#hacking source
The information gathering phase is the first step in every penetration test where we need to simulate external attackers without internal information from the target organization. This phase is crucial as poor and rushed information gathering could result in missing flaws that otherwise thorough enumeration would have uncovered.
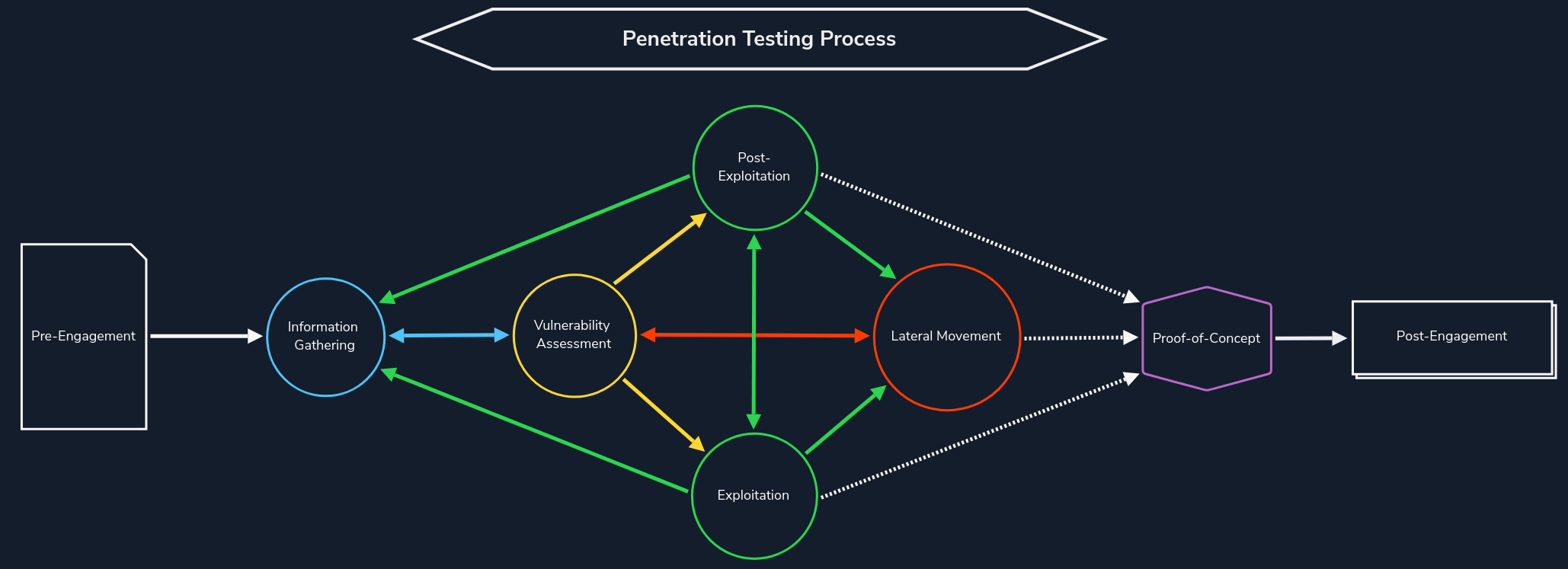
This phase helps us understand the attack surface, technologies used, and, in some cases, discover development environments or even forgotten and unmaintained infrastructure that can lead us to internal network access as they are usually less protected and monitored. Information gathering is typically an iterative process. As we discover assets (say, a subdomain or virtual host), we will need to fingerprint the technologies in use, look for hidden pages/directories, etc., which may lead us to discover another subdomain and start the process over again.
For example, we can think of it as stumbling across new subdomains during one of our penetration tests based on the SSL certificate. However, if we take a closer look at these subdomains, we will often see different technologies in use than the main company website. Subdomains and vhosts are used to present other information and perform other tasks that have been separated from the homepage. Therefore, it is essential to find out which technologies are used, what purpose they serve, and how they work. During this process, our objective is to identify as much information as we can from the following areas:
| Area | Description |
|---|---|
| Domains and Subdomains | Often, we are given a single domain or perhaps a list of domains and subdomains that belong to an organization. Many organizations do not have an accurate asset inventory and may have forgotten both domains and subdomains exposed externally. This is an essential part of the reconnaissance phase. We may come across various subdomains that map back to in-scope IP addresses, increasing the overall attack surface of our engagement (or bug bounty program). Hidden and forgotten subdomains may have old/vulnerable versions of applications or dev versions with additional functionality (a Python debugging console, for example). Bug bounty programs will often set the scope as something such as *.inlanefreight.com, meaning that all subdomains of inlanefreight.com, in this example, are in-scope (i.e., acme.inlanefreight.com, admin.inlanefreight.com, and so forth and so on). We may also discover subdomains of subdomains. For example, let's assume we discover something along the lines of admin.inlanefreight.com. We could then run further subdomain enumeration against this subdomain and perhaps find dev.admin.inlanefreight.com as a very enticing target. There are many ways to find subdomains (both passively and actively) which we will cover later in this module. |
| IP ranges | Unless we are constrained to a very specific scope, we want to find out as much about our target as possible. Finding additional IP ranges owned by our target may lead to discovering other domains and subdomains and open up our possible attack surface even wider. |
| Infrastructure | We want to learn as much about our target as possible. We need to know what technology stacks our target is using. Are their applications all ASP.NET? Do they use Django, PHP, Flask, etc.? What type(s) of APIs/web services are in use? Are they using Content Management Systems (CMS) such as WordPress, Joomla, Drupal, or DotNetNuke, which have their own types of vulnerabilities and misconfigurations that we may encounter? We also care about the web servers in use, such as IIS, Nginx, Apache, and the version numbers. If our target is running outdated frameworks or web servers, we want to dig deeper into the associated web applications. We are also interested in the types of back-end databases in use (MSSQL, MySQL, PostgreSQL, SQLite, Oracle, etc.) as this will give us an indication of the types of attacks we may be able to perform. |
| Virtual Hosts | Lastly, we want to enumerate virtual hosts (vhosts), which are similar to subdomains but indicate that an organization is hosting multiple applications on the same web server. We will cover vhost enumeration later in the module as well. |
We can break the information gathering process into two main categories:
| Category | Description |
|---|---|
| Passive information gathering | We do not interact directly with the target at this stage. Instead, we collect publicly available information using search engines, whois, certificate information, etc. The goal is to obtain as much information as possible to use as inputs to the active information gathering phase. |
| Active information gathering | We directly interact with the target at this stage. Before performing active information gathering, we need to ensure we have the required authorization to test. Otherwise, we will likely be engaging in illegal activities. Some of the techniques used in the active information gathering stage include port scanning, DNS enumeration, directory brute-forcing, virtual host enumeration, and web application crawling/spidering. |
It is crucial to keep the information that we collect well-organized as we will need various pieces of data as inputs for later phasing of the testing process. Depending on the type of assessment we are performing, we may need to include some of this enumeration data in our final report deliverable (such as an External Penetration Test). When writing up a bug bounty report, we will only need to include details relevant specifically to the bug we are reporting (i.e., a hidden subdomain that we discovered led to the disclosure of another subdomain that we leveraged to obtain remote code execution (RCE) against our target).
It is worth signing up for an account at Hackerone, perusing the program list, and choosing a few targets to reproduce all of the examples in this module. Practice makes perfect. Continuously practicing these techniques will help us hone our craft and make many of these information gathering steps second nature. As we become more comfortable with the tools and techniques shown throughout this module, we should develop our own, repeatable methodology. We may find that we like specific tools and command-line techniques for some phases of information gathering and discover different tools that we prefer for other phases. We may want to write out our own scripts to automate some of these phases as well.
Let's move on and discuss passive information gathering. For the module section examples and exercises, we will focus on Facebook, which has its own bug bounty program, PayPal, Tesla, and internal lab hosts. While performing the information gathering examples, we must be sure not to stray from the program scope, which lists in-scope and out-of-scope websites and applications and out-of-scope attacks such as physical security attacks, social engineering, the use of automated vulnerability scanners, man-in-the-middle attacks, etc.#whois #enumeration #footprinting #hacking source
We can consider WHOIS as the "white pages" for domain names. It is a TCP-based transaction-oriented query/response protocol listening on TCP port 43 by default. We can use it for querying databases containing domain names, IP addresses, or autonomous systems and provide information services to Internet users. The protocol is defined in RFC 3912. The first WHOIS directory was created in the early 1970s by Elizabeth Feinler and her team working out of Stanford University's Network Information Center (NIC). Together with her team, they created domains divided into categories based upon a computer's physical address. We can read more about the fascinating history of WHOIS here.
The WHOIS domain lookups allow us to retrieve information about the domain name of an already registered domain. The Internet Corporation of Assigned Names and Numbers (ICANN) requires that accredited registrars enter the holder's contact information, the domain's creation, and expiration dates, and other information in the Whois database immediately after registering a domain. In simple terms, the Whois database is a searchable list of all domains currently registered worldwide.
WHOIS lookups were initially performed using command-line tools. Nowadays, many web-based tools exist, but command-line options often give us the most control over our queries and help filter and sort the resultant output. Sysinternals WHOIS for Windows or Linux WHOIS command-line utility are our preferred tools for gathering information. However, there are some online versions like whois.domaintools.com we can also use.
We would get the following response from the previous command to run a whois lookup against the facebook.com domain. An example of this whois command is:
tr01ax@htb[/htb]$ export TARGET="facebook.com" # Assign our target to an environment variable
tr01ax@htb[/htb]$ whois $TARGET
Domain Name: FACEBOOK.COM
Registry Domain ID: 2320948_DOMAIN_COM-VRSN
Registrar WHOIS Server: whois.registrarsafe.com
Registrar URL: https://www.registrarsafe.com
Updated Date: 2021-09-22T19:33:41Z
Creation Date: 1997-03-29T05:00:00Z
Registrar Registration Expiration Date: 2030-03-30T04:00:00Z
Registrar: RegistrarSafe, LLC
Registrar IANA ID: 3237
Registrar Abuse Contact Email: [email protected]
Registrar Abuse Contact Phone: +1.6503087004
Domain Status: clientDeleteProhibited https://www.icann.org/epp#clientDeleteProhibited
Domain Status: clientTransferProhibited https://www.icann.org/epp#clientTransferProhibited
Domain Status: clientUpdateProhibited https://www.icann.org/epp#clientUpdateProhibited
Domain Status: serverDeleteProhibited https://www.icann.org/epp#serverDeleteProhibited
Domain Status: serverTransferProhibited https://www.icann.org/epp#serverTransferProhibited
Domain Status: serverUpdateProhibited https://www.icann.org/epp#serverUpdateProhibited
Registry Registrant ID:
Registrant Name: Domain Admin
Registrant Organization: Facebook, Inc.
Registrant Street: 1601 Willow Rd
Registrant City: Menlo Park
Registrant State/Province: CA
Registrant Postal Code: 94025
Registrant Country: US
Registrant Phone: +1.6505434800
Registrant Phone Ext:
Registrant Fax: +1.6505434800
Registrant Fax Ext:
Registrant Email: [email protected]
Registry Admin ID:
Admin Name: Domain Admin
Admin Organization: Facebook, Inc.
Admin Street: 1601 Willow Rd
Admin City: Menlo Park
Admin State/Province: CA
Admin Postal Code: 94025
Admin Country: US
Admin Phone: +1.6505434800
Admin Phone Ext:
Admin Fax: +1.6505434800
Admin Fax Ext:
Admin Email: [email protected]
Registry Tech ID:
Tech Name: Domain Admin
Tech Organization: Facebook, Inc.
Tech Street: 1601 Willow Rd
Tech City: Menlo Park
Tech State/Province: CA
Tech Postal Code: 94025
Tech Country: US
Tech Phone: +1.6505434800
Tech Phone Ext:
Tech Fax: +1.6505434800
Tech Fax Ext:
Tech Email: [email protected]
Name Server: C.NS.FACEBOOK.COM
Name Server: B.NS.FACEBOOK.COM
Name Server: A.NS.FACEBOOK.COM
Name Server: D.NS.FACEBOOK.COM
DNSSEC: unsigned
<SNIP>
We can gather the same data using whois.exe from Windows Sysinternals:
C:\htb> whois.exe facebook.com
Whois v1.21 - Domain information lookup
Copyright (C) 2005-2019 Mark Russinovich
Sysinternals - www.sysinternals.com
Connecting to COM.whois-servers.net...
WHOIS Server: whois.registrarsafe.com
Registrar URL: http://www.registrarsafe.com
Updated Date: 2021-09-22T19:33:41Z
Creation Date: 1997-03-29T05:00:00Z
Registry Expiry Date: 2030-03-30T04:00:00Z
Registrar: RegistrarSafe, LLC
Registrar IANA ID: 3237
Registrar Abuse Contact Email: [email protected]
Registrar Abuse Contact Phone: +1-650-308-7004
Domain Status: clientDeleteProhibited https://icann.org/epp#clientDeleteProhibited
Domain Status: clientTransferProhibited https://icann.org/epp#clientTransferProhibited
Domain Status: clientUpdateProhibited https://icann.org/epp#clientUpdateProhibited
Domain Status: serverDeleteProhibited https://icann.org/epp#serverDeleteProhibited
Domain Status: serverTransferProhibited https://icann.org/epp#serverTransferProhibited
Domain Status: serverUpdateProhibited https://icann.org/epp#serverUpdateProhibited
Name Server: A.NS.FACEBOOK.COM
Name Server: B.NS.FACEBOOK.COM
Name Server: C.NS.FACEBOOK.COM
Name Server: D.NS.FACEBOOK.COM
DNSSEC: unsigned
URL of the ICANN Whois Inaccuracy Complaint Form: https://www.icann.org/wicf/
>>> Last update of whois database: 2021-10-11T06:03:10Z <<<
<SNIP>
From this output, we have gathered the following information:
| Organisation | Facebook, Inc. |
| Locations | US, 94025 Menlo Park, CA, 1601 Willo Rd |
| Domain Email address | [email protected] |
| Registrar Email address | [email protected] |
| Phone number | +1.6505434800 |
| Language | English (US) |
| Registrar | RegistrarSafe, LLC |
| New Domain | fb.com |
| DNSSEC | unsigned |
| Name servers | A.NS.FACEBOOK.COM |
| B.NS.FACEBOOK.COM | |
| C.NS.FACEBOOK.COM | |
| D.NS.FACEBOOK.COM |
Though none of this information on its own is enough for us to mount an attack, it is essential data that we want to note down for later.#dns #enumeration #footprinting #hacking #dig #nslookup source
We can start looking further into the data to identify particular targets now that we have some information about our target. The Domain Name System (DNS) is an excellent place to look for this kind of information. But first, let us take a look at what DNS is.
