diff --git a/_layouts/default.html b/_layouts/default.html
index 9c762fad3d..5d05f3f6a6 100755
--- a/_layouts/default.html
+++ b/_layouts/default.html
@@ -4,9 +4,8 @@
{% assign assets_base_url = site.url %}
{% if site.cdn.jsdelivr.enabled %}
-{% assign assets_base_url = "https://cdn.jsdelivr.net/gh/" | append: site.repository | append: '@master' %}
+{% assign assets_base_url = "https://cdn.jsdelivr.net/gh/" | append: site.repository | append: '@'| append: site.cdn.jsdelivr.branch %}
{% endif %}
-{% assign assets_images_url = ' -
-
-
-
-
-
-
-
diff --git a/_layouts/page.html b/_layouts/page.html
index 7ba323b0cb..84f121ade0 100755
--- a/_layouts/page.html
+++ b/_layouts/page.html
@@ -4,7 +4,7 @@
{% assign assets_base_url = site.url %}
{% if site.cdn.jsdelivr.enabled %}
-{% assign assets_base_url = "https://cdn.jsdelivr.net/gh/" | append: site.repository | append: '@master' %}
+{% assign assets_base_url = "https://cdn.jsdelivr.net/gh/" | append: site.repository | append: '@'| append: site.cdn.jsdelivr.branch %}
{% endif %}
-
-
-
-
-
-
-
-
diff --git a/_layouts/page.html b/_layouts/page.html
index 7ba323b0cb..84f121ade0 100755
--- a/_layouts/page.html
+++ b/_layouts/page.html
@@ -4,7 +4,7 @@
{% assign assets_base_url = site.url %}
{% if site.cdn.jsdelivr.enabled %}
-{% assign assets_base_url = "https://cdn.jsdelivr.net/gh/" | append: site.repository | append: '@master' %}
+{% assign assets_base_url = "https://cdn.jsdelivr.net/gh/" | append: site.repository | append: '@'| append: site.cdn.jsdelivr.branch %}
{% endif %}
diff --git a/_layouts/post.html b/_layouts/post.html
index a544affaf9..93e302cd11 100755
--- a/_layouts/post.html
+++ b/_layouts/post.html
@@ -4,7 +4,7 @@
{% assign assets_base_url = site.url %}
{% if site.cdn.jsdelivr.enabled %}
-{% assign assets_base_url = "https://cdn.jsdelivr.net/gh/" | append: site.repository | append: '@master' %}
+{% assign assets_base_url = "https://cdn.jsdelivr.net/gh/" | append: site.repository | append: '@'| append: site.cdn.jsdelivr.branch %}
{% endif %}
@@ -45,6 +45,7 @@
{{ page.title }}
{% include sidebar-search.html %} {% include sidebar-categories-cloud.html %} + {% include sidebar-recent-update.html %} {% include sidebar-popular-repo.html %}
@@ -61,6 +61,7 @@
{{ page.title }}
{% include sidebar-search.html %}
{% include sidebar-post-nav.html %}
+ {% include sidebar-recent-update.html %}
-
-
-
-
-
-
-
- {{ page.title }}
-
- {% include sidebar-qrcode.html %}
-
-
-
-
- {% include content-header-ad.html %}
-
- {{ content }}
-
-
-
- {% include content-footer-ad.html %}
-
-
- {% include comments.html %}
-
-
- {% include sidebar-search.html %}
- {% include sidebar-post-nav.html %}
-
- +
+参考
+
+- Internet Gateway (IGW) allows instances with public IPs to access the internet.
+- NAT Gateway (NGW) allows instances with no public IPs to access the internet.
+
+## 参考
+
+[参考](https://juejin.cn/post/6949072638145003556)
+
+大部分 AWS 服务都需要以 VPC 为基础进行构建,比如最常用的 EC2,ALB,及无服务器服务 ECS Fargate。 vb
+
+当我们在一个 VPC 中创建 Subnet 时需要给 Subnet 选择一个 AZ(Availability Zone),一个 Subnet 只能选择建在一个 AZ 中。
+
+
+
+**选择region**
+
+因为国内政策法规原因,AWS 在中国的服务与 AWS Global 服务略有不同。
+
+AWS Global 的 Region 之间是通过主干网相连的,AWS 中国区的服务没有通过主干网与 AWS Global 相连,只有中国区内部两个 Region,北京和宁夏是相连接的。
+
+在创建 VPC 时并不需要添写 AZ(Availability Zone)信息,VPC 只与 Region 有关。
+
+
+
+Subnet 是最终承载大部分 AWS 服务的组件,比如 EC2, ECS Fargate,RDS。
+
+Subnet 分为两种 Private Subnet 和 Public Subnet。
+
+简单来说,不能直接访问 internet 的 Subnet 就是 Private Subnet,能直接访问 internet 的就是 Public Subnet。
+
+
+
+Security Group(SG)通过控制IP和端口来控制出站入站规则,可以用于EC2,RDS及下面将要用到的VPC Endpoint。
+
+
+
+VPC Endpoint用来直接连接VPC与AWS相关服务,比如RDS AIP,S3。
+
+当系统安全要求比较高时,EC2处于的Subnet可能被限制,无法访问internet,这时EC2就无法访问AWS的一些服务,比如SSM。
+
+这时我们可以利用VPC Endpoint把VPC和所需要访问的服务连接起来,然后EC2就可以不经internet访问到所需的服务。
+
+
+
+[参考](https://juejin.cn/post/6954169148318433288)
+
+RT(Route Table)与Subnet相关连,用来描述网络路由。IGW: Internet gateway IGW是一个独立的组件配置在VPC上,使得VPC可以访问internet
+
+我们给VPC加了IGW之后,需要修改Subnet相关的路由,确保访问Internet的请求发送到IGW。
+
+每个VPC中有一个默认的主RT,自动关联VPC内的每一个Subnet。我们现在为Subnet “ts-public-1”单独创建一个新的RT。
+
+
+
+- 新建的Subnet就是Private Subnet
+- 在Private Subnet中配置了到IGW的路由后,就变成Public Subnet
+- Public Subnet中的EC2还要再配置一个Public IP或者EIP就可以访问Internet
+- 如果EC2可以访问internet,其关联的Security Group入站规则如果允许从internet访问,那么这个EC2就可以从internet中直接访问到。
+
+
+
+1. 实践中我们把应用程序,数据库放在Private Subnet中,阻止从internet访问。把堡垒机和ALB(Application Load balancer)放在Public Subnet,允许从internet访问。
+
+2. 一般我们会建两套Public Subnet和Private Subnet,分别放在不同的AZ中,防止其中一个AZ出问题。这时如果配置NAT,也需要在两个Public Subnet中各配置一个NAT。
+
+
+
+[参考](http://www.cloudbin.cn/?tag=aws) 暂无Note
+
+## 总结
+
+VPC里多个AZ, 每个AZ都需要至少一个子网,默认是公有子网。但如果有internet访问不到的实例或者数据库,则需建个私有子网,私有子网默认不能访问internet,internet也不能访问私有子网。
+
+要走互联网必须走internet gateway,它对整个vpc生效, public subnet可直接通过IGW与互联网互联,私有子网再通过NAT走公有子网是可以访问internet的,反向不能。
+
+和互联网连接时都需要有个公网ip,这个是从amazon分配的。
+
+
+
+## Route 53
+
+**Amazon Route 53**是一种高可用、高扩展性的云DNS服务。
+
+不同的DNS记录:
+
+- **CNAME** – CNAME (Canonical Name)可以将一个域名指向另一个域名。比如将aws.xiaopeiqing.com指向xiaopeiqing.com
+- Alias记录 – 和CNAME类似,又叫做别名记录,可以将一个域名指向另一个域名。
+ - **和CNAME最大的区别是,Alias可以应用在根域(Zone Apex)。即可以为xiaopeiqing.com的根域创建Alias记录,而不能创建CNAME**
+ - 别名记录可以节省你的时间,因为Route53会自动识别别名记录所指的记录中的更改。例如,假设example.com的一个别名记录指向位于lb1-1234.us-east-2.elb.amazonaws.com上的一个ELB负载均衡器。如果该负载均衡器的IP地址发生更改,Route53将在example.com的DNS应答中自动反映这些更改,而无需对包含example.com的记录的托管区域做出任何更改。 弹性负载均衡器(ELB)没有固定的IPv4地址,在使用ELB的时候永远使用它的DNS名字。很多场景下我们需要绑定DNS记录到ELB的endpoint地址,而不绑定任何IP
diff --git a/_posts/Tech/AWS/2022-11-18-AWS Compute.md b/_posts/Tech/AWS/2022-11-18-AWS Compute.md
new file mode 100644
index 0000000000..5c602ab6fa
--- /dev/null
+++ b/_posts/Tech/AWS/2022-11-18-AWS Compute.md
@@ -0,0 +1,130 @@
+---
+layout: post
+category: AWS
+title: AWS Compute
+tags: AWS
+---
+
+## AWS Compute
+
+## AMI
+
+AMI: amazon machine image 就是一堆配置,比如什么系统,安装哪些附加软件。可使用AMI启动一个同配置的实例。 类似docker的image
+
+**Amazon Machine Image (AMI)** 是亚马逊AWS提供的系统镜像,这个AMI包含了如下的信息:
+
+- 由实例的操作系统、应用程序和应用程序相关的配置组成的模板
+- 一个指定的需要在实例启动时附加到实例的卷的信息(比方说定义了使用8 GB的General Purpose SSD卷)
+
+下图所示的是AMI的生命周期,你可以创建并注册一个AMI,并且可以使用这个AMI来创建一个EC2实例。同时你也可以将这个AMI复制到同一个AWS区域或者不同的AWS区域。你同样也可以注销这个AMI镜像。
+
+
+
+- **AMI是区域化的**,只能使用本区域的AMI来创建实例;但你可以将AMI从一个区域复制到另一个区域
+
+
+
+
+
+## 弹性伸缩(Auto Scaling)
+
+**亚马逊弹性伸缩(Auto Scaling)**能**自动地**增加/减少EC2实例的数量,从而让你的应用程序一直能保持可用的状态。
+
+你可以预定义Auto Scaling,使其在需求高峰期自动增加EC2实例,而在需求低谷自动减少EC2实例。这样不仅能让你的应用程序一直保持健康的状态,而且也节省了你为EC2实例所付出的费用。
+
+Auto Scaling 适用于那些需求稳定的应用程序,同时也适用于在每小时、每天、甚至每周都有需求变化的应用程序。
+
+- Auto Scaling能保证你一直拥有一定数量的EC2实例来分担应用程序的负载
+- Auto Scaling能带来更高的容错性、更好的可用性和更高的性价比
+- 你可以控制伸缩的策略来决定在什么时候终止和创建EC2实例,以处理动态变化的需求
+- 默认情况下,Auto Scaling能控制每一个可用区内所运行的实例数量尽量平均
+ - 为了达到这个目标,Auto Scaling在需要启动新实例的时候,会选择一个目前拥有运行实例最少的可用区
+
+Auto Scaling的构成组件:
+
+
+
+### 启动配置(Launch Configuration)
+
+- 启动配置是弹性伸缩组用来启动EC2实例的时候所使用的模板
+- 启动配置包含了镜像文件(AMI),实例类型、密钥对、安全组和挂载的存储设备
+- 一个启动配置可以关联多个Auto Scaling组
+- **启动配置一经创建不能被更改,只能删除重建**
+- 启动配置中可以使用CloudWatch的基础监控(Basic Monitoring)或者详细监控(Detail Monitoring)
+- Auto Scaling automatically creates a launch configuration directly from an EC2 instance.
+
+### 弹性伸缩组(Auto Scaling Group)
+
+- 弹性伸缩组(ASG)是弹性伸缩的核心,它包含了多个拥有类似配置/类型的EC2实例,这些实例被逻辑上认为是一样的
+- 弹性伸缩组需要的几个参数:
+ - **启动配置(Launch Configuration)**:它决定了EC2使用什么模板,模板内容包括了镜像文件(AMI),实例类型、密钥对、安全组和挂载的存储设备
+ - **最小和最大的性能**:决定了在弹性伸缩的情况下,EC2实例数量的浮动范围
+ - **所需的性能**:决定了这个弹性伸缩组要保持的运作所需要的基本的EC2实例数量;如果没有填写,则默认为其数值等同于最小的性能
+ - **可用区和子网**:定义EC2实例启动时候所在的可用区和子网信息
+ - **参数和健康检查**:参数定义了何时启动新实例,何时终止旧实例;健康检查决定了实例的健康状态。
+- **如果一个EC2实例的健康状态变成“不健康”,那么ASG会终止这个EC2实例,并且自动启动一个新的EC2实例**
+- 弹性伸缩组(ASG)只能在某一个AWS区域内运行,不能跨越多个区域
+- 如果启动配置(Launch Configuration)有更新,那么之后启动的新EC2实例会使用新的启动配置,而旧的EC2实例不受影响
+- 从AWS管理平台你可以直接删除一个弹性伸缩组(ASG);从AWS CLI你只能先将最小的性能和需求的性能两个参数设置为0,才能删除这个弹性伸缩组。
+
+
+
+## ECS
+
+**Amazon Elastic Container Service (ECS)**是一个有高度扩展性的**容器管理服务**。它可以轻松运行、停止和管理集群上的Docker容器,你可以将容器安装在EC2实例上,或者使用**Fargate**来启动你的服务和任务。
+
+Amazon ECS可以在一个区域内的多个可用区中创建高可用的应用程序容器,你可以定义集群中运行的Docker镜像和服务。而且你可以充分利用AWS内部的**Amazon ECR (Elastic Container Registry)**或者外部的Registry(比如Docker Hub或自建的Registry)来存储和提取容器镜像。
+
+
+
+我们可以将标准化的代码、运行环境、系统工具等等打包成一个标准的集装箱,这个集装箱叫做**Docker镜像**(Docker Image)。这个Docker镜像的概念类似于EC2中的AMI (Amazon Machine Image)。
+
+这些镜像文件通常会通过Dockerfile来构建,并且最终存放到**注册表(Registry)**内。这个Registry可以理解为摆放集装箱的码头,我们在需要某个类型的集装箱的时候就到码头去取。这类Registry可以是Amazon的ECR,也可以是公网上的Docker Hub,或者自己私有的Registry。
+
+
+
+
+
+### ECS创建举例
+
+
+
+
+
+## **Lambda**
+
+使用**AWS Lambda**,你无需配置和管理任何服务器和应用程序就能运行你的代码。只需要上传代码,Lambda就会处理运行并且根据需要自动进行横向扩展。因此Lambda也被称为**无服务(Serverless)**函数。
+
+要让AWS Lambda的代码执行,需要设定一些触发器(比如CloudWatch Log,CloudWatch Event,API Gateway等),因此Lambda函数被认为是**事件驱动的(Event-Driven)**。
+
+在传统的应用部署过程中,我们往往需要安装操作系统 -> 安装应用程序 -> 配置环境并部署代码,而且往往还需要不定时地为操作系统和应用程序打补丁和进行维护。使用AWS Lambda就方便很多,只需要上传代码,AWS就会在需要的时候帮你运行。我们不再需要(也无法接触)任何操作系统层面的东西,也节省了非常多的部署时间,可以更专心地编写代码。
+
+
+
+### AWS Lambda的特点
+
+- 没有服务器/无服务,或者说真实的服务器由AWS管理
+- 只需要为运行的代码付费,不需要管理服务器和操作系统
+- **持续性/自动的性能伸缩**
+- 非常便宜
+- AWS只会在代码运行期间收取相应的费用,代码未运行时不产生任何费用
+- **代码的最长执行时间是15分钟,如果代码执行时间超过15分钟,则需要将1个代码细分为多个**
+
+### 触发器有哪些
+
+- **API Gateway**
+- **AWS IoT**
+- **CloudWatch Events** 比如cron job定时任务
+- CloudWatch Logs
+- CodeCommit
+- DynamoDB
+- S3
+- SNS
+- Cognito Sync Trigger
+- SQS应该也可以?
