diff --git a/.DS_Store b/.DS_Store
index a26c31cb..c0d98df4 100644
Binary files a/.DS_Store and b/.DS_Store differ
diff --git a/English version/README.md b/English version/README.md
new file mode 100644
index 00000000..16f0d5f1
--- /dev/null
+++ b/English version/README.md
@@ -0,0 +1,566 @@
+Translated with Google Translate (corrections welcome)
+
+# 1. Copyright statement
+Please respect the author's intellectual property rights, copyright, piracy will be investigated. It is strictly forbidden to forward content without permission!
+Please work together to maintain the results of your work and supervise. It is strictly forbidden to forward content without permission!
+2018.6.27 TanJiyong
+
+# 2. Overview
+
+This project is to integrate the relevant knowledge of AI and brainstorm ideas to form a comprehensive and comprehensive collection of articles.
+
+
+# 3. Join and document specifications
+1. Seek friends, editors, and writers who are willing to continue to improve; if you are interested in cooperation, improve the book (become a co-author).
+2. All contributors who submit content will reflect the contributor's personal information in the text (eg: Daxie-West Lake University)
+3, in order to make the content more complete and thoughtful, brainstorming, welcome to Fork the project and participate in the preparation. Please note your name-unit (Dayu-Stanford University) while modifying the MD file (or direct message). Once adopted, the contributor's information will be displayed in the original text, thank you!
+4. It is recommended to use the typora-Markdown reader: https://typora.io/
+
+Setting:
+File->Preference
+- Syntax Support
+ - Inline Math
+ - Subscript
+ - Superscript
+ - Highlight
+ - Diagrams
+
+Check these items on
+
+Example:
+
+```markdown
+### 3.3.2 How to find the optimal value of the hyperparameter? (Contributor: Daxie - Stanford University)
+
+There are always some difficult hyperparameters when using machine learning algorithms. For example, weight attenuation size, Gaussian kernel width, and so on. The algorithm does not set these parameters, but instead requires you to set their values. The set value has a large effect on the result. Common practices for setting hyperparameters are:
+
+1. Guess and check: Select parameters based on experience or intuition, and iterate over.
+2. Grid Search: Let the computer try to evenly distribute a set of values within a certain range.
+3. Random search: Let the computer randomly pick a set of values.
+4. Bayesian optimization: Using Bayesian optimization of hyperparameters, it is difficult to meet the Bayesian optimization algorithm itself.
+5. Perform local optimization with good initial guessing: this is the MITIE method, which uses the BOBYQA algorithm and has a carefully chosen starting point. Since BOBYQA only looks for the nearest local optimal solution, the success of this method depends largely on whether there is a good starting point. In the case of MITIE, we know a good starting point, but this is not a universal solution, because usually you won't know where the good starting point is. On the plus side, this approach is well suited to finding local optimal solutions. I will discuss this later.
+6. The latest global optimization method for LIPO. This method has no parameters and is proven to be better than a random search method.
+```
+
+# 4. Contributions and Project Overview
+
+Submitted MD version chapter: Please check MarkDown
+
+
+# 5. More
+
+1. Seek friends, editors, and writers who are willing to continue to improve; if you are interested in cooperation, improve the book (become a co-author).
+ All contributors who submit content will reflect the contributor's personal information in the article (Dalong - West Lake University).
+
+2. Contact: Please contact scutjy2015@163.com (the only official email); WeChat Tan:
+
+ (Into the group, after the MD version is added, improved, and submitted, it is easier to enter the group and enjoy sharing knowledge to help others.)
+
+ Into the "Deep Learning 500 Questions" WeChat group please add WeChat Client 1: HQJ199508212176 Client 2: Xuwumin1203 Client 3: tianyuzy
+
+3. Markdown reader recommendation: https://typora.io/ Free and support for mathematical formulas is better.
+
+4. Note that there are now criminals pretending to be promoters, please let the partners know!
+
+5. Next, the MD version will be provided, and everyone will edit it together, so stay tuned! I hope to make suggestions and add changes!
+
+
+# 6. Contents
+
+**Chapter 1 Mathematical Foundation 1**
+
+1.1 The relationship between scalars, vectors, and tensors 1
+1.2 What is the difference between tensor and matrix? 1
+1.3 Matrix and vector multiplication results 1
+1.4 Vector and matrix norm induction 1
+1.5 How to judge a matrix to be positive? 2
+1.6 Derivative Bias Calculation 3
+What is the difference between 1.7 derivatives and partial derivatives? 3
+1.8 Eigenvalue decomposition and feature vector 3
+1.9 What is the relationship between singular values and eigenvalues? 4
+1.10 Why should machine learning use probabilities? 4
+1.11 What is the difference between a variable and a random variable? 4
+1.12 Common probability distribution? 5
+1.13 Example Understanding Conditional Probability 9
+1.14 What is the difference between joint probability and edge probability? 10
+1.15 Chain Law of Conditional Probability 10
+1.16 Independence and conditional independence 11
+1.17 Summary of Expectations, Variances, Covariances, Correlation Coefficients 11
+
+**Chapter 2 Fundamentals of Machine Learning 14**
+
+2.1 Various common algorithm illustrations 14
+2.2 Supervised learning, unsupervised learning, semi-supervised learning, weak supervised learning? 15
+2.3 What are the steps for supervised learning? 16
+2.4 Multi-instance learning? 17
+2.5 What is the difference between classification networks and regression? 17
+2.6 What is a neural network? 17
+2.7 Advantages and Disadvantages of Common Classification Algorithms? 18
+2.8 Is the correct rate good for evaluating classification algorithms? 20
+2.9 How to evaluate the classification algorithm? 20
+2.10 What kind of classifier is the best? twenty two
+2.11 The relationship between big data and deep learning 22
+2.12 Understanding Local Optimization and Global Optimization 23
+2.13 Understanding Logistic Regression 24
+2.14 What is the difference between logistic regression and naive Bayes? twenty four
+2.15 Why do you need a cost function? 25
+2.16 Principle of the function of the cost function 25
+2.17 Why is the cost function non-negative? 26
+2.18 Common cost function? 26
+2.19 Why use cross entropy instead of quadratic cost function 28
+2.20 What is a loss function? 28
+2.21 Common loss function 28
+2.22 Why does logistic regression use a logarithmic loss function? 30
+How does the logarithmic loss function measure loss? 31
+2.23 Why do gradients need to be reduced in machine learning? 32
+2.24 What are the disadvantages of the gradient descent method? 32
+2.25 Gradient descent method intuitive understanding? 32
+2.23 What is the description of the gradient descent algorithm? 33
+2.24 How to tune the gradient descent method? 35
+2.25 What is the difference between random gradients and batch gradients? 35
+2.26 Performance Comparison of Various Gradient Descent Methods 37
+2.27 Calculation of the derivative calculation diagram of the graph? 37
+2.28 Summary of Linear Discriminant Analysis (LDA) Thoughts 39
+2.29 Graphical LDA Core Ideas 39
+2.30 Principles of the second class LDA algorithm? 40
+2.30 LDA algorithm flow summary? 41
+2.31 What is the difference between LDA and PCA? 41
+2.32 LDA advantages and disadvantages? 41
+2.33 Summary of Principal Component Analysis (PCA) Thoughts 42
+2.34 Graphical PCA Core Ideas 42
+2.35 PCA algorithm reasoning 43
+2.36 Summary of PCA Algorithm Flow 44
+2.37 Main advantages and disadvantages of PCA algorithm 45
+2.38 Necessity and purpose of dimensionality reduction 45
+2.39 What is the difference between KPCA and PCA? 46
+2.40 Model Evaluation 47
+2.40.1 Common methods for model evaluation? 47
+2.40.2 Empirical error and generalization error 47
+2.40.3 Graphic under-fitting, over-fitting 48
+2.40.4 How to solve over-fitting and under-fitting? 49
+2.40.5 The main role of cross-validation? 50
+2.40.6 k fold cross validation? 50
+2.40.7 Confusion Matrix 50
+2.40.8 Error Rate and Accuracy 51
+2.40.9 Precision and recall rate 51
+2.40.10 ROC and AUC 52
+2.40.11 How to draw ROC curve? 53
+2.40.12 How to calculate TPR, FPR? 54
+2.40.13 How to calculate Auc? 56
+2.40.14 Why use Roc and Auc to evaluate the classifier? 56
+2.40.15 Intuitive understanding of AUC 56
+2.40.16 Cost-sensitive error rate and cost curve 57
+2.40.17 What are the comparison test methods for the model 59
+2.40.18 Deviation and variance 59
+2.40.19 Why use standard deviation? 60
+2.40.20 Point Estimation Thoughts 61
+2.40.21 Point Estimation Goodness Principle? 61
+2.40.22 The connection between point estimation, interval estimation, and central limit theorem? 62
+2.40.23 What causes the category imbalance? 62
+2.40.24 Common Category Unbalance Problem Resolution 62
+2.41 Decision Tree 64
+2.41.1 Basic Principles of Decision Trees 64
+2.41.2 Three elements of the decision tree? 64
+2.41.3 Decision Tree Learning Basic Algorithm 65
+2.41.4 Advantages and Disadvantages of Decision Tree Algorithms 65
+2.40.5 Concept of entropy and understanding 66
+2.40.6 Understanding of Information Gain 66
+2.40.7 The role and strategy of pruning treatment? 67
+2.41 Support Vector Machine 67
+2.41.1 What is a support vector machine 67
+2.25.2 Problems solved by the support vector machine? 68
+2.25.2 Function of the kernel function? 69
+2.25.3 Dual Problem 69
+2.25.4 Understanding Support Vector Regression 69
+2.25.5 Understanding SVM (Nuclear Function) 69
+2.25.6 What are the common kernel functions? 69
+2.25.6 Soft Interval and Regularization 73
+2.25.7 Main features and disadvantages of SVM? 73
+2.26 Bayesian 74
+2.26.1 Graphical Maximum Likelihood Estimate 74
+2.26.2 What is the difference between a naive Bayes classifier and a general Bayesian classifier? 76
+2.26.4 Plain and semi-simple Bayesian classifiers 76
+2.26.5 Three typical structures of Bayesian network 76
+2.26.6 What is the Bayesian error rate 76
+2.26.7 What is the Bayesian optimal error rate? 76
+2.27 EM algorithm to solve problems and implementation process 76
+2.28 Why is there a dimensionality disaster? 78
+2.29 How to avoid dimension disasters 82
+2.30 What is the difference and connection between clustering and dimension reduction? 82
+2.31 Differences between GBDT and random forests 83
+2.32 Comparison of four clustering methods 84
+
+**Chapter 3 Fundamentals of Deep Learning 88**
+
+3.1 Basic Concepts 88
+3.1.1 Neural network composition? 88
+3.1.2 What are the common model structures of neural networks? 90
+3.1.3 How to choose a deep learning development platform? 92
+3.1.4 Why use deep representation 92
+3.1.5 Why is deep neural network difficult to train? 93
+3.1.6 What is the difference between deep learning and machine learning? 94
+3.2 Network Operations and Calculations 95
+3.2.1 Forward Propagation and Back Propagation? 95
+3.2.2 How to calculate the output of the neural network? 97
+3.2.3 How to calculate the convolutional neural network output value? 98
+3.2.4 How do I calculate the output value of the Pooling layer output value? 101
+3.2.5 Example Understanding Back Propagation 102
+3.3 Superparameters 105
+3.3.1 What is a hyperparameter? 105
+3.3.2 How to find the optimal value of the hyperparameter? 105
+3.3.3 General procedure for hyperparameter search? 106
+3.4 Activation function 106
+3.4.1 Why do I need a nonlinear activation function? 106
+3.4.2 Common Activation Functions and Images 107
+3.4.3 Derivative calculation of common activation functions? 109
+3.4.4 What are the properties of the activation function? 110
+3.4.5 How do I choose an activation function? 110
+3.4.6 Advantages of using the ReLu activation function? 111
+3.4.7 When can I use the linear activation function? 111
+3.4.8 How to understand that Relu (<0) is a nonlinear activation function? 111
+3.4.9 How does the Softmax function be applied to multiple classifications? 112
+3.5 Batch_Size 113
+3.5.1 Why do I need Batch_Size? 113
+3.5.2 Selection of Batch_Size Values 114
+3.5.3 What are the benefits of increasing Batch_Size within a reasonable range? 114
+3.5.4 What is the disadvantage of blindly increasing Batch_Size? 114
+3.5.5 What is the impact of Batch_Size on the training effect? 114
+3.6 Normalization 115
+3.6.1 What is the meaning of normalization? 115
+3.6.2 Why Normalize 115
+3.6.3 Why can normalization improve the solution speed? 115
+3.6.4 3D illustration not normalized 116
+3.6.5 What types of normalization? 117
+3.6.6 Local response normalization
+Effect 117
+3.6.7 Understanding the local response normalization formula 117
+3.6.8 What is Batch Normalization 118
+3.6.9 Advantages of the Batch Normalization (BN) Algorithm 119
+3.6.10 Batch normalization (BN) algorithm flow 119
+3.6.11 Batch normalization and group normalization 120
+3.6.12 Weight Normalization and Batch Normalization 120
+3.7 Pre-training and fine tuning 121
+3.7.1 Why can unsupervised pre-training help deep learning? 121
+3.7.2 What is the model fine tuning fine tuning 121
+3.7.3 Is the network parameter updated when fine tuning? 122
+3.7.4 Three states of the fine-tuning model 122
+3.8 Weight Deviation Initialization 122
+3.8.1 All initialized to 0 122
+3.8.2 All initialized to the same value 123
+3.8.3 Initializing to a Small Random Number 124
+3.8.4 Calibrating the variance with 1/sqrt(n) 125
+3.8.5 Sparse Initialization (Sparse Initialazation) 125
+3.8.6 Initialization deviation 125
+3.9 Softmax 126
+3.9.1 Softmax Definition and Function 126
+3.9.2 Softmax Derivation 126
+3.10 Understand the principles and functions of One Hot Encodeing? 126
+3.11 What are the commonly used optimizers? 127
+3.12 Dropout Series Issues 128
+3.12.1 Choice of dropout rate 128
+3.27 Padding Series Issues 128
+
+**Chapter 4 Classic Network 129**
+
+4.1 LetNet5 129
+4.1.1 Model Structure 129
+4.1.2 Model Structure 129
+4.1.3 Model characteristics 131
+4.2 AlexNet 131
+4.2.1 Model structure 131
+4.2.2 Model Interpretation 131
+4.2.3 Model characteristics 135
+4.3 Visualization ZFNet-Deconvolution 135
+4.3.1 Basic ideas and processes 135
+4.3.2 Convolution and Deconvolution 136
+4.3.3 Convolution Visualization 137
+4.3.4 Comparison of ZFNe and AlexNet 139
+4.4 VGG 140
+4.1.1 Model Structure 140
+4.1.2 Model Features 140
+4.5 Network in Network 141
+4.5.1 Model Structure 141
+4.5.2 Model Innovation Points 141
+4.6 GoogleNet 143
+4.6.1 Model Structure 143
+4.6.2 Inception Structure 145
+4.6.3 Model hierarchy 146
+4.7 Inception Series 148
+4.7.1 Inception v1 148
+4.7.2 Inception v2 150
+4.7.3 Inception v3 153
+4.7.4 Inception V4 155
+4.7.5 Inception-ResNet-v2 157
+4.8 ResNet and its variants 158
+4.8.1 Reviewing ResNet 159
+4.8.2 residual block 160
+4.8.3 ResNet Architecture 162
+4.8.4 Variants of residual blocks 162
+4.8.5 ResNeXt 162
+4.8.6 Densely Connected CNN 164
+4.8.7 ResNet as a combination of small networks 165
+4.8.8 Features of Paths in ResNet 166
+4.9 Why are the current CNN models adjusted on GoogleNet, VGGNet or AlexNet? 167
+
+**Chapter 5 Convolutional Neural Network (CNN) 170**
+
+5.1 Constitutive layers of convolutional neural networks 170
+5.2 How does convolution detect edge information? 171
+5.2 Several basic definitions of convolution? 174
+5.2.1 Convolution kernel size 174
+5.2.2 Step size of the convolution kernel 174
+5.2.3 Edge Filling 174
+5.2.4 Input and Output Channels 174
+5.3 Convolution network type classification? 174
+5.3.1 Ordinary Convolution 174
+5.3.2 Expansion Convolution 175
+5.3.3 Transposition Convolution 176
+5.3.4 Separable Convolution 177
+5.3 Schematic of 12 different types of 2D convolution? 178
+5.4 What is the difference between 2D convolution and 3D convolution? 181
+5.4.1 2D Convolution 181
+5.4.2 3D Convolution 182
+5.5 What are the pooling methods? 183
+5.5.1 General Pooling 183
+5.5.2 Overlapping Pooling (OverlappingPooling) 184
+5.5.3 Spatial Pyramid Pooling 184
+5.6 1x1 convolution? 186
+5.7 What is the difference between the convolutional layer and the pooled layer? 187
+5.8 The larger the convolution kernel, the better? 189
+5.9 Can each convolution use only one size of convolution kernel? 189
+5.10 How can I reduce the amount of convolutional parameters? 190
+5.11 Convolution operations must consider both channels and zones? 191
+5.12 What are the benefits of using wide convolution? 192
+5.12.1 Narrow Convolution and Wide Convolution 192
+5.12.2 Why use wide convolution? 192
+5.13 Which depth of the convolutional layer output is the same as the number of parts? 192
+5.14 How do I get the depth of the convolutional layer output? 193
+5.15 Is the activation function usually placed after the operation of the convolutional neural network? 194
+5.16 How do you understand that the maximum pooling layer is a little smaller? 194
+5.17 Understanding Image Convolution and Deconvolution 194
+5.17.1 Image Convolution 194
+5.17.2 Image Deconvolution 196
+5.18 Image Size Calculation after Different Convolutions? 198
+5.18.1 Type division 198
+5.18.2 Calculation formula 199
+5.19 Step size, fill size and input and output relationship summary? 199
+5.19.1 No 0 padding, unit step size 200
+5.19.2 Zero fill, unit step size 200
+5.19.3 Not filled, non-unit step size 202
+5.19.4 Zero padding, non-unit step size 202
+5.20 Understanding deconvolution and checkerboard effects 204
+5.20.1 Why does the board phenomenon appear? 204
+5.20.2 What methods can avoid the checkerboard effect? 205
+5.21 CNN main calculation bottleneck? 207
+5.22 CNN parameter experience setting 207
+5.23 Summary of methods for improving generalization ability 208
+5.23.1 Main methods 208
+5.23.2 Experimental proof 208
+5.24 What are the connections and differences between CNN and CLP? 213
+5.24.1 Contact 213
+5.24.2 Differences 213
+5.25 Does CNN highlight commonality? 213
+5.25.1 Local connection 213
+5.25.2 Weight sharing 214
+5.25.3 Pooling Operations 215
+5.26 Similarities and differences between full convolution and Local-Conv 215
+5.27 Example Understanding the Role of Local-Conv 215
+5.28 Brief History of Convolutional Neural Networks 216
+
+**Chapter 6 Cyclic Neural Network (RNN) 218**
+
+6.1 What is the difference between RNNs and FNNs? 218
+6.2 Typical characteristics of RNNs? 218
+6.3 What can RNNs do? 219
+6.4 Typical applications of RNNs in NLP? 220
+6.5 What are the similarities and differences between RNNs training and traditional ANN training? 220
+6.6 Common RNNs Extensions and Improvement Models 221
+6.6.1 Simple RNNs (SRNs) 221
+6.6.2 Bidirectional RNNs 221
+6.6.3 Deep(Bidirectional) RNNs 222
+6.6.4 Echo State Networks (ESNs) 222
+6.6.5 Gated Recurrent Unit Recurrent Neural Networks 224
+6.6.6 LSTM Netwoorks 224
+6.6.7 Clockwork RNNs (CW-RNNs) 225
+
+**Chapter 7 Target Detection 228**
+
+7.1 Candidate-based target detector 228
+7.1.1 Sliding Window Detector 228
+7.1.2 Selective Search 229
+7.1.3 R-CNN 230
+7.1.4 Boundary Box Regressor 230
+7.1.5 Fast R-CNN 231
+7.1.6 ROI Pooling 233
+7.1.7 Faster R-CNN 233
+7.1.8 Candidate Area Network 234
+7.1.9 Performance of the R-CNN method 236
+7.2 Area-based full convolutional neural network (R-FCN) 237
+7.3 Single Target Detector 240
+7.3.1 Single detector 241
+7.3.2 Sliding window for prediction 241
+7.3.3 SSD 243
+7.4 YOLO Series 244
+7.4.1 Introduction to YOLOv1 244
+7.4.2 What are the advantages and disadvantages of the YOLOv1 model? 252
+7.4.3 YOLOv2 253
+7.4.4 YOLOv2 Improvement Strategy 254
+7.4.5 Training of YOLOv2 261
+7.4.6 YOLO9000 261
+7.4.7 YOLOv3 263
+7.4.8 YOLOv3 Improvements 264
+
+** Chapter 8 Image Segmentation 269**
+
+8.1 What are the disadvantages of traditional CNN-based segmentation methods? 269
+8.1 FCN 269
+8.1.1 What has the FCN changed? 269
+8.1.2 FCN network structure? 270
+8.1.3 Example of a full convolution network? 271
+8.1.4 Why is it difficult for CNN to classify pixels? 271
+8.1.5 How do the fully connected and convolved layers transform each other? 272
+8.1.6 Why can the input picture of the FCN be any size? 272
+8.1.7 What are the benefits of reshaping the weight of the fully connected layer into a convolutional layer filter? 273
+8.1.8 Deconvolutional Understanding 275
+8.1.9 Skip structure 276
+8.1.10 Model Training 277
+8.1.11 FCN Disadvantages 280
+8.2 U-Net 280
+8.3 SegNet 282
+8.4 Dilated Convolutions 283
+8.4 RefineNet 285
+8.5 PSPNet 286
+8.6 DeepLab Series 288
+8.6.1 DeepLabv1 288
+8.6.2 DeepLabv2 289
+8.6.3 DeepLabv3 289
+8.6.4 DeepLabv3+ 290
+8.7 Mask-R-CNN 293
+8.7.1 Schematic diagram of the network structure of Mask-RCNN 293
+8.7.2 RCNN pedestrian detection framework 293
+8.7.3 Mask-RCNN Technical Highlights 294
+8.8 Application of CNN in Image Segmentation Based on Weak Supervised Learning 295
+8.8.1 Scribble tag 295
+8.8.2 Image Level Marking 297
+8.8.3 DeepLab+bounding box+image-level labels 298
+8.8.4 Unified framework 299
+
+**Chapter IX Reinforcement Learning 301**
+
+9.1 Main features of intensive learning? 301
+9.2 Reinforced Learning Application Examples 302
+9.3 Differences between reinforcement learning and supervised learning and unsupervised learning 303
+9.4 What are the main algorithms for reinforcement learning? 305
+9.5 Deep Migration Reinforcement Learning Algorithm 305
+9.6 Hierarchical Depth Reinforcement Learning Algorithm 306
+9.7 Deep Memory Reinforcement Learning Algorithm 306
+9.8 Multi-agent deep reinforcement learning algorithm 307
+9.9 Strong depth
+Summary of learning algorithms 307
+
+**Chapter 10 Migration Learning 309**
+
+10.1 What is migration learning? 309
+10.2 What is multitasking? 309
+10.3 What is the significance of multitasking? 309
+10.4 What is end-to-end deep learning? 311
+10.5 End-to-end depth learning example? 311
+10.6 What are the challenges of end-to-end deep learning? 311
+10.7 End-to-end deep learning advantages and disadvantages? 312
+
+**Chapter 13 Optimization Algorithm 314**
+
+13.1 What is the difference between CPU and GPU? 314
+13.2 How to solve the problem of less training samples 315
+13.3 What sample sets are not suitable for deep learning? 315
+13.4 Is it possible to find a better algorithm than the known algorithm? 316
+13.5 What is collinearity and is there a correlation with the fit? 316
+13.6 How is the generalized linear model applied in deep learning? 316
+13.7 Causes the gradient to disappear? 317
+13.8 What are the weight initialization methods? 317
+13.9 In the heuristic optimization algorithm, how to avoid falling into the local optimal solution? 318
+13.10 How to improve the GD method in convex optimization to prevent falling into local optimal solution 319
+13.11 Common loss function? 319
+13.14 How to make feature selection? 321
+13.14.1 How to consider feature selection 321
+13.14.2 Classification of feature selection methods 321
+13.14.3 Feature selection purpose 322
+13.15 Gradient disappearance / Gradient explosion causes, and solutions 322
+13.15.1 Why use gradient update rules? 322
+13.15.2 Does the gradient disappear and the cause of the explosion? 323
+13.15.3 Solutions for Gradient Disappearance and Explosion 324
+13.16 Why does deep learning not use second-order optimization?
+13.17 How to optimize your deep learning system? 326
+13.18 Why set a single numerical evaluation indicator? 326
+13.19 Satisficing and optimizing metrics 327
+13.20 How to divide the training/development/test set 328
+13.21 How to Divide Development/Test Set Size 329
+13.22 When should I change development/test sets and metrics? 329
+13.23 What is the significance of setting the evaluation indicators? 330
+13.24 What is the avoidance of deviation? 331
+13.25 What is the TOP5 error rate? 331
+13.26 What is the human error rate? 332
+13.27 Can avoid the relationship between deviation and several error rates? 332
+13.28 How to choose to avoid deviation and Bayesian error rate? 332
+13.29 How to reduce the variance? 333
+13.30 Best estimate of Bayesian error rate 333
+13.31 How many examples of machine learning over a single human performance? 334
+13.32 How can I improve your model? 334
+13.33 Understanding Error Analysis 335
+13.34 Why is it worth the time to look at the error flag data? 336
+13.35 What is the significance of quickly setting up the initial system? 336
+13.36 Why should I train and test on different divisions? 337
+13.37 How to solve the data mismatch problem? 338
+13.38 Gradient Test Considerations? 340
+13.39 What is the random gradient drop? 341
+13.40 What is the batch gradient drop? 341
+13.41 What is the small batch gradient drop? 341
+13.42 How to configure the mini-batch gradient to drop 342
+13.43 Locally Optimal Problems 343
+13.44 Improving Algorithm Performance Ideas 346
+
+**Chapter 14 Super Parameter Adjustment 358**
+
+14.1 Debugging Processing 358
+14.2 What are the hyperparameters? 359
+14.3 How do I choose a debug value? 359
+14.4 Choosing the right range for hyperparameters 359
+14.5 How do I search for hyperparameters? 359
+
+**Chapter 15 Heterogeneous Computing, GPU and Frame Selection Guide 361**
+
+
+15.1 What is heterogeneous computing? 361
+15.2 What is a GPGPU? 361
+15.3 Introduction to GPU Architecture 361
+ 15.3.1 Why use a GPU?
+ 15.3.2 What is the core of CUDA?
+ 15.3.3 What is the role of the tensor core in the new Turing architecture for deep learning?
+ 15.3.4 What is the connection between GPU memory architecture and application performance?
+15.4 CUDA framework
+ 15.4.1 Is it difficult to do CUDA programming?
+ 15.4.2 cuDNN
+15.5 GPU hardware environment configuration recommendation
+ 15.5.1 GPU Main Performance Indicators
+ 15.5.2 Purchase Proposal
+15.6 Software Environment Construction
+ 15.6.1 Operating System Selection?
+ 15.6.2 Is the native installation still using docker?
+ 15.6.3 GPU Driver Issues
+15.7 Frame Selection
+ 15.7.1 Comparison of mainstream frameworks
+ 15.7.2 Framework details
+ 15.7.3 Which frameworks are friendly to the deployment environment?
+ 15.7.4 How to choose the framework of the mobile platform?
+15.8 Other
+ 15.8.1 Configuration of a Multi-GPU Environment
+ 15.8.2 Is it possible to distribute training?
+ 15.8.3 Can I train or deploy a model in a SPARK environment?
+ 15.8.4 How to further optimize performance?
+ 15.8.5 What is the difference between TPU and GPU?
+ 15.8.6 What is the impact of future quantum computing on AI technology such as deep learning?
+
+**References 366**
+
+Hey you look like a cool developer.
+Translate it to english.
diff --git a/English version/ch01_MathematicalBasis/Chapter 1_MathematicalBasis.md b/English version/ch01_MathematicalBasis/Chapter 1_MathematicalBasis.md
new file mode 100644
index 00000000..9c760a81
--- /dev/null
+++ b/English version/ch01_MathematicalBasis/Chapter 1_MathematicalBasis.md
@@ -0,0 +1,523 @@
+[TOC]
+
+# Chapter 1 Mathematical Foundation
+
+## 1.1 The relationship between scalars, vectors, matrices, and tensors
+**Scalar**
+A scalar represents a single number that is different from most other objects studied in linear algebra (usually an array of multiple numbers). We use italics to represent scalars. Scalars are usually given a lowercase variable name.
+
+**Vector**
+A vector represents a set of ordered numbers. By indexing in the order, we can determine each individual number. Usually we give the lowercase variable name of the vector bold, such as xx. Elements in a vector can be represented in italics with a footer. The first element of the vector $X$ is $X_1$, the second element is $X_2$, and so on. We will also indicate the type of element (real, imaginary, etc.) stored in the vector.
+
+**Matrix**
+A matrix is a collection of objects with the same features and latitudes, represented as a two-dimensional data table. The meaning is that an object is represented as a row in a matrix, and a feature is represented as a column in a matrix, and each feature has a numerical value. The name of an uppercase variable that is usually given to the matrix bold, such as $A$.
+
+**Tensor**
+In some cases, we will discuss arrays with coordinates over two dimensions. In general, the elements in an array are distributed in a regular grid of several dimensional coordinates, which we call a tensor. Use $A$ to represent the tensor "A". The element with a coordinate of $(i,j,k)$ in the tensor $A$ is denoted as $A_{(i,j,k)}$.
+
+**Relationship between the four**
+
+> The scalar is a 0th order tensor and the vector is a first order tensor. Example:
+> The scalar is the length of the stick, but you won't know where the stick is pointing.
+> Vector is not only knowing the length of the stick, but also knowing whether the stick points to the front or the back.
+> The tensor is not only knowing the length of the stick, but also knowing whether the stick points to the front or the back, and how much the stick is deflected up/down and left/right.
+
+## 1.2 What is the difference between tensor and matrix?
+- From an algebra perspective, a matrix is a generalization of vectors. The vector can be seen as a one-dimensional "table" (that is, the components are arranged in a row in order), the matrix is a two-dimensional "table" (components are arranged in the vertical and horizontal positions), then the $n$ order tensor is the so-called $n$ dimension "Form". The strict definition of tensors is described using linear mapping.
+- Geometrically, a matrix is a true geometric quantity, that is, it is something that does not change with the coordinate transformation of the frame of reference. Vectors also have this property.
+- The tensor can be expressed in a 3×3 matrix form.
+- A three-dimensional array representing the number of scalars and the representation vector can also be regarded as a matrix of 1 × 1, 1 × 3, respectively.
+
+## 1.3 Matrix and vector multiplication results
+A matrix of $m$ rows of $n$ columns is multiplied by a $n$ row vector, and finally a vector of $m$ rows is obtained. The algorithm is that each row of data in the matrix is treated as a row vector and multiplied by the vector.
+
+## 1.4 Vector and matrix norm induction
+**Vector norm**
+Define a vector as: $\vec{a}=[-5, 6, 8, -10]$. Any set of vectors is set to $\vec{x}=(x_1,x_2,...,x_N)$. The different norms are solved as follows:
+
+- 1 norm of the vector: the sum of the absolute values of the elements of the vector. The 1 norm result of the above vector $\vec{a}$ is: 29.
+
+$$
+\Vert\vec{x}\Vert_1=\sum_{i=1}^N\vert{x_i}\vert
+$$
+
+- The 2 norm of the vector: the sum of the squares of each element of the vector and the square root. The result of the 2 norm of $\vec{a}$ above is: 15.
+
+$$
+\Vert\vec{x}\Vert_2=\sqrt{\sum_{i=1}^N{\vert{x_i}\vert}^2}
+$$
+
+- Negative infinite norm of the vector: the smallest of the absolute values of all elements of the vector: the negative infinite norm of the above vector $\vec{a}$ is: 5.
+
+$$
+\Vert\vec{x}\Vert_{-\infty}=\min{|{x_i}|}
+$$
+
+- The positive infinite norm of the vector: the largest of the absolute values of all elements of the vector: the positive infinite norm of the above vector $\vec{a}$ is: 10.
+
+$$
+\Vert\vec{x}\Vert_{+\infty}=\max{|{x_i}|}
+$$
+
+- p-norm of vector:
+
+$$
+L_p=\Vert\vec{x}\Vert_p=\sqrt[p]{\sum_{i=1}^{N}|{x_i}|^p}
+$$
+
+**Matrix of the matrix**
+
+Define a matrix $A=[-1, 2, -3; 4, -6, 6]$. The arbitrary matrix is defined as: $A_{m\times n}$ with elements of $a_{ij}$.
+
+The norm of the matrix is defined as
+
+$$
+\Vert{A}\Vert_p :=\sup_{x\neq 0}\frac{\Vert{Ax}\Vert_p}{\Vert{x}\Vert_p}
+$$
+
+When the vectors take different norms, different matrix norms are obtained accordingly.
+
+- **1 norm of the matrix (column norm)**: The absolute values of the elements on each column of the matrix are first summed, and then the largest one is taken, (column and maximum), the 1 matrix of the above matrix $A$ The number first gets $[5,8,9]$, and the biggest final result is: 9.
+
+$$
+\Vert A\Vert_1=\max_{1\le j\le}\sum_{i=1}^m|{a_{ij}}|
+$$
+
+- **2 norm of matrix**: The square root of the largest eigenvalue of the matrix $A^TA$, the final result of the 2 norm of the above matrix $A$ is: 10.0623.
+
+$$
+\Vert A\Vert_2=\sqrt{\lambda_{max}(A^T A)}
+$$
+
+Where $\lambda_{max}(A^T A)$ is the maximum value of the absolute value of the eigenvalue of $A^T A$.
+- **Infinite norm of the matrix (row norm)**: The absolute values of the elements on each line of the matrix are first summed, and then the largest one (row and maximum) is taken, and the above matrix of $A$ is 1 The number first gets $[6;16]$, and the biggest final result is: 16.
+$$
+\Vert A\Vert_{\infty}=\max_{1\le i \le n}\sum_{j=1}^n |{a_{ij}}|
+$$
+
+- **Matrix kernel norm**: the sum of the singular values of the matrix (decomposed of the matrix svd), this norm can be used for low rank representation (because the minimization of the kernel norm is equivalent to minimizing the rank of the matrix - Low rank), the final result of matrix A above is: 10.9287.
+
+- **Matrix L0 norm**: the number of non-zero elements of the matrix, usually used to represent sparse, the smaller the L0 norm, the more elements, the more sparse, the final result of the above matrix $A$ is :6.
+- **Matrix L1 norm**: the sum of the absolute values of each element in the matrix, which is the optimal convex approximation of the L0 norm, so it can also represent sparseness, the final result of the above matrix $A$ is: 22 .
+- **F norm of matrix **: the sum of the squares of the elements of the matrix and the square root of the square. It is also commonly called the L2 norm of the matrix. Its advantage is that it is a convex function, which can be solved and easy to calculate. The final result of the above matrix A is: 10.0995.
+
+$$
+\Vert A\Vert_F=\sqrt{(\sum_{i=1}^m\sum_{j=1}^n{| a_{ij}|}^2)}
+$$
+
+- **Matrix L21 norm**: matrix first in each column, find the F norm of each column (can also be considered as the vector's 2 norm), and then the result obtained L1 norm (also It can be thought of as the 1 norm of the vector. It is easy to see that it is a norm between L1 and L2. The final result of the above matrix $A$ is: 17.1559.
+- **p-norm of the matrix**
+$$
+\Vert A\Vert_p=\sqrt[p]{(\sum_{i=1}^m\sum_{j=1}^n{| a_{ij}|}^p)}
+$$
+
+## 1.5 How to judge a matrix as positive?
+- the order master subtype is all greater than 0;
+- There is a reversible matrix $C$ such that $C^TC$ is equal to the matrix;
+- Positive inertia index is equal to $n$;
+- Contract in unit matrix $E$ (ie: canonical form is $E$)
+- the main diagonal elements in the standard form are all positive;
+- the eigenvalues are all positive;
+- is a measure matrix of a base.
+
+## 1.6 Derivative Bias Calculation
+**Derivative definition**:
+
+The derivative represents the ratio of the change in the value of the function to the change in the independent variable when the change in the independent variable tends to infinity. Geometric meaning is the tangent to this point. The physical meaning is the (instantaneous) rate of change at that moment.
+
+
+*Note*: In a one-way function, only one independent variable changes, that is, there is only one direction of change rate, which is why the unary function has no partial derivative. There is an average speed and instantaneous speed in physics. Average speed
+
+$$
+v=\frac{s}{t}
+$$
+
+Where $v$ represents the average speed, $s$ represents the distance, and $t$ represents the time. This formula can be rewritten as
+
+$$
+\bar{v}=\frac{\Delta s}{\Delta t}=\frac{s(t_0+\Delta t)-s(t_0)}{\Delta t}
+$$
+
+Where $\Delta s$ represents the distance between two points, and $\Delta t$ represents the time it takes to walk through this distance. When $\Delta t$ tends to 0 ($\Delta t \to 0$), that is, when the time becomes very short, the average speed becomes the instantaneous speed at time $t_0$, expressed as follows :
+
+$$
+v(t_0)=\lim_{\Delta t \to 0}{\bar{v}}=\lim_{\Delta t \to 0}{\frac{\Delta s}{\Delta t}}=\lim_ {\Delta t \to 0}{\frac{s(t_0+\Delta t)-s(t_0)}{\Delta t}}
+$$
+
+In fact, the above expression represents the derivative of the function $s$ on time $t$ at $t=t_0$. In general, the derivative is defined such that if the limit of the average rate of change exists, there is
+
+$$
+\lim_{\Delta x \to 0}{\frac{\Delta y}{\Delta x}}=\lim_{\Delta x \to 0}{\frac{f(x_0+\Delta x)-f(x_0 )}{\Delta x}}
+$$
+
+This limit is called the derivative of the function $y=f(x)$ at point $x_0$. Remember as $f'(x_0)$ or $y'\vert_{x=x_0}$ or $\frac{dy}{dx}\vert_{x=x_0}$ or $\frac{df(x)}{ Dx}\vert_{x=x_0}$.
+
+In layman's terms, the derivative is the slope of the curve at a certain point.
+
+**Partial derivative**:
+
+Since we talk about partial derivatives, there are at least two independent variables involved. Taking two independent variables as an example, z=f(x,y), from the derivative to the partial derivative, that is, from the curve to the surface. At one point on the curve, there is only one tangent. But at one point on the surface, there are countless lines of tangent. The partial derivative is the rate of change of the multivariate function along the coordinate axis.
+
+
+*Note*: Intuitively speaking, the partial derivative is the rate of change of the function along the positive direction of the coordinate axis at a certain point.
+
+Let the function $z=f(x,y)$ be defined in the field of the point $(x_0,y_0)$. When $y=y_0$, $z$ can be regarded as a unary function $f on $x$ (x,y_0)$, if the unary function is derivable at $x=x_0$, there is
+
+$$
+\lim_{\Delta x \to 0}{\frac{f(x_0+\Delta x,y_0)-f(x_0,y_0)}{\Delta x}}=A
+$$
+
+The limit of the function $A$ exists. Then say $A$ is the partial derivative of the argument $x=f(x,y)$ at the point $(x_0,y_0)$ about the argument $x$, denoted as $f_x(x_0,y_0)$ or $\ Frac{\partial z}{\partial x}\vert_{y=y_0}^{x=x_0}$ or $\frac{\partial f}{\partial x}\vert_{y=y_0}^{x= X_0}$ or $z_x\vert_{y=y_0}^{x=x_0}$.
+
+When the partial derivative is solved, another variable can be regarded as a constant and solved by ordinary derivation. For example, the partial derivative of $z=3x^2+xy$ for $x$ is $z_x=6x+y$, this When $y$ is equivalent to the coefficient of $x$.
+
+The geometric meaning of the partial derivative at a point $(x_0, y_0)$ is the intersection of the surface $z=f(x,y)$ with the face $x=x_0$ or the face $y=y_0$ at $y=y_0$ Or the slope of the tangent at $x=x_0$.
+
+## 1.7 What is the difference between the derivative and the partial derivative?
+There is no essential difference between the derivative and the partial derivative. If the limit exists, it is the limit of the ratio of the change of the function value to the change of the independent variable when the variation of the independent variable tends to zero.
+
+> - Unary function, a $y$ corresponds to a $x$, and the derivative has only one.
+> - A binary function, a $z$ corresponding to a $x$ and a $y$, has two derivatives: one is the derivative of $z$ to $x$, and the other is the derivative of $z$ to $y$, Call it a partial guide.
+> - Be careful when seeking partial derivatives. If you refer to one variable, then the other variable is constant.
+Only the amount of change is derived, and the solution of the partial derivative is transformed into the derivation of the unary function.
+
+## 1.8 Eigenvalue decomposition and eigenvectors
+- eigenvalue decomposition can obtain eigenvalues and eigenvectors;
+
+- The eigenvalue indicates how important this feature is, and the eigenvector indicates what this feature is.
+
+ If a vector $\vec{v}$ is a feature vector of the square matrix $A$, it will definitely be expressed in the following form:
+
+$$
+A\nu = \lambda \nu
+$$
+
+$\lambda$ is the eigenvalue corresponding to the feature vector $\vec{v}$. Eigenvalue decomposition is the decomposition of a matrix into the following form:
+
+$$
+A=Q\sum Q^{-1}
+$$
+
+Where $Q$ is the matrix of the eigenvectors of the matrix $A$, $\sum$ is a diagonal matrix, and each diagonal element is a eigenvalue, and the eigenvalues are arranged from large to small. The eigenvectors corresponding to these eigenvalues describe the direction of the matrix change (from the primary change to the secondary change arrangement). That is to say, the information of the matrix $A$ can be represented by its eigenvalues and eigenvectors.
+
+## 1.9 What is the relationship between singular values and eigenvalues?
+So how do singular values and eigenvalues correspond? We multiply the transpose of a matrix $A$ by $A$ and the eigenvalues of $AA^T$, which have the following form:
+
+$$
+(A^TA)V = \lambda V
+$$
+
+Here $V$ is the right singular vector above, in addition to:
+
+$$
+\sigma_i = \sqrt{\lambda_i}, u_i=\frac{1}{\sigma_i}A\mu_i
+$$
+
+Here $\sigma$ is the singular value, and $u$ is the left singular vector mentioned above. [Prove that the buddy did not give]
+The singular value $\sigma$ is similar to the eigenvalues, and is also ranked from large to small in the matrix $\sum$, and the reduction of $\sigma$ is particularly fast, in many cases, the first 10% or even the 1% singularity. The sum of the values accounts for more than 99% of the sum of all the singular values. In other words, we can also approximate the description matrix with the singular value of the previous $r$($r$ is much smaller than $m, n$), that is, the partial singular value decomposition:
+
+$$
+A_{m\times n}\approx U_{m \times r}\sum_{r\times r}V_{r \times n}^T
+$$
+
+The result of multiplying the three matrices on the right will be a matrix close to $A$. Here, the closer $r$ is to $n$, the closer the multiplication will be to $A$.
+
+## 1.10 Why should machine use probability?
+The probability of an event is a measure of the likelihood that the event will occur. Although the occurrence of an event in a randomized trial is accidental, randomized trials that can be repeated in large numbers under the same conditions tend to exhibit significant quantitative patterns.
+In addition to dealing with uncertainties, machine learning also needs to deal with random quantities. Uncertainty and randomness may come from multiple sources, using probability theory to quantify uncertainty.
+Probability theory plays a central role in machine learning because the design of machine learning algorithms often relies on probability assumptions about the data.
+
+> For example, in the course of machine learning (Andrew Ng), there is a naive Bayesian hypothesis that is an example of conditional independence. The learning algorithm makes assumptions about the content to determine if the email is spam. Assume that the probability condition that the word x appears in the message is independent of the word y, regardless of whether the message is spam or not. Obviously this assumption is not without loss of generality, because some words almost always appear at the same time. However, the end result is that this simple assumption has little effect on the results, and in any case allows us to quickly identify spam.
+
+## 1.11 What is the difference between a variable and a random variable?
+**Random variable**
+
+A real-valued function (all possible sample points) for various outcomes in a random phenomenon (a phenomenon that does not always appear the same result under certain conditions). For example, the number of passengers waiting at a bus stop at a certain time, the number of calls received by the telephone exchange at a certain time, etc., are all examples of random variables.
+The essential difference between the uncertainty of random variables and fuzzy variables is that the latter results are still uncertain, that is, ambiguity.
+
+**The difference between a variable and a random variable: **
+When the probability of the value of the variable is not 1, the variable becomes a random variable; when the probability of the random variable is 1, the random variable becomes a variable.
+
+> For example:
+> When the probability of a variable $x$ value of 100 is 1, then $x=100$ is determined and will not change unless there is further operation.
+> When the probability of the variable $x$ is 100, the probability of 50 is 0.5, and the probability of 100 is 0.5. Then the variable will change with different conditions. It is a random variable. The probability of 50 or 100 is 0.5, which is 50%.
+
+## 1.12 The relationship between random variables and probability distribution?
+
+A random variable simply represents a state that may be achieved, and a probability distribution associated with it must be given to establish the probability of each state. The method used to describe the probability of the probability of each possible state of a random variable or a cluster of random variables is the **probability distribution**.
+
+Random variables can be divided into discrete random variables and continuous random variables.
+
+The corresponding function describing its probability distribution is
+
+Probability Mass Function (PMF): Describes the probability distribution of discrete random variables, usually expressed in uppercase letters $P$.
+
+Probability Density Function (PDF): A probability distribution describing a continuous random variable, usually expressed in lowercase letters $p$.
+
+### 1.12.1 Discrete random variables and probability mass functions
+
+PMF maps each state that a random variable can take to a random variable to obtain the probability of that state.
+
+- In general, $P(x)$ represents the probability of $X=x $.
+- Sometimes to avoid confusion, explicitly write the name of the random variable $P( $x$=x) $
+- Sometimes you need to define a random variable and then formulate the probability distribution x it follows. Obey $P($x $) $
+
+PMF can act on multiple random variables simultaneously, ie joint probability distribution $P(X=x, Y=y) $* means $X=x $ and the same as $Y=y $ Probability can also be abbreviated as $P(x,y) $.
+
+If a function $P $ is a PMF of the random variable $X $, then it must satisfy the following three conditions:
+
+- $P$'s domain must be a collection of all possible states
+- $∀x∈ $x, $0 \leq P(x) \leq 1 $.
+- $∑_{x∈X} P(x)=1$. We call this property normalized
+
+### 1.12.2 Continuous Random Variables and Probability Density Functions
+
+If a function $p $ is a PDF of x, then it must satisfy the following conditions
+
+- The domain of $p$ must be a collection of all possible states of xx.
+- $∀x∈X,p(x)≥0$. Note that we do not require $p(x)≤1$ because $p(x)$ is not the specific probability of representing this state, and Is a relative size (density) of probability. The specific probability requires integration to find.
+- $∫p(x)dx=1$, the score is down, the sum is still 1, and the sum of the probabilities is still 1.
+
+Note: PDF$p(x)$ does not directly give a probability to a particular state, giving a density. In contrast, it gives a probability that the area falling within a small area of $δx$ is $ p(x)δx$. Thus, we can't find the probability of a particular state. What we can find is that the probability that a state $x$ falls within a certain interval $[a,b]$ is $ \int_{a}^{b}p(x)dx$.
+
+## 1.13 Common probability distribution
+
+### 1.13.1 Bernoulli Distribution
+
+**Bernoulli distribution** is a single binary random variable distribution, single parameter $\phi $∈[0,1] control, $\phi $ gives the probability that the random variable is equal to 1. The main properties are:
+$$
+\begin{align*}
+P(x=1) &= \phi \\
+P(x=0) &= 1-\phi \\
+P(x=x) &= \phi^x(1-\phi)^{1-x} \\
+\end{align*}
+$$
+Its expectations and variances are:
+$$
+\begin{align*}
+E_x[x] &= \phi \\
+Var_x(x) &= \phi{(1-\phi)}
+\end{align*}
+$$
+**Multinoulli distribution** is also called **category distribution**, which is a random distribution of individual *k*k values, often used to represent the distribution of **object classifications**. where $k $ is a finite value. Multinoulli distribution consists of Vector $\vec{p}\in[0,1]^{k-1} $parameterized, each component $p_i $ represents the probability of the $i $ state, and $p_k=1-1 ^Tp $.
+
+**Scope of application**: **Bernoulli distribution** is suitable for modeling **discrete **random variables.
+
+### 1.13.2 Gaussian distribution
+
+Gauss is also called Normal Distribution. The probability function is as follows:
+$$
+N(x;\mu,\sigma^2) = \sqrt{\frac{1}{2\pi\sigma^2}}exp\left ( -\frac{1}{2\sigma^2}(x -\mu)^2 \right )
+$$
+Where $\mu $ and $\sigma $ are mean and variance, respectively. The center peak x coordinate is given by $\mu $, the width of the peak is controlled by $\sigma $, and the maximum point is $x=\ Obtained at mu $, the inflection point is $x=\mu\pm\sigma $
+
+In the normal distribution, the probability of ±1$\sigma$, ±2$\sigma$, and ±3$\sigma$ are 68.3%, 95.5%, and 99.73%, respectively. These three numbers are best remembered.
+
+In addition, let $\mu=0, \sigma=1 $ Gaussian distribution be reduced to the standard normal distribution:
+$$
+N(x;\mu,\sigma^2) = \sqrt{\frac{1}{2\pi}}exp\left ( -\frac{1}{2}x^2 \right )
+$$
+Efficiently evaluate the probability density function:
+$$
+N(x;\mu,\beta^{-1})=\sqrt{\frac{\beta}{2\pi}}exp\left(-\frac{1}{2}\beta(x-\ Mu)^2\right)
+$$
+
+
+Among them, $\beta=\frac{1}{\sigma^2}$ controls the distribution precision by the parameter $\beta∈(0,\infty) $.
+
+### 1.13.3 When is a normal distribution?
+
+Q: When is a normal distribution?
+Answer: There is no prior knowledge distributed on real numbers. When I don't know which form to choose, the default choice of normal distribution is always wrong. The reasons are as follows:
+
+1. The central limit theorem tells us that many independent random variables approximate a normal distribution. In reality, many complex systems can be modeled as normally distributed noise, even if the system can be structurally decomposed.
+2. Normal distribution is the distribution with the greatest uncertainty among all probability distributions with the same variance. In other words, the normal distribution is the distribution with the least knowledge added to the model.
+
+Generalization of normal distribution:
+The normal distribution can be generalized to the $R^n$ space, which is called the **multiple normal distribution**, whose parameter is a positive definite symmetric matrix $\sum$:
+$$
+N(x;\vec\mu,\sum)=\sqrt{\frac{1}{2\pi^ndet(\sum)}}exp\left(-\frac{1}{2}(\vec{ x}-\vec{\mu})^T\sum^-1(\vec{x}-\vec{\mu})\right)
+$$
+Efficiently evaluate the probability density of mostly normal distributions:
+$$
+N(x;\vec{\mu},\vec\beta^{-1}) = \sqrt{det(\vec\beta)}{(2\pi)^n}exp\left(-\frac{ 1}{2}(\vec{x}-\vec\mu)^T\beta(\vec{x}-\vec\mu)\right)
+$$
+Here, $\vec\beta$ is a precision matrix.
+
+### 1.13.4 Exponential distribution
+
+In deep learning, the exponential distribution is used to describe the distribution of the boundary points at $x=0$. The exponential distribution is defined as follows:
+$$
+p(x;\lambda)=\lambda1_{x\geq 0}exp(-\lambda{x})
+$$
+The exponential distribution uses the indication function $I_{x>=0}$ to make the probability of a negative value of $x$ zero.
+
+### 1.13.5 Laplace Distribution
+
+A closely related probability distribution is the Laplace distribution, which allows us to set the peak of the probability mass at any point of $\mu$
+$$
+Laplace(x;\mu;\gamma)=\frac{1}{2\gamma}exp\left(-\frac{|x-\mu|}{\gamma}\right)
+$$
+
+### 1.13.6
+Dirac distribution and empirical distribution
+
+The Dirac distribution ensures that all the masses in the probability distribution are concentrated at one point. The Diract-distributed Dirac $\delta $ function (also known as the **unit pulse function**) is defined as follows:
+$$
+p(x)=\delta(x-\mu), x\neq \mu
+$$
+
+$$
+\int_{a}^{b}\delta(x-\mu)dx = 1, a < \mu < b
+$$
+
+Dirac distribution often appears as an integral part of the empirical distribution
+$$
+\hat{p}(\vec{x})=\frac{1}{m}\sum_{i=1}^{m}\delta(\vec{x}-{\vec{x}}^{ (i)})
+$$
+, where m points $x^{1},...,x^{m}$ is the given data set, **experience distribution** will have probability density $\frac{1}{m} $ Assigned to these points.
+
+When we train the model on the training set, we can assume that the empirical distribution obtained from this training set indicates the source of the sample**.
+
+** Scope of application**: The Dirac δ function is suitable for the empirical distribution of **continuous ** random variables.
+
+## 1.14 Example Understanding Conditional Probability
+The conditional probability formula is as follows:
+
+$$
+P(A/B) = P(A\cap B) / P(B)
+$$
+
+Description: The event or subset $A$ and $B$ in the same sample space $\Omega$, if an element randomly selected from $\Omega$ belongs to $B$, then the next randomly selected element The probability of belonging to $A$ is defined as the conditional probability of $A$ on the premise of $B$.
+
+
+According to the Venn diagram, it can be clearly seen that in the event of event B, the probability of event A occurring is $P(A\bigcap B)$ divided by $P(B)$.
+Example: A couple has two children. What is the probability that one of them is a girl and the other is a girl? (I have encountered interviews and written tests)
+**Exhaustive law**: Knowing that one of them is a girl, then the sample space is for men, women, women, and men, and the probability that another is still a girl is 1/3.
+**Conditional probability method**: $P(female|female)=P(female)/P(female)$, couple has two children, then its sample space is female, male, female, male, male Male, $P (female) $ is 1/4, $P (female) = 1-P (male male) = 3/4$, so the last $1/3$.
+Everyone here may misunderstand that men, women and women are in the same situation, but in fact they are different situations like brothers and sisters.
+
+## 1.15 What is the difference between joint probability and edge probability?
+**The difference:**
+Joint Probability: Joint Probability refers to a probability that, like $P(X=a, Y=b)$, contains multiple conditions, and all conditions are true at the same time. Joint probability refers to the probability that multiple random variables satisfy their respective conditions in a multivariate probability distribution.
+Edge Probability: An edge probability is the probability that an event will occur, regardless of other events. The edge probability refers to a probability similar to $P(X=a)$, $P(Y=b)$, which is only related to a single random variable.
+
+**Contact: **
+The joint distribution can find the edge distribution, but if only the edge distribution is known, the joint distribution cannot be obtained.
+
+## 1.16 The chain rule of conditional probability
+From the definition of conditional probability, the following multiplication formula can be directly derived:
+Multiplication formula Let $A, B$ be two events, and $P(A) > 0$, then
+
+$$
+P(AB) = P(B|A)P(A)
+$$
+
+Promotion
+
+$$
+P(ABC)=P(C|AB)P(B|A)P(A)
+$$
+
+In general, the induction method can be used to prove that if $P(A_1A_2...A_n)>0$, then there is
+
+$$
+P(A_1A_2...A_n)=P(A_n|A_1A_2...A_{n-1})P(A_{n-1}|A_1A_2...A_{n-2})...P(A_2 |A_1)P(A_1)
+=P(A_1)\prod_{i=2}^{n}P(A_i|A_1A_2...A_{i-1})
+$$
+
+Any multi-dimensional random variable joint probability distribution can be decomposed into a conditional probability multiplication form with only one variable.
+
+## 1.17 Independence and conditional independence
+**Independence**
+The two random variables $x$ and $y$, the probability distribution is expressed as a product of two factors, one factor containing only $x$ and the other factor containing only $y$, and the two random variables are independent.
+Conditions sometimes bring independence between events that are not independent, and sometimes they lose their independence because of the existence of this condition.
+Example: $P(XY)=P(X)P(Y)$, event $X$ is independent of event $Y$. Given $Z$ at this time,
+
+$$
+P(X,Y|Z) \not = P(X|Z)P(Y|Z)
+$$
+
+When the event is independent, the joint probability is equal to the product of the probability. This is a very good mathematical nature, but unfortunately, unconditional independence is very rare, because in most cases, events interact with each other.
+
+**Conditional independence**
+Given $Z$, $X$ and $Y$ are conditional, if and only if
+
+$$
+X\bot Y|Z \iff P(X,Y|Z) = P(X|Z)P(Y|Z)
+$$
+
+The relationship between $X$ and $Y$ depends on $Z$, not directly.
+
+>**Example** defines the following events:
+>$X$: It will rain tomorrow;
+>$Y$: Today's ground is wet;
+>$Z$: Is it raining today?
+The establishment of the >$Z$ event has an impact on both $X$ and $Y$. However, given the establishment of the $Z$ event, today's ground conditions have no effect on whether it will rain tomorrow.
+
+## 1.18 Summary of Expectation, Variance, Covariance, Correlation Coefficient
+**Expectation**
+In probability theory and statistics, the mathematical expectation (or mean, also referred to as expectation) is the sum of the probability of each possible outcome in the trial multiplied by the result. It reflects the average value of random variables.
+
+- Linear operation: $E(ax+by+c) = aE(x)+bE(y)+c$
+- Promotion form: $E(\sum_{k=1}^{n}{a_ix_i+c}) = \sum_{k=1}^{n}{a_iE(x_i)+c}$
+- Function expectation: Let $f(x)$ be a function of $x$, then the expectation of $f(x)$ is
+ - Discrete function: $E(f(x))=\sum_{k=1}^{n}{f(x_k)P(x_k)}$
+ - Continuous function: $E(f(x))=\int_{-\infty}^{+\infty}{f(x)p(x)dx}$
+
+> Note:
+>
+> - The expectation of the function is not equal to the expected function, ie $E(f(x))=f(E(x))$
+> - In general, the expectation of the product is not equal to the expected product.
+> - If $X$ and $Y$ are independent of each other, $E(xy)=E(x)E(y) $.
+
+**Variance**
+
+The variance in probability theory is used to measure the degree of deviation between a random variable and its mathematical expectation (ie, mean). Variance is a special expectation. defined as:
+
+$$
+Var(x) = E((x-E(x))^2)
+$$
+
+> Variance nature:
+>
+> 1)$Var(x) = E(x^2) -E(x)^2$
+> 2) The variance of the constant is 0;
+> 3) The variance does not satisfy the linear nature;
+> 4) If $X$ and $Y$ are independent of each other, $Var(ax+by)=a^2Var(x)+b^2Var(y)$
+
+**Covariance**
+Covariance is a measure of the linear correlation strength and variable scale of two variables. The covariance of two random variables is defined as:
+
+$$
+Cov(x,y)=E((x-E(x))(y-E(y)))
+$$
+
+Variance is a special covariance. When $X=Y$, $Cov(x,y)=Var(x)=Var(y)$.
+
+> Covariance nature:
+>
+> 1) The covariance of the independent variable is 0.
+> 2) Covariance calculation formula:
+
+$$
+Cov(\sum_{i=1}^{m}{a_ix_i}, \sum_{j=1}^{m}{b_jy_j}) = \sum_{i=1}^{m} \sum_{j=1 }^{m}{a_ib_jCov(x_iy_i)}
+$$
+
+>
+> 3) Special circumstances:
+
+$$
+Cov(a+bx, c+dy) = bdCov(x, y)
+$$
+
+**Correlation coefficient**
+The correlation coefficient is the amount by which the linear correlation between the variables is studied. The correlation coefficient of two random variables is defined as:
+
+$$
+Corr(x,y) = \frac{Cov(x,y)}{\sqrt{Var(x)Var(y)}}
+$$
+
+> The nature of the correlation coefficient:
+> 1) Bordered. The range of correlation coefficients is , which can be regarded as a dimensionless covariance.
+> 2) The closer the value is to 1, the stronger the positive correlation (linearity) of the two variables. The closer to -1, the stronger the negative correlation, and when 0, the two variables have no correlation.
diff --git a/English version/ch01_MathematicalBasis/img/ch1/conditional_probability.jpg b/English version/ch01_MathematicalBasis/img/ch1/conditional_probability.jpg
new file mode 100644
index 00000000..549310d0
Binary files /dev/null and b/English version/ch01_MathematicalBasis/img/ch1/conditional_probability.jpg differ
diff --git a/English version/ch01_MathematicalBasis/img/ch1/prob_distribution_1.png b/English version/ch01_MathematicalBasis/img/ch1/prob_distribution_1.png
new file mode 100644
index 00000000..308c16de
Binary files /dev/null and b/English version/ch01_MathematicalBasis/img/ch1/prob_distribution_1.png differ
diff --git a/English version/ch01_MathematicalBasis/img/ch1/prob_distribution_2.png b/English version/ch01_MathematicalBasis/img/ch1/prob_distribution_2.png
new file mode 100644
index 00000000..19515432
Binary files /dev/null and b/English version/ch01_MathematicalBasis/img/ch1/prob_distribution_2.png differ
diff --git a/English version/ch01_MathematicalBasis/img/ch1/prob_distribution_3.png b/English version/ch01_MathematicalBasis/img/ch1/prob_distribution_3.png
new file mode 100644
index 00000000..4303cd9d
Binary files /dev/null and b/English version/ch01_MathematicalBasis/img/ch1/prob_distribution_3.png differ
diff --git a/English version/ch01_MathematicalBasis/img/ch1/prob_distribution_4.png b/English version/ch01_MathematicalBasis/img/ch1/prob_distribution_4.png
new file mode 100644
index 00000000..2533f214
Binary files /dev/null and b/English version/ch01_MathematicalBasis/img/ch1/prob_distribution_4.png differ
diff --git a/English version/ch01_MathematicalBasis/img/ch1/prob_distribution_5.png b/English version/ch01_MathematicalBasis/img/ch1/prob_distribution_5.png
new file mode 100644
index 00000000..5c5e6544
Binary files /dev/null and b/English version/ch01_MathematicalBasis/img/ch1/prob_distribution_5.png differ
diff --git a/English version/ch01_MathematicalBasis/img/ch1/prob_distribution_6.png b/English version/ch01_MathematicalBasis/img/ch1/prob_distribution_6.png
new file mode 100644
index 00000000..8946ebc5
Binary files /dev/null and b/English version/ch01_MathematicalBasis/img/ch1/prob_distribution_6.png differ
diff --git a/English version/ch01_MathematicalBasis/img/ch1/prob_distribution_7.png b/English version/ch01_MathematicalBasis/img/ch1/prob_distribution_7.png
new file mode 100644
index 00000000..7b637f0b
Binary files /dev/null and b/English version/ch01_MathematicalBasis/img/ch1/prob_distribution_7.png differ
diff --git a/English version/ch01_MathematicalBasis/readme.md b/English version/ch01_MathematicalBasis/readme.md
new file mode 100644
index 00000000..3509a055
--- /dev/null
+++ b/English version/ch01_MathematicalBasis/readme.md
@@ -0,0 +1,14 @@
+###########################################################
+
+### Deep Learning 500 Questions - Chapter 1 Mathematical Foundation
+
+**Responsible person (in no particular order):**
+Harbin Institute of Technology doctoral student - Yuan Di
+Qiao Chenglei-Tongji University
+
+**Contributors (in no particular order):**
+Content contributors can add information
+
+Liu Yanchao - Southeast University
+Liu Yuande-Shanghai University of Technology (Content Revision)
+###########################################################
diff --git a/English version/ch02_MachineLearningFoundation/Chapter 2_TheBasisOfMachineLearning.md b/English version/ch02_MachineLearningFoundation/Chapter 2_TheBasisOfMachineLearning.md
new file mode 100644
index 00000000..370cb8c1
--- /dev/null
+++ b/English version/ch02_MachineLearningFoundation/Chapter 2_TheBasisOfMachineLearning.md
@@ -0,0 +1,2205 @@
+[TOC]
+
+
+
+# Chapter 2 Fundamentals of Machine Learning
+
+## 2.1 Understanding the essence of machine learning
+
+Machine Learning (ML), as the name suggests, lets the machine learn. Here, the machine refers to the computer, which is the physical carrier of the algorithm. You can also think of the various algorithms as a machine with input and output. So what do you want the computer to learn? For a task and its performance measurement method, an algorithm is designed to enable the algorithm to extract the laws contained in the data. This is called machine learning. If the data entered into the machine is tagged, it is called supervised learning. If the data is unlabeled, it is unsupervised learning.
+
+## 2.2 Various common algorithm icons
+
+|Regression Algorithm|Clustering Algorithm|Regularization Method|
+|:-:|:-:|:-:|
+||||
+
+| Decision Tree Learning | Bayesian Methods | Kernel-Based Algorithms |
+|:-:|:-:|:-:|
+||||
+
+|Clustering Algorithm|Association Rule Learning|Artificial Neural Network|
+|:-:|:-:|:-:|
+||||
+
+|Deep Learning|Lower Dimensional Algorithm|Integrated Algorithm|
+|:-:|:-:|:-:|
+||||
+
+## 2.3 Supervised learning, unsupervised learning, semi-supervised learning, weak supervision learning?
+There are different ways to model a problem, depending on the type of data. According to different learning methods and input data, machine learning is mainly divided into the following four learning methods.
+
+**Supervised learning**:
+1. Supervised learning is the use of examples of known correct answers to train the network. A process in which data and its one-to-one correspondence are known, a prediction model is trained, and input data is mapped to a label.
+2. Common application scenarios for supervised learning such as classification and regression.
+3. Common supervised machine learning algorithms include Support Vector Machine (SVM), Naive Bayes, Logistic Regression, K-Nearest Neighborhood (KNN), Decision Tree (Decision Tree), Random Forest, AdaBoost, and Linear Discriminant Analysis (LDA). Deep Learning is also presented in the form of supervised learning.
+
+**Unsupervised learning**:
+
+1. In unsupervised learning, data is not specifically identified and applies to situations where you have a data set but no tags. The learning model is to infer some of the internal structure of the data.
+2. Common application scenarios include learning of association rules and clustering.
+3. Common algorithms include the Apriori algorithm and the k-Means algorithm.
+
+**Semi-supervised learning**:
+
+1. In this learning mode, the input data part is marked and some parts are not marked. This learning model can be used for prediction.
+2. The application scenario includes classification and regression. The algorithm includes some extensions to commonly used supervised learning algorithms. By modeling the marked data, on the basis of this, the unlabeled data is predicted.
+3. Common algorithms such as Graph Inference or Laplacian SVM.
+
+**Weakly supervised learning**:
+
+1. Weak supervised learning can be thought of as a collection of data with multiple tags, which can be empty sets, single elements, or multiple elements containing multiple cases (no tags, one tag, and multiple tags) .
+2. The label of the data set is unreliable. The unreliable here can be incorrect mark, multiple marks, insufficient mark, local mark, etc.
+3. A process in which known data and its one-to-one weak tags train an intelligent algorithm to map input data to a stronger set of tags. The strength of the label refers to the amount of information contained in the label. For example, the label of the classification is a weak label relative to the divided label.
+4. For example, to give a picture containing a balloon, you need to get the position of the balloon in the picture and the dividing line of the balloon and the background. This is the problem that the weak tag is known to learn strong tags.
+
+ In the context of enterprise data applications, the most common ones are the models of supervised learning and unsupervised learning. In the field of image recognition, semi-supervised learning is a hot topic due to the large amount of non-identified data and a small amount of identifiable data.
+
+## 2.4 What steps are there to supervise learning?
+Supervised learning is the use of examples of known correct answers to train the network, with a clear identification or result for each set of training data. Imagine we can train a network to recognize a photo of a balloon from a photo gallery (which contains a photo of a balloon). Here are the steps we will take in this hypothetical scenario.
+
+**Step 1: Data set creation and classification**
+First, browse through your photos (datasets), identify all the photos that contain balloons, and mark them. Then, divide all the photos into a training set and a verification set. The goal is to find a function in the deep network. This function input is any photo. When the photo contains a balloon, it outputs 1, otherwise it outputs 0.
+
+**Step 2: Data Augmentation**
+When the original data is collected and labeled, the data collected generally does not necessarily contain the information under the various disturbances. The quality of the data is critical to the predictive power of the machine learning model, so data enhancement is generally performed. For image data, data enhancement generally includes image rotation, translation, color transformation, cropping, affine transformation, and the like.
+
+**Step 3: Feature Engineering**
+In general, feature engineering includes feature extraction and feature selection. The common Hand-Crafted Feature includes Scale-Invariant Feature Transform (SIFT) and Histogram of Oriented Gradient (HOG). Since the manual features are heuristic, the starting point behind the algorithm design is different. When these features are combined, there may be conflicts, how to make the performance of the combined features play out, and the original data is discriminating in the feature space. To use, the method of feature selection is needed. After the success of the deep learning method, a large part of people no longer pay attention to the feature engineering itself. Because the most commonly used Convolutional Neural Networks (CNNs) are themselves an engine for feature extraction and selection. The different network structures, regularization, and normalization methods proposed by the researchers are actually feature engineering in the context of deep learning.
+
+**Step 4: Building predictive models and losses**
+After mapping the raw data to the feature space, it means that we have a reasonable input. The next step is to build a suitable predictive model to get the output of the corresponding input. How to ensure the consistency of the output of the model and the input label, it is necessary to construct the loss function between the model prediction and the label. The common loss function (Loss Function) has cross entropy and mean square error. The process of continuously iterating through the optimization method to change the model from the initial initialization state to the predictive model step by step is actually the learning process.
+
+**Step 5: Training**
+Select the appropriate model and hyperparameter for initialization, such as the kernel function in the support vector machine, the penalty weight of the error term, and so on. After the model initialization parameters are set, the prepared feature data is input into the model, and the gap between the output and the label is continuously reduced by a suitable optimization method. When the iterative process reaches the cutoff condition, the trained model can be obtained. The most common method of optimization is the gradient descent method and its variants. The premise of using the gradient descent method is that the optimization objective function is deducible for the model.
+
+**Step 6: Verification and Model Selection**
+After training the training set image, you need to test the model. Use validation sets to verify that the model can accurately pick out photos with balloons.
+In this process, steps 2 and 3 are usually repeated by adjusting various things related to the model (hyperparameters), such as how many nodes are there, how many layers are there, and what kind of activation and loss functions are used. Actively and effectively train weights and so on to the stage of communication.
+
+**Step 7: Testing and Application**
+When you have an accurate model, you can deploy it to your application. You can publish the forecasting function as an API (Application Programming Interface) call, and you can call the API from the software to reason and give the corresponding results.
+
+## 2.5 Multi-instance learning?
+Multiple Instance Learning (MIL): A package that knows the data packets and data packets containing multiple data, trains intelligent algorithms, maps data packets to labels, and presents packages in some problems. The label for each data within.
+For example, if a video consists of many images, if it is 10,000, then we need to determine whether the video contains an object, such as a balloon. It is too time-consuming to label a frame with a balloon. It is usually time to say whether there is a balloon in this video, and you get the data of multiple examples. Not every 10000 frame of data has a balloon. As long as there is a balloon in one frame, we think that the packet has a balloon. Only when all video frames have no balloons, there is no balloon. From which part of the video (10000 photos) to learn whether there is a balloon, it is a problem of multi-instance learning.
+
+## 2.6 What is a neural network?
+A neural network is a network that connects multiple neurons in accordance with certain rules. Different neural networks have different connection rules.
+For example, Full Connected (FC) neural network, its rules include:
+
+1. There are three layers: input layer, output layer, and hidden layer.
+2. There is no connection between neurons in the same layer.
+3. The meaning of fully connected: each neuron in the Nth layer is connected to all neurons in the N-1th layer, and the output of the N-1th layer neuron is the input to the Nth layer neuron.
+4. Each connection has a weight.
+
+ **Neural Network Architecture**
+ The picture below is a neural network system, which consists of many layers. The input layer is responsible for receiving information, such as a picture of a cat. The output layer is the result of the computer's judgment on this input information, it is not a cat. The hidden layer is the transfer and processing of input information.
+ 
+
+## 2.7 Understanding Local Optimization and Global Optimization
+
+Laughing about local optimality and global optimality
+
+> Plato one day asks the teacher Socrates what is love? Socrates told him to go to the wheat field once, picking the biggest wheat ear back, not to look back, only to pick it once. Plato started out empty. His reason was that he saw it well, but he didn't know if it was the best. Once and fortunately, when he came to the end, he found that it was not as good as the previous one, so he gave up. Socrates told him: "This is love." This story makes us understand a truth, because of some uncertainty in life, so the global optimal solution is difficult to find, or does not exist at all, we should Set some qualifications, and then find the optimal solution in this range, that is, the local optimal solution - some seizures are better than empty ones, even if this seizure is just an interesting experience.
+> Plato asked one day what marriage is? Socrates told him to go to the woods once and choose the best tree to make a Christmas tree. He also refused to look back and only chose once. This time he was tired and dragged a sapling tree that looked straight, green, but a little sparse. His reason was that with the lessons of the last time, it was hard to see a seemingly good one and found time. Physical strength is not enough, and whether it is the best or not, I will get it back. Socrates told him: "This is marriage."
+
+Optimization problems are generally divided into local optimization and global optimization.
+
+1. Local optimization is to find the minimum value in a finite region of the function value space; and global optimization is to find the minimum value in the entire region of the function value space.
+2. The local minimum point of a function is the point at which its function value is less than or equal to a nearby point. But there may be points that are larger than the distance.
+3. The global minimum is the kind of feasible value whose function value is less than or equal to all.
+
+## 2.8 Classification algorithm
+
+Classification algorithms and regression algorithms are different ways of modeling the real world. The classification model considers that the output of the model is discrete. For example, nature's creatures are divided into different categories and are discrete. The output of the regression model is continuous. For example, the process of changing a person's height is a continuous process, not a discrete one.
+
+Therefore, when using the classification model or the regression model in the actual modeling process, it depends on your analysis and understanding of the task (real world).
+
+### 2.8.1 What are the advantages and disadvantages of common classification algorithms?
+
+| Algorithm | Advantages | Disadvantages |
+|:-|:-|:-|
+|Bayes Bayesian Classification | 1) The estimated parameters required are small and insensitive to missing data.
2) has a solid mathematical foundation and stable classification efficiency. |1) It is necessary to assume that the attributes are independent of each other, which is often not true. (I like to eat tomatoes and eggs, but I don't like to eat tomato scrambled eggs).
2) Need to know the prior probability.
3) There is an error rate in the classification decision. |
+|Decision Tree Decision Tree |1) No domain knowledge or parameter assumptions are required.
2) Suitable for high dimensional data.
3) Simple and easy to understand.
4) Processing a large amount of data in a short time, resulting in a feasible and effective result.
5) Ability to process both data type and regular attributes. |1) For inconsistent data for each category of samples, the information gain is biased towards those features with more values.
2) Easy to overfit.
3) Ignore the correlation between attributes.
4) Online learning is not supported. |
+|SVM support vector machine | 1) can solve the problem of machine learning in small samples.
2) Improve generalization performance.
3) can solve high-dimensional, nonlinear problems. Ultra-high-dimensional text classifications are still popular.
4) Avoid neural network structure selection and local minimum problems. |1) Sensitive to missing data.
2) Memory consumption is large and difficult to explain.
3) Running and tuning is a bit annoying. |
+|KNN K Neighbors|1) Simple thinking, mature theory, can be used for classification or regression;
2) can be used for nonlinear classification;
3) Training time complexity is O (n);
4) High accuracy, no assumptions about the data, not sensitive to the outlier; |1) The amount of calculation is too large.
2) For the problem of unbalanced sample classification, misjudgment will occur.
3) A lot of memory is needed.
4) The output is not very interpretable. |
+|Logistic Regression Logistic Regression|1) Fast.
2) Simple and easy to understand, directly see the weight of each feature.
3) The model can be easily updated to absorb new data.
4) If you want a probability framework, dynamically adjust the classification threshold. |Feature processing is complicated. There is a need for normalization and more feature engineering. |
+|Neural Network Neural Network|1) High classification accuracy.
2) Parallel processing capability.
3) Distributed storage and learning capabilities.
4) Strong robustness and not susceptible to noise. |1) A large number of parameters (network topology, threshold, threshold) are required.
2) The results are difficult to explain.
3) Training time is too long. |
+|Adaboosting|1)adaboost is a classifier with very high precision.
2) Various methods can be used to construct the sub-classifier, and the Adaboost algorithm provides the framework.
3) When using a simple classifier, the calculated results are understandable. And the weak classifier is extremely simple to construct.
4) Simple, no need to do feature screening.
5) Don't worry about overfitting. |sensitive to outlier|
+
+
+
+### 2.8.2 How to evaluate the classification algorithm?
+- **Several common terms**
+ Here are a few common model evaluation terms. Now suppose that our classification target has only two categories, which are considered positive and negative:
+ 1) True positives (TP): the number of positive cases that are correctly divided into positive examples, that is, the number of instances that are actually positive and are classified as positive by the classifier;
+ 2) False positives (FP): the number of positive examples that are incorrectly divided into positive examples, that is, the number of instances that are actually negative but are classified as positive by the classifier;
+ 3) False negatives (FN): the number of instances that are incorrectly divided into negative examples, that is, the number of instances that are actually positive but are classified as negative by the classifier;
+ 4) True negatives(TN): The number of negative cases that are correctly divided into negative examples, which are actually negative examples and are divided into negative examples by the classifier.
+
+
+
+The figure above is the confusion matrix of these four terms, and the following is explained:
+1) P = TP + FN represents the number of samples that are actually positive examples.
+2) True, False describes whether the classifier is correct.
+3) Positive and Negative are the classification results of the classifier. If the positive example is 1, the negative example is -1, ie positive=1, negative=-1. Use 1 for True, -1 for False, then the actual class label = TF\*PN, TF is true or false, and PN is positive or negative.
+4) For example, the actual class of True positives (TP) = 1 * 1 = 1 is a positive example, the actual class of False positives (FP) = (-1) \ * 1 = -1 is a negative example, False negatives ( The actual class label of FN) = (-1) \ * (-1) = 1 is a positive example, and the actual class label of True negatives (TN) = 1 * * (-1) = -1 is a negative example.
+
+
+
+- **Evaluation Indicators**
+ 1) Accuracy
+ The correct rate is our most common evaluation index, accuracy = (TP+TN)/(P+N). The correct rate is the proportion of the number of samples that are paired in all samples. Generally speaking, the higher the correct rate The better the classifier.
+ 2) Error rate (error rate)
+ The error rate is opposite to the correct rate, describing the proportion of the classifier's misclassification, error rate = (FP+FN)/(P+N). For an instance, the pairwise and the fault are mutually exclusive events, so Accuracy =1 - error rate.
+ 3) Sensitivity
+ Sensitivity = TP/P, which is the ratio of the paired pairs in all positive cases, which measures the ability of the classifier to identify positive examples.
+ 4) Specificity
+ Specificity = TN/N, which represents the proportion of pairs in all negative cases, which measures the ability of the classifier to identify negative examples.
+ 5) Precision (precision)
+ Precision=TP/(TP+FP), precision is a measure of accuracy, representing the proportion of the positive example that is divided into positive examples.
+ 6) Recall rate (recall)
+ The recall rate is a measure of coverage. There are several positive examples of the metric being divided into positive examples. Recate=TP/(TP+FN)=TP/P=sensitivity, it can be seen that the recall rate is the same as the sensitivity.
+ 7) Other evaluation indicators
+ Calculation speed: the time required for classifier training and prediction;
+ Robustness: The ability to handle missing values and outliers;
+ Scalability: The ability to handle large data sets;
+ Interpretability: The comprehensibility of the classifier's prediction criteria, such as the rules generated by the decision tree, is easy to understand, and the neural network's parameters are not well understood, we have to think of it as a black box.
+ 8) Accuracy and recall rate reflect two aspects of classifier classification performance. If you comprehensively consider the precision and recall rate, you can get a new evaluation index F1-score, also known as the comprehensive classification rate: $F1=\frac{2 \times precision \times recall}{precision + recall} $.
+
+In order to integrate the classification of multiple categories and evaluate the overall performance of the system, micro-average F1 (micro-averaging) and macro-averaging F1 (macro-averaging) are often used.
+
+(1) The macro-average F1 and the micro-average F1 are global F1 indices obtained in two different averaging modes.
+
+(2) Calculation method of macro average F1 First, F1 values are separately calculated for each category, and the arithmetic mean of these F1 values is taken as a global index.
+
+(3) The calculation method of the micro-average F1 is to first calculate the values of a, b, c, and d of each category, and then obtain the value of F1 from these values.
+
+(4) It is easy to see from the calculation of the two average F1s that the macro average F1 treats each category equally, so its value is mainly affected by the rare category, and the micro-average F1 considers each document in the document set equally, so Its value is greatly affected by common categories.
+
+
+
+- **ROC curve and PR curve**
+
+The ROC curve is an abbreviation for (Receiver Operating Characteristic Curve), which is a performance evaluation curve with sensitivity (true positive rate) as the ordinate and 1-specific (false positive rate) as the abscissa. . The ROC curves of different models for the same data set can be plotted in the same Cartesian coordinate system. The closer the ROC curve is to the upper left corner, the more reliable the corresponding model is. The model can also be evaluated by the area under the ROC curve (Area Under Curve, AUC). The larger the AUC, the more reliable the model.
+
+
+
+Figure 2.7.3 ROC curve
+
+The PR curve is an abbreviation of Precision Recall Curve, which describes the relationship between precision and recall, with recall as the abscissa and precision as the ordinate. The corresponding area AUC of the curve is actually the average accuracy (Average Precision, AP) of the evaluation index commonly used in target detection. The higher the AP, the better the model performance.
+
+### 2.8.3 Is the correct rate good for evaluating classification algorithms?
+
+Different algorithms have different characteristics, and have different performance effects on different data sets, and different algorithms are selected according to specific tasks. How to evaluate the quality of the classification algorithm, to do specific analysis of specific tasks. For the decision tree, the evaluation is mainly based on the correct rate, but other algorithms can only be evaluated with the correct rate.
+The answer is no.
+The correct rate is indeed a very intuitive and very good evaluation indicator, but sometimes the correct rate is not enough to represent an algorithm. For example, earthquake prediction is performed on a certain area, and the seismic classification attribute is divided into 0: no earthquake occurs, and 1 earthquake occurs. We all know that the probability of not happening is very great. For the classifier, if the classifier does not think about it, the class of each test sample is divided into 0, achieving a correct rate of 99%, but the problem comes. If the earthquake is really undetected, the consequences will be enormous. Obviously, the 99% correct rate classifier is not what we want. The reason for this phenomenon is mainly because the data distribution is not balanced, the data with category 1 is too small, and the misclassification of category 1 but reaching a high accuracy rate ignores the situation that the researchers themselves are most concerned about.
+
+### 2.8.4 What kind of classifier is the best?
+For a task, it is not possible for a specific classifier to satisfy or improve all of the metrics described above.
+If a classifier correctly pairs all instances, then the indicators are already optimal, but such classifiers often do not exist. For example, the earthquake prediction mentioned earlier, since it is impossible to predict the occurrence of an earthquake 100%, but the actual situation can tolerate a certain degree of false positives. Suppose that in 1000 predictions, there are 5 predictions of earthquakes. In the real situation, one earthquake occurred, and the other 4 were false positives. The correct rate dropped from 999/1000=99.9 to 996/1000=99.6. The recall rate increased from 0/1=0% to 1/1=100%. This is explained as, although the prediction error has been 4 times, but before the earthquake, the classifier can predict the right, did not miss, such a classifier is actually more significant, exactly what we want. In this case, the recall rate of the classifier is required to be as high as possible under the premise of a certain correct rate.
+
+## 2.9 Logistic Regression
+
+### 2.9.1 Regression division
+
+In the generalized linear model family, depending on the dependent variable, it can be divided as follows:
+
+1. If it is continuous, it is multiple linear regression.
+2. If it is a binomial distribution, it is a logistic regression.
+3. If it is a Poisson distribution, it is Poisson regression.
+4. If it is a negative binomial distribution, it is a negative binomial regression.
+5. The dependent variable of logistic regression can be either two-category or multi-category, but the two-category is more common and easier to explain. So the most common use in practice is the logical regression of the two classifications.
+
+### 2.9.2 Logistic regression applicability
+
+1. Used for probabilistic prediction. When used for probability prediction, the results obtained are comparable. For example, according to the model, it is predicted how much probability of a disease or a certain situation occurs under different independent variables.
+2. For classification. In fact, it is somewhat similar to the prediction. It is also based on the model. It is a probability to judge whether a person belongs to a certain disease or belongs to a certain situation, that is, to see how likely this person is to belong to a certain disease. When classifying, it is only necessary to set a threshold. The probability is higher than the threshold is one type, and the lower than the threshold is another.
+3. Look for risk factors. Look for risk factors for a disease, etc.
+4. Can only be used for linear problems. Logistic regression can only be used when the goals and characteristics are linear. Pay attention to two points when applying logistic regression: First, when it is known that the model is nonlinear, logical regression is not applicable; second, when using logistic regression, attention should be paid to selecting features that are linear with the target.
+5. Conditional independence assumptions need not be met between features, but the contributions of individual features are calculated independently.
+
+### 2.9.3 What is the difference between logistic regression and naive Bayes?
+1. Logistic regression is a discriminant model, Naive Bayes is a generation model, so all the differences between generation and discrimination are available.
+2. Naive Bayes belongs to Bayesian, logistic regression is the maximum likelihood, and the difference between two probabilistic philosophies.
+3. Naive Bayes requires a conditional independent hypothesis.
+4. Logistic regression requires that the feature parameters be linear.
+
+### 2.9.4 What is the difference between linear regression and logistic regression?
+
+(Contributor: Huang Qinjian - South China University of Technology)
+
+The output of a linear regression sample is a continuous value, $ y\in (-\infty , +\infty )$, and $y\in (0 in logistic regression)
+, 1) $, can only take 0 and 1.
+
+There are also fundamental differences in the fit function:
+
+Linear regression: $f(x)=\theta ^{T}x=\theta _{1}x _{1}+\theta _{2}x _{2}+...+\theta _{n }x _{n}$
+
+Logistic regression: $f(x)=P(y=1|x;\theta )=g(\theta ^{T}x)$, where $g(z)=\frac{1}{1+e ^{-z}}$
+
+
+It can be seen that the fitted function of the linear regression is a fit to the output variable y of f(x), and the fitted function of the logistic regression is a fit to the probability of a class 1 sample.
+
+So why do you fit with the probability of a type 1 sample, why can you fit it like this?
+
+$\theta ^{T}x=0$ is equivalent to the decision boundary of class 1 and class 0:
+
+When $\theta ^{T}x>0$, then y>0.5; if $\theta ^{T}x\rightarrow +\infty $, then $y \rightarrow 1 $, ie y is 1;
+
+
+When $\theta ^{T}x<0 $, then y<0.5; if $\theta ^{T}x\rightarrow -\infty $, then $y \rightarrow 0 $, ie y is class 0 ;
+
+At this time, the difference can be seen. In the linear regression, $\theta ^{T}x$ is the fitted function of the predicted value; in the logistic regression, $\theta ^{T}x $ is the decision boundary.
+
+| | Linear Regression | Logistic Regression |
+|:-------------:|:-------------:|:-----:|
+| Purpose | Forecast | Classification |
+| $y^{(i)}$ | Unknown | (0,1)|
+| Function | Fitting function | Predictive function |
+| Parameter Calculation | Least Squares | Maximum Likelihood Estimation |
+
+
+Explain in detail below:
+
+1. What is the relationship between the fitted function and the predictive function? Simply put, the fitting function is transformed into a logical function, which is converted to make $y^{(i)} \in (0,1)$;
+2. Can the least squares and maximum likelihood estimates be substituted for each other? Of course, the answer is no good. Let's take a look at the principle of relying on both: the maximum likelihood estimate is the parameter that makes the most likely data appear, and the natural dependence is Probability. The least squares is the calculation error loss.
+
+## 2.10 Cost function
+
+### 2.10.1 Why do you need a cost function?
+
+1. In order to obtain the parameters of the trained logistic regression model, a cost function is needed to obtain the parameters by training the cost function.
+2. The purpose function used to find the optimal solution.
+
+### 2.10.2 Principle of cost function
+In the regression problem, the cost function is used to solve the optimal solution, and the square error cost function is commonly used. There are the following hypothetical functions:
+
+$$
+h(x) = A + Bx
+$$
+
+Suppose there are two parameters, $A$ and $B$, in the function. When the parameters change, it is assumed that the function state will also change.
+As shown below:
+
+
+
+To fit the discrete points in the graph, we need to find the best $A$ and $B$ as possible to make this line more representative of all the data. How to find the optimal solution, which needs to be solved using the cost function, taking the squared error cost function as an example, assuming the function is $h(x)=\theta_0x$.
+The main idea of the square error cost function is to make the difference between the value given by the actual data and the corresponding value of the fitted line, and find the difference between the fitted line and the actual line. In practical applications, in order to avoid the impact of individual extreme data, a similar variance is used to take one-half of the variance to reduce the impact of individual data. Therefore, the cost function is derived:
+$$
+J(\theta_0, \theta_1) = \frac{1}{m}\sum_{i=1}^m(h(x^{(i)})-y^{(i)})^2
+$$
+
+**The optimal solution is the minimum value of the cost function **$\min J(\theta_0, \theta_1) $. If it is a parameter, the cost function is generally visualized by a two-dimensional curve. If it is 2 parameters, the cost function can see the effect through the 3D image. The more parameters, the more complicated.
+When the parameter is 2, the cost function is a three-dimensional image.
+
+
+
+### 2.10.3 Why is the cost function non-negative?
+There is a lower bound on the objective function. In the optimization process, if the optimization algorithm can reduce the objective function continuously, according to the monotonically bounded criterion, the optimization algorithm can prove that the convergence is effective.
+As long as the objective function of the design has a lower bound, it is basically possible, and the cost function is non-negative.
+
+### 2.10.4 Common cost function?
+1. **quadratic cost**:
+
+$$
+J = \frac{1}{2n}\sum_x\Vert y(x)-a^L(x)\Vert^2
+$$
+
+Where $J$ represents the cost function, $x$ represents the sample, $y$ represents the actual value, $a$ represents the output value, and $n$ represents the total number of samples. Using a sample as an example, the secondary cost function is:
+$$
+J = \frac{(y-a)^2}{2}
+$$
+If Gradient descent is used to adjust the size of the weight parameter, the gradient of weight $w$ and offset $b$ is derived as follows:
+$$
+\frac{\partial J}{\partial b}=(a-y)\sigma'(z)
+$$
+Where $z $ represents the input of the neuron and $\sigma $ represents the activation function. The gradient of the weight $w $ and offset $b $ is proportional to the gradient of the activation function. The larger the gradient of the activation function, the faster the weights $w $ and offset $b $ are adjusted. The faster the training converges.
+
+*Note*: The activation function commonly used in neural networks is the sigmoid function. The curve of this function is as follows:
+
+
+
+Compare the two points of 0.88 and 0.98 as shown:
+Assume that the target is to converge to 1.0. 0.88 is farther from the target 1.0, the gradient is larger, and the weight adjustment is larger. 0.98 is closer to the target 1.0, the gradient is smaller, and the weight adjustment is smaller. The adjustment plan is reasonable.
+If the target is converged to 0. 0.88 is closer to the target 0, the gradient is larger, and the weight adjustment is larger. 0.98 is far from the target 0, the gradient is relatively small, and the weight adjustment is relatively small. The adjustment plan is unreasonable.
+Cause: In the case of using the sigmoid function, the larger the initial cost (error), the slower the training.
+
+2. **Cross-entropy cost function (cross-entropy)**:
+
+$$
+J = -\frac{1}{n}\sum_x[y\ln a + (1-y)\ln{(1-a)}]
+$$
+
+Where $J$ represents the cost function, $x$ represents the sample, $y$ represents the actual value, $a$ represents the output value, and $n$ represents the total number of samples.
+The gradient of the weight $w$ and offset $b $ is derived as follows:
+$$
+\frac{\partial J}{\partial w_j}=\frac{1}{n}\sum_{x}x_j(\sigma{(z)}-y)\;,
+\frac{\partial J}{\partial b}=\frac{1}{n}\sum_{x}(\sigma{(z)}-y)
+$$
+
+The larger the error, the larger the gradient, the faster the weights $w$ and offset $b$ are adjusted, and the faster the training.
+**The quadratic cost function is suitable for the case where the output neuron is linear, and the cross entropy cost function is suitable for the case where the output neuron is a sigmoid function. **
+
+3. **log-likelihood cost**:
+Log-likelihood functions are commonly used as cost functions for softmax regression. The common practice in deep learning is to use softmax as the last layer. The commonly used cost function is the log-likelihood cost function.
+The combination of log-likelihood cost function and softmax and the combination of cross-entropy and sigmoid function are very similar. The log-likelihood cost function can be reduced to the form of a cross-entropy cost function in the case of two classifications.
+In tensorflow:
+The cross entropy function used with sigmoid: `tf.nn.sigmoid_cross_entropy_with_logits()`.
+The cross entropy function used with softmax: `tf.nn.softmax_cross_entropy_with_logits()`.
+In pytorch:
+ The cross entropy function used with sigmoid: `torch.nn.BCEWithLogitsLoss()`.
+The cross entropy function used with softmax: `torch.nn.CrossEntropyLoss()`.
+
+### 2.10.5 Why use cross entropy instead of quadratic cost function
+1. **Why not use the quadratic cost function**
+As you can see from the previous section, the partial derivative of the weight $w$ and the offset $b$ is $\frac{\partial J}{\partial w}=(ay)\sigma'(z)x$,$\frac {\partial J}{\partial b}=(ay)\sigma'(z)$, the partial derivative is affected by the derivative of the activation function, and the derivative of the sigmoid function is very small when the output is close to 0 and 1, which causes some instances to be Learning very slowly when starting training.
+
+2. **Why use cross entropy**
+The gradient of the cross entropy function weights $w$ and the offset $b$ is derived as:
+
+$$
+\frac{\partial J}{\partial w_j}=\frac{1}{n}\sum_{x}(\sigma{(a)}-y)\;,
+\frac{\partial J}{\partial b}=\frac{1}{n}\sum_{x}(\sigma{(z)}-y)
+$$
+
+It can be seen from the above formula that the speed of weight learning is affected by $\sigma{(z)}-y$, and the larger error has faster learning speed, avoiding the quadratic cost function equation due to $\sigma'{ (z)}$ The slow learning situation.
+
+## 2.11 Loss function
+
+### 2.11.1 What is a loss function?
+
+The Loss Function, also called the error function, is used to measure the operation of the algorithm. It is a non-negative real-valued function that measures the inconsistency between the predicted value of the model and the real value. Usually, $ is used.
+L(Y, f(x))$ is used to indicate. The smaller the loss function, the better the robustness of the model. The loss function is the core part of the empirical risk function and an important part of the structural risk function.
+
+### 2.11.2 Common loss function
+Machine learning optimizes the objective function in the algorithm to get the final desired result. In classification and regression problems, a loss function or a cost function is usually used as the objective function.
+The loss function is used to evaluate the extent to which the predicted value is not the same as the true value. Usually the better the loss function, the better the performance of the model.
+The loss function can be divided into an empirical risk loss function and a structural risk loss function. The empirical risk loss function refers to the difference between the predicted result and the actual result. The structural risk loss function adds a regular term to the empirical risk loss function.
+The following describes the commonly used loss function:
+
+1. **0-1 loss function**
+If the predicted value is equal to the target value, the value is 0. If they are not equal, the value is 1.
+
+$$
+L(Y, f(x)) =
+\begin{cases}
+1,& Y\ne f(x)\\
+0, & Y = f(x)
+\end{cases}
+$$
+
+Generally, in actual use, the equivalent conditions are too strict, and the conditions can be appropriately relaxed:
+
+$$
+L(Y, f(x)) =
+\begin{cases}
+1,& |Y-f(x)|\ge T\\
+0,& |Y-f(x)|< T
+\end{cases}
+$$
+
+2. **Absolute loss function**
+Similar to the 0-1 loss function, the absolute value loss function is expressed as:
+
+$$
+L(Y, f(x)) = |Y-f(x)|
+$$
+
+3. **squared loss function**
+
+$$
+L(Y, f(x)) = \sum_N{(Y-f(x))}^2
+$$
+
+This can be understood from the perspective of least squares and Euclidean distance. The principle of the least squares method is that the best fit curve should minimize and minimize the distance from all points to the regression line.
+
+4. **log logarithmic loss function**
+
+$$
+L(Y, P(Y|X)) = -\log{P(Y|X)}
+$$
+
+The common logistic regression uses the logarithmic loss function. Many people think that the loss of the functionalized square of the logistic regression is not. Logistic Regression It assumes that the sample obeys the Bernoulli distribution, and then finds the likelihood function that satisfies the distribution, and then takes the logarithm to find the extremum. The empirical risk function derived from logistic regression is to minimize the negative likelihood function. From the perspective of the loss function, it is the log loss function.
+
+5. **Exponential loss function**
+The standard form of the exponential loss function is:
+
+$$
+L(Y, f(x)) = \exp{-yf(x)}
+$$
+
+For example, AdaBoost uses the exponential loss function as a loss function.
+
+6. **Hinge loss function**
+The standard form of the Hinge loss function is as follows:
+
+$$
+L(Y) = \max{(0, 1-
+Ty)}
+$$
+
+Where y is the predicted value, the range is (-1,1), and t is the target value, which is -1 or 1.
+
+In linear support vector machines, the optimization problem can be equivalent to
+
+$$
+\underset{\min}{w,b}\sum_{i=1}^N (1-y_i(wx_i+b))+\lambda\Vert w^2\Vert
+$$
+
+The above formula is similar to the following
+
+$$
+\frac{1}{m}\sum_{i=1}^{N}l(wx_i+by_i) + \Vert w^2\Vert
+$$
+
+Where $l(wx_i+by_i)$ is the Hinge loss function and $\Vert w^2\Vert$ can be considered as a regularization.
+
+### 2.11.3 Why does Logistic Regression use a logarithmic loss function?
+Hypothetical logistic regression model
+$$
+P(y=1|x;\theta)=\frac{1}{1+e^{-\theta^{T}x}}
+$$
+Assume that the probability distribution of the logistic regression model is a Bernoulli distribution whose probability mass function is
+$$
+P(X=n)=
+\begin{cases}
+1-p, n=0\\
+ p,n=1
+\end{cases}
+$$
+Its likelihood function is
+$$
+L(\theta)=\prod_{i=1}^{m}
+P(y=1|x_i)^{y_i}P(y=0|x_i)^{1-y_i}
+$$
+Log likelihood function
+$$
+\ln L(\theta)=\sum_{i=1}^{m}[y_i\ln{P(y=1|x_i)}+(1-y_i)\ln{P(y=0|x_i) }]\\
+ =\sum_{i=1}^m[y_i\ln{P(y=1|x_i)}+(1-y_i)\ln(1-P(y=1|x_i))]
+$$
+The logarithmic function is defined on a single data point as
+$$
+Cost(y,p(y|x))=-y\ln{p(y|x)-(1-y)\ln(1-p(y|x))}
+$$
+Then the global sample loss function is:
+$$
+Cost(y,p(y|x)) = -\sum_{i=1}^m[y_i\ln p(y_i|x_i)-(1-y_i)\ln(1-p(y_i|x_i)) ]
+$$
+It can be seen that the log-like loss function and the log-likelihood function of the maximum likelihood estimation are essentially the same. So logistic regression directly uses the logarithmic loss function.
+
+### 2.11.4 How does the logarithmic loss function measure loss?
+Example:
+In the Gaussian distribution, we need to determine the mean and standard deviation.
+How to determine these two parameters? Maximum likelihood estimation is a more common method. The goal of maximum likelihood is to find some parameter values whose distributions maximize the probability of observing the data.
+Because it is necessary to calculate the full probability of all data observed, that is, the joint probability of all observed data points. Now consider the following simplification:
+
+1. Assume that the probability of observing each data point is independent of the probability of other data points.
+2. Take the natural logarithm.
+ Suppose the probability of observing a single data point $x_i(i=1,2,...n) $ is:
+$$
+P(x_i;\mu,\sigma)=\frac{1}{\sigma \sqrt{2\pi}}\exp
+\left( - \frac{(x_i-\mu)^2}{2\sigma^2} \right)
+$$
+
+
+3. Its joint probability is
+ $$
+ P(x_1,x_2,...,x_n;\mu,\sigma)=\frac{1}{\sigma \sqrt{2\pi}}\exp
+ \left( - \frac{(x_1-\mu)^2}{2\sigma^2} \right) \\ \times
+ \frac{1}{\sigma \sqrt{2\pi}}\exp
+ \left( - \frac{(x_2-\mu)^2}{2\sigma^2} \right) \times ... \times
+ \frac{1}{\sigma \sqrt{2\pi}}\exp
+ \left( - \frac{(x_n-\mu)^2}{2\sigma^2} \right)
+ $$
+
+
+ Take the natural logarithm of the above formula, you can get:
+ $$
+ \ln(P(x_1,x_2,...x_n;\mu,\sigma))=
+ \ln \left(\frac{1}{\sigma \sqrt{2\pi}} \right)
+ - \frac{(x_1-\mu)^2}{2\sigma^2} \\ +
+ \ln \left( \frac{1}{\sigma \sqrt{2\pi}} \right)
+ - \frac{(x_2-\mu)^2}{2\sigma^2} +...+
+ \ln \left( \frac{1}{\sigma \sqrt{2\pi}} \right)
+ - \frac{(x_n-\mu)^2}{2\sigma^2}
+ $$
+ According to the law of logarithm, the above formula can be reduced to:
+ $$
+ \ln(P(x_1,x_2,...x_n;\mu,\sigma))=-n\ln(\sigma)-\frac{n}{2} \ln(2\pi)\\
+ -\frac{1}{2\sigma^2}[(x_1-\mu)^2+(x_2-\mu)^2+...+(x_n-\mu)^2]
+ $$
+ Guide:
+ $$
+ \frac{\partial\ln(P(x_1,x_2,...,x_n;\mu,\sigma))}{\partial\mu}=
+ \frac{1}{\sigma^2}[x_1+x_2+...+x_n]
+ $$
+ The left half of the above equation is a logarithmic loss function. The smaller the loss function, the better, so we have a logarithmic loss function of 0, which gives:
+ $$
+ \mu=\frac{x_1+x_2+...+x_n}{n}
+ $$
+ Similarly, $\sigma $ can be calculated.
+
+## 2.12 Gradient descent
+
+### 2.12.1 Why do gradients need to be dropped in machine learning?
+
+1. Gradient descent is a type of iterative method that can be used to solve the least squares problem.
+2. When solving the model parameters of the machine learning algorithm, that is, the unconstrained optimization problem, there are mainly Gradient Descent and Least Squares.
+3. When solving the minimum value of the loss function, it can be solved step by step by the gradient descent method to obtain the minimized loss function and model parameter values.
+4. If we need to solve the maximum value of the loss function, it can be iterated by the gradient ascent method. The gradient descent method and the gradient descent method are mutually convertible.
+5. In machine learning, the gradient descent method mainly includes stochastic gradient descent method and batch gradient descent method.
+
+### 2.12.2 What are the disadvantages of the gradient descent method?
+1. Convergence slows down near the minimum value.
+2. There may be some problems when searching in a straight line.
+3. It may fall "zigzag".
+
+Gradient concepts need to be noted:
+1. A gradient is a vector, that is, it has a direction and a size;
+2. The direction of the gradient is the direction of the maximum direction derivative;
+3. The value of the gradient is the value of the maximum direction derivative.
+
+### 2.12.3 Gradient descent method intuitive understanding?
+Classical illustration of the gradient descent method:
+
+
+
+Visualization example:
+> From the above picture, if at the beginning, we are somewhere on a mountain, because there are strangers everywhere, we don’t know the way down the mountain, so we can only explore the steps based on intuition, in the process, Every time you go to a position, it will solve the gradient of the current position, go down one step along the negative direction of the gradient, that is, the current steepest position, and then continue to solve the current position gradient, and the steepest position along this step. The easiest place to go down the mountain. Constantly cycle through the gradients, and so on, step by step, until we feel that we have reached the foot of the mountain. Of course, if we go on like this, it is possible that we cannot go to the foot of the mountain, but to the low point of a certain local peak.
+Thus, as can be seen from the above explanation, the gradient descent does not necessarily find a global optimal solution, and may be a local optimal solution. Of course, if the loss function is a convex function, the solution obtained by the gradient descent method must be the global optimal solution.
+
+**Introduction of core ideas**:
+
+1. Initialize the parameters and randomly select any number within the range of values;
+2. Iterative operation:
+ a) calculate the current gradient;
+b) modify the new variable;
+c) calculate one step towards the steepest downhill direction;
+d) determine whether termination is required, if not, return a);
+3. Get the global optimal solution or close to the global optimal solution.
+
+### 2.12.4 Gradient descent algorithm description
+1. Determine the hypothesis function and loss function of the optimization model.
+ For example, for linear regression, the hypothesis function is:
+$$
+ H_\theta(x_1,x_2,...,x_n)=\theta_0+\theta_1x_1+...+\theta_nx_n
+$$
+ Where $\theta,x_i(i=1,2,...,n) $ are the model parameters and the eigenvalues of each sample.
+ For the hypothetical function, the loss function is:
+$$
+ J(\theta_0,\theta_1,...,\theta_n)=\frac{1}{2m}\sum^{m}_{j=0}(h_\theta (x^{(j)}_0)
+ ,(x^{(j)}_1),...,(x^{(j)}_n)-y_j)^2
+$$
+
+2. Related parameters are initialized.
+ Mainly initializes ${\theta}_i $, algorithm iteration step ${\alpha} $, and terminates distance ${\zeta} $. Initialization can be initialized empirically, ie ${\theta} $ is initialized to 0, and the step ${\alpha} $ is initialized to 1. The current step size is recorded as ${\varphi}_i $. Of course, it can also be randomly initialized.
+
+3. Iterative calculations.
+
+ 1) Calculate the gradient of the loss function at the current position. For ${\theta}_i$, the gradient is expressed as:
+
+$$
+\frac{\partial}{\partial \theta_i}J({\theta}_0,{\theta}_1,...,{\theta}_n)
+$$
+2) Calculate the distance at which the current position drops.
+$$
+{\varphi}_i={\alpha} \frac{\partial}{\partial \theta_i}J({\theta}_0,{\theta}_1,...,{\theta}_n)
+$$
+3) Determine if it is terminated.
+Determine if all ${\theta}_i$ gradients fall by ${\varphi}_i$ are less than the termination distance ${\zeta}$, if both are less than ${\zeta}$, the algorithm terminates, of course the value That is the final result, otherwise go to the next step.
+4) Update all ${\theta}_i$, the updated expression is:
+$$
+{\theta}_i={\theta}_i-\alpha \frac{\partial}{\partial \theta_i}J({\theta}_0,{\theta}_1,...,{\theta}_n)
+$$
+5) After the update is completed, transfer to 1).
+
+**Example **. Take linear regression as an example.
+Suppose the sample is
+$$
+(x^{(0)}_1,x^{(0)}_2,...,x^{(0)}_n,y_0),(x^{(1)}_1,x^{(1 )}_2,...,x^{(1)}_n,y_1),...,
+(x^{(m)}_1,x^{(m)}_2,...,x^{(m)}_n,y_m)
+$$
+The loss function is
+$$
+J(\theta_0,\theta_1,...,\theta_n)=\frac{1}{2m}\sum^{m}_{j=0}(h_\theta (x^{(j)}_0
+,x^{(j)}_1,...,x^{(j)}_n)-y_j)^2
+$$
+In the calculation, the partial derivative of ${\theta}_i$ is calculated as follows:
+$$
+\frac{\partial}{\partial \theta_i}J({\theta}_0,{\theta}_1,...,{\theta}_n)=\frac{1}{m}\sum^{m }_{j=0}(h_\theta (x^{(j)}_0
+,x^{(j)}_1,...,x^{(j)}_n)-y_j)x^{(j)}_i
+$$
+Let the above formula $x^{(j)}_0=1$. 4) The update expression for $\theta_i$ is:
+$$
+\theta_i=\theta_i - \alpha \frac{1}{m} \sum^{m}_{j=0}(h_\theta (x^{(j)}_0
+,x^{(j)}_1,...,x^{(j)}_n)-y_j)x^{(j)}_i
+$$
+
+
+From this, you can see
+Out, the gradient direction of the current position is determined by all samples. The purpose of $\frac{1}{m} $, $\alpha \frac{1}{m} $ is to make it easier to understand.
+
+### 2.12.5 How to tune the gradient descent method?
+When the gradient descent method is actually used, each parameter index can not reach the ideal state in one step, and the optimization of the gradient descent method is mainly reflected in the following aspects:
+1. **Algorithm iteration step $\alpha$ selection. **
+ When the algorithm parameters are initialized, the step size is sometimes initialized to 1 based on experience. The actual value depends on the data sample. You can take some values from big to small, and run the algorithm to see the iterative effect. If the loss function is smaller, the value is valid. If the value is invalid, it means to increase the step size. However, the step size is too large, sometimes causing the iteration speed to be too fast and missing the optimal solution. The step size is too small, the iteration speed is slow, and the algorithm runs for a long time.
+2. **The initial value selection of the parameter. **
+ The initial values are different, and the minimum values obtained may also be different. It is possible to obtain a local minimum due to the gradient drop. If the loss function is a convex function, it must be the optimal solution. Due to the risk of local optimal solutions, it is necessary to run the algorithm with different initial values multiple times, the minimum value of the key loss function, and the initial value of the loss function minimized.
+3. **Standardization process. **
+ Due to the different samples, the range of feature values is different, resulting in slow iteration. In order to reduce the influence of feature values, the feature data can be normalized so that the new expectation is 0 and the new variance is 1, which can save the algorithm running time.
+
+### 2.12.7 What is the difference between random gradients and batch gradients?
+Stochastic gradient descent and batch gradient descent are two main gradient descent methods whose purpose is to increase certain limits to speed up the computational solution.
+The following is a comparison of the two gradient descent methods.
+Assume that the function is
+$$
+H_\theta (x_1,x_2,...,x_3) = \theta_0 + \theta_1 + ... + \theta_n x_n
+$$
+The loss function is
+$$
+J(\theta_0, \theta_1, ... , \theta_n) =
+\frac{1}{2m} \sum^{m}_{j=0}(h_\theta (x^{(j)}_0
+,x^{(j)}_1,...,x^{(j)}_n)-y_j)^2
+$$
+Among them, $m $ is the number of samples, and $j $ is the number of parameters.
+
+1, **batch gradient descent solution ideas are as follows: **
+
+a) Get the gradient corresponding to each $\theta $:
+$$
+\frac{\partial}{\partial \theta_i}J({\theta}_0,{\theta}_1,...,{\theta}_n)=\frac{1}{m}\sum^{m }_{j=0}(h_\theta (x^{(j)}_0
+,x^{(j)}_1,...,x^{(j)}_n)-y_j)x^{(j)}_i
+$$
+b) Since it is to minimize the risk function, update $ \theta_i $ in the negative direction of the gradient of each parameter $ \theta $ :
+$$
+\theta_i=\theta_i - \frac{1}{m} \sum^{m}_{j=0}(h_\theta (x^{(j)}_0
+,x^{(j)}_1,...,x^{(j)}_n)-y_j)x^{(j)}_i
+$$
+c) It can be noticed from the above equation that although it is a global optimal solution, all data of the training set is used for each iteration. If the sample data is large, the iteration speed of this method is very slow.
+In contrast, a random gradient drop can avoid this problem.
+
+2. **The solution to the stochastic gradient descent is as follows: **
+a) Compared to all training samples compared to the batch gradient drop, the loss function in the stochastic gradient descent method corresponds to the granularity of each sample in the training set.
+The loss function can be written in the form of
+$$
+J(\theta_0, \theta_1, ... , \theta_n) =
+\frac{1}{m} \sum^{m}_{j=0}(y_i - h_\theta (x^{(j)}_0
+,x^{(j)}_1,...,x^{(j)}_n))^2 =
+\frac{1}{m} \sum^{m}_{j=0} cost(\theta,(x^j,y^j))
+$$
+b) For each parameter $ \theta $ update the gradient direction $ \theta $:
+$$
+\theta_i = \theta_i + (y_j - h_\theta (x^{(j)}_0, x^{(j)}_1, ... , x^{(j)}_n))
+$$
+c) The random gradient descent is iteratively updated by each sample.
+One problem associated with stochastic gradient descent is that the noise is much lower than the batch gradient, so that the stochastic gradient descent is not the direction of overall optimization for each iteration.
+
+**summary:**
+The stochastic gradient descent method and the batch gradient descent method are relatively extreme, and the simple comparison is as follows:
+
+| Method | Features |
+| :----------: | :----------------------------------- ------------------------ |
+| Batch gradient descent | a) Use all data to gradient down. b) The batch gradient descent method is slow in training when the sample size is large. |
+| Stochastic Gradient Descent | a) Stochastic gradient descent with a sample to gradient down. b) Training is fast.
+c) The stochastic gradient descent method uses only one sample to determine the direction of the gradient, which may result in a solution that is not optimal.
+d) In terms of convergence speed, the stochastic gradient descent method iterates one sample at a time, resulting in a large change in the iteration direction and cannot converge to the local optimal solution very quickly. |
+
+The following describes a small batch gradient descent method that combines the advantages of both methods.
+
+3, **small batch (mini-batch) gradient drop solution is as follows **
+For data with a total of $m$ samples, according to the sample data, select $n(1< n< m)$ subsamples to iterate. Its parameter $\theta$ updates the $\theta_i$ formula in the gradient direction as follows:
+$$
+\theta_i = \theta_i - \alpha \sum^{t+n-1}_{j=t}
+( h_\theta (x^{(j)}_{0}, x^{(j)}_{1}, ... , x^{(j)}_{n} ) - y_j ) x^ {j}_{i}
+$$
+
+### 2.12.8 Comparison of various gradient descent methods
+The table below briefly compares the difference between stochastic gradient descent (SGD), batch gradient descent (BGD), small batch gradient descent (mini-batch GD), and online GD:
+
+|BGD|SGD|GD|Mini-batch GD|Online GD|
+|:-:|:-:|:-:|:-:|:-:|:-:|
+| training set | fixed | fixed | fixed | real-time update |
+|Single iteration sample number | Whole training set | Single sample | Subset of training set | According to specific algorithm |
+| Algorithm Complexity | High | Low | General | Low |
+|Timeliness|Low|General|General|High|
+|convergence|stability|unstable|stable|unstable|unstable|
+
+BGD, SGD, Mini-batch GD, have been discussed before, here introduces Online GD.
+
+The difference between Online GD and mini-batch GD/SGD is that all training data is used only once and then discarded. The advantage of this is that it predicts the changing trend of the final model.
+
+Online GD is used more in the Internet field, such as the click rate (CTR) estimation model of search advertising, and the click behavior of netizens will change over time. Using the normal BGD algorithm (updated once a day) takes a long time (requires retraining of all historical data); on the other hand, it is unable to promptly feedback the user's click behavior migration. The Online GD algorithm can be migrated in real time according to the click behavior of netizens.
+
+## 2.13 Calculating the derivative calculation diagram of the graph?
+The computational graph derivative calculation is backpropagation, which is derived using chained rules and implicit functions.
+
+Suppose $z = f(u,v)$ is contiguous at point $(u,v)$, $(u,v)$ is a function of $t$, which can be guided at $t$ $z$ is the derivative of the $t$ point.
+
+According to the chain rule
+$$
+\frac{dz}{dt}=\frac{\partial z}{\partial u}.\frac{du}{dt}+\frac{\partial z}{\partial v}
+.\frac{dv}{dt}
+$$
+
+For ease of understanding, the following examples are given.
+Suppose $f(x) $ is a function of a, b, c. The chain derivation rule is as follows:
+$$
+\frac{dJ}{du}=\frac{dJ}{dv}\frac{dv}{du},\frac{dJ}{db}=\frac{dJ}{du}\frac{du}{db },\frac{dJ}{da}=\frac{dJ}{du}\frac{du}{da}
+$$
+
+The chain rule is described in words: "A composite function composed of two functions whose derivative is equal to the derivative of the value of the inner function substituted into the outer function, multiplied by the derivative of the inner function.
+
+example:
+
+$$
+f(x)=x^2,g(x)=2x+1
+$$
+
+then
+
+$$
+{f[g(x)]}'=2[g(x)] \times g'(x)=2[2x+1] \times 2=8x+1
+$$
+
+
+## 2.14 Linear Discriminant Analysis (LDA)
+
+### 2.14.1 Summary of LDA Thoughts
+
+Linear Discriminant Analysis (LDA) is a classic dimensionality reduction method. Unlike PCA, which does not consider the unsupervised dimensionality reduction technique of sample category output, LDA is a dimensionality reduction technique for supervised learning, with each sample of the data set having a category output.
+
+The LDA classification idea is briefly summarized as follows:
+1. In multi-dimensional space, the data processing classification problem is more complicated. The LDA algorithm projects the data in the multi-dimensional space onto a straight line, and converts the d-dimensional data into one-dimensional data for processing.
+2. For training data, try to project the multidimensional data onto a straight line. The projection points of the same kind of data are as close as possible, and the heterogeneous data points are as far as possible.
+3. When classifying the data, project it onto the same line and determine the category of the sample based on the position of the projected point.
+If you summarize the LDA idea in one sentence, that is, "the variance within the class after projection is the smallest, and the variance between classes is the largest".
+
+### 2.14.2 Graphical LDA Core Ideas
+Assume that there are two types of data, red and blue. These data features are two-dimensional, as shown in the following figure. Our goal is to project these data into one dimension, so that the projection points of each type of similar data are as close as possible, and the different types of data are as far as possible, that is, the distance between the red and blue data centers in the figure is as large as possible.
+
+
+
+The left and right images are two different projections.
+
+Left diagram: The projection method that allows the farthest points of different categories to be the farthest.
+
+The idea on the right: Let the data of the same category get the closest projection.
+
+As can be seen from the above figure, the red and blue data on the right are relatively concentrated in their respective regions. It can also be seen from the data distribution histogram, so the projection effect on the right is better than the one on the left. There is a clear intersection in the figure section.
+
+The above example is based on the fact that the data is two-dimensional, and the classified projection is a straight line. If the original data is multidimensional, the projected classification surface is a low-dimensional hyperplane.
+
+### 2.14.3 Principles of the second class LDA algorithm?
+Input: data set $D=\{(x_1,y_1),(x_2,y_2),...,(x_m,y_m)\} $, where sample $x_i $ is an n-dimensional vector, $y_i \ Epsilon \{C_1, C_2, ..., C_k\} $, the dimension dimension $d $ after dimension reduction. definition
+
+$N_j(j=0,1)$ is the number of samples of the $j$ class;
+
+$X_j(j=0,1)$ is a collection of $j$ class samples;
+
+$u_j(j=0,1) $ is the mean vector of the $j $ class sample;
+
+$\sum_j(j=0,1)$ is the covariance matrix of the $j$ class sample.
+
+among them
+$$
+U_j = \frac{1}{N_j} \sum_{x\epsilon X_j}x(j=0,1),
+\sum_j = \sum_{x\epsilon X_j}(x-u_j)(x-u_j)^T(j=0,1)
+$$
+Suppose the projection line is the vector $w$. For any sample $x_i$, its projection on the line $w$ is $w^tx_i$, the center point of the two categories is $u_0$, $u_1 $ is in the line $w $The projections of are $w^Tu_0$ and $w^Tu_1$ respectively.
+
+The goal of LDA is to maximize the distance between the two categories of data centers, $\| w^Tu_0 - w^Tu_1 \|^2_2$, and at the same time, hope that the covariance of the similar sample projection points is $w^T \sum_0 w$, $w^T \sum_1 w$ Try to be as small as possible, and minimize $w^T \sum_0 w - w^T \sum_1 w $ .
+definition
+Intraclass divergence matrix
+$$
+S_w = \sum_0 + \sum_1 =
+\sum_{x\epsilon X_0}(x-u_0)(x-u_0)^T +
+\sum_{x\epsilon X_1}(x-u_1)(x-u_1)^T
+$$
+Interclass divergence matrix $S_b = (u_0 - u_1)(u_0 - u_1)^T$
+
+According to the analysis, the optimization goal is
+$$
+\arg \max J(w) = \frac{\| w^Tu_0 - w^Tu_1 \|^2_2}{w^T \sum_0w + w^T \sum_1w} =
+\frac{w^T(u_0-u_1)(u_0-u_1)^Tw}{w^T(\sum_0 + \sum_1)w} =
+\frac{w^TS_bw}{w^TS_ww}
+$$
+According to the nature of the generalized Rayleigh quotient, the maximum eigenvalue of the matrix $S^{-1}_{w} S_b$ is the maximum value of $j(w)$, and the matrix $S^{-1}_{w} $The feature vector corresponding to the largest eigenvalue of $S_b$ is $w $.
+
+### 2.14.4 Summary of LDA algorithm flow?
+The LDA algorithm dimension reduction process is as follows:
+
+Input: Dataset $D = \{ (x_1,y_1), (x_2,y_2), ... ,(x_m,y_m) \}$, where the sample $x_i $ is an n-dimensional vector, $y_i\epsilon \{C_1, C_2, ..., C_k \} $, the dimension dimension $d$ after dimension reduction.
+
+Output: Divised data set $\overline{D} $ .
+
+step:
+1. Calculate the intra-class divergence matrix $S_w$.
+2. Calculate the inter-class divergence matrix $S_b $ .
+3. Calculate the matrix $S^{-1}_wS_b $ .
+4. Calculate the largest d eigenvalues for the matrix $S^{-1}_wS_b$.
+5. Calculate d eigenvectors corresponding to d eigenvalues, and record the projection matrix as W .
+6. Convert each sample of the sample set to get the new sample $P_i = W^Tx_i $ .
+7. Output a new sample set $\overline{D} = \{ (p_1,y_1),(p_2,y_2),...,(p_m,y_m) \} $
+
+### 2.14.5 What is the difference between LDA and PCA?
+
+|similarities and differences | LDA | PCA |
+|:-:|:-|:-|
+|Same point|1. Both can reduce the dimension of the data;
2. Both use the idea of matrix feature decomposition in dimension reduction;
3. Both assume that the data is Gaussian Distribution;||
+|Different points |Supervised dimensionality reduction methods;|Unsupervised dimensionality reduction methods;|
+||The dimension reduction is reduced to the k-1 dimension at most; |There is no limit on the dimension reduction;|
+|| can be used for dimensionality reduction, and can also be used for classification; | only for dimensionality reduction;
+||Select the best projection direction for classification performance;|Select the direction of the sample point projection with the largest variance;|
+||More specific, more reflective of differences between samples; | purpose is more vague; |
+
+### 2.14.6 What are the advantages and disadvantages of LDA?
+
+| Advantages and Disadvantages | Brief Description |
+|:-:|:-|
+|Advantages|1. A priori knowledge of categories can be used;
2. Supervised dimensionality reduction method for measuring differences by label and category, with a clearer purpose than PCA's ambiguity, more reflecting the sample Difference;
+|Disadvantages|1. LDA is not suitable for dimension reduction of non-Gaussian distribution samples;
2. LDA reduction is reduced to k-1 dimension at most;
3. LDA depends on variance in sample classification information instead of mean When the dimension reduction effect is not good;
4. LDA may overfit the data. |
+
+## 2.15 Principal Component Analysis (PCA)
+
+### 2.15.1 Summary of Principal Component Analysis (PCA) Thoughts
+
+1. PCA is to project high-dimensional data into a low-dimensional space by linear transformation.
+2. Projection Idea: Find the projection method that best represents the original data. Those dimensions that are dropped by the PCA can only be those that are noisy or redundant.
+3. De-redundancy: Removes linear correlation vectors that can be represented by other vectors. This amount of information is redundant.
+4. Denoising, removing the eigenvector corresponding to the smaller eigenvalue. The magnitude of the eigenvalue reflects the magnitude of the transformation in the direction of the eigenvector after the transformation. The larger the amplitude, the larger the difference in the element in this direction is to be preserved.
+5. Diagonalization matrix, find the maximal linearly irrelevant group, retain larger eigenvalues, remove smaller eigenvalues, form a projection matrix, and project the original sample matrix to obtain a new sample matrix after dimension reduction.
+6. The key to completing the PCA is the covariance matrix.
+The covariance matrix can simultaneously represent the correlation between different dimensions and the variance in each dimension.
+The covariance matrix measures the relationship between dimensions and dimensions, not between samples and samples.
+7. The reason for diagonalization is that since the non-diagonal elements are all 0 after diagonalization, the purpose of denoising is achieved. The diagonalized covariance matrix, the smaller new variance on the diagonal corresponds to those dimensions that should be removed. So we only take those dimensions that contain larger energy (characteristic values), and the rest are rounded off, that is, redundant.
+
+### 2.15.2 Graphical PCA Core Ideas
+The PCA can solve the problem that there are too many data features or cumbersome features in the training data. The core idea is to map m-dimensional features to n-dimensional (n < m), which form the principal element, which is the orthogonal feature reconstructed to represent the original data.
+
+Suppose the data set is m n-dimensional, $(x^{(1)}, x^{(2)}, \cdots, x^{(m)})$. If n=2, you need to reduce the dimension to $n'=1$. Now you want to find the data of a dimension that represents these two dimensions. The figure below has $u_1, u_2$ two vector directions, but which vector is what we want, can better represent the original data set?
+
+
+
+As can be seen from the figure, $u_1$ is better than $u_2$, why? There are two main evaluation indicators:
+1. The sample point is close enough to this line.
+2. The projection of the sample points on this line can be separated as much as possible.
+
+If the target dimension we need to reduce dimension is any other dimension, then:
+1. The sample point is close enough to the hyperplane.
+2. The projection of the sample points on this hyperplane can be separated as much as possible.
+
+### 2.15.3 PCA algorithm reasoning
+The following is based on the minimum projection distance as the evaluation index reasoning:
+
+Suppose the data set is m n-dimensional, $(x^{(1)}, x^{(2)},...,x^{(m)})$, and the data is centered. After projection transformation, the new coordinates are ${w_1, w_2,...,w_n}$, where $w$ is the standard orthogonal basis, ie $\| w \|_2 = 1$, $w^T_iw_j = 0$ .
+
+After dimension reduction, the new coordinates are $\{ w_1,2_2,...,w_n \}$, where $n'$ is the target dimension after dimension reduction. The projection of the sample point $x^{(i)}$ in the new coordinate system is $z^{(i)} = \left(z^{(i)}_1, z^{(i)}_2, . .., z^{(i)}_{n'} \right)$, where $z^{(i)}_j = w^T_j x^{(i)}$ is $x^{(i) } $ Coordinate of the jth dimension in the low dimensional coordinate system.
+
+If $z^{(i)} $ is used to recover $x^{(i)} $ , the resulting recovery data is $\widehat{x}^{(i)} = \sum^{n'} _{j=1} x^{(i)}_j w_j = Wz^{(i)}$, where $W$ is a matrix of standard orthonormal basis.
+
+Considering the entire sample set, the distance from the sample point to this hyperplane is close enough that the target becomes minimized. $\sum^m_{i=1} \| \hat{x}^{(i)} - x^{ (i)} \|^2_2$ . Reasoning about this formula, you can get:
+$$
+\sum^m_{i=1} \| \hat{x}^{(i)} - x^{(i)} \|^2_2 =
+\sum^m_{i=1} \| Wz^{(i)} - x^{(i)} \|^2_2 \\
+= \sum^m_{i=1} \left( Wz^{(i)} \right)^T \left( Wz^{(i)} \right)
+- 2\sum^m_{i=1} \left( Wz^{(i)} \right)^T x^{(i)}
++ \sum^m_{i=1} \left( x^{(i)} \right)^T x^{(i)} \\
+= \sum^m_{i=1} \left( z^{(i)} \right)^T \left( z^{(i)} \right)
+- 2\sum^m_{i=1} \left( z^{(i)} \right)^T x^{(i)}
++ \sum^m_{i=1} \left( x^{(i)} \right)^T x^{(i)} \\
+= - \sum^m_{i=1} \left( z^{(i)} \right)^T \left( z^{(i)} \right)
++ \sum^m_{i=1} \left( x^{(i)} \right)^T x^{(i)} \\
+= -tr \left( W^T \left( \sum^m_{i=1} x^{(i)} \left( x^{(i)} \right)^T \right)W \right)
++ \sum^m_{i=1} \left( x^{(i)} \right)^T x^{(i)} \\
+= -tr \left( W^TXX^TW \right)
++ \sum^m_{i=1} \left( x^{(i)} \right)^T x^{(i)}
+$$
+
+In the derivation process, $\overline{x}^{(i)} = Wz^{(i)}$ is used respectively, and the matrix transposition formula $(AB)^T = B^TA^T$,$ W^TW = I$, $z^{(i)} = W^Tx^{(i)}$ and the trace of the matrix. The last two steps are to convert the algebraic sum into a matrix form.
+Since each vector $w_j$ of $W$ is a standard orthonormal basis, $\sum^m_{i=1} x^{(i)} \left( x^{(i)} \right)^T $ is the covariance matrix of the data set, $\sum^m_{i=1} \left( x^{(i)} \right)^T x^{(i)} $ is a constant. Minimize $\sum^m_{i=1} \| \hat{x}^{(i)} - x^{(i)} \|^2_2$ is equivalent to
+$$
+\underbrace{\arg \min}_W - tr \left( W^TXX^TW \right) s.t.W^TW = I
+$$
+Use the Lagrang function to get
+$$
+J(W) = -tr(W^TXX^TW) + \lambda(W^TW - I)
+$$
+For $W$, you can get $-XX^TW + \lambda W = 0 $ , which is $ XX^TW = \lambda W $ . $ XX^T $ is a matrix of $ n' $ eigenvectors, and $\lambda$ is the eigenvalue of $ XX^T $ . $W$ is the matrix we want.
+For raw data, you only need $z^{(i)} = W^TX^{(i)}$ to reduce the original data set to the $n'$ dimension dataset of the minimum projection distance.
+
+Based on the derivation of the maximum projection variance, we will not repeat them here. Interested colleagues can refer to the information themselves.
+
+### 2.15.4 Summary of PCA algorithm flow
+Input: $n $ dimension sample set $D = \left( x^{(1)},x^{(2)},...,x^{(m)} \right) $ , target drop The dimension of the dimension is $n' $ .
+
+Output: New sample set after dimensionality reduction $D' = \left( z^{(1)}, z^{(2)},...,z^{(m)} \right)$ .
+
+The main steps are as follows:
+1. Center all the samples, $ x^{(i)} = x^{(i)} - \frac{1}{m} \sum^m_{j=1} x^{(j) } $ .
+2. Calculate the covariance matrix of the sample $XX^T $ .
+3. Perform eigenvalue decomposition on the covariance matrix $XX^T$.
+4. Take the feature vector $\{ w_1,w_2,...,w_{n'} \}$ for the largest $n' $ eigenvalues.
+5. Normalize the eigenvectors to get the eigenvector matrix $W$ .
+6. Convert each sample in the sample set $z^{(i)} = W^T x^{(i)}$ .
+7. Get the output matrix $D' = \left( z^{(1)},z^{(2)},...,z^{(n)} \right) $ .
+*Note*: In dimension reduction, sometimes the target dimension is not specified, but the principal component weighting threshold value $kk (k \epsilon(0,1]) $ is specified. The assumed $n $ eigenvalues For $\lambda_1 \geq \lambda_2 \geq ... \geq \lambda_n $ , then $n' $ can be obtained from $\sum^{n'}_{i=1} \lambda_i \geq k \times \sum^n_{i=1} \lambda_i $.
+
+### 2.15.5 Main advantages and disadvantages of PCA algorithm
+| Advantages and Disadvantages | Brief Description |
+|:-:|:-|
+|Advantages|1. It is only necessary to measure the amount of information by variance, independent of factors outside the data set. 2. Orthogonality between the principal components can eliminate the interaction between the original data components. 3. The calculation method is simple, and the main operation is eigenvalue decomposition, which is easy to implement. |
+|Disadvantages|1. The meaning of each feature dimension of the principal component has a certain ambiguity, which is not as strong as the original sample feature. 2. Non-principal components with small variances may also contain important information about sample differences, as dimensionality reduction may have an impact on subsequent data processing. |
+
+### 2.15.6 Necessity and purpose of dimensionality reduction
+**The need for dimensionality reduction**:
+1. The multicollinearity and predictive variables are related to each other. Multiple collinearity can lead to instability in the solution space, which can lead to inconsistencies in the results.
+2. The high dimensional space itself is sparse. The one-dimensional normal distribution has a value of 68% falling between positive and negative standard deviations, and only 0.02% in ten-dimensional space.
+3. Excessive variables cause redundancy in the search rules.
+4. Analysis at the variable level alone may ignore potential links between variables. For example, several predictors may fall into a group that reflects only one aspect of the data.
+
+**The purpose of dimension reduction**:
+1. Reduce the number of predictors.
+2. Make sure these variables are independent of each other.
+3. Provide a framework to explain the results. Close features, especially important features, can be clearly displayed in the data; if only two or three dimensions, it is easier to visualize.
+4. Data is easier to handle and easier to use at lower dimensions.
+5. Remove data noise.
+6. Reduce the computational overhead of the algorithm.
+
+### 2.15.7 What is the difference between KPCA and PCA?
+The premise of applying the PCA algorithm is to assume that there is a linear hyperplane and then project. So what if the data is not linear? What should I do? At this time, KPCA is needed. The dataset is mapped from $n$ dimension to linearly separable high dimension $N > n$, and then reduced from $N$ dimension to a low dimension $n' (n' 
+>
+
+### 2.16.3 Empirical error and generalization error
+
+Empirical error: also known as training error, the error of the model on the training set.
+
+Generalization error: The error of the model on the new sample set (test set) is called the "generalization error."
+
+### 2.16.4 Under-fitting, over-fitting
+Under-fitting is different from over-fitting plots depending on the coordinate method.
+1. **The horizontal axis is the number of training samples and the vertical axis is the error**
+
+
+
+As shown in the figure above, we can visually see the difference between under-fitting and over-fitting:
+
+Under-fitting of the model: there is a high error in both the training set and the test set, and the deviation of the model is large at this time;
+
+Model overfitting: has a lower error on the training set and a higher error on the test set, where the variance of the model is larger.
+
+The model is normal: there are relatively low deviations and variances on both the training set and the test set.
+
+2. **The horizontal axis is the complexity of the model and the vertical axis is the error**
+
+
+
+The red line is the Error on the test set, and the blue line is the Error on the training set.
+
+Under-fitting of the model: At the point A, the model has a high error at both the training set and the test set. At this time, the deviation of the model is large.
+
+Model overfitting: The model has a lower error on the training set at point C and a higher error on the test set. The variance of the model is larger.
+
+The model is normal: the model complexity control is optimal at point B.
+
+3. **The horizontal axis is the regular term coefficient and the vertical axis is the error**
+
+
+
+The red line is the Error on the test set, and the blue line is the Error on the training set.
+
+Under-fitting of the model: At the point C, the model has a high error at both the training set and the test set. At this time, the deviation of the model is large.
+
+Model overfitting: The model has a lower error on the training set at point A and a higher error on the test set, and the variance of the model is larger. It usually happens when the model is too complicated, such as too many parameters, which will make the prediction performance of the model weaker and increase the volatility of the data. Although the effect of the model during training can be performed perfectly, basically remembering all the characteristics of the data, but the performance of this model in the unknown data will be greatly reduced, because the simple model generalization ability is usually very weak. of.
+
+The model is normal: the model complexity control is optimal at point B.
+
+### 2.16.5 How to solve over-fitting and under-fitting?
+**How to solve the under-fitting:**
+1. Add additional feature items. Features such as combination, generalization, correlation, context features, and platform features are important means of feature addition. Sometimes insufficient feature items can lead to under-fitting of the model.
+2. Add a polynomial feature. For example, adding a linear or cubic term to a linear model makes the model more generalizable. For example, the FM model and the FFM model are actually linear models, and second-order polynomials are added to ensure a certain degree of fitting of the model.
+3. You can increase the complexity of the model.
+4. Reduce the regularization coefficient. The purpose of regularization is to prevent overfitting, but now the model has an under-fitting, you need to reduce the regularization parameters.
+
+**How to solve overfitting:**
+1. Re-clean the data, the data is not pure will lead to over-fitting, and such cases require re-cleaning of the data.
+2. Increase the number of training samples.
+3. Reduce the complexity of the model.
+4. Increase the coefficient of the regular term.
+5. Using the dropout method, the dropout method, in layman's terms, is to let the neurons not work with a certain probability during training.
+6. early stoping.
+7. Reduce the number of iterations.
+8. Increase the learning rate.
+9. Add noise data.
+10. In the tree structure, the tree can be pruned.
+
+Under-fitting and over-fitting these methods requires selection based on actual problems and actual models.
+
+### 2.16.6 The main role of cross-validation
+In order to obtain a more robust and reliable model, the generalization error of the model is evaluated, and an approximation of the model generalization error is obtained. When there are multiple models to choose from, we usually choose the model with the smallest "generalization error".
+
+There are many ways to cross-validate, but the most common ones are: leave a cross-validation, k-fold cross-validation.
+
+### 2.16.7 Understanding k-fold cross validation
+1. Divide the data set containing N samples into K shares, each containing N/K samples. One of them was selected as the test set, and the other K-1 was used as the training set. There were K cases in the test set.
+2. In each case, train the model with the training set and test the model with the test set to calculate the generalization error of the model.
+3. Cross-validation is repeated K times, each verification is performed, the average K times results or other combination methods are used, and finally a single estimation is obtained, and the final generalization error of the model is obtained.
+4. In the case of K, the generalization error of the model is averaged to obtain the final generalization error of the model.
+**Note**:
+1. Generally 2<=K<=10. The advantage of k-fold cross-validation is that it repeatedly uses randomly generated sub-samples for training and verification. Each time the results are verified once, 10-fold cross-validation is the most commonly used.
+2. The number of samples in the training set should be sufficient, generally at least 50% of the total number of samples.
+3. The training set and test set must be evenly sampled from the complete data set. The purpose of uniform sampling is to reduce the deviation between the training set, the test set, and the original data set. When the number of samples is sufficient, the effect of uniform sampling can be achieved by random sampling.
+
+### 2.16.8 Confusion matrix
+The first type of confusion matrix:
+
+|The real situation T or F| prediction is positive example 1, P| prediction is negative example 0, N|
+|:-:|:-|:-|
+|The original label is marked as 1, the prediction result is true T, false is F|TP (predicted to be 1, actual is 1)|FN (predicted to be 0, actually 1)|
+|The original label is 0, the prediction result is true T, false is F|FP (predicted to be 1, actual is 0)|TN (predicted to be 0, actually 0)|
+
+The second type of confusion matrix:
+
+|Predictive situation P or N|The actual label is 1, the predicted pair is T|the actual label is 0, and the predicted pair is T|
+|:-:|:-|:-|
+|Forecast is positive example 1, P|TP (predicted to be 1, actually 1)|FP (predicted to be 1, actually 0)|
+|Predicted as negative example 0, N|FN (predicted to be 0, actually 1)|TN (predicted to be 0, actually 0)|
+
+### 2.16.9 Error rate and accuracy
+1. Error Rate: The ratio of the number of samples with the wrong classification to the total number of samples.
+2. Accuracy: The proportion of the correct number of samples to the total number of samples.
+
+### 2.16.10 Precision and recall rate
+The results predicted by the algorithm are divided into four cases:
+1. True Positive (TP): The prediction is true, the actual is true
+2. True Negation (True NegatiVe, TN): the forecast is false, the actual is false
+3. False Positive (FP): The prediction is true, the actual is false
+4. False Negative (FN): The forecast is false, actually true
+
+Then:
+
+Precision = TP / (TP + FP)
+
+**Understanding**: The correct number of samples predicted to be positive. Distinguish the accuracy rate (correctly predicted samples, including correct predictions as positive and negative, accounting for the proportion of total samples).
+For example, in all of the patients we predicted to have malignant tumors, the percentage of patients who actually had malignant tumors was as high as possible.
+
+Recall = TP / (TP + FN)
+
+**Understanding**: The proportion of positively predicted positives as a percentage of positives in the total sample.
+For example, in all patients with malignant tumors, the percentage of patients who successfully predicted malignant tumors was as high as possible.
+
+### 2.16.11 ROC and AUC
+The full name of the ROC is "Receiver Operating Characteristic".
+
+The area of the ROC curve is AUC (Area Under the Curve).
+
+AUC is used to measure the performance of the "two-class problem" machine learning algorithm (generalization capability).
+
+The ROC curve is calculated by setting a continuous variable to a plurality of different critical values, thereby calculating a series of true rates and false positive rates, and then plotting the curves with the false positive rate and the true rate as the ordinate, under the curve. The larger the area, the higher the diagnostic accuracy. On the ROC curve, the point closest to the upper left of the graph is the critical value of both the false positive rate and the true rate.
+
+For classifiers, or classification algorithms, the evaluation indicators mainly include precision, recall, and F-score. The figure below is an example of a ROC curve.
+
+
+
+The abscissa of the ROC curve is the false positive rate (FPR) and the ordinate is the true positive rate (TPR). among them
+$$
+TPR = \frac{TP}{TP+FN} , FPR = \frac{FP}{FP+TN},
+$$
+
+The following focuses on the four points and one line in the ROC graph.
+The first point, (0,1), ie FPR=0, TPR=1, means that FN(false negative)=0, and FP(false positive)=0. This means that this is a perfect classifier that classifies all samples correctly.
+The second point, (1,0), ie FPR=1, TPR=0, means that this is the worst classifier because it successfully avoided all the correct answers.
+The third point, (0,0), that is, FPR=TPR=0, that is, FP (false positive)=TP(true positive)=0, it can be found that the classifier predicts that all samples are negative samples (negative). .
+The fourth point, (1,1), ie FPR=TPR=1, the classifier actually predicts that all samples are positive samples.
+After the above analysis, the closer the ROC curve is to the upper left corner, the better the performance of the classifier.
+
+The area covered by the ROC curve is called AUC (Area Under Curve), which can more easily judge the performance of the learner. The larger the AUC, the better the performance.
+### 2.16.12 How to draw ROC curve?
+The following figure is an example. There are 20 test samples in the figure. The “Class” column indicates the true label of each test sample (p indicates positive samples, n indicates negative samples), and “Score” indicates that each test sample is positive. The probability of the sample.
+
+step:
+1. Assume that the probability that a series of samples are classified as positive classes has been derived, sorted by size.
+2. From high to low, the “Score” value is used as the threshold threshold. When the probability that the test sample belongs to the positive sample is greater than or equal to the threshold, we consider it to be a positive sample, otherwise it is a negative sample. For example, for the fourth sample in the graph, the "Score" value is 0.6, then the samples 1, 2, 3, 4 are considered positive samples because their "Score" values are greater than or equal to 0.6, while others The samples are considered to be negative samples.
+3. Select a different threshold each time to get a set of FPR and TPR, which is a point on the ROC curve. In this way, a total of 20 sets of FPR and TPR values were obtained. The FPR and TPR are briefly understood as follows:
+4. Draw according to each coordinate point in 3).
+
+
+
+### 2.16.13 How to calculate TPR, FPR?
+1, analysis of data
+Y_true = [0, 0, 1, 1]; scores = [0.1, 0.4, 0.35, 0.8];
+2, the list
+
+| Sample | Predict the probability of belonging to P (score) | Real Category |
+| ---- | ---------------------- | -------- |
+| y[0] | 0.1 | N |
+| y[1] | 0.35 | P |
+| y[2] | 0.4 | N |
+| y[3] | 0.8 | P |
+
+3. Take the cutoff point as the score value and calculate the TPR and FPR.
+When the truncation point is 0.1:
+Explain that as long as score>=0.1, its prediction category is a positive example. Since the scores of all four samples are greater than or equal to 0.1, the prediction category for all samples is P.
+Scores = [0.1, 0.4, 0.35, 0.8]; y_true = [0, 0, 1, 1]; y_pred = [1, 1, 1, 1];
+The positive and negative examples are as follows:
+
+| Real value\predicted value | | |
+| ------------- | ---- | ---- |
+| | Positive example | Counterexample |
+| Positive example | TP=2 | FN=0 |
+| Counterexample | FP=2 | TN=0 |
+
+Therefore:
+TPR = TP / (TP + FN) = 1; FPR = FP / (TN + FP) = 1;
+
+When the cutoff point is 0.35:
+Scores = [0.1, 0.4, 0.35, 0.8]; y_true = [0, 0, 1, 1]; y_pred = [0, 1, 1, 1];
+The positive and negative examples are as follows:
+
+| Real value\predicted value | | |
+| ------------- | ---- | ---- |
+| | Positive example | Counterexample |
+| Positive example | TP=2 | FN=0 |
+| Counterexample | FP=1 | TN=1 |
+
+Therefore:
+TPR = TP / (TP + FN) = 1; FPR = FP / (TN + FP) = 0.5;
+
+When the truncation point is 0.4:
+Scores = [0.1, 0.4, 0.35, 0.8]; y_true = [0, 0, 1, 1]; y_pred = [0, 1, 0, 1];
+The positive and negative examples are as follows:
+
+| Real value\predicted value | | |
+| ------------- | ---- | ---- |
+| | Positive example | Counterexample |
+| Positive example | TP=1 | FN=1 |
+| Counterexample | FP=1 | TN=1 |
+
+Therefore:
+TPR = TP / (TP + FN) = 0.5; FPR = FP / (TN + FP) = 0.5;
+
+When the cutoff point is 0.8:
+Scores = [0.1, 0.4, 0.35, 0.8]; y_true = [0, 0, 1, 1]; y_pred = [0, 0, 0, 1];
+
+The positive and negative examples are as follows:
+
+| Real value\predicted value | | |
+| ------------- | ---- | ---- |
+| | Positive example | Counterexample |
+| Positive example | TP=1 | FN=1 |
+| Counterexample | FP=0 | TN=2 |
+
+Therefore:
+TPR = TP / (TP + FN) = 0.5; FPR = FP / (TN + FP) = 0;
+4. According to the TPR and FPR values, the FPR is plotted on the horizontal axis and the TPR is plotted on the vertical axis.
+
+### 2.16.14 How to calculate Auc?
+- Sort the coordinate points by the horizontal FPR.
+- Calculate the distance $dx$ between the $i$ coordinate point and the $i+1$ coordinate point.
+- Get the ordinate y of the $i$ (or $i+1$) coordinate points.
+- Calculate the area micro-element $ds=ydx$.
+- Accumulate the area micro-elements to get the AUC.
+
+### 2.16.15 Why use Roc and Auc to evaluate the classifier?
+There are many evaluation methods for the model. Why use ROC and AUC?
+Because the ROC curve has a very good property: when the distribution of positive and negative samples in the test set is transformed, the ROC curve can remain unchanged. In the actual data set, sample class imbalances often occur, that is, the ratio of positive and negative samples is large, and the positive and negative samples in the test data may also change with time.
+
+### 2.16.17 Intuitive understanding of AUC
+The figure below shows the values of the three AUCs:
+
+
+
+AUC is an evaluation index to measure the pros and cons of the two-category model, indicating the probability that the positive example is in front of the negative example. Other evaluation indicators have accuracy, accuracy, and recall rate, and AUC is more common than the three.
+Generally, in the classification model, the prediction results are expressed in the form of probability. If the accuracy is to be calculated, a threshold is usually set manually to convert the corresponding probability into a category, which greatly affects the accuracy of the model. Rate calculation.
+Example:
+
+Now suppose that a trained two-classifier predicts 10 positive and negative samples (5 positive cases and 5 negative examples). The best prediction result obtained by sorting the scores in high to low is [1, 1, 1, 1, 1, 0, 0, 0, 0, 0], that is, 5 positive examples are ranked in front of 5 negative examples, and the positive example is 100% in front of the negative example. Then draw its ROC curve, since it is 10 samples, we need to draw 10 points in addition to the origin, as follows:
+
+
+
+The method of traversing starts from left to right according to the score of the sample prediction result. Starting from the origin, every time you encounter 1, move the y-axis in the positive direction of the y-axis with a minimum step size of 1 unit, here is 1/5=0.2; every time you encounter 0, move to the x-axis positive direction, the x-axis minimum step size is 1 Unit, here is also 0.2. It is not difficult to see that the AUC of the above figure is equal to 1, which confirms that the probability that the positive example is in front of the negative example is indeed 100%.
+
+Assume that the prediction result sequence is [1, 1, 1, 1, 0, 1, 0, 0, 0, 0].
+
+
+
+Calculate the AUC of the above figure is 0.96 and the probability of calculating the positive example is 0.8 × 1 + 0.2 × 0.8 = 0.96 in front of the negative example, and the area of the shadow in the upper left corner is the probability that the negative example is in front of the positive example. × 0.2 = 0.04.
+
+Assume that the prediction result sequence is [1, 1, 1, 0, 1, 0, 1, 0, 0, 0].
+
+
+
+Calculate the AUC of the above figure is 0.88 and the probability of calculating the positive example and the front of the negative example is equal to 0.6 × 1 + 0.2 × 0.8 + 0.2 × 0.6 = 0.88. The area of the shaded part in the upper left corner is the negative example in front of the positive example. The probability is 0.2 × 0.2 × 3 = 0.12.
+
+### 2.16.18 Cost-sensitive error rate and cost curve
+
+Different errors can come at different costs. Taking the dichotomy as an example, set the cost matrix as follows:
+
+
+
+When the judgment is correct, the value is 0. When it is incorrect, it is $Cost_{01} $ and $Cost_{10} $ respectively.
+
+$Cost_{10}$: indicates the cost of actually being a counterexample but predicting a positive case.
+
+$Cost_{01}$: indicates the cost of being a positive example but predicting a counterexample.
+
+**Cost Sensitive Error Rate**=The sum of the error value and the cost product obtained by the model in the sample / total sample.
+Its mathematical expression is:
+$$
+E(f;D;cost)=\frac{1}{m}\left( \sum_{x_{i} \in D^{+}}({f(x_i)\neq y_i})\times Cost_{ 01}+ \sum_{x_{i} \in D^{-}}({f(x_i)\neq y_i})\times Cost_{10}\right)
+$$
+$D^{+}, D^{-} $ respectively represent samplesSet of positive and negative examples.
+
+**cost curve**:
+At an equal cost, the ROC curve does not directly reflect the expected overall cost of the model, and the cost curve can.
+The cost of the positive example of the cost curve with the horizontal axis of [0,1]:
+$$
+P(+)Cost=\frac{p*Cost_{01}}{p*Cost_{01}+(1-p)*Cost_{10}}
+$$
+Where p is the probability that the sample is a positive example.
+
+The normalized cost of the vertical axis dimension [0,1] of the cost curve:
+$$
+Cost_{norm}=\frac{FNR*p*Cost_{01}+FNR*(1-p)*Cost_{10}}{p*Cost_{01}+(1-p)*Cost_{10}}
+$$
+
+Among them, FPR is a false positive rate, and FNR=1-TPR is a false anti-interest rate.
+
+Note: Each point of the ROC corresponds to a line on the cost plane.
+
+For example, on the ROC (TPR, FPR), FNR=1-TPR is calculated, and a line segment from (0, FPR) to (1, FNR) is drawn on the cost plane, and the area is the expected overall cost under the condition. The area under the bounds of all segments, the expected overall cost of the learner under all conditions.
+
+
+
+### 2.16.19 What are the comparison test methods for the model?
+Correctness analysis: model stability analysis, robustness analysis, convergence analysis, trend analysis, extreme value analysis, etc.
+Validity analysis: error analysis, parameter sensitivity analysis, model comparison test, etc.
+Usefulness analysis: key data solving, extreme points, inflection points, trend analysis, and data validation dynamic simulation.
+Efficient analysis: Time-space complexity analysis is compared with existing ones.
+
+### 2.16.21 Why use standard deviation?
+
+The variance formula is: $S^2_{N}=\frac{1}{N}\sum_{i=1}^{N}(x_{i}-\bar{x})^{2} $
+
+The standard deviation formula is: $S_{N}=\sqrt{\frac{1}{N}\sum_{i=1}^{N}(x_{i}-\bar{x})^{2}} $
+
+The sample standard deviation formula is: $S_{N}=\sqrt{\frac{1}{N-1}\sum_{i=1}^{N}(x_{i}-\bar{x})^{ 2}} $
+
+There are three benefits to using standard deviation to represent the degree of dispersion of data points compared to variance:
+1. The number indicating the degree of dispersion is consistent with the order of magnitude of the sample data points, which is more suitable for forming perceptual cognition of data samples.
+
+2. The unit of digital representation of the degree of dispersion is consistent with the unit of sample data, making it easier to perform subsequent analysis operations.
+
+3. In the case that the sample data generally conforms to the normal distribution, the standard deviation has the characteristics of convenient estimation: 66.7% of the data points fall within the range of 1 standard deviation before and after the average, and 95% of the data points fall before and after the average Within the range of 2 standard deviations, 99% of the data points will fall within the range of 3 standard deviations before and after the mean.
+
+### 2.16.25 What causes the category imbalance?
+Class-imbalance refers to the case where the number of training examples of different categories in a classification task varies greatly.
+
+cause:
+
+Classification learning algorithms usually assume that the number of training examples for different categories is basically the same. If the number of training examples in different categories is very different, it will affect the learning results and the test results will be worse. For example, there are 998 counterexamples in the two-category problem, and there are two positive cases. The learning method only needs to return a classifier that always predicts the new sample as a counterexample, which can achieve 99.8% accuracy; however, such a classifier has no value.
+### 2.16.26 Common category imbalance problem solving method
+To prevent the impact of category imbalance on learning, it is necessary to deal with the problem of classification imbalance before constructing the classification model. The main solutions are:
+
+1, expand the data set
+
+Add data that contains small sample data, and more data can get more distribution information.
+
+2. Undersampling large types of data
+
+Reduce the number of large data samples so that they are close to the small sample size.
+Disadvantages: If you discard a large class of samples randomly during an undersampling operation, you may lose important information.
+Representative algorithm: EasyEnsemble. The idea is to use an integrated learning mechanism to divide the large class into several sets for use by different learners. This is equivalent to undersampling each learner, but it does not lose important information for the whole world.
+
+3. Oversampling small class data
+
+Oversampling: Sampling a small class of data samples to increase the number of data samples in a small class.
+
+Representative algorithms: SMOTE and ADASYN.
+
+SMOTE: Generate additional subclass sample data by interpolating the small class data in the training set.
+
+A new minority class sample generation strategy: for each minority class sample a, randomly select a sample b in the nearest neighbor of a, and then randomly select a point on the line between a and b as a newly synthesized minority class. sample.
+ADASYN: Uses a weighted distribution for different minority categories of samples based on the difficulty of learning, and produces more comprehensive data for a small number of samples that are difficult to learn. Data distribution is improved by reducing the bias introduced by class imbalance and adaptively transferring classification decision boundaries to difficult samples.
+
+4. Use new evaluation indicators
+
+If the current evaluation indicator does not apply, you should look for other convincing evaluation indicators. For example, the accuracy index is not applicable or even misleading in the classification task with unbalanced categories. Therefore, in the category unbalanced classification task, more convincing evaluation indicators are needed to evaluate the classifier.
+
+5, choose a new algorithm
+
+Different algorithms are suitable for different tasks and data, and should be compared using different algorithms.
+
+6, data cost weighting
+
+For example, when the classification task is to identify the small class, the weight of the small class sample data of the classifier can be added, and the weight of the large sample can be reduced, so that the classifier concentrates on the small sample.
+
+7, the conversion problem thinking angle
+
+For example, in the classification problem, the sample of the small class is used as the abnormal point, and the problem is transformed into the abnormal point detection or the change trend detection problem. Outlier detection is the identification of rare events. The change trend detection is distinguished from the abnormal point detection in that it is identified by detecting an unusual change trend.
+
+8, the problem is refined and analyzed
+
+Analyze and mine the problem, divide the problem into smaller problems, and see if these small problems are easier to solve.
+
+## 2.17 Decision Tree
+
+### 2.17.1 Basic Principles of Decision Trees
+The Decision Tree is a divide-and-conquer decision-making process. A difficult prediction problem is divided into two or more simple subsets through the branch nodes of the tree, which are structurally divided into different sub-problems. The process of splitting data sets by rules is recursively partitioned (Recursive Partitioning). As the depth of the tree increases, the subset of branch nodes becomes smaller and smaller, and the number of problems that need to be raised is gradually simplified. When the depth of the branch node or the simplicity of the problem satisfies a certain Stopping Rule, the branch node stops splitting. This is the top-down Cutoff Threshold method; some decision trees are also used from below. And the Pruning method.
+
+### 2.17.2 Three elements of the decision tree?
+The generation process of a decision tree is mainly divided into the following three parts:
+
+Feature selection: Select one feature from the many features in the training data as the split criterion of the current node. How to select features has many different quantitative evaluation criteria, and thus derive different decision tree algorithms.
+
+Decision Tree Generation: The child nodes are recursively generated from top to bottom according to the selected feature evaluation criteria, and the decision tree stops growing until the data set is inseparable. In terms of tree structure, recursive structure is the easiest way to understand.
+
+Pruning: Decision trees are easy to overfit, generally requiring pruning, reducing the size of the tree structure, and alleviating overfitting. The pruning technique has two types: pre-pruning and post-pruning.
+
+### 2.17.3 Decision Tree Learning Basic Algorithm
+
+
+
+### 2.17.4 Advantages and disadvantages of decision tree algorithms
+
+**The advantages of the decision tree algorithm**:
+
+1. The decision tree algorithm is easy to understand and the mechanism is simple to explain.
+
+2. The decision tree algorithm can be used for small data sets.
+
+3. The time complexity of the decision tree algorithm is small, which is the logarithm of the data points used to train the decision tree.
+
+4. The decision tree algorithm can handle numbers and data categories compared to other algorithms that intelligently analyze a type of variable.
+
+5, able to handle the problem of multiple output.
+
+6. Not sensitive to missing values.
+
+7, can handle irrelevant feature data.
+
+8, high efficiency, decision tree only needs to be constructed once, repeated use, the maximum number of calculations per prediction does not exceed the depth of the decision tree.
+
+**The disadvantages of the decision tree algorithm**:
+
+1. It is hard to predict the field of continuity.
+
+2, easy to appear over-fitting.
+
+3. When there are too many categories, the error may increase faster.
+
+4. It is not very good when dealing with data with strong feature relevance.
+
+5. For data with inconsistent sample sizes in each category, in the decision tree, the results of information gain are biased toward those with more values.
+
+### 2.17.5 The concept of entropy and understanding
+
+ Entropy: measures the uncertainty of a random variable.
+
+Definition: Assume that the possible values of the random variable X are $x_{1}, x_{2},...,x_{n}$, for each possible value $x_{i}$, the probability is $P(X=x_{i})=p_{i}, i=1, 2..., n$. The entropy of a random variable is:
+$$
+H(X)=-\sum_{i=1}^{n}p_{i}log_{2}p_{i}
+$$
+For the sample set, assume that the sample has k categories, and the probability of each category is $\frac{|C_{k}|}{|D|}$, where ${|C_{k}|}{|D| }$ is the number of samples with category k, and $|D| $ is the total number of samples. The entropy of the sample set D is:
+$$
+H(D)=-\sum_{k=1}^{k}\frac{|C_{k}|}{|D|}log_{2}\frac{|C_{k}|}{|D| }
+$$
+
+### 2.17.6 Understanding of Information Gain
+Definition: The difference in entropy before and after the data set is divided by a feature.
+Entropy can represent the uncertainty of the sample set. The larger the entropy, the greater the uncertainty of the sample. Therefore, the difference between the set entropy before and after the partition can be used to measure the effect of using the current feature on the partitioning of the sample set D.
+It is assumed that the entropy of the sample set D before division is H(D). The data set D is divided by a certain feature A, and the entropy of the divided data subset is calculated as $H(D|A)$.
+
+Then the information gain is:
+$$
+g(D,A)=H(D)-H(D|A)
+$$
+Note: In the process of building a decision tree, we always want the set to move toward the fastest-purchasing sub-sets. Therefore, we always choose the feature that maximizes the information gain to divide the current data set D.
+
+Thought: Calculate all feature partition data sets D, obtain the information gain of multiple feature partition data sets D, and select the largest from these information gains, so the partition feature of the current node is the partition used to maximize the information gain. feature.
+
+In addition, here is the information gain ratio related knowledge:
+
+Information gain ratio = penalty parameter X information gain.
+
+Information gain ratio essence: multiply a penalty parameter based on the information gain. When the number of features is large, the penalty parameter is small; when the number of features is small, the penalty parameter is large.
+
+Penalty parameter: Data set D takes feature A as the reciprocal of the entropy of the random variable.
+
+### 2.17.7 The role and strategy of pruning treatment?
+Pruning is a method used by decision tree learning algorithms to solve overfitting.
+
+In the decision tree algorithm, in order to classify the training samples as accurately as possible, the node partitioning process is repeated repeatedly, sometimes causing too many branches of the decision tree, so that the characteristics of the training sample set are regarded as generalized features, resulting in over-fitting . Therefore, pruning can be used to remove some branches to reduce the risk of overfitting.
+
+The basic strategies for pruning are prepruning and postprunint.
+
+Pre-pruning: In the decision tree generation process, the generalization performance of each node is estimated before each node is divided. If it cannot be upgraded, the division is stopped, and the current node is marked as a leaf node.
+
+Post-pruning: After generating the decision tree, the non-leaf nodes are examined from the bottom up. If the node is marked as a leaf node, the generalization performance can be improved.
+
+## 2.18 Support Vector Machine
+
+### 2.18.1 What is a support vector machine?
+Support Vector: During the process of solving, you will find that the classifier can be determined based only on part of the data. These data are called support vectors.
+
+Support Vector Machine (SVM): The meaning is a classifier that supports vector operations.
+
+In a two-dimensional environment, points R, S, G and other points near the middle black line can be seen as support vectors, which can determine the specific parameters of the classifier, black line.
+
+
+
+The support vector machine is a two-class model. Its purpose is to find a hyperplane to segment the sample. The principle of segmentation is to maximize the interval and finally transform it into a convex quadratic programming problem. The simple to complex models include:
+
+When the training samples are linearly separable, learn a linear separable support vector machine by maximizing the hard interval;
+
+When the training samples are approximately linearly separable, learn a linear support vector machine by maximizing the soft interval;
+
+When the training samples are linearly inseparable, learn a nonlinear support vector machine by kernel techniques and soft interval maximization;
+
+### 2.18.2 What problems can the support vector machine solve?
+
+**Linear classification**
+
+In the training data, each data has n attributes and a second class category flag, which we can think of in an n-dimensional space. Our goal is to find an n-1 dimensional hyperplane that divides the data into two parts, eachSome of the data belong to the same category.
+
+There are many such hyperplanes, if we want to find the best one. At this point, a constraint is added: the distance from the hyperplane to the nearest data point on each side is required to be the largest, becoming the maximum interval hyperplane. This classifier is the maximum interval classifier.
+
+**Nonlinear classification**
+
+One advantage of SVM is its support for nonlinear classification. It combines the Lagrangian multiplier method with the KKT condition, and the kernel function can produce a nonlinear classifier.
+
+### 2.18.3 Features of the nuclear function and its role?
+
+The purpose of introducing the kernel function is to project the linearly inseparable data in the original coordinate system into another space with Kernel, and try to make the data linearly separable in the new space.
+
+The wide application of the kernel function method is inseparable from its characteristics:
+
+1) The introduction of the kernel function avoids the "dimensionality disaster" and greatly reduces the amount of calculation. The dimension n of the input space has no effect on the kernel function matrix. Therefore, the kernel function method can effectively handle high-dimensional input.
+
+2) There is no need to know the form and parameters of the nonlinear transformation function Φ.
+
+3) The change of the form and parameters of the kernel function implicitly changes the mapping from the input space to the feature space, which in turn affects the properties of the feature space, and ultimately changes the performance of various kernel function methods.
+
+4) The kernel function method can be combined with different algorithms to form a variety of different kernel function-based methods, and the design of these two parts can be performed separately, and different kernel functions and algorithms can be selected for different applications.
+
+### 2.18.4 Why does SVM introduce dual problems?
+
+1. The dual problem turns the constraint in the original problem into the equality constraint in the dual problem. The dual problem is often easier to solve.
+
+2, you can naturally refer to the kernel function (the Lagrangian expression has an inner product, and the kernel function is also mapped by the inner product).
+
+3. In the optimization theory, the objective function f(x) can take many forms: if the objective function and the constraint are both linear functions of the variable x, the problem is called linear programming; if the objective function is a quadratic function, the constraint For a linear function, the optimization problem is called quadratic programming; if the objective function or the constraint is a nonlinear function, the optimization problem is called nonlinear programming. Each linear programming problem has a dual problem corresponding to it. The dual problem has very good properties. Here are a few:
+
+a, the duality of the dual problem is the original problem;
+
+b, whether the original problem is convex or not, the dual problem is a convex optimization problem;
+
+c, the dual problem can give a lower bound on the original problem;
+
+d, when certain conditions are met, the original problem is completely equivalent to the solution to the dual problem.
+
+### 2.18.5 How to understand the dual problem in SVM
+
+In the hard-space support vector machine, the solution of the problem can be transformed into a convex quadratic programming problem.
+
+Assume that the optimization goal is
+$$
+\begin{align}
+&\min_{\boldsymbol w, b}\frac{1}{2}||\boldsymbol w||^2\\
+&s.t. y_i(\boldsymbol w^T\boldsymbol x_i+b)\geq1, i=1,2,\cdots,m.\\
+\end{align} \tag{1}
+$$
+**step 1**. Conversion issues:
+$$
+\min_{\boldsymbol w, b} \max_{\alpha_i \geq 0} \left\{\frac{1}{2}||\boldsymbol w||^2 + \sum_{i=1}^m\alpha_i( 1 - y_i(\boldsymbol w^T\boldsymbol x_i+b))\right\} \tag{2}
+$$
+The above formula is equivalent to the original problem, because if the inequality constraint in (1) is satisfied, then $\alpha_i(1 - y_i(\boldsymbol w^T\boldsymbol x_i+b))$ must be taken when (2) is used to find max 0, equivalent to (1); if the inequality constraint in (1) is not satisfied, the max in (2) will get infinity. Exchange min and max to get their dual problem:
+$$
+\max_{\alpha_i \geq 0} \min_{\boldsymbol w, b} \left\{\frac{1}{2}||\boldsymbol w||^2 + \sum_{i=1}^m\alpha_i( 1 - y_i(\boldsymbol w^T\boldsymbol x_i+b))\right\}
+$$
+The dual problem after the exchange is not equal to the original problem. The solution of the above formula is less than the solution of the original problem.
+
+**step 2**. The question now is how to find the best lower bound for the optimal value of the problem (1)?
+$$
+{\frac 1 2}||\boldsymbol w||^2 < v\\
+1 - y_i(\boldsymbol w^T\boldsymbol x_i+b) \leq 0\tag{3}
+$$
+If equation (3) has no solution, then v is a lower bound of question (1). If (3) has a solution, then
+$$
+\forall \boldsymbol \alpha > 0 , \ \min_{\boldsymbol w, b} \left\{\frac{1}{2}||\boldsymbol w||^2 + \sum_{i=1}^m\alpha_i (1 - y_i(\boldsymbol w^T\boldsymbol x_i+b))\right\} < v
+$$
+From the inverse of the proposition: if
+$$
+\exists \boldsymbol \alpha > 0 , \ \min_{\boldsymbol w, b} \left\{\frac{1}{2}||\boldsymbol w||^2 + \sum_{i=1}^m\alpha_i (1 - y_i(\boldsymbol w^T\boldsymbol x_i+b))\right\} \geq v
+$$
+Then (3) no solution.
+
+Then v is the problem
+
+A lower bound of (1).
+ Ask for a good lower bound, take the maximum
+$$
+\max_{\alpha_i \geq 0} \min_{\boldsymbol w, b} \left\{\frac{1}{2}||\boldsymbol w||^2 + \sum_{i=1}^m\alpha_i( 1 - y_i(\boldsymbol w^T\boldsymbol x_i+b))\right\}
+$$
+**step 3**. Order
+$$
+L(\boldsymbol w, b,\boldsymbol a) = \frac{1}{2}||\boldsymbol w||^2 + \sum_{i=1}^m\alpha_i(1 - y_i(\boldsymbol w^T \boldsymbol x_i+b))
+$$
+$p^*$ is the minimum value of the original question, the corresponding $w, b$ are $w^*, b^*$, respectively, for any $a>0$:
+$$
+p^* = {\frac 1 2}||\boldsymbol w^*||^2 \geq L(\boldsymbol w^*, b,\boldsymbol a) \geq \min_{\boldsymbol w, b} L( \boldsymbol w, b,\boldsymbol a)
+$$
+Then $\min_{\boldsymbol w, b} L(\boldsymbol w, b,\boldsymbol a)$ is the next issue of question (1).
+
+At this point, take the maximum value to find the lower bound, that is,
+$$
+\max_{\alpha_i \geq 0} \min_{\boldsymbol w, b} L(\boldsymbol w, b,\boldsymbol a)
+$$
+
+### 2.18.7 What are the common kernel functions?
+| Kernel Functions | Expressions | Notes |
+| ---------------------------- | -------------------- ---------------------------------------- | --------- -------------------------- |
+Linear Kernel Linear Kernel | $k(x,y)=xy$ | |
+Polynomial Kernel Polynomial Kernel | $k(x,y)=(ax^{t}y+c)^{d}$ | $d>=1$ is the number of polynomials |
+Exponential Kernel Exponent Kernel Function | $k(x,y)=exp(-\frac{\left \|x-y \right \|}{2\sigma ^{2}})$ | $\sigma>0$ |
+Gaussian Kernel Gaussian Kernel Function | $k(x,y)=exp(-\frac{\left \|xy \right \|^{2}}{2\sigma ^{2}})$ | $\sigma $ is the bandwidth of the Gaussian kernel, $\sigma>0$, |
+| Laplacian Kernel Laplacian Kernel | $k(x,y)=exp(-\frac{\left \|x-y \right|}{\sigma})$ | $\sigma>0$ |
+| ANOVA Kernel | $k(x,y)=exp(-\sigma(x^{k}-y^{k})^{2})^{d}$ | |
+| Sigmoid Kernel | $k(x,y)=tanh(ax^{t}y+c)$ | $tanh$ is a hyperbolic tangent function, $a>0,c<0$ |
+
+### 2.18.9 Main features of SVM?
+
+Features:
+
+(1) The theoretical basis of the SVM method is nonlinear mapping, and the SVM uses the inner product kernel function instead of the nonlinear mapping to the high dimensional space;
+
+(2) The goal of SVM is to obtain the optimal hyperplane for feature space partitioning, and the core of SVM method is to maximize the classification margin;
+
+(3) The support vector is the training result of the SVM. The support vector plays a decisive role in the SVM classification decision.
+
+(4) SVM is a novel small sample learning method with solid theoretical foundation. It basically does not involve probability measures and laws of large numbers, but also simplifies the problems of general classification and regression.
+
+(5) The final decision function of the SVM is determined by only a few support vectors. The computational complexity depends on the number of support vectors, not the dimension of the sample space, which avoids the “dimensionality disaster” in a sense.
+
+(6) A few support vectors determine the final result, which not only helps us to grasp the key samples, “cull” a large number of redundant samples, but also destined that the method is not only simple, but also has good “robustness”. This "robustness" is mainly reflected in:
+
+1 Adding or deleting non-support vector samples has no effect on the model;
+
+2 Support vector sample sets have certain robustness;
+
+3 In some successful applications, the SVM method is not sensitive to the selection of cores.
+
+(7) The SVM learning problem can be expressed as a convex optimization problem, so the global minimum of the objective function can be found using a known effective algorithm. Other classification methods (such as rule-based classifiers and artificial neural networks) use a greedy learning-based strategy to search for hypothesis space. This method generally only obtains local optimal solutions.
+
+(8) The SVM controls the capabilities of the model by maximizing the edges of the decision boundaries. However, the user must provide other parameters, such as the use of kernel function types and the introduction of slack variables.
+
+(9) SVM can get much better results than other algorithms on small sample training sets. The SVM optimization goal is to minimize the risk of structuring, instead of minimizing the risk of learning, avoiding the problem of learning. Through the concept of margin, the structured description of the data distribution is obtained, which reduces the requirements on data size and data distribution. Ability.
+
+(10) It is a convex optimization problem, so the local optimal solution must be the advantage of the global optimal solution.
+
+### 2.18.9 SVMThe main disadvantage?
+
+(1) SVM algorithm is difficult to implement for large-scale training samples
+
+The space consumption of the SVM is mainly to store the training samples and the kernel matrix. Since the SVM solves the support vector by means of quadratic programming, the solution to the quadratic programming involves the calculation of the m-order matrix (m is the number of samples), when the number of m When large, the storage and calculation of the matrix will consume a lot of machine memory and computation time.
+
+If the amount of data is large, SVM training time will be longer, such as spam classification detection, instead of using SVM classifier, but using a simple naive bayes classifier, or using logistic regression model classification.
+
+(2) It is difficult to solve multi-classification problems with SVM
+
+The classical support vector machine algorithm only gives the algorithm of the second class classification, but in practical applications, it is generally necessary to solve the classification problem of multiple classes. It can be solved by a combination of multiple second-class support vector machines. There are mainly one-to-many combination mode, one-to-one combination mode and SVM decision tree; and then it is solved by constructing a combination of multiple classifiers. The main principle is to overcome the inherent shortcomings of SVM, combined with the advantages of other algorithms, to solve the classification accuracy of many types of problems. For example, combined with the rough set theory, a combined classifier of multiple types of problems with complementary advantages is formed.
+
+(3) sensitive to missing data, sensitive to the selection of parameters and kernel functions
+
+The performance of support vector machine performance depends mainly on the selection of kernel function, so for a practical problem, how to choose the appropriate kernel function according to the actual data model to construct SVM algorithm. The more mature kernel function and its parameters The choices are all artificial, selected according to experience, with certain randomness. In different problem areas, the kernel function should have different forms and parameters, so the domain knowledge should be introduced when selecting, but there is no A good way to solve the problem of kernel function selection.
+
+### 2.18.10 Similarities and differences between logistic regression and SVM
+
+Same point:
+
+- LR and SVM are both **classification** algorithms
+- Both LR and SVM are **supervised learning** algorithms.
+- Both LR and SVM are ** discriminant models**.
+- If the kernel function is not considered, both LR and SVM are **linear classification** algorithms, which means that their classification decision surfaces are linear.
+ Note: LR can also use the kernel function. But LR usually does not use the kernel function method. (**The amount of calculation is too large**)
+
+difference:
+
+**1, LR uses log loss, SVM uses hinge loss. **
+Logistic regression loss function:
+$$
+J(\theta)=-\frac{1}{m}\left[\sum^m_{i=1}y^{(i)}logh_{\theta}(x^{(i)})+ ( 1-y^{(i)})log(1-h_{\theta}(x^{(i)}))\right]
+$$
+The objective function of the support vector machine:
+$$
+L(w,n,a)=\frac{1}{2}||w||^2-\sum^n_{i=1}\alpha_i \left(y_i(w^Tx_i+b)-1 \right)
+$$
+The logistic regression method is based on probability theory. The probability that the sample is 1 can be represented by the sigmoid function, and then the value of the parameter is estimated by the method of maximum likelihood estimation.
+
+The support vector machine is based on the principle of geometric interval maximization,and it is considered that the classification plane with the largest geometric interval is the optimal classification plane.
+
+2. **LR is sensitive to outliers and SVM is not sensitive to outliers**.
+
+The support vector machine only considers points near the local boundary line, while logistic regression considers the global. The hyperplane found by the LR model tries to keep all points away from him, and the hyperplane that the SVM looks for is to keep only those points closest to the middle dividing line as far away as possible, that is, only those samples that support vectors.
+
+Support vector machines to change non-support vector samples do not cause changes in the decision surface.
+
+Changing any sample in a logistic regression can cause changes in the decision surface.
+
+**3, the calculation complexity is different. For massive data, SVM is less efficient and LR efficiency is higher**
+
+When the number of samples is small and the feature dimension is low, the running time of SVM and LR is relatively short, and the SVM is shorter. For accuracy, LR is significantly higher than SVM. When the sample is slightly increased, the SVM runtime begins to grow, but the accuracy has surpassed LR. Although the SVM time is long, it is within the receiving range. When the amount of data grows to 20,000, when the feature dimension increases to 200, the running time of the SVM increases dramatically, far exceeding the running time of the LR. But the accuracy rate is almost the same as LR. (The main reason for this is that a large number of non-support vectors participate in the calculation, resulting in secondary planning problems for SVM)
+
+**4. Different ways of dealing with nonlinear problems, LR mainly relies on feature structure, and must combine cross-characteristics and feature discretization. SVM can also be like this, but also through the kernel (because only the support vector participates in the core calculation, the computational complexity is not high). ** (Because the kernel function can be used, the SVM can be efficiently processed by the dual solution. LR is poor when the feature space dimension is high.)
+
+**5, SVM loss function comes with regular! ! ! (1/2 ||w||^2 in the loss function), which is why SVM is the structural risk minimization algorithm! ! ! And LR must add a regular item to the loss function! ! ! **
+
+6, SVM comes with ** structural risk minimization**, LR is ** empirical risk minimization**.
+
+7, SVM will use the kernel function and LR generally does not use [nuclear function] (https://www.cnblogs.com/huangyc/p/9940487.html).
+
+## 2.19 Bayesian classifier
+### 2.19.1 Graphical Maximum Likelihood Estimation
+
+The principle of maximum likelihood estimation is illustrated by a picture, as shown in the following figure:
+
+
+
+Example: There are two boxes with the same shape. There are 99 white balls and 1 black ball in the 1st box. There are 1 white ball and 99 black balls in the 2nd box. In one experiment, the black ball was taken out. Which box was taken out from?
+
+Generally, based on empirical thoughts, it is guessed that this black ball is most like being taken out from the No. 2 box. The "most like" described at this time has the meaning of "maximum likelihood". This idea is often called "maximum likelihood." principle".
+
+### 2.19.2 Principle of Maximum Likelihood Estimation
+
+To sum up, the purpose of the maximum likelihood estimation is to use the known sample results to reverse the most likely (maximum probability) parameter values that lead to such results.
+
+The maximum likelihood estimation is a statistical method based on the principle of maximum likelihood. The maximum likelihood estimation provides a method for estimating the model parameters given the observed data, namely: "The model has been determined and the parameters are unknown." Through several experiments, the results are observed. Using the test results to obtain a parameter value that maximizes the probability of occurrence of the sample is called maximum likelihood estimation.
+
+Since the samples in the sample set are all independent and identical, the parameter vector θ can be estimated by considering only one type of sample set D. The known sample set is:
+$$
+D=x_{1}, x_{2},...,x_{n}
+$$
+Linkehood function: The joint probability density function $P(D|\theta )$ is called the likelihood of θ relative to $x_{1}, x_{2},...,x_{n}$ function.
+$$
+l(\theta )=p(D|\theta ) =p(x_{1},x_{2},...,x_{N}|\theta )=\prod_{i=1}^{N} p(x_{i}|\theta )
+$$
+If $\hat{\theta}$ is the value of θ in the parameter space that maximizes the likelihood function $l(\theta)$, then $\hat{\theta}$ should be the "most likely" parameter value, then $\hat{\theta} $ is the maximum likelihood estimator of θ. It is a function of the sample set and is written as:
+$$
+\hat{\theta}=d(x_{1},x_{2},...,x_{N})=d(D)
+$$
+$\hat{\theta}(x_{1}, x_{2},...,x_{N})$ is called the maximum likelihood function estimate.
+
+### 2.19.3 Basic Principles of Bayesian Classifier
+
+Https://www.cnblogs.com/hxyue/p/5873566.html
+
+Https://www.cnblogs.com/super-zhang-828/p/8082500.html
+
+Bayesian decision theory uses the **false positive loss** to select the optimal category classification by using the **correlation probability known**.
+
+Suppose there are $N$ possible classification tags, denoted as $Y=\{c_1,c_2,...,c_N\}$, which category does it belong to for the sample $x$?
+
+The calculation steps are as follows:
+
+Step 1. Calculate the probability that the sample $x$ belongs to the $i$ class, ie $P(c_i|x) $;
+
+Step 2. By comparing all $P(c_i|\boldsymbol{x})$, get the best category to which the sample $x$ belongs.
+
+Step 3. Substituting the category $c_i$ and the sample $x$ into the Bayesian formula,
+$$
+P(c_i|\boldsymbol{x})=\frac{P(\boldsymbol{x}|c_i)P(c_i)}{P(\boldsymbol{x})}.
+$$
+In general, $P(c_i)$ is the prior probability, $P(\boldsymbol{x}|c_i)$ is the conditional probability, and $P(\boldsymbol{x})$ is the evidence factor for normalization. . For $P(c_i)$, you can estimate the proportion of the sample with the category $c_i$ in the training sample; in addition, since we only need to find the largest $P(\boldsymbol{x}|c_i)$, we It is not necessary to calculate $P(\boldsymbol{x})$.
+
+In order to solve the conditional probability, different methods are proposed based on different hypotheses. The naive Bayes classifier and the semi-premise Bayes classifier are introduced below.
+
+### 2.19.4 Naive Bayes Classifier
+
+Suppose the sample $x$ contains $d$ attributes, ie $x=\{ x_1,x_2,...,x_d\}$. Then there is
+$$
+P(\boldsymbol{x}|c_i)=P(x_1,x_2,\cdots,x_d|c_i).
+$$
+This joint probability is difficult to estimate directly from a limited training sample. Thus, Naive Bayesian (NB) adopted the "attribute conditional independence hypothesis": for known categories, assume that all attributes are independent of each other. Then there is
+$$
+P(x_1,x_2,\cdots,x_d|c_i)=\prod_{j=1}^d P(x_j|c_i).
+$$
+In this case, we can easily introduce the corresponding criteria:
+$$
+H_{nb}(\boldsymbol{x})=\mathop{\arg \max}_{c_i\in Y} P(c_i)\prod_{j=1}^dP(x_j|c_i).
+$$
+**Solution of conditional probability $P(x_j|c_i) $**
+
+If $x_j$ is a tag attribute, then we can estimate $P(x_j|c_i)$ by counting.
+$$
+P(x_j|c_i)=\frac{P(x_j,c_i)}{P(c_i)}\approx\frac{\#(x_j,c_i)}{\#(c_i)}.
+$$
+Where $\#(x_j,c_i)$ represents the number of times $x_j$ and common $c_{i}$ appear in the training sample.
+
+If $x_j$ is a numeric attribute, we usually assume that the first $j$ property of all samples of $c_{i}$ in the category follows a normal distribution. We first estimate the mean of the distribution $μ$ and the variance $σ$, and then calculate the probability density $P(x_j|c_i)$ of $x_j$ in this distribution.
+
+### 2.19.5 An example to understand the naive Bayes classifier
+
+The training set is as follows:
+
+Https://www.cnblogs.com/super-zhang-828/p/8082500.html
+
+| Number | Color | Roots | Knock | Texture | Umbilical | Tactile | Density | Sugar Content |
+| :--: | :--: | :-- | : :--: | :--: | :--: | :--: | :---: | :----: | --: |
+| 1 | Green | Condensation | Turbidity | Clear | Sag | Hard slip | 0.697 | 0.460 |
+| 2 | Black | Cursed | Dull | Clear | Sag | Hard slip | 0.774 | 0.376 |
+| 3 | Black | Cursed | Turbid | Clear | Hollow | Hard slip | 0.634 | 0.264 |
+4 | Green | Collapse | Dull | Clear | Hollow | Hard slip | 0.608 | 0.318 |
+| 5 | White | Cursed | Turbid | Clear | Sag | Hard slip | 0.556 | 0.215 |
+| 6 | Green | A little bit | 浊 | | Clear | slightly concave | soft sticky | 0.403 | 0.237 |
+| 7 | Black | Slightly 蜷 | 浊响 | Slightly sloppy | Slightly concave | Soft sticky | 0.481 | 0.149 |
+| 8 | Black | Slightly 蜷 | 浊 | | Clear | Slightly concave | Hard slip | 0.437 | 0.211 |
+| 9乌黑 | 蜷 蜷 | dull | slightly battered | slightly concave | hard slip | 0.666 | 0.091 |
+| 10 | Green | Tough | Crisp | Clear | Flat | Soft Sticky | 0.243 | 0.267 |
+| 11 | White | Hard | Crisp | Blur | Flat | Hard slip | 0.245 | 0.057 |
+| 12 | White | Collapse | Turbidity | Blur | Flat | Soft Sticky | 0.343 | 0.099 |
+| 13 | Green | Slightly 蜷 | 浊响 | Slightly smeared | Sag | Hard slip | 0.639 | 0.161 |
+| 14 | 白白 | 蜷 蜷 | dull | slightly paste | dent | hard slip | 0.657 | 0.198 |
+| 15 | black | slightly 蜷 | 浊 | | Clear | slightly concave | soft sticky | 0.360 | 0.370 |
+| 16 | White | Cursed | Turbid | Blurred | Flat | Hard slip | 0.593 | 0.042 |
+| 17 | Green | Collapse | Dull | Slightly Paste | Slightly concave | Hard slip | 0.719 | 0.103 |
+
+The following test example "Measure 1" is classified:
+
+Number | Color | Roots | Knock | Texture | Umbilical | Tactile | Density | Sugar Content |
+| :--: | :--: | :-- | : :--: | :--: | :--: | :--: | :---: | :----: | --: |
+| 1 | Green | Cursed | Turbid | Clear | Hollow | Hard slip | 0.697 | 0.460 | |
+
+First, estimate the class prior probability $P(c_j)$, there is
+$$
+\begin{align}
+&P (good melon = yes) = \frac{8}{17}=0.471 \newline
+&P (good melon = no) = \frac{9}{17}=0.529
+\end{align}
+$$
+Then, estimate the conditional probability for each attribute (here, for continuous attributes, assume they follow a normal distribution)
+
+
+
+Then there is
+$$
+\begin{align}
+P(&好瓜=是)\times P_{青绿|是} \times P_{蜷缩|是} \times P_{ 浊响|是} \times P_{clear|yes} \times P_{sag|is}\ Newline
+&\times P_{hard slip|yes} \times p_{density: 0.697|yes} \times p_{sugar:0.460|yes} \approx 0.063 \newline\newline
+P(&good melon=no)\times P_{green=no} \times P_{collapse|no} \times P_{turbidity|no} \times P_{clear|no} \times P_{sag|no}\ Newline
+&\times P_{hard slip|no} \times p_{density: 0.697|no} \times p_{sugar:0.460|no} \approx 6.80\times 10^{-5}
+\end{align}
+$$
+
+```
+`0.063>6.80\times 10^{-5}`
+```
+
+### 2.19.4 Naive Bayes Classifier
+
+Naïve Bayes adopts the "attribute conditional independence hypothesis". The basic idea of the semi-simple Bayesian classifier is to properly consider the interdependence information between some attributes. ** One-Dependent Estimator (ODE) is one of the most commonly used strategies for semi-simple Bayesian classifiers. As the name implies, the sole dependency assumes that each attribute depends on at most one other attribute outside the category, ie
+$$
+P(x|c_i)=\prod_{j=1}^d P(x_j|c_i,{\rm pa}_j).
+$$
+Where $pa_j$ is the property on which the attribute $x_i$ depends and becomes the parent of $x_i$. Assuming the parent attribute $pa_j$ is known, you can use the following formula to estimate $P(x_j|c_i,{\rm pa}_j)$
+$$
+P(x_j|c_i,{\rm pa}_j)=\frac{P(x_j,c_i,{\rm pa}_j)}{P(c_i,{\rm pa}_j)}.
+$$
+
+## 2.20 EM algorithm
+
+### 2.20.1 The basic idea of EM algorithm
+
+The Expectation-Maximization algorithm (EM) is a kind of optimization algorithm that performs maximum likelihood estimation by iteration. It is usually used as an alternative to the Newton iteration method to parameterize the probability model containing hidden variables or missing data. estimate.
+
+The basic idea of the maximum expectation algorithm is to calculate it alternately in two steps:
+
+The first step is to calculate the expectation (E), using the existing estimates of the hidden variables, to calculate its maximum likelihood estimate;
+
+The second step is to maximize (M) and maximize the maximum likelihood value found on the E step to calculate the value of the parameter.
+
+The parameter estimates found on step M are used in the next E-step calculation, which is alternated.
+
+### 2.20.2 EM algorithm derivation
+
+For the $m$ sample observation data $x=(x^{1}, x^{2},...,x^{m})$, now I want to find the model parameter $\theta$ of the sample, which The log-likelihood function of the maximized model distribution is:
+$$
+\theta = arg \max \limits_{\theta}\sum\limits_{i=1}^m logP(x^{(i)};\theta)
+$$
+If the obtained observation data has unobserved implicit data $z=(z^{(1)}, z^{(2)},...z^{(m)})$, maximization model The logarithm likelihood function of the distribution is:
+$$
+\theta = arg \max \limits_{\theta}\sum\limits_{i=1}^m logP(x^{(i)};\theta) = arg \max \limits_{\theta}\sum\limits_ {i=1}^m log\sum\limits_{z^{(i)}}P(x^{(i)}, z^{(i)};\theta) \tag{a}
+$$
+Since the above formula cannot directly find $\theta$, use the zooming technique:
+$$
+\begin{align} \sum\limits_{i=1}^m log\sum\limits_{z^{(i)}}P(x^{(i)}, z^{(i)};\theta ) & = \sum\limits_{i=1}^m log\sum\limits_{z^{(i)}}Q_i(z^{(i)})\frac{P(x^{(i)} , z^{(i)};\theta)}{Q_i(z^{(i)})} \\ & \geq \sum\limits_{i=1}^m \sum\limits_{z^{( i)}}Q_i(z^{(i)})log\frac{P(x^{(i)}, z^{(i)};\theta)}{Q_i(z^{(i)} )} \end{align} \tag{1}
+$$
+The above formula uses the Jensen inequality:
+$$
+Log\sum\limits_j\lambda_jy_j \geq \sum\limits_j\lambda_jlogy_j\;\;, \lambda_j \geq 0, \sum\limits_j\lambda_j =1
+$$
+And introduced an unknown new distribution $Q_i(z^{(i)})$.
+
+At this point, if you need to meet the equal sign in Jensen's inequality, there are:
+$$
+\frac{P(x^{(i)}, z^{(i)};\theta)}{Q_i(z^{(i)})} =c, c is a constant
+$$
+Since $Q_i(z^{(i)})$ is a distribution, it is satisfied
+$$
+\sum\limits_{z}Q_i(z^{(i)}) =1
+$$
+In summary, you can get:
+$$
+Q_i(z^{(i)}) = \frac{P(x^{(i)}, z^{(i)};\theta)}{\sum\limits_{z}P(x^{( i)}, z^{(i)};\theta)} = \frac{P(x^{(i)}, z^{(i)};\theta)}{P(x^{(i )};\theta)} = P( z^{(i)}|x^{(i)};\theta))
+$$
+If $Q_i(z^{(i)}) = P( z^{(i)}|x^{(i)};\theta))$ , then equation (1) is our inclusion of hidden data. A lower bound of log likelihood. If we can maximize this lower bound, we are also trying to maximize our log likelihood. That is, we need to maximize the following:
+$$
+Arg \max \limits_{\theta} \sum\limits_{i=1}^m \sum\limits_{z^{(i)}}Q_i(z^{(i)})log\frac{P(x ^{(i)}, z^{(i)};\theta)}{Q_i(z^{(i)})}
+$$
+Simplified:
+$$
+Arg \max \limits_{\theta} \sum\limits_{i=1}^m \sum\limits_{z^{(i)}}Q_i(z^{(i)})log{P(x^{ (i)}, z^{(i)};\theta)}
+$$
+The above is the M step of the EM algorithm, $\sum\limits_{z^{(i)}}Q_i(z^{(i)})log{P(x^{(i)}, z^{(i )};\theta)} $ can be understood as $logP(x^{(i)}, z^{(i)};\theta) $ based on conditional probability distribution $Q_i(z^{(i)} ) $ expectation. The above is the specific mathematical meaning of the E step and the M step in the EM algorithm.
+
+### 2.20.3 Graphical EM algorithm
+
+Considering the formula (a) in the previous section, there are hidden variables in the expression. It is difficult to find the parameter estimation directly. The EM algorithm is used to iteratively solve the maximum value of the lower bound until convergence.
+
+
+
+The purple part of the picture is our target model $p(x|\theta)$. The model is complex and difficult to find analytical solutions. In order to eliminate the influence of the hidden variable $z^{(i)}$, we can choose one not. The $r(x|\theta)$ model containing $z^{(i)}$ is such that it satisfies the condition $r(x|\theta) \leq p(x|\theta) $.
+
+The solution steps are as follows:
+
+(1) Select $\theta_1$ so that $r(x|\theta_1) = p(x|\theta_1)$, then take the maximum value for $r$ at this time and get the extreme point $\theta_2$, Implement parameter updates.
+
+(2) Repeat the above process until convergence, and always satisfy $r \leq p $.
+
+### 2.20.4 EM algorithm flow
+
+Input: Observed data $x=(x^{(1)}, x^{(2)},...x^{(m)})$, joint distribution $p(x,z ;\theta)$ , conditional distribution $p(z|x; \theta)$, maximum iterations $J$
+
+1) Randomly initialize the initial value of the model parameter $\theta$ $\theta^0$.
+
+2) $for \ j \ from \ 1 \ to \ j$:
+
+a) Step E. Calculate the conditional probability expectation of the joint distribution:
+$$
+Q_i(z^{(i)}) = P( z^{(i)}|x^{(i)},\theta^{j}))
+$$
+
+$$
+L(\theta, \theta^{j}) = \sum\limits_{i=1}^m\sum\limits_{z^{(i)}}Q_i(z^{(i)})log{P (x^{(i)}, z^{(i)};\theta)}
+$$
+
+b) M steps. Maximize $L(\theta, \theta^{j})$ and get $\theta^{j+1}$:
+$$
+\theta^{j+1} = arg \max \limits_{\theta}L(\theta, \theta^{j})
+$$
+c) If $\theta^{j+1}$ converges, the algorithm ends. Otherwise continue back to step a) for an E step iteration.
+
+Output: Model parameter $\theta $.
+
+## 2.21 Dimensionality and clustering
+
+### 2.21.1 Why does the diagram create a dimensional disaster?
+
+Http://www.visiondummy.com/2014/04/curse-dimensionality-affect-classificatIon/
+
+If the data set contains 10 photos, the photo contains both triangle and circle shapes. Now let's design a classifier for training, let this model classify other photos correctly (assuming the total number of triangles and circles is infinite), and simple, we use a feature to classify:
+
+
+
+
+
+Figure 2.21.1.a
+
+As can be seen from the above figure, if only one feature is classified, the triangle and the circle are almost evenly distributed on this line segment, and it is difficult to linearly classify 10 photos. So what happens when you add a feature:
+
+
+
+Figure 2.21.1.b
+
+After adding a feature, we found that we still couldn't find a straight line to separate the cat from the dog. So, consider adding another feature:
+
+
+
+Figure 2.21.1.c
+
+
+
+Figure 2.21.1.d
+
+At this point, you can find a plane separating the triangle from the circle.
+
+Now calculate that the different feature numbers are the density of the sample:
+
+(1) For a feature, assuming a line segment of length 5 in the feature space, the sample density is 10/5=2.
+
+(2) For two features, the feature space size is 5*5=25 and the sample density is 10/25=0.4.
+
+(3) In the case of three features, the feature space size is 5*5\*5=125, and the sample density is 10/125=0.08.
+
+By analogy, if you continue to increase the number of features, the sample density will become more and more sparse. At this time, it is easier to find a hyperplane to separate the training samples. As the number of features grows to infinity, the sample density becomes very sparse.
+
+Let's look at what happens when you map the classification results of high-dimensional space to low-dimensional space.
+
+
+
+Figure 2.21.1.e
+
+The above figure is the result of mapping the 3D feature space to the 2D feature space. Although the training samples are linearly separable in the high dimensional feature space, the results are reversed after mapping to the low dimensional space. In fact, increasing the number of features makes the high-dimensional space linearly separable, which is equivalent to training a complex nonlinear classifier in a low-dimensional space. However, this nonlinear classifier is too "smart" to learn only a few special cases. If it is used to identify test samples that have not appeared in the training sample, the results are usually not ideal and can cause over-fitting problems.
+
+
+
+Figure 2.21.1.f
+
+The linear classifier with only two features shown in the above figure is divided into some training samples. The accuracy does not seem to be as high as in Figure 2.21.1.e. However, the generalization ability ratio of linear classifiers with two features is shown. A linear classifier with three features is stronger. Because the linear classifier with two features learns not only the special case, but an overall trend, which can be better distinguished for those samples that have never appeared before. In other words, by reducing the number of features, over-fitting problems can be avoided, thereby avoiding "dimensionality disasters."
+
+
+
+From another perspective, the "dimensional disaster" is explained. Assuming that there is only one feature, the range of features is 0 to 1, and the eigenvalues of each triangle and circle are unique. If we want the training sample to cover 20% of the eigenvalue range, then we need 20% of the total number of triangles and circles. After we add a feature, 45% (0.452 = 0.2) of the total number of triangles and circles is needed to continue covering 20% of the eigenvalue range. After continuing to add a feature, 58% (0.583 = 0.2) of the total number of triangles and circles is required. As the number of features increases, more training samples are needed to cover 20% of the eigenvalue range. If there are not enough training samples, there may be over-fitting problems.
+
+Through the above example, we can see that the more the number of features, the more sparse the training samples will be, the less accurate the parameter estimates of the classifier will be, and the over-fitting problem will be more likely to occur. Another effect of the "dimension disaster" is that the sparsity of the training samples is not evenly distributed. The training samples at the center are more sparse than the surrounding training samples.
+
+
+
+Suppose there is a two-dimensional feature space, such as the rectangle shown in Figure 8, with an inscribed circle inside the rectangle. As the sample closer to the center of the circle is sparse, those samples located at the four corners of the rectangle are more difficult to classify than the samples within the circle. When the dimension becomes larger, the capacity of the feature hyperspace does not change, but the capacity of the unit circle tends to zero. In the high-dimensional space, most of the training data resides in the corner of the feature hyperspace. Data scattered in the corner is harder to classify than data in the center.
+
+### 2.21.2 How to avoid dimension disaster
+
+**To be improved! ! ! **
+
+Solve the dimensional disaster problem:
+
+Principal Component Analysis PCA, Linear Discrimination LDA
+
+Singular value decomposition simplified data, Laplacian feature mapping
+
+Lassio reduction factor method, wavelet analysis,
+
+### 2.21.3 What is the difference and connection between clustering and dimension reduction?
+
+Clustering is used to find the distribution structure inherent in data, either as a separate process, such as anomaly detection. It can also be used as a precursor to other learning tasks such as classification. Clustering is the standard unsupervised learning.
+
+1) In some recommendation systems, the type of new user needs to be determined, but it is not easy to define the “user type”. In this case, the original user data can be clustered first, and each cluster is clustered according to the clustering result. Defined as a class, and then based on these classes to train the classification model to identify the type of new user.
+
+
+
+2) Dimensionality reduction is an important method to alleviate the dimensionality disaster. It is to transform the original high-dimensional attribute space into a low-dimensional "subspace" through some mathematical transformation. It is based on the assumption that although the data samples that people usually observe are high-dimensional, what is actually related to the learning task is a low-dimensional distribution. Therefore, the description of the data can be realized through the most important feature dimensions, which is helpful for the subsequent classification. For example, the Titanic on Kaggle was still a problem. By giving a person a number of characteristics such as age, name, gender, fare, etc., to determine whether it can survive in a shipwreck. This requires first feature screening to identify the main features and make the learned models more generalizable.
+
+Both clustering and dimensionality reduction can be used as preprocessing steps for classification and other issues.
+
+
+
+But although they can achieve the reduction of data. However, the two objects are different, the clustering is for data points, and the dimension reduction is for the characteristics of the data. In addition, they have a variety of implementation methods. K-means, hierarchical clustering, density-based clustering, etc. are commonly used in clustering; PCA, Isomap, LLE, etc. are commonly used in dimension reduction.
+
+
+
+
+
+### 2.21.4 Comparison of four clustering methods
+
+http://www.cnblogs.com/William_Fire/archive/2013/02/09/2909499.html
+
+
+
+Clustering is to divide a data set into different classes or clusters according to a certain standard (such as distance criterion), so that the similarity of the data objects in the same cluster is as large as possible, and the data objects are not in the same cluster. The difference is also as large as possible. That is, after clustering, the same type of data is gathered together as much as possible, and different data is separated as much as possible.
+The main clustering algorithms can be divided into the following categories: partitioning methods, hierarchical methods, density-based methods, grid-based methods, and model-based methods. The following is a comparison and analysis of the clustering effects of the k-means clustering algorithm, the condensed hierarchical clustering algorithm, the neural network clustering algorithm SOM, and the fuzzy clustering FCM algorithm through the universal test data set.
+
+### 2.21.5 k-means clustering algorithm
+
+K-means is one of the more classical clustering algorithms in the partitioning method. Because of its high efficiency, the algorithm is widely used in clustering large-scale data. At present, many algorithms are extended and improved around the algorithm.
+The k-means algorithm uses k as a parameter to divide n objects into k clusters, so that the clusters have higher similarity and the similarity between clusters is lower. The processing of the k-means algorithm is as follows: First, k objects are randomly selected, each object initially representing the average or center of a cluster; for each remaining object, according to its distance from the center of each cluster, It is assigned to the nearest cluster; then the average of each cluster is recalculated. This process is repeated until the criterion function converges. Usually, the squared error criterion is used, which is defined as follows:
+
+$E=\sum_{i=1}^{k}\sum_{p\subset C}|p-m_{i}|^{2} $
+
+Here E is the sum of the squared errors of all objects in the database, p is the point in space, and mi is the average of cluster Ci [9]. The objective function makes the generated cluster as compact and independent as possible, and the distance metric used is the Euclidean distance, although other distance metrics can be used.
+
+The algorithm flow of the k-means clustering algorithm is as follows:
+Input: the number of databases and clusters containing n objects k;
+Output: k clusters, which minimizes the squared error criterion.
+Steps:
+(1) arbitrarily select k objects as the initial cluster center;
+(2) repeat;
+(3) Assign each object (re) to the most similar cluster based on the average of the objects in the cluster;
+(4) Update the average of the clusters, that is, calculate the average of the objects in each cluster;
+(5) until no longer changes.
+
+### 2.21.6 Hierarchical Clustering Algorithm
+
+According to the order of hierarchical decomposition, whether it is bottom-up or top-down, the hierarchical clustering algorithm is divided into a condensed hierarchical clustering algorithm and a split hierarchical clustering algorithm.
+The strategy of condensed hierarchical clustering is to first treat each object as a cluster, then merge the clusters into larger and larger clusters until all objects are in one cluster, or a certain termination condition is satisfied. Most hierarchical clusters belong to agglomerative hierarchical clustering, which differ only in the definition of similarity between clusters. The four widely used methods for measuring the distance between clusters are as follows:
+
+
+
+Here is the flow of the condensed hierarchical clustering algorithm using the minimum distance:
+
+(1) Treat each object as a class and calculate the minimum distance between the two;
+(2) Combine the two classes with the smallest distance into one new class;
+(3) Recalculate the distance between the new class and all classes;
+(4) Repeat (2), (3) until all classes are finally merged into one class.
+
+### 2.21.7 SOM clustering algorithm
+The SOM neural network [11] was proposed by the Finnish neural network expert Professor Kohonen, which assumes that there are some topologies or sequences in the input object that can be implemented from the input space (n-dimensional) to the output plane (2-dimensional). Dimensional mapping, whose mapping has topological feature retention properties, has a strong theoretical connection with actual brain processing.
+
+The SOM network consists of an input layer and an output layer. The input layer corresponds to a high-dimensional input vector, and the output layer consists of a series of ordered nodes organized on a 2-dimensional grid. The input node and the output node are connected by a weight vector. During the learning process, find the output layer unit with the shortest distance, that is, the winning unit, and update it. At the same time, the weights of the neighboring regions are updated so that the output node maintains the topological features of the input vector.
+
+Algorithm flow:
+
+(1) Network initialization, assigning an initial value to each node weight of the output layer;
+(2) randomly select the input vector from the input sample to find the weight vector with the smallest distance from the input vector;
+(3) Defining the winning unit, adjusting the weight in the vicinity of the winning unit to make it close to the input vector;
+(4) Provide new samples and conduct training;
+(5) Shrink the neighborhood radius, reduce the learning rate, and repeat until it is less than the allowable value, and output the clustering result.
+
+### 2.21.8 FCM clustering algorithm
+
+In 1965, Professor Zade of the University of California, Berkeley, first proposed the concept of 'collection'. After more than ten years of development, the fuzzy set theory has gradually been applied to various practical applications. In order to overcome the shortcomings of classification, the clustering analysis based on fuzzy set theory is presented. Cluster analysis using fuzzy mathematics is fuzzy cluster analysis [12].
+
+The FCM algorithm is an algorithm that determines the degree to which each data point belongs to a certain cluster degree by membership degree. This clustering algorithm is an improvement of the traditional hard clustering algorithm.
+
+
+
+Algorithm flow:
+
+(1) Standardized data matrix;
+(2) Establish a fuzzy similarity matrix and initialize the membership matrix;
+(3) The algorithm starts iterating until the objective function converges to a minimum value;
+(4) According to the iterative result, the class to which the data belongs is determined by the last membership matrix, and the final clustering result is displayed.
+
+3 four clustering algorithm experiments
+
+
+3.1 Test data
+
+In the experiment, IRIS [13] data set in the international UCI database dedicated to test classification and clustering algorithm was selected. The IRIS data set contains 150 sample data, which are taken from three different Iris plants, setosa. Versicolor and virginica flower samples, each data contains 4 attributes, namely the length of the bract, the width of the bract, the length of the petal, in cm. By performing different clustering algorithms on the dataset, clustering results with different precisions can be obtained.
+
+3.2 Description of test results
+
+Based on the previous algorithm principles and algorithm flow, the programming operation is performed by matlab, and the clustering results shown in Table 1 are obtained.
+
+
+
+As shown in Table 1, for the four clustering algorithms, compare them in three aspects:
+
+(1) The number of errors in the number of samples: the total number of samples of the error, that is, the sum of the number of samples in each category;
+
+(2) Running time: that is, the whole clusteringThe time spent by the process, the unit is s;
+
+(3) Average accuracy: Let the original data set have k classes, use ci to represent the i-th class, ni is the number of samples in ci, and mi is the correct number of clusters, then mi/ni is the i-th class. The accuracy of the average accuracy is:
+
+$avg=\frac{1}{k}\sum_{i=1}^{k}\frac{m_{i}}{n_{i}} $
+
+## 2.22 The difference between GBDT and random forest
+
+The same point between GBDT and random forest:
+1, are composed of multiple trees
+2, the final result is determined by multiple trees together
+
+Differences between GBDT and random forests:
+1. The tree that constitutes a random forest can be a classification tree or a regression tree; and GBDT consists only of regression trees.
+2, the trees that make up the random forest can be generated in parallel; and GBDT can only be serially generated
+3. For the final output, random forests use majority voting, etc.; while GBDT accumulates all results, or weights up and accumulate
+4. Random forest is not sensitive to outliers, GBDT is very sensitive to outliers
+5. Random forests treat training sets equally, and GBDT is a weak classifier based on weights.
+6. Random forests improve performance by reducing model variance, and GBDT improves performance by reducing model bias.
+
+## 2.23 The relationship between big data and deep learning
+
+**Big Data** is usually defined as a dataset that “beyond the capture, management, and processing capabilities of common software tools.”
+**Machine Learning** The concern is how to build a computer program using experience to automatically improve.
+**Data Mining** is the application of a specific algorithm for extracting patterns from data.
+In data mining, the focus is on the application of the algorithm, not the algorithm itself.
+
+**The relationship between machine learning and data mining** is as follows:
+Data mining is a process in which machine learning algorithms are used as a tool to extract potentially valuable patterns in a data set.
+The relationship between big data and deep learning is summarized as follows:
+
+1. Deep learning is a behavior that mimics the brain. You can learn from many related aspects of the mechanism and behavior of the object you are learning, imitating type behavior and thinking.
+2. Deep learning is helpful for the development of big data. Deep learning can help every stage of big data technology development, whether it is data analysis or mining or modeling, only deep learning, these work will be possible to achieve one by one.
+3. Deep learning has transformed the thinking of problem solving. Many times when we find problems to solve problems, taking a step by step is not a major way to solve problems. On the basis of deep learning, we need to base ourselves on the goal from the beginning to the end, in order to optimize the ultimate goal. Go to process the data and put the data into the data application platform.
+4. Deep learning of big data requires a framework. Deep learning in big data is based on a fundamental perspective. Deep learning requires a framework or a system. In general, turning your big data into reality through in-depth analysis is the most direct relationship between deep learning and big data.
+
+
+
+
+## References
+Machine Learning p74 Zhou Zhihua Decision Tree Pseudo Code
+[Neural Networks and Deep Learning CHAPTER 3](http://neuralnetworksanddeeplearning.com/chap3.html) Introducing the cross-entropy cost function
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2-1.png b/English version/ch02_MachineLearningFoundation/img/ch2/2-1.png
new file mode 100644
index 00000000..38d1b589
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2-1.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2-10.png b/English version/ch02_MachineLearningFoundation/img/ch2/2-10.png
new file mode 100644
index 00000000..ab9b095c
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2-10.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2-11.png b/English version/ch02_MachineLearningFoundation/img/ch2/2-11.png
new file mode 100644
index 00000000..5ab57c87
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2-11.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2-12.png b/English version/ch02_MachineLearningFoundation/img/ch2/2-12.png
new file mode 100644
index 00000000..38f9b1a6
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2-12.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2-13.png b/English version/ch02_MachineLearningFoundation/img/ch2/2-13.png
new file mode 100644
index 00000000..d0317d33
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2-13.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2-14.png b/English version/ch02_MachineLearningFoundation/img/ch2/2-14.png
new file mode 100644
index 00000000..53cb70ed
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2-14.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2-15.png b/English version/ch02_MachineLearningFoundation/img/ch2/2-15.png
new file mode 100644
index 00000000..fbbd76af
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2-15.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2-16.png b/English version/ch02_MachineLearningFoundation/img/ch2/2-16.png
new file mode 100644
index 00000000..614c3872
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2-16.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2-17.png b/English version/ch02_MachineLearningFoundation/img/ch2/2-17.png
new file mode 100644
index 00000000..e00c9b63
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2-17.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2-18.jpg b/English version/ch02_MachineLearningFoundation/img/ch2/2-18.jpg
new file mode 100644
index 00000000..3438ca2e
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2-18.jpg differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2-19.jpg b/English version/ch02_MachineLearningFoundation/img/ch2/2-19.jpg
new file mode 100644
index 00000000..b5e4f7c7
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2-19.jpg differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2-2.png b/English version/ch02_MachineLearningFoundation/img/ch2/2-2.png
new file mode 100644
index 00000000..8bbc66cd
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2-2.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2-20.gif b/English version/ch02_MachineLearningFoundation/img/ch2/2-20.gif
new file mode 100644
index 00000000..3b8fbfdb
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2-20.gif differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2-21.gif b/English version/ch02_MachineLearningFoundation/img/ch2/2-21.gif
new file mode 100644
index 00000000..2bca00e1
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2-21.gif differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2-22.gif b/English version/ch02_MachineLearningFoundation/img/ch2/2-22.gif
new file mode 100644
index 00000000..bc986b15
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2-22.gif differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2-4.png b/English version/ch02_MachineLearningFoundation/img/ch2/2-4.png
new file mode 100644
index 00000000..72282893
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2-4.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2-5.png b/English version/ch02_MachineLearningFoundation/img/ch2/2-5.png
new file mode 100644
index 00000000..40111f8f
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2-5.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2-6.png b/English version/ch02_MachineLearningFoundation/img/ch2/2-6.png
new file mode 100644
index 00000000..f555a6b6
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2-6.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2-7.png b/English version/ch02_MachineLearningFoundation/img/ch2/2-7.png
new file mode 100644
index 00000000..a472df88
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2-7.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2-8.png b/English version/ch02_MachineLearningFoundation/img/ch2/2-8.png
new file mode 100644
index 00000000..be239e6f
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2-8.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2-9.png b/English version/ch02_MachineLearningFoundation/img/ch2/2-9.png
new file mode 100644
index 00000000..31e457fc
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2-9.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.1/1.jpg b/English version/ch02_MachineLearningFoundation/img/ch2/2.1/1.jpg
new file mode 100644
index 00000000..13d8e28d
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.1/1.jpg differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.1/10.jpg b/English version/ch02_MachineLearningFoundation/img/ch2/2.1/10.jpg
new file mode 100644
index 00000000..ccd1eeda
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.1/10.jpg differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.1/12.jpg b/English version/ch02_MachineLearningFoundation/img/ch2/2.1/12.jpg
new file mode 100644
index 00000000..d62b27bc
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.1/12.jpg differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.1/2.jpg b/English version/ch02_MachineLearningFoundation/img/ch2/2.1/2.jpg
new file mode 100644
index 00000000..c158a94d
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.1/2.jpg differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.1/3.jpg b/English version/ch02_MachineLearningFoundation/img/ch2/2.1/3.jpg
new file mode 100644
index 00000000..918b8bb2
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.1/3.jpg differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.1/4.png b/English version/ch02_MachineLearningFoundation/img/ch2/2.1/4.png
new file mode 100644
index 00000000..ddc43d47
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.1/4.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.1/5.jpg b/English version/ch02_MachineLearningFoundation/img/ch2/2.1/5.jpg
new file mode 100644
index 00000000..3f93149f
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.1/5.jpg differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.1/6.jpg b/English version/ch02_MachineLearningFoundation/img/ch2/2.1/6.jpg
new file mode 100644
index 00000000..f91f6259
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.1/6.jpg differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.1/7.jpg b/English version/ch02_MachineLearningFoundation/img/ch2/2.1/7.jpg
new file mode 100644
index 00000000..d4d1281f
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.1/7.jpg differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.1/8.jpg b/English version/ch02_MachineLearningFoundation/img/ch2/2.1/8.jpg
new file mode 100644
index 00000000..6ccddac2
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.1/8.jpg differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.1/9.png b/English version/ch02_MachineLearningFoundation/img/ch2/2.1/9.png
new file mode 100644
index 00000000..19201b56
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.1/9.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.16.17-1.png b/English version/ch02_MachineLearningFoundation/img/ch2/2.16.17-1.png
new file mode 100644
index 00000000..83915ea4
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.16.17-1.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.16.17-2.png b/English version/ch02_MachineLearningFoundation/img/ch2/2.16.17-2.png
new file mode 100644
index 00000000..ca5e2c41
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.16.17-2.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.16.17-3.png b/English version/ch02_MachineLearningFoundation/img/ch2/2.16.17-3.png
new file mode 100644
index 00000000..511492ce
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.16.17-3.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.16.18.1.png b/English version/ch02_MachineLearningFoundation/img/ch2/2.16.18.1.png
new file mode 100644
index 00000000..23b150ed
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.16.18.1.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.16.20.1.png b/English version/ch02_MachineLearningFoundation/img/ch2/2.16.20.1.png
new file mode 100644
index 00000000..acc95fb4
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.16.20.1.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.16.4.1.jpg b/English version/ch02_MachineLearningFoundation/img/ch2/2.16.4.1.jpg
new file mode 100644
index 00000000..51a16bcb
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.16.4.1.jpg differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.16.4.2.png b/English version/ch02_MachineLearningFoundation/img/ch2/2.16.4.2.png
new file mode 100644
index 00000000..d74817f7
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.16.4.2.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.16.4.3.png b/English version/ch02_MachineLearningFoundation/img/ch2/2.16.4.3.png
new file mode 100644
index 00000000..42e4cee4
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.16.4.3.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.16/1.jpg b/English version/ch02_MachineLearningFoundation/img/ch2/2.16/1.jpg
new file mode 100644
index 00000000..64794617
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.16/1.jpg differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.16/2.jpg b/English version/ch02_MachineLearningFoundation/img/ch2/2.16/2.jpg
new file mode 100644
index 00000000..e8e8f9ce
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.16/2.jpg differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.18/1.jpg b/English version/ch02_MachineLearningFoundation/img/ch2/2.18/1.jpg
new file mode 100644
index 00000000..a14454c4
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.18/1.jpg differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.19.1.1.png b/English version/ch02_MachineLearningFoundation/img/ch2/2.19.1.1.png
new file mode 100644
index 00000000..3fd7fd8f
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.19.1.1.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.19.5A.jpg b/English version/ch02_MachineLearningFoundation/img/ch2/2.19.5A.jpg
new file mode 100644
index 00000000..a6c5feb7
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.19.5A.jpg differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.19.5B.jpg b/English version/ch02_MachineLearningFoundation/img/ch2/2.19.5B.jpg
new file mode 100644
index 00000000..ad455db6
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.19.5B.jpg differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.19.5C.png b/English version/ch02_MachineLearningFoundation/img/ch2/2.19.5C.png
new file mode 100644
index 00000000..5e499e4e
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.19.5C.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.2.09.png b/English version/ch02_MachineLearningFoundation/img/ch2/2.2.09.png
new file mode 100644
index 00000000..94e91922
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.2.09.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.2.10.png b/English version/ch02_MachineLearningFoundation/img/ch2/2.2.10.png
new file mode 100644
index 00000000..c8b9935b
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.2.10.png differ
diff --git "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.1/11.jpg" b/English version/ch02_MachineLearningFoundation/img/ch2/2.2.11.png
similarity index 58%
rename from "ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.1/11.jpg"
rename to English version/ch02_MachineLearningFoundation/img/ch2/2.2.11.png
index e615b4bc..750c2e34 100644
Binary files "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.1/11.jpg" and b/English version/ch02_MachineLearningFoundation/img/ch2/2.2.11.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.2.12.png b/English version/ch02_MachineLearningFoundation/img/ch2/2.2.12.png
new file mode 100644
index 00000000..9357b0a4
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.2.12.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.2.4.png b/English version/ch02_MachineLearningFoundation/img/ch2/2.2.4.png
new file mode 100644
index 00000000..e1e166dc
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.2.4.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.2.8.png b/English version/ch02_MachineLearningFoundation/img/ch2/2.2.8.png
new file mode 100644
index 00000000..234f4d18
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.2.8.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.20.1.jpg b/English version/ch02_MachineLearningFoundation/img/ch2/2.20.1.jpg
new file mode 100644
index 00000000..efb4f6fc
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.20.1.jpg differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.21.1.1.png b/English version/ch02_MachineLearningFoundation/img/ch2/2.21.1.1.png
new file mode 100644
index 00000000..b6205fa9
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.21.1.1.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.21.1.2.png b/English version/ch02_MachineLearningFoundation/img/ch2/2.21.1.2.png
new file mode 100644
index 00000000..ef734236
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.21.1.2.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.21.1.3.png b/English version/ch02_MachineLearningFoundation/img/ch2/2.21.1.3.png
new file mode 100644
index 00000000..246ec05e
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.21.1.3.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.21.1.4.png b/English version/ch02_MachineLearningFoundation/img/ch2/2.21.1.4.png
new file mode 100644
index 00000000..70a1d786
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.21.1.4.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.21.1.5.png b/English version/ch02_MachineLearningFoundation/img/ch2/2.21.1.5.png
new file mode 100644
index 00000000..61bd081e
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.21.1.5.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.21.1.6.png b/English version/ch02_MachineLearningFoundation/img/ch2/2.21.1.6.png
new file mode 100644
index 00000000..620857bb
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.21.1.6.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.21.1.6a.png b/English version/ch02_MachineLearningFoundation/img/ch2/2.21.1.6a.png
new file mode 100644
index 00000000..85755d61
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.21.1.6a.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.21.1.7.png b/English version/ch02_MachineLearningFoundation/img/ch2/2.21.1.7.png
new file mode 100644
index 00000000..40fbf900
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.21.1.7.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.21.3.1.png b/English version/ch02_MachineLearningFoundation/img/ch2/2.21.3.1.png
new file mode 100644
index 00000000..1b7c8051
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.21.3.1.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.25/1.png b/English version/ch02_MachineLearningFoundation/img/ch2/2.25/1.png
new file mode 100644
index 00000000..b736f4d8
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.25/1.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.27/1.png b/English version/ch02_MachineLearningFoundation/img/ch2/2.27/1.png
new file mode 100644
index 00000000..27440a49
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.27/1.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.27/2.png b/English version/ch02_MachineLearningFoundation/img/ch2/2.27/2.png
new file mode 100644
index 00000000..fd3465ef
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.27/2.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.29/1.png b/English version/ch02_MachineLearningFoundation/img/ch2/2.29/1.png
new file mode 100644
index 00000000..a3c751d1
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.29/1.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.34/1.png b/English version/ch02_MachineLearningFoundation/img/ch2/2.34/1.png
new file mode 100644
index 00000000..fff539b7
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.34/1.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.40.10/1.png b/English version/ch02_MachineLearningFoundation/img/ch2/2.40.10/1.png
new file mode 100644
index 00000000..04e82ec7
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.40.10/1.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.40.11/1.jpg b/English version/ch02_MachineLearningFoundation/img/ch2/2.40.11/1.jpg
new file mode 100644
index 00000000..c928da5d
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.40.11/1.jpg differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.40.15/1.png b/English version/ch02_MachineLearningFoundation/img/ch2/2.40.15/1.png
new file mode 100644
index 00000000..2bf0c1d8
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.40.15/1.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.40.3/1.jpg b/English version/ch02_MachineLearningFoundation/img/ch2/2.40.3/1.jpg
new file mode 100644
index 00000000..51a16bcb
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.40.3/1.jpg differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.40.3/1.png b/English version/ch02_MachineLearningFoundation/img/ch2/2.40.3/1.png
new file mode 100644
index 00000000..0a1fa4a3
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.40.3/1.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.40.3/2.20.1.jpg b/English version/ch02_MachineLearningFoundation/img/ch2/2.40.3/2.20.1.jpg
new file mode 100644
index 00000000..05e9ebe2
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.40.3/2.20.1.jpg differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.40.3/2.png b/English version/ch02_MachineLearningFoundation/img/ch2/2.40.3/2.png
new file mode 100644
index 00000000..d74817f7
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.40.3/2.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.40.3/3.png b/English version/ch02_MachineLearningFoundation/img/ch2/2.40.3/3.png
new file mode 100644
index 00000000..42e4cee4
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.40.3/3.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.5.1.png b/English version/ch02_MachineLearningFoundation/img/ch2/2.5.1.png
new file mode 100644
index 00000000..3eb29bcd
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.5.1.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.6/1.png b/English version/ch02_MachineLearningFoundation/img/ch2/2.6/1.png
new file mode 100644
index 00000000..94f75b0c
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.6/1.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.7.3.png b/English version/ch02_MachineLearningFoundation/img/ch2/2.7.3.png
new file mode 100644
index 00000000..98257154
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.7.3.png differ
diff --git a/English version/ch02_MachineLearningFoundation/img/ch2/2.9/1.png b/English version/ch02_MachineLearningFoundation/img/ch2/2.9/1.png
new file mode 100644
index 00000000..7a93ae57
Binary files /dev/null and b/English version/ch02_MachineLearningFoundation/img/ch2/2.9/1.png differ
diff --git a/English version/ch02_MachineLearningFoundation/readme.md b/English version/ch02_MachineLearningFoundation/readme.md
new file mode 100644
index 00000000..ed99a5f1
--- /dev/null
+++ b/English version/ch02_MachineLearningFoundation/readme.md
@@ -0,0 +1,16 @@
+###########################################################
+
+\### Deep Learning 500 Questions - First * Chapter xxx
+
+**Responsible person (in no particular order): **
+xxxGraduate student-xxx(xxx)
+xxxDoctoral student-xxx
+xxx-xxx
+
+**Contributors (in no particular order): **
+Content contributors can add information
+
+Liu Yanchao - Southeast University
+Liu Yuande-Shanghai University of Technology (Content Revision)
+
+###########################################################
\ No newline at end of file
diff --git a/English version/ch03_DeepLearningFoundation/ChapterIII_DeepLearningFoundation.md b/English version/ch03_DeepLearningFoundation/ChapterIII_DeepLearningFoundation.md
new file mode 100644
index 00000000..1fc4d5f1
--- /dev/null
+++ b/English version/ch03_DeepLearningFoundation/ChapterIII_DeepLearningFoundation.md
@@ -0,0 +1,1127 @@
+[TOC]
+
+# Chapter 3 Foundation of Deep Learning
+
+## 3.1 Basic Concepts
+
+### 3.1.1 Neural network composition?
+
+There are many types of neural networks, the most important of which is the multilayer perceptron. To describe the neural network in detail, let's start with the simplest neural network.
+
+**Perceived machine**
+
+The feature neuron model in the multi-layer perceptron is called the perceptron and was invented in 1957 by *Frank Rosenblatt*.
+
+The simple perceptron is shown below:
+
+
+
+Where $x_1$, $x_2$, $x_3$ is the input to the perceptron, and its output is:
+
+$$
+Output = \left\{
+\begin{aligned}
+0, \quad if \ \ \sum_i w_i x_i \leqslant threshold \\
+1, \quad if \ \ \sum_i w_i x_i > threshold
+\end{aligned}
+\right.
+$$
+
+If the perceptron is imagined as a weighted voting mechanism, for example, three judges rate a singer with a score of $4 $, $1$, $-3 $, respectively, and the weight of the $3$ score is $1. 3, 2$, the singer will eventually score $4 * 1 + 1 * 3 + (-3) * 2 = 1$. According to the rules of the game, the selected $threshold$ is $3$, indicating that only the singer's overall score is greater than $3$. Against the perceptron, the player was eliminated because
+
+$$
+\sum_i w_i x_i < threshold=3, output = 0
+$$
+
+Replace $threshold$ with $-b$ and the output becomes:
+
+$$
+Output = \left\{
+\begin{aligned}
+0, \quad if \ \ w \cdot x + b \le threshold \\
+1, \quad if \ \ w \cdot x + b > threshold
+\end{aligned}
+\right.
+$$
+
+Set the appropriate $x$ and $b$ , a simple perceptual unit's NAND gate is expressed as follows:
+
+
+
+When the input is $0$, $1$, the perceptron output is $ 0 * (-2) + 1 * (-2) + 3 = 1$.
+
+More complex perceptrons are composed of simple perceptron units:
+
+
+
+**Multilayer Perceptron**
+
+The multi-layer perceptron is promoted by the perceptron. The most important feature is that there are multiple neuron layers, so it is also called deep neural network. Each neuron in the $i$ layer of the multilayer perceptron is connected to each neuron in the $i-1$ layer compared to a separate perceptron.
+
+
+
+The output layer can have more than $1$ neurons. The hidden layer can have only $1 $ layers, or it can have multiple layers. The output layer is a neural network of multiple neurons such as the following:
+
+
+
+
+### 3.1.2 What are the common model structures of neural networks?
+
+The figure below contains most of the commonly used models:
+
+
+
+### 3.1.3 How to choose a deep learning development platform?
+
+The existing deep learning open source platforms mainly include Caffe, PyTorch, MXNet, CNTK, Theano, TensorFlow, Keras, fastai and so on. So how to choose a platform that suits you? Here are some measures for reference.
+
+**Reference 1: How easy is it to integrate with existing programming platforms and skills**
+
+Mainly the development experience and resources accumulated in the early stage, such as programming language, pre-dataset storage format and so on.
+
+**Reference 2: Closeness of ecological integration with related machine learning and data processing**
+
+Deep learning research is inseparable from various software packages such as data processing, visualization, and statistical inference. Is there a convenient data preprocessing tool before considering modeling? After modeling, is there a convenient tool for visualization, statistical inference, and data analysis?
+
+**Reference 3: Requirements and support for data volume and hardware**
+
+Deep learning is not the same amount of data in different application scenarios, which leads us to consider the issues of distributed computing and multi-GPU computing. For example, people working on computer image processing often need to segment image files and computing tasks onto multiple computer nodes for execution. At present, each deep learning platform is developing rapidly, and each platform's support for distributed computing and other scenarios is also evolving.
+
+**Reference 4: The maturity of the deep learning platform**
+
+The maturity consideration is a more subjective consideration. These factors can include: the level of activity of the community; whether it is easy to communicate with developers; the momentum of current applications.
+
+**Reference 5: Is the diversity of platform utilization? **
+
+Some platforms are specifically developed for deep learning research and applications. Some platforms have powerful optimizations for distributed computing, GPU and other architectures. Can you use these platforms/software to do other things? For example, some deep learning software can be used to solve quadratic optimization; some deep learning platforms are easily extended and used in reinforcement learning applications.
+
+### 3.1.4 Why use deep representation?
+
+1. Deep neural network is a feature-oriented learning algorithm. Shallow neurons learn some low-level simple features, such as edges and textures, directly from the input data. The deep features continue to learn more advanced features based on the shallow features that have been learned, and learn deep semantic information from a computer perspective.
+2. The number of hidden cells in the deep network is relatively small, and the number of hidden layers is large. If the shallow network wants to achieve the same calculation result, the number of cells requiring exponential growth can be achieved.
+
+### 3.1.5 Why is deep neural network difficult to train?
+
+
+1. Gradient Gradient
+ The disappearance of the gradient means that the gradient will become smaller and smaller as seen from the back and the front through the hidden layer, indicating that the learning of the front layer will be significantly slower than the learning of the latter layer, so the learning will get stuck unless the gradient becomes larger.
+
+ The reason for the disappearance of the gradient is affected by many factors, such as the size of the learning rate, the initialization of the network parameters, and the edge effect of the activation function. In the deep neural network, the gradient calculated by each neuron is passed to the previous layer, and the gradient received by the shallower neurons is affected by all previous layer gradients. If the calculated gradient value is very small, as the number of layers increases, the obtained gradient update information will decay exponentially, and the gradient disappears. The figure below shows the learning rate of different hidden layers:
+
+
+
+2. Exploding Gradient
+ In a network structure such as a deep network or a Recurrent Neural Network (RNN), gradients can accumulate in the process of network update, becoming a very large gradient, resulting in a large update of the network weight value, making the network unstable; In extreme cases, the weight value will even overflow and become a $NaN$ value, which cannot be updated anymore.
+
+3. Degeneration of the weight matrix results in a reduction in the effective degrees of freedom of the model. The degradation rate of learning in the parameter space is slowed down, which leads to the reduction of the effective dimension of the model. The available degrees of freedom of the network contribute to the gradient norm in learning. As the number of multiplication matrices (ie, network depth) increases, The product of the matrix becomes more and more degraded. In nonlinear networks with hard saturated boundaries (such as ReLU networks), as the depth increases, the degradation process becomes faster and faster. The visualization of this degradation process is shown in a 2014 paper by Duvenaud et al:
+
+
+
+As the depth increases, the input space (shown in the upper left corner) is twisted into thinner and thinner filaments at each point in the input space, and only one direction orthogonal to the filament affects the response of the network. In this direction, the network is actually very sensitive to change.
+
+### 3.1.6 What is the difference between deep learning and machine learning?
+
+Machine learning: use computer, probability theory, statistics and other knowledge to input data and let the computer learn new knowledge. The process of machine learning is to train the data to optimize the objective function.
+
+Deep learning: It is a special machine learning with powerful capabilities and flexibility. It learns to represent the world as a nested hierarchy, each representation is associated with a simpler feature, and the abstract representation is used to compute a more abstract representation.
+
+Traditional machine learning needs to define some manual features to purposefully extract target information, relying heavily on task specificity and expert experience in designing features. Deep learning can learn simple features from big data, and gradually learn from the deeper features of more complex abstraction, independent of artificial feature engineering, which is also a major reason for deep learning in the era of big data.
+
+
+
+
+
+
+
+## 3.2 Network Operations and Calculations
+
+### 3.2.1 Forward Propagation and Back Propagation?
+
+There are two main types of neural network calculations: foward propagation (FP) acts on the input of each layer, and the output is obtained by layer-by-layer calculation; backward propagation (BP) acts on the output of the network. Calculate the gradient from deep to shallow to update the network parameters.
+
+** Forward Propagation**
+
+
+
+Suppose the upper node $ i, j, k, ... $ and so on are connected to the node $ w $ of this layer, so what is the value of the node $ w $? That is, the weighting operation is performed by the nodes of $i, j, k, ... $ above and the corresponding connection weights, and the final result is added with an offset term (for simplicity in the figure) Finally, through a non-linear function (ie activation function), such as $ReLu $, $ sigmoid $ and other functions, the final result is the output of this layer node $ w $.
+
+Finally, through this method of layer by layer operation, the output layer results are obtained.
+
+**Backpropagation**
+
+
+
+Because of the final result of our forward propagation, taking the classification as an example, there is always an error in the end. How to reduce the error? One algorithm that is widely used at present is the gradient descent algorithm, but the gradient requires the partial derivative. The Chinese alphabet is used as an example to explain:
+
+Let the final error be $ E $ and the activation function of the output layer be a linear activation function, for the output then $ E $ for the output node $ y_l $ the partial derivative is $ y_l - t_l $, where $ t_l $ is the real value, $ \ Frac{\partial y_l}{\partial z_l} $ refers to the activation function mentioned above, $ z_l $ is the weighted sum mentioned above, then the $ E $ for this layer has a partial derivative of $ z_l $ Frac{\partial E}{\partial z_l} = \frac{\partial E}{\partial y_l} \frac{\partial y_l}{\partial z_l} $. In the same way, the next level is calculated as well, except that the $\frac{\partial E}{\partial y_k} $ calculation method has been changed back to the input layer, and finally $ \frac{\partial E}{ \partial x_i} = \frac{\partial E}{\partial y_j} \frac{\partial y_j}{\partial z_j} $, and $ \frac{\partial z_j}{\partial x_i} = w_i j $ . Then adjust the weights in these processes, and then continue the process of forward propagation and back propagation, and finally get a better result.
+
+### 3.2.2 How to calculate the output of the neural network?
+
+
+
+As shown in the figure above, the input layer has three nodes, which we numbered as 1, 2, and 3; the four nodes of the hidden layer are numbered 4, 5, 6, and 7; the last two nodes of the output layer are numbered 8. 9. For example, node 4 of the hidden layer is connected to the three nodes 1, 2, and 3 of the input layer, and the weights on the connection are $ w_{41}, w_{42}, w_{43} $.
+
+In order to calculate the output value of node 4, we must first get the output values of all its upstream nodes (ie nodes 1, 2, 3). Nodes 1, 2, and 3 are nodes of the input layer, so their output value is the input vector itself. According to the corresponding relationship in the above picture, you can see that the output values of nodes 1, 2, and 3 are $ x_1, x_2, x_3 $, respectively.
+
+$$
+A_4 = \sigma(w^T \cdot a) = \sigma(w_{41}x_4 + w_{42}x_2 + w_{43}a_3 + w_{4b})
+$$
+
+Where $ w_{4b} $ is the offset of node 4.
+
+Similarly, we can continue to calculate the output values of nodes 5, 6, and 7 $ a_5, a_6, a_7 $.
+
+Calculate the output value of node 8 of the output layer $ y_1 $:
+
+$$
+Y_1 = \sigma(w^T \cdot a) = \sigma(w_{84}A_4 + w_{85}a_5 + w_{86}a_6 + w_{87}a_7 + w_{8b})
+$$
+
+Where $ w_{8b} $ is the offset of node 8.
+
+For the same reason, we can also calculate $ y_2 $. So that the output values of all the nodes in the output layer are calculated, we get the output vector $ y_1, y_2 $ of the neural network when the input vectors $ x_1, x_2, x_3, x_4 $. Here we also see that the output vector has the same number of dimensions as the output layer neurons.
+
+### 3.2.3 How to calculate the output value of convolutional neural network?
+
+Suppose there is a 5\*5 image, convolved with a 3\*3 filter, and I want a 3\*3 Feature Map, as shown below:
+
+
+
+$ x_{i,j} $ represents the $ j $ column element of the $ i $ line of the image. $ w_{m,n} $ means filter $ m $ line $ n $ column weight. $ w_b $ represents the offset of $filter$. Table $a_i, _j$ shows the feature map $ i$ line $ j $ column element. $f$ represents the activation function, here the $ReLU$ function is used as an example.
+
+The convolution calculation formula is as follows:
+
+$$
+A_{i,j} = f(\sum_{m=0}^2 \sum_{n=0}^2 w_{m,n} x_{i+m, j+n} + w_b )
+$$
+
+When the step size is $1$, the feature map element $ a_{0,0} $ is calculated as follows:
+
+$$
+A_{0,0} = f(\sum_{m=0}^2 \sum_{n=0}^2 w_{m,n} x_{0+m, 0+n} + w_b )
+
+
+= relu(w_{0,0} x_{0,0} + w_{0,1} x_{0,1} + w_{0,2} x_{0,2} + w_{1,0} x_{ 1,0} + \\w_{1,1} x_{1,1} + w_{1,2} x_{1,2} + w_{2,0} x_{2,0} + w_{2, 1} x_{2,1} + w_{2,2} x_{2,2}) \\
+
+
+= 1 + 0 + 1 + 0 + 1 + 0 + 0 + 0 + 1 \\
+
+= 4
+$$
+
+The calculation process is illustrated as follows:
+
+
+
+By analogy, all Feature Maps are calculated.
+
+
+
+When the stride is 2, the Feature Map is calculated as follows
+
+
+
+Note: Image size, stride, and the size of the Feature Map after convolution are related. They satisfy the following relationship:
+
+$$
+W_2 = (W_1 - F + 2P)/S + 1\\
+H_2 = (H_1 - F + 2P)/S + 1
+$$
+
+Where $ W_2 $ is the width of the Feature Map after convolution; $ W_1 $ is the width of the image before convolution; $ F $ is the width of the filter; $ P $ is the number of Zero Padding, and Zero Padding is around the original image Make a few laps of $0$. If the value of $P$ is $1$, then make $1$ lap $0$; $S$ is the stride; $ H_2 $ is the height of the Feature Map after convolution; $ H_1 $ is the convolution The width of the image.
+
+Example: Suppose the image width is $ W_1 = 5 $, filter width $ F=3 $, Zero Padding $ P=0 $, stride $ S=2 $, $ Z $
+
+$$
+W_2 = (W_1 - F + 2P)/S + 1
+
+= (5-3+0)/2 + 1
+
+= 2
+$$
+
+The Feature Map width is 2. Similarly, we can also calculate that the Feature Map height is also 2.
+
+If the image depth before convolution is $ D $, then the corresponding filter depth must also be $ D $. Convolution calculation formula with depth greater than 1:
+
+$$
+A_{i,j} = f(\sum_{d=0}^{D-1} \sum_{m=0}^{F-1} \sum_{n=0}^{F-1} w_{ d,m,n} x_{d,i+m,j+n} + w_b)
+$$
+
+Where $D$ is the depth; $F$ is the size of the filter; $w_{d,m,n}$ represents the $d$$ layer of the filter, the $m$ line, the $n$ column Weight; $ a_{d,i,j} $ means the $d$ of the feature map, the $i$ line, the $j$ column, and the other symbols have the same meanings and are not described again.
+
+There can be multiple filters per convolutional layer. After each filter is convolved with the original image, you get a Feature Map. The depth (number) of the Feature Map after convolution is the same as the number of filters in the convolutional layer. The following illustration shows the calculation of a convolutional layer with two filters. $7*7*3$ Input, after two convolutions of $3*3*3$ filter (step size is $2$), get the output of $3*3*2$. The Zero padding in the figure is $1$, which is a $0$ around the input element.
+
+
+
+The above is the calculation method of the convolutional layer. This is a partial connection and weight sharing: each layer of neurons is only connected to the upper layer of neurons (convolution calculation rules), and the weight of the filter is the same for all neurons in the previous layer. For a convolutional layer containing two $3 * 3 * 3 $ fitlers, the number of parameters is only $ (3 * 3 * 3+1) * 2 = 56 $, and the number of parameters is the same as the previous one. The number of layers of neurons is irrelevant. Compared to a fully connected neural network, the number of parameters is greatly reduced.
+
+### 3.2.4 How to calculate the output value of the Pooling layer output value?
+
+The main role of the Pooling layer is to downsample, further reducing the number of parameters by removing unimportant samples from the Feature Map. There are many ways to pooling, the most common one is Max Pooling. Max Pooling actually takes the maximum value in the sample of n\*n as the sampled value after sampling. The figure below is 2\*2 max pooling:
+
+
+
+In addition to Max Pooing, Average Pooling is also commonly used - taking the average of each sample.
+For a Feature Map with a depth of $ D $ , each layer does Pooling independently, so the depth after Pooling is still $ D $.
+
+### 3.2.5 Example Understanding Back Propagation
+
+A typical three-layer neural network is as follows:
+
+
+
+Where Layer $ L_1 $ is the input layer, Layer $ L_2 $ is the hidden layer, and Layer $ L_3 $ is the output layer.
+
+Assuming the input dataset is $ D={x_1, x_2, ..., x_n} $, the output dataset is $ y_1, y_2, ..., y_n $.
+
+If the input and output are the same, it is a self-encoding model. If the raw data is mapped, it will get an output different from the input.
+
+Suppose you have the following network layer:
+
+
+
+The input layer contains neurons $ i_1, i_2 $, offset $ b_1 $; the hidden layer contains neurons $ h_1, h_2 $, offset $ b_2 $, and the output layer is $ o_1, o_2 $, $ W_i $ is the weight of the connection between the layers, and the activation function is the $sigmoid $ function. Take the initial value of the above parameters, as shown below:
+
+
+
+among them:
+
+- Enter the data $ i1=0.05, i2 = 0.10 $
+- Output data $ o1=0.01, o2=0.99 $;
+- Initial weights $ w1=0.15, w2=0.20, w3=0.25, w4=0.30, w5=0.40, w6=0.45, w7=0.50, w8=0.55 $
+- Target: Give the input data $ i1,i2 $ ( $0.05$ and $0.10$ ) so that the output is as close as possible to the original output $ o1,o2 $,( $0.01$ and $0.99$).
+
+** Forward Propagation**
+
+1. Input layer --> output layer
+
+Calculate the input weighted sum of neurons $ h1 $:
+
+$$
+Net_{h1} = w_1 * i_1 + w_2 * i_2 + b_1 * 1\\
+
+Net_{h1} = 0.15 * 0.05 + 0.2 * 0.1 + 0.35 * 1 = 0.3775
+$$
+
+The output of the neuron $ h1 $ $ o1 $ : (the activation function used here is the sigmoid function):
+
+$$
+Out_{h1} = \frac{1}{1 + e^{-net_{h1}}} = \frac{1}{1 + e^{-0.3775}} = 0.593269992
+$$
+
+Similarly, the output of neuron $ h2 $ can be calculated. $ o1 $:
+
+$$
+Out_{h2} = 0.596884378
+$$
+
+
+2. Implicit layer --> output layer:
+
+Calculate the values of the output layer neurons $ o1 $ and $ o2 $ :
+
+$$
+Net_{o1} = w_5 * out_{h1} + w_6 * out_{h2} + b_2 * 1
+$$
+
+$$
+Net_{o1} = 0.4 * 0.593269992 + 0.45 * 0.596884378 + 0.6 * 1 = 1.105905967
+$$
+
+$$
+Out_{o1} = \frac{1}{1 + e^{-net_{o1}}} = \frac{1}{1 + e^{1.105905967}} = 0.75136079
+$$
+
+The process of forward propagation is over. We get the output value of $ [0.75136079 , 0.772928465] $, which is far from the actual value of $ [0.01 , 0.99] $. Now we reverse the error and update the right. Value, recalculate the output.
+
+**Backpropagation **
+
+Calculate the total error
+
+Total error: (Use Square Error here)
+
+$$
+E_{total} = \sum \frac{1}{2}(target - output)^2
+$$
+
+But there are two outputs, so calculate the error of $ o1 $ and $ o2 $ respectively, the total error is the sum of the two:
+
+$E_{o1} = \frac{1}{2}(target_{o1} - out_{o1})^2
+= \frac{1}{2}(0.01 - 0.75136507)^2 = 0.274811083$.
+
+$E_{o2} = 0.023560026$.
+
+$E_{total} = E_{o1} + E_{o2} = 0.274811083 + 0.023560026 = 0.298371109$.
+
+
+2. Implicit layer --> Output layer weight update:
+
+Taking the weight parameter $ w5 $ as an example, if we want to know how much influence $ w5 $ has on the overall error, we can use the overall error to find the partial derivative of $ w5 $: (chain rule)
+
+$$
+\frac{\partial E_{total}}{\partial w5} = \frac{\partial E_{total}}{\partial out_{o1}} * \frac{\partial out_{o1}}{\partial net_{ O1}} * \frac{\partial net_{o1}}{\partial w5}
+$$
+
+The following diagram can be more intuitive to see how the error propagates back:
+
+
+
+### 3.2.6 What is the meaning of the neural network more "deep"?
+
+Premise: within a certain range.
+
+- In the case of the same number of neurons, the deep network structure has a larger capacity, and the layered combination brings an exponential expression space, which can be combined into more different types of substructures, which makes learning and representation easier. Various features.
+- An increase in the hidden layer means that the number of nesting layers of the nonlinear transformation brought by the activation function is more, you can construct more complex mappings.
+
+## 3.3 Hyperparameters
+
+### 3.3.1 What is a hyperparameter?
+
+**Super-parameter**: For example, the learning rate in the algorithm, the iterations of the gradient descent method, the hidden layers, the number of hidden layer units, and the activation function are all required. The actual situation is set, these numbers actually control the last parameter and the value, so they are called hyperparameters.
+
+### 3.3.2 How to find the optimal value of the hyperparameter?
+
+There are always some difficult parameters to adjust when using machine learning algorithms. For example, weight attenuation size, Gaussian kernel width, and so on. These parameters require manual settings, and the set values have a large impact on the results. Common methods for setting hyperparameters are:
+
+1. Guess and check: Select parameters based on experience or intuition, and iterate over.
+
+2. Grid Search: Let the computer try to evenly distribute a set of values within a certain range.
+
+3. Random search: Let the computer randomly pick a set of values.
+
+4. Bayesian optimization: Using Bayesian optimization of hyperparameters, it is difficult to meet the Bayesian optimization algorithm itself.
+
+5. The MITIE method performs local optimization under the premise of good initial guessing. It uses the BOBYQA algorithm and has a carefully chosen starting point. Since BOBYQA only looks for the nearest local optimal solution, the success of this method depends largely on whether there is a good starting point. In the case of MITIE, we know a good starting point, but this is not a universal solution, because usually you won't know where the good starting point is. On the plus side, this approach is well suited to finding local optimal solutions. I will discuss this later.
+
+6. The latest proposed global optimization method for LIPO. This method has no parameters and is proven to be better than a random search method.
+
+### 3.3.3 Superparameter search general process?
+
+The general process of hyperparameter search:
+1. Divide the data set into a training set, a validation set, and a test set.
+2. Optimize the model parameters based on the performance indicators of the model on the training set.
+3. Search the model's hyperparameters based on the model's performance metrics on the validation set.
+4. Steps 2 and 3 alternately iteratively, finalizing the parameters and hyperparameters of the model, and verifying the pros and cons of the evaluation model in the test set.
+
+Among them, the search process requires a search algorithm, generally: grid search, random search, heuristic intelligent search, Bayesian search.
+
+## 3.4 Activation function
+
+### 3.4.1 Why do I need a nonlinear activation function?
+
+**Why do I need to activate the function? **
+
+1. The activation function plays an important role in model learning and understanding very complex and nonlinear functions.
+2. The activation function can introduce nonlinear factors. If the activation function is not used, the output signal is only a simple linear function. The linear function is a first-order polynomial. The complexity of the linear equation is limited, and the ability to learn complex function mapping from the data is small. Without an activation function, the neural network will not be able to learn and simulate other complex types of data, such as images, video, audio, speech, and so on.
+3. The activation function can convert the current feature space to another space through a certain linear mapping, so that the data can be better classified.
+
+**Why does the activation function require a nonlinear function? **
+
+1. If the network is all linear, the linear combination is linear, just like a single linear classifier. This makes it impossible to approximate arbitrary functions with nonlinearities.
+2. Use a nonlinear activation function to make the network more powerful, increasing its ability to learn complex things, complex form data, and complex arbitrary function mappings that represent nonlinearities between input and output. A nonlinear activation function can be used to generate a nonlinear mapping from input to output.
+
+### 3.4.2 Common activation functions and images
+
+1. sigmoid activation function
+
+ The function is defined as: $ f(x) = \frac{1}{1 + e^{-x}} $, whose value is $ (0,1) $.
+
+ The function image is as follows:
+
+
+
+2. tanh activation function
+
+ The function is defined as: $ f(x) = tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}} $, the value range is $ (- 1,1) $.
+
+ The function image is as follows:
+
+
+
+3. Relu activation function
+
+ The function is defined as: $ f(x) = max(0, x) $ , and the value field is $ [0,+∞) $;
+
+ The function image is as follows:
+
+
+
+4. Leak Relu activation function
+
+ The function is defined as: $ f(x) = \left\{
+ \begin{aligned}
+ Ax, \quad x<0 \\
+ x, \quad x>0
+ \end{aligned}
+ \right. $, the value field is $ (-∞, +∞) $.
+
+ The image is as follows ($ a = 0.5 $):
+
+
+
+5. SoftPlus activation function
+
+ The function is defined as: $ f(x) = ln( 1 + e^x) $, and the value range is $ (0, +∞) $.
+
+ The function image is as follows:
+
+
+
+6. softmax function
+
+ The function is defined as: $ \sigma(z)_j = \frac{e^{z_j}}{\sum_{k=1}^K e^{z_k}} $.
+
+ Softmax is mostly used for multi-class neural network output.
+
+### 3.4.3 Derivative calculation of common activation functions?
+
+For common activation functions, the derivative is calculated as follows:
+
+
+
+### 3.4.4 What are the properties of the activation function?
+
+1. Nonlinearity: When the activation function is linear, a two-layer neural network can approximate all functions. But if the activation function is an identity activation function, ie $ f(x)=x $, this property is not satisfied, and if the MLP uses an identity activation function, then the entire network is waiting with the single layer neural network. Price
+2. Differentiability: This property is reflected when the optimization method is based on gradients;
+3. Monotonicity: When the activation function is monotonous, the single-layer network can guarantee a convex function;
+4. $ f(x)≈x $: When the activation function satisfies this property, if the initialization of the parameter is a random, small value, the training of the neural network will be very efficient; if this property is not met, then Set the initial value in detail;
+5. Range of output values: Gradient-based optimization methods are more stable when the output value of the activation function is finite, because the representation of the feature is more significantly affected by the finite weight; when the output of the activation function is infinite, the model Training will be more efficient, but in this case it is small and generally requires a smaller Learning Rate.
+
+### 3.4.5 How to choose an activation function?
+
+Choosing a suitable activation function is not easy. There are many factors to consider. Usually, if you are not sure which activation function works better, you can try them all and then evaluate them on the verification set or test set. Then see which one performs better, just use it.
+
+The following are common choices:
+
+1. If the output is a 0, 1 value (two-category problem), the output layer selects the sigmoid function, and then all other cells select the Relu function.
+2. If you are not sure which activation function to use on the hidden layer, then the Relu activation function is usually used. Sometimes, the tanh activation function is also used, but one advantage of Relu is that the derivative is equal to 0 when it is negative.
+3. sigmoid activation function: basically it will not be used except that the output layer is a two-class problem.
+4. tanh activation function: tanh is very good, almost suitable for all occasions.
+5. ReLu activation function: The most commonly used default function. If you are not sure which activation function to use, use ReLu or Leaky ReLu and try other activation functions.
+6. If we encounter some dead neurons, we can use the Leaky ReLU function.
+
+### 3.4.6 What are the advantages of using the ReLu activation function?
+
+1. In the case where the interval varies greatly, the derivative of the ReLu activation function or the slope of the activation function will be much larger than 0. In the program implementation is an if-else statement, and the sigmoid function needs to perform floating-point arithmetic. In practice, Using ReLu to activate function neural networks is usually faster than using sigmoid or tanh activation functions.
+2. The derivatives of the sigmoid and tanh functions will have a gradient close to 0 in the positive and negative saturation regions, which will cause the gradient to diffuse, while the Relu and Leaky ReLu functions are more constant than the 0 part, and will not produce gradient dispersion.
+3. It should be noted that when Relu enters the negative half, the gradient is 0, and the neurons are not trained at this time, resulting in so-called sparsity, which Leaky ReLu does not cause.
+
+### 3.4.7 When can I use the linear activation function?
+
+1. The output layer mostly uses a linear activation function.
+2. Some linear activation functions may be used at the hidden layer.
+3. There are very few linear activation functions commonly used.
+
+### 3.4.8 How to understand Relu (< 0) is a nonlinear activation function?
+
+The Relu activation function image is as follows:
+
+
+
+According to the image, it can be seen that it has the following characteristics:
+
+Unilateral inhibition
+2. A relatively broad excitement boundary;
+3. Sparse activation;
+
+From the image, the ReLU function is a piecewise linear function that changes all negative values to 0, while the positive values are unchanged, thus becoming a one-sided suppression.
+
+Because of this unilateral inhibition, the neurons in the neural network also have sparse activation.
+
+**Sparse activation**: From the signal point of view, the neurons only selectively respond to a small part of the input signal at the same time, a large number of signals are deliberately shielded, which can improve the learning accuracy and extract better and faster. Sparse features. When $ x<0 $, ReLU is hard saturated, and when $ x>0 $, there is no saturation problem. ReLU is able to keep the gradient from decaying when $ x>0 $, thus alleviating the gradient disappearance problem.
+
+### 3.4.9 How does the Softmax function be applied to multiple classifications?
+
+Softmax is used in the multi-classification process. It maps the output of multiple neurons to the $ (0,1) $ interval, which can be understood as a probability to be multi-classified!
+
+Suppose we have an array, $ V_i $ represents the $ i $ element in $ V $ , then the softmax value of this element is
+
+$$
+S_i = \frac{e^{V_i}}{\sum_j e^{V_j}}
+$$
+
+From the following figure, the neural network contains the input layer, and then processed by two feature layers. Finally, the softmax analyzer can get the probability under different conditions. Here, it needs to be divided into three categories, and finally get $ y=0. , y=1, y=2 probability value of $.
+
+
+
+Continuing with the picture below, the three inputs pass through softmax to get an array of $[0.05, 0.10, 0.85] $, which is the function of soft.
+
+
+
+The more visual mapping process is shown below:
+
+
+
+In the case of softmax, the original output is $3,1,-3$, which is mapped to the value of $(0,1)$ by the softmax function, and the sum of these values is $1 $( Satisfy the nature of the probability), then we can understand it as a probability, when we finally select the output node, we can select the node with the highest probability (that is, the value corresponds to the largest) as our prediction target!
+
+### 3.4.10 Cross entropy cost function definition and its derivative derivation
+
+(**Contributors: Huang Qinjian - South China University of Technology**)
+
+
+The output of the neuron is a = σ(z), where $z=\sum w_{j}i_{j}+b $ is the weighted sum of the inputs.
+
+$C=-\frac{1}{n}\sum[ylna+(1-y)ln(1-a)]$
+
+Where n is the total number of training data, summation is performed on all training inputs x, and y is the corresponding target output.
+
+Whether the expression solves the problem of slow learning is not obvious. In fact, even seeing this definition as a cost function is not obvious! Before solving the slow learning, let's see why the cross entropy can be interpreted as a cost function.
+
+There are two reasons for considering cross entropy as a cost function.
+
+First, it is non-negative, C > 0. It can be seen that all independent terms in the summation in the expression are negative, because the domain of the logarithm function is (0,1), and there is a negative sign before the sum, so the result is non- negative.
+
+Second, if the actual output of the neuron is close to the target value for all training inputs x, then the cross entropy will be close to zero.
+
+Suppose in this example, y = 0 and a ≈ 0. This is the result we think of. We see that the first term in the formula is eliminated because y = 0 and the second is actually − ln(1 −a) ≈ 0. Conversely, y = 1 and a ≈ 1. So the smaller the difference between the actual output and the target output, the lower the value of the final cross entropy. (This assumes that the output is not 0, which is 1, the actual classification is also the same)
+
+In summary, the cross entropy is non-negative and will approach zero when the neuron reaches a good rate of accuracy. These are actually the characteristics of the cost function we want. In fact, these characteristics are also available in the quadratic cost function. Therefore, cross entropy is a good choice. But the cross entropy cost function has a better feature than the quadratic cost function, which is that it avoids the problem of slow learning speed. In order to clarify this situation, we calculate the partial derivative of the cross entropy function with respect to the weight. We substitute $a={\varsigma}(z)$ into the formula and apply the two-chain rule to get:
+
+$\begin{eqnarray}\frac{\partial C}{\partial w_{j}}&=&-\frac{1}{n}\sum \frac{\partial }{\partial w_{j}}[ Ylna+(1-y)ln(1-a)]\\&=&-\frac{1}{n}\sum \frac{\partial }{\partial a}[ylna+(1-y)ln(1 -a)]*\frac{\partial a}{\partial w_{j}}\\&=&-\frac{1}{n}\sum (\frac{y}{a}-\frac{1 -y}{1-a})*\frac{\partial a}{\partial w_{j}}\\&=&-\frac{1}{n}\sum (\frac{y}{\varsigma (z)}-\frac{1-y}{1-\varsigma(z)})\frac{\partial \varsigma(z)}{\partial w_{j}}\\&=&-\frac{ 1}{n}\sum (\frac{y}{\varsigma(z)}-\frac{1-y}{1-\varsigma(z)}){\varsigma}'(z)x_{j} \end{eqnarray}$
+
+According to the definition of $\varsigma(z)=\frac{1}{1+e^{-z}}$, and some operations, we can get ${\varsigma}'(z)=\varsigma(z ) (1-\varsigma(z))$. After simplification, you can get:
+
+$\frac{\partial C}{\partial w_{j}}=\frac{1}{n}\sum x_{j}({\varsigma}(z)-y)$
+
+This is a beautiful formula. It tells us that the speed of weight learning is controlled by $\varsigma(z)-y$, which is the error in the output. Greater error and faster learning. This is the result of our intuitive expectation. In particular, this cost function also avoids the slow learning caused by ${\varsigma}'(z)$ in a similar equation in the quadratic cost function. When we use cross entropy, ${\varsigma}'(z)$ is dropped, so we no longer need to care if it gets small. This addition is the special effect of cross entropy. In fact, this is not a very miraculous thing. As we will see later, cross entropy is actually just a choice to satisfy this characteristic.
+
+According to a similar approach, we can calculate the partial derivative of the bias. I will not give a detailed process here, you can easily verify:
+
+$\frac{\partial C}{\partial b}=\frac{1}{n}\sum ({\varsigma}(z)-y) $
+
+
+Again, this avoids slow learning caused by similar ${\varsigma}'(z)$ items in the quadratic cost function.
+
+### 3.4.11 Why is Tanh faster than Sigmoid?
+
+** (Contributor: Huang Qinjian - South China University of Technology)**
+
+$tanh^{,}(x)=1-tanh(x)^{2}\in (0,1) $
+
+$s^{,}(x)=s(x)*(1-s(x))\in (0,\frac{1}{4}]$
+
+It can be seen from the above two formulas that the problem of disappearing the tanh(x) gradient is lighter than sigmoid, so Tanh converges faster than Sigmoid.
+
+## 3.5 Batch_Size
+
+### 3.5.1 Why do I need Batch_Size?
+
+The choice of Batch, the first decision is the direction of the decline.
+
+If the data set is small, it can take the form of a full data set. The benefits are:
+
+1. The direction determined by the full data set better represents the sample population and is more accurately oriented in the direction of the extreme value.
+2. Since the gradient values of different weights are very different, it is difficult to select a global learning rate. Full Batch Learning can use Rprop to update each weight individually based on gradient symbols only.
+
+For larger data sets, if you use a full data set, the downside is:
+1. With the massive growth of data sets and memory limitations, it is becoming increasingly infeasible to load all of the data at once.
+2. Iteratively in the Rprop manner, due to the sampling difference between the batches, the gradient correction values cancel each other and cannot be corrected. This was followed by a compromise with RMSProp.
+
+### 3.5.2 Selection of Batch_Size value
+
+If only one sample is trained at a time, Batch_Size = 1. The error surface of a linear neuron in the mean square error cost function is a paraboloid with an ellipse in cross section. For multi-layered neurons and nonlinear networks, the local approximation is still a paraboloid. At this time, each correction direction is corrected by the gradient direction of each sample, and the traverse is directly inconsistent, and it is difficult to achieve convergence.
+
+Since Batch_Size is a full data set or Batch_Size = 1 has its own shortcomings, can you choose a moderate Batch_Size value?
+
+At this time, a batch-grading learning method (Mini-batches Learning) can be employed. Because if the data set is sufficient, then the gradient calculated using half (or even much less) data training is almost the same as the gradient trained with all the data.
+
+### 3.5.3 What are the benefits of increasing Batch_Size within a reasonable range?
+
+1. The memory utilization is improved, and the parallelization efficiency of large matrix multiplication is improved.
+2. The number of iterations required to complete an epoch (full data set) is reduced, and the processing speed for the same amount of data is further accelerated.
+3. Within a certain range, generally, the larger the Batch_Size, the more accurate the determined direction of decline, resulting in less training shock.
+
+### 3.5.4 What is the disadvantage of blindly increasing Batch_Size?
+
+1. Memory utilization has increased, but memory capacity may not hold up.
+2. The number of iterations required to complete an epoch (full data set) is reduced. To achieve the same accuracy, the time it takes is greatly increased, and the correction of the parameters becomes slower.
+3. Batch_Size is increased to a certain extent, and its determined downward direction has not changed substantially.
+
+### 3.5.5 What is the effect of adjusting Batch_Size on the training effect?
+
+1. Batch_Size is too small, and the model performs extremely badly (error is soaring).
+2. As Batch_Size increases, the faster the same amount of data is processed.
+3. As Batch_Size increases, the number of epochs required to achieve the same accuracy is increasing.
+4. Due to the contradiction between the above two factors, Batch_Size is increased to a certain time, and the time is optimal.
+5. Since the final convergence accuracy will fall into different local extrema, Batch_Size will increase to some point and achieve the best convergence accuracy.
+
+## 3.6 Normalization
+
+### 3.6.1 What is the meaning of normalization?
+
+1. Inductive statistical distribution of unified samples. The normalized between $ 0-1 $ is the statistical probability distribution, normalized between $ -1--+1 $ is the statistical coordinate distribution.
+
+2. Whether for modeling or calculation, the basic unit of measurement is the same, the neural network is trained (probability calculation) and prediction based on the statistical probability of the sample in the event, and the value of the sigmoid function is 0 to 1. Between, the output of the last node of the network is also the same, so it is often necessary to normalize the output of the sample.
+
+3. Normalization is a statistical probability distribution unified between $ 0-1 $. When the input signals of all samples are positive, the weights connected to the first hidden layer neurons can only increase or decrease simultaneously. Small, which leads to slow learning.
+
+4. In addition, singular sample data often exists in the data. The network training time caused by the existence of singular sample data increases, and may cause the network to fail to converge. In order to avoid this situation and the convenience of data processing and speed up the network learning speed, the input signal can be normalized so that the input signals of all samples have an average value close to 0 or small compared with their mean square error.
+
+### 3.6.2 Why do you want to normalize?
+
+1. For the convenience of subsequent data processing, normalization can avoid some unnecessary numerical problems.
+2. The convergence speeds up for the program to run.
+3. The same dimension. The evaluation criteria of the sample data are different, and it is necessary to standardize and standardize the evaluation criteria. This is an application level requirement.
+4. Avoid neuron saturation. What do you mean? That is, when the activation of a neuron is saturated near 0 or 1, in these regions, the gradient is almost zero, so that during the backpropagation, the local gradient will approach 0, which effectively "kills" the gradient.
+5. Ensure that the value in the output data is small and not swallowed.
+
+### 3.6.3 Why can normalization improve the solution speed?
+
+
+
+The above figure is the optimal solution finding process that represents whether the data is uniform (the circle can be understood as a contour). The left image shows the search process without normalization, and the right image shows the normalized search process.
+
+When using the gradient descent method to find the optimal solution, it is very likely to take the "Zigzag" route (vertical contour line), which leads to the need to iterate many times to converge; the right picture normalizes the two original features. The corresponding contour line appears to be very round, and it can converge faster when the gradient is solved.
+
+Therefore, if the machine learning model uses the gradient descent method to find the optimal solution, normalization is often necessary, otherwise it is difficult to converge or even converge.
+
+### 3.6.4 3D illustration is not normalized
+
+example:
+
+Suppose $w1$ ranges in $[-10, 10]$, while $w2$ ranges in $[-100, 100]$, the gradient advances by 1 unit each time, then every time in the $w1$ direction Going forward for $1/20$, and on $w2$ is only equivalent to $1/200$! In a sense, the step forward on $ w2 $ is smaller, and $ w1 $ will "walk" faster than $ w2 $ during the search.
+
+This will result in a more bias toward the direction of $ w1 $ during the search. Go out of the "L" shape, or become the "Zigzag" shape.
+
+
+
+### 3.6.5 What types of normalization?
+
+Linear normalization
+
+$$
+X^{\prime} = \frac{x-min(x)}{max(x) - min(x)}
+$$
+
+Scope of application: It is more suitable for the case where the numerical comparison is concentrated.
+
+Disadvantages: If max and min are unstable, it is easy to make the normalization result unstable, which makes the subsequent use effect unstable.
+
+2. Standard deviation standardization
+
+$$
+X^{\prime} = \frac{x-\mu}{\sigma}
+$$
+
+Meaning: The processed data conforms to the standard normal distribution, ie the mean is 0, the standard deviation is 1 where $ \mu $ is the mean of all sample data, and $ \sigma $ is the standard deviation of all sample data.
+
+3. Nonlinear normalization
+
+Scope of application: It is often used in scenes where data differentiation is relatively large. Some values are large and some are small. The original values are mapped by some mathematical function. The method includes $ log $, exponent, tangent, and so on.
+
+### 3.6.6 Local response normalization
+
+LRN is a technical method to improve the accuracy of deep learning. LRN is generally a method after activation and pooling functions.
+
+In ALexNet, the LRN layer is proposed to create a competitive mechanism for the activity of local neurons, which makes the response larger and the value becomes relatively larger, and suppresses other neurons with less feedback, which enhances the generalization ability of the model.
+
+### 3.6.7 Understanding local response normalization
+
+The local response normalization principle is to mimic the inhibition phenomenon (side inhibition) of biologically active neurons on adjacent neurons. The formula is as follows:
+
+$$
+B_{x,y}^i = a_{x,y}^i / (k + \alpha \sum_{j=max(0, in/2)}^{min(N-1, i+n/2 )}(a_{x,y}^j)^2 )^\beta
+$$
+
+among them,
+1) $ a $: indicates the output of the convolutional layer (including the convolution operation and the pooling operation), which is a four-dimensional array [batch, height, width, channel].
+
+- batch: number of batches (one image per batch).
+- height: the height of the image.
+- width: the width of the image.
+- channel: number of channels. Can be understood as a picture of a batch of pictures after the convolution operation and outputThe number of neurons, or the depth of the image after processing.
+
+2) $ a_{x,y}^i $ means a position in the output structure $ [a,b,c,d] $, which can be understood as a certain height under a certain channel in a certain picture. The point at a certain width position, that is, the point under the $d$$ channel of the $a$$ map is the point where the b width is c.
+
+3) $ N $: $ N $ in the paper formula indicates the number of channels.
+
+4) $ a $, $ n/2 $, $ k $ respectively represent input, depth_radius, and bias in the function. The parameters $ k, n, \alpha, \beta $ are all hyperparameters, generally set $ k=2, n=5, \alpha=1*e-4, \beta=0.75 $
+
+5) $ \sum $:$ \sum $ The direction of the overlay is along the channel direction, that is, the sum of the squares of each point value is along the 3rd dimension channel direction in $ a $, which is a Points in the same direction as the front of the $n/2$ channel (minimum for the $0$$ channel) and after the $n/2$ channel (maximum for the $d-1$ channel) Sum of squares (total $ n+1 $ points). The English annotation of the function also shows that input is treated as $ d $ 3 dimensional matrix. To put it plainly, the number of channels of input is regarded as the number of 3D matrix, and the direction of superposition is also in the channel direction.
+
+A simple diagram is as follows:
+
+
+
+### 3.6.8 What is Batch Normalization?
+
+In the past, in neural network training, only the input layer data was normalized, but it was not normalized in the middle layer. Be aware that although we normalize the input data, after the input data is subjected to matrix multiplication such as $ \sigma(WX+b) $ and nonlinear operations, the data distribution is likely to be changed, and After the multi-layer operation of the deep network, the data distribution will change more and more. If we can also normalize in the middle of the network, is it possible to improve the training of the network? The answer is yes.
+
+This method of normalizing the middle layer of the neural network to make the training effect better is batch normalization (BN).
+
+### 3.6.9 Advantages of Batch Normalization (BN) Algorithm
+
+Let us talk about the advantages of the BN algorithm:
+1. Reduced artificial selection parameters. In some cases, you can cancel the dropout and L2 regular item parameters, or take a smaller L2 regular item constraint parameter;
+2. Reduced the requirement for learning rate. Now we can use the initial large learning rate or choose a smaller learning rate, and the algorithm can also quickly train convergence;
+3. Local response normalization can no longer be used. BN itself is a normalized network (local response normalization exists in the AlexNet network)
+4. Destroy the original data distribution, to some extent alleviate the over-fitting (to prevent one sample in each batch of training from being frequently selected, the literature says this can improve the accuracy by 1%).
+5. Reduce the disappearance of the gradient, speed up the convergence, and improve the training accuracy.
+
+### 3.6.10 Batch normalization (BN) algorithm flow
+
+The process of BN algorithm during training is given below.
+
+Input: The output of the previous layer $ X = {x_1, x_2, ..., x_m} $, learning parameters $ \gamma, \beta $
+
+Algorithm flow:
+
+1. Calculate the mean of the output data of the previous layer
+
+$$
+\mu_{\beta} = \frac{1}{m} \sum_{i=1}^m(x_i)
+$$
+
+Where $ m $ is the size of the training sample batch.
+
+2. Calculate the standard deviation of the output data of the previous layer
+
+$$
+\sigma_{\beta}^2 = \frac{1}{m} \sum_{i=1}^m (x_i - \mu_{\beta})^2
+$$
+
+3. Normalize and get
+
+$$
+\hat x_i = \frac{x_i + \mu_{\beta}}{\sqrt{\sigma_{\beta}^2} + \epsilon}
+$$
+
+Where $ \epsilon $ is a small value close to 0 added to avoid the denominator being 0
+
+4. Refactoring, reconstructing the data obtained by the above normalization process,
+
+$$
+Y_i = \gamma \hat x_i + \beta
+$$
+
+Among them, $ \gamma, \beta $ is a learnable parameter.
+
+Note: The above is the process of BN training, but when it is put into use, it is often just a sample, there is no so-called mean $ \mu_{\beta} $ and standard deviation $ \sigma_{\beta}^2 $. At this point, the mean $ \mu_{\beta} $ is calculated by averaging all the batch $ \mu_{\beta} $ values, and the standard deviation is $ \sigma_{\beta}^2 $ using each batch $ \sigma_{ The unbiased estimate of \beta}^2 $ is obtained.
+
+### 3.6.11 Batch normalization and group normalization comparison
+
+| Name | Features |
+| ------------------------------------------------ | :------------------------------------------------- ---------- |
+| Batch Normalization (BN) | allows various networks to be trained in parallel. However, normalization of batch dimensions can cause problems - inaccurate batch statistics estimates result in batches becoming smaller, and BN errors can increase rapidly. In training large networks and transferring features to computer vision tasks (including detection, segmentation, and video), memory consumption limits the use of small batches of BN. |
+| Group Normalization ** Group Normalization (GN) | GN groups channels into groups and calculates normalized mean and variance within each group. GN calculations are independent of batch size and their accuracy is stable across a wide range of batch sizes. |
+| Comparison | On ResNet-50 trained on ImageNet, the GN uses a batch size of 2 with an error rate that is 10.6% lower than the BN error rate; when using a typical batch, GN is comparable to BN and is superior to other targets. A variant. Moreover, GN can naturally migrate from pre-training to fine-tuning. In the target detection and segmentation in COCO and the video classification competition in Kinetics, GN can outperform its competitors, indicating that GN can effectively replace powerful BN in various tasks. |
+
+### 3.6.12 Comparison of Weight Normalization and Batch Normalization
+
+Both Weight Normalization and Batch Normalization are methods of parameter rewriting, but they are used in different ways.
+
+Weight Normalization is a normalization of the network weight $ W $ , so it is also called Weight Normalization;
+
+Batch Normalization is the normalization of input data to a layer of the network.
+
+Weight Normalization has the following three advantages over Batch Normalization:
+
+1. Weight Normalization accelerates the deep learning network parameter convergence by rewriting the weight of the deep learning network W, without introducing the dependency of minbatch, which is applicable to the RNN (LSTM) network (Batch Normalization cannot be directly used for RNN, normalization operation, reason It is: 1) the sequence processed by RNN is variable length; 2) RNN is calculated based on time step. If you use Batch Normalization directly, you need to save the mean and variance of mini btach under each time step, which is inefficient and takes up memory. .
+
+2. Batch Normalization calculates the mean and variance based on a mini batch's data, rather than based on the entire training set, which is equivalent to introducing a gradient calculation to introduce noise. Therefore, Batch Normalization is not suitable for noise-sensitive reinforcement learning and generation models (Generative model: GAN, VAE). In contrast, Weight Normalization rewrites the weight $W$ by scalar $g$ and vector $v$, and the rewrite vector $v$ is fixed, so Normalization based on Weight Normalization can be seen as less introduction than Batch Normalization The noise.
+
+3. No additional storage space is required to preserve the mean and variance of the mini batch. At the same time, when Weight Normalization is implemented, the additional computational overhead caused by the forward signal propagation and the inverse gradient calculation of the deep learning network is also small. Therefore, it is faster than normalization with Batch Normalization. However, Weight Normalization does not have Batch Normalization to fix the output Y of each layer of the network in a range of variation. Therefore, special attention should be paid to the initial value selection of parameters when using Normal Normalization.
+
+### 3.6.13 When is Batch Normalization suitable?
+
+** (Contributor: Huang Qinjian - South China University of Technology)**
+
+In CNN, BN should act before nonlinear mapping. BN can be tried when the neural network training encounters a slow convergence rate, or a situation such as a gradient explosion that cannot be trained. In addition, in general use, BN can also be added to speed up the training and improve the accuracy of the model.
+
+The applicable scenario of BN is: each mini-batch is relatively large, and the data distribution is relatively close. Before doing the training, you should do a good shuffle, otherwise the effect will be much worse. In addition, since BN needs to count the first-order statistics and second-order statistics of each mini-batch during operation, it is not applicable to dynamic network structures and RNN networks.
+
+
+## 3.7 Pre-training and fine tuning
+
+### 3.7.1 Why can unsupervised pre-training help deep learning?
+There is a problem with the deep network:
+
+1. The deeper the network, the more training samples are needed. If supervision is used, a large number of samples need to be labeled, otherwise small-scale samples are likely to cause over-fitting. There are many characteristics of deep network, and there are many multi-feature problems, such as multi-sample problem, regularization problem and feature selection problem.
+
+2. Multi-layer neural network parameter optimization is a high-order non-convex optimization problem, and often obtains a local solution with poor convergence;
+
+3. Gradient diffusion problem, the gradient calculated by the BP algorithm drops significantly with the depth forward, resulting in little contribution to the previous network parameters and slow update speed.
+
+**Solution:**
+
+Layer-by-layer greedy training, unsupervised pre-training is the first hidden layer of the training network, and then the second one is trained... Finally, these trained network parameter values are used as the initial values of the overall network parameters.
+
+After pre-training, a better local optimal solution can be obtained.
+
+### 3.7.2 What is the model fine tuning fine tuning
+
+Training with other people's parameters, modified network and their own data, so that the parameters adapt to their own data, such a process, usually called fine tuning.
+
+** Example of fine-tuning the model: **
+
+We know that CNN has made great progress in the field of image recognition. If you want to apply CNN to our own dataset, you will usually face a problem: usually our dataset will not be particularly large, generally no more than 10,000, or even less, each type of image is only a few Ten or ten. At this time, the idea of directly applying these data to train a network is not feasible, because a key factor in the success of deep learning is the training set consisting of a large number of tagged data. If we only use this data on hand, even if we use a very good network structure, we can't achieve high performance. At this time, the idea of fine-tuning can solve our problem well: we pass the model trained on ImageNet (such as Caf).feNet, VGGNet, ResNet) Fine-tune and apply to our own dataset.
+
+### 3.7.3 Is the network parameter updated when fine tuning?
+
+Answer: Will be updated.
+
+1. The process of finetune is equivalent to continuing training. The difference from direct training is when initialization.
+2. Direct training is initiated in the manner specified by the network definition.
+3. Finetune is initialized with the parameter file you already have.
+
+### 3.7.4 Three states of the fine-tuning model
+
+1. State 1: Only predict, not training.
+Features: Relatively fast and simple, it is very efficient for projects that have been trained and now actually label unknown data;
+
+2. State 2: Training, but only train the final classification layer.
+Features: The final classification of the fine-tuning model and the requirements are met, and now only on their basis for category dimension reduction.
+
+3. State 3: Full training, classification layer + previous convolution layer training
+Features: The difference with state two is very small. Of course, state three is time-consuming and requires training of GPU resources, but it is very suitable for fine-tuning into the model that you want. The prediction accuracy is also improved compared with state two.
+
+## 3.8 Weight Deviation Initialization
+
+### 3.8.1 All initialized to 0
+
+** Deviation Initialization Trap**: Both are initialized to 0.
+
+**The reason for the trap**: Because we don't know the last value of each weight in the training neural network, but if we do the proper data normalization, we can reasonably think that half of the weight is positive, the other half It is negative. The weight of ownership is initialized to 0. If the output value calculated by the neural network is the same, the gradient value calculated by the neural network in the back propagation algorithm is the same, and the parameter update value is also the same. More generally, if the weights are initialized to the same value, the network is symmetric.
+
+**Visualized understanding**: When considering the gradient drop in the neural network, imagine that you are climbing, but in a linear valley, the two sides are symmetrical peaks. Because of the symmetry, the gradient you are in can only follow the direction of the valley, not to the mountain; after you take a step, the situation remains the same. The result is that you can only converge to a maximum in the valley and not reach the mountain.
+
+### 3.8.2 All initialized to the same value
+
+Deviation Initialization Trap: Both are initialized to the same value.
+Take a three-layer network as an example:
+First look at the structure
+
+
+
+Its expression is:
+
+$$
+A_1^{(2)} = f(W_{11}^{(1)} x_1 + W_{12}^{(1)} x_2 + W_{13}^{(1)} x_3 + b_1^{( 1)})
+$$
+
+$$
+A_2^{(2)} = f(W_{21}^{(1)} x_1 + W_{22}^{(1)} x_2 + W_{23}^{(1)} x_3 + b_2^{( 1)})
+$$
+
+$$
+A_3^{(2)} = f(W_{31}^{(1)} x_1 + W_{32}^{(1)} x_2 + W_{33}^{(1)} x_3 + b_3^{( 1)})
+$$
+
+$$
+H_{W,b}(x) = a_1^{(3)} = f(W_{11}^{(2)} a_1^{(2)} + W_{12}^{(2)} a_2^ {(2)} + W_{13}^{(2)} a_3^{(2)} + b_1^{(2)})
+$$
+
+$$
+Xa_1^{(2)} = f(W_{11}^{(1)} x_1 + W_{12}^{(1)} x_2 + W_{13}^{(1)} x_3 + b_1^{( 1)})a_2^{(2)} = f(W_{21}^{(1)} x_1 + W_{22}^{(1)} x_2 + W_{23}^{(1)} x_3 +
+$$
+
+If each weight is the same, then in a multi-layer network, starting from the second layer, the input values of each layer are the same, that is, $ a1=a2=a3=.... $, since they are all the same, It is equivalent to an input, why? ?
+
+If it is a reverse transfer algorithm (see the above connection if you don't understand it here), the iterative partial derivative of the bias term and the weight term is calculated as follows
+
+$$
+\frac{\partial}{\partial W_{ij}^{(l)}} J(W,b;x,y) = a_j^{(l)} \delta_i^{(l+1)}
+
+\frac{\partial}{\partial b_{i}^{(l)}} J(W,b;x,y) = \delta_i^{(l+1)}
+$$
+
+Calculation formula for $ \delta $
+
+$$
+\delta_i^{(l)} = (\sum_{j=1}^{s_{t+1}} W_{ji}^{(l)} \delta_j^{(l+1)} ) f^{ \prime}(z_i^{(l)})
+$$
+
+
+If you are using the sigmoid function
+
+$$
+F^{\prime}(z_i^{(l)}) = a_i^{(l)}(1-a_i^{(l)})
+$$
+
+Substituting the latter two formulas, we can see that the obtained gradient descent method has the same partial derivatives, non-stop iterations, non-stopping the same, non-stop iterations, non-stop the same... and finally got The same value (weight and intercept).
+
+### 3.8.3 Initializing to a small random number
+
+Initializing the weights to very small numbers is a common solution to breaking network symmetry. The idea is that neurons are random and unique at first, so they calculate different updates and integrate themselves into the various parts of the network. An implementation of a weight matrix might look like $ W=0.01∗np.random.randn(D,H) $, where randn is sampled from a unit standard Gaussian distribution with a mean of 0. Through this formula (function), the weight vector of each neuron is initialized to a random vector sampled from the multidimensional Gaussian distribution, so the neuron points in the input direction in the input direction. It should mean that the input space has an effect on the random direction). In fact, it is also possible to randomly select decimals from a uniform distribution, but in practice it does not seem to have much effect on the final performance.
+
+Note: Warning: Not the smaller the number, the better it will perform. For example, if the weight of a neural network layer is very small, then the backpropagation algorithm will calculate a small gradient (because the gradient gradient is proportional to the weight). The "gradient signal" will be greatly reduced during the continuous back propagation of the network, and may become a problem that needs to be paid attention to in the deep network.
+
+### 3.8.4 Calibrating the variance with $ 1/\sqrt n $
+
+One problem with the above suggestions is that the distribution of the output of the randomly initialized neuron has a variance that varies as the input increases. It turns out that we can normalize the variance of the output of each neuron to 1 by scaling its weight vector by the square root of its input (ie the number of inputs). That is to say, the recommended heuristic is to initialize the weight vector of each neuron as follows: $ w=np.random.randn(n)/\sqrt n $, where n is the number of inputs . This ensures that the initial output distribution of all neurons in the network is roughly the same and empirically increases the rate of convergence.
+
+### 3.8.5 Sparse Initialization (Sparse Initialazation)
+
+Another way to solve the uncalibrated variance problem is to set all weight matrices to zero, but to break the symmetry, each neuron is randomly connected (extracted from a small Gaussian distribution as described above) Weight) to a fixed number of neurons below it. The number of a typical neuron connection can be as small as ten.
+
+### 3.8.6 Initialization deviation
+
+It is possible to initialize the deviation to zero, which is also very common, because asymmetry damage is caused by small random numbers of weights. Because ReLU has non-linear characteristics, some people like to use to set all deviations to small constant values such as 0.01, because this ensures that all ReLU units activate the fire at the very beginning and therefore can acquire and propagate some Gradient value. However, it is not clear whether this will provide continuous improvement (in fact some results indicate that doing so makes performance worse), so it is more common to simply initialize the deviation to 0.
+
+## 3.9 Softmax
+
+### 3.9.1 Softmax Definition and Function
+
+Softmax is a function of the form:
+
+$$
+P(i) = \frac{exp(\theta_i^T x)}{\sum_{k=1}^{K} exp(\theta_i^T x)}
+$$
+
+Where $ \theta_i $ and $ x $ are the column vectors, $ \theta_i^T x $ may be replaced by the function $ $ $ $ $ $ $ $ $ $ $ $ $ $ $ $ $ $ $ $ $ $ $ $ $ $ $
+
+With the softmax function, you can make $ P(i) $ range between $ [0,1] $. In regression and classification problems, usually $ \theta $ is a parameter to be sought by looking for $ \(ta) $ max $ $theta_i $ as the best parameter.
+
+However, there are many ways to make the range between $ [0,1] $, in order to add the power function of $ e $ in front of it? Reference logistic function:
+
+$$
+P(i) = \frac{1}{1+exp(-\theta_i^T x)}
+$$
+
+The function of this function is to make $ P(i) $ tend to 0 in the interval from negative infinity to 0, and to 1 in the interval from 0 to positive infinity. Similarly, the softmax function adds the power function of $ e $ for the purpose of polarization: the result of the positive sample will approach 1 and the result of the negative sample will approach 0. This makes it convenient for multiple categories (you can think of $ P(i) $ as the probability that a sample belongs to a category). It can be said that the Softmax function is a generalization of the logistic function.
+
+The softmax function can process its input, commonly referred to as logits or logit scores, between 0 and 1, and normalize the output to a sum of 1. This means that the softmax function is equivalent to the probability distribution of the classification. It is the best output activation function for network prediction of polyphenols.
+
+### 3.9.2 Softmax Derivation
+
+## 3.10 Understanding the principle and function of One Hot Encodeing?
+
+The origin of the problem
+
+In many **machine learning** tasks, features are not always continuous values, but may be categorical values.
+
+For example, consider the three characteristics:
+
+```
+["male", "female"] ["from Europe", "from US", "from Asia"]
+["uses Firefox", "uses Chrome", "uses Safari", "uses Internet Explorer"]
+```
+
+If the above features are represented by numbers, the efficiency will be much higher. E.g:
+
+```
+["male", "from US", "uses Internet Explorer"] is expressed as [0, 1, 3]
+["female", "from Asia", "uses Chrome"] means [1, 2, 1]
+```
+
+However, even after converting to a digital representation, the above data cannot be directly used in our classifier. Because the classifier tends to default data data is continuous (can calculate distance?), and is ordered (and the above 0 is not said to be higher than 1). However, according to our above representation, the numbers are not ordered, but are randomly assigned.
+
+**Individual heating code**
+
+In order to solve the above problem, one possible solution is to use One-Hot Encoding. One-Hot encoding, also known as one-bit efficient encoding, uses an N-bit status register to encode N states, each state being independent of its register bits, and at any time, only One is valid.
+
+E.g:
+
+```
+The natural status code is: 000,001,010,011,100,101
+The unique heat code is: 000001,000010,000100, 001000, 010000, 100000
+```
+
+It can be understood that for each feature, if it has m possible values, it will become m binary features after being uniquely encoded (such as the score, the feature is good, the middle, the difference becomes one-hot 100, 010, 001). Also, these features are mutually exclusive, with only one activation at a time. Therefore, the data becomes sparse.
+
+The main benefits of this are:
+
+1. Solved the problem that the classifier is not good at processing attribute data;
+2. To a certain extent, it also plays a role in expanding features.
+
+## 3.11 What are the commonly used optimizers?
+
+List separately
+
+```
+Optimizer:
+tf.train.GradientDescentOptimizer
+tf.train.AdadeltaOptimizer
+tf.train.AdagradOptimizer
+Tf.train.AdagradDAOptimizer
+tf.train.MomentumOptimizer
+tf.train.AdamOptimizer
+tf.train.FtrlOptimizer
+tf.train.ProximalGradientDescentOptimizer
+tf.train.ProximalAdagradOptimizer
+tf.train.RMSPropOptimizer
+```
+
+## 3.12 Dropout series questions
+
+### 3.12.1 Why do you want to regularize?
+1. Deep learning may have over-fitting problems - high variance, there are two solutions, one is regularization, the other is to prepare more data, this is a very reliable method, but you may not be able to prepare at all times The cost of training enough data or getting more data is high, but regularization often helps to avoid overfitting or reducing your network error.
+2. If you suspect that the neural network over-fitting the data, that is, there is a high variance problem, the first method that comes to mind may be regularization. Another way to solve the high variance is to prepare more data, which is also a very reliable method. But you may not be able to prepare enough training data from time to time, or the cost of getting more data is high, but regularization helps to avoid overfitting or reduce network errors.
+
+### 3.12.2 Why is regularization helpful in preventing overfitting?
+
+
+
+
+The left picture is high deviation, the right picture is high variance, and the middle is Just Right, which we saw in the previous lesson.
+
+### 3.12.3 Understanding dropout regularization
+Dropout can randomly remove neural units from the network. Why can it play such a big role through regularization?
+
+Intuitively understand: don't rely on any feature, because the input of the unit may be cleared at any time, so the unit propagates in this way and adds a little weight to the four inputs of the unit. By spreading the weight of ownership, dropout will generate The effect of the squared norm of the contraction weight is similar to the L2 regularization mentioned earlier; the result of implementing the dropout will compress the weight and complete some outer regularization to prevent overfitting; L2 has different attenuation for different weights. It depends on the size of the activation function multiplication.
+
+### 3.12.4 Choice of dropout rate
+
+1. After cross-validation, the implicit node dropout rate is equal to 0.5, which is the best, because the dropout randomly generates the most network structure at 0.5.
+2. dropout can also be used as a way to add noise, directly on the input. The input layer is set to a number closer to 1. Make the input change not too big (0.8)
+3. The max-normalization of the training of the parameter $ w $ is very useful for the training of dropout.
+4. Spherical radius $ c $ is a parameter that needs to be adjusted, and the validation set can be used for parameter tuning.
+5. dropout itself is very good, but dropout, max-normalization, large decaying learning rates and high momentum are better combined. For example, max-norm regularization can prevent the parameter blow up caused by large learning rate.
+6. Use the pretraining method to also help dropout training parameters. When using dropout, multiply all parameters by $ 1/p $.
+
+### 3.12.5 What are the disadvantages of dropout?
+
+One of the major drawbacks of dropout is that the cost function J is no longer explicitly defined. Each iteration will randomly remove some nodes. If you repeatedly check the performance of the gradient descent, it is actually difficult to review. The well-defined cost function J will drop after each iteration, because the cost function J we optimized is not really defined, or it is difficult to calculate to some extent, so we lost the debugging tool to draw such a picture. . I usually turn off the dropout function, set the keep-prob value to 1, and run the code to make sure that the J function is monotonically decreasing. Then open the dropout function, I hope that the code does not introduce bugs during the dropout process. I think you can try other methods as well, although we don't have statistics on the performance of these methods, but you can use them with the dropout method.
+
+## 3.13 Data Augmentation commonly used in deep learning?
+
+**(Contributor: Huang Qinjian - South China University of Technology)**
+
+- Color Jittering: Data enhancement for color: image brightness, saturation, contrast change (here the understanding of color jitter is not known);
+
+- PCA Jittering: First calculate the mean and standard deviation according to the RGB three color channels, then calculate the covariance matrix on the entire training set, perform feature decomposition, and obtain the feature vector and eigenvalue for PCA Jittering;
+
+- Random Scale: scale transformation;
+
+- Random Crop: crops and scales the image using random image difference methods; including Scale Jittering method (used by VGG and ResNet models) or scale and aspect ratio enhancement transform;
+
+- Horizontal/Vertical Flip: horizontal/vertical flip;
+
+- Shift: translation transformation;
+
+- Rotation/Reflection: rotation/affine transformation;
+
+- Noise: Gaussian noise, fuzzy processing;
+
+- Label Shuffle: an augmentation of category imbalance data;
+
+## 3.14 How to understand Internal Covariate Shift?
+
+**(Contributor: Huang Qinjian - South China University of Technology)**
+
+Why is the training of deep neural network models difficult? One of the important reasons is that the deep neural network involves the superposition of many layers, and the parameter update of each layer will cause the distribution of the input data of the upper layer to change. By layer-by-layer superposition, the input distribution of the upper layer will change very sharply. This makes it necessary for the upper layers to constantly adapt to the underlying parameter updates. In order to train the model, we need to be very careful to set the learning rate, initialization weights, and the most detailed parameter update strategy.
+
+Google summarizes this phenomenon as Internal Covariate Shift, referred to as ICS. What is ICS?
+
+Everyone knows that a classic assumption in statistical machine learning is that "the data distribution of the source domain and the target domain is consistent." If they are inconsistent, then new machine learning problems arise, such as transfer learning / domain adaptation. Covariate shift is a branch problem under the assumption of inconsistent distribution. It means that the conditional probability of source space and target space is consistent, but its edge probability is different.
+
+Everyone will find out, indeed, for the output of each layer of the neural network, because they have undergone intra-layer operation, the distribution is obviously different from the corresponding input signal distribution of each layer, and the difference will increase as the network depth increases. Large, but the sample labels they can "instruct" are still invariant, which is consistent with the definition of covariate shift. Because it is the analysis of the signal between layers, it is the reason of "internal".
+
+**What problems does ICS cause? **
+
+In short, the input data for each neuron is no longer "independently distributed."
+
+First, the upper parameters need to constantly adapt to the new input data distribution and reduce the learning speed.
+
+Second, the change in the input of the lower layer may tend to become larger or smaller, causing the upper layer to fall into the saturation region, so that the learning stops prematurely.
+
+Third, the update of each layer will affect other layers, so the parameter update strategy of each layer needs to be as cautious as possible.
+
+## 3.15 When do you use local-conv? When do you use full convolution?
+
+**(Contributor: Liang Zhicheng - Meizu Technology)**
+
+1. When the data set has a global local feature distribution, that is to say, there is a strong correlation between the local features, suitable for full convolution.
+
+2. When there are different feature distributions in different areas, it is suitable to use local-Conv.
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3-1.png b/English version/ch03_DeepLearningFoundation/img/ch3/3-1.png
new file mode 100644
index 00000000..5b065bc9
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3-1.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3-10.jpg b/English version/ch03_DeepLearningFoundation/img/ch3/3-10.jpg
new file mode 100644
index 00000000..526dfa3b
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3-10.jpg differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3-11.jpg b/English version/ch03_DeepLearningFoundation/img/ch3/3-11.jpg
new file mode 100644
index 00000000..d671beb2
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3-11.jpg differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3-12.png b/English version/ch03_DeepLearningFoundation/img/ch3/3-12.png
new file mode 100644
index 00000000..af6b11a4
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3-12.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3-13.png b/English version/ch03_DeepLearningFoundation/img/ch3/3-13.png
new file mode 100644
index 00000000..6d8799c6
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3-13.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3-14.png b/English version/ch03_DeepLearningFoundation/img/ch3/3-14.png
new file mode 100644
index 00000000..124af841
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3-14.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3-15.png b/English version/ch03_DeepLearningFoundation/img/ch3/3-15.png
new file mode 100644
index 00000000..a32940e4
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3-15.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3-16.png b/English version/ch03_DeepLearningFoundation/img/ch3/3-16.png
new file mode 100644
index 00000000..856802fc
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3-16.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3-17.gif b/English version/ch03_DeepLearningFoundation/img/ch3/3-17.gif
new file mode 100644
index 00000000..ba665c65
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3-17.gif differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3-18.png b/English version/ch03_DeepLearningFoundation/img/ch3/3-18.png
new file mode 100644
index 00000000..c17ecad8
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3-18.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3-19.png b/English version/ch03_DeepLearningFoundation/img/ch3/3-19.png
new file mode 100644
index 00000000..cd20e854
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3-19.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3-2.png b/English version/ch03_DeepLearningFoundation/img/ch3/3-2.png
new file mode 100644
index 00000000..3dbddcb4
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3-2.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3-20.gif b/English version/ch03_DeepLearningFoundation/img/ch3/3-20.gif
new file mode 100644
index 00000000..308e93d3
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3-20.gif differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3-21.png b/English version/ch03_DeepLearningFoundation/img/ch3/3-21.png
new file mode 100644
index 00000000..c4403e78
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3-21.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3-22.png b/English version/ch03_DeepLearningFoundation/img/ch3/3-22.png
new file mode 100644
index 00000000..05be6684
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3-22.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3-23.png b/English version/ch03_DeepLearningFoundation/img/ch3/3-23.png
new file mode 100644
index 00000000..2e4c9b21
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3-23.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3-24.png b/English version/ch03_DeepLearningFoundation/img/ch3/3-24.png
new file mode 100644
index 00000000..fbec6c04
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3-24.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3-25.png b/English version/ch03_DeepLearningFoundation/img/ch3/3-25.png
new file mode 100644
index 00000000..cd2f64ce
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3-25.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3-26.png b/English version/ch03_DeepLearningFoundation/img/ch3/3-26.png
new file mode 100644
index 00000000..9d67734e
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3-26.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3-27.png b/English version/ch03_DeepLearningFoundation/img/ch3/3-27.png
new file mode 100644
index 00000000..9678e96a
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3-27.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3-28.png b/English version/ch03_DeepLearningFoundation/img/ch3/3-28.png
new file mode 100644
index 00000000..ea2a6f96
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3-28.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3-29.png b/English version/ch03_DeepLearningFoundation/img/ch3/3-29.png
new file mode 100644
index 00000000..1d589b63
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3-29.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3-3.png b/English version/ch03_DeepLearningFoundation/img/ch3/3-3.png
new file mode 100644
index 00000000..c7178b54
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3-3.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3-30.png b/English version/ch03_DeepLearningFoundation/img/ch3/3-30.png
new file mode 100644
index 00000000..0296411e
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3-30.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3-31.png b/English version/ch03_DeepLearningFoundation/img/ch3/3-31.png
new file mode 100644
index 00000000..4c757ad3
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3-31.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3-32.png b/English version/ch03_DeepLearningFoundation/img/ch3/3-32.png
new file mode 100644
index 00000000..ea2a6f96
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3-32.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3-33.png b/English version/ch03_DeepLearningFoundation/img/ch3/3-33.png
new file mode 100644
index 00000000..9798bf81
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3-33.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3-34.png b/English version/ch03_DeepLearningFoundation/img/ch3/3-34.png
new file mode 100644
index 00000000..71edbcc1
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3-34.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3-35.jpg b/English version/ch03_DeepLearningFoundation/img/ch3/3-35.jpg
new file mode 100644
index 00000000..5bb87c99
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3-35.jpg differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3-36.png b/English version/ch03_DeepLearningFoundation/img/ch3/3-36.png
new file mode 100644
index 00000000..5b90a4e3
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3-36.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3-37.png b/English version/ch03_DeepLearningFoundation/img/ch3/3-37.png
new file mode 100644
index 00000000..087ae7b7
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3-37.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3-38.png b/English version/ch03_DeepLearningFoundation/img/ch3/3-38.png
new file mode 100644
index 00000000..731c159e
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3-38.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3-39.jpg b/English version/ch03_DeepLearningFoundation/img/ch3/3-39.jpg
new file mode 100644
index 00000000..50fe309f
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3-39.jpg differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3-4.png b/English version/ch03_DeepLearningFoundation/img/ch3/3-4.png
new file mode 100644
index 00000000..a6f322cd
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3-4.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3-40.png b/English version/ch03_DeepLearningFoundation/img/ch3/3-40.png
new file mode 100644
index 00000000..2303937c
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3-40.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3-41.png b/English version/ch03_DeepLearningFoundation/img/ch3/3-41.png
new file mode 100644
index 00000000..a16e2651
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3-41.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3-5.png b/English version/ch03_DeepLearningFoundation/img/ch3/3-5.png
new file mode 100644
index 00000000..d094c2c9
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3-5.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3-6.png b/English version/ch03_DeepLearningFoundation/img/ch3/3-6.png
new file mode 100644
index 00000000..10ac6d41
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3-6.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3-7.jpg b/English version/ch03_DeepLearningFoundation/img/ch3/3-7.jpg
new file mode 100644
index 00000000..3cdfc2d1
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3-7.jpg differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3-8.png b/English version/ch03_DeepLearningFoundation/img/ch3/3-8.png
new file mode 100644
index 00000000..dd13a29c
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3-8.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3-9.jpg b/English version/ch03_DeepLearningFoundation/img/ch3/3-9.jpg
new file mode 100644
index 00000000..49d4e00f
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3-9.jpg differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3.1.1.5.png b/English version/ch03_DeepLearningFoundation/img/ch3/3.1.1.5.png
new file mode 100644
index 00000000..dde211ce
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3.1.1.5.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3.1.1.6.png b/English version/ch03_DeepLearningFoundation/img/ch3/3.1.1.6.png
new file mode 100644
index 00000000..1bd76971
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3.1.1.6.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3.1.6.1.png b/English version/ch03_DeepLearningFoundation/img/ch3/3.1.6.1.png
new file mode 100644
index 00000000..e0ce77d9
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3.1.6.1.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3.12.2.1.png b/English version/ch03_DeepLearningFoundation/img/ch3/3.12.2.1.png
new file mode 100644
index 00000000..34f2d8b6
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3.12.2.1.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3.12.2.2.png b/English version/ch03_DeepLearningFoundation/img/ch3/3.12.2.2.png
new file mode 100644
index 00000000..ad3d4bd6
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3.12.2.2.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3.2.1.1.png b/English version/ch03_DeepLearningFoundation/img/ch3/3.2.1.1.png
new file mode 100644
index 00000000..160cf461
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3.2.1.1.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3.2.1.2.png b/English version/ch03_DeepLearningFoundation/img/ch3/3.2.1.2.png
new file mode 100644
index 00000000..fec7b5b1
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3.2.1.2.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3.2.2.1.png b/English version/ch03_DeepLearningFoundation/img/ch3/3.2.2.1.png
new file mode 100644
index 00000000..02dbca08
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3.2.2.1.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3.2.3.1.png b/English version/ch03_DeepLearningFoundation/img/ch3/3.2.3.1.png
new file mode 100644
index 00000000..1c4dacd9
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3.2.3.1.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3.2.3.2.png b/English version/ch03_DeepLearningFoundation/img/ch3/3.2.3.2.png
new file mode 100644
index 00000000..09f4d9e2
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3.2.3.2.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3.2.3.4.png b/English version/ch03_DeepLearningFoundation/img/ch3/3.2.3.4.png
new file mode 100644
index 00000000..03f1c6a9
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3.2.3.4.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3.2.3.5.png b/English version/ch03_DeepLearningFoundation/img/ch3/3.2.3.5.png
new file mode 100644
index 00000000..56443fd2
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3.2.3.5.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3.2.3.6.png b/English version/ch03_DeepLearningFoundation/img/ch3/3.2.3.6.png
new file mode 100644
index 00000000..bda9c5cb
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3.2.3.6.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3.2.4.1.png b/English version/ch03_DeepLearningFoundation/img/ch3/3.2.4.1.png
new file mode 100644
index 00000000..f91e8ab4
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3.2.4.1.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3.2.5.1.png b/English version/ch03_DeepLearningFoundation/img/ch3/3.2.5.1.png
new file mode 100644
index 00000000..1236163e
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3.2.5.1.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3.2.5.2.png b/English version/ch03_DeepLearningFoundation/img/ch3/3.2.5.2.png
new file mode 100644
index 00000000..c36f3bfd
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3.2.5.2.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3.2.5.3.png b/English version/ch03_DeepLearningFoundation/img/ch3/3.2.5.3.png
new file mode 100644
index 00000000..d53c8ea8
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3.2.5.3.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3.2.5.4.png b/English version/ch03_DeepLearningFoundation/img/ch3/3.2.5.4.png
new file mode 100644
index 00000000..f00cca44
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3.2.5.4.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3.4.9.1.png b/English version/ch03_DeepLearningFoundation/img/ch3/3.4.9.1.png
new file mode 100644
index 00000000..3e126ba7
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3.4.9.1.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3.4.9.2.png b/English version/ch03_DeepLearningFoundation/img/ch3/3.4.9.2.png
new file mode 100644
index 00000000..ea9b0c34
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3.4.9.2.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3.4.9.3.png b/English version/ch03_DeepLearningFoundation/img/ch3/3.4.9.3.png
new file mode 100644
index 00000000..fe1d7779
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3.4.9.3.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3.6.3.1.png b/English version/ch03_DeepLearningFoundation/img/ch3/3.6.3.1.png
new file mode 100644
index 00000000..d091389e
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3.6.3.1.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3.6.7.1.png b/English version/ch03_DeepLearningFoundation/img/ch3/3.6.7.1.png
new file mode 100644
index 00000000..4b98c00e
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3.6.7.1.png differ
diff --git a/English version/ch03_DeepLearningFoundation/img/ch3/3.8.2.1.png b/English version/ch03_DeepLearningFoundation/img/ch3/3.8.2.1.png
new file mode 100644
index 00000000..1236163e
Binary files /dev/null and b/English version/ch03_DeepLearningFoundation/img/ch3/3.8.2.1.png differ
diff --git a/English version/ch03_DeepLearningFoundation/readme.md b/English version/ch03_DeepLearningFoundation/readme.md
new file mode 100644
index 00000000..26ad0b97
--- /dev/null
+++ b/English version/ch03_DeepLearningFoundation/readme.md
@@ -0,0 +1,14 @@
+###########################################################
+
+\### Deep Learning 500 Questions - First * Chapter xxx
+
+**Responsible person (in no particular order): **
+Xxx graduate student-xxx(xxx)
+Xxx doctoral student-xxx
+Xxx-xxx
+
+
+**Contributors (in no particular order): **
+Content contributors can add information
+
+###########################################################
\ No newline at end of file
diff --git a/English version/ch04_ClassicNetwork/ChapterIV_ClassicNetwork.md b/English version/ch04_ClassicNetwork/ChapterIV_ClassicNetwork.md
new file mode 100644
index 00000000..f5c39d45
--- /dev/null
+++ b/English version/ch04_ClassicNetwork/ChapterIV_ClassicNetwork.md
@@ -0,0 +1,293 @@
+[TOC]
+
+# Chapter 4 Classic Network
+## 4.1 LeNet-5
+
+### 4.1.1 Introduction to the model
+
+LeNet-5 is a Convolutional Neural Network (CNN) $^{[1]}$ proposed by $LeCun$ for recognizing handwritten digits and machine-printed characters. The name is derived from the author $LeCun$ The name, 5 is the code name for its research, and LeNet-4 and LeNet-1 were little known before LeNet-5. LeNet-5 illustrates that the correlation between pixel features in an image can be extracted by a convolution operation shared by parameters, and a combination of convolution, downsampling (pooling), and nonlinear mapping is currently popular. The basis of most depth image recognition networks.
+
+### 4.1.2 Model structure
+
+
+
+Figure 4.1 LeNet-5 network structure
+
+As shown in Figure 4.1, LeNet-5 consists of 7 layers (the input layer is not used as the network structure), which consists of 2 convolution layers, 2 downsampling layers and 3 connection layers. The parameter configuration of the network is shown in Table 4.1. The kernel size of the downsampling layer and the fully connected layer respectively represents the sampling range and the size of the connection matrix (eg, "5\times5\times1/1,6" in the convolution kernel size indicates that the kernel size is $5\times5 \times1$, convolution kernel with a step size of $1$ and a core number of 6.)
+
+Table 4.1 LeNet-5 Network Parameter Configuration
+
+| Network Layer | Input Size | Core Size | Output Size | Trainable Parameter Quantity |
+| :-------------: | :------------------: | :----------- -----------: | :------------------: | :--------------- --------------: |
+| Convolutional Layer $C_1$ | $32\times32\times1$ | $5\times5\times1/1,6$ | $28\times28\times6$ | $(5\times5\times1+1)\times6$ |
+| Downsampling layer $S_2$ | $28\times28\times6$ | $2\times2/2$ | $14\times14\times6$ | $(1+1)\times6$ $^*$ |
+| Convolutional Layer $C_3$ | $14\times14\times6$ | $5\times5\times6/1,16$ | $10\times10\times16$ | $1516^*$ |
+| Downsampling layer $S_4$ | $10\times10\times16$ | $2\times2/2$ | $5\times5\times16$ | $(1+1)\times16$ |
+| Convolutional Layer $C_5$$^*$ | $5\times5\times16$ | $5\times5\times16/1,120$ | $1\times1\times120$ | $(5\times5\times16+1)\times120$ |
+| Full Connect Layer $F_6$ | $1\times1\times120$ | $120\times84$ | $1\times1\times84$ | $(120+1)\times84$ |
+| Output Layer | $1\times1\times84$ | $84\times10$ | $1\times1\times10$ | $(84+1)\times10$ |
+
+> $^*$ In LeNet, the downsampling operation is similar to the pooling operation, but after multiplying the sampled result by a coefficient and adding an offset term, the number of parameters sampled below is $(1+1) )\times6$ instead of zero.
+>
+> $^*$ $C_3$ Convolutional layer training parameters are not directly connected to all feature maps in $S_2$, but are connected using the sampling feature as shown in Figure 4.2 (sparse connection). The generated 16 channel feature maps are mapped according to the adjacent three feature maps, the adjacent four feature maps, the non-adjacent four feature maps, and all six feature maps. The calculated number of parameters is calculated as $6\ Times(25\times3+1)+6\times(25\times4+1)+3\times(25\times4+1)+1\times(25\times6+1)=1516$, explained in the original paper There are two reasons for using this sampling method: the number of connections is not too large (the computing power of the current year is weak); forcing the combination of different feature maps can make the mapped feature maps learn different feature patterns.
+
+
+
+Figure 4.2 Sparse connection between feature maps between $S_2$ and $C_3$
+
+> $^*$ $C_5$ The convolutional layer is shown in Figure 4.1 as a fully connected layer. The original paper explains that the convolution operation is actually used here, but the size is compressed to $1 just after the $5\times5$ convolution. Times1$, the output looks very similar to a full connection.
+
+### 4.1.3 Model Features
+- The convolutional network uses a three-layer sequence combination: convolution, downsampling (pooling), and non-linear mapping (the most important feature of LeNet-5, which forms the basis of the current deep convolutional network)
+- Extract spatial features using convolution
+- Downsampling using the mapped spatial mean
+- Non-linear mapping using $tanh$ or $sigmoid$
+- Multilayer Neural Network (MLP) as the final classifier
+- Sparse connection matrix between layers to avoid huge computational overhead
+
+## 4.2 AlexNet
+
+### 4.2.1 Introduction to the model
+
+AlexNet is the first deep convolutional neural network applied to image classification by $Alex$ $Krizhevsky $, which was 15.3% top-5 in the 2012 ILSVRC (ImageNet Large Scale Visual Recognition Competition) image classification competition. The test error rate won the first place $^{[2]}$. AlexNet uses GPU instead of CPU to make the model structure more complex in an acceptable time range. Its appearance proves the effectiveness of deep convolutional neural networks in complex models, making CNN popular in computer vision. Directly or indirectly triggered a wave of deep learning.
+
+### 4.2.2 Model structure
+
+
+
+Figure 4.3 AlexNet network structure
+
+As shown in Figure 4.3, except for downsampling (pooling layer) and Local Responsible Normalization (LRN), AlexNet consists of 8 layers. The first 5 layers are composed of convolution layers, while the remaining 3 layers are all. Connection layer. The network structure is divided into upper and lower layers, corresponding to the operation process of the two GPUs, except for some layers in the middle ($C_3$ convolutional layer and $F_{6-8}$ full connection layer will have GPU interaction), other Layer two GPUs calculate the results separately. The output of the last layer of the fully connected layer is input as $softmax$, and the probability values corresponding to 1000 image classification labels are obtained. Excluding the design of the GPU parallel structure, the AlexNet network structure is very similar to that of LeNet. The parameter configuration of the network is shown in Table 4.2.
+
+Table 4.2 AlexNet Network Parameter Configuration
+
+| Network Layer | Input Size | Core Size | Output Size | Trainable Parameter Quantity |
+| :-------------------: | :-------------------------- --------: | :--------------------------------------: | :----------------------------------: | :----------- --------------------------: |
+| Convolutional Layer $C_1$ $^*$ | $224\times224\times3$ | $11\times11\times3/4,48(\times2_{GPU})$ | $55\times55\times48(\times2_{GPU})$ | $(11\times11\times3+1)\times48\times2$ |
+| Downsampling layer $S_{max}$$^*$ | $55\times55\times48(\times2_{GPU})$ | $3\times3/2(\times2_{GPU})$ | $27\times27\times48(\ Times2_{GPU})$ | 0 |
+| Convolutional Layer $C_2$ | $27\times27\times48(\times2_{GPU})$ | $5\times5\times48/1,128(\times2_{GPU})$ | $27\times27\times128(\times2_{GPU}) $ | $(5\times5\times48+1)\times128\times2$ |
+| Downsampling layer $S_{max}$ | $27\times27\times128(\times2_{GPU})$ | $3\times3/2(\times2_{GPU})$ | $13\times13\times128(\times2_{GPU} )$ | 0 |
+| Convolutional layer $C_3$ $^*$ | $13\times13\times128\times2_{GPU}$ | $3\times3\times256/1,192(\times2_{GPU})$ | $13\times13\times192(\times2_{GPU })$ | $(3\times3\times256+1)\times192\times2$ |
+| Convolutional layer $C_4$ | $13\times13\times192(\times2_{GPU})$ | $3\times3\times192/1,192(\times2_{GPU})$ | $13\times13\times192(\times2_{GPU}) $ | $(3\times3\times192+1)\times192\times2$ |
+| Convolutional layer $C_5$ | $13\times13\times192(\times2_{GPU})$ | $3\times3\times192/1,128(\times2_{GPU})$ | $13\times13\times128(\times2_{GPU}) $ | $(3\times3\times192+1)\timEs128\times2$ |
+| Downsampling layer $S_{max}$ | $13\times13\times128(\times2_{GPU})$ | $3\times3/2(\times2_{GPU})$ | $6\times6\times128(\times2_{GPU} )$ | 0 |
+| Fully connected layer $F_6$ $^*$ | $6\times6\times128\times2_{GPU}$ | $9216\times2048(\times2_{GPU})$ | $1\times1\times2048(\times2_{GPU})$ | $(9216+1)\times2048\times2$ |
+| Fully connected layer $F_7$ | $1\times1\times2048\times2_{GPU}$ | $4096\times2048(\times2_{GPU})$ | $1\times1\times2048(\times2_{GPU})$ | $(4096+ 1)\times2048\times2$ |
+| Full Connect Layer $F_8$ | $1\times1\times2048\times2_{GPU}$ | $4096\times1000$ | $1\times1\times1000$ | $(4096+1)\times1000\times2$ |
+
+>Convolution layer $C_1$ input image data of $224\times224\times3$, respectively, after convolution convolution of $11\times11\times3$ and stride of 4 in two GPUs. Get two separate output data for $55\times55\times48$.
+>
+The downsampling layer $S_{max}$ is actually the largest pooling operation nested in the convolution, but is separately listed to distinguish the convolutional layers that do not have the largest pooling. After the pooling operation in the $C_{1-2}$ convolutional layer (before the ReLU activation operation), there is also an LRN operation for normalization of adjacent feature points.
+>
+The input of the convolutional layer $C_3$ is different from other convolutional layers. $13\times13\times192\times2_{GPU}$ means that the output of the upper layer network on the two GPUs is collected as input, so the convolution is performed. The convolution kernel dimension on the channel during operation is 384.
+>
+The input data size of the fully connected layer $F_{6-8}$ is similar to $C_3$, which is an input that combines the output of two GPU flows.
+
+
+### 4.2.3 Model Features
+- All convolutional layers use ReLU as a nonlinear mapping function to make the model converge faster
+- Training of models on multiple GPUs not only improves the training speed of the model, but also increases the scale of data usage.
+- Normalize the local features using LRN, and as a result the input to the ReLU activation function can effectively reduce the error rate
+- Overlapping max pooling, ie the pooling range z has a relationship with the step size s $z>s$ (eg $S\{max}$ in the kernel scale is $3\times3/2$), avoiding average pooling Average effect of (average pooling)
+- Use random dropout to selectively ignore individual neurons in training to avoid overfitting of the model
+
+
+
+## 4.3 ZFNet
+### 4.3.1 Introduction to the model
+
+ZFNet is a large convolutional network based on AlexNet from $Matthew$ $D. Zeiler$ and $Rob$ $Fergus$. In the 2013 ILSVRC image classification competition, it won the championship with an error rate of 11.19% (actually the original ZFNet The team is not a real champion. The original ZFNet ranked 8th with a 13.51% error rate. The real champion is the $Clarifai$ team, and the CEO of a startup company corresponding to $Clarifai$ is $Zeiler$. And $Clarifai$ has a relatively small change to ZFNet, so it is generally considered that ZFNet won the championship) $^{[3-4]}$. ZFNet is actually fine-tuning AlexNet, and visualizes the output features of each layer by means of deconvolution, further explaining why convolution operations are significant in large networks.
+
+### 4.3.2 Model structure
+
+
+
+Figure 4.4 ZFNet network structure diagram (original structure diagram and AlexNet style structure diagram)
+
+As shown in Figure 4.4, ZFNet is similar to AlexNet. It is a convolutional neural network consisting of 8 layers of networks, including 5 layers of convolutional layers and 3 layers of fully connected layers. The biggest difference between the two network architectures is that the ZFNet first-layer convolution replaces the convolution of the first-order convolution kernel $11\times11\times3/4$ in AlexNet with a convolution kernel of $7\times7\times3/2$. nuclear. In Figure 4.5, ZFNet contains more intermediate frequency information in the feature map of the first layer output than AlexNet, while the characteristic map of the first layer output of AlexNet is mostly low frequency or high frequency information, and the lack of intermediate frequency features leads to The characteristics of the subsequent network level as shown in Figure 4.5(c) are not detailed enough, and the root cause of this problem is that the convolution kernel and step size adopted by AlexNet in the first layer are too large.
+
+
+
+
+
+Figure 4.5 (a) Characteristic map of the first layer output of ZFNet (b) Characteristic map of the first layer output of AlexNet (c) Characteristic map of the output of the second layer of AlexNet (d) Characteristic map of the output of the second layer of ZFNet
+
+Table 4.3 ZFNet Network Parameter Configuration
+| Network Layer | Input Size | Core Size | Output Size | Trainable Parameter Quantity |
+| :-------------------: | :-------------------------- --------: | :--------------------------------------: | :----------------------------------: | :----------- --------------------------: |
+| Convolutional Layer $C_1$ $^*$ | $224\times224\times3$ | $7\times7\times3/2,96$ | $110\times110\times96$ | $(7\times7\times3+1)\times96$ |
+| Downsampling layer $S_{max}$ | $110\times110\times96$ | $3\times3/2$ | $55\times55\times96$ | 0 |
+| Convolutional Layer $C_2$ $^*$ | $55\times55\times96$ | $5\times5\times96/2,256$ | $26\times26\times256$ | $(5\times5\times96+1)\times256$ |
+| Downsampling layer $S_{max}$ | $26\times26\times256$ | $3\times3/2$ | $13\times13\times256$ | 0 |
+| Convolutional Layer $C_3$ | $13\times13\times256$ | $3\times3\times256/1,384$ | $13\times13\times384$ | $(3\times3\times256+1)\times384$ |
+| Convolutional layer $C_4$ | $13\times13\times384$ | $3\times3\times384/1,384$ | $13\times13\times384$ | $(3\times3\times384+1)\times384$ |
+| Convolutional layer $C_5$ | $13\times13\times384$ | $3\times3\times384/1,256$ | $13\times13\times256$ | $(3\times3\times384+1)\times256$ |
+| Downsampling layer $S_{max}$ | $13\times13\times256$ | $3\times3/2$ | $6\times6\times256$ | 0 |
+| Full Connect Layer $F_6$ | $6\times6\times256$ | $9216\times4096$ | $1\times1\times4096$ | $(9216+1)\times4096$ |
+| Full Connect Layer $F_7$ | $1\times1\times4096$ | $4096\times4096$ | $1\times1\times4096$ | $(4096+1)\times4096$ |
+| Full Connect Layer $F_8$ | $1\times1\times4096$ | $4096\times1000$ | $1\times1\times1000$ | $(4096+1)\times1000$ |
+> Convolutional layer $C_1$ is different from $C_1$ in AlexNet, using $7\times7\times3/2$ convolution kernel instead of $11\times11\times3/4 $ to make the first layer convolution output The result can include more medium frequency features, providing more choices for a diverse set of features in subsequent network layers, facilitating the capture of more detailed features.
+>
+> The convolutional layer $C_2$ uses a convolution kernel of step size 2, which is different from the convolution kernel step size of $C_2$ in AlexNet, so the output dimensions are different.
+
+### 4.3.3 Model Features
+
+ZFNet and AlexNet are almost identical in structure. Although this part belongs to the model characteristics, it should be accurately the contribution of visualization technology in the original ZFNet paper.
+
+- Visualization techniques reveal individual feature maps for each layer in the excitation model.
+- Visualization techniques allow observation of the evolution of features during the training phase and the diagnosis of potential problems with the model.
+- Visualization technology uses a multi-layer deconvolution network that returns to the input pixel space by feature activation.
+- Visualization techniques perform sensitivity analysis of the classifier output by revealing that part of the input image reveals which part is important for classification.
+- The visualization technique provides a non-parametric invariance to show which piece of the training set activates which feature map, not only the cropped input image, but also a top-down projection to expose a feature map from each block.
+- Visualization techniques rely on deconvolution operations, the inverse of convolution operations, to map features onto pixels.
+
+## 4.4 Network in Network
+
+### 4.4.1 Introduction to the model
+NetwThe ork In Network (NIN) was proposed by $Min Lin$ et al. to achieve the best level at the time of the CIFAR-10 and CIFAR-100 classification tasks, as its network structure was made up of three multi-layered perceptron stacks. NIN$^{[5]}$. NIN examines the convolution kernel design in convolutional neural networks from a new perspective, and replaces the linear mapping part in pure convolution by introducing subnetwork structures. This form of network structure stimulates more complex convolutional neural networks. The structural design of GoogLeNet's Inception structure introduced in the next section is derived from this idea.
+
+### 4.4.2 Model Structure
+
+
+Figure 4.6 NIN network structure
+
+NIN consists of three layers of multi-layer perceptual convolutional layer (MLPConv Layer). Each layer of multi-layer perceptual convolutional layer is composed of several layers of local fully connected layers and nonlinear activation functions instead of traditional convolutional layers. Linear convolution kernel used. In network inference, the multi-layer perceptron calculates the local features of the input feature map, and the weights of the products corresponding to the local feature maps of each window are shared. The convolution operation is completely consistent, the biggest difference is that the multilayer perceptron performs a nonlinear mapping of local features, while the traditional convolution method is linear. NIN's network parameter configuration table 4.4 is shown (the original paper does not give the network parameters, the parameters in the table are the compiler combined network structure diagram and CIFAR-100 data set with $3\times3$ convolution as an example).
+
+Table 4.4 NIN network parameter configuration (combined with the original paper NIN structure and CIFAR-100 data)
+
+| Network Layer | Input Size | Core Size | Output Size | Number of Parameters |
+|:------:|:-------:|:------:|:--------:|:-------:|
+| Local Fully Connected Layer $L_{11}$ $^*$ | $32\times32\times3$ | $(3\times3)\times16/1$ | $30\times30\times16$ | $(3\times3\times3+ 1)\times16$ |
+| Fully connected layer $L_{12}$ $^*$ | $30\times30\times16$ | $16\times16$ | $30\times30\times16$ | $((16+1)\times16)$ |
+| Local Full Connection Layer $L_{21}$ | $30\times30\times16$ | $(3\times3)\times64/1$ | $28\times28\times64$ | $(3\times3\times16+1)\times64 $ |
+| Fully connected layer $L_{22}$ | $28\times28\times64$ | $64\times64$ | $28\times28\times64$ | $((64+1)\times64)$ |
+| Local Full Connection Layer $L_{31}$ | $28\times28\times64$ | $(3\times3)\times100/1$ | $26\times26\times100$ | $(3\times3\times64+1)\times100 $ |
+| Fully connected layer $L_{32}$ | $26\times26\times100$ | $100\times100$ | $26\times26\times100$ | $((100+1)\times100)$ |
+| Global Average Sampling $GAP$ $^*$ | $26\times26\times100$ | $26\times26\times100/1$ | $1\times1\times100$ | $0$ |
+> The local fully connected layer $L_{11}$ is actually a windowed full join operation on the original input image, so the windowed output feature size is $30\times30$($\frac{32-3_k+1 }{1_{stride}}=30$)
+> The fully connected layer $L_{12}$ is a fully connected operation immediately following $L_{11}$. The input feature is the activated local response feature after windowing, so only need to connect $L_{11}$ and The node of $L_{12}$ is sufficient, and each partial fully connected layer and the immediately connected fully connected layer constitute a multilayer perceptual convolutional layer (MLPConv) instead of a convolution operation.
+> The global average sampling layer or the global average pooling layer $GAP$(Global Average Pooling) performs a global average pooling operation on each feature map output by $L_{32}$, directly obtaining the final number of categories, which can effectively Reduce the amount of parameters.
+
+### 4.4.3 Model Features
+
+- The use of a multi-layer perceptron structure instead of convolution filtering operation not only effectively reduces the problem of excessive parameterization caused by excessive convolution kernels, but also improves the abstraction ability of the model by introducing nonlinear mapping.
+- Using global average pooling instead of the last fully connected layer, can effectively reduce the amount of parameters (no trainable parameters), while pooling uses the information of the entire feature map, which is more robust to the transformation of spatial information, and finally obtained The output can be directly used as a confidence level for the corresponding category.
+
+## 4.5 VGGNet
+
+### 4.5.1 Introduction to the model
+
+VGGNet is a deep convolutional network structure proposed by the Visual Geometry Group (VGG) of Oxford University. They won the runner-up of the 2014 ILSVRC classification task with a 7.32% error rate (the champion was 6.65% by GoogLeNet). The error rate was won) and the error rate of 25.32% won the first place in the Localization (GoogLeNet error rate was 26.44%) $^{[5]}$, and the network name VGGNet was taken from the group name abbreviation. VGGNet was the first to reduce the error rate of image classification to less than 10%, and the idea of the $3\times3$ convolution kernel used in the network was the basis of many later models published at the 2015 International Conference on Learning Representation ( International Conference On Learning Representations (ICLR) has been cited more than 14,000 times since.
+
+### 4.5.2 Model structure
+
+
+
+Figure 4.7 VGG16 network structure
+
+In the original paper, VGGNet contains six versions of evolution, corresponding to VGG11, VGG11-LRN, VGG13, VGG16-1, VGG16-3 and VGG19, respectively. Different suffix values indicate different network layers (VGG11-LRN is represented in In the first layer, VGG11 of LRN is used. VGG16-1 indicates that the convolution kernel size of the last three convolutional blocks is $1\times1$, and the corresponding VGG16-3 indicates that the convolution kernel size is $3\. Times3$), the VGG16 introduced in this section is VGG16-3. The VGG16 in Figure 4.7 embodies the core idea of VGGNet, using the convolution combination of $3\times3$ instead of the large convolution (2 $3\times3 convolutions can have the same perception field as the $$5\times5$ convolution ), network parameter settings are shown in Table 4.5.
+
+Table 4.5 VGG16 network parameter configuration
+
+| Network Layer | Input Size | Core Size | Output Size | Number of Parameters |
+| :--------------------: | :-------------------: | :--- ------------------: | :--------------------: | :------ -----------------------: |
+| Convolutional Layer $C_{11}$ | $224\times224\times3$ | $3\times3\times64/1$ | $224\times224\times64$ | $(3\times3\times3+1)\times64$ |
+| Convolutional Layer $C_{12}$ | $224\times224\times64$ | $3\times3\times64/1$ | $224\times224\times64$ | $(3\times3\times64+1)\times64$ |
+| Downsampling layer $S_{max1}$ | $224\times224\times64$ | $2\times2/2$ | $112\times112\times64$ | $0$ |
+| Convolutional layer $C_{21}$ | $112\times112\times64$ | $3\times3\times128/1$ | $112\times112\times128$ | $(3\times3\times64+1)\times128$ |
+| Convolutional Layer $C_{22}$ | $112\times112\times128$ | $3\times3\times128/1$ | $112\times112\times128$ | $(3\times3\times128+1)\times128$ |
+| Downsampling layer $S_{max2}$ | $112\times112\times128$ | $2\times2/2$ | $56\times56\times128$ | $0$ |
+| Convolutional layer $C_{31}$ | $56\times56\times128$ | $3\times3\times256/1$ | $56\times56\times256$ | $(3\times3\times128+1)\times256$ |
+| Convolutional layer $C_{32}$ | $56\times56\times256$ | $3\times3\times256/1$ | $56\times56\times256$ | $(3\times3\times256+1)\times256$ |
+| Convolutional layer $C_{33}$ | $56\times56\times256$ | $26\times26\times256/1$ | $56\times56\times256$ | $(3\times3\times256+1)\times256$ |
+| Downsampling layer $S_{max3}$ | $56\times56\times256$ | $2\times2/2$ | $28\times28\times256$ | $0$ |
+| Convolutional Layer $C_{41}$ | $28\times28\times256$ | $3\times3\times512/1$ | $28\times28\times512$ | $(3\times3\times256+1)\times512$ |
+| Convolutional Layer $C_{42}$ | $28\times28\times512$ | $3\times3\times512/1$ | $28\times28\times512$ | $(3\times3\times512+1)\times512$ |
+| Convolutional Layer $C_{43}$ | $28\times28\times512$ | $3\times3\times512/1$ | $28\times28\times512$ | $(3\times3\times512+1)\times512$ |
+| Downsampling layer $S_{max4}$ | $28\times28\times512$ | $2\times2/2$ | $14\times14\times512$ | $0$ |
+| Convolutional Layer $C_{51}$ | $14\times14\times512$ | $3\times3\times512/1$ | $14\times14\times512$ | $(3\times3\times512+1)\times512$ |
+| Convolutional Layer $C_{52}$ | $14\times14\times512$ | $3\times3\times512/1$ | $14\times14\times512$ | $(3\times3\times512+1)\times512$ || Convolutional Layer $C_{53}$ | $14\times14\times512$ | $3\times3\times512/1$ | $14\times14\times512$ | $(3\times3\times512+1)\times512$ |
+| Downsampling layer $S_{max5}$ | $14\times14\times512$ | $2\times2/2$ | $7\times7\times512$ | $0$ |
+| Fully connected layer $FC_{1}$ | $7\times7\times512$ | $(7\times7\times512)\times4096$ | $1\times4096$ | $(7\times7\times512+1)\times4096$ |
+| Fully connected layer $FC_{2}$ | $1\times4096$ | $4096\times4096$ | $1\times4096$ | $(4096+1)\times4096$ |
+| Fully connected layer $FC_{3}$ | $1\times4096$ | $4096\times1000$ | $1\times1000$ | $(4096+1)\times1000$ |
+
+### 4.5.3 Model Features
+
+- The entire network uses the same size convolution kernel size $3\times3$ and the maximum pooled size $2\times2$.
+- The meaning of $1\times1$convolution is mainly linear transformation, while the number of input channels and the number of output channels are unchanged, and no dimensionality reduction occurs.
+- Two convolutional layers of $3\times3$ are concatenated as a convolutional layer of $5\times5$ with a receptive field size of $5\times5$. Similarly, the concatenation of three $3\times3$ convolutions is equivalent to a convolutional layer of $7\times7$. This type of connection makes the network parameters smaller, and the multi-layer activation function makes the network more capable of learning features.
+- VGGNet has a trick in training. It first trains the shallow simple network VGG11, and then reuses the weight of VGG11 to initialize VGG13. This training and initialization VGG19 can make the convergence faster during training.
+- Use multi-scale transformations in the training process to enhance the data of the original data, making the model difficult to overfit.
+
+## 4.6 GoogLeNet
+### 4.6.1 Introduction to the model
+
+As the winner of the ILSVRC classification task in 2014, GoogLeNet pressured VGGNet and other models with an error rate of 6.65%. Compared with the previous two championships ZFNet and AlexNet, the accuracy of the classification is greatly improved. From the name **GoogLe**Net, you can know that this is a network structure designed by Google engineers, and the name Goog**LeNet** is a tribute to LeNet$^{[0]}$. The core part of GoogLeNet is its internal subnet structure, Inception, which is inspired by NIN and has undergone four iterations (Inception$_{v1-4}$).
+
+
+Figure 4.8 Inception performance comparison chart
+
+### 4.6.2 Model Structure
+
+
+Figure 4.9 GoogLeNet network structure
+As shown in Figure 4.9, GoogLeNet extends the width of the network in addition to the depth of the previous convolutional neural network structure. The entire network is composed of a number of block subnetworks. This subnet constitutes the Inception structure. Figure 4.9 shows four versions of Inception: $Inception_{v1}$ uses different convolution kernels in the same layer and merges the convolution results; $Inception_{v2}$ combines the stacking of different convolution kernels, and The convolution results are merged; $Inception_{v3}$ is a deep combination attempt on the basis of $v_2$; the $Inception_{v4} $ structure is more complex than the previous version, nested in the subnet The internet.
+
+
+
+
+
+Figure 4.10 Inception$_{v1-4}$ structure diagram
+
+Table 4.6 Inception$_{v1}$ Network Parameter Configuration in GoogLeNet
+
+| Network Layer | Input Size | Core Size | Output Size | Number of Parameters |
+| :--------------------: | :-------------------: | :--- ------------------: | :--------------------: | :------ -----------------------: |
+| Convolutional layer $C_{11}$ | $H\times{W}\times{C_1}$ | $1\times1\times{C_2}/2$ | $\frac{H}{2}\times\frac {W}{2}\times{C_2}$ | $(1\times1\times{C_1}+1)\times{C_2}$ |
+| Convolutional layer $C_{21}$ | $H\times{W}\times{C_2}$ | $1\times1\times{C_2}/2$ | $\frac{H}{2}\times\frac {W}{2}\times{C_2}$ | $(1\times1\times{C_2}+1)\times{C_2}$ |
+| Convolutional Layer $C_{22}$ | $H\times{W}\times{C_2}$ | $3\times3\times{C_2}/1$ | $H\times{W}\times{C_2}/ 1$ | $(3\times3\times{C_2}+1)\times{C_2}$ |
+| Convolutional layer $C_{31}$ | $H\times{W}\times{C_1}$ | $1\times1\times{C_2}/2$ | $\frac{H}{2}\times\frac {W}{2}\times{C_2}$ | $(1\times1\times{C_1}+1)\times{C_2}$ |
+| Convolutional Layer $C_{32}$ | $H\times{W}\times{C_2}$ | $5\times5\times{C_2}/1$ | $H\times{W}\times{C_2}/ 1$ | $(5\times5\times{C_2}+1)\times{C_2}$ |
+| Downsampling layer $S_{41}$ | $H\times{W}\times{C_1}$ | $3\times3/2$ | $\frac{H}{2}\times\frac{W}{2 }\times{C_2}$ | $0$ |
+| Convolutional Layer $C_{42}$ | $\frac{H}{2}\times\frac{W}{2}\times{C_2}$ | $1\times1\times{C_2}/1$ | $ \frac{H}{2}\times\frac{W}{2}\times{C_2}$ | $(3\times3\times{C_2}+1)\times{C_2}$ |
+| Merge layer $M$ | $\frac{H}{2}\times\frac{W}{2}\times{C_2}(\times4)$ | Stitching | $\frac{H}{2}\times \frac{W}{2}\times({C_2}\times4)$ | $0$ |
+
+### 4.6.3 Model Features
+
+- The use of convolution kernels of different sizes means different sizes of receptive fields, and the final splicing means the fusion of different scale features;
+- The reason why the convolution kernel size is 1, 3 and 5 is mainly for the convenience of alignment. After setting the convolution step stride=1, as long as pad=0, 1, 2 are set respectively, the features of the same dimension can be obtained after convolution, and then these features can be directly stitched together;
+- The more the network goes to the end, the more abstract the features are, and the more susceptible fields are involved in each feature. As the number of layers increases, the proportion of 3x3 and 5x5 convolutions also increases. However, using a 5x5 convolution kernel still has a huge amount of computation. To this end, the article draws on NIN2 and uses a 1x1 convolution kernel for dimensionality reduction.
+
+## 4.7 Why are the current CNN models adjusted on GoogleNet, VGGNet or AlexNet?
+
+- Evaluation comparison: In order to make your results more convincing, when you publish your own results, you will compare them with a standard baseline and improve on the baseline. Common problems such as detection and segmentation will be based on VGG or Resnet101. Basic network.
+- Limited time and effort: In research pressure and work stress, time and energy only allow you to explore in a limited range.
+- Model innovation is difficult: Improving the basic model requires a lot of experimentation and experimentation, and requires a lot of experiment accumulation and strong inspiration. It is very likely that the input-output ratio is relatively small.
+- Resource limitations: Creating a new model requires a lot of time and computing resources, often not feasible in schools and small business teams.
+- In actual application scenarios, there are actually a large number of non-standard model configurations.
+
+## Related Literature
+
+[1] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner. Gradient-based learning applied to document recognition. *Proceedings of the IEEE*, november 1998.
+
+[2] A. Krizhevsky, I. Sutskever and G. E. Hinton. ImageNet Classification with Deep Convolutional Neural Networks. *Advances in Neural Information Processing Systems 25*. Curran Associates, Inc. 1097–1105.
+
+[3] LSVRC-2013. http://www.image-net.org/challenges/LSVRC/2013/results.php
+
+[4] M. D. Zeiler and R. Fergus. Visualizing and Understanding Convolutional Networks. *European Conference on Computer Vision*.
+
+[5] M. Lin, Q. Chen, and S. Yan. Network in network. *Computing Research Repository*, abs/1312.4400, 2013.
+
+[6] K. Simonyan and A. Zisserman. Very Deep Convolutional Networks for Large-Scale Image Recognition. *International Conference on Machine Learning*, 2015.
+
+[7] Bharath Raj. [a-simple-guide-to-the-versions-of-the-inception-network] (https://towardsdatascience.com/a-simple-guide-to-the-versions-of- The-inception-network-7fc52b863202), 2018.
+
+[8] Christian Szegedy, Sergey Ioffe, Vincent Vanhoucke, Alex Alemi. [Inception-v4, Inception-ResNet and
+the Impact of Residual Connections on Learning](https://arxiv.org/pdf/1602.07261.pdf), 2016.
+
+[9] Sik-Ho Tsang. [review-inception-v4-evolved-from-googlenet-merged-with-resnet-idea-image-classification](https://towardsdatascience.com/review-inception-v4-evolved-from-googlenet-merged-with-resnet-idea-image-classification-5e8c339d18bc), 2018.
+
+[10] Zbigniew Wojna, Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens. [Rethinking the Inception Architecture for Computer Vision](https://arxiv.org/pdf/1512.00567v3.pdf), 2015.
+
+[11] Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich. [Going deeper with convolutions](https://arxiv.org/pdf/1409.4842v1.pdf), 2014.
diff --git a/English version/ch04_ClassicNetwork/img/ch4/LeNet-5.jpg b/English version/ch04_ClassicNetwork/img/ch4/LeNet-5.jpg
new file mode 100644
index 00000000..fb65aedd
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/LeNet-5.jpg differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/alexnet.png b/English version/ch04_ClassicNetwork/img/ch4/alexnet.png
new file mode 100644
index 00000000..1a954ca5
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/alexnet.png differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/featureMap.jpg b/English version/ch04_ClassicNetwork/img/ch4/featureMap.jpg
new file mode 100644
index 00000000..2e077ef9
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/featureMap.jpg differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image10.png b/English version/ch04_ClassicNetwork/img/ch4/image10.png
new file mode 100644
index 00000000..ef7ed01d
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image10.png differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image11.GIF b/English version/ch04_ClassicNetwork/img/ch4/image11.GIF
new file mode 100644
index 00000000..ab72b16f
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image11.GIF differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image12.png b/English version/ch04_ClassicNetwork/img/ch4/image12.png
new file mode 100644
index 00000000..a8428209
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image12.png differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image13.png b/English version/ch04_ClassicNetwork/img/ch4/image13.png
new file mode 100644
index 00000000..56c7a125
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image13.png differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image14.png b/English version/ch04_ClassicNetwork/img/ch4/image14.png
new file mode 100644
index 00000000..0f52f559
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image14.png differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image15.jpeg b/English version/ch04_ClassicNetwork/img/ch4/image15.jpeg
new file mode 100644
index 00000000..2ea99b40
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image15.jpeg differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image18.jpeg b/English version/ch04_ClassicNetwork/img/ch4/image18.jpeg
new file mode 100644
index 00000000..ba94f6c7
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image18.jpeg differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image19.jpeg b/English version/ch04_ClassicNetwork/img/ch4/image19.jpeg
new file mode 100644
index 00000000..920f056f
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image19.jpeg differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image2.jpeg b/English version/ch04_ClassicNetwork/img/ch4/image2.jpeg
new file mode 100644
index 00000000..284e36e2
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image2.jpeg differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image20.jpeg b/English version/ch04_ClassicNetwork/img/ch4/image20.jpeg
new file mode 100644
index 00000000..48f8eb45
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image20.jpeg differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image21.jpeg b/English version/ch04_ClassicNetwork/img/ch4/image21.jpeg
new file mode 100644
index 00000000..6afa65c4
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image21.jpeg differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image22.jpeg b/English version/ch04_ClassicNetwork/img/ch4/image22.jpeg
new file mode 100644
index 00000000..4a46634e
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image22.jpeg differ
diff --git "a/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image23.jpeg" b/English version/ch04_ClassicNetwork/img/ch4/image23.jpeg
similarity index 100%
rename from "ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image23.jpeg"
rename to English version/ch04_ClassicNetwork/img/ch4/image23.jpeg
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image24.png b/English version/ch04_ClassicNetwork/img/ch4/image24.png
new file mode 100644
index 00000000..538640e7
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image24.png differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image25.jpeg b/English version/ch04_ClassicNetwork/img/ch4/image25.jpeg
new file mode 100644
index 00000000..536e6551
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image25.jpeg differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image26.png b/English version/ch04_ClassicNetwork/img/ch4/image26.png
new file mode 100644
index 00000000..51c7d189
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image26.png differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image27.jpeg b/English version/ch04_ClassicNetwork/img/ch4/image27.jpeg
new file mode 100644
index 00000000..6e526ee1
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image27.jpeg differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image28.jpeg b/English version/ch04_ClassicNetwork/img/ch4/image28.jpeg
new file mode 100644
index 00000000..931a1d64
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image28.jpeg differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image3.png b/English version/ch04_ClassicNetwork/img/ch4/image3.png
new file mode 100644
index 00000000..aeedc2de
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image3.png differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image31.png b/English version/ch04_ClassicNetwork/img/ch4/image31.png
new file mode 100644
index 00000000..5d238865
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image31.png differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image32.png b/English version/ch04_ClassicNetwork/img/ch4/image32.png
new file mode 100644
index 00000000..7b463dae
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image32.png differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image33.png b/English version/ch04_ClassicNetwork/img/ch4/image33.png
new file mode 100644
index 00000000..43d7908f
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image33.png differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image34.png b/English version/ch04_ClassicNetwork/img/ch4/image34.png
new file mode 100644
index 00000000..95016085
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image34.png differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image35.png b/English version/ch04_ClassicNetwork/img/ch4/image35.png
new file mode 100644
index 00000000..083675ca
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image35.png differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image36.png b/English version/ch04_ClassicNetwork/img/ch4/image36.png
new file mode 100644
index 00000000..404390cf
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image36.png differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image37.png b/English version/ch04_ClassicNetwork/img/ch4/image37.png
new file mode 100644
index 00000000..6f163002
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image37.png differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image38.png b/English version/ch04_ClassicNetwork/img/ch4/image38.png
new file mode 100644
index 00000000..2bed01bc
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image38.png differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image39.png b/English version/ch04_ClassicNetwork/img/ch4/image39.png
new file mode 100644
index 00000000..66c49a23
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image39.png differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image4.png b/English version/ch04_ClassicNetwork/img/ch4/image4.png
new file mode 100644
index 00000000..37193778
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image4.png differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image40.png b/English version/ch04_ClassicNetwork/img/ch4/image40.png
new file mode 100644
index 00000000..8643e43e
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image40.png differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image41.png b/English version/ch04_ClassicNetwork/img/ch4/image41.png
new file mode 100644
index 00000000..32bf30da
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image41.png differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image42.png b/English version/ch04_ClassicNetwork/img/ch4/image42.png
new file mode 100644
index 00000000..233128ec
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image42.png differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image43.png b/English version/ch04_ClassicNetwork/img/ch4/image43.png
new file mode 100644
index 00000000..43713358
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image43.png differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image44.png b/English version/ch04_ClassicNetwork/img/ch4/image44.png
new file mode 100644
index 00000000..c1da2658
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image44.png differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image45.png b/English version/ch04_ClassicNetwork/img/ch4/image45.png
new file mode 100644
index 00000000..f5257d08
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image45.png differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image46.png b/English version/ch04_ClassicNetwork/img/ch4/image46.png
new file mode 100644
index 00000000..3dbb5118
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image46.png differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image47.png b/English version/ch04_ClassicNetwork/img/ch4/image47.png
new file mode 100644
index 00000000..adcebabd
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image47.png differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image48.png b/English version/ch04_ClassicNetwork/img/ch4/image48.png
new file mode 100644
index 00000000..97801f04
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image48.png differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image49.png b/English version/ch04_ClassicNetwork/img/ch4/image49.png
new file mode 100644
index 00000000..883bc7b3
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image49.png differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image5.png b/English version/ch04_ClassicNetwork/img/ch4/image5.png
new file mode 100644
index 00000000..6c518d67
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image5.png differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image50.png b/English version/ch04_ClassicNetwork/img/ch4/image50.png
new file mode 100644
index 00000000..e265b45a
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image50.png differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image51.png b/English version/ch04_ClassicNetwork/img/ch4/image51.png
new file mode 100644
index 00000000..34133a06
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image51.png differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image52.png b/English version/ch04_ClassicNetwork/img/ch4/image52.png
new file mode 100644
index 00000000..a6ed65ba
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image52.png differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image53.png b/English version/ch04_ClassicNetwork/img/ch4/image53.png
new file mode 100644
index 00000000..ec92de40
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image53.png differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image54.png b/English version/ch04_ClassicNetwork/img/ch4/image54.png
new file mode 100644
index 00000000..3558da80
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image54.png differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image55.png b/English version/ch04_ClassicNetwork/img/ch4/image55.png
new file mode 100644
index 00000000..963436a2
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image55.png differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image56.png b/English version/ch04_ClassicNetwork/img/ch4/image56.png
new file mode 100644
index 00000000..c07aed22
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image56.png differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image6.png b/English version/ch04_ClassicNetwork/img/ch4/image6.png
new file mode 100644
index 00000000..f1509b8b
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image6.png differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image60.jpeg b/English version/ch04_ClassicNetwork/img/ch4/image60.jpeg
new file mode 100644
index 00000000..5f45a372
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image60.jpeg differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image61.png b/English version/ch04_ClassicNetwork/img/ch4/image61.png
new file mode 100644
index 00000000..dd7b1283
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image61.png differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image62.png b/English version/ch04_ClassicNetwork/img/ch4/image62.png
new file mode 100644
index 00000000..221fb4bd
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image62.png differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image63.png b/English version/ch04_ClassicNetwork/img/ch4/image63.png
new file mode 100644
index 00000000..38167b0c
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image63.png differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image7.png b/English version/ch04_ClassicNetwork/img/ch4/image7.png
new file mode 100644
index 00000000..0c5fe01f
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image7.png differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image8.png b/English version/ch04_ClassicNetwork/img/ch4/image8.png
new file mode 100644
index 00000000..20a6a5d2
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image8.png differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/image9.png b/English version/ch04_ClassicNetwork/img/ch4/image9.png
new file mode 100644
index 00000000..b2fc2e73
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/image9.png differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/vgg16.png b/English version/ch04_ClassicNetwork/img/ch4/vgg16.png
new file mode 100644
index 00000000..3dca57d1
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/vgg16.png differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/zfnet-layer1.png b/English version/ch04_ClassicNetwork/img/ch4/zfnet-layer1.png
new file mode 100644
index 00000000..7fb93f7f
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/zfnet-layer1.png differ
diff --git a/English version/ch04_ClassicNetwork/img/ch4/zfnet-layer2.png b/English version/ch04_ClassicNetwork/img/ch4/zfnet-layer2.png
new file mode 100644
index 00000000..c2e2f6c7
Binary files /dev/null and b/English version/ch04_ClassicNetwork/img/ch4/zfnet-layer2.png differ
diff --git a/English version/ch04_ClassicNetwork/readme.md b/English version/ch04_ClassicNetwork/readme.md
new file mode 100644
index 00000000..5072a519
--- /dev/null
+++ b/English version/ch04_ClassicNetwork/readme.md
@@ -0,0 +1,12 @@
+###########################################################
+
+### Deep Learning 500 Questions - Chapter 4 Classic Network
+
+**Responsible person (in no particular order):**
+South China Institute of Technology graduate student - Huang Qinjian (wechat: HQJ199508212176, email: csqjhuang@mail.scut.edu.cn)
+
+
+**Contributors (in no particular order):**
+Content contributors can add information
+
+###########################################################
diff --git a/README.md b/README.md
index f75c2afe..877e0ba1 100644
--- a/README.md
+++ b/README.md
@@ -1,3 +1,8 @@
+
+# 英文版本
+
+[English version](https://github.com/scutan90/DeepLearning-500-questions/tree/master/English%20version)
+
# 1. 版权声明
请尊重作者的知识产权,版权所有,翻版必究。 未经许可,严禁转发内容!
请大家一起维护自己的劳动成果,进行监督。 未经许可, 严禁转发内容!
@@ -12,7 +17,25 @@
1、寻求有愿意继续完善的朋友、编辑、写手;如有意合作,完善出书(成为共同作者)。
2、所有提交内容的贡献者,将会在文中体现贡献者个人信息(例: 大佬-西湖大学)
3、为了让内容更充实完善,集思广益,欢迎Fork该项目并参与编写。请在修改MD文件的同时(或直接留言)备注自己的姓名-单位(大佬-斯坦福大学),一经采纳,会在原文中显示贡献者的信息,谢谢!
-4、推荐使用typora-Markdown阅读器:https://typora.io/
+4、推荐使用typora-Markdown阅读器:https://typora.io/
+
+设置:
+文件->偏好设置
+
+- Markdown扩展语法
+ - 内敛公式
+ - 下标
+ - 上标
+ - 高亮
+ - 图表
+
+
+都打勾
+
+- 数学公式
+ - 自动添加序号
+
+都打勾
例子:
@@ -37,18 +60,13 @@
# 5. 更多
1. 寻求有愿意继续完善的朋友、编辑、写手; 如有意合作,完善出书(成为共同作者)。
- 所有提交内容的贡献者,将会在文中体现贡献者个人信息(大佬-西湖大学)。
+ 所有提交内容的贡献者,将会在文中体现贡献者个人信息(大佬-西湖大学)。
2. 联系方式 : 请联系scutjy2015@163.com (唯一官方邮箱); 微信Tan:
(进群先在MD版本增加、改善、提交内容后,更易进群,享受分享知识帮助他人。)
- 进群请加微信 委托人1:HQJ199508212176 委托人2:Xuwumin1203 委托人3:tianyuzy
-
-
-
- 
-
+ 
3. Markdown阅读器推荐:https://typora.io/ 免费且对于数学公式显示支持的比较好。
@@ -57,7 +75,13 @@
5. 接下来,将提供MD版本,大家一起编辑完善,敬请期待!希望踊跃提建议,补充修改内容!
-# 6. 目录
+# 6. 友情链接
+
+[FlyAI-AI竞赛平台](https://www.flyai.com/)
+
+
+
+# 7. 目录
**第一章 数学基础 1**
@@ -548,7 +572,7 @@
15.8.3 可以在SPARK环境里训练或者部署模型吗?
15.8.4 怎么进一步优化性能?
15.8.5 TPU和GPU的区别?
- 15.8.6 未来量子计算对于深度学习等AI技术的影像?
+ 15.8.6 未来量子计算对于深度学习等AI技术的影响?
**参考文献 366**
diff --git a/WechatIMG3.jpeg b/WechatIMG3.jpeg
deleted file mode 100644
index 8a693040..00000000
Binary files a/WechatIMG3.jpeg and /dev/null differ
diff --git "a/ch01_\346\225\260\345\255\246\345\237\272\347\241\200/readme.md" "b/ch01_\346\225\260\345\255\246\345\237\272\347\241\200/readme.md"
index 5564579d..4397ac7b 100644
--- "a/ch01_\346\225\260\345\255\246\345\237\272\347\241\200/readme.md"
+++ "b/ch01_\346\225\260\345\255\246\345\237\272\347\241\200/readme.md"
@@ -10,6 +10,6 @@
**贡献者(排名不分先后):**
内容贡献者可自加信息
-刘彦超-东南大学
-
+刘彦超-东南大学
+刘元德-上海理工大学(内容修订)
###########################################################
diff --git "a/ch01_\346\225\260\345\255\246\345\237\272\347\241\200/\347\254\254\344\270\200\347\253\240_\346\225\260\345\255\246\345\237\272\347\241\200.md" "b/ch01_\346\225\260\345\255\246\345\237\272\347\241\200/\347\254\254\344\270\200\347\253\240_\346\225\260\345\255\246\345\237\272\347\241\200.md"
index 27f26799..78a48323 100644
--- "a/ch01_\346\225\260\345\255\246\345\237\272\347\241\200/\347\254\254\344\270\200\347\253\240_\346\225\260\345\255\246\345\237\272\347\241\200.md"
+++ "b/ch01_\346\225\260\345\255\246\345\237\272\347\241\200/\347\254\254\344\270\200\347\253\240_\346\225\260\345\255\246\345\237\272\347\241\200.md"
@@ -2,19 +2,9 @@
# 第一章 数学基础
-> Markdown Revision 1; --update 2018/10/30 13:00
-
-> Date: 2018/10/25 -- 2018/10/30 -- 2018/11/01
-
-> Editor: 谈继勇 &乔成磊-同济大学 & 哈工大博士生-袁笛
-
-> Contact: scutjy2015@163.com & qchl0318@163.com & dyuanhit@gmail.com
-
-
-
## 1.1 标量、向量、矩阵、张量之间的联系
-**标量(scalar)**
-一个标量表示一个单独的数,它不同于线性代数中研究的其他大部分对象(通常是多个数的数组)。我们用斜体表示标量。标量通常被赋予小写的变量名称。
+**标量(scalar)**
+一个标量表示一个单独的数,它不同于线性代数中研究的其他大部分对象(通常是多个数的数组)。我们用斜体表示标量。标量通常被赋予小写的变量名称。
**向量(vector)**
一个向量表示一组有序排列的数。通过次序中的索引,我们可以确定每个单独的数。通常我们赋予向量粗体的小写变量名称,比如xx。向量中的元素可以通过带脚标的斜体表示。向量$X$的第一个元素是$X_1$,第二个元素是$X_2$,以此类推。我们也会注明存储在向量中的元素的类型(实数、虚数等)。
@@ -36,7 +26,7 @@
- 从代数角度讲, 矩阵它是向量的推广。向量可以看成一维的“表格”(即分量按照顺序排成一排), 矩阵是二维的“表格”(分量按照纵横位置排列), 那么$n$阶张量就是所谓的$n$维的“表格”。 张量的严格定义是利用线性映射来描述。
- 从几何角度讲, 矩阵是一个真正的几何量,也就是说,它是一个不随参照系的坐标变换而变化的东西。向量也具有这种特性。
- 张量可以用3×3矩阵形式来表达。
-- 表示标量的数和表示矢量的三维数组也可分别看作1×1,1×3的矩阵。
+- 表示标量的数和表示向量的三维数组也可分别看作1×1,1×3的矩阵。
## 1.3 矩阵和向量相乘结果
一个$m$行$n$列的矩阵和$n$行向量相乘,最后得到就是一个$m$行的向量。运算法则就是矩阵中的每一行数据看成一个行向量与该向量作点乘。
@@ -63,21 +53,21 @@ $$
\Vert\vec{x}\Vert_{-\infty}=\min{|{x_i}|}
$$
-- 向量的正无穷范数:向量的所有元素的绝对值中最大的:上述向量$\vec{a}$的负无穷范数结果就是:10。
+- 向量的正无穷范数:向量的所有元素的绝对值中最大的:上述向量$\vec{a}$的正无穷范数结果就是:10。
$$
\Vert\vec{x}\Vert_{+\infty}=\max{|{x_i}|}
$$
-- 向量的p范数:向量元素绝对值的p次方和的1/p次幂。
-
+- 向量的p范数:
+
$$
L_p=\Vert\vec{x}\Vert_p=\sqrt[p]{\sum_{i=1}^{N}|{x_i}|^p}
$$
**矩阵的范数**
-定义一个矩阵$A=[-1, 2, -3; 4, -6, 6]$。 任意矩阵定义为:$A_{m\times n}$,其元素为 $a_{ij}$。
+定义一个矩阵$A=[-1, 2, -3; 4, -6, 6]$。 任意矩阵定义为:$A_{m\times n}$,其元素为 $a_{ij}$。
矩阵的范数定义为
@@ -85,32 +75,30 @@ $$
\Vert{A}\Vert_p :=\sup_{x\neq 0}\frac{\Vert{Ax}\Vert_p}{\Vert{x}\Vert_p}
$$
-当向量取不同范数时, 相应得到了不同的矩阵范数。
+当向量取不同范数时, 相应得到了不同的矩阵范数。
- **矩阵的1范数(列范数)**:矩阵的每一列上的元素绝对值先求和,再从中取个最大的,(列和最大),上述矩阵$A$的1范数先得到$[5,8,9]$,再取最大的最终结果就是:9。
-
$$
\Vert A\Vert_1=\max_{1\le j\le n}\sum_{i=1}^m|{a_{ij}}|
$$
- **矩阵的2范数**:矩阵$A^TA$的最大特征值开平方根,上述矩阵$A$的2范数得到的最终结果是:10.0623。
-
+
$$
\Vert A\Vert_2=\sqrt{\lambda_{max}(A^T A)}
$$
-其中, $\lambda_{max}(A^T A)$ 为 $A^T A$ 的特征值绝对值的最大值。
-- **矩阵的无穷范数(行范数)**:矩阵的每一行上的元素绝对值先求和,再从中取个最大的,(行和最大),上述矩阵$A$的1范数先得到$[6;16]$,再取最大的最终结果就是:16。
-
+其中, $\lambda_{max}(A^T A)$ 为 $A^T A$ 的特征值绝对值的最大值。
+- **矩阵的无穷范数(行范数)**:矩阵的每一行上的元素绝对值先求和,再从中取个最大的,(行和最大),上述矩阵$A$的行范数先得到$[6;16]$,再取最大的最终结果就是:16。
$$
-\Vert A\Vert_{\infty}=\max_{1\le i \le n}\sum_{j=1}^n |{a_{ij}}|
+\Vert A\Vert_{\infty}=\max_{1\le i \le m}\sum_{j=1}^n |{a_{ij}}|
$$
- **矩阵的核范数**:矩阵的奇异值(将矩阵svd分解)之和,这个范数可以用来低秩表示(因为最小化核范数,相当于最小化矩阵的秩——低秩),上述矩阵A最终结果就是:10.9287。
- **矩阵的L0范数**:矩阵的非0元素的个数,通常用它来表示稀疏,L0范数越小0元素越多,也就越稀疏,上述矩阵$A$最终结果就是:6。
- **矩阵的L1范数**:矩阵中的每个元素绝对值之和,它是L0范数的最优凸近似,因此它也可以表示稀疏,上述矩阵$A$最终结果就是:22。
-- **矩阵的F范数**:矩阵的各个元素平方之和再开平方根,它通常也叫做矩阵的L2范数,它的优点在它是一个凸函数,可以求导求解,易于计算,上述矩阵A最终结果就是:10.0995。
+- **矩阵的F范数**:矩阵的各个元素平方之和再开平方根,它通常也叫做矩阵的L2范数,它的优点在于它是一个凸函数,可以求导求解,易于计算,上述矩阵A最终结果就是:10.0995。
$$
\Vert A\Vert_F=\sqrt{(\sum_{i=1}^m\sum_{j=1}^n{| a_{ij}|}^2)}
@@ -135,7 +123,7 @@ $$
## 1.6 导数偏导计算
**导数定义**:
-导数代表了在自变量变化趋于无穷小的时候,函数值的变化与自变量的变化的比值。几何意义是这个点的切线。物理意义是该时刻的(瞬时)变化率。
+导数代表了在自变量变化趋于无穷小的时候,函数值的变化与自变量的变化的比值。几何意义是这个点的切线。物理意义是该时刻的(瞬时)变化率。
*注意*:在一元函数中,只有一个自变量变动,也就是说只存在一个方向的变化率,这也就是为什么一元函数没有偏导数的原因。在物理学中有平均速度和瞬时速度之说。平均速度有
@@ -144,49 +132,49 @@ $$
v=\frac{s}{t}
$$
-其中$v$表示平均速度,$s$表示路程,$t$表示时间。这个公式可以改写为
+其中$v$表示平均速度,$s$表示路程,$t$表示时间。这个公式可以改写为
$$
\bar{v}=\frac{\Delta s}{\Delta t}=\frac{s(t_0+\Delta t)-s(t_0)}{\Delta t}
$$
-其中$\Delta s$表示两点之间的距离,而$\Delta t$表示走过这段距离需要花费的时间。当$\Delta t$趋向于0($\Delta t \to 0$)时,也就是时间变得很短时,平均速度也就变成了在$t_0$时刻的瞬时速度,表示成如下形式:
+其中$\Delta s$表示两点之间的距离,而$\Delta t$表示走过这段距离需要花费的时间。当$\Delta t$趋向于0($\Delta t \to 0$)时,也就是时间变得很短时,平均速度也就变成了在$t_0$时刻的瞬时速度,表示成如下形式:
$$
v(t_0)=\lim_{\Delta t \to 0}{\bar{v}}=\lim_{\Delta t \to 0}{\frac{\Delta s}{\Delta t}}=\lim_{\Delta t \to 0}{\frac{s(t_0+\Delta t)-s(t_0)}{\Delta t}}
$$
-实际上,上式表示的是路程$s$关于时间$t$的函数在$t=t_0$处的导数。一般的,这样定义导数:如果平均变化率的极限存在,即有
+实际上,上式表示的是路程$s$关于时间$t$的函数在$t=t_0$处的导数。一般的,这样定义导数:如果平均变化率的极限存在,即有
$$
\lim_{\Delta x \to 0}{\frac{\Delta y}{\Delta x}}=\lim_{\Delta x \to 0}{\frac{f(x_0+\Delta x)-f(x_0)}{\Delta x}}
$$
-则称此极限为函数 $y=f(x)$ 在点 $x_0$ 处的导数。记作 $f'(x_0)$ 或 $y'\vert_{x=x_0}$ 或 $\frac{dy}{dx}\vert_{x=x_0}$ 或 $\frac{df(x)}{dx}\vert_{x=x_0}$。
+则称此极限为函数 $y=f(x)$ 在点 $x_0$ 处的导数。记作 $f'(x_0)$ 或 $y'\vert_{x=x_0}$ 或 $\frac{dy}{dx}\vert_{x=x_0}$ 或 $\frac{df(x)}{dx}\vert_{x=x_0}$。
-通俗地说,导数就是曲线在某一点切线的斜率。
+通俗地说,导数就是曲线在某一点切线的斜率。
**偏导数**:
-既然谈到偏导数,那就至少涉及到两个自变量。以两个自变量为例,z=f(x,y),从导数到偏导数,也就是从曲线来到了曲面。曲线上的一点,其切线只有一条。但是曲面上的一点,切线有无数条。而偏导数就是指多元函数沿着坐标轴的变化率。
-
+既然谈到偏导数,那就至少涉及到两个自变量。以两个自变量为例,$z=f(x,y)$,从导数到偏导数,也就是从曲线来到了曲面。曲线上的一点,其切线只有一条。但是曲面上的一点,切线有无数条。而偏导数就是指多元函数沿着坐标轴的变化率。
+
*注意*:直观地说,偏导数也就是函数在某一点上沿坐标轴正方向的的变化率。
-设函数$z=f(x,y)$在点$(x_0,y_0)$的领域内有定义,当$y=y_0$时,$z$可以看作关于$x$的一元函数$f(x,y_0)$,若该一元函数在$x=x_0$处可导,即有
+设函数$z=f(x,y)$在点$(x_0,y_0)$的领域内有定义,当$y=y_0$时,$z$可以看作关于$x$的一元函数$f(x,y_0)$,若该一元函数在$x=x_0$处可导,即有
$$
\lim_{\Delta x \to 0}{\frac{f(x_0+\Delta x,y_0)-f(x_0,y_0)}{\Delta x}}=A
$$
-函数的极限$A$存在。那么称$A$为函数$z=f(x,y)$在点$(x_0,y_0)$处关于自变量$x$的偏导数,记作$f_x(x_0,y_0)$或$\frac{\partial z}{\partial x}\vert_{y=y_0}^{x=x_0}$或$\frac{\partial f}{\partial x}\vert_{y=y_0}^{x=x_0}$或$z_x\vert_{y=y_0}^{x=x_0}$。
+函数的极限$A$存在。那么称$A$为函数$z=f(x,y)$在点$(x_0,y_0)$处关于自变量$x$的偏导数,记作$f_x(x_0,y_0)$或$\frac{\partial z}{\partial x}\vert_{y=y_0}^{x=x_0}$或$\frac{\partial f}{\partial x}\vert_{y=y_0}^{x=x_0}$或$z_x\vert_{y=y_0}^{x=x_0}$。
-偏导数在求解时可以将另外一个变量看做常数,利用普通的求导方式求解,比如$z=3x^2+xy$关于$x$的偏导数就为$z_x=6x+y$,这个时候$y$相当于$x$的系数。
+偏导数在求解时可以将另外一个变量看做常数,利用普通的求导方式求解,比如$z=3x^2+xy$关于$x$的偏导数就为$z_x=6x+y$,这个时候$y$相当于$x$的系数。
-某点$(x_0,y_0)$处的偏导数的几何意义为曲面$z=f(x,y)$与面$x=x_0$或面$y=y_0$交线在$y=y_0$或$x=x_0$处切线的斜率。
+某点$(x_0,y_0)$处的偏导数的几何意义为曲面$z=f(x,y)$与面$x=x_0$或面$y=y_0$交线在$y=y_0$或$x=x_0$处切线的斜率。
## 1.7 导数和偏导数有什么区别?
-导数和偏导没有本质区别,如果极限存在,都是当自变量的变化量趋于0时,函数值的变化量与自变量变化量比值的极限。
+导数和偏导没有本质区别,如果极限存在,都是当自变量的变化量趋于0时,函数值的变化量与自变量变化量比值的极限。
> - 一元函数,一个$y$对应一个$x$,导数只有一个。
> - 二元函数,一个$z$对应一个$x$和一个$y$,有两个导数:一个是$z$对$x$的导数,一个是$z$对$y$的导数,称之为偏导。
@@ -204,37 +192,36 @@ A\nu = \lambda \nu
$$
$\lambda$为特征向量$\vec{v}$对应的特征值。特征值分解是将一个矩阵分解为如下形式:
-
+
$$
-A=Q\Sigma Q^{-1}
+A=Q\sum Q^{-1}
$$
-其中,$Q$是这个矩阵$A$的特征向量组成的矩阵,$\Sigma$是一个对角矩阵,每一个对角线元素就是一个特征值,里面的特征值是由大到小排列的,这些特征值所对应的特征向量就是描述这个矩阵变化方向(从主要的变化到次要的变化排列)。也就是说矩阵$A$的信息可以由其特征值和特征向量表示。
+其中,$Q$是这个矩阵$A$的特征向量组成的矩阵,$\sum$是一个对角矩阵,每一个对角线元素就是一个特征值,里面的特征值是由大到小排列的,这些特征值所对应的特征向量就是描述这个矩阵变化方向(从主要的变化到次要的变化排列)。也就是说矩阵$A$的信息可以由其特征值和特征向量表示。
## 1.9 奇异值与特征值有什么关系?
-那么奇异值和特征值是怎么对应起来的呢?我们将一个矩阵$A$的转置乘以$A$,并对$AA^T$求特征值,则有下面的形式:
+那么奇异值和特征值是怎么对应起来的呢?我们将一个矩阵$A$的转置乘以$A$,并对$A^TA$求特征值,则有下面的形式:
$$
(A^TA)V = \lambda V
$$
-这里$V$就是上面的右奇异向量,另外还有:
+这里$V$就是上面的右奇异向量,另外还有:
$$
\sigma_i = \sqrt{\lambda_i}, u_i=\frac{1}{\sigma_i}A\mu_i
$$
-这里的$\sigma$就是奇异值,$u$就是上面说的左奇异向量。【证明那个哥们也没给】
-奇异值$\sigma$跟特征值类似,在矩阵$\Sigma$中也是从大到小排列,而且$\sigma$的减少特别的快,在很多情况下,前10%甚至1%的奇异值的和就占了全部的奇异值之和的99%以上了。也就是说,我们也可以用前$r$($r$远小于$m、n$)个的奇异值来近似描述矩阵,即部分奇异值分解:
-
+这里的$\sigma$就是奇异值,$u$就是上面说的左奇异向量。【证明那个哥们也没给】
+奇异值$\sigma$跟特征值类似,在矩阵$\sum$中也是从大到小排列,而且$\sigma$的减少特别的快,在很多情况下,前10%甚至1%的奇异值的和就占了全部的奇异值之和的99%以上了。也就是说,我们也可以用前$r$($r$远小于$m、n$)个的奇异值来近似描述矩阵,即部分奇异值分解:
$$
-A_{m\times n}\approx U_{m \times r}\Sigma_{r\times r}V_{r \times n}^T
+A_{m\times n}\approx U_{m \times r}\sum_{r\times r}V_{r \times n}^T
$$
右边的三个矩阵相乘的结果将会是一个接近于$A$的矩阵,在这儿,$r$越接近于$n$,则相乘的结果越接近于$A$。
## 1.10 机器学习为什么要使用概率?
-事件的概率是衡量该事件发生的可能性的量度。虽然在一次随机试验中某个事件的发生是带有偶然性的,但那些可在相同条件下大量重复的随机试验却往往呈现出明显的数量规律。
+事件的概率是衡量该事件发生的可能性的量度。虽然在一次随机试验中某个事件的发生是带有偶然性的,但那些可在相同条件下大量重复的随机试验却往往呈现出明显的数量规律。
机器学习除了处理不确定量,也需处理随机量。不确定性和随机性可能来自多个方面,使用概率论来量化不确定性。
概率论在机器学习中扮演着一个核心角色,因为机器学习算法的设计通常依赖于对数据的概率假设。
@@ -243,7 +230,7 @@ $$
## 1.11 变量与随机变量有什么区别?
**随机变量**(random variable)
-表示随机现象(在一定条件下,并不总是出现相同结果的现象称为随机现象)中各种结果的实值函数(一切可能的样本点)。例如某一时间内公共汽车站等车乘客人数,电话交换台在一定时间内收到的呼叫次数等,都是随机变量的实例。
+表示随机现象(在一定条件下,并不总是出现相同结果的现象称为随机现象)中各种结果的实值函数(一切可能的样本点)。例如某一时间内公共汽车站等车乘客人数,电话交换台在一定时间内收到的呼叫次数等,都是随机变量的实例。
随机变量与模糊变量的不确定性的本质差别在于,后者的测定结果仍具有不确定性,即模糊性。
**变量与随机变量的区别:**
@@ -253,33 +240,161 @@ $$
> 当变量$x$值为100的概率为1的话,那么$x=100$就是确定了的,不会再有变化,除非有进一步运算.
> 当变量$x$的值为100的概率不为1,比如为50的概率是0.5,为100的概率是0.5,那么这个变量就是会随不同条件而变化的,是随机变量,取到50或者100的概率都是0.5,即50%。
-## 1.12 常见概率分布
-(https://wenku.baidu.com/view/6418b0206d85ec3a87c24028915f804d2b168707)
-
-
-
-
-
-
-
+## 1.12 随机变量与概率分布的联系?
+
+一个随机变量仅仅表示一个可能取得的状态,还必须给定与之相伴的概率分布来制定每个状态的可能性。用来描述随机变量或一簇随机变量的每一个可能的状态的可能性大小的方法,就是 **概率分布(probability distribution)**.
+
+随机变量可以分为离散型随机变量和连续型随机变量。
+
+相应的描述其概率分布的函数是
+
+概率质量函数(Probability Mass Function, PMF):描述离散型随机变量的概率分布,通常用大写字母 $P$表示。
+
+概率密度函数(Probability Density Function, PDF):描述连续型随机变量的概率分布,通常用小写字母$p$表示。
+
+### 1.12.1 离散型随机变量和概率质量函数
+
+PMF 将随机变量能够取得的每个状态映射到随机变量取得该状态的概率。
+
+- 一般而言,$P(x)$ 表示时$X=x$的概率.
+- 有时候为了防止混淆,要明确写出随机变量的名称$P($x$=x)$
+- 有时候需要先定义一个随机变量,然后制定它遵循的概率分布x服从$P($x$)$
+
+PMF 可以同时作用于多个随机变量,即联合概率分布(joint probability distribution) $P(X=x,Y=y)$*表示 $X=x$和$Y=y$同时发生的概率,也可以简写成 $P(x,y)$.
+
+如果一个函数$P$是随机变量 $X$ 的 PMF, 那么它必须满足如下三个条件
+
+- $P$的定义域必须是的所有可能状态的集合
+- $∀x∈$x, $0 \leq P(x) \leq 1 $.
+- $∑_{x∈X} P(x)=1$. 我们把这一条性质称之为 归一化的(normalized)
+
+### 1.12.2 连续型随机变量和概率密度函数
+
+如果一个函数$p$是x的PDF,那么它必须满足如下几个条件
+
+- $p$的定义域必须是 xx 的所有可能状态的集合。
+- $∀x∈X,p(x)≥0$. 注意,我们并不要求$ p(x)≤1$,因为此处 $p(x)$不是表示的对应此状态具体的概率,而是概率的一个相对大小(密度)。具体的概率,需要积分去求。
+- $∫p(x)dx=1$, 积分下来,总和还是1,概率之和还是1.
+
+注:PDF$p(x)$并没有直接对特定的状态给出概率,给出的是密度,相对的,它给出了落在面积为 $δx$的无线小的区域内的概率为$ p(x)δx$. 由此,我们无法求得具体某个状态的概率,我们可以求得的是 某个状态 $x$ 落在 某个区间$[a,b]$内的概率为$ \int_{a}^{b}p(x)dx$.
+
+## 1.13 常见概率分布
+
+### 1.13.1 Bernoulli分布
+
+**Bernoulli分布**是单个二值随机变量分布, 单参数$\phi$∈[0,1]控制,$\phi$给出随机变量等于1的概率. 主要性质有:
+$$
+\begin{align*}
+P(x=1) &= \phi \\
+P(x=0) &= 1-\phi \\
+P(x=x) &= \phi^x(1-\phi)^{1-x} \\
+\end{align*}
+$$
+其期望和方差为:
+$$
+\begin{align*}
+E_x[x] &= \phi \\
+Var_x(x) &= \phi{(1-\phi)}
+\end{align*}
+$$
+**Multinoulli分布**也叫**范畴分布**, 是单个*k*值随机分布,经常用来表示**对象分类的分布**. 其中$k$是有限值.Multinoulli分布由向量$\vec{p}\in[0,1]^{k-1}$参数化,每个分量$p_i$表示第$i$个状态的概率, 且$p_k=1-1^Tp$.
+
+**适用范围**: **伯努利分布**适合对**离散型**随机变量建模.
+
+### 1.13.2 高斯分布
+
+高斯也叫正态分布(Normal Distribution), 概率度函数如下:
+$$
+N(x;\mu,\sigma^2) = \sqrt{\frac{1}{2\pi\sigma^2}}exp\left ( -\frac{1}{2\sigma^2}(x-\mu)^2 \right )
+$$
+其中, $\mu$和$\sigma$分别是均值和方差, 中心峰值x坐标由$\mu$给出, 峰的宽度受$\sigma$控制, 最大点在$x=\mu$处取得, 拐点为$x=\mu\pm\sigma$
+
+正态分布中,±1$\sigma$、±2$\sigma$、±3$\sigma$下的概率分别是68.3%、95.5%、99.73%,这3个数最好记住。
-## 1.13 举例理解条件概率
-条件概率公式如下:
+此外, 令$\mu=0,\sigma=1$高斯分布即简化为标准正态分布:
+$$
+N(x;\mu,\sigma^2) = \sqrt{\frac{1}{2\pi}}exp\left ( -\frac{1}{2}x^2 \right )
+$$
+对概率密度函数高效求值:
+$$
+N(x;\mu,\beta^{-1})=\sqrt{\frac{\beta}{2\pi}}exp\left(-\frac{1}{2}\beta(x-\mu)^2\right)
+$$
+
+
+其中,$\beta=\frac{1}{\sigma^2}$通过参数$\beta∈(0,\infty)$来控制分布精度。
+
+### 1.13.3 何时采用正态分布?
+
+问: 何时采用正态分布?
+答: 缺乏实数上分布的先验知识, 不知选择何种形式时, 默认选择正态分布总是不会错的, 理由如下:
+
+1. 中心极限定理告诉我们, 很多独立随机变量均近似服从正态分布, 现实中很多复杂系统都可以被建模成正态分布的噪声, 即使该系统可以被结构化分解.
+2. 正态分布是具有相同方差的所有概率分布中, 不确定性最大的分布, 换句话说, 正态分布是对模型加入先验知识最少的分布.
+
+正态分布的推广:
+正态分布可以推广到$R^n$空间, 此时称为**多位正态分布**, 其参数是一个正定对称矩阵$\Sigma$:
+$$
+N(x;\vec\mu,\Sigma)=\sqrt{\frac{1}{(2\pi)^ndet(\Sigma)}}exp\left(-\frac{1}{2}(\vec{x}-\vec{\mu})^T\Sigma^{-1}(\vec{x}-\vec{\mu})\right)
+$$
+对多为正态分布概率密度高效求值:
+$$
+N(x;\vec{\mu},\vec\beta^{-1}) = \sqrt{det(\vec\beta)}{(2\pi)^n}exp\left(-\frac{1}{2}(\vec{x}-\vec\mu)^T\beta(\vec{x}-\vec\mu)\right)
+$$
+此处,$\vec\beta$是一个精度矩阵。
+### 1.13.4 指数分布
+
+深度学习中, 指数分布用来描述在$x=0$点处取得边界点的分布, 指数分布定义如下:
$$
-P(A/B) = P(A\cap B) / P(B)
+p(x;\lambda)=\lambda I_{x\geq 0}exp(-\lambda{x})
$$
+指数分布用指示函数$I_{x\geq 0}$来使$x$取负值时的概率为零。
+
+### 1.13.5 Laplace 分布
-说明:在同一个样本空间$\Omega$中的事件或者子集$A$与$B$,如果随机从$\Omega$中选出的一个元素属于$B$,那么下一个随机选择的元素属于$A$ 的概率就定义为在$B$的前提下$A$的条件概率。
+一个联系紧密的概率分布是 Laplace 分布(Laplace distribution),它允许我们在任意一点 $\mu$处设置概率质量的峰值
+$$
+Laplace(x;\mu;\gamma)=\frac{1}{2\gamma}exp\left(-\frac{|x-\mu|}{\gamma}\right)
+$$
+
+### 1.13.6 Dirac分布和经验分布
+
+Dirac分布可保证概率分布中所有质量都集中在一个点上. Diract分布的狄拉克$\delta$函数(也称为**单位脉冲函数**)定义如下:
+$$
+p(x)=\delta(x-\mu), x\neq \mu
+$$
+
+$$
+\int_{a}^{b}\delta(x-\mu)dx = 1, a < \mu < b
+$$
+
+Dirac 分布经常作为 经验分布(empirical distribution)的一个组成部分出现
+$$
+\hat{p}(\vec{x})=\frac{1}{m}\sum_{i=1}^{m}\delta(\vec{x}-{\vec{x}}^{(i)})
+$$
+, 其中, m个点$x^{1},...,x^{m}$是给定的数据集, **经验分布**将概率密度$\frac{1}{m}$赋给了这些点.
+
+当我们在训练集上训练模型时, 可以认为从这个训练集上得到的经验分布指明了**采样来源**.
+
+**适用范围**: 狄拉克δ函数适合对**连续型**随机变量的经验分布.
+
+## 1.14 举例理解条件概率
+条件概率公式如下:
+
+$$
+P(A|B) = P(A\cap B) / P(B)
+$$
+
+说明:在同一个样本空间$\Omega$中的事件或者子集$A$与$B$,如果随机从$\Omega$中选出的一个元素属于$B$,那么下一个随机选择的元素属于$A$ 的概率就定义为在$B$的前提下$A$的条件概率。

