-
-
-
-
-
-
-
- {{ page.title }}
- {% if page.subtitle %} -
-
-
- {% endif %}
-
- {% include sidebar-qrcode.html %}
-
-
-
-
-
- {{ content }}
-
-
-
-
- {% include comments.html %}
-
-
- {% include sidebar-search.html %}
- {% include sidebar-categories-cloud.html %}
-
- {% include sidebar-popular-repo.html %}
-
- Table of Contents
-
+
diff --git a/_includes/sidebar-recent-update.html b/_includes/sidebar-recent-update.html
new file mode 100755
index 0000000000..68e612e4ab
--- /dev/null
+++ b/_includes/sidebar-recent-update.html
@@ -0,0 +1,11 @@
+
+{title} ',
+ noResultsText: 'No results found',
+ limit: {{ site.simple_jekyll_search.limit }},
+ fuzzy: false,
+ exclude: ['Welcome']
+ });
+ window.onload = function(){
+ var query_text = window.location.search.substring(1);
+ var vars = query_text.split("&");
+ for (var i=0;i
diff --git a/_includes/visit-stat.html b/_includes/visit-stat.html
index b156a3fa45..23fe1ac07a 100644
--- a/_includes/visit-stat.html
+++ b/_includes/visit-stat.html
@@ -8,11 +8,5 @@
-
-
-
-
-
-
{% endif %}
\ No newline at end of file
diff --git a/_layouts/categories.html b/_layouts/categories.html
index d07595da2b..f9502c6439 100755
--- a/_layouts/categories.html
+++ b/_layouts/categories.html
@@ -4,7 +4,7 @@
{% assign assets_base_url = site.url %}
{% if site.cdn.jsdelivr.enabled %}
-{% assign assets_base_url = "https://cdn.jsdelivr.net/gh/" | append: site.repository | append: '@master' %}
+{% assign assets_base_url = "https://cdn.jsdelivr.net/gh/" | append: site.repository | append: '@'| append: site.cdn.jsdelivr.branch %}
{% endif %}
Table of Contents
+Popular Posts
+-
+ {% for post in site.posts %}
+ {% if post.recent_update== true %}
+
+ {{ post.date | date:"%Y-%m" }} {{ post.title }} +
+ {% endif %} + {% endfor %} +Search
-
+
-
@@ -24,20 +24,26 @@
{{ page.title }}
+
{{ content }}
-
diff --git a/_layouts/default.html b/_layouts/default.html
index 9c762fad3d..5d05f3f6a6 100755
--- a/_layouts/default.html
+++ b/_layouts/default.html
@@ -4,9 +4,8 @@
{% assign assets_base_url = site.url %}
{% if site.cdn.jsdelivr.enabled %}
-{% assign assets_base_url = "https://cdn.jsdelivr.net/gh/" | append: site.repository | append: '@master' %}
+{% assign assets_base_url = "https://cdn.jsdelivr.net/gh/" | append: site.repository | append: '@'| append: site.cdn.jsdelivr.branch %}
{% endif %}
-{% assign assets_images_url = ' -
-
-
-
-
-
-
-
diff --git a/_layouts/page.html b/_layouts/page.html
index 7ba323b0cb..df074664a8 100755
--- a/_layouts/page.html
+++ b/_layouts/page.html
@@ -4,7 +4,7 @@
{% assign assets_base_url = site.url %}
{% if site.cdn.jsdelivr.enabled %}
-{% assign assets_base_url = "https://cdn.jsdelivr.net/gh/" | append: site.repository | append: '@master' %}
+{% assign assets_base_url = "https://cdn.jsdelivr.net/gh/" | append: site.repository | append: '@'| append: site.cdn.jsdelivr.branch %}
{% endif %}
-
-
-
-
-
-
-
-
diff --git a/_layouts/page.html b/_layouts/page.html
index 7ba323b0cb..df074664a8 100755
--- a/_layouts/page.html
+++ b/_layouts/page.html
@@ -4,7 +4,7 @@
{% assign assets_base_url = site.url %}
{% if site.cdn.jsdelivr.enabled %}
-{% assign assets_base_url = "https://cdn.jsdelivr.net/gh/" | append: site.repository | append: '@master' %}
+{% assign assets_base_url = "https://cdn.jsdelivr.net/gh/" | append: site.repository | append: '@'| append: site.cdn.jsdelivr.branch %}
{% endif %}
+ {% include sidebar-categories-cloud.html %}
+
@@ -44,7 +44,7 @@
diff --git a/_layouts/post.html b/_layouts/post.html
index a544affaf9..08683b3491 100755
--- a/_layouts/post.html
+++ b/_layouts/post.html
@@ -4,7 +4,7 @@
{% assign assets_base_url = site.url %}
{% if site.cdn.jsdelivr.enabled %}
-{% assign assets_base_url = "https://cdn.jsdelivr.net/gh/" | append: site.repository | append: '@master' %}
+{% assign assets_base_url = "https://cdn.jsdelivr.net/gh/" | append: site.repository | append: '@'| append: site.cdn.jsdelivr.branch %}
{% endif %}
{{ page.title }}
{% include sidebar-search.html %}
{% include sidebar-categories-cloud.html %}
-
+ {% include sidebar-recent-update.html %}
{% include sidebar-popular-repo.html %}
@@ -50,17 +50,20 @@
-
-
-
-
-
diff --git a/_posts/Algorithms/leetcode/2022-07-16-2335. Minimum Amount of Time to Fill Cups.md b/_posts/Algorithms/leetcode/2022-07-16-2335. Minimum Amount of Time to Fill Cups.md
new file mode 100644
index 0000000000..77e574190c
--- /dev/null
+++ b/_posts/Algorithms/leetcode/2022-07-16-2335. Minimum Amount of Time to Fill Cups.md
@@ -0,0 +1,78 @@
+---
+layout: post
+category: leetcode
+title: 2335. Minimum Amount of Time to Fill Cups
+tags: leetcode
+---
+
+## title
+[problem link](https://leetcode.cn/problems/minimum-amount-of-time-to-fill-cups/)
+
+You have a water dispenser that can dispense cold, warm, and hot water. Every second, you can either fill up `2` cups with **different** types of water, or `1` cup of any type of water.
+
+You are given a **0-indexed** integer array `amount` of length `3` where `amount[0]`, `amount[1]`, and `amount[2]` denote the number of cold, warm, and hot water cups you need to fill respectively. Return *the **minimum** number of seconds needed to fill up all the cups*.
+
+
+
+**Example 1:**
+
+```
+Input: amount = [1,4,2]
+Output: 4
+Explanation: One way to fill up the cups is:
+Second 1: Fill up a cold cup and a warm cup.
+Second 2: Fill up a warm cup and a hot cup.
+Second 3: Fill up a warm cup and a hot cup.
+Second 4: Fill up a warm cup.
+It can be proven that 4 is the minimum number of seconds needed.
+```
+
+**Example 2:**
+
+```
+Input: amount = [5,4,4]
+Output: 7
+Explanation: One way to fill up the cups is:
+Second 1: Fill up a cold cup, and a hot cup.
+Second 2: Fill up a cold cup, and a warm cup.
+Second 3: Fill up a cold cup, and a warm cup.
+Second 4: Fill up a warm cup, and a hot cup.
+Second 5: Fill up a cold cup, and a hot cup.
+Second 6: Fill up a cold cup, and a warm cup.
+Second 7: Fill up a hot cup.
+```
+
+**Example 3:**
+
+```
+Input: amount = [5,0,0]
+Output: 5
+Explanation: Every second, we fill up a cold cup.
+```
+
+
+
+**Constraints:**
+
+- `amount.length == 3`
+- `0 <= amount[i] <= 100`
+
+## solution
+
+We can use the technique of greedy and category discussion.
+
+At every step only choose the max-2 cups to be filled.
+
+```python
+class Solution:
+ def fillCups(self, amount: List[int]) -> int:
+ a, b, c = sorted(amount, reverse=True)
+ if b + c < a:
+ return a
+ t = b + c - a
+ if t % 2 == 0:
+ return (t // 2) + a
+ # t is odd
+ return ((t - 1) // 2) + a + 1
+```
+
diff --git a/_posts/Algorithms/leetcode/2022-07-16-2336. Smallest Number in Infinite Set.md b/_posts/Algorithms/leetcode/2022-07-16-2336. Smallest Number in Infinite Set.md
new file mode 100644
index 0000000000..9ced85dc92
--- /dev/null
+++ b/_posts/Algorithms/leetcode/2022-07-16-2336. Smallest Number in Infinite Set.md
@@ -0,0 +1,81 @@
+---
+layout: post
+category: leetcode
+title: 2336. Smallest Number in Infinite Set
+tags: leetcode
+---
+
+## title
+[problem link](https://leetcode.cn/problems/smallest-number-in-infinite-set/)
+
+You have a set which contains all positive integers `[1, 2, 3, 4, 5, ...]`.
+
+Implement the `SmallestInfiniteSet` class:
+
+- `SmallestInfiniteSet()` Initializes the **SmallestInfiniteSet** object to contain **all** positive integers.
+- `int popSmallest()` **Removes** and returns the smallest integer contained in the infinite set.
+- `void addBack(int num)` **Adds** a positive integer `num` back into the infinite set, if it is **not** already in the infinite set.
+
+
+
+**Example 1:**
+
+```
+Input
+["SmallestInfiniteSet", "addBack", "popSmallest", "popSmallest", "popSmallest", "addBack", "popSmallest", "popSmallest", "popSmallest"]
+[[], [2], [], [], [], [1], [], [], []]
+Output
+[null, null, 1, 2, 3, null, 1, 4, 5]
+
+Explanation
+SmallestInfiniteSet smallestInfiniteSet = new SmallestInfiniteSet();
+smallestInfiniteSet.addBack(2); // 2 is already in the set, so no change is made.
+smallestInfiniteSet.popSmallest(); // return 1, since 1 is the smallest number, and remove it from the set.
+smallestInfiniteSet.popSmallest(); // return 2, and remove it from the set.
+smallestInfiniteSet.popSmallest(); // return 3, and remove it from the set.
+smallestInfiniteSet.addBack(1); // 1 is added back to the set.
+smallestInfiniteSet.popSmallest(); // return 1, since 1 was added back to the set and
+ // is the smallest number, and remove it from the set.
+smallestInfiniteSet.popSmallest(); // return 4, and remove it from the set.
+smallestInfiniteSet.popSmallest(); // return 5, and remove it from the set.
+```
+
+
+
+**Constraints:**
+
+- `1 <= num <= 1000`
+- At most `1000` calls will be made **in total** to `popSmallest` and `addBack`.
+
+## solution
+
+One way, we can use the heapq + set. Another way, we can divide it into two parts, maintain the smallest num and a sortedset so that no initial heap in the first.
+
+```python
+import heapq
+
+
+class SmallestInfiniteSet:
+
+ def __init__(self):
+ self.h = list(range(1, 1001, 1))
+ self.s = set(self.h)
+ heapq.heapify(self.h)
+
+ def popSmallest(self) -> int:
+ if self.h:
+ r = heapq.heappop(self.h)
+ self.s.remove(r)
+ return r
+ return -1
+
+ def addBack(self, num: int) -> None:
+ if num in self.s:
+ return
+ self.s.add(num)
+ heapq.heappush(self.h, num)
+
+```
+
+
+
diff --git "a/_posts/Algorithms/leetcode/2022-08-18-2375. \346\240\271\346\215\256\346\250\241\345\274\217\344\270\262\346\236\204\351\200\240\346\234\200\345\260\217\346\225\260\345\255\227.md" "b/_posts/Algorithms/leetcode/2022-08-18-2375. \346\240\271\346\215\256\346\250\241\345\274\217\344\270\262\346\236\204\351\200\240\346\234\200\345\260\217\346\225\260\345\255\227.md"
new file mode 100644
index 0000000000..d918b09610
--- /dev/null
+++ "b/_posts/Algorithms/leetcode/2022-08-18-2375. \346\240\271\346\215\256\346\250\241\345\274\217\344\270\262\346\236\204\351\200\240\346\234\200\345\260\217\346\225\260\345\255\227.md"
@@ -0,0 +1,79 @@
+---
+layout: post
+category: leetcode
+title: 2375. 根据模式串构造最小数字
+tags: leetcode
+---
+
+## title
+[problem link](https://leetcode.cn/problems/construct-smallest-number-from-di-string/)
+
+给你下标从 **0** 开始、长度为 `n` 的字符串 `pattern` ,它包含两种字符,`'I'` 表示 **上升** ,`'D'` 表示 **下降** 。
+
+你需要构造一个下标从 **0** 开始长度为 `n + 1` 的字符串,且它要满足以下条件:
+
+- `num` 包含数字 `'1'` 到 `'9'` ,其中每个数字 **至多** 使用一次。
+- 如果 `pattern[i] == 'I'` ,那么 `num[i] < num[i + 1]` 。
+- 如果 `pattern[i] == 'D'` ,那么 `num[i] > num[i + 1]` 。
+
+请你返回满足上述条件字典序 **最小** 的字符串 `num`。
+
+
+
+**示例 1:**
+
+```
+输入:pattern = "IIIDIDDD"
+输出:"123549876"
+解释:
+下标 0 ,1 ,2 和 4 处,我们需要使 num[i] < num[i+1] 。
+下标 3 ,5 ,6 和 7 处,我们需要使 num[i] > num[i+1] 。
+一些可能的 num 的值为 "245639871" ,"135749862" 和 "123849765" 。
+"123549876" 是满足条件最小的数字。
+注意,"123414321" 不是可行解因为数字 '1' 使用次数超过 1 次。
+```
+
+**示例 2:**
+
+```
+输入:pattern = "DDD"
+输出:"4321"
+解释:
+一些可能的 num 的值为 "9876" ,"7321" 和 "8742" 。
+"4321" 是满足条件最小的数字。
+```
+
+
+
+**提示:**
+
+- `1 <= pattern.length <= 8`
+- `pattern` 只包含字符 `'I'` 和 `'D'` 。
+
+
+## solution
+
+```python
+'''
+贪心: 数字其实就是123456789,遇到连续的D,就将连续的数字reverse, 其实就是找连续的I,连续的D,然后分段。
+'''
+class Solution:
+ def smallestNumber(self, pattern: str) -> str:
+ n = len(pattern)
+ i = 0
+ ans = []
+ while i < n:
+ if i and pattern[i] == "I":
+ i += 1
+ while i < n and pattern[i] == "I":
+ i += 1
+ ans.append(i)
+ i0 = i
+ while i < n and pattern[i] == "D":
+ i += 1
+ for x in range(i + 1, i0, -1):
+ ans.append(x)
+ return "".join(map(str, ans))
+
+```
+
diff --git "a/_posts/Algorithms/leetcode/2022-08-27-2386. \346\211\276\345\207\272\346\225\260\347\273\204\347\232\204\347\254\254 K \345\244\247\345\222\214.md" "b/_posts/Algorithms/leetcode/2022-08-27-2386. \346\211\276\345\207\272\346\225\260\347\273\204\347\232\204\347\254\254 K \345\244\247\345\222\214.md"
new file mode 100644
index 0000000000..3184ef4b94
--- /dev/null
+++ "b/_posts/Algorithms/leetcode/2022-08-27-2386. \346\211\276\345\207\272\346\225\260\347\273\204\347\232\204\347\254\254 K \345\244\247\345\222\214.md"
@@ -0,0 +1,136 @@
+---
+layout: post
+category: leetcode
+title: 2386. 找出数组的第 K 大和
+tags: leetcode
+---
+
+## title
+[problem link](https://leetcode.cn/problems/find-the-k-sum-of-an-array/)
+
+给你一个整数数组 `nums` 和一个 **正** 整数 `k` 。你可以选择数组的任一 **子序列** 并且对其全部元素求和。
+
+数组的 **第 k 大和** 定义为:可以获得的第 `k` 个 **最大** 子序列和(子序列和允许出现重复)
+
+返回数组的 **第 k 大和** 。
+
+子序列是一个可以由其他数组删除某些或不删除元素排生而来的数组,且派生过程不改变剩余元素的顺序。
+
+**注意:**空子序列的和视作 `0` 。
+
+
+
+**示例 1:**
+
+```
+输入:nums = [2,4,-2], k = 5
+输出:2
+解释:所有可能获得的子序列和列出如下,按递减顺序排列:
+- 6、4、4、2、2、0、0、-2
+数组的第 5 大和是 2 。
+```
+
+**示例 2:**
+
+```
+输入:nums = [1,-2,3,4,-10,12], k = 16
+输出:10
+解释:数组的第 16 大和是 10 。
+```
+
+
+
+**提示:**
+
+- `n == nums.length`
+- `1 <= n <= 105`
+- `-109 <= nums[i] <= 109`
+- `1 <= k <= min(2000, 2n)`
+
+## solution
+
+[参考](https://leetcode.cn/problems/find-the-k-sum-of-an-array/solution/zhuan-huan-dui-by-endlesscheng-8yiq/)
+
+要记住
+
+- 数组有序后,可以用堆动态生成子序列的和,按递增顺序,每取一个后便加下一个,同时当前也可减掉。
+- 回溯只要控制深度复杂度也可观,可用于二分等
+
+
+
+优先队列做法
+
+```python
+
+class Solution:
+ def kSum(self, nums: List[int], k: int) -> int:
+ s = 0
+ for i, x in enumerate(nums):
+ if x >= 0:
+ s += x
+ else:
+ nums[i] = -x
+ import heapq
+ h = [(-s, 0)]
+ nums.sort()
+ for _ in range(k - 1):
+ l, i = heapq.heappop(h)
+ if i < len(nums):
+ heapq.heappush(h, (l + nums[i], i + 1))
+ if i:
+ heapq.heappush(h, (l + nums[i] - nums[i - 1], i + 1))
+ return - h[0][0]
+```
+
+
+
+二分做法
+
+```python
+class BinarySearch:
+ # If you wanna binary search big integer, plz set data range, which can be used as same as big integer low and high
+ # find the first index that value >= val
+ def bisect_left(data, val, key=None):
+ l, r = 0, len(data) - 1
+ if key is None:
+ key = lambda x: data[mid]
+ while l <= r:
+ mid = (l + r) // 2
+ if key(mid) >= val:
+ r = mid - 1
+ else:
+ l = mid + 1
+ return l
+class Solution:
+ def kSum(self, nums: List[int], k: int) -> int:
+ s = 0
+ for i, x in enumerate(nums):
+ if x >= 0:
+ s += x
+ else:
+ nums[i] = -x
+ total = sum(nums)
+ nums.sort()
+
+ # 不超过limit的子序列数量
+ def count(limit):
+ cnt = 0
+
+ # 算i之后的子序列数量,不包括空序列
+ def f(cur, i):
+ nonlocal cnt
+ if cnt >= k - 1 or i >= len(nums) or cur + nums[i] > limit:
+ return
+ cnt += 1
+ f(cur + nums[i], i + 1)
+ f(cur, i + 1)
+
+ f(0, 0)
+ return cnt
+
+ j = BinarySearch.bisect_left(range(total), k - 1, key=count)
+
+ return s - j
+
+```
+
diff --git "a/_posts/Algorithms/leetcode/2022-10-09-2430. \345\257\271\345\255\227\346\257\215\344\270\262\345\217\257\346\211\247\350\241\214\347\232\204\346\234\200\345\244\247\345\210\240\351\231\244\346\225\260.md" "b/_posts/Algorithms/leetcode/2022-10-09-2430. \345\257\271\345\255\227\346\257\215\344\270\262\345\217\257\346\211\247\350\241\214\347\232\204\346\234\200\345\244\247\345\210\240\351\231\244\346\225\260.md"
new file mode 100644
index 0000000000..c3ee467c5d
--- /dev/null
+++ "b/_posts/Algorithms/leetcode/2022-10-09-2430. \345\257\271\345\255\227\346\257\215\344\270\262\345\217\257\346\211\247\350\241\214\347\232\204\346\234\200\345\244\247\345\210\240\351\231\244\346\225\260.md"
@@ -0,0 +1,131 @@
+---
+layout: post
+category: leetcode
+title: 2430. 对字母串可执行的最大删除数
+tags: leetcode
+---
+
+## title
+[problem link](https://leetcode.cn/problems/maximum-deletions-on-a-string/)
+
+给你一个仅由小写英文字母组成的字符串 `s` 。在一步操作中,你可以:
+
+- 删除 **整个字符串** `s` ,或者
+- 对于满足 `1 <= i <= s.length / 2` 的任意 `i` ,如果 `s` 中的 **前** `i` 个字母和接下来的 `i` 个字母 **相等** ,删除 **前** `i` 个字母。
+
+例如,如果 `s = "ababc"` ,那么在一步操作中,你可以删除 `s` 的前两个字母得到 `"abc"` ,因为 `s` 的前两个字母和接下来的两个字母都等于 `"ab"` 。
+
+返回删除 `s` 所需的最大操作数。
+
+
+
+**示例 1:**
+
+```
+输入:s = "abcabcdabc"
+输出:2
+解释:
+- 删除前 3 个字母("abc"),因为它们和接下来 3 个字母相等。现在,s = "abcdabc"。
+- 删除全部字母。
+一共用了 2 步操作,所以返回 2 。可以证明 2 是所需的最大操作数。
+注意,在第二步操作中无法再次删除 "abc" ,因为 "abc" 的下一次出现并不是位于接下来的 3 个字母。
+```
+
+**示例 2:**
+
+```
+输入:s = "aaabaab"
+输出:4
+解释:
+- 删除第一个字母("a"),因为它和接下来的字母相等。现在,s = "aabaab"。
+- 删除前 3 个字母("aab"),因为它们和接下来 3 个字母相等。现在,s = "aab"。
+- 删除第一个字母("a"),因为它和接下来的字母相等。现在,s = "ab"。
+- 删除全部字母。
+一共用了 4 步操作,所以返回 4 。可以证明 4 是所需的最大操作数。
+```
+
+**示例 3:**
+
+```
+输入:s = "aaaaa"
+输出:5
+解释:在每一步操作中,都可以仅删除 s 的第一个字母。
+```
+
+
+
+**提示:**
+
+- `1 <= s.length <= 4000`
+- `s` 仅由小写英文字母组成
+
+## solution
+
+[参考](https://leetcode.cn/problems/maximum-deletions-on-a-string/solution/xian-xing-dppythonjavacgo-by-endlesschen-gpx9/) 不加特例判断会超时,因此使用hash string更优
+
+```python
+class Solution:
+ def deleteString(self, s: str) -> int:
+ n = len(s)
+ if len(set(s)) == 1: return n # 特判全部相同的情况
+ lcp = [[0] * (n + 1) for _ in range(n + 1)] # lcp[i][j] 表示 s[i:] 和 s[j:] 的最长公共前缀
+ for i in range(n - 1, -1, -1):
+ for j in range(n - 1, i, -1):
+ if s[i] == s[j]:
+ lcp[i][j] = lcp[i + 1][j + 1] + 1
+ f = [0] * n
+ for i in range(n - 1, -1, -1):
+ for j in range(1, (n - i) // 2 + 1):
+ if lcp[i][i + j] >= j: # 说明 s[i:i+j] == s[i+j:i+2*j]
+ f[i] = max(f[i], f[i + j])
+ f[i] += 1
+ return f[0]
+```
+
+hash string也会超时
+
+
+
+```python
+class StringHash:
+ def __init__(self, s=""):
+ self.MOD = 998244353
+ self.BASE = 131
+ # 计算前缀哈希值
+ n = len(s)
+ P = [0] * (n + 1)
+ P[0] = 1
+ for i in range(1, n + 1, 1):
+ P[i] = P[i - 1] * self.BASE % self.MOD
+ H = [0] * (n + 1)
+ for i in range(1, n + 1, 1):
+ H[i] = (H[i - 1] * self.BASE + ord(s[i - 1])) % self.MOD
+ self.H = H
+ self.P = P
+
+ '''
+ s的[l,r]区间的hash值,闭区间, l从1开始
+ '''
+
+ def get_hash(self, l=0, r=0):
+ l, r = l + 1, r + 1
+ return (self.H[r] - self.H[l - 1] * self.P[r - l + 1] % self.MOD + self.MOD) % self.MOD
+
+
+class Solution:
+ def deleteString(self, s: str) -> int:
+ n = len(s)
+ dp = [1] * n
+ hash = StringHash(s)
+ for i in range(n - 1, -1, -1):
+ for j in range(i + 1, n):
+ if (j - i + 1) % 2 == 0:
+ mid = (i + j) // 2
+ if hash.get_hash(i, mid) == hash.get_hash(mid+1, j):
+ # print(i, j, mid)
+ dp[i] = max(dp[i], dp[mid+1]+1)
+ # print(dp[i])
+ # print(dp)
+ return dp[0]
+```
+
diff --git "a/_posts/Algorithms/leetcode/2022-10-09-6202. \344\275\277\347\224\250\346\234\272\345\231\250\344\272\272\346\211\223\345\215\260\345\255\227\345\205\270\345\272\217\346\234\200\345\260\217\347\232\204\345\255\227\347\254\246\344\270\262.md" "b/_posts/Algorithms/leetcode/2022-10-09-6202. \344\275\277\347\224\250\346\234\272\345\231\250\344\272\272\346\211\223\345\215\260\345\255\227\345\205\270\345\272\217\346\234\200\345\260\217\347\232\204\345\255\227\347\254\246\344\270\262.md"
new file mode 100644
index 0000000000..949501f164
--- /dev/null
+++ "b/_posts/Algorithms/leetcode/2022-10-09-6202. \344\275\277\347\224\250\346\234\272\345\231\250\344\272\272\346\211\223\345\215\260\345\255\227\345\205\270\345\272\217\346\234\200\345\260\217\347\232\204\345\255\227\347\254\246\344\270\262.md"
@@ -0,0 +1,119 @@
+---
+layout: post
+category: leetcode
+title: 6202. 使用机器人打印字典序最小的字符串
+tags: leetcode
+---
+
+## title
+[problem link](https://leetcode.cn/problems/using-a-robot-to-print-the-lexicographically-smallest-string/)
+
+给你一个字符串 `s` 和一个机器人,机器人当前有一个空字符串 `t` 。执行以下操作之一,直到 `s` 和 `t` **都变成空字符串:**
+
+- 删除字符串 `s` 的 **第一个** 字符,并将该字符给机器人。机器人把这个字符添加到 `t` 的尾部。
+- 删除字符串 `t` 的 **最后一个** 字符,并将该字符给机器人。机器人将该字符写到纸上。
+
+请你返回纸上能写出的字典序最小的字符串。
+
+
+
+**示例 1:**
+
+```
+输入:s = "zza"
+输出:"azz"
+解释:用 p 表示写出来的字符串。
+一开始,p="" ,s="zza" ,t="" 。
+执行第一个操作三次,得到 p="" ,s="" ,t="zza" 。
+执行第二个操作三次,得到 p="azz" ,s="" ,t="" 。
+```
+
+**示例 2:**
+
+```
+输入:s = "bac"
+输出:"abc"
+解释:用 p 表示写出来的字符串。
+执行第一个操作两次,得到 p="" ,s="c" ,t="ba" 。
+执行第二个操作两次,得到 p="ab" ,s="c" ,t="" 。
+执行第一个操作,得到 p="ab" ,s="" ,t="c" 。
+执行第二个操作,得到 p="abc" ,s="" ,t="" 。
+```
+
+**示例 3:**
+
+```
+输入:s = "bdda"
+输出:"addb"
+解释:用 p 表示写出来的字符串。
+一开始,p="" ,s="bdda" ,t="" 。
+执行第一个操作四次,得到 p="" ,s="" ,t="bdda" 。
+执行第二个操作四次,得到 p="addb" ,s="" ,t="" 。
+```
+
+
+
+**提示:**
+
+- `1 <= s.length <= 105`
+- `s` 只包含小写英文字母。
+
+## solution
+
+本题是经典贪心:求出栈序列的最小字典序。
+
+我们首先将题目描述进行转化:有一个初始为空的栈,给定字符的入栈顺序,求字典序最小的出栈序列。
+
+```python
+class Solution:
+ def robotWithString(self, s: str) -> str:
+ stack = []
+ import collections
+ counter = collections.Counter(s)
+ ans = []
+ '''
+ 栈模拟, 栈顶是最小的就弹出,否则就继续入栈等有更小的弹出
+ '''
+ for c in s:
+ # 判断后面是否还有比它小的
+ counter[c] -= 1
+ minc = c
+ for x in string.ascii_lowercase:
+ if counter[x] > 0:
+ minc = x
+ break
+ # print(c, minc)
+ stack.append(c)
+ while stack and stack[-1] <= minc:
+ ans.append(stack.pop())
+ return "".join(ans + stack[::-1])
+
+
+class Solution:
+ def robotWithString(self, s: str) -> str:
+ stack = []
+ ans = []
+ minc = [None] * (len(s) + 1)
+ t = 'z'
+ for i in range(len(s) - 1, -1, -1):
+ t = min(t, s[i])
+ minc[i] = t
+ minc[-1] = chr(ord('z') + 1)
+ '''
+ 栈模拟, 栈顶是最小的就弹出,否则就继续入栈等有更小的弹出
+ '''
+ for i, c in enumerate(s):
+ # 判断后面是否还有比它小的
+ stack.append(c)
+ while stack and stack[-1] <= minc[i + 1]:
+ ans.append(stack.pop())
+ return "".join(ans + stack)
+
+
+if __name__ == '__main__':
+ f = Solution().robotWithString
+ print("actual:", f("caba"), "should:", None)
+ print("actual:", f("bac"), "should:", None)
+ print("actual:", f("bdda"), "should:", None)
+```
+
diff --git "a/_posts/Algorithms/leetcode/2022-10-16-6207. \347\273\237\350\256\241\345\256\232\347\225\214\345\255\220\346\225\260\347\273\204\347\232\204\346\225\260\347\233\256.md" "b/_posts/Algorithms/leetcode/2022-10-16-6207. \347\273\237\350\256\241\345\256\232\347\225\214\345\255\220\346\225\260\347\273\204\347\232\204\346\225\260\347\233\256.md"
new file mode 100644
index 0000000000..3b8f7268b5
--- /dev/null
+++ "b/_posts/Algorithms/leetcode/2022-10-16-6207. \347\273\237\350\256\241\345\256\232\347\225\214\345\255\220\346\225\260\347\273\204\347\232\204\346\225\260\347\233\256.md"
@@ -0,0 +1,71 @@
+---
+layout: post
+category: leetcode
+title: 6207. 统计定界子数组的数目
+tags: leetcode
+---
+
+## title
+[problem link](https://leetcode.cn/problems/count-subarrays-with-fixed-bounds/)
+
+给你一个整数数组 `nums` 和两个整数 `minK` 以及 `maxK` 。
+
+`nums` 的定界子数组是满足下述条件的一个子数组:
+
+- 子数组中的 **最小值** 等于 `minK` 。
+- 子数组中的 **最大值** 等于 `maxK` 。
+
+返回定界子数组的数目。
+
+子数组是数组中的一个连续部分。
+
+
+
+**示例 1:**
+
+```
+输入:nums = [1,3,5,2,7,5], minK = 1, maxK = 5
+输出:2
+解释:定界子数组是 [1,3,5] 和 [1,3,5,2] 。
+```
+
+**示例 2:**
+
+```
+输入:nums = [1,1,1,1], minK = 1, maxK = 1
+输出:10
+解释:nums 的每个子数组都是一个定界子数组。共有 10 个子数组。
+```
+
+
+
+**提示:**
+
+- `2 <= nums.length <= 105`
+- `1 <= nums[i], minK, maxK <= 106`
+
+## solution
+
+双指针
+
+```python
+class Solution:
+ def countSubarrays(self, nums: List[int], minK: int, maxK: int) -> int:
+ left = -1
+ minI, maxI = -1, -1
+ ans = 0
+ for i, v in enumerate(nums):
+ if v < minK or v > maxK:
+ # 清空窗口
+ left = i
+ minI = maxI = -1
+ continue
+ if v == minK:
+ minI = i
+ if v == maxK:
+ maxI = i
+ if maxI != -1 and minI != -1:
+ ans += min(minI, maxI) - left
+ return ans
+```
+
diff --git "a/_posts/Algorithms/leetcode/2022-10-16-6211. \345\210\233\345\273\272\344\273\267\345\200\274\347\233\270\345\220\214\347\232\204\350\277\236\351\200\232\345\235\227.md" "b/_posts/Algorithms/leetcode/2022-10-16-6211. \345\210\233\345\273\272\344\273\267\345\200\274\347\233\270\345\220\214\347\232\204\350\277\236\351\200\232\345\235\227.md"
new file mode 100644
index 0000000000..e733848d31
--- /dev/null
+++ "b/_posts/Algorithms/leetcode/2022-10-16-6211. \345\210\233\345\273\272\344\273\267\345\200\274\347\233\270\345\220\214\347\232\204\350\277\236\351\200\232\345\235\227.md"
@@ -0,0 +1,90 @@
+---
+layout: post
+category: leetcode
+title: 6211. 创建价值相同的连通块
+tags: leetcode
+---
+
+## title
+[problem link](https://leetcode.cn/problems/create-components-with-same-value/)
+
+有一棵 `n` 个节点的无向树,节点编号为 `0` 到 `n - 1` 。
+
+给你一个长度为 `n` 下标从 **0** 开始的整数数组 `nums` ,其中 `nums[i]` 表示第 `i` 个节点的值。同时给你一个长度为 `n - 1` 的二维整数数组 `edges` ,其中 `edges[i] = [ai, bi]` 表示节点 `ai` 与 `bi` 之间有一条边。
+
+你可以 **删除** 一些边,将这棵树分成几个连通块。一个连通块的 **价值** 定义为这个连通块中 **所有** 节点 `i` 对应的 `nums[i]` 之和。
+
+你需要删除一些边,删除后得到的各个连通块的价值都相等。请返回你可以删除的边数 **最多** 为多少。
+
+
+
+**示例 1:**
+
+
+
+```
+输入:nums = [6,2,2,2,6], edges = [[0,1],[1,2],[1,3],[3,4]]
+输出:2
+解释:上图展示了我们可以删除边 [0,1] 和 [3,4] 。得到的连通块为 [0] ,[1,2,3] 和 [4] 。每个连通块的价值都为 6 。可以证明没有别的更好的删除方案存在了,所以答案为 2 。
+```
+
+**示例 2:**
+
+```
+输入:nums = [2], edges = []
+输出:0
+解释:没有任何边可以删除。
+```
+
+
+
+**提示:**
+
+- `1 <= n <= 2 * 104`
+- `nums.length == n`
+- `1 <= nums[i] <= 50`
+- `edges.length == n - 1`
+- `edges[i].length == 2`
+- `0 <= edges[i][0], edges[i][1] <= n - 1`
+- `edges` 表示一棵合法的树。
+
+## solution
+
+[参考](https://leetcode.cn/problems/create-components-with-same-value/solution/by-endlesscheng-u03q/)
+
+```python
+class Solution:
+ def componentValue(self, nums: List[int], edges: List[List[int]]) -> int:
+ n = len(nums)
+ import collections
+ graph = collections.defaultdict(list)
+ for u, v in edges:
+ graph[u].append(v)
+ graph[v].append(u)
+ total = sum(nums)
+ target = 0
+
+ # return the sum of subtree mod target
+ def dfs(u, fa=-1):
+ cur = nums[u]
+ for v in graph[u]:
+ if v == fa: continue
+ t = dfs(v, u)
+ if t == -1:
+ return -1
+ cur += t
+ if cur == target:
+ return 0
+ elif cur > target:
+ return -1
+ return cur
+
+ for k in range(min(n, total // max(nums)), 1, -1):
+ if total % k == 0:
+ target = total // k
+ if dfs(0, -1) == 0:
+ return k - 1
+ return 0
+
+```
+
diff --git "a/_posts/Algorithms/leetcode/2022-10-23-407. \346\216\245\351\233\250\346\260\264 II.md" "b/_posts/Algorithms/leetcode/2022-10-23-407. \346\216\245\351\233\250\346\260\264 II.md"
new file mode 100644
index 0000000000..74c45a99b1
--- /dev/null
+++ "b/_posts/Algorithms/leetcode/2022-10-23-407. \346\216\245\351\233\250\346\260\264 II.md"
@@ -0,0 +1,83 @@
+---
+layout: post
+category: leetcode
+title: 407. 接雨水 II
+tags: leetcode
+---
+
+## title
+[problem link](https://leetcode.cn/problems/trapping-rain-water-ii/)
+
+给你一个 `m x n` 的矩阵,其中的值均为非负整数,代表二维高度图每个单元的高度,请计算图中形状最多能接多少体积的雨水。
+
+
+
+**示例 1:**
+
+
+
+```
+输入: heightMap = [[1,4,3,1,3,2],[3,2,1,3,2,4],[2,3,3,2,3,1]]
+输出: 4
+解释: 下雨后,雨水将会被上图蓝色的方块中。总的接雨水量为1+2+1=4。
+```
+
+**示例 2:**
+
+
+
+```
+输入: heightMap = [[3,3,3,3,3],[3,2,2,2,3],[3,2,1,2,3],[3,2,2,2,3],[3,3,3,3,3]]
+输出: 10
+```
+
+
+
+**提示:**
+
+- `m == heightMap.length`
+- `n == heightMap[i].length`
+- `1 <= m, n <= 200`
+- `0 <= heightMap[i][j] <= 2 * 104`
+
+
+
+## solution
+
+[参考](https://leetcode.cn/problems/trapping-rain-water-ii/solution/gong-shui-san-xie-jing-dian-dijkstra-yun-13ik/)
+
+Dijkstra. 从外向内扩展,路径定义为water高度。
+
+```python
+class Directions:
+ dirs = [(0, 1), (0, -1), (1, 0), (-1, 0)]
+ diagonal_dirs = [(1, 1), (1, -1), (-1, 1), (-1, -1)]
+ all_dirs = dirs + diagonal_dirs
+
+class Solution:
+ def trapRainWater(self, heightMap: List[List[int]]) -> int:
+ m, n = len(heightMap), len(heightMap[0])
+ h = []
+ import heapq
+ dist = {}
+ for i in range(m):
+ heapq.heappush(h, (heightMap[i][0], i, 0))
+ heapq.heappush(h, (heightMap[i][n - 1], i, n - 1))
+ for j in range(1, n - 1):
+ heapq.heappush(h, (heightMap[0][j], 0, j))
+ heapq.heappush(h, (heightMap[m - 1][j], m - 1, j))
+ ans = 0
+ while h:
+ ph, x, y = heapq.heappop(h)
+ if (x, y) in dist: continue
+ dist[(x, y)] = max(heightMap[x][y], ph)
+ if ph > heightMap[x][y]:
+ ans += ph - heightMap[x][y]
+ for dx, dy in Directions.dirs:
+ nx, ny = x + dx, y + dy
+ if 0 <= nx < m and 0 <= ny < n and (nx, ny) not in dist:
+ heapq.heappush(h, (dist[(x, y)], nx, ny))
+ # print(dist)
+ return ans
+```
+
diff --git "a/_posts/Algorithms/leetcode/2022-10-23-6216. \344\275\277\346\225\260\347\273\204\347\233\270\347\255\211\347\232\204\346\234\200\345\260\217\345\274\200\351\224\200.md" "b/_posts/Algorithms/leetcode/2022-10-23-6216. \344\275\277\346\225\260\347\273\204\347\233\270\347\255\211\347\232\204\346\234\200\345\260\217\345\274\200\351\224\200.md"
new file mode 100644
index 0000000000..140d0c7964
--- /dev/null
+++ "b/_posts/Algorithms/leetcode/2022-10-23-6216. \344\275\277\346\225\260\347\273\204\347\233\270\347\255\211\347\232\204\346\234\200\345\260\217\345\274\200\351\224\200.md"
@@ -0,0 +1,75 @@
+---
+layout: post
+category: leetcode
+title: 6216. 使数组相等的最小开销
+tags: leetcode
+---
+
+## title
+[problem link](https://leetcode.cn/problems/minimum-cost-to-make-array-equal/)
+
+给你两个下标从 **0** 开始的数组 `nums` 和 `cost` ,分别包含 `n` 个 **正** 整数。
+
+你可以执行下面操作 **任意** 次:
+
+- 将 `nums` 中 **任意** 元素增加或者减小 `1` 。
+
+对第 `i` 个元素执行一次操作的开销是 `cost[i]` 。
+
+请你返回使 `nums` 中所有元素 **相等** 的 **最少** 总开销。
+
+
+
+**示例 1:**
+
+```
+输入:nums = [1,3,5,2], cost = [2,3,1,14]
+输出:8
+解释:我们可以执行以下操作使所有元素变为 2 :
+- 增加第 0 个元素 1 次,开销为 2 。
+- 减小第 1 个元素 1 次,开销为 3 。
+- 减小第 2 个元素 3 次,开销为 1 + 1 + 1 = 3 。
+总开销为 2 + 3 + 3 = 8 。
+这是最小开销。
+```
+
+**示例 2:**
+
+```
+输入:nums = [2,2,2,2,2], cost = [4,2,8,1,3]
+输出:0
+解释:数组中所有元素已经全部相等,不需要执行额外的操作。
+```
+
+
+
+**提示:**
+
+- `n == nums.length == cost.length`
+- `1 <= n <= 105`
+- `1 <= nums[i], cost[i] <= 106`
+
+## solution
+
+[参考](https://leetcode.cn/circle/discuss/uO4WuN/)
+
+
+
+```python
+class Solution:
+ def minCost(self, nums: List[int], cost: List[int]) -> int:
+ d = list(zip(nums, cost))
+ d = sorted(d)
+ mid = None
+ count = 0
+ total = sum(cost)
+ for a, b in d:
+ count += b
+ if count >= total // 2:
+ mid = a
+ break
+ return sum(abs(a - mid) * c for a, c in d)
+
+
+```
+
diff --git "a/_posts/Algorithms/leetcode/2022-10-23-6217. \344\275\277\346\225\260\347\273\204\347\233\270\344\274\274\347\232\204\346\234\200\345\260\221\346\223\215\344\275\234\346\254\241\346\225\260.md" "b/_posts/Algorithms/leetcode/2022-10-23-6217. \344\275\277\346\225\260\347\273\204\347\233\270\344\274\274\347\232\204\346\234\200\345\260\221\346\223\215\344\275\234\346\254\241\346\225\260.md"
new file mode 100644
index 0000000000..1370155333
--- /dev/null
+++ "b/_posts/Algorithms/leetcode/2022-10-23-6217. \344\275\277\346\225\260\347\273\204\347\233\270\344\274\274\347\232\204\346\234\200\345\260\221\346\223\215\344\275\234\346\254\241\346\225\260.md"
@@ -0,0 +1,103 @@
+---
+layout: post
+category: leetcode
+title: 6217. 使数组相似的最少操作次数
+tags: leetcode
+---
+
+## title
+[problem link](https://leetcode.cn/problems/minimum-number-of-operations-to-make-arrays-similar/)
+
+给你两个正整数数组 `nums` 和 `target` ,两个数组长度相等。
+
+在一次操作中,你可以选择两个 **不同** 的下标 `i` 和 `j` ,其中 `0 <= i, j < nums.length` ,并且:
+
+- 令 `nums[i] = nums[i] + 2` 且
+- 令 `nums[j] = nums[j] - 2` 。
+
+如果两个数组中每个元素出现的频率相等,我们称两个数组是 **相似** 的。
+
+请你返回将 `nums` 变得与 `target` 相似的最少操作次数。测试数据保证 `nums` 一定能变得与 `target` 相似。
+
+
+
+**示例 1:**
+
+```
+输入:nums = [8,12,6], target = [2,14,10]
+输出:2
+解释:可以用两步操作将 nums 变得与 target 相似:
+- 选择 i = 0 和 j = 2 ,nums = [10,12,4] 。
+- 选择 i = 1 和 j = 2 ,nums = [10,14,2] 。
+2 次操作是最少需要的操作次数。
+```
+
+**示例 2:**
+
+```
+输入:nums = [1,2,5], target = [4,1,3]
+输出:1
+解释:一步操作可以使 nums 变得与 target 相似:
+- 选择 i = 1 和 j = 2 ,nums = [1,4,3] 。
+```
+
+**示例 3:**
+
+```
+输入:nums = [1,1,1,1,1], target = [1,1,1,1,1]
+输出:0
+解释:数组 nums 已经与 target 相似。
+```
+
+
+
+**提示:**
+
+- `n == nums.length == target.length`
+- `1 <= n <= 105`
+- `1 <= nums[i], target[i] <= 106`
+- `nums` 一定可以变得与 `target` 相似。
+
+## solution
+
+[参考](https://leetcode.cn/problems/minimum-number-of-operations-to-make-arrays-similar/solution/by-endlesscheng-lusx/)
+
+
+
+```python
+class Solution:
+ def makeSimilar(self, nums: List[int], target: List[int]) -> int:
+ nums = sorted(nums, key=lambda x: (x % 2, x))
+ target = sorted(target, key=lambda x: (x % 2, x))
+ ans = 0
+ for i in range(len(nums)):
+ ans += abs(nums[i] - target[i])
+ return ans // 4
+
+
+class Solution:
+ def makeSimilar(self, nums: List[int], target: List[int]) -> int:
+ nums = sorted(nums)
+ target = sorted(target)
+ a = []
+ b = []
+ for v in nums:
+ if v % 2 == 1:
+ a.append(v)
+ else:
+ b.append(v)
+ c = []
+ d = []
+ for v in target:
+ if v % 2 == 1:
+ c.append(v)
+ else:
+ d.append(v)
+ ans = 0
+ for i in range(len(a)):
+ ans += abs(a[i] - c[i]) // 2
+ for i in range(len(b)):
+ ans += abs(b[i] - d[i]) // 2
+ return ans // 2
+```
+
diff --git "a/_posts/Algorithms/leetcode/2022-10-24-915. \345\210\206\345\211\262\346\225\260\347\273\204.md" "b/_posts/Algorithms/leetcode/2022-10-24-915. \345\210\206\345\211\262\346\225\260\347\273\204.md"
new file mode 100644
index 0000000000..e6de0d5396
--- /dev/null
+++ "b/_posts/Algorithms/leetcode/2022-10-24-915. \345\210\206\345\211\262\346\225\260\347\273\204.md"
@@ -0,0 +1,66 @@
+---
+layout: post
+category: leetcode
+title: 915. 分割数组
+tags: leetcode
+---
+
+## title
+[problem link](https://leetcode.cn/problems/partition-array-into-disjoint-intervals/)
+
+给定一个数组 `nums` ,将其划分为两个连续子数组 `left` 和 `right`, 使得:
+
+- `left` 中的每个元素都小于或等于 `right` 中的每个元素。
+- `left` 和 `right` 都是非空的。
+- `left` 的长度要尽可能小。
+
+*在完成这样的分组后返回 `left` 的 **长度*** 。
+
+用例可以保证存在这样的划分方法。
+
+
+
+**示例 1:**
+
+```
+输入:nums = [5,0,3,8,6]
+输出:3
+解释:left = [5,0,3],right = [8,6]
+```
+
+**示例 2:**
+
+```
+输入:nums = [1,1,1,0,6,12]
+输出:4
+解释:left = [1,1,1,0],right = [6,12]
+```
+
+
+
+**提示:**
+
+- `2 <= nums.length <= 105`
+- `0 <= nums[i] <= 106`
+- 可以保证至少有一种方法能够按题目所描述的那样对 `nums` 进行划分。
+
+## solution
+
+下面为一次遍历,使用后悔法。
+
+```python
+class Solution:
+ def partitionDisjoint(self, nums: List[int]) -> int:
+ n = len(nums)
+ leftpos = 0
+ leftmax = nums[0]
+ currentmax = nums[0]
+ for i,v in enumerate(nums):
+ currentmax = max(currentmax, v)
+ if v < leftmax:
+ leftpos = i
+ leftmax = currentmax
+ return leftpos + 1
+
+```
+
diff --git "a/_posts/Algorithms/leetcode/2022-10-29-862. \345\222\214\350\207\263\345\260\221\344\270\272 K \347\232\204\346\234\200\347\237\255\345\255\220\346\225\260\347\273\204.md" "b/_posts/Algorithms/leetcode/2022-10-29-862. \345\222\214\350\207\263\345\260\221\344\270\272 K \347\232\204\346\234\200\347\237\255\345\255\220\346\225\260\347\273\204.md"
new file mode 100644
index 0000000000..6b83df161c
--- /dev/null
+++ "b/_posts/Algorithms/leetcode/2022-10-29-862. \345\222\214\350\207\263\345\260\221\344\270\272 K \347\232\204\346\234\200\347\237\255\345\255\220\346\225\260\347\273\204.md"
@@ -0,0 +1,120 @@
+---
+layout: post
+category: leetcode
+title: 862. 和至少为 K 的最短子数组
+tags: leetcode
+---
+
+## title
+[problem link](https://leetcode.cn/problems/shortest-subarray-with-sum-at-least-k/)
+
+给你一个整数数组 `nums` 和一个整数 `k` ,找出 `nums` 中和至少为 `k` 的 **最短非空子数组** ,并返回该子数组的长度。如果不存在这样的 **子数组** ,返回 `-1` 。
+
+**子数组** 是数组中 **连续** 的一部分。
+
+
+
+
+
+**示例 1:**
+
+```
+输入:nums = [1], k = 1
+输出:1
+```
+
+**示例 2:**
+
+```
+输入:nums = [1,2], k = 4
+输出:-1
+```
+
+**示例 3:**
+
+```
+输入:nums = [2,-1,2], k = 3
+输出:3
+```
+
+
+
+**提示:**
+
+- `1 <= nums.length <= 105`
+- `-105 <= nums[i] <= 105`
+- `1 <= k <= 109`
+
+## solution
+
+单调队列
+
+```python
+'''
+主要是去除无用数据,维护右端点
+可以单调栈二分,也可以单调队列
+参考: https://leetcode.cn/problems/shortest-subarray-with-sum-at-least-k/solution/liang-zhang-tu-miao-dong-dan-diao-dui-li-9fvh/
+'''
+
+class Solution:
+ def shortestSubarray(self, nums: List[int], k: int) -> int:
+ ans = float('inf')
+ n = len(nums)
+ pre = [0]
+ for v in nums:
+ pre.append(pre[-1] + v)
+ import collections
+ q = collections.deque()
+ # 单调队列,j< i, 向右, 如果s[i] - s[j] >= k, j则不会再作为可作为答案的左端点了; 递增队列 对于s[j] >= s[i], 则j也可以舍弃
+ for i, v in enumerate(pre):
+ while q and pre[q[-1]] >= v:
+ q.pop()
+ q.append(i)
+ while q and v - pre[q[0]] >= k:
+ ans = min(ans, i - q[0])
+ q.popleft()
+ return ans if ans != float('inf') else -1
+
+
+```
+
+
+
+```python
+# 单调栈 + 二分
+class BinarySearch:
+ # If you wanna binary search big integer, plz set data range, which can be used as same as big integer low and high
+ # find the first index that value >= val
+ def bisect_left(data, val, l=None, r=None, key=None):
+ if l is None or r is None:
+ l, r = 0, len(data) - 1
+ if key is None:
+ key = lambda x: data[mid]
+ while l <= r:
+ mid = (l + r) // 2
+ if key(mid) >= val:
+ r = mid - 1
+ else:
+ l = mid + 1
+ return l
+
+class Solution:
+ def shortestSubarray(self, nums: List[int], k: int) -> int:
+ ans = float('inf')
+ pre = [0]
+ for v in nums:
+ pre.append(pre[-1] + v)
+ # print(pre)
+ q = []
+ # 单调递增栈, 栈上二分
+ for i, v in enumerate(pre):
+ while q and pre[q[-1]] >= v:
+ q.pop()
+ q.append(i)
+ t = BinarySearch.bisect_left(q, True, key=lambda x: v - pre[q[x]] < k)
+ if t - 1 >= 0:
+ ans = min(ans, i - q[t - 1])
+ return ans if ans != float('inf') else -1
+
+```
+
diff --git "a/_posts/Algorithms/leetcode/2022-11-04-1674. \344\275\277\346\225\260\347\273\204\344\272\222\350\241\245\347\232\204\346\234\200\345\260\221\346\223\215\344\275\234\346\254\241\346\225\260.md" "b/_posts/Algorithms/leetcode/2022-11-04-1674. \344\275\277\346\225\260\347\273\204\344\272\222\350\241\245\347\232\204\346\234\200\345\260\221\346\223\215\344\275\234\346\254\241\346\225\260.md"
new file mode 100644
index 0000000000..2d9cf05345
--- /dev/null
+++ "b/_posts/Algorithms/leetcode/2022-11-04-1674. \344\275\277\346\225\260\347\273\204\344\272\222\350\241\245\347\232\204\346\234\200\345\260\221\346\223\215\344\275\234\346\254\241\346\225\260.md"
@@ -0,0 +1,106 @@
+---
+layout: post
+category: leetcode
+title: 1674. 使数组互补的最少操作次数
+tags: leetcode
+---
+
+## title
+[problem link](https://leetcode.cn/problems/minimum-moves-to-make-array-complementary/)
+
+给你一个长度为 **偶数** `n` 的整数数组 `nums` 和一个整数 `limit` 。每一次操作,你可以将 `nums` 中的任何整数替换为 `1` 到 `limit` 之间的另一个整数。
+
+如果对于所有下标 `i`(**下标从** `0` **开始**),`nums[i] + nums[n - 1 - i]` 都等于同一个数,则数组 `nums` 是 **互补的** 。例如,数组 `[1,2,3,4]` 是互补的,因为对于所有下标 `i` ,`nums[i] + nums[n - 1 - i] = 5` 。
+
+返回使数组 **互补** 的 **最少** 操作次数。
+
+
+
+**示例 1:**
+
+```
+输入:nums = [1,2,4,3], limit = 4
+输出:1
+解释:经过 1 次操作,你可以将数组 nums 变成 [1,2,2,3](加粗元素是变更的数字):
+nums[0] + nums[3] = 1 + 3 = 4.
+nums[1] + nums[2] = 2 + 2 = 4.
+nums[2] + nums[1] = 2 + 2 = 4.
+nums[3] + nums[0] = 3 + 1 = 4.
+对于每个 i ,nums[i] + nums[n-1-i] = 4 ,所以 nums 是互补的。
+```
+
+**示例 2:**
+
+```
+输入:nums = [1,2,2,1], limit = 2
+输出:2
+解释:经过 2 次操作,你可以将数组 nums 变成 [2,2,2,2] 。你不能将任何数字变更为 3 ,因为 3 > limit 。
+```
+
+**示例 3:**
+
+```
+输入:nums = [1,2,1,2], limit = 2
+输出:0
+解释:nums 已经是互补的。
+```
+
+
+
+**提示:**
+
+- `n == nums.length`
+- `2 <= n <= 105`
+- `1 <= nums[i] <= limit <= 105`
+- `n` 是偶数。
+
+## solution
+
+假设 `res[x]` 表示的是,`nums[i] + nums[n - 1 - i]` 为 `x` 的时候,需要多少次操作。
+
+我们只需要计算出所有的 `x` 对应的 `res[x]`, 取最小值就好了。
+
+根据题意,`nums[i] + nums[n - 1 - i]` 最小是 `2`,即将两个数都修改为 `1`;最大是 `2 * limit`,即将两个数都修改成 `limit`。
+
+所以,`res[x]` 中 `x` 的取值范围是 `[2, 2 * limit]`。我们用一个 `res[2 * limit + 1]` 的数组就好。
+
+```python
+class Diff:
+ def __init__(self, n):
+ self.n = n
+ self.diff = [0] * (n + 1)
+
+ # 给[l,r] + val
+ def add(self, l, r, val):
+ self.diff[l] += val
+ self.diff[r + 1] -= val
+
+ # 差分数组还原成原数组
+ def restore(self):
+ ans = [0] * self.n
+ ans[0] = self.diff[0]
+ for i in range(1, self.n):
+ ans[i] = ans[i - 1] + self.diff[i]
+ return ans
+
+class Solution:
+ def minMoves(self, nums: List[int], limit: int) -> int:
+ diff = Diff(2 * limit + 1)
+ n = len(nums)
+ for i in range((len(nums) + 1) // 2):
+ a, b = nums[i], nums[n - 1 - i]
+ if a > b:
+ a, b = b, a
+ '''
+ 0: a+b
+ 2: [2, a+1) or (b+limit, 2*limit]
+ 1:
+ '''
+ diff.add(2, a, 2)
+ diff.add(b + limit + 1, 2 * limit, 2)
+ diff.add(a + 1, b + limit, 1)
+ diff.add(a + b, a + b, -1)
+ # print(diff.restore())
+ return min(diff.restore()[2:])
+```
+
diff --git "a/_posts/Algorithms/leetcode/2022-11-06-6232. \346\234\200\345\260\217\347\247\273\345\212\250\346\200\273\350\267\235\347\246\273.md" "b/_posts/Algorithms/leetcode/2022-11-06-6232. \346\234\200\345\260\217\347\247\273\345\212\250\346\200\273\350\267\235\347\246\273.md"
new file mode 100644
index 0000000000..ddaa802f80
--- /dev/null
+++ "b/_posts/Algorithms/leetcode/2022-11-06-6232. \346\234\200\345\260\217\347\247\273\345\212\250\346\200\273\350\267\235\347\246\273.md"
@@ -0,0 +1,102 @@
+---
+layout: post
+category: leetcode
+title: 6232. 最小移动总距离
+tags: leetcode
+---
+
+## title
+[problem link](https://leetcode.cn/problems/minimum-total-distance-traveled/)
+
+X 轴上有一些机器人和工厂。给你一个整数数组 `robot` ,其中 `robot[i]` 是第 `i` 个机器人的位置。再给你一个二维整数数组 `factory` ,其中 `factory[j] = [positionj, limitj]` ,表示第 `j` 个工厂的位置在 `positionj` ,且第 `j` 个工厂最多可以修理 `limitj` 个机器人。
+
+每个机器人所在的位置 **互不相同** 。每个工厂所在的位置也 **互不相同** 。注意一个机器人可能一开始跟一个工厂在 **相同的位置** 。
+
+所有机器人一开始都是坏的,他们会沿着设定的方向一直移动。设定的方向要么是 X 轴的正方向,要么是 X 轴的负方向。当一个机器人经过一个没达到上限的工厂时,这个工厂会维修这个机器人,且机器人停止移动。
+
+**任何时刻**,你都可以设置 **部分** 机器人的移动方向。你的目标是最小化所有机器人总的移动距离。
+
+请你返回所有机器人移动的最小总距离。测试数据保证所有机器人都可以被维修。
+
+**注意:**
+
+- 所有机器人移动速度相同。
+- 如果两个机器人移动方向相同,它们永远不会碰撞。
+- 如果两个机器人迎面相遇,它们也不会碰撞,它们彼此之间会擦肩而过。
+- 如果一个机器人经过了一个已经达到上限的工厂,机器人会当作工厂不存在,继续移动。
+- 机器人从位置 `x` 到位置 `y` 的移动距离为 `|y - x|` 。
+
+
+
+**示例 1:**
+
+
+
+```
+输入:robot = [0,4,6], factory = [[2,2],[6,2]]
+输出:4
+解释:如上图所示:
+- 第一个机器人从位置 0 沿着正方向移动,在第一个工厂处维修。
+- 第二个机器人从位置 4 沿着负方向移动,在第一个工厂处维修。
+- 第三个机器人在位置 6 被第二个工厂维修,它不需要移动。
+第一个工厂的维修上限是 2 ,它维修了 2 个机器人。
+第二个工厂的维修上限是 2 ,它维修了 1 个机器人。
+总移动距离是 |2 - 0| + |2 - 4| + |6 - 6| = 4 。没有办法得到比 4 更少的总移动距离。
+```
+
+**示例 2:**
+
+
+
+```
+输入:robot = [1,-1], factory = [[-2,1],[2,1]]
+输出:2
+解释:如上图所示:
+- 第一个机器人从位置 1 沿着正方向移动,在第二个工厂处维修。
+- 第二个机器人在位置 -1 沿着负方向移动,在第一个工厂处维修。
+第一个工厂的维修上限是 1 ,它维修了 1 个机器人。
+第二个工厂的维修上限是 1 ,它维修了 1 个机器人。
+总移动距离是 |2 - 1| + |(-2) - (-1)| = 2 。没有办法得到比 2 更少的总移动距离。
+```
+
+
+
+**提示:**
+
+- `1 <= robot.length, factory.length <= 100`
+- `factory[j].length == 2`
+- `-109 <= robot[i], positionj <= 109`
+- `0 <= limitj <= robot.length`
+- 测试数据保证所有机器人都可以被维修。
+
+## solution
+
+动态规划 o(nnm) 一定要往局部思考,想到动态规划才行。
+
+```python
+class Solution:
+ def minimumTotalDistance(self, robot: List[int], factory: List[List[int]]) -> int:
+ robot = sorted(robot)
+ factory = sorted(factory)
+ n = len(robot)
+
+ def f(i, j):
+ if j == 0 and i == 0:
+ return 0
+ if j == 0 or i == 0:
+ return float('inf')
+ res = float('inf')
+ cost = 0
+ for k in range(0, factory[j - 1][1] + 1):
+ if i - k < 0: break
+ if k > 0:
+ cost += abs(factory[j - 1][0] - robot[i - k])
+ # print(i, j, k, cost)
+ res = min(res, f(i - k, j - 1) + cost)
+ # print(i, j, res)
+ return res
+
+ ans = f(n, len(factory))
+ return ans
+```
+
diff --git "a/_posts/Algorithms/leetcode/2022-12-04-6256. \345\260\206\350\212\202\347\202\271\345\210\206\346\210\220\345\260\275\345\217\257\350\203\275\345\244\232\347\232\204\347\273\204.md" "b/_posts/Algorithms/leetcode/2022-12-04-6256. \345\260\206\350\212\202\347\202\271\345\210\206\346\210\220\345\260\275\345\217\257\350\203\275\345\244\232\347\232\204\347\273\204.md"
new file mode 100644
index 0000000000..a381b04ca4
--- /dev/null
+++ "b/_posts/Algorithms/leetcode/2022-12-04-6256. \345\260\206\350\212\202\347\202\271\345\210\206\346\210\220\345\260\275\345\217\257\350\203\275\345\244\232\347\232\204\347\273\204.md"
@@ -0,0 +1,160 @@
+---
+layout: post
+category: leetcode
+title: 6256. 将节点分成尽可能多的组
+tags: leetcode
+---
+
+## title
+[problem link](https://leetcode.cn/problems/divide-nodes-into-the-maximum-number-of-groups/)
+
+给你一个正整数 `n` ,表示一个 **无向** 图中的节点数目,节点编号从 `1` 到 `n` 。
+
+同时给你一个二维整数数组 `edges` ,其中 `edges[i] = [ai, bi]` 表示节点 `ai` 和 `bi` 之间有一条 **双向** 边。注意给定的图可能是不连通的。
+
+请你将图划分为 `m` 个组(编号从 **1** 开始),满足以下要求:
+
+- 图中每个节点都只属于一个组。
+- 图中每条边连接的两个点 `[ai, bi]` ,如果 `ai` 属于编号为 `x` 的组,`bi` 属于编号为 `y` 的组,那么 `|y - x| = 1` 。
+
+请你返回最多可以将节点分为多少个组(也就是最大的 `m` )。如果没办法在给定条件下分组,请你返回 `-1` 。
+
+
+
+**示例 1:**
+
+
+
+```
+输入:n = 6, edges = [[1,2],[1,4],[1,5],[2,6],[2,3],[4,6]]
+输出:4
+解释:如上图所示,
+- 节点 5 在第一个组。
+- 节点 1 在第二个组。
+- 节点 2 和节点 4 在第三个组。
+- 节点 3 和节点 6 在第四个组。
+所有边都满足题目要求。
+如果我们创建第五个组,将第三个组或者第四个组中任何一个节点放到第五个组,至少有一条边连接的两个节点所属的组编号不符合题目要求。
+```
+
+**示例 2:**
+
+```
+输入:n = 3, edges = [[1,2],[2,3],[3,1]]
+输出:-1
+解释:如果我们将节点 1 放入第一个组,节点 2 放入第二个组,节点 3 放入第三个组,前两条边满足题目要求,但第三条边不满足题目要求。
+没有任何符合题目要求的分组方式。
+```
+
+
+
+**提示:**
+
+- `1 <= n <= 500`
+- `1 <= edges.length <= 104`
+- `edges[i].length == 2`
+- `1 <= ai, bi <= n`
+- `ai != bi`
+- 两个点之间至多只有一条边。
+
+## solution
+
+```
+二分图才可以分组 / 也可以通过bfs后,比较和start点距离判断,a<->b, 则dis[a]!=dis[b]才可以分组
+```
+
+```python
+
+class Graph:
+ def bfs(graph, start):
+ '''
+ :param graph: collection.defaultdict(list)
+ :param start: start point
+ :return:
+ '''
+ q = collections.deque()
+ q.append(start)
+ visit = set()
+ visit.add(start)
+ level = 0
+ while len(q):
+ level += 1
+ for _ in range(len(q)):
+ u = q.popleft()
+ for v in graph[u]:
+ if v not in visit:
+ visit.add(v)
+ q.append(v)
+ return visit, level
+ '''
+ 划分连同分量, 返回每个联通分量的点list,可以多个联通分量
+ '''
+ def groups(self, points, graph) -> List[List[int]]:
+ groups = []
+ total_visit = set()
+ for i in points:
+ visit = set()
+ def dfs(u):
+ nonlocal visit
+ visit.add(u)
+ for v in graph[u]:
+ if v not in visit:
+ dfs(v)
+
+ if i not in total_visit:
+ dfs(i)
+ if visit:
+ for l in visit:
+ total_visit.add(l)
+ groups.append(list(visit))
+ return groups
+
+ # 判断是否是二分图,input可以是多个子连通图。graph: 链接表
+ def isBipartite(self, graph) -> bool:
+ ans = True
+ color = collections.defaultdict(int)
+ n = len(graph)
+
+ def dfs(i):
+ nonlocal ans
+ if not ans:
+ return
+ if color[i] == 0:
+ color[i] = 1
+ cur = color[i]
+ for neighbor in graph[i]:
+ if color[neighbor] == cur:
+ ans = False
+ break
+ if color[neighbor] == 0:
+ color[neighbor] = 2 if cur == 1 else 1
+ dfs(neighbor)
+
+ for i in range(n):
+ if color[i] == 0:
+ dfs(i)
+ # print(color)
+ return ans
+
+class Solution:
+ def magnificentSets(self, n: int, edges: List[List[int]]) -> int:
+ graph = collections.defaultdict(list)
+ for u, v in edges:
+ graph[u].append(v)
+ graph[v].append(u)
+ # 二分图才可以分组
+ if not Graph().isBipartite(graph):
+ return -1
+ # 划分联通分量
+ groups = Graph().groups(range(1, n + 1), graph)
+ ans = 0
+ for group in groups:
+ t = 0
+ # 对联通分量的每个节点用bfs求最大长度
+ for i in group:
+ t = max(t, Graph.bfs(graph, i)[1])
+ ans += t
+ return ans
+
+```
+
diff --git "a/_posts/Algorithms/leetcode/2022-12-25-6270. \346\257\217\347\247\215\345\255\227\347\254\246\350\207\263\345\260\221\345\217\226 K \344\270\252.md" "b/_posts/Algorithms/leetcode/2022-12-25-6270. \346\257\217\347\247\215\345\255\227\347\254\246\350\207\263\345\260\221\345\217\226 K \344\270\252.md"
new file mode 100644
index 0000000000..adcaed6940
--- /dev/null
+++ "b/_posts/Algorithms/leetcode/2022-12-25-6270. \346\257\217\347\247\215\345\255\227\347\254\246\350\207\263\345\260\221\345\217\226 K \344\270\252.md"
@@ -0,0 +1,76 @@
+---
+layout: post
+category: leetcode
+title: 6270. 每种字符至少取 K 个
+tags: leetcode
+---
+
+## title
+[problem link](https://leetcode.cn/problems/take-k-of-each-character-from-left-and-right/)
+
+给你一个由字符 `'a'`、`'b'`、`'c'` 组成的字符串 `s` 和一个非负整数 `k` 。每分钟,你可以选择取走 `s` **最左侧** 还是 **最右侧** 的那个字符。
+
+你必须取走每种字符 **至少** `k` 个,返回需要的 **最少** 分钟数;如果无法取到,则返回 `-1` 。
+
+
+
+**示例 1:**
+
+```
+输入:s = "aabaaaacaabc", k = 2
+输出:8
+解释:
+从 s 的左侧取三个字符,现在共取到两个字符 'a' 、一个字符 'b' 。
+从 s 的右侧取五个字符,现在共取到四个字符 'a' 、两个字符 'b' 和两个字符 'c' 。
+共需要 3 + 5 = 8 分钟。
+可以证明需要的最少分钟数是 8 。
+```
+
+**示例 2:**
+
+```
+输入:s = "a", k = 1
+输出:-1
+解释:无法取到一个字符 'b' 或者 'c',所以返回 -1 。
+```
+
+
+
+**提示:**
+
+- `1 <= s.length <= 105`
+- `s` 仅由字母 `'a'`、`'b'`、`'c'` 组成
+- `0 <= k <= s.length`
+
+## solution
+
+双指针。
+
+```python
+class Solution:
+ def takeCharacters(self, s: str, k: int) -> int:
+ cnt = collections.Counter()
+
+ def check(cnt):
+ for c in "abc":
+ if cnt[c] < k:
+ return False
+ return True
+
+ n = len(s)
+ r = n
+ while not check(cnt):
+ r -= 1
+ if r < 0:
+ return -1
+ cnt[s[r]] += 1
+ ans = n - r
+ for l in range(n):
+ cnt[s[l]] += 1
+ while r < n and cnt[s[r]] > k:
+ cnt[s[r]] -= 1
+ r += 1
+ ans = min(ans, l + 1 + n - r)
+ return ans
+```
+
diff --git "a/_posts/Algorithms/leetcode/2022-12-25-6272. \345\245\275\345\210\206\345\214\272\347\232\204\346\225\260\347\233\256.md" "b/_posts/Algorithms/leetcode/2022-12-25-6272. \345\245\275\345\210\206\345\214\272\347\232\204\346\225\260\347\233\256.md"
new file mode 100644
index 0000000000..787337d55e
--- /dev/null
+++ "b/_posts/Algorithms/leetcode/2022-12-25-6272. \345\245\275\345\210\206\345\214\272\347\232\204\346\225\260\347\233\256.md"
@@ -0,0 +1,79 @@
+---
+layout: post
+category: leetcode
+title: 6272. 好分区的数目
+tags: leetcode
+---
+
+## title
+[problem link](https://leetcode.cn/problems/number-of-great-partitions/)
+
+给你一个正整数数组 `nums` 和一个整数 `k` 。
+
+**分区** 的定义是:将数组划分成两个有序的 **组** ,并满足每个元素 **恰好** 存在于 **某一个** 组中。如果分区中每个组的元素和都大于等于 `k` ,则认为分区是一个好分区。
+
+返回 **不同** 的好分区的数目。由于答案可能很大,请返回对 `109 + 7` **取余** 后的结果。
+
+如果在两个分区中,存在某个元素 `nums[i]` 被分在不同的组中,则认为这两个分区不同。
+
+
+
+**示例 1:**
+
+```
+输入:nums = [1,2,3,4], k = 4
+输出:6
+解释:好分区的情况是 ([1,2,3], [4]), ([1,3], [2,4]), ([1,4], [2,3]), ([2,3], [1,4]), ([2,4], [1,3]) 和 ([4], [1,2,3]) 。
+```
+
+**示例 2:**
+
+```
+输入:nums = [3,3,3], k = 4
+输出:0
+解释:数组中不存在好分区。
+```
+
+**示例 3:**
+
+```
+输入:nums = [6,6], k = 2
+输出:2
+解释:可以将 nums[0] 放入第一个分区或第二个分区中。
+好分区的情况是 ([6], [6]) 和 ([6], [6]) 。
+```
+
+
+
+**提示:**
+
+- `1 <= nums.length, k <= 1000`
+- `1 <= nums[i] <= 109`
+
+## solution
+
+[参考](https://leetcode.cn/problems/number-of-great-partitions/solution/ni-xiang-si-wei-01-bei-bao-fang-an-shu-p-v47x/) 考虑计算**坏分区**的数目,即第一个组或第二个组的元素和小于 k*k* 的方案数。根据对称性,我们只需要计算第一个组的元素和小于 k*k* 的方案数,然后乘 22 即可。
+
+因此原问题转换成从 \textit{nums}*nums* 中选择若干元素,使得元素和小于 k*k* 的方案数,这可以用 **01 背包**求解。
+
+```python
+MOD = int(1e9 + 7)
+INF = int(1e20)
+class Math1:
+ pass
+class Solution:
+ def countPartitions(self, nums: List[int], k: int) -> int:
+ # 统计bad数量,总数减去即可。
+ if sum(nums) < 2*k:return 0
+ n = len(nums)
+ dp = [0 for _ in range(k)]
+ dp[0] = 1
+ for i, v in enumerate(nums):
+ for t in range(k-1, 0, -1):
+ if t >= v:
+ dp[t] += dp[t - v] % MOD
+ bad = sum(dp)
+ return (pow(2, n, MOD) - bad*2 + MOD) % MOD
+
+```
+
diff --git "a/_posts/Algorithms/leetcode/2022-12-25-6276. \347\273\237\350\256\241\345\220\214\344\275\215\345\274\202\346\236\204\345\255\227\347\254\246\344\270\262\346\225\260\347\233\256.md" "b/_posts/Algorithms/leetcode/2022-12-25-6276. \347\273\237\350\256\241\345\220\214\344\275\215\345\274\202\346\236\204\345\255\227\347\254\246\344\270\262\346\225\260\347\233\256.md"
new file mode 100644
index 0000000000..6754ad5df7
--- /dev/null
+++ "b/_posts/Algorithms/leetcode/2022-12-25-6276. \347\273\237\350\256\241\345\220\214\344\275\215\345\274\202\346\236\204\345\255\227\347\254\246\344\270\262\346\225\260\347\233\256.md"
@@ -0,0 +1,125 @@
+---
+layout: post
+category: leetcode
+title: 6276. 统计同位异构字符串数目
+tags: leetcode
+---
+
+## title
+[problem link](https://leetcode.cn/problems/count-anagrams/)
+
+给你一个字符串 `s` ,它包含一个或者多个单词。单词之间用单个空格 `' '` 隔开。
+
+如果字符串 `t` 中第 `i` 个单词是 `s` 中第 `i` 个单词的一个 **排列** ,那么我们称字符串 `t` 是字符串 `s` 的同位异构字符串。
+
+- 比方说,`"acb dfe"` 是 `"abc def"` 的同位异构字符串,但是 `"def cab"` 和 `"adc bef"` 不是。
+
+请你返回 `s` 的同位异构字符串的数目,由于答案可能很大,请你将它对 `109 + 7` **取余** 后返回。
+
+
+
+**示例 1:**
+
+```
+输入:s = "too hot"
+输出:18
+解释:输入字符串的一些同位异构字符串为 "too hot" ,"oot hot" ,"oto toh" ,"too toh" 以及 "too oht" 。
+```
+
+**示例 2:**
+
+```
+输入:s = "aa"
+输出:1
+解释:输入字符串只有一个同位异构字符串。
+```
+
+
+
+**提示:**
+
+- `1 <= s.length <= 105`
+- `s` 只包含小写英文字母和空格 `' '` 。
+- 相邻单词之间由单个空格隔开。
+
+## solution
+
+方法1: 大数阶乘除法,要用费马小定理。
+
+方法2: 用comb换种思路,原来是阶乘相除,可以通过comb相乘,此时无除法。
+
+```python
+MOD = 10 ** 9 + 7
+class BigIntDivide:
+ def mod_inverse(i):
+ # 调用取模的乘幂运算, pow复杂度是log(exp)即log(MOD)
+ return pow(i, MOD - 2, MOD)
+
+ def divide_mod(a, b):
+ '''
+ 计算(a/b) % MOD, 除法变乘法,前提是b和MOD互为质数
+ '''
+ # 如果有多个b,比如a/b1/b2, 那就可以递归。a*mod_inverse(b1) % mod * mod_inverse(b2) % mod这样
+ return a * BigIntDivide.mod_inverse(b) % MOD
+
+ def divide_mods(a, b=[]):
+ '''
+ 计算a /(b1*b2*b3) % MOD等形式,前提是b和MOD互为质数
+ '''
+ r = a % MOD
+ for i, v in enumerate(b):
+ r *= BigIntDivide.mod_inverse(v)
+ r %= MOD
+ return r
+
+class Math1:
+
+ import functools
+ @functools.lru_cache(None)
+ def factorial_mod_cache(n):
+ if n == 0 or n == 1:
+ return 1
+ return Math1.factorial_mod_cache(n - 1) * n % MOD
+class Solution:
+ def countAnagrams(self, s: str) -> int:
+ d = s.split(' ')
+
+ factorial_mod = Math1.factorial_mod_cache
+
+ def calcu(x):
+ import collections
+ counter = collections.Counter(x)
+ n = len(x)
+ return BigIntDivide.divide_mods(factorial_mod(n), [factorial_mod(v) for v in counter.values()])
+
+ # print(calcu("too"))
+
+ ans = 1
+ for v in d:
+ ans *= calcu(v)
+ ans %= MOD
+ return ans % MOD
+```
+
+
+
+方法2 [参考](https://leetcode.cn/problems/count-anagrams/solution/python3pailiezuh-by-musing-clarkeeae-o2zg/)
+
+
+
+```python
+MOD = 10 ** 9 + 7
+
+
+class Solution:
+ def countAnagrams(self, s: str) -> int:
+ ans = 1
+ for word in s.split():
+ n = len(word)
+ for v in Counter(word).values():
+ ans *= comb(n, v)
+ ans %= MOD
+ n -= v
+ return ans
+```
+
diff --git "a/_posts/Algorithms/leetcode/2022-12-25-6295. \346\234\200\345\260\217\345\214\226\344\270\244\344\270\252\346\225\260\347\273\204\344\270\255\347\232\204\346\234\200\345\244\247\345\200\274.md" "b/_posts/Algorithms/leetcode/2022-12-25-6295. \346\234\200\345\260\217\345\214\226\344\270\244\344\270\252\346\225\260\347\273\204\344\270\255\347\232\204\346\234\200\345\244\247\345\200\274.md"
new file mode 100644
index 0000000000..2147956263
--- /dev/null
+++ "b/_posts/Algorithms/leetcode/2022-12-25-6295. \346\234\200\345\260\217\345\214\226\344\270\244\344\270\252\346\225\260\347\273\204\344\270\255\347\232\204\346\234\200\345\244\247\345\200\274.md"
@@ -0,0 +1,87 @@
+---
+layout: post
+category: leetcode
+title: 6295. 最小化两个数组中的最大值
+tags: leetcode
+---
+
+## title
+[problem link](https://leetcode.cn/problems/minimize-the-maximum-of-two-arrays/)
+
+给你两个数组 `arr1` 和 `arr2` ,它们一开始都是空的。你需要往它们中添加正整数,使它们满足以下条件:
+
+- `arr1` 包含 `uniqueCnt1` 个 **互不相同** 的正整数,每个整数都 **不能** 被 `divisor1` **整除** 。
+- `arr2` 包含 `uniqueCnt2` 个 **互不相同** 的正整数,每个整数都 **不能** 被 `divisor2` **整除** 。
+- `arr1` 和 `arr2` 中的元素 **互不相同** 。
+
+给你 `divisor1` ,`divisor2` ,`uniqueCnt1` 和 `uniqueCnt2` ,请你返回两个数组中 **最大元素** 的 **最小值** 。
+
+
+
+**示例 1:**
+
+```
+输入:divisor1 = 2, divisor2 = 7, uniqueCnt1 = 1, uniqueCnt2 = 3
+输出:4
+解释:
+我们可以把前 4 个自然数划分到 arr1 和 arr2 中。
+arr1 = [1] 和 arr2 = [2,3,4] 。
+可以看出两个数组都满足条件。
+最大值是 4 ,所以返回 4 。
+```
+
+**示例 2:**
+
+```
+输入:divisor1 = 3, divisor2 = 5, uniqueCnt1 = 2, uniqueCnt2 = 1
+输出:3
+解释:
+arr1 = [1,2] 和 arr2 = [3] 满足所有条件。
+最大值是 3 ,所以返回 3 。
+```
+
+**示例 3:**
+
+```
+输入:divisor1 = 2, divisor2 = 4, uniqueCnt1 = 8, uniqueCnt2 = 2
+输出:15
+解释:
+最终数组为 arr1 = [1,3,5,7,9,11,13,15] 和 arr2 = [2,6] 。
+上述方案是满足所有条件的最优解。
+```
+
+
+
+**提示:**
+
+- `2 <= divisor1, divisor2 <= 105`
+- `1 <= uniqueCnt1, uniqueCnt2 < 109`
+- `2 <= uniqueCnt1 + uniqueCnt2 <= 109`
+
+## solution
+
+二分最大元素的可行值,得到的下界即为最大值的最小值。
+
+判断过程中分为三类:保证在范围内有充足的数不是第一个数的倍数;不是第二个数的倍数;不为公倍数的数总数不少于总共要取的数。根据这三个条件即得到结果。
+
+```python
+class Math1:
+ def lcm(a, b):
+ import math
+ gcd = math.gcd(a, b)
+ return int(a * b / gcd)
+
+class Solution:
+ def minimizeSet(self, divisor1: int, divisor2: int, uniqueCnt1: int, uniqueCnt2: int) -> int:
+ lcm = Math1.lcm(divisor1, divisor2)
+
+ def can(x):
+ a = x - x // divisor1 # arr1能放的数量
+ b = x - x // divisor2 # arr2能放的数量
+ c = x // lcm # arr1和2都不能放的
+ return (a >= uniqueCnt1) and (b >= uniqueCnt2) and (x - c) >= uniqueCnt1+uniqueCnt2
+ import bisect
+ r = bisect.bisect_left(range(2*uniqueCnt1 +2*uniqueCnt2), True, key=can)
+ return r
+```
+
diff --git "a/_posts/Algorithms/leetcode/2023-01-14-1819. \345\272\217\345\210\227\344\270\255\344\270\215\345\220\214\346\234\200\345\244\247\345\205\254\347\272\246\346\225\260\347\232\204\346\225\260\347\233\256.md" "b/_posts/Algorithms/leetcode/2023-01-14-1819. \345\272\217\345\210\227\344\270\255\344\270\215\345\220\214\346\234\200\345\244\247\345\205\254\347\272\246\346\225\260\347\232\204\346\225\260\347\233\256.md"
new file mode 100644
index 0000000000..7933268bd0
--- /dev/null
+++ "b/_posts/Algorithms/leetcode/2023-01-14-1819. \345\272\217\345\210\227\344\270\255\344\270\215\345\220\214\346\234\200\345\244\247\345\205\254\347\272\246\346\225\260\347\232\204\346\225\260\347\233\256.md"
@@ -0,0 +1,94 @@
+---
+layout: post
+category: leetcode
+title: 1819. 序列中不同最大公约数的数目
+tags: leetcode
+---
+
+## title
+[problem link](https://leetcode.cn/problems/number-of-different-subsequences-gcds/)
+
+给你一个由正整数组成的数组 `nums` 。
+
+数字序列的 **最大公约数** 定义为序列中所有整数的共有约数中的最大整数。
+
+- 例如,序列 `[4,6,16]` 的最大公约数是 `2` 。
+
+数组的一个 **子序列** 本质是一个序列,可以通过删除数组中的某些元素(或者不删除)得到。
+
+- 例如,`[2,5,10]` 是 `[1,2,1,**2**,4,1,**5**,**10**]` 的一个子序列。
+
+计算并返回 `nums` 的所有 **非空** 子序列中 **不同** 最大公约数的 **数目** 。
+
+
+
+**示例 1:**
+
+
+
+```
+输入:nums = [6,10,3]
+输出:5
+解释:上图显示了所有的非空子序列与各自的最大公约数。
+不同的最大公约数为 6 、10 、3 、2 和 1 。
+```
+
+**示例 2:**
+
+```
+输入:nums = [5,15,40,5,6]
+输出:7
+```
+
+
+
+**提示:**
+
+- `1 <= nums.length <= 105`
+- `1 <= nums[i] <= 2 * 105`
+
+## solution
+
+
+
+
+
+O(nlogn) 其中遍历每个数的倍数总时间复杂度为o(nlogn) 参考调和级数。 Or this [link](https://leetcode.cn/problems/number-of-different-subsequences-gcds/solution/ji-bai-100mei-ju-gcdxun-huan-you-hua-pyt-get7/)
+
+```python
+MOD = int(1e9 + 7)
+INF = int(1e20)
+
+import sortedcontainers
+import bisect
+import heapq
+class Math1:
+ def gcd_list(self, nums):
+ import math
+ cur = nums[0]
+ for i in range(1, len(nums)):
+ cur = math.gcd(cur, nums[i])
+ return cur
+
+class Solution:
+ def countDifferentSubsequenceGCDs(self, nums: List[int]) -> int:
+ n, mx = len(nums), max(nums)
+ ans = 0
+ has = [False for _ in range(mx+1)]
+ for v in nums:
+ has[v] += 1
+ gcd_list = Math1().gcd_list
+ for i in range(1, mx + 1):
+ x = []
+ for j in range(i, mx + 1, i):
+ if has[j]:
+ x.append(j)
+ if x:
+ # print(i, x)
+ p = gcd_list(x)
+ if p == i:
+ ans += 1
+ return ans
+
+```
+
diff --git "a/_posts/Algorithms/leetcode/2023-01-28-2541. \344\275\277\346\225\260\347\273\204\344\270\255\346\211\200\346\234\211\345\205\203\347\264\240\347\233\270\347\255\211\347\232\204\346\234\200\345\260\217\346\223\215\344\275\234\346\225\260 II.md" "b/_posts/Algorithms/leetcode/2023-01-28-2541. \344\275\277\346\225\260\347\273\204\344\270\255\346\211\200\346\234\211\345\205\203\347\264\240\347\233\270\347\255\211\347\232\204\346\234\200\345\260\217\346\223\215\344\275\234\346\225\260 II.md"
new file mode 100644
index 0000000000..c440f8c3ea
--- /dev/null
+++ "b/_posts/Algorithms/leetcode/2023-01-28-2541. \344\275\277\346\225\260\347\273\204\344\270\255\346\211\200\346\234\211\345\205\203\347\264\240\347\233\270\347\255\211\347\232\204\346\234\200\345\260\217\346\223\215\344\275\234\346\225\260 II.md"
@@ -0,0 +1,76 @@
+---
+layout: post
+category: leetcode
+title: 2541. 使数组中所有元素相等的最小操作数 II
+tags: leetcode
+---
+
+## title
+[problem link](https://leetcode.cn/problems/minimum-operations-to-make-array-equal-ii/)
+
+给你两个整数数组 `nums1` 和 `nums2` ,两个数组长度都是 `n` ,再给你一个整数 `k` 。你可以对数组 `nums1` 进行以下操作:
+
+- 选择两个下标 `i` 和 `j` ,将 `nums1[i]` 增加 `k` ,将 `nums1[j]` 减少 `k` 。换言之,`nums1[i] = nums1[i] + k` 且 `nums1[j] = nums1[j] - k` 。
+
+如果对于所有满足 `0 <= i < n` 都有 `num1[i] == nums2[i]` ,那么我们称 `nums1` **等于** `nums2` 。
+
+请你返回使 `nums1` 等于 `nums2` 的 **最少** 操作数。如果没办法让它们相等,请你返回 `-1` 。
+
+
+
+**示例 1:**
+
+```
+输入:nums1 = [4,3,1,4], nums2 = [1,3,7,1], k = 3
+输出:2
+解释:我们可以通过 2 个操作将 nums1 变成 nums2 。
+第 1 个操作:i = 2 ,j = 0 。操作后得到 nums1 = [1,3,4,4] 。
+第 2 个操作:i = 2 ,j = 3 。操作后得到 nums1 = [1,3,7,1] 。
+无法用更少操作使两个数组相等。
+```
+
+**示例 2:**
+
+```
+输入:nums1 = [3,8,5,2], nums2 = [2,4,1,6], k = 1
+输出:-1
+解释:无法使两个数组相等。
+```
+
+
+
+**提示:**
+
+- `n == nums1.length == nums2.length`
+- `2 <= n <= 105`
+- `0 <= nums1[i], nums2[j] <= 109`
+- `0 <= k <= 105`
+
+## solution
+
+任选两个元素,一个+k,一个-k,问最少操作次数,使这个数组和另一个数组相同。累计操作次数即可,注意k为0的情况
+
+```python
+
+class Solution:
+ def minOperations(self, nums1: List[int], nums2: List[int], k: int) -> int:
+ op1, op2 = 0, 0
+ d = []
+ for a, b in zip(nums1, nums2):
+ d.append(a - b)
+ if sum(d) != 0: return -1
+ for v in d:
+ if k == 0:
+ # k==0时特判,不能相除法了。
+ if v != 0: return -1
+ continue
+ if abs(v) % k != 0: return -1
+ if v > 0:
+ op1 += v // k
+ else:
+ op2 += (-v) // k
+ if op1 != op2:
+ return -1
+ return op1
+```
+
diff --git "a/_posts/Algorithms/leetcode/2023-01-28-2542. \346\234\200\345\244\247\345\255\220\345\272\217\345\210\227\347\232\204\345\210\206\346\225\260.md" "b/_posts/Algorithms/leetcode/2023-01-28-2542. \346\234\200\345\244\247\345\255\220\345\272\217\345\210\227\347\232\204\345\210\206\346\225\260.md"
new file mode 100644
index 0000000000..3697889093
--- /dev/null
+++ "b/_posts/Algorithms/leetcode/2023-01-28-2542. \346\234\200\345\244\247\345\255\220\345\272\217\345\210\227\347\232\204\345\210\206\346\225\260.md"
@@ -0,0 +1,90 @@
+---
+layout: post
+category: leetcode
+title: 2542. 最大子序列的分数
+tags: leetcode
+---
+
+## title
+[problem link](https://leetcode.cn/problems/maximum-subsequence-score/)
+
+给你两个下标从 **0** 开始的整数数组 `nums1` 和 `nums2` ,两者长度都是 `n` ,再给你一个正整数 `k` 。你必须从 `nums1` 中选一个长度为 `k` 的 **子序列** 对应的下标。
+
+对于选择的下标 `i0` ,`i1` ,..., `ik - 1` ,你的 **分数** 定义如下:
+
+- `nums1` 中下标对应元素求和,乘以 `nums2` 中下标对应元素的 **最小值** 。
+- 用公示表示: `(nums1[i0] + nums1[i1] +...+ nums1[ik - 1]) * min(nums2[i0] , nums2[i1], ... ,nums2[ik - 1])` 。
+
+请你返回 **最大** 可能的分数。
+
+一个数组的 **子序列** 下标是集合 `{0, 1, ..., n-1}` 中删除若干元素得到的剩余集合,也可以不删除任何元素。
+
+
+
+**示例 1:**
+
+```
+输入:nums1 = [1,3,3,2], nums2 = [2,1,3,4], k = 3
+输出:12
+解释:
+四个可能的子序列分数为:
+- 选择下标 0 ,1 和 2 ,得到分数 (1+3+3) * min(2,1,3) = 7 。
+- 选择下标 0 ,1 和 3 ,得到分数 (1+3+2) * min(2,1,4) = 6 。
+- 选择下标 0 ,2 和 3 ,得到分数 (1+3+2) * min(2,3,4) = 12 。
+- 选择下标 1 ,2 和 3 ,得到分数 (3+3+2) * min(1,3,4) = 8 。
+所以最大分数为 12 。
+```
+
+**示例 2:**
+
+```
+输入:nums1 = [4,2,3,1,1], nums2 = [7,5,10,9,6], k = 1
+输出:30
+解释:
+选择下标 2 最优:nums1[2] * nums2[2] = 3 * 10 = 30 是最大可能分数。
+```
+
+
+
+**提示:**
+
+- `n == nums1.length == nums2.length`
+- `1 <= n <= 105`
+- `0 <= nums1[i], nums2[j] <= 105`
+- `1 <= k <= n`
+
+## solution
+
+排序后,按从小到大枚举
+
+```python
+class Solution:
+ def maxScore(self, nums1: List[int], nums2: List[int], k: int) -> int:
+ a1, a2 = nums1, nums2
+ n = len(a1)
+ d = zip(a2, a1)
+ # 排序
+ d = sorted(d, key=lambda x: (x[0], x[1]))
+ # 统计每个a2元素大于a2元素对应的最大a1和
+ right_max_sumv = collections.defaultdict(int)
+ cur = 0
+ import heapq
+ h = []
+ # print(d)
+ for i in range(len(d) - 1, -1, -1):
+ b, c = d[i]
+ heapq.heappush(h, c)
+ cur += c
+ if len(h) > k:
+ x = heapq.heappop(h)
+ cur -= x
+ # print(h, cur)
+ if len(h) == k:
+ right_max_sumv[b] = cur
+ ans = 0
+ # print(right_max_sumv)
+ for k, v in right_max_sumv.items():
+ ans = max(ans, v * k)
+ return ans
+```
+
diff --git "a/_posts/Algorithms/leetcode/2023-01-28-2546. \346\211\247\350\241\214\351\200\220\344\275\215\350\277\220\347\256\227\344\275\277\345\255\227\347\254\246\344\270\262\347\233\270\347\255\211.md" "b/_posts/Algorithms/leetcode/2023-01-28-2546. \346\211\247\350\241\214\351\200\220\344\275\215\350\277\220\347\256\227\344\275\277\345\255\227\347\254\246\344\270\262\347\233\270\347\255\211.md"
new file mode 100644
index 0000000000..e067a7d306
--- /dev/null
+++ "b/_posts/Algorithms/leetcode/2023-01-28-2546. \346\211\247\350\241\214\351\200\220\344\275\215\350\277\220\347\256\227\344\275\277\345\255\227\347\254\246\344\270\262\347\233\270\347\255\211.md"
@@ -0,0 +1,58 @@
+---
+layout: post
+category: leetcode
+title: 2546. 执行逐位运算使字符串相等
+tags: leetcode
+---
+
+## title
+[problem link](https://leetcode.cn/problems/apply-bitwise-operations-to-make-strings-equal/)
+
+给你两个下标从 **0** 开始的 **二元** 字符串 `s` 和 `target` ,两个字符串的长度均为 `n` 。你可以对 `s` 执行下述操作 **任意** 次:
+
+- 选择两个 **不同** 的下标 `i` 和 `j` ,其中 `0 <= i, j < n` 。
+- 同时,将 `s[i]` 替换为 (`s[i]` **OR** `s[j]`) ,`s[j]` 替换为 (`s[i]` **XOR** `s[j]`) 。
+
+例如,如果 `s = "0110"` ,你可以选择 `i = 0` 和 `j = 2`,然后同时将 `s[0]` 替换为 (`s[0]` **OR** `s[2]` = `0` **OR** `1` = `1`),并将 `s[2]` 替换为 (`s[0]` **XOR** `s[2]` = `0` **XOR** `1` = `1`),最终得到 `s = "1110"` 。
+
+如果可以使 `s` 等于 `target` ,返回 `true` ,否则,返回 `false` 。
+
+
+
+**示例 1:**
+
+```
+输入:s = "1010", target = "0110"
+输出:true
+解释:可以执行下述操作:
+- 选择 i = 2 和 j = 0 ,得到 s = "0010".