+
+
+
+## 参考
+
+[参考](http://www.cloudbin.cn/?tag=aws)
diff --git a/_posts/Tech/AWS/2022-11-18-AWS MQ.md b/_posts/Tech/AWS/2022-11-18-AWS MQ.md
new file mode 100644
index 0000000000..d8e16b7db2
--- /dev/null
+++ b/_posts/Tech/AWS/2022-11-18-AWS MQ.md
@@ -0,0 +1,85 @@
+---
+layout: post
+category: AWS
+title: AWS MQ
+tags: AWS
+---
+
+## AWS MQ
+
+## SQS(Simple Queue Service)
+
+SQS有两种不同类型的队列,它们分别是:
+
+- **标准队列**(Standard Queue)
+- **FIFO队列**(先进先出队列)
+
+### 标准队列
+
+标准队列拥有**无限的吞吐量**,所有消息都会**至少传递一次**,并且它会尽最大努力进行排序。
+
+标准队列是默认的队列类型。
+
+
+
+### FIFO队列
+
+FIFO (First-in-first-out)队列在不使用批处理的情况下,**最多支持300TPS**(每秒300个发送、接受或删除操作)。
+
+在队列中的消息都只会**不多不少地被处理一次**。
+
+FIFO队列严格保持消息的**发送和接收顺序**。
+
+
+
+更多关于标准队列和FIFO队列的区别,可以查看[我需要哪种类型的队列?](https://docs.aws.amazon.com/zh_cn/AWSSimpleQueueService/latest/SQSDeveloperGuide/welcome.html#sqs-queue-types)
+
+### SQS的其他特点
+
+- SQS是靠应用程序去**拉取的**,而不能主动推送给应用程序,推送服务我们使用**SNS(Simple Notification Service)**
+- 消息会以256 KB的大小存放
+- 消息会在队列中保存1分钟~14天,默认时间是4天
+- 可见性超时(Visibility Timeout)
+ - 即当SQS队列收到新的消息并且被拉取走进行处理时,会触发Visibility Timeout的时间。这个消息不会被删除,而是会被设置为不可见,用来防止该消息在处理的过程中再一次被拉取
+ - 当这个消息被处理完成后,这个消息会在SQS中被删除,表示这个任务已经处理完毕
+ - 如果这个消息在Visibility Timeout时间结束之后还没有被处理完,则这个消息会设置为可见状态,等待另一个程序来进行处理
+ - 因此**同一个消息可能会被处理两次(或以上)**
+ - 这个超时时间最大可以设置为**12小时**
+- 标准SQS队列保证了每一个在队列内的消息都至少会被处理一次
+- 长轮询(Long Polling)
+ - 默认情况下,Amazon SQS使用**短轮询(Short Polling)**,即应用程序每次去查询SQS队列,SQS都会做回应(哪怕队列一直是空的)
+ - 使用了长轮训,应用程序每次去查询SQS队列,SQS队列不会马上做回应。而是等到队列里有消息可处理时,或者等到设定的超时时间再做出回应。
+ - 长轮询可以一定程度减少SQS的花销
+
+## SNS (Simple Notification Service)
+
+**SNS (Simple Notification Service)** 是一种完全托管的发布/订阅消息收发和移动通知服务,用于协调向订阅终端节点和客户端的消息分发。
+
+和**SQS (Simple Queue Service)**一样,SNS也可以轻松分离和扩展微服务,分布式系统和无服务应用程序,对程序进行**解耦**。
+
+我们可以使用SNS将消息推送到SQS消息队列中、AWS Lambda函数或者HTTP终端节点上。
+
+SNS通知还可以发送推送通知到IOS,安卓,Windows和基于百度的设备,也可以通过电子邮箱或者SMS短信的形式发送到各种不同类型的设备上。
+
+
+
+### SNS的一些特点
+
+- SNS是实时的**推送服务(Push)**,有别于SQS的**拉取服务(Pull/Poll)**
+- 拥有简单的API,可以和其他应用程序兼容
+- 可以通过多种不同的传输协议进行集成
+- 便宜、用多少付费多少的服务模型
+- 在AWS管理控制台上就可以进行简单的操作
+
+## SNS vs SQS
+
+AWS提供了[SQS](https://link.zhihu.com/?target=https%3A//console.aws.amazon.com/sqs/v2/home)和[SNS](https://link.zhihu.com/?target=https%3A//console.aws.amazon.com/sns/v3/home)。SQS是一个分布式的队列消息service,SNS是一个分布式的发布-订阅消息service。具体有人会问这两者有什么区别,这里给出了回答: [What is the difference between Amazon SNS and Amazon SQS?](https://link.zhihu.com/?target=https%3A//stackoverflow.com/questions/13681213/what-is-the-difference-between-amazon-sns-and-amazon-sqs)。 在我的实践中,SQS和SNS会结合起来使用,首先应用发布消息到SQS的queue里面,然后SNS消费这个queue的消息,放到自身的topic里面持久保存,然后其他的应用订阅这个topic,消费里面的消息。
+
+
+
+sqs是一对一,不能一对多,消息可持久化,不推只能等拉,拉完就删除。
+
+sns可一对多,不能持久化,push模型。
+
+sqs及aws笔记,更全, [link](http://www.cloudbin.cn/?p=2530)
+
diff --git a/_posts/Tech/AWS/2022-11-18-AWS Storage.md b/_posts/Tech/AWS/2022-11-18-AWS Storage.md
new file mode 100644
index 0000000000..ed5683197f
--- /dev/null
+++ b/_posts/Tech/AWS/2022-11-18-AWS Storage.md
@@ -0,0 +1,214 @@
+---
+layout: post
+category: AWS
+title: AWS Storage
+tags: AWS
+---
+
+## AWS Storage
+
+## dynamoDB
+
+[论文讲解](http://systemdesigns.blogspot.com/2016/01/dynamodb.html)
+
+[深入探讨 Amazon DynamoDB 的设计模 式、流复制和全局表](https://sides-share.s3.cn-north-1.amazonaws.com.cn/AWS+Webinar+2019/PDF/Amazon+DynamoDB+webinar.pdf)
+
+[官网](https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/Programming.LowLevelAPI.html#Programming.LowLevelAPI.DataTypeDescriptors)
+
+[AWS 如何实现数据跨区域同步](https://techsummit.ctrip.com/pdf/songye.pdf)
+
+[MongoDB 与 DynamoDB 正面交锋](https://www.modb.pro/db/432414)
+
+
+
+## EBS
+
+### EBS的特点
+
+- 亚马逊EBS卷提供了**高可用、可靠、持续性的块存储**,EBS可以依附到一个正在运行的EC2实例上
+- 如果你的EC2实例需要使用数据库或者文件系统,那么建议使用EBS作为首选的存储设备
+- EBS卷的存活可以脱离EC2实例的存活状态。也就是说在终止一个实例的时候,你可以选择保留该实例所绑定的EBS卷
+- EBS卷可以依附到**同一个可用区(AZ)**内的任何实例上
+- EBS卷可以被加密,如果进行了加密那么它存有的所有已有数据,传输的数据,以及制造的镜像都会被加密
+- **EBS卷可以通过快照(Snapshot)来进行(增量)备份,这个快照会保存在S3 (Simple Storage System)上**
+- 你可以使用任何快照来创建一个基于该快照的EBS卷,并且随时将这个EBS卷应用到**该区域**的任何实例上
+- EBS卷创建的时候已经固定了可用区,并且**只能给该可用区的实例使用**。如果需要在其他可用区使用该EBS,那么可以创建快照,并且使用该快照创建一个在其他可用区的新的EBS卷
+- **快照还可以复制到其他的AWS区域**
+
+### EBS (Elastic Block Storage)小结
+
+- EBS的不同类型,需要了解不同类型的EBS主要的使用场景
+ - 通用型SSD – GP2 (高达10,000 IOPS),适用于启动盘,低延迟的应用程序等
+ - 预配置型SSD – IO1 (超过10,000 IOPS),适用于IO密集型的数据库
+ - 吞吐量优化型HDD -ST1,适用于数据仓库,日志处理
+ - HDD Cold – SC1 – 适合较少使用的冷数据
+ - HDD, Magnetic
+- 不能将EBS挂载到多个EC2实例上,一个EBS只能挂载到1个EC2实例上。
+ - 如果有共享数据盘的需求,请使用EFS (Elastic File System)
+- 根EBS卷默认是不能进行加密的,但可以使用第三方的加密工具(例如BitLocker)对其进行加密
+ - *除了根磁盘外的其他卷是可以加密的*
+
+### EBS快照(Snapshot)小结
+
+- *EBS的快照会被保存到S3(Simple Storage System)上*
+
+- *你可以对一个EBS卷创建一个快照,这个快照会被保存到S3上*
+
+- 快照实际上是
+
+ 增量备份
+
+ ,只有在上次进行快照之后更改的数据才会被添加的S3上
+
+ - 因此第一次快照所花费的时间比较长
+ - 而第二次以后的快照所花费的时间相对短很多
+
+- 对加密的EBS卷创建快照,创建后的快照也会是加密的
+
+- 从加密的快照恢复的EBS卷也会是加密的
+
+- 你可以分享快照给其他账户或AWS市场,但仅限于这个快照是没有进行过加密的
+
+- 要为一个作为根设备的EBS卷创建快照的话,建议停止这个实例再做快照
+
+### 实例存储(Instance Store)
+
+- 实例存储也叫做**短暂性存储(Ephemeral Storage)**
+- 实例存储的实例不能被停止(只能重启或终止),如果这个实例出现故障,那么在上面的所有数据将会丢失
+- 使用EBS的实例可以被停止,停止后EBS上的数据不会丢失
+- 重启使用实例存储的实例或者重启使用EBS的实例都不会导致数据丢失
+
+
+
+## AWS EBS, S3和EFS的区别
+
+- AWS S3对于静态页面的托管、多媒体分发、版本管理、大数据分析、数据存档来说都非常有用。S3可以和AWS CloudFront结合使用而达到更快的上传和下载速度。
+- AWS EBS是可以用来做数据库或托管应用程序的持续性文件系统,EBS具有很高的IO读写速度并且即插即用。 只能被单个EC2实例访问
+- 相比前面两种存储,AWS EFS是比较新的一项服务。它提供了可以在多个EC2实例之间共享的网络文件系统,功能类似于NAS设备。可以用EFS来处理大数据分析、多媒体处理和内容管理。
+
+## S3
+
+Amazon **Simple Storage Service (S3)** 是互联网存储解决方案,它提供了一个简单的Web接口,让其存储的数据和文件在互联网的任何地方给任何人访问。
+
+文件对象存储。
+
+
+
+### S3基本特性
+
+- S3是**对象存储**,可以在S3上存储各种类型的文件,它不是**块存储**(EBS是块存储)
+- 文件大小可以从0 字节到5 TB
+ - 使用Single Operation上传只能上传*最大5 GB*的文件
+ - 使用分段上传(Multipart Upload)可以对文件进行分段上传,最大支持上传*5 TB*的文件
+- S3的总存储空间是**无限大**的
+- 文件存储在**存储桶(Bucket)**内,可以理解存储桶就是一个文件夹
+- S3的名字是需要**全球唯一**的,不能与任何区域的任何人拥有的S3重名
+- 存储桶创建之后会生成一个URL,命名类似于https://s3-ap-northeast-1.amazonaws.com/aws_xiaopeiqing_com
+ - **S3是以HTTPS的形式展现的,而非HTTP**
+ - ap-northeast-1表示了当前桶所在的区域
+ - aws_xiaopeiqing_com表示了S3存储桶的名字,全球唯一
+- S3拥有99.99%(4个9)的可用性(Availability)
+ - 可用性可以理解为系统的uptime时间,即在一个自然年内(365天)有52.56分钟系统不可用
+- S3拥有99.999999999%(11个9)的持久性(Durability)
+ - 持久性可以认为是数据完整性/数据安全性,即在一千亿个存储在S3上的文件会有大概 1 个文件是不可读的
+- S3的存储桶创建的时候可以选择所在区域(Region),但不能选择可用区(AZ),AWS会负责S3的高可用、容灾问题
+ - S3创建的时候可以选择某个AWS区域,一旦选择了就不能更改
+ - 如果要在其他区域使用该S3的内容,可以使用**跨区域复制**
+- S3拥有不同的等级(Standard, Stantard-IA, Onezone-IA, RRS, Glacier)
+- 启用了**版本控制(Version Control)**你可以恢复S3内的文件到之前的版本
+- S3可以开启生命周期管理,对文件在不同的生命周期进行不同的操作
+ - 比如,文件在创建30天后迁移到便宜的S3等级(S3-IA),再经过30天进行归档(迁移到Glacier),再过30天就进行删除
+- 要启用生命周期管理需要先启用版本控制功能
+- S3支持加密功能
+- 使用访问控制列表(Access Control Lists)和桶策略(Bucket Policy)可以控制S3的访问安全
+- 在S3上成功上传了文件,你将会得到一个**HTTP 200**的状态反馈
+
+### 不同的S3存储类型
+
+- **Standard – 默认的存储类:**如果上传对象时未注明则S3会分配这个类型的存储
+- **Standard – IA(Infrequently Accessed):**用于保存不经常访问的数据,但是需要访问的时候也能很快地访问到。存储的价格比标准S3便宜,但是读取的费用比标准的S3高,也因为如此才要把不经常访问的数据放到这种类型的S3上。并且数据跨了多个AWS地理位置。
+- **Intelligent_Tiering** 智能分层(S3 智能分层): 这种储存类别将对象存储在两个访问层中,一个是频繁访问的层,一个是不频繁访问的层;如果对象`30`天内未访问,则会被移动至不频繁访问的层,如果不频繁访问层中的对象被访问,则会被移动至频繁访问的层;频繁访问的层的存储费用与`STANDARD`一样,不频繁访问层的存储费用与`STANDARD_IA`一样,该储存类别的请求费用与`STANDARD`一样,**该储存类别有额外的监控费用**;
+- **Onezone – IA:**同上,但数据只保存到一个AWS可用区内
+- **Glacier:**非常便宜,仅用于做归档。从Glacier读取数据需要花费3-5个小时。
+- **Glacier Deep Archive:** S3 Glacier Deep Archive 是 Amazon S3 成本最低的存储类,支持每年可能访问一两次的数据的长期保留和数字预留。它是为客户设计的 – 特别是那些监管严格的行业,如金融服务、医疗保健和公共部门 – 为了满足监管合规要求,将数据集保留 7-10 年或更长时间。S3 Glacier Deep Archive 还可用于备份和灾难恢复使用案例,是成本效益高、易于管理的磁带系统替代,无论磁带系统是本地库还是非本地服务都是如此。S3 Glacier Deep Archive 是 Amazon S3 Glacier 的补充,后者适合存档,其中会定期检索数据并且每隔几分钟可能需要一些数据。存储在 S3 Glacier Deep Archive 中的所有对象都将接受复制并存储在至少三个地理分散的可用区中,受 99.999999999% 的持久性保护,并且可在 12 小时内恢复。
+
+## CloudFront CDN
+
+**Amazon CloudFront**是一种全球**内容分发网络(CDN)**服务,可以安全地以低延迟和高传输速度向浏览者分发数据、视频、应用程序和API。
+
+
+
+- **边缘站点(Edge Location)**:边缘站点是内容缓存的地方,它存在于多个网络服务提供商的机房,它和AWS区域和可用区是完全不一样的概念。截至2018年中,AWS目前一共有100多个边缘站点。
+- **源(Origin)**:这是CDN缓存的内容所使用的源,源可以是一个S3存储桶,可以是一个EC2实例,一个弹性负载均衡器(ELB)或Route53,甚至可以是AWS之外的资源。
+- **分配(Distribution)**:AWS CloudFront创建后的名字
+- 分配分为两种类型,分别是
+ - **Web Distribution**:一般的网站应用
+ - **RTMP (Real-Time Messaging Protocol)**:媒体流
+- 你不只是可以从边缘站点读取数据,你还可以往边缘站点写入数据(比如上传一个文件),边缘站点会将你写入的数据同步到源上
+- 在CloudFront上的文件会被缓存在边缘节点,缓存的时间是**TTL(Time To Live)**。文件存在超过这个时间,缓存会被自动清除
+- 如果在到达TTL时间之前,你希望更新文件,那么你也可以**手动清除缓存**,但你将会被AWS**收取一定的费用**
+
+
+
+## Multi-AZ高可用
+
+我们可以把AWS RDS数据库部署在多个**可用区(AZ)**内,以提供高可用性和故障转移支持。
+
+使用Multi-AZ部署模式,RDS会在不同的可用区内配置和维护一个主数据库和一个备用数据库,主数据库的数据会自动复制到备用数据库中。
+
+使用这种部署模式,可以为我们提供数据冗余,减少在系统备份期间的I/O冻结(上面有提到)。同时,更重要的是可以防止数据库实例的故障和单个可用区的故障。
+
+如下图所示,我们可以在两个可用区内分别部署主数据库和备用数据库。
+
+
+
+目前Multi-AZ支持以下数据库:
+
+- Oracle
+- PostgreSQL
+- MySQL
+- MariaDB
+- SQL Server
+
+值得注意的是,Aurora数据库本身就支持多可用区部署的高可用设置,因此不需要为Aurora数据库特别开启这个功能。
+
+在上次实验中我们有讲到,创建了RDS数据库之后我们会得到一个数据库的URL Endpoint。在开启Multi-AZ的情况下,这个URL Endpoints会根据主/备数据库的健康状态自动解析到IP地址。对于应用程序来说,我们只需要连接这个URL地址即可。
+
+**高可用的设置只是用来解决灾备的问题,并不能解决读取性能的问题;要提升数据库读取性能,我们需要用到Read Replicas。**
+
+
+
+### 只读副本(Read Replicas)
+
+我们可以在源数据库实例的基础上,复制一种新类型的数据库实例,称之为**只读副本(Read Replicas)**。我们对源数据库的任何更新,都会**异步**更新到只读副本中。
+
+因此,我们可以将应用程序的数据库读取功能转移到Read Replicas上,来减轻源数据库的负载。
+
+对于有大量读取需求的数据库,我们可以使用这种方式来进行灵活的数据库扩展,同时突破单个数据库实例的性能限制。
+
+Read Replicas还有如下的特点:
+
+- Read Replicas是用来提高读取性能的,不是用来做灾备的
+- 要创建Read Replicas需要源RDS实例开启了自动备份的功能
+- 可以为数据库创建最多**5个**Read Replicas
+- 可以为Read Replicas创建Read Replicas(如下图所示)
+- 每一个Read Replicas都有自己的URL Endpoint
+- 可以为一个启用了Multi-AZ的数据库创建Read Replicas
+- Read Replicas可以提升成为独立的数据库
+- 可以创建位于另一个区域(Region)的Read Replicas
+
+
+
+目前Read Replicas支持以下数据库:
+
+- Aurora
+- PostgreSQL
+- MySQL
+- MariaDB
+- Oracle
+
+https://amazonaws-china.com/cn/rds/details/read-replicas/
+
+## 参考
+
+[参考](http://www.cloudbin.cn/?p=1968)
diff --git a/_posts/Tech/AWS/2022-11-26-AWS DynamoDB.md b/_posts/Tech/AWS/2022-11-26-AWS DynamoDB.md
new file mode 100644
index 0000000000..306c83421e
--- /dev/null
+++ b/_posts/Tech/AWS/2022-11-26-AWS DynamoDB.md
@@ -0,0 +1,131 @@
+---
+layout: post
+category: AWS
+title: AWS DynamoDB
+tags: AWS
+---
+
+## AWS DynamoDB
+
+> [论文讲解](http://systemdesigns.blogspot.com/2016/01/dynamodb.html)
+
+Dynamo在某些故障的场景中将牺牲一致性。
+
+Dynamo的系统假设和要求:
+1)query model:对数据项简单的读,写是通过一个主键唯一性标识。状态存储为一个由唯一性键确定二进制对象。没有横跨多个数据项的操作,也不需要关系方案(relational schema)。这项规定是基于观察相当一部分Amazon的服务可以使用这个简单的查询模型,并不需要任何关系模式。Dynamo的目标应用程序需要存储的对象都比较小(通常小于1MB)。
+
+2)ACID属性:ACID是一种保证数据库事务可靠地处理的属性。在数据库方面的,对数据的单一的逻辑操作被称作所谓的交易。Amazon的经验表明,在保证ACID的数据存储提往往有很差的可用性。Dynamo的目标应用程序是高可用性,弱一致性(ACID“中的C”)。Dynamo不提供任何数据隔离(Isolation)保证,只允许单一的关键更新。
+
+3)efficiency:系统需运作在一般的commodity hardware上。Amazon平台的服务都有着严格的延时要求, 鉴于对状态的访问在服务操作中起着至关重要的作用,存储系统必须能够满足那些严格的SLA,服务必须能够通过配置Dynamo,使他们不断达到延时和吞吐量的要求。因此,必须在成本效率,可用性和耐用性保证之间做权衡。
+
+
+
+提供get, put操作。
+
+
+
+最终一致性。
+
+### Partition
+
+按key做partition, 一致性Hash。
+
+### Replication
+
+replica, 复制,用了NWR,让用户做一致性的选择。读数据时如果有不同版本,会所有版本数据都返回回去。
+
+### Data Versioning
+
+多版本。Vector Clock 一个Vector Clock可以理解为一个<节点编号,计数器>对的列表。每一个版本的数据都会带上一个Vector Clock。Dynamo中,最重要的是要保证写操作的高可用性,即“Always Writeable”,这样就不可避免的牺牲掉数据的一致性。如上所述,Dynamo中并没有对数据做强一致性要求,而是采用的最终一致性(eventual consistency)。若不保证各个副本的强一致性,则用户在读取数据的时候很可能读到的不是最新的数据。Dynamo中将数据的增加或删除这种操作都视为一种增加操作,即每一次操作的结果都作为一份全新的数据保存,这样也就造成了一份数据会存在多个版本,分布在不同的节点上。这种情况类似于版本管理中的多份副本同时有多人在修改。多数情况下,系统会自动合并这些版本,一旦合并尝试失败,那么冲突的解决就交给应用层来解决。这时系统表现出来的现象就是,一个GET(KEY)操作,返回的不是单一的数据,而是一个多版本的数据列表,由用户决定如何合并。这其中的关键技术就是Vector Clock。
+
+
+
+其实就是读修复。
+
+### Failure Detection
+
+临时性故障,采用Hinted Handoff提示移交机制
+
+为防止要写入节点宕机导致操作失败,采用提示移交机制将操作相关数据写入到随机节点,宕机节点恢复后可根据这些数据进行重放,最终获得数据一致性。
+
+
+
+ 以N=3为例,如果在一次写操作时发现节点A挂了,那么本应该存在A上的副本就会发送到D上,同时在D中会记录这个副本的元信息(MetaData)。其中有个标示,表明这份数据是本应该存在A上的,一旦节点D之后检测到A从故障中恢复了,D就会将这个本属于A的副本回传给A,之后删除这份数据。Dynamo中称这种技术为“Hinted Handoff”。
+
+
+
+另外为了应对整个机房掉线的故障,Dynamo中应用了一个很巧妙的方案。每次读写都会从”Preference List”列表中取出R或W个节点。那么只要在这个列表生成的时候,让其中的节点是分布于不同机房的,自然数据就写到了不同机房的节点上。
+
+
+
+对于某节点非临时性故障,利用反熵得到丢失数据进行恢复。一些数据存储有后台进程,不断查找副本之间的数据差异,将任何缺少的数据从一个副本复制到另一个副本。和基于主节点复制的复制日志不同,此反熵过程不保证任何特定的顺序复制写入,并且会引入明显的同步滞后
+
+
+
+### 表、索引
+
+> [深入探讨 Amazon DynamoDB 的设计模 式、流复制和全局表](https://sides-share.s3.cn-north-1.amazonaws.com.cn/AWS+Webinar+2019/PDF/Amazon+DynamoDB+webinar.pdf)
+
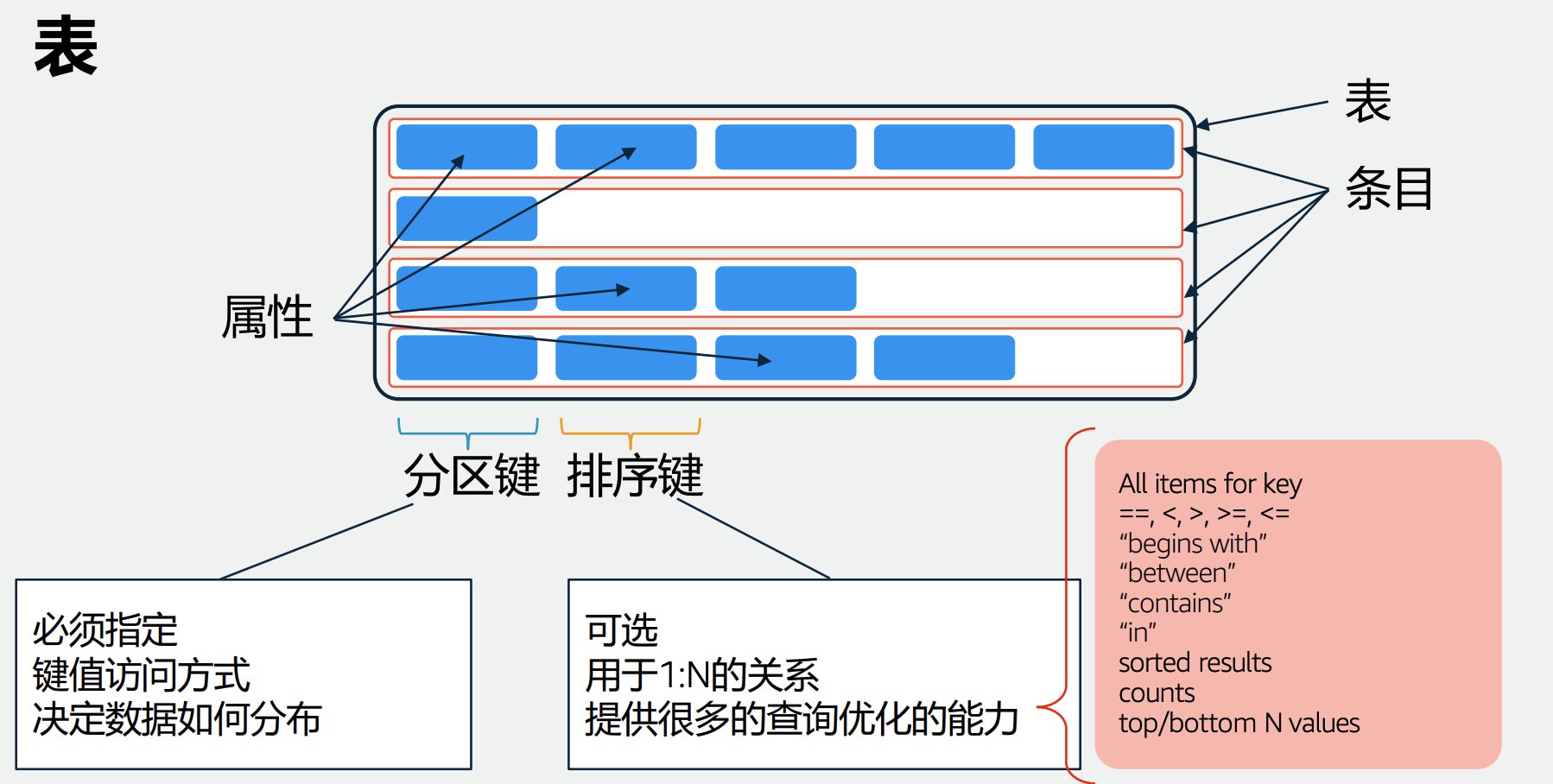
+
+
+分区键和排序键共同唯一的标识一条记录
+
+本地二级索引 Local Secondary Index (LSI) 单表上的。可以选择与表不同的排序键。同一个分区键。强一致性更新。
+
+
+
+全局二级索引 - Global Secondary Index (GSI) 可以选择与表不同的分区键以及排序键 每个索引分区会对应所有的表分区
+
+
+
+
+
+
+
+对比
+
+- Global Secondary
+ - 索引的尺寸没有上限
+ - 读写容量和表是独立的
+ - 只支持最终一致性
+- Index Local Secondary Index
+ - 索引保存在表的分区中,因此一个表 分区的尺寸的上限是10GB
+ - 使用的是表上定义的RCU和WCU
+ - 强一致性
+
+
+
+
+## 其他
+
+
+
+> [官网](https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/Programming.LowLevelAPI.html#Programming.LowLevelAPI.DataTypeDescriptors)
+
+begin_with这个操作要记得。其他后面看。
+
+
+
+> [AWS 如何实现数据跨区域同步](https://techsummit.ctrip.com/pdf/songye.pdf)
+
+没啥子东西,数据操作优先同区域内,主要靠复制。
+
+
+
+> [MongoDB 与 DynamoDB 正面交锋](https://www.modb.pro/db/432414)
+
+没啥东西
+
+
+
+> [通俗易懂之DynamoDB(一) ----分区键、排序键、GSI](https://zhuanlan.zhihu.com/p/101965292)
+
+**getItem、query和scan**
+
+这三个操作都是查询操作,效率分别是:getItem > query > scan
+
+getItem是根据primary key进行查询,可以理解为通过primary key在hashMap上查询,速度是最快的,缺点是必须知道primary key且只能查询单个,使用情况相对较少。
+
+scan是全表扫描,是最慢的一个,理论上能不用就不用,只有实在走投无路才考虑全表扫描。
+
+query是最常见的方式,在dynamoDB的使用中,我们唯一的目的就是写出高效的查询query。
diff --git a/_posts/Tech/AWS/2022-12-14-AWS CloudWatch.md b/_posts/Tech/AWS/2022-12-14-AWS CloudWatch.md
new file mode 100644
index 0000000000..38746d77c0
--- /dev/null
+++ b/_posts/Tech/AWS/2022-12-14-AWS CloudWatch.md
@@ -0,0 +1,19 @@
+---
+layout: post
+category: AWS
+title: AWS CloudWatch
+tags: AWS
+published: false
+---
+
+## AWS CloudWatch
+
+主要是Dashboard, metrics, alarms等。
+
+metrics的dimension不能用in操作。只能取1个或者不取。
+
+
+
+## 待更新
+
+期待后续...