-根据文氏图,可以很清楚地看到在事件B发生的情况下,事件A发生的概率就是$P(A\bigcap B)$除以$P(B)$。
+根据文氏图,可以很清楚地看到在事件B发生的情况下,事件A发生的概率就是$P(A\bigcap B)$除以$P(B)$。
举例:一对夫妻有两个小孩,已知其中一个是女孩,则另一个是女孩子的概率是多少?(面试、笔试都碰到过)
**穷举法**:已知其中一个是女孩,那么样本空间为男女,女女,女男,则另外一个仍然是女生的概率就是1/3。
-**条件概率法**:$P(女|女)=P(女女)/P(女)$,夫妻有两个小孩,那么它的样本空间为女女,男女,女男,男男,则$P(女女)$为1/4,$P(女)= 1-P(男男)=3/4$,所以最后$1/3$。
+**条件概率法**:$P(女|女)=P(女女)/P(女)$,夫妻有两个小孩,那么它的样本空间为女女,男女,女男,男男,则$P(女女)$为1/4,$P(女)= 1-P(男男)=3/4$,所以最后$1/3$。
这里大家可能会误解,男女和女男是同一种情况,但实际上类似姐弟和兄妹是不同情况。
-## 1.14 联合概率与边缘概率联系区别?
+## 1.15 联合概率与边缘概率联系区别?
**区别:**
联合概率:联合概率指类似于$P(X=a,Y=b)$这样,包含多个条件,且所有条件同时成立的概率。联合概率是指在多元的概率分布中多个随机变量分别满足各自条件的概率。
边缘概率:边缘概率是某个事件发生的概率,而与其它事件无关。边缘概率指类似于$P(X=a)$,$P(Y=b)$这样,仅与单个随机变量有关的概率。
@@ -287,30 +402,29 @@ $$
**联系:**
联合分布可求边缘分布,但若只知道边缘分布,无法求得联合分布。
-## 1.15 条件概率的链式法则
-由条件概率的定义,可直接得出下面的乘法公式:
-乘法公式 设$A, B$是两个事件,并且$P(A) > 0$, 则有
-
+## 1.16 条件概率的链式法则
+由条件概率的定义,可直接得出下面的乘法公式:
+乘法公式 设$A, B$是两个事件,并且$P(A) > 0$, 则有
$$
P(AB) = P(B|A)P(A)
$$
-推广
+推广
$$
P(ABC)=P(C|AB)P(B|A)P(A)
$$
-一般地,用归纳法可证:若$P(A_1A_2...A_n)>0$,则有
+一般地,用归纳法可证:若$P(A_1A_2...A_n)>0$,则有
$$
P(A_1A_2...A_n)=P(A_n|A_1A_2...A_{n-1})P(A_{n-1}|A_1A_2...A_{n-2})...P(A_2|A_1)P(A_1)
=P(A_1)\prod_{i=2}^{n}P(A_i|A_1A_2...A_{i-1})
$$
-任何多维随机变量联合概率分布,都可以分解成只有一个变量的条件概率相乘形式。
+任何多维随机变量联合概率分布,都可以分解成只有一个变量的条件概率相乘形式。
-## 1.16 独立性和条件独立性
+## 1.17 独立性和条件独立性
**独立性**
两个随机变量$x$和$y$,概率分布表示成两个因子乘积形式,一个因子只包含$x$,另一个因子只包含$y$,两个随机变量相互独立(independent)。
条件有时为不独立的事件之间带来独立,有时也会把本来独立的事件,因为此条件的存在,而失去独立性。
@@ -320,7 +434,7 @@ $$
P(X,Y|Z) \not = P(X|Z)P(Y|Z)
$$
-事件独立时,联合概率等于概率的乘积。这是一个非常好的数学性质,然而不幸的是,无条件的独立是十分稀少的,因为大部分情况下,事件之间都是互相影响的。
+事件独立时,联合概率等于概率的乘积。这是一个非常好的数学性质,然而不幸的是,无条件的独立是十分稀少的,因为大部分情况下,事件之间都是互相影响的。
**条件独立性**
给定$Z$的情况下,$X$和$Y$条件独立,当且仅当
@@ -329,7 +443,7 @@ $$
X\bot Y|Z \iff P(X,Y|Z) = P(X|Z)P(Y|Z)
$$
-$X$和$Y$的关系依赖于$Z$,而不是直接产生。
+$X$和$Y$的关系依赖于$Z$,而不是直接产生。
>**举例**定义如下事件:
>$X$:明天下雨;
@@ -337,24 +451,24 @@ $$
>$Z$:今天是否下雨;
>$Z$事件的成立,对$X$和$Y$均有影响,然而,在$Z$事件成立的前提下,今天的地面情况对明天是否下雨没有影响。
-## 1.17 期望、方差、协方差、相关系数总结
+## 1.18 期望、方差、协方差、相关系数总结
**期望**
在概率论和统计学中,数学期望(或均值,亦简称期望)是试验中每次可能结果的概率乘以其结果的总和。它反映随机变量平均取值的大小。
- 线性运算: $E(ax+by+c) = aE(x)+bE(y)+c$
-- 推广形式: $E(\sum_{k=1}^{n}{a_kx_k+c}) = \sum_{k=1}^{n}{a_kE(x_k)+c}$
+- 推广形式: $E(\sum_{k=1}^{n}{a_ix_i+c}) = \sum_{k=1}^{n}{a_iE(x_i)+c}$
- 函数期望:设$f(x)$为$x$的函数,则$f(x)$的期望为
- 离散函数: $E(f(x))=\sum_{k=1}^{n}{f(x_k)P(x_k)}$
- 连续函数: $E(f(x))=\int_{-\infty}^{+\infty}{f(x)p(x)dx}$
> 注意:
>
-> - 函数的期望不等于期望的函数,即$E(f(x))=f(E(x))$
+> - 函数的期望大于等于期望的函数(Jensen不等式),即$E(f(x))\geqslant f(E(x))$
> - 一般情况下,乘积的期望不等于期望的乘积。
> - 如果$X$和$Y$相互独立,则$E(xy)=E(x)E(y)$。
**方差**
-概率论中方差用来度量随机变量和其数学期望(即均值)之间的偏离程度。方差是一种特殊的期望。定义为:
+概率论中方差用来度量随机变量和其数学期望(即均值)之间的偏离程度。方差是一种特殊的期望。定义为:
$$
Var(x) = E((x-E(x))^2)
@@ -374,7 +488,7 @@ $$
Cov(x,y)=E((x-E(x))(y-E(y)))
$$
-方差是一种特殊的协方差。当$X=Y$时,$Cov(x,y)=Var(x)=Var(y)$。
+方差是一种特殊的协方差。当$X=Y$时,$Cov(x,y)=Var(x)=Var(y)$。
> 协方差性质:
>
@@ -400,5 +514,17 @@ Corr(x,y) = \frac{Cov(x,y)}{\sqrt{Var(x)Var(y)}}
$$
> 相关系数的性质:
-> 1)有界性。相关系数的取值范围是 ,可以看成无量纲的协方差。
+> 1)有界性。相关系数的取值范围是 [-1,1],可以看成无量纲的协方差。
> 2)值越接近1,说明两个变量正相关性(线性)越强。越接近-1,说明负相关性越强,当为0时,表示两个变量没有相关性。
+
+
+
+## 参考文献
+
+[1]Ian,Goodfellow,Yoshua,Bengio,Aaron...深度学习[M],人民邮电出版,2017
+
+[2]周志华.机器学习[M].清华大学出版社,2016.
+
+[3]同济大学数学系.高等数学(第七版)[M],高等教育出版社,2014.
+
+[4]盛骤,试式千,潘承毅等编. 概率论与数理统计(第4版)[M],高等教育出版社,2008
\ No newline at end of file
diff --git "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2-3.png" "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2-3.png"
deleted file mode 100644
index 2916190b..00000000
Binary files "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2-3.png" and /dev/null differ
diff --git "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.1/5.jpg" "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.1/5.jpg"
index 3629e729..3f93149f 100644
Binary files "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.1/5.jpg" and "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.1/5.jpg" differ
diff --git "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.16.17-1.png" "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.16.17-1.png"
new file mode 100644
index 00000000..83915ea4
Binary files /dev/null and "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.16.17-1.png" differ
diff --git "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.16.17-2.png" "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.16.17-2.png"
new file mode 100644
index 00000000..ca5e2c41
Binary files /dev/null and "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.16.17-2.png" differ
diff --git "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.16.17-3.png" "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.16.17-3.png"
new file mode 100644
index 00000000..511492ce
Binary files /dev/null and "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.16.17-3.png" differ
diff --git "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.16.18.1.png" "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.16.18.1.png"
new file mode 100644
index 00000000..23b150ed
Binary files /dev/null and "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.16.18.1.png" differ
diff --git "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.16.20.1.png" "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.16.20.1.png"
new file mode 100644
index 00000000..acc95fb4
Binary files /dev/null and "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.16.20.1.png" differ
diff --git "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.16.4.1.jpg" "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.16.4.1.jpg"
new file mode 100644
index 00000000..51a16bcb
Binary files /dev/null and "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.16.4.1.jpg" differ
diff --git "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.16.4.2.png" "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.16.4.2.png"
new file mode 100644
index 00000000..d74817f7
Binary files /dev/null and "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.16.4.2.png" differ
diff --git "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.16.4.3.png" "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.16.4.3.png"
new file mode 100644
index 00000000..42e4cee4
Binary files /dev/null and "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.16.4.3.png" differ
diff --git "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.19.1.1.png" "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.19.1.1.png"
new file mode 100644
index 00000000..3fd7fd8f
Binary files /dev/null and "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.19.1.1.png" differ
diff --git "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.19.5A.jpg" "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.19.5A.jpg"
new file mode 100644
index 00000000..a6c5feb7
Binary files /dev/null and "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.19.5A.jpg" differ
diff --git "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.19.5B.jpg" "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.19.5B.jpg"
new file mode 100644
index 00000000..ad455db6
Binary files /dev/null and "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.19.5B.jpg" differ
diff --git "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.19.5C.png" "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.19.5C.png"
new file mode 100644
index 00000000..5e499e4e
Binary files /dev/null and "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.19.5C.png" differ
diff --git "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.2.09.png" "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.2.09.png"
new file mode 100644
index 00000000..94e91922
Binary files /dev/null and "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.2.09.png" differ
diff --git "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.2.10.png" "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.2.10.png"
new file mode 100644
index 00000000..c8b9935b
Binary files /dev/null and "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.2.10.png" differ
diff --git "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.2.11.png" "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.2.11.png"
new file mode 100644
index 00000000..750c2e34
Binary files /dev/null and "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.2.11.png" differ
diff --git "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.2.12.png" "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.2.12.png"
new file mode 100644
index 00000000..9357b0a4
Binary files /dev/null and "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.2.12.png" differ
diff --git "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.2.4.png" "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.2.4.png"
new file mode 100644
index 00000000..e1e166dc
Binary files /dev/null and "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.2.4.png" differ
diff --git "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.2.8.png" "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.2.8.png"
new file mode 100644
index 00000000..234f4d18
Binary files /dev/null and "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.2.8.png" differ
diff --git "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.20.1.jpg" "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.20.1.jpg"
new file mode 100644
index 00000000..efb4f6fc
Binary files /dev/null and "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.20.1.jpg" differ
diff --git "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.21.1.1.png" "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.21.1.1.png"
new file mode 100644
index 00000000..b6205fa9
Binary files /dev/null and "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.21.1.1.png" differ
diff --git "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.21.1.2.png" "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.21.1.2.png"
new file mode 100644
index 00000000..ef734236
Binary files /dev/null and "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.21.1.2.png" differ
diff --git "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.21.1.3.png" "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.21.1.3.png"
new file mode 100644
index 00000000..246ec05e
Binary files /dev/null and "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.21.1.3.png" differ
diff --git "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.21.1.4.png" "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.21.1.4.png"
new file mode 100644
index 00000000..70a1d786
Binary files /dev/null and "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.21.1.4.png" differ
diff --git "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.21.1.5.png" "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.21.1.5.png"
new file mode 100644
index 00000000..61bd081e
Binary files /dev/null and "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.21.1.5.png" differ
diff --git "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.21.1.6.png" "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.21.1.6.png"
new file mode 100644
index 00000000..620857bb
Binary files /dev/null and "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.21.1.6.png" differ
diff --git "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.21.1.6a.png" "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.21.1.6a.png"
new file mode 100644
index 00000000..85755d61
Binary files /dev/null and "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.21.1.6a.png" differ
diff --git "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.21.1.7.png" "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.21.1.7.png"
new file mode 100644
index 00000000..40fbf900
Binary files /dev/null and "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.21.1.7.png" differ
diff --git "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.21.3.1.png" "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.21.3.1.png"
new file mode 100644
index 00000000..1b7c8051
Binary files /dev/null and "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.21.3.1.png" differ
diff --git "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.40.3/1.jpg" "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.40.3/1.jpg"
new file mode 100644
index 00000000..51a16bcb
Binary files /dev/null and "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.40.3/1.jpg" differ
diff --git "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.40.3/2.20.1.jpg" "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.40.3/2.20.1.jpg"
new file mode 100644
index 00000000..05e9ebe2
Binary files /dev/null and "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.40.3/2.20.1.jpg" differ
diff --git "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.40.3/2.png" "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.40.3/2.png"
index e5c69de4..d74817f7 100644
Binary files "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.40.3/2.png" and "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.40.3/2.png" differ
diff --git "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.40.3/3.png" "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.40.3/3.png"
index ef3d80a6..42e4cee4 100644
Binary files "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.40.3/3.png" and "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.40.3/3.png" differ
diff --git "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.5.1.png" "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.5.1.png"
new file mode 100644
index 00000000..3eb29bcd
Binary files /dev/null and "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.5.1.png" differ
diff --git "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.7.3.png" "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.7.3.png"
new file mode 100644
index 00000000..98257154
Binary files /dev/null and "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/img/ch2/2.7.3.png" differ
diff --git "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/modify_log.txt" "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/modify_log.txt"
index f0784f11..c5e0e582 100644
--- "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/modify_log.txt"
+++ "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/modify_log.txt"
@@ -18,7 +18,3 @@ modify_log---->用来记录修改日志
3. 修改modify内容
4. 修改章节内容,图片路径等
-<----qjhuang-2019-3-15---->
-1. 修改2.4错别字
-2. 修改3错别字
-
diff --git "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/readme.md" "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/readme.md"
index db45ad57..548d000c 100644
--- "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/readme.md"
+++ "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/readme.md"
@@ -1,16 +1,17 @@
###########################################################
-### 深度学习500问-第 * 章 xxx
+### 深度学习500问-第 2 章 xxx
**负责人(排名不分先后):**
xxx研究生-xxx(xxx)
xxx博士生-xxx
xxx-xxx
+刘元德-上海理工大学
**贡献者(排名不分先后):**
内容贡献者可自加信息
-刘彦超-东南大学
-
-###########################################################
\ No newline at end of file
+刘彦超-东南大学
+刘元德-上海理工大学(内容修订)
+###########################################################
diff --git "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/\347\254\254\344\272\214\347\253\240_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200.md" "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/\347\254\254\344\272\214\347\253\240_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200.md"
index 918c9e80..b4aabb60 100644
--- "a/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/\347\254\254\344\272\214\347\253\240_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200.md"
+++ "b/ch02_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200/\347\254\254\344\272\214\347\253\240_\346\234\272\345\231\250\345\255\246\344\271\240\345\237\272\347\241\200.md"
@@ -1,41 +1,38 @@
-
[TOC]
# 第二章 机器学习基础
-## 2.1 各种常见算法图示
+## 2.1 大话理解机器学习本质
-|回归算法|基于实例的算法|正则化方法|
+ 机器学习(Machine Learning, ML),顾名思义,让机器去学习。这里,机器指的是计算机,是算法运行的物理载体,你也可以把各种算法本身当做一个有输入和输出的机器。那么到底让计算机去学习什么呢?对于一个任务及其表现的度量方法,设计一种算法,让算法能够提取中数据所蕴含的规律,这就叫机器学习。如果输入机器的数据是带有标签的,就称作有监督学习。如果数据是无标签的,就是无监督学习。
+
+## 2.2 各种常见算法图示
+
+|回归算法|聚类算法|正则化方法|
|:-:|:-:|:-:|
||||
|决策树学习|贝叶斯方法|基于核的算法|
|:-:|:-:|:-:|
-||||
+||||
|聚类算法|关联规则学习|人工神经网络|
|:-:|:-:|:-:|
-||||
+||||
|深度学习|降低维度算法|集成算法|
|:-:|:-:|:-:|
-||||
+||||
-## 2.2 监督学习、非监督学习、半监督学习、弱监督学习?
-根据数据类型的不同,对一个问题的建模有不同的方式。依据不同的学习方式和输入数据,机器学习主要分为以下四种学习方式。
+## 2.3 监督学习、非监督学习、半监督学习、弱监督学习?
+ 根据数据类型的不同,对一个问题的建模有不同的方式。依据不同的学习方式和输入数据,机器学习主要分为以下四种学习方式。
**监督学习**:
-1. 监督学习是使用已知正确答案的示例来训练网络。已知数据和其一一对应的标签,训练一个智能算法,将输入数据映射到标签的过程。
+1. 监督学习是使用已知正确答案的示例来训练网络。已知数据和其一一对应的标签,训练一个预测模型,将输入数据映射到标签的过程。
2. 监督式学习的常见应用场景如分类问题和回归问题。
-3. 常见算法有逻辑回归(Logistic Regression)和反向传递神经网络(Back Propagation Neural Network)
+3. 常见的有监督机器学习算法包括支持向量机(Support Vector Machine, SVM),朴素贝叶斯(Naive Bayes),逻辑回归(Logistic Regression),K近邻(K-Nearest Neighborhood, KNN),决策树(Decision Tree),随机森林(Random Forest),AdaBoost以及线性判别分析(Linear Discriminant Analysis, LDA)等。深度学习(Deep Learning)也是大多数以监督学习的方式呈现。
**非监督式学习**:
1. 在非监督式学习中,数据并不被特别标识,适用于你具有数据集但无标签的情况。学习模型是为了推断出数据的一些内在结构。
@@ -51,170 +48,206 @@
1. 弱监督学习可以看做是有多个标记的数据集合,次集合可以是空集,单个元素,或包含多种情况(没有标记,有一个标记,和有多个标记)的多个元素。
2. 数据集的标签是不可靠的,这里的不可靠可以是标记不正确,多种标记,标记不充分,局部标记等。
3. 已知数据和其一一对应的弱标签,训练一个智能算法,将输入数据映射到一组更强的标签的过程。标签的强弱指的是标签蕴含的信息量的多少,比如相对于分割的标签来说,分类的标签就是弱标签。
-4. 举例,告诉一张包含气球的图片,需要得出气球在图片中的位置及气球和背景的分割线,这就是已知弱标签学习强标签的问题。
+4. 举例,给出一张包含气球的图片,需要得出气球在图片中的位置及气球和背景的分割线,这就是已知弱标签学习强标签的问题。
-在企业数据应用的场景下, 人们最常用的可能就是监督式学习和非监督式学习的模型。 在图像识别等领域,由于存在大量的非标识的数据和少量的可标识数据, 目前半监督式学习是一个很热的话题。
+ 在企业数据应用的场景下, 人们最常用的可能就是监督式学习和非监督式学习的模型。 在图像识别等领域,由于存在大量的非标识的数据和少量的可标识数据, 目前半监督式学习是一个很热的话题。
+
+## 2.4 监督学习有哪些步骤
+ 监督学习是使用已知正确答案的示例来训练网络,每组训练数据有一个明确的标识或结果。想象一下,我们可以训练一个网络,让其从照片库中(其中包含气球的照片)识别出气球的照片。以下就是我们在这个假设场景中所要采取的步骤。
-## 2.3 监督学习有哪些步骤
-**监督式学习**:
-监督学习是使用已知正确答案的示例来训练网络。每组训练数据有一个明确的标识或结果,想象一下,我们可以训练一个网络,让其从照片库中(其中包含气球的照片)识别出气球的照片。以下就是我们在这个假设场景中所要采取的步骤。
**步骤1:数据集的创建和分类**
-首先,浏览你的照片(数据集),确定所有包含气球的照片,并对其进行标注。然后,将所有照片分为训练集和验证集。目标就是在深度网络中找一函数,这个函数输入是任意一张照片,当照片中包含气球时,输出1,否则输出0。
-**步骤2:训练**
-选择合适的模型,模型可通过以下激活函数对每张照片进行预测。既然我们已经知道哪些是包含气球的图片,那么我们就可以告诉模型它的预测是对还是错。然后我们会将这些信息反馈(feed back)给网络。
-该算法使用的这种反馈,就是一个量化“真实答案与模型预测有多少偏差”的函数的结果。这个函数被称为成本函数(cost function),也称为目标函数(objective function),效用函数(utility function)或适应度函数(fitness function)。然后,该函数的结果用于修改一个称为反向传播(backpropagation)过程中节点之间的连接强度和偏差。
-我们会为每个图片都重复一遍此操作,而在每种情况下,算法都在尽量最小化成本函数。
-其实,我们有多种数学技术可以用来验证这个模型是正确还是错误的,但我们常用的是一个非常常见的方法,我们称之为梯度下降(gradient descent)。
-**步骤3:验证**
-当处理完训练集所有照片,接着要去测试该模型。利用验证集来来验证训练有素的模型是否可以准确地挑选出含有气球在内的照片。
-在此过程中,通常会通过调整和模型相关的各种事物(超参数)来重复步骤2和3,诸如里面有多少个节点,有多少层,哪些数学函数用于决定节点是否亮起,如何在反向传播阶段积极有效地训练权值等等。
-**步骤4:测试及应用**
-当有了一个准确的模型,就可以将该模型部署到你的应用程序中。你可以将模型定义为API调用,并且你可以从软件中调用该方法,从而进行推理并给出相应的结果。
-
-## 2.4 多实例学习?
-多实例学习(multiple instance learning) :已知包含多个数据的数据包和数据包的标签,训练智能算法,将数据包映射到标签的过程,在有的问题中也同时给出包内每个数据的标签。
-比如说一段视频由很多张图组成,假如10000张,那么我们要判断视频里是否包含某一物体,比如气球。单张标注每一帧是否有气球太耗时,通常人们看一遍说这个视频里是否有气球,就得到了多实例学习的数据。10000帧的数据不是每一个都有气球出现,只要有一帧有气球,那么我们就认为这个数据包是有气球的。只有当所有的视频帧都没有气球,才是没有气球的。从这里面学习哪一段视频(10000张)是否有气球出现就是多实例学习的问题。
-
-## 2.5 分类网络和回归的区别?
-2.3小节介绍了包含气球照片的数据集整理。当照片中包含气球时,输出1,否则输出0。此步骤通常称为分类任务(categorization task)。在这种情况下,我们进行的通常是一个结果为yes or no的训练。
-但事实上,监督学习也可以用于输出一组值,而不仅仅是0或1。例如,我们可以训练一个网络,用它来输出一张图片上有气球的概率,那么在这种情况下,输出值就是0到1之间的任意值。这些任务我们称之为回归。
+ 首先,浏览你的照片(数据集),确定所有包含气球的照片,并对其进行标注。然后,将所有照片分为训练集和验证集。目标就是在深度网络中找一函数,这个函数输入是任意一张照片,当照片中包含气球时,输出1,否则输出0。
+
+**步骤2:数据增强(Data Augmentation)**
+ 当原始数据搜集和标注完毕,一般搜集的数据并不一定包含目标在各种扰动下的信息。数据的好坏对于机器学习模型的预测能力至关重要,因此一般会进行数据增强。对于图像数据来说,数据增强一般包括,图像旋转,平移,颜色变换,裁剪,仿射变换等。
+
+**步骤3:特征工程(Feature Engineering)**
+ 一般来讲,特征工程包含特征提取和特征选择。常见的手工特征(Hand-Crafted Feature)有尺度不变特征变换(Scale-Invariant Feature Transform, SIFT),方向梯度直方图(Histogram of Oriented Gradient, HOG)等。由于手工特征是启发式的,其算法设计背后的出发点不同,将这些特征组合在一起的时候有可能会产生冲突,如何将组合特征的效能发挥出来,使原始数据在特征空间中的判别性最大化,就需要用到特征选择的方法。在深度学习方法大获成功之后,人们很大一部分不再关注特征工程本身。因为,最常用到的卷积神经网络(Convolutional Neural Networks, CNNs)本身就是一种特征提取和选择的引擎。研究者提出的不同的网络结构、正则化、归一化方法实际上就是深度学习背景下的特征工程。
+
+**步骤4:构建预测模型和损失**
+ 将原始数据映射到特征空间之后,也就意味着我们得到了比较合理的输入。下一步就是构建合适的预测模型得到对应输入的输出。而如何保证模型的输出和输入标签的一致性,就需要构建模型预测和标签之间的损失函数,常见的损失函数(Loss Function)有交叉熵、均方差等。通过优化方法不断迭代,使模型从最初的初始化状态一步步变化为有预测能力的模型的过程,实际上就是学习的过程。
+
+**步骤5:训练**
+ 选择合适的模型和超参数进行初始化,其中超参数比如支持向量机中核函数、误差项惩罚权重等。当模型初始化参数设定好后,将制作好的特征数据输入到模型,通过合适的优化方法不断缩小输出与标签之间的差距,当迭代过程到了截止条件,就可以得到训练好的模型。优化方法最常见的就是梯度下降法及其变种,使用梯度下降法的前提是优化目标函数对于模型是可导的。
+
+**步骤6:验证和模型选择**
+ 训练完训练集图片后,需要进行模型测试。利用验证集来验证模型是否可以准确地挑选出含有气球在内的照片。
+ 在此过程中,通常会通过调整和模型相关的各种事物(超参数)来重复步骤2和3,诸如里面有多少个节点,有多少层,使用怎样的激活函数和损失函数,如何在反向传播阶段积极有效地训练权值等等。
+
+**步骤7:测试及应用**
+ 当有了一个准确的模型,就可以将该模型部署到你的应用程序中。你可以将预测功能发布为API(Application Programming Interface, 应用程序编程接口)调用,并且你可以从软件中调用该API,从而进行推理并给出相应的结果。
+
+## 2.5 多实例学习?
+ 多实例学习(Multiple Instance Learning, MIL) :已知包含多个数据的数据包和数据包的标签,训练智能算法,将数据包映射到标签的过程,在有的问题中也同时给出包内每个数据的标签。
+ 比如说一段视频由很多张图组成,假如10000张,那么我们要判断视频里是否包含某一物体,比如气球。单张标注每一帧是否有气球太耗时,通常人们看一遍说这个视频里是否有气球,就得到了多示例学习的数据。10000帧的数据不是每一个都有气球出现,只要有一帧有气球,那么我们就认为这个数据包是有气球的。只有当所有的视频帧都没有气球,才是没有气球的。从这里面学习哪一段视频(10000张)是否有气球出现就是多实例学习的问题。
## 2.6 什么是神经网络?
-神经网络就是按照一定规则将多个神经元连接起来的网络。不同的神经网络,具有不同的连接规则。
-例如全连接(full connected, FC)神经网络,它的规则包括:
+ 神经网络就是按照一定规则将多个神经元连接起来的网络。不同的神经网络,具有不同的连接规则。
+例如全连接(Full Connected, FC)神经网络,它的规则包括:
+
1. 有三种层:输入层,输出层,隐藏层。
2. 同一层的神经元之间没有连接。
-3. full connected的含义:第 N 层的每个神经元和第 N-1 层的所有神经元相连,第 N-1 层神经元的输出就是第 N 层神经元的输入。
+3. fully connected的含义:第 N 层的每个神经元和第 N-1 层的所有神经元相连,第 N-1 层神经元的输出就是第 N 层神经元的输入。
4. 每个连接都有一个权值。
-**神经网络架构**
-下面这张图就是一个神经网络系统,它由很多层组成。输入层负责接收信息,比如一只猫的图片。输出层是计算机对这个输入信息的判断结果,它是不是猫。隐藏层就是对输入信息的传递和加工处理。
-
+
+ **神经网络架构**
+ 下面这张图就是一个神经网络系统,它由很多层组成。输入层负责接收信息,比如一只猫的图片。输出层是计算机对这个输入信息的判断结果,它是不是猫。隐藏层就是对输入信息的传递和加工处理。
+ 
## 2.7 理解局部最优与全局最优
-笑谈局部最优和全局最优
+ 笑谈局部最优和全局最优
-> 柏拉图有一天问老师苏格拉底什么是爱情?苏格拉底叫他到麦田走一次,摘一颗最大的麦穗回来,不许回头,只可摘一次。柏拉图空着手出来了,他的理由是,看见不错的,却不知道是不是最好的,一次次侥幸,走到尽头时,才发现还不如前面的,于是放弃。苏格拉底告诉他:“这就是爱情。”这故事让我们明白了一个道理,因为生命的一些不确定性,所以全局最优解是很难寻找到的,或者说根本就不存在,我们应该设置一些限定条件,然后在这个范围内寻找最优解,也就是局部最优解——有所斩获总比空手而归强,哪怕这种斩获只是一次有趣的经历。
-> 柏拉图有一天又问什么是婚姻?苏格拉底叫他到彬树林走一次,选一棵最好的树做圣诞树,也是不许回头,只许选一次。这次他一身疲惫地拖了一棵看起来直挺、翠绿,却有点稀疏的杉树回来,他的理由是,有了上回的教训,好不容易看见一棵看似不错的,又发现时间、体力已经快不够用了,也不管是不是最好的,就拿回来了。苏格拉底告诉他:“这就是婚姻。
+> 柏拉图有一天问老师苏格拉底什么是爱情?苏格拉底叫他到麦田走一次,摘一颗最大的麦穗回来,不许回头,只可摘一次。柏拉图空着手出来了,他的理由是,看见不错的,却不知道是不是最好的,一次次侥幸,走到尽头时,才发现还不如前面的,于是放弃。苏格拉底告诉他:“这就是爱情。”这故事让我们明白了一个道理,因为生命的一些不确定性,所以全局最优解是很难寻找到的,或者说根本就不存在,我们应该设置一些限定条件,然后在这个范围内寻找最优解,也就是局部最优解——有所斩获总比空手而归强,哪怕这种斩获只是一次有趣的经历。
+> 柏拉图有一天又问什么是婚姻?苏格拉底叫他到树林走一次,选一棵最好的树做圣诞树,也是不许回头,只许选一次。这次他一身疲惫地拖了一棵看起来直挺、翠绿,却有点稀疏的杉树回来,他的理由是,有了上回的教训,好不容易看见一棵看似不错的,又发现时间、体力已经快不够用了,也不管是不是最好的,就拿回来了。苏格拉底告诉他:“这就是婚姻。”
-优化问题一般分为局部最优和全局最优。
+ 优化问题一般分为局部最优和全局最优。
1. 局部最优,就是在函数值空间的一个有限区域内寻找最小值;而全局最优,是在函数值空间整个区域寻找最小值问题。
-2. 函数局部最小点是那种它的函数值小于或等于附近点的点。但是有可能大于较远距离的点。
+2. 函数局部最小点是它的函数值小于或等于附近点的点。但是有可能大于较远距离的点。
3. 全局最小点是那种它的函数值小于或等于所有的可行点。
## 2.8 分类算法
+ 分类算法和回归算法是对真实世界不同建模的方法。分类模型是认为模型的输出是离散的,例如大自然的生物被划分为不同的种类,是离散的。回归模型的输出是连续的,例如人的身高变化过程是一个连续过程,而不是离散的。
+
+ 因此,在实际建模过程时,采用分类模型还是回归模型,取决于你对任务(真实世界)的分析和理解。
+
### 2.8.1 常用分类算法的优缺点?
|算法|优点|缺点|
|:-|:-|:-|
-|Bayes 贝叶斯分类法|1)所需估计的参数少,对于缺失数据不敏感。2)有着坚实的数学基础,以及稳定的分类效率。|1)假设属性之间相互独立,这往往并不成立。(喜欢吃番茄、鸡蛋,却不喜欢吃番茄炒蛋)。2)需要知道先验概率。3)分类决策存在错误率。|
-|Decision Tree决策树|1)不需要任何领域知识或参数假设。2)适合高维数据。3)简单易于理解。4)短时间内处理大量数据,得到可行且效果较好的结果。5)能够同时处理数据型和常规性属性。|1)对于各类别样本数量不一致数据,信息增益偏向于那些具有更多数值的特征。2)易于过拟合。3)忽略属性之间的相关性。4)不支持在线学习。|
-|SVM支持向量机|1)可以解决小样本下机器学习的问题。2)提高泛化性能。3)可以解决高维、非线性问题。超高维文本分类仍受欢迎。4)避免神经网络结构选择和局部极小的问题。|1)对缺失数据敏感。2)内存消耗大,难以解释。3)运行和调差略烦人。|
-|KNN K近邻|1)思想简单,理论成熟,既可以用来做分类也可以用来做回归; 2)可用于非线性分类; 3)训练时间复杂度为O(n); 4)准确度高,对数据没有假设,对outlier不敏感;|1)计算量太大2)对于样本分类不均衡的问题,会产生误判。3)需要大量的内存。4)输出的可解释性不强。|
-|Logistic Regression逻辑回归|1)速度快。2)简单易于理解,直接看到各个特征的权重。3)能容易地更新模型吸收新的数据。4)如果想要一个概率框架,动态调整分类阀值。|特征处理复杂。需要归一化和较多的特征工程。|
-|Neural Network 神经网络|1)分类准确率高。2)并行处理能力强。3)分布式存储和学习能力强。4)鲁棒性较强,不易受噪声影响。|1)需要大量参数(网络拓扑、阀值、阈值)。2)结果难以解释。3)训练时间过长。|
-|Adaboosting|1)adaboost是一种有很高精度的分类器。2)可以使用各种方法构建子分类器,Adaboost算法提供的是框架。3)当使用简单分类器时,计算出的结果是可以理解的。而且弱分类器构造极其简单。4)简单,不用做特征筛选。5)不用担心overfitting。|对outlier比较敏感|
-
-### 2.8.2 正确率能很好的评估分类算法吗?
-不同算法有不同特点,在不同数据集上有不同的表现效果,根据特定的任务选择不同的算法。如何评价分类算法的好坏,要做具体任务具体分析。对于决策树,主要用正确率去评估,但是其他算法,只用正确率能很好的评估吗?
-答案是否定的。
-正确率确实是一个很直观很好的评价指标,但是有时候正确率高并不能完全代表一个算法就好。比如对某个地区进行地震预测,地震分类属性分为0:不发生地震、1发生地震。我们都知道,不发生的概率是极大的,对于分类器而言,如果分类器不加思考,对每一个测试样例的类别都划分为0,达到99%的正确率,但是,问题来了,如果真的发生地震时,这个分类器毫无察觉,那带来的后果将是巨大的。很显然,99%正确率的分类器并不是我们想要的。出现这种现象的原因主要是数据分布不均衡,类别为1的数据太少,错分了类别1但达到了很高的正确率缺忽视了研究者本身最为关注的情况。
-
-### 2.8.3 分类算法的评估方法?
-1. **几个常用的术语**
-这里首先介绍几个*常见*的 模型评价术语,现在假设我们的分类目标只有两类,计为正例(positive)和负例(negative)分别是:
- 1) True positives(TP): 被正确地划分为正例的个数,即实际为正例且被分类器划分为正例的实例数(样本数);
- 2) False positives(FP): 被错误地划分为正例的个数,即实际为负例但被分类器划分为正例的实例数;
- 3) False negatives(FN):被错误地划分为负例的个数,即实际为正例但被分类器划分为负例的实例数;
- 4) True negatives(TN): 被正确地划分为负例的个数,即实际为负例且被分类器划分为负例的实例数。
+|Bayes 贝叶斯分类法|1)所需估计的参数少,对于缺失数据不敏感。
2)有着坚实的数学基础,以及稳定的分类效率。|1)需要假设属性之间相互独立,这往往并不成立。(喜欢吃番茄、鸡蛋,却不喜欢吃番茄炒蛋)。
2)需要知道先验概率。
3)分类决策存在错误率。|
+|Decision Tree决策树|1)不需要任何领域知识或参数假设。
2)适合高维数据。
3)简单易于理解。
4)短时间内处理大量数据,得到可行且效果较好的结果。
5)能够同时处理数据型和常规性属性。|1)对于各类别样本数量不一致数据,信息增益偏向于那些具有更多数值的特征。
2)易于过拟合。
3)忽略属性之间的相关性。
4)不支持在线学习。|
+|SVM支持向量机|1)可以解决小样本下机器学习的问题。
2)提高泛化性能。
3)可以解决高维、非线性问题。超高维文本分类仍受欢迎。
4)避免神经网络结构选择和局部极小的问题。|1)对缺失数据敏感。
2)内存消耗大,难以解释。
3)运行和调参略烦人。|
+|KNN K近邻|1)思想简单,理论成熟,既可以用来做分类也可以用来做回归;
2)可用于非线性分类;
3)训练时间复杂度为O(n);
4)准确度高,对数据没有假设,对outlier不敏感;|1)计算量太大。
2)对于样本分类不均衡的问题,会产生误判。
3)需要大量的内存。
4)输出的可解释性不强。|
+|Logistic Regression逻辑回归|1)速度快。
2)简单易于理解,直接看到各个特征的权重。
3)能容易地更新模型吸收新的数据。
4)如果想要一个概率框架,动态调整分类阀值。|特征处理复杂。需要归一化和较多的特征工程。|
+|Neural Network 神经网络|1)分类准确率高。
2)并行处理能力强。
3)分布式存储和学习能力强。
4)鲁棒性较强,不易受噪声影响。|1)需要大量参数(网络拓扑、阀值、阈值)。
2)结果难以解释。
3)训练时间过长。|
+|Adaboosting|1)adaboost是一种有很高精度的分类器。
2)可以使用各种方法构建子分类器,Adaboost算法提供的是框架。
3)当使用简单分类器时,计算出的结果是可以理解的。而且弱分类器构造极其简单。
4)简单,不用做特征筛选。
5)不用担心overfitting。|对outlier比较敏感|
+
+
+
+### 2.8.2 分类算法的评估方法?
+- **几个常用术语**
+ 这里首先介绍几个常见的模型评价术语,现在假设我们的分类目标只有两类,计为正例(positive)和负例(negative)分别是:
+ 1) True positives(TP): 被正确地划分为正例的个数,即实际为正例且被分类器划分为正例的实例数;
+ 2) False positives(FP): 被错误地划分为正例的个数,即实际为负例但被分类器划分为正例的实例数;
+ 3) False negatives(FN):被错误地划分为负例的个数,即实际为正例但被分类器划分为负例的实例数;
+ 4) True negatives(TN): 被正确地划分为负例的个数,即实际为负例且被分类器划分为负例的实例数。

