| title |
categories |
tags |
classes |
typora-copy-images-to |
[Kaggle] NLP:Disaster Tweets |
|
|
wide |
..\images\2021-03-24 |
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
plt.style.use('fivethirtyeight')
import warnings
warnings.filterwarnings('ignore')# 데이터 불러오기
train_df = pd.read_csv('../input/nlp-getting-started/train.csv')
test_df = pd.read_csv('../input/nlp-getting-started/test.csv')
display(train_df.sample(10))
<style scoped>
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
</style>
|
id |
keyword |
location |
text |
target |
| 5223 |
7463 |
obliteration |
NaN |
@tiggr_ why only Squad Obliteration? |
1 |
| 3571 |
5103 |
famine |
NaN |
Robert Conquest Famine Museum Kiev @GuidoFawke... |
0 |
| 5429 |
7748 |
police |
New York, NY |
#BREAKING411 4 police officers arrested for ab... |
1 |
| 1447 |
2086 |
casualty |
NaN |
I still don't know why independence day and so... |
0 |
| 3511 |
5018 |
eyewitness |
Jammu and Kashmir |
Eyewitness accounts of survivors of Hiroshima ... |
1 |
| 821 |
1195 |
blizzard |
Himalayan Mountains |
#Tweet4Taiji is a dolphin worship group based ... |
1 |
| 6758 |
9683 |
tornado |
San Antonio, TX |
Pizza and beer in a tornado in Austin. Windy a... |
1 |
| 2593 |
3722 |
destroyed |
USA |
Black Eye 9: A space battle occurred at Star O... |
0 |
| 7519 |
10752 |
wreckage |
Mumbai |
Wreckage 'Conclusively Confirmed' as From MH37... |
1 |
| 6078 |
8684 |
sinkhole |
Haddonfield, NJ |
Georgia sinkhole closes road swallows whole po... |
1 |
# 결측치 비율 확인
train_df.isnull().sum()/train_df.shape[0]*100
id 0.000000
keyword 0.801261
location 33.272035
text 0.000000
target 0.000000
dtype: float64
# label데이터 balance 확인
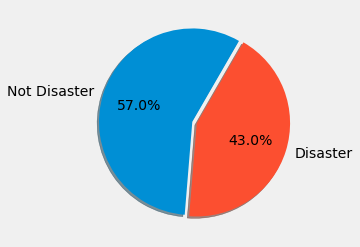
x = train_df['target'].value_counts()
plt.pie(x, labels=["Not Disaster", "Disaster"], autopct='%1.1f%%',
shadow=True, explode=(0.05, 0), startangle=60)([<matplotlib.patches.Wedge at 0x7f51f625be10>,
<matplotlib.patches.Wedge at 0x7f51f626bb10>],
[Text(-1.0977433150136204, 0.3427238164220687, 'Not Disaster'),
Text(1.0500153447956364, -0.327822780925458, 'Disaster')],
[Text(-0.6204636128337854, 0.1937134614559518, '57.0%'),
Text(0.5727356426158017, -0.17881242595934074, '43.0%')])
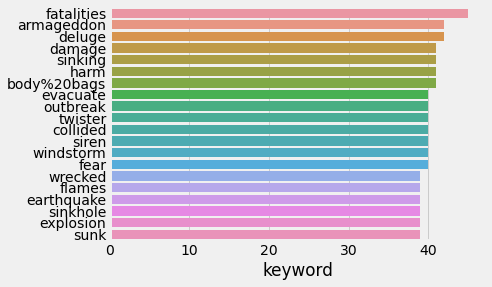
sns.barplot(y=train_df['keyword'].value_counts()[:20].index,
x=train_df['keyword'].value_counts()[:20], orient='h')<AxesSubplot:xlabel='keyword'>
grouped_df = train_df.groupby('keyword').agg(['count','sum'])
grouped_df
<style scoped>
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead tr th {
text-align: left;
}
.dataframe thead tr:last-of-type th {
text-align: right;
}
</style>
|
id |
text |
target |
|
count |
sum |
count |
sum |
count |
sum |
| keyword |
|
|
|
|
|
|
| ablaze |
36 |
2534 |
36 |
@bbcmtd Wholesale Markets ablaze http://t.co/l... |
36 |
13 |
| accident |
35 |
4263 |
35 |
'I can't have kids cuz I got in a bicycle acci... |
35 |
24 |
| aftershock |
34 |
5825 |
34 |
@afterShock_DeLo scuf ps live and the game... ... |
34 |
0 |
| airplane%20accident |
35 |
7705 |
35 |
Experts in France begin examining airplane deb... |
35 |
30 |
| ambulance |
38 |
10224 |
38 |
Early wake up call from my sister begging me t... |
38 |
20 |
