diff --git "a/src/posts/ERNIE4.5\344\270\216PaddleOCR\345\256\236\347\216\260\346\226\207\346\241\243\347\277\273\350\257\221\345\256\236\350\267\265\346\214\207\345\215\227.md" "b/src/posts/ERNIE4.5\344\270\216PaddleOCR\345\256\236\347\216\260\346\226\207\346\241\243\347\277\273\350\257\221\345\256\236\350\267\265\346\214\207\345\215\227.md"
new file mode 100644
index 0000000..fa2850f
--- /dev/null
+++ "b/src/posts/ERNIE4.5\344\270\216PaddleOCR\345\256\236\347\216\260\346\226\207\346\241\243\347\277\273\350\257\221\345\256\236\350\267\265\346\214\207\345\215\227.md"
@@ -0,0 +1,206 @@
+---
+title: 用 ERNIE 4.5 与 PaddleOCR 3.0 实现文档翻译实践指南
+date: 2025-08-09
+author:
+ name: 张晶
+ github: openvino-book
+category: community-activity
+---
+
+
+
+# 用 ERNIE 4.5 与 PaddleOCR 3.0 实现文档翻译实践指南
+
+## 一、文档翻译的挑战
+
+在全球化背景下,跨语言沟通需求日益增长,文档翻译的重要性愈发凸显。尤其是随着数字化进程加速,文档图像翻译的需求持续上升,但这一任务面临着独特的挑战:
+
+- **复杂布局解析**:文档图像常包含文本、图表、表格等多种元素,传统OCR技术在处理复杂布局时难以准确提取文本并保留原始格式
+- **多语言翻译质量**:不同语言间存在语法、词汇和文化背景差异,长句和上下文依赖翻译任务对传统工具而言颇具难度
+- **格式保留**:翻译过程中如何保持文档的原始结构和格式,是用户面临的另一大痛点
+
+你是否曾因这些问题而困扰?本文将介绍如何利用[PaddleOCR 3.0](https://www.github.com/paddlepaddle/paddleocr)和[ERNIE 4.5](https://github.com/PaddlePaddle/ERNIE)实现高质量的文档翻译解决方案。
+
+## 二、PaddleOCR 3.0与ERNIE 4.5简介
+
+### PaddleOCR 3.0
+
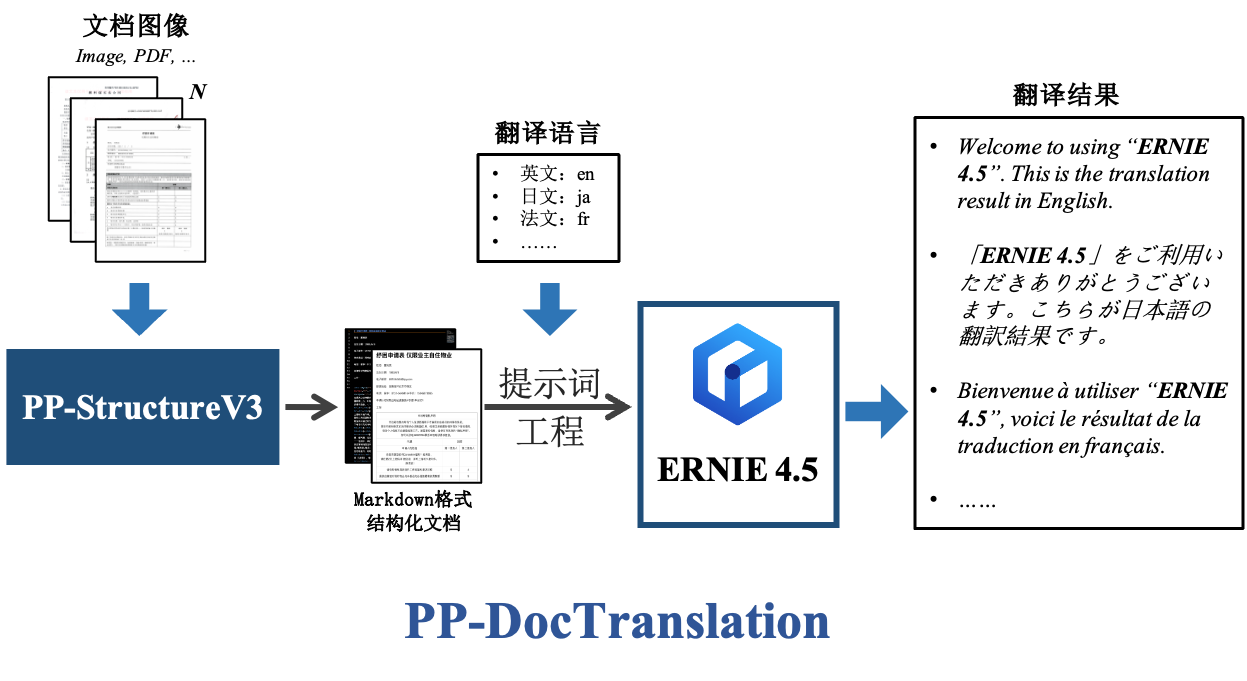
+PaddleOCR 3.0是业界领先、可直接部署的 OCR 与文档智能引擎,提供从文本识别到文档理解的全流程解决方案,提供了全场景文字识别模型PP-OCRv5、复杂文档解析PP-StructureV3和智能信息抽取PP-ChatOCRv4,其中PP-StructureV3在布局区域检测、表格识别和公式识别方面能力尤为突出,还增加了图表理解、恢复多列阅读顺序以及将结果转换为Markdown文件的功能。
+
+### ERNIE 4.5
+
+ERNIE 4.5是百度发布的开源多模态和大语言系列,含10种版本,最大达424B参数,采用创新MoE架构,支持跨模态共享与专用参数,在文本与多模态任务中表现领先。**通过结合PP-StructureV3的文档分析能力和ERNIE 4.5的翻译能力,我们可以构建一个端到端的高质量文档翻译解决方案。**
+
+
+## 三、解决方案概述
+
+本文介绍的文档翻译方案基于以下核心流程:
+
+1. 使用PP-StructureV3分析文档内容,获取结构化数据表示
+2. 将结构化数据处理为Markdown格式的文档文件
+3. 利用提示工程构建提示,调用ERNIE 4.5翻译文档内容
+
+这种方法不仅能准确识别和分析复杂文档布局,还能实现高质量的多语言翻译服务,满足用户在不同语言环境下的文档翻译需求。
+
+
+
+
+

+
+

+