+- 选择 i = 2 和 j = 1 ,得到 s = "0110".
+可以使 s 等于 target ,返回 true 。
+```
+
+**示例 2:**
+
+```
+输入:s = "11", target = "00"
+输出:false
+解释:执行任意次操作都无法使 s 等于 target 。
+```
+
+
+
+**提示:**
+
+- `n == s.length == target.length`
+- `2 <= n <= 105`
+- `s` 和 `target` 仅由数字 `0` 和 `1` 组成
+
+## solution
+
+找规律。 [参考](https://leetcode.cn/problems/apply-bitwise-operations-to-make-strings-equal/solution/nao-jin-ji-zhuan-wan-yi-xing-dai-ma-by-e-0fce/)
+
+```python
+class Solution:
+ def makeStringsEqual(self, s: str, target: str) -> bool:
+ return ('1' in s) == ('1' in target)
+```
+
diff --git "a/_posts/Algorithms/leetcode/2023-01-28-2547. \346\213\206\345\210\206\346\225\260\347\273\204\347\232\204\346\234\200\345\260\217\344\273\243\344\273\267.md" "b/_posts/Algorithms/leetcode/2023-01-28-2547. \346\213\206\345\210\206\346\225\260\347\273\204\347\232\204\346\234\200\345\260\217\344\273\243\344\273\267.md"
new file mode 100644
index 0000000000..c345b2e99a
--- /dev/null
+++ "b/_posts/Algorithms/leetcode/2023-01-28-2547. \346\213\206\345\210\206\346\225\260\347\273\204\347\232\204\346\234\200\345\260\217\344\273\243\344\273\267.md"
@@ -0,0 +1,102 @@
+---
+layout: post
+category: leetcode
+title: 2547. 拆分数组的最小代价
+tags: leetcode
+---
+
+## title
+[problem link](https://leetcode.cn/problems/minimum-cost-to-split-an-array/)
+
+给你一个整数数组 `nums` 和一个整数 `k` 。
+
+将数组拆分成一些非空子数组。拆分的 **代价** 是每个子数组中的 **重要性** 之和。
+
+令 `trimmed(subarray)` 作为子数组的一个特征,其中所有仅出现一次的数字将会被移除。
+
+- 例如,`trimmed([3,1,2,4,3,4]) = [3,4,3,4]` 。
+
+子数组的 **重要性** 定义为 `k + trimmed(subarray).length` 。
+
+- 例如,如果一个子数组是 `[1,2,3,3,3,4,4]` ,`trimmed([1,2,3,3,3,4,4]) = [3,3,3,4,4]` 。这个子数组的重要性就是 `k + 5` 。
+
+找出并返回拆分 `nums` 的所有可行方案中的最小代价。
+
+**子数组** 是数组的一个连续 **非空** 元素序列。
+
+
+
+**示例 1:**
+
+```
+输入:nums = [1,2,1,2,1,3,3], k = 2
+输出:8
+解释:将 nums 拆分成两个子数组:[1,2], [1,2,1,3,3]
+[1,2] 的重要性是 2 + (0) = 2 。
+[1,2,1,3,3] 的重要性是 2 + (2 + 2) = 6 。
+拆分的代价是 2 + 6 = 8 ,可以证明这是所有可行的拆分方案中的最小代价。
+```
+
+**示例 2:**
+
+```
+输入:nums = [1,2,1,2,1], k = 2
+输出:6
+解释:将 nums 拆分成两个子数组:[1,2], [1,2,1] 。
+[1,2] 的重要性是 2 + (0) = 2 。
+[1,2,1] 的重要性是 2 + (2) = 4 。
+拆分的代价是 2 + 4 = 6 ,可以证明这是所有可行的拆分方案中的最小代价。
+```
+
+**示例 3:**
+
+```
+输入:nums = [1,2,1,2,1], k = 5
+输出:10
+解释:将 nums 拆分成一个子数组:[1,2,1,2,1].
+[1,2,1,2,1] 的重要性是 5 + (3 + 2) = 10 。
+拆分的代价是 10 ,可以证明这是所有可行的拆分方案中的最小代价。
+```
+
+
+
+**提示:**
+
+- `1 <= nums.length <= 1000`
+- `0 <= nums[i] < nums.length`
+- `1 <= k <= 109`
+
+
+
+## solution
+
+一维DP。
+
+dp(i)表示以0...i的代价,求dp(n-1)。
+
+用map维护出现不止一次的元素个数。
+
+```python
+INF = int(1e20)
+class Solution:
+ def minCost(self, nums: List[int], k: int) -> int:
+ n = len(nums)
+ dp = [INF for _ in range(n)]
+ for i in range(n):
+ res = INF
+ cnt = collections.Counter()
+ t = 0
+ for j in range(i, -1, -1):
+ cnt[nums[j]] += 1
+ if cnt[nums[j]] == 2:
+ t += 2
+ elif cnt[nums[j]] > 2:
+ t += 1
+ res = min(res, (dp[j - 1] if j - 1 >= 0 else 0) + k + t)
+ # if i == n-1 and j == 2:
+ # print("x")
+ dp[i] = res
+ # print(dp)
+ return dp[n - 1]
+```
+
diff --git "a/_posts/Algorithms/leetcode/2023-01-29-6339. \345\260\206\347\217\240\345\255\220\346\224\276\345\205\245\350\203\214\345\214\205\344\270\255.md" "b/_posts/Algorithms/leetcode/2023-01-29-6339. \345\260\206\347\217\240\345\255\220\346\224\276\345\205\245\350\203\214\345\214\205\344\270\255.md"
new file mode 100644
index 0000000000..6a74e28a91
--- /dev/null
+++ "b/_posts/Algorithms/leetcode/2023-01-29-6339. \345\260\206\347\217\240\345\255\220\346\224\276\345\205\245\350\203\214\345\214\205\344\270\255.md"
@@ -0,0 +1,74 @@
+---
+layout: post
+category: leetcode
+title: 6339. 将珠子放入背包中
+tags: leetcode
+---
+
+## title
+[problem link](https://leetcode.cn/problems/put-marbles-in-bags/)
+
+你有 `k` 个背包。给你一个下标从 **0** 开始的整数数组 `weights` ,其中 `weights[i]` 是第 `i` 个珠子的重量。同时给你整数 `k` 。
+
+请你按照如下规则将所有的珠子放进 `k` 个背包。
+
+- 没有背包是空的。
+- 如果第 `i` 个珠子和第 `j` 个珠子在同一个背包里,那么下标在 `i` 到 `j` 之间的所有珠子都必须在这同一个背包中。
+- 如果一个背包有下标从 `i` 到 `j` 的所有珠子,那么这个背包的价格是 `weights[i] + weights[j]` 。
+
+一个珠子分配方案的 **分数** 是所有 `k` 个背包的价格之和。
+
+请你返回所有分配方案中,**最大分数** 与 **最小分数** 的 **差值** 为多少。
+
+
+
+**示例 1:**
+
+```
+输入:weights = [1,3,5,1], k = 2
+输出:4
+解释:
+分配方案 [1],[3,5,1] 得到最小得分 (1+1) + (3+1) = 6 。
+分配方案 [1,3],[5,1] 得到最大得分 (1+3) + (5+1) = 10 。
+所以差值为 10 - 6 = 4 。
+```
+
+**示例 2:**
+
+```
+输入:weights = [1, 3], k = 2
+输出:0
+解释:唯一的分配方案为 [1],[3] 。
+最大最小得分相等,所以返回 0 。
+```
+
+
+
+**提示:**
+
+- `1 <= k <= weights.length <= 105`
+- `1 <= weights[i] <= 109`
+
+## solution
+
+脑筋急转弯
+
+不要关注端点,要关注分割位置,收益就是分割位置左右两边
+
+```python
+
+class Solution:
+ def putMarbles(self, weights: List[int], k: int) -> int:
+ # 不要关注端点,要关注分割位置,收益就是分割位置左右两边
+ d = []
+ for i in range(len(weights) - 1):
+ a, b = weights[i], weights[i + 1]
+ d.append(a + b)
+ d.sort()
+ # print(d)
+ ans = -sum(d[:k - 1])
+ d = list(reversed(d))
+ ans += sum(d[:k - 1])
+ return ans
+```
+
diff --git "a/_posts/Algorithms/leetcode/2023-01-29-6340. \347\273\237\350\256\241\344\270\212\345\215\207\345\233\233\345\205\203\347\273\204.md" "b/_posts/Algorithms/leetcode/2023-01-29-6340. \347\273\237\350\256\241\344\270\212\345\215\207\345\233\233\345\205\203\347\273\204.md"
new file mode 100644
index 0000000000..8bd342be32
--- /dev/null
+++ "b/_posts/Algorithms/leetcode/2023-01-29-6340. \347\273\237\350\256\241\344\270\212\345\215\207\345\233\233\345\205\203\347\273\204.md"
@@ -0,0 +1,85 @@
+---
+layout: post
+category: leetcode
+title: 6340. 统计上升四元组
+tags: leetcode
+---
+
+## title
+[problem link](https://leetcode.cn/problems/count-increasing-quadruplets/)
+
+给你一个长度为 `n` 下标从 **0** 开始的整数数组 `nums` ,它包含 `1` 到 `n` 的所有数字,请你返回上升四元组的数目。
+
+如果一个四元组 `(i, j, k, l)` 满足以下条件,我们称它是上升的:
+
+- `0 <= i < j < k < l < n` 且
+- `nums[i] < nums[k] < nums[j] < nums[l]` 。
+
+
+
+**示例 1:**
+
+```
+输入:nums = [1,3,2,4,5]
+输出:2
+解释:
+- 当 i = 0 ,j = 1 ,k = 2 且 l = 3 时,有 nums[i] < nums[k] < nums[j] < nums[l] 。
+- 当 i = 0 ,j = 1 ,k = 2 且 l = 4 时,有 nums[i] < nums[k] < nums[j] < nums[l] 。
+没有其他的四元组,所以我们返回 2 。
+```
+
+**示例 2:**
+
+```
+输入:nums = [1,2,3,4]
+输出:0
+解释:只存在一个四元组 i = 0 ,j = 1 ,k = 2 ,l = 3 ,但是 nums[j] < nums[k] ,所以我们返回 0 。
+```
+
+
+
+**提示:**
+
+- `4 <= nums.length <= 4000`
+- `1 <= nums[i] <= nums.length`
+- `nums` 中所有数字 **互不相同** ,`nums` 是一个排列。
+
+## solution
+
+统计四元组。
+
+枚举中间的两个数。O(n2)
+
+需要预处理简化时间复杂度。
+
+```python
+class Solution:
+ def countQuadruplets(self, nums: List[int]) -> int:
+ n = len(nums)
+ # i,j,k,l. i j:
+ cnt_greater_j[j][i] = cnt
+ if nums[i] > nums[j]:
+ cnt += 1
+ i -= 1
+ ans = 0
+ for j in range(n):
+ for k in range(j + 1, n):
+ if nums[j] > nums[k]:
+ ans += cnt_less_k[k][j] * cnt_greater_j[j][k]
+ return ans
+```
+
diff --git "a/_posts/Algorithms/leetcode/2023-01-30-1664. \347\224\237\346\210\220\345\271\263\350\241\241\346\225\260\347\273\204\347\232\204\346\226\271\346\241\210\346\225\260.md" "b/_posts/Algorithms/leetcode/2023-01-30-1664. \347\224\237\346\210\220\345\271\263\350\241\241\346\225\260\347\273\204\347\232\204\346\226\271\346\241\210\346\225\260.md"
new file mode 100644
index 0000000000..9df6dbaaba
--- /dev/null
+++ "b/_posts/Algorithms/leetcode/2023-01-30-1664. \347\224\237\346\210\220\345\271\263\350\241\241\346\225\260\347\273\204\347\232\204\346\226\271\346\241\210\346\225\260.md"
@@ -0,0 +1,98 @@
+---
+layout: post
+category: leetcode
+title: 1664. 生成平衡数组的方案数
+tags: leetcode
+---
+
+## title
+[problem link](https://leetcode.cn/problems/ways-to-make-a-fair-array/)
+
+给你一个整数数组 `nums` 。你需要选择 **恰好** 一个下标(下标从 **0** 开始)并删除对应的元素。请注意剩下元素的下标可能会因为删除操作而发生改变。
+
+比方说,如果 `nums = [6,1,7,4,1]` ,那么:
+
+- 选择删除下标 `1` ,剩下的数组为 `nums = [6,7,4,1]` 。
+- 选择删除下标 `2` ,剩下的数组为 `nums = [6,1,4,1]` 。
+- 选择删除下标 `4` ,剩下的数组为 `nums = [6,1,7,4]` 。
+
+如果一个数组满足奇数下标元素的和与偶数下标元素的和相等,该数组就是一个 **平衡数组** 。
+
+请你返回删除操作后,剩下的数组 `nums` 是 **平衡数组** 的 **方案数** 。
+
+
+
+**示例 1:**
+
+```
+输入:nums = [2,1,6,4]
+输出:1
+解释:
+删除下标 0 :[1,6,4] -> 偶数元素下标为:1 + 4 = 5 。奇数元素下标为:6 。不平衡。
+删除下标 1 :[2,6,4] -> 偶数元素下标为:2 + 4 = 6 。奇数元素下标为:6 。平衡。
+删除下标 2 :[2,1,4] -> 偶数元素下标为:2 + 4 = 6 。奇数元素下标为:1 。不平衡。
+删除下标 3 :[2,1,6] -> 偶数元素下标为:2 + 6 = 8 。奇数元素下标为:1 。不平衡。
+只有一种让剩余数组成为平衡数组的方案。
+```
+
+**示例 2:**
+
+```
+输入:nums = [1,1,1]
+输出:3
+解释:你可以删除任意元素,剩余数组都是平衡数组。
+```
+
+**示例 3:**
+
+```
+输入:nums = [1,2,3]
+输出:0
+解释:不管删除哪个元素,剩下数组都不是平衡数组。
+```
+
+
+
+**提示:**
+
+- `1 <= nums.length <= 105`
+- `1 <= nums[i] <= 104`
+
+## solution
+
+找规律题
+
+当删除某个下标后,新的偶数和 = 这个下标左边的偶数和 + 这个下标右边的奇数和
+
+当删除某个下标后,新的奇数和 = 这个下标左边的奇数数和 + 这个下标右边的偶数数和
+
+```python
+
+class Solution:
+ def waysToMakeFair(self, nums: List[int]) -> int:
+ odd, even = 0, 0
+ for i, v in enumerate(nums):
+ if i % 2 == 0:
+ even += v
+ else:
+ odd += v
+ lo, le = 0, 0
+ total = sum(nums)
+ # print(total, odd, even)
+ ans = 0
+ for i, v in enumerate(nums):
+ if i % 2 == 0:
+ teven = odd - lo + le
+ if teven == total - v - teven:
+ ans += 1
+ # print(i, v, teven)
+ le += v
+ else:
+ todd = even - le + lo
+ if todd == total - v - todd:
+ ans += 1
+ # print(i, v, todd)
+ lo += v
+ return ans
+```
+
diff --git "a/_posts/Algorithms/leetcode/2023-02-03-1145. \344\272\214\345\217\211\346\240\221\347\235\200\350\211\262\346\270\270\346\210\217.md" "b/_posts/Algorithms/leetcode/2023-02-03-1145. \344\272\214\345\217\211\346\240\221\347\235\200\350\211\262\346\270\270\346\210\217.md"
new file mode 100644
index 0000000000..e7605252ee
--- /dev/null
+++ "b/_posts/Algorithms/leetcode/2023-02-03-1145. \344\272\214\345\217\211\346\240\221\347\235\200\350\211\262\346\270\270\346\210\217.md"
@@ -0,0 +1,84 @@
+---
+layout: post
+category: leetcode
+title: 1145. 二叉树着色游戏
+tags: leetcode
+---
+
+## title
+[problem link](https://leetcode.cn/problems/binary-tree-coloring-game/)
+
+有两位极客玩家参与了一场「二叉树着色」的游戏。游戏中,给出二叉树的根节点 `root`,树上总共有 `n` 个节点,且 `n` 为奇数,其中每个节点上的值从 `1` 到 `n` 各不相同。
+
+最开始时:
+
+- 「一号」玩家从 `[1, n]` 中取一个值 `x`(`1 <= x <= n`);
+- 「二号」玩家也从 `[1, n]` 中取一个值 `y`(`1 <= y <= n`)且 `y != x`。
+
+「一号」玩家给值为 `x` 的节点染上红色,而「二号」玩家给值为 `y` 的节点染上蓝色。
+
+之后两位玩家轮流进行操作,「一号」玩家先手。每一回合,玩家选择一个被他染过色的节点,将所选节点一个 **未着色** 的邻节点(即左右子节点、或父节点)进行染色(「一号」玩家染红色,「二号」玩家染蓝色)。
+
+如果(且仅在此种情况下)当前玩家无法找到这样的节点来染色时,其回合就会被跳过。
+
+若两个玩家都没有可以染色的节点时,游戏结束。着色节点最多的那位玩家获得胜利 ✌️。
+
+现在,假设你是「二号」玩家,根据所给出的输入,假如存在一个 `y` 值可以确保你赢得这场游戏,则返回 `true` ;若无法获胜,就请返回 `false` 。
+
+**示例 1 :**
+
+
+
+```
+输入:root = [1,2,3,4,5,6,7,8,9,10,11], n = 11, x = 3
+输出:true
+解释:第二个玩家可以选择值为 2 的节点。
+```
+
+**示例 2 :**
+
+```
+输入:root = [1,2,3], n = 3, x = 1
+输出:false
+```
+
+
+
+**提示:**
+
+- 树中节点数目为 `n`
+- `1 <= x <= n <= 100`
+- `n` 是奇数
+- `1 <= Node.val <= n`
+- 树中所有值 **互不相同**
+
+## solution
+
+dfs遍历。
+
+y节点肯定和x相邻,贪心。
+
+统计左子树和右子树节点个数。
+
+```python
+class Solution:
+ def btreeGameWinningMove(self, root: Optional[TreeNode], n: int, x: int) -> bool:
+ lc, rc = 0, 0
+
+ def dfs(r):
+ if r is None:
+ return 0
+ tl = dfs(r.left)
+ tr = dfs(r.right)
+ if r.val == x:
+ nonlocal lc, rc
+ lc = tl
+ rc = tr
+ return tl+tr + 1
+
+ dfs(root)
+ # print(lc, rc, n - lc - rc - 1)
+ y= max(lc, rc, n - lc - rc - 1)
+ return y > n -y
+```
+
diff --git "a/_posts/Algorithms/leetcode/2023-02-04-1798. \344\275\240\350\203\275\346\236\204\351\200\240\345\207\272\350\277\236\347\273\255\345\200\274\347\232\204\346\234\200\345\244\247\346\225\260\347\233\256.md" "b/_posts/Algorithms/leetcode/2023-02-04-1798. \344\275\240\350\203\275\346\236\204\351\200\240\345\207\272\350\277\236\347\273\255\345\200\274\347\232\204\346\234\200\345\244\247\346\225\260\347\233\256.md"
new file mode 100644
index 0000000000..17d7633ed4
--- /dev/null
+++ "b/_posts/Algorithms/leetcode/2023-02-04-1798. \344\275\240\350\203\275\346\236\204\351\200\240\345\207\272\350\277\236\347\273\255\345\200\274\347\232\204\346\234\200\345\244\247\346\225\260\347\233\256.md"
@@ -0,0 +1,76 @@
+---
+layout: post
+category: leetcode
+title: 1798. 你能构造出连续值的最大数目
+tags: leetcode
+---
+
+## title
+[problem link](https://leetcode.cn/problems/maximum-number-of-consecutive-values-you-can-make/)
+
+给你一个长度为 `n` 的整数数组 `coins` ,它代表你拥有的 `n` 个硬币。第 `i` 个硬币的值为 `coins[i]` 。如果你从这些硬币中选出一部分硬币,它们的和为 `x` ,那么称,你可以 **构造** 出 `x` 。
+
+请返回从 `0` 开始(**包括** `0` ),你最多能 **构造** 出多少个连续整数。
+
+你可能有多个相同值的硬币。
+
+
+
+**示例 1:**
+
+```
+输入:coins = [1,3]
+输出:2
+解释:你可以得到以下这些值:
+- 0:什么都不取 []
+- 1:取 [1]
+从 0 开始,你可以构造出 2 个连续整数。
+```
+
+**示例 2:**
+
+```
+输入:coins = [1,1,1,4]
+输出:8
+解释:你可以得到以下这些值:
+- 0:什么都不取 []
+- 1:取 [1]
+- 2:取 [1,1]
+- 3:取 [1,1,1]
+- 4:取 [4]
+- 5:取 [4,1]
+- 6:取 [4,1,1]
+- 7:取 [4,1,1,1]
+从 0 开始,你可以构造出 8 个连续整数。
+```
+
+**示例 3:**
+
+```
+输入:nums = [1,4,10,3,1]
+输出:20
+```
+
+
+
+**提示:**
+
+- `coins.length == n`
+- `1 <= n <= 4 * 104`
+- `1 <= coins[i] <= 4 * 104`
+
+## solution
+
+贪心。如果能构造0-x,现有y,则能构造0-x, y-x+y这俩区间了。
+
+```python
+class Solution:
+ def getMaximumConsecutive(self, coins: List[int]) -> int:
+ coins = sorted(coins)
+ x = 0
+ for v in coins:
+ if x >= v - 1:
+ x += v
+ return x + 1
+```
+
diff --git "a/_posts/Algorithms/leetcode/2023-02-05-6331. \344\270\244\344\270\252\347\272\277\346\256\265\350\216\267\345\276\227\347\232\204\346\234\200\345\244\232\345\245\226\345\223\201.md" "b/_posts/Algorithms/leetcode/2023-02-05-6331. \344\270\244\344\270\252\347\272\277\346\256\265\350\216\267\345\276\227\347\232\204\346\234\200\345\244\232\345\245\226\345\223\201.md"
new file mode 100644
index 0000000000..6c726fd5b7
--- /dev/null
+++ "b/_posts/Algorithms/leetcode/2023-02-05-6331. \344\270\244\344\270\252\347\272\277\346\256\265\350\216\267\345\276\227\347\232\204\346\234\200\345\244\232\345\245\226\345\223\201.md"
@@ -0,0 +1,70 @@
+---
+layout: post
+category: leetcode
+title: 6331. 两个线段获得的最多奖品
+tags: leetcode
+---
+
+## title
+[problem link](https://leetcode.cn/problems/maximize-win-from-two-segments/)
+
+在 **X轴** 上有一些奖品。给你一个整数数组 `prizePositions` ,它按照 **非递减** 顺序排列,其中 `prizePositions[i]` 是第 `i` 件奖品的位置。数轴上一个位置可能会有多件奖品。再给你一个整数 `k` 。
+
+你可以选择两个端点为整数的线段。每个线段的长度都必须是 `k` 。你可以获得位置在任一线段上的所有奖品(包括线段的两个端点)。注意,两个线段可能会有相交。
+
+- 比方说 `k = 2` ,你可以选择线段 `[1, 3]` 和 `[2, 4]` ,你可以获得满足 `1 <= prizePositions[i] <= 3` 或者 `2 <= prizePositions[i] <= 4` 的所有奖品 i 。
+
+请你返回在选择两个最优线段的前提下,可以获得的 **最多** 奖品数目。
+
+
+
+**示例 1:**
+
+```
+输入:prizePositions = [1,1,2,2,3,3,5], k = 2
+输出:7
+解释:这个例子中,你可以选择线段 [1, 3] 和 [3, 5] ,获得 7 个奖品。
+```
+
+**示例 2:**
+
+```
+输入:prizePositions = [1,2,3,4], k = 0
+输出:2
+解释:这个例子中,一个选择是选择线段 [3, 3] 和 [4, 4] ,获得 2 个奖品。
+```
+
+
+
+**提示:**
+
+- `1 <= prizePositions.length <= 105`
+- `1 <= prizePositions[i] <= 109`
+- `0 <= k <= 109`
+- `prizePositions` 有序非递减。
+
+
+## solution
+
+```python
+class Solution:
+ def maximizeWin(self, prizePositions: List[int], k: int) -> int:
+ n = len(prizePositions)
+ ans = 0
+ left = 0
+ pre = [0] * n
+ '''
+ 求最大的两个区间。每个区间可以双指针计算。找到一个后,只要找到左边里的最大一个就可以,可以持久化记录。
+ '''
+ for i in range(n):
+ while left <= i and prizePositions[i] - prizePositions[left] > k:
+ left += 1
+ pre[i] = i - left + 1
+ ans = max(ans, pre[i] + (pre[left - 1] if left - 1 >= 0 else 0))
+ if i > 0:
+ pre[i] = max(pre[i], pre[i - 1])
+ # print(pre)
+ return ans
+
+```
+
diff --git "a/_posts/Algorithms/leetcode/2023-02-11-2556. \344\272\214\350\277\233\345\210\266\347\237\251\351\230\265\344\270\255\347\277\273\350\275\254\346\234\200\345\244\232\344\270\200\346\254\241\344\275\277\350\267\257\345\276\204\344\270\215\350\277\236\351\200\232.md" "b/_posts/Algorithms/leetcode/2023-02-11-2556. \344\272\214\350\277\233\345\210\266\347\237\251\351\230\265\344\270\255\347\277\273\350\275\254\346\234\200\345\244\232\344\270\200\346\254\241\344\275\277\350\267\257\345\276\204\344\270\215\350\277\236\351\200\232.md"
new file mode 100644
index 0000000000..a8e2e9f2a8
--- /dev/null
+++ "b/_posts/Algorithms/leetcode/2023-02-11-2556. \344\272\214\350\277\233\345\210\266\347\237\251\351\230\265\344\270\255\347\277\273\350\275\254\346\234\200\345\244\232\344\270\200\346\254\241\344\275\277\350\267\257\345\276\204\344\270\215\350\277\236\351\200\232.md"
@@ -0,0 +1,77 @@
+---
+layout: post
+category: leetcode
+title: 2556. 二进制矩阵中翻转最多一次使路径不连通
+tags: leetcode
+---
+
+## title
+[problem link](https://leetcode.cn/problems/disconnect-path-in-a-binary-matrix-by-at-most-one-flip/)
+
+给你一个下标从 **0** 开始的 `m x n` **二进制** 矩阵 `grid` 。你可以从一个格子 `(row, col)` 移动到格子 `(row + 1, col)` 或者 `(row, col + 1)` ,前提是前往的格子值为 `1` 。如果从 `(0, 0)` 到 `(m - 1, n - 1)` 没有任何路径,我们称该矩阵是 **不连通** 的。
+
+你可以翻转 **最多一个** 格子的值(也可以不翻转)。你 **不能翻转** 格子 `(0, 0)` 和 `(m - 1, n - 1)` 。
+
+如果可以使矩阵不连通,请你返回 `true` ,否则返回 `false` 。
+
+**注意** ,翻转一个格子的值,可以使它的值从 `0` 变 `1` ,或从 `1` 变 `0` 。
+
+
+
+**示例 1:**
+
+
+
+```
+输入:grid = [[1,1,1],[1,0,0],[1,1,1]]
+输出:true
+解释:按照上图所示我们翻转蓝色格子里的值,翻转后从 (0, 0) 到 (2, 2) 没有路径。
+```
+
+**示例 2:**
+
+
+
+```
+输入:grid = [[1,1,1],[1,0,1],[1,1,1]]
+输出:false
+解释:无法翻转至多一个格子,使 (0, 0) 到 (2, 2) 没有路径。
+```
+
+
+
+**提示:**
+
+- `m == grid.length`
+- `n == grid[i].length`
+- `1 <= m, n <= 1000`
+- `1 <= m * n <= 105`
+- `grid[0][0] == grid[m - 1][n - 1] == 1`
+
+## solution
+
+判断是否有两次完全不同的路径,两次dfs,每次把当前路径去掉就行。
+
+如果两次都可以到达终点,说明至少两次完全不同的路径。
+
+```python
+
+class Solution:
+ def isPossibleToCutPath(self, grid: List[List[int]]) -> bool:
+ m, n = len(grid), len(grid[0])
+
+ def dfs(x, y):
+ if (x, y) == (m - 1, n - 1):
+ return True
+ grid[x][y] = 0
+ if x + 1 < m and grid[x + 1][y] == 1:
+ if dfs(x + 1, y):
+ return True
+ if y + 1 < n and grid[x][y + 1] == 1:
+ if dfs(x, y + 1):
+ return True
+ return False
+ return (not dfs(0, 0)) or (not dfs(0, 0))
+
+```
+
diff --git "a/_posts/Algorithms/leetcode/2023-02-11-2561. \351\207\215\346\216\222\346\260\264\346\236\234.md" "b/_posts/Algorithms/leetcode/2023-02-11-2561. \351\207\215\346\216\222\346\260\264\346\236\234.md"
new file mode 100644
index 0000000000..4111da436b
--- /dev/null
+++ "b/_posts/Algorithms/leetcode/2023-02-11-2561. \351\207\215\346\216\222\346\260\264\346\236\234.md"
@@ -0,0 +1,74 @@
+---
+layout: post
+category: leetcode
+title: 2561. 重排水果
+tags: leetcode
+---
+
+## title
+[problem link](https://leetcode.cn/problems/rearranging-fruits/)
+
+你有两个果篮,每个果篮中有 `n` 个水果。给你两个下标从 **0** 开始的整数数组 `basket1` 和 `basket2` ,用以表示两个果篮中每个水果的成本。
+
+你希望两个果篮相等。为此,可以根据需要多次执行下述操作:
+
+- 选中两个下标 `i` 和 `j` ,并交换 `basket1` 中的第 `i` 个水果和 `basket2` 中的第 `j` 个水果。
+- 交换的成本是 `min(basket1i,basket2j)` 。
+
+根据果篮中水果的成本进行排序,如果排序后结果完全相同,则认为两个果篮相等。
+
+返回使两个果篮相等的最小交换成本,如果无法使两个果篮相等,则返回 `-1` 。
+
+
+
+**示例 1:**
+
+```
+输入:basket1 = [4,2,2,2], basket2 = [1,4,1,2]
+输出:1
+解释:交换 basket1 中下标为 1 的水果和 basket2 中下标为 0 的水果,交换的成本为 1 。此时,basket1 = [4,1,2,2] 且 basket2 = [2,4,1,2] 。重排两个数组,发现二者相等。
+```
+
+**示例 2:**
+
+```
+输入:basket1 = [2,3,4,1], basket2 = [3,2,5,1]
+输出:-1
+解释:可以证明无法使两个果篮相等。
+```
+
+
+
+**提示:**
+
+- `basket1.length == bakste2.length`
+- `1 <= basket1.length <= 105`
+- `1 <= basket1i,basket2i <= 109`
+
+## solution
+
+排序+ 贪心
+
+要点:可以找最小值当中介交换,此时最小值用了两次。
+
+```python
+class Solution:
+ def minCost(self, basket1: List[int], basket2: List[int]) -> int:
+ c1, c2 = collections.Counter(basket1), collections.Counter(basket2)
+ mv = min(min(basket1), min(basket2))
+ diff = []
+ c = collections.Counter()
+ for k, v in c1.items():
+ c[k] += v
+ for k, v in c2.items():
+ c[k] -= v
+ for k, v in c.items():
+ if v == 0: continue
+ if abs(v) & 1:
+ return -1
+ diff.extend([k] * (abs(v) // 2))
+ diff.sort()
+ a = diff
+ return sum(min(x, mv * 2) for x in a[:len(a) // 2])
+```
+
diff --git "a/_posts/Algorithms/leetcode/2023-02-12-6356. \345\255\220\345\255\227\347\254\246\344\270\262\345\274\202\346\210\226\346\237\245\350\257\242.md" "b/_posts/Algorithms/leetcode/2023-02-12-6356. \345\255\220\345\255\227\347\254\246\344\270\262\345\274\202\346\210\226\346\237\245\350\257\242.md"
new file mode 100644
index 0000000000..86458e89c5
--- /dev/null
+++ "b/_posts/Algorithms/leetcode/2023-02-12-6356. \345\255\220\345\255\227\347\254\246\344\270\262\345\274\202\346\210\226\346\237\245\350\257\242.md"
@@ -0,0 +1,87 @@
+---
+layout: post
+category: leetcode
+title: 6356. 子字符串异或查询
+tags: leetcode
+---
+
+## title
+[problem link](https://leetcode.cn/problems/substring-xor-queries/)
+
+给你一个 **二进制字符串** `s` 和一个整数数组 `queries` ,其中 `queries[i] = [firsti, secondi]` 。
+
+对于第 `i` 个查询,找到 `s` 的 **最短子字符串** ,它对应的 **十进制**值 `val` 与 `firsti` **按位异或** 得到 `secondi` ,换言之,`val ^ firsti == secondi` 。
+
+第 `i` 个查询的答案是子字符串 `[lefti, righti]` 的两个端点(下标从 **0** 开始),如果不存在这样的子字符串,则答案为 `[-1, -1]` 。如果有多个答案,请你选择 `lefti` 最小的一个。
+
+请你返回一个数组 `ans` ,其中 `ans[i] = [lefti, righti]` 是第 `i` 个查询的答案。
+
+**子字符串** 是一个字符串中一段连续非空的字符序列。
+
+
+
+**示例 1:**
+
+```
+输入:s = "101101", queries = [[0,5],[1,2]]
+输出:[[0,2],[2,3]]
+解释:第一个查询,端点为 [0,2] 的子字符串为 "101" ,对应十进制数字 5 ,且 5 ^ 0 = 5 ,所以第一个查询的答案为 [0,2]。第二个查询中,端点为 [2,3] 的子字符串为 "11" ,对应十进制数字 3 ,且 3 ^ 1 = 2 。所以第二个查询的答案为 [2,3] 。
+```
+
+**示例 2:**
+
+```
+输入:s = "0101", queries = [[12,8]]
+输出:[[-1,-1]]
+解释:这个例子中,没有符合查询的答案,所以返回 [-1,-1] 。
+```
+
+**示例 3:**
+
+```
+输入:s = "1", queries = [[4,5]]
+输出:[[0,0]]
+解释:这个例子中,端点为 [0,0] 的子字符串对应的十进制值为 1 ,且 1 ^ 4 = 5 。所以答案为 [0,0] 。
+```
+
+
+
+**提示:**
+
+- `1 <= s.length <= 104`
+- `s[i]` 要么是 `'0'` ,要么是 `'1'` 。
+- `1 <= queries.length <= 105`
+- `0 <= firsti, secondi <= 109`
+
+## solution
+
+缓存下所有值,然后query时从map取即可。
+
+```python
+class Solution:
+ def substringXorQueries(self, s: str, queries: List[List[int]]) -> List[List[int]]:
+ l = len(bin(10 ** 9)[2:])
+ l = min(l, len(s))
+ m = {}
+ for a, b in queries:
+ x = a ^ b
+ m[x] = None
+ for i in range(len(s)):
+ t = 0
+ for j in range(i, min(len(s), i + l + 1), 1):
+ t <<= 1
+ t += int(s[j])
+ if t in m and m[t] is None:
+ m[t] = [i, j]
+ elif t in m and m[t][1] - m[t][0] > j - i:
+ m[t] = [i, j]
+ ans = []
+ for a, b in queries:
+ x = a ^ b
+ if m[x] is None:
+ ans.append([-1, -1])
+ else:
+ ans.append(m[x])
+ return ans
+```
+
diff --git "a/_posts/Algorithms/leetcode/2023-02-12-6357. \346\234\200\345\260\221\345\276\227\345\210\206\345\255\220\345\272\217\345\210\227.md" "b/_posts/Algorithms/leetcode/2023-02-12-6357. \346\234\200\345\260\221\345\276\227\345\210\206\345\255\220\345\272\217\345\210\227.md"
new file mode 100644
index 0000000000..e0758b8812
--- /dev/null
+++ "b/_posts/Algorithms/leetcode/2023-02-12-6357. \346\234\200\345\260\221\345\276\227\345\210\206\345\255\220\345\272\217\345\210\227.md"
@@ -0,0 +1,88 @@
+---
+layout: post
+category: leetcode
+title: 6357. 最少得分子序列
+tags: leetcode
+---
+
+## title
+[problem link](https://leetcode.cn/problems/subsequence-with-the-minimum-score/)
+
+给你两个字符串 `s` 和 `t` 。
+
+你可以从字符串 `t` 中删除任意数目的字符。
+
+如果没有从字符串 `t` 中删除字符,那么得分为 `0` ,否则:
+
+- 令 `left` 为删除字符中的最小下标。
+- 令 `right` 为删除字符中的最大下标。
+
+字符串的得分为 `right - left + 1` 。
+
+请你返回使 `t` 成为 `s` 子序列的最小得分。
+
+一个字符串的 **子序列** 是从原字符串中删除一些字符后(也可以一个也不删除),剩余字符不改变顺序得到的字符串。(比方说 `"ace"` 是 `"***a\***b***c\***d***e\***"` 的子序列,但是 `"aec"` 不是)。
+
+
+
+**示例 1:**
+
+```
+输入:s = "abacaba", t = "bzaa"
+输出:1
+解释:这个例子中,我们删除下标 1 处的字符 "z" (下标从 0 开始)。
+字符串 t 变为 "baa" ,它是字符串 "abacaba" 的子序列,得分为 1 - 1 + 1 = 1 。
+1 是能得到的最小得分。
+```
+
+**示例 2:**
+
+```
+输入:s = "cde", t = "xyz"
+输出:3
+解释:这个例子中,我们将下标为 0, 1 和 2 处的字符 "x" ,"y" 和 "z" 删除(下标从 0 开始)。
+字符串变成 "" ,它是字符串 "cde" 的子序列,得分为 2 - 0 + 1 = 3 。
+3 是能得到的最小得分。
+```
+
+
+
+**提示:**
+
+- `1 <= s.length, t.length <= 105`
+- `s` 和 `t` 都只包含小写英文字母。
+
+## solution
+
+是个思维题。
+
+实际上找s中每个位置的可以最大t的前缀和后缀即可。
+
+时间复杂度O(m+n)
+
+```python
+INF = int(1e20)
+
+
+class Solution:
+ def minimumScore(self, s: str, t: str) -> int:
+ ns, nt = len(s), len(t)
+ pre = []
+ j = 0
+ for i in range(ns):
+ if j < nt and s[i] == t[j]:
+ j += 1
+ pre.append(j)
+ # print(pre)
+ j = nt - 1
+ ans = INF
+ for i in range(ns - 1, -1, -1):
+ ans = min(ans, max(0, j - pre[i] + 1))
+ if j >= 0 and s[i] == t[j]:
+ j -= 1
+ # print(j)
+ ans = min(ans, j + 1)
+ ans = max(ans, 0)
+ return ans
+```
+
diff --git "a/_posts/Algorithms/leetcode/2023-02-19-6358. \346\233\264\346\226\260\346\225\260\347\273\204\345\220\216\345\244\204\347\220\206\346\261\202\345\222\214\346\237\245\350\257\242.md" "b/_posts/Algorithms/leetcode/2023-02-19-6358. \346\233\264\346\226\260\346\225\260\347\273\204\345\220\216\345\244\204\347\220\206\346\261\202\345\222\214\346\237\245\350\257\242.md"
new file mode 100644
index 0000000000..3b4268257b
--- /dev/null
+++ "b/_posts/Algorithms/leetcode/2023-02-19-6358. \346\233\264\346\226\260\346\225\260\347\273\204\345\220\216\345\244\204\347\220\206\346\261\202\345\222\214\346\237\245\350\257\242.md"
@@ -0,0 +1,77 @@
+---
+layout: post
+category: leetcode
+title: 6358. 更新数组后处理求和查询
+tags: leetcode
+---
+
+## title
+[problem link](https://leetcode.cn/problems/handling-sum-queries-after-update/)
+
+给你两个下标从 **0** 开始的数组 `nums1` 和 `nums2` ,和一个二维数组 `queries` 表示一些操作。总共有 3 种类型的操作:
+
+1. 操作类型 1 为 `queries[i] = [1, l, r]` 。你需要将 `nums1` 从下标 `l` 到下标 `r` 的所有 `0` 反转成 `1` 或将 `1` 反转成 `0` 。`l` 和 `r` 下标都从 **0** 开始。
+2. 操作类型 2 为 `queries[i] = [2, p, 0]` 。对于 `0 <= i < n` 中的所有下标,令 `nums2[i] = nums2[i] + nums1[i] * p` 。
+3. 操作类型 3 为 `queries[i] = [3, 0, 0]` 。求 `nums2` 中所有元素的和。
+
+请你返回一个数组,包含所有第三种操作类型的答案。
+
+
+
+**示例 1:**
+
+```
+输入:nums1 = [1,0,1], nums2 = [0,0,0], queries = [[1,1,1],[2,1,0],[3,0,0]]
+输出:[3]
+解释:第一个操作后 nums1 变为 [1,1,1] 。第二个操作后,nums2 变成 [1,1,1] ,所以第三个操作的答案为 3 。所以返回 [3] 。
+```
+
+**示例 2:**
+
+```
+输入:nums1 = [1], nums2 = [5], queries = [[2,0,0],[3,0,0]]
+输出:[5]
+解释:第一个操作后,nums2 保持不变为 [5] ,所以第二个操作的答案是 5 。所以返回 [5] 。
+```
+
+
+
+**提示:**
+
+- `1 <= nums1.length,nums2.length <= 105`
+- `nums1.length = nums2.length`
+- `1 <= queries.length <= 105`
+- `queries[i].length = 3`
+- `0 <= l <= r <= nums1.length - 1`
+- `0 <= p <= 106`
+- `0 <= nums1[i] <= 1`
+- `0 <= nums2[i] <= 109`
+
+## solution
+
+线段树板子题。
+
+```python
+
+class Solution:
+ def handleQuery(self, nums1: List[int], nums2: List[int], queries: List[List[int]]) -> List[int]:
+ sg = SegmentTree()
+ sg.op_update = SegOpUpdate.Update_Reverse
+ sg.op_collect = SegOpCollect.Collect_Sum
+ sg.build_with_data(nums1)
+ n = len(nums1)
+ total = sum(nums2)
+ ans = []
+ for v in queries:
+ if v[0] == 1:
+ l, r = v[1], v[2]
+ sg.update_interval(l, r, 1)
+ elif v[0] == 2:
+ p = v[1]
+ total += sg.query_interval(0, n-1) * p
+ elif v[0] == 3:
+ ans.append(total)
+ return ans
+
+```
+
diff --git "a/_posts/Algorithms/leetcode/2023-03-03-1487. \344\277\235\350\257\201\346\226\207\344\273\266\345\220\215\345\224\257\344\270\200.md" "b/_posts/Algorithms/leetcode/2023-03-03-1487. \344\277\235\350\257\201\346\226\207\344\273\266\345\220\215\345\224\257\344\270\200.md"
new file mode 100644
index 0000000000..1158f9a13b
--- /dev/null
+++ "b/_posts/Algorithms/leetcode/2023-03-03-1487. \344\277\235\350\257\201\346\226\207\344\273\266\345\220\215\345\224\257\344\270\200.md"
@@ -0,0 +1,104 @@
+---
+layout: post
+category: leetcode
+title: 1487. 保证文件名唯一
+tags: leetcode
+---
+
+## title
+[problem link](https://leetcode.cn/problems/making-file-names-unique/)
+
+给你一个长度为 `n` 的字符串数组 `names` 。你将会在文件系统中创建 `n` 个文件夹:在第 `i` 分钟,新建名为 `names[i]` 的文件夹。
+
+由于两个文件 **不能** 共享相同的文件名,因此如果新建文件夹使用的文件名已经被占用,系统会以 `(k)` 的形式为新文件夹的文件名添加后缀,其中 `k` 是能保证文件名唯一的 **最小正整数** 。
+
+返回长度为 *`n`* 的字符串数组,其中 `ans[i]` 是创建第 `i` 个文件夹时系统分配给该文件夹的实际名称。
+
+
+
+**示例 1:**
+
+```
+输入:names = ["pes","fifa","gta","pes(2019)"]
+输出:["pes","fifa","gta","pes(2019)"]
+解释:文件系统将会这样创建文件名:
+"pes" --> 之前未分配,仍为 "pes"
+"fifa" --> 之前未分配,仍为 "fifa"
+"gta" --> 之前未分配,仍为 "gta"
+"pes(2019)" --> 之前未分配,仍为 "pes(2019)"
+```
+
+**示例 2:**
+
+```
+输入:names = ["gta","gta(1)","gta","avalon"]
+输出:["gta","gta(1)","gta(2)","avalon"]
+解释:文件系统将会这样创建文件名:
+"gta" --> 之前未分配,仍为 "gta"
+"gta(1)" --> 之前未分配,仍为 "gta(1)"
+"gta" --> 文件名被占用,系统为该名称添加后缀 (k),由于 "gta(1)" 也被占用,所以 k = 2 。实际创建的文件名为 "gta(2)" 。
+"avalon" --> 之前未分配,仍为 "avalon"
+```
+
+**示例 3:**
+
+```
+输入:names = ["onepiece","onepiece(1)","onepiece(2)","onepiece(3)","onepiece"]
+输出:["onepiece","onepiece(1)","onepiece(2)","onepiece(3)","onepiece(4)"]
+解释:当创建最后一个文件夹时,最小的正有效 k 为 4 ,文件名变为 "onepiece(4)"。
+```
+
+**示例 4:**
+
+```
+输入:names = ["wano","wano","wano","wano"]
+输出:["wano","wano(1)","wano(2)","wano(3)"]
+解释:每次创建文件夹 "wano" 时,只需增加后缀中 k 的值即可。
+```
+
+**示例 5:**
+
+```
+输入:names = ["kaido","kaido(1)","kaido","kaido(1)"]
+输出:["kaido","kaido(1)","kaido(2)","kaido(1)(1)"]
+解释:注意,如果含后缀文件名被占用,那么系统也会按规则在名称后添加新的后缀 (k) 。
+```
+
+
+
+**提示:**
+
+- `1 <= names.length <= 5 * 10^4`
+- `1 <= names[i].length <= 20`
+- `names[i]` 由小写英文字母、数字和/或圆括号组成。
+
+## solution
+
+set去重,维护一个name的最小可用数字。只在错误时移动。
+
+```python
+class Solution:
+ def getFolderNames(self, names: List[str]) -> List[str]:
+ d = set()
+ mv = {}
+ ans = []
+ for name in names:
+ if name not in d:
+ d.add(name)
+ mv[name] = 1
+ ans.append(name)
+ continue
+ x = None
+ while True:
+ x = "{}({})".format(name, mv[name])
+ if x in d:
+ mv[name] += 1
+ else:
+ break
+ d.add(x)
+ ans.append(x)
+ mv[x] = 1
+ return ans
+
+```
+
diff --git "a/_posts/Algorithms/leetcode/2023-03-14-1605. \347\273\231\345\256\232\350\241\214\345\222\214\345\210\227\347\232\204\345\222\214\346\261\202\345\217\257\350\241\214\347\237\251\351\230\265.md" "b/_posts/Algorithms/leetcode/2023-03-14-1605. \347\273\231\345\256\232\350\241\214\345\222\214\345\210\227\347\232\204\345\222\214\346\261\202\345\217\257\350\241\214\347\237\251\351\230\265.md"
new file mode 100644
index 0000000000..fc9fc02d73
--- /dev/null
+++ "b/_posts/Algorithms/leetcode/2023-03-14-1605. \347\273\231\345\256\232\350\241\214\345\222\214\345\210\227\347\232\204\345\222\214\346\261\202\345\217\257\350\241\214\347\237\251\351\230\265.md"
@@ -0,0 +1,103 @@
+---
+layout: post
+category: leetcode
+title: 1605. 给定行和列的和求可行矩阵
+tags: leetcode
+---
+
+## title
+[problem link](https://leetcode.cn/problems/find-valid-matrix-given-row-and-column-sums/)
+
+给你两个非负整数数组 `rowSum` 和 `colSum` ,其中 `rowSum[i]` 是二维矩阵中第 `i` 行元素的和, `colSum[j]` 是第 `j` 列元素的和。换言之你不知道矩阵里的每个元素,但是你知道每一行和每一列的和。
+
+请找到大小为 `rowSum.length x colSum.length` 的任意 **非负整数** 矩阵,且该矩阵满足 `rowSum` 和 `colSum` 的要求。
+
+请你返回任意一个满足题目要求的二维矩阵,题目保证存在 **至少一个** 可行矩阵。
+
+
+
+**示例 1:**
+
+```
+输入:rowSum = [3,8], colSum = [4,7]
+输出:[[3,0],
+ [1,7]]
+解释:
+第 0 行:3 + 0 = 3 == rowSum[0]
+第 1 行:1 + 7 = 8 == rowSum[1]
+第 0 列:3 + 1 = 4 == colSum[0]
+第 1 列:0 + 7 = 7 == colSum[1]
+行和列的和都满足题目要求,且所有矩阵元素都是非负的。
+另一个可行的矩阵为:[[1,2],
+ [3,5]]
+```
+
+**示例 2:**
+
+```
+输入:rowSum = [5,7,10], colSum = [8,6,8]
+输出:[[0,5,0],
+ [6,1,0],
+ [2,0,8]]
+```
+
+**示例 3:**
+
+```
+输入:rowSum = [14,9], colSum = [6,9,8]
+输出:[[0,9,5],
+ [6,0,3]]
+```
+
+**示例 4:**
+
+```
+输入:rowSum = [1,0], colSum = [1]
+输出:[[1],
+ [0]]
+```
+
+**示例 5:**
+
+```
+输入:rowSum = [0], colSum = [0]
+输出:[[0]]
+```
+
+
+
+**提示:**
+
+- `1 <= rowSum.length, colSum.length <= 500`
+- `0 <= rowSum[i], colSum[i] <= 108`
+- `sum(rowSum) == sum(colSum)`
+
+
+
+## solution
+
+贪心,遇到个元素,就往最大了放,因为后面元素可以为0. [参考](https://leetcode.cn/problems/find-valid-matrix-given-row-and-column-sums/solution/mei-you-si-lu-yi-ge-dong-hua-miao-dong-f-eezj/)
+
+```python
+class Solution:
+ def restoreMatrix(self, rowSum: List[int], colSum: List[int]) -> List[List[int]]:
+ n, m = len(rowSum), len(colSum)
+ res = [[0 for _ in range(m)] for _ in range(n)]
+ for i, r in enumerate(rowSum):
+ for j, c in enumerate(colSum):
+ res[i][j] = min(r, c)
+ r -= res[i][j]
+ colSum[j] -= res[i][j]
+ return res
+
+
+if __name__ == '__main__':
+ f = Solution().restoreMatrix
+
+ print("actual:", f(rowSum=[3, 8], colSum=[4, 7]), "should:", [[3, 0], [1, 7]])
+ print("actual:", f(rowSum=[5, 7, 10], colSum=[8, 6, 8]), "should:", [[0, 5, 0], [6, 1, 0], [2, 0, 8]])
+ print("actual:", f(rowSum=[14, 9], colSum=[6, 9, 8]), "should:", [[0, 9, 5], [6, 0, 3]])
+ print("actual:", f(rowSum=[1, 0], colSum=[1]), "should:", [[1], [0]])
+ print("actual:", f(rowSum=[0], colSum=[0]), "should:", [[0]])
+```
+
diff --git "a/_posts/Algorithms/leetcode/2023-03-18-1615. \346\234\200\345\244\247\347\275\221\347\273\234\347\247\251.md" "b/_posts/Algorithms/leetcode/2023-03-18-1615. \346\234\200\345\244\247\347\275\221\347\273\234\347\247\251.md"
new file mode 100644
index 0000000000..8e3dc9ffed
--- /dev/null
+++ "b/_posts/Algorithms/leetcode/2023-03-18-1615. \346\234\200\345\244\247\347\275\221\347\273\234\347\247\251.md"
@@ -0,0 +1,102 @@
+---
+layout: post
+category: leetcode
+title: 1615. 最大网络秩
+tags: leetcode
+---
+
+## title
+[problem link](https://leetcode.cn/problems/maximal-network-rank/)
+
+`n` 座城市和一些连接这些城市的道路 `roads` 共同组成一个基础设施网络。每个 `roads[i] = [ai, bi]` 都表示在城市 `ai` 和 `bi` 之间有一条双向道路。
+
+两座不同城市构成的 **城市对** 的 **网络秩** 定义为:与这两座城市 **直接** 相连的道路总数。如果存在一条道路直接连接这两座城市,则这条道路只计算 **一次** 。
+
+整个基础设施网络的 **最大网络秩** 是所有不同城市对中的 **最大网络秩** 。
+
+给你整数 `n` 和数组 `roads`,返回整个基础设施网络的 **最大网络秩** 。
+
+
+
+**示例 1:**
+
+****
+
+```
+输入:n = 4, roads = [[0,1],[0,3],[1,2],[1,3]]
+输出:4
+解释:城市 0 和 1 的网络秩是 4,因为共有 4 条道路与城市 0 或 1 相连。位于 0 和 1 之间的道路只计算一次。
+```
+
+**示例 2:**
+
+****
+
+```
+输入:n = 5, roads = [[0,1],[0,3],[1,2],[1,3],[2,3],[2,4]]
+输出:5
+解释:共有 5 条道路与城市 1 或 2 相连。
+```
+
+**示例 3:**
+
+```
+输入:n = 8, roads = [[0,1],[1,2],[2,3],[2,4],[5,6],[5,7]]
+输出:5
+解释:2 和 5 的网络秩为 5,注意并非所有的城市都需要连接起来。
+```
+
+
+
+**提示:**
+
+- `2 <= n <= 100`
+- `0 <= roads.length <= n * (n - 1) / 2`
+- `roads[i].length == 2`
+- `0 <= ai, bi <= n-1`
+- `ai != bi`
+- 每对城市之间 **最多只有一条** 道路相连
+
+通过
+
+## solution
+
+贪心,直接看度最大的两组节点即可。
+
+```python
+class Solution:
+ def maximalNetworkRank(self, n: int, roads: List[List[int]]) -> int:
+ degree = collections.Counter()
+ for v in range(n):
+ degree[v] = 0
+ for a, b in roads:
+ degree[a] += 1
+ degree[b] += 1
+ import heapq
+ x = heapq.nlargest(2, set(degree.values()))
+ first, second = 0, 0
+ if len(x) >= 1:
+ first = x[0]
+ if len(x) >= 2:
+ second = x[1]
+ count2nodes = collections.defaultdict(list)
+ for k, v in degree.items():
+ count2nodes[v].append(k)
+ roads_set = set(tuple(v) for v in roads)
+ if len(count2nodes[first]) == 1:
+ u = count2nodes[first][0]
+ for v in count2nodes[second]:
+ if not ((u, v) in roads_set or (v, u) in roads_set):
+ return first + second
+ return first + second - 1
+ import math
+ n1, n2 = len(count2nodes[first]), len(count2nodes[second])
+ if math.comb(n1, 2) > len(roads):
+ return 2 * first
+ for u in count2nodes[first]:
+ for v in count2nodes[first]:
+ if u != v and (u, v) not in roads_set and (v, u) not in roads_set:
+ return first * 2
+ return max(2 * first - 1, 0)
+```
+
diff --git "a/_posts/Algorithms/leetcode/2023-04-08-1017. \350\264\237\344\272\214\350\277\233\345\210\266\350\275\254\346\215\242.md" "b/_posts/Algorithms/leetcode/2023-04-08-1017. \350\264\237\344\272\214\350\277\233\345\210\266\350\275\254\346\215\242.md"
new file mode 100644
index 0000000000..16b18800c0
--- /dev/null
+++ "b/_posts/Algorithms/leetcode/2023-04-08-1017. \350\264\237\344\272\214\350\277\233\345\210\266\350\275\254\346\215\242.md"
@@ -0,0 +1,81 @@
+---
+layout: post
+category: leetcode
+title: 1017. 负二进制转换
+tags: leetcode
+---
+
+## title
+[problem link](https://leetcode.cn/problems/convert-to-base-2/)
+
+给你一个整数 `n` ,以二进制字符串的形式返回该整数的 **负二进制(`base -2`)**表示。
+
+**注意,**除非字符串就是 `"0"`,否则返回的字符串中不能含有前导零。
+
+
+
+**示例 1:**
+
+```
+输入:n = 2
+输出:"110"
+解释:(-2)2 + (-2)1 = 2
+```
+
+**示例 2:**
+
+```
+输入:n = 3
+输出:"111"
+解释:(-2)2 + (-2)1 + (-2)0 = 3
+```
+
+**示例 3:**
+
+```
+输入:n = 4
+输出:"100"
+解释:(-2)2 = 4
+```
+
+
+
+**提示:**
+
+- `0 <= n <= 109`
+
+## solution
+
+负二进制的表达。
+
+和二进制一样,但记得要处理下-1,每一位可能是-1,0,1,要把-1转换下,变成1.
+
+```python
+class Solution:
+ def baseNeg2(self, n: int) -> str:
+ if n == 0:
+ return '0'
+ ans = []
+ b = -2
+ while n != 0:
+ x = n % b
+ ans.append(str(abs(x)))
+ if x < 0:
+ x += abs(b) # 变成正数
+ n = (n - x) // b
+ ans = ans[::-1]
+ return "".join(ans)
+```
+
+
+
+延伸
+
+
+
+转负三进制怎么办
+
+b=-3即可。它可以转任意进制。处理好负数即可。
+
+
+
diff --git "a/_posts/DailyLife/2018-02-07-\347\202\222\350\217\234.md" "b/_posts/DailyLife/2018-02-07-\347\202\222\350\217\234.md"
deleted file mode 100644
index 49258f5d0b..0000000000
--- "a/_posts/DailyLife/2018-02-07-\347\202\222\350\217\234.md"
+++ /dev/null
@@ -1,132 +0,0 @@
----
-layout: post
-category: DailyLife
-title: 炒菜
-tags: DailyLife
----
-
-## 炒菜
-
-### 土豆丝+肉丝
-
-土豆去皮变成丝。 需要先洗一遍,去掉淀粉,否则氧化发黑,可以放水里,用到再捞出来。
-
-
-
-肉丝洗3遍。
-
-
-
-热锅, 放油, 底部全湿, 放肉丝, 2勺 料酒, 2勺生抽, 半勺老抽。
-
-
-
-放土豆丝, 每5s翻炒,放鸡精, 如果老抽多了可以不放盐。 菜基本熟时放葱。
-
-
-
-
-
-### 炒卷心菜
-
-大小 长3*3大小,不要梗。
-
-
-
-热锅冷油, 油比肉丝少点。 放卷心菜, 生抽2勺, 鸡精, 葱。
-
-
-
-**要干锅时加热水。**
-
-
-
-### 五花肉+荷兰豆
-
-不需要豆油
-
-五花肉过于肥腻,需要锅里不放油 闷一会,因为不是肉丝所以没那么容易老。
-
-直到肉变色,炸出油。
-
-加蒜 加料酒,生抽老抽。因为肉比较大,可以加点水让配料入味
-
-然后放荷兰豆炒。
-
-
-
-### 蒜薹+肉丝
-
-蒜薹切段,煮50秒,捞出来,这是为了避免蒜薹熟的慢。
-
-肉丝做法 + 蒜薹。
-
-### 红烧鸡翅根
-
-鸡翅根切几道,红烧时入味
-
-鸡翅根煮熟。
-
-放油,鸡翅根,料酒,生抽,老抽
-
-加水,4分之一高度。
-
-加盐。
-
-放葱。
-
-味素。
-
-红烧到无水
-
-
-### 茄子肉丝
-茄子 切成丝:
-
-1. 先斜着切片,5mm厚即可,茄子熟时缩的多。
-
-2. 片再切丝,5mm宽
-
-肉丝做法
-
-茄子含水少,避免干锅需要加点水。
-
-
-### 芹菜肉丝
-
-芹菜:
-1. 长度2cm
-2. 宽的芹菜要中间切一刀分开
-3. 先去叶子,再去根,再切
-
-肉丝做法
-
-芹菜含水多
-
-### 红烧鸡爪
-
-洗干净 去指甲
-
-鸡爪炖2min,快熟那种
-
-油,白砂糖让溶解,蒜,
-
-放鸡爪,生抽2勺,老抽和耗油各1勺, 耗油是提现的
-
-一罐300ml的啤酒,没有啤酒就热水, 水大概刚好到鸡爪上限那, 挺多的
-
-一个八角
-
-中火20min, 直到快没有汤了
-
-葱花,味素。
-
-
-
-## 韭菜鸡蛋
-
-- 一把韭菜,4个鸡蛋。
-- 韭菜洗干净,去死皮,切根,切长度为1.5-2cm左右
-- 锅里放油,放韭菜大概8-9分熟,颜色变了就可以,捞出来韭菜去水。
-- 放油,放鸡蛋,7-8分熟,成块了,放韭菜,加鸡精,加盐。
-- 注意:韭菜2-3s就变颜色了,要勤翻
diff --git "a/_posts/English/2020-12-09-\350\213\261\350\257\255\345\255\246\344\271\240.md" "b/_posts/English/2020-12-09-\350\213\261\350\257\255\345\255\246\344\271\240.md"
new file mode 100644
index 0000000000..62a179e0d1
--- /dev/null
+++ "b/_posts/English/2020-12-09-\350\213\261\350\257\255\345\255\246\344\271\240.md"
@@ -0,0 +1,169 @@
+---
+layout: post
+category: English
+title: 英语学习
+tags: English
+---
+
+# 语法汇总
+
+[语法顺口溜](https://zhuanlan.zhihu.com/p/146873536)
+
+## 单词
+
+[语法-单词各种形式变化规则](https://mafulong.github.io/2021/01/02/%E8%AF%AD%E6%B3%95-%E5%8D%95%E8%AF%8D%E5%90%84%E7%A7%8D%E5%BD%A2%E5%BC%8F%E5%8F%98%E5%8C%96%E8%A7%84%E5%88%99/)
+
+## 介词
+
+
+
+## 从句
+
+[三大从句](https://mm.edrawsoft.cn/template/39526)
+
+[四级语法: 从句](https://mm.edrawsoft.cn/template/57209)
+
+从句时态:
+
+1. **主将从现**
+
+i will hit u when you come here
+
+if it rains, i will hit u.
+
+2. **主过从过**
+
+复合句有先后关系,过去+过去完成时, eg. when he came there, the train had gone.
+
+3. **主现从任**
+
+he tells me that u have died
+
+## 疑问句
+
+[参考个人单独blog](https://mafulong.github.io/2021/01/02/%E8%AF%AD%E6%B3%95-%E7%96%91%E9%97%AE%E5%8F%A5/)
+
+
+## 时态
+
+[参考个人单独blog](https://mafulong.github.io/2021/01/02/%E8%AF%AD%E6%B3%95-%E6%97%B6%E6%80%81/)
+
+## 倒装
+
+[参考个人单独blog](https://mafulong.github.io/2021/01/02/%E8%AF%AD%E6%B3%95-%E5%80%92%E8%A3%85%E5%8F%A5/)
+
+## 虚拟语气
+
+[参考个人单独blog](https://mafulong.github.io/2021/01/02/%E8%AF%AD%E6%B3%95-%E8%99%9A%E6%8B%9F%E8%AF%AD%E6%B0%94/)
+
+## “限制性定语从句”和“非限制性定语从句”的区别
+
+> [参考](https://zhuanlan.zhihu.com/p/30548008)
+
+> She despised people ***who flattered her***. 这是限制性的。非限制性就是表定语 非限制的
+> (她看不起**那些吹捧她的**人。)
+
+在上面的示例中,定语从句“who flattered her”起到了**限制名词**的作用(即缩小了名词的表示范围)。
+
+因此,我们称这类定语从句为**限制性定语从句**。
+
+
+
+在有些场景下,先行词的指向已经是唯一的了,此时就无法再缩小这个词的表示范围了。例如:
+
+> I made a card for mom ***who loves me most**.* (×)
+> (我给**最爱我的**那个妈妈做了一张卡片。)
+
+每个人只有一个妈妈,所以“最爱我的那个妈妈”的表述明显不合逻辑,此时我们就需要用到**非限制性定语从句**。
+
+所谓的非限制性定语从句,就是**使用“逗号”将定语从句与先行词隔开**,即:
+
+> I made a card for mom, ***who loves me most**.*
+> (我给妈妈做了一张卡片,**她最爱我**。)
+
+因为非限制性定语从句的作用是:**不直接修饰先行词,只为先行词提供一些补充的信息。**
+
+
+
+①限定性定语从句: 从句不能省略,如果省略整个句子意思不完整。
+
+非限定性定语从句: 从句可以省略,如果省略整个句子意思仍然完整 。
+
+②限定性定语从句: 先行词可以用that 引导。
+
+非限定性定语从句: 先行词不可以用that 引导。
+
+eg. I like read the book that you lend me.
+
+③限定性定语从句: 引导词有时可以省略。
+
+非限定性定语从句: 引导词不可以省略。
+
+④限定性定语从句: 主句与从句不需要用逗号隔开。
+
+非限定性定语从句: 主句与从句需要用逗号隔开。
+
+⑤限定性定语从句: 从句只修饰先行词。
+
+非限定性定语从句:从句既可以修饰先行词,也可以修饰整个句子或句子的一部分。
+
+
+
+## 逗号使用
+
+> [参考](https://zhuanlan.zhihu.com/p/46736877)
+
+1、当有三个或三个以上并列的单词或短语时,这些单词或短语要用逗号隔开,而且最后一个单词或短语一般都会用and或or连接,如:
+
+We had coffee, cheese and crackers and grapes.
+
+2、当两个前置形容词并列且可以调换顺序时,要用逗号隔开,如:
+
+He is a strong, healthy man. vs. He is a healthy, strong man.
+
+
+
+1、如果是以从句开头,则要在从句末尾用逗号隔开,如:
+
+If you are not sure about this, let me know now.
+
+2、如果开头的是介绍性短语,一般也要用逗号隔开,如:
+
+Having finally arrived in town, we went shopping.
+
+3、如果介绍性短语是以介词开头引导的,介词后面如果跟的是句子的主语,则要用逗号。则无论这个短语包含多少个单词,都无需用逗号隔开,如:
+
+Between your house on Main Street and my house on Grand Avenue, the mayor's mansion stands proudly.
+
+
+
+1、同位语,如:
+
+My best friend, Joe, arrived.
+
+2、非限定性定语从句(非限制作用,也不能用that),如:
+
+Jill, who is my sister, shut the door.
+
+3、分词短语,如:
+
+The man, knowing it was late, hurried home.
+
+# 学习资源
+
+## English学习资源
+
+计算机英语部分参考另一个博客
+
+## English-level-up-tips-for-Chinese
+
+网址:https://github.com/byoungd/English-level-up-tips-for-Chinese
+
+## github上“读”北大(北大课程资料民间整理)
+
+网址:https://lib-pku.github.io/
+
+github:https://github.com/lib-pku/libpku
+
+
+
diff --git "a/_posts/English/2021-01-02-\345\217\221\351\237\263-\351\237\263\346\240\207.md" "b/_posts/English/2021-01-01-\345\217\221\351\237\263-\351\237\263\346\240\207.md"
similarity index 69%
rename from "_posts/English/2021-01-02-\345\217\221\351\237\263-\351\237\263\346\240\207.md"
rename to "_posts/English/2021-01-01-\345\217\221\351\237\263-\351\237\263\346\240\207.md"
index 3db6572c3d..4265fca9ad 100644
--- "a/_posts/English/2021-01-02-\345\217\221\351\237\263-\351\237\263\346\240\207.md"
+++ "b/_posts/English/2021-01-01-\345\217\221\351\237\263-\351\237\263\346\240\207.md"
@@ -7,6 +7,12 @@ tags: English
## 发音-音标
+欧陆词典用的是DJ音标新版。也是咱们常用的 英的,有长短。而美音无长短,音标写法上。
+
+影响发音的因素:圆唇度、舌位高低、舌位前后。舌位影响了开头大小。因此学音标应以舌位为主。
+
+### 音标分类
+
分类1

@@ -17,28 +23,51 @@ tags: English
-æ : ai, such as trap.