diff --git "a/_posts/Tech/Algorithms/2018-01-18-\345\210\206\346\236\220\346\227\266\351\227\264\345\244\215\346\235\202\345\272\246.md" "b/_posts/Tech/Algorithms/2018-01-18-\345\210\206\346\236\220\346\227\266\351\227\264\345\244\215\346\235\202\345\272\246.md"
index 85488e17cd..4025af158b 100644
--- "a/_posts/Tech/Algorithms/2018-01-18-\345\210\206\346\236\220\346\227\266\351\227\264\345\244\215\346\235\202\345\272\246.md"
+++ "b/_posts/Tech/Algorithms/2018-01-18-\345\210\206\346\236\220\346\227\266\351\227\264\345\244\215\346\235\202\345\272\246.md"
@@ -20,8 +20,6 @@ T(n) = n^klogn if k==log(b)a
[递归的时间复杂度分析](https://blog.csdn.net/qq_36582604/article/details/81661236)
-
-
我们先看下面这个例子

@@ -30,8 +28,6 @@ T(n) = n^klogn if k==log(b)a
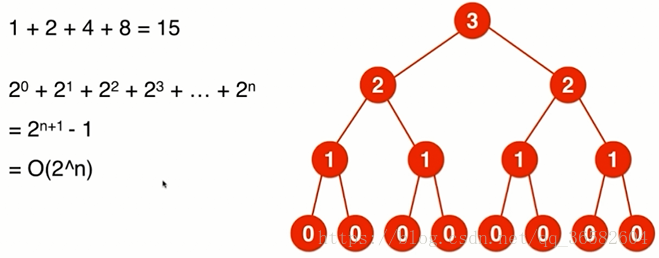
-
-
[归并排序时间复杂度分析](https://blog.csdn.net/qq_32534441/article/details/95098059)
```
@@ -39,7 +35,7 @@ T(n)=2*T(n/2)+n
第一层n, 第二层2*(n/2), 第三层4*(n/4), 每层都有个n,高度Logn
```
-[合并k个链表的时间复杂度分析](https://blog.csdn.net/qq_22080999/article/details/80669993)
+[合并 k 个链表的时间复杂度分析](https://blog.csdn.net/qq_22080999/article/details/80669993)
分治的话:
@@ -49,45 +45,42 @@ T(kn) = 2T(k/2*n) + kn
高度log2(k),每层累加都是kn, 因此最终是log2(k) * kn
```
-方法1:暴力,k个链表按顺序合并
+方法 1:暴力,k 个链表按顺序合并
时间复杂度:
(n+n)+(2n+n)+...+ ((k-1)n + n) = (1+2+...+k-1)n + (k-1)n = (1+2+...+k-1+k)n -n = (k^2+k-1)/2*n = O(k^2*n)
-方法2:将k*n个结点放到vector,再将vector排序,再将结点顺序相连
+方法 2:将 k\*n 个结点放到 vector,再将 vector 排序,再将结点顺序相连
-设有K个链表,平均每个链表有n个结点,时间复杂度:
+设有 K 个链表,平均每个链表有 n 个结点,时间复杂度:
kN*logkN +kN = O(kN*logkN)
-方法3:对k个链表进行分治,两两进行合并
+方法 3:对 k 个链表进行分治,两两进行合并
-设有k个链表,平均每个链表有n个结点,时间复杂度:
+设有 k 个链表,平均每个链表有 n 个结点,时间复杂度:
-第一轮:进行k/2次,每次处理2n个数字
+第一轮:进行 k/2 次,每次处理 2n 个数字
-第2轮,进行k/4次,每次处理4n个数字
+第 2 轮,进行 k/4 次,每次处理 4n 个数字
...
-最后一次,进行k/(2^logk)次,每次处理2^logk*n个数
-
-2n*k/2+...+2^logk*n * k/(2^logk)
-
+最后一次,进行 k/(2^logk)次,每次处理 2^logk\*n 个数
+2n*k/2+...+2^logk*n \* k/(2^logk)
## 常见算法时间复杂度
时间复杂度总结:
-prim o(e+vlogv), 主要是优先队列top v次,每次log(v), 然后边遍历总计2e.
+prim o(e+vlogv), 主要是优先队列 top v 次,每次 log(v), 然后边遍历总计 2e.
kruskal o(eloge), 主要是边的排序耗时上。
-dijsktra o(e+vlogv), 边总计e, 优先队列取了v次,每次top log(v), 这里指的斐波那契堆,该堆insert 为o(1),其他和二叉堆一致。
-
-floyd wallshal, o(n3)
+dijsktra o(e+vlogv), 边总计 e, 优先队列取了 v 次,每次 top log(v), 这里指的斐波那契堆,该堆 insert 为 o(1),其他和二叉堆一致。
-bellman-ford, o(ve), 每个边松弛一次,共循环v次,o(ve);
+floyd wallshal, o(n3)
+bellman-ford, o(ve), 每个边松弛一次,共循环 v 次,o(ve);
diff --git "a/_posts/Tech/Algorithms/2018-03-13-\345\212\250\346\200\201\350\247\204\345\210\222\344\271\213\345\205\254\345\205\261\345\255\220\345\272\217\345\210\227\345\255\220\344\270\262.md" "b/_posts/Tech/Algorithms/2018-03-13-\345\212\250\346\200\201\350\247\204\345\210\222\344\271\213\345\205\254\345\205\261\345\255\220\345\272\217\345\210\227\345\255\220\344\270\262.md"
index 4913182da9..f941661942 100644
--- "a/_posts/Tech/Algorithms/2018-03-13-\345\212\250\346\200\201\350\247\204\345\210\222\344\271\213\345\205\254\345\205\261\345\255\220\345\272\217\345\210\227\345\255\220\344\270\262.md"
+++ "b/_posts/Tech/Algorithms/2018-03-13-\345\212\250\346\200\201\350\247\204\345\210\222\344\271\213\345\205\254\345\205\261\345\255\220\345\272\217\345\210\227\345\255\220\344\270\262.md"
@@ -1,7 +1,7 @@
---
layout: post
category: Algorithms
-title: 动态规划之公共子序列子串
+title: 动态规划之公共子序列/子串/前缀
tags: Algorithms
---
@@ -183,3 +183,23 @@ public class LCString {
}
```
+
+## 最长前缀LCP Longest common prefix
+
+求两个字符串任意两个位置开头的最长公共前缀。时间复杂度o(n2) 如果是暴力需要o(n3) 枚举i,j然后到头。
+
+
+
+```scala
+class Strings:
+ def LongestCommonPrefix(a, b):
+ # lcp[i][j] 表示 s[i:] 和 s[j:] 的最长公共前缀
+ n, m = len(a), len(b)
+ lcp = [[0] * (m + 1) for _ in range(n + 1)]
+ for i in range(n - 1, -1, -1):
+ for j in range(m - 1, -1, -1):
+ if a[i] == b[j]:
+ lcp[i][j] = lcp[i + 1][j + 1] + 1
+ return lcp
+```
+
diff --git "a/_posts/Tech/Algorithms/2018-08-01-\351\230\237\345\210\227\345\222\214\346\240\210.md" "b/_posts/Tech/Algorithms/2018-08-01-\351\230\237\345\210\227\345\222\214\346\240\210.md"
index af863894ef..ef2859e924 100644
--- "a/_posts/Tech/Algorithms/2018-08-01-\351\230\237\345\210\227\345\222\214\346\240\210.md"
+++ "b/_posts/Tech/Algorithms/2018-08-01-\351\230\237\345\210\227\345\222\214\346\240\210.md"
@@ -165,4 +165,13 @@ class Solution:
-类似题目: [394. 字符串解码](https://leetcode-cn.com/problems/decode-string/)
\ No newline at end of file
+类似题目: [394. 字符串解码](https://leetcode-cn.com/problems/decode-string/)
+
+
+
+
+
+给定入栈顺序,求某个出栈顺序。
+
+1. [6202. 使用机器人打印字典序最小的字符串](https://mafulong.github.io/2022/10/09/6202.-%E4%BD%BF%E7%94%A8%E6%9C%BA%E5%99%A8%E4%BA%BA%E6%89%93%E5%8D%B0%E5%AD%97%E5%85%B8%E5%BA%8F%E6%9C%80%E5%B0%8F%E7%9A%84%E5%AD%97%E7%AC%A6%E4%B8%B2/)
+2. [栈的压入、弹出序列](https://mafulong.github.io/2018/10/20/%E6%A0%88%E7%9A%84%E5%8E%8B%E5%85%A5-%E5%BC%B9%E5%87%BA%E5%BA%8F%E5%88%97/)
\ No newline at end of file
diff --git "a/_posts/Tech/algorithms/2018-08-13-\346\254\247\346\213\211\345\233\236\350\267\257.md" "b/_posts/Tech/Algorithms/2018-08-13-\346\254\247\346\213\211\350\267\257\345\276\204.md"
similarity index 87%
rename from "_posts/Tech/algorithms/2018-08-13-\346\254\247\346\213\211\345\233\236\350\267\257.md"
rename to "_posts/Tech/Algorithms/2018-08-13-\346\254\247\346\213\211\350\267\257\345\276\204.md"
index 6b221feac6..3e19382e31 100644
--- "a/_posts/Tech/algorithms/2018-08-13-\346\254\247\346\213\211\345\233\236\350\267\257.md"
+++ "b/_posts/Tech/Algorithms/2018-08-13-\346\254\247\346\213\211\350\267\257\345\276\204.md"
@@ -1,14 +1,16 @@
---
layout: post
category: Algorithms
-title: 欧拉回路
+title: 欧拉路径
tags: Algorithms
---
## 欧拉回路定义及判断
-如果能从图的某一顶点出发,每条边恰好经过一次,这样的路线称为欧拉道路(Eulerian Path)。
+如果能从图的某一顶点出发,每条边恰好经过一次,这样的路线称为**欧拉道路(Eulerian Path)。也叫欧拉路径**
+
+如果每条边恰好经过一次,且能回到起点,这样的路线称为**欧拉回路**(Eulerian Circuit)。
+
-如果每条边恰好经过一次,且能回到起点,这样的路线称为欧拉回路(Eulerian Circuit)。
对于无向图G,当且仅当G 是连通的,且最多有两个奇点,则存在欧拉道路。
@@ -22,7 +24,7 @@ tags: Algorithms
- 通过图中所有边恰好一次且行遍所有顶点的通路称为欧拉通路。
- 通过图中所有边恰好一次且行遍所有顶点的回路称为欧拉回路。
-- 具有欧拉回路的无向图称为欧拉图。
+- **具有欧拉回路的无向图称为欧拉图。**
- 具有欧拉通路但不具有欧拉回路的无向图称为半欧拉图。
@@ -41,6 +43,10 @@ tags: Algorithms
给定一个 *n* 个点 *m* 条边的图,要求从指定的顶点出发,经过所有的边恰好一次(可以理解为给定起点的「一笔画」问题)其实就是求欧拉路径。
+如果在有欧拉回路中的图,它就求的是欧拉回路。如果非欧拉回路的图就是欧拉路径。
+
+
+
Hierholzer 算法用于在连通图中寻找欧拉路径,其流程如下:[参考](https://leetcode-cn.com/problems/reconstruct-itinerary/solution/zhong-xin-an-pai-xing-cheng-by-leetcode-solution/)
@@ -70,11 +76,17 @@ def dfs(u):
stack = stack[::-1]
```
+以上是求点的路径。 有向图还是无向图都没关系,无向图就变两个有向的边就行。
+
+
+
+如果是求边路径,pop后进入stack即可。
+
## 相关题目
-- [332. 重新安排行程](https://leetcode-cn.com/problems/reconstruct-itinerary/)
-- [753. 破解保险箱](https://leetcode-cn.com/problems/cracking-the-safe/) 求锁所有密码,就是抽象出多个节点,然后求欧拉回路.
+- [332. 重新安排行程](https://leetcode-cn.com/problems/reconstruct-itinerary/) 求欧拉路径 点的顺序
+- [753. 破解保险箱](https://leetcode-cn.com/problems/cracking-the-safe/) 求锁所有密码,就是抽象出多个节点,然后求欧拉路径.
- [5932. 合法重新排列数对](https://leetcode-cn.com/problems/valid-arrangement-of-pairs/)
diff --git "a/_posts/Tech/Algorithms/2021-01-25-\345\215\232\345\274\210\350\256\272.md" "b/_posts/Tech/Algorithms/2021-01-25-\345\215\232\345\274\210\350\256\272.md"
index 2273a453fe..b86928dd25 100644
--- "a/_posts/Tech/Algorithms/2021-01-25-\345\215\232\345\274\210\350\256\272.md"
+++ "b/_posts/Tech/Algorithms/2021-01-25-\345\215\232\345\274\210\350\256\272.md"
@@ -3,6 +3,7 @@ layout: post
category: Algorithms
title: 博弈论
tags: Algorithms
+recent_update: true
---
## 博弈论
diff --git "a/_posts/Tech/Algorithms/2021-03-11-\344\270\221\346\225\260.md" "b/_posts/Tech/Algorithms/2021-03-11-\344\270\221\346\225\260.md"
deleted file mode 100644
index b28798fa3a..0000000000
--- "a/_posts/Tech/Algorithms/2021-03-11-\344\270\221\346\225\260.md"
+++ /dev/null
@@ -1,57 +0,0 @@
----
-layout: post
-category: Algorithms
-title: 丑数
-tags: Algorithms
----
-
-## 丑数
-
-[[剑指 Offer 49. 丑数](https://leetcode-cn.com/problems/chou-shu-lcof/)
-
-[313. 超级丑数](https://leetcode-cn.com/problems/super-ugly-number/)
-
-### 使用优先队列
-
-```python
-class Solution:
- def nthSuperUglyNumber(self, n: int, primes: List[int]) -> int:
- import heapq
- hq = [1]
- res = []
- for _ in range(n):
- top = heapq.heappop(hq)
- res.append(top)
- while hq and hq[0] == top:
- heapq.heappop(hq)
- for k in primes:
- heapq.heappush(hq, top * k)
- print(res)
- return res[-1]
-```
-
-
-
-### 使用多指针
-
-```c++
-//cpp:
-class Solution {
-public://别人的代码就是精简,惭愧啊,继续学习。
- int GetUglyNumber_Solution(int index) {
- if (index < 7)return index;
- vector
+
+参考
+
+- Internet Gateway (IGW) allows instances with public IPs to access the internet.
+- NAT Gateway (NGW) allows instances with no public IPs to access the internet.