| ... |
... |
... |
... |
... |
... |
... |
| wounded |
37 |
392538 |
37 |
Gunmen kill four in El Salvador bus attack: Su... |
37 |
26 |
| wounds |
33 |
351859 |
33 |
Gunshot wound #9 is in the bicep. The only one... |
33 |
10 |
| wreck |
37 |
396215 |
37 |
@Squeaver just hangin out in star buck watchin... |
37 |
7 |
| wreckage |
39 |
419629 |
39 |
Wreckage 'Conclusively Confirmed' as From MH37... |
39 |
39 |
| wrecked |
39 |
421617 |
39 |
Wrecked an hour on YouTube with @julian_lage @... |
39 |
3 |
221 rows × 6 columns
grouped_df['proportion'] = 100*grouped_df['target']['sum']/grouped_df['target']['count']
grouped_df
<style scoped>
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead tr th {
text-align: left;
}
.dataframe thead tr:last-of-type th {
text-align: right;
}
</style>
|
id |
text |
target |
proportion |
|
count |
sum |
count |
sum |
count |
sum |
|
| keyword |
|
|
|
|
|
|
|
| ablaze |
36 |
2534 |
36 |
@bbcmtd Wholesale Markets ablaze http://t.co/l... |
36 |
13 |
36.111111 |
| accident |
35 |
4263 |
35 |
'I can't have kids cuz I got in a bicycle acci... |
35 |
24 |
68.571429 |
| aftershock |
34 |
5825 |
34 |
@afterShock_DeLo scuf ps live and the game... ... |
34 |
0 |
0.000000 |
| airplane%20accident |
35 |
7705 |
35 |
Experts in France begin examining airplane deb... |
35 |
30 |
85.714286 |
| ambulance |
38 |
10224 |
38 |
Early wake up call from my sister begging me t... |
38 |
20 |
52.631579 |
| ... |
... |
... |
... |
... |
... |
... |
... |
| wounded |
37 |
392538 |
37 |
Gunmen kill four in El Salvador bus attack: Su... |
37 |
26 |
70.270270 |
| wounds |
33 |
351859 |
33 |
Gunshot wound #9 is in the bicep. The only one... |
33 |
10 |
30.303030 |
| wreck |
37 |
396215 |
37 |
@Squeaver just hangin out in star buck watchin... |
37 |
7 |
18.918919 |
| wreckage |
39 |
419629 |
39 |
Wreckage 'Conclusively Confirmed' as From MH37... |
39 |
39 |
100.000000 |
| wrecked |
39 |
421617 |
39 |
Wrecked an hour on YouTube with @julian_lage @... |
39 |
3 |
7.692308 |
221 rows × 7 columns
grouped_df.loc[grouped_df['proportion']>=50, 'keyword truth'] = 'high'
grouped_df.loc[grouped_df['proportion']<50, 'keyword truth'] = 'low'
grouped_df
<style scoped>
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead tr th {
text-align: left;
}
.dataframe thead tr:last-of-type th {
text-align: right;
}
</style>
|
id |
text |
target |
proportion |
keyword truth |
|
count |
sum |
count |
sum |
count |
sum |
|
|
| keyword |
|
|
|
|
|
|
|
|
| ablaze |
36 |
2534 |
36 |
@bbcmtd Wholesale Markets ablaze http://t.co/l... |
36 |
13 |
36.111111 |
low |
| accident |
35 |
4263 |
35 |
'I can't have kids cuz I got in a bicycle acci... |
35 |
24 |
68.571429 |
high |
| aftershock |
34 |
5825 |
34 |
@afterShock_DeLo scuf ps live and the game... ... |
34 |
0 |
0.000000 |
low |
| airplane%20accident |
35 |
7705 |
35 |
Experts in France begin examining airplane deb... |
35 |
30 |
85.714286 |
high |
| ambulance |
38 |
10224 |
38 |
Early wake up call from my sister begging me t... |
38 |
20 |
52.631579 |
high |
| ... |
... |
... |
... |
... |
... |
... |
... |
... |
| wounded |
37 |
392538 |
37 |
Gunmen kill four in El Salvador bus attack: Su... |
37 |
26 |
70.270270 |