-
-
+### BBC经典发音教程
[可学习的bilibili视频: BBC经典发音教程](https://www.bilibili.com/video/BV1Y4411M7Ac?p=2)
+### 音标发音文字注解
+
元音:
-- /ɪ/ 舌抵下齿,双唇扁平分开,牙床近于全舌,发短促之“一”音。 是字母i或y在单词中的发音,发此音要短促而轻快。 **bit, hit, minute/minit/**
+- /ɪ/ 舌抵下齿,双唇扁平分开,牙床近于全舌,发短促之“一”音。类似军训一二一的yie。 是字母i或y在单词中的发音,发此音要短促而轻快。 **bit, hit, minute/minit/**
- /i:/ 舌抵下齿,双唇扁平作微笑状,发“一”之长音。 是字母ea、ee、ey、ie、或ei在单词中的发音,此音是长元音,一定注意把音发足。
-- /ʊ/ 双唇成圆形,牙床近于半合,舌尖不触下齿,自然而不用力,发短促之“屋”音。 是字母u、oo或ou在单词中的发音
-- /u:/ 双唇成圆形,牙床近于半合,舌尖不触下齿,自然而不用力,发 “屋”之长音。 是字母oo或ou在单词中的发音
-- /ʌ/ 双唇平放,牙床半开,舌尖抵住下龈,舌后微微升起,发短促之“阿”音 是字母o或u在单词中的发音
+
+前者嘴唇放松,双齿高度大概小指尖高。舌位低于 并 后于 后者。后者嘴唇微笑,cheese那样拉开。
+
+sit, seat。
+
+
+
+- /ʊ/ 双唇成圆形,牙床近于半合,舌尖不触下齿,自然而不用力,发短促之“屋”音。 是字母u、oo或ou在单词中的发音 book, took, foot, could, would.
+- /u:/ 双唇成圆形,牙床近于半合,舌尖不触下齿,自然而不用力,发 “屋”之长音。 是字母oo或ou在单词中的发音 goose, two, food, noon, fool
+
+前者者口型更大,舌位更低。
+
+
+
+- /ə/ 舌上抬,唇成自然状态,口半开半闭,发“厄”之短音。 是字母a、o、u、e、or、er或ur在单词中的发音. about. problem, memory. Easily. Analysis. 中央元音元音图居中,舌位和/з:/差不多
+
+- /з:/ 舌上抬,唇成自然状态,口半开半闭,发“厄”之长音。 是字母er、ir、or或ur在单词中的发音。 her, person,learn,sir, world.
+
+
+
+- /ʌ/ 双唇平放,牙床半开,舌尖抵住下龈,舌后微微升起,发短促之“阿”音 是字母o或u在单词中的发音。 but, hut, must。舌位低于/ə/
+
- /ɑ:/ 双唇张而不圆,牙床大开,舌后微升,舌尖向后升缩微离下齿,发“阿”之长音。 是字母er在闭音节或重读闭音节中的发音也是字母a在以st结尾的单词中的读音。
+
- /ɒ/ 双唇稍微向外突出圆形,舌后升起,舌尖不触下齿,发“噢”音 是字母o在单词中的发音
-- /ɔ:/ 双唇界于开闭、圆唇之间,牙床半开渐至全开,舌尖卷上再过渡为卷后。 是字母o、al、or、oar、our或oor在单词中的发音
-- /ə/ 舌上抬,唇成自然状态,口半开半闭,发“厄”之短音。 是字母a、o、u、e、or、er或ur在单词中的发音
-- /з:/ 舌上抬,唇成自然状态,口半开半闭,发“厄”之长音。 是字母er、ir、or或ur在单词中的发音
-- /e/舌近硬腭,舌尖顶下齿,牙床半开半合,作微笑状。 是字母e或ea在单词中的发音
-- /æ/ 双唇扁平,舌前微升,舌尖抵住下龈,牙床开,软腭升起,唇自然开放。 是字母a在闭音节或重读闭音节中的发音。 **和/e/的区别,前者两指宽,像绵羊叫,后者一指宽。**
+
+- /ɔ:/ 双唇界于开闭、圆唇之间,牙床半开渐至全开,舌尖卷上再过渡为卷后。 是字母o、al、or、oar、our或oor在单词中的发音. caught bought law。 这个英音和美音不一样。美音类似噢,英音类似哦。
+
+
+
+- /e/舌近硬腭,舌尖顶下齿,牙床半开半合,作微笑状。 是字母e或ea在单词中的发音。 bed, get, pet, let, met, set. 舌位比/i:/低。
+
+- /æ/ 双唇扁平,舌前微升,舌尖抵住下龈,牙床开,软腭升起,唇自然开放。 是字母a在闭音节或重读闭音节中的发音。 **和/e/的区别,前者/æ/ 两指宽,像绵羊叫,后者/e/一指宽。**
@@ -56,8 +85,8 @@ tags: English
- /ð/ 上下齿咬舌尖,送出气流,并使舌齿互相摩擦,须振动声带。类似z。 this, that, then, there
- /s/ 双唇微开,上下齿接近于合拢状态,舌尖抵住下龈,气流从牙缝送出。
- /z/ 双唇微开,上下齿接近于合拢状态,舌尖抵住下龈,气流从牙缝送出,须振动声带。
-- /∫/ 双唇微开,向前突出,舌尖升近上龈,用力将气息送出来。
-- /ʒ/ 双唇微开,向前突出,舌尖升近上龈,用力将气息送出来,须振动声带。
+- /∫/ 双唇微开,向前突出,**舌尖升近上龈**,用力将气息送出来。
+- /ʒ/ 双唇微开,向前突出,舌尖升近上龈,用力将气息送出来,须振动声带。**是声带震动版的/∫/**
- /t∫/ 双唇微开,先用舌尖抵上齿龈,突然张开,使气流外冲而成音。
- /dʒ/ 双唇微开,先用舌尖抵上齿龈,突然张开,使气流外冲而成音,须振动声带。
- /m/ 双唇闭拢,舌放平,振动声带,使气流从鼻腔出来。
@@ -68,6 +97,7 @@ tags: English
- /r/ 唇形稍圆,舌身略凹,舌尖上卷,振动声带。
- /w/ 双唇突出,呈尖圆形,舌后升向软腭,气息流过,须振动声带。
- /j/ 双唇微开,舌抵下齿贴近硬腭,气流摩擦而出。
+- /dz/ 类似汉语里资。对比/ts/
@@ -84,6 +114,8 @@ tags: English
+### 音标区分
+
**长元音和短元音区别:不是长短,是松和紧。松元音只动舌头和声带,不动嘴唇。**
**双元音和单元音区别:[e]是单元音,发声短促:dead [ded] , [ai]是双元音,有从[a]到[i]的一个过渡过程:die [dai] (双元音过渡在汉语里是没有的)**
@@ -92,10 +124,36 @@ tags: English
常见区别:
-- [辅音/m/、/n/与/ŋ/](https://www.bilibili.com/video/BV1Ae41147Ng/?spm_id_from=trigger_reload)
-- [/æ/ 和 /e/](/æ/ 和 /e/)
-- [/u:/和/u/](/u:/和/u/)
-- [清辅音θ与s](https://www.bilibili.com/video/BV1X7411S7V8?spm_id_from=333.337.search-card.all.click)
+- [辅音/m/、/n/与/ŋ/](https://www.bilibili.com/video/BV1Ae41147Ng/?spm_id_from=trigger_reload) m是闭口,n嘴唇微张但牙齿闭合,最后那个是中度张嘴。
+- [/æ/ 和 /e/](https://www.bilibili.com/video/BV1o7411M7cV?spm_id_from=333.999.0.0&vd_source=4c51dba622ffb91bed5205311847907b) ae和/e/的区别,前者两指宽,像绵羊叫,后者一指宽。
+- [双元音/aɪ/与 单元音/æ/](https://www.bilibili.com/video/BV1xg4y187CT?spm_id_from=333.999.0.0&vd_source=4c51dba622ffb91bed5205311847907b) 前者双元音后者单元音 但语速快了就无法区分了
+- [/u:/和/u/](https://www.bilibili.com/video/BV1d7411M7i1?spm_id_from=333.999.0.0)
+- [清辅音θ与s](https://www.bilibili.com/video/BV1X7411S7V8?spm_id_from=333.337.search-card.all.click) 前者 上下齿咬舌尖。 后者双唇微开,上下齿接近于合拢状态
+
+### 元音图
+
+元音图
+
+
+
+注意: 红色是汉语拼音,黄色是美国英语。不圆唇的在前,圆唇在后。开口大小就是舌位高低
+
+
+
+元音的舌面不能与硬腭接触,否则就成了辅音。
+
+
+
+这有一个看和听发音的[网站](https://tfcs.baruch.cuny.edu/consonants-vowels/)
+
+
+
+### 英语兔学习笔记
+
+可每日英语听力上看,免费。
+
+- /ɪ/舌位比/i:/低,类似军训一二一里的一。bit, fit, hit, fish. 舌位过高是错误方式,不能读 中文 币 的韵母。
+-
## 音节
@@ -117,7 +175,39 @@ tags: English
比如单词later和latter。我们把这两个词按照这种原理分开,分别就是la/ter和lat/ter。
-那么这样分完有什么意义呢,当然有意义,而且意义重大,因为它能让你正确判断单词的发音。不用看音标。看下面
+那么这样分完有什么意义呢,当然有意义,而且意义重大,因为它能让你正确判断单词的发音。不用看音标。
+
+
+
+另外 辅音+l/e结尾,也可以构成音节 apple/pl/ bicycle/baskl/
+
+### 重读音节
+
+什么是重读音节呢?首先普及一下单音节的单词是没有重读符号的,但是要重读。比如:get,let,must.say等。
+
+1. 一个音节就重读:(没有重读符号)me/mi/ lake/lek/ bread/bred/
+
+2. 一般2、3个音节的单词,重读在第一音节上 sister/'sst/ tiger/tag/
+
+ 特俗
+
+ ```python
+ \1. a开头+辅音
+
+ 举例:away/ we/ ago/gu/
+
+ \2. be/re开头
+
+ 举例:begin/bgn/ reply/rpla/
+
+ \3. de/es/im/mis开头
+
+ 举例:delay/dle/ improve/mpruv/
+ ```
+
+
+
+3. 3个或以上音节的单词,重读在倒数第三个音节上。 'family de'mocracy phy'losophy
@@ -133,22 +223,26 @@ tags: English
2、**闭音节**:英语中以一个或几个辅音字母(r w y 除外)结尾而中间只有一个元音字母的音节,称为**闭音节**。闭音节的元音字母不发它字母本身的音。
-如果这个音节在单词中是重读,那就是**重读闭音节**了。
+总结: 开音节:only元 或 者元+辅+不发音e; 闭音节: 剩下的
+
+### 重读闭音节
+
+如果这个音节在单词中是闭音节并且重读,那就是**重读闭音节**了。
重读闭音节即两个辅音中间夹一个短元音(即**“辅元辅”结尾**。)
-重读闭音节结尾,且词尾只有一个辅音字母,要**双写**。
+重读闭音节结尾,且词尾只有一个辅音字母,变ing要**双写**。
重读闭音节三要素
1.必须是重读音节;
-2.最后只有一个辅音字母;只有一个元音;
+2.最后只有一个辅音字母
3.只有一个元音,元音字母发短元音
-总结: 开音节:only元 或 者元+辅+不发音e; 闭音节: 剩下的
+
## 字母发音规则
@@ -158,6 +252,8 @@ tags: English
+
+
aeiou在非重读闭音节里,一般发/ə/, 比如doctor后面的o
@@ -241,4 +337,27 @@ z [ z ]
-
\ No newline at end of file
+
+
+
+
+## 常见单词音标
+
+who when where why what whom which
+
+while [/waɪl/](cmd://Speak/_us_/while)
+
+why [ /waɪ/](cmd://Speak/_us_/why)
+
+when [/wɛn/](cmd://Speak/_us_/when)
+
+
+
+Allow: [美 /əˈlaʊ/](cmd://Speak/_us_/allow) a lao.
+
+provide. [美 /prə'vaɪd/](cmd://Speak/_us_/provide) p rou
+
+Begin: [美 /bɪˈɡɪn/](cmd://Speak/_us_/begin) bi gin
+
+Again: [美 /ə'ɡɛn/](cmd://Speak/_us_/again) a gan
+
diff --git "a/_posts/English/2021-01-02-\345\217\221\351\237\263-\345\217\221\351\237\263\350\247\204\345\210\231.md" "b/_posts/English/2021-01-02-\345\217\221\351\237\263-\345\217\221\351\237\263\350\247\204\345\210\231.md"
index 03912e5f8b..984be368a6 100644
--- "a/_posts/English/2021-01-02-\345\217\221\351\237\263-\345\217\221\351\237\263\350\247\204\345\210\231.md"
+++ "b/_posts/English/2021-01-02-\345\217\221\351\237\263-\345\217\221\351\237\263\350\247\204\345\210\231.md"
@@ -5,44 +5,6 @@ title: 发音-发音规则
tags: English
---
-## 总结
-
-发音规则 昂克
-
-- 辅音元音连读: not at all, 如果辅音是/r/ /l/ /ŋ/, 辅音双写: for a
-- 元+元,添加连读,自动添加/j/或/w/, 只有i和u。do it, go out. /ɔː/自动加r, saw in
-- 特殊添加元音: /n/+/s/=/n ts/ since
-- 辅+辅, 三组内的略读只读后面的,所有辅音相同略读,浊音在前清辅音在后可略读前面的:v f, z s,ð θ. 不可略读:/tʃ/ /dʒ/
-- 特殊略读 nt+元音, 省略t :advantage
-- 吞音,三组里碰到后面是三组里非兄弟辅音就吞音(也包含其他非爆破辅音)。吞音保留时值和状态不发音, that cat
-- 吞音喉音停顿:/tən/ /dən/ 只留ən, written
-- 略读 h-droping: him, his, he, her
-- 略读 g-droping: doing. ing里的
-- 变音: about you. would you, rock you. /t/+/ju/;/d/+/ju/。 miss you: sh
-- 清辅音+元,清辅音浊化
-- 不同意群不连读
-- 元音+元音,如果读音相近,可以连一起,比如law office. lawwfis
-- schewa: for, of, have, or, and等,元音变成ə
-
-**总结2:**
-
-> 视频: https://www.bilibili.com/video/BV1SZ4y1K7Lr?p=6&spm_id_from=pageDriver
-
-- 元音挨着元音不容易读,所以才会区分a和an
-- 同化&异化
- - 同化:前面音 改变
- - 常见爆破音: k,t,d, 后加辅音,前面音发一半,也叫失去爆破。
- - 浊音变清音,比如have to, of course, 的v变f.
- - inperson读imperson, n->m,嘴唇闭合。
- - 同化:后面音 改变
- - 比如变复数读音
- - 相互作用
- - s+j: bless you. z+j:as you wish. t+j: meet you. d+j: did you. 类似的educate, tissue.
- - 辅音连读
- - 异化, r接元音会读r, 否则不发音
-- 省音: t,d。 来自其他视频,**t+辅音里的t省略,nt+元的t省略, nd+辅的d省略**
-- 节奏: 等时性。
-
## 重音
- 单音节
@@ -58,6 +20,22 @@ tags: English
> 链接: https://www.bilibili.com/video/av19992217?from=search&seid=14758661060311518388
+### 总结
+
+- 辅+元,**连读**: not at all, 如果辅音是/r/ /l/ /ŋ/, 辅音双写: for a
+- 元+元,添加连读,当尾元音是i和u时,自动添加/j/或/w/。do it, go out. /ɔː/自动加r, saw in
+- 特殊添加连读: /n/+/s/=/n ts/ since
+- 辅+辅,**连读**, 三组内的略读只读后面的,所有辅音相同略读,浊音在前清辅音在后可略读前面的:v f, z s,ð θ. 不可略读:/tʃ/ /dʒ/
+- 辅+辅,**吞音**,三组里碰到后面是三组里非兄弟辅音就吞音(也包含其他非爆破辅音)。吞音保留时值和状态不发音, that cat
+- 吞音喉音停顿:/tən/ /dən/ 只留ən, written
+- 略读 h-droping: him, his, he, her。 give him /givim/
+- 略读 g-droping: doing. ing里的
+- 变音: about you. would you, rock you. /t/+/ju/;/d/+/ju/。 miss you: sh
+- ~~清辅音+元,清辅音浊化~~
+- 不同意群不连读
+- 元音+元音,如果读音相近,可以连一起,比如law office. lawwfis
+- schewa: for, of, have, or, and等,元音变成ə
+
### 清辅音浊化
S后面的清辅音浊化现象可以这样归纳:清辅音跟着一个元音,前面又有一个 s ,无论是在单词的最前面还是中间,只要是在重读音节或次重读音节里,一般都读成对应浊辅音,如stand,strike,speak,sky 等等,值得一提的是strike不是不用变,而是它“tr”本来所发的音已是浊辅音,但也要变成“dr”所发的那个音 (如dream中的“dr”所发的音).
@@ -177,7 +155,225 @@ i经常弱读为e,所以give hime读为后面的,这个经常用后面的

-### 弱读 缩写 其他
--
+
+
+## 100个最常见的英语单词发音
+
+> [参考](https://www.zhihu.com/zvideo/1390373231258382336) , 包含了常见单词的弱读,比如him, to, do, of等。
+
+笔记
+
+
+
+正常schewa:
+
+- a,an,that, for, as( he's as tall as me), do, at, but, from, or, an, one, should, could, so, some, than
+
+不弱读的:
+
+- This, by, they, we, say, out, also.
+
+意群结尾p不发音,what's up
+
+1期:
+
+- the: the发音后面的/ə/ 当the后面接元音时可变成/i/
+- I am: I'm 有时只有一个音/m/, I'm sorry / m_ 'sorry/
+- you are: yer.
+- It is: /its/ 有时可省略元音 /ts/ ts cool
+- we are: /wər/
+- they are: /ðər/
+- to: tə, go to时, t变d
+- Of: /əv/ 在kind of, sort of里省略/v/, kanda
+- and: no /d/ or just /n/, ex: And I
+
+2期:
+
+- With: 后面轻音化, /θ/
+- he, him, 省略/h/, ex: what does he want
+- You: /jə/
+
+5期:
+
+- Who /u/, ex: Anyone who wants to come can come.
+
+6期:
+
+- Can /cən/
+- Him /əm/. Give him: /givem/
+
+7期:
+
+- into /ində/. 这里的t不遵循t发音规则。
+
+8期下:
+
+- Its: /ts/ 没有前面/i/了。
+
+10期下:
+
+- give是实词,但give me时弱读, give me that: gimme 省略v
+- us: əs
+
+
+
+
+
+## /t/发音
+
+[参考](https://rachelsenglish.com/podcast/004-t-pronunciations-flap-t-stop-t-true-t/)
+
+### True T
+
+开头或者重音节,或者后面接r。
+
+- True T Rule 1: At the beginning of a word
+ - Exception #1: in the TR cluster (train, try) – then it can sound like a CH
+ - Exception #2: the words to, today, tomorrow. These may begin with a Flap T.
+- True T Rule 2: At the beginning of a stressed syllable (attain, until). This includes secondary stress. In a dictionary, secondary stress is marked with this: ˌ Primary stress is marked with this: ˈ
+ - Exception: when it’s followed by R (attribute, attract)
+
+### Stop T
+
+- How to make a Stop sound: Stop T vs. No T: Buy vs. bite
+- Stop T Rule 1: When the T is followed by a consonant sound (definitely, bluntly) 后面接辅音
+ - Exception: when the sound before the T is an R. Then it’s a Stop T (partly) : r+t+辅音 ,t不变
+- Stop T Rule 2: Make the T a Stop T when it’s the last sound in a thought group. :意群结尾
+ - Exception: when the T is in a cluster, then we usually pronounce it (fact, best) :
+
+
+
+如果后面 是元音或者双元音 或者是意群的结尾,t就发音。可能是flap T, stop T
+
+### Flap T
+
+> [参考](https://www.goalsenglish.com/lessons/flap-t-sound-american-english-accent)
+
+- 类似d的发音
+- 发生flap T情况
+ - Flap T Rule 1: a T is a Flap T between two vowels or diphthongs (beautiful, city) 元音间 If a ‘t’ is between two vowels, whether in a word or between two words, it will be pronounced as a ‘soft d.’
+ - Exception: If the T begins a stressed syllable. Then it’s a True T (attain, attack) 重音上
+ - Flap T Rule 2: a T is a Flap T after an R before a vowel or diphthong (party, dirty). Applies to linked phrase: (a lot of, about it)
+ - Exception: if the T begins a stressed syllable. Then it’s a True T (partake)
+
+例子
+
+- it always
+
+### Drop T
+
+- Dropped T Rule 1: T can be dropped after N (center, internet) nt的t会省略
+ - Exception: when there is a syllable split between N and T (until, intense)
+- Dropped T Rule 2: Americans often drop the T between two other consonants (exactly, perfectly). This applies to phrases where two words link (just because)
+ - Exception: Not when the consonant before the T is an R (partly)
+
+例子
+
+- shouldn't, didn't,won't
+
+### 总结
+
+t前面是n? drop T
+
+t前面是辅音?
+
+- 后面是辅音? drop T
+- 后面是元音? stop T
+
+t前面是元音?
+
+- 后面是元音? flap T
+- 后面是辅音? drop T
+
+t是意群结尾? Stop T. p也类似。
+
+只有两个元音间的t是d,否则stop / drop
+
+
+
+杂记:
+
+t+辅音里的t省略, 其实是停顿,但和省略差不多
+
+nt比较特殊: nt+元的t省略, nd+辅的d省略
+
+## /d/发音
+
+nd+辅的d省略
+
+## 重读和弱读
+
+### 重读
+
+**一般来讲我们应该重读content words, 就是有实际内容、实际意义的词**,例如:名词,实义动词,形容词,副词,数量词。名词方面,比如像mountain, history等;实义动词就是真正发出动作的词,比如像establish, jump等;形容词比如像stunning, terrifying这样的词;副词方面比如quickly, extremely等。这些词都是有实际意义的,也就是我所说的内容词,来表达句子意义的词,所以我们应该把它们做重读的处理。
+
+
+
+**一般来讲哪些单词不重读,就是function words功能词,即那些起到语法功能作用的词,**比如像代词,介词,限定词,连词以及助动词等等,都是语法结构会运用到的词,这些词对句子的意义并不构成直接的影响。什么样的词属于限定词,比如像冠词the, a/an; some, few, my都是限定词;助动词像be动词,be, do, must这些都属于助动词;介词after, of, above, opposite, out of, on behalf of这些有介词意义的短语也包括在内。还有像连词,比如and, so, 还有代词this, him, our, you, it, 这些词在句子当中是起到语法意义的词。
+
+
+
+总结: 重读的只有副词、名词、形容词、动词。但content words有时也不会重读,如果还有其他的重读的词的话。
+
+
+
+### 弱读
+
+1、重读的单词不会出现弱读现象,要读的响亮
+
+这些词一般是表示句子含义的词,如名词,动词,副词,形容词 (today 今天, apple 苹果)
+
+
+
+2、非重读的部分的单词要读轻
+
+这些词一般起到语法功能,如介词、连词、助动词等 (and 和, but但是,for为了)
+
+
+
+
+
+弱读现象存在于句子的非重读单词部分
+
+对于句子非重读部分的单词
+
+1、如果有弱读发音,就可以进行弱读
+
+2、如果没有弱读发音,发本来的音即可
+
+
+
+不能弱读情况
+
+1、句子最后一个单词不能弱读
+
+2、特意强调的单词不能弱读,要重读
+
+
+
+## 英音美音区别
+
+todo
+
+
+
+## 其它
+
+> 视频: https://www.bilibili.com/video/BV1SZ4y1K7Lr?p=6&spm_id_from=pageDriver
+
+- 元音挨着元音不容易读,所以才会区分a和an
+- 同化&异化
+ - 同化:前面音 改变
+ - 常见爆破音: k,t,d, 后加辅音,前面音发一半,也叫失去爆破。
+ - 浊音变清音,比如have to, of course, 的v变f.
+ - inperson读imperson, n->m,嘴唇闭合。
+ - 同化:后面音 改变
+ - 比如变复数读音
+ - 相互作用
+ - s+j: bless you. z+j:as you wish. t+j: meet you. d+j: did you. 类似的educate, tissue.
+ - 辅音连读
+ - 异化, r接元音会读r, 否则不发音
+- 省音: t,d。 来自其他视频,**t+辅音里的t省略,nt+元的t省略, nd+辅的d省略**
+- 节奏: 等时性。
diff --git "a/_posts/English/2021-01-02-\350\257\255\346\263\225-\345\215\225\350\257\215\345\220\204\347\247\215\345\275\242\345\274\217\345\217\230\345\214\226\350\247\204\345\210\231.md" "b/_posts/English/2021-01-02-\350\257\255\346\263\225-\345\215\225\350\257\215\345\220\204\347\247\215\345\275\242\345\274\217\345\217\230\345\214\226\350\247\204\345\210\231.md"
index add11756d2..95c5f8eeb9 100644
--- "a/_posts/English/2021-01-02-\350\257\255\346\263\225-\345\215\225\350\257\215\345\220\204\347\247\215\345\275\242\345\274\217\345\217\230\345\214\226\350\247\204\345\210\231.md"
+++ "b/_posts/English/2021-01-02-\350\257\255\346\263\225-\345\215\225\350\257\215\345\220\204\347\247\215\345\275\242\345\274\217\345\217\230\345\214\226\350\247\204\345\210\231.md"
@@ -17,7 +17,7 @@ tags: English

-这里的辅音字母指除元音字母aeiou之外的字母,非音标发音指写法。
+下面的辅音字母指除元音字母aeiou之外的字母,非音标发音指写法。
**名词所有格's 的读音与名词复数和动词第三人称单数相同**
diff --git "a/_posts/English/2021-01-02-\350\257\255\346\263\225-\350\231\232\346\213\237\350\257\255\346\260\224.md" "b/_posts/English/2021-01-02-\350\257\255\346\263\225-\350\231\232\346\213\237\350\257\255\346\260\224.md"
index f515388fe4..0f909e5f97 100644
--- "a/_posts/English/2021-01-02-\350\257\255\346\263\225-\350\231\232\346\213\237\350\257\255\346\260\224.md"
+++ "b/_posts/English/2021-01-02-\350\257\255\346\263\225-\350\231\232\346\213\237\350\257\255\346\260\224.md"
@@ -107,3 +107,34 @@ if only(要是……就好了)与I wish一样,也用于表示与事实相
例2:In the absence of gravity, there would be no air around the earth.(如果没有重力,地球上不会有空气)
+
+
+**6. It's time that**
+
+it is time that +从句,从句要用虚拟语气,有两种方式:
+
+1、从句用作一般过去时
+
+例:It is time that we went to bed.我们该上床睡觉了。
+
+2、从句用should+动词原形不能省略
+
+例:It is time that we should go to bed.我们该睡觉了。
+
+
+
+
+
+## should省略
+
+1. 在表示建议,要求,命令,想法的动词后的从句里, 用should + 动词原形, should 可以省略.
+
+His doctor suggested that he (should) take short leave of absence.
+
+2. 在表示建议,要求,命令,想法的名词后的从句里, 用should + 动词原形, should可以省略. 如 advice, decision,agreement, command, decree, demand, determination, indication, insistence, order, preference, proposal, request, requirement, stipulation etc.
+
+His suggestion was that everyone (should) have a map.
+
+3. 在It is/was +形容词后的that 从句中用should的结构, should 可以省略. 这类形容词常见的有: advisable, anxious, compulsory, crucial, desirable, eager, essential, fitting, imperative(绝对必要), impossible, improper, important, natural, necessary, obligatory, possible, preferable, probable, recommended, urgent, vital etc.
+ It‘s natural that she (should) do so.
+
diff --git "a/_posts/English/2021-10-15-\350\256\241\347\256\227\346\234\272\350\213\261\350\257\255.md" "b/_posts/English/2021-10-15-\350\256\241\347\256\227\346\234\272\350\213\261\350\257\255.md"
index 645aafd0ad..af6477aff5 100644
--- "a/_posts/English/2021-10-15-\350\256\241\347\256\227\346\234\272\350\213\261\350\257\255.md"
+++ "b/_posts/English/2021-10-15-\350\256\241\347\256\227\346\234\272\350\213\261\350\257\255.md"
@@ -7,197 +7,81 @@ tags: English
## 计算机英语
-单词: https://www.cnblogs.com/along21/p/8075668.html
-
-## 雇佣关系词汇
-
-Employee: 员工, 包括普通雇员, 和有限公司的股东成员
-Employer: 老板(无限公司)
-Own account workers: 要申请ABN, 多见于服务业,cleaner, plumber, 某些IT从业人员。
-Family workers: 在家族企业,且没有酬劳。
-
-Full time, 也叫 permanent, 全职员工, 福利最好, 但是相应的时薪可能比较低。 福利包括, 带薪年假, 带薪病假,带薪事假,带薪育儿假,带薪公共假期, 长期服务奖励假(**Long service leave** ) , 以及彼此至少一个月的提前通知终止合同的缓冲期, 如果是公司裁退, 补贴n个月薪的补偿(为公司工作n年)。
-
-Part time, 和Full time 类似, 不过不是5天工作制, 按照合同, 每星期工作4天或更少。 其他福利类似Full time。
-
-casual, temporary, 小时工, 工钱按时薪算, 彼此可以随时终止合同。 无带薪假。
-
-contractor,
-fixed term, 合同工, 有固定的结束期限, 可能有部分福利如 带薪年假, 带薪病假,带薪事假,带薪育儿假,带薪公共假期。 具体要看合同的条款。
-
-self-employed, sole trader, 要自己申请ABN, 和公司属于合作关系,而不是雇佣关系。 提供服务以换取酬劳, 如cleaner, plumber, 某些IT从业人员等。
-
-partner, trust, company , 属于生意范畴
-
-cash in hand, 非法现金工。 官方网上没有说明, 不过大家都知道怎么回事。
-
-Apprenticeships and traineeships就是所谓的学徒, 有些工种需要满足一定期限的学徒期, 才能独自单干。
-
-## 个人单词本
-
-乐观的 optimistic
-
-悲观的 pessimistic
-
-熔断 circuit breaker circuit[/'sɝkɪt/](cmd://Speak/_us_/circuit) 电路
-
-限流 rate limiting [/reɪt/](cmd://Speak/_uk_/rate)
-
-降级 fallback,n. degrade [/dɪ'greɪd/](cmd://Speak/_uk_/degrade), v. degration.
-
-服务发现 service discovery.
-
-负载均衡 load balance
-
-访问控制列表ACL: access control list
-
-可靠性: reliance, 可用的: reliable
-
-一致性: consistency
-
-最终一致性: eventually consistency [/ɪ'ventʃʊəlɪ/](cmd://Speak/_uk_/eventually)
-
-隔离: isolation [/aɪsə'leɪʃ(ə)n/](cmd://Speak/_uk_/isolation)
-
-连接池: connection pool [/puːl/](cmd://Speak/_uk_/pool)
-
-鉴权: authentication [/ɔ:,θenti'keiʃən/](cmd://Speak/_us_/authentication)
-
-计数器法: counter method
-
-滑动窗口: sliding window
-
-滚动的: rolling [/'rəʊlɪŋ/](cmd://Speak/_uk_/rolling)
-
-流量: traffic
-
-漏桶: Leaky Bucket [美 /'liki/](cmd://Speak/_us_/leaky)令牌桶: token bucket
-
-轮询,探询: poll [ /pəʊl/](cmd://Speak/_uk_/poll)
-
-延迟: delay
-
-定时器: timer, 任务定时调度: task scheduler
-
-定时的: timed
-
-时间轮: wheeltimer
-
-优先的: prior [/'praɪə/](cmd://Speak/_uk_/prior)
-
-circular [/'sɜːkjʊlə/](cmd://Speak/_uk_/circular)环形的,circuit环形vi, 电路。
-
-缓冲 buffer
-
-层 level
-
-层级 hierarchy 分层的 hierarchical [美 /'haɪərɑrki/](cmd://Speak/_us_/hierarchy)
-
-灵活的 flexible
-
-线程安全 thread safety
-
-attribute 美 /ə'trɪbjut/
-
-boolean
-
-atomic
-
-assign
-
-aspect
-
-ratio
-
-scale
-
-access
-
-represent
-
-
-
-发音不准的: feature, module,
+计算机相关英语
+## 数学符号
+> [参考](https://www.sohu.com/a/214664854_200286)
-## 计算机英语
-
-> [参考](https://guanpengchn.github.io/awesome-pronunciation/content/L.html)
-
-access
-
-admin
-
-agile
+介词: plus, minus.
-alias [ˈeɪliəs]
+the sum a plus b. the difference a minus b.
-archive ['ɑːkaɪv]
+动词: times, is divided by
-array
+equals.
-aspect
+括号 小到大: parentheses [/pə'rɛnθəsɪz/](cmd://Speak/_uk_/parentheses), bracket, brace.
-avatar [/'ævətɑr/]
+绝对值: absolute value of a
-Azure
+幂: a**n, a to the power of n, a super n, a to the n.
-char
+上角标: a superscript b,可以直接诶读a super b.
-console
+下角标: a sub b.
-ctrl
+符号英文: operator.
-Daemon ['diːmən]
+log: log2a, log to the base 2 of a
-deque ['dek]
+开根号: nth root of a.
-event
+since, because, implies. equivalent.
-facade [fə'sɑːd] 外观模式
+区分括号: the quantity xx end of quantity.
-hidden ['hɪdn]
+
-hystrix
+部分, 指分数, that fraction.
-icon ['aɪkɑn]
+分数: a over b.
-image ['ɪmɪdʒ]
+
-integer ['ɪntɪdʒə]
+平方: square 立方: cube
-Java ['dʒɑːvə]
+p(x) 读p of x.
-linear ['lɪnɪə]
-locale [ləʊ'kɑːl]
-Lucene [ˈlu:sɪn]
+
-matrix [ˈmeɪtrɪks]
-module ['mɒdjuːl]
-nginx ['endʒɪn eks]
+## 雇佣关系词汇
-parameter [pə'ræmɪtə]
+Employee: 员工, 包括普通雇员, 和有限公司的股东成员
+Employer: 老板(无限公司)
+Own account workers: 要申请ABN, 多见于服务业,cleaner, plumber, 某些IT从业人员。
+Family workers: 在家族企业,且没有酬劳。
-replica [ˈreplɪkə]
+Full time, 也叫 permanent, 全职员工, 福利最好, 但是相应的时薪可能比较低。 福利包括, 带薪年假, 带薪病假,带薪事假,带薪育儿假,带薪公共假期, 长期服务奖励假(**Long service leave** ) , 以及彼此至少一个月的提前通知终止合同的缓冲期, 如果是公司裁退, 补贴n个月薪的补偿(为公司工作n年)。
-scale
+Part time, 和Full time 类似, 不过不是5天工作制, 按照合同, 每星期工作4天或更少。 其他福利类似Full time。
-scheme [skiːm] 方案体系
+casual, temporary, 小时工, 工钱按时薪算, 彼此可以随时终止合同。 无带薪假。
-sudo [ˈsuːduː]
+contractor,
+fixed term, 合同工, 有固定的结束期限, 可能有部分福利如 带薪年假, 带薪病假,带薪事假,带薪育儿假,带薪公共假期。 具体要看合同的条款。
-suite [swiːt]
+self-employed, sole trader, 要自己申请ABN, 和公司属于合作关系,而不是雇佣关系。 提供服务以换取酬劳, 如cleaner, plumber, 某些IT从业人员等。
-variable ['veərɪəbl]
+partner, trust, company , 属于生意范畴
-width [wɪdθ]
+cash in hand, 非法现金工。 官方网上没有说明, 不过大家都知道怎么回事。
-YouTube ['juː'tjuːb]
+Apprenticeships and traineeships就是所谓的学徒, 有些工种需要满足一定期限的学徒期, 才能独自单干。
@@ -267,51 +151,69 @@ register ['redʒistə]暂存器 寄存器
syntax ['sintæks]语法 语法
-## 数学符号
+## 编程单词2
-> [参考](https://www.sohu.com/a/214664854_200286)
+单词: https://www.cnblogs.com/along21/p/8075668.html
-介词: plus, minus.
-the sum a plus b. the difference a minus b.
-动词: times, is divided by
+## 算法面试中常用英语
-equals.
+first, the input is head of linkedlist,
-括号 小到大: parentheses [/pə'rɛnθəsɪz/](cmd://Speak/_uk_/parentheses), bracket, brace.
-绝对值: absolute value of a
-幂: a**n, a to the power of n, a super n, a to the n.
+First, the naive idea that should not be considered is we can solve it in an exhaustive approach.
-上角标: a superscript b,可以直接诶读a super b.
+better idea,
-下角标: a sub b.
-符号英文: operator.
-log: log2a, log to the base 2 of a
+how to optimize it
-开根号: nth root of a.
-since, because, implies. equivalent.
-区分括号: the quantity xx end of quantity.
+use a map to record next value,
-
+define A as the map
-部分, 指分数, that fraction.
+we can get the map that I mentioned, by one loop,
-分数: a over b.
-
-平方: square 立方: cube
-p(x) 读p of x.
+### Key Points
+- each针对个体,every强调共性。
+- shift是整体转移,常用move,move to the right.
+- 最左的leftmost, rightmost, 最多最大most, 最少最少least, maximum number
+- using the sliding window technique. shrink 收缩
+- brute force, approach
+- subtract 扣除、减去
+- intuition 直觉
+- sort the list by the starting position.
+- build the prefix sum array to xxx
+- 遍历 traverse
+- 一个循环for loop 嵌套循环 two nested loops.
+- linearly search 线性地查找 in O(n) time.
+- given its staring position s, we know that the furthest position that can over is s+e. Having the furthest positon, we binary search the index of ending xxxx.
+- Note that in this step, we greedily align xx with xxx
+- at last 最后
+- indices 是index的复数
+- look for,in the forward direction.
+- 比数量多少: less than/ more than 多少,least = 最少的, most = 最多的
+- 比值大小: 最大的greatest, 最小的smallest, smarller than/greater than 比大小。最大也可以Largest, 不过不标准Largest implies size, but greater implies value.
+- 至少包含一个includes at least one
+- track跟踪 track whether
+- trim 修剪, encounter遇到
+- roughly粗略地 大概地
+- left side. the extreme end of
+- within [a,b] 区间内
-
+
+### 例题
+
+- [6068. 毯子覆盖的最多白色砖块数](https://mafulong.github.io/2022/05/15/6068.-%E6%AF%AF%E5%AD%90%E8%A6%86%E7%9B%96%E7%9A%84%E6%9C%80%E5%A4%9A%E7%99%BD%E8%89%B2%E7%A0%96%E5%9D%97%E6%95%B0/)
+- [6069. Substring With Largest Variance](https://mafulong.github.io/2022/05/15/6069.-Substring-With-Largest-Variance/)
\ No newline at end of file
diff --git "a/_posts/English/2021-12-09-English\345\255\246\344\271\240\350\265\204\346\272\220.md" "b/_posts/English/2021-12-09-English\345\255\246\344\271\240\350\265\204\346\272\220.md"
deleted file mode 100644
index f9712561c9..0000000000
--- "a/_posts/English/2021-12-09-English\345\255\246\344\271\240\350\265\204\346\272\220.md"
+++ /dev/null
@@ -1,23 +0,0 @@
----
-layout: post
-category: English
-title: English学习资源
-tags: English
----
-
-## English学习资源
-
-计算机英语部分参考另一个博客
-
-## English-level-up-tips-for-Chinese
-
-网址:https://github.com/byoungd/English-level-up-tips-for-Chinese
-
-## github上“读”北大(北大课程资料民间整理)
-
-网址:https://lib-pku.github.io/
-
-github:https://github.com/lib-pku/libpku
-
-
-
diff --git "a/_posts/English/2021-12-11-English\350\257\255\346\263\225.md" "b/_posts/English/2021-12-11-English\350\257\255\346\263\225.md"
deleted file mode 100644
index 49c0659b8b..0000000000
--- "a/_posts/English/2021-12-11-English\350\257\255\346\263\225.md"
+++ /dev/null
@@ -1,76 +0,0 @@
----
-layout: post
-category: English
-title: English Grammmar
-tags: English
----
-
-[语法顺口溜](https://zhuanlan.zhihu.com/p/146873536)
-
-## 单词
-
-[语法-单词各种形式变化规则](https://mafulong.github.io/2021/01/02/%E8%AF%AD%E6%B3%95-%E5%8D%95%E8%AF%8D%E5%90%84%E7%A7%8D%E5%BD%A2%E5%BC%8F%E5%8F%98%E5%8C%96%E8%A7%84%E5%88%99/)
-
-## 介词
-
-参考:https://wenku.baidu.com/view/d6be381d747f5acfa1c7aa00b52acfc789eb9fad.html
-
-
-
-介词:
-
-年月周前要用 in,
-
-日子前面却不行。
-
-遇到几号要用“on”,
-
-上午下午又是“in”。
-
-要说某日上下午,
-
-用 on 换 in 才能行。
-
-午夜黄昏用 at,
-
-
-
-## 从句
-
-[三大从句](https://mm.edrawsoft.cn/template/39526)
-
-[四级语法: 从句](https://mm.edrawsoft.cn/template/57209)
-
-从句时态:
-
-1. **主将从现**
-
-i will hit u when you come here
-
-if it rains, i will hit u.
-
-2. **主过从过**
-
-复合句有先后关系,过去+过去完成时, eg. when he came there, the train had gone.
-
-3. **主现从任**
-
-he tells me that u have died
-
-## 疑问句
-
-[参考个人单独blog](https://mafulong.github.io/2021/01/02/%E8%AF%AD%E6%B3%95-%E7%96%91%E9%97%AE%E5%8F%A5/)
-
-
-## 时态
-
-[参考个人单独blog](https://mafulong.github.io/2021/01/02/%E8%AF%AD%E6%B3%95-%E6%97%B6%E6%80%81/)
-
-## 倒装
-
-[参考个人单独blog](https://mafulong.github.io/2021/01/02/%E8%AF%AD%E6%B3%95-%E5%80%92%E8%A3%85%E5%8F%A5/)
-
-## 虚拟语气
-
-[参考个人单独blog](https://mafulong.github.io/2021/01/02/%E8%AF%AD%E6%B3%95-%E8%99%9A%E6%8B%9F%E8%AF%AD%E6%B0%94/)
-
diff --git "a/_posts/English/2021-12-11-\345\215\225\350\257\215-\345\270\270\347\224\250\350\276\250\346\236\220.md" "b/_posts/English/2021-12-11-\345\215\225\350\257\215-\345\270\270\347\224\250\350\276\250\346\236\220.md"
new file mode 100644
index 0000000000..8ee9fe5072
--- /dev/null
+++ "b/_posts/English/2021-12-11-\345\215\225\350\257\215-\345\270\270\347\224\250\350\276\250\346\236\220.md"
@@ -0,0 +1,134 @@
+---
+layout: post
+category: English
+title: 单词-常用辨析
+tags: English
+---
+
+### till和until
+
+没区别 口语两个都行。until正式。
+
+两者在用法上应注意以下几点:
+
+**1.** 相关主句谓语必须是持续性动词,若是终止性动词,则应为否定式(因为终止性动词一旦被否定就成为状态,便可持续)。如:
+
+We waited until [[till](http://www.yywords.com/)] he came. 我们一直等到他来。
+
+We didn’t leave [until](http://www.yywords.com/) [till] he came. 直到他来我们才走。
+
+**2.** 引导时间状语从句时,其谓语要用现在时表示将来意义。如:
+
+I won’t leave [until](http://www.yywords.com/) he comes back tomorrow. 我要等他明天回来再走。
+
+**3.** 有时其后可跟副词、[介词](http://www.yywords.com/Article/200810/542.html)短语或从句等。如:
+
+He has been ill until recently. 他最近一直生病。
+
+She didn’t return until after twelve o’clock. 直到 12 点过后她才回来。
+
+They didn’t reach the station until after the train had left. 直到火车开走之后,他们才到达车站。
+
+[Until when](http://www.yywords.com/) are you going to stay here? 你在这儿要待到什么时候?
+
+
+
+### 影响
+
+**影响英文怎么说? 动词affect, 名字effect,非常大影响用impact。** **少用influence**, influence 会比较偏向是「思想上的影响」,会影响某个人的想法、意见、发展,或是决定,比如我们常会说「某个人影响我成为⋯⋯」、「某个人影响⋯⋯的发展」,这些就比较会使用 influence,而不是 affect。*My dad influenced me to be a teacher.*
+
+
+
+### 组成
+
+**consist of xxx**
+
+**be composed of**
+
+
+
+组成和构成
+
+https://xue.youdao.com/bbs/wenda/answer_detail?id=5499819
+
+comprise, constitute, compose, consist of
+
+
+
+Consist 的用法是 consist of,要注意这个字不会使用被动语态,所以并没有 be consisted of (X) 的用法喔,直接说“整体 consist of 部分”就可以了
+
+*Our team consists of the best players in the nation.*
+
+
+
+Comprise 同样是指“组成、构成”,但 **comprise 是个比 consist 更正式一点的字**,而且 comprise 主动及被动语态用法可以用,所以可以是“整体 comprise 部分”,也可以是“整体 be comprised of 部分”
+
+
+
+Compose 是个更正式的字,它的用法是**“整体 be composed of 部分”**,当做“由...组成”的意思时,只有被动用法喔
+
+### wait
+
+是否加for,是sb/sth就加,如果是时间就不用加
+
+wait也可以加to. I can't wait to do..等不及做
+
+**当你想表达:**
+
+**1) 等谁?(who)**
+
+**2) 等什么?(what)**
+
+wait需要加for
+
+wait for sb/sth。
+
+- She waits for the bus.
+- You need to wait here for me.
+
+
+
+
+
+**1)等多久?(how long)**
+
+**2)在哪里等?(where)**
+
+wait不加for
+
+- Wait a minute.
+
+### 可能
+
+用maybe一般
+
+probably表示有把握发生。语气比possibly大。
+
+
+
+[maybe](dic://maybe) 普通用词,美国英语多用。指某事也许如此,含不能确定意味。
+[perhaps](dic://perhaps) 普通用词,多用于英国,与maybe同义。
+[possibly](dic://possibly) 指客观上潜存着发生某种变化的可能。
+[probably](dic://probably) 一般指根据逻辑推理,估计有发生的可能,把握性较大,语气比possibly强。
+
+### 常用错
+
+> [中国程序员最容易犯的100个英语口语错误](https://github.com/eliaszon/Common-English-Mistakes-By-Chinese)
+
+How do you say xxx in English.
+
+I see.
+
+Do you get what I'm saying? / You get me? / Am I making sense? / Does this make sense? / Are we on the same page?
+
+I'm not feeling too good / I'm feeling (a little bit) under the weather
+
+reply me 有语法错误,要加 to ,reply to me
+
+weird 更常用,odd 不太常用 ( That's a little bit weird )
+
+How much is something? (问价钱)
+
+你方便吗 You got a minute? / Are you available right now? / Are you free? 不要用Are you convenient? convenient 一般针对事物、地点,不是针对人的
+
+Can you speak louder? / Can you speak up?
\ No newline at end of file
diff --git "a/_posts/English/2021-12-11-\345\215\225\350\257\215-\345\270\270\350\257\273\351\224\231.md" "b/_posts/English/2021-12-11-\345\215\225\350\257\215-\345\270\270\350\257\273\351\224\231.md"
new file mode 100644
index 0000000000..67b7531b96
--- /dev/null
+++ "b/_posts/English/2021-12-11-\345\215\225\350\257\215-\345\270\270\350\257\273\351\224\231.md"
@@ -0,0 +1,142 @@
+---
+layout: post
+category: English
+title: 单词-常读错
+tags: English
+---
+
+## 常读错
+
+boolean 美 /ˈbuliən/
+
+atomic
+
+**assign** 美 /əˈsaɪn/
+
+aspect 美 [美 /ˈæspekt/](cmd://Speak/_us_/aspect)
+
+ratio 美 /ˈreɪʃioʊ/
+
+scale
+
+access 美 /ˈækses/
+
+represent 美 /ˌreprɪˈzent/
+
+feature 美 /ˈfiːtʃər/
+
+module
+
+
+
+
+
+admin 美 /'ædmɪn/
+
+agile 美 /ˈædʒl/
+
+Scrum [美 /skrʌm/](cmd://Speak/_us_/scrum)
+
+alias [ˈeɪliəs]
+
+archive [‘ɑːkaɪv]
+
+array
+
+avatar [/’ævətɑr/]
+
+Azure
+
+char 美 /tʃɑːr/
+
+console
+
+ctrl
+
+Daemon [‘diːmən]
+
+deque [‘dek]
+
+queue 美 /kjuː/
+
+**event** (i wan t) 争议。请继续i wen t.
+
+facade [fə’sɑːd] 外观模式
+
+hidden [‘hɪdn]
+
+hystrix
+
+icon [‘aɪkɑn]
+
+image [‘ɪmɪdʒ]
+
+integer [‘ɪntɪdʒə]
+
+Java [‘dʒɑːvə]
+
+linear [‘lɪnɪə]
+
+locale [ləʊ’kɑːl]
+
+Lucene [ˈlu:sɪn]
+
+**matrix** [ˈmeɪtrɪks]
+
+nginx [‘endʒɪn eks]
+
+**parameter** [pə’ræmɪtə]
+
+replica [ˈreplɪkə]
+
+scheme [skiːm] 方案体系
+
+sudo [ˈsuːduː]
+
+suite [swiːt] *a suite of* 一系列
+
+variable 美 /ˈveriəbl/
+
+width [wɪdθ]
+
+YouTube [‘juː’tjuːb]
+
+timer 美 /'taɪmɚ/ 定时器
+
+formal 美 /ˈfɔːrml/
+
+Intrusive 侵入的 美 /ɪn'trusɪv/
+
+**redundant** 冗余的 美 /rɪˈdʌndənt/
+
+Diversity 美 /daɪˈvɜːrsəti/
+
+utilize 美 /ˈjuːtəlaɪz/
+
+execute 美 /ˈeksɪkjuːt/ execution
+
+via 美 /ˈvaɪə/ 经由,通过;凭借,借助于
+
+prepare . (p pai r)
+
+preparation 美 /ˌprepəˈreɪʃn/
+
+obviously obvious [美 /ˈɑːbviəs/](cmd://Speak/_us_/obvious) 开头不是e. 是ao 明显的
+
+**curious** 好奇的 [美 /ˈkjʊriəs/](cmd://Speak/_us_/curious)
+
+equally 美 /ˈiːkwəli/
+
+obey 美 /əˈbeɪ/ obey rules
+
+**again** 美 /ə'ɡɛn/
+
+occasionally 美 /əˈkeɪʒnəli/
+
+Library 库 [美 /'laɪbrɛri/](cmd://Speak/_us_/library)
+
+Horizontally [美 /ˌhɑrɪˈzɑntəlɪ/](cmd://Speak/_us_/horizontally) Vertically
+
+
+
+provide [美 /prə'vaɪd/](cmd://Speak/_us_/provide) 注意 不是p rao. 是p re
\ No newline at end of file
diff --git "a/_posts/English/2022-08-26-\345\215\225\350\257\215-\350\277\236\350\257\215.md" "b/_posts/English/2022-08-26-\345\215\225\350\257\215-\350\277\236\350\257\215.md"
new file mode 100644
index 0000000000..a104de79c8
--- /dev/null
+++ "b/_posts/English/2022-08-26-\345\215\225\350\257\215-\350\277\236\350\257\215.md"
@@ -0,0 +1,610 @@
+---
+layout: post
+category: English
+title: 英语-连词
+tags: English
+---
+
+# 连词
+
+
+
+## 不仅而且Not only but also
+
+[参考](https://en-grammar.xiao84.com/201612/27635.html)
+
+比较自由。also可省略, but also之间也可以加词。
+
+可连接主语、谓语动词...
+
+The Americans and the British **not only** speak the same language **but also** share a large number of social customs.
+
+
+
+Note:
+
+- ”not only A but also B”结构中的A和B通常是同等成分。因此这句话是错误的“He not only plays the piano, but also the violin.” 可以改成“He plays **not only** the piano, but also the violin”
+
+## 也(too, as well, also, either)
+
+too和as well两者都可用在肯定句或疑问句的句末。两者通常可以换用。
+
+She likes pizza as well.
+
+=She likes pizza too.
+
+
+
+- also: 常在**肯定句句中**
+- too: 常在**肯定句句末**,前面常有逗号
+- either: 常在**否定句句末** He isn't a singer either.
+
+
+
+来自欧陆词典:
+
+[also](dic://also) 比too正式一些,语气较重,只用于肯定句,一般紧靠动词。
+[too](dic://too) 语气较轻,多用于口语,在肯定句中使用,通常位于句末。
+[as well](dic://as well) 一般不用否定句,通常放在句末,强调时可放在句中。
+[either](dic://either) 用于否定句,放在句末,之前加逗号。
+[likewise](dic://likewise) 是书面语用词。
+
+
+
+也不nor
+
+He can't speak english, **nor** can I.
+
+## 除了
+
+I did **nothing but** watch it
+
+## 然而
+
+whereas
+
+Some praise him, **whereas** others condemn him
+
+
+
+## 尽管
+
+**Although** she's young, she knows a lot.
+
+In spite of sth
+
+Despite sth
+
+## 只要
+
+As long as I'm free, I will help you.
+
+**only if (连词)只有**
+
+The lawyer is paid only if he wins.
+
+当且仅当: if and only if xx
+
+## 要是xx就好了
+
+if only
+
+There had to be an answer — he was sure he could tease it out if only he had time.
+
+## 以免
+
+in case
+
+You should be careful **in case** there's a fire.
+
+## 为了
+
+We study hard in order that we can pass the team.
+
+
+
+## 刚一。。。就。
+
+推荐as soon as.
+
+**As soon as** I stepped inside,my glasses misted over.
+
+The stars came out **as soon as** darkness fell.
+
+
+
+**Hardly** I entered the room **when** the bell rang.
+
+**No sooner** had I come home **than** it began to rain.
+
+**Scarcely** had she entered the room **when** the phone rang.
+
+## 既然现在
+
+**Now that** you are on duty, you should clean the classroom.
+
+## 无论
+
+**Whether** you are sick **or** not, I'll help you.
+
+**No matter** how bad the weather is, the children will play foot-ball on the playground, not with standing
+
+**No matter** what it takes I will do the work.
+
+**Whatever** the reason, just hang in there.
+
+## 而不是
+
+They relied on brains **rather than** brawn
+
+He preferred to die **instead of** stealing.
+
+## 尽可能地快
+
+as soon as possible, soon: *adv.* 不久;即刻,马上
+
+We must correct our defects **as soon as possible.**
+
+as quickly as possible.
+
+## 如果...将会怎么样?
+
+**What if** the car breaks down?
+
+
+
+## 15类英语连接词
+
+> 参考:整理分享15类英语连接词,超级全。https://zhuanlan.zhihu.com/p/277394043
+>
+
+### 表示强调
+
+still 然而,仍然
+
+indeed 事实上
+
+apparently 显然
+
+oddly enough 奇怪的是. weird enough也行。It is weird enough that you live on the mantel.
+
+of course 当然
+
+after all 终究
+
+significantly 明显地;显著地 obviously
+
+interestingly 有趣的是
+
+also 并且,另外
+
+surely 肯定/必定地
+
+certainly 无疑地; 确定地 I certainly treasure the friendship between us very much.
+
+undoubtedly 毫无疑问地
+
+in any case 在任何情况下;无论如何
+
+anyway 反正;不管怎样;总之
+
+above all 首先,尤其是;最重要的是
+
+in fact 事实上
+
+especially 特别是
+
+obviously 很明显 [ /'ɑbvɪəsli/](cmd://Speak/_us_/obviously)
+
+clearly 无疑的
+
+例:In fact, he is not an honest man.
+
+事实上,他不是个诚实的人。
+
+
+
+### 表示比较
+
+like 就像
+
+similarly 类似的 be similar to
+
+likewise 同样的;照样的 副词。Likewise, under the papalism in the middle ages of West, papacies dominate was the leading.
+
+in the same way 以同样的方式
+
+in the same manner 以类似的方式
+
+equally 同样地;相等程度地
+
+例:I will help you solve this problem, but equally you need to give me some reward.
+
+我会帮你们解决这个问题,但是同样地,你们需要付出一些回报。
+
+
+
+### 表示对比
+
+by contrast 相比之下
+
+on the contrary 相反
+
+while 而;虽然,尽管
+
+whereas 而
+
+on the other hand 另一方面
+
+unlike 不像
+
+instead 而不是;而;相反
+
+but 但
+
+conversely 相反
+
+different from 不同于
+
+however 然而
+
+nevertheless 不过
+
+otherwise 否则
+
+yet 然而, 但是
+
+in contrast 与此相反;比较起来
+
+例:On the other hand, they are also unwilling to adopt our advice.
+
+另一方面,他们也不愿意采纳我们的建议。
+
+
+
+### 表示列举
+
+for example 例如
+
+for instance 例如
+
+such as 如
+
+take …for example 以……为例
+
+except (for) 要不是由于 *except for* 除了…以外;要不是由于
+
+to illustrate 为了说明(举例说明)
+
+例:We bought some fruits such as apples, oranges and pears.
+
+我们买了一些水果,有苹果橘子还有梨。
+
+
+
+### 表示时间
+
+later 后来;稍后;随后
+
+next 然后;其次;接下来;下一...
+
+then 然后
+
+finally 最终终于
+
+at last 最后
+
+eventually 最终 [ɪ'vɛntʃuəli/](cmd://Speak/_us_/eventually)
+
+meanwhile 与此同时
+
+from now on 从现在开始 I have made up my mind not to go skating from now on. 我决心从此不再去滑冰.
+
+at the same time 同时
+
+for the time being 暂时 adv
+
+in the end 最后
+
+immediately 立即
+
+in the meantime 在此期间;于此际;与此同时
+
+in the meanwhile 同时;在此期间
+
+recently 最近
+
+soon 很快
+
+now and then 偶尔;有时;不时 occasionally
+
+during 在…...的期间;在......期间的某个时候 The pond iced over during the night.
+
+nowadays 如今
+
+since 自……以后;自……以来;此后;之前
+
+lately 最近
+
+as soon as 一旦
+
+afterwards 后来
+
+temporarily 暂时
+
+earlier 早些时候
+
+now 现在
+
+after a while 不久;过了一会儿
+
+例:She answered the question immediately.
+
+她迅速回答了这个问题。
+
+
+
+### 表示顺序
+
+first 首先,第一
+
+second 第二
+
+third 第三
+
+then 然后
+
+finally 最后
+
+to begin with 首先,本来,一方面 To begin with, we must consider the faculties of the staff all-sidedly.
+
+first of all 首先
+
+in the first place 首先
+
+last 最后
+
+next 下一个
+
+above all 最重要的是
+
+last but not the least 最后一点,也是非常重要的一点
+
+first and most important 第一点也是最重要的一点
+
+例:First of all, you should obey rules as a student.
+
+作为一个学生,首先你要遵守学校里的规章制度。
+
+
+
+### 表示可能
+
+presumably 大概
+
+probably 可能
+
+perhaps 也许
+
+例:Perhaps he will not show up today.
+
+他今天可能不会露面了。
+
+
+
+### 表示解释
+
+in other words 换句话说
+
+in fact 事实上
+
+as a matter of fact 事实上
+
+that is 即;就是说;换言之
+
+namely 也就是;即是;换句话说 Namely, a return to white supremacy and institutional slavery.
+
+in simpler terms 简单来说 **To put it simply**, everything happens instantaneously. **In short,** the building would consist of two floors.
+
+例:He departed from his hometown, namely, London.
+
+他离开了自己的故乡,也就是伦敦。
+
+
+
+### 表示递进
+
+What is more 更重要的是;此外,而且
+
+in addition 另外,此外
+
+and 并且,以及
+
+besides 况且,再说;此外,以及
+
+also 而且;同样;还有
+
+furthermore 此外
+
+too 也;还
+
+moreover 此外;而且
+
+as well as 以及
+
+additionally 另外
+
+again 再说;又
+
+例:Susan is a beautiful girl, what is more, she works hard all the time.
+
+苏珊是个漂亮的女孩,而且,她也一直努力工作。
+
+
+
+### 表示让步
+
+although 虽然
+
+after all 毕竟
+
+in spite of …尽管……
+
+despite 尽管
+
+even if 即使
+
+even though 尽管
+
+though 虽然
+
+admittedly 不可否认
+
+whatever may happen 不管三七二十一
+
+例:Although you told a lie before, we believe in you now.
+
+虽然你以前说过谎,但我们现在相信你。
+
+
+
+### 表示转折
+
+however 然而
+
+rather than 而不是;宁可…也不愿
+
+instead of 而不是...
+
+but 但
+
+yet 然而
+
+on the other hand 另一方面
+
+unfortunately 不幸的是
+
+whereas 然而;鉴于; 反之
+
+例:However, he did not pass the exam.
+
+然而,他没有通过考试。
+
+
+
+### 表示原因
+
+for this reason 因为这个原因
+
+due to 由于
+
+thanks to 多亏了
+
+because 因为
+
+because of 由于
+
+as 因为,由于
+
+since 因为,由于
+
+owing to 由于
+
+例:She broke up with her boyfriend because of a terrible quarrel.
+
+因为大吵了一架,她和男友分手了。
+
+
+
+### 表示结果
+
+as a result 结果....
+
+thus 因此
+
+hence 因此
+
+so 所以
+
+therefore 因此
+
+accordingly 因此,于是
+
+consequently 因此;结果;所以; 从而
+
+as a consequence 因此,结果
+
+例:Therefore, I decide to make an apology to him.
+
+因此,我决定向他道歉。
+
+
+
+### 表示总结
+
+on the whole 基本上,大体上;总的来说
+
+in conclusion 总之;最后
+
+in a word 总之
+
+to sum up 总而言之;概括地说
+
+in brief 简言之
+
+in summary 总之
+
+to conclude 最后;总之
+
+to summarize 简而言之
+
+in short 总之;简言之
+
+例:In conclusion, we d better take measures as soon as possible.
+
+总之,我们最好尽可能快采取措施。
+
+
+
+### 其他连接词
+
+mostly 主要是;通常;多半地
+
+occasionally 偶尔;有时
+
+currently 目前
+
+naturally 自然而然地
+
+mainly 主要是
+
+exactly 恰好地;正是
+
+evidently 毫无疑问地; 显然
+
+frankly 坦率地说;老实说 to be honest
+
+commonly 一般;通常;普遍
+
+for this purpose 为此;有鉴于此
+
+to a large extent 在很大程度上
+
+for most of us 对我们大多数人来说
+
+in many cases 在许多情况下
+
+in this case 在这种情况下
+
+例:Frankly, I do not mind her opinions at all.
+
+坦白说,我一点都不在乎她的看法。
+
+
+
+according to 根据
+
+## 参考
+
+- https://www.sohu.com/a/330378162_100219060
+
diff --git "a/_posts/English/2022-08-27-\350\257\255\346\226\231-\344\277\235\347\240\224\345\244\215\350\257\225\345\207\206\345\244\207.md" "b/_posts/English/2022-08-27-\350\257\255\346\226\231-\344\277\235\347\240\224\345\244\215\350\257\225\345\207\206\345\244\207.md"
new file mode 100644
index 0000000000..65f64e8134
--- /dev/null
+++ "b/_posts/English/2022-08-27-\350\257\255\346\226\231-\344\277\235\347\240\224\345\244\215\350\257\225\345\207\206\345\244\207.md"
@@ -0,0 +1,82 @@
+---
+layout: post
+category: English
+title: 语料-保研复试准备
+tags: English
+---
+
+## SCI paper
+
+参与式感知激励机制算法研究 为了解决参与式感知中所收集数据在时间、空间上的分布不均而导致数据质量降低,提出一种考虑数据时空分布的激励机制,并在此机制中提出两种算法,第一种算法在数据收集总量满足需求的情况下最优化收集数据在时空上的分布,提高收集数据质量,第二种激励算法在第一种激励算法的基础上考虑总成本的降低,对多目标加权平均,同时降低总成本和优化收集数据在时空上的分布,并将这两种激励算法与固定价格的激励算法的结果进行对比,使用了Matlab, visio及Origin等编程及作图。题目为《A Time and Location Correlation Incentive Scheme for Deeply Data Gathering in Crowdsourcing Networks》
+
+As the first author, I published a SCI paper with the title 《A Time and Location Correlation Incentive Scheme for Deeply Data Gathering in Crowdsourcing Networks》,the main content is about the incentive mechanism of participatory sensing. In this paper, two algorithms are proposed to solve the problem of uneven distribution of sensed data in time and space. I mainly use matlab, origin, visio. Lastly, it is about twenty-two pages.
+
+We use a new metrics to measure the value of data in distribution dimension which the former paper lost.
+
+Dynamic and Greedy.
+
+
+
+V2
+
+It's about the incentive mechanism of participatory sensing, which is study that how to make people to help platform to get the most valuable sensing data by their smartphone with least cost, such as paying money or virtual money to people, yeah, rewarding the participated people
+
+Here's the question, what is the most valuable sensing data and how to judge it.
+
+We used a new metrics to measure the value of data in distribution dimension of time and space, which the former papers lost.
+
+In this paper, two algorithms are proposed to solve this problem.
+
+On the basis of meeting the requirements of Platform that geting enough sensed data, the first algorithm is maximize the the new metrics that I just mentioned by adjusting the rewards dynamically with a greedy algorithm. The second algorithm is to minimize the cost of the system while meeting the sensing data requirement and maximizing the new metrics.
+
+Finally, we compare our proposed scheme with existing schemes via extensive simulations. Extensive simulation results well justify the effectiveness of our scheme.
+
+I mainly use matlab, origin, visio. Lastly, it is about twenty-two pages.
+
+
+
+## 你认为最重要的学科是什么
+
+What do you think is the most important subject?
+
+《数据结构》主要介绍如何合理地组织数据、有效地存储和处理数据,正确地设计算法以及对算法的分析与评价。用计算机解决实际问题,首先要做的事情就是要把涉及问题的相关信息存储到计算机中,也就是需要把问题的信息表示为计算机可接受的数据形式,然后根据问题处理功能的要求,对存储到计算机中的数据进行处理。归结为一句话,用计算机解题首先要用合理的结构表示数据,然后才能根据相应的算法处理结构,而数据表示和数据处理正是数据结构学科要研究的内容。
+
+"Data Structure" mainly introduces how to organize data reasonably, efficiently store and process data, correctly design algorithms and analyze and evaluate algorithms. To solve practical problems with a computer, the first thing to do is to store the relevant information about the problem in the computer, that is, to represent the information of the problem as a form of data acceptable to the computer, and then to store the information according to the requirements of the problem processing function. Process the data into the computer. It comes down to one sentence. Solving a problem with a computer first requires a reasonable structure to represent the data, and then the structure can be processed according to the corresponding algorithm. Data representation and data processing are the contents of the data structure discipline.
+
+## 除了四六级证书外你还有其他证书么
+
+目前我英语方面我只有英语四六级证书,但是我打算在大四学习英语,考托福或者雅思,因为在半年前我撰写并发表了我的第一篇SCI论文,大概22页,接近两万多字,我认识到了英语的重要性,无论是英文写作还是阅读外文文献
+
+At present, I only have English CET-6 certificate in English, but I plan to study English in the senior year, test TOEFL or IELTS, because I wrote and published my first SCI paper six months ago, about 22 pages, close to 20,000. Multi-word, I realized the importance of English, whether it is writing in English or reading foreign literature.
+
+## 你如何证明你的英语能力
+
+正如我刚才所说,在半年前我撰写并发表了我的第一篇SCI论文,大概22页,接近两万多字,论文是研究参与式感知中的激励机制的,并且我也阅读了大量相关的文献,这体现了我的英文阅读和写作能力。在平时的开发中,我也经常接触英语,比如Java开发的API文档,日志信息,同时我在leetcode平台上刷题超过200道,题目都是英文的,我认识到了英语重要性,想在接下来的一年考取托福雅思,更想到哈工大继续学习,希望老师给我这样一个机会。
+
+As I said just now, I wrote and published my first SCI paper six months ago, about 22 pages, close to more than twenty thousand words. The paper is about the incentive mechanism in participatory perception, and I also read a lot. Related literature, which reflects my English reading and writing skills. In the usual development, I also often contact English, such as Java development API documentation, log information, and I brushed more than 200 words on the leetcode platform, the topics are in English, I realized the importance of English, want to pick up In the coming year, I took TOEFL IELTS and thought that Harbin Institute of Technology would continue to study. I hope the teacher will give me such an opportunity.
+
+
+
+## 学校
+
+Central South University is located in Changsha, Hunan Province. It is a 985 university and it was founded in 2000. The former principal was Zhang Yuxue. The current principal of the school is Tian Hongqi. The school motto is practical, and there are several campuses, such as the headquarters, the new campus, and the railway campus. Behind the Yuelu Mountain, there is a beautiful scenery, as well as the Swan Lake, there are many white swan black swan, and even some TV dramas are also filmed in our school. Compared with other places in the school, I prefer to eat and live in the school. In terms of eating, there are many canteens, and the dishes are so many and cheap, which is full of praise. About the school’s living, in terms of the undergraduate. There are four students in a dormitory with air conditioning and a separate bathroom. The school encourages competition and innovation, and has established many related competitions. The participation of students is also very high. In a word, I like my university very much. Here, I have laid a solid foundation for my study. Ok. That’s all. Thank you.
+
+
+
+## 家乡
+
+I come from Linjiang City of Jilin Province, which is in the northeast of China. Linjiang is named for the Yalu River. The another side of the Yalu River is North Korea. Therefore, there are rich water resources because of the yalu river. There are also some beautiful scenery, famous attractions such as Jinyinxia, Xianren Cave, and so on. The population here is small, but people are very easy-going. In addition, compare with other cities, the prices of the city are very low, even no subways. When I was in high school, I went to another place. To some extent, it is another hometown. In Jiangyuan District of Baishan City, which is the hometown of black fungus in China, the hometown of Songhua Stone in Jiangyuan District, you may find special stones in the mountains. There is also a stone pavilion that exhibits a wide variety of stones and corresponding prices. These two places are located in the eastern part of Jilin Province, so the winter is long, cold, and the frost comes early. I really like my hometown and I hope my hometown can get better. OK. That’s all. Thank you.
+
+
+
+## 家庭
+
+I come from Linjiang City, Jilin Province. There are 4 people in my family. My parents and my sister, my sister is now married who is 9 years older than me. She has a daughter and even her daughter already in the first grade. My parents don't have a high diploma, making a living by selling fish. Compared with that my father is very strict with me, my mother is very gentle to me. Anyway, I am very grateful to my parents. OK. That’s all. Thank you.
+
+## 爱好
+
+ I have many hobbies, such as swimming, playing tennis, reading, Watching American TV and running in the night. I think hobbies can make my life colorful. Besides, having some hobbies can bring knowledge to me. For example, reading is a good way to get knowledge. So I also like to get knowledge in the library, but not what I learned in class. A book I read recently is 《java concurrency》. I can not learn all from class, so reading can bring me other knowledge. They can help me to improve myself. I spend the most time watching American TV. The American dramas I have seen include Old Friends, How I meet your mother, Big Bang, Little Shelton, Agent Carter, SHIELD Agent, Game of Thrones, Broke Girls. OK. That’s all. Thank you.
+
+
+
+
\ No newline at end of file
diff --git "a/_posts/English/2022-08-27-\350\257\255\346\226\231-\347\226\221\351\227\256.md" "b/_posts/English/2022-08-27-\350\257\255\346\226\231-\347\226\221\351\227\256.md"
new file mode 100644
index 0000000000..119435a287
--- /dev/null
+++ "b/_posts/English/2022-08-27-\350\257\255\346\226\231-\347\226\221\351\227\256.md"
@@ -0,0 +1,59 @@
+---
+layout: post
+category: English
+title: 语料-疑问
+tags: English
+---
+
+### 进展怎么样?
+
+How is it going?
+
+How is it going with sb/sth? 进展怎么样
+
+Is everything going well?
+
+How are you getting on with your project?
+
+### Going on
+
+ What’s going on 发生什麼事?
+
+What’s going on?和what is happening?有相同的意思
+
+
+
+go on
+
+1. go on (doing something): 继续(做某事)
+2. go on (with something):继续(某事)
+
+
+
+1. The work is going on smoothly.
+
+ 工作正在顺利进行。
+
+## 怎么样?
+
+How does that sound?
+
+what do you say
+
+## 杂
+
+could you take a look if u have a second? 有时间的话看一下
+
+could u please help me confirm whether your feature is 100% ready
+
+你同意xx? Do you agree with sth. Are you in favor of doing/sth.
+
+How do I address you? 我怎样称呼您?(非常正式)
+
+How are you getting on? 你怎么样?(询问近况)Same as usual.还是老样子。
+
+Could you elaborate on that? 详细说明 Would you mind elaborating on something?
+
+How would you suggest we do that?
+
+let's give it a try and see if it improves performance.
\ No newline at end of file
diff --git "a/_posts/English/2022-08-27-\350\257\255\346\226\231-\351\231\210\350\277\260.md" "b/_posts/English/2022-08-27-\350\257\255\346\226\231-\351\231\210\350\277\260.md"
new file mode 100644
index 0000000000..6694a90b71
--- /dev/null
+++ "b/_posts/English/2022-08-27-\350\257\255\346\226\231-\351\231\210\350\277\260.md"
@@ -0,0 +1,766 @@
+---
+layout: post
+category: English
+title: 语料-陈述
+tags: English
+---
+
+## 个人单词本
+
+
+
+乐观的 optimistic
+
+悲观的 pessimistic
+
+熔断 circuit breaker circuit[/'sɝkɪt/](cmd://Speak/_us_/circuit) 电路
+
+限流 rate limiting [/reɪt/](cmd://Speak/_uk_/rate)
+
+降级 fallback,n. degrade [/dɪ'greɪd/](cmd://Speak/_uk_/degrade), v. degration.
+
+服务发现 service discovery.
+
+负载均衡 load balance
+
+访问控制列表ACL: access control list
+
+可靠性: reliance, 可用的: reliable
+
+一致性: consistency
+
+最终一致性: eventually consistency [/ɪ'ventʃʊəlɪ/](cmd://Speak/_uk_/eventually)
+
+隔离: isolation [/aɪsə'leɪʃ(ə)n/](cmd://Speak/_uk_/isolation)
+
+连接池: connection pool [/puːl/](cmd://Speak/_uk_/pool)
+
+鉴权: authentication [/ɔ:,θenti'keiʃən/](cmd://Speak/_us_/authentication)
+
+计数器法: counter method
+
+滑动窗口: sliding window
+
+滚动的: rolling [/'rəʊlɪŋ/](cmd://Speak/_uk_/rolling)
+
+流量: traffic
+
+漏桶: Leaky Bucket [美 /'liki/](cmd://Speak/_us_/leaky)令牌桶: token bucket
+
+轮询,探询: poll [ /pəʊl/](cmd://Speak/_uk_/poll)
+
+延迟: delay
+
+定时器: timer, 任务定时调度: task scheduler
+
+定时的: timed
+
+时间轮: wheeltimer
+
+优先的: prior [/'praɪə/](cmd://Speak/_uk_/prior)
+
+circular [/'sɜːkjʊlə/](cmd://Speak/_uk_/circular)环形的,circuit环形vi, 电路。
+
+缓冲 buffer
+
+层 level
+
+层级 hierarchy 分层的 hierarchical [美 /'haɪərɑrki/](cmd://Speak/_us_/hierarchy)
+
+灵活的 flexible
+
+线程安全 thread safety
+
+attribute 美 /ə'trɪbjut/
+
+boolean
+
+atomic
+
+assign
+
+aspect
+
+ratio
+
+scale
+
+access
+
+represent
+
+address 处理 = deal with = handle
+
+Matter 问题、事情
+
+Look into调查 。别人给了建议,可以用look into that表示正在看这个建议的方案。
+
+orchestration 编排 协调
+
+resilience 弹性
+
+cognitive 有认知的, 认识的。
+
+elaborate more detail on XX,把XX详细解释
+
+Expansion 扩容
+
+unweighted 无权重的
+
+inbound入境的; unbound 已自由的
+
+Allegiance 忠诚
+
+Approperiate 恰当的
+
+premise n 前提。 vt 引出
+
+Subsequent 随后的
+
+Shepherd vt 带领 指导
+
+suspend 暂停
+
+Inconvenience 不变,for your convenience
+
+entitlement n 授权
+
+Invocation n 祈祷 祈求
+
+merchandise 货物
+
+Catestrophic 灾难性的
+
+Instrument 仪器工具
+
+Comprehensive 广泛的,综合的
+
+procedure 程序 手续
+
+Ambiguous 模棱两可的
+
+blast redius 爆炸半径
+
+impose v 强加, imposing 壮观的,给人深刻印象的
+
+Mitigate vt 使缓和
+
+Intuitive 有直觉力的
+
+denote表示
+
+5 dogs in total. 总共
+
+Clarification 澄清
+
+look into 浏览、观察
+
+address 称呼,设法解决
+
+encryption 加密
+
+assure vt 确保 = ensure
+
+Horizontally ,
+
+artificial 人造的
+
+Exempt [美 /ɪɡˈzempt/](cmd://Speak/_us_/exempt) vt 免除 豁免
+
+Sustainable /səˈsteɪnəbl/ 可持续的
+
+Gross 恶劣的
+
+Dismiss vt 开除 解散 解雇
+
+Revenue 税收 /ˈrevənuː/
+
+Obliged adj. 感激的;有责任的;必须的
+v. 要求;约束;施恩惠(oblige的过去分词)
+
+Occasionally, temporary temporarily
+
+## 个人语料
+
+看一遍 read through
+
+联系我, reach out to me
+
+接入access
+
+the details are list in the doc as well
+
+make sure that
+
+align the context with our PMs before formal access.
+
+
+
+reproduce the bug
+
+step-by-step screenshots
+
+outset开端
+
+it is as expected.
+
+go through 经历
+
+detailed feature review
+
+formal
+
+format
+
+phase阶段
+
+correct
+
+don't hesitate to contact me.
+
+
+
+合规 compliance
+
+治理 governance [/'gʌv(ə)nəns/](cmd://Speak/_uk_/governance)
+
+be handed over to sb. 交接
+
+please contact sb
+
+
+
+that's totally fine.
+
+走查 walkthrough
+
+conduct 实施
+
+事故 failure
+
+
+
+bottleneck瓶颈。
+
+
+
+nothing but 只不过
+
+perform执行 运行
+
+throttling 油门调节
+
+
+
+favorite已经有了最的含义了,不要前面加most
+
+
+never mind
+I don't mind.
+
+work out (vt/ vi) *[work it out](dic://work it out)*
+
+I realy appreciate it.
+
+I own you one.
+
+I need to vent.发泄
+vent to.
+
+There's nothing wrong with sth.
+
+no way
+There's no way xxx
+
+
+
+I see.
+
+what I have on my agenda today.
+
+Just as I start in on my email, my phone rings
+
+
+
+“**I have a question for you**” would be correct. “I have a question to you” would be incorrect. You could, however, say something like “I have a question to ask you” instead.
+
+
+
+
+
+have a hard time doing. 做什么困难
+
+get sth in. 抽空做某事。 I try to get a snap in before the meeting. I try to get a run in before going to work
+
+be tired of doing sth
+
+change things up, 做些改变,it's time to change things up.
+
+
+
+
+
+finalize 敲定
+
+Postpone 延期 put off. meeting has been postponed to Friday.
+
+Revision 修订
+
+Variate 变量
+
+Intrusive 侵入的, in chu si v
+
+redundant 冗余的 ri dan den t
+
+enroll 登记 v
+
+
+
+
+
+
+
+
+
+
+
+How to effectively utilize, 利用
+
+thay **have** a lot **in common**. They have a little in common in their hobbies
+
+我尝试了。 I tried doing
+
+I tried ringing you several times yesterday but I couldn't get through.
+
+be responsible for doing 没有to do
+
+be resonsible to sb.
+
+fair enough: 勉强同意 部分合理
+
+
+
+我不喜欢 It's my thing
+
+
+
+I'm dying to 非常想
+
+I'd appreciate it if you'd come with me
+
+how long have you not seen him since yesterday.
+
+I'm convinced that
+
+Is it possible to
+
+It depends on sth
+
+It make no difference 没关系
+
+It make no difference whether you come or not.
+
+make a difference 有影响
+
+It would be wonderful if we could do that
+
+It is believed that
+
+
+
+
+
+Be similar to 不是with.
+
+Sure about that?
+
+I'm pretty good at
+
+Xx If there was..