-上图是这四个术语的混淆矩阵。
-1)P=TP+FN表示实际为正例的样本个数。
-2)True、False描述的是分类器是否判断正确。
-3)Positive、Negative是分类器的分类结果,如果正例计为1、负例计为-1,即positive=1、negative=-1。用1表示True,-1表示False,那么实际的类标=TF\*PN,TF为true或false,PN为positive或negative。
-4)例如True positives(TP)的实际类标=1\*1=1为正例,False positives(FP)的实际类标=(-1)\*1=-1为负例,False negatives(FN)的实际类标=(-1)\*(-1)=1为正例,True negatives(TN)的实际类标=1\*(-1)=-1为负例。
-
-2. **评价指标**
- 1) 正确率(accuracy)
- 正确率是我们最常见的评价指标,accuracy = (TP+TN)/(P+N),正确率是被分对的样本数在所有样本数中的占比,通常来说,正确率越高,分类器越好。
- 2) 错误率(error rate)
- 错误率则与正确率相反,描述被分类器错分的比例,error rate = (FP+FN)/(P+N),对某一个实例来说,分对与分错是互斥事件,所以accuracy =1 - error rate。
- 3) 灵敏度(sensitive)
- sensitive = TP/P,表示的是所有正例中被分对的比例,衡量了分类器对正例的识别能力。
- 4) 特效度(specificity)
- specificity = TN/N,表示的是所有负例中被分对的比例,衡量了分类器对负例的识别能力。
- 5) 精度(precision)
- 精度是精确性的度量,表示被分为正例的示例中实际为正例的比例,precision=TP/(TP+FP)。
- 6) 召回率(recall)
- 召回率是覆盖面的度量,度量有多个正例被分为正例,recall=TP/(TP+FN)=TP/P=sensitive,可以看到召回率与灵敏度是一样的。
- 7) 其他评价指标
- 计算速度:分类器训练和预测需要的时间;
- 鲁棒性:处理缺失值和异常值的能力;
- 可扩展性:处理大数据集的能力;
- 可解释性:分类器的预测标准的可理解性,像决策树产生的规则就是很容易理解的,而神经网络的一堆参数就不好理解,我们只好把它看成一个黑盒子。
- 8) 查准率和查全率反映了分类器分类性能的两个方面。如果综合考虑查准率与查全率,可以得到新的评价指标F1测试值,也称为综合分类率:$F1=\frac{2 \times precision \times recall}{precision + recall}$
- 为了综合多个类别的分类情况,评测系统整体性能,经常采用的还有微平均F1(micro-averaging)和宏平均F1(macro-averaging )两种指标。宏平均F1与微平均F1是以两种不同的平均方式求的全局的F1指标。其中宏平均F1的计算方法先对每个类别单独计算F1值,再取这些F1值的算术平均值作为全局指标。而微平均F1的计算方法是先累加计算各个类别的a、b、c、d的值,再由这些值求出F1值。由两种平均F1的计算方式不难看出,宏平均F1平等对待每一个类别,所以它的值主要受到稀有类别的影响,而微平均F1平等考虑文档集中的每一个文档,所以它的值受到常见类别的影响比较大。
- **ROC曲线和PR曲线**
-
-References
-[1] 李航. 统计学习方法[M]. 北京:清华大学出版社,2012.
+上图是这四个术语的混淆矩阵,做以下说明:
+ 1)P=TP+FN表示实际为正例的样本个数。
+ 2)True、False描述的是分类器是否判断正确。
+ 3)Positive、Negative是分类器的分类结果,如果正例计为1、负例计为-1,即positive=1、negative=-1。用1表示True,-1表示False,那么实际的类标=TF\*PN,TF为true或false,PN为positive或negative。
+ 4)例如True positives(TP)的实际类标=1\*1=1为正例,False positives(FP)的实际类标=(-1)\*1=-1为负例,False negatives(FN)的实际类标=(-1)\*(-1)=1为正例,True negatives(TN)的实际类标=1\*(-1)=-1为负例。
+
+
+
+- **评价指标**
+ 1) 正确率(accuracy)
+ 正确率是我们最常见的评价指标,accuracy = (TP+TN)/(P+N),正确率是被分对的样本数在所有样本数中的占比,通常来说,正确率越高,分类器越好。
+ 2) 错误率(error rate)
+ 错误率则与正确率相反,描述被分类器错分的比例,error rate = (FP+FN)/(P+N),对某一个实例来说,分对与分错是互斥事件,所以accuracy =1 - error rate。
+ 3) 灵敏度(sensitivity)
+ sensitivity = TP/P,表示的是所有正例中被分对的比例,衡量了分类器对正例的识别能力。
+ 4) 特异性(specificity)
+ specificity = TN/N,表示的是所有负例中被分对的比例,衡量了分类器对负例的识别能力。
+ 5) 精度(precision)
+ precision=TP/(TP+FP),精度是精确性的度量,表示被分为正例的示例中实际为正例的比例。
+ 6) 召回率(recall)
+ 召回率是覆盖面的度量,度量有多个正例被分为正例,recall=TP/(TP+FN)=TP/P=sensitivity,可以看到召回率与灵敏度是一样的。
+ 7) 其他评价指标
+ 计算速度:分类器训练和预测需要的时间;
+ 鲁棒性:处理缺失值和异常值的能力;
+ 可扩展性:处理大数据集的能力;
+ 可解释性:分类器的预测标准的可理解性,像决策树产生的规则就是很容易理解的,而神经网络的一堆参数就不好理解,我们只好把它看成一个黑盒子。
+ 8) 精度和召回率反映了分类器分类性能的两个方面。如果综合考虑查准率与查全率,可以得到新的评价指标F1-score,也称为综合分类率:$F1=\frac{2 \times precision \times recall}{precision + recall}$。
+
+ 为了综合多个类别的分类情况,评测系统整体性能,经常采用的还有微平均F1(micro-averaging)和宏平均F1(macro-averaging )两种指标。
+
+ (1)宏平均F1与微平均F1是以两种不同的平均方式求的全局F1指标。
+
+ (2)宏平均F1的计算方法先对每个类别单独计算F1值,再取这些F1值的算术平均值作为全局指标。
+
+ (3)微平均F1的计算方法是先累加计算各个类别的a、b、c、d的值,再由这些值求出F1值。
+
+ (4)由两种平均F1的计算方式不难看出,宏平均F1平等对待每一个类别,所以它的值主要受到稀有类别的影响,而微平均F1平等考虑文档集中的每一个文档,所以它的值受到常见类别的影响比较大。
+
+
+
+- **ROC曲线和PR曲线**
+
+ ROC曲线是(Receiver Operating Characteristic Curve,受试者工作特征曲线)的简称,是以灵敏度(真阳性率)为纵坐标,以1减去特异性(假阳性率)为横坐标绘制的性能评价曲线。可以将不同模型对同一数据集的ROC曲线绘制在同一笛卡尔坐标系中,ROC曲线越靠近左上角,说明其对应模型越可靠。也可以通过ROC曲线下面的面积(Area Under Curve, AUC)来评价模型,AUC越大,模型越可靠。
+
+
+
+ 图2.8.2.1 ROC曲线
+
+ PR曲线是Precision Recall Curve的简称,描述的是precision和recall之间的关系,以recall为横坐标,precision为纵坐标绘制的曲线。该曲线的所对应的面积AUC实际上是目标检测中常用的评价指标平均精度(Average Precision, AP)。AP越高,说明模型性能越好。
+
+### 2.8.3 正确率能很好的评估分类算法吗?
+
+ 不同算法有不同特点,在不同数据集上有不同的表现效果,根据特定的任务选择不同的算法。如何评价分类算法的好坏,要做具体任务具体分析。对于决策树,主要用正确率去评估,但是其他算法,只用正确率能很好的评估吗?
+ 答案是否定的。
+ 正确率确实是一个很直观很好的评价指标,但是有时候正确率高并不能完全代表一个算法就好。比如对某个地区进行地震预测,地震分类属性分为0:不发生地震、1发生地震。我们都知道,不发生的概率是极大的,对于分类器而言,如果分类器不加思考,对每一个测试样例的类别都划分为0,达到99%的正确率,但是,问题来了,如果真的发生地震时,这个分类器毫无察觉,那带来的后果将是巨大的。很显然,99%正确率的分类器并不是我们想要的。出现这种现象的原因主要是数据分布不均衡,类别为1的数据太少,错分了类别1但达到了很高的正确率缺忽视了研究者本身最为关注的情况。
### 2.8.4 什么样的分类器是最好的?
-对某一个任务,某个具体的分类器不可能同时满足或提高所有上面介绍的指标。
-如果一个分类器能正确分对所有的实例,那么各项指标都已经达到最优,但这样的分类器往往不存在。比如之前说的地震预测,既然不能百分百预测地震的发生,但实际情况中能容忍一定程度的误报。假设在1000次预测中,共有5次预测发生了地震,真实情况中有一次发生了地震,其他4次则为误报。正确率由原来的999/1000=99.9下降为996/10000=99.6。召回率由0/1=0%上升为1/1=100%。对此解释为,虽然预测失误了4次,但真的地震发生前,分类器能预测对,没有错过,这样的分类器实际意义更为重大,正是我们想要的。在这种情况下,在一定正确率前提下,要求分类器的召回率尽量高。
+ 对某一个任务,某个具体的分类器不可能同时满足或提高所有上面介绍的指标。
+ 如果一个分类器能正确分对所有的实例,那么各项指标都已经达到最优,但这样的分类器往往不存在。比如之前说的地震预测,既然不能百分百预测地震的发生,但实际情况中能容忍一定程度的误报。假设在1000次预测中,共有5次预测发生了地震,真实情况中有一次发生了地震,其他4次则为误报。正确率由原来的999/1000=99.9下降为996/1000=99.6。召回率由0/1=0%上升为1/1=100%。对此解释为,虽然预测失误了4次,但真的地震发生前,分类器能预测对,没有错过,这样的分类器实际意义更为重大,正是我们想要的。在这种情况下,在一定正确率前提下,要求分类器的召回率尽量高。
## 2.9 逻辑回归
-### 2.9.1 理解逻辑回归
+### 2.9.1 回归划分
-**回归划分**:
广义线性模型家族里,依据因变量不同,可以有如下划分:
-1. 如果是连续的,就是多重线性回归;
-2. 如果是二项分布,就是Logistic回归;
-3. 如果是Poisson分布,就是Poisson回归;
+
+1. 如果是连续的,就是多重线性回归。
+2. 如果是二项分布,就是逻辑回归。
+3. 如果是泊松(Poisson)分布,就是泊松回归。
4. 如果是负二项分布,就是负二项回归。
-Logistic回归的因变量可以是二分类的,也可以是多分类的,但是二分类的更为常用,也更加容易解释。所以实际中最常用的就是二分类的Logistic回归。
+5. 逻辑回归的因变量可以是二分类的,也可以是多分类的,但是二分类的更为常用,也更加容易解释。所以实际中最常用的就是二分类的逻辑回归。
+
+### 2.9.2 逻辑回归适用性
-**Logistic回归的适用性**:
-1. 用于概率预测。用于可能性预测时,得到的结果有可比性。比如根据模型进而预测在不同的自变量情况下,发生某病或某种情况的概率有多大;
+1. 用于概率预测。用于可能性预测时,得到的结果有可比性。比如根据模型进而预测在不同的自变量情况下,发生某病或某种情况的概率有多大。
2. 用于分类。实际上跟预测有些类似,也是根据模型,判断某人属于某病或属于某种情况的概率有多大,也就是看一下这个人有多大的可能性是属于某病。进行分类时,仅需要设定一个阈值即可,可能性高于阈值是一类,低于阈值是另一类。
3. 寻找危险因素。寻找某一疾病的危险因素等。
4. 仅能用于线性问题。只有当目标和特征是线性关系时,才能用逻辑回归。在应用逻辑回归时注意两点:一是当知道模型是非线性时,不适用逻辑回归;二是当使用逻辑回归时,应注意选择和目标为线性关系的特征。
5. 各特征之间不需要满足条件独立假设,但各个特征的贡献独立计算。
-### 2.9.2 逻辑回归与朴素贝叶斯有什么区别?
+### 2.9.3 逻辑回归与朴素贝叶斯有什么区别?
1. 逻辑回归是判别模型, 朴素贝叶斯是生成模型,所以生成和判别的所有区别它们都有。
2. 朴素贝叶斯属于贝叶斯,逻辑回归是最大似然,两种概率哲学间的区别。
-3. 朴素贝叶斯需要独立假设。
+3. 朴素贝叶斯需要条件独立假设。
4. 逻辑回归需要求特征参数间是线性的。
-### 2.9.3线性回归与逻辑回归的区别?(贡献者:黄钦建-华南理工大学)
+### 2.9.4 线性回归与逻辑回归的区别?
+
+(贡献者:黄钦建-华南理工大学)
-线性回归的样本的输出,都是连续值,$ y\in (-\infty ,+\infty )$,而逻辑回归中$y\in (0,1)$,只能取0和1。
+ 线性回归的样本的输出,都是连续值,$ y\in (-\infty ,+\infty )$,而逻辑回归中$y\in (0,1)$,只能取0和1。
-对于拟合函数也有本质上的差别:
+ 对于拟合函数也有本质上的差别:
-线性回归:$f(x)=\theta ^{T}x=\theta _{1}x _{1}+\theta _{2}x _{2}+...+\theta _{n}x _{n}$
+ 线性回归:$f(x)=\theta ^{T}x=\theta _{1}x _{1}+\theta _{2}x _{2}+...+\theta _{n}x _{n}$
-逻辑回归:$f(x)=P(y=1|x;\theta )=g(\theta ^{T}x)$,其中,$g(z)=\frac{1}{1+e^{-z}}$
+ 逻辑回归:$f(x)=P(y=1|x;\theta )=g(\theta ^{T}x)$,其中,$g(z)=\frac{1}{1+e^{-z}}$
-可以看出,线性回归的拟合函数,是对f(x)的输出变量y的拟合,而逻辑回归的拟合函数是对为1类的样本的概率的拟合。
+ 可以看出,线性回归的拟合函数,是对f(x)的输出变量y的拟合,而逻辑回归的拟合函数是对为1类样本的概率的拟合。
-那么,为什么要以1类样本的概率进行拟合呢,为什么可以这样拟合呢?
+ 那么,为什么要以1类样本的概率进行拟合呢,为什么可以这样拟合呢?
-$\theta ^{T}x=0$就相当于是1类和0类的决策边界:
+ $\theta ^{T}x=0$就相当于是1类和0类的决策边界:
-当$\theta ^{T}x>0$,则y>0.5;若$\theta ^{T}x\rightarrow +\infty $,则$y \rightarrow 1 $,即y为1类;
+ 当$\theta ^{T}x>0$,则y>0.5;若$\theta ^{T}x\rightarrow +\infty $,则$y \rightarrow 1 $,即y为1类;
-当$\theta ^{T}x<0$,则y<0.5;若$\theta ^{T}x\rightarrow -\infty $,则$y \rightarrow 0 $,即y为0类;
+ 当$\theta ^{T}x<0$,则y<0.5;若$\theta ^{T}x\rightarrow -\infty $,则$y \rightarrow 0 $,即y为0类;
-这个时候就能看出区别来了,在线性回归中$\theta ^{T}x$为预测值的拟合函数;而在逻辑回归中$\theta ^{T}x$为决策边界。
+这个时候就能看出区别,在线性回归中$\theta ^{T}x$为预测值的拟合函数;而在逻辑回归中$\theta ^{T}x$为决策边界。
| | 线性回归 | 逻辑回归 |
|:-------------:|:-------------:|:-----:|
@@ -226,27 +259,9 @@ $\theta ^{T}x=0$就相当于是1类和0类的决策边界:
下面具体解释一下:
-1. 拟合函数和预测函数什么关系呢?其实就是将拟合函数做了一个逻辑函数的转换,转换后使得$y^{(i)} \in (0,1)$;
+1. 拟合函数和预测函数什么关系呢?简单来说就是将拟合函数做了一个逻辑函数的转换,转换后使得$y^{(i)} \in (0,1)$;
2. 最小二乘和最大似然估计可以相互替代吗?回答当然是不行了。我们来看看两者依仗的原理:最大似然估计是计算使得数据出现的可能性最大的参数,依仗的自然是Probability。而最小二乘是计算误差损失。
-### 2.9.4 Factorization Machines(FM)模型原理
-1.FM旨在解决稀疏数据的特征组合问题,某些特征经过关联之后,就会与label之间的相关性就会提高,例如设备id与ip地址之间的特征交叉就会更好的与label之间有相关性.
-2.FM为二阶多项式模型
-
-• 假设有D维特征,𝑥 , ... , 𝑥 ,若采用线性模型,则
-$y = w_{0} +\sum_{j = 1}^{D} w_{i}x_{j}$
-• 若考虑二阶特征组合,得到模型
-$y = w_{0} +\sum_{j = 1}^{D} w_{i}x_{j} + \sum_{i = 1}^{D}\sum_{j = i + 1}^{D}w_{ij}x_{i}x_{j}$
-– 组合特征的参数一共有D(D-1)/2个,任意两个参数都是独立的
-– 数据稀疏使得二次项参数的训练很困难:
-. 每个样本都需要大量非0的$x_{j}$和$x_{i}$样本
-. 训练样本不足会导致$w_{ij}$不准确
-FM采用类似model-based协同过滤中的矩阵分解方式对二次 多项式的系数进行有效表示:
-$y = w_{0} +\sum_{j = 1}^{D} w_{i}x_{j} + \sum_{i = 1}^{D}\sum_{j = i + 1}^{D}x_{i}x_{j}$
-– FM为进一步对隐含向量只取K维
-�从而$ = \sum_{k = 1}^{K} v_{i,k}v_{j,k}$
-�– 二项式参数�之前的D(D-1)/2变成了KD个 大大降低了计算量.
-
## 2.10 代价函数
### 2.10.1 为什么需要代价函数?
@@ -255,114 +270,114 @@ $y = w_{0} +\sum_{j = 1}^{D} w_{i}x_{j} + \sum_{i = 1}^{D}\sum_{j = i + 1}^{D} 由上图,假如最开始,我们在一座大山上的某处位置,因为到处都是陌生的,不知道下山的路,所以只能摸索着根据直觉,走一步算一步,在此过程中,每走到一个位置的时候,都会求解当前位置的梯度,沿着梯度的负方向,也就是当前最陡峭的位置向下走一步,然后继续求解当前位置梯度,向这一步所在位置沿着最陡峭最易下山的位置走一步。不断循环求梯度,就这样一步步的走下去,一直走到我们觉得已经到了山脚。当然这样走下去,有可能我们不能走到山脚,而是到了某一个局部的山峰低处。
-由此,从上面的解释可以看出,梯度下降不一定能够找到全局的最优解,有可能是一个局部最优解。当然,如果损失函数是凸函数,梯度下降法得到的解就一定是全局最优解。
+ 形象化举例,由上图,假如最开始,我们在一座大山上的某处位置,因为到处都是陌生的,不知道下山的路,所以只能摸索着根据直觉,走一步算一步,在此过程中,每走到一个位置的时候,都会求解当前位置的梯度,沿着梯度的负方向,也就是当前最陡峭的位置向下走一步,然后继续求解当前位置梯度,向这一步所在位置沿着最陡峭最易下山的位置走一步。不断循环求梯度,就这样一步步地走下去,一直走到我们觉得已经到了山脚。当然这样走下去,有可能我们不能走到山脚,而是到了某一个局部的山势低处。
+ 由此,从上面的解释可以看出,梯度下降不一定能够找到全局的最优解,有可能是一个局部的最优解。当然,如果损失函数是凸函数,梯度下降法得到的解就一定是全局最优解。
+
+**核心思想归纳**:
-核心思想归纳:
1. 初始化参数,随机选取取值范围内的任意数;
2. 迭代操作:
- a) 计算当前梯度;
- b)修改新的变量;
- c)计算朝最陡的下坡方向走一步;
- d)判断是否需要终止,如否,返回a);
+ a)计算当前梯度;
+b)修改新的变量;
+c)计算朝最陡的下坡方向走一步;
+d)判断是否需要终止,如否,返回a);
3. 得到全局最优解或者接近全局最优解。
-### 2.12.4 梯度下降法算法描述?
+### 2.12.4 梯度下降法算法描述
1. 确定优化模型的假设函数及损失函数。
-举例,对于线性回归,假设函数为:
-TODO
-其中,TODO分别为模型参数、每个样本的特征值。
-对于假设函数,损失函数为:
-TODO
-2. 相关参数初始化。
-主要初始化TODO、算法迭代步长TODO、终止距离TODO。初始化时可以根据经验初始化,即TODO初始化为0,步长TODO初始化为1。当前步长记为TODO。当然,也可随机初始化。
-3. 迭代计算。
+ 举例,对于线性回归,假设函数为:
+$$
+ h_\theta(x_1,x_2,...,x_n)=\theta_0+\theta_1x_1+...+\theta_nx_n
+$$
+ 其中,$\theta_i,x_i(i=0,1,2,...,n)$分别为模型参数、每个样本的特征值。
+ 对于假设函数,损失函数为:
+$$
+ J(\theta_0,\theta_1,...,\theta_n)=\frac{1}{2m}\sum^{m}_{j=0}(h_\theta (x^{(j)}_0
+ ,x^{(j)}_1,...,x^{(j)}_n)-y_j)^2
+$$
-1) 计算当前位置时损失函数的梯度,对TODO,其梯度表示为:TODO
+2. 相关参数初始化。
+ 主要初始化${\theta}_i$、算法迭代步长${\alpha} $、终止距离${\zeta} $。初始化时可以根据经验初始化,即${\theta} $初始化为0,步长${\alpha} $初始化为1。当前步长记为${\varphi}_i $。当然,也可随机初始化。
-2) 计算当前位置下降的距离。TODO
+3. 迭代计算。
-3) 判断是否终止。
-确定是否所有TODO梯度下降的距离TODO都小于终止距离TODO,如果都小于TODO,则算法终止,当然的值即为最终结果,否则进入下一步。
-4) 更新所有的TODO,更新后的表达式为:TODO
-5) 更新完毕后转入1)。
+ 1)计算当前位置时损失函数的梯度,对${\theta}_i $,其梯度表示为:
-**举例**。以线性回归为例。
-假设样本是
-TODO
-损失函数为
-TODO
-在计算中,TODO的偏导数计算如下:
-TODO
-令上式 。4)中TODO的更新表达式为:
- TODO
-由此,可看出,当前位置的梯度方向由所有样本决定,上式中TODO的目的是为了便于理解。
+$$
+\frac{\partial}{\partial \theta_i}J({\theta}_0,{\theta}_1,...,{\theta}_n)=\frac{1}{2m}\sum^{m}_{j=0}(h_\theta (x^{(j)}_0
+ ,x^{(j)}_1,...,x^{(j)}_n)-y_j)^2
+$$
+ 2)计算当前位置下降的距离。
+$$
+{\varphi}_i={\alpha} \frac{\partial}{\partial \theta_i}J({\theta}_0,{\theta}_1,...,{\theta}_n)
+$$
+ 3)判断是否终止。
+ 确定是否所有${\theta}_i$梯度下降的距离${\varphi}_i$都小于终止距离${\zeta}$,如果都小于${\zeta}$,则算法终止,当然的值即为最终结果,否则进入下一步。
+ 4)更新所有的${\theta}_i$,更新后的表达式为:
+$$
+{\theta}_i={\theta}_i-\alpha \frac{\partial}{\partial \theta_i}J({\theta}_0,{\theta}_1,...,{\theta}_n)
+$$
+$$
+\theta_i=\theta_i - \alpha \frac{1}{m} \sum^{m}_{j=0}(h_\theta (x^{(j)}_0
+ ,x^{(j)}_1,...,x^{(j)}_n)-y_j)x^{(j)}_i
+$$
+ 5)令上式$x^{(j)}_0=1$,更新完毕后转入1)。
+ 由此,可看出,当前位置的梯度方向由所有样本决定,上式中 $\frac{1}{m}$、$\alpha \frac{1}{m}$ 的目的是为了便于理解。
### 2.12.5 如何对梯度下降法进行调优?
实际使用梯度下降法时,各项参数指标不能一步就达到理想状态,对梯度下降法调优主要体现在以下几个方面:
1. **算法迭代步长$\alpha$选择。**
-在算法参数初始化时,有时根据经验将步长 初始化为1。实际取值取决于数据样本。可以从大到小,多取一些值,分别运行算法看迭代效果,如果损失函数在变小,则取值有效。如果取值无效,说明要增大步长。但步长太大,有时会导致迭代速度过快,错过最优解。步长太小,迭代速度慢,算法运行时间长。
+ 在算法参数初始化时,有时根据经验将步长初始化为1。实际取值取决于数据样本。可以从大到小,多取一些值,分别运行算法看迭代效果,如果损失函数在变小,则取值有效。如果取值无效,说明要增大步长。但步长太大,有时会导致迭代速度过快,错过最优解。步长太小,迭代速度慢,算法运行时间长。
2. **参数的初始值选择。**
-初始值不同,获得的最小值也有可能不同,梯度下降有可能得到的是局部最小值。如果损失函数是凸函数,则一定是最优解。由于有局部最优解的风险,需要多次用不同初始值运行算法,关键损失函数的最小值,选择损失函数最小化的初值。
+ 初始值不同,获得的最小值也有可能不同,梯度下降有可能得到的是局部最小值。如果损失函数是凸函数,则一定是最优解。由于有局部最优解的风险,需要多次用不同初始值运行算法,关键损失函数的最小值,选择损失函数最小化的初值。
3. **标准化处理。**
-由于样本不同,特征取值范围也不同,导致迭代速度慢。为了减少特征取值的影响,可对特征数据标准化,使新期望为0,新方差为1,可节省算法运行时间。
+ 由于样本不同,特征取值范围也不同,导致迭代速度慢。为了减少特征取值的影响,可对特征数据标准化,使新期望为0,新方差为1,可节省算法运行时间。
-### 2.12.7 随机梯度和批量梯度区别?
-随机梯度下降和批量梯度下降是两种主要梯度下降法,其目的是增加某些限制来加速运算求解。
-引入随机梯度下降法与mini-batch梯度下降法是为了应对大数据量的计算而实现一种快速的求解。
+### 2.12.6 随机梯度和批量梯度区别?
+ 随机梯度下降(SDG)和批量梯度下降(BDG)是两种主要梯度下降法,其目的是增加某些限制来加速运算求解。
下面通过介绍两种梯度下降法的求解思路,对其进行比较。
-假设函数为
-TODO
-损失函数为
-TODO
-其中,TODO为样本个数,TODO为参数个数。
+假设函数为:
+$$
+h_\theta (x_0,x_1,...,x_3) = \theta_0 x_0 + \theta_1 x_1 + ... + \theta_n x_n
+$$
+损失函数为:
+$$
+J(\theta_0, \theta_1, ... , \theta_n) =
+ \frac{1}{2m} \sum^{m}_{j=0}(h_\theta (x^{j}_0
+ ,x^{j}_1,...,x^{j}_n)-y^j)^2
+$$
+其中,$m$为样本个数,$j$为参数个数。
1、 **批量梯度下降的求解思路如下:**
-
-a) 得到每个TODO对应的梯度:
-TODO
-
-b) 由于是求最小化风险函数,所以按每个参数TODO的梯度负方向更新TODO:
-TODO
-
-c) 从上式可以注意到,它得到的虽然是一个全局最优解,但每迭代一步,都要用到训练集所有的数据,如果样本数据 很大,这种方法迭代速度就很慢。
+a) 得到每个$ \theta $对应的梯度:
+$$
+\frac{\partial}{\partial \theta_i}J({\theta}_0,{\theta}_1,...,{\theta}_n)=\frac{1}{m}\sum^{m}_{j=0}(h_\theta (x^{j}_0
+ ,x^{j}_1,...,x^{j}_n)-y^j)x^{j}_i
+$$
+b) 由于是求最小化风险函数,所以按每个参数 $ \theta $ 的梯度负方向更新 $ \theta_i $ :
+$$
+\theta_i=\theta_i - \frac{1}{m} \sum^{m}_{j=0}(h_\theta (x^{j}_0
+ ,x^{j}_1,...,x^{j}_n)-y^j)x^{j}_i
+$$
+c) 从上式可以注意到,它得到的虽然是一个全局最优解,但每迭代一步,都要用到训练集所有的数据,如果样本数据很大,这种方法迭代速度就很慢。
相比而言,随机梯度下降可避免这种问题。
2、**随机梯度下降的求解思路如下:**
a) 相比批量梯度下降对应所有的训练样本,随机梯度下降法中损失函数对应的是训练集中每个样本的粒度。
损失函数可以写成如下这种形式,
- TODO
-
-b)对每个参数TODO按梯度方向更新 :
- TODO
-
+$$
+J(\theta_0, \theta_1, ... , \theta_n) =
+ \frac{1}{m} \sum^{m}_{j=0}(y^j - h_\theta (x^{j}_0
+ ,x^{j}_1,...,x^{j}_n))^2 =
+ \frac{1}{m} \sum^{m}_{j=0} cost(\theta,(x^j,y^j))
+$$
+b)对每个参数 $ \theta$ 按梯度方向更新 $ \theta$:
+$$
+\theta_i = \theta_i + (y^j - h_\theta (x^{j}_0, x^{j}_1, ... ,x^{j}_n))
+$$
c) 随机梯度下降是通过每个样本来迭代更新一次。
随机梯度下降伴随的一个问题是噪音较批量梯度下降要多,使得随机梯度下降并不是每次迭代都向着整体最优化方向。
**小结:**
随机梯度下降法、批量梯度下降法相对来说都比较极端,简单对比如下:
-批量梯度下降:
-a)采用所有数据来梯度下降。
-b) 批量梯度下降法在样本量很大的时候,训练速度慢。
-随机梯度下降:
-a) 随机梯度下降用一个样本来梯度下降。
-b) 训练速度很快。
-c) 随机梯度下降法仅仅用一个样本决定梯度方向,导致解有可能不是最优。
-d) 收敛速度来说,随机梯度下降法一次迭代一个样本,导致迭代方向变化很大,不能很快的收敛到局部最优解。
+| 方法 | 特点 |
+| :----------: | :----------------------------------------------------------- |
+| 批量梯度下降 | a)采用所有数据来梯度下降。
b)批量梯度下降法在样本量很大的时候,训练速度慢。 |
+| 随机梯度下降 | a)随机梯度下降用一个样本来梯度下降。
b)训练速度很快。
c)随机梯度下降法仅仅用一个样本决定梯度方向,导致解有可能不是全局最优。
d)收敛速度来说,随机梯度下降法一次迭代一个样本,导致迭代方向变化很大,不能很快的收敛到局部最优解。 |
下面介绍能结合两种方法优点的小批量梯度下降法。
-3、 **小批量(mini-batch)梯度下降的求解思路如下**
+3、 **小批量(Mini-Batch)梯度下降的求解思路如下**
对于总数为$m$个样本的数据,根据样本的数据,选取其中的$n(1< n< m)$个子样本来迭代。其参数$\theta$按梯度方向更新$\theta_i$公式如下:
-TODO
+$$
+\theta_i = \theta_i - \alpha \sum^{t+n-1}_{j=t}
+ ( h_\theta (x^{j}_{0}, x^{j}_{1}, ... , x^{j}_{n} ) - y^j ) x^{j}_{i}
+$$
-### 2.12.8 各种梯度下降法性能比较
-下表简单对比随机梯度下降(SGD)、批量梯度下降(BGD)、小批量梯度下降(mini-batch GD)、和online GD的区别,主要区别在于如何选取训练数据:
+### 2.12.7 各种梯度下降法性能比较
+ 下表简单对比随机梯度下降(SGD)、批量梯度下降(BGD)、小批量梯度下降(Mini-batch GD)、和Online GD的区别:
-|BGD|SGD|GD|Mini-batch GD|Online GD|
+||BGD|SGD|Mini-batch GD|Online GD|
|:-:|:-:|:-:|:-:|:-:|:-:|
|训练集|固定|固定|固定|实时更新|
|单次迭代样本数|整个训练集|单个样本|训练集的子集|根据具体算法定|
@@ -605,148 +700,149 @@ TODO
|时效性|低|一般|一般|高|
|收敛性|稳定|不稳定|较稳定|不稳定|
-BGD、SGD、Mini-batch GD,前面均已讨论过,这里介绍一下Online GD。
+BGD、SGD、Mini-batch GD,前面均已讨论过,这里介绍一下Online GD。
-Online GD于mini-batch GD/SGD的区别在于,所有训练数据只用一次,然后丢弃。这样做的优点在于可预测最终模型的变化趋势。
+ Online GD于Mini-batch GD/SGD的区别在于,所有训练数据只用一次,然后丢弃。这样做的优点在于可预测最终模型的变化趋势。
-Online GD在互联网领域用的较多,比如搜索广告的点击率(CTR)预估模型,网民的点击行为会随着时间改变。用普通的BGD算法(每天更新一次)一方面耗时较长(需要对所有历史数据重新训练);另一方面,无法及时反馈用户的点击行为迁移。而Online GD算法可以实时的依据网民的点击行为进行迁移。
+ Online GD在互联网领域用的较多,比如搜索广告的点击率(CTR)预估模型,网民的点击行为会随着时间改变。用普通的BGD算法(每天更新一次)一方面耗时较长(需要对所有历史数据重新训练);另一方面,无法及时反馈用户的点击行为迁移。而Online GD算法可以实时的依据网民的点击行为进行迁移。
-## 2.13 计算图的导数计算图解?
+## 2.13 计算图的导数计算?
计算图导数计算是反向传播,利用链式法则和隐式函数求导。
- 假设TODO在点TODO处偏导连续,TODO是关于TODO的函数,在TODO点可导,求TODO在TODO点的导数。
+ 假设 $z = f(u,v)$ 在点 $(u,v)$ 处偏导连续,$(u,v)$是关于 $t$ 的函数,在 $t$ 点可导,求 $z$ 在 $t$ 点的导数。
根据链式法则有
-TODO
-
- 为了便于理解,下面举例说明。
-假设$f(x)$是关于a,b,c的函数。链式求导法则如下:
-
$$
-\frac{dJ}{du}=\frac{dJ}{dv}\frac{dv}{du},\frac{dJ}{db}=\frac{dJ}{du}\frac{du}{db},\frac{dJ}{da}=\frac{dJ}{du}\frac{du}{da}
+\frac{dz}{dt}=\frac{\partial z}{\partial u}.\frac{du}{dt}+\frac{\partial z}{\partial v}
+ .\frac{dv}{dt}
$$
-链式法则用文字描述:“由两个函数凑起来的复合函数,其导数等于里边函数代入外边函数的值之导数,乘以里边函数的导数。
-
-例:
+ 链式法则用文字描述:“由两个函数凑起来的复合函数,其导数等于里边函数代入外边函数的值之导数,乘以里边函数的导数。
+ 为了便于理解,下面举例说明:
$$
f(x)=x^2,g(x)=2x+1
$$
-则
-
+ 则:
$$
-{f[g(x)]}'=2[g(x)]*g'(x)=2[2x+1]*2=8x+1
+{f[g(x)]}'=2[g(x)] \times g'(x)=2[2x+1] \times 2=8x+4
$$
## 2.14 线性判别分析(LDA)
-### 2.14.1 线性判别分析(LDA)思想总结
+### 2.14.1 LDA思想总结
-线性判别分析(Linear Discriminant Analysis,LDA)是一种经典的降维方法。
+ 线性判别分析(Linear Discriminant Analysis,LDA)是一种经典的降维方法。和主成分分析PCA不考虑样本类别输出的无监督降维技术不同,LDA是一种监督学习的降维技术,数据集的每个样本有类别输出。
-和PCA不考虑样本类别输出的无监督降维技术不同,LDA是一种监督学习的降维技术,数据集的每个样本有类别输出。
+LDA分类思想简单总结如下:
+1. 多维空间中,数据处理分类问题较为复杂,LDA算法将多维空间中的数据投影到一条直线上,将d维数据转化成1维数据进行处理。
+2. 对于训练数据,设法将多维数据投影到一条直线上,同类数据的投影点尽可能接近,异类数据点尽可能远离。
+3. 对数据进行分类时,将其投影到同样的这条直线上,再根据投影点的位置来确定样本的类别。
-LDA分类思想简单总结如下:
-1. 多维空间中,数据处理分类问题较为复杂,LDA算法将多维空间中的数据投影到一条直线上,将d维数据转化成1维数据进行处理。
-2. 对于训练数据,设法将多维数据投影到一条直线上,同类数据的投影点尽可能接近,异类数据点尽可能远离。
-3. 对数据进行分类时,将其投影到同样的这条直线上,再根据投影点的位置来确定样本的类别。
如果用一句话概括LDA思想,即“投影后类内方差最小,类间方差最大”。
### 2.14.2 图解LDA核心思想
-假设有红、蓝两类数据,这些数据特征均为二维,如下图所示。我们的目标是将这些数据投影到一维,让每一类相近的数据的投影点尽可能接近,不同类别数据尽可能远,即图中红色和蓝色数据中心之间的距离尽可能大。
+ 假设有红、蓝两类数据,这些数据特征均为二维,如下图所示。我们的目标是将这些数据投影到一维,让每一类相近的数据的投影点尽可能接近,不同类别数据尽可能远,即图中红色和蓝色数据中心之间的距离尽可能大。