high |
| wounds |
33 |
351859 |
33 |
Gunshot wound #9 is in the bicep. The only one... |
33 |
10 |
30.303030 |
low |
| wreck |
37 |
396215 |
37 |
@Squeaver just hangin out in star buck watchin... |
37 |
7 |
18.918919 |
low |
| wreckage |
39 |
419629 |
39 |
Wreckage 'Conclusively Confirmed' as From MH37... |
39 |
39 |
100.000000 |
high |
| wrecked |
39 |
421617 |
39 |
Wrecked an hour on YouTube with @julian_lage @... |
39 |
3 |
7.692308 |
low |
221 rows × 8 columns
sns.countplot(grouped_df['keyword truth'])
<AxesSubplot:xlabel='keyword truth', ylabel='count'>

#disaster tweets
wc = WordCloud(background_color="white", stopwords=STOPWORDS, max_words=500,
width=600, height=600, random_state=1)
wc.generate(" ".join(train_df[train_df['target']==1]['text'].tolist()))
plt.figure(figsize=(10,15))
plt.imshow(wc)<matplotlib.image.AxesImage at 0x7f51f5fd7a10>

#Non-disaster tweets
wc = WordCloud(background_color="white", stopwords=STOPWORDS, max_words=500,
width=600, height=600, random_state=1)
wc.generate(" ".join(train_df[train_df['target']==0]['text'].tolist()))
plt.figure(figsize=(10,15))
plt.imshow(wc)<matplotlib.image.AxesImage at 0x7f51f57bbc10>
import re
import spacy
import nltk
nltk.download('stopwords')
from nltk.corpus import stopwords
import string
from collections import Counter
punctuations = string.punctuation #구두점
stopwords = stopwords.words('english') #불용어 - 빈번하게 등장하는 조사, 의미 없는 단어들
nlp = spacy.load('en_core_web_sm')
# 불필요한 텍스트 제거
def cleanup_text1(text):
text = text.lower()
text = re.sub('\[.*?\]', '', text)
text = re.sub('https?://\S+|www\.\S+', '', text)
text = re.sub('<.*?>+', '', text)
text = re.sub('[%s]' % re.escape(string.punctuation), '', text)
text = re.sub('\n', '', text)
text = re.sub('\w*\d\w*', '', text)
return text
def cleanup_text2(docs):
texts = []
counter = 1
for doc in docs:
if counter % 1000 == 0:
print("Processed %d out of %d documents." % (counter, len(docs)))
counter += 1
doc = nlp(doc)
tokens = [tok.lemma_.lower().strip() for tok in doc if tok.lemma_ != '-PRON-'] # 인칭대명사 제거, 단어 기본형 추출
tokens = [tok for tok in tokens if tok not in stopwords and tok not in punctuations] # 불용어, 구두점 제거
tokens = ' '.join(tokens)
texts.append(tokens)
return pd.Series(texts)[nltk_data] Error loading stopwords: <urlopen error [Errno -3]
[nltk_data] Temporary failure in name resolution>
#cleanup_text1 적용
train_df['text'] = train_df['text'].apply(lambda x: cleanup_text1(x))
test_df['text'] = test_df['text'].apply(lambda x: cleanup_text1(x))
# label별 텍스트 분류
disaster_text = [text for text in train_df[train_df['target'] == 1]['text']]
not_disaster_text = [text for text in train_df[train_df['target'] == 0]['text']]
#cleanup_text2 적용
disaster_clean = cleanup_text2(disaster_text)
disaster_clean = ' '.join(disaster_clean).split()
disaster_clean = [word for word in disaster_clean if word != '\'s'] # 's 제거
not_disaster_clean = cleanup_text2(not_disaster_text)
not_disaster_clean = ' '.join(not_disaster_clean).split()
not_disaster_clean = [word for word in not_disaster_clean if word != '\'s']
# {단어:횟수} 형태의 딕셔너리로 저장
disaster_counts = Counter(disaster_clean)
not_disaster_counts = Counter(not_disaster_clean)Processed 1000 out of 3271 documents.