+
+
+
+Decent 得体的
+
+There's nothing wrong with being poor
+
+
+
+I have confidence in you.
+
+Your work is bound to be successful.
+
+I'm quite sure we will win.
+
+Don't get your hopes too high.
+
+果不其然。That figures.
+
+I can't think of any way out now.Where do I go from here?
+
+现在也想不出什么办法,我该怎么办呢?
+
+You can try another time.
+
+我很后悔错过了那次机会。I'm sorry to have missed the chance.
+
+= I regret having missed the chance.
+
+
+
+There has to be sth
+
+
+
+From/in my understanding,
+
+In my experience. Based on your past experience.
+
+
+
+We will sort it out. 我们会解决它
+
+
+
+Just out of curiosity, xxx. 出于好奇心,记住curiosity写法,不是curioustiy
+
+That's to say = that means.
+
+
+
+note that xxx 注意
+
+now that xxx 既然现在
+
+
+
+occagsionally 偶尔地
+
+temporary 临时的 temporarily.
+
+coincident. apparently/obvious. curious.
+
+I'm not sure what you mean by "gg." Can you please provide more context or clarify your request?
+
+
+
+no longer, not yet可以插入在动词前,比如been前
+
+rather than doing sth, I would like to
+
+Rather 相当,类似very It is rather cheap at this price. 相当便宜
+
+I'm rather pessimistic.
+
+
+
+
+
+So far so good, 目前还好
+
+Look if nothing else, 别的不说。
+
+You like it **the most** 最喜欢它了。
+
+with respect to 关于。 类似for
+
+regarding 替代 for, 关于;
+
+
+
+
+
+move ahead 继续,和move on差不多。 Go ahead也行。
+
+
+
+other than, 不同于 sth. 例句This means that, other than the primary key attributes, you don't have to define any attributes or data types when you create tables.
+
+along with 连同。 eg: The following are descriptions of each data type, along with examples in JSON format.
+
+Optionally 或者 Optionally, you can apply a condition to the sort key so that it returns only the items within a certain range of values.
+
+Suppose that 假设 eg: Suppose that the *Pets* table has a composite primary key consisting of *AnimalType* (partition key) and *Name* (sort key).
+
+Roughly 大概 Roughly half of them are men, half of them are women.
+
+
+
+if you are looking to do 如果你希望做xx,如果你想要
+
+well, **regardless**, it's happening 无论如何
+
+
+
+**从现在起**; 今后,,
+例句;From now on, I will begin to write my book.
+
+It's due to arrive an hour from now.从现在起一个小时就该到了。
+I'll be more careful from now on .我今后会更加小心。from now on的用法相关疑问句在特定的环境和语调下,问句具有与其形式相反的含义,即肯定中暗含否定含义。所以翻译时一定要考虑语境和语调,表达出英语的否定意义。
+
+
+
+All right, look, here's the deal
+
+To my understanding.我是这样理解的。
+
+
+
+It's as if that 它好像
+
+
+
+### looks like vs seems like
+
+后者抽象,前者是物理看见
+
+Both are very similar.
+
+-"It looks like" is something you usually say when you can physically see something.
+
+-"It seems like" is something a little more abstract. It's something you can only "detect" or guess at.
+
+ Examples: -"it seems like it will rain" -"it looks like it will rain" (these are both okay to say)
+
+-"It seems like just yesterday I was in high school" (you can't say "It looks like just yesterday I was in high school" because you can't physically "see" how much time has passed)
+
+
+
+like作为像时是介词,可以直接加宾语,同as。只有当like作为句子主要成分,如He is like a dog. 也可以说成,He looks like a dog.
+
+### ever怎么用
+
+ever用作副词,意为“曾经、以前、无论何时、总是”等。其用法比较灵活
+
+一、用于一般疑问句,意为“曾经、这以前”现代汉语中一般不译出。
+Does she ever go out at night?她通常晚上外出吗?
+Have you ever been to Beijing?你曾去过北京吗?
+
+二、用于否定句,意为“无论何时都不……,至今不曾……”。
+Nothing ever happens in the lonely village.这个遥远的小村子至今未出过事。
+We hardly ever go shopping there.我们至今未在那里买过东西。
+
+三、用于条件句,译为“曾经、有机会”。
+If you ever come to Beijing,please let me know.如果有机会来北京,请告诉我。
+If you ever have any problems,please call me.你若有问题,请打电话。
+
+四、与比较级连用,译为“以前、以往、任何时候”。
+It is raining hard than ever.雨下得比以前更大了。
+
+五、与最高级连用,译为“空前、有史以来、从来没有”。
+I think she is the best actress ever.我认为她是至今最优秀的演员。
+
+六、与疑问词连用,加强语气,译为“到底、究竟”。
+When(where)ever did you see the panda?你到底在什么时候(哪里)看见那只熊猫的?
+
+七、口语中,用于带有be的疑问句加重语气,表感叹。
+Is she ever a beauty?她真漂亮!
+
+### 也
+
+same sth as sth 不要用with。 the same as sth
+
+same for me 我也要一样的
+
+same here = me too. 我也一样 否定No, me neither
+
+same to you 你也一样
+
+It's same with her. 她也一样
+
+neither do I. 我也不是
+
+So do I 我也是
+
+
+
+## 句子翻译练习精选100句
+
+[链接](https://www.sohu.com/a/409918309_99918196)
+
+## 会议
+
+会议推迟,postpone,v
+
+the meeting had been postponed., be postponed to Friday
+
+### 开场
+
+thank you all for coming.
+
+perhaps we can make a start
+
+thanks everyone and welcome to today's meeting. lets begin.
+
+
+
+today's meeting is about ...
+
+we'll go over our budget. go over = 过一遍,类似review.
+
+需要等其它人吗 If we are all here let’s get started/ start the meeting/start.
+
+Is everyone here yet? 所有人都来了吗。
+
+let's start in 5 minutes. 5分钟后开始。
+
+
+
+
+
+### 中途
+
+很抱歉打断 Sorry to interrupt
+
+你可以接管吗, take over.
+
+If noboay has anything else to add, we can continue on to the next item. 确实是continue on to 它继续sth。
+
+
+
+let's move on to the next item. 让我们看下一点
+
+I'd like to turn it to over to sb. 会议转接给某人
+
+let's move on to the next item 让我们看下一项
+
+### 结束
+
+Before we close, let me summarize the main points
+
+Okay. It looks like we've covered the main items for the meeting today.
+
+Are there any questions before we finish?
+
+No? Okay. Thank you all for attending. That's all.
+
+
+
+If there are no other comments I’d like to wrap this meeting up.
+
+
+
+we are running out of time.
+
+
+
+## 时间
+
+over time 随着时间过去
+
+### 不久后
+
+过去的不久后。**Not long after xx.** Not long after he took office, the United States suffered an economic depression
+
+现在未来的不久后。
+
+1. **Soon**. They're tiny and chubby and so sweet to touch, and soon they'll grow up and resent you so much.
+2. **Before long**. He shall know this before long.
+
+
+
+### 时钟时间点的表达
+
+6:10 ten past six 过了
+
+5:50 ten to six 还差
+
+11:30 half past eleven 差半小时
+
+
+
+差15分钟 a quarter 刻
+
+9:15 nine fifteen ; fifteen past nine ; a quarter past nine
+
+3:45 three forty-five ; fifteen to four ; a quarter to four
+
+
+
+大约时间: 马上到, 还不到,刚过
+
+It's almost two. 马上到两点了。
+
+It's not quite two. 还不到两点。
+
+It's just after two. 刚过两点。
+
+
+
+### 世纪、年代、年、月、日的表达
+
+世纪:在十七世纪 写作:in the 17th century,读作:in the seventeenth century。 或者 在十七世纪 写作:in the 1600s,读作:in the sixteen hundreds
+
+
+
+年代: 在二十世纪三十年代 写作:in the 1930s,读作:in the thirties of the twentieth century或 in the nineteen thirties
+
+在二十世纪二十年代早期 in the early 1920s;
+
+在二十世纪五十年代中期 in the mid-1950s
+
+
+
+十月一日 写作:October 1, October 1st, 1 October, 1st October, (the) 1st of October等,其中的October都可以写成缩写形式Oct.
+
+读作:October the first或the first of October
+
+
+
+### 介词使用
+
+**若指在哪一年或哪一月,用介词in;若具体到某一天,需用介词on。**
+
+例如:
+
+She was born in 1989.
+
+She was born in August.
+
+She was born in August 1989.
+
+She was born on 2nd August, 1989.
+
+
+
+
+
+单纯地表示上下午时用in; in the morning
+
+有具体的星期或日期时用on;On Sunday morning/afternoon.
+
+有具体的时间时用at;At 6:30 tomorrow morning/afternoon.
+
+黎明、午、夜、点与分用at at night ; at 7:30
+
+
+
+将来时态in...以后
+
+- they will come back in 10 days. 他们将10天以后回来。
+- i‘ll come round in a day or two. 我一两天就回来。
+- come and see me in two days‘ time. 两天后来看我。
+
+## 听不懂怎么办
+
+My english is not that good, a little rusty 生锈的。
+
+I do not understand what you said.
+
+could you slow down a bit? 慢一点嘛 Excuse me, could you please slow down a little bit. I have trouble understanding you
+
+- Can you please repeat your question? I didn't hear your question clearly, the line was cutting off.
+- I'm sorry. Would you please repeat the question?
+- Sorry, can you say it again?
+- Excuse me, I didn't hear you. Could you please say that again?
+
+
+
+we mainly use chinese at work, and we also use english when collaborating with foreign colloeagues at the oversea offices.
+
+chinese is used mostly.
+
+
+
+I'm going to share my screen and please let me know when you can see it.
+
diff --git "a/_posts/Games/Xbox/2021-10-03-xbox\345\267\264\350\245\277\346\234\215\350\264\255\344\271\260\346\225\231\347\250\213.md" "b/_posts/Games/Xbox/2021-10-03-xbox\345\267\264\350\245\277\346\234\215\350\264\255\344\271\260\346\225\231\347\250\213.md"
deleted file mode 100644
index d8dd198080..0000000000
--- "a/_posts/Games/Xbox/2021-10-03-xbox\345\267\264\350\245\277\346\234\215\350\264\255\344\271\260\346\225\231\347\250\213.md"
+++ /dev/null
@@ -1,26 +0,0 @@
----
-layout: post
-category: Xbox
-title: xbox巴西服购买教程
-tags: Xbox
----
-
-## xbox巴西服购买教程
-
-
-
-1. 微软账号个人信息编辑,编辑所在国家,添加账单和送货地址,选巴西的。https://account.microsoft.com/profile/?fref=home.banner.profile-column.title
-
- ```
- 平台如果无法编辑删除,就新加个然后设为首选账单地址。
-
- Rua Estados Unidos, No. 1071
- 城市: CRISOLOGO
- 洲: 圣保罗州01427-001
- 巴西
- 61-21958270
- ```
-
-2. 添加付款方式,信用卡支付
-
-3. xbox登录西班牙服,记住购买时不能开加速器。选择已有购买方式就可以了。
\ No newline at end of file
diff --git a/_posts/Tech/AWS/2021-09-30-AWS Overall.md b/_posts/Tech/AWS/2021-09-30-AWS Overall.md
new file mode 100644
index 0000000000..4ee54bd11f
--- /dev/null
+++ b/_posts/Tech/AWS/2021-09-30-AWS Overall.md
@@ -0,0 +1,268 @@
+---
+layout: post
+category: AWS
+title: AWS Overall
+tags: AWS
+---
+
+## Cloud Notes
+
+IaaS、PaaS 和SaaS 的区别: 基础设施即服务(IaaS) 为云服务提供硬件,其中包括服务器、网络和存储。 平台即服务(PaaS) 除了提供IaaS 可提供的所有硬件之外,还提供操作系统和数据库。 软件即服务(SaaS) 提供了最多的支持,即为您的最终用户提供除其数据之外的所有服务。
+
+[参考](https://www.zhihu.com/question/20387284)
+
+如果你是一个网站站长,想要建立一个网站。不采用云服务,你所需要的投入大概是:买服务器,安装服务器软件,编写网站程序。
+
+现在你追随潮流,采用流行的云计算,
+
+如果你采用IaaS服务,那么意味着你就不用自己买服务器了,随便在哪家购买虚拟机,但是还是需要自己装服务器软件
+
+而如果你采用PaaS的服务,那么意味着你既不需要买服务器,也不需要自己装服务器软件,只需要自己开发网站程序
+
+如果你再进一步,购买某些在线论坛或者在线网店的服务,这意味着你也不用自己开发网站程序,只需要使用它们开发好的程序,而且他们会负责程序的升级、维护、增加服务器等,而你只需要专心运营即可,此即为SaaS。
+
+
+
+## AWS Overall Notes
+
+云从业者Note: https://github.com/Matthewow/AWS-CLF-StudyNotes
+
+
+
+很好overall: https://www.zhihu.com/question/22314873
+
+
+
+云的基础是计算、存储、网络,这三部分涵盖了互联网应用的各个方面,所有的云服务也是围绕这三部分去展开。
+
+
+
+AWS的服务是按照region来划分的,在部署自己的应用之前,需要选择region,比如美国有us-west, us-east regions, 中国有cn-north, cn-west regions。基本上按照服务用户所在的区域来选择region,服务中国的用户就选择中国的region,服务美国的用户就选择美国的region。否则这个网络传输的成本就非常高,而且中国区其独有的网络环境,导致其他地区的服务是无法访问的。一个region又划分为多个AZ (availability zone), 一般情况下,我们需要把服务器均匀分布在多个AZ,为了避免单点故障,也就是我们所说的灾备多活。
+
+
+
+选择好region后,就需要部署自己的[VPC](https://link.zhihu.com/?target=https%3A//console.aws.amazon.com/vpc/home) (virtual private cloud),一个VPC定义了一个私有隔离的网络环境。在VPC里面,我们部署所有的计算、网络资源。计算资源就是我们的服务器,AWS最出名的就是[EC2](https://link.zhihu.com/?target=https%3A//console.aws.amazon.com/ec2) (elastic compute cloud)。在部署EC2时,我们首先预估应用需要消耗的计算资源(cpu,磁盘,带宽等等),选择EC2的型号和数量。然后将所有的EC2分割成多个[ASG](https://link.zhihu.com/?target=https%3A//console.aws.amazon.com/ec2autoscaling/home) (auto scaling group), 一个ASG就相当于一个可弹性收缩的机器群,只要定义好扩容和缩容的指标,ASG就可以自己分配机器的数量。比如我们要求在EC2 CPU升到40%就扩容一倍,在CPU降到10%就缩容一倍,这样一个ASG里面机器CPU的消耗就一直均衡地保持在20%左右。具体分割成几个ASG,一般依据这个region有几个AZ来定,比如[us-east-1 region](https://www.zhihu.com/search?q=us-east-1+region&search_source=Entity&hybrid_search_source=Entity&hybrid_search_extra={"sourceType"%3A"answer"%2C"sourceId"%3A2333079486})有3个AZ,就分割成三个ASG,一个AZ部署一个ASG,这三个ASG在接受流量方面没有任何区别。接下来就是网络资源,每个VPC都有自己的ACL(acess control list),一个ACL定义了inbound rules和outbound rules,分别限制了访问IP的限制和访出IP的限制。VPC的网络资源被划分成多个子网subnets,一个subnet是一组IP地址的集合,前面说到的ASG就部署在[subnet](https://www.zhihu.com/search?q=subnet&search_source=Entity&hybrid_search_source=Entity&hybrid_search_extra={"sourceType"%3A"answer"%2C"sourceId"%3A2333079486})里面。一般来说subnet的数据量跟region AZ的数据成正比,每个AZ分配一个public subnet和一个private subnet,那么us-east-1的VPC就会有6个subnets。我们将ASG部署在private subnet里面,只允许vpc内部的IP访问,用于保护机器资源。因为public subnet是对外的,所以我们在public subnet里面部署ELB (elastic load balancer),用于接受vpc外的请求。有人会问如果我们想登录到ASG的EC2上面,应该怎么做?解决办法是在public subnet里面launch一个跳板机,我们先登录到跳板机,然后从跳板机里面登录到EC2上面。
+
+接下来就是存储资源,AWS提供多种选择,我们最熟悉的应该就是[S3](https://link.zhihu.com/?target=https%3A//s3.console.aws.amazon.com/s3/home) (simple storage service)。S3是面向对象存储的服务,可以用来做数据归档、备份、恢复,或者作为数据分析、AI、Machine learning的数据湖来使用。通俗的理解就是我们的磁盘,它存储的key就是一个目录路径,相当于磁盘的目录,value是一个object,相当于文件或者子目录。在线的存储根据功能的不同也有很多选择,比较出名的而且是我用过的有三个。第一个是[DynamoDB](https://link.zhihu.com/?target=https%3A//console.aws.amazon.com/dynamodb/home),它是document-based NoSQL DB。DynamoDB是Amazon内部使用最频繁的数据,几乎90%的存储都会选择DynamoDB,绝对地超过RDS。这个现象的原因在这篇文章[Dynamo: Amazon’s Highly Available Key-value Store](https://link.zhihu.com/?target=https%3A//www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf)里面有解释,同时DDIA (Design [data-intensive application](https://www.zhihu.com/search?q=data-intensive+application&search_source=Entity&hybrid_search_source=Entity&hybrid_search_extra={"sourceType"%3A"answer"%2C"sourceId"%3A2333079486})) 这本书也给了同样的解释。总结就是:Amazon内部的存储90%以上都是单对多的关系,DynamoDB作为一个分布式的key-value DB,在可用性、扩展性方面非常适合这种单对多的存储结构。而且DynamoDB是最终一致性,进一步增加了它的可用性。关于DynamoDB我后面会单独出一篇介绍它的blog。而对于多对多的存储,我们就会用[RDS](https://link.zhihu.com/?target=https%3A//console.aws.amazon.com/rds) (relational database service),RDS字面理解就是[关系型数据库](https://www.zhihu.com/search?q=关系型数据库&search_source=Entity&hybrid_search_source=Entity&hybrid_search_extra={"sourceType"%3A"answer"%2C"sourceId"%3A2333079486})。AWS RDS上面托管了多种关系型数据库,包括mysql、oracle、MS SQL、aurora、MariaDB和PostgreSQL这六种数据库,其中我使用过mysql和aurora。在Amazon内部,[aurora](https://link.zhihu.com/?target=https%3A//docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/CHAP_AuroraOverview.html)使用的更频繁,它是兼容mysql和PostgreSQL的结合体,具体内容可见这篇文章[Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases](https://link.zhihu.com/?target=https%3A//www.allthingsdistributed.com/files/p1041-verbitski.pdf)。我使用的最后一种存储是[AWS elasticsearch](https://link.zhihu.com/?target=https%3A//console.aws.amazon.com/esv3/home) ,当时为了实现一个搜索功能,因为涉及到模糊匹配,全文搜索,就采用了[aws es](https://www.zhihu.com/search?q=aws+es&search_source=Entity&hybrid_search_source=Entity&hybrid_search_extra={"sourceType"%3A"answer"%2C"sourceId"%3A2333079486})。aws es跟主流的es已经分道扬镳,目前在aws上面称为openSearch service。
+
+介绍完计算、网络、存储,接下来我想从应用的角度,讲讲在实际应用中,我们应该怎样使用AWS的服务。首先说消息队列,这个广泛应用的基础功能,AWS提供了[SQS](https://link.zhihu.com/?target=https%3A//console.aws.amazon.com/sqs/v2/home)和[SNS](https://link.zhihu.com/?target=https%3A//console.aws.amazon.com/sns/v3/home)。SQS是一个分布式的队列消息service,SNS是一个分布式的发布-订阅消息service。具体有人会问这两者有什么区别,这里给出了回答: [What is the difference between Amazon SNS and Amazon SQS?](https://link.zhihu.com/?target=https%3A//stackoverflow.com/questions/13681213/what-is-the-difference-between-amazon-sns-and-amazon-sqs)。 在我的实践中,SQS和SNS会结合起来使用,首先应用发布消息到SQS的queue里面,然后SNS消费这个queue的消息,放到自身的topic里面持久保存,然后其他的应用订阅这个topic,消费里面的消息。
+
+
+
+建设完一个应用,然后就是DevOps。AWS在[托管代码](https://www.zhihu.com/search?q=托管代码&search_source=Entity&hybrid_search_source=Entity&hybrid_search_extra={"sourceType"%3A"answer"%2C"sourceId"%3A2333079486})、编译代码、部署应用、监控应用方面也提供了一整套服务,从前到后,[codeCommit](https://link.zhihu.com/?target=https%3A//console.aws.amazon.com/codesuite/codecommit) -> [codeArtifact](https://link.zhihu.com/?target=https%3A//console.aws.amazon.com/codesuite/codeartifact) -> [codeBuild](https://link.zhihu.com/?target=https%3A//console.aws.amazon.com/codesuite/codebuild) -> [codeDeploy](https://link.zhihu.com/?target=https%3A//console.aws.amazon.com/codesuite/codedeploy) -> [codePipeline](https://link.zhihu.com/?target=https%3A//console.aws.amazon.com/codesuite/codepipeline)。这一套实现了应用的continuous integration和continuous deployment。在监控方面,AWS提供了[cloudWatch](https://link.zhihu.com/?target=https%3A//console.aws.amazon.com/cloudwatch),可以以应用维度收集日志,视图化监控指标。AWS还提供了一个服务叫cloudFormation,这个服务在应用迁移的过程中,非常有用。Amazon内部很多都是国际化业务,应用需要部署到各个region。cloudFormation以yaml文本的形式记录下一个应用涉及到的各个服务资源配置,放在一个template里面。迁移到不同的region时,只需要一键run coudFormation template, 就可以部署好所有的AWS资源。
+
+
+
+Notes:
+
+- region: 包含多个AZ, named by location 用aws需要选个region
+
+- AZ: availability zone. 包含一主多从的cluster,多个data center, 可以有另一个AZ继续保持主从。 region分多个AZ主要是为了容灾。
+
+- region ---> AZ ----> data center 都是一对多。 一般情况下,region之间不会保持同步,互相独立,除非客户允许。
+
+
+
+
+
+
+
+- 选择region考量: compliance, latency, price, service availability
+
+## 术语
+
+- IAM: identify and access management. 同account也是aws account level, account每月会进行计费,可以任意region里创建资源, work globally. 像s3等存储都是region level. EC2等就是AZ level. 意味着一个ec2不能分布在两个AZ。 IAM可以创建用户,然后授予权限给某个group
+
+- SQS: simple queue service
+
+- SNS: simple notification service. 发一些同事用的,比如发短信等。
+
+- Aws route 53是 aws DNS
+
+- Amazon CouldFront 是CDN
+
+- 对象存储
+
+ - S3: simple storage service
+
+- cloudwatch for monitoring
+
+- ELB: elastic load balancer
+
+- EC2是 virtual machines. 全称: elastic compute cloud. 一共三种compute资源: vm, container services, serverless
+
+- AMI: amazon machine image 就是一堆配置,比如什么系统,安装哪些附加软件。可使用AMI启动一个同配置的实例。 类似docker的image
+
+- AWS Elastic Beanstalk 是一个应用程序管理平台,可以帮助客户轻松部署和扩展 Web 应用程序和服务。它将构建块(例如 EC2、Amazon RDS、Elastic Load Balancing、AWS Auto Scaling 和 Amazon CloudWatch)的预置、应用程序的部署、运行状况监控从用户身上分离出来,让用户可以集中精力编写代码。您只需指定要部署的容器映像、CPU 和内存要求、端口映射和容器链接即可。
+
+ Elastic Beanstalk 将自动处理所有的具体事务,包括预置 Amazon ECS 集群、均衡负载、自动扩展、监控以及在集群中放置容器。如果您希望利用容器的各种优势,但只想通过上传容器映像,在开发到生产等环节部署应用程序时享受到简易性,则 Elastic Beanstalk 非常适合。如果您需要对自定义应用程序架构进行更多精细化的控制,则可以直接使用 Amazon ECS。
+
+- EBS: elastic block store. EC2也需要本地存储,这就是EBS 块存储。例如SSD等。它是外部挂载形式提供的,实例关机了,数据也还在,也可以做备份。适合那种临时数据,而非长期存储。一次只能挂载到一个AZ里的一个实例。 如果想多个实例连一个存储,可以用EFS/FSx, 前者linux,后者windows。
+
+
+
+
+
+
+
+
+
+
+
+
+
+## Example: build an application like facebook ,a social media app.
+
+AWS介绍视频: [youtube](https://www.youtube.com/watch?v=Z3SYDTMP3ME&ab_channel=AWSTrainingCenter)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+加一些安全组件,IAM负责每个附件是否可访问,account管理范围等。 KMS负责数据的加密。 ACM负责access certificate management, 比如https证书等,在ELB这块。 WAF是防火墙,比如防止Ddos攻击之类的,在elb之前。Inspectoer负责监控每个service的安全,类似容器里一个agent。
+
+
+
+
+
+
+
+codeCommit类似github这样代码仓库。
+
+## Example: WordPress
+
+[link](http://www.cloudbin.cn/?p=2647)
+
+## 考证
+
+[参考](https://zhuanlan.zhihu.com/p/138652055)
+
+先考**AWS Certified Solutions Architect - Associate** AWS 认证助理级解决方案架构师考试,这门考试更注重 AWS 的架构设计。助理级解决方案架构师需要基本了解 AWS 的几个基础的组件,比如 EC2,VPC, IAM, S3, Route53 等,掌握它们分别是什么,使用场景是什么,和传统数据中心的区别和优势等等
+
+
+
+云从业者那个可以看这个: https://github.com/Matthewow/AWS-CLF-StudyNotes
+
+
+
+
+
+## 对象存储: S3及S3 Glacier
+
+> [官网](https://aws.amazon.com/s3/storage-classes/)
+
+Amazon S3 is object-level storage, which means that if you want to change a part of a file, you have to make the change and then re-upload the entire modified file. 对象存储,比较像字节的TOS。 也是以bucket隔离的,然后bucket可设置是否公开,可设置每个文件多版本, 可作为一个静态博客的host。 [对象存储参考](https://mafulong.github.io/2022/10/06/%E5%9D%97%E5%AD%98%E5%82%A8%E5%92%8C%E5%AF%B9%E8%B1%A1%E5%AD%98%E5%82%A8%E5%92%8C%E6%96%87%E4%BB%B6%E5%AD%98%E5%82%A8/)
+
+Amazon S3 Glacier is a great storage choice when low storage cost is paramount, your data is rarely retrieved, and retrieval latency of several hours is acceptable. If your application requires fast or frequent access to your data, consider using Amazon S3. Objects stored in Amazon S3 Glacier are called *archives*. 相比s3,价格便宜,适合平时不太访问的归档数据。
+
+
+
+## 计算层:EC2
+
+
+
+3种付费方案:
+
+1. on-demand, 运行时收费,按秒计费,价格固定。
+2. Reserved instances. (RIs) 预订 选定期的,有折扣。这种情况下即便选择不预付,非运行时也算收费。 它需要绑定一个instance type.
+3. Spot instances. 类似出钱,然后aws自己评估这价格可以给几个实例这样。如果不够就掐掉实例。是最便宜的,但需要容忍突然停。
+
+Dedicated hosts: 把物理机控制也给你,贵。和其他公司隔离开。
+
+
+
+## 数据库
+
+RDB: Amazon RDS, Redshit, Aurora.
+
+NoSQL: DynamoDB, Nepture, ElastiCache
+
+
+
+
+
+## IAM
+
+
+
+IAM (Identity Access Management) 由这些东西组成:
+
+- Users
+- Groups 用户组
+- Roles 角色可以分配给AWS服务,让AWS服务有访问其他AWS资源的权限。 举个例子,我们可以赋予EC2实例一个角色,让其有访问S3的读写权限(后面课程会有关于这一点的实操)
+- Policy Documents 策略。 策略具体定义了能访问哪些AWS资源,并且能执行哪些操作(比如List, Read, Write等) 策略的文档以JSON的格式展现
+
+```
+// An example policy: allowing any access to any resource
+{
+ "Version": "2012-10-17"
+ "Statement": [
+ {
+ "Effect": "Allow",
+ "Action": "*",
+ "Resource": "*"
+ }
+ ]
+}
+```
+
+
+
+IAM 是 Global的,不属于任何一个 region
+
+Root 账号是你第一次配置账号的时候创建的,它拥有完全的 Admin aceess
+
+新 User 刚创建时是没有权限的。
+
+
+
+首先要知道, AWS 提供了许许多多种类的服务或者说资源供我们使用, 这些资源挂在我们的 AWS 账户下, 这个账户就是我们第一次用 AWS 时用邮箱和密码申请的, 以后我们所有的资源申请, 账单费用都会挂到这个户头.
+
+那么 IAM 算什么呢? IAM 不是 AWS 的专有名词, 它是一个通用概念, 全称是 Identity and Access Management, 其要解决的两个问题就是身份认证 (Authtication) 和授权 (Authorization). 为此 AWS IAM 设计了用户, 角色, 用户组, 权限策略等概念和机制
+
+
+
+场景
+
+1. 自己公司的员工想访问 AWS Console 查看所在项目组的基础设施
+2. AWS 账户里的 EC2/Lambda 实例想访问同账户下的一台 RDS
+3. 公网里用户的手机想要访问我们的后端存储(借助 API Gateway)
+
+
+
+AWS IAM 并不关心你创建的 IAM User 是给人用还是给程序用
+
+
+
+AWS 官方建议 root 用户的唯一用途, 就是[用来创建你的第一个 IAM 用户](https://link.zhihu.com/?target=https%3A//docs.aws.amazon.com/IAM/latest/UserGuide/best-practices.html%23lock-away-credentials), 把这第一个 IAM 用户设置为管理员, 然后以后的工作都用这个管理员用户来进行.
+
+
+
+## SNS vs SQS
+
+AWS提供了[SQS](https://link.zhihu.com/?target=https%3A//console.aws.amazon.com/sqs/v2/home)和[SNS](https://link.zhihu.com/?target=https%3A//console.aws.amazon.com/sns/v3/home)。SQS是一个分布式的队列消息service,SNS是一个分布式的发布-订阅消息service。具体有人会问这两者有什么区别,这里给出了回答: [What is the difference between Amazon SNS and Amazon SQS?](https://link.zhihu.com/?target=https%3A//stackoverflow.com/questions/13681213/what-is-the-difference-between-amazon-sns-and-amazon-sqs)。 在我的实践中,SQS和SNS会结合起来使用,首先应用发布消息到SQS的queue里面,然后SNS消费这个queue的消息,放到自身的topic里面持久保存,然后其他的应用订阅这个topic,消费里面的消息。
+
+
+
+sqs是一对一,不能一对多,消息可持久化,不推只能等拉,拉完就删除。
+
+sns可一对多,不能持久化,push模型。
+
+sqs及aws笔记,更全, [link](http://www.cloudbin.cn/?p=2530)
+
+
+
+## 参考
+
+[参考](http://www.cloudbin.cn/?tag=aws)
+
diff --git a/_posts/Tech/AWS/2022-10-04-AWS network.md b/_posts/Tech/AWS/2022-10-04-AWS network.md
new file mode 100644
index 0000000000..dca7abddcd
--- /dev/null
+++ b/_posts/Tech/AWS/2022-10-04-AWS network.md
@@ -0,0 +1,406 @@
+---
+layout: post
+category: AWS
+title: AWS Network
+tags: AWS
+---
+
+# AWS VPC
+
+## 名词解释
+
+[参考](https://docs.amazonaws.cn/vpc/latest/userguide/what-is-amazon-vpc.html)
+
+- **Virtual Private Cloud (VPC)**
+
+ [VPC](https://docs.amazonaws.cn/vpc/latest/userguide/configure-your-vpc.html) 是一个虚拟网络,与您在自己的数据中心中运行的传统网络极为相似。创建 VPC 后,您可以添加子网。翻译成中文是虚拟私有云。
+
+- **子网** **Subnets**
+
+ [子网](https://docs.amazonaws.cn/vpc/latest/userguide/configure-subnets.html)是您的 VPC 内的 IP 地址范围。子网必须位于单个可用区中。在添加子网后,您可以在 VPC 中部署 Amazon 资源。
+
+- **IP 寻址**
+
+ 您可以将 IPv4 地址和 IPv6 地址分配到 VPC 和子网。您还可以将您的公有 IPv4 和 IPv6 GUA 地址带到 Amazon 并将其分配到 VPC 中的资源,例如 EC2 实例、NAT 网关和网络负载均衡器。创建 VPC 时,需要为其分配一个 IPv4 CIDR 块(一系列私有 IPv4 地址)、一个 IPv6 CIDR 块或同时分配两种 CIDR 块(双堆栈)。
+
+ 私有 IPv4 地址无法通过 Internet 访问。IPv6 地址具有全球唯一性,可以配置为保持私有或通过互联网进行访问。
+
+- **路由选择**
+
+ 使用[路由表](https://docs.amazonaws.cn/vpc/latest/userguide/VPC_Route_Tables.html)决定将来自您的子网或网关的网络流量定向到何处。
+
+- **网关和端点 ** **Gateways and endpoints**
+
+ [网关](https://docs.amazonaws.cn/vpc/latest/userguide/extend-intro.html)将您的 VPC 连到其他网络。例如,使用[互联网网关](https://docs.amazonaws.cn/vpc/latest/userguide/VPC_Internet_Gateway.html)将您的 VPC 连接到网络。使用 [VPC 端点](https://docs.amazonaws.cn/vpc/latest/privatelink/privatelink-access-aws-services.html)私下连接到 Amazon Web Services,无需使用互联网网关或 NAT 设备。
+
+- **对等连接** **Peering connections**
+
+ 使用 [VPC 对等连接](https://docs.amazonaws.cn/vpc/latest/peering/)在两个 VPC 中的资源之间路由流量。
+
+- **流量镜像** **Traffic Mirroring**
+
+ 从网络接口[复制网络流量](https://docs.amazonaws.cn/vpc/latest/mirroring/),然后将其发送到安全和监控设备进行深度数据包检查。
+
+- **中转网关 ** **Transit gateways**
+
+ 将[中转网关](https://docs.amazonaws.cn/vpc/latest/userguide/extend-tgw.html)用作中央枢纽,以在 VPC、VPN 连接和 Amazon Direct Connect 连接之间路由流量。
+
+- **VPC 流日志** **VPC Flow Logs**
+
+ [流日志](https://docs.amazonaws.cn/vpc/latest/userguide/flow-logs.html)捕获有关在 VPC 中传入和传出网络接口的 IP 流量的信息。
+
+- **VPN 连接**
+
+ 使用 [Amazon Virtual Private Network (Amazon VPN)](https://docs.amazonaws.cn/vpc/latest/userguide/vpn-connections.html) 将 VPC 连接到您的本地网络。
+
+## VPC
+
+**Amazon Virtual Private Cloud (Amazon VPC)**允许你在已定义的虚拟网络内启动AWS资源。这个虚拟网络与你在数据中心中运行的传统网络极其相似,并会为你提供使用AWS的可扩展基础设施的优势。
+
+简单来说,VPC就是一个AWS用来隔离你的网络与其他客户网络的虚拟网络服务。在一个VPC里面,用户的数据会逻辑上地与其他AWS租户分离,用以保障数据安全。
+
+**可以简单地理解为一个VPC就是一个虚拟的数据中心**,在这个虚拟数据中心内我们可以创建不同的子网(公有网络和私有网络),搭建我们的网页服务器,应用服务器,数据库服务器等等服务。
+
+### VPC有如下特点
+
+- VPC内可以创建多个子网
+
+- 可以在选择的子网上启动EC2实例
+
+- 在每一个子网上分配自己规划的IP地址
+
+- 每一个子网配置自己的路由表
+
+- 创建一个Internet Gateway并且绑定到VPC上,让EC2实例可以访问互联网
+
+- VPC对你的AWS资源有更安全的保护
+
+- 部署针对实例的安全组(Security Group)
+
+- 部署针对子网的**网络控制列表(Network Access Control List)**
+
+- 一个VPC可以跨越多个可用区(AZ)
+
+- **一个子网只能在一个可用区(AZ)内**
+
+- 安全组(Security Group)是有状态的,而网络控制列表(Network Access Control List)是无状态的
+
+ - 有状态:如果入向流量被允许,则出向的响应流量会被自动允许
+- 无状态:入向规则和出向规则需要分别单独配置,互不影响
+ - 具体的区别挨踢小茶会在后续的章节详细讲解
+
+- VPC的子网掩码范围是从/28到/16,不能设置在这个范围外的子网掩码
+
+- VPC可以通过Virtual Private Gateway (VGW) 来与企业本地的数据中心相连
+
+- VPC可以通过AWS PrivateLink访问其他AWS账户托管的服务(VPC终端节点服务)
+
+
+
+### VPC Peering
+
+**VPC Peering**可是两个VPC之间的网络连接,通过此连接,你可以使用IPv4地址在两个VPC之间传输流量。这两个VPC内的实例会和如果在同一个网络一样彼此通信。
+
+- 可以通过AWS内网将一个VPC与另一个VPC相连
+- 同一个AWS账号内的2个VPC可以进行VPC Peering
+- 不同AWS账号内的VPC也可以进行VPC Peering
+- 不支持VPC Transitive Peering 不支持传递
+ - 如果VPC A和VPC B做了Peering
+ - 而且VPC B和VPC C做了Peering
+ - 那么VPC A是**不能**和VPC C进行通信的
+ - 要通信,只能将VPC A和VPC C进行Peering
+
+### 默认VPC
+
+- 在每一个区域(Region),AWS都有一个默认的VPC
+- 在这个VPC里面所有子网都绑定了一个路由表,其中有默认路由(目的地址 0.0.0.0/0)到互联网
+- 所有在默认VPC内启动的EC2实例都可以直接访问互联网
+- 在默认VPC内启动的EC2实例都会被分配公网地址和私有地址
+
+如下图所示,我们在某一个区域内有一个VPC,这个VPC的网络是172.31.0.0/16
+
+在这个VPC内有2个子网,分别是172.31.0.0/20 和 172.31.16.0/20。这两个子网内都有一个EC2实例,每一个实例拥有一个该子网的私有地址(172.31.x.x)以及一个AWS分配的公网IP地址(203.0.113.x)。
+
+这两个实例关联了一个主路由表,该路由表拥有一个访问172.31.0.0/16 VPC内流量的路由条目;还有一个目的为 0.0.0.0/0 的默认路由条目,指向Internet网关。
+
+因此这两个实例都可以通过Internet网关访问外网。
+
+
+
+### VPC终端节点(VPC Endpoints)
+
+在一般的情况下,如果你需要访问S3服务,EC2实例或者DynamoDB的资源,你需要通过Internet公网来访问这些服务。有没有更快速、更安全的访问方式呢?
+
+**VPC终端节点(VPC Endpoints)**提供了这种可能性。
+
+### PrivateLink
+
+VPC终端节点能建立VPC和一些AWS服务之间的高速、私密的“专线”。这个专线叫做PrivateLink,使用了这个技术,你无需再使用Internet网关、NAT网关、VPN或AWS Direct Connect连接就可以访问到一些AWS资源了!
+
+PrivateLink 是一种 Amazon Web Services (AWS) 的服务,它允许 AWS 中的服务与 VPC 内的资源进行安全、高速的连接,而无需通过公共 Internet。使用 PrivateLink,您可以将 AWS 中的服务(如 Amazon S3、Amazon EC2 等)作为一个私有端点,直接连接到 VPC 中的资源,从而实现私有、安全、低延迟的通信。
+
+PrivateLink 使用 AWS VPC 内部的私有 IP 地址进行通信,这意味着您可以直接访问 AWS 中的服务,而不需要通过 NAT 网关或 VPN 连接。这样不仅可以提高通信的速度和稳定性,还可以提高安全性,因为数据和流量不会经过公共 Internet,不会受到网络威胁的影响。
+
+使用 PrivateLink 时,您需要为要连接的 AWS 服务启用 PrivateLink,并在 VPC 中配置 VPC 端点。一旦配置完成,您就可以直接从 VPC 中的资源访问 AWS 服务,而不需要暴露公共 IP 地址。此外,PrivateLink 还支持跨账户连接,这意味着您可以将 AWS 服务连接到不同的 VPC 中的资源,从而实现更高的灵活性和可扩展性。
+
+### vpc peering
+
+VPC Peering 是指连接两个或多个 VPC 的网络连接。它允许您在不通过公共 Internet 的情况下直接路由流量到其他 VPC,从而实现跨 VPC 通信。这种通信是私有、安全和高效的。
+
+VPC Peering 通常用于以下情况:
+
+- 允许不同 VPC 之间的资源进行互操作,以便跨多个 VPC 进行应用程序部署
+- 实现基于 VPC 的多租户环境中的网络隔离,以确保租户之间的数据和流量不会相互干扰
+- 扩展 VPC 中的可用 IP 地址范围,以满足需要更多 IP 地址的资源的要求,而不必更改 VPC CIDR
+
+在 VPC Peering 中,不同 VPC 之间的流量不会经过公共互联网,因此通信速度更快,并且更加安全。但需要注意的是,VPC Peering 是一种单向连接,这意味着必须分别设置每个 VPC 之间的连接,才能实现完全的互通性。
+
+
+
+限制: ip 有overlap不能用。
+
+### private link 和 vpc peering区别
+
+VPC Peering 和 PrivateLink 都可以用于在 AWS 中建立安全、私有的网络连接,但它们的使用场景略有不同。
+
+VPC Peering 主要用于连接不同 VPC 之间的网络,从而实现跨 VPC 通信。而 PrivateLink 主要用于连接 AWS 服务与 VPC 内的资源进行安全、高速的连接。
+
+
+
+vpc peering是免费的,没有private link安全。
+
+private link是收费的,更安全。
+
+
+
+So when would you use VPC Peering versus PrivateLink?
+
+VPC Peering is a good choice if you want to interconnect two or more VPCs within your company. You may also use it for integrating closely with trusted partners.
+
+For sharing specific services with customers and partners, PrivateLink may be a better choice. It limits your exposure by providing access to a specific service rather than your entire network.
+
+You'll also need to use PrivateLink in a few specific scenarios:
+
+- Connecting securely to AWS services from within a VPC
+- Connecting services in VPCs with overlapping IP ranges
+- Connecting securely to on-premise services from your VPCs
+
+### 服务不一定都在vpc里
+
+服务不一定都在vpc里,比如公开可访问的s3。 但大部分服务都可以单独配置在vpc里,然后通过内部网络访问。
+
+AWS 服务并不都在 VPC 中。AWS 提供的一些基础服务,如 Amazon S3、Amazon DynamoDB、Amazon SQS 等,都是通过公共网络提供的,您可以使用公共网络连接这些服务。
+
+但是,大多数 AWS 服务都可以通过 Amazon VPC 进行访问,这意味着您可以将这些服务部署在您的 VPC 中,并通过 VPC 内部网络进行访问。例如,Amazon EC2 实例、Amazon RDS 数据库、Amazon ElastiCache 等服务都可以在 VPC 中部署,从而实现更安全、可靠的网络连接。
+
+## 工作原理
+
+[参考](https://docs.amazonaws.cn/vpc/latest/userguide/how-it-works.html)
+
+### IP 寻址
+创建 VPC 时,需要为其分配一个 IPv4 CIDR 块(一系列私有 IPv4 地址)、一个 IPv6 CIDR 块或同时分配两种 CIDR 块(双堆栈)。
+
+私有 IPv4 地址无法通过 Internet 访问。IPv6 地址具有全球唯一性,可以配置为保持私有或通过互联网进行访问。
+
+公有 IP 地址将从 Amazon 的公有 IP 地址池分配,它不与您的账户关联。在公有 IP 地址与您的实例取消关联后,该地址即释放回该池,并且不再可供您使用。您不能手动关联或取消关联公有 IP 地址。而是在某些情况下,我们从您的实例释放该公有 IP 地址,或向其分配新地址。有关更多信息,请参阅适用于 Linux 实例的 Amazon EC2 用户指南 中的公有 IP 地址。
+
+### 访问 Internet
+
+> 私有网络不能访问互联网,需要互联网网关,私有网络内部之间可通信。
+
+原定设置 VPC 包含一个互联网网关,而且每个原定设置子网都是公有子网。您在默认子网中启动的每个实例都有一个私有 IPv4 地址和一个公有 IPv4 地址。这些实例可以通过 Internet 网关与 Internet 通信。通过互联网网关,您的实例可通过 Amazon EC2 网络边界连接到 Internet。
+
+默认情况下,您启动到非默认子网中的每个实例都有一个私有 IPv4 地址,但没有公有 IPv4 地址,除非您在启动时特意指定一个,或者修改子网的公有 IP 地址属性。这些实例可以相互通信,但无法访问 Internet。
+
+您可以通过以下方式为在非默认子网中启动的实例启用 Internet 访问:将一个互联网网关附加到该实例的 VPC(如果其 VPC 不是默认 VPC),然后将一个弹性 IP 地址与该实例相关联。
+
+或者,您还可以使用网络地址转换 (NAT) 设备,以允许 VPC 中的实例发起到互联网的出站连接,但阻止来自互联网的未经请求的入站连接。NAT 将多个私有 IPv4 地址映射到一个公有 IPv4 地址。您可以使用弹性 IP 地址配置 NAT 设备,并通过互联网网关将其与互联网相连。您可以通过 NAT 设备将私有子网中的实例连接到互联网,NAT 设备会将来自实例的流量路由到互联网网关,并将所有响应路由到该实例。
+
+如果您将 IPv6 CIDR 块与 VPC 关联并为实例分配 IPv6 地址,则实例可以通过互联网网关通过 IPv6 连接到互联网。或者,实例也可以使用仅出口互联网网关经由 IPv6 发起到互联网的出站连接。IPv6 流量独立于 IPv4 流量;您的路由表必须包含单独的 IPv6 流量路由。
+
+
+
+默认情况下,默认子网为公有子网,因为主路由表会将指定发往 Internet 的子网流量发送到 Internet 网关。
+
+
+
+### NAT
+
+NAT的全程是“**Network Address Translation**”,中文解释是“**网络地址转换**”,它可以让整个机构只使用一个公有的IP地址出现在Internet上。
+
+NAT是一种把内部私有地址(192.168.1.x,10.x.x.x等)转换为Internet公有地址的协议,它一定程度上解决了公网地址不足的问题。
+
+- NAT实例需要创建在公有子网内
+
+
+
+
+
+**堡垒机(Bastion Host)**又叫做跳板机(Jump Box),主要用于运维人员远程登陆服务器的集中管理。运维人员首先登陆到这台堡垒机(公网),然后再通过堡垒机管理位于内网的所有服务器。
+
+堡垒机可以对运维人员的操作行为进行控制和审计,同时可以结合Token等技术达到更加安全的效果。
+
+## VPC场景
+
+**带单个公有子网的 VPC**: 此场景的配置包含一个有单一公有子网的 Virtual Private Cloud (VPC),以及一个 Internet 网关以启用 Internet 通信。如果您要运行单一层级且面向公众的 Web 应用程序,如博客或简单的网站,则我们建议您使用此配置。
+
+**带有公有和私有子网的 VPC (NAT)**:这个场景的配置包括一个有公有子网和私有子网的 Virtual Private Cloud (VPC)。如果您希望运行面向公众的 Web 应用程序,并同时保留不可公开访问的后端服务器,我们建议您使用此场景。常用例子是一个多层网站,其 Web 服务器位于公有子网之内,数据库服务器则位于私有子网之内。您可以设置安全性和路由,以使 Web 服务器能够与数据库服务器建立通信。
+
+公有子网中的实例可直接将出站流量发往 Internet,而私有子网中的实例不能这样做。但是,私有子网中的实例可使用位于公有子网中的网络地址转换 (NAT) 网关访问 Internet。数据库服务器可以使用 NAT 网关连接到 Internet 进行软件更新,但 Internet 不能建立到数据库服务器的连接。
+
+## Security Groups(安全组)
+
+[参考](https://zhuanlan.zhihu.com/p/151419823)
+
+VPC 网络安全组标志 VPC 中的哪些流量可以发往 EC2 实例或从 EC2 发出。安全组指定具体的入向和出向流量规则,并精确到源地址(入向)和目的地址(出向)。这些安全组是与 EC2 实例而非子网关联的。
+默认情况下,流量只允许出,不允许入。
+
+
+
+Security Group(SG)通过控制IP和端口来控制出站入站规则,可以用于EC2,RDS及下面将要用到的VPC Endpoint。
+
+
+
+## 网络ACL(NACL)
+
+**网络访问控制列表(NACL)**与安全组(Security Group)类似,它能在子网的层面控制所有入站和出站的流量,为VPC提供更加安全的保障。
+
+
+
+- 在你的**默认VPC**内会有一个默认的网络ACL(NACL),它会**允许**所有入向和出向的流量
+- 你可以创建一个自定义的网络ACL,在创建之初所有的入向和出向的流量都会被**拒绝**,除非进行手动更改
+- 对于所有VPC内的子网,每一个子网都需要关联一个网络ACL。如果没有关联任何网络ACL,那么子网会关联默认的网络ACL
+- 一个网络ACL可以关联多个子网,但一个子网只能关联一个网络ACL
+- 网络ACL包含了一系列(允许或拒绝)的规则,网络ACL会按顺序执行,一旦匹配就结束,不会再继续往下匹配
+- 网络ACL有入向和出向的规则,每一条规则都可以配置允许或者拒绝
+- 网络ACL是无状态的(安全组是有状态的)
+ - 被允许的入向流量的响应流量必须被精准的出向规则所允许(反之亦然)
+ - 一般至少需要允许临时端口(TCP 1024-65535)
+ - 关于临时端口的知识,可以参见[这里](https://docs.aws.amazon.com/zh_cn/AmazonVPC/latest/UserGuide/VPC_ACLs.html#VPC_ACLs_Ephemeral_Ports)
+
+## Difference between Internet Gateway and NAT Gateway
+
+ +
+参考
+
+- Internet Gateway (IGW) allows instances with public IPs to access the internet.
+- NAT Gateway (NGW) allows instances with no public IPs to access the internet.
+
+## 参考
+
+[参考](https://juejin.cn/post/6949072638145003556)
+
+大部分 AWS 服务都需要以 VPC 为基础进行构建,比如最常用的 EC2,ALB,及无服务器服务 ECS Fargate。 vb
+
+当我们在一个 VPC 中创建 Subnet 时需要给 Subnet 选择一个 AZ(Availability Zone),一个 Subnet 只能选择建在一个 AZ 中。
+
+
+
+**选择region**
+
+因为国内政策法规原因,AWS 在中国的服务与 AWS Global 服务略有不同。
+
+AWS Global 的 Region 之间是通过主干网相连的,AWS 中国区的服务没有通过主干网与 AWS Global 相连,只有中国区内部两个 Region,北京和宁夏是相连接的。
+
+在创建 VPC 时并不需要添写 AZ(Availability Zone)信息,VPC 只与 Region 有关。
+
+
+
+Subnet 是最终承载大部分 AWS 服务的组件,比如 EC2, ECS Fargate,RDS。
+
+Subnet 分为两种 Private Subnet 和 Public Subnet。
+
+简单来说,不能直接访问 internet 的 Subnet 就是 Private Subnet,能直接访问 internet 的就是 Public Subnet。
+
+
+
+Security Group(SG)通过控制IP和端口来控制出站入站规则,可以用于EC2,RDS及下面将要用到的VPC Endpoint。
+
+
+
+VPC Endpoint用来直接连接VPC与AWS相关服务,比如RDS AIP,S3。
+
+当系统安全要求比较高时,EC2处于的Subnet可能被限制,无法访问internet,这时EC2就无法访问AWS的一些服务,比如SSM。
+
+这时我们可以利用VPC Endpoint把VPC和所需要访问的服务连接起来,然后EC2就可以不经internet访问到所需的服务。
+
+
+
+[参考](https://juejin.cn/post/6954169148318433288)
+
+RT(Route Table)与Subnet相关连,用来描述网络路由。IGW: Internet gateway IGW是一个独立的组件配置在VPC上,使得VPC可以访问internet
+
+我们给VPC加了IGW之后,需要修改Subnet相关的路由,确保访问Internet的请求发送到IGW。
+
+每个VPC中有一个默认的主RT,自动关联VPC内的每一个Subnet。我们现在为Subnet “ts-public-1”单独创建一个新的RT。
+
+
+
+- 新建的Subnet就是Private Subnet
+- 在Private Subnet中配置了到IGW的路由后,就变成Public Subnet
+- Public Subnet中的EC2还要再配置一个Public IP或者EIP就可以访问Internet
+- 如果EC2可以访问internet,其关联的Security Group入站规则如果允许从internet访问,那么这个EC2就可以从internet中直接访问到。
+
+
+
+1. 实践中我们把应用程序,数据库放在Private Subnet中,阻止从internet访问。把堡垒机和ALB(Application Load balancer)放在Public Subnet,允许从internet访问。
+
+2. 一般我们会建两套Public Subnet和Private Subnet,分别放在不同的AZ中,防止其中一个AZ出问题。这时如果配置NAT,也需要在两个Public Subnet中各配置一个NAT。
+
+
+
+[参考](http://www.cloudbin.cn/?tag=aws) 暂无Note
+
+## 总结
+
+VPC里多个AZ, 每个AZ都需要至少一个子网,默认是公有子网。但如果有internet访问不到的实例或者数据库,则需建个私有子网,私有子网默认不能访问internet,internet也不能访问私有子网。
+
+要走互联网必须走internet gateway,它对整个vpc生效, public subnet可直接通过IGW与互联网互联,私有子网再通过NAT走公有子网是可以访问internet的,反向不能。
+
+和互联网连接时都需要有个公网ip,这个是从amazon分配的。
+
+
+
+# 跨账号访问aws service总结
+
+比如 本账号lambda访问另一个账号的DDB
+
+Lambda 跨账号访问另一个账号中的 DynamoDB 表,一共有以下几种方法:
+
+1. 使用 assumeRole API:Lambda 函数在执行时使用 assumeRole API 切换到具有访问目标账号 DynamoDB 表权限的 IAM 角色。这种方法的优点是简单易用,只需要在代码中调用 assumeRole API 即可。缺点是需要进行额外的 IAM 角色配置和权限管理,同时存在一定的安全风险,因为将 IAM 凭证直接硬编码到代码中可能会导致安全问题。
+2. 使用 VPC Peering:通过建立 VPC Peering 连接,将源账号和目标账号的 VPC 相互连接起来,实现 Lambda 函数对 DynamoDB 表的访问。这种方法的优点是简单易用,可以通过 AWS 控制台完成配置,同时具有较高的安全性。缺点是需要进行 VPC 配置和管理,且无法实现跨区域访问。
+3. 使用 PrivateLink:通过在目标账号中创建一个 PrivateLink 终端节点,将 DynamoDB 表以私有方式暴露给源账号中的 Lambda 函数,实现跨账号访问。这种方法的优点是高度安全,可以通过 AWS PrivateLink 在私有网络中实现数据的加密传输,同时支持跨区域访问。缺点是需要进行较为复杂的 VPC 和 PrivateLink 配置,且可能需要进行网络安全设置和管理。
+4. 使用 AWS Resource Access Manager(RAM):通过使用 RAM,可以在多个 AWS 账号之间共享资源,并授予其他 AWS 账号访问这些资源的权限。Lambda 函数可以将 RAM 中的资源授权给目标账号,从而实现对 DynamoDB 表的访问。这种方法的优点是可以实现资源共享和管理,并且具有高度的可扩展性。缺点是需要进行 RAM 的配置和管理,且可能需要进行跨账号 IAM 角色的授权和管理。
+
+
+
+一般来说,如果需要实现高度安全性和数据隔离,且需要支持跨区域访问,推荐使用 PrivateLink;如果只是需要简单快速地实现跨账号访问,可以选择使用 assumeRole API 或 VPC Peering。如果需要进行资源共享和管理,可以考虑使用 AWS RAM。
+
+# Route 53
+
+**Amazon Route 53**是一种高可用、高扩展性的云DNS服务。
+
+Amazon Route 53 是一种托管域名系统 (DNS) 服务,它可帮助您为您的域名注册和管理 DNS 记录。您可以使用 Route 53 将您的域名映射到您的 VPC 内的资源,如 ELB 和 Amazon S3。
+
+不同的DNS记录:
+
+- **CNAME** – CNAME (Canonical Name)可以将一个域名指向另一个域名。比如将aws.xiaopeiqing.com指向xiaopeiqing.com
+- Alias记录 – 和CNAME类似,又叫做别名记录,可以将一个域名指向另一个域名。
+ - **和CNAME最大的区别是,Alias可以应用在根域(Zone Apex)。即可以为xiaopeiqing.com的根域创建Alias记录,而不能创建CNAME**
+ - 别名记录可以节省你的时间,因为Route53会自动识别别名记录所指的记录中的更改。例如,假设example.com的一个别名记录指向位于lb1-1234.us-east-2.elb.amazonaws.com上的一个ELB负载均衡器。如果该负载均衡器的IP地址发生更改,Route53将在example.com的DNS应答中自动反映这些更改,而无需对包含example.com的记录的托管区域做出任何更改。 弹性负载均衡器(ELB)没有固定的IPv4地址,在使用ELB的时候永远使用它的DNS名字。很多场景下我们需要绑定DNS记录到ELB的endpoint地址,而不绑定任何IP
+
+# AWS Direct Connect
+
+AWS Direct Connect 是一种专用网络连接服务,它允许您通过私有连接连接到 AWS 服务。您可以使用 Direct Connect 将您的本地数据中心与您的 VPC 直接连接起来,实现更安全、更高带宽的网络连接。
+
+
+
+AWS Direct Connect 是一种联网服务,提供了通过互联网连接到AWS 的替代方案。 使用AWS Direct Connect ,以前通过Internet 传输的数据将可以借助您的设施和AWS 之间的私有网络连接进行传输。
+
+**不再需要通过网络提供商。** 描述的是本地IT数据中心和VPC连接。通过物理专线连接。
+
+AWS Direct Connect 通过标准的以太网光纤电缆将您的内部网络链接到 AWS Direct Connect 位置。电缆的一端接到您的路由器,另一端接到 AWS Direct Connect 路由器。有了这个连接,你可以创建*虚拟接口*直接公有公有访问AWS服务(例如,到 Amazon S3)或 Amazon VPC,绕过您的网络路径中的互联网服务提供商。网络 ACL 和安全组都允许 (因此可到达您的实例) 的发起 ping 的AWS Direct Connect位置提供访问AWS在与之关联的区域中。您可以将单个连接用于公有区域或AWS GovCloud (US)公有访问AWS所有其他公有区域中的服务。
+
+[参考](https://docs.aws.amazon.com/zh_cn/directconnect/latest/UserGuide/Welcome.html)
+
diff --git a/_posts/Tech/AWS/2022-11-18-AWS Compute.md b/_posts/Tech/AWS/2022-11-18-AWS Compute.md
new file mode 100644
index 0000000000..4067771a68
--- /dev/null
+++ b/_posts/Tech/AWS/2022-11-18-AWS Compute.md
@@ -0,0 +1,195 @@
+---
+layout: post
+category: AWS
+title: AWS Compute
+tags: AWS
+---
+
+## AWS Compute
+
+## AMI
+
+AMI: amazon machine image 就是一堆配置,比如什么系统,安装哪些附加软件。可使用AMI启动一个同配置的实例。 类似docker的image
+
+**Amazon Machine Image (AMI)** 是亚马逊AWS提供的系统镜像,这个AMI包含了如下的信息:
+
+- 由实例的操作系统、应用程序和应用程序相关的配置组成的模板
+- 一个指定的需要在实例启动时附加到实例的卷的信息(比方说定义了使用8 GB的General Purpose SSD卷)
+
+下图所示的是AMI的生命周期,你可以创建并注册一个AMI,并且可以使用这个AMI来创建一个EC2实例。同时你也可以将这个AMI复制到同一个AWS区域或者不同的AWS区域。你同样也可以注销这个AMI镜像。
+
+
+
+- **AMI是区域化的**,只能使用本区域的AMI来创建实例;但你可以将AMI从一个区域复制到另一个区域
+
+
+
+
+
+## 弹性伸缩(Auto Scaling)
+
+**亚马逊弹性伸缩(Auto Scaling)**能**自动地**增加/减少EC2实例的数量,从而让你的应用程序一直能保持可用的状态。
+
+你可以预定义Auto Scaling,使其在需求高峰期自动增加EC2实例,而在需求低谷自动减少EC2实例。这样不仅能让你的应用程序一直保持健康的状态,而且也节省了你为EC2实例所付出的费用。
+
+Auto Scaling 适用于那些需求稳定的应用程序,同时也适用于在每小时、每天、甚至每周都有需求变化的应用程序。
+
+- Auto Scaling能保证你一直拥有一定数量的EC2实例来分担应用程序的负载
+- Auto Scaling能带来更高的容错性、更好的可用性和更高的性价比
+- 你可以控制伸缩的策略来决定在什么时候终止和创建EC2实例,以处理动态变化的需求
+- 默认情况下,Auto Scaling能控制每一个可用区内所运行的实例数量尽量平均
+ - 为了达到这个目标,Auto Scaling在需要启动新实例的时候,会选择一个目前拥有运行实例最少的可用区
+
+Auto Scaling的构成组件:
+
+
+
+### 启动配置(Launch Configuration)
+
+- 启动配置是弹性伸缩组用来启动EC2实例的时候所使用的模板
+- 启动配置包含了镜像文件(AMI),实例类型、密钥对、安全组和挂载的存储设备
+- 一个启动配置可以关联多个Auto Scaling组
+- **启动配置一经创建不能被更改,只能删除重建**
+- 启动配置中可以使用CloudWatch的基础监控(Basic Monitoring)或者详细监控(Detail Monitoring)
+- Auto Scaling automatically creates a launch configuration directly from an EC2 instance.
+
+### 弹性伸缩组(Auto Scaling Group)
+
+- 弹性伸缩组(ASG)是弹性伸缩的核心,它包含了多个拥有类似配置/类型的EC2实例,这些实例被逻辑上认为是一样的
+- 弹性伸缩组需要的几个参数:
+ - **启动配置(Launch Configuration)**:它决定了EC2使用什么模板,模板内容包括了镜像文件(AMI),实例类型、密钥对、安全组和挂载的存储设备
+ - **最小和最大的性能**:决定了在弹性伸缩的情况下,EC2实例数量的浮动范围
+ - **所需的性能**:决定了这个弹性伸缩组要保持的运作所需要的基本的EC2实例数量;如果没有填写,则默认为其数值等同于最小的性能
+ - **可用区和子网**:定义EC2实例启动时候所在的可用区和子网信息
+ - **参数和健康检查**:参数定义了何时启动新实例,何时终止旧实例;健康检查决定了实例的健康状态。
+- **如果一个EC2实例的健康状态变成“不健康”,那么ASG会终止这个EC2实例,并且自动启动一个新的EC2实例**
+- 弹性伸缩组(ASG)只能在某一个AWS区域内运行,不能跨越多个区域
+- 如果启动配置(Launch Configuration)有更新,那么之后启动的新EC2实例会使用新的启动配置,而旧的EC2实例不受影响
+- 从AWS管理平台你可以直接删除一个弹性伸缩组(ASG);从AWS CLI你只能先将最小的性能和需求的性能两个参数设置为0,才能删除这个弹性伸缩组。
+
+
+
+## ECS
+
+**Amazon Elastic Container Service (ECS)**是一个有高度扩展性的**容器管理服务**。它可以轻松运行、停止和管理集群上的Docker容器,你可以将容器安装在EC2实例上,或者使用**Fargate**来启动你的服务和任务。
+
+Amazon ECS可以在一个区域内的多个可用区中创建高可用的应用程序容器,你可以定义集群中运行的Docker镜像和服务。而且你可以充分利用AWS内部的**Amazon ECR (Elastic Container Registry)**或者外部的Registry(比如Docker Hub或自建的Registry)来存储和提取容器镜像。
+
+
+
+我们可以将标准化的代码、运行环境、系统工具等等打包成一个标准的集装箱,这个集装箱叫做**Docker镜像**(Docker Image)。这个Docker镜像的概念类似于EC2中的AMI (Amazon Machine Image)。
+
+这些镜像文件通常会通过Dockerfile来构建,并且最终存放到**注册表(Registry)**内。这个Registry可以理解为摆放集装箱的码头,我们在需要某个类型的集装箱的时候就到码头去取。这类Registry可以是Amazon的ECR,也可以是公网上的Docker Hub,或者自己私有的Registry。
+
+
+
+
+
+### ECS创建举例
+
+
+
+
+
+## Lambda
+
+使用**AWS Lambda**,你无需配置和管理任何服务器和应用程序就能运行你的代码。只需要上传代码,Lambda就会处理运行并且根据需要自动进行横向扩展。因此Lambda也被称为**无服务(Serverless)**函数。
+
+要让AWS Lambda的代码执行,需要设定一些触发器(比如CloudWatch Log,CloudWatch Event,API Gateway等),因此Lambda函数被认为是**事件驱动的(Event-Driven)**。
+
+在传统的应用部署过程中,我们往往需要安装操作系统 -> 安装应用程序 -> 配置环境并部署代码,而且往往还需要不定时地为操作系统和应用程序打补丁和进行维护。使用AWS Lambda就方便很多,只需要上传代码,AWS就会在需要的时候帮你运行。我们不再需要(也无法接触)任何操作系统层面的东西,也节省了非常多的部署时间,可以更专心地编写代码。
+
+
+
+### AWS Lambda的特点
+
+- 没有服务器/无服务,或者说真实的服务器由AWS管理
+- 只需要为运行的代码付费,不需要管理服务器和操作系统
+- **持续性/自动的性能伸缩**
+- 非常便宜
+- AWS只会在代码运行期间收取相应的费用,代码未运行时不产生任何费用
+- **代码的最长执行时间是15分钟,如果代码执行时间超过15分钟,则需要将1个代码细分为多个**
+
+### 触发器有哪些
+
+- **API Gateway**
+- **AWS IoT**
+- **CloudWatch Events** 比如cron job定时任务
+- CloudWatch Logs
+- CodeCommit
+- DynamoDB
+- S3
+- SNS
+- Cognito Sync Trigger
+- SQS应该也可以?
+
+
+
+## 参考
+
+[参考](http://www.cloudbin.cn/?tag=aws)
+
+## Compute选型
+
+aws提供两种容器编排服务: ECS和EKS, k是kubernetes。 后者适合已经用了k8s的。
+
+AWS fargate就是serverless, ECS/EKS 可集成在Fargate上或者EC2上。 container hosting platform
+
+Serverless: 允许在服务部署级别而不是服务器部署级别来管理应用部署。类似Faas。无需关注主机管理,服务运维。
+
+
+
+ECS vs EC2
+
+- ECS和EKS: aws负责容器管理,但customer依旧需要负责底层的ec2 instances.
+
+Fargate vs Lambda
+
+- Fargate is a Container as a Service (CaaS) offering, AWS Lambda is a Function as a Service (FaaS offering).
+
+Fargate是类似k8s的工具,可以管理容器,进行编排。
+
+ECS vs Fargate
+
+- ECS delivers more control over the infrastructure, but the trade-off is the added management that comes with it. Fargate is the better option for ease of use as it takes infrastructure management out of the equation allowing you to focus on just the tasks to be run. ECS 提供了对基础设施的更多控制,但代价是随之而来的附加管理。Fargate 是易于使用的更好选择,因为它将基础设施管理排除在外,使您可以专注于要运行的任务。
+
+
+
+Serverless vs EC2/ECS:
+
+- If you want to deploy your workloads and applications without having to manage any EC2 instances, you can do that on AWS with serverless compute.
+- Serverless includes fargate, lambda.
+
+
+
+Serverless vs Lambda
+
+- the latter doesn't need the control of container
+
+
+
+两个方面
+
+- 是否要管理主机
+ - Yes: ecs, ec2
+ - No: fargate, lambda
+- 是否要管理容器,类似k8s的活。
+ - Yes: fargate, ecs, ec2.