左图和右图是两种不同的投影方式。
-左图思路:让不同类别的平均点距离最远的投影方式。
+ 左图思路:让不同类别的平均点距离最远的投影方式。
-右图思路:让同类别的数据挨得最近的投影方式。
+ 右图思路:让同类别的数据挨得最近的投影方式。
-从上图直观看出,右图红色数据和蓝色数据在各自的区域来说相对集中,根据数据分布直方图也可看出,所以右图的投影效果好于左图,左图中间直方图部分有明显交集。
+ 从上图直观看出,右图红色数据和蓝色数据在各自的区域来说相对集中,根据数据分布直方图也可看出,所以右图的投影效果好于左图,左图中间直方图部分有明显交集。
-以上例子是基于数据是二维的,分类后的投影是一条直线。如果原始数据是多维的,则投影后的分类面是一低维的超平面。
+ 以上例子是基于数据是二维的,分类后的投影是一条直线。如果原始数据是多维的,则投影后的分类面是一低维的超平面。
### 2.14.3 二类LDA算法原理?
-输入:数据集TODO,其中样本TODO是n维向量,TODO,TODO降维后的目标维度TODO。定义
+ 输入:数据集 $D=\{(\boldsymbol x_1,\boldsymbol y_1),(\boldsymbol x_2,\boldsymbol y_2),...,(\boldsymbol x_m,\boldsymbol y_m)\}$,其中样本 $\boldsymbol x_i $ 是n维向量,$\boldsymbol y_i \epsilon \{0, 1\}$,降维后的目标维度 $d$。定义
-TODO为第TODO类样本个数;
+ $N_j(j=0,1)$ 为第 $j$ 类样本个数;
-TODO为第TODO类样本的集合;
+ $X_j(j=0,1)$ 为第 $j$ 类样本的集合;
-TODO为第TODO类样本的均值向量;
+ $u_j(j=0,1)$ 为第 $j$ 类样本的均值向量;
-TODO为第TODO类样本的协方差矩阵。
+ $\sum_j(j=0,1)$ 为第 $j$ 类样本的协方差矩阵。
-其中TODO,TODO。
-
-假设投影直线是向量TODO,对任意样本TODO,它在直线TODO上的投影为TODO,两个类别的中心点TODO在直线TODO的投影分别为TODO、TODO。
-
-LDA的目标是让两类别的数据中心间的距离TODO尽量大,与此同时,希望同类样本投影点的协方差TODO、TODO尽量小,最小化TODO。
-定义
-类内散度矩阵TODO
-
-类间散度矩阵TODO
+ 其中
+$$
+u_j = \frac{1}{N_j} \sum_{\boldsymbol x\epsilon X_j}\boldsymbol x(j=0,1),
+\sum_j = \sum_{\boldsymbol x\epsilon X_j}(\boldsymbol x-u_j)(\boldsymbol x-u_j)^T(j=0,1)
+$$
+ 假设投影直线是向量 $\boldsymbol w$,对任意样本 $\boldsymbol x_i$,它在直线 $w$上的投影为 $\boldsymbol w^Tx_i$,两个类别的中心点 $u_0$, $u_1 $在直线 $w$ 的投影分别为 $\boldsymbol w^Tu_0$ 、$\boldsymbol w^Tu_1$。
-据上分析,优化目标为TODO
+ LDA的目标是让两类别的数据中心间的距离 $\| \boldsymbol w^Tu_0 - \boldsymbol w^Tu_1 \|^2_2$ 尽量大,与此同时,希望同类样本投影点的协方差$\boldsymbol w^T \sum_0 \boldsymbol w$、$\boldsymbol w^T \sum_1 \boldsymbol w$ 尽量小,最小化 $\boldsymbol w^T \sum_0 \boldsymbol w - \boldsymbol w^T \sum_1 \boldsymbol w$ 。
+ 定义
+ 类内散度矩阵
+$$
+S_w = \sum_0 + \sum_1 =
+ \sum_{\boldsymbol x\epsilon X_0}(\boldsymbol x-u_0)(\boldsymbol x-u_0)^T +
+ \sum_{\boldsymbol x\epsilon X_1}(\boldsymbol x-u_1)(\boldsymbol x-u_1)^T
+$$
+ 类间散度矩阵 $S_b = (u_0 - u_1)(u_0 - u_1)^T$
-根据广义瑞利商的性质,矩阵TODO的最大特征值为TODO的最大值,矩阵TODO的最大特征值对应的特征向量即为TODO。
+ 据上分析,优化目标为
+$$
+\mathop{\arg\max}_\boldsymbol w J(\boldsymbol w) = \frac{\| \boldsymbol w^Tu_0 - \boldsymbol w^Tu_1 \|^2_2}{\boldsymbol w^T \sum_0\boldsymbol w + \boldsymbol w^T \sum_1\boldsymbol w} =
+\frac{\boldsymbol w^T(u_0-u_1)(u_0-u_1)^T\boldsymbol w}{\boldsymbol w^T(\sum_0 + \sum_1)\boldsymbol w} =
+\frac{\boldsymbol w^TS_b\boldsymbol w}{\boldsymbol w^TS_w\boldsymbol w}
+$$
+ 根据广义瑞利商的性质,矩阵 $S^{-1}_{w} S_b$ 的最大特征值为 $J(\boldsymbol w)$ 的最大值,矩阵 $S^{-1}_{w} S_b$ 的最大特征值对应的特征向量即为 $\boldsymbol w$。
### 2.14.4 LDA算法流程总结?
LDA算法降维流程如下:
-输入:数据集TODO,其中样本TODO是n维向量,TODO,降维后的目标维度TODO。
+ 输入:数据集 $D = \{ (x_1,y_1),(x_2,y_2), ... ,(x_m,y_m) \}$,其中样本 $x_i $ 是n维向量,$y_i \epsilon \{C_1, C_2, ..., C_k\}$,降维后的目标维度 $d$ 。
-输出:降维后的数据集TODO。
+ 输出:降维后的数据集 $\overline{D} $ 。
步骤:
-1. 计算类内散度矩阵 。
-2. 计算类间散度矩阵 。
-3. 计算矩阵 。
-4. 计算矩阵 的最大的d个特征值。
-5. 计算d个特征值对应的d个特征向量,记投影矩阵为 。
-6. 转化样本集的每个样本,得到新样本 。
-7. 输出新样本集
+1. 计算类内散度矩阵 $S_w$。
+2. 计算类间散度矩阵 $S_b$ 。
+3. 计算矩阵 $S^{-1}_wS_b$ 。
+4. 计算矩阵 $S^{-1}_wS_b$ 的最大的 d 个特征值。
+5. 计算 d 个特征值对应的 d 个特征向量,记投影矩阵为 W 。
+6. 转化样本集的每个样本,得到新样本 $P_i = W^Tx_i$ 。
+7. 输出新样本集 $\overline{D} = \{ (p_1,y_1),(p_2,y_2),...,(p_m,y_m) \}$
### 2.14.5 LDA和PCA区别?
|异同点|LDA|PCA|
|:-:|:-|:-|
-|相同点|1. 两者均可以对数据进行降维;2. 两者在降维时均使用了矩阵特征分解的思想;3. 两者都假设数据符合高斯分布;|
-|不同点|有监督的降维方法|无监督的降维方法|
-||降维最多降到k-1维|降维多少没有限制|
-||可以用于降维,还可以用于分类|只用于降维|
-||选择分类性能最好的投影方向|选择样本点投影具有最大方差的方向|
-||更明确,更能反映样本间差异|目的较为模糊|
+|相同点|1. 两者均可以对数据进行降维;
2. 两者在降维时均使用了矩阵特征分解的思想;
3. 两者都假设数据符合高斯分布;||
+|不同点|有监督的降维方法;|无监督的降维方法;|
+||降维最多降到k-1维;|降维多少没有限制;|
+||可以用于降维,还可以用于分类;|只用于降维;|
+||选择分类性能最好的投影方向;|选择样本点投影具有最大方差的方向;|
+||更明确,更能反映样本间差异;|目的较为模糊;|
### 2.14.6 LDA优缺点?
|优缺点|简要说明|
|:-:|:-|
-|优点|1. 可以使用类别的先验知识;2. 以标签,类别衡量差异性的有监督降维方式,相对于PCA的模糊性,其目的更明确,更能反映样本间的差异;|
-|缺点|1. LDA不适合对非高斯分布样本进行降维;2. LDA降维最多降到k-1维;3. LDA在样本分类信息依赖方差而不是均值时,降维效果不好;4. LDA可能过度拟合数据。|
+|优点|1. 可以使用类别的先验知识;
2. 以标签、类别衡量差异性的有监督降维方式,相对于PCA的模糊性,其目的更明确,更能反映样本间的差异;|
+|缺点|1. LDA不适合对非高斯分布样本进行降维;
2. LDA降维最多降到分类数k-1维;
3. LDA在样本分类信息依赖方差而不是均值时,降维效果不好;
4. LDA可能过度拟合数据。|
## 2.15 主成分分析(PCA)
### 2.15.1 主成分分析(PCA)思想总结
-
1. PCA就是将高维的数据通过线性变换投影到低维空间上去。
2. 投影思想:找出最能够代表原始数据的投影方法。被PCA降掉的那些维度只能是那些噪声或是冗余的数据。
3. 去冗余:去除可以被其他向量代表的线性相关向量,这部分信息量是多余的。
4. 去噪声,去除较小特征值对应的特征向量,特征值的大小反映了变换后在特征向量方向上变换的幅度,幅度越大,说明这个方向上的元素差异也越大,要保留。
5. 对角化矩阵,寻找极大线性无关组,保留较大的特征值,去除较小特征值,组成一个投影矩阵,对原始样本矩阵进行投影,得到降维后的新样本矩阵。
-6. 完成PCA的关键是——协方差矩阵。
-协方差矩阵,能同时表现不同维度间的相关性以及各个维度上的方差。
-协方差矩阵度量的是维度与维度之间的关系,而非样本与样本之间。
+6. 完成PCA的关键是——协方差矩阵。协方差矩阵,能同时表现不同维度间的相关性以及各个维度上的方差。协方差矩阵度量的是维度与维度之间的关系,而非样本与样本之间。
7. 之所以对角化,因为对角化之后非对角上的元素都是0,达到去噪声的目的。对角化后的协方差矩阵,对角线上较小的新方差对应的就是那些该去掉的维度。所以我们只取那些含有较大能量(特征值)的维度,其余的就舍掉,即去冗余。
### 2.15.2 图解PCA核心思想
-PCA可解决训练数据中存在数据特征过多或特征累赘的问题。核心思想是将m维特征映射到n维(n < m),这n维形成主元,是重构出来最能代表原始数据的正交特征。
+ PCA可解决训练数据中存在数据特征过多或特征累赘的问题。核心思想是将m维特征映射到n维(n < m),这n维形成主元,是重构出来最能代表原始数据的正交特征。
-假设数据集是m个n维,$(x^{(1)}, x^{(2)}, \cdots, x^{(m)})$。如果n=2,需要降维到$n'=1$,现在想找到某一维度方向代表这两个维度的数据。下图有$u_1, u_2$两个向量方向,但是哪个向量才是我们所想要的,可以更好代表原始数据集的呢?
+ 假设数据集是m个n维,$(\boldsymbol x^{(1)}, \boldsymbol x^{(2)}, \cdots, \boldsymbol x^{(m)})$。如果$n=2$,需要降维到$n'=1$,现在想找到某一维度方向代表这两个维度的数据。下图有$u_1, u_2$两个向量方向,但是哪个向量才是我们所想要的,可以更好代表原始数据集的呢?

@@ -761,38 +857,58 @@ PCA可解决训练数据中存在数据特征过多或特征累赘的问题。
### 2.15.3 PCA算法推理
下面以基于最小投影距离为评价指标推理:
-假设数据集是m个n维,TODO,且数据进行了中心化。经过投影变换得到新坐标为TODO,其中TODO是标准正交基,即TODO,TODO。经过降维后,新坐标为TODO,其中TODO是降维后的目标维数。样本点TODO在新坐标系下的投影为TODO,其中TODO是TODO在低维坐标系里第j维的坐标。如果用TODO去恢复TODO,则得到的恢复数据为TODO,其中TODO为标准正交基组成的矩阵。
+ 假设数据集是m个n维,$(x^{(1)}, x^{(2)},...,x^{(m)})$,且数据进行了中心化。经过投影变换得到新坐标为 ${w_1,w_2,...,w_n}$,其中 $w$ 是标准正交基,即 $\| w \|_2 = 1$,$w^T_iw_j = 0$。
-考虑到整个样本集,样本点到这个超平面的距离足够近,目标变为最小化TODO。对此式进行推理,可得:
-TODO
+ 经过降维后,新坐标为 $\{ w_1,w_2,...,w_n \}$,其中 $n'$ 是降维后的目标维数。样本点 $x^{(i)}$ 在新坐标系下的投影为 $z^{(i)} = \left(z^{(i)}_1, z^{(i)}_2, ..., z^{(i)}_{n'} \right)$,其中 $z^{(i)}_j = w^T_j x^{(i)}$ 是 $x^{(i)} $ 在低维坐标系里第 j 维的坐标。
-在推导过程中,分别用到了TODO,矩阵转置公式TODO,TODO,TODO以及矩阵的迹,最后两步是将代数和转为矩阵形式。
-由于TODO的每一个向量TODO是标准正交基,TODO是数据集的协方差矩阵,TODO是一个常量。最小化TODO又可等价于
+ 如果用 $z^{(i)} $ 去恢复 $x^{(i)} $ ,则得到的恢复数据为 $\widehat{x}^{(i)} = \sum^{n'}_{j=1} x^{(i)}_j w_j = Wz^{(i)}$,其中 $W$为标准正交基组成的矩阵。
-TODO
+ 考虑到整个样本集,样本点到这个超平面的距离足够近,目标变为最小化 $\sum^m_{i=1} \| \hat{x}^{(i)} - x^{(i)} \|^2_2$ 。对此式进行推理,可得:
+$$
+\sum^m_{i=1} \| \hat{x}^{(i)} - x^{(i)} \|^2_2 =
+ \sum^m_{i=1} \| Wz^{(i)} - x^{(i)} \|^2_2 \\
+ = \sum^m_{i=1} \left( Wz^{(i)} \right)^T \left( Wz^{(i)} \right)
+ - 2\sum^m_{i=1} \left( Wz^{(i)} \right)^T x^{(i)}
+ + \sum^m_{i=1} \left( x^{(i)} \right)^T x^{(i)} \\
+ = \sum^m_{i=1} \left( z^{(i)} \right)^T \left( z^{(i)} \right)
+ - 2\sum^m_{i=1} \left( z^{(i)} \right)^T x^{(i)}
+ + \sum^m_{i=1} \left( x^{(i)} \right)^T x^{(i)} \\
+ = - \sum^m_{i=1} \left( z^{(i)} \right)^T \left( z^{(i)} \right)
+ + \sum^m_{i=1} \left( x^{(i)} \right)^T x^{(i)} \\
+ = -tr \left( W^T \left( \sum^m_{i=1} x^{(i)} \left( x^{(i)} \right)^T \right)W \right)
+ + \sum^m_{i=1} \left( x^{(i)} \right)^T x^{(i)} \\
+ = -tr \left( W^TXX^TW \right)
+ + \sum^m_{i=1} \left( x^{(i)} \right)^T x^{(i)}
+$$
+ 在推导过程中,分别用到了 $\overline{x}^{(i)} = Wz^{(i)}$ ,矩阵转置公式 $(AB)^T = B^TA^T$,$W^TW = I$,$z^{(i)} = W^Tx^{(i)}$ 以及矩阵的迹,最后两步是将代数和转为矩阵形式。
+ 由于 $W$ 的每一个向量 $w_j$ 是标准正交基,$\sum^m_{i=1} x^{(i)} \left( x^{(i)} \right)^T$ 是数据集的协方差矩阵,$\sum^m_{i=1} \left( x^{(i)} \right)^T x^{(i)} $ 是一个常量。最小化 $\sum^m_{i=1} \| \hat{x}^{(i)} - x^{(i)} \|^2_2$ 又可等价于
+$$
+\underbrace{\arg \min}_W - tr \left( W^TXX^TW \right) s.t.W^TW = I
+$$
利用拉格朗日函数可得到
-TODO
-
-对TODO求导,可得TODO,也即TODO。 是TODO个特征向量组成的矩阵, 为TODO的特征值。TODO即为我们想要的矩阵。
-对于原始数据,只需要TODO,就可把原始数据集降维到最小投影距离的TODO维数据集。
+$$
+J(W) = -tr(W^TXX^TW) + \lambda(W^TW - I)
+$$
+ 对 $W$ 求导,可得 $-XX^TW + \lambda W = 0 $ ,也即 $ XX^TW = \lambda W $ 。 $ XX^T $ 是 $ n' $ 个特征向量组成的矩阵,$\lambda$ 为$ XX^T $ 的特征值。$W$ 即为我们想要的矩阵。
+ 对于原始数据,只需要 $z^{(i)} = W^TX^{(i)}$ ,就可把原始数据集降维到最小投影距离的 $n'$ 维数据集。
-基于最大投影方差的推导,这里就不再赘述,有兴趣的同仁可自行查阅资料。
+ 基于最大投影方差的推导,这里就不再赘述,有兴趣的同仁可自行查阅资料。
### 2.15.4 PCA算法流程总结
-输入:TODO维样本集TODO,目标降维的维数TODO。
+输入:$n$ 维样本集 $D = \left( x^{(1)},x^{(2)},...,x^{(m)} \right)$ ,目标降维的维数 $n'$ 。
-输出:降维后的新样本集TODO。
+输出:降维后的新样本集 $D' = \left( z^{(1)},z^{(2)},...,z^{(m)} \right)$ 。
主要步骤如下:
-1. 对所有的样本进行中心化,TODO。
-2. 计算样本的协方差矩阵TODO。
-3. 对协方差矩阵TODO进行特征值分解。
-4. 取出最大的TODO个特征值对应的特征向量TODO。
-5. 标准化特征向量,得到特征向量矩阵TODO。
-6. 转化样本集中的每个样本TODO。
-7. 得到输出矩阵TODO。
-*注*:在降维时,有时不明确目标维数,而是指定降维到的主成分比重阈值TODO。假设TODO个特征值为TODO,则TODO可从TODO得到。
+1. 对所有的样本进行中心化,$ x^{(i)} = x^{(i)} - \frac{1}{m} \sum^m_{j=1} x^{(j)} $ 。
+2. 计算样本的协方差矩阵 $XX^T$ 。
+3. 对协方差矩阵 $XX^T$ 进行特征值分解。
+4. 取出最大的 $n' $ 个特征值对应的特征向量 $\{ w_1,w_2,...,w_{n'} \}$ 。
+5. 标准化特征向量,得到特征向量矩阵 $W$ 。
+6. 转化样本集中的每个样本 $z^{(i)} = W^T x^{(i)}$ 。
+7. 得到输出矩阵 $D' = \left( z^{(1)},z^{(2)},...,z^{(n)} \right)$ 。
+*注*:在降维时,有时不明确目标维数,而是指定降维到的主成分比重阈值 $k(k \epsilon(0,1])$ 。假设 $n$ 个特征值为 $\lambda_1 \geqslant \lambda_2 \geqslant ... \geqslant \lambda_n$ ,则 $n'$ 可从 $\sum^{n'}_{i=1} \lambda_i \geqslant k \times \sum^n_{i=1} \lambda_i $ 得到。
### 2.15.5 PCA算法主要优缺点
|优缺点|简要说明|
@@ -802,83 +918,100 @@ TODO
### 2.15.6 降维的必要性及目的
**降维的必要性**:
-1. 多重共线性--预测变量之间相互关联。多重共线性会导致解空间的不稳定,从而可能导致结果的不连贯。
-2. 高维空间本身具有稀疏性。一维正态分布有68%的值落于正负标准差之间,而在十维空间上只有0.02%。
+1. 多重共线性和预测变量之间相互关联。多重共线性会导致解空间的不稳定,从而可能导致结果的不连贯。
+2. 高维空间本身具有稀疏性。一维正态分布有68%的值落于正负标准差之间,而在十维空间上只有2%。
3. 过多的变量,对查找规律造成冗余麻烦。
4. 仅在变量层面上分析可能会忽略变量之间的潜在联系。例如几个预测变量可能落入仅反映数据某一方面特征的一个组内。
**降维的目的**:
1. 减少预测变量的个数。
2. 确保这些变量是相互独立的。
-3. 提供一个框架来解释结果。关特征,特别是重要特征更能在数据中明确的显示出来;如果只有两维或者三维的话,更便于可视化展示。
+3. 提供一个框架来解释结果。相关特征,特别是重要特征更能在数据中明确的显示出来;如果只有两维或者三维的话,更便于可视化展示。
4. 数据在低维下更容易处理、更容易使用。
5. 去除数据噪声。
6. 降低算法运算开销。
### 2.15.7 KPCA与PCA的区别?
-应用PCA算法的前提是假设存在一个线性的超平面,进而投影。那如果数据不是线性的呢?该怎么办?这时候就需要KPCA,数据集从TODO维映射到线性可分的高维TODO,然后再从TODO维降维到一个低维度TODO。
+ 应用PCA算法前提是假设存在一个线性超平面,进而投影。那如果数据不是线性的呢?该怎么办?这时候就需要KPCA,数据集从 $n$ 维映射到线性可分的高维 $N >n$,然后再从 $N$ 维降维到一个低维度 $n'(n' 训练误差大,测试误差小 → Bias大
->
-> 训练误差小,测试误差大→ Variance大 → 降VC维
->
-> 训练误差大,测试误差大→ 升VC维
+> 
+>
### 2.16.3 经验误差与泛化误差
-误差(error):一般地,我们把学习器的实际预测输出与样本的真是输出之间的差异称为“误差”
-经验误差(empirical error):也叫训练误差(training error)。模型在训练集上的误差。
+经验误差(empirical error):也叫训练误差(training error),模型在训练集上的误差。
泛化误差(generalization error):模型在新样本集(测试集)上的误差称为“泛化误差”。
@@ -886,40 +1019,44 @@ Bias(偏差),Error(误差),和Variance(方差)
根据不同的坐标方式,欠拟合与过拟合图解不同。
1. **横轴为训练样本数量,纵轴为误差**
-
+
如上图所示,我们可以直观看出欠拟合和过拟合的区别:
-模型欠拟合:在训练集以及测试集上同时具有较高的误差,此时模型的偏差较大;
+ 模型欠拟合:在训练集以及测试集上同时具有较高的误差,此时模型的偏差较大;
-模型过拟合:在训练集上具有较低的误差,在测试集上具有较高的误差,此时模型的方差较大。
+ 模型过拟合:在训练集上具有较低的误差,在测试集上具有较高的误差,此时模型的方差较大。
-模型正常:在训练集以及测试集上,同时具有相对较低的偏差以及方差。
+ 模型正常:在训练集以及测试集上,同时具有相对较低的偏差以及方差。
2. **横轴为模型复杂程度,纵轴为误差**
-
+
+
+ 红线为测试集上的Error,蓝线为训练集上的Error
-模型欠拟合:模型在点A处,在训练集以及测试集上同时具有较高的误差,此时模型的偏差较大。
+ 模型欠拟合:模型在点A处,在训练集以及测试集上同时具有较高的误差,此时模型的偏差较大。
-模型过拟合:模型在点C处,在训练集上具有较低的误差,在测试集上具有较高的误差,此时模型的方差较大。
+ 模型过拟合:模型在点C处,在训练集上具有较低的误差,在测试集上具有较高的误差,此时模型的方差较大。
-模型正常:模型复杂程度控制在点B处为最优。
+ 模型正常:模型复杂程度控制在点B处为最优。
3. **横轴为正则项系数,纵轴为误差**
-
+
-模型欠拟合:模型在点C处,在训练集以及测试集上同时具有较高的误差,此时模型的偏差较大。
+ 红线为测试集上的Error,蓝线为训练集上的Error
-模型过拟合:模型在点A处,在训练集上具有较低的误差,在测试集上具有较高的误差,此时模型的方差较大。 它通常发生在模型过于复杂的情况下,如参数过多等,会使得模型的预测性能变弱,并且增加数据的波动性。虽然模型在训练时的效果可以表现的很完美,基本上记住了数据的全部特点,但这种模型在未知数据的表现能力会大减折扣,因为简单的模型泛化能力通常都是很弱的。
+ 模型欠拟合:模型在点C处,在训练集以及测试集上同时具有较高的误差,此时模型的偏差较大。
-模型正常:模型复杂程度控制在点B处为最优。
+ 模型过拟合:模型在点A处,在训练集上具有较低的误差,在测试集上具有较高的误差,此时模型的方差较大。 它通常发生在模型过于复杂的情况下,如参数过多等,会使得模型的预测性能变弱,并且增加数据的波动性。虽然模型在训练时的效果可以表现的很完美,基本上记住了数据的全部特点,但这种模型在未知数据的表现能力会大减折扣,因为简单的模型泛化能力通常都是很弱的。
+
+ 模型正常:模型复杂程度控制在点B处为最优。
### 2.16.5 如何解决过拟合与欠拟合?
**如何解决欠拟合:**
1. 添加其他特征项。组合、泛化、相关性、上下文特征、平台特征等特征是特征添加的重要手段,有时候特征项不够会导致模型欠拟合。
-2. 添加多项式特征。例如将线性模型添加二次项或三次项使模型泛化能力更强。例如,FM模型、FFM模型,其实就是线性模型,增加了二阶多项式,保证了模型一定的拟合程度。
+2. 添加多项式特征。例如将线性模型添加二次项或三次项使模型泛化能力更强。例如,FM(Factorization Machine)模型、FFM(Field-aware Factorization Machine)模型,其实就是线性模型,增加了二阶多项式,保证了模型一定的拟合程度。
3. 可以增加模型的复杂程度。
4. 减小正则化系数。正则化的目的是用来防止过拟合的,但是现在模型出现了欠拟合,则需要减少正则化参数。
@@ -929,28 +1066,28 @@ Bias(偏差),Error(误差),和Variance(方差)
3. 降低模型复杂程度。
4. 增大正则项系数。
5. 采用dropout方法,dropout方法,通俗的讲就是在训练的时候让神经元以一定的概率不工作。
-6. early stoping。
+6. early stopping。
7. 减少迭代次数。
8. 增大学习率。
9. 添加噪声数据。
10. 树结构中,可以对树进行剪枝。
+11. 减少特征项。
欠拟合和过拟合这些方法,需要根据实际问题,实际模型,进行选择。
-### 2.16.6 交叉验证的主要作用?
-为了得到更为稳健可靠的模型,对模型的泛化误差进行评估,得到模型泛化误差的近似值。当有多个模型可以选择时,我们通常选择“泛化误差”最小的模型。
+### 2.16.6 交叉验证的主要作用
+ 为了得到更为稳健可靠的模型,对模型的泛化误差进行评估,得到模型泛化误差的近似值。当有多个模型可以选择时,我们通常选择“泛化误差”最小的模型。
-交叉验证的方法有许多种,但是最常用的是:留一交叉验证、k折交叉验证
+ 交叉验证的方法有许多种,但是最常用的是:留一交叉验证、k折交叉验证。
-### 2.16.7 k折交叉验证?
+### 2.16.7 理解k折交叉验证
1. 将含有N个样本的数据集,分成K份,每份含有N/K个样本。选择其中1份作为测试集,另外K-1份作为训练集,测试集就有K种情况。
-2. 在每种情况中,用训练集训练模型,用测试集测试模型,计算模型的泛化误差。
+2. 在每种情况中,用训练集训练模型,用测试集测试模型,计算模型的泛化误差。
3. 交叉验证重复K次,每份验证一次,平均K次的结果或者使用其它结合方式,最终得到一个单一估测,得到模型最终的泛化误差。
-4. 将K种情况下,模型的泛化误差取均值,得到模型最终的泛化误差。
-**注**:
-1. 一般2<=K<=10。 k折交叉验证的优势在于,同时重复运用随机产生的子样本进行训练和验证,每次的结果验证一次,10折交叉验证是最常用的。
-2. 训练集中样本数量要足够多,一般至少大于总样本数的50%。
-3. 训练集和测试集必须从完整的数据集中均匀取样。均匀取样的目的是希望减少训练集、测试集与原数据集之间的偏差。当样本数量足够多时,通过随机取样,便可以实现均匀取样的效果。
+4. 将K种情况下,模型的泛化误差取均值,得到模型最终的泛化误差。
+5. 一般$2\leqslant K \leqslant10$。 k折交叉验证的优势在于,同时重复运用随机产生的子样本进行训练和验证,每次的结果验证一次,10折交叉验证是最常用的。
+6. 训练集中样本数量要足够多,一般至少大于总样本数的50%。
+7. 训练集和测试集必须从完整的数据集中均匀取样。均匀取样的目的是希望减少训练集、测试集与原数据集之间的偏差。当样本数量足够多时,通过随机取样,便可以实现均匀取样的效果。
### 2.16.8 混淆矩阵
第一种混淆矩阵:
@@ -991,332 +1128,283 @@ Bias(偏差),Error(误差),和Variance(方差)
例,在所有实际上有恶性肿瘤的病人中,成功预测有恶性肿瘤的病人的百分比,越高越好。
### 2.16.11 ROC与AUC
-ROC全称是“受试者工作特征”(Receiver Operating Characteristic)。
+ ROC全称是“受试者工作特征”(Receiver Operating Characteristic)。
-ROC曲线的面积就是AUC(Area Under the Curve)。
+ ROC曲线的面积就是AUC(Area Under Curve)。
-AUC用于衡量“二分类问题”机器学习算法性能(泛化能力)。
+ AUC用于衡量“二分类问题”机器学习算法性能(泛化能力)。
-ROC曲线,通过将连续变量设定出多个不同的临界值,从而计算出一系列真正率和假正率,再以假正率为纵坐标、真正率为横坐标绘制成曲线,曲线下面积越大,诊断准确性越高。在ROC曲线上,最靠近坐标图左上方的点为假正率和真正率均较高的临界值。
+ ROC曲线,通过将连续变量设定出多个不同的临界值,从而计算出一系列真正率和假正率,再以假正率为横坐标、真正率为纵坐标绘制成曲线,曲线下面积越大,推断准确性越高。在ROC曲线上,最靠近坐标图左上方的点为假正率和真正率均较高的临界值。
-对于分类器,或者说分类算法,评价指标主要有precision,recall,F-score。下图是一个ROC曲线的示例。
+ 对于分类器,或者说分类算法,评价指标主要有Precision,Recall,F-score。下图是一个ROC曲线的示例。

-ROC曲线的横坐标为false positive rate(FPR),纵坐标为true positive rate(TPR)。其中
-TODO, TODO,
-下面着重介绍ROC曲线图中的四个点和一条线。
-第一个点,(0,1),即FPR=0, TPR=1,这意味着FN(false negative)=0,并且FP(false positive)=0。意味着这是一个完美的分类器,它将所有的样本都正确分类。
-第二个点,(1,0),即FPR=1,TPR=0,意味着这是一个最糟糕的分类器,因为它成功避开了所有的正确答案。
-第三个点,(0,0),即FPR=TPR=0,即FP(false positive)=TP(true positive)=0,可以发现该分类器预测所有的样本都为负样本(negative)。
-第四个点,(1,1),即FPR=TPR=1,分类器实际上预测所有的样本都为正样本。
-经过以上分析,ROC曲线越接近左上角,该分类器的性能越好。
+ROC曲线的横坐标为False Positive Rate(FPR),纵坐标为True Positive Rate(TPR)。其中
+$$
+TPR = \frac{TP}{TP+FN} ,FPR = \frac{FP}{FP+TN}
+$$
+
+ 下面着重介绍ROC曲线图中的四个点和一条线。
+ 第一个点(0,1),即FPR=0, TPR=1,这意味着FN(False Negative)=0,并且FP(False Positive)=0。意味着这是一个完美的分类器,它将所有的样本都正确分类。
+ 第二个点(1,0),即FPR=1,TPR=0,意味着这是一个最糟糕的分类器,因为它成功避开了所有的正确答案。
+ 第三个点(0,0),即FPR=TPR=0,即FP(False Positive)=TP(True Positive)=0,可以发现该分类器预测所有的样本都为负样本(Negative)。
+ 第四个点(1,1),即FPR=TPR=1,分类器实际上预测所有的样本都为正样本。
+ 经过以上分析,ROC曲线越接近左上角,该分类器的性能越好。
+
+ ROC曲线所覆盖的面积称为AUC(Area Under Curve),可以更直观的判断学习器的性能,AUC越大则性能越好。
-ROC曲线所覆盖的面积称为AUC(Area Under Curve),可以更直观的判断学习器的性能,AUC越大则性能越好。
### 2.16.12 如何画ROC曲线?
-http://blog.csdn.net/zdy0_2004/article/details/44948511
-下图是一个示例,图中共有20个测试样本,“Class”一栏表示每个测试样本真正的标签(p表示正样本,n表示负样本),“Score”表示每个测试样本属于正样本的概率。
+ 下图是一个示例,图中共有20个测试样本,“Class”一栏表示每个测试样本真正的标签(p表示正样本,n表示负样本),“Score”表示每个测试样本属于正样本的概率。
步骤:
-1、假设已经得出一系列样本被划分为正类的概率,按照大小排序。
-2、从高到低,依次将“Score”值作为阈值threshold,当测试样本属于正样本的概率大于或等于这个threshold时,我们认为它为正样本,否则为负样本。 举例来说,对于图中的第4个样本,其“Score”值为0.6,那么样本1,2,3,4都被认为是正样本,因为它们的“Score”值都大于等于0.6,而其他样本则都认为是负样本。
-3、每次选取一个不同的threshold,得到一组FPR和TPR,即ROC曲线上的一点。以此共得到20组FPR和TPR的值。其中FPR和TPR简单理解如下:
-4、根据3)中的每个坐标点点,画图。
+ 1、假设已经得出一系列样本被划分为正类的概率,按照大小排序。
+ 2、从高到低,依次将“Score”值作为阈值threshold,当测试样本属于正样本的概率大于或等于这个threshold时,我们认为它为正样本,否则为负样本。举例来说,对于图中的第4个样本,其“Score”值为0.6,那么样本1,2,3,4都被认为是正样本,因为它们的“Score”值都大于等于0.6,而其他样本则都认为是负样本。
+ 3、每次选取一个不同的threshold,得到一组FPR和TPR,即ROC曲线上的一点。以此共得到20组FPR和TPR的值。
+ 4、根据3、中的每个坐标点,画图。