+
+## 参考
+
+[参考](https://juejin.cn/post/6949072638145003556)
+
+大部分 AWS 服务都需要以 VPC 为基础进行构建,比如最常用的 EC2,ALB,及无服务器服务 ECS Fargate。 vb
+
+当我们在一个 VPC 中创建 Subnet 时需要给 Subnet 选择一个 AZ(Availability Zone),一个 Subnet 只能选择建在一个 AZ 中。
+
+
+
+**选择region**
+
+因为国内政策法规原因,AWS 在中国的服务与 AWS Global 服务略有不同。
+
+AWS Global 的 Region 之间是通过主干网相连的,AWS 中国区的服务没有通过主干网与 AWS Global 相连,只有中国区内部两个 Region,北京和宁夏是相连接的。
+
+在创建 VPC 时并不需要添写 AZ(Availability Zone)信息,VPC 只与 Region 有关。
+
+
+
+Subnet 是最终承载大部分 AWS 服务的组件,比如 EC2, ECS Fargate,RDS。
+
+Subnet 分为两种 Private Subnet 和 Public Subnet。
+
+简单来说,不能直接访问 internet 的 Subnet 就是 Private Subnet,能直接访问 internet 的就是 Public Subnet。
+
+
+
+Security Group(SG)通过控制IP和端口来控制出站入站规则,可以用于EC2,RDS及下面将要用到的VPC Endpoint。
+
+
+
+VPC Endpoint用来直接连接VPC与AWS相关服务,比如RDS AIP,S3。
+
+当系统安全要求比较高时,EC2处于的Subnet可能被限制,无法访问internet,这时EC2就无法访问AWS的一些服务,比如SSM。
+
+这时我们可以利用VPC Endpoint把VPC和所需要访问的服务连接起来,然后EC2就可以不经internet访问到所需的服务。
+
+
+
+[参考](https://juejin.cn/post/6954169148318433288)
+
+RT(Route Table)与Subnet相关连,用来描述网络路由。IGW: Internet gateway IGW是一个独立的组件配置在VPC上,使得VPC可以访问internet
+
+我们给VPC加了IGW之后,需要修改Subnet相关的路由,确保访问Internet的请求发送到IGW。
+
+每个VPC中有一个默认的主RT,自动关联VPC内的每一个Subnet。我们现在为Subnet “ts-public-1”单独创建一个新的RT。
+
+
+
+- 新建的Subnet就是Private Subnet
+- 在Private Subnet中配置了到IGW的路由后,就变成Public Subnet
+- Public Subnet中的EC2还要再配置一个Public IP或者EIP就可以访问Internet
+- 如果EC2可以访问internet,其关联的Security Group入站规则如果允许从internet访问,那么这个EC2就可以从internet中直接访问到。
+
+
+
+1. 实践中我们把应用程序,数据库放在Private Subnet中,阻止从internet访问。把堡垒机和ALB(Application Load balancer)放在Public Subnet,允许从internet访问。
+
+2. 一般我们会建两套Public Subnet和Private Subnet,分别放在不同的AZ中,防止其中一个AZ出问题。这时如果配置NAT,也需要在两个Public Subnet中各配置一个NAT。
+
+
+
+[参考](http://www.cloudbin.cn/?tag=aws) 暂无Note
+
+## 总结
+
+VPC里多个AZ, 每个AZ都需要至少一个子网,默认是公有子网。但如果有internet访问不到的实例或者数据库,则需建个私有子网,私有子网默认不能访问internet,internet也不能访问私有子网。
+
+要走互联网必须走internet gateway,它对整个vpc生效, public subnet可直接通过IGW与互联网互联,私有子网再通过NAT走公有子网是可以访问internet的,反向不能。
+
+和互联网连接时都需要有个公网ip,这个是从amazon分配的。
+
+
+
+## Route 53
+
+**Amazon Route 53**是一种高可用、高扩展性的云DNS服务。
+
+不同的DNS记录:
+
+- **CNAME** – CNAME (Canonical Name)可以将一个域名指向另一个域名。比如将aws.xiaopeiqing.com指向xiaopeiqing.com
+- Alias记录 – 和CNAME类似,又叫做别名记录,可以将一个域名指向另一个域名。
+ - **和CNAME最大的区别是,Alias可以应用在根域(Zone Apex)。即可以为xiaopeiqing.com的根域创建Alias记录,而不能创建CNAME**
+ - 别名记录可以节省你的时间,因为Route53会自动识别别名记录所指的记录中的更改。例如,假设example.com的一个别名记录指向位于lb1-1234.us-east-2.elb.amazonaws.com上的一个ELB负载均衡器。如果该负载均衡器的IP地址发生更改,Route53将在example.com的DNS应答中自动反映这些更改,而无需对包含example.com的记录的托管区域做出任何更改。 弹性负载均衡器(ELB)没有固定的IPv4地址,在使用ELB的时候永远使用它的DNS名字。很多场景下我们需要绑定DNS记录到ELB的endpoint地址,而不绑定任何IP
diff --git a/_posts/Tech/AWS/2022-11-18-AWS Compute.md b/_posts/Tech/AWS/2022-11-18-AWS Compute.md
new file mode 100644
index 0000000000..5c602ab6fa
--- /dev/null
+++ b/_posts/Tech/AWS/2022-11-18-AWS Compute.md
@@ -0,0 +1,130 @@
+---
+layout: post
+category: AWS
+title: AWS Compute
+tags: AWS
+---
+
+## AWS Compute
+
+## AMI
+
+AMI: amazon machine image 就是一堆配置,比如什么系统,安装哪些附加软件。可使用AMI启动一个同配置的实例。 类似docker的image
+
+**Amazon Machine Image (AMI)** 是亚马逊AWS提供的系统镜像,这个AMI包含了如下的信息:
+
+- 由实例的操作系统、应用程序和应用程序相关的配置组成的模板
+- 一个指定的需要在实例启动时附加到实例的卷的信息(比方说定义了使用8 GB的General Purpose SSD卷)
+
+下图所示的是AMI的生命周期,你可以创建并注册一个AMI,并且可以使用这个AMI来创建一个EC2实例。同时你也可以将这个AMI复制到同一个AWS区域或者不同的AWS区域。你同样也可以注销这个AMI镜像。
+
+
+
+- **AMI是区域化的**,只能使用本区域的AMI来创建实例;但你可以将AMI从一个区域复制到另一个区域
+
+
+
+
+
+## 弹性伸缩(Auto Scaling)
+
+**亚马逊弹性伸缩(Auto Scaling)**能**自动地**增加/减少EC2实例的数量,从而让你的应用程序一直能保持可用的状态。
+
+你可以预定义Auto Scaling,使其在需求高峰期自动增加EC2实例,而在需求低谷自动减少EC2实例。这样不仅能让你的应用程序一直保持健康的状态,而且也节省了你为EC2实例所付出的费用。
+
+Auto Scaling 适用于那些需求稳定的应用程序,同时也适用于在每小时、每天、甚至每周都有需求变化的应用程序。
+
+- Auto Scaling能保证你一直拥有一定数量的EC2实例来分担应用程序的负载
+- Auto Scaling能带来更高的容错性、更好的可用性和更高的性价比
+- 你可以控制伸缩的策略来决定在什么时候终止和创建EC2实例,以处理动态变化的需求
+- 默认情况下,Auto Scaling能控制每一个可用区内所运行的实例数量尽量平均
+ - 为了达到这个目标,Auto Scaling在需要启动新实例的时候,会选择一个目前拥有运行实例最少的可用区
+
+Auto Scaling的构成组件:
+
+
+
+### 启动配置(Launch Configuration)
+
+- 启动配置是弹性伸缩组用来启动EC2实例的时候所使用的模板
+- 启动配置包含了镜像文件(AMI),实例类型、密钥对、安全组和挂载的存储设备
+- 一个启动配置可以关联多个Auto Scaling组
+- **启动配置一经创建不能被更改,只能删除重建**
+- 启动配置中可以使用CloudWatch的基础监控(Basic Monitoring)或者详细监控(Detail Monitoring)
+- Auto Scaling automatically creates a launch configuration directly from an EC2 instance.
+
+### 弹性伸缩组(Auto Scaling Group)
+
+- 弹性伸缩组(ASG)是弹性伸缩的核心,它包含了多个拥有类似配置/类型的EC2实例,这些实例被逻辑上认为是一样的
+- 弹性伸缩组需要的几个参数:
+ - **启动配置(Launch Configuration)**:它决定了EC2使用什么模板,模板内容包括了镜像文件(AMI),实例类型、密钥对、安全组和挂载的存储设备
+ - **最小和最大的性能**:决定了在弹性伸缩的情况下,EC2实例数量的浮动范围
+ - **所需的性能**:决定了这个弹性伸缩组要保持的运作所需要的基本的EC2实例数量;如果没有填写,则默认为其数值等同于最小的性能
+ - **可用区和子网**:定义EC2实例启动时候所在的可用区和子网信息
+ - **参数和健康检查**:参数定义了何时启动新实例,何时终止旧实例;健康检查决定了实例的健康状态。
+- **如果一个EC2实例的健康状态变成“不健康”,那么ASG会终止这个EC2实例,并且自动启动一个新的EC2实例**
+- 弹性伸缩组(ASG)只能在某一个AWS区域内运行,不能跨越多个区域
+- 如果启动配置(Launch Configuration)有更新,那么之后启动的新EC2实例会使用新的启动配置,而旧的EC2实例不受影响
+- 从AWS管理平台你可以直接删除一个弹性伸缩组(ASG);从AWS CLI你只能先将最小的性能和需求的性能两个参数设置为0,才能删除这个弹性伸缩组。
+
+
+
+## ECS
+
+**Amazon Elastic Container Service (ECS)**是一个有高度扩展性的**容器管理服务**。它可以轻松运行、停止和管理集群上的Docker容器,你可以将容器安装在EC2实例上,或者使用**Fargate**来启动你的服务和任务。
+
+Amazon ECS可以在一个区域内的多个可用区中创建高可用的应用程序容器,你可以定义集群中运行的Docker镜像和服务。而且你可以充分利用AWS内部的**Amazon ECR (Elastic Container Registry)**或者外部的Registry(比如Docker Hub或自建的Registry)来存储和提取容器镜像。
+
+
+
+我们可以将标准化的代码、运行环境、系统工具等等打包成一个标准的集装箱,这个集装箱叫做**Docker镜像**(Docker Image)。这个Docker镜像的概念类似于EC2中的AMI (Amazon Machine Image)。
+
+这些镜像文件通常会通过Dockerfile来构建,并且最终存放到**注册表(Registry)**内。这个Registry可以理解为摆放集装箱的码头,我们在需要某个类型的集装箱的时候就到码头去取。这类Registry可以是Amazon的ECR,也可以是公网上的Docker Hub,或者自己私有的Registry。
+
+
+
+
+
+### ECS创建举例
+
+
+
+
+
+## **Lambda**
+
+使用**AWS Lambda**,你无需配置和管理任何服务器和应用程序就能运行你的代码。只需要上传代码,Lambda就会处理运行并且根据需要自动进行横向扩展。因此Lambda也被称为**无服务(Serverless)**函数。
+
+要让AWS Lambda的代码执行,需要设定一些触发器(比如CloudWatch Log,CloudWatch Event,API Gateway等),因此Lambda函数被认为是**事件驱动的(Event-Driven)**。
+
+在传统的应用部署过程中,我们往往需要安装操作系统 -> 安装应用程序 -> 配置环境并部署代码,而且往往还需要不定时地为操作系统和应用程序打补丁和进行维护。使用AWS Lambda就方便很多,只需要上传代码,AWS就会在需要的时候帮你运行。我们不再需要(也无法接触)任何操作系统层面的东西,也节省了非常多的部署时间,可以更专心地编写代码。
+
+
+
+### AWS Lambda的特点
+
+- 没有服务器/无服务,或者说真实的服务器由AWS管理
+- 只需要为运行的代码付费,不需要管理服务器和操作系统
+- **持续性/自动的性能伸缩**
+- 非常便宜
+- AWS只会在代码运行期间收取相应的费用,代码未运行时不产生任何费用
+- **代码的最长执行时间是15分钟,如果代码执行时间超过15分钟,则需要将1个代码细分为多个**
+
+### 触发器有哪些
+
+- **API Gateway**
+- **AWS IoT**
+- **CloudWatch Events** 比如cron job定时任务
+- CloudWatch Logs
+- CodeCommit
+- DynamoDB
+- S3
+- SNS
+- Cognito Sync Trigger
+- SQS应该也可以?
+
+
+
+## 参考
+
+[参考](http://www.cloudbin.cn/?tag=aws)
diff --git a/_posts/Tech/AWS/2022-11-18-AWS MQ.md b/_posts/Tech/AWS/2022-11-18-AWS MQ.md
new file mode 100644
index 0000000000..d8e16b7db2
--- /dev/null
+++ b/_posts/Tech/AWS/2022-11-18-AWS MQ.md
@@ -0,0 +1,85 @@
+---
+layout: post
+category: AWS
+title: AWS MQ
+tags: AWS
+---
+
+## AWS MQ
+
+## SQS(Simple Queue Service)
+
+SQS有两种不同类型的队列,它们分别是:
+
+- **标准队列**(Standard Queue)
+- **FIFO队列**(先进先出队列)
+
+### 标准队列
+
+标准队列拥有**无限的吞吐量**,所有消息都会**至少传递一次**,并且它会尽最大努力进行排序。
+
+标准队列是默认的队列类型。
+
+
+
+### FIFO队列
+
+FIFO (First-in-first-out)队列在不使用批处理的情况下,**最多支持300TPS**(每秒300个发送、接受或删除操作)。
+
+在队列中的消息都只会**不多不少地被处理一次**。
+
+FIFO队列严格保持消息的**发送和接收顺序**。
+
+
+
+更多关于标准队列和FIFO队列的区别,可以查看[我需要哪种类型的队列?](https://docs.aws.amazon.com/zh_cn/AWSSimpleQueueService/latest/SQSDeveloperGuide/welcome.html#sqs-queue-types)
+
+### SQS的其他特点
+
+- SQS是靠应用程序去**拉取的**,而不能主动推送给应用程序,推送服务我们使用**SNS(Simple Notification Service)**
+- 消息会以256 KB的大小存放
+- 消息会在队列中保存1分钟~14天,默认时间是4天
+- 可见性超时(Visibility Timeout)
+ - 即当SQS队列收到新的消息并且被拉取走进行处理时,会触发Visibility Timeout的时间。这个消息不会被删除,而是会被设置为不可见,用来防止该消息在处理的过程中再一次被拉取
+ - 当这个消息被处理完成后,这个消息会在SQS中被删除,表示这个任务已经处理完毕
+ - 如果这个消息在Visibility Timeout时间结束之后还没有被处理完,则这个消息会设置为可见状态,等待另一个程序来进行处理
+ - 因此**同一个消息可能会被处理两次(或以上)**
+ - 这个超时时间最大可以设置为**12小时**
+- 标准SQS队列保证了每一个在队列内的消息都至少会被处理一次
+- 长轮询(Long Polling)
+ - 默认情况下,Amazon SQS使用**短轮询(Short Polling)**,即应用程序每次去查询SQS队列,SQS都会做回应(哪怕队列一直是空的)
+ - 使用了长轮训,应用程序每次去查询SQS队列,SQS队列不会马上做回应。而是等到队列里有消息可处理时,或者等到设定的超时时间再做出回应。
+ - 长轮询可以一定程度减少SQS的花销
+
+## SNS (Simple Notification Service)
+
+**SNS (Simple Notification Service)** 是一种完全托管的发布/订阅消息收发和移动通知服务,用于协调向订阅终端节点和客户端的消息分发。
+
+和**SQS (Simple Queue Service)**一样,SNS也可以轻松分离和扩展微服务,分布式系统和无服务应用程序,对程序进行**解耦**。
+
+我们可以使用SNS将消息推送到SQS消息队列中、AWS Lambda函数或者HTTP终端节点上。
+
+SNS通知还可以发送推送通知到IOS,安卓,Windows和基于百度的设备,也可以通过电子邮箱或者SMS短信的形式发送到各种不同类型的设备上。
+
+
+
+### SNS的一些特点
+
+- SNS是实时的**推送服务(Push)**,有别于SQS的**拉取服务(Pull/Poll)**
+- 拥有简单的API,可以和其他应用程序兼容
+- 可以通过多种不同的传输协议进行集成
+- 便宜、用多少付费多少的服务模型
+- 在AWS管理控制台上就可以进行简单的操作
+
+## SNS vs SQS
+
+AWS提供了[SQS](https://link.zhihu.com/?target=https%3A//console.aws.amazon.com/sqs/v2/home)和[SNS](https://link.zhihu.com/?target=https%3A//console.aws.amazon.com/sns/v3/home)。SQS是一个分布式的队列消息service,SNS是一个分布式的发布-订阅消息service。具体有人会问这两者有什么区别,这里给出了回答: [What is the difference between Amazon SNS and Amazon SQS?](https://link.zhihu.com/?target=https%3A//stackoverflow.com/questions/13681213/what-is-the-difference-between-amazon-sns-and-amazon-sqs)。 在我的实践中,SQS和SNS会结合起来使用,首先应用发布消息到SQS的queue里面,然后SNS消费这个queue的消息,放到自身的topic里面持久保存,然后其他的应用订阅这个topic,消费里面的消息。
+
+
+
+sqs是一对一,不能一对多,消息可持久化,不推只能等拉,拉完就删除。
+
+sns可一对多,不能持久化,push模型。
+
+sqs及aws笔记,更全, [link](http://www.cloudbin.cn/?p=2530)
+
diff --git a/_posts/Tech/AWS/2022-11-18-AWS Storage.md b/_posts/Tech/AWS/2022-11-18-AWS Storage.md
new file mode 100644
index 0000000000..ed5683197f
--- /dev/null
+++ b/_posts/Tech/AWS/2022-11-18-AWS Storage.md
@@ -0,0 +1,214 @@
+---
+layout: post
+category: AWS
+title: AWS Storage
+tags: AWS
+---
+
+## AWS Storage
+
+## dynamoDB
+
+[论文讲解](http://systemdesigns.blogspot.com/2016/01/dynamodb.html)
+
+[深入探讨 Amazon DynamoDB 的设计模 式、流复制和全局表](https://sides-share.s3.cn-north-1.amazonaws.com.cn/AWS+Webinar+2019/PDF/Amazon+DynamoDB+webinar.pdf)
+
+[官网](https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/Programming.LowLevelAPI.html#Programming.LowLevelAPI.DataTypeDescriptors)
+
+[AWS 如何实现数据跨区域同步](https://techsummit.ctrip.com/pdf/songye.pdf)
+
+[MongoDB 与 DynamoDB 正面交锋](https://www.modb.pro/db/432414)
+
+
+
+## EBS
+
+### EBS的特点
+
+- 亚马逊EBS卷提供了**高可用、可靠、持续性的块存储**,EBS可以依附到一个正在运行的EC2实例上
+- 如果你的EC2实例需要使用数据库或者文件系统,那么建议使用EBS作为首选的存储设备
+- EBS卷的存活可以脱离EC2实例的存活状态。也就是说在终止一个实例的时候,你可以选择保留该实例所绑定的EBS卷
+- EBS卷可以依附到**同一个可用区(AZ)**内的任何实例上
+- EBS卷可以被加密,如果进行了加密那么它存有的所有已有数据,传输的数据,以及制造的镜像都会被加密
+- **EBS卷可以通过快照(Snapshot)来进行(增量)备份,这个快照会保存在S3 (Simple Storage System)上**
+- 你可以使用任何快照来创建一个基于该快照的EBS卷,并且随时将这个EBS卷应用到**该区域**的任何实例上
+- EBS卷创建的时候已经固定了可用区,并且**只能给该可用区的实例使用**。如果需要在其他可用区使用该EBS,那么可以创建快照,并且使用该快照创建一个在其他可用区的新的EBS卷
+- **快照还可以复制到其他的AWS区域**
+
+### EBS (Elastic Block Storage)小结
+
+- EBS的不同类型,需要了解不同类型的EBS主要的使用场景
+ - 通用型SSD – GP2 (高达10,000 IOPS),适用于启动盘,低延迟的应用程序等
+ - 预配置型SSD – IO1 (超过10,000 IOPS),适用于IO密集型的数据库
+ - 吞吐量优化型HDD -ST1,适用于数据仓库,日志处理
+ - HDD Cold – SC1 – 适合较少使用的冷数据
+ - HDD, Magnetic
+- 不能将EBS挂载到多个EC2实例上,一个EBS只能挂载到1个EC2实例上。
+ - 如果有共享数据盘的需求,请使用EFS (Elastic File System)
+- 根EBS卷默认是不能进行加密的,但可以使用第三方的加密工具(例如BitLocker)对其进行加密
+ - *除了根磁盘外的其他卷是可以加密的*
+
+### EBS快照(Snapshot)小结
+
+- *EBS的快照会被保存到S3(Simple Storage System)上*
+
+- *你可以对一个EBS卷创建一个快照,这个快照会被保存到S3上*