Processed 2000 out of 3271 documents.
Processed 3000 out of 3271 documents.
Processed 1000 out of 4342 documents.
Processed 2000 out of 4342 documents.
Processed 3000 out of 4342 documents.
Processed 4000 out of 4342 documents.
# 재난시 빈번한 단어 시각화
plt.rcParams["font.size"] = 15
plt.rcParams["figure.figsize"] = (30,15)
disaster_common_words = [word[0] for word in disaster_counts.most_common(25)]
disaster_common_counts = [word[1] for word in disaster_counts.most_common(25)]
sns.barplot(x=disaster_common_words, y=disaster_common_counts)
plt.title('Most Common Words Used in disaster')
plt.show()
# 재난이 아닐 시 빈번한 단어 시각화
not_disaster_common_words = [word[0] for word in not_disaster_counts.most_common(25)]
not_disaster_common_counts = [word[1] for word in not_disaster_counts.most_common(25)]
sns.barplot(x=not_disaster_common_words, y=not_disaster_common_counts)
plt.title('Most Common Words Used in Non_disaster')
plt.show()
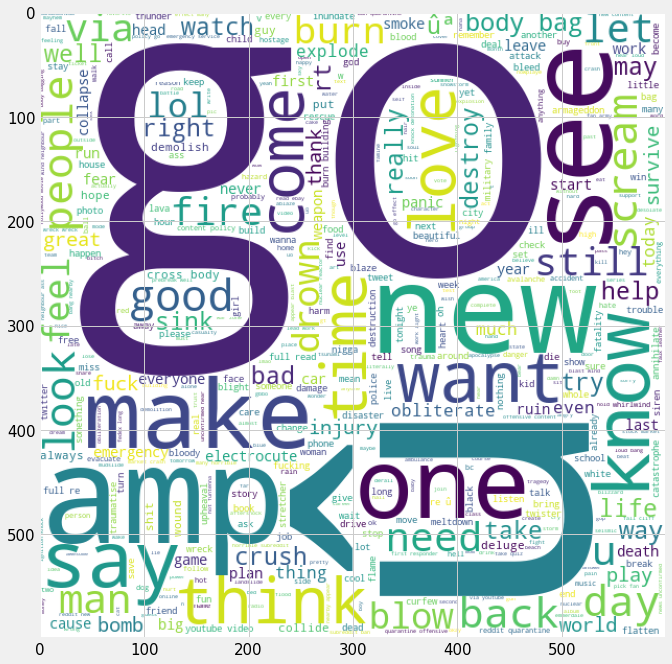
#disaster tweets
wc = WordCloud(background_color="white", stopwords=STOPWORDS, max_words=500,
width=600, height=600, random_state=1)
wc.generate(" ".join(disaster_clean))
plt.figure(figsize=(10,15))
plt.imshow(wc)<matplotlib.image.AxesImage at 0x7f51f5f0b210>
#non-disaster tweets
wc = WordCloud(background_color="white", stopwords=STOPWORDS, max_words=500,
width=600, height=600, random_state=1)
wc.generate(" ".join(not_disaster_clean))
plt.figure(figsize=(10,15))
plt.imshow(wc)<matplotlib.image.AxesImage at 0x7f51f57cf810>
from sklearn.model_selection import train_test_split
import keras
from keras.models import Sequential
from keras.initializers import Constant
from keras.layers import (LSTM,
Embedding,
BatchNormalization,
Dense,
TimeDistributed,
Dropout,
Bidirectional,
Flatten,
GlobalMaxPool1D)
from nltk.tokenize import word_tokenize
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.layers.embeddings import Embedding
from keras.callbacks import ModelCheckpoint, ReduceLROnPlateau
from keras.optimizers import Adam
from sklearn.metrics import (
precision_score,
recall_score,
f1_score,
classification_report,
accuracy_score
)train = train_df['text'].values
test = test_df['text'].values
label = train_df['target'].values
word_tokenizer = Tokenizer()
word_tokenizer.fit_on_texts(train)
vocab_length = len(word_tokenizer.word_index) + 1
def metrics(pred, y_test):
print("F1-score: ", f1_score(pred, y_test))
print("Precision: ", precision_score(pred, y_test))
print("Recall: ", recall_score(pred, y_test))
print("Accuracy: ", accuracy_score(pred, y_test))
print("-"*50)
print(classification_report(pred, y_test))
def embed(corpus):
return word_tokenizer.texts_to_sequences(corpus) #각 단어를 정수로 변환해 문장에 맞춰 순서대로 반환def plot(history, arr):
fig, ax = plt.subplots(1, 2, figsize=(20, 5))
for idx in range(2):
ax[idx].plot(history.history[arr[idx][0]])
ax[idx].plot(history.history[arr[idx][1]])
ax[idx].legend([arr[idx][0], arr[idx][1]],fontsize=18)
ax[idx].set_xlabel('A ',fontsize=16)
ax[idx].set_ylabel('B',fontsize=16)
ax[idx].set_title(arr[idx][0] + ' X ' + arr[idx][1],fontsize=16)longest_train = max(train, key=lambda sentence: len(word_tokenize(sentence)))