### 2.16.13 如何计算TPR,FPR?
1、分析数据
-y_true = [0, 0, 1, 1];
-scores = [0.1, 0.4, 0.35, 0.8];
+y_true = [0, 0, 1, 1];scores = [0.1, 0.4, 0.35, 0.8];
2、列表
-样本 预测属于P的概率(score) 真实类别
-y[0] 0.1 N
-y[2] 0.35 P
-y[1] 0.4 N
-y[3] 0.8 P
+
+| 样本 | 预测属于P的概率(score) | 真实类别 |
+| ---- | ---------------------- | -------- |
+| y[0] | 0.1 | N |
+| y[1] | 0.4 | N |
+| y[2] | 0.35 | P |
+| y[3] | 0.8 | P |
+
3、将截断点依次取为score值,计算TPR和FPR。
当截断点为0.1时:
说明只要score>=0.1,它的预测类别就是正例。 因为4个样本的score都大于等于0.1,所以,所有样本的预测类别都为P。
-scores = [0.1, 0.4, 0.35, 0.8];
-y_true = [0, 0, 1, 1];
-y_pred = [1, 1, 1, 1];
+scores = [0.1, 0.4, 0.35, 0.8];y_true = [0, 0, 1, 1];y_pred = [1, 1, 1, 1];
正例与反例信息如下:
-真实值 预测值
- 正例 反例
-正例 TP=2 FN=0
-反例 FP=2 TN=0
+
+| | 正例 | 反例 |
+| ------------- | ---- | ---- |
+| **正例** | TP=2 | FN=0 |
+| **反例** | FP=2 | TN=0 |
+
由此可得:
-TPR = TP/(TP+FN) = 1;
-FPR = FP/(TN+FP) = 1;
+TPR = TP/(TP+FN) = 1; FPR = FP/(TN+FP) = 1;
当截断点为0.35时:
-scores = [0.1, 0.4, 0.35, 0.8]
-y_true = [0, 0, 1, 1]
-y_pred = [0, 1, 1, 1]
+scores = [0.1, 0.4, 0.35, 0.8];y_true = [0, 0, 1, 1];y_pred = [0, 1, 1, 1];
正例与反例信息如下:
-真实值 预测值
- 正例 反例
-正例 TP=2 FN=0
-反例 FP=1 TN=1
+
+| | 正例 | 反例 |
+| ------------- | ---- | ---- |
+| **正例** | TP=2 | FN=0 |
+| **反例** | FP=1 | TN=1 |
+
由此可得:
-TPR = TP/(TP+FN) = 1;
-FPR = FP/(TN+FP) = 0.5;
+TPR = TP/(TP+FN) = 1; FPR = FP/(TN+FP) = 0.5;
当截断点为0.4时:
-scores = [0.1, 0.4, 0.35, 0.8];
-y_true = [0, 0, 1, 1];
-y_pred = [0, 1, 0, 1];
+scores = [0.1, 0.4, 0.35, 0.8];y_true = [0, 0, 1, 1];y_pred = [0, 1, 0, 1];
正例与反例信息如下:
-真实值 预测值
- 正例 反例
-正例 TP=1 FN=1
-反例 FP=1 TN=1
+
+| | 正例 | 反例 |
+| ------------- | ---- | ---- |
+| **正例** | TP=1 | FN=1 |
+| **反例** | FP=1 | TN=1 |
+
由此可得:
-TPR = TP/(TP+FN) = 0.5;
-FPR = FP/(TN+FP) = 0.5;
+TPR = TP/(TP+FN) = 0.5; FPR = FP/(TN+FP) = 0.5;
当截断点为0.8时:
-scores = [0.1, 0.4, 0.35, 0.8];
-y_true = [0, 0, 1, 1];
-y_pred = [0, 0, 0, 1];
+scores = [0.1, 0.4, 0.35, 0.8];y_true = [0, 0, 1, 1];y_pred = [0, 0, 0, 1];
+
正例与反例信息如下:
-真实值 预测值
- 正例 反例
-正例 TP=1 FN=1
-反例 FP=0 TN=2
+
+| | 正例 | 反例 |
+| ------------- | ---- | ---- |
+| **正例** | TP=1 | FN=1 |
+| **反例** | FP=0 | TN=2 |
+
由此可得:
-TPR = TP/(TP+FN) = 0.5;
-FPR = FP/(TN+FP) = 0;
+TPR = TP/(TP+FN) = 0.5; FPR = FP/(TN+FP) = 0;
+
4、根据TPR、FPR值,以FPR为横轴,TPR为纵轴画图。
-### 2.16.14 如何计算Auc?
-a.将坐标点按照横着FPR排序
-b.计算第i个坐标点和第i+1个坐标点的间距 dx;
-c.获取第i(或者i+1)个坐标点的纵坐标y;
-d.计算面积微元ds = ydx;
-e.对面积微元进行累加,得到AUC。
+### 2.16.14 如何计算AUC?
+- 将坐标点按照横坐标FPR排序 。
+- 计算第$i$个坐标点和第$i+1$个坐标点的间距$dx$ 。
+- 获取第$i$或者$i+1$个坐标点的纵坐标y。
+- 计算面积微元$ds=ydx$。
+- 对面积微元进行累加,得到AUC。
### 2.16.15 为什么使用Roc和Auc评价分类器?
-模型有很多评估方法,为什么还要使用ROC和AUC呢?
-因为ROC曲线有个很好的特性:当测试集中的正负样本的分布变换的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现样本类不平衡,即正负样本比例差距较大,而且测试数据中的正负样本也可能随着时间变化。
+ 模型有很多评估方法,为什么还要使用ROC和AUC呢?
+ 因为ROC曲线有个很好的特性:当测试集中的正负样本的分布变换的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现样本类不平衡,即正负样本比例差距较大,而且测试数据中的正负样本也可能随着时间变化。
-### 2.16.17 直观理解AUC
-http://blog.csdn.net/cherrylvlei/article/details/52958720
-AUC是ROC右下方的曲线面积。下图展现了三种AUC的值:
+### 2.16.16 直观理解AUC
+ 下图展现了三种AUC的值:

-AUC是衡量二分类模型优劣的一种评价指标,表示正例排在负例前面的概率。其他评价指标有精确度、准确率、召回率,而AUC比这三者更为常用。
-因为一般在分类模型中,预测结果都是以概率的形式表现,如果要计算准确率,通常都会手动设置一个阈值来将对应的概率转化成类别,这个阈值也就很大程度上影响了模型准确率的计算。
-我们不妨举一个极端的例子:一个二类分类问题一共10个样本,其中9个样本为正例,1个样本为负例,在全部判正的情况下准确率将高达90%,而这并不是我们希望的结果,尤其是在这个负例样本得分还是最高的情况下,模型的性能本应极差,从准确率上看却适得其反。而AUC能很好描述模型整体性能的高低。这种情况下,模型的AUC值将等于0(当然,通过取反可以解决小于50%的情况,不过这是另一回事了)。
+ AUC是衡量二分类模型优劣的一种评价指标,表示正例排在负例前面的概率。其他评价指标有精确度、准确率、召回率,而AUC比这三者更为常用。
+ 一般在分类模型中,预测结果都是以概率的形式表现,如果要计算准确率,通常都会手动设置一个阈值来将对应的概率转化成类别,这个阈值也就很大程度上影响了模型准确率的计算。
+ 举例:
+ 现在假设有一个训练好的二分类器对10个正负样本(正例5个,负例5个)预测,得分按高到低排序得到的最好预测结果为[1, 1, 1, 1, 1, 0, 0, 0, 0, 0],即5个正例均排在5个负例前面,正例排在负例前面的概率为100%。然后绘制其ROC曲线,由于是10个样本,除去原点我们需要描10个点,如下:
-### 2.16.18 代价敏感错误率与代价曲线
+
-http://blog.csdn.net/cug_lzt/article/details/78295140
+ 描点方式按照样本预测结果的得分高低从左至右开始遍历。从原点开始,每遇到1便向y轴正方向移动y轴最小步长1个单位,这里是1/5=0.2;每遇到0则向x轴正方向移动x轴最小步长1个单位,这里也是0.2。不难看出,上图的AUC等于1,印证了正例排在负例前面的概率的确为100%。
-不同的错误会产生不同代价。
-以二分法为例,设置代价矩阵如下:
+ 假设预测结果序列为[1, 1, 1, 1, 0, 1, 0, 0, 0, 0]。
-
+
-当判断正确的时候,值为0,不正确的时候,分别为$Cost_{01}$和$Cost_{10}$ 。
+ 计算上图的AUC为0.96与计算正例与排在负例前面的概率0.8 × 1 + 0.2 × 0.8 = 0.96相等,而左上角阴影部分的面积则是负例排在正例前面的概率0.2 × 0.2 = 0.04。
-$Cost_{10}$:表示实际为反例但预测成正例的代价。
+ 假设预测结果序列为[1, 1, 1, 0, 1, 0, 1, 0, 0, 0]。
-$Cost_{01}$:表示实际为正例但是预测为反例的代价。
+
-**代价敏感错误率**:
-$\frac{样本中由模型得到的错误值与代价乘积之和}{总样本}$
+ 计算上图的AUC为0.88与计算正例与排在负例前面的概率0.6 × 1 + 0.2 × 0.8 + 0.2 × 0.6 = 0.88相等,左上角阴影部分的面积是负例排在正例前面的概率0.2 × 0.2 × 3 = 0.12。
-其数学表达式为:
+### 2.16.17 代价敏感错误率与代价曲线
-
+不同的错误会产生不同代价。以二分法为例,设置代价矩阵如下:
-$D^{+}、D^{-}$分别代表样例集 的正例子集和反例子集。
+
-代价曲线:
-在均等代价时,ROC曲线不能直接反应出模型的期望总体代价,而代价曲线可以。
-代价曲线横轴为[0,1]的正例函数代价:
+当判断正确的时候,值为0,不正确的时候,分别为$Cost_{01}$和$Cost_{10}$ 。
-$P(+)Cost=\frac{p*Cost_{01}}{p*Cost_{01}+(1-p)*Cost_{10}}$
+$Cost_{10}$:表示实际为反例但预测成正例的代价。
+
+$Cost_{01}$:表示实际为正例但是预测为反例的代价。
+
+**代价敏感错误率**=样本中由模型得到的错误值与代价乘积之和 / 总样本。
+其数学表达式为:
+$$
+E(f;D;cost)=\frac{1}{m}\left( \sum_{x_{i} \in D^{+}}({f(x_i)\neq y_i})\times Cost_{01}+ \sum_{x_{i} \in D^{-}}({f(x_i)\neq y_i})\times Cost_{10}\right)
+$$
+$D^{+}、D^{-}$分别代表样例集的正例子集和反例子集,x是预测值,y是真实值。
+**代价曲线**:
+ 在均等代价时,ROC曲线不能直接反应出模型的期望总体代价,而代价曲线可以。
+代价曲线横轴为[0,1]的正例函数代价:
+$$
+P(+)Cost=\frac{p*Cost_{01}}{p*Cost_{01}+(1-p)*Cost_{10}}
+$$
其中p是样本为正例的概率。
代价曲线纵轴维[0,1]的归一化代价:
-$Cost_{norm}=\frac{FNR*p*Cost_{01}+FNR*(1-p)*Cost_{10}}{p*Cost_{01}+(1-p)*Cost_{10}}$
-
+$$
+Cost_{norm}=\frac{FNR*p*Cost_{01}+FNR*(1-p)*Cost_{10}}{p*Cost_{01}+(1-p)*Cost_{10}}
+$$
-其中FPR为假正例率,FNR=1-TPR为假反利率。
+其中FPR为假阳率,FNR=1-TPR为假阴率。
注:ROC每个点,对应代价平面上一条线。
例如,ROC上(TPR,FPR),计算出FNR=1-TPR,在代价平面上绘制一条从(0,FPR)到(1,FNR)的线段,面积则为该条件下期望的总体代价。所有线段下界面积,所有条件下学习器的期望总体代价。
-
+
-### 2.16.19 模型有哪些比较检验方法
-http://wenwen.sogou.com/z/q721171854.htm
+### 2.16.18 模型有哪些比较检验方法
正确性分析:模型稳定性分析,稳健性分析,收敛性分析,变化趋势分析,极值分析等。
有效性分析:误差分析,参数敏感性分析,模型对比检验等。
有用性分析:关键数据求解,极值点,拐点,变化趋势分析,用数据验证动态模拟等。
高效性分析:时空复杂度分析与现有进行比较等。
-### 2.16.20 偏差与方差
-http://blog.csdn.net/zhihua_oba/article/details/78684257
-
-方差公式为:
-
-$S_{N}^{2}=\frac{1}{N}\sum_{i=1}^{N}(x_{i}-\bar{x})^{2}$
-
-泛化误差可分解为偏差、方差与噪声之和,即
-generalization error=bias+variance+noise。
-
-噪声:描述了在当前任务上任何学习算法所能达到的期望泛化误差的下界,即刻画了学习问题本身的难度。
-假定期望噪声为零,则泛化误差可分解为偏差、方差之和,即
-generalization error=bias+variance。
-
-偏差(bias):描述的是预测值(估计值)的期望与真实值之间的差距。偏差越大,越偏离真实数据,如下图第二行所示。
+### 2.16.19 为什么使用标准差?
-方差(variance):描述的是预测值的变化范围,离散程度,也就是离其期望值的距离。方差越大,数据的分布越分散,模型的稳定程度越差。如果模型在训练集上拟合效果比较优秀,但是在测试集上拟合效果比较差劣,则方差较大,说明模型的稳定程度较差,出现这种现象可能是由于模型对训练集过拟合造成的。 如下图右列所示。
+方差公式为:$S^2_{N}=\frac{1}{N}\sum_{i=1}^{N}(x_{i}-\bar{x})^{2}$
-
+标准差公式为:$S_{N}=\sqrt{\frac{1}{N}\sum_{i=1}^{N}(x_{i}-\bar{x})^{2}}$
-简单的总结一下:
-偏差大,会造成模型欠拟合;
-方差大,会造成模型过拟合。
-
-### 2.16.21为什么使用标准差?
-
-标准差公式为:$S_{N}=\sqrt{\frac{1}{N}\sum_{i=1}^{N}(x_{i}-\bar{x})^{2}}$
-
-样本标准差公式为:$S_{N}=\sqrt{\frac{1}{N-1}\sum_{i=1}^{N}(x_{i}-\bar{x})^{2}}$
+样本标准差公式为:$S_{N}=\sqrt{\frac{1}{N-1}\sum_{i=1}^{N}(x_{i}-\bar{x})^{2}}$
与方差相比,使用标准差来表示数据点的离散程度有3个好处:
1、表示离散程度的数字与样本数据点的数量级一致,更适合对数据样本形成感性认知。
2、表示离散程度的数字单位与样本数据的单位一致,更方便做后续的分析运算。
-3、在样本数据大致符合正态分布的情况下,标准差具有方便估算的特性:66.7%的数据点落在平均值前后1个标准差的范围内、95%的数据点落在平均值前后2个标准差的范围内,而99%的数据点将会落在平均值前后3个标准差的范围内。
-### 2.16.22点估计思想
-点估计:用实际样本的一个指标来估计总体的一个指标的一种估计方法。
-
-点估计举例:比如说,我们想要了解中国人的平均身高,那么在大街上随便找了一个人,通过测量这个人的身高来估计中国人的平均身高水平;或者在淘宝上买东西的时候随便一次买到假货就说淘宝上都是假货等;这些都属于点估计。
-
-点估计主要思想:在样本数据中得到一个指标,通过这个指标来估计总体指标;比如我们用样本均数来估计总体均数,样本均数就是我们要找到的指标。
-
-### 2.16.23 点估计优良性原则?
-获取样本均数指标相对来说比较简单,但是并不是总体的所有指标都很容易在样本中得到,比如说总体的标准差用样本的哪个指标来估计呢?
+3、在样本数据大致符合正态分布的情况下,标准差具有方便估算的特性:68%的数据点落在平均值前后1个标准差的范围内、95%的数据点落在平均值前后2个标准差的范围内,而99%的数据点将会落在平均值前后3个标准差的范围内。
-优良性准则有两大类:一类是小样本准则,即在样本大小固定时的优良性准则;另一类是大样本准则,即在样本大小趋于无穷时的优良性准则。最重要的小样本优良性准则是无偏性及与此相关的一致最小方差无偏计。
-
-样本中用来估计总体的指标要符合以下规则:
-
-1.首先必须是无偏统计量。
-所谓无偏性,即数学期望等于总体相应的统计量的样本估计量。
-
-2.最小方差准则
-针对总体样本的无偏估计量不唯一的情况,需选用其他准则,例如最小方差准则。如果一个统计量具有最小方差,也就是说所有的样本点与此统计量的离差平方和最小,则这个统计量被称为最小平方无偏估计量。
-最大概率准则
-
-4、缺一交叉准则
-在非参数回归中好像用的是缺一交叉准则
-
-要明白一个原则:计算样本的任何分布、均数、标准差都是没有任何意义的,如果样本的这种计算不能反映总体的某种特性。
-
-### 2.16.24 点估计、区间估计、中心极限定理之间的联系?
-https://www.zhihu.com/question/21871331#answer-4090464
-点估计:是用样本统计量来估计总体参数,因为样本统计量为数轴上某一点值,估计的结果也以一个点的数值表示,所以称为点估计。
-
-区间估计:通过从总体中抽取的样本,根据一定的正确度与精确度的要求,构造出适当的区间,以作为总体的分布参数(或参数的函数)的真值所在范围的估计。
-中心极限定理:设从均值为、方差为;(有限)的任意一个总体中抽取样本量为n的样本,当n充分大时,样本均值的抽样分布近似服从均值为、方差为的正态分布。
-
-三者之间联系:
-
-1、中心极限定理是推断统计的理论基础,推断统计包括参数估计和假设检验,其中参数估计包括点估计和区间估计,所以说,中心极限定理也是点估计和区间估计的理论基础。
-
-2、参数估计有两种方法:点估计和区间估计,区间估计包含了点估计。
-
-相同点:都是基于一个样本作出;
-
-不同点:点估计只提供单一的估计值,而区间估计基于点估计还提供误差界限,给出了置信区间,受置信度的影响。
-
-### 2.16.25 类别不平衡产生原因?
-类别不平衡(class-imbalance)是指分类任务中不同类别的训练样例数目差别很大的情况。
+### 2.16.20 类别不平衡产生原因?
+ 类别不平衡(class-imbalance)是指分类任务中不同类别的训练样例数目差别很大的情况。
产生原因:
-通常分类学习算法都会假设不同类别的训练样例数目基本相同。如果不同类别的训练样例数目差别很大,则会影响学习结果,测试结果变差。例如二分类问题中有998个反例,正例有2个,那学习方法只需返回一个永远将新样本预测为反例的分类器,就能达到99.8%的精度;然而这样的分类器没有价值。
-### 2.16.26 常见的类别不平衡问题解决方法
-http://blog.csdn.net/u013829973/article/details/77675147
-
+ 分类学习算法通常都会假设不同类别的训练样例数目基本相同。如果不同类别的训练样例数目差别很大,则会影响学习结果,测试结果变差。例如二分类问题中有998个反例,正例有2个,那学习方法只需返回一个永远将新样本预测为反例的分类器,就能达到99.8%的精度;然而这样的分类器没有价值。
+### 2.16.21 常见的类别不平衡问题解决方法
防止类别不平衡对学习造成的影响,在构建分类模型之前,需要对分类不平衡性问题进行处理。主要解决方法有:
1、扩大数据集
-增加包含小类样本数据的数据,更多的数据能得到更多的分布信息。
+ 增加包含小类样本数据的数据,更多的数据能得到更多的分布信息。
2、对大类数据欠采样
-减少大类数据样本个数,使与小样本个数接近。
-缺点:欠采样操作时若随机丢弃大类样本,可能会丢失重要信息。
-代表算法:EasyEnsemble。利用集成学习机制,将大类划分为若干个集合供不同的学习器使用。相当于对每个学习器都进行了欠采样,但在全局来看却不会丢失重要信息。
+ 减少大类数据样本个数,使与小样本个数接近。
+ 缺点:欠采样操作时若随机丢弃大类样本,可能会丢失重要信息。
+ 代表算法:EasyEnsemble。其思想是利用集成学习机制,将大类划分为若干个集合供不同的学习器使用。相当于对每个学习器都进行欠采样,但对于全局则不会丢失重要信息。
3、对小类数据过采样
-过采样:对小类的数据样本进行采样来增加小类的数据样本个数。
+ 过采样:对小类的数据样本进行采样来增加小类的数据样本个数。
-代表算法:SMOTE和ADASYN。
+ 代表算法:SMOTE和ADASYN。
-SMOTE:通过对训练集中的小类数据进行插值来产生额外的小类样本数据。
+ SMOTE:通过对训练集中的小类数据进行插值来产生额外的小类样本数据。
-新的少数类样本产生的策略:对每个少数类样本a,在a的最近邻中随机选一个样本b,然后在a、b之间的连线上随机选一点作为新合成的少数类样本。
-ADASYN:根据学习难度的不同,对不同的少数类别的样本使用加权分布,对于难以学习的少数类的样本,产生更多的综合数据。 通过减少类不平衡引入的偏差和将分类决策边界自适应地转移到困难的样本两种手段,改善了数据分布。
+ 新的少数类样本产生的策略:对每个少数类样本a,在a的最近邻中随机选一个样本b,然后在a、b之间的连线上随机选一点作为新合成的少数类样本。
+ ADASYN:根据学习难度的不同,对不同的少数类别的样本使用加权分布,对于难以学习的少数类的样本,产生更多的综合数据。 通过减少类不平衡引入的偏差和将分类决策边界自适应地转移到困难的样本两种手段,改善了数据分布。
4、使用新评价指标
-如果当前评价指标不适用,则应寻找其他具有说服力的评价指标。比如准确度这个评价指标在类别不均衡的分类任务中并不适用,甚至进行误导。因此在类别不均衡分类任务中,需要使用更有说服力的评价指标来对分类器进行评价。
+ 如果当前评价指标不适用,则应寻找其他具有说服力的评价指标。比如准确度这个评价指标在类别不均衡的分类任务中并不适用,甚至进行误导。因此在类别不均衡分类任务中,需要使用更有说服力的评价指标来对分类器进行评价。
5、选择新算法
-不同的算法适用于不同的任务与数据,应该使用不同的算法进行比较。
+ 不同的算法适用于不同的任务与数据,应该使用不同的算法进行比较。
6、数据代价加权
-例如当分类任务是识别小类,那么可以对分类器的小类样本数据增加权值,降低大类样本的权值,从而使得分类器将重点集中在小类样本身上。
+ 例如当分类任务是识别小类,那么可以对分类器的小类样本数据增加权值,降低大类样本的权值,从而使得分类器将重点集中在小类样本身上。
7、转化问题思考角度
-例如在分类问题时,把小类的样本作为异常点,将问题转化为异常点检测或变化趋势检测问题。 异常点检测即是对那些罕见事件进行识别。变化趋势检测区别于异常点检测在于其通过检测不寻常的变化趋势来识别。
+ 例如在分类问题时,把小类的样本作为异常点,将问题转化为异常点检测或变化趋势检测问题。 异常点检测即是对那些罕见事件进行识别。变化趋势检测区别于异常点检测在于其通过检测不寻常的变化趋势来识别。
8、将问题细化分析
-对问题进行分析与挖掘,将问题划分成多个更小的问题,看这些小问题是否更容易解决。
+ 对问题进行分析与挖掘,将问题划分成多个更小的问题,看这些小问题是否更容易解决。
## 2.17 决策树
### 2.17.1 决策树的基本原理
-决策树是一种分而治之(Divide and Conquer)的决策过程。一个困难的预测问题, 通过树的分支节点, 被划分成两个或多个较为简单的子集,从结构上划分为不同的子问题。将依规则分割数据集的过程不断递归下去(Recursive Partitioning)。随着树的深度不断增加,分支节点的子集越来越小,所需要提的问题数也逐渐简化。当分支节点的深度或者问题的简单程度满足一定的停止规则(Stopping Rule)时, 该分支节点会停止劈分,此为自上而下的停止阈值(Cutoff Threshold)法;有些决策树也使用自下而上的剪枝(Pruning)法。
+
+ 决策树(Decision Tree)是一种分而治之的决策过程。一个困难的预测问题,通过树的分支节点,被划分成两个或多个较为简单的子集,从结构上划分为不同的子问题。将依规则分割数据集的过程不断递归下去(Recursive Partitioning)。随着树的深度不断增加,分支节点的子集越来越小,所需要提的问题数也逐渐简化。当分支节点的深度或者问题的简单程度满足一定的停止规则(Stopping Rule)时, 该分支节点会停止分裂,此为自上而下的停止阈值(Cutoff Threshold)法;有些决策树也使用自下而上的剪枝(Pruning)法。
### 2.17.2 决策树的三要素?
-一棵决策树的生成过程主要分为以下3个部分:
-特征选择:从训练数据中众多的特征中选择一个特征作为当前节点的分裂标准,如何选择特征有着很多不同量化评估标准标准,从而衍生出不同的决策树算法。
+ 一棵决策树的生成过程主要分为以下3个部分:
+
+ 1、特征选择:从训练数据中众多的特征中选择一个特征作为当前节点的分裂标准,如何选择特征有着很多不同量化评估标准,从而衍生出不同的决策树算法。
-决策树生成:根据选择的特征评估标准,从上至下递归地生成子节点,直到数据集不可分则停止决策树停止生长。树结构来说,递归结构是最容易理解的方式。
+ 2、决策树生成:根据选择的特征评估标准,从上至下递归地生成子节点,直到数据集不可分则决策树停止生长。树结构来说,递归结构是最容易理解的方式。
+
+ 3、剪枝:决策树容易过拟合,一般来需要剪枝,缩小树结构规模、缓解过拟合。剪枝技术有预剪枝和后剪枝两种。
-剪枝:决策树容易过拟合,一般来需要剪枝,缩小树结构规模、缓解过拟合。剪枝技术有预剪枝和后剪枝两种。
### 2.17.3 决策树学习基本算法

### 2.17.4 决策树算法优缺点
-决策树算法的优点:
+**决策树算法的优点**:
-1、理解和解释起来简单,决策树模型易想象。
+1、决策树算法易理解,机理解释起来简单。
-2、相比于其他算法需要大量数据集而已,决策树算法要求的数据集不大。
+2、决策树算法可以用于小数据集。
3、决策树算法的时间复杂度较小,为用于训练决策树的数据点的对数。
@@ -1330,7 +1418,7 @@ ADASYN:根据学习难度的不同,对不同的少数类别的样本使用
8、效率高,决策树只需要一次构建,反复使用,每一次预测的最大计算次数不超过决策树的深度。
-决策树算法的缺点:
+**决策树算法的缺点**:
1、对连续性的字段比较难预测。
@@ -1338,345 +1426,623 @@ ADASYN:根据学习难度的不同,对不同的少数类别的样本使用
3、当类别太多时,错误可能就会增加的比较快。
-4、信息缺失时处理起来比较困难,忽略了数据集中属性之间的相关性。
+4、在处理特征关联性比较强的数据时表现得不是太好。
-5、在处理特征关联性比较强的数据时表现得不是太好。
+5、对于各类别样本数量不一致的数据,在决策树当中,信息增益的结果偏向于那些具有更多数值的特征。
-6、对于各类别样本数量不一致的数据,在决策树当中,信息增益的结果偏向于那些具有更多数值的特征。
+### 2.17.5 熵的概念以及理解
-### 2.17.5熵的概念以及理解
+ 熵:度量随机变量的不确定性。
+ 定义:假设随机变量X的可能取值有$x_{1},x_{2},...,x_{n}$,对于每一个可能的取值$x_{i}$,其概率为$P(X=x_{i})=p_{i},i=1,2...,n$。随机变量的熵为:
+$$
+H(X)=-\sum_{i=1}^{n}p_{i}log_{2}p_{i}
+$$
+ 对于样本集合,假设样本有k个类别,每个类别的概率为$\frac{|C_{k}|}{|D|}$,其中 ${|C_{k}|}{|D|}$为类别为k的样本个数,$|D|$为样本总数。样本集合D的熵为:
+$$
+H(D)=-\sum_{k=1}^{k}\frac{|C_{k}|}{|D|}log_{2}\frac{|C_{k}|}{|D|}
+$$
-熵:度量随机变量的不确定性。
+### 2.17.6 信息增益的理解
-定义:假设随机变量X的可能取值有$x_{1},x_{2},...,x_{n}$,对于每一个可能的取值$x_{i}$,其概率为$P(X=x_{i})=p_{i},i=1,2...,n$。随机变量的熵为:
+ 定义:以某特征划分数据集前后的熵的差值。
+ 熵可以表示样本集合的不确定性,熵越大,样本的不确定性就越大。因此可以使用划分前后集合熵的差值来衡量使用当前特征对于样本集合D划分效果的好坏。 假设划分前样本集合D的熵为H(D)。使用某个特征A划分数据集D,计算划分后的数据子集的熵为H(D|A)。
+ 则信息增益为:
+$$
+g(D,A)=H(D)-H(D|A)
+$$
+ *注:*在决策树构建的过程中我们总是希望集合往最快到达纯度更高的子集合方向发展,因此我们总是选择使得信息增益最大的特征来划分当前数据集D。
+ 思想:计算所有特征划分数据集D,得到多个特征划分数据集D的信息增益,从这些信息增益中选择最大的,因而当前结点的划分特征便是使信息增益最大的划分所使用的特征。
+ 另外这里提一下信息增益比相关知识:
+ $信息增益比=惩罚参数\times信息增益$
+ 信息增益比本质:在信息增益的基础之上乘上一个惩罚参数。特征个数较多时,惩罚参数较小;特征个数较少时,惩罚参数较大。
+ 惩罚参数:数据集D以特征A作为随机变量的熵的倒数。
-$H(X)=-\sum_{i=1}^{n}p_{i}log_{2}p_{i}$
+### 2.17.7 剪枝处理的作用及策略?
+ 剪枝处理是决策树学习算法用来解决过拟合问题的一种办法。
-对于样本集合 ,假设样本有k个类别,每个类别的概率为$\frac{|C_{k}|}{|D|}$,其中 ${|C_{k}|}{|D|}$为类别为k的样本个数,$|D|$为样本总数。样本集合D的熵为:
-$H(D)=-\sum_{k=1}^{k}\frac{|C_{k}|}{|D|}log_{2}\frac{|C_{k}|}{|D|}$
+ 在决策树算法中,为了尽可能正确分类训练样本, 节点划分过程不断重复, 有时候会造成决策树分支过多,以至于将训练样本集自身特点当作泛化特点, 而导致过拟合。 因此可以采用剪枝处理来去掉一些分支来降低过拟合的风险。
-### 2.17.6 信息增益的理解
-定义:以某特征划分数据集前后的熵的差值。
-熵可以表示样本集合的不确定性,熵越大,样本的不确定性就越大。因此可以使用划分前后集合熵的差值来衡量使用当前特征对于样本集合D划分效果的好坏。
-假设划分前样本集合D的熵为H(D)。使用某个特征A划分数据集D,计算划分后的数据子集的熵为H(D|A)。
+ 剪枝的基本策略有预剪枝(pre-pruning)和后剪枝(post-pruning)。
-则信息增益为:
+ 预剪枝:在决策树生成过程中,在每个节点划分前先估计其划分后的泛化性能, 如果不能提升,则停止划分,将当前节点标记为叶结点。
-$g(D,A)=H(D)-H(D|A)$
+ 后剪枝:生成决策树以后,再自下而上对非叶结点进行考察, 若将此节点标记为叶结点可以带来泛化性能提升,则修改之。
-注:在决策树构建的过程中我们总是希望集合往最快到达纯度更高的子集合方向发展,因此我们总是选择使得信息增益最大的特征来划分当前数据集D。
+## 2.18 支持向量机
-思想:计算所有特征划分数据集D,得到多个特征划分数据集D的信息增益,从这些信息增益中选择最大的,因而当前结点的划分特征便是使信息增益最大的划分所使用的特征。
+### 2.18.1 什么是支持向量机
+ 支持向量:在求解的过程中,会发现只根据部分数据就可以确定分类器,这些数据称为支持向量。
-另外这里提一下信息增益比相关知识:
+ 支持向量机(Support Vector Machine,SVM):其含义是通过支持向量运算的分类器。
-信息增益比=惩罚参数X信息增益。
+ 在一个二维环境中,其中点R,S,G点和其它靠近中间黑线的点可以看作为支持向量,它们可以决定分类器,即黑线的具体参数。
-信息增益比本质:在信息增益的基础之上乘上一个惩罚参数。特征个数较多时,惩罚参数较小;特征个数较少时,惩罚参数较大。
+
-惩罚参数:数据集D以特征A作为随机变量的熵的倒数。
+ 支持向量机是一种二分类模型,它的目的是寻找一个超平面来对样本进行分割,分割的原则是边界最大化,最终转化为一个凸二次规划问题来求解。由简至繁的模型包括:
-### 2.17.7 剪枝处理的作用及策略?
-剪枝处理是决策树学习算法用来解决过拟合的一种办法。
+ 当训练样本线性可分时,通过硬边界(hard margin)最大化,学习一个线性可分支持向量机;
-在决策树算法中,为了尽可能正确分类训练样本, 节点划分过程不断重复, 有时候会造成决策树分支过多,以至于将训练样本集自身特点当作泛化特点, 而导致过拟合。 因此可以采用剪枝处理来去掉一些分支来降低过拟合的风险。
+ 当训练样本近似线性可分时,通过软边界(soft margin)最大化,学习一个线性支持向量机;
-剪枝的基本策略有预剪枝(prepruning)和后剪枝(postprunint)。
+ 当训练样本线性不可分时,通过核技巧和软边界最大化,学习一个非线性支持向量机;
-预剪枝:在决策树生成过程中,在每个节点划分前先估计其划分后的泛化性能, 如果不能提升,则停止划分,将当前节点标记为叶结点。
+### 2.18.2 支持向量机能解决哪些问题?
-后剪枝:生成决策树以后,再自下而上对非叶结点进行考察, 若将此节点标记为叶结点可以带来泛化性能提升,则修改之。
+**线性分类**
-## 2.18 支持向量机
+ 在训练数据中,每个数据都有n个的属性和一个二分类类别标志,我们可以认为这些数据在一个n维空间里。我们的目标是找到一个n-1维的超平面,这个超平面可以将数据分成两部分,每部分数据都属于同一个类别。
-### 2.18.1 什么是支持向量机
-SVM - Support Vector Machine。支持向量机,其含义是通过支持向量运算的分类器。其中“机”的意思是机器,可以理解为分类器。
+ 这样的超平面有很多,假如我们要找到一个最佳的超平面。此时,增加一个约束条件:要求这个超平面到每边最近数据点的距离是最大的,成为最大边距超平面。这个分类器即为最大边距分类器。
-什么是支持向量呢?在求解的过程中,会发现只根据部分数据就可以确定分类器,这些数据称为支持向量。
+**非线性分类**
-见下图,在一个二维环境中,其中点R,S,G点和其它靠近中间黑线的点可以看作为支持向量,它们可以决定分类器,也就是黑线的具体参数。
+ SVM的一个优势是支持非线性分类。它结合使用拉格朗日乘子法(Lagrange Multiplier)和KKT(Karush Kuhn Tucker)条件,以及核函数可以生成非线性分类器。
-
+### 2.18.3 核函数特点及其作用?
+
+ 引入核函数目的:把原坐标系里线性不可分的数据用核函数Kernel投影到另一个空间,尽量使得数据在新的空间里线性可分。
+ 核函数方法的广泛应用,与其特点是分不开的:
-### 2.18.2 支持向量机解决的问题?
-https://www.cnblogs.com/steven-yang/p/5658362.html
-解决的问题:
+1)核函数的引入避免了“维数灾难”,大大减小了计算量。而输入空间的维数n对核函数矩阵无影响。因此,核函数方法可以有效处理高维输入。
-线性分类
+2)无需知道非线性变换函数Φ的形式和参数。
-在训练数据中,每个数据都有n个的属性和一个二类类别标志,我们可以认为这些数据在一个n维空间里。我们的目标是找到一个n-1维的超平面(hyperplane),这个超平面可以将数据分成两部分,每部分数据都属于同一个类别。
+3)核函数的形式和参数的变化会隐式地改变从输入空间到特征空间的映射,进而对特征空间的性质产生影响,最终改变各种核函数方法的性能。
-其实这样的超平面有很多,我们要找到一个最佳的。因此,增加一个约束条件:这个超平面到每边最近数据点的距离是最大的。也成为最大间隔超平面(maximum-margin hyperplane)。这个分类器也成为最大间隔分类器(maximum-margin classifier)。
+4)核函数方法可以和不同的算法相结合,形成多种不同的基于核函数技术的方法,且这两部分的设计可以单独进行,并可以为不同的应用选择不同的核函数和算法。
-支持向量机是一个二类分类器。
+### 2.18.4 SVM为什么引入对偶问题?
-非线性分类
+1,对偶问题将原始问题中的约束转为了对偶问题中的等式约束,对偶问题往往更加容易求解。
-SVM的一个优势是支持非线性分类。它结合使用拉格朗日乘子法和KKT条件,以及核函数可以产生非线性分类器。
+2,可以很自然的引用核函数(拉格朗日表达式里面有内积,而核函数也是通过内积进行映射的)。
-分类器1 - 线性分类器
+3,在优化理论中,目标函数 f(x) 会有多种形式:如果目标函数和约束条件都为变量 x 的线性函数,称该问题为线性规划;如果目标函数为二次函数,约束条件为线性函数,称该最优化问题为二次规划;如果目标函数或者约束条件均为非线性函数,称该最优化问题为非线性规划。每个线性规划问题都有一个与之对应的对偶问题,对偶问题有非常良好的性质,以下列举几个:
-是一个线性函数,可以用于线性分类。一个优势是不需要样本数据。
+ a, 对偶问题的对偶是原问题;
-classifier 1:
-f(x)=xwT+b(1)
-(1)f(x)=xwT+b
+ b, 无论原始问题是否是凸的,对偶问题都是凸优化问题;
-ww 和 bb 是训练数据后产生的值。
+ c, 对偶问题可以给出原始问题一个下界;
+ d, 当满足一定条件时,原始问题与对偶问题的解是完全等价的。
-分类器2 - 非线性分类器
+### 2.18.5 如何理解SVM中的对偶问题
-支持线性分类和非线性分类。需要部分样本数据(支持向量),也就是$\alpha_i \ne 0$ 的数据。
+在硬边界支持向量机中,问题的求解可以转化为凸二次规划问题。
+ 假设优化目标为
+$$
+\begin{align}
+&\min_{\boldsymbol w, b}\frac{1}{2}||\boldsymbol w||^2\\
+&s.t. y_i(\boldsymbol w^T\boldsymbol x_i+b)\geqslant 1, i=1,2,\cdots,m.\\
+\end{align} \tag{1}
$$
-w=∑ni=1αiyixiw=∑i=1nαiyixi
+**step 1**. 转化问题:
$$
+\min_{\boldsymbol w, b} \max_{\alpha_i \geqslant 0} \left\{\frac{1}{2}||\boldsymbol w||^2 + \sum_{i=1}^m\alpha_i(1 - y_i(\boldsymbol w^T\boldsymbol x_i+b))\right\} \tag{2}
+$$
+上式等价于原问题,因为若满足(1)中不等式约束,则(2)式求max时,$\alpha_i(1 - y_i(\boldsymbol w^T\boldsymbol x_i+b))$必须取0,与(1)等价;若不满足(1)中不等式约束,(2)中求max会得到无穷大。 交换min和max获得其对偶问题:
+$$
+\max_{\alpha_i \geqslant 0} \min_{\boldsymbol w, b} \left\{\frac{1}{2}||\boldsymbol w||^2 + \sum_{i=1}^m\alpha_i(1 - y_i(\boldsymbol w^T\boldsymbol x_i+b))\right\}
+$$
+交换之后的对偶问题和原问题并不相等,上式的解小于等于原问题的解。
-classifier 2:
+**step 2**.现在的问题是如何找到问题(1) 的最优值的一个最好的下界?
+$$
+\frac{1}{2}||\boldsymbol w||^2 < v\\
+1 - y_i(\boldsymbol w^T\boldsymbol x_i+b) \leqslant 0\tag{3}
+$$
+若方程组(3)无解, 则v是问题(1)的一个下界。若(3)有解, 则
+$$
+\forall \boldsymbol \alpha > 0 , \ \min_{\boldsymbol w, b} \left\{\frac{1}{2}||\boldsymbol w||^2 + \sum_{i=1}^m\alpha_i(1 - y_i(\boldsymbol w^T\boldsymbol x_i+b))\right\} < v
+$$
+由逆否命题得:若
+$$
+\exists \boldsymbol \alpha > 0 , \ \min_{\boldsymbol w, b} \left\{\frac{1}{2}||\boldsymbol w||^2 + \sum_{i=1}^m\alpha_i(1 - y_i(\boldsymbol w^T\boldsymbol x_i+b))\right\} \geqslant v
+$$
+则(3)无解。
-f(x)=∑ni=1αiyiK(xi,x)+bherexi : training data iyi : label value of training data iαi : Lagrange multiplier of training data iK(x1,x2)=exp(−∥x1−x2∥22σ2) : kernel function(2)
-(2)f(x)=∑i=1nαiyiK(xi,x)+bherexi : training data iyi : label value of training data iαi : Lagrange multiplier of training data iK(x1,x2)=exp(−‖x1−x2‖22σ2) : kernel function
+那么v是问题
-αα, σσ 和 bb 是训练数据后产生的值。
-可以通过调节σσ来匹配维度的大小,σσ越大,维度越低。
+(1)的一个下界。
+ 要求得一个好的下界,取最大值即可
+$$
+\max_{\alpha_i \geqslant 0} \min_{\boldsymbol w, b} \left\{\frac{1}{2}||\boldsymbol w||^2 + \sum_{i=1}^m\alpha_i(1 - y_i(\boldsymbol w^T\boldsymbol x_i+b))\right\}
+$$
+**step 3**. 令
+$$
+L(\boldsymbol w, b,\boldsymbol a) = \frac{1}{2}||\boldsymbol w||^2 + \sum_{i=1}^m\alpha_i(1 - y_i(\boldsymbol w^T\boldsymbol x_i+b))
+$$
+$p^*$为原问题的最小值,对应的$w,b$分别为$w^*,b^*$,则对于任意的$a>0$:
+$$
+p^* = \frac{1}{2}||\boldsymbol w^*||^2 \geqslant L(\boldsymbol w^*, b,\boldsymbol a) \geqslant \min_{\boldsymbol w, b} L(\boldsymbol w, b,\boldsymbol a)
+$$
+则 $\min_{\boldsymbol w, b} L(\boldsymbol w, b,\boldsymbol a)$是问题(1)的一个下界。
-### 2.18.3 核函数作用?
+此时,取最大值即可求得好的下界,即
+$$
+\max_{\alpha_i \geqslant 0} \min_{\boldsymbol w, b} L(\boldsymbol w, b,\boldsymbol a)
+$$
-核函数目的:把原坐标系里线性不可分的数据用Kernel投影到另一个空间,尽量使得数据在新的空间里线性可分。
+### 2.18.7 常见的核函数有哪些?
+| 核函数 | 表达式 | 备注 |
+| ---------------------------- | ------------------------------------------------------------ | ----------------------------------- |
+| Linear Kernel线性核 | $k(x,y)=x^{t}y+c$ | |
+| Polynomial Kernel多项式核 | $k(x,y)=(ax^{t}y+c)^{d}$ | $d\geqslant1$为多项式的次数 |
+| Exponential Kernel指数核 | $k(x,y)=exp(-\frac{\left \|x-y \right \|}{2\sigma ^{2}})$ | $\sigma>0$ |
+| Gaussian Kernel高斯核 | $k(x,y)=exp(-\frac{\left \|x-y \right \|^{2}}{2\sigma ^{2}})$ | $\sigma$为高斯核的带宽,$\sigma>0$, |
+| Laplacian Kernel拉普拉斯核 | $k(x,y)=exp(-\frac{\left \|x-y \right \|}{\sigma})$ | $\sigma>0$ |
+| ANOVA Kernel | $k(x,y)=exp(-\sigma(x^{k}-y^{k})^{2})^{d}$ | |
+| Sigmoid Kernel | $k(x,y)=tanh(ax^{t}y+c)$ | $tanh$为双曲正切函数,$a>0,c<0$ |
+
+### 2.18.9 SVM主要特点?
+
+特点:
+
+(1) SVM方法的理论基础是非线性映射,SVM利用内积核函数代替向高维空间的非线性映射。
+(2) SVM的目标是对特征空间划分得到最优超平面,SVM方法核心是最大化分类边界。
+(3) 支持向量是SVM的训练结果,在SVM分类决策中起决定作用的是支持向量。
+(4) SVM是一种有坚实理论基础的新颖的适用小样本学习方法。它基本上不涉及概率测度及大数定律等,也简化了通常的分类和回归等问题。
+(5) SVM的最终决策函数只由少数的支持向量所确定,计算的复杂性取决于支持向量的数目,而不是样本空间的维数,这在某种意义上避免了“维数灾难”。
+(6) 少数支持向量决定了最终结果,这不但可以帮助我们抓住关键样本、“剔除”大量冗余样本,而且注定了该方法不但算法简单,而且具有较好的“鲁棒性”。这种鲁棒性主要体现在:
+ ①增、删非支持向量样本对模型没有影响;
+ ②支持向量样本集具有一定的鲁棒性;
+ ③有些成功的应用中,SVM方法对核的选取不敏感
+(7) SVM学习问题可以表示为凸优化问题,因此可以利用已知的有效算法发现目标函数的全局最小值。而其他分类方法(如基于规则的分类器和人工神经网络)都采用一种基于贪心学习的策略来搜索假设空间,这种方法一般只能获得局部最优解。
+(8) SVM通过最大化决策边界的边缘来控制模型的能力。尽管如此,用户必须提供其他参数,如使用核函数类型和引入松弛变量等。
+(9) SVM在小样本训练集上能够得到比其它算法好很多的结果。SVM优化目标是结构化风险最小,而不是经验风险最小,避免了过拟合问题,通过margin的概念,得到对数据分布的结构化描述,减低了对数据规模和数据分布的要求,有优秀的泛化能力。
+(10) 它是一个凸优化问题,因此局部最优解一定是全局最优解的优点。
+
+### 2.18.10 SVM主要缺点?
+
+(1) SVM算法对大规模训练样本难以实施
+ SVM的空间消耗主要是存储训练样本和核矩阵,由于SVM是借助二次规划来求解支持向量,而求解二次规划将涉及m阶矩阵的计算(m为样本的个数),当m数目很大时该矩阵的存储和计算将耗费大量的机器内存和运算时间。
+ 如果数据量很大,SVM的训练时间就会比较长,如垃圾邮件的分类检测,没有使用SVM分类器,而是使用简单的朴素贝叶斯分类器,或者是使用逻辑回归模型分类。
-核函数方法的广泛应用,与其特点是分不开的:
+(2) 用SVM解决多分类问题存在困难
-1)核函数的引入避免了“维数灾难”,大大减小了计算量。而输入空间的维数n对核函数矩阵无影响,因此,核函数方法可以有效处理高维输入。
+ 经典的支持向量机算法只给出了二类分类的算法,而在实际应用中,一般要解决多类的分类问题。可以通过多个二类支持向量机的组合来解决。主要有一对多组合模式、一对一组合模式和SVM决策树;再就是通过构造多个分类器的组合来解决。主要原理是克服SVM固有的缺点,结合其他算法的优势,解决多类问题的分类精度。如:与粗糙集理论结合,形成一种优势互补的多类问题的组合分类器。
-2)无需知道非线性变换函数Φ的形式和参数.
+(3) 对缺失数据敏感,对参数和核函数的选择敏感
-3)核函数的形式和参数的变化会隐式地改变从输入空间到特征空间的映射,进而对特征空间的性质产生影响,最终改变各种核函数方法的性能。
+ 支持向量机性能的优劣主要取决于核函数的选取,所以对于一个实际问题而言,如何根据实际的数据模型选择合适的核函数从而构造SVM算法。目前比较成熟的核函数及其参数的选择都是人为的,根据经验来选取的,带有一定的随意性。在不同的问题领域,核函数应当具有不同的形式和参数,所以在选取时候应该将领域知识引入进来,但是目前还没有好的方法来解决核函数的选取问题。
-4)核函数方法可以和不同的算法相结合,形成多种不同的基于核函数技术的方法,且这两部分的设计可以单独进行,并可以为不同的应用选择不同的核函数和算法。
+### 2.18.11 逻辑回归与SVM的异同
-### 2.18.4 对偶问题
-### 2.18.5 理解支持向量回归
-http://blog.csdn.net/liyaohhh/article/details/51077082
+相同点:
-### 2.18.6 理解SVM(核函数)
-http://blog.csdn.net/Love_wanling/article/details/69390047
+- LR和SVM都是**分类**算法。
+- LR和SVM都是**监督学习**算法。
+- LR和SVM都是**判别模型**。
+- 如果不考虑核函数,LR和SVM都是**线性分类**算法,也就是说他们的分类决策面都是线性的。
+ 说明:LR也是可以用核函数的.但LR通常不采用核函数的方法。(**计算量太大**)
-### 2.18.7 常见的核函数有哪些?
-http://blog.csdn.net/Love_wanling/article/details/69390047
+不同点:
-本文将遇到的核函数进行收集整理,分享给大家。
-http://blog.csdn.net/wsj998689aa/article/details/47027365
+**1、LR采用log损失,SVM采用合页(hinge)损失。**
+逻辑回归的损失函数:
+$$
+J(\theta)=-\frac{1}{m}\sum^m_{i=1}\left[y^{i}logh_{\theta}(x^{i})+ (1-y^{i})log(1-h_{\theta}(x^{i}))\right]
+$$
+支持向量机的目标函数:
+$$
+L(w,n,a)=\frac{1}{2}||w||^2-\sum^n_{i=1}\alpha_i \left( y_i(w^Tx_i+b)-1\right)
+$$
+ 逻辑回归方法基于概率理论,假设样本为1的概率可以用sigmoid函数来表示,然后通过**极大似然估计**的方法估计出参数的值。
+ 支持向量机基于几何**边界最大化**原理,认为存在最大几何边界的分类面为最优分类面。
-1.Linear Kernel
-线性核是最简单的核函数,核函数的数学公式如下:
+2、**LR对异常值敏感,SVM对异常值不敏感**。
-$k(x,y)=xy$
+ 支持向量机只考虑局部的边界线附近的点,而逻辑回归考虑全局。LR模型找到的那个超平面,是尽量让所有点都远离他,而SVM寻找的那个超平面,是只让最靠近中间分割线的那些点尽量远离,即只用到那些支持向量的样本。
+ 支持向量机改变非支持向量样本并不会引起决策面的变化。
+ 逻辑回归中改变任何样本都会引起决策面的变化。
-如果我们将线性核函数应用在KPCA中,我们会发现,推导之后和原始PCA算法一模一样,很多童鞋借此说“kernel is shit!!!”,这是不对的,这只是线性核函数偶尔会出现等价的形式罢了。
+3、**计算复杂度不同。对于海量数据,SVM的效率较低,LR效率比较高**
-2.Polynomial Kernel
+ 当样本较少,特征维数较低时,SVM和LR的运行时间均比较短,SVM较短一些。准确率的话,LR明显比SVM要高。当样本稍微增加些时,SVM运行时间开始增长,但是准确率赶超了LR。SVM时间虽长,但在可接受范围内。当数据量增长到20000时,特征维数增长到200时,SVM的运行时间剧烈增加,远远超过了LR的运行时间。但是准确率却和LR相差无几。(这其中主要原因是大量非支持向量参与计算,造成SVM的二次规划问题)
-多项式核实一种非标准核函数,它非常适合于正交归一化后的数据,其具体形式如下:
+4、**对非线性问题的处理方式不同**
-$k(x,y)=(ax^{t}y+c)^{d}$
+ LR主要靠特征构造,必须组合交叉特征,特征离散化。SVM也可以这样,还可以通过核函数kernel(因为只有支持向量参与核计算,计算复杂度不高)。由于可以利用核函数,SVM则可以通过对偶求解高效处理。LR则在特征空间维度很高时,表现较差。
-这个核函数是比较好用的,就是参数比较多,但是还算稳定。
+5、**SVM的损失函数就自带正则**。
+ 损失函数中的1/2||w||^2项,这就是为什么SVM是结构风险最小化算法的原因!!!而LR必须另外在损失函数上添加正则项!!!**
-3.Gaussian Kernel
+6、SVM自带**结构风险最小化**,LR则是**经验风险最小化**。
-这里说一种经典的鲁棒径向基核,即高斯核函数,鲁棒径向基核对于数据中的噪音有着较好的抗干扰能力,其参数决定了函数作用范围,超过了这个范围,数据的作用就“基本消失”。高斯核函数是这一族核函数的优秀代表,也是必须尝试的核函数,其数学形式如下:
+7、SVM会用核函数而LR一般不用核函数。
-$k(x,y)=exp(-\frac{\left \| x-y \right \|^{2}}{2\sigma ^{2}})$
+## 2.19 贝叶斯分类器
+### 2.19.1 图解极大似然估计
-虽然被广泛使用,但是这个核函数的性能对参数十分敏感,以至于有一大把的文献专门对这种核函数展开研究,同样,高斯核函数也有了很多的变种,如指数核,拉普拉斯核等。
+极大似然估计的原理,用一张图片来说明,如下图所示:
-4.Exponential Kernel
+
-指数核函数就是高斯核函数的变种,它仅仅是将向量之间的L2距离调整为L1距离,这样改动会对参数的依赖性降低,但是适用范围相对狭窄。其数学形式如下:
+ 例:有两个外形完全相同的箱子,1号箱有99只白球,1只黑球;2号箱有1只白球,99只黑球。在一次实验中,取出的是黑球,请问是从哪个箱子中取出的?
-$k(x,y)=exp(-\frac{\left \| x-y \right \|}{2\sigma ^{2}})$
+ 一般的根据经验想法,会猜测这只黑球最像是从2号箱取出,此时描述的“最像”就有“最大似然”的意思,这种想法常称为“最大似然原理”。
-5.Laplacian Kernel
+### 2.19.2 极大似然估计原理
-拉普拉斯核完全等价于指数核,唯一的区别在于前者对参数的敏感性降低,也是一种径向基核函数。
+ 总结起来,最大似然估计的目的就是:利用已知的样本结果,反推最有可能(最大概率)导致这样结果的参数值。
-$k(x,y)=exp(-\frac{\left \| x-y \right \|}{\sigma })$
+ 极大似然估计是建立在极大似然原理的基础上的一个统计方法。极大似然估计提供了一种给定观察数据来评估模型参数的方法,即:“模型已定,参数未知”。通过若干次试验,观察其结果,利用试验结果得到某个参数值能够使样本出现的概率为最大,则称为极大似然估计。
-6.ANOVA Kernel
+ 由于样本集中的样本都是独立同分布,可以只考虑一类样本集$D$,来估计参数向量$\vec\theta$。记已知的样本集为:
+$$
+D=\vec x_{1},\vec x_{2},...,\vec x_{n}
+$$
+似然函数(likelihood function):联合概率密度函数$p(D|\vec\theta )$称为相对于$\vec x_{1},\vec x_{2},...,\vec x_{n}$的$\vec\theta$的似然函数。
+$$
+l(\vec\theta )=p(D|\vec\theta ) =p(\vec x_{1},\vec x_{2},...,\vec x_{n}|\vec\theta )=\prod_{i=1}^{n}p(\vec x_{i}|\vec \theta )
+$$
+如果$\hat{\vec\theta}$是参数空间中能使似然函数$l(\vec\theta)$最大的$\vec\theta$值,则$\hat{\vec\theta}$应该是“最可能”的参数值,那么$\hat{\vec\theta}$就是$\theta$的极大似然估计量。它是样本集的函数,记作:
+$$
+\hat{\vec\theta}=d(D)= \mathop {\arg \max}_{\vec\theta} l(\vec\theta )
+$$
+$\hat{\vec\theta}(\vec x_{1},\vec x_{2},...,\vec x_{n})$称为极大似然函数估计值。
-ANOVA 核也属于径向基核函数一族,其适用于多维回归问题,数学形式如下:
+### 2.19.3 贝叶斯分类器基本原理
-$k(x,y)=exp(-\sigma(x^{k}-y^{k})^{2})^{d}$
+ 贝叶斯决策论通过**相关概率已知**的情况下利用**误判损失**来选择最优的类别分类。
+假设有$N$种可能的分类标记,记为$Y=\{c_1,c_2,...,c_N\}$,那对于样本$\boldsymbol{x}$,它属于哪一类呢?
-7.Sigmoid Kernel
+计算步骤如下:
-Sigmoid 核来源于神经网络,现在已经大量应用于深度学习,是当今机器学习的宠儿,它是S型的,所以被用作于“激活函数”。关于这个函数的性质可以说好几篇文献,大家可以随便找一篇深度学习的文章看看。
+step 1. 算出样本$\boldsymbol{x}$属于第i个类的概率,即$P(c_i|x)$;
-$k(x,y)=tanh(ax^{t}y+c)$
+step 2. 通过比较所有的$P(c_i|\boldsymbol{x})$,得到样本$\boldsymbol{x}$所属的最佳类别。
-8.Rational Quadratic Kernel
-二次有理核完完全全是作为高斯核的替代品出现,如果你觉得高斯核函数很耗时,那么不妨尝试一下这个核函数,顺便说一下,这个核函数作用域虽广,但是对参数十分敏感,慎用!!!!
+step 3. 将类别$c_i$和样本$\boldsymbol{x}$代入到贝叶斯公式中,得到:
+$$
+P(c_i|\boldsymbol{x})=\frac{P(\boldsymbol{x}|c_i)P(c_i)}{P(\boldsymbol{x})}.
+$$
+ 一般来说,$P(c_i)$为先验概率,$P(\boldsymbol{x}|c_i)$为条件概率,$P(\boldsymbol{x})$是用于归一化的证据因子。对于$P(c_i)$可以通过训练样本中类别为$c_i$的样本所占的比例进行估计;此外,由于只需要找出最大的$P(\boldsymbol{x}|c_i)$,因此我们并不需要计算$P(\boldsymbol{x})$。
+ 为了求解条件概率,基于不同假设提出了不同的方法,以下将介绍朴素贝叶斯分类器和半朴素贝叶斯分类器。
-$k(x,y)=1-\frac{\left \| x-y \right \|^{2}}{\left \| x-y \right \|^{2}+c}$
+### 2.19.4 朴素贝叶斯分类器
-### 2.18.8 软间隔与正则化
-### 2.18.9 SVM主要特点及缺点?
+ 假设样本$\boldsymbol{x}$包含$d$个属性,即$\boldsymbol{x}=\{ x_1,x_2,...,x_d\}$。于是有:
+$$
+P(\boldsymbol{x}|c_i)=P(x_1,x_2,\cdots,x_d|c_i)
+$$
+这个联合概率难以从有限的训练样本中直接估计得到。于是,朴素贝叶斯(Naive Bayesian,简称NB)采用了“属性条件独立性假设”:对已知类别,假设所有属性相互独立。于是有:
+$$
+P(x_1,x_2,\cdots,x_d|c_i)=\prod_{j=1}^d P(x_j|c_i)
+$$
+这样的话,我们就可以很容易地推出相应的判定准则了:
+$$
+h_{nb}(\boldsymbol{x})=\mathop{\arg \max}_{c_i\in Y} P(c_i)\prod_{j=1}^dP(x_j|c_i)
+$$
+**条件概率$P(x_j|c_i)$的求解**
-http://www.elecfans.com/emb/fpga/20171118582139_2.html
+如果$x_j$是标签属性,那么我们可以通过计数的方法估计$P(x_j|c_i)$
+$$
+P(x_j|c_i)=\frac{P(x_j,c_i)}{P(c_i)}\approx\frac{\#(x_j,c_i)}{\#(c_i)}
+$$
+其中,$\#(x_j,c_i)$表示在训练样本中$x_j$与$c_{i}$共同出现的次数。
+
+如果$x_j$是数值属性,通常我们假设类别中$c_{i}$的所有样本第$j$个属性的值服从正态分布。我们首先估计这个分布的均值$μ$和方差$σ$,然后计算$x_j$在这个分布中的概率密度$P(x_j|c_i)$。
+
+### 2.19.5 举例理解朴素贝叶斯分类器
+
+使用经典的西瓜训练集如下:
+
+| 编号 | 色泽 | 根蒂 | 敲声 | 纹理 | 脐部 | 触感 | 密度 | 含糖率 | 好瓜 |
+| :--: | :--: | :--: | :--: | :--: | :--: | :--: | :---: | :----: | :--: |
+| 1 | 青绿 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 0.697 | 0.460 | 是 |
+| 2 | 乌黑 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 0.774 | 0.376 | 是 |
+| 3 | 乌黑 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 0.634 | 0.264 | 是 |
+| 4 | 青绿 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 0.608 | 0.318 | 是 |
+| 5 | 浅白 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 0.556 | 0.215 | 是 |
+| 6 | 青绿 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 0.403 | 0.237 | 是 |
+| 7 | 乌黑 | 稍蜷 | 浊响 | 稍糊 | 稍凹 | 软粘 | 0.481 | 0.149 | 是 |
+| 8 | 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 硬滑 | 0.437 | 0.211 | 是 |
+| 9 | 乌黑 | 稍蜷 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 0.666 | 0.091 | 否 |
+| 10 | 青绿 | 硬挺 | 清脆 | 清晰 | 平坦 | 软粘 | 0.243 | 0.267 | 否 |
+| 11 | 浅白 | 硬挺 | 清脆 | 模糊 | 平坦 | 硬滑 | 0.245 | 0.057 | 否 |
+| 12 | 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 软粘 | 0.343 | 0.099 | 否 |
+| 13 | 青绿 | 稍蜷 | 浊响 | 稍糊 | 凹陷 | 硬滑 | 0.639 | 0.161 | 否 |
+| 14 | 浅白 | 稍蜷 | 沉闷 | 稍糊 | 凹陷 | 硬滑 | 0.657 | 0.198 | 否 |
+| 15 | 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 0.360 | 0.370 | 否 |
+| 16 | 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 硬滑 | 0.593 | 0.042 | 否 |
+| 17 | 青绿 | 蜷缩 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 0.719 | 0.103 | 否 |
+
+对下面的测试例“测1”进行 分类:
+
+| 编号 | 色泽 | 根蒂 | 敲声 | 纹理 | 脐部 | 触感 | 密度 | 含糖率 | 好瓜 |
+| :--: | :--: | :--: | :--: | :--: | :--: | :--: | :---: | :----: | :--: |
+| 测1 | 青绿 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 0.697 | 0.460 | ? |
+
+首先,估计类先验概率$P(c_j)$,有
+$$
+\begin{align}
+&P(好瓜=是)=\frac{8}{17}=0.471 \newline
+&P(好瓜=否)=\frac{9}{17}=0.529
+\end{align}
+$$
+然后,为每个属性估计条件概率(这里,对于连续属性,假定它们服从正态分布)
+$$
+P_{青绿|是}=P(色泽=青绿|好瓜=是)=\frac{3}{8}=0.375
+$$
-3.3.2.1 SVM有如下主要几个特点:
+$$
+P_{青绿|否}=P(色泽=青绿|好瓜=否)=\frac{3}{9}\approx0.333
+$$
-(1)非线性映射是SVM方法的理论基础,SVM利用内积核函数代替向高维空间的非线性映射;
-(2)对特征空间划分的最优超平面是SVM的目标,最大化分类边际的思想是SVM方法的核心;
-(3)支持向量是SVM的训练结果,在SVM分类决策中起决定作用的是支持向量。
-(4)SVM 是一种有坚实理论基础的新颖的小样本学习方法。它基本上不涉及概率测度及大数定律等,因此不同于现有的统计方法。从本质上看,它避开了从归纳到演绎的传统过程,实现了高效的从训练样本到预报样本的“转导推理”,大大简化了通常的分类和回归等问题。
-(5)SVM 的最终决策函数只由少数的支持向量所确定,计算的复杂性取决于支持向量的数目,而不是样本空间的维数,这在某种意义上避免了“维数灾难”。
-(6)少数支持向量决定了最终结果,这不但可以帮助我们抓住关键样本、“剔除”大量冗余样本,而且注定了该方法不但算法简单,而且具有较好的“鲁棒”性。这种“鲁棒”性主要体现在:
-①增、删非支持向量样本对模型没有影响;
-②支持向量样本集具有一定的鲁棒性;
-③有些成功的应用中,SVM 方法对核的选取不敏感
+$$
+P_{蜷缩|是}=P(根蒂=蜷缩|好瓜=是)=\frac{5}{8}=0.625
+$$
-3.3.2.2 SVM的两个不足:
-(1) SVM算法对大规模训练样本难以实施
-由 于SVM是借助二次规划来求解支持向量,而求解二次规划将涉及m阶矩阵的计算(m为样本的个数),当m数目很大时该矩阵的存储和计算将耗费大量的机器内存 和运算时间。针对以上问题的主要改进有有J.Platt的SMO算法、T.Joachims的SVM、C.J.C.Burges等的PCGC、张学工的 CSVM以及O.L.Mangasarian等的SOR算法。
-(2) 用SVM解决多分类问题存在困难
-经典的支持向量机算法只给出了二类分类的算法,而在数据挖掘的实际应用中,一般要解决多类的分类问题。可以通过多个二类支持向量机的组合来解决。主要有一对多组合模式、一对一组合模式和SVM决策树;再就是通过构造多个分类器的组合来解决。主要原理是克服SVM固有的缺点,结合其他算法的优势,解决多类问题的分类精度。如:与粗集理论结合,形成一种优势互补的多类问题的组合分类器。
+$$
+P_{蜷缩|否}=P(根蒂=蜷缩|好瓜=否)=\frac{3}{9}=0.333
+$$
-## 2.19 贝叶斯
-### 2.19.1 图解极大似然估计
+$$
+P_{浊响|是}=P(敲声=浊响|好瓜=是)=\frac{6}{8}=0.750
+$$
-极大似然估计 http://blog.csdn.net/zengxiantao1994/article/details/72787849
+$$
+P_{浊响|否}=P(敲声=浊响|好瓜=否)=\frac{4}{9}\approx 0.444
+$$
-极大似然估计的原理,用一张图片来说明,如下图所示:
+$$
+P_{清晰|是}=P(纹理=清晰|好瓜=是)=\frac{7}{8}= 0.875
+$$
-
+$$
+P_{清晰|否}=P(纹理=清晰|好瓜=否)=\frac{2}{9}\approx 0.222
+$$
-总结起来,最大似然估计的目的就是:利用已知的样本结果,反推最有可能(最大概率)导致这样结果的参数值。
+$$
+P_{凹陷|是}=P(脐部=凹陷|好瓜=是)=\frac{6}{8}= 0.750
+$$
-原理:极大似然估计是建立在极大似然原理的基础上的一个统计方法,是概率论在统计学中的应用。极大似然估计提供了一种给定观察数据来评估模型参数的方法,即:“模型已定,参数未知”。通过若干次试验,观察其结果,利用试验结果得到某个参数值能够使样本出现的概率为最大,则称为极大似然估计。
+$$
+P_{凹陷|否}=P(脐部=凹陷|好瓜=否)=\frac{2}{9} \approx 0.222
+$$
-由于样本集中的样本都是独立同分布,可以只考虑一类样本集D,来估计参数向量θ。记已知的样本集为:
+$$
+P_{硬滑|是}=P(触感=硬滑|好瓜=是)=\frac{6}{8}= 0.750
+$$
-$D=x_{1},x_{2},...,x_{n}$
+$$
+P_{硬滑|否}=P(触感=硬滑|好瓜=否)=\frac{6}{9} \approx 0.667
+$$
-似然函数(linkehood function):联合概率密度函数$P(D|\theta )$称为相对于$x_{1},x_{2},...,x_{n}$的θ的似然函数。
+$$
+\begin{aligned}
+\rho_{密度:0.697|是}&=\rho(密度=0.697|好瓜=是)\\&=\frac{1}{\sqrt{2 \pi}\times0.129}exp\left( -\frac{(0.697-0.574)^2}{2\times0.129^2}\right) \approx 1.959
+\end{aligned}
+$$
-$l(\theta )=p(D|\theta ) =p(x_{1},x_{2},...,x_{N}|\theta )=\prod_{i=1}^{N}p(x_{i}|\theta )$
+$$
+\begin{aligned}
+\rho_{密度:0.697|否}&=\rho(密度=0.697|好瓜=否)\\&=\frac{1}{\sqrt{2 \pi}\times0.195}exp\left( -\frac{(0.697-0.496)^2}{2\times0.195^2}\right) \approx 1.203
+\end{aligned}
+$$
-如果$\hat{\theta}$是参数空间中能使似然函数$l(\theta)$最大的θ值,则$\hat{\theta}$应该是“最可能”的参数值,那么$\hat{\theta}$就是θ的极大似然估计量。它是样本集的函数,记作:
+$$
+\begin{aligned}
+\rho_{含糖:0.460|是}&=\rho(密度=0.460|好瓜=是)\\&=\frac{1}{\sqrt{2 \pi}\times0.101}exp\left( -\frac{(0.460-0.279)^2}{2\times0.101^2}\right) \approx 0.788
+\end{aligned}
+$$
-$\hat{\theta}=d(x_{1},x_{2},...,x_{N})=d(D)$
+$$
+\begin{aligned}
+\rho_{含糖:0.460|否}&=\rho(密度=0.460|好瓜=是)\\&=\frac{1}{\sqrt{2 \pi}\times0.108}exp\left( -\frac{(0.460-0.154)^2}{2\times0.108^2}\right) \approx 0.066
+\end{aligned}
+$$
-$\hat{\theta}(x_{1},x_{2},...,x_{N})$称为极大似然函数估计值。
+于是有
+$$
+\begin{align}
+P(&好瓜=是)\times P_{青绿|是} \times P_{蜷缩|是} \times P_{浊响|是} \times P_{清晰|是} \times P_{凹陷|是}\newline
+&\times P_{硬滑|是} \times p_{密度:0.697|是} \times p_{含糖:0.460|是} \approx 0.063 \newline\newline
+P(&好瓜=否)\times P_{青绿|否} \times P_{蜷缩|否} \times P_{浊响|否} \times P_{清晰|否} \times P_{凹陷|否}\newline
+&\times P_{硬滑|否} \times p_{密度:0.697|否} \times p_{含糖:0.460|否} \approx 6.80\times 10^{-5}
+\end{align}
+$$
-### 2.19.2 朴素贝叶斯分类器和一般的贝叶斯分类器有什么区别?
-### 2.19.3 朴素与半朴素贝叶斯分类器
-### 2.19.4 贝叶斯网三种典型结构
-### 2.19.5 什么是贝叶斯错误率
-### 2.19.6 什么是贝叶斯最优错误率
-## 2.20 EM算法解决问题及实现流程
+由于$0.063>6.80\times 10^{-5}$,因此,朴素贝叶斯分类器将测试样本“测1”判别为“好瓜”。
-1.EM算法要解决的问题
+### 2.19.6 半朴素贝叶斯分类器
- 我们经常会从样本观察数据中,找出样本的模型参数。 最常用的方法就是极大化模型分布的对数似然函数。
+ 朴素贝叶斯采用了“属性条件独立性假设”,半朴素贝叶斯分类器的基本想法是适当考虑一部分属性间的相互依赖信息。**独依赖估计**(One-Dependence Estimator,简称ODE)是半朴素贝叶斯分类器最常用的一种策略。顾名思义,独依赖是假设每个属性在类别之外最多依赖一个其他属性,即:
+$$
+P(\boldsymbol{x}|c_i)=\prod_{j=1}^d P(x_j|c_i,{\rm pa}_j)
+$$
+其中$pa_j$为属性$x_i$所依赖的属性,成为$x_i$的父属性。假设父属性$pa_j$已知,那么可以使用下面的公式估计$P(x_j|c_i,{\rm pa}_j)$
+$$
+P(x_j|c_i,{\rm pa}_j)=\frac{P(x_j,c_i,{\rm pa}_j)}{P(c_i,{\rm pa}_j)}
+$$
+
+## 2.20 EM算法
+
+### 2.20.1 EM算法基本思想
-但是在一些情况下,我们得到的观察数据有未观察到的隐含数据,此时我们未知的有隐含数据和模型参数,因而无法直接用极大化对数似然函数得到模型分布的参数。怎么办呢?这就是EM算法可以派上用场的地方了。
+ 最大期望算法(Expectation-Maximization algorithm, EM),是一类通过迭代进行极大似然估计的优化算法,通常作为牛顿迭代法的替代,用于对包含隐变量或缺失数据的概率模型进行参数估计。
-EM算法解决这个的思路是使用启发式的迭代方法,既然我们无法直接求出模型分布参数,那么我们可以先猜想隐含数据(EM算法的E步),接着基于观察数据和猜测的隐含数据一起来极大化对数似然,求解我们的模型参数(EM算法的M步)。由于我们之前的隐藏数据是猜测的,所以此时得到的模型参数一般还不是我们想要的结果。不过没关系,我们基于当前得到的模型参数,继续猜测隐含数据(EM算法的E步),然后继续极大化对数似然,求解我们的模型参数(EM算法的M步)。以此类推,不断的迭代下去,直到模型分布参数基本无变化,算法收敛,找到合适的模型参数。
+ 最大期望算法基本思想是经过两个步骤交替进行计算:
-从上面的描述可以看出,EM算法是迭代求解最大值的算法,同时算法在每一次迭代时分为两步,E步和M步。一轮轮迭代更新隐含数据和模型分布参数,直到收敛,即得到我们需要的模型参数。
+ 第一步是计算期望(E),利用对隐藏变量的现有估计值,计算其最大似然估计值**;**
+ 第二步是最大化(M),最大化在E步上求得的最大似然值来计算参数的值。
-一个最直观了解EM算法思路的是K-Means算法,见之前写的K-Means聚类算法原理。
+ M步上找到的参数估计值被用于下一个E步计算中,这个过程不断交替进行。
+### 2.20.2 EM算法推导
+
+ 对于$m$个样本观察数据$x=(x^{1},x^{2},...,x^{m})$,现在想找出样本的模型参数$\theta$,其极大化模型分布的对数似然函数为:
+$$
+\theta = \mathop{\arg\max}_\theta\sum\limits_{i=1}^m logP(x^{(i)};\theta)
+$$
+如果得到的观察数据有未观察到的隐含数据$z=(z^{(1)},z^{(2)},...z^{(m)})$,极大化模型分布的对数似然函数则为:
+$$
+\theta =\mathop{\arg\max}_\theta\sum\limits_{i=1}^m logP(x^{(i)};\theta) = \mathop{\arg\max}_\theta\sum\limits_{i=1}^m log\sum\limits_{z^{(i)}}P(x^{(i)}, z^{(i)};\theta) \tag{a}
+$$
+由于上式不能直接求出$\theta$,采用缩放技巧:
+$$
+\begin{align} \sum\limits_{i=1}^m log\sum\limits_{z^{(i)}}P(x^{(i)}, z^{(i)};\theta) & = \sum\limits_{i=1}^m log\sum\limits_{z^{(i)}}Q_i(z^{(i)})\frac{P(x^{(i)}, z^{(i)};\theta)}{Q_i(z^{(i)})} \\ & \geqslant \sum\limits_{i=1}^m \sum\limits_{z^{(i)}}Q_i(z^{(i)})log\frac{P(x^{(i)}, z^{(i)};\theta)}{Q_i(z^{(i)})} \end{align} \tag{1}
+$$
+上式用到了Jensen不等式:
+$$
+log\sum\limits_j\lambda_jy_j \geqslant \sum\limits_j\lambda_jlogy_j\;\;, \lambda_j \geqslant 0, \sum\limits_j\lambda_j =1
+$$
+并且引入了一个未知的新分布$Q_i(z^{(i)})$。
-在K-Means聚类时,每个聚类簇的质心是隐含数据。我们会假设KK个初始化质心,即EM算法的E步;然后计算得到每个样本最近的质心,并把样本聚类到最近的这个质心,即EM算法的M步。重复这个E步和M步,直到质心不再变化为止,这样就完成了K-Means聚类。
+此时,如果需要满足Jensen不等式中的等号,所以有:
+$$
+\frac{P(x^{(i)}, z^{(i)};\theta)}{Q_i(z^{(i)})} =c, c为常数
+$$
+由于$Q_i(z^{(i)})$是一个分布,所以满足
+$$
+\sum\limits_{z}Q_i(z^{(i)}) =1
+$$
+综上,可得:
+$$
+Q_i(z^{(i)}) = \frac{P(x^{(i)}, z^{(i)};\theta)}{\sum\limits_{z}P(x^{(i)}, z^{(i)};\theta)} = \frac{P(x^{(i)}, z^{(i)};\theta)}{P(x^{(i)};\theta)} = P( z^{(i)}|x^{(i)};\theta)
+$$
+如果$Q_i(z^{(i)}) = P( z^{(i)}|x^{(i)};\theta)$ ,则第(1)式是我们的包含隐藏数据的对数似然的一个下界。如果我们能极大化这个下界,则也在尝试极大化我们的对数似然。即我们需要最大化下式:
+$$
+\mathop{\arg\max}_\theta \sum\limits_{i=1}^m \sum\limits_{z^{(i)}}Q_i(z^{(i)})log\frac{P(x^{(i)}, z^{(i)};\theta)}{Q_i(z^{(i)})}
+$$
+简化得:
+$$
+\mathop{\arg\max}_\theta \sum\limits_{i=1}^m \sum\limits_{z^{(i)}}Q_i(z^{(i)})log{P(x^{(i)}, z^{(i)};\theta)}
+$$
+以上即为EM算法的M步,$\sum\limits_{z^{(i)}}Q_i(z^{(i)})log{P(x^{(i)}, z^{(i)};\theta)}$可理解为$logP(x^{(i)}, z^{(i)};\theta) $基于条件概率分布$Q_i(z^{(i)}) $的期望。以上即为EM算法中E步和M步的具体数学含义。
+### 2.20.3 图解EM算法
-当然,K-Means算法是比较简单的,实际中的问题往往没有这么简单。上面对EM算法的描述还很粗糙,我们需要用数学的语言精准描述。
+ 考虑上一节中的(a)式,表达式中存在隐变量,直接找到参数估计比较困难,通过EM算法迭代求解下界的最大值到收敛为止。
-2.EM算法流程
+
-现在我们总结下EM算法的流程。
+ 图片中的紫色部分是我们的目标模型$p(x|\theta)$,该模型复杂,难以求解析解,为了消除隐变量$z^{(i)}$的影响,我们可以选择一个不包含$z^{(i)}$的模型$r(x|\theta)$,使其满足条件$r(x|\theta) \leqslant p(x|\theta) $。
-输入:观察数据x=(x(1),x(2),...x(m))x=(x(1),x(2),...x(m)),联合分布p(x,z|θ)p(x,z|θ), 条件分布p(z|x,θ)p(z|x,θ), 最大迭代次数JJ。
+求解步骤如下:
-1) 随机初始化模型参数θθ的初值θ0θ0。
+(1)选取$\theta_1$,使得$r(x|\theta_1) = p(x|\theta_1)$,然后对此时的$r$求取最大值,得到极值点$\theta_2$,实现参数的更新。
-2) for j from 1 to J开始EM算法迭代:
+(2)重复以上过程到收敛为止,在更新过程中始终满足$r \leqslant p $.
-a) E步:计算联合分布的条件概率期望:
-Qi(z(i))=P(z(i)|x(i),θj))Qi(z(i))=P(z(i)|x(i),θj))
-L(θ,θj)=∑i=1m∑z(i)Qi(z(i))logP(x(i),z(i)|θ)L(θ,θj)=∑i=1m∑z(i)Qi(z(i))logP(x(i),z(i)|θ)
+### 2.20.4 EM算法流程
-b) M步:极大化L(θ,θj)L(θ,θj),得到θj+1θj+1:
-θj+1=argmaxθL(θ,θj)θj+1=argmaxθL(θ,θj)
+输入:观察数据$x=(x^{(1)},x^{(2)},...x^{(m)})$,联合分布$p(x,z ;\theta)$,条件分布$p(z|x; \theta)$,最大迭代次数$J$
-c) 如果θj+1θj+1已收敛,则算法结束。否则继续回到步骤a)进行E步迭代。
+1)随机初始化模型参数$\theta$的初值$\theta^0$。
-输出:模型参数θθ。
+2)$for \ j \ from \ 1 \ to \ j$:
+
+ a) E步。计算联合分布的条件概率期望:
+$$
+Q_i(z^{(i)}) = P( z^{(i)}|x^{(i)}, \theta^{j})
+$$
+
+$$
+L(\theta, \theta^{j}) = \sum\limits_{i=1}^m\sum\limits_{z^{(i)}}P( z^{(i)}|x^{(i)}, \theta^{j})log{P(x^{(i)}, z^{(i)};\theta)}
+$$
+
+ b) M步。极大化$L(\theta, \theta^{j})$,得到$\theta^{j+1}$:
+$$
+\theta^{j+1} = \mathop{\arg\max}_\theta L(\theta, \theta^{j})
+$$
+ c) 如果$\theta^{j+1}$收敛,则算法结束。否则继续回到步骤a)进行E步迭代。
+
+输出:模型参数$\theta$。
## 2.21 降维和聚类
-### 2.21.1 为什么会产生维数灾难?
+### 2.21.1 图解为什么会产生“维数灾难”?
+
+ 假如数据集包含10张照片,照片中包含三角形和圆两种形状。现在来设计一个分类器进行训练,让这个分类器对其他的照片进行正确分类(假设三角形和圆的总数是无限大),简单的,我们用一个特征进行分类:
-http://blog.csdn.net/chenjianbo88/article/details/52382943
-假设地球上猫和狗的数量是无限的。由于有限的时间和计算能力,我们仅仅选取了10张照片作为训练样本。我们的目的是基于这10张照片来训练一个线性分类器,使得这个线性分类器可以对剩余的猫或狗的照片进行正确分类。我们从只用一个特征来辨别猫和狗开始:
-
+
-从图2可以看到,如果仅仅只有一个特征的话,猫和狗几乎是均匀分布在这条线段上,很难将10张照片线性分类。那么,增加一个特征后的情况会怎么样:
+ 图2.21.1.a
-
+ 从上图可看到,如果仅仅只有一个特征进行分类,三角形和圆几乎是均匀分布在这条线段上,很难将10张照片线性分类。那么,增加一个特征后的情况会怎么样:
+
+
+
+ 图2.21.1.b
增加一个特征后,我们发现仍然无法找到一条直线将猫和狗分开。所以,考虑需要再增加一个特征:
-
+
+
+ 图2.21.1.c
-此时,我们终于找到了一个平面将猫和狗分开。需要注意的是,只有一个特征时,假设特征空间是长度为5的线段,则样本密度是10/5=2。有两个特征时,特征空间大小是5*5=25,样本密度是10/25=0.4。有三个特征时,特征空间大小是5*5*5=125,样本密度是10/125=0.08。如果继续增加特征数量,样本密度会更加稀疏,也就更容易找到一个超平面将训练样本分开。因为随着特征数量趋向于无限大,样本密度非常稀疏,训练样本被分错的可能性趋向于零。当我们将高维空间的分类结果映射到低维空间时,一个严重的问题出现了:
+
-
+ 图2.21.1.d
-从图5可以看到将三维特征空间映射到二维特征空间后的结果。尽管在高维特征空间时训练样本线性可分,但是映射到低维空间后,结果正好相反。事实上,增加特征数量使得高维空间线性可分,相当于在低维空间内训练一个复杂的非线性分类器。不过,这个非线性分类器太过“聪明”,仅仅学到了一些特例。如果将其用来辨别那些未曾出现在训练样本中的测试样本时,通常结果不太理想。这其实就是我们在机器学习中学过的过拟合问题。
+ 此时,可以找到一个平面将三角形和圆分开。
-
+ 现在计算一下不同特征数是样本的密度:
-尽管图6所示的只采用2个特征的线性分类器分错了一些训练样本,准确率似乎没有图4的高,但是,采用2个特征的线性分类器的泛化能力比采用3个特征的线性分类器要强。因为,采用2个特征的线性分类器学习到的不只是特例,而是一个整体趋势,对于那些未曾出现过的样本也可以比较好地辨别开来。换句话说,通过减少特征数量,可以避免出现过拟合问题,从而避免“维数灾难”。
+ (1)一个特征时,假设特征空间时长度为5的线段,则样本密度为$10 \div 5 = 2$。
-
+ (2)两个特征时,特征空间大小为$ 5\times5 = 25$,样本密度为$10 \div 25 = 0.4$。
-图7从另一个角度诠释了“维数灾难”。假设只有一个特征时,特征的值域是0到1,每一只猫和狗的特征值都是唯一的。如果我们希望训练样本覆盖特征值值域的20%,那么就需要猫和狗总数的20%。我们增加一个特征后,为了继续覆盖特征值值域的20%就需要猫和狗总数的45%(0.45^2=0.2)。继续增加一个特征后,需要猫和狗总数的58%(0.58^3=0.2)。随着特征数量的增加,为了覆盖特征值值域的20%,就需要更多的训练样本。如果没有足够的训练样本,就可能会出现过拟合问题。
+ (3)三个特征时,特征空间大小是$ 5\times5\times5 = 125$,样本密度为$10 \div 125 = 0.08$。
-
+ 以此类推,如果继续增加特征数量,样本密度会越来越稀疏,此时,更容易找到一个超平面将训练样本分开。当特征数量增长至无限大时,样本密度就变得非常稀疏。
-通过上述例子,我们可以看到特征数量越多,训练样本就会越稀疏,分类器的参数估计就会越不准确,更加容易出现过拟合问题。“维数灾难”的另一个影响是训练样本的稀疏性并不是均匀分布的。处于中心位置的训练样本比四周的训练样本更加稀疏。
+ 下面看一下将高维空间的分类结果映射到低维空间时,会出现什么情况?
-假设有一个二维特征空间,如图8所示的矩形,在矩形内部有一个内切的圆形。由于越接近圆心的样本越稀疏,因此,相比于圆形内的样本,那些位于矩形四角的样本更加难以分类。那么,随着特征数量的增加,圆形的面积会不会变化呢?这里我们假设超立方体(hypercube)的边长d=1,那么计算半径为0.5的超球面(hypersphere)的体积(volume)的公式为:
-$V(d)=\frac{\pi ^{\frac{d}{2}}}{\Gamma (\frac{d}{2}+1)}0.5^{d}$
+
-
+ 图2.21.1.e
-从图9可以看出随着特征数量的增加,超球面的体积逐渐减小直至趋向于零,然而超立方体的体积却不变。这个结果有点出乎意料,但部分说明了分类问题中的“维数灾难”:在高维特征空间中,大多数的训练样本位于超立方体的角落。
+ 上图是将三维特征空间映射到二维特征空间后的结果。尽管在高维特征空间时训练样本线性可分,但是映射到低维空间后,结果正好相反。事实上,增加特征数量使得高维空间线性可分,相当于在低维空间内训练一个复杂的非线性分类器。不过,这个非线性分类器太过“聪明”,仅仅学到了一些特例。如果将其用来辨别那些未曾出现在训练样本中的测试样本时,通常结果不太理想,会造成过拟合问题。
-
+
- 图10显示了不同维度下,样本的分布情况。在8维特征空间中,共有2^8=256个角落,而98%的样本分布在这些角落。随着维度的不断增加,公式2将趋向于0,其中dist_max和dist_min分别表示样本到中心的最大与最小距离。
+ 图2.21.1.f
-
+ 上图所示的只采用2个特征的线性分类器分错了一些训练样本,准确率似乎没有图2.21.1.e的高,但是,采用2个特征的线性分类器的泛化能力比采用3个特征的线性分类器要强。因为,采用2个特征的线性分类器学习到的不只是特例,而是一个整体趋势,对于那些未曾出现过的样本也可以比较好地辨别开来。换句话说,通过减少特征数量,可以避免出现过拟合问题,从而避免“维数灾难”。
-因此,在高维特征空间中对于样本距离的度量失去意义。由于分类器基本都依赖于如Euclidean距离,Manhattan距离等,所以在特征数量过大时,分类器的性能就会出现下降。
+
-所以,我们如何避免“维数灾难”?图1显示了分类器的性能随着特征个数的变化不断增加,过了某一个值后,性能不升反降。这里的某一个值到底是多少呢?目前,还没有方法来确定分类问题中的这个阈值是多少,这依赖于训练样本的数量,决策边界的复杂性以及分类器的类型。理论上,如果训练样本的数量无限大,那么就不会存在“维数灾难”,我们可以采用任意多的特征来训练分类器。事实上,训练样本的数量是有限的,所以不应该采用过多的特征。此外,那些需要精确的非线性决策边界的分类器,比如neural network,knn,decision trees等的泛化能力往往并不是很好,更容易发生过拟合问题。因此,在设计这些分类器时应当慎重考虑特征的数量。相反,那些泛化能力较好的分类器,比如naive Bayesian,linear classifier等,可以适当增加特征的数量。
+ 上图从另一个角度诠释了“维数灾难”。假设只有一个特征时,特征的值域是0到1,每一个三角形和圆的特征值都是唯一的。如果我们希望训练样本覆盖特征值值域的20%,那么就需要三角形和圆总数的20%。我们增加一个特征后,为了继续覆盖特征值值域的20%就需要三角形和圆总数的45%($0.452^2\approx0.2$)。继续增加一个特征后,需要三角形和圆总数的58%($0.583^3\approx0.2$)。随着特征数量的增加,为了覆盖特征值值域的20%,就需要更多的训练样本。如果没有足够的训练样本,就可能会出现过拟合问题。
-如果给定了N个特征,我们该如何从中选出M个最优的特征?最简单粗暴的方法是尝试所有特征的组合,从中挑出M个最优的特征。事实上,这是非常花时间的,或者说不可行的。其实,已经有许多特征选择算法(feature selection algorithms)来帮助我们确定特征的数量以及选择特征。此外,还有许多特征抽取方法(feature extraction methods),比如PCA等。交叉验证(cross-validation)也常常被用于检测与避免过拟合问题。
+ 通过上述例子,我们可以看到特征数量越多,训练样本就会越稀疏,分类器的参数估计就会越不准确,更加容易出现过拟合问题。“维数灾难”的另一个影响是训练样本的稀疏性并不是均匀分布的。处于中心位置的训练样本比四周的训练样本更加稀疏。
-参考资料:
-[1] Vincent Spruyt. The Curse of Dimensionality in classification. Computer vision for dummies. 2014. [Link]
+
+
+ 假设有一个二维特征空间,如上图所示的矩形,在矩形内部有一个内切的圆形。由于越接近圆心的样本越稀疏,因此,相比于圆形内的样本,那些位于矩形四角的样本更加难以分类。当维数变大时,特征超空间的容量不变,但单位圆的容量会趋于0,在高维空间中,大多数训练数据驻留在特征超空间的角落。散落在角落的数据要比处于中心的数据难于分类。
### 2.21.2 怎样避免维数灾难
+**有待完善!!!**
+
解决维度灾难问题:
主成分分析法PCA,线性判别法LDA
@@ -1687,122 +2053,149 @@ Lassio缩减系数法、小波分析法、
### 2.21.3 聚类和降维有什么区别与联系?
-聚类用于找寻数据内在的分布结构,既可以作为一个单独的过程,比如异常检测等等。也可作为分类等其他学习任务的前驱过程。聚类是标准的无监督学习。
+ 聚类用于找寻数据内在的分布结构,既可以作为一个单独的过程,比如异常检测等等。也可作为分类等其他学习任务的前驱过程。聚类是标准的无监督学习。
-1) 在一些推荐系统中需确定新用户的类型,但定义“用户类型”却可能不太容易,此时往往可先对原油的用户数据进行聚类,根据聚类结果将每个簇定义为一个类,然后再基于这些类训练分类模型,用于判别新用户的类型。
+ 1)在一些推荐系统中需确定新用户的类型,但定义“用户类型”却可能不太容易,此时往往可先对原有的用户数据进行聚类,根据聚类结果将每个簇定义为一个类,然后再基于这些类训练分类模型,用于判别新用户的类型。
-
+
-2)而降维则是为了缓解维数灾难的一个重要方法,就是通过某种数学变换将原始高维属性空间转变为一个低维“子空间”。其基于的假设就是,虽然人们平时观测到的数据样本虽然是高维的,但是实际上真正与学习任务相关的是个低维度的分布。从而通过最主要的几个特征维度就可以实现对数据的描述,对于后续的分类很有帮助。比如对于Kaggle上的泰坦尼克号生还问题。通过给定一个人的许多特征如年龄、姓名、性别、票价等,来判断其是否能在海难中生还。这就需要首先进行特征筛选,从而能够找出主要的特征,让学习到的模型有更好的泛化性。
+ 2)而降维则是为了缓解维数灾难的一个重要方法,就是通过某种数学变换将原始高维属性空间转变为一个低维“子空间”。其基于的假设就是,虽然人们平时观测到的数据样本虽然是高维的,但是实际上真正与学习任务相关的是个低维度的分布。从而通过最主要的几个特征维度就可以实现对数据的描述,对于后续的分类很有帮助。比如对于Kaggle(数据分析竞赛平台之一)上的泰坦尼克号生还问题。通过给定一个乘客的许多特征如年龄、姓名、性别、票价等,来判断其是否能在海难中生还。这就需要首先进行特征筛选,从而能够找出主要的特征,让学习到的模型有更好的泛化性。
-聚类和降维都可以作为分类等问题的预处理步骤。
+ 聚类和降维都可以作为分类等问题的预处理步骤。

-但是他们虽然都能实现对数据的约减。但是二者适用的对象不同,聚类针对的是数据点,而降维则是对于数据的特征。另外它们着很多种实现方法。聚类中常用的有K-means、层次聚类、基于密度的聚类等;降维中常用的则PCA、Isomap、LLE等。
+ 但是他们虽然都能实现对数据的约减。但是二者适用的对象不同,聚类针对的是数据点,而降维则是对于数据的特征。另外它们有着很多种实现方法。聚类中常用的有K-means、层次聚类、基于密度的聚类等;降维中常用的则PCA、Isomap、LLE等。
+
+### 2.21.4 有哪些聚类算法优劣衡量标准
-### 2.21.4 四种聚类方法之比较
+不同聚类算法有不同的优劣和不同的适用条件。可从以下方面进行衡量判断:
+ 1、算法的处理能力:处理大的数据集的能力,即算法复杂度;处理数据噪声的能力;处理任意形状,包括有间隙的嵌套的数据的能力;
+ 2、算法是否需要预设条件:是否需要预先知道聚类个数,是否需要用户给出领域知识;
-http://www.cnblogs.com/William_Fire/archive/2013/02/09/2909499.html
+ 3、算法的数据输入属性:算法处理的结果与数据输入的顺序是否相关,也就是说算法是否独立于数据输入顺序;算法处理有很多属性数据的能力,也就是对数据维数是否敏感,对数据的类型有无要求。
- 聚类分析是一种重要的人类行为,早在孩提时代,一个人就通过不断改进下意识中的聚类模式来学会如何区分猫狗、动物植物。目前在许多领域都得到了广泛的研究和成功的应用,如用于模式识别、数据分析、图像处理、市场研究、客户分割、Web文档分类等[1]。
+### 2.21.5 聚类和分类有什么区别?
-聚类就是按照某个特定标准(如距离准则)把一个数据集分割成不同的类或簇,使得同一个簇内的数据对象的相似性尽可能大,同时不在同一个簇中的数据对象的差异性也尽可能地大。即聚类后同一类的数据尽可能聚集到一起,不同数据尽量分离。
+**聚类(Clustering) **
+ 聚类,简单地说就是把相似的东西分到一组,聚类的时候,我们并不关心某一类是什么,我们需要实现的目标只是把相似的东西聚到一起。一个聚类算法通常只需要知道如何计算相似度就可以开始工作了,因此聚类通常并不需要使用训练数据进行学习,在机器学习中属于无监督学习。
-聚类技术[2]正在蓬勃发展,对此有贡献的研究领域包括数据挖掘、统计学、机器学习、空间数据库技术、生物学以及市场营销等。各种聚类方法也被不断提出和改进,而不同的方法适合于不同类型的数据,因此对各种聚类方法、聚类效果的比较成为值得研究的课题。
+**分类(Classification) **
-1 聚类算法的分类
+ 分类,对于一个分类器,通常需要你告诉它“这个东西被分为某某类”。一般情况下,一个分类器会从它得到的训练集中进行学习,从而具备对未知数据进行分类的能力,在机器学习中属于监督学习。
-目前,有大量的聚类算法[3]。而对于具体应用,聚类算法的选择取决于数据的类型、聚类的目的。如果聚类分析被用作描述或探查的工具,可以对同样的数据尝试多种算法,以发现数据可能揭示的结果。
-
-主要的聚类算法可以划分为如下几类:划分方法、层次方法、基于密度的方法、基于网格的方法以及基于模型的方法[4-6]。
+### 2.21.6 不同聚类算法特点性能比较
-每一类中都存在着得到广泛应用的算法,例如:划分方法中的k-means[7]聚类算法、层次方法中的凝聚型层次聚类算法[8]、基于模型方法中的神经网络[9]聚类算法等。
- 目前,聚类问题的研究不仅仅局限于上述的硬聚类,即每一个数据只能被归为一类,模糊聚类[10]也是聚类分析中研究较为广泛的一个分支。模糊聚类通过隶 属函数来确定每个数据隶属于各个簇的程度,而不是将一个数据对象硬性地归类到某一簇中。目前已有很多关于模糊聚类的算法被提出,如著名的FCM算法等。
- 本文主要对k-means聚类算法、凝聚型层次聚类算法、神经网络聚类算法之SOM,以及模糊聚类的FCM算法通过通用测试数据集进行聚类效果的比较和分析。
+| 算法名称 | 可伸缩性 | 适合的数据类型 | 高维性 | 异常数据抗干扰性 | 聚类形状 | 算法效率 |
+| :----------: | :------: | :------------: | :----: | :--------------: | :------: | :------: |
+| WAVECLUSTER | 很高 | 数值型 | 很高 | 较高 | 任意形状 | 很高 |
+| ROCK | 很高 | 混合型 | 很高 | 很高 | 任意形状 | 一般 |
+| BIRCH | 较高 | 数值型 | 较低 | 较低 | 球形 | 很高 |
+| CURE | 较高 | 数值型 | 一般 | 很高 | 任意形状 | 较高 |
+| K-PROTOTYPES | 一般 | 混合型 | 较低 | 较低 | 任意形状 | 一般 |
+| DENCLUE | 较低 | 数值型 | 较高 | 一般 | 任意形状 | 较高 |
+| OPTIGRID | 一般 | 数值型 | 较高 | 一般 | 任意形状 | 一般 |
+| CLIQUE | 较高 | 数值型 | 较高 | 较高 | 任意形状 | 较低 |
+| DBSCAN | 一般 | 数值型 | 较低 | 较高 | 任意形状 | 一般 |
+| CLARANS | 较低 | 数值型 | 较低 | 较高 | 球形 | 较低 |
-2 四种常用聚类算法研究
+### 2.21.7 四种常用聚类方法之比较
-2.1 k-means聚类算法
+ 聚类就是按照某个特定标准把一个数据集分割成不同的类或簇,使得同一个簇内的数据对象的相似性尽可能大,同时不在同一个簇中的数据对象的差异性也尽可能地大。即聚类后同一类的数据尽可能聚集到一起,不同类数据尽量分离。
+ 主要的聚类算法可以划分为如下几类:划分方法、层次方法、基于密度的方法、基于网格的方法以及基于模型的方法。下面主要对k-means聚类算法、凝聚型层次聚类算法、神经网络聚类算法之SOM,以及模糊聚类的FCM算法通过通用测试数据集进行聚类效果的比较和分析。
- k-means是划分方法中较经典的聚类算法之一。由于该算法的效率高,所以在对大规模数据进行聚类时被广泛应用。目前,许多算法均围绕着该算法进行扩展和改进。
- k-means算法以k为参数,把n个对象分成k个簇,使簇内具有较高的相似度,而簇间的相似度较低。k-means算法的处理过程如下:首先,随机地 选择k个对象,每个对象初始地代表了一个簇的平均值或中心;对剩余的每个对象,根据其与各簇中心的距离,将它赋给最近的簇;然后重新计算每个簇的平均值。 这个过程不断重复,直到准则函数收敛。通常,采用平方误差准则,其定义如下:
+### 2.21.8 k-means聚类算法
- $E=\sum_{i=1}^{k}\sum_{p\subset C}|p-m_{i}|^{2}$
+k-means是划分方法中较经典的聚类算法之一。由于该算法的效率高,所以在对大规模数据进行聚类时被广泛应用。目前,许多算法均围绕着该算法进行扩展和改进。
+k-means算法以k为参数,把n个对象分成k个簇,使簇内具有较高的相似度,而簇间的相似度较低。k-means算法的处理过程如下:首先,随机地 选择k个对象,每个对象初始地代表了一个簇的平均值或中心;对剩余的每个对象,根据其与各簇中心的距离,将它赋给最近的簇;然后重新计算每个簇的平均值。 这个过程不断重复,直到准则函数收敛。通常,采用平方误差准则,其定义如下:
+$$
+E=\sum_{i=1}^{k}\sum_{p\in C_i}\left\|p-m_i\right\|^2
+$$
+ 这里E是数据中所有对象的平方误差的总和,p是空间中的点,$m_i$是簇$C_i$的平均值[9]。该目标函数使生成的簇尽可能紧凑独立,使用的距离度量是欧几里得距离,当然也可以用其他距离度量。
- 这里E是数据库中所有对象的平方误差的总和,p是空间中的点,mi是簇Ci的平均值[9]。该目标函数使生成的簇尽可能紧凑独立,使用的距离度量是欧几里得距离,当然也可以用其他距离度量。k-means聚类算法的算法流程如下:
- 输入:包含n个对象的数据库和簇的数目k;
- 输出:k个簇,使平方误差准则最小。
+**算法流程**:
+ 输入:包含n个对象的数据和簇的数目k;
+ 输出:n个对象到k个簇,使平方误差准则最小。
步骤:
(1) 任意选择k个对象作为初始的簇中心;
- (2) repeat;
- (3) 根据簇中对象的平均值,将每个对象(重新)赋予最类似的簇;
- (4) 更新簇的平均值,即计算每个簇中对象的平均值;
- (5) until不再发生变化。
+ (2) 根据簇中对象的平均值,将每个对象(重新)赋予最类似的簇;
+ (3) 更新簇的平均值,即计算每个簇中对象的平均值;
+ (4) 重复步骤(2)、(3)直到簇中心不再变化;
+
+### 2.21.9 层次聚类算法
-2.2 层次聚类算法
根据层次分解的顺序是自底向上的还是自上向下的,层次聚类算法分为凝聚的层次聚类算法和分裂的层次聚类算法。
- 凝聚型层次聚类的策略是先将每个对象作为一个簇,然后合并这些原子簇为越来越大的簇,直到所有对象都在一个簇中,或者某个终结条件被满足。绝大多数层次聚类属于凝聚型层次聚类,它们只是在簇间相似度的定义上有所不同。四种广泛采用的簇间距离度量方法如下:
+ 凝聚型层次聚类的策略是先将每个对象作为一个簇,然后合并这些原子簇为越来越大的簇,直到所有对象都在一个簇中,或者某个终结条件被满足。绝大多数层次聚类属于凝聚型层次聚类,它们只是在簇间相似度的定义上有所不同。
-
+**算法流程**:
-这里给出采用最小距离的凝聚层次聚类算法流程:
+注:以采用最小距离的凝聚层次聚类算法为例:
(1) 将每个对象看作一类,计算两两之间的最小距离;
(2) 将距离最小的两个类合并成一个新类;
(3) 重新计算新类与所有类之间的距离;
(4) 重复(2)、(3),直到所有类最后合并成一类。
-### 2.21.5 SOM聚类算法
-SOM神经网络[11]是由芬兰神经网络专家Kohonen教授提出的,该算法假设在输入对象中存在一些拓扑结构或顺序,可以实现从输入空间(n维)到输出平面(2维)的降维映射,其映射具有拓扑特征保持性质,与实际的大脑处理有很强的理论联系。
+### 2.21.10 SOM聚类算法
+ SOM神经网络[11]是由芬兰神经网络专家Kohonen教授提出的,该算法假设在输入对象中存在一些拓扑结构或顺序,可以实现从输入空间(n维)到输出平面(2维)的降维映射,其映射具有拓扑特征保持性质,与实际的大脑处理有很强的理论联系。
-SOM网络包含输入层和输出层。输入层对应一个高维的输入向量,输出层由一系列组织在2维网格上的有序节点构成,输入节点与输出节点通过权重向量连接。 学习过程中,找到与之距离最短的输出层单元,即获胜单元,对其更新。同时,将邻近区域的权值更新,使输出节点保持输入向量的拓扑特征。
+ SOM网络包含输入层和输出层。输入层对应一个高维的输入向量,输出层由一系列组织在2维网格上的有序节点构成,输入节点与输出节点通过权重向量连接。 学习过程中,找到与之距离最短的输出层单元,即获胜单元,对其更新。同时,将邻近区域的权值更新,使输出节点保持输入向量的拓扑特征。
-算法流程:
+**算法流程**:
-(1) 网络初始化,对输出层每个节点权重赋初值;
-(2) 将输入样本中随机选取输入向量,找到与输入向量距离最小的权重向量;
-(3) 定义获胜单元,在获胜单元的邻近区域调整权重使其向输入向量靠拢;
-(4) 提供新样本、进行训练;
-(5) 收缩邻域半径、减小学习率、重复,直到小于允许值,输出聚类结果。
+ (1) 网络初始化,对输出层每个节点权重赋初值;
+ (2) 从输入样本中随机选取输入向量并且归一化,找到与输入向量距离最小的权重向量;
+ (3) 定义获胜单元,在获胜单元的邻近区域调整权重使其向输入向量靠拢;
+ (4) 提供新样本、进行训练;
+ (5) 收缩邻域半径、减小学习率、重复,直到小于允许值,输出聚类结果。
-### 2.21.6 FCM聚类算法
+### 2.21.11 FCM聚类算法
-1965年美国加州大学柏克莱分校的扎德教授第一次提出了‘集合’的概念。经过十多年的发展,模糊集合理论渐渐被应用到各个实际应用方面。为克服非此即彼的分类缺点,出现了以模糊集合论为数学基础的聚类分析。用模糊数学的方法进行聚类分析,就是模糊聚类分析[12]。
-
-FCM算法是一种以隶属度来确定每个数据点属于某个聚类程度的算法。该聚类算法是传统硬聚类算法的一种改进。
-
-
+ 1965年美国加州大学柏克莱分校的扎德教授第一次提出了‘集合’的概念。经过十多年的发展,模糊集合理论渐渐被应用到各个实际应用方面。为克服非此即彼的分类缺点,出现了以模糊集合论为数学基础的聚类分析。用模糊数学的方法进行聚类分析,就是模糊聚类分析[12]。
+ FCM算法是一种以隶属度来确定每个数据点属于某个聚类程度的算法。该聚类算法是传统硬聚类算法的一种改进。
+ 设数据集$X={x_1,x_2,...,x_n}$,它的模糊$c$划分可用模糊矩阵$U=[u_{ij}]$表示,矩阵$U$的元素$u_{ij}$表示第$j(j=1,2,...,n)$个数据点属于第$i(i=1,2,...,c)$类的隶属度,$u_{ij}$满足如下条件:
+$$
+\begin{equation}
+\left\{
+\begin{array}{lr}
+\sum_{i=1}^c u_{ij}=1 \quad\forall~j
+\\u_{ij}\in[0,1] \quad\forall ~i,j
+\\\sum_{j=1}^c u_{ij}>0 \quad\forall ~i
+\end{array}
+\right.
+\end{equation}
+$$
+目前被广泛使用的聚类准则是取类内加权误差平方和的极小值。即:
+$$
+(min)J_m(U,V)=\sum^n_{j=1}\sum^c_{i=1}u^m_{ij}d^2_{ij}(x_j,v_i)
+$$
+其中$V$为聚类中心,$m$为加权指数,$d_{ij}(x_j,v_i)=||v_i-x_j||$。
-算法流程:
+**算法流程**:
(1) 标准化数据矩阵;
(2) 建立模糊相似矩阵,初始化隶属矩阵;
(3) 算法开始迭代,直到目标函数收敛到极小值;
(4) 根据迭代结果,由最后的隶属矩阵确定数据所属的类,显示最后的聚类结果。
-3 四种聚类算法试验
+### 2.21.12 四种聚类算法试验
-3.1 试验数据
+ 选取专门用于测试分类、聚类算法的国际通用的UCI数据库中的IRIS数据集,IRIS数据集包含150个样本数据,分别取自三种不同 的莺尾属植物setosa、versicolor和virginica的花朵样本,每个数据含有4个属性,即萼片长度、萼片宽度、花瓣长度、花瓣宽度,单位为cm。 在数据集上执行不同的聚类算法,可以得到不同精度的聚类结果。基于前面描述的各算法原理及流程,可初步得如下聚类结果。
-实验中,选取专门用于测试分类、聚类算法的国际通用的UCI数据库中的IRIS[13]数据集,IRIS数据集包含150个样本数据,分别取自三种不同 的莺尾属植物setosa、versicolor和virginica的花朵样本,每个数据含有4个属性,即萼片长度、萼片宽度、花瓣长度,单位为cm。 在数据集上执行不同的聚类算法,可以得到不同精度的聚类结果。
+| 聚类方法 | 聚错样本数 | 运行时间/s | 平均准确率/(%) |
+| -------- | ---------- | ---------- | ---------------- |
+| K-means | 17 | 0.146001 | 89 |
+| 层次聚类 | 51 | 0.128744 | 66 |
+| SOM | 22 | 5.267283 | 86 |
+| FCM | 12 | 0.470417 | 92 |
-3.2 试验结果说明
-文中基于前面所述各算法原理及算法流程,用matlab进行编程运算,得到表1所示聚类结果。
-
-
-
-如表1所示,对于四种聚类算法,按三方面进行比较:
-
-(1)聚错样本数:总的聚错的样本数,即各类中聚错的样本数的和;
-
-(2)运行时间:即聚类整个 过程所耗费的时间,单位为s;
-
-(3)平均准确度:设原数据集有k个类,用ci表示第i类,ni为ci中样本的个数,mi为聚类正确的个数,则mi/ni为 第i类中的精度,则平均精度为:
+**注**:
-$avg=\frac{1}{k}\sum_{i=1}^{k}\frac{m_{i}}{n_{i}}$
+(1) 聚错样本数:总的聚错的样本数,即各类中聚错的样本数的和;
+(2) 运行时间:即聚类整个过程所耗费的时间,单位为s;
+(3) 平均准确度:设原数据集有k个类,用$c_i$表示第i类,$n_i$为$c_i$中样本的个数,$m_i$为聚类正确的个数,则$m_i/n_i$为 第i类中的精度,则平均精度为:$avg=\frac{1}{k}\sum_{i=1}^{k}\frac{m_{i}}{n_{i}}$。
## 2.22 GBDT和随机森林的区别
@@ -1818,9 +2211,49 @@ GBDT和随机森林的不同点:
5、随机森林对训练集一视同仁,GBDT是基于权值的弱分类器的集成
6、随机森林是通过减少模型方差提高性能,GBDT是通过减少模型偏差提高性能
-## 2.23 大数据与深度学习之间的关系
+## 2.23 理解 One Hot Encodeing 原理及作用?
+
+问题由来:
+
+ 在很多**机器学习**任务中,特征并不总是连续值,而有可能是分类值。
+
+例如,考虑一下的三个特征:
+
+```
+["male", "female"] ["from Europe", "from US", "from Asia"]
+["uses Firefox", "uses Chrome", "uses Safari", "uses Internet Explorer"]
+```
+
+如果将上述特征用数字表示,效率会高很多。例如:
+
+```
+["male", "from US", "uses Internet Explorer"] 表示为 [0, 1, 3]
+["female", "from Asia", "uses Chrome"] 表示为 [1, 2, 1]
+```
-大数据**通常被定义为“超出常用软件工具捕获,管理和处理能力”的数据集。
+ 但是,即使转化为数字表示后,上述数据也不能直接用在我们的分类器中。因为,分类器往往默认数据数据是连续的(可以计算距离?),并且是有序的(而上面这个 0 并不是说比 1 要高级)。但是,按照我们上述的表示,数字并不是有序的,而是随机分配的。
+
+**独热编码**
+
+ 为了解决上述问题,其中一种可能的解决方法是采用独热编码(One-Hot Encoding)。独热编码即 One-Hot 编码,又称一位有效编码,其方法是使用N位状态寄存器来对 N 个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候,其中只有一位有效。
+
+例如:
+
+```
+自然状态码为:000,001,010,011,100,101
+独热编码为:000001,000010,000100,001000,010000,100000
+```
+
+ 可以这样理解,对于每一个特征,如果它有 m 个可能值,那么经过独热编码后,就变成了 m 个二元特征(如成绩这个特征有好,中,差变成 one-hot 就是 100, 010, 001)。并且,这些特征互斥,每次只有一个激活。因此,数据会变成稀疏的。
+
+这样做的好处主要有:
+
+1. 解决了分类器不好处理属性数据的问题;
+2. 在一定程度上也起到了扩充特征的作用。
+
+## 2.24 大数据与深度学习之间的关系
+
+**大数据**通常被定义为“超出常用软件工具捕获,管理和处理能力”的数据集。
**机器学习**关心的问题是如何构建计算机程序使用经验自动改进。
**数据挖掘**是从数据中提取模式的特定算法的应用。
在数据挖掘中,重点在于算法的应用,而不是算法本身。
@@ -1831,12 +2264,31 @@ GBDT和随机森林的不同点:
1. 深度学习是一种模拟大脑的行为。可以从所学习对象的机制以及行为等等很多相关联的方面进行学习,模仿类型行为以及思维。
2. 深度学习对于大数据的发展有帮助。深度学习对于大数据技术开发的每一个阶段均有帮助,不管是数据的分析还是挖掘还是建模,只有深度学习,这些工作才会有可能一一得到实现。
-3. 深度学习转变了解决问题的思维。很多时候发现问题到解决问题,走一步看一步不是一个主要的解决问题的方式了,在深度学习的基础上,要求我们从开始到最后都要基于哦那个一个目标,为了需要优化的那个最终目的去进行处理数据以及将数据放入到数据应用平台上去。
-4. 大数据的深度学习需要一个框架。在大数据方面的深度学习都是从基础的角度出发的,深度学习需要一个框架或者一个系统总而言之,将你的大数据通过深度分析变为现实这就是深度学习和大数据的最直接关系。
+3. 深度学习转变了解决问题的思维。很多时候发现问题到解决问题,走一步看一步不是一个主要的解决问题的方式了,在深度学习的基础上,要求我们从开始到最后都要基于一个目标,为了需要优化的那个最终目标去进行处理数据以及将数据放入到数据应用平台上去,这就是端到端(End to End)。
+4. 大数据的深度学习需要一个框架。在大数据方面的深度学习都是从基础的角度出发的,深度学习需要一个框架或者一个系统。总而言之,将你的大数据通过深度分析变为现实,这就是深度学习和大数据的最直接关系。
+
+
+
+## 参考文献
+[1] Goodfellow I, Bengio Y, Courville A. Deep learning[M]. MIT press, 2016.
+[2] 周志华. 机器学习[M].清华大学出版社, 2016.
+[3] Michael A. Nielsen. "Neural Networks and Deep Learning", Determination Press, 2015.
+[4] Suryansh S. Gradient Descent: All You Need to Know, 2018.
+[5] 刘建平. 梯度下降小结,EM算法的推导, 2018
+[6] 杨小兵.聚类分析中若干关键技术的研究[D]. 杭州:浙江大学, 2005.
+[7] XU Rui, Donald Wunsch 1 1. survey of clustering algorithm[J].IEEE.Transactions on Neural Networks, 2005, 16(3):645-67 8.
+[8] YI Hong, SAM K. Learning assignment order of instances for the constrained k-means clustering algorithm[J].IEEE Transactions on Systems, Man, and Cybernetics, Part B:Cybernetics,2009,39 (2):568-574.
+[9] 贺玲, 吴玲达, 蔡益朝.数据挖掘中的聚类算法综述[J].计算机应用研究, 2007, 24(1):10-13.
+[10] 孙吉贵, 刘杰, 赵连宇.聚类算法研究[J].软件学报, 2008, 19(1):48-61.
+[11] 孔英会, 苑津莎, 张铁峰等.基于数据流管理技术的配变负荷分类方法研究.中国国际供电会议, CICED2006.
+[12] 马晓艳, 唐雁.层次聚类算法研究[J].计算机科学, 2008, 34(7):34-36.
+[13] FISHER R A. Iris Plants Database https://www.ics.uci.edu/vmlearn/MLRepository.html, Authorized license.
+[14] Quinlan J R. Induction of decision trees[J]. Machine learning, 1986, 1(1): 81-106.
+[15] Breiman L. Random forests[J]. Machine learning, 2001, 45(1): 5-32.
diff --git "a/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.1.1.5.png" "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.1.1.5.png"
new file mode 100644
index 00000000..dde211ce
Binary files /dev/null and "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.1.1.5.png" differ
diff --git "a/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.1.1.6.png" "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.1.1.6.png"
new file mode 100644
index 00000000..1bd76971
Binary files /dev/null and "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.1.1.6.png" differ
diff --git "a/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.1.6.1.png" "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.1.6.1.png"
new file mode 100644
index 00000000..e0ce77d9
Binary files /dev/null and "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.1.6.1.png" differ
diff --git "a/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.12.2.1.png" "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.12.2.1.png"
new file mode 100644
index 00000000..34f2d8b6
Binary files /dev/null and "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.12.2.1.png" differ
diff --git "a/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.12.2.2.png" "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.12.2.2.png"
new file mode 100644
index 00000000..ad3d4bd6
Binary files /dev/null and "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.12.2.2.png" differ
diff --git "a/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.2.1.1.png" "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.2.1.1.png"
new file mode 100644
index 00000000..160cf461
Binary files /dev/null and "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.2.1.1.png" differ
diff --git "a/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.2.1.2.png" "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.2.1.2.png"
new file mode 100644
index 00000000..fec7b5b1
Binary files /dev/null and "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.2.1.2.png" differ
diff --git "a/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.2.2.1.png" "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.2.2.1.png"
new file mode 100644
index 00000000..02dbca08
Binary files /dev/null and "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.2.2.1.png" differ
diff --git "a/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.2.3.1.png" "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.2.3.1.png"
new file mode 100644
index 00000000..1c4dacd9
Binary files /dev/null and "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.2.3.1.png" differ
diff --git "a/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.2.3.2.png" "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.2.3.2.png"
new file mode 100644
index 00000000..09f4d9e2
Binary files /dev/null and "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.2.3.2.png" differ
diff --git "a/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.2.3.4.png" "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.2.3.4.png"
new file mode 100644
index 00000000..03f1c6a9
Binary files /dev/null and "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.2.3.4.png" differ
diff --git "a/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.2.3.5.png" "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.2.3.5.png"
new file mode 100644
index 00000000..56443fd2
Binary files /dev/null and "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.2.3.5.png" differ
diff --git "a/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.2.3.6.png" "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.2.3.6.png"
new file mode 100644
index 00000000..bda9c5cb
Binary files /dev/null and "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.2.3.6.png" differ
diff --git "a/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.2.4.1.png" "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.2.4.1.png"
new file mode 100644
index 00000000..f91e8ab4
Binary files /dev/null and "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.2.4.1.png" differ
diff --git "a/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.2.5.1.png" "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.2.5.1.png"
new file mode 100644
index 00000000..1236163e
Binary files /dev/null and "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.2.5.1.png" differ
diff --git "a/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.2.5.2.png" "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.2.5.2.png"
new file mode 100644
index 00000000..c36f3bfd
Binary files /dev/null and "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.2.5.2.png" differ
diff --git "a/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.2.5.3.png" "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.2.5.3.png"
new file mode 100644
index 00000000..d53c8ea8
Binary files /dev/null and "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.2.5.3.png" differ
diff --git "a/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.2.5.4.png" "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.2.5.4.png"
new file mode 100644
index 00000000..f00cca44
Binary files /dev/null and "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.2.5.4.png" differ
diff --git "a/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.4.9.1.png" "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.4.9.1.png"
new file mode 100644
index 00000000..3e126ba7
Binary files /dev/null and "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.4.9.1.png" differ
diff --git "a/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.4.9.2.png" "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.4.9.2.png"
new file mode 100644
index 00000000..ea9b0c34
Binary files /dev/null and "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.4.9.2.png" differ
diff --git "a/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.4.9.3.png" "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.4.9.3.png"
new file mode 100644
index 00000000..fe1d7779
Binary files /dev/null and "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.4.9.3.png" differ
diff --git "a/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.6.3.1.png" "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.6.3.1.png"
new file mode 100644
index 00000000..d091389e
Binary files /dev/null and "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.6.3.1.png" differ
diff --git "a/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.6.7.1.png" "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.6.7.1.png"
new file mode 100644
index 00000000..4b98c00e
Binary files /dev/null and "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.6.7.1.png" differ
diff --git "a/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.8.2.1.png" "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.8.2.1.png"
new file mode 100644
index 00000000..1236163e
Binary files /dev/null and "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/3.8.2.1.png" differ
diff --git "a/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/learnrate1.png" "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/learnrate1.png"
new file mode 100644
index 00000000..3f7efadc
Binary files /dev/null and "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/learnrate1.png" differ
diff --git "a/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/learnrate2.png" "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/learnrate2.png"
new file mode 100644
index 00000000..f507418d
Binary files /dev/null and "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/learnrate2.png" differ
diff --git "a/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/learnrate3.png" "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/learnrate3.png"
new file mode 100644
index 00000000..579d32ed
Binary files /dev/null and "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/learnrate3.png" differ
diff --git "a/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/learnrate4.png" "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/learnrate4.png"
new file mode 100644
index 00000000..e66fba8e
Binary files /dev/null and "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/learnrate4.png" differ
diff --git "a/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/learnrate5.png" "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/learnrate5.png"
new file mode 100644
index 00000000..5835a5ea
Binary files /dev/null and "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/img/ch3/learnrate5.png" differ
diff --git "a/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/\347\254\254\344\270\211\347\253\240_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200.md" "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/\347\254\254\344\270\211\347\253\240_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200.md"
index 9f38cd51..4e3ec832 100644
--- "a/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/\347\254\254\344\270\211\347\253\240_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200.md"
+++ "b/ch03_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200/\347\254\254\344\270\211\347\253\240_\346\267\261\345\272\246\345\255\246\344\271\240\345\237\272\347\241\200.md"
@@ -6,140 +6,116 @@
### 3.1.1 神经网络组成?
-为了描述神经网络,我们先从最简单的神经网络说起。
+神经网络类型众多,其中最为重要的是多层感知机。为了详细地描述神经网络,我们先从最简单的神经网络说起。
**感知机**
+多层感知机中的特征神经元模型称为感知机,由*Frank Rosenblatt*于1957年发明。
+
简单的感知机如下图所示:

-其输出为:
+其中$x_1$,$x_2$,$x_3$为感知机的输入,其输出为:
$$
output = \left\{
\begin{aligned}
-0, \quad if \sum_i w_i x_i \le threshold \\
-1, \quad if \sum_i w_i x_i > threshold
+0, \quad if \ \ \sum_i w_i x_i \leqslant threshold \\
+1, \quad if \ \ \sum_i w_i x_i > threshold
\end{aligned}
\right.
$$
-假如把感知机想象成一个加权投票机制,比如 3 位评委给一个歌手打分,打分分别为 4 分、1 分、-3 分,这 3 位评分的权重分别是 1、3、2,则该歌手最终得分为 $ 4 * 1 + 1 * 3 + (-3) * 2 = 1 $。按照比赛规则,选取的 threshold 为 3,说明只有歌手的综合评分大于 3 时,才可顺利晋级。对照感知机,该选手被淘汰,因为
+假如把感知机想象成一个加权投票机制,比如 3 位评委给一个歌手打分,打分分别为$ 4 $分、$1$ 分、$-3 $分,这$ 3$ 位评分的权重分别是 $1、3、2$,则该歌手最终得分为 $4 \times 1 + 1 \times 3 + (-3) \times 2 = 1$ 。按照比赛规则,选取的 $threshold$ 为 $3$,说明只有歌手的综合评分大于$ 3$ 时,才可顺利晋级。对照感知机,该选手被淘汰,因为:
$$
\sum_i w_i x_i < threshold=3, output = 0
$$
-用 $ -b $ 代替 threshold。输出变为:
+用 $-b$ 代替 $threshold$,输出变为:
$$
output = \left\{
\begin{aligned}
-0, \quad if w \cdot x + b \le 0 \\
-1, \quad if w \cdot x + b > 0
+0, \quad if \ \ \boldsymbol{w} \cdot \boldsymbol{x} + b \leqslant 0 \\
+1, \quad if \ \ \boldsymbol{w} \cdot \boldsymbol{x} + b > 0
\end{aligned}
\right.
$$
-设置合适的 $ x $ 和 $ b $,一个简单的感知机单元的与非门表示如下:
+设置合适的 $\boldsymbol{x}$ 和 $b$ ,一个简单的感知机单元的与非门表示如下:

-当输入为 $ 0,1 $ 时,感知机输出为 $ 0 * (-2) + 1 * (-2) + 3 = 1 $。
+当输入为 $0$,$1$ 时,感知机输出为 $ 0 \times (-2) + 1 \times (-2) + 3 = 1$。
复杂一些的感知机由简单的感知机单元组合而成:

-**Sigmoid单元**
-
-感知机单元的输出只有 0 和 1,实际情况中,更多的输出类别不止 0 和 1,而是 $ [0, 1] $ 上的概率值,这时候就需要 sigmoid 函数把任意实数映射到 $ [0, 1] $ 上。
-
-神经元的输入
-
-$$
-z = \sum_i w_i x_i + b
-$$
-
-假设神经元的输出采用 sigmoid 激活函数
-
-$$
-\sigma(z) = \frac{1}{1+e^{-z}}
-$$
-
-sigmoid 激活函数图像如下图所示:
-
-
-
-全连接神经网络
-即第 $ i $ 层的每个神经元和第 $ i-1 $ 层的每个神经元都有连接。
+**多层感知机**
-
+多层感知机由感知机推广而来,最主要的特点是有多个神经元层,因此也叫深度神经网络。相比于单独的感知机,多层感知机的第 $ i $ 层的每个神经元和第 $ i-1 $ 层的每个神经元都有连接。
-输出层可以不止有 1 个神经元。隐藏层可以只有 1 层,也可以有多层。输出层为多个神经元的神经网络例如下图:
+
-
+输出层可以不止有$ 1$ 个神经元。隐藏层可以只有$ 1$ 层,也可以有多层。输出层为多个神经元的神经网络例如下图所示:
+
-### 3.1.2神经网络有哪些常用模型结构?
-答案来源:[25张图让你读懂神经网络架构](https://blog.csdn.net/nicholas_liu2017/article/details/73694666)
+### 3.1.2 神经网络有哪些常用模型结构?
下图包含了大部分常用的模型:

-### 3.1.3如何选择深度学习开发平台?
+### 3.1.3 如何选择深度学习开发平台?
-现有的深度学习开源平台主要有 Caffe, Torch, MXNet, CNTK, Theano, TensorFlow, Keras 等。那如何选择一个适合自己的平台呢,下面列出一些衡量做参考。
+ 现有的深度学习开源平台主要有 Caffe, PyTorch, MXNet, CNTK, Theano, TensorFlow, Keras, fastai等。那如何选择一个适合自己的平台呢,下面列出一些衡量做参考。
**参考1:与现有编程平台、技能整合的难易程度**
-主要是前期积累的开发经验和资源,比如编程语言,前期数据集存储格式等。
+ 主要是前期积累的开发经验和资源,比如编程语言,前期数据集存储格式等。
**参考2: 与相关机器学习、数据处理生态整合的紧密程度**
-深度学习研究离不开各种数据处理、可视化、统计推断等软件包。考虑建模之前,是否具有方便的数据预处理工具?建模之后,是否具有方便的工具进行可视化、统计推断、数据分析?
+ 深度学习研究离不开各种数据处理、可视化、统计推断等软件包。考虑建模之前,是否具有方便的数据预处理工具?建模之后,是否具有方便的工具进行可视化、统计推断、数据分析。
**参考3:对数据量及硬件的要求和支持**
-深度学习在不同应用场景的数据量是不一样的,这也就导致我们可能需要考虑分布式计算、多 GPU 计算的问题。例如,对计算机图像处理研究的人员往往需要将图像文件和计算任务分部到多台计算机节点上进行执行。当下每个深度学习平台都在快速发展,每个平台对分布式计算等场景的支持也在不断演进。
+ 深度学习在不同应用场景的数据量是不一样的,这也就导致我们可能需要考虑分布式计算、多GPU计算的问题。例如,对计算机图像处理研究的人员往往需要将图像文件和计算任务分部到多台计算机节点上进行执行。当下每个深度学习平台都在快速发展,每个平台对分布式计算等场景的支持也在不断演进。
**参考4:深度学习平台的成熟程度**
-成熟程度的考量是一个比较主观的考量因素,这些因素可包括:社区的活跃程度;是否容易和开发人员进行交流;当前应用的势头。
+ 成熟程度的考量是一个比较主观的考量因素,这些因素可包括:社区的活跃程度;是否容易和开发人员进行交流;当前应用的势头。
**参考5:平台利用是否多样性?**
-有些平台是专门为深度学习研究和应用进行开发的,有些平台对分布式计算、GPU 等构架都有强大的优化,能否用这些平台/软件做其他事情?比如有些深度学习软件是可以用来求解二次型优化;有些深度学习平台很容易被扩展,被运用在强化学习的应用中。
+ 有些平台是专门为深度学习研究和应用进行开发的,有些平台对分布式计算、GPU 等构架都有强大的优化,能否用这些平台/软件做其他事情?比如有些深度学习软件是可以用来求解二次型优化;有些深度学习平台很容易被扩展,被运用在强化学习的应用中。
-### 3.1.4为什么使用深层表示?
-
-1. 深度神经网络的多层隐藏层中,前几层能学习一些低层次的简单特征,后几层能把前面简单的特征结合起来,去学习更加复杂的东西。比如刚开始检测到的是边缘信息,而后检测更为细节的信息。
+### 3.1.4 为什么使用深层表示?
+1. 深度神经网络是一种特征递进式的学习算法,浅层的神经元直接从输入数据中学习一些低层次的简单特征,例如边缘、纹理等。而深层的特征则基于已学习到的浅层特征继续学习更高级的特征,从计算机的角度学习深层的语义信息。
2. 深层的网络隐藏单元数量相对较少,隐藏层数目较多,如果浅层的网络想要达到同样的计算结果则需要指数级增长的单元数量才能达到。
-### 3.1.5为什么深层神经网络难以训练?
-
-答案来源:
-
-[为什么深层神经网络难以训练](https://blog.csdn.net/BinChasing/article/details/50300069)
-
-[为什么很难训练深度神经网络](http://mini.eastday.com/mobile/180116023302833.html)
+### 3.1.5 为什么深层神经网络难以训练?
1. 梯度消失
- 梯度消失是指通过隐藏层从后向前看,梯度会变的越来越小,说明前面层的学习会显著慢于后面层的学习,所以学习会卡住,除非梯度变大。下图是不同隐含层的学习速率;
+ 梯度消失是指通过隐藏层从后向前看,梯度会变的越来越小,说明前面层的学习会显著慢于后面层的学习,所以学习会卡住,除非梯度变大。
+
+ 梯度消失的原因受到多种因素影响,例如学习率的大小,网络参数的初始化,激活函数的边缘效应等。在深层神经网络中,每一个神经元计算得到的梯度都会传递给前一层,较浅层的神经元接收到的梯度受到之前所有层梯度的影响。如果计算得到的梯度值非常小,随着层数增多,求出的梯度更新信息将会以指数形式衰减,就会发生梯度消失。下图是不同隐含层的学习速率:

2. 梯度爆炸
- 又称exploding gradient problem,在深度网络或循环神经网络(RNN)等网络结构中,梯度可在网络更新的过程中不断累积,变成非常大的梯度,导致网络权重值的大幅更新,使得网络不稳定;在极端情况下,权重值甚至会溢出,变为NaN值,再也无法更新。 具体可参考文献:[A Gentle Introduction to Exploding Gradients in Neural Networks](https://machinelearningmastery.com/exploding-gradients-in-neural-networks/)
+ 在深度网络或循环神经网络(Recurrent Neural Network, RNN)等网络结构中,梯度可在网络更新的过程中不断累积,变成非常大的梯度,导致网络权重值的大幅更新,使得网络不稳定;在极端情况下,权重值甚至会溢出,变为$NaN$值,再也无法更新。
-3. 权重矩阵的退化导致模型的有效自由度减少。参数空间中学习的退化速度减慢,导致减少了模型的有效维数,网络的可用自由度对学习中梯度范数的贡献不均衡,随着相乘矩阵的数量(即网络深度)的增加,矩阵的乘积变得越来越退化;
+3. 权重矩阵的退化导致模型的有效自由度减少。
-在有硬饱和边界的非线性网络中(例如 ReLU 网络),随着深度增加,退化过程会变得越来越快。Duvenaud 等人 2014 年的论文里展示了关于该退化过程的可视化:
+ 参数空间中学习的退化速度减慢,导致减少了模型的有效维数,网络的可用自由度对学习中梯度范数的贡献不均衡,随着相乘矩阵的数量(即网络深度)的增加,矩阵的乘积变得越来越退化。在有硬饱和边界的非线性网络中(例如 ReLU 网络),随着深度增加,退化过程会变得越来越快。Duvenaud等人2014年的论文里展示了关于该退化过程的可视化:

@@ -147,75 +123,73 @@ sigmoid 激活函数图像如下图所示:
### 3.1.6 深度学习和机器学习有什么不同?
-机器学习:利用计算机、概率论、统计学等知识,输入数据,让计算机学会新知识。机器学习的过程,就是通过训练数据寻找目标函数。
+ **机器学习**:利用计算机、概率论、统计学等知识,输入数据,让计算机学会新知识。机器学习的过程,就是训练数据去优化目标函数。
+
+ **深度学习**:是一种特殊的机器学习,具有强大的能力和灵活性。它通过学习将世界表示为嵌套的层次结构,每个表示都与更简单的特征相关,而抽象的表示则用于计算更抽象的表示。
+
+ 传统的机器学习需要定义一些手工特征,从而有目的的去提取目标信息, 非常依赖任务的特异性以及设计特征的专家经验。而深度学习可以从大数据中先学习简单的特征,并从其逐渐学习到更为复杂抽象的深层特征,不依赖人工的特征工程,这也是深度学习在大数据时代受欢迎的一大原因。
-深度学习是机器学习的一种,现在深度学习比较火爆。在传统机器学习中,手工设计特征对学习效果很重要,但是特征工程非常繁琐。而深度学习能够从大数据中自动学习特征,这也是深度学习在大数据时代受欢迎的一大原因。
-
+
+

## 3.2 网络操作与计算
-### 3.2.1前向传播与反向传播?
-
-答案来源:[神经网络中前向传播和反向传播解析](https://blog.csdn.net/lhanchao/article/details/51419150)
+### 3.2.1 前向传播与反向传播?
-在神经网络的计算中,主要由前向传播(foward propagation,FP)和反向传播(backward propagation,BP)。
+神经网络的计算主要有两种:前向传播(foward propagation, FP)作用于每一层的输入,通过逐层计算得到输出结果;反向传播(backward propagation, BP)作用于网络的输出,通过计算梯度由深到浅更新网络参数。
**前向传播**
-
+
-假设上一层结点 $ i,j,k,... $ 等一些结点与本层的结点 $ w $ 有连接,那么结点 $ w $ 的值怎么算呢?就是通过上一层的 $ i,j,k,... $ 等结点以及对应的连接权值进行加权和运算,最终结果再加上一个偏置项(图中为了简单省略了),最后在通过一个非线性函数(即激活函数),如 ReLu,sigmoid 等函数,最后得到的结果就是本层结点 $ w $ 的输出。
+假设上一层结点 $ i,j,k,... $ 等一些结点与本层的结点 $ w $ 有连接,那么结点 $ w $ 的值怎么算呢?就是通过上一层的 $ i,j,k,... $ 等结点以及对应的连接权值进行加权和运算,最终结果再加上一个偏置项(图中为了简单省略了),最后在通过一个非线性函数(即激活函数),如 $ReLu$,$sigmoid$ 等函数,最后得到的结果就是本层结点 $ w $ 的输出。
最终不断的通过这种方法一层层的运算,得到输出层结果。
**反向传播**
-
+
由于我们前向传播最终得到的结果,以分类为例,最终总是有误差的,那么怎么减少误差呢,当前应用广泛的一个算法就是梯度下降算法,但是求梯度就要求偏导数,下面以图中字母为例讲解一下:
-设最终中误差为 $ E $,对于输出那么 $ E $ 对于输出节点 $ y_l $ 的偏导数是 $ y_l - t_l $,其中 $ t_l $ 是真实值,$ \frac{\partial y_l}{\partial z_l} $ 是指上面提到的激活函数,$ z_l $ 是上面提到的加权和,那么这一层的 $ E $ 对于 $ z_l $ 的偏导数为 $ \frac{\partial E}{\partial z_l} = \frac{\partial E}{\partial y_l} \frac{\partial y_l}{\partial z_l} $。同理,下一层也是这么计算,只不过 $ \frac{\partial E}{\partial y_k} $ 计算方法变了,一直反向传播到输入层,最后有 $ \frac{\partial E}{\partial x_i} = \frac{\partial E}{\partial y_j} \frac{\partial y_j}{\partial z_j} $,且 $ \frac{\partial z_j}{\partial x_i} = w_i j $。然后调整这些过程中的权值,再不断进行前向传播和反向传播的过程,最终得到一个比较好的结果;
-
-### 3.2.2如何计算神经网络的输出?
+设最终误差为 $ E $且输出层的激活函数为线性激活函数,对于输出那么 $ E $ 对于输出节点 $ y_l $ 的偏导数是 $ y_l - t_l $,其中 $ t_l $ 是真实值,$ \frac{\partial y_l}{\partial z_l} $ 是指上面提到的激活函数,$ z_l $ 是上面提到的加权和,那么这一层的 $ E $ 对于 $ z_l $ 的偏导数为 $ \frac{\partial E}{\partial z_l} = \frac{\partial E}{\partial y_l} \frac{\partial y_l}{\partial z_l} $。同理,下一层也是这么计算,只不过 $ \frac{\partial E}{\partial y_k} $ 计算方法变了,一直反向传播到输入层,最后有 $ \frac{\partial E}{\partial x_i} = \frac{\partial E}{\partial y_j} \frac{\partial y_j}{\partial z_j} $,且 $ \frac{\partial z_j}{\partial x_i} = w_i j $。然后调整这些过程中的权值,再不断进行前向传播和反向传播的过程,最终得到一个比较好的结果。
-答案来源:[零基础入门深度学习(3) - 神经网络和反向传播算法](https://www.zybuluo.com/hanbingtao/note/476663)
+### 3.2.2 如何计算神经网络的输出?
-
+
-如上图,输入层有三个节点,我们将其依次编号为 1、2、3;隐藏层的 4 个节点,编号依次为 4、5、6、7;最后输出层的两个节点编号为 8、9。比如,隐藏层的节点 4,它和输入层的三个节点 1、2、3 之间都有连接,其连接上的权重分别为是 $ w_{41}, w_{42}, w_{43} $。
+如上图,输入层有三个节点,我们将其依次编号为 1、2、3;隐藏层的 4 个节点,编号依次为 4、5、6、7;最后输出层的两个节点编号为 8、9。比如,隐藏层的节点 4,它和输入层的三个节点 1、2、3 之间都有连接,其连接上的权重分别为是 $ w_{41}, w_{42}, w_{43} $。
为了计算节点 4 的输出值,我们必须先得到其所有上游节点(也就是节点 1、2、3)的输出值。节点 1、2、3 是输入层的节点,所以,他们的输出值就是输入向量本身。按照上图画出的对应关系,可以看到节点 1、2、3 的输出值分别是 $ x_1, x_2, x_3 $。
$$
-a_4 = \sigma(w^T \cdot a) = \sigma(w_{41}x_4 + w_{42}x_2 + w_{43}x_3 + w_{4b})
+a_4 = \sigma(w^T \cdot a) = \sigma(w_{41}x_4 + w_{42}x_2 + w_{43}a_3 + w_{4b})
$$
-其中 $ w_{4b} $ 是节点 4 的偏置项
+其中 $ w_{4b} $ 是节点 4 的偏置项。
同样,我们可以继续计算出节点 5、6、7 的输出值 $ a_5, a_6, a_7 $。
-计算输出层的节点 8 的输出值 $ y_1 $:
+计算输出层的节点 8 的输出值 $ y_1 $:
$$
y_1 = \sigma(w^T \cdot a) = \sigma(w_{84}a_4 + w_{85}a_5 + w_{86}a_6 + w_{87}a_7 + w_{8b})
$$
-其中 $ w_{8b} $ 是节点 8 的偏置项。
+其中 $ w_{8b} $ 是节点 8 的偏置项。
-同理,我们还可以计算出 $ y_2 $。这样输出层所有节点的输出值计算完毕,我们就得到了在输入向量 $ x_1, x_2, x_3, x_4 $ 时,神经网络的输出向量 $ y_1, y_2 $ 。这里我们也看到,输出向量的维度和输出层神经元个数相同。
+同理,我们还可以计算出 $ y_2 $。这样输出层所有节点的输出值计算完毕,我们就得到了在输入向量 $ x_1, x_2, x_3, x_4 $ 时,神经网络的输出向量 $ y_1, y_2 $ 。这里我们也看到,输出向量的维度和输出层神经元个数相同。
-### 3.2.3如何计算卷积神经网络输出值?
-
-答案来源:[零基础入门深度学习(4) - 卷积神经网络](https://www.zybuluo.com/hanbingtao/note/485480)
+### 3.2.3 如何计算卷积神经网络输出值?
假设有一个 5\*5 的图像,使用一个 3\*3 的 filter 进行卷积,想得到一个 3\*3 的 Feature Map,如下所示:
-
+
-$ x_{i,j} $ 表示图像第 $ i $ 行第 $ j $ 列元素。$ w_{m,n} $ 表示 filter 第 $ m $ 行第 $ n $ 列权重。 $ w_b $ 表示 filter 的偏置项。 表示 feature map 第 $ i $ 行第 $ j $ 列元素。 $ f $ 表示激活函数,这里以 relu 函数为例。
+$ x_{i,j} $ 表示图像第 $ i $ 行第 $ j $ 列元素。$ w_{m,n} $ 表示 filter 第 $ m $ 行第 $ n $ 列权重。 $ w_b $ 表示 $filter$ 的偏置项。 表$a_i,_j$示 feature map 第 $ i$ 行第 $ j $ 列元素。 $f$ 表示激活函数,这里以$ ReLU$ 函数为例。
卷积计算公式如下:
@@ -223,47 +197,40 @@ $$
a_{i,j} = f(\sum_{m=0}^2 \sum_{n=0}^2 w_{m,n} x_{i+m, j+n} + w_b )
$$
-当步长为 1 时,计算 feature map 元素 $ a_{0,0} $ 如下:
+当步长为 $1$ 时,计算 feature map 元素 $ a_{0,0} $ 如下:
$$
a_{0,0} = f(\sum_{m=0}^2 \sum_{n=0}^2 w_{m,n} x_{0+m, 0+n} + w_b )
-
-= relu(w_{0,0} x_{0,0} + w_{0,1} x_{0,1} + w_{0,2} x_{0,2} + w_{1,0} x_{1,0} + w_{1,1} x_{1,1} + w_{1,2} x_{1,2} + w_{2,0} x_{2,0} + w_{2,1} x_{2,1} + w_{2,2} x_{2,2}) \\
-
+= relu(w_{0,0} x_{0,0} + w_{0,1} x_{0,1} + w_{0,2} x_{0,2} + w_{1,0} x_{1,0} + \\w_{1,1} x_{1,1} + w_{1,2} x_{1,2} + w_{2,0} x_{2,0} + w_{2,1} x_{2,1} + w_{2,2} x_{2,2}) \\
= 1 + 0 + 1 + 0 + 1 + 0 + 0 + 0 + 1 \\
-
= 4
$$
-结果如下:
-
-
-
其计算过程图示如下:
-
+
以此类推,计算出全部的Feature Map。
-
+
当步幅为 2 时,Feature Map计算如下
-
+
注:图像大小、步幅和卷积后的Feature Map大小是有关系的。它们满足下面的关系:
$$
-W_2 = (W_1 - F + 2P)/S + 1
+W_2 = (W_1 - F + 2P)/S + 1\\
H_2 = (H_1 - F + 2P)/S + 1
$$
-其中 $ W_2 $, 是卷积后 Feature Map 的宽度;$ W_1 $ 是卷积前图像的宽度;$ F $ 是 filter 的宽度;$ P $ 是 Zero Padding 数量,Zero Padding 是指在原始图像周围补几圈 0,如果 P 的值是 1,那么就补 1 圈 0;S 是步幅;$ H_2 $ 卷积后 Feature Map 的高度;$ H_1 $ 是卷积前图像的宽度。
+ 其中 $ W_2 $, 是卷积后 Feature Map 的宽度;$ W_1 $ 是卷积前图像的宽度;$ F $ 是 filter 的宽度;$ P $ 是 Zero Padding 数量,Zero Padding 是指在原始图像周围补几圈 $0$,如果 $P$ 的值是 $1$,那么就补 $1$ 圈 $0$;$S$ 是步幅;$ H_2 $ 卷积后 Feature Map 的高度;$ H_1 $ 是卷积前图像的宽度。
-举例:假设图像宽度 $ W_1 = 5 $,filter 宽度 $ F=3 $,Zero Padding $ P=0 $,步幅 $ S=2 $,$ Z $ 则
+ 举例:假设图像宽度 $ W_1 = 5 $,filter 宽度 $ F=3 $,Zero Padding $ P=0 $,步幅 $ S=2 $,$ Z $ 则
$$
W_2 = (W_1 - F + 2P)/S + 1
@@ -273,68 +240,66 @@ W_2 = (W_1 - F + 2P)/S + 1
= 2
$$
-说明 Feature Map 宽度是2。同样,我们也可以计算出 Feature Map 高度也是 2。
+ 说明 Feature Map 宽度是2。同样,我们也可以计算出 Feature Map 高度也是 2。
-如果卷积前的图像深度为 $ D $,那么相应的 filter 的深度也必须为 $ D $。深度大于 1 的卷积计算公式:
+如果卷积前的图像深度为 $ D $,那么相应的 filter 的深度也必须为 $ D $。深度大于 1 的卷积计算公式:
$$
a_{i,j} = f(\sum_{d=0}^{D-1} \sum_{m=0}^{F-1} \sum_{n=0}^{F-1} w_{d,m,n} x_{d,i+m,j+n} + w_b)
$$
-其中,$ D $ 是深度;$ F $ 是 filter 的大小;$ w_{d,m,n} $ 表示 filter 的第 $ d $ 层第 $ m $ 行第 $ n $ 列权重;$ a_{d,i,j} $ 表示 feature map 的第 $ d $ 层第 $ i $ 行第 $ j $ 列像素;其它的符号含义前面相同,不再赘述。
+ 其中,$ D $ 是深度;$ F $ 是 filter 的大小;$ w_{d,m,n} $ 表示 filter 的第 $ d $ 层第 $ m $ 行第 $ n $ 列权重;$ a_{d,i,j} $ 表示 feature map 的第 $ d $ 层第 $ i $ 行第 $ j $ 列像素;其它的符号含义前面相同,不再赘述。
-每个卷积层可以有多个 filter。每个 filter 和原始图像进行卷积后,都可以得到一个 Feature Map。卷积后 Feature Map 的深度(个数)和卷积层的 filter 个数是相同的。下面的图示显示了包含两个 filter 的卷积层的计算。7\*7\*3 输入,经过两个 3\*3\*3 filter 的卷积(步幅为 2),得到了 3\*3\*2 的输出。图中的 Zero padding 是 1,也就是在输入元素的周围补了一圈 0。Zero padding 对于图像边缘部分的特征提取是很有帮助的。
+ 每个卷积层可以有多个 filter。每个 filter 和原始图像进行卷积后,都可以得到一个 Feature Map。卷积后 Feature Map 的深度(个数)和卷积层的 filter 个数相同。下面的图示显示了包含两个 filter 的卷积层的计算。$7*7*3$ 输入,经过两个 $3*3*3$ filter 的卷积(步幅为 $2$),得到了 $3*3*2$ 的输出。图中的 Zero padding 是 $1$,也就是在输入元素的周围补了一圈 $0$。
-
+
-以上就是卷积层的计算方法。这里面体现了局部连接和权值共享:每层神经元只和上一层部分神经元相连(卷积计算规则),且 filter 的权值对于上一层所有神经元都是一样的。对于包含两个 $ 3 * 3 * 3 $ 的 fitler 的卷积层来说,其参数数量仅有 $ (3 * 3 * 3+1) * 2 = 56 $ 个,且参数数量与上一层神经元个数无关。与全连接神经网络相比,其参数数量大大减少了。
+ 以上就是卷积层的计算方法。这里面体现了局部连接和权值共享:每层神经元只和上一层部分神经元相连(卷积计算规则),且 filter 的权值对于上一层所有神经元都是一样的。对于包含两个 $ 3 * 3 * 3 $ 的 fitler 的卷积层来说,其参数数量仅有 $ (3 * 3 * 3+1) * 2 = 56 $ 个,且参数数量与上一层神经元个数无关。与全连接神经网络相比,其参数数量大大减少了。
### 3.2.4 如何计算 Pooling 层输出值输出值?
-Pooling 层主要的作用是下采样,通过去掉 Feature Map 中不重要的样本,进一步减少参数数量。Pooling 的方法很多,最常用的是 Max Pooling。Max Pooling 实际上就是在 n\*n 的样本中取最大值,作为采样后的样本值。下图是 2\*2 max pooling:
+ Pooling 层主要的作用是下采样,通过去掉 Feature Map 中不重要的样本,进一步减少参数数量。Pooling 的方法很多,最常用的是 Max Pooling。Max Pooling 实际上就是在 n\*n 的样本中取最大值,作为采样后的样本值。下图是 2\*2 max pooling:
-
+
-除了 Max Pooing 之外,常用的还有 Mean Pooling ——取各样本的平均值。
-对于深度为 $ D $ 的 Feature Map,各层独立做 Pooling,因此 Pooling 后的深度仍然为 $ D $。
+ 除了 Max Pooing 之外,常用的还有 Average Pooling ——取各样本的平均值。
+ 对于深度为 $ D $ 的 Feature Map,各层独立做 Pooling,因此 Pooling 后的深度仍然为 $ D $。
### 3.2.5 实例理解反向传播
-答案来源:[一文弄懂神经网络中的反向传播法——BackPropagation](http://www.cnblogs.com/charlotte77/p/5629865.html)
+ 一个典型的三层神经网络如下所示:
-一个典型的三层神经网络如下所示:
+
-
+ 其中 Layer $ L_1 $ 是输入层,Layer $ L_2 $ 是隐含层,Layer $ L_3 $ 是输出层。
-其中 Layer $ L_1 $ 是输入层,Layer $ L_2 $ 是隐含层,Layer $ L_3 $ 是输出层。
+ 假设输入数据集为 $ D={x_1, x_2, ..., x_n} $,输出数据集为 $ y_1, y_2, ..., y_n $。
-假设输入数据集为 $ D={x_1, x_2, ..., x_n} $,输出数据集为 $ y_1, y_2, ..., y_n $。
-
-如果输入和输出是一样,即为自编码模型。如果原始数据经过映射,会得到不同与输入的输出。
+ 如果输入和输出是一样,即为自编码模型。如果原始数据经过映射,会得到不同于输入的输出。
假设有如下的网络层:
-
+
-输入层包含神经元 $ i_1, i_2 $,偏置 $ b_1 $;隐含层包含神经元 $ h_1, h_2 $,偏置 $ b_2 $,输出层为 $ o_1, o_2 $,$ w_i $ 为层与层之间连接的权重,激活函数为 sigmoid 函数。对以上参数取初始值,如下图所示:
+ 输入层包含神经元 $ i_1, i_2 $,偏置 $ b_1 $;隐含层包含神经元 $ h_1, h_2 $,偏置 $ b_2 $,输出层为 $ o_1, o_2 $,$ w_i $ 为层与层之间连接的权重,激活函数为 $sigmoid$ 函数。对以上参数取初始值,如下图所示:
-
+
其中:
- 输入数据 $ i1=0.05, i2 = 0.10 $
- 输出数据 $ o1=0.01, o2=0.99 $;
- 初始权重 $ w1=0.15, w2=0.20, w3=0.25,w4=0.30, w5=0.40, w6=0.45, w7=0.50, w8=0.55 $
-- 目标:给出输入数据 $ i1,i2 $ (0.05和0.10),使输出尽可能与原始输出 $ o1,o2 $,(0.01和0.99)接近。
+- 目标:给出输入数据 $ i1,i2 $ ( $0.05$和$0.10$ ),使输出尽可能与原始输出 $ o1,o2 $,( $0.01$和$0.99$)接近。
**前向传播**
1. 输入层 --> 输出层
-计算神经元 $ h1 $ 的输入加权和:
+计算神经元 $ h1 $ 的输入加权和:
$$
-net_{h1} = w_1 * i_1 + w_2 * i_2 + b_1 * 1
+net_{h1} = w_1 * i_1 + w_2 * i_2 + b_1 * 1\\
net_{h1} = 0.15 * 0.05 + 0.2 * 0.1 + 0.35 * 1 = 0.3775
$$
@@ -354,23 +319,27 @@ $$
2. 隐含层-->输出层:
-计算输出层神经元 $ o1 $ 和 $ o2 $ 的值:
+计算输出层神经元 $ o1 $ 和 $ o2 $ 的值:
$$
net_{o1} = w_5 * out_{h1} + w_6 * out_{h2} + b_2 * 1
+$$
+$$
net_{o1} = 0.4 * 0.593269992 + 0.45 * 0.596884378 + 0.6 * 1 = 1.105905967
+$$
+$$
out_{o1} = \frac{1}{1 + e^{-net_{o1}}} = \frac{1}{1 + e^{1.105905967}} = 0.75136079
$$
-这样前向传播的过程就结束了,我们得到输出值为 $ [0.75136079 , 0.772928465] $,与实际值 $ [0.01 , 0.99] $ 相差还很远,现在我们对误差进行反向传播,更新权值,重新计算输出。
+这样前向传播的过程就结束了,我们得到输出值为 $ [0.75136079 , 0.772928465] $,与实际值 $ [0.01 , 0.99] $ 相差还很远,现在我们对误差进行反向传播,更新权值,重新计算输出。
**反向传播 **
-1. 计算总误差
+ 1.计算总误差
-总误差:(square error)
+总误差:(这里使用Square Error)
$$
E_{total} = \sum \frac{1}{2}(target - output)^2
@@ -379,16 +348,15 @@ $$
但是有两个输出,所以分别计算 $ o1 $ 和 $ o2 $ 的误差,总误差为两者之和:
$E_{o1} = \frac{1}{2}(target_{o1} - out_{o1})^2
-= \frac{1}{2}(0.01 - 0.75136507)^2 = 0.274811083$
+= \frac{1}{2}(0.01 - 0.75136507)^2 = 0.274811083$.
-$E_{o2} = 0.023560026$
+$E_{o2} = 0.023560026$.
-$E_{total} = E_{o1} + E_{o2} = 0.274811083 + 0.023560026 = 0.298371109$
+$E_{total} = E_{o1} + E_{o2} = 0.274811083 + 0.023560026 = 0.298371109$.
+ 2.隐含层 --> 输出层的权值更新:
-2. 隐含层 --> 输出层的权值更新:
-
-以权重参数 $ w5 $ 为例,如果我们想知道 $ w5 $ 对整体误差产生了多少影响,可以用整体误差对 $ w5 $ 求偏导求出:(链式法则)
+以权重参数 $ w5 $ 为例,如果我们想知道 $ w5 $ 对整体误差产生了多少影响,可以用整体误差对 $ w5 $ 求偏导求出:(链式法则)
$$
\frac{\partial E_{total}}{\partial w5} = \frac{\partial E_{total}}{\partial out_{o1}} * \frac{\partial out_{o1}}{\partial net_{o1}} * \frac{\partial net_{o1}}{\partial w5}
@@ -396,7 +364,7 @@ $$
下面的图可以更直观的看清楚误差是怎样反向传播的:
-
+
### 3.2.6 神经网络更“深”有什么意义?
@@ -409,18 +377,31 @@ $$
### 3.3.1 什么是超参数?
-超参数:比如算法中的 learning rate (学习率)、iterations (梯度下降法循环的数量)、(隐藏层数目)、(隐藏层单元数目)、choice of activation function(激活函数的选择)都需要根据实际情况来设置,这些数字实际上控制了最后的参数和的值,所以它们被称作超参数。
+ **超参数** : 在机器学习的上下文中,超参数是在开始学习过程之前设置值的参数,而不是通过训练得到的参数数据。通常情况下,需要对超参数进行优化,给学习机选择一组最优超参数,以提高学习的性能和效果。
+
+ 超参数通常存在于:
+
+ 1. 定义关于模型的更高层次的概念,如复杂性或学习能力。
+ 2. 不能直接从标准模型培训过程中的数据中学习,需要预先定义。
+ 3. 可以通过设置不同的值,训练不同的模型和选择更好的测试值来决定
+
+ 超参数具体来讲比如算法中的学习率(learning rate)、梯度下降法迭代的数量(iterations)、隐藏层数目(hidden layers)、隐藏层单元数目、激活函数( activation function)都需要根据实际情况来设置,这些数字实际上控制了最后的参数和的值,所以它们被称作超参数。
### 3.3.2 如何寻找超参数的最优值?
-在使用机器学习算法时,总有一些难搞的超参数。例如权重衰减大小,高斯核宽度等等。算法不会设置这些参数,而是需要你去设置它们的值。设置的值对结果产生较大影响。常见设置超参数的做法有:
+ 在使用机器学习算法时,总有一些难调的超参数。例如权重衰减大小,高斯核宽度等等。这些参数需要人为设置,设置的值对结果产生较大影响。常见设置超参数的方法有:
1. 猜测和检查:根据经验或直觉,选择参数,一直迭代。
+
2. 网格搜索:让计算机尝试在一定范围内均匀分布的一组值。
+
3. 随机搜索:让计算机随机挑选一组值。
+
4. 贝叶斯优化:使用贝叶斯优化超参数,会遇到贝叶斯优化算法本身就需要很多的参数的困难。
-5. 在良好初始猜测的前提下进行局部优化:这就是 MITIE 的方法,它使用 BOBYQA 算法,并有一个精心选择的起始点。由于 BOBYQA 只寻找最近的局部最优解,所以这个方法是否成功很大程度上取决于是否有一个好的起点。在 MITIE 的情况下,我们知道一个好的起点,但这不是一个普遍的解决方案,因为通常你不会知道好的起点在哪里。从好的方面来说,这种方法非常适合寻找局部最优解。稍后我会再讨论这一点。
-6. 最新提出的 LIPO 的全局优化方法。这个方法没有参数,而且经验证比随机搜索方法好。
+
+5. MITIE方法,好初始猜测的前提下进行局部优化。它使用BOBYQA算法,并有一个精心选择的起始点。由于BOBYQA只寻找最近的局部最优解,所以这个方法是否成功很大程度上取决于是否有一个好的起点。在MITIE的情况下,我们知道一个好的起点,但这不是一个普遍的解决方案,因为通常你不会知道好的起点在哪里。从好的方面来说,这种方法非常适合寻找局部最优解。稍后我会再讨论这一点。
+
+6. 最新提出的LIPO的全局优化方法。这个方法没有参数,而且经验证比随机搜索方法好。
### 3.3.3 超参数搜索一般过程?
@@ -504,7 +485,11 @@ $$
对常见激活函数,导数计算如下:
-
+| 原函数 | 函数表达式 | 导数 | 备注 |
+| --------------- | -------------------------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ |
+| Sigmoid激活函数 | $f(x)=\frac{1}{1+e^{-x}}$ | $f^{'}(x)=\frac{1}{1+e^{-x}}\left( 1- \frac{1}{1+e^{-x}} \right)=f(x)(1-f(x))$ | 当$x=10$,或$x=-10$,$f^{'}(x) \approx0$,当$x=0$$f^{'}(x) =0.25$ |
+| Tanh激活函数 | $f(x)=tanh(x)=\frac{e^x-e^{-x}}{e^x+e^{-x}}$ | $f^{'}(x)=-(tanh(x))^2$ | 当$x=10$,或$x=-10$,$f^{'}(x) \approx0$,当$x=0$$f^{`}(x) =1$ |
+| Relu激活函数 | $f(x)=max(0,x)$ | $c(u)=\begin{cases} 0,x<0 \\ 1,x>0 \\ undefined,x=0\end{cases}$ | 通常$x=0$时,给定其导数为1和0 |
### 3.4.4 激活函数有哪些性质?
@@ -516,7 +501,7 @@ $$
### 3.4.5 如何选择激活函数?
-选择一个适合的激活函数并不容易,需要考虑很多因素,通常的做法是,如果不确定哪一个激活函数效果更好,可以把它们都试试,然后在验证集或者测试集上进行评价。然后看哪一种表现的更好,就去使用它。
+ 选择一个适合的激活函数并不容易,需要考虑很多因素,通常的做法是,如果不确定哪一个激活函数效果更好,可以把它们都试试,然后在验证集或者测试集上进行评价。然后看哪一种表现的更好,就去使用它。
以下是常见的选择情况:
@@ -533,7 +518,7 @@ $$
2. sigmoid 和 tanh 函数的导数在正负饱和区的梯度都会接近于 0,这会造成梯度弥散,而 Relu 和Leaky ReLu 函数大于 0 部分都为常数,不会产生梯度弥散现象。
3. 需注意,Relu 进入负半区的时候,梯度为 0,神经元此时不会训练,产生所谓的稀疏性,而 Leaky ReLu 不会产生这个问题。
-### 3.4.7什么时候可以用线性激活函数?
+### 3.4.7 什么时候可以用线性激活函数?
1. 输出层,大多使用线性激活函数。
2. 在隐含层可能会使用一些线性激活函数。
@@ -548,16 +533,36 @@ Relu 激活函数图像如下:
根据图像可看出具有如下特点:
1. 单侧抑制;
+
2. 相对宽阔的兴奋边界;
+
3. 稀疏激活性;
-ReLU 函数从图像上看,是一个分段线性函数,把所有的负值都变为 0,而正值不变,这样就成为单侧抑制。
+ ReLU 函数从图像上看,是一个分段线性函数,把所有的负值都变为 0,而正值不变,这样就成为单侧抑制。
+
+ 因为有了这单侧抑制,才使得神经网络中的神经元也具有了稀疏激活性。
+
+ **稀疏激活性**:从信号方面来看,即神经元同时只对输入信号的少部分选择性响应,大量信号被刻意的屏蔽了,这样可以提高学习的精度,更好更快地提取稀疏特征。当 $ x<0 $ 时,ReLU 硬饱和,而当 $ x>0 $ 时,则不存在饱和问题。ReLU 能够在 $ x>0 $ 时保持梯度不衰减,从而缓解梯度消失问题。
+
+### 3.4.9 Softmax 定义及作用
+
+Softmax 是一种形如下式的函数:
+$$
+P(i) = \frac{exp(\theta_i^T x)}{\sum_{k=1}^{K} exp(\theta_i^T x)}
+$$
+ 其中,$ \theta_i $ 和 $ x $ 是列向量,$ \theta_i^T x $ 可能被换成函数关于 $ x $ 的函数 $ f_i(x) $
+
+ 通过 softmax 函数,可以使得 $ P(i) $ 的范围在 $ [0,1] $ 之间。在回归和分类问题中,通常 $ \theta $ 是待求参数,通过寻找使得 $ P(i) $ 最大的 $ \theta_i $ 作为最佳参数。
-因为有了这单侧抑制,才使得神经网络中的神经元也具有了稀疏激活性。
+ 但是,使得范围在 $ [0,1] $ 之间的方法有很多,为啥要在前面加上以 $ e $ 的幂函数的形式呢?参考 logistic 函数:
+$$
+P(i) = \frac{1}{1+exp(-\theta_i^T x)}
+$$
+ 这个函数的作用就是使得 $ P(i) $ 在负无穷到 0 的区间趋向于 0, 在 0 到正无穷的区间趋向 1,。同样 softmax 函数加入了 $ e $ 的幂函数正是为了两极化:正样本的结果将趋近于 1,而负样本的结果趋近于 0。这样为多类别提供了方便(可以把 $ P(i) $ 看做是样本属于类别的概率)。可以说,Softmax 函数是 logistic 函数的一种泛化。
-**稀疏激活性**:从信号方面来看,即神经元同时只对输入信号的少部分选择性响应,大量信号被刻意的屏蔽了,这样可以提高学习的精度,更好更快地提取稀疏特征。当 $ x<0 $ 时,ReLU 硬饱和,而当 $ x>0 $ 时,则不存在饱和问题。ReLU 能够在 $ x>0 $ 时保持梯度不衰减,从而缓解梯度消失问题。
+ softmax 函数可以把它的输入,通常被称为 logits 或者 logit scores,处理成 0 到 1 之间,并且能够把输出归一化到和为 1。这意味着 softmax 函数与分类的概率分布等价。它是一个网络预测多酚类问题的最佳输出激活函数。
-### 3.4.9 Softmax 函数如何应用于多分类?
+### 3.4.10 Softmax 函数如何应用于多分类?
softmax 用于多分类过程中,它将多个神经元的输出,映射到 $ (0,1) $ 区间内,可以看成概率来理解,从而来进行多分类!
@@ -569,22 +574,24 @@ $$
从下图看,神经网络中包含了输入层,然后通过两个特征层处理,最后通过 softmax 分析器就能得到不同条件下的概率,这里需要分成三个类别,最终会得到 $ y=0, y=1, y=2 $ 的概率值。
-
+
-继续看下面的图,三个输入通过 softmax 后得到一个数组 $ [0.05 , 0.10 , 0.85] $,这就是 soft 的功能。
+继续看下面的图,三个输入通过 softmax 后得到一个数组 $ [0.05 , 0.10 , 0.85] $,这就是 soft 的功能。
-
+
更形象的映射过程如下图所示:
-
+
- softmax 直白来说就是将原来输出是 $ 3,1,-3 $ 通过 softmax 函数一作用,就映射成为 $ (0,1) $ 的值,而这些值的累和为 $ 1 $(满足概率的性质),那么我们就可以将它理解成概率,在最后选取输出结点的时候,我们就可以选取概率最大(也就是值对应最大的)结点,作为我们的预测目标!
+ softmax 直白来说就是将原来输出是 $ 3,1,-3 $ 通过 softmax 函数一作用,就映射成为 $ (0,1) $ 的值,而这些值的累和为 $ 1 $(满足概率的性质),那么我们就可以将它理解成概率,在最后选取输出结点的时候,我们就可以选取概率最大(也就是值对应最大的)结点,作为我们的预测目标!
-### 3.4.10 交叉熵代价函数定义及其求导推导。(贡献者:黄钦建-华南理工大学)
+### 3.4.11 交叉熵代价函数定义及其求导推导
+(**贡献者:黄钦建-华南理工大学**)
- 神经元的输出就是 a = σ(z),其中$z=\sum w_{j}i_{j}+b$是输⼊的带权和。
+
+ 神经元的输出就是 a = σ(z),其中$z=\sum w_{j}i_{j}+b$是输⼊的带权和。
$C=-\frac{1}{n}\sum[ylna+(1-y)ln(1-a)]$
@@ -612,14 +619,18 @@ $\frac{\partial C}{\partial w_{j}}=\frac{1}{n}\sum x_{j}({\varsigma}(z)-y)$
根据类似的⽅法,我们可以计算出关于偏置的偏导数。我这⾥不再给出详细的过程,你可以轻易验证得到:
-$\frac{\partial C}{\partial b}=\frac{1}{n}\sum ({\varsigma}(z)-y)$
+$\frac{\partial C}{\partial b}=\frac{1}{n}\sum ({\varsigma}(z)-y)$
再⼀次, 这避免了⼆次代价函数中类似${\varsigma}'(z)$项导致的学习缓慢。
-### 3.4.11 为什么Tanh收敛速度比Sigmoid快?(贡献者:黄钦建-华南理工大学)
+### 3.4.12 为什么Tanh收敛速度比Sigmoid快?
+
+**(贡献者:黄钦建-华南理工大学)**
-$tanh^{,}(x)=1-tanh(x)^{2}\in (0,1)$
+首先看如下两个函数的求导:
+
+$tanh^{,}(x)=1-tanh(x)^{2}\in (0,1)$
$s^{,}(x)=s(x)*(1-s(x))\in (0,\frac{1}{4}]$
@@ -642,11 +653,11 @@ Batch的选择,首先决定的是下降的方向。
### 3.5.2 Batch_Size 值的选择
-假如每次只训练一个样本,即 Batch_Size = 1。线性神经元在均方误差代价函数的错误面是一个抛物面,横截面是椭圆。对于多层神经元、非线性网络,在局部依然近似是抛物面。此时,每次修正方向以各自样本的梯度方向修正,横冲直撞各自为政,难以达到收敛。
+ 假如每次只训练一个样本,即 Batch_Size = 1。线性神经元在均方误差代价函数的错误面是一个抛物面,横截面是椭圆。对于多层神经元、非线性网络,在局部依然近似是抛物面。此时,每次修正方向以各自样本的梯度方向修正,横冲直撞各自为政,难以达到收敛。
-既然 Batch_Size 为全数据集或者Batch_Size = 1都有各自缺点,可不可以选择一个适中的Batch_Size值呢?
+ 既然 Batch_Size 为全数据集或者Batch_Size = 1都有各自缺点,可不可以选择一个适中的Batch_Size值呢?
-此时,可采用批梯度下降法(Mini-batches Learning)。因为如果数据集足够充分,那么用一半(甚至少得多)的数据训练算出来的梯度与用全部数据训练出来的梯度是几乎一样的。
+ 此时,可采用批梯度下降法(Mini-batches Learning)。因为如果数据集足够充分,那么用一半(甚至少得多)的数据训练算出来的梯度与用全部数据训练出来的梯度是几乎一样的。
### 3.5.3 在合理范围内,增大Batch_Size有何好处?
@@ -662,47 +673,49 @@ Batch的选择,首先决定的是下降的方向。
### 3.5.5 调节 Batch_Size 对训练效果影响到底如何?
-1. Batch_Size 太小,模型表现效果极其糟糕(error�飙升)。
+1. Batch_Size 太小,模型表现效果极其糟糕(error飙升)。
2. 随着 Batch_Size 增大,处理相同数据量的速度越快。
3. 随着 Batch_Size 增大,达到相同精度所需要的 epoch 数量越来越多。
4. 由于上述两种因素的矛盾, Batch_Size 增大到某个时候,达到时间上的最优。
5. 由于最终收敛精度会陷入不同的局部极值,因此 Batch_Size 增大到某些时候,达到最终收敛精度上的最优。
-### 3.5.6 受限于�客观条件无法给足够的Batch Size怎么办?
-
-在极小的情况下(低于十),建议使用[Group Norm](https://arxiv.org/abs/1803.08494)。
-
## 3.6 归一化
### 3.6.1 归一化含义?
-归一化的具体作用是归纳统一样本的统计分布性。归一化在 $ 0-1$ 之间是统计的概率分布,归一化在$ -1--+1$ 之间是统计的坐标分布。归一化有同一、统一和合一的意思。无论是为了建模还是为了计算,首先基本度量单位要同一,神经网络是以样本在事件中的统计分别几率来进行训练(概率计算)和预测的,且 sigmoid 函数的取值是 0 到 1 之间的,网络最后一个节点的输出也是如此,所以经常要对样本的输出归一化处理。归一化是统一在 $ 0-1 $ 之间的统计概率分布,当所有样本的输入信号都为正值时,与第一隐含层神经元相连的权值只能同时增加或减小,从而导致学习速度很慢。另外在数据中常存在奇异样本数据,奇异样本数据存在所引起的网络训练时间增加,并可能引起网络无法收敛。为了避免出现这种情况及后面数据处理的方便,加快网络学习速度,可以对输入信号进行归一化,使得所有样本的输入信号其均值接近于 0 或与其均方差相比很小。
+1. 归纳统一样本的统计分布性。归一化在 $ 0-1$ 之间是统计的概率分布,归一化在$ -1--+1$ 之间是统计的坐标分布。
+
+2. 无论是为了建模还是为了计算,首先基本度量单位要同一,神经网络是以样本在事件中的统计分别几率来进行训练(概率计算)和预测,且 sigmoid 函数的取值是 0 到 1 之间的,网络最后一个节点的输出也是如此,所以经常要对样本的输出归一化处理。
+
+3. 归一化是统一在 $ 0-1 $ 之间的统计概率分布,当所有样本的输入信号都为正值时,与第一隐含层神经元相连的权值只能同时增加或减小,从而导致学习速度很慢。
+
+4. 另外在数据中常存在奇异样本数据,奇异样本数据存在所引起的网络训练时间增加,并可能引起网络无法收敛。为了避免出现这种情况及后面数据处理的方便,加快网络学习速度,可以对输入信号进行归一化,使得所有样本的输入信号其均值接近于 0 或与其均方差相比很小。
### 3.6.2 为什么要归一化?
1. 为了后面数据处理的方便,归一化的确可以避免一些不必要的数值问题。
-2. 为了程序运行时收敛加快。 下面图解。
+2. 为了程序运行时收敛加快。
3. 同一量纲。样本数据的评价标准不一样,需要对其量纲化,统一评价标准。这算是应用层面的需求。
4. 避免神经元饱和。啥意思?就是当神经元的激活在接近 0 或者 1 时会饱和,在这些区域,梯度几乎为 0,这样,在反向传播过程中,局部梯度就会接近 0,这会有效地“杀死”梯度。
5. 保证输出数据中数值小的不被吞食。
### 3.6.3 为什么归一化能提高求解最优解速度?
-
+
-上图是代表数据是否均一化的最优解寻解过程(圆圈可以理解为等高线)。左图表示未经归一化操作的寻解过程,右图表示经过归一化后的寻解过程。
+ 上图是代表数据是否均一化的最优解寻解过程(圆圈可以理解为等高线)。左图表示未经归一化操作的寻解过程,右图表示经过归一化后的寻解过程。
-当使用梯度下降法寻求最优解时,很有可能走“之字型”路线(垂直等高线走),从而导致需要迭代很多次才能收敛;而右图对两个原始特征进行了归一化,其对应的等高线显得很圆,在梯度下降进行求解时能较快的收敛。
+ 当使用梯度下降法寻求最优解时,很有可能走“之字型”路线(垂直等高线走),从而导致需要迭代很多次才能收敛;而右图对两个原始特征进行了归一化,其对应的等高线显得很圆,在梯度下降进行求解时能较快的收敛。
-因此如果机器学习模型使用梯度下降法求最优解时,归一化往往非常有必要,否则很难收敛甚至不能收敛。
+ 因此如果机器学习模型使用梯度下降法求最优解时,归一化往往非常有必要,否则很难收敛甚至不能收敛。
### 3.6.4 3D 图解未归一化
例子:
-假设 $ w1 $ 的范围在 $ [-10, 10] $,而 $ w2 $ 的范围在 $ [-100, 100] $,梯度每次都前进 1 单位,那么在 $ w1 $ 方向上每次相当于前进了 $ 1/20 $,而在 $ w2 $ 上只相当于 $ 1/200 $!某种意义上来说,在 $ w2 $ 上前进的步长更小一些,而 $ w1 $ 在搜索过程中会比 $ w2 $ “走”得更快。
+ 假设 $ w1 $ 的范围在 $ [-10, 10] $,而 $ w2 $ 的范围在 $ [-100, 100] $,梯度每次都前进 1 单位,那么在 $ w1 $ 方向上每次相当于前进了 $ 1/20 $,而在 $ w2 $ 上只相当于 $ 1/200 $!某种意义上来说,在 $ w2 $ 上前进的步长更小一些,而 $ w1 $ 在搜索过程中会比 $ w2 $ “走”得更快。
-这样会导致,在搜索过程中更偏向于 $ w1 $ 的方向。走出了“L”形状,或者成为“之”字形。
+ 这样会导致,在搜索过程中更偏向于 $ w1 $ 的方向。走出了“L”形状,或者成为“之”字形。

@@ -714,9 +727,9 @@ $$
x^{\prime} = \frac{x-min(x)}{max(x) - min(x)}
$$
-适用范围:比较适用在数值比较集中的情况。
+ 适用范围:比较适用在数值比较集中的情况。
-缺点:如果 max 和 min 不稳定,很容易使得归一化结果不稳定,使得后续使用效果也不稳定。
+ 缺点:如果 max 和 min 不稳定,很容易使得归一化结果不稳定,使得后续使用效果也不稳定。
2. 标准差标准化
@@ -724,30 +737,28 @@ $$
x^{\prime} = \frac{x-\mu}{\sigma}
$$
-含义:经过处理的数据符合标准正态分布,即均值为 0,标准差为 1 其中 $ \mu $ 为所有样本数据的均值,$ \sigma $ 为所有样本数据的标准差。
+ 含义:经过处理的数据符合标准正态分布,即均值为 0,标准差为 1 其中 $ \mu $ 为所有样本数据的均值,$ \sigma $ 为所有样本数据的标准差。
3. 非线性归一化
-适用范围:经常用在数据分化比较大的场景,有些数值很大,有些很小。通过一些数学函数,将原始值进行映射。该方法包括 $ log $、指数,正切等。
+ 适用范围:经常用在数据分化比较大的场景,有些数值很大,有些很小。通过一些数学函数,将原始值进行映射。该方法包括 $ log $、指数,正切等。
### 3.6.6 局部响应归一化作用
-LRN 是一种提高深度学习准确度的技术方法。LRN 一般是在激活、池化函数后的一种方法。
-
-在 ALexNet 中,提出了 LRN 层,对局部神经元的活动创建竞争机制,使其中响应比较大对值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
+ LRN 是一种提高深度学习准确度的技术方法。LRN 一般是在激活、池化函数后的一种方法。
-### 3.6.7理解局部响应归一化公式
+ 在 ALexNet 中,提出了 LRN 层,对局部神经元的活动创建竞争机制,使其中响应比较大对值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
-答案来源:[深度学习的局部响应归一化LRN(Local Response Normalization)理解](https://blog.csdn.net/yangdashi888/article/details/77918311)
+### 3.6.7 理解局部响应归一化
-局部响应归一化原理是仿造生物学上活跃的神经元对相邻神经元的抑制现象(侧抑制),根据论文其公式如下:
+ 局部响应归一化原理是仿造生物学上活跃的神经元对相邻神经元的抑制现象(侧抑制),其公式如下:
$$
b_{x,y}^i = a_{x,y}^i / (k + \alpha \sum_{j=max(0, i-n/2)}^{min(N-1, i+n/2)}(a_{x,y}^j)^2 )^\beta
$$
其中,
-1) $ a $:表示卷积层(包括卷积操作和池化操作)后的输出结果,是一个四维数组[batch,height,width,channel]。
+1) $ a $:表示卷积层(包括卷积操作和池化操作)后的输出结果,是一个四维数组[batch,height,width,channel]。
- batch:批次数(每一批为一张图片)。
- height:图片高度。
@@ -760,17 +771,17 @@ $$
4) $ a $,$ n/2 $, $ k $ 分别表示函数中的 input,depth_radius,bias。参数 $ k, n, \alpha, \beta $ 都是超参数,一般设置 $ k=2, n=5, \alpha=1*e-4, \beta=0.75 $
-5) $ \sum $:$ \sum $ 叠加的方向是沿着通道方向的,即每个点值的平方和是沿着 $ a $ 中的第 3 维 channel 方向的,也就是一个点同方向的前面 $ n/2 $ 个通道(最小为第 $ 0 $ 个通道)和后 $ n/2 $ 个通道(最大为第 $ d-1 $ 个通道)的点的平方和(共 $ n+1 $ 个点)。而函数的英文注解中也说明了把 input 当成是 $ d $ 个 3 维的矩阵,说白了就是把 input 的通道数当作 3 维矩阵的个数,叠加的方向也是在通道方向。
+5) $ \sum $:$ \sum $ 叠加的方向是沿着通道方向的,即每个点值的平方和是沿着 $ a $ 中的第 3 维 channel 方向的,也就是一个点同方向的前面 $ n/2 $ 个通道(最小为第 $ 0 $ 个通道)和后 $ n/2 $ 个通道(最大为第 $ d-1 $ 个通道)的点的平方和(共 $ n+1 $ 个点)。而函数的英文注解中也说明了把 input 当成是 $ d $ 个 3 维的矩阵,说白了就是把 input 的通道数当作 3 维矩阵的个数,叠加的方向也是在通道方向。
简单的示意图如下:
-
+
### 3.6.8 什么是批归一化(Batch Normalization)
-以前在神经网络训练中,只是对输入层数据进行归一化处理,却没有在中间层进行归一化处理。要知道,虽然我们对输入数据进行了归一化处理,但是输入数据经过 $ \sigma(WX+b) $ 这样的矩阵乘法以及非线性运算之后,其数据分布很可能被改变,而随着深度网络的多层运算之后,数据分布的变化将越来越大。如果我们能在网络的中间也进行归一化处理,是否对网络的训练起到改进作用呢?答案是肯定的。
+ 以前在神经网络训练中,只是对输入层数据进行归一化处理,却没有在中间层进行归一化处理。要知道,虽然我们对输入数据进行了归一化处理,但是输入数据经过 $ \sigma(WX+b) $ 这样的矩阵乘法以及非线性运算之后,其数据分布很可能被改变,而随着深度网络的多层运算之后,数据分布的变化将越来越大。如果我们能在网络的中间也进行归一化处理,是否对网络的训练起到改进作用呢?答案是肯定的。
-这种在神经网络中间层也进行归一化处理,使训练效果更好的方法,就是批归一化Batch Normalization(BN)。
+ 这种在神经网络中间层也进行归一化处理,使训练效果更好的方法,就是批归一化Batch Normalization(BN)。
### 3.6.9 批归一化(BN)算法的优点
@@ -795,7 +806,7 @@ $$
\mu_{\beta} = \frac{1}{m} \sum_{i=1}^m(x_i)
$$
-其中,$ m $ 是此次训练样本 batch 的大小。
+其中,$ m $ 是此次训练样本 batch 的大小。
2. 计算上一层输出数据的标准差
@@ -821,19 +832,23 @@ $$
注:上述是 BN 训练时的过程,但是当在投入使用时,往往只是输入一个样本,没有所谓的均值 $ \mu_{\beta} $ 和标准差 $ \sigma_{\beta}^2 $。此时,均值 $ \mu_{\beta} $ 是计算所有 batch $ \mu_{\beta} $ 值的平均值得到,标准差 $ \sigma_{\beta}^2 $ 采用每个batch $ \sigma_{\beta}^2 $ 的无偏估计得到。
-### 3.6.11 批归一化和群组归一化
+### 3.6.11 批归一化和群组归一化比较
-批量归一化(Batch Normalization,以下简称 BN)是深度学习发展中的一项里程碑式技术,可让各种网络并行训练。但是,批量维度进行归一化会带来一些问题——批量统计估算不准确导致批量变小时,BN 的误差会迅速增加。在训练大型网络和将特征转移到计算机视觉任务中(包括检测、分割和视频),内存消耗限制了只能使用小批量的 BN。
+| 名称 | 特点 |
+| ---------------------------------------------- | :----------------------------------------------------------- |
+| 批量归一化(Batch Normalization,以下简称 BN) | 可让各种网络并行训练。但是,批量维度进行归一化会带来一些问题——批量统计估算不准确导致批量变小时,BN 的误差会迅速增加。在训练大型网络和将特征转移到计算机视觉任务中(包括检测、分割和视频),内存消耗限制了只能使用小批量的 BN。 |
+| 群组归一化 Group Normalization (简称 GN) | GN 将通道分成组,并在每组内计算归一化的均值和方差。GN 的计算与批量大小无关,并且其准确度在各种批量大小下都很稳定。 |
+| 比较 | 在 ImageNet 上训练的 ResNet-50上,GN 使用批量大小为 2 时的错误率比 BN 的错误率低 10.6% ;当使用典型的批量时,GN 与 BN 相当,并且优于其他标归一化变体。而且,GN 可以自然地从预训练迁移到微调。在进行 COCO 中的目标检测和分割以及 Kinetics 中的视频分类比赛中,GN 可以胜过其竞争对手,表明 GN 可以在各种任务中有效地取代强大的 BN。 |
-何恺明团队在[群组归一化(Group Normalization)](http://tech.ifeng.com/a/20180324/44918599_0.shtml) 中提出群组归一化 Group Normalization (简称 GN) 作为 BN 的替代方案。
+### 3.6.12 Weight Normalization和Batch Normalization比较
-GN 将通道分成组,并在每组内计算归一化的均值和方差。GN 的计算与批量大小无关,并且其准确度在各种批量大小下都很稳定。在 ImageNet 上训练的 ResNet-50上,GN 使用批量大小为 2 时的错误率比 BN 的错误率低 10.6% ;当使用典型的批量时,GN 与 BN 相当,并且优于其他标归一化变体。而且,GN 可以自然地从预训练迁移到微调。在进行 COCO 中的目标检测和分割以及 Kinetics 中的视频分类比赛中,GN 可以胜过其竞争对手,表明 GN 可以在各种任务中有效地取代强大的 BN。
+ Weight Normalization 和 Batch Normalization 都属于参数重写(Reparameterization)的方法,只是采用的方式不同。
-### 3.6.12 Weight Normalization和Batch Normalization
+ Weight Normalization 是对网络权值$ W $ 进行 normalization,因此也称为 Weight Normalization;
-答案来源:[Weight Normalization 相比batch Normalization 有什么优点呢?](https://www.zhihu.com/question/55132852/answer/171250929)
+ Batch Normalization 是对网络某一层输入数据进行 normalization。
-Weight Normalization 和 Batch Normalization 都属于参数重写(Reparameterization)的方法,只是采用的方式不同,Weight Normalization 是对网络权值$ W $ 进行 normalization,因此也称为 Weight Normalization;Batch Normalization 是对网络某一层输入数据进行 normalization。Weight Normalization相比Batch Normalization有以下三点优势:
+ Weight Normalization相比Batch Normalization有以下三点优势:
1. Weight Normalization 通过重写深度学习网络的权重W的方式来加速深度学习网络参数收敛,没有引入 minbatch 的依赖,适用于 RNN(LSTM)网络(Batch Normalization 不能直接用于RNN,进行 normalization 操作,原因在于:1) RNN 处理的 Sequence 是变长的;2) RNN 是基于 time step 计算,如果直接使用 Batch Normalization 处理,需要保存每个 time step 下,mini btach 的均值和方差,效率低且占内存)。
@@ -841,18 +856,18 @@ Weight Normalization 和 Batch Normalization 都属于参数重写(Reparameter
3. 不需要额外的存储空间来保存 mini batch 的均值和方差,同时实现 Weight Normalization 时,对深度学习网络进行正向信号传播和反向梯度计算带来的额外计算开销也很小。因此,要比采用 Batch Normalization 进行 normalization 操作时,速度快。 但是 Weight Normalization 不具备 Batch Normalization 把网络每一层的输出 Y 固定在一个变化范围的作用。因此,采用 Weight Normalization 进行 Normalization 时需要特别注意参数初始值的选择。
-### 3.6.13 Batch Normalization在什么时候用比较合适?(贡献者:黄钦建-华南理工大学)
+### 3.6.13 Batch Normalization在什么时候用比较合适?
+
+**(贡献者:黄钦建-华南理工大学)**
-在CNN中,BN应作用在非线性映射前。在神经网络训练时遇到收敛速度很慢,或梯度爆炸等无法训练的状况时可以尝试BN来解决。另外,在一般使用情况下也可以加入BN来加快训练速度,提高模型精度。
+ 在CNN中,BN应作用在非线性映射前。在神经网络训练时遇到收敛速度很慢,或梯度爆炸等无法训练的状况时可以尝试BN来解决。另外,在一般使用情况下也可以加入BN来加快训练速度,提高模型精度。
-BN比较适用的场景是:每个mini-batch比较大,数据分布比较接近。在进行训练之前,要做好充分的shuffle,否则效果会差很多。另外,由于BN需要在运行过程中统计每个mini-batch的一阶统计量和二阶统计量,因此不适用于动态的网络结构和RNN网络。
+ BN比较适用的场景是:每个mini-batch比较大,数据分布比较接近。在进行训练之前,要做好充分的shuffle,否则效果会差很多。另外,由于BN需要在运行过程中统计每个mini-batch的一阶统计量和二阶统计量,因此不适用于动态的网络结构和RNN网络。
## 3.7 预训练与微调(fine tuning)
### 3.7.1 为什么无监督预训练可以帮助深度学习?
-答案来源:[为什么无监督的预训练可以帮助深度学习](http://blog.csdn.net/Richard_More/article/details/52334272?locationNum=3&fps=1)
-
深度网络存在问题:
1. 网络越深,需要的训练样本数越多。若用监督则需大量标注样本,不然小规模样本容易造成过拟合。深层网络特征比较多,会出现的多特征问题主要有多样本问题、规则化问题、特征选择问题。
@@ -863,21 +878,21 @@ BN比较适用的场景是:每个mini-batch比较大,数据分布比较接
**解决方法:**
-逐层贪婪训练,无监督预训练(unsupervised pre-training)即训练网络的第一个隐藏层,再训练第二个…最后用这些训练好的网络参数值作为整体网络参数的初始值。
+ 逐层贪婪训练,无监督预训练(unsupervised pre-training)即训练网络的第一个隐藏层,再训练第二个…最后用这些训练好的网络参数值作为整体网络参数的初始值。
经过预训练最终能得到比较好的局部最优解。
### 3.7.2 什么是模型微调fine tuning
-用别人的参数、修改后的网络和自己的数据进行训练,使得参数适应自己的数据,这样一个过程,通常称之为微调(fine tuning).
+ 用别人的参数、修改后的网络和自己的数据进行训练,使得参数适应自己的数据,这样一个过程,通常称之为微调(fine tuning).
**模型的微调举例说明:**
-我们知道,CNN 在图像识别这一领域取得了巨大的进步。如果想将 CNN 应用到我们自己的数据集上,这时通常就会面临一个问题:通常我们的 dataset 都不会特别大,一般不会超过 1 万张,甚至更少,每一类图片只有几十或者十几张。这时候,直接应用这些数据训练一个网络的想法就不可行了,因为深度学习成功的一个关键性因素就是大量带标签数据组成的训练集。如果只利用手头上这点数据,即使我们利用非常好的网络结构,也达不到很高的 performance。这时候,fine-tuning 的思想就可以很好解决我们的问题:我们通过对 ImageNet 上训练出来的模型(如CaffeNet,VGGNet,ResNet) 进行微调,然后应用到我们自己的数据集上。
+ 我们知道,CNN 在图像识别这一领域取得了巨大的进步。如果想将 CNN 应用到我们自己的数据集上,这时通常就会面临一个问题:通常我们的 dataset 都不会特别大,一般不会超过 1 万张,甚至更少,每一类图片只有几十或者十几张。这时候,直接应用这些数据训练一个网络的想法就不可行了,因为深度学习成功的一个关键性因素就是大量带标签数据组成的训练集。如果只利用手头上这点数据,即使我们利用非常好的网络结构,也达不到很高的 performance。这时候,fine-tuning 的思想就可以很好解决我们的问题:我们通过对 ImageNet 上训练出来的模型(如CaffeNet,VGGNet,ResNet) 进行微调,然后应用到我们自己的数据集上。
### 3.7.3 微调时候网络参数是否更新?
-会更新。
+答案:会更新。
1. finetune 的过程相当于继续训练,跟直接训练的区别是初始化的时候。
2. 直接训练是按照网络定义指定的方式初始化。
@@ -906,24 +921,34 @@ BN比较适用的场景是:每个mini-batch比较大,数据分布比较接
### 3.8.2 全都初始化为同样的值
-偏差初始化陷阱: 都初始化为一样的值。
-以一个三层网络为例:
+ 偏差初始化陷阱: 都初始化为一样的值。
+ 以一个三层网络为例:
首先看下结构
-
+
它的表达式为:
$$
a_1^{(2)} = f(W_{11}^{(1)} x_1 + W_{12}^{(1)} x_2 + W_{13}^{(1)} x_3 + b_1^{(1)})
+$$
+$$
a_2^{(2)} = f(W_{21}^{(1)} x_1 + W_{22}^{(1)} x_2 + W_{23}^{(1)} x_3 + b_2^{(1)})
+$$
+$$
a_3^{(2)} = f(W_{31}^{(1)} x_1 + W_{32}^{(1)} x_2 + W_{33}^{(1)} x_3 + b_3^{(1)})
+$$
+$$
h_{W,b}(x) = a_1^{(3)} = f(W_{11}^{(2)} a_1^{(2)} + W_{12}^{(2)} a_2^{(2)} + W_{13}^{(2)} a_3^{(2)} + b_1^{(2)})
$$
+$$
+xa_1^{(2)} = f(W_{11}^{(1)} x_1 + W_{12}^{(1)} x_2 + W_{13}^{(1)} x_3 + b_1^{(1)})a_2^{(2)} = f(W_{21}^{(1)} x_1 + W_{22}^{(1)} x_2 + W_{23}^{(1)} x_3 +
+$$
+
如果每个权重都一样,那么在多层网络中,从第二层开始,每一层的输入值都是相同的了也就是$ a1=a2=a3=.... $,既然都一样,就相当于一个输入了,为啥呢??
如果是反向传递算法(如果这里不明白请看上面的连接),其中的偏置项和权重项的迭代的偏导数计算公式如下
@@ -934,7 +959,7 @@ $$
\frac{\partial}{\partial b_{i}^{(l)}} J(W,b;x,y) = \delta_i^{(l+1)}
$$
-$ \delta $ 的计算公式
+$ \delta $ 的计算公式
$$
\delta_i^{(l)} = (\sum_{j=1}^{s_{t+1}} W_{ji}^{(l)} \delta_j^{(l+1)} ) f^{\prime}(z_i^{(l)})
@@ -951,105 +976,117 @@ $$
### 3.8.3 初始化为小的随机数
-将权重初始化为很小的数字是一个普遍的打破网络对称性的解决办法。这个想法是,神经元在一开始都是随机的、独一无二的,所以它们会计算出不同的更新,并将自己整合到整个网络的各个部分。一个权重矩阵的实现可能看起来像 $ W=0.01∗np.random.randn(D,H) $,其中 randn 是从均值为 0 的单位标准高斯分布进行取样。通过这个公式(函数),每个神经元的权重向量初始化为一个从多维高斯分布取样的随机向量,所以神经元在输入空间中指向随机的方向(so the neurons point in random direction in the input space). 应该是指输入空间对于随机方向有影响)。其实也可以从均匀分布中来随机选取小数,但是在实际操作中看起来似乎对最后的表现并没有太大的影响。
+ 将权重初始化为很小的数字是一个普遍的打破网络对称性的解决办法。这个想法是,神经元在一开始都是随机的、独一无二的,所以它们会计算出不同的更新,并将自己整合到整个网络的各个部分。一个权重矩阵的实现可能看起来像 $ W=0.01∗np.random.randn(D,H) $,其中 randn 是从均值为 0 的单位标准高斯分布进行取样。通过这个公式(函数),每个神经元的权重向量初始化为一个从多维高斯分布取样的随机向量,所以神经元在输入空间中指向随机的方向(so the neurons point in random direction in the input space). 应该是指输入空间对于随机方向有影响)。其实也可以从均匀分布中来随机选取小数,但是在实际操作中看起来似乎对最后的表现并没有太大的影响。
-备注:警告:并不是数字越小就会表现的越好。比如,如果一个神经网络层的权重非常小,那么在反向传播算法就会计算出很小的梯度(因为梯度 gradient 是与权重成正比的)。在网络不断的反向传播过程中将极大地减少“梯度信号”,并可能成为深层网络的一个需要注意的问题。
+ 备注:并不是数字越小就会表现的越好。比如,如果一个神经网络层的权重非常小,那么在反向传播算法就会计算出很小的梯度(因为梯度 gradient 是与权重成正比的)。在网络不断的反向传播过程中将极大地减少“梯度信号”,并可能成为深层网络的一个需要注意的问题。
### 3.8.4 用 $ 1/\sqrt n $ 校准方差
-上述建议的一个问题是,随机初始化神经元的输出的分布有一个随输入量增加而变化的方差。结果证明,我们可以通过将其权重向量按其输入的平方根(即输入的数量)进行缩放,从而将每个神经元的输出的方差标准化到 1。也就是说推荐的启发式方法 (heuristic) 是将每个神经元的权重向量按下面的方法进行初始化: $ w=np.random.randn(n)/\sqrt n $,其中 n 表示输入的数量。这保证了网络中所有的神经元最初的输出分布大致相同,并在经验上提高了收敛速度。
+ 上述建议的一个问题是,随机初始化神经元的输出的分布有一个随输入量增加而变化的方差。结果证明,我们可以通过将其权重向量按其输入的平方根(即输入的数量)进行缩放,从而将每个神经元的输出的方差标准化到 1。也就是说推荐的启发式方法 (heuristic) 是将每个神经元的权重向量按下面的方法进行初始化: $ w=np.random.randn(n)/\sqrt n $,其中 n 表示输入的数量。这保证了网络中所有的神经元最初的输出分布大致相同,并在经验上提高了收敛速度。
### 3.8.5 稀疏初始化(Sparse Initialazation)
-另一种解决未校准方差问题的方法是把所有的权重矩阵都设为零,但是为了打破对称性,每个神经元都是随机连接地(从如上面所介绍的一个小的高斯分布中抽取权重)到它下面的一个固定数量的神经元。一个典型的神经元连接的数目可能是小到 10 个。
+ 另一种解决未校准方差问题的方法是把所有的权重矩阵都设为零,但是为了打破对称性,每个神经元都是随机连接地(从如上面所介绍的一个小的高斯分布中抽取权重)到它下面的一个固定数量的神经元。一个典型的神经元连接的数目可能是小到 10 个。
### 3.8.6 初始化偏差
-将偏差初始化为零是可能的,也是很常见的,因为非对称性破坏是由权重的小随机数导致的。因为 ReLU 具有非线性特点,所以有些人喜欢使用将所有的偏差设定为小的常数值如 0.01,因为这样可以确保所有的 ReLU 单元在最开始就激活触发(fire)并因此能够获得和传播一些梯度值。然而,这是否能够提供持续的改善还不太清楚(实际上一些结果表明这样做反而使得性能更加糟糕),所以更通常的做法是简单地将偏差初始化为 0.
+ 将偏差初始化为零是可能的,也是很常见的,因为非对称性破坏是由权重的小随机数导致的。因为 ReLU 具有非线性特点,所以有些人喜欢使用将所有的偏差设定为小的常数值如 0.01,因为这样可以确保所有的 ReLU 单元在最开始就激活触发(fire)并因此能够获得和传播一些梯度值。然而,这是否能够提供持续的改善还不太清楚(实际上一些结果表明这样做反而使得性能更加糟糕),所以更通常的做法是简单地将偏差初始化为 0.
-## 3.9 Softmax
+## 3.9 学习率
-### 3.9.1 Softmax 定义及作用
+### 3.9.1 学习率的作用
-Softmax 是一种形如下式的函数:
+ 在机器学习中,监督式学习通过定义一个模型,并根据训练集上的数据估计最优参数。梯度下降法是一个广泛被用来最小化模型误差的参数优化算法。梯度下降法通过多次迭代,并在每一步中最小化成本函数(cost 来估计模型的参数。学习率 (learning rate),在迭代过程中会控制模型的学习进度。
-$$
-P(i) = \frac{exp(\theta_i^T x)}{\sum_{k=1}^{K} exp(\theta_i^T x)}
-$$
-
-其中,$ \theta_i $ 和 $ x $ 是列向量,$ \theta_i^T x $ 可能被换成函数关于 $ x $ 的函数 $ f_i(x) $
-
-通过 softmax 函数,可以使得 $ P(i) $ 的范围在 $ [0,1] $ 之间。在回归和分类问题中,通常 $ \theta $ 是待求参数,通过寻找使得 $ P(i) $ 最大的 $ \theta_i $ 作为最佳参数。
+ 在梯度下降法中,都是给定的统一的学习率,整个优化过程中都以确定的步长进行更新, 在迭代优化的前期中,学习率较大,则前进的步长就会较长,这时便能以较快的速度进行梯度下降,而在迭代优化的后期,逐步减小学习率的值,减小步长,这样将有助于算法的收敛,更容易接近最优解。故而如何对学习率的更新成为了研究者的关注点。
+ 在模型优化中,常用到的几种学习率衰减方法有:分段常数衰减、多项式衰减、指数衰减、自然指数衰减、余弦衰减、线性余弦衰减、噪声线性余弦衰减
-但是,使得范围在 $ [0,1] $ 之间的方法有很多,为啥要在前面加上以 $ e $ 的幂函数的形式呢?参考 logistic 函数:
+### 3.9.2 学习率衰减常用参数有哪些
-$$
-P(i) = \frac{1}{1+exp(-\theta_i^T x)}
-$$
+| 参数名称 | 参数说明 |
+| ----------------- | -------------------------------------------------- |
+| learning_rate | 初始学习率 |
+| global_step | 用于衰减计算的全局步数,非负,用于逐步计算衰减指数 |
+| decay_steps | 衰减步数,必须是正值,决定衰减周期 |
+| decay_rate | 衰减率 |
+| end_learning_rate | 最低的最终学习率 |
+| cycle | 学习率下降后是否重新上升 |
+| alpha | 最小学习率 |
+| num_periods | 衰减余弦部分的周期数 |
+| initial_variance | 噪声的初始方差 |
+| variance_decay | 衰减噪声的方差 |
-这个函数的作用就是使得 $ P(i) $ 在负无穷到 0 的区间趋向于 0, 在 0 到正无穷的区间趋向 1,。同样 softmax 函数加入了 $ e $ 的幂函数正是为了两极化:正样本的结果将趋近于 1,而负样本的结果趋近于 0。这样为多类别提供了方便(可以把 $ P(i) $ 看做是样本属于类别的概率)。可以说,Softmax 函数是 logistic 函数的一种泛化。
+### 3.9.3 分段常数衰减
-softmax 函数可以把它的输入,通常被称为 logits 或者 logit scores,处理成 0 到 1 之间,并且能够把输出归一化到和为 1。这意味着 softmax 函数与分类的概率分布等价。它是一个网络预测多酚类问题的最佳输出激活函数。
+ 分段常数衰减需要事先定义好的训练次数区间,在对应区间置不同的学习率的常数值,一般情况刚开始的学习率要大一些,之后要越来越小,要根据样本量的大小设置区间的间隔大小,样本量越大,区间间隔要小一点。下图即为分段常数衰减的学习率变化图,横坐标代表训练次数,纵坐标代表学习率。
-### 3.9.2 Softmax 推导
+
-## 3.10 理解 One Hot Encodeing 原理及作用?
+### 3.9.4 指数衰减
-问题由来
+ 以指数衰减方式进行学习率的更新,学习率的大小和训练次数指数相关,其更新规则为:
+$$
+decayed{\_}learning{\_}rate =learning{\_}rate*decay{\_}rate^{\frac{global{\_step}}{decay{\_}steps}}
+$$
+ 这种衰减方式简单直接,收敛速度快,是最常用的学习率衰减方式,如下图所示,绿色的为学习率随
+训练次数的指数衰减方式,红色的即为分段常数衰减,它在一定的训练区间内保持学习率不变。
-在很多**机器学习**任务中,特征并不总是连续值,而有可能是分类值。
+
-例如,考虑一下的三个特征:
+### 3.9.5 自然指数衰减
-```
-["male", "female"] ["from Europe", "from US", "from Asia"]
-["uses Firefox", "uses Chrome", "uses Safari", "uses Internet Explorer"]
-```
+ 它与指数衰减方式相似,不同的在于它的衰减底数是$e$,故而其收敛的速度更快,一般用于相对比较
+容易训练的网络,便于较快的收敛,其更新规则如下
+$$
+decayed{\_}learning{\_}rate =learning{\_}rate*e^{\frac{-decay{\_rate}}{global{\_}step}}
+$$
+ 下图为为分段常数衰减、指数衰减、自然指数衰减三种方式的对比图,红色的即为分段常数衰减图,阶梯型曲线。蓝色线为指数衰减图,绿色即为自然指数衰减图,很明可以看到自然指数衰减方式下的学习率衰减程度要大于一般指数衰减方式,有助于更快的收敛。
-如果将上述特征用数字表示,效率会高很多。例如:
+
-```
-["male", "from US", "uses Internet Explorer"] 表示为 [0, 1, 3]
-["female", "from Asia", "uses Chrome"] 表示为 [1, 2, 1]
-```
+### 3.9.6 多项式衰减
-但是,即使转化为数字表示后,上述数据也不能直接用在我们的分类器中。因为,分类器往往默认数据数据是连续的(可以计算距离?),并且是有序的(而上面这个 0 并不是说比 1 要高级)。但是,按照我们上述的表示,数字并不是有序的,而是随机分配的。
+ 应用多项式衰减的方式进行更新学习率,这里会给定初始学习率和最低学习率取值,然后将会按照
+给定的衰减方式将学习率从初始值衰减到最低值,其更新规则如下式所示。
+$$
+global{\_}step=min(global{\_}step,decay{\_}steps)
+$$
-**独热编码**
+$$
+decayed{\_}learning{\_}rate =(learning{\_}rate-end{\_}learning{\_}rate)* \left( 1-\frac{global{\_step}}{decay{\_}steps}\right)^{power} \\
+ +end{\_}learning{\_}rate
+$$
-为了解决上述问题,其中一种可能的解决方法是采用独热编码(One-Hot Encoding)。独热编码即 One-Hot 编码,又称一位有效编码,其方法是使用N位状态寄存器来对 N 个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候,其中只有一位有效。
+ 需要注意的是,有两个机制,降到最低学习率后,到训练结束可以一直使用最低学习率进行更新,另一个是再次将学习率调高,使用 decay_steps 的倍数,取第一个大于 global_steps 的结果,如下式所示.它是用来防止神经网络在训练的后期由于学习率过小而导致的网络一直在某个局部最小值附近震荡,这样可以通过在后期增大学习率跳出局部极小值。
+$$
+decay{\_}steps = decay{\_}steps*ceil \left( \frac{global{\_}step}{decay{\_}steps}\right)
+$$
+ 如下图所示,红色线代表学习率降低至最低后,一直保持学习率不变进行更新,绿色线代表学习率衰减到最低后,又会再次循环往复的升高降低。
-例如:
+
-```
-自然状态码为:000,001,010,011,100,101
-独热编码为:000001,000010,000100,001000,010000,100000
-```
+### 3.9.7 余弦衰减
-可以这样理解,对于每一个特征,如果它有 m 个可能值,那么经过独热编码后,就变成了 m 个二元特征(如成绩这个特征有好,中,差变成 one-hot 就是 100, 010, 001)。并且,这些特征互斥,每次只有一个激活。因此,数据会变成稀疏的。
+ 余弦衰减就是采用余弦的相关方式进行学习率的衰减,衰减图和余弦函数相似。其更新机制如下式所示:
+$$
+global{\_}step=min(global{\_}step,decay{\_}steps)
+$$
-这样做的好处主要有:
+$$
+cosine{\_}decay=0.5*\left( 1+cos\left( \pi* \frac{global{\_}step}{decay{\_}steps}\right)\right)
+$$
-1. 解决了分类器不好处理属性数据的问题;
-2. 在一定程度上也起到了扩充特征的作用。
+$$
+decayed=(1-\alpha)*cosine{\_}decay+\alpha
+$$
-## 3.11 常用的优化器有哪些
+$$
+decayed{\_}learning{\_}rate=learning{\_}rate*decayed
+$$
-分别列举
+ 如下图所示,红色即为标准的余弦衰减曲线,学习率从初始值下降到最低学习率后保持不变。蓝色的线是线性余弦衰减方式曲线,它是学习率从初始学习率以线性的方式下降到最低学习率值。绿色噪声线性余弦衰减方式。
-```
-Optimizer:
-tf.train.GradientDescentOptimizer
-tf.train.AdadeltaOptimizer
-tf.train.AdagradOptimizer
-tf.train.AdagradDAOptimizer
-tf.train.MomentumOptimizer
-tf.train.AdamOptimizer
-tf.train.FtrlOptimizer
-tf.train.ProximalGradientDescentOptimizer
-tf.train.ProximalAdagradOptimizer
-tf.train.RMSPropOptimizer
-```
+
## 3.12 Dropout 系列问题
@@ -1059,15 +1096,15 @@ tf.train.RMSPropOptimizer
### 3.12.2 为什么正则化有利于预防过拟合?
-
-
+
+
左图是高偏差,右图是高方差,中间是Just Right,这几张图我们在前面课程中看到过。
### 3.12.3 理解dropout正则化
-Dropout可以随机删除网络中的神经单元,它为什么可以通过正则化发挥如此大的作用呢?
+ Dropout可以随机删除网络中的神经单元,它为什么可以通过正则化发挥如此大的作用呢?
-直观上理解:不要依赖于任何一个特征,因为该单元的输入可能随时被清除,因此该单元通过这种方式传播下去,并为单元的四个输入增加一点权重,通过传播所有权重,dropout将产生收缩权重的平方范数的效果,和之前讲的L2正则化类似;实施dropout的结果实它会压缩权重,并完成一些预防过拟合的外层正则化;L2对不同权重的衰减是不同的,它取决于激活函数倍增的大小。
+ 直观上理解:不要依赖于任何一个特征,因为该单元的输入可能随时被清除,因此该单元通过这种方式传播下去,并为单元的四个输入增加一点权重,通过传播所有权重,dropout将产生收缩权重的平方范数的效果,和之前讲的L2正则化类似;实施dropout的结果实它会压缩权重,并完成一些预防过拟合的外层正则化;L2对不同权重的衰减是不同的,它取决于激活函数倍增的大小。
### 3.12.4 dropout率的选择
@@ -1080,10 +1117,11 @@ Dropout可以随机删除网络中的神经单元,它为什么可以通过正
### 3.12.5 dropout有什么缺点?
-dropout一大缺点就是代价函数J不再被明确定义,每次迭代,都会随机移除一些节点,如果再三检查梯度下降的性能,实际上是很难进行复查的。定义明确的代价函数J每次迭代后都会下降,因为我们所优化的代价函数J实际上并没有明确定义,或者说在某种程度上很难计算,所以我们失去了调试工具来绘制这样的图片。我通常会关闭dropout函数,将keep-prob的值设为1,运行代码,确保J函数单调递减。然后打开dropout函数,希望在dropout过程中,代码并未引入bug。我觉得你也可以尝试其它方法,虽然我们并没有关于这些方法性能的数据统计,但你可以把它们与dropout方法一起使用。
+ dropout一大缺点就是代价函数J不再被明确定义,每次迭代,都会随机移除一些节点,如果再三检查梯度下降的性能,实际上是很难进行复查的。定义明确的代价函数J每次迭代后都会下降,因为我们所优化的代价函数J实际上并没有明确定义,或者说在某种程度上很难计算,所以我们失去了调试工具来绘制这样的图片。我通常会关闭dropout函数,将keep-prob的值设为1,运行代码,确保J函数单调递减。然后打开dropout函数,希望在dropout过程中,代码并未引入bug。我觉得你也可以尝试其它方法,虽然我们并没有关于这些方法性能的数据统计,但你可以把它们与dropout方法一起使用。
+## 3.13 深度学习中常用的数据增强方法?
-## 3.13 深度学习中常用的数据增强方法(Data Augmentation)?(贡献者:黄钦建-华南理工大学)
+**(贡献者:黄钦建-华南理工大学)**
- Color Jittering:对颜色的数据增强:图像亮度、饱和度、对比度变化(此处对色彩抖动的理解不知是否得当);
@@ -1103,15 +1141,17 @@ dropout一大缺点就是代价函数J不再被明确定义,每次迭代,都
- Label Shuffle:类别不平衡数据的增广;
-## 3.14 如何理解 Internal Covariate Shift?(贡献者:黄钦建-华南理工大学)
+## 3.14 如何理解 Internal Covariate Shift?
+
+**(贡献者:黄钦建-华南理工大学)**
-深度神经网络模型的训练为什么会很困难?其中一个重要的原因是,深度神经网络涉及到很多层的叠加,而每一层的参数更新会导致上层的输入数据分布发生变化,通过层层叠加,高层的输入分布变化会非常剧烈,这就使得高层需要不断去重新适应底层的参数更新。为了训好模型,我们需要非常谨慎地去设定学习率、初始化权重、以及尽可能细致的参数更新策略。
+ 深度神经网络模型的训练为什么会很困难?其中一个重要的原因是,深度神经网络涉及到很多层的叠加,而每一层的参数更新会导致上层的输入数据分布发生变化,通过层层叠加,高层的输入分布变化会非常剧烈,这就使得高层需要不断去重新适应底层的参数更新。为了训好模型,我们需要非常谨慎地去设定学习率、初始化权重、以及尽可能细致的参数更新策略。
-Google 将这一现象总结为 Internal Covariate Shift,简称 ICS。 什么是 ICS 呢?
+ Google 将这一现象总结为 Internal Covariate Shift,简称 ICS。 什么是 ICS 呢?
-大家都知道在统计机器学习中的一个经典假设是“源空间(source domain)和目标空间(target domain)的数据分布(distribution)是一致的”。如果不一致,那么就出现了新的机器学习问题,如 transfer learning / domain adaptation 等。而 covariate shift 就是分布不一致假设之下的一个分支问题,它是指源空间和目标空间的条件概率是一致的,但是其边缘概率不同。
+ 大家都知道在统计机器学习中的一个经典假设是“源空间(source domain)和目标空间(target domain)的数据分布(distribution)是一致的”。如果不一致,那么就出现了新的机器学习问题,如 transfer learning / domain adaptation 等。而 covariate shift 就是分布不一致假设之下的一个分支问题,它是指源空间和目标空间的条件概率是一致的,但是其边缘概率不同。
-大家细想便会发现,的确,对于神经网络的各层输出,由于它们经过了层内操作作用,其分布显然与各层对应的输入信号分布不同,而且差异会随着网络深度增大而增大,可是它们所能“指示”的样本标记(label)仍然是不变的,这便符合了covariate shift的定义。由于是对层间信号的分析,也即是“internal”的来由。
+ 大家细想便会发现,的确,对于神经网络的各层输出,由于它们经过了层内操作作用,其分布显然与各层对应的输入信号分布不同,而且差异会随着网络深度增大而增大,可是它们所能“指示”的样本标记(label)仍然是不变的,这便符合了covariate shift的定义。由于是对层间信号的分析,也即是“internal”的来由。
**那么ICS会导致什么问题?**
@@ -1123,9 +1163,83 @@ Google 将这一现象总结为 Internal Covariate Shift,简称 ICS。 什么
其三,每层的更新都会影响到其它层,因此每层的参数更新策略需要尽可能的谨慎。
-## 3.15 什么时候用local-conv?什么时候用全卷积?(贡献者:梁志成-魅族科技)
-1.当数据集具有全局的局部特征分布时,也就是说局部特征之间有较强的相关性,适合用全卷积。
-2.在不同的区域有不同的特征分布时,适合用local-Conv。
+
+
+## 参考文献
+
+[1] Rosenblatt, F. The perceptron: A probabilistic model for information storage and organization in the brain.[J]. Psychological Review, 1958, 65(6):386-408.
+
+[2] Duvenaud D , Rippel O , Adams R P , et al. Avoiding pathologies in very deep networks[J]. Eprint Arxiv, 2014:202-210.
+
+[3] Rumelhart D E, Hinton G E, Williams R J. Learning representations by back-propagating errors[J]. Cognitive modeling, 1988, 5(3): 1.
+
+[4] Hecht-Nielsen R. Theory of the backpropagation neural network[M]//Neural networks for perception. Academic Press, 1992: 65-93.
+
+[5] Felice M. Which deep learning network is best for you?| CIO[J]. 2017.
+
+[6] Conneau A, Schwenk H, Barrault L, et al. Very deep convolutional networks for natural language processing[J]. arXiv preprint arXiv:1606.01781, 2016, 2.
+
+[7] Ba J, Caruana R. Do deep nets really need to be deep?[C]//Advances in neural information processing systems. 2014: 2654-2662.
+
+[8] Nielsen M A. Neural networks and deep learning[M]. USA: Determination press, 2015.
+
+[9] Goodfellow I, Bengio Y, Courville A. Deep learning[M]. MIT press, 2016.
+
+[10] 周志华. 机器学习[M].清华大学出版社, 2016.
+
+[11] Kim J, Kwon Lee J, Mu Lee K. Accurate image super-resolution using very deep convolutional networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 1646-1654.
+
+[12] Chen Y, Lin Z, Zhao X, et al. Deep learning-based classification of hyperspectral data[J]. IEEE Journal of Selected topics in applied earth observations and remote sensing, 2014, 7(6): 2094-2107.
+
+[13] Domhan T, Springenberg J T, Hutter F. Speeding up automatic hyperparameter optimization of deep neural networks by extrapolation of learning curves[C]//Twenty-Fourth International Joint Conference on Artificial Intelligence. 2015.
+
+[14] Maclaurin D, Duvenaud D, Adams R. Gradient-based hyperparameter optimization through reversible learning[C]//International Conference on Machine Learning. 2015: 2113-2122.
+
+[15] Srivastava R K, Greff K, Schmidhuber J. Training very deep networks[C]//Advances in neural information processing systems. 2015: 2377-2385.
+
+[16] Bergstra J, Bengio Y. Random search for hyper-parameter optimization[J]. Journal of Machine Learning Research, 2012, 13(Feb): 281-305.
+
+[17] Ngiam J, Khosla A, Kim M, et al. Multimodal deep learning[C]//Proceedings of the 28th international conference on machine learning (ICML-11). 2011: 689-696.
+
+[18] Deng L, Yu D. Deep learning: methods and applications[J]. Foundations and Trends® in Signal Processing, 2014, 7(3–4): 197-387.
+
+[19] Erhan D, Bengio Y, Courville A, et al. Why does unsupervised pre-training help deep learning?[J]. Journal of Machine Learning Research, 2010, 11(Feb): 625-660.
+
+[20] Dong C, Loy C C, He K, et al. Learning a deep convolutional network for image super resolution[C]//European conference on computer vision. Springer, Cham, 2014: 184-199.
+
+[21] 郑泽宇,梁博文,顾思宇.TensorFlow:实战Google深度学习框架(第2版)[M].电子工业出版社,2018.
+
+[22] 焦李成. 深度学习优化与识别[M].清华大学出版社,2017.
+
+[23] 吴岸城. 神经网络与深度学习[M].电子工业出版社,2016.
+
+[24] Wei, W.G.H., Liu, T., Song, A., et al. (2018) An Adaptive Natural Gradient Method with Adaptive Step Size in Multi�layer Perceptrons. Chinese Automation Congress, 1593-1597.
+
+[25] Y Feng, Y Li.An Overview of Deep Learning Optimization Methods and Learning Rate Attenuation Methods[J].Hans Journal of Data Mining,2018,8(4),186-200.
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git "a/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/LeNet-5.jpg" "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/LeNet-5.jpg"
new file mode 100644
index 00000000..fb65aedd
Binary files /dev/null and "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/LeNet-5.jpg" differ
diff --git "a/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/alexnet.png" "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/alexnet.png"
new file mode 100644
index 00000000..1a954ca5
Binary files /dev/null and "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/alexnet.png" differ
diff --git "a/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/featureMap.jpg" "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/featureMap.jpg"
new file mode 100644
index 00000000..2e077ef9
Binary files /dev/null and "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/featureMap.jpg" differ
diff --git "a/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image1.png" "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image1.png"
index 41dea102..69c95112 100644
Binary files "a/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image1.png" and "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image1.png" differ
diff --git "a/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image21.jpeg" "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image21.jpeg"
index c2fa5934..32b53478 100644
Binary files "a/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image21.jpeg" and "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image21.jpeg" differ
diff --git "a/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image21.png" "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image21.png"
new file mode 100644
index 00000000..d4bda094
Binary files /dev/null and "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image21.png" differ
diff --git "a/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image23.png" "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image23.png"
new file mode 100644
index 00000000..800434cd
Binary files /dev/null and "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image23.png" differ
diff --git "a/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image27.png" "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image27.png"
new file mode 100644
index 00000000..ecb4c217
Binary files /dev/null and "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image27.png" differ
diff --git "a/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image28.png" "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image28.png"
new file mode 100644
index 00000000..486eef7a
Binary files /dev/null and "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image28.png" differ
diff --git "a/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image31.png" "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image31.png"
index 5d238865..dfc81ca4 100644
Binary files "a/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image31.png" and "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image31.png" differ
diff --git "a/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image32.png" "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image32.png"
index 7b463dae..64fc988c 100644
Binary files "a/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image32.png" and "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image32.png" differ
diff --git "a/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image34.png" "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image34.png"
index 95016085..b04d68bc 100644
Binary files "a/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image34.png" and "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image34.png" differ
diff --git "a/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image35.png" "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image35.png"
index 083675ca..d18574c2 100644
Binary files "a/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image35.png" and "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image35.png" differ
diff --git "a/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image36.png" "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image36.png"
index 404390cf..89333b38 100644
Binary files "a/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image36.png" and "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image36.png" differ
diff --git "a/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image37.png" "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image37.png"
index 6f163002..21c976e7 100644
Binary files "a/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image37.png" and "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image37.png" differ
diff --git "a/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image38.png" "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image38.png"
index 2bed01bc..8bdea2d7 100644
Binary files "a/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image38.png" and "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image38.png" differ
diff --git "a/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image46.png" "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image46.png"
index 3dbb5118..9cbf8abf 100644
Binary files "a/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image46.png" and "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image46.png" differ
diff --git "a/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image47.png" "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image47.png"
index adcebabd..50618ab9 100644
Binary files "a/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image47.png" and "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image47.png" differ
diff --git "a/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image63.png" "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image63.png"
index 38167b0c..5cb3858f 100644
Binary files "a/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image63.png" and "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/image63.png" differ
diff --git "a/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/img_inception_01.png" "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/img_inception_01.png"
new file mode 100644
index 00000000..d410b750
Binary files /dev/null and "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/img_inception_01.png" differ
diff --git "a/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/img_inception_02.png" "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/img_inception_02.png"
new file mode 100644
index 00000000..495c67c0
Binary files /dev/null and "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/img_inception_02.png" differ
diff --git "a/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/img_inception_03.png" "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/img_inception_03.png"
new file mode 100644
index 00000000..9575cd47
Binary files /dev/null and "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/img_inception_03.png" differ
diff --git "a/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/img_inception_04.png" "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/img_inception_04.png"
new file mode 100644
index 00000000..db318cc2
Binary files /dev/null and "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/img_inception_04.png" differ
diff --git "a/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/img_inception_05.png" "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/img_inception_05.png"
new file mode 100644
index 00000000..6e621a4f
Binary files /dev/null and "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/img_inception_05.png" differ
diff --git "a/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/vgg16.png" "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/vgg16.png"
new file mode 100644
index 00000000..3dca57d1
Binary files /dev/null and "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/vgg16.png" differ
diff --git "a/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/zfnet-layer1.png" "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/zfnet-layer1.png"
new file mode 100644
index 00000000..7fb93f7f
Binary files /dev/null and "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/zfnet-layer1.png" differ
diff --git "a/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/zfnet-layer2.png" "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/zfnet-layer2.png"
new file mode 100644
index 00000000..c2e2f6c7
Binary files /dev/null and "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/img/ch4/zfnet-layer2.png" differ
diff --git "a/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/\347\254\254\345\233\233\347\253\240_\347\273\217\345\205\270\347\275\221\347\273\234.md" "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/\347\254\254\345\233\233\347\253\240_\347\273\217\345\205\270\347\275\221\347\273\234.md"
index 78f29c4e..1e1bec50 100644
--- "a/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/\347\254\254\345\233\233\347\253\240_\347\273\217\345\205\270\347\275\221\347\273\234.md"
+++ "b/ch04_\347\273\217\345\205\270\347\275\221\347\273\234/\347\254\254\345\233\233\347\253\240_\347\273\217\345\205\270\347\275\221\347\273\234.md"
@@ -1,239 +1,140 @@
[TOC]
-# 第四章 经典网络
-## 4.1 LeNet5
+# 第四章 经典网络解读
+## 4.1 LeNet-5
-一种典型的用来识别数字的卷积网络是LeNet-5。
-### 4.1.1 模型结构
+### 4.1.1 模型介绍
-
+ LeNet-5是由$LeCun$ 提出的一种用于识别手写数字和机器印刷字符的卷积神经网络(Convolutional Neural Network,CNN)$^{[1]}$,其命名来源于作者$LeCun$的名字,5则是其研究成果的代号,在LeNet-5之前还有LeNet-4和LeNet-1鲜为人知。LeNet-5阐述了图像中像素特征之间的相关性能够由参数共享的卷积操作所提取,同时使用卷积、下采样(池化)和非线性映射这样的组合结构,是当前流行的大多数深度图像识别网络的基础。
### 4.1.2 模型结构
-LeNet-5共有7层(不包含输入层),每层都包含可训练参数;每个层有多个Feature Map,每个FeatureMap通过一种卷积滤波器提取输入的一种特征,然后每个FeatureMap有多个神经元。
-
-- C1层是一个卷积层
- 输入图片:32 \* 32
- 卷积核大小:5 \* 5
- 卷积核种类:6
- 输出featuremap大小:28 \* 28 (32-5+1)
- 神经元数量:28 \* 28 \* 6
- 可训练参数:(5 \* 5+1) \* 6(每个滤波器5 \* 5=25个unit参数和一个bias参数,一共6个滤波器)
- 连接数:(5 \* 5+1) \* 6 \* 28 \* 28
-
-- S2层是一个下采样层
- 输入:28 \* 28
- 采样区域:2 \* 2
- 采样方式:4个输入相加,乘以一个可训练参数,再加上一个可训练偏置。结果通过sigmoid
- 采样种类:6
- 输出featureMap大小:14 \* 14(28/2)
- 神经元数量:14 \* 14 \* 6
- 可训练参数:2 \* 6(和的权+偏置)
- 连接数:(2 \* 2+1) \* 6 \* 14 \* 14
- S2中每个特征图的大小是C1中特征图大小的1/4
-
-- C3层也是一个卷积层
- 输入:S2中所有6个或者几个特征map组合
- 卷积核大小:5 \* 5
- 卷积核种类:16
- 输出featureMap大小:10 \* 10
- C3中的每个特征map是连接到S2中的所有6个或者几个特征map的,表示本层的特征map是上一层提取到的特征map的不同组合
- 存在的一个方式是:C3的前6个特征图以S2中3个相邻的特征图子集为输入。接下来6个特征图以S2中4个相邻特征图子集为输入。然后的3个以不相邻的4个特征图子集为输入。最后一个将S2中所有特征图为输入。 则:可训练参数:6 \* (3 \* 25+1)+6 \* (4 \* 25+1)+3 \* (4 \* 25+1)+(25 \* 6+1)=1516
- 连接数:10 \* 10 \* 1516=151600
-
-- S4层是一个下采样层
- 输入:10 \* 10
- 采样区域:2 \* 2
- 采样方式:4个输入相加,乘以一个可训练参数,再加上一个可训练偏置。结果通过sigmoid
- 采样种类:16
- 输出featureMap大小:5 \* 5(10/2)
- 神经元数量:5 \* 5 \* 16=400
- 可训练参数:2 \* 16=32(和的权+偏置)
- 连接数:16 \* (2 \* 2+1) \* 5 \* 5=2000
- S4中每个特征图的大小是C3中特征图大小的1/4
-
-- C5层是一个卷积层
- 输入:S4层的全部16个单元特征map(与s4全相连)
- 卷积核大小:5 \* 5
- 卷积核种类:120
- 输出featureMap大小:1 \* 1(5-5+1)
- 可训练参数/连接:120 \* (16 \* 5 \* 5+1)=48120
-
-- F6层全连接层
- 输入:c5 120维向量
- 计算方式:计算输入向量和权重向量之间的点积,再加上一个偏置,结果通过sigmoid函数
- 可训练参数:84 \* (120+1)=10164
-### 4.1.3 模型特性
-- 卷积网络使用一个3层的序列:卷积、池化、非线性——这可能是自这篇论文以来面向图像的深度学习的关键特性!
-- 使用卷积提取空间特征
-- 使用映射的空间均值进行降采样
-- tanh或sigmoids非线性
-- 多层神经网络(MLP)作为最终的分类器
-- 层间的稀疏连接矩阵以避免巨大的计算开销
-
-## 4.2 AlexNet
-
-### 4.2.1 模型介绍
-
- AlexNet在2012年ILSVRC竞赛中赢得了第一名,其Top5错误率为15.3%。AlexNet模型证明了CNN在复杂模型下的有效性,并且在可接受时间范围内,部署GPU得到了有效结果。
-
-### 4.2.2 模型结构
-
-
-
-### 4.2.3 模型解读
-
-AlexNet共8层,前五层为卷积层,后三层为全连接层。
-
-1. **conv1阶段**:
-
-
-
-
-
-- 输入图片:227 \* 227 \* 3
-- 卷积核大小:11* 11 *3
-- 卷积核数量:96
-- 滤波器stride:4
-
-- 输出featuremap大小:(227-11)/4+1=55 (227个像素减去11,然后除以4,生成54个像素,再加上被减去的11也对应生成一个像素)
-
-- 输出featuremap大小:55 \* 55
-
-- 共有96个卷积核,会生成55 \* 55 \* 96个卷积后的像素层。96个卷积核分成2组,每组48个卷积核。对应生成2组55 \* 55 \* 48的卷积后的像素层数据。
-
-- 这些像素层经过relu1单元的处理,生成激活像素层,尺寸仍为2组55 \* 55 \* 48的像素层数据。
-
-- 这些像素层经过pool运算的处理,池化运算尺度为3 \* 3,运算的步长为2,则池化后图像的尺寸为(55-3)/2+1=27。 即池化后像素的规模为27 \* 27 \* 96;
-
-- 然后经过归一化处理,归一化运算的尺度为5 \* 5;第一卷积层运算结束后形成的像素层的规模为27 \* 27 \* 96。分别对应96个卷积核所运算形成。这96层像素层分为2组,每组48个像素层,每组在一个独立的GPU上进行运算。
-
-- 反向传播时,每个卷积核对应一个偏差值。即第一层的96个卷积核对应上层输入的96个偏差值。
-
-
-2. **conv2阶段**:
-
-
-
-
-
-- 输入图片:27 \* 27 \* 96(第一层输出)
-- 为便于后续处理,每幅像素层的左右两边和上下两边都要填充2个像素
-- 27 \* 27 \* 96的像素数据分成27 \* 27 \* 48的两组像素数据,两组数据分别再两个不同的GPU中进行运算。
-- 卷积核大小:5 \* 5 \* 48
-- 滤波器stride:1
-
-- 输出featuremap大小:卷积核在移动的过程中会生成(27-5+2 \* 2)/1+1=27个像素。(27个像素减去5,正好是22,在加上上下、左右各填充的2个像素,即生成26个像素,再加上被减去的5也对应生成一个像素),行和列的27 \* 27个像素形成对原始图像卷积之后的像素层。共有256个5 \* 5 \* 48卷积核;这256个卷积核分成两组,每组针对一个GPU中的27 \* 27 \* 48的像素进行卷积运算。会生成两组27 \* 27 \* 128个卷积后的像素层。
-
-- 这些像素层经过relu2单元的处理,生成激活像素层,尺寸仍为两组27 \* 27 \* 128的像素层。
-
-- 这些像素层经过pool运算(池化运算)的处理,池化运算的尺度为3 \* 3,运算的步长为2,则池化后图像的尺寸为(57-3)/2+1=13。 即池化后像素的规模为2组13 \* 13 \* 128的像素层;
-
-- 然后经过归一化处理,归一化运算的尺度为5 \* 5;
-
-- 第二卷积层运算结束后形成的像素层的规模为2组13 \* 13 \* 128的像素层。分别对应2组128个卷积核所运算形成。每组在一个GPU上进行运算。即共256个卷积核,共2个GPU进行运算。
-
-- 反向传播时,每个卷积核对应一个偏差值。即第一层的96个卷积核对应上层输入的256个偏差值。
-
-
-3. **conv3阶段**:
-
-
-
-- 第三层输入数据为第二层输出的2组13 \* 13 \* 128的像素层;
-- 为便于后续处理,每幅像素层的左右两边和上下两边都要填充1个像素;
-- 2组像素层数据都被送至2个不同的GPU中进行运算。每个GPU中都有192个卷积核,每个卷积核的尺寸是3 \* 3 \* 256。因此,每个GPU中的卷积核都能对2组13 \* 13 \* 128的像素层的所有数据进行卷积运算。
-- 移动的步长是1个像素。
-- 运算后的卷积核的尺寸为(13-3+1 \* 2)/1+1=13(13个像素减去3,正好是10,在加上上下、左右各填充的1个像素,即生成12个像素,再加上被减去的3也对应生成一个像素),每个GPU中共13 \* 13 \* 192个卷积核。2个GPU中共13 \* 13 \* 384个卷积后的像素层。这些像素层经过relu3单元的处理,生成激活像素层,尺寸仍为2组13 \* 13 \* 192像素层,共13 \* 13 \* 384个像素层。
+
+ 图4.1 LeNet-5网络结构图
-4. **conv4阶段DFD**:
-
-
-
-
-
-- 第四层输入数据为第三层输出的2组13 \* 13 \* 192的像素层;
-
-- 为便于后续处理,每幅像素层的左右两边和上下两边都要填充1个像素;
-
-- 2组像素层数据都被送至2个不同的GPU中进行运算。每个GPU中都有192个卷积核,每个卷积核的尺寸是3 \* 3 \* 192。因此,每个GPU中的卷积核能对1组13 \* 13 \* 192的像素层的数据进行卷积运算。
-
-- 移动的步长是1个像素。
-
-- 运算后的卷积核的尺寸为(13-3+1 \* 2)/1+1=13(13个像素减去3,正好是10,在加上上下、左右各填充的1个像素,即生成12个像素,再加上被减去的3也对应生成一个像素),每个GPU中共13 \* 13 \* 192个卷积核。2个GPU中共13 \* 13 \* 384个卷积后的像素层。
-
-- 这些像素层经过relu4单元的处理,生成激活像素层,尺寸仍为2组13 \* 13 \* 192像素层,共13 \* 13 \* 384个像素层。
+ 如图4.1所示,LeNet-5一共包含7层(输入层不作为网络结构),分别由2个卷积层、2个下采样层和3个连接层组成,网络的参数配置如表4.1所示,其中下采样层和全连接层的核尺寸分别代表采样范围和连接矩阵的尺寸(如卷积核尺寸中的$“5\times5\times1/1,6”$表示核大小为$5\times5\times1$、步长为$1$且核个数为6的卷积核)。
+ 表4.1 LeNet-5网络参数配置
- 5. **conv5阶段**:
+| 网络层 | 输入尺寸 | 核尺寸 | 输出尺寸 | 可训练参数量 |
+| :-------------: | :------------------: | :----------------------: | :------------------: | :-----------------------------: |
+| 卷积层$C_1$ | $32\times32\times1$ | $5\times5\times1/1,6$ | $28\times28\times6$ | $(5\times5\times1+1)\times6$ |
+| 下采样层$S_2$ | $28\times28\times6$ | $2\times2/2$ | $14\times14\times6$ | $(1+1)\times6$ $^*$ |
+| 卷积层$C_3$ | $14\times14\times6$ | $5\times5\times6/1,16$ | $10\times10\times16$ | $1516^*$ |
+| 下采样层$S_4$ | $10\times10\times16$ | $2\times2/2$ | $5\times5\times16$ | $(1+1)\times16$ |
+| 卷积层$C_5$$^*$ | $5\times5\times16$ | $5\times5\times16/1,120$ | $1\times1\times120$ | $(5\times5\times16+1)\times120$ |
+| 全连接层$F_6$ | $1\times1\times120$ | $120\times84$ | $1\times1\times84$ | $(120+1)\times84$ |
+| 输出层 | $1\times1\times84$ | $84\times10$ | $1\times1\times10$ | $(84+1)\times10$ |
- 
+> $^*$ 在LeNet中,下采样操作和池化操作类似,但是在得到采样结果后会乘以一个系数和加上一个偏置项,所以下采样的参数个数是$(1+1)\times6$而不是零。
+>
+> $^*$ $C_3$卷积层可训练参数并未直接连接$S_2$中所有的特征图(Feature Map),而是采用如图4.2所示的采样特征方式进行连接(稀疏连接),生成的16个通道特征图中分别按照相邻3个特征图、相邻4个特征图、非相邻4个特征图和全部6个特征图进行映射,得到的参数个数计算公式为$6\times(25\times3+1)+6\times(25\times4+1)+3\times(25\times4+1)+1\times(25\times6+1)=1516$,在原论文中解释了使用这种采样方式原因包含两点:限制了连接数不至于过大(当年的计算能力比较弱);强制限定不同特征图的组合可以使映射得到的特征图学习到不同的特征模式。
-
+
-- 第五层输入数据为第四层输出的2组13 \* 13 \* 192的像素层;
-- 为便于后续处理,每幅像素层的左右两边和上下两边都要填充1个像素;
-- 2组像素层数据都被送至2个不同的GPU中进行运算。每个GPU中都有128个卷积核,每个卷积核的尺寸是3 \* 3 \* 192。因此,每个GPU中的卷积核能对1组13 \* 13 \* 192的像素层的数据进行卷积运算。
-- 移动的步长是1个像素。
-- 因此,运算后的卷积核的尺寸为(13-3+1 \* 2)/1+1=13(13个像素减去3,正好是10,在加上上下、左右各填充的1个像素,即生成12个像素,再加上被减去的3也对应生成一个像素),每个GPU中共13 \* 13 \* 128个卷积核。2个GPU中共13 \* 13 \* 256个卷积后的像素层。
-- 这些像素层经过relu5单元的处理,生成激活像素层,尺寸仍为2组13 \* 13 \* 128像素层,共13 \* 13 \* 256个像素层。
-- 2组13 \* 13 \* 128像素层分别在2个不同GPU中进行池化(pool)运算处理。池化运算的尺度为3 \* 3,运算的步长为2,则池化后图像的尺寸为(13-3)/2+1=6。 即池化后像素的规模为两组6 \* 6 \* 128的像素层数据,共6 \* 6 \* 256规模的像素层数据。
+ 图4.2 $S_2$与$C_3$之间的特征图稀疏连接
+> $^*$ $C_5$卷积层在图4.1中显示为全连接层,原论文中解释这里实际采用的是卷积操作,只是刚好在$5\times5$卷积后尺寸被压缩为$1\times1$,输出结果看起来和全连接很相似。
+### 4.1.3 模型特性
+- 卷积网络使用一个3层的序列组合:卷积、下采样(池化)、非线性映射(LeNet-5最重要的特性,奠定了目前深层卷积网络的基础)
+- 使用卷积提取空间特征
+- 使用映射的空间均值进行下采样
+- 使用$tanh$或$sigmoid$进行非线性映射
+- 多层神经网络(MLP)作为最终的分类器
+- 层间的稀疏连接矩阵以避免巨大的计算开销
+## 4.2 AlexNet
-6. **fc6阶段**:
+### 4.2.1 模型介绍
-
+ AlexNet是由$Alex$ $Krizhevsky $提出的首个应用于图像分类的深层卷积神经网络,该网络在2012年ILSVRC(ImageNet Large Scale Visual Recognition Competition)图像分类竞赛中以15.3%的top-5测试错误率赢得第一名$^{[2]}$。AlexNet使用GPU代替CPU进行运算,使得在可接受的时间范围内模型结构能够更加复杂,它的出现证明了深层卷积神经网络在复杂模型下的有效性,使CNN在计算机视觉中流行开来,直接或间接地引发了深度学习的热潮。
-
+### 4.2.2 模型结构
-- 第六层输入数据的尺寸是6 \* 6 \* 256
-- 采用6 \* 6 \* 256尺寸的滤波器对第六层的输入数据进行卷积运算
-- 共有4096个6 \* 6 \* 256尺寸的滤波器对输入数据进行卷积运算,通过4096个神经元输出运算结果;
-- 这4096个运算结果通过relu激活函数生成4096个值;
-- 通过drop运算后输出4096个本层的输出结果值。
-- 由于第六层的运算过程中,采用的滤波器的尺寸(6 \* 6 \* 256)与待处理的feature map的尺寸(6 \* 6 \* 256)相同,即滤波器中的每个系数只与feature map中的一个像素值相乘;而其它卷积层中,每个滤波器的系数都会与多个feature map中像素值相乘;因此,将第六层称为全连接层。
-- 第五层输出的6 \* 6 \* 256规模的像素层数据与第六层的4096个神经元进行全连接,然后经由relu6进行处理后生成4096个数据,再经过dropout6处理后输出4096个数据。
+
+ 图4.3 AlexNet网络结构图
+ 如图4.3所示,除去下采样(池化层)和局部响应规范化操作(Local Responsible Normalization, LRN),AlexNet一共包含8层,前5层由卷积层组成,而剩下的3层为全连接层。网络结构分为上下两层,分别对应两个GPU的操作过程,除了中间某些层($C_3$卷积层和$F_{6-8}$全连接层会有GPU间的交互),其他层两个GPU分别计算结 果。最后一层全连接层的输出作为$softmax$的输入,得到1000个图像分类标签对应的概率值。除去GPU并行结构的设计,AlexNet网络结构与LeNet十分相似,其网络的参数配置如表4.2所示。
-7. **fc7阶段**:
+ 表4.2 AlexNet网络参数配置
-
+| 网络层 | 输入尺寸 | 核尺寸 | 输出尺寸 | 可训练参数量 |
+| :-------------------: | :----------------------------------: | :--------------------------------------: | :----------------------------------: | :-------------------------------------: |
+| 卷积层$C_1$ $^*$ | $224\times224\times3$ | $11\times11\times3/4,48(\times2_{GPU})$ | $55\times55\times48(\times2_{GPU})$ | $(11\times11\times3+1)\times48\times2$ |
+| 下采样层$S_{max}$$^*$ | $55\times55\times48(\times2_{GPU})$ | $3\times3/2(\times2_{GPU})$ | $27\times27\times48(\times2_{GPU})$ | 0 |
+| 卷积层$C_2$ | $27\times27\times48(\times2_{GPU})$ | $5\times5\times48/1,128(\times2_{GPU})$ | $27\times27\times128(\times2_{GPU})$ | $(5\times5\times48+1)\times128\times2$ |
+| 下采样层$S_{max}$ | $27\times27\times128(\times2_{GPU})$ | $3\times3/2(\times2_{GPU})$ | $13\times13\times128(\times2_{GPU})$ | 0 |
+| 卷积层$C_3$ $^*$ | $13\times13\times128\times2_{GPU}$ | $3\times3\times256/1,192(\times2_{GPU})$ | $13\times13\times192(\times2_{GPU})$ | $(3\times3\times256+1)\times192\times2$ |
+| 卷积层$C_4$ | $13\times13\times192(\times2_{GPU})$ | $3\times3\times192/1,192(\times2_{GPU})$ | $13\times13\times192(\times2_{GPU})$ | $(3\times3\times192+1)\times192\times2$ |
+| 卷积层$C_5$ | $13\times13\times192(\times2_{GPU})$ | $3\times3\times192/1,128(\times2_{GPU})$ | $13\times13\times128(\times2_{GPU})$ | $(3\times3\times192+1)\times128\times2$ |
+| 下采样层$S_{max}$ | $13\times13\times128(\times2_{GPU})$ | $3\times3/2(\times2_{GPU})$ | $6\times6\times128(\times2_{GPU})$ | 0 |
+| 全连接层$F_6$ $^*$ | $6\times6\times128\times2_{GPU}$ | $9216\times2048(\times2_{GPU})$ | $1\times1\times2048(\times2_{GPU})$ | $(9216+1)\times2048\times2$ |
+| 全连接层$F_7$ | $1\times1\times2048\times2_{GPU}$ | $4096\times2048(\times2_{GPU})$ | $1\times1\times2048(\times2_{GPU})$ | $(4096+1)\times2048\times2$ |
+| 全连接层$F_8$ | $1\times1\times2048\times2_{GPU}$ | $4096\times1000$ | $1\times1\times1000$ | $(4096+1)\times1000\times2$ |
+>卷积层$C_1$输入为$224\times224\times3$的图片数据,分别在两个GPU中经过核为$11\times11\times3$、步长(stride)为4的卷积卷积后,分别得到两条独立的$55\times55\times48$的输出数据。
+>
+>下采样层$S_{max}$实际上是嵌套在卷积中的最大池化操作,但是为了区分没有采用最大池化的卷积层单独列出来。在$C_{1-2}$卷积层中的池化操作之后(ReLU激活操作之前),还有一个LRN操作,用作对相邻特征点的归一化处理。
+>
+>卷积层$C_3$ 的输入与其他卷积层不同,$13\times13\times192\times2_{GPU}$表示汇聚了上一层网络在两个GPU上的输出结果作为输入,所以在进行卷积操作时通道上的卷积核维度为384。
+>
+>全连接层$F_{6-8}$中输入数据尺寸也和$C_3$类似,都是融合了两个GPU流向的输出结果作为输入。
-- 第六层输出的4096个数据与第七层的4096个神经元进行全连接
-- 然后经由relu7进行处理后生成4096个数据,再经过dropout7处理后输出4096个数据。
+### 4.2.3 模型特性
+- 所有卷积层都使用ReLU作为非线性映射函数,使模型收敛速度更快
+- 在多个GPU上进行模型的训练,不但可以提高模型的训练速度,还能提升数据的使用规模
+- 使用LRN对局部的特征进行归一化,结果作为ReLU激活函数的输入能有效降低错误率
+- 重叠最大池化(overlapping max pooling),即池化范围z与步长s存在关系$z>s$(如$S_{max}$中核尺度为$3\times3/2$),避免平均池化(average pooling)的平均效应
+- 使用随机丢弃技术(dropout)选择性地忽略训练中的单个神经元,避免模型的过拟合
-8. **fc8阶段**:
+## 4.3 ZFNet
+### 4.3.1 模型介绍
-
+ ZFNet是由$Matthew$ $D. Zeiler$和$Rob$ $Fergus$在AlexNet基础上提出的大型卷积网络,在2013年ILSVRC图像分类竞赛中以11.19%的错误率获得冠军(实际上原ZFNet所在的队伍并不是真正的冠军,原ZFNet以13.51%错误率排在第8,真正的冠军是$Clarifai$这个队伍,而$Clarifai$这个队伍所对应的一家初创公司的CEO又是$Zeiler$,而且$Clarifai$对ZFNet的改动比较小,所以通常认为是ZFNet获得了冠军)$^{[3-4]}$。ZFNet实际上是微调(fine-tuning)了的AlexNet,并通过反卷积(Deconvolution)的方式可视化各层的输出特征图,进一步解释了卷积操作在大型网络中效果显著的原因。
-
+### 4.3.2 模型结构
-- 第七层输出的4096个数据与第八层的1000个神经元进行全连接,经过训练后输出被训练的数值。
+
+
-### 4.2.4 模型特性
-- 使用ReLU作为非线性
+ 图4.4 ZFNet网络结构图(原始结构图与AlexNet风格结构图)
-- 使用dropout技术选择性地忽略训练中的单个神经元,避免模型的过拟合
+ 如图4.4所示,ZFNet与AlexNet类似,都是由8层网络组成的卷积神经网络,其中包含5层卷积层和3层全连接层。两个网络结构最大的不同在于,ZFNet第一层卷积采用了$7\times7\times3/2$的卷积核替代了AlexNet中第一层卷积核$11\times11\times3/4$的卷积核。图4.5中ZFNet相比于AlexNet在第一层输出的特征图中包含更多中间频率的信息,而AlexNet第一层输出的特征图大多是低频或高频的信息,对中间频率特征的缺失导致后续网络层次如图4.5(c)能够学习到的特征不够细致,而导致这个问题的根本原因在于AlexNet在第一层中采用的卷积核和步长过大。
-- 重叠最大池化(overlapping max pooling),避免平均池化(average pooling)的平均效应
+
-- 使用NVIDIA GTX 580 GPU减少训练时间
+
-- 当时,GPU比CPU提供了更多的核心,可以将训练速度提升10倍,从而允许使用更大的数据集和更大的图像。
+ 图4.5 (a)ZFNet第一层输出的特征图(b)AlexNet第一层输出的特征图(c)AlexNet第二层输出的特征图(d)ZFNet第二层输出的特征图
+ 表4.3 ZFNet网络参数配置
+| 网络层 | 输入尺寸 | 核尺寸 | 输出尺寸 | 可训练参数量 |
+| :-------------------: | :----------------------------------: | :--------------------------------------: | :----------------------------------: | :-------------------------------------: |
+| 卷积层$C_1$ $^*$ | $224\times224\times3$ | $7\times7\times3/2,96$ | $110\times110\times96$ | $(7\times7\times3+1)\times96$ |
+| 下采样层$S_{max}$ | $110\times110\times96$ | $3\times3/2$ | $55\times55\times96$ | 0 |
+| 卷积层$C_2$ $^*$ | $55\times55\times96$ | $5\times5\times96/2,256$ | $26\times26\times256$ | $(5\times5\times96+1)\times256$ |
+| 下采样层$S_{max}$ | $26\times26\times256$ | $3\times3/2$ | $13\times13\times256$ | 0 |
+| 卷积层$C_3$ | $13\times13\times256$ | $3\times3\times256/1,384$ | $13\times13\times384$ | $(3\times3\times256+1)\times384$ |
+| 卷积层$C_4$ | $13\times13\times384$ | $3\times3\times384/1,384$ | $13\times13\times384$ | $(3\times3\times384+1)\times384$ |
+| 卷积层$C_5$ | $13\times13\times384$ | $3\times3\times384/1,256$ | $13\times13\times256$ | $(3\times3\times384+1)\times256$ |
+| 下采样层$S_{max}$ | $13\times13\times256$ | $3\times3/2$ | $6\times6\times256$ | 0 |
+| 全连接层$F_6$ | $6\times6\times256$ | $9216\times4096$ | $1\times1\times4096$ | $(9216+1)\times4096$ |
+| 全连接层$F_7$ | $1\times1\times4096$ | $4096\times4096$ | $1\times1\times4096$ | $(4096+1)\times4096$ |
+| 全连接层$F_8$ | $1\times1\times4096$ | $4096\times1000$ | $1\times1\times1000$ | $(4096+1)\times1000$ |
+> 卷积层$C_1$与AlexNet中的$C_1$有所不同,采用$7\times7\times3/2$的卷积核代替$11\times11\times3/4$,使第一层卷积输出的结果可以包含更多的中频率特征,对后续网络层中多样化的特征组合提供更多选择,有利于捕捉更细致的特征。
+>
+> 卷积层$C_2$采用了步长2的卷积核,区别于AlexNet中$C_2$的卷积核步长,所以输出的维度有所差异。
+### 4.3.3 模型特性
-## 4.3 可视化ZFNet-转置卷积
-### 4.3.1 基本的思想及其过程
+ ZFNet与AlexNet在结构上几乎相同,此部分虽属于模型特性,但准确地说应该是ZFNet原论文中可视化技术的贡献。
- 可视化技术揭露了激发模型中每层单独的特征图。
- 可视化技术允许观察在训练阶段特征的演变过程且诊断出模型的潜在问题。
@@ -242,429 +143,178 @@ AlexNet共8层,前五层为卷积层,后三层为全连接层。
- 可视化技术提供了一个非参数的不变性来展示来自训练集的哪一块激活哪个特征图,不仅需要裁剪输入图片,而且自上而下的投影来揭露来自每块的结构激活一个特征图。
- 可视化技术依赖于解卷积操作,即卷积操作的逆过程,将特征映射到像素上。
-### 4.3.2 卷积与转置卷积
-
-
-下图为卷积过程
-
-
-  -
-  -
-
-下图为转置卷积过程
+## 4.4 Network in Network
-
-
-
-
-下图为转置卷积过程
+## 4.4 Network in Network
-
-  -
-  -
-
+### 4.4.1 模型介绍
+ Network In Network (NIN)是由$Min Lin$等人提出,在CIFAR-10和CIFAR-100分类任务中达到当时的最好水平,因其网络结构是由三个多层感知机堆叠而被成为NIN$^{[5]}$。NIN以一种全新的角度审视了卷积神经网络中的卷积核设计,通过引入子网络结构代替纯卷积中的线性映射部分,这种形式的网络结构激发了更复杂的卷积神经网络的结构设计,其中下一节中介绍的GoogLeNet的Inception结构就是来源于这个思想。
-下面首先介绍转置卷积中涉及到的几种操作:
+### 4.4.2 模型结构
-**反池化操作**:池化操作是非可逆的,但是我们可以用一组转换变量switch在每个池化区域中通过记录最大值的位置来获得一个近似值。在转置卷积网络中,反池化操作使用这些转换来放置上述最大值的位置,保存激活的位置,其余位置都置0。
+
+ 图 4.6 NIN网络结构图
-**激活函数**:卷积网中使用非线性的ReLU来确保所有输出值总是正值。在反卷积网中也利用了ReLU。
+ NIN由三层的多层感知卷积层(MLPConv Layer)构成,每一层多层感知卷积层内部由若干层的局部全连接层和非线性激活函数组成,代替了传统卷积层中采用的线性卷积核。在网络推理(inference)时,这个多层感知器会对输入特征图的局部特征进行划窗计算,并且每个划窗的局部特征图对应的乘积的权重是共享的,这两点是和传统卷积操作完全一致的,最大的不同在于多层感知器对局部特征进行了非线性的映射,而传统卷积的方式是线性的。NIN的网络参数配置表4.4所示(原论文并未给出网络参数,表中参数为编者结合网络结构图和CIFAR-100数据集以$3\times3$卷积为例给出)。
-**转置卷积**:为了实现转置卷积,转置卷积网络使用相同卷积核的转置作为新的卷积核进行计算。
+ 表4.4 NIN网络参数配置(结合原论文NIN结构和CIFAR-100数据给出)
-
+| 网络层 | 输入尺寸 | 核尺寸 | 输出尺寸 | 参数个数 |
+|:------:|:-------:|:------:|:--------:|:-------:|
+| 局部全连接层$L_{11}$ $^*$ | $32\times32\times3$ | $(3\times3)\times16/1$ | $30\times30\times16$ | $(3\times3\times3+1)\times16$ |
+| 全连接层$L_{12}$ $^*$ | $30\times30\times16$ | $16\times16$ | $30\times30\times16$ | $((16+1)\times16)$ |
+| 局部全连接层$L_{21}$ | $30\times30\times16$ | $(3\times3)\times64/1$ | $28\times28\times64$ | $(3\times3\times16+1)\times64$ |
+| 全连接层$L_{22}$ | $28\times28\times64$ | $64\times64$ | $28\times28\times64$ | $((64+1)\times64)$ |
+| 局部全连接层$L_{31}$ | $28\times28\times64$ | $(3\times3)\times100/1$ | $26\times26\times100$ | $(3\times3\times64+1)\times100$ |
+| 全连接层$L_{32}$ | $26\times26\times100$ | $100\times100$ | $26\times26\times100$ | $((100+1)\times100)$ |
+| 全局平均采样$GAP$ $^*$ | $26\times26\times100$ | $26\times26\times100/1$ | $1\times1\times100$ | $0$ |
+> 局部全连接层$L_{11}$实际上是对原始输入图像进行划窗式的全连接操作,因此划窗得到的输出特征尺寸为$30\times30$($\frac{32-3_k+1}{1_{stride}}=30$)
+> 全连接层$L_{12}$是紧跟$L_{11}$后的全连接操作,输入的特征是划窗后经过激活的局部响应特征,因此仅需连接$L_{11}$和$L_{12}$的节点即可,而每个局部全连接层和紧接的全连接层构成代替卷积操作的多层感知卷积层(MLPConv)。
+> 全局平均采样层或全局平均池化层$GAP$(Global Average Pooling)将$L_{32}$输出的每一个特征图进行全局的平均池化操作,直接得到最后的类别数,可以有效地减少参数量。
-
- 上图左半部分是一个转置卷积层,右半部分为一个卷积层。反卷积层将会重建一个来自下一层的卷积特征近似版本。图中使用switch来记录在卷积网中进行最大池化操作时每个池化区域的局部最大值的位置,经过非池化操作之后,原来的非最大值的位置都置为0。
+### 4.4.3 模型特点
-### 4.3.3 卷积可视化
-
- 预处理:网络对输入图片进行预处理,裁剪图片中间的256x256区域,并减去整个图像每个像素的均值,然后用10个不同的对256x256图像进行224x224的裁剪(中间区域加上四个角落,以及他们的水平翻转图像),对以128个图片分的块进行随机梯度下降法来更新参数。起始学习率为0.01,动量为0.9,当验证集误差不再变化时时,手动调整学习率。在全连接网络中使用概率为0.5的dropout,并且所有权值都初始化为0.01,偏置设为0。
+- 使用多层感知机结构来代替卷积的滤波操作,不但有效减少卷积核数过多而导致的参数量暴涨问题,还能通过引入非线性的映射来提高模型对特征的抽象能力。
+- 使用全局平均池化来代替最后一个全连接层,能够有效地减少参数量(没有可训练参数),同时池化用到了整个特征图的信息,对空间信息的转换更加鲁棒,最后得到的输出结果可直接作为对应类别的置信度。
-
- 特征可视化:当输入存在一定的变化时,网络的输出结果保持不变。下图即在一个已经训练好的网络中可视化后的图。在可视化结果的右边是对应的输入图片,与重构特征相比,输入图片之间的差异性很大,而重构特征只包含那些具有判别能力的纹理特征。
+## 4.5 VGGNet
-
+### 4.5.1 模型介绍
-
- 由上图可以看到第二层应对角落和其他边缘或者颜色的结合;第三层有更加复杂的不变性,捕捉到了相似的纹理;第四层显示了特定类间显著的差异性;第五层显示了有显著构成变化的整个物体。
+ VGGNet是由牛津大学视觉几何小组(Visual Geometry Group, VGG)提出的一种深层卷积网络结构,他们以7.32%的错误率赢得了2014年ILSVRC分类任务的亚军(冠军由GoogLeNet以6.65%的错误率夺得)和25.32%的错误率夺得定位任务(Localization)的第一名(GoogLeNet错误率为26.44%)$^{[5]}$,网络名称VGGNet取自该小组名缩写。VGGNet是首批把图像分类的错误率降低到10%以内模型,同时该网络所采用的$3\times3$卷积核的思想是后来许多模型的基础,该模型发表在2015年国际学习表征会议(International Conference On Learning Representations, ICLR)后至今被引用的次数已经超过1万4千余次。
-
- 训练时的特征演变过程:当输入图片中的最强刺激源发生变化时,对应的输出特征轮廓发生剧烈变化。经过一定次数的迭代以后,底层特征趋于稳定,但更高层的特征则需要更多的迭代次数才能收敛,这表明:只有所有层都收敛时,这个分类模型才是有效的。
+### 4.5.2 模型结构
-
+
-
- **特征不变性:** 一般来说,就深度模型来说,只要深度超过七层,微小的变化对于模型的第一层都有比较大的影响,但对于较深层几乎没有没有影响。对于图像的平移、尺度、旋转的变化来说,网络的输出对于平移和尺度变化都是稳定的,但却不具有旋转不变性,除非目标图像时旋转对称的。下图为分别对平移,尺度,旋转做的分析图。
+ 图 4.7 VGG16网络结构图
-
+ 在原论文中的VGGNet包含了6个版本的演进,分别对应VGG11、VGG11-LRN、VGG13、VGG16-1、VGG16-3和VGG19,不同的后缀数值表示不同的网络层数(VGG11-LRN表示在第一层中采用了LRN的VGG11,VGG16-1表示后三组卷积块中最后一层卷积采用卷积核尺寸为$1\times1$,相应的VGG16-3表示卷积核尺寸为$3\times3$),本节介绍的VGG16为VGG16-3。图4.7中的VGG16体现了VGGNet的核心思路,使用$3\times3$的卷积组合代替大尺寸的卷积(2个$3\times3卷积即可与$$5\times5$卷积拥有相同的感受视野),网络参数设置如表4.5所示。
-
- 上图按行顺序分别为对5类图像进行不同程度的垂直方向上的平移、尺度变换、旋转对输出结果影响的分析图。按列顺序分别为原始变换图像,第一层中原始图片和变换后的图片的欧氏距离,第7层中原始图片和变换后的图片的欧氏距离,变换后图片被正确分类的概率图。
+ 表4.5 VGG16网络参数配置
-
- 可视化不仅能够看到一个训练完的模型的内部操作,而且还能帮助选择好的网络结构。
+| 网络层 | 输入尺寸 | 核尺寸 | 输出尺寸 | 参数个数 |
+| :--------------------: | :-------------------: | :---------------------: | :--------------------: | :-----------------------------: |
+| 卷积层$C_{11}$ | $224\times224\times3$ | $3\times3\times64/1$ | $224\times224\times64$ | $(3\times3\times3+1)\times64$ |
+| 卷积层$C_{12}$ | $224\times224\times64$ | $3\times3\times64/1$ | $224\times224\times64$ | $(3\times3\times64+1)\times64$ |
+| 下采样层$S_{max1}$ | $224\times224\times64$ | $2\times2/2$ | $112\times112\times64$ | $0$ |
+| 卷积层$C_{21}$ | $112\times112\times64$ | $3\times3\times128/1$ | $112\times112\times128$ | $(3\times3\times64+1)\times128$ |
+| 卷积层$C_{22}$ | $112\times112\times128$ | $3\times3\times128/1$ | $112\times112\times128$ | $(3\times3\times128+1)\times128$ |
+| 下采样层$S_{max2}$ | $112\times112\times128$ | $2\times2/2$ | $56\times56\times128$ | $0$ |
+| 卷积层$C_{31}$ | $56\times56\times128$ | $3\times3\times256/1$ | $56\times56\times256$ | $(3\times3\times128+1)\times256$ |
+| 卷积层$C_{32}$ | $56\times56\times256$ | $3\times3\times256/1$ | $56\times56\times256$ | $(3\times3\times256+1)\times256$ |
+| 卷积层$C_{33}$ | $56\times56\times256$ | $3\times3\times256/1$ | $56\times56\times256$ | $(3\times3\times256+1)\times256$ |
+| 下采样层$S_{max3}$ | $56\times56\times256$ | $2\times2/2$ | $28\times28\times256$ | $0$ |
+| 卷积层$C_{41}$ | $28\times28\times256$ | $3\times3\times512/1$ | $28\times28\times512$ | $(3\times3\times256+1)\times512$ |
+| 卷积层$C_{42}$ | $28\times28\times512$ | $3\times3\times512/1$ | $28\times28\times512$ | $(3\times3\times512+1)\times512$ |
+| 卷积层$C_{43}$ | $28\times28\times512$ | $3\times3\times512/1$ | $28\times28\times512$ | $(3\times3\times512+1)\times512$ |
+| 下采样层$S_{max4}$ | $28\times28\times512$ | $2\times2/2$ | $14\times14\times512$ | $0$ |
+| 卷积层$C_{51}$ | $14\times14\times512$ | $3\times3\times512/1$ | $14\times14\times512$ | $(3\times3\times512+1)\times512$ |
+| 卷积层$C_{52}$ | $14\times14\times512$ | $3\times3\times512/1$ | $14\times14\times512$ | $(3\times3\times512+1)\times512$ |
+| 卷积层$C_{53}$ | $14\times14\times512$ | $3\times3\times512/1$ | $14\times14\times512$ | $(3\times3\times512+1)\times512$ |
+| 下采样层$S_{max5}$ | $14\times14\times512$ | $2\times2/2$ | $7\times7\times512$ | $0$ |
+| 全连接层$FC_{1}$ | $7\times7\times512$ | $(7\times7\times512)\times4096$ | $1\times4096$ | $(7\times7\times512+1)\times4096$ |
+| 全连接层$FC_{2}$ | $1\times4096$ | $4096\times4096$ | $1\times4096$ | $(4096+1)\times4096$ |
+| 全连接层$FC_{3}$ | $1\times4096$ | $4096\times1000$ | $1\times1000$ | $(4096+1)\times1000$ |
-### 4.3.4 ZFNet和AlexNet比较
+### 4.5.3 模型特性
-
- ZFNet的网络结构实际上与AlexNet没有什么很大的变化,差异表现在AlexNet用了两块GPU的稀疏连接结构,而ZFNet只用了一块GPU的稠密连接结构;同时,由于可视化可以用来选择好的网络结构,通过可视化发现AlexNet第一层中有大量的高频和低频信息的混合,却几乎没有覆盖到中间的频率信息;且第二层中由于第一层卷积用的步长为4太大了,导致了有非常多的混叠情况;因此改变了AlexNet的第一层即将滤波器的大小11x11变成7x7,并且将步长4变成了2,下图为AlexNet网络结构与ZFNet的比较。
-
-
-
+- 整个网络都使用了同样大小的卷积核尺寸$3\times3$和最大池化尺寸$2\times2$。
+- $1\times1$卷积的意义主要在于线性变换,而输入通道数和输出通道数不变,没有发生降维。
+- 两个$3\times3$的卷积层串联相当于1个$5\times5$的卷积层,感受野大小为$5\times5$。同样地,3个$3\times3$的卷积层串联的效果则相当于1个$7\times7$的卷积层。这样的连接方式使得网络参数量更小,而且多层的激活函数令网络对特征的学习能力更强。
+- VGGNet在训练时有一个小技巧,先训练浅层的的简单网络VGG11,再复用VGG11的权重来初始化VGG13,如此反复训练并初始化VGG19,能够使训练时收敛的速度更快。
+- 在训练过程中使用多尺度的变换对原始数据做数据增强,使得模型不易过拟合。
+## 4.6 GoogLeNet
+### 4.6.1 模型介绍
-## 4.4 VGGNet
-### 4.4.1 模型结构
+ GoogLeNet作为2014年ILSVRC在分类任务上的冠军,以6.65%的错误率力压VGGNet等模型,在分类的准确率上面相比过去两届冠军ZFNet和AlexNet都有很大的提升。从名字**GoogLe**Net可以知道这是来自谷歌工程师所设计的网络结构,而名字中Goog**LeNet**更是致敬了LeNet$^{[0]}$。GoogLeNet中最核心的部分是其内部子网络结构Inception,该结构灵感来源于NIN,至今已经经历了四次版本迭代(Inception$_{v1-4}$)。
-
+
+ 图 4.8 Inception性能比较图
-### 4.4.2 模型特点
+### 4.6.2 模型结构
-
-1. 整个网络都使用了同样大小的卷积核尺寸(3 \* 3)和最大池化尺寸(2 \* 2)
-2. 1 \* 1卷积的意义主要在于线性变换,而输入通道数和输出通道数不变,没有发生降维。
-3. 两个3 \* 3的卷积层串联相当于1个5 \* 5的卷积层,即一个像素会跟周围5 \* 5的像素产生关联,可以说感受野大小为5 \* 5。而3个3 \* 3的卷积层串联的效果则相当于1个7 \* 7的卷积层。除此之外,3个串联的3 \* 3的卷积层,拥有比1个7 \* 7的卷积层更少的参数量,只有后者的(3 \* 3 \* 3)/(7 \* 7)=55%。最重要的是,3个3 \* 3的卷积层拥有比1个7 \* 7的卷积层更多的非线性变换(前者可以使用三次ReLU激活函数,而后者只有一次),使得CNN对特征的学习能力更强。
-4. VGGNet在训练时有一个小技巧,先训练级别A的简单网络,再复用A网络的权重来初始化后面的几个复杂模型,这样训练收敛的速度更快。在预测时,VGG采用Multi-Scale的方法,将图像scale到一个尺寸Q,并将图片输入卷积网络计算。然后在最后一个卷积层使用滑窗的方式进行分类预测,将不同窗口的分类结果平均,再将不同尺寸Q的结果平均得到最后结果,这样可提高图片数据的利用率并提升预测准确率。在训练中,VGGNet还使用了Multi-Scale的方法做数据增强,将原始图像缩放到不同尺寸S,然后再随机裁切224*224的图片,这样能增加很多数据量,对于防止模型过拟合有很不错的效果。
-
-## 4.5 Network in Network
-### 4.5.1 模型结构
-
-
-
-### 4.5.2 模型创新点
-
-
-论文的创新点:
-
-1. 提出了抽象能力更高的Mlpconv层
-2. 提出了Global Average Pooling(全局平均池化)层
-
-- Mlpconv层
-
-
+### 4.4.1 模型介绍
+ Network In Network (NIN)是由$Min Lin$等人提出,在CIFAR-10和CIFAR-100分类任务中达到当时的最好水平,因其网络结构是由三个多层感知机堆叠而被成为NIN$^{[5]}$。NIN以一种全新的角度审视了卷积神经网络中的卷积核设计,通过引入子网络结构代替纯卷积中的线性映射部分,这种形式的网络结构激发了更复杂的卷积神经网络的结构设计,其中下一节中介绍的GoogLeNet的Inception结构就是来源于这个思想。
-下面首先介绍转置卷积中涉及到的几种操作:
+### 4.4.2 模型结构
-**反池化操作**:池化操作是非可逆的,但是我们可以用一组转换变量switch在每个池化区域中通过记录最大值的位置来获得一个近似值。在转置卷积网络中,反池化操作使用这些转换来放置上述最大值的位置,保存激活的位置,其余位置都置0。
+
+ 图 4.6 NIN网络结构图
-**激活函数**:卷积网中使用非线性的ReLU来确保所有输出值总是正值。在反卷积网中也利用了ReLU。
+ NIN由三层的多层感知卷积层(MLPConv Layer)构成,每一层多层感知卷积层内部由若干层的局部全连接层和非线性激活函数组成,代替了传统卷积层中采用的线性卷积核。在网络推理(inference)时,这个多层感知器会对输入特征图的局部特征进行划窗计算,并且每个划窗的局部特征图对应的乘积的权重是共享的,这两点是和传统卷积操作完全一致的,最大的不同在于多层感知器对局部特征进行了非线性的映射,而传统卷积的方式是线性的。NIN的网络参数配置表4.4所示(原论文并未给出网络参数,表中参数为编者结合网络结构图和CIFAR-100数据集以$3\times3$卷积为例给出)。
-**转置卷积**:为了实现转置卷积,转置卷积网络使用相同卷积核的转置作为新的卷积核进行计算。
+ 表4.4 NIN网络参数配置(结合原论文NIN结构和CIFAR-100数据给出)
-
+| 网络层 | 输入尺寸 | 核尺寸 | 输出尺寸 | 参数个数 |
+|:------:|:-------:|:------:|:--------:|:-------:|
+| 局部全连接层$L_{11}$ $^*$ | $32\times32\times3$ | $(3\times3)\times16/1$ | $30\times30\times16$ | $(3\times3\times3+1)\times16$ |
+| 全连接层$L_{12}$ $^*$ | $30\times30\times16$ | $16\times16$ | $30\times30\times16$ | $((16+1)\times16)$ |
+| 局部全连接层$L_{21}$ | $30\times30\times16$ | $(3\times3)\times64/1$ | $28\times28\times64$ | $(3\times3\times16+1)\times64$ |
+| 全连接层$L_{22}$ | $28\times28\times64$ | $64\times64$ | $28\times28\times64$ | $((64+1)\times64)$ |
+| 局部全连接层$L_{31}$ | $28\times28\times64$ | $(3\times3)\times100/1$ | $26\times26\times100$ | $(3\times3\times64+1)\times100$ |
+| 全连接层$L_{32}$ | $26\times26\times100$ | $100\times100$ | $26\times26\times100$ | $((100+1)\times100)$ |
+| 全局平均采样$GAP$ $^*$ | $26\times26\times100$ | $26\times26\times100/1$ | $1\times1\times100$ | $0$ |
+> 局部全连接层$L_{11}$实际上是对原始输入图像进行划窗式的全连接操作,因此划窗得到的输出特征尺寸为$30\times30$($\frac{32-3_k+1}{1_{stride}}=30$)
+> 全连接层$L_{12}$是紧跟$L_{11}$后的全连接操作,输入的特征是划窗后经过激活的局部响应特征,因此仅需连接$L_{11}$和$L_{12}$的节点即可,而每个局部全连接层和紧接的全连接层构成代替卷积操作的多层感知卷积层(MLPConv)。
+> 全局平均采样层或全局平均池化层$GAP$(Global Average Pooling)将$L_{32}$输出的每一个特征图进行全局的平均池化操作,直接得到最后的类别数,可以有效地减少参数量。
-
- 上图左半部分是一个转置卷积层,右半部分为一个卷积层。反卷积层将会重建一个来自下一层的卷积特征近似版本。图中使用switch来记录在卷积网中进行最大池化操作时每个池化区域的局部最大值的位置,经过非池化操作之后,原来的非最大值的位置都置为0。
+### 4.4.3 模型特点
-### 4.3.3 卷积可视化
-
- 预处理:网络对输入图片进行预处理,裁剪图片中间的256x256区域,并减去整个图像每个像素的均值,然后用10个不同的对256x256图像进行224x224的裁剪(中间区域加上四个角落,以及他们的水平翻转图像),对以128个图片分的块进行随机梯度下降法来更新参数。起始学习率为0.01,动量为0.9,当验证集误差不再变化时时,手动调整学习率。在全连接网络中使用概率为0.5的dropout,并且所有权值都初始化为0.01,偏置设为0。
+- 使用多层感知机结构来代替卷积的滤波操作,不但有效减少卷积核数过多而导致的参数量暴涨问题,还能通过引入非线性的映射来提高模型对特征的抽象能力。
+- 使用全局平均池化来代替最后一个全连接层,能够有效地减少参数量(没有可训练参数),同时池化用到了整个特征图的信息,对空间信息的转换更加鲁棒,最后得到的输出结果可直接作为对应类别的置信度。
-
- 特征可视化:当输入存在一定的变化时,网络的输出结果保持不变。下图即在一个已经训练好的网络中可视化后的图。在可视化结果的右边是对应的输入图片,与重构特征相比,输入图片之间的差异性很大,而重构特征只包含那些具有判别能力的纹理特征。
+## 4.5 VGGNet
-
+### 4.5.1 模型介绍
-
- 由上图可以看到第二层应对角落和其他边缘或者颜色的结合;第三层有更加复杂的不变性,捕捉到了相似的纹理;第四层显示了特定类间显著的差异性;第五层显示了有显著构成变化的整个物体。
+ VGGNet是由牛津大学视觉几何小组(Visual Geometry Group, VGG)提出的一种深层卷积网络结构,他们以7.32%的错误率赢得了2014年ILSVRC分类任务的亚军(冠军由GoogLeNet以6.65%的错误率夺得)和25.32%的错误率夺得定位任务(Localization)的第一名(GoogLeNet错误率为26.44%)$^{[5]}$,网络名称VGGNet取自该小组名缩写。VGGNet是首批把图像分类的错误率降低到10%以内模型,同时该网络所采用的$3\times3$卷积核的思想是后来许多模型的基础,该模型发表在2015年国际学习表征会议(International Conference On Learning Representations, ICLR)后至今被引用的次数已经超过1万4千余次。
-
- 训练时的特征演变过程:当输入图片中的最强刺激源发生变化时,对应的输出特征轮廓发生剧烈变化。经过一定次数的迭代以后,底层特征趋于稳定,但更高层的特征则需要更多的迭代次数才能收敛,这表明:只有所有层都收敛时,这个分类模型才是有效的。
+### 4.5.2 模型结构
-
+
-
- **特征不变性:** 一般来说,就深度模型来说,只要深度超过七层,微小的变化对于模型的第一层都有比较大的影响,但对于较深层几乎没有没有影响。对于图像的平移、尺度、旋转的变化来说,网络的输出对于平移和尺度变化都是稳定的,但却不具有旋转不变性,除非目标图像时旋转对称的。下图为分别对平移,尺度,旋转做的分析图。
+ 图 4.7 VGG16网络结构图
-
+ 在原论文中的VGGNet包含了6个版本的演进,分别对应VGG11、VGG11-LRN、VGG13、VGG16-1、VGG16-3和VGG19,不同的后缀数值表示不同的网络层数(VGG11-LRN表示在第一层中采用了LRN的VGG11,VGG16-1表示后三组卷积块中最后一层卷积采用卷积核尺寸为$1\times1$,相应的VGG16-3表示卷积核尺寸为$3\times3$),本节介绍的VGG16为VGG16-3。图4.7中的VGG16体现了VGGNet的核心思路,使用$3\times3$的卷积组合代替大尺寸的卷积(2个$3\times3卷积即可与$$5\times5$卷积拥有相同的感受视野),网络参数设置如表4.5所示。
-
- 上图按行顺序分别为对5类图像进行不同程度的垂直方向上的平移、尺度变换、旋转对输出结果影响的分析图。按列顺序分别为原始变换图像,第一层中原始图片和变换后的图片的欧氏距离,第7层中原始图片和变换后的图片的欧氏距离,变换后图片被正确分类的概率图。
+ 表4.5 VGG16网络参数配置
-
- 可视化不仅能够看到一个训练完的模型的内部操作,而且还能帮助选择好的网络结构。
+| 网络层 | 输入尺寸 | 核尺寸 | 输出尺寸 | 参数个数 |
+| :--------------------: | :-------------------: | :---------------------: | :--------------------: | :-----------------------------: |
+| 卷积层$C_{11}$ | $224\times224\times3$ | $3\times3\times64/1$ | $224\times224\times64$ | $(3\times3\times3+1)\times64$ |
+| 卷积层$C_{12}$ | $224\times224\times64$ | $3\times3\times64/1$ | $224\times224\times64$ | $(3\times3\times64+1)\times64$ |
+| 下采样层$S_{max1}$ | $224\times224\times64$ | $2\times2/2$ | $112\times112\times64$ | $0$ |
+| 卷积层$C_{21}$ | $112\times112\times64$ | $3\times3\times128/1$ | $112\times112\times128$ | $(3\times3\times64+1)\times128$ |
+| 卷积层$C_{22}$ | $112\times112\times128$ | $3\times3\times128/1$ | $112\times112\times128$ | $(3\times3\times128+1)\times128$ |
+| 下采样层$S_{max2}$ | $112\times112\times128$ | $2\times2/2$ | $56\times56\times128$ | $0$ |
+| 卷积层$C_{31}$ | $56\times56\times128$ | $3\times3\times256/1$ | $56\times56\times256$ | $(3\times3\times128+1)\times256$ |
+| 卷积层$C_{32}$ | $56\times56\times256$ | $3\times3\times256/1$ | $56\times56\times256$ | $(3\times3\times256+1)\times256$ |
+| 卷积层$C_{33}$ | $56\times56\times256$ | $3\times3\times256/1$ | $56\times56\times256$ | $(3\times3\times256+1)\times256$ |
+| 下采样层$S_{max3}$ | $56\times56\times256$ | $2\times2/2$ | $28\times28\times256$ | $0$ |
+| 卷积层$C_{41}$ | $28\times28\times256$ | $3\times3\times512/1$ | $28\times28\times512$ | $(3\times3\times256+1)\times512$ |
+| 卷积层$C_{42}$ | $28\times28\times512$ | $3\times3\times512/1$ | $28\times28\times512$ | $(3\times3\times512+1)\times512$ |
+| 卷积层$C_{43}$ | $28\times28\times512$ | $3\times3\times512/1$ | $28\times28\times512$ | $(3\times3\times512+1)\times512$ |
+| 下采样层$S_{max4}$ | $28\times28\times512$ | $2\times2/2$ | $14\times14\times512$ | $0$ |
+| 卷积层$C_{51}$ | $14\times14\times512$ | $3\times3\times512/1$ | $14\times14\times512$ | $(3\times3\times512+1)\times512$ |
+| 卷积层$C_{52}$ | $14\times14\times512$ | $3\times3\times512/1$ | $14\times14\times512$ | $(3\times3\times512+1)\times512$ |
+| 卷积层$C_{53}$ | $14\times14\times512$ | $3\times3\times512/1$ | $14\times14\times512$ | $(3\times3\times512+1)\times512$ |
+| 下采样层$S_{max5}$ | $14\times14\times512$ | $2\times2/2$ | $7\times7\times512$ | $0$ |
+| 全连接层$FC_{1}$ | $7\times7\times512$ | $(7\times7\times512)\times4096$ | $1\times4096$ | $(7\times7\times512+1)\times4096$ |
+| 全连接层$FC_{2}$ | $1\times4096$ | $4096\times4096$ | $1\times4096$ | $(4096+1)\times4096$ |
+| 全连接层$FC_{3}$ | $1\times4096$ | $4096\times1000$ | $1\times1000$ | $(4096+1)\times1000$ |
-### 4.3.4 ZFNet和AlexNet比较
+### 4.5.3 模型特性
-
- ZFNet的网络结构实际上与AlexNet没有什么很大的变化,差异表现在AlexNet用了两块GPU的稀疏连接结构,而ZFNet只用了一块GPU的稠密连接结构;同时,由于可视化可以用来选择好的网络结构,通过可视化发现AlexNet第一层中有大量的高频和低频信息的混合,却几乎没有覆盖到中间的频率信息;且第二层中由于第一层卷积用的步长为4太大了,导致了有非常多的混叠情况;因此改变了AlexNet的第一层即将滤波器的大小11x11变成7x7,并且将步长4变成了2,下图为AlexNet网络结构与ZFNet的比较。
-
-
-
+- 整个网络都使用了同样大小的卷积核尺寸$3\times3$和最大池化尺寸$2\times2$。
+- $1\times1$卷积的意义主要在于线性变换,而输入通道数和输出通道数不变,没有发生降维。
+- 两个$3\times3$的卷积层串联相当于1个$5\times5$的卷积层,感受野大小为$5\times5$。同样地,3个$3\times3$的卷积层串联的效果则相当于1个$7\times7$的卷积层。这样的连接方式使得网络参数量更小,而且多层的激活函数令网络对特征的学习能力更强。
+- VGGNet在训练时有一个小技巧,先训练浅层的的简单网络VGG11,再复用VGG11的权重来初始化VGG13,如此反复训练并初始化VGG19,能够使训练时收敛的速度更快。
+- 在训练过程中使用多尺度的变换对原始数据做数据增强,使得模型不易过拟合。
+## 4.6 GoogLeNet
+### 4.6.1 模型介绍
-## 4.4 VGGNet
-### 4.4.1 模型结构
+ GoogLeNet作为2014年ILSVRC在分类任务上的冠军,以6.65%的错误率力压VGGNet等模型,在分类的准确率上面相比过去两届冠军ZFNet和AlexNet都有很大的提升。从名字**GoogLe**Net可以知道这是来自谷歌工程师所设计的网络结构,而名字中Goog**LeNet**更是致敬了LeNet$^{[0]}$。GoogLeNet中最核心的部分是其内部子网络结构Inception,该结构灵感来源于NIN,至今已经经历了四次版本迭代(Inception$_{v1-4}$)。
-
+
+ 图 4.8 Inception性能比较图
-### 4.4.2 模型特点
+### 4.6.2 模型结构
-
-1. 整个网络都使用了同样大小的卷积核尺寸(3 \* 3)和最大池化尺寸(2 \* 2)
-2. 1 \* 1卷积的意义主要在于线性变换,而输入通道数和输出通道数不变,没有发生降维。
-3. 两个3 \* 3的卷积层串联相当于1个5 \* 5的卷积层,即一个像素会跟周围5 \* 5的像素产生关联,可以说感受野大小为5 \* 5。而3个3 \* 3的卷积层串联的效果则相当于1个7 \* 7的卷积层。除此之外,3个串联的3 \* 3的卷积层,拥有比1个7 \* 7的卷积层更少的参数量,只有后者的(3 \* 3 \* 3)/(7 \* 7)=55%。最重要的是,3个3 \* 3的卷积层拥有比1个7 \* 7的卷积层更多的非线性变换(前者可以使用三次ReLU激活函数,而后者只有一次),使得CNN对特征的学习能力更强。
-4. VGGNet在训练时有一个小技巧,先训练级别A的简单网络,再复用A网络的权重来初始化后面的几个复杂模型,这样训练收敛的速度更快。在预测时,VGG采用Multi-Scale的方法,将图像scale到一个尺寸Q,并将图片输入卷积网络计算。然后在最后一个卷积层使用滑窗的方式进行分类预测,将不同窗口的分类结果平均,再将不同尺寸Q的结果平均得到最后结果,这样可提高图片数据的利用率并提升预测准确率。在训练中,VGGNet还使用了Multi-Scale的方法做数据增强,将原始图像缩放到不同尺寸S,然后再随机裁切224*224的图片,这样能增加很多数据量,对于防止模型过拟合有很不错的效果。
-
-## 4.5 Network in Network
-### 4.5.1 模型结构
-
-
-
-### 4.5.2 模型创新点
-
-
-论文的创新点:
-
-1. 提出了抽象能力更高的Mlpconv层
-2. 提出了Global Average Pooling(全局平均池化)层
-
-- Mlpconv层
-
- 传统的卷积神经网络一般来说是由线性卷积层、池化层、全连接层堆叠起来的网络,卷积层通过线性滤波器进行线性卷积运算,然后在接个非线性激活函数最终生成特征图。而这种卷积滤波器是一种GLM:(Generalized linear model)广义线性模型。然而GLM的抽象能力是比较低水平的。
-
-
- 抽象:指得到对同一概念的不同变体保持不变的特征。
-
-
- 一般用CNN进行特征提取时,其实就隐含地假设了特征是线性可分的,可实际问题往往是难以线性可分的。一般来说我们所要提取的特征一般是高度非线性的。在传统的CNN中,也许我们可以用超完备的滤波器,来提取各种潜在的特征。比如我们要提取某个特征,于是我就用了一大堆的滤波器,把所有可能的提取出来,这样就可以把我想要提取的特征也覆盖到,然而这样存在一个缺点,那就是网络太恐怖了,参数太多了。
-
-
-我们知道CNN高层特征其实是低层特征通过某种运算的组合。所以论文就根据这个想法,提出在每个局部感受野中进行更加复杂的运算,提出了对卷积层的改进算法:MLP卷积层。(这里也不知道是否有道理,因为在后面的深层网络没有提出此种说法,还是按照传统的cnn方法使用多个滤波器去学习同一特征的不同变体)。MLP中的激活函数采用的是整流线性单元(即ReLU:max(wx+b,0)。
-MLP的优点:
-
-1. 非常有效的通用函数近似器
-2. 可用BP算法训练,可以完美地融合进CNN
-3. 其本身也是一种深度模型,可以特征再利用
-
- -
-- 全局平均池化层
-
-
- 另一方面,传统的CNN最后一层都是全连接层,参数个数非常之多,容易引起过拟合(如Alexnet),一个CNN模型,大部分的参数都被全连接层给占用了,所以论文提出采用了全局均值池化替代全连接层。与传统的全连接层不同,我们对每个特征图一整张图片进行全局均值池化,这样每张特征图都可以得到一个输出。这样采用均值池化,连参数都省了,可以大大减小网络参数,避免过拟合,另一方面它有一个特点,每张特征图相当于一个输出特征,然后这个特征就表示了我们输出类的特征。
-
-
-- 全局平均池化层
-
-
- 另一方面,传统的CNN最后一层都是全连接层,参数个数非常之多,容易引起过拟合(如Alexnet),一个CNN模型,大部分的参数都被全连接层给占用了,所以论文提出采用了全局均值池化替代全连接层。与传统的全连接层不同,我们对每个特征图一整张图片进行全局均值池化,这样每张特征图都可以得到一个输出。这样采用均值池化,连参数都省了,可以大大减小网络参数,避免过拟合,另一方面它有一个特点,每张特征图相当于一个输出特征,然后这个特征就表示了我们输出类的特征。
-
- 全局平均池化的优势:
- 1. 通过加强特征图与类别的一致性,让卷积结构更简单
- 2. 不需要进行参数优化,所以这一层可以避免过拟合
- 3. 它对空间信息进行了求和,因而对输入的空间变换更具有稳定性
-
-
-在采用了微神经网络后,让局部模型有更强的抽象能力,从而让全局平均池化能具有特征图与类别之间的一致性,同时相比传统CNN采用的全连接层,不易过拟合(因为全局平均池化本身就是一种结构性的规则项)(PS:经典CNN容易过拟合,并严重依赖用dropout进行规则化)。
-
-## 4.6 GoogleNet
-### 4.6.1 模型结构

