators according to your needs.
+
+To adapt to different backends, you need to select a different `quantizer`.
+
+To develop new quantization algorithms, you need to define new `observer` and `fakequant`.
+
+If the existing `loop` does not meet your needs, you may need to make some changes to the existing `loop` based on your algorithm.
+
+## Detailed steps
+
+1. Select a quantization algorithm
+
+We recommend that you directly use the`MMArchitectureQuant` in `mmrazor/models/algorithms/quantization/mm_architecture.py`.The class `MMArchitectureQuant` inherits from class `BaseAlgorithm`.
+
+This structure is built for the model in openmmlab. If you have other requirements, you can also refer to this [document](https://mmrazor.readthedocs.io/en/main/advanced_guides/customize_architectures.html#develop-common-model-components) to design the overall framework.
+
+2. Select quantizer
+
+At present, the quantizers we support are `NativeQuantizer`, `OpenVINOQuantizer`, `TensorRTQuantizer` and `AcademicQuantizer` in `mmrazor/models/quantizers/`. `AcademicQuantizer` and `NativeQuantizer` inherit from class `BaseQuantizer` in `mmrazor/models/quantizers/base.py`:
+
+```Python
+class BaseQuantizer(BaseModule):
+ def __init__(self, tracer):
+ super().__init__()
+ self.tracer = TASK_UTILS.build(tracer)
+ @abstractmethod
+ def prepare(self, model, graph_module):
+ """tmp."""
+ pass
+ def swap_ff_with_fxff(self, model):
+ pass
+```
+
+`NativeQuantizer` is the operator we developed to adapt to the environment of mmrazor according to pytorch's official quantization logic. `AcademicQuantizer` is an operator designed for academic research to give users more space to operate.
+
+The class `OpenVINOQuantizer` and `TensorRTQuantizer` inherits from class `NativeQuantize`. They adapted `OpenVINO` and `TensorRT`backend respectively. You can also try to develop a quantizer based on other backends according to your own needs.
+
+3. Select tracer
+
+Tracer we use `CustomTracer` in `mmrazor/models/task_modules/tracer/fx/custom_tracer.py`. You can inherit this class and customize your own tracer.
+
+4. Develop new fakequant method(optional)
+
+You can use fakequants provided by pytorch in `mmrazor/models/fake_quants/torch_fake_quants.py` as core functions provider. If you want to use the fakequant methods from other papers, you can also define them yourself. Let's take lsq as an example as follows:
+
+a.Create a new file `mmrazor/models/fake_quants/lsq.py`, class `LearnableFakeQuantize` inherits from class `FakeQuantizeBase`.
+
+b. Finish the functions you need, eg: `observe_quant_params`, `calculate_qparams` and so on.
+
+```Python
+from mmrazor.registry import MODELS
+from torch.ao.quantization import FakeQuantizeBase
+
+@MODELS.register_module()
+class LearnableFakeQuantize(FakeQuantizeBase):
+ def __init__(self,
+ observer,
+ quant_min=0,
+ quant_max=255,
+ scale=1.,
+ zero_point=0.,
+ use_grad_scaling=True,
+ zero_point_trainable=False,
+ **observer_kwargs):
+ super(LearnableFakeQuantize, self).__init__()
+ pass
+
+ def observe_quant_params(self):
+ pass
+
+ def calculate_qparams(self):
+ pass
+
+ def forward(self, X):
+ pass
+```
+
+c.Import the module in `mmrazor/models/fake_quants/__init__.py`.
+
+```Python
+from .lsq import LearnableFakeQuantize
+
+__all__ = ['LearnableFakeQuantize']
+```
+
+5. Develop new observer(optional)
+
+You can directly use observers provided by pytorch in `mmrazor/models/observers/torch_observers.py` or use observers customized by yourself. Let's take `LSQObserver` as follows:
+
+a.Create a new observer file `mmrazor/models/observers/lsq.py`, class `LSQObserver` inherits from class `MinMaxObserver` and `LSQObserverMixIn`. These two observers can calculate `zero_point` and `scale`, respectively.
+
+b.Finish the functions you need, eg: `calculate_qparams` and so on.
+
+```Python
+from mmrazor.registry import MODELS
+from torch.ao.quantization.observer import MinMaxObserver
+
+class LSQObserverMixIn:
+ def __init__(self):
+ self.tensor_norm = None
+
+ @torch.jit.export
+ def _calculate_scale(self):
+ scale = 2 * self.tensor_norm / math.sqrt(self.quant_max)
+ sync_tensor(scale)
+ return scale
+
+@MODELS.register_module()
+class LSQObserver(MinMaxObserver, LSQObserverMixIn):
+ """LSQ observer.
+ Paper: Learned Step Size Quantization.
+ """
+ def __init__(self, *args, **kwargs):
+ MinMaxObserver.__init__(self, *args, **kwargs)
+ LSQObserverMixIn.__init__(self)
+
+ def forward(self, x_orig):
+ """Records the running minimum, maximum and tensor_norm of ``x``."""
+ if x_orig.numel() == 0:
+ return x_orig
+ x = x_orig.detach() # avoid keeping autograd tape
+ x = x.to(self.min_val.dtype)
+ self.tensor_norm = x.abs().mean()
+ min_val_cur, max_val_cur = torch.aminmax(x)
+ min_val = torch.min(min_val_cur, self.min_val)
+ max_val = torch.max(max_val_cur, self.max_val)
+ self.min_val.copy_(min_val)
+ self.max_val.copy_(max_val)
+ return x_orig
+
+ @torch.jit.export
+ def calculate_qparams(self):
+ """Calculates the quantization parameters."""
+ _, zero_point = MinMaxObserver.calculate_qparams(self)
+ scale = LSQObserverMixIn._calculate_scale(self)
+ return scale, zero_point
+```
+
+c.Import the module in `mmrazor/models/observers/__init__.py`
+
+```Python
+from .lsq import LSQObserver
+
+__all__ = ['LSQObserver']
+```
+
+6. Select loop or develop new loop
+
+At present, the QAT loops we support are `PTQLoop` and `QATEpochBasedLoop`, in `mmrazor/engine/runner/quantization_loops.py`. We can develop a new `LSQEpochBasedLoop` inherits from class `QATEpochBasedLoop` and finish the functions we need in LSQ method.
+
+```Python
+from mmengine.runner import EpochBasedTrainLoop
+
+@LOOPS.register_module()
+class LSQEpochBasedLoop(QATEpochBasedLoop):
+ def __init__(
+ self,
+ runner,
+ dataloader: Union[DataLoader, Dict],
+ max_epochs: int,
+ val_begin: int = 1,
+ val_interval: int = 1,
+ freeze_bn_begin: int = -1,
+ dynamic_intervals: Optional[List[Tuple[int, int]]] = None) -> None:
+ super().__init__(
+ runner,
+ dataloader,
+ max_epochs,
+ val_begin,
+ val_interval,
+ freeze_bn_begin=freeze_bn_begin,
+ dynamic_intervals=dynamic_intervals)
+
+ self.is_first_batch = True
+
+ def prepare_for_run_epoch(self):
+ pass
+
+ def prepare_for_val(self):
+ pass
+
+ def run_epoch(self) -> None:
+ pass
+```
+
+And then Import the module in `mmrazor/engine/runner/__init__.py`
+
+```Python
+from .quantization_loops import LSQEpochBasedLoop
+
+__all__ = ['LSQEpochBasedLoop']
+```
+
+7. Use the algorithm in your config file
+
+After completing the above steps, we have all the components of the qat algorithm, and now we can combine them in the config file.
+
+a.First, `_base_` stores the location of the model that needs to be quantized.
+
+b.Second, configure observer,fakequant and qscheme in `global_qconfig` in detail.
+You can configure the required quantization bit width and quantization methods in `qscheme`, such as symmetric quantization or asymmetric quantization.
+
+c.Third, build the whole mmrazor model in `model`.
+
+d.Finally, complete all the remaining required configuration files.
+
+```Python
+_base_ = ['mmcls::resnet/resnet18_8xb16_cifar10.py']
+
+global_qconfig = dict(
+ w_observer=dict(type='mmrazor.LSQPerChannelObserver'),
+ a_observer=dict(type='mmrazor.LSQObserver'),
+ w_fake_quant=dict(type='mmrazor.LearnableFakeQuantize'),
+ a_fake_quant=dict(type='mmrazor.LearnableFakeQuantize'),
+ w_qscheme=dict(
+ qdtype='qint8', bit=8, is_symmetry=True, is_symmetric_range=True),
+ a_qscheme=dict(qdtype='quint8', bit=8, is_symmetry=True),
+)
+
+model = dict(
+ _delete_=True,
+ _scope_='mmrazor',
+ type='MMArchitectureQuant',
+ data_preprocessor=dict(
+ type='mmcls.ClsDataPreprocessor',
+ num_classes=1000,
+ # RGB format normalization parameters
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ # convert image from BGR to RGB
+ to_rgb=True),
+ architecture=resnet,
+ float_checkpoint=float_ckpt,
+ quantizer=dict(
+ type='mmrazor.OpenVINOQuantizer',
+ is_qat=True,
+ global_qconfig=global_qconfig,
+ tracer=dict(
+ type='mmrazor.CustomTracer',
+ skipped_methods=[
+ 'mmcls.models.heads.ClsHead._get_loss',
+ 'mmcls.models.heads.ClsHead._get_predictions'
+ ])))
+
+# learning policy
+optim_wrapper = dict()
+param_scheduler = dict()
+model_wrapper_cfg = dict()
+
+# train, val, test setting
+train_cfg = dict(type='mmrazor.LSQEpochBasedLoop')
+val_cfg = dict()
+test_cfg = val_cfg
+```
diff --git a/internlm_langchain/knowledge_base/MMRazor/content/delivery.md b/internlm_langchain/knowledge_base/MMRazor/content/delivery.md
new file mode 100644
index 00000000..b7c842c0
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMRazor/content/delivery.md
@@ -0,0 +1,217 @@
+# Delivery
+
+## Introduction of Delivery
+
+`Delivery` is a mechanism used in **knowledge distillation**, which is to **align the intermediate results** between the teacher model and the student model by delivering and rewriting these intermediate results between them. As shown in the figure below, deliveries can be used to:
+
+- **Deliver the output of a layer of the teacher model directly to a layer of the student model.** In some knowledge distillation algorithms, we may need to deliver the output of a layer of the teacher model to the student model directly. For example, in [LAD](https://arxiv.org/abs/2108.10520) algorithm, the student model needs to obtain the label assignment of the teacher model directly.
+- **Align the inputs of the teacher model and the student model.** For example, in the MMClassification framework, some widely used data augmentations such as [mixup](https://arxiv.org/abs/1710.09412) and [CutMix](https://arxiv.org/abs/1905.04899) are not implemented in Data Pipelines but in `forward_train`, and due to the randomness of these data augmentation methods, it may lead to a gap between the input of the teacher model and the student model.
+
+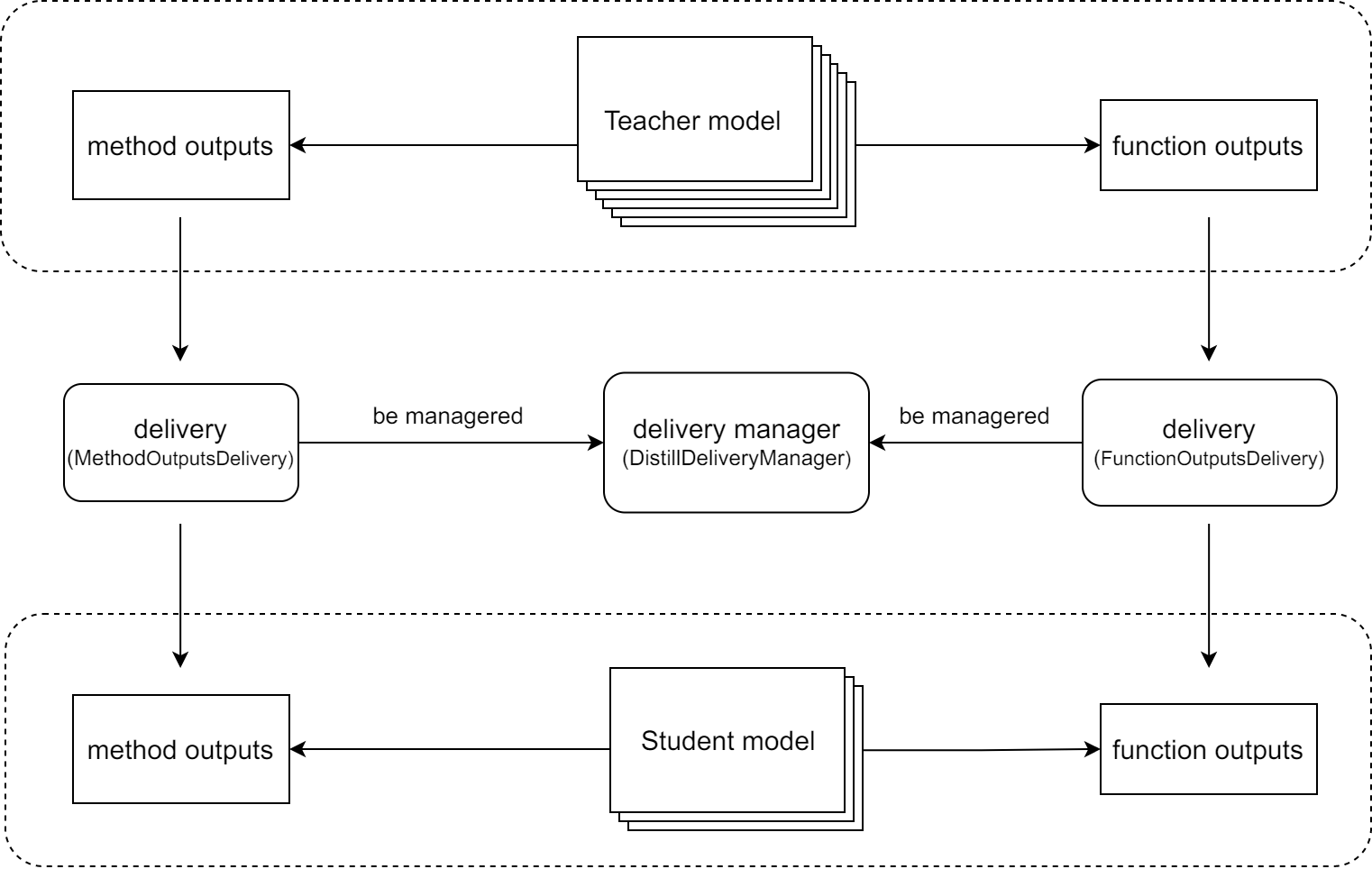
+
+In general, the delivery mechanism allows us to deliver intermediate results between the teacher model and the student model **without adding additional code**, which reduces the hard coding in the source code.
+
+## Usage of Delivery
+
+Currently, we support two deliveries: `FunctionOutputsDelivery` and `MethodOutputsDelivery`, both of which inherit from `DistillDiliver`. And these deliveries can be managed by `DistillDeliveryManager` or just be used on their own.
+
+Their relationship is shown below.
+
+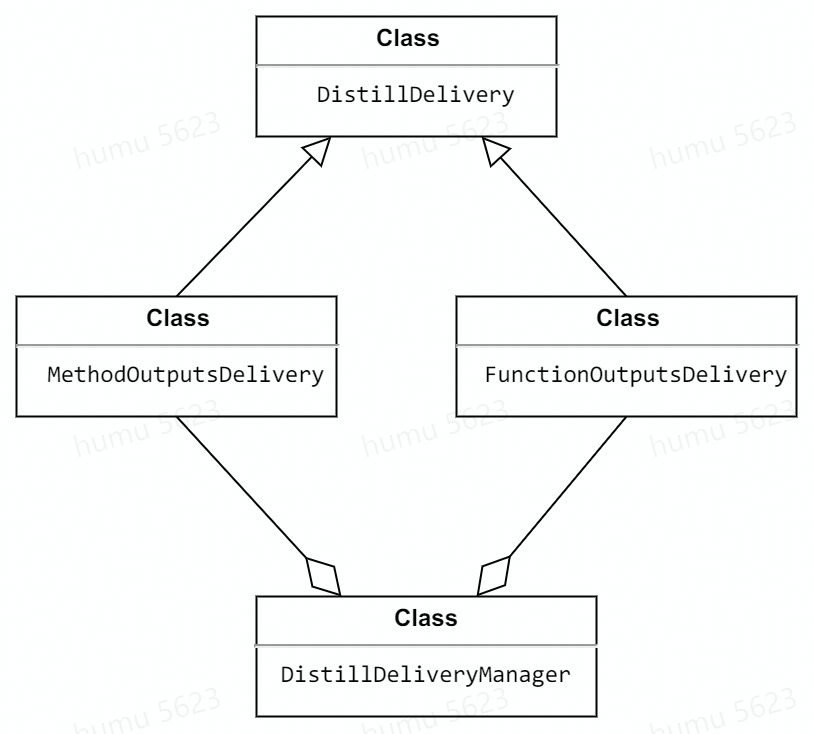
+
+### FunctionOutputsDelivery
+
+`FunctionOutputsDelivery` is used to align the **function's** intermediate results between the teacher model and the student model.
+
+```{note}
+When initializing `FunctionOutputsDelivery`, you need to pass `func_path` argument, which requires extra attention. For example,
+`anchor_inside_flags` is a function in mmdetection to check whether the
+anchors are inside the border. This function is in
+`mmdet/core/anchor/utils.py` and used in
+`mmdet/models/dense_heads/anchor_head`. Then the `func_path` should be
+`mmdet.models.dense_heads.anchor_head.anchor_inside_flags` but not
+`mmdet.core.anchor.utils.anchor_inside_flags`.
+```
+
+#### Case 1: Delivery single function's output from the teacher to the student.
+
+```Python
+import random
+from mmrazor.core import FunctionOutputsDelivery
+
+def toy_func() -> int:
+ return random.randint(0, 1000000)
+
+delivery = FunctionOutputsDelivery(max_keep_data=1, func_path='toy_module.toy_func')
+
+# override_data is False, which means that not override the data with
+# the recorded data. So it will get the original output of toy_func
+# in teacher model, and it is also recorded to be deliveried to the student.
+delivery.override_data = False
+with delivery:
+ output_teacher = toy_module.toy_func()
+
+# override_data is True, which means that override the data with
+# the recorded data, so it will get the output of toy_func
+# in teacher model rather than the student's.
+delivery.override_data = True
+with delivery:
+ output_student = toy_module.toy_func()
+
+print(output_teacher == output_student)
+```
+
+Out:
+
+```Python
+True
+```
+
+#### Case 2: Delivery multi function's outputs from the teacher to the student.
+
+If a function is executed more than once during the forward of the teacher model, all the outputs of this function will be used to override function outputs from the student model
+
+```{note}
+Delivery order is first-in first-out.
+```
+
+```Python
+delivery = FunctionOutputsDelivery(
+ max_keep_data=2, func_path='toy_module.toy_func')
+
+delivery.override_data = False
+with delivery:
+ output1_teacher = toy_module.toy_func()
+ output2_teacher = toy_module.toy_func()
+
+delivery.override_data = True
+with delivery:
+ output1_student = toy_module.toy_func()
+ output2_student = toy_module.toy_func()
+
+print(output1_teacher == output1_student and output2_teacher == output2_student)
+```
+
+Out:
+
+```Python
+True
+```
+
+### MethodOutputsDelivery
+
+`MethodOutputsDelivery` is used to align the **method's** intermediate results between the teacher model and the student model.
+
+#### Case: Align the inputs of the teacher model and the student model
+
+Here we use mixup as an example to show how to align the inputs of the teacher model and the student model.
+
+- Without Delivery
+
+```Python
+# main.py
+from mmcls.models.utils import Augments
+from mmrazor.core import MethodOutputsDelivery
+
+augments_cfg = dict(type='BatchMixup', alpha=1., num_classes=10, prob=1.0)
+augments = Augments(augments_cfg)
+
+imgs = torch.randn(2, 3, 32, 32)
+label = torch.randint(0, 10, (2,))
+
+imgs_teacher, label_teacher = augments(imgs, label)
+imgs_student, label_student = augments(imgs, label)
+
+print(torch.equal(label_teacher, label_student))
+print(torch.equal(imgs_teacher, imgs_student))
+```
+
+Out:
+
+```Python
+False
+False
+from mmcls.models.utils import Augments
+from mmrazor.core import DistillDeliveryManager
+```
+
+The results are different due to the randomness of mixup.
+
+- With Delivery
+
+```Python
+delivery = MethodOutputsDelivery(
+ max_keep_data=1, method_path='mmcls.models.utils.Augments.__call__')
+
+delivery.override_data = False
+with delivery:
+ imgs_teacher, label_teacher = augments(imgs, label)
+
+delivery.override_data = True
+with delivery:
+ imgs_student, label_student = augments(imgs, label)
+
+print(torch.equal(label_teacher, label_student))
+print(torch.equal(imgs_teacher, imgs_student))
+```
+
+Out:
+
+```Python
+True
+True
+```
+
+The randomness is eliminated by using `MethodOutputsDelivery`.
+
+### 2.3 DistillDeliveryManager
+
+`DistillDeliveryManager` is actually a context manager, used to manage delivers. When entering the ` DistillDeliveryManager`, all delivers managed will be started.
+
+With the help of `DistillDeliveryManager`, we are able to manage several different DistillDeliveries with as little code as possible, thereby reducing the possibility of errors.
+
+#### Case: Manager deliveries with DistillDeliveryManager
+
+```Python
+from mmcls.models.utils import Augments
+from mmrazor.core import DistillDeliveryManager
+
+augments_cfg = dict(type='BatchMixup', alpha=1., num_classes=10, prob=1.0)
+augments = Augments(augments_cfg)
+
+distill_deliveries = [
+ ConfigDict(type='MethodOutputs', max_keep_data=1,
+ method_path='mmcls.models.utils.Augments.__call__')]
+
+# instantiate DistillDeliveryManager
+manager = DistillDeliveryManager(distill_deliveries)
+
+imgs = torch.randn(2, 3, 32, 32)
+label = torch.randint(0, 10, (2,))
+
+manager.override_data = False
+with manager:
+ imgs_teacher, label_teacher = augments(imgs, label)
+
+manager.override_data = True
+with manager:
+ imgs_student, label_student = augments(imgs, label)
+
+print(torch.equal(label_teacher, label_student))
+print(torch.equal(imgs_teacher, imgs_student))
+```
+
+Out:
+
+```Python
+True
+True
+```
+
+## Reference
+
+\[1\] Zhang, Hongyi, et al. "mixup: Beyond empirical risk minimization." *arXiv* abs/1710.09412 (2017).
+
+\[2\] Yun, Sangdoo, et al. "Cutmix: Regularization strategy to train strong classifiers with localizable features." *ICCV* (2019).
+
+\[3\] Nguyen, Chuong H., et al. "Improving object detection by label assignment distillation." *WACV* (2022).
diff --git a/internlm_langchain/knowledge_base/MMRazor/content/faq.md b/internlm_langchain/knowledge_base/MMRazor/content/faq.md
new file mode 100644
index 00000000..318b08dc
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMRazor/content/faq.md
@@ -0,0 +1 @@
+# Frequently Asked Questions
diff --git a/internlm_langchain/knowledge_base/MMRazor/content/how_to_prune_your_model.md b/internlm_langchain/knowledge_base/MMRazor/content/how_to_prune_your_model.md
new file mode 100644
index 00000000..7a8f6005
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMRazor/content/how_to_prune_your_model.md
@@ -0,0 +1,134 @@
+# How to prune your model
+
+## Overview
+
+This section will introduce you to pruning your model. Before that, we suggest you read the document [User Guides: Pruning Framework](../../user_guides/pruning_user_guide.md) to have an overview of our pruning framework.
+
+First, we suppose your model is defined and trained using one openmmlab repo.
+Our pruning algorithms work as a wrapper of a model. To prune your model, you need to replace your model config with our algorithm config, which has a parameter 'architecture' to store your original model. The pipeline is shown below.
+
+), tensor([[[[-0.0894]]]], grad_fn=)]
+```
+
+Test Correctness of recorded results
+
+```Python
+print(torch.equal(r1.data_buffer[0], model.conv1(x)))
+print(torch.equal(r1.data_buffer[1], model.conv1(x + 1)))
+```
+
+Out:
+
+```Python
+True
+True
+```
+
+### ParameterRecorder
+
+`ParameterRecorder` is used to record the intermediate parameter of `nn.Module`. Its usage is similar to `ModuleOutputsRecorder`'s and `ModuleInputsRecorder`'s, but it instantiates with parameter name instead of module name.
+
+#### Example
+
+Suppose there is a toy Module `ToyModule` in toy_module.py.
+
+```Python
+from torch import nn
+import torch
+from mmrazor.core import ModuleOutputsRecorder
+
+class ToyModel(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.toy_conv = nn.Conv2d(1, 1, 1)
+
+ def forward(self, x):
+ return self.toy_conv(x)
+
+model = ToyModel()
+# instantiate with specifying parameter name.
+r1 = ParameterRecorder('toy_conv.weight')
+# initialize is to make specified module can be recorded by
+# registering customized forward hook.
+r1.initialize(model)
+
+print(r1.data_buffer)
+```
+
+Out:
+
+```Python
+[Parameter containing: tensor([[[[0.2971]]]], requires_grad=True)]
+```
+
+Test Correctness of recorded results
+
+```Python
+print(torch.equal(r1.data_buffer[0], model.toy_conv.weight))
+```
+
+Out:
+
+```Python
+True
+```
+
+### RecorderManager
+
+`RecorderManager` is actually context manager, which can be used to manage various types of recorders.
+
+With the help of `RecorderManager`, we can manage several different recorders with as little code as possible, which reduces the possibility of errors.
+
+#### Example
+
+Suppose there is a toy class `Toy` owned has a toy method `toy_func` in toy_module.py.
+
+```Python
+import random
+from torch import nn
+from mmrazor.core import RecorderManager
+
+class Toy():
+ def toy_func(self):
+ return random.randint(0, 1000000)
+
+class ToyModel(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.conv1 = nn.Conv2d(1, 1, 1)
+ self.conv2 = nn.Conv2d(1, 1, 1)
+ self.toy = Toy()
+
+ def forward(self, x):
+ return self.conv2(self.conv1(x)) + self.toy.toy_func()
+
+# configure multi-recorders
+conv1_rec = ConfigDict(type='ModuleOutputs', source='conv1')
+conv2_rec = ConfigDict(type='ModuleOutputs', source='conv2')
+func_rec = ConfigDict(type='MethodOutputs', source='toy_module.Toy.toy_func')
+# instantiate RecorderManager with a dict that contains recorders' configs,
+# you can customize their keys.
+manager = RecorderManager(
+ {'conv1_rec': conv1_rec,
+ 'conv2_rec': conv2_rec,
+ 'func_rec': func_rec})
+
+model = ToyModel()
+# initialize is to make specified module can be recorded by
+# registering customized forward hook.
+manager.initialize(model)
+
+x = torch.rand(1, 1, 1, 1)
+with manager:
+ out = model(x)
+
+conv2_out = manager.get_recorder('conv2_rec').get_record_data()
+print(conv2_out)
+```
+
+Out:
+
+```Python
+tensor([[[[0.5543]]]], grad_fn=)
+```
+
+Display output of `toy_func`
+
+```Python
+func_out = manager.get_recorder('func_rec').get_record_data()
+print(func_out)
+```
+
+Out:
+
+```Python
+313167
+```
diff --git a/internlm_langchain/knowledge_base/MMRazor/content/visualization.md b/internlm_langchain/knowledge_base/MMRazor/content/visualization.md
new file mode 100644
index 00000000..4642139d
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMRazor/content/visualization.md
@@ -0,0 +1,158 @@
+## ÕÅ»Ķ¦åÕī¢
+
+## ńē╣ÕŠüÕøŠÕÅ»Ķ¦åÕī¢
+
+
+
+# ĶŠōÕģźõĖĆõĖ¬ÕøŠńēć list
+results = inferencer(images)
+# ĶŠōÕć║õĖ║ÕłŚĶĪ©
+print(type(results['visualization']), results['visualization'][0].shape)
+# (512, 683, 3)
+print(type(results['predictions']), results['predictions'][0].shape)
+# (512, 683)
+
+results = inferencer(images, return_datasamples=True)
+#
+print(type(results[0]))
+#
+```
+
+### ÕłØÕ¦ŗÕī¢
+
+`MMSegInferencer` Õ┐ģķĪ╗õĮ┐ńö© `model` ÕłØÕ¦ŗÕī¢’╝īĶ»ź `model` ÕÅ»õ╗źµś»µ©ĪÕ×ŗÕÉŹń¦░µł¢õĖĆõĖ¬ `Config`’╝īńöÜĶć│ÕÅ»õ╗źµś»ķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠäŃĆé
+µ©ĪÕ×ŗÕÉŹń¦░ÕÅ»õ╗źÕ£©µ©ĪÕ×ŗńÜäÕģāµ¢ćõ╗Č’╝łconfigs/xxx/metafile.yaml’╝ēõĖŁµēŠÕł░’╝īµ»öÕ”é maskformer ńÜäõĖĆõĖ¬µ©ĪÕ×ŗÕÉŹń¦░µś» `maskformer_r50-d32_8xb2-160k_ade20k-512x512`’╝īÕ”éµ×£ĶŠōÕģźµ©ĪÕ×ŗÕÉŹń¦░’╝īµ©ĪÕ×ŗńÜäµØāķćŹÕ░åĶć¬ÕŖ©õĖŗĶĮĮŃĆéõ╗źõĖŗµś»ÕģČõ╗¢ĶŠōÕģźÕÅéµĢ░’╝Ü
+
+- weights’╝łstr’╝īÕÅ»ķĆē’╝ē- µØāķćŹńÜäĶĘ»ÕŠäŃĆéÕ”éµ×£µ£¬µīćÕ«Ü’╝īÕ╣ČõĖöµ©ĪÕ×ŗµś»Õģāµ¢ćõ╗ČõĖŁńÜ䵩ĪÕ×ŗÕÉŹń¦░’╝īÕłÖµØāķćŹÕ░åõ╗ÄÕģāµ¢ćõ╗ČÕŖĀĶĮĮŃĆéķ╗śĶ«żõĖ║ NoneŃĆé
+- classes’╝łlist’╝īÕÅ»ķĆē’╝ē- ĶŠōÕģźń▒╗Õł½ńö©õ║Äń╗ōµ×£µĖ▓µ¤ō’╝īńö▒õ║ÄÕłåÕē▓µ©ĪÕ×ŗńÜäķó䵥ŗń╗ōµ×䵜»µĀćńŁŠń┤óÕ╝ĢńÜäÕłåÕē▓ÕøŠ’╝ī`classes` µś»õĖĆõĖ¬ńøĖÕ║öńÜäµĀćńŁŠń┤óÕ╝ĢńÜäń▒╗Õł½ÕłŚĶĪ©ŃĆéĶŗź classes µ▓Īµ£ēÕ«Üõ╣ē’╝īÕÅ»Ķ¦åÕī¢ÕĘźÕģĘÕ░åķ╗śĶ«żõĮ┐ńö© `cityscapes` ńÜäń▒╗Õł½ŃĆéķ╗śĶ«żõĖ║ NoneŃĆé
+- palette’╝łlist’╝īÕÅ»ķĆē’╝ē- ĶŠōÕģźĶ░āĶē▓ńøśńö©õ║Äń╗ōµ×£µĖ▓µ¤ō’╝īÕ«āµś»Õ»╣Õ║öÕłåń▒╗ńÜäķģŹĶē▓ÕłŚĶĪ©ŃĆéĶŗź palette µ▓Īµ£ēÕ«Üõ╣ē’╝īÕÅ»Ķ¦åÕī¢ÕĘźÕģĘÕ░åķ╗śĶ«żõĮ┐ńö© `cityscapes` ńÜäĶ░āĶē▓ńøśŃĆéķ╗śĶ«żõĖ║ NoneŃĆé
+- dataset_name’╝łstr’╝īÕÅ»ķĆē’╝ē- [µĢ░µŹ«ķøåÕÉŹń¦░µł¢Õł½ÕÉŹ](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/utils/class_names.py#L302-L317)’╝īÕÅ»Ķ¦åÕī¢ÕĘźÕģĘÕ░åõĮ┐ńö©µĢ░µŹ«ķøåńÜäÕģāõ┐Īµü»’╝īÕ”éń▒╗Õł½ÕÆīķģŹĶē▓’╝īõĮå `classes` ÕÆī `palette` Õģʵ£ēµø┤ķ½śńÜäõ╝śÕģłń║¦ŃĆéķ╗śĶ«żõĖ║ NoneŃĆé
+- device’╝łstr’╝īÕÅ»ķĆē’╝ē- Ķ┐ÉĶĪīµÄ©ńÉåńÜäĶ«ŠÕżćŃĆéÕ”éµ×£µŚĀ’╝īÕłÖõ╝ÜĶć¬ÕŖ©õĮ┐ńö©ÕÅ»ńö©ńÜäĶ«ŠÕżćŃĆéķ╗śĶ«żõĖ║ NoneŃĆé
+- scope’╝łstr’╝īÕÅ»ķĆē’╝ē- µ©ĪÕ×ŗńÜäõĮ£ńö©Õ¤¤ŃĆéķ╗śĶ«żõĖ║ 'mmseg'ŃĆé
+
+### ÕÅ»Ķ¦åÕī¢ķó䵥ŗń╗ōµ×£
+
+`MMSegInferencer` µ£ē4õĖ¬ńö©õ║ÄÕÅ»Ķ¦åÕī¢ķó䵥ŗńÜäÕÅéµĢ░’╝īµé©ÕÅ»õ╗źÕ£©ÕłØÕ¦ŗÕī¢µÄ©ńÉåÕÖ©µŚČõĮ┐ńö©Õ«āõ╗¼’╝Ü
+
+- show’╝łbool’╝ē- µś»ÕÉ”Õ╝╣Õć║ń¬ŚÕÅŻµśŠńż║ÕøŠÕāÅŃĆéķ╗śĶ«żõĖ║ FalseŃĆé
+- wait_time’╝łfloat’╝ē- µśŠńż║ńÜäķŚ┤ķÜöŃĆéķ╗śĶ«żÕĆ╝õĖ║ 0ŃĆé
+- img_out_dir’╝łstr’╝ē- `out_dir` ńÜäÕŁÉńø«ÕĮĢ’╝īńö©õ║Äõ┐ØÕŁśµĖ▓µ¤ōµ£ēĶē▓ÕłåÕē▓µÄ®Ķ壒╝īÕøĀµŁżÕ”éµ×£Ķ”üõ┐ØÕŁśķó䵥ŗµÄ®Ķ壒╝īÕłÖÕ┐ģķĪ╗Õ«Üõ╣ē `out_dir`ŃĆéķ╗śĶ«żõĖ║ `vis`ŃĆé
+- opacity’╝łint’╝īfloat’╝ē- ÕłåÕē▓µÄ®Ķå£ńÜäķĆŵśÄÕ║”ŃĆéķ╗śĶ«żÕĆ╝õĖ║ 0.8ŃĆé
+
+Ķ┐Öõ║øÕÅéµĢ░ńÜäńż║õŠŗĶ»ĘÕÅéĶĆā[Õ¤║µ£¼õĮ┐ńö©](#Õ¤║µ£¼õĮ┐ńö©)
+
+### µ©ĪÕ×ŗÕłŚĶĪ©
+
+Õ£© MMSegmentation õĖŁµ£ēõĖĆõĖ¬ķØ×ÕĖĖÕ«╣µśōÕłŚÕć║µēƵ£ēµ©ĪÕ×ŗÕÉŹń¦░ńÜäµ¢╣µ│Ģ
+
+```
+>>> from mmseg.apis import MMSegInferencer
+# models µś»õĖĆõĖ¬µ©ĪÕ×ŗÕÉŹń¦░ÕłŚĶĪ©’╝īÕ«āõ╗¼Õ░åĶć¬ÕŖ©µēōÕŹ░
+>>> models = MMSegInferencer.list_models('mmseg')
+```
+
+## µÄ©ńÉå API
+
+### mmseg.apis.init_model
+
+õ╗ÄķģŹńĮ«µ¢ćõ╗ČÕłØÕ¦ŗÕī¢õĖĆõĖ¬ÕłåÕē▓ÕÖ©ŃĆé
+
+ÕÅéµĢ░’╝Ü
+
+- config’╝łstr’╝ī`Path` µł¢ `mmengine.Config`’╝ē- ķģŹńĮ«µ¢ćõ╗ČĶĘ»ÕŠäµł¢ķģŹńĮ«Õ»╣Ķ▒ĪŃĆé
+- checkpoint’╝łstr’╝īÕÅ»ķĆē’╝ē- µØāķćŹĶĘ»ÕŠäŃĆéÕ”éµ×£õĖ║ None’╝īÕłÖµ©ĪÕ×ŗÕ░åõĖŹõ╝ÜÕŖĀĶĮĮõ╗╗õĮĢµØāķćŹŃĆé
+- device’╝łstr’╝īÕÅ»ķĆē’╝ē- CPU/CUDA Ķ«ŠÕżćķĆēķĪ╣ŃĆéķ╗śĶ«żõĖ║ 'cuda:0'ŃĆé
+- cfg_options’╝łdict’╝īÕÅ»ķĆē’╝ē- ńö©õ║ÄĶ”åńø¢µēĆńö©ķģŹńĮ«õĖŁńÜ䵤Éõ║øĶ«ŠńĮ«ńÜäķĆēķĪ╣ŃĆé
+
+Ķ┐öÕø×ÕĆ╝’╝Ü
+
+- nn.Module’╝ܵ×äÕ╗║ÕźĮńÜäÕłåÕē▓ÕÖ©ŃĆé
+
+ńż║õŠŗ’╝Ü
+
+```python
+from mmseg.apis import init_model
+
+config_path = 'configs/pspnet/pspnet_r50-d8_4xb2-40k_cityscapes-512x1024.py'
+checkpoint_path = 'checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth'
+
+# ÕłØÕ¦ŗÕī¢õĖŹÕĖ”µØāķćŹńÜ䵩ĪÕ×ŗ
+model = init_model(config_path)
+
+# ÕłØÕ¦ŗÕī¢µ©ĪÕ×ŗÕ╣ČÕŖĀĶĮĮµØāķćŹ
+model = init_model(config_path, checkpoint_path)
+
+# Õ£© CPU õĖŖńÜäÕłØÕ¦ŗÕī¢µ©ĪÕ×ŗÕ╣ČÕŖĀĶĮĮµØāķćŹ
+model = init_model(config_path, checkpoint_path, 'cpu')
+```
+
+### mmseg.apis.inference_model
+
+õĮ┐ńö©ÕłåÕē▓ÕÖ©µÄ©ńÉåÕøŠÕāÅŃĆé
+
+ÕÅéµĢ░’╝Ü
+
+- model’╝łnn.Module’╝ē- ÕŖĀĶĮĮńÜäÕłåÕē▓ÕÖ©
+- imgs’╝łstr’╝īnp.ndarray µł¢ list\[str/np.ndarray\]’╝ē- ÕøŠÕāŵ¢ćõ╗ȵł¢ÕŖĀĶĮĮńÜäÕøŠÕāÅ
+
+Ķ┐öÕø×ÕĆ╝’╝Ü
+
+- `SegDataSample` µł¢ list\[`SegDataSample`\]’╝ÜÕ”éµ×£ imgs µś»ÕłŚĶĪ©µł¢Õģāń╗ä’╝īÕłÖĶ┐öÕø×ńøĖÕÉīķĢ┐Õ║”ńÜäÕłŚĶĪ©ń▒╗Õ×ŗń╗ōµ×£’╝īÕÉ”ÕłÖńø┤µÄźĶ┐öÕø×ÕłåÕē▓ń╗ōµ×£ŃĆé
+
+**µ│©µäÅ’╝Ü** [SegDataSample](https://github.com/open-mmlab/mmsegmentation/blob/1.x/mmseg/structures/seg_data_sample.py) µś» MMSegmentation ńÜäµĢ░µŹ«ń╗ōµ×äµÄźÕÅŻ’╝īńö©õĮ£õĖŹÕÉīń╗äõ╗Čõ╣ŗķŚ┤ńÜäµÄźÕÅŻŃĆé`SegDataSample` Õ«×ńÄ░µŖĮĶ▒ĪµĢ░µŹ«Õģāń┤Ā `mmengine.structures.BaseDataElement`’╝īĶ»ĘÕÅéķśģ [MMEngine](https://github.com/open-mmlab/mmengine) õĖŁńÜäµĢ░µŹ«Õģāń┤Ā[µ¢ćµĪŻ](https://mmengine.readthedocs.io/zh_CN/latest/advanced_tutorials/data_element.html)õ║åĶ¦Żµø┤ÕżÜõ┐Īµü»ŃĆé
+
+`SegDataSample` õĖŁńÜäÕÅéµĢ░ÕłåõĖ║ÕćĀõĖ¬ķā©Õłå’╝Ü
+
+- `gt_sem_seg`’╝ł`PixelData`’╝ē- Ķ»Łõ╣ēÕłåÕē▓ńÜäµĀćµ│©ŃĆé
+- `pred_sem_seg`’╝ł`PixelData`’╝ē- Ķ»Łõ╣ēÕłåÕē▓ńÜäķó䵥ŗŃĆé
+- `seg_logits`’╝ł`PixelData`’╝ē- µ©ĪÕ×ŗµ£ĆÕÉÄõĖĆÕ▒éńÜäĶŠōÕć║ń╗ōµ×£ŃĆé
+
+**µ│©µäÅ’╝Ü** [PixelData](https://github.com/open-mmlab/mmengine/blob/main/mmengine/structures/pixel_data.py) µś»ÕāÅń┤Āń║¦µĀćµ│©µł¢ķó䵥ŗńÜäµĢ░µŹ«ń╗ōµ×ä’╝īĶ»ĘÕÅéķśģ [MMEngine](https://github.com/open-mmlab/mmengine) õĖŁńÜä PixelData [µ¢ćµĪŻ](https://mmengine.readthedocs.io/en/latest/advanced_tutorials/data_element.html)õ║åĶ¦Żµø┤ÕżÜõ┐Īµü»ŃĆé
+
+ńż║õŠŗ’╝Ü
+
+```python
+from mmseg.apis import init_model, inference_model
+
+config_path = 'configs/pspnet/pspnet_r50-d8_4xb2-40k_cityscapes-512x1024.py'
+checkpoint_path = 'checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth'
+img_path = 'demo/demo.png'
+
+
+model = init_model(config_path, checkpoint_path)
+result = inference_model(model, img_path)
+```
+
+### mmseg.apis.show_result_pyplot
+
+Õ£©ÕøŠÕāÅõĖŖÕÅ»Ķ¦åÕī¢ÕłåÕē▓ń╗ōµ×£ŃĆé
+
+ÕÅéµĢ░’╝Ü
+
+- model’╝łnn.Module’╝ē- ÕŖĀĶĮĮńÜäÕłåÕē▓ÕÖ©ŃĆé
+- img’╝łstr µł¢ np.ndarray’╝ē- ÕøŠÕāŵ¢ćõ╗ČÕÉŹµł¢ÕŖĀĶĮĮńÜäÕøŠÕāÅŃĆé
+- result’╝ł`SegDataSample`’╝ē- SegDataSample ķó䵥ŗń╗ōµ×£ŃĆé
+- opacity’╝łfloat’╝ē- ń╗śÕłČÕłåÕē▓ÕøŠńÜäõĖŹķĆŵśÄÕ║”ŃĆéķ╗śĶ«żÕĆ╝õĖ║ `0.5`’╝īÕ┐ģķĪ╗Õ£© `(0’╝ī1]` ĶīāÕø┤ÕåģŃĆé
+- title’╝łstr’╝ē- pyplot ÕøŠńÜäµĀćķóśŃĆéķ╗śĶ«żÕĆ╝õĖ║ ''ŃĆé
+- draw_gt’╝łbool’╝ē- µś»ÕÉ”ń╗śÕłČ GT SegDataSampleŃĆéķ╗śĶ«żõĖ║ `True`ŃĆé
+- draw_pred’╝łdraws_pred’╝ē- µś»ÕÉ”ń╗śÕłČķó䵥ŗ SegDataSampleŃĆéķ╗śĶ«żõĖ║ `True`ŃĆé
+- wait_time’╝łfloat’╝ē- µśŠńż║ńÜäķŚ┤ķÜö’╝ī0 µś»ĶĪ©ńż║ŌĆ£µŚĀķÖÉŌĆØńÜäńē╣µ«ŖÕĆ╝ŃĆéķ╗śĶ«żõĖ║ `0`ŃĆé
+- show’╝łbool’╝ē- µś»ÕÉ”Õ▒Ģńż║ń╗śÕłČńÜäÕøŠÕāÅŃĆéķ╗śĶ«żõĖ║ `True`ŃĆé
+- save_dir’╝łstr’╝īÕÅ»ķĆē’╝ē- õĖ║µēƵ£ēÕŁśÕé©ÕÉÄń½»õ┐ØÕŁśńÜäµ¢ćõ╗ČĶĘ»ÕŠäŃĆéÕ”éµ×£õĖ║ `None`’╝īÕłÖÕÉÄń½»ÕŁśÕé©Õ░åõĖŹõ╝Üõ┐ØÕŁśõ╗╗õĮĢµĢ░µŹ«ŃĆé
+- out_file’╝łstr’╝īÕÅ»ķĆē’╝ē- ĶŠōÕć║µ¢ćõ╗ČńÜäĶĘ»ÕŠäŃĆéķ╗śĶ«żõĖ║ `None`ŃĆé
+
+Ķ┐öÕø×ÕĆ╝’╝Ü
+
+- np.ndarray’╝ÜķĆÜķüōõĖ║ RGB ńÜäń╗śÕłČÕøŠÕāÅŃĆé
+
+ńż║õŠŗ’╝Ü
+
+```python
+from mmseg.apis import init_model, inference_model, show_result_pyplot
+
+config_path = 'configs/pspnet/pspnet_r50-d8_4xb2-40k_cityscapes-512x1024.py'
+checkpoint_path = 'checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth'
+img_path = 'demo/demo.png'
+
+
+# õ╗ÄķģŹńĮ«µ¢ćõ╗ČÕÆīµØāķ揵¢ćõ╗ȵ×äÕ╗║µ©ĪÕ×ŗ
+model = init_model(config_path, checkpoint_path, device='cuda:0')
+
+# µÄ©ńÉåń╗ÖÕ«ÜÕøŠÕāÅ
+result = inference_model(model, img_path)
+
+# Õ▒Ģńż║ÕłåÕē▓ń╗ōµ×£
+vis_image = show_result_pyplot(model, img_path, result)
+
+# õ┐ØÕŁśÕÅ»Ķ¦åÕī¢ń╗ōµ×£’╝īĶŠōÕć║ÕøŠÕāÅÕ░åÕ£© `workdirs/result.png` ĶĘ»ÕŠäõĖŗµēŠÕł░
+vis_iamge = show_result_pyplot(model, img_path, result, out_file='work_dirs/result.png')
+
+# õ┐«µö╣Õ▒Ģńż║ÕøŠÕāÅńÜ䵌ČķŚ┤’╝īµ│©µäÅ 0 µś»ĶĪ©ńż║ŌĆ£µŚĀķÖÉŌĆØńÜäńē╣µ«ŖÕĆ╝
+vis_image = show_result_pyplot(model, img_path, result, wait_time=5)
+```
+
+**µ│©µäÅ’╝Ü** Õ”éµ×£ÕĮōÕēŹĶ«ŠÕżćµ▓Īµ£ēÕøŠÕĮóńö©µłĘńĢīķØó’╝īÕ╗║Ķ««Õ░å `show` Ķ«ŠńĮ«õĖ║ `False`’╝īÕ╣ȵīćÕ«Ü `out_file` µł¢ `save_dir` µØźõ┐ØÕŁśń╗ōµ×£ŃĆéÕ”éµ×£µé©µā│Õ£©ń¬ŚÕÅŻõĖŖµśŠńż║ń╗ōµ×£’╝īÕłÖõĖŹķ£ĆĶ”üńē╣µ«ŖĶ«ŠńĮ«ŃĆé
diff --git a/internlm_langchain/knowledge_base/MMSegmentation/content/4_train_test.md b/internlm_langchain/knowledge_base/MMSegmentation/content/4_train_test.md
new file mode 100644
index 00000000..f821acaf
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMSegmentation/content/4_train_test.md
@@ -0,0 +1,317 @@
+# µĢÖń©ŗ4’╝ÜõĮ┐ńö©ńÄ░µ£ēµ©ĪÕ×ŗĶ┐øĶĪīĶ«Łń╗āÕÆīµĄŗĶ»Ģ
+
+MMSegmentation µö»µīüÕ£©ÕżÜń¦ŹĶ«ŠÕżćõĖŖĶ«Łń╗āÕÆīµĄŗĶ»Ģµ©ĪÕ×ŗŃĆéÕ”éõĖŗµ¢ć’╝īÕģĘõĮōµ¢╣Õ╝ÅÕłåÕł½õĖ║ÕŹĢGPUŃĆüÕłåÕĖāÕ╝Åõ╗źÕÅŖĶ«Īń«ŚķøåńŠżńÜäĶ«Łń╗āÕÆīµĄŗĶ»ĢŃĆéķĆÜĶ┐ćµ£¼µĢÖń©ŗ’╝īµé©Õ░åń¤źµÖōÕ”éõĮĢńö© MMSegmentation µÅÉõŠøńÜäĶäܵ£¼Ķ┐øĶĪīĶ«Łń╗āÕÆīµĄŗĶ»ĢŃĆé
+
+## Õ£©ÕŹĢGPUõĖŖĶ«Łń╗āÕÆīµĄŗĶ»Ģ
+
+### Õ£©ÕŹĢGPUõĖŖĶ«Łń╗ā
+
+`tools/train.py` µ¢ćõ╗ȵÅÉõŠøõ║åÕ£©ÕŹĢGPUõĖŖķā©ńĮ▓Ķ«Łń╗āõ╗╗ÕŖĪńÜäµ¢╣µ│ĢŃĆé
+
+Õ¤║ńĪĆńö©µ│ĢÕ”éõĖŗ:
+
+```shell
+python tools/train.py ${ķģŹńĮ«µ¢ćõ╗Č} [ÕÅ»ķĆēÕÅéµĢ░]
+```
+
+- `--work-dir ${ÕĘźõĮ£ĶĘ»ÕŠä}`: ķ揵¢░µīćÕ«ÜÕĘźõĮ£ĶĘ»ÕŠä
+- `--amp`: õĮ┐ńö©Ķć¬ÕŖ©µĘĘÕÉłń▓ŠÕ║”Ķ«Īń«Ś
+- `--resume`: õ╗ÄÕĘźõĮ£ĶĘ»ÕŠäõĖŁõ┐ØÕŁśńÜäµ£Ćµ¢░µŻĆµ¤źńé╣µ¢ćõ╗Č’╝łcheckpoint’╝ēµüóÕżŹĶ«Łń╗ā
+- `--cfg-options ${ķ£Ćµø┤Ķ”åńø¢ńÜäķģŹńĮ«}`: Ķ”åńø¢ÕĘ▓ĶĮĮÕģźńÜäķģŹńĮ«õĖŁńÜäķā©ÕłåĶ«ŠńĮ«’╝īÕ╣ČõĖö õ╗ź xxx=yyy µĀ╝Õ╝ÅńÜäķö«ÕĆ╝Õ»╣ Õ░åĶó½ÕÉłÕ╣ČÕł░ķģŹńĮ«µ¢ćõ╗ČõĖŁŃĆé
+ µ»öÕ”é’╝Ü '--cfg-option model.encoder.in_channels=6'’╝ī µø┤ÕżÜń╗åĶŖéĶ»Ęń£ŗ[µīćÕ»╝](./1_config.md#Modify-config-through-script-arguments)ŃĆé
+
+õĖŗķØóµś»Õ»╣õ║ÄÕżÜGPUµĄŗĶ»ĢńÜäÕÅ»ķĆēÕÅéµĢ░:
+
+- `--launcher`: µē¦ĶĪīÕÖ©ńÜäÕÉ»ÕŖ©µ¢╣Õ╝ÅŃĆéÕģüĶ«ĖķĆēµŗ®ńÜäÕÅéµĢ░ÕĆ╝µ£ē `none`, `pytorch`, `slurm`, `mpi`ŃĆéńē╣Õł½ńÜä’╝īÕ”éµ×£Ķ«ŠńĮ«õĖ║none’╝īµĄŗĶ»ĢÕ░åķØ×ÕłåÕĖāÕ╝ŵ©ĪÕ╝ÅõĖŗĶ┐øĶĪīŃĆé
+- `--local_rank`: ÕłåÕĖāÕ╝ÅõĖŁĶ┐øń©ŗńÜäÕ║ÅÕÅĘŃĆéÕ”éµ×£µ▓Īµ£ēµīćÕ«Ü’╝īķ╗śĶ«żĶ«ŠńĮ«õĖ║0ŃĆé
+
+**µ│©µäÅ’╝Ü** ÕæĮõ╗żĶĪīÕÅéµĢ░ `--resume` ÕÆīÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁńÜäÕÅéµĢ░ `load_from` ńÜäõĖŹÕÉīõ╣ŗÕżä’╝Ü
+
+`--resume` ÕŬÕå│իܵś»ÕÉ”ń╗¦ń╗ŁõĮ┐ńö©ÕĘźõĮ£ĶĘ»ÕŠäõĖŁµ£Ćµ¢░ńÜ䵯Ƶ¤źńé╣’╝īÕ«āÕĖĖÕĖĖńö©õ║ĵüóÕżŹĶó½µäÅÕż¢µēōµ¢ŁńÜäĶ«Łń╗āŃĆé
+
+`load_from` õ╝ܵśÄńĪ«µīćÕ«ÜĶó½ĶĮĮÕģźńÜ䵯Ƶ¤źńé╣µ¢ćõ╗Č’╝īõĖöĶ«Łń╗āĶ┐Łõ╗ŻÕÖ©Õ░åõ╗Ä0Õ╝ĆÕ¦ŗ’╝īķĆÜÕĖĖńö©õ║ÄÕŠ«Ķ░āµ©ĪÕ×ŗŃĆé
+
+Õ”éµ×£µé©ÕĖīµ£øõ╗ĵīćÕ«ÜńÜ䵯Ƶ¤źńé╣õĖŖµüóÕżŹĶ«Łń╗āµé©ÕÅ»õ╗źõĮ┐ńö©’╝Ü
+
+```python
+python tools/train.py ${ķģŹńĮ«µ¢ćõ╗Č} --resume --cfg-options load_from=${µŻĆµ¤źńé╣}
+```
+
+**Õ£© CPU õĖŖĶ«Łń╗ā**: Õ”éµ×£µ£║ÕÖ©µ▓Īµ£ē GPU’╝īÕłÖÕ£© CPU õĖŖĶ«Łń╗āńÜäĶ┐ćń©ŗµś»õĖÄÕŹĢGPUĶ«Łń╗āõĖĆĶć┤ńÜäŃĆéÕ”éµ×£µ£║ÕÖ©µ£ē GPU õĮåµś»õĖŹÕĖīµ£øõĮ┐ńö©Õ«āõ╗¼’╝īµłæõ╗¼ÕŬķ£ĆĶ”üÕ£©Ķ«Łń╗āÕēŹķĆÜĶ┐ćõ╗źõĖŗµ¢╣Õ╝ÅÕģ│ķŚŁ GPU Ķ«Łń╗āÕŖ¤ĶāĮŃĆé
+
+```shell
+export CUDA_VISIBLE_DEVICES=-1
+```
+
+ńäČÕÉÄĶ┐ÉĶĪī[õĖŖµ¢╣](###Õ£©ÕŹĢGPUõĖŖĶ«Łń╗ā)Ķäܵ£¼ŃĆé
+
+### Õ£©ÕŹĢGPUõĖŖµĄŗĶ»Ģ
+
+`tools/test.py` µ¢ćõ╗ȵÅÉõŠøõ║åÕ£©ÕŹĢ GPU õĖŖÕÉ»ÕŖ©µĄŗĶ»Ģõ╗╗ÕŖĪńÜäµ¢╣µ│ĢŃĆé
+
+Õ¤║ńĪĆńö©µ│ĢÕ”éõĖŗ:
+
+```shell
+python tools/test.py ${ķģŹńĮ«µ¢ćõ╗Č} ${µ©ĪÕ×ŗµØāķ揵¢ćõ╗Č} [ÕÅ»ķĆēÕÅéµĢ░]
+```
+
+Ķ┐ÖõĖ¬ÕĘźÕģʵ£ēÕćĀõĖ¬ÕÅ»ķĆēÕÅéµĢ░’╝īÕīģµŗ¼’╝Ü
+
+- `--work-dir`: Õ”éµ×£µīćÕ«Üõ║åĶĘ»ÕŠä’╝īń╗ōµ×£õ╝Üõ┐ØÕŁśÕ£©Ķ»źĶĘ»ÕŠäõĖŗŃĆéÕ”éµ×£µ▓Īµ£ēµīćÕ«ÜÕłÖõ╝Üõ┐ØÕŁśÕ£© `work_dirs/{ķģŹńĮ«µ¢ćõ╗ČÕÉŹ}` ĶĘ»ÕŠäõĖŗ.
+- `--show`: ÕĮō `--show-dir` µ▓Īµ£ēµīćիܵŚČ’╝īÕÅ»õ╗źõĮ┐ńö©Ķ»źÕÅéµĢ░’╝īÕ£©ń©ŗÕ║ÅĶ┐ÉĶĪīĶ┐ćń©ŗõĖŁµśŠńż║ķó䵥ŗń╗ōµ×£ŃĆé
+- `--show-dir`: ń╗śÕłČõ║åÕłåÕē▓µÄ®Ķå£ÕøŠńēćńÜäÕŁśÕ驵¢ćõ╗ČÕż╣ŃĆéÕ”éµ×£µīćÕ«Üõ║åĶ»źÕÅéµĢ░’╝īÕłÖÕÅ»Ķ¦åÕī¢ńÜäÕłåÕē▓µÄ®Ķå£Õ░åĶó½õ┐ØÕŁśÕł░ `work_dir/timestamp/{µīćÕ«ÜĶĘ»ÕŠä}`.
+- `--wait-time`: ÕżÜµ¼ĪÕÅ»Ķ¦åÕī¢ń╗ōµ×£ńÜ䵌ČķŚ┤ķŚ┤ķÜöŃĆéÕĮō `--show` õĖ║µ┐Ƶ┤╗ńŖȵĆüµŚČÕÅæµīźõĮ£ńö©ŃĆéķ╗śĶ«żõĖ║2ŃĆé
+- `--cfg-options`: Õ”éµ×£Ķó½ÕģĘõĮōµīćÕ«Ü’╝īõ╗ź xxx=yyy ÕĮóÕ╝ÅńÜäķö«ÕĆ╝Õ»╣Õ░åĶó½ÕÉłÕ╣ČÕģźķģŹńĮ«µ¢ćõ╗ČõĖŁŃĆé
+
+**Õ£©CPUõĖŖµĄŗĶ»Ģ**: Õ”éµ×£µ£║ÕÖ©µ▓Īµ£ēGPU’╝īÕłÖÕ£©CPUõĖŖĶ«Łń╗āńÜäĶ┐ćń©ŗµś»õĖÄÕŹĢGPUĶ«Łń╗āõĖĆĶć┤ńÜäŃĆéÕ”éµ×£µ£║ÕÖ©µ£ēGPU’╝īõĮåµś»õĖŹÕĖīµ£øõĮ┐ńö©Õ«āõ╗¼’╝īµłæõ╗¼ÕŬķ£ĆĶ”üÕ£©Ķ«Łń╗āÕēŹķĆÜĶ┐ćõ╗źõĖŗµ¢╣Õ╝ÅÕģ│ķŚŁGPUsĶ«Łń╗āÕŖ¤ĶāĮŃĆé
+
+```shell
+export CUDA_VISIBLE_DEVICES=-1
+```
+
+ńäČÕÉÄĶ┐ÉĶĪī[õĖŖµ¢╣](###Õ£©ÕŹĢGPUõĖŖµĄŗĶ»Ģ)Ķäܵ£¼ŃĆé
+
+## ÕżÜGPUŃĆüÕżÜµ£║ÕÖ©õĖŖĶ«Łń╗āÕÆīµĄŗĶ»Ģ
+
+### Õ£©ÕżÜGPUõĖŖĶ«Łń╗ā
+
+OpenMMLab2.0 ķĆÜĶ┐ć `MMDistributedDataParallel`Õ«×ńÄ░ **ÕłåÕĖāÕ╝Å** Ķ«Łń╗āŃĆé
+
+`tools/dist_train.sh` µ¢ćõ╗ȵÅÉõŠøõ║åÕ£©Õ£©ÕżÜGPUõĖŖķā©ńĮ▓Ķ«Łń╗āõ╗╗ÕŖĪńÜäµ¢╣µ│ĢŃĆé
+
+Õ¤║ńĪĆńö©µ│ĢÕ”éõĖŗ:
+
+```shell
+sh tools/dist_train.sh ${ķģŹńĮ«µ¢ćõ╗Č} ${GPUµĢ░ķćÅ} [ÕÅ»ķĆēÕÅéµĢ░]
+```
+
+ÕÅ»ķĆēÕÅéµĢ░õĖÄ[õĖŖµ¢╣](###Õ£©ÕŹĢGPUõĖŖĶ«Łń╗ā)ńøĖÕÉīÕ╣ČõĖöĶ┐śÕó×ÕŖĀõ║åÕÅ»õ╗źµīćÕ«ÜgpuµĢ░ķćÅńÜäÕÅéµĢ░ŃĆé
+
+ńż║õŠŗ:
+
+```shell
+# µ©ĪÕ×ŗĶ«Łń╗āńÜ䵯Ƶ¤źńé╣ÕÆīµŚźÕ┐Śõ┐ØÕŁśÕ£©Ķ┐ÖõĖ¬ĶĘ»ÕŠäõĖŗ’╝Ü WORK_DIR=work_dirs/pspnet_r50-d8_4xb4-80k_ade20k-512x512/
+# Õ”éµ×£ÕĘźõĮ£ĶĘ»ÕŠäµ▓Īµ£ēĶó½Ķ«ŠÕ«Ü’╝īÕ«āÕ░åõ╝ÜĶó½Ķć¬ÕŖ©ńö¤µłÉŃĆé
+sh tools/dist_train.sh configs/pspnet/pspnet_r50-d8_4xb4-80k_ade20k-512x512.py 8 --work-dir work_dirs/pspnet_r50-d8_4xb4-80k_ade20k-512x512
+```
+
+**µ│©µäÅ**: Õ£©Ķ«Łń╗āĶ┐ćń©ŗõĖŁ’╝īµŻĆµ¤źńé╣ÕÆīµŚźÕ┐Śõ┐ØÕŁśÕ£©`work_dirs/`õĖŗńÜäķģŹńĮ«µ¢ćõ╗ČńÜäńøĖÕÉīµ¢ćõ╗ČÕż╣ń╗ōµ×äõĖŗŃĆé
+õĖŹµÄ©ĶŹÉĶć¬Õ«Üõ╣ēńÜäÕĘźõĮ£ĶĘ»ÕŠä’╝īÕøĀõĖ║Ķ»äõ╝░Ķäܵ£¼õŠØĶĄ¢õ║ĵ║ÉĶć¬ķģŹńĮ«µ¢ćõ╗ČÕÉŹńÜäĶĘ»ÕŠäŃĆéÕ”éµ×£µé©ÕĖīµ£øÕ░åµØāķćŹõ┐ØÕŁśÕ£©ÕģČõ╗¢Õ£░µ¢╣’╝īĶ»Ęńö©ń¼”ÕÅĘķōŠµÄź’╝īõŠŗÕ”é’╝Ü
+
+```shell
+ln -s ${µé©ńÜäÕĘźõĮ£ĶĘ»ÕŠä} ${MMSEG ĶĘ»ÕŠä}/work_dirs
+```
+
+### Õ£©ÕżÜGPUõĖŖµĄŗĶ»Ģ
+
+`tools/dist_test.sh` µ¢ćõ╗ȵÅÉõŠøõ║åÕ£©ÕżÜGPUõĖŖÕÉ»ÕŖ©µĄŗĶ»Ģõ╗╗ÕŖĪńÜäµ¢╣µ│ĢŃĆé
+
+Õ¤║ńĪĆńö©µ│ĢÕ”éõĖŗ:
+
+```shell
+sh tools/dist_test.sh ${ķģŹńĮ«µ¢ćõ╗Č} ${µŻĆµ¤źńé╣µ¢ćõ╗Č} ${GPUµĢ░ķćÅ} [ÕÅ»ķĆēÕÅéµĢ░]
+```
+
+ÕÅ»ķĆēÕÅéµĢ░õĖÄ[õĖŖµ¢╣](###Õ£©ÕŹĢGPUõĖŖµĄŗĶ»Ģ)ńøĖÕÉīÕ╣ČõĖöÕó×ÕŖĀõ║åÕÅ»õ╗źµīćÕ«Ü gpu µĢ░ķćÅńÜäÕÅéµĢ░ŃĆé
+
+ńż║õŠŗ:
+
+```shell
+./tools/dist_test.sh configs/pspnet/pspnet_r50-d8_4xb2-40k_cityscapes-512x1024.py \
+ checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth 4
+```
+
+### Õ£©ÕŹĢÕÅ░µ£║ÕÖ©õĖŖÕÉ»ÕŖ©ÕżÜõĖ¬õ╗╗ÕŖĪ
+
+Õ”éµ×£µé©Õ£©ÕŹĢõĖ¬µ£║ÕÖ©õĖŖĶ┐ÉĶĪīÕżÜõĖ¬õ╗╗ÕŖĪ’╝īµ»öÕ”é’╝ÜÕ£©8ÕŹĪGPUńÜäÕŹĢõĖ¬µ£║ÕÖ©õĖŖµē¦ĶĪī2õĖ¬ÕÉäķ£Ć4ÕŹĪGPUńÜäĶ«Łń╗āõ╗╗ÕŖĪ’╝īµé©ķ£ĆĶ”üõĖ║µ»ÅõĖ¬õ╗╗ÕŖĪÕģĘõĮōµīćÕ«ÜõĖŹÕÉīń½»ÕÅŻ’╝łķ╗śĶ«ż29500’╝ē’╝īõ╗ÄĶĆīķü┐ÕģŹķĆÜĶ«»Õå▓ń¬üŃĆéÕÉ”ÕłÖ’╝īõ╝ܵ£ēµŖźķöÖõ┐Īµü»ŌĆöŌĆö`RuntimeError: Address already in use`’╝łĶ┐ÉĶĪīķöÖĶ»»’╝ÜÕ£░ÕØĆĶó½õĮ┐ńö©’╝ēŃĆé
+
+Õ”éµ×£µé©õĮ┐ńö© `dist_train.sh` µØźÕÉ»ÕŖ©Ķ«Łń╗āõ╗╗ÕŖĪ’╝īµé©ÕÅ»õ╗źķĆÜĶ┐ćńÄ»ÕóāÕÅśķćÅ `PORT` Ķ«ŠńĮ«ń½»ÕÅŻŃĆé
+
+```shell
+CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 sh tools/dist_train.sh ${ķģŹńĮ«µ¢ćõ╗Č} 4
+CUDA_VISIBLE_DEVICES=4,5,6,7 PORT=29501 sh tools/dist_train.sh ${ķģŹńĮ«µ¢ćõ╗Č} 4
+```
+
+### Õ£©ÕżÜÕÅ░µ£║ÕÖ©õĖŖĶ«Łń╗ā
+
+MMSegmentation ńÜäÕłåÕĖāÕ╝ÅĶ«Łń╗āõŠØĶĄ¢ `torch.distributed`ŃĆé
+ÕøĀµŁż’╝ī ÕÅ»õ╗źķĆÜĶ┐ć PyTorch ńÜä [Ķ┐ÉĶĪīÕĘźÕģĘ launch utility](https://pytorch.org/docs/stable/distributed.html#launch-utility) µØźĶ┐øĶĪīÕłåÕĖāÕ╝ÅĶ«Łń╗āŃĆé
+
+Õ”éµ×£µé©ÕÉ»ÕŖ©ńÜäÕżÜÕÅ░µ£║ÕÖ©ń«ĆÕŹĢÕ£░ķĆÜĶ┐ćõ╗źÕż¬ńĮæĶ┐׵ğ’╝īµé©ÕÅ»õ╗źńø┤µÄźĶ┐ÉĶĪīõĖŗµ¢╣ÕæĮõ╗ż’╝Ü
+
+Õ£©ń¼¼õĖĆõĖ¬µ£║ÕÖ©õĖŖ:
+
+```shell
+NNODES=2 NODE_RANK=0 PORT=${õĖ╗ĶŖéńé╣ń½»ÕÅŻ} MASTER_ADDR=${õĖ╗ĶŖéńé╣Õ£░ÕØĆ} sh tools/dist_train.sh ${ķģŹńĮ«µ¢ćõ╗Č} ${GPUS}
+```
+
+Õ£©ń¼¼õ║īõĖ¬µ£║ÕÖ©õĖŖ:
+
+```shell
+NNODES=2 NODE_RANK=1 PORT=${õĖ╗ĶŖéńé╣ń½»ÕÅŻ} MASTER_ADDR=${õĖ╗ĶŖéńé╣Õ£░ÕØĆ} sh tools/dist_train.sh ${ķģŹńĮ«µ¢ćõ╗Č} ${GPUS}
+```
+
+ķĆÜÕĖĖ’╝īÕ”éµ×£µé©µ▓Īµ£ēõĮ┐ńö©ÕāŵŚĀķÖÉÕĖ”Õ«ĮõĖĆń▒╗ńÜäķ½śķƤńĮæń╗£’╝īĶ┐ÖõĖ¬õ╝ÜĶ┐ćń©ŗµ»öĶŠāµģóŃĆé
+
+## ķĆÜĶ┐ć Slurm ń«ĪńÉåõ╗╗ÕŖĪ
+
+[Slurm](https://slurm.schedmd.com/) µś»õĖĆõĖ¬ÕŠłÕźĮńÜäĶ«Īń«ŚķøåńŠżõĮ£õĖÜĶ░āÕ║”ń│╗ń╗¤ŃĆé
+
+### ķĆÜĶ┐ć Slurm Õ£©ķøåńŠżõĖŖĶ«Łń╗ā
+
+Õ£©õĖĆõĖ¬ńö▒Slurmń«ĪńÉåńÜäķøåńŠżõĖŖ’╝īµé©ÕÅ»õ╗źõĮ┐ńö©`slurm_train.sh`µØźÕÉ»ÕŖ©Ķ«Łń╗āõ╗╗ÕŖĪŃĆéÕ«āÕÉīµŚČµö»µīüÕŹĢĶŖéńé╣ÕÆīÕżÜĶŖéńé╣ńÜäĶ«Łń╗āŃĆé
+
+Õ¤║ńĪĆńö©µ│ĢÕ”éõĖŗ’╝Ü
+
+```shell
+[GPUS=${GPUS}] sh tools/slurm_train.sh ${ÕłåÕī║} ${õ╗╗ÕŖĪÕÉŹ} ${ķģŹńĮ«µ¢ćõ╗Č} [ÕÅ»ķĆēÕÅéµĢ░]
+```
+
+õĖŗµ¢╣µś»õĖĆõĖ¬ķĆÜĶ┐ćÕÉŹõĖ║ `dev` ńÜä Slurm ÕłåÕī║’╝īĶ░āńö©4õĖ¬ GPU µØźĶ«Łń╗ā PSPNet’╝īÕ╣ČĶ«ŠńĮ«ÕĘźõĮ£ĶĘ»ÕŠäõĖ║Õģ▒õ║½µ¢ćõ╗Čń│╗ń╗¤ŃĆé
+
+```shell
+GPUS=4 sh tools/slurm_train.sh dev pspnet configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py --work-dir work_dir/pspnet
+```
+
+µé©ÕÅ»õ╗źµŻĆµ¤ź [µ║ÉńĀü](../../../tools/slurm_train.sh) µØźµ¤źń£ŗÕģ©ķā©ńÜäÕÅéµĢ░ÕÆīńÄ»ÕóāÕÅśķćÅŃĆé
+
+### ķĆÜĶ┐ć Slurm Õ£©ķøåńŠżõĖŖµĄŗĶ»Ģ
+
+õĖÄĶ«Łń╗āõ╗╗ÕŖĪńøĖÕÉī’╝ī MMSegmentation µÅÉõŠø `slurm_test.sh` µ¢ćõ╗ČµØźÕÉ»ÕŖ©µĄŗĶ»Ģõ╗╗ÕŖĪŃĆé
+
+Õ¤║ńĪĆńö©µ│ĢÕ”éõĖŗ’╝Ü
+
+```shell
+[GPUS=${GPUS}] sh tools/slurm_test.sh ${ÕłåÕī║} ${õ╗╗ÕŖĪÕÉŹ} ${ķģŹńĮ«µ¢ćõ╗Č} ${µŻĆµ¤źńé╣µ¢ćõ╗Č} [ÕÅ»ķĆēÕÅéµĢ░]
+```
+
+µé©ÕÅ»õ╗źķĆÜĶ┐ć [µ║ÉńĀü](../../../tools/slurm_test.sh) µØźµ¤źń£ŗÕģ©ķā©ńÜäÕÅéµĢ░ÕÆīńÄ»ÕóāÕÅśķćÅŃĆé
+
+**µ│©µäÅ’╝Ü** õĮ┐ńö© Slurm µŚČ’╝īķ£ĆĶ”üĶ«ŠńĮ«ń½»ÕÅŻ’╝īÕÅ»õ╗Äõ╗źõĖŗµ¢╣Õ╝ÅõĖŁķĆēÕÅ¢õĖĆń¦ŹŃĆé
+
+1. µłæõ╗¼µø┤µÄ©ĶŹÉńÜäķĆÜĶ┐ć`--cfg-options`Ķ«ŠńĮ«ń½»ÕÅŻ’╝īÕøĀõĖ║Ķ┐ÖõĖŹõ╝ܵö╣ÕÅśÕĤզŗķģŹńĮ«’╝Ü
+
+ ```shell
+ GPUS=4 GPUS_PER_NODE=4 sh tools/slurm_train.sh ${ÕłåÕī║} ${õ╗╗ÕŖĪÕÉŹ} config1.py ${ÕĘźõĮ£ĶĘ»ÕŠä} --cfg-options env_cfg.dist_cfg.port=29500
+ GPUS=4 GPUS_PER_NODE=4 sh tools/slurm_train.sh ${õ╗╗ÕŖĪÕÉŹ} ${ÕĘźõĮ£ĶĘ»ÕŠä} config2.py ${ÕĘźõĮ£ĶĘ»ÕŠä} --cfg-options env_cfg.dist_cfg.port=29501
+ ```
+
+2. ķĆÜĶ┐ćõ┐«µö╣ķģŹńĮ«µ¢ćõ╗ČĶ«ŠńĮ«õĖŹÕÉīńÜäķĆÜĶ«»ń½»ÕÅŻ’╝Ü
+
+ Õ£© `config1.py`õĖŁ:
+
+ ```python
+ enf_cfg = dict(dist_cfg=dict(backend='nccl', port=29500))
+ ```
+
+ Õ£© `config2.py`õĖŁ’╝Ü
+
+ ```python
+ enf_cfg = dict(dist_cfg=dict(backend='nccl', port=29501))
+ ```
+
+ ńäČÕÉĵé©ÕÅ»õ╗źķĆÜĶ┐ć config1.py ÕÆī config2.py ÕÉīµŚČÕÉ»ÕŖ©õĖżõĖ¬õ╗╗ÕŖĪ’╝Ü
+
+ ```shell
+ CUDA_VISIBLE_DEVICES=0,1,2,3 GPUS=4 sh tools/slurm_train.sh ${ÕłåÕī║} ${õ╗╗ÕŖĪÕÉŹ} config1.py ${ÕĘźõĮ£ĶĘ»ÕŠä}
+ CUDA_VISIBLE_DEVICES=4,5,6,7 GPUS=4 sh tools/slurm_train.sh ${ÕłåÕī║} ${õ╗╗ÕŖĪÕÉŹ} config2.py ${ÕĘźõĮ£ĶĘ»ÕŠä}
+ ```
+
+3. Õ£©ÕæĮõ╗żĶĪīõĖŁķĆÜĶ┐ćńÄ»ÕóāÕÅśķćÅ `MASTER_PORT` Ķ«ŠńĮ«ń½»ÕÅŻ ’╝Ü
+
+```shell
+CUDA_VISIBLE_DEVICES=0,1,2,3 GPUS=4 MASTER_PORT=29500 sh tools/slurm_train.sh ${ÕłåÕī║} ${õ╗╗ÕŖĪÕÉŹ} config1.py ${ÕĘźõĮ£ĶĘ»ÕŠä}
+CUDA_VISIBLE_DEVICES=4,5,6,7 GPUS=4 MASTER_PORT=29501 sh tools/slurm_train.sh ${ÕłåÕī║} ${õ╗╗ÕŖĪÕÉŹ} config2.py ${ÕĘźõĮ£ĶĘ»ÕŠä}
+```
+
+## µĄŗĶ»ĢÕ╣Čõ┐ØÕŁśÕłåÕē▓ń╗ōµ×£
+
+### Õ¤║ńĪĆõĮ┐ńö©
+
+ÕĮōķ£ĆĶ”üõ┐ØÕŁśµĄŗĶ»ĢĶŠōÕć║ńÜäÕłåÕē▓ń╗ōµ×£’╝īńö© `--out` µīćÕ«ÜÕłåÕē▓ń╗ōµ×£ĶŠōÕć║ĶĘ»ÕŠä
+
+```shell
+python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} --out ${OUTPUT_DIR}
+```
+
+õ╗źõ┐ØÕŁśµ©ĪÕ×ŗ `fcn_r50-d8_4xb4-80k_ade20k-512x512` Õ£© ADE20K ķ¬īĶ»üµĢ░µŹ«ķøåõĖŖńÜäń╗ōµ×£õĖ║õŠŗ’╝Ü
+
+```shell
+python tools/test.py configs/fcn/fcn_r50-d8_4xb4-80k_ade20k-512x512.py ckpt/fcn_r50-d8_512x512_80k_ade20k_20200614_144016-f8ac5082.pth --out work_dirs/format_results
+```
+
+µł¢ĶĆģķĆÜĶ┐ćķģŹńĮ«µ¢ćõ╗ČÕ«Üõ╣ē `output_dir`ŃĆéõŠŗÕ”éÕ£© `configs/fcn/fcn_r50-d8_4xb4-80k_ade20k-512x512.py` µĘ╗ÕŖĀ `test_evaluator` Õ«Üõ╣ē’╝Ü
+
+```python
+test_evaluator = dict(type='IoUMetric', iou_metrics=['mIoU'], output_dir='work_dirs/format_results')
+```
+
+ńäČÕÉĵē¦ĶĪīńøĖÕÉīÕŖ¤ĶāĮńÜäÕæĮõ╗żõĖŹķ£ĆĶ”üÕåŹõĮ┐ńö© `--out`’╝Ü
+
+```shell
+python tools/test.py configs/fcn/fcn_r50-d8_4xb4-80k_ade20k-512x512.py ckpt/fcn_r50-d8_512x512_80k_ade20k_20200614_144016-f8ac5082.pth
+```
+
+ÕĮōµĄŗĶ»ĢńÜäµĢ░µŹ«ķøåµ▓Īµ£ēµÅÉõŠøµĀćµ│©’╝īĶ»äµĄŗµŚČµ▓Īµ£ēń£¤ÕĆ╝ÕÅ»õ╗źÕÅéõĖÄĶ«Īń«Ś’╝īÕøĀµŁżķ£ĆĶ”üĶ«ŠńĮ« `format_only=True`’╝ī
+ÕÉīµŚČķ£ĆĶ”üõ┐«µö╣ `test_dataloader`’╝īńö▒õ║ĵ▓Īµ£ēµĀćµ│©’╝īµłæõ╗¼ķ£ĆĶ”üÕ£©µĢ░µŹ«Õó×Õ╝║ÕÅśµŹóõĖŁÕłĀµÄē `dict(type='LoadAnnotations')`’╝īõ╗źõĖŗµś»õĖĆõĖ¬ķģŹńĮ«ńż║õŠŗ’╝Ü
+
+```python
+test_evaluator = dict(
+ type='IoUMetric',
+ iou_metrics=['mIoU'],
+ format_only=True,
+ output_dir='work_dirs/format_results')
+test_dataloader = dict(
+ batch_size=1,
+ num_workers=4,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ dataset=dict(
+ type = 'ADE20KDataset'
+ data_root='data/ade/release_test',
+ data_prefix=dict(img_path='testing'),
+ # µĄŗĶ»ĢµĢ░µŹ«ÕÅśµŹóõĖŁµ▓Īµ£ēÕŖĀĶĮĮµĀćµ│©
+ pipeline=[
+ dict(type='LoadImageFromFile'),
+ dict(type='Resize', scale=(2048, 512), keep_ratio=True),
+ dict(type='PackSegInputs')
+ ]))
+```
+
+ńäČÕÉĵē¦ĶĪīµĄŗĶ»ĢÕæĮõ╗ż’╝Ü
+
+```shell
+python tools/test.py configs/fcn/fcn_r50-d8_4xb4-80k_ade20k-512x512.py ckpt/fcn_r50-d8_512x512_80k_ade20k_20200614_144016-f8ac5082.pth
+```
+
+### µĄŗĶ»Ģ Cityscapes µĢ░µŹ«ķøåÕ╣Čõ┐ØÕŁśĶŠōÕć║ÕłåÕē▓ń╗ōµ×£
+
+µÄ©ĶŹÉõĮ┐ńö© `CityscapesMetric` µØźõ┐ØÕŁśµ©ĪÕ×ŗÕ£© Cityscapes µĢ░µŹ«ķøåõĖŖńÜ䵥ŗĶ»Ģń╗ōµ×£’╝īõ╗źõĖŗµś»õĖĆõĖ¬ķģŹńĮ«ńż║õŠŗ’╝Ü
+
+```python
+test_evaluator = dict(
+ type='CityscapesMetric',
+ format_only=True,
+ keep_results=True,
+ output_dir='work_dirs/format_results')
+test_dataloader = dict(
+ batch_size=1,
+ num_workers=4,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ dataset=dict(
+ type='CityscapesDataset',
+ data_root='data/cityscapes/',
+ data_prefix=dict(img_path='leftImg8bit/test'),
+ pipeline=[
+ dict(type='LoadImageFromFile'),
+ dict(type='Resize', scale=(2048, 1024), keep_ratio=True),
+ dict(type='PackSegInputs')
+ ]))
+```
+
+ńäČÕÉĵē¦ĶĪīńøĖÕÉīńÜäÕæĮõ╗ż’╝īõŠŗÕ”é’╝Ü
+
+```shell
+python tools/test.py configs/fcn/fcn_r18-d8_4xb2-80k_cityscapes-512x1024.py ckpt/fcn_r18-d8_512x1024_80k_cityscapes_20201225_021327-6c50f8b4.pth
+```
diff --git a/internlm_langchain/knowledge_base/MMSegmentation/content/5_deployment.md b/internlm_langchain/knowledge_base/MMSegmentation/content/5_deployment.md
new file mode 100644
index 00000000..6a2fc69a
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMSegmentation/content/5_deployment.md
@@ -0,0 +1,242 @@
+# µĢÖń©ŗ5’╝ܵ©ĪÕ×ŗķā©ńĮ▓
+
+# MMSegmentation µ©ĪÕ×ŗķā©ńĮ▓
+
+- [µĢÖń©ŗ5’╝ܵ©ĪÕ×ŗķā©ńĮ▓](#µĢÖń©ŗ5µ©ĪÕ×ŗķā©ńĮ▓)
+- [MMSegmentation µ©ĪÕ×ŗķā©ńĮ▓](#mmsegmentation-µ©ĪÕ×ŗķā©ńĮ▓)
+ - [Õ«ēĶŻģ](#Õ«ēĶŻģ)
+ - [Õ«ēĶŻģ mmseg](#Õ«ēĶŻģ-mmseg)
+ - [Õ«ēĶŻģ mmdeploy](#Õ«ēĶŻģ-mmdeploy)
+ - [µ©ĪÕ×ŗĶĮ¼µŹó](#µ©ĪÕ×ŗĶĮ¼µŹó)
+ - [µ©ĪÕ×ŗĶ¦äĶīā](#µ©ĪÕ×ŗĶ¦äĶīā)
+ - [µ©ĪÕ×ŗµÄ©ńÉå](#µ©ĪÕ×ŗµÄ©ńÉå)
+ - [ÕÉÄń½»µ©ĪÕ×ŗµÄ©ńÉå](#ÕÉÄń½»µ©ĪÕ×ŗµÄ©ńÉå)
+ - [SDK µ©ĪÕ×ŗµÄ©ńÉå](#sdk-µ©ĪÕ×ŗµÄ©ńÉå)
+ - [µ©ĪÕ×ŗµö»µīüÕłŚĶĪ©](#µ©ĪÕ×ŗµö»µīüÕłŚĶĪ©)
+ - [µ│©µäÅõ║ŗķĪ╣](#µ│©µäÅõ║ŗķĪ╣)
+
+______________________________________________________________________
+
+[MMSegmentation](https://github.com/open-mmlab/mmsegmentation/tree/main) ÕÅłń¦░`mmseg`’╝īµś»õĖĆõĖ¬Õ¤║õ║Ä PyTorch ńÜäÕ╝Ƶ║ÉÕ»╣Ķ▒ĪÕłåÕē▓ÕĘźÕģĘń«▒ŃĆéÕ«āµś» [OpenMMLab](https://openmmlab.com/) ķĪ╣ńø«ńÜäõĖĆķā©ÕłåŃĆé
+
+## Õ«ēĶŻģ
+
+### Õ«ēĶŻģ mmseg
+
+Ķ»ĘÕÅéĶĆā[Õ«śńĮæÕ«ēĶŻģµīćÕŹŚ](https://mmsegmentation.readthedocs.io/en/latest/get_started.html)ŃĆé
+
+### Õ«ēĶŻģ mmdeploy
+
+mmdeploy µ£ēõ╗źõĖŗÕćĀń¦ŹÕ«ēĶŻģµ¢╣Õ╝Å:
+
+**µ¢╣Õ╝ÅõĖĆ’╝Ü** Õ«ēĶŻģķóäń╝¢Ķ»æÕīģ
+
+Ķ»ĘÕÅéĶĆā[Õ«ēĶŻģµ”éĶ┐░](https://mmdeploy.readthedocs.io/zh_CN/latest/get_started.html#mmdeploy)
+
+**µ¢╣Õ╝Åõ║ī’╝Ü** õĖĆķö«Õ╝ÅĶäܵ£¼Õ«ēĶŻģ
+
+Õ”éµ×£ķā©ńĮ▓Õ╣│ÕÅ░µś» **Ubuntu 18.04 ÕÅŖõ╗źõĖŖńēłµ£¼**’╝ī Ķ»ĘÕÅéĶĆā[Ķäܵ£¼Õ«ēĶŻģĶ»┤µśÄ](../01-how-to-build/build_from_script.md)’╝īÕ«īµłÉÕ«ēĶŻģĶ┐ćń©ŗŃĆé
+µ»öÕ”é’╝īõ╗źõĖŗÕæĮõ╗żÕÅ»õ╗źÕ«ēĶŻģ mmdeploy õ╗źÕÅŖķģŹÕźŚńÜäµÄ©ńÉåÕ╝ĢµōÄŌĆöŌĆö`ONNX Runtime`.
+
+```shell
+git clone --recursive -b main https://github.com/open-mmlab/mmdeploy.git
+cd mmdeploy
+python3 tools/scripts/build_ubuntu_x64_ort.py $(nproc)
+export PYTHONPATH=$(pwd)/build/lib:$PYTHONPATH
+export LD_LIBRARY_PATH=$(pwd)/../mmdeploy-dep/onnxruntime-linux-x64-1.8.1/lib/:$LD_LIBRARY_PATH
+```
+
+**Ķ»┤µśÄ**:
+
+- µŖŖ `$(pwd)/build/lib` µĘ╗ÕŖĀÕł░ `PYTHONPATH`’╝īńø«ńÜ䵜»õĖ║õ║åÕŖĀĶĮĮ mmdeploy SDK python Õīģ `mmdeploy_runtime`’╝īÕ£©ń½ĀĶŖé [SDKµ©ĪÕ×ŗµÄ©ńÉå](#sdkµ©ĪÕ×ŗµÄ©ńÉå)õĖŁĶ«▓Ķ┐░ÕģČńö©µ│ĢŃĆé
+- Õ£©[õĮ┐ńö© ONNX RuntimeµÄ©ńÉåÕÉÄń½»µ©ĪÕ×ŗ](#ÕÉÄń½»µ©ĪÕ×ŗµÄ©ńÉå)µŚČ’╝īķ£ĆĶ”üÕŖĀĶĮĮĶć¬Õ«Üõ╣ēń«ŚÕŁÉÕ║ō’╝īķ£ĆĶ”üµŖŖ ONNX Runtime Õ║ōńÜäĶĘ»ÕŠäÕŖĀÕģźńÄ»ÕóāÕÅśķćÅ `LD_LIBRARY_PATH`õĖŁŃĆé
+ **µ¢╣Õ╝ÅõĖē’╝Ü** µ║ÉńĀüÕ«ēĶŻģ
+
+Õ£©µ¢╣Õ╝ÅõĖĆŃĆüõ║īķāĮµ╗ĪĶČ│õĖŹõ║åńÜäµāģÕåĄõĖŗ’╝īĶ»ĘÕÅéĶĆā[µ║ÉńĀüÕ«ēĶŻģĶ»┤µśÄ](../01-how-to-build/build_from_source.md) Õ«ēĶŻģ mmdeploy õ╗źÕÅŖµēĆķ£ĆµÄ©ńÉåÕ╝ĢµōÄŃĆé
+
+## µ©ĪÕ×ŗĶĮ¼µŹó
+
+õĮĀÕÅ»õ╗źõĮ┐ńö© [tools/deploy.py](https://github.com/open-mmlab/mmdeploy/tree/main/tools/deploy.py) µŖŖ mmseg µ©ĪÕ×ŗõĖĆķö«Õ╝ÅĶĮ¼µŹóõĖ║µÄ©ńÉåÕÉÄń½»µ©ĪÕ×ŗŃĆé
+Ķ»źÕĘźÕģĘńÜäĶ»”ń╗åõĮ┐ńö©Ķ»┤µśÄĶ»ĘÕÅéĶĆā[Ķ┐Öķćī](https://github.com/open-mmlab/mmdeploy/tree/main/docs/en/02-how-to-run/convert_model.md#usage).
+
+õ╗źõĖŗ’╝īµłæõ╗¼Õ░åµ╝öńż║Õ”éõĮĢµŖŖ `unet` ĶĮ¼µŹóõĖ║ onnx µ©ĪÕ×ŗŃĆé
+
+```shell
+cd mmdeploy
+
+# download unet model from mmseg model zoo
+mim download mmsegmentation --config unet-s5-d16_fcn_4xb4-160k_cityscapes-512x1024 --dest .
+
+# convert mmseg model to onnxruntime model with dynamic shape
+python tools/deploy.py \
+ configs/mmseg/segmentation_onnxruntime_dynamic.py \
+ unet-s5-d16_fcn_4xb4-160k_cityscapes-512x1024.py \
+ fcn_unet_s5-d16_4x4_512x1024_160k_cityscapes_20211210_145204-6860854e.pth \
+ demo/resources/cityscapes.png \
+ --work-dir mmdeploy_models/mmseg/ort \
+ --device cpu \
+ --show \
+ --dump-info
+```
+
+ĶĮ¼µŹóńÜäÕģ│ķö«õ╣ŗõĖƵś»õĮ┐ńö©µŁŻńĪ«ńÜäķģŹńĮ«µ¢ćõ╗ČŃĆéķĪ╣ńø«õĖŁÕĘ▓ÕåģńĮ«õ║åÕÉäÕÉÄń½»ķā©ńĮ▓[ķģŹńĮ«µ¢ćõ╗Č](https://github.com/open-mmlab/mmdeploy/tree/main/configs/mmseg)ŃĆé
+µ¢ćõ╗ČńÜäÕæĮÕÉŹµ©ĪÕ╝ŵś»’╝Ü
+
+```
+segmentation_{backend}-{precision}_{static | dynamic}_{shape}.py
+```
+
+ÕģČõĖŁ’╝Ü
+
+- **{backend}:** µÄ©ńÉåÕÉÄń½»ÕÉŹń¦░ŃĆéµ»öÕ”é’╝īonnxruntimeŃĆütensorrtŃĆüpplnnŃĆüncnnŃĆüopenvinoŃĆücoreml ńŁēńŁē
+- **{precision}:** µÄ©ńÉåń▓ŠÕ║”ŃĆéµ»öÕ”é’╝īfp16ŃĆüint8ŃĆéõĖŹÕĪ½ĶĪ©ńż║ fp32
+- **{static | dynamic}:** ÕŖ©µĆüŃĆüķØÖµĆü shape
+- **{shape}:** µ©ĪÕ×ŗĶŠōÕģźńÜä shape µł¢ĶĆģ shape ĶīāÕø┤
+
+Õ£©õĖŖõŠŗõĖŁ’╝īõĮĀõ╣¤ÕÅ»õ╗źµŖŖ `unet` ĶĮ¼õĖ║ÕģČõ╗¢ÕÉÄń½»µ©ĪÕ×ŗŃĆéµ»öÕ”éõĮ┐ńö©`segmentation_tensorrt-fp16_dynamic-512x1024-2048x2048.py`’╝īµŖŖµ©ĪÕ×ŗĶĮ¼õĖ║ tensorrt-fp16 µ©ĪÕ×ŗŃĆé
+
+```{tip}
+ÕĮōĶĮ¼ tensorrt µ©ĪÕ×ŗµŚČ, --device ķ£ĆĶ”üĶó½Ķ«ŠńĮ«õĖ║ "cuda"
+```
+
+## µ©ĪÕ×ŗĶ¦äĶīā
+
+Õ£©õĮ┐ńö©ĶĮ¼µŹóÕÉÄńÜ䵩ĪÕ×ŗĶ┐øĶĪīµÄ©ńÉåõ╣ŗÕēŹ’╝īµ£ēÕ┐ģĶ”üõ║åĶ¦ŻĶĮ¼µŹóń╗ōµ×£ńÜäń╗ōµ×äŃĆé Õ«āÕŁśµöŠÕ£© `--work-dir` µīćÕ«ÜńÜäĶĘ»ĶĘ»ÕŠäõĖŗŃĆé
+
+õĖŖõŠŗõĖŁńÜä`mmdeploy_models/mmseg/ort`’╝īń╗ōµ×äÕ”éõĖŗ’╝Ü
+
+```
+mmdeploy_models/mmseg/ort
+Ōö£ŌöĆŌöĆ deploy.json
+Ōö£ŌöĆŌöĆ detail.json
+Ōö£ŌöĆŌöĆ end2end.onnx
+ŌööŌöĆŌöĆ pipeline.json
+```
+
+ķćŹĶ”üńÜ䵜»’╝Ü
+
+- **end2end.onnx**: µÄ©ńÉåÕ╝Ģµōĵ¢ćõ╗ČŃĆéÕÅ»ńö© ONNX Runtime µÄ©ńÉå
+- \***.json**: mmdeploy SDK µÄ©ńÉåµēĆķ£ĆńÜä meta õ┐Īµü»
+
+µĢ┤õĖ¬µ¢ćõ╗ČÕż╣Ķó½Õ«Üõ╣ēõĖ║**mmdeploy SDK model**ŃĆ鵏óĶ©Ćõ╣ŗ’╝ī**mmdeploy SDK model**µŚóÕīģµŗ¼µÄ©ńÉåÕ╝ĢµōÄ’╝īõ╣¤Õīģµŗ¼µÄ©ńÉå meta õ┐Īµü»ŃĆé
+
+## µ©ĪÕ×ŗµÄ©ńÉå
+
+### ÕÉÄń½»µ©ĪÕ×ŗµÄ©ńÉå
+
+õ╗źõĖŖĶ┐░µ©ĪÕ×ŗĶĮ¼µŹóÕÉÄńÜä `end2end.onnx` õĖ║õŠŗ’╝īõĮĀÕÅ»õ╗źõĮ┐ńö©Õ”éõĖŗõ╗ŻńĀüĶ┐øĶĪīµÄ©ńÉå’╝Ü
+
+```python
+from mmdeploy.apis.utils import build_task_processor
+from mmdeploy.utils import get_input_shape, load_config
+import torch
+
+deploy_cfg = 'configs/mmseg/segmentation_onnxruntime_dynamic.py'
+model_cfg = './unet-s5-d16_fcn_4xb4-160k_cityscapes-512x1024.py'
+device = 'cpu'
+backend_model = ['./mmdeploy_models/mmseg/ort/end2end.onnx']
+image = './demo/resources/cityscapes.png'
+
+# read deploy_cfg and model_cfg
+deploy_cfg, model_cfg = load_config(deploy_cfg, model_cfg)
+
+# build task and backend model
+task_processor = build_task_processor(model_cfg, deploy_cfg, device)
+model = task_processor.build_backend_model(backend_model)
+
+# process input image
+input_shape = get_input_shape(deploy_cfg)
+model_inputs, _ = task_processor.create_input(image, input_shape)
+
+# do model inference
+with torch.no_grad():
+ result = model.test_step(model_inputs)
+
+# visualize results
+task_processor.visualize(
+ image=image,
+ model=model,
+ result=result[0],
+ window_name='visualize',
+ output_file='./output_segmentation.png')
+```
+
+### SDK µ©ĪÕ×ŗµÄ©ńÉå
+
+õĮĀõ╣¤ÕÅ»õ╗źÕÅéĶĆāÕ”éõĖŗõ╗ŻńĀü’╝īÕ»╣ SDK model Ķ┐øĶĪīµÄ©ńÉå’╝Ü
+
+```python
+from mmdeploy_runtime import Segmentor
+import cv2
+import numpy as np
+
+img = cv2.imread('./demo/resources/cityscapes.png')
+
+# create a classifier
+segmentor = Segmentor(model_path='./mmdeploy_models/mmseg/ort', device_name='cpu', device_id=0)
+# perform inference
+seg = segmentor(img)
+
+# visualize inference result
+## random a palette with size 256x3
+palette = np.random.randint(0, 256, size=(256, 3))
+color_seg = np.zeros((seg.shape[0], seg.shape[1], 3), dtype=np.uint8)
+for label, color in enumerate(palette):
+ color_seg[seg == label, :] = color
+# convert to BGR
+color_seg = color_seg[..., ::-1]
+img = img * 0.5 + color_seg * 0.5
+img = img.astype(np.uint8)
+cv2.imwrite('output_segmentation.png', img)
+```
+
+ķÖżõ║åpython API’╝īmmdeploy SDK Ķ┐śµÅÉõŠøõ║åĶ»ĖÕ”é CŃĆüC++ŃĆüC#ŃĆüJavańŁēÕżÜĶ»ŁĶ©ĆµÄźÕÅŻŃĆé
+õĮĀÕÅ»õ╗źÕÅéĶĆā[µĀĘõŠŗ](https://github.com/open-mmlab/mmdeploy/tree/main/demo)ÕŁ”õ╣ĀÕģČõ╗¢Ķ»ŁĶ©ĆµÄźÕÅŻńÜäõĮ┐ńö©µ¢╣µ│ĢŃĆé
+
+## µ©ĪÕ×ŗµö»µīüÕłŚĶĪ©
+
+| Model | TorchScript | OnnxRuntime | TensorRT | ncnn | PPLNN | OpenVino |
+| :-------------------------------------------------------------------------------------------------------- | :---------: | :---------: | :------: | :--: | :---: | :------: |
+| [FCN](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/fcn) | Y | Y | Y | Y | Y | Y |
+| [PSPNet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/pspnet)[\*](#static_shape) | Y | Y | Y | Y | Y | Y |
+| [DeepLabV3](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/deeplabv3) | Y | Y | Y | Y | Y | Y |
+| [DeepLabV3+](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/deeplabv3plus) | Y | Y | Y | Y | Y | Y |
+| [Fast-SCNN](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/fastscnn)[\*](#static_shape) | Y | Y | Y | N | Y | Y |
+| [UNet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/unet) | Y | Y | Y | Y | Y | Y |
+| [ANN](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/ann)[\*](#static_shape) | Y | Y | Y | N | N | N |
+| [APCNet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/apcnet) | Y | Y | Y | Y | N | N |
+| [BiSeNetV1](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/bisenetv1) | Y | Y | Y | Y | N | Y |
+| [BiSeNetV2](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/bisenetv2) | Y | Y | Y | Y | N | Y |
+| [CGNet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/cgnet) | Y | Y | Y | Y | N | Y |
+| [DMNet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/dmnet) | ? | Y | N | N | N | N |
+| [DNLNet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/dnlnet) | ? | Y | Y | Y | N | Y |
+| [EMANet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/emanet) | Y | Y | Y | N | N | Y |
+| [EncNet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/encnet) | Y | Y | Y | N | N | Y |
+| [ERFNet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/erfnet) | Y | Y | Y | Y | N | Y |
+| [FastFCN](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/fastfcn) | Y | Y | Y | Y | N | Y |
+| [GCNet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/gcnet) | Y | Y | Y | N | N | N |
+| [ICNet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/icnet)[\*](#static_shape) | Y | Y | Y | N | N | Y |
+| [ISANet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/isanet)[\*](#static_shape) | N | Y | Y | N | N | Y |
+| [NonLocal Net](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/nonlocal_net) | ? | Y | Y | Y | N | Y |
+| [OCRNet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/ocrnet) | Y | Y | Y | Y | N | Y |
+| [PointRend](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/point_rend)[\*](#static_shape) | Y | Y | Y | N | N | N |
+| [Semantic FPN](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/sem_fpn) | Y | Y | Y | Y | N | Y |
+| [STDC](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/stdc) | Y | Y | Y | Y | N | Y |
+| [UPerNet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/upernet)[\*](#static_shape) | N | Y | Y | N | N | N |
+| [DANet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/danet) | ? | Y | Y | N | N | Y |
+| [Segmenter](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/segmenter)[\*](#static_shape) | N | Y | Y | Y | N | Y |
+| [SegFormer](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/segformer)[\*](#static_shape) | ? | Y | Y | N | N | Y |
+| [SETR](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/setr) | ? | Y | N | N | N | Y |
+| [CCNet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/ccnet) | ? | N | N | N | N | N |
+| [PSANet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/psanet) | ? | N | N | N | N | N |
+| [DPT](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/dpt) | ? | N | N | N | N | N |
+
+## µ│©µäÅõ║ŗķĪ╣
+
+- µēƵ£ē mmseg µ©ĪÕ×ŗõ╗ģµö»µīü "whole" µÄ©ńÉ嵩ĪÕ╝ÅŃĆé
+
+- PSPNet’╝īFast-SCNN õ╗ģµö»µīüķØÖµĆüĶŠōÕģź’╝īÕøĀõĖ║ÕżÜµĢ░µÄ©ńÉåµĪåµ×ČńÜä [nn.AdaptiveAvgPool2d](https://github.com/open-mmlab/mmsegmentation/blob/0c87f7a0c9099844eff8e90fa3db5b0d0ca02fee/mmseg/models/decode_heads/psp_head.py#L38) õĖŹµö»µīüÕŖ©µĆüĶŠōÕģźŃĆé
+
+- Õ»╣õ║Äõ╗ģµö»µīüķØÖµĆüÕĮóńŖČńÜ䵩ĪÕ×ŗ’╝īÕ║öõĮ┐ńö©ķØÖµĆüÕĮóńŖČńÜäķā©ńĮ▓ķģŹńĮ«µ¢ćõ╗Č’╝īõŠŗÕ”é `configs/mmseg/segmentation_tensorrt_static-1024x2048.py`
+
+- Õ»╣õ║ÄÕ¢£µ¼óķā©ńĮ▓µ©ĪÕ×ŗńö¤µłÉµ”éńÄćńē╣ÕŠüÕøŠńÜäńö©µłĘ’╝īÕ░å `codebase_config = dict(with_argmax=False)` µöŠÕ£©ķā©ńĮ▓ķģŹńĮ«õĖŁÕ░▒ĶČ│Õż¤õ║åŃĆé
diff --git a/internlm_langchain/knowledge_base/MMSegmentation/content/add_datasets.md b/internlm_langchain/knowledge_base/MMSegmentation/content/add_datasets.md
new file mode 100644
index 00000000..22fbf346
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMSegmentation/content/add_datasets.md
@@ -0,0 +1,199 @@
+# µ¢░Õó×Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøå
+
+## µ¢░Õó×Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøå
+
+Õ£©Ķ┐Öķćī’╝īµłæõ╗¼Õ▒Ģńż║Õ”éõĮĢµ×äÕ╗║õĖĆõĖ¬µ¢░ńÜäµĢ░µŹ«ķøåŃĆé
+
+1. ÕłøÕ╗║õĖĆõĖ¬µ¢░µ¢ćõ╗Č `mmseg/datasets/example.py`
+
+ ```python
+ from mmseg.registry import DATASETS
+ from .basesegdataset import BaseSegDataset
+
+
+ @DATASETS.register_module()
+ class ExampleDataset(BaseSegDataset):
+
+ METAINFO = dict(
+ classes=('xxx', 'xxx', ...),
+ palette=[[x, x, x], [x, x, x], ...])
+
+ def __init__(self, aeg1, arg2):
+ pass
+ ```
+
+2. Õ£© `mmseg/datasets/__init__.py` õĖŁÕ»╝Õģźµ©ĪÕØŚ
+
+ ```python
+ from .example import ExampleDataset
+ ```
+
+3. ķĆÜĶ┐ćÕłøÕ╗║õĖĆõĖ¬µ¢░ńÜäµĢ░µŹ«ķøåķģŹńĮ«µ¢ćõ╗Č `configs/_base_/datasets/example_dataset.py` µØźõĮ┐ńö©Õ«ā
+
+ ```python
+ dataset_type = 'ExampleDataset'
+ data_root = 'data/example/'
+ ...
+ ```
+
+4. Õ£© `mmseg/utils/class_names.py` õĖŁĶĪźÕģģµĢ░µŹ«ķøåÕģāõ┐Īµü»
+
+ ```python
+ def example_classes():
+ return [
+ 'xxx', 'xxx',
+ ...
+ ]
+
+ def example_palette():
+ return [
+ [x, x, x], [x, x, x],
+ ...
+ ]
+ dataset_aliases ={
+ 'example': ['example', ...],
+ ...
+ }
+ ```
+
+**µ│©µäÅ’╝Ü** Õ”éµ×£µ¢░µĢ░µŹ«ķøåõĖŹµ╗ĪĶČ│ mmseg ńÜäĶ”üµ▒é’╝īÕłÖķ£ĆĶ”üÕ£© `tools/dataset_converters/` õĖŁÕćåÕżćõĖĆõĖ¬µĢ░µŹ«ķøåķóäÕżäńÉåĶäܵ£¼
+
+## ķĆÜĶ┐ćķ揵¢░ń╗äń╗ćµĢ░µŹ«µØźÕ«ÜÕłČµĢ░µŹ«ķøå
+
+µ£Ćń«ĆÕŹĢńÜäµ¢╣µ│Ģµś»Õ░åµé©ńÜäµĢ░µŹ«ķøåĶ┐øĶĪīĶĮ¼Õī¢’╝īÕ╣Čń╗äń╗浳ɵ¢ćõ╗ČÕż╣ńÜäÕĮóÕ╝ÅŃĆé
+
+Õ”éõĖŗńÜäµ¢ćõ╗Čń╗ōµ×äÕ░▒µś»õĖĆõĖ¬õŠŗÕŁÉŃĆé
+
+```none
+Ōö£ŌöĆŌöĆ data
+Ōöé Ōö£ŌöĆŌöĆ my_dataset
+Ōöé Ōöé Ōö£ŌöĆŌöĆ img_dir
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ train
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ xxx{img_suffix}
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ yyy{img_suffix}
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ zzz{img_suffix}
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ val
+Ōöé Ōöé Ōö£ŌöĆŌöĆ ann_dir
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ train
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ xxx{seg_map_suffix}
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ yyy{seg_map_suffix}
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ zzz{seg_map_suffix}
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ val
+
+```
+
+õĖĆõĖ¬Ķ«Łń╗āÕ»╣Õ░åńö▒ img_dir/ann_dir ķćīÕÉīµĀĘķ”¢ń╝ĆńÜäµ¢ćõ╗Čń╗䵳ÉŃĆé
+
+µ£ēõ║øµĢ░µŹ«ķøåõĖŹõ╝ÜÕÅæÕĖāµĄŗĶ»Ģķøåµł¢µĄŗĶ»ĢķøåńÜäµĀćµ│©’╝īÕ”éµ×£µ▓Īµ£ēµĄŗĶ»ĢķøåńÜäµĀćµ│©’╝īµłæõ╗¼Õ░▒µŚĀµ│ĢÕ£©µ£¼Õ£░Ķ┐øĶĪīĶ»äõ╝░µ©ĪÕ×ŗ’╝īÕøĀµŁżµłæõ╗¼Õ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁÕ░åķ¬īĶ»üķøåĶ«ŠńĮ«õĖ║ķ╗śĶ«żµĄŗĶ»ĢķøåŃĆé
+
+Õģ│õ║ÄÕ”éõĮĢµ×äÕ╗║Ķć¬ÕĘ▒ńÜäµĢ░µŹ«ķøåµł¢Õ«×ńÄ░µ¢░ńÜäµĢ░µŹ«ķøåń▒╗’╝īĶ»ĘÕÅéķśģ[µĢ░µŹ«ķøåµīćÕŹŚ](./datasets.md)õ╗źĶÄĘÕÅ¢µø┤ÕżÜĶ»”ń╗åõ┐Īµü»ŃĆé
+
+**µ│©µäÅ’╝Ü** µĀćµ│©µś»ĶʤÕøŠÕāÅÕÉīµĀĘńÜäÕĮóńŖČ (H, W)’╝īÕģČõĖŁńÜäÕāÅń┤ĀÕĆ╝ńÜäĶīāÕø┤µś» `[0, num_classes - 1]`ŃĆé
+µé©õ╣¤ÕÅ»õ╗źõĮ┐ńö© [pillow](https://pillow.readthedocs.io/en/stable/handbook/concepts.html#palette) ńÜä `'P'` µ©ĪÕ╝ÅÕÄ╗ÕłøÕ╗║ÕīģÕɽķó£Ķē▓ńÜäµĀćµ│©ŃĆé
+
+## ķĆÜĶ┐ćµĘĘÕÉłµĢ░µŹ«ÕÄ╗Õ«ÜÕłČµĢ░µŹ«ķøå
+
+MMSegmentation ÕÉīµĀʵö»µīüµĘĘÕÉłµĢ░µŹ«ķøåÕÄ╗Ķ«Łń╗āŃĆé
+ÕĮōÕēŹÕ«āµö»µīüµŗ╝µÄź (concat), ķćŹÕżŹ (repeat) ÕÆīÕżÜÕøŠµĘĘÕÉł (multi-image mix) µĢ░µŹ«ķøåŃĆé
+
+### ķćŹÕżŹµĢ░µŹ«ķøå
+
+µłæõ╗¼õĮ┐ńö© `RepeatDataset` õĮ£õĖ║ÕīģĶŻģ (wrapper) ÕÄ╗ķćŹÕżŹµĢ░µŹ«ķøåŃĆé
+õŠŗÕ”é’╝īÕüćĶ«ŠÕĤզŗµĢ░µŹ«ķøåµś» `Dataset_A`’╝īõĖ║õ║åķćŹÕżŹÕ«ā’╝īķģŹńĮ«µ¢ćõ╗ČÕ”éõĖŗ’╝Ü
+
+```python
+dataset_A_train = dict(
+ type='RepeatDataset',
+ times=N,
+ dataset=dict( # Ķ┐Öµś» Dataset_A µĢ░µŹ«ķøåńÜäÕĤզŗķģŹńĮ«
+ type='Dataset_A',
+ ...
+ pipeline=train_pipeline
+ )
+)
+```
+
+### µŗ╝µÄźµĢ░µŹ«ķøå
+
+Õ”éµ×£Ķ”üµŗ╝µÄźõĖŹÕÉīńÜäµĢ░µŹ«ķøå’╝īÕÅ»õ╗źµīēÕ”éõĖŗµ¢╣Õ╝ÅĶ┐׵ğµĢ░µŹ«ķøåķģŹńĮ«ŃĆé
+
+```python
+dataset_A_train = dict()
+dataset_B_train = dict()
+concatenate_dataset = dict(
+ type='ConcatDataset',
+ datasets=[dataset_A_train, dataset_B_train])
+```
+
+õĖŗķØ󵜻õĖĆõĖ¬µø┤ÕżŹµØéńÜäńż║õŠŗ’╝īÕ«āÕłåÕł½ķćŹÕżŹ `Dataset_A` ÕÆī `Dataset_B` N µ¼ĪÕÆī M µ¼Ī’╝īńäČÕÉÄĶ┐׵ğķćŹÕżŹńÜäµĢ░µŹ«ķøåŃĆé
+
+```python
+dataset_A_train = dict(
+ type='RepeatDataset',
+ times=N,
+ dataset=dict(
+ type='Dataset_A',
+ ...
+ pipeline=train_pipeline
+ )
+)
+dataset_A_val = dict(
+ ...
+ pipeline=test_pipeline
+)
+dataset_A_test = dict(
+ ...
+ pipeline=test_pipeline
+)
+dataset_B_train = dict(
+ type='RepeatDataset',
+ times=M,
+ dataset=dict(
+ type='Dataset_B',
+ ...
+ pipeline=train_pipeline
+ )
+)
+train_dataloader = dict(
+ dataset=dict(
+ type='ConcatDataset',
+ datasets=[dataset_A_train, dataset_B_train]))
+
+val_dataloader = dict(dataset=dataset_A_val)
+test_dataloader = dict(dataset=dataset_A_test)
+
+```
+
+µé©ÕÅ»õ╗źÕÅéĶĆā mmengine ńÜäÕ¤║ńĪƵĢ░µŹ«ķøå[µĢÖń©ŗ](https://mmengine.readthedocs.io/zh_CN/latest/advanced_tutorials/basedataset.html)õ╗źõ║åĶ¦Żµø┤ÕżÜĶ»”ń╗åõ┐Īµü»
+
+### ÕżÜÕøŠµĘĘÕÉłķøå
+
+µłæõ╗¼õĮ┐ńö© `MultiImageMixDataset` õĮ£õĖ║ÕīģĶŻģ’╝łwrapper’╝ēÕÄ╗µĘĘÕÉłÕżÜõĖ¬µĢ░µŹ«ķøåńÜäÕøŠńēćŃĆé
+`MultiImageMixDataset`ÕÅ»õ╗źĶó½ń▒╗õ╝╝ mosaic ÕÆī mixup ńÜäÕżÜÕøŠµĘĘÕÉłµĢ░µŹ«ÕóŚÕ╣┐õĮ┐ńö©ŃĆé
+
+`MultiImageMixDataset` õĖÄ `Mosaic` µĢ░µŹ«ÕóŚÕ╣┐õĖĆĶĄĘõĮ┐ńö©ńÜäõŠŗÕŁÉ’╝Ü
+
+```python
+train_pipeline = [
+ dict(type='RandomMosaic', prob=1),
+ dict(type='Resize', img_scale=(1024, 512), keep_ratio=True),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='PackSegInputs')
+]
+
+train_dataset = dict(
+ type='MultiImageMixDataset',
+ dataset=dict(
+ type=dataset_type,
+ reduce_zero_label=False,
+ img_dir=data_root + "images/train",
+ ann_dir=data_root + "annotations/train",
+ pipeline=[
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations'),
+ ]
+ ),
+ pipeline=train_pipeline
+)
+
+```
diff --git a/internlm_langchain/knowledge_base/MMSegmentation/content/add_metrics.md b/internlm_langchain/knowledge_base/MMSegmentation/content/add_metrics.md
new file mode 100644
index 00000000..0637b447
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMSegmentation/content/add_metrics.md
@@ -0,0 +1,81 @@
+# µ¢░Õó×Ķ»äµĄŗµīćµĀć
+
+## õĮ┐ńö© MMSegmentation ńÜäµ║Éõ╗ŻńĀüĶ┐øĶĪīÕ╝ĆÕÅæ
+
+Õ£©Ķ┐Öķćī’╝īµłæõ╗¼ńö© `CustomMetric` õĮ£õĖ║õŠŗÕŁÉµØźÕ▒Ģńż║Õ”éõĮĢÕ╝ĆÕÅæõĖĆõĖ¬µ¢░ńÜäĶ»äµĄŗµīćµĀćŃĆé
+
+1. ÕłøÕ╗║õĖĆõĖ¬µ¢░µ¢ćõ╗Č `mmseg/evaluation/metrics/custom_metric.py`ŃĆé
+
+ ```python
+ from typing import List, Sequence
+
+ from mmengine.evaluator import BaseMetric
+
+ from mmseg.registry import METRICS
+
+
+ @METRICS.register_module()
+ class CustomMetric(BaseMetric):
+
+ def __init__(self, arg1, arg2):
+ """
+ The metric first processes each batch of data_samples and predictions,
+ and appends the processed results to the results list. Then it
+ collects all results together from all ranks if distributed training
+ is used. Finally, it computes the metrics of the entire dataset.
+ """
+
+ def process(self, data_batch: dict, data_samples: Sequence[dict]) -> None:
+ pass
+
+ def compute_metrics(self, results: list) -> dict:
+ pass
+
+ def evaluate(self, size: int) -> dict:
+ pass
+ ```
+
+ Õ£©õĖŖķØóńÜäńż║õŠŗõĖŁ’╝ī`CustomMetric` µś» `BaseMetric` ńÜäÕŁÉń▒╗ŃĆéÕ«āµ£ēõĖēõĖ¬µ¢╣µ│Ģ’╝Ü`process`’╝ī`compute_metrics` ÕÆī `evaluate`ŃĆé
+
+ - `process()` ÕżäńÉåõĖƵē╣µĢ░µŹ«µĀʵ£¼ÕÆīķó䵥ŗŃĆéÕżäńÉåÕÉÄńÜäń╗ōµ×£ķ£ĆĶ”üµśŠńż║Õ£░õ╝Āń╗Ö `self.results` ’╝īÕ░åÕ£©ÕżäńÉåµēƵ£ēµĢ░µŹ«µĀʵ£¼ÕÉÄńö©õ║ÄĶ«Īń«ŚµīćµĀćŃĆéµø┤ÕżÜń╗åĶŖéĶ»ĘÕÅéĶĆā [MMEngine µ¢ćµĪŻ](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/design/evaluation.md)
+
+ - `compute_metrics()` ńö©õ║Äõ╗ÄÕżäńÉåÕÉÄńÜäń╗ōµ×£õĖŁĶ«Īń«ŚµīćµĀćŃĆé
+
+ - `evaluate()` µś»õĖĆõĖ¬µÄźÕÅŻ’╝īńö©õ║ÄĶ«Īń«ŚµīćµĀćÕ╣ČĶ┐öÕø×ń╗ōµ×£ŃĆéÕ«āÕ░åńö▒ `ValLoop` µł¢ `TestLoop` Õ£© `Runner` õĖŁĶ░āńö©ŃĆéÕ£©Õż¦ÕżÜµĢ░µāģÕåĄõĖŗ’╝īµé©õĖŹķ£ĆĶ”üķćŹÕåÖµŁżµ¢╣µ│Ģ’╝īõĮåÕ”éµ×£µé©µā│ÕüÜõĖĆõ║øķóØÕż¢ńÜäÕĘźõĮ£’╝īÕÅ»õ╗źķćŹÕåÖÕ«āŃĆé
+
+ **µ│©µäÅ’╝Ü** µé©ÕÅ»õ╗źÕ£©[Ķ┐Öķćī](https://github.com/open-mmlab/mmengine/blob/main/mmengine/runner/loops.py#L366) µēŠÕł░ `Runner` Ķ░āńö© `evaluate()` µ¢╣µ│ĢńÜäĶ┐ćń©ŗŃĆé`Runner` µś»Ķ«Łń╗āÕÆīµĄŗĶ»ĢĶ┐ćń©ŗńÜäµē¦ĶĪīÕÖ©’╝īµé©ÕÅ»õ╗źÕ£©[Ķ«Łń╗āÕ╝Ģµōĵ¢ćµĪŻ](./engine.md)õĖŁµēŠÕł░µ£ēÕģ│Õ«āńÜäĶ»”ń╗åõ┐Īµü»ŃĆé
+
+2. Õ£© `mmseg/evaluation/metrics/__init__.py` õĖŁÕ»╝Õģźµ¢░ńÜäµīćµĀćŃĆé
+
+ ```python
+ from .custom_metric import CustomMetric
+ __all__ = ['CustomMetric', ...]
+ ```
+
+3. Õ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁĶ«ŠńĮ«µ¢░ńÜäĶ»äµĄŗµīćµĀć
+
+ ```python
+ val_evaluator = dict(type='CustomMetric', arg1=xxx, arg2=xxx)
+ test_evaluator = dict(type='CustomMetric', arg1=xxx, arg2=xxx)
+ ```
+
+## õĮ┐ńö©ÕÅæÕĖāńēłµ£¼ńÜä MMSegmentation Ķ┐øĶĪīÕ╝ĆÕÅæ
+
+õĖŖķØóńÜäńż║õŠŗÕ▒Ģńż║õ║åÕ”éõĮĢõĮ┐ńö© MMSegmentation ńÜäµ║Éõ╗ŻńĀüÕ╝ĆÕÅæµ¢░µīćµĀćŃĆéÕ”éµ×£µé©µā│õĮ┐ńö© MMSegmentation ńÜäÕÅæÕĖāńēłµ£¼Õ╝ĆÕÅæµ¢░µīćµĀć’╝īÕÅ»õ╗źµīēńģ¦õ╗źõĖŗµŁźķ¬żµōŹõĮ£ŃĆé
+
+1. ÕłøÕ╗║õĖĆõĖ¬µ¢░µ¢ćõ╗Č `/Path/to/metrics/custom_metric.py`’╝īÕ«×ńÄ░ `process`’╝ī`compute_metrics` ÕÆī `evaluate` µ¢╣µ│Ģ’╝ī`evaluate` µ¢╣µ│Ģµś»ÕÅ»ķĆēńÜäŃĆé
+
+2. Õ£©õ╗ŻńĀüµł¢ķģŹńĮ«µ¢ćõ╗ČõĖŁÕ»╝Õģźµ¢░ńÜäµīćµĀćŃĆé
+
+ ```python
+ from path.to.metrics import CustomMetric
+ ```
+
+ µł¢ĶĆģ
+
+ ```python
+ custom_imports = dict(imports=['/Path/to/metrics'], allow_failed_imports=False)
+
+ val_evaluator = dict(type='CustomMetric', arg1=xxx, arg2=xxx)
+ test_evaluator = dict(type='CustomMetric', arg1=xxx, arg2=xxx)
+ ```
diff --git a/internlm_langchain/knowledge_base/MMSegmentation/content/add_models.md b/internlm_langchain/knowledge_base/MMSegmentation/content/add_models.md
new file mode 100644
index 00000000..e05c07c8
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMSegmentation/content/add_models.md
@@ -0,0 +1,260 @@
+# µ¢░Õó×µ©ĪÕØŚ
+
+## Õ╝ĆÕÅæµ¢░ń╗äõ╗Č
+
+µłæõ╗¼ÕÅ»õ╗źĶć¬Õ«Üõ╣ē [µ©ĪÕ×ŗµ¢ćµĪŻ](./models.md) õĖŁõ╗ŗń╗ŹńÜäµēƵ£ēń╗äõ╗Č’╝īõŠŗÕ”é**õĖ╗Õ╣▓ńĮæń╗£’╝łbackbone’╝ē**ŃĆü**Õż┤’╝łhead’╝ē**ŃĆü**µŹ¤Õż▒ÕćĮµĢ░’╝łloss function’╝ē**ÕÆī**µĢ░µŹ«ķóäÕżäńÉåÕÖ©’╝łdata preprocessor’╝ē**ŃĆé
+
+### µĘ╗ÕŖĀµ¢░ńÜäõĖ╗Õ╣▓ńĮæń╗£’╝łbackbone’╝ē
+
+Õ£©Ķ┐Öķćī’╝īµłæõ╗¼õ╗ź MobileNet õĖ║õŠŗÕ▒Ģńż║Õ”éõĮĢÕ╝ĆÕÅæµ¢░ńÜäõĖ╗Õ╣▓ńĮæń╗£ŃĆé
+
+1. ÕłøÕ╗║õĖĆõĖ¬µ¢░µ¢ćõ╗Č `mmseg/models/backbones/mobilenet.py`ŃĆé
+
+ ```python
+ import torch.nn as nn
+
+ from mmseg.registry import MODELS
+
+
+ @MODELS.register_module()
+ class MobileNet(nn.Module):
+
+ def __init__(self, arg1, arg2):
+ pass
+
+ def forward(self, x): # should return a tuple
+ pass
+
+ def init_weights(self, pretrained=None):
+ pass
+ ```
+
+2. Õ£© `mmseg/models/backbones/__init__.py` õĖŁÕ╝ĢÕģźµ©ĪÕØŚŃĆé
+
+ ```python
+ from .mobilenet import MobileNet
+ ```
+
+3. Õ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁõĮ┐ńö©Õ«āŃĆé
+
+ ```python
+ model = dict(
+ ...
+ backbone=dict(
+ type='MobileNet',
+ arg1=xxx,
+ arg2=xxx),
+ ...
+ ```
+
+### µĘ╗ÕŖĀµ¢░ńÜäÕż┤’╝łhead’╝ē
+
+Õ£© MMSegmentation õĖŁ’╝īµłæõ╗¼µÅÉõŠø [BaseDecodeHead](https://github.com/open-mmlab/mmsegmentation/blob/1.x/mmseg/models/decode_heads/decode_head.py#L17) ńö©õ║ÄÕ╝ĆÕÅæµēƵ£ēÕłåÕē▓Õż┤ŃĆé
+µēƵ£ēµ¢░Õ«×ńÄ░ńÜäĶ¦ŻńĀüÕż┤ķāĮÕ║öĶ»źõ╗ÄõĖŁµ┤Šńö¤Õć║µØźŃĆé
+µÄźõĖŗµØźµłæõ╗¼õ╗ź [PSPNet](https://arxiv.org/abs/1612.01105) õĖ║õŠŗĶ»┤µśÄÕ”éõĮĢÕ╝ĆÕÅæµ¢░ńÜäÕż┤ŃĆé
+
+ķ”¢Õģł’╝īÕ£© `mmseg/models/decode_heads/psp_head.py` õĖŁµĘ╗ÕŖĀõĖĆõĖ¬µ¢░ńÜäĶ¦ŻńĀüÕż┤ŃĆé
+PSPNet Õ«×ńÄ░õ║åńö©õ║ÄÕłåÕē▓Ķ¦ŻńĀüńÜäĶ¦ŻńĀüÕż┤ŃĆé
+õĖ║õ║åÕ«×ńÄ░Ķ¦ŻńĀüÕż┤’╝īÕ£©µ¢░µ©ĪÕØŚõĖŁµłæõ╗¼ķ£ĆĶ”üµē¦ĶĪīõ╗źõĖŗõĖēõĖ¬ÕćĮµĢ░ŃĆé
+
+```python
+from mmseg.registry import MODELS
+
+@MODELS.register_module()
+class PSPHead(BaseDecodeHead):
+
+ def __init__(self, pool_scales=(1, 2, 3, 6), **kwargs):
+ super(PSPHead, self).__init__(**kwargs)
+
+ def init_weights(self):
+ pass
+
+ def forward(self, inputs):
+ pass
+```
+
+µÄźõĖŗµØź’╝īńö©µłĘķ£ĆĶ”üÕ£© `mmseg/models/decode_heads/__init__.py` õĖŁµĘ╗ÕŖĀµ©ĪÕØŚ’╝īĶ┐ÖµĀĘńøĖÕ║öńÜäµ│©ÕåīÕÖ©Õ░▒ÕÅ»õ╗źµēŠÕł░Õ╣ČÕŖĀĶĮĮÕ«āõ╗¼ŃĆé
+
+PSPNet ńÜäķģŹńĮ«µ¢ćõ╗ČÕ”éõĖŗ
+
+```python
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ pretrained='pretrain_model/resnet50_v1c_trick-2cccc1ad.pth',
+ backbone=dict(
+ type='ResNetV1c',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ dilations=(1, 1, 2, 4),
+ strides=(1, 2, 1, 1),
+ norm_cfg=norm_cfg,
+ norm_eval=False,
+ style='pytorch',
+ contract_dilation=True),
+ decode_head=dict(
+ type='PSPHead',
+ in_channels=2048,
+ in_index=3,
+ channels=512,
+ pool_scales=(1, 2, 3, 6),
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)))
+
+```
+
+### µĘ╗ÕŖĀµ¢░ńÜ䵏¤Õż▒ÕćĮµĢ░’╝łloss’╝ē
+
+ÕüćĶ«Šµé©µā│õĖ║ÕłåÕē▓Ķ¦ŻńĀüµĘ╗ÕŖĀõĖĆõĖ¬ÕŽÕüÜ `MyLoss` ńÜäµ¢░ńÜ䵏¤Õż▒ÕćĮµĢ░ŃĆé
+Ķ”üµĘ╗ÕŖĀµ¢░ńÜ䵏¤Õż▒ÕćĮµĢ░’╝īńö©µłĘķ£ĆĶ”üÕ£© `mmseg/models/loss/my_loss.py` õĖŁÕ«×ńÄ░Õ«āŃĆé
+õ┐«ķź░ÕÖ© `weighted_loss` ÕÅ»õ╗źÕ»╣µŹ¤Õż▒ńÜäµ»ÅõĖ¬Õģāń┤ĀĶ┐øĶĪīÕŖĀµØāŃĆé
+
+```python
+import torch
+import torch.nn as nn
+
+from mmseg.registry import MODELS
+from .utils import weighted_loss
+
+@weighted_loss
+def my_loss(pred, target):
+ assert pred.size() == target.size() and target.numel() > 0
+ loss = torch.abs(pred - target)
+ return loss
+
+@MODELS.register_module()
+class MyLoss(nn.Module):
+
+ def __init__(self, reduction='mean', loss_weight=1.0):
+ super(MyLoss, self).__init__()
+ self.reduction = reduction
+ self.loss_weight = loss_weight
+
+ def forward(self,
+ pred,
+ target,
+ weight=None,
+ avg_factor=None,
+ reduction_override=None):
+ assert reduction_override in (None, 'none', 'mean', 'sum')
+ reduction = (
+ reduction_override if reduction_override else self.reduction)
+ loss = self.loss_weight * my_loss(
+ pred, target, weight, reduction=reduction, avg_factor=avg_factor)
+ return loss
+```
+
+ńäČÕÉÄ’╝īńö©µłĘķ£ĆĶ”üÕ░åÕģȵĘ╗ÕŖĀÕł░ `mmseg/models/loss/__init__.py` õĖŁŃĆé
+
+```python
+from .my_loss import MyLoss, my_loss
+
+```
+
+Ķ”üõĮ┐ńö©Õ«ā’╝īĶ»Ęõ┐«µö╣ `loss_xx` ÕŁŚµ«ĄŃĆé
+ńäČÕÉÄķ£ĆĶ”üõ┐«µö╣Õż┤õĖŁńÜä `loss_decode` ÕŁŚµ«ĄŃĆé
+`loss_weight` ÕÅ»ńö©õ║ÄÕ╣│ĶĪĪÕżÜķ揵Ź¤Õż▒ŃĆé
+
+```python
+loss_decode=dict(type='MyLoss', loss_weight=1.0))
+```
+
+### µĘ╗ÕŖĀµ¢░ńÜäµĢ░µŹ«ķóäÕżäńÉåÕÖ©’╝łdata preprocessor’╝ē
+
+Õ£© MMSegmentation 1.x ńēłµ£¼õĖŁ’╝īµłæõ╗¼õĮ┐ńö© [SegDataPreProcessor](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/models/data_preprocessor.py#L13) Õ░åµĢ░µŹ«ÕżŹÕłČÕł░ńø«µĀćĶ«ŠÕżć’╝īÕ╣ČÕ░åµĢ░µŹ«ķóäÕżäńÉåõĖ║ķ╗śĶ«żńÜ䵩ĪÕ×ŗĶŠōÕģźµĀ╝Õ╝ÅŃĆéĶ┐Öķćīµłæõ╗¼Õ░åÕ▒Ģńż║Õ”éõĮĢÕ╝ĆÕÅæõĖĆõĖ¬µ¢░ńÜäµĢ░µŹ«ķóäÕżäńÉåÕÖ©ŃĆé
+
+1. ÕłøÕ╗║õĖĆõĖ¬µ¢░µ¢ćõ╗Č `mmseg/models/my_datapreprocessor.py`ŃĆé
+
+ ```python
+ from mmengine.model import BaseDataPreprocessor
+
+ from mmseg.registry import MODELS
+
+ @MODELS.register_module()
+ class MyDataPreProcessor(BaseDataPreprocessor):
+ def __init__(self, **kwargs):
+ super().__init__(**kwargs)
+
+ def forward(self, data: dict, training: bool=False) -> Dict[str, Any]:
+ # TODO Define the logic for data pre-processing in the forward method
+ pass
+ ```
+
+2. Õ£© `mmseg/models/__init__.py` õĖŁÕ»╝ÕģźµĢ░µŹ«ķóäÕżäńÉåÕÖ©
+
+ ```python
+ from .my_datapreprocessor import MyDataPreProcessor
+ ```
+
+3. Õ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁõĮ┐ńö©Õ«āŃĆé
+
+ ```python
+ model = dict(
+ data_preprocessor=dict(type='MyDataPreProcessor)
+ ...
+ )
+ ```
+
+## Õ╝ĆÕÅæµ¢░ńÜäÕłåÕē▓ÕÖ©’╝łsegmentor’╝ē
+
+ÕłåÕē▓ÕÖ©µś»õĖĆń¦ŹµłĘÕÅ»õ╗źķĆÜĶ┐ćµĘ╗ÕŖĀĶć¬Õ«Üõ╣ēń╗äõ╗ČÕÆīÕ«Üõ╣ēń«Śµ│Ģµē¦ĶĪīķĆ╗ĶŠæµØźĶć¬Õ«Üõ╣ēÕģČń«Śµ│ĢńÜäń«Śµ│Ģµ×ȵ×äŃĆéĶ»ĘÕÅéĶĆā[µ©ĪÕ×ŗµ¢ćµĪŻ](./models.md)õ║åĶ¦Żµø┤ÕżÜĶ»”µāģŃĆé
+
+ńö▒õ║Ä MMSegmentation õĖŁńÜä [BaseSegmenter](https://github.com/open-mmlab/mmsegmentation/blob/1.x/mmseg/models/segmentors/base.py#L15) ń╗¤õĖĆõ║åÕēŹÕÉæĶ┐ćń©ŗńÜäõĖēń¦Źµ©ĪÕ╝Å’╝īõĖ║õ║åÕ╝ĆÕÅæµ¢░ńÜäÕłåÕē▓ÕÖ©’╝īńö©µłĘķ£ĆĶ”üķćŹÕåÖõĖÄ `loss`ŃĆü`predict` ÕÆī `tensor` ńøĖÕ»╣Õ║öńÜä `loss`ŃĆü`predict` ÕÆī `_forward` µ¢╣µ│ĢŃĆé
+
+Ķ┐Öķćīµłæõ╗¼Õ░åÕ▒Ģńż║Õ”éõĮĢÕ╝ĆÕÅæõĖĆõĖ¬µ¢░ńÜäÕłåÕē▓ÕÖ©ŃĆé
+
+1. ÕłøÕ╗║õĖĆõĖ¬µ¢░µ¢ćõ╗Č `mmseg/models/segmentors/my_segmentor.py`ŃĆé
+
+ ```python
+ from typing import Dict, Optional, Union
+
+ import torch
+
+ from mmseg.registry import MODELS
+ from mmseg.models import BaseSegmentor
+
+ @MODELS.register_module()
+ class MySegmentor(BaseSegmentor):
+ def __init__(self, **kwargs):
+ super().__init__(**kwargs)
+ # TODO users should build components of the network here
+
+ def loss(self, inputs: Tensor, data_samples: SampleList) -> dict:
+ """Calculate losses from a batch of inputs and data samples."""
+ pass
+
+ def predict(self, inputs: Tensor, data_samples: OptSampleList=None) -> SampleList:
+ """Predict results from a batch of inputs and data samples with post-
+ processing."""
+ pass
+
+ def _forward(self,
+ inputs: Tensor,
+ data_samples: OptSampleList = None) -> Tuple[List[Tensor]]:
+ """Network forward process.
+
+ Usually includes backbone, neck and head forward without any post-
+ processing.
+ """
+ pass
+ ```
+
+2. Õ£© `mmseg/models/segmentors/__init__.py` õĖŁÕ»╝ÕģźÕłåÕē▓ÕÖ©ŃĆé
+
+ ```python
+ from .my_segmentor import MySegmentor
+ ```
+
+3. Õ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁõĮ┐ńö©Õ«āŃĆé
+
+ ```python
+ model = dict(
+ type='MySegmentor'
+ ...
+ )
+ ```
diff --git a/internlm_langchain/knowledge_base/MMSegmentation/content/add_transforms.md b/internlm_langchain/knowledge_base/MMSegmentation/content/add_transforms.md
new file mode 100644
index 00000000..d7206680
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMSegmentation/content/add_transforms.md
@@ -0,0 +1,51 @@
+# µ¢░Õó×µĢ░µŹ«Õó×Õ╝║
+
+## Ķć¬Õ«Üõ╣ēµĢ░µŹ«Õó×Õ╝║
+
+Ķć¬Õ«Üõ╣ēµĢ░µŹ«Õó×Õ╝║Õ┐ģķĪ╗ń╗¦µē┐ `BaseTransform` Õ╣ČÕ«×ńÄ░ `transform` ÕćĮµĢ░ŃĆéĶ┐Öķćīµłæõ╗¼õĮ┐ńö©õĖĆõĖ¬ń«ĆÕŹĢńÜäń┐╗ĶĮ¼ÕÅśµŹóõĮ£õĖ║ńż║õŠŗ’╝Ü
+
+```python
+import random
+import mmcv
+from mmcv.transforms import BaseTransform, TRANSFORMS
+
+@TRANSFORMS.register_module()
+class MyFlip(BaseTransform):
+ def __init__(self, direction: str):
+ super().__init__()
+ self.direction = direction
+
+ def transform(self, results: dict) -> dict:
+ img = results['img']
+ results['img'] = mmcv.imflip(img, direction=self.direction)
+ return results
+```
+
+µŁżÕż¢’╝īµ¢░ńÜäń▒╗ķ£ĆĶ”üĶó½Õ»╝ÕģźŃĆé
+
+```python
+from .my_pipeline import MyFlip
+```
+
+Ķ┐ÖµĀĘ’╝īµłæõ╗¼Õ░▒ÕÅ»õ╗źÕ«×õŠŗÕī¢õĖĆõĖ¬ `MyFlip` Õ»╣Ķ▒ĪÕ╣ČõĮ┐ńö©Õ«āµØźÕżäńÉåµĢ░µŹ«ÕŁŚÕģĖŃĆé
+
+```python
+import numpy as np
+
+transform = MyFlip(direction='horizontal')
+data_dict = {'img': np.random.rand(224, 224, 3)}
+data_dict = transform(data_dict)
+processed_img = data_dict['img']
+```
+
+µł¢ĶĆģ’╝īµłæõ╗¼ÕÅ»õ╗źÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁńÜäµĢ░µŹ«µĄüń©ŗõĖŁõĮ┐ńö© `MyFlip` ÕÅśµŹóŃĆé
+
+```python
+pipeline = [
+ ...
+ dict(type='MyFlip', direction='horizontal'),
+ ...
+]
+```
+
+ķ£ĆĶ”üµ│©µäÅ’╝īÕ”éµ×£Ķ”üÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁõĮ┐ńö© `MyFlip`’╝īÕ┐ģķĪ╗ńĪ«õ┐ØÕ£©Ķ┐ÉĶĪīµŚČÕ»╝Õģźõ║åÕīģÕɽ `MyFlip` ńÜäµ¢ćõ╗ČŃĆé
diff --git a/internlm_langchain/knowledge_base/MMSegmentation/content/contribute_dataset.md b/internlm_langchain/knowledge_base/MMSegmentation/content/contribute_dataset.md
new file mode 100644
index 00000000..4222de32
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMSegmentation/content/contribute_dataset.md
@@ -0,0 +1,461 @@
+# Õ£© mmsegmentation projects õĖŁĶ┤Īńī«õĖĆõĖ¬µĀćÕćåµĀ╝Õ╝ÅńÜäµĢ░µŹ«ķøå
+
+- Õ£©Õ╝ĆÕ¦ŗµé©ńÜäĶ┤Īńī«µĄüń©ŗÕēŹ’╝īĶ»ĘÕģłķśģĶ»╗[ŃĆŖOpenMMLab Ķ┤Īńī«õ╗ŻńĀüµīćÕŹŚŃĆŗ](https://mmcv.readthedocs.io/zh_CN/latest/community/contributing.html)’╝īõ╗źĶ»”ń╗åńÜäõ║åĶ¦Ż OpenMMLab õ╗ŻńĀüÕ║ōńÜäõ╗ŻńĀüĶ┤Īńī«µĄüń©ŗŃĆé
+- Ķ»źµĢÖń©ŗõ╗ź [Gaofen Image Dataset (GID)](https://www.sciencedirect.com/science/article/pii/S0034425719303414) ķ½śÕłå 2 ÕÅĘÕŹ½µś¤µēƵŗŹµæäńÜäķüźµä¤ÕøŠÕāÅĶ»Łõ╣ēÕłåÕē▓µĢ░µŹ«ķøåõĮ£õĖ║µĀĘõŠŗ’╝īµØźµ╝öńż║Õ£© mmsegmentation õĖŁńÜäµĢ░µŹ«ķøåĶ┤Īńī«µĄüń©ŗŃĆé
+
+## µŁźķ¬ż 1’╝Ü ķģŹńĮ« mmsegmentation Õ╝ĆÕÅæµēĆķ£ĆÕ┐ģĶ”üńÄ»Õóā
+
+- Õ╝ĆÕÅæµēĆÕ┐ģķ£ĆńÜäńÄ»ÕóāÕ«ēĶŻģĶ»ĘÕÅéĶĆā[õĖŁµ¢ćÕ┐½ķƤÕģźķŚ©µīćÕŹŚ](https://github.com/open-mmlab/mmsegmentation/blob/main/docs/zh_cn/get_started.md)µł¢[Ķŗ▒µ¢ć get_started](https://github.com/open-mmlab/mmsegmentation/blob/main/docs/en/get_started.md)ŃĆé
+
+- Õ”éµ×£µé©ÕĘ▓Õ«ēĶŻģõ║åµ£Ćµ¢░ńēłńÜä pytorchŃĆümmcvŃĆümmengine’╝īķéŻõ╣łµé©ÕÅ»õ╗źĶĘ│Ķ┐浣źķ¬ż 1 Ķć│[µŁźķ¬ż 2](<#[µŁźķ¬ż-2](#%E6%AD%A5%E9%AA%A4-2%E4%BB%A3%E7%A0%81%E8%B4%A1%E7%8C%AE%E5%89%8D%E7%9A%84%E5%87%86%E5%A4%87%E5%B7%A5%E4%BD%9C)>)ŃĆé
+
+- **µ│©’╝Ü** Õ£©µŁżÕżäµŚĀķ£ĆÕ«ēĶŻģ mmsegmentation’╝īÕŬķ£ĆÕ«ēĶŻģÕ╝ĆÕÅæ mmsegmentation µēĆÕ┐ģķ£ĆńÜä pytorchŃĆümmcvŃĆümmengine ńŁēÕŹ│ÕÅ»ŃĆé
+
+**µ¢░Õ╗║ĶÖܵŗ¤ńÄ»Õóā’╝łÕ”éÕĘ▓µ£ēÕÉłķĆéńÜäÕ╝ĆÕÅæńÄ»Õóā’╝īÕÅ»ĶĘ│Ķ┐ć’╝ē**
+
+- õ╗Ä[Õ«śµ¢╣ńĮæń½Ö](https://docs.conda.io/en/latest/miniconda.html)õĖŗĶĮĮÕ╣ČÕ«ēĶŻģ Miniconda
+- ÕłøÕ╗║õĖĆõĖ¬ conda ńÄ»Õóā’╝īÕ╣ȵ┐Ƶ┤╗
+
+```shell
+conda create --name openmmlab python=3.8 -y
+conda activate openmmlab
+```
+
+**Õ«ēĶŻģ pytorch ’╝łÕ”éńÄ»ÕóāõĖŗÕĘ▓Õ«ēĶŻģ pytorch’╝īÕÅ»ĶĘ│Ķ┐ć’╝ē**
+
+- ÕÅéĶĆā [official instructions](https://pytorch.org/get-started/locally/) Õ«ēĶŻģ **PyTorch**
+
+**õĮ┐ńö© mim Õ«ēĶŻģ mmcvŃĆümmengine**
+
+- õĮ┐ńö© [MIM](https://github.com/open-mmlab/mim) Õ«ēĶŻģ [MMCV](https://github.com/open-mmlab/mmcv)
+
+```shell
+pip install -U openmim
+mim install mmengine
+mim install "mmcv>=2.0.0"
+```
+
+## µŁźķ¬ż 2’╝Üõ╗ŻńĀüĶ┤Īńī«ÕēŹńÜäÕćåÕżćÕĘźõĮ£
+
+### 2.1 Fork mmsegmentation õ╗ōÕ║ō
+
+- ķĆÜĶ┐浥ÅĶ¦łÕÖ©µēōÕ╝Ć[mmsegmentation Õ«śµ¢╣õ╗ōÕ║ō](https://github.com/open-mmlab/mmsegmentation/tree/main)ŃĆé
+- ńÖ╗ÕĮĢµé©ńÜä GitHub Ķ┤”µłĘ’╝īõ╗źõĖŗµŁźķ¬żÕØćķ£ĆÕ£© GitHub ńÖ╗ÕĮĢńÜäµāģÕåĄõĖŗĶ┐øĶĪīŃĆé
+- Fork mmsegmentation õ╗ōÕ║ō
+ 
+- Fork õ╣ŗÕÉÄ’╝īmmsegmentation õ╗ōÕ║ōÕ░åõ╝ÜÕć║ńÄ░Õ£©µé©ńÜäõĖ¬õ║║õ╗ōÕ║ōõĖŁŃĆé
+
+### 2.2 Õ£©µé©ńÜäõ╗ŻńĀüń╝¢ÕåÖĶĮ»õ╗ČõĖŁ git clone mmsegmentation
+
+Ķ┐Öķćīõ╗ź VSCODE õĖ║õŠŗ
+
+- µēōÕ╝Ć VSCODE’╝īµ¢░Õ╗║ń╗łń½»ń¬ŚÕÅŻÕ╣ȵ┐Ƶ┤╗µé©Õ£©[µŁźķ¬ż 1 ](#%E6%AD%A5%E9%AA%A4-1-%E9%85%8D%E7%BD%AE-mmsegmentation-%E5%BC%80%E5%8F%91%E6%89%80%E9%9C%80%E5%BF%85%E8%A6%81%E7%8E%AF%E5%A2%83)õĖŁµēĆÕ«ēĶŻģńÜäĶÖܵŗ¤ńÄ»ÕóāŃĆé
+- Õ£©µé© GitHub ńÜäõĖ¬õ║║õ╗ōÕ║ōõĖŁµēŠÕł░µé© Fork ńÜä mmsegmentation õ╗ōÕ║ō’╝īÕżŹÕłČÕģČķōŠµÄźŃĆé
+ 
+- Õ£©ń╗łń½»õĖŁµē¦ĶĪīÕæĮõ╗ż
+ ```bash
+ git clone {µé©µēĆÕżŹÕłČńÜäõĖ¬õ║║õ╗ōÕ║ōńÜäķōŠµÄź}
+ ```
+ 
+ **µ│©’╝Ü** Õ”éµÅÉńż║õ╗źõĖŗõ┐Īµü»’╝īĶ»ĘÕ£© GitHub õĖŁµĘ╗ÕŖĀ [SSH ń¦śķÆź](https://docs.github.com/en/authentication/connecting-to-github-with-ssh/generating-a-new-ssh-key-and-adding-it-to-the-ssh-agent)
+ 
+- Ķ┐øÕģź mmsegmentation ńø«ÕĮĢ’╝łõ╣ŗÕÉÄńÜäµōŹõĮ£ÕØćÕ£© mmsegmentation ńø«ÕĮĢõĖŗ’╝ēŃĆé
+ ```bash
+ cd mmsegmentation
+ ```
+- Õ£©ń╗łń½»õĖŁµē¦ĶĪīõ╗źõĖŗÕæĮõ╗ż’╝īµĘ╗ÕŖĀÕ«śµ¢╣õ╗ōÕ║ōõĖ║õĖŖµĖĖõ╗ōÕ║ōŃĆé
+ ```bash
+ git remote add upstream git@github.com:open-mmlab/mmsegmentation.git
+ ```
+- õĮ┐ńö©õ╗źõĖŗÕæĮõ╗żµŻĆµ¤ź remote µś»ÕÉ”µĘ╗ÕŖĀµłÉÕŖ¤ŃĆé
+ ```bash
+ git remote -v
+ ```
+ 
+
+### 2.3 ÕłćµŹóńø«ÕĮĢĶć│ mmsegmentation Õ╣Čõ╗ĵ║ÉńĀüÕ«ēĶŻģmmsegmentation
+
+Õ£©`mmsegmentation`ńø«ÕĮĢõĖŗµē¦ĶĪī`pip install -v -e .`’╝īķĆÜĶ┐ćµ║ÉńĀüµ×äÕ╗║µ¢╣Õ╝ÅÕ«ēĶŻģ mmsegmentaion Õ║ōŃĆé
+Õ«ēĶŻģÕ«īµłÉÕÉÄ’╝īµé©Õ░åĶāĮń£ŗÕł░Õ”éõĖŗÕøŠµēĆńż║ńÜäµ¢ćõ╗ȵĀæŃĆé
+ +
+### 2.4 ÕłćµŹóÕłåµö»õĖ║ dev-1.x
+
+µŁŻÕ”éµé©Õ£©[ mmsegmentation Õ«śńĮæ](https://github.com/open-mmlab/mmsegmentation/tree/main)µēĆĶ¦ü’╝īĶ»źõ╗ōÕ║ōµ£ēĶ«ĖÕżÜÕłåµö»’╝īķ╗śĶ«żÕłåµö»`main`õĖ║ń©│Õ«ÜńÜäÕÅæĶĪīńēłµ£¼’╝īõ╗źÕÅŖńö©õ║ÄĶ┤Īńī«ĶĆģĶ┐øĶĪīÕ╝ĆÕÅæńÜä`dev-1.x`Õłåµö»ŃĆé`dev-1.x`Õłåµö»µś»Ķ┤Īńī«ĶĆģõ╗¼ńö©µØźµÅÉõ║żÕłøµäÅÕÆī PR ńÜäÕłåµö»’╝ī`dev-1.x`Õłåµö»ńÜäÕåģÕ«╣õ╝ÜĶó½Õ橵£¤µĆ¦ńÜäÕÉłÕģźÕł░`main`Õłåµö»ŃĆé
+
+
+Õø×Õł░ VSCODE õĖŁ’╝īÕ£©ń╗łń½»µē¦ĶĪīÕæĮõ╗ż
+
+```bash
+git checkout dev-1.x
+```
+
+### 2.5 Õłøµ¢░Õ▒×õ║ÄĶć¬ÕĘ▒ńÜäµ¢░Õłåµö»
+
+Õ£©Õ¤║õ║Ä`dev-1.x`Õłåµö»õĖŗ’╝īõĮ┐ńö©Õ”éõĖŗÕæĮõ╗ż’╝īÕłøÕ╗║Õ▒×õ║ĵé©Ķć¬ÕĘ▒ńÜäÕłåµö»ŃĆé
+
+```bash
+# git checkout -b µé©ńÜäGitHubID/µé©ńÜäÕłåµö»µā│Ķ”üÕ«×ńÄ░ńÜäÕŖ¤ĶāĮńÜäÕÉŹÕŁŚ
+# git checkout -b AI-Tianlong/support_GID_dataset
+git checkout -b {µé©ńÜäGitHubID/µé©ńÜäÕłåµö»µā│Ķ”üÕ«×ńÄ░ńÜäÕŖ¤ĶāĮńÜäÕÉŹÕŁŚ}
+```
+
+### 2.6 ķģŹńĮ« pre-commit
+
+OpenMMLab õ╗ōÕ║ōÕ»╣õ╗ŻńĀüĶ┤©ķćŵ£ēńØĆĶŠāķ½śńÜäĶ”üµ▒é’╝īµēƵ£ēµÅÉõ║żńÜä PR Õ┐ģķĪ╗Ķ”üķĆÜĶ┐ćõ╗ŻńĀüµĀ╝Õ╝ŵŻĆµ¤źŃĆépre-commit Ķ»”ń╗åķģŹńĮ«ÕÅéķśģ[ķģŹńĮ« pre-commit](https://mmcv.readthedocs.io/zh_CN/latest/community/contributing.html#pre-commit)ŃĆé
+
+## µŁźķ¬ż 3’╝ÜÕ£©`mmsegmentation/projects`õĖŗĶ┤Īńī«µé©ńÜäõ╗ŻńĀü
+
+**ÕģłÕ»╣ GID µĢ░µŹ«ķøåĶ┐øĶĪīÕłåµ×É**
+
+Ķ┐Öķćīõ╗źĶ┤Īńī«ķ½śÕłå 2 ÕÅĘķüźµä¤ÕøŠÕāÅĶ»Łõ╣ēÕłåÕē▓µĢ░µŹ«ķøå GID õĖ║õŠŗ’╝īGID µĢ░µŹ«ķøåµś»ńö▒µłæÕøĮĶć¬õĖ╗ńĀöÕÅæńÜäķ½śÕłå 2 ÕÅĘÕŹ½µś¤µēƵŗŹµæäńÜäÕģēÕŁ”ķüźµä¤ÕøŠÕāŵēĆÕłøÕ╗║’╝īń╗ÅÕøŠÕāÅķóäÕżäńÉåÕÉÄÕģ▒µÅÉõŠøõ║å 150 Õ╝Ā 6800x7200 ÕāÅń┤ĀńÜä RGB õĖēķĆÜķüōķüźµä¤ÕøŠÕāÅŃĆéÕ╣ȵÅÉõŠøõ║åõĖżń¦ŹõĖŹÕÉīń▒╗Õł½µĢ░ńÜäµĢ░µŹ«µĀćµ│©’╝īõĖĆń¦Źµś»ÕīģÕɽ 5 ń▒╗µ£ēµĢłńē®õĮōńÜä RGB µĀćńŁŠ’╝īÕÅ”õĖĆń¦Źµś»ÕīģÕɽ 15 ń▒╗µ£ēµĢłńē®õĮōńÜä RGB µĀćńŁŠŃĆéµ£¼µĢÖń©ŗÕ░åķÆłÕ»╣ 5 ń▒╗µĀćńŁŠĶ┐øĶĪīµĢ░µŹ«ķøåĶ┤Īńī«µĄüń©ŗĶ«▓Ķ¦ŻŃĆé
+
+GID ńÜä 5 ń▒╗µ£ēµĢłµĀćńŁŠÕłåÕł½õĖ║’╝Ü0-ĶāīµÖ»-\[0,0,0\](mask µĀćńŁŠÕĆ╝-µĀćńŁŠÕÉŹń¦░-RGB µĀćńŁŠÕĆ╝)ŃĆü1-Õ╗║ńŁæ-\[255,0,0\]ŃĆü2-Õå£ńö░-\[0,255,0\]ŃĆü3-µŻ«µ×Ś-\[0,0,255\]ŃĆü4-ĶŹēÕ£░-\[255,255,0\]ŃĆü5-µ░┤-\[0,0,255\]ŃĆéÕ£©Ķ»Łõ╣ēÕłåÕē▓õ╗╗ÕŖĪõĖŁ’╝īµĀćńŁŠµś»õĖÄÕĤÕøŠÕ░║Õ»ĖõĖĆĶć┤ńÜäÕŹĢķĆÜķüōÕøŠÕāÅ’╝īµĀćńŁŠÕøŠÕāÅõĖŁńÜäÕāÅń┤ĀÕĆ╝õĖ║ń£¤Õ«×µĀʵ£¼ÕøŠÕāÅõĖŁÕ»╣Õ║öÕāÅń┤ĀµēĆÕīģÕɽńÜäńē®õĮōńÜäń▒╗Õł½ŃĆéGID µĢ░µŹ«ķøåµÅÉõŠøńÜ䵜»Õģʵ£ē RGB õĖēķĆÜķüōńÜäÕĮ®Ķē▓µĀćńŁŠ’╝īõĖ║õ║嵩ĪÕ×ŗńÜäĶ«Łń╗āķ£ĆĶ”üÕ░å RGB µĀćńŁŠĶĮ¼µŹóõĖ║ mask µĀćńŁŠŃĆéÕ╣ČõĖöńö▒õ║ÄÕøŠÕāÅÕ░║Õ»ĖõĖ║ 6800x7200 ÕāÅń┤Ā’╝īÕ»╣õ║Äńź×ń╗ÅńĮæń╗£ńÜäĶ«Łń╗āµØźµ£ēõ║øĶ┐ćÕż¦’╝īµēĆõ╗źÕ░åµ»ÅÕ╝ĀÕøŠÕāÅĶŻüÕłćµłÉõ║åµ▓Īµ£ēķćŹÕÅĀńÜä 512x512 ńÜäÕøŠÕāÅõ╗źõŠ┐Ķ┐øĶĪīĶ«Łń╗āŃĆé
+
+
+### 2.4 ÕłćµŹóÕłåµö»õĖ║ dev-1.x
+
+µŁŻÕ”éµé©Õ£©[ mmsegmentation Õ«śńĮæ](https://github.com/open-mmlab/mmsegmentation/tree/main)µēĆĶ¦ü’╝īĶ»źõ╗ōÕ║ōµ£ēĶ«ĖÕżÜÕłåµö»’╝īķ╗śĶ«żÕłåµö»`main`õĖ║ń©│Õ«ÜńÜäÕÅæĶĪīńēłµ£¼’╝īõ╗źÕÅŖńö©õ║ÄĶ┤Īńī«ĶĆģĶ┐øĶĪīÕ╝ĆÕÅæńÜä`dev-1.x`Õłåµö»ŃĆé`dev-1.x`Õłåµö»µś»Ķ┤Īńī«ĶĆģõ╗¼ńö©µØźµÅÉõ║żÕłøµäÅÕÆī PR ńÜäÕłåµö»’╝ī`dev-1.x`Õłåµö»ńÜäÕåģÕ«╣õ╝ÜĶó½Õ橵£¤µĆ¦ńÜäÕÉłÕģźÕł░`main`Õłåµö»ŃĆé
+
+
+Õø×Õł░ VSCODE õĖŁ’╝īÕ£©ń╗łń½»µē¦ĶĪīÕæĮõ╗ż
+
+```bash
+git checkout dev-1.x
+```
+
+### 2.5 Õłøµ¢░Õ▒×õ║ÄĶć¬ÕĘ▒ńÜäµ¢░Õłåµö»
+
+Õ£©Õ¤║õ║Ä`dev-1.x`Õłåµö»õĖŗ’╝īõĮ┐ńö©Õ”éõĖŗÕæĮõ╗ż’╝īÕłøÕ╗║Õ▒×õ║ĵé©Ķć¬ÕĘ▒ńÜäÕłåµö»ŃĆé
+
+```bash
+# git checkout -b µé©ńÜäGitHubID/µé©ńÜäÕłåµö»µā│Ķ”üÕ«×ńÄ░ńÜäÕŖ¤ĶāĮńÜäÕÉŹÕŁŚ
+# git checkout -b AI-Tianlong/support_GID_dataset
+git checkout -b {µé©ńÜäGitHubID/µé©ńÜäÕłåµö»µā│Ķ”üÕ«×ńÄ░ńÜäÕŖ¤ĶāĮńÜäÕÉŹÕŁŚ}
+```
+
+### 2.6 ķģŹńĮ« pre-commit
+
+OpenMMLab õ╗ōÕ║ōÕ»╣õ╗ŻńĀüĶ┤©ķćŵ£ēńØĆĶŠāķ½śńÜäĶ”üµ▒é’╝īµēƵ£ēµÅÉõ║żńÜä PR Õ┐ģķĪ╗Ķ”üķĆÜĶ┐ćõ╗ŻńĀüµĀ╝Õ╝ŵŻĆµ¤źŃĆépre-commit Ķ»”ń╗åķģŹńĮ«ÕÅéķśģ[ķģŹńĮ« pre-commit](https://mmcv.readthedocs.io/zh_CN/latest/community/contributing.html#pre-commit)ŃĆé
+
+## µŁźķ¬ż 3’╝ÜÕ£©`mmsegmentation/projects`õĖŗĶ┤Īńī«µé©ńÜäõ╗ŻńĀü
+
+**ÕģłÕ»╣ GID µĢ░µŹ«ķøåĶ┐øĶĪīÕłåµ×É**
+
+Ķ┐Öķćīõ╗źĶ┤Īńī«ķ½śÕłå 2 ÕÅĘķüźµä¤ÕøŠÕāÅĶ»Łõ╣ēÕłåÕē▓µĢ░µŹ«ķøå GID õĖ║õŠŗ’╝īGID µĢ░µŹ«ķøåµś»ńö▒µłæÕøĮĶć¬õĖ╗ńĀöÕÅæńÜäķ½śÕłå 2 ÕÅĘÕŹ½µś¤µēƵŗŹµæäńÜäÕģēÕŁ”ķüźµä¤ÕøŠÕāŵēĆÕłøÕ╗║’╝īń╗ÅÕøŠÕāÅķóäÕżäńÉåÕÉÄÕģ▒µÅÉõŠøõ║å 150 Õ╝Ā 6800x7200 ÕāÅń┤ĀńÜä RGB õĖēķĆÜķüōķüźµä¤ÕøŠÕāÅŃĆéÕ╣ȵÅÉõŠøõ║åõĖżń¦ŹõĖŹÕÉīń▒╗Õł½µĢ░ńÜäµĢ░µŹ«µĀćµ│©’╝īõĖĆń¦Źµś»ÕīģÕɽ 5 ń▒╗µ£ēµĢłńē®õĮōńÜä RGB µĀćńŁŠ’╝īÕÅ”õĖĆń¦Źµś»ÕīģÕɽ 15 ń▒╗µ£ēµĢłńē®õĮōńÜä RGB µĀćńŁŠŃĆéµ£¼µĢÖń©ŗÕ░åķÆłÕ»╣ 5 ń▒╗µĀćńŁŠĶ┐øĶĪīµĢ░µŹ«ķøåĶ┤Īńī«µĄüń©ŗĶ«▓Ķ¦ŻŃĆé
+
+GID ńÜä 5 ń▒╗µ£ēµĢłµĀćńŁŠÕłåÕł½õĖ║’╝Ü0-ĶāīµÖ»-\[0,0,0\](mask µĀćńŁŠÕĆ╝-µĀćńŁŠÕÉŹń¦░-RGB µĀćńŁŠÕĆ╝)ŃĆü1-Õ╗║ńŁæ-\[255,0,0\]ŃĆü2-Õå£ńö░-\[0,255,0\]ŃĆü3-µŻ«µ×Ś-\[0,0,255\]ŃĆü4-ĶŹēÕ£░-\[255,255,0\]ŃĆü5-µ░┤-\[0,0,255\]ŃĆéÕ£©Ķ»Łõ╣ēÕłåÕē▓õ╗╗ÕŖĪõĖŁ’╝īµĀćńŁŠµś»õĖÄÕĤÕøŠÕ░║Õ»ĖõĖĆĶć┤ńÜäÕŹĢķĆÜķüōÕøŠÕāÅ’╝īµĀćńŁŠÕøŠÕāÅõĖŁńÜäÕāÅń┤ĀÕĆ╝õĖ║ń£¤Õ«×µĀʵ£¼ÕøŠÕāÅõĖŁÕ»╣Õ║öÕāÅń┤ĀµēĆÕīģÕɽńÜäńē®õĮōńÜäń▒╗Õł½ŃĆéGID µĢ░µŹ«ķøåµÅÉõŠøńÜ䵜»Õģʵ£ē RGB õĖēķĆÜķüōńÜäÕĮ®Ķē▓µĀćńŁŠ’╝īõĖ║õ║嵩ĪÕ×ŗńÜäĶ«Łń╗āķ£ĆĶ”üÕ░å RGB µĀćńŁŠĶĮ¼µŹóõĖ║ mask µĀćńŁŠŃĆéÕ╣ČõĖöńö▒õ║ÄÕøŠÕāÅÕ░║Õ»ĖõĖ║ 6800x7200 ÕāÅń┤Ā’╝īÕ»╣õ║Äńź×ń╗ÅńĮæń╗£ńÜäĶ«Łń╗āµØźµ£ēõ║øĶ┐ćÕż¦’╝īµēĆõ╗źÕ░åµ»ÅÕ╝ĀÕøŠÕāÅĶŻüÕłćµłÉõ║åµ▓Īµ£ēķćŹÕÅĀńÜä 512x512 ńÜäÕøŠÕāÅõ╗źõŠ┐Ķ┐øĶĪīĶ«Łń╗āŃĆé
+ +
+### 3.1 Õ£©`mmsegmentation/projects`õĖŗÕłøÕ╗║µ¢░ńÜäķĪ╣ńø«µ¢ćõ╗ČÕż╣
+
+Õ£©`mmsegmentation/projects`õĖŗÕłøÕ╗║µ¢ćõ╗ČÕż╣`gid_dataset`
+
+
+### 3.2 Ķ┤Īńī«µé©ńÜäµĢ░µŹ«ķøåõ╗ŻńĀü
+
+õĖ║õ║åµ£Ćń╗łĶāĮÕ░åµé©Õ£© projects õĖŁĶ┤Īńī«ńÜäõ╗ŻńĀüµø┤ÕŖĀķĪ║ńĢģńÜäń¦╗ÕģźµĀĖÕ┐āÕ║ōõĖŁ’╝łÕ»╣õ╗ŻńĀüĶ”üµ▒éĶ┤©ķćŵø┤ķ½ś’╝ē’╝īķØ×ÕĖĖÕ╗║Ķ««µīēńģ¦µĀĖÕ┐āÕ║ōńÜäńø«ÕĮĢµØźń╝¢ĶŠæµé©ńÜäµĢ░µŹ«ķøåµ¢ćõ╗ČŃĆé
+Õģ│õ║ĵĢ░µŹ«ķøåµ£ē 4 õĖ¬Õ┐ģĶ”üńÜäµ¢ćõ╗Č’╝Ü
+
+- **1** `mmseg/datasets/gid.py` Õ«Üõ╣ēõ║åµĢ░µŹ«ķøåńÜäÕ░Šń╝ĆŃĆüCLASSESŃĆüPALETTEŃĆüreduce_zero_labelńŁē
+- **2** `configs/_base_/gid.py` GID µĢ░µŹ«ķøåńÜäķģŹńĮ«µ¢ćõ╗Č’╝īÕ«Üõ╣ēõ║åµĢ░µŹ«ķøåńÜä`dataset_type`’╝łµĢ░µŹ«ķøåń▒╗Õ×ŗ’╝ī`mmseg/datasets/gid.py`õĖŁµ│©ÕåīńÜäµĢ░µŹ«ķøåńÜäń▒╗ÕÉŹ’╝ēŃĆü`data_root`(µĢ░µŹ«ķøåµēĆÕ£©ńÜäµĀ╣ńø«ÕĮĢ’╝īÕ╗║Ķ««Õ░åµĢ░µŹ«ķøåķĆÜĶ┐ćĶĮ»Ķ┐׵ğńÜäµ¢╣Õ╝ÅÕ░åµĢ░µŹ«ķøåµöŠĶć│`mmsegmentation/data`)ŃĆü`train_pipline`(Ķ«Łń╗āńÜäµĢ░µŹ«µĄü)ŃĆü`test_pipline`(µĄŗĶ»ĢÕÆīķ¬īĶ»üµŚČńÜäµĢ░µŹ«µĄü)ŃĆü`img_rations`(ÕżÜÕ░║Õ║”ķó䵥ŗµŚČńÜäÕżÜÕ░║Õ║”ķģŹńĮ«)ŃĆü`tta_pipeline`’╝łÕżÜÕ░║Õ║”ķó䵥ŗ’╝ēŃĆü`train_dataloader`(Ķ«Łń╗āķøåńÜäµĢ░µŹ«ÕŖĀĶĮĮÕÖ©)ŃĆü`val_dataloader`(ķ¬īĶ»üķøåńÜäµĢ░µŹ«ÕŖĀĶĮĮÕÖ©)ŃĆü`test_dataloader`(µĄŗĶ»ĢķøåńÜäµĢ░µŹ«ÕŖĀĶĮĮÕÖ©)ŃĆü`val_evaluator`(ķ¬īĶ»üķøåńÜäĶ»äõ╝░ÕÖ©)ŃĆü`test_evaluator`(µĄŗĶ»ĢķøåńÜäĶ»äõ╝░ÕÖ©)ŃĆé
+- **3** õĮ┐ńö©õ║å GID µĢ░µŹ«ķøåńÜ䵩ĪÕ×ŗĶ«Łń╗āķģŹńĮ«µ¢ćõ╗Č
+ Ķ┐ÖõĖ¬µś»ÕÅ»ķĆēńÜä’╝īõĮåµś»Õ╝║ńāłÕ╗║Ķ««µé©µĘ╗ÕŖĀŃĆéÕ£©µĀĖÕ┐āÕ║ōõĖŁ’╝īµēĆĶ┤Īńī«ńÜäµĢ░µŹ«ķøåķ£ĆĶ”üÕÆīÕÅéĶĆāµ¢ćńī«õĖŁµēƵÅÉÕć║ńÜäń╗ōµ×£ń▓ŠÕ║”Õ»╣ķĮÉ’╝īõĖ║õ║åÕÉĵ£¤Õ░åµé©Ķ┤Īńī«ńÜäõ╗ŻńĀüÕÉłÕ╣ČÕģźµĀĖÕ┐āÕ║ōŃĆéÕ”éµé©ńÜäń«ŚÕŖøÕģģĶČ│’╝īµ£ĆÕźĮĶāĮµÅÉõŠøÕ»╣Õ║öńÜ䵩ĪÕ×ŗķģŹńĮ«µ¢ćõ╗ČÕ£©µé©Ķ┤Īńī«ńÜäµĢ░µŹ«ķøåõĖŖµēĆķ¬īĶ»üńÜäń╗ōµ×£õ╗źÕÅŖńøĖÕ║öńÜäµØāķ揵¢ćõ╗Č’╝īÕ╣ȵÆ░ÕåÖĶŠāõĖ║Ķ»”ń╗åńÜäREADME.mdµ¢ćµĪŻŃĆé[ńż║õŠŗÕÅéĶĆāń╗ōµ×£](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/deeplabv3plus#mapillary-vistas-v12)
+ 
+- **4** õĮ┐ńö©Õ”éõĖŗÕæĮõ╗żµĀ╝Õ╝Å’╝Ü µÆ░ÕåÖ`docs/zh_cn/user_guides/2_dataset_prepare.md`µØźµĘ╗ÕŖĀµé©ńÜäµĢ░µŹ«ķøåõ╗ŗń╗Ź’╝īÕīģµŗ¼õĮåõĖŹķÖÉõ║ĵĢ░µŹ«ķøåńÜäõĖŗĶĮĮµ¢╣Õ╝Å’╝īµĢ░µŹ«ķøåńø«ÕĮĢń╗ōµ×äŃĆüµĢ░µŹ«ķøåńö¤µłÉńŁēõĖĆõ║øÕ┐ģĶ”üµĆ¦ńÜäµ¢ćÕŁŚµĆ¦µÅÅĶ┐░ÕÆīĶ┐ÉĶĪīÕæĮõ╗żŃĆéõ╗źµø┤ÕźĮÕ£░ÕĖ«ÕŖ®ńö©µłĘĶāĮµø┤Õ┐½ńÜäÕ«×ńÄ░µĢ░µŹ«ķøåńÜäÕćåÕżćÕĘźõĮ£ŃĆé
+
+### 3.3 Ķ┤Īńī«`tools/dataset_converters/gid.py`
+
+ńö▒õ║Ä GID µĢ░µŹ«ķøåµś»ńö▒µ£¬ń╗ÅĶ┐ćÕłćÕłåńÜä 6800x7200 ÕøŠÕāŵēƵ×䵳ÉńÜäµĢ░µŹ«ķøå’╝īÕ╣ČõĖöµ▓Īµ£ēÕłÆÕłåĶ«Łń╗āķøåŃĆüķ¬īĶ»üķøåõĖĵĄŗĶ»ĢķøåŃĆéõ╗źÕÅŖÕģȵĀćńŁŠõĖ║ RGB ÕĮ®Ķē▓µĀćńŁŠ’╝īķ£ĆĶ”üÕ░åµĀćńŁŠĶĮ¼µŹóõĖ║ÕŹĢķĆÜķüōńÜä mask labelŃĆéõĖ║õ║åµ¢╣õŠ┐Ķ«Łń╗ā’╝īķ”¢ÕģłÕ░å GID µĢ░µŹ«ķøåĶ┐øĶĪīĶŻüÕłćÕÆīµĀćńŁŠĶĮ¼µŹó’╝īÕ╣ČĶ┐øĶĪīµĢ░µŹ«ķøåÕłÆÕłå’╝īµ×äÕ╗║õĖ║ mmsegmentation µēƵö»µīüńÜäµĀ╝Õ╝ÅŃĆé
+
+```python
+# tools/dataset_converters/gid.py
+import argparse
+import glob
+import math
+import os
+import os.path as osp
+from PIL import Image
+
+import mmcv
+import numpy as np
+from mmengine.utils import ProgressBar, mkdir_or_exist
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Convert GID dataset to mmsegmentation format')
+ parser.add_argument('dataset_img_path', help='GID images folder path')
+ parser.add_argument('dataset_label_path', help='GID labels folder path')
+ parser.add_argument('--tmp_dir', help='path of the temporary directory')
+ parser.add_argument('-o', '--out_dir', help='output path', default='data/gid')
+ parser.add_argument(
+ '--clip_size',
+ type=int,
+ help='clipped size of image after preparation',
+ default=256)
+ parser.add_argument(
+ '--stride_size',
+ type=int,
+ help='stride of clipping original images',
+ default=256)
+ args = parser.parse_args()
+ return args
+
+GID_COLORMAP = dict(
+ Background=(0, 0, 0), #0-ĶāīµÖ»-ķ╗æĶē▓
+ Building=(255, 0, 0), #1-Õ╗║ńŁæ-ń║óĶē▓
+ Farmland=(0, 255, 0), #2-Õå£ńö░-ń╗┐Ķē▓
+ Forest=(0, 0, 255), #3-µŻ«µ×Ś-ĶōØĶē▓
+ Meadow=(255, 255, 0),#4-ĶŹēÕ£░-ķ╗äĶē▓
+ Water=(0, 0, 255)#5-µ░┤-ĶōØĶē▓
+)
+palette = list(GID_COLORMAP.values())
+classes = list(GID_COLORMAP.keys())
+
+#############ńö©ÕłŚĶĪ©µØźÕŁśõĖĆõĖ¬ RGB ÕÆīõĖĆõĖ¬ń▒╗Õł½ńÜäÕ»╣Õ║ö################
+def colormap2label(palette):
+ colormap2label_list = np.zeros(256**3, dtype = np.longlong)
+ for i, colormap in enumerate(palette):
+ colormap2label_list[(colormap[0] * 256 + colormap[1])*256+colormap[2]] = i
+ return colormap2label_list
+
+#############ń╗ÖÕ«ÜķéŻõĖ¬ÕłŚĶĪ©’╝īÕÆīvis_pngńäČÕÉÄńö¤µłÉmasks_png################
+def label_indices(RGB_label, colormap2label_list):
+ RGB_label = RGB_label.astype('int32')
+ idx = (RGB_label[:, :, 0] * 256 + RGB_label[:, :, 1]) * 256 + RGB_label[:, :, 2]
+ # print(idx.shape)
+ return colormap2label_list[idx]
+
+def RGB2mask(RGB_label, colormap2label_list):
+ # RGB_label = np.array(Image.open(RGB_label).convert('RGB')) #µēōÕ╝ĆRGB_png
+ mask_label = label_indices(RGB_label, colormap2label_list) # .numpy()
+ return mask_label
+
+colormap2label_list = colormap2label(palette)
+
+def clip_big_image(image_path, clip_save_dir, args, to_label=False):
+ """
+ Original image of GID dataset is very large, thus pre-processing
+ of them is adopted. Given fixed clip size and stride size to generate
+ clipped image, the intersectionŃĆĆof width and height is determined.
+ For example, given one 6800 x 7200 original image, the clip size is
+ 256 and stride size is 256, thus it would generate 29 x 27 = 783 images
+ whose size are all 256 x 256.
+
+ """
+
+ image = mmcv.imread(image_path, channel_order='rgb')
+ # image = mmcv.bgr2gray(image)
+
+ h, w, c = image.shape
+ clip_size = args.clip_size
+ stride_size = args.stride_size
+
+ num_rows = math.ceil((h - clip_size) / stride_size) if math.ceil(
+ (h - clip_size) /
+ stride_size) * stride_size + clip_size >= h else math.ceil(
+ (h - clip_size) / stride_size) + 1
+ num_cols = math.ceil((w - clip_size) / stride_size) if math.ceil(
+ (w - clip_size) /
+ stride_size) * stride_size + clip_size >= w else math.ceil(
+ (w - clip_size) / stride_size) + 1
+
+ x, y = np.meshgrid(np.arange(num_cols + 1), np.arange(num_rows + 1))
+ xmin = x * clip_size
+ ymin = y * clip_size
+
+ xmin = xmin.ravel()
+ ymin = ymin.ravel()
+ xmin_offset = np.where(xmin + clip_size > w, w - xmin - clip_size,
+ np.zeros_like(xmin))
+ ymin_offset = np.where(ymin + clip_size > h, h - ymin - clip_size,
+ np.zeros_like(ymin))
+ boxes = np.stack([
+ xmin + xmin_offset, ymin + ymin_offset,
+ np.minimum(xmin + clip_size, w),
+ np.minimum(ymin + clip_size, h)
+ ], axis=1)
+
+ if to_label:
+ image = RGB2mask(image, colormap2label_list) #Ķ┐ÖķćīÕŠŚµö╣õĖĆõĖŗ
+
+ for count, box in enumerate(boxes):
+ start_x, start_y, end_x, end_y = box
+ clipped_image = image[start_y:end_y,
+ start_x:end_x] if to_label else image[
+ start_y:end_y, start_x:end_x, :]
+ img_name = osp.basename(image_path).replace('.tif', '')
+ img_name = img_name.replace('_label', '')
+ if count % 3 == 0:
+ mmcv.imwrite(
+ clipped_image.astype(np.uint8),
+ osp.join(
+ clip_save_dir.replace('train', 'val'),
+ f'{img_name}_{start_x}_{start_y}_{end_x}_{end_y}.png'))
+ else:
+ mmcv.imwrite(
+ clipped_image.astype(np.uint8),
+ osp.join(
+ clip_save_dir,
+ f'{img_name}_{start_x}_{start_y}_{end_x}_{end_y}.png'))
+ count += 1
+
+def main():
+ args = parse_args()
+
+ """
+ According to this paper: https://ieeexplore.ieee.org/document/9343296/
+ select 15 images contained in GID, , which cover the whole six
+ categories, to generate train set and validation set.
+
+ According to Paper: https://ieeexplore.ieee.org/document/9343296/
+
+ """
+
+ if args.out_dir is None:
+ out_dir = osp.join('data', 'gid')
+ else:
+ out_dir = args.out_dir
+
+ print('Making directories...')
+ mkdir_or_exist(osp.join(out_dir, 'img_dir', 'train'))
+ mkdir_or_exist(osp.join(out_dir, 'img_dir', 'val'))
+ mkdir_or_exist(osp.join(out_dir, 'ann_dir', 'train'))
+ mkdir_or_exist(osp.join(out_dir, 'ann_dir', 'val'))
+
+ src_path_list = glob.glob(os.path.join(args.dataset_img_path, '*.tif'))
+ print(f'Find {len(src_path_list)} pictures')
+
+ prog_bar = ProgressBar(len(src_path_list))
+
+ dst_img_dir = osp.join(out_dir, 'img_dir', 'train')
+ dst_label_dir = osp.join(out_dir, 'ann_dir', 'train')
+
+ for i, img_path in enumerate(src_path_list):
+ label_path = osp.join(args.dataset_label_path, osp.basename(img_path.replace('.tif', '_label.tif')))
+
+ clip_big_image(img_path, dst_img_dir, args, to_label=False)
+ clip_big_image(label_path, dst_label_dir, args, to_label=True)
+ prog_bar.update()
+
+ print('Done!')
+
+if __name__ == '__main__':
+ main()
+```
+
+### 3.4 Ķ┤Īńī«`mmseg/datasets/gid.py`
+
+ÕÅ»ÕÅéĶĆā[`projects/mapillary_dataset/mmseg/datasets/mapillary.py`](https://github.com/open-mmlab/mmsegmentation/blob/main/projects/mapillary_dataset/mmseg/datasets/mapillary.py)Õ╣ČÕ£©µŁżÕ¤║ńĪĆõĖŖõ┐«µö╣ńøĖÕ║öÕÅśķćÅõ╗źķĆéķģŹµé©ńÜäµĢ░µŹ«ķøåŃĆé
+
+```python
+# mmseg/datasets/gid.py
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmseg.datasets.basesegdataset import BaseSegDataset
+from mmseg.registry import DATASETS
+
+# µ│©ÕåīµĢ░µŹ«ķøåń▒╗
+@DATASETS.register_module()
+class GID_Dataset(BaseSegDataset):
+ """Gaofen Image Dataset (GID)
+
+ Dataset paper link:
+ https://www.sciencedirect.com/science/article/pii/S0034425719303414
+ https://x-ytong.github.io/project/GID.html
+
+ GID 6 classes: background(others), built-up, farmland, forest, meadow, water
+
+ In This example, select 10 images from GID dataset as training set,
+ and select 5 images as validation set.
+ The selected images are listed as follows:
+
+ GF2_PMS1__L1A0000647767-MSS1
+ GF2_PMS1__L1A0001064454-MSS1
+ GF2_PMS1__L1A0001348919-MSS1
+ GF2_PMS1__L1A0001680851-MSS1
+ GF2_PMS1__L1A0001680853-MSS1
+ GF2_PMS1__L1A0001680857-MSS1
+ GF2_PMS1__L1A0001757429-MSS1
+ GF2_PMS2__L1A0000607681-MSS2
+ GF2_PMS2__L1A0000635115-MSS2
+ GF2_PMS2__L1A0000658637-MSS2
+ GF2_PMS2__L1A0001206072-MSS2
+ GF2_PMS2__L1A0001471436-MSS2
+ GF2_PMS2__L1A0001642620-MSS2
+ GF2_PMS2__L1A0001787089-MSS2
+ GF2_PMS2__L1A0001838560-MSS2
+
+ The ``img_suffix`` is fixed to '.tif' and ``seg_map_suffix`` is
+ fixed to '.tif' for GID.
+ """
+ METAINFO = dict(
+ classes=('Others', 'Built-up', 'Farmland', 'Forest',
+ 'Meadow', 'Water'),
+
+ palette=[[0, 0, 0], [255, 0, 0], [0, 255, 0], [0, 255, 255],
+ [255, 255, 0], [0, 0, 255]])
+
+ def __init__(self,
+ img_suffix='.png',
+ seg_map_suffix='.png',
+ reduce_zero_label=None,
+ **kwargs) -> None:
+ super().__init__(
+ img_suffix=img_suffix,
+ seg_map_suffix=seg_map_suffix,
+ reduce_zero_label=reduce_zero_label,
+ **kwargs)
+```
+
+### 3.5 Ķ┤Īńī«õĮ┐ńö© GID ńÜäĶ«Łń╗ā config file
+
+```python
+_base_ = [
+ '../../../configs/_base_/models/deeplabv3plus_r50-d8.py',
+ './_base_/datasets/gid.py',
+ '../../../configs/_base_/default_runtime.py',
+ '../../../configs/_base_/schedules/schedule_240k.py'
+]
+custom_imports = dict(
+ imports=['projects.gid_dataset.mmseg.datasets.gid'])
+
+crop_size = (256, 256)
+data_preprocessor = dict(size=crop_size)
+model = dict(
+ data_preprocessor=data_preprocessor,
+ pretrained='open-mmlab://resnet101_v1c',
+ backbone=dict(depth=101),
+ decode_head=dict(num_classes=6),
+ auxiliary_head=dict(num_classes=6))
+
+```
+
+### 3.6 µÆ░ÕåÖ`docs/zh_cn/user_guides/2_dataset_prepare.md`
+
+**Gaofen Image Dataset (GID)**
+
+- GID µĢ░µŹ«ķøåÕŻգ©[µŁżÕżä](https://x-ytong.github.io/project/Five-Billion-Pixels.html)Ķ┐øĶĪīõĖŗĶĮĮŃĆé
+- GID µĢ░µŹ«ķøåÕīģÕɽ 150 Õ╝Ā 6800x7200 ńÜäÕż¦Õ░║Õ»ĖÕøŠÕāÅ’╝īµĀćńŁŠõĖ║ RGB µĀćńŁŠŃĆé
+- µŁżÕżäķĆēµŗ® 15 Õ╝ĀÕøŠÕāÅńö¤µłÉĶ«Łń╗āķøåÕÆīķ¬īĶ»üķøå’╝īĶ»ź 15 Õ╝ĀÕøŠÕāÅÕīģÕɽõ║åµēƵ£ēÕģŁń▒╗õ┐Īµü»ŃĆéµēĆķĆēńÜäÕøŠÕāÅÕÉŹń¦░Õ”éõĖŗ’╝Ü
+
+```None
+ GF2_PMS1__L1A0000647767-MSS1
+ GF2_PMS1__L1A0001064454-MSS1
+ GF2_PMS1__L1A0001348919-MSS1
+ GF2_PMS1__L1A0001680851-MSS1
+ GF2_PMS1__L1A0001680853-MSS1
+ GF2_PMS1__L1A0001680857-MSS1
+ GF2_PMS1__L1A0001757429-MSS1
+ GF2_PMS2__L1A0000607681-MSS2
+ GF2_PMS2__L1A0000635115-MSS2
+ GF2_PMS2__L1A0000658637-MSS2
+ GF2_PMS2__L1A0001206072-MSS2
+ GF2_PMS2__L1A0001471436-MSS2
+ GF2_PMS2__L1A0001642620-MSS2
+ GF2_PMS2__L1A0001787089-MSS2
+ GF2_PMS2__L1A0001838560-MSS2
+```
+
+µē¦ĶĪīõ╗źõĖŗÕæĮõ╗żĶ┐øĶĪīĶŻüÕłćÕÅŖµĀćńŁŠńÜäĶĮ¼µŹó’╝īķ£ĆĶ”üõ┐«µö╣õĖ║µé©µēĆÕŁśÕé© 15 Õ╝ĀÕøŠÕāÅÕÅŖµĀćńŁŠńÜäĶĘ»ÕŠäŃĆé
+
+```
+python projects/gid_dataset/tools/dataset_converters/gid.py [15 Õ╝ĀÕøŠÕāÅńÜäĶĘ»ÕŠä] [15 Õ╝ĀµĀćńŁŠńÜäĶĘ»ÕŠä]
+```
+
+Õ«īµłÉĶŻüÕłćÕÉÄńÜä GID µĢ░µŹ«ń╗ōµ×äÕ”éõĖŗ’╝Ü
+
+```none
+mmsegmentation
+Ōö£ŌöĆŌöĆ mmseg
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+Ōö£ŌöĆŌöĆ data
+Ōöé Ōö£ŌöĆŌöĆ gid
+Ōöé Ōöé Ōö£ŌöĆŌöĆ ann_dir
+| Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ train
+| Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ val
+Ōöé Ōöé Ōö£ŌöĆŌöĆ img_dir
+| Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ train
+| Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ val
+
+```
+
+### 3.7 Ķ┤Īńī«ńÜäõ╗ŻńĀüÕÅŖµ¢ćµĪŻķĆÜĶ┐ć`pre-commit`µŻĆµ¤ź
+
+õĮ┐ńö©ÕæĮõ╗ż
+
+```bash
+git add .
+git commit -m "µĘ╗ÕŖĀµÅÅĶ┐░"
+git push
+```
+
+### 3.8 Õ£© GitHub õĖŁÕÉæ mmsegmentation µÅÉõ║ż PR
+
+ÕģĘõĮōµŁźķ¬żÕÅ»Ķ¦ü[ŃĆŖOpenMMLab Ķ┤Īńī«õ╗ŻńĀüµīćÕŹŚŃĆŗ](https://mmcv.readthedocs.io/zh_CN/latest/community/contributing.html)
diff --git a/internlm_langchain/knowledge_base/MMSegmentation/content/customize_runtime.md b/internlm_langchain/knowledge_base/MMSegmentation/content/customize_runtime.md
new file mode 100644
index 00000000..a80aca63
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMSegmentation/content/customize_runtime.md
@@ -0,0 +1,162 @@
+# Ķć¬Õ«Üõ╣ēĶ┐ÉĶĪīĶ«ŠÕ«Ü
+
+## Õ«×ńÄ░Ķć¬Õ«Üõ╣ēķÆ®ÕŁÉ
+
+### Step 1: ÕłøÕ╗║õĖĆõĖ¬µ¢░ńÜäķÆ®ÕŁÉ
+
+MMEngine ÕĘ▓Õ«×ńÄ░õ║åĶ«Łń╗āÕÆīµĄŗĶ»ĢÕĖĖńö©ńÜä[ķÆ®ÕŁÉ](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/tutorials/hook.md),
+ÕĮōµ£ēÕ«ÜÕłČÕī¢ķ£Ćµ▒鵌Č, ÕÅ»õ╗źµīēńģ¦Õ”éõĖŗńż║õŠŗÕ«×ńÄ░ķĆéńö©õ║ÄĶć¬Ķ║½Ķ«Łń╗āķ£Ćµ▒éńÜäķÆ®ÕŁÉ, õŠŗÕ”éµā│õ┐«µö╣õĖĆõĖ¬ĶČģÕÅéµĢ░ `model.hyper_paramete` ńÜäÕĆ╝, Ķ«®Õ«āķÜÅńØĆĶ«Łń╗āĶ┐Łõ╗Żµ¼ĪµĢ░ĶĆīÕÅśÕī¢:
+
+```python
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Sequence
+
+from mmengine.hooks import Hook
+from mmengine.model import is_model_wrapper
+
+from mmseg.registry import HOOKS
+
+
+@HOOKS.register_module()
+class NewHook(Hook):
+ """Docstring for NewHook.
+ """
+
+ def __init__(self, a: int, b: int) -> None:
+ self.a = a
+ self.b = b
+
+ def before_train_iter(self,
+ runner,
+ batch_idx: int,
+ data_batch: Optional[Sequence[dict]] = None) -> None:
+ cur_iter = runner.iter
+ # ÕĮōµ©ĪÕ×ŗĶó½ÕīģÕ£© wrapper ķćīµŚČĶÄĘÕÅ¢Ķ┐ÖõĖ¬µ©ĪÕ×ŗ
+ if is_model_wrapper(runner.model):
+ model = runner.model.module
+ model.hyper_parameter = self.a * cur_iter + self.b
+```
+
+### Step 2: Õ»╝ÕģźõĖĆõĖ¬µ¢░ńÜäķÆ®ÕŁÉ
+
+õĖ║õ║åĶ«®õĖŖķØóÕ«Üõ╣ēńÜ䵩ĪÕØŚÕÅ»õ╗źĶó½µē¦ĶĪīńÜäń©ŗÕ║ÅÕÅæńÄ░, Ķ┐ÖõĖ¬µ©ĪÕØŚķ£ĆĶ”üÕģłĶó½Õ»╝ÕģźõĖ╗ÕæĮÕÉŹń®║ķŚ┤ (main namespace) ķćīķØó,
+ÕüćĶ«Š NewHook Õ£© `mmseg/engine/hooks/new_hook.py` ķćīķØó, µ£ēõĖżń¦Źµ¢╣Õ╝ÅÕÄ╗Õ«×ńÄ░Õ«ā:
+
+- õ┐«µö╣ `mmseg/engine/hooks/__init__.py` µØźÕ»╝ÕģźÕ«ā.
+ µ¢░Õ«Üõ╣ēńÜ䵩ĪÕØŚÕ║öĶ»źÕ£© `mmseg/engine/hooks/__init__.py` ķćīķØóÕ»╝Õģź, Ķ┐ÖµĀʵ│©ÕåīÕÖ©ÕÅ»õ╗źÕÅæńÄ░Õ╣ȵĘ╗ÕŖĀĶ┐ÖõĖ¬µ¢░ńÜ䵩ĪÕØŚ:
+
+```python
+from .new_hook import NewHook
+
+__all__ = [..., NewHook]
+```
+
+- Õ£©ķģŹńĮ«µ¢ćõ╗ČķćīõĮ┐ńö© custom_imports µØźµēŗÕŖ©Õ»╝ÕģźÕ«ā.
+
+```python
+custom_imports = dict(imports=['mmseg.engine.hooks.new_hook'], allow_failed_imports=False)
+```
+
+### Step 3: õ┐«µö╣ķģŹńĮ«µ¢ćõ╗Č
+
+ÕÅ»õ╗źµīēńģ¦Õ”éõĖŗµ¢╣Õ╝Å, Õ£©Ķ«Łń╗āµł¢µĄŗĶ»ĢõĖŁķģŹńĮ«Õ╣ČõĮ┐ńö©Ķć¬Õ«Üõ╣ēńÜäķÆ®ÕŁÉ. õĖŹÕÉīķÆ®ÕŁÉÕ£©ÕÉīõĖĆõĮŹńé╣ńÜäõ╝śÕģłń║¦ÕÅ»õ╗źÕÅéĶĆā[Ķ┐Öķćī](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/tutorials/hook.md#%E5%86%85%E7%BD%AE%E9%92%A9%E5%AD%90), Ķć¬Õ«Üõ╣ēķÆ®ÕŁÉÕ”éµ×£µ▓Īµ£ēµīćÕ«Üõ╝śÕģł, ķ╗śĶ«żµś» `NORMAL`.
+
+```python
+custom_hooks = [
+ dict(type='NewHook', a=a_value, b=b_value, priority='ABOVE_NORMAL')
+]
+```
+
+## Õ«×ńÄ░Ķć¬Õ«Üõ╣ēõ╝śÕī¢ÕÖ©
+
+### Step 1: ÕłøÕ╗║õĖĆõĖ¬µ¢░ńÜäõ╝śÕī¢ÕÖ©
+
+Õ”éµ×£Õó×ÕŖĀõĖĆõĖ¬ÕŽõĮ£ `MyOptimizer` ńÜäõ╝śÕī¢ÕÖ©, Õ«āµ£ēÕÅéµĢ░ `a`, `b` ÕÆī `c`. µÄ©ĶŹÉÕ£© `mmseg/engine/optimizers/my_optimizer.py` µ¢ćõ╗ČõĖŁÕ«×ńÄ░
+
+```python
+from mmseg.registry import OPTIMIZERS
+from torch.optim import Optimizer
+
+
+@OPTIMIZERS.register_module()
+class MyOptimizer(Optimizer):
+
+ def __init__(self, a, b, c)
+```
+
+### Step 2: Õ»╝ÕģźõĖĆõĖ¬µ¢░ńÜäõ╝śÕī¢ÕÖ©
+
+õĖ║õ║åĶ«®õĖŖķØóÕ«Üõ╣ēńÜ䵩ĪÕØŚÕÅ»õ╗źĶó½µē¦ĶĪīńÜäń©ŗÕ║ÅÕÅæńÄ░, Ķ┐ÖõĖ¬µ©ĪÕØŚķ£ĆĶ”üÕģłĶó½Õ»╝ÕģźõĖ╗ÕæĮÕÉŹń®║ķŚ┤ (main namespace) ķćīķØó,
+ÕüćĶ«Š `MyOptimizer` Õ£© `mmseg/engine/optimizers/my_optimizer.py` ķćīķØó, µ£ēõĖżń¦Źµ¢╣Õ╝ÅÕÄ╗Õ«×ńÄ░Õ«ā:
+
+- õ┐«µö╣ `mmseg/engine/optimizers/__init__.py` µØźÕ»╝ÕģźÕ«ā.
+ µ¢░Õ«Üõ╣ēńÜ䵩ĪÕØŚÕ║öĶ»źÕ£© `mmseg/engine/optimizers/__init__.py` ķćīķØóÕ»╝Õģź, Ķ┐ÖµĀʵ│©ÕåīÕÖ©ÕÅ»õ╗źÕÅæńÄ░Õ╣ȵĘ╗ÕŖĀĶ┐ÖõĖ¬µ¢░ńÜ䵩ĪÕØŚ:
+
+```python
+from .my_optimizer import MyOptimizer
+```
+
+- Õ£©ķģŹńĮ«µ¢ćõ╗ČķćīõĮ┐ńö© `custom_imports` µØźµēŗÕŖ©Õ»╝ÕģźÕ«ā.
+
+```python
+custom_imports = dict(imports=['mmseg.engine.optimizers.my_optimizer'], allow_failed_imports=False)
+```
+
+### Step 3: õ┐«µö╣ķģŹńĮ«µ¢ćõ╗Č
+
+ķÜÅÕÉÄķ£ĆĶ”üõ┐«µö╣ķģŹńĮ«µ¢ćõ╗Č `optim_wrapper` ķćīńÜä `optimizer` ÕÅéµĢ░, Õ”éµ×£Ķ”üõĮ┐ńö©õĮĀĶć¬ÕĘ▒ńÜäõ╝śÕī¢ÕÖ© `MyOptimizer`, ÕŁŚµ«ĄÕÅ»õ╗źĶó½õ┐«µö╣µłÉ:
+
+```python
+optim_wrapper = dict(type='OptimWrapper',
+ optimizer=dict(type='MyOptimizer',
+ a=a_value, b=b_value, c=c_value),
+ clip_grad=None)
+```
+
+## Õ«×ńÄ░Ķć¬Õ«Üõ╣ēõ╝śÕī¢ÕÖ©Õ░üĶŻģµ×äķĆĀÕÖ©
+
+### Step 1: ÕłøÕ╗║õĖĆõĖ¬µ¢░ńÜäõ╝śÕī¢ÕÖ©Õ░üĶŻģµ×äķĆĀÕÖ©
+
+µ×äķĆĀÕÖ©ÕÅ»õ╗źńö©µØźÕłøÕ╗║õ╝śÕī¢ÕÖ©, õ╝śÕī¢ÕÖ©Õīģ, õ╗źÕÅŖĶć¬Õ«Üõ╣ēµ©ĪÕ×ŗńĮæń╗£õĖŹÕÉīÕ▒éńÜäĶČģÕÅéµĢ░. õĖĆõ║øµ©ĪÕ×ŗńÜäõ╝śÕī¢ÕÖ©ÕÅ»ĶāĮõ╝ܵĀ╣µŹ«ńē╣Õ«ÜńÜäÕÅéµĢ░ĶĆīĶ░āµĢ┤, õŠŗÕ”é BatchNorm Õ▒éńÜä weight decay. õĮ┐ńö©ĶĆģÕÅ»õ╗źķĆÜĶ┐ćĶć¬Õ«Üõ╣ēõ╝śÕī¢ÕÖ©µ×äķĆĀÕÖ©µØźń▓Šń╗åÕī¢Ķ«ŠÕ«ÜõĖŹÕÉīÕÅéµĢ░ńÜäõ╝śÕī¢ńŁ¢ńĢź.
+
+```python
+from mmengine.optim import DefaultOptimWrapperConstructor
+from mmseg.registry import OPTIM_WRAPPER_CONSTRUCTORS
+
+@OPTIM_WRAPPER_CONSTRUCTORS.register_module()
+class LearningRateDecayOptimizerConstructor(DefaultOptimWrapperConstructor):
+ def __init__(self, optim_wrapper_cfg, paramwise_cfg=None):
+
+ def __call__(self, model):
+
+ return my_optimizer
+```
+
+ķ╗śĶ«żńÜäõ╝śÕī¢ÕÖ©µ×äķĆĀÕÖ©Õ£©[Ķ┐Öķćī](https://github.com/open-mmlab/mmengine/blob/main/mmengine/optim/optimizer/default_constructor.py#L19) Ķó½Õ«×ńÄ░, Õ«āõ╣¤ÕÅ»õ╗źńö©µØźõĮ£õĖ║µ¢░ńÜäõ╝śÕī¢ÕÖ©µ×äķĆĀÕÖ©ńÜ䵩ĪµØ┐.
+
+### Step 2: Õ»╝ÕģźõĖĆõĖ¬µ¢░ńÜäõ╝śÕī¢ÕÖ©Õ░üĶŻģµ×äķĆĀÕÖ©
+
+õĖ║õ║åĶ«®õĖŖķØóÕ«Üõ╣ēńÜ䵩ĪÕØŚÕÅ»õ╗źĶó½µē¦ĶĪīńÜäń©ŗÕ║ÅÕÅæńÄ░, Ķ┐ÖõĖ¬µ©ĪÕØŚķ£ĆĶ”üÕģłĶó½Õ»╝ÕģźõĖ╗ÕæĮÕÉŹń®║ķŚ┤ (main namespace) ķćīķØó, ÕüćĶ«Š `MyOptimizerConstructor` Õ£© `mmseg/engine/optimizers/my_optimizer_constructor.py` ķćīķØó, µ£ēõĖżń¦Źµ¢╣Õ╝ÅÕÄ╗Õ«×ńÄ░Õ«ā:
+
+- õ┐«µö╣ `mmseg/engine/optimizers/__init__.py` µØźÕ»╝ÕģźÕ«ā.
+ µ¢░Õ«Üõ╣ēńÜ䵩ĪÕØŚÕ║öĶ»źÕ£© `mmseg/engine/optimizers/__init__.py` ķćīķØóÕ»╝Õģź, Ķ┐ÖµĀʵ│©ÕåīÕÖ©ÕÅ»õ╗źÕÅæńÄ░Õ╣ȵĘ╗ÕŖĀĶ┐ÖõĖ¬µ¢░ńÜ䵩ĪÕØŚ:
+
+```python
+from .my_optimizer_constructor import MyOptimizerConstructor
+```
+
+- Õ£©ķģŹńĮ«µ¢ćõ╗ČķćīõĮ┐ńö© `custom_imports` µØźµēŗÕŖ©Õ»╝ÕģźÕ«ā.