+
+- 快照实际上是
+
+ 增量备份
+
+ ,只有在上次进行快照之后更改的数据才会被添加的S3上
+
+ - 因此第一次快照所花费的时间比较长
+ - 而第二次以后的快照所花费的时间相对短很多
+
+- 对加密的EBS卷创建快照,创建后的快照也会是加密的
+
+- 从加密的快照恢复的EBS卷也会是加密的
+
+- 你可以分享快照给其他账户或AWS市场,但仅限于这个快照是没有进行过加密的
+
+- 要为一个作为根设备的EBS卷创建快照的话,建议停止这个实例再做快照
+
+### 实例存储(Instance Store)
+
+- 实例存储也叫做**短暂性存储(Ephemeral Storage)**
+- 实例存储的实例不能被停止(只能重启或终止),如果这个实例出现故障,那么在上面的所有数据将会丢失
+- 使用EBS的实例可以被停止,停止后EBS上的数据不会丢失
+- 重启使用实例存储的实例或者重启使用EBS的实例都不会导致数据丢失
+
+
+
+## AWS EBS, S3和EFS的区别
+
+- AWS S3对于静态页面的托管、多媒体分发、版本管理、大数据分析、数据存档来说都非常有用。S3可以和AWS CloudFront结合使用而达到更快的上传和下载速度。
+- AWS EBS是可以用来做数据库或托管应用程序的持续性文件系统,EBS具有很高的IO读写速度并且即插即用。 只能被单个EC2实例访问
+- 相比前面两种存储,AWS EFS是比较新的一项服务。它提供了可以在多个EC2实例之间共享的网络文件系统,功能类似于NAS设备。可以用EFS来处理大数据分析、多媒体处理和内容管理。
+
+## S3
+
+Amazon **Simple Storage Service (S3)** 是互联网存储解决方案,它提供了一个简单的Web接口,让其存储的数据和文件在互联网的任何地方给任何人访问。
+
+文件对象存储。
+
+
+
+### S3基本特性
+
+- S3是**对象存储**,可以在S3上存储各种类型的文件,它不是**块存储**(EBS是块存储)
+- 文件大小可以从0 字节到5 TB
+ - 使用Single Operation上传只能上传*最大5 GB*的文件
+ - 使用分段上传(Multipart Upload)可以对文件进行分段上传,最大支持上传*5 TB*的文件
+- S3的总存储空间是**无限大**的
+- 文件存储在**存储桶(Bucket)**内,可以理解存储桶就是一个文件夹
+- S3的名字是需要**全球唯一**的,不能与任何区域的任何人拥有的S3重名
+- 存储桶创建之后会生成一个URL,命名类似于https://s3-ap-northeast-1.amazonaws.com/aws_xiaopeiqing_com
+ - **S3是以HTTPS的形式展现的,而非HTTP**
+ - ap-northeast-1表示了当前桶所在的区域
+ - aws_xiaopeiqing_com表示了S3存储桶的名字,全球唯一
+- S3拥有99.99%(4个9)的可用性(Availability)
+ - 可用性可以理解为系统的uptime时间,即在一个自然年内(365天)有52.56分钟系统不可用
+- S3拥有99.999999999%(11个9)的持久性(Durability)
+ - 持久性可以认为是数据完整性/数据安全性,即在一千亿个存储在S3上的文件会有大概 1 个文件是不可读的
+- S3的存储桶创建的时候可以选择所在区域(Region),但不能选择可用区(AZ),AWS会负责S3的高可用、容灾问题
+ - S3创建的时候可以选择某个AWS区域,一旦选择了就不能更改
+ - 如果要在其他区域使用该S3的内容,可以使用**跨区域复制**
+- S3拥有不同的等级(Standard, Stantard-IA, Onezone-IA, RRS, Glacier)
+- 启用了**版本控制(Version Control)**你可以恢复S3内的文件到之前的版本
+- S3可以开启生命周期管理,对文件在不同的生命周期进行不同的操作
+ - 比如,文件在创建30天后迁移到便宜的S3等级(S3-IA),再经过30天进行归档(迁移到Glacier),再过30天就进行删除
+- 要启用生命周期管理需要先启用版本控制功能
+- S3支持加密功能
+- 使用访问控制列表(Access Control Lists)和桶策略(Bucket Policy)可以控制S3的访问安全
+- 在S3上成功上传了文件,你将会得到一个**HTTP 200**的状态反馈
+
+### 不同的S3存储类型
+
+- **Standard – 默认的存储类:**如果上传对象时未注明则S3会分配这个类型的存储
+- **Standard – IA(Infrequently Accessed):**用于保存不经常访问的数据,但是需要访问的时候也能很快地访问到。存储的价格比标准S3便宜,但是读取的费用比标准的S3高,也因为如此才要把不经常访问的数据放到这种类型的S3上。并且数据跨了多个AWS地理位置。
+- **Intelligent_Tiering** 智能分层(S3 智能分层): 这种储存类别将对象存储在两个访问层中,一个是频繁访问的层,一个是不频繁访问的层;如果对象`30`天内未访问,则会被移动至不频繁访问的层,如果不频繁访问层中的对象被访问,则会被移动至频繁访问的层;频繁访问的层的存储费用与`STANDARD`一样,不频繁访问层的存储费用与`STANDARD_IA`一样,该储存类别的请求费用与`STANDARD`一样,**该储存类别有额外的监控费用**;
+- **Onezone – IA:**同上,但数据只保存到一个AWS可用区内
+- **Glacier:**非常便宜,仅用于做归档。从Glacier读取数据需要花费3-5个小时。
+- **Glacier Deep Archive:** S3 Glacier Deep Archive 是 Amazon S3 成本最低的存储类,支持每年可能访问一两次的数据的长期保留和数字预留。它是为客户设计的 – 特别是那些监管严格的行业,如金融服务、医疗保健和公共部门 – 为了满足监管合规要求,将数据集保留 7-10 年或更长时间。S3 Glacier Deep Archive 还可用于备份和灾难恢复使用案例,是成本效益高、易于管理的磁带系统替代,无论磁带系统是本地库还是非本地服务都是如此。S3 Glacier Deep Archive 是 Amazon S3 Glacier 的补充,后者适合存档,其中会定期检索数据并且每隔几分钟可能需要一些数据。存储在 S3 Glacier Deep Archive 中的所有对象都将接受复制并存储在至少三个地理分散的可用区中,受 99.999999999% 的持久性保护,并且可在 12 小时内恢复。
+
+## CloudFront CDN
+
+**Amazon CloudFront**是一种全球**内容分发网络(CDN)**服务,可以安全地以低延迟和高传输速度向浏览者分发数据、视频、应用程序和API。
+
+
+
+- **边缘站点(Edge Location)**:边缘站点是内容缓存的地方,它存在于多个网络服务提供商的机房,它和AWS区域和可用区是完全不一样的概念。截至2018年中,AWS目前一共有100多个边缘站点。
+- **源(Origin)**:这是CDN缓存的内容所使用的源,源可以是一个S3存储桶,可以是一个EC2实例,一个弹性负载均衡器(ELB)或Route53,甚至可以是AWS之外的资源。
+- **分配(Distribution)**:AWS CloudFront创建后的名字
+- 分配分为两种类型,分别是
+ - **Web Distribution**:一般的网站应用
+ - **RTMP (Real-Time Messaging Protocol)**:媒体流
+- 你不只是可以从边缘站点读取数据,你还可以往边缘站点写入数据(比如上传一个文件),边缘站点会将你写入的数据同步到源上
+- 在CloudFront上的文件会被缓存在边缘节点,缓存的时间是**TTL(Time To Live)**。文件存在超过这个时间,缓存会被自动清除
+- 如果在到达TTL时间之前,你希望更新文件,那么你也可以**手动清除缓存**,但你将会被AWS**收取一定的费用**
+
+
+
+## Multi-AZ高可用
+
+我们可以把AWS RDS数据库部署在多个**可用区(AZ)**内,以提供高可用性和故障转移支持。
+
+使用Multi-AZ部署模式,RDS会在不同的可用区内配置和维护一个主数据库和一个备用数据库,主数据库的数据会自动复制到备用数据库中。
+
+使用这种部署模式,可以为我们提供数据冗余,减少在系统备份期间的I/O冻结(上面有提到)。同时,更重要的是可以防止数据库实例的故障和单个可用区的故障。
+
+如下图所示,我们可以在两个可用区内分别部署主数据库和备用数据库。
+
+
+
+目前Multi-AZ支持以下数据库:
+
+- Oracle
+- PostgreSQL
+- MySQL
+- MariaDB
+- SQL Server
+
+值得注意的是,Aurora数据库本身就支持多可用区部署的高可用设置,因此不需要为Aurora数据库特别开启这个功能。
+
+在上次实验中我们有讲到,创建了RDS数据库之后我们会得到一个数据库的URL Endpoint。在开启Multi-AZ的情况下,这个URL Endpoints会根据主/备数据库的健康状态自动解析到IP地址。对于应用程序来说,我们只需要连接这个URL地址即可。
+
+**高可用的设置只是用来解决灾备的问题,并不能解决读取性能的问题;要提升数据库读取性能,我们需要用到Read Replicas。**
+
+
+
+### 只读副本(Read Replicas)
+
+我们可以在源数据库实例的基础上,复制一种新类型的数据库实例,称之为**只读副本(Read Replicas)**。我们对源数据库的任何更新,都会**异步**更新到只读副本中。
+
+因此,我们可以将应用程序的数据库读取功能转移到Read Replicas上,来减轻源数据库的负载。
+
+对于有大量读取需求的数据库,我们可以使用这种方式来进行灵活的数据库扩展,同时突破单个数据库实例的性能限制。
+
+Read Replicas还有如下的特点:
+
+- Read Replicas是用来提高读取性能的,不是用来做灾备的
+- 要创建Read Replicas需要源RDS实例开启了自动备份的功能
+- 可以为数据库创建最多**5个**Read Replicas
+- 可以为Read Replicas创建Read Replicas(如下图所示)
+- 每一个Read Replicas都有自己的URL Endpoint
+- 可以为一个启用了Multi-AZ的数据库创建Read Replicas
+- Read Replicas可以提升成为独立的数据库
+- 可以创建位于另一个区域(Region)的Read Replicas
+
+
+
+目前Read Replicas支持以下数据库:
+
+- Aurora
+- PostgreSQL
+- MySQL
+- MariaDB
+- Oracle
+
+https://amazonaws-china.com/cn/rds/details/read-replicas/
+
+## 参考
+
+[参考](http://www.cloudbin.cn/?p=1968)
diff --git a/_posts/Tech/AWS/2022-11-26-AWS DynamoDB.md b/_posts/Tech/AWS/2022-11-26-AWS DynamoDB.md
new file mode 100644
index 0000000000..306c83421e
--- /dev/null
+++ b/_posts/Tech/AWS/2022-11-26-AWS DynamoDB.md
@@ -0,0 +1,131 @@
+---
+layout: post
+category: AWS
+title: AWS DynamoDB
+tags: AWS
+---
+
+## AWS DynamoDB
+
+> [论文讲解](http://systemdesigns.blogspot.com/2016/01/dynamodb.html)
+
+Dynamo在某些故障的场景中将牺牲一致性。
+
+Dynamo的系统假设和要求:
+1)query model:对数据项简单的读,写是通过一个主键唯一性标识。状态存储为一个由唯一性键确定二进制对象。没有横跨多个数据项的操作,也不需要关系方案(relational schema)。这项规定是基于观察相当一部分Amazon的服务可以使用这个简单的查询模型,并不需要任何关系模式。Dynamo的目标应用程序需要存储的对象都比较小(通常小于1MB)。
+
+2)ACID属性:ACID是一种保证数据库事务可靠地处理的属性。在数据库方面的,对数据的单一的逻辑操作被称作所谓的交易。Amazon的经验表明,在保证ACID的数据存储提往往有很差的可用性。Dynamo的目标应用程序是高可用性,弱一致性(ACID“中的C”)。Dynamo不提供任何数据隔离(Isolation)保证,只允许单一的关键更新。
+
+3)efficiency:系统需运作在一般的commodity hardware上。Amazon平台的服务都有着严格的延时要求, 鉴于对状态的访问在服务操作中起着至关重要的作用,存储系统必须能够满足那些严格的SLA,服务必须能够通过配置Dynamo,使他们不断达到延时和吞吐量的要求。因此,必须在成本效率,可用性和耐用性保证之间做权衡。
+
+
+
+提供get, put操作。
+
+
+
+最终一致性。
+
+### Partition
+
+按key做partition, 一致性Hash。
+
+### Replication
+
+replica, 复制,用了NWR,让用户做一致性的选择。读数据时如果有不同版本,会所有版本数据都返回回去。
+
+### Data Versioning
+
+多版本。Vector Clock 一个Vector Clock可以理解为一个<节点编号,计数器>对的列表。每一个版本的数据都会带上一个Vector Clock。Dynamo中,最重要的是要保证写操作的高可用性,即“Always Writeable”,这样就不可避免的牺牲掉数据的一致性。如上所述,Dynamo中并没有对数据做强一致性要求,而是采用的最终一致性(eventual consistency)。若不保证各个副本的强一致性,则用户在读取数据的时候很可能读到的不是最新的数据。Dynamo中将数据的增加或删除这种操作都视为一种增加操作,即每一次操作的结果都作为一份全新的数据保存,这样也就造成了一份数据会存在多个版本,分布在不同的节点上。这种情况类似于版本管理中的多份副本同时有多人在修改。多数情况下,系统会自动合并这些版本,一旦合并尝试失败,那么冲突的解决就交给应用层来解决。这时系统表现出来的现象就是,一个GET(KEY)操作,返回的不是单一的数据,而是一个多版本的数据列表,由用户决定如何合并。这其中的关键技术就是Vector Clock。
+
+
+
+其实就是读修复。
+
+### Failure Detection
+
+临时性故障,采用Hinted Handoff提示移交机制
+
+为防止要写入节点宕机导致操作失败,采用提示移交机制将操作相关数据写入到随机节点,宕机节点恢复后可根据这些数据进行重放,最终获得数据一致性。
+
+
+
+ 以N=3为例,如果在一次写操作时发现节点A挂了,那么本应该存在A上的副本就会发送到D上,同时在D中会记录这个副本的元信息(MetaData)。其中有个标示,表明这份数据是本应该存在A上的,一旦节点D之后检测到A从故障中恢复了,D就会将这个本属于A的副本回传给A,之后删除这份数据。Dynamo中称这种技术为“Hinted Handoff”。
+
+
+
+另外为了应对整个机房掉线的故障,Dynamo中应用了一个很巧妙的方案。每次读写都会从”Preference List”列表中取出R或W个节点。那么只要在这个列表生成的时候,让其中的节点是分布于不同机房的,自然数据就写到了不同机房的节点上。
+
+
+
+对于某节点非临时性故障,利用反熵得到丢失数据进行恢复。一些数据存储有后台进程,不断查找副本之间的数据差异,将任何缺少的数据从一个副本复制到另一个副本。和基于主节点复制的复制日志不同,此反熵过程不保证任何特定的顺序复制写入,并且会引入明显的同步滞后
+
+
+
+### 表、索引
+
+> [深入探讨 Amazon DynamoDB 的设计模 式、流复制和全局表](https://sides-share.s3.cn-north-1.amazonaws.com.cn/AWS+Webinar+2019/PDF/Amazon+DynamoDB+webinar.pdf)
+
+
+
+分区键和排序键共同唯一的标识一条记录
+
+本地二级索引 Local Secondary Index (LSI) 单表上的。可以选择与表不同的排序键。同一个分区键。强一致性更新。
+
+
+
+全局二级索引 - Global Secondary Index (GSI) 可以选择与表不同的分区键以及排序键 每个索引分区会对应所有的表分区
+
+
+
+
+
+
+
+对比
+
+- Global Secondary
+ - 索引的尺寸没有上限
+ - 读写容量和表是独立的
+ - 只支持最终一致性
+- Index Local Secondary Index
+ - 索引保存在表的分区中,因此一个表 分区的尺寸的上限是10GB
+ - 使用的是表上定义的RCU和WCU
+ - 强一致性
+
+
+
+
+## 其他
+
+
+
+> [官网](https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/Programming.LowLevelAPI.html#Programming.LowLevelAPI.DataTypeDescriptors)
+
+begin_with这个操作要记得。其他后面看。
+
+
+
+> [AWS 如何实现数据跨区域同步](https://techsummit.ctrip.com/pdf/songye.pdf)
+
+没啥子东西,数据操作优先同区域内,主要靠复制。
+
+
+
+> [MongoDB 与 DynamoDB 正面交锋](https://www.modb.pro/db/432414)
+
+没啥东西
+
+
+
+> [通俗易懂之DynamoDB(一) ----分区键、排序键、GSI](https://zhuanlan.zhihu.com/p/101965292)
+
+**getItem、query和scan**
+
+这三个操作都是查询操作,效率分别是:getItem > query > scan
+
+getItem是根据primary key进行查询,可以理解为通过primary key在hashMap上查询,速度是最快的,缺点是必须知道primary key且只能查询单个,使用情况相对较少。
+
+scan是全表扫描,是最慢的一个,理论上能不用就不用,只有实在走投无路才考虑全表扫描。
+
+query是最常见的方式,在dynamoDB的使用中,我们唯一的目的就是写出高效的查询query。
diff --git a/_posts/Tech/AWS/2022-12-14-AWS CloudWatch.md b/_posts/Tech/AWS/2022-12-14-AWS CloudWatch.md
new file mode 100644
index 0000000000..38746d77c0
--- /dev/null
+++ b/_posts/Tech/AWS/2022-12-14-AWS CloudWatch.md
@@ -0,0 +1,19 @@
+---
+layout: post
+category: AWS
+title: AWS CloudWatch
+tags: AWS
+published: false
+---
+
+## AWS CloudWatch
+
+主要是Dashboard, metrics, alarms等。
+
+metrics的dimension不能用in操作。只能取1个或者不取。
+
+
+
+## 待更新
+
+期待后续...
diff --git "a/_posts/Tech/Algorithms/2018-01-18-\345\210\206\346\236\220\346\227\266\351\227\264\345\244\215\346\235\202\345\272\246.md" "b/_posts/Tech/Algorithms/2018-01-18-\345\210\206\346\236\220\346\227\266\351\227\264\345\244\215\346\235\202\345\272\246.md"
index 85488e17cd..4025af158b 100644
--- "a/_posts/Tech/Algorithms/2018-01-18-\345\210\206\346\236\220\346\227\266\351\227\264\345\244\215\346\235\202\345\272\246.md"
+++ "b/_posts/Tech/Algorithms/2018-01-18-\345\210\206\346\236\220\346\227\266\351\227\264\345\244\215\346\235\202\345\272\246.md"
@@ -20,8 +20,6 @@ T(n) = n^klogn if k==log(b)a
[递归的时间复杂度分析](https://blog.csdn.net/qq_36582604/article/details/81661236)
-
-
我们先看下面这个例子

@@ -30,8 +28,6 @@ T(n) = n^klogn if k==log(b)a

-
-
[归并排序时间复杂度分析](https://blog.csdn.net/qq_32534441/article/details/95098059)
```
@@ -39,7 +35,7 @@ T(n)=2*T(n/2)+n
第一层n, 第二层2*(n/2), 第三层4*(n/4), 每层都有个n,高度Logn
```
-[合并k个链表的时间复杂度分析](https://blog.csdn.net/qq_22080999/article/details/80669993)
+[合并 k 个链表的时间复杂度分析](https://blog.csdn.net/qq_22080999/article/details/80669993)
分治的话:
@@ -49,45 +45,42 @@ T(kn) = 2T(k/2*n) + kn
高度log2(k),每层累加都是kn, 因此最终是log2(k) * kn
```
-方法1:暴力,k个链表按顺序合并
+方法 1:暴力,k 个链表按顺序合并
时间复杂度:
(n+n)+(2n+n)+...+ ((k-1)n + n) = (1+2+...+k-1)n + (k-1)n = (1+2+...+k-1+k)n -n = (k^2+k-1)/2*n = O(k^2*n)
-方法2:将k*n个结点放到vector,再将vector排序,再将结点顺序相连
+方法 2:将 k\*n 个结点放到 vector,再将 vector 排序,再将结点顺序相连
-设有K个链表,平均每个链表有n个结点,时间复杂度:
+设有 K 个链表,平均每个链表有 n 个结点,时间复杂度:
kN*logkN +kN = O(kN*logkN)
-方法3:对k个链表进行分治,两两进行合并
+方法 3:对 k 个链表进行分治,两两进行合并
-设有k个链表,平均每个链表有n个结点,时间复杂度:
+设有 k 个链表,平均每个链表有 n 个结点,时间复杂度:
-第一轮:进行k/2次,每次处理2n个数字
+第一轮:进行 k/2 次,每次处理 2n 个数字
-第2轮,进行k/4次,每次处理4n个数字
+第 2 轮,进行 k/4 次,每次处理 4n 个数字
...
-最后一次,进行k/(2^logk)次,每次处理2^logk*n个数
-
-2n*k/2+...+2^logk*n * k/(2^logk)
-
+最后一次,进行 k/(2^logk)次,每次处理 2^logk\*n 个数
+2n*k/2+...+2^logk*n \* k/(2^logk)
## 常见算法时间复杂度
时间复杂度总结:
-prim o(e+vlogv), 主要是优先队列top v次,每次log(v), 然后边遍历总计2e.