The DNS is the Internet's phone book. Domain names such as hackthebox.com and inlanefreight.com allow people to access content on the Internet. Internet Protocol (IP) addresses are used to communicate between web browsers. DNS converts domain names to IP addresses, allowing browsers to access resources on the Internet.
Each Internet-connected device has a unique IP address that other machines use to locate it. DNS servers minimize the need for people to learn IP addresses like 104.17.42.72 in IPv4 or more sophisticated modern alphanumeric IP addresses like 2606:4700::6811:2b48 in IPv6. When a user types www.facebook.com into their web browser, a translation must occur between what the user types and the IP address required to reach the www.facebook.com webpage.
Some of the advantages of using DNS are:
- It allows names to be used instead of numbers to identify hosts.
- It is a lot easier to remember a name than it is to recall a number.
- By merely retargeting a name to the new numeric address, a server can change numeric addresses without having to notify everyone on the Internet.
- A single name might refer to several hosts splitting the workload between different servers.
There is a hierarchy of names in the DNS structure. The system's root, or highest level, is unnamed.
TLDs nameservers, the Top-Level Domains, might be compared to a single shelf of books in a library. The last portion of a hostname is hosted by this nameserver, which is the following stage in the search for a specific IP address (in www.facebook.com, the TLD server is com). Most TLDs have been delegated to individual country managers, who are issued codes from the ISO-3166-1 table. These are known as country-code Top-Level Domains or ccTLDs managed by a United Nations agency.
There are also a small number of "generic" Top Level Domains (gTLDs) that are not associated with a specific country or region. TLD managers have been granted responsibility for procedures and policies for the assignment of Second Level Domain Names (SLDs) and lower level hierarchies of names, according to the policy advice specified in ISO-3166-1.
A manager for each nation organizes country code domains. These managers provide a public service on behalf of the Internet community. Resource Records are the results of DNS queries and have the following structure:
Resource Record |
A domain name, usually a fully qualified domain name, is the first part of a Resource Record. If you don't use a fully qualified domain name, the zone's name where the record is located will be appended to the end of the name. |
TTL |
In seconds, the Time-To-Live (TTL) defaults to the minimum value specified in the SOA record. |
Record Class |
Internet, Hesiod, or Chaos |
Start Of Authority (SOA) |
It should be first in a zone file because it indicates the start of a zone. Each zone can only have one SOA record, and additionally, it contains the zone's values, such as a serial number and multiple expiration timeouts. |
Name Servers (NS) |
The distributed database is bound together by NS Records. They are in charge of a zone's authoritative name server and the authority for a child zone to a name server. |
IPv4 Addresses (A) |
The A record is only a mapping between a hostname and an IP address. 'Forward' zones are those with A records. |
Pointer (PTR) |
The PTR record is a mapping between an IP address and a hostname. 'Reverse' zones are those that have PTR records. |
Canonical Name (CNAME) |
An alias hostname is mapped to an A record hostname using the CNAME record. |
Mail Exchange (MX) |
The MX record identifies a host that will accept emails for a specific host. A priority value has been assigned to the specified host. Multiple MX records can exist on the same host, and a prioritized list is made consisting of the records for a specific host. |
Now that we have a clear understanding of what DNS is, let us take a look at the Nslookup command-line utility. Let us assume that a customer requested us to perform an external penetration test. Therefore, we first need to familiarize ourselves with their infrastructure and identify which hosts are publicly accessible. We can find this out using different types of DNS requests. With Nslookup, we can search for domain name servers on the Internet and ask them for information about hosts and domains. Although the tool has two modes, interactive and non-interactive, we will mainly focus on the non-interactive module.
We can query A records by just submitting a domain name. But we can also use the -query parameter to search specific resource records. Some examples are:
Querying: A Records
tr01ax@htb[/htb]$ export TARGET="facebook.com"
tr01ax@htb[/htb]$ nslookup $TARGET
Server: 1.1.1.1
Address: 1.1.1.1#53
Non-authoritative answer:
Name: facebook.com
Address: 31.13.92.36
Name: facebook.com
Address: 2a03:2880:f11c:8083:face:b00c:0:25de
We can also specify a nameserver if needed by adding @<nameserver/IP> to the command. Unlike nslookup, DIG shows us some more information that can be of importance.
Querying: A Records
tr01ax@htb[/htb]$ dig facebook.com @1.1.1.1
; <<>> DiG 9.16.1-Ubuntu <<>> facebook.com @1.1.1.1
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 58899
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 1232
;; QUESTION SECTION:
;facebook.com. IN A
;; ANSWER SECTION:
facebook.com. 169 IN A 31.13.92.36
;; Query time: 20 msec
;; SERVER: 1.1.1.1#53(1.1.1.1)
;; WHEN: Mo Okt 18 16:03:17 CEST 2021
;; MSG SIZE rcvd: 57
The entry starts with the complete domain name, including the final dot. The entry may be held in the cache for 169 seconds before the information must be requested again. The class is understandably the Internet (IN).
Querying: A Records for a Subdomain
tr01ax@htb[/htb]$ export TARGET=www.facebook.com
tr01ax@htb[/htb]$ nslookup -query=A $TARGET
Server: 1.1.1.1
Address: 1.1.1.1#53
Non-authoritative answer:
www.facebook.com canonical name = star-mini.c10r.facebook.com.
Name: star-mini.c10r.facebook.com
Address: 31.13.92.36
Querying: A Records for a Subdomain
tr01ax@htb[/htb]$ dig a www.facebook.com @1.1.1.1
; <<>> DiG 9.16.1-Ubuntu <<>> a www.facebook.com @1.1.1.1
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 15596
;; flags: qr rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 1232
;; QUESTION SECTION:
;www.facebook.com. IN A
;; ANSWER SECTION:
www.facebook.com. 3585 IN CNAME star-mini.c10r.facebook.com.
star-mini.c10r.facebook.com. 45 IN A 31.13.92.36
;; Query time: 16 msec
;; SERVER: 1.1.1.1#53(1.1.1.1)
;; WHEN: Mo Okt 18 16:11:48 CEST 2021
;; MSG SIZE rcvd: 90
Querying: PTR Records for an IP Address
tr01ax@htb[/htb]$ nslookup -query=PTR 31.13.92.36
Server: 1.1.1.1
Address: 1.1.1.1#53
Non-authoritative answer:
36.92.13.31.in-addr.arpa name = edge-star-mini-shv-01-frt3.facebook.com.
Authoritative answers can be found from:
Querying: PTR Records for an IP Address
tr01ax@htb[/htb]$ dig -x 31.13.92.36 @1.1.1.1
; <<>> DiG 9.16.1-Ubuntu <<>> -x 31.13.92.36 @1.1.1.1
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 51730
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 1232
;; QUESTION SECTION:
;36.92.13.31.in-addr.arpa. IN PTR
;; ANSWER SECTION:
36.92.13.31.in-addr.arpa. 1028 IN PTR edge-star-mini-shv-01-frt3.facebook.com.
;; Query time: 16 msec
;; SERVER: 1.1.1.1#53(1.1.1.1)
;; WHEN: Mo Okt 18 16:14:20 CEST 2021
;; MSG SIZE rcvd: 106
In this example, we are using Google as an example instead of Facebook as the last one did not respond to our query.
Querying: ANY Existing Records
tr01ax@htb[/htb]$ export TARGET="google.com"
tr01ax@htb[/htb]$ nslookup -query=ANY $TARGET
Server: 10.100.0.1
Address: 10.100.0.1#53
Non-authoritative answer:
Name: google.com
Address: 172.217.16.142
Name: google.com
Address: 2a00:1450:4001:808::200e
google.com text = "docusign=05958488-4752-4ef2-95eb-aa7ba8a3bd0e"
google.com text = "docusign=1b0a6754-49b1-4db5-8540-d2c12664b289"
google.com text = "v=spf1 include:_spf.google.com ~all"
google.com text = "MS=E4A68B9AB2BB9670BCE15412F62916164C0B20BB"
google.com text = "globalsign-smime-dv=CDYX+XFHUw2wml6/Gb8+59BsH31KzUr6c1l2BPvqKX8="
google.com text = "apple-domain-verification=30afIBcvSuDV2PLX"
google.com text = "google-site-verification=wD8N7i1JTNTkezJ49swvWW48f8_9xveREV4oB-0Hf5o"
google.com text = "facebook-domain-verification=22rm551cu4k0ab0bxsw536tlds4h95"
google.com text = "google-site-verification=TV9-DBe4R80X4v0M4U_bd_J9cpOJM0nikft0jAgjmsQ"
google.com nameserver = ns3.google.com.
google.com nameserver = ns2.google.com.
google.com nameserver = ns1.google.com.
google.com nameserver = ns4.google.com.
google.com mail exchanger = 10 aspmx.l.google.com.
google.com mail exchanger = 40 alt3.aspmx.l.google.com.
google.com mail exchanger = 20 alt1.aspmx.l.google.com.
google.com mail exchanger = 30 alt2.aspmx.l.google.com.
google.com mail exchanger = 50 alt4.aspmx.l.google.com.
google.com
origin = ns1.google.com
mail addr = dns-admin.google.com
serial = 398195569
refresh = 900
retry = 900
expire = 1800
minimum = 60
google.com rdata_257 = 0 issue "pki.goog"
Authoritative answers can be found from:
Querying: ANY Existing Records
tr01ax@htb[/htb]$ dig any google.com @8.8.8.8
; <<>> DiG 9.16.1-Ubuntu <<>> any google.com @8.8.8.8
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 49154
;; flags: qr rd ra; QUERY: 1, ANSWER: 22, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 512
;; QUESTION SECTION:
;google.com. IN ANY
;; ANSWER SECTION:
google.com. 249 IN A 142.250.184.206
google.com. 249 IN AAAA 2a00:1450:4001:830::200e
google.com. 549 IN MX 10 aspmx.l.google.com.
google.com. 3549 IN TXT "apple-domain-verification=30afIBcvSuDV2PLX"
google.com. 3549 IN TXT "facebook-domain-verification=22rm551cu4k0ab0bxsw536tlds4h95"
google.com. 549 IN MX 20 alt1.aspmx.l.google.com.
google.com. 3549 IN TXT "docusign=1b0a6754-49b1-4db5-8540-d2c12664b289"
google.com. 3549 IN TXT "v=spf1 include:_spf.google.com ~all"
google.com. 3549 IN TXT "globalsign-smime-dv=CDYX+XFHUw2wml6/Gb8+59BsH31KzUr6c1l2BPvqKX8="
google.com. 3549 IN TXT "google-site-verification=wD8N7i1JTNTkezJ49swvWW48f8_9xveREV4oB-0Hf5o"
google.com. 9 IN SOA ns1.google.com. dns-admin.google.com. 403730046 900 900 1800 60
google.com. 21549 IN NS ns1.google.com.
google.com. 21549 IN NS ns3.google.com.
google.com. 549 IN MX 50 alt4.aspmx.l.google.com.
google.com. 3549 IN TXT "docusign=05958488-4752-4ef2-95eb-aa7ba8a3bd0e"
google.com. 549 IN MX 30 alt2.aspmx.l.google.com.
google.com. 21549 IN NS ns2.google.com.
google.com. 21549 IN NS ns4.google.com.
google.com. 549 IN MX 40 alt3.aspmx.l.google.com.
google.com. 3549 IN TXT "MS=E4A68B9AB2BB9670BCE15412F62916164C0B20BB"
google.com. 3549 IN TXT "google-site-verification=TV9-DBe4R80X4v0M4U_bd_J9cpOJM0nikft0jAgjmsQ"
google.com. 21549 IN CAA 0 issue "pki.goog"
;; Query time: 16 msec
;; SERVER: 8.8.8.8#53(8.8.8.8)
;; WHEN: Mo Okt 18 16:15:22 CEST 2021
;; MSG SIZE rcvd: 922
The more recent RFC8482 specified that ANY DNS requests be abolished. Therefore, we may not receive a response to our ANY request from the DNS server or get a reference to the said RFC8482.
Querying: ANY Existing Records
tr01ax@htb[/htb]$ dig any cloudflare.com @8.8.8.8
; <<>> DiG 9.16.1-Ubuntu <<>> any cloudflare.com @8.8.8.8
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 22509
;; flags: qr rd ra ad; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 512
;; QUESTION SECTION:
;cloudflare.com. IN ANY
;; ANSWER SECTION:
cloudflare.com. 2747 IN HINFO "RFC8482" ""
cloudflare.com. 2747 IN RRSIG HINFO 13 2 3789 20211019145905 20211017125905 34505 cloudflare.com. 4/Bq8xUN96SrOhuH0bj2W6s2pXRdv5L5NWsgyTAGLAjEwwEF4y4TQuXo yGtvD3B13jr5KhdXo1VtrLLMy4OR8Q==
;; Query time: 16 msec
;; SERVER: 8.8.8.8#53(8.8.8.8)
;; WHEN: Mo Okt 18 16:16:27 CEST 2021
;; MSG SIZE rcvd: 174
Querying: TXT Records
tr01ax@htb[/htb]$ export TARGET="facebook.com"
tr01ax@htb[/htb]$ nslookup -query=TXT $TARGET
Server: 1.1.1.1
Address: 1.1.1.1#53
Non-authoritative answer:
facebook.com text = "v=spf1 redirect=_spf.facebook.com"
facebook.com text = "google-site-verification=A2WZWCNQHrGV_TWwKh6KHY90tY0SHZo_RnyMJoDaG0s"
facebook.com text = "google-site-verification=wdH5DTJTc9AYNwVunSVFeK0hYDGUIEOGb-RReU6pJlY"
Authoritative answers can be found from:
Querying: TXT Records
tr01ax@htb[/htb]$ dig txt facebook.com @1.1.1.1
; <<>> DiG 9.16.1-Ubuntu <<>> txt facebook.com @1.1.1.1
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 63771
;; flags: qr rd ra; QUERY: 1, ANSWER: 3, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 1232
;; QUESTION SECTION:
;facebook.com. IN TXT
;; ANSWER SECTION:
facebook.com. 86400 IN TXT "v=spf1 redirect=_spf.facebook.com"
facebook.com. 7200 IN TXT "google-site-verification=A2WZWCNQHrGV_TWwKh6KHY90tY0SHZo_RnyMJoDaG0s"
facebook.com. 7200 IN TXT "google-site-verification=wdH5DTJTc9AYNwVunSVFeK0hYDGUIEOGb-RReU6pJlY"
;; Query time: 24 msec
;; SERVER: 1.1.1.1#53(1.1.1.1)
;; WHEN: Mo Okt 18 16:17:46 CEST 2021
;; MSG SIZE rcvd: 249
Querying: MX Records
tr01ax@htb[/htb]$ export TARGET="facebook.com"
tr01ax@htb[/htb]$ nslookup -query=MX $TARGET
Server: 1.1.1.1
Address: 1.1.1.1#53
Non-authoritative answer:
facebook.com mail exchanger = 10 smtpin.vvv.facebook.com.