-
-
-### 4.6.2 Inception 结构
-
-
-
-对上图做以下说明:
-
-1. 采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合;
-2. 之所以卷积核大小采用1、3和5,主要是为了方便对齐。设定卷积步长stride=1之后,只要分别设定pad=0、1、2,那么卷积之后便可以得到相同维度的特征,然后这些特征就可以直接拼接在一起了;
-3. 文章说很多地方都表明pooling挺有效,所以Inception里面也嵌入了。
-4. 网络越到后面,特征越抽象,而且每个特征所涉及的感受野也更大了,因此随着层数的增加,3x3和5x5卷积的比例也要增加。
-
-但是,使用5x5的卷积核仍然会带来巨大的计算量。 为此,文章借鉴NIN2,采用1x1卷积核来进行降维。
+ 图 4.9 GoogLeNet网络结构图
+ 如图4.9中所示,GoogLeNet相比于以前的卷积神经网络结构,除了在深度上进行了延伸,还对网络的宽度进行了扩展,整个网络由许多块状子网络的堆叠而成,这个子网络构成了Inception结构。图4.9为Inception的四个版本:$Inception_{v1}$在同一层中采用不同的卷积核,并对卷积结果进行合并;$Inception_{v2}$组合不同卷积核的堆叠形式,并对卷积结果进行合并;$Inception_{v3}$则在$v_2$基础上进行深度组合的尝试;$Inception_{v4}$结构相比于前面的版本更加复杂,子网络中嵌套着子网络。
-例如:上一层的输出为100x100x128,经过具有256个输出的5x5卷积层之后(stride=1,padding=2),输出数据为100x100x256。其中,卷积层的参数为128x5x5x256。假如上一层输出先经过具有32个输出的1x1卷积层,再经过具有256个输出的5x5卷积层,那么最终的输出数据仍为为100x100x256,但卷积参数量已经减少为128x1x1x32 + 32x5x5x256,大约减少了4倍。
+$Inception_{v1}$
-具体改进后的Inception Module如下图:
+
-
+
-## 4.7 Inception 系列
-### 4.7.1 Inception v1
+$Inception_{v2}$
-
-相比于GoogLeNet之前的众多卷积神经网络而言,inception v1采用在同一层中提取不同的特征(使用不同尺寸的卷积核),并提出了卷积核的并行合并(也称为Bottleneck layer),如下图
+
-
+
-这样的结构主要有以下改进:
-1. 一层block就包含1x1卷积,3x3卷积,5x5卷积,3x3池化(使用这样的尺寸不是必需的,可以根据需要进行调整)。这样,网络中每一层都能学习到“稀疏”(3x3. 5x5)或“不稀疏”(1x1)的特征,既增加了网络的宽度,也增加了网络对尺度的适应性;
-2. 通过deep concat在每个block后合成特征,获得非线性属性。
+
-虽然这样提高了性能,但是网络的计算量实在是太大了,因此GoogLeNet借鉴了Network-in-Network的思想,使用1x1的卷积核实现降维操作,以此来减小网络的参数量(这里就不对两种结构的参数量进行定量比较了),如图所示。
+$Inception_{v3}$
-
+
-
-最后实现的inception v1网络是上图结构的顺序连接,其中不同inception模块之间使用2x2的最大池化进行下采样,如表所示。
+$Inception_{v4}$
-
+
-如表所示,实现的网络仍有一层全连接层,该层的设置是为了迁移学习的实现(下同)。
-在之前的网络中,最后都有全连接层,经实验证明,全连接层并不是很必要的,因为可能会带来以下三点不便:
- - 网络的输入需要固定
- - 参数量多
- - 易发生过拟合
-实验证明,将其替换为平均池化层(或者1x1卷积层)不仅不影响精度,还可以减少。
+
-### 4.7.2 Inception v2
+
-在V1的基础之上主要做了以下改进:
-- 使用BN层,将每一层的输出都规范化到一个N(0,1)的正态分布,这将有助于训练,因为下一层不必学习输入数据中的偏移,并且可以专注与如何更好地组合特征(也因为在v2里有较好的效果,BN层几乎是成了深度网络的必备);
-
-(在Batch-normalized论文中只增加了BN层,而之后的Inception V3的论文提及到的inception v2还做了下面的优化)
+ 图 4.10 Inception$_{v1-4}$结构图
-- 使用2个3x3的卷积代替梯度(特征图,下同)为35x35中的5x5的卷积,这样既可以获得相同的视野(经过2个3x3卷积得到的特征图大小等于1个5x5卷积得到的特征图),还具有更少的参数,还间接增加了网络的深度,如下图。
+ 表 4.6 GoogLeNet中Inception$_{v1}$网络参数配置
-
-
+| 网络层 | 输入尺寸 | 核尺寸 | 输出尺寸 | 参数个数 |
+| :--------------------: | :-------------------: | :---------------------: | :--------------------: | :-----------------------------: |
+| 卷积层$C_{11}$ | $H\times{W}\times{C_1}$ | $1\times1\times{C_2}/2$ | $\frac{H}{2}\times\frac{W}{2}\times{C_2}$ | $(1\times1\times{C_1}+1)\times{C_2}$ |
+| 卷积层$C_{21}$ | $H\times{W}\times{C_2}$ | $1\times1\times{C_2}/2$ | $\frac{H}{2}\times\frac{W}{2}\times{C_2}$ | $(1\times1\times{C_2}+1)\times{C_2}$ |
+| 卷积层$C_{22}$ | $H\times{W}\times{C_2}$ | $3\times3\times{C_2}/1$ | $H\times{W}\times{C_2}/1$ | $(3\times3\times{C_2}+1)\times{C_2}$ |
+| 卷积层$C_{31}$ | $H\times{W}\times{C_1}$ | $1\times1\times{C_2}/2$ | $\frac{H}{2}\times\frac{W}{2}\times{C_2}$ | $(1\times1\times{C_1}+1)\times{C_2}$ |
+| 卷积层$C_{32}$ | $H\times{W}\times{C_2}$ | $5\times5\times{C_2}/1$ | $H\times{W}\times{C_2}/1$ | $(5\times5\times{C_2}+1)\times{C_2}$ |
+| 下采样层$S_{41}$ | $H\times{W}\times{C_1}$ | $3\times3/2$ | $\frac{H}{2}\times\frac{W}{2}\times{C_2}$ | $0$ |
+| 卷积层$C_{42}$ | $\frac{H}{2}\times\frac{W}{2}\times{C_2}$ | $1\times1\times{C_2}/1$ | $\frac{H}{2}\times\frac{W}{2}\times{C_2}$ | $(3\times3\times{C_2}+1)\times{C_2}$ |
+| 合并层$M$ | $\frac{H}{2}\times\frac{W}{2}\times{C_2}(\times4)$ | 拼接 | $\frac{H}{2}\times\frac{W}{2}\times({C_2}\times4)$ | $0$ |
-- 3x3的卷积核表现的不错,那更小的卷积核是不是会更好呢?比如2x2。对此,v2在17x17的梯度中使用1 \* n和n \* 1这种非对称的卷积来代替n \* n的对称卷积,既降低网络的参数,又增加了网络的深度(实验证明,该结构放于网络中部,取n=7,准确率更高),如下。(基于原则3)
+### 4.6.3 模型特性
-
-  -
-  -
+- 采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合;
+- 之所以卷积核大小采用1、3和5,主要是为了方便对齐。设定卷积步长stride=1之后,只要分别设定pad=0、1、2,那么卷积之后便可以得到相同维度的特征,然后这些特征就可以直接拼接在一起了;
+- 网络越到后面,特征越抽象,而且每个特征所涉及的感受野也更大了,因此随着层数的增加,3x3和5x5卷积的比例也要增加。但是,使用5x5的卷积核仍然会带来巨大的计算量。 为此,文章借鉴NIN2,采用1x1卷积核来进行降维。
-- 在梯度为8x8时使用可以增加滤波器输出的模块(如下图),以此来产生高维的稀疏特征。
+## 4.7 为什么现在的CNN模型都是在GoogleNet、VGGNet或者AlexNet上调整的?
-
-
-- 输入从224x224变为229x229。
-
-最后实现的Inception v2的结构如下表。
-
-
-
-
-
-经过网络的改进,inception v2得到更低的识别误差率,与其他网络识别误差率对比如表所示。
-
-
-
-
-如表,inception v2相比inception v1在imagenet的数据集上,识别误差率由29%降为23.4%。
-
-### 4.7.3 Inception v3
-
-
-inception模块之间特征图的缩小,主要有下面两种方式:
-
-
-
-
-右图是先进行inception操作,再进行池化来下采样,但是这样参数量明显多于左图(比较方式同前文的降维后inception模块),因此v2采用的是左图的方式,即在不同的inception之间(35/17/8的梯度)采用池化来进行下采样。
-
-
-但是,左图这种操作会造成表达瓶颈问题,也就是说特征图的大小不应该出现急剧的衰减(只经过一层就骤降)。如果出现急剧缩减,将会丢失大量的信息,对模型的训练造成困难。
-
-因此,在2015年12月提出的Inception V3结构借鉴inception的结构设计了采用一种并行的降维结构,如下图:
-
-
-
- 具体来说,就是在35/17/8之间分别采用下面这两种方式来实现特征图尺寸的缩小,如下图:
-
-
-
-figure 5' 35/17之间的特征图尺寸减小
-
-
-
-figure 6' 17/8之间的特征图尺寸缩小
-
-这样就得到Inception v3的网络结构,如表所示。
-
-
-
-### 4.7.4 Inception V4
-
-
-其实,做到现在,Inception模块感觉已经做的差不多了,再做下去准确率应该也不会有大的改变。但是谷歌这帮人还是不放弃,非要把一个东西做到极致,改变不了Inception模块,就改变其他的。
-
-
-因此,作者Christian Szegedy设计了Inception v4的网络,将原来卷积、池化的顺次连接(网络的前几层)替换为stem模块,来获得更深的网络结构。stem模块结构如下:
-
-
-stem模块
-
-
-
-
-Inception v4 中的Inception模块(分别为Inception A Inception B Inception C)
-
-
-
-
-Inception v4中的reduction模块(分别为reduction A reduction B)
-
-
-最终得到的Inception v4结构如下图。
-
-### 4.7.5 Inception-ResNet-v2
-
-
-ResNet的结构既可以加速训练,还可以提升性能(防止梯度消失);Inception模块可以在同一层上获得稀疏或非稀疏的特征。有没有可能将两者进行优势互补呢?
-
-
-Christian Szegedy等人将两个模块的优势进行了结合,设计出了Inception-ResNet网络。
-
-
-(Inception-ResNet有v1和v2两个版本,v2表现更好且更复杂,这里只介绍了v2)
-
-
-Inception-ResNet的成功,主要是它的Inception-ResNet模块。
-
-
-Inception-ResNet v2中的Inception-ResNet模块如下图:
-
-
-
-
-Inception-ResNet模块(分别为Inception-ResNet-A Inception-ResNet-B Inception-ResNet-C)
-
-
-Inception-ResNet模块之间特征图尺寸的减小如下图。(类似于Inception v4)
-
-
-
-
-Inception-ResNet-v2中的reduction模块(分别为reduction A reduction B)
-
-
-最终得到的Inception-ResNet-v2网络结构如图(stem模块同Inception v4)。
-
-
-## 4.8 ResNet及其变体
-
-
-自从AlexNet在LSVRC2012分类比赛中取得胜利之后,深度残差网络(Deep Residual Network)可以说成为过去几年中,在计算机视觉、深度学习社区领域中最具突破性的成果了。ResNet可以实现高达数百,甚至数千个层的训练,且仍能获得超赞的性能。
-
-
-得益于其强大的表征能力,许多计算机视觉应用在图像分类以外领域的性能得到了提升,如对象检测和人脸识别。
-
-
-自从2015年ResNet进入人们的视线,并引发人们思考之后,许多研究界人员已经开始研究其成功的秘诀,并在架构中纳入了许多新的改进。本文分为两部分,第一部分我将为那些不熟悉ResNet的人提供一些相关的背景知识,第二部分我将回顾一些我最近读过的关于ResNet架构的不同变体及其论文的相关阐述。
-### 4.8.1 重新审视ResNet
-
-根据泛逼近性原理(universal approximation theorem),我们知道,如果给定足够的容量,一个具有单层的前馈网络足以表示任何函数。然而,该层可能是巨大的,且网络可能容易过度拟合数据。因此,研究界有一个共同的趋势,即我们的网络架构需要更深。
-
-
-自从AlexNet投入使用以来,最先进的卷积神经网络(CNN)架构越来越深。虽然AlexNet只有5层卷积层,但VGG网络和GoogleNet(代号也为Inception_v1)分别有19层和22层。
-
-
-但是,如果只是通过简单地将层叠加在一起,增加网络深度并不会起到什么作用。随着网络层数的增加,就会出现梯度消失问题,这就会造成网络是难以进行训练,因为梯度反向传播到前层,重复乘法可能使梯度无穷小,这造成的结果就是,随着网络加深,其性能趋于饱和,或者甚至开始迅速退化。
-
-
-
-
-增加网络深度导致性能下降
-
-
-其实早在ResNet之前,已经有过好几种方法来处理梯度消失问题,例如,在中间层增加辅助损失作为额外的监督,但遗憾的是,似乎没有一个方法可以真正解决这个问题。
-
-
-ResNet的核心思想是引入所谓的“恒等映射(identity shortcut connection)”,可以跳过一层或多层,如下图所示:
-
-
-
-### 4.8.2 残差块
-
-[Deep Residual Learning for Image Recognition](https://arxiv.org/pdf/1512.03385v1.pdf)的作者认为,堆积网络层数不应该降低网络性能,因为我们可以简单地在当前网络上堆积身份映射(层不做任何事情),并且所得到的架构将执行相同的操作。这表明,较深的模型所产生的训练误差不应该比较浅的模型高。他们假设让堆积层适应残差映射比使它们直接适应所需的底层映射要容易得多。下图的残差块可以明确地使它做到这一点。
-
-
-
-### 4.8.3 ResNet架构
-
-
-事实上,ResNet并不是第一个利用short cut、Highway Networks引入门控近路连接的。这些参数化门控制允许多少信息流过近路(shortcut)。类似的想法可以在长短期记忆网络(LSTM)单元中找到,其中存在参数化的忘记门,其控制多少信息将流向下一个时间步。因此,ResNet可以被认为是Highway Networks的一种特殊情况。
-
-
-然而,实验表明,Highway Networks的性能并不如ResNet,因为Highway Networks的解决方案空间包含ResNet,因此它应该至少表现得像ResNet一样好。这就表明,保持这些“梯度公路”干净简洁比获取更大的解决方案空间更为重要。
-
-
-照着这种直觉,论文作者改进了残差块,并提出了一个残差块的预激活变体,其中梯度可以畅通无阻地通过快速连接到任何其他的前层。论文的实验结果表明,使用原始的残差块,训练1202层ResNet所展示的性能比其训练110层对等物要差得多。
-
-
-
-### 4.8.4 ResNeXt
-
-
-S. Xie,R. Girshick,P. Dollar,Z. Tu和 K. He在[Aggregated Residual Transformations for Deep Neural Networks](http://openaccess.thecvf.com/content_cvpr_2017/papers/Xie_Aggregated_Residual_Transformations_CVPR_2017_paper.pdf)中提出了一个代号为ResNeXt的ResNet变体,它具有以下构建块:
-
-
-
-
-左:《Deep Residual Learning for Image Recognition》中所提及的构建块,右图: ResNeXt构建块 基数=32
-
-
-这可能看起来很熟悉,因为它非常类似于《IEEE计算机视觉与模式识别会议论文集》中《Going deeper with convolutions》的Inception模块,它们都遵循“拆分-转换-合并”范式,除了在这个变体中,不同路径的输出通过将它们相加在一起而被合并,而在《Going deeper with convolutions》中它们是深度连接的。另一个区别是,在《Going deeper with convolutions》中,每个路径彼此互不相同(1x1,3x3和5x5卷积),而在此架构中,所有路径共享相同的拓扑。
-
-
-作者介绍了一个称为 “基数(cardinality)”的超参数——独立路径的数量,以提供调整模型容量的新方式。实验表明,可以通过增加基数,而不是深度或宽度,来更加有效地获得准确度。作者指出,与Inception相比,这种新颖的架构更容易适应新的数据集/任务,因为它具有一个简单的范式,且只有一个超参数被调整,而Inception却具有许多超参数(如每个路径中卷积层内核大小)待调整。
-
-
-这个新颖的构建块有如下三种等效形式:
-
-
-
-实际上,“分割-变换-合并”通常是通过点分组卷积层来完成的,它将其输入分成特征映射组,并分别执行正常卷积,其输出被深度级联,然后馈送到1x1卷积层。
-
-### 4.8.5 ResNet作为小型网络的组合
-
-
-[Deep Networks with Stochastic Depth](https://arxiv.org/pdf/1603.09382.pdf)提出了一种反直觉的方式,训练一个非常深层的网络,通过在训练期间随机丢弃它的层,并在测试时间内使用完整的网络。Veit等人有一个更反直觉的发现:我们实际上可以删除一些已训练的ResNet的一些层,但仍然具有可比性能。这使得ResNet架构更加有趣,该论文亦降低了VGG网络的层,并大大降低了其性能。
-该论文首先提供了ResNet的一个简单的视图,使事情更清晰。在我们展开网络架构之后,这是很显而易见的,具有i个残差块的ResNet架构具有$2^{i}$个不同的路径(因为每个残差块提供两个独立的路径)。
-
-
-
-
-鉴于上述发现,我们很容易发现为什么在ResNet架构中删除几层,对于其性能影响不大——架构具有许多独立的有效路径,在我们删除了几层之后,它们大部分保持不变。相反,VGG网络只有一条有效的路径,所以删除一层是唯一的途径。
+- 评测对比:为了让自己的结果更有说服力,在发表自己成果的时候会同一个标准的baseline及在baseline上改进而进行比较,常见的比如各种检测分割的问题都会基于VGG或者Resnet101这样的基础网络。
+- 时间和精力有限:在科研压力和工作压力中,时间和精力只允许大家在有限的范围探索。
+- 模型创新难度大:进行基本模型的改进需要大量的实验和尝试,并且需要大量的实验积累和强大灵感,很有可能投入产出比比较小。
+- 资源限制:创造一个新的模型需要大量的时间和计算资源,往往在学校和小型商业团队不可行。
+- 在实际的应用场景中,其实是有大量的非标准模型的配置。
-
-作者还进行了实验,表明ResNet中的路径集合具有集合行为。他们是通过在测试时间删除不同数量的层,然后查看网络的性能是否与已删除层的数量平滑相关,这样的方式做到的。结果表明,网络确实表现得像集合,如下图所示:
+## 参考文献
-
+[1] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner. Gradient-based learning applied to document recognition. *Proceedings of the IEEE*, november 1998.
-### 4.8.6 ResNet中路径的特点
+[2] A. Krizhevsky, I. Sutskever and G. E. Hinton. ImageNet Classification with Deep Convolutional Neural Networks. *Advances in Neural Information Processing Systems 25*. Curran Associates, Inc. 1097–1105.
-
-最后,作者研究了ResNet中路径的特点:
+[3] LSVRC-2013. http://www.image-net.org/challenges/LSVRC/2013/results.php
-
-很明显,所有可能的路径长度的分布都遵循二项式分布,如(a)所示。大多数路径经过19到35个残差块。
+[4] M. D. Zeiler and R. Fergus. Visualizing and Understanding Convolutional Networks. *European Conference on Computer Vision*.
-
+[5] M. Lin, Q. Chen, and S. Yan. Network in network. *Computing Research Repository*, abs/1312.4400, 2013.
-
- 调查路径长度与经过其的梯度大小之间的关系,同时获得长度为k的路径的梯度幅度,作者首先将一批数据馈送给网络,随机抽取k个残差块。当反向传播梯度时,它们仅传播到采样残余块的权重层。(b)表明随着路径变长,梯度的大小迅速下降。
+[6] K. Simonyan and A. Zisserman. Very Deep Convolutional Networks for Large-Scale Image Recognition. *International Conference on Machine Learning*, 2015.
-
- 我们现在可以将每个路径长度的频率与其预期的梯度大小相乘,以了解每个长度的路径对于训练有多少帮助,如(c)所示。令人惊讶的是,大多数贡献来自长度为9至18的路径,但它们仅占总路径的一小部分,如(a)所示。这是一个非常有趣的发现,因为它表明ResNet并没有解决长路径上的梯度消失问题,而是通过缩短其有效路径,ResNet实际上能够实现训练非常深度的网络。
+[7] Bharath Raj. [a-simple-guide-to-the-versions-of-the-inception-network](https://towardsdatascience.com/a-simple-guide-to-the-versions-of-the-inception-network-7fc52b863202), 2018.
-
-答案来源:[ResNet有多大威力?最近又有了哪些变体?一文弄清](http://www.sohu.com/a/157818653_390227)
+[8] Christian Szegedy, Sergey Ioffe, Vincent Vanhoucke, Alex Alemi. [Inception-v4, Inception-ResNet and
+the Impact of Residual Connections on Learning](https://arxiv.org/pdf/1602.07261.pdf), 2016.
+[9] Sik-Ho Tsang. [review-inception-v4-evolved-from-googlenet-merged-with-resnet-idea-image-classification](https://towardsdatascience.com/review-inception-v4-evolved-from-googlenet-merged-with-resnet-idea-image-classification-5e8c339d18bc), 2018.
-## 4.9 为什么现在的CNN模型都是在GoogleNet、VGGNet或者AlexNet上调整的?
+[10] Zbigniew Wojna, Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens. [Rethinking the Inception Architecture for Computer Vision](https://arxiv.org/pdf/1512.00567v3.pdf), 2015.
-- 评测对比:为了让自己的结果更有说服力,在发表自己成果的时候会同一个标准的baseline及在baseline上改进而进行比较,常见的比如各种检测分割的问题都会基于VGG或者Resnet101这样的基础网络。
-- 时间和精力有限:在科研压力和工作压力中,时间和精力只允许大家在有限的范围探索。
-- 模型创新难度大:进行基本模型的改进需要大量的实验和尝试,并且需要大量的实验积累和强大灵感,很有可能投入产出比比较小。
-- 资源限制:创造一个新的模型需要大量的时间和计算资源,往往在学校和小型商业团队不可行。
-- 在实际的应用场景中,其实是有大量的非标准模型的配置。
+[11] Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich. [Going deeper with convolutions](https://arxiv.org/pdf/1409.4842v1.pdf), 2014.
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.11-1.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.11-1.png"
new file mode 100644
index 00000000..a8216642
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.11-1.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.12-1.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.12-1.png"
new file mode 100644
index 00000000..2e358c8e
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.12-1.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.13-1.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.13-1.png"
new file mode 100644
index 00000000..16e488dd
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.13-1.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.13-2.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.13-2.png"
new file mode 100644
index 00000000..fd10e0f7
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.13-2.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.14.1.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.14.1.png"
new file mode 100644
index 00000000..4be4e132
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.14.1.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.19.1-2.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.19.1-2.png"
new file mode 100644
index 00000000..56914569
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.19.1-2.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.19.1-3.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.19.1-3.png"
new file mode 100644
index 00000000..f5e21a8c
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.19.1-3.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.19.2-5.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.19.2-5.png"
new file mode 100644
index 00000000..65a81696
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.19.2-5.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.27.1.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.27.1.png"
new file mode 100644
index 00000000..38b23d23
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.27.1.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.27.2.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.27.2.png"
new file mode 100644
index 00000000..66afa642
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.27.2.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.27.3.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.27.3.png"
new file mode 100644
index 00000000..65fb2168
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.27.3.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.6.1.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.6.1.png"
new file mode 100644
index 00000000..066cf692
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.6.1.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.6.2.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.6.2.png"
new file mode 100644
index 00000000..73af604d
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.6.2.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.8-1.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.8-1.png"
new file mode 100644
index 00000000..ea5aba50
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.8-1.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/Image-process.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/Image-process.png"
new file mode 100644
index 00000000..968d70d3
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/Image-process.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/NLP.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/NLP.png"
new file mode 100644
index 00000000..3e57aac0
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/NLP.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/audio-recognition.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/audio-recognition.png"
new file mode 100644
index 00000000..13ef5466
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/audio-recognition.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/audio.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/audio.png"
new file mode 100644
index 00000000..41736397
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/audio.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/cat-blur-gaussian.jpg" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/cat-blur-gaussian.jpg"
new file mode 100644
index 00000000..b3ccd0c4
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/cat-blur-gaussian.jpg" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/cat-boxblur.jpg" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/cat-boxblur.jpg"
new file mode 100644
index 00000000..4ad35d48
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/cat-boxblur.jpg" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/cat-crop.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/cat-crop.png"
new file mode 100644
index 00000000..cf1cf4ef
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/cat-crop.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/cat-edgeDetect-2.jpg" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/cat-edgeDetect-2.jpg"
new file mode 100644
index 00000000..b07b28ed
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/cat-edgeDetect-2.jpg" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/cat-edgeDetect.jpg" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/cat-edgeDetect.jpg"
new file mode 100644
index 00000000..4c7e8e8e
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/cat-edgeDetect.jpg" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/cat-sharpen.jpg" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/cat-sharpen.jpg"
new file mode 100644
index 00000000..653b0d72
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/cat-sharpen.jpg" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/cat.jpg" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/cat.jpg"
new file mode 100644
index 00000000..280bdce0
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/cat.jpg" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/conv-same.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/conv-same.png"
new file mode 100644
index 00000000..f98611a9
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/conv-same.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/conv-valid.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/conv-valid.png"
new file mode 100644
index 00000000..329ced51
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/conv-valid.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/conv.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/conv.png"
new file mode 100644
index 00000000..bbd74167
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/conv.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/convolution.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/convolution.png"
new file mode 100644
index 00000000..5865fee0
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/convolution.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/full-connected.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/full-connected.png"
new file mode 100644
index 00000000..5bdc5f5e
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/full-connected.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/general_pooling.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/general_pooling.png"
new file mode 100644
index 00000000..e2d56675
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/general_pooling.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/img67.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/img67.png"
deleted file mode 100644
index 96910125..00000000
Binary files "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/img67.png" and /dev/null differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/local-connected.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/local-connected.png"
new file mode 100644
index 00000000..86f484a9
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/local-connected.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/local-conv.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/local-conv.png"
new file mode 100644
index 00000000..d445ee81
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/local-conv.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/overlap_pooling.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/overlap_pooling.png"
new file mode 100644
index 00000000..99273114
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/overlap_pooling.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/spatial_pooling.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/spatial_pooling.png"
new file mode 100644
index 00000000..1503603d
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/spatial_pooling.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/\347\254\254\344\272\224\347\253\240 \345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234\357\274\210CNN\357\274\211.md" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/\347\254\254\344\272\224\347\253\240 \345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234\357\274\210CNN\357\274\211.md"
index 4839b927..c5067069 100644
--- "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/\347\254\254\344\272\224\347\253\240 \345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234\357\274\210CNN\357\274\211.md"
+++ "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/\347\254\254\344\272\224\347\253\240 \345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234\357\274\210CNN\357\274\211.md"
@@ -2,716 +2,455 @@
-# 第五章 卷积神经网络(CNN)
+# 第五章 卷积神经网络(CNN)
-标签(空格分隔): 原创性 深度学习 协作
-卷积神经网络负责人:
+ 卷积神经网络是一种用来处理局部和整体相关性的计算网络结构,被应用在图像识别、自然语言处理甚至是语音识别领域,因为图像数据具有显著的局部与整体关系,其在图像识别领域的应用获得了巨大的成功。
-重庆大学研究生-刘畅 787913208@qq.com;
-
-铪星创新科技联合创始人-杨文英;
-
- Markdown Revision 1;
- Date: 2018/11/08
- Editor: 李骁丹-杜克大学
- Contact: xiaodan.li@duke.edu
## 5.1 卷积神经网络的组成层
-在卷积神经网络中,一般包含5种类型的层:
-> * 输入层
-> * 卷积运算层
-> * 激活函数层
-> * 池化层
-> * 全连接层
-
-**输入层**主要包含对原始图像进行预处理,包括白化、归一化、去均值等等。
-
-**卷积运算层**主要使用滤波器,通过设定步长、深度等参数,对输入进行不同层次的特征提取。滤波器中的参数可以通过反向传播算法进行学习。
-
-**激活函数层**主要是将卷积层的输出做一个非线性映射。常见的激活函数包括sigmoid,tanh,Relu等。
-
-**池化层**主要是用于参数量压缩。可以减轻过拟合情况。常见的有平均池化和最大值池化,不包含需要学习的参数。
-**全连接层**主要是指两层网络,所有神经元之间都有权重连接。常见用于网络的最后一层,用于计算类别得分。
+ 以图像分类任务为例,在表5.1所示卷积神经网络中,一般包含5种类型的网络层次结构:
-## 5.2 卷积如何检测边缘信息?
-卷积运算是卷积神经网络最基本的组成部分。在神经网络中,以物体识别为例,特征的检测情况可大致做一下划分。前几层检测到的是一些边缘特征,中间几层检测到的是物体的局部区域,靠后的几层检测到的是完整物体。每个阶段特征的形成都是由多组滤波器来完成的。而其中的边缘检测部分是由滤波器来完成的。在传统的图像处理方法里面,有许多边缘检测算子,如canny算子。使用固定的模板来进行边缘检测。
+ 表5.1 卷积神经网络的组成
-先介绍一个概念,过滤器:
+| CNN层次结构 | 输出尺寸 | 作用 |
+| :---------: | :-------------------------------: | :----------------------------------------------------------- |
+| 输入层 | $W_1\times H_1\times 3$ | 卷积网络的原始输入,可以是原始或预处理后的像素矩阵 |
+| 卷积层 | $W_1\times H_1\times K$ | 参数共享、局部连接,利用平移不变性从全局特征图提取局部特征 |
+| 激活层 | $W_1\times H_1\times K$ | 将卷积层的输出结果进行非线性映射 |
+| 池化层 | $W_2\times H_2\times K$ | 进一步筛选特征,可以有效减少后续网络层次所需的参数量 |
+| 全连接层 | $(W_2 \cdot H_2 \cdot K)\times C$ | 将多维特征展平为2维特征,通常低维度特征对应任务的学习目标(类别或回归值) |
-
+> $W_1\times H_1\times 3$对应原始图像或经过预处理的像素值矩阵,3对应RGB图像的通道;$K$表示卷积层中卷积核(滤波器)的个数;$W_2\times H_2$ 为池化后特征图的尺度,在全局池化中尺度对应$1\times 1$;$(W_2 \cdot H_2 \cdot K)$是将多维特征压缩到1维之后的大小,$C$对应的则是图像类别个数。
-这是一个3*3的过滤器,是一个矩阵,数值如上所示。
+### 5.1.1 输入层
-假设我们有一个6*6的灰度图像:
+ 输入层(Input Layer)通常是输入卷积神经网络的原始数据或经过预处理的数据,可以是图像识别领域中原始三维的多彩图像,也可以是音频识别领域中经过傅利叶变换的二维波形数据,甚至是自然语言处理中一维表示的句子向量。以图像分类任务为例,输入层输入的图像一般包含RGB三个通道,是一个由长宽分别为$H$和$W$组成的3维像素值矩阵$H\times W \times 3$,卷积网络会将输入层的数据传递到一系列卷积、池化等操作进行特征提取和转化,最终由全连接层对特征进行汇总和结果输出。根据计算能力、存储大小和模型结构的不同,卷积神经网络每次可以批量处理的图像个数不尽相同,若指定输入层接收到的图像个数为$N$,则输入层的输出数据为$N\times H\times W\times 3$。
-
-把这个图像与过滤器进行卷积运算,卷积运算在此处用“*”表示。
+### 5.1.2 卷积层
-
+ 卷积层(Convolution Layer)通常用作对输入层输入数据进行特征提取,通过卷积核矩阵对原始数据中隐含关联性的一种抽象。卷积操作原理上其实是对两张像素矩阵进行点乘求和的数学操作,其中一个矩阵为输入的数据矩阵,另一个矩阵则为卷积核(滤波器或特征矩阵),求得的结果表示为原始图像中提取的特定局部特征。图5.1表示卷积操作过程中的不同填充策略,上半部分采用零填充,下半部分采用有效卷积(舍弃不能完整运算的边缘部分)。
+ 
+ 图5.1 卷积操作示意图
-如图深蓝色区域所示,过滤器在图像左上方3*3的范围内,逐一加权相加,得到-5。
+### 5.1.3 激活层
-同理,将过滤器右移进行相同操作,再下移,直到过滤器对准图像右下角最后一格。依次运算得到一个4*4的矩阵。
+ 激活层(Activation Layer)负责对卷积层抽取的特征进行激活,由于卷积操作是由输入矩阵与卷积核矩阵进行相差的线性变化关系,需要激活层对其进行非线性的映射。激活层主要由激活函数组成,即在卷积层输出结果的基础上嵌套一个非线性函数,让输出的特征图具有非线性关系。卷积网络中通常采用ReLU来充当激活函数(还包括tanh和sigmoid等)ReLU的函数形式如公式(5-1)所示,能够限制小于0的值为0,同时大于等于0的值保持不变。
+$$
+f(x)=\begin{cases}
+ 0 &\text{if } x<0 \\
+ x &\text{if } x\ge 0
+\end{cases}
+\tag{5-1}
+$$
-在了解了过滤器以及卷积运算后,让我们看看为何过滤器能检测物体边缘:
+### 5.1.4 池化层
+ 池化层又称为降采样层(Downsampling Layer),作用是对感受域内的特征进行筛选,提取区域内最具代表性的特征,能够有效地降低输出特征尺度,进而减少模型所需要的参数量。按操作类型通常分为最大池化(Max Pooling)、平均池化(Average Pooling)和求和池化(Sum Pooling),它们分别提取感受域内最大、平均与总和的特征值作为输出,最常用的是最大池化。
-举一个最简单的例子:
+### 5.1.5 全连接层
+ 全连接层(Full Connected Layer)负责对卷积神经网络学习提取到的特征进行汇总,将多维的特征输入映射为二维的特征输出,高维表示样本批次,低位常常对应任务目标。
-
-这张图片如上所示,左半边全是白的,右半边全是灰的,我们仍然使用之前的过滤器,对该图片进行卷积处理:
+## 5.2 卷积在图像中有什么直观作用
-
+ 在卷积神经网络中,卷积常用来提取图像的特征,但不同层次的卷积操作提取到的特征类型是不相同的,特征类型粗分如表5.2所示。
+ 表5.2 卷积提取的特征类型
-可以看到,最终得到的结果中间是一段白色,两边为灰色,于是垂直边缘被找到了。为什么呢?因为在6*6图像中红框标出来的部分,也就是图像中的分界线所在部分,与过滤器进行卷积,结果是30。而在不是分界线的所有部分进行卷积,结果都为0.
+| 卷积层次 | 特征类型 |
+| :------: | :------: |
+| 浅层卷积 | 边缘特征 |
+| 中层卷积 | 局部特征 |
+| 深层卷积 | 全局特征 |
-在这个图中,白色的分界线很粗,那是因为6\*6的图像尺寸过小,对于1000\*1000的图像,我们会发现在最终结果中,分界线较细但很明显。
+图像与不同卷积核的卷积可以用来执行边缘检测、锐化和模糊等操作。表5.3显示了应用不同类型的卷积核(滤波器)后的各种卷积图像。
+ 表5.3 一些常见卷积核的作用
-这就是检测物体垂直边缘的例子,水平边缘的话只需将过滤器旋转90度。
+| 卷积作用 | 卷积核 | 卷积后图像 |
+| :----------------------: | :----------------------------------------------------------: | :-----------------------------------------------: |
+| 输出原图 | $\begin{bmatrix} 0 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 0 \end{bmatrix}$ |  |
+| 边缘检测(突出边缘差异) | $\begin{bmatrix} 1 & 0 & -1 \\ 0 & 0 & 0 \\ -1 & 0 & 1 \end{bmatrix}$ |  |
+| 边缘检测(突出中间值) | $\begin{bmatrix} -1 & -1 & -1 \\ -1 & 8 & -1 \\ -1 & -1 & -1 \end{bmatrix}$ |  |
+| 图像锐化 | $\begin{bmatrix} 0 & -1 & 0 \\ -1 & 5 & -1 \\ 0 & -1 & 0 \end{bmatrix}$ |  |
+| 方块模糊 | $\begin{bmatrix} 1 & 1 & 1 \\ 1 & 1 & 1 \\ 1 & 1 & 1 \end{bmatrix} \times \frac{1}{9}$ |  |
+| 高斯模糊 | $\begin{bmatrix} 1 & 2 & 1 \\ 2 & 4 & 2 \\ 1 & 2 & 1 \end{bmatrix} \times \frac{1}{16}$ |  |
-## 5.3 卷积层中的几个基本参数?
+## 5.3 卷积层有哪些基本参数?
-在卷积层中,有一些我们常用的参数,定义如下
+ 卷积层中需要用到卷积核(滤波器或特征检测器)与图像特征矩阵进行点乘运算,利用卷积核与对应的特征感受域进行划窗式运算时,需要设定卷积核对应的大小、步长、个数以及填充的方式,如表5.4所示。
-### 5.3.1 卷积核大小
-英文名是Kernel Size:卷积核的大小定义了卷积的感受野。二维卷积的核大小选择通常是3,即3×3。
-### 5.3.2 卷积核的步长
-英文名是Stride: Stride定义了卷积核在卷积过程中的步长。虽然它的默认值通常为1,但我们可以将步长设置为2,可以实现类似于pooling的下采样功能。
-### 5.3.3 边缘填充
-英文名是Padding: Padding用于填充输入图像的边界。一个(半)填充的卷积将使空间输出维度与输入相等,而如果卷积核大于1,则对于未被填充的图像,卷积后将会使图像一些边界消失。
-### 5.3.4 输入和输出通道
-英文名是 Input/Output Channels 一个卷积层接受一定数量的输入通道I,并计算一个特定数量的输出通道O,这一层所需的参数可以由I*O*K计算,K等于卷积核中参数的数量。
+ 表5.4 卷积层的基本参数
-## 5.4 卷积的网络类型分类?
-### 5.4.1 普通卷积
-普通卷积即如下图所示,使用一个固定大小的滤波器,对图像进行加权提特征。
-
-### 5.4.2 扩张卷积
-扩张卷积,又称为带孔(atrous)卷积或者空洞(dilated)卷积。在使用扩张卷积时,会引入一个称作扩张率(dilation rate)的参数。该参数定义了卷积核内参数间的行(列)间隔数。例如下图所示,一个3×3的卷积核,扩张率为2,它的感受野与5×5卷积核相同,而仅使用9个参数。这样做的好处是,在参数量不变的情况下,可以获得更大的感受野。扩张卷积在实时分割领域应用非常广泛。
-
-### 5.4.3 转置卷积
-转置卷积也就是反卷积(deconvolution)。虽然有些人经常直接叫它反卷积,但严格意义上讲是不合适的,因为它不符合一个反卷积的概念。反卷积确实存在,但它们在深度学习领域并不常见。一个实际的反卷积会恢复卷积的过程。想象一下,将一个图像放入一个卷积层中。现在把输出传递到一个黑盒子里,然后你的原始图像会再次出来。这个黑盒子就完成了一个反卷积。这是一个卷积层的数学逆过程。
+| 参数名 | 作用 | 常见设置 |
+| :-----------------------: | :----------------------------------------------------------- | :----------------------------------------------------------- |
+| 卷积核大小 (Kernel Size) | 卷积核的大小定义了卷积的感受野 | 在过去常设为5,如LeNet-5;现在多设为3,通过堆叠$3\times3$的卷积核来达到更大的感受域 |
+| 卷积核步长 (Stride) | 定义了卷积核在卷积过程中的步长 | 常见设置为1,表示滑窗距离为1,可以覆盖所有相邻位置特征的组合;当设置为更大值时相当于对特征组合降采样 |
+| 填充方式 (Padding) | 在卷积核尺寸不能完美匹配输入的图像矩阵时需要进行一定的填充策略 | 设置为'SAME'表示对不足卷积核大小的边界位置进行某种填充(通常零填充)以保证卷积输出维度与与输入维度一致;当设置为'VALID'时则对不足卷积尺寸的部分进行舍弃,输出维度就无法保证与输入维度一致 |
+| 输入通道数 (In Channels) | 指定卷积操作时卷积核的深度 | 默认与输入的特征矩阵通道数(深度)一致;在某些压缩模型中会采用通道分离的卷积方式 |
+| 输出通道数 (Out Channels) | 指定卷积核的个数 | 若设置为与输入通道数一样的大小,可以保持输入输出维度的一致性;若采用比输入通道数更小的值,则可以减少整体网络的参数量 |
-一个转置的卷积在某种程度上是相似的,因为它产生的空间分辨率是跟反卷积后产生的分辨率相同。不同之处是在卷积核值上执行的实际数学操作。转置卷积层使用的是常规的卷积,但是它能够恢复其空间变换。
+> 卷积操作维度变换公式:
+>
+> $O_d =\begin{cases} \lceil \frac{(I_d - k_{size})+ 1)}{s}\rceil ,& \text{padding=VALID}\\ \lceil \frac{I_d}{s}\rceil,&\text{padding=SAME} \end{cases}$
+>
+> 其中,$I_d$为输入维度,$O_d$为输出维度,$k_{size}$为卷积核大小,$s$为步长
-在这一点上,让我们来看一个具体的例子:
-将5×5的图像送到一个卷积层。步长设置为2,无边界填充,而卷积核是3×3。结果得到了2×2的图像。如果我们想要逆向该过程,则需要数学上的逆运算,以便从输入的每个像素值中生成9个值。然后,我们将步长设置为2来遍历输出图像。这就是一个反卷积过程。
-
-转置卷积的实现过程则不同。为了保证输出将是一个5×5的图像,在使用卷积运算时,我们需要在输入上执行一些特别的填充。而这一过程并不是逆转了卷积运算,它仅仅是重新构造了之前的空间分辨率并进行了卷积运算。这样的做法并不是数学上的逆过程,但是很适用于编码-解码器(Encoder-Decoder)架构。我们就可以把图像的上采样(upscaling)和卷积操作结合起来,而不是做两个分离的过程。
-
+## 5.4 卷积核有什么类型?
-### 5.4.4 可分离卷积
-在一个可分离卷积中,我们可以将内核操作拆分成多个步骤。我们用y = conv(x,k)表示卷积,其中y是输出图像,x是输入图像,k是核大小。这一步很简单。接下来,我们假设k可以由下面这个等式计算得出:k = k1.dot(k2)。这将使它成为一个可分离的卷积,因为我们可以通过对k1和k2做2个一维卷积来取得相同的结果,而不是用k做二维卷积。
+ 常见的卷积主要是由连续紧密的卷积核对输入的图像特征进行滑窗式点乘求和操作,除此之外还有其他类型的卷积核在不同的任务中会用到,具体分类如表5.5所示。
+ 表5.5 卷积核分类
-
+| 卷积类别 | 示意图 | 作用 |
+| :----------------------------: | :---------------------------: | :----------------------------------------------------------- |
+| 标准卷积 |  | 最常用的卷积核,连续紧密的矩阵形式可以提取图像区域中的相邻像素之间的关联关系,$3\times3$的卷积核可以获得$3\times3$像素范围的感受视野 |
+| 扩张卷积(带孔卷积或空洞卷积) |  | 引入一个称作扩张率(Dilation Rate)的参数,使同样尺寸的卷积核可以获得更大的感受视野,相应的在相同感受视野的前提下比普通卷积采用更少的参数。同样是$3\times3$的卷积核尺寸,扩张卷积可以提取$5\times5$范围的区域特征,在实时图像分割领域广泛应用 |
+| 转置卷积 |  | 先对原始特征矩阵进行填充使其维度扩大到适配卷积目标输出维度,然后进行普通的卷积操作的一个过程,其输入到输出的维度变换关系恰好与普通卷积的变换关系相反,但这个变换并不是真正的逆变换操作,通常称为转置卷积(Transpose Convolution)而不是反卷积(Deconvolution)。转置卷积常见于目标检测领域中对小目标的检测和图像分割领域还原输入图像尺度。 |
+| 可分离卷积 |  | 标准的卷积操作是同时对原始图像$H\times W\times C$三个方向的卷积运算,假设有$K$个相同尺寸的卷积核,这样的卷积操作需要用到的参数为$H\times W\times C\times K$个;若将长宽与深度方向的卷积操作分离出变为$H\times W$与$C$的两步卷积操作,则同样的卷积核个数$K$,只需要$(H\times W + C)\times K$个参数,便可得到同样的输出尺度。可分离卷积(Seperable Convolution)通常应用在模型压缩或一些轻量的卷积神经网络中,如MobileNet$^{[1]}$、Xception$^{[2]}$等 |
-以图像处理中的Sobel算子为例。你可以通过乘以向量[1,0,-1]和[1,2,1] .T获得相同的核大小。在执行相同的操作时,你只需要6个参数,而不是9个。上面的示例显示了所谓的空间可分离卷积。即将一个二维的卷积分离成两个一维卷积的操作。在神经网络中,为了减少网络参数,加速网络运算速度。我们通常使用的是一种叫深度可分离卷积的神经网络。
-## 5.5 图解12种不同类型的2D卷积?
+## 5.5 二维卷积与三维卷积有什么区别?
-http://www.sohu.com/a/159591827_390227
+- **二维卷积**
+ 二维卷积操作如图5.3所示,为了更直观的说明,分别展示在单通道和多通道输入中,对单个通道输出的卷积操作。在单通道输入的情况下,若输入卷积核尺寸为 $(k_h, k_w, 1)$,卷积核在输入图像的空间维度上进行滑窗操作,每次滑窗和 $(k_h, k_w)$窗口内的值进行卷积操作,得到输出图像中的一个值。在多通道输入的情况下,假定输入图像特征通道数为3,卷积核尺寸则为$(k_h, k_w, 3)$,每次滑窗与3个通道上的$(k_h, k_w)$窗口内的所有值进行卷积操作,得到输出图像中的一个值。
-## 5.6 2D卷积与3D卷积有什么区别?
-### 5.6.1 2D卷积
-二维卷积操作如图所示,为了更直观的说明,分别展示了单通道和多通道的操作。假定只使用了1个滤波器,即输出图像只有一个channel。其中,针对单通道,输入图像的channel为1,卷积核尺寸为 (k_h, k_w, 1),卷积核在输入图像的空间维度上进行滑窗操作,每次滑窗和 (k_h, k_w)窗口内的值进行卷积操作,得到输出图像中的一个值。针对多通道,假定输入图像的channel为3,卷积核尺寸则为 (k_h, k_w, 3),则每次滑窗与3个channels上的 (k_h, k_w)窗口内的所有值进行卷积操作,得到输出图像中的一个值。
+
-
-### 5.6.2 3D卷积
-3D卷积操作如图所示,同样分为单通道和多通道,且假定只使用1个滤波器,即输出图像仅有一个channel。其中,针对单通道,与2D卷积不同之处在于,输入图像多了一个length维度,卷积核也多了一个k_l维度,因此3D卷积核的尺寸为(k_h, k_w, k_l),每次滑窗与 (k_h, k_w, k_l)窗口内的值进行相关操作,得到输出3D图像中的一个值.针对多通道,则与2D卷积的操作一样,每次滑窗与3个channels上的 (k_h, k_w, k_l) 窗口内的所有值进行相关操作,得到输出3D图像中的一个值。
+- **三维卷积**
+ 3D卷积操作如图所示,同样分为单通道和多通道,且假定只使用1个卷积核,即输出图像仅有一个通道。对于单通道输入,与2D卷积不同之处在于,输入图像多了一个深度(depth)维度,卷积核也多了一个$k_d$维度,因此3D卷积核的尺寸为$(k_h, k_w, k_d)$,每次滑窗与$(k_h, k_w, k_d)$窗口内的值进行相关操作,得到输出3D图像中的一个值。对于多通道输入,则与2D卷积的操作一样,每次滑窗与3个channels上的$(k_h, k_w, k_d)$窗口内的所有值进行相关操作,得到输出3D图像中的一个值。
-
+
## 5.7 有哪些池化方法?
-在构建卷积神经网络时,经常会使用池化操作,而池化层往往在卷积层后面,通过池化操作来降低卷积层输出的特征维度,同时可以防止过拟合现象。池化操作可以降低图像维度的原因,本质上是因为图像具有一种“静态性”的属性,这个意思是说在一个图像区域有用的特征极有可能在另一个区域同样有用。因此,为了描述一个大的图像,很直观的想法就是对不同位置的特征进行聚合统计。例如,可以计算图像在固定区域上特征的平均值 (或最大值)来代表这个区域的特征。[1]
-### 5.7.1 一般池化(General Pooling)
-池化操作与卷积操作不同,过程如下图。
+ 池化操作通常也叫做子采样(Subsampling)或降采样(Downsampling),在构建卷积神经网络时,往往会用在卷积层之后,通过池化来降低卷积层输出的特征维度,有效减少网络参数的同时还可以防止过拟合现象。池化操作可以降低图像维度的原因,本质上是因为图像具有一种“静态性”的属性,这个意思是说在一个图像区域有用的特征极有可能在另一个区域同样有用。因此,为了描述一个大的图像,很直观的想法就是对不同位置的特征进行聚合统计。例如,可以计算图像在固定区域上特征的平均值 (或最大值)来代表这个区域的特征。
+ 表5.6 池化分类
-
-池化操作过程如图所示,对固定区域的特征,使用某一个值来表示。最常见的池化操作有两种,分为平均池化mean pooling和最大池化max pooling
+| 池化类型 | 示意图 | 作用 |
+| :-----------------------------------------: | :-----------------------------------------------: | :----------------------------------------------------------- |
+| 一般池化(General Pooling) |  | 通常包括最大池化(Max Pooling)和平均池化(Mean Pooling)。以最大池化为例,池化范围$(2\times2)$和滑窗步长$(stride=2)$ 相同,仅提取一次相同区域的范化特征。 |
+| 重叠池化(Overlapping Pooling) |  | 与一般池化操作相同,但是池化范围$P_{size}$与滑窗步长$stride$关系为$P_{size}>stride$,同一区域内的像素特征可以参与多次滑窗提取,得到的特征表达能力更强,但计算量更大。 |
+| 空间金字塔池化$^*$(Spatial Pyramid Pooling) |  | 在进行多尺度目标的训练时,卷积层允许输入的图像特征尺度是可变的,紧接的池化层若采用一般的池化方法会使得不同的输入特征输出相应变化尺度的特征,而卷积神经网络中最后的全连接层则无法对可变尺度进行运算,因此需要对不同尺度的输出特征采样到相同输出尺度。 |
-1、平均池化:计算图像区域的平均值作为该区域池化后的值。
+> SPPNet$^{[3]}$就引入了空间池化的组合,对不同输出尺度采用不同的滑窗大小和步长以确保输出尺度相同$(win_{size}=\lceil \frac{in}{out}\rceil; stride=\lfloor \frac{in}{out}\rfloor; )$,同时用如金字塔式叠加的多种池化尺度组合,以提取更加丰富的图像特征。常用于多尺度训练和目标检测中的区域提议网络(Region Proposal Network)的兴趣区域(Region of Interest)提取
-2、最大池化:选图像区域的最大值作为该区域池化后的值。
-上述的池化过程,相邻的池化窗口间没有重叠部分。
-### 5.7.2 重叠池化(General Pooling)
-重叠池化即是一种相邻池化窗口之间会有重叠区域的池化技术。论文中[2]中,作者使用了重叠池化,其他的设置都不变的情况下,top-1和top-5 的错误率分别减少了0.4% 和0.3%。
-### 5.7.3 空金字塔池化(Spatial Pyramid Pooling)
-空间金字塔池化可以将任意尺度的图像卷积特征转化为相同维度,这不仅可以让CNN处理任意尺度的图像,还能避免cropping和warping操作,导致一些信息的丢失。一般的卷积神经网络都需要固定输入图像大小,这是因为全连接层的输入需要固定输入维度,但在卷积操作时并没有对图像大小有限制,所以作者提出了空间金字塔池化方法,先让图像进行卷积操作,然后使用SPP方法转化成维度相同的特征,最后输入到全连接层。
-
+## 5.8 $1\times1$卷积作用?
-根据论文作者所述,空间金字塔池化的思想来自于Spatial Pyramid Model,它是将一个pooling过程变成了多个尺度的pooling。用不同大小的池化窗口作用于卷积特征,这样就可以得到1X1,2X2,4X4的池化结果,由于conv5中共有256个滤波器,所以得到1个256维的特征,4个256个特征,以及16个256维的特征,然后把这21个256维特征链接起来输入全连接层,通过这种方式把不同大小的图像转化成相同维度的特征。
+ NIN(Network in Network)$^{[4]}$是第一篇探索$1\times1$卷积核的论文,这篇论文通过在卷积层中使用MLP替代传统线性的卷积核,使单层卷积层内具有非线性映射的能力,也因其网络结构中嵌套MLP子网络而得名NIN。NIN对不同通道的特征整合到MLP自网络中,让不同通道的特征能够交互整合,使通道之间的信息得以流通,其中的MLP子网络恰恰可以用$1\times1$的卷积进行代替。
-
+ GoogLeNet$^{[5]}$则采用$1\times1$卷积核来减少模型的参数量。在原始版本的Inception模块中,由于每一层网络采用了更多的卷积核,大大增加了模型的参数量。此时在每一个较大卷积核的卷积层前引入$1\times1$卷积,可以通过分离通道与宽高卷积来减少模型参数量。以图5.2为例,在不考虑参数偏置项的情况下,若输入和输出的通道数为$C_1=16$,则左半边网络模块所需的参数为$(1\times1+3\times3+5\times5+0)\times C_1\times C_1=8960$;假定右半边网络模块采用的$1\times1$卷积通道数为$C_2=8$$(满足C_1>C_2)$,则右半部分的网络结构所需参数量为$(1\times1\times (3C_1+C_2)+3\times3\times C_2 +5\times5\times C_2)\times C_1=5248$ ,可以在不改变模型表达能力的前提下大大减少所使用的参数量。
-对于不同的图像,如果想要得到相同大小的pooling结果,就需要根据图像大小动态的计算池化窗口大小和步长。假设conv5输出的大小为a*a,需要得到n*n大小的池化结果,可以让窗口大小sizeX为[a/n],步长为[a/n]。下图展示了以conv5输出大小是13*13为例,spp算法的各层参数。
+
-
+ 图5.2 Inception模块
-总结来说,SPP方法其实就是一种使用多个尺度的池化方法,可以获取图像中的多尺度信息。在卷积神经网络中加入SPP后,可以让CNN处理任意大小的输入,这让模型变得更加的灵活。
+综上所述,$1\times 1$卷积的作用主要为以下两点:
-## 5.8 1x1卷积作用?
-1×1的卷积主要有以下两个方面的作用:
-
-1. 实现信息的跨通道交互和整合。
-
-2. 对卷积核通道数进行降维和升维,减小参数量。
-
-下面详细解释一下:
-**第一点 实现信息的跨通道交互和整合**
-对1×1卷积层的探讨最初是出现在NIN的结构,论文作者的动机是利用MLP代替传统的线性卷积核,从而提高网络的表达能力。文中从跨通道池化的角度进行解释,认为文中提出的MLP其实等价于在传统卷积核后面接cccp层,从而实现多个feature map的线性组合,实现跨通道的信息整合。而查看代码实现,cccp层即等价于1×1卷积层。
-**第二点 对卷积核通道数进行降维和升维,减小参数量**
-1x1卷积层能带来降维和升维的效果,在一系列的GoogLeNet中体现的最明显。对于每一个Inception模块(如下图),左图是原始模块,右图是加入1×1卷积进行降维的模块。虽然左图的卷积核都比较小,但是当输入和输出的通道数很大时,卷积核的参数量也会变的很大,而右图加入1×1卷积后可以降低输入的通道数,因此卷积核参数、运算复杂度也就大幅度下降。以GoogLeNet的3a模块为例,输入的feature map是28×28×192,3a模块中1×1卷积通道为64,3×3卷积通道为128,5×5卷积通道为32,如果是左图结构,那么卷积核参数为1×1×192×64+3×3×192×128+5×5×192×32,而右图对3×3和5×5卷积层前分别加入了通道数为96和16的1×1卷积层,这样卷积核参数就变成了1×1×192×64+(1×1×192×96+3×3×96×128)+(1×1×192×16+5×5×16×32),参数大约减少到原来的三分之一。同时在并行pooling层后面加入1×1卷积层后也可以降低输出的feature map数量,左图pooling后feature map是不变的,再加卷积层得到的feature map,会使输出的feature map扩大到416,如果每个模块都这样,网络的输出会越来越大。而右图在pooling后面加了通道数为32的1×1卷积,使得输出的feature map数降到了256。GoogLeNet利用1×1的卷积降维后,得到了更为紧凑的网络结构,虽然总共有22层,但是参数数量却只是8层AlexNet的十二分之一,当然其中也有丢掉全连接层的原因。
-
-
-而非常经典的ResNet结构,同样也使用了1×1卷积,并且是在3×3卷积层的前后都使用了,不仅进行了降维,还进行了升维,使得卷积层的输入和输出的通道数都减小,参数数量进一步减少,如下图结构所示。
-
-
+- 实现信息的跨通道交互和整合。
+- 对卷积核通道数进行降维和升维,减小参数量。
## 5.9 卷积层和池化层有什么区别?
-首先可以从结构上可以看出,卷积之后输出层的维度减小,深度变深。但池化层深度不变。同时池化可以把很多数据用最大值或者平均值代替。目的是降低数据量。降低训练的参数。对于输入层,当其中像素在邻域发生微小位移时,池化层的输出是不变的,从而能提升鲁棒性。而卷积则是把数据通过一个卷积核变化成特征,便于后面的分离。
+ 卷积层核池化层在结构上具有一定的相似性,都是对感受域内的特征进行提取,并且根据步长设置获取到不同维度的输出,但是其内在操作是有本质区别的,如表5.7所示。
-1:卷积
+| | 卷积层 | 池化层 |
+| :--------: | :------------------------------------: | :------------------------------: |
+| **结构** | 零填充时输出维度不变,而通道数改变 | 通常特征维度会降低,通道数不变 |
+| **稳定性** | 输入特征发生细微改变时,输出结果会改变 | 感受域内的细微变化不影响输出结果 |
+| **作用** | 感受域内提取局部关联特征 | 感受域内提取泛化特征,降低维度 |
+| **参数量** | 与卷积核尺寸、卷积核个数相关 | 不引入额外参数 |
-当从一个大尺寸图像中随机选取一小块,比如说 8x8 作为样本,并且从这个小块样本中学习到了一些特征,这时我们可以把从这个 8x8 样本中学习到的特征作为探测器,应用到这个图像的任意地方中去。特别是,我们可以用从 8x8 样本中所学习到的特征跟原本的大尺寸图像作卷积,从而对这个大尺寸图像上的任一位置获得一个不同特征的激活值。
-下面给出一个具体的例子:假设你已经从一个 96x96 的图像中学习到了它的一个 8x8 的样本所具有的特征,假设这是由有 100 个隐含单元的自编码完成的。为了得到卷积特征,需要对 96x96 的图像的每个 8x8 的小块图像区域都进行卷积运算。也就是说,抽取 8x8 的小块区域,并且从起始坐标开始依次标记为(1,1),(1,2),...,一直到(89,89),然后对抽取的区域逐个运行训练过的稀疏自编码来得到特征的激活值。在这个例子里,显然可以得到 100 个集合,每个集合含有 89x89 个卷积特征。
-
+## 5.10 卷积核是否一定越大越好?
-2:说下池化,其实池化很容易理解,先看图:
+ 在早期的卷积神经网络中(如LeNet-5、AlexNet),用到了一些较大的卷积核($11\times11$和$5\times 5$),受限于当时的计算能力和模型结构的设计,无法将网络叠加得很深,因此卷积网络中的卷积层需要设置较大的卷积核以获取更大的感受域。但是这种大卷积核反而会导致计算量大幅增加,不利于训练更深层的模型,相应的计算性能也会降低。后来的卷积神经网络(VGG、GoogLeNet等),发现通过堆叠2个$3\times 3$卷积核可以获得与$5\times 5$卷积核相同的感受视野,同时参数量会更少($3×3×2+1$ < $ 5×5×1+1$),$3\times 3$卷积核被广泛应用在许多卷积神经网络中。因此可以认为,在大多数情况下通过堆叠较小的卷积核比直接采用单个更大的卷积核会更加有效。
-转自: http://blog.csdn.net/silence1214/article/details/11809947
+ 但是,这并不是表示更大的卷积核就没有作用,在某些领域应用卷积神经网络时仍然可以采用较大的卷积核。譬如在自然语言处理领域,由于文本内容不像图像数据可以对特征进行很深层的抽象,往往在该领域的特征提取只需要较浅层的神经网络即可。在将卷积神经网络应用在自然语言处理领域时,通常都是较为浅层的卷积层组成,但是文本特征有时又需要有较广的感受域让模型能够组合更多的特征(如词组和字符),此时直接采用较大的卷积核将是更好的选择。
-
+ 综上所述,卷积核的大小并没有绝对的优劣,需要视具体的应用场景而定,但是极大和极小的卷积核都是不合适的,单独的$1\times 1$极小卷积核只能用作分离卷积而不能对输入的原始特征进行有效的组合,极大的卷积核通常会组合过多的无意义特征从而浪费了大量的计算资源。
-比如上方左侧矩阵A是20*20的矩阵要进行大小为10*10的池化,那么左侧图中的红色就是10*10的大小,对应到右侧的矩阵,右侧每个元素的值,是左侧红色矩阵每个元素的值得和再处于红色矩阵的元素个数,也就是平均值形式的池化。
-3:上面说了下卷积和池化,再说下计算中需要注意到的。在代码中使用的是彩色图,彩色图有3个通道,那么对于每一个通道来说要单独进行卷积和池化,有一个地方尤其是进行卷积的时候要注意到,隐藏层的每一个值是对应到一幅图的3个通道穿起来的,所以分3个通道进行卷积之后要加起来,正好才能对应到一个隐藏层的神经元上,也就是一个feature上去。
-## 5.10 卷积核是否一定越大越好?
-首先,给出答案。不是。
-在AlexNet网络结构中,用到了一些非常大的卷积核,比如11×11、5×5卷积核。之前研究者的想法是,卷积核越大,receptive field(感受野)越大,因此获得的特征越好。虽说如此,但是大的卷积核会导致计算量大幅增加,不利于训练更深层的模型,而相应的计算性能也会降低。于是在VGG、Inception网络中,实验发现利用2个3×3卷积核的组合比1个5×5卷积核的效果更佳,同时参数量(3×3×2+1 VS 5×5×1+1)会更少,因此后来3×3卷积核被广泛应用在各种模型中。
+## 5.11 每层卷积是否只能用一种尺寸的卷积核?
-多个小卷积核的叠加使用远比一个大卷积核单独使用效果要好的多,在连通性不变的情况下,大大降低了参数量和计算复杂度。当然,卷积核也不是越小越好,对于特别稀疏的数据,当使用比较小的卷积核的时候可能无法表示其特征,如果采用较大的卷积核则会导致复杂度极大的增加。
+ 经典的神经网络一般都属于层叠式网络,每层仅用一个尺寸的卷积核,如VGG结构中使用了大量的$3×3$卷积层。事实上,同一层特征图可以分别使用多个不同尺寸的卷积核,以获得不同尺度的特征,再把这些特征结合起来,得到的特征往往比使用单一卷积核的要好,如GoogLeNet、Inception系列的网络,均是每层使用了多个卷积核结构。如图5.3所示,输入的特征在同一层分别经过$1×1$、$3×3$和$5×5$三种不同尺寸的卷积核,再将分别得到的特征进行整合,得到的新特征可以看作不同感受域提取的特征组合,相比于单一卷积核会有更强的表达能力。
-总而言之,我们多倾向于选择多个相对小的卷积核来进行卷积。
+
-## 5.11 每层卷积是否只能用一种尺寸的卷积核?
-经典的神经网络,都属于层叠式网络,并且每层仅用一个尺寸的卷积核,例如VGG结构中使用了大量的3×3卷积层。事实上,同一层feature map可以分别使用多个不同尺寸的卷积核,以获得不同尺度的特征,再把这些特征结合起来,得到的特征往往比使用单一卷积核的要好,例如GoogLeNet、Inception系列的网络,均是每层使用了多个卷积核结构。如下图所示,输入的feature map在同一层,分别经过1×1、3×3、5×5三种不同尺寸的卷积核,再将分别得到的特征进行组合。
-
+ 图5.3 Inception模块结构
## 5.12 怎样才能减少卷积层参数量?
-发明GoogleNet的团队发现,如果仅仅引入多个尺寸的卷积核,会带来大量的额外的参数,受到Network In Network中1×1卷积核的启发,为了解决这个问题,他们往Inception结构中加入了一些1×1的卷积核,如图所示:
+减少卷积层参数量的方法可以简要地归为以下几点:
-
+- 使用堆叠小卷积核代替大卷积核:VGG网络中2个$3\times 3$的卷积核可以代替1个$5\times 5$的卷积核
+- 使用分离卷积操作:将原本$K\times K\times C$的卷积操作分离为$K\times K\times 1$和$1\times1\times C$的两部分操作
+- 添加$1\times 1$的卷积操作:与分离卷积类似,但是通道数可变,在$K\times K\times C_1$卷积前添加$1\times1\times C_2$的卷积核(满足$C_2 注1:(Avy pooling现在不怎么用了,方法是对每一个2*2的区域元素求和,再除以4,得到主要特征),而一般的filter取2*2,最大取3*3,stride取2,压缩为原来的1/4.
->注2:这里的pooling操作是特征图缩小,有可能影响网络的准确度,因此可以通过增加特征图的深度来弥补。
-## 5.19 理解图像卷积与反卷积
+## 5.15 理解转置卷积与棋盘效应
-### 5.19.1 图像卷积
+### 5.15.1 标准卷积
+在理解转置卷积之前,需要先理解标准卷积的运算方式。
首先给出一个输入输出结果