+prim o(e+vlogv), 主要是优先队列 top v 次,每次 log(v), 然后边遍历总计 2e.
kruskal o(eloge), 主要是边的排序耗时上。
-dijsktra o(e+vlogv), 边总计e, 优先队列取了v次,每次top log(v), 这里指的斐波那契堆,该堆insert 为o(1),其他和二叉堆一致。
-
-floyd wallshal, o(n3)
+dijsktra o(e+vlogv), 边总计 e, 优先队列取了 v 次,每次 top log(v), 这里指的斐波那契堆,该堆 insert 为 o(1),其他和二叉堆一致。
-bellman-ford, o(ve), 每个边松弛一次,共循环v次,o(ve);
+floyd wallshal, o(n3)
+bellman-ford, o(ve), 每个边松弛一次,共循环 v 次,o(ve);
diff --git "a/_posts/Tech/Algorithms/2018-03-13-\345\212\250\346\200\201\350\247\204\345\210\222\344\271\213\345\205\254\345\205\261\345\255\220\345\272\217\345\210\227\345\255\220\344\270\262.md" "b/_posts/Tech/Algorithms/2018-03-13-\345\212\250\346\200\201\350\247\204\345\210\222\344\271\213\345\205\254\345\205\261\345\255\220\345\272\217\345\210\227\345\255\220\344\270\262.md"
index 4913182da9..f941661942 100644
--- "a/_posts/Tech/Algorithms/2018-03-13-\345\212\250\346\200\201\350\247\204\345\210\222\344\271\213\345\205\254\345\205\261\345\255\220\345\272\217\345\210\227\345\255\220\344\270\262.md"
+++ "b/_posts/Tech/Algorithms/2018-03-13-\345\212\250\346\200\201\350\247\204\345\210\222\344\271\213\345\205\254\345\205\261\345\255\220\345\272\217\345\210\227\345\255\220\344\270\262.md"
@@ -1,7 +1,7 @@
---
layout: post
category: Algorithms
-title: 动态规划之公共子序列子串
+title: 动态规划之公共子序列/子串/前缀
tags: Algorithms
---
@@ -183,3 +183,23 @@ public class LCString {
}
```
+
+## 最长前缀LCP Longest common prefix
+
+求两个字符串任意两个位置开头的最长公共前缀。时间复杂度o(n2) 如果是暴力需要o(n3) 枚举i,j然后到头。
+
+
+
+```scala
+class Strings:
+ def LongestCommonPrefix(a, b):
+ # lcp[i][j] 表示 s[i:] 和 s[j:] 的最长公共前缀
+ n, m = len(a), len(b)
+ lcp = [[0] * (m + 1) for _ in range(n + 1)]
+ for i in range(n - 1, -1, -1):
+ for j in range(m - 1, -1, -1):
+ if a[i] == b[j]:
+ lcp[i][j] = lcp[i + 1][j + 1] + 1
+ return lcp
+```
+
diff --git "a/_posts/Tech/Algorithms/2018-08-01-\351\230\237\345\210\227\345\222\214\346\240\210.md" "b/_posts/Tech/Algorithms/2018-08-01-\351\230\237\345\210\227\345\222\214\346\240\210.md"
index af863894ef..ef2859e924 100644
--- "a/_posts/Tech/Algorithms/2018-08-01-\351\230\237\345\210\227\345\222\214\346\240\210.md"
+++ "b/_posts/Tech/Algorithms/2018-08-01-\351\230\237\345\210\227\345\222\214\346\240\210.md"
@@ -165,4 +165,13 @@ class Solution:
-类似题目: [394. 字符串解码](https://leetcode-cn.com/problems/decode-string/)
\ No newline at end of file
+类似题目: [394. 字符串解码](https://leetcode-cn.com/problems/decode-string/)
+
+
+
+
+
+给定入栈顺序,求某个出栈顺序。
+
+1. [6202. 使用机器人打印字典序最小的字符串](https://mafulong.github.io/2022/10/09/6202.-%E4%BD%BF%E7%94%A8%E6%9C%BA%E5%99%A8%E4%BA%BA%E6%89%93%E5%8D%B0%E5%AD%97%E5%85%B8%E5%BA%8F%E6%9C%80%E5%B0%8F%E7%9A%84%E5%AD%97%E7%AC%A6%E4%B8%B2/)
+2. [栈的压入、弹出序列](https://mafulong.github.io/2018/10/20/%E6%A0%88%E7%9A%84%E5%8E%8B%E5%85%A5-%E5%BC%B9%E5%87%BA%E5%BA%8F%E5%88%97/)
\ No newline at end of file
diff --git "a/_posts/Tech/algorithms/2018-08-13-\346\254\247\346\213\211\345\233\236\350\267\257.md" "b/_posts/Tech/Algorithms/2018-08-13-\346\254\247\346\213\211\350\267\257\345\276\204.md"
similarity index 87%
rename from "_posts/Tech/algorithms/2018-08-13-\346\254\247\346\213\211\345\233\236\350\267\257.md"
rename to "_posts/Tech/Algorithms/2018-08-13-\346\254\247\346\213\211\350\267\257\345\276\204.md"
index 6b221feac6..3e19382e31 100644
--- "a/_posts/Tech/algorithms/2018-08-13-\346\254\247\346\213\211\345\233\236\350\267\257.md"
+++ "b/_posts/Tech/Algorithms/2018-08-13-\346\254\247\346\213\211\350\267\257\345\276\204.md"
@@ -1,14 +1,16 @@
---
layout: post
category: Algorithms
-title: 欧拉回路
+title: 欧拉路径
tags: Algorithms
---
## 欧拉回路定义及判断
-如果能从图的某一顶点出发,每条边恰好经过一次,这样的路线称为欧拉道路(Eulerian Path)。
+如果能从图的某一顶点出发,每条边恰好经过一次,这样的路线称为**欧拉道路(Eulerian Path)。也叫欧拉路径**
+
+如果每条边恰好经过一次,且能回到起点,这样的路线称为**欧拉回路**(Eulerian Circuit)。
+
-如果每条边恰好经过一次,且能回到起点,这样的路线称为欧拉回路(Eulerian Circuit)。
对于无向图G,当且仅当G 是连通的,且最多有两个奇点,则存在欧拉道路。
@@ -22,7 +24,7 @@ tags: Algorithms
- 通过图中所有边恰好一次且行遍所有顶点的通路称为欧拉通路。
- 通过图中所有边恰好一次且行遍所有顶点的回路称为欧拉回路。
-- 具有欧拉回路的无向图称为欧拉图。
+- **具有欧拉回路的无向图称为欧拉图。**
- 具有欧拉通路但不具有欧拉回路的无向图称为半欧拉图。
@@ -41,6 +43,10 @@ tags: Algorithms
给定一个 *n* 个点 *m* 条边的图,要求从指定的顶点出发,经过所有的边恰好一次(可以理解为给定起点的「一笔画」问题)其实就是求欧拉路径。
+如果在有欧拉回路中的图,它就求的是欧拉回路。如果非欧拉回路的图就是欧拉路径。
+
+
+
Hierholzer 算法用于在连通图中寻找欧拉路径,其流程如下:[参考](https://leetcode-cn.com/problems/reconstruct-itinerary/solution/zhong-xin-an-pai-xing-cheng-by-leetcode-solution/)
@@ -70,11 +76,17 @@ def dfs(u):
stack = stack[::-1]
```
+以上是求点的路径。 有向图还是无向图都没关系,无向图就变两个有向的边就行。
+
+
+
+如果是求边路径,pop后进入stack即可。
+
## 相关题目
-- [332. 重新安排行程](https://leetcode-cn.com/problems/reconstruct-itinerary/)
-- [753. 破解保险箱](https://leetcode-cn.com/problems/cracking-the-safe/) 求锁所有密码,就是抽象出多个节点,然后求欧拉回路.
+- [332. 重新安排行程](https://leetcode-cn.com/problems/reconstruct-itinerary/) 求欧拉路径 点的顺序
+- [753. 破解保险箱](https://leetcode-cn.com/problems/cracking-the-safe/) 求锁所有密码,就是抽象出多个节点,然后求欧拉路径.
- [5932. 合法重新排列数对](https://leetcode-cn.com/problems/valid-arrangement-of-pairs/)
diff --git "a/_posts/Tech/Algorithms/2021-01-25-\345\215\232\345\274\210\350\256\272.md" "b/_posts/Tech/Algorithms/2021-01-25-\345\215\232\345\274\210\350\256\272.md"
index 2273a453fe..b86928dd25 100644
--- "a/_posts/Tech/Algorithms/2021-01-25-\345\215\232\345\274\210\350\256\272.md"
+++ "b/_posts/Tech/Algorithms/2021-01-25-\345\215\232\345\274\210\350\256\272.md"
@@ -3,6 +3,7 @@ layout: post
category: Algorithms
title: 博弈论
tags: Algorithms
+recent_update: true
---
## 博弈论
diff --git "a/_posts/Tech/Algorithms/2021-03-11-\344\270\221\346\225\260.md" "b/_posts/Tech/Algorithms/2021-03-11-\344\270\221\346\225\260.md"
deleted file mode 100644
index b28798fa3a..0000000000
--- "a/_posts/Tech/Algorithms/2021-03-11-\344\270\221\346\225\260.md"
+++ /dev/null
@@ -1,57 +0,0 @@
----
-layout: post
-category: Algorithms
-title: 丑数
-tags: Algorithms
----
-
-## 丑数
-
-[[剑指 Offer 49. 丑数](https://leetcode-cn.com/problems/chou-shu-lcof/)
-
-[313. 超级丑数](https://leetcode-cn.com/problems/super-ugly-number/)
-
-### 使用优先队列
-
-```python
-class Solution:
- def nthSuperUglyNumber(self, n: int, primes: List[int]) -> int:
- import heapq
- hq = [1]
- res = []
- for _ in range(n):
- top = heapq.heappop(hq)
- res.append(top)
- while hq and hq[0] == top:
- heapq.heappop(hq)
- for k in primes:
- heapq.heappush(hq, top * k)
- print(res)
- return res[-1]
-```
-
-
-
-### 使用多指针
-
-```c++
-//cpp:
-class Solution {
-public://别人的代码就是精简,惭愧啊,继续学习。
- int GetUglyNumber_Solution(int index) {
- if (index < 7)return index;
- vector -
-
## 复杂的复杂度计算
### 幂函数和对数函数和指数函数对比
-
-

### 调和级数

+这里有用到: [link](https://leetcode.cn/problems/number-of-different-subsequences-gcds/solution/ji-bai-100mei-ju-gcdxun-huan-you-hua-pyt-get7/)
+
### 二项式定理

@@ -53,16 +95,20 @@ tags: Algorithms
## 中位数
-在一步操作中,你可以使数组中的一个元素加 `1` 或者减 `1` ,所有数都靠近**中位数**可使所有数组元素相等时移动数最少。 相关题目: [最少移动次数使数组元素相等 II](https://leetcode-cn.com/problems/minimum-moves-to-equal-array-elements-ii/)
+在一步操作中,你可以使数组中的一个元素加 `1` 或者减 `1` ,所有数都靠近**中位数**可使所有数组元素相等时移动数最少。 相关题目: [最少移动次数使数组元素相等 II](https://leetcode-cn.com/problems/minimum-moves-to-equal-array-elements-ii/)
+即中位数到所有数距离和最小,如果是偶数,可以在中位数两侧的数据构成的区间内任意取值,对结果无影响证明:
+
+
+另一个相似题目:有cost,需转化拆分,然后再算中位数,[6216. 使数组相等的最小开销](https://mafulong.github.io/2022/10/23/6216.-%E4%BD%BF%E6%95%B0%E7%BB%84%E7%9B%B8%E7%AD%89%E7%9A%84%E6%9C%80%E5%B0%8F%E5%BC%80%E9%94%80/)
## 素数
-### 判断是否素数和求1-n的素数求某数的素数
+### 判断是否素数 o(sqrt(N))
```python
-# 判断某数是否是素数
+# 判断某数是否是素数 o(sqrt(n))
def is_prime(a):
if a <= 1: return False
import math
@@ -71,7 +117,16 @@ def is_prime(a):
return True
-# 求1-n每个数的素数,以下时间复杂度O(n) 朴素筛法
+```
+
+### 求 1-n 的所有素数 筛法 o(N)
+
+#### 埃氏筛法
+
+```python
+# 求1-n每个数的素数,以下时间复杂度O(nloglogn) 接近o(n)
+# 如果我们从小到大考虑每个数,然后同时把当前这个数的所有(比自己大的)倍数记为合数,那么运行结束的时候没有被标记的数就是素数了。
+# Eratosthenes 筛法(埃拉托斯特尼筛法,简称埃氏筛法)
def get_all_prime(n):
a = [False] * n
res = []
@@ -82,21 +137,31 @@ def get_all_prime(n):
for j in range(2 * i, n, i):
a[j] = True
return res
+```
+
+#### **线性筛法** 也称为 **Euler 筛法**(欧拉筛法)
+
+埃氏筛法仍有优化空间,它会将一个合数重复多次标记。有没有什么办法省掉无意义的步骤呢?答案是肯定的。
-# 求某数的质因数列表,比如8,是[(2,3)], 6是[(2,1),(3,1)]
-def calcu(a):
- counter = collections.Counter()
- prime = get_all_prime(a + 1)
- for p in prime:
- while a % p == 0:
- counter[p] += 1
- a /= p
- return counter.items()
+如果能让每个合数都只被标记一次,那么时间复杂度就可以降到 o(n)了。
+
+```python
+def get_all_prime(n):
+ a = [False] * n
+ res = []
+ for i in range(2, n):
+ if a[i]: continue
+ # a[i]是素数
+ res.append(i)
+ for j in range(2 * i, n, i):
+ if a[j]: break # 多了个这行
+ a[j] = True
+ return res
```
## 平方数
-[先看Cyc2018](http://www.cyc2018.xyz/%E7%AE%97%E6%B3%95/Leetcode%20%E9%A2%98%E8%A7%A3/Leetcode%20%E9%A2%98%E8%A7%A3%20-%20%E6%95%B0%E5%AD%A6.html#_1-%E5%B9%B3%E6%96%B9%E6%95%B0)
+[先看 Cyc2018](http://www.cyc2018.xyz/%E7%AE%97%E6%B3%95/Leetcode%20%E9%A2%98%E8%A7%A3/Leetcode%20%E9%A2%98%E8%A7%A3%20-%20%E6%95%B0%E5%AD%A6.html#_1-%E5%B9%B3%E6%96%B9%E6%95%B0)
### 生成所有平方数
@@ -106,8 +171,6 @@ def calcu(a):
间隔为等差数列,使用这个特性可以得到从 1 开始的平方序列。
-
-
### 3 的 n 次方
[Power of Three (Easy)](https://leetcode-cn.com/problems/power-of-three/description/)
@@ -118,33 +181,96 @@ public boolean isPowerOfThree(int n) {
}
```
-## 因数
+## 除法
+
+```python
+ # b % a == 0
+ # 表示b能被a整除,a可以整除b, 被除数永远都是有这个『被』
+```
+
+表示b能被a整除,a可以整除b, 被除数永远都是有这个『被』
+
+
+
+大整数除法,除法中取模。
+
+
+
+## 因数理论
### 素数分解
-每一个数都可以分解成素数的乘积,例如 84 = 22 * 31 * 50 * 71 * 110 * 130 * 170 * …
+每一个数都可以分解成素数的乘积,例如 84 = 22 _ 31 _ 50 _ 71 _ 110 _ 130 _ 170 \* …
### 整除
-令 x = 2m0 * 3m1 * 5m2 * 7m3 * 11m4 * …
+令 x = 2m0 _ 3m1 _ 5m2 _ 7m3 _ 11m4 \* …
-令 y = 2n0 * 3n1 * 5n2 * 7n3 * 11n4 * …
+令 y = 2n0 _ 3n1 _ 5n2 _ 7n3 _ 11n4 \* …
如果 x 整除 y(y mod x == 0),则对于所有 i,mi <= ni。
-### 最大公约数最小公倍数
+### 最大公约数最小公倍数的素数表示
+
+每个质因数的乘积
+
+x 和 y 的最大公约数为:gcd(x,y) = 2min(m0,n0) _ 3min(m1,n1) _ 5min(m2,n2) \* ...
+
+x 和 y 的最小公倍数为:lcm(x,y) = 2max(m0,n0) _ 3max(m1,n1) _ 5max(m2,n2) \* ...
+
+### 约数个数和约数之和
+
+如果 N = p1^c1 _ p2^c2 _ ... _pk^ck
+约数个数: (c1 + 1) _ (c2 + 1) _ ... _ (ck + 1)
+约数之和: (p1^0 + p1^1 + ... + p1^c1) _ ... _ (pk^0 + pk^1 + ... + pk^ck)
+
+
-x 和 y 的最大公约数为:gcd(x,y) = 2min(m0,n0) * 3min(m1,n1) * 5min(m2,n2) * ...
+## 因数相关问题
-x 和 y 的最小公倍数为:lcm(x,y) = 2max(m0,n0) * 3max(m1,n1) * 5max(m2,n2) * ...
+### 试除法求所有约数:
-### 求质因数和对应计数
+#### 求一个数的因子列表 o(sqrt(n))
-o(n)近似
+o(sqrt(n))
+
+```python
+divisors = []
+d = 1
+while d * d <= k: # 预处理 k 的所有因子
+ if k % d == 0:
+ divisors.append(d)
+ if d * d < k: # 避免 d= k/d的情况,此时如果append会重复
+ divisors.append(k / d)
+ d += 1
+```
+
+#### 统计 1-n 每个数的因子列表 o(nlogn)
+
+o(nlogn)
+
+```python
+MX = 100001
+divisors = [[] for _ in range(MX)] # 每个value就是key的因子列表,乘积肯定>value,因为因子之间可能有倍数
+for i in range(1, MX): # 预处理每个数的所有因子,时间复杂度 O(MlogM),M=1e5
+ for j in range(i, MX, i):
+ divisors[j].append(i)
+```
+
+### 分解质因数
+
+#### 求某数质因数列表 o(sqrt(N))
+
+o(sqrt(N))
+
+求某数的质因数列表,比如 8,是[2,2,2]
+
+枚举[2, sqrt(n)+1), 如果是质因数,就接着除,最大大于 1,它本身就是质数。
+
+也叫 求欧拉函数
```python
# 求质因数列表
-# Python Version
def breakdown(N):
result = []
from math import sqrt
@@ -158,54 +284,175 @@ def breakdown(N):
return result
```
-### 统计1-n每个数的因子列表
+#### 统计 1-n 每个数的质因数列表
-o(nlogn)
+筛法求欧拉函数
+
+类似,暂时不写。
+
+### gcd 求最大公约数和最小公倍数 欧几里得算法
+
+欧几里得算法
```python
-MX = 100001
-divisors = [[] for _ in range(MX)] # 每个value就是key的因子列表,乘积肯定>value,因为因子之间可能有倍数
-for i in range(1, MX): # 预处理每个数的所有因子,时间复杂度 O(MlogM),M=1e5
- for j in range(i, MX, i):
- divisors[j].append(i)
+class Math1:
+ def gcd(self, a, b):
+ if b == 0:
+ return a
+ return self.gcd(b, a % b)
```
-### 求一个数的因子列表
+最小公倍数就是 a\*b/gcd(a,b)
-o(sqrt(n))
+
+
+### 多个数求最大公约数和最小公倍数
+
+多个数的最大公约数:
```python
-divisors = []
-d = 1
-while d * d <= k: # 预处理 k 的所有因子
- if k % d == 0:
- divisors.append(d)
- if d * d < k: # 避免 d= k/d的情况,此时如果append会重复
- divisors.append(k / d)
- d += 1
+def gcd_list(self, nums):
+ import math
+ cur = nums[0]
+ for i in range(1, len(nums)):
+ cur = math.gcd(cur, nums[i])
+ return cur
```
-### gcd求最大公约数:
+多个数的最小公倍数:
-```c++
-int gcd(int a, int b) {
- return b == 0 ? a : gcd(b, a%b);
-}
+> 注意这里不是直接多个数乘积除以他们的gcd呀,而且不断一个一个加计算的。
-int gcd(int a, int b) {
- while (b != 0) {
- int t = a%b;
- a = b;
- b = t;
- }
- return a;
-}
+```python
+def lcm_list(self, nums):
+ import math
+ prod = 1
+ for v in nums:
+ prod = prod * v / math.gcd(prod, v)
+ return prod
+```
+
+### 1到n里有多少个数可整除a?
+
+```python
+n//a
+```
+
+
+
+### 1到n里有多少个a的因数?