+ - No: lambda
+
+
+
+
+
+虚拟机相比容器好处,重要的是资源隔离。
+
+- 拥有完整操作系统
+- 异质环境
+- 安全
+
+容器好处:
+
+- 速度和可移植性,启动只有几秒钟,虚拟机要几分钟
+- 可扩展性,通过编排器,自动扩展。
+- 模块化
+- 易于更新。
\ No newline at end of file
diff --git a/_posts/Tech/AWS/2022-11-18-AWS MQ.md b/_posts/Tech/AWS/2022-11-18-AWS MQ.md
new file mode 100644
index 0000000000..3a848ebd31
--- /dev/null
+++ b/_posts/Tech/AWS/2022-11-18-AWS MQ.md
@@ -0,0 +1,100 @@
+---
+layout: post
+category: AWS
+title: AWS MQ
+tags: AWS
+---
+
+## AWS MQ
+
+## SQS(Simple Queue Service)
+
+SQS有两种不同类型的队列,它们分别是:
+
+- **标准队列**(Standard Queue)
+- **FIFO队列**(先进先出队列)
+
+### 标准队列
+
+标准队列拥有**无限的吞吐量**,所有消息都会**至少传递一次**,并且它会尽最大努力进行排序。
+
+标准队列是默认的队列类型。
+
+
+
+### FIFO队列
+
+FIFO (First-in-first-out)队列在不使用批处理的情况下,**最多支持300TPS**(每秒300个发送、接受或删除操作)。
+
+在队列中的消息都只会**不多不少地被处理一次**。
+
+FIFO队列严格保持消息的**发送和接收顺序**。
+
+
+
+更多关于标准队列和FIFO队列的区别,可以查看[我需要哪种类型的队列?](https://docs.aws.amazon.com/zh_cn/AWSSimpleQueueService/latest/SQSDeveloperGuide/welcome.html#sqs-queue-types)
+
+### SQS的其他特点
+
+- SQS是靠应用程序去**拉取的**,而不能主动推送给应用程序,推送服务我们使用**SNS(Simple Notification Service)**
+- 消息会以256 KB的大小存放
+- 消息会在队列中保存1分钟~14天,默认时间是4天
+- 可见性超时(Visibility Timeout)
+ - 即当SQS队列收到新的消息并且被拉取走进行处理时,会触发Visibility Timeout的时间。这个消息不会被删除,而是会被设置为不可见,用来防止该消息在处理的过程中再一次被拉取
+ - 当这个消息被处理完成后,这个消息会在SQS中被删除,表示这个任务已经处理完毕
+ - 如果这个消息在Visibility Timeout时间结束之后还没有被处理完,则这个消息会设置为可见状态,等待另一个程序来进行处理
+ - 因此**同一个消息可能会被处理两次(或以上)**
+ - 这个超时时间最大可以设置为**12小时**
+- 标准SQS队列保证了每一个在队列内的消息都至少会被处理一次
+- 长轮询(Long Polling)
+ - 默认情况下,Amazon SQS使用**短轮询(Short Polling)**,即应用程序每次去查询SQS队列,SQS都会做回应(哪怕队列一直是空的)
+ - 使用了长轮训,应用程序每次去查询SQS队列,SQS队列不会马上做回应。而是等到队列里有消息可处理时,或者等到设定的超时时间再做出回应。
+ - 长轮询可以一定程度减少SQS的花销
+
+## SNS (Simple Notification Service)
+
+**SNS (Simple Notification Service)** 是一种完全托管的发布/订阅消息收发和移动通知服务,用于协调向订阅终端节点和客户端的消息分发。
+
+SNS是一项 Web 服务,用于协调和管理向订阅终端节点或客户交付或发送消息的过程。在 Amazon SNS 中有两种类型的客户端:发布者和订阅者,也称为生产者和消费者。发布者通过创建消息并将消息发送至主题与订阅者进行异步交流,主题是一个逻辑访问点和通信渠道。订阅者(即 Web 服务器、电子邮件地址、Amazon SQS 队列、AWS Lambda 函数)在其订阅主题后通过受支持协议(即 Amazon SQS、HTTP/S、电子邮件、SMS、Lambda)中的一种使用或接收消息或通知。
+
+我们可以使用SNS将消息推送到SQS消息队列中、AWS Lambda函数或者HTTP终端节点上。
+
+SNS通知还可以发送推送通知到IOS,安卓,Windows和基于百度的设备,也可以通过电子邮箱或者SMS短信的形式发送到各种不同类型的设备上。
+
+
+
+
+
+在创建SNS Topic时的一些选项:
+
+- Encryption: 代表是否对Topic中的消息进行加密。如果需要处理的数据中有敏感信息,应做此设置。
+- Delivery retry policy (HTTP/S): 默认为3,也就说尝试三次后,消息还没有送到的话,就会彻底丢失。因此在使用SNS的时候,一旦出现这种情况,就应该使用DLQ来做容错。
+
+### SNS的一些特点
+
+- SNS是实时的**推送服务(Push)**,有别于SQS的**拉取服务(Pull/Poll)**
+- 拥有简单的API,可以和其他应用程序兼容
+- 可以通过多种不同的传输协议进行集成
+- 便宜、用多少付费多少的服务模型
+- 在AWS管理控制台上就可以进行简单的操作
+
+## SNS vs SQS
+
+AWS提供了[SQS](https://link.zhihu.com/?target=https%3A//console.aws.amazon.com/sqs/v2/home)和[SNS](https://link.zhihu.com/?target=https%3A//console.aws.amazon.com/sns/v3/home)。SQS是一个分布式的队列消息service,SNS是一个分布式的发布-订阅消息service。具体有人会问这两者有什么区别,这里给出了回答: [What is the difference between Amazon SNS and Amazon SQS?](https://link.zhihu.com/?target=https%3A//stackoverflow.com/questions/13681213/what-is-the-difference-between-amazon-sns-and-amazon-sqs)。 在我的实践中,SQS和SNS会结合起来使用,首先应用发布消息到SQS的queue里面,然后SNS消费这个queue的消息,放到自身的topic里面持久保存,然后其他的应用订阅这个topic,消费里面的消息。
+
+
+
+sqs是一对一,不能一对多,消息可持久化,不推只能等拉,拉完就删除。
+
+sns可一对多,不能持久化,push模型。
+
+sqs及aws笔记,更全, [link](http://www.cloudbin.cn/?p=2530)
+
+
+
+个人觉得 sns是推 能力的一个抽象。比如推送,mq里的push,都是推。aws把推给抽象出来。就可以让用户像搭积木一样使用。
+
+
+
+
+
diff --git a/_posts/Tech/AWS/2022-11-18-AWS Storage.md b/_posts/Tech/AWS/2022-11-18-AWS Storage.md
new file mode 100644
index 0000000000..bf2a5141d9
--- /dev/null
+++ b/_posts/Tech/AWS/2022-11-18-AWS Storage.md
@@ -0,0 +1,225 @@
+---
+layout: post
+category: AWS
+title: AWS Storage
+tags: AWS
+---
+
+## AWS Storage
+
+## dynamoDB
+
+[论文讲解](http://systemdesigns.blogspot.com/2016/01/dynamodb.html)
+
+[深入探讨 Amazon DynamoDB 的设计模 式、流复制和全局表](https://sides-share.s3.cn-north-1.amazonaws.com.cn/AWS+Webinar+2019/PDF/Amazon+DynamoDB+webinar.pdf)
+
+[官网](https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/Programming.LowLevelAPI.html#Programming.LowLevelAPI.DataTypeDescriptors)
+
+[AWS 如何实现数据跨区域同步](https://techsummit.ctrip.com/pdf/songye.pdf)
+
+[MongoDB 与 DynamoDB 正面交锋](https://www.modb.pro/db/432414)
+
+
+
+## EBS
+
+### EBS的特点
+
+- 亚马逊EBS卷提供了**高可用、可靠、持续性的块存储**,EBS可以依附到一个正在运行的EC2实例上
+- 如果你的EC2实例需要使用数据库或者文件系统,那么建议使用EBS作为首选的存储设备
+- EBS卷的存活可以脱离EC2实例的存活状态。也就是说在终止一个实例的时候,你可以选择保留该实例所绑定的EBS卷
+- EBS卷可以依附到**同一个可用区(AZ)**内的任何实例上
+- EBS卷可以被加密,如果进行了加密那么它存有的所有已有数据,传输的数据,以及制造的镜像都会被加密
+- **EBS卷可以通过快照(Snapshot)来进行(增量)备份,这个快照会保存在S3 (Simple Storage System)上**
+- 你可以使用任何快照来创建一个基于该快照的EBS卷,并且随时将这个EBS卷应用到**该区域**的任何实例上
+- EBS卷创建的时候已经固定了可用区,并且**只能给该可用区的实例使用**。如果需要在其他可用区使用该EBS,那么可以创建快照,并且使用该快照创建一个在其他可用区的新的EBS卷
+- **快照还可以复制到其他的AWS区域**
+
+### EBS (Elastic Block Storage)小结
+
+- EBS的不同类型,需要了解不同类型的EBS主要的使用场景
+ - 通用型SSD – GP2 (高达10,000 IOPS),适用于启动盘,低延迟的应用程序等
+ - 预配置型SSD – IO1 (超过10,000 IOPS),适用于IO密集型的数据库
+ - 吞吐量优化型HDD -ST1,适用于数据仓库,日志处理
+ - HDD Cold – SC1 – 适合较少使用的冷数据
+ - HDD, Magnetic
+- 不能将EBS挂载到多个EC2实例上,一个EBS只能挂载到1个EC2实例上。
+ - 如果有共享数据盘的需求,请使用EFS (Elastic File System)
+- 根EBS卷默认是不能进行加密的,但可以使用第三方的加密工具(例如BitLocker)对其进行加密
+ - *除了根磁盘外的其他卷是可以加密的*
+
+### EBS快照(Snapshot)小结
+
+- *EBS的快照会被保存到S3(Simple Storage System)上*
+
+- *你可以对一个EBS卷创建一个快照,这个快照会被保存到S3上*
+
+- 快照实际上是
+
+ 增量备份
+
+ ,只有在上次进行快照之后更改的数据才会被添加的S3上
+
+ - 因此第一次快照所花费的时间比较长
+ - 而第二次以后的快照所花费的时间相对短很多
+
+- 对加密的EBS卷创建快照,创建后的快照也会是加密的
+
+- 从加密的快照恢复的EBS卷也会是加密的
+
+- 你可以分享快照给其他账户或AWS市场,但仅限于这个快照是没有进行过加密的
+
+- 要为一个作为根设备的EBS卷创建快照的话,建议停止这个实例再做快照
+
+### 实例存储(Instance Store)
+
+- 实例存储也叫做**短暂性存储(Ephemeral Storage)**
+- 实例存储的实例不能被停止(只能重启或终止),如果这个实例出现故障,那么在上面的所有数据将会丢失
+- 使用EBS的实例可以被停止,停止后EBS上的数据不会丢失
+- 重启使用实例存储的实例或者重启使用EBS的实例都不会导致数据丢失
+
+
+
+## AWS EBS, S3和EFS的区别
+
+- AWS S3对于静态页面的托管、多媒体分发、版本管理、大数据分析、数据存档来说都非常有用。S3可以和AWS CloudFront结合使用而达到更快的上传和下载速度。
+- AWS EBS是可以用来做数据库或托管应用程序的持续性文件系统,EBS具有很高的IO读写速度并且即插即用。 只能被单个EC2实例访问
+- 相比前面两种存储,AWS EFS是比较新的一项服务。它提供了可以在多个EC2实例之间共享的网络文件系统,功能类似于NAS设备。可以用EFS来处理大数据分析、多媒体处理和内容管理。
+
+## S3
+
+Amazon **Simple Storage Service (S3)** 是互联网存储解决方案,它提供了一个简单的Web接口,让其存储的数据和文件在互联网的任何地方给任何人访问。
+
+文件对象存储。
+
+
+
+### S3基本特性
+
+- S3是**对象存储**,可以在S3上存储各种类型的文件,它不是**块存储**(EBS是块存储)
+- 文件大小可以从0 字节到5 TB
+ - 使用Single Operation上传只能上传*最大5 GB*的文件
+ - 使用分段上传(Multipart Upload)可以对文件进行分段上传,最大支持上传*5 TB*的文件
+- S3的总存储空间是**无限大**的
+- 文件存储在**存储桶(Bucket)**内,可以理解存储桶就是一个文件夹
+- S3的名字是需要**全球唯一**的,不能与任何区域的任何人拥有的S3重名
+- 存储桶创建之后会生成一个URL,命名类似于https://s3-ap-northeast-1.amazonaws.com/aws_xiaopeiqing_com
+ - **S3是以HTTPS的形式展现的,而非HTTP**
+ - ap-northeast-1表示了当前桶所在的区域
+ - aws_xiaopeiqing_com表示了S3存储桶的名字,全球唯一
+- S3拥有99.99%(4个9)的可用性(Availability)
+ - 可用性可以理解为系统的uptime时间,即在一个自然年内(365天)有52.56分钟系统不可用
+- S3拥有99.999999999%(11个9)的持久性(Durability)
+ - 持久性可以认为是数据完整性/数据安全性,即在一千亿个存储在S3上的文件会有大概 1 个文件是不可读的
+- S3的存储桶创建的时候可以选择所在区域(Region),但不能选择可用区(AZ),AWS会负责S3的高可用、容灾问题
+ - S3创建的时候可以选择某个AWS区域,一旦选择了就不能更改
+ - 如果要在其他区域使用该S3的内容,可以使用**跨区域复制**
+- S3拥有不同的等级(Standard, Stantard-IA, Onezone-IA, RRS, Glacier)
+- 启用了**版本控制(Version Control)**你可以恢复S3内的文件到之前的版本
+- S3可以开启生命周期管理,对文件在不同的生命周期进行不同的操作
+ - 比如,文件在创建30天后迁移到便宜的S3等级(S3-IA),再经过30天进行归档(迁移到Glacier),再过30天就进行删除
+- 要启用生命周期管理需要先启用版本控制功能
+- S3支持加密功能
+- 使用访问控制列表(Access Control Lists)和桶策略(Bucket Policy)可以控制S3的访问安全
+- 在S3上成功上传了文件,你将会得到一个**HTTP 200**的状态反馈
+
+### 不同的S3存储类型
+
+- **Standard – 默认的存储类:**如果上传对象时未注明则S3会分配这个类型的存储
+- **Standard – IA(Infrequently Accessed):**用于保存不经常访问的数据,但是需要访问的时候也能很快地访问到。存储的价格比标准S3便宜,但是读取的费用比标准的S3高,也因为如此才要把不经常访问的数据放到这种类型的S3上。并且数据跨了多个AWS地理位置。
+- **Intelligent_Tiering** 智能分层(S3 智能分层): 这种储存类别将对象存储在两个访问层中,一个是频繁访问的层,一个是不频繁访问的层;如果对象`30`天内未访问,则会被移动至不频繁访问的层,如果不频繁访问层中的对象被访问,则会被移动至频繁访问的层;频繁访问的层的存储费用与`STANDARD`一样,不频繁访问层的存储费用与`STANDARD_IA`一样,该储存类别的请求费用与`STANDARD`一样,**该储存类别有额外的监控费用**;
+- **Onezone – IA:**同上,但数据只保存到一个AWS可用区内
+- **Glacier:**非常便宜,仅用于做归档。从Glacier读取数据需要花费3-5个小时。
+- **Glacier Deep Archive:** S3 Glacier Deep Archive 是 Amazon S3 成本最低的存储类,支持每年可能访问一两次的数据的长期保留和数字预留。它是为客户设计的 – 特别是那些监管严格的行业,如金融服务、医疗保健和公共部门 – 为了满足监管合规要求,将数据集保留 7-10 年或更长时间。S3 Glacier Deep Archive 还可用于备份和灾难恢复使用案例,是成本效益高、易于管理的磁带系统替代,无论磁带系统是本地库还是非本地服务都是如此。S3 Glacier Deep Archive 是 Amazon S3 Glacier 的补充,后者适合存档,其中会定期检索数据并且每隔几分钟可能需要一些数据。存储在 S3 Glacier Deep Archive 中的所有对象都将接受复制并存储在至少三个地理分散的可用区中,受 99.999999999% 的持久性保护,并且可在 12 小时内恢复。
+
+## CloudFront CDN
+
+**Amazon CloudFront**是一种全球**内容分发网络(CDN)**服务,可以安全地以低延迟和高传输速度向浏览者分发数据、视频、应用程序和API。
+
+
+
+- **边缘站点(Edge Location)**:边缘站点是内容缓存的地方,它存在于多个网络服务提供商的机房,它和AWS区域和可用区是完全不一样的概念。截至2018年中,AWS目前一共有100多个边缘站点。
+- **源(Origin)**:这是CDN缓存的内容所使用的源,源可以是一个S3存储桶,可以是一个EC2实例,一个弹性负载均衡器(ELB)或Route53,甚至可以是AWS之外的资源。
+- **分配(Distribution)**:AWS CloudFront创建后的名字
+- 分配分为两种类型,分别是
+ - **Web Distribution**:一般的网站应用
+ - **RTMP (Real-Time Messaging Protocol)**:媒体流
+- 你不只是可以从边缘站点读取数据,你还可以往边缘站点写入数据(比如上传一个文件),边缘站点会将你写入的数据同步到源上
+- 在CloudFront上的文件会被缓存在边缘节点,缓存的时间是**TTL(Time To Live)**。文件存在超过这个时间,缓存会被自动清除
+- 如果在到达TTL时间之前,你希望更新文件,那么你也可以**手动清除缓存**,但你将会被AWS**收取一定的费用**
+
+## ES
+
+AWS ES有两种node
+
+1. decicated master node 数量只能3-5。Dedicated Master 节点不太可能成为性能瓶颈,因为它们主要负责管理集群状态和协调分片分配等任务,并不会直接处理客户端的读写请求。相反,数据节点才是 AWS ES 集群中的性能瓶颈,因为它们需要实际检索和处理文档数据,对系统资源的消耗较大。
+2. 普通node,和es一样。
+
+每个node都有存储的一个限制。node数量增加,则性能增加。
+
+## Multi-AZ高可用
+
+是多个AZ里配置一个主,其它从,类似同城多机房架构。
+
+
+
+我们可以把AWS RDS数据库部署在多个**可用区(AZ)**内,以提供高可用性和故障转移支持。
+
+使用Multi-AZ部署模式,RDS会在不同的可用区内配置和维护一个主数据库和一个备用数据库,主数据库的数据会自动复制到备用数据库中。
+
+使用这种部署模式,可以为我们提供数据冗余,减少在系统备份期间的I/O冻结(上面有提到)。同时,更重要的是可以防止数据库实例的故障和单个可用区的故障。
+
+如下图所示,我们可以在两个可用区内分别部署主数据库和备用数据库。
+
+
+
+目前Multi-AZ支持以下数据库:
+
+- Oracle
+- PostgreSQL
+- MySQL
+- MariaDB
+- SQL Server
+
+值得注意的是,Aurora数据库本身就支持多可用区部署的高可用设置,因此不需要为Aurora数据库特别开启这个功能。
+
+在上次实验中我们有讲到,创建了RDS数据库之后我们会得到一个数据库的URL Endpoint。在开启Multi-AZ的情况下,这个URL Endpoints会根据主/备数据库的健康状态自动解析到IP地址。对于应用程序来说,我们只需要连接这个URL地址即可。
+
+**高可用的设置只是用来解决灾备的问题,并不能解决读取性能的问题;要提升数据库读取性能,我们需要用到Read Replicas。**
+
+
+
+### 只读副本(Read Replicas)
+
+我们可以在源数据库实例的基础上,复制一种新类型的数据库实例,称之为**只读副本(Read Replicas)**。我们对源数据库的任何更新,都会**异步**更新到只读副本中。
+
+因此,我们可以将应用程序的数据库读取功能转移到Read Replicas上,来减轻源数据库的负载。
+
+对于有大量读取需求的数据库,我们可以使用这种方式来进行灵活的数据库扩展,同时突破单个数据库实例的性能限制。
+
+Read Replicas还有如下的特点:
+
+- Read Replicas是用来提高读取性能的,不是用来做灾备的
+- 要创建Read Replicas需要源RDS实例开启了自动备份的功能
+- 可以为数据库创建最多**5个**Read Replicas
+- 可以为Read Replicas创建Read Replicas(如下图所示)
+- 每一个Read Replicas都有自己的URL Endpoint
+- 可以为一个启用了Multi-AZ的数据库创建Read Replicas
+- Read Replicas可以提升成为独立的数据库
+- 可以创建位于另一个区域(Region)的Read Replicas
+
+
+
+目前Read Replicas支持以下数据库:
+
+- Aurora
+- PostgreSQL
+- MySQL
+- MariaDB
+- Oracle
+
+https://amazonaws-china.com/cn/rds/details/read-replicas/
+
+## 参考
+
+[参考](http://www.cloudbin.cn/?p=1968)
diff --git a/_posts/Tech/AWS/2022-11-26-AWS DynamoDB.md b/_posts/Tech/AWS/2022-11-26-AWS DynamoDB.md
new file mode 100644
index 0000000000..821e551848
--- /dev/null
+++ b/_posts/Tech/AWS/2022-11-26-AWS DynamoDB.md
@@ -0,0 +1,142 @@
+---
+layout: post
+category: AWS
+title: AWS DynamoDB
+tags: AWS
+---
+
+## 表、索引
+
+> [深入探讨 Amazon DynamoDB 的设计模 式、流复制和全局表](https://sides-share.s3.cn-north-1.amazonaws.com.cn/AWS+Webinar+2019/PDF/Amazon+DynamoDB+webinar.pdf)
+
+
+
+分区键和排序键共同唯一的标识一条记录
+
+本地二级索引 Local Secondary Index (LSI) 单表上的。可以选择与表不同的排序键。同一个分区键。强一致性更新。
+
+
+全局二级索引 - Global Secondary Index (GSI) 可以选择与表不同的分区键以及排序键 每个索引分区会对应所有的表分区
+
+
+
+
+
+
+
+对比
+
+- Global Secondary
+ - 索引的尺寸没有上限
+ - 读写容量和表是独立的
+ - 只支持最终一致性
+- Index Local Secondary Index
+ - 索引保存在表的分区中,因此一个表 分区的尺寸的上限是10GB
+ - 使用的是表上定义的RCU和WCU
+ - 强一致性
+
+索引指向的是实际存储,可以理解为空间指针。并不是数据的拷贝。像mysql B树指向主键一样。
+
+## 实现
+
+> [论文讲解](http://systemdesigns.blogspot.com/2016/01/dynamodb.html)
+
+Dynamo在某些故障的场景中将牺牲一致性。
+
+Dynamo的系统假设和要求:
+1)query model:对数据项简单的读,写是通过一个主键唯一性标识。状态存储为一个由唯一性键确定二进制对象。没有横跨多个数据项的操作,也不需要关系方案(relational schema)。这项规定是基于观察相当一部分Amazon的服务可以使用这个简单的查询模型,并不需要任何关系模式。Dynamo的目标应用程序需要存储的对象都比较小(通常小于1MB)。
+
+2)ACID属性:ACID是一种保证数据库事务可靠地处理的属性。在数据库方面的,对数据的单一的逻辑操作被称作所谓的交易。Amazon的经验表明,在保证ACID的数据存储提往往有很差的可用性。Dynamo的目标应用程序是高可用性,弱一致性(ACID“中的C”)。Dynamo不提供任何数据隔离(Isolation)保证,只允许单一的关键更新。
+
+3)efficiency:系统需运作在一般的commodity hardware上。Amazon平台的服务都有着严格的延时要求, 鉴于对状态的访问在服务操作中起着至关重要的作用,存储系统必须能够满足那些严格的SLA,服务必须能够通过配置Dynamo,使他们不断达到延时和吞吐量的要求。因此,必须在成本效率,可用性和耐用性保证之间做权衡。
+
+
+
+提供get, put操作。
+
+
+
+最终一致性。
+
+### Partition
+
+按key做partition, 一致性Hash。
+
+### Replication
+
+replica, 复制,用了NWR,让用户做一致性的选择。读数据时如果有不同版本,会所有版本数据都返回回去。
+
+### Data Versioning
+
+多版本。Vector Clock 一个Vector Clock可以理解为一个<节点编号,计数器>对的列表。每一个版本的数据都会带上一个Vector Clock。Dynamo中,最重要的是要保证写操作的高可用性,即“Always Writeable”,这样就不可避免的牺牲掉数据的一致性。如上所述,Dynamo中并没有对数据做强一致性要求,而是采用的最终一致性(eventual consistency)。若不保证各个副本的强一致性,则用户在读取数据的时候很可能读到的不是最新的数据。Dynamo中将数据的增加或删除这种操作都视为一种增加操作,即每一次操作的结果都作为一份全新的数据保存,这样也就造成了一份数据会存在多个版本,分布在不同的节点上。这种情况类似于版本管理中的多份副本同时有多人在修改。多数情况下,系统会自动合并这些版本,一旦合并尝试失败,那么冲突的解决就交给应用层来解决。这时系统表现出来的现象就是,一个GET(KEY)操作,返回的不是单一的数据,而是一个多版本的数据列表,由用户决定如何合并。这其中的关键技术就是Vector Clock。
+
+
+
+其实就是读修复。
+
+### Failure Detection
+
+临时性故障,采用Hinted Handoff提示移交机制
+
+为防止要写入节点宕机导致操作失败,采用提示移交机制将操作相关数据写入到随机节点,宕机节点恢复后可根据这些数据进行重放,最终获得数据一致性。
+
+
+
+ 以N=3为例,如果在一次写操作时发现节点A挂了,那么本应该存在A上的副本就会发送到D上,同时在D中会记录这个副本的元信息(MetaData)。其中有个标示,表明这份数据是本应该存在A上的,一旦节点D之后检测到A从故障中恢复了,D就会将这个本属于A的副本回传给A,之后删除这份数据。Dynamo中称这种技术为“Hinted Handoff”。
+
+
+
+另外为了应对整个机房掉线的故障,Dynamo中应用了一个很巧妙的方案。每次读写都会从”Preference List”列表中取出R或W个节点。那么只要在这个列表生成的时候,让其中的节点是分布于不同机房的,自然数据就写到了不同机房的节点上。
+
+
+
+对于某节点非临时性故障,利用反熵得到丢失数据进行恢复。一些数据存储有后台进程,不断查找副本之间的数据差异,将任何缺少的数据从一个副本复制到另一个副本。和基于主节点复制的复制日志不同,此反熵过程不保证任何特定的顺序复制写入,并且会引入明显的同步滞后
+
+
+
+## 事务
+
+> [官网wiki](https://docs.aws.amazon.com/zh_cn/amazondynamodb/latest/developerguide/transactions.html)
+
+支持事务,所有操作必须成功完成,否则不会进行任何更改。
+
+隔离级别:
+
+1. 可序列化
+2. 读已提交
+
+
+
+## 其他
+
+
+
+> [官网](https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/Programming.LowLevelAPI.html#Programming.LowLevelAPI.DataTypeDescriptors)
+
+begin_with这个操作要记得。其他后面看。begin_with是字符串前缀匹配,应该用了字典树等加速。
+
+
+
+> [AWS 如何实现数据跨区域同步](https://techsummit.ctrip.com/pdf/songye.pdf)
+
+没啥子东西,数据操作优先同区域内,主要靠复制。
+
+
+
+> [MongoDB 与 DynamoDB 正面交锋](https://www.modb.pro/db/432414)
+
+没啥东西
+
+
+
+> [通俗易懂之DynamoDB(一) ----分区键、排序键、GSI](https://zhuanlan.zhihu.com/p/101965292)
+
+**getItem、query和scan**
+
+这三个操作都是查询操作,效率分别是:getItem > query > scan
+
+getItem是根据primary key进行查询,可以理解为通过primary key在hashMap上查询,速度是最快的,缺点是必须知道primary key且只能查询单个,使用情况相对较少。
+
+scan是全表扫描,是最慢的一个,理论上能不用就不用,只有实在走投无路才考虑全表扫描。
+
+query是最常见的方式,在dynamoDB的使用中,我们唯一的目的就是写出高效的查询query。
diff --git a/_posts/Tech/AWS/2022-12-14-AWS CloudWatch.md b/_posts/Tech/AWS/2022-12-14-AWS CloudWatch.md
new file mode 100644
index 0000000000..38746d77c0
--- /dev/null
+++ b/_posts/Tech/AWS/2022-12-14-AWS CloudWatch.md
@@ -0,0 +1,19 @@
+---
+layout: post
+category: AWS
+title: AWS CloudWatch
+tags: AWS
+published: false
+---
+
+## AWS CloudWatch
+
+主要是Dashboard, metrics, alarms等。
+
+metrics的dimension不能用in操作。只能取1个或者不取。
+
+
+
+## 待更新
+
+期待后续...
diff --git a/_posts/Tech/AWS/2023-02-09-AWS IAM.md b/_posts/Tech/AWS/2023-02-09-AWS IAM.md
new file mode 100644
index 0000000000..9329ff06ec
--- /dev/null
+++ b/_posts/Tech/AWS/2023-02-09-AWS IAM.md
@@ -0,0 +1,346 @@
+---
+layout: post
+category: AWS
+title: AWS IAM
+tags: AWS
+---
+
+## AWS IAM
+
+
+
+首先要知道, AWS 提供了许许多多种类的服务或者说资源供我们使用, 这些资源挂在我们的 AWS 账户下, 这个账户就是我们第一次用 AWS 时用邮箱和密码申请的, 以后我们所有的资源申请, 账单费用都会挂到这个户头.
+
+那么 IAM 算什么呢? IAM 不是 AWS 的专有名词, 它是一个通用概念, 全称是 Identity and Access Management, 其要解决的两个问题就是身份认证 (Authtication) 和授权 (Authorization). 为此 AWS IAM 设计了用户, 角色, 用户组, 权限策略等概念和机制
+
+
+
+IAM (Identity Access Management) 由这些东西组成:
+
+- Users
+- Groups 用户组
+- Roles 角色可以分配给AWS服务,让AWS服务有访问其他AWS资源的权限。 举个例子,我们可以赋予EC2实例一个角色,让其有访问S3的读写权限(后面课程会有关于这一点的实操)
+- Policy Documents 策略。 策略具体定义了能访问哪些AWS资源,并且能执行哪些操作(比如List, Read, Write等) 策略的文档以JSON的格式展现
+
+```
+// An example policy: allowing any access to any resource
+{
+ "Version": "2012-10-17"
+ "Statement": [
+ {
+ "Effect": "Allow",
+ "Action": "*",
+ "Resource": "*"
+ }
+ ]
+}
+```
+
+
+
+IAM 是 Global的,不属于任何一个 region
+
+
+
+
+
+## IAM Entities
+
+首先 IAM 为了能够同时照顾到 “人” 和 “非人“ 这两类资源访问者, 使用了一个概念叫做 Entity(实体), 目前 IAM 里有两种 Entity: IAM User 和 IAM Role. 一般来说公司可以为每个程序员创建一个 IAM User 的实体, 让他们能够访问 AWS Console做一些权限之内的事情; 而对于非人的程序, 一般的实践则是创建 IAM Role, 然后令这程序 “假装”(Assume) 这个角色, 这样它就有了这个角色的权限, 一个 IAM Role 可以让很多程序一起假装, 不过要想假装 Role 的话, 必须得是 AWS 里的资源才行, 这是当然的, 像上面第三个例子, 公网的设备想访问我们的存储资源, 首先要通过 API Gateway, 由 API Gateway 来完成这个假装动作.
+
+## Users
+
+在 AWS 里,一个 IAM user 和 unix 下的一个用户几乎等价。你可以创建任意数量的用户,为其分配登录 AWS management console 所需要的密码,以及使用 AWS CLI(或其他使用 AWS SDK 的应用)所需要的密钥。你可以赋予用户管理员的权限,使其能够任意操作 AWS 的所有服务,也可以依照 Principle of least privilege,只授权合适的权限。下面是使用 AWS CLI 创建一个用户的示例:
+
+```
+saws> aws iam create-user --user-name tyrchen
+{
+ "User": {
+ "CreateDate": "2015-11-03T23:05:05.353Z",
+ "Arn": "arn:aws:iam::
+
+参考
+
+- Internet Gateway (IGW) allows instances with public IPs to access the internet.
+- NAT Gateway (NGW) allows instances with no public IPs to access the internet.
+
+## 参考
+
+[参考](https://juejin.cn/post/6949072638145003556)
+
+大部分 AWS 服务都需要以 VPC 为基础进行构建,比如最常用的 EC2,ALB,及无服务器服务 ECS Fargate。 vb
+
+当我们在一个 VPC 中创建 Subnet 时需要给 Subnet 选择一个 AZ(Availability Zone),一个 Subnet 只能选择建在一个 AZ 中。
+
+
+
+**选择region**
+
+因为国内政策法规原因,AWS 在中国的服务与 AWS Global 服务略有不同。
+
+AWS Global 的 Region 之间是通过主干网相连的,AWS 中国区的服务没有通过主干网与 AWS Global 相连,只有中国区内部两个 Region,北京和宁夏是相连接的。
+
+在创建 VPC 时并不需要添写 AZ(Availability Zone)信息,VPC 只与 Region 有关。
+
+
+
+Subnet 是最终承载大部分 AWS 服务的组件,比如 EC2, ECS Fargate,RDS。
+
+Subnet 分为两种 Private Subnet 和 Public Subnet。
+
+简单来说,不能直接访问 internet 的 Subnet 就是 Private Subnet,能直接访问 internet 的就是 Public Subnet。
+
+
+
+Security Group(SG)通过控制IP和端口来控制出站入站规则,可以用于EC2,RDS及下面将要用到的VPC Endpoint。
+
+
+
+VPC Endpoint用来直接连接VPC与AWS相关服务,比如RDS AIP,S3。
+
+当系统安全要求比较高时,EC2处于的Subnet可能被限制,无法访问internet,这时EC2就无法访问AWS的一些服务,比如SSM。
+
+这时我们可以利用VPC Endpoint把VPC和所需要访问的服务连接起来,然后EC2就可以不经internet访问到所需的服务。
+
+
+
+[参考](https://juejin.cn/post/6954169148318433288)
+
+RT(Route Table)与Subnet相关连,用来描述网络路由。IGW: Internet gateway IGW是一个独立的组件配置在VPC上,使得VPC可以访问internet
+
+我们给VPC加了IGW之后,需要修改Subnet相关的路由,确保访问Internet的请求发送到IGW。
+
+每个VPC中有一个默认的主RT,自动关联VPC内的每一个Subnet。我们现在为Subnet “ts-public-1”单独创建一个新的RT。
+
+
+
+- 新建的Subnet就是Private Subnet
+- 在Private Subnet中配置了到IGW的路由后,就变成Public Subnet
+- Public Subnet中的EC2还要再配置一个Public IP或者EIP就可以访问Internet
+- 如果EC2可以访问internet,其关联的Security Group入站规则如果允许从internet访问,那么这个EC2就可以从internet中直接访问到。
+
+
+
+1. 实践中我们把应用程序,数据库放在Private Subnet中,阻止从internet访问。把堡垒机和ALB(Application Load balancer)放在Public Subnet,允许从internet访问。
+
+2. 一般我们会建两套Public Subnet和Private Subnet,分别放在不同的AZ中,防止其中一个AZ出问题。这时如果配置NAT,也需要在两个Public Subnet中各配置一个NAT。
+
+
+
+[参考](http://www.cloudbin.cn/?tag=aws) 暂无Note
+
+## 总结
+
+VPC里多个AZ, 每个AZ都需要至少一个子网,默认是公有子网。但如果有internet访问不到的实例或者数据库,则需建个私有子网,私有子网默认不能访问internet,internet也不能访问私有子网。
+
+要走互联网必须走internet gateway,它对整个vpc生效, public subnet可直接通过IGW与互联网互联,私有子网再通过NAT走公有子网是可以访问internet的,反向不能。
+
+和互联网连接时都需要有个公网ip,这个是从amazon分配的。
+
+
+
+# 跨账号访问aws service总结
+
+比如 本账号lambda访问另一个账号的DDB
+
+Lambda 跨账号访问另一个账号中的 DynamoDB 表,一共有以下几种方法:
+
+1. 使用 assumeRole API:Lambda 函数在执行时使用 assumeRole API 切换到具有访问目标账号 DynamoDB 表权限的 IAM 角色。这种方法的优点是简单易用,只需要在代码中调用 assumeRole API 即可。缺点是需要进行额外的 IAM 角色配置和权限管理,同时存在一定的安全风险,因为将 IAM 凭证直接硬编码到代码中可能会导致安全问题。
+2. 使用 VPC Peering:通过建立 VPC Peering 连接,将源账号和目标账号的 VPC 相互连接起来,实现 Lambda 函数对 DynamoDB 表的访问。这种方法的优点是简单易用,可以通过 AWS 控制台完成配置,同时具有较高的安全性。缺点是需要进行 VPC 配置和管理,且无法实现跨区域访问。
+3. 使用 PrivateLink:通过在目标账号中创建一个 PrivateLink 终端节点,将 DynamoDB 表以私有方式暴露给源账号中的 Lambda 函数,实现跨账号访问。这种方法的优点是高度安全,可以通过 AWS PrivateLink 在私有网络中实现数据的加密传输,同时支持跨区域访问。缺点是需要进行较为复杂的 VPC 和 PrivateLink 配置,且可能需要进行网络安全设置和管理。
+4. 使用 AWS Resource Access Manager(RAM):通过使用 RAM,可以在多个 AWS 账号之间共享资源,并授予其他 AWS 账号访问这些资源的权限。Lambda 函数可以将 RAM 中的资源授权给目标账号,从而实现对 DynamoDB 表的访问。这种方法的优点是可以实现资源共享和管理,并且具有高度的可扩展性。缺点是需要进行 RAM 的配置和管理,且可能需要进行跨账号 IAM 角色的授权和管理。
+
+
+
+一般来说,如果需要实现高度安全性和数据隔离,且需要支持跨区域访问,推荐使用 PrivateLink;如果只是需要简单快速地实现跨账号访问,可以选择使用 assumeRole API 或 VPC Peering。如果需要进行资源共享和管理,可以考虑使用 AWS RAM。
+
+# Route 53
+
+**Amazon Route 53**是一种高可用、高扩展性的云DNS服务。
+
+Amazon Route 53 是一种托管域名系统 (DNS) 服务,它可帮助您为您的域名注册和管理 DNS 记录。您可以使用 Route 53 将您的域名映射到您的 VPC 内的资源,如 ELB 和 Amazon S3。
+
+不同的DNS记录:
+
+- **CNAME** – CNAME (Canonical Name)可以将一个域名指向另一个域名。比如将aws.xiaopeiqing.com指向xiaopeiqing.com
+- Alias记录 – 和CNAME类似,又叫做别名记录,可以将一个域名指向另一个域名。
+ - **和CNAME最大的区别是,Alias可以应用在根域(Zone Apex)。即可以为xiaopeiqing.com的根域创建Alias记录,而不能创建CNAME**
+ - 别名记录可以节省你的时间,因为Route53会自动识别别名记录所指的记录中的更改。例如,假设example.com的一个别名记录指向位于lb1-1234.us-east-2.elb.amazonaws.com上的一个ELB负载均衡器。如果该负载均衡器的IP地址发生更改,Route53将在example.com的DNS应答中自动反映这些更改,而无需对包含example.com的记录的托管区域做出任何更改。 弹性负载均衡器(ELB)没有固定的IPv4地址,在使用ELB的时候永远使用它的DNS名字。很多场景下我们需要绑定DNS记录到ELB的endpoint地址,而不绑定任何IP
+
+# AWS Direct Connect
+
+AWS Direct Connect 是一种专用网络连接服务,它允许您通过私有连接连接到 AWS 服务。您可以使用 Direct Connect 将您的本地数据中心与您的 VPC 直接连接起来,实现更安全、更高带宽的网络连接。
+
+
+
+AWS Direct Connect 是一种联网服务,提供了通过互联网连接到AWS 的替代方案。 使用AWS Direct Connect ,以前通过Internet 传输的数据将可以借助您的设施和AWS 之间的私有网络连接进行传输。
+
+**不再需要通过网络提供商。** 描述的是本地IT数据中心和VPC连接。通过物理专线连接。
+
+AWS Direct Connect 通过标准的以太网光纤电缆将您的内部网络链接到 AWS Direct Connect 位置。电缆的一端接到您的路由器,另一端接到 AWS Direct Connect 路由器。有了这个连接,你可以创建*虚拟接口*直接公有公有访问AWS服务(例如,到 Amazon S3)或 Amazon VPC,绕过您的网络路径中的互联网服务提供商。网络 ACL 和安全组都允许 (因此可到达您的实例) 的发起 ping 的AWS Direct Connect位置提供访问AWS在与之关联的区域中。您可以将单个连接用于公有区域或AWS GovCloud (US)公有访问AWS所有其他公有区域中的服务。
+
+[参考](https://docs.aws.amazon.com/zh_cn/directconnect/latest/UserGuide/Welcome.html)
+
diff --git a/_posts/Tech/AWS/2022-11-18-AWS Compute.md b/_posts/Tech/AWS/2022-11-18-AWS Compute.md
new file mode 100644
index 0000000000..4067771a68
--- /dev/null
+++ b/_posts/Tech/AWS/2022-11-18-AWS Compute.md
@@ -0,0 +1,195 @@
+---
+layout: post
+category: AWS
+title: AWS Compute
+tags: AWS
+---
+
+## AWS Compute
+
+## AMI
+
+AMI: amazon machine image 就是一堆配置,比如什么系统,安装哪些附加软件。可使用AMI启动一个同配置的实例。 类似docker的image
+
+**Amazon Machine Image (AMI)** 是亚马逊AWS提供的系统镜像,这个AMI包含了如下的信息:
+
+- 由实例的操作系统、应用程序和应用程序相关的配置组成的模板
+- 一个指定的需要在实例启动时附加到实例的卷的信息(比方说定义了使用8 GB的General Purpose SSD卷)
+
+下图所示的是AMI的生命周期,你可以创建并注册一个AMI,并且可以使用这个AMI来创建一个EC2实例。同时你也可以将这个AMI复制到同一个AWS区域或者不同的AWS区域。你同样也可以注销这个AMI镜像。
+
+
+
+- **AMI是区域化的**,只能使用本区域的AMI来创建实例;但你可以将AMI从一个区域复制到另一个区域
+
+
+
+
+
+## 弹性伸缩(Auto Scaling)
+
+**亚马逊弹性伸缩(Auto Scaling)**能**自动地**增加/减少EC2实例的数量,从而让你的应用程序一直能保持可用的状态。
+
+你可以预定义Auto Scaling,使其在需求高峰期自动增加EC2实例,而在需求低谷自动减少EC2实例。这样不仅能让你的应用程序一直保持健康的状态,而且也节省了你为EC2实例所付出的费用。
+
+Auto Scaling 适用于那些需求稳定的应用程序,同时也适用于在每小时、每天、甚至每周都有需求变化的应用程序。
+
+- Auto Scaling能保证你一直拥有一定数量的EC2实例来分担应用程序的负载
+- Auto Scaling能带来更高的容错性、更好的可用性和更高的性价比
+- 你可以控制伸缩的策略来决定在什么时候终止和创建EC2实例,以处理动态变化的需求
+- 默认情况下,Auto Scaling能控制每一个可用区内所运行的实例数量尽量平均
+ - 为了达到这个目标,Auto Scaling在需要启动新实例的时候,会选择一个目前拥有运行实例最少的可用区
+
+Auto Scaling的构成组件:
+
+
+
+### 启动配置(Launch Configuration)
+
+- 启动配置是弹性伸缩组用来启动EC2实例的时候所使用的模板
+- 启动配置包含了镜像文件(AMI),实例类型、密钥对、安全组和挂载的存储设备
+- 一个启动配置可以关联多个Auto Scaling组
+- **启动配置一经创建不能被更改,只能删除重建**
+- 启动配置中可以使用CloudWatch的基础监控(Basic Monitoring)或者详细监控(Detail Monitoring)
+- Auto Scaling automatically creates a launch configuration directly from an EC2 instance.
+
+### 弹性伸缩组(Auto Scaling Group)
+
+- 弹性伸缩组(ASG)是弹性伸缩的核心,它包含了多个拥有类似配置/类型的EC2实例,这些实例被逻辑上认为是一样的
+- 弹性伸缩组需要的几个参数:
+ - **启动配置(Launch Configuration)**:它决定了EC2使用什么模板,模板内容包括了镜像文件(AMI),实例类型、密钥对、安全组和挂载的存储设备
+ - **最小和最大的性能**:决定了在弹性伸缩的情况下,EC2实例数量的浮动范围
+ - **所需的性能**:决定了这个弹性伸缩组要保持的运作所需要的基本的EC2实例数量;如果没有填写,则默认为其数值等同于最小的性能
+ - **可用区和子网**:定义EC2实例启动时候所在的可用区和子网信息
+ - **参数和健康检查**:参数定义了何时启动新实例,何时终止旧实例;健康检查决定了实例的健康状态。
+- **如果一个EC2实例的健康状态变成“不健康”,那么ASG会终止这个EC2实例,并且自动启动一个新的EC2实例**
+- 弹性伸缩组(ASG)只能在某一个AWS区域内运行,不能跨越多个区域
+- 如果启动配置(Launch Configuration)有更新,那么之后启动的新EC2实例会使用新的启动配置,而旧的EC2实例不受影响
+- 从AWS管理平台你可以直接删除一个弹性伸缩组(ASG);从AWS CLI你只能先将最小的性能和需求的性能两个参数设置为0,才能删除这个弹性伸缩组。
+
+
+
+## ECS
+
+**Amazon Elastic Container Service (ECS)**是一个有高度扩展性的**容器管理服务**。它可以轻松运行、停止和管理集群上的Docker容器,你可以将容器安装在EC2实例上,或者使用**Fargate**来启动你的服务和任务。
+
+Amazon ECS可以在一个区域内的多个可用区中创建高可用的应用程序容器,你可以定义集群中运行的Docker镜像和服务。而且你可以充分利用AWS内部的**Amazon ECR (Elastic Container Registry)**或者外部的Registry(比如Docker Hub或自建的Registry)来存储和提取容器镜像。
+
+
+
+我们可以将标准化的代码、运行环境、系统工具等等打包成一个标准的集装箱,这个集装箱叫做**Docker镜像**(Docker Image)。这个Docker镜像的概念类似于EC2中的AMI (Amazon Machine Image)。
+
+这些镜像文件通常会通过Dockerfile来构建,并且最终存放到**注册表(Registry)**内。这个Registry可以理解为摆放集装箱的码头,我们在需要某个类型的集装箱的时候就到码头去取。这类Registry可以是Amazon的ECR,也可以是公网上的Docker Hub,或者自己私有的Registry。
+
+
+
+
+
+### ECS创建举例
+
+
+
+
+
+## Lambda
+
+使用**AWS Lambda**,你无需配置和管理任何服务器和应用程序就能运行你的代码。只需要上传代码,Lambda就会处理运行并且根据需要自动进行横向扩展。因此Lambda也被称为**无服务(Serverless)**函数。
+
+要让AWS Lambda的代码执行,需要设定一些触发器(比如CloudWatch Log,CloudWatch Event,API Gateway等),因此Lambda函数被认为是**事件驱动的(Event-Driven)**。
+
+在传统的应用部署过程中,我们往往需要安装操作系统 -> 安装应用程序 -> 配置环境并部署代码,而且往往还需要不定时地为操作系统和应用程序打补丁和进行维护。使用AWS Lambda就方便很多,只需要上传代码,AWS就会在需要的时候帮你运行。我们不再需要(也无法接触)任何操作系统层面的东西,也节省了非常多的部署时间,可以更专心地编写代码。
+
+
+
+### AWS Lambda的特点
+
+- 没有服务器/无服务,或者说真实的服务器由AWS管理
+- 只需要为运行的代码付费,不需要管理服务器和操作系统
+- **持续性/自动的性能伸缩**
+- 非常便宜
+- AWS只会在代码运行期间收取相应的费用,代码未运行时不产生任何费用
+- **代码的最长执行时间是15分钟,如果代码执行时间超过15分钟,则需要将1个代码细分为多个**
+
+### 触发器有哪些
+
+- **API Gateway**
+- **AWS IoT**
+- **CloudWatch Events** 比如cron job定时任务
+- CloudWatch Logs
+- CodeCommit
+- DynamoDB
+- S3
+- SNS
+- Cognito Sync Trigger
+- SQS应该也可以?
+
+
+
+## 参考
+
+[参考](http://www.cloudbin.cn/?tag=aws)
+
+## Compute选型
+
+aws提供两种容器编排服务: ECS和EKS, k是kubernetes。 后者适合已经用了k8s的。
+
+AWS fargate就是serverless, ECS/EKS 可集成在Fargate上或者EC2上。 container hosting platform
+
+Serverless: 允许在服务部署级别而不是服务器部署级别来管理应用部署。类似Faas。无需关注主机管理,服务运维。
+
+
+
+ECS vs EC2
+
+- ECS和EKS: aws负责容器管理,但customer依旧需要负责底层的ec2 instances.
+
+Fargate vs Lambda
+
+- Fargate is a Container as a Service (CaaS) offering, AWS Lambda is a Function as a Service (FaaS offering).
+
+Fargate是类似k8s的工具,可以管理容器,进行编排。
+
+ECS vs Fargate
+
+- ECS delivers more control over the infrastructure, but the trade-off is the added management that comes with it. Fargate is the better option for ease of use as it takes infrastructure management out of the equation allowing you to focus on just the tasks to be run. ECS 提供了对基础设施的更多控制,但代价是随之而来的附加管理。Fargate 是易于使用的更好选择,因为它将基础设施管理排除在外,使您可以专注于要运行的任务。
+
+
+
+Serverless vs EC2/ECS:
+
+- If you want to deploy your workloads and applications without having to manage any EC2 instances, you can do that on AWS with serverless compute.
+- Serverless includes fargate, lambda.
+
+
+
+Serverless vs Lambda
+
+- the latter doesn't need the control of container
+
+
+
+两个方面
+
+- 是否要管理主机
+ - Yes: ecs, ec2
+ - No: fargate, lambda
+- 是否要管理容器,类似k8s的活。
+ - Yes: fargate, ecs, ec2.
+ - No: lambda
+
+
+
+
+
+虚拟机相比容器好处,重要的是资源隔离。
+
+- 拥有完整操作系统
+- 异质环境
+- 安全
+
+容器好处:
+
+- 速度和可移植性,启动只有几秒钟,虚拟机要几分钟
+- 可扩展性,通过编排器,自动扩展。
+- 模块化
+- 易于更新。
\ No newline at end of file
diff --git a/_posts/Tech/AWS/2022-11-18-AWS MQ.md b/_posts/Tech/AWS/2022-11-18-AWS MQ.md
new file mode 100644
index 0000000000..3a848ebd31
--- /dev/null
+++ b/_posts/Tech/AWS/2022-11-18-AWS MQ.md
@@ -0,0 +1,100 @@
+---
+layout: post
+category: AWS
+title: AWS MQ
+tags: AWS
+---
+
+## AWS MQ
+
+## SQS(Simple Queue Service)
+
+SQS有两种不同类型的队列,它们分别是:
+
+- **标准队列**(Standard Queue)
+- **FIFO队列**(先进先出队列)
+
+### 标准队列
+
+标准队列拥有**无限的吞吐量**,所有消息都会**至少传递一次**,并且它会尽最大努力进行排序。
+
+标准队列是默认的队列类型。
+
+
+
+### FIFO队列
+
+FIFO (First-in-first-out)队列在不使用批处理的情况下,**最多支持300TPS**(每秒300个发送、接受或删除操作)。
+
+在队列中的消息都只会**不多不少地被处理一次**。
+
+FIFO队列严格保持消息的**发送和接收顺序**。
+
+
+
+更多关于标准队列和FIFO队列的区别,可以查看[我需要哪种类型的队列?](https://docs.aws.amazon.com/zh_cn/AWSSimpleQueueService/latest/SQSDeveloperGuide/welcome.html#sqs-queue-types)
+
+### SQS的其他特点
+
+- SQS是靠应用程序去**拉取的**,而不能主动推送给应用程序,推送服务我们使用**SNS(Simple Notification Service)**
+- 消息会以256 KB的大小存放
+- 消息会在队列中保存1分钟~14天,默认时间是4天
+- 可见性超时(Visibility Timeout)
+ - 即当SQS队列收到新的消息并且被拉取走进行处理时,会触发Visibility Timeout的时间。这个消息不会被删除,而是会被设置为不可见,用来防止该消息在处理的过程中再一次被拉取
+ - 当这个消息被处理完成后,这个消息会在SQS中被删除,表示这个任务已经处理完毕
+ - 如果这个消息在Visibility Timeout时间结束之后还没有被处理完,则这个消息会设置为可见状态,等待另一个程序来进行处理
+ - 因此**同一个消息可能会被处理两次(或以上)**
+ - 这个超时时间最大可以设置为**12小时**
+- 标准SQS队列保证了每一个在队列内的消息都至少会被处理一次
+- 长轮询(Long Polling)
+ - 默认情况下,Amazon SQS使用**短轮询(Short Polling)**,即应用程序每次去查询SQS队列,SQS都会做回应(哪怕队列一直是空的)
+ - 使用了长轮训,应用程序每次去查询SQS队列,SQS队列不会马上做回应。而是等到队列里有消息可处理时,或者等到设定的超时时间再做出回应。
+ - 长轮询可以一定程度减少SQS的花销
+
+## SNS (Simple Notification Service)
+
+**SNS (Simple Notification Service)** 是一种完全托管的发布/订阅消息收发和移动通知服务,用于协调向订阅终端节点和客户端的消息分发。
+
+SNS是一项 Web 服务,用于协调和管理向订阅终端节点或客户交付或发送消息的过程。在 Amazon SNS 中有两种类型的客户端:发布者和订阅者,也称为生产者和消费者。发布者通过创建消息并将消息发送至主题与订阅者进行异步交流,主题是一个逻辑访问点和通信渠道。订阅者(即 Web 服务器、电子邮件地址、Amazon SQS 队列、AWS Lambda 函数)在其订阅主题后通过受支持协议(即 Amazon SQS、HTTP/S、电子邮件、SMS、Lambda)中的一种使用或接收消息或通知。
+
+我们可以使用SNS将消息推送到SQS消息队列中、AWS Lambda函数或者HTTP终端节点上。
+
+SNS通知还可以发送推送通知到IOS,安卓,Windows和基于百度的设备,也可以通过电子邮箱或者SMS短信的形式发送到各种不同类型的设备上。
+
+
+
+
+
+在创建SNS Topic时的一些选项:
+
+- Encryption: 代表是否对Topic中的消息进行加密。如果需要处理的数据中有敏感信息,应做此设置。
+- Delivery retry policy (HTTP/S): 默认为3,也就说尝试三次后,消息还没有送到的话,就会彻底丢失。因此在使用SNS的时候,一旦出现这种情况,就应该使用DLQ来做容错。
+
+### SNS的一些特点
+
+- SNS是实时的**推送服务(Push)**,有别于SQS的**拉取服务(Pull/Poll)**
+- 拥有简单的API,可以和其他应用程序兼容
+- 可以通过多种不同的传输协议进行集成
+- 便宜、用多少付费多少的服务模型
+- 在AWS管理控制台上就可以进行简单的操作
+
+## SNS vs SQS
+
+AWS提供了[SQS](https://link.zhihu.com/?target=https%3A//console.aws.amazon.com/sqs/v2/home)和[SNS](https://link.zhihu.com/?target=https%3A//console.aws.amazon.com/sns/v3/home)。SQS是一个分布式的队列消息service,SNS是一个分布式的发布-订阅消息service。具体有人会问这两者有什么区别,这里给出了回答: [What is the difference between Amazon SNS and Amazon SQS?](https://link.zhihu.com/?target=https%3A//stackoverflow.com/questions/13681213/what-is-the-difference-between-amazon-sns-and-amazon-sqs)。 在我的实践中,SQS和SNS会结合起来使用,首先应用发布消息到SQS的queue里面,然后SNS消费这个queue的消息,放到自身的topic里面持久保存,然后其他的应用订阅这个topic,消费里面的消息。
+
+
+
+sqs是一对一,不能一对多,消息可持久化,不推只能等拉,拉完就删除。
+
+sns可一对多,不能持久化,push模型。
+
+sqs及aws笔记,更全, [link](http://www.cloudbin.cn/?p=2530)
+
+
+
+个人觉得 sns是推 能力的一个抽象。比如推送,mq里的push,都是推。aws把推给抽象出来。就可以让用户像搭积木一样使用。
+
+
+
+
+
diff --git a/_posts/Tech/AWS/2022-11-18-AWS Storage.md b/_posts/Tech/AWS/2022-11-18-AWS Storage.md
new file mode 100644
index 0000000000..bf2a5141d9
--- /dev/null
+++ b/_posts/Tech/AWS/2022-11-18-AWS Storage.md
@@ -0,0 +1,225 @@
+---
+layout: post
+category: AWS
+title: AWS Storage
+tags: AWS
+---
+
+## AWS Storage
+
+## dynamoDB
+
+[论文讲解](http://systemdesigns.blogspot.com/2016/01/dynamodb.html)
+
+[深入探讨 Amazon DynamoDB 的设计模 式、流复制和全局表](https://sides-share.s3.cn-north-1.amazonaws.com.cn/AWS+Webinar+2019/PDF/Amazon+DynamoDB+webinar.pdf)
+
+[官网](https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/Programming.LowLevelAPI.html#Programming.LowLevelAPI.DataTypeDescriptors)
+
+[AWS 如何实现数据跨区域同步](https://techsummit.ctrip.com/pdf/songye.pdf)
+
+[MongoDB 与 DynamoDB 正面交锋](https://www.modb.pro/db/432414)
+
+
+
+## EBS
+
+### EBS的特点
+
+- 亚马逊EBS卷提供了**高可用、可靠、持续性的块存储**,EBS可以依附到一个正在运行的EC2实例上
+- 如果你的EC2实例需要使用数据库或者文件系统,那么建议使用EBS作为首选的存储设备
+- EBS卷的存活可以脱离EC2实例的存活状态。也就是说在终止一个实例的时候,你可以选择保留该实例所绑定的EBS卷
+- EBS卷可以依附到**同一个可用区(AZ)**内的任何实例上
+- EBS卷可以被加密,如果进行了加密那么它存有的所有已有数据,传输的数据,以及制造的镜像都会被加密
+- **EBS卷可以通过快照(Snapshot)来进行(增量)备份,这个快照会保存在S3 (Simple Storage System)上**
+- 你可以使用任何快照来创建一个基于该快照的EBS卷,并且随时将这个EBS卷应用到**该区域**的任何实例上
+- EBS卷创建的时候已经固定了可用区,并且**只能给该可用区的实例使用**。如果需要在其他可用区使用该EBS,那么可以创建快照,并且使用该快照创建一个在其他可用区的新的EBS卷
+- **快照还可以复制到其他的AWS区域**
+
+### EBS (Elastic Block Storage)小结
+
+- EBS的不同类型,需要了解不同类型的EBS主要的使用场景
+ - 通用型SSD – GP2 (高达10,000 IOPS),适用于启动盘,低延迟的应用程序等
+ - 预配置型SSD – IO1 (超过10,000 IOPS),适用于IO密集型的数据库
+ - 吞吐量优化型HDD -ST1,适用于数据仓库,日志处理
+ - HDD Cold – SC1 – 适合较少使用的冷数据
+ - HDD, Magnetic
+- 不能将EBS挂载到多个EC2实例上,一个EBS只能挂载到1个EC2实例上。
+ - 如果有共享数据盘的需求,请使用EFS (Elastic File System)
+- 根EBS卷默认是不能进行加密的,但可以使用第三方的加密工具(例如BitLocker)对其进行加密
+ - *除了根磁盘外的其他卷是可以加密的*
+
+### EBS快照(Snapshot)小结
+
+- *EBS的快照会被保存到S3(Simple Storage System)上*
+
+- *你可以对一个EBS卷创建一个快照,这个快照会被保存到S3上*
+
+- 快照实际上是
+
+ 增量备份
+
+ ,只有在上次进行快照之后更改的数据才会被添加的S3上
+
+ - 因此第一次快照所花费的时间比较长
+ - 而第二次以后的快照所花费的时间相对短很多
+
+- 对加密的EBS卷创建快照,创建后的快照也会是加密的
+
+- 从加密的快照恢复的EBS卷也会是加密的
+
+- 你可以分享快照给其他账户或AWS市场,但仅限于这个快照是没有进行过加密的
+
+- 要为一个作为根设备的EBS卷创建快照的话,建议停止这个实例再做快照
+
+### 实例存储(Instance Store)
+
+- 实例存储也叫做**短暂性存储(Ephemeral Storage)**
+- 实例存储的实例不能被停止(只能重启或终止),如果这个实例出现故障,那么在上面的所有数据将会丢失
+- 使用EBS的实例可以被停止,停止后EBS上的数据不会丢失
+- 重启使用实例存储的实例或者重启使用EBS的实例都不会导致数据丢失
+
+
+
+## AWS EBS, S3和EFS的区别
+
+- AWS S3对于静态页面的托管、多媒体分发、版本管理、大数据分析、数据存档来说都非常有用。S3可以和AWS CloudFront结合使用而达到更快的上传和下载速度。
+- AWS EBS是可以用来做数据库或托管应用程序的持续性文件系统,EBS具有很高的IO读写速度并且即插即用。 只能被单个EC2实例访问
+- 相比前面两种存储,AWS EFS是比较新的一项服务。它提供了可以在多个EC2实例之间共享的网络文件系统,功能类似于NAS设备。可以用EFS来处理大数据分析、多媒体处理和内容管理。
+
+## S3
+
+Amazon **Simple Storage Service (S3)** 是互联网存储解决方案,它提供了一个简单的Web接口,让其存储的数据和文件在互联网的任何地方给任何人访问。
+
+文件对象存储。
+
+
+
+### S3基本特性
+
+- S3是**对象存储**,可以在S3上存储各种类型的文件,它不是**块存储**(EBS是块存储)
+- 文件大小可以从0 字节到5 TB
+ - 使用Single Operation上传只能上传*最大5 GB*的文件
+ - 使用分段上传(Multipart Upload)可以对文件进行分段上传,最大支持上传*5 TB*的文件
+- S3的总存储空间是**无限大**的
+- 文件存储在**存储桶(Bucket)**内,可以理解存储桶就是一个文件夹
+- S3的名字是需要**全球唯一**的,不能与任何区域的任何人拥有的S3重名
+- 存储桶创建之后会生成一个URL,命名类似于https://s3-ap-northeast-1.amazonaws.com/aws_xiaopeiqing_com
+ - **S3是以HTTPS的形式展现的,而非HTTP**
+ - ap-northeast-1表示了当前桶所在的区域
+ - aws_xiaopeiqing_com表示了S3存储桶的名字,全球唯一
+- S3拥有99.99%(4个9)的可用性(Availability)
+ - 可用性可以理解为系统的uptime时间,即在一个自然年内(365天)有52.56分钟系统不可用
+- S3拥有99.999999999%(11个9)的持久性(Durability)
+ - 持久性可以认为是数据完整性/数据安全性,即在一千亿个存储在S3上的文件会有大概 1 个文件是不可读的
+- S3的存储桶创建的时候可以选择所在区域(Region),但不能选择可用区(AZ),AWS会负责S3的高可用、容灾问题
+ - S3创建的时候可以选择某个AWS区域,一旦选择了就不能更改
+ - 如果要在其他区域使用该S3的内容,可以使用**跨区域复制**
+- S3拥有不同的等级(Standard, Stantard-IA, Onezone-IA, RRS, Glacier)
+- 启用了**版本控制(Version Control)**你可以恢复S3内的文件到之前的版本
+- S3可以开启生命周期管理,对文件在不同的生命周期进行不同的操作
+ - 比如,文件在创建30天后迁移到便宜的S3等级(S3-IA),再经过30天进行归档(迁移到Glacier),再过30天就进行删除
+- 要启用生命周期管理需要先启用版本控制功能
+- S3支持加密功能
+- 使用访问控制列表(Access Control Lists)和桶策略(Bucket Policy)可以控制S3的访问安全
+- 在S3上成功上传了文件,你将会得到一个**HTTP 200**的状态反馈
+
+### 不同的S3存储类型
+
+- **Standard – 默认的存储类:**如果上传对象时未注明则S3会分配这个类型的存储
+- **Standard – IA(Infrequently Accessed):**用于保存不经常访问的数据,但是需要访问的时候也能很快地访问到。存储的价格比标准S3便宜,但是读取的费用比标准的S3高,也因为如此才要把不经常访问的数据放到这种类型的S3上。并且数据跨了多个AWS地理位置。
+- **Intelligent_Tiering** 智能分层(S3 智能分层): 这种储存类别将对象存储在两个访问层中,一个是频繁访问的层,一个是不频繁访问的层;如果对象`30`天内未访问,则会被移动至不频繁访问的层,如果不频繁访问层中的对象被访问,则会被移动至频繁访问的层;频繁访问的层的存储费用与`STANDARD`一样,不频繁访问层的存储费用与`STANDARD_IA`一样,该储存类别的请求费用与`STANDARD`一样,**该储存类别有额外的监控费用**;
+- **Onezone – IA:**同上,但数据只保存到一个AWS可用区内
+- **Glacier:**非常便宜,仅用于做归档。从Glacier读取数据需要花费3-5个小时。
+- **Glacier Deep Archive:** S3 Glacier Deep Archive 是 Amazon S3 成本最低的存储类,支持每年可能访问一两次的数据的长期保留和数字预留。它是为客户设计的 – 特别是那些监管严格的行业,如金融服务、医疗保健和公共部门 – 为了满足监管合规要求,将数据集保留 7-10 年或更长时间。S3 Glacier Deep Archive 还可用于备份和灾难恢复使用案例,是成本效益高、易于管理的磁带系统替代,无论磁带系统是本地库还是非本地服务都是如此。S3 Glacier Deep Archive 是 Amazon S3 Glacier 的补充,后者适合存档,其中会定期检索数据并且每隔几分钟可能需要一些数据。存储在 S3 Glacier Deep Archive 中的所有对象都将接受复制并存储在至少三个地理分散的可用区中,受 99.999999999% 的持久性保护,并且可在 12 小时内恢复。
+
+## CloudFront CDN
+
+**Amazon CloudFront**是一种全球**内容分发网络(CDN)**服务,可以安全地以低延迟和高传输速度向浏览者分发数据、视频、应用程序和API。
+
+
+
+- **边缘站点(Edge Location)**:边缘站点是内容缓存的地方,它存在于多个网络服务提供商的机房,它和AWS区域和可用区是完全不一样的概念。截至2018年中,AWS目前一共有100多个边缘站点。
+- **源(Origin)**:这是CDN缓存的内容所使用的源,源可以是一个S3存储桶,可以是一个EC2实例,一个弹性负载均衡器(ELB)或Route53,甚至可以是AWS之外的资源。
+- **分配(Distribution)**:AWS CloudFront创建后的名字
+- 分配分为两种类型,分别是
+ - **Web Distribution**:一般的网站应用
+ - **RTMP (Real-Time Messaging Protocol)**:媒体流
+- 你不只是可以从边缘站点读取数据,你还可以往边缘站点写入数据(比如上传一个文件),边缘站点会将你写入的数据同步到源上
+- 在CloudFront上的文件会被缓存在边缘节点,缓存的时间是**TTL(Time To Live)**。文件存在超过这个时间,缓存会被自动清除
+- 如果在到达TTL时间之前,你希望更新文件,那么你也可以**手动清除缓存**,但你将会被AWS**收取一定的费用**
+
+## ES
+
+AWS ES有两种node
+
+1. decicated master node 数量只能3-5。Dedicated Master 节点不太可能成为性能瓶颈,因为它们主要负责管理集群状态和协调分片分配等任务,并不会直接处理客户端的读写请求。相反,数据节点才是 AWS ES 集群中的性能瓶颈,因为它们需要实际检索和处理文档数据,对系统资源的消耗较大。
+2. 普通node,和es一样。
+
+每个node都有存储的一个限制。node数量增加,则性能增加。
+
+## Multi-AZ高可用
+
+是多个AZ里配置一个主,其它从,类似同城多机房架构。
+
+
+
+我们可以把AWS RDS数据库部署在多个**可用区(AZ)**内,以提供高可用性和故障转移支持。
+
+使用Multi-AZ部署模式,RDS会在不同的可用区内配置和维护一个主数据库和一个备用数据库,主数据库的数据会自动复制到备用数据库中。
+
+使用这种部署模式,可以为我们提供数据冗余,减少在系统备份期间的I/O冻结(上面有提到)。同时,更重要的是可以防止数据库实例的故障和单个可用区的故障。
+
+如下图所示,我们可以在两个可用区内分别部署主数据库和备用数据库。
+
+
+
+目前Multi-AZ支持以下数据库:
+
+- Oracle
+- PostgreSQL
+- MySQL
+- MariaDB
+- SQL Server
+
+值得注意的是,Aurora数据库本身就支持多可用区部署的高可用设置,因此不需要为Aurora数据库特别开启这个功能。
+
+在上次实验中我们有讲到,创建了RDS数据库之后我们会得到一个数据库的URL Endpoint。在开启Multi-AZ的情况下,这个URL Endpoints会根据主/备数据库的健康状态自动解析到IP地址。对于应用程序来说,我们只需要连接这个URL地址即可。
+
+**高可用的设置只是用来解决灾备的问题,并不能解决读取性能的问题;要提升数据库读取性能,我们需要用到Read Replicas。**
+
+
+
+### 只读副本(Read Replicas)
+
+我们可以在源数据库实例的基础上,复制一种新类型的数据库实例,称之为**只读副本(Read Replicas)**。我们对源数据库的任何更新,都会**异步**更新到只读副本中。
+
+因此,我们可以将应用程序的数据库读取功能转移到Read Replicas上,来减轻源数据库的负载。
+
+对于有大量读取需求的数据库,我们可以使用这种方式来进行灵活的数据库扩展,同时突破单个数据库实例的性能限制。
+
+Read Replicas还有如下的特点:
+
+- Read Replicas是用来提高读取性能的,不是用来做灾备的
+- 要创建Read Replicas需要源RDS实例开启了自动备份的功能
+- 可以为数据库创建最多**5个**Read Replicas
+- 可以为Read Replicas创建Read Replicas(如下图所示)
+- 每一个Read Replicas都有自己的URL Endpoint
+- 可以为一个启用了Multi-AZ的数据库创建Read Replicas
+- Read Replicas可以提升成为独立的数据库
+- 可以创建位于另一个区域(Region)的Read Replicas
+
+
+
+目前Read Replicas支持以下数据库:
+
+- Aurora
+- PostgreSQL
+- MySQL
+- MariaDB
+- Oracle
+
+https://amazonaws-china.com/cn/rds/details/read-replicas/
+
+## 参考
+
+[参考](http://www.cloudbin.cn/?p=1968)
diff --git a/_posts/Tech/AWS/2022-11-26-AWS DynamoDB.md b/_posts/Tech/AWS/2022-11-26-AWS DynamoDB.md
new file mode 100644
index 0000000000..821e551848
--- /dev/null
+++ b/_posts/Tech/AWS/2022-11-26-AWS DynamoDB.md
@@ -0,0 +1,142 @@
+---
+layout: post
+category: AWS
+title: AWS DynamoDB
+tags: AWS
+---
+
+## 表、索引
+
+> [深入探讨 Amazon DynamoDB 的设计模 式、流复制和全局表](https://sides-share.s3.cn-north-1.amazonaws.com.cn/AWS+Webinar+2019/PDF/Amazon+DynamoDB+webinar.pdf)
+
+
+
+分区键和排序键共同唯一的标识一条记录
+
+本地二级索引 Local Secondary Index (LSI) 单表上的。可以选择与表不同的排序键。同一个分区键。强一致性更新。
+
+
+全局二级索引 - Global Secondary Index (GSI) 可以选择与表不同的分区键以及排序键 每个索引分区会对应所有的表分区
+
+
+
+
+
+
+
+对比
+
+- Global Secondary
+ - 索引的尺寸没有上限
+ - 读写容量和表是独立的
+ - 只支持最终一致性
+- Index Local Secondary Index
+ - 索引保存在表的分区中,因此一个表 分区的尺寸的上限是10GB
+ - 使用的是表上定义的RCU和WCU
+ - 强一致性
+
+索引指向的是实际存储,可以理解为空间指针。并不是数据的拷贝。像mysql B树指向主键一样。
+
+## 实现
+
+> [论文讲解](http://systemdesigns.blogspot.com/2016/01/dynamodb.html)
+
+Dynamo在某些故障的场景中将牺牲一致性。
+
+Dynamo的系统假设和要求:
+1)query model:对数据项简单的读,写是通过一个主键唯一性标识。状态存储为一个由唯一性键确定二进制对象。没有横跨多个数据项的操作,也不需要关系方案(relational schema)。这项规定是基于观察相当一部分Amazon的服务可以使用这个简单的查询模型,并不需要任何关系模式。Dynamo的目标应用程序需要存储的对象都比较小(通常小于1MB)。
+
+2)ACID属性:ACID是一种保证数据库事务可靠地处理的属性。在数据库方面的,对数据的单一的逻辑操作被称作所谓的交易。Amazon的经验表明,在保证ACID的数据存储提往往有很差的可用性。Dynamo的目标应用程序是高可用性,弱一致性(ACID“中的C”)。Dynamo不提供任何数据隔离(Isolation)保证,只允许单一的关键更新。
+
+3)efficiency:系统需运作在一般的commodity hardware上。Amazon平台的服务都有着严格的延时要求, 鉴于对状态的访问在服务操作中起着至关重要的作用,存储系统必须能够满足那些严格的SLA,服务必须能够通过配置Dynamo,使他们不断达到延时和吞吐量的要求。因此,必须在成本效率,可用性和耐用性保证之间做权衡。
+
+
+
+提供get, put操作。
+
+
+
+最终一致性。
+
+### Partition
+
+按key做partition, 一致性Hash。
+
+### Replication
+
+replica, 复制,用了NWR,让用户做一致性的选择。读数据时如果有不同版本,会所有版本数据都返回回去。
+
+### Data Versioning
+
+多版本。Vector Clock 一个Vector Clock可以理解为一个<节点编号,计数器>对的列表。每一个版本的数据都会带上一个Vector Clock。Dynamo中,最重要的是要保证写操作的高可用性,即“Always Writeable”,这样就不可避免的牺牲掉数据的一致性。如上所述,Dynamo中并没有对数据做强一致性要求,而是采用的最终一致性(eventual consistency)。若不保证各个副本的强一致性,则用户在读取数据的时候很可能读到的不是最新的数据。Dynamo中将数据的增加或删除这种操作都视为一种增加操作,即每一次操作的结果都作为一份全新的数据保存,这样也就造成了一份数据会存在多个版本,分布在不同的节点上。这种情况类似于版本管理中的多份副本同时有多人在修改。多数情况下,系统会自动合并这些版本,一旦合并尝试失败,那么冲突的解决就交给应用层来解决。这时系统表现出来的现象就是,一个GET(KEY)操作,返回的不是单一的数据,而是一个多版本的数据列表,由用户决定如何合并。这其中的关键技术就是Vector Clock。
+
+
+
+其实就是读修复。
+
+### Failure Detection
+
+临时性故障,采用Hinted Handoff提示移交机制
+
+为防止要写入节点宕机导致操作失败,采用提示移交机制将操作相关数据写入到随机节点,宕机节点恢复后可根据这些数据进行重放,最终获得数据一致性。
+
+
+
+ 以N=3为例,如果在一次写操作时发现节点A挂了,那么本应该存在A上的副本就会发送到D上,同时在D中会记录这个副本的元信息(MetaData)。其中有个标示,表明这份数据是本应该存在A上的,一旦节点D之后检测到A从故障中恢复了,D就会将这个本属于A的副本回传给A,之后删除这份数据。Dynamo中称这种技术为“Hinted Handoff”。
+
+
+
+另外为了应对整个机房掉线的故障,Dynamo中应用了一个很巧妙的方案。每次读写都会从”Preference List”列表中取出R或W个节点。那么只要在这个列表生成的时候,让其中的节点是分布于不同机房的,自然数据就写到了不同机房的节点上。
+
+
+
+对于某节点非临时性故障,利用反熵得到丢失数据进行恢复。一些数据存储有后台进程,不断查找副本之间的数据差异,将任何缺少的数据从一个副本复制到另一个副本。和基于主节点复制的复制日志不同,此反熵过程不保证任何特定的顺序复制写入,并且会引入明显的同步滞后
+
+
+
+## 事务
+
+> [官网wiki](https://docs.aws.amazon.com/zh_cn/amazondynamodb/latest/developerguide/transactions.html)
+
+支持事务,所有操作必须成功完成,否则不会进行任何更改。
+
+隔离级别:
+
+1. 可序列化
+2. 读已提交
+
+
+
+## 其他
+
+
+
+> [官网](https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/Programming.LowLevelAPI.html#Programming.LowLevelAPI.DataTypeDescriptors)
+
+begin_with这个操作要记得。其他后面看。begin_with是字符串前缀匹配,应该用了字典树等加速。
+
+
+
+> [AWS 如何实现数据跨区域同步](https://techsummit.ctrip.com/pdf/songye.pdf)
+
+没啥子东西,数据操作优先同区域内,主要靠复制。
+
+
+
+> [MongoDB 与 DynamoDB 正面交锋](https://www.modb.pro/db/432414)
+
+没啥东西
+
+
+
+> [通俗易懂之DynamoDB(一) ----分区键、排序键、GSI](https://zhuanlan.zhihu.com/p/101965292)
+
+**getItem、query和scan**
+
+这三个操作都是查询操作,效率分别是:getItem > query > scan
+
+getItem是根据primary key进行查询,可以理解为通过primary key在hashMap上查询,速度是最快的,缺点是必须知道primary key且只能查询单个,使用情况相对较少。
+
+scan是全表扫描,是最慢的一个,理论上能不用就不用,只有实在走投无路才考虑全表扫描。
+
+query是最常见的方式,在dynamoDB的使用中,我们唯一的目的就是写出高效的查询query。
diff --git a/_posts/Tech/AWS/2022-12-14-AWS CloudWatch.md b/_posts/Tech/AWS/2022-12-14-AWS CloudWatch.md
new file mode 100644
index 0000000000..38746d77c0
--- /dev/null
+++ b/_posts/Tech/AWS/2022-12-14-AWS CloudWatch.md
@@ -0,0 +1,19 @@
+---
+layout: post
+category: AWS
+title: AWS CloudWatch
+tags: AWS
+published: false
+---
+
+## AWS CloudWatch
+
+主要是Dashboard, metrics, alarms等。
+
+metrics的dimension不能用in操作。只能取1个或者不取。
+
+
+
+## 待更新
+
+期待后续...
diff --git a/_posts/Tech/AWS/2023-02-09-AWS IAM.md b/_posts/Tech/AWS/2023-02-09-AWS IAM.md
new file mode 100644
index 0000000000..9329ff06ec
--- /dev/null
+++ b/_posts/Tech/AWS/2023-02-09-AWS IAM.md
@@ -0,0 +1,346 @@
+---
+layout: post
+category: AWS
+title: AWS IAM
+tags: AWS
+---
+
+## AWS IAM
+
+
+
+首先要知道, AWS 提供了许许多多种类的服务或者说资源供我们使用, 这些资源挂在我们的 AWS 账户下, 这个账户就是我们第一次用 AWS 时用邮箱和密码申请的, 以后我们所有的资源申请, 账单费用都会挂到这个户头.
+
+那么 IAM 算什么呢? IAM 不是 AWS 的专有名词, 它是一个通用概念, 全称是 Identity and Access Management, 其要解决的两个问题就是身份认证 (Authtication) 和授权 (Authorization). 为此 AWS IAM 设计了用户, 角色, 用户组, 权限策略等概念和机制
+
+
+
+IAM (Identity Access Management) 由这些东西组成:
+
+- Users
+- Groups 用户组
+- Roles 角色可以分配给AWS服务,让AWS服务有访问其他AWS资源的权限。 举个例子,我们可以赋予EC2实例一个角色,让其有访问S3的读写权限(后面课程会有关于这一点的实操)
+- Policy Documents 策略。 策略具体定义了能访问哪些AWS资源,并且能执行哪些操作(比如List, Read, Write等) 策略的文档以JSON的格式展现
+
+```
+// An example policy: allowing any access to any resource
+{
+ "Version": "2012-10-17"
+ "Statement": [
+ {
+ "Effect": "Allow",
+ "Action": "*",
+ "Resource": "*"
+ }
+ ]
+}
+```
+
+
+
+IAM 是 Global的,不属于任何一个 region
+
+
+
+
+
+## IAM Entities
+
+首先 IAM 为了能够同时照顾到 “人” 和 “非人“ 这两类资源访问者, 使用了一个概念叫做 Entity(实体), 目前 IAM 里有两种 Entity: IAM User 和 IAM Role. 一般来说公司可以为每个程序员创建一个 IAM User 的实体, 让他们能够访问 AWS Console做一些权限之内的事情; 而对于非人的程序, 一般的实践则是创建 IAM Role, 然后令这程序 “假装”(Assume) 这个角色, 这样它就有了这个角色的权限, 一个 IAM Role 可以让很多程序一起假装, 不过要想假装 Role 的话, 必须得是 AWS 里的资源才行, 这是当然的, 像上面第三个例子, 公网的设备想访问我们的存储资源, 首先要通过 API Gateway, 由 API Gateway 来完成这个假装动作.
+
+## Users
+
+在 AWS 里,一个 IAM user 和 unix 下的一个用户几乎等价。你可以创建任意数量的用户,为其分配登录 AWS management console 所需要的密码,以及使用 AWS CLI(或其他使用 AWS SDK 的应用)所需要的密钥。你可以赋予用户管理员的权限,使其能够任意操作 AWS 的所有服务,也可以依照 Principle of least privilege,只授权合适的权限。下面是使用 AWS CLI 创建一个用户的示例:
+
+```
+saws> aws iam create-user --user-name tyrchen
+{
+ "User": {
+ "CreateDate": "2015-11-03T23:05:05.353Z",
+ "Arn": "arn:aws:iam:::user/tyrchen",
+ "UserName": "tyrchen",
+ "UserId": "AIDAISBVIGXYRRQLDDC3A",
+ "Path": "/"
+ }
+}
+```
+
+当然,这样创建的用户是没有任何权限的,甚至无法登录,你可以用下面的命令进一步为用户关联群组,设置密码和密钥:
+
+```
+saws> aws iam add-user-to-group --user-name --group-name
+saws> aws iam create-login-profile --user-name --password
+saws> aws iam create-access-key --user-name
+```
+
+IAM User 创建了之后, 就可以将这个实体给到某个员工让他使用, 第一次给员工时可能是将用户名和初始密码告知他, 员工登陆后可以自行修改密码. 这里用户名 + 密码就是这个 IAM User 的认证信息 (Credentials), 不过 Credentials 可不光是只有用户名 + 密码这一种形式, 还可以是 Access Key ID + Secret Acces Key 的形式, 更进一步的, 还可以是 MFA 的形式. 用户名 + 密码一般用于员工认为登陆 AWS Console 界面, Access Key 则一般用于 AWS CLI, 用户脚本这种程序访问方式. 用户或者程序通过提供 Credentials 来向 AWS IAM 证明自己, 获得合法身份 (Identity), IAM 根据这个身份来做进一步的权限审查.
+
+
+
+## Groups
+
+群组(groups)也等同于常见的 unix group。将一个用户添加到一个群组里,可以自动获得这个群组所具有的权限。在一家小的创业公司里,其 AWS 账号下可能会建立这些群组:
+
+- Admins:拥有全部资源的访问权限
+- Devs:拥有大部分资源的访问权限,但可能不具备一些关键性的权限,如创建用户
+- Ops:拥有部署的权限
+- Stakeholders:拥有只读权限,一般给 manager 查看信息之用
+
+还需要为其添加 policy:
+
+`saws> aws iam attach-group-policy --group-name --policy-arn`
+
+在前面的例子和这个例子里,我们都看到了 ARN 这个关键字。ARN 是 Amazon Resource Names 的缩写,在 AWS 里,创建的任何资源有其全局唯一的 ARN。ARN 是一个很重要的概念,它是访问控制可以到达的最小粒度。在使用 AWS SDK 时,我们也需要 ARN 来操作对应的资源。
+
+
+
+群组中授权增加、删除或者修改时,这些变更都会适用于所有用户。有些时候最好不要将授权直接分配给用户。
+
+## Roles
+
+角色(roles)类似于用户,但没有任何访问凭证(密码或者密钥),它一般被赋予某个资源(包括用户)
+
+role都是短期凭证。
+
+
+
+对于非人的程序, 一般的实践则是创建 IAM Role, 然后令这程序 “假装”(Assume) 这个角色, 这样它就有了这个角色的权限, 一个 IAM Role 可以让很多程序一起假装, 不过要想假装 Role 的话, 必须得是 AWS 里的资源才行
+
+
+
+Credentials 就是认证信息,比如用户名+密码 或者AccessID + Secret Access Key等。
+
+在 Credentials 这一点上, IAM Role 和 IAM User 不同, 因为 IAM Role 没有 Credentials, 或者准确地说是没有固定的 Credentials, 实际上当假装一个角色来获得对某资源的访问权时, 临时的 Credentials 会被生成, 但这是 AWS IAM 底层的实现机理, 从用户这一面上从来不需要操心配置角色的 Credentials, 所以我们就可以按照角色没有 Credentials 来理解. 至于为什么角色没有 Credentials, 那是因为角色只能由 AWS 自身的其他资源所假装, 比如由 EC2, Lambda 来假装, 而当你已经取得了这些资源的操作权限时, 你实际上已经通过 IAM User 的用户名密码或者 Access Key 证明了自己的身份, 所以再假装某个角色的时候, 就不需要再证明身份了.
+
+虽然说我们部署在 EC2 里的程序, 一般是通过假装角色来获得对某资源的访问权限, 但是 AWS IAM 并不关心你创建的 IAM User 是给人用还是给程序用, 我们给程序创建一个 IAM User, 然后将其 Access Key 嵌到程序代码中令其获得对资源的访问权限也是可以的. 我们可以根据自己的场景灵活决定.
+
+
+
+场景
+
+1. 自己公司的员工想访问 AWS Console 查看所在项目组的基础设施
+ 1. AWS User. 可以通过Group管理。
+2. AWS 账户里的 EC2/Lambda 实例想访问同账户下的一台 RDS
+ 1. 给EC2添加Role。User也行,但要AK,SK啥的不方便
+3. 公网里用户的手机想要访问我们的后端存储(借助 API Gateway)
+ 1. 借助API Gateway, 给它加Role
+
+
+
+AWS IAM 并不关心你创建的 IAM User 是给人用还是给程序用。
+
+
+
+另外 角色也可以给User, 但基本都是使用角色进行跨账户访问。 系统管理员可以创建角色,在一个账户中授权给用户,可以在另一个账户中访问资源。
+
+
+
+那权限挂在User上还是角色上?可以看下面这个例子。角色不该轻易给User。
+
+一个用户可能在应用中将数据存储到AWS S3 bucket中。为了保护应用数据的完整性,用户并没有被给予授权来直接对bucket进行编写。在这样的例子中,在运行应用的AWS EC2实例中使用角色将有助于分配授权。
+
+
+
+一个lambda or 一个ecs只能有一个执行角色。可以lambda里的configration里看到。除了这个执行角色添加policy,也可以assume成其它role,但一次只能assume成一个。可以通过API手动切换。
+
+
+
+## Root User
+
+Root 账号是你第一次配置账号的时候创建的,它拥有完全的 Admin aceess
+
+新 User 刚创建时是没有权限的。
+
+AWS 官方建议 root 用户的唯一用途, 就是[用来创建你的第一个 IAM 用户](https://link.zhihu.com/?target=https%3A//docs.aws.amazon.com/IAM/latest/UserGuide/best-practices.html%23lock-away-credentials), 把这第一个 IAM 用户设置为管理员, 然后以后的工作都用这个管理员用户来进行.
+
+
+
+## 策略 policy document
+
+AWS 下的权限都通过 policy document 描述
+
+IAM 策略可以直接附加到用户、组或角色上。
+
+policy 是用 JSON 来描述的,主要包含 Statement,也就是这个 policy 拥有的权限的陈述,一言以蔽之,即:**谁**在什么**条件**下能对哪些**资源**的哪些**操作**进行**处理**。也就是所谓的撰写 policy 的**PARCE**原则:
+
+- Principal:谁 主体指代一个用户、角色或 AWS 服务,这些主体可以请求访问 AWS 资源。
+- Action:哪些操作
+- Resource:哪些资源
+- Condition:什么条件
+- Effect:怎么处理(Allow/Deny)
+
+
+
+一个 IAM policy 包含一个或多个 JSON 对象,每个对象都包含一个 policy 的名称和一个 policy 的定义。这个定义通常包含了一个或多个 Statement 对象,每个 Statement 定义了一组操作、资源和条件,以及授予或拒绝这些操作的效果。**看起来,其实就是一个策略是多个json文件,每个json文件就下面有一个Version这样的json。**
+
+
+
+下面讲讲 policy 的执行规则,它也是几乎所有访问控制方案的通用规则:
+
+- 默认情况下,一切资源的一切行为的访问都是 Deny
+- 如果在 policy 里显式 Deny,则最终的结果是 Deny
+- 否则,如果在 policy 里是 Allow,则最终结果是 Allow
+- 否则,最终结果是 Deny
+
+
+
+我们看一个允许对 S3 进行只读操作的 policy:
+
+```
+{
+ "Version": "2012-10-17",
+ "Statement": [
+ {
+ "Effect": "Allow",
+ "Action": [
+ "s3:Get*",
+ "s3:List*"
+ ],
+ "Resource": "*"
+ }
+ ]
+}
+```
+
+其中,Effect 是 Allow,允许 policy 中所有列出的权限,Resource 是`*`,代表任意 S3 的资源,Action 有两个:`s3:Get*`和`s3:List*`,允许列出 S3 下的资源目录,及获取某个具体的 S3 Object。
+
+在这个 policy 里,Principal 和 Condition 都没有出现。如果对资源的访问没有任何附加条件,是不需要 Condition 的;而这条 policy 的使用者是用户相关的 principal(users, groups, roles),当其被添加到某个用户身上时,自然获得了 principal 的属性,所以这里不必指明,也不能指明。
+
+
+
+policy支持variable. 允许用户在 policy 里使用 AWS 预置的一些变量,比如`${aws:username}`。 可以实现用户只能访问S3自己文件夹这样的能力。
+
+一个角色可以attach多个policy。
+
+
+
+## 信任策略
+
+> A want to assume as B. 信任策略加在B上。
+
+在AWS中,当实体A需要访问某些资源,但没有直接访问这些资源的权限时,可以通过Assume Role操作来获取一个临时凭证,该凭证赋予实体A访问资源的权限。在这种情况下,实体A必须信任另一个实体B,以便它可以Assume Role操作,并且只有在实体B的策略允许时,才能访问资源。
+
+
+
+此时A的信任关系里有B。B有个assumeRole的policy。信任关系决定了谁可以assume成它。
+
+总之,IAM的信任关系是AWS中的一种授权机制,用于允许一个实体代表另一个实体访问资源,并确保只有授权的实体可以访问这些资源。
+
+
+
+## AssumeRole policy配置
+
+> A want to assume as B. assume policy加在A上。
+>
+> 所以实际上,A和B都需要加,一个是policy,一个是信任策略的policy. refer: https://nelson.cloud/aws-iam-allowing-a-role-to-assume-another-role/
+
+AssumeRole 权限是一种 IAM 权限,用于授予 IAM 实体(如 IAM 用户或角色)调用 `AssumeRole` API 的权限。通过调用 `AssumeRole` API,实体可以获取其他 IAM 角色的权限并扮演该角色,从而访问该角色可访问的 AWS 资源。
+
+
+
+**使用场景**
+
+1. 跨账户访问资源:AssumeRole 可以用于授予一个 AWS 账户中的 IAM 实体(如 IAM 用户或角色)访问另一个 AWS 账户中的资源的权限。
+2. 使用跨服务角色:如果您在一个服务中运行了一个应用程序,该应用程序需要访问另一个 AWS 服务中的资源,但是您不想直接授予该应用程序访问该服务的权限,可以使用 AssumeRole 为应用程序创建一个跨服务角色。该角色可以通过 AssumeRole API 访问该服务,并且您可以在角色策略中限制访问该服务的权限。
+
+
+
+[参考](https://nelson.cloud/aws-iam-allowing-a-role-to-assume-another-role/)
+
+同账号
+
+- B增加trust relationship即可
+
+不同账号
+
+- B增加trust relationship
+- A增加policy。
+
+
+
+一次至多只能assume成一个角色,只能调用api来assume。
+
+
+
+## Best Practices
+
+每年的[ AWS re:invent ](https://reinvent.awsevents.com/)大会,都会有一个 session:Top 10 AWS IAM Best Practices,感兴趣的读者可以去[ YouTube 搜索](https://www.youtube.com/results?search_query=Top+10+AWS+IAM+Best+Practices)。[ 2015 年的 top 10(top 11)](https://www.youtube.com/watch?v=_wiGpBQGCjU)如下:
+
+1. users: create individual users
+2. permissions: Grant least priviledge
+3. groups: manage permissions with groups
+4. conditions: restrict priviledged access further with conditions
+5. auditing: enable cloudTrail to get logs of API calls
+6. password: configure a strong password policy
+7. rotate: rotate security credentials regularly.