Authoritative answers can be found from:
Querying: MX Records
tr01ax@htb[/htb]$ dig mx facebook.com @1.1.1.1
; <<>> DiG 9.16.1-Ubuntu <<>> mx facebook.com @1.1.1.1
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 9392
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 1232
;; QUESTION SECTION:
;facebook.com. IN MX
;; ANSWER SECTION:
facebook.com. 3600 IN MX 10 smtpin.vvv.facebook.com.
;; Query time: 40 msec
;; SERVER: 1.1.1.1#53(1.1.1.1)
;; WHEN: Mo Okt 18 16:18:22 CEST 2021
;; MSG SIZE rcvd: 68
So far, we have gathered A, NS, MX, and CNAME records with the nslookup and dig commands. Organizations are given IP addresses on the Internet, but they aren't always their owners. They might rely on ISPs and hosting provides that lease smaller netblocks to them.
We can combine some of the results gathered via nslookup with the whois database to determine if our target organization uses hosting providers. This combination looks like the following example:
Nslookup
tr01ax@htb[/htb]$ export TARGET="facebook.com"
tr01ax@htb[/htb]$ nslookup $TARGET
Server: 1.1.1.1
Address: 1.1.1.1#53
Non-authoritative answer:
Name: facebook.com
Address: 157.240.199.35
Name: facebook.com
Address: 2a03:2880:f15e:83:face:b00c:0:25de
WHOIS
tr01ax@htb[/htb]$ whois 157.240.199.35
NetRange: 157.240.0.0 - 157.240.255.255
CIDR: 157.240.0.0/16
NetName: THEFA-3
NetHandle: NET-157-240-0-0-1
Parent: NET157 (NET-157-0-0-0-0)
NetType: Direct Assignment
OriginAS:
Organization: Facebook, Inc. (THEFA-3)
RegDate: 2015-05-14
Updated: 2015-05-14
Ref: https://rdap.arin.net/registry/ip/157.240.0.0
OrgName: Facebook, Inc.
OrgId: THEFA-3
Address: 1601 Willow Rd.
City: Menlo Park
StateProv: CA
PostalCode: 94025
Country: US
RegDate: 2004-08-11
Updated: 2012-04-17
Ref: https://rdap.arin.net/registry/entity/THEFA-3
OrgAbuseHandle: OPERA82-ARIN
OrgAbuseName: Operations
OrgAbusePhone: +1-650-543-4800
OrgAbuseEmail: [email protected]
OrgAbuseRef: https://rdap.arin.net/registry/entity/OPERA82-ARIN
OrgTechHandle: OPERA82-ARIN
OrgTechName: Operations
OrgTechPhone: +1-650-543-4800
OrgTechEmail: [email protected]
OrgTechRef: https://rdap.arin.net/registry/entity/OPERA82-ARIN
```#footprinting #enumeration #hacking #subdomain #theharvester [source](https://academy.hackthebox.com/module/144/section/1252)
---
Subdomain enumeration refers to mapping all available subdomains within a domain name. It increases our attack surface and may uncover hidden management backend panels or intranet web applications that network administrators expected to keep hidden using the "security by obscurity" strategy. At this point, we will only perform passive subdomain enumeration using third-party services or publicly available information. Still, we will expand the information we gather in future active subdomain enumeration activities.
---
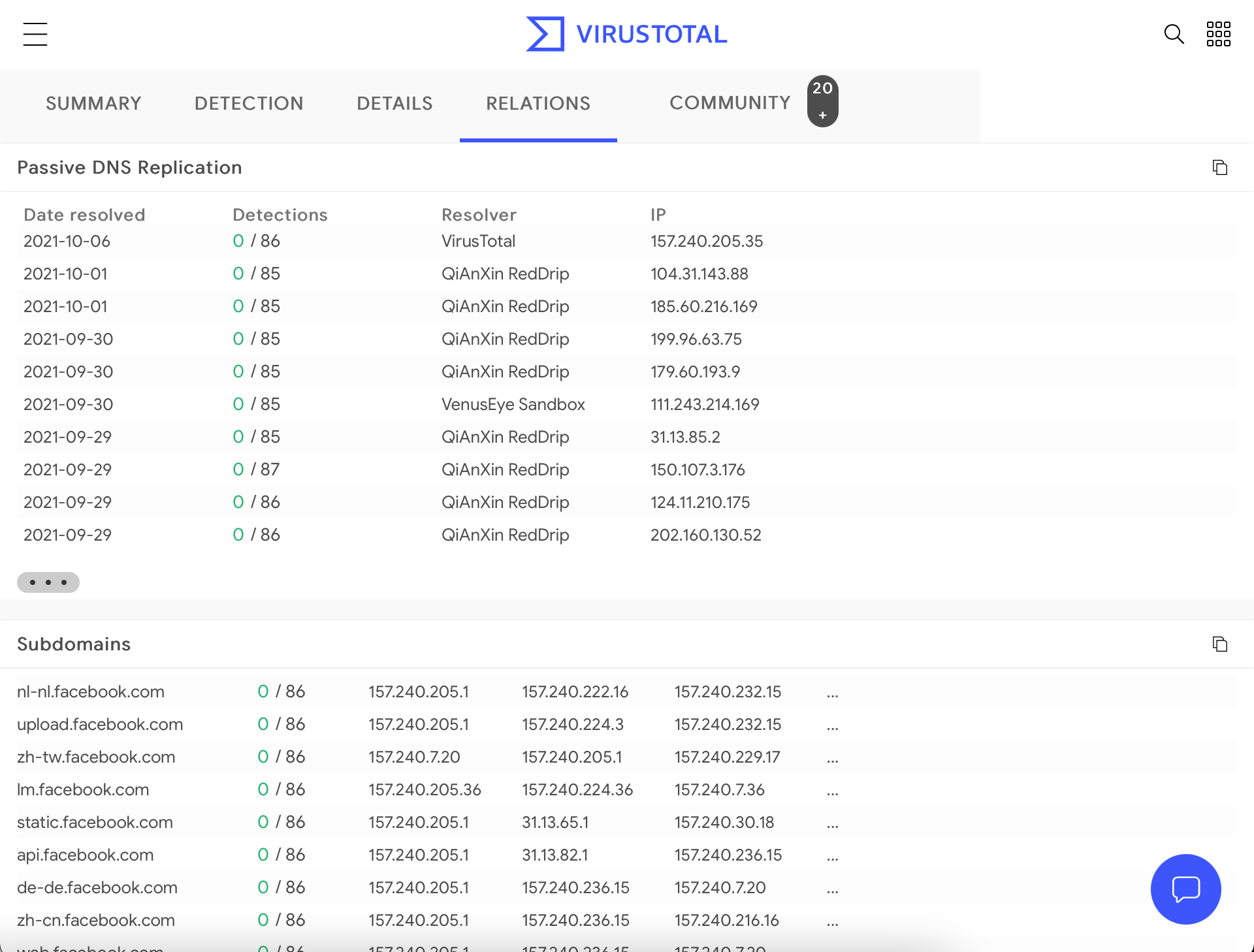
## VirusTotal
VirusTotal maintains its DNS replication service, which is developed by preserving DNS resolutions made when users visit URLs given by them. To receive information about a domain, type the domain name into the search bar and click on the "Relations" tab.
---
## Certificates
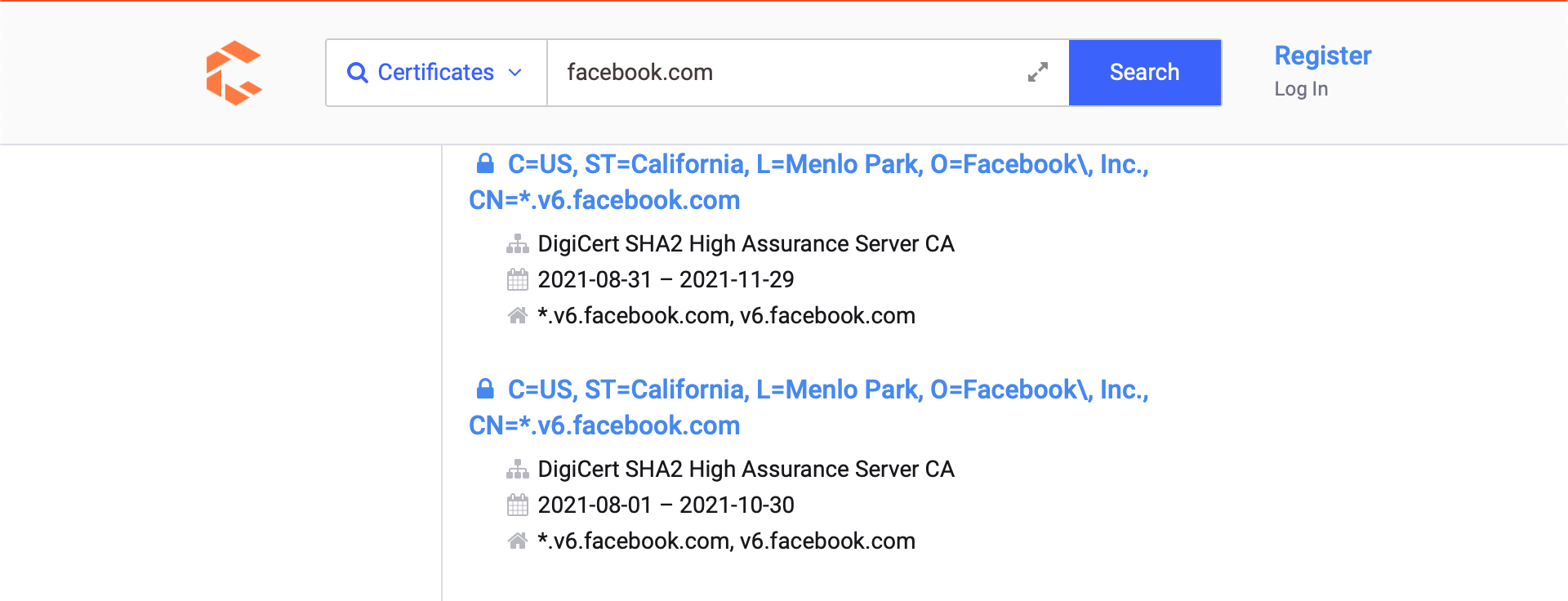
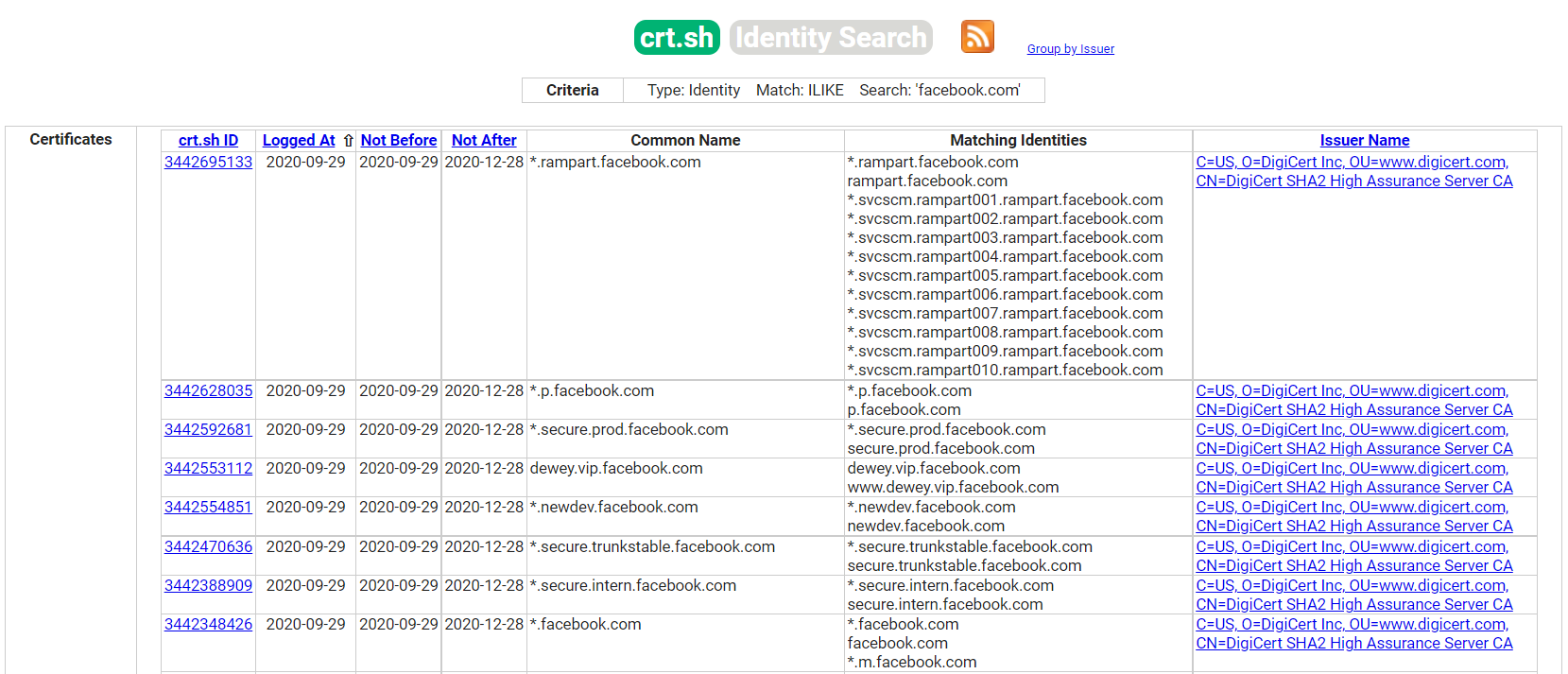
Another interesting source of information we can use to extract subdomains is SSL/TLS certificates. The main reason is Certificate Transparency (CT), a project that requires every SSL/TLS certificate issued by a Certificate Authority (CA) to be published in a publicly accessible log.
We will learn how to examine CT logs to discover additional domain names and subdomains for a target organization using two primary resources:
- [https://censys.io](https://censys.io)
- [https://crt.sh](https://crt.sh)
We can navigate to https://search.censys.io/certificates or https://crt.sh and introduce the domain name of our target organization to start discovering new subdomains.