+
+```python
+custom_imports = dict(imports=['mmseg.engine.optimizers.my_optimizer_constructor'], allow_failed_imports=False)
+```
+
+### Step 3: õ┐«µö╣ķģŹńĮ«µ¢ćõ╗Č
+
+ķÜÅÕÉÄķ£ĆĶ”üõ┐«µö╣ķģŹńĮ«µ¢ćõ╗Č `optim_wrapper` ķćīńÜä `constructor` ÕÅéµĢ░, Õ”éµ×£Ķ”üõĮ┐ńö©õĮĀĶć¬ÕĘ▒ńÜäõ╝śÕī¢ÕÖ©Õ░üĶŻģµ×äķĆĀÕÖ© `MyOptimizerConstructor`, ÕŁŚµ«ĄÕÅ»õ╗źĶó½õ┐«µö╣µłÉ:
+
+```python
+optim_wrapper = dict(type='OptimWrapper',
+ constructor='MyOptimizerConstructor',
+ clip_grad=None)
+```
diff --git a/internlm_langchain/knowledge_base/MMSegmentation/content/data_flow.md b/internlm_langchain/knowledge_base/MMSegmentation/content/data_flow.md
new file mode 100644
index 00000000..20dbe07e
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMSegmentation/content/data_flow.md
@@ -0,0 +1,90 @@
+# µĢ░µŹ«µĄü
+
+Õ£©µ£¼ń½ĀĶŖéõĖŁ’╝īµłæõ╗¼Õ░åõ╗ŗń╗Ź [Runner](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/runner.html) ń«ĪńÉåńÜäÕåģķā©µ©ĪÕØŚõ╣ŗķŚ┤ńÜäµĢ░µŹ«µĄüÕÆīµĢ░µŹ«µĀ╝Õ╝Åń║”Õ«ÜŃĆé
+
+## µĢ░µŹ«µĄüµ”éĶ┐░
+
+[Runner](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/design/runner.md) ńøĖÕĮōõ║Ä MMEngine õĖŁńÜäŌĆ£ķøåµłÉÕÖ©ŌĆØŃĆéÕ«āĶ”åńø¢õ║åµĪåµ×ČńÜäµēƵ£ēµ¢╣ķØó’╝īÕ╣ČĶé®Ķ┤¤ńØĆń╗äń╗ćÕÆīĶ░āÕ║”ÕćĀõ╣ĵēƵ£ēµ©ĪÕØŚńÜäĶ┤Żõ╗╗’╝īĶ┐ÖµäÅÕæ│ńØĆÕÉ䵩ĪÕØŚõ╣ŗķŚ┤ńÜäµĢ░µŹ«µĄüõ╣¤ńö▒ `Runner` µÄ¦ÕłČŃĆé Õ”é [MMEngine õĖŁńÜä Runner µ¢ćµĪŻ](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/runner.html)µēĆńż║’╝īõĖŗÕøŠÕ▒Ģńż║õ║åÕ¤║µ£¼ńÜäµĢ░µŹ«µĄüŃĆé
+
+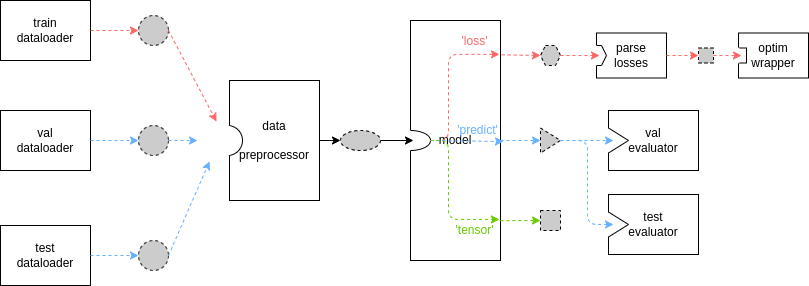
+
+ĶÖÜń║┐ĶŠ╣µĪåŃĆüńü░Ķē▓ÕĪ½ÕģģÕĮóńŖČõ╗ŻĶĪ©õĖŹÕÉīńÜäµĢ░µŹ«µĀ╝Õ╝Å’╝īĶĆīÕ«×Õ┐āµĪåĶĪ©ńż║µ©ĪÕØŚ/µ¢╣µ│ĢŃĆéńö▒õ║Ä MMEngine µ×üÕż¦ńÜäńüĄµ┤╗µĆ¦ÕÆīÕÅ»µē®Õ▒ĢµĆ¦’╝īõĖĆõ║øķćŹĶ”üńÜäÕ¤║ń▒╗ÕÅ»õ╗źĶó½ń╗¦µē┐’╝īÕ╣ČõĖöÕ«āõ╗¼ńÜäµ¢╣µ│ĢÕÅ»õ╗źĶó½Ķ”åÕåÖŃĆé õĖŖÕøŠµēĆńż║µĢ░µŹ«µĄüõ╗ģķĆéńö©õ║ÄÕĮōńö©µłĘµ▓Īµ£ēĶć¬Õ«Üõ╣ē `Runner` õĖŁńÜä `TrainLoop`ŃĆü`ValLoop` ÕÆī `TestLoop`’╝īÕ╣ČõĖöµ▓Īµ£ēÕ£©ÕģČĶć¬Õ«Üõ╣ēµ©ĪÕ×ŗõĖŁĶ”åÕåÖ `train_step`ŃĆü`val_step` ÕÆī `test_step` µ¢╣µ│ĢµŚČŃĆéMMSegmentation õĖŁ loop ńÜäķ╗śĶ«żĶ«ŠńĮ«Õ”éõĖŗ’╝ÜõĮ┐ńö©`IterBasedTrainLoop` Ķ«Łń╗āµ©ĪÕ×ŗ’╝īÕģ▒Ķ«Ī 20000 µ¼ĪĶ┐Łõ╗Ż’╝īÕ╣ČõĖöÕ£©µ»Å 2000 µ¼ĪĶ┐Łõ╗ŻÕÉÄĶ┐øĶĪīõĖƵ¼Īķ¬īĶ»üŃĆé
+
+```python
+train_cfg = dict(type='IterBasedTrainLoop', max_iters=20000, val_interval=2000)
+val_cfg = dict(type='ValLoop')
+test_cfg = dict(type='TestLoop')
+```
+
+Õ£©õĖŖÕøŠõĖŁ’╝īń║óĶē▓ń║┐ĶĪ©ńż║ [train_step](./models.md#train_step)’╝īÕ£©µ»Åµ¼ĪĶ«Łń╗āĶ┐Łõ╗ŻõĖŁ’╝īµĢ░µŹ«ÕŖĀĶĮĮÕÖ©’╝łdataloader’╝ēõ╗ÄÕŁśÕé©õĖŁÕŖĀĶĮĮÕøŠÕāÅÕ╣Čõ╝ĀĶŠōÕł░µĢ░µŹ«ķóäÕżäńÉåÕÖ©’╝łdata preprocessor’╝ē’╝īµĢ░µŹ«ķóäÕżäńÉåÕÖ©õ╝ÜÕ░åÕøŠÕāŵöŠÕł░ńē╣Õ«ÜńÜäĶ«ŠÕżćõĖŖ’╝īÕ╣ČÕ░åµĢ░µŹ«ÕĀåÕÅĀÕł░µē╣ÕżäńÉåõĖŁ’╝īõ╣ŗÕÉĵ©ĪÕ×ŗµÄźÕÅŚµē╣ÕżäńÉåµĢ░µŹ«õĮ£õĖ║ĶŠōÕģź’╝īµ£ĆÕÉÄÕ░嵩ĪÕ×ŗńÜäĶŠōÕć║ÕÅæķĆüń╗Öõ╝śÕī¢ÕÖ©’╝łoptimizer’╝ēŃĆéĶōØĶē▓ń║┐ĶĪ©ńż║ [val_step](./models.md#val_step) ÕÆī [test_step](./models.md#test_step)ŃĆéĶ┐ÖõĖżõĖ¬Ķ┐ćń©ŗńÜäµĢ░µŹ«µĄüķÖżõ║嵩ĪÕ×ŗĶŠōÕć║õĖÄ `train_step` õĖŹÕÉīÕż¢’╝īÕģČõĮÖÕØćÕÆī `train_step` ń▒╗õ╝╝ŃĆéńö▒õ║ÄÕ£©Ķ»äõ╝░µŚČµ©ĪÕ×ŗÕÅéµĢ░õ╝ÜĶó½Õå╗ń╗ō’╝īÕøĀµŁżµ©ĪÕ×ŗńÜäĶŠōÕć║Õ░åĶó½õ╝ĀķĆÆń╗Ö [Evaluator](./evaluation.md#ioumetric)ŃĆé
+µØźĶ«Īń«ŚµīćµĀćŃĆé
+
+## MMSegmentation õĖŁńÜäµĢ░µŹ«µĄüń║”Õ«Ü
+
+Õ£©õĖŖķØóńÜäÕøŠõĖŁ’╝īµłæõ╗¼ÕÅ»õ╗źń£ŗÕł░Õ¤║µ£¼ńÜäµĢ░µŹ«µĄüŃĆéÕ£©µ£¼ĶŖéõĖŁ’╝īµłæõ╗¼Õ░åÕłåÕł½õ╗ŗń╗ŹµĢ░µŹ«µĄüõĖŁµČēÕÅŖńÜäµĢ░µŹ«ńÜäµĀ╝Õ╝Åń║”Õ«ÜŃĆé
+
+### µĢ░µŹ«ÕŖĀĶĮĮÕÖ©Õł░µĢ░µŹ«ķóäÕżäńÉåÕÖ©
+
+µĢ░µŹ«ÕŖĀĶĮĮÕÖ©’╝łDataLoader’╝ēµś» MMEngine ńÜäĶ«Łń╗āÕÆīµĄŗĶ»ĢµĄüń©ŗõĖŁńÜäõĖĆõĖ¬ķćŹĶ”üń╗äõ╗ČŃĆé
+õ╗ĵ”éÕ┐ĄõĖŖĶ«▓’╝īÕ«āµ║Éõ║Ä [PyTorch](https://pytorch.org/) Õ╣Čõ┐صīüõĖĆĶć┤ŃĆéDataLoader õ╗ĵ¢ćõ╗Čń│╗ń╗¤ÕŖĀĶĮĮµĢ░µŹ«’╝īÕĤզŗµĢ░µŹ«ķĆÜĶ┐ćµĢ░µŹ«ÕćåÕżćµĄüń©ŗÕÉÄĶó½ÕÅæķĆüń╗ÖµĢ░µŹ«ķóäÕżäńÉåÕÖ©ŃĆé
+
+MMSegmentation Õ£© [PackSegInputs](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/datasets/transforms/formatting.py#L12) õĖŁÕ«Üõ╣ēõ║åķ╗śĶ«żµĢ░µŹ«µĀ╝Õ╝Å’╝ī Õ«āµś» `train_pipeline` ÕÆī `test_pipeline` ńÜäµ£ĆÕÉÄõĖĆõĖ¬ń╗äõ╗ČŃĆéµ£ēÕģ│µĢ░µŹ«ĶĮ¼µŹó `pipeline` ńÜäµø┤ÕżÜõ┐Īµü»’╝īĶ»ĘÕÅéķśģ[µĢ░µŹ«ĶĮ¼µŹóµ¢ćµĪŻ](./transforms.md)ŃĆé
+
+Õ£©µ▓Īµ£ēõ╗╗õĮĢõ┐«µö╣ńÜäµāģÕåĄõĖŗ’╝īPackSegInputs ńÜäĶ┐öÕø×ÕĆ╝ķĆÜÕĖĖµś»õĖĆõĖ¬ÕīģÕɽ `inputs` ÕÆī `data_samples` ńÜä `dict`ŃĆéõ╗źõĖŗõ╝¬õ╗ŻńĀüÕ▒Ģńż║õ║å mmseg õĖŁµĢ░µŹ«ÕŖĀĶĮĮÕÖ©ĶŠōÕć║ńÜäµĢ░µŹ«ń▒╗Õ×ŗ’╝īÕ«āµś»õ╗ĵĢ░µŹ«ķøåõĖŁĶÄĘÕÅ¢ńÜäõĖƵē╣µĢ░µŹ«µĀʵ£¼’╝īµĢ░µŹ«ÕŖĀĶĮĮÕÖ©Õ░åÕ«āõ╗¼µēōÕīģµłÉõĖĆõĖ¬ÕŁŚÕģĖÕłŚĶĪ©ŃĆé`inputs` µś»ĶŠōÕģźĶ┐øµ©ĪÕ×ŗńÜäÕ╝ĀķćÅÕłŚĶĪ©’╝ī`data_samples` ÕīģÕɽõ║åĶŠōÕģźÕøŠÕāÅńÜä meta information ÕÆīńøĖÕ║öńÜä ground truthŃĆé
+
+```python
+dict(
+ inputs=List[torch.Tensor],
+ data_samples=List[SegDataSample]
+)
+```
+
+**µ│©µäÅ’╝Ü** [SegDataSample](https://github.com/open-mmlab/mmsegmentation/blob/1.x/mmseg/structures/seg_data_sample.py) µś» MMSegmentation ńÜäµĢ░µŹ«ń╗ōµ×äµÄźÕÅŻ’╝īńö©õ║ÄĶ┐׵ğõĖŹÕÉīń╗äõ╗ČŃĆé`SegDataSample` Õ«×ńÄ░õ║åµŖĮĶ▒ĪµĢ░µŹ«Õģāń┤Ā `mmengine.structures.BaseDataElement`’╝īµø┤ÕżÜõ┐Īµü»Ķ»ĘÕ£© [MMEngine](https://github.com/open-mmlab/mmengine) õĖŁÕÅéķśģ [SegDataSample µ¢ćµĪŻ](./structures.md)ÕÆī[µĢ░µŹ«Õģāń┤Āµ¢ćµĪŻ](https://mmengine.readthedocs.io/zh_CN/latest/advanced_tutorials/data_element.html)ŃĆé
+
+### µĢ░µŹ«ķóäÕżäńÉåÕÖ©Õł░µ©ĪÕ×ŗ
+
+ĶÖĮńäČÕ£©[õĖŖķØóńÜäÕøŠ](##µĢ░µŹ«µĄüµ”éĶ┐░)õĖŁÕłåÕ╝Ćń╗śÕłČõ║åµĢ░µŹ«ķóäÕżäńÉåÕÖ©ÕÆīµ©ĪÕ×ŗ’╝īõĮåµĢ░µŹ«ķóäÕżäńÉåÕÖ©µś»µ©ĪÕ×ŗńÜäõĖĆķā©Õłå’╝īÕøĀµŁżÕÅ»õ╗źÕ£©[µ©ĪÕ×ŗµĢÖń©ŗ](./models.md)õĖŁµēŠÕł░µĢ░µŹ«ķóäÕżäńÉåÕÖ©ń½ĀĶŖéŃĆé
+
+µĢ░µŹ«ķóäÕżäńÉåÕÖ©ńÜäĶ┐öÕø×ÕĆ╝µś»õĖĆõĖ¬ÕīģÕɽ `inputs` ÕÆī `data_samples` ńÜäÕŁŚÕģĖ’╝īÕģČõĖŁ `inputs` µś»µē╣ÕżäńÉåÕøŠÕāÅńÜä 4D Õ╝ĀķćÅ’╝ī`data_samples` õĖŁµĘ╗ÕŖĀõ║åõĖĆõ║øńö©õ║ĵĢ░µŹ«ķóäÕżäńÉåńÜäķóØÕż¢Õģāõ┐Īµü»ŃĆéÕĮōõ╝ĀķĆÆń╗ÖńĮæń╗£µŚČ’╝īÕŁŚÕģĖÕ░åĶó½Ķ¦ŻÕīģõĖ║õĖżõĖ¬ÕĆ╝ŃĆé õ╗źõĖŗõ╝¬õ╗ŻńĀüÕ▒Ģńż║õ║åµĢ░µŹ«ķóäÕżäńÉåÕÖ©ńÜäĶ┐öÕø×ÕĆ╝ÕÆīµ©ĪÕ×ŗńÜäĶŠōÕģźÕĆ╝ŃĆé
+
+```python
+dict(
+ inputs=torch.Tensor,
+ data_samples=List[SegDataSample]
+)
+```
+
+```python
+class Network(BaseSegmentor):
+
+ def forward(self, inputs: torch.Tensor, data_samples: List[SegDataSample], mode: str):
+ pass
+```
+
+**µ│©µäÅ’╝Ü** µ©ĪÕ×ŗńÜäÕēŹÕÉæõ╝ĀµÆŁµ£ē 3 ń¦Źµ©ĪÕ╝Å’╝īńö▒ĶŠōÕģźÕÅéµĢ░ mode µÄ¦ÕłČ’╝īµø┤ÕżÜõ┐Īµü»Ķ»ĘÕÅéķśģ[µ©ĪÕ×ŗµĢÖń©ŗ](./models.md)ŃĆé
+
+### µ©ĪÕ×ŗĶŠōÕć║
+
+Õ”é[µ©ĪÕ×ŗµĢÖń©ŗ](./models.md#forward) ***’╝ł[õĖŁµ¢ćķōŠµÄźÕŠģµø┤µ¢░](./models.md#forward)’╝ē*** µēƵÅÉÕł░ńÜä 3 ń¦ŹÕēŹÕÉæõ╝ĀµÆŁÕģʵ£ē 3 ń¦ŹĶŠōÕć║ŃĆé
+`train_step` ÕÆī `test_step`’╝łµł¢ `val_step`’╝ēÕłåÕł½Õ»╣Õ║öõ║Ä `'loss'` ÕÆī `'predict'`ŃĆé
+
+Õ£© `test_step` µł¢ `val_step` õĖŁ’╝īµÄ©ńÉåń╗ōµ×£õ╝ÜĶó½õ╝ĀķĆÆń╗Ö `Evaluator` ŃĆéµé©ÕÅ»õ╗źÕÅéķśģ[Ķ»äõ╝░µ¢ćµĪŻ](./evaluation.md)µØźĶÄĘÕÅ¢µø┤ÕżÜÕģ│õ║Ä `Evaluator` ńÜäõ┐Īµü»ŃĆé
+
+Õ£©µÄ©ńÉåÕÉÄ’╝īMMSegmentation õĖŁńÜä [BaseSegmentor](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/models/segmentors/base.py#L15) õ╝ÜÕ»╣µÄ©ńÉåń╗ōµ×£Ķ┐øĶĪīń«ĆÕŹĢńÜäÕÉÄÕżäńÉåõ╗źµēōÕīģµÄ©ńÉåń╗ōµ×£ŃĆéńź×ń╗ÅńĮæń╗£ńö¤µłÉńÜäÕłåÕē▓ logits’╝īń╗ÅĶ┐ć `argmax` µōŹõĮ£ÕÉÄńÜäÕłåÕē▓ mask ÕÆī ground truth’╝łÕ”éµ×£ÕŁśÕ£©’╝ēÕ░åĶó½µēōÕīģÕł░ń▒╗õ╝╝ `SegDataSample` ńÜäÕ«×õŠŗŃĆé [postprocess_result](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/models/segmentors/base.py#L132) ńÜäĶ┐öÕø×ÕĆ╝µś»õĖĆõĖ¬ **`SegDataSample`ńÜä`List`**ŃĆéõĖŗÕøŠµśŠńż║õ║åĶ┐Öõ║ø `SegDataSample` Õ«×õŠŗńÜäÕģ│ķö«Õ▒׵ƦŃĆé
+
+
+
+õĖĵĢ░µŹ«ķóäÕżäńÉåÕÖ©õĖĆĶć┤’╝īµŹ¤Õż▒ÕćĮµĢ░õ╣¤µś»µ©ĪÕ×ŗńÜäõĖĆķā©Õłå’╝īÕ«āµś»[Ķ¦ŻńĀüÕż┤](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/models/decode_heads/decode_head.py#L142)ńÜäÕ▒׵Ʀõ╣ŗõĖĆŃĆé
+
+Õ£© MMSegmentation õĖŁ’╝ī`decode_head` ńÜä [loss_by_feat](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/models/decode_heads/decode_head.py#L291) µ¢╣µ│Ģµś»ńö©õ║ÄĶ«Īń«ŚµŹ¤Õż▒ńÜäń╗¤õĖƵğÕÅŻŃĆé
+
+ÕÅéµĢ░’╝Ü
+
+- seg_logits (Tensor)’╝ÜĶ¦ŻńĀüÕż┤ÕēŹÕÉæÕćĮµĢ░ńÜäĶŠōÕć║
+- batch_data_samples (List\[SegDataSample\])’╝ÜÕłåÕē▓µĢ░µŹ«µĀʵ£¼’╝īķĆÜÕĖĖÕīģµŗ¼Õ”é `metainfo` ÕÆī `gt_sem_seg` ńŁēõ┐Īµü»
+
+Ķ┐öÕø×ÕĆ╝’╝Ü
+
+- dict\[str, Tensor\]’╝ÜõĖĆõĖ¬µŹ¤Õż▒ń╗äõ╗ČńÜäÕŁŚÕģĖ
+
+**µ│©µäÅ’╝Ü** `train_step` Õ░åµŹ¤Õż▒õ╝ĀķĆÆĶ┐ø OptimWrapper õ╗źµø┤µ¢░µ©ĪÕ×ŗõĖŁńÜäµØāķ插╝īµø┤ÕżÜõ┐Īµü»Ķ»ĘÕÅéķśģ [train_step](./models.md#train_step)ŃĆé
diff --git a/internlm_langchain/knowledge_base/MMSegmentation/content/datasets.md b/internlm_langchain/knowledge_base/MMSegmentation/content/datasets.md
new file mode 100644
index 00000000..b45f2d22
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMSegmentation/content/datasets.md
@@ -0,0 +1,363 @@
+# µĢ░µŹ«ķøå
+
+Õ£© MMSegmentation ń«Śµ│ĢÕ║ōõĖŁ, µēƵ£ē Dataset ń▒╗ńÜäÕŖ¤ĶāĮµ£ēõĖżõĖ¬: ÕŖĀĶĮĮ[ķóäÕżäńÉå](../user_guides/2_dataset_prepare.md) õ╣ŗÕÉÄńÜäµĢ░µŹ«ķøåńÜäõ┐Īµü», ÕÆīÕ░åµĢ░µŹ«ķĆüÕģź[µĢ░µŹ«ķøåÕÅśµŹóµĄüµ░┤ń║┐](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/datasets/basesegdataset.py#L141) õĖŁ, Ķ┐øĶĪī[µĢ░µŹ«ÕÅśµŹóµōŹõĮ£](./transforms.md). ÕŖĀĶĮĮńÜäµĢ░µŹ«ķøåõ┐Īµü»Õīģµŗ¼õĖżń▒╗: Õģāõ┐Īµü» (meta information), µĢ░µŹ«ķøåµ£¼Ķ║½ńÜäõ┐Īµü», õŠŗÕ”éµĢ░µŹ«ķøåµĆ╗Õģ▒ńÜäń▒╗Õł½, ÕÆīÕ«āõ╗¼Õ»╣Õ║öĶ░āĶē▓ńøśõ┐Īµü»: µĢ░µŹ«õ┐Īµü» (data information) µś»µīćµ»Åń╗äµĢ░µŹ«õĖŁÕøŠńēćÕÆīÕ»╣Õ║öµĀćńŁŠńÜäĶĘ»ÕŠä. õĖŗµ¢ćõĖŁõ╗ŗń╗Źõ║å MMSegmentation 1.x õĖŁµĢ░µŹ«ķøåńÜäÕĖĖńö©µÄźÕÅŻ, ÕÆī mmseg µĢ░µŹ«ķøåÕ¤║ń▒╗õĖŁµĢ░µŹ«õ┐Īµü»ÕŖĀĶĮĮõĖÄõ┐«µö╣µĢ░µŹ«ķøåń▒╗Õł½ńÜäķĆ╗ĶŠæ, õ╗źÕÅŖµĢ░µŹ«ķøåõĖĵĢ░µŹ«ÕÅśµŹóµĄüµ░┤ń║┐ (pipeline) ńÜäÕģ│ń│╗.
+
+## ÕĖĖńö©µÄźÕÅŻ
+
+õ╗ź Cityscapes õĖ║õŠŗ, õ╗ŗń╗ŹµĢ░µŹ«ķøåÕĖĖńö©µÄźÕÅŻ. Õ”éķ£ĆĶ┐ÉĶĪīõ╗źõĖŗńż║õŠŗ, Ķ»ĘÕ£©ÕĮōÕēŹÕĘźõĮ£ńø«ÕĮĢõĖŗńÜä `data` ńø«ÕĮĢõĖŗĶĮĮÕ╣Č[ķóäÕżäńÉå](../user_guides/2_dataset_prepare.md#cityscapes) Cityscapes µĢ░µŹ«ķøå.
+
+Õ«×õŠŗÕī¢ Cityscapes Ķ«Łń╗āµĢ░µŹ«ķøå:
+
+```python
+from mmengine.registry import init_default_scope
+from mmseg.datasets import CityscapesDataset
+
+init_default_scope('mmseg')
+
+data_root = 'data/cityscapes/'
+data_prefix=dict(img_path='leftImg8bit/train', seg_map_path='gtFine/train')
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations'),
+ dict(type='RandomCrop', crop_size=(512, 1024), cat_max_ratio=0.75),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='PackSegInputs')
+]
+
+dataset = CityscapesDataset(data_root=data_root, data_prefix=data_prefix, test_mode=False, pipeline=train_pipeline)
+```
+
+µ¤źń£ŗĶ«Łń╗āµĢ░µŹ«ķøåķĢ┐Õ║”:
+
+```python
+print(len(dataset))
+
+2975
+```
+
+ĶÄĘÕÅ¢µĢ░µŹ«õ┐Īµü», µĢ░µŹ«õ┐Īµü»ńÜäń▒╗Õ×ŗµś»õĖĆõĖ¬ÕŁŚÕģĖ, Õīģµŗ¼ `'img_path'` ÕŁŚµ«ĄńÜäÕŁśµöŠÕøŠńēćńÜäĶĘ»ÕŠäÕÆī `'seg_map_path'` ÕŁŚµ«ĄÕŁśµöŠÕłåÕē▓µĀćµ│©ńÜäĶĘ»ÕŠä, õ╗źÕÅŖµĀćńŁŠķ揵śĀÕ░äńÜäÕŁŚµ«Ą `'label_map'` ÕÆī `'reduce_zero_label'`(õĖ╗Ķ”üÕŖ¤ĶāĮÕ£©õĖŗµ¢ćõĖŁõ╗ŗń╗Ź), Ķ┐śµ£ēÕŁśµöŠÕĘ▓ÕŖĀĶĮĮµĀćńŁŠÕŁŚµ«Ą `'seg_fields'`, ÕÆīÕĮōÕēŹµĀʵ£¼ńÜäń┤óÕ╝ĢÕŁŚµ«Ą `'sample_idx'`.
+
+```python
+# ĶÄĘÕÅ¢µĢ░µŹ«ķøåõĖŁń¼¼õĖĆń╗äµĀʵ£¼ńÜäµĢ░µŹ«õ┐Īµü»
+print(dataset.get_data_info(0))
+
+{'img_path': 'data/cityscapes/leftImg8bit/train/aachen/aachen_000000_000019_leftImg8bit.png',
+ 'seg_map_path': 'data/cityscapes/gtFine/train/aachen/aachen_000000_000019_gtFine_labelTrainIds.png',
+ 'label_map': None,
+ 'reduce_zero_label': False,
+ 'seg_fields': [],
+ 'sample_idx': 0}
+```
+
+ĶÄĘÕÅ¢µĢ░µŹ«ķøåÕģāõ┐Īµü», MMSegmentation ńÜäµĢ░µŹ«ķøåÕģāõ┐Īµü»ńÜäń▒╗Õ×ŗÕÉīµĀʵś»õĖĆõĖ¬ÕŁŚÕģĖ, Õīģµŗ¼ `'classes'` ÕŁŚµ«ĄÕŁśµöŠµĢ░µŹ«ķøåń▒╗Õł½, `'palette'` ÕŁśµöŠµĢ░µŹ«ķøåń▒╗Õł½Õ»╣Õ║öńÜäÕÅ»Ķ¦åÕī¢µŚČĶ░āĶē▓ńøśńÜäķó£Ķē▓, õ╗źÕÅŖµĀćńŁŠķ揵śĀÕ░äńÜäÕŁŚµ«Ą `'label_map'` ÕÆī `'reduce_zero_label'`.
+
+```python
+print(dataset.metainfo)
+
+{'classes': ('road',
+ 'sidewalk',
+ 'building',
+ 'wall',
+ 'fence',
+ 'pole',
+ 'traffic light',
+ 'traffic sign',
+ 'vegetation',
+ 'terrain',
+ 'sky',
+ 'person',
+ 'rider',
+ 'car',
+ 'truck',
+ 'bus',
+ 'train',
+ 'motorcycle',
+ 'bicycle'),
+ 'palette': [[128, 64, 128],
+ [244, 35, 232],
+ [70, 70, 70],
+ [102, 102, 156],
+ [190, 153, 153],
+ [153, 153, 153],
+ [250, 170, 30],
+ [220, 220, 0],
+ [107, 142, 35],
+ [152, 251, 152],
+ [70, 130, 180],
+ [220, 20, 60],
+ [255, 0, 0],
+ [0, 0, 142],
+ [0, 0, 70],
+ [0, 60, 100],
+ [0, 80, 100],
+ [0, 0, 230],
+ [119, 11, 32]],
+ 'label_map': None,
+ 'reduce_zero_label': False}
+```
+
+µĢ░µŹ«ķøå `__getitem__` µ¢╣µ│ĢńÜäĶ┐öÕø×ÕĆ╝, µś»ń╗ÅĶ┐ćµĢ░µŹ«Õó×Õ╝║ńÜäµĀʵ£¼µĢ░µŹ«ńÜäĶŠōÕć║, ÕÉīµĀĘõ╣¤µś»õĖĆõĖ¬ÕŁŚÕģĖ, Õīģµŗ¼õĖżõĖ¬ÕŁŚµ«Ą, `'inputs'` ÕŁŚµ«Ąµś»ÕĮōÕēŹµĀʵ£¼ń╗ÅĶ┐ćµĢ░µŹ«Õó×Õ╝║µōŹõĮ£ńÜäÕøŠÕāÅ, ń▒╗Õ×ŗõĖ║ torch.Tensor, `'data_samples'` ÕŁŚµ«ĄÕŁśµöŠńÜäµĢ░µŹ«ń▒╗Õ×ŗµś» MMSegmentation 1.x µ¢░µĘ╗ÕŖĀńÜäµĢ░µŹ«ń╗ōµ×ä [`Segdatasample`](./structures.md), ÕģČõĖŁ`gt_sem_seg` ÕŁŚµ«Ąµś»ń╗ÅĶ┐ćµĢ░µŹ«Õó×Õ╝║ńÜäµĀćńŁŠµĢ░µŹ«.
+
+```python
+print(dataset[0])
+
+{'inputs': tensor([[[131, 130, 130, ..., 23, 23, 23],
+ [132, 132, 132, ..., 23, 22, 23],
+ [134, 133, 133, ..., 23, 23, 23],
+ ...,
+ [ 66, 67, 67, ..., 71, 71, 71],
+ [ 66, 67, 66, ..., 68, 68, 68],
+ [ 67, 67, 66, ..., 70, 70, 70]],
+
+ [[143, 143, 142, ..., 28, 28, 29],
+ [145, 145, 145, ..., 28, 28, 29],
+ [145, 145, 145, ..., 27, 28, 29],
+ ...,
+ [ 75, 75, 76, ..., 80, 81, 81],
+ [ 75, 76, 75, ..., 80, 80, 80],
+ [ 77, 76, 76, ..., 82, 82, 82]],
+
+ [[126, 125, 126, ..., 21, 21, 22],
+ [127, 127, 128, ..., 21, 21, 22],
+ [127, 127, 126, ..., 21, 21, 22],
+ ...,
+ [ 63, 63, 64, ..., 69, 69, 70],
+ [ 64, 65, 64, ..., 69, 69, 69],
+ [ 65, 66, 66, ..., 72, 71, 71]]], dtype=torch.uint8),
+ 'data_samples':
+
+### 3.1 Õ£©`mmsegmentation/projects`õĖŗÕłøÕ╗║µ¢░ńÜäķĪ╣ńø«µ¢ćõ╗ČÕż╣
+
+Õ£©`mmsegmentation/projects`õĖŗÕłøÕ╗║µ¢ćõ╗ČÕż╣`gid_dataset`
+
+
+### 3.2 Ķ┤Īńī«µé©ńÜäµĢ░µŹ«ķøåõ╗ŻńĀü
+
+õĖ║õ║åµ£Ćń╗łĶāĮÕ░åµé©Õ£© projects õĖŁĶ┤Īńī«ńÜäõ╗ŻńĀüµø┤ÕŖĀķĪ║ńĢģńÜäń¦╗ÕģźµĀĖÕ┐āÕ║ōõĖŁ’╝łÕ»╣õ╗ŻńĀüĶ”üµ▒éĶ┤©ķćŵø┤ķ½ś’╝ē’╝īķØ×ÕĖĖÕ╗║Ķ««µīēńģ¦µĀĖÕ┐āÕ║ōńÜäńø«ÕĮĢµØźń╝¢ĶŠæµé©ńÜäµĢ░µŹ«ķøåµ¢ćõ╗ČŃĆé
+Õģ│õ║ĵĢ░µŹ«ķøåµ£ē 4 õĖ¬Õ┐ģĶ”üńÜäµ¢ćõ╗Č’╝Ü
+
+- **1** `mmseg/datasets/gid.py` Õ«Üõ╣ēõ║åµĢ░µŹ«ķøåńÜäÕ░Šń╝ĆŃĆüCLASSESŃĆüPALETTEŃĆüreduce_zero_labelńŁē
+- **2** `configs/_base_/gid.py` GID µĢ░µŹ«ķøåńÜäķģŹńĮ«µ¢ćõ╗Č’╝īÕ«Üõ╣ēõ║åµĢ░µŹ«ķøåńÜä`dataset_type`’╝łµĢ░µŹ«ķøåń▒╗Õ×ŗ’╝ī`mmseg/datasets/gid.py`õĖŁµ│©ÕåīńÜäµĢ░µŹ«ķøåńÜäń▒╗ÕÉŹ’╝ēŃĆü`data_root`(µĢ░µŹ«ķøåµēĆÕ£©ńÜäµĀ╣ńø«ÕĮĢ’╝īÕ╗║Ķ««Õ░åµĢ░µŹ«ķøåķĆÜĶ┐ćĶĮ»Ķ┐׵ğńÜäµ¢╣Õ╝ÅÕ░åµĢ░µŹ«ķøåµöŠĶć│`mmsegmentation/data`)ŃĆü`train_pipline`(Ķ«Łń╗āńÜäµĢ░µŹ«µĄü)ŃĆü`test_pipline`(µĄŗĶ»ĢÕÆīķ¬īĶ»üµŚČńÜäµĢ░µŹ«µĄü)ŃĆü`img_rations`(ÕżÜÕ░║Õ║”ķó䵥ŗµŚČńÜäÕżÜÕ░║Õ║”ķģŹńĮ«)ŃĆü`tta_pipeline`’╝łÕżÜÕ░║Õ║”ķó䵥ŗ’╝ēŃĆü`train_dataloader`(Ķ«Łń╗āķøåńÜäµĢ░µŹ«ÕŖĀĶĮĮÕÖ©)ŃĆü`val_dataloader`(ķ¬īĶ»üķøåńÜäµĢ░µŹ«ÕŖĀĶĮĮÕÖ©)ŃĆü`test_dataloader`(µĄŗĶ»ĢķøåńÜäµĢ░µŹ«ÕŖĀĶĮĮÕÖ©)ŃĆü`val_evaluator`(ķ¬īĶ»üķøåńÜäĶ»äõ╝░ÕÖ©)ŃĆü`test_evaluator`(µĄŗĶ»ĢķøåńÜäĶ»äõ╝░ÕÖ©)ŃĆé
+- **3** õĮ┐ńö©õ║å GID µĢ░µŹ«ķøåńÜ䵩ĪÕ×ŗĶ«Łń╗āķģŹńĮ«µ¢ćõ╗Č
+ Ķ┐ÖõĖ¬µś»ÕÅ»ķĆēńÜä’╝īõĮåµś»Õ╝║ńāłÕ╗║Ķ««µé©µĘ╗ÕŖĀŃĆéÕ£©µĀĖÕ┐āÕ║ōõĖŁ’╝īµēĆĶ┤Īńī«ńÜäµĢ░µŹ«ķøåķ£ĆĶ”üÕÆīÕÅéĶĆāµ¢ćńī«õĖŁµēƵÅÉÕć║ńÜäń╗ōµ×£ń▓ŠÕ║”Õ»╣ķĮÉ’╝īõĖ║õ║åÕÉĵ£¤Õ░åµé©Ķ┤Īńī«ńÜäõ╗ŻńĀüÕÉłÕ╣ČÕģźµĀĖÕ┐āÕ║ōŃĆéÕ”éµé©ńÜäń«ŚÕŖøÕģģĶČ│’╝īµ£ĆÕźĮĶāĮµÅÉõŠøÕ»╣Õ║öńÜ䵩ĪÕ×ŗķģŹńĮ«µ¢ćõ╗ČÕ£©µé©Ķ┤Īńī«ńÜäµĢ░µŹ«ķøåõĖŖµēĆķ¬īĶ»üńÜäń╗ōµ×£õ╗źÕÅŖńøĖÕ║öńÜäµØāķ揵¢ćõ╗Č’╝īÕ╣ȵÆ░ÕåÖĶŠāõĖ║Ķ»”ń╗åńÜäREADME.mdµ¢ćµĪŻŃĆé[ńż║õŠŗÕÅéĶĆāń╗ōµ×£](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/deeplabv3plus#mapillary-vistas-v12)
+ 
+- **4** õĮ┐ńö©Õ”éõĖŗÕæĮõ╗żµĀ╝Õ╝Å’╝Ü µÆ░ÕåÖ`docs/zh_cn/user_guides/2_dataset_prepare.md`µØźµĘ╗ÕŖĀµé©ńÜäµĢ░µŹ«ķøåõ╗ŗń╗Ź’╝īÕīģµŗ¼õĮåõĖŹķÖÉõ║ĵĢ░µŹ«ķøåńÜäõĖŗĶĮĮµ¢╣Õ╝Å’╝īµĢ░µŹ«ķøåńø«ÕĮĢń╗ōµ×äŃĆüµĢ░µŹ«ķøåńö¤µłÉńŁēõĖĆõ║øÕ┐ģĶ”üµĆ¦ńÜäµ¢ćÕŁŚµĆ¦µÅÅĶ┐░ÕÆīĶ┐ÉĶĪīÕæĮõ╗żŃĆéõ╗źµø┤ÕźĮÕ£░ÕĖ«ÕŖ®ńö©µłĘĶāĮµø┤Õ┐½ńÜäÕ«×ńÄ░µĢ░µŹ«ķøåńÜäÕćåÕżćÕĘźõĮ£ŃĆé
+
+### 3.3 Ķ┤Īńī«`tools/dataset_converters/gid.py`
+
+ńö▒õ║Ä GID µĢ░µŹ«ķøåµś»ńö▒µ£¬ń╗ÅĶ┐ćÕłćÕłåńÜä 6800x7200 ÕøŠÕāŵēƵ×䵳ÉńÜäµĢ░µŹ«ķøå’╝īÕ╣ČõĖöµ▓Īµ£ēÕłÆÕłåĶ«Łń╗āķøåŃĆüķ¬īĶ»üķøåõĖĵĄŗĶ»ĢķøåŃĆéõ╗źÕÅŖÕģȵĀćńŁŠõĖ║ RGB ÕĮ®Ķē▓µĀćńŁŠ’╝īķ£ĆĶ”üÕ░åµĀćńŁŠĶĮ¼µŹóõĖ║ÕŹĢķĆÜķüōńÜä mask labelŃĆéõĖ║õ║åµ¢╣õŠ┐Ķ«Łń╗ā’╝īķ”¢ÕģłÕ░å GID µĢ░µŹ«ķøåĶ┐øĶĪīĶŻüÕłćÕÆīµĀćńŁŠĶĮ¼µŹó’╝īÕ╣ČĶ┐øĶĪīµĢ░µŹ«ķøåÕłÆÕłå’╝īµ×äÕ╗║õĖ║ mmsegmentation µēƵö»µīüńÜäµĀ╝Õ╝ÅŃĆé
+
+```python
+# tools/dataset_converters/gid.py
+import argparse
+import glob
+import math
+import os
+import os.path as osp
+from PIL import Image
+
+import mmcv
+import numpy as np
+from mmengine.utils import ProgressBar, mkdir_or_exist
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Convert GID dataset to mmsegmentation format')
+ parser.add_argument('dataset_img_path', help='GID images folder path')
+ parser.add_argument('dataset_label_path', help='GID labels folder path')
+ parser.add_argument('--tmp_dir', help='path of the temporary directory')
+ parser.add_argument('-o', '--out_dir', help='output path', default='data/gid')
+ parser.add_argument(
+ '--clip_size',
+ type=int,
+ help='clipped size of image after preparation',
+ default=256)
+ parser.add_argument(
+ '--stride_size',
+ type=int,
+ help='stride of clipping original images',
+ default=256)
+ args = parser.parse_args()
+ return args
+
+GID_COLORMAP = dict(
+ Background=(0, 0, 0), #0-ĶāīµÖ»-ķ╗æĶē▓
+ Building=(255, 0, 0), #1-Õ╗║ńŁæ-ń║óĶē▓
+ Farmland=(0, 255, 0), #2-Õå£ńö░-ń╗┐Ķē▓
+ Forest=(0, 0, 255), #3-µŻ«µ×Ś-ĶōØĶē▓
+ Meadow=(255, 255, 0),#4-ĶŹēÕ£░-ķ╗äĶē▓
+ Water=(0, 0, 255)#5-µ░┤-ĶōØĶē▓
+)
+palette = list(GID_COLORMAP.values())
+classes = list(GID_COLORMAP.keys())
+
+#############ńö©ÕłŚĶĪ©µØźÕŁśõĖĆõĖ¬ RGB ÕÆīõĖĆõĖ¬ń▒╗Õł½ńÜäÕ»╣Õ║ö################
+def colormap2label(palette):
+ colormap2label_list = np.zeros(256**3, dtype = np.longlong)
+ for i, colormap in enumerate(palette):
+ colormap2label_list[(colormap[0] * 256 + colormap[1])*256+colormap[2]] = i
+ return colormap2label_list
+
+#############ń╗ÖÕ«ÜķéŻõĖ¬ÕłŚĶĪ©’╝īÕÆīvis_pngńäČÕÉÄńö¤µłÉmasks_png################
+def label_indices(RGB_label, colormap2label_list):
+ RGB_label = RGB_label.astype('int32')
+ idx = (RGB_label[:, :, 0] * 256 + RGB_label[:, :, 1]) * 256 + RGB_label[:, :, 2]
+ # print(idx.shape)
+ return colormap2label_list[idx]
+
+def RGB2mask(RGB_label, colormap2label_list):
+ # RGB_label = np.array(Image.open(RGB_label).convert('RGB')) #µēōÕ╝ĆRGB_png
+ mask_label = label_indices(RGB_label, colormap2label_list) # .numpy()
+ return mask_label
+
+colormap2label_list = colormap2label(palette)
+
+def clip_big_image(image_path, clip_save_dir, args, to_label=False):
+ """
+ Original image of GID dataset is very large, thus pre-processing
+ of them is adopted. Given fixed clip size and stride size to generate
+ clipped image, the intersectionŃĆĆof width and height is determined.
+ For example, given one 6800 x 7200 original image, the clip size is
+ 256 and stride size is 256, thus it would generate 29 x 27 = 783 images
+ whose size are all 256 x 256.
+
+ """
+
+ image = mmcv.imread(image_path, channel_order='rgb')
+ # image = mmcv.bgr2gray(image)
+
+ h, w, c = image.shape
+ clip_size = args.clip_size
+ stride_size = args.stride_size
+
+ num_rows = math.ceil((h - clip_size) / stride_size) if math.ceil(
+ (h - clip_size) /
+ stride_size) * stride_size + clip_size >= h else math.ceil(
+ (h - clip_size) / stride_size) + 1
+ num_cols = math.ceil((w - clip_size) / stride_size) if math.ceil(
+ (w - clip_size) /
+ stride_size) * stride_size + clip_size >= w else math.ceil(
+ (w - clip_size) / stride_size) + 1
+
+ x, y = np.meshgrid(np.arange(num_cols + 1), np.arange(num_rows + 1))
+ xmin = x * clip_size
+ ymin = y * clip_size
+
+ xmin = xmin.ravel()
+ ymin = ymin.ravel()
+ xmin_offset = np.where(xmin + clip_size > w, w - xmin - clip_size,
+ np.zeros_like(xmin))
+ ymin_offset = np.where(ymin + clip_size > h, h - ymin - clip_size,
+ np.zeros_like(ymin))
+ boxes = np.stack([
+ xmin + xmin_offset, ymin + ymin_offset,
+ np.minimum(xmin + clip_size, w),
+ np.minimum(ymin + clip_size, h)
+ ], axis=1)
+
+ if to_label:
+ image = RGB2mask(image, colormap2label_list) #Ķ┐ÖķćīÕŠŚµö╣õĖĆõĖŗ
+
+ for count, box in enumerate(boxes):
+ start_x, start_y, end_x, end_y = box
+ clipped_image = image[start_y:end_y,
+ start_x:end_x] if to_label else image[
+ start_y:end_y, start_x:end_x, :]
+ img_name = osp.basename(image_path).replace('.tif', '')
+ img_name = img_name.replace('_label', '')
+ if count % 3 == 0:
+ mmcv.imwrite(
+ clipped_image.astype(np.uint8),
+ osp.join(
+ clip_save_dir.replace('train', 'val'),
+ f'{img_name}_{start_x}_{start_y}_{end_x}_{end_y}.png'))
+ else:
+ mmcv.imwrite(
+ clipped_image.astype(np.uint8),
+ osp.join(
+ clip_save_dir,
+ f'{img_name}_{start_x}_{start_y}_{end_x}_{end_y}.png'))
+ count += 1
+
+def main():
+ args = parse_args()
+
+ """
+ According to this paper: https://ieeexplore.ieee.org/document/9343296/
+ select 15 images contained in GID, , which cover the whole six
+ categories, to generate train set and validation set.
+
+ According to Paper: https://ieeexplore.ieee.org/document/9343296/
+
+ """
+
+ if args.out_dir is None:
+ out_dir = osp.join('data', 'gid')
+ else:
+ out_dir = args.out_dir
+
+ print('Making directories...')
+ mkdir_or_exist(osp.join(out_dir, 'img_dir', 'train'))
+ mkdir_or_exist(osp.join(out_dir, 'img_dir', 'val'))
+ mkdir_or_exist(osp.join(out_dir, 'ann_dir', 'train'))
+ mkdir_or_exist(osp.join(out_dir, 'ann_dir', 'val'))
+
+ src_path_list = glob.glob(os.path.join(args.dataset_img_path, '*.tif'))
+ print(f'Find {len(src_path_list)} pictures')
+
+ prog_bar = ProgressBar(len(src_path_list))
+
+ dst_img_dir = osp.join(out_dir, 'img_dir', 'train')
+ dst_label_dir = osp.join(out_dir, 'ann_dir', 'train')
+
+ for i, img_path in enumerate(src_path_list):
+ label_path = osp.join(args.dataset_label_path, osp.basename(img_path.replace('.tif', '_label.tif')))
+
+ clip_big_image(img_path, dst_img_dir, args, to_label=False)
+ clip_big_image(label_path, dst_label_dir, args, to_label=True)
+ prog_bar.update()
+
+ print('Done!')
+
+if __name__ == '__main__':
+ main()
+```
+
+### 3.4 Ķ┤Īńī«`mmseg/datasets/gid.py`
+
+ÕÅ»ÕÅéĶĆā[`projects/mapillary_dataset/mmseg/datasets/mapillary.py`](https://github.com/open-mmlab/mmsegmentation/blob/main/projects/mapillary_dataset/mmseg/datasets/mapillary.py)Õ╣ČÕ£©µŁżÕ¤║ńĪĆõĖŖõ┐«µö╣ńøĖÕ║öÕÅśķćÅõ╗źķĆéķģŹµé©ńÜäµĢ░µŹ«ķøåŃĆé
+
+```python
+# mmseg/datasets/gid.py
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmseg.datasets.basesegdataset import BaseSegDataset
+from mmseg.registry import DATASETS
+
+# µ│©ÕåīµĢ░µŹ«ķøåń▒╗
+@DATASETS.register_module()
+class GID_Dataset(BaseSegDataset):
+ """Gaofen Image Dataset (GID)
+
+ Dataset paper link:
+ https://www.sciencedirect.com/science/article/pii/S0034425719303414
+ https://x-ytong.github.io/project/GID.html
+
+ GID 6 classes: background(others), built-up, farmland, forest, meadow, water
+
+ In This example, select 10 images from GID dataset as training set,
+ and select 5 images as validation set.
+ The selected images are listed as follows:
+
+ GF2_PMS1__L1A0000647767-MSS1
+ GF2_PMS1__L1A0001064454-MSS1
+ GF2_PMS1__L1A0001348919-MSS1
+ GF2_PMS1__L1A0001680851-MSS1
+ GF2_PMS1__L1A0001680853-MSS1
+ GF2_PMS1__L1A0001680857-MSS1
+ GF2_PMS1__L1A0001757429-MSS1
+ GF2_PMS2__L1A0000607681-MSS2
+ GF2_PMS2__L1A0000635115-MSS2
+ GF2_PMS2__L1A0000658637-MSS2
+ GF2_PMS2__L1A0001206072-MSS2
+ GF2_PMS2__L1A0001471436-MSS2
+ GF2_PMS2__L1A0001642620-MSS2
+ GF2_PMS2__L1A0001787089-MSS2
+ GF2_PMS2__L1A0001838560-MSS2
+
+ The ``img_suffix`` is fixed to '.tif' and ``seg_map_suffix`` is
+ fixed to '.tif' for GID.
+ """
+ METAINFO = dict(
+ classes=('Others', 'Built-up', 'Farmland', 'Forest',
+ 'Meadow', 'Water'),
+
+ palette=[[0, 0, 0], [255, 0, 0], [0, 255, 0], [0, 255, 255],
+ [255, 255, 0], [0, 0, 255]])
+
+ def __init__(self,
+ img_suffix='.png',
+ seg_map_suffix='.png',
+ reduce_zero_label=None,
+ **kwargs) -> None:
+ super().__init__(
+ img_suffix=img_suffix,
+ seg_map_suffix=seg_map_suffix,
+ reduce_zero_label=reduce_zero_label,
+ **kwargs)
+```
+
+### 3.5 Ķ┤Īńī«õĮ┐ńö© GID ńÜäĶ«Łń╗ā config file
+
+```python
+_base_ = [
+ '../../../configs/_base_/models/deeplabv3plus_r50-d8.py',
+ './_base_/datasets/gid.py',
+ '../../../configs/_base_/default_runtime.py',
+ '../../../configs/_base_/schedules/schedule_240k.py'
+]
+custom_imports = dict(
+ imports=['projects.gid_dataset.mmseg.datasets.gid'])
+
+crop_size = (256, 256)
+data_preprocessor = dict(size=crop_size)
+model = dict(
+ data_preprocessor=data_preprocessor,
+ pretrained='open-mmlab://resnet101_v1c',
+ backbone=dict(depth=101),
+ decode_head=dict(num_classes=6),
+ auxiliary_head=dict(num_classes=6))
+
+```
+
+### 3.6 µÆ░ÕåÖ`docs/zh_cn/user_guides/2_dataset_prepare.md`
+
+**Gaofen Image Dataset (GID)**
+
+- GID µĢ░µŹ«ķøåÕŻգ©[µŁżÕżä](https://x-ytong.github.io/project/Five-Billion-Pixels.html)Ķ┐øĶĪīõĖŗĶĮĮŃĆé
+- GID µĢ░µŹ«ķøåÕīģÕɽ 150 Õ╝Ā 6800x7200 ńÜäÕż¦Õ░║Õ»ĖÕøŠÕāÅ’╝īµĀćńŁŠõĖ║ RGB µĀćńŁŠŃĆé
+- µŁżÕżäķĆēµŗ® 15 Õ╝ĀÕøŠÕāÅńö¤µłÉĶ«Łń╗āķøåÕÆīķ¬īĶ»üķøå’╝īĶ»ź 15 Õ╝ĀÕøŠÕāÅÕīģÕɽõ║åµēƵ£ēÕģŁń▒╗õ┐Īµü»ŃĆéµēĆķĆēńÜäÕøŠÕāÅÕÉŹń¦░Õ”éõĖŗ’╝Ü
+
+```None
+ GF2_PMS1__L1A0000647767-MSS1
+ GF2_PMS1__L1A0001064454-MSS1
+ GF2_PMS1__L1A0001348919-MSS1
+ GF2_PMS1__L1A0001680851-MSS1
+ GF2_PMS1__L1A0001680853-MSS1
+ GF2_PMS1__L1A0001680857-MSS1
+ GF2_PMS1__L1A0001757429-MSS1
+ GF2_PMS2__L1A0000607681-MSS2
+ GF2_PMS2__L1A0000635115-MSS2
+ GF2_PMS2__L1A0000658637-MSS2
+ GF2_PMS2__L1A0001206072-MSS2
+ GF2_PMS2__L1A0001471436-MSS2
+ GF2_PMS2__L1A0001642620-MSS2
+ GF2_PMS2__L1A0001787089-MSS2
+ GF2_PMS2__L1A0001838560-MSS2
+```
+
+µē¦ĶĪīõ╗źõĖŗÕæĮõ╗żĶ┐øĶĪīĶŻüÕłćÕÅŖµĀćńŁŠńÜäĶĮ¼µŹó’╝īķ£ĆĶ”üõ┐«µö╣õĖ║µé©µēĆÕŁśÕé© 15 Õ╝ĀÕøŠÕāÅÕÅŖµĀćńŁŠńÜäĶĘ»ÕŠäŃĆé
+
+```
+python projects/gid_dataset/tools/dataset_converters/gid.py [15 Õ╝ĀÕøŠÕāÅńÜäĶĘ»ÕŠä] [15 Õ╝ĀµĀćńŁŠńÜäĶĘ»ÕŠä]
+```
+
+Õ«īµłÉĶŻüÕłćÕÉÄńÜä GID µĢ░µŹ«ń╗ōµ×äÕ”éõĖŗ’╝Ü
+
+```none
+mmsegmentation
+Ōö£ŌöĆŌöĆ mmseg
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+Ōö£ŌöĆŌöĆ data
+Ōöé Ōö£ŌöĆŌöĆ gid
+Ōöé Ōöé Ōö£ŌöĆŌöĆ ann_dir
+| Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ train
+| Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ val
+Ōöé Ōöé Ōö£ŌöĆŌöĆ img_dir
+| Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ train
+| Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ val
+
+```
+
+### 3.7 Ķ┤Īńī«ńÜäõ╗ŻńĀüÕÅŖµ¢ćµĪŻķĆÜĶ┐ć`pre-commit`µŻĆµ¤ź
+
+õĮ┐ńö©ÕæĮõ╗ż
+
+```bash
+git add .
+git commit -m "µĘ╗ÕŖĀµÅÅĶ┐░"
+git push
+```
+
+### 3.8 Õ£© GitHub õĖŁÕÉæ mmsegmentation µÅÉõ║ż PR
+
+ÕģĘõĮōµŁźķ¬żÕÅ»Ķ¦ü[ŃĆŖOpenMMLab Ķ┤Īńī«õ╗ŻńĀüµīćÕŹŚŃĆŗ](https://mmcv.readthedocs.io/zh_CN/latest/community/contributing.html)
diff --git a/internlm_langchain/knowledge_base/MMSegmentation/content/customize_runtime.md b/internlm_langchain/knowledge_base/MMSegmentation/content/customize_runtime.md
new file mode 100644
index 00000000..a80aca63
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMSegmentation/content/customize_runtime.md
@@ -0,0 +1,162 @@
+# Ķć¬Õ«Üõ╣ēĶ┐ÉĶĪīĶ«ŠÕ«Ü
+
+## Õ«×ńÄ░Ķć¬Õ«Üõ╣ēķÆ®ÕŁÉ
+
+### Step 1: ÕłøÕ╗║õĖĆõĖ¬µ¢░ńÜäķÆ®ÕŁÉ
+
+MMEngine ÕĘ▓Õ«×ńÄ░õ║åĶ«Łń╗āÕÆīµĄŗĶ»ĢÕĖĖńö©ńÜä[ķÆ®ÕŁÉ](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/tutorials/hook.md),
+ÕĮōµ£ēÕ«ÜÕłČÕī¢ķ£Ćµ▒鵌Č, ÕÅ»õ╗źµīēńģ¦Õ”éõĖŗńż║õŠŗÕ«×ńÄ░ķĆéńö©õ║ÄĶć¬Ķ║½Ķ«Łń╗āķ£Ćµ▒éńÜäķÆ®ÕŁÉ, õŠŗÕ”éµā│õ┐«µö╣õĖĆõĖ¬ĶČģÕÅéµĢ░ `model.hyper_paramete` ńÜäÕĆ╝, Ķ«®Õ«āķÜÅńØĆĶ«Łń╗āĶ┐Łõ╗Żµ¼ĪµĢ░ĶĆīÕÅśÕī¢:
+
+```python
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Sequence
+
+from mmengine.hooks import Hook
+from mmengine.model import is_model_wrapper
+
+from mmseg.registry import HOOKS
+
+
+@HOOKS.register_module()
+class NewHook(Hook):
+ """Docstring for NewHook.
+ """
+
+ def __init__(self, a: int, b: int) -> None:
+ self.a = a
+ self.b = b
+
+ def before_train_iter(self,
+ runner,
+ batch_idx: int,
+ data_batch: Optional[Sequence[dict]] = None) -> None:
+ cur_iter = runner.iter
+ # ÕĮōµ©ĪÕ×ŗĶó½ÕīģÕ£© wrapper ķćīµŚČĶÄĘÕÅ¢Ķ┐ÖõĖ¬µ©ĪÕ×ŗ
+ if is_model_wrapper(runner.model):
+ model = runner.model.module
+ model.hyper_parameter = self.a * cur_iter + self.b
+```
+
+### Step 2: Õ»╝ÕģźõĖĆõĖ¬µ¢░ńÜäķÆ®ÕŁÉ
+
+õĖ║õ║åĶ«®õĖŖķØóÕ«Üõ╣ēńÜ䵩ĪÕØŚÕÅ»õ╗źĶó½µē¦ĶĪīńÜäń©ŗÕ║ÅÕÅæńÄ░, Ķ┐ÖõĖ¬µ©ĪÕØŚķ£ĆĶ”üÕģłĶó½Õ»╝ÕģźõĖ╗ÕæĮÕÉŹń®║ķŚ┤ (main namespace) ķćīķØó,
+ÕüćĶ«Š NewHook Õ£© `mmseg/engine/hooks/new_hook.py` ķćīķØó, µ£ēõĖżń¦Źµ¢╣Õ╝ÅÕÄ╗Õ«×ńÄ░Õ«ā:
+
+- õ┐«µö╣ `mmseg/engine/hooks/__init__.py` µØźÕ»╝ÕģźÕ«ā.
+ µ¢░Õ«Üõ╣ēńÜ䵩ĪÕØŚÕ║öĶ»źÕ£© `mmseg/engine/hooks/__init__.py` ķćīķØóÕ»╝Õģź, Ķ┐ÖµĀʵ│©ÕåīÕÖ©ÕÅ»õ╗źÕÅæńÄ░Õ╣ȵĘ╗ÕŖĀĶ┐ÖõĖ¬µ¢░ńÜ䵩ĪÕØŚ:
+
+```python
+from .new_hook import NewHook
+
+__all__ = [..., NewHook]
+```
+
+- Õ£©ķģŹńĮ«µ¢ćõ╗ČķćīõĮ┐ńö© custom_imports µØźµēŗÕŖ©Õ»╝ÕģźÕ«ā.
+
+```python
+custom_imports = dict(imports=['mmseg.engine.hooks.new_hook'], allow_failed_imports=False)
+```
+
+### Step 3: õ┐«µö╣ķģŹńĮ«µ¢ćõ╗Č
+
+ÕÅ»õ╗źµīēńģ¦Õ”éõĖŗµ¢╣Õ╝Å, Õ£©Ķ«Łń╗āµł¢µĄŗĶ»ĢõĖŁķģŹńĮ«Õ╣ČõĮ┐ńö©Ķć¬Õ«Üõ╣ēńÜäķÆ®ÕŁÉ. õĖŹÕÉīķÆ®ÕŁÉÕ£©ÕÉīõĖĆõĮŹńé╣ńÜäõ╝śÕģłń║¦ÕÅ»õ╗źÕÅéĶĆā[Ķ┐Öķćī](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/tutorials/hook.md#%E5%86%85%E7%BD%AE%E9%92%A9%E5%AD%90), Ķć¬Õ«Üõ╣ēķÆ®ÕŁÉÕ”éµ×£µ▓Īµ£ēµīćÕ«Üõ╝śÕģł, ķ╗śĶ«żµś» `NORMAL`.
+
+```python
+custom_hooks = [
+ dict(type='NewHook', a=a_value, b=b_value, priority='ABOVE_NORMAL')
+]
+```
+
+## Õ«×ńÄ░Ķć¬Õ«Üõ╣ēõ╝śÕī¢ÕÖ©
+
+### Step 1: ÕłøÕ╗║õĖĆõĖ¬µ¢░ńÜäõ╝śÕī¢ÕÖ©
+
+Õ”éµ×£Õó×ÕŖĀõĖĆõĖ¬ÕŽõĮ£ `MyOptimizer` ńÜäõ╝śÕī¢ÕÖ©, Õ«āµ£ēÕÅéµĢ░ `a`, `b` ÕÆī `c`. µÄ©ĶŹÉÕ£© `mmseg/engine/optimizers/my_optimizer.py` µ¢ćõ╗ČõĖŁÕ«×ńÄ░
+
+```python
+from mmseg.registry import OPTIMIZERS
+from torch.optim import Optimizer
+
+
+@OPTIMIZERS.register_module()
+class MyOptimizer(Optimizer):
+
+ def __init__(self, a, b, c)
+```
+
+### Step 2: Õ»╝ÕģźõĖĆõĖ¬µ¢░ńÜäõ╝śÕī¢ÕÖ©
+
+õĖ║õ║åĶ«®õĖŖķØóÕ«Üõ╣ēńÜ䵩ĪÕØŚÕÅ»õ╗źĶó½µē¦ĶĪīńÜäń©ŗÕ║ÅÕÅæńÄ░, Ķ┐ÖõĖ¬µ©ĪÕØŚķ£ĆĶ”üÕģłĶó½Õ»╝ÕģźõĖ╗ÕæĮÕÉŹń®║ķŚ┤ (main namespace) ķćīķØó,
+ÕüćĶ«Š `MyOptimizer` Õ£© `mmseg/engine/optimizers/my_optimizer.py` ķćīķØó, µ£ēõĖżń¦Źµ¢╣Õ╝ÅÕÄ╗Õ«×ńÄ░Õ«ā:
+
+- õ┐«µö╣ `mmseg/engine/optimizers/__init__.py` µØźÕ»╝ÕģźÕ«ā.
+ µ¢░Õ«Üõ╣ēńÜ䵩ĪÕØŚÕ║öĶ»źÕ£© `mmseg/engine/optimizers/__init__.py` ķćīķØóÕ»╝Õģź, Ķ┐ÖµĀʵ│©ÕåīÕÖ©ÕÅ»õ╗źÕÅæńÄ░Õ╣ȵĘ╗ÕŖĀĶ┐ÖõĖ¬µ¢░ńÜ䵩ĪÕØŚ:
+
+```python
+from .my_optimizer import MyOptimizer
+```
+
+- Õ£©ķģŹńĮ«µ¢ćõ╗ČķćīõĮ┐ńö© `custom_imports` µØźµēŗÕŖ©Õ»╝ÕģźÕ«ā.
+
+```python
+custom_imports = dict(imports=['mmseg.engine.optimizers.my_optimizer'], allow_failed_imports=False)
+```
+
+### Step 3: õ┐«µö╣ķģŹńĮ«µ¢ćõ╗Č
+
+ķÜÅÕÉÄķ£ĆĶ”üõ┐«µö╣ķģŹńĮ«µ¢ćõ╗Č `optim_wrapper` ķćīńÜä `optimizer` ÕÅéµĢ░, Õ”éµ×£Ķ”üõĮ┐ńö©õĮĀĶć¬ÕĘ▒ńÜäõ╝śÕī¢ÕÖ© `MyOptimizer`, ÕŁŚµ«ĄÕÅ»õ╗źĶó½õ┐«µö╣µłÉ:
+
+```python
+optim_wrapper = dict(type='OptimWrapper',
+ optimizer=dict(type='MyOptimizer',
+ a=a_value, b=b_value, c=c_value),
+ clip_grad=None)
+```
+
+## Õ«×ńÄ░Ķć¬Õ«Üõ╣ēõ╝śÕī¢ÕÖ©Õ░üĶŻģµ×äķĆĀÕÖ©
+
+### Step 1: ÕłøÕ╗║õĖĆõĖ¬µ¢░ńÜäõ╝śÕī¢ÕÖ©Õ░üĶŻģµ×äķĆĀÕÖ©
+
+µ×äķĆĀÕÖ©ÕÅ»õ╗źńö©µØźÕłøÕ╗║õ╝śÕī¢ÕÖ©, õ╝śÕī¢ÕÖ©Õīģ, õ╗źÕÅŖĶć¬Õ«Üõ╣ēµ©ĪÕ×ŗńĮæń╗£õĖŹÕÉīÕ▒éńÜäĶČģÕÅéµĢ░. õĖĆõ║øµ©ĪÕ×ŗńÜäõ╝śÕī¢ÕÖ©ÕÅ»ĶāĮõ╝ܵĀ╣µŹ«ńē╣Õ«ÜńÜäÕÅéµĢ░ĶĆīĶ░āµĢ┤, õŠŗÕ”é BatchNorm Õ▒éńÜä weight decay. õĮ┐ńö©ĶĆģÕÅ»õ╗źķĆÜĶ┐ćĶć¬Õ«Üõ╣ēõ╝śÕī¢ÕÖ©µ×äķĆĀÕÖ©µØźń▓Šń╗åÕī¢Ķ«ŠÕ«ÜõĖŹÕÉīÕÅéµĢ░ńÜäõ╝śÕī¢ńŁ¢ńĢź.
+
+```python
+from mmengine.optim import DefaultOptimWrapperConstructor
+from mmseg.registry import OPTIM_WRAPPER_CONSTRUCTORS
+
+@OPTIM_WRAPPER_CONSTRUCTORS.register_module()
+class LearningRateDecayOptimizerConstructor(DefaultOptimWrapperConstructor):
+ def __init__(self, optim_wrapper_cfg, paramwise_cfg=None):
+
+ def __call__(self, model):
+
+ return my_optimizer
+```
+
+ķ╗śĶ«żńÜäõ╝śÕī¢ÕÖ©µ×äķĆĀÕÖ©Õ£©[Ķ┐Öķćī](https://github.com/open-mmlab/mmengine/blob/main/mmengine/optim/optimizer/default_constructor.py#L19) Ķó½Õ«×ńÄ░, Õ«āõ╣¤ÕÅ»õ╗źńö©µØźõĮ£õĖ║µ¢░ńÜäõ╝śÕī¢ÕÖ©µ×äķĆĀÕÖ©ńÜ䵩ĪµØ┐.
+
+### Step 2: Õ»╝ÕģźõĖĆõĖ¬µ¢░ńÜäõ╝śÕī¢ÕÖ©Õ░üĶŻģµ×äķĆĀÕÖ©
+
+õĖ║õ║åĶ«®õĖŖķØóÕ«Üõ╣ēńÜ䵩ĪÕØŚÕÅ»õ╗źĶó½µē¦ĶĪīńÜäń©ŗÕ║ÅÕÅæńÄ░, Ķ┐ÖõĖ¬µ©ĪÕØŚķ£ĆĶ”üÕģłĶó½Õ»╝ÕģźõĖ╗ÕæĮÕÉŹń®║ķŚ┤ (main namespace) ķćīķØó, ÕüćĶ«Š `MyOptimizerConstructor` Õ£© `mmseg/engine/optimizers/my_optimizer_constructor.py` ķćīķØó, µ£ēõĖżń¦Źµ¢╣Õ╝ÅÕÄ╗Õ«×ńÄ░Õ«ā:
+
+- õ┐«µö╣ `mmseg/engine/optimizers/__init__.py` µØźÕ»╝ÕģźÕ«ā.
+ µ¢░Õ«Üõ╣ēńÜ䵩ĪÕØŚÕ║öĶ»źÕ£© `mmseg/engine/optimizers/__init__.py` ķćīķØóÕ»╝Õģź, Ķ┐ÖµĀʵ│©ÕåīÕÖ©ÕÅ»õ╗źÕÅæńÄ░Õ╣ȵĘ╗ÕŖĀĶ┐ÖõĖ¬µ¢░ńÜ䵩ĪÕØŚ:
+
+```python
+from .my_optimizer_constructor import MyOptimizerConstructor
+```
+
+- Õ£©ķģŹńĮ«µ¢ćõ╗ČķćīõĮ┐ńö© `custom_imports` µØźµēŗÕŖ©Õ»╝ÕģźÕ«ā.
+
+```python
+custom_imports = dict(imports=['mmseg.engine.optimizers.my_optimizer_constructor'], allow_failed_imports=False)
+```
+
+### Step 3: õ┐«µö╣ķģŹńĮ«µ¢ćõ╗Č
+
+ķÜÅÕÉÄķ£ĆĶ”üõ┐«µö╣ķģŹńĮ«µ¢ćõ╗Č `optim_wrapper` ķćīńÜä `constructor` ÕÅéµĢ░, Õ”éµ×£Ķ”üõĮ┐ńö©õĮĀĶć¬ÕĘ▒ńÜäõ╝śÕī¢ÕÖ©Õ░üĶŻģµ×äķĆĀÕÖ© `MyOptimizerConstructor`, ÕŁŚµ«ĄÕÅ»õ╗źĶó½õ┐«µö╣µłÉ:
+
+```python
+optim_wrapper = dict(type='OptimWrapper',
+ constructor='MyOptimizerConstructor',
+ clip_grad=None)
+```
diff --git a/internlm_langchain/knowledge_base/MMSegmentation/content/data_flow.md b/internlm_langchain/knowledge_base/MMSegmentation/content/data_flow.md
new file mode 100644
index 00000000..20dbe07e
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMSegmentation/content/data_flow.md
@@ -0,0 +1,90 @@
+# µĢ░µŹ«µĄü
+
+Õ£©µ£¼ń½ĀĶŖéõĖŁ’╝īµłæõ╗¼Õ░åõ╗ŗń╗Ź [Runner](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/runner.html) ń«ĪńÉåńÜäÕåģķā©µ©ĪÕØŚõ╣ŗķŚ┤ńÜäµĢ░µŹ«µĄüÕÆīµĢ░µŹ«µĀ╝Õ╝Åń║”Õ«ÜŃĆé
+
+## µĢ░µŹ«µĄüµ”éĶ┐░
+
+[Runner](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/design/runner.md) ńøĖÕĮōõ║Ä MMEngine õĖŁńÜäŌĆ£ķøåµłÉÕÖ©ŌĆØŃĆéÕ«āĶ”åńø¢õ║åµĪåµ×ČńÜäµēƵ£ēµ¢╣ķØó’╝īÕ╣ČĶé®Ķ┤¤ńØĆń╗äń╗ćÕÆīĶ░āÕ║”ÕćĀõ╣ĵēƵ£ēµ©ĪÕØŚńÜäĶ┤Żõ╗╗’╝īĶ┐ÖµäÅÕæ│ńØĆÕÉ䵩ĪÕØŚõ╣ŗķŚ┤ńÜäµĢ░µŹ«µĄüõ╣¤ńö▒ `Runner` µÄ¦ÕłČŃĆé Õ”é [MMEngine õĖŁńÜä Runner µ¢ćµĪŻ](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/runner.html)µēĆńż║’╝īõĖŗÕøŠÕ▒Ģńż║õ║åÕ¤║µ£¼ńÜäµĢ░µŹ«µĄüŃĆé
+
+
+
+ĶÖÜń║┐ĶŠ╣µĪåŃĆüńü░Ķē▓ÕĪ½ÕģģÕĮóńŖČõ╗ŻĶĪ©õĖŹÕÉīńÜäµĢ░µŹ«µĀ╝Õ╝Å’╝īĶĆīÕ«×Õ┐āµĪåĶĪ©ńż║µ©ĪÕØŚ/µ¢╣µ│ĢŃĆéńö▒õ║Ä MMEngine µ×üÕż¦ńÜäńüĄµ┤╗µĆ¦ÕÆīÕÅ»µē®Õ▒ĢµĆ¦’╝īõĖĆõ║øķćŹĶ”üńÜäÕ¤║ń▒╗ÕÅ»õ╗źĶó½ń╗¦µē┐’╝īÕ╣ČõĖöÕ«āõ╗¼ńÜäµ¢╣µ│ĢÕÅ»õ╗źĶó½Ķ”åÕåÖŃĆé õĖŖÕøŠµēĆńż║µĢ░µŹ«µĄüõ╗ģķĆéńö©õ║ÄÕĮōńö©µłĘµ▓Īµ£ēĶć¬Õ«Üõ╣ē `Runner` õĖŁńÜä `TrainLoop`ŃĆü`ValLoop` ÕÆī `TestLoop`’╝īÕ╣ČõĖöµ▓Īµ£ēÕ£©ÕģČĶć¬Õ«Üõ╣ēµ©ĪÕ×ŗõĖŁĶ”åÕåÖ `train_step`ŃĆü`val_step` ÕÆī `test_step` µ¢╣µ│ĢµŚČŃĆéMMSegmentation õĖŁ loop ńÜäķ╗śĶ«żĶ«ŠńĮ«Õ”éõĖŗ’╝ÜõĮ┐ńö©`IterBasedTrainLoop` Ķ«Łń╗āµ©ĪÕ×ŗ’╝īÕģ▒Ķ«Ī 20000 µ¼ĪĶ┐Łõ╗Ż’╝īÕ╣ČõĖöÕ£©µ»Å 2000 µ¼ĪĶ┐Łõ╗ŻÕÉÄĶ┐øĶĪīõĖƵ¼Īķ¬īĶ»üŃĆé
+
+```python
+train_cfg = dict(type='IterBasedTrainLoop', max_iters=20000, val_interval=2000)
+val_cfg = dict(type='ValLoop')
+test_cfg = dict(type='TestLoop')
+```
+
+Õ£©õĖŖÕøŠõĖŁ’╝īń║óĶē▓ń║┐ĶĪ©ńż║ [train_step](./models.md#train_step)’╝īÕ£©µ»Åµ¼ĪĶ«Łń╗āĶ┐Łõ╗ŻõĖŁ’╝īµĢ░µŹ«ÕŖĀĶĮĮÕÖ©’╝łdataloader’╝ēõ╗ÄÕŁśÕé©õĖŁÕŖĀĶĮĮÕøŠÕāÅÕ╣Čõ╝ĀĶŠōÕł░µĢ░µŹ«ķóäÕżäńÉåÕÖ©’╝łdata preprocessor’╝ē’╝īµĢ░µŹ«ķóäÕżäńÉåÕÖ©õ╝ÜÕ░åÕøŠÕāŵöŠÕł░ńē╣Õ«ÜńÜäĶ«ŠÕżćõĖŖ’╝īÕ╣ČÕ░åµĢ░µŹ«ÕĀåÕÅĀÕł░µē╣ÕżäńÉåõĖŁ’╝īõ╣ŗÕÉĵ©ĪÕ×ŗµÄźÕÅŚµē╣ÕżäńÉåµĢ░µŹ«õĮ£õĖ║ĶŠōÕģź’╝īµ£ĆÕÉÄÕ░嵩ĪÕ×ŗńÜäĶŠōÕć║ÕÅæķĆüń╗Öõ╝śÕī¢ÕÖ©’╝łoptimizer’╝ēŃĆéĶōØĶē▓ń║┐ĶĪ©ńż║ [val_step](./models.md#val_step) ÕÆī [test_step](./models.md#test_step)ŃĆéĶ┐ÖõĖżõĖ¬Ķ┐ćń©ŗńÜäµĢ░µŹ«µĄüķÖżõ║嵩ĪÕ×ŗĶŠōÕć║õĖÄ `train_step` õĖŹÕÉīÕż¢’╝īÕģČõĮÖÕØćÕÆī `train_step` ń▒╗õ╝╝ŃĆéńö▒õ║ÄÕ£©Ķ»äõ╝░µŚČµ©ĪÕ×ŗÕÅéµĢ░õ╝ÜĶó½Õå╗ń╗ō’╝īÕøĀµŁżµ©ĪÕ×ŗńÜäĶŠōÕć║Õ░åĶó½õ╝ĀķĆÆń╗Ö [Evaluator](./evaluation.md#ioumetric)ŃĆé
+µØźĶ«Īń«ŚµīćµĀćŃĆé
+
+## MMSegmentation õĖŁńÜäµĢ░µŹ«µĄüń║”Õ«Ü
+
+Õ£©õĖŖķØóńÜäÕøŠõĖŁ’╝īµłæõ╗¼ÕÅ»õ╗źń£ŗÕł░Õ¤║µ£¼ńÜäµĢ░µŹ«µĄüŃĆéÕ£©µ£¼ĶŖéõĖŁ’╝īµłæõ╗¼Õ░åÕłåÕł½õ╗ŗń╗ŹµĢ░µŹ«µĄüõĖŁµČēÕÅŖńÜäµĢ░µŹ«ńÜäµĀ╝Õ╝Åń║”Õ«ÜŃĆé
+
+### µĢ░µŹ«ÕŖĀĶĮĮÕÖ©Õł░µĢ░µŹ«ķóäÕżäńÉåÕÖ©
+
+µĢ░µŹ«ÕŖĀĶĮĮÕÖ©’╝łDataLoader’╝ēµś» MMEngine ńÜäĶ«Łń╗āÕÆīµĄŗĶ»ĢµĄüń©ŗõĖŁńÜäõĖĆõĖ¬ķćŹĶ”üń╗äõ╗ČŃĆé
+õ╗ĵ”éÕ┐ĄõĖŖĶ«▓’╝īÕ«āµ║Éõ║Ä [PyTorch](https://pytorch.org/) Õ╣Čõ┐صīüõĖĆĶć┤ŃĆéDataLoader õ╗ĵ¢ćõ╗Čń│╗ń╗¤ÕŖĀĶĮĮµĢ░µŹ«’╝īÕĤզŗµĢ░µŹ«ķĆÜĶ┐ćµĢ░µŹ«ÕćåÕżćµĄüń©ŗÕÉÄĶó½ÕÅæķĆüń╗ÖµĢ░µŹ«ķóäÕżäńÉåÕÖ©ŃĆé
+
+MMSegmentation Õ£© [PackSegInputs](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/datasets/transforms/formatting.py#L12) õĖŁÕ«Üõ╣ēõ║åķ╗śĶ«żµĢ░µŹ«µĀ╝Õ╝Å’╝ī Õ«āµś» `train_pipeline` ÕÆī `test_pipeline` ńÜäµ£ĆÕÉÄõĖĆõĖ¬ń╗äõ╗ČŃĆéµ£ēÕģ│µĢ░µŹ«ĶĮ¼µŹó `pipeline` ńÜäµø┤ÕżÜõ┐Īµü»’╝īĶ»ĘÕÅéķśģ[µĢ░µŹ«ĶĮ¼µŹóµ¢ćµĪŻ](./transforms.md)ŃĆé
+
+Õ£©µ▓Īµ£ēõ╗╗õĮĢõ┐«µö╣ńÜäµāģÕåĄõĖŗ’╝īPackSegInputs ńÜäĶ┐öÕø×ÕĆ╝ķĆÜÕĖĖµś»õĖĆõĖ¬ÕīģÕɽ `inputs` ÕÆī `data_samples` ńÜä `dict`ŃĆéõ╗źõĖŗõ╝¬õ╗ŻńĀüÕ▒Ģńż║õ║å mmseg õĖŁµĢ░µŹ«ÕŖĀĶĮĮÕÖ©ĶŠōÕć║ńÜäµĢ░µŹ«ń▒╗Õ×ŗ’╝īÕ«āµś»õ╗ĵĢ░µŹ«ķøåõĖŁĶÄĘÕÅ¢ńÜäõĖƵē╣µĢ░µŹ«µĀʵ£¼’╝īµĢ░µŹ«ÕŖĀĶĮĮÕÖ©Õ░åÕ«āõ╗¼µēōÕīģµłÉõĖĆõĖ¬ÕŁŚÕģĖÕłŚĶĪ©ŃĆé`inputs` µś»ĶŠōÕģźĶ┐øµ©ĪÕ×ŗńÜäÕ╝ĀķćÅÕłŚĶĪ©’╝ī`data_samples` ÕīģÕɽõ║åĶŠōÕģźÕøŠÕāÅńÜä meta information ÕÆīńøĖÕ║öńÜä ground truthŃĆé
+
+```python
+dict(
+ inputs=List[torch.Tensor],
+ data_samples=List[SegDataSample]
+)
+```
+
+**µ│©µäÅ’╝Ü** [SegDataSample](https://github.com/open-mmlab/mmsegmentation/blob/1.x/mmseg/structures/seg_data_sample.py) µś» MMSegmentation ńÜäµĢ░µŹ«ń╗ōµ×äµÄźÕÅŻ’╝īńö©õ║ÄĶ┐׵ğõĖŹÕÉīń╗äõ╗ČŃĆé`SegDataSample` Õ«×ńÄ░õ║åµŖĮĶ▒ĪµĢ░µŹ«Õģāń┤Ā `mmengine.structures.BaseDataElement`’╝īµø┤ÕżÜõ┐Īµü»Ķ»ĘÕ£© [MMEngine](https://github.com/open-mmlab/mmengine) õĖŁÕÅéķśģ [SegDataSample µ¢ćµĪŻ](./structures.md)ÕÆī[µĢ░µŹ«Õģāń┤Āµ¢ćµĪŻ](https://mmengine.readthedocs.io/zh_CN/latest/advanced_tutorials/data_element.html)ŃĆé
+
+### µĢ░µŹ«ķóäÕżäńÉåÕÖ©Õł░µ©ĪÕ×ŗ
+
+ĶÖĮńäČÕ£©[õĖŖķØóńÜäÕøŠ](##µĢ░µŹ«µĄüµ”éĶ┐░)õĖŁÕłåÕ╝Ćń╗śÕłČõ║åµĢ░µŹ«ķóäÕżäńÉåÕÖ©ÕÆīµ©ĪÕ×ŗ’╝īõĮåµĢ░µŹ«ķóäÕżäńÉåÕÖ©µś»µ©ĪÕ×ŗńÜäõĖĆķā©Õłå’╝īÕøĀµŁżÕÅ»õ╗źÕ£©[µ©ĪÕ×ŗµĢÖń©ŗ](./models.md)õĖŁµēŠÕł░µĢ░µŹ«ķóäÕżäńÉåÕÖ©ń½ĀĶŖéŃĆé
+
+µĢ░µŹ«ķóäÕżäńÉåÕÖ©ńÜäĶ┐öÕø×ÕĆ╝µś»õĖĆõĖ¬ÕīģÕɽ `inputs` ÕÆī `data_samples` ńÜäÕŁŚÕģĖ’╝īÕģČõĖŁ `inputs` µś»µē╣ÕżäńÉåÕøŠÕāÅńÜä 4D Õ╝ĀķćÅ’╝ī`data_samples` õĖŁµĘ╗ÕŖĀõ║åõĖĆõ║øńö©õ║ĵĢ░µŹ«ķóäÕżäńÉåńÜäķóØÕż¢Õģāõ┐Īµü»ŃĆéÕĮōõ╝ĀķĆÆń╗ÖńĮæń╗£µŚČ’╝īÕŁŚÕģĖÕ░åĶó½Ķ¦ŻÕīģõĖ║õĖżõĖ¬ÕĆ╝ŃĆé õ╗źõĖŗõ╝¬õ╗ŻńĀüÕ▒Ģńż║õ║åµĢ░µŹ«ķóäÕżäńÉåÕÖ©ńÜäĶ┐öÕø×ÕĆ╝ÕÆīµ©ĪÕ×ŗńÜäĶŠōÕģźÕĆ╝ŃĆé
+
+```python
+dict(
+ inputs=torch.Tensor,
+ data_samples=List[SegDataSample]
+)
+```
+
+```python
+class Network(BaseSegmentor):
+
+ def forward(self, inputs: torch.Tensor, data_samples: List[SegDataSample], mode: str):
+ pass
+```
+
+**µ│©µäÅ’╝Ü** µ©ĪÕ×ŗńÜäÕēŹÕÉæõ╝ĀµÆŁµ£ē 3 ń¦Źµ©ĪÕ╝Å’╝īńö▒ĶŠōÕģźÕÅéµĢ░ mode µÄ¦ÕłČ’╝īµø┤ÕżÜõ┐Īµü»Ķ»ĘÕÅéķśģ[µ©ĪÕ×ŗµĢÖń©ŗ](./models.md)ŃĆé
+
+### µ©ĪÕ×ŗĶŠōÕć║
+
+Õ”é[µ©ĪÕ×ŗµĢÖń©ŗ](./models.md#forward) ***’╝ł[õĖŁµ¢ćķōŠµÄźÕŠģµø┤µ¢░](./models.md#forward)’╝ē*** µēƵÅÉÕł░ńÜä 3 ń¦ŹÕēŹÕÉæõ╝ĀµÆŁÕģʵ£ē 3 ń¦ŹĶŠōÕć║ŃĆé
+`train_step` ÕÆī `test_step`’╝łµł¢ `val_step`’╝ēÕłåÕł½Õ»╣Õ║öõ║Ä `'loss'` ÕÆī `'predict'`ŃĆé
+
+Õ£© `test_step` µł¢ `val_step` õĖŁ’╝īµÄ©ńÉåń╗ōµ×£õ╝ÜĶó½õ╝ĀķĆÆń╗Ö `Evaluator` ŃĆéµé©ÕÅ»õ╗źÕÅéķśģ[Ķ»äõ╝░µ¢ćµĪŻ](./evaluation.md)µØźĶÄĘÕÅ¢µø┤ÕżÜÕģ│õ║Ä `Evaluator` ńÜäõ┐Īµü»ŃĆé
+
+Õ£©µÄ©ńÉåÕÉÄ’╝īMMSegmentation õĖŁńÜä [BaseSegmentor](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/models/segmentors/base.py#L15) õ╝ÜÕ»╣µÄ©ńÉåń╗ōµ×£Ķ┐øĶĪīń«ĆÕŹĢńÜäÕÉÄÕżäńÉåõ╗źµēōÕīģµÄ©ńÉåń╗ōµ×£ŃĆéńź×ń╗ÅńĮæń╗£ńö¤µłÉńÜäÕłåÕē▓ logits’╝īń╗ÅĶ┐ć `argmax` µōŹõĮ£ÕÉÄńÜäÕłåÕē▓ mask ÕÆī ground truth’╝łÕ”éµ×£ÕŁśÕ£©’╝ēÕ░åĶó½µēōÕīģÕł░ń▒╗õ╝╝ `SegDataSample` ńÜäÕ«×õŠŗŃĆé [postprocess_result](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/models/segmentors/base.py#L132) ńÜäĶ┐öÕø×ÕĆ╝µś»õĖĆõĖ¬ **`SegDataSample`ńÜä`List`**ŃĆéõĖŗÕøŠµśŠńż║õ║åĶ┐Öõ║ø `SegDataSample` Õ«×õŠŗńÜäÕģ│ķö«Õ▒׵ƦŃĆé
+
+
+
+õĖĵĢ░µŹ«ķóäÕżäńÉåÕÖ©õĖĆĶć┤’╝īµŹ¤Õż▒ÕćĮµĢ░õ╣¤µś»µ©ĪÕ×ŗńÜäõĖĆķā©Õłå’╝īÕ«āµś»[Ķ¦ŻńĀüÕż┤](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/models/decode_heads/decode_head.py#L142)ńÜäÕ▒׵Ʀõ╣ŗõĖĆŃĆé
+
+Õ£© MMSegmentation õĖŁ’╝ī`decode_head` ńÜä [loss_by_feat](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/models/decode_heads/decode_head.py#L291) µ¢╣µ│Ģµś»ńö©õ║ÄĶ«Īń«ŚµŹ¤Õż▒ńÜäń╗¤õĖƵğÕÅŻŃĆé
+
+ÕÅéµĢ░’╝Ü
+
+- seg_logits (Tensor)’╝ÜĶ¦ŻńĀüÕż┤ÕēŹÕÉæÕćĮµĢ░ńÜäĶŠōÕć║
+- batch_data_samples (List\[SegDataSample\])’╝ÜÕłåÕē▓µĢ░µŹ«µĀʵ£¼’╝īķĆÜÕĖĖÕīģµŗ¼Õ”é `metainfo` ÕÆī `gt_sem_seg` ńŁēõ┐Īµü»
+
+Ķ┐öÕø×ÕĆ╝’╝Ü
+
+- dict\[str, Tensor\]’╝ÜõĖĆõĖ¬µŹ¤Õż▒ń╗äõ╗ČńÜäÕŁŚÕģĖ
+
+**µ│©µäÅ’╝Ü** `train_step` Õ░åµŹ¤Õż▒õ╝ĀķĆÆĶ┐ø OptimWrapper õ╗źµø┤µ¢░µ©ĪÕ×ŗõĖŁńÜäµØāķ插╝īµø┤ÕżÜõ┐Īµü»Ķ»ĘÕÅéķśģ [train_step](./models.md#train_step)ŃĆé
diff --git a/internlm_langchain/knowledge_base/MMSegmentation/content/datasets.md b/internlm_langchain/knowledge_base/MMSegmentation/content/datasets.md
new file mode 100644
index 00000000..b45f2d22
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMSegmentation/content/datasets.md
@@ -0,0 +1,363 @@
+# µĢ░µŹ«ķøå
+
+Õ£© MMSegmentation ń«Śµ│ĢÕ║ōõĖŁ, µēƵ£ē Dataset ń▒╗ńÜäÕŖ¤ĶāĮµ£ēõĖżõĖ¬: ÕŖĀĶĮĮ[ķóäÕżäńÉå](../user_guides/2_dataset_prepare.md) õ╣ŗÕÉÄńÜäµĢ░µŹ«ķøåńÜäõ┐Īµü», ÕÆīÕ░åµĢ░µŹ«ķĆüÕģź[µĢ░µŹ«ķøåÕÅśµŹóµĄüµ░┤ń║┐](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/datasets/basesegdataset.py#L141) õĖŁ, Ķ┐øĶĪī[µĢ░µŹ«ÕÅśµŹóµōŹõĮ£](./transforms.md). ÕŖĀĶĮĮńÜäµĢ░µŹ«ķøåõ┐Īµü»Õīģµŗ¼õĖżń▒╗: Õģāõ┐Īµü» (meta information), µĢ░µŹ«ķøåµ£¼Ķ║½ńÜäõ┐Īµü», õŠŗÕ”éµĢ░µŹ«ķøåµĆ╗Õģ▒ńÜäń▒╗Õł½, ÕÆīÕ«āõ╗¼Õ»╣Õ║öĶ░āĶē▓ńøśõ┐Īµü»: µĢ░µŹ«õ┐Īµü» (data information) µś»µīćµ»Åń╗äµĢ░µŹ«õĖŁÕøŠńēćÕÆīÕ»╣Õ║öµĀćńŁŠńÜäĶĘ»ÕŠä. õĖŗµ¢ćõĖŁõ╗ŗń╗Źõ║å MMSegmentation 1.x õĖŁµĢ░µŹ«ķøåńÜäÕĖĖńö©µÄźÕÅŻ, ÕÆī mmseg µĢ░µŹ«ķøåÕ¤║ń▒╗õĖŁµĢ░µŹ«õ┐Īµü»ÕŖĀĶĮĮõĖÄõ┐«µö╣µĢ░µŹ«ķøåń▒╗Õł½ńÜäķĆ╗ĶŠæ, õ╗źÕÅŖµĢ░µŹ«ķøåõĖĵĢ░µŹ«ÕÅśµŹóµĄüµ░┤ń║┐ (pipeline) ńÜäÕģ│ń│╗.
+
+## ÕĖĖńö©µÄźÕÅŻ
+
+õ╗ź Cityscapes õĖ║õŠŗ, õ╗ŗń╗ŹµĢ░µŹ«ķøåÕĖĖńö©µÄźÕÅŻ. Õ”éķ£ĆĶ┐ÉĶĪīõ╗źõĖŗńż║õŠŗ, Ķ»ĘÕ£©ÕĮōÕēŹÕĘźõĮ£ńø«ÕĮĢõĖŗńÜä `data` ńø«ÕĮĢõĖŗĶĮĮÕ╣Č[ķóäÕżäńÉå](../user_guides/2_dataset_prepare.md#cityscapes) Cityscapes µĢ░µŹ«ķøå.
+
+Õ«×õŠŗÕī¢ Cityscapes Ķ«Łń╗āµĢ░µŹ«ķøå:
+
+```python
+from mmengine.registry import init_default_scope
+from mmseg.datasets import CityscapesDataset
+
+init_default_scope('mmseg')
+
+data_root = 'data/cityscapes/'
+data_prefix=dict(img_path='leftImg8bit/train', seg_map_path='gtFine/train')
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations'),
+ dict(type='RandomCrop', crop_size=(512, 1024), cat_max_ratio=0.75),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='PackSegInputs')
+]
+
+dataset = CityscapesDataset(data_root=data_root, data_prefix=data_prefix, test_mode=False, pipeline=train_pipeline)
+```
+
+µ¤źń£ŗĶ«Łń╗āµĢ░µŹ«ķøåķĢ┐Õ║”:
+
+```python
+print(len(dataset))
+
+2975
+```
+
+ĶÄĘÕÅ¢µĢ░µŹ«õ┐Īµü», µĢ░µŹ«õ┐Īµü»ńÜäń▒╗Õ×ŗµś»õĖĆõĖ¬ÕŁŚÕģĖ, Õīģµŗ¼ `'img_path'` ÕŁŚµ«ĄńÜäÕŁśµöŠÕøŠńēćńÜäĶĘ»ÕŠäÕÆī `'seg_map_path'` ÕŁŚµ«ĄÕŁśµöŠÕłåÕē▓µĀćµ│©ńÜäĶĘ»ÕŠä, õ╗źÕÅŖµĀćńŁŠķ揵śĀÕ░äńÜäÕŁŚµ«Ą `'label_map'` ÕÆī `'reduce_zero_label'`(õĖ╗Ķ”üÕŖ¤ĶāĮÕ£©õĖŗµ¢ćõĖŁõ╗ŗń╗Ź), Ķ┐śµ£ēÕŁśµöŠÕĘ▓ÕŖĀĶĮĮµĀćńŁŠÕŁŚµ«Ą `'seg_fields'`, ÕÆīÕĮōÕēŹµĀʵ£¼ńÜäń┤óÕ╝ĢÕŁŚµ«Ą `'sample_idx'`.
+
+```python
+# ĶÄĘÕÅ¢µĢ░µŹ«ķøåõĖŁń¼¼õĖĆń╗äµĀʵ£¼ńÜäµĢ░µŹ«õ┐Īµü»
+print(dataset.get_data_info(0))
+
+{'img_path': 'data/cityscapes/leftImg8bit/train/aachen/aachen_000000_000019_leftImg8bit.png',
+ 'seg_map_path': 'data/cityscapes/gtFine/train/aachen/aachen_000000_000019_gtFine_labelTrainIds.png',
+ 'label_map': None,
+ 'reduce_zero_label': False,
+ 'seg_fields': [],
+ 'sample_idx': 0}
+```
+
+ĶÄĘÕÅ¢µĢ░µŹ«ķøåÕģāõ┐Īµü», MMSegmentation ńÜäµĢ░µŹ«ķøåÕģāõ┐Īµü»ńÜäń▒╗Õ×ŗÕÉīµĀʵś»õĖĆõĖ¬ÕŁŚÕģĖ, Õīģµŗ¼ `'classes'` ÕŁŚµ«ĄÕŁśµöŠµĢ░µŹ«ķøåń▒╗Õł½, `'palette'` ÕŁśµöŠµĢ░µŹ«ķøåń▒╗Õł½Õ»╣Õ║öńÜäÕÅ»Ķ¦åÕī¢µŚČĶ░āĶē▓ńøśńÜäķó£Ķē▓, õ╗źÕÅŖµĀćńŁŠķ揵śĀÕ░äńÜäÕŁŚµ«Ą `'label_map'` ÕÆī `'reduce_zero_label'`.
+
+```python
+print(dataset.metainfo)
+
+{'classes': ('road',
+ 'sidewalk',
+ 'building',
+ 'wall',
+ 'fence',
+ 'pole',
+ 'traffic light',
+ 'traffic sign',
+ 'vegetation',
+ 'terrain',
+ 'sky',
+ 'person',
+ 'rider',
+ 'car',
+ 'truck',
+ 'bus',
+ 'train',
+ 'motorcycle',
+ 'bicycle'),
+ 'palette': [[128, 64, 128],
+ [244, 35, 232],
+ [70, 70, 70],
+ [102, 102, 156],
+ [190, 153, 153],
+ [153, 153, 153],
+ [250, 170, 30],
+ [220, 220, 0],
+ [107, 142, 35],
+ [152, 251, 152],
+ [70, 130, 180],
+ [220, 20, 60],
+ [255, 0, 0],
+ [0, 0, 142],
+ [0, 0, 70],
+ [0, 60, 100],
+ [0, 80, 100],
+ [0, 0, 230],
+ [119, 11, 32]],
+ 'label_map': None,
+ 'reduce_zero_label': False}
+```
+
+µĢ░µŹ«ķøå `__getitem__` µ¢╣µ│ĢńÜäĶ┐öÕø×ÕĆ╝, µś»ń╗ÅĶ┐ćµĢ░µŹ«Õó×Õ╝║ńÜäµĀʵ£¼µĢ░µŹ«ńÜäĶŠōÕć║, ÕÉīµĀĘõ╣¤µś»õĖĆõĖ¬ÕŁŚÕģĖ, Õīģµŗ¼õĖżõĖ¬ÕŁŚµ«Ą, `'inputs'` ÕŁŚµ«Ąµś»ÕĮōÕēŹµĀʵ£¼ń╗ÅĶ┐ćµĢ░µŹ«Õó×Õ╝║µōŹõĮ£ńÜäÕøŠÕāÅ, ń▒╗Õ×ŗõĖ║ torch.Tensor, `'data_samples'` ÕŁŚµ«ĄÕŁśµöŠńÜäµĢ░µŹ«ń▒╗Õ×ŗµś» MMSegmentation 1.x µ¢░µĘ╗ÕŖĀńÜäµĢ░µŹ«ń╗ōµ×ä [`Segdatasample`](./structures.md), ÕģČõĖŁ`gt_sem_seg` ÕŁŚµ«Ąµś»ń╗ÅĶ┐ćµĢ░µŹ«Õó×Õ╝║ńÜäµĀćńŁŠµĢ░µŹ«.
+
+```python
+print(dataset[0])
+
+{'inputs': tensor([[[131, 130, 130, ..., 23, 23, 23],
+ [132, 132, 132, ..., 23, 22, 23],
+ [134, 133, 133, ..., 23, 23, 23],
+ ...,
+ [ 66, 67, 67, ..., 71, 71, 71],
+ [ 66, 67, 66, ..., 68, 68, 68],
+ [ 67, 67, 66, ..., 70, 70, 70]],
+
+ [[143, 143, 142, ..., 28, 28, 29],
+ [145, 145, 145, ..., 28, 28, 29],
+ [145, 145, 145, ..., 27, 28, 29],
+ ...,
+ [ 75, 75, 76, ..., 80, 81, 81],
+ [ 75, 76, 75, ..., 80, 80, 80],
+ [ 77, 76, 76, ..., 82, 82, 82]],
+
+ [[126, 125, 126, ..., 21, 21, 22],
+ [127, 127, 128, ..., 21, 21, 22],
+ [127, 127, 126, ..., 21, 21, 22],
+ ...,
+ [ 63, 63, 64, ..., 69, 69, 70],
+ [ 64, 65, 64, ..., 69, 69, 69],
+ [ 65, 66, 66, ..., 72, 71, 71]]], dtype=torch.uint8),
+ 'data_samples':
+ _gt_sem_seg:
+ )}
+```
+
+## BaseSegDataset
+
+ńö▒õ║Ä MMSegmentation õĖŁńÜäµēƵ£ēµĢ░µŹ«ķøåńÜäÕ¤║µ£¼ÕŖ¤ĶāĮÕØćÕīģµŗ¼(1) ÕŖĀĶĮĮ[µĢ░µŹ«ķøåķóäÕżäńÉå](../user_guides/2_dataset_prepare.md) õ╣ŗÕÉÄńÜäµĢ░µŹ«õ┐Īµü»ÕÆī (2) Õ░åµĢ░µŹ«ķĆüÕģźµĢ░µŹ«ÕÅśµŹóµĄüµ░┤ń║┐õĖŁĶ┐øĶĪīµĢ░µŹ«ÕÅśµŹó, ÕøĀµŁżÕ£© MMSegmentation õĖŁÕ░åÕģČõĖŁńÜäÕģ▒ÕÉīµÄźÕÅŻµŖĮĶ▒ĪµłÉ [`BaseSegDataset`](https://mmsegmentation.readthedocs.io/zh_CN/latest/api.html?highlight=BaseSegDataset#mmseg.datasets.BaseSegDataset)’╝īÕ«āń╗¦µē┐Ķć¬ [MMEngine ńÜä `BaseDataset`](https://github.com/open-mmlab/mmengine/blob/main/docs/en/advanced_tutorials/basedataset.md), ķüĄÕŠ¬ OpenMMLab µĢ░µŹ«ķøåÕłØÕ¦ŗÕī¢ń╗¤õĖƵĄüń©ŗ, µö»µīüķ½śµĢłńÜäÕåģķā©µĢ░µŹ«ÕŁśÕ驵Ā╝Õ╝Å, µö»µīüµĢ░µŹ«ķøåµŗ╝µÄźŃĆüµĢ░µŹ«ķøåķćŹÕżŹķććµĀĘńŁēÕŖ¤ĶāĮ.
+Õ£© MMSegmentation BaseSegDataset õĖŁķ揵¢░Õ«Üõ╣ēõ║å**µĢ░µŹ«õ┐Īµü»ÕŖĀĶĮĮµ¢╣µ│Ģ**’╝ł`load_data_list`’╝ēÕÆīÕ╣ȵ¢░Õó×õ║å `get_label_map` µ¢╣µ│Ģńö©µØź**õ┐«µö╣µĢ░µŹ«ķøåńÜäń▒╗Õł½õ┐Īµü»**.
+
+### µĢ░µŹ«õ┐Īµü»ÕŖĀĶĮĮ
+
+µĢ░µŹ«õ┐Īµü»ÕŖĀĶĮĮńÜäÕåģÕ«╣µś»µĀʵ£¼µĢ░µŹ«ńÜäÕøŠńēćĶĘ»ÕŠäÕÆīµĀćńŁŠĶĘ»ÕŠä, ÕģĘõĮōÕ«×ńÄ░Õ£© MMSegmentation ńÜä BaseSegDataset ńÜä [`load_data_list`](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/datasets/basesegdataset.py#L231) õĖŁ.
+õĖ╗Ķ”üµ£ēõĖżń¦ŹĶÄĘÕÅ¢ÕøŠńēćÕÆīµĀćńŁŠńÜäĶĘ»ÕŠäµ¢╣µ│Ģ, Õ”éµ×£ÕĮōµĢ░µŹ«ķøåńø«ÕĮĢµīēõ╗źõĖŗńø«ÕĮĢń╗ōµ×äń╗äń╗ć, [`load_data_list`](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/datasets/basesegdataset.py#L231)) õ╝ܵĀ╣µŹ«µĢ░µŹ«ĶĘ»ÕŠäÕÆīÕÉÄń╝ĆµØźĶ¦Żµ×É.
+
+```
+Ōö£ŌöĆŌöĆ data
+Ōöé Ōö£ŌöĆŌöĆ my_dataset
+Ōöé Ōöé Ōö£ŌöĆŌöĆ img_dir
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ train
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ xxx{img_suffix}
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ yyy{img_suffix}
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ val
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ zzz{img_suffix}
+Ōöé Ōöé Ōö£ŌöĆŌöĆ ann_dir
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ train
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ xxx{seg_map_suffix}
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ yyy{seg_map_suffix}
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ val
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ zzz{seg_map_suffix}
+```
+
+õŠŗÕ”é ADE20k µĢ░µŹ«ķøåń╗ōµ×äÕ”éõĖŗµēĆńż║:
+
+```
+Ōö£ŌöĆŌöĆ ade
+Ōöé Ōö£ŌöĆŌöĆ ADEChallengeData2016
+Ōöé Ōöé Ōö£ŌöĆŌöĆ annotations
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ training
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ ADE_train_00000001.png
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ ...
+Ōöé Ōöé Ōöé ŌöéŌöĆŌöĆ validation
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ ADE_val_00000001.png
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ ...
+Ōöé Ōöé Ōö£ŌöĆŌöĆ images
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ training
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ ADE_train_00000001.jpg
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ ...
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ validation
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ ADE_val_00000001.jpg
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ ...
+```
+
+Õ«×õŠŗÕī¢ ADE20k µĢ░µŹ«ķøåµŚČ’╝īĶŠōÕģźÕøŠńēćÕÆīµĀćńŁŠńÜäĶĘ»ÕŠäÕÆīÕÉÄń╝Ć:
+
+```python
+from mmseg.datasets import ADE20KDataset
+
+ADE20KDataset(data_root = 'data/ade/ADEChallengeData2016',
+ data_prefix=dict(img_path='images/training', seg_map_path='annotations/training'),
+ img_suffix='.jpg',
+ seg_map_suffix='.png',
+ reduce_zero_label=True’╝ē
+```
+
+Õ”éµ×£µĢ░µŹ«ķøåµ£ēµĀćµ│©µ¢ćõ╗Č, Õ«×õŠŗÕī¢µĢ░µŹ«ķøåµŚČõ╝ܵĀ╣µŹ«ĶŠōÕģźńÜäµĢ░µŹ«ķøåµĀćµ│©µ¢ćõ╗ČÕŖĀĶĮĮµĢ░µŹ«õ┐Īµü». õŠŗÕ”é, PascalContext µĢ░µŹ«ķøåÕ«×õŠŗ, ĶŠōÕģźµĀćµ│©µ¢ćõ╗ČńÜäÕåģÕ«╣õĖ║:
+
+```python
+2008_000008
+...
+```
+
+Õ«×õŠŗÕī¢µŚČķ£ĆĶ”üÕ«Üõ╣ē `ann_file`
+
+```python
+PascalContextDataset(data_root='data/VOCdevkit/VOC2010/',
+ data_prefix=dict(img_path='JPEGImages', seg_map_path='SegmentationClassContext'),
+ ann_file='ImageSets/SegmentationContext/train.txt')
+```
+
+### µĢ░µŹ«ķøåń▒╗Õł½õ┐«µö╣
+
+- ķĆÜĶ┐ćĶŠōÕģź metainfo õ┐«µö╣
+ `BaseSegDataset` ńÜäÕŁÉń▒╗Õģāõ┐Īµü»Õ£©µĢ░µŹ«ķøåÕ«×ńÄ░µŚČÕ«Üõ╣ēõĖ║ń▒╗ÕÅśķćÅ’╝īõŠŗÕ”é Cityscapes ńÜä `METAINFO` ÕÅśķćÅ:
+
+```python
+class CityscapesDataset(BaseSegDataset):
+ """Cityscapes dataset.
+
+ The ``img_suffix`` is fixed to '_leftImg8bit.png' and ``seg_map_suffix`` is
+ fixed to '_gtFine_labelTrainIds.png' for Cityscapes dataset.
+ """
+ METAINFO = dict(
+ classes=('road', 'sidewalk', 'building', 'wall', 'fence', 'pole',
+ 'traffic light', 'traffic sign', 'vegetation', 'terrain',
+ 'sky', 'person', 'rider', 'car', 'truck', 'bus', 'train',
+ 'motorcycle', 'bicycle'),
+ palette=[[128, 64, 128], [244, 35, 232], [70, 70, 70], [102, 102, 156],
+ [190, 153, 153], [153, 153, 153], [250, 170,
+ 30], [220, 220, 0],
+ [107, 142, 35], [152, 251, 152], [70, 130, 180],
+ [220, 20, 60], [255, 0, 0], [0, 0, 142], [0, 0, 70],
+ [0, 60, 100], [0, 80, 100], [0, 0, 230], [119, 11, 32]])
+
+```
+
+Ķ┐ÖķćīńÜä `'classes'` õĖŁÕ«Üõ╣ēõ║å Cityscapes µĢ░µŹ«ķøåµĀćńŁŠõĖŁńÜäń▒╗Õł½ÕÉŹ, Õ”éµ×£Ķ«Łń╗āµŚČÕŬÕģ│µ│©ÕćĀõĖ¬õ║żķĆÜÕĘźÕģĘń▒╗Õł½, **Õ┐ĮńĢźÕģČõ╗¢ń▒╗Õł½**,
+Õ£©Õ«×õŠŗÕī¢ Cityscapes µĢ░µŹ«ķøåµŚČķĆÜĶ┐ćÕ«Üõ╣ē `metainfo` ĶŠōÕģźÕÅéµĢ░ńÜä classes ńÜäÕŁŚµ«ĄµØźõ┐«µö╣µĢ░µŹ«ķøåńÜäÕģāõ┐Īµü»:
+
+```python
+from mmseg.datasets import CityscapesDataset
+
+data_root = 'data/cityscapes/'
+data_prefix=dict(img_path='leftImg8bit/train', seg_map_path='gtFine/train')
+# metainfo õĖŁÕŬõ┐ØńĢÖõ╗źõĖŗ classes
+metainfo=dict(classes=( 'car', 'truck', 'bus', 'train', 'motorcycle', 'bicycle'))
+dataset = CityscapesDataset(data_root=data_root, data_prefix=data_prefix, metainfo=metainfo)
+
+print(dataset.metainfo)
+
+{'classes': ('car', 'truck', 'bus', 'train', 'motorcycle', 'bicycle'),
+ 'palette': [[0, 0, 142],
+ [0, 0, 70],
+ [0, 60, 100],
+ [0, 80, 100],
+ [0, 0, 230],
+ [119, 11, 32],
+ [128, 64, 128],
+ [244, 35, 232],
+ [70, 70, 70],
+ [102, 102, 156],
+ [190, 153, 153],
+ [153, 153, 153],
+ [250, 170, 30],
+ [220, 220, 0],
+ [107, 142, 35],
+ [152, 251, 152],
+ [70, 130, 180],
+ [220, 20, 60],
+ [255, 0, 0]],
+ # ń▒╗Õł½ń┤óÕ╝ĢõĖ║ 255 ńÜäÕāÅń┤Ā’╝īÕ£©Ķ«Īń«ŚµŹ¤Õż▒µŚČõ╝ÜĶó½Õ┐ĮńĢź
+ 'label_map': {0: 255,
+ 1: 255,
+ 2: 255,
+ 3: 255,
+ 4: 255,
+ 5: 255,
+ 6: 255,
+ 7: 255,
+ 8: 255,
+ 9: 255,
+ 10: 255,
+ 11: 255,
+ 12: 255,
+ 13: 0,
+ 14: 1,
+ 15: 2,
+ 16: 3,
+ 17: 4,
+ 18: 5},
+ 'reduce_zero_label': False}
+```
+
+ÕÅ»õ╗źń£ŗÕł░, µĢ░µŹ«ķøåÕģāõ┐Īµü»ńÜäń▒╗Õł½ÕÆīķ╗śĶ«ż Cityscapes õĖŹÕÉī. Õ╣ČõĖö, Õ«Üõ╣ēõ║åµĀćńŁŠķ揵śĀÕ░äńÜäÕŁŚµ«Ą `label_map` ńö©µØźõ┐«µö╣µ»ÅõĖ¬ÕłåÕē▓µÄ®Ķå£õĖŖńÜäÕāÅń┤ĀńÜäń▒╗Õł½ń┤óÕ╝Ģ, ÕłåÕē▓µĀćńŁŠń▒╗Õł½õ╝ܵĀ╣µŹ« `label_map`, Õ░åń▒╗Õł½ķ揵śĀÕ░ä, [ÕģĘõĮōÕ«×ńÄ░](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/datasets/basesegdataset.py#L151):
+
+```python
+gt_semantic_seg_copy = gt_semantic_seg.copy()
+for old_id, new_id in results['label_map'].items():
+ gt_semantic_seg[gt_semantic_seg_copy == old_id] = new_id
+```
+
+- ķĆÜĶ┐ć `reduce_zero_label` õ┐«µö╣
+ Õ»╣õ║ÄÕĖĖĶ¦üńÜäÕ┐ĮńĢź 0 ÕÅʵĀćńŁŠńÜäÕ£║µÖ», `BaseSegDataset` ńÜäÕŁÉń▒╗õĖŁÕÅ»õ╗źńö© `reduce_zero_label` ĶŠōÕģźÕÅéµĢ░µØźµÄ¦ÕłČŃĆé`reduce_zero_label` (ķ╗śĶ«żõĖ║ `False`)
+ ńö©µØźµÄ¦ÕłČµś»ÕÉ”Õ░åµĀćńŁŠ 0 Õ┐ĮńĢź, ÕĮōĶ»źÕÅéµĢ░õĖ║ `True` µŚČ(µ£ĆÕĖĖĶ¦üńÜäÕ║öńö©µś» ADE20k µĢ░µŹ«ķøå), Õ»╣ÕłåÕē▓µĀćńŁŠõĖŁń¼¼ 0 õĖ¬ń▒╗Õł½Õ»╣Õ║öńÜäń▒╗Õł½ń┤óÕ╝Ģµö╣õĖ║ 255 (MMSegmentation µ©ĪÕ×ŗõĖŁĶ«Īń«ŚµŹ¤Õż▒µŚČ, ķ╗śĶ«żÕ┐ĮńĢź 255), ÕģČõ╗¢ń▒╗Õł½Õ»╣Õ║öńÜäń▒╗Õł½ń┤óÕ╝ĢÕćÅõĖĆ:
+
+```python
+gt_semantic_seg[gt_semantic_seg == 0] = 255
+gt_semantic_seg = gt_semantic_seg - 1
+gt_semantic_seg[gt_semantic_seg == 254] = 255
+```
+
+## µĢ░µŹ«ķøåõĖĵĢ░µŹ«ÕÅśµŹóµĄüµ░┤ń║┐
+
+Õ£©ÕĖĖńö©µÄźÕÅŻńÜäõŠŗÕŁÉõĖŁÕÅ»õ╗źń£ŗÕł░, ĶŠōÕģźńÜäÕÅéµĢ░õĖŁÕ«Üõ╣ēõ║åµĢ░µŹ«ÕÅśµŹóµĄüµ░┤ń║┐ÕÅéµĢ░ `pipeline`, µĢ░µŹ«ķøå `__getitem__` µ¢╣µ│ĢĶ┐öÕø×ń╗ÅĶ┐ćµĢ░µŹ«ÕÅśµŹóńÜäÕĆ╝.
+ÕĮōµĢ░µŹ«ķøåĶŠōÕģźÕÅéµĢ░µ▓Īµ£ēÕ«Üõ╣ē pipeline, Ķ┐öÕø×ÕĆ╝ÕÆī `get_data_info` µ¢╣µ│ĢĶ┐öÕø×ÕĆ╝ńøĖÕÉī, õŠŗÕ”é:
+
+```python
+from mmseg.datasets import CityscapesDataset
+
+data_root = 'data/cityscapes/'
+data_prefix=dict(img_path='leftImg8bit/train', seg_map_path='gtFine/train')
+dataset = CityscapesDataset(data_root=data_root, data_prefix=data_prefix, test_mode=False)
+
+print(dataset[0])
+
+{'img_path': 'data/cityscapes/leftImg8bit/train/aachen/aachen_000000_000019_leftImg8bit.png',
+ 'seg_map_path': 'data/cityscapes/gtFine/train/aachen/aachen_000000_000019_gtFine_labelTrainIds.png',
+ 'label_map': None,
+ 'reduce_zero_label': False,
+ 'seg_fields': [],
+ 'sample_idx': 0}
+```
diff --git a/internlm_langchain/knowledge_base/MMSegmentation/content/engine.md b/internlm_langchain/knowledge_base/MMSegmentation/content/engine.md
new file mode 100644
index 00000000..79b4c8d2
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMSegmentation/content/engine.md
@@ -0,0 +1,281 @@
+# Ķ«Łń╗āÕ╝ĢµōÄ
+
+MMEngine Õ«Üõ╣ēõ║åõĖĆõ║ø[Õ¤║ńĪĆÕŠ¬ńÄ»µÄ¦ÕłČÕÖ©](https://github.com/open-mmlab/mmengine/blob/main/mmengine/runner/loops.py) õŠŗÕ”éÕ¤║õ║ÄĶĮ«µ¼ĪńÜäĶ«Łń╗āÕŠ¬ńÄ» (`EpochBasedTrainLoop`), Õ¤║õ║ÄĶ┐Łõ╗Żµ¼ĪµĢ░ńÜäĶ«Łń╗āÕŠ¬ńÄ» (`IterBasedTrainLoop`), µĀćÕćåńÜäķ¬īĶ»üÕŠ¬ńÄ» (`ValLoop`) ÕÆīµĀćÕćåńÜ䵥ŗĶ»ĢÕŠ¬ńÄ» (`TestLoop`).
+OpenMMLab ńÜäń«Śµ│ĢÕ║ōÕ”é MMSegmentation Õ░嵩ĪÕ×ŗĶ«Łń╗ā, µĄŗĶ»ĢÕÆīµÄ©ńÉåµŖĮĶ▒ĪõĖ║µē¦ĶĪīÕÖ©(`Runner`) µØźÕżäńÉå. ńö©µłĘÕÅ»õ╗źńø┤µÄźõĮ┐ńö© MMEngine õĖŁńÜäķ╗śĶ«żµē¦ĶĪīÕÖ©, õ╣¤ÕÅ»õ╗źÕ»╣µē¦ĶĪīÕÖ©Ķ┐øĶĪīõ┐«µö╣õ╗źµ╗ĪĶČ│Õ«ÜÕłČÕī¢ķ£Ćµ▒é. Ķ┐ÖõĖ¬µ¢ćµĪŻõĖ╗Ķ”üõ╗ŗń╗Źńö©µłĘÕ”éõĮĢķģŹńĮ«ÕĘ▓µ£ēńÜäĶ┐ÉĶĪīĶ«ŠÕ«Ü, ķÆ®ÕŁÉÕÆīõ╝śÕī¢ÕÖ©ńÜäÕ¤║µ£¼µ”éÕ┐ĄõĖÄõĮ┐ńö©µ¢╣µ│Ģ.
+
+## ķģŹńĮ«Ķ┐ÉĶĪīĶ«ŠÕ«Ü
+
+### ķģŹńĮ«Ķ«Łń╗āķĢ┐Õ║”
+
+ÕŠ¬ńÄ»µÄ¦ÕłČÕÖ©µīćńÜ䵜»Ķ«Łń╗ā, ķ¬īĶ»üÕÆīµĄŗĶ»ĢµŚČńÜäµē¦ĶĪīµĄüń©ŗ, Õ£©ķģŹńĮ«µ¢ćõ╗ČķćīķØóõĮ┐ńö© `train_cfg`, `val_cfg` ÕÆī `test_cfg` µØźµ×äÕ╗║Ķ┐Öõ║øµĄüń©ŗ. MMSegmentation Õ£© `configs/_base_/schedules` µ¢ćõ╗ČÕż╣ķćīķØóńÜä `train_cfg` Ķ«ŠńĮ«ÕĖĖńö©ńÜäĶ«Łń╗āķĢ┐Õ║”.
+õŠŗÕ”é, õĮ┐ńö©Õ¤║õ║ÄĶ┐Łõ╗Żµ¼ĪµĢ░ńÜäĶ«Łń╗āÕŠ¬ńÄ» (`IterBasedTrainLoop`) ÕÄ╗Ķ«Łń╗ā 80,000 õĖ¬Ķ┐Łõ╗Żµ¼ĪµĢ░, Õ╣ČõĖöµ»Å 8,000 iteration ÕüÜõĖƵ¼Īķ¬īĶ»ü, ÕÅ»õ╗źÕ”éõĖŗĶ«ŠńĮ«:
+
+```python
+train_cfg = dict(type='IterBasedTrainLoop', max_iters=80000, val_interval=8000)
+```
+
+### ķģŹńĮ«Ķ«Łń╗āõ╝śÕī¢ÕÖ©
+
+Ķ┐Öķćīµś»õĖĆõĖ¬ SGD õ╝śÕī¢ÕÖ©ńÜäõŠŗÕŁÉ:
+
+```python
+optim_wrapper = dict(
+ type='OptimWrapper',
+ optimizer=dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0005),
+ clip_grad=None)
+```
+
+OpenMMLab µö»µīü PyTorch ķćīķØóµēƵ£ēńÜäõ╝śÕī¢ÕÖ©, µø┤ÕżÜń╗åĶŖéÕÅ»õ╗źÕÅéĶĆā MMEngine [õ╝śÕī¢ÕÖ©µ¢ćµĪŻ](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/tutorials/optim_wrapper.md).
+
+ķ£ĆĶ”üÕ╝║Ķ░āńÜ䵜», `optim_wrapper` µś» `runner` ńÜäÕÅśķćÅ, µēĆõ╗źķ£ĆĶ”üķģŹńĮ«õ╝śÕī¢ÕÖ©µŚČķģŹńĮ«ńÜäÕŁŚµ«Ąµś» `optim_wrapper` ÕŁŚµ«Ą. µø┤ÕżÜÕģ│õ║Äõ╝śÕī¢ÕÖ©ńÜäõĮ┐ńö©µ¢╣µ│Ģ, ÕÅ»õ╗źń£ŗõĖŗķØóõ╝śÕī¢ÕÖ©ńÜäń½ĀĶŖé.
+
+### ķģŹńĮ«Ķ«Łń╗āÕÅéµĢ░Ķ░āÕ║”ÕÖ©
+
+Õ£©ķģŹńĮ«Ķ«Łń╗āÕÅéµĢ░Ķ░āÕ║”ÕÖ©ÕēŹ, µÄ©ĶŹÉÕģłõ║åĶ¦Ż [MMEngine µ¢ćµĪŻ](https://github.com/open-mmlab/mmengine/blob/main/docs/en/tutorials/param_scheduler.md) ķćīķØóÕģ│õ║ÄÕÅéµĢ░Ķ░āÕ║”ÕÖ©ńÜäÕ¤║µ£¼µ”éÕ┐Ą.
+
+õ╗źõĖŗµś»õĖĆõĖ¬ÕÅéµĢ░Ķ░āÕ║”ÕÖ©ńÜäõŠŗÕŁÉ, Ķ«Łń╗āµŚČÕēŹ 1,000 õĖ¬ iteration µŚČķććńö©ń║┐µĆ¦ÕÅśÕī¢ńÜäÕŁ”õ╣ĀńÄćńŁ¢ńĢźõĮ£õĖ║Ķ«Łń╗āķóäńāŁ, õ╗Ä 1,000 iteration õ╣ŗÕÉÄńø┤Õł░µ£ĆÕÉÄ 16,000 õĖ¬ iteration µŚČÕłÖķććńö©ķ╗śĶ«żńÜäÕżÜķĪ╣Õ╝ÅÕŁ”õ╣ĀńÄćĶĪ░ÕćÅ:
+
+```python
+param_scheduler = [
+ dict(type='LinearLR', by_epoch=False, start_factor=0.1, begin=0, end=1000),
+ dict(
+ type='PolyLR',
+ eta_min=1e-4,
+ power=0.9,
+ begin=1000,
+ end=160000,
+ by_epoch=False,
+ )
+]
+```
+
+µ│©µäÅ: ÕĮōõ┐«µö╣ `train_cfg` ķćīķØó `max_iters` ńÜ䵌ČÕĆÖ, Ķ»ĘńĪ«õ┐ØÕÅéµĢ░Ķ░āÕ║”ÕÖ© `param_scheduler` ķćīķØóńÜäÕÅéµĢ░õ╣¤Ķó½ÕÉīµŚČõ┐«µö╣.
+
+## ķÆ®ÕŁÉ (Hook)
+
+### õ╗ŗń╗Ź
+
+OpenMMLab Õ░嵩ĪÕ×ŗĶ«Łń╗āÕÆīµĄŗĶ»ĢĶ┐ćń©ŗµŖĮĶ▒ĪõĖ║ `Runner`, µÅÆÕģźķÆ®ÕŁÉÕÅ»õ╗źÕ«×ńÄ░Õ£© `Runner` õĖŁõĖŹÕÉīńÜäĶ«Łń╗āÕÆīµĄŗĶ»ĢĶŖéńé╣ (õŠŗÕ”é "µ»ÅõĖ¬Ķ«Łń╗ā iter ÕēŹÕÉÄ", "µ»ÅõĖ¬ķ¬īĶ»ü iter ÕēŹÕÉÄ" ńŁēõĖŹÕÉīķśČµ«Ą) µēĆķ£ĆĶ”üńÜäńøĖÕ║öÕŖ¤ĶāĮ. µø┤ÕżÜķÆ®ÕŁÉµ£║ÕłČńÜäõ╗ŗń╗ŹÕÅ»õ╗źÕÅéĶĆā[Ķ┐Öķćī](https://www.calltutors.com/blog/what-is-hook).
+
+`Runner` õĖŁµēĆõĮ┐ńö©ńÜäķÆ®ÕŁÉÕłåõĖ║õĖżń▒╗:
+
+- ķ╗śĶ«żķÆ®ÕŁÉ (default hooks)
+
+Õ«āõ╗¼Õ«×ńÄ░õ║åĶ«Łń╗āµŚČµēĆÕ┐ģķ£ĆńÜäÕŖ¤ĶāĮ, Õ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁńö© `default_hooks` Õ«Üõ╣ēõ╝Āń╗Ö `Runner`, `Runner` ķĆÜĶ┐ć [`register_default_hooks`](https://github.com/open-mmlab/mmengine/blob/main/mmengine/runner/runner.py#L1780) µ¢╣µ│Ģµ│©Õåī.
+ķÆ®ÕŁÉµ£ēÕ»╣Õ║öńÜäõ╝śÕģłń║¦, õ╝śÕģłń║¦ĶČŖķ½ś, ĶČŖµŚ®Ķó½µē¦ĶĪīÕÖ©Ķ░āńö©. Õ”éµ×£õ╝śÕģłń║¦õĖƵĀĘ, Ķó½Ķ░āńö©ńÜäķĪ║Õ║ÅÕÆīķÆ®ÕŁÉµ│©ÕåīńÜäķĪ║Õ║ÅõĖĆĶć┤.
+õĖŹÕ╗║Ķ««ńö©µłĘõ┐«µö╣ķ╗śĶ«żķÆ®ÕŁÉńÜäõ╝śÕģłń║¦, ÕÅ»õ╗źÕÅéĶĆā [mmengine hooks µ¢ćµĪŻ](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/tutorials/hook.md) õ║åĶ¦ŻķÆ®ÕŁÉõ╝śÕģłń║¦ńÜäÕ«Üõ╣ē.
+õĖŗķØ󵜻 MMSegmentation õĖŁµēĆńö©Õł░ńÜäķ╗śĶ«żķÆ®ÕŁÉ’╝Ü
+
+| ķÆ®ÕŁÉ | ÕŖ¤ĶāĮ | õ╝śÕģłń║¦ |
+| :--------------------------------------------------------------------------------------------------------------------: | :---------------------------------------------------------------------------------------------: | :---------------: |
+| [IterTimerHook](https://github.com/open-mmlab/mmengine/blob/main/mmengine/hooks/iter_timer_hook.py) | Ķ«░ÕĮĢ iteration ĶŖ▒Ķ┤╣ńÜ䵌ČķŚ┤. | NORMAL (50) |
+| [LoggerHook](https://github.com/open-mmlab/mmengine/blob/main/mmengine/hooks/logger_hook.py) | õ╗Ä `Runner` ķćīõĖŹÕÉīńÜäń╗äõ╗ČõĖŁµöČķøåµŚźÕ┐ŚĶ«░ÕĮĢ, Õ╣ČÕ░åÕģČĶŠōÕć║Õł░ń╗łń½», JSON µ¢ćõ╗Č, tensorboard, wandb ńŁēõĖŗµĖĖ. | BELOW_NORMAL (60) |
+| [ParamSchedulerHook](https://github.com/open-mmlab/mmengine/blob/main/mmengine/hooks/param_scheduler_hook.py) | µø┤µ¢░õ╝śÕī¢ÕÖ©ķćīķØóńÜäõĖĆõ║øĶČģÕÅéµĢ░, õŠŗÕ”éÕŁ”õ╣ĀńÄćńÜäÕŖ©ķćÅ. | LOW (70) |
+| [CheckpointHook](https://github.com/open-mmlab/mmengine/blob/main/mmengine/hooks/checkpoint_hook.py) | Ķ¦äÕŠŗµĆ¦Õ£░õ┐ØÕŁś checkpoint µ¢ćõ╗Č. | VERY_LOW (90) |
+| [DistSamplerSeedHook](https://github.com/open-mmlab/mmengine/blob/main/mmengine/hooks/sampler_seed_hook.py) | ńĪ«õ┐ØÕłåÕĖāÕ╝ÅķććµĀĘÕÖ© shuffle µś»µēōÕ╝ĆńÜä. | NORMAL (50) |
+| [SegVisualizationHook](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/visualization/local_visualizer.py) | ÕÅ»Ķ¦åÕī¢ķ¬īĶ»üÕÆīµĄŗĶ»ĢĶ┐ćń©ŗķćīńÜäķó䵥ŗń╗ōµ×£. | NORMAL (50) |
+
+MMSegmentation õ╝ÜÕ£© [`defualt_hooks`](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/_base_/schedules/schedule_160k.py#L19-L25) ķćīķØóµ│©ÕåīõĖĆõ║øĶ«Łń╗āµēĆÕ┐ģķ£ĆÕŖ¤ĶāĮńÜäķÆ®ÕŁÉ::
+
+```python
+default_hooks = dict(
+ timer=dict(type='IterTimerHook'),
+ logger=dict(type='LoggerHook', interval=50, log_metric_by_epoch=False),
+ param_scheduler=dict(type='ParamSchedulerHook'),
+ checkpoint=dict(type='CheckpointHook', by_epoch=False, interval=32000),
+ sampler_seed=dict(type='DistSamplerSeedHook'),
+ visualization=dict(type='SegVisualizationHook'))
+```
+
+õ╗źõĖŖķ╗śĶ«żķÆ®ÕŁÉķÖż `SegVisualizationHook` Õż¢ķāĮµś»Õ£© MMEngine õĖŁµēĆÕ«×ńÄ░, `SegVisualizationHook` µś»Õ£© MMSegmentation ķćīĶó½Õ«×ńÄ░ńÜäķÆ®ÕŁÉ, õ╣ŗÕÉÄõ╝ÜõĖōķŚ©õ╗ŗń╗Ź.
+
+- õ┐«µö╣ķ╗śĶ«żńÜäķÆ®ÕŁÉ
+
+õ╗ź `default_hooks` ķćīķØóńÜä `logger` ÕÆī `checkpoint` õĖ║õŠŗ, µłæõ╗¼µØźõ╗ŗń╗ŹÕ”éõĮĢõ┐«µö╣ `default_hooks` õĖŁķ╗śĶ«żńÜäķÆ®ÕŁÉ.
+
+(1) µ©ĪÕ×ŗõ┐ØÕŁśķģŹńĮ«
+
+`default_hooks` õĮ┐ńö© `checkpoint` ÕŁŚµ«ĄµØźÕłØÕ¦ŗÕī¢[µ©ĪÕ×ŗõ┐ØÕŁśķÆ®ÕŁÉ (CheckpointHook)](https://github.com/open-mmlab/mmengine/blob/main/mmengine/hooks/checkpoint_hook.py#L19).
+
+```python
+checkpoint = dict(type='CheckpointHook', interval=1)
+```
+
+ńö©µłĘÕÅ»õ╗źĶ«ŠńĮ« `max_keep_ckpts` µØźÕŬõ┐ØÕŁśÕ░æķćÅńÜ䵯Ƶ¤źńé╣µł¢ĶĆģńö© `save_optimizer` µØźÕå│իܵś»ÕÉ”õ┐ØÕŁś optimizer ńÜäõ┐Īµü».
+µø┤ÕżÜńøĖÕģ│ÕÅéµĢ░ńÜäń╗åĶŖéÕÅ»õ╗źÕÅéĶĆā[Ķ┐Öķćī](https://mmengine.readthedocs.io/zh_CN/latest/api/generated/mmengine.hooks.CheckpointHook.html#checkpointhook).
+
+(2) µŚźÕ┐ŚķģŹńĮ«
+
+`µŚźÕ┐ŚķÆ®ÕŁÉ (LoggerHook)` Ķó½ńö©µØźµöČķøå `µē¦ĶĪīÕÖ© (Runner)` ķćīķØóõĖŹÕÉīń╗äõ╗ČńÜ䵌źÕ┐Śõ┐Īµü»ńäČÕÉÄÕåÖÕģźń╗łń½», JSON µ¢ćõ╗Č, tensorboard ÕÆī wandb ńŁēÕ£░µ¢╣.
+
+```python
+logger=dict(type='LoggerHook', interval=10)
+```
+
+Õ£©µ£Ćµ¢░ńÜä 1.x ńēłµ£¼ńÜä MMSegmentation ķćīķØó, õĖĆõ║øµŚźÕ┐ŚķÆ®ÕŁÉ (LoggerHook) õŠŗÕ”é `TextLoggerHook`, `WandbLoggerHook` ÕÆī `TensorboardLoggerHook` Õ░åõĖŹÕåŹĶó½õĮ┐ńö©.
+õĮ£õĖ║µø┐õ╗Ż, MMEngine õĮ┐ńö© `LogProcessor` µØźÕżäńÉåõĖŖĶ┐░ķÆ®ÕŁÉÕżäńÉåńÜäõ┐Īµü», Õ«āõ╗¼ńÄ░Õ£©Õ£© [`MessageHub`](https://github.com/open-mmlab/mmengine/blob/main/mmengine/logging/message_hub.py#L17),
+[`WandbVisBackend`](https://github.com/open-mmlab/mmengine/blob/main/mmengine/visualization/vis_backend.py#L324) ÕÆī [`TensorboardVisBackend`](https://github.com/open-mmlab/mmengine/blob/main/mmengine/visualization/vis_backend.py#L472) ķćīķØó.
+
+ÕģĘõĮōõĮ┐ńö©µ¢╣µ│ĢÕ”éõĖŗ, ķģŹńĮ«ÕÅ»Ķ¦åÕī¢ÕÖ©ÕÆīÕÉīµŚČµīćÕ«ÜÕÅ»Ķ¦åÕī¢ÕÉÄń½», Ķ┐ÖķćīõĮ┐ńö© Tensorboard õĮ£õĖ║ÕÅ»Ķ¦åÕī¢ÕÖ©ńÜäÕÉÄń½»:
+
+```python
+# TensorboardVisBackend
+visualizer = dict(
+ type='SegLocalVisualizer', vis_backends=[dict(type='TensorboardVisBackend')], name='visualizer')
+```
+
+Õģ│õ║ĵø┤ÕżÜńøĖÕģ│ńö©µ│Ģ, ÕÅ»õ╗źÕÅéĶĆā [MMEngine ÕÅ»Ķ¦åÕī¢ÕÉÄń½»ńö©µłĘµĢÖń©ŗ](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/advanced_tutorials/visualization.md).
+
+- Ķć¬Õ«Üõ╣ēķÆ®ÕŁÉ (custom hooks)
+
+Ķć¬Õ«Üõ╣ēķÆ®ÕŁÉÕ£©ķģŹńĮ«ķĆÜĶ┐ć `custom_hooks` Õ«Üõ╣ē, `Runner` ķĆÜĶ┐ć [`register_custom_hooks`](https://github.com/open-mmlab/mmengine/blob/main/mmengine/runner/runner.py#L1820) µ¢╣µ│Ģµ│©Õåī.
+Ķć¬Õ«Üõ╣ēķÆ®ÕŁÉõ╝śÕģłń║¦ķ£ĆĶ”üÕ£©ķģŹńĮ«µ¢ćõ╗ČķćīĶ«ŠńĮ«, Õ”éµ×£µ▓Īµ£ēĶ«ŠńĮ«, ÕłÖõ╝ÜĶó½ķ╗śĶ«żĶ«ŠńĮ«õĖ║ `NORMAL`. õĖŗķØ󵜻ķā©Õłå MMEngine õĖŁÕ«×ńÄ░ńÜäĶć¬Õ«Üõ╣ēķÆ®ÕŁÉ:
+
+| ķÆ®ÕŁÉ | ńö©µ│Ģ |
+| :----------------------------------------------------------------------------------------------------: | :------------------------------------------------------------------------------------------: |
+| [EMAHook](https://github.com/open-mmlab/mmengine/blob/main/mmengine/hooks/ema_hook.py) | Õ£©µ©ĪÕ×ŗĶ«Łń╗āµŚČõĮ┐ńö©µīćµĢ░µ╗æÕŖ©Õ╣│ÕØć (Exponential Moving Average, EMA). |
+| [EmptyCacheHook](https://github.com/open-mmlab/mmengine/blob/main/mmengine/hooks/empty_cache_hook.py) | Õ£©Ķ«Łń╗āµŚČķćŖµöŠµēƵ£ēµ▓Īµ£ēĶó½ń╝ōÕŁśÕŹĀńö©ńÜä GPU µśŠÕŁś. |
+| [SyncBuffersHook](https://github.com/open-mmlab/mmengine/blob/main/mmengine/hooks/sync_buffer_hook.py) | Õ£©µ»ÅõĖ¬Ķ«Łń╗ā Epoch ń╗ōµØ¤µŚČÕÉīµŁźµ©ĪÕ×ŗ buffer ķćīńÜäÕÅéµĢ░õŠŗÕ”é BN ķćīńÜä `running_mean` ÕÆī `running_var`. |
+
+õ╗źõĖŗµś» `EMAHook` ńÜäńö©õŠŗ, ķģŹńĮ«µ¢ćõ╗ČõĖŁ, Õ░åÕĘ▓ń╗ÅÕ«×ńÄ░ńÜäĶć¬Õ«Üõ╣ēķÆ®ÕŁÉńÜäķģŹńĮ«õĮ£õĖ║ `custom_hooks` ÕłŚĶĪ©õĖŁńÜ䵳ÉÕæś.
+
+```python
+custom_hooks = [
+ dict(type='EMAHook', start_iters=500, priority='NORMAL')
+]
+```
+
+### SegVisualizationHook
+
+MMSegmentation Õ«×ńÄ░õ║å [`SegVisualizationHook`](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/engine/hooks/visualization_hook.py#L17), ńö©µØźÕ£©ķ¬īĶ»üÕÆīµĄŗĶ»ĢµŚČÕÅ»Ķ¦åÕī¢ķó䵥ŗń╗ōµ×£.
+`SegVisualizationHook` ķćŹÕåÖõ║åÕ¤║ń▒╗ `Hook` õĖŁńÜä `_after_iter` µ¢╣µ│Ģ, Õ£©ķ¬īĶ»üµł¢µĄŗĶ»ĢµŚČ, µĀ╣µŹ«µīćÕ«ÜńÜäĶ┐Łõ╗Żµ¼ĪµĢ░ķŚ┤ķÜöĶ░āńö© `visualizer` ńÜä `add_datasample` µ¢╣µ│Ģń╗śÕłČĶ»Łõ╣ēÕłåÕē▓ń╗ōµ×£, ÕģĘõĮōÕ«×ńÄ░Õ”éõĖŗ:
+
+```python
+...
+@HOOKS.register_module()
+class SegVisualizationHook(Hook):
+...
+ def _after_iter(self,
+ runner: Runner,
+ batch_idx: int,
+ data_batch: dict,
+ outputs: Sequence[SegDataSample],
+ mode: str = 'val') -> None:
+...
+ # Õ”éµ×£µś»Ķ«Łń╗āķśČµ«Ąµł¢ĶĆģ self.draw õĖ║ False ÕłÖńø┤µÄźĶĘ│Õć║
+ if self.draw is False or mode == 'train':
+ return
+...
+ if self.every_n_inner_iters(batch_idx, self.interval):
+ for output in outputs:
+ img_path = output.img_path
+ img_bytes = self.file_client.get(img_path)
+ img = mmcv.imfrombytes(img_bytes, channel_order='rgb')
+ window_name = f'{mode}_{osp.basename(img_path)}'
+
+ self._visualizer.add_datasample(
+ window_name,
+ img,
+ data_sample=output,
+ show=self.show,
+ wait_time=self.wait_time,
+ step=runner.iter)
+
+```
+
+Õģ│õ║ÄÕÅ»Ķ¦åÕī¢µø┤ÕżÜńÜäń╗åĶŖéÕÅ»õ╗źµ¤źń£ŗ[Ķ┐Öķćī](../user_guides/visualization.md).
+
+## õ╝śÕī¢ÕÖ©
+
+Õ£©õĖŖķØóķģŹńĮ«Ķ┐ÉĶĪīĶ«ŠÕ«Üķćī, µłæõ╗¼ń╗ÖÕć║õ║åķģŹńĮ«Ķ«Łń╗āõ╝śÕī¢ÕÖ©ńÜäń«ĆÕŹĢńż║õŠŗ. µ£¼ń½ĀĶŖéÕ░åĶ┐øõĖƵŁźĶ»”ń╗åõ╗ŗń╗ŹÕ£© MMSegmentation ķćīÕ”éõĮĢķģŹńĮ«õ╝śÕī¢ÕÖ©.
+
+### õ╝śÕī¢ÕÖ©Õ░üĶŻģ
+
+OpenMMLab 2.0 Ķ«ŠĶ«Īõ║åõ╝śÕī¢ÕÖ©Õ░üĶŻģ, Õ«āµö»µīüõĖŹÕÉīńÜäĶ«Łń╗āńŁ¢ńĢź, Õīģµŗ¼µĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗āŃĆüµó»Õ║”ń┤»ÕŖĀÕÆīµó»Õ║”µł¬µ¢ŁńŁē, ńö©µłĘÕÅ»õ╗źµĀ╣µŹ«ķ£Ćµ▒éķĆēµŗ®ÕÉłķĆéńÜäĶ«Łń╗āńŁ¢ńĢź.
+õ╝śÕī¢ÕÖ©Õ░üĶŻģĶ┐śÕ«Üõ╣ēõ║åõĖĆÕźŚµĀćÕćåńÜäÕÅéµĢ░µø┤µ¢░µĄüń©ŗ, ńö©µłĘÕÅ»õ╗źÕ¤║õ║ÄĶ┐ÖõĖĆÕźŚµĄüń©ŗ, Õ£©ÕÉīõĖĆÕźŚõ╗ŻńĀüķćī, Õ«×ńÄ░õĖŹÕÉīĶ«Łń╗āńŁ¢ńĢźńÜäÕłćµŹó. Õ”éµ×£µā│õ║åĶ¦Żµø┤ÕżÜ, ÕÅ»õ╗źÕÅéĶĆā [MMEngine õ╝śÕī¢ÕÖ©Õ░üĶŻģµ¢ćµĪŻ](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/tutorials/optim_wrapper.md).
+
+õ╗źõĖŗµś» MMSegmentation õĖŁÕĖĖńö©ńÜäõĮ┐ńö©µ¢╣µ│Ģ:
+
+#### ķģŹńĮ« PyTorch µö»µīüńÜäõ╝śÕī¢ÕÖ©
+
+OpenMMLab 2.0 µö»µīü PyTorch ÕĤńö¤µēƵ£ēõ╝śÕī¢ÕÖ©, ÕÅéĶĆā[Ķ┐Öķćī](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/tutorials/optim_wrapper.md#%E7%AE%80%E5%8D%95%E9%85%8D%E7%BD%AE).
+
+Õ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁĶ«ŠńĮ«Ķ«Łń╗āµŚČ `Runner` µēĆõĮ┐ńö©ńÜäõ╝śÕī¢ÕÖ©, ķ£ĆĶ”üÕ«Üõ╣ē `optim_wrapper`, ĶĆīõĖŹµś» `optimizer`, õĖŗķØ󵜻õĖĆõĖ¬ķģŹńĮ«Ķ«Łń╗āõĖŁõ╝śÕī¢ÕÖ©ńÜäõŠŗÕŁÉ:
+
+```python
+optim_wrapper = dict(
+ type='OptimWrapper',
+ optimizer=dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0005),
+ clip_grad=None)
+```
+
+#### ķģŹńĮ«µó»Õ║”ĶŻüÕē¬
+
+ÕĮōµ©ĪÕ×ŗĶ«Łń╗āķ£ĆĶ”üõĮ┐ńö©µó»Õ║”ĶŻüÕē¬ńÜäĶ«Łń╗āµŖĆÕʦÕ╝Å, ÕÅ»õ╗źµīēńģ¦Õ”éõĖŗńż║õŠŗĶ┐øĶĪīķģŹńĮ«:
+
+```python
+optimizer = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0001)
+optim_wrapper = dict(type='OptimWrapper', optimizer=optimizer,
+ clip_grad=dict(max_norm=0.01, norm_type=2))
+```
+
+Ķ┐Öķćī `max_norm` µīćńÜ䵜»ĶŻüÕē¬ÕÉĵó»Õ║”ńÜäµ£ĆÕż¦ÕĆ╝, `norm_type` µīćńÜ䵜»ĶŻüÕē¬µó»Õ║”µŚČõĮ┐ńö©ńÜäĶīāµĢ░. ńøĖÕģ│µ¢╣µ│ĢÕÅ»ÕÅéĶĆā [torch.nn.utils.clip_grad_norm\_](https://pytorch.org/docs/stable/generated/torch.nn.utils.clip_grad_norm_.html).
+
+#### ķģŹńĮ«µĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗ā
+
+ÕĮōķ£ĆĶ”üõĮ┐ńö©µĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗āķÖŹõĮÄÕåģÕŁśµŚČ, ÕÅ»õ╗źõĮ┐ńö© `AmpOptimWrapper`, ÕģĘõĮōķģŹńĮ«Õ”éõĖŗ:
+
+```python
+optimizer = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0001)
+optim_wrapper = dict(type='AmpOptimWrapper', optimizer=optimizer)
+```
+
+[`AmpOptimWrapper`](https://github.com/open-mmlab/mmengine/blob/main/mmengine/optim/optimizer/amp_optimizer_wrapper.py#L20) õĖŁ `loss_scale` ńÜäķ╗śĶ«żĶ«ŠńĮ«µś» `dynamic`.
+
+#### ķģŹńĮ«µ©ĪÕ×ŗńĮæń╗£õĖŹÕÉīÕ▒éńÜäĶČģÕÅéµĢ░
+
+Õ£©µ©ĪÕ×ŗĶ«Łń╗āõĖŁ, Õ”éµ×£µā│Õ£©õ╝śÕī¢ÕÖ©ķćīõĖ║õĖŹÕÉīÕÅéµĢ░ÕłåÕł½Ķ«ŠńĮ«õ╝śÕī¢ńŁ¢ńĢź, õŠŗÕ”éĶ«ŠńĮ«õĖŹÕÉīńÜäÕŁ”õ╣ĀńÄćŃĆüµØāķćŹĶĪ░ÕćÅńŁēĶČģÕÅéµĢ░, ÕÅ»õ╗źķĆÜĶ┐ćĶ«ŠńĮ«ķģŹńĮ«µ¢ćõ╗Čķćī `optim_wrapper` õĖŁńÜä `paramwise_cfg` µØźÕ«×ńÄ░.
+
+õĖŗķØóńÜäķģŹńĮ«µ¢ćõ╗Čõ╗ź [ViT `optim_wrapper`](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/vit/vit_vit-b16-ln_mln_upernet_8xb2-160k_ade20k-512x512.py#L15-L27) õĖ║õŠŗõ╗ŗń╗Ź `paramwise_cfg` ÕÅéµĢ░õĮ┐ńö©.
+Ķ«Łń╗āµŚČÕ░å `pos_embed`, `mask_token`, `norm` µ©ĪÕØŚńÜä weight decay ÕÅéµĢ░ńÜäń│╗µĢ░Ķ«ŠńĮ«µłÉ 0.
+ÕŹ│: Õ£©Ķ«Łń╗āµŚČ, Ķ┐Öõ║øµ©ĪÕØŚńÜä weight decay Õ░åĶó½ÕÅśõĖ║ `weight_decay * decay_mult`=0.
+
+```python
+optimizer = dict(
+ type='AdamW', lr=0.00006, betas=(0.9, 0.999), weight_decay=0.01)
+optim_wrapper = dict(
+ type='OptimWrapper',
+ optimizer=optimizer,
+ paramwise_cfg=dict(
+ custom_keys={
+ 'pos_embed': dict(decay_mult=0.),
+ 'cls_token': dict(decay_mult=0.),
+ 'norm': dict(decay_mult=0.)
+ }))
+```
+
+ÕģČõĖŁ `decay_mult` µīćńÜ䵜»Õ»╣Õ║öÕÅéµĢ░ńÜäµØāķćŹĶĪ░ÕćÅńÜäń│╗µĢ░.
+Õģ│õ║ĵø┤ÕżÜ `paramwise_cfg` ńÜäõĮ┐ńö©ÕÅ»õ╗źÕ£© [MMEngine õ╝śÕī¢ÕÖ©Õ░üĶŻģµ¢ćµĪŻ](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/tutorials/optim_wrapper.md) ķćīķØóµ¤źÕł░.
+
+### õ╝śÕī¢ÕÖ©Õ░üĶŻģµ×äķĆĀÕÖ©
+
+ķ╗śĶ«żńÜäõ╝śÕī¢ÕÖ©Õ░üĶŻģµ×äķĆĀÕÖ© [`DefaultOptimWrapperConstructor`](https://github.com/open-mmlab/mmengine/blob/main/mmengine/optim/optimizer/default_constructor.py#L19) µĀ╣µŹ«ĶŠōÕģźńÜä `optim_wrapper` ÕÆī `optim_wrapper` õĖŁÕ«Üõ╣ēńÜä `paramwise_cfg` µØźµ×äÕ╗║Ķ«Łń╗āõĖŁõĮ┐ńö©ńÜäõ╝śÕī¢ÕÖ©. ÕĮō [`DefaultOptimWrapperConstructor`](https://github.com/open-mmlab/mmengine/blob/main/mmengine/optim/optimizer/default_constructor.py#L19) ÕŖ¤ĶāĮõĖŹĶāĮµ╗ĪĶČ│ķ£Ćµ▒鵌Č, ÕÅ»õ╗źĶć¬Õ«Üõ╣ēõ╝śÕī¢ÕÖ©Õ░üĶŻģµ×äķĆĀÕÖ©µØźÕ«×ńÄ░ĶČģÕÅéµĢ░ńÜäķģŹńĮ«.
+
+MMSegmentation õĖŁńÜäÕ«×ńÄ░õ║å [`LearningRateDecayOptimizerConstructor`](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/engine/optimizers/layer_decay_optimizer_constructor.py#L104), ÕÅ»õ╗źÕ»╣õ╗ź ConvNeXt, BEiT ÕÆī MAE õĖ║ķ¬©Õ╣▓ńĮæń╗£ńÜ䵩ĪÕ×ŗĶ«Łń╗āµŚČ, ķ¬©Õ╣▓ńĮæń╗£ńÜ䵩ĪÕ×ŗÕÅéµĢ░ńÜäÕŁ”õ╣ĀńÄćµīēńģ¦Õ«Üõ╣ēńÜäĶĪ░Õćŵ»öõŠŗ’╝ł`decay_rate`’╝ēķĆÉÕ▒éķĆÆÕćÅ, Õ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁńÜäķģŹńĮ«Õ”éõĖŗ:
+
+```python
+optim_wrapper = dict(
+ _delete_=True,
+ type='AmpOptimWrapper',
+ optimizer=dict(
+ type='AdamW', lr=0.0001, betas=(0.9, 0.999), weight_decay=0.05),
+ paramwise_cfg={
+ 'decay_rate': 0.9,
+ 'decay_type': 'stage_wise',
+ 'num_layers': 12
+ },
+ constructor='LearningRateDecayOptimizerConstructor',
+ loss_scale='dynamic')
+```
+
+`_delete_=True` ńÜäõĮ£ńö©µś» OpenMMLab Config õĖŁńÜäÕ┐ĮńĢźń╗¦µē┐ńÜäķģŹńĮ«, Õ£©Ķ»źõ╗ŻńĀüńē浫ĄõĖŁÕ┐ĮńĢźń╗¦µē┐ńÜä `optim_wrapper` ķģŹńĮ«, µø┤ÕżÜ `_delete_` ÕŁŚµ«ĄńÜäÕåģÕ«╣ÕÅ»õ╗źÕÅéĶĆā [MMEngine µ¢ćµĪŻ](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/advanced_tutorials/config.md#%E5%88%A0%E9%99%A4%E5%AD%97%E5%85%B8%E4%B8%AD%E7%9A%84-key).
diff --git a/internlm_langchain/knowledge_base/MMSegmentation/content/evaluation.md b/internlm_langchain/knowledge_base/MMSegmentation/content/evaluation.md
new file mode 100644
index 00000000..dc93a46e
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMSegmentation/content/evaluation.md
@@ -0,0 +1,158 @@
+# µ©ĪÕ×ŗĶ»äµĄŗ
+
+µ©ĪÕ×ŗĶ»äµĄŗĶ┐ćń©ŗõ╝ÜÕłåÕł½Õ£© [ValLoop](https://github.com/open-mmlab/mmengine/blob/main/mmengine/runner/loops.py#L300) ÕÆī [TestLoop](https://github.com/open-mmlab/mmengine/blob/main/mmengine/runner/loops.py#L373) õĖŁĶó½µē¦ĶĪī’╝īńö©µłĘÕÅ»õ╗źÕ£©Ķ«Łń╗āµ£¤ķŚ┤µł¢õĮ┐ńö©ķģŹńĮ«µ¢ćõ╗ČõĖŁń«ĆÕŹĢĶ«ŠńĮ«ńÜ䵥ŗĶ»ĢĶäܵ£¼Ķ┐øĶĪīµ©ĪÕ×ŗµĆ¦ĶāĮĶ»äõ╝░ŃĆé`ValLoop` ÕÆī `TestLoop` Õ▒×õ║Ä [Runner](https://github.com/open-mmlab/mmengine/blob/main/mmengine/runner/runner.py#L59)’╝īÕ«āõ╗¼õ╝ÜÕ£©ń¼¼õĖƵ¼ĪĶó½Ķ░āńö©µŚČµ×äÕ╗║ŃĆéńö▒õ║Ä `dataloader` õĖÄ `evaluator` µś»Õ┐ģķ£ĆńÜäÕÅéµĢ░’╝īµēĆõ╗źĶ”üµłÉÕŖ¤µ×äÕ╗║ `ValLoop`’╝īÕ£©µ×äÕ╗║ `Runner` µŚČÕ┐ģķĪ╗Ķ«ŠńĮ« `val_dataloader` ÕÆī `val_evaluator`’╝ī`TestLoop` õ║”ńäČŃĆéµ£ēÕģ│ Runner Ķ«ŠĶ«ĪńÜäµø┤ÕżÜõ┐Īµü»’╝īĶ»ĘÕÅéķśģ [MMEngine](https://github.com/open-mmlab/mmengine) ńÜä[µ¢ćµĪŻ](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/design/runner.md)ŃĆé
+
+
+  +
+ µĄŗĶ»Ģ/ķ¬īĶ»ü µĢ░µŹ«µĄü
+
+
+Õ£© MMSegmentation õĖŁ’╝īķ╗śĶ«żµāģÕåĄõĖŗ’╝īµłæõ╗¼Õ░å dataloader ÕÆī metrics ńÜäĶ«ŠńĮ«ÕåÖÕ£©µĢ░µŹ«ķøåķģŹńĮ«µ¢ćõ╗ČõĖŁ’╝īÕ╣ČÕ░å evaluation loop ńÜäķģŹńĮ«ÕåÖÕ£© `schedule_x` ķģŹńĮ«µ¢ćõ╗ČõĖŁŃĆé
+
+õŠŗÕ”é’╝īÕ£© ADE20K ķģŹńĮ«µ¢ćõ╗Č `configs/_base_/dataset/ADE20K.py` õĖŁ’╝īÕ£©ń¼¼37Õł░48ĶĪī’╝īµłæõ╗¼ķģŹńĮ«õ║å `val_dataloader`’╝īÕ£©ń¼¼51ĶĪī’╝īµłæõ╗¼ķĆēµŗ® `IoUMetric` õĮ£õĖ║ evaluator’╝īÕ╣ČĶ«ŠńĮ« `mIoU` õĮ£õĖ║µīćµĀć’╝Ü
+
+```python
+val_dataloader = dict(
+ batch_size=1,
+ num_workers=4,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_prefix=dict(
+ img_path='images/validation',
+ seg_map_path='annotations/validation'),
+ pipeline=test_pipeline))
+
+val_evaluator = dict(type='IoUMetric', iou_metrics=['mIoU'])
+```
+
+õĖ║õ║åĶāĮÕż¤Õ£©Ķ«Łń╗āµ£¤ķŚ┤Ķ┐øĶĪīĶ»äõ╝░µ©ĪÕ×ŗ’╝īµłæõ╗¼Õ░åĶ»äõ╝░ķģŹńĮ«µĘ╗ÕŖĀÕł░õ║å `configs/schedules/schedule_40k.py` µ¢ćõ╗ČńÜäń¼¼15Ķć│16ĶĪī’╝Ü
+
+```python
+train_cfg = dict(type='IterBasedTrainLoop', max_iters=40000, val_interval=4000)
+val_cfg = dict(type='ValLoop')
+```
+
+õĮ┐ńö©õ╗źõĖŖõĖżń¦ŹĶ«ŠńĮ«’╝īMMSegmentation Õ£© 40K Ķ┐Łõ╗ŻĶ«Łń╗āµ£¤ķŚ┤’╝īµ»Å 4000 µ¼ĪĶ┐Łõ╗ŻĶ┐øĶĪīõĖƵ¼Īµ©ĪÕ×ŗ **mIoU** µīćµĀćńÜäĶ»äõ╝░ŃĆé
+
+Õ”éµ×£µłæõ╗¼ÕĖīµ£øÕ£©Ķ«Łń╗āÕÉĵĄŗĶ»Ģµ©ĪÕ×ŗ’╝īÕłÖķ£ĆĶ”üÕ░å `test_dataloader`ŃĆü`test_evaluator` ÕÆī `test_cfg` ķģŹńĮ«µĘ╗ÕŖĀÕł░ķģŹńĮ«µ¢ćõ╗ČõĖŁŃĆé
+
+```python
+test_dataloader = dict(
+ batch_size=1,
+ num_workers=4,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_prefix=dict(
+ img_path='images/validation',
+ seg_map_path='annotations/validation'),
+ pipeline=test_pipeline))
+
+test_evaluator = dict(type='IoUMetric', iou_metrics=['mIoU'])
+test_cfg = dict(type='TestLoop')
+```
+
+Õ£© MMSegmentation õĖŁ’╝īķ╗śĶ«żµāģÕåĄõĖŗ’╝ī`test_dataloader` ÕÆī `test_evaluator` ńÜäĶ«ŠńĮ«õĖÄ `ValLoop` ńÜä dataloader ÕÆī evaluator ńøĖÕÉī’╝īµłæõ╗¼ÕÅ»õ╗źõ┐«µö╣Ķ┐Öõ║øĶ«ŠńĮ«õ╗źµ╗ĪĶČ│µłæõ╗¼ńÜäķ£ĆĶ”üŃĆé
+
+## IoUMetric
+
+MMSegmentation Õ¤║õ║Ä [MMEngine](https://github.com/open-mmlab/mmengine) µÅÉõŠøńÜä [BaseMetric](https://github.com/open-mmlab/mmengine/blob/main/mmengine/evaluator/metric.py) Õ«×ńÄ░ [IoUMetric](https://github.com/open-mmlab/mmsegmentation/blob/1.x/mmseg/evaluation/metrics/iou_metric.py) ÕÆī [CityscapesMetric](https://github.com/open-mmlab/mmsegmentation/blob/1.x/mmseg/evaluation/metrics/citys_metric.py)’╝īõ╗źĶ»äõ╝░µ©ĪÕ×ŗńÜäµĆ¦ĶāĮŃĆéµ£ēÕģ│ń╗¤õĖĆĶ»äõ╝░µÄźÕÅŻńÜäµø┤ÕżÜĶ»”ń╗åõ┐Īµü»’╝īĶ»ĘÕÅéķśģ[µ¢ćµĪŻ](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/evaluation.html)ŃĆé
+
+Ķ┐Öķćīµłæõ╗¼ń«ĆĶ”üõ╗ŗń╗Ź `IoUMetric` ńÜäÕÅéµĢ░ÕÆīõĖżń¦ŹõĖ╗Ķ”üµ¢╣µ│ĢŃĆé
+
+ķÖżõ║å `collect_device` ÕÆī `prefix` õ╣ŗÕż¢’╝ī`IoUMetric` ńÜäµ×äÕ╗║Ķ┐śÕīģÕɽõĖĆõ║øÕģČõ╗¢ÕÅéµĢ░ŃĆé
+
+µ×äķĆĀÕćĮµĢ░ńÜäÕÅéµĢ░’╝Ü
+
+- ignore_index’╝łint’╝ē- Õ░åÕ£©Ķ»äõ╝░õĖŁÕ┐ĮńĢźńÜäń▒╗Õł½ń┤óÕ╝ĢŃĆéķ╗śĶ«żÕĆ╝’╝Ü255ŃĆé
+- iou_metrics’╝łlist\[str\] | str’╝ē- ķ£ĆĶ”üĶ«Īń«ŚńÜäµīćµĀć’╝īÕÅ»ķĆēķĪ╣Õīģµŗ¼ 'mIoU'ŃĆü'mDice' ÕÆī 'mFscore'ŃĆé
+- nan_to_num’╝łint’╝īÕÅ»ķĆē’╝ē- Õ”éµ×£µīćÕ«Ü’╝īNaN ÕĆ╝Õ░åĶó½ńö©µłĘÕ«Üõ╣ēńÜäµĢ░ÕŁŚµø┐µŹóŃĆéķ╗śĶ«żÕĆ╝’╝ÜNoneŃĆé
+- beta’╝łint’╝ē- Õå│Õ«Üń╗╝ÕÉłĶ»äÕłåõĖŁ recall ńÜäµØāķćŹŃĆéķ╗śĶ«żÕĆ╝’╝Ü1ŃĆé
+- collect_device’╝łstr’╝ē- ńö©õ║ÄÕ£©ÕłåÕĖāÕ╝ÅĶ«Łń╗āµ£¤ķŚ┤õ╗ÄõĖŹÕÉīĶ┐øń©ŗµöČķøåń╗ōµ×£ńÜäĶ«ŠÕżćÕÉŹń¦░ŃĆéÕ┐ģķĪ╗µś» 'cpu' µł¢ 'gpu'ŃĆéķ╗śĶ«żõĖ║ 'cpu'ŃĆé
+- prefix’╝łstr’╝īÕÅ»ķĆē’╝ē- Õ░åµĘ╗ÕŖĀÕł░µīćµĀćÕÉŹń¦░õĖŁńÜäÕēŹń╝Ć’╝īõ╗źµČłķÖżõĖŹÕÉī evaluator ńÜäÕÉīÕÉŹµīćµĀćńÜ䵣¦õ╣ēŃĆéÕ”éµ×£ÕÅéµĢ░õĖŁµ£¬µÅÉõŠøÕēŹń╝Ć’╝īÕłÖÕ░åõĮ┐ńö© self.default_prefix Ķ┐øĶĪīµø┐õ╗ŻŃĆéķ╗śĶ«żõĖ║ NoneŃĆé
+
+`IoUMetric` Õ«×ńÄ░ IoU µīćµĀćńÜäĶ«Īń«Ś’╝ī`IoUMetric` ńÜäõĖżõĖ¬µĀĖÕ┐āµ¢╣µ│Ģµś» `process` ÕÆī `compute_metrics`ŃĆé
+
+- `process` µ¢╣µ│ĢÕżäńÉåõĖƵē╣ data ÕÆī data_samplesŃĆé
+- `compute_metrics` µ¢╣µ│ĢµĀ╣µŹ«ÕżäńÉåńÜäń╗ōµ×£Ķ«Īń«ŚµīćµĀćŃĆé
+
+### IoUMetric.process
+
+ÕÅéµĢ░’╝Ü
+
+- data_batch’╝łAny’╝ē- µØźĶć¬ dataloader ńÜäõĖƵē╣µĢ░µŹ«ŃĆé
+- data_samples’╝łSequence\[dict\]’╝ē- µ©ĪÕ×ŗńÜäõĖƵē╣ĶŠōÕć║ŃĆé
+
+Ķ┐öÕø×ÕĆ╝’╝Ü
+
+µŁżµ¢╣µ│Ģµ▓Īµ£ēĶ┐öÕø×ÕĆ╝’╝īÕøĀõĖ║ÕżäńÉåńÜäń╗ōµ×£Õ░åÕŁśÕé©Õ£© `self.results` õĖŁ’╝īõ╗źÕ£©ÕżäńÉåÕ«īµēƵ£ēµē╣µ¼ĪÕÉÄĶ┐øĶĪīµīćµĀćńÜäĶ«Īń«ŚŃĆé
+
+### IoUMetric.compute_metrics
+
+ÕÅéµĢ░’╝Ü
+
+- results’╝łlist’╝ē- µ»ÅõĖ¬µē╣µ¼ĪńÜäÕżäńÉåń╗ōµ×£ŃĆé
+
+Ķ┐öÕø×ÕĆ╝’╝Ü
+
+- Dict\[str’╝īfloat\] - Ķ«Īń«ŚńÜäµīćµĀćŃĆéµīćµĀćńÜäÕÉŹń¦░õĖ║ key’╝īÕĆ╝µś»ńøĖÕ║öńÜäń╗ōµ×£ŃĆékey õĖ╗Ķ”üÕīģµŗ¼ **aAcc**ŃĆü**mIoU**ŃĆü**mAcc**ŃĆü**mDice**ŃĆü**mFscore**ŃĆü**mPrecision**ŃĆü**mPrecall**ŃĆé
+
+## CityscapesMetric
+
+`CityscapesMetric` õĮ┐ńö©ńö▒ Cityscapes Õ«śµ¢╣µÅÉõŠøńÜä [CityscapesScripts](https://github.com/mcordts/cityscapesScripts) Ķ┐øĶĪīµ©ĪÕ×ŗµĆ¦ĶāĮńÜäĶ»äõ╝░ŃĆé
+
+### õĮ┐ńö©µ¢╣µ│Ģ
+
+Õ£©õĮ┐ńö©õ╣ŗÕēŹ’╝īĶ»ĘÕģłÕ«ēĶŻģ `cityscapesscripts` Õīģ’╝Ü
+
+```shell
+pip install cityscapesscripts
+```
+
+ńö▒õ║Ä `IoUMetric` Õ£© MMSegmentation õĖŁõĮ£õĖ║ķ╗śĶ«żńÜä evaluator õĮ┐ńö©’╝īÕ”éµ×£µé©µā│õĮ┐ńö© `CityscapesMetric`’╝īÕłÖķ£ĆĶ”üĶć¬Õ«Üõ╣ēķģŹńĮ«µ¢ćõ╗ČŃĆéÕ£©Ķć¬Õ«Üõ╣ēķģŹńĮ«µ¢ćõ╗ČõĖŁ’╝īÕ║öµīēÕ”éõĖŗµ¢╣Õ╝ŵø┐µŹóķ╗śĶ«ż evaluatorŃĆé
+
+```python
+val_evaluator = dict(type='CityscapesMetric', output_dir='tmp')
+test_evaluator = val_evaluator
+```
+
+### µÄźÕÅŻ
+
+µ×äķĆĀÕćĮµĢ░ńÜäÕÅéµĢ░’╝Ü
+
+- output_dir (str) - ķó䵥ŗń╗ōµ×£ĶŠōÕć║ńÜäĶĘ»ÕŠä
+- ignore_index (int) - Õ░åÕ£©Ķ»äõ╝░õĖŁÕ┐ĮńĢźńÜäń▒╗Õł½ń┤óÕ╝ĢŃĆéķ╗śĶ«żÕĆ╝’╝Ü255ŃĆé
+- format_only (bool) - ÕŬõĖ║µÅÉõ║żĶ┐øĶĪīń╗ōµ×£µĀ╝Õ╝ÅÕī¢ĶĆīõĖŹĶ┐øĶĪīĶ»äõ╝░ŃĆéÕĮōµé©ÕĖīµ£øÕ░åń╗ōµ×£µĀ╝Õ╝ÅÕī¢õĖ║ńē╣իܵĀ╝Õ╝ÅÕ╣ČÕ░åÕģȵÅÉõ║żń╗ÖµĄŗĶ»Ģµ£ŹÕŖĪÕÖ©µŚČµ£ēńö©ŃĆéķ╗śĶ«żõĖ║ FalseŃĆé
+- keep_results (bool) - µś»ÕÉ”õ┐ØńĢÖń╗ōµ×£ŃĆéÕĮō `format_only` õĖ║ True µŚČ’╝ī`keep_results` Õ┐ģķĪ╗õĖ║ TrueŃĆéķ╗śĶ«żõĖ║ FalseŃĆé
+- collect_device (str) - ńö©õ║ÄÕ£©ÕłåÕĖāÕ╝ÅĶ«Łń╗āµ£¤ķŚ┤õ╗ÄõĖŹÕÉīĶ┐øń©ŗµöČķøåń╗ōµ×£ńÜäĶ«ŠÕżćÕÉŹń¦░ŃĆéÕ┐ģķĪ╗µś» 'cpu' µł¢ 'gpu'ŃĆéķ╗śĶ«żõĖ║ 'cpu'ŃĆé
+- prefix (str’╝īÕÅ»ķĆē) - Õ░åµĘ╗ÕŖĀÕł░µīćµĀćÕÉŹń¦░õĖŁńÜäÕēŹń╝Ć’╝īõ╗źµČłķÖżõĖŹÕÉī evaluator ńÜäÕÉīÕÉŹµīćµĀćńÜ䵣¦õ╣ēŃĆéÕ”éµ×£ÕÅéµĢ░õĖŁµ£¬µÅÉõŠøÕēŹń╝Ć’╝īÕłÖÕ░åõĮ┐ńö© self.default_prefix Ķ┐øĶĪīµø┐õ╗ŻŃĆéķ╗śĶ«żõĖ║ NoneŃĆé
+
+#### CityscapesMetric.process
+
+Ķ»źµ¢╣µ│ĢÕ░åÕ£©ÕøŠÕāÅõĖŖń╗śÕłČ mask’╝īÕ╣ČÕ░åń╗śÕłČńÜäÕøŠÕāÅõ┐ØÕŁśÕł░ `work_dir` õĖŁŃĆé
+
+ÕÅéµĢ░’╝Ü
+
+- data_batch’╝łdict’╝ē- µØźĶć¬ dataloader ńÜäõĖƵē╣µĢ░µŹ«ŃĆé
+- data_samples’╝łSequence\[dict\]’╝ē- µ©ĪÕ×ŗńÜäõĖƵē╣ĶŠōÕć║ŃĆé
+
+Ķ┐öÕø×ÕĆ╝’╝Ü
+
+µŁżµ¢╣µ│Ģµ▓Īµ£ēĶ┐öÕø×ÕĆ╝’╝īÕøĀõĖ║ÕżäńÉåńÜäń╗ōµ×£Õ░åÕŁśÕé©Õ£© `self.results` õĖŁ’╝īõ╗źÕ£©ÕżäńÉåÕ«īµēƵ£ēµē╣µ¼ĪÕÉÄĶ┐øĶĪīµīćµĀćńÜäĶ«Īń«ŚŃĆé
+
+#### CityscapesMetric.compute_metrics
+
+µŁżµ¢╣µ│ĢÕ░åĶ░āńö© `cityscapessscripts.evaluation.evalPixelLevelSemanticLabeling` ÕĘźÕģĘµØźĶ«Īń«ŚµīćµĀćŃĆé
+
+ÕÅéµĢ░’╝Ü
+
+- results’╝łlist’╝ē- µĢ░µŹ«ķøåńÜ䵥ŗĶ»Ģń╗ōµ×£ŃĆé
+
+Ķ┐öÕø×ÕĆ╝’╝Ü
+
+- dict\[str:float\] - Cityscapes Ķ»äµĄŗń╗ōµ×£ŃĆé
diff --git a/internlm_langchain/knowledge_base/MMSegmentation/content/faq.md b/internlm_langchain/knowledge_base/MMSegmentation/content/faq.md
new file mode 100644
index 00000000..fa97963e
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMSegmentation/content/faq.md
@@ -0,0 +1,121 @@
+# ÕĖĖĶ¦üķŚ«ķóśĶ¦ŻńŁö’╝łFAQ’╝ē
+
+µłæõ╗¼Õ£©Ķ┐ÖķćīÕłŚÕć║õ║åõĮ┐ńö©µŚČńÜäõĖĆõ║øÕĖĖĶ¦üķŚ«ķóśÕÅŖÕģČńøĖÕ║öńÜäĶ¦ŻÕå│µ¢╣µĪłŃĆé Õ”éµ×£µé©ÕÅæńÄ░µ£ēõĖĆõ║øķŚ«ķóśĶó½ķüŚµ╝Å’╝īĶ»ĘķÜŵŚČµÅÉ PR õĖ░Õ»īĶ┐ÖõĖ¬ÕłŚĶĪ©ŃĆé Õ”éµ×£µé©µŚĀµ│ĢÕ£©µŁżĶÄĘÕŠŚÕĖ«ÕŖ®’╝īĶ»ĘõĮ┐ńö© [issue µ©ĪµØ┐](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/.github/ISSUE_TEMPLATE/error-report.md/)ÕłøÕ╗║ķŚ«ķóś’╝īõĮåµś»Ķ»ĘÕ£©µ©ĪµØ┐õĖŁÕĪ½ÕåÖµēƵ£ēÕ┐ģÕĪ½õ┐Īµü»’╝īĶ┐Öµ£ēÕŖ®õ║ĵłæõ╗¼µø┤Õ┐½Õ«ÜõĮŹķŚ«ķóśŃĆé
+
+## Õ«ēĶŻģ
+
+Õģ╝Õ«╣ńÜä MMSegmentation ÕÆī MMCV ńēłµ£¼Õ”éõĖŗŃĆéĶ»ĘÕ«ēĶŻģµŁŻńĪ«ńēłµ£¼ńÜä MMCV õ╗źķü┐ÕģŹÕ«ēĶŻģķŚ«ķóśŃĆé
+
+| MMSegmentation version | MMCV version | MMEngine version | MMClassification (optional) version | MMDetection (optional) version |
+| :--------------------: | :----------------------------: | :---------------: | :---------------------------------: | :----------------------------: |
+| dev-1.x branch | mmcv >= 2.0.0 | MMEngine >= 0.7.4 | mmpretrain>=1.0.0rc7 | mmdet >= 3.0.0 |
+| main branch | mmcv >= 2.0.0 | MMEngine >= 0.7.4 | mmpretrain>=1.0.0rc7 | mmdet >= 3.0.0 |
+| 1.1.1 | mmcv >= 2.0.0 | MMEngine >= 0.7.4 | mmpretrain>=1.0.0rc7 | mmdet >= 3.0.0 |
+| 1.1.0 | mmcv >= 2.0.0 | MMEngine >= 0.7.4 | mmpretrain>=1.0.0rc7 | mmdet >= 3.0.0 |
+| 1.0.0 | mmcv >= 2.0.0rc4 | MMEngine >= 0.7.1 | mmcls==1.0.0rc6 | mmdet >= 3.0.0 |
+| 1.0.0rc6 | mmcv >= 2.0.0rc4 | MMEngine >= 0.5.0 | mmcls>=1.0.0rc0 | mmdet >= 3.0.0rc6 |
+| 1.0.0rc5 | mmcv >= 2.0.0rc4 | MMEngine >= 0.2.0 | mmcls>=1.0.0rc0 | mmdet>=3.0.0rc6 |
+| 1.0.0rc4 | mmcv == 2.0.0rc3 | MMEngine >= 0.1.0 | mmcls>=1.0.0rc0 | mmdet>=3.0.0rc4, \<=3.0.0rc5 |
+| 1.0.0rc3 | mmcv == 2.0.0rc3 | MMEngine >= 0.1.0 | mmcls>=1.0.0rc0 | mmdet>=3.0.0rc4, \<=3.0.0rc5 |
+| 1.0.0rc2 | mmcv == 2.0.0rc3 | MMEngine >= 0.1.0 | mmcls>=1.0.0rc0 | mmdet>=3.0.0rc4, \<=3.0.0rc5 |
+| 1.0.0rc1 | mmcv >= 2.0.0rc1, \<=2.0.0rc3> | MMEngine >= 0.1.0 | mmcls>=1.0.0rc0 | Not required |
+| 1.0.0rc0 | mmcv >= 2.0.0rc1, \<=2.0.0rc3> | MMEngine >= 0.1.0 | mmcls>=1.0.0rc0 | Not required |
+
+Õ”éµ×£µé©ÕĘ▓ń╗ÅÕ«ēĶŻģõ║åńēłµ£¼õĖŹÕÉłķĆéńÜä mmcv’╝īĶ»ĘÕģłĶ┐ÉĶĪī`pip uninstall mmcv`ÕŹĖĶĮĮÕĘ▓Õ«ēĶŻģńÜä mmcv’╝īÕ”éµé©ÕģłÕēŹÕ«ēĶŻģńÜäõĖ║ mmcv-full’╝łÕŁśÕ£©õ║Ä OpenMMLab 1.x’╝ē’╝īĶ»ĘĶ┐ÉĶĪī`pip uninstall mmcv-full`Ķ┐øĶĪīÕŹĖĶĮĮŃĆé
+
+- Õ”éÕć║ńÄ░ "No module named 'mmcv'"
+ 1. õĮ┐ńö©`pip uninstall mmcv`ÕŹĖĶĮĮńÄ»ÕóāõĖŁńÄ░µ£ēńÜä mmcv
+ 2. µīēńģ¦[Õ«ēĶŻģĶ»┤µśÄ](../get_started.md)Õ«ēĶŻģÕ»╣Õ║öńÜä mmcv
+
+## Õ”éõĮĢĶÄĘń¤źµ©ĪÕ×ŗĶ«Łń╗āµŚČķ£ĆĶ”üńÜ䵜ŠÕŹĪµĢ░ķćÅ
+
+- ń£ŗµ©ĪÕ×ŗńÜä config µ¢ćõ╗ČÕæĮÕÉŹŃĆéÕÅ»õ╗źÕÅéĶĆā[õ║åĶ¦ŻķģŹńĮ«µ¢ćõ╗Č](../user_guides/1_config.md)õĖŁńÜä`ķģŹńĮ«µ¢ćõ╗ČÕæĮÕÉŹķŻÄµĀ╝`ķā©ÕłåŃĆéµ»öÕ”é’╝īÕ»╣õ║ÄÕÉŹÕŁŚõĖ║`segformer_mit-b0_8xb1-160k_cityscapes-1024x1024.py`ńÜä config µ¢ćõ╗Č’╝ī`8xb1`õ╗ŻĶĪ©Ķ«Łń╗āÕģČÕ»╣Õ║öńÜ䵩ĪÕ×ŗķ£ĆĶ”üńÜäÕŹĪµĢ░õĖ║ 8’╝īµ»ÅÕ╝ĀÕŹĪõĖŁńÜä batch size õĖ║ 1ŃĆé
+- ń£ŗµ©ĪÕ×ŗńÜä log µ¢ćõ╗ČŃĆéńé╣Õ╝ĆĶ»źµ©ĪÕ×ŗńÜä log µ¢ćõ╗Č’╝īÕ╣ČÕ£©ÕģČõĖŁµÉ£ń┤ó`nGPU`’╝īÕ£©`nGPU`ÕÉÄńÜäµĢ░ÕŁŚõĖ¬µĢ░ÕŹ│Ķ«Łń╗āµŚČµēĆķ£ĆńÜäÕŹĪµĢ░ŃĆéµ»öÕ”é’╝īÕ£© log µ¢ćõ╗ČõĖŁµÉ£ń┤ó`nGPU`ÕŠŚÕł░`nGPU 0,1,2,3,4,5,6,7`ńÜäĶ«░ÕĮĢ’╝īÕłÖĶ»┤µśÄĶ«Łń╗āĶ»źµ©ĪÕ×ŗķ£ĆĶ”üõĮ┐ńö©Õģ½Õ╝ĀÕŹĪŃĆé
+
+## auxiliary head µś»õ╗Ćõ╣ł
+
+ń«ĆÕŹĢµØźĶ»┤’╝īĶ┐Öµś»õĖĆõĖ¬µÅÉķ½śÕćåńĪ«ńÄćńÜäµĘ▒Õ║”ńøæńØŻµŖƵ£»ŃĆéÕ£©Ķ«Łń╗āķśČµ«Ą’╝ī`decode_head`ńö©õ║ÄĶŠōÕć║Ķ»Łõ╣ēÕłåÕē▓ńÜäń╗ōµ×£’╝ī`auxiliary_head` ÕŬµś»Õó×ÕŖĀõ║åõĖĆõĖ¬ĶŠģÕŖ®µŹ¤Õż▒’╝īÕģČõ║¦ńö¤ńÜäÕłåÕē▓ń╗ōµ×£Õ»╣õĮĀńÜ䵩ĪÕ×ŗń╗ōµ×£µ▓Īµ£ēÕĮ▒ÕōŹ’╝īõ╗ģÕ£©Õ£©Ķ«Łń╗āõĖŁĶĄĘõĮ£ńö©ŃĆéµé©ÕÅ»õ╗źķśģĶ»╗Ķ┐Öń»ć[Ķ«║µ¢ć](https://arxiv.org/pdf/1612.01105.pdf)õ║åĶ¦Żµø┤ÕżÜõ┐Īµü»ŃĆé
+
+## Ķ┐ÉĶĪīµĄŗĶ»ĢĶäܵ£¼µŚČÕ”éõĮĢĶŠōÕć║ń╗śÕłČÕłåÕē▓µÄ®Ķå£ńÜäÕøŠÕāÅ
+
+Õ£©µĄŗĶ»ĢĶäܵ£¼õĖŁ’╝īµłæõ╗¼µÅÉõŠøõ║å`--out`ÕÅéµĢ░µØźµÄ¦ÕłČµś»ÕÉ”ĶŠōÕć║õ┐ØÕŁśķó䵥ŗńÜäÕłåÕē▓µÄ®Ķå£ÕøŠÕāÅŃĆéµé©ÕÅ»õ╗źĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗żĶŠōÕć║µĄŗĶ»Ģń╗ōµ×£’╝Ü
+
+```shell
+python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} --out ${OUTPUT_DIR}
+```
+
+µø┤ÕżÜńö©õŠŗń╗åĶŖéÕÅ»µ¤źķśģ[µ¢ćµĪŻ](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/docs/zh_cn/user_guides/4_train_test.md#%E6%B5%8B%E8%AF%95%E5%B9%B6%E4%BF%9D%E5%AD%98%E5%88%86%E5%89%B2%E7%BB%93%E6%9E%9C)’╝ī[PR #2712](https://github.com/open-mmlab/mmsegmentation/pull/2712) õ╗źÕÅŖ[Ķ┐üń¦╗µ¢ćµĪŻ](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/docs/zh_cn/migration/interface.md#%E6%B5%8B%E8%AF%95%E5%90%AF%E5%8A%A8)õ║åĶ¦ŻńøĖÕģ│Ķ»┤µśÄŃĆé
+
+## Õ”éõĮĢÕżäńÉåõ║īÕĆ╝ÕłåÕē▓õ╗╗ÕŖĪ?
+
+MMSegmentation õĮ┐ńö© `num_classes` ÕÆī `out_channels` µØźµÄ¦ÕłČµ©ĪÕ×ŗµ£ĆÕÉÄõĖĆÕ▒é `self.conv_seg` ńÜäĶŠōÕć║ŃĆéµø┤ÕżÜń╗åĶŖéÕÅ»õ╗źÕÅéĶĆā [Ķ┐Öķćī](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/mmseg/models/decode_heads/decode_head.py)ŃĆé
+
+`num_classes` Õ║öĶ»źÕÆīµĢ░µŹ«ķøåµ£¼Ķ║½ń▒╗Õł½õĖ¬µĢ░õĖĆĶć┤’╝īÕĮōµś»õ║īÕĆ╝ÕłåÕē▓µŚČ’╝īµĢ░µŹ«ķøåÕŬµ£ēÕēŹµÖ»ÕÆīĶāīµÖ»õĖżń▒╗’╝īµēĆõ╗ź `num_classes` õĖ║ 2. `out_channels` µÄ¦ÕłČµ©ĪÕ×ŗµ£ĆÕÉÄõĖĆÕ▒éńÜäĶŠōÕć║ńÜäķĆÜķüōµĢ░’╝īķĆÜÕĖĖÕÆī `num_classes` ńøĖńŁē’╝īõĮåÕĮōõ║īÕĆ╝ÕłåÕē▓µŚČÕĆÖ’╝īÕÅ»õ╗źµ£ēõĖżń¦ŹÕżäńÉåµ¢╣µ│Ģ, ÕłåÕł½µś»’╝Ü
+
+- Ķ«ŠńĮ« `out_channels=2`’╝īÕ£©Ķ«Łń╗āµŚČõ╗ź Cross Entropy Loss õĮ£õĖ║µŹ¤Õż▒ÕćĮµĢ░’╝īÕ£©µÄ©ńÉåµŚČõĮ┐ńö© `F.softmax()` ÕĮÆõĖĆÕī¢ logits ÕĆ╝’╝īńäČÕÉÄķĆÜĶ┐ć `argmax()` ÕŠŚÕł░µ»ÅõĖ¬ÕāÅń┤ĀńÜäķó䵥ŗń╗ōµ×£ŃĆé
+
+- Ķ«ŠńĮ« `out_channels=1`’╝īÕ£©Ķ«Łń╗āµŚČõ╗ź Binary Cross Entropy Loss õĮ£õĖ║µŹ¤Õż▒ÕćĮµĢ░’╝īÕ£©µÄ©ńÉåµŚČõĮ┐ńö© `F.sigmoid()` ÕÆī `threshold` ÕŠŚÕł░ķó䵥ŗń╗ōµ×£’╝ī`threshold` ķ╗śĶ«żõĖ║ 0.3ŃĆé
+
+Õ»╣õ║ÄÕ«×ńÄ░õĖŖĶ┐░õĖżń¦ŹĶ«Īń«Śõ║īÕĆ╝ÕłåÕē▓ńÜäµ¢╣µ│Ģ’╝īķ£ĆĶ”üÕ£© `decode_head` ÕÆī `auxiliary_head` ńÜäķģŹńĮ«ķćīõ┐«µö╣ŃĆéõĖŗķØóµś»Õ»╣µĀĘõŠŗ [pspnet_unet_s5-d16.py](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/configs/_base_/models/pspnet_unet_s5-d16.py) ÕüÜÕć║ńÜäÕ»╣Õ║öõ┐«µö╣ŃĆé
+
+- (1) `num_classes=2`, `out_channels=2` Õ╣ČÕ£© `CrossEntropyLoss` ķćīķØóĶ«ŠńĮ« `use_sigmoid=False`ŃĆé
+
+```python
+decode_head=dict(
+ type='PSPHead',
+ in_channels=64,
+ in_index=4,
+ num_classes=2,
+ out_channels=2,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+auxiliary_head=dict(
+ type='FCNHead',
+ in_channels=128,
+ in_index=3,
+ num_classes=2,
+ out_channels=2,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
+```
+
+- (2) `num_classes=2`, `out_channels=1` Õ╣ČÕ£© `CrossEntropyLoss` ķćīķØóĶ«ŠńĮ« `use_sigmoid=True`.
+
+```python
+decode_head=dict(
+ type='PSPHead',
+ in_channels=64,
+ in_index=4,
+ num_classes=2,
+ out_channels=1,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0)),
+auxiliary_head=dict(
+ type='FCNHead',
+ in_channels=128,
+ in_index=3,
+ num_classes=2,
+ out_channels=1,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=True, loss_weight=0.4)),
+```
+
+## `reduce_zero_label` ńÜäõĮ£ńö©
+
+µĢ░µŹ«ķøåõĖŁ `reduce_zero_label` ÕÅéµĢ░ń▒╗Õ×ŗõĖ║ÕĖāÕ░öń▒╗Õ×ŗ’╝īķ╗śĶ«żõĖ║ False’╝īÕ«āńÜäÕŖ¤ĶāĮµś»õĖ║õ║åÕ┐ĮńĢźµĢ░µŹ«ķøå label 0ŃĆéÕģĘõĮōÕüܵ│Ģµś»Õ░å label 0 µö╣õĖ║ 255’╝īÕģČõĮÖ label ńøĖÕ║öń╝¢ÕÅĘÕćÅ 1’╝īÕÉīµŚČ decode head ķćīÕ░å 255 Ķ«ŠõĖ║ ignore index’╝īÕŹ│õĖŹÕÅéõĖÄ loss Ķ«Īń«ŚŃĆé
+õ╗źõĖŗµś» `reduce_zero_label` ÕģĘõĮōÕ«×ńÄ░ķĆ╗ĶŠæ:
+
+```python
+if self.reduce_zero_label:
+ # avoid using underflow conversion
+ gt_semantic_seg[gt_semantic_seg == 0] = 255
+ gt_semantic_seg = gt_semantic_seg - 1
+ gt_semantic_seg[gt_semantic_seg == 254] = 255
+```
+
+Õģ│õ║ĵé©ńÜäµĢ░µŹ«ķøåµś»ÕÉ”ķ£ĆĶ”üõĮ┐ńö© reduce_zero_label’╝īµ£ēõ╗źõĖŗõĖżń▒╗µāģÕåĄ’╝Ü
+
+- õŠŗÕ”éÕ£© [Potsdam](https://github.com/open-mmlab/mmsegmentation/blob/1.x/docs/en/user_guides/2_dataset_prepare.md#isprs-potsdam) µĢ░µŹ«ķøåõĖŖ’╝īµ£ē 0-õĖŹķĆŵ░┤ķØóŃĆü1-Õ╗║ńŁæŃĆü2-õĮÄń¤«µżŹĶó½ŃĆü3-µĀæŃĆü4-µ▒ĮĶĮ”ŃĆü5-µØéõ╣▒’╝īÕģŁń▒╗ŃĆéõĮåĶ»źµĢ░µŹ«ķøåµÅÉõŠøõ║åõĖżń¦Ź RGB µĀćńŁŠ’╝īõĖĆń¦ŹõĖ║ÕøŠÕāÅĶŠ╣ń╝śÕżäµ£ēķ╗æĶē▓ÕāÅń┤ĀńÜäµĀćńŁŠ’╝īÕÅ”õĖĆń¦Źµś»µ▓Īµ£ēķ╗æĶē▓ĶŠ╣ń╝śńÜäµĀćńŁŠŃĆéÕ»╣õ║ĵ£ēķ╗æĶē▓ĶŠ╣ń╝śńÜäµĀćńŁŠ’╝īÕ£© [dataset_converters.py](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/tools/dataset_converters/potsdam.py)õĖŁ’╝īÕģČÕ░åķ╗æĶē▓ĶŠ╣ń╝śĶĮ¼µŹóõĖ║ label 0’╝īÕģČõĮÖµĀćńŁŠÕłåÕł½õĖ║ 1-õĖŹķĆŵ░┤ķØóŃĆü2-Õ╗║ńŁæŃĆü3-õĮÄń¤«µżŹĶó½ŃĆü4-µĀæŃĆü5-µ▒ĮĶĮ”ŃĆü6-µØéõ╣▒’╝īķéŻõ╣łµŁżµŚČ’╝īÕ░▒Õ║öĶ»źÕ£©µĢ░µŹ«ķøå [potsdam.py](https://github.com/open-mmlab/mmsegmentation/blob/ff95416c3b5ce8d62b9289f743531398efce534f/mmseg/datasets/potsdam.py#L23) õĖŁÕ░å`reduce_zero_label=True`ŃĆéÕ”éµ×£õĮ┐ńö©ńÜ䵜»µ▓Īµ£ēķ╗æĶē▓ĶŠ╣ń╝śńÜäµĀćńŁŠ’╝īķéŻõ╣ł mask label õĖŁÕŬµ£ē 0-5’╝īµŁżµŚČÕ░▒Õ║öĶ»źõĮ┐`reduce_zero_label=False`ŃĆéķ£ĆĶ”üń╗ōÕÉłµé©ńÜäÕ«×ķÖģµāģÕåĄµØźõĮ┐ńö©ŃĆé
+- õŠŗÕ”éÕ£©ń¼¼ 0 ń▒╗õĖ║ background ń▒╗Õł½ńÜäµĢ░µŹ«ķøåõĖŖ’╝īÕ”éµ×£µé©µ£Ćń╗łµś»ķ£ĆĶ”üÕ░åĶāīµÖ»ÕÆīµé©ńÜäÕģČõĮÖń▒╗Õł½ÕłåÕ╝ƵŚČ’╝īµś»õĖŹķ£ĆĶ”üõĮ┐ńö©`reduce_zero_label`ńÜä’╝īµŁżµŚČÕ£©µĢ░µŹ«ķøåõĖŁÕ║öĶ»źÕ░åÕģČĶ«ŠńĮ«õĖ║`reduce_zero_label=False`
+
+**µ│©µäÅ:** õĮ┐ńö© `reduce_zero_label` Ķ»ĘńĪ«Ķ«żµĢ░µŹ«ķøåÕĤզŗń▒╗Õł½õĖ¬µĢ░’╝īÕ”éµ×£ÕŬµ£ēõĖżń▒╗’╝īķ£ĆĶ”üÕģ│ķŚŁ `reduce_zero_label` ÕŹ│Ķ«ŠńĮ« `reduce_zero_label=False`ŃĆé
diff --git a/internlm_langchain/knowledge_base/MMSegmentation/content/get_started.md b/internlm_langchain/knowledge_base/MMSegmentation/content/get_started.md
new file mode 100644
index 00000000..b92ab334
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMSegmentation/content/get_started.md
@@ -0,0 +1,209 @@
+# Õ╝ĆÕ¦ŗ’╝ÜÕ«ēĶŻģÕÆīĶ┐ÉĶĪī MMSeg
+
+## ķóäÕżćń¤źĶ»å
+
+µ£¼µĢÖń©ŗõĖŁ’╝īµłæõ╗¼Õ░åõ╝ܵ╝öńż║Õ”éõĮĢõĮ┐ńö© PyTorch ÕćåÕżćńÄ»ÕóāŃĆé
+
+MMSegmentation ÕÅ»õ╗źÕ£© Linux, Windows ÕÆī macOS ń│╗ń╗¤õĖŖĶ┐ÉĶĪī’╝īÕ╣ČõĖöķ£ĆĶ”üÕ«ēĶŻģ Python 3.7+, CUDA 10.2+ ÕÆī PyTorch 1.8+
+
+**µ│©µäÅ:**
+Õ”éµ×£µé©ÕĘ▓ń╗ÅÕ«ēĶŻģõ║å PyTorch, ÕÅ»õ╗źĶĘ│Ķ┐ćĶ»źķā©Õłå’╝īńø┤µÄźÕł░[õĖŗõĖĆÕ░ÅĶŖé](##Õ«ēĶŻģ)ŃĆéÕÉ”ÕłÖ’╝īµé©ÕÅ»õ╗źµīēńģ¦õ╗źõĖŗµŁźķ¬żµōŹõĮ£ŃĆé
+
+**µŁźķ¬ż 0.** õ╗Ä[Õ«śµ¢╣ńĮæń½Ö](https://docs.conda.io/en/latest/miniconda.html)õĖŗĶĮĮÕ╣ČÕ«ēĶŻģ Miniconda
+
+**µŁźķ¬ż 1.** ÕłøÕ╗║õĖĆõĖ¬ conda ńÄ»Õóā’╝īÕ╣ȵ┐Ƶ┤╗
+
+```shell
+conda create --name openmmlab python=3.8 -y
+conda activate openmmlab
+```
+
+**Step 2.** ÕÅéĶĆā [official instructions](https://pytorch.org/get-started/locally/) Õ«ēĶŻģ PyTorch
+
+Õ£© GPU Õ╣│ÕÅ░õĖŖ’╝Ü
+
+```shell
+conda install pytorch torchvision -c pytorch
+```
+
+Õ£© CPU Õ╣│ÕÅ░õĖŖ
+
+```shell
+conda install pytorch torchvision cpuonly -c pytorch
+```
+
+## Õ«ēĶŻģ
+
+µłæõ╗¼Õ╗║Ķ««ńö©µłĘķüĄÕŠ¬µłæõ╗¼ńÜäµ£ĆõĮ│Õ«×ĶĘĄµØźÕ«ēĶŻģ MMSegmentation ŃĆéõĮåµś»µĢ┤õĖ¬Ķ┐ćń©ŗµś»ķ½śÕ║”Ķć¬Õ«Üõ╣ēńÜäŃĆéµø┤ÕżÜõ┐Īµü»Ķ»ĘÕÅéĶ¦ü[Ķć¬Õ«Üõ╣ēÕ«ēĶŻģ](##Ķć¬Õ«Üõ╣ēÕ«ēĶŻģ)ķā©ÕłåŃĆé
+
+### µ£ĆõĮ│Õ«×ĶĘĄ
+
+**µŁźķ¬ż 0.** õĮ┐ńö© [MIM](https://github.com/open-mmlab/mim) Õ«ēĶŻģ [MMCV](https://github.com/open-mmlab/mmcv)
+
+```shell
+pip install -U openmim
+mim install mmengine
+mim install "mmcv>=2.0.0"
+```
+
+**µŁźķ¬ż 1.** Õ«ēĶŻģ MMSegmentation
+
+µāģÕåĄ a: Õ”éµ×£µé©µā│ń½ŗÕł╗Õ╝ĆÕÅæÕÆīĶ┐ÉĶĪī mmsegmentation’╝īµé©ÕÅ»ķĆÜĶ┐ćµ║ÉńĀüÕ«ēĶŻģ’╝Ü
+
+```shell
+git clone -b main https://github.com/open-mmlab/mmsegmentation.git
+cd mmsegmentation
+pip install -v -e .
+# '-v' ĶĪ©ńż║Ķ»”ń╗嵩ĪÕ╝Å’╝īµø┤ÕżÜńÜäĶŠōÕć║
+# '-e' ĶĪ©ńż║õ╗źÕÅ»ń╝¢ĶŠæµ©ĪÕ╝ÅÕ«ēĶŻģÕĘźń©ŗ’╝ī
+# ÕøĀµŁżÕ»╣õ╗ŻńĀüµēĆÕüÜńÜäõ╗╗õĮĢõ┐«µö╣ķāĮńö¤µĢł’╝īµŚĀķ£Ćķ揵¢░Õ«ēĶŻģ
+```
+
+µāģÕåĄ b: Õ”éµ×£µé©µŖŖ mmsegmentation õĮ£õĖ║õŠØĶĄ¢Õ║ōµł¢ĶĆģń¼¼õĖēµ¢╣Õ║ō’╝īÕÅ»õ╗źķĆÜĶ┐ć pip Õ«ēĶŻģ’╝Ü
+
+```shell
+pip install "mmsegmentation>=1.0.0"
+```
+
+### ķ¬īĶ»üµś»ÕɔիēĶŻģµłÉÕŖ¤
+
+õĖ║õ║åķ¬īĶ»ü MMSegmentation µś»ÕÉ”µŁŻńĪ«Õ«ēĶŻģ’╝īµłæõ╗¼µÅÉõŠøõ║åõĖĆõ║øńż║õŠŗõ╗ŻńĀüµØźĶ┐ÉĶĪīõĖĆõĖ¬µÄ©ńÉå demo ŃĆé
+
+**µŁźķ¬ż 1.** õĖŗĶĮĮķģŹńĮ«µ¢ćõ╗ČÕÆīµ©ĪÕ×ŗµ¢ćõ╗Č
+
+```shell
+mim download mmsegmentation --config pspnet_r50-d8_4xb2-40k_cityscapes-512x1024 --dest .
+```
+
+Ķ»źõĖŗĶĮĮĶ┐ćń©ŗÕÅ»ĶāĮķ£ĆĶ”üĶŖ▒Ķ┤╣ÕćĀÕłåķƤ’╝īĶ┐ÖÕÅ¢Õå│õ║ĵé©ńÜäńĮæń╗£ńÄ»ÕóāŃĆéÕĮōõĖŗĶĮĮń╗ōµØ¤’╝īµé©Õ░åń£ŗÕł░õ╗źõĖŗõĖżõĖ¬µ¢ćõ╗ČÕ£©µé©ÕĮōÕēŹÕĘźõĮ£ńø«ÕĮĢ’╝Ü`pspnet_r50-d8_4xb2-40k_cityscapes-512x1024.py` ÕÆī `pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth`
+
+**µŁźķ¬ż 2.** ķ¬īĶ»üµÄ©ńÉå demo
+
+ķĆēķĪ╣ (a). Õ”éµ×£µé©ķĆÜĶ┐ćµ║ÉńĀüÕ«ēĶŻģõ║å mmsegmentation’╝īĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗żÕŹ│ÕÅ»’╝Ü
+
+```shell
+python demo/image_demo.py demo/demo.png configs/pspnet/pspnet_r50-d8_4xb2-40k_cityscapes-512x1024.py pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth --device cuda:0 --out-file result.jpg
+```
+
+µé©Õ░åÕ£©ÕĮōÕēŹµ¢ćõ╗ČÕż╣õĖŁń£ŗÕł░õĖĆõĖ¬µ¢░ÕøŠÕāÅ `result.jpg`’╝īÕģČõĖŁµēƵ£ēńø«µĀćķāĮĶ”åńø¢õ║åÕłåÕē▓ mask
+
+ķĆēķĪ╣ (b). Õ”éµ×£µé©ķĆÜĶ┐ć pip Õ«ēĶŻģ mmsegmentation, µēōÕ╝Ƶé©ńÜä python Ķ¦ŻķćŖÕÖ©’╝īÕżŹÕłČń▓śĶ┤┤õ╗źõĖŗõ╗ŻńĀü’╝Ü
+
+```python
+from mmseg.apis import inference_model, init_model, show_result_pyplot
+import mmcv
+
+config_file = 'pspnet_r50-d8_4xb2-40k_cityscapes-512x1024.py'
+checkpoint_file = 'pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth'
+
+# µĀ╣µŹ«ķģŹńĮ«µ¢ćõ╗ČÕÆīµ©ĪÕ×ŗµ¢ćõ╗ČÕ╗║ń½ŗµ©ĪÕ×ŗ
+model = init_model(config_file, checkpoint_file, device='cuda:0')
+
+# Õ£©ÕŹĢÕ╝ĀÕøŠÕāÅõĖŖµĄŗĶ»ĢÕ╣ČÕÅ»Ķ¦åÕī¢
+img = 'demo/demo.png' # or img = mmcv.imread(img), Ķ┐ÖµĀĘõ╗ģķ£ĆõĖŗĶĮĮõĖƵ¼Ī
+result = inference_model(model, img)
+# Õ£©µ¢░ńÜäń¬ŚÕÅŻÕÅ»Ķ¦åÕī¢ń╗ōµ×£
+show_result_pyplot(model, img, result, show=True)
+# µł¢ĶĆģÕ░åÕÅ»Ķ¦åÕī¢ń╗ōµ×£õ┐ØÕŁśÕł░ÕøŠÕāŵ¢ćõ╗ČÕż╣õĖŁ
+# µé©ÕÅ»õ╗źõ┐«µö╣ÕłåÕē▓ map ńÜäķĆŵśÄÕ║” (0, 1].
+show_result_pyplot(model, img, result, show=True, out_file='result.jpg', opacity=0.5)
+# Õ£©õĖƵ«ĄĶ¦åķóæõĖŖµĄŗĶ»ĢÕ╣ČÕÅ»Ķ¦åÕī¢ÕłåÕē▓ń╗ōµ×£
+video = mmcv.VideoReader('video.mp4')
+for frame in video:
+ result = inference_segmentor(model, frame)
+ show_result_pyplot(model, result, wait_time=1)
+```
+
+µé©ÕÅ»õ╗źõ┐«µö╣õĖŖķØóńÜäõ╗ŻńĀüµØźµĄŗĶ»ĢÕŹĢõĖ¬ÕøŠÕāŵł¢Ķ¦åķóæ’╝īĶ┐ÖõĖżõĖ¬ķĆēķĪ╣ķāĮÕÅ»õ╗źķ¬īĶ»üÕ«ēĶŻģµś»ÕÉ”µłÉÕŖ¤ŃĆé
+
+### Ķć¬Õ«Üõ╣ēÕ«ēĶŻģ
+
+#### CUDA ńēłµ£¼
+
+ÕĮōÕ«ēĶŻģ PyTorch ńÜ䵌ČÕĆÖ’╝īµé©ķ£ĆĶ”üµīćÕ«Ü CUDA ńÜäńēłµ£¼’╝ī Õ”éµ×£µé©õĖŹńĪ«Õ«ÜķĆēµŗ®Õō¬õĖ¬ńēłµ£¼’╝īĶ»ĘķüĄÕŠ¬µłæõ╗¼ńÜäÕ╗║Ķ««’╝Ü
+
+- Õ»╣õ║ÄÕ¤║õ║Ä Ampere ńÜä NVIDIA GPUs, õŠŗÕ”é GeForce 30 ń│╗ÕłŚÕÆī NVIDIA A100, Õ┐ģķĪ╗Ķ”üµ▒鵜» CUDA 11.
+- Õ»╣õ║ĵø┤ĶĆüńÜä NVIDIA GPUs, CUDA 11 is backward compatible, but CUDA 10.2 µÅÉõŠøõ║åµø┤ÕźĮńÜäÕģ╝Õ«╣µĆ¦’╝īõ╗źÕÅŖµø┤ÕŖĀńÜäĶĮ╗ķćÅÕī¢
+
+Ķ»ĘńĪ«õ┐Ø GPU ķ®▒ÕŖ©µ╗ĪĶČ│µ£ĆÕ░ÅńÜäńēłµ£¼ķ£Ćµ▒éŃĆéĶ»”µāģĶ»ĘÕÅéĶĆāĶ┐ÖõĖ¬[ĶĪ©µĀ╝](https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html#cuda-major-component-versions__table-cuda-toolkit-driver-versions)
+
+**µ│©µäÅ:**
+Õ”éµ×£µé©µīēńģ¦µłæõ╗¼ńÜäµ£ĆõĮ│Õ«×ĶĘĄ’╝īÕ«ēĶŻģ CUDA Ķ┐ÉĶĪīÕ║ōÕ░▒ĶČ│Õż¤õ║å’╝īÕøĀõĖ║õĖŹķ£ĆĶ”ü CUDA õ╗ŻńĀüÕ£©µ£¼Õ£░ń╝¢Ķ»æŃĆé õĮåµś»Õ”éµ×£µé©ÕĖīµ£øõ╗ĵ║ÉńĀüń╝¢Ķ»æ MMCV µł¢ĶĆģķ£ĆĶ”üÕ╝ĆÕÅæÕģČõ╗¢ńÜä CUDA ń«ŚÕŁÉ’╝īµé©ķ£ĆĶ”üõ╗Ä NVIDIA ńÜä[Õ«śńĮæ](https://developer.nvidia.com/cuda-downloads)Õ«ēĶŻģÕ«īµĢ┤ńÜä CUDA ÕĘźÕģĘ’╝īÕÉīµŚČÕ«āńÜäńēłµ£¼ķ£ĆĶ”üõĖÄ PyTorch ńÜä CUDA ńēłµ£¼Õī╣ķģŹŃĆéÕŹ│ `conda install` ÕæĮõ╗żõĖŁµīćÕ«ÜńÜä cudatoolkit ńēłµ£¼ŃĆé
+
+#### õĖŹõĮ┐ńö© MIM Õ«ēĶŻģ MMCV
+
+MMCV ÕīģÕɽ C++ ÕÆī CUDA µē®Õ▒Ģ’╝īÕøĀµŁżõĖÄ PyTorch ńÜäõŠØĶĄ¢µ¢╣Õ╝ŵ»öĶŠāÕżŹµØéŃĆéMIM Ķć¬ÕŖ©Ķ¦ŻÕå│õ║åĶ┐Öń¦ŹõŠØĶĄ¢Õģ│ń│╗’╝īõĮ┐Õ«ēĶŻģµø┤Õ«╣µśōŃĆéńäČĶĆī’╝īMIM õ╣¤Õ╣ČõĖŹµś»Õ┐ģķĪ╗ńÜäŃĆé
+
+õĖ║õ║åõĮ┐ńö© pip ĶĆīõĖŹµś» MIM Õ«ēĶŻģ MMCV, Ķ»ĘÕÅéĶĆā [MMCV Õ«ēĶŻģµīćÕŹŚ](https://mmcv.readthedocs.io/en/latest/get_started/installation.html). Ķ┐Öķ£ĆĶ”üµēŗÕŖ©µīćÕ«ÜõĖĆõĖ¬Õ¤║õ║Ä PyTorch ńēłµ£¼ÕÅŖÕģČ CUDA ńēłµ£¼ńÜä find-url.
+
+õŠŗÕ”é’╝īõ╗źõĖŗÕæĮõ╗żÕÅ»õĖ║ PyTorch 1.10.x and CUDA 11.3 Õ«ēĶŻģ mmcv==2.0.0
+
+```shell
+pip install mmcv==2.0.0 -f https://download.openmmlab.com/mmcv/dist/cu113/torch1.10/index.html
+```
+
+#### Õ£©õ╗ģµ£ē CPU ńÜäÕ╣│ÕÅ░Õ«ēĶŻģ
+
+MMSegmentation ÕÅ»õ╗źÕ£©õ╗ģµ£ē CPU ńÜäńēłµ£¼õĖŖĶ┐ÉĶĪīŃĆéÕ£© CPU µ©ĪÕ╝Å’╝īµé©ÕÅ»õ╗źĶ«Łń╗ā’╝łķ£ĆĶ”ü MMCV ńēłµ£¼ >= 2.0.0’╝ē’╝īµĄŗĶ»ĢÕÆīµÄ©ńÉ嵩ĪÕ×ŗŃĆé
+
+#### Õ£© Google Colab õĖŖÕ«ēĶŻģ
+
+[Google Colab](https://research.google.com/) ķĆÜÕĖĖÕĘ▓ń╗ÅÕ«ēĶŻģõ║å PyTorch’╝īÕøĀµŁżµłæõ╗¼õ╗ģķ£ĆĶ”üķĆÜĶ┐ćõ╗źõĖŗÕæĮõ╗żÕ«ēĶŻģ MMCV ÕÆī MMSegmentationŃĆé
+
+**µŁźķ¬ż 1.** õĮ┐ńö© [MIM](https://github.com/open-mmlab/mim) Õ«ēĶŻģ [MMCV](https://github.com/open-mmlab/mmcv)
+
+```shell
+!pip3 install openmim
+!mim install mmengine
+!mim install "mmcv>=2.0.0"
+```
+
+**Step 2.** ķĆÜĶ┐ćµ║ÉńĀüÕ«ēĶŻģ MMSegmentation
+
+```shell
+!git clone https://github.com/open-mmlab/mmsegmentation.git
+%cd mmsegmentation
+!git checkout main
+!pip install -e .
+```
+
+**Step 3.** ķ¬īĶ»ü
+
+```python
+import mmseg
+print(mmseg.__version__)
+# ńż║õŠŗĶŠōÕć║: 1.0.0
+```
+
+**µ│©µäÅ:**
+Õ£© Jupyter õĖŁ, µä¤ÕÅ╣ÕÅĘ `!` ńö©õ║ÄĶ░āńö©Õż¢ķā©ÕÅ»µē¦ĶĪīÕæĮõ╗ż’╝ī`%cd` µś»õĖĆõĖ¬ [magic command](https://ipython.readthedocs.io/en/stable/interactive/magics.html#magic-cd) ÕÅ»õ╗źµö╣ÕÅśÕĮōÕēŹ python ńÜäÕĘźõĮ£ńø«ÕĮĢŃĆé
+
+### ķĆÜĶ┐ć Docker õĮ┐ńö© MMSegmentation
+
+µłæõ╗¼µÅÉõŠøõ║åõĖĆõĖ¬ [Dockerfile](https://github.com/open-mmlab/mmsegmentation/blob/master/docker/Dockerfile) µØźÕ╗║ń½ŗµśĀÕāÅŃĆéńĪ«õ┐صé©ńÜä [docker ńēłµ£¼](https://docs.docker.com/engine/install/) >=19.03.