length_long_sentence = len(word_tokenize(longest_train))
#각 행 길이를 맞춰줌 (sequences, maxlen, dtype, padding, truncating, value)
#padding/truncating=['pre','post']-숫자를 채우거나 삭제할 때 앞부터 or 뒤부터
#value-채우는 값, default는 0
padded_sentences = pad_sequences(embed(train), length_long_sentence, padding='post')
test_sentences = pad_sequences(embed(test), length_long_sentence, padding='post')
#단어: array 형태의 dictiionary
embeddings_dictionary = dict()
embedding_dim = 100
glove_file = open('../input/glove-file/glove.6B.100d.txt')
for line in glove_file:
records = line.split()
word = records[0]
vector_dimensions = np.asarray(records[1:], dtype='float32')
embeddings_dictionary[word] = vector_dimensions
glove_file.close()#train데이터에 있는 단어들과 glove파일 내의 array값들 연결
embedding_matrix = np.zeros((vocab_length, embedding_dim))
for word, index in word_tokenizer.word_index.items():
embedding_vector = embeddings_dictionary.get(word)
if embedding_vector is not None:
embedding_matrix[index] = embedding_vectorX_train, X_test, y_train, y_test = train_test_split(
padded_sentences,
label,
test_size=0.3
)def BLSTM():
model = Sequential()
model.add(Embedding(input_dim=embedding_matrix.shape[0],
output_dim=embedding_matrix.shape[1],
weights = [embedding_matrix],
input_length=length_long_sentence))
model.add(Bidirectional(LSTM(length_long_sentence, return_sequences = True, recurrent_dropout=0.2)))
#Bidirectional-양방향 학습
#length_long_sentence-출력의 개수
#return_sequences=True-LSTM의 중간 스텝의 출력 모두 사용
model.add(GlobalMaxPool1D())
model.add(BatchNormalization())
model.add(Dropout(0.5))
model.add(Dense(length_long_sentence, activation = "relu"))
model.add(Dropout(0.5))
model.add(Dense(length_long_sentence, activation = "relu"))
model.add(Dropout(0.5))
model.add(Dense(1, activation = 'sigmoid'))
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy'])
return modelmodel = BLSTM()
checkpoint = ModelCheckpoint(
'model.h5',
monitor = 'val_loss',
verbose = 1,
save_best_only = True
)
#에폭마다 현재 가중치 저장
#val_loss가 좋아지지 않으면 덮어쓰지 않음
reduce_lr = ReduceLROnPlateau(
monitor = 'val_loss',
factor = 0.2,
verbose = 1,
patience = 2,
min_lr = 0.001
)
#val_loss가 향상되지 않을 때 학습률을 작게 함
#new_lr = lr*factor
#patience만큼의 에폭 동안 개선되지 않을 경우 호출
history = model.fit(
X_train,
y_train,
epochs = 10,
batch_size = 32,
validation_data = [X_test, y_test],
verbose = 1,
callbacks = [reduce_lr, checkpoint]
)Epoch 1/10
167/167 [==============================] - 16s 62ms/step - loss: 0.7585 - accuracy: 0.5747 - val_loss: 0.0000e+00 - val_accuracy: 0.0000e+00
Epoch 00001: val_loss improved from inf to 0.00000, saving model to model.h5
Epoch 2/10
167/167 [==============================] - 10s 58ms/step - loss: 0.5923 - accuracy: 0.7070 - val_loss: 0.0000e+00 - val_accuracy: 0.0000e+00
Epoch 00002: val_loss did not improve from 0.00000
Epoch 3/10
167/167 [==============================] - 10s 59ms/step - loss: 0.5189 - accuracy: 0.7674 - val_loss: 0.0000e+00 - val_accuracy: 0.0000e+00
Epoch 00003: ReduceLROnPlateau reducing learning rate to 0.001.