Although the website is excellent, we would like to have this information organized and be able to combine it with other sources found throughout the information-gathering process. Let us perform a curl request to the target website asking for a JSON output as this is more manageable for us to process. We can do this via the following commands:
#### Certificate Transparency
Certificate Transparency
```shell-session
tr01ax@htb[/htb]$ export TARGET="facebook.com"
tr01ax@htb[/htb]$ curl -s "https://crt.sh/?q=${TARGET}&output=json" | jq -r '.[] | "\(.name_value)\n\(.common_name)"' | sort -u > "${TARGET}_crt.sh.txt"
Certificate Transparency
tr01ax@htb[/htb]$ head -n20 facebook.com_crt.sh.txt
*.adtools.facebook.com
*.ak.facebook.com
*.ak.fbcdn.net
*.alpha.facebook.com
*.assistant.facebook.com
*.beta.facebook.com
*.channel.facebook.com
*.cinyour.facebook.com
*.cinyourrc.facebook.com
*.connect.facebook.com
*.cstools.facebook.com
*.ctscan.facebook.com
*.dev.facebook.com
*.dns.facebook.com
*.extern.facebook.com
*.extools.facebook.com
*.f--facebook.com
*.facebook.com
*.facebookcorewwwi.onion
*.facebookmail.com
curl -s |
Issue the request with minimal output. |
https://crt.sh/?q=<DOMAIN>&output=json |
Ask for the json output. |
jq -r '.[]' "\(.name_value)\n\(.common_name)"' |
Process the json output and print certificate's name value and common name one per line. |
sort -u |
Sort alphabetically the output provided and removes duplicates. |
We also can manually perform this operation against a target using OpenSSL via:
Certificate Transparency
tr01ax@htb[/htb]$ export TARGET="facebook.com"
tr01ax@htb[/htb]$ export PORT="443"
tr01ax@htb[/htb]$ openssl s_client -ign_eof 2>/dev/null <<<$'HEAD / HTTP/1.0\r\n\r' -connect "${TARGET}:${PORT}" | openssl x509 -noout -text -in - | grep 'DNS' | sed -e 's|DNS:|\n|g' -e 's|^\*.*||g' | tr -d ',' | sort -u
*.facebook.com
*.facebook.net
*.fbcdn.net
*.fbsbx.com
*.m.facebook.com
*.messenger.com
*.xx.fbcdn.net
*.xy.fbcdn.net
*.xz.fbcdn.net
facebook.com
messenger.com
We have learned how to acquire helpful information from our target organization, like subdomains, naming patterns, alternate TLDs, IP ranges, etc., using third-party services without interacting directly with their infrastructure or relying on automated tools. Now, we will learn how to enumerate subdomains using tools and previously obtained information.
TheHarvester is a simple-to-use yet powerful and effective tool for early-stage penetration testing and red team engagements. We can use it to gather information to help identify a company's attack surface. The tool collects emails, names, subdomains, IP addresses, and URLs from various public data sources for passive information gathering. For now, we will use the following modules:
| Baidu | Baidu search engine. |
Bufferoverun |
Uses data from Rapid7's Project Sonar - www.rapid7.com/research/project-sonar/ |
| Crtsh | Comodo Certificate search. |
| Hackertarget | Online vulnerability scanners and network intelligence to help organizations. |
Otx |
AlienVault Open Threat Exchange - https://otx.alienvault.com |
| Rapiddns | DNS query tool, which makes querying subdomains or sites using the same IP easy. |
| Sublist3r | Fast subdomains enumeration tool for penetration testers |
| Threatcrowd | Open source threat intelligence. |
| Threatminer | Data mining for threat intelligence. |
Trello |
Search Trello boards (Uses Google search) |
| Urlscan | A sandbox for the web that is a URL and website scanner. |
Vhost |
Bing virtual hosts search. |
| Virustotal | Domain search. |
| Zoomeye | A Chinese version of Shodan. |
To automate this, we will create a file called sources.txt with the following contents.
TheHarvester
tr01ax@htb[/htb]$ cat sources.txt
baidu
bufferoverun
crtsh
hackertarget
otx
projecdiscovery
rapiddns
sublist3r
threatcrowd
trello
urlscan
vhost
virustotal
zoomeye
Once the file is created, we will execute the following commands to gather information from these sources.
TheHarvester
tr01ax@htb[/htb]$ export TARGET="facebook.com"
tr01ax@htb[/htb]$ cat sources.txt | while read source; do theHarvester -d "${TARGET}" -b $source -f "${source}_${TARGET}";done
<SNIP>
*******************************************************************
* _ _ _ *
* | |_| |__ ___ /\ /\__ _ _ ____ _____ ___| |_ ___ _ __ *
* | __| _ \ / _ \ / /_/ / _` | '__\ \ / / _ \/ __| __/ _ \ '__| *
* | |_| | | | __/ / __ / (_| | | \ V / __/\__ \ || __/ | *
* \__|_| |_|\___| \/ /_/ \__,_|_| \_/ \___||___/\__\___|_| *
* *
* theHarvester 4.0.0 *
* Coded by Christian Martorella *
* Edge-Security Research *
* [email protected] *
* *
*******************************************************************
[*] Target: facebook.com
[*] Searching Urlscan.
[*] ASNS found: 29
--------------------
AS12578
AS13335
AS13535
AS136023
AS14061
AS14618
AS15169
AS15817
<SNIP>
When the process finishes, we can extract all the subdomains found and sort them via the following command:
TheHarvester
tr01ax@htb[/htb]$ cat *.json | jq -r '.hosts[]' 2>/dev/null | cut -d':' -f 1 | sort -u > "${TARGET}_theHarvester.txt"
Now we can merge all the passive reconnaissance files via:
TheHarvester
tr01ax@htb[/htb]$ cat facebook.com_*.txt | sort -u > facebook.com_subdomains_passive.txt
tr01ax@htb[/htb]$ cat facebook.com_subdomains_passive.txt | wc -l
11947
So far, we have managed to find 11947 subdomains merging the passive reconnaissance result files. It is important to note here that there are many more methods to find subdomains passively. More possibilities are shown, for example, in the OSINT: Corporate Recon module.#hacking #enumeration #footprinting #netcraft source
Netcraft can offer us information about the servers without even interacting with them, and this is something valuable from a passive information gathering point of view. We can use the service by visiting https://sitereport.netcraft.com and entering the target domain.
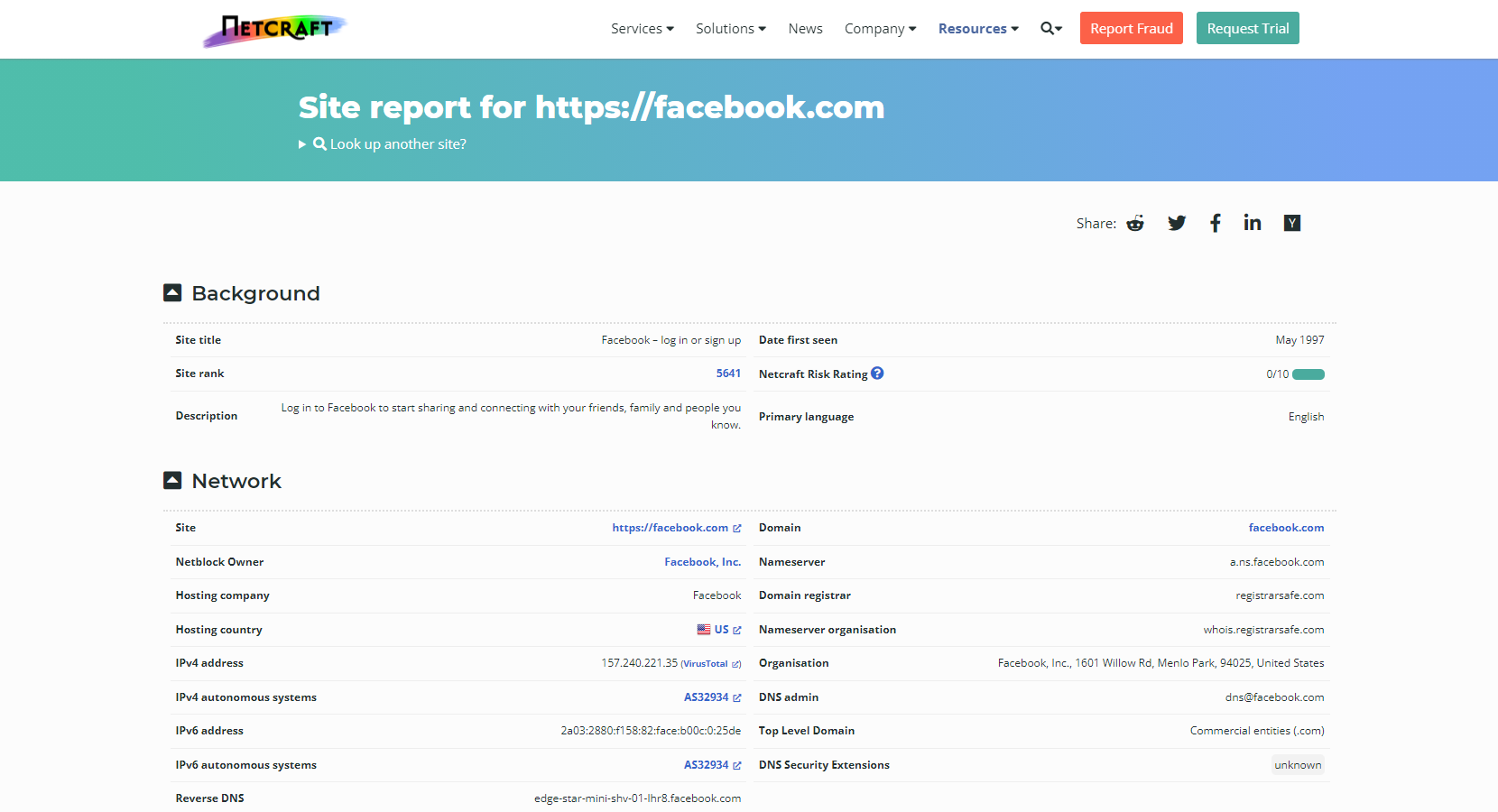
Some interesting details we can observe from the report are:
Background |
General information about the domain, including the date it was first seen by Netcraft crawlers. |
Network |
Information about the netblock owner, hosting company, nameservers, etc. |
Hosting history |
Latest IPs used, webserver, and target OS. |
We need to pay special attention to the latest IPs used. Sometimes we can spot the actual IP address from the webserver before it was placed behind a load balancer, web application firewall, or IDS, allowing us to connect directly to it if the configuration allows it. This kind of technology could interfere with or alter our future testing activities.
The Internet Archive is an American digital library that provides free public access to digitalized materials, including websites, collected automatically via its web crawlers.
We can access several versions of these websites using the Wayback Machine to find old versions that may have interesting comments in the source code or files that should not be there. This tool can be used to find older versions of a website at a point in time. Let's take a website running WordPress, for example. We may not find anything interesting while assessing it using manual methods and automated tools, so we search for it using Wayback Machine and find a version that utilizes a specific (now vulnerable) plugin. Heading back to the current version of the site, we find that the plugin was not removed properly and can still be accessed via the wp-content directory. We can then utilize it to gain remote code execution on the host and a nice bounty.
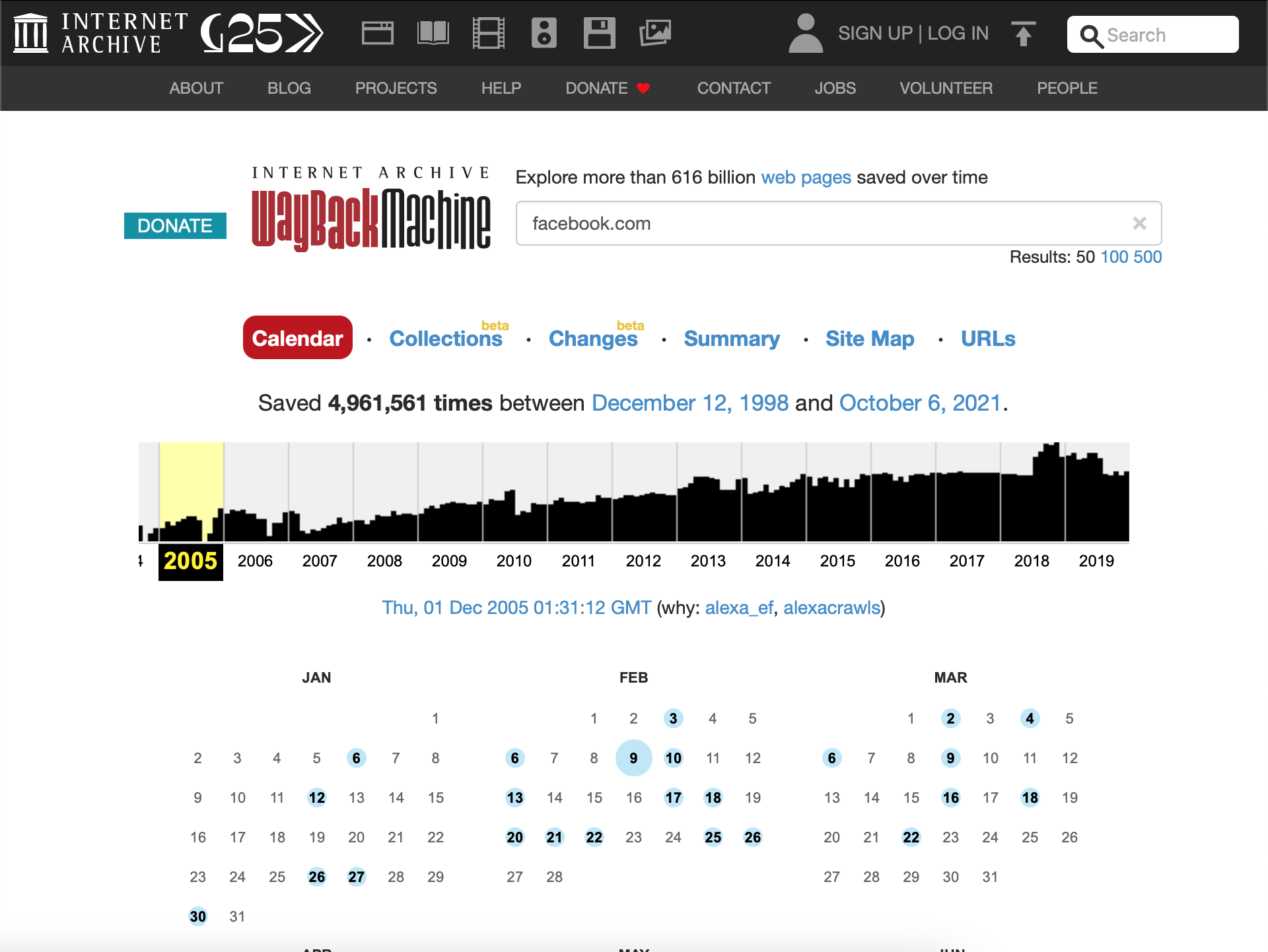
We can check one of the first versions of facebook.com captured on December 1, 2005, which is interesting, perhaps gives us a sense of nostalgia but is also extremely useful for us as security researchers.