+
+[参考另一个博客](https://mafulong.github.io/2018/04/30/%E8%AE%A1%E7%AE%97n%E7%9A%84%E9%98%B6%E4%B9%98%E4%B8%AD%E6%9C%89%E5%A4%9A%E5%B0%91%E4%B8%AAk/)
+
+```python
+ def calcu(x,a):
+ '''
+ 1-x中有多少个因数a, 比如1-26里有5,10, 15, 20, 各自1个5, 5*5两个5,一共6个
+ '''
+ r = 0
+ while x:
+ # 贡献5的数量,贡献5*5的数量,贡献5*5*5的数量
+ r += x //a
+ x //= a
+ return r
+ print(calcu(26, 5))
+```
+
+
+
+## 大整数取模问题
+
+### 大数相乘取模
+
+```python
+ def prod(d=[], mod=10 ** 9 + 7):
+ r = d[0] % mod
+ for v in d[1:]:
+ r *= v
+ r %= mod
+ return r
+```
+
+
+
+### 大数相除取模 费马小定理
+
+如果a/b,然后a和b都是大数要取模,这时不能相乘取模来计算
+
+`(a/b)%c=(a%c)/(b%c)`是**不成立**的
+
+
+
+> [除法取模](https://leetcode.cn/problems/count-anagrams/solution/by-simpleson-crwb/)
+
+```python
+
+# 原: i//j%MOD
+# 现: i*modInverse(j)%MOD
+MOD = int(1e9 + 7)
+
+class BigIntDivide:
+ def mod_inverse(sefl, i):
+ # 调用取模的乘幂运算, pow复杂度是log(exp)即log(MOD)
+ return pow(i, MOD - 2, MOD)
+
+ def divide_mod(self, a, b):
+ '''
+ 计算(a/b) % MOD, 除法变乘法,前提是b和MOD互为质数
+ '''
+ # 如果有多个b,比如a/b1/b2, 那就可以递归。a*mod_inverse(b1) % mod * mod_inverse(b2) % mod这样
+ return a * self.mod_inverse(b) % MOD
+
+ def divide_mods(self, a, b=[]):
+ '''
+ 计算a /(b1*b2*b3) % MOD等形式,前提是b和MOD互为质数
+ '''
+ r = a % MOD
+ for i, v in enumerate(b):
+ r *= self.mod_inverse(v)
+ r %= MOD
+ return r
+
+
+```
+
+
+
+### 大数幂取模
+
+```python
+r = pow(base=2, exp=3, mod=3)
+print(r)
+```
+
+
+
+## 阶乘
+
+```python
+import math
+math.factorial(3)
```
-最小公倍数就是a*b/gcd(a,b)
+
+
+## 分配问题
+
+### a能否分成满足条件的两份,其中只能分给指定一份
+
+[2513. 最小化两个数组中的最大值](https://leetcode.cn/problems/minimize-the-maximum-of-two-arrays/) 给你两个数组 arr1 和 arr2 ,它们一开始都是空的。你需要往它们中添加正整数,使它们满足以下条件:
+
+arr1 包含 uniqueCnt1 个 互不相同 的正整数,每个整数都 不能 被 divisor1 整除 。
+arr2 包含 uniqueCnt2 个 互不相同 的正整数,每个整数都 不能 被 divisor2 整除 。
+arr1 和 arr2 中的元素 互不相同 。
+给你 divisor1 ,divisor2 ,uniqueCnt1 和 uniqueCnt2 ,请你返回两个数组中 最大元素 的 最小值 。
+参考, [link](https://leetcode.cn/circle/discuss/YeBDQY/view/B8caF0/)
+
+**Key**: 判断过程中分为三类:保证在范围内有充足的数不是第一个数的倍数;不是第二个数的倍数;不为公倍数的数总数不少于总共要取的数。根据这三个条件即得到结果。
+
## 进制转换
```c++
@@ -222,11 +469,9 @@ int gcd(int a, int b) {
[可以参考](https://blog.csdn.net/u013349653/article/details/51367453)
- 十进制小数转二进制数:“乘以2取整,顺序排列”(乘2取整法)
-
- 例: (0.625)10= (0.101)2
-
+十进制小数转二进制数:“乘以 2 取整,顺序排列”(乘 2 取整法)
+例: (0.625)10= (0.101)2
-
-
## 复杂的复杂度计算
### 幂函数和对数函数和指数函数对比
-
-

### 调和级数

+这里有用到: [link](https://leetcode.cn/problems/number-of-different-subsequences-gcds/solution/ji-bai-100mei-ju-gcdxun-huan-you-hua-pyt-get7/)
+
### 二项式定理

@@ -53,16 +95,20 @@ tags: Algorithms
## 中位数
-在一步操作中,你可以使数组中的一个元素加 `1` 或者减 `1` ,所有数都靠近**中位数**可使所有数组元素相等时移动数最少。 相关题目: [最少移动次数使数组元素相等 II](https://leetcode-cn.com/problems/minimum-moves-to-equal-array-elements-ii/)
+在一步操作中,你可以使数组中的一个元素加 `1` 或者减 `1` ,所有数都靠近**中位数**可使所有数组元素相等时移动数最少。 相关题目: [最少移动次数使数组元素相等 II](https://leetcode-cn.com/problems/minimum-moves-to-equal-array-elements-ii/)
+即中位数到所有数距离和最小,如果是偶数,可以在中位数两侧的数据构成的区间内任意取值,对结果无影响证明:
+
+
+另一个相似题目:有cost,需转化拆分,然后再算中位数,[6216. 使数组相等的最小开销](https://mafulong.github.io/2022/10/23/6216.-%E4%BD%BF%E6%95%B0%E7%BB%84%E7%9B%B8%E7%AD%89%E7%9A%84%E6%9C%80%E5%B0%8F%E5%BC%80%E9%94%80/)
## 素数
-### 判断是否素数和求1-n的素数求某数的素数
+### 判断是否素数 o(sqrt(N))
```python
-# 判断某数是否是素数
+# 判断某数是否是素数 o(sqrt(n))
def is_prime(a):
if a <= 1: return False
import math
@@ -71,7 +117,16 @@ def is_prime(a):
return True
-# 求1-n每个数的素数,以下时间复杂度O(n) 朴素筛法
+```
+
+### 求 1-n 的所有素数 筛法 o(N)
+
+#### 埃氏筛法
+
+```python
+# 求1-n每个数的素数,以下时间复杂度O(nloglogn) 接近o(n)
+# 如果我们从小到大考虑每个数,然后同时把当前这个数的所有(比自己大的)倍数记为合数,那么运行结束的时候没有被标记的数就是素数了。
+# Eratosthenes 筛法(埃拉托斯特尼筛法,简称埃氏筛法)
def get_all_prime(n):
a = [False] * n
res = []
@@ -82,21 +137,31 @@ def get_all_prime(n):
for j in range(2 * i, n, i):
a[j] = True
return res
+```
+
+#### **线性筛法** 也称为 **Euler 筛法**(欧拉筛法)
+
+埃氏筛法仍有优化空间,它会将一个合数重复多次标记。有没有什么办法省掉无意义的步骤呢?答案是肯定的。
-# 求某数的质因数列表,比如8,是[(2,3)], 6是[(2,1),(3,1)]
-def calcu(a):
- counter = collections.Counter()
- prime = get_all_prime(a + 1)
- for p in prime:
- while a % p == 0:
- counter[p] += 1
- a /= p
- return counter.items()
+如果能让每个合数都只被标记一次,那么时间复杂度就可以降到 o(n)了。
+
+```python
+def get_all_prime(n):
+ a = [False] * n
+ res = []
+ for i in range(2, n):
+ if a[i]: continue
+ # a[i]是素数
+ res.append(i)
+ for j in range(2 * i, n, i):
+ if a[j]: break # 多了个这行
+ a[j] = True
+ return res
```
## 平方数
-[先看Cyc2018](http://www.cyc2018.xyz/%E7%AE%97%E6%B3%95/Leetcode%20%E9%A2%98%E8%A7%A3/Leetcode%20%E9%A2%98%E8%A7%A3%20-%20%E6%95%B0%E5%AD%A6.html#_1-%E5%B9%B3%E6%96%B9%E6%95%B0)
+[先看 Cyc2018](http://www.cyc2018.xyz/%E7%AE%97%E6%B3%95/Leetcode%20%E9%A2%98%E8%A7%A3/Leetcode%20%E9%A2%98%E8%A7%A3%20-%20%E6%95%B0%E5%AD%A6.html#_1-%E5%B9%B3%E6%96%B9%E6%95%B0)
### 生成所有平方数
@@ -106,8 +171,6 @@ def calcu(a):
间隔为等差数列,使用这个特性可以得到从 1 开始的平方序列。
-
-
### 3 的 n 次方
[Power of Three (Easy)](https://leetcode-cn.com/problems/power-of-three/description/)
@@ -118,33 +181,96 @@ public boolean isPowerOfThree(int n) {
}
```
-## 因数
+## 除法
+
+```python
+ # b % a == 0
+ # 表示b能被a整除,a可以整除b, 被除数永远都是有这个『被』
+```
+
+表示b能被a整除,a可以整除b, 被除数永远都是有这个『被』
+
+
+
+大整数除法,除法中取模。
+
+
+
+## 因数理论
### 素数分解
-每一个数都可以分解成素数的乘积,例如 84 = 22 * 31 * 50 * 71 * 110 * 130 * 170 * …
+每一个数都可以分解成素数的乘积,例如 84 = 22 _ 31 _ 50 _ 71 _ 110 _ 130 _ 170 \* …
### 整除
-令 x = 2m0 * 3m1 * 5m2 * 7m3 * 11m4 * …
+令 x = 2m0 _ 3m1 _ 5m2 _ 7m3 _ 11m4 \* …
-令 y = 2n0 * 3n1 * 5n2 * 7n3 * 11n4 * …
+令 y = 2n0 _ 3n1 _ 5n2 _ 7n3 _ 11n4 \* …
如果 x 整除 y(y mod x == 0),则对于所有 i,mi <= ni。
-### 最大公约数最小公倍数
+### 最大公约数最小公倍数的素数表示
+
+每个质因数的乘积
+
+x 和 y 的最大公约数为:gcd(x,y) = 2min(m0,n0) _ 3min(m1,n1) _ 5min(m2,n2) \* ...
+
+x 和 y 的最小公倍数为:lcm(x,y) = 2max(m0,n0) _ 3max(m1,n1) _ 5max(m2,n2) \* ...
+
+### 约数个数和约数之和
+
+如果 N = p1^c1 _ p2^c2 _ ... _pk^ck
+约数个数: (c1 + 1) _ (c2 + 1) _ ... _ (ck + 1)
+约数之和: (p1^0 + p1^1 + ... + p1^c1) _ ... _ (pk^0 + pk^1 + ... + pk^ck)
+
+
-x 和 y 的最大公约数为:gcd(x,y) = 2min(m0,n0) * 3min(m1,n1) * 5min(m2,n2) * ...
+## 因数相关问题
-x 和 y 的最小公倍数为:lcm(x,y) = 2max(m0,n0) * 3max(m1,n1) * 5max(m2,n2) * ...
+### 试除法求所有约数:
-### 求质因数和对应计数
+#### 求一个数的因子列表 o(sqrt(n))
-o(n)近似
+o(sqrt(n))
+
+```python
+divisors = []
+d = 1
+while d * d <= k: # 预处理 k 的所有因子
+ if k % d == 0:
+ divisors.append(d)
+ if d * d < k: # 避免 d= k/d的情况,此时如果append会重复
+ divisors.append(k / d)
+ d += 1
+```
+
+#### 统计 1-n 每个数的因子列表 o(nlogn)
+
+o(nlogn)
+
+```python
+MX = 100001
+divisors = [[] for _ in range(MX)] # 每个value就是key的因子列表,乘积肯定>value,因为因子之间可能有倍数
+for i in range(1, MX): # 预处理每个数的所有因子,时间复杂度 O(MlogM),M=1e5
+ for j in range(i, MX, i):
+ divisors[j].append(i)
+```
+
+### 分解质因数
+
+#### 求某数质因数列表 o(sqrt(N))
+
+o(sqrt(N))
+
+求某数的质因数列表,比如 8,是[2,2,2]
+
+枚举[2, sqrt(n)+1), 如果是质因数,就接着除,最大大于 1,它本身就是质数。
+
+也叫 求欧拉函数
```python
# 求质因数列表
-# Python Version
def breakdown(N):
result = []
from math import sqrt
@@ -158,54 +284,175 @@ def breakdown(N):
return result
```
-### 统计1-n每个数的因子列表
+#### 统计 1-n 每个数的质因数列表
-o(nlogn)
+筛法求欧拉函数
+
+类似,暂时不写。
+
+### gcd 求最大公约数和最小公倍数 欧几里得算法
+
+欧几里得算法
```python
-MX = 100001
-divisors = [[] for _ in range(MX)] # 每个value就是key的因子列表,乘积肯定>value,因为因子之间可能有倍数
-for i in range(1, MX): # 预处理每个数的所有因子,时间复杂度 O(MlogM),M=1e5
- for j in range(i, MX, i):
- divisors[j].append(i)
+class Math1:
+ def gcd(self, a, b):
+ if b == 0:
+ return a
+ return self.gcd(b, a % b)
```
-### 求一个数的因子列表
+最小公倍数就是 a\*b/gcd(a,b)
-o(sqrt(n))
+
+
+### 多个数求最大公约数和最小公倍数
+
+多个数的最大公约数:
```python
-divisors = []
-d = 1
-while d * d <= k: # 预处理 k 的所有因子
- if k % d == 0:
- divisors.append(d)
- if d * d < k: # 避免 d= k/d的情况,此时如果append会重复
- divisors.append(k / d)
- d += 1
+def gcd_list(self, nums):
+ import math
+ cur = nums[0]
+ for i in range(1, len(nums)):
+ cur = math.gcd(cur, nums[i])
+ return cur
```
-### gcd求最大公约数:
+多个数的最小公倍数:
-```c++
-int gcd(int a, int b) {
- return b == 0 ? a : gcd(b, a%b);
-}
+> 注意这里不是直接多个数乘积除以他们的gcd呀,而且不断一个一个加计算的。
-int gcd(int a, int b) {
- while (b != 0) {
- int t = a%b;
- a = b;
- b = t;
- }
- return a;
-}
+```python
+def lcm_list(self, nums):
+ import math
+ prod = 1
+ for v in nums:
+ prod = prod * v / math.gcd(prod, v)
+ return prod
+```
+
+### 1到n里有多少个数可整除a?
+
+```python
+n//a
+```
+
+
+
+### 1到n里有多少个a的因数?
+
+[参考另一个博客](https://mafulong.github.io/2018/04/30/%E8%AE%A1%E7%AE%97n%E7%9A%84%E9%98%B6%E4%B9%98%E4%B8%AD%E6%9C%89%E5%A4%9A%E5%B0%91%E4%B8%AAk/)
+
+```python
+ def calcu(x,a):
+ '''
+ 1-x中有多少个因数a, 比如1-26里有5,10, 15, 20, 各自1个5, 5*5两个5,一共6个
+ '''
+ r = 0
+ while x:
+ # 贡献5的数量,贡献5*5的数量,贡献5*5*5的数量
+ r += x //a
+ x //= a
+ return r
+ print(calcu(26, 5))
+```
+
+
+
+## 大整数取模问题
+
+### 大数相乘取模
+
+```python
+ def prod(d=[], mod=10 ** 9 + 7):
+ r = d[0] % mod
+ for v in d[1:]:
+ r *= v
+ r %= mod
+ return r
+```
+
+
+
+### 大数相除取模 费马小定理
+
+如果a/b,然后a和b都是大数要取模,这时不能相乘取模来计算
+
+`(a/b)%c=(a%c)/(b%c)`是**不成立**的
+
+
+
+> [除法取模](https://leetcode.cn/problems/count-anagrams/solution/by-simpleson-crwb/)
+
+```python
+
+# 原: i//j%MOD
+# 现: i*modInverse(j)%MOD
+MOD = int(1e9 + 7)
+
+class BigIntDivide:
+ def mod_inverse(sefl, i):
+ # 调用取模的乘幂运算, pow复杂度是log(exp)即log(MOD)
+ return pow(i, MOD - 2, MOD)
+
+ def divide_mod(self, a, b):
+ '''
+ 计算(a/b) % MOD, 除法变乘法,前提是b和MOD互为质数
+ '''
+ # 如果有多个b,比如a/b1/b2, 那就可以递归。a*mod_inverse(b1) % mod * mod_inverse(b2) % mod这样
+ return a * self.mod_inverse(b) % MOD
+
+ def divide_mods(self, a, b=[]):
+ '''
+ 计算a /(b1*b2*b3) % MOD等形式,前提是b和MOD互为质数
+ '''
+ r = a % MOD
+ for i, v in enumerate(b):
+ r *= self.mod_inverse(v)
+ r %= MOD
+ return r
+
+
+```
+
+
+
+### 大数幂取模
+
+```python
+r = pow(base=2, exp=3, mod=3)
+print(r)
+```
+
+
+
+## 阶乘
+
+```python
+import math
+math.factorial(3)
```
-最小公倍数就是a*b/gcd(a,b)
+
+
+## 分配问题
+
+### a能否分成满足条件的两份,其中只能分给指定一份
+
+[2513. 最小化两个数组中的最大值](https://leetcode.cn/problems/minimize-the-maximum-of-two-arrays/) 给你两个数组 arr1 和 arr2 ,它们一开始都是空的。你需要往它们中添加正整数,使它们满足以下条件:
+
+arr1 包含 uniqueCnt1 个 互不相同 的正整数,每个整数都 不能 被 divisor1 整除 。
+arr2 包含 uniqueCnt2 个 互不相同 的正整数,每个整数都 不能 被 divisor2 整除 。
+arr1 和 arr2 中的元素 互不相同 。
+给你 divisor1 ,divisor2 ,uniqueCnt1 和 uniqueCnt2 ,请你返回两个数组中 最大元素 的 最小值 。
+参考, [link](https://leetcode.cn/circle/discuss/YeBDQY/view/B8caF0/)
+
+**Key**: 判断过程中分为三类:保证在范围内有充足的数不是第一个数的倍数;不是第二个数的倍数;不为公倍数的数总数不少于总共要取的数。根据这三个条件即得到结果。
+
## 进制转换
```c++
@@ -222,11 +469,9 @@ int gcd(int a, int b) {
[可以参考](https://blog.csdn.net/u013349653/article/details/51367453)
- 十进制小数转二进制数:“乘以2取整,顺序排列”(乘2取整法)
-
- 例: (0.625)10= (0.101)2
-
+十进制小数转二进制数:“乘以 2 取整,顺序排列”(乘 2 取整法)
+例: (0.625)10= (0.101)2
 @@ -242,7 +487,23 @@ int gcd(int a, int b) {
## 幂
-### 快速幂
+### 快速幂 O(logk)
+
+求 m^k mod p,时间复杂度 O(logk)。
+
+```c++
+int qmi(int m, int k, int p)
+{
+ int res = 1 % p, t = m;
+ while (k)
+ {
+ if (k&1) res = res * t % p;
+ t = t * t % p;
+ k >>= 1;
+ }
+ return res;
+}
+```
### 求根号
@@ -252,7 +513,7 @@ int gcd(int a, int b) {
### 求根号变种 小数精度
-`while l<=r`不用变,只需要变步长即可。eps可以比期望精度再小一个量级。
+`while l<=r`不用变,只需要变步长即可。eps 可以比期望精度再小一个量级。
```python
@@ -277,8 +538,6 @@ if __name__ == '__main__':
print(f(0.04, 1e-10))
```
+## Acwing 数学
-
-## Acwing数学
-
-[参考](https://www.acwing.com/file_system/file/content/whole/index/content/3273/) 本文只涉及部分
+[参考](https://www.acwing.com/file_system/file/content/whole/index/content/3273/) 本文只涉及部分
diff --git "a/_posts/Tech/Algorithms/2022-07-31-\347\256\200\345\215\225\345\233\276\347\232\204\346\234\200\345\244\247\347\216\257\346\234\200\351\225\277\351\223\276.md" "b/_posts/Tech/Algorithms/2022-07-31-\347\256\200\345\215\225\345\233\276\347\232\204\346\234\200\345\244\247\347\216\257\346\234\200\351\225\277\351\223\276.md"
new file mode 100644
index 0000000000..60c620721d
--- /dev/null
+++ "b/_posts/Tech/Algorithms/2022-07-31-\347\256\200\345\215\225\345\233\276\347\232\204\346\234\200\345\244\247\347\216\257\346\234\200\351\225\277\351\223\276.md"
@@ -0,0 +1,127 @@
+---
+layout: post
+category: Algorithms
+title: 简单图的最大环最长链
+tags: Algorithms
+---
+
+## 最大环最长链
+
+https://www.cnblogs.com/lfri/p/15758120.html
+
+最大环是针对的是出度为1的图,否则会多环重合。
+
+最长链是无环的图,求一个最长路径的长度。
+
+
+
+## 最大环
+
+### 有向图
+
+有多种方法:
+
+- 一种是先用拓扑排序将外链去掉,再dfs每一个环
+- DFS: 另一种是从某一点出发,记录途径的点,如果遇到已经访问过的点,说明找到了环的入口。减去起始点到入口的距离,就是环的长度。
+- 还有一种有并查集,对于`x->y`,如果`x`和`y`同属于一个集合,说明形成了一个环。
+
+
+
+dfs代码
+
+```python
+class Solution:
+ def longestCycle(self, edges: List[int]) -> int:
+ n = len(edges)
+ vis = collections.defaultdict(bool)
+ ans = -1
+ for i in range(n):
+ if vis[i]: continue
+ path = []
+ cur = i
+ while not vis[cur]:
+ vis[cur] = True
+ path.append(cur)
+ cur = edges[cur]
+ if cur == -1: break
+ if cur == -1: continue
+ for j in range(len(path)):
+ if path[j] == cur:
+ t = len(path) - j
+ ans = max(ans, t)
+ break
+ return ans
+```
+
+### 无向图
+
+和有向图类似,略
+
+## 最长链
+
+等价问题: [310. 最小高度树](https://leetcode.cn/problems/minimum-height-trees/)
+
+### 有向图
+
+这里有一个很重要的问题,有环怎么办?
