Client spews errors in JupyterLab during compute #5472
Description
In recent versions of distributed, during a compute, tons of errors sometimes start spewing out in JupyterLab like this:
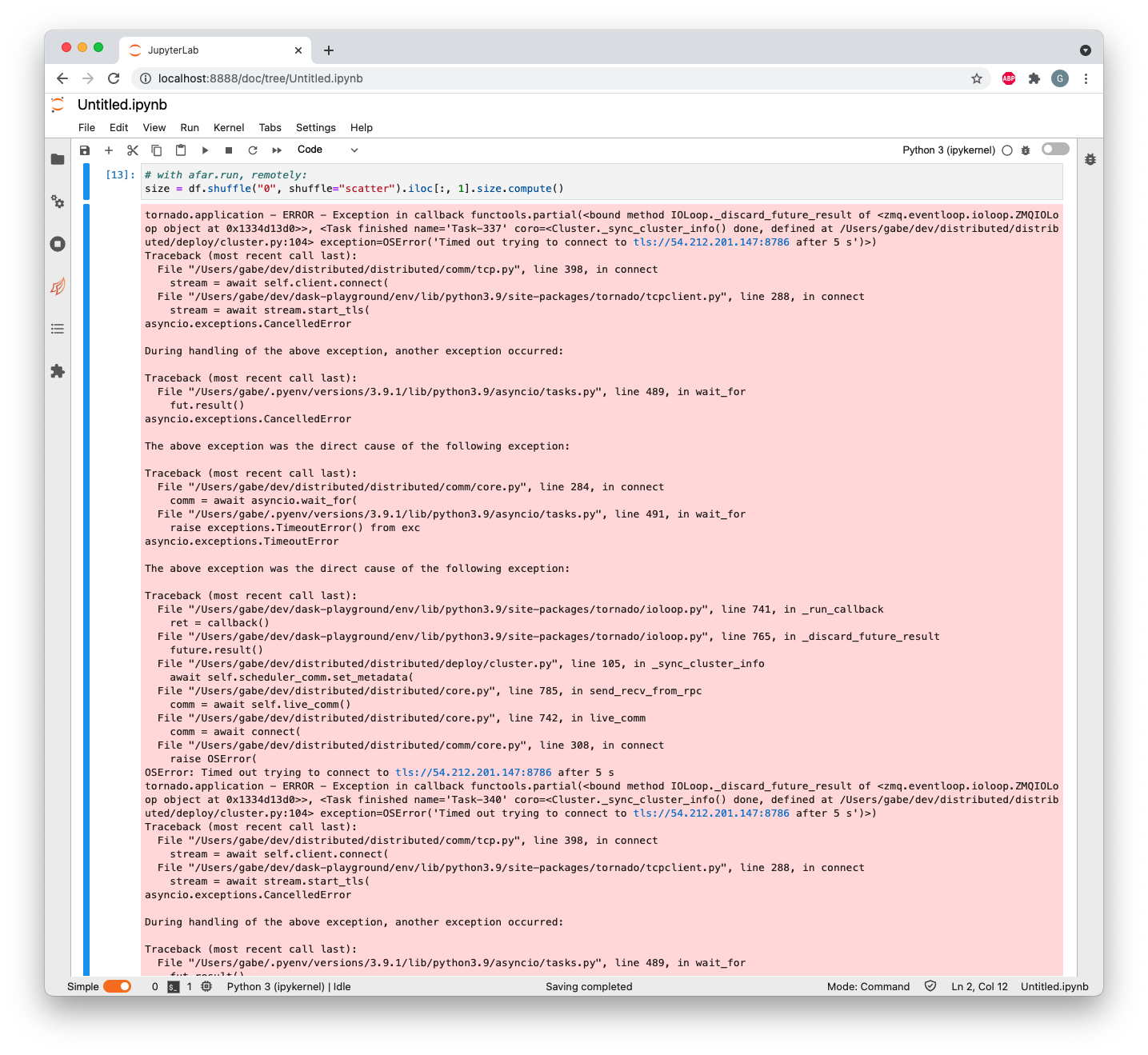
I've heard other people complain about this too.