We can also use the tool waybackurls to inspect URLs saved by Wayback Machine and look for specific keywords. Provided we have Go set up correctly on our host, we can install the tool as follows:
tr01ax@htb[/htb]$ go install github.com/tomnomnom/waybackurls@latest
To get a list of crawled URLs from a domain with the date it was obtained, we can add the -dates switch to our command as follows:
tr01ax@htb[/htb]$ waybackurls -dates https://facebook.com > waybackurls.txt
tr01ax@htb[/htb]$ cat waybackurls.txt
2018-05-20T09:46:07Z http://www.facebook.com./
2018-05-20T10:07:12Z https://www.facebook.com/
2018-05-20T10:18:51Z http://www.facebook.com/#!/pages/Welcome-Baby/143392015698061?ref=tsrobots.txt
2018-05-20T10:19:19Z http://www.facebook.com/
2018-05-20T16:00:13Z http://facebook.com
2018-05-21T22:12:55Z https://www.facebook.com
2018-05-22T15:14:09Z http://www.facebook.com
2018-05-22T17:34:48Z http://www.facebook.com/#!/Syerah?v=info&ref=profile/robots.txt
2018-05-23T11:03:47Z http://www.facebook.com/#!/Bin595
<SNIP>
If we want to access a specific resource, we need to place the URL in the search menu and navigate to the date when the snapshot was created. As stated previously, Wayback Machine can be a handy tool and should not be overlooked. It can very likely lead to us discovering forgotten assets, pages, etc., which can lead to discovering a flaw.source #hacking #enumeration #footprinting
A web application's infrastructure is what keeps it running and allows it to function. Web servers are directly involved in any web application's operation. Some of the most popular are Apache, Nginx, and Microsoft IIS, among others.
If we discover the webserver behind the target application, it can give us a good idea of what operating system is running on the back-end server. For example, if we find out the IIS version running, we can infer the Windows OS version in use by mapping the IIS version back to the Windows version that it comes installed on by default. Some default installations are:
- IIS 6.0: Windows Server 2003
- IIS 7.0-8.5: Windows Server 2008 / Windows Server 2008R2
- IIS 10.0 (v1607-v1709): Windows Server 2016
- IIS 10.0 (v1809-): Windows Server 2019
Although this is usually correct when dealing with Windows, we can not be sure in the case of Linux or BSD-based distributions as they can run different web server versions in the case of Nginx or Apache. This kind of technology could interfere with or alter our future testing activities. Nevertheless, if we deal with a web server, we will not be able to find any fingerprints about the server in HTML or JS.
We need to discover as much information as possible from the webserver to understand its functionality, which can affect future testing. For example, URL rewriting functionality, load balancing, script engines used on the server, or an Intrusion detection system (IDS) in place may impede some of our testing activities.
The first thing we can do to identify the webserver version is to look at the response headers.
HTTP Headers
tr01ax@htb[/htb]$ curl -I "http://${TARGET}"
HTTP/1.1 200 OK
Date: Thu, 23 Sep 2021 15:10:42 GMT
Server: Apache/2.4.25 (Debian)
X-Powered-By: PHP/7.3.5
Link: <http://192.168.10.10/wp-json/>; rel="https://api.w.org/"
Content-Type: text/html; charset=UTF-8
There are also other characteristics to take into account while fingerprinting web servers in the response headers. These are:
-
X-Powered-By header: This header can tell us what the web app is using. We can see values like PHP, ASP.NET, JSP, etc.
-
Cookies: Cookies are another attractive value to look at as each technology by default has its cookies. Some of the default cookie values are:
- .NET:
ASPSESSIONID<RANDOM>=<COOKIE_VALUE> - PHP:
PHPSESSID=<COOKIE_VALUE> - JAVA:
JSESSION=<COOKIE_VALUE>
- .NET:
HTTP Headers
tr01ax@htb[/htb]$ curl -I http://${TARGET}
HTTP/1.1 200 OK
Host: randomtarget.com
Date: Thu, 23 Sep 2021 15:12:21 GMT
Connection: close
X-Powered-By: PHP/7.4.21
Set-Cookie: PHPSESSID=gt02b1pqla35cvmmb2bcli96ml; path=/
Expires: Thu, 19 Nov 1981 08:52:00 GMT
Cache-Control: no-store, no-cache, must-revalidate
Pragma: no-cache
Content-type: text/html; charset=UTF-8
Other available tools analyze common web server characteristics by probing them and comparing their responses with a database of signatures to guess information like web server version, installed modules, and enabled services. Some of these tools are:
Whatweb recognizes web technologies, including content management systems (CMS), blogging platforms, statistic/analytics packages, JavaScript libraries, web servers, and embedded devices. We recommend reading the whatweb help menu via whatweb -h to understand the available options, like the aggression level controls or verbose output. In this case, we will use an aggression level of 3 via the -a flag and verbose output via -v.
WhatWeb
tr01ax@htb[/htb]$ whatweb -a3 https://www.facebook.com -v
WhatWeb report for https://www.facebook.com
Status : 200 OK
Title : <None>
IP : 31.13.92.36
Country : IRELAND, IE
Summary : Strict-Transport-Security[max-age=15552000; preload], PasswordField[pass], Script[text/javascript], X-XSS-Protection[0], HTML5, X-Frame-Options[DENY], Meta-Refresh-Redirect[/?_fb_noscript=1], UncommonHeaders[x-fb-rlafr,x-content-type-options,x-fb-debug,alt-svc]
Detected Plugins:
[ HTML5 ]
HTML version 5, detected by the doctype declaration
[ Meta-Refresh-Redirect ]
Meta refresh tag is a deprecated URL element that can be
used to optionally wait x seconds before reloading the
current page or loading a new page. More info:
https://secure.wikimedia.org/wikipedia/en/wiki/Meta_refresh
String : /?_fb_noscript=1
[ PasswordField ]
find password fields
String : pass (from field name)
[ Script ]
This plugin detects instances of script HTML elements and
returns the script language/type.
String : text/javascript
[ Strict-Transport-Security ]
Strict-Transport-Security is an HTTP header that restricts
a web browser from accessing a website without the security
of the HTTPS protocol.
String : max-age=15552000; preload
[ UncommonHeaders ]
Uncommon HTTP server headers. The blacklist includes all
the standard headers and many non standard but common ones.
Interesting but fairly common headers should have their own
plugins, eg. x-powered-by, server and x-aspnet-version.
Info about headers can be found at www.http-stats.com
String : x-fb-rlafr,x-content-type-options,x-fb-debug,alt-svc (from headers)
[ X-Frame-Options ]
This plugin retrieves the X-Frame-Options value from the
HTTP header. - More Info:
http://msdn.microsoft.com/en-us/library/cc288472%28VS.85%29.
aspx
String : DENY
[ X-XSS-Protection ]
This plugin retrieves the X-XSS-Protection value from the
HTTP header. - More Info:
http://msdn.microsoft.com/en-us/library/cc288472%28VS.85%29.
aspx
String : 0
HTTP Headers:
HTTP/1.1 200 OK
Vary: Accept-Encoding
Content-Encoding: gzip
x-fb-rlafr: 0
Pragma: no-cache
Cache-Control: private, no-cache, no-store, must-revalidate
Expires: Sat, 01 Jan 2000 00:00:00 GMT
X-Content-Type-Options: nosniff
X-XSS-Protection: 0
X-Frame-Options: DENY
Strict-Transport-Security: max-age=15552000; preload
Content-Type: text/html; charset="utf-8"
X-FB-Debug: r2w+sMJ7lVrMjS/ETitC6cNpJXma0r3fbt0rIlnTPAfQqTc+U4PQopVL7sR/6YA/ZKRkqP1wMPoFdUfMBP1JSA==
Date: Wed, 06 Oct 2021 09:04:27 GMT
Alt-Svc: h3=":443"; ma=3600, h3-29=":443"; ma=3600,h3-27=":443"; ma=3600
Connection: close
WhatWeb report for https://www.facebook.com/?_fb_noscript=1
Status : 200 OK
Title : <None>
IP : 31.13.92.36
Country : IRELAND, IE
Summary : Cookies[noscript], Strict-Transport-Security[max-age=15552000; preload], PasswordField[pass], Script[text/javascript], X-XSS-Protection[0], HTML5, X-Frame-Options[DENY], UncommonHeaders[x-fb-rlafr,x-content-type-options,x-fb-debug,alt-svc]
Detected Plugins:
[ Cookies ]
Display the names of cookies in the HTTP headers. The
values are not returned to save on space.
String : noscript
[ HTML5 ]
HTML version 5, detected by the doctype declaration
[ PasswordField ]
find password fields
String : pass (from field name)
[ Script ]
This plugin detects instances of script HTML elements and
returns the script language/type.
String : text/javascript
[ Strict-Transport-Security ]
Strict-Transport-Security is an HTTP header that restricts
a web browser from accessing a website without the security
of the HTTPS protocol.
String : max-age=15552000; preload
[ UncommonHeaders ]
Uncommon HTTP server headers. The blacklist includes all
the standard headers and many non standard but common ones.
Interesting but fairly common headers should have their own
plugins, eg. x-powered-by, server and x-aspnet-version.
Info about headers can be found at www.http-stats.com
String : x-fb-rlafr,x-content-type-options,x-fb-debug,alt-svc (from headers)
[ X-Frame-Options ]
This plugin retrieves the X-Frame-Options value from the
HTTP header. - More Info:
http://msdn.microsoft.com/en-us/library/cc288472%28VS.85%29.
aspx
String : DENY
[ X-XSS-Protection ]
This plugin retrieves the X-XSS-Protection value from the
HTTP header. - More Info:
http://msdn.microsoft.com/en-us/library/cc288472%28VS.85%29.
aspx
String : 0
HTTP Headers:
HTTP/1.1 200 OK
Vary: Accept-Encoding
Content-Encoding: gzip
Set-Cookie: noscript=1; path=/; domain=.facebook.com; secure
x-fb-rlafr: 0
Pragma: no-cache
Cache-Control: private, no-cache, no-store, must-revalidate
Expires: Sat, 01 Jan 2000 00:00:00 GMT
X-Content-Type-Options: nosniff
X-XSS-Protection: 0
X-Frame-Options: DENY
Strict-Transport-Security: max-age=15552000; preload
Content-Type: text/html; charset="utf-8"
X-FB-Debug: 7bEryjJ3tsTb/ap562d5L6KUJyJJ3bJh9XoamIo2lCVrX4cK/VAGbLx7muaAwnyobVm9myC3fQ+CXJqkk0eacg==
Date: Wed, 06 Oct 2021 09:04:31 GMT
Alt-Svc: h3=":443"; ma=3600, h3-29=":443"; ma=3600,h3-27=":443"; ma=3600
Connection: close
We also would want to install Wappalyzer as a browser extension. It has similar functionality to Whatweb, but the results are displayed while navigating the target URL.
WafW00f is a web application firewall (WAF) fingerprinting tool that sends requests and analyses responses to determine if a security solution is in place. We can install it with the following command:
Installing WafW00f
tr01ax@htb[/htb]$ sudo apt install wafw00f -y
We can use options like -a to check all possible WAFs in place instead of stopping scanning at the first match, read targets from an input file via the -i flag, or proxy the requests using the -p option.
Installing WafW00f
tr01ax@htb[/htb]$ wafw00f -v https://www.tesla.com
______
/ \
( Woof! )
\ ____/ )
,, ) (_
.-. - _______ ( |__|
()``; |==|_______) .)|__|
/ (' /|\ ( |__|
( / ) / | \ . |__|
\(_)_)) / | \ |__|
~ WAFW00F : v2.1.0 ~
The Web Application Firewall Fingerprinting Toolkit
[*] Checking https://www.tesla.com
[+] The site https://www.tesla.com is behind CacheWall (Varnish) WAF.
[~] Number of requests: 2
Aquatone is a tool for automatic and visual inspection of websites across many hosts and is convenient for quickly gaining an overview of HTTP-based attack surfaces by scanning a list of configurable ports, visiting the website with a headless Chrome browser, and taking a screenshot. This is helpful, especially when dealing with huge subdomain lists. Aquatone is not installed by default in Parrot Linux, so we will need to install via the following commands.
Installing Aquatone
tr01ax@htb[/htb]$ sudo apt install golang chromium-driver
tr01ax@htb[/htb]$ go get github.com/michenriksen/aquatone
tr01ax@htb[/htb]$ export PATH="$PATH":"$HOME/go/bin"
After this, we need to explore some options:
Aquatone Options
tr01ax@htb[/htb]$ aquatone --help
Usage of aquatone:
-chrome-path string
Full path to the Chrome/Chromium executable to use. By default, aquatone will search for Chrome or Chromium
-debug
Print debugging information
-http-timeout int
Timeout in miliseconds for HTTP requests (default 3000)
-nmap
Parse input as Nmap/Masscan XML
-out string
Directory to write files to (default ".")
