|
1 | | -<p align="center"> |
2 | | - <a href="https://cueobserve.cuebook.ai" target="_blank"> |
3 | | - <img alt="CueObserve Logo" width="300" src="docs/images/cueObserve.png"> |
4 | | - </a> |
5 | | -</p> |
6 | | -<p align="center"> |
7 | | - <a href="https://codeclimate.com/github/cuebook/CueObserve/maintainability"><img src="https://api.codeclimate.com/v1/badges/a70e071b59d5dbc38846/maintainability" /></a> |
8 | | - <a href="https://codeclimate.com/github/cuebook/CueObserve/test_coverage"><img src="https://api.codeclimate.com/v1/badges/a70e071b59d5dbc38846/test_coverage" /></a> |
9 | | - <a href="https://github.com/cuebook/cueobserve/actions/workflows/pr_checks.yml"> |
10 | | - <img src="https://github.com/cuebook/cueobserve/actions/workflows/pr_checks.yml/badge.svg" alt="Test Coverage"> |
11 | | - </a> |
12 | | - <a href="https://github.com/cuebook/cueobserve/blob/main/LICENSE.md"> |
13 | | - <img src="https://img.shields.io/github/license/cuebook/cueobserve" alt="License"> |
14 | | - </a> |
15 | | -</p> |
16 | | -<br> |
| 1 | +# Overview |
| 2 | + |
| 3 | +[](https://cueobserve.cuebook.ai) |
| 4 | + |
| 5 | +[](https://codeclimate.com/github/cuebook/CueObserve/maintainability) [](https://codeclimate.com/github/cuebook/CueObserve/test\_coverage) [ ](https://github.com/cuebook/cueobserve/actions/workflows/pr\_checks.yml)[](https://github.com/cuebook/cueobserve/blob/main/LICENSE.md) |
| 6 | + |
| 7 | + |
17 | 8 |
|
18 | 9 | CueObserve helps you monitor your metrics. Know when, where, and why a metric isn't right. |
19 | 10 |
|
20 | 11 | CueObserve uses **timeseries Anomaly detection** to find **where** and **when** a metric isn't right. It then offers **one-click Root Cause analysis** so that you know **why** a metric isn't right. |
21 | 12 |
|
22 | 13 | CueObserve works with data in your SQL data warehouses and databases. It currently supports Snowflake, BigQuery, Redshift, Druid, Postgres, MySQL, SQL Server and ClickHouse. |
23 | 14 |
|
| 15 | +.png>) .png>) |
24 | 16 |
|
25 | | - |
26 | | - |
| 17 | +### Getting Started |
27 | 18 |
|
28 | | - |
29 | | -## Getting Started |
30 | 19 | Install via Docker |
31 | 20 |
|
32 | 21 | ``` |
33 | 22 | wget https://raw.githubusercontent.com/cuebook/CueObserve/latest_release/docker-compose.yml -q -O cueobserve-docker-compose.yml |
34 | 23 | docker-compose -f cueobserve-docker-compose.yml up -d |
35 | 24 | ``` |
36 | | -Now visit [http://localhost:3000](http://localhost:3000) in your browser. |
37 | 25 |
|
38 | | -## Demo Video |
39 | | -<a href="http://www.youtube.com/watch?feature=player_embedded&v=VZvgNa65GQU" target="_blank"> |
40 | | - <img src="http://img.youtube.com/vi/VZvgNa65GQU/hqdefault.jpg" alt="Watch CueObserve video"/> |
41 | | -</a> |
| 26 | +Now visit [http://localhost:3000](http://localhost:3000) in your browser. |
| 27 | + |
| 28 | +### Demo Video |
| 29 | + |
| 30 | +[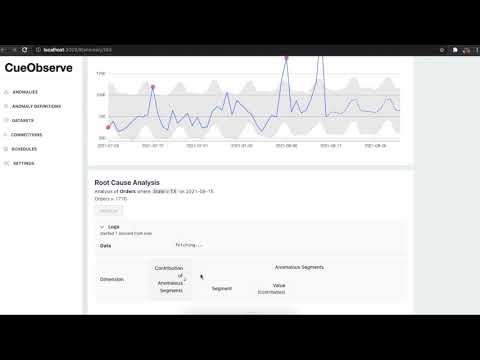](http://www.youtube.com/watch?feature=player\_embedded\&v=VZvgNa65GQU) |
| 31 | + |
| 32 | +### How it works |
42 | 33 |
|
43 | | -## How it works |
44 | 34 | You write a SQL GROUP BY query, map its columns as dimensions and measures, and save it as a virtual Dataset. |
45 | 35 |
|
46 | | - |
| 36 | +.png>) |
47 | 37 |
|
48 | | - |
| 38 | +.png>) |
49 | 39 |
|
50 | 40 | You then define one or more anomaly detection jobs on the dataset. |
51 | 41 |
|
52 | | - |
| 42 | +.png>) |
53 | 43 |
|