+
+```shell
+# ķĆÜĶ┐ć PyTorch 1.11, CUDA 11.3 Õ╗║ń½ŗµśĀÕāÅ
+# Õ”éµ×£µé©õĮ┐ńö©ÕģČõ╗¢ńēłµ£¼’╝īõ┐«µö╣ Dockerfile ÕŹ│ÕÅ»
+docker build -t mmsegmentation docker/
+```
+
+Ķ┐ÉĶĪī’╝Ü
+
+```shell
+docker run --gpus all --shm-size=8g -it -v {DATA_DIR}:/mmsegmentation/data mmsegmentation
+```
+
+### ÕÅ»ķĆēõŠØĶĄ¢
+
+#### Õ«ēĶŻģ GDAL
+
+[GDAL](https://gdal.org/) µś»õĖĆõĖ¬ńö©õ║ĵĀģµĀ╝ÕÆīń¤óķćÅÕ£░ńÉåń®║ķŚ┤µĢ░µŹ«µĀ╝Õ╝ÅńÜäĶĮ¼µŹóÕ║ōŃĆéÕ«ēĶŻģ GDAL ÕÅ»õ╗źĶ»╗ÕÅ¢ÕżŹµØéµĀ╝Õ╝ÅÕÆīµ×üÕż¦ńÜäķüźµä¤ÕøŠÕāÅŃĆé
+
+```shell
+conda install GDAL
+```
+
+## ķŚ«ķóśĶ¦ŻńŁö
+
+Õ”éµ×£µé©Õ£©Õ«ēĶŻģĶ┐ćń©ŗõĖŁķüćÕł░õ║åÕģČõ╗¢ķŚ«ķóś’╝īĶ»Ęń¼¼õĖƵŚČķŚ┤µ¤źķśģ [FAQ](notes/faq.md) µ¢ćõ╗ČŃĆéÕ”éµ×£µ▓Īµ£ēµēŠÕł░ńŁöµĪł’╝īµé©õ╣¤ÕÅ»õ╗źÕ£© GitHub õĖŖµÅÉÕć║ [issue](https://github.com/open-mmlab/mmsegmentation/issues/new/choose)
diff --git a/internlm_langchain/knowledge_base/MMSegmentation/content/interface.md b/internlm_langchain/knowledge_base/MMSegmentation/content/interface.md
new file mode 100644
index 00000000..42f91bf5
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMSegmentation/content/interface.md
@@ -0,0 +1,523 @@
+# õ╗Ä MMSegmentation 0.x Ķ┐üń¦╗
+
+## Õ╝ĢĶ©Ć
+
+µ£¼µīćÕŹŚõ╗ŗń╗Źõ║å MMSegmentation 0.x ÕÆī MMSegmentation1.x Õ£©ĶĪ©ńÄ░ÕÆī API µ¢╣ķØóńÜäÕ¤║µ£¼Õī║Õł½’╝īõ╗źÕÅŖĶ┐Öõ║øõĖÄĶ┐üń¦╗Ķ┐ćń©ŗńÜäÕģ│ń│╗ŃĆé
+
+## µ¢░ńÜäõŠØĶĄ¢
+
+MMSegmentation 1.x õŠØĶĄ¢õ║ÄõĖĆõ║øµ¢░ńÜäĶĮ»õ╗ČÕīģ’╝īµé©ÕÅ»õ╗źÕćåÕżćõĖĆõĖ¬µ¢░ńÜäÕ╣▓ÕćĆńÄ»Õóā’╝īńäČÕÉĵĀ╣µŹ«[Õ«ēĶŻģµĢÖń©ŗ](../get_started.md)ķ揵¢░Õ«ēĶŻģŃĆé
+
+µł¢µēŗÕŖ©Õ«ēĶŻģõ╗źõĖŗĶĮ»õ╗ČÕīģŃĆé
+
+1. [MMEngine](https://github.com/open-mmlab/mmengine)’╝ÜMMEngine µś» OpenMMLab 2.0 µ×ȵ×äńÜäµĀĖÕ┐ā’╝īµłæõ╗¼Õ░åĶ«ĖÕżÜõĖÄĶ«Īń«Śµ£║Ķ¦åĶ¦ēµŚĀÕģ│ńÜäÕåģÕ«╣õ╗Ä MMCV µŗåÕłåÕł░ MMEngine õĖŁŃĆé
+
+2. [MMCV](https://github.com/open-mmlab/mmcv)’╝ÜOpenMMLab ńÜäĶ«Īń«Śµ£║Ķ¦åĶ¦ēÕīģŃĆéĶ┐ÖõĖŹµś»õĖĆõĖ¬µ¢░ńÜäõŠØĶĄ¢’╝īõĮåµé©ķ£ĆĶ”üÕ░åÕģČÕŹćń║¦Õł░ **2.0.0** µł¢õ╗źõĖŖńÜäńēłµ£¼ŃĆé
+
+3. [MMClassification](https://github.com/open-mmlab/mmclassification)’╝łÕÅ»ķĆē’╝ē’╝ÜOpenMMLab ńÜäÕøŠÕāÅÕłåń▒╗ÕĘźÕģĘń«▒ÕÆīÕ¤║ÕćåŃĆéĶ┐ÖõĖŹµś»õĖĆõĖ¬µ¢░ńÜäõŠØĶĄ¢’╝īõĮåµé©ķ£ĆĶ”üÕ░åÕģČÕŹćń║¦Õł░ **1.0.0rc6** ńēłµ£¼ŃĆé
+
+4. [MMDetection](https://github.com/open-mmlab/mmdetection)(ÕÅ»ķĆē): OpenMMLab ńÜäńø«µĀ浯ƵĄŗÕĘźÕģĘń«▒ÕÆīÕ¤║ÕćåŃĆéĶ┐ÖõĖŹµś»õĖĆõĖ¬µ¢░ńÜäõŠØĶĄ¢’╝īõĮåµé©ķ£ĆĶ”üÕ░åÕģČÕŹćń║¦Õł░ **3.0.0** µł¢õ╗źõĖŖńÜäńēłµ£¼ŃĆé
+
+## ÕÉ»ÕŖ©Ķ«Łń╗ā
+
+OpenMMLab 2.0 ńÜäõĖ╗Ķ”üµö╣Ķ┐øµś»ÕÅæÕĖāõ║å MMEngine’╝īÕ«āõĖ║ÕÉ»ÕŖ©Ķ«Łń╗āõ╗╗ÕŖĪńÜäń╗¤õĖƵğÕÅŻµÅÉõŠøõ║åķĆÜńö©õĖöÕ╝║Õż¦ńÜäµē¦ĶĪīÕÖ©ŃĆé
+
+õĖÄ MMSeg 0.x ńøĖµ»ö’╝īMMSeg 1.x Õ£© `tools/train.py` õĖŁµÅÉõŠøńÜäÕæĮõ╗żĶĪīÕÅéµĢ░µø┤Õ░æ
+
+
+
+
+## µĄŗĶ»ĢÕÉ»ÕŖ©
+
+õĖÄĶ«Łń╗āÕÉ»ÕŖ©ń▒╗õ╝╝’╝īMMSegmentation 1.x ńÜ䵥ŗĶ»ĢÕÉ»ÕŖ©Ķäܵ£¼Õ£© tools/test.py õĖŁõ╗ģµÅÉõŠøÕģ│ķö«ÕæĮõ╗żĶĪīÕÅéµĢ░’╝īõ╗źõĖŗµś»µĄŗĶ»ĢÕÉ»ÕŖ©Ķäܵ£¼ńÜäÕī║Õł½’╝īµø┤ÕżÜÕģ│õ║ĵĄŗĶ»ĢÕÉ»ÕŖ©ńÜäń╗åĶŖéĶ»ĘÕÅéĶĆā[Ķ┐Öķćī](../user_guides/4_train_test.md)ŃĆé
+
+
+
+
+## ķģŹńĮ«µ¢ćõ╗Č
+
+### µ©ĪÕ×ŗĶ«ŠńĮ«
+
+`model.backend`ŃĆü`model.neck`ŃĆü`model.decode_head` ÕÆī `model.loss` ÕŁŚµ«Ąµ▓Īµ£ēµø┤µö╣ŃĆé
+
+µĘ╗ÕŖĀ `model.data_preprocessor` ÕŁŚµ«Ąõ╗źķģŹńĮ« `DataPreProcessor`’╝īÕīģµŗ¼’╝Ü
+
+- `mean`’╝łSequence’╝īÕÅ»ķĆē’╝ē’╝ÜRŃĆüGŃĆüB ķĆÜķüōńÜäÕāÅń┤ĀÕ╣│ÕØćÕĆ╝ŃĆéķ╗śĶ«żõĖ║ NoneŃĆé
+
+- `std`’╝łSequence’╝īÕÅ»ķĆē’╝ē’╝ÜRŃĆüGŃĆüB ķĆÜķüōńÜäÕāÅń┤ĀµĀćÕćåÕĘ«ŃĆéķ╗śĶ«żõĖ║ NoneŃĆé
+
+- `size`’╝łSequence’╝īÕÅ»ķĆē’╝ē’╝ÜÕø║Õ«ÜńÜäÕĪ½ÕģģÕż¦Õ░ÅŃĆé
+
+- `size_divisor`’╝łint’╝īÕÅ»ķĆē’╝ē’╝ÜÕĪ½ÕģģÕøŠÕāÅÕÅ»õ╗źĶó½ÕĮōÕēŹÕĆ╝µĢ┤ķÖżŃĆé
+
+- `seg_pad_val`’╝łfloat’╝īÕÅ»ķĆē’╝ē’╝ÜÕłåÕē▓ÕøŠńÜäÕĪ½ÕģģÕĆ╝ŃĆéķ╗śĶ«żÕĆ╝’╝Ü255ŃĆé
+
+- `padding_mode`’╝łstr’╝ē’╝ÜÕĪ½Õģģń▒╗Õ×ŗŃĆéķ╗śĶ«żÕĆ╝’╝Ü'constant'ŃĆé
+
+ - constant’╝ÜÕĖĖķćÅÕĆ╝ÕĪ½Õģģ’╝īÕĆ╝ńö▒ pad_val µīćÕ«ÜŃĆé
+
+- `bgr_to_rgb`’╝łbool’╝ē’╝ܵś»ÕÉ”Õ░åÕøŠÕāÅõ╗Ä BGR ĶĮ¼µŹóõĖ║ RGBŃĆéķ╗śĶ«żõĖ║ FalseŃĆé
+
+- `rgb_to_bgr`’╝łbool’╝ē’╝ܵś»ÕÉ”Õ░åÕøŠÕāÅõ╗Ä RGB ĶĮ¼µŹóõĖ║ BGRŃĆéķ╗śĶ«żõĖ║ FalseŃĆé
+
+**µ│©’╝Ü**
+µ£ēÕģ│Ķ»”ń╗åõ┐Īµü»’╝īĶ»ĘÕÅéķśģ[µ©ĪÕ×ŗµ¢ćµĪŻ](../advanced_guides/models.md)ŃĆé
+
+### µĢ░µŹ«ķøåĶ«ŠńĮ«
+
+**data** ńÜäµø┤µö╣’╝Ü
+
+ÕĤńēł `data` ÕŁŚµ«ĄĶó½µŗåÕłåõĖ║ `train_dataloader`ŃĆü`val_dataloader` ÕÆī `test_dataloader`’╝īÕģüĶ«Ėµłæõ╗¼õ╗źń╗åń▓ÆÕ║”ķģŹńĮ«Õ«āõ╗¼ŃĆéõŠŗÕ”é’╝īµé©ÕÅ»õ╗źÕ£©Ķ«Łń╗āÕÆīµĄŗĶ»Ģµ£¤ķŚ┤µīćÕ«ÜõĖŹÕÉīńÜäķććµĀĘÕÖ©ÕÆīµē╣µ¼ĪÕż¦Õ░ÅŃĆé
+`samples_per_gpu` ķćŹÕæĮÕÉŹõĖ║ `batch_size`ŃĆé
+`workers_per_gpu` ķćŹÕæĮÕÉŹõĖ║ `num_workers`ŃĆé
+
+
+
+
+**µĢ░µŹ«Õó×Õ╝║ÕÅśµŹóµĄüń©ŗ**ÕÅśµø┤
+
+- ÕĤզŗµĀ╝Õ╝ÅĶĮ¼µŹó **`ToTensor`**ŃĆü**`ImageToTensor`**ŃĆü**`Collect`** ń╗äÕÉłõĖ║ [`PackSegInputs`](mmseg.datasets.transforms.PackSegInputs)
+- µłæõ╗¼õĖŹÕ╗║Ķ««Õ£©µĢ░µŹ«ķøåµĄüń©ŗõĖŁµē¦ĶĪī **`Normalize`** ÕÆī **Pad**ŃĆéĶ»ĘÕ░åÕģČõ╗ĵĄüń©ŗõĖŁÕłĀķÖż’╝īÕ╣ČÕ░åÕģČĶ«ŠńĮ«Õ£© `data_preprocessor` ÕŁŚµ«ĄõĖŁŃĆé
+- MMSeg 1.x õĖŁÕĤզŗńÜä **`Resize`** ÕĘ▓µø┤µö╣õĖ║ **`RandomResize `**’╝īĶŠōÕģźÕÅéµĢ░ `img_scale` ķćŹÕæĮÕÉŹõĖ║ `scale`’╝ī`keep_ratio` ńÜäķ╗śĶ«żÕĆ╝õ┐«µö╣õĖ║ FalseŃĆé
+- ÕĤզŗńÜä `test_pipeline` Õ░åÕŹĢÕ░║Õ║”ÕÆīÕżÜÕ░║Õ║”µĄŗĶ»Ģń╗ōÕÉłÕ£©õĖĆĶĄĘ’╝īÕ£© MMSeg 1.x õĖŁ’╝īµłæõ╗¼Õ░åÕģČÕłåõĖ║ `test_pipeline` ÕÆī `tta_pipeline`ŃĆé
+
+**µ│©’╝Ü**
+µłæõ╗¼Õ░åõĖĆõ║øµĢ░µŹ«ĶĮ¼µŹóÕĘźõĮ£ĶĮ¼ń¦╗Õł░µĢ░µŹ«ķóäÕżäńÉåÕÖ©õĖŁ’╝īÕ”éÕĮÆõĖĆÕī¢’╝īĶ»ĘÕÅéķśģ[µ¢ćµĪŻ](package.md)õ║åĶ¦Żµø┤ÕżÜĶ»”ń╗åõ┐Īµü»ŃĆé
+
+Ķ«Łń╗āµĄüń©ŗ
+
+
+
+
+µĄŗĶ»ĢµĄüń©ŗ
+
+
+
+
+**`evaluation`** õĖŁńÜäµø┤µö╣’╝Ü
+
+- **`evaluation`** ÕŁŚµ«ĄĶó½µŗåÕłåõĖ║ `val_evaluator` ÕÆī `test_evaluator `ŃĆéĶĆīõĖöõĖŹÕåŹµö»µīü `interval` ÕÆī `save_best` ÕÅéµĢ░ŃĆé
+ `interval` ÕĘ▓ń¦╗ÕŖ©Õł░ `train_cfg.val_interval`’╝ī`save_best` ÕĘ▓ń¦╗ÕŖ©Õł░ `default_hooks.checkpoint.save_best`ŃĆé`pre_eval` ÕĘ▓ÕłĀķÖżŃĆé
+- `IoU` ÕĘ▓µø┤µö╣õĖ║ `IoUMetric`ŃĆé
+
+
+
+
+### Optimizer ÕÆī Schedule Ķ«ŠńĮ«
+
+**`optimizer`** ÕÆī **`optimizer_config`** õĖŁńÜäµø┤µö╣’╝Ü
+
+- ńÄ░Õ£©µłæõ╗¼õĮ┐ńö© `optim_wrapper` ÕŁŚµ«ĄµØźµīćÕ«Üõ╝śÕī¢Ķ┐ćń©ŗńÜäµēƵ£ēķģŹńĮ«ŃĆéõ╗źÕÅŖ `optimizer` µś» `optim_wrapper` ńÜäõĖĆõĖ¬ÕŁÉÕŁŚµ«ĄŃĆé
+- `paramwise_cfg` õ╣¤µś» `optim_wrapper` ńÜäõĖĆõĖ¬ÕŁÉÕŁŚµ«Ą’╝īõ╗źµø┐õ╗Ż `optimizer`ŃĆé
+- `optimizer_config` ńÄ░Õ£©Ķó½ÕłĀķÖż’╝īÕ«āńÜäµēƵ£ēķģŹńĮ«ķāĮĶó½ń¦╗ÕŖ©Õł░ `optim_wrapper` õĖŁŃĆé
+- `grad_clip` ķćŹÕæĮÕÉŹõĖ║ `clip_grad`ŃĆé
+
+
+
+
+**`lr_config`** õĖŁńÜäµø┤µö╣’╝Ü
+
+- µłæõ╗¼Õ░å `lr_config` ÕŁŚµ«ĄÕłĀķÖż’╝īÕ╣ČõĮ┐ńö©µ¢░ńÜä `param_scheduler` µø┐õ╗ŻŃĆé
+- µłæõ╗¼ÕłĀķÖżõ║åõĖÄ `warmup` ńøĖÕģ│ńÜäÕÅéµĢ░’╝īÕøĀõĖ║µłæõ╗¼õĮ┐ńö© scheduler ń╗äÕÉłµØźÕ«×ńÄ░Ķ»źÕŖ¤ĶāĮŃĆé
+
+µ¢░ńÜä scheduler ń╗äÕÉłµ£║ÕłČķØ×ÕĖĖńüĄµ┤╗’╝īµé©ÕÅ»õ╗źõĮ┐ńö©Õ«āµØźĶ«ŠĶ«ĪÕżÜń¦ŹÕŁ”õ╣ĀńÄć/ÕŖ©ķćŵø▓ń║┐ŃĆéµ£ēÕģ│Ķ»”ń╗åõ┐Īµü»’╝īĶ»ĘÕÅéĶ¦ü[µĢÖń©ŗ](TODO)ŃĆé
+
+
+
+
+**`runner`** õĖŁńÜäµø┤µö╣’╝Ü
+
+ÕĤńēł `runner` ÕŁŚµ«ĄõĖŁńÜäÕż¦ÕżÜµĢ░ķģŹńĮ«Ķó½ń¦╗ÕŖ©Õł░ `train_cfg`ŃĆü`val_cfg` ÕÆī `test_cfg` õĖŁ’╝īõ╗źÕ£©Ķ«Łń╗āŃĆüķ¬īĶ»üÕÆīµĄŗĶ»ĢõĖŁķģŹńĮ« loopŃĆé
+
+
+
+
+õ║ŗÕ«×õĖŖ’╝īÕ£© OpenMMLab 2.0 õĖŁ’╝īµłæõ╗¼Õ╝ĢÕģźõ║å `Loop` µØźµÄ¦ÕłČĶ«Łń╗āŃĆüķ¬īĶ»üÕÆīµĄŗĶ»ĢõĖŁńÜäĶĪīõĖ║ŃĆé`Runner` ńÜäÕŖ¤ĶāĮõ╣¤ÕÅæńö¤õ║åÕÅśÕī¢ŃĆéµé©ÕÅ»õ╗źÕ£© [MMMEngine](https://github.com/open-mmlab/mmengine/) ńÜä[µē¦ĶĪīÕÖ©µĢÖń©ŗ](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/design/runner.md) õĖŁµēŠÕł░µø┤ÕżÜńÜäĶ»”ń╗åõ┐Īµü»ŃĆé
+
+### Ķ┐ÉĶĪīµŚČĶ«ŠńĮ«
+
+**`checkpoint_config`** ÕÆī **`log_config`** õĖŁńÜäµø┤µö╣’╝Ü
+
+`checkpoint_config` Ķó½ń¦╗ÕŖ©Õł░ `default_hooks.checkpoint` õĖŁ’╝ī`log_config` Ķó½ń¦╗ÕŖ©Õł░ `default_hooks.logger` õĖŁŃĆé
+Õ╣ČõĖöµłæõ╗¼Õ░åĶ«ĖÕżÜķÆ®ÕŁÉĶ«ŠńĮ«õ╗ÄĶäܵ£¼õ╗ŻńĀüń¦╗ÕŖ©Õł░Ķ┐ÉĶĪīµŚČķģŹńĮ«ńÜä `default_hooks` ÕŁŚµ«ĄõĖŁŃĆé
+
+```python
+default_hooks = dict(
+ # Ķ«░ÕĮĢµ»Åµ¼ĪĶ┐Łõ╗ŻńÜ䵌ČķŚ┤ŃĆé
+ timer=dict(type='IterTimerHook'),
+
+ # µ»Å50µ¼ĪĶ┐Łõ╗ŻµēōÕŹ░õĖƵ¼ĪµŚźÕ┐ŚŃĆé
+ logger=dict(type='LoggerHook', interval=50, log_metric_by_epoch=False),
+
+ # ÕÉ»ńö©ÕÅéµĢ░Ķ░āÕ║”ń©ŗÕ║ÅŃĆé
+ param_scheduler=dict(type='ParamSchedulerHook'),
+
+ # µ»Å2000µ¼ĪĶ┐Łõ╗Żõ┐ØÕŁśõĖƵ¼ĪµŻĆµ¤źńé╣ŃĆé
+ checkpoint=dict(type='CheckpointHook', by_epoch=False, interval=2000),
+
+ # Õ£©ÕłåÕĖāÕ╝ÅńÄ»ÕóāõĖŁĶ«ŠńĮ«ķććµĀĘÕÖ©ń¦ŹÕŁÉŃĆé
+ sampler_seed=dict(type='DistSamplerSeedHook'),
+
+ # ķ¬īĶ»üń╗ōµ×£ÕÅ»Ķ¦åÕī¢ŃĆé
+ visualization=dict(type='SegVisualizationHook'))
+```
+
+µŁżÕż¢’╝īµłæõ╗¼Õ░åÕĤńēł logger µŗåÕłåõĖ║ logger ÕÆī visualizerŃĆélogger ńö©õ║ÄĶ«░ÕĮĢõ┐Īµü»’╝īvisualizer ńö©õ║ÄÕ£©õĖŹÕÉīńÜäÕÉÄń½»µśŠńż║ logger’╝īÕ”é terminal ÕÆī TensorBoardŃĆé
+
+
+
+
+**`load_from`** ÕÆī **`resume_from`** õĖŁńÜäµø┤µö╣’╝Ü
+
+- ÕłĀķÖż `resume_from`ŃĆ鵳æõ╗¼õĮ┐ńö© `resume` ÕÆī `load_from` µØźµø┐µŹóÕ«āŃĆé
+ - Õ”éµ×£ `resume=True` õĖö `load_from` õĖ║ **not None**’╝īÕłÖõ╗Ä `load_from` õĖŁńÜ䵯Ƶ¤źńé╣µüóÕżŹĶ«Łń╗āŃĆé
+ - Õ”éµ×£ `resume=True` õĖö `load_from` õĖ║ **None**’╝īÕłÖÕ░ØĶ»Ģõ╗ÄÕĘźõĮ£ńø«ÕĮĢõĖŁńÜäµ£Ćµ¢░µŻĆµ¤źńé╣µüóÕżŹŃĆé
+ - Õ”éµ×£ `resume=False` õĖö `load_from` õĖ║ **not None**’╝īÕłÖÕŬÕŖĀĶĮĮµŻĆµ¤źńé╣’╝īĶĆīõĖŹń╗¦ń╗ŁĶ«Łń╗āŃĆé
+ - Õ”éµ×£ `resume=False` õĖö `load_from` õĖ║ **None**’╝īÕłÖõĖŹÕŖĀĶĮĮµł¢µüóÕżŹŃĆé
+
+**`dist_params`** õĖŁńÜäµø┤µö╣’╝Ü`dist_params` ÕŁŚµ«ĄńÄ░Õ£©µś» `env_cfg` ńÜäÕŁÉÕŁŚµ«ĄŃĆéÕ╣ČõĖö `env_cfg` õĖŁĶ┐śµ£ēõĖĆõ║øµ¢░ńÜäķģŹńĮ«ŃĆé
+
+```python
+env_cfg = dict(
+ # µś»ÕÉ”ÕÉ»ńö© cudnn_benchmark
+ cudnn_benchmark=False,
+
+ # Ķ«ŠńĮ«ÕżÜĶ┐øń©ŗÕÅéµĢ░
+ mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0),
+
+ # Ķ«ŠńĮ«ÕłåÕĖāÕ╝ÅÕÅéµĢ░
+ dist_cfg=dict(backend='nccl'),
+)
+```
+
+**`workflow`** ńÜäµö╣ÕŖ©:`workflow` ńøĖÕģ│ÕŖ¤ĶāĮĶó½ÕłĀķÖżŃĆé
+
+µ¢░ÕŁŚµ«Ą **`visualizer`**’╝Üvisualizer µś» OpenMMLab 2.0 õĮōń│╗ń╗ōµ×äõĖŁńÜäµ¢░Ķ«ŠĶ«ĪŃĆ鵳æõ╗¼Õ£© runner õĖŁõĮ┐ńö© visualizer Õ«×õŠŗµØźÕżäńÉåń╗ōµ×£ÕÆīµŚźÕ┐ŚÕÅ»Ķ¦åÕī¢’╝īÕ╣Čõ┐ØÕŁśÕł░õĖŹÕÉīńÜäÕÉÄń½»ŃĆéµø┤ÕżÜĶ»”ń╗åõ┐Īµü»’╝īĶ»ĘÕÅéķśģ[ÕÅ»Ķ¦åÕī¢µĢÖń©ŗ](../user_guides/visualization.md)ŃĆé
+
+µ¢░ÕŁŚµ«Ą **`default_scope`**’╝ܵɣń┤óµēƵ£ēµ│©Õåīµ©ĪÕØŚńÜäĶĄĘńé╣ŃĆéMMSegmentation õĖŁńÜä `default_scope` õĖ║ `mmseg`ŃĆéĶ»ĘÕÅéĶ¦ü[µ│©ÕåīÕÖ©µĢÖń©ŗ](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/advanced_tutorials/registry.md)õ║åĶ¦Żµø┤ÕżÜĶ»”µāģŃĆé
diff --git a/internlm_langchain/knowledge_base/MMSegmentation/content/model_zoo.md b/internlm_langchain/knowledge_base/MMSegmentation/content/model_zoo.md
new file mode 100644
index 00000000..bd572157
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMSegmentation/content/model_zoo.md
@@ -0,0 +1,152 @@
+# µĀćÕćåõĖĵ©ĪÕ×ŗÕ║ō
+
+## Õģ▒ÕÉīĶ«ŠÕ«Ü
+
+- µłæõ╗¼ķ╗śĶ«żõĮ┐ńö© 4 ÕŹĪÕłåÕĖāÕ╝ÅĶ«Łń╗ā
+- µēƵ£ē PyTorch ķŻÄµĀ╝ńÜä ImageNet ķóäĶ«Łń╗āńĮæń╗£ńö▒µłæõ╗¼Ķć¬ÕĘ▒Ķ«Łń╗ā’╝īÕÆī [Ķ«║µ¢ć](https://arxiv.org/pdf/1812.01187.pdf) õ┐صīüõĖĆĶć┤ŃĆé
+ µłæõ╗¼ńÜä ResNet ńĮæń╗£µś»Õ¤║õ║Ä ResNetV1c ńÜäÕÅśń¦Ź’╝īÕ£©Ķ┐ÖķćīĶŠōÕģźÕ▒éńÜä 7x7 ÕŹĘń¦»Ķó½ 3õĖ¬ 3x3 ÕÅ¢õ╗Ż
+- õĖ║õ║åÕ£©õĖŹÕÉīńÜäńĪ¼õ╗ČõĖŖõ┐صīüõĖĆĶć┤’╝īµłæõ╗¼õ╗ź `torch.cuda.max_memory_allocated()` ńÜäµ£ĆÕż¦ÕĆ╝õĮ£õĖ║ GPU ÕŹĀńö©ńÄć’╝īÕÉīµŚČĶ«ŠńĮ« `torch.backends.cudnn.benchmark=False`ŃĆé
+ µ│©µäÅ’╝īĶ┐ÖķĆÜÕĖĖµ»ö `nvidia-smi` µśŠńż║ńÜäĶ”üÕ░æ
+- µłæõ╗¼õ╗źńĮæń╗£ forward ÕÆīÕÉÄÕżäńÉåńÜ䵌ČķŚ┤ÕŖĀÕÆīõĮ£õĖ║µÄ©ńÉåµŚČķŚ┤’╝īķÖżÕÄ╗µĢ░µŹ«ÕŖĀĶĮĮµŚČķŚ┤ŃĆ鵳æõ╗¼õĮ┐ńö©Ķäܵ£¼ `tools/benchmark.py` µØźĶÄĘÕÅ¢µÄ©ńÉåµŚČķŚ┤’╝īÕ«āÕ£© `torch.backends.cudnn.benchmark=False` ńÜäĶ«ŠÕ«ÜõĖŗ’╝īĶ«Īń«Ś 200 Õ╝ĀÕøŠńēćńÜäÕ╣│ÕØćµÄ©ńÉåµŚČķŚ┤
+- Õ£©µĪåµ×ČõĖŁ’╝īµ£ēõĖżń¦ŹµÄ©ńÉ嵩ĪÕ╝Å
+ - `slide` µ©ĪÕ╝Å’╝łµ╗æÕŖ©µ©ĪÕ╝Å’╝ē’╝ܵĄŗĶ»ĢńÜäķģŹńĮ«µ¢ćõ╗ČÕŁŚµ«Ą `test_cfg` õ╝ܵś» `dict(mode='slide', crop_size=(769, 769), stride=(513, 513))`.
+ Õ£©Ķ┐ÖõĖ¬µ©ĪÕ╝ÅõĖŗ’╝īõ╗ÄÕĤÕøŠõĖŁĶŻüÕē¬ÕżÜõĖ¬Õ░ÅÕøŠÕłåÕł½ĶŠōÕģźńĮæń╗£õĖŁĶ┐øĶĪīµÄ©ńÉåŃĆéÕ░ÅÕøŠńÜäÕż¦Õ░ÅÕÆīÕ░ÅÕøŠõ╣ŗķŚ┤ńÜäĶĘØń”╗ńö▒ `crop_size` ÕÆī `stride` Õå│Õ«Ü’╝īķćŹÕÉłÕī║Õ¤¤õ╝ÜĶ┐øĶĪīÕ╣│ÕØć
+ - `whole` µ©ĪÕ╝Å ’╝łÕģ©ÕøŠµ©ĪÕ╝Å’╝ē’╝ܵĄŗĶ»ĢńÜäķģŹńĮ«µ¢ćõ╗ČÕŁŚµ«Ą `test_cfg` õ╝ܵś» `dict(mode='whole')`. Õ£©Ķ┐ÖõĖ¬µ©ĪÕ╝ÅõĖŗ’╝īÕģ©ÕøŠõ╝ÜĶó½ńø┤µÄźĶŠōÕģźÕł░ńĮæń╗£õĖŁĶ┐øĶĪīµÄ©ńÉåŃĆé
+ Õ»╣õ║Ä 769x769 õĖŗĶ«Łń╗āńÜ䵩ĪÕ×ŗ’╝īµłæõ╗¼ķ╗śĶ«żõĮ┐ńö© `slide` Ķ┐øĶĪīµÄ©ńÉå’╝īÕģČõĮÖµ©ĪÕ×ŗńö© `whole` Ķ┐øĶĪīµÄ©ńÉå
+- Õ»╣õ║ÄĶŠōÕģźÕż¦Õ░ÅõĖ║ 8x+1 ’╝łµ»öÕ”é769’╝ē’╝īµłæõ╗¼õĮ┐ńö© `align_corners=True`ŃĆéÕģČõĮÖµāģÕåĄ’╝īÕ»╣õ║ÄĶŠōÕģźÕż¦Õ░ÅõĖ║ 8x (µ»öÕ”é 512’╝ī1024)’╝īµłæõ╗¼õĮ┐ńö© `align_corners=False`
+
+## Õ¤║ń║┐
+
+### FCN
+
+Ķ»ĘÕÅéĶĆā [FCN](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/fcn) ĶÄĘÕŠŚĶ»”ń╗åõ┐Īµü»ŃĆé
+
+### PSPNet
+
+Ķ»ĘÕÅéĶĆā [PSPNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/pspnet) ĶÄĘÕŠŚĶ»”ń╗åõ┐Īµü»ŃĆé
+
+### DeepLabV3
+
+Ķ»ĘÕÅéĶĆā [DeepLabV3](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/deeplabv3) ĶÄĘÕŠŚĶ»”ń╗åõ┐Īµü»ŃĆé
+
+### PSANet
+
+Ķ»ĘÕÅéĶĆā [PSANet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/psanet) ĶÄĘÕŠŚĶ»”ń╗åõ┐Īµü»ŃĆé
+
+### DeepLabV3+
+
+Ķ»ĘÕÅéĶĆā [DeepLabV3+](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/deeplabv3plus) ĶÄĘÕŠŚĶ»”ń╗åõ┐Īµü»ŃĆé
+
+### UPerNet
+
+Ķ»ĘÕÅéĶĆā [UPerNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/upernet) ĶÄĘÕŠŚĶ»”ń╗åõ┐Īµü»ŃĆé
+
+### NonLocal Net
+
+Ķ»ĘÕÅéĶĆā [NonLocal Net](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/nlnet) ĶÄĘÕŠŚĶ»”ń╗åõ┐Īµü»ŃĆé
+
+### EncNet
+
+Ķ»ĘÕÅéĶĆā [EncNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/encnet) ĶÄĘÕŠŚĶ»”ń╗åõ┐Īµü»ŃĆé
+
+### CCNet
+
+Ķ»ĘÕÅéĶĆā [CCNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/ccnet) ĶÄĘÕŠŚĶ»”ń╗åõ┐Īµü»ŃĆé
+
+### DANet
+
+Ķ»ĘÕÅéĶĆā [DANet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/danet) ĶÄĘÕŠŚĶ»”ń╗åõ┐Īµü»ŃĆé
+
+### APCNet
+
+Ķ»ĘÕÅéĶĆā [APCNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/apcnet) ĶÄĘÕŠŚĶ»”ń╗åõ┐Īµü»ŃĆé
+
+### HRNet
+
+Ķ»ĘÕÅéĶĆā [HRNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/hrnet) ĶÄĘÕŠŚĶ»”ń╗åõ┐Īµü»ŃĆé
+
+### GCNet
+
+Ķ»ĘÕÅéĶĆā [GCNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/gcnet) ĶÄĘÕŠŚĶ»”ń╗åõ┐Īµü»ŃĆé
+
+### DMNet
+
+Ķ»ĘÕÅéĶĆā [DMNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/dmnet) ĶÄĘÕŠŚĶ»”ń╗åõ┐Īµü»ŃĆé
+
+### ANN
+
+Ķ»ĘÕÅéĶĆā [ANN](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/ann) ĶÄĘÕŠŚĶ»”ń╗åõ┐Īµü»ŃĆé
+
+### OCRNet
+
+Ķ»ĘÕÅéĶĆā [OCRNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/ocrnet) ĶÄĘÕŠŚĶ»”ń╗åõ┐Īµü»ŃĆé
+
+### Fast-SCNN
+
+Ķ»ĘÕÅéĶĆā [Fast-SCNN](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/fastscnn) ĶÄĘÕŠŚĶ»”ń╗åõ┐Īµü»ŃĆé
+
+### ResNeSt
+
+Ķ»ĘÕÅéĶĆā [ResNeSt](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/resnest) ĶÄĘÕŠŚĶ»”ń╗åõ┐Īµü»ŃĆé
+
+### Semantic FPN
+
+Ķ»ĘÕÅéĶĆā [Semantic FPN](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/semfpn) ĶÄĘÕŠŚĶ»”ń╗åõ┐Īµü»ŃĆé
+
+### PointRend
+
+Ķ»ĘÕÅéĶĆā [PointRend](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/point_rend) ĶÄĘÕŠŚĶ»”ń╗åõ┐Īµü»ŃĆé
+
+### MobileNetV2
+
+Ķ»ĘÕÅéĶĆā [MobileNetV2](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/mobilenet_v2) ĶÄĘÕŠŚĶ»”ń╗åõ┐Īµü»ŃĆé
+
+### MobileNetV3
+
+Ķ»ĘÕÅéĶĆā [MobileNetV3](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/mobilenet_v3) ĶÄĘÕŠŚĶ»”ń╗åõ┐Īµü»ŃĆé
+
+### EMANet
+
+Ķ»ĘÕÅéĶĆā [EMANet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/emanet) ĶÄĘÕŠŚĶ»”ń╗åõ┐Īµü»ŃĆé
+
+### DNLNet
+
+Ķ»ĘÕÅéĶĆā [DNLNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/dnlnet) ĶÄĘÕŠŚĶ»”ń╗åõ┐Īµü»ŃĆé
+
+### CGNet
+
+Ķ»ĘÕÅéĶĆā [CGNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/cgnet) ĶÄĘÕŠŚĶ»”ń╗åõ┐Īµü»ŃĆé
+
+### Mixed Precision (FP16) Training
+
+Ķ»ĘÕÅéĶĆā [Mixed Precision (FP16) Training Õ£© BiSeNetV2 Ķ«Łń╗āńÜäµĀĘõŠŗ](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/bisenetv2/bisenetv2_fcn_fp16_4x4_1024x1024_160k_cityscapes.py) ĶÄĘÕŠŚĶ»”ń╗åõ┐Īµü»ŃĆé
+
+## ķƤÕ║”µĀćÕ«Ü’╝łÕŠģµø┤µ¢░’╝ē
+
+### ńĪ¼õ╗Č
+
+- 8 NVIDIA Tesla V100 (32G) GPUs
+- Intel(R) Xeon(R) Gold 6148 CPU @ 2.40GHz
+
+### ĶĮ»õ╗ČńÄ»Õóā
+
+- Python 3.7
+- PyTorch 1.5
+- CUDA 10.1
+- CUDNN 7.6.03
+- NCCL 2.4.08
+
+### Ķ«Łń╗āķƤÕ║”
+
+õĖ║õ║åÕģ¼Õ╣│µ»öĶŠā’╝īµłæõ╗¼Õģ©ķā©õĮ┐ńö© ResNet-101V1c Ķ┐øĶĪīµĀćÕ«ÜŃĆéĶŠōÕģźÕż¦Õ░ÅõĖ║ 1024x512’╝īµē╣ķćŵĀʵ£¼µĢ░õĖ║ 2ŃĆé
+
+Ķ«Łń╗āķƤÕ║”Õ”éõĖŗĶĪ©’╝īµīćµĀćõĖ║µ»Åµ¼ĪĶ┐Łõ╗ŻńÜ䵌ČķŚ┤’╝īõ╗źń¦ÆõĖ║ÕŹĢõĮŹ’╝īĶČŖõĮÄĶČŖÕ┐½ŃĆé
+
+| Implementation | PSPNet (s/iter) | DeepLabV3+ (s/iter) |
+| --------------------------------------------------------------------------- | --------------- | ------------------- |
+| [MMSegmentation](https://github.com/open-mmlab/mmsegmentation) | **0.83** | **0.85** |
+| [SegmenTron](https://github.com/LikeLy-Journey/SegmenTron) | 0.84 | 0.85 |
+| [CASILVision](https://github.com/CSAILVision/semantic-segmentation-pytorch) | 1.15 | N/A |
+| [vedaseg](https://github.com/Media-Smart/vedaseg) | 0.95 | 1.25 |
+
+µ│©µäÅ’╝ÜDeepLabV3+ ńÜäĶŠōÕć║µŁźķĢ┐õĖ║ 8ŃĆé
diff --git a/internlm_langchain/knowledge_base/MMSegmentation/content/models.md b/internlm_langchain/knowledge_base/MMSegmentation/content/models.md
new file mode 100644
index 00000000..6eb22517
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMSegmentation/content/models.md
@@ -0,0 +1,177 @@
+# µ©ĪÕ×ŗ
+
+µłæõ╗¼ķĆÜÕĖĖÕ░åµĘ▒Õ║”ÕŁ”õ╣Āõ╗╗ÕŖĪõĖŁńÜäńź×ń╗ÅńĮæń╗£Õ«Üõ╣ēõĖ║µ©ĪÕ×ŗ’╝īĶ┐ÖõĖ¬µ©ĪÕ×ŗÕŹ│µś»ń«Śµ│ĢńÜäµĀĖÕ┐āŃĆé[MMEngine](https://github.com/open-mmlab/mmengine) µŖĮĶ▒ĪÕć║õ║åõĖĆõĖ¬ń╗¤õĖƵ©ĪÕ×ŗ [BaseModel](https://github.com/open-mmlab/mmengine/blob/main/mmengine/model/base_model/base_model.py#L16) õ╗źµĀćÕćåÕī¢Ķ«Łń╗āŃĆüµĄŗĶ»ĢÕÆīÕģČõ╗¢Ķ┐ćń©ŗŃĆéMMSegmentation Õ«×ńÄ░ńÜäµēƵ£ēµ©ĪÕ×ŗķāĮń╗¦µē┐Ķć¬ `BaseModel`’╝īÕ╣ČõĖöÕ£© MMSegmention õĖŁ’╝īµłæõ╗¼Õ«×ńÄ░õ║åÕēŹÕÉæõ╝ĀµÆŁÕ╣ČõĖ║Ķ»Łõ╣ēÕłåÕē▓ń«Śµ│ĢµĘ╗ÕŖĀõ║åõĖĆõ║øÕŖ¤ĶāĮŃĆé
+
+## ÕĖĖńö©ń╗äõ╗Č
+
+### ÕłåÕē▓ÕÖ©’╝łSegmentor’╝ē
+
+Õ£© MMSegmentation õĖŁ’╝īµłæõ╗¼Õ░åńĮæń╗£µ×ȵ×äµŖĮĶ▒ĪõĖ║**ÕłåÕē▓ÕÖ©**’╝īÕ«āµś»õĖĆõĖ¬ÕīģÕɽńĮæń╗£µēƵ£ēń╗äõ╗ČńÜ䵩ĪÕ×ŗŃĆ鵳æõ╗¼ÕĘ▓ń╗ÅÕ«×ńÄ░õ║å**ń╝¢ńĀüÕÖ©Ķ¦ŻńĀüÕÖ©’╝łEncoderDecoder’╝ē**ÕÆī**ń║¦Ķüöń╝¢ńĀüÕÖ©Ķ¦ŻńĀüÕÖ©’╝łCascadeEncoderDecoder’╝ē**’╝īÕ«āõ╗¼ķĆÜÕĖĖńö▒**µĢ░µŹ«ķóäÕżäńÉåÕÖ©**ŃĆü**ķ¬©Õ╣▓ńĮæń╗£**ŃĆü**Ķ¦ŻńĀüÕż┤**ÕÆī**ĶŠģÕŖ®Õż┤**ń╗䵳ÉŃĆé
+
+### µĢ░µŹ«ķóäÕżäńÉåÕÖ©’╝łData preprocessor’╝ē
+
+**µĢ░µŹ«ķóäÕżäńÉåÕÖ©**µś»Õ░åµĢ░µŹ«ÕżŹÕłČÕł░ńø«µĀćĶ«ŠÕżćÕ╣ČÕ░åµĢ░µŹ«ķóäÕżäńÉåõĖ║µ©ĪÕ×ŗĶŠōÕģźµĀ╝Õ╝ÅńÜäķā©ÕłåŃĆé
+
+### õĖ╗Õ╣▓ńĮæń╗£’╝łBackbone’╝ē
+
+**õĖ╗Õ╣▓ńĮæń╗£**µś»Õ░åÕøŠÕāÅĶĮ¼µŹóõĖ║ńē╣ÕŠüÕøŠńÜäķā©Õłå’╝īõŠŗÕ”éµ▓Īµ£ēµ£ĆÕÉÄÕģ©Ķ┐׵ğÕ▒éńÜä **ResNet-50**ŃĆé
+
+### ķółķā©’╝łNeck’╝ē
+
+**ķółķā©**µś»Ķ┐׵ğõĖ╗Õ╣▓ńĮæń╗£ÕÆīÕż┤ńÜäķā©ÕłåŃĆéÕ«āÕ»╣õĖ╗Õ╣▓ńĮæń╗£ńö¤µłÉńÜäÕĤզŗńē╣ÕŠüÕøŠĶ┐øĶĪīõĖĆõ║øµö╣Ķ┐øµł¢ķ揵¢░ķģŹńĮ«ŃĆéõŠŗÕ”é **Feature Pyramid Network’╝łFPN’╝ē**ŃĆé
+
+### Ķ¦ŻńĀüÕż┤’╝łDecode head’╝ē
+
+**Ķ¦ŻńĀüÕż┤**µś»Õ░åńē╣ÕŠüÕøŠĶĮ¼µŹóõĖ║ÕłåÕē▓µÄ®Ķå£ńÜäķā©Õłå’╝īõŠŗÕ”é **PSPNet**ŃĆé
+
+### ĶŠģÕŖ®Õż┤’╝łAuxiliary head’╝ē
+
+**ĶŠģÕŖ®Õż┤**µś»õĖĆõĖ¬ÕÅ»ķĆēń╗äõ╗Č’╝īÕ«āÕ░åńē╣ÕŠüÕøŠĶĮ¼µŹóõĖ║õ╗ģńö©õ║ÄĶ«Īń«ŚĶŠģÕŖ®µŹ¤Õż▒ńÜäÕłåÕē▓µÄ®Ķå£ŃĆé
+
+## Õ¤║µ£¼µÄźÕÅŻ
+
+MMSegmentation Õ░üĶŻģ `BaseModel` Õ╣ČÕ«×ńÄ░õ║å [BaseSegmentor](https://github.com/open-mmlab/mmsegmentation/blob/1.x/mmseg/models/segmentors/base.py#L15) ń▒╗’╝īõĖ╗Ķ”üµÅÉõŠø `forward`ŃĆü`train_step`ŃĆü`val_step` ÕÆī `test_step` µÄźÕÅŻŃĆéµÄźõĖŗµØźÕ░åĶ»”ń╗åõ╗ŗń╗ŹĶ┐Öõ║øµÄźÕÅŻŃĆé
+
+### forward
+
+
+  +
+ ń╝¢ńĀüÕÖ©Ķ¦ŻńĀüÕÖ©µĢ░µŹ«µĄü
+
+
+
+ 
ń║¦Ķüöń╝¢ńĀüÕÖ©Ķ¦ŻńĀüÕÖ©µĢ░µŹ«µĄü
+
+
+`forward` µ¢╣µ│ĢĶ┐öÕø×Ķ«Łń╗āŃĆüķ¬īĶ»üŃĆüµĄŗĶ»ĢÕÆīń«ĆÕŹĢµÄ©ńÉåĶ┐ćń©ŗńÜ䵏¤Õż▒µł¢ķó䵥ŗŃĆé
+
+Ķ»źµ¢╣µ│ĢÕ║öµÄźÕÅŚõĖēń¦Źµ©ĪÕ╝Å’╝ÜŌĆ£tensorŌĆØŃĆüŌĆ£predictŌĆØ ÕÆī ŌĆ£lossŌĆØ’╝Ü
+
+- ŌĆ£tensorŌĆØ’╝ÜÕēŹÕÉæµÄ©ńÉåµĢ┤õĖ¬ńĮæń╗£Õ╣ČĶ┐öÕø×Õ╝Āķćŵł¢Õ╝ĀķćŵĢ░ń╗ä’╝īµŚĀķ£Ćõ╗╗õĮĢÕÉÄÕżäńÉå’╝īõĖÄÕĖĖĶ¦üńÜä `nn.Module` ńøĖÕÉīŃĆé
+- ŌĆ£predictŌĆØ’╝ÜÕēŹÕÉæµÄ©ńÉåÕ╣ČĶ┐öÕø×ķó䵥ŗÕĆ╝’╝īĶ┐Öõ║øķó䵥ŗÕĆ╝Õ░åĶó½Õ«īÕģ©ÕżäńÉåÕł░ `SegDataSample` ÕłŚĶĪ©õĖŁŃĆé
+- ŌĆ£lossŌĆØ’╝ÜÕēŹÕÉæµÄ©ńÉåÕ╣ȵĀ╣µŹ«ń╗ÖÕ«ÜńÜäĶŠōÕģźÕÆīµĢ░µŹ«µĀʵ£¼Ķ┐öÕø×µŹ¤Õż▒ńÜä`ÕŁŚÕģĖ`ŃĆé
+
+**µ│©’╝Ü**[SegDataSample](https://github.com/open-mmlab/mmsegmentation/blob/1.x/mmseg/structures/seg_data_sample.py) µś» MMSegmentation ńÜäµĢ░µŹ«ń╗ōµ×äµÄźÕÅŻ’╝īńö©õĮ£õĖŹÕÉīń╗äõ╗Čõ╣ŗķŚ┤ńÜäµÄźÕÅŻŃĆé`SegDataSample` Õ«×ńÄ░õ║åµŖĮĶ▒ĪµĢ░µŹ«Õģāń┤Ā `mmengine.structures.BaseDataElement`’╝īĶ»ĘÕÅéķśģ [MMMEngine](https://github.com/open-mmlab/mmengine) õĖŁńÜä [SegDataSample µ¢ćµĪŻ](https://mmsegmentation.readthedocs.io/zh_CN/1.x/advanced_guides/structures.html)ÕÆī[µĢ░µŹ«Õģāń┤Āµ¢ćµĪŻ](https://mmengine.readthedocs.io/zh_CN/latest/advanced_tutorials/data_element.html)õ║åĶ¦Żµø┤ÕżÜõ┐Īµü»ŃĆé
+
+µ│©µäÅ’╝īµŁżµ¢╣µ│ĢõĖŹÕżäńÉåÕ£© `train_step` µ¢╣µ│ĢõĖŁÕ«īµłÉńÜäÕÅŹÕÉæõ╝ĀµÆŁµł¢õ╝śÕī¢ÕÖ©µø┤µ¢░ŃĆé
+
+ÕÅéµĢ░’╝Ü
+
+- inputs’╝łtorch.Tensor’╝ē- ķĆÜÕĖĖõĖ║ÕĮóńŖȵś»’╝łN, C, ...) ńÜäĶŠōÕģźÕ╝ĀķćÅŃĆé
+- data_sample’╝łlist\[[SegDataSample](https://github.com/open-mmlab/mmsegmentation/blob/1.x/mmseg/structures/seg_data_sample.py)\]) - ÕłåÕē▓µĢ░µŹ«µĀʵ£¼ŃĆéÕ«āķĆÜÕĖĖÕīģµŗ¼ `metainfo` ÕÆī `gt_sem_seg` ńŁēõ┐Īµü»ŃĆéķ╗śĶ«żÕĆ╝õĖ║ NoneŃĆé
+- mode (str) - Ķ┐öÕø×õ╗Ćõ╣łń▒╗Õ×ŗńÜäÕĆ╝ŃĆéķ╗śĶ«żõĖ║ 'tensor'ŃĆé
+
+Ķ┐öÕø×ÕĆ╝’╝Ü
+
+- `dict` µł¢ `list`’╝Ü
+ - Õ”éµ×£ `mode == "loss"`’╝īÕłÖĶ┐öÕø×ńö©õ║ÄÕÅŹÕÉæĶ┐ćń©ŗÕÆīµŚźÕ┐ŚĶ«░ÕĮĢńÜ䵏¤Õż▒Õ╝ĀķćÅ`ÕŁŚÕģĖ`ŃĆé
+ - Õ”éµ×£ `mode == "predict"`’╝īÕłÖĶ┐öÕø× `SegDataSample` ńÜä`ÕłŚĶĪ©`’╝īµÄ©ńÉåń╗ōµ×£Õ░åĶó½ķĆÆÕó×Õ£░µĘ╗ÕŖĀÕł░õ╝ĀķĆÆń╗Ö forward µ¢╣µ│ĢńÜä `data_sample` ÕÅéµĢ░õĖŁ’╝īµ»ÅõĖ¬ `SegDataSeample` ÕīģÕɽõ╗źõĖŗÕģ│ķö«Ķ»Ź’╝Ü
+ - pred_sm_seg (`PixelData`)’╝ÜĶ»Łõ╣ēÕłåÕē▓ńÜäķó䵥ŗŃĆé
+ - seg_logits (`PixelData`)’╝ܵĀćÕćåÕī¢ÕēŹĶ»Łõ╣ēÕłåÕē▓ńÜäķó䵥ŗµīćµĀćŃĆé
+ - Õ”éµ×£ `mode == "tensor"`’╝īÕłÖĶ┐öÕø×`Õ╝ĀķćÅ`µł¢`Õ╝ĀķćŵĢ░ń╗ä`ńÜä`ÕŁŚÕģĖ`õ╗źõŠøĶć¬Õ«Üõ╣ēõĮ┐ńö©ŃĆé
+
+### ķó䵥ŗµ©ĪÕ╝Å
+
+µłæõ╗¼Õ£©[ķģŹńĮ«µ¢ćµĪŻ](../user_guides/1_config.md)õĖŁń«ĆĶ”üµÅÅĶ┐░õ║嵩ĪÕ×ŗķģŹńĮ«ńÜäÕŁŚµ«Ą’╝īĶ┐Öķćīµłæõ╗¼Ķ»”ń╗åõ╗ŗń╗Ź `model.test_cfg` ÕŁŚµ«ĄŃĆé`model.test_cfg` ńö©õ║ÄµÄ¦ÕłČÕēŹÕÉæĶĪīõĖ║’╝ī`"predict"` µ©ĪÕ╝ÅõĖŗńÜä `forward` µ¢╣µ│ĢÕÅ»õ╗źÕ£©õĖżń¦Źµ©ĪÕ╝ÅõĖŗĶ┐ÉĶĪī’╝Ü
+
+- `whole_inference`’╝ÜÕ”éµ×£ `cfg.model.test_cfg.mode == 'whole'`’╝īÕłÖµ©ĪÕ×ŗÕ░åõĮ┐ńö©Õ«īµĢ┤ÕøŠÕāÅĶ┐øĶĪīµÄ©ńÉåŃĆé
+
+ `whole_inference` µ©ĪÕ╝ÅńÜäõĖĆõĖ¬ńż║õŠŗķģŹńĮ«’╝Ü
+
+ ```python
+ model = dict(
+ type='EncoderDecoder'
+ ...
+ test_cfg=dict(mode='whole')
+ )
+ ```
+
+- `slide_inference`’╝ÜÕ”éµ×£ `cfg.model.test_cfg.mode == ŌĆśslideŌĆÖ`’╝īÕłÖµ©ĪÕ×ŗÕ░åķĆÜĶ┐ćµ╗æÕŖ©ń¬ŚÕÅŻĶ┐øĶĪīµÄ©ńÉåŃĆé**µ│©µäÅ’╝Ü** Õ”éµ×£ķĆēµŗ® `slide` µ©ĪÕ╝Å’╝īĶ┐śÕ║öµīćÕ«Ü `cfg.model.test_cfg.stride` ÕÆī `cfg.model.test_cfg.crop_size`ŃĆé
+
+ `slide_inference` µ©ĪÕ╝ÅńÜäõĖĆõĖ¬ńż║õŠŗķģŹńĮ«’╝Ü
+
+ ```python
+ model = dict(
+ type='EncoderDecoder'
+ ...
+ test_cfg=dict(mode='slide', crop_size=256, stride=170)
+ )
+ ```
+
+### train_step
+
+`train_step` µ¢╣µ│ĢĶ░āńö© `loss` µ©ĪÕ╝ÅńÜäÕēŹÕÉæµÄźÕÅŻõ╗źĶÄĘÕŠŚµŹ¤Õż▒`ÕŁŚÕģĖ`ŃĆé`BaseModel` ń▒╗Õ«×ńÄ░ķ╗śĶ«żńÜ䵩ĪÕ×ŗĶ«Łń╗āĶ┐ćń©ŗ’╝īÕīģµŗ¼ķóäÕżäńÉåŃĆüµ©ĪÕ×ŗÕēŹÕÉæõ╝ĀµÆŁŃĆüµŹ¤Õż▒Ķ«Īń«ŚŃĆüõ╝śÕī¢ÕÆīÕÅŹÕÉæõ╝ĀµÆŁŃĆé
+
+ÕÅéµĢ░’╝Ü
+
+- data (dict or tuple or list) - õ╗ĵĢ░µŹ«ķøåķććµĀĘńÜäµĢ░µŹ«ŃĆéÕ£© MMSegmentation õĖŁ’╝īµĢ░µŹ«ÕŁŚÕģĖÕīģÕɽ `inputs` ÕÆī `data_samples` õĖżõĖ¬ÕŁŚµ«ĄŃĆé
+- optim_wrapper (OptimWrapper) - ńö©õ║ĵø┤µ¢░µ©ĪÕ×ŗÕÅéµĢ░ńÜä OptimWrapper Õ«×õŠŗŃĆé
+
+**µ│©’╝Ü**[OptimWrapper](https://github.com/open-mmlab/mmengine/blob/main/mmengine/optim/optimizer/optimizer_wrapper.py#L17) µÅÉõŠøõ║åõĖĆõĖ¬ńö©õ║ĵø┤µ¢░ÕÅéµĢ░ńÜäķĆÜńö©µÄźÕÅŻ’╝īĶ»ĘÕÅéķśģ [MMMEngine](https://github.com/open-mmlab/mmengine) õĖŁńÜäõ╝śÕī¢ÕÖ©Õ░üĶŻģ[µ¢ćµĪŻ](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/optim_wrapper.html)õ║åĶ¦Żµø┤ÕżÜõ┐Īµü»ŃĆé
+
+Ķ┐öÕø×ÕĆ╝’╝Ü
+
+-Dict\[str, `torch.Tensor`\]’╝Üńö©õ║ÄĶ«░ÕĮĢµŚźÕ┐ŚńÜäÕ╝ĀķćÅńÜä`ÕŁŚÕģĖ`ŃĆé
+
+
+  +
+ train_step µĢ░µŹ«µĄü
+
+
+### val_step
+
+`val_step` µ¢╣µ│ĢĶ░āńö© `predict` µ©ĪÕ╝ÅńÜäÕēŹÕÉæµÄźÕÅŻÕ╣ČĶ┐öÕø×ķó䵥ŗń╗ōµ×£’╝īķó䵥ŗń╗ōµ×£Õ░åĶ┐øõĖƵŁźĶó½õ╝ĀķĆÆń╗ÖĶ»äµĄŗÕÖ©ńÜäĶ┐øń©ŗµÄźÕÅŻÕÆīķÆ®ÕŁÉńÜä `after_val_inter` µÄźÕÅŻŃĆé
+
+ÕÅéµĢ░’╝Ü
+
+- data (`dict` or `tuple` or `list`) - õ╗ĵĢ░µŹ«ķøåõĖŁķććµĀĘńÜäµĢ░µŹ«ŃĆéÕ£© MMSegmentation õĖŁ’╝īµĢ░µŹ«ÕŁŚÕģĖÕīģÕɽ `inputs` ÕÆī `data_samples` õĖżõĖ¬ÕŁŚµ«ĄŃĆé
+
+Ķ┐öÕø×ÕĆ╝’╝Ü
+
+- `list` - ń╗ÖիܵĢ░µŹ«ńÜäķó䵥ŗń╗ōµ×£ŃĆé
+
+
+  +
+ test_step/val_step µĢ░µŹ«µĄü
+
+
+### test_step
+
+`BaseModel` õĖŁ `test_step` õĖÄ `val_step` ńÜäÕ«×ńÄ░ńøĖÕÉīŃĆé
+
+## µĢ░µŹ«ķóäÕżäńÉåÕÖ©’╝łData Preprocessor’╝ē
+
+MMSegmentation Õ«×ńÄ░ńÜä [SegDataPreProcessor](https://github.com/open-mmlab/mmsegmentation/blob/1.x/mmseg/models/data_preprocessor.py#L13) ń╗¦µē┐Ķć¬ńö▒ [MMEngine](https://github.com/open-mmlab/mmengine) Õ«×ńÄ░ńÜä [BaseDataPreprocessor](https://github.com/open-mmlab/mmengine/blob/main/mmengine/model/base_model/data_preprocessor.py#L18)’╝īµÅÉõŠøµĢ░µŹ«ķóäÕżäńÉåÕÆīÕ░åµĢ░µŹ«ÕżŹÕłČÕł░ńø«µĀćĶ«ŠÕżćńÜäÕŖ¤ĶāĮŃĆé
+
+Runner Õ£©µ×äÕ╗║ķśČµ«ĄÕ░嵩ĪÕ×ŗõ╝ĀķĆüÕł░µīćÕ«ÜńÜäĶ«ŠÕżć’╝īĶĆī [SegDataPreProcessor](https://github.com/open-mmlab/mmsegmentation/blob/1.x/mmseg/models/data_preprocessor.py#L13) Õ£© `train_step`ŃĆü`val_step` ÕÆī `test_step` õĖŁÕ░åµĢ░µŹ«õ╝ĀķĆüÕł░µīćÕ«ÜĶ«ŠÕżć’╝īõ╣ŗÕÉÄÕżäńÉåÕÉÄńÜäµĢ░µŹ«Õ░åĶó½Ķ┐øõĖƵŁźõ╝ĀķĆÆń╗Öµ©ĪÕ×ŗŃĆé
+
+`SegDataPreProcessor` µ×äķĆĀÕćĮµĢ░ńÜäÕÅéµĢ░’╝Ü
+
+- mean (Sequence\[Number\], ÕÅ»ķĆē) - RŃĆüGŃĆüB ķĆÜķüōńÜäÕāÅń┤ĀÕ╣│ÕØćÕĆ╝ŃĆéķ╗śĶ«żõĖ║ NoneŃĆé
+- std (Sequence\[Number\], ÕÅ»ķĆē) - RŃĆüGŃĆüB ķĆÜķüōńÜäÕāÅń┤ĀµĀćÕćåÕĘ«ŃĆéķ╗śĶ«żõĖ║ NoneŃĆé
+- size (tuple, ÕÅ»ķĆē) - Õø║Õ«ÜńÜäÕĪ½ÕģģÕż¦Õ░ÅŃĆé
+- size_divisor (int, ÕÅ»ķĆē) - ÕĪ½ÕģģÕż¦Õ░ÅńÜäķÖżµ│ĢÕøĀÕŁÉŃĆé
+- pad_val (float, ÕÅ»ķĆē) - ÕĪ½ÕģģÕĆ╝ŃĆéķ╗śĶ«żÕĆ╝’╝Ü0ŃĆé
+- seg_pad_val (float, ÕÅ»ķĆē) - ÕłåÕē▓ÕøŠńÜäÕĪ½ÕģģÕĆ╝ŃĆéķ╗śĶ«żÕĆ╝’╝Ü255ŃĆé
+- bgr_to_rgb (bool) - µś»ÕÉ”Õ░åÕøŠÕāÅõ╗Ä BGR ĶĮ¼µŹóõĖ║ RGBŃĆéķ╗śĶ«żõĖ║ FalseŃĆé
+- rgb_to_bgr (bool) - µś»ÕÉ”Õ░åÕøŠÕāÅõ╗Ä RGB ĶĮ¼µŹóõĖ║ BGRŃĆéķ╗śĶ«żõĖ║ FalseŃĆé
+- batch_augments (list\[dict\], ÕÅ»ķĆē) - µē╣ķćÅÕī¢ńÜäµĢ░µŹ«Õó×Õ╝║ŃĆéķ╗śĶ«żÕĆ╝õĖ║ NoneŃĆé
+
+µĢ░µŹ«Õ░åµīēÕ”éõĖŗµ¢╣Õ╝ÅÕżäńÉå’╝Ü
+
+- µöČķøåµĢ░µŹ«Õ╣ČÕ░åÕģČń¦╗ÕŖ©Õł░ńø«µĀćĶ«ŠÕżćŃĆé
+- ńö©Õ«Üõ╣ēńÜä `pad_val` Õ░åĶŠōÕģźÕĪ½ÕģģÕł░ĶŠōÕģźÕż¦Õ░Å’╝īÕ╣Čńö©Õ«Üõ╣ēńÜä `seg_Pad_val` ÕĪ½ÕģģÕłåÕē▓ÕøŠŃĆé
+- Õ░åĶŠōÕģźÕĀåµĀłÕł░ batch_inputŃĆé
+- Õ”éµ×£ĶŠōÕģźńÜäÕĮóńŖČõĖ║ (3, H, W)’╝īÕłÖÕ░åĶŠōÕģźõ╗Ä BGR ĶĮ¼µŹóõĖ║ RGBŃĆé
+- õĮ┐ńö©Õ«Üõ╣ēńÜäµĀćÕćåÕĘ«ÕÆīÕ╣│ÕØćÕĆ╝µĀćÕćåÕī¢ÕøŠÕāÅŃĆé
+- Õ£©Ķ«Łń╗āµ£¤ķŚ┤Ķ┐øĶĪīÕ”é Mixup ÕÆī Cutmix ńÜäµē╣ķćÅÕī¢µĢ░µŹ«Õó×Õ╝║ŃĆé
+
+`forward` µ¢╣µ│ĢńÜäÕÅéµĢ░’╝Ü
+
+- data (dict) - õ╗ĵĢ░µŹ«ÕŖĀĶĮĮÕÖ©ķććµĀĘńÜäµĢ░µŹ«ŃĆé
+- training (bool) - µś»ÕÉ”ÕÉ»ńö©Ķ«Łń╗āµŚČµĢ░µŹ«Õó×Õ╝║ŃĆé
+
+`forward` µ¢╣µ│ĢńÜäĶ┐öÕø×ÕĆ╝’╝Ü
+
+- Dict’╝ÜõĖĵ©ĪÕ×ŗĶŠōÕģźµĀ╝Õ╝ÅńøĖÕÉīńÜäµĢ░µŹ«ŃĆé
diff --git a/internlm_langchain/knowledge_base/MMSegmentation/content/modelzoo_statistics.md b/internlm_langchain/knowledge_base/MMSegmentation/content/modelzoo_statistics.md
new file mode 100644
index 00000000..b057575a
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMSegmentation/content/modelzoo_statistics.md
@@ -0,0 +1,102 @@
+# µ©ĪÕ×ŗÕ║ōń╗¤Ķ«ĪµĢ░µŹ«
+
+- Ķ«║µ¢ćµĢ░ķćÅ: 47
+
+ - ALGORITHM: 36
+ - BACKBONE: 11
+
+- µ©ĪÕ×ŗµĢ░ķćÅ: 612
+
+ - \[ALGORITHM\] [ANN](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/ann) (16 ckpts)
+
+ - \[ALGORITHM\] [APCNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/apcnet) (12 ckpts)
+
+ - \[BACKBONE\] [BEiT](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/beit) (2 ckpts)
+
+ - \[ALGORITHM\] [BiSeNetV1](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/bisenetv1) (11 ckpts)
+
+ - \[ALGORITHM\] [BiSeNetV2](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/bisenetv2) (4 ckpts)
+
+ - \[ALGORITHM\] [CCNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/ccnet) (16 ckpts)
+
+ - \[ALGORITHM\] [CGNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/cgnet) (2 ckpts)
+
+ - \[BACKBONE\] [ConvNeXt](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/convnext) (6 ckpts)
+
+ - \[ALGORITHM\] [DANet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/danet) (16 ckpts)
+
+ - \[ALGORITHM\] [DeepLabV3](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/deeplabv3) (41 ckpts)
+
+ - \[ALGORITHM\] [DeepLabV3+](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/deeplabv3plus) (42 ckpts)
+
+ - \[ALGORITHM\] [DMNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/dmnet) (12 ckpts)
+
+ - \[ALGORITHM\] [DNLNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/dnlnet) (12 ckpts)
+
+ - \[ALGORITHM\] [DPT](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/dpt) (1 ckpts)
+
+ - \[ALGORITHM\] [EMANet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/emanet) (4 ckpts)
+
+ - \[ALGORITHM\] [EncNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/encnet) (12 ckpts)
+
+ - \[ALGORITHM\] [ERFNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/erfnet) (1 ckpts)
+
+ - \[ALGORITHM\] [FastFCN](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/fastfcn) (12 ckpts)
+
+ - \[ALGORITHM\] [Fast-SCNN](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/fastscnn) (1 ckpts)
+
+ - \[ALGORITHM\] [FCN](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/fcn) (41 ckpts)
+
+ - \[ALGORITHM\] [GCNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/gcnet) (16 ckpts)
+
+ - \[BACKBONE\] [HRNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/hrnet) (37 ckpts)
+
+ - \[ALGORITHM\] [ICNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/icnet) (12 ckpts)
+
+ - \[ALGORITHM\] [ISANet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/isanet) (16 ckpts)
+
+ - \[ALGORITHM\] [K-Net](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/knet) (7 ckpts)
+
+ - \[BACKBONE\] [MAE](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/mae) (1 ckpts)
+
+ - \[ALGORITHM\] [Mask2Former](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/mask2former) (13 ckpts)
+
+ - \[ALGORITHM\] [MaskFormer](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/maskformer) (4 ckpts)
+
+ - \[BACKBONE\] [MobileNetV2](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/mobilenet_v2) (8 ckpts)
+
+ - \[BACKBONE\] [MobileNetV3](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/mobilenet_v3) (4 ckpts)
+
+ - \[ALGORITHM\] [NonLocal Net](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/nonlocal_net) (16 ckpts)
+
+ - \[ALGORITHM\] [OCRNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/ocrnet) (24 ckpts)
+
+ - \[ALGORITHM\] [PointRend](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/point_rend) (4 ckpts)
+
+ - \[BACKBONE\] [PoolFormer](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/poolformer) (5 ckpts)
+
+ - \[ALGORITHM\] [PSANet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/psanet) (16 ckpts)
+
+ - \[ALGORITHM\] [PSPNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/pspnet) (54 ckpts)
+
+ - \[BACKBONE\] [ResNeSt](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/resnest) (8 ckpts)
+
+ - \[ALGORITHM\] [SegFormer](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/segformer) (13 ckpts)
+
+ - \[ALGORITHM\] [Segmenter](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/segmenter) (5 ckpts)
+
+ - \[ALGORITHM\] [Semantic FPN](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/sem_fpn) (4 ckpts)
+
+ - \[ALGORITHM\] [SETR](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/setr) (7 ckpts)
+
+ - \[ALGORITHM\] [STDC](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/stdc) (4 ckpts)
+
+ - \[BACKBONE\] [Swin Transformer](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/swin) (6 ckpts)
+
+ - \[BACKBONE\] [Twins](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/twins) (12 ckpts)
+
+ - \[ALGORITHM\] [UNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/unet) (25 ckpts)
+
+ - \[ALGORITHM\] [UPerNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/upernet) (16 ckpts)
+
+ - \[BACKBONE\] [Vision Transformer](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/vit) (11 ckpts)
diff --git a/internlm_langchain/knowledge_base/MMSegmentation/content/npu.md b/internlm_langchain/knowledge_base/MMSegmentation/content/npu.md
new file mode 100644
index 00000000..d50439d0
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMSegmentation/content/npu.md
@@ -0,0 +1,39 @@
+# NPU (ÕŹÄõĖ║ µśćĶģŠ)
+
+## õĮ┐ńö©µ¢╣µ│Ģ
+
+Ķ»ĘÕÅéĶĆā [MMCV ńÜäÕ«ēĶŻģµ¢ćµĪŻ](https://mmcv.readthedocs.io/en/latest/get_started/build.html#build-mmcv-full-on-ascend-npu-machine) µØźÕ«ēĶŻģ NPU ńēłµ£¼ńÜä MMCVŃĆé
+
+õ╗źõĖŗÕ▒Ģńż║ÕŹĢµ£║ÕøøÕŹĪÕ£║µÖ»ńÜäĶ┐ÉĶĪīµīćõ╗ż:
+
+```shell
+bash tools/dist_train.sh configs/deeplabv3/deeplabv3_r50-d8_4xb2-40k_cityscapes-512x1024.py 4
+```
+
+õ╗źõĖŗÕ▒Ģńż║ÕŹĢµ£║ÕŹĢÕŹĪõĖŗńÜäĶ┐ÉĶĪīµīćõ╗ż:
+
+```shell
+python tools/train.py configs/deeplabv3/deeplabv3_r50-d8_4xb2-40k_cityscapes-512x1024.py
+```
+
+## µ©ĪÕ×ŗķ¬īĶ»üń╗ōµ×£
+
+| Model | mIoU | Config | Download |
+| :-----------------: | :---: | :----------------------------------------------------------------------------------------------------------------------------------------- | :------------------------------------------------------------------------------------------------------------------------------------------ |
+| [deeplabv3](<>) | 78.85 | [config](https://github.com/open-mmlab/mmsegmentation/tree/1.x/configs/deeplabv3/deeplabv3_r50-d8_4xb2-40k_cityscapes-512x1024.py) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/device/npu/deeplabv3_r50-d8_4xb2-40k_cityscapes-512x1024_20230115_205626.json) |
+| [deeplabv3plus](<>) | 79.23 | [config](https://github.com/open-mmlab/mmsegmentation/tree/1.x/configs/deeplabv3plus/deeplabv3plus_r50-d8_4xb2-40k_cityscapes-512x1024.py) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/device/npu/deeplabv3plus_r50-d8_4xb2-40k_cityscapes-512x1024_20230116_043450.json) |
+| [hrnet](<>) | 78.1 | [config](https://github.com/open-mmlab/mmsegmentation/tree/1.x/configs/hrnet/fcn_hr18_4xb2-40k_cityscapes-512x1024.py) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/device/npu/fcn_hr18_4xb2-40k_cityscapes-512x1024_20230116_215821.json) |
+| [fcn](<>) | 74.15 | [config](https://github.com/open-mmlab/mmsegmentation/tree/1.x/configs/fcn/fcn_r50-d8_4xb2-40k_cityscapes-512x1024.py) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/device/npu/fcn_r50-d8_4xb2-40k_cityscapes-512x1024_20230111_083014.json) |
+| [icnet](<>) | 69.25 | [config](https://github.com/open-mmlab/mmsegmentation/tree/1.x/configs/icnet/icnet_r50-d8_4xb2-80k_cityscapes-832x832.py) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/device/npu/icnet_r50-d8_4xb2-80k_cityscapes-832x832_20230119_002929.json) |
+| [pspnet](<>) | 77.21 | [config](https://github.com/open-mmlab/mmsegmentation/tree/1.x/configs/pspnet/pspnet_r50b-d8_4xb2-80k_cityscapes-512x1024.py) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/device/npu/pspnet_r50b-d8_4xb2-80k_cityscapes-512x1024_20230114_042721.json) |
+| [unet](<>) | 68.86 | [config](https://github.com/open-mmlab/mmsegmentation/tree/1.x/configs/unet/unet-s5-d16_fcn_4xb4-160k_cityscapes-512x1024.py) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/device/npu/unet-s5-d16_fcn_4xb4-160k_cityscapes-512x1024_20230129_224750.json) |
+| [upernet](<>) | 77.81 | [config](https://github.com/open-mmlab/mmsegmentation/tree/1.x/configs/upernet/upernet_r50_4xb2-40k_cityscapes-512x1024.py) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/device/npu/upernet_r50_4xb2-40k_cityscapes-512x1024_20230129_014634.json) |
+| [apcnet](<>) | 78.02 | [config](https://github.com/open-mmlab/mmsegmentation/tree/1.x/configs/apcnet/apcnet_r50-d8_4xb2-40k_cityscapes-512x1024.py) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/device/npu/apcnet_r50-d8_4xb2-40k_cityscapes-512x1024_20230209_212545.json) |
+| [bisenetv1](<>) | 76.04 | [config](https://github.com/open-mmlab/mmsegmentation/tree/1.x/configs/bisenetv1/bisenetv1_r50-d32_4xb4-160k_cityscapes-1024x1024.py) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/device/npu/bisenetv1_r50-d32_4xb4-160k_cityscapes-1024x1024_20230201_023946.json) |
+| [bisenetv2](<>) | 72.44 | [config](https://github.com/open-mmlab/mmsegmentation/tree/1.x/configs/bisenetv2/bisenetv2_fcn_4xb4-amp-160k_cityscapes-1024x1024.py) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/device/npu/bisenetv2_fcn_4xb4-amp-160k_cityscapes-1024x1024_20230205_215606.json) |
+
+**µ│©µäÅ:**
+
+- Õ”éµ×£µ▓Īµ£ēńē╣Õł½µĀćĶ«░’╝īNPU õĖŖńÜäõĮ┐ńö©µĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗āńÜäń╗ōµ×£õĖÄõĮ┐ńö© FP32 ńÜä GPU õĖŖńÜäń╗ōµ×£ńøĖÕÉīŃĆé
+
+**õ╗źõĖŖµ©ĪÕ×ŗń╗ōµ×£ńö▒ÕŹÄõĖ║µśćĶģŠÕøóķś¤µÅÉõŠø**
diff --git a/internlm_langchain/knowledge_base/MMSegmentation/content/overview.md b/internlm_langchain/knowledge_base/MMSegmentation/content/overview.md
new file mode 100644
index 00000000..ed147956
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMSegmentation/content/overview.md
@@ -0,0 +1,75 @@
+# µ”éĶ┐░
+
+µ£¼ń½ĀĶŖéÕÉæµé©õ╗ŗń╗Ź MMSegmentation µĪåµ×Čõ╗źÕÅŖĶ»Łõ╣ēÕłåÕē▓ńøĖÕģ│ńÜäÕ¤║µ£¼µ”éÕ┐ĄŃĆ鵳æõ╗¼Ķ┐śµÅÉõŠøõ║åÕģ│õ║Ä MMSegmentation ńÜäĶ»”ń╗åµĢÖń©ŗķōŠµÄźŃĆé
+
+## õ╗Ćõ╣łµś»Ķ»Łõ╣ēÕłåÕē▓’╝¤
+
+Ķ»Łõ╣ēÕłåÕē▓µś»Õ░åÕøŠÕāÅõĖŁÕ▒×õ║ÄÕÉīõĖĆńø«µĀćń▒╗Õł½ńÜäķā©ÕłåĶüÜń▒╗Õ£©õĖĆĶĄĘńÜäõ╗╗ÕŖĪŃĆéÕ«āõ╣¤µś»õĖĆń¦ŹÕāÅń┤Āń║¦ķó䵥ŗõ╗╗ÕŖĪ’╝īÕøĀõĖ║ÕøŠÕāÅõĖŁńÜäµ»ÅõĖĆõĖ¬ÕāÅń┤ĀķāĮÕ░åµĀ╣µŹ«ń▒╗Õł½Ķ┐øĶĪīÕłåń▒╗ŃĆéĶ»źõ╗╗ÕŖĪńÜäõĖĆõ║øńż║õŠŗÕ¤║Õćåµ£ē [Cityscapes](https://www.cityscapes-dataset.com/benchmarks/), [PASCAL VOC](http://host.robots.ox.ac.uk/pascal/VOC/voc2012/) ÕÆī [ADE20K](https://groups.csail.mit.edu/vision/datasets/ADE20K/) ŃĆéķĆÜÕĖĖńö©Õ╣│ÕØćõ║żÕ╣ȵ»ö (Mean IoU) ÕÆīÕāÅń┤ĀÕćåńĪ«ńÄć (Pixel Accuracy) Ķ┐ÖõĖżõĖ¬µīćµĀćµØźĶ»äõ╝░µ©ĪÕ×ŗŃĆé
+
+## õ╗Ćõ╣łµś» MMSegmentation?
+
+MMSegmentation µś»õĖĆõĖ¬ÕĘźÕģĘń«▒’╝īÕ«āõĖ║Ķ»Łõ╣ēÕłåÕē▓õ╗╗ÕŖĪńÜäń╗¤õĖĆÕ«×ńÄ░ÕÆīµ©ĪÕ×ŗĶ»äõ╝░µÅÉõŠøõ║åõĖĆõĖ¬µĪåµ×Č’╝īÕ╣ČõĖöķ½śĶ┤©ķćÅÕ«×ńÄ░õ║åÕĖĖńö©ńÜäĶ»Łõ╣ēÕłåÕē▓µ¢╣µ│ĢÕÆīµĢ░µŹ«ķøåŃĆé
+
+MMSeg õĖ╗Ķ”üÕīģÕɽõ║å apis, structures, datasets, models, engine, evaluation ÕÆī visualization Ķ┐ÖõĖāõĖ¬õĖ╗Ķ”üķā©ÕłåŃĆé
+
+- **apis** µÅÉõŠøõ║嵩ĪÕ×ŗµÄ©ńÉåńÜäķ½śń║¦api
+
+- **structures** µÅÉõŠøõ║åÕłåÕē▓õ╗╗ÕŖĪńÜäµĢ░µŹ«ń╗ōµ×ä `SegDataSample`
+
+- **datasets** µö»µīüńö©õ║ÄĶ»Łõ╣ēÕłåÕē▓ńÜäÕżÜń¦ŹµĢ░µŹ«ķøå
+
+ - **transforms** ÕīģÕÉ½ÕżÜń¦ŹµĢ░µŹ«Õó×Õ╝║ÕÅśµŹó
+
+- **models** µś»ÕłåÕē▓ÕÖ©µ£ĆķćŹĶ”üńÜäķā©Õłå’╝īÕīģÕɽõ║åÕłåÕē▓ÕÖ©ńÜäõĖŹÕÉīń╗äõ╗Č
+
+ - **segmentors** Õ«Üõ╣ēõ║åµēƵ£ēÕłåÕē▓µ©ĪÕ×ŗń▒╗
+ - **data_preprocessors** ńö©õ║ÄķóäÕżäńÉ嵩ĪÕ×ŗńÜäĶŠōÕģźµĢ░µŹ«
+ - **backbones** ÕīģÕɽÕÉäń¦Źķ¬©Õ╣▓ńĮæń╗£’╝īÕÅ»Õ░åÕøŠÕāŵśĀÕ░äõĖ║ńē╣ÕŠüÕøŠ
+ - **necks** ÕīģÕɽÕÉäń¦Źµ©ĪÕ×ŗķółķā©ń╗äõ╗Č’╝īńö©õ║ÄĶ┐×µÄźÕłåÕē▓Õż┤ÕÆīķ¬©Õ╣▓ńĮæń╗£
+ - **decode_heads** ÕīģÕɽÕÉäń¦ŹÕłåÕē▓Õż┤’╝īÕ░åńē╣ÕŠüÕøŠõĮ£õĖ║ĶŠōÕģź’╝īÕ╣Čķó䵥ŗÕłåÕē▓ń╗ōµ×£
+ - **losses** ÕīģÕɽÕÉäń¦ŹµŹ¤Õż▒ÕćĮµĢ░
+
+- **engine** µś»Ķ┐ÉĶĪīµŚČń╗äõ╗ČńÜäõĖĆķā©Õłå’╝īµē®Õ▒Ģõ║å [MMEngine](https://github.com/open-mmlab/mmengine) ńÜäÕŖ¤ĶāĮ
+
+ - **optimizers** µÅÉõŠøõ║åõ╝śÕī¢ÕÖ©ÕÆīõ╝śÕī¢ÕÖ©Õ░üĶŻģ
+ - **hooks** µÅÉõŠøõ║å runner ńÜäÕÉäń¦ŹķÆ®ÕŁÉ
+
+- **evaluation** µÅÉõŠøõ║åĶ»äõ╝░µ©ĪÕ×ŗµĆ¦ĶāĮńÜäõĖŹÕÉīµīćµĀć
+
+- **visualization** ÕłåÕē▓ń╗ōµ×£ńÜäÕÅ»Ķ¦åÕī¢ÕĘźÕģĘ
+
+## Õ”éõĮĢõĮ┐ńö©µ£¼µīćÕŹŚ’╝¤
+
+õ╗źõĖŗµś»Ķ»”ń╗åµŁźķ¬ż’╝īÕ░åÕĖ”µé©õĖƵŁźµŁźÕŁ”õ╣ĀÕ”éõĮĢõĮ┐ńö© MMSegmentation :
+
+1. µ£ēÕģ│Õ«ēĶŻģĶ»┤µśÄ’╝īĶ»ĘÕÅéķśģ [Õ╝ĆÕ¦ŗõĮĀńÜäń¼¼õĖƵŁź](get_started.md)ŃĆé
+
+2. Õ»╣õ║ÄÕłØÕŁ”ĶĆģµØźĶ»┤’╝īMMSegmentation µś»Õ╝ĆÕ¦ŗĶ»Łõ╣ēÕłåÕē▓õ╣ŗµŚģńÜäµ£ĆÕźĮķĆēµŗ®’╝īÕøĀõĖ║Ķ┐ÖķćīÕ«×ńÄ░õ║åĶ«ĖÕżÜ SOTA µ©ĪÕ×ŗõ╗źÕÅŖń╗ÅÕģĖńÜ䵩ĪÕ×ŗ [model](model_zoo.md) ŃĆéÕÅ”Õż¢’╝īÕ░åÕÉäń▒╗ń╗äõ╗ČÕÆīķ½śń║¦ API ńĄÉÕÉłõĮ┐ńö©’╝īÕÅ»õ╗źµø┤õŠ┐µŹĘńÜäµē¦ĶĪīÕłåÕē▓õ╗╗ÕŖĪŃĆéÕģ│õ║Ä MMSegmentation ńÜäÕ¤║µ£¼ńö©µ│Ģ’╝īĶ»ĘÕÅéĶĆāõĖŗķØóńÜäµĢÖń©ŗ’╝Ü
+
+ - [ķģŹńĮ«](user_guides/1_config.md)
+ - [µĢ░µŹ«ķóäÕżäńÉå](user_guides/2_dataset_prepare.md)
+ - [µÄ©ńÉå](user_guides/3_inference.md)
+ - [Ķ«Łń╗āÕÆīµĄŗĶ»Ģ](user_guides/4_train_test.md)
+
+3. Õ”éµ×£õĮĀµā│õ║åĶ¦Ż MMSegmentation ÕĘźõĮ£ńÜäÕ¤║µ£¼ń▒╗ÕÆīÕŖ¤ĶāĮ’╝īĶ»ĘÕÅéĶĆāõĖŗķØóńÜäµĢÖń©ŗµØźµĘ▒ÕģźńĀöń®Č’╝Ü
+
+ - [µĢ░µŹ«µĄü](advanced_guides/data_flow.md)
+ - [ń╗ōµ×ä](advanced_guides/structures.md)
+ - [µ©ĪÕ×ŗ](advanced_guides/models.md)
+ - [µĢ░µŹ«ķøå](advanced_guides/datasets.md)
+ - [Ķ»äõ╝░](advanced_guides/evaluation.md)
+
+4. MMSegmentation õ╣¤õĖ║ńö©µłĘĶć¬Õ«Üõ╣ēÕÆīõĖĆõ║øÕēŹµ▓┐ńÜäńĀöń®ČµÅÉõŠøõ║åµĢÖń©ŗ’╝īĶ»ĘÕÅéĶĆāõĖŗķØóńÜäµĢÖń©ŗµØźÕ╗║ń½ŗõĮĀĶć¬ÕĘ▒ńÜäÕłåÕē▓ķĪ╣ńø«’╝Ü
+
+ - [µĘ╗ÕŖĀµ¢░ńÜ䵩ĪÕ×ŗ](advanced_guides/add_models.md)
+ - [µĘ╗ÕŖĀµ¢░ńÜäµĢ░µŹ«ķøå](advanced_guides/add_datasets.md)
+ - [µĘ╗ÕŖĀµ¢░ńÜä transform](advanced_guides/add_transforms.md)
+ - [Ķć¬Õ«Üõ╣ē runtime](advanced_guides/customize_runtime.md)
+
+5. Õ”éµ×£µé©µø┤ń夵éē MMSegmentation v0.x , õ╗źõĖŗµś» MMSegmentation v0.x Ķ┐üń¦╗Õł░ v1.x ńÜäµ¢ćµĪŻ
+
+ - [Ķ┐üń¦╗](migration/index.rst)
+
+## ÕÅéĶĆāµØźµ║É
+
+- https://paperswithcode.com/task/semantic-segmentation/codeless#task-home
diff --git a/internlm_langchain/knowledge_base/MMSegmentation/content/package.md b/internlm_langchain/knowledge_base/MMSegmentation/content/package.md
new file mode 100644
index 00000000..19e5f18c
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMSegmentation/content/package.md
@@ -0,0 +1,113 @@
+# Õīģń╗ōµ×äµø┤µö╣
+
+µ£¼ĶŖéÕīģÕɽµé©Õ»╣ MMSeg 0.x ÕÆī 1.x õ╣ŗķŚ┤ńÜäÕÅśÕī¢ÕÅ»ĶāĮµä¤Õł░ÕźĮÕźćńÜäÕåģÕ«╣ŃĆé
+
+
+
+
+## ÕĘ▓ÕłĀķÖżńÜäÕīģ
+
+### `mmseg.core`
+
+Õ£© OpenMMLab 2.0 õĖŁ’╝ī`core` ÕīģÕĘ▓Ķó½ÕłĀķÖżŃĆé`core` ńÜä `hooks` ÕÆī `optimizers` Ķó½ń¦╗ÕŖ©Õł░õ║å `mmseg.engine` õĖŁ’╝īĶĆī `core` õĖŁńÜä `evaluation` ńø«ÕēŹµś» mmseg.evaluationŃĆé
+
+## `mmseg.ops`
+
+`ops` ÕīģÕɽ `encoding` ÕÆī `wrappers`’╝īÕ«āõ╗¼Ķó½ń¦╗Õł░õ║å `mmseg.models.utils` õĖŁŃĆé
+
+## Õó×ÕŖĀńÜäÕīģ
+
+### `mmseg.engine`
+
+OpenMMLab 2.0 Õó×ÕŖĀõ║åõĖĆõĖ¬µ¢░ńÜäµĘ▒Õ║”ÕŁ”õ╣ĀĶ«Łń╗āÕ¤║ńĪĆÕ║ō MMEngineŃĆéÕ«āµś»µēƵ£ē OpenMMLab õ╗ŻńĀüÕ║ōńÜäĶ«Łń╗āÕ╝ĢµōÄŃĆé
+mmseg ńÜä `engine` Õīģµś»õĖĆõ║øńö©õ║ÄĶ»Łõ╣ēÕłåÕē▓õ╗╗ÕŖĪńÜäÕ«ÜÕłČµ©ĪÕØŚ’╝īÕ”é `SegVisualizationHook` ńö©õ║ÄÕÅ»Ķ¦åÕī¢ÕłåÕē▓µÄ®Ķå£ŃĆé
+
+### `mmseg.structure`
+
+Õ£© OpenMMLab 2.0 õĖŁ’╝īµłæõ╗¼õĖ║Ķ«Īń«Śµ£║Ķ¦åĶ¦ēõ╗╗ÕŖĪĶ«ŠĶ«Īõ║åµĢ░µŹ«ń╗ōµ×ä’╝īÕ£© mmseg õĖŁ’╝īµłæõ╗¼Õ£© `structure` ÕīģõĖŁÕ«×ńÄ░õ║å `SegDataSample`ŃĆé
+
+### `mmseg.evaluation`
+
+µłæõ╗¼Õ░åµēƵ£ēĶ»äõ╝░µīćµĀćķāĮń¦╗ÕŖ©Õł░õ║å `mmseg.evaluation` õĖŁŃĆé
+
+### `mmseg.registry`
+
+µłæõ╗¼Õ░å MMSegmentation õĖŁµēƵ£ēń▒╗Õ×ŗµ©ĪÕØŚńÜäµ│©ÕåīÕ«×ńÄ░ń¦╗ÕŖ©Õł░ `mmseg.registry` õĖŁŃĆé
+
+## õ┐«µö╣ńÜäÕīģ
+
+### `mmseg.apis`
+
+OpenMMLab 2.0 Õ░ØĶ»Ģµö»µīüĶ«Īń«Śµ£║Ķ¦åĶ¦ēńÜäÕżÜõ╗╗ÕŖĪń╗¤õĖƵğÕÅŻ’╝īÕ╣ČÕÅæÕĖāõ║åµø┤Õ╝║ńÜä [`Runner`](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/design/runner.md)’╝īÕøĀµŁż MMSeg 1.x ÕłĀķÖżõ║å `train.py` ÕÆī `test.py` õĖŁńÜ䵩ĪÕØŚ’╝īÕ╣ČÕ░å `init_segmentor` ķćŹÕæĮÕÉŹõĖ║ `init_model`’╝īÕ░å `inference_segmentor` ķćŹÕæĮÕÉŹõĖ║ `inference_model`ŃĆé
+
+õ╗źõĖŗµś» `mmseg.apis` ńÜäµø┤µö╣’╝Ü
+
+| ÕćĮµĢ░ | ÕÅśÕī¢ |
+| :-------------------: | :--------------------------------------------- |
+| `init_segmentor` | ķćŹÕæĮÕÉŹõĖ║ `init_model` |
+| `inference_segmentor` | ķćŹÕæĮÕÉŹõĖ║ `inference_model` |
+| `show_result_pyplot` | Õ¤║õ║Ä `SegLocalVisualizer` Õ«×ńÄ░ |
+| `train_model` | ÕłĀķÖż’╝īõĮ┐ńö© `runner.train` Ķ«Łń╗āŃĆé |
+| `multi_gpu_test` | ÕłĀķÖż’╝īõĮ┐ńö© `runner.test` µĄŗĶ»ĢŃĆé |
+| `single_gpu_test` | ÕłĀķÖż’╝īõĮ┐ńö© `runner.test` µĄŗĶ»ĢŃĆé |
+| `set_random_seed` | ÕłĀķÖż’╝īõĮ┐ńö© `mmengine.runner.set_random_seed`ŃĆé |
+| `init_random_seed` | ÕłĀķÖż’╝īõĮ┐ńö© `mmengine.dist.sync_random_seed`ŃĆé |
+
+### `mmseg.datasets`
+
+OpenMMLab 2.0 Õ░å `BaseDataset` Õ«Üõ╣ēõĖ║µĢ░µŹ«ķøåńÜäÕćĮµĢ░ÕÆīµÄźÕÅŻ’╝īMMSegmentation 1.x õ╣¤ķüĄÕŠ¬µŁżÕŹÅĶ««’╝īÕ╣ČÕ«Üõ╣ēõ║åõ╗Ä `BaseDataset` ń╗¦µē┐ńÜä `BaseSegDataset`ŃĆéMMCV 2.x µöČķøåÕżÜń¦Źõ╗╗ÕŖĪńÜäķĆÜńö©µĢ░µŹ«ĶĮ¼µŹó’╝īõŠŗÕ”éÕłåń▒╗ŃĆüµŻĆµĄŗŃĆüÕłåÕē▓’╝īÕøĀµŁż MMSegmentation 1.x õĮ┐ńö©Ķ┐Öõ║øµĢ░µŹ«ĶĮ¼µŹóÕ╣ČÕ░åÕģČõ╗Ä mmseg.dataset õĖŁÕłĀķÖżŃĆé
+
+| Õīģ/µ©ĪÕØŚ | µø┤µö╣ |
+| :-------------------: | :----------------------------------------------------------------------------------- |
+| `mmseg.pipelines` | ń¦╗ÕŖ©Õł░ `mmcv.transforms` õĖŁ |
+| `mmseg.sampler` | ń¦╗ÕŖ©Õł░ `mmengine.dataset.sampler` õĖŁ |
+| `CustomDataset` | ķćŹÕæĮÕÉŹõĖ║ `BaseSegDataset` Õ╣Čõ╗Ä MMEngine õĖŁńÜä `BaseDataset` ń╗¦µē┐ |
+| `DefaultFormatBundle` | µø┐µŹóõĖ║ `PackSegInputs` |
+| `LoadImageFromFile` | ń¦╗ÕŖ©Õł░ `mmcv.transforms.LoadImageFromFile` õĖŁ |
+| `LoadAnnotations` | ń¦╗ÕŖ©Õł░ `mmcv.transforms.LoadAnnotations` õĖŁ |
+| `Resize` | ń¦╗ÕŖ©Õł░ `mmcv.transforms` õĖŁÕ╣ȵŗåÕłåõĖ║ `Resize`’╝ī`RandomResize` ÕÆī `RandomChoiceResize` |
+| `RandomFlip` | ń¦╗ÕŖ©Õł░ `mmcv.transforms.RandomFlip` õĖŁ |
+| `Pad` | ń¦╗ÕŖ©Õł░ `mmcv.transforms.Pad` õĖŁ |
+| `Normalize` | ń¦╗ÕŖ©Õł░ `mmcv.transforms.Normalize` õĖŁ |
+| `Compose` | ń¦╗ÕŖ©Õł░ `mmcv.transforms.Compose` õĖŁ |
+| `ImageToTensor` | ń¦╗ÕŖ©Õł░ `mmcv.transforms.ImageToTensor` õĖŁ |
+
+### `mmseg.models`
+
+`models` µ▓Īµ£ēÕż¬Õż¦ÕÅśÕī¢’╝īÕŬµś»õ╗Äõ╗źÕēŹńÜä `mmseg.ops` µĘ╗ÕŖĀõ║å `encoding` ÕÆī `wrappers`
diff --git a/internlm_langchain/knowledge_base/MMSegmentation/content/structures.md b/internlm_langchain/knowledge_base/MMSegmentation/content/structures.md
new file mode 100644
index 00000000..958e011a
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMSegmentation/content/structures.md
@@ -0,0 +1,102 @@
+# µĢ░µŹ«ń╗ōµ×ä
+
+õĖ║õ║åń╗¤õĖƵ©ĪÕ×ŗÕÆīÕÉäÕŖ¤ĶāĮµ©ĪÕØŚõ╣ŗķŚ┤ńÜäĶŠōÕģźÕÆīĶŠōÕć║ńÜäµÄźÕÅŻ, Õ£© OpenMMLab 2.0 MMEngine õĖŁÕ«Üõ╣ēõ║åõĖĆÕźŚµŖĮĶ▒ĪµĢ░µŹ«ń╗ōµ×ä, Õ«×ńÄ░õ║åÕ¤║ńĪĆńÜäÕó×/ÕłĀ/µ¤ź/µö╣ÕŖ¤ĶāĮ, µö»µīüõĖŹÕÉīĶ«ŠÕżćķŚ┤ńÜäµĢ░µŹ«Ķ┐üń¦╗, õ╣¤µö»µīüõ║åÕ”é
+`.cpu()`, `.cuda()`, `.get()` ÕÆī `.detach()` ńÜäń▒╗ÕŁŚÕģĖÕÆīÕ╝ĀķćÅńÜäµōŹõĮ£ŃĆéÕģĘõĮōÕÅ»õ╗źÕÅéĶĆā [MMEngine µ¢ćµĪŻ](https://github.com/open-mmlab/mmengine/blob/main/docs/en/advanced_tutorials/data_element.md)ŃĆé
+
+ÕÉīµĀĘńÜä, MMSegmentation õ║”ķüĄÕŠ¬õ║å OpenMMLab 2.0 ÕÉ䵩ĪÕØŚķŚ┤ńÜäµÄźÕÅŻÕŹÅĶ««, Õ«Üõ╣ēõ║å `SegDataSample` ńö©µØźÕ░üĶŻģĶ»Łõ╣ēÕłåÕē▓õ╗╗ÕŖĪµēĆķ£ĆĶ”üńÜäµĢ░µŹ«ŃĆé
+
+## Ķ»Łõ╣ēÕłåÕē▓µĢ░µŹ« SegDataSample
+
+[SegDataSample](mmseg.structures.SegDataSample) Õīģµŗ¼õ║åõĖēõĖ¬õĖ╗Ķ”üµĢ░µŹ«ÕŁŚµ«Ą `gt_sem_seg`, `pred_sem_seg` ÕÆī `seg_logits`, ÕłåÕł½ńö©µØźÕŁśµöŠµĀćµ│©õ┐Īµü», ķó䵥ŗń╗ōµ×£ÕÆīķó䵥ŗńÜäµ£¬ÕĮÆõĖĆÕī¢ÕēŹńÜä logits ÕĆ╝ŃĆé
+
+| ÕŁŚµ«Ą | ń▒╗Õ×ŗ | µÅÅĶ┐░ |
+| -------------- | ------------------------- | ------------------------------- |
+| gt_sem_seg | [`PixelData`](#pixeldata) | ÕøŠÕāŵĀćµ│©õ┐Īµü». |
+| pred_instances | [`PixelData`](#pixeldata) | ÕøŠÕāÅķó䵥ŗń╗ōµ×£. |
+| seg_logits | [`PixelData`](#pixeldata) | µ©ĪÕ×ŗķó䵥ŗµ£¬ÕĮÆõĖĆÕī¢ÕēŹńÜä logits ÕĆ╝. |
+
+õ╗źõĖŗńż║õŠŗõ╗ŻńĀüÕ▒Ģńż║õ║å `SegDataSample` ńÜäõĮ┐ńö©µ¢╣µ│Ģ’╝Ü
+
+```python
+import torch
+from mmengine.structures import PixelData
+from mmseg.structures import SegDataSample
+
+img_meta = dict(img_shape=(4, 4, 3),
+ pad_shape=(4, 4, 3))
+data_sample = SegDataSample()
+# Õ«Üõ╣ē gt_segmentations ńö©õ║ÄÕ░üĶŻģµ©ĪÕ×ŗńÜäĶŠōÕć║õ┐Īµü»
+gt_segmentations = PixelData(metainfo=img_meta)
+gt_segmentations.data = torch.randint(0, 2, (1, 4, 4))
+
+# Õó×ÕŖĀÕÆīÕżäńÉå SegDataSampleŃĆĆõĖŁńÜäÕ▒׵Ʀ
+data_sample.gt_sem_seg = gt_segmentations
+assert 'gt_sem_seg' in data_sample
+assert 'data' in data_sample.gt_sem_seg
+assert 'img_shape' in data_sample.gt_sem_seg.metainfo_keys()
+print(data_sample.gt_sem_seg.shape)
+'''
+(4, 4)
+'''
+print(data_sample)
+'''
+
+) at 0x1c2aae44d60>
+'''
+
+# ÕłĀķÖżÕÆīõ┐«µö╣ SegDataSampleŃĆĆõĖŁńÜäÕ▒׵Ʀ
+data_sample = SegDataSample()
+gt_segmentations = PixelData(metainfo=img_meta)
+gt_segmentations.data = torch.randint(0, 2, (1, 4, 4))
+data_sample.gt_sem_seg = gt_segmentations
+data_sample.gt_sem_seg.set_metainfo(dict(img_shape=(4,4,9), pad_shape=(4,4,9)))
+del data_sample.gt_sem_seg.img_shape
+
+# ń▒╗Õ╝ĀķćÅńÜäµōŹõĮ£
+data_sample = SegDataSample()
+gt_segmentations = PixelData(metainfo=img_meta)
+gt_segmentations.data = torch.randint(0, 2, (1, 4, 4))
+cuda_gt_segmentations = gt_segmentations.cuda()
+cuda_gt_segmentations = gt_segmentations.to('cuda:0')
+cpu_gt_segmentations = cuda_gt_segmentations.cpu()
+cpu_gt_segmentations = cuda_gt_segmentations.to('cpu')
+```
+
+## Õ£© SegDataSample õĖŁĶć¬Õ«Üõ╣ēµ¢░ńÜäÕ▒׵Ʀ
+
+Õ”éµ×£õĮĀµā│Õ£© `SegDataSample` õĖŁĶć¬Õ«Üõ╣ēµ¢░ńÜäÕ▒׵Ʀ’╝īõĮĀÕÅ»õ╗źÕÅéĶĆāõĖŗķØóńÜä [SegDataSample](https://github.com/open-mmlab/mmsegmentation/blob/1.x/mmseg/structures/seg_data_sample.py) ńż║õŠŗ:
+
+```python
+class SegDataSample(BaseDataElement):
+ ...
+
+ @property
+ def xxx_property(self) -> xxxData:
+ return self._xxx_property
+
+ @xxx_property.setter
+ def xxx_property(self, value: xxxData) -> None:
+ self.set_field(value, '_xxx_property', dtype=xxxData)
+
+ @xxx_property.deleter
+ def xxx_property(self) -> None:
+ del self._xxx_property
+```
+
+Ķ┐ÖµĀĘõĖĆõĖ¬µ¢░ńÜäÕ▒׵Ʀ `xxx_property` Õ░▒Õ░åĶó½Õó×ÕŖĀÕł░ `SegDataSample` ķćīķØóõ║åŃĆé
diff --git a/internlm_langchain/knowledge_base/MMSegmentation/content/training_tricks.md b/internlm_langchain/knowledge_base/MMSegmentation/content/training_tricks.md
new file mode 100644
index 00000000..e5b8e4da
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMSegmentation/content/training_tricks.md
@@ -0,0 +1,74 @@
+# Ķ«Łń╗āµŖĆÕʦ
+
+MMSegmentation µö»µīüÕ”éõĖŗĶ«Łń╗āµŖĆÕʦ’╝Ü
+
+## õĖ╗Õ╣▓ńĮæń╗£ÕÆīĶ¦ŻńĀüÕż┤ń╗äõ╗ČõĮ┐ńö©õĖŹÕÉīńÜäÕŁ”õ╣ĀńÄć (Learning Rate, LR)
+
+Õ£©Ķ»Łõ╣ēÕłåÕē▓ķćī’╝īõĖĆõ║øµ¢╣µ│Ģõ╝ÜĶ«®Ķ¦ŻńĀüÕż┤ń╗äõ╗ČńÜäÕŁ”õ╣ĀńÄćÕż¦õ║ÄõĖ╗Õ╣▓ńĮæń╗£ńÜäÕŁ”õ╣ĀńÄć’╝īĶ┐ÖµĀĘÕÅ»õ╗źĶÄĘÕŠŚµø┤ÕźĮńÜäĶĪ©ńÄ░µł¢µø┤Õ┐½ńÜäµöȵĢøŃĆé
+
+Õ£© MMSegmentation ķćīķØó’╝īµé©õ╣¤ÕÅ»õ╗źÕ£©ķģŹńĮ«µ¢ćõ╗ČķćīµĘ╗ÕŖĀÕ”éõĖŗĶĪīµØźĶ«®Ķ¦ŻńĀüÕż┤ń╗äõ╗ČńÜäÕŁ”õ╣ĀńÄ浜»õĖ╗Õ╣▓ń╗äõ╗ČńÜä10ÕĆŹŃĆé
+
+```python
+optim_wrapper=dict(
+ paramwise_cfg = dict(
+ custom_keys={
+ 'head': dict(lr_mult=10.)}))
+```
+
+ķĆÜĶ┐ćĶ┐Öń¦Źõ┐«µö╣’╝īõ╗╗õĮĢĶó½Õłåń╗äÕł░ `'head'` ńÜäÕÅéµĢ░ńÜäÕŁ”õ╣ĀńÄćķāĮÕ░åõ╣śõ╗ź10ŃĆéµé©õ╣¤ÕÅ»õ╗źÕÅéńģ¦ [MMEngine µ¢ćµĪŻ](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/optim_wrapper.html#id6) ĶÄĘÕÅ¢µø┤Ķ»”ń╗åńÜäõ┐Īµü»ŃĆé
+
+## Õ£©ń║┐ķÜŠµĀʵ£¼µī¢µÄś (Online Hard Example Mining, OHEM)
+
+MMSegmentation õĖŁÕ«×ńÄ░õ║åÕāÅń┤ĀķććµĀĘÕÖ©’╝īĶ«Łń╗āµŚČÕÅ»õ╗źÕ»╣ńē╣Õ«ÜÕāÅń┤ĀĶ┐øĶĪīķććµĀĘ’╝īõŠŗÕ”é OHEM(Online Hard Example Mining)’╝īÕÅ»õ╗źĶ¦ŻÕå│µĀʵ£¼õĖŹÕ╣│ĶĪĪķŚ«ķóś’╝ī
+Õ”éõĖŗõŠŗÕŁÉµś»õĮ┐ńö© PSPNet Ķ«Łń╗āÕ╣Čķććńö© OHEM ńŁ¢ńĢźńÜäķģŹńĮ«’╝Ü
+
+```python
+_base_ = './pspnet_r50-d8_512x1024_40k_cityscapes.py'
+model=dict(
+ decode_head=dict(
+ sampler=dict(type='OHEMPixelSampler', thresh=0.7, min_kept=100000)) )
+```
+
+ķĆÜĶ┐ćĶ┐Öń¦Źµ¢╣Õ╝Å’╝īÕŬµ£ēńĮ«õ┐ĪÕłåµĢ░Õ£©0.7õ╗źõĖŗńÜäÕāÅń┤ĀÕĆ╝ńé╣õ╝ÜĶó½µŗ┐µØźĶ«Łń╗āŃĆéÕ£©Ķ«Łń╗āµŚČµłæõ╗¼Ķć│Õ░æĶ”üõ┐ØńĢÖ100000õĖ¬ÕāÅń┤ĀÕĆ╝ńé╣ŃĆéÕ”éµ×£ `thresh` Õ╣ȵ£¬Ķó½µīćÕ«Ü’╝īÕēŹ `min_kept`
+õĖ¬µŹ¤Õż▒ńÜäÕāÅń┤ĀÕĆ╝ńé╣µēŹõ╝ÜĶó½ķĆēµŗ®ŃĆé
+
+## ń▒╗Õł½Õ╣│ĶĪĪµŹ¤Õż▒ (Class Balanced Loss)
+
+Õ»╣õ║ÄõĖŹÕ╣│ĶĪĪń▒╗Õł½ÕłåÕĖāńÜäµĢ░µŹ«ķøå’╝īµé©õ╣¤Ķ«ĖÕÅ»õ╗źµö╣ÕÅśµ»ÅõĖ¬ń▒╗Õł½ńÜ䵏¤Õż▒µØāķćŹŃĆéĶ┐Öķćīõ╗ź cityscapes µĢ░µŹ«ķøåõĖ║õŠŗ’╝Ü
+
+```python
+_base_ = './pspnet_r50-d8_512x1024_40k_cityscapes.py'
+model=dict(
+ decode_head=dict(
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0,
+ # DeepLab Õ»╣ cityscapes õĮ┐ńö©Ķ┐Öń¦ŹµØāķćŹ
+ class_weight=[0.8373, 0.9180, 0.8660, 1.0345, 1.0166, 0.9969, 0.9754,
+ 1.0489, 0.8786, 1.0023, 0.9539, 0.9843, 1.1116, 0.9037,
+ 1.0865, 1.0955, 1.0865, 1.1529, 1.0507])))
+```
+
+`class_weight` Õ░åĶó½õĮ£õĖ║ `weight` ÕÅéµĢ░’╝īõ╝ĀķĆÆń╗Ö `CrossEntropyLoss`ŃĆéĶ»”ń╗åõ┐Īµü»Ķ»ĘÕÅéńģ¦ [PyTorch µ¢ćµĪŻ](https://pytorch.org/docs/stable/nn.html?highlight=crossentropy#torch.nn.CrossEntropyLoss) ŃĆé
+
+## ÕÉīµŚČõĮ┐ńö©ÕżÜń¦ŹµŹ¤Õż▒ÕćĮµĢ░ (Multiple Losses)
+
+Õ»╣õ║ÄĶ«Łń╗āµŚČµŹ¤Õż▒ÕćĮµĢ░ńÜäĶ«Īń«Ś’╝īµłæõ╗¼ńø«ÕēŹµö»µīüÕżÜõĖ¬µŹ¤Õż▒ÕćĮµĢ░ÕÉīµŚČõĮ┐ńö©ŃĆé õ╗ź `unet` õĮ┐ńö© `DRIVE` µĢ░µŹ«ķøåĶ«Łń╗āõĖ║õŠŗ’╝ī
+õĮ┐ńö© `CrossEntropyLoss` ÕÆī `DiceLoss` ńÜä `1:3` ńÜäÕŖĀµØāÕÆīõĮ£õĖ║µŹ¤Õż▒ÕćĮµĢ░ŃĆéķģŹńĮ«µ¢ćõ╗ČÕåÖõĖ║:
+
+```python
+_base_ = './fcn_unet_s5-d16_64x64_40k_drive.py'
+model = dict(
+ decode_head=dict(loss_decode=[
+ dict(type='CrossEntropyLoss', loss_name='loss_ce', loss_weight=1.0),
+ dict(type='DiceLoss', loss_name='loss_dice', loss_weight=3.0)
+ ]),
+ auxiliary_head=dict(loss_decode=[
+ dict(type='CrossEntropyLoss', loss_name='loss_ce', loss_weight=1.0),
+ dict(type='DiceLoss', loss_name='loss_dice', loss_weight=3.0)
+ ]),
+)
+```
+
+ķĆÜĶ┐ćĶ┐Öń¦Źµ¢╣Õ╝Å’╝īńĪ«Õ«ÜĶ«Łń╗āĶ┐ćń©ŗõĖŁµŹ¤Õż▒ÕćĮµĢ░ńÜäµØāķćŹ `loss_weight` ÕÆīÕ£©Ķ«Łń╗āµŚźÕ┐ŚķćīńÜäÕÉŹÕŁŚ `loss_name`ŃĆé
+
+µ│©µäÅ’╝Ü `loss_name` ńÜäÕÉŹÕŁŚÕ┐ģķĪ╗ÕĖ”µ£ē `loss_` ÕēŹń╝Ć’╝īĶ┐ÖµĀĘÕ«āµēŹĶāĮĶó½Õīģµŗ¼Õ£©Ķ«Īń«ŚÕøŠķćīŃĆé
diff --git a/internlm_langchain/knowledge_base/MMSegmentation/content/transforms.md b/internlm_langchain/knowledge_base/MMSegmentation/content/transforms.md
new file mode 100644
index 00000000..e5f3bebf
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMSegmentation/content/transforms.md
@@ -0,0 +1,119 @@
+# µĢ░µŹ«Õó×Õ╝║ÕÅśÕī¢
+
+Õ£©µ£¼µĢÖń©ŗõĖŁ’╝īµłæõ╗¼Õ░åõ╗ŗń╗Ź MMSegmentation õĖŁµĢ░µŹ«Õó×Õ╝║ÕÅśÕī¢µĄüń©ŗńÜäĶ«ŠĶ«ĪŃĆé
+
+µ£¼µīćÕŹŚńÜäń╗ōµ×äÕ”éõĖŗ’╝Ü
+
+- [µĢ░µŹ«Õó×Õ╝║ÕÅśÕī¢](#µĢ░µŹ«Õó×Õ╝║ÕÅśÕī¢)
+ - [µĢ░µŹ«Õó×Õ╝║ÕÅśÕī¢µĄüń©ŗĶ«ŠĶ«Ī](#µĢ░µŹ«Õó×Õ╝║ÕÅśÕī¢µĄüń©ŗĶ«ŠĶ«Ī)
+ - [µĢ░µŹ«ÕŖĀĶĮĮ](#µĢ░µŹ«ÕŖĀĶĮĮ)
+ - [ķóäÕżäńÉå](#ķóäÕżäńÉå)
+ - [µĀ╝Õ╝Åõ┐«µö╣](#µĀ╝Õ╝Åõ┐«µö╣)
+
+## µĢ░µŹ«Õó×Õ╝║ÕÅśÕī¢µĄüń©ŗĶ«ŠĶ«Ī
+
+µīēńģ¦µā»õŠŗ’╝īµłæõ╗¼õĮ┐ńö© `Dataset` ÕÆī `DataLoader` ÕżÜĶ┐øń©ŗÕ£░ÕŖĀĶĮĮµĢ░µŹ«ŃĆé`Dataset` Ķ┐öÕø×õĖĵ©ĪÕ×ŗ forward µ¢╣µ│ĢńÜäÕÅéµĢ░ńøĖÕ»╣Õ║öńÜäµĢ░µŹ«ķĪ╣ńÜäÕŁŚÕģĖŃĆéńö▒õ║ÄĶ»Łõ╣ēÕłåÕē▓õĖŁńÜäµĢ░µŹ«ÕÅ»ĶāĮÕż¦Õ░ÅõĖŹÕÉī’╝īµłæõ╗¼Õ£© MMCV õĖŁÕ╝ĢÕģźõ║åõĖĆń¦Źµ¢░ńÜä `DataContainer` ń▒╗Õ×ŗ’╝īõ╗źÕĖ«ÕŖ®µöČķøåÕÆīÕłåÕÅæõĖŹÕÉīÕż¦Õ░ÅńÜäµĢ░µŹ«ŃĆéÕÅéĶ¦ü[µŁżÕżä](https://github.com/open-mmlab/mmcv/blob/master/mmcv/parallel/data_container.py)õ║åĶ¦Żµø┤ÕżÜĶ»”µāģŃĆé
+
+Õ£© MMSegmentation ńÜä 1.x ńēłµ£¼õĖŁ’╝īµēƵ£ēµĢ░µŹ«ĶĮ¼µŹóķāĮń╗¦µē┐Ķć¬ [`BaseTransform`](https://github.com/open-mmlab/mmcv/blob/2.x/mmcv/transforms/base.py#L6).
+
+ĶĮ¼µŹóńÜäĶŠōÕģźÕÆīĶŠōÕć║ń▒╗Õ×ŗķāĮµś»ÕŁŚÕģĖŃĆéõĖĆõĖ¬ń«ĆÕŹĢńÜäńż║õŠŗÕ”éõĖŗ’╝Ü
+
+```python
+>>> from mmseg.datasets.transforms import LoadAnnotations
+>>> transforms = LoadAnnotations()
+>>> img_path = './data/cityscapes/leftImg8bit/train/aachen/aachen_000000_000019_leftImg8bit.png.png'
+>>> gt_path = './data/cityscapes/gtFine/train/aachen/aachen_000015_000019_gtFine_instanceTrainIds.png'
+>>> results = dict(
+>>> img_path=img_path,
+>>> seg_map_path=gt_path,
+>>> reduce_zero_label=False,
+>>> seg_fields=[])
+>>> data_dict = transforms(results)
+>>> print(data_dict.keys())
+dict_keys(['img_path', 'seg_map_path', 'reduce_zero_label', 'seg_fields', 'gt_seg_map'])
+```
+
+µĢ░µŹ«ÕćåÕżćµĄüń©ŗÕÆīµĢ░µŹ«ķøåµś»Ķ¦ŻĶĆ”ńÜäŃĆéķĆÜÕĖĖ’╝īµĢ░µŹ«ķøåÕ«Üõ╣ēÕ”éõĮĢÕżäńÉåµĀćµ│©’╝īµĢ░µŹ«µĄüń©ŗÕ«Üõ╣ēÕćåÕżćµĢ░µŹ«ÕŁŚÕģĖńÜäµēƵ£ēµŁźķ¬żŃĆ鵥üń©ŗńö▒õĖĆń│╗ÕłŚµōŹõĮ£ń╗䵳ÉŃĆéµ»ÅõĖ¬µōŹõĮ£ķāĮÕ░åÕŁŚÕģĖõĮ£õĖ║ĶŠōÕģź’╝īÕ╣ČõĖ║µÄźõĖŗµØźńÜäĶĮ¼µŹóĶŠōÕć║ÕŁŚÕģĖŃĆé
+
+µōŹõĮ£ÕłåõĖ║µĢ░µŹ«ÕŖĀĶĮĮŃĆüķóäÕżäńÉåŃĆüµĀ╝Õ╝Åõ┐«µö╣ÕÆīµĄŗĶ»ĢµĢ░µŹ«Õó×Õ╝║ŃĆé
+
+Ķ┐Öķćīµś» PSPNet ńÜ䵥üń©ŗńż║õŠŗ’╝Ü
+
+```python
+crop_size = (512, 1024)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations'),
+ dict(
+ type='RandomResize',
+ scale=(2048, 1024),
+ ratio_range=(0.5, 2.0),
+ keep_ratio=True),
+ dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='PhotoMetricDistortion'),
+ dict(type='PackSegInputs')
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='Resize', scale=(2048, 1024), keep_ratio=True),
+ # add loading annotation after ``Resize`` because ground truth
+ # does not need to resize data transform
+ dict(type='LoadAnnotations'),
+ dict(type='PackSegInputs')
+]
+```
+
+Õ»╣õ║ĵ»ÅõĖ¬µōŹõĮ£’╝īµłæõ╗¼ÕłŚÕć║õ║å `µĘ╗ÕŖĀ`/`µø┤µ¢░`/`ÕłĀķÖż` ńøĖÕģ│ńÜäÕŁŚÕģĖÕŁŚµ«ĄŃĆéÕ£©µĄüń©ŗÕēŹ’╝īµłæõ╗¼ÕÅ»õ╗źõ╗ĵĢ░µŹ«ķøåńø┤µÄźĶÄĘÕŠŚńÜäõ┐Īµü»µś» `img_path` ÕÆī `seg_map_path`ŃĆé
+
+### µĢ░µŹ«ÕŖĀĶĮĮ
+
+`LoadImageFromFile`’╝Üõ╗ĵ¢ćõ╗ČÕŖĀĶĮĮÕøŠÕāÅŃĆé
+
+- µĘ╗ÕŖĀ’╝Ü`img`’╝ī`img_shape`’╝ī`ori_shape`
+
+`LoadAnnotations`’╝ÜÕŖĀĶĮĮµĢ░µŹ«ķøåµÅÉõŠøńÜäĶ»Łõ╣ēÕłåÕē▓ÕøŠŃĆé
+
+- µĘ╗ÕŖĀ’╝Ü`seg_fields`’╝ī`gt_seg_map`
+
+### ķóäÕżäńÉå
+
+`RandomResize`’╝ÜķÜŵ£║Ķ░āµĢ┤ÕøŠÕāÅÕÆīÕłåÕē▓ÕøŠÕż¦Õ░ÅŃĆé
+
+-µĘ╗ÕŖĀ’╝Ü`scale`’╝ī`scale_factor`’╝ī`keep_ratio`
+-µø┤µ¢░’╝Ü`img`’╝ī`img_shape`’╝ī`gt_seg_map`
+
+`Resize`’╝ÜĶ░āµĢ┤ÕøŠÕāÅÕÆīÕłåÕē▓ÕøŠńÜäÕż¦Õ░ÅŃĆé
+
+-µĘ╗ÕŖĀ’╝Ü`scale`’╝ī`scale_factor`’╝ī`keep_ratio`
+-µø┤µ¢░’╝Ü`img`’╝ī`gt_seg_map`’╝ī`img_shape`
+
+`RandomCrop`’╝ÜķÜŵ£║ĶŻüÕē¬ÕøŠÕāÅÕÆīÕłåÕē▓ÕøŠŃĆé
+
+-µø┤µ¢░’╝Ü`img`’╝ī`gt_seg_map`’╝ī`img_shape`
+
+`RandomFlip`’╝Üń┐╗ĶĮ¼ÕøŠÕāÅÕÆīÕłåÕē▓ÕøŠŃĆé
+
+-µĘ╗ÕŖĀ’╝Ü`flip`’╝ī`flip_direction`
+-µø┤µ¢░’╝Ü`img`’╝ī`gt_seg_map`
+
+`PhotoMetricDistortion`’╝ܵīēķĪ║Õ║ÅÕ»╣ÕøŠÕāÅÕ║öńö©ÕģēÕ║”Õż▒ń£¤’╝īµ»ÅõĖ¬ÕÅśµŹóńÜäÕ║öńö©µ”éńÄćõĖ║ 0.5ŃĆéķÜŵ£║Õ»╣µ»öÕ║”ńÜäõĮŹńĮ«µś»ń¼¼õ║īµł¢ÕĆƵĢ░ń¼¼õ║ī’╝łÕłåÕł½õĖ║õĖŗķØóńÜ䵩ĪÕ╝Å 0 µł¢ 1’╝ēŃĆé
+
+```
+1.ķÜŵ£║õ║«Õ║”
+2.ķÜŵ£║Õ»╣µ»öÕ║”’╝łµ©ĪÕ╝Å 0’╝ē
+3.Õ░åķó£Ķē▓õ╗Ä BGR ĶĮ¼µŹóõĖ║ HSV
+4.ķÜŵ£║ķź▒ÕÆīÕ║”
+5.ķÜŵ£║Ķē▓Ķ░ā
+6.Õ░åķó£Ķē▓õ╗Ä HSV ĶĮ¼µŹóõĖ║ BGR
+7.ķÜŵ£║Õ»╣µ»öÕ║”’╝łµ©ĪÕ╝Å 1’╝ē
+```
+
+- µø┤µ¢░’╝Ü`img`
+
+### µĀ╝Õ╝Åõ┐«µö╣
+
+`PackSegInputs`’╝ÜõĖ║Ķ»Łõ╣ēÕłåµ«ĄµēōÕīģĶŠōÕģźµĢ░µŹ«ŃĆé
+
+- µĘ╗ÕŖĀ’╝Ü`inputs`’╝ī`data_sample`
+- ÕłĀķÖż’╝Üńö▒ `meta_keys` µīćÕ«ÜńÜä keys’╝łÕÉłÕ╣ČÕł░ data_sample ńÜä metainfo õĖŁ’╝ē’╝īµēƵ£ēÕģČõ╗¢ keys
diff --git a/internlm_langchain/knowledge_base/MMSegmentation/content/useful_tools.md b/internlm_langchain/knowledge_base/MMSegmentation/content/useful_tools.md
new file mode 100644
index 00000000..acbacb95
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMSegmentation/content/useful_tools.md
@@ -0,0 +1,368 @@
+## ÕĖĖńö©ÕĘźÕģĘ’╝łÕŠģµø┤µ¢░’╝ē
+
+ķÖżõ║åĶ«Łń╗āÕÆīµĄŗĶ»ĢńÜäĶäܵ£¼’╝īµłæõ╗¼Õ£© `tools/` µ¢ćõ╗ČÕż╣ĶĘ»ÕŠäõĖŗĶ┐śµÅÉõŠøĶ«ĖÕżÜµ£ēńö©ńÜäÕĘźÕģĘŃĆé
+
+### Ķ«Īń«ŚÕÅéµĢ░ķćÅ’╝łparams’╝ēÕÆīĶ«Īń«ŚķćÅ’╝ł FLOPs’╝ē (Ķ»Ģķ¬īµĆ¦)
+
+µłæõ╗¼Õ¤║õ║Ä [flops-counter.pytorch](https://github.com/sovrasov/flops-counter.pytorch)
+µÅÉõŠøõ║åõĖĆõĖ¬ńö©õ║ÄĶ«Īń«Śń╗Öիܵ©ĪÕ×ŗÕÅéµĢ░ķćÅÕÆīĶ«Īń«ŚķćÅńÜäĶäܵ£¼ŃĆé
+
+```shell
+python tools/get_flops.py ${CONFIG_FILE} [--shape ${INPUT_SHAPE}]
+```
+
+µé©Õ░åÕŠŚÕł░Õ”éõĖŗńÜäń╗ōµ×£’╝Ü
+
+```none
+==============================
+Input shape: (3, 2048, 1024)
+Flops: 1429.68 GMac
+Params: 48.98 M
+==============================
+```
+
+**µ│©µäÅ**: Ķ┐ÖõĖ¬ÕĘźÕģĘõ╗Źńäȵś»Ķ»Ģķ¬īµĆ¦ńÜä’╝īµłæõ╗¼µŚĀµ│Ģõ┐ØĶ»üµĢ░ÕŁŚµś»µŁŻńĪ«ńÜäŃĆéµé©ÕÅ»õ╗źµŗ┐Ķ┐Öõ║øń╗ōµ×£ÕüÜń«ĆÕŹĢńÜäÕ«×ķ¬īńÜäÕ»╣ńģ¦’╝īÕ£©ÕåÖµŖƵ£»µ¢ćµĪŻµŖźÕæŖµł¢ĶĆģĶ«║µ¢ćÕēŹµé©ķ£ĆĶ”üÕåŹµ¼ĪńĪ«Ķ«żõĖĆõĖŗŃĆé
+
+(1) Ķ«Īń«ŚķćÅõĖÄĶŠōÕģźńÜäÕĮóńŖȵ£ēÕģ│’╝īĶĆīÕÅéµĢ░ķćÅõĖÄĶŠōÕģźńÜäÕĮóńŖȵŚĀÕģ│’╝īķ╗śĶ«żńÜäĶŠōÕģźÕĮóńŖȵś» (1, 3, 1280, 800)’╝ø
+(2) õĖĆõ║øĶ┐Éń«ŚµōŹõĮ£’╝īÕ”é GN ÕÆīÕģČõ╗¢Õ«ÜÕłČńÜäĶ┐Éń«ŚµōŹõĮ£µ▓Īµ£ēÕŖĀÕģźÕł░Ķ«Īń«ŚķćÅńÜäĶ«Īń«ŚõĖŁŃĆé
+
+### ÕÅæÕĖāµ©ĪÕ×ŗ
+
+Õ£©µé©õĖŖõ╝ĀõĖĆõĖ¬µ©ĪÕ×ŗÕł░õ║æµ£ŹÕŖĪÕÖ©õ╣ŗÕēŹ’╝īµé©ķ£ĆĶ”üÕüÜõ╗źõĖŗÕćĀµŁź’╝Ü
+(1) Õ░嵩ĪÕ×ŗµØāķćŹĶĮ¼µłÉ CPU Õ╝ĀķćÅ’╝ø
+(2) ÕłĀķÖżĶ«░ÕĮĢõ╝śÕī¢ÕÖ©ńŖȵĆü (optimizer states)ńÜäńøĖÕģ│õ┐Īµü»’╝ø
+(3) Ķ«Īń«ŚµŻĆµ¤źńé╣µ¢ćõ╗Č (checkpoint file) ńÜäÕōłÕĖīń╝¢ńĀü’╝łhash id’╝ēÕ╣ČõĖöÕ░åÕōłÕĖīń╝¢ńĀüÕŖĀÕł░µ¢ćõ╗ČÕÉŹõĖŁŃĆé
+
+```shell
+python tools/publish_model.py ${INPUT_FILENAME} ${OUTPUT_FILENAME}
+```
+
+õŠŗÕ”é’╝ī
+
+```shell
+python tools/publish_model.py work_dirs/pspnet/latest.pth psp_r50_hszhao_200ep.pth
+```
+
+µ£Ćń╗łĶŠōÕć║µ¢ćõ╗ČÕ░åµś» `psp_r50_512x1024_40ki_cityscapes-{hash id}.pth`ŃĆé
+
+### Õ»╝Õć║ ONNX (Ķ»Ģķ¬īµĆ¦)
+
+µłæõ╗¼µÅÉõŠøõ║åõĖĆõĖ¬Ķäܵ£¼µØźÕ»╝Õć║µ©ĪÕ×ŗÕł░ [ONNX](https://github.com/onnx/onnx) µĀ╝Õ╝ÅŃĆéĶó½ĶĮ¼µŹóńÜ䵩ĪÕ×ŗÕÅ»õ╗źķĆÜĶ┐ćÕĘźÕģĘ [Netron](https://github.com/lutzroeder/netron)
+µØźÕÅ»Ķ¦åÕī¢ŃĆéķÖżµŁżõ╗źÕż¢’╝īµłæõ╗¼ÕÉīµĀʵö»µīüÕ»╣ PyTorch ÕÆī ONNX µ©ĪÕ×ŗńÜäĶŠōÕć║ń╗ōµ×£ÕüÜÕ»╣µ»öŃĆé
+
+```bash
+python tools/pytorch2onnx.py \
+ ${CONFIG_FILE} \
+ --checkpoint ${CHECKPOINT_FILE} \
+ --output-file ${ONNX_FILE} \
+ --input-img ${INPUT_IMG} \
+ --shape ${INPUT_SHAPE} \
+ --rescale-shape ${RESCALE_SHAPE} \
+ --show \
+ --verify \
+ --dynamic-export \
+ --cfg-options \
+ model.test_cfg.mode="whole"
+```
+
+ÕÉäõĖ¬ÕÅéµĢ░ńÜäµÅÅĶ┐░:
+
+- `config` : µ©ĪÕ×ŗķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠä
+- `--checkpoint` : µ©ĪÕ×ŗµŻĆµ¤źńé╣µ¢ćõ╗ČńÜäĶĘ»ÕŠä
+- `--output-file`: ĶŠōÕć║ńÜä ONNX µ©ĪÕ×ŗńÜäĶĘ»ÕŠäŃĆéÕ”éµ×£µ▓Īµ£ēõĖōķŚ©µīćÕ«Ü’╝īÕ«āķ╗śĶ«żµś» `tmp.onnx`
+- `--input-img` : ńö©µØźĶĮ¼µŹóÕÆīÕÅ»Ķ¦åÕī¢ńÜäõĖĆÕ╝ĀĶŠōÕģźÕøŠÕāÅńÜäĶĘ»ÕŠä
+- `--shape`: µ©ĪÕ×ŗńÜäĶŠōÕģźÕ╝ĀķćÅńÜäķ½śÕÆīÕ«ĮŃĆéÕ”éµ×£µ▓Īµ£ēõĖōķŚ©µīćÕ«Ü’╝īÕ«āÕ░åĶó½Ķ«ŠńĮ«µłÉ `test_pipeline` ńÜä `img_scale`
+- `--rescale-shape`: µö╣ÕÅśĶŠōÕć║ńÜäÕĮóńŖČŃĆéĶ«ŠńĮ«Ķ┐ÖõĖ¬ÕĆ╝µØźķü┐ÕģŹ OOM’╝īÕ«āõ╗ģÕ£© `slide` µ©ĪÕ╝ÅõĖŗÕÅ»õ╗źńö©
+- `--show`: µś»ÕÉ”µēōÕŹ░ĶŠōÕć║µ©ĪÕ×ŗńÜäń╗ōµ×äŃĆéÕ”éµ×£µ▓Īµ£ēĶó½õĖōķŚ©µīćÕ«Ü’╝īÕ«āÕ░åĶó½Ķ«ŠńĮ«µłÉ `False`
+- `--verify`: µś»ÕÉ”ķ¬īĶ»üõĖĆõĖ¬ĶŠōÕć║µ©ĪÕ×ŗńÜ䵣ŻńĪ«µĆ¦ (correctness)ŃĆéÕ”éµ×£µ▓Īµ£ēĶó½õĖōķŚ©µīćÕ«Ü’╝īÕ«āÕ░åĶó½Ķ«ŠńĮ«µłÉ `False`
+- `--dynamic-export`: µś»Õɔջ╝Õć║ÕĮóńŖČÕÅśÕī¢ńÜäĶŠōÕģźõĖÄĶŠōÕć║ńÜä ONNX µ©ĪÕ×ŗŃĆéÕ”éµ×£µ▓Īµ£ēĶó½õĖōķŚ©µīćÕ«Ü’╝īÕ«āÕ░åĶó½Ķ«ŠńĮ«µłÉ `False`
+- `--cfg-options`: µø┤µ¢░ķģŹńĮ«ķĆēķĪ╣
+
+**µ│©µäÅ**: Ķ┐ÖõĖ¬ÕĘźÕģĘõ╗Źńäȵś»Ķ»Ģķ¬īµĆ¦ńÜä’╝īńø«ÕēŹõĖĆõ║øĶć¬Õ«Üõ╣ēµōŹõĮ£Ķ┐śµ▓Īµ£ēĶó½µö»µīü
+
+### Ķ»äõ╝░ ONNX µ©ĪÕ×ŗ
+
+µłæõ╗¼µÅÉõŠø `tools/deploy_test.py` ÕÄ╗Ķ»äõ╝░õĖŹÕÉīÕÉÄń½»ńÜä ONNX µ©ĪÕ×ŗŃĆé
+
+#### ÕģłÕå│µØĪõ╗Č
+
+- Õ«ēĶŻģ onnx ÕÆī onnxruntime-gpu
+
+ ```shell
+ pip install onnx onnxruntime-gpu
+ ```
+
+- ÕÅéĶĆā [Õ”éõĮĢÕ£© MMCV ķćīµ×äÕ╗║ tensorrt µÅÆõ╗Č](https://mmcv.readthedocs.io/en/latest/tensorrt_plugin.html#how-to-build-tensorrt-plugins-in-mmcv) Õ«ēĶŻģTensorRT (ÕÅ»ķĆē)
+
+#### õĮ┐ńö©µ¢╣µ│Ģ
+
+```bash
+python tools/deploy_test.py \
+ ${CONFIG_FILE} \
+ ${MODEL_FILE} \
+ ${BACKEND} \
+ --out ${OUTPUT_FILE} \
+ --eval ${EVALUATION_METRICS} \
+ --show \
+ --show-dir ${SHOW_DIRECTORY} \
+ --cfg-options ${CFG_OPTIONS} \
+ --eval-options ${EVALUATION_OPTIONS} \
+ --opacity ${OPACITY} \
+```
+
+ÕÉäõĖ¬ÕÅéµĢ░ńÜäµÅÅĶ┐░:
+
+- `config`: µ©ĪÕ×ŗķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠä
+- `model`: Ķó½ĶĮ¼µŹóńÜ䵩ĪÕ×ŗµ¢ćõ╗ČńÜäĶĘ»ÕŠä
+- `backend`: µÄ©ńÉåńÜäÕÉÄń½»’╝īÕÅ»ķĆēķĪ╣’╝Ü`onnxruntime`’╝ī `tensorrt`
+- `--out`: ĶŠōÕć║ń╗ōµ×£µłÉ pickle µĀ╝Õ╝ŵ¢ćõ╗ČńÜäĶĘ»ÕŠä
+- `--format-only` : õĖŹĶ»äõ╝░ńø┤µÄźń╗ÖĶŠōÕć║ń╗ōµ×£ńÜäµĀ╝Õ╝ÅŃĆéķĆÜÕĖĖńö©Õ£©ÕĮōµé©µā│µŖŖń╗ōµ×£ĶŠōÕć║µłÉõĖĆõ║øµĄŗĶ»Ģµ£ŹÕŖĪÕÖ©ķ£ĆĶ”üńÜäńē╣իܵĀ╝Õ╝ŵŚČŃĆéÕ”éµ×£µ▓Īµ£ēĶó½õĖōķŚ©µīćÕ«Ü’╝īÕ«āÕ░åĶó½Ķ«ŠńĮ«µłÉ `False`ŃĆé µ│©µäÅĶ┐ÖõĖ¬ÕÅéµĢ░µś»ńö© `--eval` µØź **µēŗÕŖ©µĘ╗ÕŖĀ**
+- `--eval`: Ķ»äõ╝░µīćµĀć’╝īÕÅ¢Õå│õ║ĵ»ÅõĖ¬µĢ░µŹ«ķøåńÜäĶ”üµ▒é’╝īõŠŗÕ”é "mIoU" µś»Õż¦ÕżÜµĢ░µŹ«ķøåńÜäµīćµĀćĶĆī "cityscapes" õ╗ģķÆłÕ»╣ Cityscapes µĢ░µŹ«ķøåŃĆéµ│©µäÅĶ┐ÖõĖ¬ÕÅéµĢ░µś»ńö© `--format-only` µØź **µēŗÕŖ©µĘ╗ÕŖĀ**
+- `--show`: µś»ÕÉ”Õ▒Ģńż║ń╗ōµ×£
+- `--show-dir`: µČéõĖŖń╗ōµ×£ńÜäÕøŠÕāÅĶó½õ┐ØÕŁśńÜäµ¢ćõ╗ČÕż╣ńÜäĶĘ»ÕŠä
+- `--cfg-options`: ķćŹÕåÖķģŹńĮ«µ¢ćõ╗ČķćīńÜäõĖĆõ║øĶ«ŠńĮ«’╝ī`xxx=yyy` µĀ╝Õ╝ÅńÜäķö«ÕĆ╝Õ»╣Õ░åĶó½Ķ”åńø¢Õł░ķģŹńĮ«µ¢ćõ╗Čķćī
+- `--eval-options`: Ķć¬Õ«Üõ╣ēńÜäĶ»äõ╝░ńÜäķĆēķĪ╣’╝ī `xxx=yyy` µĀ╝Õ╝ÅńÜäķö«ÕĆ╝Õ»╣Õ░åµłÉõĖ║ `dataset.evaluate()` ÕćĮµĢ░ńÜäÕÅéµĢ░ÕÅśķćÅ
+- `--opacity`: µČéõĖŖń╗ōµ×£ńÜäÕłåÕē▓ÕøŠńÜäķĆŵśÄÕ║”’╝īĶīāÕø┤Õ£© (0, 1\] õ╣ŗķŚ┤
+
+#### ń╗ōµ×£ÕÆīµ©ĪÕ×ŗ
+
+| µ©ĪÕ×ŗ | ķģŹńĮ«µ¢ćõ╗Č | µĢ░µŹ«ķøå | Ķ»äõ╗ʵīćµĀć | PyTorch | ONNXRuntime | TensorRT-fp32 | TensorRT-fp16 |
+| :--------: | :---------------------------------------------: | :--------: | :------: | :-----: | :---------: | :-----------: | :-----------: |
+| FCN | fcn_r50-d8_512x1024_40k_cityscapes.py | cityscapes | mIoU | 72.2 | 72.2 | 72.2 | 72.2 |
+| PSPNet | pspnet_r50-d8_512x1024_40k_cityscapes.py | cityscapes | mIoU | 77.8 | 77.8 | 77.8 | 77.8 |
+| deeplabv3 | deeplabv3_r50-d8_512x1024_40k_cityscapes.py | cityscapes | mIoU | 79.0 | 79.0 | 79.0 | 79.0 |
+| deeplabv3+ | deeplabv3plus_r50-d8_512x1024_40k_cityscapes.py | cityscapes | mIoU | 79.6 | 79.5 | 79.5 | 79.5 |
+| PSPNet | pspnet_r50-d8_769x769_40k_cityscapes.py | cityscapes | mIoU | 78.2 | 78.1 | | |
+| deeplabv3 | deeplabv3_r50-d8_769x769_40k_cityscapes.py | cityscapes | mIoU | 78.5 | 78.3 | | |
+| deeplabv3+ | deeplabv3plus_r50-d8_769x769_40k_cityscapes.py | cityscapes | mIoU | 78.9 | 78.7 | | |
+
+**µ│©µäÅ**: TensorRT õ╗ģÕ£©õĮ┐ńö© `whole mode` µĄŗĶ»Ģµ©ĪÕ╝ŵŚČńÜäķģŹńĮ«µ¢ćõ╗ČķćīÕÅ»ńö©ŃĆé
+
+### Õ»╝Õć║ TorchScript (Ķ»Ģķ¬īµĆ¦)
+
+µłæõ╗¼ÕÉīµĀʵÅÉõŠøõĖĆõĖ¬Ķäܵ£¼ÕÄ╗µŖŖµ©ĪÕ×ŗÕ»╝Õć║µłÉ [TorchScript](https://pytorch.org/docs/stable/jit.html) µĀ╝Õ╝ÅŃĆéµé©ÕÅ»õ╗źõĮ┐ńö© pytorch C++ API [LibTorch](https://pytorch.org/docs/stable/cpp_index.html) ÕÄ╗µÄ©ńÉåĶ«Łń╗āÕźĮńÜ䵩ĪÕ×ŗŃĆé
+Ķó½ĶĮ¼µŹóńÜ䵩ĪÕ×ŗĶāĮĶó½ÕāÅ [Netron](https://github.com/lutzroeder/netron) ńÜäÕĘźÕģĘµØźÕÅ»Ķ¦åÕī¢ŃĆ鵣żÕż¢’╝īµłæõ╗¼Ķ┐śµö»µīü PyTorch ÕÆī TorchScript µ©ĪÕ×ŗńÜäĶŠōÕć║ń╗ōµ×£ńÜäµ»öĶŠāŃĆé
+
+```shell
+python tools/pytorch2torchscript.py \
+ ${CONFIG_FILE} \
+ --checkpoint ${CHECKPOINT_FILE} \
+ --output-file ${ONNX_FILE}
+ --shape ${INPUT_SHAPE}
+ --verify \
+ --show
+```
+
+ÕÉäõĖ¬ÕÅéµĢ░ńÜäµÅÅĶ┐░:
+
+- `config` : pytorch µ©ĪÕ×ŗńÜäķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠä
+- `--checkpoint` : pytorch µ©ĪÕ×ŗńÜ䵯Ƶ¤źńé╣µ¢ćõ╗ČńÜäĶĘ»ÕŠä
+- `--output-file`: TorchScript µ©ĪÕ×ŗĶŠōÕć║ńÜäĶĘ»ÕŠä’╝īÕ”éµ×£µ▓Īµ£ēĶó½õĖōķŚ©µīćÕ«Ü’╝īÕ«āÕ░åĶó½Ķ«ŠńĮ«µłÉ `tmp.pt`
+- `--input-img` : ńö©µØźĶĮ¼µŹóÕÆīÕÅ»Ķ¦åÕī¢ńÜäĶŠōÕģźÕøŠÕāÅńÜäĶĘ»ÕŠä
+- `--shape`: µ©ĪÕ×ŗńÜäĶŠōÕģźÕ╝ĀķćÅńÜäÕ«ĮÕÆīķ½śŃĆéÕ”éµ×£µ▓Īµ£ēĶó½õĖōķŚ©µīćÕ«Ü’╝īÕ«āÕ░åĶó½Ķ«ŠńĮ«µłÉ `512 512`
+- `--show`: µś»ÕÉ”µēōÕŹ░ĶŠōÕć║µ©ĪÕ×ŗńÜäĶ┐ĮĶĖ¬ÕøŠ (traced graph)’╝īÕ”éµ×£µ▓Īµ£ēĶó½õĖōķŚ©µīćÕ«Ü’╝īÕ«āÕ░åĶó½Ķ«ŠńĮ«µłÉ `False`
+- `--verify`: µś»ÕÉ”ķ¬īĶ»üõĖĆõĖ¬ĶŠōÕć║µ©ĪÕ×ŗńÜ䵣ŻńĪ«µĆ¦ (correctness)’╝īÕ”éµ×£µ▓Īµ£ēĶó½õĖōķŚ©µīćÕ«Ü’╝īÕ«āÕ░åĶó½Ķ«ŠńĮ«µłÉ `False`
+
+**µ│©µäÅ**: ńø«ÕēŹõ╗ģµö»µīü PyTorch>=1.8.0 ńēłµ£¼
+
+**µ│©µäÅ**: Ķ┐ÖõĖ¬ÕĘźÕģĘõ╗Źńäȵś»Ķ»Ģķ¬īµĆ¦ńÜä’╝īõĖĆõ║øĶć¬Õ«Üõ╣ēµōŹõĮ£ń¼”ńø«ÕēŹĶ┐śõĖŹĶó½µö»µīü
+
+õŠŗÕŁÉ:
+
+- Õ»╝Õć║ PSPNet Õ£© cityscapes µĢ░µŹ«ķøåõĖŖńÜä pytorch µ©ĪÕ×ŗ
+
+ ```shell
+ python tools/pytorch2torchscript.py configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py \
+ --checkpoint checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth \
+ --output-file checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pt \
+ --shape 512 1024
+ ```
+
+### Õ»╝Õć║ TensorRT (Ķ»Ģķ¬īµĆ¦)
+
+õĖĆõĖ¬Õ»╝Õć║ [ONNX](https://github.com/onnx/onnx) µ©ĪÕ×ŗµłÉ [TensorRT](https://developer.nvidia.com/tensorrt) µĀ╝Õ╝ÅńÜäĶäܵ£¼
+
+ÕģłÕå│µØĪõ╗Č
+
+- µīēńģ¦ [ONNXRuntime in mmcv](https://mmcv.readthedocs.io/en/latest/deployment/onnxruntime_op.html) ÕÆī [TensorRT plugin in mmcv](https://github.com/open-mmlab/mmcv/blob/master/docs/en/deployment/tensorrt_plugin.md) ’╝īńö© ONNXRuntime Ķć¬Õ«Üõ╣ēĶ┐Éń«Ś (custom ops) ÕÆī TensorRT µÅÆõ╗ČÕ«ēĶŻģ `mmcv-full`
+- õĮ┐ńö© [pytorch2onnx](#convert-to-onnx-experimental) Õ░嵩ĪÕ×ŗõ╗Ä PyTorch ĶĮ¼µłÉ ONNX
+
+õĮ┐ńö©µ¢╣µ│Ģ
+
+```bash
+python ${MMSEG_PATH}/tools/onnx2tensorrt.py \
+ ${CFG_PATH} \
+ ${ONNX_PATH} \
+ --trt-file ${OUTPUT_TRT_PATH} \
+ --min-shape ${MIN_SHAPE} \
+ --max-shape ${MAX_SHAPE} \
+ --input-img ${INPUT_IMG} \
+ --show \
+ --verify
+```
+
+ÕÉäõĖ¬ÕÅéµĢ░ńÜäµÅÅĶ┐░:
+
+- `config` : µ©ĪÕ×ŗńÜäķģŹńĮ«µ¢ćõ╗Č
+- `model` : ĶŠōÕģźńÜä ONNX µ©ĪÕ×ŗńÜäĶĘ»ÕŠä
+- `--trt-file` : ĶŠōÕć║ńÜä TensorRT Õ╝ĢµōÄńÜäĶĘ»ÕŠä
+- `--max-shape` : µ©ĪÕ×ŗńÜäĶŠōÕģźńÜäµ£ĆÕż¦ÕĮóńŖČ
+- `--min-shape` : µ©ĪÕ×ŗńÜäĶŠōÕģźńÜäµ£ĆÕ░ÅÕĮóńŖČ
+- `--fp16` : ÕüÜ fp16 µ©ĪÕ×ŗĶĮ¼µŹó
+- `--workspace-size` : Õ£© GiB ķćīńÜäµ£ĆÕż¦ÕĘźõĮ£ń®║ķŚ┤Õż¦Õ░Å (Max workspace size)
+- `--input-img` : ńö©µØźÕÅ»Ķ¦åÕī¢ńÜäÕøŠÕāÅ
+- `--show` : ÕüÜń╗ōµ×£ńÜäÕÅ»Ķ¦åÕī¢
+- `--dataset` : Palette provider, ķ╗śĶ«żõĖ║ `CityscapesDataset`
+- `--verify` : ķ¬īĶ»ü ONNXRuntime ÕÆī TensorRT ńÜäĶŠōÕć║
+- `--verbose` : ÕĮōÕłøÕ╗║ TensorRT Õ╝ĢµōĵŚČ’╝īµś»ÕÉ”Ķ»”ń╗åÕüÜõ┐Īµü»µŚźÕ┐ŚŃĆéķ╗śĶ«żõĖ║ False
+
+**µ│©µäÅ**: õ╗ģÕ£©Õģ©ÕøŠµĄŗĶ»Ģµ©ĪÕ╝Å (whole mode) õĖŗµĄŗĶ»ĢĶ┐ć
+
+## ÕģČõ╗¢ÕåģÕ«╣
+
+### µēōÕŹ░Õ«īµĢ┤ńÜäķģŹńĮ«µ¢ćõ╗Č
+
+`tools/print_config.py` õ╝ÜķĆÉÕŁŚķĆÉÕÅźńÜäµēōÕŹ░µĢ┤õĖ¬ķģŹńĮ«µ¢ćõ╗Č’╝īÕ▒ĢÕ╝ƵēƵ£ēńÜäÕ»╝ÕģźŃĆé
+
+```shell
+python tools/print_config.py \
+ ${CONFIG} \
+ --graph \
+ --cfg-options ${OPTIONS [OPTIONS...]} \
+```
+
+ÕÉäõĖ¬ÕÅéµĢ░ńÜäµÅÅĶ┐░:
+
+- `config` : pytorch µ©ĪÕ×ŗńÜäķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠä
+- `--graph` : µś»ÕÉ”µēōÕŹ░µ©ĪÕ×ŗńÜäÕøŠ (models graph)
+- `--cfg-options`: Ķć¬Õ«Üõ╣ēµø┐µŹóķģŹńĮ«µ¢ćõ╗ČńÜäķĆēķĪ╣
+
+### Õ»╣Ķ«Łń╗āµŚźÕ┐Ś (training logs) ńö╗ÕøŠ
+
+`tools/analyze_logs.py` õ╝Üńö╗Õć║ń╗ÖÕ«ÜńÜäĶ«Łń╗āµŚźÕ┐Śµ¢ćõ╗ČńÜä loss/mIoU µø▓ń║┐’╝īķ”¢Õģłķ£ĆĶ”ü `pip install seaborn` Õ«ēĶŻģõŠØĶĄ¢ÕīģŃĆé
+
+```shell
+python tools/analyze_logs.py xxx.log.json [--keys ${KEYS}] [--legend ${LEGEND}] [--backend ${BACKEND}] [--style ${STYLE}] [--out ${OUT_FILE}]
+```
+
+ńż║õŠŗ:
+
+- Õ»╣ mIoU, mAcc, aAcc µīćµĀćńö╗ÕøŠ
+
+ ```shell
+ python tools/analyze_logs.py log.json --keys mIoU mAcc aAcc --legend mIoU mAcc aAcc
+ ```
+
+- Õ»╣ loss µīćµĀćńö╗ÕøŠ
+
+ ```shell
+ python tools/analyze_logs.py log.json --keys loss --legend loss
+ ```
+
+### ĶĮ¼µŹóÕģČõ╗¢õ╗ōÕ║ōńÜäµØāķćŹ
+
+`tools/model_converters/` µÅÉõŠøõ║åĶŗźÕ╣▓õĖ¬ķóäĶ«Łń╗āµØāķćŹĶĮ¼µŹóĶäܵ£¼’╝īµö»µīüÕ░åÕģČõ╗¢õ╗ōÕ║ōńÜäķóäĶ«Łń╗āµØāķćŹńÜä key ĶĮ¼µŹóõĖ║õĖÄ MMSegmentation ńøĖÕī╣ķģŹńÜä keyŃĆé
+
+#### ViT Swin MiT Transformer µ©ĪÕ×ŗ
+
+- ViT
+
+`tools/model_converters/vit2mmseg.py` Õ░å timm ķóäĶ«Łń╗āµ©ĪÕ×ŗĶĮ¼µŹóÕł░ MMSegmentationŃĆé
+
+```shell
+python tools/model_converters/vit2mmseg.py ${SRC} ${DST}
+```
+
+- Swin
+
+ `tools/model_converters/swin2mmseg.py` Õ░åÕ«śµ¢╣ķóäĶ«Łń╗āµ©ĪÕ×ŗĶĮ¼µŹóÕł░ MMSegmentationŃĆé
+
+ ```shell
+ python tools/model_converters/swin2mmseg.py ${SRC} ${DST}
+ ```
+
+- SegFormer
+
+ `tools/model_converters/mit2mmseg.py` Õ░åÕ«śµ¢╣ķóäĶ«Łń╗āµ©ĪÕ×ŗĶĮ¼µŹóÕł░ MMSegmentationŃĆé
+
+ ```shell
+ python tools/model_converters/mit2mmseg.py ${SRC} ${DST}
+ ```
+
+## µ©ĪÕ×ŗµ£ŹÕŖĪ
+
+õĖ║õ║åńö© [`TorchServe`](https://pytorch.org/serve/) µ£ŹÕŖĪ `MMSegmentation` ńÜ䵩ĪÕ×ŗ ’╝ī µé©ÕÅ»õ╗źķüĄÕŠ¬Õ”éõĖŗµĄüń©ŗ:
+
+### 1. Õ░å model õ╗ÄŃĆĆMMSegmentation ĶĮ¼µŹóÕł░ TorchServe
+
+```shell
+python tools/mmseg2torchserve.py ${CONFIG_FILE} ${CHECKPOINT_FILE} \
+--output-folder ${MODEL_STORE} \
+--model-name ${MODEL_NAME}
+```
+
+**µ│©µäÅ**: ${MODEL_STORE} ķ£ĆĶ”üĶ«ŠńĮ«õĖ║µ¤ÉõĖ¬µ¢ćõ╗ČÕż╣ńÜäń╗ØÕ»╣ĶĘ»ÕŠä
+
+### 2. µ×äÕ╗║ `mmseg-serve` Õ«╣ÕÖ©ķĢ£ÕāÅ (docker image)
+
+```shell
+docker build -t mmseg-serve:latest docker/serve/
+```
+
+### 3. Ķ┐ÉĶĪī `mmseg-serve`
+
+Ķ»Ęµ¤źķśģÕ«śµ¢╣µ¢ćµĪŻ: [õĮ┐ńö©Õ«╣ÕÖ©Ķ┐ÉĶĪī TorchServe](https://github.com/pytorch/serve/blob/master/docker/README.md#running-torchserve-in-a-production-docker-environment)
+
+õĖ║õ║åÕ£© GPU ńÄ»ÕóāõĖŗõĮ┐ńö©, µé©ķ£ĆĶ”üÕ«ēĶŻģ [nvidia-docker](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html). ĶŗźÕ£© CPU ńÄ»ÕóāõĖŗõĮ┐ńö©’╝īµé©ÕÅ»õ╗źÕ┐ĮńĢźµĘ╗ÕŖĀ `--gpus` ÕÅéµĢ░ŃĆé
+
+ńż║õŠŗ:
+
+```shell
+docker run --rm \
+--cpus 8 \
+--gpus device=0 \
+-p8080:8080 -p8081:8081 -p8082:8082 \
+--mount type=bind,source=$MODEL_STORE,target=/home/model-server/model-store \
+mmseg-serve:latest
+```
+
+ķśģĶ»╗Õģ│õ║ĵĩńÉå (8080), ń«ĪńÉå (8081) ÕÆīµīćµĀć (8082) APIs ńÜä [µ¢ćµĪŻ](https://github.com/pytorch/serve/blob/072f5d088cce9bb64b2a18af065886c9b01b317b/docs/rest_api.md) ŃĆé
+
+### 4. µĄŗĶ»Ģķā©ńĮ▓
+
+```shell
+curl -O https://raw.githubusercontent.com/open-mmlab/mmsegmentation/master/resources/3dogs.jpg
+curl http://127.0.0.1:8080/predictions/${MODEL_NAME} -T 3dogs.jpg -o 3dogs_mask.png
+```
+
+ÕŠŚÕł░ńÜäÕōŹÕ║öÕ░åµś»õĖĆõĖ¬ ".png" ńÜäÕłåÕē▓µÄ®ńĀü.
+
+µé©ÕÅ»õ╗źµīēńģ¦Õ”éõĖŗµ¢╣µ│ĢÕÅ»Ķ¦åÕī¢ĶŠōÕć║:
+
+```python
+import matplotlib.pyplot as plt
+import mmcv
+plt.imshow(mmcv.imread("3dogs_mask.png", "grayscale"))
+plt.show()
+```
+
+ń£ŗÕł░ńÜäõĖ£Ķź┐Õ░åõ╝ÜÕÆīõĖŗÕøŠń▒╗õ╝╝:
+
+
+
+ńäČÕÉĵé©ÕÅ»õ╗źõĮ┐ńö© `test_torchserve.py` µ»öĶŠā torchserve ÕÆī pytorch ńÜäń╗ōµ×£’╝īÕ╣ČÕ░åÕ«āõ╗¼ÕÅ»Ķ¦åÕī¢ŃĆé
+
+```shell
+python tools/torchserve/test_torchserve.py ${IMAGE_FILE} ${CONFIG_FILE} ${CHECKPOINT_FILE} ${MODEL_NAME}
+[--inference-addr ${INFERENCE_ADDR}] [--result-image ${RESULT_IMAGE}] [--device ${DEVICE}]
+```
+
+ńż║õŠŗ’╝Ü
+
+```shell
+python tools/torchserve/test_torchserve.py \
+demo/demo.png \
+configs/fcn/fcn_r50-d8_512x1024_40k_cityscapes.py \
+checkpoint/fcn_r50-d8_512x1024_40k_cityscapes_20200604_192608-efe53f0d.pth \
+fcn
+```
diff --git a/internlm_langchain/knowledge_base/MMSegmentation/content/visualization.md b/internlm_langchain/knowledge_base/MMSegmentation/content/visualization.md
new file mode 100644
index 00000000..2ef020ba
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMSegmentation/content/visualization.md
@@ -0,0 +1,173 @@
+# ÕÅ»Ķ¦åÕī¢
+
+MMSegmentation 1.x µÅÉõŠøõ║åń«ĆõŠ┐ńÜäµ¢╣Õ╝ÅńøæµÄ¦Ķ«Łń╗āµŚČńÜäńŖȵĆüõ╗źÕÅŖÕÅ»Ķ¦åÕī¢Õ£©µ©ĪÕ×ŗķó䵥ŗµŚČńÜäµĢ░µŹ«ŃĆé
+
+## Ķ«Łń╗āńŖȵĆüńøæµÄ¦
+
+MMSegmentation 1.x õĮ┐ńö© TensorBoard µØźńøæµÄ¦Ķ«Łń╗āµŚČÕĆÖńÜäńŖȵĆüŃĆé
+
+### TensorBoard ńÜäķģŹńĮ«
+
+Õ«ēĶŻģ TensorBoard ńÜäĶ┐ćń©ŗÕÅ»õ╗źµīēńģ¦ [Õ«śµ¢╣Õ«ēĶŻģµīćÕŹŚ](https://www.tensorflow.org/install) ’╝īÕģĘõĮōńÜ䵣źķ¬żÕ”éõĖŗ’╝Ü
+
+```shell
+pip install tensorboardX
+pip install future tensorboard
+```
+
+Õ£©ķģŹńĮ«µ¢ćõ╗Č `default_runtime.py` ńÜä `vis_backend` õĖŁµĘ╗ÕŖĀ `TensorboardVisBackend`ŃĆé
+
+```python
+vis_backends = [dict(type='LocalVisBackend'),
+ dict(type='TensorboardVisBackend')]
+visualizer = dict(
+ type='SegLocalVisualizer', vis_backends=vis_backends, name='visualizer')
+```
+
+### µŻĆµ¤ź TensorBoard õĖŁńÜäµĀćķćÅ
+
+ÕÉ»ÕŖ©Ķ«Łń╗āÕ«×ķ¬īńÜäÕæĮõ╗żÕ”éõĖŗ
+
+```shell
+python tools/train.py configs/pspnet/pspnet_r50-d8_4xb4-80k_ade20k-512x512.py --work-dir work_dir/test_visual
+```
+
+Õ╝ĆÕ¦ŗĶ«Łń╗āÕÉĵēŠÕł░ `work_dir` õĖŁńÜä `vis_data` ĶĘ»ÕŠä’╝īõŠŗÕ”é’╝ܵ£¼µ¼Īńē╣իܵĄŗĶ»ĢńÜä vis_data ĶĘ»ÕŠäÕ”éõĖŗµēĆńż║’╝Ü
+
+```shell
+work_dirs/test_visual/20220810_115248/vis_data
+```
+
+vis_data ĶĘ»ÕŠäõĖŁńÜäµĀćķćŵ¢ćõ╗ČÕīģµŗ¼õ║åÕŁ”õ╣ĀńÄćŃĆüµŹ¤Õż▒ÕćĮµĢ░ÕÆī data_time ńŁē’╝īĶ┐śĶ«░ÕĮĢõ║åµīćµĀćń╗ōµ×£’╝īµé©ÕÅ»õ╗źÕÅéĶĆā MMEngine õĖŁńÜä [Ķ«░ÕĮĢµŚźÕ┐ŚµĢÖń©ŗ](https://mmengine.readthedocs.io/zh_CN/latest/advanced_tutorials/logging.html) õĖŁńÜ䵌źÕ┐ŚµĢÖń©ŗµØźÕĖ«ÕŖ®Ķ«░ÕĮĢĶć¬ÕĘ▒Õ«Üõ╣ēńÜäµĢ░µŹ«ŃĆé Tensorboard ńÜäÕÅ»Ķ¦åÕī¢ń╗ōµ×£õĮ┐ńö©õĖŗķØóńÜäÕæĮõ╗żµē¦ĶĪī’╝Ü
+
+```shell
+tensorboard --logdir work_dirs/test_visual/20220810_115248/vis_data
+```
+
+## µĢ░µŹ«ÕÆīń╗ōµ×£ńÜäÕÅ»Ķ¦åÕī¢
+
+### µ©ĪÕ×ŗµĄŗĶ»Ģµł¢ķ¬īĶ»üµ£¤ķŚ┤ńÜäÕÅ»Ķ¦åÕī¢µĢ░µŹ«µĀʵ£¼
+
+MMSegmentation µÅÉõŠøõ║å `SegVisualizationHook` ’╝īÕ«āµś»õĖĆõĖ¬ÕÅ»õ╗źńö©õ║ÄÕÅ»Ķ¦åÕī¢ ground truth ÕÆīÕ£©µ©ĪÕ×ŗµĄŗĶ»ĢÕÆīķ¬īĶ»üµ£¤ķŚ┤ńÜäķó䵥ŗÕłåÕē▓ń╗ōµ×£ńÜä[ķÆ®ÕŁÉ](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/hook.html) ŃĆé Õ«āńÜäķģŹńĮ«Õ£© `default_hooks` õĖŁ’╝īµø┤ÕżÜĶ»”ń╗åõ┐Īµü»Ķ»ĘÕÅéĶ¦ü [µē¦ĶĪīÕÖ©µĢÖń©ŗ](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/runner.html)ŃĆé
+
+õŠŗÕ”é’╝īÕ£© `_base_/schedules/schedule_20k.py` õĖŁ’╝īõ┐«µö╣ `SegVisualizationHook` ķģŹńĮ«’╝īÕ░å `draw` Ķ«ŠńĮ«õĖ║ `True` õ╗źÕÉ»ńö©ńĮæń╗£µÄ©ńÉåń╗ōµ×£ńÜäÕŁśÕé©’╝ī`interval` ĶĪ©ńż║ķó䵥ŗń╗ōµ×£ńÜäķććµĀĘķŚ┤ķÜö’╝ī Ķ«ŠńĮ«õĖ║ 1 µŚČ’╝īÕ░åõ┐ØÕŁśńĮæń╗£ńÜäµ»ÅõĖ¬µÄ©ńÉåń╗ōµ×£ŃĆé `interval` ķ╗śĶ«żĶ«ŠńĮ«õĖ║ 50’╝Ü
+
+```python
+default_hooks = dict(
+ timer=dict(type='IterTimerHook'),
+ logger=dict(type='LoggerHook', interval=50, log_metric_by_epoch=False),
+ param_scheduler=dict(type='ParamSchedulerHook'),
+ checkpoint=dict(type='CheckpointHook', by_epoch=False, interval=2000),
+ sampler_seed=dict(type='DistSamplerSeedHook'),
+ visualization=dict(type='SegVisualizationHook', draw=True, interval=1))
+
+```
+
+ÕÉ»ÕŖ©Ķ«Łń╗āÕ«×ķ¬īÕÉÄ’╝īÕÅ»Ķ¦åÕī¢ń╗ōµ×£Õ░åÕ£© validation loop ÕŁśÕé©Õł░µ£¼Õ£░µ¢ćõ╗ČÕż╣õĖŁ’╝īµł¢ĶĆģÕ£©õĖĆõĖ¬µĢ░µŹ«ķøåõĖŖÕÉ»ÕŖ©Ķ»äõ╝░µ©ĪÕ×ŗµŚČ’╝īķó䵥ŗń╗ōµ×£Õ░åÕŁśÕé©Õ£©µ£¼Õ£░ŃĆéµ£¼Õ£░ńÜäÕÅ»Ķ¦åÕī¢ńÜäÕŁśÕé©ń╗ōµ×£õ┐ØÕŁśÕ£© `$WORK_DIRS/vis_data` õĖŗńÜä `vis_image` õĖŁ’╝īõŠŗÕ”é’╝Ü
+
+```shell
+work_dirs/test_visual/20220810_115248/vis_data/vis_image
+```
+
+ÕÅ”Õż¢’╝īÕ”éµ×£Õ£© `vis_backends` õĖŁµĘ╗ÕŖĀ `TensorboardVisBackend` ’╝īÕ”é [TensorBoard ńÜäķģŹńĮ«](###TensorBoardńÜäķģŹńĮ«)’╝īµłæõ╗¼Ķ┐śÕÅ»õ╗źĶ┐ÉĶĪīõĖŗķØóńÜäÕæĮõ╗żÕ£© TensorBoard õĖŁµ¤źń£ŗÕ«āõ╗¼’╝Ü
+
+```shell
+tensorboard --logdir work_dirs/test_visual/20220810_115248/vis_data
+```
+
+### ÕÅ»Ķ¦åÕī¢ÕŹĢõĖ¬µĢ░µŹ«µĀʵ£¼
+
+Õ”éµ×£õĮĀµā│ÕÅ»Ķ¦åÕī¢ÕŹĢõĖ¬µĀʵ£¼µĢ░µŹ«’╝īµłæõ╗¼Õ╗║Ķ««õĮ┐ńö© `SegLocalVisualizer` ŃĆé
+
+`SegLocalVisualizer`µś»ń╗¦µē┐Ķć¬ MMEngine õĖŁ`Visualizer` ń▒╗ńÜäÕŁÉń▒╗’╝īķĆéńö©õ║Ä MMSegmentation ÕÅ»Ķ¦åÕī¢’╝īµ£ēÕģ│`Visualizer`ńÜäĶ»”ń╗åõ┐Īµü»Ķ»ĘÕÅéĶĆāÕ£© MMEngine õĖŁńÜä[ÕÅ»Ķ¦åÕī¢µĢÖń©ŗ](https://mmengine.readthedocs.io/zh_CN/latest/advanced_tutorials/visualization.html) ŃĆé
+
+õ╗źõĖŗµś»õĖĆõĖ¬Õģ│õ║Ä `SegLocalVisualizer` ńÜäńż║õŠŗ’╝īķ”¢ÕģłõĮĀÕÅ»õ╗źõĮ┐ńö©õĖŗķØóńÜäÕæĮõ╗żõĖŗĶĮĮĶ┐ÖõĖ¬µĪłõŠŗõĖŁńÜäµĢ░µŹ«’╝Ü
+
+
+ dataset:
+ type:
+ data_path: ./data
+ #more arguments for processor function...
+
+argparse_cfg:
+ data:
+ bind_to: processor_cfg.dataset.data_path
+ help: the path of data
+ #more option arguments for command line...
+```
+
+The `processor_cfg` specifies a processor function and its dataset module
+In adittion, the `data_path` argument of the dataset is "./data".
+The `argparse_cfg` create a option argument `data` which is bound to `data_path`.
+
+Note that, mmskeleton will import processor function or modules according to the given path by the priority of `local directory > system python path > mmskeleton`.
+
+
+
+With this configuration, the application can be started by:
+```shell
+mmskl $CONFIG_FILE [--data $DATA_PATH]
+```
+
+
+
+
+
diff --git a/internlm_langchain/knowledge_base/MMSkeleton/content/CUSTOM_DATASET.md b/internlm_langchain/knowledge_base/MMSkeleton/content/CUSTOM_DATASET.md
new file mode 100644
index 00000000..ab3f2363
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMSkeleton/content/CUSTOM_DATASET.md
@@ -0,0 +1,99 @@
+## Custom Skeleton-based Dataset
+mmskeleton accepts two formats of skeleton data, `.npy` and `.json`.
+We recommend users to store their dataset as `.json` files.
+Please follow the below example to build a custom dataset.
+
+### Build dataset from videos
+
+We have prepared a mini video set including three 10-seconds clips in the `resource/data_example` with the structure:
+
+ resource/dataset_example
+ Ōö£ŌöĆŌöĆ skateboarding.mp4
+ Ōö£ŌöĆŌöĆ clean_and_jerk.mp4
+ ŌööŌöĆŌöĆ ta_chi.mp4
+
+
+Run this command for building skeleton-based dataset for them:
+```
+mmskl configs/utils/build_dataset_example.yaml [--gpus $GPUS]
+```
+mmskeleton extracts skeleton sequences for each video via performing **person detection** and **pose estimation** on all frames.
+A few `.json` files will be stored under `data/dataset_example` if you did not change default arguments. The directory layout is shown here:
+
+ data/dataset_example
+ Ōö£ŌöĆŌöĆ skateboarding.json
+ Ōö£ŌöĆŌöĆ clean_and_jerk.json
+ ŌööŌöĆŌöĆ ta_chi.json
+
+All annotations share the same basic data structure like below:
+```javascript
+{
+ "info":
+ {
+ "video_name": "skateboarding.mp4",
+ "resolution": [340, 256],
+ "num_frame": 300,
+ "num_keypoints": 17,
+ "keypoint_channels": ["x", "y", "score"],
+ "version": "1.0"
+ },
+ "annotations":
+ [
+ {
+ "frame_index": 0,
+ "id": 0,
+ "person_id": null,
+ "keypoints": [[x, y, score], [x, y, score], ...]
+ },
+ ...
+ ],
+ "category_id": 0,
+}
+```
+
+After that, train the st-gcn model by:
+```
+mmskl configs/recognition/st_gcn/dataset_example/train.yaml
+```
+and test the model by:
+```
+mmskl configs/recognition/st_gcn/dataset_example/test.yaml --checkpoint $CHECKPOINT_PATH
+```
+
+### Build your own dataset
+
+If you want to use mmskeleton on your own **skeleton-based data**, the simplest method is reformatting
+your data format to `.json` files with the basic structure we mentioned above.
+Or you can design another data feeder to replace [our data feeder](../mmskeleton/datasets/recognition.py),
+and specify it by changing `processor_cfg.dataset_cfg.name` in your training configuration file.
+
+If you want to use mmskeleton on your own **video dataset**,
+just follow the above tutorial to build the skeleton-based dataset for videos.
+Note that, in the above example, the groundtruth of `category_id` is from [another annotation file](../resource/category_annotation_example.json) with the structure:
+```javascript
+{
+ "categories": [
+ "skateboarding",
+ "clean_and_jerk",
+ "ta_chi"
+ ],
+ "annotations": {
+ "clean_and_jerk.mp4": {
+ "category_id": 1
+ },
+ "skateboarding.mp4": {
+ "category_id": 0
+ },
+ "ta_chi.mp4": {
+ "category_id": 2
+ }
+ }
+}
+```
+The `category_id` will be set to `-1` if the category annotations miss.
+
+You can build dataset by:
+```
+mmskl configs/utils/build_dataset_example.yaml --video_dir $VIDEO_DIR --category_annotation $VIDEO_ANNOTATION --out_dir $OUT_DIR [--gpus $GPUS]
+```
+To change the person detector, pose estimator or other arguments, modify the `build_dataset_example.yaml`.
diff --git a/internlm_langchain/knowledge_base/MMSkeleton/content/GETTING_STARTED.md b/internlm_langchain/knowledge_base/MMSkeleton/content/GETTING_STARTED.md
new file mode 100644
index 00000000..6e9248af
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMSkeleton/content/GETTING_STARTED.md
@@ -0,0 +1,87 @@
+## Getting Started
+
+### Installation
+
+a. [Optional] Create a [conda](www.anaconda.com/distribution/) virtual environment and activate it:
+
+``` shell
+conda create -n open-mmlab python=3.7 -y
+conda activate open-mmlab
+```
+
+b. Install PyTorch and torchvision (CUDA is required):
+``` shell
+# CUDA 9.2
+conda install pytorch==1.2.0 torchvision==0.4.0 cudatoolkit=9.2 -c pytorch
+
+# CUDA 10.0
+conda install pytorch==1.2.0 torchvision==0.4.0 cudatoolkit=10.0 -c pytorch
+```
+The higher versions are not covered by tests.
+
+c. Clone mmskeleton from github:
+
+``` shell
+git clone https://github.com/open-mmlab/mmskeleton.git
+cd mmskeleton
+```
+
+d. Install mmskeleton:
+
+``` shell
+python setup.py develop
+```
+
+e. Install nms for person estimation:
+``` shell
+cd mmskeleton/ops/nms/
+python setup_linux.py develop
+cd ../../../
+```
+
+f. [Optional] Install mmdetection for person detection:
+
+``` shell
+python setup.py develop --mmdet
+```
+In the event of a failure installation, please install [mmdetection](https://github.com/open-mmlab/mmdetection/blob/master/docs/INSTALL.md) manually.
+
+g. To verify that mmskeleton and mmdetection installed correctly, use:
+```shell
+python mmskl.py pose_demo [--gpus $GPUS]
+# or "python mmskl.py pose_demo_HD [--gpus $GPUS]" for a higher accuracy
+```
+An generated video as below will be saved under the prompted path.
+
+
+```
+
+#### NTU RGB+D
+NTU RGB+D can be downloaded from [their website](http://rose1.ntu.edu.sg/datasets/actionrecognition.asp).
+Only the **3D skeletons**(5.8GB) modality is required in our experiments. After that, this command should be used to build the database for training or evaluation on mmskeleton:
+```
+python deprecated/tools/data_processing/ntu_gendata.py --data_path
+```
+where the `````` is the directory path of 3D skeletons annotations of the NTU RGB+D dataset you download.
diff --git a/internlm_langchain/knowledge_base/MMSkeleton/content/START_POSE_ESTIMATION.md b/internlm_langchain/knowledge_base/MMSkeleton/content/START_POSE_ESTIMATION.md
new file mode 100644
index 00000000..bbf16eec
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMSkeleton/content/START_POSE_ESTIMATION.md
@@ -0,0 +1,64 @@
+## Start Pose Estimation
+
+We provide a demo for video-based pose estimation:
+```shell
+mmskl pose_demo [--video $VIDEO_PATH] [--gpus $GPUS] [--$MORE_OPTIONS]
+```
+This demo predict pose sequences via sequentially feeding frames into the image-based human detector and the pose estimator. By default, they are **cascade-rcnn** [1] and **hrnet** [2] respectively.
+We test our demo on 8 gpus of TITAN X and get a realtime speed (27.1fps). To check the full usage, please run `mmskl pose_demo -h`. You can also refer to [pose_demo.yaml](../configs/pose_estimation/hrnet/pose_demo.yaml) for detailed configurations.
+
+We also provide another demo `pose_demo_HD` with a slower but more powerful detector **htc** [3]. Similarly, run:
+```shell
+mmskl pose_demo_HD [--video $VIDEO_PATH] [--gpus $GPUS] [--$MORE_OPTIONS]
+```
+
+
+### High-level APIs for testing images
+
+Here is an example of building the pose estimator and test given images.
+```python
+import mmcv
+from mmskeleton.apis import init_pose_estimator, inference_pose_estimator
+
+cfg = mmcv.Config.fromfile('configs/apis/pose_estimator.cascade_rcnn+hrnet.yaml')
+video = mmcv.VideoReader('resource/data_example/skateboarding.mp4')
+
+model = init_pose_estimator(**cfg, device=0)
+for i, frame in enumerate(video):
+ result = inference_pose_estimator(model, frame)
+ print('Process the frame {}'.format(i))
+
+ # process the result here
+
+```
+
+### Training and Test a Pose Estimator
+Comming soon...