-ports string
Ports to scan on hosts. Supported list aliases: small, medium, large, xlarge (default "80,443,8000,8080,8443")
-proxy string
Proxy to use for HTTP requests
-resolution string
screenshot resolution (default "1440,900")
-save-body
Save response bodies to files (default true)
-scan-timeout int
Timeout in miliseconds for port scans (default 100)
-screenshot-timeout int
Timeout in miliseconds for screenshots (default 30000)
-session string
Load Aquatone session file and generate HTML report
-silent
Suppress all output except for errors
-template-path string
Path to HTML template to use for report
-threads int
Number of concurrent threads (default number of logical CPUs)
-version
Print current Aquatone version
Now, it's time to use cat in our subdomain list and pipe the command to aquatone via:
Aquatone Options
tr01ax@htb[/htb]$ cat facebook_aquatone.txt | aquatone -out ./aquatone -screenshot-timeout 1000
aquatone v1.7.0 started at 2021-10-06T10:14:42+01:00
Targets : 30
Threads : 2
Ports : 80, 443, 8000, 8080, 8443
Output dir : aquatone
edge-star-shv-01-cdg2.facebook.com: port 80 open
edge-extern-shv-01-waw1.facebook.com: port 80 open
whatsapp-chatd-edge-shv-01-ams4.facebook.com: port 80 open
edge-secure-shv-01-ham3.facebook.com: port 80 open
sv-se.facebook.com: port 80 open
ko.facebook.com: port 80 open
whatsapp-chatd-msgr-mini-edge-shv-01-lis1.facebook.com: port 80 open
synthetic-e2e-elbprod-sli-shv-01-otp1.facebook.com: port 80 open
edge-star-shv-01-cdg2.facebook.com: port 443 open
edge-extern-shv-01-waw1.facebook.com: port 443 open
whatsapp-chatd-edge-shv-01-ams4.facebook.com: port 443 open
http://edge-star-shv-01-cdg2.facebook.com/: 200 OK
http://edge-extern-shv-01-waw1.facebook.com/: 200 OK
edge-secure-shv-01-ham3.facebook.com: port 443 open
ondemand-edge-shv-01-cph2.facebook.com: port 443 open
sv-se.facebook.com: port 443 open
http://edge-secure-shv-01-ham3.facebook.com/: 200 OK
ko.facebook.com: port 443 open
whatsapp-chatd-msgr-mini-edge-shv-01-lis1.facebook.com: port 443 open
http://sv-se.facebook.com/: 200 OK
http://ko.facebook.com/: 200 OK
synthetic-e2e-elbprod-sli-shv-01-otp1.facebook.com: port 443 open
http://synthetic-e2e-elbprod-sli-shv-01-otp1.facebook.com/: 400 default_vip_400
https://edge-star-shv-01-cdg2.facebook.com/: 200 OK
https://edge-extern-shv-01-waw1.facebook.com/: 200 OK
http://edge-star-shv-01-cdg2.facebook.com/: screenshot timed out
http://edge-extern-shv-01-waw1.facebook.com/: screenshot timed out
https://edge-secure-shv-01-ham3.facebook.com/: 200 OK
https://sv-se.facebook.com/: 200 OK
https://ko.facebook.com/: 200 OK
http://edge-secure-shv-01-ham3.facebook.com/: screenshot timed out
http://sv-se.facebook.com/: screenshot timed out
http://ko.facebook.com/: screenshot timed out
https://synthetic-e2e-elbprod-sli-shv-01-otp1.facebook.com/: 400 default_vip_400
http://synthetic-e2e-elbprod-sli-shv-01-otp1.facebook.com/: screenshot successful
https://edge-star-shv-01-cdg2.facebook.com/: screenshot timed out
https://edge-extern-shv-01-waw1.facebook.com/: screenshot timed out
https://edge-secure-shv-01-ham3.facebook.com/: screenshot timed out
https://sv-se.facebook.com/: screenshot timed out
https://ko.facebook.com/: screenshot timed out
https://synthetic-e2e-elbprod-sli-shv-01-otp1.facebook.com/: screenshot successful
Calculating page structures... done
Clustering similar pages... done
Generating HTML report... done
Writing session file...Time:
- Started at : 2021-10-06T10:14:42+01:00
- Finished at : 2021-10-06T10:15:01+01:00
- Duration : 19s
Requests:
- Successful : 12
- Failed : 5
- 2xx : 10
- 3xx : 0
- 4xx : 2
- 5xx : 0
Screenshots:
- Successful : 2
- Failed : 10
Wrote HTML report to: aquatone/aquatone_report.html
When it finishes, we will have a file called aquatone_report.html where we can see screenshots, technologies identified, server response headers, and HTML.
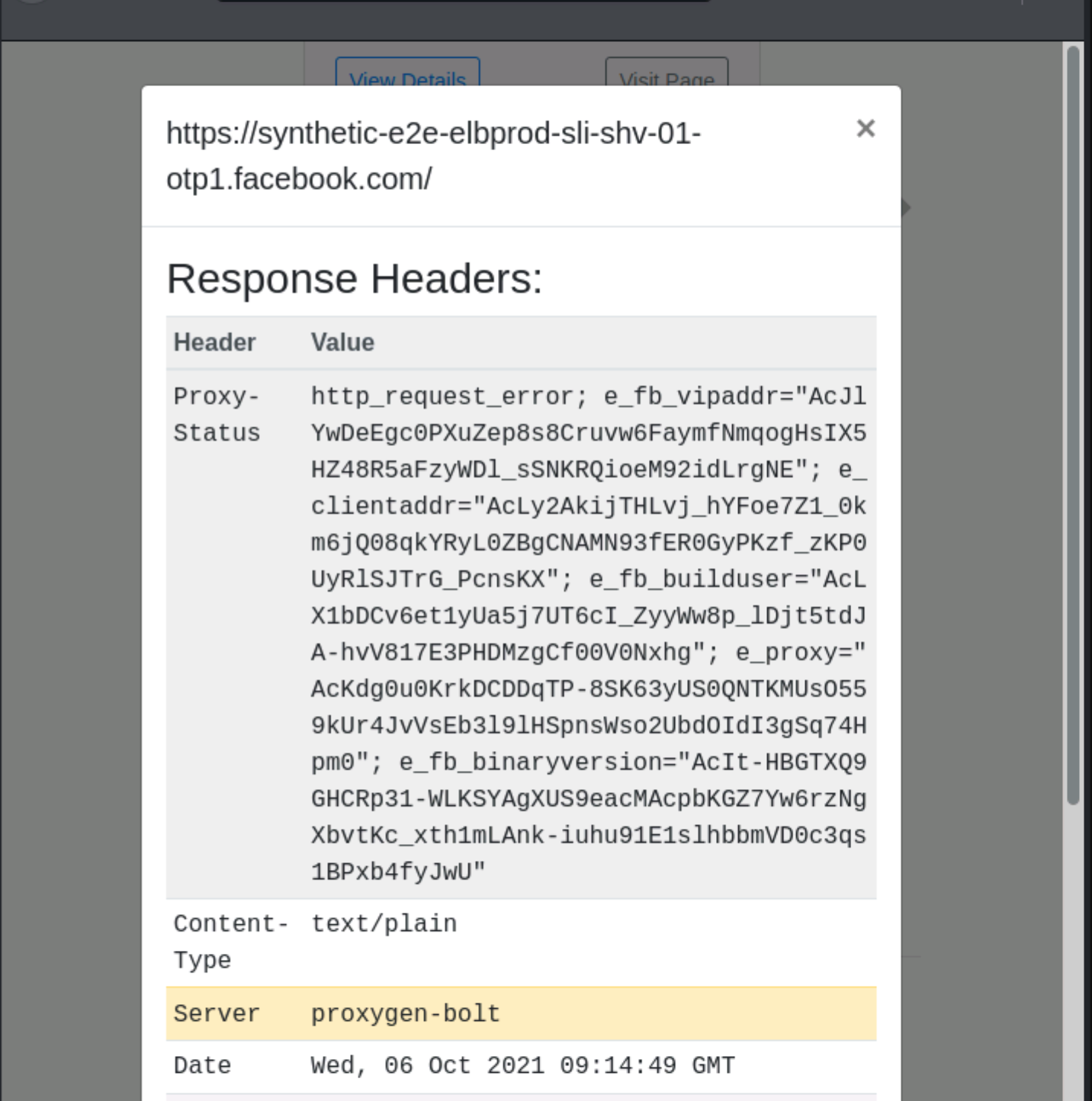
We can perform active subdomain enumeration probing the infrastructure managed by the target organization or the 3rd party DNS servers we have previously identified. In this case, the amount of traffic generated can lead to the detection of our reconnaissance activities.
The zone transfer is how a secondary DNS server receives information from the primary DNS server and updates it. The master-slave approach is used to organize DNS servers within a domain, with the slaves receiving updated DNS information from the master DNS. The master DNS server should be configured to enable zone transfers from secondary (slave) DNS servers, although this might be misconfigured.
For example, we will use the https://hackertarget.com/zone-transfer/ service and the zonetransfer.me domain to have an idea of the information that can be obtained via this technique.
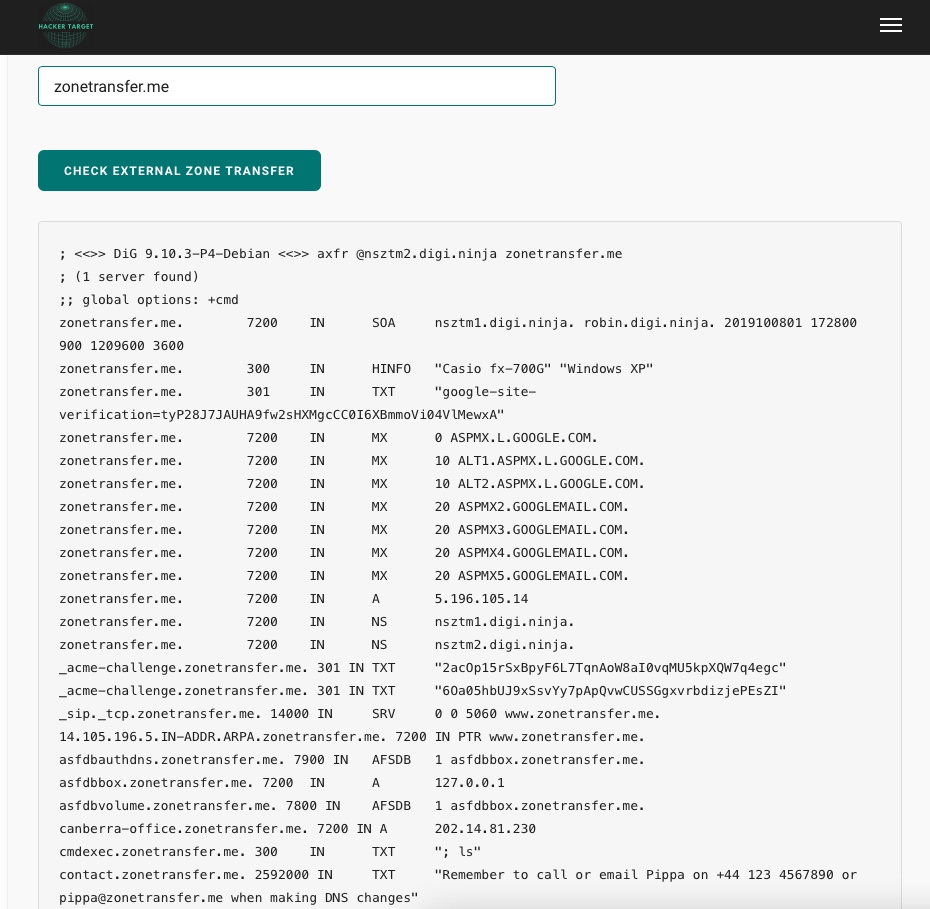
A manual approach will be the following set of commands:
- Identifying Nameservers
tr01ax@htb[/htb]$ nslookup -type=NS zonetransfer.me
Server: 10.100.0.1
Address: 10.100.0.1#53
Non-authoritative answer:
zonetransfer.me nameserver = nsztm2.digi.ninja.
zonetransfer.me nameserver = nsztm1.digi.ninja.
- Perform the Zone transfer using
-type=anyand-query=AXFRparameters
- Testing for ANY and AXFR Zone Transfer
tr01ax@htb[/htb]$ nslookup -type=any -query=AXFR zonetransfer.me nsztm1.digi.ninja
Server: nsztm1.digi.ninja
Address: 81.4.108.41#53
zonetransfer.me
origin = nsztm1.digi.ninja
mail addr = robin.digi.ninja
serial = 2019100801
refresh = 172800
retry = 900
expire = 1209600
minimum = 3600
zonetransfer.me hinfo = "Casio fx-700G" "Windows XP"
zonetransfer.me text = "google-site-verification=tyP28J7JAUHA9fw2sHXMgcCC0I6XBmmoVi04VlMewxA"
zonetransfer.me mail exchanger = 0 ASPMX.L.GOOGLE.COM.
zonetransfer.me mail exchanger = 10 ALT1.ASPMX.L.GOOGLE.COM.
zonetransfer.me mail exchanger = 10 ALT2.ASPMX.L.GOOGLE.COM.
zonetransfer.me mail exchanger = 20 ASPMX2.GOOGLEMAIL.COM.
zonetransfer.me mail exchanger = 20 ASPMX3.GOOGLEMAIL.COM.
zonetransfer.me mail exchanger = 20 ASPMX4.GOOGLEMAIL.COM.
zonetransfer.me mail exchanger = 20 ASPMX5.GOOGLEMAIL.COM.
Name: zonetransfer.me
Address: 5.196.105.14
zonetransfer.me nameserver = nsztm1.digi.ninja.
zonetransfer.me nameserver = nsztm2.digi.ninja.
_acme-challenge.zonetransfer.me text = "6Oa05hbUJ9xSsvYy7pApQvwCUSSGgxvrbdizjePEsZI"
_sip._tcp.zonetransfer.me service = 0 0 5060 www.zonetransfer.me.
14.105.196.5.IN-ADDR.ARPA.zonetransfer.me name = www.zonetransfer.me.
asfdbauthdns.zonetransfer.me afsdb = 1 asfdbbox.zonetransfer.me.
Name: asfdbbox.zonetransfer.me
Address: 127.0.0.1
asfdbvolume.zonetransfer.me afsdb = 1 asfdbbox.zonetransfer.me.
Name: canberra-office.zonetransfer.me
Address: 202.14.81.230
cmdexec.zonetransfer.me text = "; ls"
contact.zonetransfer.me text = "Remember to call or email Pippa on +44 123 4567890 or [email protected] when making DNS changes"
Name: dc-office.zonetransfer.me
Address: 143.228.181.132
Name: deadbeef.zonetransfer.me
Address: dead:beaf::
dr.zonetransfer.me loc = 53 20 56.558 N 1 38 33.526 W 0.00m 1m 10000m 10m
DZC.zonetransfer.me text = "AbCdEfG"
email.zonetransfer.me naptr = 1 1 "P" "E2U+email" "" email.zonetransfer.me.zonetransfer.me.
Name: email.zonetransfer.me
Address: 74.125.206.26
Hello.zonetransfer.me text = "Hi to Josh and all his class"
Name: home.zonetransfer.me
Address: 127.0.0.1
Info.zonetransfer.me text = "ZoneTransfer.me service provided by Robin Wood - [email protected]. See http://digi.ninja/projects/zonetransferme.php for more information."
internal.zonetransfer.me nameserver = intns1.zonetransfer.me.
internal.zonetransfer.me nameserver = intns2.zonetransfer.me.
Name: intns1.zonetransfer.me
Address: 81.4.108.41
Name: intns2.zonetransfer.me
Address: 167.88.42.94
Name: office.zonetransfer.me
Address: 4.23.39.254
Name: ipv6actnow.org.zonetransfer.me
Address: 2001:67c:2e8:11::c100:1332
Name: owa.zonetransfer.me
Address: 207.46.197.32
robinwood.zonetransfer.me text = "Robin Wood"
rp.zonetransfer.me rp = robin.zonetransfer.me. robinwood.zonetransfer.me.
sip.zonetransfer.me naptr = 2 3 "P" "E2U+sip" "!^.*$!sip:[email protected]!" .
sqli.zonetransfer.me text = "' or 1=1 --"
sshock.zonetransfer.me text = "() { :]}; echo ShellShocked"
staging.zonetransfer.me canonical name = www.sydneyoperahouse.com.