+8. MFA: enable MFA (Multi-Factor Authentication) for priviledged users
+9. sharing: use IAM roles to share access
+10. roles: use IAM roles for EC2 instances
+11. root: reduce or remove use of root
+
+这 11 条 best practices 很清晰,我就不详细解释了。
+
+按照上面的原则,如果一个用户只需要访问 AWS management console,那么不要为其创建密钥;反之,如果一个用户只使用 AWS CLI,则不要为其创建密码。一切不必要的,都是多余的——这就是安全之道。
+
+
+
+一个由来已久的信息安全原则就是用户应该且只能拥有他们执行的职责的授权。这也就是最小授权原则,旨在最小化可信用户对于信息系统产生的不利影响。
+
+在授权给群组时,也应该使用最小授权。只授权给有需要的群组的成员。如果一些群组成员需要额外的授权,然后创建额外的群组,并为他们分配额外的授权。需要额外授权的用户可以分配到这两个群组中。IAM群组和角色可以让系统管理员按需为用户和应用授权。
+
+
+
+## 总结
+
+- 定义群组管理类似的用户。用户都是需要密码等认证的。
+
+- 用户上没有policy,都通过群组管理
+
+- 定义角色保护应用,比如只想某EC2访问,就给EC2加角色,而不是加User上。
+
+- 角色比User的一个好处就是不需要认证信息,因为本身就是AWS自带认证信息。所以给非人的资源一般都是角色。当然EC2也可以是User,访问时需要AK,SK啥的,不如角色方便。
+
+- 角色分给User目的就是使用角色进行跨账户访问。
+
+- User的credential 两种: 用户名+密码, ak+sk。角色不需要这类东西,自己天然就带了,像psm一样。
+
+- IAM策略可以分配给AWS账号、IAM用户、IAM组、IAM角色等AWS资源。
+
+- cdk里ecs要发sns,需要给ecs授权。cdk里可以把sns topic传入ecs,然后把ecs service那个role(只有1个),grant相应权限即可。一个EC2只能有一个执行角色。
+
+- 让另一个aws账号的sqs订阅当前账号的sns加权限时,可以直接给另一个aws account加权限。sns有access policy
+
+- 账号A的ddb暴露给账号b的服务c,可以账号A里创建一个角色,然后创建一个Policy, grant c the role.即principle是c。
+
+- 一个lambda只能有一个执行角色,不能同时有多个。但可以通过assumeAPI手动切换,意味着每次都切换因此不合理。所以直接操作执行角色授予权限就行,可以IAM里配置执行角色assume成其他。
+
+- 一个 IAM 角色可以通过 AssumeRole API 来同时 assume 多个角色,从而获取这些角色的权限。这种做法称为角色链 (Role chaining)。直接看上面AssumeRole部分。
+
+- SQS access policy如果只有一个Id,那就是defaultPolicy。Amazon SQS 默认的访问策略(access policy)不包含任何明确的权限规则,它允许任何 AWS 账户中的任何用户对队列进行读写操作。但注意,lambda执行角色还需要添加消费的权限,例如,为 Lambda 函数执行角色添加`AmazonSQSFullAccess`策略。相当于权限都是两方的,两个都需要愿意才行。
+
+
+
+许多 AWS 服务都支持单独的执行角色,这些角色允许服务执行操作而不需要使用您的 AWS 凭证。以下是一些支持单独执行角色的常见 AWS 服务:
+
+- Amazon EC2:实例角色
+- AWS Lambda:执行角色
+- Amazon ECS:任务角色
+- Amazon EKS:服务角色
+- Amazon S3:存储桶策略
+- Amazon SQS:队列策略
+- Amazon SNS:主题策略
+- Amazon Kinesis Data Streams:流策略
+- Amazon RDS:实例角色
+- Amazon Redshift:集群 IAM 角色
+
+这些执行角色通常是与 AWS Identity and Access Management (IAM) 配合使用的,它们允许您授予 AWS 服务和资源执行所需操作的最小权限,从而提高安全性和可管理性。此外,许多服务还提供了自定义权限策略,以便您更精细地控制执行角色的权限。
+
+
+
+
+
+## 参考
+
+- [AWS 系列:深入了解 IAM 和访问控制](https://www.infoq.cn/article/aws-iam-dive-in)
+
+- [AWS IAM 深入理解](https://zhuanlan.zhihu.com/p/432934574)
\ No newline at end of file
diff --git a/_posts/Tech/AWS/2023-02-10-AWS Cloudformation And CDK.md b/_posts/Tech/AWS/2023-02-10-AWS Cloudformation And CDK.md
new file mode 100644
index 0000000000..1029d6d231
--- /dev/null
+++ b/_posts/Tech/AWS/2023-02-10-AWS Cloudformation And CDK.md
@@ -0,0 +1,149 @@
+---
+layout: post
+category: AWS
+title: AWS Cloudformation And CDK
+tags: AWS
+---
+
+# AWS Cloudformation
+
+cloudFormation以yaml文本的形式记录下一个应用涉及到的各个服务资源配置,放在一个template里面。迁移到不同的region时,只需要一键run coudFormation template, 就可以部署好所有的AWS资源。
+
+也叫AWS 堆栈
+
+## 为什么使用 CloudFormation?
+
+**基础设施即代码:**CloudFormation 使我们只用一个步骤就可以创建一个“资源堆栈”。资源是我们创建的东西(EC2 实例、VPC、子网等等),一组这样的资源称为堆栈。我们可以编写一个模板,使用它可以很容易地按照我们的意愿通过一个步骤创建一个网络堆栈。这比通过管理控制台或 CLI 手动创建网络更快,而且可重复,一致性更好。我们可以将模板签入源代码控制,并在任何时候根据需要把它用于任何目的。
+
+
+
+**可升级:**我们可以通过修改 CloudFormation 模板来修改网络堆栈,然后根据修改后的模板修改堆栈。CloudFormation 足够智能,可以通过修改堆栈来匹配模板。
+
+
+
+**可重用**:我们可以重用这个模板,在不同时期、不同区域创建多个不用用途的网络。
+
+
+
+**漂移检测:**CloudFormation 有一个新特性(截止到 2018 年 11 月),可以让我们知道资源是否已经“漂移”出了最初的配置。这可能发生在管理员手动更改资源时,这通常不是成熟的组织所鼓励的做法。
+
+
+
+**用完即弃:**我们很容易在用完之后把堆栈删除。
+
+
+
+## 使用
+
+CloudFormation 支持 JSON 或 YAML,我们将使用后者。主要原因是:1)句法不那么讲究,2)能够在工作中添加注释
+
+比如一个[VPC示例](https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-ec2-vpc.html)
+
+然后AWS控制台。 登录,选择任何区域。在菜单中找到 CloudFormation,如果需要的话,使用搜索功能。登入后,点击“创建堆栈”。选择“上传你自己的模板”选项,然后单击“下一步”。就可以创建堆栈了,还可以看到事件和资源。
+
+这些事件将显示你的 VPC 是在什么时候创建的,以及它是在什么时候成功创建的。当堆栈中的最后一个资源被创建时,堆栈的状态将更改为已成功创建。
+
+有一个重要的概念需要注意,如果在创建堆栈时遇到任何错误,整个堆栈(所有资源)将回滚。这种行为可以被重写,但通常这样就行!通常情况下,从头开始执行每一步要容易得多。
+
+如果堆栈失败,它仍然会显示在堆栈列表中,即使堆栈中没有资源。这样做是为了给你时间来调查错误。确定问题后,使用“删除堆栈”操作。
+
+## 参考
+
+- [AWS CloudFormation简介](https://juejin.cn/post/7122039768124227614)
+
+- [如何使用 CloudFormation 构建 VPC(第一部分)](https://www.infoq.cn/article/hsaedm*2we5jmh9tfjeg)
+
+# CDK
+
+ AWS **Cloud Development Kit**
+
+
+
+The AWS Cloud Development Kit (CDK) provides some of the same benefits of CloudFormation but with a few key differences.
+
+The CDK is an infrastructure-as-code solution that you can use with several popular programming languages. In other words, it's like CloudFormation, but using a language you already know. The CDK also contains command line tools to create infrastructure-as-code templates and to instantiate, update, and tear down stacks.
+
+
+
+CDK和Cloud Formation很像,但一个区别是它可以用自己知道的一个语言,比如typescript来写这样。
+
+CDK 把 CloudFormation 抽象了一层。它使用 TypeScript 等程序语言,把 CloudFormation 的模板包装成了一个领域专用语言(domain-specific language),CDK 的编译器会把这个语言再转译成 CloudFormation 模板。
+
+CDK更好用。但底层实际也是CloudFormation。
+
+
+
+CDK 教程: [官网](https://aws.amazon.com/cn/getting-started/guides/setup-cdk/module-three/?trk=31aeab24-3bd8-472c-a670-df09849e33f8&sc_channel=el)
+
+**cdk deploy** 命令会将您的 TypeScript 编译为 JavaScript,同时创建一个 CloudFormation 更改集来部署此更改。
+
+
+
+## CDK教程
+
+### cdk命令
+
+```scala
+cdk diff compare deployed stack with current state 将指定的堆栈及其依赖关系与已部署的堆栈或本地 CloudFormation 模板进行比较
+
+cdk deploy 命令会将您的 TypeScript 编译为 JavaScript,同时创建一个 CloudFormation 更改集来部署此更改。 deploy this stack to your default AWS account/region
+
+cdk synth emits the synthesized CloudFormation template
+cdk init --language typescript
+cdk list (ls) 列出应用程序中的堆栈
+```
+
+cdk bootstrp只有在用一些kms等特殊资源时才有用
+
+
+
+
+
+自定义ts主要在lib文件夹中。
+
+## 基础设施
+
+
+
+在深入探讨代码的编写之前,我们需要解释和安装 **[AWS CDK 构造库模块](https://docs.aws.amazon.com/cdk/api/v2/docs/aws-construct-library.html)**。 构造可以代表单个 AWS 资源,例如 Amazon Simple Storage Service(Amazon S3)存储桶,也可以是由多个 AWS 相关资源组成的更高级别的抽象。 AWS 构造库由几个模块组成。 对于本教程,我们需要 Amazon EC2 模块,该模块中还包括对 Amazon VPC 的支持。
+
+要安装 Amazon EC2 模块,我们将使用 **npm**。 在项目目录中运行以下命令:
+
+```bash
+npm install @aws-cdk/aws-ec2
+```
+
+该命令安装所有必需的模块。如果查看您的 **package.json** 文件,就会看到该文件也添加到此处。
+
+
+
+事例code
+
+```scala
+import * as cdk from 'aws-cdk-lib';
+import { Construct } from 'constructs';
+import * as ec2 from 'aws-cdk-lib/aws-ec2';
+// import * as sqs from 'aws-cdk-lib/aws-sqs';
+
+export class CdkDemoStack extends cdk.Stack {
+ constructor(scope: Construct, id: string, props?: cdk.StackProps) {
+ super(scope, id, props);
+
+ // The code that defines your stack goes here
+ // We have created the VPC object from the VPC class
+ new ec2.Vpc(this, 'mainVPC', {
+ // This is where you can define how many AZs you want to use
+ maxAzs: 2,
+ // This is where you can define the subnet configuration per AZ
+ subnetConfiguration: [
+ {
+ cidrMask: 24,
+ name: 'public-subnet',
+ subnetType: ec2.SubnetType.PUBLIC,
+ }
+ ]
+ });
+ }
+}
+```
+
diff --git "a/_posts/Tech/Algorithms/2018-01-18-\345\210\206\346\236\220\346\227\266\351\227\264\345\244\215\346\235\202\345\272\246.md" "b/_posts/Tech/Algorithms/2018-01-18-\345\210\206\346\236\220\346\227\266\351\227\264\345\244\215\346\235\202\345\272\246.md"
index 85488e17cd..4025af158b 100644
--- "a/_posts/Tech/Algorithms/2018-01-18-\345\210\206\346\236\220\346\227\266\351\227\264\345\244\215\346\235\202\345\272\246.md"
+++ "b/_posts/Tech/Algorithms/2018-01-18-\345\210\206\346\236\220\346\227\266\351\227\264\345\244\215\346\235\202\345\272\246.md"
@@ -20,8 +20,6 @@ T(n) = n^klogn if k==log(b)a
[递归的时间复杂度分析](https://blog.csdn.net/qq_36582604/article/details/81661236)
-
-
我们先看下面这个例子

@@ -30,8 +28,6 @@ T(n) = n^klogn if k==log(b)a
-
-
[归并排序时间复杂度分析](https://blog.csdn.net/qq_32534441/article/details/95098059)
```
@@ -39,7 +35,7 @@ T(n)=2*T(n/2)+n
第一层n, 第二层2*(n/2), 第三层4*(n/4), 每层都有个n,高度Logn
```
-[合并k个链表的时间复杂度分析](https://blog.csdn.net/qq_22080999/article/details/80669993)
+[合并 k 个链表的时间复杂度分析](https://blog.csdn.net/qq_22080999/article/details/80669993)
分治的话:
@@ -49,45 +45,42 @@ T(kn) = 2T(k/2*n) + kn
高度log2(k),每层累加都是kn, 因此最终是log2(k) * kn
```
-方法1:暴力,k个链表按顺序合并
+方法 1:暴力,k 个链表按顺序合并
时间复杂度:
(n+n)+(2n+n)+...+ ((k-1)n + n) = (1+2+...+k-1)n + (k-1)n = (1+2+...+k-1+k)n -n = (k^2+k-1)/2*n = O(k^2*n)
-方法2:将k*n个结点放到vector,再将vector排序,再将结点顺序相连
+方法 2:将 k\*n 个结点放到 vector,再将 vector 排序,再将结点顺序相连
-设有K个链表,平均每个链表有n个结点,时间复杂度:
+设有 K 个链表,平均每个链表有 n 个结点,时间复杂度:
kN*logkN +kN = O(kN*logkN)
-方法3:对k个链表进行分治,两两进行合并
+方法 3:对 k 个链表进行分治,两两进行合并
-设有k个链表,平均每个链表有n个结点,时间复杂度:
+设有 k 个链表,平均每个链表有 n 个结点,时间复杂度:
-第一轮:进行k/2次,每次处理2n个数字
+第一轮:进行 k/2 次,每次处理 2n 个数字
-第2轮,进行k/4次,每次处理4n个数字
+第 2 轮,进行 k/4 次,每次处理 4n 个数字
...
-最后一次,进行k/(2^logk)次,每次处理2^logk*n个数
-
-2n*k/2+...+2^logk*n * k/(2^logk)
-
+最后一次,进行 k/(2^logk)次,每次处理 2^logk\*n 个数
+2n*k/2+...+2^logk*n \* k/(2^logk)
## 常见算法时间复杂度
时间复杂度总结:
-prim o(e+vlogv), 主要是优先队列top v次,每次log(v), 然后边遍历总计2e.
+prim o(e+vlogv), 主要是优先队列 top v 次,每次 log(v), 然后边遍历总计 2e.
kruskal o(eloge), 主要是边的排序耗时上。
-dijsktra o(e+vlogv), 边总计e, 优先队列取了v次,每次top log(v), 这里指的斐波那契堆,该堆insert 为o(1),其他和二叉堆一致。
-
-floyd wallshal, o(n3)
+dijsktra o(e+vlogv), 边总计 e, 优先队列取了 v 次,每次 top log(v), 这里指的斐波那契堆,该堆 insert 为 o(1),其他和二叉堆一致。
-bellman-ford, o(ve), 每个边松弛一次,共循环v次,o(ve);
+floyd wallshal, o(n3)
+bellman-ford, o(ve), 每个边松弛一次,共循环 v 次,o(ve);
diff --git "a/_posts/Tech/Algorithms/2018-03-13-\345\212\250\346\200\201\350\247\204\345\210\222\344\271\213\345\205\254\345\205\261\345\255\220\345\272\217\345\210\227\345\255\220\344\270\262.md" "b/_posts/Tech/Algorithms/2018-03-13-\345\212\250\346\200\201\350\247\204\345\210\222\344\271\213\345\205\254\345\205\261\345\255\220\345\272\217\345\210\227\345\255\220\344\270\262.md"
index 4913182da9..f941661942 100644
--- "a/_posts/Tech/Algorithms/2018-03-13-\345\212\250\346\200\201\350\247\204\345\210\222\344\271\213\345\205\254\345\205\261\345\255\220\345\272\217\345\210\227\345\255\220\344\270\262.md"
+++ "b/_posts/Tech/Algorithms/2018-03-13-\345\212\250\346\200\201\350\247\204\345\210\222\344\271\213\345\205\254\345\205\261\345\255\220\345\272\217\345\210\227\345\255\220\344\270\262.md"
@@ -1,7 +1,7 @@
---
layout: post
category: Algorithms
-title: 动态规划之公共子序列子串
+title: 动态规划之公共子序列/子串/前缀
tags: Algorithms
---
@@ -183,3 +183,23 @@ public class LCString {
}
```
+
+## 最长前缀LCP Longest common prefix
+
+求两个字符串任意两个位置开头的最长公共前缀。时间复杂度o(n2) 如果是暴力需要o(n3) 枚举i,j然后到头。
+
+
+
+```scala
+class Strings:
+ def LongestCommonPrefix(a, b):
+ # lcp[i][j] 表示 s[i:] 和 s[j:] 的最长公共前缀
+ n, m = len(a), len(b)
+ lcp = [[0] * (m + 1) for _ in range(n + 1)]
+ for i in range(n - 1, -1, -1):
+ for j in range(m - 1, -1, -1):
+ if a[i] == b[j]:
+ lcp[i][j] = lcp[i + 1][j + 1] + 1
+ return lcp
+```
+
diff --git "a/_posts/Tech/Algorithms/2018-03-13-\345\233\236\346\272\257\346\263\225\345\222\214\346\216\222\345\210\227\347\273\204\345\220\210.md" "b/_posts/Tech/Algorithms/2018-03-13-\345\233\236\346\272\257\346\263\225\345\222\214\346\216\222\345\210\227\347\273\204\345\220\210.md"
index ff312327cc..ca30800030 100644
--- "a/_posts/Tech/Algorithms/2018-03-13-\345\233\236\346\272\257\346\263\225\345\222\214\346\216\222\345\210\227\347\273\204\345\220\210.md"
+++ "b/_posts/Tech/Algorithms/2018-03-13-\345\233\236\346\272\257\346\263\225\345\222\214\346\216\222\345\210\227\347\273\204\345\220\210.md"
@@ -259,27 +259,28 @@ int main() {
[the link](https://leetcode.com/problems/subsets/)
-```java
-public List> subsets(int[] nums) {
- List> list = new ArrayList<>();
- Arrays.sort(nums);
- backtrack(list, new ArrayList<>(), nums, 0);
- return list;
-}
+```python
+class Solution:
+ def subsets(self, nums: List[int]) -> List[List[int]]:
+ res = []
+ def backtrack(nums, start, tempList: List[int], res):
+ res.append(tempList.copy())
+ for i in range(start, len(nums)):
+ tempList.append(nums[i])
+ backtrack(nums, i + 1, tempList, res)
+ tempList.pop()
+ return
+
+
+ backtrack(nums, 0, [], res)
+ print(res)
+ return res
-private void backtrack(List> list , List tempList, int [] nums, int start){
- list.add(new ArrayList<>(tempList));
- for(int i = start; i < nums.length; i++){
- tempList.add(nums[i]);
- backtrack(list, tempList, nums, i + 1);
- tempList.remove(tempList.size() - 1);
- }
-}
```
#### 有重复
-[the link]( https://leetcode.com/problems/subsets-ii/)
+[the link]( https://leetcode.cn/problems/subsets-ii/)
```
[
@@ -294,23 +295,24 @@ private void backtrack(List> list , List tempList, int []
这个注意是有duplicate的,所以要注意
-```java
-public List> subsetsWithDup(int[] nums) {
- List> list = new ArrayList<>();
- Arrays.sort(nums);
- backtrack(list, new ArrayList<>(), nums, 0);
- return list;
-}
+```python
+class Solution:
+ def subsetsWithDup(self, nums: List[int]) -> List[List[int]]:
+ def backtrack(nums, start, tempList: List[int], res):
+ res.append(tempList.copy())
+ for i in range(start, len(nums)):
+ if i > start and nums[i] == nums[i-1]:
+ continue
+ tempList.append(nums[i])
+ backtrack(nums, i + 1, tempList, res)
+ tempList.pop()
+ return
-private void backtrack(List> list, List tempList, int [] nums, int start){
- list.add(new ArrayList<>(tempList));
- for(int i = start; i < nums.length; i++){
- if(i > start && nums[i] == nums[i-1]) continue; // skip duplicates
- tempList.add(nums[i]);
- backtrack(list, tempList, nums, i + 1);
- tempList.remove(tempList.size() - 1);
- }
-}
+ nums.sort()
+ res = []
+ backtrack(nums, 0, [], res)
+ print(res)
+ return res
```
也可以设置visit数组
diff --git "a/_posts/Tech/Algorithms/2018-08-01-\351\230\237\345\210\227\345\222\214\346\240\210.md" "b/_posts/Tech/Algorithms/2018-08-01-\351\230\237\345\210\227\345\222\214\346\240\210.md"
index af863894ef..ef2859e924 100644
--- "a/_posts/Tech/Algorithms/2018-08-01-\351\230\237\345\210\227\345\222\214\346\240\210.md"
+++ "b/_posts/Tech/Algorithms/2018-08-01-\351\230\237\345\210\227\345\222\214\346\240\210.md"
@@ -165,4 +165,13 @@ class Solution:
-类似题目: [394. 字符串解码](https://leetcode-cn.com/problems/decode-string/)
\ No newline at end of file
+类似题目: [394. 字符串解码](https://leetcode-cn.com/problems/decode-string/)
+
+
+
+
+
+给定入栈顺序,求某个出栈顺序。
+
+1. [6202. 使用机器人打印字典序最小的字符串](https://mafulong.github.io/2022/10/09/6202.-%E4%BD%BF%E7%94%A8%E6%9C%BA%E5%99%A8%E4%BA%BA%E6%89%93%E5%8D%B0%E5%AD%97%E5%85%B8%E5%BA%8F%E6%9C%80%E5%B0%8F%E7%9A%84%E5%AD%97%E7%AC%A6%E4%B8%B2/)
+2. [栈的压入、弹出序列](https://mafulong.github.io/2018/10/20/%E6%A0%88%E7%9A%84%E5%8E%8B%E5%85%A5-%E5%BC%B9%E5%87%BA%E5%BA%8F%E5%88%97/)
\ No newline at end of file
diff --git "a/_posts/Tech/algorithms/2018-08-13-\346\254\247\346\213\211\345\233\236\350\267\257.md" "b/_posts/Tech/Algorithms/2018-08-13-\346\254\247\346\213\211\350\267\257\345\276\204.md"
similarity index 87%
rename from "_posts/Tech/algorithms/2018-08-13-\346\254\247\346\213\211\345\233\236\350\267\257.md"
rename to "_posts/Tech/Algorithms/2018-08-13-\346\254\247\346\213\211\350\267\257\345\276\204.md"
index 6b221feac6..3e19382e31 100644
--- "a/_posts/Tech/algorithms/2018-08-13-\346\254\247\346\213\211\345\233\236\350\267\257.md"
+++ "b/_posts/Tech/Algorithms/2018-08-13-\346\254\247\346\213\211\350\267\257\345\276\204.md"
@@ -1,14 +1,16 @@
---
layout: post
category: Algorithms
-title: 欧拉回路
+title: 欧拉路径
tags: Algorithms
---
## 欧拉回路定义及判断
-如果能从图的某一顶点出发,每条边恰好经过一次,这样的路线称为欧拉道路(Eulerian Path)。
+如果能从图的某一顶点出发,每条边恰好经过一次,这样的路线称为**欧拉道路(Eulerian Path)。也叫欧拉路径**
+
+如果每条边恰好经过一次,且能回到起点,这样的路线称为**欧拉回路**(Eulerian Circuit)。
+
-如果每条边恰好经过一次,且能回到起点,这样的路线称为欧拉回路(Eulerian Circuit)。
对于无向图G,当且仅当G 是连通的,且最多有两个奇点,则存在欧拉道路。
@@ -22,7 +24,7 @@ tags: Algorithms
- 通过图中所有边恰好一次且行遍所有顶点的通路称为欧拉通路。
- 通过图中所有边恰好一次且行遍所有顶点的回路称为欧拉回路。
-- 具有欧拉回路的无向图称为欧拉图。
+- **具有欧拉回路的无向图称为欧拉图。**
- 具有欧拉通路但不具有欧拉回路的无向图称为半欧拉图。
@@ -41,6 +43,10 @@ tags: Algorithms
给定一个 *n* 个点 *m* 条边的图,要求从指定的顶点出发,经过所有的边恰好一次(可以理解为给定起点的「一笔画」问题)其实就是求欧拉路径。
+如果在有欧拉回路中的图,它就求的是欧拉回路。如果非欧拉回路的图就是欧拉路径。
+
+
+
Hierholzer 算法用于在连通图中寻找欧拉路径,其流程如下:[参考](https://leetcode-cn.com/problems/reconstruct-itinerary/solution/zhong-xin-an-pai-xing-cheng-by-leetcode-solution/)
@@ -70,11 +76,17 @@ def dfs(u):
stack = stack[::-1]
```
+以上是求点的路径。 有向图还是无向图都没关系,无向图就变两个有向的边就行。
+
+
+
+如果是求边路径,pop后进入stack即可。
+
## 相关题目
-- [332. 重新安排行程](https://leetcode-cn.com/problems/reconstruct-itinerary/)
-- [753. 破解保险箱](https://leetcode-cn.com/problems/cracking-the-safe/) 求锁所有密码,就是抽象出多个节点,然后求欧拉回路.
+- [332. 重新安排行程](https://leetcode-cn.com/problems/reconstruct-itinerary/) 求欧拉路径 点的顺序
+- [753. 破解保险箱](https://leetcode-cn.com/problems/cracking-the-safe/) 求锁所有密码,就是抽象出多个节点,然后求欧拉路径.
- [5932. 合法重新排列数对](https://leetcode-cn.com/problems/valid-arrangement-of-pairs/)
diff --git "a/_posts/Tech/Algorithms/2021-01-25-\345\215\232\345\274\210\350\256\272.md" "b/_posts/Tech/Algorithms/2021-01-25-\345\215\232\345\274\210\350\256\272.md"
index 2273a453fe..b86928dd25 100644
--- "a/_posts/Tech/Algorithms/2021-01-25-\345\215\232\345\274\210\350\256\272.md"
+++ "b/_posts/Tech/Algorithms/2021-01-25-\345\215\232\345\274\210\350\256\272.md"
@@ -3,6 +3,7 @@ layout: post
category: Algorithms
title: 博弈论
tags: Algorithms
+recent_update: true
---
## 博弈论
diff --git "a/_posts/Tech/Algorithms/2021-03-11-\344\270\221\346\225\260.md" "b/_posts/Tech/Algorithms/2021-03-11-\344\270\221\346\225\260.md"
deleted file mode 100644
index b28798fa3a..0000000000
--- "a/_posts/Tech/Algorithms/2021-03-11-\344\270\221\346\225\260.md"
+++ /dev/null
@@ -1,57 +0,0 @@
----
-layout: post
-category: Algorithms
-title: 丑数
-tags: Algorithms
----
-
-## 丑数
-
-[[剑指 Offer 49. 丑数](https://leetcode-cn.com/problems/chou-shu-lcof/)
-
-[313. 超级丑数](https://leetcode-cn.com/problems/super-ugly-number/)
-
-### 使用优先队列
-
-```python
-class Solution:
- def nthSuperUglyNumber(self, n: int, primes: List[int]) -> int:
- import heapq
- hq = [1]
- res = []
- for _ in range(n):
- top = heapq.heappop(hq)
- res.append(top)
- while hq and hq[0] == top:
- heapq.heappop(hq)
- for k in primes:
- heapq.heappush(hq, top * k)
- print(res)
- return res[-1]
-```
-
-
-
-### 使用多指针
-
-```c++
-//cpp:
-class Solution {
-public://别人的代码就是精简,惭愧啊,继续学习。
- int GetUglyNumber_Solution(int index) {
- if (index < 7)return index;
- vector res(index);
- res[0] = 1;
- int t2 = 0, t3 = 0, t5 = 0, i;
- for (i = 1; i < index; ++i)
- {
- res[i] = min(res[t2] * 2, min(res[t3] * 3, res[t5] * 5));
- if (res[i] == res[t2] * 2)t2++;
- if (res[i] == res[t3] * 3)t3++;
- if (res[i] == res[t5] * 5)t5++;
- }
- return res[index - 1];
- }
-};
-```
-
diff --git "a/_posts/Tech/Algorithms/2021-03-11-\345\244\232\350\267\257\345\275\222\345\271\266 \344\270\221\346\225\260.md" "b/_posts/Tech/Algorithms/2021-03-11-\345\244\232\350\267\257\345\275\222\345\271\266 \344\270\221\346\225\260.md"
new file mode 100644
index 0000000000..bbf460d84d
--- /dev/null
+++ "b/_posts/Tech/Algorithms/2021-03-11-\345\244\232\350\267\257\345\275\222\345\271\266 \344\270\221\346\225\260.md"
@@ -0,0 +1,124 @@
+---
+layout: post
+category: Algorithms
+title: 多路归并 丑数
+tags: Algorithms
+---
+
+[找第k小及变种,个人另一篇博客,内容有重合](https://mafulong.github.io/2022/01/03/%E6%89%BE%E7%AC%ACk%E5%B0%8F%E5%8F%8A%E5%8F%98%E7%A7%8D/)
+
+
+
+## 丑数
+
+[[剑指 Offer 49. 丑数](https://leetcode-cn.com/problems/chou-shu-lcof/)
+
+
+
+### 使用优先队列
+
+```python
+class Solution:
+ def nthSuperUglyNumber(self, n: int, primes: List[int]) -> int:
+ import heapq
+ hq = [1]
+ res = []
+ for _ in range(n):
+ top = heapq.heappop(hq)
+ res.append(top)
+ while hq and hq[0] == top:
+ heapq.heappop(hq)
+ for k in primes:
+ heapq.heappush(hq, top * k)
+ print(res)
+ return res[-1]
+```
+
+
+
+### 使用多指针
+
+```c++
+//cpp:
+class Solution {
+public:/
+ int GetUglyNumber_Solution(int index) {
+ if (index < 7)return index;
+ vector res(index);
+ res[0] = 1;
+ int t2 = 0, t3 = 0, t5 = 0, i;
+ for (i = 1; i < index; ++i)
+ {
+ res[i] = min(res[t2] * 2, min(res[t3] * 3, res[t5] * 5));
+ if (res[i] == res[t2] * 2)t2++;
+ if (res[i] == res[t3] * 3)t3++;
+ if (res[i] == res[t5] * 5)t5++;
+ }
+ return res[index - 1];
+ }
+};
+```
+
+多路归并。
+
+## 超级丑数
+
+不只2,3,5
+
+
+
+[313. 超级丑数](https://leetcode-cn.com/problems/super-ugly-number/)
+
+```python
+class Solution:
+ def nthSuperUglyNumber(self, n: int, primes: List[int]) -> int:
+ import heapq
+ hpush, hpop = heapq.heappush,heapq.heappop
+ h = []
+ for i in range(len(primes)):
+ hpush(h, (primes[i], i, 0))
+ ans = [1]
+ for i in range(1,n):
+ if not h:
+ return -1
+ val = h[0][0]
+ ans.append(val)
+ while h and h[0][0] == val:
+ _,j,idx = hpop(h)
+ # print(idx,ans)
+ hpush(h, (ans[idx]*primes[j], j, idx+1))
+ return ans[-1]
+
+
+```
+
+
+
+## 其它多路归并
+
+- [373. 查找和最小的K对数字](https://mafulong.github.io/2022/01/03/373.-%E6%9F%A5%E6%89%BE%E5%92%8C%E6%9C%80%E5%B0%8F%E7%9A%84K%E5%AF%B9%E6%95%B0%E5%AD%97/) 给定两个以升序排列的整数数组 `nums1` 和 `nums2` , 以及一个整数 `k` 。定义一对值 `(u,v)`,其中第一个元素来自 `nums1`,第二个元素来自 `nums2` 。请找到和最小的 `k` 个数对 `(u1,v1)`, ` (u2,v2)` ... `(uk,vk)` 。
+
+```python
+class Solution:
+ def kSmallestPairs(self, nums1: List[int], nums2: List[int], k: int) -> List[List[int]]:
+ # equal with 多路链表归并,用heap取最小那个,然后移动指针,也就是超级丑数
+ # 性能o(klog(k))
+ import heapq
+ h = []
+ for j in range(min(len(nums2),k)):
+ heapq.heappush(h, (nums1[0]+nums2[j], 0, j))
+ res = []
+ while k > 0 and h:
+ _,i,j = heapq.heappop(h)
+ res.append([nums1[i], nums2[j]])
+ if i+1 < len(nums1):
+ heapq.heappush(h, (nums1[i+1]+nums2[j], i+1,j))
+ k-=1
+ return res
+```
+
+
+
+- [有序矩阵的 Kth Element](https://leetcode-cn.com/problems/kth-smallest-element-in-a-sorted-matrix/description/)
+ - 多路归并
+ - 二分法更优。
diff --git "a/_posts/Tech/Algorithms/2021-06-21-\345\215\225\350\260\203\351\230\237\345\210\227\345\222\214\345\215\225\350\260\203\346\240\210.md" "b/_posts/Tech/Algorithms/2021-06-21-\345\215\225\350\260\203\351\230\237\345\210\227\345\222\214\345\215\225\350\260\203\346\240\210.md"
index ceae6d6f9c..ef926ee344 100644
--- "a/_posts/Tech/Algorithms/2021-06-21-\345\215\225\350\260\203\351\230\237\345\210\227\345\222\214\345\215\225\350\260\203\346\240\210.md"
+++ "b/_posts/Tech/Algorithms/2021-06-21-\345\215\225\350\260\203\351\230\237\345\210\227\345\222\214\345\215\225\350\260\203\346\240\210.md"
@@ -96,6 +96,48 @@ class Solution:
求左边右边, 最小的大于等于arr[i]的位置,一种方式是sortedList, 一种方式是sorted(range(N), lambda x:arr[x])
+### 最大宽度 最大上升坡
+
+求最大坡度, 坡度定义: i < j 且 A[i] <= A[j]。这样的坡的宽度为 j - i。找每个元素比它大的最后一个位置
+可以按https://leetcode.cn/submissions/detail/208988818/ 中,按val对range(n)排序,o(nlogn),此时对排序位置i的元素最大坡度就是右边最大j。此时右边元素都不小于当前元素。
+
+```python
+class Solution:
+ def maxWidthRamp(self, nums: List[int]) -> int:
+ ans = 0
+ m = float('inf')
+ for i in sorted(range(len(nums)), key=lambda x: nums[x]):
+ ans = max(ans, i - m)
+ m = min(m, i)
+ return ans
+```
+
+也可以单调栈o(n)求,先求正序递减栈,然后倒序枚举,如果比栈顶大,则栈顶元素后续就无用可pop了
+
+```python
+
+class Solution:
+ def maxWidthRamp(self, nums: List[int]) -> int:
+ ans = 0
+ stack = []
+ for i, v in enumerate(nums):
+ if not stack or v < nums[stack[-1]]:
+ stack.append(i)
+ # print(stack)
+ for i in range(len(nums) - 1, -1, -1):
+ while stack and nums[i] >= nums[stack[-1]]:
+ ans = max(ans, i - stack.pop())
+ return ans
+
+```
+
+
+
+类似题目:
+
+- [1124. 表现良好的最长时间段](https://leetcode.cn/problems/longest-well-performing-interval/) 先转化成+1,-1的list,然后求前缀和的最长坡度,要求`a[i] < a[j]` 。解法和上面一致。
+
+
## 单调队列
@@ -146,4 +188,3 @@ class Solution:
- [862. 和至少为 K 的最短子数组](https://leetcode-cn.com/problems/shortest-subarray-with-sum-at-least-k/) 求前缀和,对前缀和队列递增,求最大差值。
-
diff --git "a/_posts/Tech/Algorithms/2021-08-12-\345\233\236\346\226\207.md" "b/_posts/Tech/Algorithms/2021-08-12-\345\233\236\346\226\207.md"
index e782af0844..ce69a52ac5 100644
--- "a/_posts/Tech/Algorithms/2021-08-12-\345\233\236\346\226\207.md"
+++ "b/_posts/Tech/Algorithms/2021-08-12-\345\233\236\346\226\207.md"
@@ -9,7 +9,7 @@ tags: Algorithms
-#### Manacher 算法
+#### Manacher 算法
给你一个字符串 `s`,找到 `s` 中最长的回文子串。
@@ -19,8 +19,12 @@ tags: Algorithms
这里边长0表示a,边长1表示aaa
-```
- n = len(s)
+```python
+ '''
+ 须先变为回文皆奇数长度, 可提前转换: s1 = '#' + '#'.join(list(s)) + '#'
+ '''
+
+ n = len(s)
arm_len = [0] * n
def expand(left, right):
@@ -42,6 +46,23 @@ tags: Algorithms
right = i + arm_len[i]
```
+时间复杂度o(n).
+
+
+
+根据以上得到的arm_len 判断某个子串是不是回文。
+
+```python
+ def is_palindrome(s, i, j, armlen):
+ mid = (i + j) // 2 # 前半部分或中间
+ # 找中心点,然后对应到s1上
+ t = 2 * mid + 1
+ if (j - i + 1) % 2 == 0:
+ t += 1
+ return armlen[t] >= j - i + 1
+
+```
+
## 回文技巧
@@ -49,3 +70,10 @@ tags: Algorithms
DP:
- 用 P(i,j) 表示字符串 s 的第 i到 j 个字母组成的串(下文表示成 s[i:j])是否为回文串 . 变成区间dp
+
+
+
+## 应用
+
+- [647. 回文子串](https://leetcode.cn/problems/palindromic-substrings/) 给你一个字符串 `s` ,请你统计并返回这个字符串中 **回文子串** 的数目。1.中心扩展o(n2), 2. manacher o(n)
+- [6236. 不重叠回文子字符串的最大数目](https://leetcode.cn/problems/maximum-number-of-non-overlapping-palindrome-substrings/) 实际是dp,判断s(i,j)是不是回文。
diff --git "a/_posts/Tech/Algorithms/2021-09-08-\347\212\266\346\200\201\345\216\213\347\274\251.md" "b/_posts/Tech/Algorithms/2021-09-08-\347\212\266\346\200\201\345\216\213\347\274\251.md"
index ea30e809e2..85843010a6 100644
--- "a/_posts/Tech/Algorithms/2021-09-08-\347\212\266\346\200\201\345\216\213\347\274\251.md"
+++ "b/_posts/Tech/Algorithms/2021-09-08-\347\212\266\346\200\201\345\216\213\347\274\251.md"
@@ -3,6 +3,7 @@ layout: post
category: Algorithms
title: 状态压缩
tags: Algorithms
+recent_update: true
---
## 状态压缩
diff --git a/_posts/Tech/Algorithms/2021-12-05-BFS.md b/_posts/Tech/Algorithms/2021-12-05-BFS.md
index d5097a7ac7..ffd0c10075 100644
--- a/_posts/Tech/Algorithms/2021-12-05-BFS.md
+++ b/_posts/Tech/Algorithms/2021-12-05-BFS.md
@@ -11,29 +11,22 @@ tags: Algorithms
- 在append时检查visit标记和设置visit标记
- 只能解决长度为1的问题
-```
-const visited = {}
-function bfs() {
- let q = new Queue()
- q.push(初始状态)
- while(q.length) {
- let i = q.pop()
- if (visited[i]) continue
- for (i的可抵达状态j) {
- if (j 合法) {
- q.push(j)
- }
- }
- }
- // 找到所有合法解
-}
-```
+
+
+也可以在queue pop时再check 是否visit和标记visit,时间复杂度加边数。
+
+
题目:
- [求最少转弯的路径](https://mafulong.github.io/2018/08/27/bfs%E6%9C%80%E5%B0%8F%E8%BD%AC%E5%BC%AF%E8%B7%AF%E5%BE%84/) 每次转弯时加1
- [126. 单词接龙 II](https://leetcode.cn/problems/word-ladder-ii/) 输入所有bfs路径,层次遍历 + dfs回溯pre.
+## 从外向内扩展
+
+- [407. 接雨水 II](https://leetcode.cn/problems/trapping-rain-water-ii/) 从外向内dijkstra。
+- [417. 太平洋大西洋水流问题](https://leetcode.cn/problems/pacific-atlantic-water-flow/) 从外向内bfs/dfs。
+
## 双向BFS
> [双向bfs模板参考](https://leetcode-cn.com/problems/open-the-lock/solution/gong-shui-san-xie-yi-ti-shuang-jie-shuan-wyr9/)
diff --git "a/_posts/Tech/Algorithms/2021-12-23-\344\270\200\350\207\264\346\200\247hash.md" "b/_posts/Tech/Algorithms/2021-12-23-\344\270\200\350\207\264\346\200\247hash.md"
index 8b0b8fa32a..cf90d17eaa 100644
--- "a/_posts/Tech/Algorithms/2021-12-23-\344\270\200\350\207\264\346\200\247hash.md"
+++ "b/_posts/Tech/Algorithms/2021-12-23-\344\270\200\350\207\264\346\200\247hash.md"
@@ -5,6 +5,8 @@ title: 一致性hash
tags: Algorithms
---
+# 一致性hash
+
## 一致性hash
1. 首先,我们将hash算法的值域映射成一个具有232 次方个桶的空间中,即0~(232)-1的数字空间。现在我们可以将这些数字头尾相连,组合成一个闭合的环形。
@@ -104,4 +106,44 @@ class HashSeverMgr(object):
## 参考
- [一致性 hash 原理及实现(python 版)](https://xie.infoq.cn/article/e7182d18df48bc26eeb30b207)
-- [图解一致性hash算法和实现](https://aijishu.com/a/1060000000007241)
\ No newline at end of file
+- [图解一致性hash算法和实现](https://aijishu.com/a/1060000000007241)
+
+## 补充
+
+增加节点/删除节点都需要先执行挪数据这个操作,如果没这个操作,可能会读空,但读空范围因为一致性hash的存在,导致影响有限,对于缓存应该是没关系的,如果是持久化的就需要备份,不能让读空。
+
+
+
+# hash slot
+
+集群:
+是一个提供多个Redis(分布式)节点间共享数据的程序集。
+集群部署
+Redis 集群的键空间被分割为 16384 hash个槽(slot), 集群的最大节点数量也是 16384 个
+
+分片:
+ Redis Cluster在设计中没有使用一致性哈希(Consistency Hashing),而是使用数据分片引入哈希槽(hash slot)来实现;
+
+一个 Redis Cluster包含16384(0~16383)即2^14个哈希槽,存储在Redis Cluster中的所有键都会被映射到这些slot中,集群中的每个键都属于这16384个哈希槽中的一个,集群使用公式slot=CRC16(key)/16384来计算key属于哪个槽,其中CRC16(key)语句用于计算key的CRC16 校验和。
+
+
+
+这种结构很容易添加或者删除节点. 比如如果我想新添加个节点D, 我需要从节点 A, B, C中得部分槽到D上. 如果我像移除节点A,需要将A中得槽移到B和C节点上,然后将没有任何槽的A节点从集群中移除即可. 由于从一个节点将哈希槽移动到另一个节点并不会停止服务, 所**以无论添加删除或者改变某个节点的哈希槽的数量都不会造成集群不可用的状态.**
+
+
+
+数据迁移
+数据迁移可以理解为slot(槽)和key的迁移,这个功能很重要,极大地方便了集群做线性扩展,以及**实现平滑的扩容或缩容。**
+
+
+
+
+
+和一致性哈希相比
+
+1. 它并不是闭合的,key的定位规则是**根据CRC-16(key)%16384的值来判断属于哪个槽区,从而判断该key属于哪个节点**,而一致性哈希是根据hash(key)的值来顺时针找第一个hash(ip)的节点,从而确定key存储在哪个节点。
+2. 一致性哈希是创建虚拟节点来实现节点宕机后的数据转移并保证数据的安全性和集群的可用性的, 当节点不可用时,分摊给多个其他节点,因为虚节点的存在。redis cluster是采用master节点有多个slave节点机制来保证数据的完整性的,master节点写入数据,slave节点同步数据。当master节点挂机后,slave节点会通过选举机制选举出一个节点变成master节点,实现高可用。但是这里有一点需要考虑,如果master节点存在热点缓存,某一个时刻某个key的访问急剧增高,这时该mater节点可能操劳过度而死,随后从节点选举为主节点后,同样宕机,一次类推,造成缓存雪崩即热点缓存问题。
+
+
+
+两者都是要挪数据的!
\ No newline at end of file
diff --git "a/_posts/Tech/Algorithms/2022-05-01-\346\225\260\345\255\246.md" "b/_posts/Tech/Algorithms/2022-05-01-\346\225\260\345\255\246.md"
index d776a249c9..487b8959fe 100644
--- "a/_posts/Tech/Algorithms/2022-05-01-\346\225\260\345\255\246.md"
+++ "b/_posts/Tech/Algorithms/2022-05-01-\346\225\260\345\255\246.md"
@@ -5,8 +5,6 @@ title: 数学
tags: Algorithms
---
-
-
## 排列组合
> [参考](https://baike.baidu.com/item/%E6%8E%92%E5%88%97%E7%BB%84%E5%90%88/706498)
@@ -19,8 +17,64 @@ tags: Algorithms

+
+
+另外 C(0,0) = 1, 0 的为 1。
+
+组合数性质
+
+
+
+### 大组合数求解边模
+
+利用组合数性质. o(n2)
+
+```python
+ def comb_mod(self, n, m, mod=10 ** 9 + 7):
+ '''
+ 大组合数计算C(n,m),边求边mod, 利用组合数性质C(n,m) = 1*C(n-1,m-1) + C(n-1,m)
+ '''
+ dp = [[0 for _ in range(n+1)] for _ in range(n+1)]
+ dp[0][0] = 1
+ for i in range(1, n+1):
+ dp[i][0] = 1
+ for j in range(1, i+1):
+ dp[i][j] = (dp[i-1][j-1] + dp[i-1][j]) % mod
+ return dp[n][m]
+
+```
+
+组合数求和公式
+
+
+
+
+
+### python中排列组合
+
+```python
+ # 组合
+ math.comb # n! / (k! * (n - k)!)
+ math.perm # n! / (n - k)!
+
+```
+
+
+
+
+
+### 求组合数 小球放盒子
+
+> [参考2](https://www.luogu.com.cn/blog/chengni5673/dang-xiao-qiu-yu-shang-he-zi)
+
+默认问题为 n 个小球放到 m 个盒子里,题型共有三项要求,球是否相同,盒子是否相同,能否有空盒。
+
+- 球相同,盒子不同,不能有空盒。 实质就是把 n 个小球分为 m 组。插板法。 `C(n-1,m-1)`
+- 球相同,盒子不同,可以有空盒。对于每个盒子,我们都给他一个球,那么上一个问题就和这问题一样了,所以我们可以看做自己有 n+m 个小球,然后我们在排列完之后在每一组都删去一个小球,这样就能枚举出有空盒的情况了。`C(n+m-1,m-1)`
+- 其他复杂情况看参考。
+
## 等差等比数列
> [参考](https://wenku.baidu.com/view/0c5e350102020740be1e9b79.html)
@@ -29,20 +83,18 @@ tags: Algorithms
 -
-
## 复杂的复杂度计算
### 幂函数和对数函数和指数函数对比
-
-

### 调和级数

+这里有用到: [link](https://leetcode.cn/problems/number-of-different-subsequences-gcds/solution/ji-bai-100mei-ju-gcdxun-huan-you-hua-pyt-get7/)
+
### 二项式定理

@@ -53,16 +105,20 @@ tags: Algorithms
## 中位数
-在一步操作中,你可以使数组中的一个元素加 `1` 或者减 `1` ,所有数都靠近**中位数**可使所有数组元素相等时移动数最少。 相关题目: [最少移动次数使数组元素相等 II](https://leetcode-cn.com/problems/minimum-moves-to-equal-array-elements-ii/)
+在一步操作中,你可以使数组中的一个元素加 `1` 或者减 `1` ,所有数都靠近**中位数**可使所有数组元素相等时移动数最少。 相关题目: [最少移动次数使数组元素相等 II](https://leetcode-cn.com/problems/minimum-moves-to-equal-array-elements-ii/)
+即中位数到所有数距离和最小,如果是偶数,可以在中位数两侧的数据构成的区间内任意取值,对结果无影响证明:
+
+
+另一个相似题目:有cost,需转化拆分,然后再算中位数,[6216. 使数组相等的最小开销](https://mafulong.github.io/2022/10/23/6216.-%E4%BD%BF%E6%95%B0%E7%BB%84%E7%9B%B8%E7%AD%89%E7%9A%84%E6%9C%80%E5%B0%8F%E5%BC%80%E9%94%80/)
## 素数
-### 判断是否素数和求1-n的素数求某数的素数
+### 判断是否素数 o(sqrt(N))
```python
-# 判断某数是否是素数
+# 判断某数是否是素数 o(sqrt(n))
def is_prime(a):
if a <= 1: return False
import math
@@ -71,7 +127,16 @@ def is_prime(a):
return True
-# 求1-n每个数的素数,以下时间复杂度O(n) 朴素筛法
+```
+
+### 求 1-n 的所有素数 筛法 o(N)
+
+#### 埃氏筛法
+
+```python
+# 求1-n每个数的素数,以下时间复杂度O(nloglogn) 接近o(n)
+# 如果我们从小到大考虑每个数,然后同时把当前这个数的所有(比自己大的)倍数记为合数,那么运行结束的时候没有被标记的数就是素数了。
+# Eratosthenes 筛法(埃拉托斯特尼筛法,简称埃氏筛法)
def get_all_prime(n):
a = [False] * n
res = []
@@ -82,21 +147,31 @@ def get_all_prime(n):
for j in range(2 * i, n, i):
a[j] = True
return res
+```
-# 求某数的质因数列表,比如8,是[(2,3)], 6是[(2,1),(3,1)]
-def calcu(a):
- counter = collections.Counter()
- prime = get_all_prime(a + 1)
- for p in prime:
- while a % p == 0:
- counter[p] += 1
- a /= p
- return counter.items()
+#### **线性筛法** 也称为 **Euler 筛法**(欧拉筛法)
+
+埃氏筛法仍有优化空间,它会将一个合数重复多次标记。有没有什么办法省掉无意义的步骤呢?答案是肯定的。
+
+如果能让每个合数都只被标记一次,那么时间复杂度就可以降到 o(n)了。
+
+```python
+def get_all_prime(n):
+ a = [False] * n
+ res = []
+ for i in range(2, n):
+ if a[i]: continue
+ # a[i]是素数
+ res.append(i)
+ for j in range(2 * i, n, i):
+ if a[j]: break # 多了个这行
+ a[j] = True
+ return res
```
## 平方数
-[先看Cyc2018](http://www.cyc2018.xyz/%E7%AE%97%E6%B3%95/Leetcode%20%E9%A2%98%E8%A7%A3/Leetcode%20%E9%A2%98%E8%A7%A3%20-%20%E6%95%B0%E5%AD%A6.html#_1-%E5%B9%B3%E6%96%B9%E6%95%B0)
+[先看 Cyc2018](http://www.cyc2018.xyz/%E7%AE%97%E6%B3%95/Leetcode%20%E9%A2%98%E8%A7%A3/Leetcode%20%E9%A2%98%E8%A7%A3%20-%20%E6%95%B0%E5%AD%A6.html#_1-%E5%B9%B3%E6%96%B9%E6%95%B0)
### 生成所有平方数
@@ -106,8 +181,6 @@ def calcu(a):
间隔为等差数列,使用这个特性可以得到从 1 开始的平方序列。
-
-
### 3 的 n 次方
[Power of Three (Easy)](https://leetcode-cn.com/problems/power-of-three/description/)
@@ -118,33 +191,114 @@ public boolean isPowerOfThree(int n) {
}
```
-## 因数
+## 除法
+
+```python
+ # b % a == 0
+ # 表示b能被a整除,a可以整除b, 被除数永远都是有这个『被』
+```
+
+表示b能被a整除,a可以整除b, 被除数永远都是有这个『被』
+
+
+
+大整数除法,除法中取模。
+
+## 有负数的除法求模 不同语言可能不同
+
+比如a 除以 b,求对应商和余数。不同语言可能不同
+
+计算-7 Mod 4
+
+那么:a = -7;b = 4;
+
+第一步:求整数商c,c应该是-1.75,如进行求模运算c = -2(向负无穷方向舍入),求余运算则c = -1(向0方向舍入);
+
+第二步:计算模和余数的公式相同,但因c的值不同,求模时r = 1,求余时r = -3。
+
+ 当符号不一致时,结果不一样。求模运算结果的符号和b一致,求余运算结果的符号和a一致。
+
+在C/C++, C#, JAVA, PHP这几门主流语言中,%运算符都是做取余运算,而在python中的%是做取模运算。
+
+
+
+**python求商是向负无穷靠近,而其他是靠近0.**
+
+## 因数理论
### 素数分解
-每一个数都可以分解成素数的乘积,例如 84 = 22 * 31 * 50 * 71 * 110 * 130 * 170 * …
+每一个数都可以分解成素数的乘积,例如 84 = 22 _ 31 _ 50 _ 71 _ 110 _ 130 _ 170 \* …
### 整除
-令 x = 2m0 * 3m1 * 5m2 * 7m3 * 11m4 * …
+令 x = 2m0 _ 3m1 _ 5m2 _ 7m3 _ 11m4 \* …
-令 y = 2n0 * 3n1 * 5n2 * 7n3 * 11n4 * …
+令 y = 2n0 _ 3n1 _ 5n2 _ 7n3 _ 11n4 \* …
如果 x 整除 y(y mod x == 0),则对于所有 i,mi <= ni。
-### 最大公约数最小公倍数
+### 最大公约数最小公倍数的素数表示
+
+每个质因数的乘积
+
+x 和 y 的最大公约数为:gcd(x,y) = 2min(m0,n0) _ 3min(m1,n1) _ 5min(m2,n2) \* ...
+
+x 和 y 的最小公倍数为:lcm(x,y) = 2max(m0,n0) _ 3max(m1,n1) _ 5max(m2,n2) \* ...
+
+### 约数个数和约数之和
+
+如果 N = p1^c1 _ p2^c2 _ ... _pk^ck
+约数个数: (c1 + 1) _ (c2 + 1) _ ... _ (ck + 1)
+约数之和: (p1^0 + p1^1 + ... + p1^c1) _ ... _ (pk^0 + pk^1 + ... + pk^ck)
-x 和 y 的最大公约数为:gcd(x,y) = 2min(m0,n0) * 3min(m1,n1) * 5min(m2,n2) * ...
-x 和 y 的最小公倍数为:lcm(x,y) = 2max(m0,n0) * 3max(m1,n1) * 5max(m2,n2) * ...
-### 求质因数和对应计数
+## 因数相关问题
-o(n)近似
+### 试除法求所有约数:
+
+#### 求一个数的因子列表 o(sqrt(n))
+
+o(sqrt(n))
+
+```python
+divisors = []
+d = 1
+while d * d <= k: # 预处理 k 的所有因子
+ if k % d == 0:
+ divisors.append(d)
+ if d * d < k: # 避免 d= k/d的情况,此时如果append会重复
+ divisors.append(k / d)
+ d += 1
+```
+
+#### 统计 1-n 每个数的因子列表 o(nlogn)
+
+o(nlogn)
+
+```python
+MX = 100001
+divisors = [[] for _ in range(MX)] # 每个value就是key的因子列表,乘积肯定>value,因为因子之间可能有倍数
+for i in range(1, MX): # 预处理每个数的所有因子,时间复杂度 O(MlogM),M=1e5
+ for j in range(i, MX, i):
+ divisors[j].append(i)
+```
+
+### 分解质因数
+
+#### 求某数质因数列表 o(sqrt(N))
+
+o(sqrt(N))
+
+求某数的质因数列表,比如 8,是[2,2,2]
+
+枚举[2, sqrt(n)+1), 如果是质因数,就接着除,最大大于 1,它本身就是质数。
+
+也叫 求欧拉函数
```python
# 求质因数列表
-# Python Version
def breakdown(N):
result = []
from math import sqrt
@@ -158,76 +312,248 @@ def breakdown(N):
return result
```
-### 统计1-n每个数的因子列表
+#### 统计 1-n 每个数的质因数列表
-o(nlogn)
+筛法求欧拉函数
+
+类似,暂时不写。
+
+### gcd 求最大公约数和最小公倍数 欧几里得算法
+
+欧几里得算法
```python
-MX = 100001
-divisors = [[] for _ in range(MX)] # 每个value就是key的因子列表,乘积肯定>value,因为因子之间可能有倍数
-for i in range(1, MX): # 预处理每个数的所有因子,时间复杂度 O(MlogM),M=1e5
- for j in range(i, MX, i):
- divisors[j].append(i)
+class Math1:
+ def gcd(self, a, b):
+ if b == 0:
+ return a
+ return self.gcd(b, a % b)
```
-### 求一个数的因子列表
+最小公倍数就是 a\*b/gcd(a,b)
+
-o(sqrt(n))
+
+### gcd性质
+
+如果ax+by=1, 则gcd(x,y) = 1
+
+
+
+### 多个数求最大公约数和最小公倍数
+
+多个数的最大公约数:
```python
-divisors = []
-d = 1
-while d * d <= k: # 预处理 k 的所有因子
- if k % d == 0:
- divisors.append(d)
- if d * d < k: # 避免 d= k/d的情况,此时如果append会重复
- divisors.append(k / d)
- d += 1
+def gcd_list(self, nums):
+ import math
+ cur = nums[0]
+ for i in range(1, len(nums)):
+ cur = math.gcd(cur, nums[i])
+ return cur
```
-### gcd求最大公约数:
+多个数的最小公倍数:
-```c++
-int gcd(int a, int b) {
- return b == 0 ? a : gcd(b, a%b);
-}
+> 注意这里不是直接多个数乘积除以他们的gcd呀,而且不断一个一个加计算的。
-int gcd(int a, int b) {
- while (b != 0) {
- int t = a%b;
- a = b;
- b = t;
- }
- return a;
-}
+```python
+def lcm_list(self, nums):
+ import math
+ prod = 1
+ for v in nums:
+ prod = prod * v / math.gcd(prod, v)
+ return prod
+```
+
+### 1到n里有多少个数可整除a?
+
+```python
+n//a
```
-最小公倍数就是a*b/gcd(a,b)
+
+
+### 1到n里有多少个a的因数?
+
+[参考另一个博客](https://mafulong.github.io/2018/04/30/%E8%AE%A1%E7%AE%97n%E7%9A%84%E9%98%B6%E4%B9%98%E4%B8%AD%E6%9C%89%E5%A4%9A%E5%B0%91%E4%B8%AAk/)
+
+```python
+ def calcu(x,a):
+ '''
+ 1-x中有多少个因数a, 比如1-26里有5,10, 15, 20, 各自1个5, 5*5两个5,一共6个
+ '''
+ r = 0
+ while x:
+ # 贡献5的数量,贡献5*5的数量,贡献5*5*5的数量
+ r += x //a
+ x //= a
+ return r
+ print(calcu(26, 5))
+```
+
+
+
+## 大整数取模问题
+
+### 大数相乘取模
+
+```python
+ def prod(d=[], mod=10 ** 9 + 7):
+ r = d[0] % mod
+ for v in d[1:]:
+ r *= v
+ r %= mod
+ return r
+```
+
+
+
+### 大数相除取模 费马小定理
+
+如果a/b,然后a和b都是大数要取模,这时不能相乘取模来计算
+
+`(a/b)%c=(a%c)/(b%c)`是**不成立**的
+
+
+
+> [除法取模](https://leetcode.cn/problems/count-anagrams/solution/by-simpleson-crwb/)
+
+```python
+
+# 原: i//j%MOD
+# 现: i*modInverse(j)%MOD
+MOD = int(1e9 + 7)
+
+class BigIntDivide:
+ def mod_inverse(sefl, i):
+ # 调用取模的乘幂运算, pow复杂度是log(exp)即log(MOD)
+ return pow(i, MOD - 2, MOD)
+
+ def divide_mod(self, a, b):
+ '''
+ 计算(a/b) % MOD, 除法变乘法,前提是b和MOD互为质数
+ '''
+ # 如果有多个b,比如a/b1/b2, 那就可以递归。a*mod_inverse(b1) % mod * mod_inverse(b2) % mod这样
+ return a * self.mod_inverse(b) % MOD
+
+ def divide_mods(self, a, b=[]):
+ '''
+ 计算a /(b1*b2*b3) % MOD等形式,前提是b和MOD互为质数
+ '''
+ r = a % MOD
+ for i, v in enumerate(b):
+ r *= self.mod_inverse(v)
+ r %= MOD
+ return r
+
+
+```
+
+
+
+### 大数幂取模
+
+```python
+r = pow(base=2, exp=3, mod=3)
+print(r)
+```
+
+
+
+## 阶乘
+
+```python
+import math
+math.factorial(3)
+```
+
+
+
+## 分配问题
+
+### a能否分成满足条件的两份,其中只能分给指定一份
+
+[2513. 最小化两个数组中的最大值](https://leetcode.cn/problems/minimize-the-maximum-of-two-arrays/) 给你两个数组 arr1 和 arr2 ,它们一开始都是空的。你需要往它们中添加正整数,使它们满足以下条件:
+
+arr1 包含 uniqueCnt1 个 互不相同 的正整数,每个整数都 不能 被 divisor1 整除 。
+arr2 包含 uniqueCnt2 个 互不相同 的正整数,每个整数都 不能 被 divisor2 整除 。
+arr1 和 arr2 中的元素 互不相同 。
+给你 divisor1 ,divisor2 ,uniqueCnt1 和 uniqueCnt2 ,请你返回两个数组中 最大元素 的 最小值 。
+
+
+
+参考, [link](https://leetcode.cn/circle/discuss/YeBDQY/view/B8caF0/)
+
+**Key**: 判断过程中分为三类:保证在范围内有充足的数不是第一个数的倍数;不是第二个数的倍数;不为公倍数的数总数不少于总共要取的数。根据这三个条件即得到结果。
+
+## 位运算
+
+a xor b ==c 则 a = b xor c.
## 进制转换
```c++
- int a, b;
- vector
-
-
## 复杂的复杂度计算
### 幂函数和对数函数和指数函数对比
-
-

### 调和级数

+这里有用到: [link](https://leetcode.cn/problems/number-of-different-subsequences-gcds/solution/ji-bai-100mei-ju-gcdxun-huan-you-hua-pyt-get7/)
+
### 二项式定理

@@ -53,16 +105,20 @@ tags: Algorithms
## 中位数
-在一步操作中,你可以使数组中的一个元素加 `1` 或者减 `1` ,所有数都靠近**中位数**可使所有数组元素相等时移动数最少。 相关题目: [最少移动次数使数组元素相等 II](https://leetcode-cn.com/problems/minimum-moves-to-equal-array-elements-ii/)
+在一步操作中,你可以使数组中的一个元素加 `1` 或者减 `1` ,所有数都靠近**中位数**可使所有数组元素相等时移动数最少。 相关题目: [最少移动次数使数组元素相等 II](https://leetcode-cn.com/problems/minimum-moves-to-equal-array-elements-ii/)
+即中位数到所有数距离和最小,如果是偶数,可以在中位数两侧的数据构成的区间内任意取值,对结果无影响证明:
+
+
+另一个相似题目:有cost,需转化拆分,然后再算中位数,[6216. 使数组相等的最小开销](https://mafulong.github.io/2022/10/23/6216.-%E4%BD%BF%E6%95%B0%E7%BB%84%E7%9B%B8%E7%AD%89%E7%9A%84%E6%9C%80%E5%B0%8F%E5%BC%80%E9%94%80/)
## 素数
-### 判断是否素数和求1-n的素数求某数的素数
+### 判断是否素数 o(sqrt(N))
```python
-# 判断某数是否是素数
+# 判断某数是否是素数 o(sqrt(n))
def is_prime(a):
if a <= 1: return False
import math
@@ -71,7 +127,16 @@ def is_prime(a):
return True
-# 求1-n每个数的素数,以下时间复杂度O(n) 朴素筛法
+```
+
+### 求 1-n 的所有素数 筛法 o(N)
+
+#### 埃氏筛法
+
+```python
+# 求1-n每个数的素数,以下时间复杂度O(nloglogn) 接近o(n)
+# 如果我们从小到大考虑每个数,然后同时把当前这个数的所有(比自己大的)倍数记为合数,那么运行结束的时候没有被标记的数就是素数了。
+# Eratosthenes 筛法(埃拉托斯特尼筛法,简称埃氏筛法)
def get_all_prime(n):
a = [False] * n
res = []
@@ -82,21 +147,31 @@ def get_all_prime(n):
for j in range(2 * i, n, i):
a[j] = True
return res
+```
-# 求某数的质因数列表,比如8,是[(2,3)], 6是[(2,1),(3,1)]
-def calcu(a):
- counter = collections.Counter()
- prime = get_all_prime(a + 1)
- for p in prime:
- while a % p == 0:
- counter[p] += 1
- a /= p
- return counter.items()
+#### **线性筛法** 也称为 **Euler 筛法**(欧拉筛法)
+
+埃氏筛法仍有优化空间,它会将一个合数重复多次标记。有没有什么办法省掉无意义的步骤呢?答案是肯定的。
+
+如果能让每个合数都只被标记一次,那么时间复杂度就可以降到 o(n)了。
+
+```python
+def get_all_prime(n):
+ a = [False] * n
+ res = []
+ for i in range(2, n):
+ if a[i]: continue
+ # a[i]是素数
+ res.append(i)
+ for j in range(2 * i, n, i):
+ if a[j]: break # 多了个这行
+ a[j] = True
+ return res
```
## 平方数
-[先看Cyc2018](http://www.cyc2018.xyz/%E7%AE%97%E6%B3%95/Leetcode%20%E9%A2%98%E8%A7%A3/Leetcode%20%E9%A2%98%E8%A7%A3%20-%20%E6%95%B0%E5%AD%A6.html#_1-%E5%B9%B3%E6%96%B9%E6%95%B0)
+[先看 Cyc2018](http://www.cyc2018.xyz/%E7%AE%97%E6%B3%95/Leetcode%20%E9%A2%98%E8%A7%A3/Leetcode%20%E9%A2%98%E8%A7%A3%20-%20%E6%95%B0%E5%AD%A6.html#_1-%E5%B9%B3%E6%96%B9%E6%95%B0)
### 生成所有平方数
@@ -106,8 +181,6 @@ def calcu(a):
间隔为等差数列,使用这个特性可以得到从 1 开始的平方序列。
-
-
### 3 的 n 次方
[Power of Three (Easy)](https://leetcode-cn.com/problems/power-of-three/description/)
@@ -118,33 +191,114 @@ public boolean isPowerOfThree(int n) {
}
```
-## 因数
+## 除法
+
+```python
+ # b % a == 0
+ # 表示b能被a整除,a可以整除b, 被除数永远都是有这个『被』
+```
+
+表示b能被a整除,a可以整除b, 被除数永远都是有这个『被』
+
+
+
+大整数除法,除法中取模。
+
+## 有负数的除法求模 不同语言可能不同
+
+比如a 除以 b,求对应商和余数。不同语言可能不同
+
+计算-7 Mod 4
+
+那么:a = -7;b = 4;
+
+第一步:求整数商c,c应该是-1.75,如进行求模运算c = -2(向负无穷方向舍入),求余运算则c = -1(向0方向舍入);
+
+第二步:计算模和余数的公式相同,但因c的值不同,求模时r = 1,求余时r = -3。
+
+ 当符号不一致时,结果不一样。求模运算结果的符号和b一致,求余运算结果的符号和a一致。
+
+在C/C++, C#, JAVA, PHP这几门主流语言中,%运算符都是做取余运算,而在python中的%是做取模运算。
+
+
+
+**python求商是向负无穷靠近,而其他是靠近0.**
+
+## 因数理论
### 素数分解
-每一个数都可以分解成素数的乘积,例如 84 = 22 * 31 * 50 * 71 * 110 * 130 * 170 * …
+每一个数都可以分解成素数的乘积,例如 84 = 22 _ 31 _ 50 _ 71 _ 110 _ 130 _ 170 \* …
### 整除
-令 x = 2m0 * 3m1 * 5m2 * 7m3 * 11m4 * …
+令 x = 2m0 _ 3m1 _ 5m2 _ 7m3 _ 11m4 \* …
-令 y = 2n0 * 3n1 * 5n2 * 7n3 * 11n4 * …
+令 y = 2n0 _ 3n1 _ 5n2 _ 7n3 _ 11n4 \* …
如果 x 整除 y(y mod x == 0),则对于所有 i,mi <= ni。
-### 最大公约数最小公倍数
+### 最大公约数最小公倍数的素数表示
+
+每个质因数的乘积
+
+x 和 y 的最大公约数为:gcd(x,y) = 2min(m0,n0) _ 3min(m1,n1) _ 5min(m2,n2) \* ...
+
+x 和 y 的最小公倍数为:lcm(x,y) = 2max(m0,n0) _ 3max(m1,n1) _ 5max(m2,n2) \* ...
+
+### 约数个数和约数之和
+
+如果 N = p1^c1 _ p2^c2 _ ... _pk^ck
+约数个数: (c1 + 1) _ (c2 + 1) _ ... _ (ck + 1)
+约数之和: (p1^0 + p1^1 + ... + p1^c1) _ ... _ (pk^0 + pk^1 + ... + pk^ck)
-x 和 y 的最大公约数为:gcd(x,y) = 2min(m0,n0) * 3min(m1,n1) * 5min(m2,n2) * ...
-x 和 y 的最小公倍数为:lcm(x,y) = 2max(m0,n0) * 3max(m1,n1) * 5max(m2,n2) * ...
-### 求质因数和对应计数
+## 因数相关问题
-o(n)近似
+### 试除法求所有约数:
+
+#### 求一个数的因子列表 o(sqrt(n))
+
+o(sqrt(n))
+
+```python
+divisors = []
+d = 1
+while d * d <= k: # 预处理 k 的所有因子
+ if k % d == 0:
+ divisors.append(d)
+ if d * d < k: # 避免 d= k/d的情况,此时如果append会重复
+ divisors.append(k / d)
+ d += 1
+```
+
+#### 统计 1-n 每个数的因子列表 o(nlogn)
+
+o(nlogn)
+
+```python
+MX = 100001
+divisors = [[] for _ in range(MX)] # 每个value就是key的因子列表,乘积肯定>value,因为因子之间可能有倍数
+for i in range(1, MX): # 预处理每个数的所有因子,时间复杂度 O(MlogM),M=1e5
+ for j in range(i, MX, i):
+ divisors[j].append(i)
+```
+
+### 分解质因数
+
+#### 求某数质因数列表 o(sqrt(N))
+
+o(sqrt(N))
+
+求某数的质因数列表,比如 8,是[2,2,2]
+
+枚举[2, sqrt(n)+1), 如果是质因数,就接着除,最大大于 1,它本身就是质数。
+
+也叫 求欧拉函数
```python
# 求质因数列表
-# Python Version
def breakdown(N):
result = []
from math import sqrt
@@ -158,76 +312,248 @@ def breakdown(N):
return result
```
-### 统计1-n每个数的因子列表
+#### 统计 1-n 每个数的质因数列表
-o(nlogn)
+筛法求欧拉函数
+
+类似,暂时不写。
+
+### gcd 求最大公约数和最小公倍数 欧几里得算法
+
+欧几里得算法
```python
-MX = 100001
-divisors = [[] for _ in range(MX)] # 每个value就是key的因子列表,乘积肯定>value,因为因子之间可能有倍数
-for i in range(1, MX): # 预处理每个数的所有因子,时间复杂度 O(MlogM),M=1e5
- for j in range(i, MX, i):
- divisors[j].append(i)
+class Math1:
+ def gcd(self, a, b):
+ if b == 0:
+ return a
+ return self.gcd(b, a % b)
```
-### 求一个数的因子列表
+最小公倍数就是 a\*b/gcd(a,b)
+
-o(sqrt(n))
+
+### gcd性质
+
+如果ax+by=1, 则gcd(x,y) = 1
+
+
+
+### 多个数求最大公约数和最小公倍数
+
+多个数的最大公约数:
```python
-divisors = []
-d = 1
-while d * d <= k: # 预处理 k 的所有因子
- if k % d == 0:
- divisors.append(d)
- if d * d < k: # 避免 d= k/d的情况,此时如果append会重复
- divisors.append(k / d)
- d += 1
+def gcd_list(self, nums):
+ import math
+ cur = nums[0]
+ for i in range(1, len(nums)):
+ cur = math.gcd(cur, nums[i])
+ return cur
```
-### gcd求最大公约数:
+多个数的最小公倍数:
-```c++
-int gcd(int a, int b) {
- return b == 0 ? a : gcd(b, a%b);
-}
+> 注意这里不是直接多个数乘积除以他们的gcd呀,而且不断一个一个加计算的。
-int gcd(int a, int b) {
- while (b != 0) {
- int t = a%b;
- a = b;
- b = t;
- }
- return a;
-}
+```python
+def lcm_list(self, nums):
+ import math
+ prod = 1
+ for v in nums:
+ prod = prod * v / math.gcd(prod, v)
+ return prod
+```
+
+### 1到n里有多少个数可整除a?
+
+```python
+n//a
```
-最小公倍数就是a*b/gcd(a,b)
+
+
+### 1到n里有多少个a的因数?
+
+[参考另一个博客](https://mafulong.github.io/2018/04/30/%E8%AE%A1%E7%AE%97n%E7%9A%84%E9%98%B6%E4%B9%98%E4%B8%AD%E6%9C%89%E5%A4%9A%E5%B0%91%E4%B8%AAk/)
+
+```python
+ def calcu(x,a):
+ '''
+ 1-x中有多少个因数a, 比如1-26里有5,10, 15, 20, 各自1个5, 5*5两个5,一共6个
+ '''
+ r = 0
+ while x:
+ # 贡献5的数量,贡献5*5的数量,贡献5*5*5的数量
+ r += x //a
+ x //= a
+ return r
+ print(calcu(26, 5))
+```
+
+
+
+## 大整数取模问题
+
+### 大数相乘取模
+
+```python
+ def prod(d=[], mod=10 ** 9 + 7):
+ r = d[0] % mod
+ for v in d[1:]:
+ r *= v
+ r %= mod
+ return r
+```
+
+
+
+### 大数相除取模 费马小定理
+
+如果a/b,然后a和b都是大数要取模,这时不能相乘取模来计算
+
+`(a/b)%c=(a%c)/(b%c)`是**不成立**的
+
+
+
+> [除法取模](https://leetcode.cn/problems/count-anagrams/solution/by-simpleson-crwb/)
+
+```python
+
+# 原: i//j%MOD
+# 现: i*modInverse(j)%MOD
+MOD = int(1e9 + 7)
+
+class BigIntDivide:
+ def mod_inverse(sefl, i):
+ # 调用取模的乘幂运算, pow复杂度是log(exp)即log(MOD)
+ return pow(i, MOD - 2, MOD)
+
+ def divide_mod(self, a, b):
+ '''
+ 计算(a/b) % MOD, 除法变乘法,前提是b和MOD互为质数
+ '''
+ # 如果有多个b,比如a/b1/b2, 那就可以递归。a*mod_inverse(b1) % mod * mod_inverse(b2) % mod这样
+ return a * self.mod_inverse(b) % MOD
+
+ def divide_mods(self, a, b=[]):
+ '''
+ 计算a /(b1*b2*b3) % MOD等形式,前提是b和MOD互为质数
+ '''
+ r = a % MOD
+ for i, v in enumerate(b):
+ r *= self.mod_inverse(v)
+ r %= MOD
+ return r
+
+
+```
+
+
+
+### 大数幂取模
+
+```python
+r = pow(base=2, exp=3, mod=3)
+print(r)
+```
+
+
+
+## 阶乘
+
+```python
+import math
+math.factorial(3)
+```
+
+
+
+## 分配问题
+
+### a能否分成满足条件的两份,其中只能分给指定一份
+
+[2513. 最小化两个数组中的最大值](https://leetcode.cn/problems/minimize-the-maximum-of-two-arrays/) 给你两个数组 arr1 和 arr2 ,它们一开始都是空的。你需要往它们中添加正整数,使它们满足以下条件:
+
+arr1 包含 uniqueCnt1 个 互不相同 的正整数,每个整数都 不能 被 divisor1 整除 。
+arr2 包含 uniqueCnt2 个 互不相同 的正整数,每个整数都 不能 被 divisor2 整除 。
+arr1 和 arr2 中的元素 互不相同 。
+给你 divisor1 ,divisor2 ,uniqueCnt1 和 uniqueCnt2 ,请你返回两个数组中 最大元素 的 最小值 。
+
+
+
+参考, [link](https://leetcode.cn/circle/discuss/YeBDQY/view/B8caF0/)
+
+**Key**: 判断过程中分为三类:保证在范围内有充足的数不是第一个数的倍数;不是第二个数的倍数;不为公倍数的数总数不少于总共要取的数。根据这三个条件即得到结果。
+
+## 位运算
+
+a xor b ==c 则 a = b xor c.
## 进制转换
```c++
- int a, b;
- vector v;
- cin >> a >> b;
- while (a != 0) {
- v.push_back(a%b);
- a = a / b;
- }
+ def baseX(self, n, x):
+ '''
+ 进制转换,10进制变x进制
+ :return: 数组,每个数是该位上数
+ '''
+ ans = []
+ while n != 0:
+ n, b = divmod(n, x)
+ ans.append(b)
+ ans.reverse()
+ return ans
+
+ def base10(self, n=[], x=2):
+ '''
+ 从x进制转成10进制
+ '''
+ ans = 0
+ for v in n:
+ ans *= x
+ ans += v
+ return ans
```
-### 小数的进制转换
+### 负进制的转换
-[可以参考](https://blog.csdn.net/u013349653/article/details/51367453)
+[负二进制转换](https://leetcode.cn/problems/convert-to-base-2/)
+
+[个人blog 1017. 负二进制转换](https://mafulong.github.io/2023/04/08/1017.-%E8%B4%9F%E4%BA%8C%E8%BF%9B%E5%88%B6%E8%BD%AC%E6%8D%A2/) 可以任何负进制转换
+
+```python
+class Solution:
+ def baseNeg2(self, n: int) -> str:
+ if n == 0:
+ return '0'
+ ans = []
+ b = -2
+ while n != 0:
+ x = n % b
+ ans.append(str(abs(x)))
+ if x < 0:
+ x += abs(b) # 变成正数
+ n = (n - x) // b
+ ans = ans[::-1]
+ return "".join(ans)
+```
- 十进制小数转二进制数:“乘以2取整,顺序排列”(乘2取整法)
- 例: (0.625)10= (0.101)2
+### 小数的进制转换
+
+[可以参考](https://blog.csdn.net/u013349653/article/details/51367453)
+
+十进制小数转二进制数:“乘以 2 取整,顺序排列”(乘 2 取整法)
+
+例: (0.625)10= (0.101)2
+
 ## 容斥原理
@@ -242,7 +568,23 @@ int gcd(int a, int b) {
## 幂
-### 快速幂
+### 快速幂 O(logk)
+
+求 m^k mod p,时间复杂度 O(logk)。
+
+```c++
+int qmi(int m, int k, int p)
+{
+ int res = 1 % p, t = m;
+ while (k)
+ {
+ if (k&1) res = res * t % p;
+ t = t * t % p;
+ k >>= 1;
+ }
+ return res;
+}
+```
### 求根号
@@ -252,7 +594,7 @@ int gcd(int a, int b) {
### 求根号变种 小数精度
-`while l<=r`不用变,只需要变步长即可。eps可以比期望精度再小一个量级。
+`while l<=r`不用变,只需要变步长即可。eps 可以比期望精度再小一个量级。
```python
@@ -277,8 +619,6 @@ if __name__ == '__main__':
print(f(0.04, 1e-10))
```
+## Acwing 数学
-
-## Acwing数学
-
-[参考](https://www.acwing.com/file_system/file/content/whole/index/content/3273/) 本文只涉及部分
+[参考](https://www.acwing.com/file_system/file/content/whole/index/content/3273/) 本文只涉及部分
diff --git "a/_posts/Tech/Algorithms/2022-07-31-\347\256\200\345\215\225\345\233\276\347\232\204\346\234\200\345\244\247\347\216\257\346\234\200\351\225\277\351\223\276.md" "b/_posts/Tech/Algorithms/2022-07-31-\347\256\200\345\215\225\345\233\276\347\232\204\346\234\200\345\244\247\347\216\257\346\234\200\351\225\277\351\223\276.md"
new file mode 100644
index 0000000000..60c620721d
--- /dev/null
+++ "b/_posts/Tech/Algorithms/2022-07-31-\347\256\200\345\215\225\345\233\276\347\232\204\346\234\200\345\244\247\347\216\257\346\234\200\351\225\277\351\223\276.md"
@@ -0,0 +1,127 @@
+---
+layout: post
+category: Algorithms
+title: 简单图的最大环最长链
+tags: Algorithms
+---
+
+## 最大环最长链
+
+https://www.cnblogs.com/lfri/p/15758120.html
+
+最大环是针对的是出度为1的图,否则会多环重合。
+
+最长链是无环的图,求一个最长路径的长度。
+
+
+
+## 最大环
+
+### 有向图
+
+有多种方法:
+
+- 一种是先用拓扑排序将外链去掉,再dfs每一个环
+- DFS: 另一种是从某一点出发,记录途径的点,如果遇到已经访问过的点,说明找到了环的入口。减去起始点到入口的距离,就是环的长度。
+- 还有一种有并查集,对于`x->y`,如果`x`和`y`同属于一个集合,说明形成了一个环。
+
+
+
+dfs代码
+
+```python
+class Solution:
+ def longestCycle(self, edges: List[int]) -> int:
+ n = len(edges)
+ vis = collections.defaultdict(bool)
+ ans = -1
+ for i in range(n):
+ if vis[i]: continue
+ path = []
+ cur = i
+ while not vis[cur]:
+ vis[cur] = True
+ path.append(cur)
+ cur = edges[cur]
+ if cur == -1: break
+ if cur == -1: continue
+ for j in range(len(path)):
+ if path[j] == cur:
+ t = len(path) - j
+ ans = max(ans, t)
+ break
+ return ans
+```
+
+### 无向图
+
+和有向图类似,略
+
+## 最长链
+
+等价问题: [310. 最小高度树](https://leetcode.cn/problems/minimum-height-trees/)
+
+### 有向图
+
+这里有一个很重要的问题,有环怎么办?