+有环的情况下,求最长链是没有意义的。要么保证无环,要么是求连接到环上的链的长度。
+例如求连接到环上的链的长度,需要从入度为0的节点开始,递推计算,于是采用拓扑序。
+
+
+
+```c++
+int TopologicalSort(vector
@@ -242,7 +487,23 @@ int gcd(int a, int b) {
## 幂
-### 快速幂
+### 快速幂 O(logk)
+
+求 m^k mod p,时间复杂度 O(logk)。
+
+```c++
+int qmi(int m, int k, int p)
+{
+ int res = 1 % p, t = m;
+ while (k)
+ {
+ if (k&1) res = res * t % p;
+ t = t * t % p;
+ k >>= 1;
+ }
+ return res;
+}
+```
### 求根号
@@ -252,7 +513,7 @@ int gcd(int a, int b) {
### 求根号变种 小数精度
-`while l<=r`不用变,只需要变步长即可。eps可以比期望精度再小一个量级。
+`while l<=r`不用变,只需要变步长即可。eps 可以比期望精度再小一个量级。
```python
@@ -277,8 +538,6 @@ if __name__ == '__main__':
print(f(0.04, 1e-10))
```
+## Acwing 数学
-
-## Acwing数学
-
-[参考](https://www.acwing.com/file_system/file/content/whole/index/content/3273/) 本文只涉及部分
+[参考](https://www.acwing.com/file_system/file/content/whole/index/content/3273/) 本文只涉及部分
diff --git "a/_posts/Tech/Algorithms/2022-07-31-\347\256\200\345\215\225\345\233\276\347\232\204\346\234\200\345\244\247\347\216\257\346\234\200\351\225\277\351\223\276.md" "b/_posts/Tech/Algorithms/2022-07-31-\347\256\200\345\215\225\345\233\276\347\232\204\346\234\200\345\244\247\347\216\257\346\234\200\351\225\277\351\223\276.md"
new file mode 100644
index 0000000000..60c620721d
--- /dev/null
+++ "b/_posts/Tech/Algorithms/2022-07-31-\347\256\200\345\215\225\345\233\276\347\232\204\346\234\200\345\244\247\347\216\257\346\234\200\351\225\277\351\223\276.md"
@@ -0,0 +1,127 @@
+---
+layout: post
+category: Algorithms
+title: 简单图的最大环最长链
+tags: Algorithms
+---
+
+## 最大环最长链
+
+https://www.cnblogs.com/lfri/p/15758120.html
+
+最大环是针对的是出度为1的图,否则会多环重合。
+
+最长链是无环的图,求一个最长路径的长度。
+
+
+
+## 最大环
+
+### 有向图
+
+有多种方法:
+
+- 一种是先用拓扑排序将外链去掉,再dfs每一个环
+- DFS: 另一种是从某一点出发,记录途径的点,如果遇到已经访问过的点,说明找到了环的入口。减去起始点到入口的距离,就是环的长度。
+- 还有一种有并查集,对于`x->y`,如果`x`和`y`同属于一个集合,说明形成了一个环。
+
+
+
+dfs代码
+
+```python
+class Solution:
+ def longestCycle(self, edges: List[int]) -> int:
+ n = len(edges)
+ vis = collections.defaultdict(bool)
+ ans = -1
+ for i in range(n):
+ if vis[i]: continue
+ path = []
+ cur = i
+ while not vis[cur]:
+ vis[cur] = True
+ path.append(cur)
+ cur = edges[cur]
+ if cur == -1: break
+ if cur == -1: continue
+ for j in range(len(path)):
+ if path[j] == cur:
+ t = len(path) - j
+ ans = max(ans, t)
+ break
+ return ans
+```
+
+### 无向图
+
+和有向图类似,略
+
+## 最长链
+
+等价问题: [310. 最小高度树](https://leetcode.cn/problems/minimum-height-trees/)
+
+### 有向图
+
+这里有一个很重要的问题,有环怎么办?
+有环的情况下,求最长链是没有意义的。要么保证无环,要么是求连接到环上的链的长度。
+例如求连接到环上的链的长度,需要从入度为0的节点开始,递推计算,于是采用拓扑序。
+
+
+
+```c++
+int TopologicalSort(vector +这里的ZAB为何是最终一致性而不是强一致性?[参考](https://www.zhihu.com/question/455703356/answer/1847949827)
+
+- 写是强一致性,单领导者模型,写需要majority保证,脑裂情况下也可以写强一致
+- 读两种接口,1:读单个机器的,2:只读主的。但脑裂时多个主还是不能强一致性。
+- etcd做了读的优化,读时也需要majority,需要大伙同意认为它是主,但牺牲了效率。
+
+这里的一致性是从读写方面,写一致性,都写成功,读一致性,从提供的读接口任意时刻咋读都一样。和事务一致性不太一样。
+
## 分布式互斥方法(集中,民主协商,轮值ceo(令牌))
diff --git "a/_posts/Tech/DistributedSystem/2021-12-26-etcd\345\222\214raft.md" "b/_posts/Tech/DistributedSystem/2021-12-26-etcd\345\222\214raft.md"
index 3fd12cdff4..0bf8fbfdf5 100644
--- "a/_posts/Tech/DistributedSystem/2021-12-26-etcd\345\222\214raft.md"
+++ "b/_posts/Tech/DistributedSystem/2021-12-26-etcd\345\222\214raft.md"
@@ -3,6 +3,7 @@ layout: post
category: DistributedSystem
title: etcd和raft
tags: DistributedSystem
+recent_update: true
---
# etcd
diff --git "a/_posts/Tech/DistributedSystem/2022-11-26-\346\227\240\344\270\273\345\244\215\345\210\266\347\263\273\347\273\237.md" "b/_posts/Tech/DistributedSystem/2022-11-26-\346\227\240\344\270\273\345\244\215\345\210\266\347\263\273\347\273\237.md"
new file mode 100644
index 0000000000..ee018bc3b1
--- /dev/null
+++ "b/_posts/Tech/DistributedSystem/2022-11-26-\346\227\240\344\270\273\345\244\215\345\210\266\347\263\273\347\273\237.md"
@@ -0,0 +1,63 @@
+---
+layout: post
+category: DistributedSystem
+title: 无主复制系统
+tags: DistributedSystem
+---
+
+为什么需要复制数据? - 允许系统在部分节点出现故障后继续工作(增加可用性) - 地理上保持数据离用户更近(减少延迟) - 扩展可以提供查询的机器数量(增加读吞吐)
+
+复制算法: 1. 单主复制:所有客户端都将写入操作发送到主节点上,该节点负责将数据更改事件发送到其它副本。每个副本都可以接受读请求,但内容可能是过期值。 2. 多主复制:系统中存在多个主节点,每个都可以接受请求,客户端将写请求发送到其中一个主节点上,该节点负责将数据更改事件同步到其它主节点和自己的从节点。 3. 无主复制:客户端将写请求发送多个节点上,读取时从多个节点上并行读取,以此检测和纠正某些过期数据。
+
+主从复制可参考 [link](https://iswade.github.io/database/replication/)
+
+## 无主复制
+
+单主、多主复制思路都是:客户端向一个主节点发写请求,而DB系统负责将写请求复制到其他副本。主节点决定写顺序,从节点按相同顺序应用主节点发送的写日志。
+
+某些数据存储系统采用不同设计:放弃主节点,允许任何副本直接接受客户端的写。最早的复制数据系统就是无主节点的(或称之为去中心复制、无中心复制),但后来在关系数据库主导时代,这个想法几乎被忘却。在亚马逊将其用于其内部的Dynamo系统后,它再一次成为流行的DB架构。 Riak,Cassandra和Voldemort都是由Dynamo启发的无主复制模型的开源数据存储,所以这类数据库也被称为*Dynamo风格*。
+
+
+
+在一些无主实现中,客户端直接将写请求发到多副本,而另一些实现中,有一个协调者(coordinator)节点代表客户端进行写入,但与主节点的数据库不同,协调者不负责维护写入顺序。这种设计差异对DB使用方式有深远影响。
+
+
+
+失效节点重新上线,而客户端开始读取它。节点失效期间发生的任何写入在该节点都尚未同步,因此读取可能得到过期数据。
+
+为解决该问题,当一个客户端从DB读数据时,它不是向1个副本发送请求,而是并行发送到多副本。客户端可能会从不同节点获得不同响应,即来自一个节点的最新值和来自另一个节点的旧值。可利用版本号确定哪个值更新。
+
+### 读修复和反熵
+
+复制模型应确保所有数据最终复制到所有副本。在一个失效节点重新上线后,它如何赶上错过的写入呢?
+
+Dynamo风格的数据存储系统常机制:
+
+#### 读修复(Read repair)
+
+当客户端并行读取多副本时,可检测到过期的返回值。客户端可判断副本3是过期值,然后将新值写入该副本。适用于读密集场景
+
+#### 反熵过程(Anti-entropy process)
+
+一些数据存储有后台进程,不断查找副本之间的数据差异,将任何缺少的数据从一个副本复制到另一个副本。和基于主节点复制的复制日志不同,此反熵过程不保证任何特定的顺序复制写入,并且会引入明显的同步滞后
+
+
+
+并非所有系统都实现这俩方案。如Voldemort目前无反熵过程。若无反熵过程,由于【读修复】只在发生读取时才可能执行修复,那些很少访问的数据有可能在某些副本中已丢失而无法再检测到,从而降低了写的持久性。
+
+
+
+反熵就是树形的hash,用于快速比较数据是否一致的。
+
+
+
+## 参考
+
+- [**无主复制系统(1)-节点故障时写DB**](https://blog.51cto.com/u_11440114/5550577)
+- [**无主复制系统(2)-读写quorum**](https://blog.51cto.com/u_11440114/5550582)
+
+
+
+
+
+TODO: 需要读下ddia.
diff --git a/_posts/Tech/ElasticSearch/2020-12-08-ElasticSearch.md b/_posts/Tech/ElasticSearch/2020-12-08-ElasticSearch.md
index de4939df98..5eda1601ec 100644
--- a/_posts/Tech/ElasticSearch/2020-12-08-ElasticSearch.md
+++ b/_posts/Tech/ElasticSearch/2020-12-08-ElasticSearch.md
@@ -3,6 +3,7 @@ layout: post
category: ElasticSearch
title: ElasticSearch(ES)原理
tags: ElasticSearch
+recent_update: true
---
## Part1: ES介绍及核心概念
diff --git "a/_posts/Tech/FrontEnd/2017-12-03-css\345\255\246\344\271\240\347\254\224\350\256\260.md" "b/_posts/Tech/FrontEnd/2017-12-03-css\345\255\246\344\271\240\347\254\224\350\256\260.md"
index 1df5eb98e6..a76bfdfb2d 100644
--- "a/_posts/Tech/FrontEnd/2017-12-03-css\345\255\246\344\271\240\347\254\224\350\256\260.md"
+++ "b/_posts/Tech/FrontEnd/2017-12-03-css\345\255\246\344\271\240\347\254\224\350\256\260.md"
@@ -4,7 +4,39 @@ category: FrontEnd
title: CSS笔记
tags: FrontEnd
---
+# 概述
+
+CSS:Cascading Style Sheet,层叠样式表。CSS 的作用就是给 HTML 页面标签添加各种样式,**定义网页的显示效果**。简单一句话:CSS 将网页**内容和显示样式进行分离**,提高了显示功能。
+
+**CSS 优点:**
+
+1. 使数据和显示分开
+2. 降低网络流量
+3. 使整个网站视觉效果一致
+4. 使开发效率提高了(耦合性降低,一个人负责写 html,一个人负责写 css)
+
+比如说,有一个样式需要在一百个页面上显示,如果是 html 来实现,那要写一百遍,现在有了 css,只要写一遍。现在,html 只提供数据和一些控件,完全交给 css 提供各种各样的样式。
+
+重点:盒子模型、浮动、定位
+
+
+
+CSS 的书写方式,实就是问你 CSS 的代码放在哪个位置。CSS 代码理论上的位置是任意的,**但通常写在`
+
+
+
+这里的ZAB为何是最终一致性而不是强一致性?[参考](https://www.zhihu.com/question/455703356/answer/1847949827)
+
+- 写是强一致性,单领导者模型,写需要majority保证,脑裂情况下也可以写强一致
+- 读两种接口,1:读单个机器的,2:只读主的。但脑裂时多个主还是不能强一致性。
+- etcd做了读的优化,读时也需要majority,需要大伙同意认为它是主,但牺牲了效率。
+
+这里的一致性是从读写方面,写一致性,都写成功,读一致性,从提供的读接口任意时刻咋读都一样。和事务一致性不太一样。
+
## 分布式互斥方法(集中,民主协商,轮值ceo(令牌))

diff --git "a/_posts/Tech/DistributedSystem/2021-12-26-etcd\345\222\214raft.md" "b/_posts/Tech/DistributedSystem/2021-12-26-etcd\345\222\214raft.md"
index 3fd12cdff4..0bf8fbfdf5 100644
--- "a/_posts/Tech/DistributedSystem/2021-12-26-etcd\345\222\214raft.md"
+++ "b/_posts/Tech/DistributedSystem/2021-12-26-etcd\345\222\214raft.md"
@@ -3,6 +3,7 @@ layout: post
category: DistributedSystem
title: etcd和raft
tags: DistributedSystem
+recent_update: true
---
# etcd
diff --git "a/_posts/Tech/DistributedSystem/2022-11-26-\346\227\240\344\270\273\345\244\215\345\210\266\347\263\273\347\273\237.md" "b/_posts/Tech/DistributedSystem/2022-11-26-\346\227\240\344\270\273\345\244\215\345\210\266\347\263\273\347\273\237.md"
new file mode 100644
index 0000000000..ee018bc3b1
--- /dev/null
+++ "b/_posts/Tech/DistributedSystem/2022-11-26-\346\227\240\344\270\273\345\244\215\345\210\266\347\263\273\347\273\237.md"
@@ -0,0 +1,63 @@
+---
+layout: post
+category: DistributedSystem
+title: 无主复制系统
+tags: DistributedSystem
+---
+
+为什么需要复制数据? - 允许系统在部分节点出现故障后继续工作(增加可用性) - 地理上保持数据离用户更近(减少延迟) - 扩展可以提供查询的机器数量(增加读吞吐)
+
+复制算法: 1. 单主复制:所有客户端都将写入操作发送到主节点上,该节点负责将数据更改事件发送到其它副本。每个副本都可以接受读请求,但内容可能是过期值。 2. 多主复制:系统中存在多个主节点,每个都可以接受请求,客户端将写请求发送到其中一个主节点上,该节点负责将数据更改事件同步到其它主节点和自己的从节点。 3. 无主复制:客户端将写请求发送多个节点上,读取时从多个节点上并行读取,以此检测和纠正某些过期数据。
+
+主从复制可参考 [link](https://iswade.github.io/database/replication/)
+
+## 无主复制
+
+单主、多主复制思路都是:客户端向一个主节点发写请求,而DB系统负责将写请求复制到其他副本。主节点决定写顺序,从节点按相同顺序应用主节点发送的写日志。
+
+某些数据存储系统采用不同设计:放弃主节点,允许任何副本直接接受客户端的写。最早的复制数据系统就是无主节点的(或称之为去中心复制、无中心复制),但后来在关系数据库主导时代,这个想法几乎被忘却。在亚马逊将其用于其内部的Dynamo系统后,它再一次成为流行的DB架构。 Riak,Cassandra和Voldemort都是由Dynamo启发的无主复制模型的开源数据存储,所以这类数据库也被称为*Dynamo风格*。
+
+
+
+在一些无主实现中,客户端直接将写请求发到多副本,而另一些实现中,有一个协调者(coordinator)节点代表客户端进行写入,但与主节点的数据库不同,协调者不负责维护写入顺序。这种设计差异对DB使用方式有深远影响。
+
+
+
+失效节点重新上线,而客户端开始读取它。节点失效期间发生的任何写入在该节点都尚未同步,因此读取可能得到过期数据。
+
+为解决该问题,当一个客户端从DB读数据时,它不是向1个副本发送请求,而是并行发送到多副本。客户端可能会从不同节点获得不同响应,即来自一个节点的最新值和来自另一个节点的旧值。可利用版本号确定哪个值更新。
+
+### 读修复和反熵
+
+复制模型应确保所有数据最终复制到所有副本。在一个失效节点重新上线后,它如何赶上错过的写入呢?
+
+Dynamo风格的数据存储系统常机制:
+
+#### 读修复(Read repair)
+
+当客户端并行读取多副本时,可检测到过期的返回值。客户端可判断副本3是过期值,然后将新值写入该副本。适用于读密集场景
+
+#### 反熵过程(Anti-entropy process)
+
+一些数据存储有后台进程,不断查找副本之间的数据差异,将任何缺少的数据从一个副本复制到另一个副本。和基于主节点复制的复制日志不同,此反熵过程不保证任何特定的顺序复制写入,并且会引入明显的同步滞后
+
+
+
+并非所有系统都实现这俩方案。如Voldemort目前无反熵过程。若无反熵过程,由于【读修复】只在发生读取时才可能执行修复,那些很少访问的数据有可能在某些副本中已丢失而无法再检测到,从而降低了写的持久性。
+
+
+
+反熵就是树形的hash,用于快速比较数据是否一致的。
+
+
+
+## 参考
+
+- [**无主复制系统(1)-节点故障时写DB**](https://blog.51cto.com/u_11440114/5550577)
+- [**无主复制系统(2)-读写quorum**](https://blog.51cto.com/u_11440114/5550582)
+
+
+
+
+
+TODO: 需要读下ddia.
diff --git a/_posts/Tech/ElasticSearch/2020-12-08-ElasticSearch.md b/_posts/Tech/ElasticSearch/2020-12-08-ElasticSearch.md
index de4939df98..5eda1601ec 100644
--- a/_posts/Tech/ElasticSearch/2020-12-08-ElasticSearch.md
+++ b/_posts/Tech/ElasticSearch/2020-12-08-ElasticSearch.md
@@ -3,6 +3,7 @@ layout: post
category: ElasticSearch
title: ElasticSearch(ES)原理
tags: ElasticSearch
+recent_update: true
---
## Part1: ES介绍及核心概念
diff --git "a/_posts/Tech/FrontEnd/2017-12-03-css\345\255\246\344\271\240\347\254\224\350\256\260.md" "b/_posts/Tech/FrontEnd/2017-12-03-css\345\255\246\344\271\240\347\254\224\350\256\260.md"
index 1df5eb98e6..a76bfdfb2d 100644
--- "a/_posts/Tech/FrontEnd/2017-12-03-css\345\255\246\344\271\240\347\254\224\350\256\260.md"
+++ "b/_posts/Tech/FrontEnd/2017-12-03-css\345\255\246\344\271\240\347\254\224\350\256\260.md"
@@ -4,7 +4,39 @@ category: FrontEnd
title: CSS笔记
tags: FrontEnd
---
+# 概述
+
+CSS:Cascading Style Sheet,层叠样式表。CSS 的作用就是给 HTML 页面标签添加各种样式,**定义网页的显示效果**。简单一句话:CSS 将网页**内容和显示样式进行分离**,提高了显示功能。
+
+**CSS 优点:**
+
+1. 使数据和显示分开
+2. 降低网络流量
+3. 使整个网站视觉效果一致
+4. 使开发效率提高了(耦合性降低,一个人负责写 html,一个人负责写 css)
+
+比如说,有一个样式需要在一百个页面上显示,如果是 html 来实现,那要写一百遍,现在有了 css,只要写一遍。现在,html 只提供数据和一些控件,完全交给 css 提供各种各样的样式。
+
+重点:盒子模型、浮动、定位
+
+
+
+CSS 的书写方式,实就是问你 CSS 的代码放在哪个位置。CSS 代码理论上的位置是任意的,**但通常写在`
+
+
+
+
+
+
+
+ AAAA
+
+