Name: alltcpportsopen.firewall.test.zonetransfer.me
Address: 127.0.0.1
testing.zonetransfer.me canonical name = www.zonetransfer.me.
Name: vpn.zonetransfer.me
Address: 174.36.59.154
Name: www.zonetransfer.me
Address: 5.196.105.14
xss.zonetransfer.me text = "'><script>alert('Boo')</script>"
zonetransfer.me
origin = nsztm1.digi.ninja
mail addr = robin.digi.ninja
serial = 2019100801
refresh = 172800
retry = 900
expire = 1209600
minimum = 3600
If we manage to perform a successful zone transfer for a domain, there is no need to continue enumerating this particular domain as this will extract all the available information.
Gobuster is a tool that we can use to perform subdomain enumeration. It is especially interesting for us the patterns options as we have learned some naming conventions from the passive information gathering we can use to discover new subdomains following the same pattern.
We can use a wordlist from Seclists repository along with gobuster if we are looking for words in patterns instead of numbers. Remember that during our passive subdomain enumeration activities, we found a pattern lert-api-shv-{NUMBER}-sin6.facebook.com. We can use this pattern to discover additional subdomains. The first step will be to create a patterns.txt file with the patterns previously discovered, for example:
GoBuster - patterns.txt
lert-api-shv-{GOBUSTER}-sin6
atlas-pp-shv-{GOBUSTER}-sin6
The next step will be to launch gobuster using the dns module, specifying the following options:
dns: Launch the DNS module-q: Don't print the banner and other noise.-r: Use custom DNS server-d: A target domain name-p: Path to the patterns file-w: Path to the wordlist-o: Output file
In our case, this will be the command.
Gobuster - DNS
tr01ax@htb[/htb]$ export TARGET="facebook.com"
tr01ax@htb[/htb]$ export NS="d.ns.facebook.com"
tr01ax@htb[/htb]$ export WORDLIST="numbers.txt"
tr01ax@htb[/htb]$ gobuster dns -q -r "${NS}" -d "${TARGET}" -w "${WORDLIST}" -p ./patterns.txt -o "gobuster_${TARGET}.txt"
Found: lert-api-shv-01-sin6.facebook.com
Found: atlas-pp-shv-01-sin6.facebook.com
Found: atlas-pp-shv-02-sin6.facebook.com
Found: atlas-pp-shv-03-sin6.facebook.com
Found: lert-api-shv-03-sin6.facebook.com
Found: lert-api-shv-02-sin6.facebook.com
Found: lert-api-shv-04-sin6.facebook.com
Found: atlas-pp-shv-04-sin6.facebook.com
We can now see a list of subdomains appearing while Gobuster is performing the enumeration checks.
#enumeration #footprinting #hacking #vhost
A virtual host (vHost) is a feature that allows several websites to be hosted on a single server. This is an excellent solution if you have many websites and don't want to go through the time-consuming (and expensive) process of setting up a new web server for each one. Imagine having to set up a different webserver for a mobile and desktop version of the same page. There are two ways to configure virtual hosts:
IP-based virtual hostingName-based virtual hosting
For this type, a host can have multiple network interfaces. Multiple IP addresses, or interface aliases, can be configured on each network interface of a host. The servers or virtual servers running on the host can bind to one or more IP addresses. This means that different servers can be addressed under different IP addresses on this host. From the client's point of view, the servers are independent of each other.
The distinction for which domain the service was requested is made at the application level. For example, several domain names, such as admin.inlanefreight.htb and backup.inlanefreight.htb, can refer to the same IP. Internally on the server, these are separated and distinguished using different folders. Using this example, on a Linux server, the vHost admin.inlanefreight.htb could point to the folder /var/www/admin. For backup.inlanefreight.htb the folder name would then be adapted and could look something like /var/www/backup.
During our subdomain discovering activities, we have seen some subdomains having the same IP address that can either be virtual hosts or, in some cases, different servers sitting behind a proxy.
Imagine we have identified a web server at 192.168.10.10 during an internal pentest, and it shows a default website using the following command. Are there any virtual hosts present?
Name-based Virtual Hosting
tr01ax@htb[/htb]$ curl -s http://192.168.10.10
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
Let's make a cURL request sending a domain previously identified during the information gathering in the HOST header. We can do that like so:
Name-based Virtual Hosting
tr01ax@htb[/htb]$ curl -s http://192.168.10.10 -H "Host: randomtarget.com"
<html>
<head>
<title>Welcome to randomtarget.com!</title>
</head>
<body>
<h1>Success! The randomtarget.com server block is working!</h1>
</body>
</html>
Now we can automate this by using a dictionary file of possible vhost names (such as /opt/useful/SecLists/Discovery/DNS/namelist.txt on the Pwnbox) and examining the Content-Length header to look for any differences.
vHosts List
app
blog
dev-admin
forum
help
m
my
shop
some
store
support
www
vHost Fuzzing
tr01ax@htb[/htb]$ cat ./vhosts | while read vhost;do echo "\n********\nFUZZING: ${vhost}\n********";curl -s -I http://192.168.10.10 -H "HOST: ${vhost}.randomtarget.com" | grep "Content-Length: ";done
********
FUZZING: app
********
Content-Length: 612
********
FUZZING: blog
********
Content-Length: 612
********
FUZZING: dev-admin
********
Content-Length: 120
********
FUZZING: forum
********
Content-Length: 612
********
FUZZING: help
********
Content-Length: 612
********
FUZZING: m
********
Content-Length: 612
********
FUZZING: my
********
Content-Length: 612
********
FUZZING: shop
********
Content-Length: 612
********
FUZZING: some
********
Content-Length: 195
********
FUZZING: store
********
Content-Length: 612
********
FUZZING: support
********
Content-Length: 612
********
FUZZING: www
********
Content-Length: 185
We have successfully identified a virtual host called dev-admin, which we can access using a cURL request.
vHost Fuzzing
tr01ax@htb[/htb]$ curl -s http://192.168.10.10 -H "Host: dev-admin.randomtarget.com"
<!DOCTYPE html>
<html>
<body>
<h1>Randomtarget.com Admin Website</h1>
<p>You shouldn't be here!</p>
</body>
</html>
We can use this manual approach for a small list of virtual hosts, but it will not be feasible if we have an extensive list. Using ffuf, we can speed up the process and filter based on parameters present in the response. Let's replicate the same process we did with ffuf, but first, let's look at some of its options.
vHost Fuzzing
MATCHER OPTIONS:
-mc Match HTTP status codes, or "all" for everything. (default: 200,204,301,302,307,401,403,405)
-ml Match amount of lines in response
-mr Match regexp
-ms Match HTTP response size
-mw Match amount of words in response
FILTER OPTIONS:
-fc Filter HTTP status codes from response. Comma separated list of codes and ranges
-fl Filter by amount of lines in response. Comma separated list of line counts and ranges
-fr Filter regexp
-fs Filter HTTP response size. Comma separated list of sizes and ranges
-fw Filter by amount of words in response. Comma separated list of word counts and ranges
We can match or filter responses based on different options. The web server responds with a default and static website every time we issue an invalid virtual host in the HOST header. We can use the filter by size -fs option to discard the default response as it will always have the same size.
vHost Fuzzing
tr01ax@htb[/htb]$ ffuf -w ./vhosts -u http://192.168.10.10 -H "HOST: FUZZ.randomtarget.com" -fs 612
/'___\ /'___\ /'___\
/\ \__/ /\ \__/ __ __ /\ \__/
\ \ ,__\\ \ ,__\/\ \/\ \ \ \ ,__\
\ \ \_/ \ \ \_/\ \ \_\ \ \ \ \_/
\ \_\ \ \_\ \ \____/ \ \_\
\/_/ \/_/ \/___/ \/_/
v1.1.0-git
________________________________________________
:: Method : GET
:: URL : http://192.168.10.10
:: Wordlist : FUZZ: ./vhosts
:: Header : Host: FUZZ.randomtarget.com
:: Follow redirects : false
:: Calibration : false
:: Timeout : 10
:: Threads : 40
:: Matcher : Response status: 200,204,301,302,307,401,403,405
:: Filter : Response size: 612
________________________________________________
dev-admin [Status: 200, Size: 120, Words: 7, Lines: 12]
www [Status: 200, Size: 185, Words: 41, Lines: 9]
some [Status: 200, Size: 195, Words: 41, Lines: 9]
:: Progress: [12/12] :: Job [1/1] :: 0 req/sec :: Duration: [0:00:00] :: Errors: 0 ::
where:
-w: Path to our wordlist-u: URL we want to fuzz-H "HOST: FUZZ.randomtarget.com": This is theHOSTHeader, and the wordFUZZwill be used as the fuzzing point.-fs 612: Filter responses with a size of 612, default response size in this case.#enumeration #footprinting #hacking #crawling source
Crawling a website is the systematic or automatic process of exploring a website to list all of the resources encountered along the way. It shows us the structure of the website we are auditing and an overview of the attack surface we will be testing in the future. We use the crawling process to find as many pages and subdirectories belonging to a website as possible.
Zed Attack Proxy (ZAP) is an open-source web proxy that belongs to the Open Web Application Security Project (OWASP). It allows us to perform manual and automated security testing on web applications. Using it as a proxy server will enable us to intercept and manipulate all the traffic that passes through it.
We can use the spidering functionality following the next steps. Open ZAP, and on the top-right corner, open the browser.
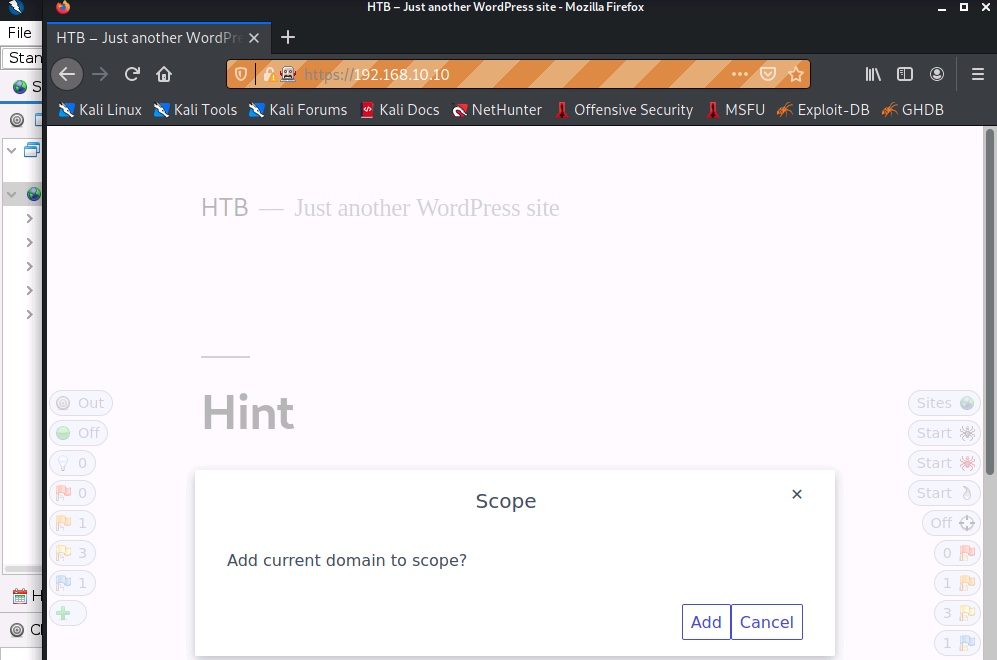
Write the website in the address bar and add it to the scope using the first entry in the left menu.
Head back to the ZAP Window, right-click on the target website, click on the Attack menu, and then the Spider submenu.
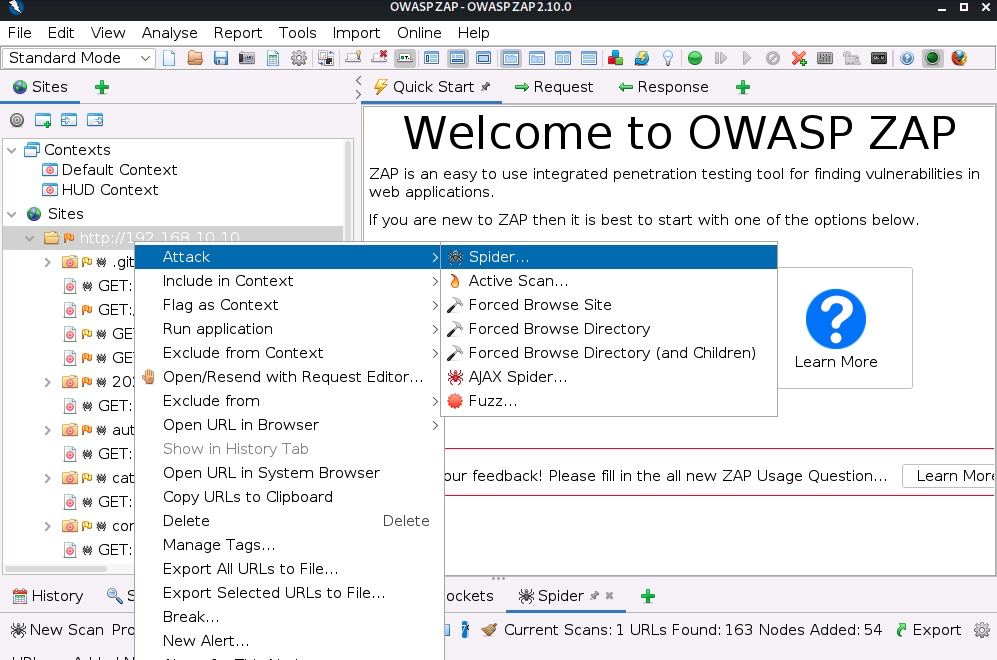
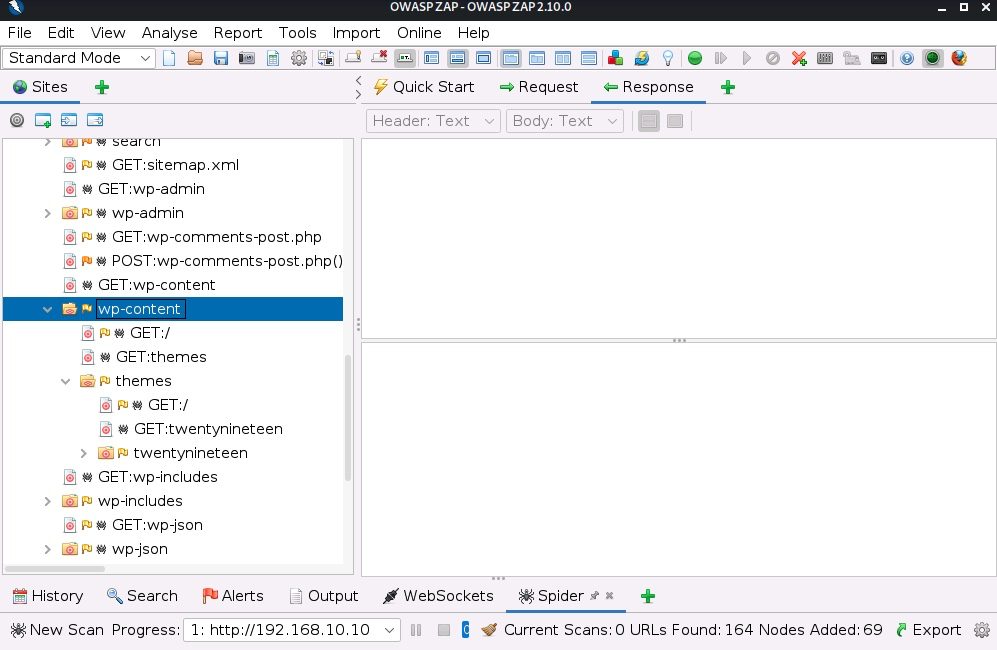
Once the process has finished, we can see the resources discovered by the spidering process.