+
+
+
+### Reference
+```
+@inproceedings{cai2018cascade,
+ title={Cascade r-cnn: Delving into high quality object detection},
+ author={Cai, Zhaowei and Vasconcelos, Nuno},
+ booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
+ pages={6154--6162},
+ year={2018}
+}
+
+@article{sun2019deep,
+ title={Deep high-resolution representation learning for human pose estimation},
+ author={Sun, Ke and Xiao, Bin and Liu, Dong and Wang, Jingdong},
+ journal={arXiv preprint arXiv:1902.09212},
+ year={2019}
+}
+
+@inproceedings{chen2019hybrid,
+ title={Hybrid task cascade for instance segmentation},
+ author={Chen, Kai and Pang, Jiangmiao and Wang, Jiaqi and Xiong, Yu and Li, Xiaoxiao and Sun, Shuyang and Feng, Wansen and Liu, Ziwei and Shi, Jianping and Ouyang, Wanli and others},
+ booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
+ pages={4974--4983},
+ year={2019}
+}
+```
\ No newline at end of file
diff --git a/internlm_langchain/knowledge_base/MMSkeleton/content/START_RECOGNITION.md b/internlm_langchain/knowledge_base/MMSkeleton/content/START_RECOGNITION.md
new file mode 100644
index 00000000..4bbdce4d
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMSkeleton/content/START_RECOGNITION.md
@@ -0,0 +1,62 @@
+## Start Action Recognition Using ST-GCN
+
+This repository holds the codebase for the paper:
+
+**Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition** Sijie Yan, Yuanjun Xiong and Dahua Lin, AAAI 2018. [[Arxiv Preprint]](https://arxiv.org/abs/1801.07455)
+
+
| textdet |
+ _base_ | +datasets | +icdar_datasets.py ctw1500.py ... |
+ µĢ░µŹ«ķøåķģŹńĮ« | +
| schedules | +schedule_adam_600e.py ... |
+ Ķ«Łń╗āńŁ¢ńĢźķģŹńĮ« | +||
| default_runtime.py |
+ - | +ńÄ»ÕóāķģŹńĮ« ķ╗śĶ«żhookķģŹńĮ« µŚźÕ┐ŚķģŹńĮ« µØāķćŹÕŖĀĶĮĮķģŹńĮ« Ķ»äµĄŗķģŹńĮ« ÕÅ»Ķ¦åÕī¢ķģŹńĮ« |
+ ||
| dbnet | +_base_dbnet_resnet18_fpnc.py | +- | +ńĮæń╗£ķģŹńĮ« µĢ░µŹ«µĄüµ░┤ń║┐ |
+ |
| dbnet_resnet18_fpnc_1200e_icdar2015.py | +- | +Dataloader ķģŹńĮ« µĢ░µŹ«µĄüµ░┤ń║┐(Optional) |
+
+
+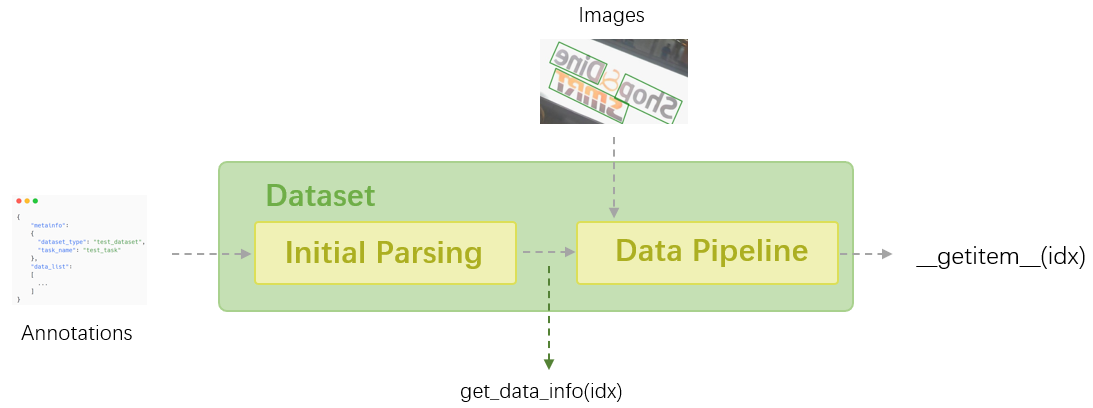
+
+
+
+Õ£©µ£¼µĢÖń©ŗõĖŁ’╝īµłæõ╗¼Õ░åõ╗ŗń╗Ź Dataset ń▒╗ńÜäõĖĆõ║øÕĖĖĶ¦üµÄźÕÅŻ’╝īõ╗źÕÅŖ MMOCR õĖŁ Dataset Õ«×ńÄ░ńÜäõĮ┐ńö©õ╗źÕÅŖÕ«āõ╗¼µö»µīüńÜäµ│©ķćŖń▒╗Õ×ŗŃĆé
+
+```{tip}
+Dataset ń▒╗µö»µīüõĖĆõ║øķ½śń║¦ÕŖ¤ĶāĮ’╝īõŠŗÕ”éµćÆÕŖĀĶĮĮŃĆüµĢ░µŹ«Õ║ÅÕłŚÕī¢ŃĆüÕł®ńö©ÕÉäń¦ŹµĢ░µŹ«ķøåÕīģĶŻģÕÖ©µē¦ĶĪīµĢ░µŹ«Ķ┐׵ğŃĆüķćŹÕżŹÕÆīń▒╗Õł½Õ╣│ĶĪĪŃĆéĶ┐Öõ║øÕåģÕ«╣Õ░åõĖŹÕ£©µ£¼µĢÖń©ŗõĖŁõ╗ŗń╗Ź’╝īõĮåµé©ÕÅ»õ╗źķśģĶ»╗ {external+mmengine:doc}`MMEngine: BaseDataset `pred_scores`
`gt_polygons` | `recall`
`precision`
`hmean` | +| [WordMetric](#wordmetric) | µ¢ćµ£¼Ķ»åÕł½ | `pred_text`
`gt_text` | `word_acc`
`word_acc_ignore_case`
`word_acc_ignore_case_symbol` | +| [CharMetric](#charmetric) | µ¢ćµ£¼Ķ»åÕł½ | `pred_text`
`gt_text` | `char_recall`
`char_precision` | +| [OneMinusNEDMetric](#oneminusnedmetric) | µ¢ćµ£¼Ķ»åÕł½ | `pred_text`
`gt_text` | `1-N.E.D` | +| [F1Metric](#f1metric) | Õģ│ķö«õ┐Īµü»µŖĮÕÅ¢ | `pred_labels`
`gt_labels` | `macro_f1`
`micro_f1` | + +ķĆÜÕĖĖµØźĶ»┤’╝īµ»ÅõĖĆń▒╗õ╗╗ÕŖĪµēĆķććńö©ńÜäĶ»äµĄŗµĀćÕćåµś»ń║”Õ«Üõ┐ŚµłÉńÜä’╝īńö©µłĘõĖĆĶł¼µŚĀķĪ╗µĘ▒Õģźõ║åĶ¦Żµł¢µēŗÕŖ©õ┐«µö╣Ķ»äµĄŗµ¢╣µ│ĢńÜäÕåģķā©Õ«×ńÄ░ŃĆéńäČĶĆī’╝īõĖ║õ║åµ¢╣õŠ┐ńö©µłĘÕ«×ńÄ░µø┤ÕŖĀÕ«ÜÕłČÕī¢ńÜäķ£Ćµ▒é’╝īµ£¼µ¢ćµĪŻÕ░åĶ┐øõĖƵŁźõ╗ŗń╗Źõ║å MMOCR ÕåģńĮ«Ķ»äµĄŗń«Śµ│ĢńÜäÕģĘõĮōÕ«×ńÄ░ńŁ¢ńĢź’╝īõ╗źÕÅŖÕÅ»ķģŹńĮ«ÕÅéµĢ░ŃĆé + +### HmeanIOUMetric + +[HmeanIOUMetric](mmocr.evaluation.metrics.hmean_iou_metric.HmeanIOUMetric) µś»µ¢ćµ£¼µŻĆµĄŗõ╗╗ÕŖĪõĖŁÕ║öńö©µ£ĆÕ╣┐µ│øńÜäĶ»äµĄŗµīćµĀćõ╣ŗõĖĆ’╝īÕøĀÕģČĶ«Īń«Śõ║åµŻĆµĄŗń▓ŠÕ║”’╝łPrecision’╝ēõĖÄÕżÕø×ńÄć’╝łRecall’╝ēõ╣ŗķŚ┤ńÜäĶ░āÕÆīÕ╣│ÕØćµĢ░’╝łHarmonic mean, H-mean’╝ē’╝īµĢģÕŠŚÕÉŹ `HmeanIOUMetric`ŃĆéĶ«░ń▓ŠÕ║”õĖ║ *P*’╝īÕżÕø×ńÄćõĖ║ *R*’╝īÕłÖ `HmeanIOUMetric` ÕÅ»ńö▒õĖŗÕ╝ÅĶ«Īń«ŚÕŠŚÕł░’╝Ü + +```{math} +H = \frac{2}{\frac{1}{P} + \frac{1}{R}} = \frac{2PR}{P+R} +``` + +ÕÅ”Õż¢’╝īńö▒õ║ÄÕģČńŁēõ╗Ęõ║Ä {math}`\beta = 1` µŚČńÜä F-score (ÕÅłń¦░ F-measure µł¢ F-metric)’╝ī`HmeanIOUMetric` µ£ēµŚČõ╣¤Ķó½ÕåÖõĮ£ `F1Metric` µł¢ `f1-score` ńŁē’╝Ü + +```{math} +F_1=(1+\beta^2)\cdot\frac{PR}{\beta^2\cdot P+R} = \frac{2PR}{P+R} +``` + +Õ£© MMOCR ńÜäĶ«ŠĶ«ĪõĖŁ’╝ī`HmeanIOUMetric` ńÜäĶ«Īń«ŚÕÅ»õ╗źµ”éµŗ¼õĖ║õ╗źõĖŗÕćĀõĖ¬µŁźķ¬ż’╝Ü + +1. Ķ┐ćµ╗żµŚĀµĢłńÜäķó䵥ŗĶŠ╣ńĢīńøÆ + + - õŠØµŹ«ńĮ«õ┐ĪÕ║”ķśłÕĆ╝ `pred_score_thrs` Ķ┐ćµ╗żµÄēÕŠŚÕłåĶŠāõĮÄńÜäķó䵥ŗĶŠ╣ńĢīńøÆ + - õŠØµŹ« `ignore_precision_thr` ķśłÕĆ╝Ķ┐ćµ╗żµÄēõĖÄ `ignored` µĀʵ£¼ķćŹÕÉłÕ║”Ķ┐ćķ½śńÜäķó䵥ŗĶŠ╣ńĢīńøÆ + + ÕĆ╝ÕŠŚµ│©µäÅńÜ䵜»’╝ī`pred_score_thrs` ķ╗śĶ«żÕ░å**Ķć¬ÕŖ©µÉ£ń┤ó**õĖĆÕ«ÜĶīāÕø┤ÕåģńÜä**µ£ĆõĮ│ķśłÕĆ╝**’╝īńö©µłĘõ╣¤ÕÅ»õ╗źķĆÜĶ┐ćµēŗÕŖ©õ┐«µö╣ķģŹńĮ«µ¢ćõ╗ČµØźĶć¬Õ«Üõ╣ēµÉ£ń┤óĶīāÕø┤’╝Ü + + ```python + # HmeanIOUMetric ķ╗śĶ«żõ╗ź 0.1 õĖ║µŁźķĢ┐µÉ£ń┤ó [0.3, 0.9] ĶīāÕø┤ÕåģńÜäµ£ĆõĮ│ÕŠŚÕłåķśłÕĆ╝ + val_evaluator = dict(type='HmeanIOUMetric', pred_score_thrs=dict(start=0.3, stop=0.9, step=0.1)) + ``` + +2. Ķ«Īń«Ś IoU ń¤®ķśĄ + + - Õ£©µĢ░µŹ«ÕżäńÉåķśČµ«Ą’╝ī`HmeanIOUMetric` õ╝ÜĶ«Īń«ŚÕ╣Čń╗┤µŖżõĖĆõĖ¬ {math}`M \times N` ńÜä IoU ń¤®ķśĄ `iou_metric`’╝īõ╗źµ¢╣õŠ┐ÕÉÄń╗ŁńÜäĶŠ╣ńĢīńøÆķģŹÕ»╣µŁźķ¬żŃĆéÕģČõĖŁ’╝īM ÕÆī N ÕłåÕł½õĖ║µĀćńŁŠĶŠ╣ńĢīńøÆõĖÄĶ┐ćµ╗żÕÉÄķó䵥ŗĶŠ╣ńĢīńøÆńÜäµĢ░ķćÅŃĆéńö▒µŁż’╝īĶ»źń¤®ķśĄńÜäµ»ÅõĖ¬Õģāń┤ĀķāĮÕŁśµöŠõ║åń¼¼ m õĖ¬µĀćńŁŠĶŠ╣ńĢīńøÆõĖÄń¼¼ n õĖ¬ķó䵥ŗĶŠ╣ńĢīńøÆõ╣ŗķŚ┤ńÜäõ║żÕ╣ȵ»ö’╝łIoU’╝ēŃĆé + +3. Õ¤║õ║ÄńøĖÕ║öńÜäķģŹÕ»╣ńŁ¢ńĢźń╗¤Ķ«ĪĶāĮĶó½ÕćåńĪ«Õī╣ķģŹńÜä GT µĀʵ£¼µĢ░ + + Õ░Įń«Ī `HmeanIOUMetric` ÕÅ»õ╗źńö▒Õø║Õ«ÜńÜäÕģ¼Õ╝ÅĶ«Īń«ŚÕÅ¢ÕŠŚ’╝īõĖŹÕÉīńÜäõ╗╗ÕŖĪµł¢ń«Śµ│ĢÕ║ōÕåģķā©ńÜäÕģĘõĮōÕ«×ńÄ░õ╗ŹÕÅ»ĶāĮÕŁśÕ£©õĖĆõ║øń╗åÕŠ«ÕĘ«Õł½ŃĆéĶ┐Öõ║øÕĘ«Õ╝éõĖ╗Ķ”üõĮōńÄ░Õ£©ķććńö©õĖŹÕÉīńÜäńŁ¢ńĢźµØźÕī╣ķģŹń£¤Õ«×õĖÄķó䵥ŗĶŠ╣ńĢīńøÆ’╝īõ╗ÄĶĆīÕ»╝Ķć┤µ£Ćń╗łÕŠŚÕłåńÜäÕĘ«ĶĘØŃĆéńø«ÕēŹ’╝īMMOCR Õåģķā©ńÜä `HmeanIOUMetric` Õģ▒µö»µīüõĖżń¦ŹõĖŹÕÉīńÜäÕī╣ķģŹńŁ¢ńĢź’╝īÕŹ│ `vanilla` õĖÄ `max_matching`ŃĆéÕ”éõĖŗµēĆńż║’╝īńö©µłĘÕÅ»õ╗źķĆÜĶ┐ćõ┐«µö╣ķģŹńĮ«µ¢ćõ╗ČµØźµīćÕ«ÜõĖŹÕÉīńÜäÕī╣ķģŹńŁ¢ńĢźŃĆé + + - `vanilla` Õī╣ķģŹńŁ¢ńĢź + + `HmeanIOUMetric` ķ╗śĶ«żķććńö© `vanilla` Õī╣ķģŹńŁ¢ńĢź’╝īĶ»źÕ«×ńÄ░õĖÄ MMOCR 0.x ńēłµ£¼õĖŁńÜä `hmean-iou` ÕÅŖ ICDAR ń│╗ÕłŚ**Õ«śµ¢╣µ¢ćµ£¼µŻĆµĄŗń½×ĶĄøńÜäĶ»äµĄŗµĀćÕćåõ┐صīüõĖĆĶć┤**’╝īķććńö©ÕģłÕł░ÕģłÕŠŚńÜäÕī╣ķģŹµ¢╣Õ╝ÅÕ»╣µĀćńŁŠĶŠ╣ńĢīńøÆ’╝łGround-truth bbox’╝ēõĖÄķó䵥ŗĶŠ╣ńĢīńøÆ’╝łPredicted bbox’╝ēĶ┐øĶĪīķģŹÕ»╣ŃĆé + + ```python + # õĖŹµīćÕ«Ü strategy µŚČ’╝īHmeanIOUMetric ķ╗śĶ«żķććńö© 'vanilla' Õī╣ķģŹńŁ¢ńĢź + val_evaluator = dict(type='HmeanIOUMetric') + ``` + + - `max_matching` Õī╣ķģŹńŁ¢ńĢź + + ķÆłÕ»╣ńÄ░µ£ēÕī╣ķģŹµ£║ÕłČõĖŁńÜäõĖŹÕ«īÕ¢äõ╣ŗÕżä’╝īMMOCR ń«Śµ│ĢÕ║ōÕ«×ńÄ░õ║åõĖĆÕźŚµø┤ķ½śµĢłńÜäÕī╣ķģŹńŁ¢ńĢź’╝īńö©õ╗źµ£ĆÕż¦Õī¢Õī╣ķģŹµĢ░ńø«ŃĆé + + ```python + # µīćÕ«Üķććńö© 'max_matching' Õī╣ķģŹńŁ¢ńĢź + val_evaluator = dict(type='HmeanIOUMetric', strategy='max_matching') + ``` + + ```{note} + µłæõ╗¼Õ╗║Ķ««ķØóÕÉæÕŁ”µ£»ńĀöń®ČńÜäÕ╝ĆÕÅæńö©µłĘķććńö©ķ╗śĶ«żńÜä `vanilla` Õī╣ķģŹńŁ¢ńĢź’╝īõ╗źõ┐ØĶ»üõĖÄÕģČõ╗¢Ķ«║µ¢ćńÜäÕ»╣µ»öń╗ōµ×£õ┐صīüõĖĆĶć┤ŃĆéĶĆīķØóÕÉæÕĘźõĖÜÕ║öńö©ńÜäÕ╝ĆÕÅæńö©µłĘÕłÖÕÅ»õ╗źķććńö© `max_matching` Õī╣ķģŹńŁ¢ńĢź’╝īõ╗źĶÄĘÕŠŚń▓ŠÕćåńÜäń╗ōµ×£ŃĆé + ``` + +4. µĀ╣µŹ«õĖŖµ¢ćõ╗ŗń╗ŹńÜä `HmeanIOUMetric` Õģ¼Õ╝ÅĶ«Īń«Śµ£Ćń╗łńÜäĶ»äµĄŗÕŠŚÕłå + +### WordMetric + +[WordMetric](mmocr.evaluation.metrics.recog_metric.WordMetric) Õ«×ńÄ░õ║å**ÕŹĢĶ»Źń║¦Õł½**ńÜäµ¢ćµ£¼Ķ»åÕł½Ķ»äµĄŗµīćµĀć’╝īÕ╣ČÕåģńĮ«õ║å `exact`’╝ī`ignore_case`’╝īÕÅŖ `ignore_case_symbol` õĖēń¦Źµ¢ćµ£¼Õī╣ķģŹµ©ĪÕ╝Å’╝īńö©µłĘÕÅ»õ╗źÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁõ┐«µö╣ `mode` ÕŁŚµ«ĄµØźĶć¬ńö▒ń╗äÕÉłĶŠōÕć║õĖĆń¦Źµł¢ÕżÜń¦Źµ¢ćµ£¼Õī╣ķģŹµ©ĪÕ╝ÅõĖŗńÜä `WordMetric` ÕŠŚÕłåŃĆé + +```python +# Õ£©µ¢ćµ£¼Ķ»åÕł½õ╗╗ÕŖĪõĖŁõĮ┐ńö© WordMetric Ķ»äµĄŗ +val_evaluator = [ + dict(type='WordMetric', mode=['exact', 'ignore_case', 'ignore_case_symbol']) +] +``` + +- `exact`’╝ÜÕģ©Õī╣ķģŹµ©ĪÕ╝Å’╝īÕŹ│’╝īķó䵥ŗõĖĵĀćńŁŠÕ«īÕģ©õĖĆĶć┤µēŹĶāĮĶó½Ķ«░ÕĮĢõĖ║µŁŻńĪ«µĀʵ£¼ŃĆé +- `ignore_case`’╝ÜÕ┐ĮńĢźÕż¦Õ░ÅÕåÖńÜäÕī╣ķģŹµ©ĪÕ╝ÅŃĆé +- `ignore_case_symbol`’╝ÜÕ┐ĮńĢźÕż¦Õ░ÅÕåÖÕÅŖń¼”ÕÅĘńÜäÕī╣ķģŹµ©ĪÕ╝Å’╝īĶ┐Öõ╣¤µś»Õż¦ķā©ÕłåÕŁ”µ£»Ķ«║µ¢ćõĖŁµŖźÕæŖńÜäµ¢ćµ£¼Ķ»åÕł½ÕćåńĪ«ńÄć’╝øMMOCR µŖźÕæŖńÜäĶ»åÕł½µ©ĪÕ×ŗµĆ¦ĶāĮķ╗śĶ«żķććńö©Ķ»źÕī╣ķģŹµ©ĪÕ╝ÅŃĆé + +ÕüćĶ«Šń£¤Õ«×µĀćńŁŠõĖ║ `MMOCR!`’╝īµ©ĪÕ×ŗńÜäĶŠōÕć║ń╗ōµ×£õĖ║ `mmocr`’╝īÕłÖõĖēń¦ŹÕī╣ķģŹµ©ĪÕ╝ÅõĖŗńÜä `WordMetric` ÕŠŚÕłåÕłåÕł½õĖ║’╝Ü`{'exact': 0, 'ignore_case': 0, 'ignore_case_symbol': 1}`ŃĆé + +### CharMetric + +[CharMetric](mmocr.evaluation.metrics.recog_metric.CharMetric) Õ«×ńÄ░õ║å**õĖŹÕī║ÕłåÕż¦Õ░ÅÕåÖ**ńÜä**ÕŁŚń¼”ń║¦Õł½**ńÜäµ¢ćµ£¼Ķ»åÕł½Ķ»äµĄŗµīćµĀćŃĆé + +```python +# Õ£©µ¢ćµ£¼Ķ»åÕł½õ╗╗ÕŖĪõĖŁõĮ┐ńö© CharMetric Ķ»äµĄŗ +val_evaluator = [dict(type='CharMetric')] +``` + +ÕģĘõĮōĶĆīĶ©Ć’╝ī`CharMetric` õ╝ÜĶŠōÕć║õĖżõĖ¬Ķ»äµĄŗĶ»äµĄŗµīćµĀć’╝īÕŹ│ÕŁŚń¼”ń▓ŠÕ║” `char_precision` ÕÆīÕŁŚń¼”ÕżÕø×ńÄć `char_recall`ŃĆéĶ«ŠµŁŻńĪ«ķó䵥ŗńÜäÕŁŚń¼”’╝łTrue Positive’╝ēµĢ░ķćÅõĖ║ {math}`\sigma_{tp}`’╝īÕłÖń▓ŠÕ║” *P* ÕÆīÕżÕø×ńÄć *R* ÕÅ»ńö▒õĖŗÕ╝ÅĶ«Īń«ŚÕÅ¢ÕŠŚ’╝Ü + +```{math} +P=\frac{\sigma_{tp}}{\sigma_{pred}}, R = \frac{\sigma_{tp}}{\sigma_{gt}} +``` + +ÕģČõĖŁ’╝ī{math}`\sigma_{gt}` õĖÄ {math}`\sigma_{pred}` ÕłåÕł½õĖ║µĀćńŁŠµ¢ćµ£¼õĖÄķó䵥ŗµ¢ćµ£¼µēĆÕīģÕɽńÜäÕŁŚń¼”µĆ╗µĢ░ŃĆé + +õŠŗÕ”é’╝īÕüćĶ«ŠµĀćńŁŠµ¢ćµ£¼õĖ║ "MM**O**CR"’╝īķó䵥ŗµ¢ćµ£¼õĖ║ "mm**0**cR**1**"’╝īÕłÖõĮ┐ńö© `CharMetric` Ķ»äµĄŗµīćµĀćńÜäÕŠŚÕłåõĖ║’╝Ü + +```{math} +P=\frac{4}{6}, R=\frac{4}{5} +``` + +### OneMinusNEDMetric + +[`OneMinusNEDMetric(1-N.E.D)`](mmocr.evaluation.metrics.recog_metric.OneMinusNEDMetric) ÕĖĖńö©õ║ÄõĖŁµ¢ćµł¢Ķŗ▒µ¢ć**µ¢ćµ£¼ĶĪīń║¦Õł½**µĀćµ│©ńÜäµ¢ćµ£¼Ķ»åÕł½Ķ»äµĄŗ’╝īõĖŹÕÉīõ║ÄÕģ©Õī╣ķģŹńÜäĶ»äµĄŗµĀćÕćåĶ”üµ▒éķó䵥ŗõĖÄń£¤Õ«×µĀʵ£¼Õ«īÕģ©õĖĆĶć┤’╝īĶ»źĶ»äµĄŗµīćµĀćõĮ┐ńö©ÕĮÆõĖĆÕī¢ńÜä[ń╝¢ĶŠæĶĘØń”╗](https://en.wikipedia.org/wiki/Edit_distance)’╝łEdit Distance’╝īÕÅłÕÉŹĶÄ▒µĖ®µ¢»ÕØ”ĶĘØń”╗ Levenshtein Distance’╝ēµØźµĄŗķćÅķó䵥ŗµ¢ćµ£¼õĖÄń£¤Õ«×µ¢ćµ£¼õ╣ŗķŚ┤ńÜäÕĘ«Õ╝éµĆ¦’╝īõ╗ÄĶĆīÕ£©Ķ»äµĄŗķĢ┐µ¢ćµ£¼µĀʵ£¼µŚČĶāĮÕż¤µø┤ÕźĮÕ£░Õī║ÕłåÕć║µ©ĪÕ×ŗńÜäµĆ¦ĶāĮÕĘ«Õ╝éŃĆéÕüćĶ«Šń£¤Õ«×ÕÆīķó䵥ŗµ¢ćµ£¼ÕłåÕł½õĖ║ {math}`s_i` ÕÆī {math}`\hat{s_i}`’╝īÕģČķĢ┐Õ║”ÕłåÕł½õĖ║ {math}`l_{i}` ÕÆī {math}`\hat{l_i}`’╝īÕłÖ `OneMinusNEDMetric` ÕŠŚÕłåÕÅ»ńö▒õĖŗÕ╝ÅĶ«Īń«ŚÕŠŚÕł░’╝Ü + +```{math} +score = 1 - \frac{1}{N}\sum_{i=1}^{N}\frac{D(s_i, \hat{s_{i}})}{max(l_{i},\hat{l_{i}})} +``` + +ÕģČõĖŁ’╝ī*N* µś»µĀʵ£¼µĆ╗µĢ░’╝ī{math}`D(s_1, s_2)` õĖ║õĖżõĖ¬ÕŁŚń¼”õĖ▓õ╣ŗķŚ┤ńÜäń╝¢ĶŠæĶĘØń”╗ŃĆé + +õŠŗÕ”é’╝īÕüćĶ«Šń£¤Õ«×µĀćńŁŠõĖ║ "OpenMMLabMMOCR"’╝īµ©ĪÕ×ŗ A ńÜäķó䵥ŗń╗ōµ×£õĖ║ "0penMMLabMMOCR", µ©ĪÕ×ŗ B ńÜäķó䵥ŗń╗ōµ×£õĖ║ "uvwxyz"’╝īÕłÖķććńö©Õģ©Õī╣ķģŹÕÆī `OneMinusNEDMetric` Ķ»äµĄŗµīćµĀćńÜäń╗ōµ×£ÕłåÕł½õĖ║: + +| | | | +| ------ | ------ | ---------- | +| | Õģ©Õī╣ķģŹ | 1 - N.E.D. | +| µ©ĪÕ×ŗ A | 0 | 0.92857 | +| µ©ĪÕ×ŗ B | 0 | 0 | + +ńö▒õĖŖĶĪ©ÕÅ»õ╗źÕÅæńÄ░’╝īÕ░Įń«Īµ©ĪÕ×ŗ A õ╗ģķó䵥ŗķöÖõ║åõĖĆõĖ¬ÕŁŚµ»Ź’╝īĶĆīµ©ĪÕ×ŗ B Õģ©ķā©ķó䵥ŗķöÖĶ»»’╝īÕ£©õĮ┐ńö©Õģ©Õī╣ķģŹńÜäĶ»äµĄŗµīćµĀ浌Ȓ╝īĶ┐ÖõĖżõĖ¬µ©ĪÕ×ŗńÜäÕŠŚÕłåķāĮõĖ║0’╝øĶĆīõĮ┐ńö© `OneMinuesNEDMetric` ńÜäĶ»äµĄŗµīćµĀćÕłÖĶāĮÕż¤µø┤ÕźĮÕ£░Õī║Õłåµ©ĪÕ×ŗÕ£©**ķĢ┐µ¢ćµ£¼**õĖŖńÜäµĆ¦ĶāĮÕĘ«Õ╝éŃĆé + +### F1Metric + +[F1Metric](mmocr.evaluation.metrics.f_metric.F1Metric) Õ«×ńÄ░õ║åķÆłÕ»╣ KIE õ╗╗ÕŖĪńÜä F1-Metric Ķ»äµĄŗµīćµĀć’╝īÕ╣ȵÅÉõŠøõ║å `micro` ÕÆī `macro` õĖżń¦ŹĶ»äµĄŗµ©ĪÕ╝ÅŃĆé + +```python +val_evaluator = [ + dict(type='F1Metric', mode=['micro', 'macro'], +] +``` + +- `micro` µ©ĪÕ╝Å’╝ÜõŠØµŹ« True Positive’╝īFalse Negative’╝īÕÅŖ False Positive µĆ╗µĢ░µØźĶ«Īń«ŚÕģ©Õ▒Ć F1-Metric ÕŠŚÕłåŃĆé + +- `macro` µ©ĪÕ╝Å’╝ÜõŠØµŹ«ń▒╗Õł½µĀćńŁŠĶ«Īń«Śµ»ÅõĖĆń▒╗ńÜä F1-Metric’╝īÕ╣ȵ▒éÕ╣│ÕØćÕĆ╝ŃĆé + +### Ķć¬Õ«Üõ╣ēĶ»äµĄŗµīćµĀć + +Õ»╣õ║ÄĶ┐Įµ▒éµø┤ķ½śÕ«ÜÕłČÕī¢ÕŖ¤ĶāĮńÜäńö©µłĘ’╝īMMOCR õ╣¤µö»µīüĶć¬Õ«Üõ╣ēÕ«×ńÄ░õĖŹÕÉīń▒╗Õ×ŗńÜäĶ»äµĄŗµīćµĀćŃĆéõĖĆĶł¼µØźĶ»┤’╝īńö©µłĘÕŬķ£ĆĶ”üµ¢░Õ╗║Ķć¬Õ«Üõ╣ēĶ»äµĄŗµīćµĀćń▒╗ `CustomizedMetric` Õ╣Čń╗¦µē┐ {external+mmengine:doc}`MMEngine: BaseMetric
+  +
+
+
+```{note}
+Õ”éµ×£õĮĀÕ£©µ▓Īµ£ē GUI ńÜäµ£ŹÕŖĪÕÖ©õĖŖĶ┐ÉĶĪī MMOCR’╝īµł¢ĶĆģµś»ķĆÜĶ┐ćń”üńö© X11 ĶĮ¼ÕÅæńÜä SSH ķܦķüōĶ┐ÉĶĪīĶ»źµīćõ╗ż’╝ī`show` ķĆēķĪ╣Õ░åõĖŹĶĄĘõĮ£ńö©ŃĆéńäČĶĆī’╝īõĮĀõ╗ŹńäČÕÅ»õ╗źķĆÜĶ┐ćĶ«ŠńĮ« `out_dir` ÕÆī `save_vis=True` ÕÅéµĢ░Õ░åÕÅ»Ķ¦åÕī¢µĢ░µŹ«õ┐ØÕŁśÕł░µ¢ćõ╗ČŃĆéķśģĶ»╗ [Õé©ÕŁśń╗ōµ×£](#Õé©ÕŁśń╗ōµ×£) õ║åĶ¦ŻĶ»”µāģŃĆé
+```
+
+µĀ╣µŹ«ÕłØÕ¦ŗÕī¢ÕÅéµĢ░’╝ī`MMOCRInferencer`ÕÅ»õ╗źÕ£©õĖŹÕÉīµ©ĪÕ╝ÅõĖŗĶ┐ÉĶĪīŃĆéõŠŗÕ”é’╝īÕ”éµ×£ÕłØÕ¦ŗÕī¢µŚČµīćÕ«Üõ║å `det`ŃĆü`rec` ÕÆī `kie`’╝īÕ«āÕÅ»õ╗źÕ£© KIE µ©ĪÕ╝ÅõĖŗĶ┐ÉĶĪīŃĆé
+
+::::{tabs}
+
+:::{code-tab} python
+>>> kie = MMOCRInferencer(det='DBNet', rec='SAR', kie='SDMGR')
+>>> kie('demo/demo_kie.jpeg', show=True)
+:::
+
+:::{code-tab} bash ÕæĮõ╗żĶĪī
+python tools/infer.py demo/demo_kie.jpeg --det DBNet --rec SAR --kie SDMGR --show
+:::
+
+::::
+
+ÕÅ»Ķ¦åÕī¢ń╗ōµ×£Õ”éõĖŗ’╝Ü
+
+
+
+  +
+
+
++ +ÕÅ»õ╗źĶ¦üÕł░’╝īMMOCRInferencer ńÜä Python µÄźÕÅŻõĖÄÕæĮõ╗żĶĪīµÄźÕÅŻńÜäõĮ┐ńö©µ¢╣µ│ĢķØ×ÕĖĖńøĖõ╝╝ŃĆéõĖŗµ¢ćÕ░åõ╗ź Python µÄźÕÅŻõĖ║õŠŗ’╝īõ╗ŗń╗Ź MMOCRInferencer ńÜäÕģĘõĮōńö©µ│ĢŃĆéÕģ│õ║ÄÕæĮõ╗żĶĪīµÄźÕÅŻńÜäµø┤ÕżÜõ┐Īµü»’╝īĶ»ĘÕÅéĶĆā [ÕæĮõ╗żĶĪīµÄźÕÅŻ](#ÕæĮõ╗żĶĪīµÄźÕÅŻ)ŃĆé + + +```` + +````{group-tab} µĀćÕćåµÄ©ńÉåÕÖ© + +ķĆÜÕĖĖ’╝īOpenMMLab õĖŁńÜäµēƵ£ēµĀćÕćåµÄ©ńÉåÕÖ©ķāĮÕģʵ£ēķØ×ÕĖĖńøĖõ╝╝ńÜäµÄźÕÅŻŃĆéõĖŗķØóńÜäõŠŗÕŁÉÕ▒Ģńż║õ║åÕ”éõĮĢõĮ┐ńö© `TextDetInferencer` Õ»╣ÕŹĢõĖ¬ÕøŠÕāÅĶ┐øĶĪīµÄ©ńÉåŃĆé + +```python +>>> from mmocr.apis import TextDetInferencer +>>> # Ķ»╗ÕÅ¢µ©ĪÕ×ŗ +>>> inferencer = TextDetInferencer(model='DBNet') +>>> # µÄ©ńÉå +>>> inferencer('demo/demo_text_ocr.jpg', show=True) +``` + +ÕÅ»Ķ¦åÕī¢ń╗ōµ×£Õ”éÕøŠ’╝Ü + +
+  +
+
+
+````
+
+`````
+
+## ÕłØÕ¦ŗÕī¢
+
+µ»ÅõĖ¬µÄ©ńÉåÕÖ©Õ┐ģķĪ╗õĮ┐ńö©õĖĆõĖ¬µ©ĪÕ×ŗĶ┐øĶĪīÕłØÕ¦ŗÕī¢ŃĆéÕłØÕ¦ŗÕī¢µŚČ’╝īÕÅ»õ╗źµēŗÕŖ©ķĆēµŗ®µÄ©ńÉåĶ«ŠÕżćŃĆé
+
+### µ©ĪÕ×ŗÕłØÕ¦ŗÕī¢
+
+`````{tabs}
+
+````{group-tab} MMOCRInferencer
+
+Õ»╣õ║ĵ»ÅõĖ¬õ╗╗ÕŖĪ’╝ī`MMOCRInferencer` ķ£ĆĶ”üõĖżõĖ¬ÕÅéµĢ░ `xxx` ÕÆī `xxx_weights` ’╝łõŠŗÕ”é `det` ÕÆī `det_weights`’╝ēõ╗źÕ»╣µ©ĪÕ×ŗĶ┐øĶĪīÕłØÕ¦ŗÕī¢ŃĆ鵣żÕżäÕ░åõ╗ź`det`ÕÆī`det_weights`õĖ║õŠŗµØźĶ»┤µśÄõĖĆõ║øÕģĖÕ×ŗńÜäÕłØÕ¦ŗÕī¢µ©ĪÕ×ŗńÜäµ¢╣µ│ĢŃĆé
+
+- Ķ”üńö© MMOCR ńÜäķóäĶ«Łń╗āµ©ĪÕ×ŗĶ┐øĶĪīµÄ©ńÉå’╝īÕŬķ£ĆĶ”üµŖŖÕ«āńÜäÕÉŹÕŁŚõ╝Āń╗ÖÕÅéµĢ░ `det`’╝īµØāķćŹÕ░åĶć¬ÕŖ©õ╗Ä OpenMMLab ńÜ䵩ĪÕ×ŗÕ║ōõĖŁõĖŗĶĮĮÕÆīÕŖĀĶĮĮŃĆé[µŁżÕżä](../modelzoo.md#µØāķćŹ)Ķ«░ÕĮĢõ║å MMOCR õĖŁÕÅ»õ╗źķĆÜĶ┐ćĶ»źµ¢╣µ│ĢÕłØÕ¦ŗÕī¢ńÜäµēƵ£ēµ©ĪÕ×ŗŃĆé
+
+ ```python
+ >>> MMOCRInferencer(det='DBNet')
+ ```
+
+- Ķ”üÕŖĀĶĮĮĶć¬Õ«Üõ╣ēńÜäķģŹńĮ«ÕÆīµØāķ插╝īõĮĀÕÅ»õ╗źµŖŖķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠäõ╝Āń╗Ö `det`’╝īµŖŖµØāķćŹńÜäĶĘ»ÕŠäõ╝Āń╗Ö `det_weights`ŃĆé
+
+ ```python
+ >>> MMOCRInferencer(det='path/to/dbnet_config.py', det_weights='path/to/dbnet.pth')
+ ```
+
+Õ”éµ×£ķ£ĆĶ”üµ¤źń£ŗµø┤ÕżÜńÜäÕłØÕ¦ŗÕī¢µ¢╣µ│Ģ’╝īĶ»Ęńé╣Õć╗ŌĆ£µĀćÕćåµÄ©ńÉåÕÖ©ŌĆØķĆēķĪ╣ÕŹĪŃĆé
+
+````
+
+````{group-tab} µĀćÕćåµÄ©ńÉåÕÖ©
+
+µ»ÅõĖ¬µĀćÕćåńÜä `Inferencer` ķāĮµÄźÕÅŚõĖżõĖ¬ÕÅéµĢ░’╝ī`model` ÕÆī `weights` ŃĆéÕ£© MMOCRInferencer õĖŁ’╝īĶ┐ÖõĖżõĖ¬ÕÅéµĢ░ÕłåÕł½Õ»╣Õ║ö `xxx` ÕÆī `xxx_weights` ’╝łõŠŗÕ”é `det` ÕÆī `det_weights`’╝ēŃĆé
+
+- `model` µÄźÕÅŚµ©ĪÕ×ŗńÜäÕÉŹń¦░µł¢ķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠäõĮ£õĖ║ĶŠōÕģźŃĆ鵩ĪÕ×ŗńÜäÕÉŹń¦░õ╗Ä [model-index.yml](https://github.com/open-mmlab/mmocr/blob/1.x/model-index.yml) õĖŁńÜ䵩ĪÕ×ŗńÜäÕģāµ¢ćõ╗Č’╝ł[ńż║õŠŗ](https://github.com/open-mmlab/mmocr/blob/1.x/configs/textdet/dbnet/metafile.yml) ’╝ēõĖŁĶÄĘÕÅ¢ŃĆéõĮĀÕÅ»õ╗źÕ£©[µŁżÕżä](../modelzoo.md#µØāķćŹ)µēŠÕł░ÕÅ»ńö©µØāķćŹńÜäÕłŚĶĪ©ŃĆé
+
+- `weights` µÄźÕÅŚµØāķ揵¢ćõ╗ČńÜäĶĘ»ÕŠäŃĆé
+
+
++ +µŁżÕżäÕłŚõĖŠõ║åõĖĆõ║øÕĖĖĶ¦üńÜäÕłØÕ¦ŗÕī¢µ©ĪÕ×ŗńÜäµ¢╣µ│ĢŃĆé + +- õĮĀÕÅ»õ╗źķĆÜĶ┐ćõ╝ĀķĆƵ©ĪÕ×ŗńÜäÕÉŹń¦░ń╗Ö `model` µØźµÄ©ńÉå MMOCR ńÜäķóäĶ«Łń╗āµ©ĪÕ×ŗŃĆéµØāķćŹÕ░åõ╝ÜĶć¬ÕŖ©õ╗Ä OpenMMLab ńÜ䵩ĪÕ×ŗÕ║ōõĖŁõĖŗĶĮĮÕ╣ČÕŖĀĶĮĮŃĆé + + ```python + >>> from mmocr.apis import TextDetInferencer + >>> inferencer = TextDetInferencer(model='DBNet') + ``` + + ```{note} + µ©ĪÕ×ŗõĖĵĩńÉåÕÖ©ńÜäõ╗╗ÕŖĪń¦Źń▒╗Õ┐ģķĪ╗Õī╣ķģŹŃĆé + ``` + + õĮĀÕÅ»õ╗źķĆÜĶ┐ćÕ░åµØāķćŹńÜäĶĘ»ÕŠäµł¢ URL õ╝ĀķĆÆń╗Ö `weights` µØźĶ«®µÄ©ńÉåÕÖ©ÕŖĀĶĮĮĶć¬Õ«Üõ╣ēńÜäµØāķćŹŃĆé + + ```python + >>> inferencer = TextDetInferencer(model='DBNet', weights='path/to/dbnet.pth') + ``` + +- Õ”éµ×£µ£ēĶć¬Õ«Üõ╣ēńÜäķģŹńĮ«ÕÆīµØāķ插╝īõĮĀÕÅ»õ╗źÕ░åķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠäõ╝ĀķĆÆń╗Ö `model`’╝īÕ░åµØāķćŹńÜäĶĘ»ÕŠäõ╝ĀķĆÆń╗Ö `weights`ŃĆé + + ```python + >>> inferencer = TextDetInferencer(model='path/to/dbnet_config.py', weights='path/to/dbnet.pth') + ``` + +- ķ╗śĶ«żµāģÕåĄõĖŗ’╝ī[MMEngine](https://github.com/open-mmlab/mmengine/) õ╝ÜÕ£©Ķ«Łń╗āµ©ĪÕ×ŗµŚČĶć¬ÕŖ©Õ░åķģŹńĮ«µ¢ćõ╗ČĶĮ¼Õé©Õł░µØāķ揵¢ćõ╗ČõĖŁŃĆéÕ”éµ×£õĮĀµ£ēõĖĆõĖ¬Õ£© MMEngine õĖŖĶ«Łń╗āńÜäµØāķ插╝īõĮĀõ╣¤ÕÅ»õ╗źÕ░åµØāķ揵¢ćõ╗ČńÜäĶĘ»ÕŠäõ╝ĀķĆÆń╗Ö `weights`’╝īĶĆīõĖŹķ£ĆĶ”üµīćÕ«Ü `model`’╝Ü + + ```python + >>> # Õ”éµ×£µŚĀµ│ĢÕ£©µØāķćŹõĖŁµēŠÕł░ķģŹńĮ«µ¢ćõ╗Č’╝īÕłÖõ╝ÜÕ╝ĢÕÅæķöÖĶ»» + >>> inferencer = TextDetInferencer(weights='path/to/dbnet.pth') + ``` + +- õ╝ĀķĆÆķģŹńĮ«µ¢ćõ╗ČÕł░ `model` ĶĆīõĖŹµīćÕ«Ü `weight` ÕłÖõ╝Üõ║¦ńö¤õĖĆõĖ¬ķÜŵ£║ÕłØÕ¦ŗÕī¢ńÜ䵩ĪÕ×ŗŃĆé + +```` +````` + +### µÄ©ńÉåĶ«ŠÕżć + +µ»ÅõĖ¬µÄ©ńÉåÕÖ©Õ«×õŠŗķāĮõ╝ÜĶʤõĖĆõĖ¬Ķ«ŠÕżćń╗æÕ«ÜŃĆéķ╗śĶ«żµāģÕåĄõĖŗ’╝īµ£ĆõĮ│Ķ«ŠÕżćµś»ńö▒ [MMEngine](https://github.com/open-mmlab/mmengine/) Ķć¬ÕŖ©Õå│Õ«ÜńÜäŃĆéõĮĀõ╣¤ÕÅ»õ╗źķĆÜĶ┐ćµīćÕ«Ü `device` ÕÅéµĢ░µØźµö╣ÕÅśĶ«ŠÕżćŃĆéõŠŗÕ”é’╝īõĮĀÕÅ»õ╗źõĮ┐ńö©õ╗źõĖŗõ╗ŻńĀüÕ£© GPU 1õĖŖÕłøÕ╗║õĖĆõĖ¬µÄ©ńÉåÕÖ©ŃĆé + +`````{tabs} + +````{group-tab} MMOCRInferencer + +```python +>>> inferencer = MMOCRInferencer(det='DBNet', device='cuda:1') +``` + +```` + +````{group-tab} µĀćÕćåµÄ©ńÉåÕÖ© + +```python +>>> inferencer = TextDetInferencer(model='DBNet', device='cuda:1') +``` + +```` + +````` + +Õ”éĶ”üÕ£© CPU õĖŖÕłøÕ╗║õĖĆõĖ¬µÄ©ńÉåÕÖ©’╝Ü + +`````{tabs} + +````{group-tab} MMOCRInferencer + +```python +>>> inferencer = MMOCRInferencer(det='DBNet', device='cpu') +``` + +```` + +````{group-tab} µĀćÕćåµÄ©ńÉåÕÖ© + +```python +>>> inferencer = TextDetInferencer(model='DBNet', device='cpu') +``` + +```` + +````` + +Ķ»ĘÕÅéĶĆā [torch.device](torch.device) õ║åĶ¦Ż `device` ÕÅéµĢ░µö»µīüńÜäµēƵ£ēÕĮóÕ╝ÅŃĆé + +## µÄ©ńÉå + +ÕĮōµÄ©ńÉåÕÖ©ÕłØÕ¦ŗÕī¢ÕÉÄ’╝īõĮĀÕÅ»õ╗źńø┤µÄźõ╝ĀÕģźĶ”üµÄ©ńÉåńÜäÕĤզŗµĢ░µŹ«’╝īõ╗ÄĶ┐öÕø×ÕĆ╝õĖŁĶÄĘÕÅ¢µÄ©ńÉåń╗ōµ×£ŃĆé + +### ĶŠōÕģź + +`````{tabs} + +````{tab} MMOCRInferencer / TextDetInferencer / TextRecInferencer / TextSpottingInferencer + +ĶŠōÕģźÕÅ»õ╗źµś»õ╗źõĖŗõ╗╗µäÅõĖĆń¦ŹµĀ╝Õ╝Å’╝Ü + +- str: ÕøŠÕāÅńÜäĶĘ»ÕŠä/URLŃĆé + + ```python + >>> inferencer('demo/demo_text_ocr.jpg') + ``` + +- array: ÕøŠÕāÅńÜä numpy µĢ░ń╗äŃĆéÕ«āÕ║öĶ»źµś» BGR µĀ╝Õ╝ÅŃĆé + + ```python + >>> import mmcv + >>> array = mmcv.imread('demo/demo_text_ocr.jpg') + >>> inferencer(array) + ``` + +- list: Õ¤║µ£¼ń▒╗Õ×ŗńÜäÕłŚĶĪ©ŃĆéÕłŚĶĪ©õĖŁńÜäµ»ÅõĖ¬Õģāń┤ĀķāĮÕ░åÕŹĢńŗ¼ÕżäńÉåŃĆé + + ```python + >>> inferencer(['img_1.jpg', 'img_2.jpg]) + >>> # ÕłŚĶĪ©ÕåģµĘĘÕÉłń▒╗Õ×ŗõ╣¤µś»ÕģüĶ«ĖńÜä + >>> inferencer(['img_1.jpg', array]) + ``` + +- str: ńø«ÕĮĢńÜäĶĘ»ÕŠäŃĆéńø«ÕĮĢõĖŁńÜäµēƵ£ēÕøŠÕāÅķāĮÕ░åĶó½ÕżäńÉåŃĆé + + ```python + >>> inferencer('tests/data/det_toy_dataset/imgs/test/') + ``` + +```` + +````{tab} KIEInferencer + +ĶŠōÕģźÕÅ»õ╗źµś»õĖĆõĖ¬ÕŁŚÕģĖµł¢ĶĆģõĖĆõĖ¬ÕŁŚÕģĖÕłŚĶĪ©’╝īÕģČõĖŁµ»ÅõĖ¬ÕŁŚÕģĖÕīģÕɽõ╗źõĖŗķö«’╝Ü + +- `img` (str µł¢ĶĆģ ndarray): ÕøŠÕāÅńÜäĶĘ»ÕŠäµł¢ÕøŠÕāŵ£¼Ķ║½ŃĆéÕ”éµ×£ KIE µÄ©ńÉåÕÖ©Õ£©µŚĀÕÅ»Ķ¦åµ©ĪÕ╝ÅõĖŗõĮ┐ńö©’╝īÕłÖõĖŹķ£ĆĶ”üµŁżķö«ŃĆéÕ”éµ×£Õ«āµś»õĖĆõĖ¬ numpy µĢ░ń╗ä’╝īÕłÖÕ║öĶ»źµś» BGR ķĪ║Õ║Åń╝¢ńĀüńÜäÕøŠńēćŃĆé +- `img_shape` (tuple(int, int)): ÕøŠÕāÅńÜäÕĮóńŖČ (H, W)ŃĆéõ╗ģÕ£© KIE µÄ©ńÉåÕÖ©Õ£©µŚĀÕÅ»Ķ¦åµ©ĪÕ╝ÅõĖŗõĮ┐ńö©õĖöµ▓Īµ£ēµÅÉõŠø `img` µŚČµēŹķ£ĆĶ”üŃĆé +- `instances` (list[dict]): Õ«×õŠŗÕłŚĶĪ©ŃĆé + +µ»ÅõĖ¬ `instance` ķāĮÕ║öĶ»źÕīģÕɽõ╗źõĖŗķö«’╝Ü + +```python +{ + # õĖĆõĖ¬ÕĄīÕźŚÕłŚĶĪ©’╝īÕģČõĖŁÕīģÕɽ 4 õĖ¬µĢ░ÕŁŚ’╝īĶĪ©ńż║Õ«×õŠŗńÜäĶŠ╣ńĢīµĪå’╝īķĪ║Õ║ÅõĖ║ (x1, y1, x2, y2) + "bbox": np.array([[x1, y1, x2, y2], [x1, y1, x2, y2], ...], + dtype=np.int32), + + # µ¢ćµ£¼ÕłŚĶĪ© + "texts": ['text1', 'text2', ...], +} +``` + +```` +````` + +### ĶŠōÕć║ + +ķ╗śĶ«żµāģÕåĄõĖŗ’╝īµ»ÅõĖ¬µÄ©ńÉåÕÖ©ķāĮõ╗źÕŁŚÕģĖµĀ╝Õ╝ÅĶ┐öÕø×ķó䵥ŗń╗ōµ×£ŃĆé + +- `visualization` ÕīģÕɽÕÅ»Ķ¦åÕī¢ńÜäķó䵥ŗń╗ōµ×£ŃĆéõĮåķ╗śĶ«żµāģÕåĄõĖŗ’╝īÕ«āµś»õĖĆõĖ¬ń®║ÕłŚĶĪ©’╝īķÖżķØ× `return_vis=True`ŃĆé + +- `predictions` ÕīģÕɽõ╗ź json-ÕÅ»Õ║ÅÕłŚÕī¢µĀ╝Õ╝ÅĶ┐öÕø×ńÜäķó䵥ŗń╗ōµ×£ŃĆéÕ”éõĖŗµēĆńż║’╝īÕåģÕ«╣ÕøĀõ╗╗ÕŖĪń▒╗Õ×ŗĶĆīÕ╝éŃĆé + + `````{tabs} + + :::{group-tab} MMOCRInferencer + + ```python + { + 'predictions' : [ + # µ»ÅõĖ¬Õ«×õŠŗķāĮÕ»╣Õ║öõ║ÄõĖĆõĖ¬ĶŠōÕģźÕøŠÕāÅ + { + 'det_polygons': [...], # 2d ÕłŚĶĪ©’╝īķĢ┐Õ║”õĖ║ (N,)’╝īµĀ╝Õ╝ÅõĖ║ [x1, y1, x2, y2, ...] + 'det_scores': [...], # µĄ«ńé╣ÕłŚĶĪ©’╝īķĢ┐Õ║”õĖ║’╝łN, ’╝ē + 'det_bboxes': [...], # 2d ÕłŚĶĪ©’╝īÕĮóńŖČõĖ║ (N, 4)’╝īµĀ╝Õ╝ÅõĖ║ [min_x, min_y, max_x, max_y] + 'rec_texts': [...], # ÕŁŚń¼”õĖ▓ÕłŚĶĪ©’╝īķĢ┐Õ║”õĖ║’╝łN, ’╝ē + 'rec_scores': [...], # µĄ«ńé╣ÕłŚĶĪ©’╝īķĢ┐Õ║”õĖ║’╝łN, ’╝ē + 'kie_labels': [...], # ĶŖéńé╣µĀćńŁŠ’╝īķĢ┐Õ║”õĖ║ (N, ) + 'kie_scores': [...], # ĶŖéńé╣ńĮ«õ┐ĪÕ║”’╝īķĢ┐Õ║”õĖ║ (N, ) + 'kie_edge_scores': [...], # ĶŠ╣ķó䵥ŗńĮ«õ┐ĪÕ║”, ÕĮóńŖČõĖ║ (N, N) + 'kie_edge_labels': [...] # ĶŠ╣µĀćńŁŠ, ÕĮóńŖČõĖ║ (N, N) + }, + ... + ], + 'visualization' : [ + array(..., dtype=uint8), + ] + } + ``` + + ::: + + ````{group-tab} µĀćÕćåµÄ©ńÉåÕÖ© + + ::::{tabs} + :::{code-tab} python TextDetInferencer + + { + 'predictions' : [ + # µ»ÅõĖ¬Õ«×õŠŗķāĮÕ»╣Õ║öõ║ÄõĖĆõĖ¬ĶŠōÕģźÕøŠÕāÅ + { + 'polygons': [...], # 2d ÕłŚĶĪ©’╝īķĢ┐Õ║”õĖ║ (N,)’╝īµĀ╝Õ╝ÅõĖ║ [x1, y1, x2, y2, ...] + 'bboxes': [...], # 2d ÕłŚĶĪ©’╝īÕĮóńŖČõĖ║ (N, 4)’╝īµĀ╝Õ╝ÅõĖ║ [min_x, min_y, max_x, max_y] + 'scores': [...] # µĄ«ńé╣ÕłŚĶĪ©’╝īķĢ┐Õ║”õĖ║’╝łN, ’╝ē + }, + ... + ] + 'visualization' : [ + array(..., dtype=uint8), + ] + } + ::: + + :::{code-tab} python TextRecInferencer + { + 'predictions' : [ + # µ»ÅõĖ¬Õ«×õŠŗķāĮÕ»╣Õ║öõ║ÄõĖĆõĖ¬ĶŠōÕģźÕøŠÕāÅ + { + 'text': '...', # ÕŁŚń¼”õĖ▓ + 'scores': 0.1, # µĄ«ńé╣ + }, + ... + ] + 'visualization' : [ + array(..., dtype=uint8), + ] + } + ::: + + :::{code-tab} python TextSpottingInferencer + { + 'predictions' : [ + # µ»ÅõĖ¬Õ«×õŠŗķāĮÕ»╣Õ║öõ║ÄõĖĆõĖ¬ĶŠōÕģźÕøŠÕāÅ + { + 'polygons': [...], # 2d ÕłŚĶĪ©’╝īķĢ┐Õ║”õĖ║ (N,)’╝īµĀ╝Õ╝ÅõĖ║ [x1, y1, x2, y2, ...] + 'bboxes': [...], # 2d ÕłŚĶĪ©’╝īÕĮóńŖČõĖ║ (N, 4)’╝īµĀ╝Õ╝ÅõĖ║ [min_x, min_y, max_x, max_y] + 'scores': [...] # µĄ«ńé╣ÕłŚĶĪ©’╝īķĢ┐Õ║”õĖ║’╝łN, ’╝ē + 'texts': ['...',] # ÕŁŚń¼”õĖ▓ÕłŚĶĪ©’╝īķĢ┐Õ║”õĖ║’╝łN, ’╝ē + }, + ] + 'visualization' : [ + array(..., dtype=uint8), + ] + } + ::: + + :::{code-tab} python KIEInferencer + { + 'predictions' : [ + # µ»ÅõĖ¬Õ«×õŠŗķāĮÕ»╣Õ║öõ║ÄõĖĆõĖ¬ĶŠōÕģźÕøŠÕāÅ + { + 'labels': [...], # ĶŖéńé╣µĀćńŁŠ’╝īķĢ┐Õ║”õĖ║ (N, ) + 'scores': [...], # ĶŖéńé╣ńĮ«õ┐ĪÕ║”’╝īķĢ┐Õ║”õĖ║ (N, ) + 'edge_scores': [...], # ĶŠ╣ķó䵥ŗńĮ«õ┐ĪÕ║”, ÕĮóńŖČõĖ║ (N, N) + 'edge_labels': [...], # ĶŠ╣µĀćńŁŠ, ÕĮóńŖČõĖ║ (N, N) + }, + ] + 'visualization' : [ + array(..., dtype=uint8), + ] + } + ::: + :::: + ```` + + ````` + +Õ”éµ×£õĮĀµā│Ķ”üõ╗ĵ©ĪÕ×ŗõĖŁĶÄĘÕÅ¢ÕĤզŗĶŠōÕć║’╝īÕÅ»õ╗źÕ░å `return_datasamples` Ķ«ŠńĮ«õĖ║ `True` µØźĶÄĘÕÅ¢ÕĤզŗńÜä [DataSample](structures.md)’╝īÕ«āÕ░åÕŁśÕé©Õ£© `predictions` õĖŁŃĆé + +### Õé©ÕŁśń╗ōµ×£ + +ķÖżõ║åõ╗ÄĶ┐öÕø×ÕĆ╝õĖŁĶÄĘÕÅ¢ķó䵥ŗń╗ōµ×£’╝īõĮĀĶ┐śÕÅ»õ╗źķĆÜĶ┐ćĶ«ŠńĮ« `out_dir` ÕÆī `save_pred`/`save_vis` ÕÅéµĢ░Õ░åķó䵥ŗń╗ōµ×£ÕÆīÕÅ»Ķ¦åÕī¢ń╗ōµ×£Õ»╝Õć║Õł░µ¢ćõ╗ČõĖŁŃĆé + +```python +>>> inferencer('img_1.jpg', out_dir='outputs/', save_pred=True, save_vis=True) +``` + +ń╗ōµ×£ńø«ÕĮĢń╗ōµ×äÕ”éõĖŗ’╝Ü + +```text +outputs +Ōö£ŌöĆŌöĆ preds +Ōöé ŌööŌöĆŌöĆ img_1.json +ŌööŌöĆŌöĆ vis + ŌööŌöĆŌöĆ img_1.jpg +``` + +µ¢ćõ╗ČÕÉŹõĖÄÕ»╣Õ║öńÜäĶŠōÕģźÕøŠÕāŵ¢ćõ╗ČÕÉŹńøĖÕÉīŃĆé Õ”éµ×£ĶŠōÕģźÕøŠÕāŵś»µĢ░ń╗ä’╝īÕłÖµ¢ćõ╗ČÕÉŹÕ░åµś»õ╗Ä0Õ╝ĆÕ¦ŗńÜäµĢ░ÕŁŚŃĆé + +### µē╣ķćŵĩńÉå + +õĮĀÕÅ»õ╗źķĆÜĶ┐ćĶ«ŠńĮ« `batch_size` µØźĶć¬Õ«Üõ╣ēµē╣ķćŵĩńÉåńÜäµē╣Õż¦Õ░ÅŃĆé ķ╗śĶ«żµē╣Õż¦Õ░ÅõĖ║ 1ŃĆé + +## API + +Ķ┐ÖķćīÕłŚÕć║õ║åµÄ©ńÉåÕÖ©Ķ»”Õ░ĮńÜäÕÅéµĢ░ÕłŚĶĪ©ŃĆé + +````{tabs} + +```{group-tab} MMOCRInferencer + +**MMOCRInferencer.\_\_init\_\_():** + +| ÕÅéµĢ░ | ń▒╗Õ×ŗ | ķ╗śĶ«żÕĆ╝ | µÅÅĶ┐░ | +| ------------- | ----------------------------------------- | ------ | ------------------------------------------------------------------------------------------------------------------------------ | +| `det` | str µł¢ [µØāķćŹ](../modelzoo.html#id2), ÕÅ»ķĆē | None | ķóäĶ«Łń╗āńÜäµ¢ćµ£¼µŻĆµĄŗń«Śµ│ĢŃĆéÕ«āµś»ķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠäµł¢ĶĆģµś» metafile õĖŁÕ«Üõ╣ēńÜ䵩ĪÕ×ŗÕÉŹń¦░ŃĆé | +| `det_weights` | str, ÕÅ»ķĆē | None | det µ©ĪÕ×ŗńÜäµØāķ揵¢ćõ╗ČńÜäĶĘ»ÕŠäŃĆé | +| `rec` | str µł¢ [µØāķćŹ](../modelzoo.html#id2), ÕÅ»ķĆē | None | ķóäĶ«Łń╗āńÜäµ¢ćµ£¼Ķ»åÕł½ń«Śµ│ĢŃĆéÕ«āµś»ķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠäµł¢ĶĆģµś» metafile õĖŁÕ«Üõ╣ēńÜ䵩ĪÕ×ŗÕÉŹń¦░ŃĆé | +| `rec_weights` | str, ÕÅ»ķĆē | None | rec µ©ĪÕ×ŗńÜäµØāķ揵¢ćõ╗ČńÜäĶĘ»ÕŠäŃĆé | +| `kie` \[1\] | str µł¢ [µØāķćŹ](../modelzoo.html#id2), ÕÅ»ķĆē | None | ķóäĶ«Łń╗āńÜäÕģ│ķö«õ┐Īµü»µÅÉÕÅ¢ń«Śµ│ĢŃĆéÕ«āµś»ķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠäµł¢ĶĆģµś» metafile õĖŁÕ«Üõ╣ēńÜ䵩ĪÕ×ŗÕÉŹń¦░ŃĆé | +| `kie_weights` | str, ÕÅ»ķĆē | None | kie µ©ĪÕ×ŗńÜäµØāķ揵¢ćõ╗ČńÜäĶĘ»ÕŠäŃĆé | +| `device` | str, ÕÅ»ķĆē | None | µÄ©ńÉåõĮ┐ńö©ńÜäĶ«ŠÕżć’╝īµÄźÕÅŚ `torch.device` ÕģüĶ«ĖńÜäµēƵ£ēÕŁŚń¼”õĖ▓ŃĆéõŠŗÕ”é’╝ī'cuda:0' µł¢ 'cpu'ŃĆéÕ”éµ×£õĖ║ None’╝īÕ░åĶć¬ÕŖ©õĮ┐ńö©ÕÅ»ńö©Ķ«ŠÕżćŃĆé ķ╗śĶ«żõĖ║ NoneŃĆé | + +\[1\]: ÕĮōÕÉīµŚČµīćÕ«Üõ║åµ¢ćµ£¼µŻĆµĄŗÕÆīĶ»åÕł½µ©ĪÕ×ŗµŚČ’╝ī`kie` µēŹõ╝Üńö¤µĢłŃĆé + +**MMOCRInferencer.\_\_call\_\_()** + +| ÕÅéµĢ░ | ń▒╗Õ×ŗ | ķ╗śĶ«żÕĆ╝ | µÅÅĶ┐░ | +| -------------------- | ----------------------- | ---------- | ---------------------------------------------------------------------------------------------- | +| `inputs` | str/list/tuple/np.array | **Õ┐ģķ£Ć** | Õ«āÕÅ»õ╗źµś»õĖĆõĖ¬ÕøŠńēć/µ¢ćõ╗ČÕż╣ńÜäĶĘ»ÕŠä’╝īõĖĆõĖ¬ numpy µĢ░ń╗ä’╝īµł¢ĶĆģµś»õĖĆõĖ¬ÕīģÕɽÕøŠńēćĶĘ»ÕŠäµł¢ numpy µĢ░ń╗äńÜäÕłŚĶĪ©/Õģāń╗ä | +| `return_datasamples` | bool | False | µś»ÕÉ”Õ░åń╗ōµ×£õĮ£õĖ║ DataSample Ķ┐öÕø×ŃĆéÕ”éµ×£õĖ║ False’╝īń╗ōµ×£Õ░åĶó½µēōÕīģµłÉõĖĆõĖ¬ÕŁŚÕģĖŃĆé | +| `batch_size` | int | 1 | µÄ©ńÉåńÜäµē╣Õż¦Õ░ÅŃĆé | +| `det_batch_size` | int, ÕÅ»ķĆē | None | µÄ©ńÉåńÜäµē╣Õż¦Õ░Å (µ¢ćµ£¼µŻĆµĄŗµ©ĪÕ×ŗ)ŃĆéÕ”éµ×£õĖŹõĖ║ None’╝īÕłÖĶ”åńø¢ batch_sizeŃĆé | +| `rec_batch_size` | int, ÕÅ»ķĆē | None | µÄ©ńÉåńÜäµē╣Õż¦Õ░Å (µ¢ćµ£¼Ķ»åÕł½µ©ĪÕ×ŗ)ŃĆéÕ”éµ×£õĖŹõĖ║ None’╝īÕłÖĶ”åńø¢ batch_sizeŃĆé | +| `kie_batch_size` | int, ÕÅ»ķĆē | None | µÄ©ńÉåńÜäµē╣Õż¦Õ░Å (Õģ│ķö«õ┐Īµü»µÅÉÕÅ¢µ©ĪÕ×ŗ)ŃĆéÕ”éµ×£õĖŹõĖ║ None’╝īÕłÖĶ”åńø¢ batch_sizeŃĆé | +| `return_vis` | bool | False | µś»ÕÉ”Ķ┐öÕø×ÕÅ»Ķ¦åÕī¢ń╗ōµ×£ŃĆé | +| `print_result` | bool | False | µś»ÕÉ”Õ░åµÄ©ńÉåń╗ōµ×£µēōÕŹ░Õł░µÄ¦ÕłČÕÅ░ŃĆé | +| `show` | bool | False | µś»Õɔգ©Õ╝╣Õć║ń¬ŚÕÅŻõĖŁµśŠńż║ÕÅ»Ķ¦åÕī¢ń╗ōµ×£ŃĆé | +| `wait_time` | float | 0 | Õ╝╣ń¬ŚÕ▒Ģńż║ÕÅ»Ķ¦åÕī¢ń╗ōµ×£ńÜ䵌ČķŚ┤ķŚ┤ķÜöŃĆé | +| `out_dir` | str | `results/` | ń╗ōµ×£ńÜäĶŠōÕć║ńø«ÕĮĢŃĆé | +| `save_vis` | bool | False | µś»ÕÉ”Õ░åÕÅ»Ķ¦åÕī¢ń╗ōµ×£õ┐ØÕŁśÕł░ `out_dir`ŃĆé | +| `save_pred` | bool | False | µś»ÕÉ”Õ░åµÄ©ńÉåń╗ōµ×£õ┐ØÕŁśÕł░ `out_dir`ŃĆé | + +``` + +```{group-tab} µĀćÕćåµÄ©ńÉåÕÖ© + +**Inferencer.\_\_init\_\_():** + +| ÕÅéµĢ░ | ń▒╗Õ×ŗ | ķ╗śĶ«żÕĆ╝ | µÅÅĶ┐░ | +| --------- | ----------------------------------------- | ------ | ---------------------------------------------------------------------------------------------------------------------------------- | +| `model` | str µł¢ [µØāķćŹ](../modelzoo.html#id2), ÕÅ»ķĆē | None | ĶĘ»ÕŠäÕł░ķģŹńĮ«µ¢ćõ╗ȵł¢ĶĆģÕ£© metafile õĖŁÕ«Üõ╣ēńÜ䵩ĪÕ×ŗÕÉŹń¦░ŃĆé | +| `weights` | str, ÕÅ»ķĆē | None | µØāķ揵¢ćõ╗ČńÜäĶĘ»ÕŠäŃĆé | +| `device` | str, ÕÅ»ķĆē | None | µÄ©ńÉåõĮ┐ńö©ńÜäĶ«ŠÕżć’╝īµÄźÕÅŚ `torch.device` ÕģüĶ«ĖńÜäµēƵ£ēÕŁŚń¼”õĖ▓ŃĆé õŠŗÕ”é’╝ī'cuda:0' µł¢ 'cpu'ŃĆé Õ”éµ×£õĖ║ None’╝īÕłÖÕ░åĶć¬ÕŖ©õĮ┐ńö©ÕÅ»ńö©Ķ«ŠÕżćŃĆé ķ╗śĶ«żõĖ║ NoneŃĆé | + +**Inferencer.\_\_call\_\_()** + +| ÕÅéµĢ░ | ń▒╗Õ×ŗ | ķ╗śĶ«żÕĆ╝ | µÅÅĶ┐░ | +| -------------------- | ----------------------- | ---------- | ----------------------------------------------------------------------------------- | +| `inputs` | str/list/tuple/np.array | **Õ┐ģķ£Ć** | ÕÅ»õ╗źµś»ÕøŠÕāÅńÜäĶĘ»ÕŠä/µ¢ćõ╗ČÕż╣’╝īnp µĢ░ń╗䵳¢ÕłŚĶĪ©/Õģāń╗ä’╝łÕĖ”µ£ēÕøŠÕāÅĶĘ»ÕŠäµł¢ np µĢ░ń╗ä’╝ē | +| `return_datasamples` | bool | False | µś»ÕÉ”Õ░åń╗ōµ×£õĮ£õĖ║ DataSamples Ķ┐öÕø×ŃĆé Õ”éµ×£õĖ║ False’╝īÕłÖń╗ōµ×£Õ░åĶó½µēōÕīģÕł░õĖĆõĖ¬ dict õĖŁŃĆé | +| `batch_size` | int | 1 | µÄ©ńÉåµē╣Õż¦Õ░ÅŃĆé | +| `progress_bar` | bool | True | µś»ÕÉ”µśŠńż║Ķ┐øÕ║”µØĪŃĆé | +| `return_vis` | bool | False | µś»ÕÉ”Ķ┐öÕø×ÕÅ»Ķ¦åÕī¢ń╗ōµ×£ŃĆé | +| `print_result` | bool | False | µś»ÕÉ”Õ░åµÄ©ńÉåń╗ōµ×£µēōÕŹ░Õł░µÄ¦ÕłČÕÅ░ŃĆé | +| `show` | bool | False | µś»Õɔգ©Õ╝╣Õć║ń¬ŚÕÅŻõĖŁµśŠńż║ÕÅ»Ķ¦åÕī¢ń╗ōµ×£ŃĆé | +| `wait_time` | float | 0 | Õ╝╣ń¬ŚÕ▒Ģńż║ÕÅ»Ķ¦åÕī¢ń╗ōµ×£ńÜ䵌ČķŚ┤ķŚ┤ķÜöŃĆé | +| `draw_pred` | bool | True | µś»ÕÉ”ń╗śÕłČķó䵥ŗńÜäĶŠ╣ńĢīµĪåŃĆé *õ╗ģķĆéńö©õ║Ä `TextDetInferencer` ÕÆī `TextSpottingInferencer`ŃĆé* | +| `out_dir` | str | `results/` | ń╗ōµ×£ńÜäĶŠōÕć║ńø«ÕĮĢŃĆé | +| `save_vis` | bool | False | µś»ÕÉ”Õ░åÕÅ»Ķ¦åÕī¢ń╗ōµ×£õ┐ØÕŁśÕł░ `out_dir`ŃĆé | +| `save_pred` | bool | False | µś»ÕÉ”Õ░åµÄ©ńÉåń╗ōµ×£õ┐ØÕŁśÕł░ `out_dir`ŃĆé | + +``` +```` + +## ÕæĮõ╗żĶĪīµÄźÕÅŻ + +```{note} +Ķ»źĶŖéõ╗ģķĆéńö©õ║Ä `MMOCRInferencer`. +``` + +`MMOCRInferencer` ńÜäÕæĮõ╗żĶĪīÕĮóÕ╝ÅÕÅ»õ╗źķĆÜĶ┐ć `tools/infer.py` Ķ░āńö©’╝īÕż¦Ķć┤ÕĮóÕ╝ÅÕ”éõĖŗ’╝Ü + +```bash +python tools/infer.py INPUT_PATH [--det DET] [--det-weights ...] ... +``` + +ÕģČõĖŁ’╝ī`INPUT_PATH` õĖ║Õ┐ģķĪ╗ÕŁŚµ«Ą’╝īÕåģÕ«╣Õ║öÕĮōõĖ║µīćÕÉæÕøŠńē浳¢µ¢ćõ╗Čńø«ÕĮĢńÜäĶĘ»ÕŠäŃĆéÕģČõ╗¢ÕÅéµĢ░õĖÄ Python µÄźÕÅŻķüĄÕŠ¬ńÜ䵜ĀÕ░äÕģ│ń│╗Õ”éõĖŗ’╝Ü + +- Õ£©ÕæĮõ╗żĶĪīõĖŁĶ░āńö©ÕÅéµĢ░µŚČ’╝īķ£ĆĶ”üÕ£© Python µÄźÕÅŻńÜäÕÅéµĢ░ÕēŹķØóÕŖĀõĖŖõĖżõĖ¬`-`’╝īńäČÕÉĵŖŖõĖŗÕłÆń║┐`_`µø┐µŹóµłÉĶ┐×ÕŁŚń¼”`-`ŃĆéõŠŗÕ”é’╝ī `out_dir` õ╝ÜÕÅśµłÉ `--out-dir`ŃĆé +- Õ»╣õ║ÄÕĖāÕ░öń▒╗Õ×ŗńÜäÕÅéµĢ░’╝īÕ░åÕÅéµĢ░µöŠÕ£©ÕæĮõ╗żõĖŁÕ░▒ńøĖÕĮōõ║ÄÕ░åÕģȵīćÕ«ÜõĖ║ TrueŃĆéõŠŗÕ”é’╝ī `--show` õ╝ÜÕ░å `show` ÕÅéµĢ░µīćÕ«ÜõĖ║ TrueŃĆé + +µŁżÕż¢’╝īÕæĮõ╗żĶĪīõĖŁķ╗śĶ«żõĖŹõ╝ÜÕø×µśŠµÄ©ńÉåń╗ōµ×£’╝īõĮĀÕÅ»õ╗źķĆÜĶ┐ć `--print-result` ÕÅéµĢ░µØźµ¤źń£ŗµÄ©ńÉåń╗ōµ×£ŃĆé + +õĖŗķØ󵜻õĖĆõĖ¬õŠŗÕŁÉ’╝Ü + +```bash +python tools/infer.py demo/demo_text_ocr.jpg --det DBNet --rec SAR --show --print-result +``` + +Ķ┐ÉĶĪīĶ»źÕæĮõ╗ż’╝īÕÅ»õ╗źÕŠŚÕł░Õ”éõĖŗń╗ōµ×£’╝Ü + +```bash +{'predictions': [{'rec_texts': ['CBank', 'Docbcba', 'GROUP', 'MAUN', 'CROBINSONS', 'AOCOC', '916M3', 'BOO9', 'Oven', 'BRANDS', 'ARETAIL', '14', '70
+  +
+
+
++ +```bash +# Ķ»åÕł½ń╗ōµ×£ +{'predictions': [{'rec_texts': ['cbanks', 'docecea', 'grouf', 'pwate', 'chobnsonsg', 'soxee', 'oeioh', 'c', 'sones', 'lbrandec', 'sretalg', '11', 'to8', 'round', 'sale', 'year', +'ally', 'sie', 'sall'], 'rec_scores': [...], 'det_polygons': [...], 'det_scores': +[...]}]} +``` + +```{note} +Õ”éµ×£õĮĀÕ£©µ▓Īµ£ē GUI ńÜäµ£ŹÕŖĪÕÖ©õĖŖĶ┐ÉĶĪī MMOCR’╝īµł¢ĶĆģķĆÜĶ┐ćµ▓Īµ£ēÕ╝ĆÕÉ» X11 ĶĮ¼ÕÅæńÜä SSH ķܦķüōĶ┐ÉĶĪī MMOCR’╝īõĮĀÕÅ»ĶāĮµŚĀµ│Ģń£ŗÕł░Õ╝╣Õć║ńÜäń¬ŚÕÅŻŃĆé +``` + +## Ķć¬Õ«Üõ╣ēÕ«ēĶŻģ + +### CUDA ńēłµ£¼ + +Õ«ēĶŻģ PyTorch µŚČ’╝īķ£ĆĶ”üµīćÕ«Ü CUDA ńēłµ£¼ŃĆéÕ”éµ×£µé©õĖŹµĖģµźÜķĆēµŗ®Õō¬õĖ¬’╝īĶ»ĘķüĄÕŠ¬µłæõ╗¼ńÜäÕ╗║Ķ««’╝Ü + +- Õ»╣õ║Ä Ampere µ×ȵ×äńÜä NVIDIA GPU’╝īõŠŗÕ”é GeForce 30 series õ╗źÕÅŖ NVIDIA A100’╝īCUDA 11 µś»Õ┐ģķ£ĆńÜäŃĆé +- Õ»╣õ║ĵø┤µŚ®ńÜä NVIDIA GPU’╝īCUDA 11 µś»ÕÉæÕēŹÕģ╝Õ«╣ńÜä’╝īõĮå CUDA 10.2 ĶāĮÕż¤µÅÉõŠøµø┤ÕźĮńÜäÕģ╝Õ«╣µĆ¦’╝īõ╣¤µø┤ÕŖĀĶĮ╗ķćÅŃĆé + +Ķ»ĘńĪ«õ┐ØõĮĀńÜä GPU ķ®▒ÕŖ©ńēłµ£¼µ╗ĪĶČ│µ£ĆõĮÄńÜäńēłµ£¼ķ£Ćµ▒é’╝īÕÅéķśģ[Ķ┐ÖÕ╝ĀĶĪ©](https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html#cuda-major-component-versions__table-cuda-toolkit-driver-versions)ŃĆé + +```{note} +Õ”éµ×£µīēńģ¦µłæõ╗¼ńÜäµ£ĆõĮ│Õ«×ĶĘĄĶ┐øĶĪīÕ«ēĶŻģ’╝īCUDA Ķ┐ÉĶĪīµŚČÕ║ōÕ░▒ĶČ│Õż¤õ║å’╝īÕøĀõĖ║µłæõ╗¼µÅÉõŠøńøĖÕģ│ CUDA õ╗ŻńĀüńÜäķóäń╝¢Ķ»æ’╝īõĮĀõĖŹķ£ĆĶ”üĶ┐øĶĪīµ£¼Õ£░ń╝¢Ķ»æŃĆé +õĮåÕ”éµ×£õĮĀÕĖīµ£øõ╗ĵ║ÉńĀüĶ┐øĶĪī MMCV ńÜäń╝¢Ķ»æ’╝īµł¢µś»Ķ┐øĶĪīÕģČõ╗¢ CUDA ń«ŚÕŁÉńÜäÕ╝ĆÕÅæ’╝īķéŻõ╣łÕ░▒Õ┐ģķĪ╗Õ«ēĶŻģÕ«īµĢ┤ńÜä CUDA ÕĘźÕģĘķōŠ’╝īÕÅéĶ¦ü +[NVIDIA Õ«śńĮæ](https://developer.nvidia.com/cuda-downloads)’╝īÕÅ”Õż¢Ķ┐śķ£ĆĶ”üńĪ«õ┐ØĶ»ź CUDA ÕĘźÕģĘķōŠńÜäńēłµ£¼õĖÄ PyTorch Õ«ēĶŻģµŚČ +ńÜäķģŹńĮ«ńøĖÕī╣ķģŹ’╝łÕ”éńö© `conda install` Õ«ēĶŻģ PyTorch µŚČµīćÕ«ÜńÜä cudatoolkit ńēłµ£¼’╝ēŃĆé +``` + +### õĖŹõĮ┐ńö© MIM Õ«ēĶŻģ MMCV + +MMCV ÕīģÕɽ C++ ÕÆī CUDA µē®Õ▒Ģ’╝īÕøĀµŁżÕģČÕ»╣ PyTorch ńÜäõŠØĶĄ¢µ»öĶŠāÕżŹµØéŃĆéMIM õ╝ÜĶć¬ÕŖ©Ķ¦Żµ×ÉĶ┐Öõ║ø +õŠØĶĄ¢’╝īķĆēµŗ®ÕÉłķĆéńÜä MMCV ķóäń╝¢Ķ»æÕīģ’╝īõĮ┐Õ«ēĶŻģµø┤ń«ĆÕŹĢ’╝īõĮåÕ«āÕ╣ČõĖŹµś»Õ┐ģķ£ĆńÜäŃĆé + +Ķ”üõĮ┐ńö© pip ĶĆīõĖŹµś» MIM µØźÕ«ēĶŻģ MMCV’╝īĶ»ĘķüĄńģ¦ [MMCV Õ«ēĶŻģµīćÕŹŚ](https://mmcv.readthedocs.io/zh_CN/latest/get_started/installation.html)ŃĆé +Õ«āķ£ĆĶ”üõĮĀńö©µīćÕ«Ü url ńÜäÕĮóÕ╝ŵēŗÕŖ©µīćÕ«ÜÕ»╣Õ║öńÜä PyTorch ÕÆī CUDA ńēłµ£¼ŃĆé + +õĖŠõĖ¬õŠŗÕŁÉ’╝īÕ”éõĖŗÕæĮõ╗żÕ░åõ╝ÜÕ«ēĶŻģÕ¤║õ║Ä PyTorch 1.10.x ÕÆī CUDA 11.3 ń╝¢Ķ»æńÜä mmcv-fullŃĆé + +```shell +pip install 'mmcv>=2.0.0rc1' -f https://download.openmmlab.com/mmcv/dist/cu113/torch1.10/index.html +``` + +### Õ£© CPU ńÄ»ÕóāõĖŁÕ«ēĶŻģ + +MMOCR ÕÅ»õ╗źõ╗ģÕ£© CPU ńÄ»ÕóāõĖŁÕ«ēĶŻģ’╝īÕ£© CPU µ©ĪÕ╝ÅõĖŗ’╝īõĮĀÕÅ»õ╗źÕ«īµłÉĶ«Łń╗ā’╝łķ£ĆĶ”ü MMCV ńēłµ£¼ >= 1.4.4’╝ēŃĆüµĄŗĶ»ĢÕÆīµ©ĪÕ×ŗµÄ©ńÉåńŁēµēƵ£ēµōŹõĮ£ŃĆé + +Õ£© CPU µ©ĪÕ╝ÅõĖŗ’╝īMMCV õĖŁńÜäõ╗źõĖŗń«ŚÕŁÉÕ░åõĖŹÕÅ»ńö©’╝Ü + +- Deformable Convolution +- Modulated Deformable Convolution +- ROI pooling +- SyncBatchNorm + +Õ”éµ×£õĮĀÕ░ØĶ»ĢõĮ┐ńö©ńö©Õł░õ║åõ╗źõĖŖń«ŚÕŁÉńÜ䵩ĪÕ×ŗĶ┐øĶĪīĶ«Łń╗āŃĆüµĄŗĶ»Ģµł¢µÄ©ńÉå’╝īń©ŗÕ║ÅÕ░åõ╝ܵŖźķöÖŃĆéõ╗źõĖŗõĖ║ÕÅ»ĶāĮÕÅŚÕł░ÕĮ▒ÕōŹńÜ䵩ĪÕ×ŗÕłŚĶĪ©’╝Ü + +| ń«ŚÕŁÉ | µ©ĪÕ×ŗ | +| :-----------------------------------------------------: | :-----------------------------------------------------: | +| Deformable Convolution/Modulated Deformable Convolution | DBNet (r50dcnv2), DBNet++ (r50dcnv2), FCENet (r50dcnv2) | +| SyncBatchNorm | PANet, PSENet | + +### ķĆÜĶ┐ć Docker õĮ┐ńö© MMOCR + +µłæõ╗¼µÅÉõŠøõ║åõĖĆõĖ¬ [Dockerfile](https://github.com/open-mmlab/mmocr/blob/master/docker/Dockerfile) µ¢ćõ╗Čõ╗źÕ╗║ń½ŗ docker ķĢ£ÕāÅ ŃĆé + +```shell +# build an image with PyTorch 1.6, CUDA 10.1 +docker build -t mmocr docker/ +``` + +õĮ┐ńö©õ╗źõĖŗÕæĮõ╗żĶ┐ÉĶĪīŃĆé + +```shell +docker run --gpus all --shm-size=8g -it -v {Õ«×ķÖģµĢ░µŹ«ńø«ÕĮĢ}:/mmocr/data mmocr +``` + +## Õ»╣ MMEngineŃĆüMMCV ÕÆī MMDetection ńÜäńēłµ£¼õŠØĶĄ¢ + +õĖ║õ║åńĪ«õ┐Øõ╗ŻńĀüÕ«×ńÄ░ńÜ䵣ŻńĪ«µĆ¦’╝īMMOCR µ»ÅõĖ¬ńēłµ£¼ķāĮµ£ēÕÅ»ĶāĮµö╣ÕÅśÕ»╣ MMEngineŃĆüMMCV ÕÆī MMDetection ńēłµ£¼ńÜäõŠØĶĄ¢ŃĆéĶ»ĘµĀ╣µŹ«õ╗źõĖŗĶĪ©µĀ╝ńĪ«õ┐Øńēłµ£¼õ╣ŗķŚ┤ńÜäńøĖõ║ÆÕī╣ķģŹŃĆé + +| MMOCR | MMEngine | MMCV | MMDetection | +| -------------- | --------------------------- | -------------------------- | --------------------------- | +| dev-1.x | 0.7.1 \<= mmengine \< 1.1.0 | 2.0.0rc4 \<= mmcv \< 2.1.0 | 3.0.0rc5 \<= mmdet \< 3.2.0 | +| 1.0.1 | 0.7.1 \<= mmengine \< 1.1.0 | 2.0.0rc4 \<= mmcv \< 2.1.0 | 3.0.0rc5 \<= mmdet \< 3.2.0 | +| 1.0.0 | 0.7.1 \<= mmengine \< 1.0.0 | 2.0.0rc4 \<= mmcv \< 2.1.0 | 3.0.0rc5 \<= mmdet \< 3.1.0 | +| 1.0.0rc6 | 0.6.0 \<= mmengine \< 1.0.0 | 2.0.0rc4 \<= mmcv \< 2.1.0 | 3.0.0rc5 \<= mmdet \< 3.1.0 | +| 1.0.0rc\[4-5\] | 0.1.0 \<= mmengine \< 1.0.0 | 2.0.0rc1 \<= mmcv \< 2.1.0 | 3.0.0rc0 \<= mmdet \< 3.1.0 | +| 1.0.0rc\[0-3\] | 0.0.0 \<= mmengine \< 0.2.0 | 2.0.0rc1 \<= mmcv \< 2.1.0 | 3.0.0rc0 \<= mmdet \< 3.1.0 | diff --git a/internlm_langchain/knowledge_base/MMOCR/content/kie.md b/internlm_langchain/knowledge_base/MMOCR/content/kie.md new file mode 100644 index 00000000..ce8d1462 --- /dev/null +++ b/internlm_langchain/knowledge_base/MMOCR/content/kie.md @@ -0,0 +1,40 @@ +# Õģ│ķö«õ┐Īµü»µÅÉÕÅ¢ + +```{note} +µłæõ╗¼µŁŻÕŖ¬ÕŖøÕŠĆ [Dataset Preparer](./dataset_preparer.md) õĖŁÕó×ÕŖĀµø┤ÕżÜµĢ░µŹ«ķøåŃĆéÕ»╣õ║Ä [Dataset Preparer](./dataset_preparer.md) µÜéµ£¬ĶāĮÕ«īµĢ┤µö»µīüńÜäµĢ░µŹ«ķøå’╝īµ£¼ķĪĄµÅÉõŠøõ║åõĖĆń│╗ÕłŚµēŗÕŖ©õĖŗĶĮĮńÜ䵣źķ¬ż’╝īõŠøµ£ēķ£ĆĶ”üńÜäńö©µłĘõĮ┐ńö©ŃĆé +``` + +## µ”éĶ¦ł + +Õģ│ķö«õ┐Īµü»µÅÉÕÅ¢õ╗╗ÕŖĪńÜäµĢ░µŹ«ķøå’╝īµ¢ćõ╗Čńø«ÕĮĢÕ║öµīēÕ”éõĖŗķģŹńĮ«’╝Ü + +```text +ŌööŌöĆŌöĆ wildreceipt + Ōö£ŌöĆŌöĆ class_list.txt + Ōö£ŌöĆŌöĆ dict.txt + Ōö£ŌöĆŌöĆ image_files + Ōö£ŌöĆŌöĆ test.txt + ŌööŌöĆŌöĆ train.txt +``` + +## ÕćåÕżćµŁźķ¬ż + +### WildReceipt + +- õĖŗĶĮĮÕ╣ČĶ¦ŻÕÄŗ [wildreceipt.tar](https://download.openmmlab.com/mmocr/data/wildreceipt.tar) + +### WildReceiptOpenset + +- ÕćåÕżćÕźĮ [WildReceipt](#WildReceipt)ŃĆé +- ĶĮ¼µŹó WildReceipt µłÉ OpenSet µĀ╝Õ╝Å: + +```bash +# õĮĀÕÅ»õ╗źĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗żõ╗źĶÄĘÕÅ¢µø┤ÕżÜÕÅ»ńö©ÕÅéµĢ░’╝Ü +# python tools/data/kie/closeset_to_openset.py -h +python tools/data/kie/closeset_to_openset.py data/wildreceipt/train.txt data/wildreceipt/openset_train.txt +python tools/data/kie/closeset_to_openset.py data/wildreceipt/test.txt data/wildreceipt/openset_test.txt +``` + +```{note} +[Ķ┐Öń»ćµĢÖń©ŗ](../tutorials/kie_closeset_openset.md)ķćīĶ«▓Ķ┐░õ║åµø┤ÕżÜ CloseSet ÕÆī OpenSet µĢ░µŹ«µĀ╝Õ╝Åõ╣ŗķŚ┤ńÜäÕī║Õł½ŃĆé +``` diff --git a/internlm_langchain/knowledge_base/MMOCR/content/model.md b/internlm_langchain/knowledge_base/MMOCR/content/model.md new file mode 100644 index 00000000..0e276513 --- /dev/null +++ b/internlm_langchain/knowledge_base/MMOCR/content/model.md @@ -0,0 +1,5 @@ +# ķóäĶ«Łń╗āµ©ĪÕ×ŗĶ┐üń¦╗µīćÕŹŚ + +ńö▒õ║ÄÕ£©µ¢░ńēłµ£¼õĖŁµłæõ╗¼Õ»╣µ©ĪÕ×ŗńÜäń╗ōµ×äĶ┐øĶĪīõ║åÕż¦ķćÅńÜäķ揵×äÕÆīõ┐«ÕżŹ’╝īMMOCR 1.x Õ╣ČõĖŹĶāĮńø┤µÄźĶ»╗ÕģźµŚ¦ńēłńÜäķóäĶ«Łń╗āµØāķćŹŃĆ鵳æõ╗¼Õ£©ńĮæń½ÖõĖŖÕÉīµŁźµø┤µ¢░õ║åµēƵ£ēµ©ĪÕ×ŗńÜäķóäĶ«Łń╗āµØāķćŹÕÆīlog’╝īõŠøµ£ēķ£ĆĶ”üńÜäńö©µłĘõĮ┐ńö©ŃĆé + +µŁżÕż¢’╝īµłæõ╗¼µŁŻÕ£©Ķ┐øĶĪīķÆłÕ»╣µ¢ćµ£¼µŻĆµĄŗõ╗╗ÕŖĪńÜäµØāķćŹĶ┐üń¦╗ÕĘźÕģĘńÜäÕ╝ĆÕÅæ’╝īÕ╣ČĶ«ĪÕłÆõ║ÄĶ┐æµ£¤ńēłµ£¼ÕåģÕÅæÕĖāŃĆéńö▒õ║ĵ¢ćµ£¼Ķ»åÕł½ÕÆīÕģ│ķö«õ┐Īµü»µÅÉÕÅ¢µ©ĪÕ×ŗµö╣ÕŖ©Ķ┐ćÕż¦’╝īõĖöĶ┐üń¦╗µś»µ£ēµŹ¤ńÜä’╝īµłæõ╗¼µÜ鵌ČõĖŹĶ«ĪÕłÆõĮ£ńøĖÕ║öµö»µīüŃĆéÕ”éµ×£µé©µ£ēÕģĘõĮōńÜäķ£Ćµ▒é’╝īµ¼óĶ┐ÄķĆÜĶ┐ć [Issue](https://github.com/open-mmlab/mmocr/issues) ÕÉæµłæõ╗¼µÅÉķŚ«ŃĆé diff --git a/internlm_langchain/knowledge_base/MMOCR/content/models.md b/internlm_langchain/knowledge_base/MMOCR/content/models.md new file mode 100644 index 00000000..7ec449d5 --- /dev/null +++ b/internlm_langchain/knowledge_base/MMOCR/content/models.md @@ -0,0 +1,3 @@ +# µ©ĪÕ×ŗ\[ÕŠģµø┤µ¢░\] + +ÕŠģµø┤µ¢░ diff --git a/internlm_langchain/knowledge_base/MMOCR/content/news.md b/internlm_langchain/knowledge_base/MMOCR/content/news.md new file mode 100644 index 00000000..e1ca6f91 --- /dev/null +++ b/internlm_langchain/knowledge_base/MMOCR/content/news.md @@ -0,0 +1,19 @@ +# MMOCR 1.x µø┤µ¢░µ▒ćµĆ╗ + +µŁżÕżäÕłŚÕć║õ║å MMOCR 1.x ńøĖÕ»╣õ║Ä 0.x ńēłµ£¼ńÜäķćŹÕż¦µø┤µ¢░ŃĆé + +1. µ×ȵ×äÕŹćń║¦’╝ÜMMOCR 1.x µś»Õ¤║õ║Ä [MMEngine](https://github.com/open-mmlab/mmengine)’╝īµÅÉõŠøõ║åõĖĆõĖ¬ķĆÜńö©ńÜäŃĆüÕ╝║Õż¦ńÜäµē¦ĶĪīÕÖ©’╝īÕģüĶ«Ėµø┤ńüĄµ┤╗ńÜäÕ«ÜÕłČ’╝īµÅÉõŠøõ║åń╗¤õĖĆńÜäĶ«Łń╗āÕÆīµĄŗĶ»ĢÕģźÕÅŻŃĆé + +2. ń╗¤õĖƵğÕÅŻ’╝ÜMMOCR 1.x ń╗¤õĖĆõ║åµĢ░µŹ«ķøåŃĆüµ©ĪÕ×ŗŃĆüĶ»äõ╝░ÕÆīÕÅ»Ķ¦åÕī¢ńÜäµÄźÕÅŻÕÆīÕåģķā©ķĆ╗ĶŠæŃĆéµö»µīüµø┤Õ╝║ńÜäµē®Õ▒ĢµĆ¦ŃĆé + +3. ĶĘ©ķĪ╣ńø«Ķ░āńö©’╝ÜÕÅŚńøŖõ║Äń╗¤õĖĆńÜäĶ«ŠĶ«Ī’╝īõĮĀÕÅ»õ╗źõĮ┐ńö©ÕģČõ╗¢OpenMMLabķĪ╣ńø«õĖŁÕ«×ńÄ░ńÜ䵩ĪÕ×ŗ’╝īÕ”éMMDetŃĆé µłæõ╗¼µÅÉõŠøõ║åõĖĆõĖ¬õŠŗÕŁÉ’╝īĶ»┤µśÄÕ”éõĮĢķĆÜĶ┐ćMMDetWrapperõĮ┐ńö©MMDetectionńÜäMask R-CNNŃĆ鵤źń£ŗµłæõ╗¼ńÜäµ¢ćµĪŻõ╗źõ║åĶ¦Żµø┤ÕżÜń╗åĶŖéŃĆéµø┤ÕżÜńÜäÕīģĶŻģÕÖ©Õ░åÕ£©µ£¬µØźÕÅæÕĖāŃĆé + +4. µø┤Õ╝║ńÜäÕÅ»Ķ¦åÕī¢’╝ܵłæõ╗¼µÅÉõŠøõ║åõĖĆń│╗ÕłŚÕÅ»Ķ¦åÕī¢ÕĘźÕģĘ’╝ī ńö©µłĘńÄ░Õ£©ÕÅ»õ╗źµø┤µ¢╣õŠ┐ÕÅ»Ķ¦åÕī¢µĢ░µŹ«ŃĆé + +5. µø┤ÕżÜńÜäµ¢ćµĪŻÕÆīµĢÖń©ŗ’╝ܵłæõ╗¼Õó×ÕŖĀõ║åµø┤ÕżÜńÜäµĢÖń©ŗ’╝īķÖŹõĮÄńö©µłĘńÜäÕŁ”õ╣ĀķŚ©µ¦øŃĆé + +6. õĖĆń½ÖÕ╝ŵĢ░µŹ«ÕćåÕżć’╝ÜÕćåÕżćµĢ░µŹ«ķøåÕĘ▓ń╗ÅõĖŹÕåŹµś»ķÜŠõ║ŗŃĆéõĮ┐ńö©µłæõ╗¼ńÜä [Dataset Preparer](https://mmocr.readthedocs.io/zh_CN/dev-1.x/user_guides/data_prepare/dataset_preparer.html)’╝īõĖĆĶĪīÕæĮõ╗żÕŹ│ÕÅ»Ķ«®ÕżÜõĖ¬µĢ░µŹ«ķøåÕćåÕżćÕ░▒ń╗¬ŃĆé + +7. µŗźµŖ▒µø┤ÕżÜ `projects/`: µłæõ╗¼µÄ©Õć║õ║å `projects/` µ¢ćõ╗ČÕż╣’╝īńö©õ║ÄÕŁśµöŠõĖĆõ║øÕ«×ķ¬īµĆ¦ńÜäµ¢░ńē╣µĆ¦ŃĆüµĪåµ×ČÕÆīµ©ĪÕ×ŗŃĆ鵳æõ╗¼Õ»╣Ķ┐ÖõĖ¬µ¢ćõ╗ČÕż╣õĖŗńÜäõ╗ŻńĀüĶ¦äĶīāõĖŹõĮ£Ķ┐ćÕżÜĶ”üµ▒é’╝īÕŖøµ▒éĶ«®ńżŠÕī║ńÜäµēƵ£ēµā│µ│Ģń¼¼õĖƵŚČķŚ┤ÕŠŚÕł░Õ«×ńÄ░ÕÆīÕ▒Ģńż║ŃĆéĶ»Ęµ¤źń£ŗµłæõ╗¼ńÜä[µĀĘõŠŗ project](https://github.com/open-mmlab/mmocr/blob/dev-1.x/projects/example_project/) õ╗źõ║åĶ¦Żµø┤ÕżÜŃĆé + +8. µø┤ÕżÜµ¢░µ©ĪÕ×ŗ’╝ÜMMOCR 1.0 µö»µīüõ║åµø┤ÕżÜµ©ĪÕ×ŗÕÆīµ©ĪÕ×ŗń¦Źń▒╗ŃĆé diff --git a/internlm_langchain/knowledge_base/MMOCR/content/overview.md b/internlm_langchain/knowledge_base/MMOCR/content/overview.md new file mode 100644 index 00000000..bbd72139 --- /dev/null +++ b/internlm_langchain/knowledge_base/MMOCR/content/overview.md @@ -0,0 +1,3 @@ +# Ķ«ŠĶ«ĪńÉåÕ┐ĄõĖÄńē╣µĆ¦\[ÕŠģµø┤µ¢░\] + +ÕŠģµø┤µ¢░ diff --git a/internlm_langchain/knowledge_base/MMOCR/content/quick_run.md b/internlm_langchain/knowledge_base/MMOCR/content/quick_run.md new file mode 100644 index 00000000..bcca7370 --- /dev/null +++ b/internlm_langchain/knowledge_base/MMOCR/content/quick_run.md @@ -0,0 +1,201 @@ +# Õ┐½ķƤĶ┐ÉĶĪī + +Ķ┐ÖõĖ¬ń½ĀĶŖéõ╝Üõ╗ŗń╗Ź MMOCR ńÜäõĖĆõ║øÕ¤║µ£¼ÕŖ¤ĶāĮŃĆ鵳æõ╗¼ÕüćĶ«ŠõĮĀÕĘ▓ń╗Å[õ╗ĵ║ÉńĀüÕ«ēĶŻģõ║å MMOCR](install.md#best-practices)ŃĆ鵣żÕż¢’╝īõĮĀõ╣¤ÕÅ»õ╗źķĆÜĶ┐ć[µĢÖń©ŗ Notebook](https://colab.research.google.com/github/open-mmlab/mmocr/blob/dev-1.x/demo/tutorial.ipynb)µØźõ║åĶ¦ŻÕ”éõĮĢÕ£©õ║żõ║ÆÕ╝ÅńÄ»ÕóāõĖŗÕ«×ńÄ░µÄ©ńÉåŃĆüĶ«Łń╗āÕÆīµĄŗĶ»ĢŃĆé + +## µÄ©ńÉå + +Õ£© MMOCR ńÜäµĀ╣ńø«ÕĮĢõĖŗĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗ż’╝Ü + +```shell +python tools/infer.py demo/demo_text_ocr.jpg --det DBNet --rec CRNN --show --print-result +``` + +õĮĀÕÅ»õ╗źń£ŗÕł░Õ╝╣Õć║ńÜäķó䵥ŗń╗ōµ×£’╝īõ╗źÕÅŖÕ£©µÄ¦ÕłČÕÅ░õĖŁµēōÕŹ░Õć║ńÜäµÄ©ńÉåń╗ōµ×£ŃĆé + +
+
+
+
++ +```bash +# Ķ»åÕł½ń╗ōµ×£ +{'predictions': [{'rec_texts': ['cbanks', 'docecea', 'grouf', 'pwate', 'chobnsonsg', 'soxee', 'oeioh', 'c', 'sones', 'lbrandec', 'sretalg', '11', 'to8', 'round', 'sale', 'year', +'ally', 'sie', 'sall'], 'rec_scores': [...], 'det_polygons': [...], 'det_scores': +[...]}]} +``` + +```{note} +Õ”éµ×£õĮĀÕ£©µ▓Īµ£ē GUI ńÜäµ£ŹÕŖĪÕÖ©õĖŖĶ┐ÉĶĪī MMOCR’╝īµł¢ĶĆģķĆÜĶ┐ćµ▓Īµ£ēÕ╝ĆÕÉ» X11 ĶĮ¼ÕÅæńÜä SSH ķܦķüōĶ┐ÉĶĪī MMOCR’╝īõĮĀÕÅ»ĶāĮµŚĀµ│Ģń£ŗÕł░Õ╝╣Õć║ńÜäń¬ŚÕÅŻŃĆé +``` + +Õ»╣ MMOCR õĖŁµÄ©ńÉåµÄźÕÅŻµø┤õĖ║Ķ»”ń╗åńÜäĶ»┤µśÄ’╝īÕÅ»õ╗źÕ£©[Ķ┐Öķćī](../user_guides/inference.md)µēŠÕł░ŃĆé + +ķÖżõ║åõĮ┐ńö©µłæõ╗¼µÅÉõŠøÕźĮńÜäķóäĶ«Łń╗āµ©ĪÕ×ŗ’╝īńö©µłĘõ╣¤ÕÅ»õ╗źÕ£©Ķć¬ÕĘ▒ńÜäµĢ░µŹ«ķøåõĖŖĶ«Łń╗āµĄüĶĪīµ©ĪÕ×ŗŃĆéµÄźõĖŗµØźµłæõ╗¼õ╗źÕ£©Ķ┐ĘõĮĀńÜä [ICDAR 2015](https://rrc.cvc.uab.es/?ch=4&com=downloads) µĢ░µŹ«ķøåõĖŖĶ«Łń╗ā DBNet õĖ║õŠŗ’╝īÕĖ”Õż¦Õ«Čń夵éē MMOCR ńÜäÕ¤║µ£¼ÕŖ¤ĶāĮŃĆé + +## ÕćåÕżćµĢ░µŹ«ķøå + +ńö▒õ║Ä OCR õ╗╗ÕŖĪńÜäµĢ░µŹ«ķøåń¦Źń▒╗ÕżÜµĀĘ’╝īµĀ╝Õ╝ÅõĖŹõĖĆ’╝īõĖŹÕł®õ║ÄÕżÜµĢ░µŹ«ķøåńÜäÕłćµŹóÕÆīĶüöÕÉłĶ«Łń╗ā’╝īÕøĀµŁż MMOCR ń║”Õ«Üõ║åõĖĆń¦Ź[ń╗¤õĖĆńÜäµĢ░µŹ«µĀ╝Õ╝Å](../user_guides/dataset_prepare.md)’╝īÕ╣ČķÆłÕ»╣ÕĖĖńö©ńÜä OCR µĢ░µŹ«ķøåµÅÉõŠøõ║å[õĖĆķö«Õ╝ŵĢ░µŹ«ÕćåÕżćĶäܵ£¼](../user_guides/data_prepare/dataset_preparer.md)ŃĆéķĆÜÕĖĖ’╝īĶ”üÕ£© MMOCR õĖŁõĮ┐ńö©µĢ░µŹ«ķøå’╝īõĮĀÕŬķ£ĆĶ”üµīēńģ¦Õ»╣Õ║öµŁźķ¬żĶ┐ÉĶĪīµīćõ╗żÕŹ│ÕÅ»ŃĆé + +```{note} +õĮåµłæõ╗¼õ║”µĘ▒ń¤ź’╝īµĢłńÄćÕ░▒µś»ńö¤ÕæĮŌĆöŌĆöÕ░żÕģČÕ»╣µā│Ķ”üÕ┐½ķƤõĖŖµēŗ MMOCR ńÜäõĮĀµØźĶ»┤ŃĆé +``` + +Õ£©Ķ┐Öķćī’╝īµłæõ╗¼ÕćåÕżćõ║åõĖĆõĖ¬ńö©õ║ĵ╝öńż║ńÜäń▓Šń«Ćńēł ICDAR 2015 µĢ░µŹ«ķøåŃĆéõĖŗĶĮĮµłæõ╗¼ķóäÕģłÕćåÕżćÕźĮńÜä[ÕÄŗń╝®Õīģ](https://download.openmmlab.com/mmocr/data/icdar2015/mini_icdar2015.tar.gz)’╝īĶ¦ŻÕÄŗÕł░ mmocr ńÜä `data/` ńø«ÕĮĢõĖŗ’╝īÕ░▒ĶāĮÕŠŚÕł░µłæõ╗¼ÕćåÕżćÕźĮńÜäÕøŠńēćÕÆīµĀćµ│©µ¢ćõ╗ČŃĆé + +```Bash +wget https://download.openmmlab.com/mmocr/data/icdar2015/mini_icdar2015.tar.gz +mkdir -p data/ +tar xzvf mini_icdar2015.tar.gz -C data/ +``` + +## õ┐«µö╣ķģŹńĮ« + +ÕćåÕżćÕźĮµĢ░µŹ«ķøåÕÉÄ’╝īµłæõ╗¼µÄźõĖŗµØźÕ░▒ķ£ĆĶ”üķĆÜĶ┐ćõ┐«µö╣ķģŹńĮ«ńÜäµ¢╣Õ╝ŵīćÕ«ÜĶ«Łń╗āķøåńÜäõĮŹńĮ«ÕÆīĶ«Łń╗āÕÅéµĢ░ŃĆé + +Õ£©Ķ┐ÖõĖ¬õŠŗÕŁÉõĖŁ’╝īµłæõ╗¼Õ░åõ╝ÜĶ«Łń╗āõĖĆõĖ¬õ╗ź resnet18 õĮ£õĖ║ķ¬©Õ╣▓ńĮæń╗£’╝łbackbone’╝ēńÜä DBNetŃĆéńö▒õ║Ä MMOCR ÕĘ▓ń╗ŵ£ēķÆłÕ»╣Õ«īµĢ┤ ICDAR 2015 µĢ░µŹ«ķøåńÜäķģŹńĮ« ’╝ł`configs/textdet/dbnet/dbnet_resnet18_fpnc_1200e_icdar2015.py`’╝ē’╝īµłæõ╗¼ÕŬķ£ĆĶ”üÕ£©Õ«āńÜäÕ¤║ńĪĆõĖŖõĮ£Õć║õĖĆńé╣õ┐«µö╣ŃĆé + +µłæõ╗¼ķ”¢Õģłķ£ĆĶ”üõ┐«µö╣µĢ░µŹ«ķøåńÜäĶĘ»ÕŠäŃĆéÕ£©Ķ┐ÖõĖ¬ķģŹńĮ«õĖŁ’╝īÕż¦ķā©ÕłåÕģ│ķö«ńÜäķģŹńĮ«µ¢ćõ╗ČķāĮÕ£© `_base_` õĖŁĶó½Õ»╝Õģź’╝īÕ”éµĢ░µŹ«Õ║ōńÜäķģŹńĮ«Õ░▒µØźĶć¬ `configs/textdet/_base_/datasets/icdar2015.py`ŃĆéµēōÕ╝ĆĶ»źµ¢ćõ╗Č’╝īµŖŖń¼¼õĖĆĶĪī `icdar2015_textdet_data_root` µīćÕÉæńÜäĶĘ»ÕŠäµø┐µŹó’╝Ü + +```Python +icdar2015_textdet_data_root = 'data/mini_icdar2015' +``` + +ÕÅ”Õż¢’╝īÕøĀõĖ║µĢ░µŹ«ķøåÕ░║Õ»Ėń╝®Õ░Åõ║å’╝īµłæõ╗¼õ╣¤Ķ”üńøĖÕ║öÕ£░ÕćÅÕ░æĶ«Łń╗āńÜäĶĮ«µ¼ĪÕł░ 400’╝īń╝®ń¤Łķ¬īĶ»üÕÆīÕé©ÕŁśµØāķćŹńÜäķŚ┤ķÜöÕł░10ĶĮ«’╝īÕ╣ȵöŠÕ╝āÕŁ”õ╣ĀńÄćĶĪ░ÕćÅńŁ¢ńĢźŃĆéńø┤µÄźµŖŖõ╗źõĖŗÕćĀĶĪīķģŹńĮ«µöŠÕģź `configs/textdet/dbnet/dbnet_resnet18_fpnc_1200e_icdar2015.py`ÕŹ│ÕÅ»ńö¤µĢł’╝Ü + +```Python +# µ»Å 10 õĖ¬ epoch Õé©ÕŁśõĖƵ¼ĪµØāķ插╝īõĖöÕŬõ┐ØńĢÖµ£ĆÕÉÄõĖĆõĖ¬µØāķćŹ +default_hooks = dict( + checkpoint=dict( + type='CheckpointHook', + interval=10, + max_keep_ckpts=1, + )) +# Ķ«ŠńĮ«µ£ĆÕż¦ epoch µĢ░õĖ║ 400’╝īµ»Å 10 õĖ¬ epoch Ķ┐ÉĶĪīõĖƵ¼Īķ¬īĶ»ü +train_cfg = dict(type='EpochBasedTrainLoop', max_epochs=400, val_interval=10) +# õ╗żÕŁ”õ╣ĀńÄćõĖ║ÕĖĖķćÅ’╝īÕŹ│õĖŹĶ┐øĶĪīÕŁ”õ╣ĀńÄćĶĪ░ÕćÅ +param_scheduler = [dict(type='ConstantLR', factor=1.0),] +``` + +Ķ┐Öķćī’╝īµłæõ╗¼ķĆÜĶ┐ćķģŹńĮ«ńÜäń╗¦µē┐ ({external+mmengine:doc}`MMEngine: Config
+
+ 
+
+
+```{note}
+µ£ēÕģ│µø┤ÕżÜÕÅ»Ķ¦åÕī¢ÕŖ¤ĶāĮńÜäõ╗ŗń╗Ź’╝īĶ»ĘÕÅéķśģ[Ķ┐Öķćī](../user_guides/visualization.md)ŃĆé
+```
diff --git a/internlm_langchain/knowledge_base/MMOCR/content/structures.md b/internlm_langchain/knowledge_base/MMOCR/content/structures.md
new file mode 100644
index 00000000..857a356f
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMOCR/content/structures.md
@@ -0,0 +1,219 @@
+# µĢ░µŹ«Õģāń┤ĀõĖĵĢ░µŹ«ń╗ōµ×ä
+
+MMOCR Õ¤║õ║Ä {external+mmengine:doc}`MMEngine: µŖĮĶ▒ĪµĢ░µŹ«µÄźÕÅŻ +
+
+
+
+(ń╗┐Ķē▓µĪåõĖ║ń£¤Õ«×µĀćµ│©’╝īń║óĶē▓µĪåõĖ║ķó䵥ŗń╗ōµ×£)
+
+
+
+
+
+
+
+’╝łń╗┐Ķē▓ÕŁŚõĮōõĖ║ń£¤Õ«×µĀćµ│©’╝īń║óĶē▓ÕŁŚõĮōõĖ║ķó䵥ŗń╗ōµ×£’╝ē
+
+
+
+
+
+
+
+’╝łõ╗ÄÕĘ”Ķć│ÕÅ│ÕłåÕł½õĖ║’╝ÜÕĤÕøŠ’╝īµ¢ćµ£¼µŻĆµĄŗÕÆīĶ»åÕł½ń╗ōµ×£’╝īµ¢ćµ£¼Õłåń▒╗ń╗ōµ×£’╝īÕģ│ń│╗ÕøŠ’╝ē
+
+
+
+```bash
+# ńż║õŠŗ1’╝ܵ»ÅķŚ┤ķÜö 2 ń¦Æń╗śÕłČÕć║
+python tools/test.py configs/textdet/dbnet/dbnet_r50dcnv2_fpnc_1200e_icdar2015.py dbnet_r50.pth --show --wait-time 2
+
+# ńż║õŠŗ2’╝ÜÕ»╣õ║ÄõĖŹµö»µīüÕøŠÕĮóÕī¢ńĢīķØóńÜäń│╗ń╗¤’╝łÕ”éĶ«Īń«ŚķøåńŠżńŁē’╝ē’╝īÕÅ»õ╗źÕ░åÕÅ»Ķ¦åÕī¢ń╗ōµ×£ÕŁśÕģźµīćÕ«ÜĶĘ»ÕŠä
+python tools/test.py configs/textdet/dbnet/dbnet_r50dcnv2_fpnc_1200e_icdar2015.py dbnet_r50.pth --show-dir ./vis_results
+```
+
+`tools/test.py` õĖŁÕÅ»Ķ¦åÕī¢ńøĖÕģ│ÕÅéµĢ░Ķ»┤µśÄ’╝Ü
+
+| ÕÅéµĢ░ | ń▒╗Õ×ŗ | Ķ»┤µśÄ |
+| ----------- | ----- | -------------------------------- |
+| --show | bool | µś»ÕÉ”ń╗śÕłČÕÅ»Ķ¦åÕī¢ń╗ōµ×£ŃĆé |
+| --show-dir | str | ÕÅ»Ķ¦åÕī¢ÕøŠńēćÕŁśÕé©ĶĘ»ÕŠäŃĆé |
+| --wait-time | float | ÕÅ»Ķ¦åÕī¢ķŚ┤ķÜöµŚČķŚ┤’╝łń¦Æ’╝ē’╝īķ╗śĶ«żõĖ║ 2ŃĆé |
+
+### µĄŗĶ»ĢµŚČµĢ░µŹ«Õó×Õ╝║
+
+µĄŗĶ»ĢµŚČÕó×Õ╝║’╝īµīćńÜ䵜»Õ£©µÄ©ńÉå’╝łķó䵥ŗ’╝ēķśČµ«Ą’╝īÕ░åÕĤզŗÕøŠńēćĶ┐øĶĪīµ░┤Õ╣│ń┐╗ĶĮ¼ŃĆüÕ×éńø┤ń┐╗ĶĮ¼ŃĆüÕ»╣Ķ¦Æń║┐ń┐╗ĶĮ¼ŃĆüµŚŗĶĮ¼Ķ¦ÆÕ║”ńŁēµĢ░µŹ«Õó×Õ╝║µōŹõĮ£’╝īÕŠŚÕł░ÕżÜÕ╝ĀÕøŠ’╝īÕłåÕł½Ķ┐øĶĪīµÄ©ńÉå’╝īÕåŹÕ»╣ÕżÜõĖ¬ń╗ōµ×£Ķ┐øĶĪīń╗╝ÕÉłÕłåµ×É’╝īÕŠŚÕł░µ£Ćń╗łĶŠōÕć║ń╗ōµ×£ŃĆé
+õĖ║µŁż’╝īMMOCR µÅÉõŠøõ║åõĖĆķö«Õ╝ŵĄŗĶ»ĢµŚČµĢ░µŹ«Õó×Õ╝║’╝īõ╗ģķ£ĆÕ£©µĄŗĶ»ĢµŚČµĘ╗ÕŖĀ `--tta` ÕÅéµĢ░ÕŹ│ÕÅ»ŃĆé
+
+```{note}
+TTA õ╗ģµö»µīüµ¢ćµ£¼Ķ»åÕł½µ©ĪÕ×ŗŃĆé
+```
+
+```bash
+python tools/test.py configs/textrecog/crnn/crnn_mini-vgg_5e_mj.py checkpoints/crnn_mini-vgg_5e_mj.pth --tta
+```
diff --git a/internlm_langchain/knowledge_base/MMOCR/content/transforms.md b/internlm_langchain/knowledge_base/MMOCR/content/transforms.md
new file mode 100644
index 00000000..cc07c986
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMOCR/content/transforms.md
@@ -0,0 +1,227 @@
+# µĢ░µŹ«ÕÅśµŹóõĖĵĄüµ░┤ń║┐
+
+Õ£© MMOCR ńÜäĶ«ŠĶ«ĪõĖŁ’╝īµĢ░µŹ«ķøåńÜäµ×äÕ╗║õĖĵĢ░µŹ«ÕćåÕżćµś»ńøĖõ║ÆĶ¦ŻĶĆ”ńÜäŃĆéõ╣¤Õ░▒µś»Ķ»┤’╝ī[`OCRDataset`](mmocr.datasets.ocr_dataset.OCRDataset) ńŁēµĢ░µŹ«ķøåµ×äÕ╗║ń▒╗Ķ┤¤Ķ┤ŻÕ«īµłÉµĀćµ│©µ¢ćõ╗ČńÜäĶ»╗ÕÅ¢õĖÄĶ¦Żµ×ÉÕŖ¤ĶāĮ’╝øĶĆīµĢ░µŹ«ÕÅśµŹóµ¢╣µ│Ģ’╝łData Transforms’╝ēÕłÖĶ┐øõĖƵŁźÕ«×ńÄ░õ║åµĢ░µŹ«ķóäÕżäńÉåŃĆüµĢ░µŹ«Õó×Õ╝║ŃĆüµĢ░µŹ«µĀ╝Õ╝ÅÕī¢ńŁēńøĖÕģ│ÕŖ¤ĶāĮŃĆéńø«ÕēŹ’╝īÕ”éõĖŗĶĪ©µēĆńż║’╝īMMOCR õĖŁÕģ▒Õ«×ńÄ░õ║å 5 ń▒╗µĢ░µŹ«ÕÅśµŹóµ¢╣µ│Ģ’╝Ü
+
+| | | |
+| -------------- | --------------------------------------------------------------------- | ------------------------------------------------------------------- |
+| µĢ░µŹ«ÕÅśµŹóń▒╗Õ×ŗ | Õ»╣Õ║öµ¢ćõ╗Č | ÕŖ¤ĶāĮĶ»┤µśÄ |
+| µĢ░µŹ«Ķ»╗ÕÅ¢ | loading.py | Õ«×ńÄ░õ║åõĖŹÕÉīµĀ╝Õ╝ŵĢ░µŹ«ńÜäĶ»╗ÕÅ¢ÕŖ¤ĶāĮŃĆé |
+| µĢ░µŹ«µĀ╝Õ╝ÅÕī¢ | formatting.py | Õ«īµłÉõĖŹÕÉīõ╗╗ÕŖĪµēĆķ£ĆµĢ░µŹ«ńÜäµĀ╝Õ╝ÅÕī¢ÕŖ¤ĶāĮŃĆé |
+| ĶĘ©Õ║ōµĢ░µŹ«ķĆéķģŹÕÖ© | adapters.py | Ķ┤¤Ķ┤Ż OpenMMLab ķĪ╣ńø«ÕåģĶĘ©Õ║ōĶ░āńö©ńÜäµĢ░µŹ«µĀ╝Õ╝ÅĶĮ¼µŹóÕŖ¤ĶāĮŃĆé |
+| µĢ░µŹ«Õó×Õ╝║ | ocr_transforms.pytextdet_transforms.py
textrecog_transforms.py | Õ«×ńÄ░õ║åõĖŹÕÉīõ╗╗ÕŖĪõĖŗńÜäÕÉäń▒╗µĢ░µŹ«Õó×Õ╝║µ¢╣µ│ĢŃĆé | +| ÕīģĶŻģń▒╗ | wrappers.py | Õ«×ńÄ░õ║åÕ»╣ ImgAug ńŁēÕĖĖńö©ń«Śµ│ĢÕ║ōńÜäÕīģĶŻģ’╝īõĮ┐ÕģČķĆéķģŹ MMOCR ńÜäÕåģķā©µĢ░µŹ«µĀ╝Õ╝ÅŃĆé | + +ńö▒õ║ĵ»ÅõĖĆõĖ¬µĢ░µŹ«ÕÅśµŹóń▒╗õ╣ŗķŚ┤ķāĮµś»ńøĖõ║Æńŗ¼ń½ŗńÜä’╝īÕøĀµŁż’╝īÕ£©ń║”Õ«ÜÕźĮÕø║Õ«ÜńÜäµĢ░µŹ«ÕŁśÕé©ÕŁŚµ«ĄÕÉÄ’╝īµłæõ╗¼ÕÅ»õ╗źõŠ┐µŹĘÕ£░ķććńö©õ╗╗µäÅńÜäµĢ░µŹ«ÕÅśµŹóń╗äÕÉłµØźµ×äÕ╗║µĢ░µŹ«µĄüµ░┤ń║┐’╝łPipeline’╝ēŃĆéÕ”éõĖŗÕøŠµēĆńż║’╝īÕ£© MMOCR õĖŁ’╝īõĖĆõĖ¬ÕģĖÕ×ŗńÜäĶ«Łń╗āµĢ░µŹ«µĄüµ░┤ń║┐õĖ╗Ķ”üńö▒**µĢ░µŹ«Ķ»╗ÕÅ¢**ŃĆü**ÕøŠÕāÅÕó×Õ╝║**õ╗źÕÅŖ**µĢ░µŹ«µĀ╝Õ╝ÅÕī¢**õĖēķā©Õłåµ×䵳ɒ╝īńö©µłĘÕŬķ£ĆĶ”üÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁÕ«Üõ╣ēńøĖÕģ│ńÜäµĢ░µŹ«µĄüµ░┤ń║┐ÕłŚĶĪ©’╝īÕ╣ȵīćÕ«ÜÕģĘõĮōµēĆķ£ĆńÜäµĢ░µŹ«ÕÅśµŹóń▒╗ÕÅŖÕģČÕÅéµĢ░ÕŹ│ÕÅ»’╝Ü + +
+
+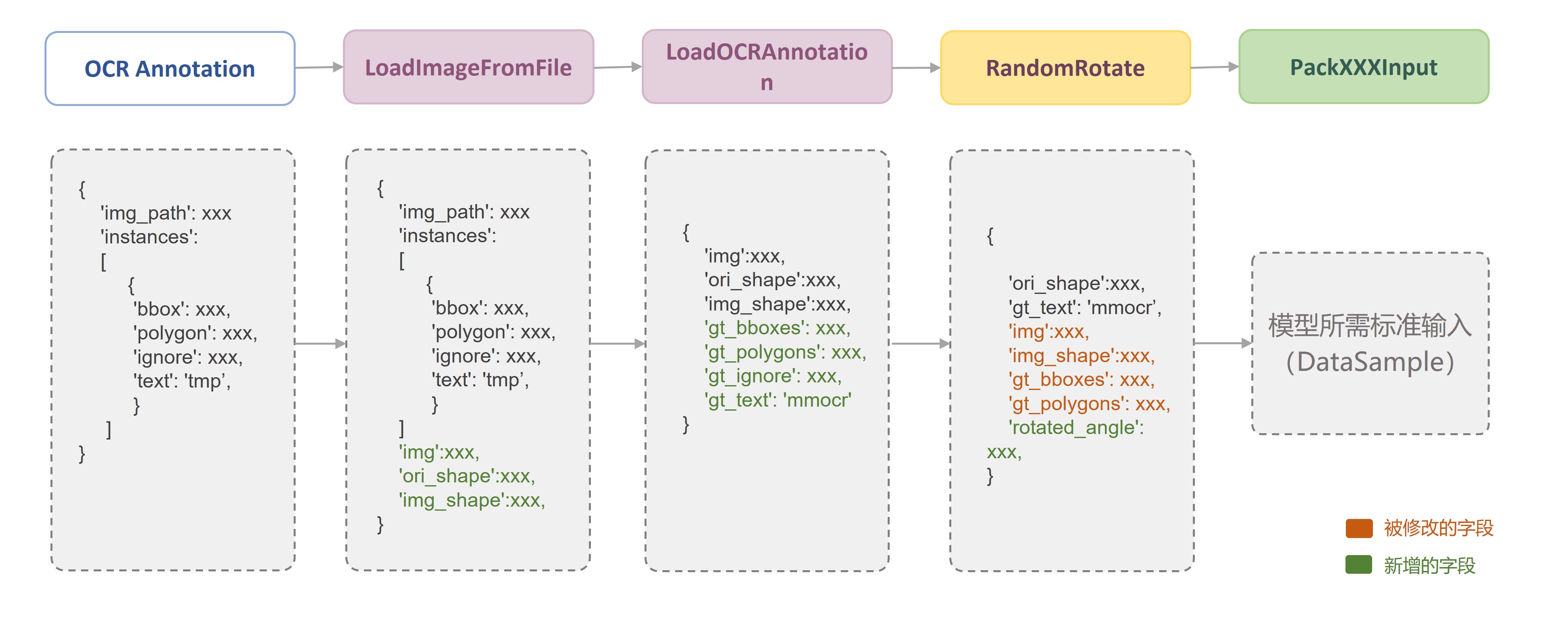
+
+
+
+```python
+train_pipeline_r18 = [
+ # µĢ░µŹ«Ķ»╗ÕÅ¢’╝łÕøŠÕāÅ’╝ē
+ dict(
+ type='LoadImageFromFile',
+ color_type='color_ignore_orientation'),
+ # µĢ░µŹ«Ķ»╗ÕÅ¢’╝łµĀćµ│©’╝ē
+ dict(
+ type='LoadOCRAnnotations',
+ with_polygon=True,
+ with_bbox=True,
+ with_label=True,
+ ),
+ # õĮ┐ńö© ImgAug õĮ£µĢ░µŹ«Õó×Õ╝║
+ dict(
+ type='ImgAugWrapper',
+ args=[['Fliplr', 0.5],
+ dict(cls='Affine', rotate=[-10, 10]), ['Resize', [0.5, 3.0]]]),
+ # õĮ┐ńö© MMOCR ÕåģńĮ«ńÜäÕøŠÕāÅÕó×Õ╝║
+ dict(type='RandomCrop', min_side_ratio=0.1),
+ dict(type='Resize', scale=(640, 640), keep_ratio=True),
+ dict(type='Pad', size=(640, 640)),
+ # µĢ░µŹ«µĀ╝Õ╝ÅÕī¢
+ dict(
+ type='PackTextDetInputs',
+ meta_keys=('img_path', 'ori_shape', 'img_shape'))
+]
+```
+
+```{tip}
+µø┤ÕżÜµ£ēÕģ│µĢ░µŹ«µĄüµ░┤ń║┐ķģŹńĮ«ńÜäµĢÖń©ŗÕÅ»Ķ¦ü[ķģŹńĮ«µ¢ćµĪŻ](../user_guides/config.md#µĢ░µŹ«µĄüµ░┤ń║┐ķģŹńĮ«)ŃĆéõĖŗķØó’╝īµłæõ╗¼Õ░åń«ĆÕŹĢõ╗ŗń╗Ź MMOCR õĖŁÕĘ▓µö»µīüńÜäµĢ░µŹ«ÕÅśµŹóń▒╗Õ×ŗŃĆé
+```
+
+Õ»╣õ║ĵ»ÅõĖĆõĖ¬µĢ░µŹ«ÕÅśµŹóµ¢╣µ│Ģ’╝īMMOCR ķāĮõĖźµĀ╝µīēńģ¦µ¢ćµĪŻÕŁŚń¼”õĖ▓’╝łdocstring’╝ēĶ¦äĶīāÕ£©µ║ÉńĀüõĖŁµÅÉõŠøõ║åĶ»”ń╗åńÜäõ╗ŻńĀüµ│©ķćŖŃĆéõŠŗÕ”é’╝īµ»ÅõĖĆõĖ¬µĢ░µŹ«ĶĮ¼µŹóń▒╗ńÜäÕż┤ķā©µłæõ╗¼ķāĮµ│©ķćŖõ║å ŌĆ£ķ£Ćµ▒éÕŁŚµ«ĄŌĆØ’╝ł`Required keys`’╝ē’╝ī ŌĆ£õ┐«µö╣ÕŁŚµ«ĄŌĆØ’╝ł`Modified Keys`’╝ēõĖÄ ŌĆ£µĘ╗ÕŖĀÕŁŚµ«ĄŌĆØ’╝ł`Added Keys`’╝ēŃĆéÕģČõĖŁ’╝īŌĆ£ķ£Ćµ▒éÕŁŚµ«ĄŌĆØõ╗ŻĶĪ©Ķ»źµĢ░µŹ«ĶĮ¼µŹóµ¢╣µ│ĢÕ»╣õ║ÄĶŠōÕģźµĢ░µŹ«µēĆķ£ĆÕīģÕÉ½ÕŁŚµ«ĄńÜäÕ╝║ÕłČķ£Ćµ▒é’╝īĶĆīŌĆ£õ┐«µö╣ÕŁŚµ«ĄŌĆØõĖÄŌĆ£µĘ╗ÕŖĀÕŁŚµ«ĄŌĆØÕłÖĶĪ©µśÄĶ»źµ¢╣µ│ĢÕÅ»ĶāĮõ╝ÜÕ£©ÕĤµ£ēµĢ░µŹ«Õ¤║ńĪĆõ╣ŗõĖŖõ┐«µö╣µł¢µĘ╗ÕŖĀńÜäÕŁŚµ«ĄŃĆéõŠŗÕ”é’╝ī`LoadImageFromFile` Õ«×ńÄ░õ║åÕøŠńēćńÜäĶ»╗ÕÅ¢ÕŖ¤ĶāĮ’╝īÕģČķ£Ćµ▒éÕŁŚµ«ĄõĖ║ÕøŠÕāÅńÜäÕŁśÕé©ĶĘ»ÕŠä `img_path`’╝īĶĆīõ┐«µö╣ÕŁŚµ«ĄÕłÖÕīģµŗ¼õ║åĶ»╗ÕģźńÜäÕøŠÕāÅõ┐Īµü» `img`’╝īõ╗źÕÅŖÕøŠńēćÕĮōÕēŹÕ░║Õ»Ė `img_shape`’╝īÕøŠńēćÕĤզŗÕ░║Õ»Ė `ori_shape` ńŁēÕøŠńēćÕ▒׵ƦŃĆé
+
+```python
+@TRANSFORMS.register_module()
+class LoadImageFromFile(MMCV_LoadImageFromFile):
+ # Õ£©µ»ÅõĖĆõĖ¬µĢ░µŹ«ÕÅśµŹóµ¢╣µ│ĢńÜäÕż┤ķā©’╝īµłæõ╗¼ķāĮµÅÉõŠøõ║åĶ»”ń╗åńÜäõ╗ŻńĀüµ│©ķćŖŃĆé
+ """Load an image from file.
+
+ Required Keys:
+
+ - img_path
+
+ Modified Keys:
+
+ - img
+ - img_shape
+ - ori_shape
+ """
+```
+
+```{note}
+Õ£© MMOCR ńÜäµĢ░µŹ«µĄüµ░┤ń║┐õĖŁ’╝īÕøŠÕāÅÕÅŖµĀćńŁŠńŁēõ┐Īµü»Ķó½ń╗¤õĖĆõ┐ØÕŁśÕ£©ÕŁŚÕģĖõĖŁŃĆéķĆÜĶ┐ćń╗¤õĖĆńÜäÕŁŚµ«ĄÕÉŹ’╝īµłæõ╗¼ÕÅ»õ╗źÕ£©õĖŹÕÉīńÜäµĢ░µŹ«ÕÅśµŹóµ¢╣µ│ĢķŚ┤ńüĄµ┤╗Õ£░õ╝ĀķĆƵĢ░µŹ«ŃĆéÕøĀµŁż’╝īõ║åĶ¦Ż MMOCR õĖŁÕĖĖńö©ńÜäń║”Õ«ÜÕŁŚµ«ĄÕÉŹµś»ķØ×ÕĖĖķćŹĶ”üńÜäŃĆé
+```
+
+õĖ║µ¢╣õŠ┐ńö©µłĘµ¤źĶ»ó’╝īõĖŗĶĪ©ÕłŚÕć║õ║å MMOCR õĖŁÕÉäµĢ░µŹ«ĶĮ¼µŹó’╝łData Transform’╝ēń▒╗ÕĖĖńö©ńÜäÕŁŚµ«Ąń║”Õ«ÜÕÆīĶ»┤µśÄŃĆé
+
+| | | |
+| ---------------- | --------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------ |
+| ÕŁŚµ«Ą | ń▒╗Õ×ŗ | Ķ»┤µśÄ |
+| img | `np.array(dtype=np.uint8)` | ÕøŠÕāÅõ┐Īµü»’╝īÕĮóńŖČõĖ║ `(h, w, c)`ŃĆé |
+| img_shape | `tuple(int, int)` | ÕĮōÕēŹÕøŠÕāÅÕ░║Õ»Ė `(h, w)`ŃĆé |
+| ori_shape | `tuple(int, int)` | ÕøŠÕāÅÕ£©ÕłØÕ¦ŗÕī¢µŚČńÜäÕ░║Õ»Ė `(h, w)`ŃĆé |
+| scale | `tuple(int, int)` | ÕŁśµöŠńö©µłĘÕ£© Resize ń│╗ÕłŚµĢ░µŹ«ÕÅśµŹó’╝łTransform’╝ēõĖŁµīćÕ«ÜńÜäńø«µĀćÕøŠÕāÅÕ░║Õ»Ė `(h, w)`ŃĆéµ│©µäÅ’╝ÜĶ»źÕĆ╝µ£¬Õ┐ģõĖÄÕÅśµŹóÕÉÄńÜäÕ«×ķÖģÕøŠÕāÅÕ░║Õ»ĖńøĖń¼”ŃĆé |
+| scale_factor | `tuple(float, float)` | ÕŁśµöŠńö©µłĘÕ£© Resize ń│╗ÕłŚµĢ░µŹ«ÕÅśµŹó’╝łTransform’╝ēõĖŁµīćÕ«ÜńÜäńø«µĀćÕøŠÕāÅń╝®µöŠÕøĀÕŁÉ `(w_scale, h_scale)`ŃĆéµ│©µäÅ’╝ÜĶ»źÕĆ╝µ£¬Õ┐ģõĖÄÕÅśµŹóÕÉÄńÜäÕ«×ķÖģÕøŠÕāÅÕ░║Õ»ĖńøĖń¼”ŃĆé |
+| keep_ratio | `bool` | µś»ÕÉ”µīēńŁēµ»öõŠŗÕ»╣ÕøŠÕāÅĶ┐øĶĪīń╝®µöŠŃĆé |
+| flip | `bool` | ÕøŠÕāŵś»ÕÉ”Ķó½ń┐╗ĶĮ¼ŃĆé |
+| flip_direction | `str` | ń┐╗ĶĮ¼µ¢╣ÕÉæŃĆéÕÅ»ķĆēķĪ╣õĖ║ `horizontal`, `vertical`, `diagonal`ŃĆé |
+| gt_bboxes | `np.array(dtype=np.float32)` | µ¢ćµ£¼Õ«×õŠŗĶŠ╣ńĢīµĪåńÜäń£¤Õ«×µĀćńŁŠŃĆé |
+| gt_polygons | `list[np.array(dtype=np.float32)` | µ¢ćµ£¼Õ«×õŠŗĶŠ╣ńĢīÕżÜĶŠ╣ÕĮóńÜäń£¤Õ«×µĀćńŁŠŃĆé |
+| gt_bboxes_labels | `np.array(dtype=np.int64)` | µ¢ćµ£¼Õ«×õŠŗÕ»╣Õ║öńÜäń▒╗Õł½µĀćńŁŠŃĆéÕ£© MMOCR õĖŁķĆÜÕĖĖõĖ║ 0’╝īõ╗Żµīć "text" ń▒╗Õł½ŃĆé |
+| gt_texts | `list[str]` | õĖĵ¢ćµ£¼Õ«×õŠŗÕ»╣Õ║öńÜäÕŁŚń¼”õĖ▓µĀćµ│©ŃĆé |
+| gt_ignored | `np.array(dtype=np.bool_)` | µś»ÕÉ”Ķ”üÕ£©Ķ«Īń«Śńø«µĀ浌ČÕ┐ĮńĢźĶ»źÕ«×õŠŗ’╝łńö©õ║ĵŻĆµĄŗõ╗╗ÕŖĪõĖŁ’╝ēŃĆé |
+
+## µĢ░µŹ«Ķ»╗ÕÅ¢ - loading.py
+
+µĢ░µŹ«Ķ»╗ÕÅ¢ń▒╗õĖ╗Ķ”üÕ«×ńÄ░õ║åõĖŹÕÉīµ¢ćõ╗ȵĀ╝Õ╝ÅŃĆüÕÉÄń½»Ķ»╗ÕÅ¢ÕøŠńēćÕÅŖÕŖĀĶĮĮµĀćµ│©õ┐Īµü»ńÜäÕŖ¤ĶāĮŃĆéńø«ÕēŹ’╝īMMOCR Õåģķā©Õģ▒Õ«×ńÄ░õ║åõ╗źõĖŗµĢ░µŹ«Ķ»╗ÕÅ¢ń▒╗ńÜä Data Transforms’╝Ü
+
+| | | | |
+| ------------------ | --------------------------------------------------------- | -------------------------------------------------------------- | --------------------------------------------------------------- |
+| µĢ░µŹ«ĶĮ¼µŹóń▒╗ÕÉŹń¦░ | ķ£Ćµ▒éÕŁŚµ«Ą | õ┐«µö╣/µĘ╗ÕŖĀÕŁŚµ«Ą | Ķ»┤µśÄ |
+| LoadImageFromFile | `img_path` | `img``img_shape`
`ori_shape` | õ╗ÄÕøŠńēćĶĘ»ÕŠäĶ»╗ÕÅ¢ÕøŠńēć’╝īµö»µīüÕżÜń¦Źµ¢ćõ╗ČÕŁśÕé©ÕÉÄń½»’╝łÕ”é `disk`, `http`, `petrel` ńŁē’╝ēÕÅŖÕøŠńēćĶ¦ŻńĀüÕÉÄń½»’╝łÕ”é `cv2`, `turbojpeg`, `pillow`, `tifffile`ńŁē’╝ēŃĆé | +| LoadOCRAnnotations | `bbox`
`bbox_label`
`polygon`
`ignore`
`text` | `gt_bboxes`
`gt_bboxes_labels`
`gt_polygons`
`gt_ignored`
`gt_texts` | Ķ¦Żµ×É OCR õ╗╗ÕŖĪµēĆķ£ĆńÜäµĀćµ│©õ┐Īµü»ŃĆé | +| LoadKIEAnnotations | `bboxes` `bbox_labels` `edge_labels`
`texts` | `gt_bboxes`
`gt_bboxes_labels`
`gt_edge_labels`
`gt_texts`
`ori_shape` | Ķ¦Żµ×É KIE õ╗╗ÕŖĪµēĆķ£ĆńÜäµĀćµ│©õ┐Īµü»ŃĆé | + +## µĢ░µŹ«Õó×Õ╝║ - xxx_transforms.py + +µĢ░µŹ«Õó×Õ╝║µś»µ¢ćµ£¼µŻĆµĄŗŃĆüĶ»åÕł½ńŁēõ╗╗ÕŖĪõĖŁÕ┐ģõĖŹÕÅ»Õ░æńÜ䵥üń©ŗõ╣ŗõĖĆŃĆéńø«ÕēŹ’╝īMMOCR õĖŁÕģ▒Õ«×ńÄ░õ║åµĢ░ÕŹüń¦Źµ¢ćµ£¼ķóåÕ¤¤ÕåģÕĖĖńö©ńÜäµĢ░µŹ«Õó×Õ╝║µ©ĪÕØŚ’╝īõŠØµŹ«ÕģČõ╗╗ÕŖĪń▒╗Õ×ŗ’╝īÕłåÕł½õĖ║ķĆÜńö© OCR µĢ░µŹ«Õó×Õ╝║µ©ĪÕØŚ [ocr_transforms.py](/mmocr/datasets/transforms/ocr_transforms.py)’╝īµ¢ćµ£¼µŻĆµĄŗµĢ░µŹ«Õó×Õ╝║µ©ĪÕØŚ [textdet_transforms.py](/mmocr/datasets/transforms/textdet_transforms.py)’╝īõ╗źÕÅŖµ¢ćµ£¼Ķ»åÕł½µĢ░µŹ«Õó×Õ╝║µ©ĪÕØŚ [textrecog_transforms.py](/mmocr/datasets/transforms/textrecog_transforms.py)ŃĆé + +ÕģĘõĮōĶĆīĶ©Ć’╝ī`ocr_transforms.py` õĖŁÕ«×ńÄ░õ║åķÜŵ£║Õē¬ĶŻüŃĆüķÜŵ£║µŚŗĶĮ¼ńŁēÕÉäõ╗╗ÕŖĪķĆÜńö©ńÜäµĢ░µŹ«Õó×Õ╝║µ©ĪÕØŚ’╝Ü + +| | | | | +| -------------- | -------------------------------------------------------------- | -------------------------------------------------------------- | -------------------------------------------------------------- | +| µĢ░µŹ«ĶĮ¼µŹóń▒╗ÕÉŹń¦░ | ķ£Ćµ▒éÕŁŚµ«Ą | õ┐«µö╣/µĘ╗ÕŖĀÕŁŚµ«Ą | Ķ»┤µśÄ | +| RandomCrop | `img`
`gt_bboxes`
`gt_bboxes_labels`
`gt_polygons`
`gt_ignored`
`gt_texts` (optional) | `img`
`img_shape`
`gt_bboxes`
`gt_bboxes_labels`
`gt_polygons`
`gt_ignored`
`gt_texts` (optional) | ķÜŵ£║ĶŻüÕē¬’╝īÕ╣ČńĪ«õ┐ØĶŻüÕē¬ÕÉÄńÜäÕøŠńēćĶć│Õ░æÕīģÕɽõĖĆõĖ¬µ¢ćµ£¼Õ«×õŠŗŃĆéÕÅ»ķĆēÕÅéµĢ░õĖ║ `min_side_ratio`’╝īńö©õ╗źµÄ¦ÕłČĶŻüÕē¬ÕøŠńēćńÜäń¤ŁĶŠ╣ÕŹĀÕĤզŗÕøŠńēćńÜäµ»öõŠŗ’╝īķ╗śĶ«żÕĆ╝õĖ║ `0.4`ŃĆé | +| RandomRotate | `img`
`img_shape`
`gt_bboxes` (optional)
`gt_polygons` (optional) | `img`
`img_shape`
`gt_bboxes` (optional)
`gt_polygons` (optional)
`rotated_angle` | ķÜŵ£║µŚŗĶĮ¼’╝īÕ╣ČÕÅ»ķĆēµŗ®Õ»╣µŚŗĶĮ¼ÕÉÄÕøŠÕāÅńÜäķ╗æĶŠ╣Ķ┐øĶĪīÕĪ½ÕģģŃĆé | +| | | | | + +`textdet_transforms.py` ÕłÖÕ«×ńÄ░õ║åµ¢ćµ£¼µŻĆµĄŗõ╗╗ÕŖĪõĖŁÕĖĖńö©ńÜäµĢ░µŹ«Õó×Õ╝║µ©ĪÕØŚ’╝Ü + +| | | | | +| ----------------- | ------------------------------------- | ------------------------------------------------------------------- | -------------------------------------------------------------------- | +| µĢ░µŹ«ĶĮ¼µŹóń▒╗ÕÉŹń¦░ | ķ£Ćµ▒éÕŁŚµ«Ą | õ┐«µö╣/µĘ╗ÕŖĀÕŁŚµ«Ą | Ķ»┤µśÄ | +| RandomFlip | `img`
`gt_bboxes`
`gt_polygons` | `img`
`gt_bboxes`
`gt_polygons`
`flip`
`flip_direction` | ķÜŵ£║ń┐╗ĶĮ¼’╝īµö»µīüµ░┤Õ╣│ŃĆüÕ×éńø┤ÕÆīÕ»╣Ķ¦ÆõĖēń¦Źµ¢╣ÕÉæńÜäÕøŠÕāÅń┐╗ĶĮ¼ŃĆéķ╗śĶ«żõĮ┐ńö©µ░┤Õ╣│ń┐╗ĶĮ¼ŃĆé | +| FixInvalidPolygon | `gt_polygons`
`gt_ignored` | `gt_polygons`
`gt_ignored` | Ķć¬ÕŖ©õ┐«ÕżŹµł¢Õ┐ĮńĢźķØ×µ│ĢÕżÜĶŠ╣ÕĮóµĀćµ│©ŃĆé | + +`textrecog_transforms.py` õĖŁÕ«×ńÄ░õ║åµ¢ćµ£¼Ķ»åÕł½õ╗╗ÕŖĪõĖŁÕĖĖńö©ńÜäµĢ░µŹ«Õó×Õ╝║µ©ĪÕØŚ’╝Ü + +| | | | | +| --------------- | -------- | ----------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------- | +| µĢ░µŹ«ĶĮ¼µŹóń▒╗ÕÉŹń¦░ | ķ£Ćµ▒éÕŁŚµ«Ą | õ┐«µö╣/µĘ╗ÕŖĀÕŁŚµ«Ą | Ķ»┤µśÄ | +| RescaleToHeight | `img` | `img`
`img_shape`
`scale`
`scale_factor`
`keep_ratio` | ń╝®µöŠÕøŠÕāÅĶć│µīćÕ«Üķ½śÕ║”’╝īÕ╣ČÕ░ĮÕÅ»ĶāĮõ┐صīüķĢ┐Õ«Įµ»öõĖŹÕÅśŃĆéÕĮō `min_width` ÕÅŖ `max_width` Ķó½µīćիܵŚČ’╝īķĢ┐Õ«Įµ»öÕłÖÕÅ»ĶāĮõ╝ÜĶó½µö╣ÕÅśŃĆé | +| | | | | + +```{warning} +õ╗źõĖŖĶĪ©µĀ╝õ╗ģķĆēµŗ®µĆ¦Õ£░Õ»╣ķā©ÕłåµĢ░µŹ«Õó×Õ╝║µ¢╣µ│ĢõĮ£ń«ĆĶ”üõ╗ŗń╗Ź’╝īµø┤ÕżÜµĢ░µŹ«Õó×Õ╝║µ¢╣µ│Ģõ╗ŗń╗ŹĶ»ĘÕÅéĶĆā[API µ¢ćµĪŻ](../api.rst)µł¢ķśģĶ»╗õ╗ŻńĀüÕåģńÜäµ¢ćµĪŻµ│©ķćŖŃĆé +``` + +## µĢ░µŹ«µĀ╝Õ╝ÅÕī¢ - formatting.py + +µĢ░µŹ«µĀ╝Õ╝ÅÕī¢Ķ┤¤Ķ┤ŻÕ░åÕøŠÕāÅŃĆüń£¤Õ«×µĀćńŁŠõ╗źÕÅŖÕģČÕ«āÕĖĖńö©õ┐Īµü»ńŁēµēōÕīģµłÉõĖĆõĖ¬ÕŁŚÕģĖŃĆéõĖŹÕÉīńÜäõ╗╗ÕŖĪķĆÜÕĖĖõŠØĶĄ¢õ║ÄõĖŹÕÉīńÜäµĢ░µŹ«µĀ╝Õ╝ÅÕī¢µĢ░µŹ«ÕÅśµŹóń▒╗ŃĆéõŠŗÕ”é’╝Ü + +| | | | | +| ------------------- | -------- | ------------- | ------------------------------------------ | +| µĢ░µŹ«ĶĮ¼µŹóń▒╗ÕÉŹń¦░ | ķ£Ćµ▒éÕŁŚµ«Ą | õ┐«µö╣/µĘ╗ÕŖĀÕŁŚµ«Ą | Ķ»┤µśÄ | +| PackTextDetInputs | - | - | ńö©õ║ĵēōÕīģµ¢ćµ£¼µŻĆµĄŗõ╗╗ÕŖĪµēĆķ£ĆĶ”üńÜäĶŠōÕģźõ┐Īµü»ŃĆé | +| PackTextRecogInputs | - | - | ńö©õ║ĵēōÕīģµ¢ćµ£¼Ķ»åÕł½õ╗╗ÕŖĪµēĆķ£ĆĶ”üńÜäĶŠōÕģźõ┐Īµü»ŃĆé | +| PackKIEInputs | - | - | ńö©õ║ĵēōÕīģÕģ│ķö«õ┐Īµü»µŖĮÕÅ¢õ╗╗ÕŖĪµēĆķ£ĆĶ”üńÜäĶŠōÕģźõ┐Īµü»ŃĆé | + +## ĶĘ©Õ║ōµĢ░µŹ«ķĆéķģŹÕÖ© - adapters.py + +ĶĘ©Õ║ōµĢ░µŹ«ķĆéķģŹÕÖ©µēōķĆÜõ║å MMOCR õĖÄÕģČõ╗¢ OpenMMLab ń│╗ÕłŚń«Śµ│ĢÕ║ōÕ”é [MMDetection](https://github.com/open-mmlab/mmdetection) õ╣ŗķŚ┤ńÜäµĢ░µŹ«µĀ╝Õ╝Å’╝īõĮ┐ÕŠŚĶĘ©ķĪ╣ńø«Ķ░āńö©ÕģČÕ«āÕ╝Ƶ║Éń«Śµ│ĢÕ║ōńÜäķģŹńĮ«µ¢ćõ╗ČÕÅŖń«Śµ│ĢµłÉõĖ║õ║åÕÅ»ĶāĮŃĆéńø«ÕēŹ’╝īMMOCR Õ«×ńÄ░õ║å `MMDet2MMOCR` õ╗źÕÅŖ `MMOCR2MMDet`’╝īõĮ┐ÕŠŚµĢ░µŹ«ÕÅ»õ╗źÕ£© MMDetection õĖÄ MMOCR ńÜäµĀ╝Õ╝Åõ╣ŗķŚ┤Ķć¬ńö▒ĶĮ¼µŹó’╝øÕƤÕŖ®Ķ┐Öõ║øķĆéķģŹĶĮ¼µŹóÕÖ©’╝īńö©µłĘÕÅ»õ╗źÕ£© MMOCR ń«Śµ│ĢÕ║ōÕåģķā©ĶĮ╗µØŠĶ░āńö©õ╗╗õĮĢ MMDetection ÕĘ▓µö»µīüńÜ䵯ƵĄŗń«Śµ│Ģ’╝īÕ╣ČÕ£© OCR ńøĖÕģ│µĢ░µŹ«ķøåõĖŖĶ┐øĶĪīĶ«Łń╗āŃĆéõŠŗÕ”é’╝īµłæõ╗¼õ╗ź Mask R-CNN õĖ║õŠŗµÅÉõŠøõ║å[µĢÖń©ŗ](#todo)’╝īÕ▒Ģńż║õ║åÕ”éõĮĢÕ£© MMOCR õĖŁõĮ┐ńö© MMDetection ńÜ䵯ƵĄŗń«Śµ│ĢĶ«Łń╗āµ¢ćµ£¼µŻĆµĄŗÕÖ©ŃĆé + +| | | | | +| -------------- | -------------------------------------------- | ----------------------------- | ---------------------------------------------- | +| µĢ░µŹ«ĶĮ¼µŹóń▒╗ÕÉŹń¦░ | ķ£Ćµ▒éÕŁŚµ«Ą | õ┐«µö╣/µĘ╗ÕŖĀÕŁŚµ«Ą | Ķ»┤µśÄ | +| MMDet2MMOCR | `gt_masks` `gt_ignore_flags` | `gt_polygons`
`gt_ignored` | Õ░å MMDet õĖŁķććńö©ńÜäÕŁŚµ«ĄĶĮ¼µŹóõĖ║Õ»╣Õ║öńÜä MMOCR ÕŁŚµ«ĄŃĆé | +| MMOCR2MMDet | `img_shape`
`gt_polygons`
`gt_ignored` | `gt_masks` `gt_ignore_flags` | Õ░å MMOCR õĖŁķććńö©ńÜäÕŁŚµ«ĄĶĮ¼µŹóõĖ║Õ»╣Õ║öńÜä MMDet ÕŁŚµ«ĄŃĆé | + +## ÕīģĶŻģń▒╗ - wrappers.py + +õĖ║õ║åµ¢╣õŠ┐ńö©µłĘÕ£© MMOCR Õåģķā©µŚĀń╝ØĶ░āńö©ÕĖĖńö©ńÜä CV ń«Śµ│ĢÕ║ō’╝īµłæõ╗¼Õ£© wrappers.py õĖŁµÅÉõŠøõ║åńøĖÕ║öńÜäÕīģĶŻģń▒╗ŃĆéÕģČõĖ╗Ķ”üµēōķĆÜõ║å MMOCR õĖÄÕģČÕ«āń¼¼õĖēµ¢╣ń«Śµ│ĢÕ║ōõ╣ŗķŚ┤ńÜäµĢ░µŹ«µĀ╝Õ╝ÅÕÆīĶĮ¼µŹóµĀćÕćå’╝īõĮ┐ÕŠŚńö©µłĘÕÅ»õ╗źÕ£© MMOCR ńÜäķģŹńĮ«µ¢ćõ╗ČÕåģńø┤µÄźķģŹńĮ«õĮ┐ńö©Ķ┐Öõ║øń¼¼õĖēµ¢╣Õ║ōµÅÉõŠøńÜäµĢ░µŹ«ÕÅśµŹóµ¢╣µ│ĢŃĆéńø«ÕēŹµö»µīüńÜäÕīģĶŻģń▒╗µ£ē’╝Ü + +| | | | | +| ------------------ | ------------------------------------------------------------ | ------------------------------------------------------------- | ------------------------------------------------------------- | +| µĢ░µŹ«ĶĮ¼µŹóń▒╗ÕÉŹń¦░ | ķ£Ćµ▒éÕŁŚµ«Ą | õ┐«µö╣/µĘ╗ÕŖĀÕŁŚµ«Ą | Ķ»┤µśÄ | +| ImgAugWrapper | `img`
`gt_polygons` (optional for text recognition)
`gt_bboxes` (optional for text recognition)
`gt_bboxes_labels` (optional for text recognition)
`gt_ignored` (optional for text recognition)
`gt_texts` (optional) | `img`
`gt_polygons` (optional for text recognition)
`gt_bboxes` (optional for text recognition)
`gt_bboxes_labels` (optional for text recognition)
`gt_ignored` (optional for text recognition)
`img_shape` (optional)
`gt_texts` (optional) | [ImgAug](https://github.com/aleju/imgaug) ÕīģĶŻģń▒╗’╝īńö©õ║ĵēōķĆÜ ImgAug õĖÄ MMOCR ńÜäµĢ░µŹ«µĀ╝Õ╝ÅÕÅŖķģŹńĮ«’╝īµ¢╣õŠ┐ńö©µłĘĶ░āńö© ImgAug Õ«×ńÄ░ńÜäõĖĆń│╗ÕłŚµĢ░µŹ«Õó×Õ╝║µ¢╣µ│ĢŃĆé | +| TorchVisionWrapper | `img` | `img`
`img_shape` | [TorchVision](https://github.com/pytorch/vision) ÕīģĶŻģń▒╗’╝īńö©õ║ĵēōķĆÜ TorchVision õĖÄ MMOCR ńÜäµĢ░µŹ«µĀ╝Õ╝ÅÕÅŖķģŹńĮ«’╝īµ¢╣õŠ┐ńö©µłĘĶ░āńö© `torchvision.transforms` õĖŁÕ«×ńÄ░ńÜäõĖĆń│╗ÕłŚµĢ░µŹ«ÕÅśµŹóµ¢╣µ│ĢŃĆé | + +### `ImgAugWrapper` ńż║õŠŗ + +õŠŗÕ”é’╝īÕ£©ÕĤńö¤ńÜä ImgAug õĖŁ’╝īµłæõ╗¼ÕÅ»õ╗źµīēńģ¦Õ”éõĖŗõ╗ŻńĀüÕ«Üõ╣ēõĖĆõĖ¬ `Sequential` ń▒╗Õ×ŗńÜäµĢ░µŹ«Õó×Õ╝║µĄüń©ŗ’╝īÕ»╣ÕøŠÕāÅÕłåÕł½Ķ┐øĶĪīķÜŵ£║ń┐╗ĶĮ¼ŃĆüķÜŵ£║µŚŗĶĮ¼ÕÆīķÜŵ£║ń╝®µöŠ’╝Ü + +```python +import imgaug.augmenters as iaa + +aug = iaa.Sequential( + iaa.Fliplr(0.5), # õ╗źµ”éńÄć 0.5 Ķ┐øĶĪīµ░┤Õ╣│ń┐╗ĶĮ¼ + iaa.Affine(rotate=(-10, 10)), # ķÜŵ£║µŚŗĶĮ¼ -10 Õł░ 10 Õ║” + iaa.Resize((0.5, 3.0)) # ķÜŵ£║ń╝®µöŠÕł░ 50% Õł░ 300% ńÜäÕ░║Õ»Ė +) +``` + +ĶĆīÕ£© MMOCR õĖŁ’╝īµłæõ╗¼ÕÅ»õ╗źķĆÜĶ┐ć `ImgAugWrapper` ÕīģĶŻģń▒╗’╝īÕ░åõĖŖĶ┐░µĢ░µŹ«Õó×Õ╝║µĄüń©ŗńø┤µÄźķģŹńĮ«Õł░ `train_pipeline` õĖŁ’╝Ü + +```python +dict( + type='ImgAugWrapper', + args=[ + ['Fliplr', 0.5], + dict(cls='Affine', rotate=[-10, 10]), + ['Resize', [0.5, 3.0]], + ] +) +``` + +ÕģČõĖŁ’╝ī`args` ÕÅéµĢ░µÄźµöČõĖĆõĖ¬ÕłŚĶĪ©’╝īÕłŚĶĪ©õĖŁńÜäµ»ÅõĖ¬Õģāń┤ĀÕÅ»õ╗źµś»õĖĆõĖ¬ÕłŚĶĪ©’╝īõ╣¤ÕÅ»õ╗źµś»õĖĆõĖ¬ÕŁŚÕģĖŃĆéÕ”éµ×£µś»ÕłŚĶĪ©’╝īÕłÖÕłŚĶĪ©ńÜäń¼¼õĖĆõĖ¬Õģāń┤ĀõĖ║ `imgaug.augmenters` õĖŁńÜäń▒╗ÕÉŹ’╝īÕÉÄķØóńÜäÕģāń┤ĀõĖ║Ķ»źń▒╗ńÜäÕłØÕ¦ŗÕī¢ÕÅéµĢ░’╝øÕ”éµ×£µś»ÕŁŚÕģĖ’╝īÕłÖÕŁŚÕģĖńÜä `cls` ķö«Õ»╣Õ║ö `imgaug.augmenters` õĖŁńÜäń▒╗ÕÉŹ’╝īÕģČõ╗¢ķö«ÕĆ╝Õ»╣ÕłÖÕ»╣Õ║öĶ»źń▒╗ńÜäÕłØÕ¦ŗÕī¢ÕÅéµĢ░ŃĆé + +### `TorchVisionWrapper` ńż║õŠŗ + +õŠŗÕ”é’╝īÕ£©ÕĤńö¤ńÜä TorchVision õĖŁ’╝īµłæõ╗¼ÕÅ»õ╗źµīēńģ¦Õ”éõĖŗõ╗ŻńĀüÕ«Üõ╣ēõĖĆõĖ¬ `Compose` ń▒╗Õ×ŗńÜäµĢ░µŹ«ÕÅśµŹóµĄüń©ŗ’╝īÕ»╣ÕøŠÕāÅĶ┐øĶĪīĶē▓ÕĮ®µŖ¢ÕŖ©’╝Ü + +```python +import torchvision.transforms as transforms + +aug = transforms.Compose([ + transforms.ColorJitter( + brightness=32.0 / 255, # õ║«Õ║”µŖ¢ÕŖ©ĶīāÕø┤ + saturation=0.5) # ķź▒ÕÆīÕ║”µŖ¢ÕŖ©ĶīāÕø┤ +]) +``` + +ĶĆīÕ£© MMOCR õĖŁ’╝īµłæõ╗¼ÕÅ»õ╗źķĆÜĶ┐ć `TorchVisionWrapper` ÕīģĶŻģń▒╗’╝īÕ░åõĖŖĶ┐░µĢ░µŹ«ÕÅśµŹóµĄüń©ŗńø┤µÄźķģŹńĮ«Õł░ `train_pipeline` õĖŁ’╝Ü + +```python +dict( + type='TorchVisionWrapper', + op='ColorJitter', + brightness=32.0 / 255, + saturation=0.5 +) +``` + +ÕģČõĖŁ’╝ī`op` ÕÅéµĢ░õĖ║ `torchvision.transforms` õĖŁńÜäń▒╗ÕÉŹ’╝īÕÉÄķØóńÜäÕÅéµĢ░ÕłÖÕ»╣Õ║öĶ»źń▒╗ńÜäÕłØÕ¦ŗÕī¢ÕÅéµĢ░ŃĆé diff --git a/internlm_langchain/knowledge_base/MMOCR/content/useful_tools.md b/internlm_langchain/knowledge_base/MMOCR/content/useful_tools.md new file mode 100644 index 00000000..2a607245 --- /dev/null +++ b/internlm_langchain/knowledge_base/MMOCR/content/useful_tools.md @@ -0,0 +1,241 @@ +# ÕĖĖńö©ÕĘźÕģĘ + +## ÕÅ»Ķ¦åÕī¢ÕĘźÕģĘ + +### µĢ░µŹ«ķøåÕÅ»Ķ¦åÕī¢ÕĘźÕģĘ + +MMOCR µÅÉõŠøõ║åµĢ░µŹ«ķøåÕÅ»Ķ¦åÕī¢ÕĘźÕģĘ `tools/visualizations/browse_datasets.py` õ╗źĶŠģÕŖ®ńö©µłĘµÄƵ¤źÕÅ»ĶāĮķüćÕł░ńÜäµĢ░µŹ«ķøåńøĖÕģ│ńÜäķŚ«ķóśŃĆéńö©µłĘÕŬķ£ĆĶ”üµīćիܵēĆõĮ┐ńö©ńÜäĶ«Łń╗āķģŹńĮ«µ¢ćõ╗Č’╝łķĆÜÕĖĖÕŁśµöŠÕ£©Õ”é `configs/textdet/dbnet/xxx.py` µ¢ćõ╗ČõĖŁ’╝ēµł¢µĢ░µŹ«ķøåķģŹńĮ«’╝łķĆÜÕĖĖÕŁśµöŠÕ£© `configs/textdet/_base_/datasets/xxx.py` µ¢ćõ╗ČõĖŁ’╝ēĶĘ»ÕŠäŃĆéĶ»źÕĘźÕģĘÕ░åõŠØµŹ«ĶŠōÕģźńÜäķģŹńĮ«µ¢ćõ╗Čń▒╗Õ×ŗĶć¬ÕŖ©Õ░åń╗ÅĶ┐ćµĢ░µŹ«µĄüµ░┤ń║┐’╝łdata pipeline’╝ēÕżäńÉåĶ┐ćńÜäÕøŠÕāÅÕÅŖÕģČÕ»╣Õ║öńÜäµĀćńŁŠ’╝īµł¢ÕĤզŗÕøŠńēćÕÅŖÕģČÕ»╣Õ║öńÜäµĀćńŁŠń╗śÕłČÕć║µØźŃĆé + +#### µö»µīüÕÅéµĢ░ + +```bash +python tools/visualizations/browse_dataset.py \ + ${CONFIG_FILE} \ + [-o, --output-dir ${OUTPUT_DIR}] \ + [-p, --phase ${DATASET_PHASE}] \ + [-m, --mode ${DISPLAY_MODE}] \ + [-t, --task ${DATASET_TASK}] \ + [-n, --show-number ${NUMBER_IMAGES_DISPLAY}] \ + [-i, --show-interval ${SHOW_INTERRVAL}] \ + [--cfg-options ${CFG_OPTIONS}] +``` + +| ÕÅéµĢ░ÕÉŹ | ń▒╗Õ×ŗ | µÅÅĶ┐░ | +| ------------------- | ------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------ | +| config | str | (Õ┐ģķĪ╗) ķģŹńĮ«µ¢ćõ╗ČĶĘ»ÕŠäŃĆé | +| -o, --output-dir | str | Õ”éµ×£ÕøŠÕĮóÕī¢ńĢīķØóõĖŹÕÅ»ńö©’╝īĶ»ĘµīćÕ«ÜõĖĆõĖ¬ĶŠōÕć║ĶĘ»ÕŠäµØźõ┐ØÕŁśÕÅ»Ķ¦åÕī¢ń╗ōµ×£ŃĆé | +| -p, --phase | str | ńö©õ║ĵīćÕ«Üķ£ĆĶ”üÕÅ»Ķ¦åÕī¢ńÜäµĢ░µŹ«ķøåÕłćńēć’╝īÕ”é "train", "test", "val"ŃĆéÕĮōµĢ░µŹ«ķøåÕŁśÕ£©ÕżÜõĖ¬ÕÅśń¦ŹµŚČ’╝īõ╣¤ÕÅ»õ╗źķĆÜĶ┐ćĶ»źÕÅéµĢ░µØźµīćÕ«ÜÕŠģÕÅ»Ķ¦åÕī¢ńÜäÕłćńēćŃĆé | +| -m, --mode | `original`, `transformed`, `pipeline` | ńö©õ║ĵīćիܵĢ░µŹ«ÕÅ»Ķ¦åÕī¢ńÜ䵩ĪÕ╝ÅŃĆé`original`’╝ÜÕĤզŗµ©ĪÕ╝Å’╝īõ╗ģÕÅ»Ķ¦åÕī¢µĢ░µŹ«ķøåńÜäÕĤզŗµĀćµ│©’╝ø`transformed`’╝ÜÕÅśµŹóµ©ĪÕ╝Å’╝īÕ▒Ģńż║ń╗ÅĶ┐ćµēƵ£ēµĢ░µŹ«ÕÅśµŹóµŁźķ¬żńÜäµ£Ćń╗łÕøŠÕāÅ’╝ø`pipeline`’╝ܵĄüµ░┤ń║┐µ©ĪÕ╝Å’╝īÕ▒Ģńż║µĢ░µŹ«ÕÅśµŹóĶ┐ćń©ŗõĖŁµ»ÅõĖĆõĖ¬õĖŁķŚ┤µŁźķ¬żńÜäÕÅśµŹóÕøŠÕāÅŃĆéķ╗śĶ«żõĮ┐ńö© `transformed` ÕÅśµŹóµ©ĪÕ╝ÅŃĆé | +| -t, --task | `auto`, `textdet`, `textrecog` | ńö©õ║ĵīćÕ«ÜÕÅ»Ķ¦åÕī¢µĢ░µŹ«ķøåńÜäõ╗╗ÕŖĪń▒╗Õ×ŗŃĆé`auto`’╝ÜĶć¬ÕŖ©µ©ĪÕ╝Å’╝īÕ░åõŠØµŹ«ń╗ÖÕ«ÜńÜäķģŹńĮ«µ¢ćõ╗ČĶć¬ÕŖ©ķĆēµŗ®ÕÉłķĆéńÜäõ╗╗ÕŖĪń▒╗Õ×ŗ’╝īÕ”éµ×£µŚĀµ│ĢĶć¬ÕŖ©ĶÄĘÕÅ¢õ╗╗ÕŖĪń▒╗Õ×ŗ’╝īÕłÖķ£ĆĶ”üńö©µłĘµēŗÕŖ©µīćÕ«ÜõĖ║ `textdet` µ¢ćµ£¼µŻĆµĄŗõ╗╗ÕŖĪ µł¢ `textrecog` µ¢ćµ£¼Ķ»åÕł½õ╗╗ÕŖĪŃĆéķ╗śĶ«żķććńö© `auto` Ķć¬ÕŖ©µ©ĪÕ╝ÅŃĆé | +| -n, --show-number | int | µīćÕ«Üķ£ĆĶ”üÕÅ»Ķ¦åÕī¢ńÜäµĀʵ£¼µĢ░ķćÅŃĆéĶŗźĶ»źÕÅéµĢ░ń╝║ń£üÕłÖķ╗śĶ«żÕ░åÕÅ»Ķ¦åÕī¢Õģ©ķā©ÕøŠńēćŃĆé | +| -i, --show-interval | float | ÕÅ»Ķ¦åÕī¢ÕøŠÕāÅķŚ┤ķÜöµŚČķŚ┤’╝īķ╗śĶ«żõĖ║ 2 ń¦ÆŃĆé | +| --cfg-options | float | ńö©õ║ÄĶ”åńø¢ķģŹńĮ«µ¢ćõ╗ČõĖŁńÜäÕÅéµĢ░’╝īĶ»”Ķ¦ü[ńż║õŠŗ](./config.md#command-line-modification)ŃĆé | + +#### ńö©µ│Ģńż║õŠŗ + +õ╗źõĖŗńż║õŠŗµ╝öńż║õ║åÕ”éõĮĢõĮ┐ńö©Ķ»źÕĘźÕģĘÕÅ»Ķ¦åÕī¢ "DBNet_R50_icdar2015" µ©ĪÕ×ŗõĮ┐ńö©ńÜäĶ«Łń╗āµĢ░µŹ«ŃĆé + +```Bash +# õĮ┐ńö©ķ╗śĶ«żÕÅéµĢ░ÕÅ»Ķ¦åÕī¢ "dbnet_r50dcn_v2_fpnc_1200e_icadr2015" µ©ĪÕ×ŗńÜäĶ«Łń╗āµĢ░µŹ« +python tools/visualizations/browse_dataset.py configs/textdet/dbnet/dbnet_resnet50-dcnv2_fpnc_1200e_icdar2015.py +``` + +ķ╗śĶ«żµāģÕåĄõĖŗ’╝īÕÅ»Ķ¦åÕī¢µ©ĪÕ╝ÅõĖ║ "transformed"’╝īµé©Õ░åń£ŗÕł░ń╗Åńö▒µĢ░µŹ«µĄüµ░┤ń║┐ÕÅśµŹóĶ┐ćÕÉÄńÜäÕøŠÕāÅÕÆīµĀćµ│©’╝Ü + +
+
+ +
+
+
+Õ”éµ×£ÕŬµā│µ¤źń£ŗķó䵥ŗń╗ōµ×£õ┐Īµü»ÕÅ»õ╗źÕŬĶ«®`draw_pred=True`
+
+```Python
+visualization = _base_.default_hooks.visualization
+visualization.update(
+ dict(enable=True, show=True, draw_gt=False, draw_pred=True))
+```
+
+
+
+ +
+
+
+Õ£© `test.py` Ķ┐ćń©ŗõĖŁĶ┐øõĖƵŁźń«ĆÕī¢’╝īµÅÉõŠøõ║å `--show` ÕÆī `--show-dir`õĖżõĖ¬ÕÅéµĢ░’╝īµŚĀķ£Ćõ┐«µö╣ķģŹńĮ«ÕŹ│ÕÅ»Ķ¦åÕī¢µĄŗĶ»ĢĶ┐ćń©ŗõĖŁń╗śÕłČµĀćµ│©ÕÆīķó䵥ŗń╗ōµ×£ŃĆé
+
+```Shell
+# Õ▒Ģńż║test ń╗ōµ×£
+python tools/test.py configs/textdet/dbnet/dbnet_resnet18_fpnc_1200e_icdar2015.py dbnet_r18_fpnc_1200e_icdar2015/epoch_400.pth --show
+
+# µīćÕ«Üķó䵥ŗń╗ōµ×£ńÜäÕŁśÕé©õĮŹńĮ«
+python tools/test.py configs/textdet/dbnet/dbnet_resnet18_fpnc_1200e_icdar2015.py dbnet_r18_fpnc_1200e_icdar2015/epoch_400.pth --show-dir imgs/
+```
+
+
+
+
+
diff --git a/internlm_langchain/knowledge_base/MMOCR/content/visualizers.md b/internlm_langchain/knowledge_base/MMOCR/content/visualizers.md
new file mode 100644
index 00000000..323dc0a2
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMOCR/content/visualizers.md
@@ -0,0 +1,3 @@
+# ÕÅ»Ķ¦åÕī¢ń╗äõ╗Č\[ÕŠģµø┤µ¢░\]
+
+ÕŠģµø┤µ¢░
diff --git a/internlm_langchain/knowledge_base/MMOCR/vector_store/index.faiss b/internlm_langchain/knowledge_base/MMOCR/vector_store/index.faiss
new file mode 100644
index 00000000..3e74d49d
Binary files /dev/null and b/internlm_langchain/knowledge_base/MMOCR/vector_store/index.faiss differ
diff --git a/internlm_langchain/knowledge_base/MMPose/content/2d_animal_keypoint.md b/internlm_langchain/knowledge_base/MMPose/content/2d_animal_keypoint.md
new file mode 100644
index 00000000..28b0b726
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPose/content/2d_animal_keypoint.md
@@ -0,0 +1,545 @@
+# 2D Animal Keypoint Dataset
+
+It is recommended to symlink the dataset root to `$MMPOSE/data`.
+If your folder structure is different, you may need to change the corresponding paths in config files.
+
+MMPose supported datasets:
+
+- [Animal-Pose](#animal-pose) \[ [Homepage](https://sites.google.com/view/animal-pose/) \]
+- [AP-10K](#ap-10k) \[ [Homepage](https://github.com/AlexTheBad/AP-10K/) \]
+- [Horse-10](#horse-10) \[ [Homepage](http://www.mackenziemathislab.org/horse10) \]
+- [MacaquePose](#macaquepose) \[ [Homepage](http://www.pri.kyoto-u.ac.jp/datasets/macaquepose/index.html) \]
+- [Vinegar Fly](#vinegar-fly) \[ [Homepage](https://github.com/jgraving/DeepPoseKit-Data) \]
+- [Desert Locust](#desert-locust) \[ [Homepage](https://github.com/jgraving/DeepPoseKit-Data) \]
+- [Gr├®vyŌĆÖs Zebra](#grvys-zebra) \[ [Homepage](https://github.com/jgraving/DeepPoseKit-Data) \]
+- [ATRW](#atrw) \[ [Homepage](https://cvwc2019.github.io/challenge.html) \]
+- [Animal Kingdom](#Animal-Kindom) \[ [Homepage](https://openaccess.thecvf.com/content/CVPR2022/html/Ng_Animal_Kingdom_A_Large_and_Diverse_Dataset_for_Animal_Behavior_CVPR_2022_paper.html) \]
+
+## Animal-Pose
+
+
+
+
+
+
+
+Animal-Pose (ICCV'2019)
+ +```bibtex +@InProceedings{Cao_2019_ICCV, + author = {Cao, Jinkun and Tang, Hongyang and Fang, Hao-Shu and Shen, Xiaoyong and Lu, Cewu and Tai, Yu-Wing}, + title = {Cross-Domain Adaptation for Animal Pose Estimation}, + booktitle = {The IEEE International Conference on Computer Vision (ICCV)}, + month = {October}, + year = {2019} +} +``` + +
+  +
+
+
+For [Animal-Pose](https://sites.google.com/view/animal-pose/) dataset, we prepare the dataset as follows:
+
+1. Download the images of [PASCAL VOC2012](http://host.robots.ox.ac.uk/pascal/VOC/voc2012/#data), especially the five categories (dog, cat, sheep, cow, horse), which we use as trainval dataset.
+2. Download the [test-set](https://drive.google.com/drive/folders/1DwhQobZlGntOXxdm7vQsE4bqbFmN3b9y?usp=sharing) images with raw annotations (1000 images, 5 categories).
+3. We have pre-processed the annotations to make it compatible with MMPose. Please download the annotation files from [annotations](https://download.openmmlab.com/mmpose/datasets/animalpose_annotations.tar). If you would like to generate the annotations by yourself, please check our dataset parsing [codes](/tools/dataset_converters/parse_animalpose_dataset.py).
+
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+`ŌöĆŌöĆ data
+ ŌöéŌöĆŌöĆ animalpose
+ Ōöé
+ Ōöé-- VOC2012
+ Ōöé Ōöé-- Annotations
+ Ōöé Ōöé-- ImageSets
+ Ōöé Ōöé-- JPEGImages
+ Ōöé Ōöé-- SegmentationClass
+ Ōöé Ōöé-- SegmentationObject
+ Ōöé
+ Ōöé-- animalpose_image_part2
+ Ōöé Ōöé-- cat
+ Ōöé Ōöé-- cow
+ Ōöé Ōöé-- dog
+ Ōöé Ōöé-- horse
+ Ōöé Ōöé-- sheep
+ Ōöé
+ Ōöé-- annotations
+ Ōöé Ōöé-- animalpose_train.json
+ Ōöé |-- animalpose_val.json
+ Ōöé |-- animalpose_trainval.json
+ Ōöé Ōöé-- animalpose_test.json
+ Ōöé
+ Ōöé-- PASCAL2011_animal_annotation
+ Ōöé Ōöé-- cat
+ Ōöé Ōöé |-- 2007_000528_1.xml
+ Ōöé Ōöé |-- 2007_000549_1.xml
+ Ōöé Ōöé Ōöé-- ...
+ Ōöé Ōöé-- cow
+ Ōöé Ōöé-- dog
+ Ōöé Ōöé-- horse
+ Ōöé Ōöé-- sheep
+ Ōöé
+ Ōöé-- annimalpose_anno2
+ Ōöé Ōöé-- cat
+ Ōöé Ōöé |-- ca1.xml
+ Ōöé Ōöé |-- ca2.xml
+ Ōöé Ōöé Ōöé-- ...
+ Ōöé Ōöé-- cow
+ Ōöé Ōöé-- dog
+ Ōöé Ōöé-- horse
+ Ōöé Ōöé-- sheep
+
+```
+
+The official dataset does not provide the official train/val/test set split.
+We choose the images from PascalVOC for train & val. In total, we have 3608 images and 5117 annotations for train+val, where
+2798 images with 4000 annotations are used for training, and 810 images with 1117 annotations are used for validation.
+Those images from other sources (1000 images with 1000 annotations) are used for testing.
+
+## AP-10K
+
+
+
+
+
+
+
+AP-10K (NeurIPS'2021)
+ +```bibtex +@misc{yu2021ap10k, + title={AP-10K: A Benchmark for Animal Pose Estimation in the Wild}, + author={Hang Yu and Yufei Xu and Jing Zhang and Wei Zhao and Ziyu Guan and Dacheng Tao}, + year={2021}, + eprint={2108.12617}, + archivePrefix={arXiv}, + primaryClass={cs.CV} +} +``` + +
+  +
+
+
+For [AP-10K](https://github.com/AlexTheBad/AP-10K/) dataset, images and annotations can be downloaded from [download](https://drive.google.com/file/d/1-FNNGcdtAQRehYYkGY1y4wzFNg4iWNad/view?usp=sharing).
+Note, this data and annotation data is for non-commercial use only.
+
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+`ŌöĆŌöĆ data
+ ŌöéŌöĆŌöĆ ap10k
+ Ōöé-- annotations
+ Ōöé Ōöé-- ap10k-train-split1.json
+ Ōöé |-- ap10k-train-split2.json
+ Ōöé |-- ap10k-train-split3.json
+ Ōöé Ōöé-- ap10k-val-split1.json
+ Ōöé |-- ap10k-val-split2.json
+ Ōöé |-- ap10k-val-split3.json
+ Ōöé |-- ap10k-test-split1.json
+ Ōöé |-- ap10k-test-split2.json
+ Ōöé |-- ap10k-test-split3.json
+ Ōöé-- data
+ Ōöé Ōöé-- 000000000001.jpg
+ Ōöé Ōöé-- 000000000002.jpg
+ Ōöé Ōöé-- ...
+
+```
+
+The annotation files in 'annotation' folder contains 50 labeled animal species. There are total 10,015 labeled images with 13,028 instances in the AP-10K dataset. We randonly split them into train, val, and test set following the ratio of 7:1:2.
+
+## Horse-10
+
+
+
+
+
+
+
+Horse-10 (WACV'2021)
+ +```bibtex +@inproceedings{mathis2021pretraining, + title={Pretraining boosts out-of-domain robustness for pose estimation}, + author={Mathis, Alexander and Biasi, Thomas and Schneider, Steffen and Yuksekgonul, Mert and Rogers, Byron and Bethge, Matthias and Mathis, Mackenzie W}, + booktitle={Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision}, + pages={1859--1868}, + year={2021} +} +``` + +
+  +
+
+
+For [Horse-10](http://www.mackenziemathislab.org/horse10) dataset, images can be downloaded from [download](http://www.mackenziemathislab.org/horse10).
+Please download the annotation files from [horse10_annotations](https://download.openmmlab.com/mmpose/datasets/horse10_annotations.tar). Note, this data and annotation data is for non-commercial use only, per the authors (see http://horse10.deeplabcut.org for more information).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+`ŌöĆŌöĆ data
+ ŌöéŌöĆŌöĆ horse10
+ Ōöé-- annotations
+ Ōöé Ōöé-- horse10-train-split1.json
+ Ōöé |-- horse10-train-split2.json
+ Ōöé |-- horse10-train-split3.json
+ Ōöé Ōöé-- horse10-test-split1.json
+ Ōöé |-- horse10-test-split2.json
+ Ōöé |-- horse10-test-split3.json
+ Ōöé-- labeled-data
+ Ōöé Ōöé-- BrownHorseinShadow
+ Ōöé Ōöé-- BrownHorseintoshadow
+ Ōöé Ōöé-- ...
+
+```
+
+## MacaquePose
+
+
+
+
+
+
+
+MacaquePose (bioRxiv'2020)
+ +```bibtex +@article{labuguen2020macaquepose, + title={MacaquePose: A novel ŌĆśin the wildŌĆÖmacaque monkey pose dataset for markerless motion capture}, + author={Labuguen, Rollyn and Matsumoto, Jumpei and Negrete, Salvador and Nishimaru, Hiroshi and Nishijo, Hisao and Takada, Masahiko and Go, Yasuhiro and Inoue, Ken-ichi and Shibata, Tomohiro}, + journal={bioRxiv}, + year={2020}, + publisher={Cold Spring Harbor Laboratory} +} +``` + +
+  +
+
+
+For [MacaquePose](http://www.pri.kyoto-u.ac.jp/datasets/macaquepose/index.html) dataset, images can be downloaded from [download](http://www.pri.kyoto-u.ac.jp/datasets/macaquepose/index.html).
+Please download the annotation files from [macaque_annotations](https://download.openmmlab.com/mmpose/datasets/macaque_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+`ŌöĆŌöĆ data
+ ŌöéŌöĆŌöĆ macaque
+ Ōöé-- annotations
+ Ōöé Ōöé-- macaque_train.json
+ Ōöé |-- macaque_test.json
+ Ōöé-- images
+ Ōöé Ōöé-- 01418849d54b3005.jpg
+ Ōöé Ōöé-- 0142d1d1a6904a70.jpg
+ Ōöé Ōöé-- 01ef2c4c260321b7.jpg
+ Ōöé Ōöé-- 020a1c75c8c85238.jpg
+ Ōöé Ōöé-- 020b1506eef2557d.jpg
+ Ōöé Ōöé-- ...
+
+```
+
+Since the official dataset does not provide the test set, we randomly select 12500 images for training, and the rest for evaluation (see [code](/tools/dataset/parse_macaquepose_dataset.py)).
+
+## Vinegar Fly
+
+
+
+
+
+
+
+Vinegar Fly (Nature Methods'2019)
+ +```bibtex +@article{pereira2019fast, + title={Fast animal pose estimation using deep neural networks}, + author={Pereira, Talmo D and Aldarondo, Diego E and Willmore, Lindsay and Kislin, Mikhail and Wang, Samuel S-H and Murthy, Mala and Shaevitz, Joshua W}, + journal={Nature methods}, + volume={16}, + number={1}, + pages={117--125}, + year={2019}, + publisher={Nature Publishing Group} +} +``` + +
+  +
+
+
+For [Vinegar Fly](https://github.com/jgraving/DeepPoseKit-Data) dataset, images can be downloaded from [vinegar_fly_images](https://download.openmmlab.com/mmpose/datasets/vinegar_fly_images.tar).
+Please download the annotation files from [vinegar_fly_annotations](https://download.openmmlab.com/mmpose/datasets/vinegar_fly_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+`ŌöĆŌöĆ data
+ ŌöéŌöĆŌöĆ fly
+ Ōöé-- annotations
+ Ōöé Ōöé-- fly_train.json
+ Ōöé |-- fly_test.json
+ Ōöé-- images
+ Ōöé Ōöé-- 0.jpg
+ Ōöé Ōöé-- 1.jpg
+ Ōöé Ōöé-- 2.jpg
+ Ōöé Ōöé-- 3.jpg
+ Ōöé Ōöé-- ...
+
+```
+
+Since the official dataset does not provide the test set, we randomly select 90% images for training, and the rest (10%) for evaluation (see [code](/tools/dataset_converters/parse_deepposekit_dataset.py)).
+
+## Desert Locust
+
+
+
+
+
+
+
+Desert Locust (Elife'2019)
+ +```bibtex +@article{graving2019deepposekit, + title={DeepPoseKit, a software toolkit for fast and robust animal pose estimation using deep learning}, + author={Graving, Jacob M and Chae, Daniel and Naik, Hemal and Li, Liang and Koger, Benjamin and Costelloe, Blair R and Couzin, Iain D}, + journal={Elife}, + volume={8}, + pages={e47994}, + year={2019}, + publisher={eLife Sciences Publications Limited} +} +``` + +
+  +
+
+
+For [Desert Locust](https://github.com/jgraving/DeepPoseKit-Data) dataset, images can be downloaded from [locust_images](https://download.openmmlab.com/mmpose/datasets/locust_images.tar).
+Please download the annotation files from [locust_annotations](https://download.openmmlab.com/mmpose/datasets/locust_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+`ŌöĆŌöĆ data
+ ŌöéŌöĆŌöĆ locust
+ Ōöé-- annotations
+ Ōöé Ōöé-- locust_train.json
+ Ōöé |-- locust_test.json
+ Ōöé-- images
+ Ōöé Ōöé-- 0.jpg
+ Ōöé Ōöé-- 1.jpg
+ Ōöé Ōöé-- 2.jpg
+ Ōöé Ōöé-- 3.jpg
+ Ōöé Ōöé-- ...
+
+```
+
+Since the official dataset does not provide the test set, we randomly select 90% images for training, and the rest (10%) for evaluation (see [code](/tools/dataset_converters/parse_deepposekit_dataset.py)).
+
+## Gr├®vyŌĆÖs Zebra
+
+
+
+
+
+
+
+Gr├®vyŌĆÖs Zebra (Elife'2019)
+ +```bibtex +@article{graving2019deepposekit, + title={DeepPoseKit, a software toolkit for fast and robust animal pose estimation using deep learning}, + author={Graving, Jacob M and Chae, Daniel and Naik, Hemal and Li, Liang and Koger, Benjamin and Costelloe, Blair R and Couzin, Iain D}, + journal={Elife}, + volume={8}, + pages={e47994}, + year={2019}, + publisher={eLife Sciences Publications Limited} +} +``` + +
+  +
+
+
+For [Gr├®vyŌĆÖs Zebra](https://github.com/jgraving/DeepPoseKit-Data) dataset, images can be downloaded from [zebra_images](https://download.openmmlab.com/mmpose/datasets/zebra_images.tar).
+Please download the annotation files from [zebra_annotations](https://download.openmmlab.com/mmpose/datasets/zebra_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+`ŌöĆŌöĆ data
+ ŌöéŌöĆŌöĆ zebra
+ Ōöé-- annotations
+ Ōöé Ōöé-- zebra_train.json
+ Ōöé |-- zebra_test.json
+ Ōöé-- images
+ Ōöé Ōöé-- 0.jpg
+ Ōöé Ōöé-- 1.jpg
+ Ōöé Ōöé-- 2.jpg
+ Ōöé Ōöé-- 3.jpg
+ Ōöé Ōöé-- ...
+
+```
+
+Since the official dataset does not provide the test set, we randomly select 90% images for training, and the rest (10%) for evaluation (see [code](/tools/dataset_converters/parse_deepposekit_dataset.py)).
+
+## ATRW
+
+
+
+
+
+
+
+ATRW (ACM MM'2020)
+ +```bibtex +@inproceedings{li2020atrw, + title={ATRW: A Benchmark for Amur Tiger Re-identification in the Wild}, + author={Li, Shuyuan and Li, Jianguo and Tang, Hanlin and Qian, Rui and Lin, Weiyao}, + booktitle={Proceedings of the 28th ACM International Conference on Multimedia}, + pages={2590--2598}, + year={2020} +} +``` + +
+  +
+
+
+ATRW captures images of the Amur tiger (also known as Siberian tiger, Northeast-China tiger) in the wild.
+For [ATRW](https://cvwc2019.github.io/challenge.html) dataset, please download images from
+[Pose_train](https://lilablobssc.blob.core.windows.net/cvwc2019/train/atrw_pose_train.tar.gz),
+[Pose_val](https://lilablobssc.blob.core.windows.net/cvwc2019/train/atrw_pose_val.tar.gz), and
+[Pose_test](https://lilablobssc.blob.core.windows.net/cvwc2019/test/atrw_pose_test.tar.gz).
+Note that in the ATRW official annotation files, the key "file_name" is written as "filename". To make it compatible with
+other coco-type json files, we have modified this key.
+Please download the modified annotation files from [atrw_annotations](https://download.openmmlab.com/mmpose/datasets/atrw_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+`ŌöĆŌöĆ data
+ ŌöéŌöĆŌöĆ atrw
+ Ōöé-- annotations
+ Ōöé Ōöé-- keypoint_train.json
+ Ōöé Ōöé-- keypoint_val.json
+ Ōöé Ōöé-- keypoint_trainval.json
+ Ōöé-- images
+ Ōöé Ōöé-- train
+ Ōöé Ōöé Ōöé-- 000002.jpg
+ Ōöé Ōöé Ōöé-- 000003.jpg
+ Ōöé Ōöé Ōöé-- ...
+ Ōöé Ōöé-- val
+ Ōöé Ōöé Ōöé-- 000001.jpg
+ Ōöé Ōöé Ōöé-- 000013.jpg
+ Ōöé Ōöé Ōöé-- ...
+ Ōöé Ōöé-- test
+ Ōöé Ōöé Ōöé-- 000000.jpg
+ Ōöé Ōöé Ōöé-- 000004.jpg
+ Ōöé Ōöé Ōöé-- ...
+
+```
+
+## Animal Kingdom
+
+
+
+
+  +
+
+
+```bibtex
+@inproceedings{Ng_2022_CVPR,
+ author = {Ng, Xun Long and Ong, Kian Eng and Zheng, Qichen and Ni, Yun and Yeo, Si Yong and Liu, Jun},
+ title = {Animal Kingdom: A Large and Diverse Dataset for Animal Behavior Understanding},
+ booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
+ month = {June},
+ year = {2022},
+ pages = {19023-19034}
+ }
+```
+
+For [Animal Kingdom](https://github.com/sutdcv/Animal-Kingdom) dataset, images can be downloaded from [here](https://forms.office.com/pages/responsepage.aspx?id=drd2NJDpck-5UGJImDFiPVRYpnTEMixKqPJ1FxwK6VZUQkNTSkRISTNORUI2TDBWMUpZTlQ5WUlaSyQlQCN0PWcu).
+Please Extract dataset under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+`ŌöĆŌöĆ data
+ ŌöéŌöĆŌöĆ ak
+ |--annotations
+ Ōöé Ōöé-- ak_P1
+ Ōöé Ōöé Ōöé-- train.json
+ Ōöé Ōöé Ōöé-- test.json
+ Ōöé Ōöé-- ak_P2
+ Ōöé Ōöé Ōöé-- train.json
+ Ōöé Ōöé Ōöé-- test.json
+ Ōöé Ōöé-- ak_P3_amphibian
+ Ōöé Ōöé Ōöé-- train.json
+ Ōöé Ōöé Ōöé-- test.json
+ Ōöé Ōöé-- ak_P3_bird
+ Ōöé Ōöé Ōöé-- train.json
+ Ōöé Ōöé Ōöé-- test.json
+ Ōöé Ōöé-- ak_P3_fish
+ Ōöé Ōöé Ōöé-- train.json
+ Ōöé Ōöé Ōöé-- test.json
+ Ōöé Ōöé-- ak_P3_mammal
+ Ōöé Ōöé Ōöé-- train.json
+ Ōöé Ōöé Ōöé-- test.json
+ Ōöé Ōöé-- ak_P3_reptile
+ Ōöé Ōöé-- train.json
+ Ōöé Ōöé-- test.json
+ Ōöé-- images
+ Ōöé Ōöé-- AAACXZTV
+ Ōöé Ōöé Ōöé--AAACXZTV_f000059.jpg
+ Ōöé Ōöé Ōöé--...
+ Ōöé Ōöé-- AAAUILHH
+ Ōöé Ōöé Ōöé--AAAUILHH_f000098.jpg
+ Ōöé Ōöé Ōöé--...
+ Ōöé Ōöé-- ...
+```
diff --git a/internlm_langchain/knowledge_base/MMPose/content/2d_body_keypoint.md b/internlm_langchain/knowledge_base/MMPose/content/2d_body_keypoint.md
new file mode 100644
index 00000000..4448ebe8
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPose/content/2d_body_keypoint.md
@@ -0,0 +1,588 @@
+# 2D Body Keypoint Datasets
+
+It is recommended to symlink the dataset root to `$MMPOSE/data`.
+If your folder structure is different, you may need to change the corresponding paths in config files.
+
+MMPose supported datasets:
+
+- Images
+ - [COCO](#coco) \[ [Homepage](http://cocodataset.org/) \]
+ - [MPII](#mpii) \[ [Homepage](http://human-pose.mpi-inf.mpg.de/) \]
+ - [MPII-TRB](#mpii-trb) \[ [Homepage](https://github.com/kennymckormick/Triplet-Representation-of-human-Body) \]
+ - [AI Challenger](#aic) \[ [Homepage](https://github.com/AIChallenger/AI_Challenger_2017) \]
+ - [CrowdPose](#crowdpose) \[ [Homepage](https://github.com/Jeff-sjtu/CrowdPose) \]
+ - [OCHuman](#ochuman) \[ [Homepage](https://github.com/liruilong940607/OCHumanApi) \]
+ - [MHP](#mhp) \[ [Homepage](https://lv-mhp.github.io/dataset) \]
+ - [Human-Art](#humanart) \[ [Homepage](https://idea-research.github.io/HumanArt/) \]
+- Videos
+ - [PoseTrack18](#posetrack18) \[ [Homepage](https://posetrack.net/users/download.php) \]
+ - [sub-JHMDB](#sub-jhmdb-dataset) \[ [Homepage](http://jhmdb.is.tue.mpg.de/dataset) \]
+
+## COCO
+
+
+
+
+
+
+COCO (ECCV'2014)
+ +```bibtex +@inproceedings{lin2014microsoft, + title={Microsoft coco: Common objects in context}, + author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence}, + booktitle={European conference on computer vision}, + pages={740--755}, + year={2014}, + organization={Springer} +} +``` + +
+  +
+
+
+For [COCO](http://cocodataset.org/) data, please download from [COCO download](http://cocodataset.org/#download), 2017 Train/Val is needed for COCO keypoints training and validation.
+[HRNet-Human-Pose-Estimation](https://github.com/HRNet/HRNet-Human-Pose-Estimation) provides person detection result of COCO val2017 to reproduce our multi-person pose estimation results.
+Please download from [OneDrive](https://1drv.ms/f/s!AhIXJn_J-blWzzDXoz5BeFl8sWM-) or [GoogleDrive](https://drive.google.com/drive/folders/1fRUDNUDxe9fjqcRZ2bnF_TKMlO0nB_dk?usp=sharing).
+Optionally, to evaluate on COCO'2017 test-dev, please download the [image-info](https://download.openmmlab.com/mmpose/datasets/person_keypoints_test-dev-2017.json).
+Download and extract them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+`ŌöĆŌöĆ data
+ ŌöéŌöĆŌöĆ coco
+ Ōöé-- annotations
+ Ōöé Ōöé-- person_keypoints_train2017.json
+ Ōöé |-- person_keypoints_val2017.json
+ Ōöé |-- person_keypoints_test-dev-2017.json
+ |-- person_detection_results
+ | |-- COCO_val2017_detections_AP_H_56_person.json
+ | |-- COCO_test-dev2017_detections_AP_H_609_person.json
+ Ōöé-- train2017
+ Ōöé Ōöé-- 000000000009.jpg
+ Ōöé Ōöé-- 000000000025.jpg
+ Ōöé Ōöé-- 000000000030.jpg
+ Ōöé Ōöé-- ...
+ `-- val2017
+ Ōöé-- 000000000139.jpg
+ Ōöé-- 000000000285.jpg
+ Ōöé-- 000000000632.jpg
+ Ōöé-- ...
+
+```
+
+## MPII
+
+
+
+
+
+
+
+MPII (CVPR'2014)
+ +```bibtex +@inproceedings{andriluka14cvpr, + author = {Mykhaylo Andriluka and Leonid Pishchulin and Peter Gehler and Schiele, Bernt}, + title = {2D Human Pose Estimation: New Benchmark and State of the Art Analysis}, + booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, + year = {2014}, + month = {June} +} +``` + +
+  +
+
+
+For [MPII](http://human-pose.mpi-inf.mpg.de/) data, please download from [MPII Human Pose Dataset](http://human-pose.mpi-inf.mpg.de/).
+We have converted the original annotation files into json format, please download them from [mpii_annotations](https://download.openmmlab.com/mmpose/datasets/mpii_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+`ŌöĆŌöĆ data
+ ŌöéŌöĆŌöĆ mpii
+ |ŌöĆŌöĆ annotations
+ | |ŌöĆŌöĆ mpii_gt_val.mat
+ | |ŌöĆŌöĆ mpii_test.json
+ | |ŌöĆŌöĆ mpii_train.json
+ | |ŌöĆŌöĆ mpii_trainval.json
+ | `ŌöĆŌöĆ mpii_val.json
+ `ŌöĆŌöĆ images
+ |ŌöĆŌöĆ 000001163.jpg
+ |ŌöĆŌöĆ 000003072.jpg
+
+```
+
+During training and inference, the prediction result will be saved as '.mat' format by default. We also provide a tool to convert this '.mat' to more readable '.json' format.
+
+```shell
+python tools/dataset/mat2json ${PRED_MAT_FILE} ${GT_JSON_FILE} ${OUTPUT_PRED_JSON_FILE}
+```
+
+For example,
+
+```shell
+python tools/dataset/mat2json work_dirs/res50_mpii_256x256/pred.mat data/mpii/annotations/mpii_val.json pred.json
+```
+
+## MPII-TRB
+
+
+
+
+
+
+
+MPII-TRB (ICCV'2019)
+ +```bibtex +@inproceedings{duan2019trb, + title={TRB: A Novel Triplet Representation for Understanding 2D Human Body}, + author={Duan, Haodong and Lin, Kwan-Yee and Jin, Sheng and Liu, Wentao and Qian, Chen and Ouyang, Wanli}, + booktitle={Proceedings of the IEEE International Conference on Computer Vision}, + pages={9479--9488}, + year={2019} +} +``` + +
+  +
+
+
+For [MPII-TRB](https://github.com/kennymckormick/Triplet-Representation-of-human-Body) data, please download from [MPII Human Pose Dataset](http://human-pose.mpi-inf.mpg.de/).
+Please download the annotation files from [mpii_trb_annotations](https://download.openmmlab.com/mmpose/datasets/mpii_trb_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+`ŌöĆŌöĆ data
+ ŌöéŌöĆŌöĆ mpii
+ |ŌöĆŌöĆ annotations
+ | |ŌöĆŌöĆ mpii_trb_train.json
+ | |ŌöĆŌöĆ mpii_trb_val.json
+ `ŌöĆŌöĆ images
+ |ŌöĆŌöĆ 000001163.jpg
+ |ŌöĆŌöĆ 000003072.jpg
+
+```
+
+## AIC
+
+
+
+
+
+
+
+AI Challenger (ArXiv'2017)
+ +```bibtex +@article{wu2017ai, + title={Ai challenger: A large-scale dataset for going deeper in image understanding}, + author={Wu, Jiahong and Zheng, He and Zhao, Bo and Li, Yixin and Yan, Baoming and Liang, Rui and Wang, Wenjia and Zhou, Shipei and Lin, Guosen and Fu, Yanwei and others}, + journal={arXiv preprint arXiv:1711.06475}, + year={2017} +} +``` + +
+  +
+
+
+For [AIC](https://github.com/AIChallenger/AI_Challenger_2017) data, please download from [AI Challenger 2017](https://github.com/AIChallenger/AI_Challenger_2017), 2017 Train/Val is needed for keypoints training and validation.
+Please download the annotation files from [aic_annotations](https://download.openmmlab.com/mmpose/datasets/aic_annotations.tar).
+Download and extract them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+`ŌöĆŌöĆ data
+ ŌöéŌöĆŌöĆ aic
+ Ōöé-- annotations
+ Ōöé Ōöé-- aic_train.json
+ Ōöé |-- aic_val.json
+ Ōöé-- ai_challenger_keypoint_train_20170902
+ Ōöé Ōöé-- keypoint_train_images_20170902
+ Ōöé Ōöé Ōöé-- 0000252aea98840a550dac9a78c476ecb9f47ffa.jpg
+ Ōöé Ōöé Ōöé-- 000050f770985ac9653198495ef9b5c82435d49c.jpg
+ Ōöé Ōöé Ōöé-- ...
+ `-- ai_challenger_keypoint_validation_20170911
+ Ōöé-- keypoint_validation_images_20170911
+ Ōöé-- 0002605c53fb92109a3f2de4fc3ce06425c3b61f.jpg
+ Ōöé-- 0003b55a2c991223e6d8b4b820045bd49507bf6d.jpg
+ Ōöé-- ...
+```
+
+## CrowdPose
+
+
+
+
+
+
+
+CrowdPose (CVPR'2019)
+ +```bibtex +@article{li2018crowdpose, + title={CrowdPose: Efficient Crowded Scenes Pose Estimation and A New Benchmark}, + author={Li, Jiefeng and Wang, Can and Zhu, Hao and Mao, Yihuan and Fang, Hao-Shu and Lu, Cewu}, + journal={arXiv preprint arXiv:1812.00324}, + year={2018} +} +``` + +
+  +
+
+
+For [CrowdPose](https://github.com/Jeff-sjtu/CrowdPose) data, please download from [CrowdPose](https://github.com/Jeff-sjtu/CrowdPose).
+Please download the annotation files and human detection results from [crowdpose_annotations](https://download.openmmlab.com/mmpose/datasets/crowdpose_annotations.tar).
+For top-down approaches, we follow [CrowdPose](https://arxiv.org/abs/1812.00324) to use the [pre-trained weights](https://pjreddie.com/media/files/yolov3.weights) of [YOLOv3](https://github.com/eriklindernoren/PyTorch-YOLOv3) to generate the detected human bounding boxes.
+For model training, we follow [HigherHRNet](https://github.com/HRNet/HigherHRNet-Human-Pose-Estimation) to train models on CrowdPose train/val dataset, and evaluate models on CrowdPose test dataset.
+Download and extract them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+`ŌöĆŌöĆ data
+ ŌöéŌöĆŌöĆ crowdpose
+ Ōöé-- annotations
+ Ōöé Ōöé-- mmpose_crowdpose_train.json
+ Ōöé Ōöé-- mmpose_crowdpose_val.json
+ Ōöé Ōöé-- mmpose_crowdpose_trainval.json
+ Ōöé Ōöé-- mmpose_crowdpose_test.json
+ Ōöé Ōöé-- det_for_crowd_test_0.1_0.5.json
+ Ōöé-- images
+ Ōöé-- 100000.jpg
+ Ōöé-- 100001.jpg
+ Ōöé-- 100002.jpg
+ Ōöé-- ...
+```
+
+## OCHuman
+
+
+
+
+
+
+
+OCHuman (CVPR'2019)
+ +```bibtex +@inproceedings{zhang2019pose2seg, + title={Pose2seg: Detection free human instance segmentation}, + author={Zhang, Song-Hai and Li, Ruilong and Dong, Xin and Rosin, Paul and Cai, Zixi and Han, Xi and Yang, Dingcheng and Huang, Haozhi and Hu, Shi-Min}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={889--898}, + year={2019} +} +``` + +
+
+
+
+For [OCHuman](https://github.com/liruilong940607/OCHumanApi) data, please download the images and annotations from [OCHuman](https://github.com/liruilong940607/OCHumanApi),
+Move them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+`ŌöĆŌöĆ data
+ ŌöéŌöĆŌöĆ ochuman
+ Ōöé-- annotations
+ Ōöé Ōöé-- ochuman_coco_format_val_range_0.00_1.00.json
+ Ōöé |-- ochuman_coco_format_test_range_0.00_1.00.json
+ |-- images
+ Ōöé-- 000001.jpg
+ Ōöé-- 000002.jpg
+ Ōöé-- 000003.jpg
+ Ōöé-- ...
+
+```
+
+## MHP
+
+
+
+
+
+
+
+MHP (ACM MM'2018)
+ +```bibtex +@inproceedings{zhao2018understanding, + title={Understanding humans in crowded scenes: Deep nested adversarial learning and a new benchmark for multi-human parsing}, + author={Zhao, Jian and Li, Jianshu and Cheng, Yu and Sim, Terence and Yan, Shuicheng and Feng, Jiashi}, + booktitle={Proceedings of the 26th ACM international conference on Multimedia}, + pages={792--800}, + year={2018} +} +``` + +
+  +
+
+
+For [MHP](https://lv-mhp.github.io/dataset) data, please download from [MHP](https://lv-mhp.github.io/dataset).
+Please download the annotation files from [mhp_annotations](https://download.openmmlab.com/mmpose/datasets/mhp_annotations.tar.gz).
+Please download and extract them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+`ŌöĆŌöĆ data
+ ŌöéŌöĆŌöĆ mhp
+ Ōöé-- annotations
+ Ōöé Ōöé-- mhp_train.json
+ Ōöé Ōöé-- mhp_val.json
+ Ōöé
+ `-- train
+ Ōöé Ōöé-- images
+ Ōöé Ōöé Ōöé-- 1004.jpg
+ Ōöé Ōöé Ōöé-- 10050.jpg
+ Ōöé Ōöé Ōöé-- ...
+ Ōöé
+ `-- val
+ Ōöé Ōöé-- images
+ Ōöé Ōöé Ōöé-- 10059.jpg
+ Ōöé Ōöé Ōöé-- 10068.jpg
+ Ōöé Ōöé Ōöé-- ...
+ Ōöé
+ `-- test
+ Ōöé Ōöé-- images
+ Ōöé Ōöé Ōöé-- 1005.jpg
+ Ōöé Ōöé Ōöé-- 10052.jpg
+ Ōöé Ōöé Ōöé-- ...~~~~
+```
+
+## Human-Art dataset
+
+
+
+
+
+
+
+Human-Art (CVPR'2023)
+ +```bibtex +@inproceedings{ju2023humanart, + title={Human-Art: A Versatile Human-Centric Dataset Bridging Natural and Artificial Scenes}, + author={Ju, Xuan and Zeng, Ailing and Jianan, Wang and Qiang, Xu and Lei, Zhang}, + booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), + year={2023}} +``` + +
+
+
+
+For [Human-Art](https://idea-research.github.io/HumanArt/) data, please download the images and annotation files from [its website](https://idea-research.github.io/HumanArt/). You need to fill in the [data form](https://docs.google.com/forms/d/e/1FAIpQLScroT_jvw6B9U2Qca1_cl5Kmmu1ceKtlh6DJNmWLte8xNEhEw/viewform) to get access to the data.
+Move them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+|ŌöĆŌöĆ data
+ ŌöéŌöĆŌöĆ HumanArt
+ Ōöé-- images
+ Ōöé Ōöé-- 2D_virtual_human
+ Ōöé Ōöé |-- cartoon
+ Ōöé Ōöé | |-- 000000000000.jpg
+ Ōöé Ōöé | |-- ...
+ Ōöé Ōöé |-- digital_art
+ Ōöé Ōöé |-- ...
+ Ōöé |-- 3D_virtual_human
+ Ōöé |-- real_human
+ |-- annotations
+ Ōöé Ōöé-- validation_humanart.json
+ Ōöé Ōöé-- training_humanart_coco.json
+ |-- person_detection_results
+ Ōöé Ōöé-- HumanArt_validation_detections_AP_H_56_person.json
+```
+
+You can choose whether to download other annotation files in Human-Art. If you want to use additional annotation files (e.g. validation set of cartoon), you need to edit the corresponding code in config file.
+
+## PoseTrack18
+
+
+
+
+
+
+
+PoseTrack18 (CVPR'2018)
+ +```bibtex +@inproceedings{andriluka2018posetrack, + title={Posetrack: A benchmark for human pose estimation and tracking}, + author={Andriluka, Mykhaylo and Iqbal, Umar and Insafutdinov, Eldar and Pishchulin, Leonid and Milan, Anton and Gall, Juergen and Schiele, Bernt}, + booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition}, + pages={5167--5176}, + year={2018} +} +``` + +
+  +
+
+
+For [PoseTrack18](https://posetrack.net/users/download.php) data, please download from [PoseTrack18](https://posetrack.net/users/download.php).
+Please download the annotation files from [posetrack18_annotations](https://download.openmmlab.com/mmpose/datasets/posetrack18_annotations.tar).
+We have merged the video-wise separated official annotation files into two json files (posetrack18_train & posetrack18_val.json). We also generate the [mask files](https://download.openmmlab.com/mmpose/datasets/posetrack18_mask.tar) to speed up training.
+For top-down approaches, we use [MMDetection](https://github.com/open-mmlab/mmdetection) pre-trained [Cascade R-CNN](https://download.openmmlab.com/mmdetection/v2.0/cascade_rcnn/cascade_rcnn_x101_64x4d_fpn_20e_coco/cascade_rcnn_x101_64x4d_fpn_20e_coco_20200509_224357-051557b1.pth) (X-101-64x4d-FPN) to generate the detected human bounding boxes.
+Please download and extract them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+`ŌöĆŌöĆ data
+ ŌöéŌöĆŌöĆ posetrack18
+ Ōöé-- annotations
+ Ōöé Ōöé-- posetrack18_train.json
+ Ōöé Ōöé-- posetrack18_val.json
+ Ōöé Ōöé-- posetrack18_val_human_detections.json
+ Ōöé Ōöé-- train
+ Ōöé Ōöé Ōöé-- 000001_bonn_train.json
+ Ōöé Ōöé Ōöé-- 000002_bonn_train.json
+ Ōöé Ōöé Ōöé-- ...
+ Ōöé Ōöé-- val
+ Ōöé Ōöé Ōöé-- 000342_mpii_test.json
+ Ōöé Ōöé Ōöé-- 000522_mpii_test.json
+ Ōöé Ōöé Ōöé-- ...
+ Ōöé `-- test
+ Ōöé Ōöé-- 000001_mpiinew_test.json
+ Ōöé Ōöé-- 000002_mpiinew_test.json
+ Ōöé Ōöé-- ...
+ Ōöé
+ `-- images
+ Ōöé Ōöé-- train
+ Ōöé Ōöé Ōöé-- 000001_bonn_train
+ Ōöé Ōöé Ōöé Ōöé-- 000000.jpg
+ Ōöé Ōöé Ōöé Ōöé-- 000001.jpg
+ Ōöé Ōöé Ōöé Ōöé-- ...
+ Ōöé Ōöé Ōöé-- ...
+ Ōöé Ōöé-- val
+ Ōöé Ōöé Ōöé-- 000342_mpii_test
+ Ōöé Ōöé Ōöé Ōöé-- 000000.jpg
+ Ōöé Ōöé Ōöé Ōöé-- 000001.jpg
+ Ōöé Ōöé Ōöé Ōöé-- ...
+ Ōöé Ōöé Ōöé-- ...
+ Ōöé `-- test
+ Ōöé Ōöé-- 000001_mpiinew_test
+ Ōöé Ōöé Ōöé-- 000000.jpg
+ Ōöé Ōöé Ōöé-- 000001.jpg
+ Ōöé Ōöé Ōöé-- ...
+ Ōöé Ōöé-- ...
+ `-- mask
+ Ōöé-- train
+ Ōöé Ōöé-- 000002_bonn_train
+ Ōöé Ōöé Ōöé-- 000000.jpg
+ Ōöé Ōöé Ōöé-- 000001.jpg
+ Ōöé Ōöé Ōöé-- ...
+ Ōöé Ōöé-- ...
+ `-- val
+ Ōöé-- 000522_mpii_test
+ Ōöé Ōöé-- 000000.jpg
+ Ōöé Ōöé-- 000001.jpg
+ Ōöé Ōöé-- ...
+ Ōöé-- ...
+```
+
+The official evaluation tool for PoseTrack should be installed from GitHub.
+
+```shell
+pip install git+https://github.com/svenkreiss/poseval.git
+```
+
+## sub-JHMDB dataset
+
+
+
+
+
+
+
+RSN (ECCV'2020)
+ +```bibtex +@misc{cai2020learning, + title={Learning Delicate Local Representations for Multi-Person Pose Estimation}, + author={Yuanhao Cai and Zhicheng Wang and Zhengxiong Luo and Binyi Yin and Angang Du and Haoqian Wang and Xinyu Zhou and Erjin Zhou and Xiangyu Zhang and Jian Sun}, + year={2020}, + eprint={2003.04030}, + archivePrefix={arXiv}, + primaryClass={cs.CV} +} +``` + +
+  +
+
+
+For [sub-JHMDB](http://jhmdb.is.tue.mpg.de/dataset) data, please download the [images](<(http://files.is.tue.mpg.de/jhmdb/Rename_Images.tar.gz)>) from [JHMDB](http://jhmdb.is.tue.mpg.de/dataset),
+Please download the annotation files from [jhmdb_annotations](https://download.openmmlab.com/mmpose/datasets/jhmdb_annotations.tar).
+Move them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+`ŌöĆŌöĆ data
+ ŌöéŌöĆŌöĆ jhmdb
+ Ōöé-- annotations
+ Ōöé Ōöé-- Sub1_train.json
+ Ōöé |-- Sub1_test.json
+ Ōöé Ōöé-- Sub2_train.json
+ Ōöé |-- Sub2_test.json
+ Ōöé Ōöé-- Sub3_train.json
+ Ōöé |-- Sub3_test.json
+ |-- Rename_Images
+ Ōöé-- brush_hair
+ Ōöé Ōöé--April_09_brush_hair_u_nm_np1_ba_goo_0
+ | Ōöé Ōöé--00001.png
+ | Ōöé Ōöé--00002.png
+ Ōöé-- catch
+ Ōöé-- ...
+
+```
diff --git a/internlm_langchain/knowledge_base/MMPose/content/2d_face_keypoint.md b/internlm_langchain/knowledge_base/MMPose/content/2d_face_keypoint.md
new file mode 100644
index 00000000..62f66bd8
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPose/content/2d_face_keypoint.md
@@ -0,0 +1,384 @@
+# 2D Face Keypoint Datasets
+
+It is recommended to symlink the dataset root to `$MMPOSE/data`.
+If your folder structure is different, you may need to change the corresponding paths in config files.
+
+MMPose supported datasets:
+
+- [300W](#300w-dataset) \[ [Homepage](https://ibug.doc.ic.ac.uk/resources/300-W/) \]
+- [WFLW](#wflw-dataset) \[ [Homepage](https://wywu.github.io/projects/LAB/WFLW.html) \]
+- [AFLW](#aflw-dataset) \[ [Homepage](https://www.tugraz.at/institute/icg/research/team-bischof/lrs/downloads/aflw/) \]
+- [COFW](#cofw-dataset) \[ [Homepage](http://www.vision.caltech.edu/xpburgos/ICCV13/) \]
+- [COCO-WholeBody-Face](#coco-wholebody-face) \[ [Homepage](https://github.com/jin-s13/COCO-WholeBody/) \]
+- [LaPa](#lapa-dataset) \[ [Homepage](https://github.com/JDAI-CV/lapa-dataset) \]
+
+## 300W Dataset
+
+
+
+
+
+
+
+300W (IMAVIS'2016)
+ +```bibtex +@article{sagonas2016300, + title={300 faces in-the-wild challenge: Database and results}, + author={Sagonas, Christos and Antonakos, Epameinondas and Tzimiropoulos, Georgios and Zafeiriou, Stefanos and Pantic, Maja}, + journal={Image and vision computing}, + volume={47}, + pages={3--18}, + year={2016}, + publisher={Elsevier} +} +``` + +
+  +
+
+
+For 300W data, please download images from [300W Dataset](https://ibug.doc.ic.ac.uk/resources/300-W/).
+Please download the annotation files from [300w_annotations](https://download.openmmlab.com/mmpose/datasets/300w_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+`ŌöĆŌöĆ data
+ ŌöéŌöĆŌöĆ 300w
+ |ŌöĆŌöĆ annotations
+ | |ŌöĆŌöĆ face_landmarks_300w_train.json
+ | |ŌöĆŌöĆ face_landmarks_300w_valid.json
+ | |ŌöĆŌöĆ face_landmarks_300w_valid_common.json
+ | |ŌöĆŌöĆ face_landmarks_300w_valid_challenge.json
+ | |ŌöĆŌöĆ face_landmarks_300w_test.json
+ `ŌöĆŌöĆ images
+ |ŌöĆŌöĆ afw
+ | |ŌöĆŌöĆ 1051618982_1.jpg
+ | |ŌöĆŌöĆ 111076519_1.jpg
+ | ...
+ |ŌöĆŌöĆ helen
+ | |ŌöĆŌöĆ trainset
+ | | |ŌöĆŌöĆ 100032540_1.jpg
+ | | |ŌöĆŌöĆ 100040721_1.jpg
+ | | ...
+ | |ŌöĆŌöĆ testset
+ | | |ŌöĆŌöĆ 296814969_3.jpg
+ | | |ŌöĆŌöĆ 2968560214_1.jpg
+ | | ...
+ |ŌöĆŌöĆ ibug
+ | |ŌöĆŌöĆ image_003_1.jpg
+ | |ŌöĆŌöĆ image_004_1.jpg
+ | ...
+ |ŌöĆŌöĆ lfpw
+ | |ŌöĆŌöĆ trainset
+ | | |ŌöĆŌöĆ image_0001.png
+ | | |ŌöĆŌöĆ image_0002.png
+ | | ...
+ | |ŌöĆŌöĆ testset
+ | | |ŌöĆŌöĆ image_0001.png
+ | | |ŌöĆŌöĆ image_0002.png
+ | | ...
+ `ŌöĆŌöĆ Test
+ |ŌöĆŌöĆ 01_Indoor
+ | |ŌöĆŌöĆ indoor_001.png
+ | |ŌöĆŌöĆ indoor_002.png
+ | ...
+ `ŌöĆŌöĆ 02_Outdoor
+ |ŌöĆŌöĆ outdoor_001.png
+ |ŌöĆŌöĆ outdoor_002.png
+ ...
+```
+
+## WFLW Dataset
+
+
+
+
+
+
+
+WFLW (CVPR'2018)
+ +```bibtex +@inproceedings{wu2018look, + title={Look at boundary: A boundary-aware face alignment algorithm}, + author={Wu, Wayne and Qian, Chen and Yang, Shuo and Wang, Quan and Cai, Yici and Zhou, Qiang}, + booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition}, + pages={2129--2138}, + year={2018} +} +``` + +
+  +
+
+
+For WFLW data, please download images from [WFLW Dataset](https://wywu.github.io/projects/LAB/WFLW.html).
+Please download the annotation files from [wflw_annotations](https://download.openmmlab.com/mmpose/datasets/wflw_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+`ŌöĆŌöĆ data
+ ŌöéŌöĆŌöĆ wflw
+ |ŌöĆŌöĆ annotations
+ | |ŌöĆŌöĆ face_landmarks_wflw_train.json
+ | |ŌöĆŌöĆ face_landmarks_wflw_test.json
+ | |ŌöĆŌöĆ face_landmarks_wflw_test_blur.json
+ | |ŌöĆŌöĆ face_landmarks_wflw_test_occlusion.json
+ | |ŌöĆŌöĆ face_landmarks_wflw_test_expression.json
+ | |ŌöĆŌöĆ face_landmarks_wflw_test_largepose.json
+ | |ŌöĆŌöĆ face_landmarks_wflw_test_illumination.json
+ | |ŌöĆŌöĆ face_landmarks_wflw_test_makeup.json
+ |
+ `ŌöĆŌöĆ images
+ |ŌöĆŌöĆ 0--Parade
+ | |ŌöĆŌöĆ 0_Parade_marchingband_1_1015.jpg
+ | |ŌöĆŌöĆ 0_Parade_marchingband_1_1031.jpg
+ | ...
+ |ŌöĆŌöĆ 1--Handshaking
+ | |ŌöĆŌöĆ 1_Handshaking_Handshaking_1_105.jpg
+ | |ŌöĆŌöĆ 1_Handshaking_Handshaking_1_107.jpg
+ | ...
+ ...
+```
+
+## AFLW Dataset
+
+
+
+
+
+
+
+For AFLW data, please download images from [AFLW Dataset](https://www.tugraz.at/institute/icg/research/team-bischof/lrs/downloads/aflw/).
+Please download the annotation files from [aflw_annotations](https://download.openmmlab.com/mmpose/datasets/aflw_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+`ŌöĆŌöĆ data
+ ŌöéŌöĆŌöĆ aflw
+ |ŌöĆŌöĆ annotations
+ | |ŌöĆŌöĆ face_landmarks_aflw_train.json
+ | |ŌöĆŌöĆ face_landmarks_aflw_test_frontal.json
+ | |ŌöĆŌöĆ face_landmarks_aflw_test.json
+ `ŌöĆŌöĆ images
+ |ŌöĆŌöĆ flickr
+ |ŌöĆŌöĆ 0
+ | |ŌöĆŌöĆ image00002.jpg
+ | |ŌöĆŌöĆ image00013.jpg
+ | ...
+ |ŌöĆŌöĆ 2
+ | |ŌöĆŌöĆ image00004.jpg
+ | |ŌöĆŌöĆ image00006.jpg
+ | ...
+ `ŌöĆŌöĆ 3
+ |ŌöĆŌöĆ image00032.jpg
+ |ŌöĆŌöĆ image00035.jpg
+ ...
+```
+
+## COFW Dataset
+
+
+
+AFLW (ICCVW'2011)
+ +```bibtex +@inproceedings{koestinger2011annotated, + title={Annotated facial landmarks in the wild: A large-scale, real-world database for facial landmark localization}, + author={Koestinger, Martin and Wohlhart, Paul and Roth, Peter M and Bischof, Horst}, + booktitle={2011 IEEE international conference on computer vision workshops (ICCV workshops)}, + pages={2144--2151}, + year={2011}, + organization={IEEE} +} +``` + +
+
+
+COFW (ICCV'2013)
+ +```bibtex +@inproceedings{burgos2013robust, + title={Robust face landmark estimation under occlusion}, + author={Burgos-Artizzu, Xavier P and Perona, Pietro and Doll{\'a}r, Piotr}, + booktitle={Proceedings of the IEEE international conference on computer vision}, + pages={1513--1520}, + year={2013} +} +``` + +
+  +
+
+
+For COFW data, please download from [COFW Dataset (Color Images)](http://www.vision.caltech.edu/xpburgos/ICCV13/Data/COFW_color.zip).
+Move `COFW_train_color.mat` and `COFW_test_color.mat` to `data/cofw/` and make them look like:
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+`ŌöĆŌöĆ data
+ ŌöéŌöĆŌöĆ cofw
+ |ŌöĆŌöĆ COFW_train_color.mat
+ |ŌöĆŌöĆ COFW_test_color.mat
+```
+
+Run the following script under `{MMPose}/data`
+
+`python tools/dataset_converters/parse_cofw_dataset.py`
+
+And you will get
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+`ŌöĆŌöĆ data
+ ŌöéŌöĆŌöĆ cofw
+ |ŌöĆŌöĆ COFW_train_color.mat
+ |ŌöĆŌöĆ COFW_test_color.mat
+ |ŌöĆŌöĆ annotations
+ | |ŌöĆŌöĆ cofw_train.json
+ | |ŌöĆŌöĆ cofw_test.json
+ |ŌöĆŌöĆ images
+ |ŌöĆŌöĆ 000001.jpg
+ |ŌöĆŌöĆ 000002.jpg
+```
+
+## COCO-WholeBody (Face)
+
+
+
+
+
+
+
+COCO-WholeBody-Face (ECCV'2020)
+ +```bibtex +@inproceedings{jin2020whole, + title={Whole-Body Human Pose Estimation in the Wild}, + author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping}, + booktitle={Proceedings of the European Conference on Computer Vision (ECCV)}, + year={2020} +} +``` + +
+  +
+
+
+For [COCO-WholeBody](https://github.com/jin-s13/COCO-WholeBody/) dataset, images can be downloaded from [COCO download](http://cocodataset.org/#download), 2017 Train/Val is needed for COCO keypoints training and validation.
+Download COCO-WholeBody annotations for COCO-WholeBody annotations for [Train](https://drive.google.com/file/d/1thErEToRbmM9uLNi1JXXfOsaS5VK2FXf/view?usp=sharing) / [Validation](https://drive.google.com/file/d/1N6VgwKnj8DeyGXCvp1eYgNbRmw6jdfrb/view?usp=sharing) (Google Drive).
+Download person detection result of COCO val2017 from [OneDrive](https://1drv.ms/f/s!AhIXJn_J-blWzzDXoz5BeFl8sWM-) or [GoogleDrive](https://drive.google.com/drive/folders/1fRUDNUDxe9fjqcRZ2bnF_TKMlO0nB_dk?usp=sharing).
+Download and extract them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+`ŌöĆŌöĆ data
+ ŌöéŌöĆŌöĆ coco
+ Ōöé-- annotations
+ Ōöé Ōöé-- coco_wholebody_train_v1.0.json
+ Ōöé |-- coco_wholebody_val_v1.0.json
+ |-- person_detection_results
+ | |-- COCO_val2017_detections_AP_H_56_person.json
+ Ōöé-- train2017
+ Ōöé Ōöé-- 000000000009.jpg
+ Ōöé Ōöé-- 000000000025.jpg
+ Ōöé Ōöé-- 000000000030.jpg
+ Ōöé Ōöé-- ...
+ `-- val2017
+ Ōöé-- 000000000139.jpg
+ Ōöé-- 000000000285.jpg
+ Ōöé-- 000000000632.jpg
+ Ōöé-- ...
+
+```
+
+Please also install the latest version of [Extended COCO API](https://github.com/jin-s13/xtcocoapi) to support COCO-WholeBody evaluation:
+
+`pip install xtcocotools`
+
+## LaPa
+
+
+
+
+
+
+
+LaPa (AAAI'2020)
+ +```bibtex +@inproceedings{liu2020new, + title={A New Dataset and Boundary-Attention Semantic Segmentation for Face Parsing.}, + author={Liu, Yinglu and Shi, Hailin and Shen, Hao and Si, Yue and Wang, Xiaobo and Mei, Tao}, + booktitle={AAAI}, + pages={11637--11644}, + year={2020} +} +``` + +
+  +
+
+
+For [LaPa](https://github.com/JDAI-CV/lapa-dataset) dataset, images can be downloaded from [their github page](https://github.com/JDAI-CV/lapa-dataset).
+
+Download and extract them under $MMPOSE/data, and use our `tools/dataset_converters/lapa2coco.py` to make them look like this:
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+`ŌöĆŌöĆ data
+ ŌöéŌöĆŌöĆ LaPa
+ Ōöé-- annotations
+ Ōöé Ōöé-- lapa_train.json
+ Ōöé |-- lapa_val.json
+ Ōöé |-- lapa_test.json
+ | |-- lapa_trainval.json
+ Ōöé-- train
+ Ōöé Ōöé-- images
+ Ōöé Ōöé-- labels
+ Ōöé Ōöé-- landmarks
+ Ōöé-- val
+ Ōöé Ōöé-- images
+ Ōöé Ōöé-- labels
+ Ōöé Ōöé-- landmarks
+ `-- test
+ Ōöé Ōöé-- images
+ Ōöé Ōöé-- labels
+ Ōöé Ōöé-- landmarks
+
+```
diff --git a/internlm_langchain/knowledge_base/MMPose/content/2d_fashion_landmark.md b/internlm_langchain/knowledge_base/MMPose/content/2d_fashion_landmark.md
new file mode 100644
index 00000000..25b7fd7c
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPose/content/2d_fashion_landmark.md
@@ -0,0 +1,3 @@
+# 2Dµ£ŹĶŻģÕģ│ķö«ńé╣µĢ░µŹ«ķøå
+
+ÕåģÕ«╣Õ╗║Ķ«ŠõĖŁŌĆ”ŌĆ”
diff --git a/internlm_langchain/knowledge_base/MMPose/content/2d_hand_keypoint.md b/internlm_langchain/knowledge_base/MMPose/content/2d_hand_keypoint.md
new file mode 100644
index 00000000..aade3585
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPose/content/2d_hand_keypoint.md
@@ -0,0 +1,348 @@
+# 2D Hand Keypoint Datasets
+
+It is recommended to symlink the dataset root to `$MMPOSE/data`.
+If your folder structure is different, you may need to change the corresponding paths in config files.
+
+MMPose supported datasets:
+
+- [OneHand10K](#onehand10k) \[ [Homepage](https://www.yangangwang.com/papers/WANG-MCC-2018-10.html) \]
+- [FreiHand](#freihand-dataset) \[ [Homepage](https://lmb.informatik.uni-freiburg.de/projects/freihand/) \]
+- [CMU Panoptic HandDB](#cmu-panoptic-handdb) \[ [Homepage](http://domedb.perception.cs.cmu.edu/handdb.html) \]
+- [InterHand2.6M](#interhand26m) \[ [Homepage](https://mks0601.github.io/InterHand2.6M/) \]
+- [RHD](#rhd-dataset) \[ [Homepage](https://lmb.informatik.uni-freiburg.de/resources/datasets/RenderedHandposeDataset.en.html) \]
+- [COCO-WholeBody-Hand](#coco-wholebody-hand) \[ [Homepage](https://github.com/jin-s13/COCO-WholeBody/) \]
+
+## OneHand10K
+
+
+
+
+
+
+
+OneHand10K (TCSVT'2019)
+ +```bibtex +@article{wang2018mask, + title={Mask-pose cascaded cnn for 2d hand pose estimation from single color image}, + author={Wang, Yangang and Peng, Cong and Liu, Yebin}, + journal={IEEE Transactions on Circuits and Systems for Video Technology}, + volume={29}, + number={11}, + pages={3258--3268}, + year={2018}, + publisher={IEEE} +} +``` + +
+  +
+
+
+For [OneHand10K](https://www.yangangwang.com/papers/WANG-MCC-2018-10.html) data, please download from [OneHand10K Dataset](https://www.yangangwang.com/papers/WANG-MCC-2018-10.html).
+Please download the annotation files from [onehand10k_annotations](https://download.openmmlab.com/mmpose/datasets/onehand10k_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+`ŌöĆŌöĆ data
+ ŌöéŌöĆŌöĆ onehand10k
+ |ŌöĆŌöĆ annotations
+ | |ŌöĆŌöĆ onehand10k_train.json
+ | |ŌöĆŌöĆ onehand10k_test.json
+ `ŌöĆŌöĆ Train
+ | |ŌöĆŌöĆ source
+ | |ŌöĆŌöĆ 0.jpg
+ | |ŌöĆŌöĆ 1.jpg
+ | ...
+ `ŌöĆŌöĆ Test
+ |ŌöĆŌöĆ source
+ |ŌöĆŌöĆ 0.jpg
+ |ŌöĆŌöĆ 1.jpg
+
+```
+
+## FreiHAND Dataset
+
+
+
+
+
+
+
+FreiHand (ICCV'2019)
+ +```bibtex +@inproceedings{zimmermann2019freihand, + title={Freihand: A dataset for markerless capture of hand pose and shape from single rgb images}, + author={Zimmermann, Christian and Ceylan, Duygu and Yang, Jimei and Russell, Bryan and Argus, Max and Brox, Thomas}, + booktitle={Proceedings of the IEEE International Conference on Computer Vision}, + pages={813--822}, + year={2019} +} +``` + +
+
+
+
+For [FreiHAND](https://lmb.informatik.uni-freiburg.de/projects/freihand/) data, please download from [FreiHand Dataset](https://lmb.informatik.uni-freiburg.de/resources/datasets/FreihandDataset.en.html).
+Since the official dataset does not provide validation set, we randomly split the training data into 8:1:1 for train/val/test.
+Please download the annotation files from [freihand_annotations](https://download.openmmlab.com/mmpose/datasets/frei_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+`ŌöĆŌöĆ data
+ ŌöéŌöĆŌöĆ freihand
+ |ŌöĆŌöĆ annotations
+ | |ŌöĆŌöĆ freihand_train.json
+ | |ŌöĆŌöĆ freihand_val.json
+ | |ŌöĆŌöĆ freihand_test.json
+ `ŌöĆŌöĆ training
+ |ŌöĆŌöĆ rgb
+ | |ŌöĆŌöĆ 00000000.jpg
+ | |ŌöĆŌöĆ 00000001.jpg
+ | ...
+ |ŌöĆŌöĆ mask
+ |ŌöĆŌöĆ 00000000.jpg
+ |ŌöĆŌöĆ 00000001.jpg
+ ...
+```
+
+## CMU Panoptic HandDB
+
+
+
+
+
+
+
+CMU Panoptic HandDB (CVPR'2017)
+ +```bibtex +@inproceedings{simon2017hand, + title={Hand keypoint detection in single images using multiview bootstrapping}, + author={Simon, Tomas and Joo, Hanbyul and Matthews, Iain and Sheikh, Yaser}, + booktitle={Proceedings of the IEEE conference on Computer Vision and Pattern Recognition}, + pages={1145--1153}, + year={2017} +} +``` + +
+
+
+
+For [CMU Panoptic HandDB](http://domedb.perception.cs.cmu.edu/handdb.html), please download from [CMU Panoptic HandDB](http://domedb.perception.cs.cmu.edu/handdb.html).
+Following [Simon et al](https://arxiv.org/abs/1704.07809), panoptic images (hand143_panopticdb) and MPII & NZSL training sets (manual_train) are used for training, while MPII & NZSL test set (manual_test) for testing.
+Please download the annotation files from [panoptic_annotations](https://download.openmmlab.com/mmpose/datasets/panoptic_annotations.tar).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+`ŌöĆŌöĆ data
+ ŌöéŌöĆŌöĆ panoptic
+ |ŌöĆŌöĆ annotations
+ | |ŌöĆŌöĆ panoptic_train.json
+ | |ŌöĆŌöĆ panoptic_test.json
+ |
+ `ŌöĆŌöĆ hand143_panopticdb
+ | |ŌöĆŌöĆ imgs
+ | | |ŌöĆŌöĆ 00000000.jpg
+ | | |ŌöĆŌöĆ 00000001.jpg
+ | | ...
+ |
+ `ŌöĆŌöĆ hand_labels
+ |ŌöĆŌöĆ manual_train
+ | |ŌöĆŌöĆ 000015774_01_l.jpg
+ | |ŌöĆŌöĆ 000015774_01_r.jpg
+ | ...
+ |
+ `ŌöĆŌöĆ manual_test
+ |ŌöĆŌöĆ 000648952_02_l.jpg
+ |ŌöĆŌöĆ 000835470_01_l.jpg
+ ...
+```
+
+## InterHand2.6M
+
+
+
+
+
+
+
+InterHand2.6M (ECCV'2020)
+ +```bibtex +@InProceedings{Moon_2020_ECCV_InterHand2.6M, +author = {Moon, Gyeongsik and Yu, Shoou-I and Wen, He and Shiratori, Takaaki and Lee, Kyoung Mu}, +title = {InterHand2.6M: A Dataset and Baseline for 3D Interacting Hand Pose Estimation from a Single RGB Image}, +booktitle = {European Conference on Computer Vision (ECCV)}, +year = {2020} +} +``` + +
+  +
+
+
+For [InterHand2.6M](https://mks0601.github.io/InterHand2.6M/), please download from [InterHand2.6M](https://mks0601.github.io/InterHand2.6M/).
+Please download the annotation files from [annotations](https://drive.google.com/drive/folders/1pWXhdfaka-J0fSAze0MsajN0VpZ8e8tO).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+`ŌöĆŌöĆ data
+ ŌöéŌöĆŌöĆ interhand2.6m
+ |ŌöĆŌöĆ annotations
+ | |ŌöĆŌöĆ all
+ | |ŌöĆŌöĆ human_annot
+ | |ŌöĆŌöĆ machine_annot
+ | |ŌöĆŌöĆ skeleton.txt
+ | |ŌöĆŌöĆ subject.txt
+ |
+ `ŌöĆŌöĆ images
+ | |ŌöĆŌöĆ train
+ | | |-- Capture0 ~ Capture26
+ | |ŌöĆŌöĆ val
+ | | |-- Capture0
+ | |ŌöĆŌöĆ test
+ | | |-- Capture0 ~ Capture7
+```
+
+## RHD Dataset
+
+
+
+
+
+
+
+RHD (ICCV'2017)
+ +```bibtex +@TechReport{zb2017hand, + author={Christian Zimmermann and Thomas Brox}, + title={Learning to Estimate 3D Hand Pose from Single RGB Images}, + institution={arXiv:1705.01389}, + year={2017}, + note="https://arxiv.org/abs/1705.01389", + url="https://lmb.informatik.uni-freiburg.de/projects/hand3d/" +} +``` + +
+  +
+
+
+For [RHD Dataset](https://lmb.informatik.uni-freiburg.de/resources/datasets/RenderedHandposeDataset.en.html), please download from [RHD Dataset](https://lmb.informatik.uni-freiburg.de/resources/datasets/RenderedHandposeDataset.en.html).
+Please download the annotation files from [rhd_annotations](https://download.openmmlab.com/mmpose/datasets/rhd_annotations.zip).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+`ŌöĆŌöĆ data
+ ŌöéŌöĆŌöĆ rhd
+ |ŌöĆŌöĆ annotations
+ | |ŌöĆŌöĆ rhd_train.json
+ | |ŌöĆŌöĆ rhd_test.json
+ `ŌöĆŌöĆ training
+ | |ŌöĆŌöĆ color
+ | | |ŌöĆŌöĆ 00000.jpg
+ | | |ŌöĆŌöĆ 00001.jpg
+ | |ŌöĆŌöĆ depth
+ | | |ŌöĆŌöĆ 00000.jpg
+ | | |ŌöĆŌöĆ 00001.jpg
+ | |ŌöĆŌöĆ mask
+ | | |ŌöĆŌöĆ 00000.jpg
+ | | |ŌöĆŌöĆ 00001.jpg
+ `ŌöĆŌöĆ evaluation
+ | |ŌöĆŌöĆ color
+ | | |ŌöĆŌöĆ 00000.jpg
+ | | |ŌöĆŌöĆ 00001.jpg
+ | |ŌöĆŌöĆ depth
+ | | |ŌöĆŌöĆ 00000.jpg
+ | | |ŌöĆŌöĆ 00001.jpg
+ | |ŌöĆŌöĆ mask
+ | | |ŌöĆŌöĆ 00000.jpg
+ | | |ŌöĆŌöĆ 00001.jpg
+```
+
+## COCO-WholeBody (Hand)
+
+
+
+
+
+
+
+COCO-WholeBody-Hand (ECCV'2020)
+ +```bibtex +@inproceedings{jin2020whole, + title={Whole-Body Human Pose Estimation in the Wild}, + author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping}, + booktitle={Proceedings of the European Conference on Computer Vision (ECCV)}, + year={2020} +} +``` + +
+
+
+
+For [COCO-WholeBody](https://github.com/jin-s13/COCO-WholeBody/) dataset, images can be downloaded from [COCO download](http://cocodataset.org/#download), 2017 Train/Val is needed for COCO keypoints training and validation.
+Download COCO-WholeBody annotations for COCO-WholeBody annotations for [Train](https://drive.google.com/file/d/1thErEToRbmM9uLNi1JXXfOsaS5VK2FXf/view?usp=sharing) / [Validation](https://drive.google.com/file/d/1N6VgwKnj8DeyGXCvp1eYgNbRmw6jdfrb/view?usp=sharing) (Google Drive).
+Download person detection result of COCO val2017 from [OneDrive](https://1drv.ms/f/s!AhIXJn_J-blWzzDXoz5BeFl8sWM-) or [GoogleDrive](https://drive.google.com/drive/folders/1fRUDNUDxe9fjqcRZ2bnF_TKMlO0nB_dk?usp=sharing).
+Download and extract them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+`ŌöĆŌöĆ data
+ ŌöéŌöĆŌöĆ coco
+ Ōöé-- annotations
+ Ōöé Ōöé-- coco_wholebody_train_v1.0.json
+ Ōöé |-- coco_wholebody_val_v1.0.json
+ |-- person_detection_results
+ | |-- COCO_val2017_detections_AP_H_56_person.json
+ Ōöé-- train2017
+ Ōöé Ōöé-- 000000000009.jpg
+ Ōöé Ōöé-- 000000000025.jpg
+ Ōöé Ōöé-- 000000000030.jpg
+ Ōöé Ōöé-- ...
+ `-- val2017
+ Ōöé-- 000000000139.jpg
+ Ōöé-- 000000000285.jpg
+ Ōöé-- 000000000632.jpg
+ Ōöé-- ...
+```
+
+Please also install the latest version of [Extended COCO API](https://github.com/jin-s13/xtcocoapi) to support COCO-WholeBody evaluation:
+
+`pip install xtcocotools`
diff --git a/internlm_langchain/knowledge_base/MMPose/content/2d_wholebody_keypoint.md b/internlm_langchain/knowledge_base/MMPose/content/2d_wholebody_keypoint.md
new file mode 100644
index 00000000..a082c657
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPose/content/2d_wholebody_keypoint.md
@@ -0,0 +1,133 @@
+# 2D Wholebody Keypoint Datasets
+
+It is recommended to symlink the dataset root to `$MMPOSE/data`.