For searchability, here are some of the logs:
Details
tornado.application - ERROR - Exception in callback functools.partial(<bound method IOLoop._discard_future_result of <zmq.eventloop.ioloop.ZMQIOLoop object at 0x1334d13d0>>, <Task finished name='Task-337' coro=<Cluster._sync_cluster_info() done, defined at /Users/gabe/dev/distributed/distributed/deploy/cluster.py:104> exception=OSError('Timed out trying to connect to tls://54.212.201.147:8786 after 5 s')>)
Traceback (most recent call last):
File "/Users/gabe/dev/distributed/distributed/comm/tcp.py", line 398, in connect
stream = await self.client.connect(
File "/Users/gabe/dev/dask-playground/env/lib/python3.9/site-packages/tornado/tcpclient.py", line 288, in connect
stream = await stream.start_tls(
asyncio.exceptions.CancelledError
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/Users/gabe/.pyenv/versions/3.9.1/lib/python3.9/asyncio/tasks.py", line 489, in wait_for
fut.result()
asyncio.exceptions.CancelledError
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/Users/gabe/dev/distributed/distributed/comm/core.py", line 284, in connect
comm = await asyncio.wait_for(
File "/Users/gabe/.pyenv/versions/3.9.1/lib/python3.9/asyncio/tasks.py", line 491, in wait_for
raise exceptions.TimeoutError() from exc
asyncio.exceptions.TimeoutError
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/Users/gabe/dev/dask-playground/env/lib/python3.9/site-packages/tornado/ioloop.py", line 741, in _run_callback
ret = callback()
File "/Users/gabe/dev/dask-playground/env/lib/python3.9/site-packages/tornado/ioloop.py", line 765, in _discard_future_result
future.result()
File "/Users/gabe/dev/distributed/distributed/deploy/cluster.py", line 105, in _sync_cluster_info
await self.scheduler_comm.set_metadata(
File "/Users/gabe/dev/distributed/distributed/core.py", line 785, in send_recv_from_rpc
comm = await self.live_comm()
File "/Users/gabe/dev/distributed/distributed/core.py", line 742, in live_comm
comm = await connect(
File "/Users/gabe/dev/distributed/distributed/comm/core.py", line 308, in connect
raise OSError(
OSError: Timed out trying to connect to tls://54.212.201.147:8786 after 5 s
tornado.application - ERROR - Exception in callback functools.partial(<bound method IOLoop._discard_future_result of <zmq.eventloop.ioloop.ZMQIOLoop object at 0x1334d13d0>>, <Task finished name='Task-340' coro=<Cluster._sync_cluster_info() done, defined at /Users/gabe/dev/distributed/distributed/deploy/cluster.py:104> exception=OSError('Timed out trying to connect to tls://54.212.201.147:8786 after 5 s')>)
Traceback (most recent call last):
File "/Users/gabe/dev/distributed/distributed/comm/tcp.py", line 398, in connect
stream = await self.client.connect(
File "/Users/gabe/dev/dask-playground/env/lib/python3.9/site-packages/tornado/tcpclient.py", line 288, in connect
stream = await stream.start_tls(
asyncio.exceptions.CancelledError
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/Users/gabe/.pyenv/versions/3.9.1/lib/python3.9/asyncio/tasks.py", line 489, in wait_for
fut.result()
asyncio.exceptions.CancelledError
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/Users/gabe/dev/distributed/distributed/comm/core.py", line 284, in connect
comm = await asyncio.wait_for(
File "/Users/gabe/.pyenv/versions/3.9.1/lib/python3.9/asyncio/tasks.py", line 491, in wait_for
raise exceptions.TimeoutError() from exc
asyncio.exceptions.TimeoutError
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/Users/gabe/dev/dask-playground/env/lib/python3.9/site-packages/tornado/ioloop.py", line 741, in _run_callback
ret = callback()
File "/Users/gabe/dev/dask-playground/env/lib/python3.9/site-packages/tornado/ioloop.py", line 765, in _discard_future_result
future.result()
File "/Users/gabe/dev/distributed/distributed/deploy/cluster.py", line 105, in _sync_cluster_info
await self.scheduler_comm.set_metadata(
File "/Users/gabe/dev/distributed/distributed/core.py", line 785, in send_recv_from_rpc
comm = await self.live_comm()
File "/Users/gabe/dev/distributed/distributed/core.py", line 742, in live_comm
comm = await connect(
File "/Users/gabe/dev/distributed/distributed/comm/core.py", line 308, in connect
raise OSError(
OSError: Timed out trying to connect to tls://54.212.201.147:8786 after 5 s
tornado.application - ERROR - Exception in callback functools.partial(<bound method IOLoop._discard_future_result of <zmq.eventloop.ioloop.ZMQIOLoop object at 0x1334d13d0>>, <Task finished name='Task-349' coro=<Cluster._sync_cluster_info() done, defined at /Users/gabe/dev/distributed/distributed/deploy/cluster.py:104> exception=OSError('Timed out trying to connect to tls://54.212.201.147:8786 after 5 s')>)
Traceback (most recent call last):
File "/Users/gabe/dev/distributed/distributed/comm/tcp.py", line 398, in connect
stream = await self.client.connect(
File "/Users/gabe/dev/dask-playground/env/lib/python3.9/site-packages/tornado/tcpclient.py", line 288, in connect
stream = await stream.start_tls(
asyncio.exceptions.CancelledError
From reading the traceback, it appears to be unhandled exceptions in the new cluster<->scheduler synced dict from #5033. I'd guess that when the scheduler gets overwhelmed from any of the myriad of things that can block its event loop, something breaks. I'm not sure why it stays broken and the comm doesn't reconnect, but after one failure it seems you'll get this message once per second.
- There should be error handling in the cluster info syncing; at a minimum, any error here should be handled and logged, but not allowed to propagate up
- Why is this error happening, and why does it not seem to recover?
Metadata
Metadata
Assignees
Labels
No labels