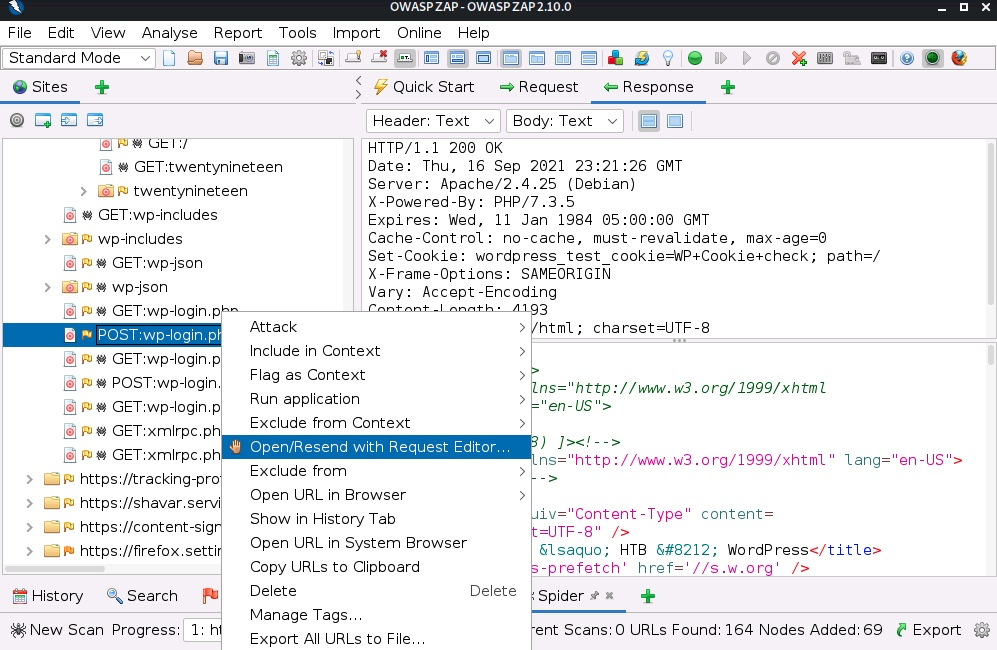
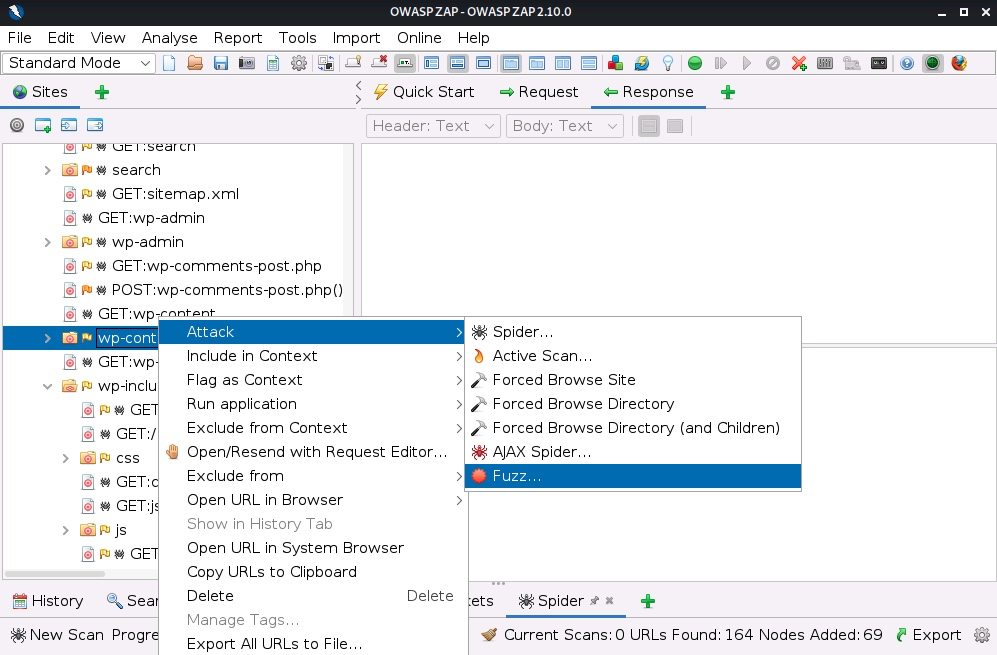
One handy feature of ZAP is the built-in Fuzzer and Manual Request Editor. We can send any request to them to alter it manually or fuzz it with a list of payloads by right-clicking on the request and using the menu "Open/Resend with Request Editor..." or the "Fuzz..." submenu under the Attack menu.
ZAP has excellent documentation that can help you to get used to it quickly. For a more detailed study on ZAP, check out the Using Web Proxies module on HTB Academy.
ZAP spidering module only enumerates the resources it finds in links and forms, but it can miss important information such as hidden folders or backup files.
We can use ffuf to discover files and folders that we cannot spot by simply browsing the website. All we need to do is launch ffuf with a list of folders names and instruct it to look recursively through them.
tr01ax@htb[/htb]$ ffuf -recursion -recursion-depth 1 -u http://192.168.10.10/FUZZ -w /opt/useful/SecLists/Discovery/Web-Content/raft-small-directories-lowercase.txt
/'___\ /'___\ /'___\
/\ \__/ /\ \__/ __ __ /\ \__/
\ \ ,__\\ \ ,__\/\ \/\ \ \ \ ,__\
\ \ \_/ \ \ \_/\ \ \_\ \ \ \ \_/
\ \_\ \ \_\ \ \____/ \ \_\
\/_/ \/_/ \/___/ \/_/
v1.1.0-git
________________________________________________
:: Method : GET
:: URL : http://192.168.10.10/FUZZ
:: Wordlist : FUZZ: /opt/useful/SecLists/Discovery/Web-Content/raft-small-directories-lowercase.txt
:: Follow redirects : false
:: Calibration : false
:: Timeout : 10
:: Threads : 40
:: Matcher : Response status: 200,204,301,302,307,401,403,405
________________________________________________
wp-admin [Status: 301, Size: 317, Words: 20, Lines: 10]
[INFO] Adding a new job to the queue: http://192.168.10.10/wp-admin/FUZZ
wp-includes [Status: 301, Size: 320, Words: 20, Lines: 10]
[INFO] Adding a new job to the queue: http://192.168.10.10/wp-includes/FUZZ
wp-content [Status: 301, Size: 319, Words: 20, Lines: 10]
[INFO] Adding a new job to the queue: http://192.168.10.10/wp-content/FUZZ
admin [Status: 302, Size: 0, Words: 1, Lines: 1]
login [Status: 302, Size: 0, Words: 1, Lines: 1]
feed [Status: 301, Size: 0, Words: 1, Lines: 1]
[INFO] Adding a new job to the queue: http://192.168.10.10/feed/FUZZ
...
-recursion: Activates the recursive scan.-recursion-depth: Specifies the maximum depth to scan.-u: Our target URL, andFUZZwill be the injection point.-w: Path to our wordlist.
We can see in the image how ffuf creates new jobs for every detected folder. This task can be very resource-intensive for the target server. If the website responds slower than usual, we can lower the rate of requests using the -rate parameter.
The module Attacking Web Applications with Ffuf goes much deeper into ffuf usage and showcases many of the techniques taught in this module.
It is typical for the webserver and the web application to handle the files it needs to function. However, it is common to find backup or unreferenced files that can have important information or credentials. Backup or unreferenced files can be generated by creating snapshots, different versions of a file, or from a text editor without the web developer's knowledge. There are some lists of common extensions we can find in the raft-[ small | medium | large ]-extensions.txt files from SecLists.
We will combine some of the folders we have found before, a list of common extensions, and some words extracted from the website to see if we can find something that should not be there. The first step will be to create a file with the following folder names and save it as folders.txt.
wp-admin
wp-content
wp-includes
Next, we will extract some keywords from the website using CeWL. We will instruct the tool to extract words with a minimum length of 5 characters -m5, convert them to lowercase --lowercase and save them into a file called wordlist.txt -w <FILE>:
tr01ax@htb[/htb]$ cewl -m5 --lowercase -w wordlist.txt http://192.168.10.10
The next step will be to combine everything in ffuf to see if we can find some juicy information. For this, we will use the following parameters in ffuf:
-w: We separate the wordlists by coma and add an alias to them to inject them as fuzzing points later-u: Our target URL with the fuzzing points.
tr01ax@htb[/htb]$ ffuf -w ./folders.txt:FOLDERS,./wordlist.txt:WORDLIST,./extensions.txt:EXTENSIONS -u http://192.168.10.10/FOLDERS/WORDLISTEXTENSIONS
/'___\ /'___\ /'___\
/\ \__/ /\ \__/ __ __ /\ \__/
\ \ ,__\\ \ ,__\/\ \/\ \ \ \ ,__\
\ \ \_/ \ \ \_/\ \ \_\ \ \ \ \_/
\ \_\ \ \_\ \ \____/ \ \_\
\/_/ \/_/ \/___/ \/_/
v1.1.0-git
________________________________________________
:: Method : GET
:: URL : http://192.168.10.10/FOLDERS/WORDLISTEXTENSIONS
:: Wordlist : FOLDERS: ./folders.txt
:: Wordlist : WORDLIST: ./wordlist.txt
:: Wordlist : EXTENSIONS: ./extensions.txt
:: Follow redirects : false
:: Calibration : false
:: Timeout : 10
:: Threads : 40
:: Matcher : Response status: 200,204,301,302,307,401,403,405
________________________________________________
[Status: 200, Size: 8, Words: 1, Lines: 2]
* EXTENSIONS: ~
* FOLDERS: wp-content
* WORDLIST: secret
[Status: 200, Size: 0, Words: 1, Lines: 1]
* FOLDERS: wp-includes
* WORDLIST: comment
* EXTENSIONS: .php
[Status: 302, Size: 0, Words: 1, Lines: 1]
* FOLDERS: wp-admin
* WORDLIST: comment
* EXTENSIONS: .php
...
tr01ax@htb[/htb]$ curl http://192.168.10.10/wp-content/secret~
Oooops!
Following this approach, we have successfully found a secret file.#dns #enumeration #hacking #subdomain
get subdomains via crt.sh site and a curl command
export TARGET="facebook.com"
curl -s "https://crt.sh/?q=${TARGET}&output=json" | jq -r '.[] | "\(.name_value)\n\(.common_name)"' | sort -u > "${TARGET}_crt.sh.txt"
what does it do?:
curl -s |
Issue the request with minimal output. |
https://crt.sh/?q=<DOMAIN>&output=json |
Ask for the json output. |
jq -r '.[]' "\(.name_value)\n\(.common_name)"' |
Process the json output and print certificate's name value and common name one per line. |
sort -u |
Sort alphabetically the output provided and removes duplicates. |
Same thing can be done with openssl:
export TARGET="facebook.com"
export PORT="443"
openssl s_client -ign_eof 2>/dev/null <<<$'HEAD / HTTP/1.0\r\n\r' -connect "${TARGET}:${PORT}" | openssl x509 -noout -text -in - | grep 'DNS' | sed -e 's|DNS:|\n|g' -e 's|^\*.*||g' | tr -d ',' | sort -u
TheHarvester is a simple-to-use yet powerful and effective tool for early-stage penetration testing and red team engagements. We can use it to gather information to help identify a company's attack surface. The tool collects emails, names, subdomains, IP addresses, and URLs from various public data sources for passive information gathering.
For now, we will use the following modules:
| Baidu | Baidu search engine. |
Bufferoverun |
Uses data from Rapid7's Project Sonar - www.rapid7.com/research/project-sonar/ |
| Crtsh | Comodo Certificate search. |
| Hackertarget | Online vulnerability scanners and network intelligence to help organizations. |
Otx |
AlienVault Open Threat Exchange - https://otx.alienvault.com |
| Rapiddns | DNS query tool, which makes querying subdomains or sites using the same IP easy. |
| Sublist3r | Fast subdomains enumeration tool for penetration testers |
| Threatcrowd | Open source threat intelligence. |
| Threatminer | Data mining for threat intelligence. |
Trello |
Search Trello boards (Uses Google search) |
| Urlscan | A sandbox for the web that is a URL and website scanner. |
Vhost |
Bing virtual hosts search. |
| Virustotal | Domain search. |
| Zoomeye | A Chinese version of Shodan. |
To automate this, we will create a file called sources.txt with the following contents.
TheHarvester
tr01ax@htb[/htb]$ cat sources.txt
baidu
bufferoverun
crtsh
hackertarget
otx
projecdiscovery
rapiddns
sublist3r
threatcrowd
trello
urlscan
vhost
virustotal
zoomeye
then we can execute:
export TARGET="facebook.com"
cat sources.txt | while read source; do theHarvester -d "${TARGET}" -b $source -f "${source}_${TARGET}";done
When the process finishes, we can extract all the subdomains found and sort them via the following command:
tr01ax@htb[/htb]$ cat *.json | jq -r '.hosts[]' 2>/dev/null | cut -d':' -f 1 | sort -u > "${TARGET}_theHarvester.txt"
Now we can merge all the passive reconnaissance files via:
tr01ax@htb[/htb]$ cat facebook.com_*.txt | sort -u > facebook.com_subdomains_passive.txt
tr01ax@htb[/htb]$ cat facebook.com_subdomains_passive.txt | wc -l
11947
So far, we have managed to find 11947 subdomains merging the passive reconnaissance result files. It is important to note here that there are many more methods to find subdomains passively. More possibilities are shown, for example, in the OSINT: Corporate Recon module.