+If your folder structure is different, you may need to change the corresponding paths in config files.
+
+MMPose supported datasets:
+
+- [COCO-WholeBody](#coco-wholebody) \[ [Homepage](https://github.com/jin-s13/COCO-WholeBody/) \]
+- [Halpe](#halpe) \[ [Homepage](https://github.com/Fang-Haoshu/Halpe-FullBody/) \]
+
+## COCO-WholeBody
+
+
+
+
+
+
+
+COCO-WholeBody (ECCV'2020)
+ +```bibtex +@inproceedings{jin2020whole, + title={Whole-Body Human Pose Estimation in the Wild}, + author={Jin, Sheng and Xu, Lumin and Xu, Jin and Wang, Can and Liu, Wentao and Qian, Chen and Ouyang, Wanli and Luo, Ping}, + booktitle={Proceedings of the European Conference on Computer Vision (ECCV)}, + year={2020} +} +``` + +
+  +
+
+
+For [COCO-WholeBody](https://github.com/jin-s13/COCO-WholeBody/) dataset, images can be downloaded from [COCO download](http://cocodataset.org/#download), 2017 Train/Val is needed for COCO keypoints training and validation.
+Download COCO-WholeBody annotations for COCO-WholeBody annotations for [Train](https://drive.google.com/file/d/1thErEToRbmM9uLNi1JXXfOsaS5VK2FXf/view?usp=sharing) / [Validation](https://drive.google.com/file/d/1N6VgwKnj8DeyGXCvp1eYgNbRmw6jdfrb/view?usp=sharing) (Google Drive).
+Download person detection result of COCO val2017 from [OneDrive](https://1drv.ms/f/s!AhIXJn_J-blWzzDXoz5BeFl8sWM-) or [GoogleDrive](https://drive.google.com/drive/folders/1fRUDNUDxe9fjqcRZ2bnF_TKMlO0nB_dk?usp=sharing).
+Download and extract them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+`ŌöĆŌöĆ data
+ ŌöéŌöĆŌöĆ coco
+ Ōöé-- annotations
+ Ōöé Ōöé-- coco_wholebody_train_v1.0.json
+ Ōöé |-- coco_wholebody_val_v1.0.json
+ |-- person_detection_results
+ | |-- COCO_val2017_detections_AP_H_56_person.json
+ Ōöé-- train2017
+ Ōöé Ōöé-- 000000000009.jpg
+ Ōöé Ōöé-- 000000000025.jpg
+ Ōöé Ōöé-- 000000000030.jpg
+ Ōöé Ōöé-- ...
+ `-- val2017
+ Ōöé-- 000000000139.jpg
+ Ōöé-- 000000000285.jpg
+ Ōöé-- 000000000632.jpg
+ Ōöé-- ...
+
+```
+
+Please also install the latest version of [Extended COCO API](https://github.com/jin-s13/xtcocoapi) (version>=1.5) to support COCO-WholeBody evaluation:
+
+`pip install xtcocotools`
+
+## Halpe
+
+
+
+
+
+
+
+Halpe (CVPR'2020)
+ +```bibtex +@inproceedings{li2020pastanet, + title={PaStaNet: Toward Human Activity Knowledge Engine}, + author={Li, Yong-Lu and Xu, Liang and Liu, Xinpeng and Huang, Xijie and Xu, Yue and Wang, Shiyi and Fang, Hao-Shu and Ma, Ze and Chen, Mingyang and Lu, Cewu}, + booktitle={CVPR}, + year={2020} +} +``` + +
+  +
+
+
+For [Halpe](https://github.com/Fang-Haoshu/Halpe-FullBody/) dataset, please download images and annotations from [Halpe download](https://github.com/Fang-Haoshu/Halpe-FullBody).
+The images of the training set are from [HICO-Det](https://drive.google.com/open?id=1QZcJmGVlF9f4h-XLWe9Gkmnmj2z1gSnk) and those of the validation set are from [COCO](http://images.cocodataset.org/zips/val2017.zip).
+Download person detection result of COCO val2017 from [OneDrive](https://1drv.ms/f/s!AhIXJn_J-blWzzDXoz5BeFl8sWM-) or [GoogleDrive](https://drive.google.com/drive/folders/1fRUDNUDxe9fjqcRZ2bnF_TKMlO0nB_dk?usp=sharing).
+Download and extract them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+`ŌöĆŌöĆ data
+ ŌöéŌöĆŌöĆ halpe
+ Ōöé-- annotations
+ Ōöé Ōöé-- halpe_train_v1.json
+ Ōöé |-- halpe_val_v1.json
+ |-- person_detection_results
+ | |-- COCO_val2017_detections_AP_H_56_person.json
+ Ōöé-- hico_20160224_det
+ Ōöé Ōöé-- anno_bbox.mat
+ Ōöé Ōöé-- anno.mat
+ Ōöé Ōöé-- README
+ Ōöé Ōöé-- images
+ Ōöé Ōöé Ōöé-- train2015
+ Ōöé Ōöé Ōöé Ōöé-- HICO_train2015_00000001.jpg
+ Ōöé Ōöé Ōöé Ōöé-- HICO_train2015_00000002.jpg
+ Ōöé Ōöé Ōöé Ōöé-- HICO_train2015_00000003.jpg
+ Ōöé Ōöé Ōöé Ōöé-- ...
+ Ōöé Ōöé Ōöé-- test2015
+ Ōöé Ōöé-- tools
+ Ōöé Ōöé-- ...
+ `-- val2017
+ Ōöé-- 000000000139.jpg
+ Ōöé-- 000000000285.jpg
+ Ōöé-- 000000000632.jpg
+ Ōöé-- ...
+
+```
+
+Please also install the latest version of [Extended COCO API](https://github.com/jin-s13/xtcocoapi) (version>=1.5) to support Halpe evaluation:
+
+`pip install xtcocotools`
diff --git a/internlm_langchain/knowledge_base/MMPose/content/3d_body_keypoint.md b/internlm_langchain/knowledge_base/MMPose/content/3d_body_keypoint.md
new file mode 100644
index 00000000..82e21010
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPose/content/3d_body_keypoint.md
@@ -0,0 +1,199 @@
+# 3D Body Keypoint Datasets
+
+It is recommended to symlink the dataset root to `$MMPOSE/data`.
+If your folder structure is different, you may need to change the corresponding paths in config files.
+
+MMPose supported datasets:
+
+- [Human3.6M](#human36m) \[ [Homepage](http://vision.imar.ro/human3.6m/description.php) \]
+- [CMU Panoptic](#cmu-panoptic) \[ [Homepage](http://domedb.perception.cs.cmu.edu/) \]
+- [Campus/Shelf](#campus-and-shelf) \[ [Homepage](http://campar.in.tum.de/Chair/MultiHumanPose) \]
+
+## Human3.6M
+
+
+
+
+
+
+
+Human3.6M (TPAMI'2014)
+ +```bibtex +@article{h36m_pami, + author = {Ionescu, Catalin and Papava, Dragos and Olaru, Vlad and Sminchisescu, Cristian}, + title = {Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments}, + journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence}, + publisher = {IEEE Computer Society}, + volume = {36}, + number = {7}, + pages = {1325-1339}, + month = {jul}, + year = {2014} +} +``` + +
+  +
+
+
+For [Human3.6M](http://vision.imar.ro/human3.6m/description.php), please download from the official website and run the [preprocessing script](/tools/dataset_converters/preprocess_h36m.py), which will extract camera parameters and pose annotations at full framerate (50 FPS) and downsampled framerate (10 FPS). The processed data should have the following structure:
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+`ŌöĆŌöĆ data
+ Ōö£ŌöĆŌöĆ h36m
+ Ōö£ŌöĆŌöĆ annotation_body3d
+ | Ōö£ŌöĆŌöĆ cameras.pkl
+ | Ōö£ŌöĆŌöĆ fps50
+ | | Ōö£ŌöĆŌöĆ h36m_test.npz
+ | | Ōö£ŌöĆŌöĆ h36m_train.npz
+ | | Ōö£ŌöĆŌöĆ joint2d_rel_stats.pkl
+ | | Ōö£ŌöĆŌöĆ joint2d_stats.pkl
+ | | Ōö£ŌöĆŌöĆ joint3d_rel_stats.pkl
+ | | `ŌöĆŌöĆ joint3d_stats.pkl
+ | `ŌöĆŌöĆ fps10
+ | Ōö£ŌöĆŌöĆ h36m_test.npz
+ | Ōö£ŌöĆŌöĆ h36m_train.npz
+ | Ōö£ŌöĆŌöĆ joint2d_rel_stats.pkl
+ | Ōö£ŌöĆŌöĆ joint2d_stats.pkl
+ | Ōö£ŌöĆŌöĆ joint3d_rel_stats.pkl
+ | `ŌöĆŌöĆ joint3d_stats.pkl
+ `ŌöĆŌöĆ images
+ Ōö£ŌöĆŌöĆ S1
+ | Ōö£ŌöĆŌöĆ S1_Directions_1.54138969
+ | | Ōö£ŌöĆŌöĆ S1_Directions_1.54138969_00001.jpg
+ | | Ōö£ŌöĆŌöĆ S1_Directions_1.54138969_00002.jpg
+ | | Ōö£ŌöĆŌöĆ ...
+ | Ōö£ŌöĆŌöĆ ...
+ Ōö£ŌöĆŌöĆ S5
+ Ōö£ŌöĆŌöĆ S6
+ Ōö£ŌöĆŌöĆ S7
+ Ōö£ŌöĆŌöĆ S8
+ Ōö£ŌöĆŌöĆ S9
+ `ŌöĆŌöĆ S11
+```
+
+## CMU Panoptic
+
+
+
+
+
+CMU Panoptic (ICCV'2015)
+ +```bibtex +@Article = {joo_iccv_2015, +author = {Hanbyul Joo, Hao Liu, Lei Tan, Lin Gui, Bart Nabbe, Iain Matthews, Takeo Kanade, Shohei Nobuhara, and Yaser Sheikh}, +title = {Panoptic Studio: A Massively Multiview System for Social Motion Capture}, +booktitle = {ICCV}, +year = {2015} +} +``` + +
+  +
+
+
+Please follow [voxelpose-pytorch](https://github.com/microsoft/voxelpose-pytorch) to prepare this dataset.
+
+1. Download the dataset by following the instructions in [panoptic-toolbox](https://github.com/CMU-Perceptual-Computing-Lab/panoptic-toolbox) and extract them under `$MMPOSE/data/panoptic`.
+
+2. Only download those sequences that are needed. You can also just download a subset of camera views by specifying the number of views (HD_Video_Number) and changing the camera order in `./scripts/getData.sh`. The used sequences and camera views can be found in [VoxelPose](https://arxiv.org/abs/2004.06239). Note that the sequence "160906_band3" might not be available due to errors on the server of CMU Panoptic.
+
+3. Note that we only use HD videos, calibration data, and 3D Body Keypoint in the codes. You can comment out other irrelevant codes such as downloading 3D Face data in `./scripts/getData.sh`.
+
+The directory tree should be like this:
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+`ŌöĆŌöĆ data
+ Ōö£ŌöĆŌöĆ panoptic
+ Ōö£ŌöĆŌöĆ 16060224_haggling1
+ | | Ōö£ŌöĆŌöĆ hdImgs
+ | | Ōö£ŌöĆŌöĆ hdvideos
+ | | Ōö£ŌöĆŌöĆ hdPose3d_stage1_coco19
+ | | Ōö£ŌöĆŌöĆ calibration_160224_haggling1.json
+ Ōö£ŌöĆŌöĆ 160226_haggling1
+ Ōö£ŌöĆŌöĆ ...
+```
+
+## Campus and Shelf
+
+
+
+
+
+Campus and Shelf (CVPR'2014)
+ +```bibtex +@inproceedings {belagian14multi, + title = {{3D} Pictorial Structures for Multiple Human Pose Estimation}, + author = {Belagiannis, Vasileios and Amin, Sikandar and Andriluka, Mykhaylo and Schiele, Bernt and Navab + Nassir and Ilic, Slobo + booktitle = {IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR)}, + year = {2014}, + month = {June}, + organization={IEEE} +} +``` + +
+  +
+
+
+Please follow [voxelpose-pytorch](https://github.com/microsoft/voxelpose-pytorch) to prepare these two datasets.
+
+1. Please download the datasets from the [official website](http://campar.in.tum.de/Chair/MultiHumanPose) and extract them under `$MMPOSE/data/campus` and `$MMPOSE/data/shelf`, respectively. The original data include images as well as the ground truth pose file `actorsGT.mat`.
+
+2. We directly use the processed camera parameters from [voxelpose-pytorch](https://github.com/microsoft/voxelpose-pytorch). You can download them from this repository and place in under `$MMPOSE/data/campus/calibration_campus.json` and `$MMPOSE/data/shelf/calibration_shelf.json`, respectively.
+
+3. Like [Voxelpose](https://github.com/microsoft/voxelpose-pytorch), due to the limited and incomplete annotations of the two datasets, we don't train the model using this dataset. Instead, we directly use the 2D pose estimator trained on COCO, and use independent 3D human poses from the CMU Panoptic dataset to train our 3D model. It lies in `${MMPOSE}/data/panoptic_training_pose.pkl`.
+
+4. Like [Voxelpose](https://github.com/microsoft/voxelpose-pytorch), for testing, we first estimate 2D poses and generate 2D heatmaps for these two datasets. You can download the predicted poses from [voxelpose-pytorch](https://github.com/microsoft/voxelpose-pytorch) and place them in `$MMPOSE/data/campus/pred_campus_maskrcnn_hrnet_coco.pkl` and `$MMPOSE/data/shelf/pred_shelf_maskrcnn_hrnet_coco.pkl`, respectively. You can also use the models trained on COCO dataset (like HigherHRNet) to generate 2D heatmaps directly.
+
+The directory tree should be like this:
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+`ŌöĆŌöĆ data
+ Ōö£ŌöĆŌöĆ panoptic_training_pose.pkl
+ Ōö£ŌöĆŌöĆ campus
+ | Ōö£ŌöĆŌöĆ Camera0
+ | | | Ōö£ŌöĆŌöĆ campus4-c0-00000.png
+ | | | Ōö£ŌöĆŌöĆ ...
+ | | | Ōö£ŌöĆŌöĆ campus4-c0-01999.png
+ | ...
+ | Ōö£ŌöĆŌöĆ Camera2
+ | | | Ōö£ŌöĆŌöĆ campus4-c2-00000.png
+ | | | Ōö£ŌöĆŌöĆ ...
+ | | | Ōö£ŌöĆŌöĆ campus4-c2-01999.png
+ | Ōö£ŌöĆŌöĆ calibration_campus.json
+ | Ōö£ŌöĆŌöĆ pred_campus_maskrcnn_hrnet_coco.pkl
+ | Ōö£ŌöĆŌöĆ actorsGT.mat
+ Ōö£ŌöĆŌöĆ shelf
+ | Ōö£ŌöĆŌöĆ Camera0
+ | | | Ōö£ŌöĆŌöĆ img_000000.png
+ | | | Ōö£ŌöĆŌöĆ ...
+ | | | Ōö£ŌöĆŌöĆ img_003199.png
+ | ...
+ | Ōö£ŌöĆŌöĆ Camera4
+ | | | Ōö£ŌöĆŌöĆ img_000000.png
+ | | | Ōö£ŌöĆŌöĆ ...
+ | | | Ōö£ŌöĆŌöĆ img_003199.png
+ | Ōö£ŌöĆŌöĆ calibration_shelf.json
+ | Ōö£ŌöĆŌöĆ pred_shelf_maskrcnn_hrnet_coco.pkl
+ | Ōö£ŌöĆŌöĆ actorsGT.mat
+```
diff --git a/internlm_langchain/knowledge_base/MMPose/content/3d_body_mesh.md b/internlm_langchain/knowledge_base/MMPose/content/3d_body_mesh.md
new file mode 100644
index 00000000..aced63c8
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPose/content/3d_body_mesh.md
@@ -0,0 +1,342 @@
+# 3D Body Mesh Recovery Datasets
+
+It is recommended to symlink the dataset root to `$MMPOSE/data`.
+If your folder structure is different, you may need to change the corresponding paths in config files.
+
+To achieve high-quality human mesh estimation, we use multiple datasets for training.
+The following items should be prepared for human mesh training:
+
+
+
+- [3D Body Mesh Recovery Datasets](#3d-body-mesh-recovery-datasets)
+ - [Notes](#notes)
+ - [Annotation Files for Human Mesh Estimation](#annotation-files-for-human-mesh-estimation)
+ - [SMPL Model](#smpl-model)
+ - [COCO](#coco)
+ - [Human3.6M](#human36m)
+ - [MPI-INF-3DHP](#mpi-inf-3dhp)
+ - [LSP](#lsp)
+ - [LSPET](#lspet)
+ - [CMU MoShed Data](#cmu-moshed-data)
+
+
+
+## Notes
+
+### Annotation Files for Human Mesh Estimation
+
+For human mesh estimation, we use multiple datasets for training.
+The annotation of different datasets are preprocessed to the same format. Please
+follow the [preprocess procedure](https://github.com/nkolot/SPIN/tree/master/datasets/preprocess)
+of SPIN to generate the annotation files or download the processed files from
+[here](https://download.openmmlab.com/mmpose/datasets/mesh_annotation_files.zip),
+and make it look like this:
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+`ŌöĆŌöĆ data
+ ŌöéŌöĆŌöĆ mesh_annotation_files
+ Ōö£ŌöĆŌöĆ coco_2014_train.npz
+ Ōö£ŌöĆŌöĆ h36m_valid_protocol1.npz
+ Ōö£ŌöĆŌöĆ h36m_valid_protocol2.npz
+ Ōö£ŌöĆŌöĆ hr-lspet_train.npz
+ Ōö£ŌöĆŌöĆ lsp_dataset_original_train.npz
+ Ōö£ŌöĆŌöĆ mpi_inf_3dhp_train.npz
+ ŌööŌöĆŌöĆ mpii_train.npz
+```
+
+### SMPL Model
+
+```bibtex
+@article{loper2015smpl,
+ title={SMPL: A skinned multi-person linear model},
+ author={Loper, Matthew and Mahmood, Naureen and Romero, Javier and Pons-Moll, Gerard and Black, Michael J},
+ journal={ACM transactions on graphics (TOG)},
+ volume={34},
+ number={6},
+ pages={1--16},
+ year={2015},
+ publisher={ACM New York, NY, USA}
+}
+```
+
+For human mesh estimation, SMPL model is used to generate the human mesh.
+Please download the [gender neutral SMPL model](http://smplify.is.tue.mpg.de/),
+[joints regressor](https://download.openmmlab.com/mmpose/datasets/joints_regressor_cmr.npy)
+and [mean parameters](https://download.openmmlab.com/mmpose/datasets/smpl_mean_params.npz)
+under `$MMPOSE/models/smpl`, and make it look like this:
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ ...
+Ōö£ŌöĆŌöĆ models
+ ŌöéŌöĆŌöĆ smpl
+ Ōö£ŌöĆŌöĆ joints_regressor_cmr.npy
+ Ōö£ŌöĆŌöĆ smpl_mean_params.npz
+ ŌööŌöĆŌöĆ SMPL_NEUTRAL.pkl
+```
+
+## COCO
+
+
+
+
+
+
+
+For [COCO](http://cocodataset.org/) data, please download from [COCO download](http://cocodataset.org/#download). COCO'2014 Train is needed for human mesh estimation training.
+Download and extract them under $MMPOSE/data, and make them look like this:
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+`ŌöĆŌöĆ data
+ ŌöéŌöĆŌöĆ coco
+ Ōöé-- train2014
+ Ōöé Ōö£ŌöĆŌöĆ COCO_train2014_000000000009.jpg
+ Ōöé Ōö£ŌöĆŌöĆ COCO_train2014_000000000025.jpg
+ Ōöé Ōö£ŌöĆŌöĆ COCO_train2014_000000000030.jpg
+ | Ōöé-- ...
+
+```
+
+## Human3.6M
+
+
+
+COCO (ECCV'2014)
+ +```bibtex +@inproceedings{lin2014microsoft, + title={Microsoft coco: Common objects in context}, + author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{\'a}r, Piotr and Zitnick, C Lawrence}, + booktitle={European conference on computer vision}, + pages={740--755}, + year={2014}, + organization={Springer} +} +``` + +
+
+
+For [Human3.6M](http://vision.imar.ro/human3.6m/description.php), we use the MoShed data provided in [HMR](https://github.com/akanazawa/hmr) for training.
+However, due to license limitations, we are not allowed to redistribute the MoShed data.
+
+For the evaluation on Human3.6M dataset, please follow the
+[preprocess procedure](https://github.com/nkolot/SPIN/tree/master/datasets/preprocess)
+of SPIN to extract test images from
+[Human3.6M](http://vision.imar.ro/human3.6m/description.php) original videos,
+and make it look like this:
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+`ŌöĆŌöĆ data
+ ŌöéŌöĆŌöĆ Human3.6M
+ Ōö£ŌöĆŌöĆ images
+ ┬Ā┬Ā Ōö£ŌöĆŌöĆ S11_Directions_1.54138969_000001.jpg
+ ┬Ā┬Ā Ōö£ŌöĆŌöĆ S11_Directions_1.54138969_000006.jpg
+ ┬Ā┬Ā Ōö£ŌöĆŌöĆ S11_Directions_1.54138969_000011.jpg
+ ┬Ā┬Ā Ōö£ŌöĆŌöĆ ...
+```
+
+The download of Human3.6M dataset is quite difficult, you can also download the
+[zip file](https://drive.google.com/file/d/1WnRJD9FS3NUf7MllwgLRJJC-JgYFr8oi/view?usp=sharing)
+of the test images. However, due to the license limitations, we are not allowed to
+redistribute the images either. So the users need to download the original video and
+extract the images by themselves.
+
+## MPI-INF-3DHP
+
+
+
+```bibtex
+@inproceedings{mono-3dhp2017,
+ author = {Mehta, Dushyant and Rhodin, Helge and Casas, Dan and Fua, Pascal and Sotnychenko, Oleksandr and Xu, Weipeng and Theobalt, Christian},
+ title = {Monocular 3D Human Pose Estimation In The Wild Using Improved CNN Supervision},
+ booktitle = {3D Vision (3DV), 2017 Fifth International Conference on},
+ url = {http://gvv.mpi-inf.mpg.de/3dhp_dataset},
+ year = {2017},
+ organization={IEEE},
+ doi={10.1109/3dv.2017.00064},
+}
+```
+
+For [MPI-INF-3DHP](http://gvv.mpi-inf.mpg.de/3dhp-dataset/), please follow the
+[preprocess procedure](https://github.com/nkolot/SPIN/tree/master/datasets/preprocess)
+of SPIN to sample images, and make them like this:
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+`ŌöĆŌöĆ data
+ Ōö£ŌöĆŌöĆ mpi_inf_3dhp_test_set
+ Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ TS1
+ Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ TS2
+ Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ TS3
+ Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ TS4
+ Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ TS5
+ Ōöé┬Ā┬Ā ŌööŌöĆŌöĆ TS6
+ Ōö£ŌöĆŌöĆ S1
+ Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ Seq1
+ Ōöé┬Ā┬Ā ŌööŌöĆŌöĆ Seq2
+ Ōö£ŌöĆŌöĆ S2
+ Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ Seq1
+ Ōöé┬Ā┬Ā ŌööŌöĆŌöĆ Seq2
+ Ōö£ŌöĆŌöĆ S3
+ Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ Seq1
+ Ōöé┬Ā┬Ā ŌööŌöĆŌöĆ Seq2
+ Ōö£ŌöĆŌöĆ S4
+ Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ Seq1
+ Ōöé┬Ā┬Ā ŌööŌöĆŌöĆ Seq2
+ Ōö£ŌöĆŌöĆ S5
+ Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ Seq1
+ Ōöé┬Ā┬Ā ŌööŌöĆŌöĆ Seq2
+ Ōö£ŌöĆŌöĆ S6
+ Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ Seq1
+ Ōöé┬Ā┬Ā ŌööŌöĆŌöĆ Seq2
+ Ōö£ŌöĆŌöĆ S7
+ Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ Seq1
+ Ōöé┬Ā┬Ā ŌööŌöĆŌöĆ Seq2
+ ŌööŌöĆŌöĆ S8
+ Ōö£ŌöĆŌöĆ Seq1
+ ŌööŌöĆŌöĆ Seq2
+```
+
+## LSP
+
+
+
+```bibtex
+@inproceedings{johnson2010clustered,
+ title={Clustered Pose and Nonlinear Appearance Models for Human Pose Estimation.},
+ author={Johnson, Sam and Everingham, Mark},
+ booktitle={bmvc},
+ volume={2},
+ number={4},
+ pages={5},
+ year={2010},
+ organization={Citeseer}
+}
+```
+
+For [LSP](https://sam.johnson.io/research/lsp.html), please download the high resolution version
+[LSP dataset original](http://sam.johnson.io/research/lsp_dataset_original.zip).
+Extract them under `$MMPOSE/data`, and make them look like this:
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+`ŌöĆŌöĆ data
+ ŌöéŌöĆŌöĆ lsp_dataset_original
+ Ōö£ŌöĆŌöĆ images
+ ┬Ā┬Ā Ōö£ŌöĆŌöĆ im0001.jpg
+ ┬Ā┬Ā Ōö£ŌöĆŌöĆ im0002.jpg
+ ┬Ā┬Ā ŌööŌöĆŌöĆ ...
+```
+
+## LSPET
+
+
+
+```bibtex
+@inproceedings{johnson2011learning,
+ title={Learning effective human pose estimation from inaccurate annotation},
+ author={Johnson, Sam and Everingham, Mark},
+ booktitle={CVPR 2011},
+ pages={1465--1472},
+ year={2011},
+ organization={IEEE}
+}
+```
+
+For [LSPET](https://sam.johnson.io/research/lspet.html), please download its high resolution form
+[HR-LSPET](http://datasets.d2.mpi-inf.mpg.de/hr-lspet/hr-lspet.zip).
+Extract them under `$MMPOSE/data`, and make them look like this:
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+`ŌöĆŌöĆ data
+ ŌöéŌöĆŌöĆ lspet_dataset
+ Ōö£ŌöĆŌöĆ images
+ Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ im00001.jpg
+ Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ im00002.jpg
+ Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ im00003.jpg
+ Ōöé┬Ā┬Ā ŌööŌöĆŌöĆ ...
+ ŌööŌöĆŌöĆ joints.mat
+```
+
+## CMU MoShed Data
+
+
+
+```bibtex
+@inproceedings{kanazawa2018end,
+ title={End-to-end recovery of human shape and pose},
+ author={Kanazawa, Angjoo and Black, Michael J and Jacobs, David W and Malik, Jitendra},
+ booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
+ pages={7122--7131},
+ year={2018}
+}
+```
+
+Real-world SMPL parameters are used for the adversarial training in human mesh estimation.
+The MoShed data provided in [HMR](https://github.com/akanazawa/hmr) is included in this
+[zip file](https://download.openmmlab.com/mmpose/datasets/mesh_annotation_files.zip).
+Please download and extract it under `$MMPOSE/data`, and make it look like this:
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+`ŌöĆŌöĆ data
+ ŌöéŌöĆŌöĆ mesh_annotation_files
+ Ōö£ŌöĆŌöĆ CMU_mosh.npz
+ ŌööŌöĆŌöĆ ...
+```
diff --git a/internlm_langchain/knowledge_base/MMPose/content/3d_hand_keypoint.md b/internlm_langchain/knowledge_base/MMPose/content/3d_hand_keypoint.md
new file mode 100644
index 00000000..2b1f4d39
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPose/content/3d_hand_keypoint.md
@@ -0,0 +1,59 @@
+# 3D Hand Keypoint Datasets
+
+It is recommended to symlink the dataset root to `$MMPOSE/data`.
+If your folder structure is different, you may need to change the corresponding paths in config files.
+
+MMPose supported datasets:
+
+- [InterHand2.6M](#interhand26m) \[ [Homepage](https://mks0601.github.io/InterHand2.6M/) \]
+
+## InterHand2.6M
+
+
+
+Human3.6M (TPAMI'2014)
+ +```bibtex +@article{h36m_pami, + author = {Ionescu, Catalin and Papava, Dragos and Olaru, Vlad and Sminchisescu, Cristian}, + title = {Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments}, + journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence}, + publisher = {IEEE Computer Society}, + volume = {36}, + number = {7}, + pages = {1325-1339}, + month = {jul}, + year = {2014} +} +``` + +
+
+
+InterHand2.6M (ECCV'2020)
+ +```bibtex +@InProceedings{Moon_2020_ECCV_InterHand2.6M, +author = {Moon, Gyeongsik and Yu, Shoou-I and Wen, He and Shiratori, Takaaki and Lee, Kyoung Mu}, +title = {InterHand2.6M: A Dataset and Baseline for 3D Interacting Hand Pose Estimation from a Single RGB Image}, +booktitle = {European Conference on Computer Vision (ECCV)}, +year = {2020} +} +``` + +
+  +
+
+
+For [InterHand2.6M](https://mks0601.github.io/InterHand2.6M/), please download from [InterHand2.6M](https://mks0601.github.io/InterHand2.6M/).
+Please download the annotation files from [annotations](https://drive.google.com/drive/folders/1pWXhdfaka-J0fSAze0MsajN0VpZ8e8tO).
+Extract them under {MMPose}/data, and make them look like this:
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+`ŌöĆŌöĆ data
+ ŌöéŌöĆŌöĆ interhand2.6m
+ |ŌöĆŌöĆ annotations
+ | |ŌöĆŌöĆ all
+ | |ŌöĆŌöĆ human_annot
+ | |ŌöĆŌöĆ machine_annot
+ | |ŌöĆŌöĆ skeleton.txt
+ | |ŌöĆŌöĆ subject.txt
+ |
+ `ŌöĆŌöĆ images
+ | |ŌöĆŌöĆ train
+ | | |-- Capture0 ~ Capture26
+ | |ŌöĆŌöĆ val
+ | | |-- Capture0
+ | |ŌöĆŌöĆ test
+ | | |-- Capture0 ~ Capture7
+```
diff --git a/internlm_langchain/knowledge_base/MMPose/content/advanced_training.md b/internlm_langchain/knowledge_base/MMPose/content/advanced_training.md
new file mode 100644
index 00000000..dd02a766
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPose/content/advanced_training.md
@@ -0,0 +1,104 @@
+# ķ½śń║¦Ķ«Łń╗āĶ«ŠńĮ«
+
+## µüóÕżŹĶ«Łń╗ā
+
+µüóÕżŹĶ«Łń╗āµś»µīćõ╗Äõ╣ŗÕēŹµ¤Éµ¼ĪĶ«Łń╗āõ┐ØÕŁśõĖŗµØźńÜäńŖȵĆüÕ╝ĆÕ¦ŗń╗¦ń╗ŁĶ«Łń╗ā’╝īĶ┐ÖķćīńÜäńŖȵĆüÕīģµŗ¼µ©ĪÕ×ŗńÜäµØāķćŹŃĆüõ╝śÕī¢ÕÖ©ÕÆīõ╝śÕī¢ÕÖ©ÕÅéµĢ░Ķ░āµĢ┤ńŁ¢ńĢźńÜäńŖȵĆüŃĆé
+
+### Ķć¬ÕŖ©µüóÕżŹĶ«Łń╗ā
+
+ńö©µłĘÕÅ»õ╗źÕ£©Ķ«Łń╗āÕæĮõ╗żµ£ĆÕÉÄÕŖĀõĖŖ `--resume` µüóÕżŹĶ«Łń╗ā’╝īń©ŗÕ║Åõ╝ÜĶć¬ÕŖ©õ╗Ä `work_dirs` õĖŁÕŖĀĶĮĮµ£Ćµ¢░ńÜäµØāķ揵¢ćõ╗ȵüóÕżŹĶ«Łń╗āŃĆéÕ”éµ×£ `work_dir` õĖŁµ£ēµ£Ćµ¢░ńÜä `checkpoint`’╝łõŠŗÕ”éĶ»źĶ«Łń╗āÕ£©õĖŖõĖƵ¼ĪĶ«Łń╗āµŚČĶó½õĖŁµ¢Ł’╝ē’╝īÕłÖõ╝Üõ╗ÄĶ»ź `checkpoint` µüóÕżŹĶ«Łń╗ā’╝īÕÉ”ÕłÖ’╝łõŠŗÕ”éõĖŖõĖƵ¼ĪĶ«Łń╗āĶ┐śµ▓ĪµØźÕŠŚÕÅŖõ┐ØÕŁś `checkpoint` µł¢ĶĆģÕÉ»ÕŖ©õ║åµ¢░ńÜäĶ«Łń╗āõ╗╗ÕŖĪ’╝ēõ╝Üķ揵¢░Õ╝ĆÕ¦ŗĶ«Łń╗āŃĆé
+
+õĖŗķØ󵜻õĖĆõĖ¬µüóÕżŹĶ«Łń╗āńÜäńż║õŠŗ:
+
+```shell
+python tools/train.py configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_res50_8xb64-210e_coco-256x192.py --resume
+```
+
+### µīćÕ«Ü Checkpoint µüóÕżŹĶ«Łń╗ā
+
+õĮĀõ╣¤ÕÅ»õ╗źÕ»╣ `--resume` µīćÕ«Ü `checkpoint` ĶĘ»ÕŠä’╝īMMPose õ╝ÜĶć¬ÕŖ©Ķ»╗ÕÅ¢Ķ»ź `checkpoint` Õ╣Čõ╗ÄõĖŁµüóÕżŹĶ«Łń╗ā’╝īÕæĮõ╗żÕ”éõĖŗ’╝Ü
+
+```shell
+python tools/train.py configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_res50_8xb64-210e_coco-256x192.py \
+ --resume work_dirs/td-hm_res50_8xb64-210e_coco-256x192/latest.pth
+```
+
+Õ”éµ×£õĮĀÕĖīµ£øµēŗÕŖ©Õ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁµīćÕ«Ü `checkpoint` ĶĘ»ÕŠä’╝īķÖżõ║åĶ«ŠńĮ« `resume=True`’╝īĶ┐śķ£ĆĶ”üĶ«ŠńĮ« `load_from` ÕÅéµĢ░ŃĆéķ£ĆĶ”üµ│©µäÅńÜ䵜»’╝īÕ”éµ×£ÕŬĶ«ŠńĮ«õ║å `load_from` ĶĆīµ▓Īµ£ēĶ«ŠńĮ« `resume=True`’╝īÕłÖÕŬõ╝ÜÕŖĀĶĮĮ `checkpoint` õĖŁńÜäµØāķćŹÕ╣Čķ揵¢░Õ╝ĆÕ¦ŗĶ«Łń╗ā’╝īĶĆīõĖŹµś»µÄźńØĆõ╣ŗÕēŹńÜäńŖȵĆüń╗¦ń╗ŁĶ«Łń╗āŃĆé
+
+õĖŗķØóńÜäõŠŗÕŁÉõĖÄõĖŖķØóµīćÕ«Ü `--resume` ÕÅéµĢ░ńÜäõŠŗÕŁÉńŁēõ╗Ę’╝Ü
+
+```python
+resume = True
+load_from = 'work_dirs/td-hm_res50_8xb64-210e_coco-256x192/latest.pth'
+# model settings
+model = dict(
+ ## ÕåģÕ«╣ń£üńĢź ##
+ )
+```
+
+## Ķć¬ÕŖ©µĘĘÕÉłń▓ŠÕ║”’╝łAMP’╝ēĶ«Łń╗ā
+
+µĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗āÕ£©õĖŹµö╣ÕÅśµ©ĪÕ×ŗŃĆüõĖŹķÖŹõĮĵ©ĪÕ×ŗĶ«Łń╗āń▓ŠÕ║”ńÜäÕēŹµÅÉõĖŗ’╝īÕÅ»õ╗źń╝®ń¤ŁĶ«Łń╗āµŚČķŚ┤’╝īķÖŹõĮÄÕŁśÕé©ķ£Ćµ▒é’╝īÕøĀĶĆīĶāĮµö»µīüµø┤Õż¦ńÜä batch sizeŃĆüµø┤Õż¦µ©ĪÕ×ŗÕÆīÕ░║Õ»Ėµø┤Õż¦ńÜäĶŠōÕģźńÜäĶ«Łń╗āŃĆé
+
+Õ”éµ×£Ķ”üÕ╝ĆÕÉ»Ķć¬ÕŖ©µĘĘÕÉłń▓ŠÕ║”’╝łAMP’╝ēĶ«Łń╗ā’╝īÕ£©Ķ«Łń╗āÕæĮõ╗żµ£ĆÕÉÄÕŖĀõĖŖ --amp ÕŹ│ÕÅ»’╝ī ÕæĮõ╗żÕ”éõĖŗ’╝Ü
+
+```shell
+python tools/train.py ${CONFIG_FILE} --amp
+```
+
+ÕģĘõĮōõŠŗÕŁÉÕ”éõĖŗ’╝Ü
+
+```shell
+python tools/train.py configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_res50_8xb64-210e_coco-256x192.py --amp
+```
+
+## Ķ«ŠńĮ«ķÜŵ£║ń¦ŹÕŁÉ
+
+Õ”éµ×£µā│Ķ”üÕ£©Ķ«Łń╗āµŚČµīćÕ«ÜķÜŵ£║ń¦ŹÕŁÉ’╝īÕÅ»õ╗źõĮ┐ńö©õ╗źõĖŗÕæĮõ╗ż’╝Ü
+
+```shell
+python ./tools/train.py \
+ ${CONFIG} \ # ķģŹńĮ«µ¢ćõ╗ČĶĘ»ÕŠä
+ --cfg-options randomness.seed=2023 \ # Ķ«ŠńĮ«ķÜŵ£║ń¦ŹÕŁÉõĖ║ 2023
+ [randomness.diff_rank_seed=True] \ # µĀ╣µŹ« rank µØźĶ«ŠńĮ«õĖŹÕÉīńÜäń¦ŹÕŁÉŃĆé
+ [randomness.deterministic=True] # µŖŖ cuDNN ÕÉÄń½»ńĪ«Õ«ÜµĆ¦ķĆēķĪ╣Ķ«ŠńĮ«õĖ║ True
+# [] õ╗ŻĶĪ©ÕÅ»ķĆēÕÅéµĢ░’╝īÕ«×ķÖģĶŠōÕģźÕæĮõ╗żĶĪīµŚČ’╝īõĖŹńö©ĶŠōÕģź []
+```
+
+randomness µ£ēõĖēõĖ¬ÕÅéµĢ░ÕÅ»Ķ«ŠńĮ«’╝īÕģĘõĮōÕɽõ╣ēÕ”éõĖŗ’╝Ü
+
+- `randomness.seed=2023` ’╝īĶ«ŠńĮ«ķÜŵ£║ń¦ŹÕŁÉõĖ║ `2023`ŃĆé
+
+- `randomness.diff_rank_seed=True`’╝īµĀ╣µŹ« `rank` µØźĶ«ŠńĮ«õĖŹÕÉīńÜäń¦ŹÕŁÉ’╝ī`diff_rank_seed` ķ╗śĶ«żõĖ║ `False`ŃĆé
+
+- `randomness.deterministic=True`’╝īµŖŖ `cuDNN` ÕÉÄń½»ńĪ«Õ«ÜµĆ¦ķĆēķĪ╣Ķ«ŠńĮ«õĖ║ `True`’╝īÕŹ│µŖŖ `torch.backends.cudnn.deterministic` Ķ«ŠõĖ║ `True`’╝īµŖŖ `torch.backends.cudnn.benchmark` Ķ«ŠõĖ║ `False`ŃĆé`deterministic` ķ╗śĶ«żõĖ║ `False`ŃĆéµø┤ÕżÜń╗åĶŖéĶ¦ü [Pytorch Randomness](https://pytorch.org/docs/stable/notes/randomness.html)ŃĆé
+
+Õ”éµ×£õĮĀÕĖīµ£øµēŗÕŖ©Õ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁµīćÕ«ÜķÜŵ£║ń¦ŹÕŁÉ’╝īÕÅ»õ╗źÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁĶ«ŠńĮ« `random_seed` ÕÅéµĢ░’╝īÕģĘõĮōÕ”éõĖŗ’╝Ü
+
+```python
+randomness = dict(seed=2023)
+# model settings
+model = dict(
+ ## ÕåģÕ«╣ń£üńĢź ##
+ )
+```
+
+## õĮ┐ńö© Tensorboard ÕÅ»Ķ¦åÕī¢Ķ«Łń╗āĶ┐ćń©ŗ
+
+Õ«ēĶŻģ Tensorboard ńÄ»Õóā
+
+```shell
+pip install tensorboard
+```
+
+Õ£© config µ¢ćõ╗ČõĖŁµĘ╗ÕŖĀ tensorboard ķģŹńĮ«
+
+```python
+visualizer = dict(vis_backends=[dict(type='LocalVisBackend'),dict(type='TensorboardVisBackend')])
+```
+
+Ķ┐ÉĶĪīĶ«Łń╗āÕæĮõ╗żÕÉÄ’╝ītensorboard µ¢ćõ╗Čõ╝Üńö¤µłÉÕ£©ÕÅ»Ķ¦åÕī¢µ¢ćõ╗ČÕż╣ `work_dir/${CONFIG}/${TIMESTAMP}/vis_data` õĖŗ’╝īĶ┐ÉĶĪīõĖŗķØóńÜäÕæĮõ╗żÕ░▒ÕÅ»õ╗źÕ£©ńĮæķĪĄķōŠµÄźõĮ┐ńö© tensorboard µ¤źń£ŗ lossŃĆüÕŁ”õ╣ĀńÄćÕÆīń▓ŠÕ║”ńŁēõ┐Īµü»ŃĆé
+
+```shell
+tensorboard --logdir work_dir/${CONFIG}/${TIMESTAMP}/vis_data
+```
diff --git a/internlm_langchain/knowledge_base/MMPose/content/changelog.md b/internlm_langchain/knowledge_base/MMPose/content/changelog.md
new file mode 100644
index 00000000..68beeeb0
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPose/content/changelog.md
@@ -0,0 +1,1316 @@
+# Changelog
+
+## **v1.0.0rc1 (14/10/2022)**
+
+**Highlights**
+
+- Release RTMPose, a high-performance real-time pose estimation algorithm with cross-platform deployment and inference support. See details at the [project page](/projects/rtmpose/)
+- Support several new algorithms: ViTPose (arXiv'2022), CID (CVPR'2022), DEKR (CVPR'2021)
+- Add Inferencer, a convenient inference interface that perform pose estimation and visualization on images, videos and webcam streams with only one line of code
+- Introduce *Project*, a new form for rapid and easy implementation of new algorithms and features in MMPose, which is more handy for community contributors
+
+**New Features**
+
+- Support RTMPose ([#1971](https://github.com/open-mmlab/mmpose/pull/1971), [#2024](https://github.com/open-mmlab/mmpose/pull/2024), [#2028](https://github.com/open-mmlab/mmpose/pull/2028), [#2030](https://github.com/open-mmlab/mmpose/pull/2030), [#2040](https://github.com/open-mmlab/mmpose/pull/2040), [#2057](https://github.com/open-mmlab/mmpose/pull/2057))
+- Support Inferencer ([#1969](https://github.com/open-mmlab/mmpose/pull/1969))
+- Support ViTPose ([#1876](https://github.com/open-mmlab/mmpose/pull/1876), [#2056](https://github.com/open-mmlab/mmpose/pull/2056), [#2058](https://github.com/open-mmlab/mmpose/pull/2058)’╝ī [#2065](https://github.com/open-mmlab/mmpose/pull/2065))
+- Support CID ([#1907](https://github.com/open-mmlab/mmpose/pull/1907))
+- Support DEKR ([#1834](https://github.com/open-mmlab/mmpose/pull/1834), [#1901](https://github.com/open-mmlab/mmpose/pull/1901))
+- Support training with multiple datasets ([#1767](https://github.com/open-mmlab/mmpose/pull/1767), [#1930](https://github.com/open-mmlab/mmpose/pull/1930), [#1938](https://github.com/open-mmlab/mmpose/pull/1938), [#2025](https://github.com/open-mmlab/mmpose/pull/2025))
+- Add *project* to allow rapid and easy implementation of new models and features ([#1914](https://github.com/open-mmlab/mmpose/pull/1914))
+
+**Improvements**
+
+- Improve documentation quality ([#1846](https://github.com/open-mmlab/mmpose/pull/1846), [#1858](https://github.com/open-mmlab/mmpose/pull/1858), [#1872](https://github.com/open-mmlab/mmpose/pull/1872), [#1899](https://github.com/open-mmlab/mmpose/pull/1899), [#1925](https://github.com/open-mmlab/mmpose/pull/1925), [#1945](https://github.com/open-mmlab/mmpose/pull/1945), [#1952](https://github.com/open-mmlab/mmpose/pull/1952), [#1990](https://github.com/open-mmlab/mmpose/pull/1990), [#2023](https://github.com/open-mmlab/mmpose/pull/2023), [#2042](https://github.com/open-mmlab/mmpose/pull/2042))
+- Support visualizing keypoint indices ([#2051](https://github.com/open-mmlab/mmpose/pull/2051))
+- Support OpenPose style visualization ([#2055](https://github.com/open-mmlab/mmpose/pull/2055))
+- Accelerate image transpose in data pipelines with tensor operation ([#1976](https://github.com/open-mmlab/mmpose/pull/1976))
+- Support auto-import modules from registry ([#1961](https://github.com/open-mmlab/mmpose/pull/1961))
+- Support keypoint partition metric ([#1944](https://github.com/open-mmlab/mmpose/pull/1944))
+- Support SimCC 1D-heatmap visualization ([#1912](https://github.com/open-mmlab/mmpose/pull/1912))
+- Support saving predictions and data metainfo in demos ([#1814](https://github.com/open-mmlab/mmpose/pull/1814), [#1879](https://github.com/open-mmlab/mmpose/pull/1879))
+- Support SimCC with DARK ([#1870](https://github.com/open-mmlab/mmpose/pull/1870))
+- Remove Gaussian blur for offset maps in UDP-regress ([#1815](https://github.com/open-mmlab/mmpose/pull/1815))
+- Refactor encoding interface of Codec for better extendibility and easier configuration ([#1781](https://github.com/open-mmlab/mmpose/pull/1781))
+- Support evaluating CocoMetric without annotation file ([#1722](https://github.com/open-mmlab/mmpose/pull/1722))
+- Improve unit tests ([#1765](https://github.com/open-mmlab/mmpose/pull/1765))
+
+**Bug Fixes**
+
+- Fix repeated warnings from different ranks ([#2053](https://github.com/open-mmlab/mmpose/pull/2053))
+- Avoid frequent scope switching when using mmdet inference api ([#2039](https://github.com/open-mmlab/mmpose/pull/2039))
+- Remove EMA parameters and message hub data when publishing model checkpoints ([#2036](https://github.com/open-mmlab/mmpose/pull/2036))
+- Fix metainfo copying in dataset class ([#2017](https://github.com/open-mmlab/mmpose/pull/2017))
+- Fix top-down demo bug when there is no object detected ([#2007](https://github.com/open-mmlab/mmpose/pull/2007))
+- Fix config errors ([#1882](https://github.com/open-mmlab/mmpose/pull/1882), [#1906](https://github.com/open-mmlab/mmpose/pull/1906), [#1995](https://github.com/open-mmlab/mmpose/pull/1995))
+- Fix image demo failure when GUI is unavailable ([#1968](https://github.com/open-mmlab/mmpose/pull/1968))
+- Fix bug in AdaptiveWingLoss ([#1953](https://github.com/open-mmlab/mmpose/pull/1953))
+- Fix incorrect importing of RepeatDataset which is deprecated ([#1943](https://github.com/open-mmlab/mmpose/pull/1943))
+- Fix bug in bottom-up datasets that ignores images without instances ([#1752](https://github.com/open-mmlab/mmpose/pull/1752), [#1936](https://github.com/open-mmlab/mmpose/pull/1936))
+- Fix upstream dependency issues ([#1867](https://github.com/open-mmlab/mmpose/pull/1867), [#1921](https://github.com/open-mmlab/mmpose/pull/1921))
+- Fix evaluation issues and update results ([#1763](https://github.com/open-mmlab/mmpose/pull/1763), [#1773](https://github.com/open-mmlab/mmpose/pull/1773), [#1780](https://github.com/open-mmlab/mmpose/pull/1780), [#1850](https://github.com/open-mmlab/mmpose/pull/1850), [#1868](https://github.com/open-mmlab/mmpose/pull/1868))
+- Fix local registry missing warnings ([#1849](https://github.com/open-mmlab/mmpose/pull/1849))
+- Remove deprecated scripts for model deployment ([#1845](https://github.com/open-mmlab/mmpose/pull/1845))
+- Fix a bug in input transformation in BaseHead ([#1843](https://github.com/open-mmlab/mmpose/pull/1843))
+- Fix an interface mismatch with MMDetection in webcam demo ([#1813](https://github.com/open-mmlab/mmpose/pull/1813))
+- Fix a bug in heatmap visualization that causes incorrect scale ([#1800](https://github.com/open-mmlab/mmpose/pull/1800))
+- Add model metafiles ([#1768](https://github.com/open-mmlab/mmpose/pull/1768))
+
+## **v1.0.0rc0 (14/10/2022)**
+
+**New Features**
+
+- Support 4 light-weight pose estimation algorithms: [SimCC](https://doi.org/10.48550/arxiv.2107.03332) (ECCV'2022), [Debias-IPR](https://openaccess.thecvf.com/content/ICCV2021/papers/Gu_Removing_the_Bias_of_Integral_Pose_Regression_ICCV_2021_paper.pdf) (ICCV'2021), [IPR](https://arxiv.org/abs/1711.08229) (ECCV'2018), and [DSNT](https://arxiv.org/abs/1801.07372v2) (ArXiv'2018) ([#1628](https://github.com/open-mmlab/mmpose/pull/1628))
+
+**Migrations**
+
+- Add Webcam API in MMPose 1.0 ([#1638](https://github.com/open-mmlab/mmpose/pull/1638), [#1662](https://github.com/open-mmlab/mmpose/pull/1662)) @Ben-Louis
+- Add codec for Associative Embedding (beta) ([#1603](https://github.com/open-mmlab/mmpose/pull/1603)) @ly015
+
+**Improvements**
+
+- Add a colab tutorial for MMPose 1.0 ([#1660](https://github.com/open-mmlab/mmpose/pull/1660)) @Tau-J
+- Add model index in config folder ([#1710](https://github.com/open-mmlab/mmpose/pull/1710), [#1709](https://github.com/open-mmlab/mmpose/pull/1709), [#1627](https://github.com/open-mmlab/mmpose/pull/1627)) @ly015, @Tau-J, @Ben-Louis
+- Update and improve documentation ([#1692](https://github.com/open-mmlab/mmpose/pull/1692), [#1656](https://github.com/open-mmlab/mmpose/pull/1656), [#1681](https://github.com/open-mmlab/mmpose/pull/1681), [#1677](https://github.com/open-mmlab/mmpose/pull/1677), [#1664](https://github.com/open-mmlab/mmpose/pull/1664), [#1659](https://github.com/open-mmlab/mmpose/pull/1659)) @Tau-J, @Ben-Louis, @liqikai9
+- Improve config structures and formats ([#1651](https://github.com/open-mmlab/mmpose/pull/1651)) @liqikai9
+
+**Bug Fixes**
+
+- Update mmengine version requirements ([#1715](https://github.com/open-mmlab/mmpose/pull/1715)) @Ben-Louis
+- Update dependencies of pre-commit hooks ([#1705](https://github.com/open-mmlab/mmpose/pull/1705)) @Ben-Louis
+- Fix mmcv version in DockerFile ([#1704](https://github.com/open-mmlab/mmpose/pull/1704))
+- Fix a bug in setting dataset metainfo in configs ([#1684](https://github.com/open-mmlab/mmpose/pull/1684)) @ly015
+- Fix a bug in UDP training ([#1682](https://github.com/open-mmlab/mmpose/pull/1682)) @liqikai9
+- Fix a bug in Dark decoding ([#1676](https://github.com/open-mmlab/mmpose/pull/1676)) @liqikai9
+- Fix bugs in visualization ([#1671](https://github.com/open-mmlab/mmpose/pull/1671), [#1668](https://github.com/open-mmlab/mmpose/pull/1668), [#1657](https://github.com/open-mmlab/mmpose/pull/1657)) @liqikai9, @Ben-Louis
+- Fix incorrect flops calculation ([#1669](https://github.com/open-mmlab/mmpose/pull/1669)) @liqikai9
+- Fix `tensor.tile` compatibility issue for pytorch 1.6 ([#1658](https://github.com/open-mmlab/mmpose/pull/1658)) @ly015
+- Fix compatibility with `MultilevelPixelData` ([#1647](https://github.com/open-mmlab/mmpose/pull/1647)) @liqikai9
+
+## **v1.0.0beta (1/09/2022)**
+
+We are excited to announce the release of MMPose 1.0.0beta.
+MMPose 1.0.0beta is the first version of MMPose 1.x, a part of the OpenMMLab 2.0 projects.
+Built upon the new [training engine](https://github.com/open-mmlab/mmengine),
+MMPose 1.x unifies the interfaces of dataset, models, evaluation, and visualization with faster training and testing speed.
+It also provide a general semi-supervised object detection framework, and more strong baselines.
+
+**Highlights**
+
+- **New engines**. MMPose 1.x is based on [MMEngine](https://github.com/open-mmlab/mmengine), which provides a general and powerful runner that allows more flexible customizations and significantly simplifies the entrypoints of high-level interfaces.
+
+- **Unified interfaces**. As a part of the OpenMMLab 2.0 projects, MMPose 1.x unifies and refactors the interfaces and internal logics of train, testing, datasets, models, evaluation, and visualization. All the OpenMMLab 2.0 projects share the same design in those interfaces and logics to allow the emergence of multi-task/modality algorithms.
+
+- **More documentation and tutorials**. We add a bunch of documentation and tutorials to help users get started more smoothly. Read it [here](https://mmpose.readthedocs.io/en/latest/).
+
+**Breaking Changes**
+
+In this release, we made lots of major refactoring and modifications. Please refer to the [migration guide](../migration.md) for details and migration instructions.
+
+## **v0.28.1 (28/07/2022)**
+
+This release is meant to fix the compatibility with the latest mmcv v1.6.1
+
+## **v0.28.0 (06/07/2022)**
+
+**Highlights**
+
+- Support [TCFormer](https://openaccess.thecvf.com/content/CVPR2022/html/Zeng_Not_All_Tokens_Are_Equal_Human-Centric_Visual_Analysis_via_Token_CVPR_2022_paper.html) backbone, CVPR'2022 ([#1447](https://github.com/open-mmlab/mmpose/pull/1447), [#1452](https://github.com/open-mmlab/mmpose/pull/1452)) @zengwang430521
+
+- Add [RLE](https://arxiv.org/abs/2107.11291) models on COCO dataset ([#1424](https://github.com/open-mmlab/mmpose/pull/1424)) @Indigo6, @Ben-Louis, @ly015
+
+- Update swin models with better performance ([#1467](https://github.com/open-mmlab/mmpose/pull/1434)) @jin-s13
+
+**New Features**
+
+- Support [TCFormer](https://openaccess.thecvf.com/content/CVPR2022/html/Zeng_Not_All_Tokens_Are_Equal_Human-Centric_Visual_Analysis_via_Token_CVPR_2022_paper.html) backbone, CVPR'2022 ([#1447](https://github.com/open-mmlab/mmpose/pull/1447), [#1452](https://github.com/open-mmlab/mmpose/pull/1452)) @zengwang430521
+
+- Add [RLE](https://arxiv.org/abs/2107.11291) models on COCO dataset ([#1424](https://github.com/open-mmlab/mmpose/pull/1424)) @Indigo6, @Ben-Louis, @ly015
+
+- Support layer decay optimizer constructor and learning rate decay optimizer constructor ([#1423](https://github.com/open-mmlab/mmpose/pull/1423)) @jin-s13
+
+**Improvements**
+
+- Improve documentation quality ([#1416](https://github.com/open-mmlab/mmpose/pull/1416), [#1421](https://github.com/open-mmlab/mmpose/pull/1421), [#1423](https://github.com/open-mmlab/mmpose/pull/1423), [#1426](https://github.com/open-mmlab/mmpose/pull/1426), [#1458](https://github.com/open-mmlab/mmpose/pull/1458), [#1463](https://github.com/open-mmlab/mmpose/pull/1463)) @ly015, @liqikai9
+
+- Support installation by [mim](https://github.com/open-mmlab/mim) ([#1425](https://github.com/open-mmlab/mmpose/pull/1425)) @liqikai9
+
+- Support PAVI logger ([#1434](https://github.com/open-mmlab/mmpose/pull/1434)) @EvelynWang-0423
+
+- Add progress bar for some demos ([#1454](https://github.com/open-mmlab/mmpose/pull/1454)) @liqikai9
+
+- Webcam API supports quick device setting in terminal commands ([#1466](https://github.com/open-mmlab/mmpose/pull/1466)) @ly015
+
+- Update swin models with better performance ([#1467](https://github.com/open-mmlab/mmpose/pull/1434)) @jin-s13
+
+**Bug Fixes**
+
+- Rename `custom_hooks_config` to `custom_hooks` in configs to align with the documentation ([#1427](https://github.com/open-mmlab/mmpose/pull/1427)) @ly015
+
+- Fix deadlock issue in Webcam API ([#1430](https://github.com/open-mmlab/mmpose/pull/1430)) @ly015
+
+- Fix smoother configs in video 3D demo ([#1457](https://github.com/open-mmlab/mmpose/pull/1457)) @ly015
+
+## **v0.27.0 (07/06/2022)**
+
+**Highlights**
+
+- Support hand gesture recognition
+
+ - Try the demo for gesture recognition
+ - Learn more about the algorithm, dataset and experiment results
+
+- Major upgrade to the Webcam API
+
+ - Tutorials (EN|zh_CN)
+ - [API Reference](https://mmpose.readthedocs.io/en/latest/api.html#mmpose-apis-webcam)
+ - Demo
+
+**New Features**
+
+- Support gesture recognition algorithm [MTUT](https://openaccess.thecvf.com/content_CVPR_2019/html/Abavisani_Improving_the_Performance_of_Unimodal_Dynamic_Hand-Gesture_Recognition_With_Multimodal_CVPR_2019_paper.html) CVPR'2019 and dataset [NVGesture](https://openaccess.thecvf.com/content_cvpr_2016/html/Molchanov_Online_Detection_and_CVPR_2016_paper.html) CVPR'2016 ([#1380](https://github.com/open-mmlab/mmpose/pull/1380)) @Ben-Louis
+
+**Improvements**
+
+- Upgrade Webcam API and related documents ([#1393](https://github.com/open-mmlab/mmpose/pull/1393), [#1404](https://github.com/open-mmlab/mmpose/pull/1404), [#1413](https://github.com/open-mmlab/mmpose/pull/1413)) @ly015
+
+- Support exporting COCO inference result without the annotation file ([#1368](https://github.com/open-mmlab/mmpose/pull/1368)) @liqikai9
+
+- Replace markdownlint with mdformat in CI to avoid the dependence on ruby [#1382](https://github.com/open-mmlab/mmpose/pull/1382) @ly015
+
+- Improve documentation quality ([#1385](https://github.com/open-mmlab/mmpose/pull/1385), [#1394](https://github.com/open-mmlab/mmpose/pull/1394), [#1395](https://github.com/open-mmlab/mmpose/pull/1395), [#1408](https://github.com/open-mmlab/mmpose/pull/1408)) @chubei-oppen, @ly015, @liqikai9
+
+**Bug Fixes**
+
+- Fix xywh->xyxy bbox conversion in dataset sanity check ([#1367](https://github.com/open-mmlab/mmpose/pull/1367)) @jin-s13
+
+- Fix a bug in two-stage 3D keypoint demo ([#1373](https://github.com/open-mmlab/mmpose/pull/1373)) @ly015
+
+- Fix out-dated settings in PVT configs ([#1376](https://github.com/open-mmlab/mmpose/pull/1376)) @ly015
+
+- Fix myst settings for document compiling ([#1381](https://github.com/open-mmlab/mmpose/pull/1381)) @ly015
+
+- Fix a bug in bbox transform ([#1384](https://github.com/open-mmlab/mmpose/pull/1384)) @ly015
+
+- Fix inaccurate description of `min_keypoints` in tracking apis ([#1398](https://github.com/open-mmlab/mmpose/pull/1398)) @pallgeuer
+
+- Fix warning with `torch.meshgrid` ([#1402](https://github.com/open-mmlab/mmpose/pull/1402)) @pallgeuer
+
+- Remove redundant transformer modules from `mmpose.datasets.backbones.utils` ([#1405](https://github.com/open-mmlab/mmpose/pull/1405)) @ly015
+
+## **v0.26.0 (05/05/2022)**
+
+**Highlights**
+
+- Support [RLE (Residual Log-likelihood Estimation)](https://arxiv.org/abs/2107.11291), ICCV'2021 ([#1259](https://github.com/open-mmlab/mmpose/pull/1259)) @Indigo6, @ly015
+
+- Support [Swin Transformer](https://arxiv.org/abs/2103.14030), ICCV'2021 ([#1300](https://github.com/open-mmlab/mmpose/pull/1300)) @yumendecc, @ly015
+
+- Support [PVT](https://arxiv.org/abs/2102.12122), ICCV'2021 and [PVTv2](https://arxiv.org/abs/2106.13797), CVMJ'2022 ([#1343](https://github.com/open-mmlab/mmpose/pull/1343)) @zengwang430521
+
+- Speed up inference and reduce CPU usage by optimizing the pre-processing pipeline ([#1320](https://github.com/open-mmlab/mmpose/pull/1320)) @chenxinfeng4, @liqikai9
+
+**New Features**
+
+- Support [RLE (Residual Log-likelihood Estimation)](https://arxiv.org/abs/2107.11291), ICCV'2021 ([#1259](https://github.com/open-mmlab/mmpose/pull/1259)) @Indigo6, @ly015
+
+- Support [Swin Transformer](https://arxiv.org/abs/2103.14030), ICCV'2021 ([#1300](https://github.com/open-mmlab/mmpose/pull/1300)) @yumendecc, @ly015
+
+- Support [PVT](https://arxiv.org/abs/2102.12122), ICCV'2021 and [PVTv2](https://arxiv.org/abs/2106.13797), CVMJ'2022 ([#1343](https://github.com/open-mmlab/mmpose/pull/1343)) @zengwang430521
+
+- Support [FPN](https://openaccess.thecvf.com/content_cvpr_2017/html/Lin_Feature_Pyramid_Networks_CVPR_2017_paper.html), CVPR'2017 ([#1300](https://github.com/open-mmlab/mmpose/pull/1300)) @yumendecc, @ly015
+
+**Improvements**
+
+- Speed up inference and reduce CPU usage by optimizing the pre-processing pipeline ([#1320](https://github.com/open-mmlab/mmpose/pull/1320)) @chenxinfeng4, @liqikai9
+
+- Video demo supports models that requires multi-frame inputs ([#1300](https://github.com/open-mmlab/mmpose/pull/1300)) @liqikai9, @jin-s13
+
+- Update benchmark regression list ([#1328](https://github.com/open-mmlab/mmpose/pull/1328)) @ly015, @liqikai9
+
+- Remove unnecessary warnings in `TopDownPoseTrack18VideoDataset` ([#1335](https://github.com/open-mmlab/mmpose/pull/1335)) @liqikai9
+
+- Improve documentation quality ([#1313](https://github.com/open-mmlab/mmpose/pull/1313), [#1305](https://github.com/open-mmlab/mmpose/pull/1305)) @Ben-Louis, @ly015
+
+- Update deprecating settings in configs ([#1317](https://github.com/open-mmlab/mmpose/pull/1317)) @ly015
+
+**Bug Fixes**
+
+- Fix a bug in human skeleton grouping that may skip the matching process unexpectedly when `ignore_to_much` is True ([#1341](https://github.com/open-mmlab/mmpose/pull/1341)) @daixinghome
+
+- Fix a GPG key error that leads to CI failure ([#1354](https://github.com/open-mmlab/mmpose/pull/1354)) @ly015
+
+- Fix bugs in distributed training script ([#1338](https://github.com/open-mmlab/mmpose/pull/1338), [#1298](https://github.com/open-mmlab/mmpose/pull/1298)) @ly015
+
+- Fix an upstream bug in xtoccotools that causes incorrect AP(M) results ([#1308](https://github.com/open-mmlab/mmpose/pull/1308)) @jin-s13, @ly015
+
+- Fix indentiation errors in the colab tutorial ([#1298](https://github.com/open-mmlab/mmpose/pull/1298)) @YuanZi1501040205
+
+- Fix incompatible model weight initialization with other OpenMMLab codebases ([#1329](https://github.com/open-mmlab/mmpose/pull/1329)) @274869388
+
+- Fix HRNet FP16 checkpoints download URL ([#1309](https://github.com/open-mmlab/mmpose/pull/1309)) @YinAoXiong
+
+- Fix typos in `body3d_two_stage_video_demo.py` ([#1295](https://github.com/open-mmlab/mmpose/pull/1295)) @mucozcan
+
+**Breaking Changes**
+
+- Refactor bbox processing in datasets and pipelines ([#1311](https://github.com/open-mmlab/mmpose/pull/1311)) @ly015, @Ben-Louis
+
+- The bbox format conversion (xywh to center-scale) and random translation are moved from the dataset to the pipeline. The comparison between new and old version is as below:
+
+v0.26.0v0.25.0Dataset
+(e.g. [TopDownCOCODataset](https://github.com/open-mmlab/mmpose/blob/master/mmpose/datasets/datasets/top_down/topdown_coco_dataset.py))
+
+... # Data sample only contains bbox rec.append({ 'bbox': obj\['clean_bbox\]\[:4\], ... })
+
+
+
+
+
+
+
+Õ»╣õ║Ä [Animal-Pose](https://sites.google.com/view/animal-pose/)’╝īÕÅ»õ╗źõ╗Ä[Õ«śµ¢╣ńĮæń½Ö](https://sites.google.com/view/animal-pose/)õĖŗĶĮĮÕøŠÕāÅÕÆīµĀćµ│©ŃĆéĶäܵ£¼ `tools/dataset_converters/parse_animalpose_dataset.py` Õ░åÕĤզŗµĀćµ│©ĶĮ¼µŹóõĖ║ MMPose Õģ╝Õ«╣ńÜäµĀ╝Õ╝ÅŃĆéķóäÕżäńÉåńÜä[µĀćµ│©µ¢ćõ╗Č](https://download.openmmlab.com/mmpose/datasets/animalpose_annotations.tar)ÕÅ»ńö©ŃĆéÕ”éµ×£µé©µā│Ķć¬ÕĘ▒ńö¤µłÉµĀćµ│©’╝īĶ»Ęµīēńģ¦õ╗źõĖŗµŁźķ¬żµōŹõĮ£’╝Ü
+
+1. õĖŗĶĮĮÕøŠńēćõĖĵĀćµ│©õ┐Īµü»Õ╣ČĶ¦ŻÕÄŗÕł░ `$MMPOSE/data`’╝īµīēńģ¦õ╗źõĖŗµĀ╝Õ╝Åń╗äń╗ć’╝Ü
+
+ ```text
+ mmpose
+ Ōö£ŌöĆŌöĆ mmpose
+ Ōö£ŌöĆŌöĆ docs
+ Ōö£ŌöĆŌöĆ tests
+ Ōö£ŌöĆŌöĆ tools
+ Ōö£ŌöĆŌöĆ configs
+ `ŌöĆŌöĆ data
+ ŌöéŌöĆŌöĆ animalpose
+ Ōöé
+ Ōöé-- VOC2012
+ Ōöé Ōöé-- Annotations
+ Ōöé Ōöé-- ImageSets
+ Ōöé Ōöé-- JPEGImages
+ Ōöé Ōöé-- SegmentationClass
+ Ōöé Ōöé-- SegmentationObject
+ Ōöé
+ Ōöé-- animalpose_image_part2
+ Ōöé Ōöé-- cat
+ Ōöé Ōöé-- cow
+ Ōöé Ōöé-- dog
+ Ōöé Ōöé-- horse
+ Ōöé Ōöé-- sheep
+ Ōöé
+ Ōöé-- PASCAL2011_animal_annotation
+ Ōöé Ōöé-- cat
+ Ōöé Ōöé |-- 2007_000528_1.xml
+ Ōöé Ōöé |-- 2007_000549_1.xml
+ Ōöé Ōöé Ōöé-- ...
+ Ōöé Ōöé-- cow
+ Ōöé Ōöé-- dog
+ Ōöé Ōöé-- horse
+ Ōöé Ōöé-- sheep
+ Ōöé
+ Ōöé-- annimalpose_anno2
+ Ōöé Ōöé-- cat
+ Ōöé Ōöé |-- ca1.xml
+ Ōöé Ōöé |-- ca2.xml
+ Ōöé Ōöé Ōöé-- ...
+ Ōöé Ōöé-- cow
+ Ōöé Ōöé-- dog
+ Ōöé Ōöé-- horse
+ Ōöé Ōöé-- sheep
+ ```
+
+2. Ķ┐ÉĶĪīĶäܵ£¼
+
+ ```bash
+ python tools/dataset_converters/parse_animalpose_dataset.py
+ ```
+
+ ńö¤µłÉńÜäµĀćµ│©µ¢ćõ╗ČÕ░åõ┐ØÕŁśÕ£© `$MMPOSE/data/animalpose/annotations` õĖŁŃĆé
+
+Õ╝Ƶ║ÉõĮ£ĶĆģµ▓Īµ£ēµÅÉõŠøÕ«śµ¢╣ńÜä train/val/test ÕłÆÕłå’╝īµłæõ╗¼ķĆēµŗ®µØźĶć¬ PascalVOC ńÜäÕøŠńēćõĮ£õĖ║ train & val’╝ītrain+val õĖĆÕģ▒ 3600 Õ╝ĀÕøŠńēć’╝ī5117 õĖ¬µĀćµ│©ŃĆéÕģČõĖŁ 2798 Õ╝ĀÕøŠńēć’╝ī4000 õĖ¬µĀćµ│©ńö©õ║ÄĶ«Łń╗ā’╝ī810 Õ╝ĀÕøŠńēć’╝ī1117 õĖ¬µĀćµ│©ńö©õ║Äķ¬īĶ»üŃĆ鵥ŗĶ»ĢķøåÕīģÕɽ 1000 Õ╝ĀÕøŠńēć’╝ī1000 õĖ¬µĀćµ│©ńö©õ║ÄĶ»äõ╝░ŃĆé
+
+## COFW µĢ░µŹ«ķøå
+
+Animal-Pose (ICCV'2019)
+ +```bibtex +@InProceedings{Cao_2019_ICCV, + author = {Cao, Jinkun and Tang, Hongyang and Fang, Hao-Shu and Shen, Xiaoyong and Lu, Cewu and Tai, Yu-Wing}, + title = {Cross-Domain Adaptation for Animal Pose Estimation}, + booktitle = {The IEEE International Conference on Computer Vision (ICCV)}, + month = {October}, + year = {2019} +} +``` + +
+
+
+Õ»╣õ║Ä COFW µĢ░µŹ«ķøå’╝īĶ»Ęõ╗Ä [COFW Dataset (Color Images)](https://data.caltech.edu/records/20099) Ķ┐øĶĪīõĖŗĶĮĮŃĆé
+
+Õ░å `COFW_train_color.mat` ÕÆī `COFW_test_color.mat` ń¦╗ÕŖ©Õł░ `$MMPOSE/data/cofw/`’╝īńĪ«õ┐ØÕ«āõ╗¼µīēńģ¦õ╗źõĖŗµĀ╝Õ╝Åń╗äń╗ć’╝Ü
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+`ŌöĆŌöĆ data
+ ŌöéŌöĆŌöĆ cofw
+ |ŌöĆŌöĆ COFW_train_color.mat
+ |ŌöĆŌöĆ COFW_test_color.mat
+```
+
+Ķ┐ÉĶĪī `pip install h5py` Õ«ēĶŻģõŠØĶĄ¢’╝īńäČÕÉÄÕ£© `$MMPOSE` õĖŗĶ┐ÉĶĪīĶäܵ£¼’╝Ü
+
+```bash
+python tools/dataset_converters/parse_cofw_dataset.py
+```
+
+µ£Ćń╗łń╗ōµ×£õĖ║’╝Ü
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+`ŌöĆŌöĆ data
+ ŌöéŌöĆŌöĆ cofw
+ |ŌöĆŌöĆ COFW_train_color.mat
+ |ŌöĆŌöĆ COFW_test_color.mat
+ |ŌöĆŌöĆ annotations
+ | |ŌöĆŌöĆ cofw_train.json
+ | |ŌöĆŌöĆ cofw_test.json
+ |ŌöĆŌöĆ images
+ |ŌöĆŌöĆ 000001.jpg
+ |ŌöĆŌöĆ 000002.jpg
+```
+
+## DeepposeKit µĢ░µŹ«ķøå
+
+COFW (ICCV'2013)
+ +```bibtex +@inproceedings{burgos2013robust, + title={Robust face landmark estimation under occlusion}, + author={Burgos-Artizzu, Xavier P and Perona, Pietro and Doll{\'a}r, Piotr}, + booktitle={Proceedings of the IEEE international conference on computer vision}, + pages={1513--1520}, + year={2013} +} +``` + +
+
+
+Õ»╣õ║Ä [Vinegar Fly](https://github.com/jgraving/DeepPoseKit-Data)’╝ī[Desert Locust](https://github.com/jgraving/DeepPoseKit-Data), ÕÆī [Gr├®vyŌĆÖs Zebra](https://github.com/jgraving/DeepPoseKit-Data) µĢ░µŹ«ķøå’╝īĶ»Ęõ╗Ä [DeepPoseKit-Data](https://github.com/jgraving/DeepPoseKit-Data) õĖŗĶĮĮµĢ░µŹ«ŃĆé
+
+`tools/dataset_converters/parse_deepposekit_dataset.py` Ķäܵ£¼ÕÅ»õ╗źÕ░åÕĤզŗµĀćµ│©ĶĮ¼µŹóõĖ║ MMPose µö»µīüńÜäµĀ╝Õ╝ÅŃĆ鵳æõ╗¼ÕĘ▓ń╗ÅĶĮ¼µŹóÕźĮńÜäµĀćµ│©µ¢ćõ╗ČÕÅ»õ╗źÕ£©Ķ┐ÖķćīõĖŗĶĮĮ’╝Ü
+
+- [vinegar_fly_annotations](https://download.openmmlab.com/mmpose/datasets/vinegar_fly_annotations.tar)
+- [locust_annotations](https://download.openmmlab.com/mmpose/datasets/locust_annotations.tar)
+- [zebra_annotations](https://download.openmmlab.com/mmpose/datasets/zebra_annotations.tar)
+
+Õ”éµ×£õĮĀÕĖīµ£øĶć¬ÕĘ▒ĶĮ¼µŹóµĢ░µŹ«’╝īĶ»Ęµīēńģ¦õ╗źõĖŗµŁźķ¬żµōŹõĮ£’╝Ü
+
+1. õĖŗĶĮĮÕĤզŗÕøŠńēćÕÆīµĀćµ│©’╝īÕ╣ČĶ¦ŻÕÄŗÕł░ `$MMPOSE/data`’╝īÕ░åÕ«āõ╗¼µīēńģ¦õ╗źõĖŗµĀ╝Õ╝Åń╗äń╗ć’╝Ü
+
+ ```text
+ mmpose
+ Ōö£ŌöĆŌöĆ mmpose
+ Ōö£ŌöĆŌöĆ docs
+ Ōö£ŌöĆŌöĆ tests
+ Ōö£ŌöĆŌöĆ tools
+ Ōö£ŌöĆŌöĆ configs
+ `ŌöĆŌöĆ data
+ |
+ |ŌöĆŌöĆ DeepPoseKit-Data
+ | `ŌöĆŌöĆ datasets
+ | |ŌöĆŌöĆ fly
+ | | |ŌöĆŌöĆ annotation_data_release.h5
+ | | |ŌöĆŌöĆ skeleton.csv
+ | | |ŌöĆŌöĆ ...
+ | |
+ | |ŌöĆŌöĆ locust
+ | | |ŌöĆŌöĆ annotation_data_release.h5
+ | | |ŌöĆŌöĆ skeleton.csv
+ | | |ŌöĆŌöĆ ...
+ | |
+ | `ŌöĆŌöĆ zebra
+ | |ŌöĆŌöĆ annotation_data_release.h5
+ | |ŌöĆŌöĆ skeleton.csv
+ | |ŌöĆŌöĆ ...
+ |
+ ŌöéŌöĆŌöĆ fly
+ `-- images
+ Ōöé-- 0.jpg
+ Ōöé-- 1.jpg
+ Ōöé-- ...
+ ```
+
+ ÕøŠńēćõ╣¤ÕÅ»õ╗źÕ£© [vinegar_fly_images](https://download.openmmlab.com/mmpose/datasets/vinegar_fly_images.tar)’╝ī[locust_images](https://download.openmmlab.com/mmpose/datasets/locust_images.tar) ÕÆī[zebra_images](https://download.openmmlab.com/mmpose/datasets/zebra_images.tar) õĖŗĶĮĮŃĆé
+
+2. Ķ┐ÉĶĪīĶäܵ£¼’╝Ü
+
+ ```bash
+ python tools/dataset_converters/parse_deepposekit_dataset.py
+ ```
+
+ ńö¤µłÉńÜäµĀćµ│©µ¢ćõ╗ČÕ░åõ┐ØÕŁśÕ£© $MMPOSE/data/fly/annotations`’╝ī`$MMPOSE/data/locust/annotations`ÕÆī`$MMPOSE/data/zebra/annotations\` õĖŁŃĆé
+
+ńö▒õ║ÄÕ«śµ¢╣µĢ░µŹ«ķøåõĖŁµ▓Īµ£ēµÅÉõŠøµĄŗĶ»Ģķøå’╝īµłæõ╗¼ķÜŵ£║ķĆēµŗ®õ║å 90% ńÜäÕøŠńēćńö©õ║ÄĶ«Łń╗ā’╝īÕē®õĖŗńÜä 10% ńö©õ║ĵĄŗĶ»ĢŃĆé
+
+## Macaque µĢ░µŹ«ķøå
+
+Desert Locust (Elife'2019)
+ +```bibtex +@article{graving2019deepposekit, + title={DeepPoseKit, a software toolkit for fast and robust animal pose estimation using deep learning}, + author={Graving, Jacob M and Chae, Daniel and Naik, Hemal and Li, Liang and Koger, Benjamin and Costelloe, Blair R and Couzin, Iain D}, + journal={Elife}, + volume={8}, + pages={e47994}, + year={2019}, + publisher={eLife Sciences Publications Limited} +} +``` + +
+
+
+Õ»╣õ║Ä [MacaquePose](http://www2.ehub.kyoto-u.ac.jp/datasets/macaquepose/index.html) µĢ░µŹ«ķøå’╝īĶ»Ęõ╗Ä [Ķ┐Öķćī](http://www2.ehub.kyoto-u.ac.jp/datasets/macaquepose/index.html) õĖŗĶĮĮµĢ░µŹ«ŃĆé
+
+`tools/dataset_converters/parse_macaquepose_dataset.py` Ķäܵ£¼ÕÅ»õ╗źÕ░åÕĤզŗµĀćµ│©ĶĮ¼µŹóõĖ║ MMPose µö»µīüńÜäµĀ╝Õ╝ÅŃĆ鵳æõ╗¼ÕĘ▓ń╗ÅĶĮ¼µŹóÕźĮńÜäµĀćµ│©µ¢ćõ╗ČÕÅ»õ╗źÕ£© [Ķ┐Öķćī](https://download.openmmlab.com/mmpose/datasets/macaque_annotations.tar) õĖŗĶĮĮŃĆé
+
+Õ”éµ×£õĮĀÕĖīµ£øĶć¬ÕĘ▒ĶĮ¼µŹóµĢ░µŹ«’╝īĶ»Ęµīēńģ¦õ╗źõĖŗµŁźķ¬żµōŹõĮ£’╝Ü
+
+1. õĖŗĶĮĮÕĤզŗÕøŠńēćÕÆīµĀćµ│©’╝īÕ╣ČĶ¦ŻÕÄŗÕł░ `$MMPOSE/data`’╝īÕ░åÕ«āõ╗¼µīēńģ¦õ╗źõĖŗµĀ╝Õ╝Åń╗äń╗ć’╝Ü
+
+ ```text
+ mmpose
+ Ōö£ŌöĆŌöĆ mmpose
+ Ōö£ŌöĆŌöĆ docs
+ Ōö£ŌöĆŌöĆ tests
+ Ōö£ŌöĆŌöĆ tools
+ Ōö£ŌöĆŌöĆ configs
+ `ŌöĆŌöĆ data
+ ŌöéŌöĆŌöĆ macaque
+ Ōöé-- annotations.csv
+ Ōöé-- images
+ Ōöé Ōöé-- 01418849d54b3005.jpg
+ Ōöé Ōöé-- 0142d1d1a6904a70.jpg
+ Ōöé Ōöé-- 01ef2c4c260321b7.jpg
+ Ōöé Ōöé-- 020a1c75c8c85238.jpg
+ Ōöé Ōöé-- 020b1506eef2557d.jpg
+ Ōöé Ōöé-- ...
+ ```
+
+2. Ķ┐ÉĶĪīĶäܵ£¼’╝Ü
+
+ ```bash
+ python tools/dataset_converters/parse_macaquepose_dataset.py
+ ```
+
+ ńö¤µłÉńÜäµĀćµ│©µ¢ćõ╗ČÕ░åõ┐ØÕŁśÕ£© `$MMPOSE/data/macaque/annotations` õĖŁŃĆé
+
+ńö▒õ║ÄÕ«śµ¢╣µĢ░µŹ«ķøåõĖŁµ▓Īµ£ēµÅÉõŠøµĄŗĶ»Ģķøå’╝īµłæõ╗¼ķÜŵ£║ķĆēµŗ®õ║å 90% ńÜäÕøŠńēćńö©õ║ÄĶ«Łń╗ā’╝īÕē®õĖŗńÜä 10% ńö©õ║ĵĄŗĶ»ĢŃĆé
+
+## Human3.6M µĢ░µŹ«ķøå
+
+MacaquePose (bioRxiv'2020)
+ +```bibtex +@article{labuguen2020macaquepose, + title={MacaquePose: A novel ŌĆśin the wildŌĆÖmacaque monkey pose dataset for markerless motion capture}, + author={Labuguen, Rollyn and Matsumoto, Jumpei and Negrete, Salvador and Nishimaru, Hiroshi and Nishijo, Hisao and Takada, Masahiko and Go, Yasuhiro and Inoue, Ken-ichi and Shibata, Tomohiro}, + journal={bioRxiv}, + year={2020}, + publisher={Cold Spring Harbor Laboratory} +} +``` + +
+
+
+Õ»╣õ║Ä [Human3.6M](http://vision.imar.ro/human3.6m/description.php) µĢ░µŹ«ķøå’╝īĶ»Ęõ╗ÄÕ«śńĮæõĖŗĶĮĮµĢ░µŹ«’╝īµöŠńĮ«Õł░ `$MMPOSE/data/h36m` õĖŗŃĆé
+
+ńäČÕÉĵē¦ĶĪī [ķóäÕżäńÉåĶäܵ£¼](/tools/dataset_converters/preprocess_h36m.py)ŃĆé
+
+```bash
+python tools/dataset_converters/preprocess_h36m.py --metadata {path to metadata.xml} --original data/h36m
+```
+
+Ķ┐ÖÕ░åÕ£©Õģ©ÕĖ¦ńÄć’╝ł50 FPS’╝ēÕÆīķÖŹķóæÕĖ¦ńÄć’╝ł10 FPS’╝ēõĖŗµÅÉÕÅ¢ńøĖµ£║ÕÅéµĢ░ÕÆīÕ¦┐ÕŖ┐µ│©ķćŖŃĆéÕżäńÉåÕÉÄńÜäµĢ░µŹ«Õ║öÕģʵ£ēõ╗źõĖŗń╗ōµ×ä’╝Ü
+
+```text
+mmpose
+Ōö£ŌöĆŌöĆ mmpose
+Ōö£ŌöĆŌöĆ docs
+Ōö£ŌöĆŌöĆ tests
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+`ŌöĆŌöĆ data
+ Ōö£ŌöĆŌöĆ h36m
+ Ōö£ŌöĆŌöĆ annotation_body3d
+ | Ōö£ŌöĆŌöĆ cameras.pkl
+ | Ōö£ŌöĆŌöĆ fps50
+ | | Ōö£ŌöĆŌöĆ h36m_test.npz
+ | | Ōö£ŌöĆŌöĆ h36m_train.npz
+ | | Ōö£ŌöĆŌöĆ joint2d_rel_stats.pkl
+ | | Ōö£ŌöĆŌöĆ joint2d_stats.pkl
+ | | Ōö£ŌöĆŌöĆ joint3d_rel_stats.pkl
+ | | `ŌöĆŌöĆ joint3d_stats.pkl
+ | `ŌöĆŌöĆ fps10
+ | Ōö£ŌöĆŌöĆ h36m_test.npz
+ | Ōö£ŌöĆŌöĆ h36m_train.npz
+ | Ōö£ŌöĆŌöĆ joint2d_rel_stats.pkl
+ | Ōö£ŌöĆŌöĆ joint2d_stats.pkl
+ | Ōö£ŌöĆŌöĆ joint3d_rel_stats.pkl
+ | `ŌöĆŌöĆ joint3d_stats.pkl
+ `ŌöĆŌöĆ images
+ Ōö£ŌöĆŌöĆ S1
+ | Ōö£ŌöĆŌöĆ S1_Directions_1.54138969
+ | | Ōö£ŌöĆŌöĆ S1_Directions_1.54138969_00001.jpg
+ | | Ōö£ŌöĆŌöĆ S1_Directions_1.54138969_00002.jpg
+ | | Ōö£ŌöĆŌöĆ ...
+ | Ōö£ŌöĆŌöĆ ...
+ Ōö£ŌöĆŌöĆ S5
+ Ōö£ŌöĆŌöĆ S6
+ Ōö£ŌöĆŌöĆ S7
+ Ōö£ŌöĆŌöĆ S8
+ Ōö£ŌöĆŌöĆ S9
+ `ŌöĆŌöĆ S11
+```
+
+ńäČÕÉÄ’╝īµĀćµ│©õ┐Īµü»ķ£ĆĶ”üĶĮ¼µŹóõĖ║ MMPose µö»µīüńÜä COCO µĀ╝Õ╝ÅŃĆéĶ┐ÖÕÅ»õ╗źķĆÜĶ┐ćĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗żÕ«īµłÉ’╝Ü
+
+```bash
+python tools/dataset_converters/h36m_to_coco.py
+```
+
+## MPII µĢ░µŹ«ķøå
+
+Human3.6M (TPAMI'2014)
+ +```bibtex +@article{h36m_pami, + author = {Ionescu, Catalin and Papava, Dragos and Olaru, Vlad and Sminchisescu, Cristian}, + title = {Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments}, + journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence}, + publisher = {IEEE Computer Society}, + volume = {36}, + number = {7}, + pages = {1325-1339}, + month = {jul}, + year = {2014} +} +``` + +
+
+
+Õ»╣õ║Ä [MPII](http://human-pose.mpi-inf.mpg.de/) µĢ░µŹ«ķøå’╝īĶ»Ęõ╗ÄÕ«śńĮæõĖŗĶĮĮµĢ░µŹ«’╝īµöŠńĮ«Õł░ `$MMPOSE/data/mpii` õĖŗŃĆé
+
+µłæõ╗¼µÅÉõŠøõ║åõĖĆõĖ¬Ķäܵ£¼µØźÕ░å `.mat` µĀ╝Õ╝ÅńÜäµĀćµ│©µ¢ćõ╗ČĶĮ¼µŹóõĖ║ `.json` µĀ╝Õ╝ÅŃĆéĶ┐ÖÕÅ»õ╗źķĆÜĶ┐ćĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗żÕ«īµłÉ’╝Ü
+
+```shell
+python tools/dataset_converters/mat2json ${PRED_MAT_FILE} ${GT_JSON_FILE} ${OUTPUT_PRED_JSON_FILE}
+```
+
+õŠŗÕ”é’╝Ü
+
+```shell
+python tools/dataset/mat2json work_dirs/res50_mpii_256x256/pred.mat data/mpii/annotations/mpii_val.json pred.json
+```
+
+## Label Studio µĢ░µŹ«ķøå
+
+MPII (CVPR'2014)
+ +```bibtex +@inproceedings{andriluka14cvpr, + author = {Mykhaylo Andriluka and Leonid Pishchulin and Peter Gehler and Schiele, Bernt}, + title = {2D Human Pose Estimation: New Benchmark and State of the Art Analysis}, + booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, + year = {2014}, + month = {June} +} +``` + +
+
+
+Õ»╣õ║Ä [Label Studio](https://github.com/heartexlabs/label-studio/) ńö©µłĘ’╝īĶ»ĘõŠØńģ¦ [Label Studio ĶĮ¼µŹóÕĘźÕģʵ¢ćµĪŻ](./label_studio.md) õĖŁńÜäµ¢╣µ│ĢĶ┐øĶĪīµĀćµ│©’╝īÕ╣ČÕ░åń╗ōµ×£Õ»╝Õć║õĖ║ Label Studio µĀćÕćåńÜä `.json` µ¢ćõ╗Č’╝īÕ░å `Labeling Interface` õĖŁńÜä `Code` õ┐ØÕŁśõĖ║ `.xml` µ¢ćõ╗ČŃĆé
+
+µłæõ╗¼µÅÉõŠøõ║åõĖĆõĖ¬Ķäܵ£¼µØźÕ░å Label Studio µĀćÕćåńÜä `.json` µĀ╝Õ╝ŵĀćµ│©µ¢ćõ╗ČĶĮ¼µŹóõĖ║ COCO µĀćÕćåńÜä `.json` µĀ╝Õ╝ÅŃĆéĶ┐ÖÕÅ»õ╗źķĆÜĶ┐ćĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗żÕ«īµłÉ’╝Ü
+
+```shell
+python tools/dataset_converters/labelstudio2coco.py ${LS_JSON_FILE} ${LS_XML_FILE} ${OUTPUT_COCO_JSON_FILE}
+```
+
+õŠŗÕ”é’╝Ü
+
+```shell
+python tools/dataset_converters/labelstudio2coco.py config.xml project-1-at-2023-05-13-09-22-91b53efa.json output/result.json
+```
diff --git a/internlm_langchain/knowledge_base/MMPose/content/ecosystem.md b/internlm_langchain/knowledge_base/MMPose/content/ecosystem.md
new file mode 100644
index 00000000..b0027cfa
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPose/content/ecosystem.md
@@ -0,0 +1,3 @@
+# Ecosystem
+
+Coming soon.
diff --git a/internlm_langchain/knowledge_base/MMPose/content/faq.md b/internlm_langchain/knowledge_base/MMPose/content/faq.md
new file mode 100644
index 00000000..b1e69983
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPose/content/faq.md
@@ -0,0 +1,148 @@
+# FAQ
+
+We list some common issues faced by many users and their corresponding solutions here.
+Feel free to enrich the list if you find any frequent issues and have ways to help others to solve them.
+If the contents here do not cover your issue, please create an issue using the [provided templates](/.github/ISSUE_TEMPLATE/error-report.md) and make sure you fill in all required information in the template.
+
+## Installation
+
+Compatibility issue between MMCV and MMPose; "AssertionError: MMCV==xxx is used but incompatible. Please install mmcv>=xxx, \<=xxx."
+
+Here are the version correspondences between `mmdet`, `mmcv` and `mmpose`:
+
+- mmdet 2.x \<=> mmpose 0.x \<=> mmcv 1.x
+- mmdet 3.x \<=> mmpose 1.x \<=> mmcv 2.x
+
+Detailed compatible MMPose and MMCV versions are shown as below. Please choose the correct version of MMCV to avoid installation issues.
+
+### MMPose 1.x
+
+| MMPose version | MMCV/MMEngine version |
+| :------------: | :-----------------------------: |
+| 1.1.0 | mmcv>=2.0.1, mmengine>=0.8.0 |
+| 1.0.0 | mmcv>=2.0.0, mmengine>=0.7.0 |
+| 1.0.0rc1 | mmcv>=2.0.0rc4, mmengine>=0.6.0 |
+| 1.0.0rc0 | mmcv>=2.0.0rc0, mmengine>=0.0.1 |
+| 1.0.0b0 | mmcv>=2.0.0rc0, mmengine>=0.0.1 |
+
+### MMPose 0.x
+
+| MMPose version | MMCV version |
+| :------------: | :-----------------------: |
+| 0.x | mmcv-full>=1.3.8, \<1.8.0 |
+| 0.29.0 | mmcv-full>=1.3.8, \<1.7.0 |
+| 0.28.1 | mmcv-full>=1.3.8, \<1.7.0 |
+| 0.28.0 | mmcv-full>=1.3.8, \<1.6.0 |
+| 0.27.0 | mmcv-full>=1.3.8, \<1.6.0 |
+| 0.26.0 | mmcv-full>=1.3.8, \<1.6.0 |
+| 0.25.1 | mmcv-full>=1.3.8, \<1.6.0 |
+| 0.25.0 | mmcv-full>=1.3.8, \<1.5.0 |
+| 0.24.0 | mmcv-full>=1.3.8, \<1.5.0 |
+| 0.23.0 | mmcv-full>=1.3.8, \<1.5.0 |
+| 0.22.0 | mmcv-full>=1.3.8, \<1.5.0 |
+| 0.21.0 | mmcv-full>=1.3.8, \<1.5.0 |
+| 0.20.0 | mmcv-full>=1.3.8, \<1.4.0 |
+| 0.19.0 | mmcv-full>=1.3.8, \<1.4.0 |
+| 0.18.0 | mmcv-full>=1.3.8, \<1.4.0 |
+| 0.17.0 | mmcv-full>=1.3.8, \<1.4.0 |
+| 0.16.0 | mmcv-full>=1.3.8, \<1.4.0 |
+| 0.14.0 | mmcv-full>=1.1.3, \<1.4.0 |
+| 0.13.0 | mmcv-full>=1.1.3, \<1.4.0 |
+| 0.12.0 | mmcv-full>=1.1.3, \<1.3 |
+| 0.11.0 | mmcv-full>=1.1.3, \<1.3 |
+| 0.10.0 | mmcv-full>=1.1.3, \<1.3 |
+| 0.9.0 | mmcv-full>=1.1.3, \<1.3 |
+| 0.8.0 | mmcv-full>=1.1.1, \<1.2 |
+| 0.7.0 | mmcv-full>=1.1.1, \<1.2 |
+
+- **Unable to install xtcocotools**
+
+ 1. Try to install it using pypi manually `pip install xtcocotools`.
+ 2. If step1 does not work. Try to install it from [source](https://github.com/jin-s13/xtcocoapi).
+
+ ```
+ git clone https://github.com/jin-s13/xtcocoapi
+ cd xtcocoapi
+ python setup.py install
+ ```
+
+- **No matching distribution found for xtcocotools>=1.6**
+
+ 1. Install cython by `pip install cython`.
+ 2. Install xtcocotools from [source](https://github.com/jin-s13/xtcocoapi).
+
+ ```
+ git clone https://github.com/jin-s13/xtcocoapi
+ cd xtcocoapi
+ python setup.py install
+ ```
+
+- **"No module named 'mmcv.ops'"; "No module named 'mmcv.\_ext'"**
+
+ 1. Uninstall existing mmcv in the environment using `pip uninstall mmcv`.
+ 2. Install mmcv-full following the [installation instruction](https://mmcv.readthedocs.io/en/latest/#installation).
+
+## Data
+
+- **What if my custom dataset does not have bounding box label?**
+
+ We can estimate the bounding box of a person as the minimal box that tightly bounds all the keypoints.
+
+- **What is `COCO_val2017_detections_AP_H_56_person.json`? Can I train pose models without it?**
+
+ "COCO_val2017_detections_AP_H_56_person.json" contains the "detected" human bounding boxes for COCO validation set, which are generated by FasterRCNN.
+ One can choose to use gt bounding boxes to evaluate models, by setting `bbox_file=None''` in `val_dataloader.dataset` in config. Or one can use detected boxes to evaluate
+ the generalizability of models, by setting `bbox_file='COCO_val2017_detections_AP_H_56_person.json'`.
+
+## Training
+
+- **RuntimeError: Address already in use**
+
+ Set the environment variables `MASTER_PORT=XXX`. For example,
+ `MASTER_PORT=29517 GPUS=16 GPUS_PER_NODE=8 CPUS_PER_TASK=2 ./tools/slurm_train.sh Test res50 configs/body_2d_keypoint/topdown_regression/coco/td-reg_res50_8xb64-210e_coco-256x192.py work_dirs/res50_coco_256x192`
+
+- **"Unexpected keys in source state dict" when loading pre-trained weights**
+
+ It's normal that some layers in the pretrained model are not used in the pose model. ImageNet-pretrained classification network and the pose network may have different architectures (e.g. no classification head). So some unexpected keys in source state dict is actually expected.
+
+- **How to use trained models for backbone pre-training ?**
+
+ Refer to [Migration - Step3: Model - Backbone](../migration.md).
+
+ When training, the unexpected keys will be ignored.
+
+- **How to visualize the training accuracy/loss curves in real-time ?**
+
+ Use `TensorboardLoggerHook` in `log_config` like
+
+ ```python
+ log_config=dict(interval=20, hooks=[dict(type='TensorboardLoggerHook')])
+ ```
+
+ You can refer to [user_guides/visualization.md](../user_guides/visualization.md).
+
+- **Log info is NOT printed**
+
+ Use smaller log interval. For example, change `interval=50` to `interval=1` in the config.
+
+## Evaluation
+
+- **How to evaluate on MPII test dataset?**
+ Since we do not have the ground-truth for test dataset, we cannot evaluate it 'locally'.
+ If you would like to evaluate the performance on test set, you have to upload the pred.mat (which is generated during testing) to the official server via email, according to [the MPII guideline](http://human-pose.mpi-inf.mpg.de/#evaluation).
+
+- **For top-down 2d pose estimation, why predicted joint coordinates can be out of the bounding box (bbox)?**
+ We do not directly use the bbox to crop the image. bbox will be first transformed to center & scale, and the scale will be multiplied by a factor (1.25) to include some context. If the ratio of width/height is different from that of model input (possibly 192/256), we will adjust the bbox.
+
+## Inference
+
+- **How to run mmpose on CPU?**
+
+ Run demos with `--device=cpu`.
+
+- **How to speed up inference?**
+
+ For top-down models, try to edit the config file. For example,
+
+ 1. set `flip_test=False` in `init_cfg` in the config file.
+ 2. use faster human bounding box detector, see [MMDetection](https://mmdetection.readthedocs.io/zh_CN/3.x/model_zoo.html).
diff --git a/internlm_langchain/knowledge_base/MMPose/content/guide_to_framework.md b/internlm_langchain/knowledge_base/MMPose/content/guide_to_framework.md
new file mode 100644
index 00000000..349abf23
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPose/content/guide_to_framework.md
@@ -0,0 +1,682 @@
+# 20 ÕłåķƤõ║åĶ¦Ż MMPose µ×ȵ×äĶ«ŠĶ«Ī
+
+MMPose 1.0 õĖÄõ╣ŗÕēŹńÜäńēłµ£¼µ£ēĶŠāÕż¦µö╣ÕŖ©’╝īÕ»╣ķā©Õłåµ©ĪÕØŚĶ┐øĶĪīõ║åķ揵¢░Ķ«ŠĶ«ĪÕÆīń╗äń╗ć’╝īķÖŹõĮÄõ╗ŻńĀüÕåŚõĮÖÕ║”’╝īµÅÉÕŹćĶ┐ÉĶĪīµĢłńÄć’╝īķÖŹõĮÄÕŁ”õ╣ĀķÜŠÕ║”ŃĆé
+
+MMPose 1.0 ķććńö©õ║åÕģ©µ¢░ńÜ䵩ĪÕØŚń╗ōµ×äĶ«ŠĶ«Īõ╗źń▓Šń«Ćõ╗ŻńĀü’╝īµÅÉÕŹćĶ┐ÉĶĪīµĢłńÄć’╝īķÖŹõĮÄÕŁ”õ╣ĀķÜŠÕ║”ŃĆéÕ»╣õ║ĵ£ēõĖĆիܵĘ▒Õ║”ÕŁ”õ╣ĀÕ¤║ńĪĆńÜäńö©µłĘ’╝īµ£¼ń½ĀĶŖéµÅÉõŠøõ║åÕ»╣ MMPose µ×ȵ×äĶ«ŠĶ«ĪńÜäµĆ╗õĮōõ╗ŗń╗ŹŃĆéõĖŹĶ«║õĮĀµś»**µŚ¦ńēł MMPose ńÜäńö©µłĘ**’╝īĶ┐śµś»**ÕĖīµ£øńø┤µÄźõ╗Ä MMPose 1.0 õĖŖµēŗńÜäµ¢░ńö©µłĘ**’╝īķāĮÕÅ»õ╗źķĆÜĶ┐ćµ£¼µĢÖń©ŗõ║åĶ¦ŻÕ”éõĮĢµ×äÕ╗║õĖĆõĖ¬Õ¤║õ║Ä MMPose 1.0 ńÜäķĪ╣ńø«ŃĆé
+
+```{note}
+µ£¼µĢÖń©ŗÕīģÕɽõ║åõĮ┐ńö© MMPose 1.0 µŚČÕ╝ĆÕÅæĶĆģõ╝ÜÕģ│Õ┐āńÜäÕåģÕ«╣’╝Ü
+
+- µĢ┤õĮōõ╗ŻńĀüµ×ȵ×äõĖÄĶ«ŠĶ«ĪķĆ╗ĶŠæ
+
+- Õ”éõĮĢńö©configµ¢ćõ╗Čń«ĪńÉ嵩ĪÕØŚ
+
+- Õ”éõĮĢõĮ┐ńö©Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøå
+
+- Õ”éõĮĢµĘ╗ÕŖĀµ¢░ńÜ䵩ĪÕØŚ’╝łķ¬©Õ╣▓ńĮæń╗£ŃĆüµ©ĪÕ×ŗÕż┤ķā©ŃĆüµŹ¤Õż▒ÕćĮµĢ░ńŁē’╝ē
+```
+
+õ╗źõĖŗµś»Ķ┐Öń»ćµĢÖń©ŗńÜäńø«ÕĮĢ’╝Ü
+
+- [20 ÕłåķƤõ║åĶ¦Ż MMPose µ×ȵ×äĶ«ŠĶ«Ī](#20-ÕłåķƤõ║åĶ¦Ż-mmpose-µ×ȵ×äĶ«ŠĶ«Ī)
+ - [µĆ╗Ķ¦ł](#µĆ╗Ķ¦ł)
+ - [Step1’╝ÜķģŹńĮ«µ¢ćõ╗Č](#step1ķģŹńĮ«µ¢ćõ╗Č)
+ - [Step2’╝ܵĢ░µŹ«](#step2µĢ░µŹ«)
+ - [µĢ░µŹ«ķøåÕģāõ┐Īµü»](#µĢ░µŹ«ķøåÕģāõ┐Īµü»)
+ - [µĢ░µŹ«ķøå](#µĢ░µŹ«ķøå)
+ - [µĢ░µŹ«µĄüµ░┤ń║┐](#µĢ░µŹ«µĄüµ░┤ń║┐)
+ - [i. µĢ░µŹ«Õó×Õ╝║](#i-µĢ░µŹ«Õó×Õ╝║)
+ - [ii. µĢ░µŹ«ÕÅśµŹó](#ii-µĢ░µŹ«ÕÅśµŹó)
+ - [iii. µĢ░µŹ«ń╝¢ńĀü](#iii-µĢ░µŹ«ń╝¢ńĀü)
+ - [iv. µĢ░µŹ«µēōÕīģ](#iv-µĢ░µŹ«µēōÕīģ)
+ - [Step3: µ©ĪÕ×ŗ](#step3-µ©ĪÕ×ŗ)
+ - [ÕēŹÕżäńÉåÕÖ©’╝łDataPreprocessor’╝ē](#ÕēŹÕżäńÉåÕÖ©datapreprocessor)
+ - [õĖ╗Õ╣▓ńĮæń╗£’╝łBackbone’╝ē](#õĖ╗Õ╣▓ńĮæń╗£backbone)
+ - [ķółķā©µ©ĪÕØŚ’╝łNeck’╝ē](#ķółķā©µ©ĪÕØŚneck)
+ - [ķó䵥ŗÕż┤’╝łHead’╝ē](#ķó䵥ŗÕż┤head)
+
+## µĆ╗Ķ¦ł
+
+
+
+õĖĆĶł¼µØźĶ»┤’╝īÕ╝ĆÕÅæĶĆģÕ£©ķĪ╣ńø«Õ╝ĆÕÅæĶ┐ćń©ŗõĖŁń╗ÅÕĖĖµÄźĶ¦”ÕåģÕ«╣ńÜäõĖ╗Ķ”üµ£ē**õ║öõĖ¬**µ¢╣ķØó’╝Ü
+
+- **ķĆÜńö©**’╝ÜńÄ»ÕóāŃĆüķÆ®ÕŁÉ’╝łHook’╝ēŃĆüµ©ĪÕ×ŗµØāķćŹÕŁśÕÅ¢’╝łCheckpoint’╝ēŃĆüµŚźÕ┐Ś’╝łLogger’╝ēńŁē
+
+- **µĢ░µŹ«**’╝ܵĢ░µŹ«ķøåŃĆüµĢ░µŹ«Ķ»╗ÕÅ¢’╝łDataloader’╝ēŃĆüµĢ░µŹ«Õó×Õ╝║ńŁē
+
+- **Ķ«Łń╗ā**’╝Üõ╝śÕī¢ÕÖ©ŃĆüÕŁ”õ╣ĀńÄćĶ░āµĢ┤ńŁē
+
+- **µ©ĪÕ×ŗ**’╝ÜõĖ╗Õ╣▓ńĮæń╗£ŃĆüķółķā©µ©ĪÕØŚ’╝łNeck’╝ēŃĆüķó䵥ŗÕż┤µ©ĪÕØŚ’╝łHead’╝ēŃĆüµŹ¤Õż▒ÕćĮµĢ░ńŁē
+
+- **Ķ»äµĄŗ**’╝ÜĶ»äµĄŗµīćµĀć’╝łMetric’╝ēŃĆüĶ»äµĄŗÕÖ©’╝łEvaluator’╝ēńŁē
+
+ÕģČõĖŁ**ķĆÜńö©**ŃĆü**Ķ«Łń╗ā**ÕÆī**Ķ»äµĄŗ**ńøĖÕģ│ńÜ䵩ĪÕØŚÕŠĆÕŠĆńö▒Ķ«Łń╗āµĪåµ×ȵÅÉõŠø’╝īÕ╝ĆÕÅæĶĆģÕŬķ£ĆĶ”üĶ░āńö©ÕÆīĶ░āµĢ┤ÕÅéµĢ░’╝īõĖŹķ£ĆĶ”üĶć¬ĶĪīÕ«×ńÄ░’╝īÕ╝ĆÕÅæĶĆģõĖ╗Ķ”üÕ«×ńÄ░ńÜ䵜»**µĢ░µŹ«**ÕÆī**µ©ĪÕ×ŗ**ķā©ÕłåŃĆé
+
+## Step1’╝ÜķģŹńĮ«µ¢ćõ╗Č
+
+Õ£©MMPoseõĖŁ’╝īµłæõ╗¼ķĆÜÕĖĖ python µĀ╝Õ╝ÅńÜäķģŹńĮ«µ¢ćõ╗Č’╝īńö©õ║ĵĢ┤õĖ¬ķĪ╣ńø«ńÜäÕ«Üõ╣ēŃĆüÕÅéµĢ░ń«ĪńÉå’╝īÕøĀµŁżµłæõ╗¼Õ╝║ńāłÕ╗║Ķ««ń¼¼õĖƵ¼ĪµÄźĶ¦” MMPose ńÜäÕ╝ĆÕÅæĶĆģ’╝īµ¤źķśģ [ķģŹńĮ«µ¢ćõ╗Č](./user_guides/configs.md) ÕŁ”õ╣ĀķģŹńĮ«µ¢ćõ╗ČńÜäÕ«Üõ╣ēŃĆé
+
+ķ£ĆĶ”üµ│©µäÅńÜ䵜»’╝īµēƵ£ēµ¢░Õó×ńÜ䵩ĪÕØŚķāĮķ£ĆĶ”üõĮ┐ńö©µ│©ÕåīÕÖ©’╝łRegistry’╝ēĶ┐øĶĪīµ│©Õåī’╝īÕ╣ČÕ£©Õ»╣Õ║öńø«ÕĮĢńÜä `__init__.py` õĖŁĶ┐øĶĪī `import`’╝īõ╗źõŠ┐ĶāĮÕż¤õĮ┐ńö©ķģŹńĮ«µ¢ćõ╗ȵ×äÕ╗║ÕģČÕ«×õŠŗŃĆé
+
+## Step2’╝ܵĢ░µŹ«
+
+MMPose µĢ░µŹ«ńÜäń╗äń╗ćõĖ╗Ķ”üÕīģÕɽõĖēõĖ¬µ¢╣ķØó’╝Ü
+
+- µĢ░µŹ«ķøåÕģāõ┐Īµü»
+
+- µĢ░µŹ«ķøå
+
+- µĢ░µŹ«µĄüµ░┤ń║┐
+
+### µĢ░µŹ«ķøåÕģāõ┐Īµü»
+
+Õģāõ┐Īµü»µīćÕģĘõĮōµĀćµ│©õ╣ŗÕż¢ńÜäµĢ░µŹ«ķøåõ┐Īµü»ŃĆéÕ¦┐µĆüõ╝░Ķ«ĪµĢ░µŹ«ķøåńÜäÕģāõ┐Īµü»ķĆÜÕĖĖÕīģµŗ¼’╝ÜÕģ│ķö«ńé╣ÕÆīķ¬©ķ¬╝Ķ┐׵ğńÜäÕ«Üõ╣ēŃĆüÕ»╣ń¦░µĆ¦ŃĆüÕģ│ķö«ńé╣µĆ¦Ķ┤©’╝łÕ”éÕģ│ķö«ńé╣µØāķćŹŃĆüµĀćµ│©µĀćÕćåÕĘ«ŃĆüµēĆÕ▒×õĖŖõĖŗÕŹŖĶ║½’╝ēńŁēŃĆéĶ┐Öõ║øõ┐Īµü»Õ£©µĢ░µŹ«Õ£©µĢ░µŹ«ÕżäńÉåŃĆüµ©ĪÕ×ŗĶ«Łń╗āÕÆīµĄŗĶ»ĢõĖŁµ£ēķćŹĶ”üõĮ£ńö©ŃĆéÕ£© MMPose õĖŁ’╝īµĢ░µŹ«ķøåńÜäÕģāõ┐Īµü»õĮ┐ńö© python µĀ╝Õ╝ÅńÜäķģŹńĮ«µ¢ćõ╗Čõ┐ØÕŁś’╝īõĮŹõ║Ä `$MMPOSE/configs/_base_/datasets` ńø«ÕĮĢõĖŗŃĆé
+
+Õ£© MMPose õĖŁõĮ┐ńö©Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåµŚČ’╝īõĮĀķ£ĆĶ”üÕó×ÕŖĀÕ»╣Õ║öńÜäÕģāõ┐Īµü»ķģŹńĮ«µ¢ćõ╗ČŃĆéõ╗ź MPII µĢ░µŹ«ķøå’╝ł`$MMPOSE/configs/_base_/datasets/mpii.py`’╝ēõĖ║õŠŗ’╝Ü
+
+```Python
+dataset_info = dict(
+ dataset_name='mpii',
+ paper_info=dict(
+ author='Mykhaylo Andriluka and Leonid Pishchulin and '
+ 'Peter Gehler and Schiele, Bernt',
+ title='2D Human Pose Estimation: New Benchmark and '
+ 'State of the Art Analysis',
+ container='IEEE Conference on Computer Vision and '
+ 'Pattern Recognition (CVPR)',
+ year='2014',
+ homepage='http://human-pose.mpi-inf.mpg.de/',
+ ),
+ keypoint_info={
+ 0:
+ dict(
+ name='right_ankle',
+ id=0,
+ color=[255, 128, 0],
+ type='lower',
+ swap='left_ankle'),
+ ## ÕåģÕ«╣ń£üńĢź
+ },
+ skeleton_info={
+ 0:
+ dict(link=('right_ankle', 'right_knee'), id=0, color=[255, 128, 0]),
+ ## ÕåģÕ«╣ń£üńĢź
+ },
+ joint_weights=[
+ 1.5, 1.2, 1., 1., 1.2, 1.5, 1., 1., 1., 1., 1.5, 1.2, 1., 1., 1.2, 1.5
+ ],
+ # õĮ┐ńö© COCO µĢ░µŹ«ķøåõĖŁµÅÉõŠøńÜä sigmas ÕĆ╝
+ sigmas=[
+ 0.089, 0.083, 0.107, 0.107, 0.083, 0.089, 0.026, 0.026, 0.026, 0.026,
+ 0.062, 0.072, 0.179, 0.179, 0.072, 0.062
+ ])
+```
+
+Õ£©µ©ĪÕ×ŗķģŹńĮ«µ¢ćõ╗ČõĖŁ’╝īõĮĀķ£ĆĶ”üõĖ║Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåµīćÕ«ÜÕ»╣Õ║öńÜäÕģāõ┐Īµü»ķģŹńĮ«µ¢ćõ╗ČŃĆéÕüćÕ”éĶ»źÕģāõ┐Īµü»ķģŹńĮ«µ¢ćõ╗ČĶĘ»ÕŠäõĖ║ `$MMPOSE/configs/_base_/datasets/custom.py`’╝īµīćիܵ¢╣Õ╝ÅÕ”éõĖŗ’╝Ü
+
+```python
+# dataset and dataloader settings
+dataset_type = 'MyCustomDataset' # or 'CocoDataset'
+train_dataloader = dict(
+ batch_size=2,
+ dataset=dict(
+ type=dataset_type,
+ data_root='root/of/your/train/data',
+ ann_file='path/to/your/train/json',
+ data_prefix=dict(img='path/to/your/train/img'),
+ # µīćÕ«ÜÕ»╣Õ║öńÜäÕģāõ┐Īµü»ķģŹńĮ«µ¢ćõ╗Č
+ metainfo=dict(from_file='configs/_base_/datasets/custom.py'),
+ ...),
+ )
+val_dataloader = dict(
+ batch_size=2,
+ dataset=dict(
+ type=dataset_type,
+ data_root='root/of/your/val/data',
+ ann_file='path/to/your/val/json',
+ data_prefix=dict(img='path/to/your/val/img'),
+ # µīćÕ«ÜÕ»╣Õ║öńÜäÕģāõ┐Īµü»ķģŹńĮ«µ¢ćõ╗Č
+ metainfo=dict(from_file='configs/_base_/datasets/custom.py'),
+ ...),
+ )
+test_dataloader = val_dataloader
+```
+
+### µĢ░µŹ«ķøå
+
+Õ£© MMPose õĖŁõĮ┐ńö©Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåµŚČ’╝īµłæõ╗¼µÄ©ĶŹÉÕ░åµĢ░µŹ«ĶĮ¼Õī¢õĖ║ÕĘ▓µö»µīüńÜäµĀ╝Õ╝Å’╝łÕ”é COCO µł¢ MPII’╝ē’╝īÕ╣Čńø┤µÄźõĮ┐ńö©µłæõ╗¼µÅÉõŠøńÜäÕ»╣Õ║öµĢ░µŹ«ķøåÕ«×ńÄ░ŃĆéÕ”éµ×£Ķ┐Öń¦Źµ¢╣Õ╝ÅõĖŹÕÅ»ĶĪī’╝īÕłÖńö©µłĘķ£ĆĶ”üÕ«×ńÄ░Ķć¬ÕĘ▒ńÜäµĢ░µŹ«ķøåń▒╗ŃĆé
+
+MMPose õĖŁńÜäÕż¦ķā©Õłå 2D Õģ│ķö«ńé╣µĢ░µŹ«ķøå**õ╗ź COCO ÕĮóÕ╝Åń╗äń╗ć**’╝īõĖ║µŁżµłæõ╗¼µÅÉõŠøõ║åÕ¤║ń▒╗ [BaseCocoStyleDataset](/mmpose/datasets/datasets/base/base_coco_style_dataset.py)ŃĆ鵳æõ╗¼µÄ©ĶŹÉńö©µłĘń╗¦µē┐Ķ»źÕ¤║ń▒╗’╝īÕ╣ȵīēķ£ĆķćŹÕåÖÕ«āńÜäµ¢╣µ│Ģ’╝łķĆÜÕĖĖµś» `__init__()` ÕÆī `_load_annotations()` µ¢╣µ│Ģ’╝ē’╝īõ╗źµē®Õ▒ĢÕł░µ¢░ńÜä 2D Õģ│ķö«ńé╣µĢ░µŹ«ķøåŃĆé
+
+```{note}
+Õģ│õ║ÄCOCOµĢ░µŹ«µĀ╝Õ╝ÅńÜäĶ»”ń╗åĶ»┤µśÄĶ»ĘÕÅéĶĆā [COCO](./dataset_zoo/2d_body_keypoint.md) ŃĆé
+```
+
+```{note}
+Õ£© MMPose õĖŁ bbox ńÜäµĢ░µŹ«µĀ╝Õ╝Åķććńö© `xyxy`’╝īĶĆīõĖŹµś» `xywh`’╝īĶ┐ÖõĖÄ [MMDetection](https://github.com/open-mmlab/mmdetection) ńŁēÕģČõ╗¢ OpenMMLab µłÉÕæśõ┐صīüõĖĆĶć┤ŃĆéõĖ║õ║åÕ«×ńÄ░õĖŹÕÉī bbox µĀ╝Õ╝Åõ╣ŗķŚ┤ńÜäĶĮ¼µŹó’╝īµłæõ╗¼µÅÉõŠøõ║åõĖ░Õ»īńÜäÕćĮµĢ░’╝Ü`bbox_xyxy2xywh`ŃĆü`bbox_xywh2xyxy`ŃĆü`bbox_xyxy2cs`ńŁēŃĆéĶ┐Öõ║øÕćĮµĢ░Õ«Üõ╣ēÕ£©`$MMPOSE/mmpose/structures/bbox/transforms.py`ŃĆé
+```
+
+õĖŗķØóµłæõ╗¼õ╗źMPIIµĢ░µŹ«ķøåńÜäÕ«×ńÄ░’╝ł`$MMPOSE/mmpose/datasets/datasets/body/mpii_dataset.py`’╝ēõĖ║õŠŗ’╝Ü
+
+```Python
+@DATASETS.register_module()
+class MpiiDataset(BaseCocoStyleDataset):
+ METAINFO: dict = dict(from_file='configs/_base_/datasets/mpii.py')
+
+ def __init__(self,
+ ## ÕåģÕ«╣ń£üńĢź
+ headbox_file: Optional[str] = None,
+ ## ÕåģÕ«╣ń£üńĢź):
+
+ if headbox_file:
+ if data_mode != 'topdown':
+ raise ValueError(
+ f'{self.__class__.__name__} is set to {data_mode}: '
+ 'mode, while "headbox_file" is only '
+ 'supported in topdown mode.')
+
+ if not test_mode:
+ raise ValueError(
+ f'{self.__class__.__name__} has `test_mode==False` '
+ 'while "headbox_file" is only '
+ 'supported when `test_mode==True`.')
+
+ headbox_file_type = headbox_file[-3:]
+ allow_headbox_file_type = ['mat']
+ if headbox_file_type not in allow_headbox_file_type:
+ raise KeyError(
+ f'The head boxes file type {headbox_file_type} is not '
+ f'supported. Should be `mat` but got {headbox_file_type}.')
+ self.headbox_file = headbox_file
+
+ super().__init__(
+ ## ÕåģÕ«╣ń£üńĢź
+ )
+
+ def _load_annotations(self) -> List[dict]:
+ """Load data from annotations in MPII format."""
+ check_file_exist(self.ann_file)
+ with open(self.ann_file) as anno_file:
+ anns = json.load(anno_file)
+
+ if self.headbox_file:
+ check_file_exist(self.headbox_file)
+ headbox_dict = loadmat(self.headbox_file)
+ headboxes_src = np.transpose(headbox_dict['headboxes_src'],
+ [2, 0, 1])
+ SC_BIAS = 0.6
+
+ data_list = []
+ ann_id = 0
+
+ # mpii bbox scales are normalized with factor 200.
+ pixel_std = 200.
+
+ for idx, ann in enumerate(anns):
+ center = np.array(ann['center'], dtype=np.float32)
+ scale = np.array([ann['scale'], ann['scale']],
+ dtype=np.float32) * pixel_std
+
+ # Adjust center/scale slightly to avoid cropping limbs
+ if center[0] != -1:
+ center[1] = center[1] + 15. / pixel_std * scale[1]
+
+ # MPII uses matlab format, index is 1-based,
+ # we should first convert to 0-based index
+ center = center - 1
+
+ # unify shape with coco datasets
+ center = center.reshape(1, -1)
+ scale = scale.reshape(1, -1)
+ bbox = bbox_cs2xyxy(center, scale)
+
+ # load keypoints in shape [1, K, 2] and keypoints_visible in [1, K]
+ keypoints = np.array(ann['joints']).reshape(1, -1, 2)
+ keypoints_visible = np.array(ann['joints_vis']).reshape(1, -1)
+
+ data_info = {
+ 'id': ann_id,
+ 'img_id': int(ann['image'].split('.')[0]),
+ 'img_path': osp.join(self.data_prefix['img'], ann['image']),
+ 'bbox_center': center,
+ 'bbox_scale': scale,
+ 'bbox': bbox,
+ 'bbox_score': np.ones(1, dtype=np.float32),
+ 'keypoints': keypoints,
+ 'keypoints_visible': keypoints_visible,
+ }
+
+ if self.headbox_file:
+ # calculate the diagonal length of head box as norm_factor
+ headbox = headboxes_src[idx]
+ head_size = np.linalg.norm(headbox[1] - headbox[0], axis=0)
+ head_size *= SC_BIAS
+ data_info['head_size'] = head_size.reshape(1, -1)
+
+ data_list.append(data_info)
+ ann_id = ann_id + 1
+
+ return data_list
+```
+
+Õ£©Õ»╣MPIIµĢ░µŹ«ķøåĶ┐øĶĪīµö»µīüµŚČ’╝īńö▒õ║ÄMPIIķ£ĆĶ”üĶ»╗Õģź `head_size` õ┐Īµü»µØźĶ«Īń«Ś `PCKh`’╝īÕøĀµŁżµłæõ╗¼Õ£©`__init__()`õĖŁÕó×ÕŖĀõ║å `headbox_file`’╝īÕ╣ČķćŹĶĮĮõ║å `_load_annotations()` µØźÕ«īµłÉµĢ░µŹ«ń╗äń╗ćŃĆé
+
+Õ”éµ×£Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåµŚĀµ│ĢĶó½ `BaseCocoStyleDataset` µö»µīü’╝īõĮĀķ£ĆĶ”üńø┤µÄźń╗¦µē┐ [MMEngine](https://github.com/open-mmlab/mmengine) õĖŁµÅÉõŠøńÜä `BaseDataset` Õ¤║ń▒╗ŃĆéÕģĘõĮōµ¢╣µ│ĢĶ»ĘÕÅéĶĆāńøĖÕģ│[µ¢ćµĪŻ](https://mmengine.readthedocs.io/en/latest/advanced_tutorials/basedataset.html)ŃĆé
+
+### µĢ░µŹ«µĄüµ░┤ń║┐
+
+õĖĆõĖ¬ÕģĖÕ×ŗńÜäµĢ░µŹ«µĄüµ░┤ń║┐ķģŹńĮ«Õ”éõĖŗ’╝Ü
+
+```Python
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(type='RandomBBoxTransform'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+test_pipeline = [
+ dict(type='LoadImage'),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='PackPoseInputs')
+]
+```
+
+Õ£©Õģ│ķö«ńé╣µŻĆµĄŗõ╗╗ÕŖĪõĖŁ’╝īµĢ░µŹ«õĖĆĶł¼õ╝ÜÕ£©õĖēõĖ¬Õ░║Õ║”ń®║ķŚ┤õĖŁÕÅśµŹó’╝Ü
+
+- **ÕĤզŗÕøŠńēćń®║ķŚ┤**’╝ÜÕøŠńēćÕŁśÕ驵ŚČńÜäÕĤզŗń®║ķŚ┤’╝īõĖŹÕÉīÕøŠńēćńÜäÕ░║Õ»ĖõĖŹõĖĆÕ«ÜńøĖÕÉī
+
+- **ĶŠōÕģźÕøŠńēćń®║ķŚ┤**’╝ܵ©ĪÕ×ŗĶŠōÕģźńÜäÕøŠńēćÕ░║Õ║”ń®║ķŚ┤’╝īµēƵ£ē**ÕøŠńēć**ÕÆī**µĀćµ│©**Ķó½ń╝®µöŠÕł░ĶŠōÕģźÕ░║Õ║”’╝īÕ”é `256x256`’╝ī`256x192` ńŁē
+
+- **ĶŠōÕć║Õ░║Õ║”ń®║ķŚ┤**’╝ܵ©ĪÕ×ŗĶŠōÕć║ÕÆīĶ«Łń╗āńøæńØŻõ┐Īµü»µēĆÕ£©ńÜäÕ░║Õ║”ń®║ķŚ┤’╝īÕ”é`64x64(ńāŁÕŖøÕøŠ)`’╝ī`1x1(Õø×ÕĮÆÕØɵĀćÕĆ╝)`ńŁē
+
+µĢ░µŹ«Õ£©õĖēõĖ¬ń®║ķŚ┤õĖŁÕÅśµŹóńÜ䵥üń©ŗÕ”éÕøŠµēĆńż║’╝Ü
+
+
+
+Õ£©MMPoseõĖŁ’╝īµĢ░µŹ«ÕÅśµŹóµēĆķ£ĆĶ”üńÜ䵩ĪÕØŚÕ£©`$MMPOSE/mmpose/datasets/transforms`ńø«ÕĮĢõĖŗ’╝īÕ«āõ╗¼ńÜäÕĘźõĮ£µĄüń©ŗÕ”éÕøŠµēĆńż║’╝Ü
+
+
+
+#### i. µĢ░µŹ«Õó×Õ╝║
+
+µĢ░µŹ«Õó×Õ╝║õĖŁÕĖĖńö©ńÜäÕÅśµŹóÕŁśµöŠÕ£© `$MMPOSE/mmpose/datasets/transforms/common_transforms.py` õĖŁ’╝īÕ”é `RandomFlip`ŃĆü`RandomHalfBody` ńŁēŃĆé
+
+Õ»╣õ║Ä top-down µ¢╣µ│Ģ’╝ī`Shift`ŃĆü`Rotate`ŃĆü`Resize` µōŹõĮ£ńö▒ `RandomBBoxTransform`µØźÕ«×ńÄ░’╝øÕ»╣õ║Ä bottom-up µ¢╣µ│Ģ’╝īĶ┐Öõ║øÕłÖµś»ńö▒ `BottomupRandomAffine` Õ«×ńÄ░ŃĆé
+
+```{note}
+ÕĆ╝ÕŠŚµ│©µäÅńÜ䵜»’╝īÕż¦ķā©ÕłåµĢ░µŹ«ÕÅśµŹóķāĮõŠØĶĄ¢õ║Ä `bbox_center` ÕÆī `bbox_scale`’╝īÕ«āõ╗¼ÕÅ»õ╗źķĆÜĶ┐ć `GetBBoxCenterScale` µØźÕŠŚÕł░ŃĆé
+```
+
+#### ii. µĢ░µŹ«ÕÅśµŹó
+
+µłæõ╗¼õĮ┐ńö©õ╗┐Õ░äÕÅśµŹó’╝īÕ░åÕøŠÕāÅÕÆīÕØɵĀćµĀćµ│©õ╗ÄÕĤզŗÕøŠńēćń®║ķŚ┤ÕÅśµŹóÕł░ĶŠōÕģźÕøŠńēćń®║ķŚ┤ŃĆéĶ┐ÖõĖƵōŹõĮ£Õ£© top-down µ¢╣µ│ĢõĖŁńö▒ `TopdownAffine` Õ«īµłÉ’╝īÕ£© bottom-up µ¢╣µ│ĢõĖŁÕłÖńö▒ `BottomupRandomAffine` Õ«īµłÉŃĆé
+
+#### iii. µĢ░µŹ«ń╝¢ńĀü
+
+Õ£©µ©ĪÕ×ŗĶ«Łń╗āµŚČ’╝īµĢ░µŹ«õ╗ÄÕĤզŗń®║ķŚ┤ÕÅśµŹóÕł░ĶŠōÕģźÕøŠńēćń®║ķŚ┤ÕÉÄ’╝īķ£ĆĶ”üõĮ┐ńö© `GenerateTarget` µØźńö¤µłÉĶ«Łń╗āµēĆķ£ĆńÜäńøæńØŻńø«µĀć’╝łµ»öÕ”éńö©ÕØɵĀćÕĆ╝ńö¤µłÉķ½śµ¢»ńāŁÕøŠ’╝ē’╝īµłæõ╗¼Õ░åĶ┐ÖõĖĆĶ┐ćń©ŗń¦░õĖ║ń╝¢ńĀü’╝łEncode’╝ē’╝īÕÅŹõ╣ŗ’╝īķĆÜĶ┐ćķ½śµ¢»ńāŁÕøŠÕŠŚÕł░Õ»╣Õ║öÕØɵĀćÕĆ╝ńÜäĶ┐ćń©ŗń¦░õĖ║Ķ¦ŻńĀü’╝łDecode’╝ēŃĆé
+
+Õ£© MMPose õĖŁ’╝īµłæõ╗¼Õ░åń╝¢ńĀüÕÆīĶ¦ŻńĀüĶ┐ćń©ŗķøåÕÉłµłÉõĖĆõĖ¬ń╝¢Ķ¦ŻńĀüÕÖ©’╝łCodec’╝ē’╝īÕ£©ÕģČõĖŁÕ«×ńÄ░ `encode()` ÕÆī `decode()`ŃĆé
+
+ńø«ÕēŹ MMPose µö»µīüńö¤µłÉõ╗źõĖŗń▒╗Õ×ŗńÜäńøæńØŻńø«µĀć’╝Ü
+
+- `heatmap`: ķ½śµ¢»ńāŁÕøŠ
+
+- `keypoint_label`: Õģ│ķö«ńé╣µĀćńŁŠ’╝łÕ”éÕĮÆõĖĆÕī¢ńÜäÕØɵĀćÕĆ╝’╝ē
+
+- `keypoint_xy_label`: ÕŹĢõĖ¬ÕØɵĀćĶĮ┤Õģ│ķö«ńé╣µĀćńŁŠ
+
+- `heatmap+keypoint_label`: ÕÉīµŚČńö¤µłÉķ½śµ¢»ńāŁÕøŠÕÆīÕģ│ķö«ńé╣µĀćńŁŠ
+
+- `multiscale_heatmap`: ÕżÜÕ░║Õ║”ķ½śµ¢»ńāŁÕøŠ
+
+ńö¤µłÉńÜäńøæńØŻńø«µĀćõ╝ܵīēõ╗źõĖŗÕģ│ķö«ÕŁŚĶ┐øĶĪīÕ░üĶŻģ’╝Ü
+
+- `heatmaps`’╝Üķ½śµ¢»ńāŁÕøŠ
+
+- `keypoint_labels`’╝ÜÕģ│ķö«ńé╣µĀćńŁŠ’╝łÕ”éÕĮÆõĖĆÕī¢ńÜäÕØɵĀćÕĆ╝’╝ē
+
+- `keypoint_x_labels`’╝Üx ĶĮ┤Õģ│ķö«ńé╣µĀćńŁŠ
+
+- `keypoint_y_labels`’╝Üy ĶĮ┤Õģ│ķö«ńé╣µĀćńŁŠ
+
+- `keypoint_weights`’╝ÜÕģ│ķö«ńé╣µØāķćŹ
+
+```Python
+@TRANSFORMS.register_module()
+class GenerateTarget(BaseTransform):
+ """Encode keypoints into Target.
+
+ Added Keys (depends on the args):
+ - heatmaps
+ - keypoint_labels
+ - keypoint_x_labels
+ - keypoint_y_labels
+ - keypoint_weights
+ """
+```
+
+ÕĆ╝ÕŠŚµ│©µäÅńÜ䵜»’╝īµłæõ╗¼Õ»╣ top-down ÕÆī bottom-up ńÜäµĢ░µŹ«µĀ╝Õ╝ÅĶ┐øĶĪīõ║åń╗¤õĖĆ’╝īĶ┐ÖµäÅÕæ│ńØƵĀćµ│©õ┐Īµü»õĖŁõ╝ܵ¢░Õó×õĖĆõĖ¬ń╗┤Õ║”µØźõ╗ŻĶĪ©ÕÉīõĖĆÕ╝ĀÕøŠķćīńÜäõĖŹÕÉīńø«µĀć’╝łÕ”éõ║║’╝ē’╝īµĀ╝Õ╝ÅõĖ║’╝Ü
+
+```Python
+[batch_size, num_instances, num_keypoints, dim_coordinates]
+```
+
+- top-down’╝Ü`[B, 1, K, D]`
+
+- Bottom-up: `[B, N, K, D]`
+
+ÕĮōÕēŹÕĘ▓ń╗ŵö»µīüńÜäń╝¢Ķ¦ŻńĀüÕÖ©Õ«Üõ╣ēÕ£© `$MMPOSE/mmpose/codecs` ńø«ÕĮĢõĖŗ’╝īÕ”éµ×£õĮĀķ£ĆĶ”üĶć¬Õ«Üµ¢░ńÜäń╝¢Ķ¦ŻńĀüÕÖ©’╝īÕÅ»õ╗źÕēŹÕŠĆ[ń╝¢Ķ¦ŻńĀüÕÖ©](./user_guides/codecs.md)õ║åĶ¦Żµø┤ÕżÜĶ»”µāģŃĆé
+
+#### iv. µĢ░µŹ«µēōÕīģ
+
+µĢ░µŹ«ń╗ÅĶ┐ćÕēŹÕżäńÉåÕÅśµŹóÕÉÄ’╝īµ£Ćń╗łķ£ĆĶ”üķĆÜĶ┐ć `PackPoseInputs` µēōÕīģµłÉµĢ░µŹ«µĀʵ£¼ŃĆéĶ»źµōŹõĮ£Õ«Üõ╣ēÕ£© `$MMPOSE/mmpose/datasets/transforms/formatting.py` õĖŁŃĆé
+
+µēōÕīģĶ┐ćń©ŗõ╝ÜÕ░åµĢ░µŹ«µĄüµ░┤ń║┐õĖŁńö©ÕŁŚÕģĖ `results` ÕŁśÕé©ńÜäµĢ░µŹ«ĶĮ¼µŹóµłÉńö© MMPose µēĆķ£ĆńÜäµĀćÕćåµĢ░µŹ«ń╗ōµ×ä’╝ī Õ”é `InstanceData`’╝ī`PixelData`’╝ī`PoseDataSample` ńŁēŃĆé
+
+ÕģĘõĮōĶĆīĶ©Ć’╝īµłæõ╗¼Õ░åµĢ░µŹ«µĀʵ£¼ÕåģÕ«╣ÕłåõĖ║ `gt`’╝łµĀćµ│©ń£¤ÕĆ╝’╝ē ÕÆī `pred`’╝łµ©ĪÕ×ŗķó䵥ŗ’╝ēõĖżķā©Õłå’╝īÕ«āõ╗¼ķāĮÕīģÕɽõ╗źõĖŗµĢ░µŹ«ķĪ╣’╝Ü
+
+- **instances**(numpy.array)’╝ÜÕ«×õŠŗń║¦Õł½ńÜäÕĤզŗµĀćµ│©µł¢ķó䵥ŗń╗ōµ×£’╝īÕ▒×õ║ÄÕĤզŗÕ░║Õ║”ń®║ķŚ┤
+
+- **instance_labels**(torch.tensor)’╝ÜÕ«×õŠŗń║¦Õł½ńÜäĶ«Łń╗āµĀćńŁŠ’╝łÕ”éÕĮÆõĖĆÕī¢ńÜäÕØɵĀćÕĆ╝ŃĆüÕģ│ķö«ńé╣ÕÅ»Ķ¦üµĆ¦’╝ē’╝īÕ▒×õ║ÄĶŠōÕć║Õ░║Õ║”ń®║ķŚ┤
+
+- **fields**(torch.tensor)’╝ÜÕāÅń┤Āń║¦Õł½ńÜäĶ«Łń╗āµĀćńŁŠ’╝łÕ”éķ½śµ¢»ńāŁÕøŠ’╝ēµł¢ķó䵥ŗń╗ōµ×£’╝īÕ▒×õ║ÄĶŠōÕć║Õ░║Õ║”ń®║ķŚ┤
+
+õĖŗķØ󵜻 `PoseDataSample` Õ║ĢÕ▒éÕ«×ńÄ░ńÜäõŠŗÕŁÉ’╝Ü
+
+```Python
+def get_pose_data_sample(self):
+ # meta
+ pose_meta = dict(
+ img_shape=(600, 900), # [h, w, c]
+ crop_size=(256, 192), # [h, w]
+ heatmap_size=(64, 48), # [h, w]
+ )
+
+ # gt_instances
+ gt_instances = InstanceData()
+ gt_instances.bboxes = np.random.rand(1, 4)
+ gt_instances.keypoints = np.random.rand(1, 17, 2)
+
+ # gt_instance_labels
+ gt_instance_labels = InstanceData()
+ gt_instance_labels.keypoint_labels = torch.rand(1, 17, 2)
+ gt_instance_labels.keypoint_weights = torch.rand(1, 17)
+
+ # pred_instances
+ pred_instances = InstanceData()
+ pred_instances.keypoints = np.random.rand(1, 17, 2)
+ pred_instances.keypoint_scores = np.random.rand(1, 17)
+
+ # gt_fields
+ gt_fields = PixelData()
+ gt_fields.heatmaps = torch.rand(17, 64, 48)
+
+ # pred_fields
+ pred_fields = PixelData()
+ pred_fields.heatmaps = torch.rand(17, 64, 48)
+ data_sample = PoseDataSample(
+ gt_instances=gt_instances,
+ pred_instances=pred_instances,
+ gt_fields=gt_fields,
+ pred_fields=pred_fields,
+ metainfo=pose_meta)
+
+ return data_sample
+```
+
+## Step3: µ©ĪÕ×ŗ
+
+Õ£© MMPose 1.0õĖŁ’╝īµ©ĪÕ×ŗńö▒õ╗źõĖŗÕćĀķā©Õłåµ×䵳ɒ╝Ü
+
+- **ķóäÕżäńÉåÕÖ©’╝łDataPreprocessor’╝ē**’╝ÜÕ«īµłÉÕøŠÕāÅÕĮÆõĖĆÕī¢ÕÆīķĆÜķüōĶĮ¼µŹóńŁēÕēŹÕżäńÉå
+
+- **õĖ╗Õ╣▓ńĮæń╗£ ’╝łBackbone’╝ē**’╝Üńö©õ║Äńē╣ÕŠüµÅÉÕÅ¢
+
+- **ķółķā©µ©ĪÕØŚ’╝łNeck’╝ē**’╝ÜGAP’╝īFPN ńŁēÕÅ»ķĆēķĪ╣
+
+- **ķó䵥ŗÕż┤’╝łHead’╝ē**’╝Üńö©õ║ÄÕ«×ńÄ░µĀĖÕ┐āń«Śµ│ĢÕŖ¤ĶāĮÕÆīµŹ¤Õż▒ÕćĮµĢ░Õ«Üõ╣ē
+
+µłæõ╗¼Õ£© `$MMPOSE/models/pose_estimators/base.py` õĖŗõĖ║Õ¦┐µĆüõ╝░Ķ«Īµ©ĪÕ×ŗÕ«Üõ╣ēõ║åõĖĆõĖ¬Õ¤║ń▒╗ `BasePoseEstimator`’╝īµēƵ£ēńÜ䵩ĪÕ×ŗ’╝łÕ”é `TopdownPoseEstimator`’╝ēķāĮķ£ĆĶ”üń╗¦µē┐Ķ┐ÖõĖ¬Õ¤║ń▒╗’╝īÕ╣ČķćŹĶĮĮÕ»╣Õ║öńÜäµ¢╣µ│ĢŃĆé
+
+Õ£©µ©ĪÕ×ŗńÜä `forward()` µ¢╣µ│ĢõĖŁµÅÉõŠøõ║åõĖēń¦ŹõĖŹÕÉīńÜ䵩ĪÕ╝Å’╝Ü
+
+- `mode == 'loss'`’╝ÜĶ┐öÕø×µŹ¤Õż▒ÕćĮµĢ░Ķ«Īń«ŚńÜäń╗ōµ×£’╝īńö©õ║ĵ©ĪÕ×ŗĶ«Łń╗ā
+
+- `mode == 'predict'`’╝ÜĶ┐öÕø×ĶŠōÕģźÕ░║Õ║”õĖŗńÜäķó䵥ŗń╗ōµ×£’╝īńö©õ║ĵ©ĪÕ×ŗµÄ©ńÉå
+
+- `mode == 'tensor'`’╝ÜĶ┐öÕø×ĶŠōÕć║Õ░║Õ║”õĖŗńÜ䵩ĪÕ×ŗĶŠōÕć║’╝īÕŹ│ÕŬĶ┐øĶĪīµ©ĪÕ×ŗÕēŹÕÉæõ╝ĀµÆŁ’╝īńö©õ║ĵ©ĪÕ×ŗÕ»╝Õć║
+
+Õ╝ĆÕÅæĶĆģķ£ĆĶ”üÕ£© `PoseEstimator` õĖŁµīēńģ¦µ©ĪÕ×ŗń╗ōµ×äĶ░āńö©Õ»╣Õ║öńÜä `Registry` ’╝īÕ»╣µ©ĪÕØŚĶ┐øĶĪīÕ«×õŠŗÕī¢ŃĆéõ╗ź top-down µ©ĪÕ×ŗõĖ║õŠŗ’╝Ü
+
+```Python
+@MODELS.register_module()
+class TopdownPoseEstimator(BasePoseEstimator):
+ def __init__(self,
+ backbone: ConfigType,
+ neck: OptConfigType = None,
+ head: OptConfigType = None,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None):
+ super().__init__(data_preprocessor, init_cfg)
+
+ self.backbone = MODELS.build(backbone)
+
+ if neck is not None:
+ self.neck = MODELS.build(neck)
+
+ if head is not None:
+ self.head = MODELS.build(head)
+```
+
+### ÕēŹÕżäńÉåÕÖ©’╝łDataPreprocessor’╝ē
+
+õ╗Ä MMPose 1.0 Õ╝ĆÕ¦ŗ’╝īµłæõ╗¼Õ£©µ©ĪÕ×ŗõĖŁµĘ╗ÕŖĀõ║åµ¢░ńÜäÕēŹÕżäńÉåÕÖ©µ©ĪÕØŚ’╝īńö©õ╗źÕ«īµłÉÕøŠÕāÅÕĮÆõĖĆÕī¢ŃĆüķĆÜķüōķĪ║Õ║ÅÕÅśµŹóńŁēµōŹõĮ£ŃĆéĶ┐ÖµĀĘÕüÜńÜäÕźĮÕżäµś»ÕÅ»õ╗źÕł®ńö© GPU ńŁēĶ«ŠÕżćńÜäĶ«Īń«ŚĶāĮÕŖøÕŖĀÕ┐½Ķ«Īń«Ś’╝īÕ╣ČõĮ┐µ©ĪÕ×ŗÕ£©Õ»╝Õć║ÕÆīķā©ńĮ▓µŚČµø┤ÕģĘÕ«īµĢ┤µĆ¦ŃĆé
+
+Õ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁ’╝īõĖĆõĖ¬ÕĖĖĶ¦üńÜä `data_preprocessor` Õ”éõĖŗ’╝Ü
+
+```Python
+data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+```
+
+Õ«āõ╝ÜÕ░åĶŠōÕģźÕøŠńēćńÜäķĆÜķüōķĪ║Õ║Åõ╗Ä `bgr` ĶĮ¼µŹóõĖ║ `rgb`’╝īÕ╣ȵĀ╣µŹ« `mean` ÕÆī `std` Ķ┐øĶĪīµĢ░µŹ«ÕĮÆõĖĆÕī¢ŃĆé
+
+### õĖ╗Õ╣▓ńĮæń╗£’╝łBackbone’╝ē
+
+MMPose Õ«×ńÄ░ńÜäõĖ╗Õ╣▓ńĮæń╗£ÕŁśµöŠÕ£© `$MMPOSE/mmpose/models/backbones` ńø«ÕĮĢõĖŗŃĆé
+
+Õ£©Õ«×ķÖģÕ╝ĆÕÅæõĖŁ’╝īÕ╝ĆÕÅæĶĆģń╗ÅÕĖĖõ╝ÜõĮ┐ńö©ķóäĶ«Łń╗āńÜäńĮæń╗£µØāķćŹĶ┐øĶĪīĶ┐üń¦╗ÕŁ”õ╣Ā’╝īĶ┐ÖĶāĮµ£ēµĢłµÅÉÕŹćµ©ĪÕ×ŗÕ£©Õ░ŵĢ░µŹ«ķøåõĖŖńÜäµĆ¦ĶāĮŃĆé Õ£© MMPose õĖŁ’╝īÕŬķ£ĆĶ”üÕ£©ķģŹńĮ«µ¢ćõ╗Č `backbone` ńÜä `init_cfg` õĖŁĶ«ŠńĮ«’╝Ü
+
+```Python
+init_cfg=dict(
+ type='Pretrained',
+ checkpoint='PATH/TO/YOUR_MODEL_WEIGHTS.pth'),
+```
+
+Õ”éµ×£õĮĀµā│ÕŬÕŖĀĶĮĮõĖĆõĖ¬Ķ«Łń╗āÕźĮńÜä checkpoint ńÜä backbone ķā©Õłå’╝īõĮĀķ£ĆĶ”üµī浜ÄõĖĆõĖŗÕēŹń╝Ć `prefix`:
+
+```Python
+init_cfg=dict(
+ type='Pretrained',
+ prefix='backbone.',
+ checkpoint='PATH/TO/YOUR_CHECKPOINT.pth'),
+```
+
+ÕģČõĖŁ `checkpoint` µŚóÕÅ»õ╗źµś»µ£¼Õ£░ĶĘ»ÕŠä’╝īõ╣¤ÕÅ»õ╗źµś»õĖŗĶĮĮķōŠµÄźŃĆéÕøĀµŁż’╝īÕ”éµ×£õĮĀµā│õĮ┐ńö© Torchvision µÅÉõŠøńÜäķóäĶ«Łń╗āµ©ĪÕ×ŗ’╝łµ»öÕ”éResNet50’╝ē’╝īÕÅ»õ╗źõĮ┐ńö©’╝Ü
+
+```Python
+init_cfg=dict(
+ type='Pretrained',
+ checkpoint='torchvision://resnet50')
+```
+
+ķÖżõ║åĶ┐Öõ║øÕĖĖńö©ńÜäõĖ╗Õ╣▓ńĮæń╗£õ╗źÕż¢’╝īõĮĀĶ┐śÕÅ»õ╗źõ╗Ä MMClassification ńŁēÕģČõ╗¢ OpenMMLab ķĪ╣ńø«õĖŁµ¢╣õŠ┐Õ£░Ķ┐üń¦╗õĖ╗Õ╣▓ńĮæń╗£’╝īÕ«āõ╗¼ķāĮķüĄÕŠ¬ÕÉīõĖĆÕźŚķģŹńĮ«µ¢ćõ╗ȵĀ╝Õ╝Å’╝īÕ╣ȵÅÉõŠøõ║åķóäĶ«Łń╗āµØāķćŹÕÅ»õŠøõĮ┐ńö©ŃĆé
+
+ķ£ĆĶ”üÕ╝║Ķ░āńÜ䵜»’╝īÕ”éµ×£õĮĀÕŖĀÕģźõ║åµ¢░ńÜäõĖ╗Õ╣▓ńĮæń╗£’╝īķ£ĆĶ”üÕ£©µ©ĪÕ×ŗÕ«Üõ╣ēµŚČĶ┐øĶĪīµ│©Õåī’╝Ü
+
+```Python
+@MODELS.register_module()
+class YourBackbone(BaseBackbone):
+```
+
+ÕÉīµŚČÕ£© `$MMPOSE/mmpose/models/backbones/__init__.py` õĖŗĶ┐øĶĪī `import`’╝īÕ╣ČÕŖĀÕģźÕł░ `__all__` õĖŁ’╝īµēŹĶāĮĶó½ķģŹńĮ«µ¢ćõ╗ȵŁŻńĪ«Õ£░Ķ░āńö©ŃĆé
+
+### ķółķā©µ©ĪÕØŚ’╝łNeck’╝ē
+
+ķółķā©µ©ĪÕØŚķĆÜÕĖĖµś»õ╗ŗõ║ÄõĖ╗Õ╣▓ńĮæń╗£ÕÆīķó䵥ŗÕż┤õ╣ŗķŚ┤ńÜ䵩ĪÕØŚ’╝īÕ£©ķā©Õłåµ©ĪÕ×ŗń«Śµ│ĢõĖŁõ╝Üńö©Õł░’╝īÕĖĖĶ¦üńÜäķółķā©µ©ĪÕØŚµ£ē’╝Ü
+
+- Global Average Pooling (GAP)
+
+- Feature Pyramid Networks (FPN)
+
+- Feature Map Processor (FMP)
+
+ `FeatureMapProcessor` µś»õĖĆõĖ¬ķĆÜńö©ńÜä PyTorch µ©ĪÕØŚ’╝īµŚ©Õ£©ķĆÜĶ┐ćķĆēµŗ®ŃĆüµŗ╝µÄźÕÆīń╝®µöŠńŁēķØ×ÕÅéµĢ░ÕÅśµŹóÕ░åõĖ╗Õ╣▓ńĮæń╗£ĶŠōÕć║ńÜäńē╣ÕŠüÕøŠĶĮ¼µŹóµłÉķĆéÕÉłķó䵥ŗÕż┤ńÜäµĀ╝Õ╝ÅŃĆéõ╗źõĖŗµś»õĖĆõ║øµōŹõĮ£ńÜäķģŹńĮ«µ¢╣Õ╝ÅÕÅŖµĢłµ×£ńż║µäÅÕøŠ:
+
+ - ķĆēµŗ®µōŹõĮ£
+
+ ```python
+ neck=dict(type='FeatureMapProcessor', select_index=0)
+ ```
+
+ Label Studio
+ +```bibtex +@misc{Label Studio, + title={{Label Studio}: Data labeling software}, + url={https://github.com/heartexlabs/label-studio}, + note={Open source software available from https://github.com/heartexlabs/label-studio}, + author={ + Maxim Tkachenko and + Mikhail Malyuk and + Andrey Holmanyuk and + Nikolai Liubimov}, + year={2020-2022}, +} +``` + ++ + - µŗ╝µÄźµōŹõĮ£ + + ```python + neck=dict(type='FeatureMapProcessor', concat=True) + ``` + +
+ + µŗ╝µÄźõ╣ŗÕēŹ’╝īÕģČÕ«āńē╣ÕŠüÕøŠõ╝ÜĶó½ń╝®µöŠÕł░ÕÆīÕ║ÅÕÅĘõĖ║ 0 ńÜäńē╣ÕŠüÕøŠńøĖÕÉīńÜäÕ░║Õ»ĖŃĆé + + - ń╝®µöŠµōŹõĮ£ + + ```python + neck=dict(type='FeatureMapProcessor', scale_factor=2.0) + ``` + +