54 | 44 | When an anomaly detection job runs, CueObserve does the following: |
| 45 | + |
55 | 46 | 1. Executes the SQL GROUP BY query on your data warehouse and stores the result as a Pandas dataframe. |
56 | 47 | 2. Generates one or more timeseries from the dataframe, as defined in your anomaly detection job. |
57 | 48 | 3. Generates a forecast for each timeseries using [Prophet](https://github.com/facebook/prophet). |
58 | 49 | 4. Creates a visual card for each timeseries. Marks the card as an anomaly if the last data point is anomalous. |
59 | 50 |
|
60 | | -## Features |
61 | | -- Automated SQL to timeseries transformation. |
62 | | -- Run anomaly detection on the aggregate metric or split it by any dimension. Limit the split to significant dimension values. |
63 | | -- Use Prophet or simple mathematical rules to detect anomalies. |
64 | | -- In-built Scheduler. CueObserve uses Celery as the executor and celery-beat as the scheduler. |
65 | | -- Slack alerts when anomalies are detected. |
66 | | -- Monitoring. Slack alert when a job fails. CueObserve maintains detailed logs. |
| 51 | +### Features |
| 52 | + |
| 53 | +* Automated SQL to timeseries transformation. |
| 54 | +* Run anomaly detection on the aggregate metric or split it by any dimension. Limit the split to significant dimension values. |
| 55 | +* Use Prophet or simple mathematical rules to detect anomalies. |
| 56 | +* In-built Scheduler. CueObserve uses Celery as the executor and celery-beat as the scheduler. |
| 57 | +* Slack alerts when anomalies are detected. |
| 58 | +* Monitoring. Slack alert when a job fails. CueObserve maintains detailed logs. |
67 | 59 |
|
68 | | -### Limitations |
69 | | -- Currently supports Prophet for timeseries forecasting. |
70 | | -- Not being built for real-time anomaly detection on streaming data. |
| 60 | +#### Limitations |
71 | 61 |
|
72 | | -## Support |
73 | | -For general help using CueObserve, read the [documentation](https://cueobserve.cuebook.ai/), or go to [Github Discussions](https://github.com/cuebook/cueobserve/discussions). |
| 62 | +* Currently supports Prophet for timeseries forecasting. |
| 63 | +* Not being built for real-time anomaly detection on streaming data. |
| 64 | + |
| 65 | +### Support |
| 66 | + |
| 67 | +For general help using CueObserve, read the [documentation](https://cueobserve.cuebook.ai), or go to [Github Discussions](https://github.com/cuebook/cueobserve/discussions). |
74 | 68 |
|
75 | 69 | To report a bug or request a feature, open an [issue](https://github.com/cuebook/cueobserve/issues). |
76 | 70 |
|
77 | | -## Contributing |
78 | | -We'd love contributions to CueObserve. Before you contribute, please first discuss the change you wish to make via an [issue](https://github.com/cuebook/cueobserve/issues) or a [discussion](https://github.com/cuebook/cueobserve/discussions). Contributors are expected to adhere to our [code of conduct](https://github.com/cuebook/cueobserve/blob/main/CODE_OF_CONDUCT.md). |
| 71 | +### Contributing |
| 72 | + |
| 73 | +We'd love contributions to CueObserve. Before you contribute, please first discuss the change you wish to make via an [issue](https://github.com/cuebook/cueobserve/issues) or a [discussion](https://github.com/cuebook/cueobserve/discussions). Contributors are expected to adhere to our [code of conduct](https://github.com/cuebook/cueobserve/blob/main/CODE\_OF\_CONDUCT.md). |
0 commit comments