+有环的情况下,求最长链是没有意义的。要么保证无环,要么是求连接到环上的链的长度。
+例如求连接到环上的链的长度,需要从入度为0的节点开始,递推计算,于是采用拓扑序。
+
+
+
+```c++
+int TopologicalSort(vector
## 容斥原理
@@ -242,7 +568,23 @@ int gcd(int a, int b) {
## 幂
-### 快速幂
+### 快速幂 O(logk)
+
+求 m^k mod p,时间复杂度 O(logk)。
+
+```c++
+int qmi(int m, int k, int p)
+{
+ int res = 1 % p, t = m;
+ while (k)
+ {
+ if (k&1) res = res * t % p;
+ t = t * t % p;
+ k >>= 1;
+ }
+ return res;
+}
+```
### 求根号
@@ -252,7 +594,7 @@ int gcd(int a, int b) {
### 求根号变种 小数精度
-`while l<=r`不用变,只需要变步长即可。eps可以比期望精度再小一个量级。
+`while l<=r`不用变,只需要变步长即可。eps 可以比期望精度再小一个量级。
```python
@@ -277,8 +619,6 @@ if __name__ == '__main__':
print(f(0.04, 1e-10))
```
+## Acwing 数学
-
-## Acwing数学
-
-[参考](https://www.acwing.com/file_system/file/content/whole/index/content/3273/) 本文只涉及部分
+[参考](https://www.acwing.com/file_system/file/content/whole/index/content/3273/) 本文只涉及部分
diff --git "a/_posts/Tech/Algorithms/2022-07-31-\347\256\200\345\215\225\345\233\276\347\232\204\346\234\200\345\244\247\347\216\257\346\234\200\351\225\277\351\223\276.md" "b/_posts/Tech/Algorithms/2022-07-31-\347\256\200\345\215\225\345\233\276\347\232\204\346\234\200\345\244\247\347\216\257\346\234\200\351\225\277\351\223\276.md"
new file mode 100644
index 0000000000..60c620721d
--- /dev/null
+++ "b/_posts/Tech/Algorithms/2022-07-31-\347\256\200\345\215\225\345\233\276\347\232\204\346\234\200\345\244\247\347\216\257\346\234\200\351\225\277\351\223\276.md"
@@ -0,0 +1,127 @@
+---
+layout: post
+category: Algorithms
+title: 简单图的最大环最长链
+tags: Algorithms
+---
+
+## 最大环最长链
+
+https://www.cnblogs.com/lfri/p/15758120.html
+
+最大环是针对的是出度为1的图,否则会多环重合。
+
+最长链是无环的图,求一个最长路径的长度。
+
+
+
+## 最大环
+
+### 有向图
+
+有多种方法:
+
+- 一种是先用拓扑排序将外链去掉,再dfs每一个环
+- DFS: 另一种是从某一点出发,记录途径的点,如果遇到已经访问过的点,说明找到了环的入口。减去起始点到入口的距离,就是环的长度。
+- 还有一种有并查集,对于`x->y`,如果`x`和`y`同属于一个集合,说明形成了一个环。
+
+
+
+dfs代码
+
+```python
+class Solution:
+ def longestCycle(self, edges: List[int]) -> int:
+ n = len(edges)
+ vis = collections.defaultdict(bool)
+ ans = -1
+ for i in range(n):
+ if vis[i]: continue
+ path = []
+ cur = i
+ while not vis[cur]:
+ vis[cur] = True
+ path.append(cur)
+ cur = edges[cur]
+ if cur == -1: break
+ if cur == -1: continue
+ for j in range(len(path)):
+ if path[j] == cur:
+ t = len(path) - j
+ ans = max(ans, t)
+ break
+ return ans
+```
+
+### 无向图
+
+和有向图类似,略
+
+## 最长链
+
+等价问题: [310. 最小高度树](https://leetcode.cn/problems/minimum-height-trees/)
+
+### 有向图
+
+这里有一个很重要的问题,有环怎么办?
+有环的情况下,求最长链是没有意义的。要么保证无环,要么是求连接到环上的链的长度。
+例如求连接到环上的链的长度,需要从入度为0的节点开始,递推计算,于是采用拓扑序。
+
+
+
+```c++
+int TopologicalSort(vector& favorite) {
+ int n = favorite.size();
+ vector vis(n, false);
+ vectorin(n, 0);
+ vectordp(n, 1);
+ queue q;
+ for(int i = 0;i < n;i++) in[favorite[i]]++;
+ for(int i = 0;i < n;i++) {
+ if(in[i] == 0) q.push(i);
+ }
+ while(!q.empty()) {
+ int cur = q.front();
+ q.pop();
+ // cout << cur << " ";
+ dp[favorite[cur]] = max(dp[favorite[cur]], dp[cur] + 1);
+ if(--in[favorite[cur]] == 0) q.push(favorite[cur]);
+ }
+ // dp[i] 表示到达i的最长链的长度
+ int two_point_sum = 0; // 题目相关部分
+ for(int i = 0;i < n;i++) {
+ if(i == favorite[favorite[i]]) two_point_sum += dp[i];
+ }
+ return two_point_sum;
+}
+```
+
+### 无向无环图
+
+- 也可以和有向图一样,拓扑序+dp
+- 还有一种有趣的方法,两次dfs。可以证明,从任一点出发,dfs能走到的最远点一定是"直径"的一个端点,然后从这个端点出发,dfs得到另一个端点。 参考下面【路径最长的两个叶子节点】
+
+例如[Leetcode310最小树高度](https://leetcode.cn/problems/minimum-height-trees/solution/zui-xiao-gao-du-shu-by-leetcode-solution-6v6f/),等价于求树的直径
+第一次dfs找到一个端点,再从这个端点出发dfs找到另一个端点,最后在写个dfs得到路径
+
+
+
+### DFS/BFS 求最长链
+
+> [参考](https://leetcode.cn/problems/minimum-height-trees/solution/zui-xiao-gao-du-shu-by-leetcode-solution-6v6f/)
+
+可以利用以下算法找到图中距离最远的两个节点与它们之间的路径:
+
+以任意节点 pp 出现,利用广度优先搜索或者深度优先搜索找到以 pp 为起点的最长路径的终点 xx;
+
+以节点 xx 出发,找到以 xx 为起点的最长路径的终点 yy;
+
+xx 到 yy 之间的路径即为图中的最长路径,找到路径的中间节点即为根节点。
+
+上述算法的证明可以参考「[算法导论习题解答 9-1](http://courses.csail.mit.edu/6.046/fall01/handouts/ps9sol.pdf)」。
+
+
+
+## 参考
+
+- [图的最大环最长链](https://www.cnblogs.com/lfri/p/15758120.html)
diff --git "a/_posts/Tech/Algorithms/2022-08-19-\346\225\260\344\275\215DP.md" "b/_posts/Tech/Algorithms/2022-08-19-\346\225\260\344\275\215DP.md"
new file mode 100644
index 0000000000..ffdd366c48
--- /dev/null
+++ "b/_posts/Tech/Algorithms/2022-08-19-\346\225\260\344\275\215DP.md"
@@ -0,0 +1,91 @@
+---
+layout: post
+category: Algorithms
+title: 数位DP
+tags: Algorithms
+---
+
+## 数位DP
+
+数位:把一个数字按照个、十、百、千等等一位一位地拆开,关注它每一位上的数字。如果拆的是十进制数,那么每一位数字都是 0~9,其他进制可类比十进制。
+
+数位 DP:用来解决一类特定问题,这种问题比较好辨认,一般具有这几个特征:
+
+1. 要求统计满足一定条件的数的数量(即,最终目的为计数);
+2. 这些条件经过转化后可以使用「数位」的思想去理解和判断;
+3. 输入会提供一个数字区间(有时也只提供上界)来作为统计的限制;
+4. 上界很大(比如 ),暴力枚举验证会超时。
+
+
+
+比如统计[a,b] 之间的满足某个条件的数,这个b可能是1e15这样。 注定无法枚举。此类就可以数位DP, 然后a到b形式也可以变成f(b) -f(a)差分来统一处理。记得a这个本身单个可能要额外减去。
+
+## 模板
+
+1. 记忆化搜索
+2. 关键参数: 数位i, 用过数字mask, is_limit是否是受限,is_num前面是否填了数字.后面两个参数可适用于其它数位 DP 题目。
+
+该模板对应[视频](https://www.bilibili.com/video/BV1rS4y1s721?vd_source=9d3646ab1738010f91f766880db9c1c6)
+
+题目: [2376. 统计特殊整数](https://leetcode.cn/problems/count-special-integers/)
+
+> 如果一个正整数每一个数位都是 **互不相同** 的,我们称它是 **特殊整数** 。
+>
+> 给你一个 **正** 整数 `n` ,请你返回区间 `[1, n]` 之间特殊整数的数目。
+
+```python
+class Solution:
+ def countSpecialNumbers(self, n: int) -> int:
+ # 数位dp
+ s = str(n)
+ import functools
+ '''
+ 记忆化搜索,i表示计算数位i, mark表示用过的数字
+ 返回从数位i开始填数字,前面填数字的集合为mask, 能构造出整数的数量
+ is_limit表示是否前i-1位是s对应位上的,即最大受限值max了,如果是则当前数字上线是s[i],而不是'9'
+ is_num表示前面是否填了数字,如果为True,则当前可从0开始,否则只能从1开始,后续会有个数位变成True, 从该数位开始是真实数字
+ '''
+ @functools.lru_cache(None)
+ def f(i: int, mask: int, is_limit: bool, is_num: bool):
+ if i == len(s):
+ # 最后一位了,合法则return 1
+ return int(is_num)
+ res = 0
+ if not is_num:
+ # 此时已经有前缀0了,因此不受限
+ res += f(i + 1, mask, False, False)
+ # 数位i的上限
+ up = int(s[i]) if is_limit else 9
+ # 如果是is_num, 则可以从0开始,否则只能从1开始,毕竟是第一位数字
+ for d in range(1 - int(is_num), up + 1):
+ if (mask >> d) & 1 == 0:
+ # 没用过该数字
+ res += f(i + 1, mask | (1 << d), is_limit and d == up, True)
+ return res
+
+ # 第一位就受限,因此is_limit = True
+ return f(0, 0, True, False)
+
+```
+
+## 应用
+
+- [902. 最大为 N 的数字组合](https://leetcode.cn/problems/numbers-at-most-n-given-digit-set/) 求1-N的使用了digits里数字的数量,没有0, f(i: int, is_limit: bool, is_num: bool)
+
+- [233. 数字 1 的个数](https://leetcode.cn/problems/number-of-digit-one/) 给定一个整数 `n`,计算所有小于等于 `n` 的非负整数中数字 `1` 出现的个数。def f(i: int, ones: int, is_limit: bool, is_num: bool): ones是当前已用ones的数量。
+
+- [面试题 17.06. 2出现的次数](https://leetcode.cn/problems/number-of-2s-in-range-lcci/) 和数字1的个数类似。
+
+- [600. 不含连续1的非负整数](https://leetcode.cn/problems/non-negative-integers-without-consecutive-ones/) 给定一个正整数 `n` ,返回范围在 `[0, n]` 都非负整数中,其二进制表示不包含 **连续的 1** 的个数。def f(i: int, last_is_one: bool, is_limit: bool)
+
+- [1012. 至少有 1 位重复的数字](https://leetcode.cn/problems/numbers-with-repeated-digits/) 等价为n-完全不重复个数
+
+- [1397. 找到所有好字符串](https://leetcode.cn/problems/find-all-good-strings/)
+
+- 给你两个长度为 n 的字符串 s1 和 s2 ,以及一个字符串 evil 。请你返回 好字符串 的数目。好字符串 的定义为:它的长度为 n ,字典序大于等于 s1 ,字典序小于等于 s2 ,且不包含 evil 为子字符串。 难点在于要动态维护kmp,先求evil的next数组,然后把匹配j当dp参数传递下去。
+
+
+
+## 参考
+
+https://leetcode.cn/problems/count-special-integers/solution/shu-wei-dp-mo-ban-by-endlesscheng-xtgx/
diff --git "a/_posts/Tech/Algorithms/2022-10-10-\345\255\227\347\254\246\344\270\262hash.md" "b/_posts/Tech/Algorithms/2022-10-10-\345\255\227\347\254\246\344\270\262hash.md"
new file mode 100644
index 0000000000..83d09a4b43
--- /dev/null
+++ "b/_posts/Tech/Algorithms/2022-10-10-\345\255\227\347\254\246\344\270\262hash.md"
@@ -0,0 +1,73 @@
+---
+layout: post
+category: Algorithms
+title: 字符串hash
+tags: Algorithms
+---
+
+## 字符串hash
+
+字符串hash得到hash值,用于o(1)时间复杂度判断是否相等。在提前计算好整个字符串的预处理情况下,可快速比较某两子串是否相等。
+
+
+
+[oi wiki参考](https://oi-wiki.org/string/hash/)
+
+
+
+
+
+
+
+## 模板
+
+```python
+class StringHash:
+ def __init__(self, s=""):
+ self.MOD = 998244353
+ self.BASE = 131
+ # 计算前缀哈希值
+ n = len(s)
+ P = [0] * (n + 1)
+ P[0] = 1
+ for i in range(1, n + 1, 1):
+ P[i] = P[i - 1] * self.BASE % self.MOD
+ H = [0] * (n + 1)
+ for i in range(1, n + 1, 1):
+ H[i] = (H[i - 1] * self.BASE + ord(s[i - 1])) % self.MOD
+ self.H = H
+ self.P = P
+
+ '''
+ s的[l,r]区间的hash值,闭区间, l从1开始
+ '''
+
+ def get_hash(self, l=0, r=0):
+ l, r = l + 1, r + 1
+ return (self.H[r] - self.H[l - 1] * self.P[r - l + 1] % self.MOD + self.MOD) % self.MOD
+
+示例: https://leetcode.cn/problems/maximum-deletions-on-a-string/submissions/
+class Solution:
+ def deleteString(self, s: str) -> int:
+ n = len(s)
+ dp = [1] * n
+ hash = StringHash(s)
+ for i in range(n - 1, -1, -1):
+ for j in range(i + 1, n):
+ if (j - i + 1) % 2 == 0:
+ mid = (i + j) // 2
+ if hash.get_hash(i, mid) == hash.get_hash(mid+1, j):
+ # print(i, j, mid)
+ dp[i] = max(dp[i], dp[mid+1]+1)
+ # print(dp[i])
+ # print(dp)
+ return dp[0]
+```
+
+
+
+## 题目
+
+
+
+题目: https://leetcode.cn/problems/maximum-deletions-on-a-string/solution/by-tsreaper-9xkh/
diff --git "a/_posts/Tech/Algorithms/2022-10-16-\345\217\214\346\214\207\351\222\210.md" "b/_posts/Tech/Algorithms/2022-10-16-\345\217\214\346\214\207\351\222\210.md"
new file mode 100644
index 0000000000..66fdad41f9
--- /dev/null
+++ "b/_posts/Tech/Algorithms/2022-10-16-\345\217\214\346\214\207\351\222\210.md"
@@ -0,0 +1,39 @@
+---
+layout: post
+category: Algorithms
+title: 双指针
+tags: Algorithms
+---
+
+## 双指针
+
+
+
+1. 统计子数组数目,枚举右边界,左边界视情况而定。比如求子数组数目,要求子数组包含两个值,那枚举i,j就等于有两个值的最后最小坐标,每次结果可加i-j+1, 实例题目 [6207. 统计定界子数组的数目](https://leetcode.cn/problems/count-subarrays-with-fixed-bounds/) [题解](https://leetcode.cn/problems/count-subarrays-with-fixed-bounds/solution/hua-dong-chuang-by-yi-wei-8-c7h7/)
+
+2. [3Sum](https://leetcode-cn.com/problems/3sum/) 排序+双指针
+
+3. [Longest Repeating Character Replacement](https://leetcode-cn.com/problems/longest-repeating-character-replacement/) 给你一个仅由大写英文字母组成的字符串,你可以将任意位置上的字符替换成另外的字符,总共可最多替换 k 次。在执行上述操作后,找到包含重复字母的最长子串的长度。
+
+ 解答: **双指针。这个双指针属于left每次只移动一次,记得看下。**
+
+4. [11. 盛最多水的容器](https://leetcode.cn/problems/container-with-most-water/) 多个柱子,挑两个柱子,统计最多能接多少水,双指针,不断缩小两边矮的那个
+
+5. [1438. 绝对差不超过限制的最长连续子数组](https://leetcode-cn.com/problems/longest-continuous-subarray-with-absolute-diff-less-than-or-equal-to-limit/) 给你一个整数数组 nums ,和一个表示限制的整数 limit,请你返回最长连续子数组的长度,该子数组中的任意两个元素之间的绝对差必须小于或者等于 limit 。 维护max, min的队列,同时双指针,不断移动左指针。
+
+6. [6270. 每种字符至少取 K 个](https://mafulong.github.io/2022/12/25/6270.-%E6%AF%8F%E7%A7%8D%E5%AD%97%E7%AC%A6%E8%87%B3%E5%B0%91%E5%8F%96-K-%E4%B8%AA/) 给你一个由字符 `'a'`、`'b'`、`'c'` 组成的字符串 `s` 和一个非负整数 `k` 。每分钟,你可以选择取走 `s` **最左侧** 还是 **最右侧** 的那个字符。
+
+ 你必须取走每种字符 **至少** `k` 个,返回需要的 **最少** 分钟数
+
+7. [1658. 将 x 减到 0 的最小操作数](https://leetcode.cn/problems/minimum-operations-to-reduce-x-to-zero/)
+
+8. 给你一个整数数组 nums 和一个整数 x 。每一次操作时,你应当移除数组 nums 最左边或最右边的元素,然后从 x 中减去该元素的值。请注意,需要 修改 数组以供接下来的操作使用。
+
+ 如果可以将 x 恰好 减到 0 ,返回 最小操作数 ;否则,返回 -1 。
+
+ 反向思考,找最大子数组。
+
+
+
+
+
diff --git "a/_posts/Tech/Algorithms/2023-01-15-\346\240\221\345\275\242DP\345\222\214\346\215\242\346\240\271DP.md" "b/_posts/Tech/Algorithms/2023-01-15-\346\240\221\345\275\242DP\345\222\214\346\215\242\346\240\271DP.md"
new file mode 100644
index 0000000000..42b522f152
--- /dev/null
+++ "b/_posts/Tech/Algorithms/2023-01-15-\346\240\221\345\275\242DP\345\222\214\346\215\242\346\240\271DP.md"
@@ -0,0 +1,281 @@
+---
+layout: post
+category: Algorithms
+title: 树形DP和换根DP
+tags: Algorithms
+---
+
+## 树形DP和换根DP
+
+[oi wiki](https://oi-wiki.org/dp/tree/)
+
+## 树形DP
+
+固定一个根节点。在树上做DP. 往往是树dfs遍历,先子树再基于子树结果对当前节点DP递推到根节点。
+
+
+
+对于图转树的DFS遍历,其实就是无向树。
+
+```python
+class DoubleTree:
+ def tree_dfs(graph, root):
+ '''
+ 这种树上dfs不需要维护visit记录,只需要记录遍历刀当前节点的parent就可以了。时间复杂度o(n)
+ '''
+ import collections
+ p = collections.defaultdict(lambda: -1)
+
+ def dfs(u):
+ if len(graph[u]) == 1 and u in p:
+ print("is leaf")
+ for v in graph[u]:
+ if p[u] != v: # 非访问过
+ # 多次生效,针对多个v
+ p[v] = u
+ dfs(v)
+
+ def dfs_p(u, p):
+ if len(graph[u]) == 1 and u != root:
+ # 判断叶子节点时要用和这个双重判断
+
+ print("is leaf")
+ for v in graph[u]:
+ if v != p:
+ dfs_p(v, u)
+
+
+```
+
+
+
+也可以通过 g[0].append(-1) # 防止根节点被认作叶子
+
+
+
+
+
+经典树形DP
+
+- [124. 二叉树中的最大路径和](https://leetcode.cn/problems/binary-tree-maximum-path-sum/) 给你一个二叉树的根节点 `root` ,返回其 **最大路径和** 。
+
+ ```python
+ class Solution:
+ ans = float('-inf')
+
+ def maxPathSum(self, root: TreeNode) -> int:
+ def dfs(node):
+ if not node:
+ return 0
+ l = dfs(node.left)
+ r = dfs(node.right)
+ self.ans = max(self.ans, max(l, 0) + max(r, 0) + node.val)
+ return max(l, r, 0) + node.val
+ dfs(root)
+ return self.ans
+ ```
+
+
+
+- [310. 最小高度树](https://leetcode.cn/problems/minimum-height-trees/)
+- [6294. 最大价值和与最小价值和的差值](https://leetcode.cn/problems/difference-between-maximum-and-minimum-price-sum/) 求最长直径,随便固定一个点为root。 树形DP
+- [2246. 相邻字符不同的最长路径](https://leetcode.cn/problems/longest-path-with-different-adjacent-characters/) 和最大路径和一样
+
+
+
+
+
+## 换根DP
+
+- [参考](https://leetcode.cn/problems/difference-between-maximum-and-minimum-price-sum/solution/huan-gen-dong-tai-gui-hua-jie-fa-by-vcli-gaii/)
+
+换根DP就是再已知u节点为根节点的情况下,取u节点的一个孩子节点作为新的根节点,不断递归,求出所有节点为根节点情况时的结果。这其实就是一个二次dfs的过程。
+
+第一次dfs是处理0节点为根节点的情况。
+
+第二次dfs是0节点换根到其中子节点,并不断重复的dfs.
+
+两次dfs都是在一个双向图上做遍历。因此要用`dfs(u, p)`这种dfs方式。
+
+```scala
+ def dfs(u, p):
+ # dp[u] 根据子节点的预处理数组更新, optional
+ for v in graph[u]:
+ if v == p: continue
+ # xxxx
+ # 预处理数组更新, h0[u] = xxx, h0[v] = xxx, optional
+ # dp[u] 更新作为非根时变换, optional
+ # dp[v] 更新作为根时变换, optional
+ dfs(v, u) # 换根
+ # 恢复dp[u], dp[v], 预处理数组到u为根节点时的状态
+```
+
+第二次dfs时,u节点已经是根节点了,如果有预处理数组,则u的子节点的值已经转成正确的了,计算机u节点的dp值就可以根据u的子节点预处理数组计算了。
+
+换根到子节点前,也需要更新下预处理数组中关于u节点的信息,因此换根后u节点就是子节点了。
+
+记住每次改变只有u 和 v的dp值改变,以及预处理数组中关于u和v的值改变。
+
+
+
+
+
+通常题目:
+
+- 求满足条件的根的可能数量
+- 求每个节点为根时的一个结果。
+
+时间复杂度通常是O(n)
+
+
+
+换根时预处理数组转换
+
+- 孩子节点数目size。[834. 树中距离之和](https://leetcode.cn/problems/sum-of-distances-in-tree/)
+- 孩子最大高度。[310. 最小高度树](https://leetcode.cn/problems/minimum-height-trees/)
+- 孩子最长路径节点价值和。类似最大高度。[2538. 最大价值和与最小价值和的差值](https://leetcode.cn/problems/difference-between-maximum-and-minimum-price-sum/)
+
+
+
+
+
+**旧版:**
+
+
+
+树形 DP 中的换根 DP 问题又被称为二次扫描,通常不会指定根结点,并且根结点的变化会对一些值,例如子结点深度和、点权和等产生影响。
+
+通常需要两次 DFS,第一次 DFS 预处理诸如深度,点权和之类的信息,在第二次 DFS 开始运行换根动态规划。
+
+第二次dfs时,把父节点作为子树。来调整。比如 [参考](https://zhuanlan.zhihu.com/p/437753260)
+
+
+
+需要计算出换根后的值的变化。 然后枚举根。
+
+
+
+每次换根只能换相邻的。否则影响其它节点计算。只有相邻时只影响相邻的。而且枚举的一定是根,而不是第三个点为根的情况的相邻递推。
+
+换根后不用恢复数据,因为是邻接点递推的。其它的没用。
+
+
+
+
+记住每次改变只有u 和 v的dp值改变。[详细](https://leetcode.cn/problems/sum-of-distances-in-tree/solution/shu-zhong-ju-chi-zhi-he-by-leetcode-solution/)
+
+
+- [834. 树中距离之和](https://leetcode.cn/problems/sum-of-distances-in-tree/) 给定一个无向、连通的树。树中有 `n` 个标记为 `0...n-1` 的节点以及 `n-1` 条边 。返回长度为 `n` 的数组 `answer` ,其中 `answer[i]` 是树中第 `i` 个节点与所有其他节点之间的距离之和。
+- [310. 最小高度树](https://leetcode.cn/problems/minimum-height-trees/) [参考题解](https://leetcode.cn/problems/difference-between-maximum-and-minimum-price-sum/solution/huan-gen-dong-tai-gui-hua-jie-fa-by-vcli-gaii/)
+
+```python
+class Solution:
+ def findMinHeightTrees(self, n: int, edges: List[List[int]]) -> List[int]:
+ graph = collections.defaultdict(list)
+ for a, b in edges:
+ graph[a].append(b)
+ graph[b].append(a)
+ h0 = [0 for _ in range(n)]
+
+ def dfs(u, p):
+ nonlocal h0
+ l = 0
+ for v in graph[u]:
+ if v == p: continue
+ l = max(l, dfs(v, u) + 1)
+ h0[u] = l
+ return l
+
+ dfs(0, -1)
+ # print(h0)
+
+ dp = [0] * n
+
+ def dfs2(u, p):
+ nonlocal dp
+ # 此时就是u为root,每次进入函数都是已经换根为u了。此时孩子的h0是准的,h0[u]是不准的,需要根据孩子重新计算
+ first, second = -1, -1
+ for v in graph[u]:
+ if h0[v] >= first:
+ second = first
+ first = h0[v]
+ elif h0[v] >= second:
+ second = h0[v]
+ dp[u] = first + 1
+ # print(u, dp[u])
+ for v in graph[u]:
+ if v == p: continue
+ # 假设u与v换根
+ h0[u] = first if h0[v] != first else second
+ h0[u] += 1
+ dfs2(v, u)
+
+ dfs2(0, -1)
+ # print(dp)
+ minv = min(dp)
+ ans = []
+ for i in range(n):
+ if dp[i] == minv:
+ ans.append(i)
+ return ans
+
+```
+
+
+
+- [6294. 最大价值和与最小价值和的差值](https://leetcode.cn/problems/difference-between-maximum-and-minimum-price-sum/) 换根DP
+
+```python
+class Solution:
+ def maxOutput(self, n: int, edges: List[List[int]], price: List[int]) -> int:
+ graph = collections.defaultdict(list)
+ for a, b in edges:
+ graph[a].append(b)
+ graph[b].append(a)
+ # 求最大价值和
+ h0 = [0 for _ in range(n)]
+
+
+ # 第一次遍历,统计以0为根的结果
+ def dfs(u, p):
+ nonlocal h0
+ l = price[u]
+ for v in graph[u]:
+ if v == p: continue
+ dfs(v, u)
+ l = max(l, price[u] + h0[v])
+ h0[u] = l
+ return l
+
+ dfs(0, -1)
+ # print(h0)
+
+ dp = [0] * n
+
+ def dfs2(u, p):
+ nonlocal dp
+ # 此时就是u为root,每次进入函数都是已经换根为u了。此时孩子的h0是准的,h0[u]是不准的,需要根据孩子重新计算下h0[u]
+ first, second = 0, 0
+ dp[u] = 0
+ for v in graph[u]:
+ # 此时不能continue,因为p是有用的,u为root,无p
+ # if v == p: continue
+ if h0[v] >= first:
+ second = first
+ first = h0[v]
+ elif h0[v] >= second:
+ second = h0[v]
+ # 以u为根情况下 h0和dp的值
+ dp[u] = first
+ h0[u] = first + price[u]
+ # print(u, dp[u], first, second)
+ for v in graph[u]:
+ if v == p: continue
+ # 假设u与v换根
+ h0[u] = price[u] + (first if (h0[v] != first) else second)
+ dfs2(v, u)
+
+ dfs2(0, -1)
+ return max(dp)
+```
+
diff --git "a/_posts/Tech/Algorithms/2023-01-29-\347\273\237\350\256\241\345\233\233\345\205\203\347\273\204\344\271\213\344\270\255\351\227\264\346\236\232\344\270\276.md" "b/_posts/Tech/Algorithms/2023-01-29-\347\273\237\350\256\241\345\233\233\345\205\203\347\273\204\344\271\213\344\270\255\351\227\264\346\236\232\344\270\276.md"
new file mode 100644
index 0000000000..087462b364
--- /dev/null
+++ "b/_posts/Tech/Algorithms/2023-01-29-\347\273\237\350\256\241\345\233\233\345\205\203\347\273\204\344\271\213\344\270\255\351\227\264\346\236\232\344\270\276.md"
@@ -0,0 +1,23 @@
+---
+layout: post
+category: Algorithms
+title: 统计四元组之中间枚举
+tags: Algorithms
+---
+
+## 统计四元组之技巧 中间枚举
+
+有些题目是让统计四元组之类的数量。
+
+此时就可以枚举中间的。
+
+通常可以应用些预处理来降低时间复杂度。
+
+
+
+应用
+
+- [6340. 统计上升四元组](https://leetcode.cn/contest/weekly-contest-330/problems/count-increasing-quadruplets/) [参考](https://leetcode.cn/circle/discuss/LWLEFc/view/4dIQzE/)
+
+- [2242. 节点序列的最大得分](https://leetcode.cn/problems/maximum-score-of-a-node-sequence/)
+
diff --git "a/_posts/Tech/docker/2019-07-27-docker\345\205\245\351\227\250.md" "b/_posts/Tech/Container/2019-07-27-docker\345\205\245\351\227\250.md"
similarity index 71%
rename from "_posts/Tech/docker/2019-07-27-docker\345\205\245\351\227\250.md"
rename to "_posts/Tech/Container/2019-07-27-docker\345\205\245\351\227\250.md"
index fc13204ab1..c84a3ca942 100644
--- "a/_posts/Tech/docker/2019-07-27-docker\345\205\245\351\227\250.md"
+++ "b/_posts/Tech/Container/2019-07-27-docker\345\205\245\351\227\250.md"
@@ -1,14 +1,32 @@
---
layout: post
-category: Docker
+category: Container
title: docker入门
tags: Docker
---
# docker入门
+Docker 是一种商业容器化平台和运行时环境,它可帮助开发人员构建、部署和运行容器。它采用客户端-服务器架构,通过单个 API 提供简单的命令和自动化功能。
+
+Docker 还提供一个工具包,它常用于将应用打包为不可变的容器镜像,即通过编写 [Dockerfile](https://docs.docker.com/engine/reference/builder/),然后运行相应的[命令](https://docs.docker.com/engine/reference/commandline/build/)来使用 Docker 服务器构建镜像。开发人员可以不使用 Docker 创建容器,但使用 Docker 平台可以让创建过程更加便捷。然后,可以将这些容器镜像部署到任何支持容器的平台上运行,例如 Kubernetes、Docker Swarm、Mesos 或 HashiCorp Nomad。
+
+
+
+运行容器前需要编写Docker File,通过 dockerFile 生成镜像,然后才能运行 Docker 容器。
+
+Docker File 定义了运行镜像(image)所需的所有内容,包括操作系统和软件安装位置。一般情况下都不需要从头开始编写 Docker File,在 Docker Hub 中有来自世界各地的工程师编写好的镜像,你可以基于此修改。
+
+虚拟化技术已经走过了三个时代,没有容器化技术的演进就不会有 Docker 技术的诞生。
+
+
+
+
+
+
## 简单三部曲
+
[官方参考](https://docs.docker.com/get-started/)
可运行以下脚本
diff --git a/_posts/Tech/Container/2023-03-08-k8s.md b/_posts/Tech/Container/2023-03-08-k8s.md
new file mode 100644
index 0000000000..e80af9532d
--- /dev/null
+++ b/_posts/Tech/Container/2023-03-08-k8s.md
@@ -0,0 +1,75 @@
+---
+layout: post
+category: Container
+title: k8s
+tags: Container
+---
+
+## k8s
+
+Kubernetes(有时也称为 K8s)是一个广受欢迎的开源平台,可以跨越网络资源集群来编排容器运行时系统。不论有无 Docker,均可使用 Kubernetes。
+
+Kubernetes 最初由 Google 开发,该公司需要一种全新方式来每周大规模运行数十亿个容器。2014 年,Kubernetes 由 Google 以开源形式发布,现被广泛认为是容器和分布式应用部署领域的市场领导者和行业标准编排工具。[Google 表示](https://queue.acm.org/detail.cfm?id=2898444),Kubernetes 的“主要设计目标是简化复杂分布式系统的部署与管理,同时仍然受益于容器带来的更高利用率。”
+
+Kubernetes 将一系列容器捆绑成一组,并在同一台机器上进行管理,以减少网络开销并提高资源使用效率。例如,应用服务器、Redis 缓存和 SQL 数据库便是此此类容器集。Docker 容器的特点是每个容器一个进程。
+
+
+
+## 有了容器为何需要k8s
+
+Docker 提供容器的生命周期管理和,[Docker](https://link.segmentfault.com/?enc=IMFQZ%2BeeI7dBtplzfKTw3Q%3D%3D.QrUq9Oz3A4oa%2FwDSC9RDPSISW7u34lI46PhRGInHHOd%2FKKe2YyzXmnKCZGw9CC0hpYMMItTK6AbXm9HYoRZOa%2BtgNwetTCKuJGbbTcKQNFYN%2BlWlCIRn74EYt%2F1F3aPyKA%2BfIIibdZ9su%2FMIH%2FRvPzUKfJOThlhxIyD2kjiU%2Fvu7oza%2BKL88Kk%2FGxDx2X9VfEc4fdK5wG1oU3iJ908sMJiptGxQIBfacr%2BUM52e20DvJL1hYtzoNKoDQfv4On%2FOW2jrjskVIsJWpnTrGE5bc%2FJrfSHU0PHMTc2%2BS1ztWR7neofBwAWqTnjMyJoZqKtE5) 镜像构建运行时容器。它的主要优点是将将软件/应用程序运行所需的设置和依赖项打包到一个容器中,从而实现了可移植性等优点。
+
+[Kubernetes](https://link.segmentfault.com/?enc=W81xiwGoNRkvUPq6WfcWfg%3D%3D.KxqHDaD%2B%2BR2FaIDFTlmkFD756ZnXYK2ioDgLAwRRq2JjkLmkagG3T2%2BjXlwt%2Byi%2Bpv%2BL84c%2FuffzfvOX1auNr2bqdSSokkIoVL1OCHAyS8P8sB8GLoYna5%2B%2FvBqtDP59%2FmlGrala2AmkscHWKr7M7gTvRZBRtmRfWLswIJXeDLFAYSeyTjskXGU6uy45eiiDlLHI6%2B9sZLmf3a9UfYRcxM5vq47c%2FY9eTnRQu7%2Bal3nFanU2bjFCeg91DLprZi9qwrq40VKU8104ofE9iFZ96ljUk25mFBf5sXRbv0QJ14Doi2542WRqrtfuOTxc3a4J) 用于关联和编排在多个主机上运行的容器。
+
+
+
+尽管Docker为容器化的应用程序提供了开放标准,但随着容器越来越多出现了一系列新问题:
+
+- 如何协调和调度这些容器?
+- 如何在升级应用程序时不会中断服务?
+- 如何监视应用程序的运行状况?
+- 如何批量重新启动容器里的程序?
+
+解决这些问题需要容器编排技术,可以将众多机器抽象,对外呈现出一台超大机器。现在业界比较流行的有:k8s、Mesos、Docker Swarm。
+
+在业务发展初期只有几个微服务,这时用 Docker 就足够了,但随着业务规模逐渐扩大,容器越来越多,运维人员的工作越来越复杂,这个时候就需要编排系统解救opers。
+
+
+
+
+
+## k8s架构
+
+K8s总体来说是主从架构模式Master - Slave架构,master节点负责调度、管理,slave节点负责具体程序的运行和节点服务,在K8s里面,主节点一般叫做master node,从节点叫做worker node。所有的主节点和从节点一起组成了K8s集群,在集群里面master和slave都可以是多个,是一个多主多从的集群架构。
+
+### 2.1 K8s Master Node核心组件
+
+
+- **API Server**:作用是K8s的请求入口提供能力,API Server组件负责接收K8s所有的命令请求,不管是UI控制台还是命令行都会经过API Server组件,API Server负责接收具体的命令请求,去通知其它组件工作。
+- **Scheduler**:是K8s调度所有worker节点的调度组件,当K8s需要部署服务时,通过Scheduler调度组件来负责调度具体的Worker Node节点来进行服务的部署工作。
+- **Controller Manager**:监控K8s所有的Worker Node,对工作节点的性能和工作状态监控,例如某个节点的服务挂了以后,Controller Manager组件就会立马感知到,然后通知Scheduler组件去调度选择Worker Node来重新部署服务。Controller Manager是由多个Controller组成:`Node Controller`、`Service Controller`、`Volume Controller`等
+- **etcd**:K8s默认的数据信息存储服务,是一个基于Raft算法的分布式KV服务器,类似于ZK功能。etcd存储了K8s的关心配置和用户配置数据。
+
+
+### 2.2 K8s Worker Node核心组件
+
+
+- Kubelet:工作节点的监视器,并且负责和Master Node进行通信,定时的向Master Node上报工作节点的服务状态,并且负责接收Master Node发来的各种命令。
+- Kube Proxy:工作节点的网络代理组件,负责基础通信能力。
+- Container Runtime:工作节点的运行时环境。
+
+
+## 3.K8s核心概念
+
+### 3.1 Deployment
+
+Deployment负责创建和更新应用程序的实例,创建Deployment后,K8s的Master节点会将应用程序实例调度到集群中各个Worker节点上。Pod是K8s最小的编排单位,K8s要支持弹性扩容、负载均衡就得需要一个Controller来管理,Deployment就是来控制和编排应用程序。 在Deployment的配置文件里面可以指定需要部署的Pod标签、Pod个数等。
+
+### 3.2 Pod
+
+Pod是K8s编排容器的最小逻辑单元,Pod也相当于是一个逻辑主机的概念负责管理具体的应用实例,包括1个或多个Docker容器,一般是一对一关系。 Pod同样也有yaml配置文件,在配置文件里面可以配置暴露的端口、服务标签、镜像信息等。
+
+### 3.3 Service
+
+Service是K8s里面的一个抽象的概念,Service是一组Pod的逻辑集合,给这些Pod提供服务发现、负载的能力。 虽然每一个Pod都有自己的IP和端口,但是Pod的IP并不会暴露给外部;访问Pod必须通过Service,Service提供流量的接收。Service可以通过配置Type来对外暴露访问入口,默认是ClusterIP模式(在几群的内部IP上公开Servcie),除了这个默认模式外,还提供NodePort、LoadBalancer等。 Service同样提供了yaml文件配置,可以配置例如暴露端口、Pod的选择等。
+
diff --git "a/_posts/Tech/Database/2021-01-09-\346\225\260\346\215\256\345\272\223\345\257\271\346\257\224.md" "b/_posts/Tech/Database/2021-01-09-\346\225\260\346\215\256\345\272\223\345\257\271\346\257\224.md"
index 0f45d5872d..1d12cfacdb 100644
--- "a/_posts/Tech/Database/2021-01-09-\346\225\260\346\215\256\345\272\223\345\257\271\346\257\224.md"
+++ "b/_posts/Tech/Database/2021-01-09-\346\225\260\346\215\256\345\272\223\345\257\271\346\257\224.md"
@@ -270,4 +270,19 @@ Google 发布了第一个列型存储数据库 [Bigtable](http://www.read.seas.h
- 排行榜或者得分数据
- 临时数据,如购物车
- 频繁访问的(“热”)表
-- 元数据/查找表
\ No newline at end of file
+- 元数据/查找表
+
+
+
+## NoSQL
+
+> [参考](https://aws.amazon.com/cn/nosql/)
+
+### 为什么应该使用 NoSQL 数据库?
+
+NoSQL 数据库非常适合许多现代应用程序,例如移动、Web 和游戏等应用程序,它们需要灵活、可扩展、高性能和功能强大的数据库以提供卓越的用户体验。
+
+- **灵活性:**NoSQL 数据库通常提供灵活的架构,以实现更快速、更多的迭代开发。灵活的数据模型使 NoSQL 数据库成为半结构化和非结构化数据的理想之选。
+- **可扩展性:**NoSQL 数据库通常被设计为通过使用分布式硬件集群来横向扩展,而不是通过添加昂贵和强大的服务器来纵向扩展。一些云提供商在后台将这些操作处理为完全托管服务。
+- **高性能:**NoSQL 数据库针对特定的数据模型和访问模式进行了优化,这与尝试使用关系数据库完成类似功能相比可实现更高的性能。
+- **强大的功能:**NoSQL 数据库提供功能强大的 API 和数据类型,专门针对其各自的数据模型而构建。
\ No newline at end of file
diff --git a/_posts/Tech/DistributedSystem/2018-11-22-consul.md b/_posts/Tech/DistributedSystem/2018-11-22-consul.md
index 8f9d81f2b3..7014ad4166 100644
--- a/_posts/Tech/DistributedSystem/2018-11-22-consul.md
+++ b/_posts/Tech/DistributedSystem/2018-11-22-consul.md
@@ -29,7 +29,7 @@ Consul使用gossip协议管理成员关系、广播消息到整个集群,他

-
+图里的client不是consul里的,是consul使用者。
## 实现原理
diff --git a/_posts/Tech/DistributedSystem/2020-12-15-SOA.md b/_posts/Tech/DistributedSystem/2020-12-15-SOA.md
index 9242fbf352..b1516a5a4f 100644
--- a/_posts/Tech/DistributedSystem/2020-12-15-SOA.md
+++ b/_posts/Tech/DistributedSystem/2020-12-15-SOA.md
@@ -20,12 +20,9 @@ SOA是支持面向服务的架构方式。面向服务是一种从服务、基
-### 知乎对此描述
+### 解释
-作者:光太狼
-链接:https://www.zhihu.com/question/42061683/answer/251131634
-来源:知乎
-著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
+Refer: https://www.zhihu.com/question/42061683/answer/251131634
@@ -63,3 +60,45 @@ SOA粗暴理解:把系统按照实际业务,拆分成刚刚好大小的、
## SOA和微服务microservice的区别
+我们应该将SOA视为微服务的超集。
+
+
+
+| **SOA架构** | **微服务架构** |
+| ---------------------------------------- | ---------------------------------------- |
+| 最大化应用服务的可重用性 | 关注于解耦 |
+| 系统的变化需要修改整体结构 | 系统的变化是创造一种新的服务 |
+| DevOps和持续交付正在变得流行,但不是主流 | 专注于DevOps和持续交付 |
+| 专注于业务功能的可重用性 | 更加重视“边界上下文”的概念 |
+| 对于通信,它使用企业服务总线(ESB) | 对于通信使用不那么复杂和简单的消息系统 |
+| 支持多种消息协议 | 使用轻量级协议,如HTTP,REST或Thrift API |
+| 为部署到它的所有服务使用通用平台 | 应用服务器并未真正使用,通常使用云平台 |
+| 使用容器(如Docker)不太受欢迎 | 容器与微服务一起工作得很好 |
+| SOA服务共享数据存储 | 每个微服务可以具有独立的数据存储 |
+| 共同治理和标准 | 轻松治理,更加注重团队协作和选择自由度 |
+
+我将在上表中显示的某些方面进一步详细说明,并进一步解释其中的差异:
+
+- 开发 - 在这两种体系结构中,可以使用不同的编程语言和工具开发服务,从而为开发团队带来技术多样性。可以在多个团队中组织开发,但是,在SOA中,每个团队都需要了解常见的通信机制。另一方面,通过微服务,服务可以独立于其他服务运行和部署。因此,更容易经常部署新版本的微服务或独立扩展服务。您可以在此处进一步了解微服务的这些优点。
+
+- “绑定上下文” - SOA鼓励共享组件,而微服务试图通过“绑定上下文”最小化共享。绑定上下文指的是将组件及其数据作为单个单元耦合,具有最小的依赖性。由于SOA依赖于多种服务来满足业务请求,因此基于SOA构建的系统可能比微服务慢。
+
+- 通信 - 在SOA中,ESB可能成为影响整个系统的单点故障。由于每个服务都通过ESB进行通信,如果其中一个服务速度变慢,它可能会阻塞ESB请求该服务。另一方面,微服务在容错方面要好得多。例如,如果一个微服务有内存故障,那么只有那个微服务会受到影响。所有其他微服务将继续定期处理请求。
+
+- 互操作性 - SOA通过其消息传递中间件组件促进多个异构协议的使用。微服务试图通过减少集成选择的数量来简化架构模式。**因此,如果要在异构环境中使用不同协议集成多个系统,则需要考虑SOA。如果可以通过相同的远程访问协议访问所有服务,那么微服务对您来说是更好的选择。**
+
+- 大小 - 最后但并非最不重要的是,**SOA和微服务之间的主要区别在于大小和范围。微服务中的前缀“微”指的是内部组件的粒度,这意味着它们必须比SOA趋向于小得多。微服务中的服务组件通常只有一个目的,他们做得很好。另一方面,在SOA中,服务通常包含更多的业务功能,并且它们通常作为完整的子系统实现。**
+
+
+
+人们不能简单地说一个架构比另一个架构好。它主要取决于您正在构建的应用程序的目的。**SOA更适合需要与许多其他应用程序集成的大型复杂企业应用程序环境。** 话虽这么说,**较小的应用程序不适合SOA,因为它们不需要消息传递中间件组件。** 另一方面,**微服务更适合于较小且分区良好的基于Web的系统。此外,如果您正在开发移动或Web应用程序,那么微服务可以让您作为开发人员获得更大的控制权。** 最后,我们可以得出结论,因为它们用于不同的目的 - **微服务和SOA确实是不同类型的架构。**
+
+
+
+
+
+SOA范围大,着眼于整个企业,而微服务范围小,着眼于应用。
+
+**SOA是与企业服务的公开性密切相关的,关注的范围更大,是应用与应用之间的通信、服务公开。**
+
+**微服务是与应用架构紧密相关的,关注的范围小,只关注应用本身的范围。**
diff --git "a/_posts/Tech/DistributedSystem/2021-01-09-\345\210\206\345\270\203\345\274\217\344\272\213\345\212\241.md" "b/_posts/Tech/DistributedSystem/2021-01-09-\345\210\206\345\270\203\345\274\217\344\272\213\345\212\241.md"
index 451b6f264b..cde54a6f67 100644
--- "a/_posts/Tech/DistributedSystem/2021-01-09-\345\210\206\345\270\203\345\274\217\344\272\213\345\212\241.md"
+++ "b/_posts/Tech/DistributedSystem/2021-01-09-\345\210\206\345\270\203\345\274\217\344\272\213\345\212\241.md"
@@ -96,6 +96,11 @@ __两阶段提交协议解决的是分布式数据库数据强一致性问题__
针对两阶段提交存在的问题,三阶段提交协议通过引入一个 **预询盘** 阶段,以及超时策略来减少整个集群的阻塞时间,提升系统性能。三阶段提交的三个阶段分别为:预询盘(can_commit)、预提交(pre_commit),以及事务提交(do_commit)。
+
+
+1. 引入canCommit阶段减少**同步阻塞**。
+2. 引入超时减少**单点故障**,没有协调者消息并超时了,直接 commit
+
#### 第一阶段:预询盘
该阶段协调者会去询问各个参与者是否能够正常执行事务,参与者根据自身情况回复一个预估值,相对于真正的执行事务,这个过程是轻量的,具体步骤如下:
diff --git "a/_posts/Tech/DistributedSystem/2021-01-09-\345\210\206\345\270\203\345\274\217\347\256\227\346\263\225\345\222\214\345\215\217\350\256\256.md" "b/_posts/Tech/DistributedSystem/2021-01-09-\345\210\206\345\270\203\345\274\217\347\256\227\346\263\225\345\222\214\345\215\217\350\256\256.md"
index 98418ccab5..37b316420d 100644
--- "a/_posts/Tech/DistributedSystem/2021-01-09-\345\210\206\345\270\203\345\274\217\347\256\227\346\263\225\345\222\214\345\215\217\350\256\256.md"
+++ "b/_posts/Tech/DistributedSystem/2021-01-09-\345\210\206\345\270\203\345\274\217\347\256\227\346\263\225\345\222\214\345\215\217\350\256\256.md"
@@ -3,6 +3,7 @@ layout: post
category: DistributedSystem
title: 分布式算法和协议
tags: DistributedSystem
+recent_update: true
---
## 分布式算法和协议-思维导图
@@ -37,6 +38,14 @@ tags: DistributedSystem
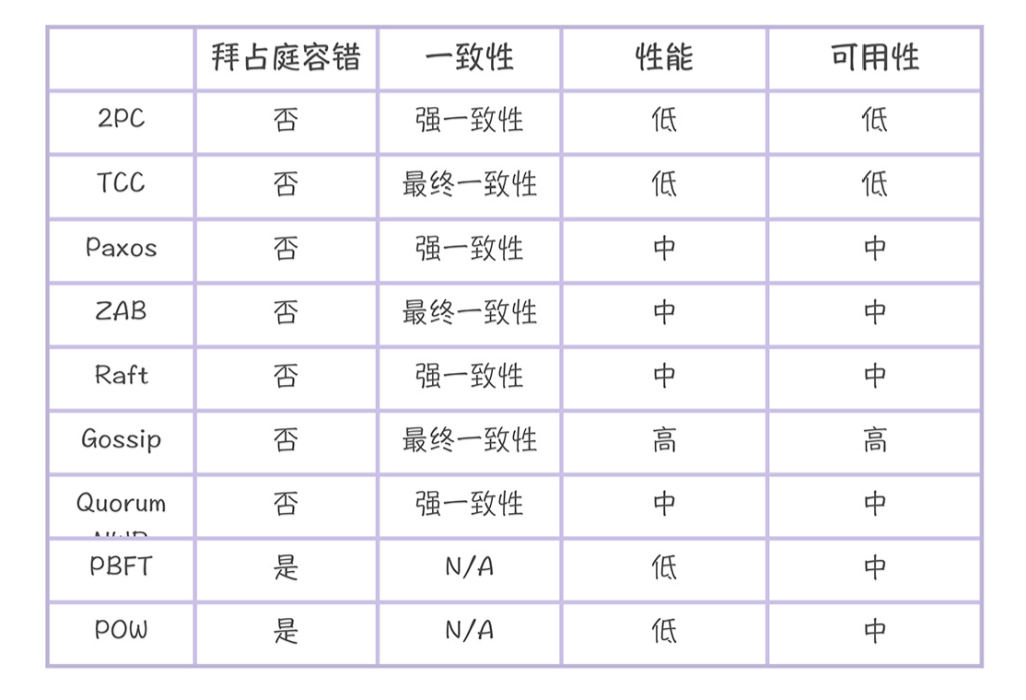 +这里的ZAB为何是最终一致性而不是强一致性?[参考](https://www.zhihu.com/question/455703356/answer/1847949827)
+
+- 写是强一致性,单领导者模型,写需要majority保证,脑裂情况下也可以写强一致
+- 读两种接口,1:读单个机器的,2:只读主的。但脑裂时多个主还是不能强一致性。
+- etcd做了读的优化,读时也需要majority(多数同意),需要大伙同意认为它是主,但牺牲了效率。
+
+这里的一致性是从读写方面,写一致性,都写成功,读一致性,从提供的读接口任意时刻咋读都一样。和事务一致性不太一样。
+
## 分布式互斥方法(集中,民主协商,轮值ceo(令牌))
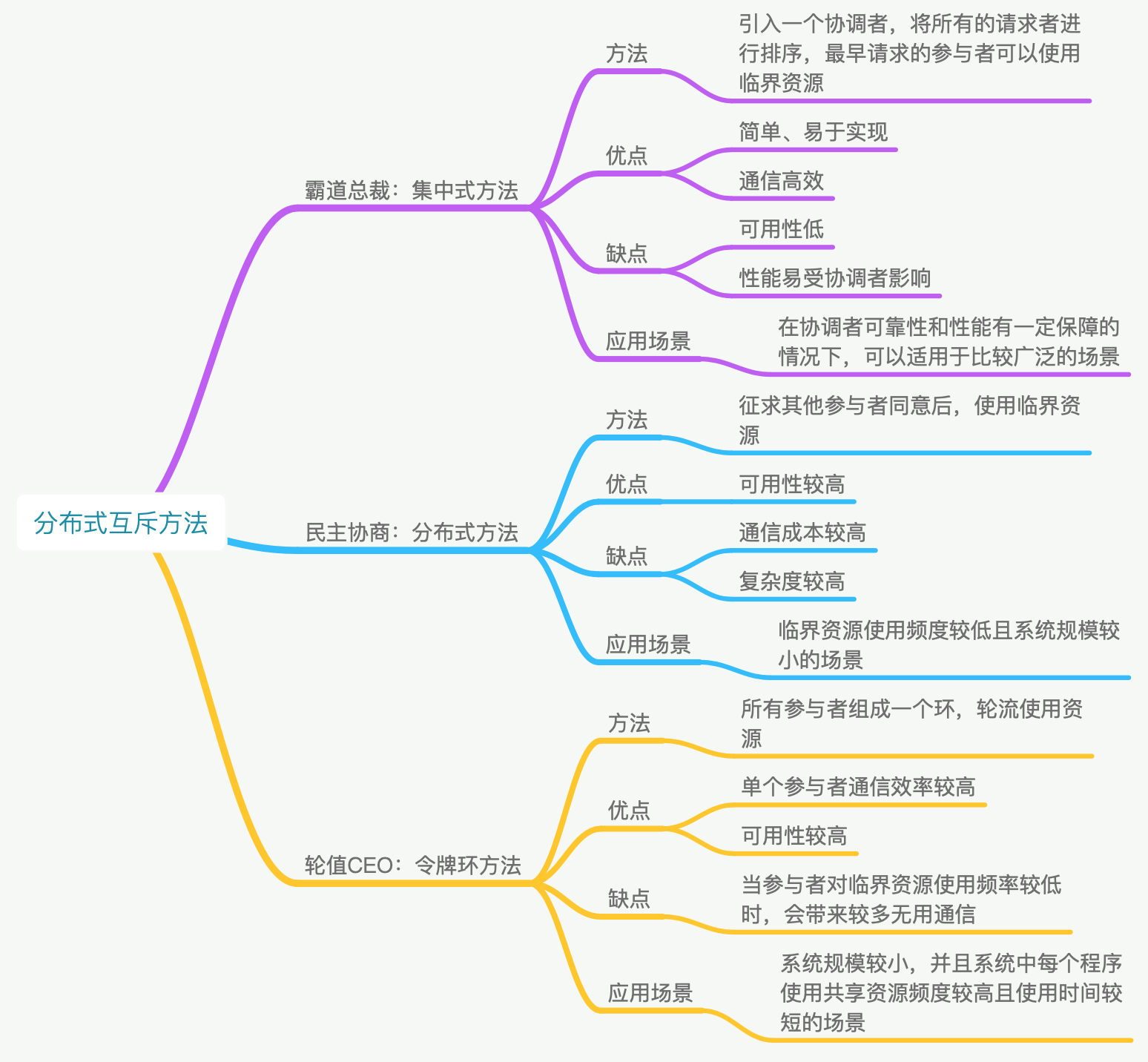
diff --git "a/_posts/Tech/DistributedSystem/2021-12-26-etcd\345\222\214raft.md" "b/_posts/Tech/DistributedSystem/2021-12-26-etcd\345\222\214raft.md"
index 3fd12cdff4..0bf8fbfdf5 100644
--- "a/_posts/Tech/DistributedSystem/2021-12-26-etcd\345\222\214raft.md"
+++ "b/_posts/Tech/DistributedSystem/2021-12-26-etcd\345\222\214raft.md"
@@ -3,6 +3,7 @@ layout: post
category: DistributedSystem
title: etcd和raft
tags: DistributedSystem
+recent_update: true
---
# etcd
diff --git a/_posts/Tech/DistributedSystem/2022-02-21-zookeeper.md b/_posts/Tech/DistributedSystem/2022-02-21-zookeeper.md
new file mode 100644
index 0000000000..e1e4daccb6
--- /dev/null
+++ b/_posts/Tech/DistributedSystem/2022-02-21-zookeeper.md
@@ -0,0 +1,40 @@
+---
+layout: post
+category: DistributedSystem
+title: zookeeper
+tags: DistributedSystem
+---
+
+## zookeeper
+
+
+
+了解zk: [参考](https://segmentfault.com/a/1190000022431516)
+
+zk有序树形节点实现分布式锁: [参考](http://www.cyc2018.xyz/%E5%85%B6%E5%AE%83/%E7%B3%BB%E7%BB%9F%E8%AE%BE%E8%AE%A1/%E5%88%86%E5%B8%83%E5%BC%8F.html#zookeeper-%E7%9A%84%E6%9C%89%E5%BA%8F%E8%8A%82%E7%82%B9)
+
+- Kafka 选举就用的这个。leader选举。
+
+paxos执行过程: [参考](http://www.cyc2018.xyz/%E5%85%B6%E5%AE%83/%E7%B3%BB%E7%BB%9F%E8%AE%BE%E8%AE%A1/%E5%88%86%E5%B8%83%E5%BC%8F.html#%E6%9C%80%E7%BB%88%E4%B8%80%E8%87%B4%E6%80%A7)
+
+zk基于zab协议,是个paxos的变种。
+
+zk的所有副本都可以提供读服务,与此相对应的,只有主节点可以提供写服务。
+
+选举原则:数据最新or ID最大的节点作为主。
+
+## QA
+
+### zk会脑裂吗
+
+不会脑裂。默认 **只有获得超过半数节点的投票, 才能选举出leader.** 因此只会有一个leader存在。可能会有部分节点没有follow leader。这些节点已经挂了。
+
+### zk or ZAB为何是最终一致性而不是强一致性
+
+[参考](https://www.zhihu.com/question/455703356/answer/1847949827)
+
+- 写是强一致性,单领导者模型,写需要majority保证(写节点超过一半),脑裂情况下也可以写强一致
+- 读两种接口,1:读单个机器的,2:只读主的。如果是后者就是强一致性的。
+- etcd做了读的优化,读时也需要majority,需要大伙同意认为它是主,但牺牲了效率。
+
+这里的一致性是从读写方面,写一致性,都写成功,读一致性,从提供的读接口任意时刻咋读都一样。和事务一致性不太一样。
\ No newline at end of file
diff --git "a/_posts/Tech/DistributedSystem/2022-11-26-\346\227\240\344\270\273\345\244\215\345\210\266\347\263\273\347\273\237.md" "b/_posts/Tech/DistributedSystem/2022-11-26-\346\227\240\344\270\273\345\244\215\345\210\266\347\263\273\347\273\237.md"
new file mode 100644
index 0000000000..ee018bc3b1
--- /dev/null
+++ "b/_posts/Tech/DistributedSystem/2022-11-26-\346\227\240\344\270\273\345\244\215\345\210\266\347\263\273\347\273\237.md"
@@ -0,0 +1,63 @@
+---
+layout: post
+category: DistributedSystem
+title: 无主复制系统
+tags: DistributedSystem
+---
+
+为什么需要复制数据? - 允许系统在部分节点出现故障后继续工作(增加可用性) - 地理上保持数据离用户更近(减少延迟) - 扩展可以提供查询的机器数量(增加读吞吐)
+
+复制算法: 1. 单主复制:所有客户端都将写入操作发送到主节点上,该节点负责将数据更改事件发送到其它副本。每个副本都可以接受读请求,但内容可能是过期值。 2. 多主复制:系统中存在多个主节点,每个都可以接受请求,客户端将写请求发送到其中一个主节点上,该节点负责将数据更改事件同步到其它主节点和自己的从节点。 3. 无主复制:客户端将写请求发送多个节点上,读取时从多个节点上并行读取,以此检测和纠正某些过期数据。
+
+主从复制可参考 [link](https://iswade.github.io/database/replication/)
+
+## 无主复制
+
+单主、多主复制思路都是:客户端向一个主节点发写请求,而DB系统负责将写请求复制到其他副本。主节点决定写顺序,从节点按相同顺序应用主节点发送的写日志。
+
+某些数据存储系统采用不同设计:放弃主节点,允许任何副本直接接受客户端的写。最早的复制数据系统就是无主节点的(或称之为去中心复制、无中心复制),但后来在关系数据库主导时代,这个想法几乎被忘却。在亚马逊将其用于其内部的Dynamo系统后,它再一次成为流行的DB架构。 Riak,Cassandra和Voldemort都是由Dynamo启发的无主复制模型的开源数据存储,所以这类数据库也被称为*Dynamo风格*。
+
+
+
+在一些无主实现中,客户端直接将写请求发到多副本,而另一些实现中,有一个协调者(coordinator)节点代表客户端进行写入,但与主节点的数据库不同,协调者不负责维护写入顺序。这种设计差异对DB使用方式有深远影响。
+
+
+
+失效节点重新上线,而客户端开始读取它。节点失效期间发生的任何写入在该节点都尚未同步,因此读取可能得到过期数据。
+
+为解决该问题,当一个客户端从DB读数据时,它不是向1个副本发送请求,而是并行发送到多副本。客户端可能会从不同节点获得不同响应,即来自一个节点的最新值和来自另一个节点的旧值。可利用版本号确定哪个值更新。
+
+### 读修复和反熵
+
+复制模型应确保所有数据最终复制到所有副本。在一个失效节点重新上线后,它如何赶上错过的写入呢?
+
+Dynamo风格的数据存储系统常机制:
+
+#### 读修复(Read repair)
+
+当客户端并行读取多副本时,可检测到过期的返回值。客户端可判断副本3是过期值,然后将新值写入该副本。适用于读密集场景
+
+#### 反熵过程(Anti-entropy process)
+
+一些数据存储有后台进程,不断查找副本之间的数据差异,将任何缺少的数据从一个副本复制到另一个副本。和基于主节点复制的复制日志不同,此反熵过程不保证任何特定的顺序复制写入,并且会引入明显的同步滞后
+
+
+
+并非所有系统都实现这俩方案。如Voldemort目前无反熵过程。若无反熵过程,由于【读修复】只在发生读取时才可能执行修复,那些很少访问的数据有可能在某些副本中已丢失而无法再检测到,从而降低了写的持久性。
+
+
+
+反熵就是树形的hash,用于快速比较数据是否一致的。
+
+
+
+## 参考
+
+- [**无主复制系统(1)-节点故障时写DB**](https://blog.51cto.com/u_11440114/5550577)
+- [**无主复制系统(2)-读写quorum**](https://blog.51cto.com/u_11440114/5550582)
+
+
+
+
+
+TODO: 需要读下ddia.
diff --git a/_posts/Tech/DistributedSystem/2023-03-19-service mesh.md b/_posts/Tech/DistributedSystem/2023-03-19-service mesh.md
new file mode 100644
index 0000000000..990d79635e
--- /dev/null
+++ b/_posts/Tech/DistributedSystem/2023-03-19-service mesh.md
@@ -0,0 +1,34 @@
+---
+layout: post
+category: DistributedSystem
+title: service mesh
+tags: DistributedSystem
+---
+
+## service mesh
+
+在TCP出现之后,机器之间的网络通信不再是一个难题,以GFS/BigTable/MapReduce为代表的分布式系统得以蓬勃发展。这时,分布式系统特有的通信语义又出现了,如熔断策略、负载均衡、服务发现、认证和授权、quota限制、trace和监控等等,于是服务根据业务需求来实现一部分所需的通信语义。
+
+service mesh就实现了这种通信语义。
+
+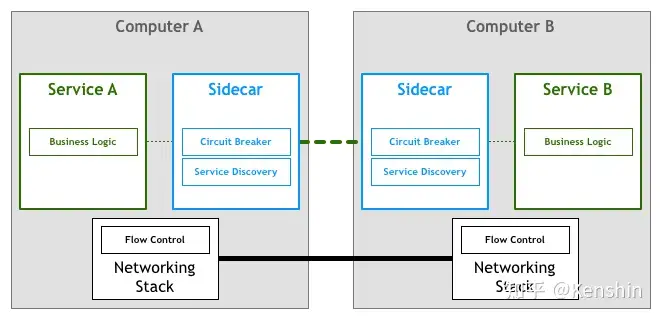
+
+服务网格是一个基础设施层,用于处理服务间通信。云原生应用有着复杂的服务拓扑,服务网格保证请求在这些拓扑中可靠地穿梭。在实际应用当中,服务网格通常是由一系列轻量级的网络代理组成的,它们与应用程序部署在一起,但对应用程序透明。
+
+**`Service Mesh`目的是解决系统架构微服务化后的服务间通信和治理问题。** 服务网格由`Sidecar`节点组成,这个模式的精髓在于实现了数据面(业务逻辑)和控制面的解耦。具体到[微服务](https://so.csdn.net/so/search?q=微服务&spm=1001.2101.3001.7020)架构中,即给每一个微服务实例同步部署一个`Sidecar`。可以sidecar形式和应用程序部署到一起。
+
+
+
+Service Mesh具有如下优点:
+
+- 屏蔽分布式系统通信的复杂性(负载均衡、服务发现、认证授权、监控追踪、流量控制等等),服务只用关注业务逻辑;
+- 真正的语言无关,服务可以用任何语言编写,只需和Service Mesh通信即可;
+- 对应用透明,Service Mesh组件可以单独升级;
+
+
+
+
+
+## 参考
+
+- [什么是 Service Mesh](https://zhuanlan.zhihu.com/p/61901608)
\ No newline at end of file
diff --git a/_posts/Tech/ElasticSearch/2020-12-08-ElasticSearch.md b/_posts/Tech/ElasticSearch/2020-12-08-ElasticSearch.md
index de4939df98..5eda1601ec 100644
--- a/_posts/Tech/ElasticSearch/2020-12-08-ElasticSearch.md
+++ b/_posts/Tech/ElasticSearch/2020-12-08-ElasticSearch.md
@@ -3,6 +3,7 @@ layout: post
category: ElasticSearch
title: ElasticSearch(ES)原理
tags: ElasticSearch
+recent_update: true
---
## Part1: ES介绍及核心概念
diff --git "a/_posts/Tech/FrontEnd/2017-12-03-css\345\255\246\344\271\240\347\254\224\350\256\260.md" "b/_posts/Tech/FrontEnd/2017-12-03-css\345\255\246\344\271\240\347\254\224\350\256\260.md"
index 1df5eb98e6..a76bfdfb2d 100644
--- "a/_posts/Tech/FrontEnd/2017-12-03-css\345\255\246\344\271\240\347\254\224\350\256\260.md"
+++ "b/_posts/Tech/FrontEnd/2017-12-03-css\345\255\246\344\271\240\347\254\224\350\256\260.md"
@@ -4,7 +4,39 @@ category: FrontEnd
title: CSS笔记
tags: FrontEnd
---
+# 概述
+
+CSS:Cascading Style Sheet,层叠样式表。CSS 的作用就是给 HTML 页面标签添加各种样式,**定义网页的显示效果**。简单一句话:CSS 将网页**内容和显示样式进行分离**,提高了显示功能。
+
+**CSS 优点:**
+
+1. 使数据和显示分开
+2. 降低网络流量
+3. 使整个网站视觉效果一致
+4. 使开发效率提高了(耦合性降低,一个人负责写 html,一个人负责写 css)
+
+比如说,有一个样式需要在一百个页面上显示,如果是 html 来实现,那要写一百遍,现在有了 css,只要写一遍。现在,html 只提供数据和一些控件,完全交给 css 提供各种各样的样式。
+
+重点:盒子模型、浮动、定位
+
+
+
+CSS 的书写方式,实就是问你 CSS 的代码放在哪个位置。CSS 代码理论上的位置是任意的,**但通常写在`
+
+
+
+这里的ZAB为何是最终一致性而不是强一致性?[参考](https://www.zhihu.com/question/455703356/answer/1847949827)
+
+- 写是强一致性,单领导者模型,写需要majority保证,脑裂情况下也可以写强一致
+- 读两种接口,1:读单个机器的,2:只读主的。但脑裂时多个主还是不能强一致性。
+- etcd做了读的优化,读时也需要majority(多数同意),需要大伙同意认为它是主,但牺牲了效率。
+
+这里的一致性是从读写方面,写一致性,都写成功,读一致性,从提供的读接口任意时刻咋读都一样。和事务一致性不太一样。
+
## 分布式互斥方法(集中,民主协商,轮值ceo(令牌))

diff --git "a/_posts/Tech/DistributedSystem/2021-12-26-etcd\345\222\214raft.md" "b/_posts/Tech/DistributedSystem/2021-12-26-etcd\345\222\214raft.md"
index 3fd12cdff4..0bf8fbfdf5 100644
--- "a/_posts/Tech/DistributedSystem/2021-12-26-etcd\345\222\214raft.md"
+++ "b/_posts/Tech/DistributedSystem/2021-12-26-etcd\345\222\214raft.md"
@@ -3,6 +3,7 @@ layout: post
category: DistributedSystem
title: etcd和raft
tags: DistributedSystem
+recent_update: true
---
# etcd
diff --git a/_posts/Tech/DistributedSystem/2022-02-21-zookeeper.md b/_posts/Tech/DistributedSystem/2022-02-21-zookeeper.md
new file mode 100644
index 0000000000..e1e4daccb6
--- /dev/null
+++ b/_posts/Tech/DistributedSystem/2022-02-21-zookeeper.md
@@ -0,0 +1,40 @@
+---
+layout: post
+category: DistributedSystem
+title: zookeeper
+tags: DistributedSystem
+---
+
+## zookeeper
+
+
+
+了解zk: [参考](https://segmentfault.com/a/1190000022431516)
+
+zk有序树形节点实现分布式锁: [参考](http://www.cyc2018.xyz/%E5%85%B6%E5%AE%83/%E7%B3%BB%E7%BB%9F%E8%AE%BE%E8%AE%A1/%E5%88%86%E5%B8%83%E5%BC%8F.html#zookeeper-%E7%9A%84%E6%9C%89%E5%BA%8F%E8%8A%82%E7%82%B9)
+
+- Kafka 选举就用的这个。leader选举。
+
+paxos执行过程: [参考](http://www.cyc2018.xyz/%E5%85%B6%E5%AE%83/%E7%B3%BB%E7%BB%9F%E8%AE%BE%E8%AE%A1/%E5%88%86%E5%B8%83%E5%BC%8F.html#%E6%9C%80%E7%BB%88%E4%B8%80%E8%87%B4%E6%80%A7)
+
+zk基于zab协议,是个paxos的变种。
+
+zk的所有副本都可以提供读服务,与此相对应的,只有主节点可以提供写服务。
+
+选举原则:数据最新or ID最大的节点作为主。
+
+## QA
+
+### zk会脑裂吗
+
+不会脑裂。默认 **只有获得超过半数节点的投票, 才能选举出leader.** 因此只会有一个leader存在。可能会有部分节点没有follow leader。这些节点已经挂了。
+
+### zk or ZAB为何是最终一致性而不是强一致性
+
+[参考](https://www.zhihu.com/question/455703356/answer/1847949827)
+
+- 写是强一致性,单领导者模型,写需要majority保证(写节点超过一半),脑裂情况下也可以写强一致
+- 读两种接口,1:读单个机器的,2:只读主的。如果是后者就是强一致性的。
+- etcd做了读的优化,读时也需要majority,需要大伙同意认为它是主,但牺牲了效率。
+
+这里的一致性是从读写方面,写一致性,都写成功,读一致性,从提供的读接口任意时刻咋读都一样。和事务一致性不太一样。
\ No newline at end of file
diff --git "a/_posts/Tech/DistributedSystem/2022-11-26-\346\227\240\344\270\273\345\244\215\345\210\266\347\263\273\347\273\237.md" "b/_posts/Tech/DistributedSystem/2022-11-26-\346\227\240\344\270\273\345\244\215\345\210\266\347\263\273\347\273\237.md"
new file mode 100644
index 0000000000..ee018bc3b1
--- /dev/null
+++ "b/_posts/Tech/DistributedSystem/2022-11-26-\346\227\240\344\270\273\345\244\215\345\210\266\347\263\273\347\273\237.md"
@@ -0,0 +1,63 @@
+---
+layout: post
+category: DistributedSystem
+title: 无主复制系统
+tags: DistributedSystem
+---
+
+为什么需要复制数据? - 允许系统在部分节点出现故障后继续工作(增加可用性) - 地理上保持数据离用户更近(减少延迟) - 扩展可以提供查询的机器数量(增加读吞吐)
+
+复制算法: 1. 单主复制:所有客户端都将写入操作发送到主节点上,该节点负责将数据更改事件发送到其它副本。每个副本都可以接受读请求,但内容可能是过期值。 2. 多主复制:系统中存在多个主节点,每个都可以接受请求,客户端将写请求发送到其中一个主节点上,该节点负责将数据更改事件同步到其它主节点和自己的从节点。 3. 无主复制:客户端将写请求发送多个节点上,读取时从多个节点上并行读取,以此检测和纠正某些过期数据。
+
+主从复制可参考 [link](https://iswade.github.io/database/replication/)
+
+## 无主复制
+
+单主、多主复制思路都是:客户端向一个主节点发写请求,而DB系统负责将写请求复制到其他副本。主节点决定写顺序,从节点按相同顺序应用主节点发送的写日志。
+
+某些数据存储系统采用不同设计:放弃主节点,允许任何副本直接接受客户端的写。最早的复制数据系统就是无主节点的(或称之为去中心复制、无中心复制),但后来在关系数据库主导时代,这个想法几乎被忘却。在亚马逊将其用于其内部的Dynamo系统后,它再一次成为流行的DB架构。 Riak,Cassandra和Voldemort都是由Dynamo启发的无主复制模型的开源数据存储,所以这类数据库也被称为*Dynamo风格*。
+
+
+
+在一些无主实现中,客户端直接将写请求发到多副本,而另一些实现中,有一个协调者(coordinator)节点代表客户端进行写入,但与主节点的数据库不同,协调者不负责维护写入顺序。这种设计差异对DB使用方式有深远影响。
+
+
+
+失效节点重新上线,而客户端开始读取它。节点失效期间发生的任何写入在该节点都尚未同步,因此读取可能得到过期数据。
+
+为解决该问题,当一个客户端从DB读数据时,它不是向1个副本发送请求,而是并行发送到多副本。客户端可能会从不同节点获得不同响应,即来自一个节点的最新值和来自另一个节点的旧值。可利用版本号确定哪个值更新。
+
+### 读修复和反熵
+
+复制模型应确保所有数据最终复制到所有副本。在一个失效节点重新上线后,它如何赶上错过的写入呢?
+
+Dynamo风格的数据存储系统常机制:
+
+#### 读修复(Read repair)
+
+当客户端并行读取多副本时,可检测到过期的返回值。客户端可判断副本3是过期值,然后将新值写入该副本。适用于读密集场景
+
+#### 反熵过程(Anti-entropy process)
+
+一些数据存储有后台进程,不断查找副本之间的数据差异,将任何缺少的数据从一个副本复制到另一个副本。和基于主节点复制的复制日志不同,此反熵过程不保证任何特定的顺序复制写入,并且会引入明显的同步滞后
+
+
+
+并非所有系统都实现这俩方案。如Voldemort目前无反熵过程。若无反熵过程,由于【读修复】只在发生读取时才可能执行修复,那些很少访问的数据有可能在某些副本中已丢失而无法再检测到,从而降低了写的持久性。
+
+
+
+反熵就是树形的hash,用于快速比较数据是否一致的。
+
+
+
+## 参考
+
+- [**无主复制系统(1)-节点故障时写DB**](https://blog.51cto.com/u_11440114/5550577)
+- [**无主复制系统(2)-读写quorum**](https://blog.51cto.com/u_11440114/5550582)
+
+
+
+
+
+TODO: 需要读下ddia.
diff --git a/_posts/Tech/DistributedSystem/2023-03-19-service mesh.md b/_posts/Tech/DistributedSystem/2023-03-19-service mesh.md
new file mode 100644
index 0000000000..990d79635e
--- /dev/null
+++ b/_posts/Tech/DistributedSystem/2023-03-19-service mesh.md
@@ -0,0 +1,34 @@
+---
+layout: post
+category: DistributedSystem
+title: service mesh
+tags: DistributedSystem
+---
+
+## service mesh
+
+在TCP出现之后,机器之间的网络通信不再是一个难题,以GFS/BigTable/MapReduce为代表的分布式系统得以蓬勃发展。这时,分布式系统特有的通信语义又出现了,如熔断策略、负载均衡、服务发现、认证和授权、quota限制、trace和监控等等,于是服务根据业务需求来实现一部分所需的通信语义。
+
+service mesh就实现了这种通信语义。
+
+
+
+服务网格是一个基础设施层,用于处理服务间通信。云原生应用有着复杂的服务拓扑,服务网格保证请求在这些拓扑中可靠地穿梭。在实际应用当中,服务网格通常是由一系列轻量级的网络代理组成的,它们与应用程序部署在一起,但对应用程序透明。
+
+**`Service Mesh`目的是解决系统架构微服务化后的服务间通信和治理问题。** 服务网格由`Sidecar`节点组成,这个模式的精髓在于实现了数据面(业务逻辑)和控制面的解耦。具体到[微服务](https://so.csdn.net/so/search?q=微服务&spm=1001.2101.3001.7020)架构中,即给每一个微服务实例同步部署一个`Sidecar`。可以sidecar形式和应用程序部署到一起。
+
+
+
+Service Mesh具有如下优点:
+
+- 屏蔽分布式系统通信的复杂性(负载均衡、服务发现、认证授权、监控追踪、流量控制等等),服务只用关注业务逻辑;
+- 真正的语言无关,服务可以用任何语言编写,只需和Service Mesh通信即可;
+- 对应用透明,Service Mesh组件可以单独升级;
+
+
+
+
+
+## 参考
+
+- [什么是 Service Mesh](https://zhuanlan.zhihu.com/p/61901608)
\ No newline at end of file
diff --git a/_posts/Tech/ElasticSearch/2020-12-08-ElasticSearch.md b/_posts/Tech/ElasticSearch/2020-12-08-ElasticSearch.md
index de4939df98..5eda1601ec 100644
--- a/_posts/Tech/ElasticSearch/2020-12-08-ElasticSearch.md
+++ b/_posts/Tech/ElasticSearch/2020-12-08-ElasticSearch.md
@@ -3,6 +3,7 @@ layout: post
category: ElasticSearch
title: ElasticSearch(ES)原理
tags: ElasticSearch
+recent_update: true
---
## Part1: ES介绍及核心概念
diff --git "a/_posts/Tech/FrontEnd/2017-12-03-css\345\255\246\344\271\240\347\254\224\350\256\260.md" "b/_posts/Tech/FrontEnd/2017-12-03-css\345\255\246\344\271\240\347\254\224\350\256\260.md"
index 1df5eb98e6..a76bfdfb2d 100644
--- "a/_posts/Tech/FrontEnd/2017-12-03-css\345\255\246\344\271\240\347\254\224\350\256\260.md"
+++ "b/_posts/Tech/FrontEnd/2017-12-03-css\345\255\246\344\271\240\347\254\224\350\256\260.md"
@@ -4,7 +4,39 @@ category: FrontEnd
title: CSS笔记
tags: FrontEnd
---
+# 概述
+
+CSS:Cascading Style Sheet,层叠样式表。CSS 的作用就是给 HTML 页面标签添加各种样式,**定义网页的显示效果**。简单一句话:CSS 将网页**内容和显示样式进行分离**,提高了显示功能。
+
+**CSS 优点:**
+
+1. 使数据和显示分开
+2. 降低网络流量
+3. 使整个网站视觉效果一致
+4. 使开发效率提高了(耦合性降低,一个人负责写 html,一个人负责写 css)
+
+比如说,有一个样式需要在一百个页面上显示,如果是 html 来实现,那要写一百遍,现在有了 css,只要写一遍。现在,html 只提供数据和一些控件,完全交给 css 提供各种各样的样式。
+
+重点:盒子模型、浮动、定位
+
+
+
+CSS 的书写方式,实就是问你 CSS 的代码放在哪个位置。CSS 代码理论上的位置是任意的,**但通常写在`
+
+
+
{{ page.title }}
{{ content }} - diff --git a/_layouts/wiki.html b/_layouts/wiki.html deleted file mode 100755 index 68c3ac2e32..0000000000 --- a/_layouts/wiki.html +++ /dev/null @@ -1,46 +0,0 @@ ---- -layout: default ---- - -{% assign assets_base_url = site.url %} -{% if site.cdn.jsdelivr.enabled %} -{% assign assets_base_url = "https://cdn.jsdelivr.net/gh/" | append: site.repository | append: '@master' %} -{% endif %} -
-
-
-
-
-
-
-
- {{ page.title }}
-
- {% include sidebar-qrcode.html %}
-
-
-
-
- {% include content-header-ad.html %}
-
- {{ content }}
-
-
-
- {% include content-footer-ad.html %}
-
-
- {% include comments.html %}
-
-
- {% include sidebar-search.html %}
- {% include sidebar-post-nav.html %}
-
-
+
+参考
+
+- Internet Gateway (IGW) allows instances with public IPs to access the internet.