+ +### ķó䵥ŗÕż┤’╝łHead’╝ē + +ķĆÜÕĖĖµØźĶ»┤’╝īķó䵥ŗÕż┤µś»µ©ĪÕ×ŗń«Śµ│ĢÕ«×ńÄ░ńÜäµĀĖÕ┐ā’╝īńö©õ║ÄµÄ¦ÕłČµ©ĪÕ×ŗńÜäĶŠōÕć║’╝īÕ╣ČĶ┐øĶĪīµŹ¤Õż▒ÕćĮµĢ░Ķ«Īń«ŚŃĆé + +MMPose õĖŁ Head ńøĖÕģ│ńÜ䵩ĪÕØŚÕ«Üõ╣ēÕ£© `$MMPOSE/mmpose/models/heads` ńø«ÕĮĢõĖŗ’╝īÕ╝ĆÕÅæĶĆģÕ£©Ķć¬Õ«Üõ╣ēķó䵥ŗÕż┤µŚČķ£ĆĶ”üń╗¦µē┐µłæõ╗¼µÅÉõŠøńÜäÕ¤║ń▒╗ `BaseHead`’╝īÕ╣ČķćŹĶĮĮõ╗źõĖŗõĖēõĖ¬µ¢╣µ│ĢÕ»╣Õ║öµ©ĪÕ×ŗµÄ©ńÉåńÜäõĖēń¦Źµ©ĪÕ╝Å’╝Ü + +- forward() + +- predict() + +- loss() + +ÕģĘõĮōĶĆīĶ©Ć’╝ī`predict()` Ķ┐öÕø×ńÜäÕ║öµś»ĶŠōÕģźÕøŠńēćÕ░║Õ║”õĖŗńÜäń╗ōµ×£’╝īÕøĀµŁżķ£ĆĶ”üĶ░āńö© `self.decode()` Õ»╣ńĮæń╗£ĶŠōÕć║Ķ┐øĶĪīĶ¦ŻńĀü’╝īĶ┐ÖõĖĆĶ┐ćń©ŗÕ«×ńÄ░Õ£© `BaseHead` õĖŁÕĘ▓ń╗ÅÕ«×ńÄ░’╝īÕ«āõ╝ÜĶ░āńö©ń╝¢Ķ¦ŻńĀüÕÖ©µÅÉõŠøńÜä `decode()` µ¢╣µ│ĢµØźÕ«īµłÉĶ¦ŻńĀüŃĆé + +ÕÅ”õĖƵ¢╣ķØó’╝īµłæõ╗¼õ╝ÜÕ£© `predict()` õĖŁĶ┐øĶĪīµĄŗĶ»ĢµŚČÕó×Õ╝║ŃĆéÕ£©Ķ┐øĶĪīķó䵥ŗµŚČ’╝īõĖĆõĖ¬ÕĖĖĶ¦üńÜ䵥ŗĶ»ĢµŚČÕó×Õ╝║µŖĆÕʦµś»Ķ┐øĶĪīń┐╗ĶĮ¼ķøåµłÉŃĆéÕŹ│’╝īÕ░åõĖĆÕ╝ĀÕøŠńēćÕģłĶ┐øĶĪīõĖƵ¼ĪµÄ©ńÉå’╝īÕåŹÕ░åÕøŠńēćµ░┤Õ╣│ń┐╗ĶĮ¼Ķ┐øĶĪīõĖƵ¼ĪµÄ©ńÉå’╝īµÄ©ńÉåńÜäń╗ōµ×£ÕåŹµ¼Īµ░┤Õ╣│ń┐╗ĶĮ¼Õø×ÕÄ╗’╝īÕ»╣õĖżµ¼ĪµÄ©ńÉåńÜäń╗ōµ×£Ķ┐øĶĪīÕ╣│ÕØćŃĆéĶ┐ÖõĖ¬µŖĆÕʦĶāĮµ£ēµĢłµÅÉÕŹćµ©ĪÕ×ŗńÜäķó䵥ŗń©│Õ«ÜµĆ¦ŃĆé + +õĖŗķØóµś»Õ£© `RegressionHead` õĖŁÕ«Üõ╣ē `predict()` ńÜäõŠŗÕŁÉ’╝Ü + +```Python +def predict(self, + feats: Tuple[Tensor], + batch_data_samples: OptSampleList, + test_cfg: ConfigType = {}) -> Predictions: + """Predict results from outputs.""" + + if test_cfg.get('flip_test', False): + # TTA: flip test -> feats = [orig, flipped] + assert isinstance(feats, list) and len(feats) == 2 + flip_indices = batch_data_samples[0].metainfo['flip_indices'] + input_size = batch_data_samples[0].metainfo['input_size'] + _feats, _feats_flip = feats + _batch_coords = self.forward(_feats) + _batch_coords_flip = flip_coordinates( + self.forward(_feats_flip), + flip_indices=flip_indices, + shift_coords=test_cfg.get('shift_coords', True), + input_size=input_size) + batch_coords = (_batch_coords + _batch_coords_flip) * 0.5 + else: + batch_coords = self.forward(feats) # (B, K, D) + + batch_coords.unsqueeze_(dim=1) # (B, N, K, D) + preds = self.decode(batch_coords) +``` + +`loss()`ķÖżõ║åĶ┐øĶĪīµŹ¤Õż▒ÕćĮµĢ░ńÜäĶ«Īń«Ś’╝īĶ┐śõ╝ÜĶ┐øĶĪī accuracy ńŁēĶ«Łń╗āµŚČµīćµĀćńÜäĶ«Īń«Ś’╝īÕ╣ČķĆÜĶ┐ćõĖĆõĖ¬ÕŁŚÕģĖ `losses` µØźõ╝ĀķĆÆ: + +```Python + # calculate accuracy +_, avg_acc, _ = keypoint_pck_accuracy( + pred=to_numpy(pred_coords), + gt=to_numpy(keypoint_labels), + mask=to_numpy(keypoint_weights) > 0, + thr=0.05, + norm_factor=np.ones((pred_coords.size(0), 2), dtype=np.float32)) + +acc_pose = torch.tensor(avg_acc, device=keypoint_labels.device) +losses.update(acc_pose=acc_pose) +``` + +µ»ÅõĖ¬ batch ńÜäµĢ░µŹ«ķāĮµēōÕīģµłÉõ║å `batch_data_samples`ŃĆéõ╗ź Regression-based µ¢╣µ│ĢõĖ║õŠŗ’╝īĶ«Łń╗āµēĆķ£ĆńÜäÕĮÆõĖĆÕī¢ńÜäÕØɵĀćÕĆ╝ÕÆīÕģ│ķö«ńé╣µØāķćŹÕÅ»õ╗źńö©Õ”éõĖŗµ¢╣Õ╝ÅĶÄĘÕÅ¢’╝Ü + +```Python +keypoint_labels = torch.cat( + [d.gt_instance_labels.keypoint_labels for d in batch_data_samples]) +keypoint_weights = torch.cat([ + d.gt_instance_labels.keypoint_weights for d in batch_data_samples +]) +``` + +õ╗źõĖŗõĖ║ `RegressionHead` õĖŁÕ«īµĢ┤ńÜä `loss()` Õ«×ńÄ░’╝Ü + +```Python +def loss(self, + inputs: Tuple[Tensor], + batch_data_samples: OptSampleList, + train_cfg: ConfigType = {}) -> dict: + """Calculate losses from a batch of inputs and data samples.""" + + pred_outputs = self.forward(inputs) + + keypoint_labels = torch.cat( + [d.gt_instance_labels.keypoint_labels for d in batch_data_samples]) + keypoint_weights = torch.cat([ + d.gt_instance_labels.keypoint_weights for d in batch_data_samples + ]) + + # calculate losses + losses = dict() + loss = self.loss_module(pred_outputs, keypoint_labels, + keypoint_weights.unsqueeze(-1)) + + if isinstance(loss, dict): + losses.update(loss) + else: + losses.update(loss_kpt=loss) + + # calculate accuracy + _, avg_acc, _ = keypoint_pck_accuracy( + pred=to_numpy(pred_outputs), + gt=to_numpy(keypoint_labels), + mask=to_numpy(keypoint_weights) > 0, + thr=0.05, + norm_factor=np.ones((pred_outputs.size(0), 2), dtype=np.float32)) + acc_pose = torch.tensor(avg_acc, device=keypoint_labels.device) + losses.update(acc_pose=acc_pose) + + return losses +``` diff --git a/internlm_langchain/knowledge_base/MMPose/content/how_to_deploy.md b/internlm_langchain/knowledge_base/MMPose/content/how_to_deploy.md new file mode 100644 index 00000000..b4fead87 --- /dev/null +++ b/internlm_langchain/knowledge_base/MMPose/content/how_to_deploy.md @@ -0,0 +1,3 @@ +# How to Deploy MMPose Models + +Coming soon. diff --git a/internlm_langchain/knowledge_base/MMPose/content/implement_new_models.md b/internlm_langchain/knowledge_base/MMPose/content/implement_new_models.md new file mode 100644 index 00000000..4a10b0c3 --- /dev/null +++ b/internlm_langchain/knowledge_base/MMPose/content/implement_new_models.md @@ -0,0 +1,3 @@ +# Implement New Models + +Coming soon. diff --git a/internlm_langchain/knowledge_base/MMPose/content/inference.md b/internlm_langchain/knowledge_base/MMPose/content/inference.md new file mode 100644 index 00000000..0844bc61 --- /dev/null +++ b/internlm_langchain/knowledge_base/MMPose/content/inference.md @@ -0,0 +1,267 @@ +# õĮ┐ńö©ńÄ░µ£ēµ©ĪÕ×ŗĶ┐øĶĪīµÄ©ńÉå + +MMPoseõĖ║Õ¦┐µĆüõ╝░Ķ«ĪµÅÉõŠøõ║åÕż¦ķćÅÕÅ»õ╗źõ╗Ä[µ©ĪÕ×ŗÕ║ō](https://mmpose.readthedocs.io/en/latest/model_zoo.html)õĖŁµēŠÕł░ńÜäķó䵥ŗĶ«Łń╗āµ©ĪÕ×ŗŃĆéµ£¼µīćÕŹŚÕ░åµ╝öńż║**Õ”éõĮĢµē¦ĶĪīµÄ©ńÉå**’╝īµł¢õĮ┐ńö©Ķ«Łń╗āĶ┐ćńÜ䵩ĪÕ×ŗÕ»╣µÅÉõŠøńÜäÕøŠÕāŵł¢Ķ¦åķóæĶ┐ÉĶĪīÕ¦┐µĆüõ╝░Ķ«ĪŃĆé + +µ£ēÕģ│Õ£©µĀćÕćåµĢ░µŹ«ķøåõĖŖµĄŗĶ»ĢńÄ░µ£ēµ©ĪÕ×ŗńÜäĶ»┤µśÄ’╝īĶ»ĘÕÅéķśģµ£¼µīćÕŹŚŃĆé + +Õ£©MMPose’╝īµ©ĪÕ×ŗńö▒ķģŹńĮ«µ¢ćõ╗ČÕ«Üõ╣ē’╝īĶĆīÕģČÕĘ▓Ķ«Īń«ŚÕźĮńÜäÕÅéµĢ░ÕŁśÕé©Õ£©µØāķ揵¢ćõ╗Č’╝łcheckpoint file’╝ēõĖŁŃĆéµé©ÕÅ»õ╗źÕ£©[µ©ĪÕ×ŗÕ║ō](https://mmpose.readthedocs.io/en/latest/model_zoo.html)õĖŁµēŠÕł░µ©ĪÕ×ŗķģŹńĮ«µ¢ćõ╗ČÕÆīńøĖÕ║öńÜäµØāķ揵¢ćõ╗ČńÜäURLŃĆ鵳æõ╗¼Õ╗║Ķ««õ╗ÄõĮ┐ńö©HRNetµ©ĪÕ×ŗńÜä[ķģŹńĮ«µ¢ćõ╗Č](https://github.com/open-mmlab/mmpose/blob/main/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192.py)ÕÆī[µØāķ揵¢ćõ╗Č](https://download.openmmlab.com/mmpose/v1/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192-81c58e40_20220909.pth)Õ╝ĆÕ¦ŗŃĆé + +## µÄ©ńÉåÕÖ©’╝Üń╗¤õĖĆńÜäµÄ©ńÉåµÄźÕÅŻ + +MMPoseµÅÉõŠøõ║åõĖĆõĖ¬Ķó½ń¦░õĖ║`MMPoseInferencer`ńÜäŃĆüÕģ©ķØóńÜäµÄ©ńÉåAPIŃĆéĶ┐ÖõĖ¬APIõĮ┐ÕŠŚńö©µłĘÕŠŚõ╗źõĮ┐ńö©µēƵ£ēMMPoseµö»µīüńÜ䵩ĪÕ×ŗµØźÕ»╣ÕøŠÕāÅÕÆīĶ¦åķóæĶ┐øĶĪīµ©ĪÕ×ŗµÄ©ńÉåŃĆ鵣żÕż¢’╝īĶ»źAPIÕÅ»õ╗źÕ«īµłÉµÄ©ńÉåń╗ōµ×£Ķć¬ÕŖ©Õī¢’╝īÕ╣ȵ¢╣õŠ┐ńö©µłĘõ┐ØÕŁśķó䵥ŗń╗ōµ×£ŃĆé + +### Õ¤║µ£¼ńö©µ│Ģ + +`MMPoseInferencer`ÕÅ»õ╗źÕ£©õ╗╗õĮĢPythonń©ŗÕ║ÅõĖŁĶó½ńö©µØźµē¦ĶĪīÕ¦┐µĆüõ╝░Ķ«Īõ╗╗ÕŖĪŃĆéõ╗źõĖŗµś»Õ£©õĖĆõĖ¬Õ£©Python ShellõĖŁõĮ┐ńö©ķóäĶ«Łń╗āńÜäõ║║õĮōÕ¦┐µĆüµ©ĪÕ×ŗÕ»╣ń╗ÖÕ«ÜÕøŠÕāÅĶ┐øĶĪīµÄ©ńÉåńÜäńż║õŠŗŃĆé + +```python +from mmpose.apis import MMPoseInferencer + +img_path = 'tests/data/coco/000000000785.jpg' # Õ░åimg_pathµø┐µŹóń╗ÖõĮĀĶć¬ÕĘ▒ńÜäĶĘ»ÕŠä + +# õĮ┐ńö©µ©ĪÕ×ŗÕł½ÕÉŹÕłøÕ╗║µÄ©µ¢ŁÕÖ© +inferencer = MMPoseInferencer('human') + +# MMPoseInferencerķććńö©õ║åµā░µĆ¦µÄ©µ¢Łµ¢╣µ│Ģ’╝īÕ£©ń╗ÖÕ«ÜĶŠōÕģźµŚČÕłøÕ╗║õĖĆõĖ¬ķó䵥ŗńö¤µłÉÕÖ© +result_generator = inferencer(img_path, show=True) +result = next(result_generator) +``` + +Õ”éµ×£õĖĆÕłćµŁŻÕĖĖ’╝īõĮĀÕ░åÕ£©õĖĆõĖ¬µ¢░ń¬ŚÕÅŻõĖŁń£ŗÕł░õĖŗÕøŠ’╝Ü + + + +`result` ÕÅśķćŵś»õĖĆõĖ¬ÕīģÕɽõĖżõĖ¬ķö«ÕĆ╝ `'visualization'` ÕÆī `'predictions'` ńÜäÕŁŚÕģĖŃĆé + +- `'visualization'` ķö«Õ»╣Õ║öńÜäÕĆ╝µś»õĖĆõĖ¬ÕłŚĶĪ©’╝īĶ»źÕłŚĶĪ©’╝Ü + - ÕīģÕɽÕÅ»Ķ¦åÕī¢ń╗ōµ×£’╝īõŠŗÕ”éĶŠōÕģźÕøŠÕāÅŃĆüõ╝░Ķ«ĪÕ¦┐µĆüńÜäµĀćĶ«░’╝īõ╗źÕÅŖÕÅ»ķĆēńÜäķó䵥ŗńāŁÕøŠŃĆé + - Õ”éµ×£µ▓Īµ£ēµīćÕ«Ü `return_vis` ÕÅéµĢ░’╝īĶ»źÕłŚĶĪ©Õ░åõ┐صīüõĖ║ń®║ŃĆé +- `'predictions'` ķö«Õ»╣Õ║öńÜäÕĆ╝µś»’╝Ü + - õĖĆõĖ¬ÕīģÕɽµ»ÅõĖ¬µŻĆµĄŗÕ«×õŠŗńÜäķóäõ╝░Õģ│ķö«ńé╣ńÜäÕłŚĶĪ©ŃĆé + +`result` ÕŁŚÕģĖńÜäń╗ōµ×äÕ”éõĖŗµēĆńż║’╝Ü + +```python +result = { + 'visualization': [ + # Õģāń┤ĀµĢ░ķćÅ’╝Übatch_size’╝łķ╗śĶ«żõĖ║1’╝ē + vis_image_1, + ... + ], + 'predictions': [ + # µ»ÅÕ╝ĀÕøŠÕāÅńÜäÕ¦┐µĆüõ╝░Ķ«Īń╗ōµ×£ + # Õģāń┤ĀµĢ░ķćÅ’╝Übatch_size’╝łķ╗śĶ«żõĖ║1’╝ē + [ + # µ»ÅõĖ¬µŻĆµĄŗÕł░ńÜäÕ«×õŠŗńÜäÕ¦┐µĆüõ┐Īµü» + # Õģāń┤ĀµĢ░ķćÅ’╝ܵŻĆµĄŗÕł░ńÜäÕ«×õŠŗµĢ░ + {'keypoints': ..., # Õ«×õŠŗ 1 + 'keypoint_scores': ..., + ... + }, + {'keypoints': ..., # Õ«×õŠŗ 2 + 'keypoint_scores': ..., + ... + }, + ] + ... + ] +} +``` + +Ķ┐śÕÅ»õ╗źõĮ┐ńö©ńö©õ║Äńö©õ║ĵĩµ¢ŁńÜä**ÕæĮõ╗żĶĪīńĢīķØóÕĘźÕģĘ**’╝łCLI, command-line interface’╝ē: `demo/inferencer_demo.py`ŃĆéĶ┐ÖõĖ¬ÕĘźÕģĘÕģüĶ«Ėńö©µłĘõĮ┐ńö©õ╗źõĖŗÕæĮõ╗żõĮ┐ńö©ńøĖÕÉīńÜ䵩ĪÕ×ŗÕÆīĶŠōÕģźµē¦ĶĪīµÄ©ńÉå’╝Ü + +```python +python demo/inferencer_demo.py 'tests/data/coco/000000000785.jpg' \ + --pose2d 'human' --show --pred-out-dir 'predictions' +``` + +ķó䵥ŗń╗ōµ×£Õ░åĶó½õ┐ØÕŁśÕ£©ĶĘ»ÕŠä`predictions/000000000785.json`ŃĆéõĮ£õĖ║õĖĆõĖ¬API’╝ī`inferencer_demo.py`ńÜäĶŠōÕģźÕÅéµĢ░õĖÄ`MMPoseInferencer`ńÜäńøĖÕÉīŃĆéÕēŹĶĆģĶāĮÕż¤ÕżäńÉåõĖĆń│╗ÕłŚĶŠōÕģźń▒╗Õ×ŗ’╝īÕīģµŗ¼õ╗źõĖŗÕåģÕ«╣’╝Ü + +- ÕøŠÕāÅĶĘ»ÕŠä + +- Ķ¦åķóæĶĘ»ÕŠä + +- µ¢ćõ╗ČÕż╣ĶĘ»ÕŠä’╝łĶ┐Öõ╝ÜÕ»╝Ķć┤Ķ»źµ¢ćõ╗ČÕż╣õĖŁńÜäµēƵ£ēÕøŠÕāÅķāĮĶó½µÄ©µ¢ŁÕć║µØź’╝ē + +- ĶĪ©ńż║ÕøŠÕāÅńÜä numpy array (Õ£©ÕæĮõ╗żĶĪīńĢīķØóÕĘźÕģĘõĖŁµ£¬µö»µīü) + +- ĶĪ©ńż║ÕøŠÕāÅńÜä numpy array ÕłŚĶĪ© (Õ£©ÕæĮõ╗żĶĪīńĢīķØóÕĘźÕģĘõĖŁµ£¬µö»µīü) + +- µæäÕāÅÕż┤’╝łÕ£©Ķ┐Öń¦ŹµāģÕåĄõĖŗ’╝īĶŠōÕģźÕÅéµĢ░Õ║öĶ»źĶ«ŠńĮ«õĖ║`webcam`µł¢`webcam:{CAMERA_ID}`’╝ē + +ÕĮōĶŠōÕģźÕ»╣Õ║öõ║ÄÕżÜõĖ¬ÕøŠÕāŵŚČ’╝īõŠŗÕ”éĶŠōÕģźõĖ║**Ķ¦åķóæ**µł¢**µ¢ćõ╗ČÕż╣**ĶĘ»ÕŠäµŚČ’╝īµÄ©ńÉåńö¤µłÉÕÖ©Õ┐ģķĪ╗Ķó½ķüŹÕÄå’╝īõ╗źõŠ┐µÄ©ńÉåÕÖ©Õ»╣Ķ¦åķóæ/µ¢ćõ╗ČÕż╣õĖŁńÜäµēƵ£ēÕĖ¦/ÕøŠÕāÅĶ┐øĶĪīµÄ©ńÉåŃĆéõ╗źõĖŗµś»õĖĆõĖ¬ńż║õŠŗ’╝Ü + +```python +folder_path = 'tests/data/coco' + +result_generator = inferencer(folder_path, show=True) +results = [result for result in result_generator] +``` + +Õ£©Ķ┐ÖõĖ¬ńż║õŠŗõĖŁ’╝ī`inferencer` µÄźÕÅŚ `folder_path` õĮ£õĖ║ĶŠōÕģź’╝īÕ╣ČĶ┐öÕø×õĖĆõĖ¬ńö¤µłÉÕÖ©Õ»╣Ķ▒Ī’╝ł`result_generator`’╝ē’╝īńö©õ║Äńö¤µłÉµÄ©ńÉåń╗ōµ×£ŃĆéķĆÜĶ┐ćķüŹÕÄå `result_generator` Õ╣ČÕ░åµ»ÅõĖ¬ń╗ōµ×£ÕŁśÕé©Õ£© `results` ÕłŚĶĪ©õĖŁ’╝īµé©ÕÅ»õ╗źĶÄĘÕŠŚĶ¦åķóæ/µ¢ćõ╗ČÕż╣õĖŁµēƵ£ēÕĖ¦/ÕøŠÕāÅńÜäµÄ©ńÉåń╗ōµ×£ŃĆé + +### Ķć¬Õ«Üõ╣ēÕ¦┐µĆüõ╝░Ķ«Īµ©ĪÕ×ŗ + +`MMPoseInferencer`µÅÉõŠøõ║åÕćĀń¦ŹÕÅ»ńö©õ║ÄĶć¬Õ«Üõ╣ēµēĆõĮ┐ńö©ńÜ䵩ĪÕ×ŗńÜäµ¢╣µ│Ģ’╝Ü + +```python +# õĮ┐ńö©µ©ĪÕ×ŗÕł½ÕÉŹµ×äÕ╗║µÄ©µ¢ŁÕÖ© +inferencer = MMPoseInferencer('human') + +# õĮ┐ńö©µ©ĪÕ×ŗķģŹńĮ«ÕÉŹµ×äÕ╗║µÄ©µ¢ŁÕÖ© +inferencer = MMPoseInferencer('td-hm_hrnet-w32_8xb64-210e_coco-256x192') + +# õĮ┐ńö©µ©ĪÕ×ŗķģŹńĮ«µ¢ćõ╗ČÕÆīµØāķ揵¢ćõ╗ČńÜäĶĘ»ÕŠäµł¢ URL µ×äÕ╗║µÄ©µ¢ŁÕÖ© +inferencer = MMPoseInferencer( + pose2d='configs/body_2d_keypoint/topdown_heatmap/coco/' \ + 'td-hm_hrnet-w32_8xb64-210e_coco-256x192.py', + pose2d_weights='https://download.openmmlab.com/mmpose/top_down/' \ + 'hrnet/hrnet_w32_coco_256x192-c78dce93_20200708.pth' +) +``` + +µ©ĪÕ×ŗÕł½ÕÉŹńÜäÕ«īµĢ┤ÕłŚĶĪ©ÕÅ»õ╗źÕ£©µ©ĪÕ×ŗÕł½ÕÉŹķā©ÕłåõĖŁµēŠÕł░ŃĆé + +µŁżÕż¢’╝īĶć¬ķĪČÕÉæõĖŗńÜäÕ¦┐µĆüõ╝░Ķ«ĪÕÖ©Ķ┐śķ£ĆĶ”üõĖĆõĖ¬Õ»╣Ķ▒ĪµŻĆµĄŗµ©ĪÕ×ŗŃĆé`MMPoseInferencer`ĶāĮÕż¤µÄ©µ¢Łńö©MMPoseµö»µīüńÜäµĢ░µŹ«ķøåĶ«Łń╗āńÜ䵩ĪÕ×ŗńÜäÕ«×õŠŗń▒╗Õ×ŗ’╝īńäČÕÉĵ×äÕ╗║Õ┐ģĶ”üńÜäÕ»╣Ķ▒ĪµŻĆµĄŗµ©ĪÕ×ŗŃĆéńö©µłĘõ╣¤ÕÅ»õ╗źķĆÜĶ┐ćõ╗źõĖŗµ¢╣Õ╝ŵēŗÕŖ©µīćիܵŻĆµĄŗµ©ĪÕ×ŗ: + +```python +# ķĆÜĶ┐ćÕł½ÕÉŹµīćիܵŻĆµĄŗµ©ĪÕ×ŗ +# ÕÅ»ńö©ńÜäÕł½ÕÉŹÕīģµŗ¼ŌĆ£humanŌĆØŃĆüŌĆ£handŌĆØŃĆüŌĆ£faceŌĆØŃĆüŌĆ£animalŌĆØŃĆü +# õ╗źÕÅŖmmdetõĖŁÕ«Üõ╣ēńÜäõ╗╗õĮĢÕģČõ╗¢Õł½ÕÉŹ +inferencer = MMPoseInferencer( + # ÕüćĶ«ŠÕ¦┐µĆüõ╝░Ķ«ĪÕÖ©µś»Õ£©Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåõĖŖĶ«Łń╗āńÜä + pose2d='custom_human_pose_estimator.py', + pose2d_weights='custom_human_pose_estimator.pth', + det_model='human' +) + +# õĮ┐ńö©µ©ĪÕ×ŗķģŹńĮ«ÕÉŹń¦░µīćիܵŻĆµĄŗµ©ĪÕ×ŗ +inferencer = MMPoseInferencer( + pose2d='human', + det_model='yolox_l_8x8_300e_coco', + det_cat_ids=[0], # µīćÕ«Ü'human'ń▒╗ńÜäń▒╗Õł½id +) + +# õĮ┐ńö©µ©ĪÕ×ŗķģŹńĮ«µ¢ćõ╗ČÕÆīµØāķ揵¢ćõ╗ČńÜäĶĘ»ÕŠäµł¢URLµ×äÕ╗║µÄ©µ¢ŁÕÖ© +inferencer = MMPoseInferencer( + pose2d='human', + det_model=f'{PATH_TO_MMDET}/configs/yolox/yolox_l_8x8_300e_coco.py', + det_weights='https://download.openmmlab.com/mmdetection/v2.0/' \ + 'yolox/yolox_l_8x8_300e_coco/' \ + 'yolox_l_8x8_300e_coco_20211126_140236-d3bd2b23.pth', + det_cat_ids=[0], # µīćÕ«Ü'human'ń▒╗ńÜäń▒╗Õł½id +) +``` + +### ĶĮ¼Õé©ń╗ōµ×£ + +Õ£©µē¦ĶĪīÕ¦┐µĆüõ╝░Ķ«ĪµÄ©ńÉåõ╗╗ÕŖĪõ╣ŗÕÉÄ’╝īµé©ÕÅ»ĶāĮÕĖīµ£øõ┐ØÕŁśń╗ōµ×£õ╗źõŠøĶ┐øõĖƵŁźÕłåµ×ɵł¢ÕżäńÉåŃĆéµ£¼ĶŖéÕ░åµīćÕ»╝µé©Õ░åķó䵥ŗńÜäÕģ│ķö«ńé╣ÕÆīÕÅ»Ķ¦åÕī¢ń╗ōµ×£õ┐ØÕŁśÕł░µ£¼Õ£░ŃĆé + +Ķ”üÕ░åķó䵥ŗõ┐ØÕŁśÕ£©JSONµ¢ćõ╗ČõĖŁ’╝īÕ£©Ķ┐ÉĶĪī`MMPoseInferencer`ńÜäÕ«×õŠŗ`inferencer`µŚČõĮ┐ńö©`pred_out_dir`ÕÅéµĢ░: + +```python +result_generator = inferencer(img_path, pred_out_dir='predictions') +result = next(result_generator) +``` + +ķó䵥ŗń╗ōµ×£Õ░åõ╗źJSONµĀ╝Õ╝Åõ┐ØÕŁśÕ£©`predictions/`µ¢ćõ╗ČÕż╣õĖŁ’╝īµ»ÅõĖ¬µ¢ćõ╗Čõ╗źńøĖÕ║öńÜäĶŠōÕģźÕøŠÕāŵł¢Ķ¦åķóæńÜäÕÉŹń¦░ÕæĮÕÉŹŃĆé + +Õ»╣õ║ĵø┤ķ½śń║¦ńÜäÕ£║µÖ»’╝īĶ┐śÕÅ»õ╗źńø┤µÄźõ╗Ä`inferencer`Ķ┐öÕø×ńÜä`result`ÕŁŚÕģĖõĖŁĶ«┐ķŚ«ķó䵥ŗń╗ōµ×£ŃĆéÕģČõĖŁ’╝ī`predictions`ÕīģÕɽĶŠōÕģźÕøŠÕāŵł¢Ķ¦åķóæõĖŁµ»ÅõĖ¬ÕŹĢńŗ¼Õ«×õŠŗńÜäķó䵥ŗÕģ│ķö«ńé╣ÕłŚĶĪ©ŃĆéńäČÕÉÄ’╝īµé©ÕÅ»õ╗źõĮ┐ńö©µé©Õ¢£µ¼óńÜäµ¢╣µ│ĢµōŹõĮ£µł¢ÕŁśÕé©Ķ┐Öõ║øń╗ōµ×£ŃĆé + +Ķ»ĘĶ«░õĮÅ’╝īÕ”éµ×£õĮĀµā│Õ░åÕÅ»Ķ¦åÕī¢ÕøŠÕāÅÕÆīķó䵥ŗµ¢ćõ╗Čõ┐ØÕŁśÕ£©õĖĆõĖ¬µ¢ćõ╗ČÕż╣õĖŁ’╝īõĮĀÕÅ»õ╗źõĮ┐ńö©`out_dir`ÕÅéµĢ░’╝Ü + +```python +result_generator = inferencer(img_path, out_dir='output') +result = next(result_generator) +``` + +Õ£©Ķ┐Öń¦ŹµāģÕåĄõĖŗ’╝īÕÅ»Ķ¦åÕī¢ÕøŠÕāÅÕ░åõ┐ØÕŁśÕ£©`output/visualization/`µ¢ćõ╗ČÕż╣õĖŁ’╝īĶĆīķó䵥ŗÕ░åÕŁśÕé©Õ£©`output/forecasts/`µ¢ćõ╗ČÕż╣õĖŁŃĆé + +### ÕÅ»Ķ¦åÕī¢ + +µÄ©ńÉåÕÖ©`inferencer`ÕÅ»õ╗źĶć¬ÕŖ©Õ»╣ĶŠōÕģźńÜäÕøŠÕāŵł¢Ķ¦åķóæĶ┐øĶĪīķó䵥ŗŃĆéÕÅ»Ķ¦åÕī¢ń╗ōµ×£ÕÅ»õ╗źµśŠńż║Õ£©õĖĆõĖ¬µ¢░ńÜäń¬ŚÕÅŻõĖŁ’╝īÕ╣Čõ┐ØÕŁśÕ£©µ£¼Õ£░ŃĆé + +Ķ”üÕ£©µ¢░ń¬ŚÕÅŻõĖŁµ¤źń£ŗÕÅ»Ķ¦åÕī¢ń╗ōµ×£’╝īĶ»ĘõĮ┐ńö©õ╗źõĖŗõ╗ŻńĀü’╝Ü + +Ķ»Ęµ│©µäÅ’╝Ü + +- Õ”éµ×£ĶŠōÕģźĶ¦åķóæµØźĶć¬ńĮæń╗£µæäÕāÅÕż┤’╝īķ╗śĶ«żµāģÕåĄõĖŗÕ░åÕ£©µ¢░ń¬ŚÕÅŻõĖŁµśŠńż║ÕÅ»Ķ¦åÕī¢ń╗ōµ×£’╝īõ╗źµŁżĶ«®ńö©µłĘń£ŗÕł░ĶŠōÕģź + +- Õ”éµ×£Õ╣│ÕÅ░õĖŖµ▓Īµ£ēGUI’╝īĶ┐ÖõĖ¬µŁźķ¬żÕÅ»ĶāĮõ╝ÜÕŹĪõĮÅ + +Ķ”üÕ░åÕÅ»Ķ¦åÕī¢ń╗ōµ×£õ┐ØÕŁśÕ£©µ£¼Õ£░’╝īÕÅ»õ╗źÕāÅĶ┐ÖµĀʵīćÕ«Ü`vis_out_dir`ÕÅéµĢ░: + +```python +result_generator = inferencer(img_path, vis_out_dir='vis_results') +result = next(result_generator) +``` + +ĶŠōÕģźÕøŠńē浳¢Ķ¦åķóæńÜäÕÅ»Ķ¦åÕī¢ķó䵥ŗń╗ōµ×£Õ░åõ┐ØÕŁśÕ£©`vis_results/`µ¢ćõ╗ČÕż╣õĖŁ + +Õ£©Õ╝ĆÕż┤Õ▒Ģńż║ńÜäµ╗æķø¬ÕøŠõĖŁ’╝īÕ¦┐µĆüńÜäÕÅ»Ķ¦åÕī¢õ╝░Ķ«Īń╗ōµ×£ńö▒Õģ│ķö«ńé╣’╝łńö©Õ«×Õ┐āÕ£åµÅÅń╗ś’╝ēÕÆīķ¬©µ×Č’╝łńö©ń║┐µØĪĶĪ©ńż║’╝ēń╗䵳ÉŃĆéĶ┐Öõ║øĶ¦åĶ¦ēÕģāń┤ĀńÜäķ╗śĶ«żÕż¦Õ░ÅÕÅ»ĶāĮõĖŹõ╝Üõ║¦ńö¤õ╗żõ║║µ╗ĪµäÅńÜäń╗ōµ×£ŃĆéńö©µłĘÕÅ»õ╗źõĮ┐ńö©`radius`ÕÆī`thickness`ÕÅéµĢ░µØźĶ░āµĢ┤Õ£åńÜäÕż¦Õ░ÅÕÆīń║┐ńÜäń▓Śń╗å’╝īÕ”éõĖŗµēĆńż║’╝Ü + +```python +result_generator = inferencer(img_path, show=True, radius=4, thickness=2) +result = next(result_generator) +``` + +### µÄ©ńÉåÕÖ©ÕÅéµĢ░ + +`MMPoseInferencer`µÅÉõŠøõ║åÕÉäń¦ŹĶć¬Õ«Üõ╣ēÕ¦┐µĆüõ╝░Ķ«ĪŃĆüÕÅ»Ķ¦åÕī¢ÕÆīõ┐ØÕŁśķó䵥ŗń╗ōµ×£ńÜäÕÅéµĢ░ŃĆéõĖŗķØóµś»ÕłØÕ¦ŗÕī¢µÄ©µ¢ŁÕÖ©µŚČÕÅ»ńö©ńÜäÕÅéµĢ░ÕłŚĶĪ©ÕÅŖÕ»╣Ķ┐Öõ║øÕÅéµĢ░ńÜäµÅÅĶ┐░’╝Ü + +| Argument | Description | +| ---------------- | ------------------------------------------------------------ | +| `pose2d` | µīćÕ«Ü 2D Õ¦┐µĆüõ╝░Ķ«Īµ©ĪÕ×ŗńÜ䵩ĪÕ×ŗÕł½ÕÉŹŃĆüķģŹńĮ«µ¢ćõ╗ČÕÉŹń¦░µł¢ķģŹńĮ«µ¢ćõ╗ČĶĘ»ÕŠäŃĆé | +| `pose2d_weights` | µīćÕ«Ü 2D Õ¦┐µĆüõ╝░Ķ«Īµ©ĪÕ×ŗµØāķ揵¢ćõ╗ČńÜäURLµł¢µ£¼Õ£░ĶĘ»ÕŠäŃĆé | +| `pose3d` | µīćÕ«Ü 3D Õ¦┐µĆüõ╝░Ķ«Īµ©ĪÕ×ŗńÜ䵩ĪÕ×ŗÕł½ÕÉŹŃĆüķģŹńĮ«µ¢ćõ╗ČÕÉŹń¦░µł¢ķģŹńĮ«µ¢ćõ╗ČĶĘ»ÕŠäŃĆé | +| `pose3d_weights` | µīćÕ«Ü 3D Õ¦┐µĆüõ╝░Ķ«Īµ©ĪÕ×ŗµØāķ揵¢ćõ╗ČńÜäURLµł¢µ£¼Õ£░ĶĘ»ÕŠäŃĆé | +| `det_model` | µīćÕ«ÜÕ»╣Ķ▒ĪµŻĆµĄŗµ©ĪÕ×ŗńÜ䵩ĪÕ×ŗÕł½ÕÉŹŃĆüķģŹńĮ«µ¢ćõ╗ČÕÉŹµł¢ķģŹńĮ«µ¢ćõ╗ČĶĘ»ÕŠäŃĆé | +| `det_weights` | µīćÕ«ÜÕ»╣Ķ▒ĪµŻĆµĄŗµ©ĪÕ×ŗµØāķ揵¢ćõ╗ČńÜä URL µł¢µ£¼Õ£░ĶĘ»ÕŠäŃĆé | +| `det_cat_ids` | µīćÕ«ÜõĖÄĶ”üµŻĆµĄŗńÜäÕ»╣Ķ▒Īń▒╗Õ»╣Õ║öńÜäń▒╗Õł½ id ÕłŚĶĪ©ŃĆé | +| `device` | µē¦ĶĪīµÄ©ńÉåńÜäĶ«ŠÕżćŃĆéÕ”éµ×£õĖ║ `None`’╝īµÄ©ńÉåÕÖ©Õ░åķĆēµŗ®µ£ĆÕÉłķĆéńÜäõĖĆõĖ¬ŃĆé | +| `scope` | Õ«Üõ╣ēµ©ĪÕ×ŗµ©ĪÕØŚńÜäÕÉŹń¦░ń®║ķŚ┤ | + +µÄ©ńÉåÕÖ©Ķó½Ķ«ŠĶ«Īńö©õ║ÄÕÅ»Ķ¦åÕī¢ÕÆīõ┐ØÕŁśķó䵥ŗŃĆéõ╗źõĖŗĶĪ©µĀ╝ÕłŚÕć║õ║åÕ£©õĮ┐ńö© `MMPoseInferencer` Ķ┐øĶĪīµÄ©µ¢ŁµŚČÕÅ»ńö©ńÜäÕÅéµĢ░ÕłŚĶĪ©’╝īõ╗źÕÅŖÕ«āõ╗¼õĖÄ 2D ÕÆī 3D µÄ©ńÉåÕÖ©ńÜäÕģ╝Õ«╣µĆ¦’╝Ü + +| ÕÅéµĢ░ | µÅÅĶ┐░ | 2D | 3D | +| ------------------------ | -------------------------------------------------------------------------------------------------------------------------- | --- | --- | +| `show` | µÄ¦ÕłČµś»Õɔգ©Õ╝╣Õć║ń¬ŚÕÅŻõĖŁµśŠńż║ÕøŠÕāŵł¢Ķ¦åķóæŃĆé | Ō£ö’ĖÅ | Ō£ö’ĖÅ | +| `radius` | Ķ«ŠńĮ«ÕÅ»Ķ¦åÕī¢Õģ│ķö«ńé╣ńÜäÕŹŖÕŠäŃĆé | Ō£ö’ĖÅ | Ō£ö’ĖÅ | +| `thickness` | ńĪ«Õ«ÜÕÅ»Ķ¦åÕī¢ķōŠµÄźńÜäÕÄÜÕ║”ŃĆé | Ō£ö’ĖÅ | Ō£ö’ĖÅ | +| `kpt_thr` | Ķ«ŠńĮ«Õģ│ķö«ńé╣ÕłåµĢ░ķśłÕĆ╝ŃĆéÕłåµĢ░ĶČģĶ┐浣żķśłÕĆ╝ńÜäÕģ│ķö«ńé╣Õ░åĶó½µśŠńż║ŃĆé | Ō£ö’ĖÅ | Ō£ö’ĖÅ | +| `draw_bbox` | Õå│իܵś»ÕÉ”µśŠńż║Õ«×õŠŗńÜäĶŠ╣ńĢīµĪåŃĆé | Ō£ö’ĖÅ | Ō£ö’ĖÅ | +| `draw_heatmap` | Õå│իܵś»ÕÉ”ń╗śÕłČķó䵥ŗńÜäńāŁÕøŠŃĆé | Ō£ö’ĖÅ | ŌØī | +| `black_background` | Õå│իܵś»Õɔգ©ķ╗æĶē▓ĶāīµÖ»õĖŖµśŠńż║ķóäõ╝░ńÜäÕ¦┐ÕŖ┐ŃĆé | Ō£ö’ĖÅ | ŌØī | +| `skeleton_style` | Ķ«ŠńĮ«ķ¬©µ×ȵĀĘÕ╝ÅŃĆéÕÅ»ķĆēķĪ╣Õīģµŗ¼ 'mmpose'’╝łķ╗śĶ«ż’╝ēÕÆī 'openpose'ŃĆé | Ō£ö’ĖÅ | ŌØī | +| `use_oks_tracking` | Õå│իܵś»Õɔգ©Ķ┐ĮĶĖ¬õĖŁõĮ┐ńö©OKSõĮ£õĖ║ńøĖõ╝╝Õ║”µĄŗķćÅŃĆé | ŌØī | Ō£ö’ĖÅ | +| `tracking_thr` | Ķ«ŠńĮ«Ķ┐ĮĶĖ¬ńÜäńøĖõ╝╝Õ║”ķśłÕĆ╝ŃĆé | ŌØī | Ō£ö’ĖÅ | +| `norm_pose_2d` | Õå│իܵś»ÕÉ”Õ░åĶŠ╣ńĢīµĪåń╝®µöŠĶć│µĢ░µŹ«ķøåńÜäÕ╣│ÕØćĶŠ╣ńĢīµĪåÕ░║Õ»Ė’╝īÕ╣ČÕ░åĶŠ╣ńĢīµĪåń¦╗Ķć│µĢ░µŹ«ķøåńÜäÕ╣│ÕØćĶŠ╣ńĢīµĪåõĖŁÕ┐āŃĆé | ŌØī | Ō£ö’ĖÅ | +| `rebase_keypoint_height` | Õå│իܵś»ÕÉ”Õ░åµ£ĆõĮÄÕģ│ķö«ńé╣ńÜäķ½śÕ║”ńĮ«õĖ║ 0ŃĆé | ŌØī | Ō£ö’ĖÅ | +| `return_vis` | Õå│իܵś»Õɔգ©ń╗ōµ×£õĖŁÕīģÕɽÕÅ»Ķ¦åÕī¢ÕøŠÕāÅŃĆé | Ō£ö’ĖÅ | Ō£ö’ĖÅ | +| `vis_out_dir` | Õ«Üõ╣ēõ┐ØÕŁśÕÅ»Ķ¦åÕī¢ÕøŠÕāÅńÜäµ¢ćõ╗ČÕż╣ĶĘ»ÕŠäŃĆéÕ”éµ×£µ£¬Ķ«ŠńĮ«’╝īÕ░åõĖŹõ┐ØÕŁśÕÅ»Ķ¦åÕī¢ÕøŠÕāÅŃĆé | Ō£ö’ĖÅ | Ō£ö’ĖÅ | +| `return_datasample` | Õå│իܵś»ÕÉ”õ╗ź `PoseDataSample` µĀ╝Õ╝ÅĶ┐öÕø×ķó䵥ŗŃĆé | Ō£ö’ĖÅ | Ō£ö’ĖÅ | +| `pred_out_dir` | µīćÕ«Üõ┐ØÕŁśķó䵥ŗńÜäµ¢ćõ╗ČÕż╣ĶĘ»ÕŠäŃĆéÕ”éµ×£µ£¬Ķ«ŠńĮ«’╝īÕ░åõĖŹõ┐ØÕŁśķó䵥ŗŃĆé | Ō£ö’ĖÅ | Ō£ö’ĖÅ | +| `out_dir` | Õ”éµ×£ `vis_out_dir` µł¢ `pred_out_dir` µ£¬Ķ«ŠńĮ«’╝īÕ«āõ╗¼Õ░åÕłåÕł½Ķ«ŠńĮ«õĖ║ `f'{out_dir}/visualization'` µł¢ `f'{out_dir}/predictions'`ŃĆé | Ō£ö’ĖÅ | Ō£ö’ĖÅ | + +### µ©ĪÕ×ŗÕł½ÕÉŹ + +MMPoseõĖ║ÕĖĖńö©µ©ĪÕ×ŗµÅÉõŠøõ║åõĖĆń╗äķóäÕ«Üõ╣ēńÜäÕł½ÕÉŹŃĆéÕ£©ÕłØÕ¦ŗÕī¢ `MMPoseInferencer` µŚČ’╝īĶ┐Öõ║øÕł½ÕÉŹÕÅ»õ╗źńö©õĮ£ń«ĆńĢźńÜäĶĪ©ĶŠŠµ¢╣Õ╝Å’╝īĶĆīõĖŹµś»µīćÕ«ÜÕ«īµĢ┤ńÜ䵩ĪÕ×ŗķģŹńĮ«ÕÉŹń¦░ŃĆéõĖŗķØ󵜻ÕÅ»ńö©ńÜ䵩ĪÕ×ŗÕł½ÕÉŹÕÅŖÕģČÕ»╣Õ║öńÜäķģŹńĮ«ÕÉŹń¦░ńÜäÕłŚĶĪ©’╝Ü + +| Õł½ÕÉŹ | ķģŹńĮ«µ¢ćõ╗ČÕÉŹń¦░ | Õ»╣Õ║öõ╗╗ÕŖĪ | Õ¦┐µĆüõ╝░Ķ«Īµ©ĪÕ×ŗ | µŻĆµĄŗµ©ĪÕ×ŗ | +| --------- | -------------------------------------------------- | ------------------------------- | ------------- | ------------------- | +| animal | rtmpose-m_8xb64-210e_ap10k-256x256 | Animal pose estimation | RTMPose-m | RTMDet-m | +| human | rtmpose-m_8xb256-420e_aic-coco-256x192 | Human pose estimation | RTMPose-m | RTMDet-m | +| face | rtmpose-m_8xb64-60e_wflw-256x256 | Face keypoint detection | RTMPose-m | yolox-s | +| hand | rtmpose-m_8xb32-210e_coco-wholebody-hand-256x256 | Hand keypoint detection | RTMPose-m | ssdlite_mobilenetv2 | +| wholebody | rtmpose-m_8xb64-270e_coco-wholebody-256x192 | Human wholebody pose estimation | RTMPose-m | RTMDet-m | +| vitpose | td-hm_ViTPose-base-simple_8xb64-210e_coco-256x192 | Human pose estimation | ViTPose-base | RTMDet-m | +| vitpose-s | td-hm_ViTPose-small-simple_8xb64-210e_coco-256x192 | Human pose estimation | ViTPose-small | RTMDet-m | +| vitpose-b | td-hm_ViTPose-base-simple_8xb64-210e_coco-256x192 | Human pose estimation | ViTPose-base | RTMDet-m | +| vitpose-l | td-hm_ViTPose-large-simple_8xb64-210e_coco-256x192 | Human pose estimation | ViTPose-large | RTMDet-m | +| vitpose-h | td-hm_ViTPose-huge-simple_8xb64-210e_coco-256x192 | Human pose estimation | ViTPose-huge | RTMDet-m | + +µŁżÕż¢’╝īńö©µłĘÕÅ»õ╗źõĮ┐ńö©ÕæĮõ╗żĶĪīńĢīķØóÕĘźÕģʵśŠńż║µēƵ£ēÕÅ»ńö©ńÜäÕł½ÕÉŹ’╝īõĮ┐ńö©õ╗źõĖŗÕæĮõ╗ż: + +```shell +python demo/inferencer_demo.py --show-alias +``` diff --git a/internlm_langchain/knowledge_base/MMPose/content/installation.md b/internlm_langchain/knowledge_base/MMPose/content/installation.md new file mode 100644 index 00000000..ef515c80 --- /dev/null +++ b/internlm_langchain/knowledge_base/MMPose/content/installation.md @@ -0,0 +1,248 @@ +# Õ«ēĶŻģ + +µłæõ╗¼µÄ©ĶŹÉńö©µłĘµīēńģ¦µłæõ╗¼ńÜäµ£ĆõĮ│Õ«×ĶĘĄµØźÕ«ēĶŻģ MMPoseŃĆéõĮåķÖżµŁżõ╣ŗÕż¢’╝īÕ”éµ×£µé©µā│µĀ╣µŹ« +µé©ńÜäõ╣Āµā»Õ«īµłÉÕ«ēĶŻģµĄüń©ŗ’╝īõ╣¤ÕÅ»õ╗źÕÅéĶ¦ü [Ķć¬Õ«Üõ╣ēÕ«ēĶŻģ](#Ķć¬Õ«Üõ╣ēÕ«ēĶŻģ) õĖĆĶŖéµØźĶÄĘÕÅ¢µø┤ÕżÜõ┐Īµü»ŃĆé + +- [Õ«ēĶŻģ](#Õ«ēĶŻģ) + - [õŠØĶĄ¢ńÄ»Õóā](#õŠØĶĄ¢ńÄ»Õóā) + - [µ£ĆõĮ│Õ«×ĶĘĄ](#µ£ĆõĮ│Õ«×ĶĘĄ) + - [õ╗ĵ║ÉńĀüÕ«ēĶŻģ MMPose](#õ╗ĵ║ÉńĀüÕ«ēĶŻģ-mmpose) + - [õĮ£õĖ║ Python ÕīģÕ«ēĶŻģ](#õĮ£õĖ║-python-ÕīģÕ«ēĶŻģ) + - [ķ¬īĶ»üÕ«ēĶŻģ](#ķ¬īĶ»üÕ«ēĶŻģ) + - [Ķć¬Õ«Üõ╣ēÕ«ēĶŻģ](#Ķć¬Õ«Üõ╣ēÕ«ēĶŻģ) + - [CUDA ńēłµ£¼](#cuda-ńēłµ£¼) + - [õĖŹõĮ┐ńö© MIM Õ«ēĶŻģ MMEngine](#õĖŹõĮ┐ńö©-mim-Õ«ēĶŻģ-mmengine) + - [Õ£© CPU ńÄ»ÕóāõĖŁÕ«ēĶŻģ](#Õ£©-cpu-ńÄ»ÕóāõĖŁÕ«ēĶŻģ) + - [Õ£© Google Colab õĖŁÕ«ēĶŻģ](#Õ£©-google-colab-õĖŁÕ«ēĶŻģ) + - [ķĆÜĶ┐ć Docker õĮ┐ńö© MMPose](#ķĆÜĶ┐ć-docker-õĮ┐ńö©-mmpose) + - [µĢģķÜ£Ķ¦ŻÕå│](#µĢģķÜ£Ķ¦ŻÕå│) + +## õŠØĶĄ¢ńÄ»Õóā + +Õ£©µ£¼ĶŖéõĖŁ’╝īµłæõ╗¼Õ░åµ╝öńż║Õ”éõĮĢÕćåÕżć PyTorch ńøĖÕģ│ńÜäõŠØĶĄ¢ńÄ»ÕóāŃĆé + +MMPose ķĆéńö©õ║Ä LinuxŃĆüWindows ÕÆī macOSŃĆéÕ«āķ£ĆĶ”ü Python 3.7+ŃĆüCUDA 9.2+ ÕÆī PyTorch 1.8+ŃĆé + +Õ”éµ×£µé©Õ»╣ķģŹńĮ« PyTorch ńÄ»ÕóāÕĘ▓ń╗ÅÕŠłń夵éē’╝īÕ╣ČõĖöÕĘ▓ń╗ÅÕ«īµłÉõ║åķģŹńĮ«’╝īÕÅ»õ╗źńø┤µÄźĶ┐øÕģźõĖŗõĖĆĶŖé’╝Ü[Õ«ēĶŻģ](#Õ«ēĶŻģ-mmpose)ŃĆéÕÉ”ÕłÖ’╝īĶ»ĘõŠØńģ¦õ╗źõĖŗµŁźķ¬żÕ«īµłÉķģŹńĮ«ŃĆé + +**ń¼¼ 1 µŁź** õ╗Ä[Õ«śńĮæ](https://docs.conda.io/en/latest/miniconda.html) õĖŗĶĮĮÕ╣ČÕ«ēĶŻģ MinicondaŃĆé + +**ń¼¼ 2 µŁź** ÕłøÕ╗║õĖĆõĖ¬ conda ĶÖܵŗ¤ńÄ»ÕóāÕ╣ȵ┐Ƶ┤╗Õ«āŃĆé + +```shell +conda create --name openmmlab python=3.8 -y +conda activate openmmlab +``` + +**ń¼¼ 3 µŁź** µīēńģ¦[Õ«śµ¢╣µīćÕŹŚ](https://pytorch.org/get-started/locally/) Õ«ēĶŻģ PyTorchŃĆéõŠŗÕ”é’╝Ü + +Õ£© GPU Õ╣│ÕÅ░’╝Ü + +```shell +conda install pytorch torchvision -c pytorch +``` + +```{warning} +õ╗źõĖŖÕæĮõ╗żõ╝ÜĶć¬ÕŖ©Õ«ēĶŻģµ£Ćµ¢░ńēłńÜä PyTorch õĖÄÕ»╣Õ║öńÜä cudatoolkit’╝īĶ»ĘµŻĆµ¤źÕ«āõ╗¼µś»ÕÉ”õĖĵé©ńÜäńÄ»ÕóāÕī╣ķģŹŃĆé +``` + +Õ£© CPU Õ╣│ÕÅ░’╝Ü + +```shell +conda install pytorch torchvision cpuonly -c pytorch +``` + +**ń¼¼ 4 µŁź** õĮ┐ńö© [MIM](https://github.com/open-mmlab/mim) Õ«ēĶŻģ [MMEngine](https://github.com/open-mmlab/mmengine) ÕÆī [MMCV](https://github.com/open-mmlab/mmcv/tree/2.x) + +```shell +pip install -U openmim +mim install mmengine +mim install "mmcv>=2.0.1" +``` + +Ķ»Ęµ│©µäÅ’╝īMMPose õĖŁńÜäõĖĆõ║øµÄ©ńÉåńż║õŠŗĶäܵ£¼ķ£ĆĶ”üõĮ┐ńö© [MMDetection](https://github.com/open-mmlab/mmdetection) (mmdet) µŻĆµĄŗõ║║õĮōŃĆéÕ”éµ×£µé©µā│Ķ┐ÉĶĪīĶ┐Öõ║øńż║õŠŗĶäܵ£¼’╝īÕÅ»õ╗źķĆÜĶ┐ćĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗żÕ«ēĶŻģ mmdet: + +```shell +mim install "mmdet>=3.1.0" +``` + +## µ£ĆõĮ│Õ«×ĶĘĄ + +µĀ╣µŹ«ÕģĘõĮōķ£Ćµ▒é’╝īµłæõ╗¼µö»µīüõĖżń¦ŹÕ«ēĶŻģµ©ĪÕ╝Å: õ╗ĵ║ÉńĀüÕ«ēĶŻģ’╝łµÄ©ĶŹÉ’╝ēÕÆīõĮ£õĖ║ Python ÕīģÕ«ēĶŻģ + +### õ╗ĵ║ÉńĀüÕ«ēĶŻģ’╝łµÄ©ĶŹÉ’╝ē + +Õ”éµ×£Õ¤║õ║Ä MMPose µĪåµ×ČÕ╝ĆÕÅæĶć¬ÕĘ▒ńÜäõ╗╗ÕŖĪ’╝īķ£ĆĶ”üµĘ╗ÕŖĀµ¢░ńÜäÕŖ¤ĶāĮ’╝īµ»öՔ鵢░ńÜ䵩ĪÕ×ŗµł¢µś»µĢ░µŹ«ķøå’╝īµł¢ĶĆģõĮ┐ńö©µłæõ╗¼µÅÉõŠøńÜäÕÉäń¦ŹÕĘźÕģĘŃĆéõ╗ĵ║ÉńĀüµīēÕ”éõĖŗµ¢╣Õ╝ÅÕ«ēĶŻģ mmpose’╝Ü + +```shell +git clone https://github.com/open-mmlab/mmpose.git +cd mmpose +pip install -r requirements.txt +pip install -v -e . +# "-v" ĶĪ©ńż║ĶŠōÕć║µø┤ÕżÜÕ«ēĶŻģńøĖÕģ│ńÜäõ┐Īµü» +# "-e" ĶĪ©ńż║õ╗źÕÅ»ń╝¢ĶŠæÕĮóÕ╝ÅÕ«ēĶŻģ’╝īĶ┐ÖµĀĘÕÅ»õ╗źÕ£©õĖŹķ揵¢░Õ«ēĶŻģńÜäµāģÕåĄõĖŗ’╝īĶ«®µ£¼Õ£░õ┐«µö╣ńø┤µÄźńö¤µĢł +``` + +### õĮ£õĖ║ Python ÕīģÕ«ēĶŻģ + +Õ”éµ×£ÕŬµś»ÕĖīµ£øĶ░āńö© MMPose ńÜäµÄźÕÅŻ’╝īµł¢ĶĆģÕ£©Ķć¬ÕĘ▒ńÜäķĪ╣ńø«õĖŁÕ»╝Õģź MMPose õĖŁńÜ䵩ĪÕØŚŃĆéńø┤µÄźõĮ┐ńö© mim Õ«ēĶŻģÕŹ│ÕÅ»ŃĆé + +```shell +mim install "mmpose>=1.1.0" +``` + +## ķ¬īĶ»üÕ«ēĶŻģ + +õĖ║õ║åķ¬īĶ»ü MMPose µś»ÕɔիēĶŻģµŁŻńĪ«’╝īµé©ÕÅ»õ╗źķĆÜĶ┐ćõ╗źõĖŗµŁźķ¬żĶ┐ÉĶĪīµ©ĪÕ×ŗµÄ©ńÉåŃĆé + +**ń¼¼ 1 µŁź** µłæõ╗¼ķ£ĆĶ”üõĖŗĶĮĮķģŹńĮ«µ¢ćõ╗ČÕÆīµ©ĪÕ×ŗµØāķ揵¢ćõ╗Č + +```shell +mim download mmpose --config td-hm_hrnet-w48_8xb32-210e_coco-256x192 --dest . +``` + +õĖŗĶĮĮĶ┐ćń©ŗÕŠĆÕŠĆķ£ĆĶ”üÕćĀń¦Æµł¢µø┤ÕżÜńÜ䵌ČķŚ┤’╝īĶ┐ÖÕÅ¢Õå│õ║ĵé©ńÜäńĮæń╗£ńÄ»ÕóāŃĆéÕ«īµłÉõ╣ŗÕÉÄ’╝īµé©õ╝ÜÕ£©ÕĮōÕēŹńø«ÕĮĢõĖŗµēŠÕł░Ķ┐ÖõĖżõĖ¬µ¢ćõ╗Č’╝Ü`td-hm_hrnet-w48_8xb32-210e_coco-256x192.py` ÕÆī `hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth`, ÕłåÕł½µś»ķģŹńĮ«µ¢ćõ╗ČÕÆīÕ»╣Õ║öńÜ䵩ĪÕ×ŗµØāķ揵¢ćõ╗ČŃĆé + +**ń¼¼ 2 µŁź** ķ¬īĶ»üµÄ©ńÉåńż║õŠŗ + +Õ”éµ×£µé©µś»**õ╗ĵ║ÉńĀüÕ«ēĶŻģ**ńÜä mmpose’╝īÕÅ»õ╗źńø┤µÄźĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗żĶ┐øĶĪīķ¬īĶ»ü’╝Ü + +```shell +python demo/image_demo.py \ + tests/data/coco/000000000785.jpg \ + td-hm_hrnet-w48_8xb32-210e_coco-256x192.py \ + hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth \ + --out-file vis_results.jpg \ + --draw-heatmap +``` + +Õ”éµ×£õĖĆÕłćķĪ║Õł®’╝īµé©Õ░åõ╝ÜÕŠŚÕł░Ķ┐ÖµĀĘńÜäÕÅ»Ķ¦åÕī¢ń╗ōµ×£’╝Ü + + + +õ╗ŻńĀüõ╝ÜÕ░åķó䵥ŗńÜäÕģ│ķö«ńé╣ÕÆīńāŁÕøŠń╗śÕłČÕ£©ÕøŠÕāÅõĖŁńÜäõ║║õĮōõĖŖ’╝īÕ╣Čõ┐ØÕŁśÕł░ÕĮōÕēŹµ¢ćõ╗ČÕż╣õĖŗńÜä `vis_results.jpg`ŃĆé + +Õ”éµ×£µé©µś»**õĮ£õĖ║ Python ÕīģÕ«ēĶŻģ**’╝īÕÅ»õ╗źµēōÕ╝Ƶé©ńÜä Python Ķ¦ŻķćŖÕÖ©’╝īÕżŹÕłČÕ╣Čń▓śĶ┤┤Õ”éõĖŗõ╗ŻńĀü’╝Ü + +```python +from mmpose.apis import inference_topdown, init_model +from mmpose.utils import register_all_modules + +register_all_modules() + +config_file = 'td-hm_hrnet-w48_8xb32-210e_coco-256x192.py' +checkpoint_file = 'hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth' +model = init_model(config_file, checkpoint_file, device='cpu') # or device='cuda:0' + +# Ķ»ĘÕćåÕżćÕźĮõĖĆÕ╝ĀÕĖ”µ£ēõ║║õĮōńÜäÕøŠńēć +results = inference_topdown(model, 'demo.jpg') +``` + +ńż║õŠŗÕøŠńēć `demo.jpg` ÕÅ»õ╗źõ╗Ä [Github](https://raw.githubusercontent.com/open-mmlab/mmpose/main/tests/data/coco/000000000785.jpg) õĖŗĶĮĮŃĆé +µÄ©ńÉåń╗ōµ×£µś»õĖĆõĖ¬ `PoseDataSample` ÕłŚĶĪ©’╝īķó䵥ŗń╗ōµ×£Õ░åõ╝Üõ┐ØÕŁśÕ£© `pred_instances` õĖŁ’╝īÕīģµŗ¼µŻĆµĄŗÕł░ńÜäÕģ│ķö«ńé╣õĮŹńĮ«ÕÆīńĮ«õ┐ĪÕ║”ŃĆé + +## Ķć¬Õ«Üõ╣ēÕ«ēĶŻģ + +### CUDA ńēłµ£¼ + +Õ«ēĶŻģ PyTorch µŚČ’╝īķ£ĆĶ”üµīćÕ«Ü CUDA ńēłµ£¼ŃĆéÕ”éµ×£µé©õĖŹµĖģµźÜķĆēµŗ®Õō¬õĖ¬’╝īĶ»ĘķüĄÕŠ¬µłæõ╗¼ńÜäÕ╗║Ķ««’╝Ü + +- Õ»╣õ║Ä Ampere µ×ȵ×äńÜä NVIDIA GPU’╝īõŠŗÕ”é GeForce 30 ń│╗ÕłŚ õ╗źÕÅŖ NVIDIA A100’╝īCUDA 11 µś»Õ┐ģķ£ĆńÜäŃĆé +- Õ»╣õ║ĵø┤µŚ®ńÜä NVIDIA GPU’╝īCUDA 11 µś»ÕÉæÕÉÄÕģ╝Õ«╣ (backward compatible) ńÜä’╝īõĮå CUDA 10.2 ĶāĮÕż¤µÅÉõŠøµø┤ÕźĮńÜäÕģ╝Õ«╣µĆ¦’╝īõ╣¤µø┤ÕŖĀĶĮ╗ķćÅŃĆé + +Ķ»ĘńĪ«õ┐صé©ńÜä GPU ķ®▒ÕŖ©ńēłµ£¼µ╗ĪĶČ│µ£ĆõĮÄńÜäńēłµ£¼ķ£Ćµ▒é’╝īÕÅéķśģ[Ķ┐ÖÕ╝ĀĶĪ©](https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html#cuda-major-component-versions__table-cuda-toolkit-driver-versions)ŃĆé + +```{note} +Õ”éµ×£µīēńģ¦µłæõ╗¼ńÜäµ£ĆõĮ│Õ«×ĶĘĄĶ┐øĶĪīÕ«ēĶŻģ’╝īCUDA Ķ┐ÉĶĪīµŚČÕ║ōÕ░▒ĶČ│Õż¤õ║å’╝īÕøĀõĖ║µłæõ╗¼µÅÉõŠøńøĖÕģ│ CUDA õ╗ŻńĀüńÜäķóäń╝¢Ķ»æ’╝īµé©õĖŹķ£ĆĶ”üĶ┐øĶĪīµ£¼Õ£░ń╝¢Ķ»æŃĆé +õĮåÕ”éµ×£µé©ÕĖīµ£øõ╗ĵ║ÉńĀüĶ┐øĶĪī MMCV ńÜäń╝¢Ķ»æ’╝īµł¢µś»Ķ┐øĶĪīÕģČõ╗¢ CUDA ń«ŚÕŁÉńÜäÕ╝ĆÕÅæ’╝īķéŻõ╣łÕ░▒Õ┐ģķĪ╗Õ«ēĶŻģÕ«īµĢ┤ńÜä CUDA ÕĘźÕģĘķōŠ’╝īÕÅéĶ¦ü +[NVIDIA Õ«śńĮæ](https://developer.nvidia.com/cuda-downloads)’╝īÕÅ”Õż¢Ķ┐śķ£ĆĶ”üńĪ«õ┐ØĶ»ź CUDA ÕĘźÕģĘķōŠńÜäńēłµ£¼õĖÄ PyTorch Õ«ēĶŻģµŚČ +ńÜäķģŹńĮ«ńøĖÕī╣ķģŹ’╝łÕ”éńö© `conda install` Õ«ēĶŻģ PyTorch µŚČµīćÕ«ÜńÜä cudatoolkit ńēłµ£¼’╝ēŃĆé +``` + +### õĖŹõĮ┐ńö© MIM Õ«ēĶŻģ MMEngine + +ĶŗźõĖŹõĮ┐ńö© mim Õ«ēĶŻģ MMEngine’╝īĶ»ĘķüĄÕŠ¬ [ MMEngine Õ«ēĶŻģµīćÕŹŚ](https://mmengine.readthedocs.io/zh_CN/latest/get_started/installation.html). + +õŠŗÕ”é’╝īµé©ÕÅ»õ╗źķĆÜĶ┐ćõ╗źõĖŗÕæĮõ╗żÕ«ēĶŻģ MMEngine: + +```shell +pip install mmengine +``` + +### õĖŹõĮ┐ńö© MIM Õ«ēĶŻģ MMCV + +MMCV ÕīģÕɽ C++ ÕÆī CUDA µē®Õ▒Ģ’╝īÕøĀµŁżÕģČÕ»╣ PyTorch ńÜäõŠØĶĄ¢µ»öĶŠāÕżŹµØéŃĆéMIM õ╝ÜĶć¬ÕŖ©Ķ¦Żµ×ÉĶ┐Öõ║ø +õŠØĶĄ¢’╝īķĆēµŗ®ÕÉłķĆéńÜä MMCV ķóäń╝¢Ķ»æÕīģ’╝īõĮ┐Õ«ēĶŻģµø┤ń«ĆÕŹĢ’╝īõĮåÕ«āÕ╣ČõĖŹµś»Õ┐ģķ£ĆńÜäŃĆé + +ĶŗźõĖŹõĮ┐ńö© mim µØźÕ«ēĶŻģ MMCV’╝īĶ»ĘķüĄńģ¦ [MMCV Õ«ēĶŻģµīćÕŹŚ](https://mmcv.readthedocs.io/zh_CN/2.x/get_started/installation.html)ŃĆé +Õ«āķ£ĆĶ”üµé©ńö©µīćÕ«Ü url ńÜäÕĮóÕ╝ŵēŗÕŖ©µīćÕ«ÜÕ»╣Õ║öńÜä PyTorch ÕÆī CUDA ńēłµ£¼ŃĆé + +õĖŠõĖ¬õŠŗÕŁÉ’╝īÕ”éõĖŗÕæĮõ╗żÕ░åõ╝ÜÕ«ēĶŻģÕ¤║õ║Ä PyTorch 1.10.x ÕÆī CUDA 11.3 ń╝¢Ķ»æńÜä mmcvŃĆé + +```shell +pip install 'mmcv>=2.0.1' -f https://download.openmmlab.com/mmcv/dist/cu113/torch1.10/index.html +``` + +### Õ£© CPU ńÄ»ÕóāõĖŁÕ«ēĶŻģ + +MMPose ÕÅ»õ╗źõ╗ģÕ£© CPU ńÄ»ÕóāõĖŁÕ«ēĶŻģ’╝īÕ£© CPU µ©ĪÕ╝ÅõĖŗ’╝īµé©ÕÅ»õ╗źÕ«īµłÉĶ«Łń╗āŃĆüµĄŗĶ»ĢÕÆīµ©ĪÕ×ŗµÄ©ńÉåńŁēµēƵ£ēµōŹõĮ£ŃĆé + +Õ£© CPU µ©ĪÕ╝ÅõĖŗ’╝īMMCV ńÜäķā©ÕłåÕŖ¤ĶāĮÕ░åõĖŹÕÅ»ńö©’╝īķĆÜÕĖĖµś»õĖĆõ║ø GPU ń╝¢Ķ»æńÜäń«ŚÕŁÉ’╝īÕ”é `Deformable Convolution`ŃĆéMMPose õĖŁÕż¦ķā©ÕłåńÜ䵩ĪÕ×ŗķāĮõĖŹõ╝ÜõŠØĶĄ¢Ķ┐Öõ║øń«ŚÕŁÉ’╝īõĮåµś»Õ”éµ×£µé©Õ░ØĶ»ĢõĮ┐ńö©ÕīģÕɽĶ┐Öõ║øń«ŚÕŁÉńÜ䵩ĪÕ×ŗµØźĶ┐ÉĶĪīĶ«Łń╗āŃĆüµĄŗĶ»Ģµł¢µÄ©ńÉå’╝īÕ░åõ╝ܵŖźķöÖŃĆé + +### Õ£© Google Colab õĖŁÕ«ēĶŻģ + +[Google Colab](https://colab.research.google.com/) ķĆÜÕĖĖÕĘ▓ń╗ÅÕīģÕɽõ║å PyTorch ńÄ»Õóā’╝īÕøĀµŁżµłæõ╗¼ÕŬķ£ĆĶ”üÕ«ēĶŻģ MMEngine, MMCV ÕÆī MMPose ÕŹ│ÕÅ»’╝īÕæĮõ╗żÕ”éõĖŗ’╝Ü + +**ń¼¼ 1 µŁź** õĮ┐ńö© [MIM](https://github.com/open-mmlab/mim) Õ«ēĶŻģ [MMEngine](https://github.com/open-mmlab/mmengine) ÕÆī [MMCV](https://github.com/open-mmlab/mmcv/tree/2.x) + +```shell +!pip3 install openmim +!mim install mmengine +!mim install "mmcv>=2.0.1" +``` + +**ń¼¼ 2 µŁź** õ╗ĵ║ÉńĀüÕ«ēĶŻģ mmpose + +```shell +!git clone https://github.com/open-mmlab/mmpose.git +%cd mmpose +!pip install -e . +``` + +**ń¼¼ 3 µŁź** ķ¬īĶ»ü + +```python +import mmpose +print(mmpose.__version__) +# ķóäµ£¤ĶŠōÕć║’╝Ü 1.1.0 +``` + +```{note} +Õ£© Jupyter õĖŁ’╝īµä¤ÕÅ╣ÕÅĘ `!` ńö©õ║ĵē¦ĶĪīÕż¢ķā©ÕæĮõ╗ż’╝īĶĆī `%cd` µś»õĖĆõĖ¬[ķŁöµ£»ÕæĮõ╗ż](https://ipython.readthedocs.io/en/stable/interactive/magics.html#magic-cd)’╝īńö©õ║ÄÕłćµŹó Python ńÜäÕĘźõĮ£ĶĘ»ÕŠäŃĆé +``` + +### ķĆÜĶ┐ć Docker õĮ┐ńö© MMPose + +MMPose µÅÉõŠø [Dockerfile](https://github.com/open-mmlab/mmpose/blob/master/docker/Dockerfile) +ńö©õ║ĵ×äÕ╗║ķĢ£ÕāÅŃĆéĶ»ĘńĪ«õ┐صé©ńÜä [Docker ńēłµ£¼](https://docs.docker.com/engine/install/) >=19.03ŃĆé + +```shell +# µ×äÕ╗║ķ╗śĶ«żńÜä PyTorch 1.8.0’╝īCUDA 10.1 ńēłµ£¼ķĢ£ÕāÅ +# Õ”éµ×£µé©ÕĖīµ£øõĮ┐ńö©ÕģČõ╗¢ńēłµ£¼’╝īĶ»Ęõ┐«µö╣ Dockerfile +docker build -t mmpose docker/ +``` + +**µ│©µäÅ**’╝ÜĶ»ĘńĪ«õ┐صé©ÕĘ▓ń╗ÅÕ«ēĶŻģõ║å [nvidia-container-toolkit](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html#docker)ŃĆé + +ńö©õ╗źõĖŗÕæĮõ╗żĶ┐ÉĶĪī Docker ķĢ£ÕāÅ’╝Ü + +```shell +docker run --gpus all --shm-size=8g -it -v {DATA_DIR}:/mmpose/data mmpose +``` + +`{DATA_DIR}` µś»µé©µ£¼Õ£░ÕŁśµöŠńö©õ║Ä MMPose Ķ«Łń╗āŃĆüµĄŗĶ»ĢŃĆüµÄ©ńÉåńŁēµĄüń©ŗńÜäµĢ░µŹ«ńø«ÕĮĢŃĆé + +## µĢģķÜ£Ķ¦ŻÕå│ + +Õ”éµ×£µé©Õ£©Õ«ēĶŻģĶ┐ćń©ŗõĖŁķüćÕł░õ║åõ╗Ćõ╣łķŚ«ķóś’╝īĶ»ĘÕģłµ¤źķśģ[ÕĖĖĶ¦üķŚ«ķóś](faq.md)ŃĆéÕ”éµ×£µ▓Īµ£ēµēŠÕł░Ķ¦ŻÕå│µ¢╣µ│Ģ’╝īÕÅ»õ╗źÕ£© GitHub +õĖŖ[µÅÉÕć║ issue](https://github.com/open-mmlab/mmpose/issues/new/choose)ŃĆé diff --git a/internlm_langchain/knowledge_base/MMPose/content/label_studio.md b/internlm_langchain/knowledge_base/MMPose/content/label_studio.md new file mode 100644 index 00000000..94cbd641 --- /dev/null +++ b/internlm_langchain/knowledge_base/MMPose/content/label_studio.md @@ -0,0 +1,76 @@ +# Label Studio µĀćµ│©ÕĘźÕģĘĶĮ¼COCOĶäܵ£¼ + +[Label Studio](https://labelstud.io/) µś»õĖƵ¼ŠÕ╣┐ÕÅŚµ¼óĶ┐ÄńÜäµĘ▒Õ║”ÕŁ”õ╣ĀµĀćµ│©ÕĘźÕģĘ’╝īÕÅ»õ╗źÕ»╣ÕżÜń¦Źõ╗╗ÕŖĪĶ┐øĶĪīµĀćµ│©’╝īńäČĶĆīÕ»╣õ║ÄÕģ│ķö«ńé╣µĀćµ│©’╝īLabel Studio µŚĀµ│Ģńø┤µÄźÕ»╝Õć║µłÉ MMPose µēĆķ£ĆĶ”üńÜä COCO µĀ╝Õ╝ÅŃĆéµ£¼µ¢ćÕ░åõ╗ŗń╗ŹÕ”éõĮĢõĮ┐ńö©Label Studio µĀćµ│©Õģ│ķö«ńé╣µĢ░µŹ«’╝īÕ╣ČÕł®ńö© [labelstudio2coco.py](../../../tools/dataset_converters/labelstudio2coco.py) ÕĘźÕģĘÕ░åÕģČĶĮ¼µŹóõĖ║Ķ«Łń╗āµēĆķ£ĆńÜäµĀ╝Õ╝ÅŃĆé + +## Label Studio µĀćµ│©Ķ”üµ▒é + +µĀ╣µŹ« COCO µĀ╝Õ╝ÅńÜäĶ”üµ▒é’╝īµ»ÅõĖ¬µĀćµ│©ńÜäÕ«×õŠŗõĖŁķāĮķ£ĆĶ”üÕīģÕɽÕģ│ķö«ńé╣ŃĆüÕłåÕē▓ÕÆī bbox ńÜäõ┐Īµü»’╝īńäČĶĆī Label Studio Õ£©µĀćµ│©µŚČõ╝ÜÕ░åĶ┐Öõ║øõ┐Īµü»ÕłåµĢŻÕ£©õĖŹÕÉīńÜäÕ«×õŠŗõĖŁ’╝īÕøĀµŁżķ£ĆĶ”üµīēõĖĆÕ«ÜĶ¦äÕłÖĶ┐øĶĪīµĀćµ│©’╝īµēŹĶāĮµŁŻÕĖĖõĮ┐ńö©ÕÉÄń╗ŁńÜäĶäܵ£¼ŃĆé + +1. µĀćńŁŠµÄźÕÅŻĶ«ŠńĮ« + +Õ»╣õ║ÄõĖĆõĖ¬µ¢░Õ╗║ńÜä Label Studio ķĪ╣ńø«’╝īķ”¢ÕģłĶ”üĶ«ŠńĮ«Õ«āńÜäµĀćńŁŠµÄźÕÅŻŃĆéĶ┐Öķćīķ£ĆĶ”üµ£ēõĖēń¦Źń▒╗Õ×ŗńÜäµĀćµ│©’╝Ü`KeyPointLabels`ŃĆü`PolygonLabels`ŃĆü`RectangleLabels`’╝īÕłåÕł½Õ»╣Õ║ö COCO µĀ╝Õ╝ÅõĖŁńÜä`keypoints`ŃĆü`segmentation`ŃĆü`bbox`ŃĆéõ╗źõĖŗµś»õĖĆõĖ¬µĀćńŁŠµÄźÕÅŻńÜäńż║õŠŗ’╝īÕÅ»õ╗źÕ£©ķĪ╣ńø«ńÜä`Settings`õĖŁµēŠÕł░`Labeling Interface`’╝īńé╣Õć╗`Code`’╝īń▓śĶ┤┤õĮ┐ńö©Ķ»źńż║õŠŗŃĆé + +```xml +
+ +µ£ēõ║øÕģ│ķö«ńé╣’╝łõŠŗÕ”éŌĆ£ÕĘ”µēŗŌĆØ’╝ēÕ£©õĖżõĖ¬µĢ░µŹ«ķøåõĖŁķāĮµ£ēÕ«Üõ╣ē’╝īõĮåÕ«āõ╗¼Õģʵ£ēõĖŹÕÉīńÜäÕ║ÅÕÅĘŃĆéÕģĘõĮōµØźĶ»┤’╝īŌĆ£ÕĘ”µēŗŌĆØÕģ│ķö«ńé╣Õ£© COCO µĢ░µŹ«ķøåõĖŁńÜäÕ║ÅÕÅĘõĖ║ 9’╝īÕ£©AICµĢ░µŹ«ķøåõĖŁńÜäÕ║ÅÕÅĘõĖ║ 5ŃĆ鵣żÕż¢’╝īµ»ÅõĖ¬µĢ░µŹ«ķøåķāĮÕīģÕɽńŗ¼ńē╣ńÜäÕģ│ķö«ńé╣’╝īÕÅ”õĖĆõĖ¬µĢ░µŹ«ķøåõĖŁõĖŹÕŁśÕ£©ŃĆéõŠŗÕ”é’╝īķØóķā©Õģ│ķö«ńé╣’╝łÕ║ÅÕÅĘõĖ║0ŃĆ£4’╝ēõ╗ģÕ£© COCO µĢ░µŹ«ķøåõĖŁÕ«Üõ╣ē’╝īĶĆīŌĆ£Õż┤ķĪČŌĆØ’╝łÕ║ÅÕÅĘõĖ║ 12’╝ēÕÆīŌĆ£ķółķā©ŌĆØ’╝łÕ║ÅÕÅĘõĖ║ 13’╝ēÕģ│ķö«ńé╣õ╗ģÕ£© AIC µĢ░µŹ«ķøåõĖŁÕŁśÕ£©ŃĆéõ╗źõĖŗńÜäń╗┤µü®ÕøŠµśŠńż║õ║åõĖżõĖ¬µĢ░µŹ«ķøåõĖŁÕģ│ķö«ńé╣õ╣ŗķŚ┤ńÜäÕģ│ń│╗ŃĆé + +
+ +µÄźõĖŗµØź’╝īµłæõ╗¼õ╝Üõ╗ŗń╗ŹõĖżń¦ŹµĘĘÕÉłµĢ░µŹ«ķøåńÜäµ¢╣Õ╝Å’╝Ü + +- [Õ░å AIC ÕÉłÕģź COCO µĢ░µŹ«ķøå](#Õ░å-aic-ÕÉłÕģź-coco-µĢ░µŹ«ķøå) +- [ÕÉłÕ╣Č AIC ÕÆī COCO µĢ░µŹ«ķøå](#ÕÉłÕ╣Č-aic-ÕÆī-coco-µĢ░µŹ«ķøå) + +### Õ░å AIC ÕÉłÕģź COCO µĢ░µŹ«ķøå + +Õ”éµ×£ńö©µłĘµā│µÅÉķ½śÕģȵ©ĪÕ×ŗÕ£© COCO µł¢ń▒╗õ╝╝µĢ░µŹ«ķøåõĖŖńÜäµĆ¦ĶāĮ’╝īÕÅ»õ╗źÕ░å AIC µĢ░µŹ«ķøåõĮ£õĖ║ĶŠģÕŖ®µĢ░µŹ«ŃĆ鵣żµŚČÕ║öĶ»źõ╗ģķĆēµŗ® AIC µĢ░µŹ«ķøåõĖŁõĖÄ COCO µĢ░µŹ«ķøåÕģ▒õ║½ńÜäÕģ│ķö«ńé╣’╝īÕ┐ĮńĢźÕģČõĮÖÕģ│ķö«ńé╣ŃĆ鵣żÕż¢’╝īĶ┐śķ£ĆĶ”üÕ░åĶ┐Öõ║øĶó½ķĆēµŗ®ńÜäÕģ│ķö«ńé╣Õ£© AIC µĢ░µŹ«ķøåõĖŁńÜäÕ║ÅÕÅĘĶ┐øĶĪīĶĮ¼µŹó’╝īõ╗źÕī╣ķģŹÕ£© COCO µĢ░µŹ«ķøåõĖŁÕ»╣Õ║öÕģ│ķö«ńé╣ńÜäÕ║ÅÕÅĘŃĆé + +
+ +Õ£©Ķ┐Öń¦ŹµāģÕåĄõĖŗ’╝īµØźĶć¬ COCO ńÜäµĢ░µŹ«õĖŹķ£ĆĶ”üĶ┐øĶĪīĶĮ¼µŹóŃĆ鵣żµŚČ COCO µĢ░µŹ«ķøåÕÅ»ķĆÜĶ┐ćÕ”éõĖŗµ¢╣Õ╝ÅķģŹńĮ«’╝Ü + +```python +dataset_coco = dict( + type='CocoDataset', + data_root='data/coco/', + ann_file='annotations/person_keypoints_train2017.json', + data_prefix=dict(img='train2017/'), + pipeline=[], # `pipeline` Õ║öõĖ║ń®║ÕłŚĶĪ©’╝īÕøĀõĖ║ COCO µĢ░µŹ«õĖŹķ£ĆĶ”üĶĮ¼µŹó +) +``` + +Õ»╣õ║Ä AIC µĢ░µŹ«ķøå’╝īķ£ĆĶ”üĶĮ¼µŹóÕģ│ķö«ńé╣ńÜäķĪ║Õ║ÅŃĆéMMPose µÅÉõŠøõ║åõĖĆõĖ¬ `KeypointConverter` ĶĮ¼µŹóÕÖ©µØźÕ«×ńÄ░Ķ┐ÖõĖĆńé╣ŃĆéõ╗źõĖŗµś»ķģŹńĮ« AIC ÕŁÉµĢ░µŹ«ķøåńÜäńż║õŠŗ’╝Ü + +```python +dataset_aic = dict( + type='AicDataset', + data_root='data/aic/', + ann_file='annotations/aic_train.json', + data_prefix=dict(img='ai_challenger_keypoint_train_20170902/' + 'keypoint_train_images_20170902/'), + pipeline=[ + dict( + type='KeypointConverter', + num_keypoints=17, # õĖÄ COCO µĢ░µŹ«ķøåÕģ│ķö«ńé╣µĢ░õĖĆĶć┤ + mapping=[ # ķ£ĆĶ”üÕłŚÕć║µēƵ£ēÕĖ”ĶĮ¼µŹóÕģ│ķö«ńé╣ńÜäÕ║ÅÕÅĘ + (0, 6), # 0 (AIC õĖŁńÜäÕ║ÅÕÅĘ) -> 6 (COCO õĖŁńÜäÕ║ÅÕÅĘ) + (1, 8), + (2, 10), + (3, 5), + (4, 7), + (5, 9), + (6, 12), + (7, 14), + (8, 16), + (9, 11), + (10, 13), + (11, 15), + ]) + ], +) +``` + +`KeypointConverter` õ╝ÜÕ░åÕĤÕ║ÅÕÅĘÕ£© 0 Õł░ 11 õ╣ŗķŚ┤ńÜäÕģ│ķö«ńé╣ńÜäÕ║ÅÕÅĘĶĮ¼µŹóõĖ║Õ£© 5 Õł░ 16 õ╣ŗķŚ┤ńÜäÕ»╣Õ║öÕ║ÅÕÅĘŃĆéÕÉīµŚČ’╝īÕ£© AIC õĖŁÕ║ÅÕÅĘõĖ║õĖ║ 12 ÕÆī 13 ńÜäÕģ│ķö«ńé╣Õ░åĶó½ÕłĀķÖżŃĆéÕÅ”Õż¢’╝īńø«µĀćÕ║ÅÕÅĘÕ£© 0 Õł░ 4 õ╣ŗķŚ┤ńÜäÕģ│ķö«ńé╣Õ£© `mapping` ÕÅéµĢ░õĖŁµ▓Īµ£ēÕ«Üõ╣ē’╝īĶ┐Öõ║øńé╣Õ░åĶó½Ķ«ŠõĖ║õĖŹÕÅ»Ķ¦ü’╝īÕ╣ČõĖöõĖŹõ╝ÜÕ£©Ķ«Łń╗āõĖŁõĮ┐ńö©ŃĆé + +ÕŁÉµĢ░µŹ«ķøåķāĮÕ«īµłÉķģŹńĮ«ÕÉÄ, µĘĘÕÉłµĢ░µŹ«ķøå `CombinedDataset` ÕÅ»õ╗źķĆÜĶ┐ćÕ”éõĖŗµ¢╣Õ╝ÅķģŹńĮ«: + +```python +dataset = dict( + type='CombinedDataset', + # µĘĘÕÉłµĢ░µŹ«ķøåÕģ│ķö«ńé╣ķĪ║Õ║ÅÕÆī COCO µĢ░µŹ«ķøåńøĖÕÉī’╝ī + # µēĆõ╗źõĮ┐ńö© COCO µĢ░µŹ«ķøåńÜäµÅÅĶ┐░õ┐Īµü» + metainfo=dict(from_file='configs/_base_/datasets/coco.py'), + datasets=[dataset_coco, dataset_aic], + # `train_pipeline` ÕīģÕɽõ║åÕĖĖńö©ńÜäµĢ░µŹ«ķóäÕżäńÉå’╝ī + # µ»öÕ”éÕøŠńēćĶ»╗ÕÅ¢ŃĆüµĢ░µŹ«Õó×Õ╣┐ńŁē + pipeline=train_pipeline, +) +``` + +MMPose µÅÉõŠøõ║åõĖĆõ╗ĮÕ«īµĢ┤ńÜä [ķģŹńĮ«µ¢ćõ╗Č](https://github.com/open-mmlab/mmpose/blob/dev-1.x/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-aic-256x192-merge.py) µØźÕ░å AIC ÕÉłÕģź COCO µĢ░µŹ«ķøåÕ╣Čńö©õ║ÄĶ«Łń╗āńĮæń╗£ŃĆéńö©µłĘÕÅ»õ╗źµ¤źķśģĶ┐ÖõĖ¬µ¢ćõ╗Čõ╗źĶÄĘÕÅ¢µø┤ÕżÜń╗åĶŖé’╝īµł¢ĶĆģÕÅéĶĆāĶ┐ÖõĖ¬µ¢ćõ╗ČµØźµ×äÕ╗║µ¢░ńÜäµĘĘÕÉłµĢ░µŹ«ķøåŃĆé + +### ÕÉłÕ╣Č AIC ÕÆī COCO µĢ░µŹ«ķøå + +Õ░å AIC ÕÉłÕģź COCO µĢ░µŹ«ķøåńÜäĶ┐ćń©ŗõĖŁõĖóÕ╝āõ║åķā©Õłå AIC µĢ░µŹ«ķøåõĖŁńÜäµĀćµ│©õ┐Īµü»ŃĆéÕ”éµ×£ńö©µłĘµā│Ķ”üõĮ┐ńö©õĖżõĖ¬µĢ░µŹ«ķøåõĖŁńÜäµēƵ£ēõ┐Īµü»’╝īÕÅ»õ╗źÕ░åõĖżõĖ¬µĢ░µŹ«ķøåÕÉłÕ╣Č’╝īÕŹ│Õ£©õĖżõĖ¬µĢ░µŹ«ķøåõĖŁÕÅ¢Õģ│ķö«ńé╣ńÜäÕ╣ČķøåŃĆé + +
+ +Õ£©Ķ┐Öń¦ŹµāģÕåĄõĖŗ’╝īCOCO ÕÆī AIC µĢ░µŹ«ķøåķāĮķ£ĆĶ”üõĮ┐ńö© `KeypointConverter` µØźĶ░āµĢ┤Õ«āõ╗¼Õģ│ķö«ńé╣ńÜäķĪ║Õ║Å’╝Ü + +```python +dataset_coco = dict( + type='CocoDataset', + data_root='data/coco/', + ann_file='annotations/person_keypoints_train2017.json', + data_prefix=dict(img='train2017/'), + pipeline=[ + dict( + type='KeypointConverter', + num_keypoints=19, # Õ╣ČķøåõĖŁµ£ē 19 õĖ¬Õģ│ķö«ńé╣ + mapping=[ + (0, 0), + (1, 1), + # ń£üńĢź + (16, 16), + ]) + ]) + +dataset_aic = dict( + type='AicDataset', + data_root='data/aic/', + ann_file='annotations/aic_train.json', + data_prefix=dict(img='ai_challenger_keypoint_train_20170902/' + 'keypoint_train_images_20170902/'), + pipeline=[ + dict( + type='KeypointConverter', + num_keypoints=19, # Õ╣ČķøåõĖŁµ£ē 19 õĖ¬Õģ│ķö«ńé╣ + mapping=[ + (0, 6), + # ń£üńĢź + (12, 17), + (13, 18), + ]) + ], +) +``` + +ÕÉłÕ╣ČÕÉÄńÜäµĢ░µŹ«ķøåµ£ē 19 õĖ¬Õģ│ķö«ńé╣’╝īĶ┐ÖõĖÄ COCO µł¢ AIC µĢ░µŹ«ķøåķāĮõĖŹÕÉī’╝īÕøĀµŁżķ£ĆĶ”üõĖĆõĖ¬µ¢░ńÜäµĢ░µŹ«ķøåµÅÅĶ┐░õ┐Īµü»µ¢ćõ╗ČŃĆé[coco_aic.py](https://github.com/open-mmlab/mmpose/blob/dev-1.x/configs/_base_/datasets/coco_aic.py) µś»õĖĆõĖ¬µÅÅĶ┐░õ┐Īµü»µ¢ćõ╗ČńÜäńż║õŠŗ’╝īÕ«āÕ¤║õ║Ä [coco.py](https://github.com/open-mmlab/mmpose/blob/dev-1.x/configs/_base_/datasets/coco.py) Õ╣ČĶ┐øĶĪīõ║åõ╗źõĖŗÕćĀńé╣õ┐«µö╣: + +- µĘ╗ÕŖĀõ║å AIC µĢ░µŹ«ķøåńÜäµ¢ćń½Āõ┐Īµü»’╝ø +- Õ£© `keypoint_info` õĖŁµĘ╗ÕŖĀõ║åŌĆ£Õż┤ķĪČŌĆØÕÆīŌĆ£ķółķā©ŌĆØĶ┐ÖõĖżõĖ¬ÕŬգ© AIC õĖŁÕ«Üõ╣ēńÜäÕģ│ķö«ńé╣’╝ø +- Õ£© `skeleton_info` õĖŁµĘ╗ÕŖĀõ║åŌĆ£Õż┤ķĪČŌĆØÕÆīŌĆ£ķółķā©ŌĆØķŚ┤ńÜäĶ┐×ń║┐’╝ø +- µŗōÕ▒Ģ `joint_weights` ÕÆī `sigmas` õ╗źµĘ╗ÕŖĀµ¢░Õó×Õģ│ķö«ńé╣ńÜäõ┐Īµü»ŃĆé + +Õ«īµłÉõ╗źõĖŖµŁźķ¬żÕÉÄ’╝īÕÉłÕ╣ȵĢ░µŹ«ķøå `CombinedDataset` ÕÅ»õ╗źķĆÜĶ┐ćõ╗źõĖŗµ¢╣Õ╝ÅķģŹńĮ«’╝Ü + +```python +dataset = dict( + type='CombinedDataset', + # õĮ┐ńö©µ¢░ńÜäµÅÅĶ┐░õ┐Īµü»µ¢ćõ╗Č + metainfo=dict(from_file='configs/_base_/datasets/coco_aic.py'), + datasets=[dataset_coco, dataset_aic], + # `train_pipeline` ÕīģÕɽõ║åÕĖĖńö©ńÜäµĢ░µŹ«ķóäÕżäńÉå’╝ī + # µ»öÕ”éÕøŠńēćĶ»╗ÕÅ¢ŃĆüµĢ░µŹ«Õó×Õ╣┐ńŁē + pipeline=train_pipeline, +) +``` + +µŁżÕż¢’╝īÕ£©õĮ┐ńö©µĘĘÕÉłµĢ░µŹ«ķøåµŚČ’╝īńö▒õ║ÄÕģ│ķö«ńé╣µĢ░ķćÅńÜäÕÅśÕī¢’╝īµ©ĪÕ×ŗńÜäĶŠōÕć║ķĆÜķüōµĢ░õ╣¤Ķ”üÕüÜńøĖÕ║öĶ░āµĢ┤ŃĆéÕ”éµ×£ńö©µłĘńö©µĘĘÕÉłµĢ░µŹ«ķøåĶ«Łń╗āõ║嵩ĪÕ×ŗ’╝īõĮåµś»Ķ”üÕ£© COCO µĢ░µŹ«ķøåõĖŖĶ»äõ╝░µ©ĪÕ×ŗ’╝īÕ░▒ķ£ĆĶ”üõ╗ĵ©ĪÕ×ŗĶŠōÕć║ńÜäÕģ│ķö«ńé╣õĖŁÕÅ¢Õć║õĖĆõĖ¬ÕŁÉķøåµØźÕī╣ķģŹ COCO õĖŁńÜäÕģ│ķö«ńé╣µĀ╝Õ╝ÅŃĆéÕÅ»õ╗źķĆÜĶ┐ć `test_cfg` õĖŁńÜä `output_keypoint_indices` ÕÅéµĢ░Ķć¬Õ«Üõ╣ēµŁżÕŁÉķøåŃĆéĶ┐ÖõĖ¬ [ķģŹńĮ«µ¢ćõ╗Č](https://github.com/open-mmlab/mmpose/blob/dev-1.x/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-aic-256x192-combine.py) Õ▒Ģńż║õ║åÕ”éõĮĢńö© AIC ÕÆī COCO ÕÉłÕ╣ČÕÉÄńÜäµĢ░µŹ«ķøåĶ«Łń╗āµ©ĪÕ×ŗÕ╣ČÕ£© COCO µĢ░µŹ«ķøåõĖŖĶ┐øĶĪīµĄŗĶ»ĢŃĆéńö©µłĘÕÅ»õ╗źµ¤źķśģĶ┐ÖõĖ¬µ¢ćõ╗Čõ╗źĶÄĘÕÅ¢µø┤ÕżÜń╗åĶŖé’╝īµł¢ĶĆģÕÅéĶĆāĶ┐ÖõĖ¬µ¢ćõ╗ČµØźµ×äÕ╗║µ¢░ńÜäµĘĘÕÉłµĢ░µŹ«ķøåŃĆé diff --git a/internlm_langchain/knowledge_base/MMPose/content/model_analysis.md b/internlm_langchain/knowledge_base/MMPose/content/model_analysis.md new file mode 100644 index 00000000..234dc5be --- /dev/null +++ b/internlm_langchain/knowledge_base/MMPose/content/model_analysis.md @@ -0,0 +1,100 @@ +# Model Analysis + +## ń╗¤Ķ«Īµ©ĪÕ×ŗÕÅéµĢ░ķćÅõĖÄĶ«Īń«ŚķćÅ + +MMPose µÅÉõŠøõ║å `tools/analysis_tools/get_flops.py` µØźń╗¤Ķ«Īµ©ĪÕ×ŗńÜäÕÅéµĢ░ķćÅõĖÄĶ«Īń«ŚķćÅŃĆé + +```shell +python tools/analysis_tools/get_flops.py ${CONFIG_FILE} [--shape ${INPUT_SHAPE}] [--cfg-options ${CFG_OPTIONS}] +``` + +ÕÅéµĢ░Ķ»┤µśÄ’╝Ü + +`CONFIG_FILE` : µ©ĪÕ×ŗķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠäŃĆé + +`--shape`: µ©ĪÕ×ŗńÜäĶŠōÕģźÕ╝ĀķćÅÕĮóńŖČŃĆé + +`--input-constructor`: Õ”éµ×£µīćÕ«ÜõĖ║ `batch`’╝īÕ░åõ╝Üńö¤µłÉõĖĆõĖ¬ `batch tensor` µØźĶ«Īń«Ś FLOPsŃĆé + +`--batch-size`’╝ÜÕ”éµ×£ `--input-constructor` µīćÕ«ÜõĖ║ `batch`’╝īÕ░åõ╝Üńö¤µłÉõĖĆõĖ¬ķÜŵ£║ `tensor`’╝īÕĮóńŖČõĖ║ `(batch_size, 3, **input_shape)` µØźĶ«Īń«Ś FLOPsŃĆé + +`--cfg-options`: Õ”éµ×£µīćÕ«Ü’╝īÕÅ»ķĆēńÜä `cfg` ńÜäķö«ÕĆ╝Õ»╣Õ░åõ╝ÜĶó½ÕÉłÕ╣ČÕł░ķģŹńĮ«µ¢ćõ╗ČõĖŁŃĆé + +ńż║õŠŗ’╝Ü + +```shell +python tools/analysis_tools/get_flops.py configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192.py +``` + +ń╗ōµ×£Õ”éõĖŗ’╝Ü + +```text +============================== +Input shape: (1, 3, 256, 192) +Flops: 7.7 GFLOPs +Params: 28.54 M +============================== +``` + +```{note} +ńø«ÕēŹĶ»źÕĘźÕģĘõ╗ŹÕżäõ║ÄÕ«×ķ¬īķśČµ«Ą’╝īµłæõ╗¼õĖŹĶāĮõ┐ØĶ»üń╗¤Ķ«Īń╗ōµ×£ń╗ØÕ»╣µŁŻńĪ«’╝īõĖĆõ║øń«ŚÕŁÉ’╝łµ»öÕ”é GN µł¢Ķć¬Õ«Üõ╣ēń«ŚÕŁÉ’╝ēµ▓Īµ£ēĶó½ń╗¤Ķ«ĪÕł░ FLOPs õĖŁŃĆé +``` + +## Õłåµ×ÉĶ«Łń╗āµŚźÕ┐Ś + +MMPose µÅÉõŠøõ║å `tools/analysis_tools/analyze_logs.py` µØźÕ»╣Ķ«Łń╗āµŚźÕ┐ŚĶ┐øĶĪīń«ĆÕŹĢńÜäÕłåµ×É’╝īÕīģµŗ¼’╝Ü + +- Õ░åµŚźÕ┐Śń╗śÕłČµłÉµŹ¤Õż▒ÕÆīń▓ŠÕ║”µø▓ń║┐ÕøŠ +- ń╗¤Ķ«ĪĶ«Łń╗āķƤÕ║” + +### ń╗śÕłČµŹ¤Õż▒ÕÆīń▓ŠÕ║”µø▓ń║┐ÕøŠ + +Ķ»źÕŖ¤ĶāĮõŠØĶĄ¢õ║Ä `seaborn`’╝īĶ»ĘÕģłĶ┐ÉĶĪī `pip install seaborn` Õ«ēĶŻģõŠØĶĄ¢ÕīģŃĆé + + + +```shell +python tools/analysis_tools/analyze_logs.py plot_curve ${JSON_LOGS} [--keys ${KEYS}] [--title ${TITLE}] [--legend ${LEGEND}] [--backend ${BACKEND}] [--style ${STYLE}] [--out ${OUT_FILE}] +``` + +ńż║õŠŗ’╝Ü + +- ń╗śÕłČµŹ¤Õż▒µø▓ń║┐ + + ```shell + python tools/analysis_tools/analyze_logs.py plot_curve log.json --keys loss_kpt --legend loss_kpt + ``` + +- ń╗śÕłČń▓ŠÕ║”µø▓ń║┐Õ╣ČÕ»╝Õć║õĖ║ PDF µ¢ćõ╗Č + + ```shell + python tools/analysis_tools/analyze_logs.py plot_curve log.json --keys acc_pose --out results.pdf + ``` + +- Õ░åÕżÜõĖ¬µŚźÕ┐Śµ¢ćõ╗Čń╗śÕłČÕ£©ÕÉīõĖĆÕ╝ĀÕøŠõĖŖ + + ```shell + python tools/analysis_tools/analyze_logs.py plot_curve log1.json log2.json --keys loss_kpt --legend run1 run2 --title loss_kpt --out loss_kpt.png + ``` + +### ń╗¤Ķ«ĪĶ«Łń╗āķƤÕ║” + +```shell +python tools/analysis_tools/analyze_logs.py cal_train_time ${JSON_LOGS} [--include-outliers] +``` + +ńż║õŠŗ’╝Ü + +```shell +python tools/analysis_tools/analyze_logs.py cal_train_time log.json +``` + +ń╗ōµ×£Õ”éõĖŗ’╝Ü + +```text +-----Analyze train time of hrnet_w32_256x192.json----- +slowest epoch 56, average time is 0.6924 +fastest epoch 1, average time is 0.6502 +time std over epochs is 0.0085 +average iter time: 0.6688 s/iter +``` diff --git a/internlm_langchain/knowledge_base/MMPose/content/overview.md b/internlm_langchain/knowledge_base/MMPose/content/overview.md new file mode 100644 index 00000000..a790cd3b --- /dev/null +++ b/internlm_langchain/knowledge_base/MMPose/content/overview.md @@ -0,0 +1,76 @@ +# µ”éĶ┐░ + +µ£¼ń½ĀÕ░åÕÉæõĮĀõ╗ŗń╗Ź MMPose ńÜäµĢ┤õĮōµĪåµ×Č’╝īÕ╣ȵÅÉõŠøĶ»”ń╗åńÜäµĢÖń©ŗķōŠµÄźŃĆé + +## õ╗Ćõ╣łµś» MMPose + + + +MMPose µś»õĖƵ¼ŠÕ¤║õ║Ä Pytorch ńÜäÕ¦┐µĆüõ╝░Ķ«ĪÕ╝Ƶ║ÉÕĘźÕģĘń«▒’╝īµś» OpenMMLab ķĪ╣ńø«ńÜ䵳ÉÕæśõ╣ŗõĖĆ’╝īÕīģÕɽõ║åõĖ░Õ»īńÜä 2D ÕżÜõ║║Õ¦┐µĆüõ╝░Ķ«ĪŃĆü2D µēŗķā©Õ¦┐µĆüõ╝░Ķ«ĪŃĆü2D õ║║ĶäĖÕģ│ķö«ńé╣µŻĆµĄŗŃĆü133Õģ│ķö«ńé╣Õģ©Ķ║½õ║║õĮōÕ¦┐µĆüõ╝░Ķ«ĪŃĆüÕŖ©ńē®Õģ│ķö«ńé╣µŻĆµĄŗŃĆüµ£Źķź░Õģ│ķö«ńé╣µŻĆµĄŗńŁēń«Śµ│Ģõ╗źÕÅŖńøĖÕģ│ńÜäń╗äõ╗ČÕÆīµ©ĪÕØŚ’╝īõĖŗķØóµś»Õ«āńÜäµĢ┤õĮōµĪåµ×Č’╝Ü + +MMPose ńö▒ **8** õĖ¬õĖ╗Ķ”üķā©Õłåń╗䵳ɒ╝īapisŃĆüstructuresŃĆüdatasetsŃĆücodecsŃĆümodelsŃĆüengineŃĆüevaluation ÕÆī visualizationŃĆé + +- **apis** µÅÉõŠøńö©õ║ĵ©ĪÕ×ŗµÄ©ńÉåńÜäķ½śń║¦ API + +- **structures** µÅÉõŠø bboxŃĆükeypoint ÕÆī PoseDataSample ńŁēµĢ░µŹ«ń╗ōµ×ä + +- **datasets** µö»µīüńö©õ║ÄÕ¦┐µĆüõ╝░Ķ«ĪńÜäÕÉäń¦ŹµĢ░µŹ«ķøå + + - **transforms** ÕīģÕɽÕÉäń¦ŹµĢ░µŹ«Õó×Õ╝║ÕÅśµŹó + +- **codecs** µÅÉõŠøÕ¦┐µĆüń╝¢Ķ¦ŻńĀüÕÖ©’╝Üń╝¢ńĀüÕÖ©ńö©õ║ÄÕ░åÕ¦┐µĆüõ┐Īµü»’╝łķĆÜÕĖĖõĖ║Õģ│ķö«ńé╣ÕØɵĀć’╝ēń╝¢ńĀüõĖ║µ©ĪÕ×ŗÕŁ”õ╣Āńø«µĀć’╝łÕ”éńāŁÕŖøÕøŠ’╝ē’╝īĶ¦ŻńĀüÕÖ©ÕłÖńö©õ║ÄÕ░嵩ĪÕ×ŗĶŠōÕć║Ķ¦ŻńĀüõĖ║Õ¦┐µĆüõ╝░Ķ«Īń╗ōµ×£ + +- **models** õ╗źµ©ĪÕØŚÕī¢ń╗ōµ×äµÅÉõŠøõ║åÕ¦┐µĆüõ╝░Ķ«Īµ©ĪÕ×ŗńÜäÕÉäń▒╗ń╗äõ╗Č + + - **pose_estimators** Õ«Üõ╣ēõ║åµēƵ£ēÕ¦┐µĆüõ╝░Ķ«Īµ©ĪÕ×ŗń▒╗ + - **data_preprocessors** ńö©õ║ÄķóäÕżäńÉ嵩ĪÕ×ŗńÜäĶŠōÕģźµĢ░µŹ« + - **backbones** ÕīģÕɽÕÉäń¦Źķ¬©Õ╣▓ńĮæń╗£ + - **necks** ÕīģÕɽÕÉäń¦Źµ©ĪÕ×ŗķółķā©ń╗äõ╗Č + - **heads** ÕīģÕɽÕÉäń¦Źµ©ĪÕ×ŗÕż┤ķā© + - **losses** ÕīģÕɽÕÉäń¦ŹµŹ¤Õż▒ÕćĮµĢ░ + +- **engine** ÕīģÕɽõĖÄÕ¦┐µĆüõ╝░Ķ«Īõ╗╗ÕŖĪńøĖÕģ│ńÜäĶ┐ÉĶĪīµŚČń╗äõ╗Č + + - **hooks** µÅÉõŠøĶ┐ÉĶĪīµŚČńÜäÕÉäń¦ŹķÆ®ÕŁÉ + +- **evaluation** µÅÉõŠøÕÉäń¦ŹĶ»äõ╝░µ©ĪÕ×ŗµĆ¦ĶāĮńÜäµīćµĀć + +- **visualization** ńö©õ║ÄÕÅ»Ķ¦åÕī¢Õģ│ķö«ńé╣ķ¬©µ×ČÕÆīńāŁÕŖøÕøŠńŁēõ┐Īµü» + +## Õ”éõĮĢõĮ┐ńö©µ£¼µīćÕŹŚ + +ķÆłÕ»╣õĖŹÕÉīń▒╗Õ×ŗńÜäńö©µłĘ’╝īµłæõ╗¼ÕćåÕżćõ║åĶ»”ń╗åńÜäµīćÕŹŚ’╝Ü + +1. Õ«ēĶŻģĶ»┤µśÄ’╝Ü + + - [Õ«ēĶŻģ](./installation.md) + +2. MMPose ńÜäÕ¤║µ£¼õĮ┐ńö©µ¢╣µ│Ģ’╝Ü + + - [20 ÕłåķƤõĖŖµēŗµĢÖń©ŗ](./guide_to_framework.md) + - [Demos](./demos.md) + - [µ©ĪÕ×ŗµÄ©ńÉå](./user_guides/inference.md) + - [ķģŹńĮ«µ¢ćõ╗Č](./user_guides/configs.md) + - [ÕćåÕżćµĢ░µŹ«ķøå](./user_guides/prepare_datasets.md) + - [Ķ«Łń╗āõĖĵĄŗĶ»Ģ](./user_guides/train_and_test.md) + +3. Õ»╣õ║ÄÕĖīµ£øÕ¤║õ║Ä MMPose Ķ┐øĶĪīÕ╝ĆÕÅæńÜäńĀöń®ČĶĆģÕÆīÕ╝ĆÕÅæĶĆģ’╝Ü + + - [ń╝¢Ķ¦ŻńĀüÕÖ©](./advanced_guides/codecs.md) + - [µĢ░µŹ«µĄü](./advanced_guides/dataflow.md) + - [Õ«×ńÄ░µ¢░µ©ĪÕ×ŗ](./advanced_guides/implement_new_models.md) + - [Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøå](./advanced_guides/customize_datasets.md) + - [Ķć¬Õ«Üõ╣ēµĢ░µŹ«ÕÅśµŹó](./advanced_guides/customize_transforms.md) + - [Ķć¬Õ«Üõ╣ēõ╝śÕī¢ÕÖ©](./advanced_guides/customize_optimizer.md) + - [Ķć¬Õ«Üõ╣ēµŚźÕ┐Ś](./advanced_guides/customize_logging.md) + - [µ©ĪÕ×ŗķā©ńĮ▓](./advanced_guides/how_to_deploy.md) + - [µ©ĪÕ×ŗÕłåµ×ÉÕĘźÕģĘ](./advanced_guides/model_analysis.md) + - [Ķ┐üń¦╗µīćÕŹŚ](./migration.md) + +4. Õ»╣õ║ÄÕĖīµ£øÕŖĀÕģźÕ╝Ƶ║ÉńżŠÕī║’╝īÕÉæ MMPose Ķ┤Īńī«õ╗ŻńĀüńÜäńĀöń®ČĶĆģÕÆīÕ╝ĆÕÅæĶĆģ’╝Ü + + - [ÕÅéõĖÄĶ┤Īńī«õ╗ŻńĀü](./contribution_guide.md) + +5. Õ»╣õ║ÄõĮ┐ńö©Ķ┐ćń©ŗõĖŁńÜäÕĖĖĶ¦üķŚ«ķóś’╝Ü + + - [FAQ](./faq.md) diff --git a/internlm_langchain/knowledge_base/MMPose/content/prepare_datasets.md b/internlm_langchain/knowledge_base/MMPose/content/prepare_datasets.md new file mode 100644 index 00000000..8b7d651e --- /dev/null +++ b/internlm_langchain/knowledge_base/MMPose/content/prepare_datasets.md @@ -0,0 +1,221 @@ +# ÕćåÕżćµĢ░µŹ«ķøå + +Õ£©Ķ┐Öõ╗Įµ¢ćµĪŻÕ░åµīćÕ»╝Õ”éõĮĢõĖ║ MMPose ÕćåÕżćµĢ░µŹ«ķøå’╝īÕīģµŗ¼õĮ┐ńö©ÕåģńĮ«µĢ░µŹ«ķøåŃĆüÕłøÕ╗║Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåŃĆüń╗ōÕÉłµĢ░µŹ«ķøåĶ┐øĶĪīĶ«Łń╗āŃĆüµĄÅĶ¦łÕÆīõĖŗĶĮĮµĢ░µŹ«ķøåŃĆé + +## õĮ┐ńö©ÕåģńĮ«µĢ░µŹ«ķøå + +**µŁźķ¬żõĖĆ**: ÕćåÕżćµĢ░µŹ« + +MMPose µö»µīüÕżÜń¦Źõ╗╗ÕŖĪÕÆīńøĖÕ║öńÜäµĢ░µŹ«ķøåŃĆéõĮĀÕÅ»õ╗źÕ£© [µĢ░µŹ«ķøåõ╗ōÕ║ō](https://mmpose.readthedocs.io/en/latest/dataset_zoo.html) õĖŁµēŠÕł░Õ«āõ╗¼ŃĆéõĖ║õ║åµŁŻńĪ«ÕćåÕżćõĮĀńÜäµĢ░µŹ«’╝īĶ»Ęµīēńģ¦õĮĀķĆēµŗ®ńÜäµĢ░µŹ«ķøåńÜäµīćÕŹŚĶ┐øĶĪīµōŹõĮ£ŃĆé + +**µŁźķ¬żõ║ī**: Õ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁĶ┐øĶĪīµĢ░µŹ«ķøåĶ«ŠńĮ« + +Õ£©Õ╝ĆÕ¦ŗĶ«Łń╗āµł¢Ķ»äõ╝░µ©ĪÕ×ŗõ╣ŗÕēŹ’╝īõĮĀÕ┐ģķĪ╗ķģŹńĮ«µĢ░µŹ«ķøåĶ«ŠńĮ«ŃĆéõ╗ź [`td-hm_hrnet-w32_8xb64-210e_coco-256x192.py`](/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192.py) õĖ║õŠŗ’╝īÕ«āÕÅ»õ╗źńö©õ║ÄÕ£© COCO µĢ░µŹ«ķøåõĖŖĶ«Łń╗āµł¢Ķ»äõ╝░ HRNet Õ¦┐µĆüõ╝░Ķ«ĪÕÖ©ŃĆéõĖŗķØóµłæõ╗¼µĄÅĶ¦łõĖĆõĖŗµĢ░µŹ«ķøåķģŹńĮ«’╝Ü + +- Õ¤║ńĪƵĢ░µŹ«ķøåÕÅéµĢ░ + + ```python + # base dataset settings + dataset_type = 'CocoDataset' + data_mode = 'topdown' + data_root = 'data/coco/' + ``` + + - `dataset_type` µīćիܵĢ░µŹ«ķøåńÜäń▒╗ÕÉŹŃĆéńö©µłĘÕÅ»õ╗źÕÅéĶĆā [µĢ░µŹ«ķøå API](https://mmpose.readthedocs.io/en/latest/api.html#datasets) µØźµēŠÕł░õ╗¢õ╗¼µā│Ķ”üńÜäµĢ░µŹ«ķøåńÜäń▒╗ÕÉŹŃĆé + - `data_mode` Õå│Õ«Üõ║åµĢ░µŹ«ķøåńÜäĶŠōÕć║µĀ╝Õ╝Å’╝īµ£ēõĖżõĖ¬ķĆēķĪ╣ÕÅ»ńö©’╝Ü`'topdown'` ÕÆī `'bottomup'`ŃĆéÕ”éµ×£ `data_mode='topdown'`’╝īµĢ░µŹ«Õģāń┤ĀĶĪ©ńż║õĖĆõĖ¬Õ«×õŠŗÕÅŖÕģČÕ¦┐µĆü’╝øÕÉ”ÕłÖ’╝īõĖĆõĖ¬µĢ░µŹ«Õģāń┤Āõ╗ŻĶĪ©õĖĆÕ╝ĀÕøŠÕāÅ’╝īÕīģÕÉ½ÕżÜõĖ¬Õ«×õŠŗÕÆīÕ¦┐µĆüŃĆé + - `data_root` µīćիܵĢ░µŹ«ķøåńÜäµĀ╣ńø«ÕĮĢŃĆé + +- µĢ░µŹ«ÕżäńÉåµĄüń©ŗ + + ```python + # pipelines + train_pipeline = [ + dict(type='LoadImage'), + dict(type='GetBBoxCenterScale'), + dict(type='RandomFlip', direction='horizontal'), + dict(type='RandomHalfBody'), + dict(type='RandomBBoxTransform'), + dict(type='TopdownAffine', input_size=codec['input_size']), + dict(type='GenerateTarget', encoder=codec), + dict(type='PackPoseInputs') + ] + val_pipeline = [ + dict(type='LoadImage'), + dict(type='GetBBoxCenterScale'), + dict(type='TopdownAffine', input_size=codec['input_size']), + dict(type='PackPoseInputs') + ] + ``` + + `train_pipeline` ÕÆī `val_pipeline` ÕłåÕł½Õ«Üõ╣ēõ║åĶ«Łń╗āÕÆīĶ»äõ╝░ķśČµ«ĄÕżäńÉåµĢ░µŹ«Õģāń┤ĀńÜ䵣źķ¬żŃĆéķÖżõ║åÕŖĀĶĮĮÕøŠÕāÅÕÆīµēōÕīģĶŠōÕģźõ╣ŗÕż¢’╝ī`train_pipeline` õĖ╗Ķ”üÕīģÕɽµĢ░µŹ«Õó×Õ╝║µŖƵ£»ÕÆīńø«µĀćńö¤µłÉÕÖ©’╝īĶĆī `val_pipeline` ÕłÖõĖōµ│©õ║ÄÕ░åµĢ░µŹ«Õģāń┤ĀĶĮ¼µŹóõĖ║ń╗¤õĖĆńÜäµĀ╝Õ╝ÅŃĆé + +- µĢ░µŹ«ÕŖĀĶĮĮÕÖ© + + ```python + # data loaders + train_dataloader = dict( + batch_size=64, + num_workers=2, + persistent_workers=True, + sampler=dict(type='DefaultSampler', shuffle=True), + dataset=dict( + type=dataset_type, + data_root=data_root, + data_mode=data_mode, + ann_file='annotations/person_keypoints_train2017.json', + data_prefix=dict(img='train2017/'), + pipeline=train_pipeline, + )) + val_dataloader = dict( + batch_size=32, + num_workers=2, + persistent_workers=True, + drop_last=False, + sampler=dict(type='DefaultSampler', shuffle=False, round_up=False), + dataset=dict( + type=dataset_type, + data_root=data_root, + data_mode=data_mode, + ann_file='annotations/person_keypoints_val2017.json', + bbox_file='data/coco/person_detection_results/' + 'COCO_val2017_detections_AP_H_56_person.json', + data_prefix=dict(img='val2017/'), + test_mode=True, + pipeline=val_pipeline, + )) + test_dataloader = val_dataloader + ``` + + Ķ┐ÖõĖ¬ķā©Õłåµś»ķģŹńĮ«µĢ░µŹ«ķøåńÜäÕģ│ķö«ŃĆéķÖżõ║åÕēŹķØóĶ«©Ķ«║Ķ┐ćńÜäÕ¤║ńĪƵĢ░µŹ«ķøåÕÅéµĢ░ÕÆīµĢ░µŹ«ÕżäńÉåµĄüń©ŗõ╣ŗÕż¢’╝īĶ┐ÖķćīĶ┐śÕ«Üõ╣ēõ║åÕģČõ╗¢ķćŹĶ”üńÜäÕÅéµĢ░ŃĆé`batch_size` Õå│Õ«Üõ║åµ»ÅõĖ¬ GPU ńÜä batch size’╝ø`ann_file` µīćÕ«Üõ║åµĢ░µŹ«ķøåńÜäµ│©ķćŖµ¢ćõ╗Č’╝ø`data_prefix` µīćÕ«Üõ║åÕøŠÕāŵ¢ćõ╗ČÕż╣ŃĆé`bbox_file` õ╗ģÕ£© top-down µĢ░µŹ«ķøåńÜä val/test µĢ░µŹ«ÕŖĀĶĮĮÕÖ©õĖŁõĮ┐ńö©’╝īńö©õ║ĵÅÉõŠøµŻĆµĄŗÕł░ńÜäĶŠ╣ńĢīµĪåõ┐Īµü»ŃĆé + +µłæõ╗¼µÄ©ĶŹÉõ╗ÄõĮ┐ńö©ńøĖÕÉīµĢ░µŹ«ķøåńÜäķģŹńĮ«µ¢ćõ╗ČõĖŁÕżŹÕłČµĢ░µŹ«ķøåķģŹńĮ«’╝īĶĆīõĖŹµś»õ╗ÄÕż┤Õ╝ĆÕ¦ŗń╝¢ÕåÖ’╝īõ╗źµ£ĆÕ░ÅÕī¢µĮ£Õ£©ńÜäķöÖĶ»»ŃĆéķĆÜĶ┐ćĶ┐ÖµĀĘÕüÜ’╝īńö©µłĘÕÅ»õ╗źµĀ╣µŹ«ķ£ĆĶ”üĶ┐øĶĪīÕ┐ģĶ”üńÜäõ┐«µö╣’╝īõ╗ÄĶĆīńĪ«õ┐صø┤ÕÅ»ķØĀÕÆīķ½śµĢłńÜäĶ«ŠńĮ«Ķ┐ćń©ŗŃĆé + +## õĮ┐ńö©Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøå + +[Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøå](../advanced_guides/customize_datasets.md) µīćÕŹŚµÅÉõŠøõ║åÕ”éõĮĢµ×äÕ╗║Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåńÜäĶ»”ń╗åõ┐Īµü»ŃĆéÕ£©µ£¼ĶŖéõĖŁ’╝īµłæõ╗¼Õ░åÕ╝║Ķ░āõĖĆõ║øõĮ┐ńö©ÕÆīķģŹńĮ«Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåńÜäÕģ│ķö«µŖĆÕʦŃĆé + +- ńĪ«Õ«ÜµĢ░µŹ«ķøåń▒╗ÕÉŹŃĆéÕ”éµ×£õĮĀÕ░åµĢ░µŹ«ķøåķćŹń╗äõĖ║ COCO µĀ╝Õ╝Å’╝īõĮĀÕÅ»õ╗źń«ĆÕŹĢÕ£░õĮ┐ńö© `CocoDataset` õĮ£õĖ║ `dataset_type` ńÜäÕĆ╝ŃĆéÕÉ”ÕłÖ’╝īõĮĀÕ░åķ£ĆĶ”üõĮ┐ńö©õĮĀµĘ╗ÕŖĀńÜäĶć¬Õ«Üõ╣ēµĢ░µŹ«ķøåń▒╗ńÜäÕÉŹń¦░ŃĆé + +- µīćÕ«ÜÕģāõ┐Īµü»ķģŹńĮ«µ¢ćõ╗ČŃĆéMMPose 1.x ķććńö©õ║åõĖÄ MMPose 0.x õĖŹÕÉīńÜäńŁ¢ńĢźµØźµīćÕ«ÜÕģāõ┐Īµü»ŃĆéÕ£© MMPose 1.x õĖŁ’╝īńö©µłĘÕÅ»õ╗źµīēńģ¦õ╗źõĖŗµ¢╣Õ╝ŵīćÕ«ÜÕģāõ┐Īµü»ķģŹńĮ«µ¢ćõ╗Č’╝Ü + + ```python + train_dataloader = dict( + ... + dataset=dict( + type=dataset_type, + data_root='root/of/your/train/data', + ann_file='path/to/your/train/json', + data_prefix=dict(img='path/to/your/train/img'), + # specify dataset meta information + metainfo=dict(from_file='configs/_base_/datasets/custom.py'), + ...), + ) + ``` + + µ│©µäÅ’╝ī`metainfo` ÕÅéµĢ░Õ┐ģķĪ╗Õ£© val/test µĢ░µŹ«ÕŖĀĶĮĮÕÖ©õĖŁµīćÕ«ÜŃĆé + +## õĮ┐ńö©µĘĘÕÉłµĢ░µŹ«ķøåĶ┐øĶĪīĶ«Łń╗ā + +MMPose µÅÉõŠøõ║åõĖĆõĖ¬µ¢╣õŠ┐õĖöÕżÜÕŖ¤ĶāĮńÜäĶ¦ŻÕå│µ¢╣µĪł’╝īńö©õ║ÄĶ«Łń╗āµĘĘÕÉłµĢ░µŹ«ķøåŃĆéĶ»ĘÕÅéĶĆā[µĘĘÕÉłµĢ░µŹ«ķøåĶ«Łń╗ā](./mixed_datasets.md)ŃĆé + +## µĄÅĶ¦łµĢ░µŹ«ķøå + +`tools/analysis_tools/browse_dataset.py` ÕĖ«ÕŖ®ńö©µłĘÕÅ»Ķ¦åÕī¢Õ£░µĄÅĶ¦łÕ¦┐µĆüµĢ░µŹ«ķøå’╝īµł¢Õ░åÕøŠÕāÅõ┐ØÕŁśÕł░µīćÕ«ÜńÜäńø«ÕĮĢŃĆé + +```shell +python tools/misc/browse_dataset.py ${CONFIG} [-h] [--output-dir ${OUTPUT_DIR}] [--not-show] [--phase ${PHASE}] [--mode ${MODE}] [--show-interval ${SHOW_INTERVAL}] +``` + +| ARGS | Description | +| -------------------------------- | ---------------------------------------------------------------------------------------------------------- | +| `CONFIG` | ķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠä | +| `--output-dir OUTPUT_DIR` | õ┐ØÕŁśÕÅ»Ķ¦åÕī¢ń╗ōµ×£ńÜäńø«µĀćµ¢ćõ╗ČÕż╣ŃĆéÕ”éµ×£õĖŹµīćÕ«Ü’╝īÕÅ»Ķ¦åÕī¢ńÜäń╗ōµ×£Õ░åõĖŹõ╝ÜĶó½õ┐ØÕŁś | +| `--not-show` | õĖŹķĆéńö©Õż¢ķā©ń¬ŚÕÅŻµśŠńż║ÕÅ»Ķ¦åÕī¢ńÜäń╗ōµ×£ | +| `--phase {train, val, test}` | µĢ░µŹ«ķøåķĆēķĪ╣ | +| `--mode {original, transformed}` | µīćÕ«ÜÕÅ»Ķ¦åÕī¢ÕøŠńēćń▒╗Õ×ŗŃĆé `original` õĖ║õĖŹõĮ┐ńö©µĢ░µŹ«Õó×Õ╝║ńÜäÕĤզŗÕøŠńēćÕÅŖµĀćµ│©ÕÅ»Ķ¦åÕī¢; `transformed` õĖ║ń╗ÅĶ┐ćÕó×Õ╝║ÕÉÄńÜäÕÅ»Ķ¦åÕī¢ | +| `--show-interval SHOW_INTERVAL` | µśŠńż║ÕøŠńēćńÜ䵌ČķŚ┤ķŚ┤ķÜö | + +õŠŗÕ”é’╝īńö©µłĘµā│Ķ”üÕÅ»Ķ¦åÕī¢ COCO µĢ░µŹ«ķøåõĖŁńÜäÕøŠÕāÅÕÆīµĀćµ│©’╝īÕÅ»õ╗źõĮ┐ńö©’╝Ü + +```shell +python tools/misc/browse_dataset.py configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-e210_coco-256x192.py --mode original +``` + +µŻĆµĄŗµĪåÕÆīÕģ│ķö«ńé╣Õ░åĶó½ń╗śÕłČÕ£©ÕĤզŗÕøŠÕāÅõĖŖŃĆéõĖŗķØ󵜻õĖĆõĖ¬õŠŗÕŁÉ’╝Ü + + +ÕĤզŗÕøŠÕāÅÕ£©Ķó½ĶŠōÕģźµ©ĪÕ×ŗõ╣ŗÕēŹķ£ĆĶ”üĶó½ÕżäńÉåŃĆéõĖ║õ║åÕÅ»Ķ¦åÕī¢ķóäÕżäńÉåÕÉÄńÜäÕøŠÕāÅÕÆīµĀćµ│©’╝īńö©µłĘķ£ĆĶ”üÕ░åÕÅéµĢ░ `mode` õ┐«µö╣õĖ║ `transformed`ŃĆéõŠŗÕ”é’╝Ü + +```shell +python tools/misc/browse_dataset.py configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-e210_coco-256x192.py --mode transformed +``` + +Ķ┐Öµś»õĖĆõĖ¬ÕżäńÉåÕÉÄńÜäµĀʵ£¼’╝Ü + + + +ńāŁÕøŠńø«µĀćÕ░åõĖÄõ╣ŗõĖĆĶĄĘÕÅ»Ķ¦åÕī¢’╝īÕ”éµ×£Õ«āµś»Õ£© pipeline õĖŁńö¤µłÉńÜäŃĆé + +## ńö© MIM õĖŗĶĮĮµĢ░µŹ«ķøå + +ķĆÜĶ┐ćõĮ┐ńö© [OpenDataLab](https://opendatalab.com/)’╝īµé©ÕÅ»õ╗źńø┤µÄźõĖŗĶĮĮÕ╝Ƶ║ɵĢ░µŹ«ķøåŃĆéķĆÜĶ┐ćÕ╣│ÕÅ░ńÜäµÉ£ń┤óÕŖ¤ĶāĮ’╝īµé©ÕÅ»õ╗źÕ┐½ķƤĶĮ╗µØŠÕ£░µēŠÕł░õ╗¢õ╗¼µŁŻÕ£©Õ»╗µēŠńÜäµĢ░µŹ«ķøåŃĆéõĮ┐ńö©Õ╣│ÕÅ░õĖŖńÜäµĀ╝Õ╝ÅÕī¢µĢ░µŹ«ķøå’╝īµé©ÕÅ»õ╗źķ½śµĢłÕ£░ĶĘ©µĢ░µŹ«ķøåµē¦ĶĪīõ╗╗ÕŖĪŃĆé + +Õ”éµ×£µé©õĮ┐ńö© MIM õĖŗĶĮĮ’╝īĶ»ĘńĪ«õ┐Øńēłµ£¼Õż¦õ║Ä v0.3.8ŃĆéµé©ÕÅ»õ╗źõĮ┐ńö©õ╗źõĖŗÕæĮõ╗żĶ┐øĶĪīµø┤µ¢░ŃĆüÕ«ēĶŻģŃĆüńÖ╗ÕĮĢÕÆīµĢ░µŹ«ķøåõĖŗĶĮĮ’╝Ü + +```shell +# upgrade your MIM +pip install -U openmim + +# install OpenDataLab CLI tools +pip install -U opendatalab +# log in OpenDataLab, registry +odl login + +# download coco2017 and preprocess by MIM +mim download mmpose --dataset coco2017 +``` + +### ÕĘ▓µö»µīüńÜäµĢ░µŹ«ķøå + +õĖŗķØ󵜻µö»µīüńÜäµĢ░µŹ«ķøåÕłŚĶĪ©’╝īµø┤ÕżÜµĢ░µŹ«ķøåÕ░åÕ£©õ╣ŗÕÉĵīüń╗Łµø┤µ¢░’╝Ü + +#### õ║║õĮōµĢ░µŹ«ķøå + +| Dataset name | Download command | +| ------------- | ----------------------------------------- | +| COCO 2017 | `mim download mmpose --dataset coco2017` | +| MPII | `mim download mmpose --dataset mpii` | +| AI Challenger | `mim download mmpose --dataset aic` | +| CrowdPose | `mim download mmpose --dataset crowdpose` | + +#### õ║║ĶäĖµĢ░µŹ«ķøå + +| Dataset name | Download command | +| ------------ | ------------------------------------ | +| LaPa | `mim download mmpose --dataset lapa` | +| 300W | `mim download mmpose --dataset 300w` | +| WFLW | `mim download mmpose --dataset wflw` | + +#### µēŗķā©µĢ░µŹ«ķøå + +| Dataset name | Download command | +| ------------ | ------------------------------------------ | +| OneHand10K | `mim download mmpose --dataset onehand10k` | +| FreiHand | `mim download mmpose --dataset freihand` | +| HaGRID | `mim download mmpose --dataset hagrid` | + +#### Õģ©Ķ║½µĢ░µŹ«ķøå + +| Dataset name | Download command | +| ------------ | ------------------------------------- | +| Halpe | `mim download mmpose --dataset halpe` | + +#### ÕŖ©ńē®µĢ░µŹ«ķøå + +| Dataset name | Download command | +| ------------ | ------------------------------------- | +| AP-10K | `mim download mmpose --dataset ap10k` | + +#### µ£ŹĶŻģµĢ░µŹ«ķøå + +Coming Soon diff --git a/internlm_langchain/knowledge_base/MMPose/content/projects.md b/internlm_langchain/knowledge_base/MMPose/content/projects.md new file mode 100644 index 00000000..460d8583 --- /dev/null +++ b/internlm_langchain/knowledge_base/MMPose/content/projects.md @@ -0,0 +1,20 @@ +# Projects based on MMPose + +There are many projects built upon MMPose. We list some of them as examples of how to extend MMPose for your own projects. As the page might not be completed, please feel free to create a PR to update this page. + +## Projects as an extension + +Some projects extend the boundary of MMPose for deployment or other research fields. They reveal the potential of what MMPose can do. We list several of them as below. + +- [Anime Face Detector](https://github.com/hysts/anime-face-detector): An anime face landmark detection toolbox. +- [PosePipeline](https://github.com/peabody124/PosePipeline): Open-Source Human Pose Estimation Pipeline for Clinical Research + +## Projects of papers + +There are also projects released with papers. Some of the papers are published in top-tier conferences (CVPR, ICCV, and ECCV), the others are also highly influential. We list some of these works as a reference for the community to develop and compare new pose estimation algorithms. Methods already supported and maintained by MMPose are not listed. + +- Pose for Everything: Towards Category-Agnostic Pose Estimation, ECCV 2022. [\[paper\]](https://arxiv.org/abs/2207.10387)[\[github\]](https://github.com/luminxu/Pose-for-Everything) +- UniFormer: Unified Transformer for Efficient Spatiotemporal Representation Learning, ICLR 2022. [\[paper\]](https://arxiv.org/abs/2201.04676)[\[github\]](https://github.com/Sense-X/UniFormer) +- Poseur:Direct Human Pose Regression with Transformers, ECCV 2022. [\[paper\]](https://arxiv.org/abs/2201.07412)[\[github\]](https://github.com/aim-uofa/Poseur) +- ViTAEv2: Vision Transformer Advanced by Exploring Inductive Bias for Image Recognition and Beyond, NeurIPS 2022. [\[paper\]](https://arxiv.org/abs/2106.03348)[\[github\]](https://github.com/ViTAE-Transformer/ViTAE-Transformer) +- Dite-HRNet:Dynamic Lightweight High-Resolution Network for Human Pose Estimation, IJCAI-ECAI 2021. [\[paper\]](https://arxiv.org/abs/2204.10762)[\[github\]](https://github.com/ZiyiZhang27/Dite-HRNet) diff --git a/internlm_langchain/knowledge_base/MMPose/content/pytorch_2.md b/internlm_langchain/knowledge_base/MMPose/content/pytorch_2.md new file mode 100644 index 00000000..4892e554 --- /dev/null +++ b/internlm_langchain/knowledge_base/MMPose/content/pytorch_2.md @@ -0,0 +1,14 @@ +# PyTorch 2.0 Compatibility and Benchmarks + +MMPose 1.0.0 is now compatible with PyTorch 2.0, ensuring that users can leverage the latest features and performance improvements offered by the PyTorch 2.0 framework when using MMPose. With the integration of inductor, users can expect faster model speeds. The table below shows several example models: + +| Model | Training Speed | Memory | +| :-------- | :---------------------: | :-----------: | +| ViTPose-B | 29.6% Ōåæ (0.931 ŌåÆ 0.655) | 10586 ŌåÆ 10663 | +| ViTPose-S | 33.7% Ōåæ (0.563 ŌåÆ 0.373) | 6091 ŌåÆ 6170 | +| HRNet-w32 | 12.8% Ōåæ (0.553 ŌåÆ 0.482) | 9849 ŌåÆ 10145 | +| HRNet-w48 | 37.1% Ōåæ (0.437 ŌåÆ 0.275) | 7319 ŌåÆ 7394 | +| RTMPose-t | 6.3% Ōåæ (1.533 ŌåÆ 1.437) | 6292 ŌåÆ 6489 | +| RTMPose-s | 13.1% Ōåæ (1.645 ŌåÆ 1.430) | 9013 ŌåÆ 9208 | + +- Pytorch 2.0 test, add projects doc and refactor by @LareinaM in [PR#2136](https://github.com/open-mmlab/mmpose/pull/2136) diff --git a/internlm_langchain/knowledge_base/MMPose/content/quick_run.md b/internlm_langchain/knowledge_base/MMPose/content/quick_run.md new file mode 100644 index 00000000..55c2d63b --- /dev/null +++ b/internlm_langchain/knowledge_base/MMPose/content/quick_run.md @@ -0,0 +1,188 @@ +# Õ┐½ķƤõĖŖµēŗ + +Õ£©Ķ┐ÖõĖĆń½Āķćī’╝īµłæõ╗¼Õ░åÕĖ”ķóåõĮĀĶĄ░Ķ┐ćMMPoseÕĘźõĮ£µĄüń©ŗõĖŁÕģ│ķö«ńÜäõĖāõĖ¬µŁźķ¬ż’╝īÕĖ«ÕŖ®õĮĀÕ┐½ķƤõĖŖµēŗ’╝Ü + +1. õĮ┐ńö©ķóäĶ«Łń╗āµ©ĪÕ×ŗĶ┐øĶĪīµÄ©ńÉå +2. ÕćåÕżćµĢ░µŹ«ķøå +3. ÕćåÕżćķģŹńĮ«µ¢ćõ╗Č +4. ÕÅ»Ķ¦åÕī¢Ķ«Łń╗āÕøŠńēć +5. Ķ«Łń╗ā +6. µĄŗĶ»Ģ +7. ÕÅ»Ķ¦åÕī¢ + +## Õ«ēĶŻģ + +Ķ»Ęµ¤źń£ŗ[Õ«ēĶŻģµīćÕŹŚ](./installation.md)’╝īõ╗źõ║åĶ¦ŻÕ«īµĢ┤µŁźķ¬żŃĆé + +## Õ┐½ķƤÕ╝ĆÕ¦ŗ + +### õĮ┐ńö©ķóäĶ«Łń╗āµ©ĪÕ×ŗĶ┐øĶĪīµÄ©ńÉå + +õĮĀÕÅ»õ╗źķĆÜĶ┐ćõ╗źõĖŗÕæĮõ╗żµØźõĮ┐ńö©ķóäĶ«Łń╗āµ©ĪÕ×ŗÕ»╣ÕŹĢÕ╝ĀÕøŠńēćĶ┐øĶĪīĶ»åÕł½’╝Ü + +```Bash +python demo/image_demo.py \ + tests/data/coco/000000000785.jpg \ + configs/body_2d_keypoint/topdown_regression/coco/td-reg_res50_rle-8xb64-210e_coco-256x192.py\ + https://download.openmmlab.com/mmpose/top_down/deeppose/deeppose_res50_coco_256x192_rle-2ea9bb4a_20220616.pth +``` + +Ķ»źÕæĮõ╗żõĖŁńö©Õł░õ║åµĄŗĶ»ĢÕøŠńēćŃĆüÕ«īµĢ┤ńÜäķģŹńĮ«µ¢ćõ╗ČŃĆüķóäĶ«Łń╗āµ©ĪÕ×ŗ’╝īÕ”éµ×£MMPoseÕ«ēĶŻģµŚĀĶ»»’╝īÕ░åõ╝ÜÕ╝╣Õć║õĖĆõĖ¬µ¢░ń¬ŚÕÅŻ’╝īÕ»╣µŻĆµĄŗń╗ōµ×£Ķ┐øĶĪīÕÅ»Ķ¦åÕī¢µśŠńż║’╝Ü + + + +µø┤ÕżÜµ╝öńż║Ķäܵ£¼ńÜäĶ»”ń╗åÕÅéµĢ░Ķ»┤µśÄÕÅ»õ╗źÕ£© [µ©ĪÕ×ŗµÄ©ńÉå](./user_guides/inference.md) õĖŁµēŠÕł░ŃĆé + +### ÕćåÕżćµĢ░µŹ«ķøå + +MMPoseµö»µīüÕÉäń¦ŹõĖŹÕÉīńÜäõ╗╗ÕŖĪ’╝īµłæõ╗¼µÅÉõŠøõ║åÕ»╣Õ║öńÜäµĢ░µŹ«ķøåÕćåÕżćµĢÖń©ŗŃĆé + +- [2Dõ║║õĮōÕģ│ķö«ńé╣](./dataset_zoo/2d_body_keypoint.md) + +- [3Dõ║║õĮōÕģ│ķö«ńé╣](./dataset_zoo/3d_body_keypoint.md) + +- [2Dõ║║µēŗÕģ│ķö«ńé╣](./dataset_zoo/2d_hand_keypoint.md) + +- [3Dõ║║µēŗÕģ│ķö«ńé╣](./dataset_zoo/3d_hand_keypoint.md) + +- [2Dõ║║ĶäĖÕģ│ķö«ńé╣](./dataset_zoo/2d_face_keypoint.md) + +- [2DÕģ©Ķ║½õ║║õĮōÕģ│ķö«ńé╣](./dataset_zoo/2d_wholebody_keypoint.md) + +- [2Dµ£Źķź░Õģ│ķö«ńé╣](./dataset_zoo/2d_fashion_landmark.md) + +- [2DÕŖ©ńē®Õģ│ķö«ńé╣](./dataset_zoo/2d_animal_keypoint.md) + +õĮĀÕÅ»õ╗źÕ£©ŃĆÉ2Dõ║║õĮōÕģ│ķö«ńé╣µĢ░µŹ«ķøåŃĆæ>ŃĆÉCOCOŃĆæõĖŗµēŠÕł░COCOµĢ░µŹ«ķøåńÜäÕćåÕżćµĢÖń©ŗ’╝īÕ╣ȵīēńģ¦µĢÖń©ŗÕ«īµłÉµĢ░µŹ«ķøåńÜäõĖŗĶĮĮÕÆīµĢ┤ńÉåŃĆé + +```{note} +Õ£©MMPoseõĖŁ’╝īµłæõ╗¼Õ╗║Ķ««Õ░åCOCOµĢ░µŹ«ķøåÕŁśµöŠÕł░µ¢░Õ╗║ńÜä `$MMPOSE/data` ńø«ÕĮĢõĖŗŃĆé +``` + +### ÕćåÕżćķģŹńĮ«µ¢ćõ╗Č + +MMPoseµŗźµ£ēõĖĆÕźŚÕ╝║Õż¦ńÜäķģŹńĮ«ń│╗ń╗¤’╝īńö©õ║Äń«ĪńÉåĶ«Łń╗āµēĆķ£ĆńÜäõĖĆń│╗ÕłŚÕ┐ģĶ”üÕÅéµĢ░’╝Ü + +- **ķĆÜńö©**’╝ÜńÄ»ÕóāŃĆüHookŃĆüCheckpointŃĆüLoggerŃĆüTimerńŁē + +- **µĢ░µŹ«**’╝ÜDatasetŃĆüDataloaderŃĆüµĢ░µŹ«Õó×Õ╝║ńŁē + +- **Ķ«Łń╗ā**’╝Üõ╝śÕī¢ÕÖ©ŃĆüÕŁ”õ╣ĀńÄćĶ░āµĢ┤ńŁē + +- **µ©ĪÕ×ŗ**’╝ÜBackboneŃĆüNeckŃĆüHeadŃĆüµŹ¤Õż▒ÕćĮµĢ░ńŁē + +- **Ķ»äµĄŗ**’╝ÜMetrics + +Õ£©`$MMPOSE/configs`ńø«ÕĮĢõĖŗ’╝īµłæõ╗¼µÅÉõŠøõ║åÕż¦ķćÅÕēŹµ▓┐Ķ«║µ¢ćµ¢╣µ│ĢńÜäķģŹńĮ«µ¢ćõ╗Č’╝īÕÅ»õŠøńø┤µÄźõĮ┐ńö©ÕÆīÕÅéĶĆāŃĆé + +Ķ”üÕ£©COCOµĢ░µŹ«ķøåõĖŖĶ«Łń╗āÕ¤║õ║ÄResNet50ńÜäRLEµ©ĪÕ×ŗµŚČ’╝īµēĆķ£ĆńÜäķģŹńĮ«µ¢ćõ╗ČõĖ║’╝Ü + +```Bash +$MMPOSE/configs/body_2d_keypoint/topdown_regression/coco/td-reg_res50_rle-8xb64-210e_coco-256x192.py +``` + +µłæõ╗¼ķ£ĆĶ”üÕ░åķģŹńĮ«µ¢ćõ╗ČõĖŁńÜä data_root ÕÅśķćÅõ┐«µö╣õĖ║COCOµĢ░µŹ«ķøåÕŁśµöŠĶĘ»ÕŠä’╝Ü + +```Python +data_root = 'data/coco' +``` + +```{note} +µä¤Õģ┤ĶČŻńÜäĶ»╗ĶĆģõ╣¤ÕÅ»õ╗źµ¤źķśģ [ķģŹńĮ«µ¢ćõ╗Č](./user_guides/configs.md) µØźĶ┐øõĖƵŁźÕŁ”õ╣ĀMMPoseµēĆõĮ┐ńö©ńÜäķģŹńĮ«ń│╗ń╗¤ŃĆé +``` + +### ÕÅ»Ķ¦åÕī¢Ķ«Łń╗āÕøŠńēć + +Õ£©Õ╝ĆÕ¦ŗĶ«Łń╗āõ╣ŗÕēŹ’╝īµłæõ╗¼Ķ┐śÕÅ»õ╗źÕ»╣Ķ«Łń╗āÕøŠńēćĶ┐øĶĪīÕÅ»Ķ¦åÕī¢’╝īµŻĆµ¤źĶ«Łń╗āÕøŠńē浜»ÕÉ”µŁŻńĪ«Ķ┐øĶĪīõ║åµĢ░µŹ«Õó×Õ╝║ŃĆé + +µłæõ╗¼µÅÉõŠøõ║åńøĖÕ║öńÜäÕÅ»Ķ¦åÕī¢Ķäܵ£¼’╝Ü + +```Bash +python tools/misc/browse_dastaset.py \ + configs/body_2d_keypoint/topdown_regression/coco/td-reg_res50_rle-8xb64-210e_coco-256x192.py \ + --mode transformed +``` + + + +### Ķ«Łń╗ā + +ńĪ«Õ«ÜµĢ░µŹ«µŚĀĶ»»ÕÉÄ’╝īĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗żÕÉ»ÕŖ©Ķ«Łń╗ā’╝Ü + +```Bash +python tools/train.py configs/body_2d_keypoint/topdown_regression/coco/td-reg_res50_rle-8xb64-210e_coco-256x192.py +``` + +```{note} +MMPoseõĖŁķøåµłÉõ║åÕż¦ķćÅÕ«×ńö©Ķ«Łń╗ātrickÕÆīÕŖ¤ĶāĮ’╝Ü + +- ÕŁ”õ╣ĀńÄćwarmupÕÆīscheduling + +- ImageNetķóäĶ«Łń╗āµØāķćŹ + +- Ķć¬ÕŖ©ÕŁ”õ╣ĀńÄćń╝®µöŠŃĆüĶć¬ÕŖ©batch sizeń╝®µöŠ + +- CPUĶ«Łń╗āŃĆüÕżÜµ£║ÕżÜÕŹĪĶ«Łń╗āŃĆüķøåńŠżĶ«Łń╗ā + +- HardDiskŃĆüLMDBŃĆüPetrelŃĆüHTTPńŁēõĖŹÕÉīµĢ░µŹ«ÕÉÄń½» + +- µĘĘÕÉłń▓ŠÕ║”µĄ«ńé╣Ķ«Łń╗ā + +- TensorBoard +``` + +### µĄŗĶ»Ģ + +Õ£©õĖŹµīćÕ«ÜķóØÕż¢ÕÅéµĢ░µŚČ’╝īĶ«Łń╗āńÜäµØāķćŹÕÆīµŚźÕ┐Śõ┐Īµü»õ╝Üķ╗śĶ«żÕŁśÕé©Õł░`$MMPOSE/work_dirs`ńø«ÕĮĢõĖŗ’╝īµ£Ćõ╝śńÜ䵩ĪÕ×ŗµØāķćŹÕŁśµöŠÕ£©`$MMPOSE/work_dir/best_coco`ńø«ÕĮĢõĖŗŃĆé + +µłæõ╗¼ÕÅ»õ╗źķĆÜĶ┐ćÕ”éõĖŗµīćõ╗żµĄŗĶ»Ģµ©ĪÕ×ŗÕ£©COCOķ¬īĶ»üķøåõĖŖńÜäń▓ŠÕ║”’╝Ü + +```Bash +python tools/test.py \ + configs/body_2d_keypoint/topdown_regression/coco/td-reg_res50_rle-8xb64-210e_coco-256x192.py \ + work_dir/best_coco/AP_epoch_20.pth +``` + +Õ£©COCOķ¬īĶ»üķøåõĖŖĶ»äµĄŗń╗ōµ×£µĀĘõŠŗÕ”éõĖŗ’╝Ü + +```Bash + Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets= 20 ] = 0.704 + Average Precision (AP) @[ IoU=0.50 | area= all | maxDets= 20 ] = 0.883 + Average Precision (AP) @[ IoU=0.75 | area= all | maxDets= 20 ] = 0.777 + Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets= 20 ] = 0.667 + Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets= 20 ] = 0.769 + Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 20 ] = 0.751 + Average Recall (AR) @[ IoU=0.50 | area= all | maxDets= 20 ] = 0.920 + Average Recall (AR) @[ IoU=0.75 | area= all | maxDets= 20 ] = 0.815 + Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets= 20 ] = 0.709 + Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets= 20 ] = 0.811 +08/23 12:04:42 - mmengine - INFO - Epoch(test) [3254/3254] coco/AP: 0.704168 coco/AP .5: 0.883134 coco/AP .75: 0.777015 coco/AP (M): 0.667207 coco/AP (L): 0.768644 coco/AR: 0.750913 coco/AR .5: 0.919710 coco/AR .75: 0.815334 coco/AR (M): 0.709232 coco/AR (L): 0.811334 +``` + +```{note} +Õ”éµ×£ķ£ĆĶ”üµĄŗĶ»Ģµ©ĪÕ×ŗÕ£©ÕģČõ╗¢µĢ░µŹ«ķøåõĖŖńÜäĶĪ©ńÄ░’╝īÕÅ»õ╗źÕēŹÕŠĆ [Ķ«Łń╗āõĖĵĄŗĶ»Ģ](./user_guides/train_and_test.md) µ¤źń£ŗŃĆé +``` + +### ÕÅ»Ķ¦åÕī¢ + +ķÖżõ║åÕ»╣Õģ│ķö«ńé╣ķ¬©µ×ČńÜäÕÅ»Ķ¦åÕī¢õ╗źÕż¢’╝īµłæõ╗¼Ķ┐śµö»µīüÕ»╣ńāŁÕ║”ÕøŠĶ┐øĶĪīÕÅ»Ķ¦åÕī¢’╝īõĮĀÕŬķ£ĆĶ”üÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁĶ«ŠńĮ«`output_heatmap=True`’╝Ü + +```Python +model = dict( + ## ÕåģÕ«╣ń£üńĢź + test_cfg = dict( + ## ÕåģÕ«╣ń£üńĢź + output_heatmaps=True + ) +) +``` + +µł¢Õ£©ÕæĮõ╗żĶĪīõĖŁµĘ╗ÕŖĀ`--cfg-options='model.test_cfg.output_heatmaps=True'`ŃĆé + +ÕÅ»Ķ¦åÕī¢µĢłµ×£Õ”éõĖŗ’╝Ü + + + +```{note} +Õ”éµ×£õĮĀÕĖīµ£øµĘ▒ÕģźÕ£░ÕŁ”õ╣ĀMMPose’╝īÕ░åÕģČÕ║öńö©Õł░Ķć¬ÕĘ▒ńÜäķĪ╣ńø«ÕĮōõĖŁ’╝īµłæõ╗¼ÕćåÕżćõ║åõĖĆõ╗ĮĶ»”ń╗åńÜä [Ķ┐üń¦╗µīćÕŹŚ](./migration.md) ŃĆé +``` diff --git a/internlm_langchain/knowledge_base/MMPose/content/train_and_test.md b/internlm_langchain/knowledge_base/MMPose/content/train_and_test.md new file mode 100644 index 00000000..452eddc9 --- /dev/null +++ b/internlm_langchain/knowledge_base/MMPose/content/train_and_test.md @@ -0,0 +1,5 @@ +# Ķ«Łń╗āõĖĵĄŗĶ»Ģ + +õĖŁµ¢ćÕåģÕ«╣Õ╗║Ķ«ŠõĖŁ’╝īµÜ鵌ČĶ»Ęµ¤źķśģ[Ķŗ▒µ¢ćńēłµ¢ćµĪŻ](../../en/user_guides/train_and_test.md) + +Õ”éµ×£µé©µä┐µäÅÕÅéõĖÄõĖŁµ¢ćµ¢ćµĪŻńÜäń┐╗Ķ»æõĖÄń╗┤µŖż’╝īµłæõ╗¼Õøóķś¤Õ░åÕŹüÕłåµä¤Ķ░óµé©ńÜäĶ┤Īńī«’╝üµ¼óĶ┐ÄÕŖĀÕģźµłæõ╗¼ńÜäńżŠÕī║ńŠżõĖĵłæõ╗¼ÕÅ¢ÕŠŚĶüöń│╗’╝īµł¢ńø┤µÄźµīēńģ¦ [Õ”éõĮĢń╗Ö MMPose Ķ┤Īńī«õ╗ŻńĀü](../contribution_guide.md) Õ£© GitHub õĖŖµÅÉõ║ż Pull RequestŃĆé diff --git a/internlm_langchain/knowledge_base/MMPose/content/useful_tools.md b/internlm_langchain/knowledge_base/MMPose/content/useful_tools.md new file mode 100644 index 00000000..f2ceb771 --- /dev/null +++ b/internlm_langchain/knowledge_base/MMPose/content/useful_tools.md @@ -0,0 +1,5 @@ +# ÕĖĖńö©ÕĘźÕģĘ + +õĖŁµ¢ćÕåģÕ«╣Õ╗║Ķ«ŠõĖŁ’╝īµÜ鵌ČĶ»Ęµ¤źķśģ[Ķŗ▒µ¢ćńēłµ¢ćµĪŻ](../../en/user_guides/useful_tools.md) + +Õ”éµ×£µé©µä┐µäÅÕÅéõĖÄõĖŁµ¢ćµ¢ćµĪŻńÜäń┐╗Ķ»æõĖÄń╗┤µŖż’╝īµłæõ╗¼Õøóķś¤Õ░åÕŹüÕłåµä¤Ķ░óµé©ńÜäĶ┤Īńī«’╝üµ¼óĶ┐ÄÕŖĀÕģźµłæõ╗¼ńÜäńżŠÕī║ńŠżõĖĵłæõ╗¼ÕÅ¢ÕŠŚĶüöń│╗’╝īµł¢ńø┤µÄźµīēńģ¦ [Õ”éõĮĢń╗Ö MMPose Ķ┤Īńī«õ╗ŻńĀü](../contribution_guide.md) Õ£© GitHub õĖŖµÅÉõ║ż Pull RequestŃĆé diff --git a/internlm_langchain/knowledge_base/MMPose/content/visualization.md b/internlm_langchain/knowledge_base/MMPose/content/visualization.md new file mode 100644 index 00000000..a584eb45 --- /dev/null +++ b/internlm_langchain/knowledge_base/MMPose/content/visualization.md @@ -0,0 +1,5 @@ +# ÕÅ»Ķ¦åÕī¢ + +õĖŁµ¢ćÕåģÕ«╣Õ╗║Ķ«ŠõĖŁ’╝īµÜ鵌ČĶ»Ęµ¤źķśģ[Ķŗ▒µ¢ćńēłµ¢ćµĪŻ](../../en/user_guides/visualization.md) + +Õ”éµ×£µé©µä┐µäÅÕÅéõĖÄõĖŁµ¢ćµ¢ćµĪŻńÜäń┐╗Ķ»æõĖÄń╗┤µŖż’╝īµłæõ╗¼Õøóķś¤Õ░åÕŹüÕłåµä¤Ķ░óµé©ńÜäĶ┤Īńī«’╝üµ¼óĶ┐ÄÕŖĀÕģźµłæõ╗¼ńÜäńżŠÕī║ńŠżõĖĵłæõ╗¼ÕÅ¢ÕŠŚĶüöń│╗’╝īµł¢ńø┤µÄźµīēńģ¦ [Õ”éõĮĢń╗Ö MMPose Ķ┤Īńī«õ╗ŻńĀü](../contribution_guide.md) Õ£© GitHub õĖŖµÅÉõ║ż Pull RequestŃĆé diff --git a/internlm_langchain/knowledge_base/MMPose/vector_store/index.faiss b/internlm_langchain/knowledge_base/MMPose/vector_store/index.faiss new file mode 100644 index 00000000..844a8a0b Binary files /dev/null and b/internlm_langchain/knowledge_base/MMPose/vector_store/index.faiss differ diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/cam_visualization.md b/internlm_langchain/knowledge_base/MMPreTrain/content/cam_visualization.md new file mode 100644 index 00000000..94d5ed17 --- /dev/null +++ b/internlm_langchain/knowledge_base/MMPreTrain/content/cam_visualization.md @@ -0,0 +1,164 @@ +# ń▒╗Õł½µ┐Ƶ┤╗ÕøŠ’╝łCAM’╝ēÕÅ»Ķ¦åÕī¢ + +## ń▒╗Õł½µ┐Ƶ┤╗ÕøŠÕÅ»Ķ¦åÕī¢ÕĘźÕģĘõ╗ŗń╗Ź + +MMPretrain µÅÉõŠø `tools/visualization/vis_cam.py` ÕĘźÕģĘµØźÕÅ»Ķ¦åÕī¢ń▒╗Õł½µ┐Ƶ┤╗ÕøŠŃĆéĶ»ĘõĮ┐ńö© `pip install "grad-cam>=1.3.6"` Õ«ēĶŻģõŠØĶĄ¢ńÜä [pytorch-grad-cam](https://github.com/jacobgil/pytorch-grad-cam)ŃĆé + +ńø«ÕēŹµö»µīüńÜäµ¢╣µ│Ģµ£ē’╝Ü + +| Method | What it does | +| :----------: | :-----------------------------------------------------------------------------------------------: | +| GradCAM | õĮ┐ńö©Õ╣│ÕØćµó»Õ║”Õ»╣ 2D µ┐Ƶ┤╗Ķ┐øĶĪīÕŖĀµØā | +| GradCAM++ | ń▒╗õ╝╝ GradCAM’╝īõĮåõĮ┐ńö©õ║åõ║īķśČµó»Õ║” | +| XGradCAM | ń▒╗õ╝╝ GradCAM’╝īõĮåķĆÜĶ┐ćÕĮÆõĖĆÕī¢ńÜäµ┐Ƶ┤╗Õ»╣µó»Õ║”Ķ┐øĶĪīõ║åÕŖĀµØā | +| EigenCAM | õĮ┐ńö© 2D µ┐Ƶ┤╗ńÜäń¼¼õĖĆõĖ╗µłÉÕłå’╝łµŚĀµ│ĢÕī║Õłåń▒╗Õł½’╝īõĮåµĢłµ×£õ╝╝õ╣ÄõĖŹķöÖ’╝ē | +| EigenGradCAM | ń▒╗õ╝╝ EigenCAM’╝īõĮåµö»µīüń▒╗Õł½Õī║Õłå’╝īõĮ┐ńö©õ║åµ┐Ƶ┤╗ * µó»Õ║”ńÜäń¼¼õĖĆõĖ╗µłÉÕłå’╝īń£ŗĶĄĘµØźÕÆī GradCAM ÕĘ«õĖŹÕżÜ’╝īõĮåµś»µø┤Õ╣▓ÕćĆ | +| LayerCAM | õĮ┐ńö©µŁŻµó»Õ║”Õ»╣µ┐Ƶ┤╗Ķ┐øĶĪīń®║ķŚ┤ÕŖĀµØā’╝īÕ»╣õ║ĵĄģÕ▒éµ£ēµø┤ÕźĮńÜäµĢłµ×£ | + +õ╣¤ÕÅ»õ╗źõĮ┐ńö©µ¢░ńēłµ£¼ `pytorch-grad-cam` µö»µīüńÜäµø┤ÕżÜ CAM µ¢╣µ│Ģ’╝īõĮåµłæõ╗¼Õ░ܵ£¬ķ¬īĶ»üÕÅ»ńö©µĆ¦ŃĆé + +**ÕæĮõ╗żĶĪī**’╝Ü + +```bash +python tools/visualization/vis_cam.py \ + ${IMG} \ + ${CONFIG_FILE} \ + ${CHECKPOINT} \ + [--target-layers ${TARGET-LAYERS}] \ + [--preview-model] \ + [--method ${METHOD}] \ + [--target-category ${TARGET-CATEGORY}] \ + [--save-path ${SAVE_PATH}] \ + [--vit-like] \ + [--num-extra-tokens ${NUM-EXTRA-TOKENS}] + [--aug_smooth] \ + [--eigen_smooth] \ + [--device ${DEVICE}] \ + [--cfg-options ${CFG-OPTIONS}] +``` + +**µēƵ£ēÕÅéµĢ░ńÜäĶ»┤µśÄ**’╝Ü + +- `img`’╝Üńø«µĀćÕøŠńēćĶĘ»ÕŠäŃĆé +- `config`’╝ܵ©ĪÕ×ŗķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠäŃĆé +- `checkpoint`’╝ܵØāķćŹĶĘ»ÕŠäŃĆé +- `--target-layers`’╝ܵēƵ¤źń£ŗńÜäńĮæń╗£Õ▒éÕÉŹń¦░’╝īÕÅ»ĶŠōÕģźõĖĆõĖ¬µł¢ĶĆģÕżÜõĖ¬ńĮæń╗£Õ▒é’╝īÕ”éµ×£õĖŹĶ«ŠńĮ«’╝īÕ░åõĮ┐ńö©µ£ĆÕÉÄõĖĆõĖ¬`block`õĖŁńÜä`norm`Õ▒éŃĆé +- `--preview-model`’╝ܵś»ÕÉ”µ¤źń£ŗµ©ĪÕ×ŗµēƵ£ēńĮæń╗£Õ▒éŃĆé +- `--method`’╝Üń▒╗Õł½µ┐Ƶ┤╗ÕøŠÕøŠÕÅ»Ķ¦åÕī¢ńÜäµ¢╣µ│Ģ’╝īńø«ÕēŹµö»µīü `GradCAM`, `GradCAM++`, `XGradCAM`, `EigenCAM`, `EigenGradCAM`, `LayerCAM`’╝īõĖŹÕī║ÕłåÕż¦Õ░ÅÕåÖŃĆéÕ”éµ×£õĖŹĶ«ŠńĮ«’╝īķ╗śĶ«żõĖ║ `GradCAM`ŃĆé +- `--target-category`’╝ܵ¤źń£ŗńÜäńø«µĀćń▒╗Õł½’╝īÕ”éµ×£õĖŹĶ«ŠńĮ«’╝īõĮ┐ńö©µ©ĪÕ×ŗµŻĆµĄŗÕć║µØźńÜäń▒╗Õł½ÕüÜõĖ║ńø«µĀćń▒╗Õł½ŃĆé +- `--save-path`’╝Üõ┐ØÕŁśńÜäÕÅ»Ķ¦åÕī¢ÕøŠńēćńÜäĶĘ»ÕŠä’╝īķ╗śĶ«żõĖŹõ┐ØÕŁśŃĆé +- `--eigen-smooth`’╝ܵś»ÕÉ”õĮ┐ńö©õĖ╗µłÉÕłåķÖŹõĮÄÕÖ¬ķ¤│’╝īķ╗śĶ«żõĖŹÕ╝ĆÕÉ»ŃĆé +- `--vit-like`: µś»ÕÉ”õĖ║ `ViT` ń▒╗õ╝╝ńÜä Transformer-based ńĮæń╗£ +- `--num-extra-tokens`: `ViT` ń▒╗ńĮæń╗£ńÜäķóØÕż¢ńÜä tokens ķĆÜķüōµĢ░’╝īķ╗śĶ«żõĮ┐ńö©õĖ╗Õ╣▓ńĮæń╗£ńÜä `num_extra_tokens`ŃĆé +- `--aug-smooth`’╝ܵś»ÕÉ”õĮ┐ńö©µĄŗĶ»ĢµŚČÕó×Õ╝║ +- `--device`’╝ÜõĮ┐ńö©ńÜäĶ«Īń«ŚĶ«ŠÕżć’╝īÕ”éµ×£õĖŹĶ«ŠńĮ«’╝īķ╗śĶ«żõĖ║'cpu'ŃĆé +- `--cfg-options`’╝ÜÕ»╣ķģŹńĮ«µ¢ćõ╗ČńÜäõ┐«µö╣’╝īÕÅéĶĆā[ÕŁ”õ╣ĀķģŹńĮ«µ¢ćõ╗Č](../user_guides/config.md)ŃĆé + +```{note} +Õ£©µīćÕ«Ü `--target-layers` µŚČ’╝īÕ”éµ×£õĖŹń¤źķüōµ©ĪÕ×ŗµ£ēÕō¬õ║øńĮæń╗£Õ▒é’╝īÕÅ»õĮ┐ńö©ÕæĮõ╗żĶĪīµĘ╗ÕŖĀ `--preview-model` µ¤źń£ŗµēƵ£ēńĮæń╗£Õ▒éÕÉŹń¦░’╝ø +``` + +## Õ”éõĮĢÕÅ»Ķ¦åÕī¢ CNN ńĮæń╗£ńÜäń▒╗Õł½µ┐Ƶ┤╗ÕøŠ’╝łÕ”é ResNet-50’╝ē + +`--target-layers` Õ£© `Resnet-50` õĖŁńÜäõĖĆõ║øńż║õŠŗÕ”éõĖŗ’╝Ü + +- `'backbone.layer4'`’╝īĶĪ©ńż║ń¼¼ÕøøõĖ¬ `ResLayer` Õ▒éńÜäĶŠōÕć║ŃĆé +- `'backbone.layer4.2'` ĶĪ©ńż║ń¼¼ÕøøõĖ¬ `ResLayer` Õ▒éõĖŁń¼¼õĖēõĖ¬ `BottleNeck` ÕØŚńÜäĶŠōÕć║ŃĆé +- `'backbone.layer4.2.conv1'` ĶĪ©ńż║õĖŖĶ┐░ `BottleNeck` ÕØŚõĖŁ `conv1` Õ▒éńÜäĶŠōÕć║ŃĆé + +1. õĮ┐ńö©õĖŹÕÉīµ¢╣µ│ĢÕÅ»Ķ¦åÕī¢ `ResNet50`’╝īķ╗śĶ«ż `target-category` õĖ║µ©ĪÕ×ŗµŻĆµĄŗńÜäń╗ōµ×£’╝īõĮ┐ńö©ķ╗śĶ«żµÄ©Õ»╝ńÜä `target-layers`ŃĆé + + ```shell + python tools/visualization/vis_cam.py \ + demo/bird.JPEG \ + configs/resnet/resnet50_8xb32_in1k.py \ + https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_batch256_imagenet_20200708-cfb998bf.pth \ + --method GradCAM + # GradCAM++, XGradCAM, EigenCAM, EigenGradCAM, LayerCAM + ``` + + | Image | GradCAM | GradCAM++ | EigenGradCAM | LayerCAM | + | ------------------------------------ | --------------------------------------- | ----------------------------------------- | -------------------------------------------- | ---------------------------------------- | + |
+
+## õ╗ÄÕøŠÕāÅõĖŁµÅÉÕÅ¢ńē╣ÕŠü
+
+õĖÄ `model.extract_feat` ńøĖµ»ö’╝ī`FeatureExtractor` ńö©õ║Äńø┤µÄźõ╗ÄÕøŠÕāŵ¢ćõ╗ČõĖŁµÅÉÕÅ¢ńē╣ÕŠü’╝īĶĆīõĖŹµś»õ╗ÄõĖƵē╣Õ╝ĀķćÅõĖŁµÅÉÕÅ¢ńē╣ÕŠüŃĆéń«ĆÕŹĢĶ»┤’╝ī`model.extract_feat` ńÜäĶŠōÕģźµś» `torch.Tensor`’╝ī`FeatureExtractor` ńÜäĶŠōÕģźµś»ÕøŠÕāÅŃĆé
+
+```
+>>> from mmpretrain import FeatureExtractor, get_model
+>>> model = get_model('resnet50_8xb32_in1k', backbone=dict(out_indices=(0, 1, 2, 3)))
+>>> extractor = FeatureExtractor(model)
+>>> features = extractor('https://github.com/open-mmlab/mmpretrain/raw/main/demo/demo.JPEG')[0]
+>>> features[0].shape, features[1].shape, features[2].shape, features[3].shape
+(torch.Size([256]), torch.Size([512]), torch.Size([1024]), torch.Size([2048]))
+```
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/log_result_analysis.md b/internlm_langchain/knowledge_base/MMPreTrain/content/log_result_analysis.md
new file mode 100644
index 00000000..748a9076
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/log_result_analysis.md
@@ -0,0 +1,223 @@
+# µŚźÕ┐ŚÕłåµ×ÉÕĘźÕģĘ
+
+## µŚźÕ┐ŚÕłåµ×É
+
+### µŚźÕ┐ŚÕłåµ×ÉÕĘźÕģĘõ╗ŗń╗Ź
+
+`tools/analysis_tools/analyze_logs.py` Ķäܵ£¼ń╗śÕłČµīćÕ«Üķö«ÕĆ╝ńÜäÕÅśÕī¢µø▓ń║┐ŃĆé
+
+
+ +
+
diff --git a/internlm_langchain/knowledge_base/MMPreTrain/content/t-sne_visualization.md b/internlm_langchain/knowledge_base/MMPreTrain/content/t-sne_visualization.md
new file mode 100644
index 00000000..124e915e
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMPreTrain/content/t-sne_visualization.md
@@ -0,0 +1,85 @@
+# t-ÕłåÕĖāķÜŵ£║ķé╗Õ¤¤ÕĄīÕģź’╝łt-SNE’╝ēÕÅ»Ķ¦åÕī¢
+
+## t-ÕłåÕĖāķÜŵ£║ķé╗Õ¤¤ÕĄīÕģźÕÅ»Ķ¦åÕī¢ÕĘźÕģĘõ╗ŗń╗Ź
+
+MMPretrain µÅÉõŠø `tools/visualization/vis_tsne.py` ÕĘźÕģĘµØźńö©t-SNEÕÅ»Ķ¦åÕī¢ÕøŠÕāÅńÜäńē╣ÕŠüÕĄīÕģźŃĆéĶ»ĘõĮ┐ńö© `pip install scikit-learn` Õ«ēĶŻģ `sklearn` µØźĶ«Īń«Śt-SNEŃĆé
+
+**ÕæĮõ╗ż**’╝Ü
+
+```bash
+python tools/visualization/vis_tsne.py \
+ CONFIG \
+ [--checkpoint CHECKPOINT] \
+ [--work-dir WORK_DIR] \
+ [--test-cfg TEST_CFG] \
+ [--vis-stage {backbone,neck,pre_logits}]
+ [--class-idx ${CLASS_IDX} [CLASS_IDX ...]]
+ [--max-num-class MAX_NUM_CLASS]
+ [--max-num-samples MAX_NUM_SAMPLES]
+ [--cfg-options CFG_OPTIONS [CFG_OPTIONS ...]]
+ [--device DEVICE]
+ [--legend]
+ [--show]
+ [--n-components N_COMPONENTS]
+ [--perplexity PERPLEXITY]
+ [--early-exaggeration EARLY_EXAGGERATION]
+ [--learning-rate LEARNING_RATE]
+ [--n-iter N_ITER]
+ [--n-iter-without-progress N_ITER_WITHOUT_PROGRESS]
+ [--init INIT]
+```
+
+**µēƵ£ēÕÅéµĢ░ńÜäĶ»┤µśÄ**’╝Ü
+
+- `CONFIG`: t-SNE ķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠäŃĆé
+- `--checkpoint CHECKPOINT`: µ©ĪÕ×ŗµØāķ揵¢ćõ╗ČńÜäĶĘ»ÕŠäŃĆé
+- `--work-dir WORK_DIR`: õ┐ØÕŁśµŚźÕ┐ŚÕÆīÕÅ»Ķ¦åÕī¢ÕøŠÕāÅńÜäńø«ÕĮĢŃĆé
+- `--test-cfg TEST_CFG`: ńö©µØźÕŖĀĶĮĮ test_dataloader ķģŹńĮ«ńÜä t-SNE ķģŹńĮ«µ¢ćõ╗ČńÜäĶĘ»ÕŠäŃĆé
+- `--vis-stage {backbone,neck,pre_logits}`: µ©ĪÕ×ŗÕÅ»Ķ¦åÕī¢ńÜäķśČµ«ĄŃĆé
+- `--class-idx CLASS_IDX [CLASS_IDX ...]`: ńö©µØźĶ«Īń«Ś t-SNE ńÜäń▒╗Õł½ŃĆé
+- `--max-num-class MAX_NUM_CLASS`: ÕēŹ N õĖ¬Ķó½Õ║öńö© t-SNE ń«Śµ│ĢńÜäń▒╗Õł½’╝īķ╗śĶ«żõĖ║20ŃĆé
+- `--max-num-samples MAX_NUM_SAMPLES`: µ»ÅõĖ¬ń▒╗Õł½õĖŁµ£ĆÕż¦ńÜäµĀʵ£¼µĢ░’╝īÕĆ╝ĶČŖķ½śķ£ĆĶ”üńÜäĶ«Īń«ŚµŚČķŚ┤ĶČŖķĢ┐’╝īķ╗śĶ«żõĖ║100ŃĆé
+- `--cfg-options CFG_OPTIONS [CFG_OPTIONS ...]`: Ķ”åńø¢Ķó½õĮ┐ńö©ńÜäķģŹńĮ«õĖŁńÜäõĖĆõ║øĶ«ŠÕ«Ü’╝īÕĮóÕ”é xxx=yyy µĀ╝Õ╝ÅńÜäÕģ│ķö«ÕŁŚ-ÕĆ╝Õ»╣õ╝ÜĶó½ÕÉłÕ╣ČÕł░ķģŹńĮ«µ¢ćõ╗ČõĖŁŃĆéÕ”éµ×£Ķó½Ķ”åńø¢ńÜäÕĆ╝µś»õĖĆõĖ¬ÕłŚĶĪ©’╝īÕ«āÕ║öĶ»źÕĮóÕ”é key="[a,b]" µł¢ĶĆģ key=a,b ŃĆéÕ«āĶ┐śÕģüĶ«ĖÕĄīÕźŚńÜäÕłŚĶĪ©/Õģāń╗äÕĆ╝’╝īõŠŗÕ”é key="[(a,b),(c,d)]" ŃĆéµ│©µäÅÕ╝ĢÕÅʵś»Õ┐ģķ£ĆńÜä’╝īĶĆīõĖöõĖŹÕģüĶ«Ėµ£ēń®║µĀ╝ŃĆé
+- `--device DEVICE`: ńö©õ║ĵĩńÉåńÜäĶ«ŠÕżćŃĆé
+- `--legend`: µśŠńż║µēƵ£ēń▒╗Õł½ńÜäÕøŠõŠŗŃĆé
+- `--show`: Õ£©ÕøŠÕĮóń¬ŚÕÅŻõĖŁµśŠńż║ń╗ōµ×£ŃĆé
+- `--n-components N_COMPONENTS`: ń╗ōµ×£ńÜäń╗┤µĢ░ŃĆé
+- `--perplexity PERPLEXITY`: ÕżŹµØéÕ║”õĖÄÕģČõ╗¢µĄüÕĮóÕŁ”õ╣Āń«Śµ│ĢõĖŁõĮ┐ńö©ńÜäµ£ĆĶ┐æķé╗ńÜäµĢ░ķćŵ£ēÕģ│ŃĆé
+- `--early-exaggeration EARLY_EXAGGERATION`: µÄ¦ÕłČÕĤń®║ķŚ┤õĖŁńÜäĶć¬ńäČĶüÜń▒╗Õ£©ÕĄīÕģźń®║ķŚ┤õĖŁńÜäń┤¦Õ»åń©ŗÕ║”õ╗źÕÅŖÕ«āõ╗¼õ╣ŗķŚ┤ńÜäń®║ķŚ┤Õż¦Õ░ÅŃĆé
+- `--learning-rate LEARNING_RATE`: t-SNE ńÜäÕŁ”õ╣ĀńÄćķĆÜÕĖĖÕ£©[10.0, 1000.0]ńÜäĶīāÕø┤ÕåģŃĆéÕ”éµ×£ÕŁ”õ╣ĀńÄćÕż¬ķ½ś’╝īµĢ░µŹ«ÕÅ»ĶāĮń£ŗĶĄĘµØźÕāÅõĖĆõĖ¬ńÉā’╝īÕģČõĖŁõ╗╗õĮĢõĖĆńé╣õĖÄÕ«āµ£ĆĶ┐æńÜäķé╗Õ▒ģĶ┐æõ╝╝ńŁēĶĘØŃĆéÕ”éµ×£ÕŁ”õ╣ĀńÄćÕż¬õĮÄ’╝īÕż¦ÕżÜµĢ░ńé╣ÕÅ»ĶāĮń£ŗĶĄĘµØźĶó½ÕÄŗń╝®Õ£©õĖĆõĖ¬ÕćĀõ╣ĵ▓Īµ£ēÕ╝éÕĖĖÕĆ╝ńÜäÕ»åķøåńé╣õ║æõĖŁŃĆé
+- `--n-iter N_ITER`: õ╝śÕī¢ńÜäµ£ĆÕż¦Ķ┐Łõ╗Żµ¼ĪµĢ░ŃĆéÕ║öĶ»źĶć│Õ░æõĖ║250ŃĆé
+- `--n-iter-without-progress N_ITER_WITHOUT_PROGRESS`: Õ£©µłæõ╗¼õĖŁµŁóõ╝śÕī¢õ╣ŗÕēŹ’╝īµ£ĆÕż¦ńÜäµ▓Īµ£ēĶ┐øÕ▒ĢńÜäĶ┐Łõ╗Żµ¼ĪµĢ░ŃĆé
+- `--init INIT`: ÕłØÕ¦ŗÕī¢µ¢╣µ│ĢŃĆé
+
+## Õ”éõĮĢÕÅ»Ķ¦åÕī¢Õłåń▒╗µ©ĪÕ×ŗńÜät-SNE’╝łÕ”é ResNet’╝ē
+
+õ╗źõĖŗµś»Õ£©CIFAR-10µĢ░µŹ«ķøåõĖŖĶ«Łń╗āńÜä ResNet-18 ÕÆī ResNet-50 µ©ĪÕ×ŗõĖŖĶ┐ÉĶĪī t-SNE ÕÅ»Ķ¦åÕī¢ńÜäõĖżõĖ¬µĀĘõŠŗ’╝Ü
+
+```shell
+python tools/visualization/vis_tsne.py \
+ configs/resnet/resnet18_8xb16_cifar10.py \
+ --checkpoint https://download.openmmlab.com/mmclassification/v0/resnet/resnet18_b16x8_cifar10_20210528-bd6371c8.pth
+
+python tools/visualization/vis_tsne.py \
+ configs/resnet/resnet50_8xb16_cifar10.py \
+ --checkpoint https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_b16x8_cifar10_20210528-f54bfad9.pth
+```
+
+| ResNet-18 | ResNet-50 |
+| ---------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------- |
+| 

+  +
+
+  +
+



+ +
+
+ÕÅ»Ķ¦åÕī¢ÕÅ»õ╗źń╗ÖµĘ▒Õ║”ÕŁ”õ╣ĀńÜ䵩ĪÕ×ŗĶ«Łń╗āÕÆīµĄŗĶ»ĢĶ┐ćń©ŗµÅÉõŠøńø┤Ķ¦éĶ¦ŻķćŖŃĆé
+
+MMRazor õĖŁ’╝īÕ░åõĮ┐ńö© MMEngine µÅÉõŠøńÜä `Visualizer` ÕÅ»Ķ¦åÕī¢ÕÖ©µÉŁķģŹ MMRazor Ķć¬ÕĖ”ńÜä `Recorder`ń╗äõ╗ČńÜäµĢ░µŹ«Ķ«░ÕĮĢÕŖ¤ĶāĮ’╝īĶ┐øĶĪīńē╣ÕŠüÕøŠÕÅ»Ķ¦åÕī¢’╝īÕģČÕģĘÕżćÕ”éõĖŗÕŖ¤ĶāĮ’╝Ü
+
+- µö»µīüÕ¤║ńĪĆń╗śÕøŠµÄźÕÅŻõ╗źÕÅŖńē╣ÕŠüÕøŠÕÅ»Ķ¦åÕī¢ŃĆé
+- µö»µīüķĆēµŗ®µ©ĪÕ×ŗõĖŁńÜäõ╗╗µäÅõĮŹńé╣µØźÕŠŚÕł░ńē╣ÕŠüÕøŠ’╝īÕīģÕɽ `pixel_wise_max` ’╝ī`squeeze_mean` ’╝ī `select_max` ’╝ī `topk` Õøøń¦ŹµśŠńż║µ¢╣Õ╝Å’╝īńö©µłĘĶ┐śÕÅ»õ╗źõĮ┐ńö© `arrangement` Ķć¬Õ«Üõ╣ēńē╣ÕŠüÕøŠµśŠńż║ńÜäÕĖāÕ▒Ƶ¢╣Õ╝ÅŃĆé
+
+## ńē╣ÕŠüÕøŠń╗śÕłČ
+
+õĮĀÕÅ»õ╗źĶ░āńö© `tools/visualizations/vis_configs/feature_visualization.py` µØźń«ĆÕŹĢÕ┐½µŹĘÕ£░ÕŠŚÕł░ÕŹĢÕ╝ĀÕøŠńēćÕŹĢõĖ¬µ©ĪÕ×ŗńÜäÕÅ»Ķ¦åÕī¢ń╗ōµ×£ŃĆé
+
+õĖ║õ║åµ¢╣õŠ┐ńÉåĶ¦Ż’╝īÕ░åÕģČõĖ╗Ķ”üÕÅéµĢ░ńÜäÕŖ¤ĶāĮµó│ńÉåÕ”éõĖŗ’╝Ü
+
+- `img`’╝ÜķĆēµŗ®Ķ”üńö©õ║Äńē╣ÕŠüÕøŠÕÅ»Ķ¦åÕī¢ńÜäÕøŠńēć’╝īµö»µīüÕŹĢÕ╝ĀÕøŠńē浳¢ĶĆģÕøŠńēćĶĘ»ÕŠäÕłŚĶĪ©ŃĆé
+
+- `config`’╝ÜķĆēµŗ®ń«Śµ│ĢńÜäķģŹńĮ«µ¢ćõ╗ČŃĆé
+
+- `vis_config`’╝ÜÕÅ»Ķ¦åÕī¢ÕŖ¤ĶāĮķ£ĆÕƤÕŖ®ÕÅ»ķģŹńĮ«ńÜä `Recorder` ń╗äõ╗ČĶÄĘÕÅ¢µ©ĪÕ×ŗõĖŁńö©µłĘĶć¬Õ«Üõ╣ēõĮŹńé╣ńÜäńē╣ÕŠüÕøŠ’╝ī
+ ńö©µłĘÕÅ»õ╗źÕ░å `Recorder` ńøĖÕģ│ķģŹńĮ«µ¢ćõ╗ȵöŠÕģź `vis_config` õĖŁŃĆé MMRazorµÅÉõŠøõ║åÕ»╣backboneÕÅŖneck
+ ĶŠōÕć║Ķ┐øĶĪīÕÅ»Ķ¦åÕī¢Õ»╣Õ║öńÜäconfigµ¢ćõ╗Č’╝īĶ»”Ķ¦ü `configs/visualizations`
+
+- `checkpoint`’╝ÜķĆēµŗ®Õ»╣Õ║öń«Śµ│ĢńÜäµØāķ揵¢ćõ╗ČŃĆé
+
+- `--out-file`’╝ÜÕ░åÕŠŚÕł░ńÜäńē╣ÕŠüÕøŠõ┐ØÕŁśÕł░µ£¼Õ£░’╝īÕ╣ȵīćÕ«ÜĶĘ»ÕŠäÕÆīµ¢ćõ╗ČÕÉŹŃĆéĶŗźµ▓Īµ£ēķĆēÕ«Ü’╝īÕłÖõ╝Üńø┤µÄźµśŠńż║ńē╣ÕŠüÕøŠŃĆé
+
+- `--device`’╝ܵīćÕ«Üńö©õ║ĵĩńÉåÕøŠńēćńÜäńĪ¼õ╗Č’╝ī`--device cuda’╝Ü0` ĶĪ©ńż║õĮ┐ńö©ń¼¼ 1 Õ╝Ā GPU µÄ©ńÉå’╝ī`--device cpu` ĶĪ©ńż║ńö© CPU µÄ©ńÉåŃĆé
+
+- `--repo`’╝ܵ©ĪÕ×ŗÕ»╣Õ║öńÜäń«Śµ│ĢÕ║ōŃĆé`--repo mmdet` ĶĪ©ńż║µ©ĪÕ×ŗõĖ║µŻĆµĄŗµ©ĪÕ×ŗŃĆé
+
+- `--use-norm`’╝ܵś»ÕÉ”Õ░åĶÄĘÕÅ¢ńÜäńē╣ÕŠüÕøŠĶ┐øĶĪībatch normalizationÕÉÄÕåŹµśŠńż║ŃĆé
+
+- `--overlaid`’╝ܵś»ÕÉ”Õ░åńē╣ÕŠüÕøŠĶ”åńø¢Õ£©ÕĤÕøŠõ╣ŗõĖŖŃĆéĶŗźĶ«ŠõĖ║True’╝īĶĆāĶÖæÕł░ĶŠōÕģźńÜäńē╣ÕŠüÕøŠķĆÜÕĖĖķØ×ÕĖĖÕ░Å’╝īÕćĮµĢ░ķ╗śĶ«żÕ░åńē╣ÕŠüÕøŠĶ┐øĶĪīõĖŖķććµĀĘÕÉĵ¢╣õŠ┐Ķ┐øĶĪīÕÅ»Ķ¦åÕī¢ŃĆé
+
+- `--channel-reduction`’╝ÜĶŠōÕģźńÜä Tensor õĖĆĶł¼µś»Õīģµŗ¼ÕżÜõĖ¬ķĆÜķüōńÜä’╝ī`channel_reduction` ÕÅéµĢ░ÕÅ»õ╗źÕ░åÕżÜõĖ¬ķĆÜķüōÕÄŗń╝®õĖ║ÕŹĢķĆÜķüō’╝īńäČÕÉÄÕÆīÕøŠńēćĶ┐øĶĪīÕÅĀÕŖĀµśŠńż║’╝īµ£ēõ╗źõĖŗõĖēõĖ¬ÕÅéµĢ░ÕÅ»õ╗źĶ«ŠńĮ«’╝Ü
+
+ - `pixel_wise_max`’╝ÜÕ░åĶŠōÕģźńÜä C ń╗┤Õ║”ķććńö© max ÕćĮµĢ░ÕÄŗń╝®õĖ║õĖĆõĖ¬ķĆÜķüō’╝īĶŠōÕć║ń╗┤Õ║”ÕÅśõĖ║ (1, H, W)ŃĆé
+ - `squeeze_mean`’╝ÜÕ░åĶŠōÕģźńÜä C ń╗┤Õ║”ķććńö© mean ÕćĮµĢ░ÕÄŗń╝®õĖ║õĖĆõĖ¬ķĆÜķüō’╝īĶŠōÕć║ń╗┤Õ║”ÕÅśµłÉ (1, H, W)ŃĆé
+ - `select_max`’╝Üõ╗ÄĶŠōÕģźńÜä C ń╗┤Õ║”õĖŁÕģłÕ£©ń®║ķŚ┤ń╗┤Õ║” sum’╝īń╗┤Õ║”ÕÅśµłÉ (C, )’╝īńäČÕÉÄķĆēµŗ®ÕĆ╝µ£ĆÕż¦ńÜäķĆÜķüōŃĆé
+ - `None`’╝ÜĶĪ©ńż║õĖŹķ£ĆĶ”üÕÄŗń╝®’╝īµŁżµŚČÕÅ»õ╗źķĆÜĶ┐ć `topk` ÕÅéµĢ░ÕÅ»ķĆēµŗ®µ┐Ƶ┤╗Õ║”µ£Ćķ½śńÜä `topk` õĖ¬ńē╣ÕŠüÕøŠµśŠńż║ŃĆé
+
+- `--topk`’╝ÜÕŬµ£ēÕ£© `channel_reduction` ÕÅéµĢ░õĖ║ `None` ńÜäµāģÕåĄõĖŗ’╝ī `topk` ÕÅéµĢ░µēŹõ╝Üńö¤µĢł’╝īÕģČõ╝ܵīēńģ¦µ┐Ƶ┤╗Õ║”µÄÆÕ║ÅķĆēµŗ® `topk` õĖ¬ķĆÜķüō’╝īńäČÕÉÄÕÆīÕøŠńēćĶ┐øĶĪīÕÅĀÕŖĀµśŠńż║’╝īÕ╣ČõĖöµŁżµŚČõ╝ÜķĆÜĶ┐ć `--arrangement` ÕÅéµĢ░µīćիܵśŠńż║ńÜäÕĖāÕ▒Ć’╝īĶ»źÕÅéµĢ░ĶĪ©ńż║õĖ║õĖĆõĖ¬µĢ░ń╗ä’╝īõĖżõĖ¬µĢ░ÕŁŚķ£ĆĶ”üõ╗źń®║µĀ╝ÕłåÕ╝Ć’╝īõŠŗÕ”é’╝Ü `--topk 5 --arrangement 2 3` ĶĪ©ńż║õ╗ź `2ĶĪī 3ÕłŚ` µśŠńż║µ┐Ƶ┤╗Õ║”µÄÆÕ║ŵ£Ćķ½śńÜä 5 Õ╝Āńē╣ÕŠüÕøŠ’╝ī `--topk 7 --arrangement 3 3` ĶĪ©ńż║õ╗ź `3ĶĪī 3ÕłŚ` µśŠńż║µ┐Ƶ┤╗Õ║”µÄÆÕ║ŵ£Ćķ½śńÜä 7 Õ╝Āńē╣ÕŠüÕøŠŃĆé
+
+ - Õ”éµ×£ topk õĖŹµś» -1’╝īÕłÖõ╝ܵīēńģ¦µ┐Ƶ┤╗Õ║”µÄÆÕ║ÅķĆēµŗ® topk õĖ¬ķĆÜķüōµśŠńż║ŃĆé
+ - Õ”éµ×£ topk = -1’╝īµŁżµŚČķĆÜķüō C Õ┐ģķĪ╗µś» 1 µł¢ĶĆģ 3 ĶĪ©ńż║ĶŠōÕģźµĢ░µŹ«µś»ÕøŠńēć’╝īÕÉ”ÕłÖµŖźķöÖµÅÉńż║ńö©µłĘÕ║öĶ»źĶ«ŠńĮ« `channel_reduction` µØźÕÄŗń╝®ķĆÜķüōŃĆé
+
+- `--arrangement`’╝Üńē╣ÕŠüÕøŠńÜäµÄÆÕĖāŃĆéÕĮō `channel_reduction` õĖŹµś»NoneõĖötopk > 0µŚČµēŹõ╝ܵ£ēńö©ŃĆé
+
+- `--resize-shape`’╝ÜÕĮō`--overlaid`õĖ║TrueµŚČ’╝īµś»ÕÉ”ķ£ĆĶ”üÕ░åÕĤÕøŠÕÆīńē╣ÕŠüÕøŠresizeõĖ║µ¤ÉõĖĆÕ░║Õ»ĖŃĆé
+
+- `--cfg-options`’╝Üńö▒õ║ÄõĖŹÕÉīń«Śµ│ĢÕ║ōńÜävisualizerµŗźµ£ēńē╣õŠŗÕī¢ńÜäadd_datasampleµ¢╣µ│Ģ’╝īÕ”émmdetńÜävisualizer
+ µŗźµ£ē `pred_score_thr` õĮ£õĖ║ĶŠōÕģźÕÅéµĢ░’╝īÕÅ»õ╗źÕ£©`--cfg-options`ÕŖĀÕģźõĖĆõ║øńē╣õŠŗÕī¢ńÜäĶ«ŠńĮ«ŃĆé
+
+ń▒╗õ╝╝ńÜä’╝īńö©µłĘÕÅ»õ╗źķĆÜĶ┐ćĶ░āńö© `tools/visualizations/vis_configs/feature_diff_visualization.py` µØźÕŠŚÕł░
+ÕŹĢÕ╝ĀÕøŠńēćõĖżõĖ¬µ©ĪÕ×ŗńÜäńē╣ÕŠüÕĘ«Õ╝éÕÅ»Ķ¦åÕī¢ń╗ōµ×£’╝īńö©µ│ĢõĖÄõĖŖĶ┐░ń▒╗õ╝╝’╝īÕĘ«Õ╝éõĖ║’╝Ü
+
+- `config1` / `config2`’╝ÜķĆēµŗ®ń«Śµ│Ģ1/2ńÜäķģŹńĮ«µ¢ćõ╗ČŃĆé
+- `checkpoint1` / `checkpoint2`’╝ÜķĆēµŗ®Õ»╣Õ║öń«Śµ│Ģ1/2ńÜäµØāķ揵¢ćõ╗ČŃĆé
+
+## ńö©µ│Ģńż║õŠŗ
+
+õ╗źķóäĶ«Łń╗āÕźĮńÜä RetinaNet-r101 õĖÄ RetinaNet-r50 µ©ĪÕ×ŗõĖ║õŠŗ:
+
+Ķ»ĘµÅÉÕēŹõĖŗĶĮĮ RetinaNet-r101 õĖÄ RetinaNet-r50 µ©ĪÕ×ŗµØāķćŹÕł░µ£¼õ╗ōÕ║ōµĀ╣ĶĘ»ÕŠäõĖŗ’╝Ü
+
+```shell
+cd mmrazor
+wget https://download.openmmlab.com/mmdetection/v2.0/retinanet/retinanet_r101_fpn_2x_coco/retinanet_r101_fpn_2x_coco_20200131-5560aee8.pth
+wget https://download.openmmlab.com/mmdetection/v2.0/retinanet/retinanet_r50_fpn_2x_coco/retinanet_r50_fpn_2x_coco_20200131-fdb43119.pth
+```
+
+(1) Õ░åÕżÜķĆÜķüōńē╣ÕŠüÕøŠķććńö© `pixel_wise_max` ÕÅéµĢ░ÕÄŗń╝®õĖ║ÕŹĢķĆÜķüōÕ╣ȵśŠńż║, ķĆÜĶ┐ćµÅÉÕÅ¢ `neck` Õ▒éĶŠōÕć║Ķ┐øĶĪīńē╣ÕŠüÕøŠÕÅ»Ķ¦åÕī¢’╝łĶ┐ÖķćīÕŬµśŠńż║õ║åÕēŹ4õĖ¬stageńÜäńē╣ÕŠüÕøŠ’╝ē’╝Ü
+
+```shell
+python tools/visualizations/feature_visualization.py \
+ tools/visualizations/demo.jpg \
+ PATH/TO/THE/CONFIG \
+ tools/visualizations/vis_configs/fpn_feature_visualization.py \
+ retinanet_r101_fpn_2x_coco_20200131-5560aee8.pth \
+ --repo mmdet --use-norm --overlaid
+ --channel-reduction pixel_wise_max
+```
+
+
+
+ +
+
+
+(2) Õ░åÕżÜķĆÜķüōńē╣ÕŠüÕøŠķććńö© `select_max` ÕÅéµĢ░ÕÄŗń╝®õĖ║ÕŹĢķĆÜķüōÕ╣ȵśŠńż║, ķĆÜĶ┐ćµÅÉÕÅ¢ `neck` Õ▒éĶŠōÕć║Ķ┐øĶĪīńē╣ÕŠüÕøŠÕÅ»Ķ¦åÕī¢’╝łĶ┐ÖķćīÕŬµśŠńż║õ║åÕēŹ4õĖ¬stageńÜäńē╣ÕŠüÕøŠ’╝ē’╝Ü
+
+```shell
+python tools/visualizations/feature_visualization.py \
+ tools/visualizations/demo.jpg \
+ PATH/TO/THE/CONFIG \
+ tools/visualizations/vis_configs/fpn_feature_visualization.py \
+ retinanet_r101_fpn_2x_coco_20200131-5560aee8.pth \
+ --repo mmdet --overlaid
+ --channel-reduction select_max
+```
+
+
+
+ +
+
+
+(3) Õ░åÕżÜķĆÜķüōńē╣ÕŠüÕøŠķććńö© `squeeze_mean` ÕÅéµĢ░ÕÄŗń╝®õĖ║ÕŹĢķĆÜķüōÕ╣ȵśŠńż║, ķĆÜĶ┐ćµÅÉÕÅ¢ `neck` Õ▒éĶŠōÕć║Ķ┐øĶĪīńē╣ÕŠüÕøŠÕÅ»Ķ¦åÕī¢’╝łĶ┐ÖķćīÕŬµśŠńż║õ║åÕēŹ4õĖ¬stageńÜäńē╣ÕŠüÕøŠ’╝ē’╝Ü
+
+```shell
+python tools/visualizations/feature_visualization.py \
+ tools/visualizations/demo.jpg \
+ PATH/TO/THE/CONFIG \
+ tools/visualizations/vis_configs/fpn_feature_visualization.py \
+ retinanet_r101_fpn_2x_coco_20200131-5560aee8.pth \
+ --repo mmdet --overlaid
+ --channel-reduction squeeze_mean
+```
+
+
+
+ +
+
+
+(4) Õ░åÕżÜķĆÜķüōńē╣ÕŠüÕøŠķććńö© `squeeze_mean` ÕÅéµĢ░ÕÄŗń╝®õĖ║ÕŹĢķĆÜķüōÕ╣ȵśŠńż║, ķĆÜĶ┐ćµÅÉÕÅ¢ `neck` Õ▒éĶŠōÕć║Ķ┐øĶĪīńē╣ÕŠüÕøŠÕÅ»Ķ¦åÕī¢’╝łĶ┐ÖķćīÕŬµśŠńż║õ║åÕēŹ4õĖ¬stageńÜäńē╣ÕŠüÕøŠ’╝ē’╝Ü
+
+```shell
+python tools/visualizations/feature_visualization.py \
+ tools/visualizations/demo.jpg \
+ PATH/TO/THE/CONFIG \
+ tools/visualizations/vis_configs/fpn_feature_visualization.py \
+ retinanet_r101_fpn_2x_coco_20200131-5560aee8.pth \
+ --repo mmdet --overlaid
+ --channel-reduction squeeze_mean
+```
+
+
+
+ +
+
+
+(5) Õ░åÕżÜķĆÜķüōńÜäõĖżõĖ¬µ©ĪÕ×ŗńÜäńē╣ÕŠüÕøŠÕĘ«Õ╝éķććńö© `pixel_wise_max` ÕÅéµĢ░ÕÄŗń╝®õĖ║ÕŹĢķĆÜķüōÕ╣ȵśŠńż║, Ķ┐ÖķćīÕŬµśŠńż║õ║åÕēŹ4õĖ¬stageńÜäńē╣ÕŠüÕøŠÕĘ«Õ╝é’╝Ü
+
+```shell
+python tools/visualizations/feature_diff_visualization.py \
+ tools/visualizations/demo.jpg \
+ PATH/TO/THE/CONFIG1 \
+ PATH/TO/THE/CONFIG2 \
+ tools/visualizations/vis_configs/fpn_feature_diff_visualization.py.py \
+ retinanet_r101_fpn_2x_coco_20200131-5560aee8.pth \
+ retinanet_r50_fpn_2x_coco_20200131-fdb43119.pth \
+ --repo mmdet --use-norm --overlaid
+ --channel-reduction pixel_wise_max
+```
+
+
+
+ +
+
diff --git a/internlm_langchain/knowledge_base/MMRazor/vector_store/index.faiss b/internlm_langchain/knowledge_base/MMRazor/vector_store/index.faiss
new file mode 100644
index 00000000..e2dfe715
Binary files /dev/null and b/internlm_langchain/knowledge_base/MMRazor/vector_store/index.faiss differ
diff --git a/internlm_langchain/knowledge_base/MMRotate/content/customize_config.md b/internlm_langchain/knowledge_base/MMRotate/content/customize_config.md
new file mode 100644
index 00000000..5b62f665
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMRotate/content/customize_config.md
@@ -0,0 +1,337 @@
+# µĢÖń©ŗ 1’╝ÜÕŁ”õ╣ĀķģŹńĮ«µ¢ćõ╗Č
+
+µłæõ╗¼Õ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁµö»µīüõ║åń╗¦µē┐ÕÆīµ©ĪÕØŚÕī¢’╝īĶ┐ÖõŠ┐õ║ÄĶ┐øĶĪīÕÉäń¦ŹÕ«×ķ¬īŃĆé
+Õ”éµ×£ķ£ĆĶ”üµŻĆµ¤źķģŹńĮ«µ¢ćõ╗Č’╝īÕÅ»õ╗źķĆÜĶ┐ćĶ┐ÉĶĪī `python tools/misc/print_config.py /PATH/TO/CONFIG` µØźµ¤źń£ŗÕ«īµĢ┤ńÜäķģŹńĮ«ŃĆé
+mmrotate µś»Õ╗║ń½ŗÕ£© [mmdet](https://github.com/open-mmlab/mmdetection) õ╣ŗõĖŖńÜä’╝ī
+ÕøĀµŁżÕ╝║ńāłÕ╗║Ķ««ÕŁ”õ╣Ā [mmdet](https://mmdetection.readthedocs.io/en/latest/) ńÜäÕ¤║µ£¼ń¤źĶ»åŃĆé
+
+## ķĆÜĶ┐ćĶäܵ£¼ÕÅéµĢ░õ┐«µö╣ķģŹńĮ«
+
+ÕĮōĶ┐ÉĶĪī `tools/train.py` µł¢ĶĆģ `tools/test.py` µŚČ’╝īÕÅ»õ╗źķĆÜĶ┐ć `--cfg-options` µØźõ┐«µö╣ķģŹńĮ«ŃĆé
+
+- µø┤µ¢░ÕŁŚÕģĖķōŠńÜäķģŹńĮ«
+
+ ÕÅ»õ╗źµīēńģ¦ÕĤզŗķģŹńĮ«µ¢ćõ╗ČõĖŁńÜä dict ķö«ķĪ║Õ║ÅÕ£░µīćÕ«ÜķģŹńĮ«ķóäķĆēķĪ╣ŃĆé
+ õŠŗÕ”é’╝īõĮ┐ńö© `--cfg-options model.backbone.norm_eval=False` Õ░嵩ĪÕ×ŗõĖ╗Õ╣▓ńĮæń╗£õĖŁńÜäµēƵ£ē BN µ©ĪÕØŚķāĮµö╣õĖ║ `train` µ©ĪÕ╝ÅŃĆé
+
+- µø┤µ¢░ķģŹńĮ«ÕłŚĶĪ©õĖŁńÜäķö«
+
+ Õ£©ķģŹńĮ«µ¢ćõ╗Čķćī’╝īõĖĆõ║øÕŁŚÕģĖÕ×ŗńÜäķģŹńĮ«Ķó½ÕīģÕɽգ©ÕłŚĶĪ©õĖŁŃĆéõŠŗÕ”é’╝īµĢ░µŹ«Ķ«Łń╗āµĄüń©ŗ `data.train.pipeline` ķĆÜÕĖĖµś»õĖĆõĖ¬ÕłŚĶĪ©’╝īµ»öÕ”é `[dict(type='LoadImageFromFile'), ...]`ŃĆé Õ”éµ×£ķ£ĆĶ”üÕ░å `'LoadImageFromFile'` µö╣µłÉ `'LoadImageFromWebcam'` ’╝īķ£ĆĶ”üÕåÖµłÉõĖŗĶ┐░ÕĮóÕ╝Å’╝Ü `--cfg-options data.train.pipeline.0.type=LoadImageFromWebcam`ŃĆé
+
+- µø┤µ¢░ÕłŚĶĪ©µł¢Õģāń╗äńÜäÕĆ╝
+
+ Õ”éµ×£Ķ”üµø┤µ¢░ńÜäÕĆ╝µś»ÕłŚĶĪ©µł¢Õģāń╗äŃĆéõŠŗÕ”é’╝īķģŹńĮ«µ¢ćõ╗ČķĆÜÕĖĖĶ«ŠńĮ« `workflow=[('train', 1)]`’╝īÕ”éµ×£ķ£ĆĶ”üµö╣ÕÅśĶ┐ÖõĖ¬ķö«’╝īÕÅ»õ╗źķĆÜĶ┐ć `--cfg-options workflow="[(train,1),(val,1)]"` µØźķ揵¢░Ķ«ŠńĮ«ŃĆéķ£ĆĶ”üµ│©µäÅ’╝īÕ╝ĢÕÅĘ " µś»µö»µīüÕłŚĶĪ©µł¢Õģāń╗äµĢ░µŹ«ń▒╗Õ×ŗµēĆÕ┐ģķ£ĆńÜä’╝īÕ╣ČõĖöÕ£©µīćÕ«ÜÕĆ╝ńÜäÕ╝ĢÕÅĘÕåģ**õĖŹÕģüĶ«Ė**µ£ēń®║µĀ╝ŃĆé
+
+## ķģŹńĮ«µ¢ćõ╗ČÕÉŹń¦░ķŻÄµĀ╝
+
+µłæõ╗¼ķüĄÕŠ¬õ╗źõĖŗµĀĘÕ╝ÅµØźÕæĮÕÉŹķģŹńĮ«µ¢ćõ╗ČŃĆéÕ╗║Ķ««Ķ┤Īńī«ĶĆģķüĄÕŠ¬ńøĖÕÉīńÜäķŻÄµĀ╝ŃĆé
+
+```text
+{model}_[model setting]_{backbone}_{neck}_[norm setting]_[misc]_[gpu x batch_per_gpu]_{dataset}_{data setting}_{angle version}
+```
+
+`{xxx}` µś»Ķó½Ķ”üµ▒éńÜäµ¢ćõ╗Č `[yyy]` µś»ÕÅ»ķĆēńÜäŃĆé
+
+- `{model}`’╝Ü µ©ĪÕ×ŗń¦Źń▒╗’╝īõŠŗÕ”é `rotated_faster_rcnn`, `rotated_retinanet` ńŁēŃĆé
+- `[model setting]`’╝Ü ńē╣Õ«ÜńÜ䵩ĪÕ×ŗ’╝īõŠŗÕ”é `hbb` for `rotated_retinanet` ńŁēŃĆé
+- `{backbone}`’╝Ü õĖ╗Õ╣▓ńĮæń╗£ń¦Źń▒╗õŠŗÕ”é `r50` (ResNet-50), `swin_tiny` (SWIN-tiny) ŃĆé
+- `{neck}`’╝Ü Neck µ©ĪÕ×ŗńÜäń¦Źń▒╗Õīģµŗ¼ `fpn`, `refpn`ŃĆé
+- `[norm_setting]`’╝Ü ķ╗śĶ«żõĮ┐ńö© `bn` (Batch Normalization)’╝īÕģČõ╗¢µīćÕ«ÜÕÅ»õ╗źµ£ē `gn` (Group Normalization)’╝ī `syncbn` (Synchronized Batch Normalization) ńŁēŃĆé `gn-head`/`gn-neck` ĶĪ©ńż║ GN õ╗ģÕ║öńö©õ║ÄńĮæń╗£ńÜä Head µł¢ Neck’╝ī `gn-all` ĶĪ©ńż║ GN ńö©õ║ĵĢ┤õĖ¬µ©ĪÕ×ŗ’╝ī õŠŗÕ”éõĖ╗Õ╣▓ńĮæń╗£ŃĆüNeck ÕÆī HeadŃĆé
+- `[misc]`’╝Ü µ©ĪÕ×ŗõĖŁÕÉäÕ╝ÅÕÉäµĀĘńÜäĶ«ŠńĮ«/µÅÆõ╗Č’╝īõŠŗÕ”é `dconv`ŃĆü `gcb`ŃĆü `attention`ŃĆü`albu`ŃĆü `mstrain` ńŁēŃĆé
+- `[gpu x batch_per_gpu]`’╝Ü GPU µĢ░ķćÅÕÆīµ»ÅõĖ¬ GPU ńÜäµĀʵ£¼µĢ░’╝īķ╗śĶ«żõĮ┐ńö© `1xb2`ŃĆé
+- `{dataset}`’╝ܵĢ░µŹ«ķøå’╝īõŠŗÕ”é `dota`ŃĆé
+- `{angle version}`’╝ܵŚŗĶĮ¼Õ«Üõ╣ēµ¢╣Õ╝Å’╝īõŠŗÕ”é `oc`, `le135` µł¢ĶĆģ `le90`ŃĆé
+
+## RotatedRetinaNet ķģŹńĮ«µ¢ćõ╗Čńż║õŠŗ
+
+õĖ║õ║åÕĖ«ÕŖ®ńö©µłĘÕ»╣ MMRotate µŻĆµĄŗń│╗ń╗¤õĖŁńÜäÕ«īµĢ┤ķģŹńĮ«ÕÆīµ©ĪÕØŚµ£ēõĖĆõĖ¬Õ¤║µ£¼ńÜäõ║åĶ¦Ż
+µłæõ╗¼Õ»╣õĮ┐ńö© ResNet50 ÕÆī FPN ńÜä RotatedRetinaNet ńÜäķģŹńĮ«µ¢ćõ╗ČĶ┐øĶĪīń«ĆĶ”üµ│©ķćŖĶ»┤µśÄŃĆéµø┤Ķ»”ń╗åńÜäńö©µ│ĢÕÆīÕÉäõĖ¬µ©ĪÕØŚÕ»╣Õ║öńÜäµø┐õ╗Żµ¢╣µĪł’╝īĶ»ĘÕÅéĶĆā API µ¢ćµĪŻŃĆé
+
+```python
+angle_version = 'oc' # µŚŗĶĮ¼Õ«Üõ╣ēµ¢╣Õ╝Å
+model = dict(
+ type='RotatedRetinaNet', # µŻĆµĄŗÕÖ©(detector)ÕÉŹń¦░
+ backbone=dict( # õĖ╗Õ╣▓ńĮæń╗£ńÜäķģŹńĮ«µ¢ćõ╗Č
+ type='ResNet', # # õĖ╗Õ╣▓ńĮæń╗£ńÜäń▒╗Õł½
+ depth=50, # õĖ╗Õ╣▓ńĮæń╗£ńÜäµĘ▒Õ║”
+ num_stages=4, # õĖ╗Õ╣▓ńĮæń╗£ķśČµ«Ą(stages)ńÜäµĢ░ńø«
+ out_indices=(0, 1, 2, 3), # µ»ÅõĖ¬ķśČµ«Ąõ║¦ńö¤ńÜäńē╣ÕŠüÕøŠĶŠōÕć║ńÜäń┤óÕ╝Ģ
+ frozen_stages=1, # ń¼¼õĖĆõĖ¬ķśČµ«ĄńÜäµØāķćŹĶó½Õå╗ń╗ō
+ zero_init_residual=False, # µś»Õɔջ╣µ«ŗÕĘ«ÕØŚ(resblocks)õĖŁńÜäµ£ĆÕÉÄõĖĆõĖ¬ÕĮÆõĖĆÕī¢Õ▒éõĮ┐ńö©ķøČÕłØÕ¦ŗÕī¢(zero init)Ķ«®Õ«āõ╗¼ĶĪ©ńÄ░õĖ║Ķć¬Ķ║½
+ norm_cfg=dict( # ÕĮÆõĖĆÕī¢Õ▒é(norm layer)ńÜäķģŹńĮ«ķĪ╣
+ type='BN', # ÕĮÆõĖĆÕī¢Õ▒éńÜäń▒╗Õł½’╝īķĆÜÕĖĖµś» BN µł¢ GN
+ requires_grad=True), # µś»ÕÉ”Ķ«Łń╗āÕĮÆõĖĆÕī¢ķćīńÜä gamma ÕÆī beta
+ norm_eval=True, # µś»ÕÉ”Õå╗ń╗ō BN ķćīńÜäń╗¤Ķ«ĪķĪ╣
+ style='pytorch', # õĖ╗Õ╣▓ńĮæń╗£ńÜäķŻÄµĀ╝’╝ī'pytorch' µäŵĆصś»µŁźķĢ┐õĖ║2ńÜäÕ▒éõĖ║ 3x3 ÕŹĘń¦»’╝ī 'caffe' µäŵĆصś»µŁźķĢ┐õĖ║2ńÜäÕ▒éõĖ║ 1x1 ÕŹĘń¦»ŃĆé
+ init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')), # ÕŖĀĶĮĮķĆÜĶ┐ć ImageNet ķóäĶ«Łń╗āńÜ䵩ĪÕ×ŗ
+ neck=dict(
+ type='FPN', # µŻĆµĄŗÕÖ©ńÜä neck µś» FPN’╝ī µłæõ╗¼ÕÉīµĀʵö»µīü 'ReFPN'
+ in_channels=[256, 512, 1024, 2048], # ĶŠōÕģźķĆÜķüōµĢ░’╝īĶ┐ÖõĖÄõĖ╗Õ╣▓ńĮæń╗£ńÜäĶŠōÕć║ķĆÜķüōõĖĆĶć┤
+ out_channels=256, # ķćæÕŁŚÕĪöńē╣ÕŠüÕøŠµ»ÅõĖĆÕ▒éńÜäĶŠōÕć║ķĆÜķüō
+ start_level=1, # ńö©õ║ĵ×äÕ╗║ńē╣ÕŠüķćæÕŁŚÕĪöńÜäõĖ╗Õ╣▓ńĮæń╗£ĶĄĘÕ¦ŗĶŠōÕģźÕ▒éń┤óÕ╝ĢÕĆ╝
+ add_extra_convs='on_input', # Õå│իܵś»Õɔգ©ÕĤզŗńē╣ÕŠüÕøŠõ╣ŗõĖŖµĘ╗ÕŖĀÕŹĘń¦»Õ▒é
+ num_outs=5), # Õå│Õ«ÜĶŠōÕć║ÕżÜÕ░æõĖ¬Õ░║Õ║”ńÜäńē╣ÕŠüÕøŠ(scales)
+ bbox_head=dict(
+ type='RotatedRetinaHead',# bbox_head ńÜäń▒╗Õ×ŗµś» 'RRetinaHead'
+ num_classes=15, # Õłåń▒╗ńÜäń▒╗Õł½µĢ░ķćÅ
+ in_channels=256, # bbox head ĶŠōÕģźķĆÜķüōµĢ░
+ stacked_convs=4, # head ÕŹĘń¦»Õ▒éńÜäÕ▒éµĢ░
+ feat_channels=256, # head ÕŹĘń¦»Õ▒éńÜäńē╣ÕŠüķĆÜķüō
+ assign_by_circumhbbox='oc', # obb2hbb ńÜ䵌ŗĶĮ¼Õ«Üõ╣ēµ¢╣Õ╝Å
+ anchor_generator=dict( # ķöÜńé╣(Anchor)ńö¤µłÉÕÖ©ńÜäķģŹńĮ«
+ type='RotatedAnchorGenerator', # ķöÜńé╣ńö¤µłÉÕÖ©ń▒╗Õł½
+ octave_base_scale=4, # RetinaNet ńö©õ║Äńö¤µłÉķöÜńé╣ńÜäĶČģÕÅéµĢ░’╝īńē╣ÕŠüÕøŠ anchor ńÜäÕ¤║µ£¼Õ░║Õ║”ŃĆéÕĆ╝ĶČŖÕż¦’╝īµēƵ£ē anchor ńÜäÕ░║Õ║”ķāĮõ╝ÜÕÅśÕż¦ŃĆé
+ scales_per_octave=3, # RetinaNet ńö©õ║Äńö¤µłÉķöÜńé╣ńÜäĶČģÕÅéµĢ░’╝īµ»ÅõĖ¬ńē╣ÕŠüÕøŠµ£ē3õĖ¬Õ░║Õ║”
+ ratios=[1.0, 0.5, 2.0], # ķ½śÕ║”ÕÆīÕ«ĮÕ║”õ╣ŗķŚ┤ńÜäµ»öńÄć
+ strides=[8, 16, 32, 64, 128]), # ķöÜńö¤µłÉÕÖ©ńÜ䵣źÕ╣ģŃĆéĶ┐ÖõĖÄ FPN ńē╣ÕŠüµŁźÕ╣ģõĖĆĶć┤ŃĆéÕ”éµ×£µ£¬Ķ«ŠńĮ« base_sizes’╝īÕłÖÕĮōÕēŹµŁźÕ╣ģÕĆ╝Õ░åĶó½Ķ¦åõĖ║ base_sizesŃĆé
+ bbox_coder=dict( # Õ£©Ķ«Łń╗āÕÆīµĄŗĶ»Ģµ£¤ķŚ┤Õ»╣µĪåĶ┐øĶĪīń╝¢ńĀüÕÆīĶ¦ŻńĀü
+ type='DeltaXYWHAOBBoxCoder', # µĪåń╝¢ńĀüÕÖ©ńÜäń▒╗Õł½
+ angle_range='oc', # µĪåń╝¢ńĀüÕÖ©ńÜ䵌ŗĶĮ¼Õ«Üõ╣ēµ¢╣Õ╝Å
+ norm_factor=None, # µĪåń╝¢ńĀüÕÖ©ńÜäĶīāµĢ░
+ edge_swap=False, # Ķ«ŠńĮ«µś»ÕÉ”ÕÉ»ńö©µĪåń╝¢ńĀüÕÖ©ńÜäĶŠ╣ń╝śõ║żµŹó
+ proj_xy=False, # Ķ«ŠńĮ«µś»ÕÉ”ÕÉ»ńö©µĪåń╝¢ńĀüÕÖ©ńÜäµŖĢÕĮ▒
+ target_means=(0.0, 0.0, 0.0, 0.0, 0.0), # ńö©õ║Äń╝¢ńĀüÕÆīĶ¦ŻńĀüµĪåńÜäńø«µĀćÕØćÕĆ╝
+ target_stds=(1.0, 1.0, 1.0, 1.0, 1.0)), # ńö©õ║Äń╝¢ńĀüÕÆīĶ¦ŻńĀüµĪåńÜäµĀćÕćåÕĘ«
+ loss_cls=dict( # Õłåń▒╗Õłåµö»ńÜ䵏¤Õż▒ÕćĮµĢ░ķģŹńĮ«
+ type='FocalLoss', # Õłåń▒╗Õłåµö»ńÜ䵏¤Õż▒ÕćĮµĢ░ń▒╗Õ×ŗ
+ use_sigmoid=True, # µś»ÕÉ”õĮ┐ńö© sigmoid
+ gamma=2.0, # Focal Loss ńö©õ║ÄĶ¦ŻÕå│ķÜŠµśōõĖŹÕØćĶĪĪńÜäÕÅéµĢ░ gamma
+ alpha=0.25, # Focal Loss ńö©õ║ÄĶ¦ŻÕå│µĀʵ£¼µĢ░ķćÅõĖŹÕØćĶĪĪńÜäÕÅéµĢ░ alpha
+ loss_weight=1.0), # Õłåń▒╗Õłåµö»ńÜ䵏¤Õż▒µØāķćŹ
+ loss_bbox=dict( # Õø×ÕĮÆÕłåµö»ńÜ䵏¤Õż▒ÕćĮµĢ░ķģŹńĮ«
+ type='L1Loss', # Õø×ÕĮÆÕłåµö»ńÜ䵏¤Õż▒ń▒╗Õ×ŗ
+ loss_weight=1.0)), # Õø×ÕĮÆÕłåµö»ńÜ䵏¤Õż▒µØāķćŹ
+ train_cfg=dict( # Ķ«Łń╗āĶČģÕÅéµĢ░ńÜäķģŹńĮ«
+ assigner=dict( # ÕłåķģŹÕÖ©(assigner)ńÜäķģŹńĮ«
+ type='MaxIoUAssigner', # ÕłåķģŹÕÖ©ńÜäń▒╗Õ×ŗ
+ pos_iou_thr=0.5, # IoU >= 0.5(ķśłÕĆ╝) Ķó½Ķ¦åõĖ║µŁŻµĀʵ£¼
+ neg_iou_thr=0.4, # IoU < 0.4(ķśłÕĆ╝) Ķó½Ķ¦åõĖ║Ķ┤¤µĀʵ£¼
+ min_pos_iou=0, # Õ░åµĪåõĮ£õĖ║µŁŻµĀʵ£¼ńÜäµ£ĆÕ░Å IoU ķśłÕĆ╝
+ ignore_iof_thr=-1, # Õ┐ĮńĢź bbox ńÜä IoF ķśłÕĆ╝
+ iou_calculator=dict(type='RBboxOverlaps2D')), # IoU ńÜäĶ«Īń«ŚÕÖ©ń▒╗Õ×ŗ
+ allowed_border=-1, # ÕĪ½Õģģµ£ēµĢłķöÜńé╣(anchor)ÕÉÄÕģüĶ«ĖńÜäĶŠ╣µĪå
+ pos_weight=-1, # Ķ«Łń╗āµ£¤ķŚ┤µŁŻµĀʵ£¼ńÜäµØāķćŹ
+ debug=False), # µś»ÕÉ”Ķ«ŠńĮ«Ķ░āĶ»Ģ(debug)µ©ĪÕ╝Å
+ test_cfg=dict( # µĄŗĶ»ĢĶČģÕÅéµĢ░ńÜäķģŹńĮ«
+ nms_pre=2000, # NMS ÕēŹńÜä box µĢ░
+ min_bbox_size=0, # box ÕģüĶ«ĖńÜäµ£ĆÕ░ÅÕ░║Õ»Ė
+ score_thr=0.05, # bbox ńÜäÕłåµĢ░ķśłÕĆ╝
+ nms=dict(iou_thr=0.1), # NMS ńÜäķśłÕĆ╝
+ max_per_img=2000)) # µ»ÅÕ╝ĀÕøŠÕāÅńÜäµ£ĆÕż¦µŻĆµĄŗµ¼ĪµĢ░
+dataset_type = 'DOTADataset' # µĢ░µŹ«ķøåń▒╗Õ×ŗ’╝īĶ┐ÖÕ░åĶó½ńö©µØźÕ«Üõ╣ēµĢ░µŹ«ķøå
+data_root = '../datasets/split_1024_dota1_0/' # µĢ░µŹ«ńÜäµĀ╣ĶĘ»ÕŠä
+img_norm_cfg = dict( # ÕøŠÕāÅÕĮÆõĖĆÕī¢ķģŹńĮ«’╝īńö©µØźÕĮÆõĖĆÕī¢ĶŠōÕģźńÜäÕøŠÕāÅ
+ mean=[123.675, 116.28, 103.53], # ķóäĶ«Łń╗āķćīńö©õ║ÄķóäĶ«Łń╗āõĖ╗Õ╣▓ńĮæń╗£µ©ĪÕ×ŗńÜäÕ╣│ÕØćÕĆ╝
+ std=[58.395, 57.12, 57.375], # ķóäĶ«Łń╗āķćīńö©õ║ÄķóäĶ«Łń╗āõĖ╗Õ╣▓ńĮæń╗£µ©ĪÕ×ŗńÜäµĀćÕćåÕĘ«
+ to_rgb=True) # ķóäĶ«Łń╗āķćīńö©õ║ÄķóäĶ«Łń╗āõĖ╗Õ╣▓ńĮæń╗£ńÜäÕøŠÕāÅńÜäķĆÜķüōķĪ║Õ║Å
+train_pipeline = [ # Ķ«Łń╗āµĄüń©ŗ
+ dict(type='LoadImageFromFile'), # ń¼¼ 1 õĖ¬µĄüń©ŗ’╝īõ╗ĵ¢ćõ╗ČĶĘ»ÕŠäķćīÕŖĀĶĮĮÕøŠÕāÅ
+ dict(type='LoadAnnotations', # ń¼¼ 2 õĖ¬µĄüń©ŗ’╝īÕ»╣õ║ÄÕĮōÕēŹÕøŠÕāÅ’╝īÕŖĀĶĮĮÕ«āńÜäµ│©ķćŖõ┐Īµü»
+ with_bbox=True), # µś»ÕÉ”ÕŖĀĶĮĮµĀćµ│©µĪå(bounding box)’╝ī ńø«µĀ浯ƵĄŗķ£ĆĶ”üĶ«ŠńĮ«õĖ║ True
+ dict(type='RResize', # ÕÅśÕī¢ÕøŠÕāÅÕÆīÕģȵ│©ķćŖÕż¦Õ░ÅńÜäµĢ░µŹ«Õó×Õ╣┐ńÜ䵥üń©ŗ
+ img_scale=(1024, 1024)), # ÕøŠÕāÅńÜäµ£ĆÕż¦Ķ¦äµ©Ī
+ dict(type='RRandomFlip', # ń┐╗ĶĮ¼ÕøŠÕāÅÕÆīÕģȵ│©ķćŖÕż¦Õ░ÅńÜäµĢ░µŹ«Õó×Õ╣┐ńÜ䵥üń©ŗ
+ flip_ratio=0.5, # ń┐╗ĶĮ¼ÕøŠÕāÅńÜäµ”éńÄć
+ version='oc'), # Õ«Üõ╣ēµŚŗĶĮ¼ńÜäµ¢╣Õ╝Å
+ dict(
+ type='Normalize', # ÕĮÆõĖĆÕī¢ÕĮōÕēŹÕøŠÕāÅńÜäµĢ░µŹ«Õó×Õ╣┐ńÜ䵥üń©ŗ
+ mean=[123.675, 116.28, 103.53], # Ķ┐Öõ║øķö«õĖÄ img_norm_cfg õĖĆĶć┤’╝ī
+ std=[58.395, 57.12, 57.375], # ÕøĀõĖ║ img_norm_cfg Ķó½ńö©õĮ£ÕÅéµĢ░
+ to_rgb=True),
+ dict(type='Pad', # ÕĪ½ÕģģÕĮōÕēŹÕøŠÕāÅÕł░µīćÕ«ÜÕż¦Õ░ÅńÜäµĢ░µŹ«Õó×Õ╣┐ńÜ䵥üń©ŗ
+ size_divisor=32), # ÕĪ½ÕģģÕøŠÕāÅÕÅ»õ╗źĶó½ÕĮōÕēŹÕĆ╝µĢ┤ķÖż
+ dict(type='DefaultFormatBundle'), # µĄüń©ŗķćīµöČķøåµĢ░µŹ«ńÜäķ╗śĶ«żµĀ╝Õ╝ÅÕīģ
+ dict(type='Collect', # Õå│իܵĢ░µŹ«õĖŁÕō¬õ║øķö«Õ║öĶ»źõ╝ĀķĆÆń╗ÖµŻĆµĄŗÕÖ©ńÜ䵥üń©ŗ
+ keys=['img', 'gt_bboxes', 'gt_labels'])
+]
+test_pipeline = [ # µĄŗĶ»ĢµĄüń©ŗ
+ dict(type='LoadImageFromFile'), # ń¼¼ 1 õĖ¬µĄüń©ŗ’╝īõ╗ĵ¢ćõ╗ČĶĘ»ÕŠäķćīÕŖĀĶĮĮÕøŠÕāÅ
+ dict(
+ type='MultiScaleFlipAug', # Õ░üĶŻģµĄŗĶ»ĢµŚČµĢ░µŹ«Õó×Õ╣┐(test time augmentations)
+ img_scale=(1024, 1024), # Õå│իܵĄŗĶ»ĢµŚČÕÅ»µö╣ÕÅśÕøŠÕāÅńÜäµ£ĆÕż¦Ķ¦äµ©ĪŃĆéńö©õ║ĵö╣ÕÅśÕøŠÕāÅÕż¦Õ░ÅńÜ䵥üń©ŗ
+ flip=False, # µĄŗĶ»ĢµŚČµś»ÕÉ”ń┐╗ĶĮ¼ÕøŠÕāÅ
+ transforms=[
+ dict(type='RResize'), # õĮ┐ńö©µö╣ÕÅśÕøŠÕāÅÕż¦Õ░ÅńÜäµĢ░µŹ«Õó×Õ╣┐
+ dict(
+ type='Normalize', # ÕĮÆõĖĆÕī¢ķģŹńĮ«ķĪ╣’╝īÕĆ╝µØźĶć¬ img_norm_cfg
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ to_rgb=True),
+ dict(type='Pad', # Õ░åķģŹńĮ«õ╝ĀķĆÆń╗ÖÕÅ»Ķó½ 32 µĢ┤ķÖżńÜäÕøŠÕāÅ
+ size_divisor=32),
+ dict(type='DefaultFormatBundle'), # ńö©õ║ÄÕ£©ń«ĪķüōõĖŁµöČķøåµĢ░µŹ«ńÜäķ╗śĶ«żµĀ╝Õ╝ÅÕīģ
+ dict(type='Collect', # µöČķøåµĄŗĶ»ĢµŚČÕ┐ģķĪ╗ńÜäķö«ńÜäµöČķøåµĄüń©ŗ
+ keys=['img'])
+ ])
+]
+data = dict(
+ samples_per_gpu=2, # ÕŹĢõĖ¬ GPU ńÜä Batch size
+ workers_per_gpu=2, # ÕŹĢõĖ¬ GPU ÕłåķģŹńÜäµĢ░µŹ«ÕŖĀĶĮĮń║┐ń©ŗµĢ░
+ train=dict( # Ķ«Łń╗āµĢ░µŹ«ķøåķģŹńĮ«
+ type='DOTADataset', # µĢ░µŹ«ķøåńÜäń▒╗Õł½
+ ann_file=
+ '../datasets/split_1024_dota1_0/trainval/annfiles/', # µ│©ķćŖµ¢ćõ╗ČĶĘ»ÕŠä
+ img_prefix=
+ '../datasets/split_1024_dota1_0/trainval/images/', # ÕøŠńēćĶĘ»ÕŠäÕēŹń╝Ć
+ pipeline=[ # µĄüń©ŗ, Ķ┐Öµś»ńö▒õ╣ŗÕēŹÕłøÕ╗║ńÜä train_pipeline õ╝ĀķĆÆńÜä
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations', with_bbox=True),
+ dict(type='RResize', img_scale=(1024, 1024)),
+ dict(type='RRandomFlip', flip_ratio=0.5, version='oc'),
+ dict(
+ type='Normalize',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ to_rgb=True),
+ dict(type='Pad', size_divisor=32),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels'])
+ ],
+ version='oc'),
+ val=dict( # ķ¬īĶ»üµĢ░µŹ«ķøåńÜäķģŹńĮ«
+ type='DOTADataset',
+ ann_file=
+ '../datasets/split_1024_dota1_0/trainval/annfiles/',
+ img_prefix=
+ '../datasets/split_1024_dota1_0/trainval/images/',
+ pipeline=[
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(1024, 1024),
+ flip=False,
+ transforms=[
+ dict(type='RResize'),
+ dict(
+ type='Normalize',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ to_rgb=True),
+ dict(type='Pad', size_divisor=32),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img'])
+ ])
+ ],
+ version='oc'),
+ test=dict( # µĄŗĶ»ĢµĢ░µŹ«ķøåķģŹńĮ«’╝īõ┐«µö╣µĄŗĶ»ĢÕ╝ĆÕÅæ/µĄŗĶ»Ģ(test-dev/test)µÅÉõ║żńÜä ann_file
+ type='DOTADataset',
+ ann_file=
+ '../datasets/split_1024_dota1_0/test/images/',
+ img_prefix=
+ '../datasets/split_1024_dota1_0/test/images/',
+ pipeline=[ # ńö▒õ╣ŗÕēŹÕłøÕ╗║ńÜä test_pipeline õ╝ĀķĆÆńÜ䵥üń©ŗ
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(1024, 1024),
+ flip=False,
+ transforms=[
+ dict(type='RResize'),
+ dict(
+ type='Normalize',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ to_rgb=True),
+ dict(type='Pad', size_divisor=32),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img'])
+ ])
+ ],
+ version='oc'))
+evaluation = dict( # evaluation hook ńÜäķģŹńĮ«
+ interval=12, # ķ¬īĶ»üńÜäķŚ┤ķÜö
+ metric='mAP') # ķ¬īĶ»üµ£¤ķŚ┤õĮ┐ńö©ńÜäµīćµĀć
+optimizer = dict( # ńö©õ║ĵ×äÕ╗║õ╝śÕī¢ÕÖ©ńÜäķģŹńĮ«µ¢ćõ╗Č
+ type='SGD', # õ╝śÕī¢ÕÖ©ń▒╗Õ×ŗ
+ lr=0.0025, # õ╝śÕī¢ÕÖ©ńÜäÕŁ”õ╣ĀńÄć
+ momentum=0.9, # ÕŖ©ķćÅ(Momentum)
+ weight_decay=0.0001) # SGD ńÜäĶĪ░ÕćŵØāķćŹ(weight decay)
+optimizer_config = dict( # optimizer hook ńÜäķģŹńĮ«µ¢ćõ╗Č
+ grad_clip=dict(
+ max_norm=35,
+ norm_type=2))
+lr_config = dict( # ÕŁ”õ╣ĀńÄćĶ░āµĢ┤ķģŹńĮ«’╝īńö©õ║ĵ│©Õåī LrUpdater hook
+ policy='step', # Ķ░āÕ║”µĄüń©ŗ(scheduler)ńÜäńŁ¢ńĢź
+ warmup='linear', # ķóäńāŁ(warmup)ńŁ¢ńĢź’╝īõ╣¤µö»µīü `exp` ÕÆī `constant`
+ warmup_iters=500, # ķóäńāŁńÜäĶ┐Łõ╗Żµ¼ĪµĢ░
+ warmup_ratio=0.3333333333333333, # ńö©õ║ÄķóäńāŁńÜäĶĄĘÕ¦ŗÕŁ”õ╣ĀńÄćńÜäµ»öńÄć
+ step=[8, 11]) # ĶĪ░ÕćÅÕŁ”õ╣ĀńÄćńÜäĶĄĘµŁóÕø×ÕÉłµĢ░
+runner = dict(
+ type='EpochBasedRunner', # Õ░åõĮ┐ńö©ńÜä runner ńÜäń▒╗Õł½ (õŠŗÕ”é IterBasedRunner µł¢ EpochBasedRunner)
+ max_epochs=12) # runner µĆ╗Õø×ÕÉł(epoch)µĢ░’╝ī Õ»╣õ║Ä IterBasedRunner õĮ┐ńö© `max_iters`
+checkpoint_config = dict( # checkpoint hook ńÜäķģŹńĮ«µ¢ćõ╗Č
+ interval=12) # õ┐ØÕŁśńÜäķŚ┤ķÜöµś» 12
+log_config = dict( # register logger hook ńÜäķģŹńĮ«µ¢ćõ╗Č
+ interval=50, # µēōÕŹ░µŚźÕ┐ŚńÜäķŚ┤ķÜö
+ hooks=[
+ # dict(type='TensorboardLoggerHook') # ÕÉīµĀʵö»µīü Tensorboard µŚźÕ┐Ś
+ dict(type='TextLoggerHook')
+ ]) # ńö©õ║ÄĶ«░ÕĮĢĶ«Łń╗āĶ┐ćń©ŗńÜäĶ«░ÕĮĢÕÖ©(logger)
+dist_params = dict(backend='nccl') # ńö©õ║ÄĶ«ŠńĮ«ÕłåÕĖāÕ╝ÅĶ«Łń╗āńÜäÕÅéµĢ░’╝īń½»ÕÅŻõ╣¤ÕÉīµĀĘÕÅ»Ķó½Ķ«ŠńĮ«
+log_level = 'INFO' # µŚźÕ┐ŚńÜäń║¦Õł½
+load_from = None # õ╗ÄõĖĆõĖ¬ń╗ÖÕ«ÜĶĘ»ÕŠäķćīÕŖĀĶĮĮµ©ĪÕ×ŗõĮ£õĖ║ķóäĶ«Łń╗āµ©ĪÕ×ŗ’╝īÕ«āÕ╣ČõĖŹõ╝ܵȳĶĆŚĶ«Łń╗āµŚČķŚ┤
+resume_from = None # õ╗Äń╗ÖÕ«ÜĶĘ»ÕŠäķćīµüóÕżŹµŻĆµ¤źńé╣(checkpoints)’╝īĶ«Łń╗āµ©ĪÕ╝ÅÕ░åõ╗ĵŻĆµ¤źńé╣õ┐ØÕŁśńÜäĶĮ«µ¼ĪÕ╝ĆÕ¦ŗµüóÕżŹĶ«Łń╗āŃĆé
+workflow = [('train', 1)] # runner ńÜäÕĘźõĮ£µĄüń©ŗ’╝ī[('train', 1)] ĶĪ©ńż║ÕŬµ£ēõĖĆõĖ¬ÕĘźõĮ£µĄüõĖöÕĘźõĮ£µĄüõ╗ģµē¦ĶĪīõĖƵ¼ĪŃĆéµĀ╣µŹ« total_epochs ÕĘźõĮ£µĄüĶ«Łń╗ā 12 õĖ¬Õø×ÕÉł(epoch)ŃĆé
+work_dir = './work_dirs/rotated_retinanet_hbb_r50_fpn_1x_dota_oc' # ńö©õ║Äõ┐ØÕŁśÕĮōÕēŹÕ«×ķ¬īńÜ䵩ĪÕ×ŗµŻĆµ¤źńé╣(checkpoints)ÕÆīµŚźÕ┐ŚńÜäńø«ÕĮĢ
+```
+
+## ÕĖĖĶ¦üķŚ«ķóś (FAQ)
+
+### õĮ┐ńö©ķģŹńĮ«µ¢ćõ╗ČķćīńÜäõĖŁķŚ┤ÕÅśķćÅ
+
+ķģŹńĮ«µ¢ćõ╗Čķćīõ╝ÜõĮ┐ńö©õĖĆõ║øõĖŁķŚ┤ÕÅśķćÅ’╝īõŠŗÕ”éµĢ░µŹ«ķøåķćīńÜä `train_pipeline`/`test_pipeline`ŃĆé
+ÕĆ╝ÕŠŚµ│©µäÅńÜ䵜»’╝īÕ£©õ┐«µö╣ÕŁÉķģŹńĮ«õĖŁńÜäõĖŁķŚ┤ÕÅśķćŵŚČ’╝īķ£ĆĶ”üÕåŹµ¼ĪÕ░åõĖŁķŚ┤ÕÅśķćÅõ╝ĀķĆÆÕł░ńøĖÕ║öńÜäÕŁŚµ«ĄõĖŁŃĆé
+õŠŗÕ”é’╝īµłæõ╗¼µā│õĮ┐ńö©ń”╗ń║┐ÕżÜÕ░║Õ║”ńŁ¢ńĢź (multi scale strategy)µØźĶ«Łń╗ā RoI-TransŃĆé `train_pipeline` µś»µłæõ╗¼µā│Ķ”üõ┐«µö╣ńÜäõĖŁķŚ┤ÕÅśķćÅŃĆé
+
+```python
+_base_ = ['./roi_trans_r50_fpn_1x_dota_le90.py']
+
+data_root = '../datasets/split_ms_dota1_0/'
+angle_version = 'le90'
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations', with_bbox=True),
+ dict(type='RResize', img_scale=(1024, 1024)),
+ dict(
+ type='RRandomFlip',
+ flip_ratio=[0.25, 0.25, 0.25],
+ direction=['horizontal', 'vertical', 'diagonal'],
+ version=angle_version),
+ dict(
+ type='PolyRandomRotate',
+ rotate_ratio=0.5,
+ angles_range=180,
+ auto_bound=False,
+ version=angle_version),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size_divisor=32),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels'])
+]
+data = dict(
+ train=dict(
+ pipeline=train_pipeline,
+ ann_file=data_root + 'trainval/annfiles/',
+ img_prefix=data_root + 'trainval/images/'),
+ val=dict(
+ ann_file=data_root + 'trainval/annfiles/',
+ img_prefix=data_root + 'trainval/images/'),
+ test=dict(
+ ann_file=data_root + 'test/images/',
+ img_prefix=data_root + 'test/images/'))
+```
+
+µłæõ╗¼ķ”¢ÕģłÕ«Üõ╣ēµ¢░ńÜä `train_pipeline`/`test_pipeline` ńäČÕÉÄõ╝ĀķĆÆÕł░ `data` ķćīŃĆé
+
+ÕÉīµĀĘńÜä’╝īÕ”éµ×£µłæõ╗¼µā│õ╗Ä `SyncBN` ÕłćµŹóÕł░ `BN` µł¢ĶĆģ `MMSyncBN`’╝īµłæõ╗¼ķ£ĆĶ”üõ┐«µö╣ķģŹńĮ«µ¢ćõ╗ČķćīńÜäµ»ÅõĖĆõĖ¬ `norm_cfg`ŃĆé
+
+```python
+_base_ = './roi_trans_r50_fpn_1x_dota_le90.py'
+norm_cfg = dict(type='BN', requires_grad=True)
+model = dict(
+ backbone=dict(norm_cfg=norm_cfg),
+ neck=dict(norm_cfg=norm_cfg),
+ ...)
+```
diff --git a/internlm_langchain/knowledge_base/MMRotate/content/customize_dataset.md b/internlm_langchain/knowledge_base/MMRotate/content/customize_dataset.md
new file mode 100644
index 00000000..38fb294b
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMRotate/content/customize_dataset.md
@@ -0,0 +1,234 @@
+# µĢÖń©ŗ 2’╝ÜĶć¬Õ«Üõ╣ēµĢ░µŹ«ķøå
+
+## µö»µīüµ¢░ńÜäµĢ░µŹ«µĀ╝Õ╝Å
+
+Ķ”üµö»µīüµ¢░ńÜäµĢ░µŹ«µĀ╝Õ╝Å’╝īµé©ÕÅ»õ╗źÕ░åÕ«āõ╗¼ĶĮ¼µŹóõĖ║ńÄ░µ£ēńÜäµĀ╝Õ╝Å’╝łDOTA µĀ╝Õ╝Å’╝ēŃĆéµé©ÕÅ»õ╗źķĆēµŗ®ń”╗ń║┐’╝łÕ£©ķĆÜĶ┐ćĶäܵ£¼Ķ«Łń╗āõ╣ŗÕēŹ’╝ēµł¢Õ£©ń║┐’╝łÕ«×µ¢Įµ¢░µĢ░µŹ«ķøåÕ╣ČÕ£©Ķ«Łń╗āµŚČĶ┐øĶĪīĶĮ¼µŹó’╝ēĶ┐øĶĪīĶĮ¼µŹóŃĆé
+Õ£© MMRotate õĖŁ’╝īµłæõ╗¼Õ╗║Ķ««Õ░åµĢ░µŹ«ĶĮ¼µŹóõĖ║ DOTA µĀ╝Õ╝ÅÕ╣Čń”╗ń║┐Ķ┐øĶĪīĶĮ¼µŹó’╝īÕ”éµŁżµé©ÕŬķ£ĆÕ£©µĢ░µŹ«ĶĮ¼µŹóÕÉÄõ┐«µö╣ config ńÜäµĢ░µŹ«µĀćµ│©ĶĘ»ÕŠäÕÆīń▒╗Õł½ÕŹ│ÕÅ»ŃĆé
+
+### Õ░åµ¢░µĢ░µŹ«µĀ╝Õ╝Åķ揵×äõĖ║ńÄ░µ£ēµĀ╝Õ╝Å
+
+µ£Ćń«ĆÕŹĢńÜäµ¢╣µ│Ģµś»Õ░åµĢ░µŹ«ķøåĶĮ¼µŹóõĖ║ńÄ░µ£ēµĢ░µŹ«ķøåµĀ╝Õ╝Å (DOTA) ŃĆé
+
+DOTA µĀ╝Õ╝ÅńÜäµ│©Ķ¦Ż txt µ¢ćõ╗Č’╝Ü
+
+```text
+184 2875 193 2923 146 2932 137 2885 plane 0
+66 2095 75 2142 21 2154 11 2107 plane 0
+...
+```
+
+µ»ÅĶĪīõ╗ŻĶĪ©õĖĆõĖ¬Õ»╣Ķ▒Ī’╝īÕ╣ČÕ░åÕģČĶ«░ÕĮĢõĖ║õĖĆõĖ¬ 10 ń╗┤µĢ░ń╗ä `A` ŃĆé
+
+- `A[0:8]`: ÕżÜĶŠ╣ÕĮóńÜäµĀ╝Õ╝Å `(x1, y1, x2, y2, x3, y3, x4, y4)` ŃĆé
+- `A[8]`: ń▒╗Õł½
+- `A[9]`: Õø░ķÜŠ
+
+Õ£©µĢ░µŹ«ķóäÕżäńÉåõ╣ŗÕÉÄ’╝īńö©µłĘÕÅ»õ╗źķĆÜĶ┐ćõĖżõĖ¬µŁźķ¬żµØźĶ«Łń╗āÕģʵ£ēńÄ░µ£ēµĀ╝Õ╝Å’╝łõŠŗÕ”é DOTA µĀ╝Õ╝Å’╝ēńÜäĶć¬Õ«Üõ╣ēµ¢░µĢ░µŹ«ķøå’╝Ü
+
+1. õ┐«µö╣ķģŹńĮ«µ¢ćõ╗Čõ╗źõĮ┐ńö©Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåŃĆé
+2. µŻĆµ¤źĶć¬Õ«Üõ╣ēµĢ░µŹ«ķøåńÜäµĀćµ│©ŃĆé
+
+õĖŗķØóń╗ÖÕć║õĖżõĖ¬õŠŗÕŁÉÕ▒Ģńż║õĖŖĶ┐░õĖżõĖ¬µŁźķ¬ż’╝īÕ«āõĮ┐ńö©õĖĆõĖ¬Ķć¬Õ«Üõ╣ēńÜä 5 ń▒╗ COCO µĀ╝Õ╝ÅńÜäµĢ░µŹ«ķøåµØźĶ«Łń╗āõĖĆõĖ¬ńÄ░µ£ēńÜä Cascade Mask R-CNN R50-FPN µŻĆµĄŗÕÖ©ŃĆé
+
+#### 1. õ┐«µö╣ķģŹńĮ«µ¢ćõ╗Čõ╗źõĮ┐ńö©Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøå
+
+ķģŹńĮ«µ¢ćõ╗ČńÜäõ┐«µö╣õĖ╗Ķ”üµČēÕÅŖõĖżõĖ¬µ¢╣ķØó:
+
+1. `data` ķā©ÕłåŃĆéÕģĘõĮōµØźĶ»┤’╝īµé©ķ£ĆĶ”üÕ£© `data.train`, `data.val` ÕÆī `data.test` õĖŁµśŠÕ╝ŵĘ╗ÕŖĀ classes ÕŁŚµ«ĄŃĆé
+
+2. `model` ķā©ÕłåõĖŁńÜä ` num_classes` Õ▒׵ƦÕÅśķćÅŃĆéńē╣Õł½µś»Õ░åµēƵ£ē num_classes ńÜäķ╗śĶ«żÕĆ╝’╝łõŠŗÕ”é COCO õĖŁńÜä 80’╝ēĶ”åńø¢Õł░µé©ńÜäń▒╗Õł½ń╝¢ÕÅĘõĖŁŃĆé
+
+Õ£© `configs/my_custom_config.py` :
+
+```python
+
+# µ¢░ķģŹńĮ«ń╗¦µē┐õ║åÕ¤║ńĪĆķģŹńĮ«ńö©õ║Äń¬üÕć║µśŠńż║Õ┐ģĶ”üńÜäõ┐«µö╣
+_base_ = './rotated_retinanet_hbb_r50_fpn_1x_dota_oc'
+
+# 1. µĢ░µŹ«ķøåńÜäĶ«ŠńĮ«
+dataset_type = 'DOTADataset'
+classes = ('a', 'b', 'c', 'd', 'e')
+data = dict(
+ samples_per_gpu=2,
+ workers_per_gpu=2,
+ train=dict(
+ type=dataset_type,
+
+ # µ│©µäÅÕ░åõĮĀńÜäń▒╗ÕÉŹµĘ╗ÕŖĀÕł░ÕŁŚµ«Ą `classes`
+ classes=classes,
+ ann_file='path/to/your/train/annotation_data',
+ img_prefix='path/to/your/train/image_data'),
+ val=dict(
+ type=dataset_type,
+
+ # µ│©µäÅÕ░åõĮĀńÜäń▒╗ÕÉŹµĘ╗ÕŖĀÕł░ÕŁŚµ«Ą `classes`
+ classes=classes,
+ ann_file='path/to/your/val/annotation_data',
+ img_prefix='path/to/your/val/image_data'),
+ test=dict(
+ type=dataset_type,
+
+ # µ│©µäÅÕ░åõĮĀńÜäń▒╗ÕÉŹµĘ╗ÕŖĀÕł░ÕŁŚµ«Ą `classes`
+ classes=classes,
+ ann_file='path/to/your/test/annotation_data',
+ img_prefix='path/to/your/test/image_data'))
+
+# 2. µ©ĪÕ×ŗĶ«ŠńĮ«
+model = dict(
+ bbox_head=dict(
+ type='RotatedRetinaHead',
+ # µśŠÕ╝ÅÕ░åµēƵ£ē `num_classes` ÕŁŚµ«Ąõ╗Ä 15 ķćŹÕåÖõĖ║ 5ŃĆéŃĆé
+ num_classes=15))
+```
+
+#### 2. µ¤źń£ŗĶć¬Õ«Üõ╣ēµĢ░µŹ«ķøåńÜäµĀćµ│©
+
+ÕüćĶ«Šµé©ńÜäĶć¬Õ«Üõ╣ēµĢ░µŹ«ķøåµś» DOTA µĀ╝Õ╝Å’╝īĶ»ĘńĪ«õ┐صé©Õ£©Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøåõĖŁÕģʵ£ēµŁŻńĪ«ńÜäµĀćµ│©’╝Ü
+
+- ķģŹńĮ«µ¢ćõ╗ČõĖŁńÜä `classes` ÕŁŚµ«ĄÕ║öĶ»źõĖÄ txt µĀćµ│©ńÜä `A[8]` õ┐صīüÕ«īÕģ©ńøĖÕÉīńÜäÕģāń┤ĀÕÆīńøĖÕÉīńÜäķĪ║Õ║ÅŃĆé
+ MMRotate õ╝ÜĶć¬ÕŖ©ńÜäÕ░å `categories` õĖŁõĖŹĶ┐×ń╗ŁńÜä `id` µśĀÕ░äÕł░Ķ┐×ń╗ŁńÜäµĀćńŁŠń┤óÕ╝ĢõĖŁ’╝īµēĆõ╗źÕ£© `categories` õĖŁ `name` ńÜäÕŁŚń¼”õĖ▓ķĪ║Õ║Åõ╝ÜÕĮ▒ÕōŹµĀćńŁŠń┤óÕ╝ĢńÜäķĪ║Õ║ÅŃĆéÕÉīµŚČ’╝īķģŹńĮ«µ¢ćõ╗ČõĖŁ `classes` ńÜäÕŁŚń¼”õĖ▓ķĪ║Õ║Åõ╣¤õ╝ÜÕĮ▒ÕōŹķó䵥ŗĶŠ╣ńĢīµĪåÕÅ»Ķ¦åÕī¢Ķ┐ćń©ŗõĖŁńÜäµĀćńŁŠµ¢ćµ£¼õ┐Īµü»ŃĆé
+
+## ķĆÜĶ┐ćÕ░üĶŻģÕÖ©Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøå
+
+MMRotate Ķ┐śµö»µīüĶ«ĖÕżÜµĢ░µŹ«ķøåÕ░üĶŻģÕÖ©Õ»╣µĢ░µŹ«ķøåĶ┐øĶĪīµĘĘÕÉłµł¢õ┐«µö╣µĢ░µŹ«ķøåńÜäÕłåÕĖāõ╗źĶ┐øĶĪīĶ«Łń╗āŃĆéńø«ÕēŹÕ«āµö»µīüõĖēõĖ¬µĢ░µŹ«ķøåÕ░üĶŻģÕÖ©’╝īÕ”éõĖŗµēĆńż║’╝Ü
+
+- `RepeatDataset`: ń«ĆÕŹĢÕ£░ķćŹÕżŹµĢ┤õĖ¬µĢ░µŹ«ķøåŃĆé
+- `ClassBalancedDataset`: õ╗źń▒╗Õ╣│ĶĪĪńÜäµ¢╣Õ╝ÅķćŹÕżŹµĢ░µŹ«ķøåŃĆé
+- `ConcatDataset`: µŗ╝µÄźµĢ░µŹ«ķøåŃĆé
+
+### ķćŹÕżŹµĢ░µŹ«ķøå
+
+µłæõ╗¼õĮ┐ńö© `RepeatDataset` õĮ£õĖ║Õ░üĶŻģÕÖ©µØźķćŹÕżŹĶ┐ÖõĖ¬µĢ░µŹ«ķøåŃĆéõŠŗÕ”é’╝īÕüćĶ«ŠÕĤզŗµĢ░µŹ«ķøåµś» `Dataset_A`’╝īµłæõ╗¼Õ░▒ķćŹÕżŹõĖĆķüŹĶ┐ÖõĖ¬µĢ░µŹ«ķøåŃĆéķģŹńĮ«õ┐Īµü»Õ”éõĖŗµēĆńż║’╝Ü
+
+```python
+dataset_A_train = dict(
+ type='RepeatDataset',
+ times=N,
+ dataset=dict( # Ķ┐Öµś» Dataset_A ńÜäÕĤզŗķģŹńĮ«õ┐Īµü»
+ type='Dataset_A',
+ ...
+ pipeline=train_pipeline
+ )
+ )
+```
+
+### ń▒╗Õł½Õ╣│ĶĪĪµĢ░µŹ«ķøå
+
+µłæõ╗¼õĮ┐ńö© `ClassBalancedDataset` õĮ£õĖ║Õ░üĶŻģÕÖ©’╝īµĀ╣µŹ«ń▒╗Õł½ķóæńÄćķćŹÕżŹµĢ░µŹ«ķøåŃĆéĶ┐ÖõĖ¬µĢ░µŹ«ķøåńÜäķćŹÕżŹµōŹõĮ£ `ClassBalancedDataset` ķ£ĆĶ”üÕ«×õŠŗÕī¢ÕćĮµĢ░ `self.get_cat_ids(idx)` ńÜäµö»µīüŃĆéõŠŗÕ”é’╝ī`Dataset_A` ķ£ĆĶ”üõĮ┐ńö©`oversample_thr=1e-3`’╝īķģŹńĮ«õ┐Īµü»Õ”éõĖŗµēĆńż║’╝Ü
+
+```python
+dataset_A_train = dict(
+ type='ClassBalancedDataset',
+ oversample_thr=1e-3,
+ dataset=dict( # This is the original config of Dataset_A
+ type='Dataset_A',
+ ...
+ pipeline=train_pipeline
+ )
+ )
+```
+
+### µŗ╝µÄźµĢ░µŹ«ķøå
+
+Ķ┐Öķćīńö©õĖēń¦Źµ¢╣Õ╝ÅÕ»╣µĢ░µŹ«ķøåĶ┐øĶĪīµŗ╝µÄźŃĆé
+
+1. Õ”éµ×£Ķ”üµŗ╝µÄźńÜäµĢ░µŹ«ķøåÕ▒×õ║ÄÕÉīõĖĆń▒╗Õ×ŗõĖöÕģʵ£ēõĖŹÕÉīńÜäµĀćµ│©µ¢ćõ╗Č’╝īÕłÖÕÅ»õ╗źķĆÜĶ┐ćÕ”éõĖŗµēĆńż║ńÜäķģŹńĮ«õ┐Īµü»µØźµŗ╝µÄźµĢ░µŹ«ķøå’╝Ü
+
+ ````python
+ dataset_A_train = dict(
+ type='Dataset_A',
+ ann_file = ['anno_file_1', 'anno_file_2'],
+ pipeline=train_pipeline
+ )
+ ```Õ”éµ×£µŗ╝µÄźÕÉÄńÜäµĢ░µŹ«ķøåńö©õ║ĵĄŗĶ»Ģµł¢Ķ»äõ╝░’╝īµłæõ╗¼Ķ┐Öń¦Źµ¢╣Õ╝ŵś»ÕÅ»õ╗źµö»µīüÕ»╣µ»ÅõĖ¬µĢ░µŹ«ķøåÕłåÕł½Ķ┐øĶĪīĶ»äõ╝░ŃĆéÕ”éµ×£Ķ”üµĄŗĶ»ĢńÜäµĢ┤õĖ¬µŗ╝µÄźµĢ░µŹ«ķøå’╝īÕ”éõĖŗµēĆńż║µé©ÕÅ»õ╗źńø┤µÄźķĆÜĶ┐ćĶ«ŠńĮ« separate_eval=False µØźÕ«×ńÄ░ŃĆé
+
+ ```python
+ dataset_A_train = dict(
+ type='Dataset_A',
+ ann_file = ['anno_file_1', 'anno_file_2'],
+ separate_eval=False,
+ pipeline=train_pipeline
+ )
+ ````
+
+2. Õ”éµ×£µé©Ķ”üµŗ╝µÄźõĖŹÕÉīńÜäµĢ░µŹ«ķøå’╝īµé©ÕÅ»õ╗źķĆÜĶ┐ćÕ”éõĖŗµēĆńż║ńÜäµ¢╣µ│ĢÕ»╣µŗ╝µÄźµĢ░µŹ«ķøåķģŹńĮ«õ┐Īµü»Ķ┐øĶĪīĶ«ŠńĮ«ŃĆé
+
+ ````python
+ dataset_A_train = dict()
+ dataset_B_train = dict()
+ data = dict(
+ imgs_per_gpu=2,
+ workers_per_gpu=2,
+ train = [
+ dataset_A_train,
+ dataset_B_train
+ ],
+ val = dataset_A_val,
+ test = dataset_A_test
+ )
+ ```Õ”éµ×£µŗ╝µÄźÕÉÄńÜäµĢ░µŹ«ķøåńö©õ║ĵĄŗĶ»Ģµł¢Ķ»äõ╝░’╝īĶ┐Öń¦Źµ¢╣Õ╝ÅĶ┐śµö»µīüÕ»╣µ»ÅõĖ¬µĢ░µŹ«ķøåÕłåÕł½Ķ┐øĶĪīĶ»äõ╝░ŃĆé
+
+ ````
+
+3. µłæõ╗¼õ╣¤µö»µīüÕ”éõĖŗµēĆńż║ńÜäµ¢╣µ│ĢÕ»╣ `ConcatDataset` Ķ┐øĶĪīµśÄńĪ«ńÜäÕ«Üõ╣ēŃĆé
+
+ ````python
+ dataset_A_val = dict()
+ dataset_B_val = dict()
+ data = dict(
+ imgs_per_gpu=2,
+ workers_per_gpu=2,
+ train=dataset_A_train,
+ val=dict(
+ type='ConcatDataset',
+ datasets=[dataset_A_val, dataset_B_val],
+ separate_eval=False))
+ ```Ķ┐Öń¦Źµ¢╣Õ╝ÅÕģüĶ«Ėńö©µłĘķĆÜĶ┐ćĶ«ŠńĮ« `separate_eval=False` Õ░åµēƵ£ēµĢ░µŹ«ķøåĶĮ¼õĖ║ÕŹĢõĖ¬µĢ░µŹ«ķøåĶ┐øĶĪīĶ»äõ╝░ŃĆé
+
+ ````
+
+**ń¼öĶ«░:**
+
+1. ÕüćĶ«ŠµĢ░µŹ«ķøåÕ£©Ķ»äõ╝░µ£¤ķŚ┤õĮ┐ńö© `self.data_infos`’╝īÕ░▒Ķ”üµŖŖķĆēķĪ╣Ķ«ŠńĮ«õĖ║ `separate_eval=False`ŃĆéÕøĀõĖ║ COCO µĢ░µŹ«ķøåõĖŹÕ«īÕģ©õŠØĶĄ¢ `self.data_infos` Ķ┐øĶĪīĶ»äõ╝░’╝īµēĆõ╗ź COCO µĢ░µŹ«ķøåÕ╣ČõĖŹµö»µīüĶ┐Öń¦ŹĶ«ŠńĮ«µōŹõĮ£ŃĆéµ▓Īµ£ēÕ£©ń╗äÕÉłõĖŹÕÉīń▒╗Õ×ŗńÜäµĢ░µŹ«ķøåÕ╣ČÕ»╣ÕģČĶ┐øĶĪīµĢ┤õĮōĶ»äõ╝░ńÜäÕ£║µÖ»Ķ┐øĶĪīµĄŗĶ»Ģ’╝īÕøĀµŁżµłæõ╗¼õĖŹÕ╗║Ķ««õĮ┐ńö©Ķ┐ÖµĀĘńÜäµōŹõĮ£ŃĆé
+2. õĖŹµö»µīüĶ»äõ╝░ `ClassBalancedDataset` ÕÆī `RepeatDataset`’╝īµēĆõ╗źõ╣¤õĖŹµö»µīüĶ»äõ╝░Ķ┐Öõ║øń▒╗Õ×ŗńÜäõĖ▓Ķüöń╗äÕÉłÕÉÄńÜäµĢ░µŹ«ķøåŃĆé
+
+õĖĆõĖ¬µø┤ÕżŹµØéńÜäõŠŗÕŁÉ’╝īÕłåÕł½Õ░å `Dataset_A` ÕÆī `Dataset_B` ķćŹÕżŹ N µ¼ĪÕÆī M µ¼Ī’╝īńäČÕÉÄÕ░åķćŹÕżŹńÜäµĢ░µŹ«ķøåĶ┐׵ğĶĄĘµØź’╝īÕ”éõĖŗµēĆńż║ŃĆé
+
+```python
+dataset_A_train = dict(
+ type='RepeatDataset',
+ times=N,
+ dataset=dict(
+ type='Dataset_A',
+ ...
+ pipeline=train_pipeline
+ )
+)
+dataset_A_val = dict(
+ ...
+ pipeline=test_pipeline
+)
+dataset_A_test = dict(
+ ...
+ pipeline=test_pipeline
+)
+dataset_B_train = dict(
+ type='RepeatDataset',
+ times=M,
+ dataset=dict(
+ type='Dataset_B',
+ ...
+ pipeline=train_pipeline
+ )
+)
+data = dict(
+ imgs_per_gpu=2,
+ workers_per_gpu=2,
+ train = [
+ dataset_A_train,
+ dataset_B_train
+ ],
+ val = dataset_A_val,
+ test = dataset_A_test
+)
+```
diff --git a/internlm_langchain/knowledge_base/MMRotate/content/customize_models.md b/internlm_langchain/knowledge_base/MMRotate/content/customize_models.md
new file mode 100644
index 00000000..407186ff
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMRotate/content/customize_models.md
@@ -0,0 +1,318 @@
+# µĢÖń©ŗ 3: Ķć¬Õ«Üõ╣ēµ©ĪÕ×ŗ
+
+µłæõ╗¼Õż¦Ķć┤Õ░嵩ĪÕ×ŗń╗äõ╗ČÕłåõĖ║õ║å 5 ń¦Źń▒╗Õ×ŗŃĆé
+
+- õĖ╗Õ╣▓ńĮæń╗£ (Backbone): ķĆÜÕĖĖµś»õĖĆõĖ¬Õģ©ÕŹĘń¦»ńĮæń╗£ (FCN)’╝īńö©µØźµÅÉÕÅ¢ńē╣ÕŠüÕøŠ’╝īµ»öՔ鵫ŗÕĘ«ńĮæń╗£ (ResNet)ŃĆéõ╣¤ÕÅ»õ╗źµś»Õ¤║õ║ÄĶ¦åĶ¦ē Transformer ńÜäńĮæń╗£’╝īµ»öÕ”é Swin Transformer ńŁēŃĆé
+- Neck: õĖ╗Õ╣▓ńĮæń╗£ÕÆīõ╗╗ÕŖĪÕż┤ (Head) õ╣ŗķŚ┤ńÜäĶ┐׵ğń╗äõ╗Č’╝īµ»öÕ”é FPN, ReFPNŃĆé
+- õ╗╗ÕŖĪÕż┤ (Head): ńö©õ║ĵ¤Éń¦ŹÕģĘõĮōõ╗╗ÕŖĪ’╝łµ»öÕ”éĶŠ╣ńĢīµĪåķó䵥ŗ’╝ēńÜäń╗äõ╗ČŃĆé
+- Õī║Õ¤¤ńē╣ÕŠüµÅÉÕÅ¢ÕÖ© (Roi Extractor): ńö©õ║Äõ╗Äńē╣ÕŠüÕøŠõĖŖµÅÉÕÅ¢Õī║Õ¤¤ńē╣ÕŠüńÜäń╗äõ╗Č’╝īµ»öÕ”é RoI Align RotatedŃĆé
+- µŹ¤Õż▒ (loss): õ╗╗ÕŖĪÕż┤õĖŖńö©õ║ÄĶ«Īń«ŚµŹ¤Õż▒ÕćĮµĢ░ńÜäń╗äõ╗Č’╝īµ»öÕ”é FocalLoss, GWDLoss, and KFIoULossŃĆé
+
+## Õ╝ĆÕÅæµ¢░ńÜäń╗äõ╗Č
+
+### µĘ╗ÕŖĀµ¢░ńÜäõĖ╗Õ╣▓ńĮæń╗£
+
+Ķ┐Öķćī’╝īµłæõ╗¼õ╗ź MobileNet õĖ║õŠŗµØźÕ▒Ģńż║Õ”éõĮĢÕ╝ĆÕÅæµ¢░ń╗äõ╗ČŃĆé
+
+#### 1. Õ«Üõ╣ēõĖĆõĖ¬µ¢░ńÜäõĖ╗Õ╣▓ńĮæń╗£’╝łõ╗ź MobileNet õĖ║õŠŗ’╝ē
+
+µ¢░Õ╗║µ¢ćõ╗Č `mmrotate/models/backbones/mobilenet.py`ŃĆé
+
+```python
+import torch.nn as nn
+
+from mmrotate.models.builder import ROTATED_BACKBONES
+
+
+@ROTATED_BACKBONES.register_module()
+class MobileNet(nn.Module):
+
+ def __init__(self, arg1, arg2):
+ pass
+
+ def forward(self, x): # should return a tuple
+ pass
+```
+
+#### 2. Õ»╝Õģźµ©ĪÕØŚ
+
+õĮĀÕÅ»õ╗źÕ░åõĖŗķØóńÜäõ╗ŻńĀüµĘ╗ÕŖĀÕł░ `mmrotate/models/backbones/__init__.py` õĖŁ’╝Ü
+
+```python
+from .mobilenet import MobileNet
+```
+
+µł¢ĶĆģµĘ╗ÕŖĀÕ”éõĖŗõ╗ŻńĀü
+
+```python
+custom_imports = dict(
+ imports=['mmrotate.models.backbones.mobilenet'],
+ allow_failed_imports=False)
+```
+
+Õł░ķģŹńĮ«µ¢ćõ╗ČõĖŁõ╗źķü┐ÕģŹõ┐«µö╣ÕĤզŗõ╗ŻńĀüŃĆé
+
+#### 3. Õ£©õĮĀńÜäķģŹńĮ«µ¢ćõ╗ČõĖŁõĮ┐ńö©Ķ»źõĖ╗Õ╣▓ńĮæń╗£
+
+```python
+model = dict(
+ ...