Epoch 00003: val_loss did not improve from 0.00000
Epoch 4/10
167/167 [==============================] - 10s 59ms/step - loss: 0.4662 - accuracy: 0.8142 - val_loss: 0.0000e+00 - val_accuracy: 0.0000e+00
Epoch 00004: val_loss did not improve from 0.00000
Epoch 5/10
167/167 [==============================] - 10s 57ms/step - loss: 0.4459 - accuracy: 0.8218 - val_loss: 0.0000e+00 - val_accuracy: 0.0000e+00
Epoch 00005: ReduceLROnPlateau reducing learning rate to 0.001.
Epoch 00005: val_loss did not improve from 0.00000
Epoch 6/10
167/167 [==============================] - 10s 59ms/step - loss: 0.4165 - accuracy: 0.8322 - val_loss: 0.0000e+00 - val_accuracy: 0.0000e+00
Epoch 00006: val_loss did not improve from 0.00000
Epoch 7/10
167/167 [==============================] - 10s 57ms/step - loss: 0.3925 - accuracy: 0.8531 - val_loss: 0.0000e+00 - val_accuracy: 0.0000e+00
Epoch 00007: ReduceLROnPlateau reducing learning rate to 0.001.
Epoch 00007: val_loss did not improve from 0.00000
Epoch 8/10
167/167 [==============================] - 10s 58ms/step - loss: 0.3679 - accuracy: 0.8556 - val_loss: 0.0000e+00 - val_accuracy: 0.0000e+00
Epoch 00008: val_loss did not improve from 0.00000
Epoch 9/10
167/167 [==============================] - 10s 59ms/step - loss: 0.3484 - accuracy: 0.8652 - val_loss: 0.0000e+00 - val_accuracy: 0.0000e+00
Epoch 00009: ReduceLROnPlateau reducing learning rate to 0.001.
Epoch 00009: val_loss did not improve from 0.00000
Epoch 10/10
167/167 [==============================] - 10s 57ms/step - loss: 0.3380 - accuracy: 0.8720 - val_loss: 0.0000e+00 - val_accuracy: 0.0000e+00
Epoch 00010: val_loss did not improve from 0.00000