+- NAT Gateway (NGW) allows instances with no public IPs to access the internet.
+
+## 参考
+
+[参考](https://juejin.cn/post/6949072638145003556)
+
+大部分 AWS 服务都需要以 VPC 为基础进行构建,比如最常用的 EC2,ALB,及无服务器服务 ECS Fargate。 vb
+
+当我们在一个 VPC 中创建 Subnet 时需要给 Subnet 选择一个 AZ(Availability Zone),一个 Subnet 只能选择建在一个 AZ 中。
+
+
+
+**选择region**
+
+因为国内政策法规原因,AWS 在中国的服务与 AWS Global 服务略有不同。
+
+AWS Global 的 Region 之间是通过主干网相连的,AWS 中国区的服务没有通过主干网与 AWS Global 相连,只有中国区内部两个 Region,北京和宁夏是相连接的。
+
+在创建 VPC 时并不需要添写 AZ(Availability Zone)信息,VPC 只与 Region 有关。
+
+
+
+Subnet 是最终承载大部分 AWS 服务的组件,比如 EC2, ECS Fargate,RDS。
+
+Subnet 分为两种 Private Subnet 和 Public Subnet。
+
+简单来说,不能直接访问 internet 的 Subnet 就是 Private Subnet,能直接访问 internet 的就是 Public Subnet。
+
+
+
+Security Group(SG)通过控制IP和端口来控制出站入站规则,可以用于EC2,RDS及下面将要用到的VPC Endpoint。
+
+
+
+VPC Endpoint用来直接连接VPC与AWS相关服务,比如RDS AIP,S3。
+
+当系统安全要求比较高时,EC2处于的Subnet可能被限制,无法访问internet,这时EC2就无法访问AWS的一些服务,比如SSM。
+
+这时我们可以利用VPC Endpoint把VPC和所需要访问的服务连接起来,然后EC2就可以不经internet访问到所需的服务。
+
+
+
+[参考](https://juejin.cn/post/6954169148318433288)
+
+RT(Route Table)与Subnet相关连,用来描述网络路由。IGW: Internet gateway IGW是一个独立的组件配置在VPC上,使得VPC可以访问internet
+
+我们给VPC加了IGW之后,需要修改Subnet相关的路由,确保访问Internet的请求发送到IGW。
+
+每个VPC中有一个默认的主RT,自动关联VPC内的每一个Subnet。我们现在为Subnet “ts-public-1”单独创建一个新的RT。
+
+
+
+- 新建的Subnet就是Private Subnet
+- 在Private Subnet中配置了到IGW的路由后,就变成Public Subnet
+- Public Subnet中的EC2还要再配置一个Public IP或者EIP就可以访问Internet
+- 如果EC2可以访问internet,其关联的Security Group入站规则如果允许从internet访问,那么这个EC2就可以从internet中直接访问到。
+
+
+
+1. 实践中我们把应用程序,数据库放在Private Subnet中,阻止从internet访问。把堡垒机和ALB(Application Load balancer)放在Public Subnet,允许从internet访问。
+
+2. 一般我们会建两套Public Subnet和Private Subnet,分别放在不同的AZ中,防止其中一个AZ出问题。这时如果配置NAT,也需要在两个Public Subnet中各配置一个NAT。
+
+
+
+[参考](http://www.cloudbin.cn/?tag=aws) 暂无Note
+
+## 总结
+
+VPC里多个AZ, 每个AZ都需要至少一个子网,默认是公有子网。但如果有internet访问不到的实例或者数据库,则需建个私有子网,私有子网默认不能访问internet,internet也不能访问私有子网。
+
+要走互联网必须走internet gateway,它对整个vpc生效, public subnet可直接通过IGW与互联网互联,私有子网再通过NAT走公有子网是可以访问internet的,反向不能。
+
+和互联网连接时都需要有个公网ip,这个是从amazon分配的。
+
+
+
+# 跨账号访问aws service总结
+
+比如 本账号lambda访问另一个账号的DDB
+
+Lambda 跨账号访问另一个账号中的 DynamoDB 表,一共有以下几种方法:
+
+1. 使用 assumeRole API:Lambda 函数在执行时使用 assumeRole API 切换到具有访问目标账号 DynamoDB 表权限的 IAM 角色。这种方法的优点是简单易用,只需要在代码中调用 assumeRole API 即可。缺点是需要进行额外的 IAM 角色配置和权限管理,同时存在一定的安全风险,因为将 IAM 凭证直接硬编码到代码中可能会导致安全问题。
+2. 使用 VPC Peering:通过建立 VPC Peering 连接,将源账号和目标账号的 VPC 相互连接起来,实现 Lambda 函数对 DynamoDB 表的访问。这种方法的优点是简单易用,可以通过 AWS 控制台完成配置,同时具有较高的安全性。缺点是需要进行 VPC 配置和管理,且无法实现跨区域访问。
+3. 使用 PrivateLink:通过在目标账号中创建一个 PrivateLink 终端节点,将 DynamoDB 表以私有方式暴露给源账号中的 Lambda 函数,实现跨账号访问。这种方法的优点是高度安全,可以通过 AWS PrivateLink 在私有网络中实现数据的加密传输,同时支持跨区域访问。缺点是需要进行较为复杂的 VPC 和 PrivateLink 配置,且可能需要进行网络安全设置和管理。
+4. 使用 AWS Resource Access Manager(RAM):通过使用 RAM,可以在多个 AWS 账号之间共享资源,并授予其他 AWS 账号访问这些资源的权限。Lambda 函数可以将 RAM 中的资源授权给目标账号,从而实现对 DynamoDB 表的访问。这种方法的优点是可以实现资源共享和管理,并且具有高度的可扩展性。缺点是需要进行 RAM 的配置和管理,且可能需要进行跨账号 IAM 角色的授权和管理。
+
+
+
+一般来说,如果需要实现高度安全性和数据隔离,且需要支持跨区域访问,推荐使用 PrivateLink;如果只是需要简单快速地实现跨账号访问,可以选择使用 assumeRole API 或 VPC Peering。如果需要进行资源共享和管理,可以考虑使用 AWS RAM。
+
+# Route 53
+
+**Amazon Route 53**是一种高可用、高扩展性的云DNS服务。
+
+Amazon Route 53 是一种托管域名系统 (DNS) 服务,它可帮助您为您的域名注册和管理 DNS 记录。您可以使用 Route 53 将您的域名映射到您的 VPC 内的资源,如 ELB 和 Amazon S3。
+
+不同的DNS记录:
+
+- **CNAME** – CNAME (Canonical Name)可以将一个域名指向另一个域名。比如将aws.xiaopeiqing.com指向xiaopeiqing.com
+- Alias记录 – 和CNAME类似,又叫做别名记录,可以将一个域名指向另一个域名。
+ - **和CNAME最大的区别是,Alias可以应用在根域(Zone Apex)。即可以为xiaopeiqing.com的根域创建Alias记录,而不能创建CNAME**
+ - 别名记录可以节省你的时间,因为Route53会自动识别别名记录所指的记录中的更改。例如,假设example.com的一个别名记录指向位于lb1-1234.us-east-2.elb.amazonaws.com上的一个ELB负载均衡器。如果该负载均衡器的IP地址发生更改,Route53将在example.com的DNS应答中自动反映这些更改,而无需对包含example.com的记录的托管区域做出任何更改。 弹性负载均衡器(ELB)没有固定的IPv4地址,在使用ELB的时候永远使用它的DNS名字。很多场景下我们需要绑定DNS记录到ELB的endpoint地址,而不绑定任何IP
+
+# AWS Direct Connect
+
+AWS Direct Connect 是一种专用网络连接服务,它允许您通过私有连接连接到 AWS 服务。您可以使用 Direct Connect 将您的本地数据中心与您的 VPC 直接连接起来,实现更安全、更高带宽的网络连接。
+
+
+
+AWS Direct Connect 是一种联网服务,提供了通过互联网连接到AWS 的替代方案。 使用AWS Direct Connect ,以前通过Internet 传输的数据将可以借助您的设施和AWS 之间的私有网络连接进行传输。
+
+**不再需要通过网络提供商。** 描述的是本地IT数据中心和VPC连接。通过物理专线连接。
+
+AWS Direct Connect 通过标准的以太网光纤电缆将您的内部网络链接到 AWS Direct Connect 位置。电缆的一端接到您的路由器,另一端接到 AWS Direct Connect 路由器。有了这个连接,你可以创建*虚拟接口*直接公有公有访问AWS服务(例如,到 Amazon S3)或 Amazon VPC,绕过您的网络路径中的互联网服务提供商。网络 ACL 和安全组都允许 (因此可到达您的实例) 的发起 ping 的AWS Direct Connect位置提供访问AWS在与之关联的区域中。您可以将单个连接用于公有区域或AWS GovCloud (US)公有访问AWS所有其他公有区域中的服务。
+
+[参考](https://docs.aws.amazon.com/zh_cn/directconnect/latest/UserGuide/Welcome.html)
+
diff --git a/_posts/Tech/AWS/2022-11-18-AWS Compute.md b/_posts/Tech/AWS/2022-11-18-AWS Compute.md
new file mode 100644
index 0000000000..4067771a68
--- /dev/null
+++ b/_posts/Tech/AWS/2022-11-18-AWS Compute.md
@@ -0,0 +1,195 @@
+---
+layout: post
+category: AWS
+title: AWS Compute
+tags: AWS
+---
+
+## AWS Compute
+
+## AMI
+
+AMI: amazon machine image 就是一堆配置,比如什么系统,安装哪些附加软件。可使用AMI启动一个同配置的实例。 类似docker的image
+
+**Amazon Machine Image (AMI)** 是亚马逊AWS提供的系统镜像,这个AMI包含了如下的信息:
+
+- 由实例的操作系统、应用程序和应用程序相关的配置组成的模板
+- 一个指定的需要在实例启动时附加到实例的卷的信息(比方说定义了使用8 GB的General Purpose SSD卷)
+
+下图所示的是AMI的生命周期,你可以创建并注册一个AMI,并且可以使用这个AMI来创建一个EC2实例。同时你也可以将这个AMI复制到同一个AWS区域或者不同的AWS区域。你同样也可以注销这个AMI镜像。
+
+
+
+- **AMI是区域化的**,只能使用本区域的AMI来创建实例;但你可以将AMI从一个区域复制到另一个区域
+
+
+
+
+
+## 弹性伸缩(Auto Scaling)
+
+**亚马逊弹性伸缩(Auto Scaling)**能**自动地**增加/减少EC2实例的数量,从而让你的应用程序一直能保持可用的状态。
+
+你可以预定义Auto Scaling,使其在需求高峰期自动增加EC2实例,而在需求低谷自动减少EC2实例。这样不仅能让你的应用程序一直保持健康的状态,而且也节省了你为EC2实例所付出的费用。
+
+Auto Scaling 适用于那些需求稳定的应用程序,同时也适用于在每小时、每天、甚至每周都有需求变化的应用程序。
+
+- Auto Scaling能保证你一直拥有一定数量的EC2实例来分担应用程序的负载
+- Auto Scaling能带来更高的容错性、更好的可用性和更高的性价比
+- 你可以控制伸缩的策略来决定在什么时候终止和创建EC2实例,以处理动态变化的需求
+- 默认情况下,Auto Scaling能控制每一个可用区内所运行的实例数量尽量平均
+ - 为了达到这个目标,Auto Scaling在需要启动新实例的时候,会选择一个目前拥有运行实例最少的可用区
+
+Auto Scaling的构成组件:
+
+
+
+### 启动配置(Launch Configuration)
+
+- 启动配置是弹性伸缩组用来启动EC2实例的时候所使用的模板
+- 启动配置包含了镜像文件(AMI),实例类型、密钥对、安全组和挂载的存储设备
+- 一个启动配置可以关联多个Auto Scaling组
+- **启动配置一经创建不能被更改,只能删除重建**
+- 启动配置中可以使用CloudWatch的基础监控(Basic Monitoring)或者详细监控(Detail Monitoring)
+- Auto Scaling automatically creates a launch configuration directly from an EC2 instance.
+
+### 弹性伸缩组(Auto Scaling Group)
+
+- 弹性伸缩组(ASG)是弹性伸缩的核心,它包含了多个拥有类似配置/类型的EC2实例,这些实例被逻辑上认为是一样的
+- 弹性伸缩组需要的几个参数:
+ - **启动配置(Launch Configuration)**:它决定了EC2使用什么模板,模板内容包括了镜像文件(AMI),实例类型、密钥对、安全组和挂载的存储设备
+ - **最小和最大的性能**:决定了在弹性伸缩的情况下,EC2实例数量的浮动范围
+ - **所需的性能**:决定了这个弹性伸缩组要保持的运作所需要的基本的EC2实例数量;如果没有填写,则默认为其数值等同于最小的性能
+ - **可用区和子网**:定义EC2实例启动时候所在的可用区和子网信息
+ - **参数和健康检查**:参数定义了何时启动新实例,何时终止旧实例;健康检查决定了实例的健康状态。
+- **如果一个EC2实例的健康状态变成“不健康”,那么ASG会终止这个EC2实例,并且自动启动一个新的EC2实例**
+- 弹性伸缩组(ASG)只能在某一个AWS区域内运行,不能跨越多个区域
+- 如果启动配置(Launch Configuration)有更新,那么之后启动的新EC2实例会使用新的启动配置,而旧的EC2实例不受影响
+- 从AWS管理平台你可以直接删除一个弹性伸缩组(ASG);从AWS CLI你只能先将最小的性能和需求的性能两个参数设置为0,才能删除这个弹性伸缩组。
+
+
+
+## ECS
+
+**Amazon Elastic Container Service (ECS)**是一个有高度扩展性的**容器管理服务**。它可以轻松运行、停止和管理集群上的Docker容器,你可以将容器安装在EC2实例上,或者使用**Fargate**来启动你的服务和任务。
+
+Amazon ECS可以在一个区域内的多个可用区中创建高可用的应用程序容器,你可以定义集群中运行的Docker镜像和服务。而且你可以充分利用AWS内部的**Amazon ECR (Elastic Container Registry)**或者外部的Registry(比如Docker Hub或自建的Registry)来存储和提取容器镜像。
+
+
+
+我们可以将标准化的代码、运行环境、系统工具等等打包成一个标准的集装箱,这个集装箱叫做**Docker镜像**(Docker Image)。这个Docker镜像的概念类似于EC2中的AMI (Amazon Machine Image)。
+
+这些镜像文件通常会通过Dockerfile来构建,并且最终存放到**注册表(Registry)**内。这个Registry可以理解为摆放集装箱的码头,我们在需要某个类型的集装箱的时候就到码头去取。这类Registry可以是Amazon的ECR,也可以是公网上的Docker Hub,或者自己私有的Registry。
+
+
+
+
+
+### ECS创建举例
+
+
+
+
+
+## Lambda
+
+使用**AWS Lambda**,你无需配置和管理任何服务器和应用程序就能运行你的代码。只需要上传代码,Lambda就会处理运行并且根据需要自动进行横向扩展。因此Lambda也被称为**无服务(Serverless)**函数。
+
+要让AWS Lambda的代码执行,需要设定一些触发器(比如CloudWatch Log,CloudWatch Event,API Gateway等),因此Lambda函数被认为是**事件驱动的(Event-Driven)**。
+
+在传统的应用部署过程中,我们往往需要安装操作系统 -> 安装应用程序 -> 配置环境并部署代码,而且往往还需要不定时地为操作系统和应用程序打补丁和进行维护。使用AWS Lambda就方便很多,只需要上传代码,AWS就会在需要的时候帮你运行。我们不再需要(也无法接触)任何操作系统层面的东西,也节省了非常多的部署时间,可以更专心地编写代码。
+
+
+
+### AWS Lambda的特点
+
+- 没有服务器/无服务,或者说真实的服务器由AWS管理
+- 只需要为运行的代码付费,不需要管理服务器和操作系统
+- **持续性/自动的性能伸缩**
+- 非常便宜
+- AWS只会在代码运行期间收取相应的费用,代码未运行时不产生任何费用
+- **代码的最长执行时间是15分钟,如果代码执行时间超过15分钟,则需要将1个代码细分为多个**
+
+### 触发器有哪些
+
+- **API Gateway**
+- **AWS IoT**
+- **CloudWatch Events** 比如cron job定时任务
+- CloudWatch Logs
+- CodeCommit
+- DynamoDB
+- S3
+- SNS
+- Cognito Sync Trigger
+- SQS应该也可以?
+
+
+
+## 参考
+
+[参考](http://www.cloudbin.cn/?tag=aws)
+
+## Compute选型
+
+aws提供两种容器编排服务: ECS和EKS, k是kubernetes。 后者适合已经用了k8s的。
+
+AWS fargate就是serverless, ECS/EKS 可集成在Fargate上或者EC2上。 container hosting platform
+
+Serverless: 允许在服务部署级别而不是服务器部署级别来管理应用部署。类似Faas。无需关注主机管理,服务运维。
+
+
+
+ECS vs EC2
+
+- ECS和EKS: aws负责容器管理,但customer依旧需要负责底层的ec2 instances.
+
+Fargate vs Lambda
+
+- Fargate is a Container as a Service (CaaS) offering, AWS Lambda is a Function as a Service (FaaS offering).
+
+Fargate是类似k8s的工具,可以管理容器,进行编排。
+
+ECS vs Fargate
+
+- ECS delivers more control over the infrastructure, but the trade-off is the added management that comes with it. Fargate is the better option for ease of use as it takes infrastructure management out of the equation allowing you to focus on just the tasks to be run. ECS 提供了对基础设施的更多控制,但代价是随之而来的附加管理。Fargate 是易于使用的更好选择,因为它将基础设施管理排除在外,使您可以专注于要运行的任务。
+
+
+
+Serverless vs EC2/ECS:
+
+- If you want to deploy your workloads and applications without having to manage any EC2 instances, you can do that on AWS with serverless compute.
+- Serverless includes fargate, lambda.
+
+
+
+Serverless vs Lambda
+
+- the latter doesn't need the control of container
+
+
+
+两个方面
+
+- 是否要管理主机
+ - Yes: ecs, ec2
+ - No: fargate, lambda
+- 是否要管理容器,类似k8s的活。
+ - Yes: fargate, ecs, ec2.
+ - No: lambda
+
+
+
+
+
+虚拟机相比容器好处,重要的是资源隔离。
+
+- 拥有完整操作系统
+- 异质环境
+- 安全
+
+容器好处:
+
+- 速度和可移植性,启动只有几秒钟,虚拟机要几分钟
+- 可扩展性,通过编排器,自动扩展。
+- 模块化
+- 易于更新。
\ No newline at end of file
diff --git a/_posts/Tech/AWS/2022-11-18-AWS MQ.md b/_posts/Tech/AWS/2022-11-18-AWS MQ.md
new file mode 100644
index 0000000000..3a848ebd31
--- /dev/null
+++ b/_posts/Tech/AWS/2022-11-18-AWS MQ.md
@@ -0,0 +1,100 @@
+---
+layout: post
+category: AWS
+title: AWS MQ
+tags: AWS
+---
+
+## AWS MQ
+
+## SQS(Simple Queue Service)
+
+SQS有两种不同类型的队列,它们分别是:
+
+- **标准队列**(Standard Queue)
+- **FIFO队列**(先进先出队列)
+
+### 标准队列
+
+标准队列拥有**无限的吞吐量**,所有消息都会**至少传递一次**,并且它会尽最大努力进行排序。
+
+标准队列是默认的队列类型。
+
+
+
+### FIFO队列
+
+FIFO (First-in-first-out)队列在不使用批处理的情况下,**最多支持300TPS**(每秒300个发送、接受或删除操作)。
+
+在队列中的消息都只会**不多不少地被处理一次**。
+
+FIFO队列严格保持消息的**发送和接收顺序**。
+
+
+
+更多关于标准队列和FIFO队列的区别,可以查看[我需要哪种类型的队列?](https://docs.aws.amazon.com/zh_cn/AWSSimpleQueueService/latest/SQSDeveloperGuide/welcome.html#sqs-queue-types)
+
+### SQS的其他特点
+
+- SQS是靠应用程序去**拉取的**,而不能主动推送给应用程序,推送服务我们使用**SNS(Simple Notification Service)**
+- 消息会以256 KB的大小存放
+- 消息会在队列中保存1分钟~14天,默认时间是4天
+- 可见性超时(Visibility Timeout)
+ - 即当SQS队列收到新的消息并且被拉取走进行处理时,会触发Visibility Timeout的时间。这个消息不会被删除,而是会被设置为不可见,用来防止该消息在处理的过程中再一次被拉取
+ - 当这个消息被处理完成后,这个消息会在SQS中被删除,表示这个任务已经处理完毕
+ - 如果这个消息在Visibility Timeout时间结束之后还没有被处理完,则这个消息会设置为可见状态,等待另一个程序来进行处理
+ - 因此**同一个消息可能会被处理两次(或以上)**
+ - 这个超时时间最大可以设置为**12小时**
+- 标准SQS队列保证了每一个在队列内的消息都至少会被处理一次
+- 长轮询(Long Polling)
+ - 默认情况下,Amazon SQS使用**短轮询(Short Polling)**,即应用程序每次去查询SQS队列,SQS都会做回应(哪怕队列一直是空的)
+ - 使用了长轮训,应用程序每次去查询SQS队列,SQS队列不会马上做回应。而是等到队列里有消息可处理时,或者等到设定的超时时间再做出回应。
+ - 长轮询可以一定程度减少SQS的花销
+
+## SNS (Simple Notification Service)
+
+**SNS (Simple Notification Service)** 是一种完全托管的发布/订阅消息收发和移动通知服务,用于协调向订阅终端节点和客户端的消息分发。
+
+SNS是一项 Web 服务,用于协调和管理向订阅终端节点或客户交付或发送消息的过程。在 Amazon SNS 中有两种类型的客户端:发布者和订阅者,也称为生产者和消费者。发布者通过创建消息并将消息发送至主题与订阅者进行异步交流,主题是一个逻辑访问点和通信渠道。订阅者(即 Web 服务器、电子邮件地址、Amazon SQS 队列、AWS Lambda 函数)在其订阅主题后通过受支持协议(即 Amazon SQS、HTTP/S、电子邮件、SMS、Lambda)中的一种使用或接收消息或通知。
+
+我们可以使用SNS将消息推送到SQS消息队列中、AWS Lambda函数或者HTTP终端节点上。
+
+SNS通知还可以发送推送通知到IOS,安卓,Windows和基于百度的设备,也可以通过电子邮箱或者SMS短信的形式发送到各种不同类型的设备上。
+
+
+
+
+
+在创建SNS Topic时的一些选项:
+
+- Encryption: 代表是否对Topic中的消息进行加密。如果需要处理的数据中有敏感信息,应做此设置。
+- Delivery retry policy (HTTP/S): 默认为3,也就说尝试三次后,消息还没有送到的话,就会彻底丢失。因此在使用SNS的时候,一旦出现这种情况,就应该使用DLQ来做容错。
+
+### SNS的一些特点
+
+- SNS是实时的**推送服务(Push)**,有别于SQS的**拉取服务(Pull/Poll)**
+- 拥有简单的API,可以和其他应用程序兼容
+- 可以通过多种不同的传输协议进行集成
+- 便宜、用多少付费多少的服务模型
+- 在AWS管理控制台上就可以进行简单的操作
+
+## SNS vs SQS
+
+AWS提供了[SQS](https://link.zhihu.com/?target=https%3A//console.aws.amazon.com/sqs/v2/home)和[SNS](https://link.zhihu.com/?target=https%3A//console.aws.amazon.com/sns/v3/home)。SQS是一个分布式的队列消息service,SNS是一个分布式的发布-订阅消息service。具体有人会问这两者有什么区别,这里给出了回答: [What is the difference between Amazon SNS and Amazon SQS?](https://link.zhihu.com/?target=https%3A//stackoverflow.com/questions/13681213/what-is-the-difference-between-amazon-sns-and-amazon-sqs)。 在我的实践中,SQS和SNS会结合起来使用,首先应用发布消息到SQS的queue里面,然后SNS消费这个queue的消息,放到自身的topic里面持久保存,然后其他的应用订阅这个topic,消费里面的消息。
+
+
+
+sqs是一对一,不能一对多,消息可持久化,不推只能等拉,拉完就删除。
+
+sns可一对多,不能持久化,push模型。
+
+sqs及aws笔记,更全, [link](http://www.cloudbin.cn/?p=2530)
+
+
+
+个人觉得 sns是推 能力的一个抽象。比如推送,mq里的push,都是推。aws把推给抽象出来。就可以让用户像搭积木一样使用。
+
+
+
+
+
diff --git a/_posts/Tech/AWS/2022-11-18-AWS Storage.md b/_posts/Tech/AWS/2022-11-18-AWS Storage.md
new file mode 100644
index 0000000000..bf2a5141d9
--- /dev/null
+++ b/_posts/Tech/AWS/2022-11-18-AWS Storage.md
@@ -0,0 +1,225 @@
+---
+layout: post
+category: AWS
+title: AWS Storage
+tags: AWS
+---
+
+## AWS Storage
+
+## dynamoDB
+
+[论文讲解](http://systemdesigns.blogspot.com/2016/01/dynamodb.html)
+
+[深入探讨 Amazon DynamoDB 的设计模 式、流复制和全局表](https://sides-share.s3.cn-north-1.amazonaws.com.cn/AWS+Webinar+2019/PDF/Amazon+DynamoDB+webinar.pdf)
+
+[官网](https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/Programming.LowLevelAPI.html#Programming.LowLevelAPI.DataTypeDescriptors)
+
+[AWS 如何实现数据跨区域同步](https://techsummit.ctrip.com/pdf/songye.pdf)
+
+[MongoDB 与 DynamoDB 正面交锋](https://www.modb.pro/db/432414)
+
+
+
+## EBS
+
+### EBS的特点
+
+- 亚马逊EBS卷提供了**高可用、可靠、持续性的块存储**,EBS可以依附到一个正在运行的EC2实例上
+- 如果你的EC2实例需要使用数据库或者文件系统,那么建议使用EBS作为首选的存储设备
+- EBS卷的存活可以脱离EC2实例的存活状态。也就是说在终止一个实例的时候,你可以选择保留该实例所绑定的EBS卷
+- EBS卷可以依附到**同一个可用区(AZ)**内的任何实例上
+- EBS卷可以被加密,如果进行了加密那么它存有的所有已有数据,传输的数据,以及制造的镜像都会被加密
+- **EBS卷可以通过快照(Snapshot)来进行(增量)备份,这个快照会保存在S3 (Simple Storage System)上**
+- 你可以使用任何快照来创建一个基于该快照的EBS卷,并且随时将这个EBS卷应用到**该区域**的任何实例上
+- EBS卷创建的时候已经固定了可用区,并且**只能给该可用区的实例使用**。如果需要在其他可用区使用该EBS,那么可以创建快照,并且使用该快照创建一个在其他可用区的新的EBS卷
+- **快照还可以复制到其他的AWS区域**
+
+### EBS (Elastic Block Storage)小结
+
+- EBS的不同类型,需要了解不同类型的EBS主要的使用场景
+ - 通用型SSD – GP2 (高达10,000 IOPS),适用于启动盘,低延迟的应用程序等
+ - 预配置型SSD – IO1 (超过10,000 IOPS),适用于IO密集型的数据库
+ - 吞吐量优化型HDD -ST1,适用于数据仓库,日志处理
+ - HDD Cold – SC1 – 适合较少使用的冷数据
+ - HDD, Magnetic
+- 不能将EBS挂载到多个EC2实例上,一个EBS只能挂载到1个EC2实例上。
+ - 如果有共享数据盘的需求,请使用EFS (Elastic File System)
+- 根EBS卷默认是不能进行加密的,但可以使用第三方的加密工具(例如BitLocker)对其进行加密
+ - *除了根磁盘外的其他卷是可以加密的*
+
+### EBS快照(Snapshot)小结
+
+- *EBS的快照会被保存到S3(Simple Storage System)上*
+
+- *你可以对一个EBS卷创建一个快照,这个快照会被保存到S3上*
+
+- 快照实际上是
+
+ 增量备份
+
+ ,只有在上次进行快照之后更改的数据才会被添加的S3上
+
+ - 因此第一次快照所花费的时间比较长
+ - 而第二次以后的快照所花费的时间相对短很多
+
+- 对加密的EBS卷创建快照,创建后的快照也会是加密的
+
+- 从加密的快照恢复的EBS卷也会是加密的
+
+- 你可以分享快照给其他账户或AWS市场,但仅限于这个快照是没有进行过加密的
+
+- 要为一个作为根设备的EBS卷创建快照的话,建议停止这个实例再做快照
+
+### 实例存储(Instance Store)
+
+- 实例存储也叫做**短暂性存储(Ephemeral Storage)**
+- 实例存储的实例不能被停止(只能重启或终止),如果这个实例出现故障,那么在上面的所有数据将会丢失
+- 使用EBS的实例可以被停止,停止后EBS上的数据不会丢失
+- 重启使用实例存储的实例或者重启使用EBS的实例都不会导致数据丢失
+
+
+
+## AWS EBS, S3和EFS的区别
+
+- AWS S3对于静态页面的托管、多媒体分发、版本管理、大数据分析、数据存档来说都非常有用。S3可以和AWS CloudFront结合使用而达到更快的上传和下载速度。
+- AWS EBS是可以用来做数据库或托管应用程序的持续性文件系统,EBS具有很高的IO读写速度并且即插即用。 只能被单个EC2实例访问
+- 相比前面两种存储,AWS EFS是比较新的一项服务。它提供了可以在多个EC2实例之间共享的网络文件系统,功能类似于NAS设备。可以用EFS来处理大数据分析、多媒体处理和内容管理。
+
+## S3
+
+Amazon **Simple Storage Service (S3)** 是互联网存储解决方案,它提供了一个简单的Web接口,让其存储的数据和文件在互联网的任何地方给任何人访问。
+
+文件对象存储。
+
+
+
+### S3基本特性
+
+- S3是**对象存储**,可以在S3上存储各种类型的文件,它不是**块存储**(EBS是块存储)
+- 文件大小可以从0 字节到5 TB
+ - 使用Single Operation上传只能上传*最大5 GB*的文件
+ - 使用分段上传(Multipart Upload)可以对文件进行分段上传,最大支持上传*5 TB*的文件
+- S3的总存储空间是**无限大**的
+- 文件存储在**存储桶(Bucket)**内,可以理解存储桶就是一个文件夹
+- S3的名字是需要**全球唯一**的,不能与任何区域的任何人拥有的S3重名
+- 存储桶创建之后会生成一个URL,命名类似于https://s3-ap-northeast-1.amazonaws.com/aws_xiaopeiqing_com
+ - **S3是以HTTPS的形式展现的,而非HTTP**
+ - ap-northeast-1表示了当前桶所在的区域
+ - aws_xiaopeiqing_com表示了S3存储桶的名字,全球唯一
+- S3拥有99.99%(4个9)的可用性(Availability)
+ - 可用性可以理解为系统的uptime时间,即在一个自然年内(365天)有52.56分钟系统不可用
+- S3拥有99.999999999%(11个9)的持久性(Durability)
+ - 持久性可以认为是数据完整性/数据安全性,即在一千亿个存储在S3上的文件会有大概 1 个文件是不可读的
+- S3的存储桶创建的时候可以选择所在区域(Region),但不能选择可用区(AZ),AWS会负责S3的高可用、容灾问题
+ - S3创建的时候可以选择某个AWS区域,一旦选择了就不能更改
+ - 如果要在其他区域使用该S3的内容,可以使用**跨区域复制**
+- S3拥有不同的等级(Standard, Stantard-IA, Onezone-IA, RRS, Glacier)
+- 启用了**版本控制(Version Control)**你可以恢复S3内的文件到之前的版本
+- S3可以开启生命周期管理,对文件在不同的生命周期进行不同的操作
+ - 比如,文件在创建30天后迁移到便宜的S3等级(S3-IA),再经过30天进行归档(迁移到Glacier),再过30天就进行删除
+- 要启用生命周期管理需要先启用版本控制功能
+- S3支持加密功能
+- 使用访问控制列表(Access Control Lists)和桶策略(Bucket Policy)可以控制S3的访问安全
+- 在S3上成功上传了文件,你将会得到一个**HTTP 200**的状态反馈
+
+### 不同的S3存储类型
+
+- **Standard – 默认的存储类:**如果上传对象时未注明则S3会分配这个类型的存储
+- **Standard – IA(Infrequently Accessed):**用于保存不经常访问的数据,但是需要访问的时候也能很快地访问到。存储的价格比标准S3便宜,但是读取的费用比标准的S3高,也因为如此才要把不经常访问的数据放到这种类型的S3上。并且数据跨了多个AWS地理位置。
+- **Intelligent_Tiering** 智能分层(S3 智能分层): 这种储存类别将对象存储在两个访问层中,一个是频繁访问的层,一个是不频繁访问的层;如果对象`30`天内未访问,则会被移动至不频繁访问的层,如果不频繁访问层中的对象被访问,则会被移动至频繁访问的层;频繁访问的层的存储费用与`STANDARD`一样,不频繁访问层的存储费用与`STANDARD_IA`一样,该储存类别的请求费用与`STANDARD`一样,**该储存类别有额外的监控费用**;
+- **Onezone – IA:**同上,但数据只保存到一个AWS可用区内
+- **Glacier:**非常便宜,仅用于做归档。从Glacier读取数据需要花费3-5个小时。
+- **Glacier Deep Archive:** S3 Glacier Deep Archive 是 Amazon S3 成本最低的存储类,支持每年可能访问一两次的数据的长期保留和数字预留。它是为客户设计的 – 特别是那些监管严格的行业,如金融服务、医疗保健和公共部门 – 为了满足监管合规要求,将数据集保留 7-10 年或更长时间。S3 Glacier Deep Archive 还可用于备份和灾难恢复使用案例,是成本效益高、易于管理的磁带系统替代,无论磁带系统是本地库还是非本地服务都是如此。S3 Glacier Deep Archive 是 Amazon S3 Glacier 的补充,后者适合存档,其中会定期检索数据并且每隔几分钟可能需要一些数据。存储在 S3 Glacier Deep Archive 中的所有对象都将接受复制并存储在至少三个地理分散的可用区中,受 99.999999999% 的持久性保护,并且可在 12 小时内恢复。
+
+## CloudFront CDN
+
+**Amazon CloudFront**是一种全球**内容分发网络(CDN)**服务,可以安全地以低延迟和高传输速度向浏览者分发数据、视频、应用程序和API。
+
+
+
+- **边缘站点(Edge Location)**:边缘站点是内容缓存的地方,它存在于多个网络服务提供商的机房,它和AWS区域和可用区是完全不一样的概念。截至2018年中,AWS目前一共有100多个边缘站点。
+- **源(Origin)**:这是CDN缓存的内容所使用的源,源可以是一个S3存储桶,可以是一个EC2实例,一个弹性负载均衡器(ELB)或Route53,甚至可以是AWS之外的资源。
+- **分配(Distribution)**:AWS CloudFront创建后的名字
+- 分配分为两种类型,分别是
+ - **Web Distribution**:一般的网站应用
+ - **RTMP (Real-Time Messaging Protocol)**:媒体流
+- 你不只是可以从边缘站点读取数据,你还可以往边缘站点写入数据(比如上传一个文件),边缘站点会将你写入的数据同步到源上
+- 在CloudFront上的文件会被缓存在边缘节点,缓存的时间是**TTL(Time To Live)**。文件存在超过这个时间,缓存会被自动清除
+- 如果在到达TTL时间之前,你希望更新文件,那么你也可以**手动清除缓存**,但你将会被AWS**收取一定的费用**
+
+## ES
+
+AWS ES有两种node
+
+1. decicated master node 数量只能3-5。Dedicated Master 节点不太可能成为性能瓶颈,因为它们主要负责管理集群状态和协调分片分配等任务,并不会直接处理客户端的读写请求。相反,数据节点才是 AWS ES 集群中的性能瓶颈,因为它们需要实际检索和处理文档数据,对系统资源的消耗较大。
+2. 普通node,和es一样。
+
+每个node都有存储的一个限制。node数量增加,则性能增加。
+
+## Multi-AZ高可用
+
+是多个AZ里配置一个主,其它从,类似同城多机房架构。
+
+
+
+我们可以把AWS RDS数据库部署在多个**可用区(AZ)**内,以提供高可用性和故障转移支持。
+
+使用Multi-AZ部署模式,RDS会在不同的可用区内配置和维护一个主数据库和一个备用数据库,主数据库的数据会自动复制到备用数据库中。
+
+使用这种部署模式,可以为我们提供数据冗余,减少在系统备份期间的I/O冻结(上面有提到)。同时,更重要的是可以防止数据库实例的故障和单个可用区的故障。
+
+如下图所示,我们可以在两个可用区内分别部署主数据库和备用数据库。
+
+
+
+目前Multi-AZ支持以下数据库:
+
+- Oracle
+- PostgreSQL
+- MySQL
+- MariaDB
+- SQL Server
+
+值得注意的是,Aurora数据库本身就支持多可用区部署的高可用设置,因此不需要为Aurora数据库特别开启这个功能。
+
+在上次实验中我们有讲到,创建了RDS数据库之后我们会得到一个数据库的URL Endpoint。在开启Multi-AZ的情况下,这个URL Endpoints会根据主/备数据库的健康状态自动解析到IP地址。对于应用程序来说,我们只需要连接这个URL地址即可。
+
+**高可用的设置只是用来解决灾备的问题,并不能解决读取性能的问题;要提升数据库读取性能,我们需要用到Read Replicas。**
+
+
+
+### 只读副本(Read Replicas)
+
+我们可以在源数据库实例的基础上,复制一种新类型的数据库实例,称之为**只读副本(Read Replicas)**。我们对源数据库的任何更新,都会**异步**更新到只读副本中。
+
+因此,我们可以将应用程序的数据库读取功能转移到Read Replicas上,来减轻源数据库的负载。
+
+对于有大量读取需求的数据库,我们可以使用这种方式来进行灵活的数据库扩展,同时突破单个数据库实例的性能限制。
+
+Read Replicas还有如下的特点:
+
+- Read Replicas是用来提高读取性能的,不是用来做灾备的
+- 要创建Read Replicas需要源RDS实例开启了自动备份的功能
+- 可以为数据库创建最多**5个**Read Replicas
+- 可以为Read Replicas创建Read Replicas(如下图所示)
+- 每一个Read Replicas都有自己的URL Endpoint
+- 可以为一个启用了Multi-AZ的数据库创建Read Replicas
+- Read Replicas可以提升成为独立的数据库
+- 可以创建位于另一个区域(Region)的Read Replicas
+
+
+
+目前Read Replicas支持以下数据库:
+
+- Aurora
+- PostgreSQL
+- MySQL
+- MariaDB
+- Oracle
+
+https://amazonaws-china.com/cn/rds/details/read-replicas/
+
+## 参考
+
+[参考](http://www.cloudbin.cn/?p=1968)
diff --git a/_posts/Tech/AWS/2022-11-26-AWS DynamoDB.md b/_posts/Tech/AWS/2022-11-26-AWS DynamoDB.md
new file mode 100644
index 0000000000..821e551848
--- /dev/null
+++ b/_posts/Tech/AWS/2022-11-26-AWS DynamoDB.md
@@ -0,0 +1,142 @@
+---
+layout: post
+category: AWS
+title: AWS DynamoDB
+tags: AWS
+---
+
+## 表、索引
+
+> [深入探讨 Amazon DynamoDB 的设计模 式、流复制和全局表](https://sides-share.s3.cn-north-1.amazonaws.com.cn/AWS+Webinar+2019/PDF/Amazon+DynamoDB+webinar.pdf)
+
+
+
+分区键和排序键共同唯一的标识一条记录
+
+本地二级索引 Local Secondary Index (LSI) 单表上的。可以选择与表不同的排序键。同一个分区键。强一致性更新。
+
+
+全局二级索引 - Global Secondary Index (GSI) 可以选择与表不同的分区键以及排序键 每个索引分区会对应所有的表分区
+
+
+
+
+
+
+
+对比
+
+- Global Secondary
+ - 索引的尺寸没有上限
+ - 读写容量和表是独立的
+ - 只支持最终一致性
+- Index Local Secondary Index
+ - 索引保存在表的分区中,因此一个表 分区的尺寸的上限是10GB
+ - 使用的是表上定义的RCU和WCU
+ - 强一致性
+
+索引指向的是实际存储,可以理解为空间指针。并不是数据的拷贝。像mysql B树指向主键一样。
+
+## 实现
+
+> [论文讲解](http://systemdesigns.blogspot.com/2016/01/dynamodb.html)
+
+Dynamo在某些故障的场景中将牺牲一致性。
+
+Dynamo的系统假设和要求:
+1)query model:对数据项简单的读,写是通过一个主键唯一性标识。状态存储为一个由唯一性键确定二进制对象。没有横跨多个数据项的操作,也不需要关系方案(relational schema)。这项规定是基于观察相当一部分Amazon的服务可以使用这个简单的查询模型,并不需要任何关系模式。Dynamo的目标应用程序需要存储的对象都比较小(通常小于1MB)。
+
+2)ACID属性:ACID是一种保证数据库事务可靠地处理的属性。在数据库方面的,对数据的单一的逻辑操作被称作所谓的交易。Amazon的经验表明,在保证ACID的数据存储提往往有很差的可用性。Dynamo的目标应用程序是高可用性,弱一致性(ACID“中的C”)。Dynamo不提供任何数据隔离(Isolation)保证,只允许单一的关键更新。
+
+3)efficiency:系统需运作在一般的commodity hardware上。Amazon平台的服务都有着严格的延时要求, 鉴于对状态的访问在服务操作中起着至关重要的作用,存储系统必须能够满足那些严格的SLA,服务必须能够通过配置Dynamo,使他们不断达到延时和吞吐量的要求。因此,必须在成本效率,可用性和耐用性保证之间做权衡。
+
+
+
+提供get, put操作。
+
+
+
+最终一致性。
+
+### Partition
+
+按key做partition, 一致性Hash。
+
+### Replication
+
+replica, 复制,用了NWR,让用户做一致性的选择。读数据时如果有不同版本,会所有版本数据都返回回去。
+
+### Data Versioning
+
+多版本。Vector Clock 一个Vector Clock可以理解为一个<节点编号,计数器>对的列表。每一个版本的数据都会带上一个Vector Clock。Dynamo中,最重要的是要保证写操作的高可用性,即“Always Writeable”,这样就不可避免的牺牲掉数据的一致性。如上所述,Dynamo中并没有对数据做强一致性要求,而是采用的最终一致性(eventual consistency)。若不保证各个副本的强一致性,则用户在读取数据的时候很可能读到的不是最新的数据。Dynamo中将数据的增加或删除这种操作都视为一种增加操作,即每一次操作的结果都作为一份全新的数据保存,这样也就造成了一份数据会存在多个版本,分布在不同的节点上。这种情况类似于版本管理中的多份副本同时有多人在修改。多数情况下,系统会自动合并这些版本,一旦合并尝试失败,那么冲突的解决就交给应用层来解决。这时系统表现出来的现象就是,一个GET(KEY)操作,返回的不是单一的数据,而是一个多版本的数据列表,由用户决定如何合并。这其中的关键技术就是Vector Clock。
+
+
+
+其实就是读修复。
+
+### Failure Detection
+
+临时性故障,采用Hinted Handoff提示移交机制
+
+为防止要写入节点宕机导致操作失败,采用提示移交机制将操作相关数据写入到随机节点,宕机节点恢复后可根据这些数据进行重放,最终获得数据一致性。
+
+
+
+ 以N=3为例,如果在一次写操作时发现节点A挂了,那么本应该存在A上的副本就会发送到D上,同时在D中会记录这个副本的元信息(MetaData)。其中有个标示,表明这份数据是本应该存在A上的,一旦节点D之后检测到A从故障中恢复了,D就会将这个本属于A的副本回传给A,之后删除这份数据。Dynamo中称这种技术为“Hinted Handoff”。
+
+
+
+另外为了应对整个机房掉线的故障,Dynamo中应用了一个很巧妙的方案。每次读写都会从”Preference List”列表中取出R或W个节点。那么只要在这个列表生成的时候,让其中的节点是分布于不同机房的,自然数据就写到了不同机房的节点上。
+
+
+
+对于某节点非临时性故障,利用反熵得到丢失数据进行恢复。一些数据存储有后台进程,不断查找副本之间的数据差异,将任何缺少的数据从一个副本复制到另一个副本。和基于主节点复制的复制日志不同,此反熵过程不保证任何特定的顺序复制写入,并且会引入明显的同步滞后
+
+
+
+## 事务
+
+> [官网wiki](https://docs.aws.amazon.com/zh_cn/amazondynamodb/latest/developerguide/transactions.html)
+
+支持事务,所有操作必须成功完成,否则不会进行任何更改。
+
+隔离级别:
+
+1. 可序列化
+2. 读已提交
+
+
+
+## 其他
+
+
+
+> [官网](https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/Programming.LowLevelAPI.html#Programming.LowLevelAPI.DataTypeDescriptors)
+
+begin_with这个操作要记得。其他后面看。begin_with是字符串前缀匹配,应该用了字典树等加速。
+
+
+
+> [AWS 如何实现数据跨区域同步](https://techsummit.ctrip.com/pdf/songye.pdf)
+
+没啥子东西,数据操作优先同区域内,主要靠复制。
+
+
+
+> [MongoDB 与 DynamoDB 正面交锋](https://www.modb.pro/db/432414)
+
+没啥东西
+
+
+
+> [通俗易懂之DynamoDB(一) ----分区键、排序键、GSI](https://zhuanlan.zhihu.com/p/101965292)
+
+**getItem、query和scan**
+
+这三个操作都是查询操作,效率分别是:getItem > query > scan
+
+getItem是根据primary key进行查询,可以理解为通过primary key在hashMap上查询,速度是最快的,缺点是必须知道primary key且只能查询单个,使用情况相对较少。
+
+scan是全表扫描,是最慢的一个,理论上能不用就不用,只有实在走投无路才考虑全表扫描。
+
+query是最常见的方式,在dynamoDB的使用中,我们唯一的目的就是写出高效的查询query。
diff --git a/_posts/Tech/AWS/2022-12-14-AWS CloudWatch.md b/_posts/Tech/AWS/2022-12-14-AWS CloudWatch.md
new file mode 100644
index 0000000000..38746d77c0
--- /dev/null
+++ b/_posts/Tech/AWS/2022-12-14-AWS CloudWatch.md
@@ -0,0 +1,19 @@
+---
+layout: post
+category: AWS
+title: AWS CloudWatch
+tags: AWS
+published: false
+---
+
+## AWS CloudWatch
+
+主要是Dashboard, metrics, alarms等。
+
+metrics的dimension不能用in操作。只能取1个或者不取。
+
+
+
+## 待更新
+
+期待后续...
diff --git a/_posts/Tech/AWS/2023-02-09-AWS IAM.md b/_posts/Tech/AWS/2023-02-09-AWS IAM.md
new file mode 100644
index 0000000000..9329ff06ec
--- /dev/null
+++ b/_posts/Tech/AWS/2023-02-09-AWS IAM.md
@@ -0,0 +1,346 @@
+---
+layout: post
+category: AWS
+title: AWS IAM
+tags: AWS
+---
+
+## AWS IAM
+
+
+
+首先要知道, AWS 提供了许许多多种类的服务或者说资源供我们使用, 这些资源挂在我们的 AWS 账户下, 这个账户就是我们第一次用 AWS 时用邮箱和密码申请的, 以后我们所有的资源申请, 账单费用都会挂到这个户头.
+
+那么 IAM 算什么呢? IAM 不是 AWS 的专有名词, 它是一个通用概念, 全称是 Identity and Access Management, 其要解决的两个问题就是身份认证 (Authtication) 和授权 (Authorization). 为此 AWS IAM 设计了用户, 角色, 用户组, 权限策略等概念和机制
+
+
+
+IAM (Identity Access Management) 由这些东西组成:
+
+- Users
+- Groups 用户组
+- Roles 角色可以分配给AWS服务,让AWS服务有访问其他AWS资源的权限。 举个例子,我们可以赋予EC2实例一个角色,让其有访问S3的读写权限(后面课程会有关于这一点的实操)
+- Policy Documents 策略。 策略具体定义了能访问哪些AWS资源,并且能执行哪些操作(比如List, Read, Write等) 策略的文档以JSON的格式展现
+
+```
+// An example policy: allowing any access to any resource
+{
+ "Version": "2012-10-17"
+ "Statement": [
+ {
+ "Effect": "Allow",
+ "Action": "*",
+ "Resource": "*"
+ }
+ ]
+}
+```
+
+
+
+IAM 是 Global的,不属于任何一个 region
+
+
+
+
+
+## IAM Entities
+
+首先 IAM 为了能够同时照顾到 “人” 和 “非人“ 这两类资源访问者, 使用了一个概念叫做 Entity(实体), 目前 IAM 里有两种 Entity: IAM User 和 IAM Role. 一般来说公司可以为每个程序员创建一个 IAM User 的实体, 让他们能够访问 AWS Console做一些权限之内的事情; 而对于非人的程序, 一般的实践则是创建 IAM Role, 然后令这程序 “假装”(Assume) 这个角色, 这样它就有了这个角色的权限, 一个 IAM Role 可以让很多程序一起假装, 不过要想假装 Role 的话, 必须得是 AWS 里的资源才行, 这是当然的, 像上面第三个例子, 公网的设备想访问我们的存储资源, 首先要通过 API Gateway, 由 API Gateway 来完成这个假装动作.
+
+## Users
+
+在 AWS 里,一个 IAM user 和 unix 下的一个用户几乎等价。你可以创建任意数量的用户,为其分配登录 AWS management console 所需要的密码,以及使用 AWS CLI(或其他使用 AWS SDK 的应用)所需要的密钥。你可以赋予用户管理员的权限,使其能够任意操作 AWS 的所有服务,也可以依照 Principle of least privilege,只授权合适的权限。下面是使用 AWS CLI 创建一个用户的示例:
+
+```
+saws> aws iam create-user --user-name tyrchen
+{
+ "User": {
+ "CreateDate": "2015-11-03T23:05:05.353Z",
+ "Arn": "arn:aws:iam::
-
-
## 复杂的复杂度计算
### 幂函数和对数函数和指数函数对比
-
-

### 调和级数

+这里有用到: [link](https://leetcode.cn/problems/number-of-different-subsequences-gcds/solution/ji-bai-100mei-ju-gcdxun-huan-you-hua-pyt-get7/)
+
### 二项式定理

@@ -53,16 +105,20 @@ tags: Algorithms
## 中位数
-在一步操作中,你可以使数组中的一个元素加 `1` 或者减 `1` ,所有数都靠近**中位数**可使所有数组元素相等时移动数最少。 相关题目: [最少移动次数使数组元素相等 II](https://leetcode-cn.com/problems/minimum-moves-to-equal-array-elements-ii/)
+在一步操作中,你可以使数组中的一个元素加 `1` 或者减 `1` ,所有数都靠近**中位数**可使所有数组元素相等时移动数最少。 相关题目: [最少移动次数使数组元素相等 II](https://leetcode-cn.com/problems/minimum-moves-to-equal-array-elements-ii/)
+即中位数到所有数距离和最小,如果是偶数,可以在中位数两侧的数据构成的区间内任意取值,对结果无影响证明:
+
+
+另一个相似题目:有cost,需转化拆分,然后再算中位数,[6216. 使数组相等的最小开销](https://mafulong.github.io/2022/10/23/6216.-%E4%BD%BF%E6%95%B0%E7%BB%84%E7%9B%B8%E7%AD%89%E7%9A%84%E6%9C%80%E5%B0%8F%E5%BC%80%E9%94%80/)
## 素数
-### 判断是否素数和求1-n的素数求某数的素数
+### 判断是否素数 o(sqrt(N))
```python
-# 判断某数是否是素数
+# 判断某数是否是素数 o(sqrt(n))
def is_prime(a):
if a <= 1: return False
import math
@@ -71,7 +127,16 @@ def is_prime(a):
return True
-# 求1-n每个数的素数,以下时间复杂度O(n) 朴素筛法
+```
+
+### 求 1-n 的所有素数 筛法 o(N)
+
+#### 埃氏筛法
+
+```python
+# 求1-n每个数的素数,以下时间复杂度O(nloglogn) 接近o(n)
+# 如果我们从小到大考虑每个数,然后同时把当前这个数的所有(比自己大的)倍数记为合数,那么运行结束的时候没有被标记的数就是素数了。
+# Eratosthenes 筛法(埃拉托斯特尼筛法,简称埃氏筛法)
def get_all_prime(n):
a = [False] * n
res = []
@@ -82,21 +147,31 @@ def get_all_prime(n):
for j in range(2 * i, n, i):
a[j] = True
return res
+```
-# 求某数的质因数列表,比如8,是[(2,3)], 6是[(2,1),(3,1)]
-def calcu(a):
- counter = collections.Counter()
- prime = get_all_prime(a + 1)
- for p in prime:
- while a % p == 0:
- counter[p] += 1
- a /= p
- return counter.items()
+#### **线性筛法** 也称为 **Euler 筛法**(欧拉筛法)
+
+埃氏筛法仍有优化空间,它会将一个合数重复多次标记。有没有什么办法省掉无意义的步骤呢?答案是肯定的。
+
+如果能让每个合数都只被标记一次,那么时间复杂度就可以降到 o(n)了。
+
+```python
+def get_all_prime(n):
+ a = [False] * n
+ res = []
+ for i in range(2, n):
+ if a[i]: continue
+ # a[i]是素数
+ res.append(i)
+ for j in range(2 * i, n, i):
+ if a[j]: break # 多了个这行
+ a[j] = True
+ return res
```
## 平方数
-[先看Cyc2018](http://www.cyc2018.xyz/%E7%AE%97%E6%B3%95/Leetcode%20%E9%A2%98%E8%A7%A3/Leetcode%20%E9%A2%98%E8%A7%A3%20-%20%E6%95%B0%E5%AD%A6.html#_1-%E5%B9%B3%E6%96%B9%E6%95%B0)
+[先看 Cyc2018](http://www.cyc2018.xyz/%E7%AE%97%E6%B3%95/Leetcode%20%E9%A2%98%E8%A7%A3/Leetcode%20%E9%A2%98%E8%A7%A3%20-%20%E6%95%B0%E5%AD%A6.html#_1-%E5%B9%B3%E6%96%B9%E6%95%B0)
### 生成所有平方数
@@ -106,8 +181,6 @@ def calcu(a):
间隔为等差数列,使用这个特性可以得到从 1 开始的平方序列。
-
-
### 3 的 n 次方
[Power of Three (Easy)](https://leetcode-cn.com/problems/power-of-three/description/)
@@ -118,33 +191,114 @@ public boolean isPowerOfThree(int n) {
}
```
-## 因数
+## 除法
+
+```python
+ # b % a == 0
+ # 表示b能被a整除,a可以整除b, 被除数永远都是有这个『被』
+```
+
+表示b能被a整除,a可以整除b, 被除数永远都是有这个『被』
+
+
+
+大整数除法,除法中取模。
+
+## 有负数的除法求模 不同语言可能不同
+
+比如a 除以 b,求对应商和余数。不同语言可能不同
+
+计算-7 Mod 4
+
+那么:a = -7;b = 4;
+
+第一步:求整数商c,c应该是-1.75,如进行求模运算c = -2(向负无穷方向舍入),求余运算则c = -1(向0方向舍入);
+
+第二步:计算模和余数的公式相同,但因c的值不同,求模时r = 1,求余时r = -3。
+
+ 当符号不一致时,结果不一样。求模运算结果的符号和b一致,求余运算结果的符号和a一致。
+
+在C/C++, C#, JAVA, PHP这几门主流语言中,%运算符都是做取余运算,而在python中的%是做取模运算。
+
+
+
+**python求商是向负无穷靠近,而其他是靠近0.**
+
+## 因数理论
### 素数分解
-每一个数都可以分解成素数的乘积,例如 84 = 22 * 31 * 50 * 71 * 110 * 130 * 170 * …
+每一个数都可以分解成素数的乘积,例如 84 = 22 _ 31 _ 50 _ 71 _ 110 _ 130 _ 170 \* …
### 整除
-令 x = 2m0 * 3m1 * 5m2 * 7m3 * 11m4 * …
+令 x = 2m0 _ 3m1 _ 5m2 _ 7m3 _ 11m4 \* …
-令 y = 2n0 * 3n1 * 5n2 * 7n3 * 11n4 * …
+令 y = 2n0 _ 3n1 _ 5n2 _ 7n3 _ 11n4 \* …
如果 x 整除 y(y mod x == 0),则对于所有 i,mi <= ni。
-### 最大公约数最小公倍数
+### 最大公约数最小公倍数的素数表示
+
+每个质因数的乘积
+
+x 和 y 的最大公约数为:gcd(x,y) = 2min(m0,n0) _ 3min(m1,n1) _ 5min(m2,n2) \* ...
+
+x 和 y 的最小公倍数为:lcm(x,y) = 2max(m0,n0) _ 3max(m1,n1) _ 5max(m2,n2) \* ...
+
+### 约数个数和约数之和
+
+如果 N = p1^c1 _ p2^c2 _ ... _pk^ck
+约数个数: (c1 + 1) _ (c2 + 1) _ ... _ (ck + 1)
+约数之和: (p1^0 + p1^1 + ... + p1^c1) _ ... _ (pk^0 + pk^1 + ... + pk^ck)
-x 和 y 的最大公约数为:gcd(x,y) = 2min(m0,n0) * 3min(m1,n1) * 5min(m2,n2) * ...
-x 和 y 的最小公倍数为:lcm(x,y) = 2max(m0,n0) * 3max(m1,n1) * 5max(m2,n2) * ...
-### 求质因数和对应计数
+## 因数相关问题
-o(n)近似
+### 试除法求所有约数:
+
+#### 求一个数的因子列表 o(sqrt(n))
+
+o(sqrt(n))
+
+```python
+divisors = []
+d = 1
+while d * d <= k: # 预处理 k 的所有因子
+ if k % d == 0:
+ divisors.append(d)
+ if d * d < k: # 避免 d= k/d的情况,此时如果append会重复
+ divisors.append(k / d)
+ d += 1
+```
+
+#### 统计 1-n 每个数的因子列表 o(nlogn)
+
+o(nlogn)
+
+```python
+MX = 100001
+divisors = [[] for _ in range(MX)] # 每个value就是key的因子列表,乘积肯定>value,因为因子之间可能有倍数
+for i in range(1, MX): # 预处理每个数的所有因子,时间复杂度 O(MlogM),M=1e5
+ for j in range(i, MX, i):
+ divisors[j].append(i)
+```
+
+### 分解质因数
+
+#### 求某数质因数列表 o(sqrt(N))
+
+o(sqrt(N))
+
+求某数的质因数列表,比如 8,是[2,2,2]
+
+枚举[2, sqrt(n)+1), 如果是质因数,就接着除,最大大于 1,它本身就是质数。
+
+也叫 求欧拉函数
```python
# 求质因数列表
-# Python Version
def breakdown(N):
result = []
from math import sqrt
@@ -158,76 +312,248 @@ def breakdown(N):
return result
```
-### 统计1-n每个数的因子列表
+#### 统计 1-n 每个数的质因数列表
-o(nlogn)
+筛法求欧拉函数
+
+类似,暂时不写。
+
+### gcd 求最大公约数和最小公倍数 欧几里得算法
+
+欧几里得算法
```python
-MX = 100001
-divisors = [[] for _ in range(MX)] # 每个value就是key的因子列表,乘积肯定>value,因为因子之间可能有倍数
-for i in range(1, MX): # 预处理每个数的所有因子,时间复杂度 O(MlogM),M=1e5
- for j in range(i, MX, i):
- divisors[j].append(i)
+class Math1:
+ def gcd(self, a, b):
+ if b == 0:
+ return a
+ return self.gcd(b, a % b)
```
-### 求一个数的因子列表
+最小公倍数就是 a\*b/gcd(a,b)
+
-o(sqrt(n))
+
+### gcd性质
+
+如果ax+by=1, 则gcd(x,y) = 1
+
+
+
+### 多个数求最大公约数和最小公倍数
+
+多个数的最大公约数:
```python
-divisors = []
-d = 1
-while d * d <= k: # 预处理 k 的所有因子
- if k % d == 0:
- divisors.append(d)
- if d * d < k: # 避免 d= k/d的情况,此时如果append会重复
- divisors.append(k / d)
- d += 1
+def gcd_list(self, nums):
+ import math
+ cur = nums[0]
+ for i in range(1, len(nums)):
+ cur = math.gcd(cur, nums[i])
+ return cur
```
-### gcd求最大公约数:
+多个数的最小公倍数:
-```c++
-int gcd(int a, int b) {
- return b == 0 ? a : gcd(b, a%b);
-}
+> 注意这里不是直接多个数乘积除以他们的gcd呀,而且不断一个一个加计算的。
-int gcd(int a, int b) {
- while (b != 0) {
- int t = a%b;
- a = b;
- b = t;
- }
- return a;
-}
+```python
+def lcm_list(self, nums):
+ import math
+ prod = 1
+ for v in nums:
+ prod = prod * v / math.gcd(prod, v)
+ return prod
+```
+
+### 1到n里有多少个数可整除a?
+
+```python
+n//a
```
-最小公倍数就是a*b/gcd(a,b)
+
+
+### 1到n里有多少个a的因数?
+
+[参考另一个博客](https://mafulong.github.io/2018/04/30/%E8%AE%A1%E7%AE%97n%E7%9A%84%E9%98%B6%E4%B9%98%E4%B8%AD%E6%9C%89%E5%A4%9A%E5%B0%91%E4%B8%AAk/)
+
+```python
+ def calcu(x,a):
+ '''
+ 1-x中有多少个因数a, 比如1-26里有5,10, 15, 20, 各自1个5, 5*5两个5,一共6个
+ '''
+ r = 0
+ while x:
+ # 贡献5的数量,贡献5*5的数量,贡献5*5*5的数量
+ r += x //a
+ x //= a
+ return r
+ print(calcu(26, 5))
+```
+
+
+
+## 大整数取模问题
+
+### 大数相乘取模
+
+```python
+ def prod(d=[], mod=10 ** 9 + 7):
+ r = d[0] % mod
+ for v in d[1:]:
+ r *= v
+ r %= mod
+ return r
+```
+
+
+
+### 大数相除取模 费马小定理
+
+如果a/b,然后a和b都是大数要取模,这时不能相乘取模来计算
+
+`(a/b)%c=(a%c)/(b%c)`是**不成立**的
+
+
+
+> [除法取模](https://leetcode.cn/problems/count-anagrams/solution/by-simpleson-crwb/)
+
+```python
+
+# 原: i//j%MOD
+# 现: i*modInverse(j)%MOD
+MOD = int(1e9 + 7)
+
+class BigIntDivide:
+ def mod_inverse(sefl, i):
+ # 调用取模的乘幂运算, pow复杂度是log(exp)即log(MOD)
+ return pow(i, MOD - 2, MOD)
+
+ def divide_mod(self, a, b):
+ '''
+ 计算(a/b) % MOD, 除法变乘法,前提是b和MOD互为质数
+ '''
+ # 如果有多个b,比如a/b1/b2, 那就可以递归。a*mod_inverse(b1) % mod * mod_inverse(b2) % mod这样
+ return a * self.mod_inverse(b) % MOD
+
+ def divide_mods(self, a, b=[]):
+ '''
+ 计算a /(b1*b2*b3) % MOD等形式,前提是b和MOD互为质数
+ '''
+ r = a % MOD
+ for i, v in enumerate(b):
+ r *= self.mod_inverse(v)
+ r %= MOD
+ return r
+
+
+```
+
+
+
+### 大数幂取模
+
+```python
+r = pow(base=2, exp=3, mod=3)
+print(r)
+```
+
+
+
+## 阶乘
+
+```python
+import math
+math.factorial(3)
+```
+
+
+
+## 分配问题
+
+### a能否分成满足条件的两份,其中只能分给指定一份
+
+[2513. 最小化两个数组中的最大值](https://leetcode.cn/problems/minimize-the-maximum-of-two-arrays/) 给你两个数组 arr1 和 arr2 ,它们一开始都是空的。你需要往它们中添加正整数,使它们满足以下条件:
+
+arr1 包含 uniqueCnt1 个 互不相同 的正整数,每个整数都 不能 被 divisor1 整除 。
+arr2 包含 uniqueCnt2 个 互不相同 的正整数,每个整数都 不能 被 divisor2 整除 。
+arr1 和 arr2 中的元素 互不相同 。
+给你 divisor1 ,divisor2 ,uniqueCnt1 和 uniqueCnt2 ,请你返回两个数组中 最大元素 的 最小值 。
+
+
+
+参考, [link](https://leetcode.cn/circle/discuss/YeBDQY/view/B8caF0/)
+
+**Key**: 判断过程中分为三类:保证在范围内有充足的数不是第一个数的倍数;不是第二个数的倍数;不为公倍数的数总数不少于总共要取的数。根据这三个条件即得到结果。
+
+## 位运算
+
+a xor b ==c 则 a = b xor c.
## 进制转换
```c++
- int a, b;
- vector
## 容斥原理
@@ -242,7 +568,23 @@ int gcd(int a, int b) {
## 幂
-### 快速幂
+### 快速幂 O(logk)
+
+求 m^k mod p,时间复杂度 O(logk)。
+
+```c++
+int qmi(int m, int k, int p)
+{
+ int res = 1 % p, t = m;
+ while (k)
+ {
+ if (k&1) res = res * t % p;
+ t = t * t % p;
+ k >>= 1;
+ }
+ return res;
+}
+```
### 求根号
@@ -252,7 +594,7 @@ int gcd(int a, int b) {
### 求根号变种 小数精度
-`while l<=r`不用变,只需要变步长即可。eps可以比期望精度再小一个量级。
+`while l<=r`不用变,只需要变步长即可。eps 可以比期望精度再小一个量级。
```python
@@ -277,8 +619,6 @@ if __name__ == '__main__':
print(f(0.04, 1e-10))
```
+## Acwing 数学
-
-## Acwing数学
-
-[参考](https://www.acwing.com/file_system/file/content/whole/index/content/3273/) 本文只涉及部分
+[参考](https://www.acwing.com/file_system/file/content/whole/index/content/3273/) 本文只涉及部分
diff --git "a/_posts/Tech/Algorithms/2022-07-31-\347\256\200\345\215\225\345\233\276\347\232\204\346\234\200\345\244\247\347\216\257\346\234\200\351\225\277\351\223\276.md" "b/_posts/Tech/Algorithms/2022-07-31-\347\256\200\345\215\225\345\233\276\347\232\204\346\234\200\345\244\247\347\216\257\346\234\200\351\225\277\351\223\276.md"
new file mode 100644
index 0000000000..60c620721d
--- /dev/null
+++ "b/_posts/Tech/Algorithms/2022-07-31-\347\256\200\345\215\225\345\233\276\347\232\204\346\234\200\345\244\247\347\216\257\346\234\200\351\225\277\351\223\276.md"
@@ -0,0 +1,127 @@
+---
+layout: post
+category: Algorithms
+title: 简单图的最大环最长链
+tags: Algorithms
+---
+
+## 最大环最长链
+
+https://www.cnblogs.com/lfri/p/15758120.html
+
+最大环是针对的是出度为1的图,否则会多环重合。
+
+最长链是无环的图,求一个最长路径的长度。
+
+
+
+## 最大环
+
+### 有向图
+
+有多种方法:
+
+- 一种是先用拓扑排序将外链去掉,再dfs每一个环
+- DFS: 另一种是从某一点出发,记录途径的点,如果遇到已经访问过的点,说明找到了环的入口。减去起始点到入口的距离,就是环的长度。
+- 还有一种有并查集,对于`x->y`,如果`x`和`y`同属于一个集合,说明形成了一个环。
+
+
+
+dfs代码
+
+```python
+class Solution:
+ def longestCycle(self, edges: List[int]) -> int:
+ n = len(edges)
+ vis = collections.defaultdict(bool)
+ ans = -1
+ for i in range(n):
+ if vis[i]: continue
+ path = []
+ cur = i
+ while not vis[cur]:
+ vis[cur] = True
+ path.append(cur)
+ cur = edges[cur]
+ if cur == -1: break
+ if cur == -1: continue
+ for j in range(len(path)):
+ if path[j] == cur:
+ t = len(path) - j
+ ans = max(ans, t)
+ break
+ return ans
+```
+
+### 无向图
+
+和有向图类似,略
+
+## 最长链
+
+等价问题: [310. 最小高度树](https://leetcode.cn/problems/minimum-height-trees/)
+
+### 有向图
+
+这里有一个很重要的问题,有环怎么办?
+有环的情况下,求最长链是没有意义的。要么保证无环,要么是求连接到环上的链的长度。
+例如求连接到环上的链的长度,需要从入度为0的节点开始,递推计算,于是采用拓扑序。
+
+
+
+```c++
+int TopologicalSort(vector
+这里的ZAB为何是最终一致性而不是强一致性?[参考](https://www.zhihu.com/question/455703356/answer/1847949827)
+
+- 写是强一致性,单领导者模型,写需要majority保证,脑裂情况下也可以写强一致
+- 读两种接口,1:读单个机器的,2:只读主的。但脑裂时多个主还是不能强一致性。
+- etcd做了读的优化,读时也需要majority(多数同意),需要大伙同意认为它是主,但牺牲了效率。
+
+这里的一致性是从读写方面,写一致性,都写成功,读一致性,从提供的读接口任意时刻咋读都一样。和事务一致性不太一样。
+
## 分布式互斥方法(集中,民主协商,轮值ceo(令牌))

diff --git "a/_posts/Tech/DistributedSystem/2021-12-26-etcd\345\222\214raft.md" "b/_posts/Tech/DistributedSystem/2021-12-26-etcd\345\222\214raft.md"
index 3fd12cdff4..0bf8fbfdf5 100644
--- "a/_posts/Tech/DistributedSystem/2021-12-26-etcd\345\222\214raft.md"
+++ "b/_posts/Tech/DistributedSystem/2021-12-26-etcd\345\222\214raft.md"
@@ -3,6 +3,7 @@ layout: post
category: DistributedSystem
title: etcd和raft
tags: DistributedSystem
+recent_update: true
---
# etcd
diff --git a/_posts/Tech/DistributedSystem/2022-02-21-zookeeper.md b/_posts/Tech/DistributedSystem/2022-02-21-zookeeper.md
new file mode 100644
index 0000000000..e1e4daccb6
--- /dev/null
+++ b/_posts/Tech/DistributedSystem/2022-02-21-zookeeper.md
@@ -0,0 +1,40 @@
+---
+layout: post
+category: DistributedSystem
+title: zookeeper
+tags: DistributedSystem
+---
+
+## zookeeper
+
+
+
+了解zk: [参考](https://segmentfault.com/a/1190000022431516)
+
+zk有序树形节点实现分布式锁: [参考](http://www.cyc2018.xyz/%E5%85%B6%E5%AE%83/%E7%B3%BB%E7%BB%9F%E8%AE%BE%E8%AE%A1/%E5%88%86%E5%B8%83%E5%BC%8F.html#zookeeper-%E7%9A%84%E6%9C%89%E5%BA%8F%E8%8A%82%E7%82%B9)
+
+- Kafka 选举就用的这个。leader选举。
+
+paxos执行过程: [参考](http://www.cyc2018.xyz/%E5%85%B6%E5%AE%83/%E7%B3%BB%E7%BB%9F%E8%AE%BE%E8%AE%A1/%E5%88%86%E5%B8%83%E5%BC%8F.html#%E6%9C%80%E7%BB%88%E4%B8%80%E8%87%B4%E6%80%A7)
+
+zk基于zab协议,是个paxos的变种。
+
+zk的所有副本都可以提供读服务,与此相对应的,只有主节点可以提供写服务。
+
+选举原则:数据最新or ID最大的节点作为主。
+
+## QA
+
+### zk会脑裂吗
+
+不会脑裂。默认 **只有获得超过半数节点的投票, 才能选举出leader.** 因此只会有一个leader存在。可能会有部分节点没有follow leader。这些节点已经挂了。
+
+### zk or ZAB为何是最终一致性而不是强一致性
+
+[参考](https://www.zhihu.com/question/455703356/answer/1847949827)
+
+- 写是强一致性,单领导者模型,写需要majority保证(写节点超过一半),脑裂情况下也可以写强一致
+- 读两种接口,1:读单个机器的,2:只读主的。如果是后者就是强一致性的。
+- etcd做了读的优化,读时也需要majority,需要大伙同意认为它是主,但牺牲了效率。
+
+这里的一致性是从读写方面,写一致性,都写成功,读一致性,从提供的读接口任意时刻咋读都一样。和事务一致性不太一样。
\ No newline at end of file
diff --git "a/_posts/Tech/DistributedSystem/2022-11-26-\346\227\240\344\270\273\345\244\215\345\210\266\347\263\273\347\273\237.md" "b/_posts/Tech/DistributedSystem/2022-11-26-\346\227\240\344\270\273\345\244\215\345\210\266\347\263\273\347\273\237.md"
new file mode 100644
index 0000000000..ee018bc3b1
--- /dev/null
+++ "b/_posts/Tech/DistributedSystem/2022-11-26-\346\227\240\344\270\273\345\244\215\345\210\266\347\263\273\347\273\237.md"
@@ -0,0 +1,63 @@
+---
+layout: post
+category: DistributedSystem
+title: 无主复制系统
+tags: DistributedSystem
+---
+
+为什么需要复制数据? - 允许系统在部分节点出现故障后继续工作(增加可用性) - 地理上保持数据离用户更近(减少延迟) - 扩展可以提供查询的机器数量(增加读吞吐)
+
+复制算法: 1. 单主复制:所有客户端都将写入操作发送到主节点上,该节点负责将数据更改事件发送到其它副本。每个副本都可以接受读请求,但内容可能是过期值。 2. 多主复制:系统中存在多个主节点,每个都可以接受请求,客户端将写请求发送到其中一个主节点上,该节点负责将数据更改事件同步到其它主节点和自己的从节点。 3. 无主复制:客户端将写请求发送多个节点上,读取时从多个节点上并行读取,以此检测和纠正某些过期数据。
+
+主从复制可参考 [link](https://iswade.github.io/database/replication/)
+
+## 无主复制
+
+单主、多主复制思路都是:客户端向一个主节点发写请求,而DB系统负责将写请求复制到其他副本。主节点决定写顺序,从节点按相同顺序应用主节点发送的写日志。
+
+某些数据存储系统采用不同设计:放弃主节点,允许任何副本直接接受客户端的写。最早的复制数据系统就是无主节点的(或称之为去中心复制、无中心复制),但后来在关系数据库主导时代,这个想法几乎被忘却。在亚马逊将其用于其内部的Dynamo系统后,它再一次成为流行的DB架构。 Riak,Cassandra和Voldemort都是由Dynamo启发的无主复制模型的开源数据存储,所以这类数据库也被称为*Dynamo风格*。
+
+
+
+在一些无主实现中,客户端直接将写请求发到多副本,而另一些实现中,有一个协调者(coordinator)节点代表客户端进行写入,但与主节点的数据库不同,协调者不负责维护写入顺序。这种设计差异对DB使用方式有深远影响。
+
+
+
+失效节点重新上线,而客户端开始读取它。节点失效期间发生的任何写入在该节点都尚未同步,因此读取可能得到过期数据。
+
+为解决该问题,当一个客户端从DB读数据时,它不是向1个副本发送请求,而是并行发送到多副本。客户端可能会从不同节点获得不同响应,即来自一个节点的最新值和来自另一个节点的旧值。可利用版本号确定哪个值更新。
+
+### 读修复和反熵
+
+复制模型应确保所有数据最终复制到所有副本。在一个失效节点重新上线后,它如何赶上错过的写入呢?
+
+Dynamo风格的数据存储系统常机制:
+
+#### 读修复(Read repair)
+
+当客户端并行读取多副本时,可检测到过期的返回值。客户端可判断副本3是过期值,然后将新值写入该副本。适用于读密集场景
+
+#### 反熵过程(Anti-entropy process)
+
+一些数据存储有后台进程,不断查找副本之间的数据差异,将任何缺少的数据从一个副本复制到另一个副本。和基于主节点复制的复制日志不同,此反熵过程不保证任何特定的顺序复制写入,并且会引入明显的同步滞后
+
+
+
+并非所有系统都实现这俩方案。如Voldemort目前无反熵过程。若无反熵过程,由于【读修复】只在发生读取时才可能执行修复,那些很少访问的数据有可能在某些副本中已丢失而无法再检测到,从而降低了写的持久性。
+
+
+
+反熵就是树形的hash,用于快速比较数据是否一致的。
+
+
+
+## 参考
+
+- [**无主复制系统(1)-节点故障时写DB**](https://blog.51cto.com/u_11440114/5550577)
+- [**无主复制系统(2)-读写quorum**](https://blog.51cto.com/u_11440114/5550582)
+
+
+
+
+
+TODO: 需要读下ddia.
diff --git a/_posts/Tech/DistributedSystem/2023-03-19-service mesh.md b/_posts/Tech/DistributedSystem/2023-03-19-service mesh.md
new file mode 100644
index 0000000000..990d79635e
--- /dev/null
+++ b/_posts/Tech/DistributedSystem/2023-03-19-service mesh.md
@@ -0,0 +1,34 @@
+---
+layout: post
+category: DistributedSystem
+title: service mesh
+tags: DistributedSystem
+---
+
+## service mesh
+
+在TCP出现之后,机器之间的网络通信不再是一个难题,以GFS/BigTable/MapReduce为代表的分布式系统得以蓬勃发展。这时,分布式系统特有的通信语义又出现了,如熔断策略、负载均衡、服务发现、认证和授权、quota限制、trace和监控等等,于是服务根据业务需求来实现一部分所需的通信语义。
+
+service mesh就实现了这种通信语义。
+
+
+
+服务网格是一个基础设施层,用于处理服务间通信。云原生应用有着复杂的服务拓扑,服务网格保证请求在这些拓扑中可靠地穿梭。在实际应用当中,服务网格通常是由一系列轻量级的网络代理组成的,它们与应用程序部署在一起,但对应用程序透明。
+
+**`Service Mesh`目的是解决系统架构微服务化后的服务间通信和治理问题。** 服务网格由`Sidecar`节点组成,这个模式的精髓在于实现了数据面(业务逻辑)和控制面的解耦。具体到[微服务](https://so.csdn.net/so/search?q=微服务&spm=1001.2101.3001.7020)架构中,即给每一个微服务实例同步部署一个`Sidecar`。可以sidecar形式和应用程序部署到一起。
+
+
+
+Service Mesh具有如下优点:
+
+- 屏蔽分布式系统通信的复杂性(负载均衡、服务发现、认证授权、监控追踪、流量控制等等),服务只用关注业务逻辑;
+- 真正的语言无关,服务可以用任何语言编写,只需和Service Mesh通信即可;
+- 对应用透明,Service Mesh组件可以单独升级;
+
+
+
+
+
+## 参考
+
+- [什么是 Service Mesh](https://zhuanlan.zhihu.com/p/61901608)
\ No newline at end of file
diff --git a/_posts/Tech/ElasticSearch/2020-12-08-ElasticSearch.md b/_posts/Tech/ElasticSearch/2020-12-08-ElasticSearch.md
index de4939df98..5eda1601ec 100644
--- a/_posts/Tech/ElasticSearch/2020-12-08-ElasticSearch.md
+++ b/_posts/Tech/ElasticSearch/2020-12-08-ElasticSearch.md
@@ -3,6 +3,7 @@ layout: post
category: ElasticSearch
title: ElasticSearch(ES)原理
tags: ElasticSearch
+recent_update: true
---
## Part1: ES介绍及核心概念
diff --git "a/_posts/Tech/FrontEnd/2017-12-03-css\345\255\246\344\271\240\347\254\224\350\256\260.md" "b/_posts/Tech/FrontEnd/2017-12-03-css\345\255\246\344\271\240\347\254\224\350\256\260.md"
index 1df5eb98e6..a76bfdfb2d 100644
--- "a/_posts/Tech/FrontEnd/2017-12-03-css\345\255\246\344\271\240\347\254\224\350\256\260.md"
+++ "b/_posts/Tech/FrontEnd/2017-12-03-css\345\255\246\344\271\240\347\254\224\350\256\260.md"
@@ -4,7 +4,39 @@ category: FrontEnd
title: CSS笔记
tags: FrontEnd
---
+# 概述
+
+CSS:Cascading Style Sheet,层叠样式表。CSS 的作用就是给 HTML 页面标签添加各种样式,**定义网页的显示效果**。简单一句话:CSS 将网页**内容和显示样式进行分离**,提高了显示功能。
+
+**CSS 优点:**
+
+1. 使数据和显示分开
+2. 降低网络流量
+3. 使整个网站视觉效果一致
+4. 使开发效率提高了(耦合性降低,一个人负责写 html,一个人负责写 css)
+
+比如说,有一个样式需要在一百个页面上显示,如果是 html 来实现,那要写一百遍,现在有了 css,只要写一遍。现在,html 只提供数据和一些控件,完全交给 css 提供各种各样的样式。
+
+重点:盒子模型、浮动、定位
+
+
+
+CSS 的书写方式,实就是问你 CSS 的代码放在哪个位置。CSS 代码理论上的位置是任意的,**但通常写在`
+
+
+
+
+
+
+
+ AAAA
+
+