+ backbone=dict(
+ type='MobileNet',
+ arg1=xxx,
+ arg2=xxx),
+ ...
+```
+
+### µĘ╗ÕŖĀµ¢░ńÜä Neck
+
+#### 1. Õ«Üõ╣ēõĖĆõĖ¬ Neck’╝łõ╗ź PAFPN õĖ║õŠŗ’╝ē
+
+µ¢░Õ╗║µ¢ćõ╗Č `mmrotate/models/necks/pafpn.py`ŃĆé
+
+```python
+from mmrotate.models.builder import ROTATED_NECKS
+
+@ROTATED_NECKS.register_module()
+class PAFPN(nn.Module):
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ num_outs,
+ start_level=0,
+ end_level=-1,
+ add_extra_convs=False):
+ pass
+
+ def forward(self, inputs):
+ # implementation is ignored
+ pass
+```
+
+#### 2. Õ»╝ÕģźĶ»źµ©ĪÕØŚ
+
+õĮĀÕÅ»õ╗źµĘ╗ÕŖĀõĖŗĶ┐░õ╗ŻńĀüÕł░ `mmrotate/models/necks/__init__.py` õĖŁ
+
+```python
+from .pafpn import PAFPN
+```
+
+µł¢ĶĆģµĘ╗ÕŖĀ
+
+```python
+custom_imports = dict(
+ imports=['mmrotate.models.necks.pafpn.py'],
+ allow_failed_imports=False)
+```
+
+Õł░ķģŹńĮ«µ¢ćõ╗ČõĖŁõ╗źķü┐ÕģŹõ┐«µö╣ÕĤզŗõ╗ŻńĀüŃĆé
+
+#### 3. õ┐«µö╣ķģŹńĮ«µ¢ćõ╗Č
+
+```python
+neck=dict(
+ type='PAFPN',
+ in_channels=[256, 512, 1024, 2048],
+ out_channels=256,
+ num_outs=5)
+```
+
+### µĘ╗ÕŖĀµ¢░ńÜä Head
+
+Ķ┐Öķćī’╝īµłæõ╗¼õ╗ź [Double Head R-CNN](https://arxiv.org/abs/1904.06493) õĖ║õŠŗµØźÕ▒Ģńż║Õ”éõĮĢµĘ╗ÕŖĀõĖĆõĖ¬µ¢░ńÜä HeadŃĆé
+
+ķ”¢Õģł’╝īµĘ╗ÕŖĀõĖĆõĖ¬µ¢░ńÜä bbox head Õł░ `mmrotate/models/roi_heads/bbox_heads/double_bbox_head.py`ŃĆé
+Double Head R-CNN Õ£©ńø«µĀ浯ƵĄŗõĖŖÕ«×ńÄ░õ║åõĖĆõĖ¬µ¢░ńÜä bbox headŃĆéõĖ║õ║åÕ«×ńÄ░ bbox head’╝īµłæõ╗¼ķ£ĆĶ”üõĮ┐ńö©Õ”éõĖŗńÜäµ¢░µ©ĪÕØŚõĖŁõĖēõĖ¬ÕćĮµĢ░ŃĆé
+
+```python
+from mmrotate.models.builder import ROTATED_HEADS
+from mmrotate.models.roi_heads.bbox_heads.bbox_head import BBoxHead
+
+@ROTATED_HEADS.register_module()
+class DoubleConvFCBBoxHead(BBoxHead):
+ r"""Bbox head used in Double-Head R-CNN
+
+ /-> cls
+ /-> shared convs ->
+ \-> reg
+ roi features
+ /-> cls
+ \-> shared fc ->
+ \-> reg
+ """ # noqa: W605
+
+ def __init__(self,
+ num_convs=0,
+ num_fcs=0,
+ conv_out_channels=1024,
+ fc_out_channels=1024,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ **kwargs):
+ kwargs.setdefault('with_avg_pool', True)
+ super(DoubleConvFCBBoxHead, self).__init__(**kwargs)
+
+
+ def forward(self, x_cls, x_reg):
+
+```
+
+ńäČÕÉÄ’╝īՔ鵣ēÕ┐ģĶ”ü’╝īµłæõ╗¼ķ£ĆĶ”üÕ«×ńÄ░õĖĆõĖ¬µ¢░ńÜä RoI HeadŃĆ鵳æõ╗¼µēōń«Śõ╗Ä `StandardRoIHead` ń╗¦µē┐Õć║µ¢░ńÜä `DoubleHeadRoIHead`ŃĆ鵳æõ╗¼ÕÅæńÄ░ `StandardRoIHead` ÕĘ▓ń╗ÅÕ«×ńÄ░õ║åõĖŗĶ┐░ÕćĮµĢ░ŃĆé
+
+```python
+import torch
+
+from mmdet.core import bbox2result, bbox2roi, build_assigner, build_sampler
+from mmrotate.models.builder import ROTATED_HEADS, build_head, build_roi_extractor
+from mmrotate.models.roi_heads.base_roi_head import BaseRoIHead
+from mmrotate.models.roi_heads.test_mixins import BBoxTestMixin, MaskTestMixin
+
+
+@ROTATED_HEADS.register_module()
+class StandardRoIHead(BaseRoIHead, BBoxTestMixin, MaskTestMixin):
+ """Simplest base roi head including one bbox head and one mask head.
+ """
+
+ def init_assigner_sampler(self):
+
+ def init_bbox_head(self, bbox_roi_extractor, bbox_head):
+
+ def forward_dummy(self, x, proposals):
+
+
+ def forward_train(self,
+ x,
+ img_metas,
+ proposal_list,
+ gt_bboxes,
+ gt_labels,
+ gt_bboxes_ignore=None,
+ gt_masks=None):
+
+ def _bbox_forward(self, x, rois):
+
+ def _bbox_forward_train(self, x, sampling_results, gt_bboxes, gt_labels,
+ img_metas):
+
+ def simple_test(self,
+ x,
+ proposal_list,
+ img_metas,
+ proposals=None,
+ rescale=False):
+ """Test without augmentation."""
+
+```
+
+Double Head ńÜäõ┐«µö╣õĖ╗Ķ”üÕ£© \_bbox_forward ńÜäķĆ╗ĶŠæõĖŁ’╝īõĖöÕ«āõ╗Ä `StandardRoIHead` õĖŁń╗¦µē┐õ║åÕģČõ╗¢ķĆ╗ĶŠæŃĆé
+Õ£© `mmrotate/models/roi_heads/double_roi_head.py` õĖŁ, µłæõ╗¼Õ«×ńÄ░Õ”éõĖŗńÜäµ¢░ńÜä RoI Head:
+
+```python
+from mmrotate.models.builder import ROTATED_HEADS
+from mmrotate.models.roi_heads.standard_roi_head import StandardRoIHead
+
+
+@ROTATED_HEADS.register_module()
+class DoubleHeadRoIHead(StandardRoIHead):
+ """RoI head for Double Head RCNN
+
+ https://arxiv.org/abs/1904.06493
+ """
+
+ def __init__(self, reg_roi_scale_factor, **kwargs):
+ super(DoubleHeadRoIHead, self).__init__(**kwargs)
+ self.reg_roi_scale_factor = reg_roi_scale_factor
+
+ def _bbox_forward(self, x, rois):
+ bbox_cls_feats = self.bbox_roi_extractor(
+ x[:self.bbox_roi_extractor.num_inputs], rois)
+ bbox_reg_feats = self.bbox_roi_extractor(
+ x[:self.bbox_roi_extractor.num_inputs],
+ rois,
+ roi_scale_factor=self.reg_roi_scale_factor)
+ if self.with_shared_head:
+ bbox_cls_feats = self.shared_head(bbox_cls_feats)
+ bbox_reg_feats = self.shared_head(bbox_reg_feats)
+ cls_score, bbox_pred = self.bbox_head(bbox_cls_feats, bbox_reg_feats)
+
+ bbox_results = dict(
+ cls_score=cls_score,
+ bbox_pred=bbox_pred,
+ bbox_feats=bbox_cls_feats)
+ return bbox_results
+```
+
+µ£ĆÕÉÄ’╝īńö©µłĘķ£ĆĶ”üµŖŖĶ┐ÖõĖ¬µ¢░µ©ĪÕØŚµĘ╗ÕŖĀÕł░ `mmrotate/models/bbox_heads/__init__.py` õ╗źÕÅŖ `mmrotate/models/roi_heads/__init__.py` õĖŁŃĆé Ķ┐ÖµĀĘ’╝īµ│©Õåīµ£║ÕłČÕ░▒ĶāĮµēŠÕł░Õ╣ČÕŖĀĶĮĮÕ«āõ╗¼ŃĆé
+
+ÕÅ”Õż¢’╝īńö©µłĘõ╣¤ÕÅ»õ╗źµĘ╗ÕŖĀ
+
+```python
+custom_imports=dict(
+ imports=['mmrotate.models.roi_heads.double_roi_head', 'mmrotate.models.bbox_heads.double_bbox_head'])
+```
+
+Õł░ķģŹńĮ«µ¢ćõ╗ČõĖŁµØźÕ«×ńÄ░ÕÉīµĀĘńÜäńø«ńÜäŃĆé
+
+### µĘ╗ÕŖĀµ¢░ńÜ䵏¤Õż▒
+
+ÕüćĶ«ŠõĮĀµā│µĘ╗ÕŖĀõĖĆõĖ¬µ¢░ńÜ䵏¤Õż▒ `MyLoss` ńö©õ║ÄĶŠ╣ńĢīµĪåÕø×ÕĮÆŃĆé
+õĖ║õ║åµĘ╗ÕŖĀõĖĆõĖ¬µ¢░ńÜ䵏¤Õż▒ÕćĮµĢ░’╝īńö©µłĘķ£ĆĶ”üÕ£© `mmrotate/models/losses/my_loss.py` õĖŁÕ«×ńÄ░ŃĆé
+ĶŻģķź░ÕÖ© `weighted_loss` ÕÅ»õ╗źõĮ┐µŹ¤Õż▒µ»ÅõĖ¬ķā©ÕłåÕŖĀµØāŃĆé
+
+```python
+import torch
+import torch.nn as nn
+
+from mmrotate.models.builder import ROTATED_LOSSES
+from mmdet.models.losses.utils import weighted_loss
+
+@weighted_loss
+def my_loss(pred, target):
+ assert pred.size() == target.size() and target.numel() > 0
+ loss = torch.abs(pred - target)
+ return loss
+
+@ROTATED_LOSSES.register_module()
+class MyLoss(nn.Module):
+
+ def __init__(self, reduction='mean', loss_weight=1.0):
+ super(MyLoss, self).__init__()
+ self.reduction = reduction
+ self.loss_weight = loss_weight
+
+ def forward(self,
+ pred,
+ target,
+ weight=None,
+ avg_factor=None,
+ reduction_override=None):
+ assert reduction_override in (None, 'none', 'mean', 'sum')
+ reduction = (
+ reduction_override if reduction_override else self.reduction)
+ loss_bbox = self.loss_weight * my_loss(
+ pred, target, weight, reduction=reduction, avg_factor=avg_factor)
+ return loss_bbox
+```
+
+ńäČÕÉÄ’╝īńö©µłĘķ£ĆĶ”üµŖŖõĖŗķØóńÜäõ╗ŻńĀüÕŖĀÕł░ `mmrotate/models/losses/__init__.py` õĖŁŃĆé
+
+```python
+from .my_loss import MyLoss, my_loss
+
+```
+
+µł¢ĶĆģ’╝īõĮĀÕÅ»õ╗źµĘ╗ÕŖĀ’╝Ü
+
+```python
+custom_imports=dict(
+ imports=['mmrotate.models.losses.my_loss'])
+```
+
+Õł░ķģŹńĮ«µ¢ćõ╗ČµØźÕ«×ńÄ░ńøĖÕÉīńÜäńø«ńÜäŃĆé
+
+ÕøĀõĖ║ MyLoss µś»ńö©õ║ÄÕø×ÕĮÆńÜä’╝īõĮĀķ£ĆĶ”üÕ£© Head õĖŁõ┐«µö╣ `loss_bbox` ÕŁŚµ«Ą’╝Ü
+
+```python
+loss_bbox=dict(type='MyLoss', loss_weight=1.0))
+```
diff --git a/internlm_langchain/knowledge_base/MMRotate/content/customize_runtime.md b/internlm_langchain/knowledge_base/MMRotate/content/customize_runtime.md
new file mode 100644
index 00000000..8099c09d
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMRotate/content/customize_runtime.md
@@ -0,0 +1,322 @@
+# µĢÖń©ŗ 4: Ķć¬Õ«Üõ╣ēĶ«Łń╗āĶ«ŠńĮ«
+
+## Ķć¬Õ«Üõ╣ēõ╝śÕī¢Ķ«ŠńĮ«
+
+### Ķć¬Õ«Üõ╣ē Pytorch µö»µīüńÜäõ╝śÕī¢ÕÖ©
+
+µłæõ╗¼ÕĘ▓ń╗ŵö»µīüõ║åÕģ©ķā© Pytorch Ķć¬ÕĖ”ńÜäõ╝śÕī¢ÕÖ©’╝īÕö»õĖĆķ£ĆĶ”üõ┐«µö╣ńÜäÕ░▒µś»ķģŹńĮ«µ¢ćõ╗ČõĖŁ `optimizer` ķā©ÕłåŃĆé
+õŠŗÕ”é’╝īÕ”éµ×£µé©µā│õĮ┐ńö© `ADAM` (µ│©µäÅÕ”éõĖŗµōŹõĮ£ÕÅ»ĶāĮõ╝ÜĶ«®µ©ĪÕ×ŗĶĪ©ńÄ░õĖŗķÖŹ)’╝īÕÅ»õ╗źõĮ┐ńö©Õ”éõĖŗõ┐«µö╣’╝Ü
+
+```python
+optimizer = dict(type='Adam', lr=0.0003, weight_decay=0.0001)
+```
+
+õĖ║õ║åõ┐«µö╣µ©ĪÕ×ŗĶ«Łń╗āńÜäÕŁ”õ╣ĀńÄć’╝īõĮ┐ńö©ĶĆģõ╗ģķ£Ćõ┐«µö╣ķģŹńĮ«µ¢ćõ╗Čķćī `optimizer` ńÜä `lr` ÕŹ│ÕÅ»ŃĆé
+õĮ┐ńö©ĶĆģÕÅ»õ╗źÕÅéĶĆā PyTorch ńÜä [API doc](https://pytorch.org/docs/stable/optim.html?highlight=optim#module-torch.optim) ńø┤µÄźĶ«ŠńĮ«ÕÅéµĢ░ŃĆé
+
+### Ķć¬Õ«Üõ╣ēńö©µłĘĶć¬ÕĘ▒Õ«×ńÄ░ńÜäõ╝śÕī¢ÕÖ©
+
+#### 1. Õ«Üõ╣ēõĖĆõĖ¬µ¢░ńÜäõ╝śÕī¢ÕÖ©
+
+õĖĆõĖ¬Ķć¬Õ«Üõ╣ēńÜäõ╝śÕī¢ÕÖ©ÕÅ»õ╗źĶ┐ÖµĀĘÕ«Üõ╣ē’╝Ü
+
+ÕüćÕ”éµé©µā│Õó×ÕŖĀõĖĆõĖ¬ÕŽÕüÜ `MyOptimizer` ńÜäõ╝śÕī¢ÕÖ©’╝īÕ«āńÜäÕÅéµĢ░ÕłåÕł½µ£ē `a`, `b`, ÕÆī `c`ŃĆé
+µé©ķ£ĆĶ”üÕłøÕ╗║õĖĆõĖ¬ÕÉŹõĖ║ `mmrotate/core/optimizer` ńÜäµ¢░µ¢ćõ╗ČÕż╣’╝øńäČÕÉÄÕÅéĶĆāÕ”éõĖŗõ╗ŻńĀüµ«ĄÕ£© `mmrotate/core/optimizer/my_optimizer.py` µ¢ćõ╗ČõĖŁÕ«×ńÄ░µ¢░ńÜäõ╝śÕī¢ÕÖ©:
+
+```python
+from mmdet.core.optimizer.registry import OPTIMIZERS
+from torch.optim import Optimizer
+
+
+@OPTIMIZERS.register_module()
+class MyOptimizer(Optimizer):
+
+ def __init__(self, a, b, c)
+
+```
+
+#### 2. Õó×ÕŖĀõ╝śÕī¢ÕÖ©Õł░µ│©ÕåīĶĪ© (registry)
+
+õĖ║õ║åĶāĮÕż¤õĮ┐ÕŠŚõĖŖĶ┐░µĘ╗ÕŖĀńÜ䵩ĪÕØŚĶó½ `mmrotate` ÕÅæńÄ░’╝īķ£ĆĶ”üÕģłÕ░åĶ»źµ©ĪÕØŚµĘ╗ÕŖĀÕł░õĖ╗ÕæĮÕÉŹń®║ķŚ┤’╝łmain namespace’╝ēŃĆé
+
+- õ┐«µö╣ `mmrotate/core/optimizer/__init__.py` µ¢ćõ╗ČµØźÕ»╝ÕģźĶ»źµ©ĪÕØŚŃĆé
+
+ µ¢░ńÜäĶó½Õ«Üõ╣ēńÜ䵩ĪÕØŚÕ║öĶ»źĶó½Õ»╝ÕģźÕł░ `mmrotate/core/optimizer/__init__.py` õĖŁ’╝īĶ┐ÖµĀʵ│©ÕåīĶĪ©µēŹõ╝ÜÕÅæńÄ░µ¢░ńÜ䵩ĪÕØŚÕ╣ȵĘ╗ÕŖĀÕ«ā’╝Ü
+
+```python
+from .my_optimizer import MyOptimizer
+```
+
+- Õ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁõĮ┐ńö© `custom_imports` µØźµēŗÕŖ©µĘ╗ÕŖĀĶ»źµ©ĪÕØŚ
+
+```python
+custom_imports = dict(imports=['mmrotate.core.optimizer.my_optimizer'], allow_failed_imports=False)
+```
+
+`mmrotate.core.optimizer.my_optimizer` µ©ĪÕØŚÕ░åõ╝ÜÕ£©ń©ŗÕ║ÅÕ╝ĆÕ¦ŗĶó½Õ»╝Õģź’╝īÕ╣ČõĖö `MyOptimizer` ń▒╗Õ░åõ╝ÜĶć¬ÕŖ©µ│©ÕåīŃĆé
+ķ£ĆĶ”üµ│©µäÅÕŬµ£ēÕīģÕɽ `MyOptimizer` ń▒╗ńÜäÕīģ (package) Õ║öÕĮōĶó½Õ»╝ÕģźŃĆé
+ĶĆī `mmrotate.core.optimizer.my_optimizer.MyOptimizer` **õĖŹĶāĮ** Ķó½ńø┤µÄźÕ»╝ÕģźŃĆé
+
+õ║ŗÕ«×õĖŖ’╝īÕ£©Ķ┐Öń¦ŹÕ»╝Õģźµ¢╣Õ╝ÅõĖŗńö©µłĘÕÅ»õ╗źńö©Õ«īÕģ©õĖŹÕÉīńÜäµ¢ćõ╗ČÕż╣ń╗ōµ×ä’╝īÕŬĶ”üĶ┐ÖõĖƵ©ĪÕØŚńÜäµĀ╣ńø«ÕĮĢÕĘ▓ń╗ÅĶó½µĘ╗ÕŖĀÕł░ `PYTHONPATH` ķćīķØóŃĆé
+
+#### 3. Õ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁµīćÕ«Üõ╝śÕī¢ÕÖ©
+
+õ╣ŗÕÉĵé©ÕÅ»õ╗źÕ£©ķģŹńĮ«µ¢ćõ╗ČńÜä `optimizer` ķā©ÕłåķćīķØóõĮ┐ńö© `MyOptimizer`ŃĆé
+Õ£©ķģŹńĮ«µ¢ćõ╗Čķćī’╝īõ╝śÕī¢ÕÖ©µīēńģ¦Õ”éõĖŗÕĮóÕ╝ÅĶó½Õ«Üõ╣ēÕ£© `optimizer` ķā©Õłåķćī’╝Ü
+
+```python
+optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
+```
+
+Ķ”üõĮ┐ńö©ńö©µłĘĶć¬Õ«Üõ╣ēńÜäõ╝śÕī¢ÕÖ©’╝īĶ┐Öķā©ÕłåÕ║öĶ»źµö╣µłÉ’╝Ü
+
+```python
+optimizer = dict(type='MyOptimizer', a=a_value, b=b_value, c=c_value)
+```
+
+### Ķć¬Õ«Üõ╣ēõ╝śÕī¢ÕÖ©ńÜäµ×äķĆĀÕćĮµĢ░ (constructor)
+
+µ£ēõ║øµ©ĪÕ×ŗńÜäõ╝śÕī¢ÕÖ©ÕÅ»ĶāĮµ£ēõĖĆõ║øńē╣Õł½ÕÅéµĢ░ķģŹńĮ«’╝īõŠŗÕ”éµē╣ÕĮÆõĖĆÕī¢Õ▒é (BatchNorm layers) ńÜäµØāķćŹĶĪ░ÕćÅń│╗µĢ░ (weight decay)ŃĆé
+ńö©µłĘÕÅ»õ╗źķĆÜĶ┐ćĶć¬Õ«Üõ╣ēõ╝śÕī¢ÕÖ©ńÜäµ×äķĆĀÕćĮµĢ░ÕÄ╗ÕŠ«Ķ░āĶ┐Öõ║øń╗åń▓ÆÕ║”ÕÅéµĢ░ŃĆé
+
+```python
+from mmcv.utils import build_from_cfg
+
+from mmcv.runner.optimizer import OPTIMIZER_BUILDERS, OPTIMIZERS
+from mmrotate.utils import get_root_logger
+from .my_optimizer import MyOptimizer
+
+
+@OPTIMIZER_BUILDERS.register_module()
+class MyOptimizerConstructor(object):
+
+ def __init__(self, optimizer_cfg, paramwise_cfg=None):
+
+ def __call__(self, model):
+
+ return my_optimizer
+
+```
+
+`mmcv` ķ╗śĶ«żńÜäõ╝śÕī¢ÕÖ©µ×äķĆĀÕćĮµĢ░Õ«×ńÄ░ÕÅ»õ╗źÕÅéĶĆā [Ķ┐Öķćī](https://github.com/open-mmlab/mmcv/blob/9ecd6b0d5ff9d2172c49a182eaa669e9f27bb8e7/mmcv/runner/optimizer/default_constructor.py#L11) ’╝īĶ┐Öõ╣¤ÕÅ»õ╗źõĮ£õĖ║µ¢░ńÜäõ╝śÕī¢ÕÖ©µ×äķĆĀÕćĮµĢ░ńÜ䵩ĪµØ┐ŃĆé
+
+### ÕģČõ╗¢ķģŹńĮ«
+
+õ╝śÕī¢ÕÖ©µ£¬Õ«×ńÄ░ńÜäµŖĆÕʦÕ║öĶ»źķĆÜĶ┐ćõ┐«µö╣õ╝śÕī¢ÕÖ©µ×äķĆĀÕćĮµĢ░’╝łÕ”éĶ«ŠńĮ«Õ¤║õ║ÄÕÅéµĢ░ńÜäÕŁ”õ╣ĀńÄć’╝ēµł¢ĶĆģķÆ®ÕŁÉ’╝łhooks’╝ēÕÄ╗Õ«×ńÄ░ŃĆ鵳æõ╗¼ÕłŚÕć║õĖĆõ║øÕĖĖĶ¦üńÜäĶ«ŠńĮ«’╝īÕ«āõ╗¼ÕÅ»õ╗źń©│իܵł¢ÕŖĀķƤµ©ĪÕ×ŗńÜäĶ«Łń╗āŃĆé
+Õ”éµ×£µé©µ£ēµø┤ÕżÜńÜäĶ«ŠńĮ«’╝īµ¼óĶ┐ÄÕ£© PR ÕÆī issue ķćīķØóµÅÉÕć║ŃĆé
+
+- __õĮ┐ńö©µó»Õ║”ĶŻüÕē¬ (gradient clip) µØźń©│Õ«ÜĶ«Łń╗ā__:
+ õĖĆõ║øµ©ĪÕ×ŗķ£ĆĶ”üµó»Õ║”ĶŻüÕē¬µØźń©│Õ«ÜĶ«Łń╗āĶ┐ćń©ŗŃĆéõĮ┐ńö©µ¢╣Õ╝ÅÕ”éõĖŗ’╝Ü
+
+ ```python
+ optimizer_config = dict(
+ _delete_=True, grad_clip=dict(max_norm=35, norm_type=2))
+ ```
+
+ Õ”éµ×£µé©ńÜäķģŹńĮ«ń╗¦µē┐õ║åÕĘ▓ń╗ÅĶ«ŠńĮ«õ║å `optimizer_config` ńÜäÕ¤║ńĪĆķģŹńĮ«’╝łbase config’╝ē’╝īõĮĀÕÅ»ĶāĮķ£ĆĶ”üĶ«ŠńĮ« `_delete_=True` µØźĶ”åńø¢õĖŹÕ┐ģĶ”üńÜäķģŹńĮ«ÕÅéµĢ░ŃĆéĶ»ĘÕÅéĶĆā [ķģŹńĮ«µ¢ćµĪŻ](https://mmdetection.readthedocs.io/en/latest/tutorials/config.html) õ║åĶ¦Żµø┤ÕżÜń╗åĶŖéŃĆé
+
+- __õĮ┐ńö©ÕŖ©ķćÅĶ░āÕ║”ÕŖĀķƤµ©ĪÕ×ŗµöȵĢø__:
+ µłæõ╗¼µö»µīüÕŖ©ķćÅĶ¦äÕłÆÕÖ©’╝łMomentum scheduler’╝ē’╝īõ╗źÕ«×ńÄ░µĀ╣µŹ«ÕŁ”õ╣ĀńÄćĶ░āĶŖ鵩ĪÕ×ŗõ╝śÕī¢Ķ┐ćń©ŗõĖŁńÜäÕŖ©ķćÅĶ«ŠńĮ«’╝īĶ┐ÖÕÅ»õ╗źõĮ┐µ©ĪÕ×ŗõ╗źµø┤Õ┐½ķƤÕ║”µöȵĢøŃĆé
+ ÕŖ©ķćÅĶ¦äÕłÆÕÖ©ń╗ÅÕĖĖõĖÄÕŁ”õ╣ĀńÄćĶ¦äÕłÆÕÖ©’╝łLR scheduler’╝ēõĖĆĶĄĘõĮ┐ńö©’╝īõŠŗÕ”éõĖŗķØóńÜäķģŹńĮ«ń╗ÅÕĖĖĶó½ńö©õ║Ä 3D µŻĆµĄŗµ©ĪÕ×ŗĶ«Łń╗āõĖŁõ╗źÕŖĀķƤµöȵĢøŃĆéµø┤ÕżÜń╗åĶŖéĶ»ĘÕÅéĶĆā [CyclicLrUpdater](https://github.com/open-mmlab/mmcv/blob/f48241a65aebfe07db122e9db320c31b685dc674/mmcv/runner/hooks/lr_updater.py#L327) ÕÆī [CyclicMomentumUpdater](https://github.com/open-mmlab/mmcv/blob/f48241a65aebfe07db122e9db320c31b685dc674/mmcv/runner/hooks/momentum_updater.py#L130)ŃĆé
+
+ ```python
+ lr_config = dict(
+ policy='cyclic',
+ target_ratio=(10, 1e-4),
+ cyclic_times=1,
+ step_ratio_up=0.4,
+ )
+ momentum_config = dict(
+ policy='cyclic',
+ target_ratio=(0.85 / 0.95, 1),
+ cyclic_times=1,
+ step_ratio_up=0.4,
+ )
+ ```
+
+## Ķć¬Õ«Üõ╣ēĶ«Łń╗āĶ«ĪÕłÆ
+
+ķ╗śĶ«żÕ£░’╝īµłæõ╗¼õĮ┐ńö© 1x Ķ«ĪÕłÆ’╝ł1x schedule’╝ēńÜ䵣źĶ┐øÕŁ”õ╣ĀńÄć’╝łstep learning rate’╝ē’╝īĶ┐ÖÕ£© MMCV õĖŁĶó½ń¦░õĖ║ [`StepLRHook`](https://github.com/open-mmlab/mmcv/blob/f48241a65aebfe07db122e9db320c31b685dc674/mmcv/runner/hooks/lr_updater.py#L153)ŃĆé
+µłæõ╗¼µö»µīüÕŠłÕżÜÕģČõ╗¢ńÜäÕŁ”õ╣ĀńÄćĶ¦äÕłÆÕÖ©’╝īÕÅéĶĆā [Ķ┐Öķćī](https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/lr_updater.py) ’╝īõŠŗÕ”é `CosineAnnealing` ÕÆī `Poly`ŃĆéõĖŗķØ󵜻õĖĆõ║øõŠŗÕŁÉ’╝Ü
+
+- `Poly` :
+
+ ```python
+ lr_config = dict(policy='poly', power=0.9, min_lr=1e-4, by_epoch=False)
+ ```
+
+- `ConsineAnnealing` :
+
+ ```python
+ lr_config = dict(
+ policy='CosineAnnealing',
+ warmup='linear',
+ warmup_iters=1000,
+ warmup_ratio=1.0 / 10,
+ min_lr_ratio=1e-5)
+ ```
+
+## Ķć¬Õ«Üõ╣ēÕĘźõĮ£µĄü (workflow)
+
+ÕĘźõĮ£µĄüµś»õĖĆõĖ¬õĖōķŚ©Õ«Üõ╣ēĶ┐ÉĶĪīķĪ║Õ║ÅÕÆīĶĮ«µĢ░’╝łepochs’╝ēńÜäÕłŚĶĪ©ŃĆé
+ķ╗śĶ«żµāģÕåĄõĖŗÕ«āĶ«ŠńĮ«µłÉ’╝Ü
+
+```python
+workflow = [('train', 1)]
+```
+
+Ķ┐Öµś»µīćĶ«Łń╗ā 1 õĖ¬ epochŃĆé
+µ£ēµŚČÕĆÖńö©µłĘÕÅ»ĶāĮµā│µŻĆµ¤źõĖĆõ║øµ©ĪÕ×ŗÕ£©ķ¬īĶ»üķøåõĖŖńÜäµīćµĀć’╝īÕ”éµŹ¤Õż▒ÕćĮµĢ░ÕĆ╝’╝łLoss’╝ēÕÆīÕćåńĪ«µĆ¦’╝łAccuracy’╝ēŃĆé
+Õ£©Ķ┐Öń¦ŹµāģÕåĄõĖŗ’╝īµłæõ╗¼ÕÅ»õ╗źÕ░åÕĘźõĮ£µĄüĶ«ŠńĮ«õĖ║’╝Ü
+
+```python
+[('train', 1), ('val', 1)]
+```
+
+Ķ┐ÖµĀĘõ╗źµØź’╝ī 1 õĖ¬ epoch Ķ«Łń╗ā’╝ī1 õĖ¬ epoch ķ¬īĶ»üÕ░åõ║żµø┐Ķ┐ÉĶĪīŃĆé
+
+**µ│©µäÅ**:
+
+1. µ©ĪÕ×ŗÕÅéµĢ░Õ£©ķ¬īĶ»üńÜäķśČµ«ĄõĖŹõ╝ÜĶó½Ķć¬ÕŖ©µø┤µ¢░ŃĆé
+2. ķģŹńĮ«µ¢ćõ╗ČķćīńÜäķö«ÕĆ╝ `total_epochs` õ╗ģµÄ¦ÕłČĶ«Łń╗āńÜä epochs µĢ░ńø«’╝īĶĆīõĖŹõ╝ÜÕĮ▒ÕōŹķ¬īĶ»üÕĘźõĮ£µĄüŃĆé
+3. ÕĘźõĮ£µĄü `[('train', 1), ('val', 1)]` ÕÆī `[('train', 1)]` Õ░åõĖŹõ╝ܵö╣ÕÅś `EvalHook` ńÜäĶĪīõĖ║’╝īÕøĀõĖ║ `EvalHook` Ķó½ `after_train_epoch`
+ Ķ░āńö©ĶĆīõĖöķ¬īĶ»üńÜäÕĘźõĮ£µĄüõ╗ģõ╗ģÕĮ▒ÕōŹķĆÜĶ┐ćĶ░āńö© `after_val_epoch` ńÜäķÆ®ÕŁÉ (hooks)ŃĆéÕøĀµŁż’╝ī `[('train', 1), ('val', 1)]` ÕÆī `[('train', 1)]`
+ ńÜäÕī║Õł½õ╗ģÕ£©õ║Ä runner Õ░åÕ£©µ»Åµ¼ĪĶ«Łń╗āķśČµ«Ą’╝łtraining epoch’╝ēń╗ōµØ¤ÕÉÄĶ«Īń«ŚÕ£©ķ¬īĶ»üķøåõĖŖńÜ䵏¤Õż▒ŃĆé
+
+## Ķć¬Õ«Üõ╣ēķÆ® (hooks)
+
+### Ķć¬Õ«Üõ╣ēńö©µłĘĶć¬ÕĘ▒Õ«×ńÄ░ńÜäķÆ®ÕŁÉ’╝łhooks’╝ē
+
+#### 1. Õ«×ńÄ░õĖĆõĖ¬µ¢░ńÜäķÆ®ÕŁÉ’╝łhook’╝ē
+
+Õ£©µ¤Éõ║øµāģÕåĄõĖŗ’╝īńö©µłĘÕÅ»ĶāĮķ£ĆĶ”üÕ«×ńÄ░õĖĆõĖ¬µ¢░ńÜäķÆ®ÕŁÉŃĆé MMRotate µö»µīüĶ«Łń╗āõĖŁńÜäĶć¬Õ«Üõ╣ēķÆ®ÕŁÉŃĆé ÕøĀµŁż’╝īńö©µłĘÕÅ»õ╗źńø┤µÄźÕ£© mmrotate µł¢ÕģČÕ¤║õ║Ä mmdet ńÜäõ╗ŻńĀüÕ║ōõĖŁÕ«×ńÄ░ķÆ®ÕŁÉ’╝īÕ╣ČķĆÜĶ┐ćõ╗ģÕ£©Ķ«Łń╗āõĖŁõ┐«µö╣ķģŹńĮ«µØźõĮ┐ńö©ķÆ®ÕŁÉŃĆé
+Ķ┐Öķćīµłæõ╗¼õĖŠõĖĆõĖ¬õŠŗÕŁÉ’╝ÜÕ£© mmrotate õĖŁÕłøÕ╗║õĖĆõĖ¬µ¢░ńÜäķÆ®ÕŁÉÕ╣ČÕ£©Ķ«Łń╗āõĖŁõĮ┐ńö©Õ«āŃĆé
+
+```python
+from mmcv.runner import HOOKS, Hook
+
+
+@HOOKS.register_module()
+class MyHook(Hook):
+
+ def __init__(self, a, b):
+ pass
+
+ def before_run(self, runner):
+ pass
+
+ def after_run(self, runner):
+ pass
+
+ def before_epoch(self, runner):
+ pass
+
+ def after_epoch(self, runner):
+ pass
+
+ def before_iter(self, runner):
+ pass
+
+ def after_iter(self, runner):
+ pass
+```
+
+ńö©µłĘķ£ĆĶ”üµĀ╣µŹ«ķÆ®ÕŁÉńÜäÕŖ¤ĶāĮµīćÕ«ÜķÆ®ÕŁÉÕ£©Ķ«Łń╗āÕÉäķśČµ«ĄõĖŁ’╝ł `before_run` , `after_run` , `before_epoch` , `after_epoch` , `before_iter` , `after_iter`’╝ēÕüÜõ╗Ćõ╣łŃĆé
+
+#### 2. µ│©Õåīµ¢░ńÜäķÆ®ÕŁÉ’╝łhook’╝ē
+
+µÄźõĖŗµØźµłæõ╗¼ķ£ĆĶ”üÕ»╝Õģź `MyHook`ŃĆéÕ”éµ×£µ¢ćõ╗ČńÜäĶĘ»ÕŠäµś» `mmrotate/core/utils/my_hook.py` ’╝īµ£ēõĖżń¦Źµ¢╣Õ╝ÅÕ»╝Õģź’╝Ü
+
+- õ┐«µö╣ `mmrotate/core/utils/__init__.py` µ¢ćõ╗ČµØźÕ»╝Õģź
+
+ µ¢░Õ«Üõ╣ēńÜ䵩ĪÕØŚķ£ĆĶ”üÕ£© `mmrotate/core/utils/__init__.py` Õ»╝Õģź’╝īµ│©ÕåīĶĪ©µēŹõ╝ÜÕÅæńÄ░Õ╣ȵĘ╗ÕŖĀĶ»źµ©ĪÕØŚ’╝Ü
+
+```python
+from .my_hook import MyHook
+```
+
+- Õ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁõĮ┐ńö© `custom_imports` µØźµēŗÕŖ©Õ»╝Õģź
+
+```python
+custom_imports = dict(imports=['mmrotate.core.utils.my_hook'], allow_failed_imports=False)
+```
+
+#### 3. õ┐«µö╣ķģŹńĮ«
+
+```python
+custom_hooks = [
+ dict(type='MyHook', a=a_value, b=b_value)
+]
+```
+
+µé©õ╣¤ÕÅ»õ╗źķĆÜĶ┐ćķģŹńĮ«ķö«ÕĆ╝ `priority` õĖ║ `'NORMAL'` µł¢ `'HIGHEST'` µØźĶ«ŠńĮ«ķÆ®ÕŁÉńÜäõ╝śÕģłń║¦’╝Ü
+
+```python
+custom_hooks = [
+ dict(type='MyHook', a=a_value, b=b_value, priority='NORMAL')
+]
+```
+
+ķ╗śĶ«żÕ£░’╝īķÆ®ÕŁÉńÜäõ╝śÕģłń║¦Õ£©µ│©ÕåīµŚČĶó½Ķ«ŠńĮ«õĖ║ `NORMAL`ŃĆé
+
+### õĮ┐ńö© MMCV õĖŁÕ«×ńÄ░ńÜäķÆ®ÕŁÉ (hooks)
+
+Õ”éµ×£ķÆ®ÕŁÉÕĘ▓ń╗ÅÕ£© MMCV ķćīÕ«×ńÄ░õ║å’╝īµé©ÕÅ»õ╗źńø┤µÄźõ┐«µö╣ķģŹńĮ«µ¢ćõ╗ČµØźõĮ┐ńö©ķÆ®ÕŁÉŃĆé
+
+#### 4. ńż║õŠŗ: `NumClassCheckHook`
+
+µłæõ╗¼Õ«×ńÄ░õ║åõĖĆõĖ¬Ķć¬Õ«Üõ╣ēńÜäķÆ®ÕŁÉ [NumClassCheckHook](https://github.com/open-mmlab/mmdetection/blob/master/mmdet/datasets/utils.py) ’╝īńö©µØźµŻĆķ¬ī head õĖŁńÜä `num_classes` µś»ÕÉ”õĖÄ `dataset` õĖŁńÜä `CLASSSES` ķĢ┐Õ║”Õī╣ķģŹŃĆé
+
+µłæõ╗¼Õ£© [default_runtime.py](https://github.com/open-mmlab/mmdetection/blob/master/configs/_base_/default_runtime.py) õĖŁÕ»╣ÕģČĶ┐øĶĪīĶ«ŠńĮ«ŃĆé
+
+```python
+custom_hooks = [dict(type='NumClassCheckHook')]
+```
+
+### õ┐«µö╣ķ╗śĶ«żĶ┐ÉĶĪīµīéķÆ®
+
+µ£ēõĖĆõ║øÕĖĖĶ¦üńÜäķÆ®ÕŁÉÕ╣ČõĖŹķĆÜĶ┐ć `custom_hooks` µ│©Õåī’╝īĶ┐Öõ║øķÆ®ÕŁÉÕīģµŗ¼’╝Ü
+
+- log_config
+- checkpoint_config
+- evaluation
+- lr_config
+- optimizer_config
+- momentum_config
+
+Ķ┐Öõ║øķÆ®ÕŁÉõĖŁ’╝īÕŬµ£ēĶ«░ÕĮĢÕÖ©ķÆ®ÕŁÉ’╝łlogger hook’╝ēµś» `VERY_LOW` õ╝śÕģłń║¦’╝īÕģČõ╗¢ķÆ®ÕŁÉńÜäõ╝śÕģłń║¦õĖ║ `NORMAL`ŃĆé
+ÕēŹķØóµÅÉÕł░ńÜäµĢÖń©ŗÕĘ▓ń╗Åõ╗ŗń╗Źõ║åÕ”éõĮĢõ┐«µö╣ `optimizer_config` , `momentum_config` õ╗źÕÅŖ `lr_config`ŃĆé
+Ķ┐Öķćīµłæõ╗¼õ╗ŗń╗ŹõĖĆõĖŗÕ”éõĮĢÕżäńÉå `log_config` , `checkpoint_config` õ╗źÕÅŖ `evaluation`ŃĆé
+
+#### Checkpoint config
+
+MMCV runner Õ░åõĮ┐ńö© `checkpoint_config` µØźÕłØÕ¦ŗÕī¢ [`CheckpointHook`](https://github.com/open-mmlab/mmcv/blob/9ecd6b0d5ff9d2172c49a182eaa669e9f27bb8e7/mmcv/runner/hooks/checkpoint.py#L9)ŃĆé
+
+```python
+checkpoint_config = dict(interval=1)
+```
+
+ńö©µłĘÕÅ»õ╗źĶ«ŠńĮ« `max_keep_ckpts` µØźõ╗ģõ┐ØÕŁśõĖĆÕ░Åķā©ÕłåµŻĆµ¤źńé╣’╝łcheckpoint’╝ēµł¢ĶĆģķĆÜĶ┐ćĶ«ŠńĮ« `save_optimizer` µØźÕå│իܵś»ÕÉ”õ┐ØÕŁśõ╝śÕī¢ÕÖ©ńÜäńŖȵĆüÕŁŚÕģĖ (state dict of optimizer)ŃĆéµø┤ÕżÜõĮ┐ńö©ÕÅéµĢ░ńÜäń╗åĶŖéĶ»ĘÕÅéĶĆā [Ķ┐Öķćī](https://mmcv.readthedocs.io/en/latest/api.html#mmcv.runner.CheckpointHook)ŃĆé
+
+#### Log config
+
+`log_config` ÕīģĶŻ╣õ║åĶ«ĖÕżÜµŚźÕ┐ŚķÆ® (logger hooks) ĶĆīõĖöĶāĮÕÄ╗Ķ«ŠńĮ«ķŚ┤ķÜö (intervals)ŃĆéńÄ░Õ£© MMCV µö»µīü `WandbLoggerHook` ’╝ī `MlflowLoggerHook` ÕÆī `TensorboardLoggerHook`ŃĆé
+Ķ»”ń╗åńÜäõĮ┐ńö©Ķ»ĘÕÅéńģ¦ [µ¢ćµĪŻ](https://mmcv.readthedocs.io/en/latest/api.html#mmcv.runner.LoggerHook)ŃĆé
+
+```python
+log_config = dict(
+ interval=50,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ dict(type='TensorboardLoggerHook')
+ ])
+```
+
+#### Evaluation config
+
+`evaluation` ńÜäķģŹńĮ«µ¢ćõ╗ČÕ░åĶó½ńö©µØźÕłØÕ¦ŗÕī¢ [`EvalHook`](https://github.com/open-mmlab/mmdetection/blob/7a404a2c000620d52156774a5025070d9e00d918/mmdet/core/evaluation/eval_hooks.py#L8)ŃĆé
+ķÖżõ║å `interval` ķö«’╝īÕģČõ╗¢ńÜäÕāÅ `metric` Ķ┐ÖµĀĘńÜäÕÅéµĢ░Õ░åĶó½õ╝ĀķĆÆń╗Ö `dataset.evaluate()`ŃĆé
+
+```python
+evaluation = dict(interval=1, metric='bbox')
+```
diff --git a/internlm_langchain/knowledge_base/MMRotate/content/faq.md b/internlm_langchain/knowledge_base/MMRotate/content/faq.md
new file mode 100644
index 00000000..f16e46d0
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMRotate/content/faq.md
@@ -0,0 +1,126 @@
+# ÕĖĖĶ¦üķŚ«ķóśĶ¦ŻńŁö
+
+µłæõ╗¼Õ£©Ķ┐ÖķćīÕłŚÕć║õ║åõĮ┐ńö©µŚČńÜäõĖĆõ║øÕĖĖĶ¦üķŚ«ķóśÕÅŖÕģČńøĖÕ║öńÜäĶ¦ŻÕå│µ¢╣µĪłŃĆé Õ”éµ×£µé©ÕÅæńÄ░µ£ēõĖĆõ║øķŚ«ķóśĶó½ķüŚµ╝Å’╝īĶ»ĘķÜŵŚČµÅÉ PR õĖ░Õ»īĶ┐ÖõĖ¬ÕłŚĶĪ©ŃĆéÕ”éµ×£µé©µŚĀµ│ĢÕ£©µŁżĶÄĘÕŠŚÕĖ«ÕŖ®’╝īĶ»ĘõĮ┐ńö© [issueµ©ĪµØ┐](https://github.com/open-mmlab/mmdetection/blob/master/.github/ISSUE_TEMPLATE/error-report.md/) ÕłøÕ╗║ķŚ«ķóś’╝īõĮåµś»Ķ»ĘÕ£©µ©ĪµØ┐õĖŁÕĪ½ÕåÖµēƵ£ēÕ┐ģÕĪ½õ┐Īµü»’╝īĶ┐Öµ£ēÕŖ®õ║ĵłæõ╗¼µø┤Õ┐½Õ«ÜõĮŹķŚ«ķóśŃĆé
+
+## MMCV Õ«ēĶŻģńøĖÕģ│
+
+- MMCV õĖÄ MMDetection ńÜäÕģ╝Õ«╣ķŚ«ķóś: "ConvWS is already registered in conv layer"; "AssertionError: MMCV==xxx is used but incompatible. Please install mmcv>=xxx, \<=xxx."
+
+MMRotate ÕÆī MMCV, MMDet ńēłµ£¼Õģ╝Õ«╣µĆ¦Õ”éõĖŗµēĆńż║’╝īķ£ĆĶ”üÕ«ēĶŻģµŁŻńĪ«ńÜäńēłµ£¼õ╗źķü┐ÕģŹÕ«ēĶŻģÕć║ńÄ░ķŚ«ķóśŃĆé
+
+| MMRotate ńēłµ£¼ | MMCV ńēłµ£¼ | MMDetection ńēłµ£¼ |
+| :-----------: | :-----------------------: | :----------------------: |
+| main | mmcv-full>=1.5.3, \<1.8.0 | mmdet >= 2.25.1, \<3.0.0 |
+| 0.3.4 | mmcv-full>=1.5.3, \<1.8.0 | mmdet >= 2.25.1, \<3.0.0 |
+| 0.3.3 | mmcv-full>=1.5.3, \<1.7.0 | mmdet >= 2.25.1, \<3.0.0 |
+| 0.3.2 | mmcv-full>=1.5.3, \<1.7.0 | mmdet >= 2.25.1, \<3.0.0 |
+| 0.3.1 | mmcv-full>=1.4.5, \<1.6.0 | mmdet >= 2.22.0, \<3.0.0 |
+| 0.3.0 | mmcv-full>=1.4.5, \<1.6.0 | mmdet >= 2.22.0, \<3.0.0 |
+| 0.2.0 | mmcv-full>=1.4.5, \<1.5.0 | mmdet >= 2.19.0, \<3.0.0 |
+| 0.1.1 | mmcv-full>=1.4.5, \<1.5.0 | mmdet >= 2.19.0, \<3.0.0 |
+| 0.1.0 | mmcv-full>=1.4.5, \<1.5.0 | mmdet >= 2.19.0, \<3.0.0 |
+
+- "No module named 'mmcv.ops'"; "No module named 'mmcv.\_ext'".
+
+ ÕĤÕøĀµś»Õ«ēĶŻģõ║å `mmcv` ĶĆīõĖŹµś» `mmcv-full`ŃĆé
+
+ 1. õĮ┐ńö© `pip uninstall mmcv` ÕŹĖĶĮĮŃĆé
+ 2. µĀ╣µŹ« [Õ«ēĶŻģĶ»┤µśÄ](install#best-practices) Õ«ēĶŻģ `mmcv-full`ŃĆé
+
+## PyTorch/CUDA ńÄ»ÕóāńøĖÕģ│
+
+- "RTX 30 series card fails when building MMCV or MMDet"
+
+ 1. ÕĖĖĶ¦üµŖźķöÖõ┐Īµü»õĖ║ `nvcc fatal: Unsupported gpu architecture 'compute_86'` µäŵĆصś»õĮĀńÜäń╝¢Ķ»æÕÖ©Õ║öĶ»źõĖ║ sm_86 Ķ┐øĶĪīõ╝śÕī¢’╝īõŠŗÕ”é’╝ī Ķŗ▒õ╝¤ĶŠŠ 30 ń│╗ÕłŚńÜ䵜ŠÕŹĪ’╝īõĮåĶ┐ÖµĀĘńÜäõ╝śÕī¢ CUDA toolkit 11.0 Õ╣ČõĖŹµö»µīüŃĆé
+ µŁżĶ¦ŻÕå│µ¢╣µĪłķĆÜĶ┐ćµĘ╗ÕŖĀ `MMCV_WITH_OPS=1 MMCV_CUDA_ARGS='-gencode=arch=compute_80,code=sm_80' pip install -e .` µØźõ┐«µö╣ń╝¢Ķ»æµĀćÕ┐Ś’╝īĶ┐ÖÕæŖĶ»ēń╝¢Ķ»æÕÖ© `nvcc` õĖ║ **sm_80** Ķ┐øĶĪīõ╝śÕī¢’╝īõŠŗÕ”é Nvidia A100’╝īÕ░Įń«Ī A100 õĖŹÕÉīõ║Ä 30 ń│╗ÕłŚńÜ䵜ŠÕŹĪ’╝īõĮåõ╗¢õ╗¼õĮ┐ńö©ńøĖõ╝╝ńÜäÕøŠńüĄµ×ȵ×äŃĆéĶ┐Öń¦ŹĶ¦ŻÕå│µ¢╣µĪłÕÅ»ĶāĮõ╝ÜõĖ¦Õż▒õĖĆõ║øµĆ¦ĶāĮõĮåńÜäńĪ«µ£ēµĢłŃĆé
+ 2. PyTorch Õ╝ĆÕÅæĶĆģÕĘ▓ń╗ÅÕ£© [pytorch/pytorch#47585](https://github.com/pytorch/pytorch/pull/47585) µø┤µ¢░õ║å PyTorch ķ╗śĶ«żńÜäń╝¢Ķ»æµĀćÕ┐Ś’╝īµēĆõ╗źõĮ┐ńö© PyTorch-nightly ÕÅ»ĶāĮõ╣¤ĶāĮĶ¦ŻÕå│Ķ┐ÖõĖ¬ķŚ«ķóś’╝īõĮåµś»µłæõ╗¼Õ»╣µŁżÕ╣ȵ▓Īµ£ēķ¬īĶ»üĶ┐Öń¦Źµ¢╣Õ╝ŵś»ÕÉ”µ£ēµĢłŃĆé
+
+- "invalid device function" or "no kernel image is available for execution".
+
+ 1. µŻĆµ¤źµé©ńÜä cuda Ķ┐ÉĶĪīµŚČńēłµ£¼(õĖĆĶł¼Õ£© `/usr/local/`)ŃĆüµīćõ╗ż `nvcc --version` µśŠńż║ńÜäńēłµ£¼õ╗źÕÅŖ `conda list cudatoolkit` µīćõ╗żµśŠÕ╝ÅńÜäńēłµ£¼µś»ÕÉ”Õī╣ķģŹŃĆé
+ 2. ķĆÜĶ┐ćĶ┐ÉĶĪī `python mmdet/utils/collect_env.py` µØźµŻĆµ¤źµś»ÕÉ”õĖ║ÕĮōÕēŹńÜäGPUµ×ȵ×äń╝¢Ķ»æõ║åµŁŻńĪ«ńÜä PyTorchŃĆütorchvision ÕÆī MMCV’╝īõĮĀÕÅ»ĶāĮķ£ĆĶ”üĶ«ŠńĮ« `TORCH_CUDA_ARCH_LIST` µØźķ揵¢░Õ«ēĶŻģ MMCVŃĆéÕÅ»õ╗źÕÅéĶĆā [GPU µ×ȵ×äĶĪ©](https://docs.nvidia.com/cuda/cuda-compiler-driver-nvcc/index.html#gpu-feature-list)’╝īÕŹ│ķĆÜĶ┐ćĶ┐ÉĶĪī `TORCH_CUDA_ARCH_LIST=7.0 pip install mmcv-full` õĖ║ Volta GPU ń╝¢Ķ»æ MMCVŃĆéĶ┐Öń¦Źµ×ȵ×äõĖŹÕī╣ķģŹńÜäķŚ«ķóśõĖĆĶł¼õ╝ÜÕć║ńÄ░Õ£©õĮ┐ńö©õĖĆõ║øµŚ¦Õ×ŗÕÅĘńÜä GPU µŚČÕĆÖ’╝īõŠŗÕ”é’╝īTesla K80ŃĆé
+ 3. µŻĆµ¤źĶ┐ÉĶĪīńÄ»Õóāµś»ÕÉ”õĖÄ mmcv/mmdet ń╝¢Ķ»æµŚČńøĖÕÉī’╝īõŠŗÕ”é’╝īµé©ÕÅ»ĶāĮõĮ┐ńö© CUDA 10.0 ń╝¢Ķ»æ MMCV’╝īõĮåÕ£© CUDA 9.0 ńÄ»ÕóāõĖŁĶ┐ÉĶĪīÕ«āŃĆé
+
+- "undefined symbol" or "cannot open xxx.so".
+
+ 1. Õ”éµ×£Ķ┐Öõ║ø symbols Õ▒×õ║Ä CUDA/C++ (õŠŗÕ”é’╝īlibcudart.so µł¢ĶĆģ GLIBCXX)’╝īµŻĆµ¤ź CUDA/GCC Ķ┐ÉĶĪīµŚČńÄ»Õóāµś»ÕÉ”õĖÄń╝¢Ķ»æ MMCV ńÜäõĖĆĶć┤ŃĆéõŠŗÕ”éõĮ┐ńö© `python mmdet/utils/collect_env.py` µŻĆµ¤ź `"MMCV Compiler"`/`"MMCV CUDA Compiler"` µś»ÕÉ”ÕÆī `"GCC"`/`"CUDA_HOME"` õĖĆĶć┤ŃĆé
+ 2. Õ”éµ×£Ķ┐Öõ║ø symbols Õ▒×õ║Ä PyTorch’╝ī(õŠŗÕ”é’╝īsymbols containing caffeŃĆüaten ÕÆī TH)’╝ī µŻĆµ¤źÕĮōÕēŹ PyTorch ńēłµ£¼µś»ÕÉ”õĖÄń╝¢Ķ»æ MMCV ńÜäńēłµ£¼õĖĆĶć┤ŃĆé
+ 3. Ķ┐ÉĶĪī `python mmdet/utils/collect_env.py` µŻĆµ¤ź PyTorchŃĆütorchvisionŃĆüMMCV ńŁēńÜäń╝¢Ķ»æńÄ»ÕóāõĖÄĶ┐ÉĶĪīńÄ»ÕóāõĖĆĶć┤ŃĆé
+
+- "setuptools.sandbox.UnpickleableException: DistutilsSetupError("each element of 'ext_modules' option must be an Extension instance or 2-tuple")"
+
+ 1. Õ”éµ×£õĮĀÕ£©õĮ┐ńö© miniconda ĶĆīõĖŹµś» anaconda’╝īµŻĆµ¤źµś»ÕÉ”µŁŻńĪ«ńÜäÕ«ēĶŻģõ║å Cython Õ”é [#3379](https://github.com/open-mmlab/mmdetection/issues/3379)ŃĆéµé©ķ£ĆĶ”üÕģłµēŗÕŖ©Õ«ēĶŻģ Cpython ńäČÕÉÄĶ┐ÉÕæĮõ╗ż `pip install -r requirements.txt`ŃĆé
+ 2. µŻĆµ¤źńÄ»ÕóāõĖŁńÜä `setuptools`ŃĆü`Cython` ÕÆī `PyTorch` ńøĖõ║Æõ╣ŗķŚ┤ńēłµ£¼µś»ÕÉ”Õī╣ķģŹŃĆé
+
+- "Segmentation fault".
+
+ 1. µŻĆµ¤ź GCC ńÜäńēłµ£¼Õ╣ČõĮ┐ńö© GCC 5.4’╝īķĆÜÕĖĖµś»ÕøĀõĖ║ PyTorch ńēłµ£¼õĖÄ GCC ńēłµ£¼õĖŹÕī╣ķģŹ ’╝łõŠŗÕ”é’╝īÕ»╣õ║Ä Pytorch GCC \< 4.9)’╝īµłæõ╗¼µÄ©ĶŹÉńö©µłĘõĮ┐ńö© GCC 5.4’╝īµłæõ╗¼õ╣¤õĖŹµÄ©ĶŹÉõĮ┐ńö© GCC 5.5’╝ī ÕøĀõĖ║µ£ēÕÅŹķ”ł GCC 5.5 õ╝ÜÕ»╝Ķć┤ "segmentation fault" Õ╣ČõĖöÕłćµŹóÕł░ GCC 5.4 Õ░▒ÕÅ»õ╗źĶ¦ŻÕå│ķŚ«ķóśŃĆé
+
+ 2. µŻĆµ¤źµś»µś»ÕÉ” PyTorch Ķó½µŁŻńĪ«ńÜäÕ«ēĶŻģÕ╣ČÕÅ»õ╗źõĮ┐ńö© CUDA ń«ŚÕŁÉ’╝īõŠŗÕ”éÕ£©ń╗łń½»õĖŁķö«ÕģźÕ”éõĖŗńÜäµīćõ╗żŃĆé
+
+ ```shell
+ python -c 'import torch; print(torch.cuda.is_available())'
+ ```
+
+ Õ╣ČÕłżµ¢Łµś»ÕÉ”µś»ÕÉ”Ķ┐öÕø× TrueŃĆé
+
+ 3. Õ”éµ×£ `torch` ńÜäÕ«ēĶŻģµś»µŁŻńĪ«ńÜä’╝īµŻĆµ¤źµś»ÕÉ”µŁŻńĪ«ń╝¢Ķ»æõ║å MMCVŃĆé
+
+ ```shell
+ python -c 'import mmcv; import mmcv.ops'
+ ```
+
+ Õ”éµ×£ MMCV Ķó½µŁŻńĪ«ńÜäÕ«ēĶŻģõ║å’╝īķéŻõ╣łõĖŖķØóńÜäõĖżµØĪµīćõ╗żõĖŹõ╝ܵ£ēķŚ«ķóśŃĆé
+
+ 4. Õ”éµ×£ MMCV õĖÄ PyTorch ķāĮĶó½µŁŻńĪ«Õ«ēĶŻģõ║å’╝īÕłÖõĮ┐ńö© `ipdb`ŃĆü`pdb` Ķ«ŠńĮ«µ¢Łńé╣’╝īńø┤µÄźµ¤źµēŠÕō¬õĖĆķā©ÕłåńÜäõ╗ŻńĀüÕ»╝Ķć┤õ║å `segmentation fault`ŃĆé
+
+## E2CNN
+
+- "ImportError: cannot import name 'container_bacs' from 'torch.\_six'"
+
+ 1. Ķ┐Öµś»ÕøĀõĖ║ `container_abcs` Õ£© PyTorch 1.9 õ╣ŗÕÉÄĶó½ń¦╗ķÖż.
+
+ 2. Õ░åµ¢ćõ╗Č `python3.7/site-packages/e2cnn/nn/modules/module_list.py` õĖŁńÜä
+
+ ```shell
+ from torch.six import container_abcs
+ ```
+
+ µø┐µŹóµłÉ
+
+ ```shell
+ TORCH_MAJOR = int(torch.__version__.split('.')[0])
+ TORCH_MINOR = int(torch.__version__.split('.')[1])
+ if TORCH_MAJOR ==1 and TORCH_MINOR < 8:
+ from torch.six import container_abcs
+ else:
+ import collections.abs as container_abcs
+ ```
+
+ 3. µł¢ĶĆģķÖŹõĮÄ Pytorch ńÜäńēłµ£¼ŃĆé
+
+## Training ńøĖÕģ│
+
+- "Loss goes Nan"
+
+ 1. µŻĆµ¤źµĢ░µŹ«ńÜäµĀćµ│©µś»ÕÉ”µŁŻÕĖĖ’╝īķĢ┐µł¢Õ«ĮõĖ║ 0 ńÜäµĪåÕÅ»ĶāĮõ╝ÜÕ»╝Ķć┤Õø×ÕĮÆ loss ÕÅśõĖ║ nan’╝īõĖĆõ║øÕ░ÅÕ░║Õ»Ė’╝łÕ«ĮÕ║”µł¢ķ½śÕ║”Õ░Åõ║Ä 1’╝ēńÜäµĪåÕ£©µĢ░µŹ«Õó×Õ╝║’╝łõŠŗÕ”é’╝īinstaboost’╝ēÕÉÄõ╣¤õ╝ÜÕ»╝Ķć┤µŁżķŚ«ķóśŃĆéÕøĀµŁż’╝īÕÅ»õ╗źµŻĆµ¤źµĀćµ│©Õ╣ČĶ┐ćµ╗żµÄēķéŻõ║øńē╣Õł½Õ░ÅńöÜĶć│ķØóń¦»õĖ║ 0 ńÜäµĪå’╝īÕ╣ČÕģ│ķŚŁõĖĆõ║øÕÅ»ĶāĮõ╝ÜÕ»╝Ķć┤ 0 ķØóń¦»µĪåÕć║ńÄ░µĢ░µŹ«Õó×Õ╝║ŃĆé
+ 2. ķÖŹõĮÄÕŁ”õ╣ĀńÄć’╝Üńö▒õ║ĵ¤Éõ║øÕĤÕøĀ’╝īõŠŗÕ”é batch size Õż¦Õ░ÅńÜäÕÅśÕī¢’╝īÕ»╝Ķć┤ÕĮōÕēŹÕŁ”õ╣ĀńÄćÕÅ»ĶāĮÕż¬Õż¦ŃĆéµé©ÕÅ»õ╗źķÖŹõĮÄõĖ║ÕÅ»õ╗źń©│Õ«ÜĶ«Łń╗āµ©ĪÕ×ŗńÜäÕĆ╝ŃĆé
+ 3. Õ╗ČķĢ┐ warm up ńÜ䵌ČķŚ┤’╝ÜõĖĆõ║øµ©ĪÕ×ŗÕ£©Ķ«Łń╗āÕłØÕ¦ŗµŚČÕ»╣ÕŁ”õ╣ĀńÄćÕŠłµĢŵ䤒╝īµé©ÕÅ»õ╗źµŖŖ `warmup_iters` õ╗Ä 500 µø┤µö╣õĖ║ 1000 µł¢ 2000ŃĆé
+ 4. µĘ╗ÕŖĀ gradient clipping: õĖĆõ║øµ©ĪÕ×ŗķ£ĆĶ”üµó»Õ║”ĶŻüÕē¬µØźń©│Õ«ÜĶ«Łń╗āĶ┐ćń©ŗŃĆéķ╗śĶ«żńÜä `grad_clip` µś» `None`’╝īõĮĀÕÅ»õ╗źÕ£© config Ķ«ŠńĮ« `optimizer_config=dict(_delete_=True, grad_clip=dict(max_norm=35, norm_type=2))`ŃĆé Õ”éµ×£õĮĀńÜä config µ▓Īµ£ēń╗¦µē┐õ╗╗õĮĢÕīģÕɽ `optimizer_config=dict(grad_clip=None)`’╝īõĮĀÕÅ»õ╗źńø┤µÄźĶ«ŠńĮ« `optimizer_config=dict(grad_clip=dict(max_norm=35, norm_type=2))`ŃĆé
+
+- "GPU out of memory"
+
+ 1. ÕŁśÕ£©Õż¦ķćÅ ground truth boxes µł¢ĶĆģÕż¦ķćÅ anchor ńÜäÕ£║µÖ»’╝īÕÅ»ĶāĮÕ£© assigner õ╝Ü OOMŃĆéµé©ÕÅ»õ╗źÕ£© assigner ńÜäķģŹńĮ«õĖŁĶ«ŠńĮ« `gpu_assign_thr=N`’╝īĶ┐ÖµĀĘÕĮōĶČģĶ┐ć N õĖ¬ GT boxes µŚČ’╝īassigner õ╝ÜķĆÜĶ┐ć CPU Ķ«Īń«Ś IoUŃĆé
+ 2. Õ£© backbone õĖŁĶ«ŠńĮ« `with_cp=True`ŃĆéĶ┐ÖõĮ┐ńö© PyTorch õĖŁńÜä `sublinear strategy` µØźķÖŹõĮÄ backbone ÕŹĀńö©ńÜä GPU µśŠÕŁśŃĆé
+ 3. ķĆÜĶ┐ćÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁĶ«ŠńĮ« `fp16 = dict(loss_scale='dynamic')` µØźÕ░ØĶ»ĢµĘĘÕÉłń▓ŠÕ║”Ķ«Łń╗āŃĆé
+
+- "RuntimeError: Expected to have finished reduction in the prior iteration before starting a new one"
+
+ 1. ķöÖĶ»»ĶĪ©µśÄ’╝īµé©ńÜ䵩ĪÕØŚµ£ēµ▓Īńö©õ║Äõ║¦ńö¤µŹ¤Õż▒ńÜäÕÅéµĢ░’╝īĶ┐Öń¦ŹńÄ░Ķ▒ĪÕÅ»ĶāĮµś»ńö▒õ║ÄÕ£© DDP µ©ĪÕ╝ÅõĖŗĶ┐ÉĶĪīõ╗ŻńĀüõĖŁńÜäõĖŹÕÉīÕłåµö»ķĆĀµłÉńÜäŃĆé
+ 2. µé©ÕÅ»õ╗źÕ£©ķģŹńĮ«õĖŁĶ«ŠńĮ« `find_unused_parameters = True` µØźĶ¦ŻÕå│õĖŖĶ┐░ķŚ«ķóś’╝īµł¢ĶĆģµēŗÕŖ©µ¤źµēŠķéŻõ║øµ£¬õĮ┐ńö©ńÜäÕÅéµĢ░ŃĆé
+
+## Evaluation ńøĖÕģ│
+
+- õĮ┐ńö© COCO Dataset ńÜ䵥ŗĶ»äµÄźÕÅŻµŚČ’╝īµĄŗĶ»äń╗ōµ×£õĖŁ AP µł¢ĶĆģ AR = -1ŃĆé
+ 1. µĀ╣µŹ« COCO µĢ░µŹ«ķøåńÜäÕ«Üõ╣ē’╝īõĖĆÕ╝ĀÕøŠÕāÅõĖŁńÜäõĖŁńŁēńē®õĮōõĖÄÕ░Åńē®õĮōķØóń¦»ńÜäķśłÕĆ╝ÕłåÕł½õĖ║ 9216’╝ł96\*96’╝ēõĖÄ 1024’╝ł32\*32’╝ēŃĆé
+ 2. Õ”éµ×£Õ£©µ¤ÉõĖ¬Õī║ķŚ┤µ▓Īµ£ēńē®õĮōÕŹ│ GT’╝īAP õĖÄ AR Õ░åĶó½Ķ«ŠńĮ«õĖ║ -1ŃĆé
diff --git a/internlm_langchain/knowledge_base/MMRotate/content/get_started.md b/internlm_langchain/knowledge_base/MMRotate/content/get_started.md
new file mode 100644
index 00000000..9fc4dd1c
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMRotate/content/get_started.md
@@ -0,0 +1,155 @@
+## ÕćåÕżćµĢ░µŹ«ķøå
+
+ÕģĘõĮōńÜäń╗åĶŖéÕÅ»õ╗źÕÅéĶĆā [ÕćåÕżćµĢ░µŹ«](https://github.com/open-mmlab/mmrotate/tree/main/tools/data) õĖŗĶĮĮÕ╣Čń╗äń╗ćµĢ░µŹ«ķøåŃĆé
+
+## µĄŗĶ»ĢõĖĆõĖ¬µ©ĪÕ×ŗ
+
+- ÕŹĢõĖ¬ GPU
+- ÕŹĢõĖ¬ĶŖéńé╣ÕżÜõĖ¬ GPU
+- ÕżÜõĖ¬ĶŖéńé╣ÕżÜõĖ¬ GPU
+
+µé©ÕÅ»õ╗źõĮ┐ńö©õ╗źõĖŗÕæĮõ╗żµØźµÄ©ńÉåµĢ░µŹ«ķøåŃĆé
+
+```shell
+# ÕŹĢõĖ¬ GPU
+python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [optional arguments]
+
+# ÕżÜõĖ¬ GPU
+./tools/dist_test.sh ${CONFIG_FILE} ${CHECKPOINT_FILE} ${GPU_NUM} [optional arguments]
+
+# slurm ńÄ»ÕóāõĖŁÕżÜõĖ¬ĶŖéńé╣
+python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [optional arguments] --launcher slurm
+```
+
+õŠŗÕŁÉ:
+
+Õ£© DOTA-1.0 µĢ░µŹ«ķøåµÄ©ńÉå RotatedRetinaNet Õ╣Čńö¤µłÉÕÄŗń╝®µ¢ćõ╗Čńö©õ║ÄÕ£©ń║┐[µÅÉõ║ż](https://captain-whu.github.io/DOTA/evaluation.html) (ķ”¢ÕģłĶ»Ęõ┐«µö╣ [data_root](https://github.com/open-mmlab/mmrotate/tree/main/configs/_base_/datasets/dotav1.py))ŃĆé
+
+```shell
+python ./tools/test.py \
+ configs/rotated_retinanet/rotated_retinanet_obb_r50_fpn_1x_dota_le90.py \
+ checkpoints/SOME_CHECKPOINT.pth --format-only \
+ --eval-options submission_dir=work_dirs/Task1_results
+```
+
+µł¢ĶĆģ
+
+```shell
+./tools/dist_test.sh \
+ configs/rotated_retinanet/rotated_retinanet_obb_r50_fpn_1x_dota_le90.py \
+ checkpoints/SOME_CHECKPOINT.pth 1 --format-only \
+ --eval-options submission_dir=work_dirs/Task1_results
+```
+
+µé©ÕÅ»õ╗źõ┐«µö╣ [data_root](https://github.com/open-mmlab/mmrotate/tree/main/configs/_base_/datasets/dotav1.py) õĖŁµĄŗĶ»ĢķøåńÜäĶĘ»ÕŠäõĖ║ķ¬īĶ»üķøåµł¢Ķ«Łń╗āķøåĶĘ»ÕŠäńö©õ║Äń”╗ń║┐ńÜäķ¬īĶ»üŃĆé
+
+```shell
+python ./tools/test.py \
+ configs/rotated_retinanet/rotated_retinanet_obb_r50_fpn_1x_dota_le90.py \
+ checkpoints/SOME_CHECKPOINT.pth --eval mAP
+```
+
+µł¢ĶĆģ
+
+```shell
+./tools/dist_test.sh \
+ configs/rotated_retinanet/rotated_retinanet_obb_r50_fpn_1x_dota_le90.py \
+ checkpoints/SOME_CHECKPOINT.pth 1 --eval mAP
+```
+
+µé©õ╣¤ÕÅ»õ╗źÕÅ»Ķ¦åÕī¢ń╗ōµ×£ŃĆé
+
+```shell
+python ./tools/test.py \
+ configs/rotated_retinanet/rotated_retinanet_obb_r50_fpn_1x_dota_le90.py \
+ checkpoints/SOME_CHECKPOINT.pth \
+ --show-dir work_dirs/vis
+```
+
+## Ķ«Łń╗āõĖĆõĖ¬µ©ĪÕ×ŗ
+
+### ÕŹĢ GPU Ķ«Łń╗ā
+
+```shell
+python tools/train.py ${CONFIG_FILE} [optional arguments]
+```
+
+Õ”éµ×£µé©µā│Õ£©ÕæĮõ╗żĶĪīõĖŁµīćÕ«ÜÕĘźõĮ£ĶĘ»ÕŠä’╝īµé©ÕÅ»õ╗źÕó×ÕŖĀÕÅéµĢ░ `--work_dir ${YOUR_WORK_DIR}`ŃĆé
+
+### ÕżÜ GPU Ķ«Łń╗ā
+
+```shell
+./tools/dist_train.sh ${CONFIG_FILE} ${GPU_NUM} [optional arguments]
+```
+
+ÕÅ»ķĆēÕÅéµĢ░Õīģµŗ¼:
+
+- `--no-validate` (**õĖŹÕ╗║Ķ««**): ķ╗śĶ«żµāģÕåĄõĖŗõ╗ŻńĀüÕ░åÕ£©Ķ«Łń╗āµ£¤ķŚ┤Ķ┐øĶĪīĶ»äõ╝░ŃĆéķĆÜĶ┐ćĶ«ŠńĮ« `--no-validate` Õģ│ķŚŁĶ«Łń╗āµ£¤ķŚ┤Ķ┐øĶĪīĶ»äõ╝░ŃĆé
+- `--work-dir ${WORK_DIR}`: Ķ”åńø¢ķģŹńĮ«µ¢ćõ╗ČõĖŁµīćÕ«ÜńÜäÕĘźõĮ£ńø«ÕĮĢŃĆé
+- `--resume-from ${CHECKPOINT_FILE}`: õ╗Äõ╗źÕēŹńÜ䵯Ƶ¤źńé╣µüóÕżŹĶ«Łń╗āŃĆé
+
+`resume-from` ÕÆī `load-from` ńÜäõĖŹÕÉīńé╣’╝Ü
+
+`resume-from` Ķ»╗ÕÅ¢µ©ĪÕ×ŗńÜäµØāķćŹÕÆīõ╝śÕī¢ÕÖ©ńÜäńŖȵĆü’╝īÕ╣ČõĖö epoch õ╣¤õ╝Üń╗¦µē┐õ║ĵīćÕ«ÜńÜ䵯Ƶ¤źńé╣ŃĆéķĆÜÕĖĖńö©õ║ĵüóÕżŹµäÅÕż¢õĖŁµ¢ŁńÜäĶ«Łń╗āĶ┐ćń©ŗŃĆé
+`load-from` ÕŬĶ»╗ÕÅ¢µ©ĪÕ×ŗńÜäµØāķćŹÕ╣ČõĖöĶ«Łń╗āńÜä epoch õ╝Üõ╗Ä 0 Õ╝ĆÕ¦ŗŃĆéķĆÜÕĖĖńö©õ║ÄÕŠ«Ķ░āŃĆé
+
+### õĮ┐ńö©ÕżÜÕÅ░µ£║ÕÖ©Ķ«Łń╗ā
+
+Õ”éµ×£µé©µā│õĮ┐ńö©ńö▒ ethernet Ķ┐׵ğĶĄĘµØźńÜäÕżÜÕÅ░µ£║ÕÖ©’╝ī µé©ÕÅ»õ╗źõĮ┐ńö©õ╗źõĖŗÕæĮõ╗ż:
+
+Õ£©ń¼¼õĖĆÕÅ░µ£║ÕÖ©õĖŖ:
+
+```shell
+NNODES=2 NODE_RANK=0 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR sh tools/dist_train.sh $CONFIG $GPUS
+```
+
+Õ£©ń¼¼õ║īÕÅ░µ£║ÕÖ©õĖŖ:
+
+```shell
+NNODES=2 NODE_RANK=1 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR sh tools/dist_train.sh $CONFIG $GPUS
+```
+
+õĮåµś»’╝īÕ”éµ×£µé©õĖŹõĮ┐ńö©ķ½śķƤńĮæĶĘ»Ķ┐׵ğĶ┐ÖÕćĀÕÅ░µ£║ÕÖ©ńÜäĶ»Ø’╝īĶ«Łń╗āÕ░åõ╝ÜķØ×ÕĖĖµģóŃĆé
+
+### õĮ┐ńö© Slurm µØźń«ĪńÉåõ╗╗ÕŖĪ
+
+Õ”éµ×£µé©Õ£© [slurm](https://slurm.schedmd.com/) ń«ĪńÉåńÜäķøåńŠżõĖŖĶ┐ÉĶĪī MMRotate’╝īµé©ÕÅ»õ╗źõĮ┐ńö©Ķäܵ£¼ `slurm_train.sh` (µŁżĶäܵ£¼Ķ┐śµö»µīüÕŹĢµ£║Ķ«Łń╗ā)ŃĆé
+
+```shell
+[GPUS=${GPUS}] ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} ${CONFIG_FILE} ${WORK_DIR}
+```
+
+Õ”éµ×£µé©µ£ēÕżÜÕÅ░µ£║ÕÖ©ĶüöńĮæ’╝īµé©ÕÅ»õ╗źÕÅéĶĆā PyTorch [launch utility](https://pytorch.org/docs/stable/distributed_deprecated.html#launch-utility)ŃĆé
+Õ”éµ×£µé©µ▓Īµ£ēÕāÅ InfiniBand Ķ┐ÖµĀĘńÜäķ½śķƤńĮæń╗£’╝īĶ«Łń╗āķƤÕ║”ķĆÜÕĖĖõ╝ÜÕŠłµģóŃĆé
+
+### Õ£©õĖĆÕÅ░µ£║ÕÖ©õĖŖÕÉ»ÕŖ©ÕżÜõĖ¬õĮ£õĖÜ
+
+Õ”éµ×£µé©Õ£©õĖĆÕÅ░µ£║ÕÖ©õĖŖÕÉ»ÕŖ©ÕżÜõĖ¬õĮ£õĖÜ’╝īÕ”éÕ£©õĖĆÕÅ░µ£║ÕÖ©õĖŖõĮ┐ńö© 8 Õ╝Ā GPU Ķ«Łń╗ā 2 õĖ¬õĮ£õĖÜ’╝īµ»ÅõĖ¬õĮ£õĖÜõĮ┐ńö© 4 Õ╝Ā GPU ’╝īµé©ķ£ĆĶ”üõĖ║µ»ÅõĖ¬õĮ£õĖܵīćÕ«ÜõĖŹÕÉīńÜäń½»ÕÅŻÕÅĘ(ķ╗śĶ«żõĖ║ 29500 )Ķ┐øĶĆīķü┐ÕģŹķĆÜĶ«»Õå▓ń¬üŃĆé
+
+Õ”éµ×£µé©õĮ┐ńö© `dist_train.sh` ÕÉ»ÕŖ©Ķ«Łń╗ā’╝īµé©ÕÅ»õ╗źÕ£©ÕæĮõ╗żĶĪīõĖŁµīćÕ«Üń½»ÕÅŻÕÅĘŃĆé
+
+```shell
+CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 ./tools/dist_train.sh ${CONFIG_FILE} 4
+CUDA_VISIBLE_DEVICES=4,5,6,7 PORT=29501 ./tools/dist_train.sh ${CONFIG_FILE} 4
+```
+
+Õ”éµ×£µé©ķĆÜĶ┐ć Slurm ÕÉ»ÕŖ©Ķ«Łń╗ā’╝īµé©ķ£ĆĶ”üõ┐«µö╣ķģŹńĮ«µ¢ćõ╗Č(ķĆÜÕĖĖµś»ķģŹńĮ«µ¢ćõ╗ČÕ║Ģķā©ńÜäń¼¼ 6 ĶĪī)Ķ┐øĶĆīĶ«ŠńĮ«õĖŹÕÉīńÜäķĆÜĶ«»ń½»ÕÅŻŃĆé
+
+Õ£© `config1.py` õĖŁ,
+
+```python
+dist_params = dict(backend='nccl', port=29500)
+```
+
+Õ£© `config2.py` õĖŁ,
+
+```python
+dist_params = dict(backend='nccl', port=29501)
+```
+
+õ╣ŗÕÉĵé©ÕÅ»õ╗źõĮ┐ńö© `config1.py` ÕÆī `config2.py` Õ╝ĆÕÉ»õĖżõĖ¬õĮ£õĖÜŃĆé
+
+```shell
+CUDA_VISIBLE_DEVICES=0,1,2,3 GPUS=4 ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} config1.py ${WORK_DIR}
+CUDA_VISIBLE_DEVICES=4,5,6,7 GPUS=4 ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} config2.py ${WORK_DIR}
+```
diff --git a/internlm_langchain/knowledge_base/MMRotate/content/install.md b/internlm_langchain/knowledge_base/MMRotate/content/install.md
new file mode 100644
index 00000000..6c6eca32
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMRotate/content/install.md
@@ -0,0 +1,174 @@
+## õŠØĶĄ¢
+
+Õ£©µ£¼ĶŖéõĖŁ’╝īµłæõ╗¼Õ░åµ╝öńż║Õ”éõĮĢõĮ┐ńö©PyTorchÕćåÕżćńÄ»ÕóāŃĆé
+
+MMRotate ĶāĮÕż¤Õ£© Linux ÕÆī Windows õĖŖĶ┐ÉĶĪīŃĆéÕ«āõŠØĶĄ¢õ║Ä Python 3.7+, CUDA 9.2+ ÕÆī PyTorch 1.6+ŃĆé
+
+```{note}
+Õ”éµ×£µé©Õ»╣ PyTorch µ£ēń╗Åķ¬īÕ╣ČõĖöÕĘ▓ń╗ÅÕ«ēĶŻģõ║åÕ«ā’╝īÕŬķ£ĆĶĘ│Ķ┐浣żķā©ÕłåÕ╣ČĶĘ│Õł░ [õĖŗõĖĆĶŖé](#Õ«ēĶŻģ) ŃĆéÕÉ”ÕłÖ’╝īµé©ÕÅ»õ╗źµīēńģ¦õ╗źõĖŗµŁźķ¬żĶ┐øĶĪīÕćåÕżćŃĆé
+```
+
+**ń¼¼0µŁź’╝Ü** õ╗Ä [Õ«śńĮæ](https://docs.conda.io/en/latest/miniconda.html) õĖŗĶĮĮÕ╣ČÕ«ēĶŻģ MinicondaŃĆé
+
+**ń¼¼1µŁź’╝Ü** ÕłøÕ╗║õĖĆõĖ¬ conda ńÄ»ÕóāÕ╣ȵ┐Ƶ┤╗Õ«ā.
+
+```shell
+conda create --name openmmlab python=3.8 -y
+conda activate openmmlab
+```
+
+**ń¼¼2µŁź’╝Ü** µĀ╣µŹ« [Õ«śµ¢╣Ķ»┤µśÄ](https://pytorch.org/get-started/locally/) Õ«ēĶŻģ PyTorch, õŠŗÕ”é’╝Ü
+
+```shell
+conda install pytorch==1.8.0 torchvision==0.9.0 cudatoolkit=10.2 -c pytorch
+```
+
+## Õ«ēĶŻģ
+
+µłæõ╗¼Õ╗║Ķ««ńö©µłĘµīēńģ¦µłæõ╗¼ńÜäµ£ĆõĮ│Õ«×ĶĘĄÕ«ēĶŻģ MMRotateŃĆéńäČĶĆī’╝īµĢ┤õĖ¬Ķ┐ćń©ŗµś»ķ½śÕ║”ÕŻիÜÕłČńÜäŃĆéµ£ēÕģ│Ķ»”ń╗åõ┐Īµü»’╝īĶ»ĘÕÅéķśģ [Ķć¬Õ«Üõ╣ēÕ«ēĶŻģ](#%E8%87%AA%E5%AE%9A%E4%B9%89%E5%AE%89%E8%A3%85) ķā©ÕłåŃĆé
+
+### µ£ĆõĮ│Õ«×ĶĘĄ
+
+**ń¼¼0µŁź’╝Ü** õĮ┐ńö© [MIM](https://github.com/open-mmlab/mim) Õ«ēĶŻģ [MMCV](https://github.com/open-mmlab/mmcv) ÕÆī [MMDetection](https://github.com/open-mmlab/mmdetection)
+
+```shell
+pip install -U openmim
+mim install mmcv-full
+mim install mmdet\<3.0.0
+```
+
+**ń¼¼1µŁź’╝Ü** Õ«ēĶŻģ MMRotate.
+
+µĪłõŠŗa’╝ÜÕ”éµ×£µé©ńø┤µÄźÕ╝ĆÕÅæÕ╣ČĶ┐ÉĶĪī mmrotate’╝īĶ»Ęõ╗ĵ║Éõ╗ŻńĀüÕ«ēĶŻģ’╝Ü
+
+```shell
+git clone https://github.com/open-mmlab/mmrotate.git
+cd mmrotate
+pip install -v -e .
+# "-v" ĶĪ©ńż║Ķ»”ń╗åµł¢µø┤ÕżÜĶŠōÕć║
+# "-e" ĶĪ©ńż║õ╗źÕÅ»ń╝¢ĶŠæµ©ĪÕ╝ÅÕ«ēĶŻģķĪ╣ńø«’╝ī
+# ÕøĀµŁż’╝īÕ»╣õ╗ŻńĀüĶ┐øĶĪīńÜäõ╗╗õĮĢµ£¼Õ£░õ┐«µö╣ķāĮÕ░åÕ£©õĖŹķ揵¢░Õ«ēĶŻģńÜäµāģÕåĄõĖŗńö¤µĢłŃĆé
+```
+
+µĪłõŠŗb’╝ÜÕ”éµ×£Õ░å mmrotate õĮ£õĖ║õŠØĶĄ¢ķĪ╣µł¢ń¼¼õĖēµ¢╣ĶĮ»õ╗ČÕīģ’╝īĶ»ĘõĮ┐ńö© pip Õ«ēĶŻģÕ«ā’╝Ü
+
+```shell
+pip install mmrotate
+```
+
+### ķ¬īĶ»ü
+
+õĖ║õ║åķ¬īĶ»üµś»ÕÉ”µŁŻńĪ«Õ«ēĶŻģõ║å MMRotate’╝īµłæõ╗¼µÅÉõŠøõ║åõĖĆõ║øńż║õŠŗõ╗ŻńĀüµØźĶ┐ÉĶĪīµÄ©ńÉåµ╝öńż║ŃĆé
+
+**ń¼¼1µŁź’╝Ü** µłæõ╗¼ķ£ĆĶ”üõĖŗĶĮĮķģŹńĮ«µ¢ćõ╗ČÕÆīµŻĆµ¤źńé╣µ¢ćõ╗ČŃĆé
+
+```shell
+mim download mmrotate --config oriented_rcnn_r50_fpn_1x_dota_le90 --dest .
+```
+
+õĖŗĶĮĮķ£ĆĶ”üÕćĀń¦ÆķƤµł¢µø┤ķĢ┐µŚČķŚ┤’╝īÕģĘõĮōÕÅ¢Õå│õ║ĵé©ńÜäńĮæń╗£ńÄ»ÕóāŃĆéÕĮōõĖŗĶĮĮÕ«īµłÉõ╣ŗÕÉÄ’╝īµé©Õ░åõ╝ÜÕ£©ÕĮōÕēŹµ¢ćõ╗ČÕż╣õĖŗµēŠÕł░ `oriented_rcnn_r50_fpn_1x_dota_le90.py` ÕÆī `oriented_rcnn_r50_fpn_1x_dota_le90-6d2b2ce0.pth` Ķ┐ÖõĖżõĖ¬µ¢ćõ╗ČŃĆé
+
+**ń¼¼2µŁź’╝Ü** ķ¬īĶ»üµÄ©ńÉåµ╝öńż║
+
+ķĆēķĪ╣’╝ła’╝ē’╝ÜÕ”éµ×£õ╗ĵ║Éõ╗ŻńĀüÕ«ēĶŻģ mmrotate’╝īÕŬķ£ĆĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗żŃĆé
+
+```shell
+python demo/image_demo.py demo/demo.jpg oriented_rcnn_r50_fpn_1x_dota_le90.py oriented_rcnn_r50_fpn_1x_dota_le90-6d2b2ce0.pth --out-file result.jpg
+```
+
+µé©Õ░åÕ£©ÕĮōÕēŹńø«ÕĮĢõĖŗń£ŗÕł░õĖĆÕ╝ĀÕÉŹõĖ║ `result.jpg` ńÜäµ¢░ÕøŠńēć’╝īÕģČõĖŁµŚŗĶĮ¼ĶŠ╣ńĢīµĪåń╗śÕłČÕ£©µ▒ĮĶĮ”ŃĆüÕģ¼Õģ▒µ▒ĮĶĮ”ńŁēńø«µĀćõĖŖŃĆé
+
+ķĆēķĪ╣’╝łb’╝ē’╝ÜÕ”éµ×£õĮ┐ńö© pip Õ«ēĶŻģ mmrotate’╝īĶ»ĘµēōÕ╝Ć python Ķ¦ŻķćŖÕÖ©Õ╣ČÕżŹÕłČÕÆīń▓śĶ┤┤õ╗źõĖŗõ╗ŻńĀüŃĆé
+
+```python
+from mmdet.apis import init_detector, inference_detector
+import mmrotate
+
+config_file = 'oriented_rcnn_r50_fpn_1x_dota_le90.py'
+checkpoint_file = 'oriented_rcnn_r50_fpn_1x_dota_le90-6d2b2ce0.pth'
+model = init_detector(config_file, checkpoint_file, device='cuda:0')
+inference_detector(model, 'demo/demo.jpg')
+```
+
+µé©Õ░åń£ŗÕł░µēōÕŹ░ńÜäµĢ░ń╗äÕłŚĶĪ©’╝īĶĪ©ńż║µŻĆµĄŗÕł░ńÜ䵌ŗĶĮ¼ĶŠ╣ńĢīµĪåŃĆé
+
+### Ķć¬Õ«Üõ╣ēÕ«ēĶŻģ
+
+#### CUDA ńēłµ£¼
+
+Õ«ēĶŻģ PyTorch µŚČ’╝īķ£ĆĶ”üµīćÕ«Ü CUDA ńÜäńēłµ£¼ŃĆéÕ”éµ×£µé©õĖŹµĖģµźÜķĆēµŗ®Õō¬õĖĆõĖ¬’╝īĶ»ĘķüĄÕŠ¬µłæõ╗¼ńÜäÕ╗║Ķ««’╝Ü
+
+- Õ»╣õ║ÄÕ¤║õ║ÄÕ«ēÕ¤╣µ×ȵ×äńÜä NVIDIA GPU’╝īÕ”é GeForce 30 ń│╗ÕłŚÕÆī NVIDIA A100’╝īÕ┐ģķĪ╗õĮ┐ńö© CUDA 11ŃĆé
+- Õ»╣õ║ÄĶŠāµŚ¦ńÜä NVIDIA GPU’╝īCUDA 11 ÕÉæÕÉÄÕģ╝Õ«╣’╝īõĮå CUDA 10.2 µø┤ĶĮ╗ķćÅÕ╣ČõĖöÕģʵ£ēµø┤ÕźĮńÜäÕģ╝Õ«╣µĆ¦ŃĆé
+
+Ķ»ĘńĪ«õ┐Ø GPU ķ®▒ÕŖ©ń©ŗÕ║ŵ╗ĪĶČ│µ£ĆõĮÄńēłµ£¼Ķ”üµ▒éŃĆé Ķ»Ęµ¤źĶ»ó [ĶĪ©µĀ╝](https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html#cuda-major-component-versions__table-cuda-toolkit-driver-versions) õ╗źĶÄĘÕŠŚµø┤ÕżÜõ┐Īµü»ŃĆé
+
+```{note}
+Õ”éµ×£ķüĄÕŠ¬µłæõ╗¼ńÜäµ£ĆõĮ│Õ«×ĶĘĄ’╝īÕ«ēĶŻģ CUDA Ķ┐ÉĶĪīµŚČÕ║ōÕ░▒ĶČ│Õż¤õ║å’╝īÕøĀõĖ║õĖŹõ╝ÜÕ£©µ£¼Õ£░ń╝¢Ķ»æ CUDA õ╗ŻńĀüŃĆéõĮåµś»’╝īÕ”éµ×£µé©ÕĖīµ£øõ╗ĵ║Éõ╗ŻńĀüÕżäń╝¢Ķ»æ MMCV µł¢Õ╝ĆÕÅæÕģČõ╗¢ CUDA ń«ŚÕŁÉ’╝īÕłÖķ£ĆĶ”üõ╗Ä NVIDIA ńÜä [ńĮæń½Ö](https://developer.nvidia.com/cuda-downloads) Õ«ēĶŻģÕ«īµĢ┤ńÜä CUDA ÕĘźÕģĘÕīģ’╝īÕģČńēłµ£¼Õ║öõĖÄ PyTorch ńÜä CUDA ńēłµ£¼Õī╣ķģŹŃĆéõŠŗÕ”éõĮ┐ńö© `conda install` ÕæĮõ╗żµīćÕ«Ü cudatoolkit ńÜäńēłµ£¼ŃĆé
+```
+
+#### õĖŹõĮ┐ńö© MIM Õ«ēĶŻģ MMCV
+
+MMCV ÕīģÕɽ C++ ÕÆī CUDA µē®Õ▒Ģ’╝īÕøĀµŁżõ╗źÕżŹµØéńÜäµ¢╣Õ╝ÅõŠØĶĄ¢õ║Ä PyTorchŃĆéMIM õ╝ÜĶć¬ÕŖ©Ķ¦ŻÕå│µŁżń▒╗õŠØĶĄ¢Õģ│ń│╗’╝īÕ╣ČõĮ┐Õ«ēĶŻģµø┤Õ«╣µśōŃĆéńäČĶĆī’╝īĶ┐ÖõĖŹµś»Õ┐ģķĪ╗ńÜäŃĆé
+
+Ķ”üõĮ┐ńö© pip ĶĆīõĖŹµś» MIM Õ«ēĶŻģ MMCV’╝īĶ»ĘķüĄÕŠ¬ [MMCV Õ«ēĶŻģµīćÕŹŚ](https://mmcv.readthedocs.io/en/latest/get_started/installation.html) ŃĆé Ķ┐Öķ£ĆĶ”üµĀ╣µŹ« PyTorch ńēłµ£¼ÕÅŖÕģČ CUDA ńēłµ£¼µēŗÕŖ©µīćÕ«Ü find-urlŃĆé
+
+õŠŗÕ”é, õ╗źõĖŗÕæĮõ╗żÕ«ēĶŻģõ║åõĖ║ PyTorch 1.9.x ÕÆī CUDA 10.2 µ×äÕ╗║ńÜä mmcv-fullŃĆé
+
+```shell
+pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu102/torch1.8/index.html
+```
+
+#### Õ£© Google Colab Õ«ēĶŻģ
+
+[Google Colab](https://research.google.com/) ķĆÜÕĖĖÕĘ▓ń╗ÅÕ«ēĶŻģõ║å PyTorch’╝ī
+ÕøĀµŁż’╝īµłæõ╗¼ÕŬķ£ĆĶ”üõĮ┐ńö©õ╗źõĖŗÕæĮõ╗żÕ«ēĶŻģ MMCV ÕÆī MMDetectionŃĆé
+
+**ń¼¼1µŁź’╝Ü** õĮ┐ńö© [MIM](https://github.com/open-mmlab/mim) Õ«ēĶŻģ [MMCV](https://github.com/open-mmlab/mmcv) ÕÆī [MMDetection](https://github.com/open-mmlab/mmdetection) ŃĆé
+
+```shell
+!pip3 install -U openmim
+!mim install mmcv-full
+!mim install mmdet
+```
+
+**ń¼¼2µŁź’╝Ü** õ╗ĵ║ÉńĀüÕ«ēĶŻģ MMRotateŃĆé
+
+```shell
+!git clone https://github.com/open-mmlab/mmrotate.git
+%cd mmrotate
+!pip install -e .
+```
+
+**ń¼¼3µŁź’╝Ü** ķ¬īĶ»üŃĆé
+
+```python
+import mmrotate
+print(mmrotate.__version__)
+# Example output: 0.3.1
+```
+
+```{note}
+Õ£©JupyterõĖŁ’╝īµä¤ÕÅ╣ÕÅĘ `!` ńö©õ║ÄĶ░āńö©Õż¢ķā©ÕÅ»µē¦ĶĪīµ¢ćõ╗Č’╝ī`%cd` µś»õĖĆõĖ¬ [ķŁöµ£»ÕæĮõ╗ż](https://ipython.readthedocs.io/en/stable/interactive/magics.html#magic-cd) ńö©õ║ĵø┤µö╣ Python ńÜäÕĮōÕēŹÕĘźõĮ£ńø«ÕĮĢŃĆé
+```
+
+#### Õ£© Docker ķĢ£ÕāÅõĖŁõĮ┐ńö© MMRotate
+
+µłæõ╗¼µÅÉõŠøõ║å [Dockerfile](https://github.com/open-mmlab/mmrotate/tree/main/docker/Dockerfile) ńö©õ║ÄÕłøÕ╗║ķĢ£ÕāÅŃĆé Ķ»ĘńĪ«õ┐صé©ńÜä [docker ńēłµ£¼](https://docs.docker.com/engine/install/) >=19.03ŃĆé
+
+```shell
+# build an image with PyTorch 1.6, CUDA 10.1
+# If you prefer other versions, just modified the Dockerfile
+docker build -t mmrotate docker/
+```
+
+õĮ┐ńö©õĖŗÕłŚÕæĮõ╗żĶ┐ÉĶĪī
+
+```shell
+docker run --gpus all --shm-size=8g -it -v {DATA_DIR}:/mmrotate/data mmrotate
+```
+
+### µĢģķÜ£µÄÆķÖż
+
+Õ”éµ×£µé©Õ£©Õ«ēĶŻģĶ┐ćń©ŗõĖŁķüćÕł░õĖĆõ║øķŚ«ķóś’╝īĶ»ĘÕģłµ¤źń£ŗ [FAQ](faq.md) ķĪĄķØóŃĆé
+Õ”éµ×£µ▓Īµ£ēµēŠÕł░Ķ¦ŻÕå│µ¢╣µĪł’╝īµé©ÕÅ»õ╗źÕ£© GIthub õĖŖ [µÅÉķŚ«](https://github.com/open-mmlab/mmrotate/issues/new/choose) ŃĆé
diff --git a/internlm_langchain/knowledge_base/MMRotate/content/intro.md b/internlm_langchain/knowledge_base/MMRotate/content/intro.md
new file mode 100644
index 00000000..680bbb00
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMRotate/content/intro.md
@@ -0,0 +1,227 @@
+# ÕŁ”õ╣ĀÕ¤║ńĪĆń¤źĶ»å
+
+µ£¼ń½ĀÕ░åÕÉæµé©õ╗ŗń╗ŹµŚŗĶĮ¼ńø«µĀ浯ƵĄŗńÜäÕ¤║µ£¼µ”éÕ┐Ą’╝īõ╗źÕÅŖµŚŗĶĮ¼ńø«µĀ浯ƵĄŗńÜäµĪåµ×Č MMRotate’╝īÕ╣ȵÅÉõŠøõ║åĶ»”ń╗åµĢÖń©ŗńÜäķōŠµÄźŃĆé
+
+## õ╗Ćõ╣łµś»µŚŗĶĮ¼ńø«µĀ浯ƵĄŗ
+
+### ķŚ«ķóśÕ«Üõ╣ē
+
+ÕÅŚńøŖõ║ÄķĆÜńö©µŻĆµĄŗńÜäĶō¼ÕŗāÕÅæÕ▒Ģ’╝īńø«ÕēŹń╗ØÕż¦ÕżÜµĢ░ńÜ䵌ŗĶĮ¼µŻĆµĄŗµ©ĪÕ×ŗķāĮµś»Õ¤║õ║Äń╗ÅÕģĖńÜäķĆÜńö©µŻĆµĄŗÕÖ©ŃĆéķÜÅńØƵŻĆµĄŗõ╗╗ÕŖĪńÜäÕÅæÕ▒Ģ’╝ī
+µ░┤Õ╣│µĪåÕ£©õĖĆõ║øń╗åÕłåķóåÕ¤¤õĖŖÕĘ▓ń╗ŵŚĀµ│Ģµ╗ĪĶČ│ńĀöń®Čõ║║ÕæśńÜäķ£Ćµ▒éŃĆéķĆÜĶ┐ćķ揵¢░Õ«Üõ╣ēńø«µĀćĶĪ©ńż║ÕĮóÕ╝Åõ╗źÕÅŖÕó×ÕŖĀÕø×ÕĮÆĶć¬ńö▒Õ║”µĢ░ķćÅ
+ńÜäµōŹõĮ£µØźÕ«×ńÄ░µŚŗĶĮ¼ń¤®ÕĮóµĪåŃĆüÕøøĶŠ╣ÕĮóńöÜĶć│õ╗╗µäÅÕĮóńŖȵŻĆµĄŗ’╝īµłæõ╗¼ń¦░õ╣ŗõĖ║µŚŗĶĮ¼ńø«µĀ浯ƵĄŗŃĆéÕ”éõĮĢµø┤ÕŖĀķ½śµĢłÕ£░Ķ┐øĶĪīķ½śń▓ŠÕ║”
+ńÜ䵌ŗĶĮ¼ńø«µĀ浯ƵĄŗÕĘ▓µłÉõĖ║ÕĮōõĖŗńÜäńĀöń®ČńāŁńé╣ŃĆéõĖŗķØóÕłŚõĖŠõĖĆõ║øµŚŗĶĮ¼ńø«µĀ浯ƵĄŗÕĘ▓ń╗ÅĶó½Õ║öńö©µł¢ĶĆģµ£ēÕĘ©Õż¦µĮ£ÕŖøńÜäķóåÕ¤¤’╝Ü
+õ║║ĶäĖĶ»åÕł½ŃĆüÕ£║µÖ»µ¢ćÕŁŚŃĆüķüźµä¤ÕĮ▒ÕāÅŃĆüĶć¬ÕŖ©ķ®Šķ®ČŃĆüÕī╗ÕŁ”ÕøŠÕāÅŃĆüµ£║ÕÖ©õ║║µŖōÕÅ¢ńŁēŃĆé
+
+### õ╗Ćõ╣łµś»µŚŗĶĮ¼µĪå
+
+µŚŗĶĮ¼ńø«µĀ浯ƵĄŗõĖÄķĆÜńö©ńø«µĀ浯ƵĄŗµ£ĆÕż¦ńÜäõĖŹÕÉīÕ░▒µś»ńö©µŚŗĶĮ¼µĪåµĀćµ│©µØźõ╗Żµø┐µ░┤Õ╣│µĪåµĀćµ│©’╝īÕ«āõ╗¼ńÜäÕ«Üõ╣ēÕ”éõĖŗ’╝Ü
+
+- µ░┤Õ╣│µĪå: Õ«Įµ▓┐ `x` ĶĮ┤µ¢╣ÕÉæ’╝īķ½śµ▓┐ `y` ĶĮ┤µ¢╣ÕÉæńÜäń¤®ÕĮóŃĆéķĆÜÕĖĖÕÅ»õ╗źńö©2õĖ¬Õ»╣Ķ¦ÆķĪČńé╣ńÜäÕØɵĀćĶĪ©ńż║
+ `(x_i, y_i)` (i = 1, 2)’╝īõ╣¤ÕÅ»õ╗źńö©õĖŁÕ┐āńé╣ÕØɵĀćõ╗źÕÅŖÕ«ĮÕÆīķ½śĶĪ©ńż║
+ `(x_center, y_center, width, height)`ŃĆé
+- µŚŗĶĮ¼µĪå: ńö▒µ░┤Õ╣│µĪåń╗ĢõĖŁÕ┐āńé╣µŚŗĶĮ¼õĖĆõĖ¬Ķ¦ÆÕ║” `angle` ÕŠŚÕł░’╝īķĆÜĶ┐ćµĘ╗ÕŖĀõĖĆõĖ¬Õ╝¦Õ║”ÕÅéµĢ░ÕŠŚÕł░ÕģȵŚŗĶĮ¼µĪåÕ«Üõ╣ēµ│Ģ
+ `(x_center, y_center, width, height, theta)`ŃĆéÕģČõĖŁ’╝ī`theta = angle * pi / 180`’╝ī
+ ÕŹĢõĮŹõĖ║ `rad`ŃĆéÕĮōµŚŗĶĮ¼ńÜäĶ¦ÆÕ║”õĖ║90┬░ńÜäÕĆŹµĢ░µŚČ’╝īµŚŗĶĮ¼µĪåķĆĆÕī¢õĖ║µ░┤Õ╣│µĪåŃĆéµĀćµ│©ĶĮ»õ╗ČÕ»╝Õć║ńÜ䵌ŗĶĮ¼µĪåµĀćµ│©ķĆÜÕĖĖõĖ║ÕżÜĶŠ╣ÕĮó
+ `(xr_i, yr_i)` (i = 1, 2, 3, 4)’╝īÕ£©Ķ«Łń╗āµŚČķ£ĆĶ”üĶĮ¼µŹóõĖ║µŚŗĶĮ¼µĪåÕ«Üõ╣ēµ│ĢŃĆé
+
+```{note}
+Õ£© MMRotate õĖŁ’╝īĶ¦ÆÕ║”ÕÅéµĢ░ńÜäÕŹĢõĮŹÕØćõĖ║Õ╝¦Õ║”ŃĆé
+```
+
+### µŚŗĶĮ¼µ¢╣ÕÉæ
+
+µŚŗĶĮ¼µĪåÕÅ»õ╗źńö▒µ░┤Õ╣│µĪåń╗ĢÕģČõĖŁÕ┐āńé╣ķĪ║µŚČķÆłµŚŗĶĮ¼µł¢ķĆåµŚČķÆłµŚŗĶĮ¼ÕŠŚÕł░ŃĆ鵌ŗĶĮ¼µ¢╣ÕÉæÕÆīÕØɵĀćń│╗ńÜäķĆēµŗ®Õ»åÕłćńøĖÕģ│ŃĆé
+ÕøŠÕāÅń®║ķŚ┤ķććńö©ÕÅ│µēŗÕØɵĀćń│╗ `(y’╝īx)`’╝īÕģČõĖŁ y µś»`õĖŖ->õĖŗ`’╝īx µś»`ÕĘ”->ÕÅ│`ŃĆé
+µŁżµŚČÕŁśÕ£©2ń¦ŹńøĖÕÅŹńÜ䵌ŗĶĮ¼µ¢╣ÕÉæ’╝Ü
+
+- ķĪ║µŚČķÆł (`CW`)
+
+`CW` ńÜäńż║µäÅÕøŠ
+
+```
+0-------------------> x (0 rad)
+| A-------------B
+| | |
+| | box h
+| | angle=0 |
+| D------w------C
+v
+y (pi/2 rad)
+
+```
+
+`CW` ńÜ䵌ŗĶĮ¼ń¤®ķśĄ
+
+```{math}
+\begin{pmatrix}
+\cos\alpha & -\sin\alpha \\
+\sin\alpha & \cos\alpha
+\end{pmatrix}
+```
+
+`CW` ńÜ䵌ŗĶĮ¼ÕÅśµŹó
+
+```{math}
+P_A=
+\begin{pmatrix} x_A \\ y_A\end{pmatrix}
+=
+\begin{pmatrix} x_{center} \\ y_{center}\end{pmatrix} +
+\begin{pmatrix}\cos\alpha & -\sin\alpha \\
+\sin\alpha & \cos\alpha\end{pmatrix}
+\begin{pmatrix} -0.5w \\ -0.5h\end{pmatrix} \\
+=
+\begin{pmatrix} x_{center}-0.5w\cos\alpha+0.5h\sin\alpha
+\\
+y_{center}-0.5w\sin\alpha-0.5h\cos\alpha\end{pmatrix}
+```
+
+- ķĆåµŚČķÆł (`CCW`)
+
+`CCW` ńÜäńż║µäÅÕøŠ
+
+```
+0-------------------> x (0 rad)
+| A-------------B
+| | |
+| | box h
+| | angle=0 |
+| D------w------C
+v
+y (-pi/2 rad)
+
+```
+
+`CCW` ńÜ䵌ŗĶĮ¼ń¤®ķśĄ
+
+```{math}
+\begin{pmatrix}
+\cos\alpha & \sin\alpha \\
+-\sin\alpha & \cos\alpha
+\end{pmatrix}
+```
+
+`CCW` ńÜ䵌ŗĶĮ¼ÕÅśµŹó
+
+```{math}
+P_A=
+\begin{pmatrix} x_A \\ y_A\end{pmatrix}
+=
+\begin{pmatrix} x_{center} \\ y_{center}\end{pmatrix} +
+\begin{pmatrix}\cos\alpha & \sin\alpha \\
+-\sin\alpha & \cos\alpha\end{pmatrix}
+\begin{pmatrix} -0.5w \\ -0.5h\end{pmatrix} \\
+=
+\begin{pmatrix} x_{center}-0.5w\cos\alpha-0.5h\sin\alpha
+\\
+y_{center}+0.5w\sin\alpha-0.5h\cos\alpha\end{pmatrix}
+```
+
+Õ£©MMCVõĖŁÕÅ»õ╗źĶ«ŠńĮ«µŚŗĶĮ¼µ¢╣ÕÉæńÜäń«ŚÕŁÉµ£ē’╝Ü
+
+- box_iou_rotated (ķ╗śĶ«żõĖ║ `CW`)
+- nms_rotated (ķ╗śĶ«żõĖ║ `CW`)
+- RoIAlignRotated (ķ╗śĶ«żõĖ║ `CCW`)
+- RiRoIAlignRotated (ķ╗śĶ«żõĖ║ `CCW`)ŃĆé
+
+```{note}
+Õ£©MMRotate õĖŁ’╝īµŚŗĶĮ¼µĪåńÜ䵌ŗĶĮ¼µ¢╣ÕÉæÕØćõĖ║ `CW`ŃĆé
+```
+
+### µŚŗĶĮ¼µĪåÕ«Üõ╣ēµ│Ģ
+
+ńö▒õ║Ä `theta` Õ«Üõ╣ēĶīāÕø┤ńÜäõĖŹÕÉī’╝īÕ£©µŚŗĶĮ¼ńø«µĀ浯ƵĄŗõĖŁķĆɵĖɵ┤Šńö¤Õć║Õ”éõĖŗ3ń¦ŹµŚŗĶĮ¼µĪåÕ«Üõ╣ēµ│Ģ’╝Ü
+
+- {math}`D_{oc^{\prime}}` : OpenCV Õ«Üõ╣ēµ│Ģ’╝ī`angleŌłł(0, 90┬░]`’╝ī`thetaŌłł(0, pi / 2]`’╝ī `width` õĖÄ `x` µŁŻÕŹŖĶĮ┤õ╣ŗķŚ┤ńÜäÕż╣Ķ¦ÆõĖ║µŁŻńÜäķöÉĶ¦ÆŃĆéĶ»źÕ«Üõ╣ēµ│Ģµ║Éõ║Ä OpenCV õĖŁńÜä `cv2.minAreaRect` ÕćĮµĢ░’╝ī
+ ÕģČĶ┐öÕø×ÕĆ╝õĖ║ `(0, 90┬░]`ŃĆé
+- {math}`D_{le135}` : ķĢ┐ĶŠ╣ 135┬░ Õ«Üõ╣ēµ│Ģ’╝ī`angleŌłł[-45┬░, 135┬░)`’╝ī`thetaŌłł[-pi / 4, 3 * pi / 4)` Õ╣ČõĖö `width > height`ŃĆé
+- {math}`D_{le90}` : ķĢ┐ĶŠ╣ 90┬░ Õ«Üõ╣ēµ│Ģ’╝ī`angleŌłł[-90┬░, 90┬░)`’╝ī`thetaŌłł[-pi / 2, pi / 2)` Õ╣ČõĖö `width > height`ŃĆé
+
+
+
+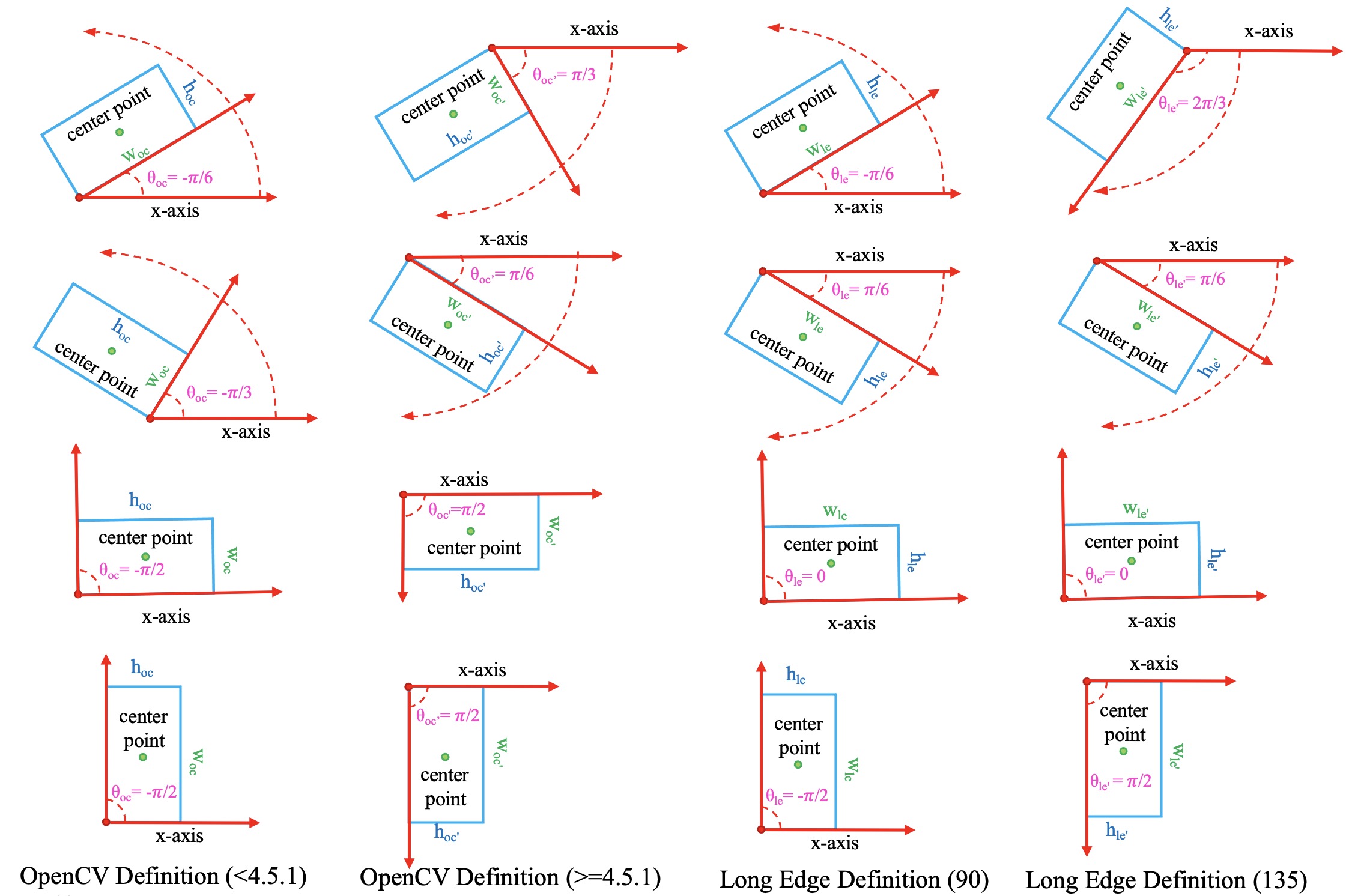 +
+
+
+õĖēń¦ŹÕ«Üõ╣ēµ│Ģõ╣ŗķŚ┤ńÜäĶĮ¼µŹóÕģ│ń│╗Õ£© MMRotate Õåģķā©Õ╣ČõĖŹµČēÕÅŖ’╝īÕøĀµŁżõĖŹÕżÜÕüÜõ╗ŗń╗ŹŃĆéÕ”éµ×£µā│õ║åĶ¦Żµø┤ÕżÜńÜäń╗åĶŖé’╝īÕÅ»õ╗źÕÅéĶĆāĶ┐Öń»ć[ÕŹÜÕ«ó](https://zhuanlan.zhihu.com/p/459018810)ŃĆé
+
+```{note}
+MMRotate ÕÉīµŚČµö»µīüõĖŖĶ┐░õĖēń¦ŹµŚŗĶĮ¼µĪåÕ«Üõ╣ēµ│Ģ’╝īÕÅ»õ╗źķĆÜĶ┐ćķģŹńĮ«µ¢ćõ╗ČńüĄµ┤╗ÕłćµŹóŃĆé
+```
+
+ķ£ĆĶ”üµ│©µäÅńÜ䵜»’╝īÕ£© 4.5.1 õ╣ŗÕēŹńÜäńēłµ£¼õĖŁ’╝ī`cv2.minAreaRect` ńÜäĶ┐öÕø×ÕĆ╝õĖ║ `[-90┬░, 0┬░)`
+’╝ł[ÕÅéĶĆāĶĄäµ¢Ö](https://github.com/opencv/opencv/issues/19749)’╝ēŃĆéõĖ║õ║åõŠ┐õ║ÄÕī║Õłå’╝ī
+Õ░åĶĆüńēłµ£¼ńÜä OpenCV Õ«Üõ╣ēµ│ĢĶ«░õĮ£ {math}`D_{oc}`ŃĆé
+
+- {math}`D_{oc^{\prime}}`: OpenCV Õ«Üõ╣ēµ│Ģ’╝ī`opencv>=4.5.1`’╝ī`angleŌłł(0, 90┬░]`’╝ī`thetaŌłł(0, pi / 2]`ŃĆé
+- {math}`D_{oc}`: ĶĆüńēłńÜä OpenCV Õ«Üõ╣ēµ│Ģ’╝ī`opencv<4.5.1`’╝ī`angleŌłł[-90┬░, 0┬░)`’╝ī`thetaŌłł[-pi / 2, 0)`ŃĆé
+
+
+
+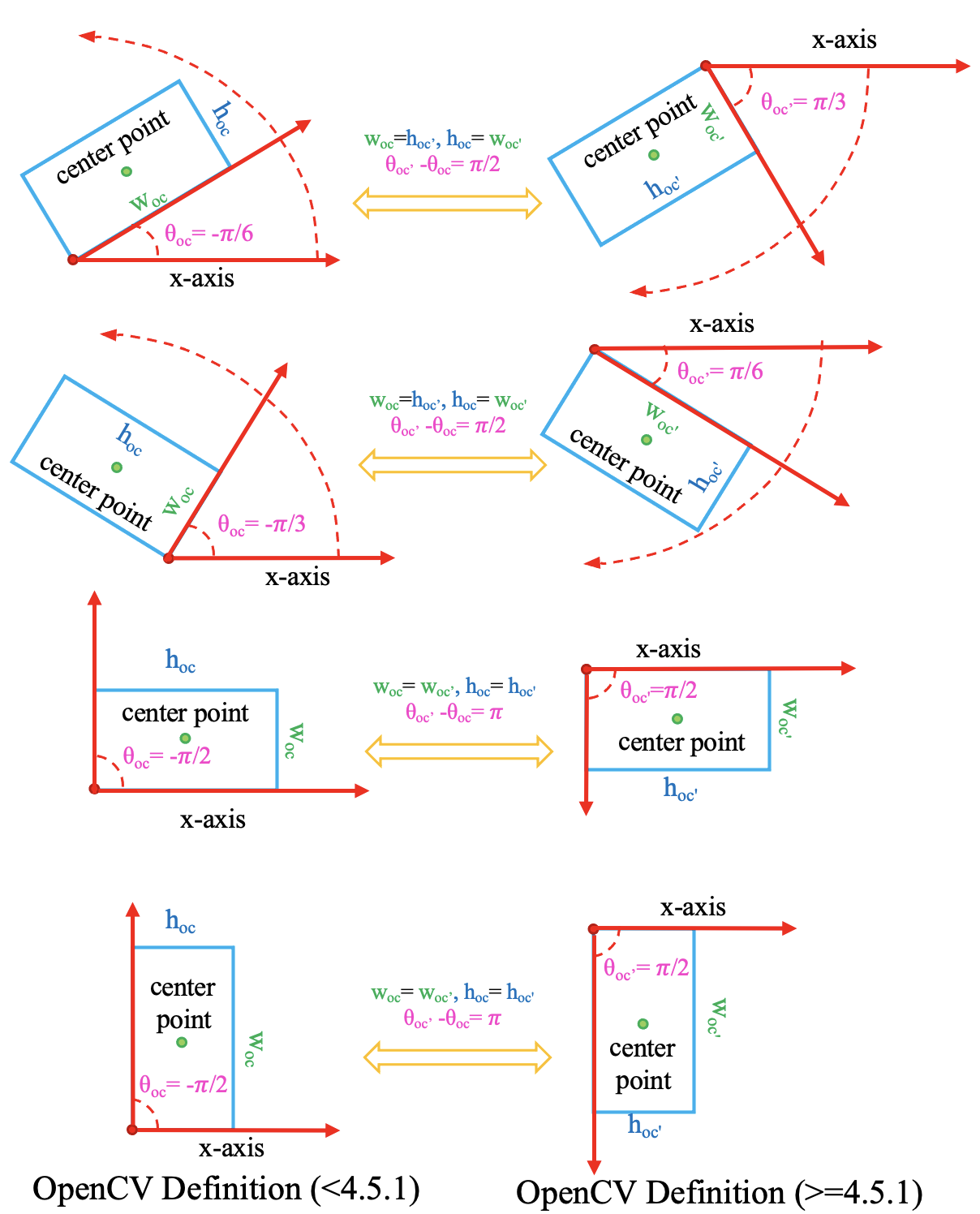 +
+
+
+õĖżń¦Ź OpenCV Õ«Üõ╣ēµ│ĢńÜäĶĮ¼µŹóÕģ│ń│╗Õ”éõĖŗ’╝Ü
+
+```{math}
+D_{oc^{\prime}}\left( w_{oc^{\prime}},h_{oc^{\prime}},\theta _{oc^{\prime}} \right) =\begin{cases}
+ D_{oc}\left( h_{oc},w_{oc},\theta _{oc}+\pi /2 \right) , otherwise\\
+ D_{oc}\left( w_{oc},h_{oc},\theta _{oc}+\pi \right) ,\theta _{oc}=-\pi /2\\
+\end{cases}
+\\
+D_{oc}\left( w_{oc},h_{oc},\theta _{oc} \right) =\begin{cases}
+ D_{oc^{\prime}}\left( h_{oc^{\prime}},w_{oc^{\prime}},\theta _{oc^{\prime}}-\pi /2 \right) , otherwise\\
+ D_{oc^{\prime}}\left( w_{oc^{\prime}},h_{oc^{\prime}},\theta _{oc^{\prime}}-\pi \right) , \theta _{oc^{\prime}}=\pi /2\\
+\end{cases}
+```
+
+```{note}
+õĖŹń«Īµé©õĮ┐ńö©ńÜä OpenCV ńēłµ£¼µś»ÕżÜÕ░æ, MMRotate ķāĮõ╝ÜÕ░å OpenCV Õ«Üõ╣ēµ│ĢńÜä theta ĶĮ¼µŹóõĖ║ (0, pi / 2]ŃĆé
+```
+
+### Ķ»äõ╝░
+
+Ķ»äõ╝░ mAP ńÜäõ╗ŻńĀüõĖŁµČēÕÅŖ IoU ńÜäĶ«Īń«Ś’╝īÕÅ»õ╗źńø┤µÄźĶ«Īń«ŚµŚŗĶĮ¼µĪå IoU’╝īõ╣¤ÕÅ»õ╗źÕ░åµŚŗĶĮ¼µĪåĶĮ¼µŹóõĖ║ÕżÜĶŠ╣ÕĮó’╝īńäČÕÉÄ
+Ķ«Īń«ŚÕżÜĶŠ╣ÕĮó IoU (DOTA Õ£©ń║┐Ķ»äõ╝░õĮ┐ńö©ńÜ䵜»Ķ«Īń«ŚÕżÜĶŠ╣ÕĮó IoU)ŃĆé
+
+## õ╗Ćõ╣łµś» MMRotate
+
+MMRotate µś»õĖĆõĖ¬õĖ║µŚŗĶĮ¼ńø«µĀ浯ƵĄŗµ¢╣µ│ĢµÅÉõŠøń╗¤õĖĆĶ«Łń╗āÕÆīĶ»äõ╝░µĪåµ×ČńÜäÕĘźÕģĘń«▒’╝īõ╗źõĖŗµś»ÕģȵĢ┤õĮōµĪåµ×Č’╝Ü:
+
+
+
+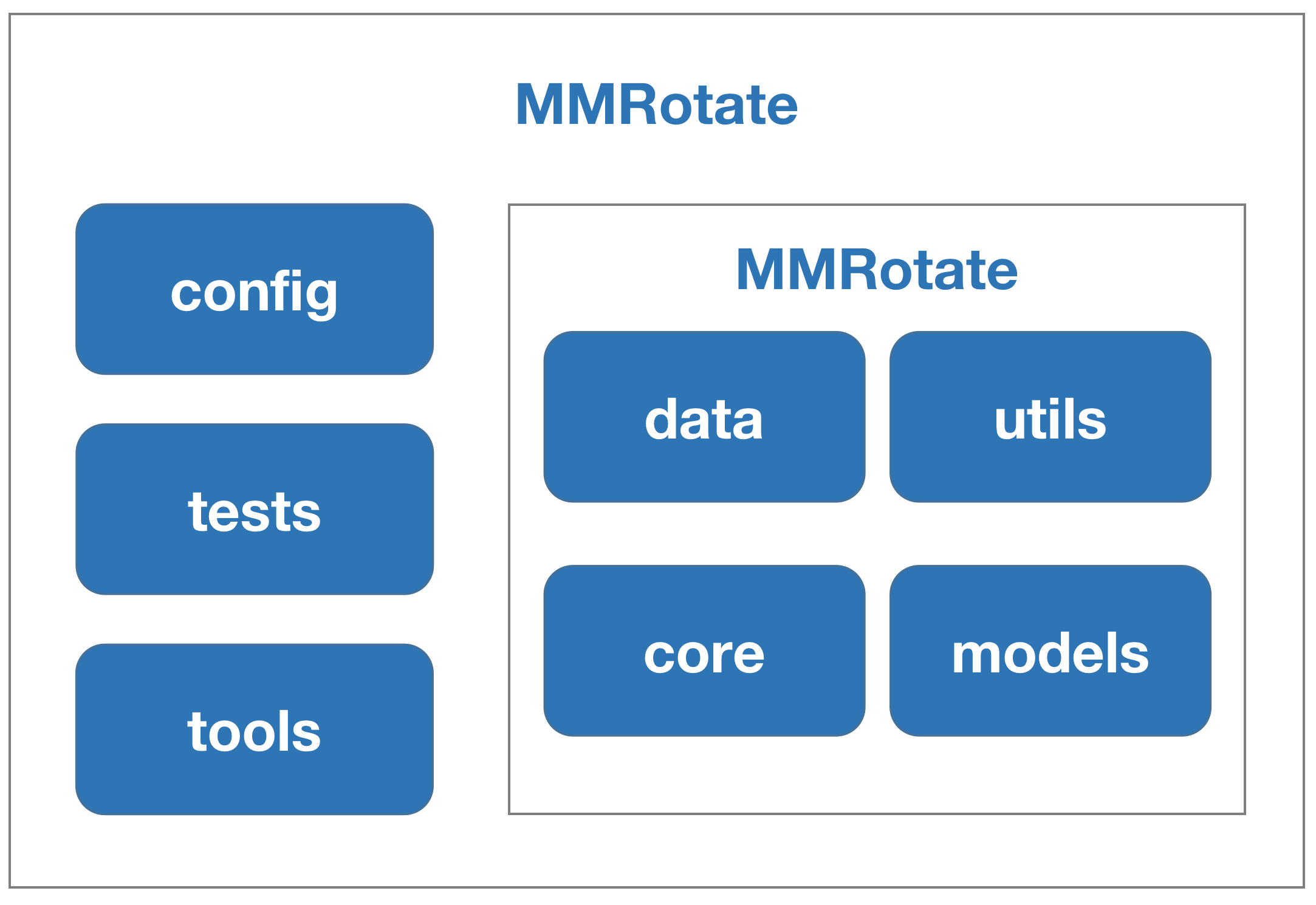 +
+
+
+MMRotate Õīģµŗ¼ÕøøõĖ¬ķā©Õłå, `datasets`, `models`, `core` and `apis`.
+
+- `datasets` ńö©õ║ĵĢ░µŹ«ÕŖĀĶĮĮÕÆīµĢ░µŹ«Õó×Õ╝║ŃĆé Õ£©Ķ┐Öķā©Õłå,µłæõ╗¼µö»µīüõ║åÕÉäń¦ŹµŚŗĶĮ¼ńø«µĀ浯ƵĄŗµĢ░µŹ«ķøåÕÆīµĢ░µŹ«Õó×Õ╝║ķóäÕżäńÉåŃĆé
+
+- `models` Õīģµŗ¼µ©ĪÕ×ŗÕÆīµŹ¤Õż▒ÕćĮµĢ░ŃĆé
+
+- `core` õĖ║µ©ĪÕ×ŗĶ«Łń╗āÕÆīĶ»äõ╝░µÅÉõŠøÕĘźÕģĘŃĆé
+
+- `apis` õĖ║µ©ĪÕ×ŗĶ«Łń╗āŃĆüµĄŗĶ»ĢÕÆīµÄ©ńÉåµÅÉõŠøķ½śń║¦ APIŃĆé
+
+MMRotate ńÜ䵩ĪÕØŚĶ«ŠĶ«ĪÕ”éõĖŗÕøŠµēĆńż║’╝Ü
+
+
+
+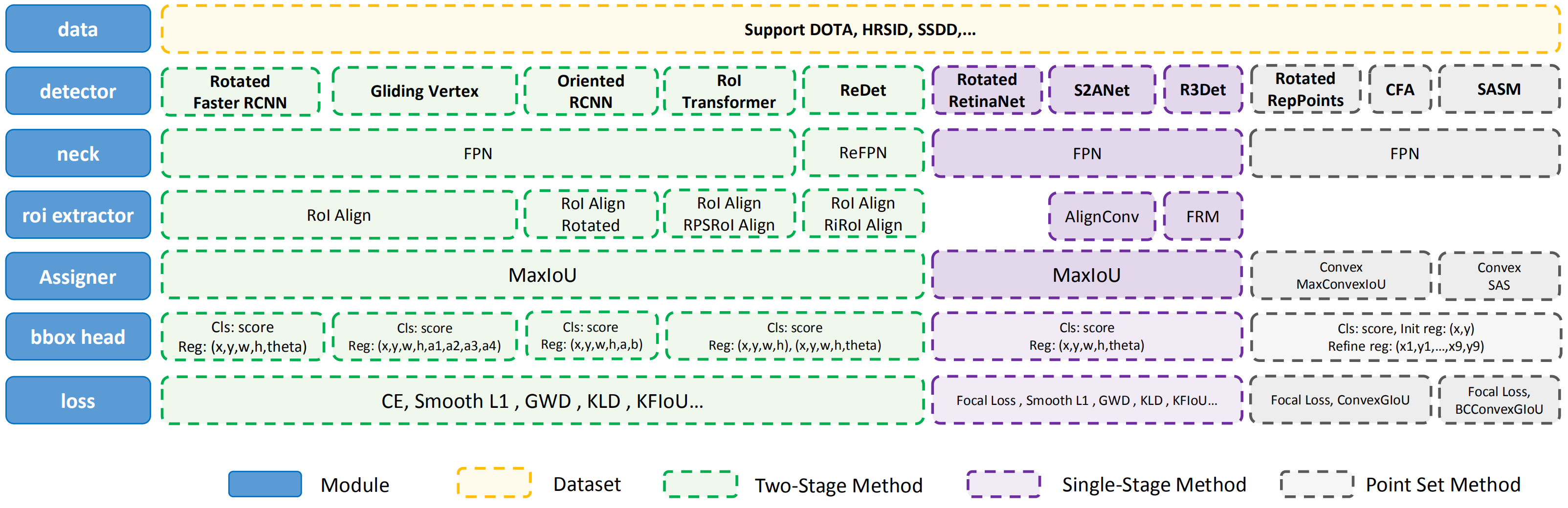 +
+
+
+ÕģČõĖŁńö▒õ║ĵŚŗĶĮ¼µĪåÕ«Üõ╣ēµ│ĢõĖŹÕÉīĶĆīķ£ĆĶ”üµ│©µäÅńÜäÕ£░µ¢╣µ£ēÕ”éõĖŗÕćĀõĖ¬’╝Ü
+
+- Ķ»╗ÕÅ¢µĀćµ│©
+- µĢ░µŹ«Õó×Õ╝║
+- µīćµ┤ŠµĀʵ£¼
+- Ķ»äõ╝░µīćµĀć
+
+## Õ”éõĮĢõĮ┐ńö©µĢÖń©ŗ
+
+õĖŗķØ󵜻 MMRotate Ķ»”ń╗åńÜäÕłåµŁźµīćÕŹŚ:
+
+1. Õģ│õ║ÄÕ«ēĶŻģĶ»┤µśÄ, Ķ»ĘÕÅéķśģ [Õ«ēĶŻģ](install.md).
+
+2. [Õ╝ĆÕ¦ŗ](get_started.md) õ╗ŗń╗Źõ║å MMRotate ńÜäÕ¤║µ£¼ńö©µ│Ģ.
+
+3. Õ”éµ×£µā│Ķ”üµø┤ÕŖĀµĘ▒Õģźõ║åĶ¦Ż MMRotate’╝īĶ»ĘÕÅéķśģõ╗źõĖŗµĢÖń©ŗ:
+
+- [ķģŹńĮ«](tutorials/customize_config.md)
+- [Ķć¬Õ«Üõ╣ēµĢ░µŹ«ķøå](tutorials/customize_dataset.md)
+- [Ķć¬Õ«Üõ╣ēµ©ĪÕ×ŗ](tutorials/customize_models.md)
+- [Ķć¬Õ«Üõ╣ēĶ┐ÉĶĪīµŚČ](tutorials/customize_runtime.md)
diff --git a/internlm_langchain/knowledge_base/MMRotate/content/model_zoo.md b/internlm_langchain/knowledge_base/MMRotate/content/model_zoo.md
new file mode 100644
index 00000000..b8bdc3b2
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMRotate/content/model_zoo.md
@@ -0,0 +1,75 @@
+## Õ¤║ÕćåÕÆīµ©ĪÕ×ŗÕ║ō
+
+- [Rotated RetinaNet-OBB/HBB](https://github.com/open-mmlab/mmrotate/tree/main/configs/rotated_retinanet/README.md) (
+ ICCV'2017)
+- [Rotated FasterRCNN-OBB](https://github.com/open-mmlab/mmrotate/tree/main/configs/rotated_faster_rcnn/README.md) (
+ TPAMI'2017)
+- [Rotated RepPoints-OBB](https://github.com/open-mmlab/mmrotate/tree/main/configs/rotated_reppoints/README.md) (
+ ICCV'2019)
+- [Rotated FCOS](https://github.com/open-mmlab/mmrotate/tree/main/configs/rotated_fcos/README.md) (ICCV'2019)
+- [RoI Transformer](https://github.com/open-mmlab/mmrotate/tree/main/configs/roi_trans/README.md) (CVPR'2019)
+- [Gliding Vertex](https://github.com/open-mmlab/mmrotate/tree/main/configs/gliding_vertex/README.md) (TPAMI'2020)
+- [Rotated ATSS-OBB](https://github.com/open-mmlab/mmrotate/tree/main/configs/rotated_atss/README.md) (CVPR'2020)
+- [CSL](https://github.com/open-mmlab/mmrotate/tree/main/configs/csl/README.md) (ECCV'2020)
+- [R3Det](https://github.com/open-mmlab/mmrotate/tree/main/configs/r3det/README.md) (AAAI'2021)
+- [S2A-Net](https://github.com/open-mmlab/mmrotate/tree/main/configs/s2anet/README.md) (TGRS'2021)
+- [ReDet](https://github.com/open-mmlab/mmrotate/tree/main/configs/redet/README.md) (CVPR'2021)
+- [Beyond Bounding-Box](https://github.com/open-mmlab/mmrotate/tree/main/configs/cfa/README.md) (CVPR'2021)
+- [Oriented R-CNN](https://github.com/open-mmlab/mmrotate/tree/main/configs/oriented_rcnn/README.md) (ICCV'2021)
+- [GWD](https://github.com/open-mmlab/mmrotate/tree/main/configs/gwd/README.md) (ICML'2021)
+- [KLD](https://github.com/open-mmlab/mmrotate/tree/main/configs/kld/README.md) (NeurIPS'2021)
+- [SASM](configs/sasm_reppoints/README.md) (AAAI'2022)
+- [KFIoU](https://github.com/open-mmlab/mmrotate/tree/main/configs/kfiou/README.md) (arXiv)
+- [G-Rep](https://github.com/open-mmlab/mmrotate/tree/main/configs/g_reppoints/README.md) (stay tuned)
+
+### DOTA v1.0 µĢ░µŹ«ķøåõĖŖńÜäń╗ōµ×£
+
+| ķ¬©Õ╣▓ńĮæń╗£ | mAP | Ķ¦ÆÕ║”ń╝¢ńĀüµ¢╣Õ╝Å | Ķ«Łń╗āńŁ¢ńĢź | µśŠÕŁśÕŹĀńö© (GB) | µÄ©ńÉåµŚČķŚ┤ (fps) | Õó×Õ╝║µ¢╣µ│Ģ | µē╣ķćÅÕż¦Õ░Å | ķģŹńĮ« | õĖŗĶĮĮ |
+| :------------------------: | :---: | :----------: | :------: | :-----------: | :------------: | :------: | :------: | :-----------------------------------------------------------------------------------------------------------------------------------------------: | :----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
+| ResNet50 (1024,1024,200) | 59.44 | oc | 1x | 3.45 | 15.6 | - | 2 | [rotated_reppoints_r50_fpn_1x_dota_oc](../../configs/rotated_reppoints/rotated_reppoints_r50_fpn_1x_dota_oc.py) | [model](https://download.openmmlab.com/mmrotate/v0.1.0/rotated_reppoints/rotated_reppoints_r50_fpn_1x_dota_oc/rotated_reppoints_r50_fpn_1x_dota_oc-d38ce217.pth) \| [log](https://download.openmmlab.com/mmrotate/v0.1.0/rotated_reppoints/rotated_reppoints_r50_fpn_1x_dota_oc/rotated_reppoints_r50_fpn_1x_dota_oc_20220205_145010.log.json) |
+| ResNet50 (1024,1024,200) | 64.55 | oc | 1x | 3.38 | 15.7 | - | 2 | [rotated_retinanet_hbb_r50_fpn_1x_dota_oc](../../configs/rotated_retinanet/rotated_retinanet_hbb_r50_fpn_1x_dota_oc.py) | [model](https://download.openmmlab.com/mmrotate/v0.1.0/rotated_retinanet/rotated_retinanet_hbb_r50_fpn_1x_dota_oc/rotated_retinanet_hbb_r50_fpn_1x_dota_oc-e8a7c7df.pth) \| [log](https://download.openmmlab.com/mmrotate/v0.1.0/rotated_retinanet/rotated_retinanet_hbb_r50_fpn_1x_dota_oc/rotated_retinanet_hbb_r50_fpn_1x_dota_oc_20220121_095315.log.json) |
+| ResNet50 (1024,1024,200) | 65.59 | oc | 1x | 3.12 | 18.5 | - | 2 | [rotated_atss_hbb_r50_fpn_1x_dota_oc](../../configs/rotated_atss/rotated_atss_hbb_r50_fpn_1x_dota_oc.py) | [model](https://download.openmmlab.com/mmrotate/v0.1.0/rotated_atss/rotated_atss_hbb_r50_fpn_1x_dota_oc/rotated_atss_hbb_r50_fpn_1x_dota_oc-eaa94033.pth) \| [log](https://download.openmmlab.com/mmrotate/v0.1.0/rotated_atss/rotated_atss_hbb_r50_fpn_1x_dota_oc/rotated_atss_hbb_r50_fpn_1x_dota_oc_20220402_002230.log.json) |
+| ResNet50 (1024,1024,200) | 66.45 | oc | 1x | 3.53 | 15.3 | - | 2 | [sasm_reppoints_r50_fpn_1x_dota_oc](../../configs/sasm/sasm_reppoints_r50_fpn_1x_dota_oc.py) | [model](https://download.openmmlab.com/mmrotate/v0.1.0/sasm/sasm_reppoints_r50_fpn_1x_dota_oc/sasm_reppoints_r50_fpn_1x_dota_oc-6d9edded.pth) \| [log](https://download.openmmlab.com/mmrotate/v0.1.0/sasm/sasm_reppoints_r50_fpn_1x_dota_oc/sasm_reppoints_r50_fpn_1x_dota_oc_20220205_144938.log.json) |
+| ResNet50 (1024,1024,200) | 68.42 | le90 | 1x | 3.38 | 16.9 | - | 2 | [rotated_retinanet_obb_r50_fpn_1x_dota_le90](../../configs/rotated_retinanet/rotated_retinanet_obb_r50_fpn_1x_dota_le90.py) | [model](https://download.openmmlab.com/mmrotate/v0.1.0/rotated_retinanet/rotated_retinanet_obb_r50_fpn_1x_dota_le90/rotated_retinanet_obb_r50_fpn_1x_dota_le90-c0097bc4.pth) \| [log](https://download.openmmlab.com/mmrotate/v0.1.0/rotated_retinanet/rotated_retinanet_obb_r50_fpn_1x_dota_le90/rotated_retinanet_obb_r50_fpn_1x_dota_le90_20220128_130740.log.json) |
+| ResNet50 (1024,1024,200) | 68.79 | le90 | 1x | 2.36 | 22.4 | - | 2 | [rotated_retinanet_obb_r50_fpn_fp16_1x_dota_le90](../../configs/rotated_retinanet_obb_r50_fpn_fp16_1x_dota_le90.py) | [model](https://download.openmmlab.com/mmrotate/v0.1.0/rotated_retinanet/rotated_retinanet_obb_r50_fpn_fp16_1x_dota_le90/rotated_retinanet_obb_r50_fpn_fp16_1x_dota_le90-01de71b5.pth) \| [log](https://download.openmmlab.com/mmrotate/v0.1.0/rotated_retinanet/rotated_retinanet_obb_r50_fpn_fp16_1x_dota_le90/rotated_retinanet_obb_r50_fpn_fp16_1x_dota_le90_20220303_183714.log.json) |
+| ResNet50 (1024,1024,200) | 69.49 | le135 | 1x | 4.05 | 8.6 | - | 2 | [g_reppoints_r50_fpn_1x_dota_le135](../../configs/g_reppoints/g_reppoints_r50_fpn_1x_dota_le135.py) | [model](https://download.openmmlab.com/mmrotate/v0.1.0/g_reppoints/g_reppoints_r50_fpn_1x_dota_le135/g_reppoints_r50_fpn_1x_dota_le135-b840eed7.pth) \| [log](https://download.openmmlab.com/mmrotate/v0.1.0/g_reppoints/g_reppoints_r50_fpn_1x_dota_le135/g_reppoints_r50_fpn_1x_dota_le135_20220202_233631.log.json) |
+| ResNet50 (1024,1024,200) | 69.51 | le90 | 1x | 4.40 | 24.0 | - | 2 | [rotated_retinanet_obb_csl_gaussian_r50_fpn_fp16_1x_dota_le90](../../configs/csl/rotated_retinanet_obb_csl_gaussian_r50_fpn_fp16_1x_dota_le90.py) | [model](https://download.openmmlab.com/mmrotate/v0.1.0/csl/rotated_retinanet_obb_csl_gaussian_r50_fpn_fp16_1x_dota_le90/rotated_retinanet_obb_csl_gaussian_r50_fpn_fp16_1x_dota_le90-b4271aed.pth) \| [log](https://download.openmmlab.com/mmrotate/v0.1.0/csl/rotated_retinanet_obb_csl_gaussian_r50_fpn_fp16_1x_dota_le90/rotated_retinanet_obb_csl_gaussian_r50_fpn_fp16_1x_dota_le90_20220321_010033.log.json) |
+| ResNet50 (1024,1024,200) | 69.55 | oc | 1x | 3.39 | 15.5 | - | 2 | [rotated_retinanet_hbb_gwd_r50_fpn_1x_dota_oc](../../configs/gwd/rotated_retinanet_hbb_gwd_r50_fpn_1x_dota_oc.py) | [model](https://download.openmmlab.com/mmrotate/v0.1.0/gwd/rotated_retinanet_hbb_gwd_r50_fpn_1x_dota_oc/rotated_retinanet_hbb_gwd_r50_fpn_1x_dota_oc-41fd7805.pth) \| [log](https://download.openmmlab.com/mmrotate/v0.1.0/gwd/rotated_retinanet_hbb_gwd_r50_fpn_1x_dota_oc/rotated_retinanet_hbb_gwd_r50_fpn_1x_dota_oc_20220120_152421.log.json) |
+| ResNet50 (1024,1024,200) | 69.60 | le90 | 1x | 3.38 | 15.1 | - | 2 | [rotated_retinanet_hbb_kfiou_r50_fpn_1x_dota_le90](../../configs/kfiou/rotated_retinanet_hbb_kfiou_r50_fpn_1x_dota_le90.py) | [model](https://download.openmmlab.com/mmrotate/v0.1.0/kfiou/rotated_retinanet_hbb_kfiou_r50_fpn_1x_dota_le90/rotated_retinanet_hbb_kfiou_r50_fpn_1x_dota_le90-03e02f75.pth) \| [log](https://download.openmmlab.com/mmrotate/v0.1.0/kfiou/rotated_retinanet_hbb_kfiou_r50_fpn_1x_dota_le90/rotated_retinanet_hbb_kfiou_r50_fpn_1x_dota_le90_20220209_173225.log.json) |
+| ResNet50 (1024,1024,200) | 69.63 | le135 | 1x | 3.45 | 16.1 | - | 2 | [cfa_r50_fpn_1x_dota_le135](../../configs/cfa/cfa_r50_fpn_1x_dota_le135.py) | [model](https://download.openmmlab.com/mmrotate/v0.1.0/cfa/cfa_r50_fpn_1x_dota_le135/cfa_r50_fpn_1x_dota_le135-aed1cbc6.pth) \| [log](https://download.openmmlab.com/mmrotate/v0.1.0/cfa/cfa_r50_fpn_1x_dota_le135/cfa_r50_fpn_1x_dota_le135_20220205_144859.log.json) |
+| ResNet50 (1024,1024,200) | 69.76 | oc | 1x | 3.39 | 15.6 | - | 2 | [rotated_retinanet_hbb_kfiou_r50_fpn_1x_dota_oc](../../configs/kfiou/rotated_retinanet_hbb_kfiou_r50_fpn_1x_dota_oc.py) | [model](https://download.openmmlab.com/mmrotate/v0.1.0/kfiou/rotated_retinanet_hbb_kfiou_r50_fpn_1x_dota_oc/rotated_retinanet_hbb_kfiou_r50_fpn_1x_dota_oc-c00be030.pth) \| [log](https://download.openmmlab.com/mmrotate/v0.1.0/kfiou/rotated_retinanet_hbb_kfiou_r50_fpn_1x_dota_oc/rotated_retinanet_hbb_kfiou_r50_fpn_1x_dota_oc_20220126_081643.log.json) |
+| ResNet50 (1024,1024,200) | 69.77 | le135 | 1x | 3.38 | 15.3 | - | 2 | [rotated_retinanet_hbb_kfiou_r50_fpn_1x_dota_le135](../../configs/kfiou/rotated_retinanet_hbb_kfiou_r50_fpn_1x_dota_le135.py) | [model](https://download.openmmlab.com/mmrotate/v0.1.0/kfiou/rotated_retinanet_hbb_kfiou_r50_fpn_1x_dota_le135/rotated_retinanet_hbb_kfiou_r50_fpn_1x_dota_le135-0eaa4156.pth) \| [log](https://download.openmmlab.com/mmrotate/v0.1.0/kfiou/rotated_retinanet_hbb_kfiou_r50_fpn_1x_dota_le135/rotated_retinanet_hbb_kfiou_r50_fpn_1x_dota_le135_20220209_173257.log.json) |
+| ResNet50 (1024,1024,200) | 69.79 | le135 | 1x | 3.38 | 17.2 | - | 2 | [rotated_retinanet_obb_r50_fpn_1x_dota_le135](../../configs/rotated_retinanet/rotated_retinanet_obb_r50_fpn_1x_dota_le135.py) | [model](https://download.openmmlab.com/mmrotate/v0.1.0/rotated_retinanet/rotated_retinanet_obb_r50_fpn_1x_dota_le135/rotated_retinanet_obb_r50_fpn_1x_dota_le135-e4131166.pth) \| [log](https://download.openmmlab.com/mmrotate/v0.1.0/rotated_retinanet/rotated_retinanet_obb_r50_fpn_1x_dota_le135/rotated_retinanet_obb_r50_fpn_1x_dota_le135_20220128_130755.log.json) |
+| ResNet50 (1024,1024,200) | 69.80 | oc | 1x | 3.54 | 12.4 | - | 2 | [r3det_r50_fpn_1x_dota_oc](../../configs/r3det/r3det_r50_fpn_1x_dota_oc.py) | [model](https://download.openmmlab.com/mmrotate/v0.1.0/r3det/r3det_r50_fpn_1x_dota_oc/r3det_r50_fpn_1x_dota_oc-b1fb045c.pth) \| [log](https://download.openmmlab.com/mmrotate/v0.1.0/r3det/r3det_r50_fpn_1x_dota_oc/r3det_r50_fpn_1x_dota_oc_20220126_191226.log.json) |
+| ResNet50 (1024,1024,200) | 69.94 | oc | 1x | 3.39 | 15.6 | - | 2 | [rotated_retinanet_hbb_kld_r50_fpn_1x_dota_oc](../../configs/kld/rotated_retinanet_hbb_kld_r50_fpn_1x_dota_oc.py) | [model](https://download.openmmlab.com/mmrotate/v0.1.0/kld/rotated_retinanet_hbb_kld_r50_fpn_1x_dota_oc/rotated_retinanet_hbb_kld_r50_fpn_1x_dota_oc-49c1f937.pth) \| [log](https://download.openmmlab.com/mmrotate/v0.1.0/kld/rotated_retinanet_hbb_kld_r50_fpn_1x_dota_oc/rotated_retinanet_hbb_kld_r50_fpn_1x_dota_oc_20220125_201832.log.json) |
+| ResNet50 (1024,1024,200) | 70.18 | oc | 1x | 3.23 | 15.6 | - | 2 | [r3det_tiny_r50_fpn_1x_dota_oc](../../configs/r3det/r3det_tiny_r50_fpn_1x_dota_oc.py) | [model](https://download.openmmlab.com/mmrotate/v0.1.0/r3det/r3det_tiny_r50_fpn_1x_dota_oc/r3det_tiny_r50_fpn_1x_dota_oc-c98a616c.pth) \| [log](https://download.openmmlab.com/mmrotate/v0.1.0/r3det/r3det_tiny_r50_fpn_1x_dota_oc/r3det_tiny_r50_fpn_1x_dota_oc_20220209_171624.log.json) |
+| ResNet50 (1024,1024,200) | 70.64 | le90 | 1x | 3.12 | 18.2 | - | 2 | [rotated_atss_obb_r50_fpn_1x_dota_le90](../../configs/rotated_atss/rotated_atss_obb_r50_fpn_1x_dota_le90.py) | [model](https://download.openmmlab.com/mmrotate/v0.1.0/rotated_atss/rotated_atss_obb_r50_fpn_1x_dota_le90/rotated_atss_obb_r50_fpn_1x_dota_le90-e029ca06.pth) \| [log](https://download.openmmlab.com/mmrotate/v0.1.0/rotated_atss/rotated_atss_obb_r50_fpn_1x_dota_le90/rotated_atss_obb_r50_fpn_1x_dota_le90_20220402_002048.log.json) |
+| ResNet50 (1024,1024,200) | 70.70 | le90 | 1x | 4.18 | | - | 2 | [rotated_fcos_sep_angle_r50_fpn_1x_dota_le90](../../configs/rotated_fcos/rotated_fcos_sep_angle_r50_fpn_1x_dota_le90.py) | [model](https://download.openmmlab.com/mmrotate/v0.1.0/rotated_fcos/rotated_fcos_sep_angle_r50_fpn_1x_dota_le90/rotated_fcos_sep_angle_r50_fpn_1x_dota_le90-0be71a0c.pth) \| [log](https://download.openmmlab.com/mmrotate/v0.1.0/rotated_fcos/rotated_fcos_sep_angle_r50_fpn_1x_dota_le90/rotated_fcos_sep_angle_r50_fpn_1x_dota_le90_20220409_023250.log.json) |
+| ResNet50 (1024,1024,200) | 71.28 | le90 | 1x | 4.18 | | - | 2 | [rotated_fcos_r50_fpn_1x_dota_le90](../../configs/rotated_fcos/rotated_fcos_r50_fpn_1x_dota_le90.py) | [model](https://download.openmmlab.com/mmrotate/v0.1.0/rotated_fcos/rotated_fcos_r50_fpn_1x_dota_le90/rotated_fcos_r50_fpn_1x_dota_le90-d87568ed.pth) \| [log](https://download.openmmlab.com/mmrotate/v0.1.0/rotated_fcos/rotated_fcos_r50_fpn_1x_dota_le90/rotated_fcos_r50_fpn_1x_dota_le90_20220413_163526.log.json) |
+| ResNet50 (1024,1024,200) | 71.76 | le90 | 1x | 4.23 | | - | 2 | [rotated_fcos_csl_gaussian_r50_fpn_1x_dota_le90](../../configs/rotated_fcos/rotated_fcos_csl_gaussian_r50_fpn_1x_dota_le90.py) | [model](https://download.openmmlab.com/mmrotate/v0.1.0/rotated_fcos/rotated_fcos_csl_gaussian_r50_fpn_1x_dota_le90/rotated_fcos_csl_gaussian_r50_fpn_1x_dota_le90-4e044ad2.pth) \| [log](https://download.openmmlab.com/mmrotate/v0.1.0/rotated_fcos/rotated_fcos_csl_gaussian_r50_fpn_1x_dota_le90/rotated_fcos_csl_gaussian_r50_fpn_1x_dota_le90_20220409_080616.log.json) |
+| ResNet50 (1024,1024,200) | 71.83 | oc | 1x | 3.54 | 12.4 | - | 2 | [r3det_kld_r50_fpn_1x_dota_oc](../../configs/kld/r3det_kld_r50_fpn_1x_dota_oc.py) | [model](https://download.openmmlab.com/mmrotate/v0.1.0/kld/r3det_kld_r50_fpn_1x_dota_oc/r3det_kld_r50_fpn_1x_dota_oc-31866226.pth) \| [log](https://download.openmmlab.com/mmrotate/v0.1.0/kld/r3det_kld_r50_fpn_1x_dota_oc/r3det_kld_r50_fpn_1x_dota_oc_20220210_114049.log.json) |
+| ResNet50 (1024,1024,200) | 71.89 | le90 | 1x | 4.18 | | - | 2 | [rotated_fcos_kld_r50_fpn_1x_dota_le90](../../configs/rotated_fcos/rotated_fcos_kld_r50_fpn_1x_dota_le90.py) | [model](https://download.openmmlab.com/mmrotate/v0.1.0/rotated_fcos/rotated_fcos_kld_r50_fpn_1x_dota_le90/rotated_fcos_kld_r50_fpn_1x_dota_le90-ecafdb2b.pth) \| [log](https://download.openmmlab.com/mmrotate/v0.1.0/rotated_fcos/rotated_fcos_kld_r50_fpn_1x_dota_le90/rotated_fcos_kld_r50_fpn_1x_dota_le90_20220409_202939.log.json) |
+| ResNet50 (1024,1024,200) | 71.94 | le135 | 1x | 3.45 | 16.1 | - | 2 | [oriented_reppoints_r50_fpn_1x_dota_le135](../../configs/oriented_reppoints/oriented_reppoints_r50_fpn_1x_dota_le135.py) | [model](https://download.openmmlab.com/mmrotate/v0.1.0/orientedreppoints/oriented_reppoints_r50_fpn_1x_dota_le135/oriented_reppoints_r50_fpn_1x_dota_le135-ef072de9.pth) \| [log](https://download.openmmlab.com/mmrotate/v0.1.0/orientedreppoints/oriented_reppoints_r50_fpn_1x_dota_le135/oriented_reppoints_r50_fpn_1x_dota_le135_20220505_092853.log.json) |
+| ResNet50 (1024,1024,200) | 72.29 | le135 | 1x | 3.19 | 18.8 | - | 2 | [rotated_atss_obb_r50_fpn_1x_dota_le135](../../configs/rotated_atss/rotated_atss_obb_r50_fpn_1x_dota_le135.py) | [model](https://download.openmmlab.com/mmrotate/v0.1.0/rotated_atss/rotated_atss_obb_r50_fpn_1x_dota_le135/rotated_atss_obb_r50_fpn_1x_dota_le135-eab7bc12.pth) \| [log](https://download.openmmlab.com/mmrotate/v0.1.0/rotated_atss/rotated_atss_obb_r50_fpn_1x_dota_le135/rotated_atss_obb_r50_fpn_1x_dota_le135_20220402_002138.log.json) |
+| ResNet50 (1024,1024,200) | 72.68 | oc | 1x | 3.62 | 12.2 | - | 2 | [r3det_kfiou_ln_r50_fpn_1x_dota_oc](../../configs/kfiou/r3det_kfiou_ln_r50_fpn_1x_dota_oc.py) | [model](https://download.openmmlab.com/mmrotate/v0.1.0/kfiou/r3det_kfiou_ln_r50_fpn_1x_dota_oc/r3det_kfiou_ln_r50_fpn_1x_dota_oc-8e7f049d.pth) \| [log](https://download.openmmlab.com/mmrotate/v0.1.0/kfiou/r3det_kfiou_ln_r50_fpn_1x_dota_oc/r3det_kfiou_ln_r50_fpn_1x_dota_oc_20220123_074507.log.json) |
+| ResNet50 (1024,1024,200) | 72.76 | oc | 1x | 3.44 | 14.0 | - | 2 | [r3det_tiny_kld_r50_fpn_1x_dota_oc](../../configs/kld/r3det_tiny_kld_r50_fpn_1x_dota_oc.py) | [model](https://download.openmmlab.com/mmrotate/v0.1.0/kld/r3det_tiny_kld_r50_fpn_1x_dota_oc/r3det_tiny_kld_r50_fpn_1x_dota_oc-589e142a.pth) \| [log](https://download.openmmlab.com/mmrotate/v0.1.0/kld/r3det_tiny_kld_r50_fpn_1x_dota_oc/r3det_tiny_kld_r50_fpn_1x_dota_oc_20220209_172917.log.json) |
+| ResNet50 (1024,1024,200) | 73.23 | le90 | 1x | 8.45 | 16.4 | - | 2 | [gliding_vertex_r50_fpn_1x_dota_le90](../../configs/gliding_vertex/gliding_vertex_r50_fpn_1x_dota_le90.py) | [model](https://download.openmmlab.com/mmrotate/v0.1.0/gliding_vertex/gliding_vertex_r50_fpn_1x_dota_le90/gliding_vertex_r50_fpn_1x_dota_le90-12e7423c.pth) \| [log](https://download.openmmlab.com/mmrotate/v0.1.0/gliding_vertex/gliding_vertex_r50_fpn_1x_dota_le90/gliding_vertex_r50_fpn_1x_dota_le90_20220129_085529.log.json) |
+| ResNet50 (1024,1024,200) | 73.40 | le90 | 1x | 8.46 | 16.5 | - | 2 | [rotated_faster_rcnn_r50_fpn_1x_dota_le90](../../configs/rotated_faster_rcnn/rotated_faster_rcnn_r50_fpn_1x_dota_le90.py) | [model](https://download.openmmlab.com/mmrotate/v0.1.0/rotated_faster_rcnn/rotated_faster_rcnn_r50_fpn_1x_dota_le90/rotated_faster_rcnn_r50_fpn_1x_dota_le90-0393aa5c.pth) \| [log](https://download.openmmlab.com/mmrotate/v0.1.0/rotated_faster_rcnn/rotated_faster_rcnn_r50_fpn_1x_dota_le90/rotated_faster_rcnn_r50_fpn_1x_dota_le90_20220131_082156.log.json) |
+| ResNet50 (1024,1024,200) | 73.45 | oc | 40e | 3.45 | 16.1 | - | 2 | [cfa_r50_fpn_40e_dota_oc](../../configs/cfa/cfa_r50_fpn_40e_dota_oc.py) | [model](https://download.openmmlab.com/mmrotate/v0.1.0/cfa/cfa_r50_fpn_40e_dota_oc/cfa_r50_fpn_40e_dota_oc-2f387232.pth) \| [log](https://download.openmmlab.com/mmrotate/v0.1.0/cfa/cfa_r50_fpn_40e_dota_oc/cfa_r50_fpn_40e_dota_oc_20220209_171237.log.json) |
+| ResNet50 (1024,1024,200) | 73.91 | le135 | 1x | 3.14 | 15.5 | - | 2 | [s2anet_r50_fpn_1x_dota_le135](../../configs/s2anet/s2anet_r50_fpn_1x_dota_le135.py) | [model](https://download.openmmlab.com/mmrotate/v0.1.0/s2anet/s2anet_r50_fpn_1x_dota_le135/s2anet_r50_fpn_1x_dota_le135-5dfcf396.pth) \| [log](https://download.openmmlab.com/mmrotate/v0.1.0/s2anet/s2anet_r50_fpn_1x_dota_le135/s2anet_r50_fpn_1x_dota_le135_20220124_163529.log.json) |
+| ResNet50 (1024,1024,200) | 74.19 | le135 | 1x | 2.17 | 17.4 | - | 2 | [s2anet_r50_fpn_fp16_1x_dota_le135](../../configs/s2anet_r50_fpn_fp16_1x_dota_le135.py) | [model](https://download.openmmlab.com/mmrotate/v0.1.0/s2anet/s2anet_r50_fpn_fp16_1x_dota_le135/s2anet_r50_fpn_fp16_1x_dota_le135-5cac515c.pth) \| [log](https://download.openmmlab.com/mmrotate/v0.1.0/s2anet/s2anet_r50_fpn_fp16_1x_dota_le135/s2anet_r50_fpn_fp16_1x_dota_le135_20220303_194910.log.json) |
+| ResNet50 (1024,1024,200) | 75.63 | le90 | 1x | 7.37 | 21.2 | - | 2 | [oriented_rcnn_r50_fpn_fp16_1x_dota_le90](../../configs/oriented_rcnn_r50_fpn_fp16_1x_dota_le90.py) | [model](https://download.openmmlab.com/mmrotate/v0.1.0/oriented_rcnn/oriented_rcnn_r50_fpn_fp16_1x_dota_le90/oriented_rcnn_r50_fpn_fp16_1x_dota_le90-57c88621.pth) \| [log](https://download.openmmlab.com/mmrotate/v0.1.0/oriented_rcnn/oriented_rcnn_r50_fpn_fp16_1x_dota_le90/oriented_rcnn_r50_fpn_fp16_1x_dota_le90_20220303_195049.log.json) |
+| ResNet50 (1024,1024,200) | 75.69 | le90 | 1x | 8.46 | 16.2 | - | 2 | [oriented_rcnn_r50_fpn_1x_dota_le90](../../configs/oriented_rcnn/oriented_rcnn_r50_fpn_1x_dota_le90.py) | [model](https://download.openmmlab.com/mmrotate/v0.1.0/oriented_rcnn/oriented_rcnn_r50_fpn_1x_dota_le90/oriented_rcnn_r50_fpn_1x_dota_le90-6d2b2ce0.pth) \| [log](https://download.openmmlab.com/mmrotate/v0.1.0/oriented_rcnn/oriented_rcnn_r50_fpn_1x_dota_le90/oriented_rcnn_r50_fpn_1x_dota_le90_20220127_100150.log.json) |
+| ResNet50 (1024,1024,200) | 75.75 | le90 | 1x | 7.56 | 19.3 | - | 2 | [roi_trans_r50_fpn_fp16_1x_dota_le90](../../configs/roi_trans_r50_fpn_fp16_1x_dota_le90.py) | [model](https://download.openmmlab.com/mmrotate/v0.1.0/roi_trans/roi_trans_r50_fpn_fp16_1x_dota_le90/roi_trans_r50_fpn_fp16_1x_dota_le90-62eb88b1.pth) \| [log](https://download.openmmlab.com/mmrotate/v0.1.0/roi_trans/roi_trans_r50_fpn_fp16_1x_dota_le90/roi_trans_r50_fpn_fp16_1x_dota_le90_20220303_193513.log.json) |
+| ReResNet50 (1024,1024,200) | 75.99 | le90 | 1x | 7.71 | 13.3 | - | 2 | [redet_re50_refpn_fp16_1x_dota_le90](../../configs/redet_re50_refpn_fp16_1x_dota_le90.py) | [model](https://download.openmmlab.com/mmrotate/v0.1.0/redet/redet_re50_refpn_fp16_1x_dota_le90/redet_re50_refpn_fp16_1x_dota_le90-1e34da2d.pth) \| [log](https://download.openmmlab.com/mmrotate/v0.1.0/redet/redet_re50_refpn_fp16_1x_dota_le90/redet_re50_refpn_fp16_1x_dota_le90_20220303_194725.log.json) |
+| ResNet50 (1024,1024,200) | 76.08 | le90 | 1x | 8.67 | 14.4 | - | 2 | [roi_trans_r50_fpn_1x_dota_le90](../../configs/roi_trans/roi_trans_r50_fpn_1x_dota_le90.py) | [model](https://download.openmmlab.com/mmrotate/v0.1.0/roi_trans/roi_trans_r50_fpn_1x_dota_le90/roi_trans_r50_fpn_1x_dota_le90-d1f0b77a.pth) \| [log](https://download.openmmlab.com/mmrotate/v0.1.0/roi_trans/roi_trans_r50_fpn_1x_dota_le90/roi_trans_r50_fpn_1x_dota_le90_20220130_132727.log.json) |
+| ResNet50 (1024,1024,500) | 76.50 | le90 | 1x | | 17.5 | MS+RR | 2 | [rotated_retinanet_obb_r50_fpn_1x_dota_ms_rr_le90](../../configs/rotated_retinanet/rotated_retinanet_obb_r50_fpn_1x_dota_ms_rr_le90.py) | [model](https://download.openmmlab.com/mmrotate/v0.1.0/rotated_retinanet/rotated_retinanet_obb_r50_fpn_1x_dota_ms_rr_le90/rotated_retinanet_obb_r50_fpn_1x_dota_ms_rr_le90-1da1ec9c.pth) \| [log](https://download.openmmlab.com/mmrotate/v0.1.0/rotated_retinanet/rotated_retinanet_obb_r50_fpn_1x_dota_ms_rr_le90/rotated_retinanet_obb_r50_fpn_1x_dota_ms_rr_le90_20220210_114843.log.json) |
+| ReResNet50 (1024,1024,200) | 76.68 | le90 | 1x | 9.32 | 10.9 | - | 2 | [redet_re50_refpn_1x_dota_le90](../../configs/redet/redet_re50_refpn_1x_dota_le90.py) | [model](https://download.openmmlab.com/mmrotate/v0.1.0/redet/redet_re50_fpn_1x_dota_le90/redet_re50_fpn_1x_dota_le90-724ab2da.pth) \| [log](https://download.openmmlab.com/mmrotate/v0.1.0/redet/redet_re50_fpn_1x_dota_le90/redet_re50_fpn_1x_dota_le90_20220130_132751.log.json) |
+| Swin-tiny (1024,1024,200) | 77.51 | le90 | 1x | | 10.9 | - | 2 | [roi_trans_swin_tiny_fpn_1x_dota_le90](../../configs/roi_trans/roi_trans_swin_tiny_fpn_1x_dota_le90.py) | [model](https://download.openmmlab.com/mmrotate/v0.1.0/roi_trans/roi_trans_swin_tiny_fpn_1x_dota_le90/roi_trans_swin_tiny_fpn_1x_dota_le90-ddeee9ae.pth) \| [log](https://download.openmmlab.com/mmrotate/v0.1.0/roi_trans/roi_trans_swin_tiny_fpn_1x_dota_le90/roi_trans_swin_tiny_fpn_1x_dota_le90_20220131_083622.log.json) |
+| ResNet50 (1024,1024,500) | 79.66 | le90 | 1x | | 14.4 | MS+RR | 2 | [roi_trans_r50_fpn_1x_dota_ms_rr_le90](../../configs/roi_trans/roi_trans_r50_fpn_1x_dota_ms_rr_le90.py) | [model](https://download.openmmlab.com/mmrotate/v0.1.0/roi_trans/roi_trans_r50_fpn_1x_dota_ms_rr_le90/roi_trans_r50_fpn_1x_dota_ms_rr_le90-fa99496f.pth) \| [log](https://download.openmmlab.com/mmrotate/v0.1.0/roi_trans/roi_trans_r50_fpn_1x_dota_ms_rr_le90/roi_trans_r50_fpn_1x_dota_ms_rr_le90_20220205_171729.log.json) |
+| ReResNet50 (1024,1024,500) | 79.87 | le90 | 1x | | 10.9 | MS+RR | 2 | [redet_re50_refpn_1x_dota_ms_rr_le90](../../configs/redet/redet_re50_refpn_1x_dota_ms_rr_le90.py) | [model](https://download.openmmlab.com/mmrotate/v0.1.0/redet/redet_re50_fpn_1x_dota_ms_rr_le90/redet_re50_fpn_1x_dota_ms_rr_le90-fc9217b5.pth) \| [log](https://download.openmmlab.com/mmrotate/v0.1.0/redet/redet_re50_fpn_1x_dota_ms_rr_le90/redet_re50_fpn_1x_dota_ms_rr_le90_20220206_105343.log.json) |
+
+- `MS` ĶĪ©ńż║ÕżÜÕ░║Õ║”ÕøŠÕāÅÕó×Õ╝║ŃĆé
+- `RR` ĶĪ©ńż║ķÜŵ£║µŚŗĶĮ¼Õó×Õ╝║ŃĆé
+
+õĖŖĶ┐░µ©ĪÕ×ŗķāĮµś»õĮ┐ńö© 1 * 1080ti/2080ti Ķ«Łń╗āÕŠŚÕł░ńÜä’╝īÕ╣ČõĖöÕ£© 1 * 2080ti õĖŖĶ┐øĶĪīµÄ©ńÉåµĄŗĶ»ĢŃĆé
diff --git a/internlm_langchain/knowledge_base/MMRotate/content/useful_tools.md b/internlm_langchain/knowledge_base/MMRotate/content/useful_tools.md
new file mode 100644
index 00000000..fb7fffb1
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMRotate/content/useful_tools.md
@@ -0,0 +1,283 @@
+ķÖżõ║åĶ«Łń╗āÕÆīµĄŗĶ»ĢĶäܵ£¼’╝īµłæõ╗¼Õ£© `tools/` µ¢ćõ╗ČÕż╣ÕåģĶ┐śµÅÉõŠøõ║åõĖĆõ║øµ£ēńö©ńÜäÕĘźÕģĘŃĆé
+
+## µŚźÕ┐ŚÕłåµ×É
+
+`tools/analysis_tools/analyze_logs.py` ķĆÜĶ┐ćń╗ÖÕ«ÜńÜ䵌źÕ┐Śµ¢ćõ╗Čń╗śÕłČ loss/mAP µø▓ń║┐ŃĆé ķ£Ćķ”¢Õģłµē¦ĶĪī `pip install seaborn` Õ«ēĶŻģõŠØĶĄ¢ŃĆé
+
+```shell
+python tools/analysis_tools/analyze_logs.py plot_curve [--keys ${KEYS}] [--title ${TITLE}] [--legend ${LEGEND}] [--backend ${BACKEND}] [--style ${STYLE}] [--out ${OUT_FILE}]
+```
+
+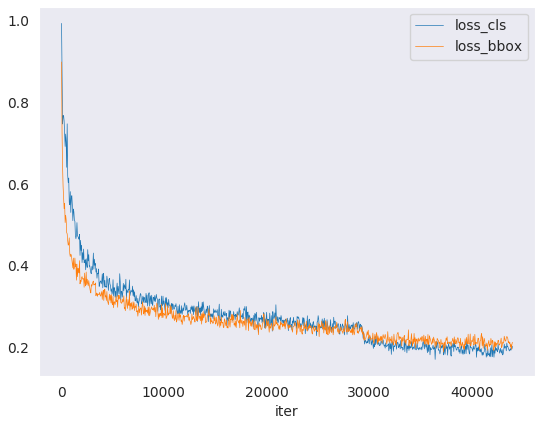
+
+ńż║õŠŗ:
+
+- ń╗śÕłČµ¤Éµ¼Īµē¦ĶĪīńÜäÕłåń▒╗µŹ¤Õż▒
+
+ ```shell
+ python tools/analysis_tools/analyze_logs.py plot_curve log.json --keys loss_cls --legend loss_cls
+ ```
+
+- ń╗śÕłČµ¤Éµ¼Īµē¦ĶĪīńÜäÕłåń▒╗ÕÆīÕø×ÕĮƵŹ¤Õż▒’╝īÕÉīµŚČÕ░åÕøŠÕāÅõ┐ØÕŁśÕł░ pdf µ¢ćõ╗Č
+
+ ```shell
+ python tools/analysis_tools/analyze_logs.py plot_curve log.json --keys loss_cls loss_bbox --out losses.pdf
+ ```
+
+- Õ£©ÕÉīõĖĆÕ╝ĀÕøŠÕāÅõĖŁµ»öĶŠāõĖżµ¼Īµē¦ĶĪīńÜä mAP
+
+ ```shell
+ python tools/analysis_tools/analyze_logs.py plot_curve log1.json log2.json --keys bbox_mAP --legend run1 run2
+ ```
+
+- Ķ«Īń«ŚÕ╣│ÕØćĶ«Łń╗āķƤÕ║”
+
+ ```shell
+ python tools/analysis_tools/analyze_logs.py cal_train_time log.json [--include-outliers]
+ ```
+
+ ķóäĶ«ĪĶŠōÕć║Õ”éõĖŗ
+
+ ```text
+ -----Analyze train time of work_dirs/some_exp/20190611_192040.log.json-----
+ slowest epoch 11, average time is 1.2024
+ fastest epoch 1, average time is 1.1909
+ time std over epochs is 0.0028
+ average iter time: 1.1959 s/iter
+ ```
+
+## ÕÅ»Ķ¦åÕī¢
+
+### ÕÅ»Ķ¦åÕī¢µĢ░µŹ«ķøå
+
+`tools/misc/browse_dataset.py` ÕĖ«ÕŖ®ńö©µłĘµĄÅĶ¦łµŻĆµĄŗńÜäµĢ░µŹ«ķøå’╝łÕīģµŗ¼ÕøŠÕāÅÕÆīµŻĆµĄŗµĪåńÜäµĀćµ│©’╝ē’╝īµł¢Õ░åÕøŠÕāÅõ┐ØÕŁśÕł░µīćÕ«Üńø«ÕĮĢŃĆé
+
+```shell
+python tools/misc/browse_dataset.py ${CONFIG} [-h] [--skip-type ${SKIP_TYPE[SKIP_TYPE...]}] [--output-dir ${OUTPUT_DIR}] [--not-show] [--show-interval ${SHOW_INTERVAL}]
+```
+
+## µ©ĪÕ×ŗķā©ńĮ▓
+
+õĖ║õ║åõĮ┐ńö© [`TorchServe`](https://pytorch.org/serve/) ķā©ńĮ▓õĖĆõĖ¬ `MMRotate` µ©ĪÕ×ŗ’╝īķ£ĆĶ”üĶ┐øĶĪīõ╗źõĖŗÕćĀµŁź’╝Ü
+
+### 1. ĶĮ¼µŹó MMRotate µ©ĪÕ×ŗĶć│ TorchServe
+
+```shell
+python tools/deployment/mmrotate2torchserve.py ${CONFIG_FILE} ${CHECKPOINT_FILE} \
+--output-folder ${MODEL_STORE} \
+--model-name ${MODEL_NAME}
+```
+
+ńż║õŠŗ:
+
+```shell
+wget -P checkpoint \
+https://download.openmmlab.com/mmrotate/v0.1.0/rotated_faster_rcnn/rotated_faster_rcnn_r50_fpn_1x_dota_le90/rotated_faster_rcnn_r50_fpn_1x_dota_le90-0393aa5c.pth
+
+python tools/deployment/mmrotate2torchserve.py configs/rotated_faster_rcnn/rotated_faster_rcnn_r50_fpn_1x_dota_le90.py checkpoint/rotated_faster_rcnn_r50_fpn_1x_dota_le90-0393aa5c.pth \
+--output-folder ${MODEL_STORE} \
+--model-name rotated_faster_rcnn
+```
+
+**Note**: ${MODEL_STORE} ķ£ĆĶ”üµś»õĖĆõĖ¬µ¢ćõ╗ČÕż╣ńÜäń╗ØÕ»╣ĶĘ»ÕŠäŃĆé
+
+### 2. µ×äÕ╗║ `mmrotate-serve` docker ķĢ£ÕāÅ
+
+```shell
+docker build -t mmrotate-serve:latest docker/serve/
+```
+
+### 3. Ķ┐ÉĶĪī `mmrotate-serve` ķĢ£ÕāÅ
+
+Ķ»ĘÕÅéĶĆāÕ«śµ¢╣µ¢ćµĪŻ [Õ¤║õ║Ä docker Ķ┐ÉĶĪī TorchServe](https://github.com/pytorch/serve/blob/master/docker/README.md#running-torchserve-in-a-production-docker-environment).