plot(history, [['loss', 'val_loss'],['accuracy', 'val_accuracy']])

loss, accuracy = model.evaluate(X_test, y_test)
print('Loss:', loss)
print('Accuracy:', accuracy)72/72 [==============================] - 1s 11ms/step - loss: 0.4768 - accuracy: 0.7942
Loss: 0.47684410214424133
Accuracy: 0.7942206859588623
preds = model.predict_classes(X_test)
metrics(preds, y_test)
F1-score: 0.7232037691401648
Precision: 0.6329896907216495
Recall: 0.8434065934065934
Accuracy: 0.7942206654991243
--------------------------------------------------
precision recall f1-score support
0 0.91 0.77 0.84 1556
1 0.63 0.84 0.72 728
accuracy 0.79 2284
macro avg 0.77 0.81 0.78 2284
weighted avg 0.82 0.79 0.80 2284
model.load_weights('model.h5')
preds = model.predict_classes(X_test)
metrics(preds, y_test)F1-score: 0.7090754877014419
Precision: 0.8618556701030928
Recall: 0.6023054755043228
Accuracy: 0.6996497373029772
--------------------------------------------------
precision recall f1-score support
0 0.58 0.85 0.69 896
1 0.86 0.60 0.71 1388
accuracy 0.70 2284
macro avg 0.72 0.73 0.70 2284
weighted avg 0.75 0.70 0.70 2284
submission = pd.read_csv('../input/nlp-getting-started/sample_submission.csv')
submission.target = model.predict_classes(test_sentences)
submission.to_csv("submission.csv", index=False)
submission.target.value_counts().plot.bar();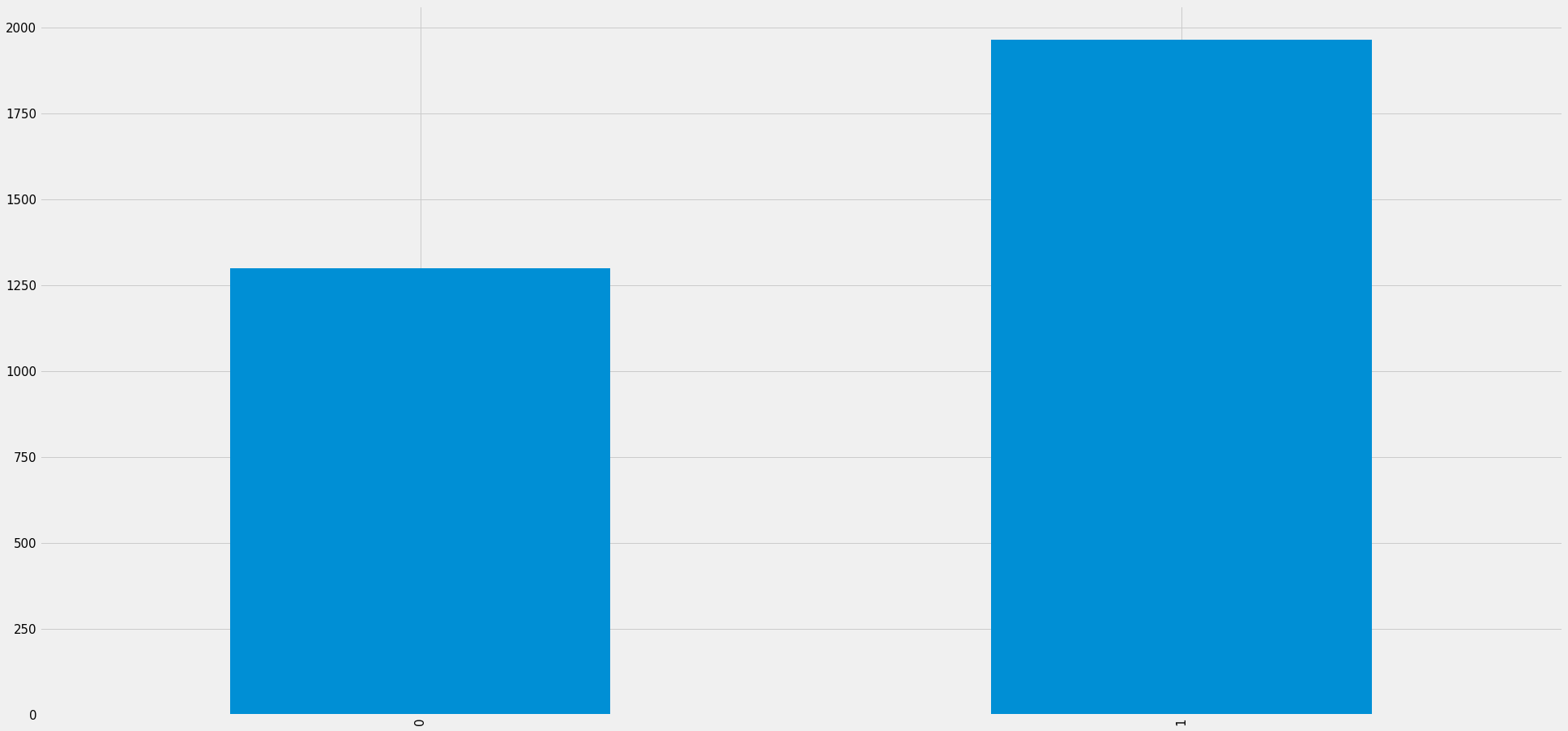
<style scoped>
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
</style>
|
id |
target |
| 0 |
0 |
1 |
| 1 |
2 |
1 |
| 2 |
3 |
1 |
| 3 |
9 |
1 |
| 4 |
11 |
1 |
| ... |
... |
... |
| 3258 |
10861 |
1 |
| 3259 |
10865 |
1 |
| 3260 |
10868 |
1 |
| 3261 |
10874 |
1 |
| 3262 |
10875 |
1 |
3263 rows × 2 columns