+
+õĖ║õ║åõĮ┐ķĢ£ÕāÅĶāĮÕż¤õĮ┐ńö© GPU ĶĄäµ║É’╝īķ£ĆĶ”üÕ«ēĶŻģ [nvidia-docker](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html)ŃĆéõ╣ŗÕÉÄÕÅ»õ╗źõ╝ĀķĆÆ `--gpus` ÕÅéµĢ░õ╗źÕ£© GPU õĖŖĶ┐ÉĶĪīŃĆé
+
+ńż║õŠŗ’╝Ü
+
+```shell
+docker run --rm \
+--cpus 8 \
+--gpus device=0 \
+-p8080:8080 -p8081:8081 -p8082:8082 \
+--mount type=bind,source=$MODEL_STORE,target=/home/model-server/model-store \
+mmrotate-serve:latest
+```
+
+ÕÅéĶĆā [Ķ»źµ¢ćµĪŻ](https://github.com/pytorch/serve/blob/master/docs/rest_api.md) õ║åĶ¦ŻÕģ│õ║ĵĩńÉå (8080)’╝īń«ĪńÉå (8081) ÕÆīµīćµĀć (8082) ńŁē API ńÜäõ┐Īµü»ŃĆé
+
+### 4. µĄŗĶ»Ģķā©ńĮ▓
+
+```shell
+curl -O https://raw.githubusercontent.com/open-mmlab/mmrotate/main/demo/demo.jpg
+curl http://127.0.0.1:8080/predictions/${MODEL_NAME} -T demo.jpg
+```
+
+µé©Õ║öĶ»źĶÄĘÕŠŚń▒╗õ╝╝õ║Äõ╗źõĖŗÕåģÕ«╣ńÜäÕōŹÕ║ö’╝Ü
+
+```json
+[
+ {
+ "class_name": "small-vehicle",
+ "bbox": [
+ 584.9473266601562,
+ 327.2749938964844,
+ 38.45665740966797,
+ 16.898427963256836,
+ -0.7229751944541931
+ ],
+ "score": 0.9766026139259338
+ },
+ {
+ "class_name": "small-vehicle",
+ "bbox": [
+ 152.0239715576172,
+ 305.92572021484375,
+ 43.144744873046875,
+ 18.85024642944336,
+ 0.014928221702575684
+ ],
+ "score": 0.972826361656189
+ },
+ {
+ "class_name": "large-vehicle",
+ "bbox": [
+ 160.58056640625,
+ 437.3690185546875,
+ 55.6795654296875,
+ 19.31710433959961,
+ 0.007036328315734863
+ ],
+ "score": 0.888836681842804
+ },
+ {
+ "class_name": "large-vehicle",
+ "bbox": [
+ 666.2868041992188,
+ 1011.3961181640625,
+ 60.396209716796875,
+ 21.821645736694336,
+ 0.8549195528030396
+ ],
+ "score": 0.8240180015563965
+ }
+]
+```
+
+ÕÅ”Õż¢’╝īõĮĀõ╣¤ÕÅ»õ╗źõĮ┐ńö© `test_torchserver.py` µØźµ»öĶŠā TorchServe ÕÆī PyTorch ńÜäń╗ōµ×£’╝īÕ╣ČĶ┐øĶĪīÕÅ»Ķ¦åÕī¢ŃĆé
+
+```shell
+python tools/deployment/test_torchserver.py ${IMAGE_FILE} ${CONFIG_FILE} ${CHECKPOINT_FILE} ${MODEL_NAME}
+[--inference-addr ${INFERENCE_ADDR}] [--device ${DEVICE}] [--score-thr ${SCORE_THR}]
+```
+
+ńż║õŠŗ’╝Ü
+
+```shell
+python tools/deployment/test_torchserver.py \
+demo/demo.jpg \
+configs/rotated_faster_rcnn/rotated_faster_rcnn_r50_fpn_1x_dota_le90.py \
+rotated_faster_rcnn_r50_fpn_1x_dota_le90-0393aa5c.pth \
+rotated_fater_rcnn
+```
+
+## µ©ĪÕ×ŗÕżŹµØéÕ║”
+
+`tools/analysis_tools/get_flops.py` µś»µö╣ń╝¢Ķć¬ [flops-counter.pytorch](https://github.com/sovrasov/flops-counter.pytorch) ńÜäĶäܵ£¼’╝īńö©õ║ÄĶ«Īń«Śń╗Öիܵ©ĪÕ×ŗńÜä FLOPs ÕÆīÕÅéµĢ░ķćÅŃĆé
+
+```shell
+python tools/analysis_tools/get_flops.py ${CONFIG_FILE} [--shape ${INPUT_SHAPE}]
+```
+
+ķóäĶ«ĪĶŠōÕć║Õ”éõĖŗ
+
+```text
+==============================
+Input shape: (3, 1024, 1024)
+Flops: 215.92 GFLOPs
+Params: 36.42 M
+==============================
+```
+
+**µ│©µäÅ**: µŁżÕĘźÕģĘõ╗ŹÕżäõ║ÄÕ«×ķ¬īķśČµ«Ą’╝īµłæõ╗¼Õ╣ČõĖŹĶāĮõ┐ØĶ»üĶ«Īń«Śń╗ōµ×£µś»ń╗ØÕ»╣µŁŻńĪ«ńÜäŃĆéõĮĀÕÅ»õ╗źÕ░åń╗ōµ×£ńö©õ║Äń«ĆÕŹĢńÜäµ»öĶŠā’╝ī
+õĮåÕ£©µŖƵ£»µŖźÕæŖµł¢Ķ«║µ¢ćõĖŁķććńö©õ╣ŗÕēŹĶ»Ęõ╗öń╗åµŻĆµ¤ź
+
+1. FLOPs õĖÄĶŠōÕģźÕż¦Õ░ÅńøĖÕģ│’╝īõĮåÕÅéµĢ░ķćÅõĖÄÕģȵŚĀÕģ│ŃĆéķ╗śĶ«żĶŠōÕģźÕż¦Õ░ŵś»(1, 3, 1024, 1024)ŃĆé
+2. õĖĆõ║øń«ŚÕŁÉõŠŗÕ”é DCN µł¢Ķć¬Õ«Üõ╣ēń«ŚÕŁÉÕ╣ȵ£¬ÕīģÕɽգ© FLOPs Ķ«Īń«ŚõĖŁ’╝īµēĆõ╗ź S2A-Net ÕÆīÕ¤║õ║Ä RepPoints ńÜ䵩ĪÕ×ŗńÜä FLOPs Ķ«Īń«Śµś»ķöÖĶ»»ńÜäŃĆé
+ Ķ»”ń╗åõ┐Īµü»Ķ»Ęµ¤źń£ŗ [`mmcv.cnn.get_model_complexity_info()`](https://github.com/open-mmlab/mmcv/blob/master/mmcv/cnn/utils/flops_counter.py)ŃĆé
+3. õĖżķśČµ«ĄµŻĆµĄŗÕÖ©ńÜä FLOPs ÕÅ¢Õå│õ║ÄÕĆÖķĆēńÜäµĢ░ķćÅŃĆé
+
+### ÕćåÕżćÕÅæÕĖāµ©ĪÕ×ŗ
+
+`tools/model_converters/publish_model.py` ÕĖ«ÕŖ®ńö©µłĘÕćåÕżćõ╗¢õ╗¼Õ░åÕÅæÕĖāńÜ䵩ĪÕ×ŗŃĆé
+
+Õ£©Õ░嵩ĪÕ×ŗõĖŖõ╝ĀÕł░ AWS õ╣ŗÕēŹ’╝īõĮĀÕÅ»ĶāĮķ£ĆĶ”ü
+
+1. Õ░嵩ĪÕ×ŗµØāķćŹĶĮ¼µŹóĶć│ CPU
+2. ÕłĀķÖżõ╝śÕī¢ÕÖ©ńÜäńŖȵĆü
+3. Ķ«Īń«ŚµØāķ揵¢ćõ╗ČńÜäÕōłÕĖīÕĆ╝Õ╣ČķÖäÕŖĀÕł░µ¢ćõ╗ČÕÉŹÕÉÄ
+
+```shell
+python tools/model_converters/publish_model.py ${INPUT_FILENAME} ${OUTPUT_FILENAME}
+```
+
+õŠŗÕ”é,
+
+```shell
+python tools/model_converters/publish_model.py work_dirs/rotated_faster_rcnn/latest.pth rotated_faster_rcnn_r50_fpn_1x_dota_le90_20190801.pth
+```
+
+µ£Ćń╗łĶŠōÕć║ńÜäµ¢ćõ╗ČÕÉŹµś» `rotated_faster_rcnn_r50_fpn_1x_dota_le90_20190801-{hash id}.pth`ŃĆé
+
+## Õ¤║ÕćåµĄŗĶ»Ģ
+
+### FPS Õ¤║Õćå
+
+`tools/analysis_tools/benchmark.py` ÕĖ«ÕŖ®ńö©µłĘĶ«Īń«Ś FPSŃĆé FPS ÕĆ╝Õīģµŗ¼µ©ĪÕ×ŗÕēŹÕÉæõ╝ĀµÆŁÕÆīÕÉÄÕżäńÉåŃĆéõĖ║õ║åÕŠŚÕł░µø┤ÕćåńĪ«ńÜäµĢ░ÕĆ╝’╝īńø«ÕēŹÕŬµö»µīüÕŹĢ GPU ÕłåÕĖāÕ╝ÅÕÉ»ÕŖ©ŃĆé
+
+```shell
+python -m torch.distributed.launch --nproc_per_node=1 --master_port=${PORT} tools/analysis_tools/benchmark.py \
+ ${CONFIG} \
+ ${CHECKPOINT} \
+ [--repeat-num ${REPEAT_NUM}] \
+ [--max-iter ${MAX_ITER}] \
+ [--log-interval ${LOG_INTERVAL}] \
+ --launcher pytorch
+```
+
+ńż║õŠŗ: ÕüćĶ«ŠõĮĀÕĘ▓ń╗ÅõĖŗĶĮĮõ║å `Rotated Faster R-CNN` µ©ĪÕ×ŗµØāķćŹÕł░ `checkpoints/` µ¢ćõ╗ČÕż╣
+
+```shell
+python -m torch.distributed.launch --nproc_per_node=1 --master_port=29500 tools/analysis_tools/benchmark.py \
+ configs/rotated_faster_rcnn/rotated_faster_rcnn_r50_fpn_1x_dota_le90.py \
+ checkpoints/rotated_faster_rcnn_r50_fpn_1x_dota_le90-0393aa5c.pth \
+ --launcher pytorch
+```
+
+## µØéķĪ╣
+
+### µēōÕŹ░Õ«īµĢ┤ķģŹńĮ«µ¢ćõ╗Č
+
+`tools/misc/print_config.py` ĶŠōÕć║µĢ┤õĖ¬ķģŹńĮ«µ¢ćõ╗ČÕ╣ȵĢ┤ÕÉłÕģȵēƵ£ēÕ»╝ÕģźŃĆé
+
+```shell
+python tools/misc/print_config.py ${CONFIG} [-h] [--options ${OPTIONS [OPTIONS...]}]
+```
+
+## µĘʵĘåń¤®ķśĄ
+
+µĘʵĘåń¤®ķśĄµś»ķó䵥ŗń╗ōµ×£ńÜäµ”éĶ”ü
+
+`tools/analysis_tools/confusion_matrix.py` ÕÅ»õ╗źÕłåµ×Éķó䵥ŗń╗ōµ×£Õ╣Čń╗śÕłČµĘʵĘåń¤®ķśĄŃĆé
+
+ķ”¢Õģłµē¦ĶĪī `tools/test.py` Õ░åµŻĆµĄŗń╗ōµ×£õ┐ØÕŁśõĖ║ `.pkl` µ¢ćõ╗ČŃĆé
+
+õ╣ŗÕÉĵē¦ĶĪī
+
+```
+python tools/analysis_tools/confusion_matrix.py ${CONFIG} ${DETECTION_RESULTS} ${SAVE_DIR} --show
+```
+
+õĮĀõ╝ÜÕŠŚÕł░õĖĆõĖ¬ń▒╗õ╝╝õ║ÄõĖŗÕøŠńÜäµĘʵĘåń¤®ķśĄ:
+
+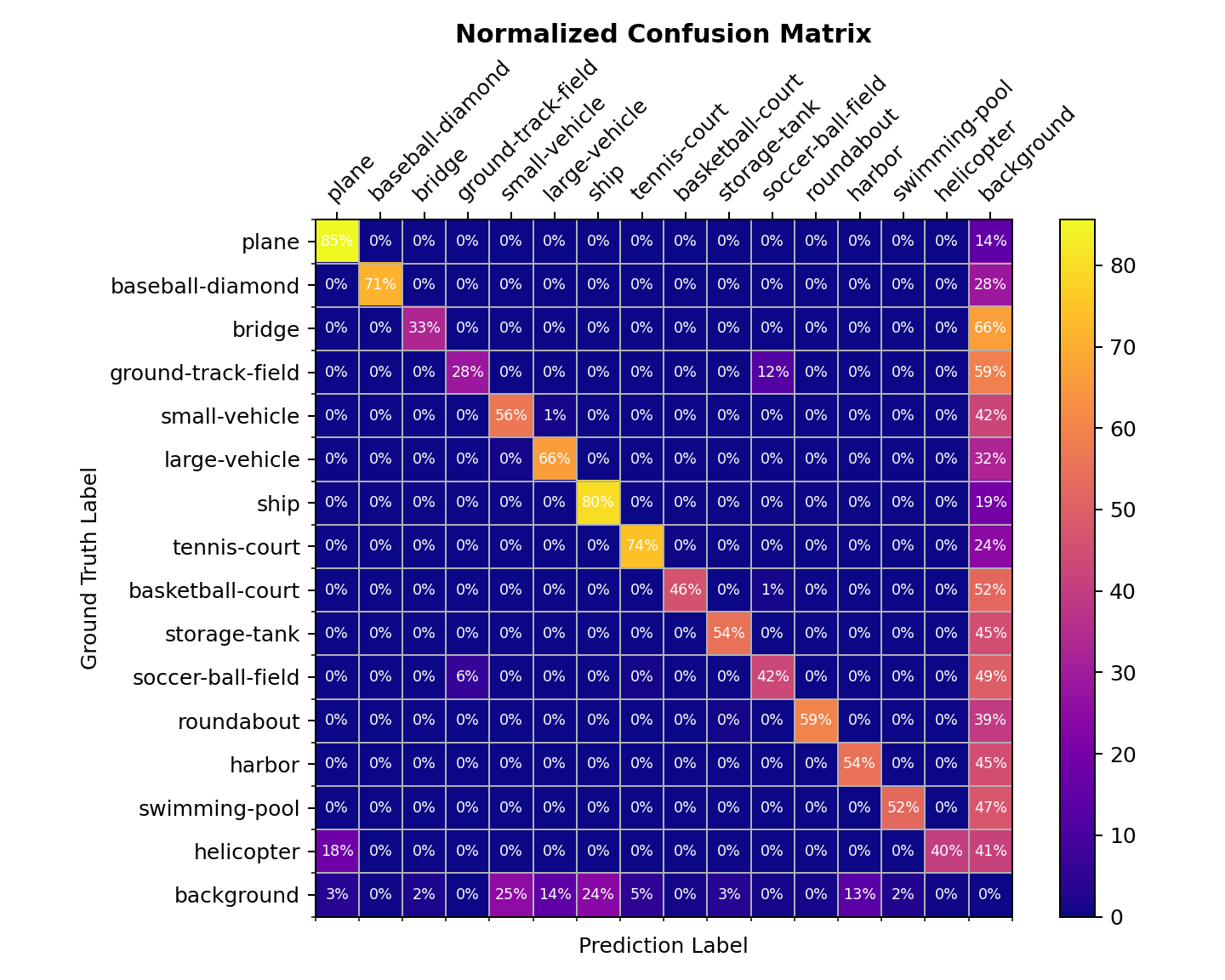
diff --git a/internlm_langchain/knowledge_base/MMRotate/vector_store/index.faiss b/internlm_langchain/knowledge_base/MMRotate/vector_store/index.faiss
new file mode 100644
index 00000000..b7434bbe
Binary files /dev/null and b/internlm_langchain/knowledge_base/MMRotate/vector_store/index.faiss differ
diff --git a/internlm_langchain/knowledge_base/MMSegmentation/content/1_config.md b/internlm_langchain/knowledge_base/MMSegmentation/content/1_config.md
new file mode 100644
index 00000000..dfcf0f96
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMSegmentation/content/1_config.md
@@ -0,0 +1,577 @@
+# µĢÖń©ŗ1’╝Üõ║åĶ¦ŻķģŹńĮ«µ¢ćõ╗Č
+
+µłæõ╗¼Õ░嵩ĪÕØŚÕī¢ÕÆīń╗¦µē┐µĆ¦Ķ«ŠĶ«ĪĶ׏ÕģźÕł░µłæõ╗¼ńÜäķģŹńĮ«µ¢ćõ╗Čń│╗ń╗¤õĖŁ’╝īµ¢╣õŠ┐Ķ┐øĶĪīÕÉäń¦ŹÕ«×ķ¬īŃĆéÕ”éµ×£µé©µā│µ¤źń£ŗķģŹńĮ«µ¢ćõ╗Č’╝īõĮĀÕÅ»õ╗źĶ┐ÉĶĪī `python tools/misc/print_config.py /PATH/TO/CONFIG` µØźµ¤źń£ŗÕ«īµĢ┤ńÜäķģŹńĮ«µ¢ćõ╗ČŃĆéõĮĀõ╣¤ÕÅ»õ╗źķĆÜĶ┐ćõ╝ĀķĆÆÕÅéµĢ░ `--cfg-options xxx.yyy=zzz` µØźµ¤źń£ŗµø┤µ¢░ńÜäķģŹńĮ«õ┐Īµü»ŃĆé
+
+## ķģŹńĮ«µ¢ćõ╗ČńÜäń╗ōµ×ä
+
+Õ£© `config/_base_ ` µ¢ćõ╗ČÕż╣õĖŗķØóµ£ē4ń¦ŹÕ¤║µ£¼ń╗äõ╗Čń▒╗Õ×ŗ’╝Ü µĢ░µŹ«ķøå(dataset)’╝īµ©ĪÕ×ŗ(model)’╝īĶ«Łń╗āńŁ¢ńĢź(schedule)ÕÆīĶ┐ÉĶĪīµŚČńÜäķ╗śĶ«żĶ«ŠńĮ«(default runtime)ŃĆéĶ«ĖÕżÜµ©ĪÕ×ŗķāĮÕÅ»õ╗źÕŠłÕ«╣µśōÕ£░ķĆÜĶ┐ćń╗äÕÉłĶ┐Öõ║øń╗äõ╗ČĶ┐øĶĪīÕ«×ńÄ░’╝īµ»öÕ”é DeepLabV3’╝īPSPNetŃĆéõĮ┐ńö© `_base_` õĖŗńÜäń╗äõ╗ȵ×äÕ╗║ńÜäķģŹńĮ«õ┐Īµü»ÕŽÕüÜÕĤզŗķģŹńĮ« (primitive)ŃĆé
+
+Õ»╣õ║ÄÕÉīõĖĆõĖ¬µ¢ćõ╗ČÕż╣õĖŗńÜäµēƵ£ēķģŹńĮ«µ¢ćõ╗Č’╝īÕ╗║Ķ««**ÕŬµ£ēõĖĆõĖ¬**Õ»╣Õ║öńÜä**ÕĤզŗķģŹńĮ«µ¢ćõ╗Č**ŃĆéµēƵ£ēÕģČõ╗¢ńÜäķģŹńĮ«µ¢ćõ╗ČķāĮÕ║öĶ»źń╗¦µē┐Ķć¬Ķ┐ÖõĖ¬ÕĤզŗķģŹńĮ«µ¢ćõ╗Č’╝īõ╗ÄĶĆīõ┐ØĶ»üµ»ÅõĖ¬ķģŹńĮ«µ¢ćõ╗ČńÜäµ£ĆÕż¦ń╗¦µē┐µĘ▒Õ║”õĖ║ 3ŃĆé
+
+õĖ║õ║åõŠ┐õ║ÄńÉåĶ¦Ż’╝īµłæõ╗¼Õ╗║Ķ««ńżŠÕī║Ķ┤Īńī«ĶĆģõ╗ÄńÄ░µ£ēńÜäµ¢╣µ│Ģń╗¦µē┐ŃĆéõŠŗÕ”é’╝īÕ”éµ×£µé©Õ£© DeepLabV3 Õ¤║ńĪĆõĖŖĶ┐øĶĪīõ║åõĖĆõ║øõ┐«µö╣’╝īńö©µłĘÕÅ»õ╗źÕģłķĆÜĶ┐ćµīćÕ«Ü `_base_ = ../deeplabv3/deeplabv3_r50-d8_4xb2-40k_cityscapes-512x1024.py` ń╗¦µē┐Õ¤║µ£¼ńÜä DeepLabV3 ń╗ōµ×ä’╝īńäČÕÉÄÕ£©ķģŹńĮ«µ¢ćõ╗ČõĖŁõ┐«µö╣Õ┐ģĶ”üńÜäÕŁŚµ«ĄŃĆé
+
+Õ”éµ×£õĮĀµŁŻÕ£©µ×äÕ╗║õĖĆõĖ¬Õģ©µ¢░ńÜäµ¢╣µ│Ģ’╝īÕ«āõĖŹõĖÄńÄ░µ£ēńÜäõ╗╗õĮĢµ¢╣µ│ĢÕģ▒õ║½Õ¤║µ£¼ń╗äõ╗Č’╝īµé©ÕÅ»õ╗źÕ£©`config`õĖŗÕłøÕ╗║õĖĆõĖ¬µ¢░ńÜäµ¢ćõ╗ČÕż╣`xxxnet` ’╝īĶ»”ń╗åµ¢ćµĪŻĶ»ĘÕÅéĶĆā[mmengine](https://mmengine.readthedocs.io/en/latest/tutorials/config.html)ŃĆé
+
+## ķģŹńĮ«µ¢ćõ╗ČÕæĮÕÉŹķŻÄµĀ╝
+
+µłæõ╗¼ķüĄÕŠ¬õ╗źõĖŗµĀ╝Õ╝ÅµØźÕæĮÕÉŹķģŹńĮ«µ¢ćõ╗Č’╝īÕ╗║Ķ««ńżŠÕī║Ķ┤Īńī«ĶĆģķüĄÕŠ¬ńøĖÕÉīńÜäķŻÄµĀ╝ŃĆé
+
+```text
+{algorithm name}_{model component names [component1]_[component2]_[...]}_{training settings}_{training dataset information}_{testing dataset information}
+```
+
+ķģŹńĮ«µ¢ćõ╗ČńÜäµ¢ćõ╗ČÕÉŹÕłåõĖ║õ║öõĖ¬ķā©Õłå’╝īń╗䵳ɵ¢ćõ╗ČÕÉŹµ»ÅõĖĆõĖ¬ķā©ÕłåÕÆīń╗äõ╗Čõ╣ŗķŚ┤ķāĮńö©`_`Ķ┐׵ğ’╝īµ»ÅõĖ¬ķā©Õłåµł¢ń╗äõ╗ČõĖŁńÜäµ»ÅõĖ¬ÕŹĢĶ»ŹķāĮĶ”üńö©`-`Ķ┐׵ğŃĆé
+
+- `{algorithm name}`: ń«Śµ│ĢńÜäÕÉŹń¦░’╝īÕ”é `deeplabv3`, `pspnet` ńŁēŃĆé
+- `{model component names}`: ń«Śµ│ĢõĖŁõĮ┐ńö©ńÜäń╗äõ╗ČÕÉŹń¦░’╝īÕ”éõĖ╗Õ╣▓(backbone)ŃĆüĶ¦ŻńĀüÕż┤(head)ńŁēŃĆéõŠŗÕ”é’╝ī`r50-d8 `ĶĪ©ńż║õĮ┐ńö©ResNet50õĖ╗Õ╣▓ńĮæń╗£’╝īÕ╣ČõĮ┐ńö©õĖ╗Õ╣▓ńĮæń╗£ńÜä8ÕĆŹõĖŗķććµĀĘĶŠōÕć║õĮ£õĖ║õĖŗõĖĆń║¦ńÜäĶŠōÕģźŃĆé
+- `{training settings}`: Ķ«Łń╗āµŚČńÜäÕÅéµĢ░Ķ«ŠńĮ«’╝īÕ”é `batch size`ŃĆüµĢ░µŹ«Õó×Õ╝║(augmentation)ŃĆüµŹ¤Õż▒ÕćĮµĢ░(loss)ŃĆüÕŁ”õ╣ĀńÄćĶ░āÕ║”ÕÖ©(learning rate scheduler)ÕÆīĶ«Łń╗āĶĮ«µĢ░(epochs/iterations)ŃĆéõŠŗÕ”é: `4xb4-ce-linearlr-40K` µäÅÕæ│ńØĆõĮ┐ńö©4õĖ¬gpu’╝īµ»ÅõĖ¬gpu4õĖ¬ÕøŠÕāÅ’╝īõĮ┐ńö©õ║żÕÅēńåĄµŹ¤Õż▒ÕćĮµĢ░(CrossEntropy)’╝īń║┐µĆ¦ÕŁ”õ╣ĀńÄćĶ░āÕ║”ń©ŗÕ║Å’╝īĶ«Łń╗ā40K iterationsŃĆé
+ õĖĆõ║øń╝®ÕåÖ:
+ - `{gpu x batch_per_gpu}`: GPUµĢ░ķćÅÕÆīµ»ÅõĖ¬GPUńÜäµĀʵ£¼µĢ░ŃĆé`bN ` ĶĪ©ńż║µ»ÅõĖ¬GPUńÜäbatch sizeõĖ║N’╝īÕ”é `8xb2` õĖ║8õĖ¬gpu x µ»ÅõĖ¬gpu2Õ╝ĀÕøŠÕāÅńÜäń╝®ÕåÖŃĆéÕ”éµ×£µ£¬µÅÉÕÅŖ’╝īÕłÖķ╗śĶ«żõĮ┐ńö© `4xb4 `ŃĆé
+ - `{schedule}`: Ķ«Łń╗āĶ«ĪÕłÆ’╝īķĆēķĪ╣µ£ē`20k`’╝ī`40k`ńŁēŃĆé`20k ` ÕÆī `40k` ÕłåÕł½ĶĪ©ńż║20000µ¼ĪĶ┐Łõ╗Ż(iterations)ÕÆī40000µ¼ĪĶ┐Łõ╗Ż(iterations)ŃĆé
+- `{training dataset information}`: Ķ«Łń╗āµĢ░µŹ«ķøåÕÉŹń¦░’╝īÕ”é `cityscapes `’╝ī `ade20k ` ńŁē’╝īõ╗źÕÅŖĶŠōÕģźÕłåĶŠ©ńÄćŃĆéõŠŗÕ”é: `cityscapes-768x768 `ĶĪ©ńż║õĮ┐ńö© `cityscapes` µĢ░µŹ«ķøåĶ┐øĶĪīĶ«Łń╗ā’╝īĶŠōÕģźÕłåĶŠ©ńÄćõĖ║`768x768 `ŃĆé
+- `{testing dataset information}` (ÕÅ»ķĆē): µĄŗĶ»ĢµĢ░µŹ«ķøåÕÉŹń¦░ŃĆéÕĮōµé©ńÜ䵩ĪÕ×ŗÕ£©õĖĆõĖ¬µĢ░µŹ«ķøåõĖŖĶ«Łń╗āõĮåÕ£©ÕÅ”õĖĆõĖ¬µĢ░µŹ«ķøåõĖŖµĄŗĶ»ĢµŚČ’╝īĶ»ĘÕ░åµĄŗĶ»ĢµĢ░µŹ«ķøåÕÉŹń¦░µĘ╗ÕŖĀÕł░µŁżÕżäŃĆéÕ”éµ×£µ▓Īµ£ēĶ┐ÖõĖĆķā©Õłå’╝īÕłÖµäÅÕæ│ńØƵ©ĪÕ×ŗµś»Õ£©ÕÉīõĖĆõĖ¬µĢ░µŹ«ķøåõĖŖĶ┐øĶĪīĶ«Łń╗āÕÆīµĄŗĶ»ĢńÜäŃĆé
+
+## PSPNet ńÜäõĖĆõĖ¬õŠŗÕŁÉ
+
+õĖ║õ║åÕĖ«ÕŖ®ńö©µłĘń夵éēÕ»╣Ķ┐ÖõĖ¬ńÄ░õ╗ŻĶ»Łõ╣ēÕłåÕē▓ń│╗ń╗¤ńÜäÕ«īµĢ┤ķģŹńĮ«µ¢ćõ╗ČÕÆīµ©ĪÕØŚ’╝īµłæõ╗¼Õ»╣õĮ┐ńö©ResNet50V1cõĮ£õĖ║õĖ╗Õ╣▓ńĮæń╗£ńÜäPSPNetńÜäķģŹńĮ«µ¢ćõ╗ČõĮ£Õ”éõĖŗńÜäń«ĆĶ”üµ│©ķćŖÕÆīĶ»┤µśÄŃĆéĶ”üõ║åĶ¦Żµø┤Ķ»”ń╗åńÜäńö©µ│ĢÕÆīµ»ÅõĖ¬µ©ĪÕØŚÕ»╣Õ║öńÜäµø┐µŹóµ¢╣µ│Ģ’╝īĶ»ĘÕÅéķśģAPIµ¢ćµĪŻŃĆé
+
+```python
+_base_ = [
+ '../_base_/models/pspnet_r50-d8.py', '../_base_/datasets/cityscapes.py',
+ '../_base_/default_runtime.py', '../_base_/schedules/schedule_40k.py'
+] # µłæõ╗¼ÕÅ»õ╗źÕ£©Õ¤║µ£¼ķģŹńĮ«µ¢ćõ╗ČńÜäÕ¤║ńĪĆõĖŖ µ×äÕ╗║µ¢░ńÜäķģŹńĮ«µ¢ćõ╗Č
+crop_size = (512, 1024)
+data_preprocessor = dict(size=crop_size)
+model = dict(data_preprocessor=data_preprocessor)
+```
+
+`_base_/models/pspnet_r50-d8.py`µś»õĮ┐ńö©ResNet50V1cõĮ£õĖ║õĖ╗Õ╣▓ńĮæń╗£ńÜäPSPNetńÜäÕ¤║µ£¼µ©ĪÕ×ŗķģŹńĮ«µ¢ćõ╗ČŃĆé
+
+```python
+# µ©ĪÕ×ŗĶ«ŠńĮ«
+norm_cfg = dict(type='SyncBN', requires_grad=True) # ÕłåÕē▓µĪåµ×ČķĆÜÕĖĖõĮ┐ńö© SyncBN
+data_preprocessor = dict( # µĢ░µŹ«ķóäÕżäńÉåńÜäķģŹńĮ«ķĪ╣’╝īķĆÜÕĖĖÕīģµŗ¼ÕøŠÕāÅńÜäÕĮÆõĖĆÕī¢ÕÆīÕó×Õ╝║
+ type='SegDataPreProcessor', # µĢ░µŹ«ķóäÕżäńÉåńÜäń▒╗Õ×ŗ
+ mean=[123.675, 116.28, 103.53], # ńö©õ║ÄÕĮÆõĖĆÕī¢ĶŠōÕģźÕøŠÕāÅńÜäÕ╣│ÕØćÕĆ╝
+ std=[58.395, 57.12, 57.375], # ńö©õ║ÄÕĮÆõĖĆÕī¢ĶŠōÕģźÕøŠÕāÅńÜäµĀćÕćåÕĘ«
+ bgr_to_rgb=True, # µś»ÕÉ”Õ░åÕøŠÕāÅõ╗Ä BGR ĶĮ¼õĖ║ RGB
+ pad_val=0, # ÕøŠÕāÅńÜäÕĪ½ÕģģÕĆ╝
+ seg_pad_val=255) # 'gt_seg_map'ńÜäÕĪ½ÕģģÕĆ╝
+model = dict(
+ type='EncoderDecoder', # ÕłåÕē▓ÕÖ©(segmentor)ńÜäÕÉŹÕŁŚ
+ data_preprocessor=data_preprocessor,
+ pretrained='open-mmlab://resnet50_v1c', # ÕŖĀĶĮĮõĮ┐ńö© ImageNet ķóäĶ«Łń╗āńÜäõĖ╗Õ╣▓ńĮæń╗£
+ backbone=dict(
+ type='ResNetV1c', # õĖ╗Õ╣▓ńĮæń╗£ńÜäń▒╗Õł½’╝īµø┤ÕżÜń╗åĶŖéĶ»ĘÕÅéĶĆā mmseg/models/backbones/resnet.py
+ depth=50, # õĖ╗Õ╣▓ńĮæń╗£ńÜäµĘ▒Õ║”’╝īķĆÜÕĖĖõĖ║ 50 ÕÆī 101
+ num_stages=4, # õĖ╗Õ╣▓ńĮæń╗£ńŖȵĆü(stages)ńÜäµĢ░ńø«
+ out_indices=(0, 1, 2, 3), # µ»ÅõĖ¬ńŖȵĆü(stage)õ║¦ńö¤ńÜäńē╣ÕŠüÕøŠĶŠōÕć║ńÜäń┤óÕ╝Ģ
+ dilations=(1, 1, 2, 4), # µ»ÅõĖĆÕ▒é(layer)ńÜäń®║Õ┐āńÄć(dilation rate)
+ strides=(1, 2, 1, 1), # µ»ÅõĖĆÕ▒é(layer)ńÜ䵣źķĢ┐(stride)
+ norm_cfg=norm_cfg, # ÕĮÆõĖĆÕī¢Õ▒é(norm layer)ńÜäķģŹńĮ«ķĪ╣
+ norm_eval=False, # µś»ÕÉ”Õå╗ń╗ō BN ķćīńÜäń╗¤Ķ«ĪķĪ╣
+ style='pytorch', # õĖ╗Õ╣▓ńĮæń╗£ńÜäķŻÄµĀ╝’╝ī'pytorch' µäŵĆصś»µŁźķĢ┐õĖ║2ńÜäÕ▒éõĖ║ 3x3 ÕŹĘń¦»’╝ī 'caffe' µäŵĆصś»µŁźķĢ┐õĖ║2ńÜäÕ▒éõĖ║ 1x1 ÕŹĘń¦»
+ contract_dilation=True), # ÕĮōń®║µ┤×ńÄć > 1, µś»ÕÉ”ÕÄŗń╝®ń¼¼õĖĆõĖ¬ń®║µ┤×Õ▒é
+ decode_head=dict(
+ type='PSPHead', # Ķ¦ŻńĀüÕż┤(decode head)ńÜäń▒╗Õł½ŃĆéÕÅ»ńö©ķĆēķĪ╣Ķ»ĘÕÅé mmseg/models/decode_heads
+ in_channels=2048, # Ķ¦ŻńĀüÕż┤ńÜäĶŠōÕģźķĆÜķüōµĢ░
+ in_index=3, # Ķó½ķĆēµŗ®ńē╣ÕŠüÕøŠ(feature map)ńÜäń┤óÕ╝Ģ
+ channels=512, # Ķ¦ŻńĀüÕż┤õĖŁķŚ┤µĆü(intermediate)ńÜäķĆÜķüōµĢ░
+ pool_scales=(1, 2, 3, 6), # PSPHead Õ╣│ÕØćµ▒ĀÕī¢(avg pooling)ńÜäĶ¦äµ©Ī(scales)ŃĆé ń╗åĶŖéĶ»ĘÕÅéĶĆāµ¢ćń½ĀÕåģÕ«╣
+ dropout_ratio=0.1, # Ķ┐øÕģźµ£ĆÕÉÄÕłåń▒╗Õ▒é(classification layer)õ╣ŗÕēŹńÜä dropout µ»öõŠŗ
+ num_classes=19, # ÕłåÕē▓ÕēŹµÖ»ńÜäń¦Źń▒╗µĢ░ńø«ŃĆé ķĆÜÕĖĖµāģÕåĄõĖŗ’╝īcityscapes õĖ║19’╝īVOCõĖ║21’╝īADE20k õĖ║150
+ norm_cfg=norm_cfg, # ÕĮÆõĖĆÕī¢Õ▒éńÜäķģŹńĮ«ķĪ╣
+ align_corners=False, # Ķ¦ŻńĀüĶ┐ćń©ŗõĖŁĶ░āµĢ┤Õż¦Õ░Å(resize)ńÜä align_corners ÕÅéµĢ░
+ loss_decode=dict( # Ķ¦ŻńĀüÕż┤(decode_head)ķćīńÜ䵏¤Õż▒ÕćĮµĢ░ńÜäķģŹńĮ«ķĪ╣
+ type='CrossEntropyLoss', # ÕłåÕē▓µŚČõĮ┐ńö©ńÜ䵏¤Õż▒ÕćĮµĢ░ńÜäń▒╗Õł½
+ use_sigmoid=False, # ÕłåÕē▓µŚČµś»ÕÉ”õĮ┐ńö© sigmoid µ┐Ƶ┤╗
+ loss_weight=1.0)), # Ķ¦ŻńĀüÕż┤ńÜ䵏¤Õż▒µØāķćŹ
+ auxiliary_head=dict(
+ type='FCNHead', # ĶŠģÕŖ®Õż┤(auxiliary head)ńÜäń¦Źń▒╗ŃĆéÕÅ»ńö©ķĆēķĪ╣Ķ»ĘÕÅéĶĆā mmseg/models/decode_heads
+ in_channels=1024, # ĶŠģÕŖ®Õż┤ńÜäĶŠōÕģźķĆÜķüōµĢ░
+ in_index=2, # Ķó½ķĆēµŗ®ńÜäńē╣ÕŠüÕøŠ(feature map)ńÜäń┤óÕ╝Ģ
+ channels=256, # ĶŠģÕŖ®Õż┤õĖŁķŚ┤µĆü(intermediate)ńÜäķĆÜķüōµĢ░
+ num_convs=1, # FCNHead ķćīÕŹĘń¦»(convs)ńÜäµĢ░ńø«’╝īĶŠģÕŖ®Õż┤õĖŁķĆÜÕĖĖõĖ║1
+ concat_input=False, # Õ£©Õłåń▒╗Õ▒é(classification layer)õ╣ŗÕēŹµś»ÕÉ”Ķ┐׵ğ(concat)ĶŠōÕģźÕÆīÕŹĘń¦»ńÜäĶŠōÕć║
+ dropout_ratio=0.1, # Ķ┐øÕģźµ£ĆÕÉÄÕłåń▒╗Õ▒é(classification layer)õ╣ŗÕēŹńÜä dropout µ»öõŠŗ
+ num_classes=19, # ÕłåÕē▓ÕēŹµÖ»ńÜäń¦Źń▒╗µĢ░ńø«ŃĆé ķĆÜÕĖĖµāģÕåĄõĖŗ’╝īcityscapes õĖ║19’╝īVOCõĖ║21’╝īADE20k õĖ║150
+ norm_cfg=norm_cfg, # ÕĮÆõĖĆÕī¢Õ▒éńÜäķģŹńĮ«ķĪ╣
+ align_corners=False, # Ķ¦ŻńĀüĶ┐ćń©ŗõĖŁĶ░āµĢ┤Õż¦Õ░Å(resize)ńÜä align_corners ÕÅéµĢ░
+ loss_decode=dict( # ĶŠģÕŖ®Õż┤(auxiliary head)ķćīńÜ䵏¤Õż▒ÕćĮµĢ░ńÜäķģŹńĮ«ķĪ╣
+ type='CrossEntropyLoss', # ÕłåÕē▓µŚČõĮ┐ńö©ńÜ䵏¤Õż▒ÕćĮµĢ░ńÜäń▒╗Õł½
+ use_sigmoid=False, # ÕłåÕē▓µŚČµś»ÕÉ”õĮ┐ńö© sigmoid µ┐Ƶ┤╗
+ loss_weight=0.4)), # ĶŠģÕŖ®Õż┤µŹ¤Õż▒ńÜäµØāķ插╝īķ╗śĶ«żĶ«ŠńĮ«õĖ║0.4
+ # µ©ĪÕ×ŗĶ«Łń╗āÕÆīµĄŗĶ»ĢĶ«ŠńĮ«ķĪ╣
+ train_cfg=dict(), # train_cfg ÕĮōÕēŹõ╗ģµś»õĖĆõĖ¬ÕŹĀõĮŹń¼”
+ test_cfg=dict(mode='whole')) # µĄŗĶ»Ģµ©ĪÕ╝Å’╝īÕÅ»ķĆēÕÅéµĢ░õĖ║ 'whole' ÕÆī 'slide'. 'whole': Õ£©µĢ┤Õ╝ĀÕøŠÕāÅõĖŖÕģ©ÕŹĘń¦»(fully-convolutional)µĄŗĶ»ĢŃĆé 'slide': Õ£©ĶŠōÕģźÕøŠÕāÅõĖŖÕüܵ╗æń¬Śķó䵥ŗ
+```
+
+`_base_/datasets/cityscapes.py`µś»µĢ░µŹ«ķøåńÜäÕ¤║µ£¼ķģŹńĮ«µ¢ćõ╗ČŃĆé
+
+```python
+# µĢ░µŹ«ķøåĶ«ŠńĮ«
+dataset_type = 'CityscapesDataset' # µĢ░µŹ«ķøåń▒╗Õ×ŗ’╝īĶ┐ÖÕ░åĶó½ńö©µØźÕ«Üõ╣ēµĢ░µŹ«ķøå
+data_root = 'data/cityscapes/' # µĢ░µŹ«ńÜäµĀ╣ĶĘ»ÕŠä
+crop_size = (512, 1024) # Ķ«Łń╗āµŚČńÜäĶŻüÕē¬Õż¦Õ░Å
+train_pipeline = [ # Ķ«Łń╗āµĄüń©ŗ
+ dict(type='LoadImageFromFile'), # ń¼¼1õĖ¬µĄüń©ŗ’╝īõ╗ĵ¢ćõ╗ČĶĘ»ÕŠäķćīÕŖĀĶĮĮÕøŠÕāÅ
+ dict(type='LoadAnnotations'), # ń¼¼2õĖ¬µĄüń©ŗ’╝īÕ»╣õ║ÄÕĮōÕēŹÕøŠÕāÅ’╝īÕŖĀĶĮĮÕ«āńÜäµĀćµ│©ÕøŠÕāÅ
+ dict(type='RandomResize', # Ķ░āµĢ┤ĶŠōÕģźÕøŠÕāÅÕż¦Õ░Å(resize)ÕÆīÕģȵĀćµ│©ÕøŠÕāÅńÜäµĢ░µŹ«Õó×Õ╣┐µĄüń©ŗ
+ scale=(2048, 1024), # ÕøŠÕāÅĶŻüÕē¬ńÜäÕż¦Õ░Å
+ ratio_range=(0.5, 2.0), # µĢ░µŹ«Õó×Õ╣┐ńÜäµ»öõŠŗĶīāÕø┤
+ keep_ratio=True), # Ķ░āµĢ┤ÕøŠÕāÅÕż¦Õ░ŵŚČµś»ÕÉ”õ┐صīüń║Ąµ©¬µ»ö
+ dict(type='RandomCrop', # ķÜŵ£║ĶŻüÕē¬ÕĮōÕēŹÕøŠÕāÅÕÆīÕģȵĀćµ│©ÕøŠÕāÅńÜäµĢ░µŹ«Õó×Õ╣┐µĄüń©ŗ
+ crop_size=crop_size, # ķÜŵ£║ĶŻüÕē¬ńÜäÕż¦Õ░Å
+ cat_max_ratio=0.75), # ÕŹĢõĖ¬ń▒╗Õł½ÕÅ»õ╗źÕĪ½ÕģģńÜäµ£ĆÕż¦Õī║Õ¤¤ńÜäµ»ö
+ dict(type='RandomFlip', # ń┐╗ĶĮ¼ÕøŠÕāÅÕÆīÕģȵĀćµ│©ÕøŠÕāÅńÜäµĢ░µŹ«Õó×Õ╣┐µĄüń©ŗ
+ prob=0.5), # ń┐╗ĶĮ¼ÕøŠÕāÅńÜäµ”éńÄć
+ dict(type='PhotoMetricDistortion'), # ÕģēÕŁ”õĖŖõĮ┐ńö©õĖĆõ║øµ¢╣µ│ĢµēŁµø▓ÕĮōÕēŹÕøŠÕāÅÕÆīÕģȵĀćµ│©ÕøŠÕāÅńÜäµĢ░µŹ«Õó×Õ╣┐µĄüń©ŗ
+ dict(type='PackSegInputs') # µēōÕīģńö©õ║ÄĶ»Łõ╣ēÕłåÕē▓ńÜäĶŠōÕģźµĢ░µŹ«
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'), # ń¼¼1õĖ¬µĄüń©ŗ’╝īõ╗ĵ¢ćõ╗ČĶĘ»ÕŠäķćīÕŖĀĶĮĮÕøŠÕāÅ
+ dict(type='Resize', # õĮ┐ńö©Ķ░āµĢ┤ÕøŠÕāÅÕż¦Õ░Å(resize)Õó×Õ╝║
+ scale=(2048, 1024), # ÕøŠÕāÅń╝®µöŠńÜäÕż¦Õ░Å
+ keep_ratio=True), # Õ£©Ķ░āµĢ┤ÕøŠÕāÅÕż¦Õ░ŵŚČµś»ÕÉ”õ┐ØńĢÖķĢ┐Õ«Įµ»ö
+ # Õ£©' Resize 'õ╣ŗÕÉĵĘ╗ÕŖĀµĀćµ│©ÕøŠÕāÅ
+ # õĖŹķ£ĆĶ”üÕüÜĶ░āµĢ┤ÕøŠÕāÅÕż¦Õ░Å(resize)ńÜäµĢ░µŹ«ÕÅśµŹó
+ dict(type='LoadAnnotations'), # ÕŖĀĶĮĮµĢ░µŹ«ķøåµÅÉõŠøńÜäĶ»Łõ╣ēÕłåÕē▓µĀćµ│©
+ dict(type='PackSegInputs') # µēōÕīģńö©õ║ÄĶ»Łõ╣ēÕłåÕē▓ńÜäĶŠōÕģźµĢ░µŹ«
+]
+train_dataloader = dict( # Ķ«Łń╗āµĢ░µŹ«ÕŖĀĶĮĮÕÖ©(dataloader)ńÜäķģŹńĮ«
+ batch_size=2, # µ»ÅõĖĆõĖ¬GPUńÜäbatch sizeÕż¦Õ░Å
+ num_workers=2, # õĖ║µ»ÅõĖĆõĖ¬GPUķóäĶ»╗ÕÅ¢µĢ░µŹ«ńÜäĶ┐øń©ŗõĖ¬µĢ░
+ persistent_workers=True, # Õ£©õĖĆõĖ¬epochń╗ōµØ¤ÕÉÄÕģ│ķŚŁworkerĶ┐øń©ŗ’╝īÕÅ»õ╗źÕŖĀÕ┐½Ķ«Łń╗āķƤÕ║”
+ sampler=dict(type='InfiniteSampler', shuffle=True), # Ķ«Łń╗āµŚČĶ┐øĶĪīķÜŵ£║µ┤Śńēī(shuffle)
+ dataset=dict( # Ķ«Łń╗āµĢ░µŹ«ķøåķģŹńĮ«
+ type=dataset_type, # µĢ░µŹ«ķøåń▒╗Õ×ŗ’╝īĶ»”Ķ¦ümmseg/datassets/
+ data_root=data_root, # µĢ░µŹ«ķøåńÜäµĀ╣ńø«ÕĮĢ
+ data_prefix=dict(
+ img_path='leftImg8bit/train', seg_map_path='gtFine/train'), # Ķ«Łń╗āµĢ░µŹ«ńÜäÕēŹń╝Ć
+ pipeline=train_pipeline)) # µĢ░µŹ«ÕżäńÉåµĄüń©ŗ’╝īÕ«āķĆÜĶ┐ćõ╣ŗÕēŹÕłøÕ╗║ńÜätrain_pipelineõ╝ĀķĆÆŃĆé
+val_dataloader = dict(
+ batch_size=1, # µ»ÅõĖĆõĖ¬GPUńÜäbatch sizeÕż¦Õ░Å
+ num_workers=4, # õĖ║µ»ÅõĖĆõĖ¬GPUķóäĶ»╗ÕÅ¢µĢ░µŹ«ńÜäĶ┐øń©ŗõĖ¬µĢ░
+ persistent_workers=True, # Õ£©õĖĆõĖ¬epochń╗ōµØ¤ÕÉÄÕģ│ķŚŁworkerĶ┐øń©ŗ’╝īÕÅ»õ╗źÕŖĀÕ┐½Ķ«Łń╗āķƤÕ║”
+ sampler=dict(type='DefaultSampler', shuffle=False), # Ķ«Łń╗āµŚČõĖŹĶ┐øĶĪīķÜŵ£║µ┤Śńēī(shuffle)
+ dataset=dict( # µĄŗĶ»ĢµĢ░µŹ«ķøåķģŹńĮ«
+ type=dataset_type, # µĢ░µŹ«ķøåń▒╗Õ×ŗ’╝īĶ»”Ķ¦ümmseg/datassets/
+ data_root=data_root, # µĢ░µŹ«ķøåńÜäµĀ╣ńø«ÕĮĢ
+ data_prefix=dict(
+ img_path='leftImg8bit/val', seg_map_path='gtFine/val'), # µĄŗĶ»ĢµĢ░µŹ«ńÜäÕēŹń╝Ć
+ pipeline=test_pipeline)) # µĢ░µŹ«ÕżäńÉåµĄüń©ŗ’╝īÕ«āķĆÜĶ┐ćõ╣ŗÕēŹÕłøÕ╗║ńÜätest_pipelineõ╝ĀķĆÆŃĆé
+test_dataloader = val_dataloader
+# ń▓ŠÕ║”Ķ»äõ╝░µ¢╣µ│Ģ’╝īµłæõ╗¼Õ£©Ķ┐ÖķćīõĮ┐ńö© IoUMetric Ķ┐øĶĪīĶ»äõ╝░
+val_evaluator = dict(type='IoUMetric', iou_metrics=['mIoU'])
+test_evaluator = val_evaluator
+```
+
+`_base_/schedules/schedule_40k.py`
+
+```python
+# optimizer
+optimizer = dict(type='SGD', # õ╝śÕī¢ÕÖ©ń¦Źń▒╗’╝īµø┤ÕżÜń╗åĶŖéÕÅ»ÕÅéĶĆā https://github.com/open-mmlab/mmengine/blob/main/mmengine/optim/optimizer/default_constructor.py
+ lr=0.01, # õ╝śÕī¢ÕÖ©ńÜäÕŁ”õ╣ĀńÄć’╝īÕÅéµĢ░ńÜäõĮ┐ńö©ń╗åĶŖéĶ»ĘÕÅéńģ¦Õ»╣Õ║öńÜä PyTorch µ¢ćµĪŻ
+ momentum=0.9, # ÕŖ©ķćÅÕż¦Õ░Å (Momentum)
+ weight_decay=0.0005) # SGD ńÜäµØāķćŹĶĪ░ÕćÅ (weight decay)
+optim_wrapper = dict(type='OptimWrapper', # õ╝śÕī¢ÕÖ©ÕīģĶŻģÕÖ©(Optimizer wrapper)õĖ║µø┤µ¢░ÕÅéµĢ░µÅÉõŠøõ║åõĖĆõĖ¬Õģ¼Õģ▒µÄźÕÅŻ
+ optimizer=optimizer, # ńö©õ║ĵø┤µ¢░µ©ĪÕ×ŗÕÅéµĢ░ńÜäõ╝śÕī¢ÕÖ©(Optimizer)
+ clip_grad=None) # Õ”éµ×£ 'clip_grad' õĖŹµś»None’╝īÕ«āÕ░åµś» ' torch.nn.utils.clip_grad' ńÜäÕÅéµĢ░ŃĆé
+# ÕŁ”õ╣ĀńŁ¢ńĢź
+param_scheduler = [
+ dict(
+ type='PolyLR', # Ķ░āÕ║”µĄüń©ŗńÜäńŁ¢ńĢź’╝īÕÉīµĀʵö»µīü Step, CosineAnnealing, Cyclic ńŁē. Ķ»Ęõ╗Ä https://github.com/open-mmlab/mmengine/blob/main/mmengine/optim/scheduler/lr_scheduler.py ÕÅéĶĆā LrUpdater ńÜäń╗åĶŖé
+ eta_min=1e-4, # Ķ«Łń╗āń╗ōµØ¤µŚČńÜäµ£ĆÕ░ÅÕŁ”õ╣ĀńÄć
+ power=0.9, # ÕżÜķĪ╣Õ╝ÅĶĪ░ÕćÅ (polynomial decay) ńÜäÕ╣é
+ begin=0, # Õ╝ĆÕ¦ŗµø┤µ¢░ÕÅéµĢ░ńÜ䵌ČķŚ┤µŁź(step)
+ end=40000, # Õü£µŁóµø┤µ¢░ÕÅéµĢ░ńÜ䵌ČķŚ┤µŁź(step)
+ by_epoch=False) # µś»ÕÉ”µīēńģ¦ epoch Ķ«Īń«ŚĶ«Łń╗āµŚČķŚ┤
+]
+# 40k iteration ńÜäĶ«Łń╗āĶ«ĪÕłÆ
+train_cfg = dict(type='IterBasedTrainLoop', max_iters=40000, val_interval=4000)
+val_cfg = dict(type='ValLoop')
+test_cfg = dict(type='TestLoop')
+# ķ╗śĶ«żķÆ®ÕŁÉ(hook)ķģŹńĮ«
+default_hooks = dict(
+ timer=dict(type='IterTimerHook'), # Ķ«░ÕĮĢĶ┐Łõ╗ŻĶ┐ćń©ŗõĖŁĶŖ▒Ķ┤╣ńÜ䵌ČķŚ┤
+ logger=dict(type='LoggerHook', interval=50, log_metric_by_epoch=False), # õ╗Ä'Runner'ńÜäõĖŹÕÉīń╗äõ╗ȵöČķøåÕÆīÕåÖÕģźµŚźÕ┐Ś
+ param_scheduler=dict(type='ParamSchedulerHook'), # µø┤µ¢░õ╝śÕī¢ÕÖ©õĖŁńÜäõĖĆõ║øĶČģÕÅéµĢ░’╝īõŠŗÕ”éÕŁ”õ╣ĀńÄć
+ checkpoint=dict(type='CheckpointHook', by_epoch=False, interval=4000), # իܵ£¤õ┐ØÕŁśµŻĆµ¤źńé╣(checkpoint)
+ sampler_seed=dict(type='DistSamplerSeedHook')) # ńö©õ║ÄÕłåÕĖāÕ╝ÅĶ«Łń╗āńÜäµĢ░µŹ«ÕŖĀĶĮĮķććµĀĘÕÖ©
+```
+
+in `_base_/default_runtime.py`
+
+```python
+# Õ░åµ│©ÕåīĶĪ©ńÜäķ╗śĶ«żĶīāÕø┤Ķ«ŠńĮ«õĖ║mmseg
+default_scope = 'mmseg'
+# environment
+env_cfg = dict(
+ cudnn_benchmark=True,
+ mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0),
+ dist_cfg=dict(backend='nccl'),
+)
+log_level = 'INFO'
+log_processor = dict(by_epoch=False)
+load_from = None # õ╗ĵ¢ćõ╗ČõĖŁÕŖĀĶĮĮµŻĆµ¤źńé╣(checkpoint)
+resume = False # µś»ÕÉ”õ╗ÄÕĘ▓µ£ēńÜ䵩ĪÕ×ŗµüóÕżŹ
+```
+
+Ķ┐Öõ║øķāĮµś»ńö©õ║ÄĶ«Łń╗āÕÆīµĄŗĶ»ĢPSPNetńÜäķģŹńĮ«µ¢ćõ╗Č’╝īĶ”üÕŖĀĶĮĮÕÆīĶ¦Żµ×ÉÕ«āõ╗¼’╝īµłæõ╗¼ÕÅ»õ╗źõĮ┐ńö©[MMEngine](https://github.com/open-mmlab/mmengine)Õ«×ńÄ░ńÜä[Config](https://mmengine.readthedocs.io/en/latest/tutorials/config.html)ŃĆé
+
+```python
+from mmengine.config import Config
+
+cfg = Config.fromfile('configs/pspnet/pspnet_r50-d8_4xb2-40k_cityscapes-512x1024.py')
+print(cfg.train_dataloader)
+```
+
+```shell
+{'batch_size': 2,
+ 'num_workers': 2,
+ 'persistent_workers': True,
+ 'sampler': {'type': 'InfiniteSampler', 'shuffle': True},
+ 'dataset': {'type': 'CityscapesDataset',
+ 'data_root': 'data/cityscapes/',
+ 'data_prefix': {'img_path': 'leftImg8bit/train',
+ 'seg_map_path': 'gtFine/train'},
+ 'pipeline': [{'type': 'LoadImageFromFile'},
+ {'type': 'LoadAnnotations'},
+ {'type': 'RandomResize',
+ 'scale': (2048, 1024),
+ 'ratio_range': (0.5, 2.0),
+ 'keep_ratio': True},
+ {'type': 'RandomCrop', 'crop_size': (512, 1024), 'cat_max_ratio': 0.75},
+ {'type': 'RandomFlip', 'prob': 0.5},
+ {'type': 'PhotoMetricDistortion'},
+ {'type': 'PackSegInputs'}]}}
+```
+
+`cfg `µś»`mmengine.config.Config `ńÜäõĖĆõĖ¬Õ«×õŠŗŃĆéÕ«āńÜäµÄźÕÅŻõĖÄdictÕ»╣Ķ▒ĪńøĖÕÉī’╝īõ╣¤ÕģüĶ«ĖÕ░åķģŹńĮ«ÕĆ╝õĮ£õĖ║Õ▒׵ƦĶ«┐ķŚ«ŃĆéµø┤ÕżÜõ┐Īµü»Ķ»ĘÕÅéĶ¦ü[MMEngine](https://github.com/open-mmlab/mmengine)õĖŁńÜä[config tutorial](https://mmengine.readthedocs.io/en/latest/tutorials/config.html)ŃĆé
+
+## FAQ
+
+### Õ┐ĮńĢźÕ¤║ńĪĆķģŹńĮ«µ¢ćõ╗ČķćīńÜäõĖĆõ║øÕŁŚµ«Ą
+
+µ£ēµŚČ’╝īµé©ÕÅ»õ╗źĶ«ŠńĮ«`_delete_=True `µØźÕ┐ĮńĢźÕ¤║µ£¼ķģŹńĮ«µ¢ćõ╗ČõĖŁńÜ䵤Éõ║øÕŁŚµ«ĄŃĆéµé©ÕÅ»õ╗źÕÅéĶĆā[MMEngine](https://github.com/open-mmlab/mmengine)õĖŁńÜä[config tutorial](https://mmengine.readthedocs.io/en/latest/tutorials/config.html)µØźĶÄĘÕŠŚõĖĆõ║øń«ĆÕŹĢńÜäµīćÕ»╝ŃĆé
+
+õŠŗÕ”é’╝īÕ£©MMSegmentationõĖŁ’╝īÕ”éµ×£µé©µā│Õ£©õĖŗķØóńÜäķģŹńĮ«µ¢ćõ╗Č`pspnet.py `õĖŁõ┐«µö╣PSPNetńÜäõĖ╗Õ╣▓ńĮæń╗£:
+
+```python
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ pretrained='torchvision://resnet50',
+ backbone=dict(
+ type='ResNetV1c',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ dilations=(1, 1, 2, 4),
+ strides=(1, 2, 1, 1),
+ norm_cfg=norm_cfg,
+ norm_eval=False,
+ style='pytorch',
+ contract_dilation=True),
+ decode_head=dict(
+ type='PSPHead',
+ in_channels=2048,
+ in_index=3,
+ channels=512,
+ pool_scales=(1, 2, 3, 6),
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)))
+```
+
+ńö©õ╗źõĖŗõ╗ŻńĀüÕŖĀĶĮĮÕ╣ČĶ¦Żµ×ÉķģŹńĮ«µ¢ćõ╗Č`pspnet.py`:
+
+```python
+from mmengine.config import Config
+
+cfg = Config.fromfile('pspnet.py')
+print(cfg.model)
+```
+
+```shell
+{'type': 'EncoderDecoder',
+ 'pretrained': 'torchvision://resnet50',
+ 'backbone': {'type': 'ResNetV1c',
+ 'depth': 50,
+ 'num_stages': 4,
+ 'out_indices': (0, 1, 2, 3),
+ 'dilations': (1, 1, 2, 4),
+ 'strides': (1, 2, 1, 1),
+ 'norm_cfg': {'type': 'SyncBN', 'requires_grad': True},
+ 'norm_eval': False,
+ 'style': 'pytorch',
+ 'contract_dilation': True},
+ 'decode_head': {'type': 'PSPHead',
+ 'in_channels': 2048,
+ 'in_index': 3,
+ 'channels': 512,
+ 'pool_scales': (1, 2, 3, 6),
+ 'dropout_ratio': 0.1,
+ 'num_classes': 19,
+ 'norm_cfg': {'type': 'SyncBN', 'requires_grad': True},
+ 'align_corners': False,
+ 'loss_decode': {'type': 'CrossEntropyLoss',
+ 'use_sigmoid': False,
+ 'loss_weight': 1.0}}}
+```
+
+`ResNet`ÕÆī`HRNet`õĮ┐ńö©õĖŹÕÉīńÜäÕģ│ķö«ÕŁŚµ×äÕ╗║’╝īń╝¢ÕåÖõĖĆõĖ¬µ¢░ńÜäķģŹńĮ«µ¢ćõ╗Č`hrnet.py`’╝īÕ”éõĖŗµēĆńż║:
+
+```python
+_base_ = 'pspnet.py'
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ pretrained='open-mmlab://msra/hrnetv2_w32',
+ backbone=dict(
+ _delete_=True,
+ type='HRNet',
+ norm_cfg=norm_cfg,
+ extra=dict(
+ stage1=dict(
+ num_modules=1,
+ num_branches=1,
+ block='BOTTLENECK',
+ num_blocks=(4, ),
+ num_channels=(64, )),
+ stage2=dict(
+ num_modules=1,
+ num_branches=2,
+ block='BASIC',
+ num_blocks=(4, 4),
+ num_channels=(32, 64)),
+ stage3=dict(
+ num_modules=4,
+ num_branches=3,
+ block='BASIC',
+ num_blocks=(4, 4, 4),
+ num_channels=(32, 64, 128)),
+ stage4=dict(
+ num_modules=3,
+ num_branches=4,
+ block='BASIC',
+ num_blocks=(4, 4, 4, 4),
+ num_channels=(32, 64, 128, 256)))))
+```
+
+ńö©õ╗źõĖŗõ╗ŻńĀüÕŖĀĶĮĮÕ╣ČĶ¦Żµ×ÉķģŹńĮ«µ¢ćõ╗Č`hrnet.py`:
+
+```python
+from mmengine.config import Config
+cfg = Config.fromfile('hrnet.py')
+print(cfg.model)
+```
+
+```shell
+{'type': 'EncoderDecoder',
+ 'pretrained': 'open-mmlab://msra/hrnetv2_w32',
+ 'backbone': {'type': 'HRNet',
+ 'norm_cfg': {'type': 'SyncBN', 'requires_grad': True},
+ 'extra': {'stage1': {'num_modules': 1,
+ 'num_branches': 1,
+ 'block': 'BOTTLENECK',
+ 'num_blocks': (4,),
+ 'num_channels': (64,)},
+ 'stage2': {'num_modules': 1,
+ 'num_branches': 2,
+ 'block': 'BASIC',
+ 'num_blocks': (4, 4),
+ 'num_channels': (32, 64)},
+ 'stage3': {'num_modules': 4,
+ 'num_branches': 3,
+ 'block': 'BASIC',
+ 'num_blocks': (4, 4, 4),
+ 'num_channels': (32, 64, 128)},
+ 'stage4': {'num_modules': 3,
+ 'num_branches': 4,
+ 'block': 'BASIC',
+ 'num_blocks': (4, 4, 4, 4),
+ 'num_channels': (32, 64, 128, 256)}}},
+ 'decode_head': {'type': 'PSPHead',
+ 'in_channels': 2048,
+ 'in_index': 3,
+ 'channels': 512,
+ 'pool_scales': (1, 2, 3, 6),
+ 'dropout_ratio': 0.1,
+ 'num_classes': 19,
+ 'norm_cfg': {'type': 'SyncBN', 'requires_grad': True},
+ 'align_corners': False,
+ 'loss_decode': {'type': 'CrossEntropyLoss',
+ 'use_sigmoid': False,
+ 'loss_weight': 1.0}}}
+```
+
+`_delete_=True` Õ░åńö©µ¢░ńÜäķö«ÕÄ╗µø┐µŹó `backbone` ÕŁŚµ«ĄÕåģµēƵ£ēµŚ¦ńÜäķö«ŃĆé
+
+### õĮ┐ńö©ķģŹńĮ«µ¢ćõ╗ČķćīńÜäõĖŁķŚ┤ÕÅśķćÅ
+
+ķģŹńĮ«µ¢ćõ╗ČõĖŁõ╝ÜõĮ┐ńö©õĖĆõ║øõĖŁķŚ┤ÕÅśķćÅ’╝īõŠŗÕ”éµĢ░µŹ«ķøå(datasets)ÕŁŚµ«ĄķćīńÜä `train_pipeline`/`test_pipeline`ŃĆé ķ£ĆĶ”üµ│©µäÅńÜ䵜»’╝īÕ£©ÕŁÉķģŹńĮ«µ¢ćõ╗Čķćīõ┐«µö╣õĖŁķŚ┤ÕÅśķćŵŚČ’╝īµé©ķ£ĆĶ”üÕåŹµ¼Īõ╝ĀķĆÆĶ┐Öõ║øÕÅśķćÅń╗ÖÕ»╣Õ║öńÜäÕŁŚµ«ĄŃĆéõŠŗÕ”é’╝īµłæõ╗¼µā│µö╣ÕÅśÕ£©Ķ«Łń╗āµł¢µĄŗĶ»ĢPSPNetµŚČķććńö©ńÜäÕżÜÕ░║Õ║”ńŁ¢ńĢź (multi scale strategy)’╝ī`train_pipeline`/`test_pipeline` µś»µłæõ╗¼ķ£ĆĶ”üõ┐«µö╣ńÜäõĖŁķŚ┤ÕÅśķćÅŃĆé
+
+```python
+_base_ = '../pspnet/pspnet_r50-d8_4xb4-40k_cityscpaes-512x1024.py'
+crop_size = (512, 1024)
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations'),
+ dict(type='RandomResize',
+ img_scale=(2048, 1024),
+ ratio_range=(1., 2.),
+ keep_ration=True),
+ dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
+ dict(type='RandomFlip', flip_ratio=0.5),
+ dict(type='PhotoMetricDistortion'),
+ dict(type='PackSegInputs'),
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='Resize',
+ scale=(2048, 1024),
+ keep_ratio=True),
+ dict(type='LoadAnnotations'),
+ dict(type='PackSegInputs')
+]
+train_dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_prefix=dict(
+ img_path='leftImg8bit/train', seg_map_path='gtFine/train'),
+ pipeline=train_pipeline)
+test_dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_prefix=dict(
+ img_path='leftImg8bit/val', seg_map_path='gtFine/val'),
+ pipeline=test_pipeline)
+train_dataloader = dict(dataset=train_dataset)
+val_dataloader = dict(dataset=test_dataset)
+test_dataloader = val_dataloader
+```
+
+µłæõ╗¼ķ”¢Õģłķ£ĆĶ”üÕ«Üõ╣ēµ¢░ńÜä `train_pipeline`/`test_pipeline` ńäČÕÉÄõ╝ĀķĆÆÕł░ `dataset` ķćīŃĆé
+
+ń▒╗õ╝╝ńÜä’╝īÕ”éµ×£µłæõ╗¼µā│õ╗Ä `SyncBN` ÕłćµŹóÕł░ `BN` µł¢ĶĆģ `MMSyncBN`’╝īµłæõ╗¼ķ£ĆĶ”üµø┐µŹóķģŹńĮ«µ¢ćõ╗ČķćīńÜäµ»ÅõĖĆõĖ¬ `norm_cfg`ŃĆé
+
+```python
+_base_ = '../pspnet/pspnet_r50-d8_4xb4-40k_cityscpaes-512x1024.py'
+norm_cfg = dict(type='BN', requires_grad=True)
+model = dict(
+ backbone=dict(norm_cfg=norm_cfg),
+ decode_head=dict(norm_cfg=norm_cfg),
+ auxiliary_head=dict(norm_cfg=norm_cfg))
+```
+
+## ķĆÜĶ┐ćĶäܵ£¼ÕÅéµĢ░õ┐«µö╣ķģŹńĮ«µ¢ćõ╗Č
+
+Õ£©[training script](https://github.com/open-mmlab/mmsegmentation/blob/1.x/tools/train.py)ÕÆī[testing script](https://github.com/open-mmlab/mmsegmentation/blob/1.x/tools/test.py)õĖŁ’╝īµłæõ╗¼µö»µīüĶäܵ£¼ÕÅéµĢ░ `--cfg-options`’╝īÕ«āÕÅ»õ╗źÕĖ«ÕŖ®ńö©µłĘĶ”åńø¢µēĆõĮ┐ńö©ńÜäķģŹńĮ«õĖŁńÜäõĖĆõ║øĶ«ŠńĮ«’╝ī`xxx=yyy` µĀ╝Õ╝ÅńÜäķö«ÕĆ╝Õ»╣Õ░åÕÉłÕ╣ČÕł░ķģŹńĮ«µ¢ćõ╗ČõĖŁŃĆé
+
+õŠŗÕ”é’╝īĶ┐Öµś»õĖĆõĖ¬ń«ĆÕī¢ńÜäĶäܵ£¼ `demo_script.py `:
+
+```python
+import argparse
+
+from mmengine.config import Config, DictAction
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Script Example')
+ parser.add_argument('config', help='train config file path')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+ args = parser.parse_args()
+ return args
+
+def main():
+ args = parse_args()
+
+ cfg = Config.fromfile(args.config)
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+
+ print(cfg)
+
+if __name__ == '__main__':
+ main()
+```
+
+õĖĆõĖ¬ķģŹńĮ«µ¢ćõ╗Čńż║õŠŗ `demo_config.py` Õ”éõĖŗµēĆńż║:
+
+```python
+backbone = dict(
+ type='ResNetV1c',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ dilations=(1, 1, 2, 4),
+ strides=(1, 2, 1, 1),
+ norm_eval=False,
+ style='pytorch',
+ contract_dilation=True)
+```
+
+Ķ┐ÉĶĪī `demo_script.py`:
+
+```shell
+python demo_script.py demo_config.py
+```
+
+```shell
+Config (path: demo_config.py): {'backbone': {'type': 'ResNetV1c', 'depth': 50, 'num_stages': 4, 'out_indices': (0, 1, 2, 3), 'dilations': (1, 1, 2, 4), 'strides': (1, 2, 1, 1), 'norm_eval': False, 'style': 'pytorch', 'contract_dilation': True}}
+```
+
+ķĆÜĶ┐ćĶäܵ£¼ÕÅéµĢ░õ┐«µö╣ķģŹńĮ«:
+
+```shell
+python demo_script.py demo_config.py --cfg-options backbone.depth=101
+```
+
+```shell
+Config (path: demo_config.py): {'backbone': {'type': 'ResNetV1c', 'depth': 101, 'num_stages': 4, 'out_indices': (0, 1, 2, 3), 'dilations': (1, 1, 2, 4), 'strides': (1, 2, 1, 1), 'norm_eval': False, 'style': 'pytorch', 'contract_dilation': True}}
+```
+
+- µø┤µ¢░ÕłŚĶĪ©/Õģāń╗äńÜäÕĆ╝ŃĆé
+
+ Õ”éµ×£Ķ”üµø┤µ¢░ńÜäÕĆ╝µś»õĖĆõĖ¬ list µł¢ tupleŃĆéõŠŗÕ”é’╝īķ£ĆĶ”üÕ£©ķģŹńĮ«µ¢ćõ╗Č `demo_config.py ` ńÜä `backbone ` õĖŁĶ«ŠńĮ« `stride =(1,2,1,1) `ŃĆé
+ Õ”éµ×£µé©µā│µø┤µö╣Ķ┐ÖõĖ¬ķö«’╝īõĮĀÕÅ»õ╗źńö©õĖżń¦Źµ¢╣Õ╝ÅĶ┐øĶĪīµīćÕ«Ü:
+
+ 1. `--cfg-options backbone.strides="(1, 1, 1, 1)"`. µ│©µäÅÕ╝ĢÕÅĘ " µś»µö»µīü list/tuple µĢ░µŹ«ń▒╗Õ×ŗµēĆÕ┐ģķ£ĆńÜäŃĆé
+
+ ```shell
+ python demo_script.py demo_config.py --cfg-options backbone.strides="(1, 1, 1, 1)"
+ ```
+
+ ```shell
+ Config (path: demo_config.py): {'backbone': {'type': 'ResNetV1c', 'depth': 50, 'num_stages': 4, 'out_indices': (0, 1, 2, 3), 'dilations': (1, 1, 2, 4), 'strides': (1, 1, 1, 1), 'norm_eval': False, 'style': 'pytorch', 'contract_dilation': True}}
+ ```
+
+ 2. `--cfg-options backbone.strides=1,1,1,1`. µ│©µäÅ’╝īÕ£©µīćÕ«ÜńÜäÕĆ╝õĖŁ**õĖŹÕģüĶ«Ė**µ£ēń®║µĀ╝ŃĆé
+
+ ÕÅ”Õż¢’╝īÕ”éµ×£ÕĤµØźńÜäń▒╗Õ×ŗµś»tuple’╝īķĆÜĶ┐ćĶ┐Öń¦Źµ¢╣Õ╝Åõ┐«µö╣ÕÉÄõ╝ÜĶć¬ÕŖ©ĶĮ¼µŹóõĖ║listŃĆé
+
+ ```shell
+ python demo_script.py demo_config.py --cfg-options backbone.strides=1,1,1,1
+ ```
+
+ ```shell
+ Config (path: demo_config.py): {'backbone': {'type': 'ResNetV1c', 'depth': 50, 'num_stages': 4, 'out_indices': (0, 1, 2, 3), 'dilations': (1, 1, 2, 4), 'strides': [1, 1, 1, 1], 'norm_eval': False, 'style': 'pytorch', 'contract_dilation': True}}
+ ```
+
+```{note}
+ Ķ┐Öń¦Źõ┐«µö╣µ¢╣µ│Ģõ╗ģµö»µīüõ┐«µö╣stringŃĆüintŃĆüfloatŃĆübooleanŃĆüNoneŃĆülistÕÆītupleń▒╗Õ×ŗńÜäķģŹńĮ«ķĪ╣ŃĆé
+ ÕģĘõĮōµØźĶ»┤’╝īÕ»╣õ║ÄlistÕÆītupleń▒╗Õ×ŗńÜäķģŹńĮ«ķĪ╣’╝īÕ«āõ╗¼Õåģķā©ńÜäÕģāń┤Āõ╣¤Õ┐ģķĪ╗µś»õĖŖĶ┐░õĖāń¦Źń▒╗Õ×ŗõ╣ŗõĖĆŃĆé
+```
diff --git a/internlm_langchain/knowledge_base/MMSegmentation/content/2_dataset_prepare.md b/internlm_langchain/knowledge_base/MMSegmentation/content/2_dataset_prepare.md
new file mode 100644
index 00000000..c6b13970
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMSegmentation/content/2_dataset_prepare.md
@@ -0,0 +1,714 @@
+# µĢÖń©ŗ2’╝ÜÕćåÕżćµĢ░µŹ«ķøå
+
+µłæõ╗¼Õ╗║Ķ««Õ░åµĢ░µŹ«ķøåµĀ╣ńø«ÕĮĢń¼”ÕÅĘķōŠµÄźÕł░ `$MMSEGMENTATION/data`ŃĆé
+Õ”éµ×£µé©ńÜäńø«ÕĮĢń╗ōµ×äõĖŹÕÉī’╝īµé©ÕÅ»ĶāĮķ£ĆĶ”üµø┤µö╣ķģŹńĮ«µ¢ćõ╗ČõĖŁńøĖÕ║öńÜäĶĘ»ÕŠäŃĆé
+Õ»╣õ║ÄõĖŁÕøĮÕóāÕåģńÜäńö©µłĘ’╝īµłæõ╗¼õ╣¤µÄ©ĶŹÉķĆÜĶ┐ćÕ╝Ƶ║ɵĢ░µŹ«Õ╣│ÕÅ░ [OpenDataLab](https://opendatalab.com/) µØźõĖŗĶĮĮdsdlµĀćÕćåµĢ░µŹ«’╝īõ╗źĶÄĘÕŠŚµø┤ÕźĮńÜäõĖŗĶĮĮÕÆīõĮ┐ńö©õĮōķ¬ī’╝īĶ┐Öķćīµ£ēõĖĆõĖ¬õĖŗĶĮĮdsdlµĢ░µŹ«ķøåÕ╣ČĶ┐øĶĪīĶ«Łń╗āńÜäµĪłõŠŗ[DSDLReadme](../../../configs/dsdl/README.md)’╝īµ¼óĶ┐ÄÕ░ØĶ»ĢŃĆé
+
+```none
+mmsegmentation
+Ōö£ŌöĆŌöĆ mmseg
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+Ōö£ŌöĆŌöĆ data
+Ōöé Ōö£ŌöĆŌöĆ cityscapes
+Ōöé Ōöé Ōö£ŌöĆŌöĆ leftImg8bit
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ train
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ val
+Ōöé Ōöé Ōö£ŌöĆŌöĆ gtFine
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ train
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ val
+Ōöé Ōö£ŌöĆŌöĆ VOCdevkit
+Ōöé Ōöé Ōö£ŌöĆŌöĆ VOC2012
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ JPEGImages
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ SegmentationClass
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ ImageSets
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ Segmentation
+Ōöé Ōöé Ōö£ŌöĆŌöĆ VOC2010
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ JPEGImages
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ SegmentationClassContext
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ ImageSets
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ SegmentationContext
+Ōöé Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ train.txt
+Ōöé Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ val.txt
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ trainval_merged.json
+Ōöé Ōöé Ōö£ŌöĆŌöĆ VOCaug
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ dataset
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ cls
+Ōöé Ōö£ŌöĆŌöĆ ade
+Ōöé Ōöé Ōö£ŌöĆŌöĆ ADEChallengeData2016
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ annotations
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ training
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ validation
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ images
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ training
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ validation
+Ōöé Ōö£ŌöĆŌöĆ coco_stuff10k
+Ōöé Ōöé Ōö£ŌöĆŌöĆ images
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ train2014
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ test2014
+Ōöé Ōöé Ōö£ŌöĆŌöĆ annotations
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ train2014
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ test2014
+Ōöé Ōöé Ōö£ŌöĆŌöĆ imagesLists
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ train.txt
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ test.txt
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ all.txt
+Ōöé Ōö£ŌöĆŌöĆ coco_stuff164k
+Ōöé Ōöé Ōö£ŌöĆŌöĆ images
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ train2017
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ val2017
+Ōöé Ōöé Ōö£ŌöĆŌöĆ annotations
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ train2017
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ val2017
+Ōöé Ōö£ŌöĆŌöĆ CHASE_DB1
+Ōöé Ōöé Ōö£ŌöĆŌöĆ images
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ training
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ validation
+Ōöé Ōöé Ōö£ŌöĆŌöĆ annotations
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ training
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ validation
+Ōöé Ōö£ŌöĆŌöĆ DRIVE
+Ōöé Ōöé Ōö£ŌöĆŌöĆ images
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ training
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ validation
+Ōöé Ōöé Ōö£ŌöĆŌöĆ annotations
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ training
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ validation
+Ōöé Ōö£ŌöĆŌöĆ HRF
+Ōöé Ōöé Ōö£ŌöĆŌöĆ images
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ training
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ validation
+Ōöé Ōöé Ōö£ŌöĆŌöĆ annotations
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ training
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ validation
+Ōöé Ōö£ŌöĆŌöĆ STARE
+Ōöé Ōöé Ōö£ŌöĆŌöĆ images
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ training
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ validation
+Ōöé Ōöé Ōö£ŌöĆŌöĆ annotations
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ training
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ validation
+| Ōö£ŌöĆŌöĆ dark_zurich
+| Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ gps
+| Ōöé┬Ā┬Ā Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ val
+| Ōöé┬Ā┬Ā Ōöé┬Ā┬Ā ŌööŌöĆŌöĆ val_ref
+| Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ gt
+| Ōöé┬Ā┬Ā Ōöé┬Ā┬Ā ŌööŌöĆŌöĆ val
+| Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ LICENSE.txt
+| Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ lists_file_names
+| Ōöé┬Ā┬Ā Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ val_filenames.txt
+| Ōöé┬Ā┬Ā Ōöé┬Ā┬Ā ŌööŌöĆŌöĆ val_ref_filenames.txt
+| Ōöé┬Ā┬Ā Ōö£ŌöĆŌöĆ README.md
+| Ōöé┬Ā┬Ā ŌööŌöĆŌöĆ rgb_anon
+| Ōöé┬Ā┬Ā | Ōö£ŌöĆŌöĆ val
+| Ōöé┬Ā┬Ā | ŌööŌöĆŌöĆ val_ref
+| Ōö£ŌöĆŌöĆ NighttimeDrivingTest
+| | Ōö£ŌöĆŌöĆ gtCoarse_daytime_trainvaltest
+| | Ōöé┬Ā┬Ā ŌööŌöĆŌöĆ test
+| | Ōöé┬Ā┬Ā ŌööŌöĆŌöĆ night
+| | ŌööŌöĆŌöĆ leftImg8bit
+| | | ŌööŌöĆŌöĆ test
+| | | ŌööŌöĆŌöĆ night
+Ōöé Ōö£ŌöĆŌöĆ loveDA
+Ōöé Ōöé Ōö£ŌöĆŌöĆ img_dir
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ train
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ val
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ test
+Ōöé Ōöé Ōö£ŌöĆŌöĆ ann_dir
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ train
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ val
+Ōöé Ōö£ŌöĆŌöĆ potsdam
+Ōöé Ōöé Ōö£ŌöĆŌöĆ img_dir
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ train
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ val
+Ōöé Ōöé Ōö£ŌöĆŌöĆ ann_dir
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ train
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ val
+Ōöé Ōö£ŌöĆŌöĆ vaihingen
+Ōöé Ōöé Ōö£ŌöĆŌöĆ img_dir
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ train
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ val
+Ōöé Ōöé Ōö£ŌöĆŌöĆ ann_dir
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ train
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ val
+Ōöé Ōö£ŌöĆŌöĆ iSAID
+Ōöé Ōöé Ōö£ŌöĆŌöĆ img_dir
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ train
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ val
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ test
+Ōöé Ōöé Ōö£ŌöĆŌöĆ ann_dir
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ train
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ val
+Ōöé Ōö£ŌöĆŌöĆ synapse
+Ōöé Ōöé Ōö£ŌöĆŌöĆ img_dir
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ train
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ val
+Ōöé Ōöé Ōö£ŌöĆŌöĆ ann_dir
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ train
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ val
+Ōöé Ōö£ŌöĆŌöĆ REFUGE
+Ōöé Ōöé Ōö£ŌöĆŌöĆ images
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ training
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ validation
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ test
+Ōöé Ōöé Ōö£ŌöĆŌöĆ annotations
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ training
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ validation
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ test
+Ōöé Ōö£ŌöĆŌöĆ mapillary
+Ōöé Ōöé Ōö£ŌöĆŌöĆ training
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ images
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ v1.2
+| Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ instances
+| Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ labels
+| Ōöé┬Ā┬Ā Ōöé┬Ā┬Ā Ōöé ŌööŌöĆŌöĆ panoptic
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ v2.0
+| Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ instances
+| Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ labels
+| Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ panoptic
+| Ōöé┬Ā┬Ā Ōöé┬Ā┬Ā Ōöé ŌööŌöĆŌöĆ polygons
+Ōöé Ōöé Ōö£ŌöĆŌöĆ validation
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ images
+| Ōöé Ōöé Ōö£ŌöĆŌöĆ v1.2
+| Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ instances
+| Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ labels
+| Ōöé┬Ā┬Ā Ōöé┬Ā┬Ā Ōöé ŌööŌöĆŌöĆ panoptic
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ v2.0
+| Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ instances
+| Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ labels
+| Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ panoptic
+| Ōöé┬Ā┬Ā Ōöé┬Ā┬Ā Ōöé ŌööŌöĆŌöĆ polygons
+Ōöé Ōö£ŌöĆŌöĆ bdd100k
+Ōöé Ōöé Ōö£ŌöĆŌöĆ images
+Ōöé Ōöé Ōöé ŌööŌöĆŌöĆ 10k
+| Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ test
+| Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ train
+| Ōöé┬Ā┬Ā Ōöé┬Ā┬Ā Ōöé ŌööŌöĆŌöĆ val
+Ōöé Ōöé ŌööŌöĆŌöĆ labels
+Ōöé Ōöé Ōöé ŌööŌöĆŌöĆ sem_seg
+| Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ colormaps
+| Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆtrain
+| Ōöé Ōöé Ōöé Ōöé ŌööŌöĆŌöĆval
+| Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ masks
+| Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆtrain
+| Ōöé Ōöé Ōöé Ōöé ŌööŌöĆŌöĆval
+| Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ polygons
+| Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆsem_seg_train.json
+| Ōöé Ōöé Ōöé Ōöé ŌööŌöĆŌöĆsem_seg_val.json
+| Ōöé┬Ā┬Ā Ōöé┬Ā┬Ā Ōöé ŌööŌöĆŌöĆ rles
+| Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆsem_seg_train.json
+| Ōöé Ōöé Ōöé Ōöé ŌööŌöĆŌöĆsem_seg_val.json
+```
+
+## Cityscapes
+
+Cityscapes [Õ«śµ¢╣ńĮæń½Ö](https://www.cityscapes-dataset.com/)ÕÅ»õ╗źõĖŗĶĮĮ Cityscapes µĢ░µŹ«ķøå’╝īµīēńģ¦Õ«śńĮæĶ”üµ▒éµ│©ÕåīÕ╣ČńÖ╗ķÖåÕÉÄ’╝īµĢ░µŹ«ÕÅ»õ╗źÕ£©[Ķ┐Öķćī](https://www.cityscapes-dataset.com/downloads/)µēŠÕł░ŃĆé
+
+µīēńģ¦µā»õŠŗ’╝ī`**labelTrainIds.png` ńö©õ║Ä cityscapes Ķ«Łń╗āŃĆé
+µłæõ╗¼µÅÉõŠøõ║åõĖĆõĖ¬Õ¤║õ║Ä [cityscapesscripts](https://github.com/mcordts/cityscapesScripts) ńÜä[Ķäܵ£¼](https://github.com/open-mmlab/mmsegmentation/blob/1.x/tools/dataset_converters/cityscapes.py)ńö©õ║Äńö¤µłÉ `**labelTrainIds.png`ŃĆé
+
+```shell
+# --nproc ĶĪ©ńż║ 8 õĖ¬ĶĮ¼µŹóĶ┐øń©ŗ’╝īõ╣¤ÕÅ»õ╗źń£üńĢźŃĆé
+python tools/dataset_converters/cityscapes.py data/cityscapes --nproc 8
+```
+
+## Pascal VOC
+
+Pascal VOC 2012 ÕÅ»õ╗Ä[µŁżÕżä](http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar)õĖŗĶĮĮŃĆé
+µŁżÕż¢’╝īPascal VOC µĢ░µŹ«ķøåńÜäµ£Ćµ¢░ÕĘźõĮ£ķĆÜÕĖĖÕł®ńö©ķóØÕż¢ńÜäÕó×Õ╝║µĢ░µŹ«’╝īÕÅ»õ╗źÕ£©[Ķ┐Öķćī](http://www.eecs.berkeley.edu/Research/Projects/CS/vision/grouping/semantic_contours/benchmark.tgz)µēŠÕł░ŃĆé
+
+Õ”éµ×£µé©µā│õĮ┐ńö©Õó×Õ╝║ńÜä VOC µĢ░µŹ«ķøå’╝īĶ»ĘĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗żÕ░åÕó×Õ╝║µĢ░µŹ«ńÜäµĀćµ│©ĶĮ¼µŹóõĖ║µŁŻńĪ«ńÜäµĀ╝Õ╝ÅŃĆé
+
+```shell
+# --nproc ĶĪ©ńż║ 8 õĖ¬ĶĮ¼µŹóĶ┐øń©ŗ’╝īõ╣¤ÕÅ»õ╗źń£üńĢźŃĆé
+python tools/dataset_converters/voc_aug.py data/VOCdevkit data/VOCdevkit/VOCaug --nproc 8
+```
+
+Ķ»ĘÕÅéĶĆā[µŗ╝µÄźµĢ░µŹ«ķøåµ¢ćµĪŻ](../advanced_guides/add_datasets.md#µŗ╝µÄźµĢ░µŹ«ķøå)ÕÅŖ [voc_aug ķģŹńĮ«ńż║õŠŗ](../../../configs/_base_/datasets/pascal_voc12_aug.py)õ╗źĶ»”ń╗åõ║åĶ¦ŻÕ”éõĮĢÕ░åÕ«āõ╗¼µŗ╝µÄźÕ╣ČÕÉłÕ╣ČĶ«Łń╗āŃĆé
+
+## ADE20K
+
+ADE20K ńÜäĶ«Łń╗āÕÆīķ¬īĶ»üķøåÕÅ»õ╗źõ╗ÄĶ┐ÖõĖ¬[ķōŠµÄź](http://data.csail.mit.edu/places/ADEchallenge/ADEChallengeData2016.zip)õĖŗĶĮĮŃĆé
+Õ”éµ×£ķ£ĆĶ”üõĖŗĶĮĮµĄŗĶ»ĢµĢ░µŹ«ķøå’╝īÕÅ»õ╗źÕ£©[Õ«śńĮæ](http://host.robots.ox.ac.uk/)µ│©ÕåīÕÉÄ’╝īõĖŗĶĮĮ[µĄŗĶ»Ģķøå](http://host.robots.ox.ac.uk:8080/eval/downloads/VOC2010test.tar)ŃĆé
+
+## Pascal Context
+
+Pascal Context ńÜäĶ«Łń╗āÕÆīķ¬īĶ»üķøåÕÅ»õ╗źõ╗Ä[µŁżÕżä](http://host.robots.ox.ac.uk/pascal/VOC/voc2010/VOCtrainval_03-May-2010.tar)õĖŗĶĮĮŃĆéµ│©ÕåīÕÉÄ’╝īµé©õ╣¤ÕÅ»õ╗źõ╗Ä[µŁżÕżä](http://host.robots.ox.ac.uk:8080/eval/downloads/VOC2010test.tar)õĖŗĶĮĮµĄŗĶ»ĢķøåŃĆé
+
+õ╗ÄÕĤզŗµĢ░µŹ«ķøåõĖŁµŖĮÕć║ķā©ÕłåµĢ░µŹ«õĮ£õĖ║ķ¬īĶ»üķøå’╝īµé©ÕÅ»õ╗źõ╗Ä[µŁżÕżä](https://codalabuser.blob.core.windows.net/public/trainval_merged.json)õĖŗĶĮĮ trainval_merged.json µ¢ćõ╗ČŃĆé
+
+Ķ»ĘÕģłÕ«ēĶŻģ [Detail](https://github.com/zhanghang1989/detail-api) ÕĘźÕģĘńäČÕÉÄĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗żÕ░åµĀćµ│©ĶĮ¼µŹóõĖ║µŁŻńĪ«ńÜäµĀ╝Õ╝ÅŃĆé
+
+```shell
+python tools/dataset_converters/pascal_context.py data/VOCdevkit data/VOCdevkit/VOC2010/trainval_merged.json
+```
+
+## COCO Stuff 10k
+
+µĢ░µŹ«ÕÅ»õ╗źķĆÜĶ┐ć wget Õ£©[Ķ┐Öķćī](http://calvin.inf.ed.ac.uk/wp-content/uploads/data/cocostuffdataset/cocostuff-10k-v1.1.zip)õĖŗĶĮĮŃĆé
+
+Õ»╣õ║Ä COCO Stuff 10k µĢ░µŹ«ķøå’╝īĶ»ĘĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗żõĖŗĶĮĮÕ╣ČĶĮ¼µŹóµĢ░µŹ«ķøåŃĆé
+
+```shell
+# õĖŗĶĮĮ
+mkdir coco_stuff10k && cd coco_stuff10k
+wget http://calvin.inf.ed.ac.uk/wp-content/uploads/data/cocostuffdataset/cocostuff-10k-v1.1.zip
+
+# Ķ¦ŻÕÄŗ
+unzip cocostuff-10k-v1.1.zip
+
+# --nproc ĶĪ©ńż║ 8 õĖ¬ĶĮ¼µŹóĶ┐øń©ŗ’╝īõ╣¤ÕÅ»õ╗źń£üńĢźŃĆé
+python tools/dataset_converters/coco_stuff10k.py /path/to/coco_stuff10k --nproc 8
+```
+
+µīēńģ¦µā»õŠŗ’╝ī`/path/to/coco_stuff164k/annotations/*2014/*_labelTrainIds.png` õĖŁńÜä mask µĀćµ│©ńö©õ║Ä COCO Stuff 10k ńÜäĶ«Łń╗āÕÆīµĄŗĶ»ĢŃĆé
+
+## COCO Stuff 164k
+
+Õ»╣õ║Ä COCO Stuff 164k µĢ░µŹ«ķøå’╝īĶ»ĘĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗żõĖŗĶĮĮÕ╣ČĶĮ¼µŹóÕó×Õ╝║ńÜäµĢ░µŹ«ķøåŃĆé
+
+```shell
+# õĖŗĶĮĮ
+mkdir coco_stuff164k && cd coco_stuff164k
+wget http://images.cocodataset.org/zips/train2017.zip
+wget http://images.cocodataset.org/zips/val2017.zip
+wget http://calvin.inf.ed.ac.uk/wp-content/uploads/data/cocostuffdataset/stuffthingmaps_trainval2017.zip
+
+# Ķ¦ŻÕÄŗ
+unzip train2017.zip -d images/
+unzip val2017.zip -d images/
+unzip stuffthingmaps_trainval2017.zip -d annotations/
+
+# --nproc ĶĪ©ńż║ 8 õĖ¬ĶĮ¼µŹóĶ┐øń©ŗ’╝īõ╣¤ÕÅ»õ╗źń£üńĢźŃĆé
+python tools/dataset_converters/coco_stuff164k.py /path/to/coco_stuff164k --nproc 8
+```
+
+µīēńģ¦µā»õŠŗ’╝ī`/path/to/coco_stuff164k/annotations/*2017/*_labelTrainIds.png` õĖŁńÜä mask µĀćµ│©ńö©õ║Ä COCO Stuff 164k ńÜäĶ«Łń╗āÕÆīµĄŗĶ»ĢŃĆé
+
+µŁżµĢ░µŹ«ķøåńÜäĶ»”ń╗åõ┐Īµü»ÕŻգ©[µŁżÕżä](https://github.com/nightrome/cocostuff#downloads)µēŠÕł░ŃĆé
+
+## CHASE DB1
+
+CHASE DB1 ńÜäĶ«Łń╗āÕÆīķ¬īĶ»üķøåÕÅ»õ╗źõ╗Ä[µŁżÕżä](https://staffnet.kingston.ac.uk/~ku15565/CHASE_DB1/assets/CHASEDB1.zip)õĖŗĶĮĮŃĆé
+
+Ķ»ĘĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗ż’╝īÕćåÕżć CHASE DB1 µĢ░µŹ«ķøå’╝Ü
+
+```shell
+python tools/dataset_converters/chase_db1.py /path/to/CHASEDB1.zip
+```
+
+Ķ»źĶäܵ£¼Õ░åĶć¬ÕŖ©Ķ░āµĢ┤µĢ░µŹ«ķøåńø«ÕĮĢń╗ōµ×ä’╝īõĮ┐Õģȵ╗ĪĶČ│ MMSegmentation µĢ░µŹ«ķøåÕŖĀĶĮĮĶ”üµ▒éŃĆé
+
+## DRIVE
+
+µīēńģ¦[Õ«śńĮæ](https://drive.grand-challenge.org/)Ķ”üµ▒é’╝īµ│©ÕåīÕ╣ČńÖ╗ķÖåÕÉÄ’╝īõŠ┐ÕÅ»õ╗źõĖŗĶĮĮ DRIVE ńÜäĶ«Łń╗āÕÆīķ¬īĶ»üµĢ░µŹ«ķøåŃĆé
+
+Ķ”üÕ░å DRIVE µĢ░µŹ«ķøåĶĮ¼µŹóõĖ║ MMSegmentation ńÜäµĀ╝Õ╝Å’╝īĶ»ĘĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗ż’╝Ü
+
+```shell
+python tools/dataset_converters/drive.py /path/to/training.zip /path/to/test.zip
+```
+
+Ķ»źĶäܵ£¼Õ░åĶć¬ÕŖ©Ķ░āµĢ┤µĢ░µŹ«ķøåńø«ÕĮĢń╗ōµ×ä’╝īõĮ┐Õģȵ╗ĪĶČ│ MMSegmentation µĢ░µŹ«ķøåÕŖĀĶĮĮĶ”üµ▒éŃĆé
+
+## HRF
+
+Ķ»ĘõĖŗĶĮĮ [health.zip](https://www5.cs.fau.de/fileadmin/research/datasets/fundus-images/healthy.zip)ŃĆü[glaucoma.zip](https://www5.cs.fau.de/fileadmin/research/datasets/fundus-images/glaucoma.zip)ŃĆü[diabetic_retinopathy.zip](https://www5.cs.fau.de/fileadmin/research/datasets/fundus-images/diabetic_retinopathy.zip)ŃĆü[healthy_manualsegm.zip](https://www5.cs.fau.de/fileadmin/research/datasets/fundus-images/healthy_manualsegm.zip)ŃĆü[glaucoma_manualsegm.zip](https://www5.cs.fau.de/fileadmin/research/datasets/fundus-images/glaucoma_manualsegm.zip) ÕÆī [diabetic_retinopathy_manualsegm.zip](https://www5.cs.fau.de/fileadmin/research/datasets/fundus-images/diabetic_retinopathy_manualsegm.zip)’╝īµŚĀķ£ĆĶ¦ŻÕÄŗ’╝īÕÅ»õ╗źńø┤µÄźĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗ż’╝īÕćåÕżć HRF µĢ░µŹ«ķøå’╝Ü
+
+```shell
+python tools/dataset_converters/hrf.py /path/to/healthy.zip /path/to/healthy_manualsegm.zip /path/to/glaucoma.zip /path/to/glaucoma_manualsegm.zip /path/to/diabetic_retinopathy.zip /path/to/diabetic_retinopathy_manualsegm.zip
+```
+
+Ķ»źĶäܵ£¼Õ░åĶć¬ÕŖ©Ķ░āµĢ┤µĢ░µŹ«ķøåńø«ÕĮĢń╗ōµ×ä’╝īõĮ┐Õģȵ╗ĪĶČ│ MMSegmentation µĢ░µŹ«ķøåÕŖĀĶĮĮĶ”üµ▒éŃĆé
+
+## STARE
+
+Ķ»ĘõĖŗĶĮĮ [stare images.tar](http://cecas.clemson.edu/~ahoover/stare/probing/stare-images.tar)ŃĆü[labels-ah.tar](http://cecas.clemson.edu/~ahoover/stare/probing/labels-ah.tar) ÕÆī [labels-vk.tar](http://cecas.clemson.edu/~ahoover/stare/probing/labels-vk.tar)’╝īµŚĀķ£ĆĶ¦ŻÕÄŗ’╝īÕÅ»õ╗źńø┤µÄźĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗ż’╝īÕćåÕżć STARE µĢ░µŹ«ķøå’╝Ü
+
+```shell
+python tools/dataset_converters/stare.py /path/to/stare-images.tar /path/to/labels-ah.tar /path/to/labels-vk.tar
+```
+
+Ķ»źĶäܵ£¼Õ░åĶć¬ÕŖ©Ķ░āµĢ┤µĢ░µŹ«ķøåńø«ÕĮĢń╗ōµ×ä’╝īõĮ┐Õģȵ╗ĪĶČ│ MMSegmentation µĢ░µŹ«ķøåÕŖĀĶĮĮĶ”üµ▒éŃĆé
+
+## Dark Zurich
+
+ńö▒õ║ĵłæõ╗¼ÕŬµö»µīüÕ£©µŁżµĢ░µŹ«ķøåõĖŖńÜ䵩ĪÕ×ŗµĄŗĶ»Ģ’╝īÕøĀµŁżµé©ÕŬķ£ĆĶ”üõĖŗĶĮĮÕ╣ČĶ¦ŻÕÄŗ[ķ¬īĶ»üµĢ░µŹ«ķøå](https://data.vision.ee.ethz.ch/csakarid/shared/GCMA_UIoU/Dark_Zurich_val_anon.zip)ŃĆé
+
+## Nighttime Driving
+
+ńö▒õ║ĵłæõ╗¼ÕŬµö»µīüÕ£©µŁżµĢ░µŹ«ķøåõĖŖńÜ䵩ĪÕ×ŗµĄŗĶ»Ģ’╝īÕøĀµŁżµé©ÕŬķ£ĆĶ”üõĖŗĶĮĮÕ╣ČĶ¦ŻÕÄŗ[ķ¬īĶ»üµĢ░µŹ«ķøå](http://data.vision.ee.ethz.ch/daid/NighttimeDriving/NighttimeDrivingTest.zip)ŃĆé
+
+## LoveDA
+
+µĢ░µŹ«ÕÅ»õ╗źõ╗Ä[µŁżÕżä](https://drive.google.com/drive/folders/1ibYV0qwn4yuuh068Rnc-w4tPi0U0c-ti?usp=sharing)õĖŗĶĮĮ LaveDA µĢ░µŹ«ķøåŃĆé
+
+µł¢ĶĆģÕÅ»õ╗źõ╗Ä [zenodo](https://zenodo.org/record/5706578#.YZvN7SYRXdF) õĖŗĶĮĮŃĆéõĖŗĶĮĮÕÉÄ’╝īµŚĀķ£ĆĶ¦ŻÕÄŗ’╝īńø┤µÄźĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗ż’╝Ü
+
+```shell
+# õĖŗĶĮĮ Train.zip
+wget https://zenodo.org/record/5706578/files/Train.zip
+# õĖŗĶĮĮ Val.zip
+wget https://zenodo.org/record/5706578/files/Val.zip
+# õĖŗĶĮĮ Test.zip
+wget https://zenodo.org/record/5706578/files/Test.zip
+```
+
+Ķ»ĘÕ»╣õ║Ä LoveDA µĢ░µŹ«ķøå’╝īĶ»ĘĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗żĶ░āµĢ┤µĢ░µŹ«ķøåńø«ÕĮĢŃĆé
+
+```shell
+python tools/dataset_converters/loveda.py /path/to/loveDA
+```
+
+ÕÅ»Õ░嵩ĪÕ×ŗÕ»╣ LoveDA ńÜ䵥ŗĶ»ĢķøåńÜäķó䵥ŗń╗ōµ×£õĖŖõ╝ĀĶć│Õł░µĢ░µŹ«ķøå[µĄŗĶ»Ģµ£ŹÕŖĪÕÖ©](https://codalab.lisn.upsaclay.fr/competitions/421)’╝īµ¤źń£ŗĶ»äµĄŗń╗ōµ×£ŃĆé
+
+µ£ēÕģ│ LoveDA ńÜäµø┤ÕżÜĶ»”ń╗åõ┐Īµü»’╝īÕÅ»µ¤źń£ŗ[µŁżÕżä](https://github.com/Junjue-Wang/LoveDA).
+
+## ISPRS Potsdam
+
+[Potsdam](https://www.isprs.org/education/benchmarks/UrbanSemLab/2d-sem-label-potsdam.aspx) Õ¤ÄÕĖéĶ»Łõ╣ēÕłåÕē▓µĢ░µŹ«ķøåńö©õ║Ä 2D Ķ»Łõ╣ēÕłåÕē▓ń½×ĶĄø ŌĆöŌĆö PotsdamŃĆé
+
+µĢ░µŹ«ķøåÕÅ»õ╗źÕ£©ń½×ĶĄø[õĖ╗ķĪĄ](https://www.isprs.org/education/benchmarks/UrbanSemLab/default.aspx)õĖŖĶ»Ęµ▒éĶÄĘÕŠŚŃĆé
+Ķ┐Öķćīõ╣¤µÅÉõŠøõ║å[BaiduNetdisk](https://pan.baidu.com/s/1K-cLVZnd1X7d8c26FQ-nGg?pwd=mseg)’╝īµÅÉÕÅ¢ńĀü’╝ÜmsegŃĆü [Google Drive](https://drive.google.com/drive/folders/1w3EJuyUGet6_qmLwGAWZ9vw5ogeG0zLz?usp=sharing)õ╗źÕÅŖ[OpenDataLab](https://opendatalab.com/ISPRS_Potsdam/download)ŃĆé
+Õ«×ķ¬īõĖŁķ£ĆĶ”üõĖŗĶĮĮ '2_Ortho_RGB.zip' ÕÆī '5_Labels_all_noBoundary.zip'ŃĆé
+
+Õ»╣õ║Ä Potsdam µĢ░µŹ«ķøå’╝īĶ»ĘĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗żĶ░āµĢ┤µĢ░µŹ«ķøåńø«ÕĮĢŃĆé
+
+```shell
+python tools/dataset_converters/potsdam.py /path/to/potsdam
+```
+
+Õ£©µłæõ╗¼ńÜäķ╗śĶ«żĶ«ŠńĮ«õĖŁ’╝īÕ░åńö¤µłÉ 3456 Õ╝ĀÕøŠÕāÅńö©õ║ÄĶ«Łń╗āÕÆī 2016 Õ╝ĀÕøŠÕāÅńö©õ║Äķ¬īĶ»üŃĆé
+
+## ISPRS Vaihingen
+
+[Vaihingen](https://www.isprs.org/education/benchmarks/UrbanSemLab/2d-sem-label-vaihingen.aspx) Õ¤ÄÕĖéĶ»Łõ╣ēÕłåÕē▓µĢ░µŹ«ķøåńö©õ║Ä 2D Ķ»Łõ╣ēÕłåÕē▓ń½×ĶĄø ŌĆöŌĆö VaihingenŃĆé
+
+µĢ░µŹ«ķøåÕÅ»õ╗źÕ£©ń½×ĶĄø[õĖ╗ķĪĄ](https://www.isprs.org/education/benchmarks/UrbanSemLab/default.aspx)õĖŖĶ»Ęµ▒éĶÄĘÕŠŚŃĆé
+Ķ┐Öķćīõ╣¤µÅÉõŠøõ║å[BaiduNetdisk](https://pan.baidu.com/s/109D3WLrLafsuYtLeerLiiA?pwd=mseg)’╝īµÅÉÕÅ¢ńĀü’╝Ümseg ŃĆü [Google Drive](https://drive.google.com/drive/folders/1w3NhvLVA2myVZqOn2pbiDXngNC7NTP_t?usp=sharing)ŃĆé
+Õ«×ķ¬īõĖŁķ£ĆĶ”üõĖŗĶĮĮ 'ISPRS_semantic_labeling_Vaihingen.zip' ÕÆī 'ISPRS_semantic_labeling_Vaihingen_ground_truth_eroded_COMPLETE.zip'ŃĆé
+
+Õ»╣õ║Ä Vaihingen µĢ░µŹ«ķøå’╝īĶ»ĘĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗żĶ░āµĢ┤µĢ░µŹ«ķøåńø«ÕĮĢŃĆé
+
+```shell
+python tools/dataset_converters/vaihingen.py /path/to/vaihingen
+```
+
+Õ£©µłæõ╗¼ńÜäķ╗śĶ«żĶ«ŠńĮ«’╝ł`clip_size`=512, `stride_size`=256’╝ēõĖŁ’╝īÕ░åńö¤µłÉ 344 Õ╝ĀÕøŠÕāÅńö©õ║ÄĶ«Łń╗āÕÆī 398 Õ╝ĀÕøŠÕāÅńö©õ║Äķ¬īĶ»üŃĆé
+
+## iSAID
+
+iSAID µĢ░µŹ«ķøåÕÅ»õ╗Ä [DOTA-v1.0](https://captain-whu.github.io/DOTA/dataset.html) õĖŗĶĮĮĶ«Łń╗ā/ķ¬īĶ»ü/µĄŗĶ»ĢµĢ░µŹ«ķøåńÜäÕøŠÕāŵĢ░µŹ«’╝ī
+
+Õ╣Čõ╗Ä [iSAID](https://captain-whu.github.io/iSAID/dataset.html)õĖŗĶĮĮĶ«Łń╗ā/ķ¬īĶ»üµĢ░µŹ«ķøåńÜäµĀćµ│©µĢ░µŹ«ŃĆé
+
+Ķ»źµĢ░µŹ«ķøåµś»Ķł¬ń®║ÕøŠÕāÅÕ«×õŠŗÕłåÕē▓ÕÆīĶ»Łõ╣ēÕłåÕē▓õ╗╗ÕŖĪńÜäÕż¦Ķ¦äµ©ĪµĢ░µŹ«ķøåŃĆé
+
+õĖŗĶĮĮ iSAID µĢ░µŹ«ķøåÕÉÄ’╝īµé©ÕÅ»ĶāĮķ£ĆĶ”üµīēńģ¦õ╗źõĖŗń╗ōµ×äĶ┐øĶĪīµĢ░µŹ«ķøåÕćåÕżćŃĆé
+
+```none
+Ōö£ŌöĆŌöĆ data
+Ōöé Ōö£ŌöĆŌöĆ iSAID
+Ōöé Ōöé Ōö£ŌöĆŌöĆ train
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ images
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ part1.zip
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ part2.zip
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ part3.zip
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ Semantic_masks
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ images.zip
+Ōöé Ōöé Ōö£ŌöĆŌöĆ val
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ images
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ part1.zip
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ Semantic_masks
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ images.zip
+Ōöé Ōöé Ōö£ŌöĆŌöĆ test
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ images
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ part1.zip
+Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ part2.zip
+```
+
+```shell
+python tools/dataset_converters/isaid.py /path/to/iSAID
+```
+
+Õ£©µłæõ╗¼ńÜäķ╗śĶ«żĶ«ŠńĮ«’╝ł`patch_width`=896, `patch_height`=896, `overlap_area`=384’╝ēõĖŁ’╝īÕ░åńö¤µłÉ 33978 Õ╝ĀÕøŠÕāÅńö©õ║ÄĶ«Łń╗āÕÆī 11644 Õ╝ĀÕøŠÕāÅńö©õ║Äķ¬īĶ»üŃĆé
+
+## LIP(Look Into Person) dataset
+
+Ķ»źµĢ░µŹ«ķøåÕÅ»õ╗źõ╗Ä[µŁżķĪĄķØó](https://lip.sysuhcp.com/overview.php)õĖŗĶĮĮŃĆé
+
+Ķ»ĘĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗żµØźĶ¦ŻÕÄŗµĢ░µŹ«ķøåŃĆé
+
+```shell
+unzip LIP.zip
+cd LIP
+unzip TrainVal_images.zip
+unzip TrainVal_parsing_annotations.zip
+cd TrainVal_parsing_annotations
+unzip TrainVal_parsing_annotations.zip
+mv train_segmentations ../
+mv val_segmentations ../
+cd ..
+```
+
+LIP µĢ░µŹ«ķøåńÜäÕåģÕ«╣Õīģµŗ¼’╝Ü
+
+```none
+Ōö£ŌöĆŌöĆ data
+Ōöé Ōö£ŌöĆŌöĆ LIP
+Ōöé Ōöé Ōö£ŌöĆŌöĆ train_images
+Ōöé┬Ā┬Ā Ōöé Ōöé Ōö£ŌöĆŌöĆ 1000_1234574.jpg
+Ōöé┬Ā┬Ā Ōöé Ōöé Ōö£ŌöĆŌöĆ ...
+Ōöé Ōöé Ōö£ŌöĆŌöĆ train_segmentations
+Ōöé┬Ā┬Ā Ōöé Ōöé Ōö£ŌöĆŌöĆ 1000_1234574.png
+Ōöé┬Ā┬Ā Ōöé Ōöé Ōö£ŌöĆŌöĆ ...
+Ōöé Ōöé Ōö£ŌöĆŌöĆ val_images
+Ōöé┬Ā┬Ā Ōöé Ōöé Ōö£ŌöĆŌöĆ 100034_483681.jpg
+Ōöé┬Ā┬Ā Ōöé Ōöé Ōö£ŌöĆŌöĆ ...
+Ōöé Ōöé Ōö£ŌöĆŌöĆ val_segmentations
+Ōöé┬Ā┬Ā Ōöé Ōöé Ōö£ŌöĆŌöĆ 100034_483681.png
+Ōöé┬Ā┬Ā Ōöé Ōöé Ōö£ŌöĆŌöĆ ...
+```
+
+## Synapse dataset
+
+µŁżµĢ░µŹ«ķøåÕÅ»õ╗źõ╗Ä[µŁżķĪĄķØó](https://www.synapse.org/#!Synapse:syn3193805/wiki/)õĖŗĶĮĮŃĆé
+
+ķüĄÕŠ¬ [TransUNet](https://arxiv.org/abs/2102.04306) ńÜäµĢ░µŹ«ÕćåÕżćĶ«ŠÕ«Ü’╝īÕ░åÕĤզŗĶ«Łń╗āķøå’╝ł30 µ¼Īµē½µÅÅ’╝ēµŗåÕłåõĖ║µ¢░ńÜäĶ«Łń╗āķøå’╝ł18 µ¼Īµē½µÅÅ’╝ēÕÆīķ¬īĶ»üķøå’╝ł12 µ¼Īµē½µÅÅ’╝ēŃĆéĶ»ĘĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗żµØźÕćåÕżćµĢ░µŹ«ķøåŃĆé
+
+```shell
+unzip RawData.zip
+cd ./RawData/Training
+```
+
+ńäČÕÉÄÕłøÕ╗║ `train.txt` ÕÆī `val.txt` õ╗źµŗåÕłåµĢ░µŹ«ķøåŃĆé
+
+µĀ╣µŹ« TransUnet’╝īõ╗źõĖŗµś»µĢ░µŹ«ķøåńÜäÕłÆÕłåŃĆé
+
+train.txt
+
+```none
+img0005.nii.gz
+img0006.nii.gz
+img0007.nii.gz
+img0009.nii.gz
+img0010.nii.gz
+img0021.nii.gz
+img0023.nii.gz
+img0024.nii.gz
+img0026.nii.gz
+img0027.nii.gz
+img0028.nii.gz
+img0030.nii.gz
+img0031.nii.gz
+img0033.nii.gz
+img0034.nii.gz
+img0037.nii.gz
+img0039.nii.gz
+img0040.nii.gz
+```
+
+val.txt
+
+```none
+img0008.nii.gz
+img0022.nii.gz
+img0038.nii.gz
+img0036.nii.gz
+img0032.nii.gz
+img0002.nii.gz
+img0029.nii.gz
+img0003.nii.gz
+img0001.nii.gz
+img0004.nii.gz
+img0025.nii.gz
+img0035.nii.gz
+```
+
+synapse µĢ░µŹ«ķøåńÜäÕåģÕ«╣Õīģµŗ¼’╝Ü
+
+```none
+Ōö£ŌöĆŌöĆ Training
+Ōöé Ōö£ŌöĆŌöĆ img
+Ōöé Ōöé Ōö£ŌöĆŌöĆ img0001.nii.gz
+Ōöé Ōöé Ōö£ŌöĆŌöĆ img0002.nii.gz
+Ōöé Ōöé Ōö£ŌöĆŌöĆ ...
+Ōöé Ōö£ŌöĆŌöĆ label
+Ōöé Ōöé Ōö£ŌöĆŌöĆ label0001.nii.gz
+Ōöé Ōöé Ōö£ŌöĆŌöĆ label0002.nii.gz
+Ōöé Ōöé Ōö£ŌöĆŌöĆ ...
+Ōöé Ōö£ŌöĆŌöĆ train.txt
+Ōöé Ōö£ŌöĆŌöĆ val.txt
+```
+
+ńäČÕÉÄ’╝īõĮ┐ńö©µŁżÕæĮõ╗żĶĮ¼µŹó synapse µĢ░µŹ«ķøåŃĆé
+
+```shell
+python tools/dataset_converters/synapse.py --dataset-path /path/to/synapse
+```
+
+µ│©µäÅ’╝īMMSegmentation ńÜäķ╗śĶ«żĶ»äõ╝░µīćµĀć’╝łõŠŗÕ”é mean dice value’╝ēµś»Õ£© 2D ÕłćńēćÕøŠÕāÅõĖŖĶ«Īń«ŚńÜä’╝īĶ┐ÖõĖÄ [TransUNet](https://arxiv.org/abs/2102.04306) ńŁēõĖĆõ║øĶ«║µ¢ćõĖŁńÜä 3D µē½µÅÅń╗ōµ×£µś»õĖŹÕÉīńÜäŃĆé
+
+## REFUGE
+
+Õ£© [REFUGE Challenge](https://refuge.grand-challenge.org) Õ«śńĮæõĖŖµ│©ÕåīÕ╣ČõĖŗĶĮĮ [REFUGE µĢ░µŹ«ķøå](https://refuge.grand-challenge.org/REFUGE2Download)ŃĆé
+
+ńäČÕÉÄ’╝īĶ¦ŻÕÄŗ `REFUGE2.zip`’╝īÕĤզŗµĢ░µŹ«ķøåńÜäÕåģÕ«╣Õīģµŗ¼’╝Ü
+
+```none
+Ōö£ŌöĆŌöĆ REFUGE2
+Ōöé Ōö£ŌöĆŌöĆ REFUGE2
+Ōöé Ōöé Ōö£ŌöĆŌöĆ Annotation-Training400.zip
+Ōöé Ōöé Ōö£ŌöĆŌöĆ REFUGE-Test400.zip
+Ōöé Ōöé Ōö£ŌöĆŌöĆ REFUGE-Test-GT.zip
+Ōöé Ōöé Ōö£ŌöĆŌöĆ REFUGE-Training400.zip
+Ōöé Ōöé Ōö£ŌöĆŌöĆ REFUGE-Validation400.zip
+Ōöé Ōöé Ōö£ŌöĆŌöĆ REFUGE-Validation400-GT.zip
+Ōöé Ōö£ŌöĆŌöĆ __MACOSX
+```
+
+Ķ»ĘĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗żĶĮ¼µŹó REFUGE µĢ░µŹ«ķøå’╝Ü
+
+```shell
+python tools/convert_datasets/refuge.py --raw_data_root=/path/to/refuge/REFUGE2/REFUGE2
+```
+
+Ķäܵ£¼õ╝ÜÕ░åńø«ÕĮĢń╗ōµ×äĶĮ¼µŹóÕ”éõĖŗ’╝Ü
+
+```none
+Ōöé Ōö£ŌöĆŌöĆ REFUGE
+Ōöé Ōöé Ōö£ŌöĆŌöĆ images
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ training
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ validation
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ test
+Ōöé Ōöé Ōö£ŌöĆŌöĆ annotations
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ training
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ validation
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ test
+```
+
+ÕīģÕɽ 400 Õ╝Āńö©õ║ÄĶ«Łń╗āńÜäÕøŠÕāÅŃĆü400 Õ╝Āńö©õ║Äķ¬īĶ»üńÜäÕøŠÕāÅÕÆī 400 Õ╝Āńö©õ║ĵĄŗĶ»ĢńÜäÕøŠÕāÅ’╝īĶ┐ÖõĖÄ REFUGE 2018 µĢ░µŹ«ķøåńøĖÕÉīŃĆé
+
+## Mapillary Vistas Datasets
+
+- Mapillary Vistas [Õ«śµ¢╣ńĮæń½Ö](https://www.mapillary.com/dataset/vistas) ÕÅ»õ╗źõĖŗĶĮĮ Mapillary Vistas µĢ░µŹ«ķøå’╝īµīēńģ¦Õ«śńĮæĶ”üµ▒éµ│©ÕåīÕ╣ČńÖ╗ķÖåÕÉÄ’╝īµĢ░µŹ«ÕÅ»õ╗źÕ£©[Ķ┐Öķćī](https://www.mapillary.com/dataset/vistas)µēŠÕł░ŃĆé
+
+- Mapillary Vistas µĢ░µŹ«ķøåõĮ┐ńö© 8-bit with color-palette µØźÕŁśÕ驵ĀćńŁŠŃĆéõĖŹķ£ĆĶ”üĶ┐øĶĪīĶĮ¼µŹóµōŹõĮ£ŃĆé
+
+- ÕüćĶ«Šµé©ÕĘ▓Õ░åµĢ░µŹ«ķøå zip µ¢ćõ╗ȵöŠÕ£© `mmsegmentation/data/mapillary` õĖŁ
+
+- Ķ»ĘĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗żµØźĶ¦ŻÕÄŗµĢ░µŹ«ķøåŃĆé
+
+ ```bash
+ cd data/mapillary
+ unzip An-ZjB1Zm61yAZG0ozTymz8I8NqI4x0MrYrh26dq7kPgfu8vf9ImrdaOAVOFYbJ2pNAgUnVGBmbue9lTgdBOb5BbKXIpFs0fpYWqACbrQDChAA2fdX0zS9PcHu7fY8c-FOvyBVxPNYNFQuM.zip
+ ```
+
+- Ķ¦ŻÕÄŗÕÉÄ’╝īµé©Õ░åĶÄĘÕŠŚń▒╗õ╝╝õ║ĵŁżń╗ōµ×äńÜä Mapillary Vistas µĢ░µŹ«ķøåŃĆéĶ»Łõ╣ēÕłåÕē▓ mask µĀćńŁŠÕ£© `labels` µ¢ćõ╗ČÕż╣õĖŁŃĆé
+
+ ```none
+ mmsegmentation
+ Ōö£ŌöĆŌöĆ mmseg
+ Ōö£ŌöĆŌöĆ tools
+ Ōö£ŌöĆŌöĆ configs
+ Ōö£ŌöĆŌöĆ data
+ Ōöé Ōö£ŌöĆŌöĆ mapillary
+ Ōöé Ōöé Ōö£ŌöĆŌöĆ training
+ Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ images
+ Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ v1.2
+ | Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ instances
+ | Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ labels
+ | Ōöé┬Ā┬Ā Ōöé┬Ā┬Ā Ōöé ŌööŌöĆŌöĆ panoptic
+ Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ v2.0
+ | Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ instances
+ | Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ labels
+ | Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ panoptic
+ | Ōöé┬Ā┬Ā Ōöé┬Ā┬Ā Ōöé ŌööŌöĆŌöĆ polygons
+ Ōöé Ōöé Ōö£ŌöĆŌöĆ validation
+ Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ images
+ | Ōöé Ōöé Ōö£ŌöĆŌöĆ v1.2
+ | Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ instances
+ | Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ labels
+ | Ōöé┬Ā┬Ā Ōöé┬Ā┬Ā Ōöé ŌööŌöĆŌöĆ panoptic
+ Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ v2.0
+ | Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ instances
+ | Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ labels
+ | Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ panoptic
+ | Ōöé┬Ā┬Ā Ōöé┬Ā┬Ā Ōöé ŌööŌöĆŌöĆ polygons
+ ```
+
+- µé©ÕÅ»õ╗źÕ£©ķģŹńĮ«õĖŁõĮ┐ńö© `MapillaryDataset_v1` ÕÆī `Mapillary Dataset_v2` Ķ«ŠńĮ«µĢ░µŹ«ķøåńēłµ£¼ŃĆé
+ Õ£©µŁżÕżä [V1.2](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/_base_/datasets/mapillary_v1.py) ÕÆī [V2.0](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/_base_/datasets/mapillary_v2.py) µ¤źń£ŗ Mapillary Vistas µĢ░µŹ«ķøåķģŹńĮ«µ¢ćõ╗Č
+
+## LEVIR-CD
+
+[LEVIR-CD](https://justchenhao.github.io/LEVIR/) Õż¦Ķ¦äµ©Īķüźµä¤Õ╗║ńŁæÕÅśÕī¢µŻĆµĄŗµĢ░µŹ«ķøåŃĆé
+
+µĢ░µŹ«ķøåÕÅ»õ╗źÕ£©[õĖ╗ķĪĄ](https://justchenhao.github.io/LEVIR/)õĖŖĶ»Ęµ▒éĶÄĘÕŠŚŃĆé
+
+µĢ░µŹ«ķøåńÜäĶĪźÕģģńēłµ£¼ÕÅ»õ╗źÕ£©[õĖ╗ķĪĄ](https://github.com/S2Looking/Dataset)õĖŖĶ»Ęµ▒éĶÄĘÕŠŚŃĆé
+
+Ķ»ĘõĖŗĶĮĮµĢ░µŹ«ķøåńÜäĶĪźÕģģńēłµ£¼’╝īńäČÕÉÄĶ¦ŻÕÄŗ `LEVIR-CD+.zip`’╝īµĢ░µŹ«ķøåńÜäÕåģÕ«╣Õīģµŗ¼’╝Ü
+
+```none
+Ōöé Ōö£ŌöĆŌöĆ LEVIR-CD+
+Ōöé Ōöé Ōö£ŌöĆŌöĆ train
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ A
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ B
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ label
+Ōöé Ōöé Ōö£ŌöĆŌöĆ test
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ A
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ B
+Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ label
+```
+
+Õ»╣õ║Ä LEVIR-CD µĢ░µŹ«ķøå’╝īĶ»ĘĶ┐ÉĶĪīõ╗źõĖŗÕæĮõ╗żµŚĀķćŹÕÅĀĶŻüÕē¬ÕĮ▒ÕāÅ’╝Ü
+
+```shell
+python tools/dataset_converters/levircd.py --dataset-path /path/to/LEVIR-CD+ --out_dir /path/to/LEVIR-CD
+```
+
+ĶŻüÕē¬ÕÉÄńÜäÕĮ▒ÕāÅÕż¦Õ░ÅõĖ║256x256’╝īõĖÄÕĤĶ«║µ¢ćõ┐صīüõĖĆĶć┤ŃĆé
+
+## BDD100K
+
+- ÕÅ»õ╗źõ╗Ä[Õ«śµ¢╣ńĮæń½Ö](https://bdd-data.berkeley.edu/) õĖŗĶĮĮ BDD100KµĢ░µŹ«ķøå’╝łĶ»Łõ╣ēÕłåÕē▓õ╗╗ÕŖĪõĖ╗Ķ”üµś»10KµĢ░µŹ«ķøå’╝ē’╝īµīēńģ¦Õ«śńĮæĶ”üµ▒éµ│©ÕåīÕ╣ČńÖ╗ķÖåÕÉÄ’╝īµĢ░µŹ«ÕÅ»õ╗źÕ£©[Ķ┐Öķćī](https://bdd-data.berkeley.edu/portal.html#download)µēŠÕł░ŃĆé
+
+- ÕøŠÕāŵĢ░µŹ«Õ»╣Õ║öńÜäÕÉŹń¦░µś»µś»`10K Images`, Ķ»Łõ╣ēÕłåÕē▓µĀćµ│©Õ»╣Õ║öńÜäÕÉŹń¦░µś»`Segmentation`
+
+- õĖŗĶĮĮÕÉÄ’╝īÕÅ»õ╗źõĮ┐ńö©õ╗źõĖŗõ╗ŻńĀüĶ┐øĶĪīĶ¦ŻÕÄŗ
+
+ ```bash
+ unzip ~/bdd100k_images_10k.zip -d ~/mmsegmentation/data/
+ unzip ~/bdd100k_sem_seg_labels_trainval.zip -d ~/mmsegmentation/data/
+ ```
+
+Õ░▒ÕÅ»õ╗źÕŠŚÕł░õ╗źõĖŗµ¢ćõ╗Čń╗ōµ×äõ║å’╝Ü
+
+```none
+mmsegmentation
+Ōö£ŌöĆŌöĆ mmseg
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+Ōö£ŌöĆŌöĆ data
+Ōöé Ōö£ŌöĆŌöĆ bdd100k
+Ōöé Ōöé Ōö£ŌöĆŌöĆ images
+Ōöé Ōöé Ōöé ŌööŌöĆŌöĆ 10k
+| Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ test
+| Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ train
+| Ōöé┬Ā┬Ā Ōöé┬Ā┬Ā Ōöé ŌööŌöĆŌöĆ val
+Ōöé Ōöé ŌööŌöĆŌöĆ labels
+Ōöé Ōöé Ōöé ŌööŌöĆŌöĆ sem_seg
+| Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ colormaps
+| Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆtrain
+| Ōöé Ōöé Ōöé Ōöé ŌööŌöĆŌöĆval
+| Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ masks
+| Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆtrain
+| Ōöé Ōöé Ōöé Ōöé ŌööŌöĆŌöĆval
+| Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ polygons
+| Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆsem_seg_train.json
+| Ōöé Ōöé Ōöé Ōöé ŌööŌöĆŌöĆsem_seg_val.json
+| Ōöé┬Ā┬Ā Ōöé┬Ā┬Ā Ōöé ŌööŌöĆŌöĆ rles
+| Ōöé Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆsem_seg_train.json
+| Ōöé Ōöé Ōöé Ōöé ŌööŌöĆŌöĆsem_seg_val.json
+```
diff --git a/internlm_langchain/knowledge_base/MMSegmentation/content/3_inference.md b/internlm_langchain/knowledge_base/MMSegmentation/content/3_inference.md
new file mode 100644
index 00000000..0afcb4b0
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMSegmentation/content/3_inference.md
@@ -0,0 +1,244 @@
+# µĢÖń©ŗ3’╝ÜõĮ┐ńö©ķóäĶ«Łń╗āµ©ĪÕ×ŗµÄ©ńÉå
+
+MMSegmentation Õ£© [Model Zoo](../Model_Zoo.md) õĖŁõĖ║Ķ»Łõ╣ēÕłåÕē▓µÅÉõŠøõ║åķóäĶ«Łń╗āńÜ䵩ĪÕ×ŗ’╝īÕ╣ȵö»µīüÕżÜõĖ¬µĀćÕćåµĢ░µŹ«ķøå’╝īÕīģµŗ¼ CityscapesŃĆüADE20K ńŁēŃĆé
+µ£¼Ķ»┤µśÄÕ░åÕ▒Ģńż║Õ”éõĮĢõĮ┐ńö©ńÄ░µ£ēµ©ĪÕ×ŗÕ»╣ń╗ÖÕ«ÜÕøŠÕāÅĶ┐øĶĪīµÄ©ńÉåŃĆé
+Õģ│õ║ÄÕ”éõĮĢÕ£©µĀćÕćåµĢ░µŹ«ķøåõĖŖµĄŗĶ»ĢńÄ░µ£ēµ©ĪÕ×ŗ’╝īĶ»ĘÕÅéķśģµ£¼[µīćÕŹŚ](./4_train_test.md)
+
+MMSegmentation õĖ║ńö©µłĘµÅÉõŠøõ║åµĢ░õĖ¬µÄźÕÅŻ’╝īõ╗źõŠ┐ĶĮ╗µØŠõĮ┐ńö©ķóäĶ«Łń╗āńÜ䵩ĪÕ×ŗĶ┐øĶĪīµÄ©ńÉåŃĆé
+
+- [µĢÖń©ŗ3’╝ÜõĮ┐ńö©ķóäĶ«Łń╗āµ©ĪÕ×ŗµÄ©ńÉå](#µĢÖń©ŗ3õĮ┐ńö©ķóäĶ«Łń╗āµ©ĪÕ×ŗµÄ©ńÉå)
+ - [µÄ©ńÉåÕÖ©](#µÄ©ńÉåÕÖ©)
+ - [Õ¤║µ£¼õĮ┐ńö©](#Õ¤║µ£¼õĮ┐ńö©)
+ - [ÕłØÕ¦ŗÕī¢](#ÕłØÕ¦ŗÕī¢)
+ - [ÕÅ»Ķ¦åÕī¢ķó䵥ŗń╗ōµ×£](#ÕÅ»Ķ¦åÕī¢ķó䵥ŗń╗ōµ×£)
+ - [µ©ĪÕ×ŗÕłŚĶĪ©](#µ©ĪÕ×ŗÕłŚĶĪ©)
+ - [µÄ©ńÉå API](#µÄ©ńÉå-api)
+ - [mmseg.apis.init_model](#mmsegapisinit_model)
+ - [mmseg.apis.inference_model](#mmsegapisinference_model)
+ - [mmseg.apis.show_result_pyplot](#mmsegapisshow_result_pyplot)
+
+## µÄ©ńÉåÕÖ©
+
+Õ£© MMSegmentation õĖŁ’╝īµłæõ╗¼µÅÉõŠøõ║åµ£Ć**µ¢╣õŠ┐ńÜä**µ¢╣Õ╝Å `MMSegInferencer` µØźõĮ┐ńö©µ©ĪÕ×ŗŃĆéµé©ÕŬķ£Ć 3 ĶĪīõ╗ŻńĀüÕ░▒ÕÅ»õ╗źĶÄĘÕŠŚÕøŠÕāÅńÜäÕłåÕē▓µÄ®Ķå£ŃĆé
+
+### Õ¤║µ£¼õĮ┐ńö©
+
+õ╗źõĖŗńż║õŠŗÕ▒Ģńż║õ║åÕ”éõĮĢõĮ┐ńö© `MMSegInferencer` Õ»╣ÕŹĢõĖ¬ÕøŠÕāŵē¦ĶĪīµÄ©ńÉåŃĆé
+
+```
+>>> from mmseg.apis import MMSegInferencer
+>>> # Õ░嵩ĪÕ×ŗÕŖĀĶĮĮÕł░ÕåģÕŁśõĖŁ
+>>> inferencer = MMSegInferencer(model='deeplabv3plus_r18-d8_4xb2-80k_cityscapes-512x1024')
+>>> # µÄ©ńÉå
+>>> inferencer('demo/demo.png', show=True)
+```
+
+ÕÅ»Ķ¦åÕī¢ń╗ōµ×£Õ║öÕ”éõĖŗµēĆńż║’╝Ü
+
+
+
+  +
+
+
+µŁżÕż¢’╝īµé©ÕÅ»õ╗źõĮ┐ńö© `MMSegInferencer` µØźÕżäńÉåõĖĆõĖ¬ÕīģÕÉ½ÕżÜÕ╝ĀÕøŠńēćńÜä `list`’╝Ü
+
+```
+# ĶŠōÕģźõĖĆõĖ¬ÕøŠńēć list
+>>> images = [image1, image2, ...] # image1 ÕÅ»õ╗źµś»µ¢ćõ╗ČĶĘ»ÕŠäµł¢ np.ndarray
+>>> inferencer(images, show=True, wait_time=0.5) # wait_time µś»Õ╗ČĶ┐¤µŚČķŚ┤’╝ī0 ĶĪ©ńż║µŚĀķÖÉ
+
+# µł¢ĶŠōÕģźÕøŠÕāÅńø«ÕĮĢ
+>>> images = $IMAGESDIR
+>>> inferencer(images, show=True, wait_time=0.5)
+
+# õ┐ØÕŁśÕÅ»Ķ¦åÕī¢µĖ▓µ¤ōÕĮ®Ķē▓ÕłåÕē▓ÕøŠÕÆīķó䵥ŗń╗ōµ×£
+# out_dir µś»õ┐ØÕŁśĶŠōÕć║ń╗ōµ×£ńÜäńø«ÕĮĢ’╝īimg_out_dir ÕÆī pred_out_dir õĖ║ out_dir ńÜäÕŁÉńø«ÕĮĢ
+# õ╗źõ┐ØÕŁśÕÅ»Ķ¦åÕī¢µĖ▓µ¤ōÕĮ®Ķē▓ÕłåÕē▓ÕøŠÕÆīķó䵥ŗń╗ōµ×£
+>>> inferencer(images, out_dir='outputs', img_out_dir='vis', pred_out_dir='pred')
+```
+
+µÄ©ńÉåÕÖ©µ£ēõĖĆõĖ¬ÕÅ»ķĆēÕÅéµĢ░ `return_datasamples`’╝īÕģČķ╗śĶ«żÕĆ╝õĖ║ False’╝īµÄ©ńÉåÕÖ©ńÜäĶ┐öÕø×ÕĆ╝ķ╗śĶ«żõĖ║ `dict` ń▒╗Õ×ŗ’╝īÕīģµŗ¼ 'visualization' ÕÆī 'predictions' õĖżõĖ¬ keyŃĆé
+Õ”éµ×£ `return_datasamples=True` µÄ©ńÉåÕÖ©Õ░åĶ┐öÕø× [`SegDataSample`](../advanced_guides/structures.md) µł¢ÕģČÕłŚĶĪ©ŃĆé
+
+```
+result = inferencer('demo/demo.png')
+# ń╗ōµ×£µś»õĖĆõĖ¬ÕīģÕɽ 'visualization' ÕÆī 'predictions' õĖżõĖ¬ key ńÜä `dict`
+# 'visualization' ÕīģÕɽÕĮ®Ķē▓ÕłåÕē▓ÕøŠ
+print(result['visualization'].shape)
+# (512, 683, 3)
+
+# 'predictions' ÕīģÕɽÕĖ”µ£ēµĀćńŁŠń┤óÕ╝ĢńÜäÕłåÕē▓µÄ®Ķå£
+print(result['predictions'].shape)
+# (512, 683)
+
+result = inferencer('demo/demo.png', return_datasamples=True)
+print(type(result))
+#
+
+
+### 2.4 ÕłćµŹóÕłåµö»õĖ║ dev-1.x
+
+µŁŻÕ”éµé©Õ£©[ mmsegmentation Õ«śńĮæ](https://github.com/open-mmlab/mmsegmentation/tree/main)µēĆĶ¦ü’╝īĶ»źõ╗ōÕ║ōµ£ēĶ«ĖÕżÜÕłåµö»’╝īķ╗śĶ«żÕłåµö»`main`õĖ║ń©│Õ«ÜńÜäÕÅæĶĪīńēłµ£¼’╝īõ╗źÕÅŖńö©õ║ÄĶ┤Īńī«ĶĆģĶ┐øĶĪīÕ╝ĆÕÅæńÜä`dev-1.x`Õłåµö»ŃĆé`dev-1.x`Õłåµö»µś»Ķ┤Īńī«ĶĆģõ╗¼ńö©µØźµÅÉõ║żÕłøµäÅÕÆī PR ńÜäÕłåµö»’╝ī`dev-1.x`Õłåµö»ńÜäÕåģÕ«╣õ╝ÜĶó½Õ橵£¤µĆ¦ńÜäÕÉłÕģźÕł░`main`Õłåµö»ŃĆé
+
+
+Õø×Õł░ VSCODE õĖŁ’╝īÕ£©ń╗łń½»µē¦ĶĪīÕæĮõ╗ż
+
+```bash
+git checkout dev-1.x
+```
+
+### 2.5 Õłøµ¢░Õ▒×õ║ÄĶć¬ÕĘ▒ńÜäµ¢░Õłåµö»
+
+Õ£©Õ¤║õ║Ä`dev-1.x`Õłåµö»õĖŗ’╝īõĮ┐ńö©Õ”éõĖŗÕæĮõ╗ż’╝īÕłøÕ╗║Õ▒×õ║ĵé©Ķć¬ÕĘ▒ńÜäÕłåµö»ŃĆé
+
+```bash
+# git checkout -b µé©ńÜäGitHubID/µé©ńÜäÕłåµö»µā│Ķ”üÕ«×ńÄ░ńÜäÕŖ¤ĶāĮńÜäÕÉŹÕŁŚ
+# git checkout -b AI-Tianlong/support_GID_dataset
+git checkout -b {µé©ńÜäGitHubID/µé©ńÜäÕłåµö»µā│Ķ”üÕ«×ńÄ░ńÜäÕŖ¤ĶāĮńÜäÕÉŹÕŁŚ}
+```
+
+### 2.6 ķģŹńĮ« pre-commit
+
+OpenMMLab õ╗ōÕ║ōÕ»╣õ╗ŻńĀüĶ┤©ķćŵ£ēńØĆĶŠāķ½śńÜäĶ”üµ▒é’╝īµēƵ£ēµÅÉõ║żńÜä PR Õ┐ģķĪ╗Ķ”üķĆÜĶ┐ćõ╗ŻńĀüµĀ╝Õ╝ŵŻĆµ¤źŃĆépre-commit Ķ»”ń╗åķģŹńĮ«ÕÅéķśģ[ķģŹńĮ« pre-commit](https://mmcv.readthedocs.io/zh_CN/latest/community/contributing.html#pre-commit)ŃĆé
+
+## µŁźķ¬ż 3’╝ÜÕ£©`mmsegmentation/projects`õĖŗĶ┤Īńī«µé©ńÜäõ╗ŻńĀü
+
+**ÕģłÕ»╣ GID µĢ░µŹ«ķøåĶ┐øĶĪīÕłåµ×É**
+
+Ķ┐Öķćīõ╗źĶ┤Īńī«ķ½śÕłå 2 ÕÅĘķüźµä¤ÕøŠÕāÅĶ»Łõ╣ēÕłåÕē▓µĢ░µŹ«ķøå GID õĖ║õŠŗ’╝īGID µĢ░µŹ«ķøåµś»ńö▒µłæÕøĮĶć¬õĖ╗ńĀöÕÅæńÜäķ½śÕłå 2 ÕÅĘÕŹ½µś¤µēƵŗŹµæäńÜäÕģēÕŁ”ķüźµä¤ÕøŠÕāŵēĆÕłøÕ╗║’╝īń╗ÅÕøŠÕāÅķóäÕżäńÉåÕÉÄÕģ▒µÅÉõŠøõ║å 150 Õ╝Ā 6800x7200 ÕāÅń┤ĀńÜä RGB õĖēķĆÜķüōķüźµä¤ÕøŠÕāÅŃĆéÕ╣ȵÅÉõŠøõ║åõĖżń¦ŹõĖŹÕÉīń▒╗Õł½µĢ░ńÜäµĢ░µŹ«µĀćµ│©’╝īõĖĆń¦Źµś»ÕīģÕɽ 5 ń▒╗µ£ēµĢłńē®õĮōńÜä RGB µĀćńŁŠ’╝īÕÅ”õĖĆń¦Źµś»ÕīģÕɽ 15 ń▒╗µ£ēµĢłńē®õĮōńÜä RGB µĀćńŁŠŃĆéµ£¼µĢÖń©ŗÕ░åķÆłÕ»╣ 5 ń▒╗µĀćńŁŠĶ┐øĶĪīµĢ░µŹ«ķøåĶ┤Īńī«µĄüń©ŗĶ«▓Ķ¦ŻŃĆé
+
+GID ńÜä 5 ń▒╗µ£ēµĢłµĀćńŁŠÕłåÕł½õĖ║’╝Ü0-ĶāīµÖ»-\[0,0,0\](mask µĀćńŁŠÕĆ╝-µĀćńŁŠÕÉŹń¦░-RGB µĀćńŁŠÕĆ╝)ŃĆü1-Õ╗║ńŁæ-\[255,0,0\]ŃĆü2-Õå£ńö░-\[0,255,0\]ŃĆü3-µŻ«µ×Ś-\[0,0,255\]ŃĆü4-ĶŹēÕ£░-\[255,255,0\]ŃĆü5-µ░┤-\[0,0,255\]ŃĆéÕ£©Ķ»Łõ╣ēÕłåÕē▓õ╗╗ÕŖĪõĖŁ’╝īµĀćńŁŠµś»õĖÄÕĤÕøŠÕ░║Õ»ĖõĖĆĶć┤ńÜäÕŹĢķĆÜķüōÕøŠÕāÅ’╝īµĀćńŁŠÕøŠÕāÅõĖŁńÜäÕāÅń┤ĀÕĆ╝õĖ║ń£¤Õ«×µĀʵ£¼ÕøŠÕāÅõĖŁÕ»╣Õ║öÕāÅń┤ĀµēĆÕīģÕɽńÜäńē®õĮōńÜäń▒╗Õł½ŃĆéGID µĢ░µŹ«ķøåµÅÉõŠøńÜ䵜»Õģʵ£ē RGB õĖēķĆÜķüōńÜäÕĮ®Ķē▓µĀćńŁŠ’╝īõĖ║õ║嵩ĪÕ×ŗńÜäĶ«Łń╗āķ£ĆĶ”üÕ░å RGB µĀćńŁŠĶĮ¼µŹóõĖ║ mask µĀćńŁŠŃĆéÕ╣ČõĖöńö▒õ║ÄÕøŠÕāÅÕ░║Õ»ĖõĖ║ 6800x7200 ÕāÅń┤Ā’╝īÕ»╣õ║Äńź×ń╗ÅńĮæń╗£ńÜäĶ«Łń╗āµØźµ£ēõ║øĶ┐ćÕż¦’╝īµēĆõ╗źÕ░åµ»ÅÕ╝ĀÕøŠÕāÅĶŻüÕłćµłÉõ║åµ▓Īµ£ēķćŹÕÅĀńÜä 512x512 ńÜäÕøŠÕāÅõ╗źõŠ┐Ķ┐øĶĪīĶ«Łń╗āŃĆé
+
+
+### 3.1 Õ£©`mmsegmentation/projects`õĖŗÕłøÕ╗║µ¢░ńÜäķĪ╣ńø«µ¢ćõ╗ČÕż╣
+
+Õ£©`mmsegmentation/projects`õĖŗÕłøÕ╗║µ¢ćõ╗ČÕż╣`gid_dataset`
+
+
+### 3.2 Ķ┤Īńī«µé©ńÜäµĢ░µŹ«ķøåõ╗ŻńĀü
+
+õĖ║õ║åµ£Ćń╗łĶāĮÕ░åµé©Õ£© projects õĖŁĶ┤Īńī«ńÜäõ╗ŻńĀüµø┤ÕŖĀķĪ║ńĢģńÜäń¦╗ÕģźµĀĖÕ┐āÕ║ōõĖŁ’╝łÕ»╣õ╗ŻńĀüĶ”üµ▒éĶ┤©ķćŵø┤ķ½ś’╝ē’╝īķØ×ÕĖĖÕ╗║Ķ««µīēńģ¦µĀĖÕ┐āÕ║ōńÜäńø«ÕĮĢµØźń╝¢ĶŠæµé©ńÜäµĢ░µŹ«ķøåµ¢ćõ╗ČŃĆé
+Õģ│õ║ĵĢ░µŹ«ķøåµ£ē 4 õĖ¬Õ┐ģĶ”üńÜäµ¢ćõ╗Č’╝Ü
+
+- **1** `mmseg/datasets/gid.py` Õ«Üõ╣ēõ║åµĢ░µŹ«ķøåńÜäÕ░Šń╝ĆŃĆüCLASSESŃĆüPALETTEŃĆüreduce_zero_labelńŁē
+- **2** `configs/_base_/gid.py` GID µĢ░µŹ«ķøåńÜäķģŹńĮ«µ¢ćõ╗Č’╝īÕ«Üõ╣ēõ║åµĢ░µŹ«ķøåńÜä`dataset_type`’╝łµĢ░µŹ«ķøåń▒╗Õ×ŗ’╝ī`mmseg/datasets/gid.py`õĖŁµ│©ÕåīńÜäµĢ░µŹ«ķøåńÜäń▒╗ÕÉŹ’╝ēŃĆü`data_root`(µĢ░µŹ«ķøåµēĆÕ£©ńÜäµĀ╣ńø«ÕĮĢ’╝īÕ╗║Ķ««Õ░åµĢ░µŹ«ķøåķĆÜĶ┐ćĶĮ»Ķ┐׵ğńÜäµ¢╣Õ╝ÅÕ░åµĢ░µŹ«ķøåµöŠĶć│`mmsegmentation/data`)ŃĆü`train_pipline`(Ķ«Łń╗āńÜäµĢ░µŹ«µĄü)ŃĆü`test_pipline`(µĄŗĶ»ĢÕÆīķ¬īĶ»üµŚČńÜäµĢ░µŹ«µĄü)ŃĆü`img_rations`(ÕżÜÕ░║Õ║”ķó䵥ŗµŚČńÜäÕżÜÕ░║Õ║”ķģŹńĮ«)ŃĆü`tta_pipeline`’╝łÕżÜÕ░║Õ║”ķó䵥ŗ’╝ēŃĆü`train_dataloader`(Ķ«Łń╗āķøåńÜäµĢ░µŹ«ÕŖĀĶĮĮÕÖ©)ŃĆü`val_dataloader`(ķ¬īĶ»üķøåńÜäµĢ░µŹ«ÕŖĀĶĮĮÕÖ©)ŃĆü`test_dataloader`(µĄŗĶ»ĢķøåńÜäµĢ░µŹ«ÕŖĀĶĮĮÕÖ©)ŃĆü`val_evaluator`(ķ¬īĶ»üķøåńÜäĶ»äõ╝░ÕÖ©)ŃĆü`test_evaluator`(µĄŗĶ»ĢķøåńÜäĶ»äõ╝░ÕÖ©)ŃĆé
+- **3** õĮ┐ńö©õ║å GID µĢ░µŹ«ķøåńÜ䵩ĪÕ×ŗĶ«Łń╗āķģŹńĮ«µ¢ćõ╗Č
+ Ķ┐ÖõĖ¬µś»ÕÅ»ķĆēńÜä’╝īõĮåµś»Õ╝║ńāłÕ╗║Ķ««µé©µĘ╗ÕŖĀŃĆéÕ£©µĀĖÕ┐āÕ║ōõĖŁ’╝īµēĆĶ┤Īńī«ńÜäµĢ░µŹ«ķøåķ£ĆĶ”üÕÆīÕÅéĶĆāµ¢ćńī«õĖŁµēƵÅÉÕć║ńÜäń╗ōµ×£ń▓ŠÕ║”Õ»╣ķĮÉ’╝īõĖ║õ║åÕÉĵ£¤Õ░åµé©Ķ┤Īńī«ńÜäõ╗ŻńĀüÕÉłÕ╣ČÕģźµĀĖÕ┐āÕ║ōŃĆéÕ”éµé©ńÜäń«ŚÕŖøÕģģĶČ│’╝īµ£ĆÕźĮĶāĮµÅÉõŠøÕ»╣Õ║öńÜ䵩ĪÕ×ŗķģŹńĮ«µ¢ćõ╗ČÕ£©µé©Ķ┤Īńī«ńÜäµĢ░µŹ«ķøåõĖŖµēĆķ¬īĶ»üńÜäń╗ōµ×£õ╗źÕÅŖńøĖÕ║öńÜäµØāķ揵¢ćõ╗Č’╝īÕ╣ȵÆ░ÕåÖĶŠāõĖ║Ķ»”ń╗åńÜäREADME.mdµ¢ćµĪŻŃĆé[ńż║õŠŗÕÅéĶĆāń╗ōµ×£](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/deeplabv3plus#mapillary-vistas-v12)
+ 
+- **4** õĮ┐ńö©Õ”éõĖŗÕæĮõ╗żµĀ╝Õ╝Å’╝Ü µÆ░ÕåÖ`docs/zh_cn/user_guides/2_dataset_prepare.md`µØźµĘ╗ÕŖĀµé©ńÜäµĢ░µŹ«ķøåõ╗ŗń╗Ź’╝īÕīģµŗ¼õĮåõĖŹķÖÉõ║ĵĢ░µŹ«ķøåńÜäõĖŗĶĮĮµ¢╣Õ╝Å’╝īµĢ░µŹ«ķøåńø«ÕĮĢń╗ōµ×äŃĆüµĢ░µŹ«ķøåńö¤µłÉńŁēõĖĆõ║øÕ┐ģĶ”üµĆ¦ńÜäµ¢ćÕŁŚµĆ¦µÅÅĶ┐░ÕÆīĶ┐ÉĶĪīÕæĮõ╗żŃĆéõ╗źµø┤ÕźĮÕ£░ÕĖ«ÕŖ®ńö©µłĘĶāĮµø┤Õ┐½ńÜäÕ«×ńÄ░µĢ░µŹ«ķøåńÜäÕćåÕżćÕĘźõĮ£ŃĆé
+
+### 3.3 Ķ┤Īńī«`tools/dataset_converters/gid.py`
+
+ńö▒õ║Ä GID µĢ░µŹ«ķøåµś»ńö▒µ£¬ń╗ÅĶ┐ćÕłćÕłåńÜä 6800x7200 ÕøŠÕāŵēƵ×䵳ÉńÜäµĢ░µŹ«ķøå’╝īÕ╣ČõĖöµ▓Īµ£ēÕłÆÕłåĶ«Łń╗āķøåŃĆüķ¬īĶ»üķøåõĖĵĄŗĶ»ĢķøåŃĆéõ╗źÕÅŖÕģȵĀćńŁŠõĖ║ RGB ÕĮ®Ķē▓µĀćńŁŠ’╝īķ£ĆĶ”üÕ░åµĀćńŁŠĶĮ¼µŹóõĖ║ÕŹĢķĆÜķüōńÜä mask labelŃĆéõĖ║õ║åµ¢╣õŠ┐Ķ«Łń╗ā’╝īķ”¢ÕģłÕ░å GID µĢ░µŹ«ķøåĶ┐øĶĪīĶŻüÕłćÕÆīµĀćńŁŠĶĮ¼µŹó’╝īÕ╣ČĶ┐øĶĪīµĢ░µŹ«ķøåÕłÆÕłå’╝īµ×äÕ╗║õĖ║ mmsegmentation µēƵö»µīüńÜäµĀ╝Õ╝ÅŃĆé
+
+```python
+# tools/dataset_converters/gid.py
+import argparse
+import glob
+import math
+import os
+import os.path as osp
+from PIL import Image
+
+import mmcv
+import numpy as np
+from mmengine.utils import ProgressBar, mkdir_or_exist
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Convert GID dataset to mmsegmentation format')
+ parser.add_argument('dataset_img_path', help='GID images folder path')
+ parser.add_argument('dataset_label_path', help='GID labels folder path')
+ parser.add_argument('--tmp_dir', help='path of the temporary directory')
+ parser.add_argument('-o', '--out_dir', help='output path', default='data/gid')
+ parser.add_argument(
+ '--clip_size',
+ type=int,
+ help='clipped size of image after preparation',
+ default=256)
+ parser.add_argument(
+ '--stride_size',
+ type=int,
+ help='stride of clipping original images',
+ default=256)
+ args = parser.parse_args()
+ return args
+
+GID_COLORMAP = dict(
+ Background=(0, 0, 0), #0-ĶāīµÖ»-ķ╗æĶē▓
+ Building=(255, 0, 0), #1-Õ╗║ńŁæ-ń║óĶē▓
+ Farmland=(0, 255, 0), #2-Õå£ńö░-ń╗┐Ķē▓
+ Forest=(0, 0, 255), #3-µŻ«µ×Ś-ĶōØĶē▓
+ Meadow=(255, 255, 0),#4-ĶŹēÕ£░-ķ╗äĶē▓
+ Water=(0, 0, 255)#5-µ░┤-ĶōØĶē▓
+)
+palette = list(GID_COLORMAP.values())
+classes = list(GID_COLORMAP.keys())
+
+#############ńö©ÕłŚĶĪ©µØźÕŁśõĖĆõĖ¬ RGB ÕÆīõĖĆõĖ¬ń▒╗Õł½ńÜäÕ»╣Õ║ö################
+def colormap2label(palette):
+ colormap2label_list = np.zeros(256**3, dtype = np.longlong)
+ for i, colormap in enumerate(palette):
+ colormap2label_list[(colormap[0] * 256 + colormap[1])*256+colormap[2]] = i
+ return colormap2label_list
+
+#############ń╗ÖÕ«ÜķéŻõĖ¬ÕłŚĶĪ©’╝īÕÆīvis_pngńäČÕÉÄńö¤µłÉmasks_png################
+def label_indices(RGB_label, colormap2label_list):
+ RGB_label = RGB_label.astype('int32')
+ idx = (RGB_label[:, :, 0] * 256 + RGB_label[:, :, 1]) * 256 + RGB_label[:, :, 2]
+ # print(idx.shape)
+ return colormap2label_list[idx]
+
+def RGB2mask(RGB_label, colormap2label_list):
+ # RGB_label = np.array(Image.open(RGB_label).convert('RGB')) #µēōÕ╝ĆRGB_png
+ mask_label = label_indices(RGB_label, colormap2label_list) # .numpy()
+ return mask_label
+
+colormap2label_list = colormap2label(palette)
+
+def clip_big_image(image_path, clip_save_dir, args, to_label=False):
+ """
+ Original image of GID dataset is very large, thus pre-processing
+ of them is adopted. Given fixed clip size and stride size to generate
+ clipped image, the intersectionŃĆĆof width and height is determined.
+ For example, given one 6800 x 7200 original image, the clip size is
+ 256 and stride size is 256, thus it would generate 29 x 27 = 783 images
+ whose size are all 256 x 256.
+
+ """
+
+ image = mmcv.imread(image_path, channel_order='rgb')
+ # image = mmcv.bgr2gray(image)
+
+ h, w, c = image.shape
+ clip_size = args.clip_size
+ stride_size = args.stride_size
+
+ num_rows = math.ceil((h - clip_size) / stride_size) if math.ceil(
+ (h - clip_size) /
+ stride_size) * stride_size + clip_size >= h else math.ceil(
+ (h - clip_size) / stride_size) + 1
+ num_cols = math.ceil((w - clip_size) / stride_size) if math.ceil(
+ (w - clip_size) /
+ stride_size) * stride_size + clip_size >= w else math.ceil(
+ (w - clip_size) / stride_size) + 1
+
+ x, y = np.meshgrid(np.arange(num_cols + 1), np.arange(num_rows + 1))
+ xmin = x * clip_size
+ ymin = y * clip_size
+
+ xmin = xmin.ravel()
+ ymin = ymin.ravel()
+ xmin_offset = np.where(xmin + clip_size > w, w - xmin - clip_size,
+ np.zeros_like(xmin))
+ ymin_offset = np.where(ymin + clip_size > h, h - ymin - clip_size,
+ np.zeros_like(ymin))
+ boxes = np.stack([
+ xmin + xmin_offset, ymin + ymin_offset,
+ np.minimum(xmin + clip_size, w),
+ np.minimum(ymin + clip_size, h)
+ ], axis=1)
+
+ if to_label:
+ image = RGB2mask(image, colormap2label_list) #Ķ┐ÖķćīÕŠŚµö╣õĖĆõĖŗ
+
+ for count, box in enumerate(boxes):
+ start_x, start_y, end_x, end_y = box
+ clipped_image = image[start_y:end_y,
+ start_x:end_x] if to_label else image[
+ start_y:end_y, start_x:end_x, :]
+ img_name = osp.basename(image_path).replace('.tif', '')
+ img_name = img_name.replace('_label', '')
+ if count % 3 == 0:
+ mmcv.imwrite(
+ clipped_image.astype(np.uint8),
+ osp.join(
+ clip_save_dir.replace('train', 'val'),
+ f'{img_name}_{start_x}_{start_y}_{end_x}_{end_y}.png'))
+ else:
+ mmcv.imwrite(
+ clipped_image.astype(np.uint8),
+ osp.join(
+ clip_save_dir,
+ f'{img_name}_{start_x}_{start_y}_{end_x}_{end_y}.png'))
+ count += 1
+
+def main():
+ args = parse_args()
+
+ """
+ According to this paper: https://ieeexplore.ieee.org/document/9343296/
+ select 15 images contained in GID, , which cover the whole six
+ categories, to generate train set and validation set.
+
+ According to Paper: https://ieeexplore.ieee.org/document/9343296/
+
+ """
+
+ if args.out_dir is None:
+ out_dir = osp.join('data', 'gid')
+ else:
+ out_dir = args.out_dir
+
+ print('Making directories...')
+ mkdir_or_exist(osp.join(out_dir, 'img_dir', 'train'))
+ mkdir_or_exist(osp.join(out_dir, 'img_dir', 'val'))
+ mkdir_or_exist(osp.join(out_dir, 'ann_dir', 'train'))
+ mkdir_or_exist(osp.join(out_dir, 'ann_dir', 'val'))
+
+ src_path_list = glob.glob(os.path.join(args.dataset_img_path, '*.tif'))
+ print(f'Find {len(src_path_list)} pictures')
+
+ prog_bar = ProgressBar(len(src_path_list))
+
+ dst_img_dir = osp.join(out_dir, 'img_dir', 'train')
+ dst_label_dir = osp.join(out_dir, 'ann_dir', 'train')
+
+ for i, img_path in enumerate(src_path_list):
+ label_path = osp.join(args.dataset_label_path, osp.basename(img_path.replace('.tif', '_label.tif')))
+
+ clip_big_image(img_path, dst_img_dir, args, to_label=False)
+ clip_big_image(label_path, dst_label_dir, args, to_label=True)
+ prog_bar.update()
+
+ print('Done!')
+
+if __name__ == '__main__':
+ main()
+```
+
+### 3.4 Ķ┤Īńī«`mmseg/datasets/gid.py`
+
+ÕÅ»ÕÅéĶĆā[`projects/mapillary_dataset/mmseg/datasets/mapillary.py`](https://github.com/open-mmlab/mmsegmentation/blob/main/projects/mapillary_dataset/mmseg/datasets/mapillary.py)Õ╣ČÕ£©µŁżÕ¤║ńĪĆõĖŖõ┐«µö╣ńøĖÕ║öÕÅśķćÅõ╗źķĆéķģŹµé©ńÜäµĢ░µŹ«ķøåŃĆé
+
+```python
+# mmseg/datasets/gid.py
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmseg.datasets.basesegdataset import BaseSegDataset
+from mmseg.registry import DATASETS
+
+# µ│©ÕåīµĢ░µŹ«ķøåń▒╗
+@DATASETS.register_module()
+class GID_Dataset(BaseSegDataset):
+ """Gaofen Image Dataset (GID)
+
+ Dataset paper link:
+ https://www.sciencedirect.com/science/article/pii/S0034425719303414
+ https://x-ytong.github.io/project/GID.html
+
+ GID 6 classes: background(others), built-up, farmland, forest, meadow, water
+
+ In This example, select 10 images from GID dataset as training set,
+ and select 5 images as validation set.
+ The selected images are listed as follows:
+
+ GF2_PMS1__L1A0000647767-MSS1
+ GF2_PMS1__L1A0001064454-MSS1
+ GF2_PMS1__L1A0001348919-MSS1
+ GF2_PMS1__L1A0001680851-MSS1
+ GF2_PMS1__L1A0001680853-MSS1
+ GF2_PMS1__L1A0001680857-MSS1
+ GF2_PMS1__L1A0001757429-MSS1
+ GF2_PMS2__L1A0000607681-MSS2
+ GF2_PMS2__L1A0000635115-MSS2
+ GF2_PMS2__L1A0000658637-MSS2
+ GF2_PMS2__L1A0001206072-MSS2
+ GF2_PMS2__L1A0001471436-MSS2
+ GF2_PMS2__L1A0001642620-MSS2
+ GF2_PMS2__L1A0001787089-MSS2
+ GF2_PMS2__L1A0001838560-MSS2
+
+ The ``img_suffix`` is fixed to '.tif' and ``seg_map_suffix`` is
+ fixed to '.tif' for GID.
+ """
+ METAINFO = dict(
+ classes=('Others', 'Built-up', 'Farmland', 'Forest',
+ 'Meadow', 'Water'),
+
+ palette=[[0, 0, 0], [255, 0, 0], [0, 255, 0], [0, 255, 255],
+ [255, 255, 0], [0, 0, 255]])
+
+ def __init__(self,
+ img_suffix='.png',
+ seg_map_suffix='.png',
+ reduce_zero_label=None,
+ **kwargs) -> None:
+ super().__init__(
+ img_suffix=img_suffix,
+ seg_map_suffix=seg_map_suffix,
+ reduce_zero_label=reduce_zero_label,
+ **kwargs)
+```
+
+### 3.5 Ķ┤Īńī«õĮ┐ńö© GID ńÜäĶ«Łń╗ā config file
+
+```python
+_base_ = [
+ '../../../configs/_base_/models/deeplabv3plus_r50-d8.py',
+ './_base_/datasets/gid.py',
+ '../../../configs/_base_/default_runtime.py',
+ '../../../configs/_base_/schedules/schedule_240k.py'
+]
+custom_imports = dict(
+ imports=['projects.gid_dataset.mmseg.datasets.gid'])
+
+crop_size = (256, 256)
+data_preprocessor = dict(size=crop_size)
+model = dict(
+ data_preprocessor=data_preprocessor,
+ pretrained='open-mmlab://resnet101_v1c',
+ backbone=dict(depth=101),
+ decode_head=dict(num_classes=6),
+ auxiliary_head=dict(num_classes=6))
+
+```
+
+### 3.6 µÆ░ÕåÖ`docs/zh_cn/user_guides/2_dataset_prepare.md`
+
+**Gaofen Image Dataset (GID)**
+
+- GID µĢ░µŹ«ķøåÕŻգ©[µŁżÕżä](https://x-ytong.github.io/project/Five-Billion-Pixels.html)Ķ┐øĶĪīõĖŗĶĮĮŃĆé
+- GID µĢ░µŹ«ķøåÕīģÕɽ 150 Õ╝Ā 6800x7200 ńÜäÕż¦Õ░║Õ»ĖÕøŠÕāÅ’╝īµĀćńŁŠõĖ║ RGB µĀćńŁŠŃĆé
+- µŁżÕżäķĆēµŗ® 15 Õ╝ĀÕøŠÕāÅńö¤µłÉĶ«Łń╗āķøåÕÆīķ¬īĶ»üķøå’╝īĶ»ź 15 Õ╝ĀÕøŠÕāÅÕīģÕɽõ║åµēƵ£ēÕģŁń▒╗õ┐Īµü»ŃĆéµēĆķĆēńÜäÕøŠÕāÅÕÉŹń¦░Õ”éõĖŗ’╝Ü
+
+```None
+ GF2_PMS1__L1A0000647767-MSS1
+ GF2_PMS1__L1A0001064454-MSS1
+ GF2_PMS1__L1A0001348919-MSS1
+ GF2_PMS1__L1A0001680851-MSS1
+ GF2_PMS1__L1A0001680853-MSS1
+ GF2_PMS1__L1A0001680857-MSS1
+ GF2_PMS1__L1A0001757429-MSS1
+ GF2_PMS2__L1A0000607681-MSS2
+ GF2_PMS2__L1A0000635115-MSS2
+ GF2_PMS2__L1A0000658637-MSS2
+ GF2_PMS2__L1A0001206072-MSS2
+ GF2_PMS2__L1A0001471436-MSS2
+ GF2_PMS2__L1A0001642620-MSS2
+ GF2_PMS2__L1A0001787089-MSS2
+ GF2_PMS2__L1A0001838560-MSS2
+```
+
+µē¦ĶĪīõ╗źõĖŗÕæĮõ╗żĶ┐øĶĪīĶŻüÕłćÕÅŖµĀćńŁŠńÜäĶĮ¼µŹó’╝īķ£ĆĶ”üõ┐«µö╣õĖ║µé©µēĆÕŁśÕé© 15 Õ╝ĀÕøŠÕāÅÕÅŖµĀćńŁŠńÜäĶĘ»ÕŠäŃĆé
+
+```
+python projects/gid_dataset/tools/dataset_converters/gid.py [15 Õ╝ĀÕøŠÕāÅńÜäĶĘ»ÕŠä] [15 Õ╝ĀµĀćńŁŠńÜäĶĘ»ÕŠä]
+```
+
+Õ«īµłÉĶŻüÕłćÕÉÄńÜä GID µĢ░µŹ«ń╗ōµ×äÕ”éõĖŗ’╝Ü
+
+```none
+mmsegmentation
+Ōö£ŌöĆŌöĆ mmseg
+Ōö£ŌöĆŌöĆ tools
+Ōö£ŌöĆŌöĆ configs
+Ōö£ŌöĆŌöĆ data
+Ōöé Ōö£ŌöĆŌöĆ gid
+Ōöé Ōöé Ōö£ŌöĆŌöĆ ann_dir
+| Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ train
+| Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ val
+Ōöé Ōöé Ōö£ŌöĆŌöĆ img_dir
+| Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ train
+| Ōöé Ōöé Ōöé Ōö£ŌöĆŌöĆ val
+
+```
+
+### 3.7 Ķ┤Īńī«ńÜäõ╗ŻńĀüÕÅŖµ¢ćµĪŻķĆÜĶ┐ć`pre-commit`µŻĆµ¤ź
+
+õĮ┐ńö©ÕæĮõ╗ż
+
+```bash
+git add .
+git commit -m "µĘ╗ÕŖĀµÅÅĶ┐░"
+git push
+```
+
+### 3.8 Õ£© GitHub õĖŁÕÉæ mmsegmentation µÅÉõ║ż PR
+
+ÕģĘõĮōµŁźķ¬żÕÅ»Ķ¦ü[ŃĆŖOpenMMLab Ķ┤Īńī«õ╗ŻńĀüµīćÕŹŚŃĆŗ](https://mmcv.readthedocs.io/zh_CN/latest/community/contributing.html)
diff --git a/internlm_langchain/knowledge_base/MMSegmentation/content/customize_runtime.md b/internlm_langchain/knowledge_base/MMSegmentation/content/customize_runtime.md
new file mode 100644
index 00000000..a80aca63
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMSegmentation/content/customize_runtime.md
@@ -0,0 +1,162 @@
+# Ķć¬Õ«Üõ╣ēĶ┐ÉĶĪīĶ«ŠÕ«Ü
+
+## Õ«×ńÄ░Ķć¬Õ«Üõ╣ēķÆ®ÕŁÉ
+
+### Step 1: ÕłøÕ╗║õĖĆõĖ¬µ¢░ńÜäķÆ®ÕŁÉ
+
+MMEngine ÕĘ▓Õ«×ńÄ░õ║åĶ«Łń╗āÕÆīµĄŗĶ»ĢÕĖĖńö©ńÜä[ķÆ®ÕŁÉ](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/tutorials/hook.md),
+ÕĮōµ£ēÕ«ÜÕłČÕī¢ķ£Ćµ▒鵌Č, ÕÅ»õ╗źµīēńģ¦Õ”éõĖŗńż║õŠŗÕ«×ńÄ░ķĆéńö©õ║ÄĶć¬Ķ║½Ķ«Łń╗āķ£Ćµ▒éńÜäķÆ®ÕŁÉ, õŠŗÕ”éµā│õ┐«µö╣õĖĆõĖ¬ĶČģÕÅéµĢ░ `model.hyper_paramete` ńÜäÕĆ╝, Ķ«®Õ«āķÜÅńØĆĶ«Łń╗āĶ┐Łõ╗Żµ¼ĪµĢ░ĶĆīÕÅśÕī¢:
+
+```python
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Sequence
+
+from mmengine.hooks import Hook
+from mmengine.model import is_model_wrapper
+
+from mmseg.registry import HOOKS
+
+
+@HOOKS.register_module()
+class NewHook(Hook):
+ """Docstring for NewHook.
+ """
+
+ def __init__(self, a: int, b: int) -> None:
+ self.a = a
+ self.b = b
+
+ def before_train_iter(self,
+ runner,
+ batch_idx: int,
+ data_batch: Optional[Sequence[dict]] = None) -> None:
+ cur_iter = runner.iter
+ # ÕĮōµ©ĪÕ×ŗĶó½ÕīģÕ£© wrapper ķćīµŚČĶÄĘÕÅ¢Ķ┐ÖõĖ¬µ©ĪÕ×ŗ
+ if is_model_wrapper(runner.model):
+ model = runner.model.module
+ model.hyper_parameter = self.a * cur_iter + self.b
+```
+
+### Step 2: Õ»╝ÕģźõĖĆõĖ¬µ¢░ńÜäķÆ®ÕŁÉ
+
+õĖ║õ║åĶ«®õĖŖķØóÕ«Üõ╣ēńÜ䵩ĪÕØŚÕÅ»õ╗źĶó½µē¦ĶĪīńÜäń©ŗÕ║ÅÕÅæńÄ░, Ķ┐ÖõĖ¬µ©ĪÕØŚķ£ĆĶ”üÕģłĶó½Õ»╝ÕģźõĖ╗ÕæĮÕÉŹń®║ķŚ┤ (main namespace) ķćīķØó,
+ÕüćĶ«Š NewHook Õ£© `mmseg/engine/hooks/new_hook.py` ķćīķØó, µ£ēõĖżń¦Źµ¢╣Õ╝ÅÕÄ╗Õ«×ńÄ░Õ«ā:
+
+- õ┐«µö╣ `mmseg/engine/hooks/__init__.py` µØźÕ»╝ÕģźÕ«ā.
+ µ¢░Õ«Üõ╣ēńÜ䵩ĪÕØŚÕ║öĶ»źÕ£© `mmseg/engine/hooks/__init__.py` ķćīķØóÕ»╝Õģź, Ķ┐ÖµĀʵ│©ÕåīÕÖ©ÕÅ»õ╗źÕÅæńÄ░Õ╣ȵĘ╗ÕŖĀĶ┐ÖõĖ¬µ¢░ńÜ䵩ĪÕØŚ:
+
+```python
+from .new_hook import NewHook
+
+__all__ = [..., NewHook]
+```
+
+- Õ£©ķģŹńĮ«µ¢ćõ╗ČķćīõĮ┐ńö© custom_imports µØźµēŗÕŖ©Õ»╝ÕģźÕ«ā.
+
+```python
+custom_imports = dict(imports=['mmseg.engine.hooks.new_hook'], allow_failed_imports=False)
+```
+
+### Step 3: õ┐«µö╣ķģŹńĮ«µ¢ćõ╗Č
+
+ÕÅ»õ╗źµīēńģ¦Õ”éõĖŗµ¢╣Õ╝Å, Õ£©Ķ«Łń╗āµł¢µĄŗĶ»ĢõĖŁķģŹńĮ«Õ╣ČõĮ┐ńö©Ķć¬Õ«Üõ╣ēńÜäķÆ®ÕŁÉ. õĖŹÕÉīķÆ®ÕŁÉÕ£©ÕÉīõĖĆõĮŹńé╣ńÜäõ╝śÕģłń║¦ÕÅ»õ╗źÕÅéĶĆā[Ķ┐Öķćī](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/tutorials/hook.md#%E5%86%85%E7%BD%AE%E9%92%A9%E5%AD%90), Ķć¬Õ«Üõ╣ēķÆ®ÕŁÉÕ”éµ×£µ▓Īµ£ēµīćÕ«Üõ╝śÕģł, ķ╗śĶ«żµś» `NORMAL`.
+
+```python
+custom_hooks = [
+ dict(type='NewHook', a=a_value, b=b_value, priority='ABOVE_NORMAL')
+]
+```
+
+## Õ«×ńÄ░Ķć¬Õ«Üõ╣ēõ╝śÕī¢ÕÖ©
+
+### Step 1: ÕłøÕ╗║õĖĆõĖ¬µ¢░ńÜäõ╝śÕī¢ÕÖ©
+
+Õ”éµ×£Õó×ÕŖĀõĖĆõĖ¬ÕŽõĮ£ `MyOptimizer` ńÜäõ╝śÕī¢ÕÖ©, Õ«āµ£ēÕÅéµĢ░ `a`, `b` ÕÆī `c`. µÄ©ĶŹÉÕ£© `mmseg/engine/optimizers/my_optimizer.py` µ¢ćõ╗ČõĖŁÕ«×ńÄ░
+
+```python
+from mmseg.registry import OPTIMIZERS
+from torch.optim import Optimizer
+
+
+@OPTIMIZERS.register_module()
+class MyOptimizer(Optimizer):
+
+ def __init__(self, a, b, c)
+```
+
+### Step 2: Õ»╝ÕģźõĖĆõĖ¬µ¢░ńÜäõ╝śÕī¢ÕÖ©
+
+õĖ║õ║åĶ«®õĖŖķØóÕ«Üõ╣ēńÜ䵩ĪÕØŚÕÅ»õ╗źĶó½µē¦ĶĪīńÜäń©ŗÕ║ÅÕÅæńÄ░, Ķ┐ÖõĖ¬µ©ĪÕØŚķ£ĆĶ”üÕģłĶó½Õ»╝ÕģźõĖ╗ÕæĮÕÉŹń®║ķŚ┤ (main namespace) ķćīķØó,
+ÕüćĶ«Š `MyOptimizer` Õ£© `mmseg/engine/optimizers/my_optimizer.py` ķćīķØó, µ£ēõĖżń¦Źµ¢╣Õ╝ÅÕÄ╗Õ«×ńÄ░Õ«ā:
+
+- õ┐«µö╣ `mmseg/engine/optimizers/__init__.py` µØźÕ»╝ÕģźÕ«ā.
+ µ¢░Õ«Üõ╣ēńÜ䵩ĪÕØŚÕ║öĶ»źÕ£© `mmseg/engine/optimizers/__init__.py` ķćīķØóÕ»╝Õģź, Ķ┐ÖµĀʵ│©ÕåīÕÖ©ÕÅ»õ╗źÕÅæńÄ░Õ╣ȵĘ╗ÕŖĀĶ┐ÖõĖ¬µ¢░ńÜ䵩ĪÕØŚ:
+
+```python
+from .my_optimizer import MyOptimizer
+```
+
+- Õ£©ķģŹńĮ«µ¢ćõ╗ČķćīõĮ┐ńö© `custom_imports` µØźµēŗÕŖ©Õ»╝ÕģźÕ«ā.
+
+```python
+custom_imports = dict(imports=['mmseg.engine.optimizers.my_optimizer'], allow_failed_imports=False)
+```
+
+### Step 3: õ┐«µö╣ķģŹńĮ«µ¢ćõ╗Č
+
+ķÜÅÕÉÄķ£ĆĶ”üõ┐«µö╣ķģŹńĮ«µ¢ćõ╗Č `optim_wrapper` ķćīńÜä `optimizer` ÕÅéµĢ░, Õ”éµ×£Ķ”üõĮ┐ńö©õĮĀĶć¬ÕĘ▒ńÜäõ╝śÕī¢ÕÖ© `MyOptimizer`, ÕŁŚµ«ĄÕÅ»õ╗źĶó½õ┐«µö╣µłÉ:
+
+```python
+optim_wrapper = dict(type='OptimWrapper',
+ optimizer=dict(type='MyOptimizer',
+ a=a_value, b=b_value, c=c_value),
+ clip_grad=None)
+```
+
+## Õ«×ńÄ░Ķć¬Õ«Üõ╣ēõ╝śÕī¢ÕÖ©Õ░üĶŻģµ×äķĆĀÕÖ©
+
+### Step 1: ÕłøÕ╗║õĖĆõĖ¬µ¢░ńÜäõ╝śÕī¢ÕÖ©Õ░üĶŻģµ×äķĆĀÕÖ©
+
+µ×äķĆĀÕÖ©ÕÅ»õ╗źńö©µØźÕłøÕ╗║õ╝śÕī¢ÕÖ©, õ╝śÕī¢ÕÖ©Õīģ, õ╗źÕÅŖĶć¬Õ«Üõ╣ēµ©ĪÕ×ŗńĮæń╗£õĖŹÕÉīÕ▒éńÜäĶČģÕÅéµĢ░. õĖĆõ║øµ©ĪÕ×ŗńÜäõ╝śÕī¢ÕÖ©ÕÅ»ĶāĮõ╝ܵĀ╣µŹ«ńē╣Õ«ÜńÜäÕÅéµĢ░ĶĆīĶ░āµĢ┤, õŠŗÕ”é BatchNorm Õ▒éńÜä weight decay. õĮ┐ńö©ĶĆģÕÅ»õ╗źķĆÜĶ┐ćĶć¬Õ«Üõ╣ēõ╝śÕī¢ÕÖ©µ×äķĆĀÕÖ©µØźń▓Šń╗åÕī¢Ķ«ŠÕ«ÜõĖŹÕÉīÕÅéµĢ░ńÜäõ╝śÕī¢ńŁ¢ńĢź.
+
+```python
+from mmengine.optim import DefaultOptimWrapperConstructor
+from mmseg.registry import OPTIM_WRAPPER_CONSTRUCTORS
+
+@OPTIM_WRAPPER_CONSTRUCTORS.register_module()
+class LearningRateDecayOptimizerConstructor(DefaultOptimWrapperConstructor):
+ def __init__(self, optim_wrapper_cfg, paramwise_cfg=None):
+
+ def __call__(self, model):
+
+ return my_optimizer
+```
+
+ķ╗śĶ«żńÜäõ╝śÕī¢ÕÖ©µ×äķĆĀÕÖ©Õ£©[Ķ┐Öķćī](https://github.com/open-mmlab/mmengine/blob/main/mmengine/optim/optimizer/default_constructor.py#L19) Ķó½Õ«×ńÄ░, Õ«āõ╣¤ÕÅ»õ╗źńö©µØźõĮ£õĖ║µ¢░ńÜäõ╝śÕī¢ÕÖ©µ×äķĆĀÕÖ©ńÜ䵩ĪµØ┐.
+
+### Step 2: Õ»╝ÕģźõĖĆõĖ¬µ¢░ńÜäõ╝śÕī¢ÕÖ©Õ░üĶŻģµ×äķĆĀÕÖ©
+
+õĖ║õ║åĶ«®õĖŖķØóÕ«Üõ╣ēńÜ䵩ĪÕØŚÕÅ»õ╗źĶó½µē¦ĶĪīńÜäń©ŗÕ║ÅÕÅæńÄ░, Ķ┐ÖõĖ¬µ©ĪÕØŚķ£ĆĶ”üÕģłĶó½Õ»╝ÕģźõĖ╗ÕæĮÕÉŹń®║ķŚ┤ (main namespace) ķćīķØó, ÕüćĶ«Š `MyOptimizerConstructor` Õ£© `mmseg/engine/optimizers/my_optimizer_constructor.py` ķćīķØó, µ£ēõĖżń¦Źµ¢╣Õ╝ÅÕÄ╗Õ«×ńÄ░Õ«ā:
+
+- õ┐«µö╣ `mmseg/engine/optimizers/__init__.py` µØźÕ»╝ÕģźÕ«ā.
+ µ¢░Õ«Üõ╣ēńÜ䵩ĪÕØŚÕ║öĶ»źÕ£© `mmseg/engine/optimizers/__init__.py` ķćīķØóÕ»╝Õģź, Ķ┐ÖµĀʵ│©ÕåīÕÖ©ÕÅ»õ╗źÕÅæńÄ░Õ╣ȵĘ╗ÕŖĀĶ┐ÖõĖ¬µ¢░ńÜ䵩ĪÕØŚ:
+
+```python
+from .my_optimizer_constructor import MyOptimizerConstructor
+```
+
+- Õ£©ķģŹńĮ«µ¢ćõ╗ČķćīõĮ┐ńö© `custom_imports` µØźµēŗÕŖ©Õ»╝ÕģźÕ«ā.
+
+```python
+custom_imports = dict(imports=['mmseg.engine.optimizers.my_optimizer_constructor'], allow_failed_imports=False)
+```
+
+### Step 3: õ┐«µö╣ķģŹńĮ«µ¢ćõ╗Č
+
+ķÜÅÕÉÄķ£ĆĶ”üõ┐«µö╣ķģŹńĮ«µ¢ćõ╗Č `optim_wrapper` ķćīńÜä `constructor` ÕÅéµĢ░, Õ”éµ×£Ķ”üõĮ┐ńö©õĮĀĶć¬ÕĘ▒ńÜäõ╝śÕī¢ÕÖ©Õ░üĶŻģµ×äķĆĀÕÖ© `MyOptimizerConstructor`, ÕŁŚµ«ĄÕÅ»õ╗źĶó½õ┐«µö╣µłÉ:
+
+```python
+optim_wrapper = dict(type='OptimWrapper',
+ constructor='MyOptimizerConstructor',
+ clip_grad=None)
+```
diff --git a/internlm_langchain/knowledge_base/MMSegmentation/content/data_flow.md b/internlm_langchain/knowledge_base/MMSegmentation/content/data_flow.md
new file mode 100644
index 00000000..20dbe07e
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMSegmentation/content/data_flow.md
@@ -0,0 +1,90 @@
+# µĢ░µŹ«µĄü
+
+Õ£©µ£¼ń½ĀĶŖéõĖŁ’╝īµłæõ╗¼Õ░åõ╗ŗń╗Ź [Runner](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/runner.html) ń«ĪńÉåńÜäÕåģķā©µ©ĪÕØŚõ╣ŗķŚ┤ńÜäµĢ░µŹ«µĄüÕÆīµĢ░µŹ«µĀ╝Õ╝Åń║”Õ«ÜŃĆé
+
+## µĢ░µŹ«µĄüµ”éĶ┐░
+
+[Runner](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/design/runner.md) ńøĖÕĮōõ║Ä MMEngine õĖŁńÜäŌĆ£ķøåµłÉÕÖ©ŌĆØŃĆéÕ«āĶ”åńø¢õ║åµĪåµ×ČńÜäµēƵ£ēµ¢╣ķØó’╝īÕ╣ČĶé®Ķ┤¤ńØĆń╗äń╗ćÕÆīĶ░āÕ║”ÕćĀõ╣ĵēƵ£ēµ©ĪÕØŚńÜäĶ┤Żõ╗╗’╝īĶ┐ÖµäÅÕæ│ńØĆÕÉ䵩ĪÕØŚõ╣ŗķŚ┤ńÜäµĢ░µŹ«µĄüõ╣¤ńö▒ `Runner` µÄ¦ÕłČŃĆé Õ”é [MMEngine õĖŁńÜä Runner µ¢ćµĪŻ](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/runner.html)µēĆńż║’╝īõĖŗÕøŠÕ▒Ģńż║õ║åÕ¤║µ£¼ńÜäµĢ░µŹ«µĄüŃĆé
+
+
+
+ĶÖÜń║┐ĶŠ╣µĪåŃĆüńü░Ķē▓ÕĪ½ÕģģÕĮóńŖČõ╗ŻĶĪ©õĖŹÕÉīńÜäµĢ░µŹ«µĀ╝Õ╝Å’╝īĶĆīÕ«×Õ┐āµĪåĶĪ©ńż║µ©ĪÕØŚ/µ¢╣µ│ĢŃĆéńö▒õ║Ä MMEngine µ×üÕż¦ńÜäńüĄµ┤╗µĆ¦ÕÆīÕÅ»µē®Õ▒ĢµĆ¦’╝īõĖĆõ║øķćŹĶ”üńÜäÕ¤║ń▒╗ÕÅ»õ╗źĶó½ń╗¦µē┐’╝īÕ╣ČõĖöÕ«āõ╗¼ńÜäµ¢╣µ│ĢÕÅ»õ╗źĶó½Ķ”åÕåÖŃĆé õĖŖÕøŠµēĆńż║µĢ░µŹ«µĄüõ╗ģķĆéńö©õ║ÄÕĮōńö©µłĘµ▓Īµ£ēĶć¬Õ«Üõ╣ē `Runner` õĖŁńÜä `TrainLoop`ŃĆü`ValLoop` ÕÆī `TestLoop`’╝īÕ╣ČõĖöµ▓Īµ£ēÕ£©ÕģČĶć¬Õ«Üõ╣ēµ©ĪÕ×ŗõĖŁĶ”åÕåÖ `train_step`ŃĆü`val_step` ÕÆī `test_step` µ¢╣µ│ĢµŚČŃĆéMMSegmentation õĖŁ loop ńÜäķ╗śĶ«żĶ«ŠńĮ«Õ”éõĖŗ’╝ÜõĮ┐ńö©`IterBasedTrainLoop` Ķ«Łń╗āµ©ĪÕ×ŗ’╝īÕģ▒Ķ«Ī 20000 µ¼ĪĶ┐Łõ╗Ż’╝īÕ╣ČõĖöÕ£©µ»Å 2000 µ¼ĪĶ┐Łõ╗ŻÕÉÄĶ┐øĶĪīõĖƵ¼Īķ¬īĶ»üŃĆé
+
+```python
+train_cfg = dict(type='IterBasedTrainLoop', max_iters=20000, val_interval=2000)
+val_cfg = dict(type='ValLoop')
+test_cfg = dict(type='TestLoop')
+```
+
+Õ£©õĖŖÕøŠõĖŁ’╝īń║óĶē▓ń║┐ĶĪ©ńż║ [train_step](./models.md#train_step)’╝īÕ£©µ»Åµ¼ĪĶ«Łń╗āĶ┐Łõ╗ŻõĖŁ’╝īµĢ░µŹ«ÕŖĀĶĮĮÕÖ©’╝łdataloader’╝ēõ╗ÄÕŁśÕé©õĖŁÕŖĀĶĮĮÕøŠÕāÅÕ╣Čõ╝ĀĶŠōÕł░µĢ░µŹ«ķóäÕżäńÉåÕÖ©’╝łdata preprocessor’╝ē’╝īµĢ░µŹ«ķóäÕżäńÉåÕÖ©õ╝ÜÕ░åÕøŠÕāŵöŠÕł░ńē╣Õ«ÜńÜäĶ«ŠÕżćõĖŖ’╝īÕ╣ČÕ░åµĢ░µŹ«ÕĀåÕÅĀÕł░µē╣ÕżäńÉåõĖŁ’╝īõ╣ŗÕÉĵ©ĪÕ×ŗµÄźÕÅŚµē╣ÕżäńÉåµĢ░µŹ«õĮ£õĖ║ĶŠōÕģź’╝īµ£ĆÕÉÄÕ░嵩ĪÕ×ŗńÜäĶŠōÕć║ÕÅæķĆüń╗Öõ╝śÕī¢ÕÖ©’╝łoptimizer’╝ēŃĆéĶōØĶē▓ń║┐ĶĪ©ńż║ [val_step](./models.md#val_step) ÕÆī [test_step](./models.md#test_step)ŃĆéĶ┐ÖõĖżõĖ¬Ķ┐ćń©ŗńÜäµĢ░µŹ«µĄüķÖżõ║嵩ĪÕ×ŗĶŠōÕć║õĖÄ `train_step` õĖŹÕÉīÕż¢’╝īÕģČõĮÖÕØćÕÆī `train_step` ń▒╗õ╝╝ŃĆéńö▒õ║ÄÕ£©Ķ»äõ╝░µŚČµ©ĪÕ×ŗÕÅéµĢ░õ╝ÜĶó½Õå╗ń╗ō’╝īÕøĀµŁżµ©ĪÕ×ŗńÜäĶŠōÕć║Õ░åĶó½õ╝ĀķĆÆń╗Ö [Evaluator](./evaluation.md#ioumetric)ŃĆé
+µØźĶ«Īń«ŚµīćµĀćŃĆé
+
+## MMSegmentation õĖŁńÜäµĢ░µŹ«µĄüń║”Õ«Ü
+
+Õ£©õĖŖķØóńÜäÕøŠõĖŁ’╝īµłæõ╗¼ÕÅ»õ╗źń£ŗÕł░Õ¤║µ£¼ńÜäµĢ░µŹ«µĄüŃĆéÕ£©µ£¼ĶŖéõĖŁ’╝īµłæõ╗¼Õ░åÕłåÕł½õ╗ŗń╗ŹµĢ░µŹ«µĄüõĖŁµČēÕÅŖńÜäµĢ░µŹ«ńÜäµĀ╝Õ╝Åń║”Õ«ÜŃĆé
+
+### µĢ░µŹ«ÕŖĀĶĮĮÕÖ©Õł░µĢ░µŹ«ķóäÕżäńÉåÕÖ©
+
+µĢ░µŹ«ÕŖĀĶĮĮÕÖ©’╝łDataLoader’╝ēµś» MMEngine ńÜäĶ«Łń╗āÕÆīµĄŗĶ»ĢµĄüń©ŗõĖŁńÜäõĖĆõĖ¬ķćŹĶ”üń╗äõ╗ČŃĆé
+õ╗ĵ”éÕ┐ĄõĖŖĶ«▓’╝īÕ«āµ║Éõ║Ä [PyTorch](https://pytorch.org/) Õ╣Čõ┐صīüõĖĆĶć┤ŃĆéDataLoader õ╗ĵ¢ćõ╗Čń│╗ń╗¤ÕŖĀĶĮĮµĢ░µŹ«’╝īÕĤզŗµĢ░µŹ«ķĆÜĶ┐ćµĢ░µŹ«ÕćåÕżćµĄüń©ŗÕÉÄĶó½ÕÅæķĆüń╗ÖµĢ░µŹ«ķóäÕżäńÉåÕÖ©ŃĆé
+
+MMSegmentation Õ£© [PackSegInputs](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/datasets/transforms/formatting.py#L12) õĖŁÕ«Üõ╣ēõ║åķ╗śĶ«żµĢ░µŹ«µĀ╝Õ╝Å’╝ī Õ«āµś» `train_pipeline` ÕÆī `test_pipeline` ńÜäµ£ĆÕÉÄõĖĆõĖ¬ń╗äõ╗ČŃĆéµ£ēÕģ│µĢ░µŹ«ĶĮ¼µŹó `pipeline` ńÜäµø┤ÕżÜõ┐Īµü»’╝īĶ»ĘÕÅéķśģ[µĢ░µŹ«ĶĮ¼µŹóµ¢ćµĪŻ](./transforms.md)ŃĆé
+
+Õ£©µ▓Īµ£ēõ╗╗õĮĢõ┐«µö╣ńÜäµāģÕåĄõĖŗ’╝īPackSegInputs ńÜäĶ┐öÕø×ÕĆ╝ķĆÜÕĖĖµś»õĖĆõĖ¬ÕīģÕɽ `inputs` ÕÆī `data_samples` ńÜä `dict`ŃĆéõ╗źõĖŗõ╝¬õ╗ŻńĀüÕ▒Ģńż║õ║å mmseg õĖŁµĢ░µŹ«ÕŖĀĶĮĮÕÖ©ĶŠōÕć║ńÜäµĢ░µŹ«ń▒╗Õ×ŗ’╝īÕ«āµś»õ╗ĵĢ░µŹ«ķøåõĖŁĶÄĘÕÅ¢ńÜäõĖƵē╣µĢ░µŹ«µĀʵ£¼’╝īµĢ░µŹ«ÕŖĀĶĮĮÕÖ©Õ░åÕ«āõ╗¼µēōÕīģµłÉõĖĆõĖ¬ÕŁŚÕģĖÕłŚĶĪ©ŃĆé`inputs` µś»ĶŠōÕģźĶ┐øµ©ĪÕ×ŗńÜäÕ╝ĀķćÅÕłŚĶĪ©’╝ī`data_samples` ÕīģÕɽõ║åĶŠōÕģźÕøŠÕāÅńÜä meta information ÕÆīńøĖÕ║öńÜä ground truthŃĆé
+
+```python
+dict(
+ inputs=List[torch.Tensor],
+ data_samples=List[SegDataSample]
+)
+```
+
+**µ│©µäÅ’╝Ü** [SegDataSample](https://github.com/open-mmlab/mmsegmentation/blob/1.x/mmseg/structures/seg_data_sample.py) µś» MMSegmentation ńÜäµĢ░µŹ«ń╗ōµ×äµÄźÕÅŻ’╝īńö©õ║ÄĶ┐׵ğõĖŹÕÉīń╗äõ╗ČŃĆé`SegDataSample` Õ«×ńÄ░õ║åµŖĮĶ▒ĪµĢ░µŹ«Õģāń┤Ā `mmengine.structures.BaseDataElement`’╝īµø┤ÕżÜõ┐Īµü»Ķ»ĘÕ£© [MMEngine](https://github.com/open-mmlab/mmengine) õĖŁÕÅéķśģ [SegDataSample µ¢ćµĪŻ](./structures.md)ÕÆī[µĢ░µŹ«Õģāń┤Āµ¢ćµĪŻ](https://mmengine.readthedocs.io/zh_CN/latest/advanced_tutorials/data_element.html)ŃĆé
+
+### µĢ░µŹ«ķóäÕżäńÉåÕÖ©Õł░µ©ĪÕ×ŗ
+
+ĶÖĮńäČÕ£©[õĖŖķØóńÜäÕøŠ](##µĢ░µŹ«µĄüµ”éĶ┐░)õĖŁÕłåÕ╝Ćń╗śÕłČõ║åµĢ░µŹ«ķóäÕżäńÉåÕÖ©ÕÆīµ©ĪÕ×ŗ’╝īõĮåµĢ░µŹ«ķóäÕżäńÉåÕÖ©µś»µ©ĪÕ×ŗńÜäõĖĆķā©Õłå’╝īÕøĀµŁżÕÅ»õ╗źÕ£©[µ©ĪÕ×ŗµĢÖń©ŗ](./models.md)õĖŁµēŠÕł░µĢ░µŹ«ķóäÕżäńÉåÕÖ©ń½ĀĶŖéŃĆé
+
+µĢ░µŹ«ķóäÕżäńÉåÕÖ©ńÜäĶ┐öÕø×ÕĆ╝µś»õĖĆõĖ¬ÕīģÕɽ `inputs` ÕÆī `data_samples` ńÜäÕŁŚÕģĖ’╝īÕģČõĖŁ `inputs` µś»µē╣ÕżäńÉåÕøŠÕāÅńÜä 4D Õ╝ĀķćÅ’╝ī`data_samples` õĖŁµĘ╗ÕŖĀõ║åõĖĆõ║øńö©õ║ĵĢ░µŹ«ķóäÕżäńÉåńÜäķóØÕż¢Õģāõ┐Īµü»ŃĆéÕĮōõ╝ĀķĆÆń╗ÖńĮæń╗£µŚČ’╝īÕŁŚÕģĖÕ░åĶó½Ķ¦ŻÕīģõĖ║õĖżõĖ¬ÕĆ╝ŃĆé õ╗źõĖŗõ╝¬õ╗ŻńĀüÕ▒Ģńż║õ║åµĢ░µŹ«ķóäÕżäńÉåÕÖ©ńÜäĶ┐öÕø×ÕĆ╝ÕÆīµ©ĪÕ×ŗńÜäĶŠōÕģźÕĆ╝ŃĆé
+
+```python
+dict(
+ inputs=torch.Tensor,
+ data_samples=List[SegDataSample]
+)
+```
+
+```python
+class Network(BaseSegmentor):
+
+ def forward(self, inputs: torch.Tensor, data_samples: List[SegDataSample], mode: str):
+ pass
+```
+
+**µ│©µäÅ’╝Ü** µ©ĪÕ×ŗńÜäÕēŹÕÉæõ╝ĀµÆŁµ£ē 3 ń¦Źµ©ĪÕ╝Å’╝īńö▒ĶŠōÕģźÕÅéµĢ░ mode µÄ¦ÕłČ’╝īµø┤ÕżÜõ┐Īµü»Ķ»ĘÕÅéķśģ[µ©ĪÕ×ŗµĢÖń©ŗ](./models.md)ŃĆé
+
+### µ©ĪÕ×ŗĶŠōÕć║
+
+Õ”é[µ©ĪÕ×ŗµĢÖń©ŗ](./models.md#forward) ***’╝ł[õĖŁµ¢ćķōŠµÄźÕŠģµø┤µ¢░](./models.md#forward)’╝ē*** µēƵÅÉÕł░ńÜä 3 ń¦ŹÕēŹÕÉæõ╝ĀµÆŁÕģʵ£ē 3 ń¦ŹĶŠōÕć║ŃĆé
+`train_step` ÕÆī `test_step`’╝łµł¢ `val_step`’╝ēÕłåÕł½Õ»╣Õ║öõ║Ä `'loss'` ÕÆī `'predict'`ŃĆé
+
+Õ£© `test_step` µł¢ `val_step` õĖŁ’╝īµÄ©ńÉåń╗ōµ×£õ╝ÜĶó½õ╝ĀķĆÆń╗Ö `Evaluator` ŃĆéµé©ÕÅ»õ╗źÕÅéķśģ[Ķ»äõ╝░µ¢ćµĪŻ](./evaluation.md)µØźĶÄĘÕÅ¢µø┤ÕżÜÕģ│õ║Ä `Evaluator` ńÜäõ┐Īµü»ŃĆé
+
+Õ£©µÄ©ńÉåÕÉÄ’╝īMMSegmentation õĖŁńÜä [BaseSegmentor](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/models/segmentors/base.py#L15) õ╝ÜÕ»╣µÄ©ńÉåń╗ōµ×£Ķ┐øĶĪīń«ĆÕŹĢńÜäÕÉÄÕżäńÉåõ╗źµēōÕīģµÄ©ńÉåń╗ōµ×£ŃĆéńź×ń╗ÅńĮæń╗£ńö¤µłÉńÜäÕłåÕē▓ logits’╝īń╗ÅĶ┐ć `argmax` µōŹõĮ£ÕÉÄńÜäÕłåÕē▓ mask ÕÆī ground truth’╝łÕ”éµ×£ÕŁśÕ£©’╝ēÕ░åĶó½µēōÕīģÕł░ń▒╗õ╝╝ `SegDataSample` ńÜäÕ«×õŠŗŃĆé [postprocess_result](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/models/segmentors/base.py#L132) ńÜäĶ┐öÕø×ÕĆ╝µś»õĖĆõĖ¬ **`SegDataSample`ńÜä`List`**ŃĆéõĖŗÕøŠµśŠńż║õ║åĶ┐Öõ║ø `SegDataSample` Õ«×õŠŗńÜäÕģ│ķö«Õ▒׵ƦŃĆé
+
+
+
+õĖĵĢ░µŹ«ķóäÕżäńÉåÕÖ©õĖĆĶć┤’╝īµŹ¤Õż▒ÕćĮµĢ░õ╣¤µś»µ©ĪÕ×ŗńÜäõĖĆķā©Õłå’╝īÕ«āµś»[Ķ¦ŻńĀüÕż┤](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/models/decode_heads/decode_head.py#L142)ńÜäÕ▒׵Ʀõ╣ŗõĖĆŃĆé
+
+Õ£© MMSegmentation õĖŁ’╝ī`decode_head` ńÜä [loss_by_feat](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/models/decode_heads/decode_head.py#L291) µ¢╣µ│Ģµś»ńö©õ║ÄĶ«Īń«ŚµŹ¤Õż▒ńÜäń╗¤õĖƵğÕÅŻŃĆé
+
+ÕÅéµĢ░’╝Ü
+
+- seg_logits (Tensor)’╝ÜĶ¦ŻńĀüÕż┤ÕēŹÕÉæÕćĮµĢ░ńÜäĶŠōÕć║
+- batch_data_samples (List\[SegDataSample\])’╝ÜÕłåÕē▓µĢ░µŹ«µĀʵ£¼’╝īķĆÜÕĖĖÕīģµŗ¼Õ”é `metainfo` ÕÆī `gt_sem_seg` ńŁēõ┐Īµü»
+
+Ķ┐öÕø×ÕĆ╝’╝Ü
+
+- dict\[str, Tensor\]’╝ÜõĖĆõĖ¬µŹ¤Õż▒ń╗äõ╗ČńÜäÕŁŚÕģĖ
+
+**µ│©µäÅ’╝Ü** `train_step` Õ░åµŹ¤Õż▒õ╝ĀķĆÆĶ┐ø OptimWrapper õ╗źµø┤µ¢░µ©ĪÕ×ŗõĖŁńÜäµØāķ插╝īµø┤ÕżÜõ┐Īµü»Ķ»ĘÕÅéķśģ [train_step](./models.md#train_step)ŃĆé
diff --git a/internlm_langchain/knowledge_base/MMSegmentation/content/datasets.md b/internlm_langchain/knowledge_base/MMSegmentation/content/datasets.md
new file mode 100644
index 00000000..b45f2d22
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMSegmentation/content/datasets.md
@@ -0,0 +1,363 @@
+# µĢ░µŹ«ķøå
+
+Õ£© MMSegmentation ń«Śµ│ĢÕ║ōõĖŁ, µēƵ£ē Dataset ń▒╗ńÜäÕŖ¤ĶāĮµ£ēõĖżõĖ¬: ÕŖĀĶĮĮ[ķóäÕżäńÉå](../user_guides/2_dataset_prepare.md) õ╣ŗÕÉÄńÜäµĢ░µŹ«ķøåńÜäõ┐Īµü», ÕÆīÕ░åµĢ░µŹ«ķĆüÕģź[µĢ░µŹ«ķøåÕÅśµŹóµĄüµ░┤ń║┐](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/datasets/basesegdataset.py#L141) õĖŁ, Ķ┐øĶĪī[µĢ░µŹ«ÕÅśµŹóµōŹõĮ£](./transforms.md). ÕŖĀĶĮĮńÜäµĢ░µŹ«ķøåõ┐Īµü»Õīģµŗ¼õĖżń▒╗: Õģāõ┐Īµü» (meta information), µĢ░µŹ«ķøåµ£¼Ķ║½ńÜäõ┐Īµü», õŠŗÕ”éµĢ░µŹ«ķøåµĆ╗Õģ▒ńÜäń▒╗Õł½, ÕÆīÕ«āõ╗¼Õ»╣Õ║öĶ░āĶē▓ńøśõ┐Īµü»: µĢ░µŹ«õ┐Īµü» (data information) µś»µīćµ»Åń╗äµĢ░µŹ«õĖŁÕøŠńēćÕÆīÕ»╣Õ║öµĀćńŁŠńÜäĶĘ»ÕŠä. õĖŗµ¢ćõĖŁõ╗ŗń╗Źõ║å MMSegmentation 1.x õĖŁµĢ░µŹ«ķøåńÜäÕĖĖńö©µÄźÕÅŻ, ÕÆī mmseg µĢ░µŹ«ķøåÕ¤║ń▒╗õĖŁµĢ░µŹ«õ┐Īµü»ÕŖĀĶĮĮõĖÄõ┐«µö╣µĢ░µŹ«ķøåń▒╗Õł½ńÜäķĆ╗ĶŠæ, õ╗źÕÅŖµĢ░µŹ«ķøåõĖĵĢ░µŹ«ÕÅśµŹóµĄüµ░┤ń║┐ (pipeline) ńÜäÕģ│ń│╗.
+
+## ÕĖĖńö©µÄźÕÅŻ
+
+õ╗ź Cityscapes õĖ║õŠŗ, õ╗ŗń╗ŹµĢ░µŹ«ķøåÕĖĖńö©µÄźÕÅŻ. Õ”éķ£ĆĶ┐ÉĶĪīõ╗źõĖŗńż║õŠŗ, Ķ»ĘÕ£©ÕĮōÕēŹÕĘźõĮ£ńø«ÕĮĢõĖŗńÜä `data` ńø«ÕĮĢõĖŗĶĮĮÕ╣Č[ķóäÕżäńÉå](../user_guides/2_dataset_prepare.md#cityscapes) Cityscapes µĢ░µŹ«ķøå.
+
+Õ«×õŠŗÕī¢ Cityscapes Ķ«Łń╗āµĢ░µŹ«ķøå:
+
+```python
+from mmengine.registry import init_default_scope
+from mmseg.datasets import CityscapesDataset
+
+init_default_scope('mmseg')
+
+data_root = 'data/cityscapes/'
+data_prefix=dict(img_path='leftImg8bit/train', seg_map_path='gtFine/train')
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations'),
+ dict(type='RandomCrop', crop_size=(512, 1024), cat_max_ratio=0.75),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='PackSegInputs')
+]
+
+dataset = CityscapesDataset(data_root=data_root, data_prefix=data_prefix, test_mode=False, pipeline=train_pipeline)
+```
+
+µ¤źń£ŗĶ«Łń╗āµĢ░µŹ«ķøåķĢ┐Õ║”:
+
+```python
+print(len(dataset))
+
+2975
+```
+
+ĶÄĘÕÅ¢µĢ░µŹ«õ┐Īµü», µĢ░µŹ«õ┐Īµü»ńÜäń▒╗Õ×ŗµś»õĖĆõĖ¬ÕŁŚÕģĖ, Õīģµŗ¼ `'img_path'` ÕŁŚµ«ĄńÜäÕŁśµöŠÕøŠńēćńÜäĶĘ»ÕŠäÕÆī `'seg_map_path'` ÕŁŚµ«ĄÕŁśµöŠÕłåÕē▓µĀćµ│©ńÜäĶĘ»ÕŠä, õ╗źÕÅŖµĀćńŁŠķ揵śĀÕ░äńÜäÕŁŚµ«Ą `'label_map'` ÕÆī `'reduce_zero_label'`(õĖ╗Ķ”üÕŖ¤ĶāĮÕ£©õĖŗµ¢ćõĖŁõ╗ŗń╗Ź), Ķ┐śµ£ēÕŁśµöŠÕĘ▓ÕŖĀĶĮĮµĀćńŁŠÕŁŚµ«Ą `'seg_fields'`, ÕÆīÕĮōÕēŹµĀʵ£¼ńÜäń┤óÕ╝ĢÕŁŚµ«Ą `'sample_idx'`.
+
+```python
+# ĶÄĘÕÅ¢µĢ░µŹ«ķøåõĖŁń¼¼õĖĆń╗äµĀʵ£¼ńÜäµĢ░µŹ«õ┐Īµü»
+print(dataset.get_data_info(0))
+
+{'img_path': 'data/cityscapes/leftImg8bit/train/aachen/aachen_000000_000019_leftImg8bit.png',
+ 'seg_map_path': 'data/cityscapes/gtFine/train/aachen/aachen_000000_000019_gtFine_labelTrainIds.png',
+ 'label_map': None,
+ 'reduce_zero_label': False,
+ 'seg_fields': [],
+ 'sample_idx': 0}
+```
+
+ĶÄĘÕÅ¢µĢ░µŹ«ķøåÕģāõ┐Īµü», MMSegmentation ńÜäµĢ░µŹ«ķøåÕģāõ┐Īµü»ńÜäń▒╗Õ×ŗÕÉīµĀʵś»õĖĆõĖ¬ÕŁŚÕģĖ, Õīģµŗ¼ `'classes'` ÕŁŚµ«ĄÕŁśµöŠµĢ░µŹ«ķøåń▒╗Õł½, `'palette'` ÕŁśµöŠµĢ░µŹ«ķøåń▒╗Õł½Õ»╣Õ║öńÜäÕÅ»Ķ¦åÕī¢µŚČĶ░āĶē▓ńøśńÜäķó£Ķē▓, õ╗źÕÅŖµĀćńŁŠķ揵śĀÕ░äńÜäÕŁŚµ«Ą `'label_map'` ÕÆī `'reduce_zero_label'`.
+
+```python
+print(dataset.metainfo)
+
+{'classes': ('road',
+ 'sidewalk',
+ 'building',
+ 'wall',
+ 'fence',
+ 'pole',
+ 'traffic light',
+ 'traffic sign',
+ 'vegetation',
+ 'terrain',
+ 'sky',
+ 'person',
+ 'rider',
+ 'car',
+ 'truck',
+ 'bus',
+ 'train',
+ 'motorcycle',
+ 'bicycle'),
+ 'palette': [[128, 64, 128],
+ [244, 35, 232],
+ [70, 70, 70],
+ [102, 102, 156],
+ [190, 153, 153],
+ [153, 153, 153],
+ [250, 170, 30],
+ [220, 220, 0],
+ [107, 142, 35],
+ [152, 251, 152],
+ [70, 130, 180],
+ [220, 20, 60],
+ [255, 0, 0],
+ [0, 0, 142],
+ [0, 0, 70],
+ [0, 60, 100],
+ [0, 80, 100],
+ [0, 0, 230],
+ [119, 11, 32]],
+ 'label_map': None,
+ 'reduce_zero_label': False}
+```
+
+µĢ░µŹ«ķøå `__getitem__` µ¢╣µ│ĢńÜäĶ┐öÕø×ÕĆ╝, µś»ń╗ÅĶ┐ćµĢ░µŹ«Õó×Õ╝║ńÜäµĀʵ£¼µĢ░µŹ«ńÜäĶŠōÕć║, ÕÉīµĀĘõ╣¤µś»õĖĆõĖ¬ÕŁŚÕģĖ, Õīģµŗ¼õĖżõĖ¬ÕŁŚµ«Ą, `'inputs'` ÕŁŚµ«Ąµś»ÕĮōÕēŹµĀʵ£¼ń╗ÅĶ┐ćµĢ░µŹ«Õó×Õ╝║µōŹõĮ£ńÜäÕøŠÕāÅ, ń▒╗Õ×ŗõĖ║ torch.Tensor, `'data_samples'` ÕŁŚµ«ĄÕŁśµöŠńÜäµĢ░µŹ«ń▒╗Õ×ŗµś» MMSegmentation 1.x µ¢░µĘ╗ÕŖĀńÜäµĢ░µŹ«ń╗ōµ×ä [`Segdatasample`](./structures.md), ÕģČõĖŁ`gt_sem_seg` ÕŁŚµ«Ąµś»ń╗ÅĶ┐ćµĢ░µŹ«Õó×Õ╝║ńÜäµĀćńŁŠµĢ░µŹ«.
+
+```python
+print(dataset[0])
+
+{'inputs': tensor([[[131, 130, 130, ..., 23, 23, 23],
+ [132, 132, 132, ..., 23, 22, 23],
+ [134, 133, 133, ..., 23, 23, 23],
+ ...,
+ [ 66, 67, 67, ..., 71, 71, 71],
+ [ 66, 67, 66, ..., 68, 68, 68],
+ [ 67, 67, 66, ..., 70, 70, 70]],
+
+ [[143, 143, 142, ..., 28, 28, 29],
+ [145, 145, 145, ..., 28, 28, 29],
+ [145, 145, 145, ..., 27, 28, 29],
+ ...,
+ [ 75, 75, 76, ..., 80, 81, 81],
+ [ 75, 76, 75, ..., 80, 80, 80],
+ [ 77, 76, 76, ..., 82, 82, 82]],
+
+ [[126, 125, 126, ..., 21, 21, 22],
+ [127, 127, 128, ..., 21, 21, 22],
+ [127, 127, 126, ..., 21, 21, 22],
+ ...,
+ [ 63, 63, 64, ..., 69, 69, 70],
+ [ 64, 65, 64, ..., 69, 69, 69],
+ [ 65, 66, 66, ..., 72, 71, 71]]], dtype=torch.uint8),
+ 'data_samples':
+ | ÕŖ¤ĶāĮ | +ÕĤńēł | +µ¢░ńēł | +
| ÕŖĀĶĮĮķóäĶ«Łń╗āµ©ĪÕ×ŗ | +--load_from=$CHECKPOINT | +--cfg-options load_from=$CHECKPOINT | +
| õ╗Äńē╣իܵŻĆµ¤źńé╣µüóÕżŹĶ«Łń╗ā | +--resume-from=$CHECKPOINT | +--resume=$CHECKPOINT | +
| õ╗ĵ£Ćµ¢░ńÜ䵯Ƶ¤źńé╣µüóÕżŹĶ«Łń╗ā | +--auto-resume | +--resume='auto' | +
| Ķ«Łń╗āµ£¤ķŚ┤µś»ÕÉ”õĖŹĶ»äõ╝░µŻĆµ¤źńé╣ | +--no-validate | +--cfg-options val_cfg=None val_dataloader=None val_evaluator=None | +
| µīćÕ«ÜĶ«Łń╗āĶ«ŠÕżć | +--gpu-id=$DEVICE_ID | +- | +
| µś»ÕÉ”õĖ║õĖŹÕÉīĶ┐øń©ŗĶ«ŠńĮ«õĖŹÕÉīńÜäń¦ŹÕŁÉ | +--diff-seed | +--cfg-options randomness.diff_rank_seed=True | +µś»ÕÉ”õĖ║ CUDNN ÕÉÄń½»Ķ«ŠńĮ«ńĪ«Õ«ÜµĆ¦ķĆēķĪ╣ | +--deterministic | +--cfg-options randomness.deterministic=True | +
| ÕŖ¤ĶāĮ | +0.x | +1.x | +
| µīćÕ«ÜĶ»äµĄŗµīćµĀć | +--eval mIoU | +--cfg-options test_evaluator.type=IoUMetric | +
| µĄŗĶ»ĢµŚČµĢ░µŹ«Õó×Õ╝║ | +--aug-test | +--tta | +
| µĄŗĶ»ĢµŚČµś»ÕÉ”ÕŬõ┐ØÕŁśķó䵥ŗń╗ōµ×£õĖŹĶ«Īń«ŚĶ»äµĄŗµīćµĀć | +--format-only | +--cfg-options test_evaluator.format_only=True | +
| ÕĤńēł | ++ +```python +data = dict( + samples_per_gpu=4, + workers_per_gpu=4, + train=dict(...), + val=dict(...), + test=dict(...), +) +``` + + | +
| µ¢░ńēł | ++ +```python +train_dataloader = dict( + batch_size=4, + num_workers=4, + dataset=dict(...), + sampler=dict(type='DefaultSampler', shuffle=True) # Õ┐ģķĪ╗ +) + +val_dataloader = dict( + batch_size=4, + num_workers=4, + dataset=dict(...), + sampler=dict(type='DefaultSampler', shuffle=False) # Õ┐ģķĪ╗ +) + +test_dataloader = val_dataloader +``` + + | +
| ÕĤńēł | ++ +```python +train_pipeline = [ + dict(type='LoadImageFromFile'), + dict(type='LoadAnnotations', reduce_zero_label=True), + dict(type='Resize', img_scale=(2560, 640), ratio_range=(0.5, 2.0)), + dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75), + dict(type='RandomFlip', prob=0.5), + dict(type='PhotoMetricDistortion'), + dict(type='Normalize', **img_norm_cfg), + dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255), + dict(type='DefaultFormatBundle'), + dict(type='Collect', keys=['img', 'gt_semantic_seg']), +] +``` + + | +
| µ¢░ńēł | ++ +```python +train_pipeline = [ + dict(type='LoadImageFromFile'), + dict(type='LoadAnnotations', reduce_zero_label=True), + dict( + type='RandomResize', + scale=(2560, 640), + ratio_range=(0.5, 2.0), + keep_ratio=True), + dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75), + dict(type='RandomFlip', prob=0.5), + dict(type='PhotoMetricDistortion'), + dict(type='PackSegInputs') +] +``` + + | +
| ÕĤńēł | ++ +```python +test_pipeline = [ + dict(type='LoadImageFromFile'), + dict( + type='MultiScaleFlipAug', + img_scale=(2560, 640), + # img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75], + flip=False, + transforms=[ + dict(type='Resize', keep_ratio=True), + dict(type='RandomFlip'), + dict(type='Normalize', **img_norm_cfg), + dict(type='ImageToTensor', keys=['img']), + dict(type='Collect', keys=['img']), + ]) +] +``` + + | +
| µ¢░ńēł | ++ +```python +test_pipeline = [ + dict(type='LoadImageFromFile'), + dict(type='Resize', scale=(2560, 640), keep_ratio=True), + dict(type='LoadAnnotations', reduce_zero_label=True), + dict(type='PackSegInputs') +] +img_ratios = [0.5, 0.75, 1.0, 1.25, 1.5, 1.75] +tta_pipeline = [ + dict(type='LoadImageFromFile', backend_args=None), + dict( + type='TestTimeAug', + transforms=[ + [ + dict(type='Resize', scale_factor=r, keep_ratio=True) + for r in img_ratios + ], + [ + dict(type='RandomFlip', prob=0., direction='horizontal'), + dict(type='RandomFlip', prob=1., direction='horizontal') + ], [dict(type='LoadAnnotations')], [dict(type='PackSegInputs')] + ]) +] +``` + + | +
| ÕĤńēł | ++ +```python +evaluation = dict(interval=2000, metric='mIoU', pre_eval=True) +``` + + | +
| µ¢░ńēł | ++ +```python +val_evaluator = dict(type='IoUMetric', iou_metrics=['mIoU']) +test_evaluator = val_evaluator +``` + + | +
| ÕĤńēł | ++ +```python +optimizer = dict(type='AdamW', lr=0.0001, weight_decay=0.0005) +optimizer_config = dict(grad_clip=dict(max_norm=1, norm_type=2)) +``` + + | +
| µ¢░ńēł | ++ +```python +optim_wrapper = dict( + type='OptimWrapper', + optimizer=dict(type='AdamW', lr=0.0001, weight_decay=0.0005), + clip_grad=dict(max_norm=1, norm_type=2)) +``` + + | +
| ÕĤńēł | ++ +```python +lr_config = dict( + policy='poly', + warmup='linear', + warmup_iters=1500, + warmup_ratio=1e-6, + power=1.0, + min_lr=0.0, + by_epoch=False) +``` + + | +
| µ¢░ńēł | ++ +```python +param_scheduler = [ + dict( + type='LinearLR', start_factor=1e-6, by_epoch=False, begin=0, end=1500), + dict( + type='PolyLR', + power=1.0, + begin=1500, + end=160000, + eta_min=0.0, + by_epoch=False, + ) +] +``` + + | +
| ÕĤńēł | ++ +```python +runner = dict(type='IterBasedRunner', max_iters=20000) +``` + + | +
| µ¢░ńēł | ++ +```python +# `val_interval` µś»µŚ¦ńēłµ£¼ńÜä `evaluation.interval`ŃĆé +train_cfg = dict(type='IterBasedTrainLoop', max_iters=20000, val_interval=2000) +val_cfg = dict(type='ValLoop') # õĮ┐ńö©ķ╗śĶ«żńÜäķ¬īĶ»üÕŠ¬ńÄ»ŃĆé +test_cfg = dict(type='TestLoop') # õĮ┐ńö©ķ╗śĶ«żńÜ䵥ŗĶ»ĢÕŠ¬ńÄ»ŃĆé +``` + + | +
| ÕĤńēł | ++ +```python +log_config = dict( + interval=100, + hooks=[ + dict(type='TextLoggerHook'), + dict(type='TensorboardLoggerHook'), + ]) +``` + + | +
| µ¢░ńēł | ++ +```python +default_hooks = dict( + ... + logger=dict(type='LoggerHook', interval=100), +) +vis_backends = [dict(type='LocalVisBackend'), + dict(type='TensorboardVisBackend')] +visualizer = dict( + type='SegLocalVisualizer', vis_backends=vis_backends, name='visualizer') +``` + + | +
+
+
+ | MMSegmentation 0.x | +MMSegmentation 1.x | +
| mmseg.api | +mmseg.api | +
| - mmseg.core | ++ mmseg.engine | +
| mmseg.datasets | +mmseg.datasets | +
| mmseg.models | +mmseg.models | +
| - mmseg.ops | ++ mmseg.structure | +
| mmseg.utils | +mmseg.utils | +
| + | + mmseg.evaluation | +
| + | + mmseg.registry | +
+ +
+
+
+```shell
+wget https://user-images.githubusercontent.com/24582831/189833109-eddad58f-f777-4fc0-b98a-6bd429143b06.png --output-document aachen_000000_000019_leftImg8bit.png
+wget https://user-images.githubusercontent.com/24582831/189833143-15f60f8a-4d1e-4cbb-a6e7-5e2233869fac.png --output-document aachen_000000_000019_gtFine_labelTrainIds.png
+```
+
+ńäČÕÉÄõĮĀÕÅ»õ╗źµēŠÕł░õ╗¢õ╗¼µ£¼Õ£░ńÜäĶĘ»ÕŠäÕÆīõĮ┐ńö©õĖŗķØóńÜäĶäܵ£¼µ¢ćõ╗ČÕ»╣ÕģČĶ┐øĶĪīÕÅ»Ķ¦åÕī¢’╝Ü
+
+```python
+import mmcv
+import os.path as osp
+import torch
+
+# `PixelData` µś» MMEngine õĖŁńö©õ║ÄÕ«Üõ╣ēÕāÅń┤Āń║¦µĀćµ│©µł¢ķó䵥ŗńÜäµĢ░µŹ«ń╗ōµ×äŃĆé
+# Ķ»ĘÕÅéĶĆāõĖŗķØóńÜäMMEngineµĢ░µŹ«ń╗ōµ×äµĢÖń©ŗµ¢ćõ╗Č’╝Ü
+# https://mmengine.readthedocs.io/zh_CN/latest/advanced_tutorials/data_element.html#pixeldata
+
+from mmengine.structures import PixelData
+
+# `SegDataSample` µś»Õ£© MMSegmentation õĖŁÕ«Üõ╣ēńÜäõĖŹÕÉīń╗äõ╗Čõ╣ŗķŚ┤ńÜäµĢ░µŹ«ń╗ōµ×äµÄźÕÅŻ’╝ī
+# Õ«āÕīģµŗ¼ ground truthŃĆüĶ»Łõ╣ēÕłåÕē▓ńÜäķó䵥ŗń╗ōµ×£ÕÆīķó䵥ŗķĆ╗ĶŠæŃĆé
+# Ķ»”µāģĶ»ĘÕÅéĶĆāõĖŗķØóńÜä `SegDataSample` µĢÖń©ŗµ¢ćõ╗Č’╝Ü
+# https://github.com/open-mmlab/mmsegmentation/blob/1.x/docs/en/advanced_guides/structures.md
+
+from mmseg.structures import SegDataSample
+from mmseg.visualization import SegLocalVisualizer
+
+out_file = 'out_file_cityscapes'
+save_dir = './work_dirs'
+
+image = mmcv.imread(
+ osp.join(
+ osp.dirname(__file__),
+ './aachen_000000_000019_leftImg8bit.png'
+ ),
+ 'color')
+sem_seg = mmcv.imread(
+ osp.join(
+ osp.dirname(__file__),
+ './aachen_000000_000019_gtFine_labelTrainIds.png' # noqa
+ ),
+ 'unchanged')
+sem_seg = torch.from_numpy(sem_seg)
+gt_sem_seg_data = dict(data=sem_seg)
+gt_sem_seg = PixelData(**gt_sem_seg_data)
+data_sample = SegDataSample()
+data_sample.gt_sem_seg = gt_sem_seg
+
+seg_local_visualizer = SegLocalVisualizer(
+ vis_backends=[dict(type='LocalVisBackend')],
+ save_dir=save_dir)
+
+# µĢ░µŹ«ķøåńÜäÕģāõ┐Īµü»ķĆÜÕĖĖÕīģµŗ¼ń▒╗ÕÉŹńÜä `classes` ÕÆī
+# ńö©õ║ÄÕÅ»Ķ¦åÕī¢µ»ÅõĖ¬ÕēŹµÖ»ķó£Ķē▓ńÜä `palette` ŃĆé
+# µēƵ£ēń▒╗ÕÉŹÕÆīĶ░āĶē▓µØ┐ķāĮÕ£©µŁżµ¢ćõ╗ČõĖŁÕ«Üõ╣ē’╝Ü
+# https://github.com/open-mmlab/mmsegmentation/blob/1.x/mmseg/utils/class_names.py
+
+seg_local_visualizer.dataset_meta = dict(
+ classes=('road', 'sidewalk', 'building', 'wall', 'fence',
+ 'pole', 'traffic light', 'traffic sign',
+ 'vegetation', 'terrain', 'sky', 'person', 'rider',
+ 'car', 'truck', 'bus', 'train', 'motorcycle',
+ 'bicycle'),
+ palette=[[128, 64, 128], [244, 35, 232], [70, 70, 70],
+ [102, 102, 156], [190, 153, 153], [153, 153, 153],
+ [250, 170, 30], [220, 220, 0], [107, 142, 35],
+ [152, 251, 152], [70, 130, 180], [220, 20, 60],
+ [255, 0, 0], [0, 0, 142], [0, 0, 70],
+ [0, 60, 100], [0, 80, 100], [0, 0, 230],
+ [119, 11, 32]])
+
+# ÕĮō`show=True`µŚČ’╝īńø┤µÄźµśŠńż║ń╗ōµ×£’╝ī
+# ÕĮō `show=False`µŚČ’╝īń╗ōµ×£Õ░åõ┐ØÕŁśÕ£©µ£¼Õ£░µ¢ćõ╗ČÕż╣õĖŁŃĆé
+
+seg_local_visualizer.add_datasample(out_file, image,
+ data_sample, show=False)
+```
+
+ÕÅ»Ķ¦åÕī¢ÕÉÄńÜäÕøŠÕāÅń╗ōµ×£ÕÆīÕ«āńÜäÕ»╣Õ║öńÜä ground truth ÕøŠÕāÅÕÅ»õ╗źÕ£© `./work_dirs/vis_data/vis_image/` ĶĘ»ÕŠäµēŠÕł░’╝īµ¢ćõ╗ČÕÉŹÕŁŚµś»’╝Ü`out_file_cityscapes_0.png` ’╝Ü
+
+
+
+ +
+
+
+Õ”éµ×£õĮĀµā│ń¤źķüōµø┤ÕżÜńÜäÕģ│õ║ÄÕÅ»Ķ¦åÕī¢ńÜäõĮ┐ńö©µīćÕ╝Ģ’╝īõĮĀÕÅ»õ╗źÕÅéĶĆā MMEngine õĖŁńÜä[ÕÅ»Ķ¦åÕī¢µĢÖń©ŗ](<[https://mmengine.readthedocs.io/en/latest/advanced_tutorials/visualization.html](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/advanced_tutorials/visualization.md)>)
diff --git a/internlm_langchain/knowledge_base/MMSegmentation/content/visualization_feature_map.md b/internlm_langchain/knowledge_base/MMSegmentation/content/visualization_feature_map.md
new file mode 100644
index 00000000..fda99bb5
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMSegmentation/content/visualization_feature_map.md
@@ -0,0 +1,201 @@
+# wandbĶ«░ÕĮĢńē╣ÕŠüÕøŠÕÅ»Ķ¦åÕī¢
+
+MMSegmentation 1.x µÅÉõŠøõ║å Weights & Biases ńÜäÕÉÄń½»µö»µīü’╝īµ¢╣õŠ┐Õ»╣ķĪ╣ńø«õ╗ŻńĀüń╗ōµ×£ńÜäÕÅ»Ķ¦åÕī¢ÕÆīń«ĪńÉåŃĆé
+
+## WandbńÜäķģŹńĮ«
+
+Õ«ēĶŻģ Weights & Biases ńÜäĶ┐ćń©ŗÕÅ»õ╗źÕÅéĶĆā [Õ«śµ¢╣Õ«ēĶŻģµīćÕŹŚ](https://docs.wandb.ai/quickstart)’╝īÕģĘõĮōńÜ䵣źķ¬żÕ”éõĖŗ:
+
+```shell
+pip install wandb
+wandb login
+```
+
+Õ£© `vis_backend` õĖŁµĘ╗ÕŖĀ `WandbVisBackend`ŃĆé
+
+```python
+vis_backends=[dict(type='LocalVisBackend'),
+ dict(type='TensorboardVisBackend'),
+ dict(type='WandbVisBackend')]
+```
+
+## µĄŗĶ»ĢµĢ░µŹ«ÕÆīń╗ōµ×£ÕÅŖńē╣ÕŠüÕøŠńÜäÕÅ»Ķ¦åÕī¢
+
+`SegLocalVisualizer` µś»ń╗¦µē┐Ķć¬ MMEngine õĖŁ `Visualizer` ń▒╗ńÜäÕŁÉń▒╗’╝īķĆéńö©õ║Ä MMSegmentation ÕÅ»Ķ¦åÕī¢’╝īµ£ēÕģ│ `Visualizer` ńÜäĶ»”ń╗åõ┐Īµü»Ķ»ĘÕÅéĶĆāÕ£© MMEngine õĖŁńÜä[ÕÅ»Ķ¦åÕī¢µĢÖń©ŗ](https://mmengine.readthedocs.io/zh_CN/latest/advanced_tutorials/visualization.html) ŃĆé
+
+õ╗źõĖŗµś»õĖĆõĖ¬Õģ│õ║Ä `SegLocalVisualizer` ńÜäńż║õŠŗ’╝īķ”¢ÕģłõĮĀÕÅ»õ╗źõĮ┐ńö©õĖŗķØóńÜäÕæĮõ╗żõĖŗĶĮĮĶ┐ÖõĖ¬µĪłõŠŗõĖŁńÜäµĢ░µŹ«’╝Ü
+
+
+
+
+
+
+```shell
+wget https://user-images.githubusercontent.com/24582831/189833109-eddad58f-f777-4fc0-b98a-6bd429143b06.png --output-document aachen_000000_000019_leftImg8bit.png
+wget https://user-images.githubusercontent.com/24582831/189833143-15f60f8a-4d1e-4cbb-a6e7-5e2233869fac.png --output-document aachen_000000_000019_gtFine_labelTrainIds.png
+
+wget https://download.openmmlab.com/mmsegmentation/v0.5/ann/ann_r50-d8_512x1024_40k_cityscapes/ann_r50-d8_512x1024_40k_cityscapes_20200605_095211-049fc292.pth
+
+```
+
+```python
+# Copyright (c) OpenMMLab. All rights reserved.
+from argparse import ArgumentParser
+from typing import Type
+
+import mmcv
+import torch
+import torch.nn as nn
+
+from mmengine.model import revert_sync_batchnorm
+from mmengine.structures import PixelData
+from mmseg.apis import inference_model, init_model
+from mmseg.structures import SegDataSample
+from mmseg.utils import register_all_modules
+from mmseg.visualization import SegLocalVisualizer
+
+
+class Recorder:
+ """record the forward output feature map and save to data_buffer."""
+
+ def __init__(self) -> None:
+ self.data_buffer = list()
+
+ def __enter__(self, ):
+ self._data_buffer = list()
+
+ def record_data_hook(self, model: nn.Module, input: Type, output: Type):
+ self.data_buffer.append(output)
+
+ def __exit__(self, *args, **kwargs):
+ pass
+
+
+def visualize(args, model, recorder, result):
+ seg_visualizer = SegLocalVisualizer(
+ vis_backends=[dict(type='WandbVisBackend')],
+ save_dir='temp_dir',
+ alpha=0.5)
+ seg_visualizer.dataset_meta = dict(
+ classes=model.dataset_meta['classes'],
+ palette=model.dataset_meta['palette'])
+
+ image = mmcv.imread(args.img, 'color')
+
+ seg_visualizer.add_datasample(
+ name='predict',
+ image=image,
+ data_sample=result,
+ draw_gt=False,
+ draw_pred=True,
+ wait_time=0,
+ out_file=None,
+ show=False)
+
+ # add feature map to wandb visualizer
+ for i in range(len(recorder.data_buffer)):
+ feature = recorder.data_buffer[i][0] # remove the batch
+ drawn_img = seg_visualizer.draw_featmap(
+ feature, image, channel_reduction='select_max')
+ seg_visualizer.add_image(f'feature_map{i}', drawn_img)
+
+ if args.gt_mask:
+ sem_seg = mmcv.imread(args.gt_mask, 'unchanged')
+ sem_seg = torch.from_numpy(sem_seg)
+ gt_mask = dict(data=sem_seg)
+ gt_mask = PixelData(**gt_mask)
+ data_sample = SegDataSample()
+ data_sample.gt_sem_seg = gt_mask
+
+ seg_visualizer.add_datasample(
+ name='gt_mask',
+ image=image,
+ data_sample=data_sample,
+ draw_gt=True,
+ draw_pred=False,
+ wait_time=0,
+ out_file=None,
+ show=False)
+
+ seg_visualizer.add_image('image', image)
+
+
+def main():
+ parser = ArgumentParser(
+ description='Draw the Feature Map During Inference')
+ parser.add_argument('img', help='Image file')
+ parser.add_argument('config', help='Config file')
+ parser.add_argument('checkpoint', help='Checkpoint file')
+ parser.add_argument('--gt_mask', default=None, help='Path of gt mask file')
+ parser.add_argument('--out-file', default=None, help='Path to output file')
+ parser.add_argument(
+ '--device', default='cuda:0', help='Device used for inference')
+ parser.add_argument(
+ '--opacity',
+ type=float,
+ default=0.5,
+ help='Opacity of painted segmentation map. In (0, 1] range.')
+ parser.add_argument(
+ '--title', default='result', help='The image identifier.')
+ args = parser.parse_args()
+
+ register_all_modules()
+
+ # build the model from a config file and a checkpoint file
+ model = init_model(args.config, args.checkpoint, device=args.device)
+ if args.device == 'cpu':
+ model = revert_sync_batchnorm(model)
+
+ # show all named module in the model and use it in source list below
+ for name, module in model.named_modules():
+ print(name)
+
+ source = [
+ 'decode_head.fusion.stages.0.query_project.activate',
+ 'decode_head.context.stages.0.key_project.activate',
+ 'decode_head.context.bottleneck.activate'
+ ]
+ source = dict.fromkeys(source)
+
+ count = 0
+ recorder = Recorder()
+ # registry the forward hook
+ for name, module in model.named_modules():
+ if name in source:
+ count += 1
+ module.register_forward_hook(recorder.record_data_hook)
+ if count == len(source):
+ break
+
+ with recorder:
+ # test a single image, and record feature map to data_buffer
+ result = inference_model(model, args.img)
+
+ visualize(args, model, recorder, result)
+
+
+if __name__ == '__main__':
+ main()
+
+```
+
+Õ░åõĖŖĶ┐░õ╗ŻńĀüõ┐ØÕŁśõĖ║ feature_map_visual.py’╝īÕ£©ń╗łń½»µē¦ĶĪīÕ”éõĖŗõ╗ŻńĀü
+
+```shell
+python feature_map_visual.py ${ÕøŠÕāÅ} ${ķģŹńĮ«µ¢ćõ╗Č} ${µŻĆµ¤źńé╣µ¢ćõ╗Č} [ÕÅ»ķĆēÕÅéµĢ░]
+```
+
+µĀĘõŠŗ
+
+```shell
+python feature_map_visual.py \
+aachen_000000_000019_leftImg8bit.png \
+configs/ann/ann_r50-d8_4xb2-40k_cityscapes-512x1024.py \
+ann_r50-d8_512x1024_40k_cityscapes_20200605_095211-049fc292.pth \
+--gt_mask aachen_000000_000019_gtFine_labelTrainIds.png
+```
+
+ÕÅ»Ķ¦åÕī¢ÕÉÄńÜäÕøŠÕāÅń╗ōµ×£ÕÆīÕ«āńÜäÕ»╣Õ║öńÜä feature mapÕøŠÕāÅõ╝ÜÕć║ńÄ░Õ£©wandbĶ┤”µłĘõĖŁ
+
+
+
+ +
+
diff --git a/internlm_langchain/knowledge_base/MMSegmentation/vector_store/index.faiss b/internlm_langchain/knowledge_base/MMSegmentation/vector_store/index.faiss
new file mode 100644
index 00000000..05f74a44
Binary files /dev/null and b/internlm_langchain/knowledge_base/MMSegmentation/vector_store/index.faiss differ
diff --git a/internlm_langchain/knowledge_base/MMSkeleton/content/CONTRIBUTING.md b/internlm_langchain/knowledge_base/MMSkeleton/content/CONTRIBUTING.md
new file mode 100644
index 00000000..32d9604f
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMSkeleton/content/CONTRIBUTING.md
@@ -0,0 +1,27 @@
+# Contributing to MMSkeleton
+
+All kinds of contributions are welcome, including but not limited to the following.
+
+- Fixes (typo, bugs)
+- New features and components
+
+## Workflow
+
+1. fork and pull the latest mmskeleton
+2. checkout a new branch (do not use master branch for PRs)
+3. commit your changes
+4. create a PR
+
+Note
+- If you plan to add some new features that involve large changes, it is encouraged to open an issue for discussion first.
+- If you are the author of some papers and would like to include your method to mmskeleton,
+please contact Sijie Yan (yysijie@gmail). We will much appreciate your contribution.
+
+## Code style
+
+### Python
+We adopt [PEP8](https://www.python.org/dev/peps/pep-0008/) as the preferred code style.
+We use [flake8](http://flake8.pycqa.org/en/latest/) as the linter and [yapf](https://github.com/google/yapf) as the formatter.
+Please upgrade to the latest yapf (>=0.27.0) and refer to the [configuration](../.style.yapf).
+
+>Before you create a PR, make sure that your code lints and is formatted by yapf.
\ No newline at end of file
diff --git a/internlm_langchain/knowledge_base/MMSkeleton/content/CREATE_APPLICATION.md b/internlm_langchain/knowledge_base/MMSkeleton/content/CREATE_APPLICATION.md
new file mode 100644
index 00000000..0b56cb97
--- /dev/null
+++ b/internlm_langchain/knowledge_base/MMSkeleton/content/CREATE_APPLICATION.md
@@ -0,0 +1,44 @@
+## Create an MMSkeleton Application
+
+MMSkeleton provides various models, datasets, apis, operators for various applications,
+such as pose estimation, human detection, action recognition and dataset building.
+The workflow of a application is defined by a **processor**, which is usually a python function.
+
+In MMSkeleton, an application is defined in a configuration file.
+It is a `.json`, `.yaml` or `.py` file including `processor_cfg` field.
+Here is an example:
+
+```yaml
+# yaml
+
+processor_cfg:
+ type:
+
+  +
+