-那他是怎样计算的呢?
+那是怎样计算的呢?
卷积的时候需要对卷积核进行180的旋转,同时卷积核中心与需计算的图像像素对齐,输出结构为中心对齐像素的一个新的像素值,计算例子如下:
-
+
这样计算出左上角(即第一行第一列)像素的卷积后像素值。
给出一个更直观的例子,从左到右看,原像素经过卷积由1变成-8。
-
-
-通过滑动卷积核,就可以得到整张图片的卷积结果
-
-
-
-### 5.19.2 图像反卷积
-
-这里提到的反卷积跟1维信号处理的反卷积计算是很不一样的,FCN作者称为backwards convolution,有人称Deconvolution layer is a very unfortunate name and should rather be called a transposed convolutional layer. 我们可以知道,在CNN中有con layer与pool layer,con layer进行对图像卷积提取特征,pool layer 对图像缩小一半筛选重要特征,对于经典的图像识别CNN网络,如IMAGENET,最后输出结果是1X1X1000,1000是类别种类,1x1得到的是。FCN作者,或者后来对end to end研究的人员,就是对最终1x1的结果使用反卷积(事实上FCN作者最后的输出不是1X1,是图片大小的32分之一,但不影响反卷积的使用)。
-
-这里图像的反卷积与full卷积原理是一样的,使用了这一种反卷积手段使得图像可以变大,FCN作者使用的方法是这里所说反卷积的一种变体,这样就可以获得相应的像素值,图像可以实现end to end。
+
-
-
-
+通过滑动卷积核,就可以得到整张图片的卷积结果。
-这里说另外一种反卷积做法,假设原图是3*3,首先使用上采样让图像变成7*7,可以看到图像多了很多空白的像素点。使用一个3*3的卷积核对图像进行滑动步长为1的valid卷积,得到一个5*5的图像,我们知道的是使用上采样扩大图片,使用反卷积填充图像内容,使得图像内容变得丰富,这也是CNN输出end to end结果的一种方法。韩国作者Hyeonwoo Noh使用VGG16层CNN网络后面加上对称的16层反卷积与上采样网络实现end to end 输出,其不同层上采样与反卷积变化效果如下:
-
-
-
-经过上面的解释与推导,对卷积有基本的了解,但是在图像上的deconvolution究竟是怎么一回事,可能还是不能够很好的理解,因此这里再对这个过程解释一下。 目前使用得最多的deconvolution有2种,上文都已经介绍。
-
-* 方法1:full卷积, 完整的卷积可以使得原来的定义域变大。
-* 方法2:记录pooling index,然后扩大空间,再用卷积填充。
+### 5.15.2 转置卷积
图像的deconvolution过程如下:
-
+
输入:2x2, 卷积核:4x4, 滑动步长:3, 输出:7x7
-即输入为2x2的图片经过4x4的卷积核进行步长为3的反卷积的过程
+过程如下:
1. 输入图片每个像素进行一次full卷积,根据full卷积大小计算可以知道每个像素的卷积后大小为 1+4-1=4, 即4x4大小的特征图,输入有4个像素所以4个4x4的特征图
-2. 将4个特征图进行步长为3的fusion(即相加); 例如红色的特征图仍然是在原来输入位置(左上角),绿色还是在原来的位置(右上角),步长为3是指每隔3个像素进行fusion,重叠部分进行相加,即输出的第1行第4列是由红色特阵图的第一行第四列与绿色特征图的第一行第一列相加得到,其他如此类推。
-
-可以看出翻卷积的大小是由卷积核大小与滑动步长决定, in是输入大小, k是卷积核大小, s是滑动步长, out是输出大小 得到 out = (in - 1) * s + k 上图过程就是, (2 - 1) * 3 + 4 = 7
-
-## 5.20 不同卷积后图像大小计算?
-
-### 5.20.1 类型划分
-
-2维卷积的计算分为了3类:1.full 2.same 3. valid
-
-1、**full**
-
-
-
-蓝色为原图像,白色为对应卷积所增加的padding,通常全部为0,绿色是卷积后图片。图6的卷积的滑动是从卷积核右下角与图片左上角重叠开始进行卷积,滑动步长为1,卷积核的中心元素对应卷积后图像的像素点。可以看到卷积后的图像是4X4,比原图2X2大了,我们还记1维卷积大小是n1+n2-1,这里原图是2X2,卷积核3X3,卷积后结果是4X4,与一维完全对应起来了。其实这才是完整的卷积计算,其他比它小的卷积结果都是省去了部分像素的卷积
-
-2、**same**
-
-
-3、**valid**
+2. 将4个特征图进行步长为3的相加; 输出的位置和输入的位置相同。步长为3是指每隔3个像素进行相加,重叠部分进行相加,即输出的第1行第4列是由红色特阵图的第一行第四列与绿色特征图的第一行第一列相加得到,其他如此类推。
-
+ 可以看出翻卷积的大小是由卷积核大小与滑动步长决定, in是输入大小, k是卷积核大小, s是滑动步长, out是输出大小 得到 out = (in - 1) * s + k 上图过程就是, (2 - 1) * 3 + 4 = 7。
-### 5.20.2 计算公式
-这里,我们可以总结出full,same,valid三种卷积后图像大小的计算公式:
+### 5.15.3 棋盘效应
-1. full: 滑动步长为1,图片大小为N1xN1,卷积核大小为N2xN2,卷积后图像大小:N1+N2-1 x N1+N2-1。
-2. same: 滑动步长为1,图片大小为N1xN1,卷积核大小为N2xN2,卷积后图像大小:N1xN1。
-3. valid:滑动步长为S,图片大小为N1xN1,卷积核大小为N2xN2,卷积后图像大小:(N1-N2)/S+1 x (N1-N2)/S+1。
+## 5.16 卷积神经网络的参数设置
+ 卷积神经网络中常见的参数在其他类型的神经网络中也是类似的,但是参数的设置还得结合具体的任务才能设置在合理的范围,具体的参数列表如表XX所示。
+ 表XX 卷积神经网络常见参数
-## 5.21 步长、填充大小与输入输出关系总结?
+| 参数名 | 常见设置 | 参数说明 |
+| :----: | :-----: | :---- |
+| 学习率(Learning Rate) | $0-1$ | 反向传播网络中更新权值矩阵的步长,在一些常见的网络中会在固定迭代次数或模型不再收敛后对学习率进行指数下降(如$lr=lr\times 0.1$)。当学习率越大计算误差对权值矩阵的影响越大,容易在某个局部最优解附近震荡;越小的学习率对网络权值的更新越精细,但是需要花费更多的时间去迭代 |
+| 批次大小(Batch Size) | $1-N$ | 批次大小指定一次性流入模型的数据样本个数,根据任务和计算性能限制判断实际取值,在一些图像任务中往往由于计算性能和存储容量限制只能选取较小的值。在相同迭代次数的前提下,数值越大模型越稳定,泛化能力越强,损失值曲线越平滑,模型也更快地收敛,但是每次迭代需要花费更多的时间 |
+| 数据轮次(Epoch) | $1-N$ | 数据轮次指定所有训练数据在模型中训练的次数,根据数据集规模和分布情况会设置为不同的值。当模型较为简单或训练数据规模较小时,通常轮次不宜过高,否则模型容易过拟合;模型较为复杂或训练数据规模足够大时,可适当提高数据的训练轮次。 |
+| 权重衰减系数(Weight Decay) | $0-0.001$ | 模型训练过程中反向传播权值更新的权重衰减值 |
-在设计深度学习网络的时候,需要计算输入尺寸和输出尺寸,那么就要设计卷积层的的各种参数。这里有一些设计时候的计算公式,方便得到各层的参数。
+## 5.17 提高卷积神经网络的泛化能力
+ 卷积神经网络与其他类型的神经网络类似,在采用反向传播进行训练的过程中比较依赖输入的数据分布,当数据分布较为极端的情况下容易导致模型欠拟合或过拟合,表XX记录了提高卷积网络泛化能力的方法。
+ 表XX 提高卷积网络化能力的方法
-这里简化下,约定:
+| 方法 | 说明 |
+| :---: | :--- |
+| 使用更多数据 | 在有条件的前提下,尽可能多地获取训练数据是最理想的方法,更多的数据可以让模型得到充分的学习,也更容易提高泛化能力 |
+| 使用更大批次 | 在相同迭代次数和学习率的条件下,每批次采用更多的数据将有助于模型更好的学习到正确的模式,模型输出结果也会更加稳定 |
+| 调整数据分布 | 大多数场景下的数据分布是不均匀的,模型过多地学习某类数据容易导致其输出结果偏向于该类型的数据,此时通过调整输入的数据分布可以一定程度提高泛化能力 |
+| 调整目标函数 | 在某些情况下,目标函数的选择会影响模型的泛化能力,如目标函数$f(y,y')=|y-y'|$在某类样本已经识别较为准确而其他样本误差较大的侵害概况下,不同类别在计算损失结果的时候距离权重是相同的,若将目标函数改成$f(y,y')=(y-y')^2$则可以使误差小的样本计算损失的梯度比误差大的样本更小,进而有效地平衡样本作用,提高模型泛化能力 |
+| 调整网络结构 | 在浅层卷积神经网络中,参数量较少往往使模型的泛化能力不足而导致欠拟合,此时通过叠加卷积层可以有效地增加网络参数,提高模型表达能力;在深层卷积网络中,若没有充足的训练数据则容易导致模型过拟合,此时通过简化网络结构减少卷积层数可以起到提高模型泛化能力的作用 |
+| 数据增强 | 数据增强又叫数据增广,在有限数据的前提下通过平移、旋转、加噪声等一些列变换来增加训练数据,同类数据的表现形式也变得更多样,有助于模型提高泛化能力,需要注意的是数据变化应尽可能不破坏元数数据的主体特征(如在图像分类任务中对图像进行裁剪时不能将分类主体目标裁出边界)。 |
+| 权值正则化 | 权值正则化就是通常意义上的正则化,一般是在损失函数中添加一项权重矩阵的正则项作为惩罚项,用来惩罚损失值较小时网络权重过大的情况,此时往往是网络权值过拟合了数据样本(如$Loss=f(WX+b,y')+\frac{\lambda}{\eta}\sum{|W|}$)。 |
+| 屏蔽网络节点 | 该方法可以认为是网络结构上的正则化,通过随机性地屏蔽某些神经元的输出让剩余激活的神经元作用,可以使模型的容错性更强。 |
+> 对大多数神经网络模型同样通用
-
-### 5.21.1 没有0填充,单位步长
+## 5.18 卷积神经网络在不同领域的应用
+ 卷积神经网络中的卷积操作是其关键组成,而卷积操作只是一种数学运算方式,实际上对不同类型的数值表示数据都是通用的,尽管这些数值可能表示的是图像像素值、文本序列中单个字符或是语音片段中单字的音频。只要使原始数据能够得到有效地数值化表示,卷积神经网络能够在不同的领域中得到应用,要关注的是如何将卷积的特性更好地在不同领域中应用,如表XX所示。
+ 表XX 卷积神经网络不同领域的应用
+| 应用领域 | 输入数据图示 | 说明 |
+| :-----: | :----------: | :-- |
+| 图像处理 |  | 卷积神经网络在图像处理领域有非常广泛的应用,这是因为图像数据本身具有的局部完整性非常 |
+| 自然语言处理 |  | |
+| 语音处理 |  | |
-
+### 5.18.1 联系
-### 5.21.2 零填充,单位步长
+ 自然语言处理是对一维信号(词序列)做操作。
+ 计算机视觉是对二维(图像)或三维(视频流)信号做操作。
-
+### 5.18.2 区别
-<1>半填充
-
+ 自然语言处理的输入数据通常是离散取值(例如表示一个单词或字母通常表示为词典中的one hot向量),计算机视觉则是连续取值(比如归一化到0,1之间的灰度值)。CNN有两个主要特点,区域不变性(location invariance)和组合性(Compositionality)。
-<2>全填充
-
-
-参考图如下图所示
-
-
-
-
-### 5.21.3 不填充,非单位步长
+1. 区域不变性:滤波器在每层的输入向量(图像)上滑动,检测的是局部信息,然后通过pooling取最大值或均值。pooling这步综合了局部特征,失去了每个特征的位置信息。这很适合基于图像的任务,比如要判断一幅图里有没有猫这种生物,你可能不会去关心这只猫出现在图像的哪个区域。但是在NLP里,词语在句子或是段落里出现的位置,顺序,都是很重要的信息。
+2. 局部组合性:CNN中,每个滤波器都把较低层的局部特征组合生成较高层的更全局化的特征。这在CV里很好理解,像素组合成边缘,边缘生成形状,最后把各种形状组合起来得到复杂的物体表达。在语言里,当然也有类似的组合关系,但是远不如图像来的直接。而且在图像里,相邻像素必须是相关的,相邻的词语却未必相关。
-
+## 5.19 卷积神经网络凸显共性的方法?
-### 5.21.4 零填充,非单位步长
+### 5.19.1 局部连接
-
-
-
-
+ 我们首先了解一个概念,感受野,即每个神经元仅与输入神经元相连接的一块区域。
+在图像卷积操作中,神经元在空间维度上是局部连接,但在深度上是全连接。局部连接的思想,是受启发于生物学里的视觉系统结构,视觉皮层的神经元就是仅用局部接受信息。对于二维图像,局部像素关联性较强。这种局部连接保证了训练后的滤波器能够对局部特征有最强的响应,使神经网络可以提取数据的局部特征;
+下图是一个很经典的图示,左边是全连接,右边是局部连接。
-http://blog.csdn.net/u011692048/article/details/77572024
-https://arxiv.org/pdf/1603.07285.pdf
+
-## 5.22 理解反卷积和棋盘效应
+对于一个1000 × 1000的输入图像而言,如果下一个隐藏层的神经元数目为10^6个,采用全连接则有1000 × 1000 × 10^6 = 10^12个权值参数,如此巨大的参数量几乎难以训练;而采用局部连接,隐藏层的每个神经元仅与图像中10 × 10的局部图像相连接,那么此时的权值参数数量为10 × 10 × 10^6 = 10^8,将直接减少4个数量级。
-### 5.22.1 为什么出现棋盘现象?
+### 5.19.2 权值共享
-图像生成网络的上采样部分通常用反卷积网络,不合理的卷积核大小和步长会使反卷积操作产生棋盘效应 (checkerboard artifacts)。
+ 权值共享,即计算同一深度的神经元时采用的卷积核参数是共享的。权值共享在一定程度上讲是有意义的,是由于在神经网络中,提取的底层边缘特征与其在图中的位置无关。但是在另一些场景中是无意的,如在人脸识别任务,我们期望在不同的位置学到不同的特征。
+需要注意的是,权重只是对于同一深度切片的神经元是共享的。在卷积层中,通常采用多组卷积核提取不同的特征,即对应的是不同深度切片的特征,而不同深度切片的神经元权重是不共享。相反,偏置这一权值对于同一深度切片的所有神经元都是共享的。
+权值共享带来的好处是大大降低了网络的训练难度。如下图,假设在局部连接中隐藏层的每一个神经元连接的是一个10 × 10的局部图像,因此有10 × 10个权值参数,将这10 × 10个权值参数共享给剩下的神经元,也就是说隐藏层中10^6个神经元的权值参数相同,那么此时不管隐藏层神经元的数目是多少,需要训练的参数就是这 10 × 10个权值参数(也就是卷积核的大小)。
-
-
+
-重叠图案也在二维中形成。两个轴上的不均匀重叠相乘,产生不同亮度的棋盘状图案。
+这里就体现了卷积神经网络的奇妙之处,使用少量的参数,却依然能有非常出色的性能。上述仅仅是提取图像一种特征的过程。如果要多提取出一些特征,可以增加多个卷积核,不同的卷积核能够得到图像不同尺度下的特征,称之为特征图(feature map)。
-事实上,不均匀重叠往往在二维上更极端!因为两个模式相乘,所以它的不均匀性是原来的平方。例如,在一个维度中,一个步长为2,大小为3的反卷积的输出是其输入的两倍,但在二维中,输出是输入的4倍。
+### 5.19.3 池化操作
-现在,生成图像时,神经网络通常使用多层反卷积,从一系列较低分辨率的描述中迭代建立更大的图像。虽然这些堆栈的反卷积可以消除棋盘效应,但它们经常混合,在更多尺度上产生棋盘效应。
+池化操作与多层次结构一起,实现了数据的降维,将低层次的局部特征组合成为较高层次的特征,从而对整个图片进行表示。如下图:
-直观地看,假设生成的图像中包含1只黑猫。黑猫身体部分的像素颜色应平滑过渡,或极端地说,该部分应全为黑色。实际生成的图像中该部分却有深深浅浅的近黑方块组成,很像棋盘的网格,即棋盘效应。
+
-https://distill.pub/2016/deconv-checkerboard/
-http://blog.csdn.net/shadow_guo/article/details/52862161
+## 5.20 全连接、局部连接、全卷积与局部卷积
+ 大多数神经网络中高层网络通常会采用全连接层(Global Connected Layer),通过多对多的连接方式对特征进行全局汇总,可以有效地提取全局信息。但是全连接的方式需要大量的参数,是神经网络中最占资源的部分之一,因此就需要由局部连接(Local Connected Layer),仅在局部区域范围内产生神经元连接,能够有效地减少参数量。根据卷积操作的作用范围可以分为全卷积(Global Convolution)和局部卷积(Local Convolution)。实际上这里所说的全卷积就是标准卷积,即在整个输入特征维度范围内采用相同的卷积核参数进行运算,全局共享参数的连接方式可以使神经元之间的连接参数大大减少;局部卷积又叫平铺卷积(Tiled Convolution)或非共享卷积(Unshared Convolution),是局部连接与全卷积的折衷。四者的比较如表XX所示。
+ 表XX 卷积网络中连接方式的对比
-### 5.22.2 有哪些方法可以避免棋盘效应?
+| 连接方式 | 示意图 | 说明 |
+| :------: | :---: | :--- |
+| 全连接 |  | 层间神经元完全连接,每个输出神经元可以获取到所有输入神经元的信息,有利于信息汇总,常置于网络末层;连接与连接之间独立参数,大量的连接大大增加模型的参数规模。 |
+| 局部连接 |  | 层间神经元只有局部范围内的连接,在这个范围内采用全连接的方式,超过这个范围的神经元则没有连接;连接与连接之间独立参数,相比于全连接减少了感受域外的连接,有效减少参数规模 |
+| 全卷积 |  | 层间神经元只有局部范围内的连接,在这个范围内采用全连接的方式,连接所采用的参数在不同感受域之间共享,有利于提取特定模式的特征;相比于局部连接,共用感受域之间的参数可以进一步减少参数量。 |
+| 局部卷积 |  | 层间神经元只有局部范围内的连接,感受域内采用全连接的方式,而感受域之间间隔采用局部连接与全卷积的连接方式;相比与全卷积成倍引入额外参数,但有更强的灵活性和表达能力;相比于局部连接,可以有效控制参数量 |
-(1)第一种方法是用到的反卷积核的大小可被步长整除,从而避免重叠效应。与最近成功用于图像超分辨率的技术“子像素卷积”(sub-pixel convolution)等价。
-
+## 5.21 局部卷积的应用
-(2)另一种方法是从卷积操作中分离出对卷积后更高分辨率的特征图上采样来计算特征。例如,可以先缩放图像(最近邻插值或双线性插值),再卷积。
+并不是所有的卷积都会进行权重共享,在某些特定任务中,会使用不权重共享的卷积。下面通过人脸这一任务来进行讲解。在读人脸方向的一些paper时,会发现很多都会在最后加入一个Local Connected Conv,也就是不进行权重共享的卷积层。总的来说,这一步的作用就是使用3D模型来将人脸对齐,从而使CNN发挥最大的效果。
+
-
+截取论文中的一部分图,经过3D对齐以后,形成的图像均是152×152,输入到上述的网络结构中。该结构的参数如下:
-反卷积与不同缩放卷积方法都是线性操作,并可用矩阵去解释。对于每个输出窗口,反卷积操作的输入唯一,缩放卷积会以阻碍高频棋盘效应的方式来隐式地集中权重(weight-tying)。
+Conv:32个11×11×3的卷积核,
-#### 缩放卷积
+Max-pooling: 3×3,stride=2,
-缩放卷积为线性操作:假设原图像为A,经过插值后的图像为A+B;用卷积核C对插值缩放后的图像卷积,得到最终的图像 ,其中*为卷积操作。则可将缩放卷积分解为原图像卷积和插值增量图像卷积,或卷积的原图像和卷积的插值增量图像。
+Conv: 16个9×9的卷积核,
-C为卷积操作的卷积核。此时为上采样,理解为反卷积操作中的卷积核。
+Local-Conv: 16个9×9的卷积核,
-(1)最近邻缩放卷积
+Local-Conv: 16个7×7的卷积核,
-
+Local-Conv: 16个5×5的卷积核,
-发现,插值增量图像表示的矩阵为原图像表示的矩阵下移1行。可将原图像矩阵看成环形队列(队列最后1行的输出送入队列的第1行)。
+Fully-connected: 4096维,
-(2)双线性缩放卷积
+Softmax: 4030维。
-
+前三层的目的在于提取低层次的特征,比如简单的边和纹理。其中Max-pooling层使得卷积的输出对微小的偏移情况更加鲁棒。但不能使用更多的Max-pooling层,因为太多的Max-pooling层会使得网络损失图像信息。全连接层将上一层的每个单元和本层的所有单元相连,用来捕捉人脸图像不同位置特征之间的相关性。最后使用softmax层用于人脸分类。
+中间三层都是使用参数不共享的卷积核,之所以使用参数不共享,有如下原因:
-发现,插值增量图像可细分为原图像表示的矩阵下移1行后乘以1/2与原图像表示的矩阵上移1行后乘以1/2。
+(1)对齐的人脸图片中,不同的区域会有不同的统计特征,因此并不存在特征的局部稳定性,所以使用相同的卷积核会导致信息的丢失。
-## 5.23 CNN主要的计算瓶颈
+(2)不共享的卷积核并不增加inference时特征的计算量,仅会增加训练时的计算量。
+使用不共享的卷积核,由于需要训练的参数量大大增加,因此往往需要通过其他方法增加数据量。
-CNN的训练主要是在卷积层和子采样层的交互上,其主要的计算瓶颈是:
-* 1)前向传播过程:下采样每个卷积层的maps;
-* 2)反向传播过程:上采样高层子采样层的灵敏度map,以匹配底层的卷积层输出maps的大小;
-* 3)sigmoid的运用和求导。
+## 5.22 NetVLAD池化 (贡献者:熊楚原-中国人民大学)
-举例:
+NetVLAD是论文\[15\]提出的一个局部特征聚合的方法。
-对于第一和第二个问题,我们考虑的是如何用Matlab内置的图像处理函数去实现上采样和下采样的操作。对于上采样,imresize函数可以搞定,但需要很大的开销。一个比较快速的版本是使用Kronecker乘积函数kron。通过一个全一矩阵ones来和我们需要上采样的矩阵进行Kronecker乘积,就可以实现上采样的效果。对于前向传播过程中的下采样,imresize并没有提供在缩小图像的过程中还计算nxn块内像素的和的功能,所以没法用。一个比较好和快速的方法是用一个全一的卷积核来卷积图像,然后简单的通过标准的索引方法来采样最后卷积结果。例如,如果下采样的域是2x2的,那么我们可以用2x2的元素全是1的卷积核来卷积图像。然后再卷积后的图像中,我们每个2个点采集一次数据,y=x(1:2:end,1:2:end),这样就可以得到了两倍下采样,同时执行求和的效果。
+在传统的网络里面,例如VGG啊,最后一层卷积层输出的特征都是类似于Batchsize x 3 x 3 x 512的这种东西,然后会经过FC聚合,或者进行一个Global Average Pooling(NIN里的做法),或者怎么样,变成一个向量型的特征,然后进行Softmax or 其他的Loss。
-对于第三个问题,实际上有些人以为Matlab中对sigmoid函数进行inline的定义会更快,其实不然,Matlab与C/C++等等语言不一样,Matlab的inline反而比普通的函数定义更费时间。所以,我们可以直接在代码中使用计算sigmoid函数及其导数的真实代码。
+这种方法说简单点也就是输入一个图片或者什么的结构性数据,然后经过特征提取得到一个长度固定的向量,之后可以用度量的方法去进行后续的操作,比如分类啊,检索啊,相似度对比等等。
-## 5.24 卷积神经网络的经验参数设置
-对于卷积神经网络的参数设置,没有很明确的指导原则,以下仅是一些经验集合。
+那么NetVLAD考虑的主要是最后一层卷积层输出的特征这里,我们不想直接进行欠采样或者全局映射得到特征,对于最后一层输出的W x H x D,设计一个新的池化,去聚合一个“局部特征“,这即是NetVLAD的作用。
-1、learning-rate 学习率:学习率越小,模型收敛花费的时间就越长,但是可以逐步稳健的提高模型精确度。一般初始设置为0.1,然后每次除以0.2或者0.5来改进,得到最终值;
+NetVLAD的一个输入是一个W x H x D的图像特征,例如VGG-Net最后的3 x 3 x 512这样的矩阵,在网络中还需加一个维度为Batchsize。
-2、batch-size 样本批次容量:影响模型的优化程度和收敛速度,需要参考你的数据集大小来设置,具体问题具体分析,一般使用32或64,在计算资源允许的情况下,可以使用大batch进行训练。有论文提出,大batch可以加速训练速度,并取得更鲁棒的结果;
+NetVLAD还需要另输入一个标量K即表示VLAD的聚类中心数量,它主要是来构成一个矩阵C,是通过原数据算出来的每一个$W \times H$特征的聚类中心,C的shape即$C: K \times D$,然后根据三个输入,VLAD是计算下式的V:
-3、weight-decay 权重衰减:用来在反向传播中更新权重和偏置,一般设置为0.005或0.001;
+$$V(j, k) = \sum_{i=1}^{N}{a_k(x_i)(x_i(j) - c_k(j))}$$
-4、epoch-number 训练次数:包括所有训练样本的一个正向传递和一个反向传递,训练至模型收敛即可;(注:和迭代次数iteration不一样)
-总之,不是训练的次数越多,测试精度就会越高。会有各种原因导致过拟合,比如一种可能是预训练的模型太复杂,而使用的数据集样本数量太少,种类太单一。
+其中j表示维度,从1到D,可以看到V的j是和输入与c对应的,对每个类别k,都对所有的x进行了计算,如果$x_i$属于当前类别k,$a_k=1$,否则$a_k=0$,计算每一个x和它聚类中心的残差,然后把残差加起来,即是每个类别k的结果,最后分别L2正则后拉成一个长向量后再做L2正则,正则非常的重要,因为这样才能统一所有聚类算出来的值,而残差和的目的主要是消减不同聚类上的分布不均,两者共同作用才能得到最后正常的输出。
-## 5.25 提高泛化能力的方法总结(代码示例)
-本节主要以代码示例来说明可以提高网络泛化能力的方法。
-代码实验是基于mnist数据集,mnist是一个从0到9的手写数字集合,共有60000张训练图片,10000张测试图片。每张图片大小是28*28大小。目的就是通过各种手段,来构建一个高精度的分类神经网络。
-### 5.25.1 手段
-一般来说,提高泛化能力的方法主要有以下几个:
-> * 使用正则化技术
-> * 增加神经网络层数
-> * 使用恰当的代价函数
-> * 使用权重初始化技术
-> * 人为增广训练集
-> * 使用dropout技术
-
-### 5.25.2 主要方法
-下面我们通过实验结果来判断每种手段的效果。
-
-(1)普通的全连接神经网络
-网络结构使用一个隐藏层,其中包含100个隐藏神经元,输入层是784,输出层是one-hot编码的形式,最后一层是Softmax层。损失函数采用对数似然代价函数,60次迭代,学习速率η=0.1,随机梯度下降的小批量数据(mini-SGD)大小为10,没使用正则化。在测试集上得到的结果是97.8%,代码如下:
-```python
->>> import network3
->>> from network3 import Network
->>> from network3 import ConvPoolLayer, FullyConnectedLayer, SoftmaxLayer
->>> training_data, validation_data, test_data = network3.load_data_shared()
->>> mini_batch_size = 10
->>> net = Network([FullyConnectedLayer(n_in=784, n_out=100),
- SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
->>> net.SGD(training_data, 60, mini_batch_size, 0.1, validation_data, test_data)
-```
-(2)使用卷积神经网络 — 仅一个卷积层
-输入层是卷积层,卷积核大小是5*5,一共20个特征映射。最大池化层的大小为2*2。后面接一层100个隐藏神经元的全连接层。结构如图所示
-
-在这个结构中,我们把卷积层和池化层看做是训练图像的特征提取,而后的全连接层则是一个更抽象层次的特征提取,整合全局信息。同样设定是60次迭代,批量数据大小是10,学习率是0.1.代码如下,
-```python
->>> net = Network([
- ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),
- filter_shape=(20, 1, 5, 5),
- poolsize=(2, 2)),
- FullyConnectedLayer(n_in=20*12*12, n_out=100),
- SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
->>> net.SGD(training_data, 60, mini_batch_size, 0.1,
- validation_data, test_data)
-```
-经过三次运行取平均后,准确率是98.78%,提高得较多。错误率降低了1/3。
-
-(3)使用卷积神经网络 — 两个卷积层
-我们接着插入第二个卷积层,把它插入在之前结构的池化层和全连接层之间,同样是使用5*5的局部感受野,2*2的池化层。
-```python
->>> net = Network([
- ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),
- filter_shape=(20, 1, 5, 5),
- poolsize=(2, 2)),
- ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12),
- filter_shape=(40, 20, 5, 5),
- poolsize=(2, 2)),
- FullyConnectedLayer(n_in=40*4*4, n_out=100),
- SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
->>> net.SGD(training_data, 60, mini_batch_size, 0.1, validation_data, test_data)
-```
-这一次,准确率达到了99.06%。
-
-(4)使用卷积神经网络 — 两个卷积层+线性修正单元(ReLU)+正则化
-上面的网络结构,我们使用的是Sigmod激活函数,现在我们换成线性修正激活函数ReLU ,同样设定参数为60次迭代,学习速率η=0.03,使用L2正则化,正则化参数λ=0.1,代码如下:
-```python
->>> from network3 import ReLU
->>> net = Network([
- ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),
- filter_shape=(20, 1, 5, 5),
- poolsize=(2, 2),
- activation_fn=ReLU),
- ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12),
- filter_shape=(40, 20, 5, 5),
- poolsize=(2, 2),
- activation_fn=ReLU),
- FullyConnectedLayer(n_in=40*4*4, n_out=100, activation_fn=ReLU),
- SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
->>> net.SGD(training_data, 60, mini_batch_size, 0.03,
- validation_data, test_data, lmbda=0.1)
-```
-这一次,准确率达到了99.23%,超过了使用sigmoid激活函数的99.06%. ReLU的优势是当取最大极限时,梯度不会饱和。
-
-(5)卷积神经网络 —两个卷基层+线性修正单元(ReLU)+正则化+拓展数据集
-拓展训练集数据的一个简单方法是将每个训练图像由一个像素来代替,无论是上一个像素,下一个像素,或者左右的像素。其他的方法也有改变亮度,改变分辨率,图片旋转,扭曲,位移等。我们把50000幅图像人为拓展到250000幅图像。使用与第四小节一样的网络,因为我们训练时使用了5倍的数据,所以减少了过拟合的风险。
-```python
->>> expanded_training_data, _, _ = network3.load_data_shared(
- "../data/mnist_expanded.pkl.gz")
->>> net = Network([
- ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),
- filter_shape=(20, 1, 5, 5),
- poolsize=(2, 2),
- activation_fn=ReLU),
- ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12),
- filter_shape=(40, 20, 5, 5),
- poolsize=(2, 2),
- activation_fn=ReLU),
- FullyConnectedLayer(n_in=40*4*4, n_out=100, activation_fn=ReLU),
- SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
->>> net.SGD(expanded_training_data, 60, mini_batch_size, 0.03,
- validation_data, test_data, lmbda=0.1)
-```
-这次得到了99.37的训练正确率。
-
-(6)卷积神经网络 — 两个卷基层+线性修正单元(ReLU)+正则化+拓展数据集+继续插入额外的全连接层
-继续上面的网络,我们拓展全连接层的规模,使用300个隐藏神经元和1000个神经元的额精度分别是99.46%和99.43%.
-```python
->>> net = Network([
- ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),
- filter_shape=(20, 1, 5, 5),
- poolsize=(2, 2),
- activation_fn=ReLU),
- ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12),
- filter_shape=(40, 20, 5, 5),
- poolsize=(2, 2),
- activation_fn=ReLU),
- FullyConnectedLayer(n_in=40*4*4, n_out=100, activation_fn=ReLU),
- FullyConnectedLayer(n_in=100, n_out=100, activation_fn=ReLU),
- SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
->>> net.SGD(expanded_training_data, 60, mini_batch_size, 0.03,
- validation_data, test_data, lmbda=0.1)
-```
-这次取得了99.43%的精度。拓展后的网络并没有帮助太多。
-
-(7)卷积神经网络 — 两个卷基层+线性修正单元(ReLU)+拓展数据集+继续插入额外的全连接层+dropout技术
-dropout的基本思想就是在训练网络时随机的移除单独的激活值,使得模型更稀疏,不太依赖于训练数据的特质。我们尝试应用dropout到最终的全连接层(而不是在卷积层)。由于训练时间,将迭代次数设置为40,全连接层使用1000个隐藏神经元,因为dropout会丢弃一些神经元。Dropout是一种非常有效且能提高泛化能力,降低过拟合的方法!
-```python
->>> net = Network([
- ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),
- filter_shape=(20, 1, 5, 5),
- poolsize=(2, 2),
- activation_fn=ReLU),
- ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12),
- filter_shape=(40, 20, 5, 5),
- poolsize=(2, 2),
- activation_fn=ReLU),
- FullyConnectedLayer(
- n_in=40*4*4, n_out=1000, activation_fn=ReLU, p_dropout=0.5),
- FullyConnectedLayer(
- n_in=1000, n_out=1000, activation_fn=ReLU, p_dropout=0.5),
- SoftmaxLayer(n_in=1000, n_out=10, p_dropout=0.5)],
- mini_batch_size)
->>> net.SGD(expanded_training_data, 40, mini_batch_size, 0.03,
- validation_data, test_data)
-```
-使用dropout,得到了99.60%的准确率。
-
-(8)卷积神经网络 — 两个卷基层+线性修正单元(ReLU)+正则化+拓展数据集+继续插入额外的全连接层+弃权技术+组合网络
-组合网络类似于随机森林或者adaboost的集成方法,创建几个神经网络,让他们投票来决定最好的分类。我们训练了5个不同的神经网络,每个都大到了99.60%的准去率,用这5个网络来进行投票表决一个图像的分类。
-采用这种集成方法,精度又得到了微小的提升,达到了99.67%。
-
-## 5.26 CNN在CV与NLP领域运用的联系与区别?
-
-### 5.26.1 联系
-
-自然语言处理是对一维信号(词序列)做操作。
-计算机视觉是对二维(图像)或三维(视频流)信号做操作。
-
-### 5.26.2 区别
-
-自然语言处理的输入数据通常是离散取值(例如表示一个单词或字母通常表示为词典中的one hot向量),计算机视觉则是连续取值(比如归一化到0,1之间的灰度值)。CNN有两个主要特点,区域不变性(location invariance)和组合性(Compositionality)。
+输入与输出如下图所示:
-1. 区域不变性:滤波器在每层的输入向量(图像)上滑动,检测的是局部信息,然后通过pooling取最大值或均值。pooling这步综合了局部特征,失去了每个特征的位置信息。这很适合基于图像的任务,比如要判断一幅图里有没有猫这种生物,你可能不会去关心这只猫出现在图像的哪个区域。但是在NLP里,词语在句子或是段落里出现的位置,顺序,都是很重要的信息。
-2. 局部组合性:CNN中,每个滤波器都把较低层的局部特征组合生成较高层的更全局化的特征。这在CV里很好理解,像素组合成边缘,边缘生成形状,最后把各种形状组合起来得到复杂的物体表达。在语言里,当然也有类似的组合关系,但是远不如图像来的直接。而且在图像里,相邻像素必须是相关的,相邻的词语却未必相关。
+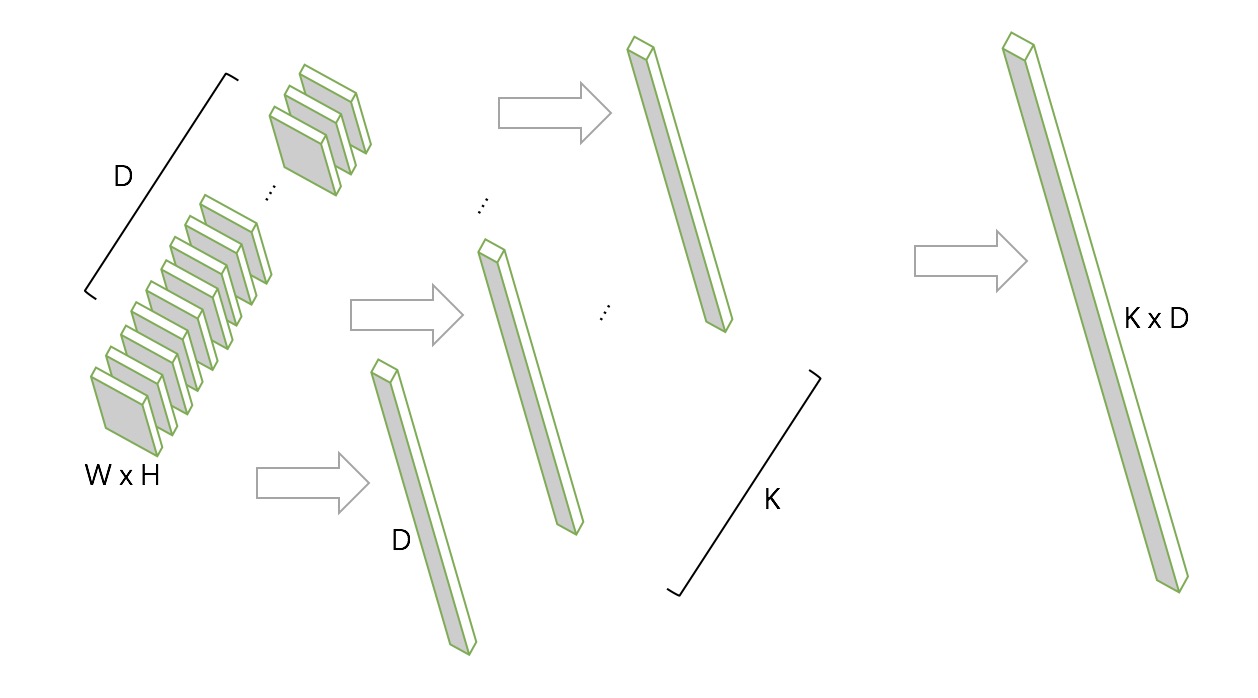
-## 5.27 卷积神经网络凸显共性的方法?
-### 5.27.1 局部连接
-我们首先了解一个概念,感受野,即每个神经元仅与输入神经元相连接的一块区域。
-在图像卷积操作中,神经元在空间维度上是局部连接,但在深度上是全连接。局部连接的思想,是受启发于生物学里的视觉系统结构,视觉皮层的神经元就是仅用局部接受信息。对于二维图像,局部像素关联性较强。这种局部连接保证了训练后的滤波器能够对局部特征有最强的响应,使神经网络可以提取数据的局部特征;
-下图是一个很经典的图示,左边是全连接,右边是局部连接。
+中间得到的K个D维向量即是对D个x都进行了与聚类中心计算残差和的过程,最终把K个D维向量合起来后进行即得到最终输出的$K \times D$长度的一维向量。
-
+而VLAD本身是不可微的,因为上面的a要么是0要么是1,表示要么当前描述x是当前聚类,要么不是,是个离散的,NetVLAD为了能够在深度卷积网络里使用反向传播进行训练,对a进行了修正。
-对于一个1000 × 1000的输入图像而言,如果下一个隐藏层的神经元数目为10^6个,采用全连接则有1000 × 1000 × 10^6 = 10^12个权值参数,如此巨大的参数量几乎难以训练;而采用局部连接,隐藏层的每个神经元仅与图像中10 × 10的局部图像相连接,那么此时的权值参数数量为10 × 10 × 10^6 = 10^8,将直接减少4个数量级。
+那么问题就是如何重构一个a,使其能够评估当前的这个x和各个聚类的关联程度?用softmax来得到:
-### 5.27.2 权值共享
-权值共享,即计算同一深度的神经元时采用的卷积核参数是共享的。权值共享在一定程度上讲是有意义的,是由于在神经网络中,提取的底层边缘特征与其在图中的位置无关。但是在另一些场景中是无意的,如在人脸识别任务,我们期望在不同的位置学到不同的特征。
-需要注意的是,权重只是对于同一深度切片的神经元是共享的。在卷积层中,通常采用多组卷积核提取不同的特征,即对应的是不同深度切片的特征,而不同深度切片的神经元权重是不共享。相反,偏置这一权值对于同一深度切片的所有神经元都是共享的。
-权值共享带来的好处是大大降低了网络的训练难度。如下图,假设在局部连接中隐藏层的每一个神经元连接的是一个10 × 10的局部图像,因此有10 × 10个权值参数,将这10 × 10个权值参数共享给剩下的神经元,也就是说隐藏层中10^6个神经元的权值参数相同,那么此时不管隐藏层神经元的数目是多少,需要训练的参数就是这 10 × 10个权值参数(也就是卷积核的大小)。
+$$a_k = \frac{e^{W_k^T x_i + b_k}}{e^{W_{k'}^T x_i + b_{k'}}}$$
-
+将这个把上面的a替换后,即是NetVLAD的公式,可以进行反向传播更新参数。
-这里就体现了卷积神经网络的奇妙之处,使用少量的参数,却依然能有非常出色的性能。上述仅仅是提取图像一种特征的过程。如果要多提取出一些特征,可以增加多个卷积核,不同的卷积核能够得到图像不同尺度下的特征,称之为特征图(feature map)。
+所以一共有三个可训练参数,上式a中的$W: K \times D$,上式a中的$b: K \times 1$,聚类中心$c: K \times D$,而原始VLAD只有一个参数c。
-### 5.27.3 池化操作
+最终池化得到的输出是一个恒定的K x D的一维向量(经过了L2正则),如果带Batchsize,输出即为Batchsize x (K x D)的二维矩阵。
-池化操作与多层次结构一起,实现了数据的降维,将低层次的局部特征组合成为较高层次的特征,从而对整个图片进行表示。如下图:
+NetVLAD作为池化层嵌入CNN网络即如下图所示,
-
+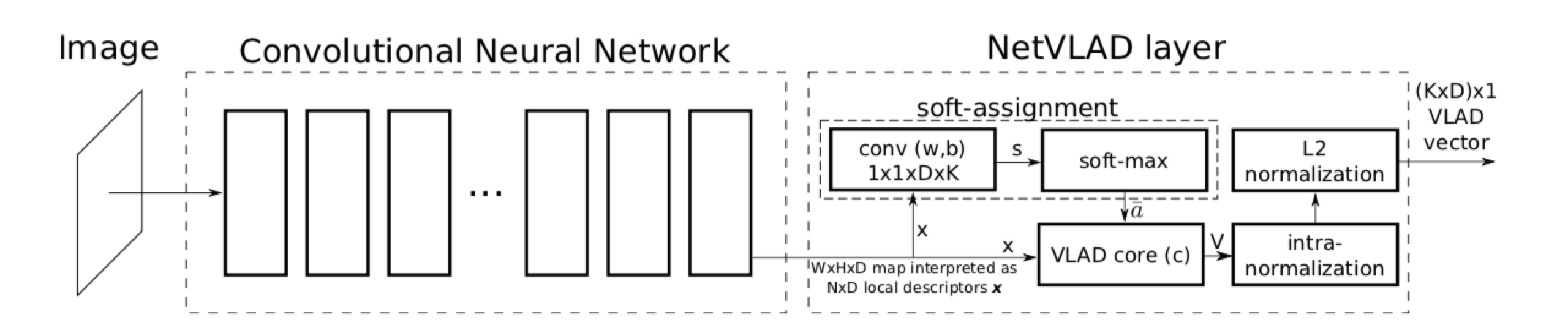
-## 5.28 全卷积与Local-Conv的异同点
+原论文中采用将传统图像检索方法VLAD进行改进后应用在CNN的池化部分作为一种另类的局部特征池化,在场景检索上取得了很好的效果。
-如果每一个点的处理使用相同的Filter,则为全卷积,如果使用不同的Filter,则为Local-Conv。
+后续相继又提出了ActionVLAD、ghostVLAD等改进。
-## 5.29 举例理解Local-Conv的作用
-并不是所有的卷积都会进行权重共享,在某些特定任务中,会使用不权重共享的卷积。下面通过人脸这一任务来进行讲解。在读人脸方向的一些paper时,会发现很多都会在最后加入一个Local Connected Conv,也就是不进行权重共享的卷积层。总的来说,这一步的作用就是使用3D模型来将人脸对齐,从而使CNN发挥最大的效果。
-
-截取论文中的一部分图,经过3D对齐以后,形成的图像均是152×152,输入到上述的网络结构中。该结构的参数如下:
+## 参考文献
-Conv:32个11×11×3的卷积核
+[1] 卷积神经网络研究综述[J]. 计算机学报, 2017, 40(6):1229-1251.
-max-pooling: 3×3,stride=2,
+[2] 常亮, 邓小明, 周明全,等. 图像理解中的卷积神经网络[J]. 自动化学报, 2016, 42(9):1300-1312.
-Conv: 16个9×9的卷积核,
+[3] Chua L O. CNN: A Paradigm for Complexity[M]// CNN a paradigm for complexity /. 1998.
-Local-Conv: 16个9×9的卷积核,
+[4] He K, Gkioxari G, Dollar P, et al. Mask R-CNN[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, PP(99):1-1.
-Local-Conv: 16个7×7的卷积核,
+[5] Hoochang S, Roth H R, Gao M, et al. Deep Convolutional Neural Networks for Computer-Aided Detection: CNN Architectures, Dataset Characteristics and Transfer Learning[J]. IEEE Transactions on Medical Imaging, 2016, 35(5):1285-1298.
-Local-Conv: 16个5×5的卷积核,
+[6] 许可. 卷积神经网络在图像识别上的应用的研究[D]. 浙江大学, 2012.
-Fully-connected: 4096维
+[7] 陈先昌. 基于卷积神经网络的深度学习算法与应用研究[D]. 浙江工商大学, 2014.
-Softmax: 4030维。
+[8] [CS231n Convolutional Neural Networks for Visual Recognition, Stanford](http://cs231n.github.io/convolutional-networks/)
-前三层的目的在于提取低层次的特征,比如简单的边和纹理。其中Max-pooling层使得卷积的输出对微小的偏移情况更加鲁棒。但不能使用更多的Max-pooling层,因为太多的Max-pooling层会使得网络损失图像信息。全连接层将上一层的每个单元和本层的所有单元相连,用来捕捉人脸图像不同位置特征之间的相关性。最后使用softmax层用于人脸分类。
-中间三层都是使用参数不共享的卷积核,之所以使用参数不共享,有如下原因:
+[9] [Machine Learning is Fun! Part 3: Deep Learning and Convolutional Neural Networks](https://medium.com/@ageitgey/machine-learning-is-fun-part-3-deep-learning-and-convolutional-neural-networks-f40359318721#.2gfx5zcw3)
-(1)对齐的人脸图片中,不同的区域会有不同的统计特征,因此并不存在特征的局部稳定性,所以使用相同的卷积核会导致信息的丢失。
+[10] cs231n 动态卷积图:
-(2)不共享的卷积核并不增加inference时特征的计算量,仅会增加训练时的计算量。
-使用不共享的卷积核,由于需要训练的参数量大大增加,因此往往需要通过其他方法增加数据量。
+[11] Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks[C]//Advances in neural information processing systems. 2012: 1097-1105.
+[12] Sun Y, Wang X, Tang X. Deep learning face representation from predicting 10,000 classes[C]//Computer Vision and Pattern Recognition (CVPR), 2014 IEEE Conference on. IEEE, 2014: 1891-1898.
-## 5.30 简述卷积神经网络进化史
+[13] 魏秀参.解析深度学习——卷积神经网络原理与视觉实践[M].电子工业出版社, 2018
-主要讨论CNN的发展,并且引用刘昕博士的思路,对CNN的发展作一个更加详细的介绍,将按下图的CNN发展史进行描述
+[14] Jianxin W U , Gao B B , Wei X S , et al. Resource-constrained deep learning: challenges and practices[J]. Scientia Sinica(Informationis), 2018.
-
+[15] Arandjelovic R , Gronat P , Torii A , et al. [IEEE 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) - Las Vegas, NV, USA (2016.6.27-2016.6.30)] 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) - NetVLAD: CNN Architecture for Weakly Supervised Place Recognition[C]// 2016:5297-5307.
- 1. 列表项
-http://mp.weixin.qq.com/s?__biz=MzI1NTE4NTUwOQ==&mid=2650324619&idx=1&sn=ca1aed9e42d8f020d0971e62148e13be&scene=1&srcid=0503De6zpYN01gagUvn0Ht8D#wechat_redirect
-CNN的演化路径可以总结为以下几个方向:
-> * 进化之路一:网络结构加深
-> * 进化之路二:加强卷积功能
-> * 进化之路三:从分类到检测
-> * 进化之路四:新增功能模块
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.1.jpg" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.1.jpg"
new file mode 100644
index 00000000..3e36b5e5
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.1.jpg" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.10.jpg" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.10.jpg"
new file mode 100644
index 00000000..bf73d3ee
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.10.jpg" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.11.jpg" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.11.jpg"
new file mode 100644
index 00000000..f08bd84f
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.11.jpg" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.12.jpg" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.12.jpg"
new file mode 100644
index 00000000..f1f4696a
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.12.jpg" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.13.jpg" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.13.jpg"
new file mode 100644
index 00000000..614ee0d4
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.13.jpg" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.14.jpg" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.14.jpg"
new file mode 100644
index 00000000..9ab176bb
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.14.jpg" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.15.jpg" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.15.jpg"
new file mode 100644
index 00000000..0166dcf8
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.15.jpg" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.16.jpg" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.16.jpg"
new file mode 100644
index 00000000..602c7a65
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.16.jpg" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.17.jpg" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.17.jpg"
new file mode 100644
index 00000000..c207c2cd
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.17.jpg" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.18.jpg" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.18.jpg"
new file mode 100644
index 00000000..35440710
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.18.jpg" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.19.jpg" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.19.jpg"
new file mode 100644
index 00000000..b93246b2
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.19.jpg" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.2.jpg" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.2.jpg"
new file mode 100644
index 00000000..8eea0b2f
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.2.jpg" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.3.jpg" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.3.jpg"
new file mode 100644
index 00000000..caa59035
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.3.jpg" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.4.jpg" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.4.jpg"
new file mode 100644
index 00000000..30ba7ba4
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.4.jpg" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.5.jpg" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.5.jpg"
new file mode 100644
index 00000000..2f99e164
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.5.jpg" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.6.jpg" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.6.jpg"
new file mode 100644
index 00000000..609998e9
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.6.jpg" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.7.jpg" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.7.jpg"
new file mode 100644
index 00000000..0ac364ae
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.7.jpg" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.8.jpg" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.8.jpg"
new file mode 100644
index 00000000..a05add55
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.8.jpg" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.9.jpg" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.9.jpg"
new file mode 100644
index 00000000..c715b0d2
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.9.jpg" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM1.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM1.png"
new file mode 100644
index 00000000..448438f5
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM1.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM10.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM10.png"
new file mode 100644
index 00000000..15a8daeb
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM10.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM11.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM11.png"
new file mode 100644
index 00000000..6cabdc5c
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM11.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM12.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM12.png"
new file mode 100644
index 00000000..a6bbe153
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM12.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM2.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM2.png"
new file mode 100644
index 00000000..f49c66e8
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM2.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM3.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM3.png"
new file mode 100644
index 00000000..4a0514b6
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM3.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM4.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM4.png"
new file mode 100644
index 00000000..c2f129a0
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM4.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM5.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM5.png"
new file mode 100644
index 00000000..06733d21
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM5.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM6.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM6.png"
new file mode 100644
index 00000000..965b7c0c
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM6.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM7.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM7.png"
new file mode 100644
index 00000000..e6e2595b
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM7.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM8.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM8.png"
new file mode 100644
index 00000000..03f50fba
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM8.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM9.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM9.png"
new file mode 100644
index 00000000..228098dc
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM9.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.1_1.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.1_1.png"
new file mode 100644
index 00000000..368cd799
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.1_1.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.1_1.vsd" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.1_1.vsd"
new file mode 100644
index 00000000..06b735da
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.1_1.vsd" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.2_1.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.2_1.png"
index 33b2c6a6..b6fecf97 100644
Binary files "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.2_1.png" and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.2_1.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.2_1.vsd" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.2_1.vsd"
new file mode 100644
index 00000000..13906f56
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.2_1.vsd" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.2_2.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.2_2.png"
new file mode 100644
index 00000000..8e429841
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.2_2.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.2_2.vsd" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.2_2.vsd"
new file mode 100644
index 00000000..38d407ea
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.2_2.vsd" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.1_1.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.1_1.png"
index e54ddb20..f378b3c4 100644
Binary files "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.1_1.png" and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.1_1.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.1_1.vsd" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.1_1.vsd"
new file mode 100644
index 00000000..ad24ad55
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.1_1.vsd" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.2_1.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.2_1.png"
index fb138c4a..b0a50032 100644
Binary files "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.2_1.png" and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.2_1.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.2_1.vsd" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.2_1.vsd"
new file mode 100644
index 00000000..6d0d7125
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.2_1.vsd" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.3_1.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.3_1.png"
index 7f80bc81..51ffefdf 100644
Binary files "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.3_1.png" and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.3_1.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.3_1.vsd" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.3_1.vsd"
new file mode 100644
index 00000000..63023bf8
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.3_1.vsd" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.4_1.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.4_1.png"
index bb72ba58..2893b568 100644
Binary files "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.4_1.png" and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.4_1.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.4_1.vsdx" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.4_1.vsdx"
new file mode 100644
index 00000000..aed23155
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.4_1.vsdx" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.4_2.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.4_2.png"
index bd62b394..ca3329ea 100644
Binary files "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.4_2.png" and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.4_2.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.4_2.vsdx" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.4_2.vsdx"
new file mode 100644
index 00000000..9a6ad422
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.4_2.vsdx" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.4_3.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.4_3.png"
index bbd1e296..a39ae760 100644
Binary files "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.4_3.png" and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.4_3.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.4_3.vsdx" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.4_3.vsdx"
new file mode 100644
index 00000000..be7ceb9b
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.4_3.vsdx" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.5_1.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.5_1.png"
index 9659ecc2..90454a4e 100644
Binary files "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.5_1.png" and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.5_1.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.5_1.vsdx" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.5_1.vsdx"
new file mode 100644
index 00000000..5dccfa42
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.5_1.vsdx" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.6_1.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.6_1.png"
index 899da6a9..1b11373c 100644
Binary files "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.6_1.png" and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.6_1.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.6_1.vsdx" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.6_1.vsdx"
new file mode 100644
index 00000000..e0df0ad9
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.6_1.vsdx" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.6_2.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.6_2.png"
index 038c1815..cb920ce6 100644
Binary files "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.6_2.png" and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.6_2.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.6_2.vsdx" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.6_2.vsdx"
new file mode 100644
index 00000000..892f40bf
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.6_2.vsdx" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.7_1.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.7_1.png"
index 5e72863d..271ed19c 100644
Binary files "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.7_1.png" and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.7_1.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.7_1.vsdx" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.7_1.vsdx"
new file mode 100644
index 00000000..74495301
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.7_1.vsdx" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/rnnbp.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/rnnbp.png"
new file mode 100644
index 00000000..fc6ebf23
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/rnnbp.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/sigmoid.jpg" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/sigmoid.jpg"
new file mode 100644
index 00000000..1d5a2628
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/sigmoid.jpg" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/tanh.jpg" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/tanh.jpg"
new file mode 100644
index 00000000..cebe1b07
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/tanh.jpg" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/\347\254\254\345\205\255\347\253\240_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN).md" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/\347\254\254\345\205\255\347\253\240_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN).md"
index aef232d6..c5601a46 100644
--- "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/\347\254\254\345\205\255\347\253\240_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN).md"
+++ "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/\347\254\254\345\205\255\347\253\240_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN).md"
@@ -4,99 +4,133 @@
# 第六章 循环神经网络(RNN)
- Markdown Revision 2;
- Date: 2018/11/07
- Editor: 李骁丹-杜克大学
- Contact: xiaodan.li@duke.edu
-
- Markdown Revision 1;
- Date: 2018/10/26
- Editor: 杨国峰-中国农业科学院
- Contact: tectalll@gmail.com
-
-新增 https://blog.csdn.net/zhaojc1995/article/details/80572098
-RNN发展简述?
-为什么需要RNN?
-RNN的结构及变体
-标准RNN的前向输出流程?
-RNN的训练方法——BPTT?
-什么是长期依赖(Long-Term Dependencies)问题?
-LSTM 网络是什么?
-LSTM 的核心思想?
-如何逐步理解LSTM?
-常见的RNNs扩展和改进模型
-RNN种类?
-讲解CNN+RNN的各种组合方式 http://www.elecfans.com/d/775895.html
-RNN学习和实践过程中常常碰到的疑问
-## CNN和RNN的对比 http://www.elecfans.com/d/775895.html
-1、CNN卷积神经网络与RNN递归神经网络直观图
-2、相同点:
-2.1. 传统神经网络的扩展。
-2.2. 前向计算产生结果,反向计算模型更新。
-2.3. 每层神经网络横向可以多个神经元共存,纵向可以有多层神经网络连接。
-3、不同点
-3.1. CNN空间扩展,神经元与特征卷积;RNN时间扩展,神经元与多个时间输出计算
-3.2. RNN可以用于描述时间上连续状态的输出,有记忆功能,CNN用于静态输出
-3.3. CNN高级100+深度,RNN深度有限
-
-
-
-http://blog.csdn.net/heyongluoyao8/article/details/48636251
-
## 6.1 为什么需要RNN?
-http://ai.51cto.com/art/201711/559441.htm
-神经网络可以当做是能够拟合任意函数的黑盒子,只要训练数据足够,给定特定的x,就能得到希望的y,结构图如下:
-将神经网络模型训练好之后,在输入层给定一个x,通过网络之后就能够在输出层得到特定的y,那么既然有了这么强大的模型,为什么还需要RNN(循环神经网络)呢?
-他们都只能单独的取处理一个个的输入,前一个输入和后一个输入是完全没有关系的。但是,某些任务需要能够更好的处理序列的信息,即前面的输入和后面的输入是有关系的。
-比如,当我们在理解一句话意思时,孤立的理解这句话的每个词是不够的,我们需要处理这些词连接起来的整个序列; 当我们处理视频的时候,我们也不能只单独的去分析每一帧,而要分析这些帧连接起来的整个序列。
+ 时间序列数据是指在不同时间点上收集到的数据,这类数据反映了某一事物、现象等随时间的变化状态或程度。一般的神经网络,在训练数据足够、算法模型优越的情况下,给定特定的x,就能得到期望y。其一般处理单个的输入,前一个输入和后一个输入完全无关,但实际应用中,某些任务需要能够更好的处理序列的信息,即前面的输入和后面的输入是有关系的。比如:
-以nlp的一个最简单词性标注任务来说,将我 吃 苹果 三个单词标注词性为 我/nn 吃/v 苹果/nn。
+ 当我们在理解一句话意思时,孤立的理解这句话的每个词不足以理解整体意思,我们通常需要处理这些词连接起来的整个序列; 当我们处理视频的时候,我们也不能只单独的去分析每一帧,而要分析这些帧连接起来的整个序列。为了解决一些这样类似的问题,能够更好的处理序列的信息,RNN就由此诞生了。
-那么这个任务的输入就是:
+## 6.2 图解RNN基本结构
-我 吃 苹果 (已经分词好的句子)
+### 6.2.1 基本的单层网络结构
-这个任务的输出是:
+ 在进一步了解RNN之前,先给出最基本的单层网络结构,输入是x,经过变换Wx+b和激活函数f得到输出y:
-我/nn 吃/v 苹果/nn(词性标注好的句子)
+
-对于这个任务来说,我们当然可以直接用普通的神经网络来做,给网络的训练数据格式了就是我-> 我/nn 这样的多个单独的单词->词性标注好的单词。
+### 6.2.2 图解经典RNN结构
-但是很明显,一个句子中,前一个单词其实对于当前单词的词性预测是有很大影响的,比如预测苹果的时候,由于前面的吃是一个动词,那么很显然苹果作为名词的概率就会远大于动词的概率,因为动词后面接名词很常见,而动词后面接动词很少见。
+ 在实际应用中,我们还会遇到很多序列形的数据,如:
-所以为了解决一些这样类似的问题,能够更好的处理序列的信息,RNN就诞生了。
+- 自然语言处理问题。x1可以看做是第一个单词,x2可以看做是第二个单词,依次类推。
-## 6.1 RNN种类?
-https://www.cnblogs.com/rucwxb/p/8047401.html
-1. sequence-to-sequence:输入输出都是一个序列。例如股票预测中的RNN,输入是前N天价格,输出明天的股市价格。
+- 语音处理。此时,x1、x2、x3……是每帧的声音信号。
-2. sequence-to-vector:输入是一个序列,输出单一向量。
+- 时间序列问题。例如每天的股票价格等等。
-3. vector-to-sequence:输入单一向量,输出一个序列。
+ 其单个序列如下图所示:
-4.Encoder-Decoder:输入sequence-to-vector,称作encoder,输出vector-to-sequence,称作decoder。
+ 
-这是一个delay模型,经过一段延迟,即把所有输入都读取后,在decoder中获取输入并输出一个序列。这个模型在机器翻译中使用较广泛,源语言输在入放入encoder,浓缩在状态信息中,生成目标语言时,可以生成一个不长度的目标语言序列。
+ 前面介绍了诸如此类的序列数据用原始的神经网络难以建模,基于此,RNN引入了隐状态$h$(hidden state),$h$可对序列数据提取特征,接着再转换为输出。
-## RNN train的时候,Loss波动很大
-https://www.jianshu.com/p/30b253561337
-由于RNN特有的memory会影响后期其他的RNN的特点,梯度时大时小,learning rate没法个性化的调整,导致RNN在train的过程中,Loss是震荡起伏的……
-为了解决RNN的这个问题,在train的时候,可以有个clipping的方式,当梯度大于某个临界值,直接截断,用这个临界值作为梯度的大小,防止飞出去…(居然还能这么操作,66666)
+ 为了便于理解,先计算$h_1$:
-## 6.1 RNNs和FNNs有什么区别?
+ 
-1. 不同于传统的前馈神经网络(FNNs),RNNs引入了定向循环,能够处理输入之间前后关联问题。
-2. RNNs可以记忆之前步骤的训练信息。
-**定向循环结构如下图所示**:
+ 注:图中的圆圈表示向量,箭头表示对向量做变换。
-
+ RNN中,每个步骤使用的参数$U,W,b$相同,$h_2$的计算方式和$h_1$类似,其计算结果如下:
+
+ 
+
+ 计算$h_3$,$h_4$也相似,可得:
+
+ 
+
+ 接下来,计算RNN的输出$y_1$,采用$Softmax$作为激活函数,根据$y_n=f(Wx+b)$,得$y_1$:
+
+ 
+
+ 使用和$y_1$相同的参数$V,c$,得到$y_1,y_2,y_3,y_4$的输出结构:
+
+ 
+
+ 以上即为最经典的RNN结构,其输入为$x_1,x_2,x_3,x_4$,输出为$y_1,y_2,y_3,y_4$,当然实际中最大值为$y_n$,这里为了便于理解和展示,只计算4个输入和输出。从以上结构可看出,RNN结构的输入和输出等长。
+
+### 6.2.3 vector-to-sequence结构
+
+ 有时我们要处理的问题输入是一个单独的值,输出是一个序列。此时,有两种主要建模方式:
+
+ 方式一:可只在其中的某一个序列进行计算,比如序列第一个进行输入计算,其建模方式如下:
+
+
+
+ 方式二:把输入信息X作为每个阶段的输入,其建模方式如下:
+
+
+
+### 6.2.4 sequence-to-vector结构
+
+ 有时我们要处理的问题输入是一个序列,输出是一个单独的值,此时通常在最后的一个序列上进行输出变换,其建模如下所示:
+
+ 
+
+### 6.2.5 Encoder-Decoder结构
+
+ 原始的sequence-to-sequence结构的RNN要求序列等长,然而我们遇到的大部分问题序列都是不等长的,如机器翻译中,源语言和目标语言的句子往往并没有相同的长度。
+
+ 其建模步骤如下:
+
+ **步骤一**:将输入数据编码成一个上下文向量$c$,这部分称为Encoder,得到$c$有多种方式,最简单的方法就是把Encoder的最后一个隐状态赋值给$c$,还可以对最后的隐状态做一个变换得到$c$,也可以对所有的隐状态做变换。其示意如下所示:
+
+ 
-## 6.2 RNNs典型特点?
+ **步骤二**:用另一个RNN网络(我们将其称为Decoder)对其进行编码,方法一是将步骤一中的$c$作为初始状态输入到Decoder,示意图如下所示:
+
+ 
+
+方法二是将$c$作为Decoder的每一步输入,示意图如下所示:
+
+ 
+
+### 6.2.6 以上三种结构各有怎样的应用场景
+
+| 网络结构 | 结构图示 | 应用场景举例 |
+| -------- | :---------------------: | ------------------------------------------------------------ |
+| 1 vs N |  | 1、从图像生成文字,输入为图像的特征,输出为一段句子
-
+- 采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合;
+- 之所以卷积核大小采用1、3和5,主要是为了方便对齐。设定卷积步长stride=1之后,只要分别设定pad=0、1、2,那么卷积之后便可以得到相同维度的特征,然后这些特征就可以直接拼接在一起了;
+- 网络越到后面,特征越抽象,而且每个特征所涉及的感受野也更大了,因此随着层数的增加,3x3和5x5卷积的比例也要增加。但是,使用5x5的卷积核仍然会带来巨大的计算量。 为此,文章借鉴NIN2,采用1x1卷积核来进行降维。
-- 在梯度为8x8时使用可以增加滤波器输出的模块(如下图),以此来产生高维的稀疏特征。
+## 4.7 为什么现在的CNN模型都是在GoogleNet、VGGNet或者AlexNet上调整的?
-
-
-- 输入从224x224变为229x229。
-
-最后实现的Inception v2的结构如下表。
-
-
-
-
-
-经过网络的改进,inception v2得到更低的识别误差率,与其他网络识别误差率对比如表所示。
-
-
-
-
-如表,inception v2相比inception v1在imagenet的数据集上,识别误差率由29%降为23.4%。
-
-### 4.7.3 Inception v3
-
-
-inception模块之间特征图的缩小,主要有下面两种方式:
-
-
-
-
-右图是先进行inception操作,再进行池化来下采样,但是这样参数量明显多于左图(比较方式同前文的降维后inception模块),因此v2采用的是左图的方式,即在不同的inception之间(35/17/8的梯度)采用池化来进行下采样。
-
-
-但是,左图这种操作会造成表达瓶颈问题,也就是说特征图的大小不应该出现急剧的衰减(只经过一层就骤降)。如果出现急剧缩减,将会丢失大量的信息,对模型的训练造成困难。
-
-因此,在2015年12月提出的Inception V3结构借鉴inception的结构设计了采用一种并行的降维结构,如下图:
-
-
-
- 具体来说,就是在35/17/8之间分别采用下面这两种方式来实现特征图尺寸的缩小,如下图:
-
-
-
-figure 5' 35/17之间的特征图尺寸减小
-
-
-
-figure 6' 17/8之间的特征图尺寸缩小
-
-这样就得到Inception v3的网络结构,如表所示。
-
-
-
-### 4.7.4 Inception V4
-
-
-其实,做到现在,Inception模块感觉已经做的差不多了,再做下去准确率应该也不会有大的改变。但是谷歌这帮人还是不放弃,非要把一个东西做到极致,改变不了Inception模块,就改变其他的。
-
-
-因此,作者Christian Szegedy设计了Inception v4的网络,将原来卷积、池化的顺次连接(网络的前几层)替换为stem模块,来获得更深的网络结构。stem模块结构如下:
-
-
-stem模块
-
-
-
-
-Inception v4 中的Inception模块(分别为Inception A Inception B Inception C)
-
-
-
-
-Inception v4中的reduction模块(分别为reduction A reduction B)
-
-
-最终得到的Inception v4结构如下图。
-
-### 4.7.5 Inception-ResNet-v2
-
-
-ResNet的结构既可以加速训练,还可以提升性能(防止梯度消失);Inception模块可以在同一层上获得稀疏或非稀疏的特征。有没有可能将两者进行优势互补呢?
-
-
-Christian Szegedy等人将两个模块的优势进行了结合,设计出了Inception-ResNet网络。
-
-
-(Inception-ResNet有v1和v2两个版本,v2表现更好且更复杂,这里只介绍了v2)
-
-
-Inception-ResNet的成功,主要是它的Inception-ResNet模块。
-
-
-Inception-ResNet v2中的Inception-ResNet模块如下图:
-
-
-
-
-Inception-ResNet模块(分别为Inception-ResNet-A Inception-ResNet-B Inception-ResNet-C)
-
-
-Inception-ResNet模块之间特征图尺寸的减小如下图。(类似于Inception v4)
-
-
-
-
-Inception-ResNet-v2中的reduction模块(分别为reduction A reduction B)
-
-
-最终得到的Inception-ResNet-v2网络结构如图(stem模块同Inception v4)。
-
-
-## 4.8 ResNet及其变体
-
-
-自从AlexNet在LSVRC2012分类比赛中取得胜利之后,深度残差网络(Deep Residual Network)可以说成为过去几年中,在计算机视觉、深度学习社区领域中最具突破性的成果了。ResNet可以实现高达数百,甚至数千个层的训练,且仍能获得超赞的性能。
-
-
-得益于其强大的表征能力,许多计算机视觉应用在图像分类以外领域的性能得到了提升,如对象检测和人脸识别。
-
-
-自从2015年ResNet进入人们的视线,并引发人们思考之后,许多研究界人员已经开始研究其成功的秘诀,并在架构中纳入了许多新的改进。本文分为两部分,第一部分我将为那些不熟悉ResNet的人提供一些相关的背景知识,第二部分我将回顾一些我最近读过的关于ResNet架构的不同变体及其论文的相关阐述。
-### 4.8.1 重新审视ResNet
-
-根据泛逼近性原理(universal approximation theorem),我们知道,如果给定足够的容量,一个具有单层的前馈网络足以表示任何函数。然而,该层可能是巨大的,且网络可能容易过度拟合数据。因此,研究界有一个共同的趋势,即我们的网络架构需要更深。
-
-
-自从AlexNet投入使用以来,最先进的卷积神经网络(CNN)架构越来越深。虽然AlexNet只有5层卷积层,但VGG网络和GoogleNet(代号也为Inception_v1)分别有19层和22层。
-
-
-但是,如果只是通过简单地将层叠加在一起,增加网络深度并不会起到什么作用。随着网络层数的增加,就会出现梯度消失问题,这就会造成网络是难以进行训练,因为梯度反向传播到前层,重复乘法可能使梯度无穷小,这造成的结果就是,随着网络加深,其性能趋于饱和,或者甚至开始迅速退化。
-
-
-
-
-增加网络深度导致性能下降
-
-
-其实早在ResNet之前,已经有过好几种方法来处理梯度消失问题,例如,在中间层增加辅助损失作为额外的监督,但遗憾的是,似乎没有一个方法可以真正解决这个问题。
-
-
-ResNet的核心思想是引入所谓的“恒等映射(identity shortcut connection)”,可以跳过一层或多层,如下图所示:
-
-
-
-### 4.8.2 残差块
-
-[Deep Residual Learning for Image Recognition](https://arxiv.org/pdf/1512.03385v1.pdf)的作者认为,堆积网络层数不应该降低网络性能,因为我们可以简单地在当前网络上堆积身份映射(层不做任何事情),并且所得到的架构将执行相同的操作。这表明,较深的模型所产生的训练误差不应该比较浅的模型高。他们假设让堆积层适应残差映射比使它们直接适应所需的底层映射要容易得多。下图的残差块可以明确地使它做到这一点。
-
-
-
-### 4.8.3 ResNet架构
-
-
-事实上,ResNet并不是第一个利用short cut、Highway Networks引入门控近路连接的。这些参数化门控制允许多少信息流过近路(shortcut)。类似的想法可以在长短期记忆网络(LSTM)单元中找到,其中存在参数化的忘记门,其控制多少信息将流向下一个时间步。因此,ResNet可以被认为是Highway Networks的一种特殊情况。
-
-
-然而,实验表明,Highway Networks的性能并不如ResNet,因为Highway Networks的解决方案空间包含ResNet,因此它应该至少表现得像ResNet一样好。这就表明,保持这些“梯度公路”干净简洁比获取更大的解决方案空间更为重要。
-
-
-照着这种直觉,论文作者改进了残差块,并提出了一个残差块的预激活变体,其中梯度可以畅通无阻地通过快速连接到任何其他的前层。论文的实验结果表明,使用原始的残差块,训练1202层ResNet所展示的性能比其训练110层对等物要差得多。
-
-
-
-### 4.8.4 ResNeXt
-
-
-S. Xie,R. Girshick,P. Dollar,Z. Tu和 K. He在[Aggregated Residual Transformations for Deep Neural Networks](http://openaccess.thecvf.com/content_cvpr_2017/papers/Xie_Aggregated_Residual_Transformations_CVPR_2017_paper.pdf)中提出了一个代号为ResNeXt的ResNet变体,它具有以下构建块:
-
-
-
-
-左:《Deep Residual Learning for Image Recognition》中所提及的构建块,右图: ResNeXt构建块 基数=32
-
-
-这可能看起来很熟悉,因为它非常类似于《IEEE计算机视觉与模式识别会议论文集》中《Going deeper with convolutions》的Inception模块,它们都遵循“拆分-转换-合并”范式,除了在这个变体中,不同路径的输出通过将它们相加在一起而被合并,而在《Going deeper with convolutions》中它们是深度连接的。另一个区别是,在《Going deeper with convolutions》中,每个路径彼此互不相同(1x1,3x3和5x5卷积),而在此架构中,所有路径共享相同的拓扑。
-
-
-作者介绍了一个称为 “基数(cardinality)”的超参数——独立路径的数量,以提供调整模型容量的新方式。实验表明,可以通过增加基数,而不是深度或宽度,来更加有效地获得准确度。作者指出,与Inception相比,这种新颖的架构更容易适应新的数据集/任务,因为它具有一个简单的范式,且只有一个超参数被调整,而Inception却具有许多超参数(如每个路径中卷积层内核大小)待调整。
-
-
-这个新颖的构建块有如下三种等效形式:
-
-
-
-实际上,“分割-变换-合并”通常是通过点分组卷积层来完成的,它将其输入分成特征映射组,并分别执行正常卷积,其输出被深度级联,然后馈送到1x1卷积层。
-
-### 4.8.5 ResNet作为小型网络的组合
-
-
-[Deep Networks with Stochastic Depth](https://arxiv.org/pdf/1603.09382.pdf)提出了一种反直觉的方式,训练一个非常深层的网络,通过在训练期间随机丢弃它的层,并在测试时间内使用完整的网络。Veit等人有一个更反直觉的发现:我们实际上可以删除一些已训练的ResNet的一些层,但仍然具有可比性能。这使得ResNet架构更加有趣,该论文亦降低了VGG网络的层,并大大降低了其性能。
-该论文首先提供了ResNet的一个简单的视图,使事情更清晰。在我们展开网络架构之后,这是很显而易见的,具有i个残差块的ResNet架构具有$2^{i}$个不同的路径(因为每个残差块提供两个独立的路径)。
-
-
-
-
-鉴于上述发现,我们很容易发现为什么在ResNet架构中删除几层,对于其性能影响不大——架构具有许多独立的有效路径,在我们删除了几层之后,它们大部分保持不变。相反,VGG网络只有一条有效的路径,所以删除一层是唯一的途径。
+- 评测对比:为了让自己的结果更有说服力,在发表自己成果的时候会同一个标准的baseline及在baseline上改进而进行比较,常见的比如各种检测分割的问题都会基于VGG或者Resnet101这样的基础网络。
+- 时间和精力有限:在科研压力和工作压力中,时间和精力只允许大家在有限的范围探索。
+- 模型创新难度大:进行基本模型的改进需要大量的实验和尝试,并且需要大量的实验积累和强大灵感,很有可能投入产出比比较小。
+- 资源限制:创造一个新的模型需要大量的时间和计算资源,往往在学校和小型商业团队不可行。
+- 在实际的应用场景中,其实是有大量的非标准模型的配置。
-
-作者还进行了实验,表明ResNet中的路径集合具有集合行为。他们是通过在测试时间删除不同数量的层,然后查看网络的性能是否与已删除层的数量平滑相关,这样的方式做到的。结果表明,网络确实表现得像集合,如下图所示:
+## 参考文献
-
+[1] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner. Gradient-based learning applied to document recognition. *Proceedings of the IEEE*, november 1998.
-### 4.8.6 ResNet中路径的特点
+[2] A. Krizhevsky, I. Sutskever and G. E. Hinton. ImageNet Classification with Deep Convolutional Neural Networks. *Advances in Neural Information Processing Systems 25*. Curran Associates, Inc. 1097–1105.
-
-最后,作者研究了ResNet中路径的特点:
+[3] LSVRC-2013. http://www.image-net.org/challenges/LSVRC/2013/results.php
-
-很明显,所有可能的路径长度的分布都遵循二项式分布,如(a)所示。大多数路径经过19到35个残差块。
+[4] M. D. Zeiler and R. Fergus. Visualizing and Understanding Convolutional Networks. *European Conference on Computer Vision*.
-
+[5] M. Lin, Q. Chen, and S. Yan. Network in network. *Computing Research Repository*, abs/1312.4400, 2013.
-
- 调查路径长度与经过其的梯度大小之间的关系,同时获得长度为k的路径的梯度幅度,作者首先将一批数据馈送给网络,随机抽取k个残差块。当反向传播梯度时,它们仅传播到采样残余块的权重层。(b)表明随着路径变长,梯度的大小迅速下降。
+[6] K. Simonyan and A. Zisserman. Very Deep Convolutional Networks for Large-Scale Image Recognition. *International Conference on Machine Learning*, 2015.
-
- 我们现在可以将每个路径长度的频率与其预期的梯度大小相乘,以了解每个长度的路径对于训练有多少帮助,如(c)所示。令人惊讶的是,大多数贡献来自长度为9至18的路径,但它们仅占总路径的一小部分,如(a)所示。这是一个非常有趣的发现,因为它表明ResNet并没有解决长路径上的梯度消失问题,而是通过缩短其有效路径,ResNet实际上能够实现训练非常深度的网络。
+[7] Bharath Raj. [a-simple-guide-to-the-versions-of-the-inception-network](https://towardsdatascience.com/a-simple-guide-to-the-versions-of-the-inception-network-7fc52b863202), 2018.
-
-答案来源:[ResNet有多大威力?最近又有了哪些变体?一文弄清](http://www.sohu.com/a/157818653_390227)
+[8] Christian Szegedy, Sergey Ioffe, Vincent Vanhoucke, Alex Alemi. [Inception-v4, Inception-ResNet and
+the Impact of Residual Connections on Learning](https://arxiv.org/pdf/1602.07261.pdf), 2016.
+[9] Sik-Ho Tsang. [review-inception-v4-evolved-from-googlenet-merged-with-resnet-idea-image-classification](https://towardsdatascience.com/review-inception-v4-evolved-from-googlenet-merged-with-resnet-idea-image-classification-5e8c339d18bc), 2018.
-## 4.9 为什么现在的CNN模型都是在GoogleNet、VGGNet或者AlexNet上调整的?
+[10] Zbigniew Wojna, Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens. [Rethinking the Inception Architecture for Computer Vision](https://arxiv.org/pdf/1512.00567v3.pdf), 2015.
-- 评测对比:为了让自己的结果更有说服力,在发表自己成果的时候会同一个标准的baseline及在baseline上改进而进行比较,常见的比如各种检测分割的问题都会基于VGG或者Resnet101这样的基础网络。
-- 时间和精力有限:在科研压力和工作压力中,时间和精力只允许大家在有限的范围探索。
-- 模型创新难度大:进行基本模型的改进需要大量的实验和尝试,并且需要大量的实验积累和强大灵感,很有可能投入产出比比较小。
-- 资源限制:创造一个新的模型需要大量的时间和计算资源,往往在学校和小型商业团队不可行。
-- 在实际的应用场景中,其实是有大量的非标准模型的配置。
+[11] Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich. [Going deeper with convolutions](https://arxiv.org/pdf/1409.4842v1.pdf), 2014.
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.11-1.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.11-1.png"
new file mode 100644
index 00000000..a8216642
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.11-1.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.12-1.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.12-1.png"
new file mode 100644
index 00000000..2e358c8e
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.12-1.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.13-1.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.13-1.png"
new file mode 100644
index 00000000..16e488dd
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.13-1.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.13-2.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.13-2.png"
new file mode 100644
index 00000000..fd10e0f7
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.13-2.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.14.1.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.14.1.png"
new file mode 100644
index 00000000..4be4e132
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.14.1.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.19.1-2.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.19.1-2.png"
new file mode 100644
index 00000000..56914569
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.19.1-2.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.19.1-3.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.19.1-3.png"
new file mode 100644
index 00000000..f5e21a8c
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.19.1-3.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.19.2-5.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.19.2-5.png"
new file mode 100644
index 00000000..65a81696
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.19.2-5.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.27.1.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.27.1.png"
new file mode 100644
index 00000000..38b23d23
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.27.1.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.27.2.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.27.2.png"
new file mode 100644
index 00000000..66afa642
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.27.2.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.27.3.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.27.3.png"
new file mode 100644
index 00000000..65fb2168
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.27.3.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.6.1.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.6.1.png"
new file mode 100644
index 00000000..066cf692
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.6.1.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.6.2.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.6.2.png"
new file mode 100644
index 00000000..73af604d
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.6.2.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.8-1.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.8-1.png"
new file mode 100644
index 00000000..ea5aba50
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/5.8-1.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/Image-process.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/Image-process.png"
new file mode 100644
index 00000000..968d70d3
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/Image-process.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/NLP.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/NLP.png"
new file mode 100644
index 00000000..3e57aac0
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/NLP.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/audio-recognition.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/audio-recognition.png"
new file mode 100644
index 00000000..13ef5466
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/audio-recognition.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/audio.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/audio.png"
new file mode 100644
index 00000000..41736397
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/audio.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/cat-blur-gaussian.jpg" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/cat-blur-gaussian.jpg"
new file mode 100644
index 00000000..b3ccd0c4
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/cat-blur-gaussian.jpg" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/cat-boxblur.jpg" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/cat-boxblur.jpg"
new file mode 100644
index 00000000..4ad35d48
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/cat-boxblur.jpg" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/cat-crop.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/cat-crop.png"
new file mode 100644
index 00000000..cf1cf4ef
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/cat-crop.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/cat-edgeDetect-2.jpg" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/cat-edgeDetect-2.jpg"
new file mode 100644
index 00000000..b07b28ed
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/cat-edgeDetect-2.jpg" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/cat-edgeDetect.jpg" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/cat-edgeDetect.jpg"
new file mode 100644
index 00000000..4c7e8e8e
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/cat-edgeDetect.jpg" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/cat-sharpen.jpg" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/cat-sharpen.jpg"
new file mode 100644
index 00000000..653b0d72
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/cat-sharpen.jpg" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/cat.jpg" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/cat.jpg"
new file mode 100644
index 00000000..280bdce0
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/cat.jpg" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/conv-same.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/conv-same.png"
new file mode 100644
index 00000000..f98611a9
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/conv-same.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/conv-valid.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/conv-valid.png"
new file mode 100644
index 00000000..329ced51
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/conv-valid.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/conv.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/conv.png"
new file mode 100644
index 00000000..bbd74167
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/conv.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/convolution.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/convolution.png"
new file mode 100644
index 00000000..5865fee0
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/convolution.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/full-connected.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/full-connected.png"
new file mode 100644
index 00000000..5bdc5f5e
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/full-connected.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/general_pooling.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/general_pooling.png"
new file mode 100644
index 00000000..e2d56675
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/general_pooling.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/img67.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/img67.png"
deleted file mode 100644
index 96910125..00000000
Binary files "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/img67.png" and /dev/null differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/local-connected.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/local-connected.png"
new file mode 100644
index 00000000..86f484a9
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/local-connected.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/local-conv.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/local-conv.png"
new file mode 100644
index 00000000..d445ee81
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/local-conv.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/overlap_pooling.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/overlap_pooling.png"
new file mode 100644
index 00000000..99273114
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/overlap_pooling.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/spatial_pooling.png" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/spatial_pooling.png"
new file mode 100644
index 00000000..1503603d
Binary files /dev/null and "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/img/ch5/spatial_pooling.png" differ
diff --git "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/\347\254\254\344\272\224\347\253\240 \345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234\357\274\210CNN\357\274\211.md" "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/\347\254\254\344\272\224\347\253\240 \345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234\357\274\210CNN\357\274\211.md"
index 4839b927..c5067069 100644
--- "a/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/\347\254\254\344\272\224\347\253\240 \345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234\357\274\210CNN\357\274\211.md"
+++ "b/ch05_\345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234(CNN)/\347\254\254\344\272\224\347\253\240 \345\215\267\347\247\257\347\245\236\347\273\217\347\275\221\347\273\234\357\274\210CNN\357\274\211.md"
@@ -2,716 +2,455 @@
-# 第五章 卷积神经网络(CNN)
+# 第五章 卷积神经网络(CNN)
-标签(空格分隔): 原创性 深度学习 协作
-卷积神经网络负责人:
+ 卷积神经网络是一种用来处理局部和整体相关性的计算网络结构,被应用在图像识别、自然语言处理甚至是语音识别领域,因为图像数据具有显著的局部与整体关系,其在图像识别领域的应用获得了巨大的成功。
-重庆大学研究生-刘畅 787913208@qq.com;
-
-铪星创新科技联合创始人-杨文英;
-
- Markdown Revision 1;
- Date: 2018/11/08
- Editor: 李骁丹-杜克大学
- Contact: xiaodan.li@duke.edu
## 5.1 卷积神经网络的组成层
-在卷积神经网络中,一般包含5种类型的层:
-> * 输入层
-> * 卷积运算层
-> * 激活函数层
-> * 池化层
-> * 全连接层
-
-**输入层**主要包含对原始图像进行预处理,包括白化、归一化、去均值等等。
-
-**卷积运算层**主要使用滤波器,通过设定步长、深度等参数,对输入进行不同层次的特征提取。滤波器中的参数可以通过反向传播算法进行学习。
-
-**激活函数层**主要是将卷积层的输出做一个非线性映射。常见的激活函数包括sigmoid,tanh,Relu等。
-
-**池化层**主要是用于参数量压缩。可以减轻过拟合情况。常见的有平均池化和最大值池化,不包含需要学习的参数。
-**全连接层**主要是指两层网络,所有神经元之间都有权重连接。常见用于网络的最后一层,用于计算类别得分。
+ 以图像分类任务为例,在表5.1所示卷积神经网络中,一般包含5种类型的网络层次结构:
-## 5.2 卷积如何检测边缘信息?
-卷积运算是卷积神经网络最基本的组成部分。在神经网络中,以物体识别为例,特征的检测情况可大致做一下划分。前几层检测到的是一些边缘特征,中间几层检测到的是物体的局部区域,靠后的几层检测到的是完整物体。每个阶段特征的形成都是由多组滤波器来完成的。而其中的边缘检测部分是由滤波器来完成的。在传统的图像处理方法里面,有许多边缘检测算子,如canny算子。使用固定的模板来进行边缘检测。
+ 表5.1 卷积神经网络的组成
-先介绍一个概念,过滤器:
+| CNN层次结构 | 输出尺寸 | 作用 |
+| :---------: | :-------------------------------: | :----------------------------------------------------------- |
+| 输入层 | $W_1\times H_1\times 3$ | 卷积网络的原始输入,可以是原始或预处理后的像素矩阵 |
+| 卷积层 | $W_1\times H_1\times K$ | 参数共享、局部连接,利用平移不变性从全局特征图提取局部特征 |
+| 激活层 | $W_1\times H_1\times K$ | 将卷积层的输出结果进行非线性映射 |
+| 池化层 | $W_2\times H_2\times K$ | 进一步筛选特征,可以有效减少后续网络层次所需的参数量 |
+| 全连接层 | $(W_2 \cdot H_2 \cdot K)\times C$ | 将多维特征展平为2维特征,通常低维度特征对应任务的学习目标(类别或回归值) |
-
+> $W_1\times H_1\times 3$对应原始图像或经过预处理的像素值矩阵,3对应RGB图像的通道;$K$表示卷积层中卷积核(滤波器)的个数;$W_2\times H_2$ 为池化后特征图的尺度,在全局池化中尺度对应$1\times 1$;$(W_2 \cdot H_2 \cdot K)$是将多维特征压缩到1维之后的大小,$C$对应的则是图像类别个数。
-这是一个3*3的过滤器,是一个矩阵,数值如上所示。
+### 5.1.1 输入层
-假设我们有一个6*6的灰度图像:
+ 输入层(Input Layer)通常是输入卷积神经网络的原始数据或经过预处理的数据,可以是图像识别领域中原始三维的多彩图像,也可以是音频识别领域中经过傅利叶变换的二维波形数据,甚至是自然语言处理中一维表示的句子向量。以图像分类任务为例,输入层输入的图像一般包含RGB三个通道,是一个由长宽分别为$H$和$W$组成的3维像素值矩阵$H\times W \times 3$,卷积网络会将输入层的数据传递到一系列卷积、池化等操作进行特征提取和转化,最终由全连接层对特征进行汇总和结果输出。根据计算能力、存储大小和模型结构的不同,卷积神经网络每次可以批量处理的图像个数不尽相同,若指定输入层接收到的图像个数为$N$,则输入层的输出数据为$N\times H\times W\times 3$。
-
-把这个图像与过滤器进行卷积运算,卷积运算在此处用“*”表示。
+### 5.1.2 卷积层
-
+ 卷积层(Convolution Layer)通常用作对输入层输入数据进行特征提取,通过卷积核矩阵对原始数据中隐含关联性的一种抽象。卷积操作原理上其实是对两张像素矩阵进行点乘求和的数学操作,其中一个矩阵为输入的数据矩阵,另一个矩阵则为卷积核(滤波器或特征矩阵),求得的结果表示为原始图像中提取的特定局部特征。图5.1表示卷积操作过程中的不同填充策略,上半部分采用零填充,下半部分采用有效卷积(舍弃不能完整运算的边缘部分)。
+ 
+ 图5.1 卷积操作示意图
-如图深蓝色区域所示,过滤器在图像左上方3*3的范围内,逐一加权相加,得到-5。
+### 5.1.3 激活层
-同理,将过滤器右移进行相同操作,再下移,直到过滤器对准图像右下角最后一格。依次运算得到一个4*4的矩阵。
+ 激活层(Activation Layer)负责对卷积层抽取的特征进行激活,由于卷积操作是由输入矩阵与卷积核矩阵进行相差的线性变化关系,需要激活层对其进行非线性的映射。激活层主要由激活函数组成,即在卷积层输出结果的基础上嵌套一个非线性函数,让输出的特征图具有非线性关系。卷积网络中通常采用ReLU来充当激活函数(还包括tanh和sigmoid等)ReLU的函数形式如公式(5-1)所示,能够限制小于0的值为0,同时大于等于0的值保持不变。
+$$
+f(x)=\begin{cases}
+ 0 &\text{if } x<0 \\
+ x &\text{if } x\ge 0
+\end{cases}
+\tag{5-1}
+$$
-在了解了过滤器以及卷积运算后,让我们看看为何过滤器能检测物体边缘:
+### 5.1.4 池化层
+ 池化层又称为降采样层(Downsampling Layer),作用是对感受域内的特征进行筛选,提取区域内最具代表性的特征,能够有效地降低输出特征尺度,进而减少模型所需要的参数量。按操作类型通常分为最大池化(Max Pooling)、平均池化(Average Pooling)和求和池化(Sum Pooling),它们分别提取感受域内最大、平均与总和的特征值作为输出,最常用的是最大池化。
-举一个最简单的例子:
+### 5.1.5 全连接层
+ 全连接层(Full Connected Layer)负责对卷积神经网络学习提取到的特征进行汇总,将多维的特征输入映射为二维的特征输出,高维表示样本批次,低位常常对应任务目标。
-
-这张图片如上所示,左半边全是白的,右半边全是灰的,我们仍然使用之前的过滤器,对该图片进行卷积处理:
+## 5.2 卷积在图像中有什么直观作用
-
+ 在卷积神经网络中,卷积常用来提取图像的特征,但不同层次的卷积操作提取到的特征类型是不相同的,特征类型粗分如表5.2所示。
+ 表5.2 卷积提取的特征类型
-可以看到,最终得到的结果中间是一段白色,两边为灰色,于是垂直边缘被找到了。为什么呢?因为在6*6图像中红框标出来的部分,也就是图像中的分界线所在部分,与过滤器进行卷积,结果是30。而在不是分界线的所有部分进行卷积,结果都为0.
+| 卷积层次 | 特征类型 |
+| :------: | :------: |
+| 浅层卷积 | 边缘特征 |
+| 中层卷积 | 局部特征 |
+| 深层卷积 | 全局特征 |
-在这个图中,白色的分界线很粗,那是因为6\*6的图像尺寸过小,对于1000\*1000的图像,我们会发现在最终结果中,分界线较细但很明显。
+图像与不同卷积核的卷积可以用来执行边缘检测、锐化和模糊等操作。表5.3显示了应用不同类型的卷积核(滤波器)后的各种卷积图像。
+ 表5.3 一些常见卷积核的作用
-这就是检测物体垂直边缘的例子,水平边缘的话只需将过滤器旋转90度。
+| 卷积作用 | 卷积核 | 卷积后图像 |
+| :----------------------: | :----------------------------------------------------------: | :-----------------------------------------------: |
+| 输出原图 | $\begin{bmatrix} 0 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 0 \end{bmatrix}$ |  |
+| 边缘检测(突出边缘差异) | $\begin{bmatrix} 1 & 0 & -1 \\ 0 & 0 & 0 \\ -1 & 0 & 1 \end{bmatrix}$ |  |
+| 边缘检测(突出中间值) | $\begin{bmatrix} -1 & -1 & -1 \\ -1 & 8 & -1 \\ -1 & -1 & -1 \end{bmatrix}$ |  |
+| 图像锐化 | $\begin{bmatrix} 0 & -1 & 0 \\ -1 & 5 & -1 \\ 0 & -1 & 0 \end{bmatrix}$ |  |
+| 方块模糊 | $\begin{bmatrix} 1 & 1 & 1 \\ 1 & 1 & 1 \\ 1 & 1 & 1 \end{bmatrix} \times \frac{1}{9}$ |  |
+| 高斯模糊 | $\begin{bmatrix} 1 & 2 & 1 \\ 2 & 4 & 2 \\ 1 & 2 & 1 \end{bmatrix} \times \frac{1}{16}$ |  |
-## 5.3 卷积层中的几个基本参数?
+## 5.3 卷积层有哪些基本参数?
-在卷积层中,有一些我们常用的参数,定义如下
+ 卷积层中需要用到卷积核(滤波器或特征检测器)与图像特征矩阵进行点乘运算,利用卷积核与对应的特征感受域进行划窗式运算时,需要设定卷积核对应的大小、步长、个数以及填充的方式,如表5.4所示。
-### 5.3.1 卷积核大小
-英文名是Kernel Size:卷积核的大小定义了卷积的感受野。二维卷积的核大小选择通常是3,即3×3。
-### 5.3.2 卷积核的步长
-英文名是Stride: Stride定义了卷积核在卷积过程中的步长。虽然它的默认值通常为1,但我们可以将步长设置为2,可以实现类似于pooling的下采样功能。
-### 5.3.3 边缘填充
-英文名是Padding: Padding用于填充输入图像的边界。一个(半)填充的卷积将使空间输出维度与输入相等,而如果卷积核大于1,则对于未被填充的图像,卷积后将会使图像一些边界消失。
-### 5.3.4 输入和输出通道
-英文名是 Input/Output Channels 一个卷积层接受一定数量的输入通道I,并计算一个特定数量的输出通道O,这一层所需的参数可以由I*O*K计算,K等于卷积核中参数的数量。
+ 表5.4 卷积层的基本参数
-## 5.4 卷积的网络类型分类?
-### 5.4.1 普通卷积
-普通卷积即如下图所示,使用一个固定大小的滤波器,对图像进行加权提特征。
-
-### 5.4.2 扩张卷积
-扩张卷积,又称为带孔(atrous)卷积或者空洞(dilated)卷积。在使用扩张卷积时,会引入一个称作扩张率(dilation rate)的参数。该参数定义了卷积核内参数间的行(列)间隔数。例如下图所示,一个3×3的卷积核,扩张率为2,它的感受野与5×5卷积核相同,而仅使用9个参数。这样做的好处是,在参数量不变的情况下,可以获得更大的感受野。扩张卷积在实时分割领域应用非常广泛。
-
-### 5.4.3 转置卷积
-转置卷积也就是反卷积(deconvolution)。虽然有些人经常直接叫它反卷积,但严格意义上讲是不合适的,因为它不符合一个反卷积的概念。反卷积确实存在,但它们在深度学习领域并不常见。一个实际的反卷积会恢复卷积的过程。想象一下,将一个图像放入一个卷积层中。现在把输出传递到一个黑盒子里,然后你的原始图像会再次出来。这个黑盒子就完成了一个反卷积。这是一个卷积层的数学逆过程。
+| 参数名 | 作用 | 常见设置 |
+| :-----------------------: | :----------------------------------------------------------- | :----------------------------------------------------------- |
+| 卷积核大小 (Kernel Size) | 卷积核的大小定义了卷积的感受野 | 在过去常设为5,如LeNet-5;现在多设为3,通过堆叠$3\times3$的卷积核来达到更大的感受域 |
+| 卷积核步长 (Stride) | 定义了卷积核在卷积过程中的步长 | 常见设置为1,表示滑窗距离为1,可以覆盖所有相邻位置特征的组合;当设置为更大值时相当于对特征组合降采样 |
+| 填充方式 (Padding) | 在卷积核尺寸不能完美匹配输入的图像矩阵时需要进行一定的填充策略 | 设置为'SAME'表示对不足卷积核大小的边界位置进行某种填充(通常零填充)以保证卷积输出维度与与输入维度一致;当设置为'VALID'时则对不足卷积尺寸的部分进行舍弃,输出维度就无法保证与输入维度一致 |
+| 输入通道数 (In Channels) | 指定卷积操作时卷积核的深度 | 默认与输入的特征矩阵通道数(深度)一致;在某些压缩模型中会采用通道分离的卷积方式 |
+| 输出通道数 (Out Channels) | 指定卷积核的个数 | 若设置为与输入通道数一样的大小,可以保持输入输出维度的一致性;若采用比输入通道数更小的值,则可以减少整体网络的参数量 |
-一个转置的卷积在某种程度上是相似的,因为它产生的空间分辨率是跟反卷积后产生的分辨率相同。不同之处是在卷积核值上执行的实际数学操作。转置卷积层使用的是常规的卷积,但是它能够恢复其空间变换。
+> 卷积操作维度变换公式:
+>
+> $O_d =\begin{cases} \lceil \frac{(I_d - k_{size})+ 1)}{s}\rceil ,& \text{padding=VALID}\\ \lceil \frac{I_d}{s}\rceil,&\text{padding=SAME} \end{cases}$
+>
+> 其中,$I_d$为输入维度,$O_d$为输出维度,$k_{size}$为卷积核大小,$s$为步长
-在这一点上,让我们来看一个具体的例子:
-将5×5的图像送到一个卷积层。步长设置为2,无边界填充,而卷积核是3×3。结果得到了2×2的图像。如果我们想要逆向该过程,则需要数学上的逆运算,以便从输入的每个像素值中生成9个值。然后,我们将步长设置为2来遍历输出图像。这就是一个反卷积过程。
-
-转置卷积的实现过程则不同。为了保证输出将是一个5×5的图像,在使用卷积运算时,我们需要在输入上执行一些特别的填充。而这一过程并不是逆转了卷积运算,它仅仅是重新构造了之前的空间分辨率并进行了卷积运算。这样的做法并不是数学上的逆过程,但是很适用于编码-解码器(Encoder-Decoder)架构。我们就可以把图像的上采样(upscaling)和卷积操作结合起来,而不是做两个分离的过程。
-
+## 5.4 卷积核有什么类型?
-### 5.4.4 可分离卷积
-在一个可分离卷积中,我们可以将内核操作拆分成多个步骤。我们用y = conv(x,k)表示卷积,其中y是输出图像,x是输入图像,k是核大小。这一步很简单。接下来,我们假设k可以由下面这个等式计算得出:k = k1.dot(k2)。这将使它成为一个可分离的卷积,因为我们可以通过对k1和k2做2个一维卷积来取得相同的结果,而不是用k做二维卷积。
+ 常见的卷积主要是由连续紧密的卷积核对输入的图像特征进行滑窗式点乘求和操作,除此之外还有其他类型的卷积核在不同的任务中会用到,具体分类如表5.5所示。
+ 表5.5 卷积核分类
-
+| 卷积类别 | 示意图 | 作用 |
+| :----------------------------: | :---------------------------: | :----------------------------------------------------------- |
+| 标准卷积 |  | 最常用的卷积核,连续紧密的矩阵形式可以提取图像区域中的相邻像素之间的关联关系,$3\times3$的卷积核可以获得$3\times3$像素范围的感受视野 |
+| 扩张卷积(带孔卷积或空洞卷积) |  | 引入一个称作扩张率(Dilation Rate)的参数,使同样尺寸的卷积核可以获得更大的感受视野,相应的在相同感受视野的前提下比普通卷积采用更少的参数。同样是$3\times3$的卷积核尺寸,扩张卷积可以提取$5\times5$范围的区域特征,在实时图像分割领域广泛应用 |
+| 转置卷积 |  | 先对原始特征矩阵进行填充使其维度扩大到适配卷积目标输出维度,然后进行普通的卷积操作的一个过程,其输入到输出的维度变换关系恰好与普通卷积的变换关系相反,但这个变换并不是真正的逆变换操作,通常称为转置卷积(Transpose Convolution)而不是反卷积(Deconvolution)。转置卷积常见于目标检测领域中对小目标的检测和图像分割领域还原输入图像尺度。 |
+| 可分离卷积 |  | 标准的卷积操作是同时对原始图像$H\times W\times C$三个方向的卷积运算,假设有$K$个相同尺寸的卷积核,这样的卷积操作需要用到的参数为$H\times W\times C\times K$个;若将长宽与深度方向的卷积操作分离出变为$H\times W$与$C$的两步卷积操作,则同样的卷积核个数$K$,只需要$(H\times W + C)\times K$个参数,便可得到同样的输出尺度。可分离卷积(Seperable Convolution)通常应用在模型压缩或一些轻量的卷积神经网络中,如MobileNet$^{[1]}$、Xception$^{[2]}$等 |
-以图像处理中的Sobel算子为例。你可以通过乘以向量[1,0,-1]和[1,2,1] .T获得相同的核大小。在执行相同的操作时,你只需要6个参数,而不是9个。上面的示例显示了所谓的空间可分离卷积。即将一个二维的卷积分离成两个一维卷积的操作。在神经网络中,为了减少网络参数,加速网络运算速度。我们通常使用的是一种叫深度可分离卷积的神经网络。
-## 5.5 图解12种不同类型的2D卷积?
+## 5.5 二维卷积与三维卷积有什么区别?
-http://www.sohu.com/a/159591827_390227
+- **二维卷积**
+ 二维卷积操作如图5.3所示,为了更直观的说明,分别展示在单通道和多通道输入中,对单个通道输出的卷积操作。在单通道输入的情况下,若输入卷积核尺寸为 $(k_h, k_w, 1)$,卷积核在输入图像的空间维度上进行滑窗操作,每次滑窗和 $(k_h, k_w)$窗口内的值进行卷积操作,得到输出图像中的一个值。在多通道输入的情况下,假定输入图像特征通道数为3,卷积核尺寸则为$(k_h, k_w, 3)$,每次滑窗与3个通道上的$(k_h, k_w)$窗口内的所有值进行卷积操作,得到输出图像中的一个值。
-## 5.6 2D卷积与3D卷积有什么区别?
-### 5.6.1 2D卷积
-二维卷积操作如图所示,为了更直观的说明,分别展示了单通道和多通道的操作。假定只使用了1个滤波器,即输出图像只有一个channel。其中,针对单通道,输入图像的channel为1,卷积核尺寸为 (k_h, k_w, 1),卷积核在输入图像的空间维度上进行滑窗操作,每次滑窗和 (k_h, k_w)窗口内的值进行卷积操作,得到输出图像中的一个值。针对多通道,假定输入图像的channel为3,卷积核尺寸则为 (k_h, k_w, 3),则每次滑窗与3个channels上的 (k_h, k_w)窗口内的所有值进行卷积操作,得到输出图像中的一个值。
+
-
-### 5.6.2 3D卷积
-3D卷积操作如图所示,同样分为单通道和多通道,且假定只使用1个滤波器,即输出图像仅有一个channel。其中,针对单通道,与2D卷积不同之处在于,输入图像多了一个length维度,卷积核也多了一个k_l维度,因此3D卷积核的尺寸为(k_h, k_w, k_l),每次滑窗与 (k_h, k_w, k_l)窗口内的值进行相关操作,得到输出3D图像中的一个值.针对多通道,则与2D卷积的操作一样,每次滑窗与3个channels上的 (k_h, k_w, k_l) 窗口内的所有值进行相关操作,得到输出3D图像中的一个值。
+- **三维卷积**
+ 3D卷积操作如图所示,同样分为单通道和多通道,且假定只使用1个卷积核,即输出图像仅有一个通道。对于单通道输入,与2D卷积不同之处在于,输入图像多了一个深度(depth)维度,卷积核也多了一个$k_d$维度,因此3D卷积核的尺寸为$(k_h, k_w, k_d)$,每次滑窗与$(k_h, k_w, k_d)$窗口内的值进行相关操作,得到输出3D图像中的一个值。对于多通道输入,则与2D卷积的操作一样,每次滑窗与3个channels上的$(k_h, k_w, k_d)$窗口内的所有值进行相关操作,得到输出3D图像中的一个值。
-
+
## 5.7 有哪些池化方法?
-在构建卷积神经网络时,经常会使用池化操作,而池化层往往在卷积层后面,通过池化操作来降低卷积层输出的特征维度,同时可以防止过拟合现象。池化操作可以降低图像维度的原因,本质上是因为图像具有一种“静态性”的属性,这个意思是说在一个图像区域有用的特征极有可能在另一个区域同样有用。因此,为了描述一个大的图像,很直观的想法就是对不同位置的特征进行聚合统计。例如,可以计算图像在固定区域上特征的平均值 (或最大值)来代表这个区域的特征。[1]
-### 5.7.1 一般池化(General Pooling)
-池化操作与卷积操作不同,过程如下图。
+ 池化操作通常也叫做子采样(Subsampling)或降采样(Downsampling),在构建卷积神经网络时,往往会用在卷积层之后,通过池化来降低卷积层输出的特征维度,有效减少网络参数的同时还可以防止过拟合现象。池化操作可以降低图像维度的原因,本质上是因为图像具有一种“静态性”的属性,这个意思是说在一个图像区域有用的特征极有可能在另一个区域同样有用。因此,为了描述一个大的图像,很直观的想法就是对不同位置的特征进行聚合统计。例如,可以计算图像在固定区域上特征的平均值 (或最大值)来代表这个区域的特征。
+ 表5.6 池化分类
-
-池化操作过程如图所示,对固定区域的特征,使用某一个值来表示。最常见的池化操作有两种,分为平均池化mean pooling和最大池化max pooling
+| 池化类型 | 示意图 | 作用 |
+| :-----------------------------------------: | :-----------------------------------------------: | :----------------------------------------------------------- |
+| 一般池化(General Pooling) |  | 通常包括最大池化(Max Pooling)和平均池化(Mean Pooling)。以最大池化为例,池化范围$(2\times2)$和滑窗步长$(stride=2)$ 相同,仅提取一次相同区域的范化特征。 |
+| 重叠池化(Overlapping Pooling) |  | 与一般池化操作相同,但是池化范围$P_{size}$与滑窗步长$stride$关系为$P_{size}>stride$,同一区域内的像素特征可以参与多次滑窗提取,得到的特征表达能力更强,但计算量更大。 |
+| 空间金字塔池化$^*$(Spatial Pyramid Pooling) |  | 在进行多尺度目标的训练时,卷积层允许输入的图像特征尺度是可变的,紧接的池化层若采用一般的池化方法会使得不同的输入特征输出相应变化尺度的特征,而卷积神经网络中最后的全连接层则无法对可变尺度进行运算,因此需要对不同尺度的输出特征采样到相同输出尺度。 |
-1、平均池化:计算图像区域的平均值作为该区域池化后的值。
+> SPPNet$^{[3]}$就引入了空间池化的组合,对不同输出尺度采用不同的滑窗大小和步长以确保输出尺度相同$(win_{size}=\lceil \frac{in}{out}\rceil; stride=\lfloor \frac{in}{out}\rfloor; )$,同时用如金字塔式叠加的多种池化尺度组合,以提取更加丰富的图像特征。常用于多尺度训练和目标检测中的区域提议网络(Region Proposal Network)的兴趣区域(Region of Interest)提取
-2、最大池化:选图像区域的最大值作为该区域池化后的值。
-上述的池化过程,相邻的池化窗口间没有重叠部分。
-### 5.7.2 重叠池化(General Pooling)
-重叠池化即是一种相邻池化窗口之间会有重叠区域的池化技术。论文中[2]中,作者使用了重叠池化,其他的设置都不变的情况下,top-1和top-5 的错误率分别减少了0.4% 和0.3%。
-### 5.7.3 空金字塔池化(Spatial Pyramid Pooling)
-空间金字塔池化可以将任意尺度的图像卷积特征转化为相同维度,这不仅可以让CNN处理任意尺度的图像,还能避免cropping和warping操作,导致一些信息的丢失。一般的卷积神经网络都需要固定输入图像大小,这是因为全连接层的输入需要固定输入维度,但在卷积操作时并没有对图像大小有限制,所以作者提出了空间金字塔池化方法,先让图像进行卷积操作,然后使用SPP方法转化成维度相同的特征,最后输入到全连接层。
-
+## 5.8 $1\times1$卷积作用?
-根据论文作者所述,空间金字塔池化的思想来自于Spatial Pyramid Model,它是将一个pooling过程变成了多个尺度的pooling。用不同大小的池化窗口作用于卷积特征,这样就可以得到1X1,2X2,4X4的池化结果,由于conv5中共有256个滤波器,所以得到1个256维的特征,4个256个特征,以及16个256维的特征,然后把这21个256维特征链接起来输入全连接层,通过这种方式把不同大小的图像转化成相同维度的特征。
+ NIN(Network in Network)$^{[4]}$是第一篇探索$1\times1$卷积核的论文,这篇论文通过在卷积层中使用MLP替代传统线性的卷积核,使单层卷积层内具有非线性映射的能力,也因其网络结构中嵌套MLP子网络而得名NIN。NIN对不同通道的特征整合到MLP自网络中,让不同通道的特征能够交互整合,使通道之间的信息得以流通,其中的MLP子网络恰恰可以用$1\times1$的卷积进行代替。
-
+ GoogLeNet$^{[5]}$则采用$1\times1$卷积核来减少模型的参数量。在原始版本的Inception模块中,由于每一层网络采用了更多的卷积核,大大增加了模型的参数量。此时在每一个较大卷积核的卷积层前引入$1\times1$卷积,可以通过分离通道与宽高卷积来减少模型参数量。以图5.2为例,在不考虑参数偏置项的情况下,若输入和输出的通道数为$C_1=16$,则左半边网络模块所需的参数为$(1\times1+3\times3+5\times5+0)\times C_1\times C_1=8960$;假定右半边网络模块采用的$1\times1$卷积通道数为$C_2=8$$(满足C_1>C_2)$,则右半部分的网络结构所需参数量为$(1\times1\times (3C_1+C_2)+3\times3\times C_2 +5\times5\times C_2)\times C_1=5248$ ,可以在不改变模型表达能力的前提下大大减少所使用的参数量。
-对于不同的图像,如果想要得到相同大小的pooling结果,就需要根据图像大小动态的计算池化窗口大小和步长。假设conv5输出的大小为a*a,需要得到n*n大小的池化结果,可以让窗口大小sizeX为[a/n],步长为[a/n]。下图展示了以conv5输出大小是13*13为例,spp算法的各层参数。
+
-
+ 图5.2 Inception模块
-总结来说,SPP方法其实就是一种使用多个尺度的池化方法,可以获取图像中的多尺度信息。在卷积神经网络中加入SPP后,可以让CNN处理任意大小的输入,这让模型变得更加的灵活。
+综上所述,$1\times 1$卷积的作用主要为以下两点:
-## 5.8 1x1卷积作用?
-1×1的卷积主要有以下两个方面的作用:
-
-1. 实现信息的跨通道交互和整合。
-
-2. 对卷积核通道数进行降维和升维,减小参数量。
-
-下面详细解释一下:
-**第一点 实现信息的跨通道交互和整合**
-对1×1卷积层的探讨最初是出现在NIN的结构,论文作者的动机是利用MLP代替传统的线性卷积核,从而提高网络的表达能力。文中从跨通道池化的角度进行解释,认为文中提出的MLP其实等价于在传统卷积核后面接cccp层,从而实现多个feature map的线性组合,实现跨通道的信息整合。而查看代码实现,cccp层即等价于1×1卷积层。
-**第二点 对卷积核通道数进行降维和升维,减小参数量**
-1x1卷积层能带来降维和升维的效果,在一系列的GoogLeNet中体现的最明显。对于每一个Inception模块(如下图),左图是原始模块,右图是加入1×1卷积进行降维的模块。虽然左图的卷积核都比较小,但是当输入和输出的通道数很大时,卷积核的参数量也会变的很大,而右图加入1×1卷积后可以降低输入的通道数,因此卷积核参数、运算复杂度也就大幅度下降。以GoogLeNet的3a模块为例,输入的feature map是28×28×192,3a模块中1×1卷积通道为64,3×3卷积通道为128,5×5卷积通道为32,如果是左图结构,那么卷积核参数为1×1×192×64+3×3×192×128+5×5×192×32,而右图对3×3和5×5卷积层前分别加入了通道数为96和16的1×1卷积层,这样卷积核参数就变成了1×1×192×64+(1×1×192×96+3×3×96×128)+(1×1×192×16+5×5×16×32),参数大约减少到原来的三分之一。同时在并行pooling层后面加入1×1卷积层后也可以降低输出的feature map数量,左图pooling后feature map是不变的,再加卷积层得到的feature map,会使输出的feature map扩大到416,如果每个模块都这样,网络的输出会越来越大。而右图在pooling后面加了通道数为32的1×1卷积,使得输出的feature map数降到了256。GoogLeNet利用1×1的卷积降维后,得到了更为紧凑的网络结构,虽然总共有22层,但是参数数量却只是8层AlexNet的十二分之一,当然其中也有丢掉全连接层的原因。
-
-
-而非常经典的ResNet结构,同样也使用了1×1卷积,并且是在3×3卷积层的前后都使用了,不仅进行了降维,还进行了升维,使得卷积层的输入和输出的通道数都减小,参数数量进一步减少,如下图结构所示。
-
-
+- 实现信息的跨通道交互和整合。
+- 对卷积核通道数进行降维和升维,减小参数量。
## 5.9 卷积层和池化层有什么区别?
-首先可以从结构上可以看出,卷积之后输出层的维度减小,深度变深。但池化层深度不变。同时池化可以把很多数据用最大值或者平均值代替。目的是降低数据量。降低训练的参数。对于输入层,当其中像素在邻域发生微小位移时,池化层的输出是不变的,从而能提升鲁棒性。而卷积则是把数据通过一个卷积核变化成特征,便于后面的分离。
+ 卷积层核池化层在结构上具有一定的相似性,都是对感受域内的特征进行提取,并且根据步长设置获取到不同维度的输出,但是其内在操作是有本质区别的,如表5.7所示。
-1:卷积
+| | 卷积层 | 池化层 |
+| :--------: | :------------------------------------: | :------------------------------: |
+| **结构** | 零填充时输出维度不变,而通道数改变 | 通常特征维度会降低,通道数不变 |
+| **稳定性** | 输入特征发生细微改变时,输出结果会改变 | 感受域内的细微变化不影响输出结果 |
+| **作用** | 感受域内提取局部关联特征 | 感受域内提取泛化特征,降低维度 |
+| **参数量** | 与卷积核尺寸、卷积核个数相关 | 不引入额外参数 |
-当从一个大尺寸图像中随机选取一小块,比如说 8x8 作为样本,并且从这个小块样本中学习到了一些特征,这时我们可以把从这个 8x8 样本中学习到的特征作为探测器,应用到这个图像的任意地方中去。特别是,我们可以用从 8x8 样本中所学习到的特征跟原本的大尺寸图像作卷积,从而对这个大尺寸图像上的任一位置获得一个不同特征的激活值。
-下面给出一个具体的例子:假设你已经从一个 96x96 的图像中学习到了它的一个 8x8 的样本所具有的特征,假设这是由有 100 个隐含单元的自编码完成的。为了得到卷积特征,需要对 96x96 的图像的每个 8x8 的小块图像区域都进行卷积运算。也就是说,抽取 8x8 的小块区域,并且从起始坐标开始依次标记为(1,1),(1,2),...,一直到(89,89),然后对抽取的区域逐个运行训练过的稀疏自编码来得到特征的激活值。在这个例子里,显然可以得到 100 个集合,每个集合含有 89x89 个卷积特征。
-
+## 5.10 卷积核是否一定越大越好?
-2:说下池化,其实池化很容易理解,先看图:
+ 在早期的卷积神经网络中(如LeNet-5、AlexNet),用到了一些较大的卷积核($11\times11$和$5\times 5$),受限于当时的计算能力和模型结构的设计,无法将网络叠加得很深,因此卷积网络中的卷积层需要设置较大的卷积核以获取更大的感受域。但是这种大卷积核反而会导致计算量大幅增加,不利于训练更深层的模型,相应的计算性能也会降低。后来的卷积神经网络(VGG、GoogLeNet等),发现通过堆叠2个$3\times 3$卷积核可以获得与$5\times 5$卷积核相同的感受视野,同时参数量会更少($3×3×2+1$ < $ 5×5×1+1$),$3\times 3$卷积核被广泛应用在许多卷积神经网络中。因此可以认为,在大多数情况下通过堆叠较小的卷积核比直接采用单个更大的卷积核会更加有效。
-转自: http://blog.csdn.net/silence1214/article/details/11809947
+ 但是,这并不是表示更大的卷积核就没有作用,在某些领域应用卷积神经网络时仍然可以采用较大的卷积核。譬如在自然语言处理领域,由于文本内容不像图像数据可以对特征进行很深层的抽象,往往在该领域的特征提取只需要较浅层的神经网络即可。在将卷积神经网络应用在自然语言处理领域时,通常都是较为浅层的卷积层组成,但是文本特征有时又需要有较广的感受域让模型能够组合更多的特征(如词组和字符),此时直接采用较大的卷积核将是更好的选择。
-
+ 综上所述,卷积核的大小并没有绝对的优劣,需要视具体的应用场景而定,但是极大和极小的卷积核都是不合适的,单独的$1\times 1$极小卷积核只能用作分离卷积而不能对输入的原始特征进行有效的组合,极大的卷积核通常会组合过多的无意义特征从而浪费了大量的计算资源。
-比如上方左侧矩阵A是20*20的矩阵要进行大小为10*10的池化,那么左侧图中的红色就是10*10的大小,对应到右侧的矩阵,右侧每个元素的值,是左侧红色矩阵每个元素的值得和再处于红色矩阵的元素个数,也就是平均值形式的池化。
-3:上面说了下卷积和池化,再说下计算中需要注意到的。在代码中使用的是彩色图,彩色图有3个通道,那么对于每一个通道来说要单独进行卷积和池化,有一个地方尤其是进行卷积的时候要注意到,隐藏层的每一个值是对应到一幅图的3个通道穿起来的,所以分3个通道进行卷积之后要加起来,正好才能对应到一个隐藏层的神经元上,也就是一个feature上去。
-## 5.10 卷积核是否一定越大越好?
-首先,给出答案。不是。
-在AlexNet网络结构中,用到了一些非常大的卷积核,比如11×11、5×5卷积核。之前研究者的想法是,卷积核越大,receptive field(感受野)越大,因此获得的特征越好。虽说如此,但是大的卷积核会导致计算量大幅增加,不利于训练更深层的模型,而相应的计算性能也会降低。于是在VGG、Inception网络中,实验发现利用2个3×3卷积核的组合比1个5×5卷积核的效果更佳,同时参数量(3×3×2+1 VS 5×5×1+1)会更少,因此后来3×3卷积核被广泛应用在各种模型中。
+## 5.11 每层卷积是否只能用一种尺寸的卷积核?
-多个小卷积核的叠加使用远比一个大卷积核单独使用效果要好的多,在连通性不变的情况下,大大降低了参数量和计算复杂度。当然,卷积核也不是越小越好,对于特别稀疏的数据,当使用比较小的卷积核的时候可能无法表示其特征,如果采用较大的卷积核则会导致复杂度极大的增加。
+ 经典的神经网络一般都属于层叠式网络,每层仅用一个尺寸的卷积核,如VGG结构中使用了大量的$3×3$卷积层。事实上,同一层特征图可以分别使用多个不同尺寸的卷积核,以获得不同尺度的特征,再把这些特征结合起来,得到的特征往往比使用单一卷积核的要好,如GoogLeNet、Inception系列的网络,均是每层使用了多个卷积核结构。如图5.3所示,输入的特征在同一层分别经过$1×1$、$3×3$和$5×5$三种不同尺寸的卷积核,再将分别得到的特征进行整合,得到的新特征可以看作不同感受域提取的特征组合,相比于单一卷积核会有更强的表达能力。
-总而言之,我们多倾向于选择多个相对小的卷积核来进行卷积。
+
-## 5.11 每层卷积是否只能用一种尺寸的卷积核?
-经典的神经网络,都属于层叠式网络,并且每层仅用一个尺寸的卷积核,例如VGG结构中使用了大量的3×3卷积层。事实上,同一层feature map可以分别使用多个不同尺寸的卷积核,以获得不同尺度的特征,再把这些特征结合起来,得到的特征往往比使用单一卷积核的要好,例如GoogLeNet、Inception系列的网络,均是每层使用了多个卷积核结构。如下图所示,输入的feature map在同一层,分别经过1×1、3×3、5×5三种不同尺寸的卷积核,再将分别得到的特征进行组合。
-
+ 图5.3 Inception模块结构
## 5.12 怎样才能减少卷积层参数量?
-发明GoogleNet的团队发现,如果仅仅引入多个尺寸的卷积核,会带来大量的额外的参数,受到Network In Network中1×1卷积核的启发,为了解决这个问题,他们往Inception结构中加入了一些1×1的卷积核,如图所示:
+减少卷积层参数量的方法可以简要地归为以下几点:
-
+- 使用堆叠小卷积核代替大卷积核:VGG网络中2个$3\times 3$的卷积核可以代替1个$5\times 5$的卷积核
+- 使用分离卷积操作:将原本$K\times K\times C$的卷积操作分离为$K\times K\times 1$和$1\times1\times C$的两部分操作
+- 添加$1\times 1$的卷积操作:与分离卷积类似,但是通道数可变,在$K\times K\times C_1$卷积前添加$1\times1\times C_2$的卷积核(满足$C_2 注1:(Avy pooling现在不怎么用了,方法是对每一个2*2的区域元素求和,再除以4,得到主要特征),而一般的filter取2*2,最大取3*3,stride取2,压缩为原来的1/4.
->注2:这里的pooling操作是特征图缩小,有可能影响网络的准确度,因此可以通过增加特征图的深度来弥补。
-## 5.19 理解图像卷积与反卷积
+## 5.15 理解转置卷积与棋盘效应
-### 5.19.1 图像卷积
+### 5.15.1 标准卷积
+在理解转置卷积之前,需要先理解标准卷积的运算方式。
首先给出一个输入输出结果

-那他是怎样计算的呢?
+那是怎样计算的呢?
卷积的时候需要对卷积核进行180的旋转,同时卷积核中心与需计算的图像像素对齐,输出结构为中心对齐像素的一个新的像素值,计算例子如下:
-
+
这样计算出左上角(即第一行第一列)像素的卷积后像素值。
给出一个更直观的例子,从左到右看,原像素经过卷积由1变成-8。
-
-
-通过滑动卷积核,就可以得到整张图片的卷积结果
-
-
-
-### 5.19.2 图像反卷积
-
-这里提到的反卷积跟1维信号处理的反卷积计算是很不一样的,FCN作者称为backwards convolution,有人称Deconvolution layer is a very unfortunate name and should rather be called a transposed convolutional layer. 我们可以知道,在CNN中有con layer与pool layer,con layer进行对图像卷积提取特征,pool layer 对图像缩小一半筛选重要特征,对于经典的图像识别CNN网络,如IMAGENET,最后输出结果是1X1X1000,1000是类别种类,1x1得到的是。FCN作者,或者后来对end to end研究的人员,就是对最终1x1的结果使用反卷积(事实上FCN作者最后的输出不是1X1,是图片大小的32分之一,但不影响反卷积的使用)。
-
-这里图像的反卷积与full卷积原理是一样的,使用了这一种反卷积手段使得图像可以变大,FCN作者使用的方法是这里所说反卷积的一种变体,这样就可以获得相应的像素值,图像可以实现end to end。
+
-
-
-
+通过滑动卷积核,就可以得到整张图片的卷积结果。
-这里说另外一种反卷积做法,假设原图是3*3,首先使用上采样让图像变成7*7,可以看到图像多了很多空白的像素点。使用一个3*3的卷积核对图像进行滑动步长为1的valid卷积,得到一个5*5的图像,我们知道的是使用上采样扩大图片,使用反卷积填充图像内容,使得图像内容变得丰富,这也是CNN输出end to end结果的一种方法。韩国作者Hyeonwoo Noh使用VGG16层CNN网络后面加上对称的16层反卷积与上采样网络实现end to end 输出,其不同层上采样与反卷积变化效果如下:
-
-
-
-经过上面的解释与推导,对卷积有基本的了解,但是在图像上的deconvolution究竟是怎么一回事,可能还是不能够很好的理解,因此这里再对这个过程解释一下。 目前使用得最多的deconvolution有2种,上文都已经介绍。
-
-* 方法1:full卷积, 完整的卷积可以使得原来的定义域变大。
-* 方法2:记录pooling index,然后扩大空间,再用卷积填充。
+### 5.15.2 转置卷积
图像的deconvolution过程如下:
-
+
输入:2x2, 卷积核:4x4, 滑动步长:3, 输出:7x7
-即输入为2x2的图片经过4x4的卷积核进行步长为3的反卷积的过程
+过程如下:
1. 输入图片每个像素进行一次full卷积,根据full卷积大小计算可以知道每个像素的卷积后大小为 1+4-1=4, 即4x4大小的特征图,输入有4个像素所以4个4x4的特征图
-2. 将4个特征图进行步长为3的fusion(即相加); 例如红色的特征图仍然是在原来输入位置(左上角),绿色还是在原来的位置(右上角),步长为3是指每隔3个像素进行fusion,重叠部分进行相加,即输出的第1行第4列是由红色特阵图的第一行第四列与绿色特征图的第一行第一列相加得到,其他如此类推。
-
-可以看出翻卷积的大小是由卷积核大小与滑动步长决定, in是输入大小, k是卷积核大小, s是滑动步长, out是输出大小 得到 out = (in - 1) * s + k 上图过程就是, (2 - 1) * 3 + 4 = 7
-
-## 5.20 不同卷积后图像大小计算?
-
-### 5.20.1 类型划分
-
-2维卷积的计算分为了3类:1.full 2.same 3. valid
-
-1、**full**
-
-
-
-蓝色为原图像,白色为对应卷积所增加的padding,通常全部为0,绿色是卷积后图片。图6的卷积的滑动是从卷积核右下角与图片左上角重叠开始进行卷积,滑动步长为1,卷积核的中心元素对应卷积后图像的像素点。可以看到卷积后的图像是4X4,比原图2X2大了,我们还记1维卷积大小是n1+n2-1,这里原图是2X2,卷积核3X3,卷积后结果是4X4,与一维完全对应起来了。其实这才是完整的卷积计算,其他比它小的卷积结果都是省去了部分像素的卷积
-
-2、**same**
-
-
-3、**valid**
+2. 将4个特征图进行步长为3的相加; 输出的位置和输入的位置相同。步长为3是指每隔3个像素进行相加,重叠部分进行相加,即输出的第1行第4列是由红色特阵图的第一行第四列与绿色特征图的第一行第一列相加得到,其他如此类推。
-
+ 可以看出翻卷积的大小是由卷积核大小与滑动步长决定, in是输入大小, k是卷积核大小, s是滑动步长, out是输出大小 得到 out = (in - 1) * s + k 上图过程就是, (2 - 1) * 3 + 4 = 7。
-### 5.20.2 计算公式
-这里,我们可以总结出full,same,valid三种卷积后图像大小的计算公式:
+### 5.15.3 棋盘效应
-1. full: 滑动步长为1,图片大小为N1xN1,卷积核大小为N2xN2,卷积后图像大小:N1+N2-1 x N1+N2-1。
-2. same: 滑动步长为1,图片大小为N1xN1,卷积核大小为N2xN2,卷积后图像大小:N1xN1。
-3. valid:滑动步长为S,图片大小为N1xN1,卷积核大小为N2xN2,卷积后图像大小:(N1-N2)/S+1 x (N1-N2)/S+1。
+## 5.16 卷积神经网络的参数设置
+ 卷积神经网络中常见的参数在其他类型的神经网络中也是类似的,但是参数的设置还得结合具体的任务才能设置在合理的范围,具体的参数列表如表XX所示。
+ 表XX 卷积神经网络常见参数
-## 5.21 步长、填充大小与输入输出关系总结?
+| 参数名 | 常见设置 | 参数说明 |
+| :----: | :-----: | :---- |
+| 学习率(Learning Rate) | $0-1$ | 反向传播网络中更新权值矩阵的步长,在一些常见的网络中会在固定迭代次数或模型不再收敛后对学习率进行指数下降(如$lr=lr\times 0.1$)。当学习率越大计算误差对权值矩阵的影响越大,容易在某个局部最优解附近震荡;越小的学习率对网络权值的更新越精细,但是需要花费更多的时间去迭代 |
+| 批次大小(Batch Size) | $1-N$ | 批次大小指定一次性流入模型的数据样本个数,根据任务和计算性能限制判断实际取值,在一些图像任务中往往由于计算性能和存储容量限制只能选取较小的值。在相同迭代次数的前提下,数值越大模型越稳定,泛化能力越强,损失值曲线越平滑,模型也更快地收敛,但是每次迭代需要花费更多的时间 |
+| 数据轮次(Epoch) | $1-N$ | 数据轮次指定所有训练数据在模型中训练的次数,根据数据集规模和分布情况会设置为不同的值。当模型较为简单或训练数据规模较小时,通常轮次不宜过高,否则模型容易过拟合;模型较为复杂或训练数据规模足够大时,可适当提高数据的训练轮次。 |
+| 权重衰减系数(Weight Decay) | $0-0.001$ | 模型训练过程中反向传播权值更新的权重衰减值 |
-在设计深度学习网络的时候,需要计算输入尺寸和输出尺寸,那么就要设计卷积层的的各种参数。这里有一些设计时候的计算公式,方便得到各层的参数。
+## 5.17 提高卷积神经网络的泛化能力
+ 卷积神经网络与其他类型的神经网络类似,在采用反向传播进行训练的过程中比较依赖输入的数据分布,当数据分布较为极端的情况下容易导致模型欠拟合或过拟合,表XX记录了提高卷积网络泛化能力的方法。
+ 表XX 提高卷积网络化能力的方法
-这里简化下,约定:
+| 方法 | 说明 |
+| :---: | :--- |
+| 使用更多数据 | 在有条件的前提下,尽可能多地获取训练数据是最理想的方法,更多的数据可以让模型得到充分的学习,也更容易提高泛化能力 |
+| 使用更大批次 | 在相同迭代次数和学习率的条件下,每批次采用更多的数据将有助于模型更好的学习到正确的模式,模型输出结果也会更加稳定 |
+| 调整数据分布 | 大多数场景下的数据分布是不均匀的,模型过多地学习某类数据容易导致其输出结果偏向于该类型的数据,此时通过调整输入的数据分布可以一定程度提高泛化能力 |
+| 调整目标函数 | 在某些情况下,目标函数的选择会影响模型的泛化能力,如目标函数$f(y,y')=|y-y'|$在某类样本已经识别较为准确而其他样本误差较大的侵害概况下,不同类别在计算损失结果的时候距离权重是相同的,若将目标函数改成$f(y,y')=(y-y')^2$则可以使误差小的样本计算损失的梯度比误差大的样本更小,进而有效地平衡样本作用,提高模型泛化能力 |
+| 调整网络结构 | 在浅层卷积神经网络中,参数量较少往往使模型的泛化能力不足而导致欠拟合,此时通过叠加卷积层可以有效地增加网络参数,提高模型表达能力;在深层卷积网络中,若没有充足的训练数据则容易导致模型过拟合,此时通过简化网络结构减少卷积层数可以起到提高模型泛化能力的作用 |
+| 数据增强 | 数据增强又叫数据增广,在有限数据的前提下通过平移、旋转、加噪声等一些列变换来增加训练数据,同类数据的表现形式也变得更多样,有助于模型提高泛化能力,需要注意的是数据变化应尽可能不破坏元数数据的主体特征(如在图像分类任务中对图像进行裁剪时不能将分类主体目标裁出边界)。 |
+| 权值正则化 | 权值正则化就是通常意义上的正则化,一般是在损失函数中添加一项权重矩阵的正则项作为惩罚项,用来惩罚损失值较小时网络权重过大的情况,此时往往是网络权值过拟合了数据样本(如$Loss=f(WX+b,y')+\frac{\lambda}{\eta}\sum{|W|}$)。 |
+| 屏蔽网络节点 | 该方法可以认为是网络结构上的正则化,通过随机性地屏蔽某些神经元的输出让剩余激活的神经元作用,可以使模型的容错性更强。 |
+> 对大多数神经网络模型同样通用
-
-### 5.21.1 没有0填充,单位步长
+## 5.18 卷积神经网络在不同领域的应用
+ 卷积神经网络中的卷积操作是其关键组成,而卷积操作只是一种数学运算方式,实际上对不同类型的数值表示数据都是通用的,尽管这些数值可能表示的是图像像素值、文本序列中单个字符或是语音片段中单字的音频。只要使原始数据能够得到有效地数值化表示,卷积神经网络能够在不同的领域中得到应用,要关注的是如何将卷积的特性更好地在不同领域中应用,如表XX所示。
+ 表XX 卷积神经网络不同领域的应用
+| 应用领域 | 输入数据图示 | 说明 |
+| :-----: | :----------: | :-- |
+| 图像处理 |  | 卷积神经网络在图像处理领域有非常广泛的应用,这是因为图像数据本身具有的局部完整性非常 |
+| 自然语言处理 |  | |
+| 语音处理 |  | |
-
+### 5.18.1 联系
-### 5.21.2 零填充,单位步长
+ 自然语言处理是对一维信号(词序列)做操作。
+ 计算机视觉是对二维(图像)或三维(视频流)信号做操作。
-
+### 5.18.2 区别
-<1>半填充
-
+ 自然语言处理的输入数据通常是离散取值(例如表示一个单词或字母通常表示为词典中的one hot向量),计算机视觉则是连续取值(比如归一化到0,1之间的灰度值)。CNN有两个主要特点,区域不变性(location invariance)和组合性(Compositionality)。
-<2>全填充
-
-
-参考图如下图所示
-
-
-
-
-### 5.21.3 不填充,非单位步长
+1. 区域不变性:滤波器在每层的输入向量(图像)上滑动,检测的是局部信息,然后通过pooling取最大值或均值。pooling这步综合了局部特征,失去了每个特征的位置信息。这很适合基于图像的任务,比如要判断一幅图里有没有猫这种生物,你可能不会去关心这只猫出现在图像的哪个区域。但是在NLP里,词语在句子或是段落里出现的位置,顺序,都是很重要的信息。
+2. 局部组合性:CNN中,每个滤波器都把较低层的局部特征组合生成较高层的更全局化的特征。这在CV里很好理解,像素组合成边缘,边缘生成形状,最后把各种形状组合起来得到复杂的物体表达。在语言里,当然也有类似的组合关系,但是远不如图像来的直接。而且在图像里,相邻像素必须是相关的,相邻的词语却未必相关。
-
+## 5.19 卷积神经网络凸显共性的方法?
-### 5.21.4 零填充,非单位步长
+### 5.19.1 局部连接
-
-
-
-
+ 我们首先了解一个概念,感受野,即每个神经元仅与输入神经元相连接的一块区域。
+在图像卷积操作中,神经元在空间维度上是局部连接,但在深度上是全连接。局部连接的思想,是受启发于生物学里的视觉系统结构,视觉皮层的神经元就是仅用局部接受信息。对于二维图像,局部像素关联性较强。这种局部连接保证了训练后的滤波器能够对局部特征有最强的响应,使神经网络可以提取数据的局部特征;
+下图是一个很经典的图示,左边是全连接,右边是局部连接。
-http://blog.csdn.net/u011692048/article/details/77572024
-https://arxiv.org/pdf/1603.07285.pdf
+
-## 5.22 理解反卷积和棋盘效应
+对于一个1000 × 1000的输入图像而言,如果下一个隐藏层的神经元数目为10^6个,采用全连接则有1000 × 1000 × 10^6 = 10^12个权值参数,如此巨大的参数量几乎难以训练;而采用局部连接,隐藏层的每个神经元仅与图像中10 × 10的局部图像相连接,那么此时的权值参数数量为10 × 10 × 10^6 = 10^8,将直接减少4个数量级。
-### 5.22.1 为什么出现棋盘现象?
+### 5.19.2 权值共享
-图像生成网络的上采样部分通常用反卷积网络,不合理的卷积核大小和步长会使反卷积操作产生棋盘效应 (checkerboard artifacts)。
+ 权值共享,即计算同一深度的神经元时采用的卷积核参数是共享的。权值共享在一定程度上讲是有意义的,是由于在神经网络中,提取的底层边缘特征与其在图中的位置无关。但是在另一些场景中是无意的,如在人脸识别任务,我们期望在不同的位置学到不同的特征。
+需要注意的是,权重只是对于同一深度切片的神经元是共享的。在卷积层中,通常采用多组卷积核提取不同的特征,即对应的是不同深度切片的特征,而不同深度切片的神经元权重是不共享。相反,偏置这一权值对于同一深度切片的所有神经元都是共享的。
+权值共享带来的好处是大大降低了网络的训练难度。如下图,假设在局部连接中隐藏层的每一个神经元连接的是一个10 × 10的局部图像,因此有10 × 10个权值参数,将这10 × 10个权值参数共享给剩下的神经元,也就是说隐藏层中10^6个神经元的权值参数相同,那么此时不管隐藏层神经元的数目是多少,需要训练的参数就是这 10 × 10个权值参数(也就是卷积核的大小)。
-
-
+
-重叠图案也在二维中形成。两个轴上的不均匀重叠相乘,产生不同亮度的棋盘状图案。
+这里就体现了卷积神经网络的奇妙之处,使用少量的参数,却依然能有非常出色的性能。上述仅仅是提取图像一种特征的过程。如果要多提取出一些特征,可以增加多个卷积核,不同的卷积核能够得到图像不同尺度下的特征,称之为特征图(feature map)。
-事实上,不均匀重叠往往在二维上更极端!因为两个模式相乘,所以它的不均匀性是原来的平方。例如,在一个维度中,一个步长为2,大小为3的反卷积的输出是其输入的两倍,但在二维中,输出是输入的4倍。
+### 5.19.3 池化操作
-现在,生成图像时,神经网络通常使用多层反卷积,从一系列较低分辨率的描述中迭代建立更大的图像。虽然这些堆栈的反卷积可以消除棋盘效应,但它们经常混合,在更多尺度上产生棋盘效应。
+池化操作与多层次结构一起,实现了数据的降维,将低层次的局部特征组合成为较高层次的特征,从而对整个图片进行表示。如下图:
-直观地看,假设生成的图像中包含1只黑猫。黑猫身体部分的像素颜色应平滑过渡,或极端地说,该部分应全为黑色。实际生成的图像中该部分却有深深浅浅的近黑方块组成,很像棋盘的网格,即棋盘效应。
+
-https://distill.pub/2016/deconv-checkerboard/
-http://blog.csdn.net/shadow_guo/article/details/52862161
+## 5.20 全连接、局部连接、全卷积与局部卷积
+ 大多数神经网络中高层网络通常会采用全连接层(Global Connected Layer),通过多对多的连接方式对特征进行全局汇总,可以有效地提取全局信息。但是全连接的方式需要大量的参数,是神经网络中最占资源的部分之一,因此就需要由局部连接(Local Connected Layer),仅在局部区域范围内产生神经元连接,能够有效地减少参数量。根据卷积操作的作用范围可以分为全卷积(Global Convolution)和局部卷积(Local Convolution)。实际上这里所说的全卷积就是标准卷积,即在整个输入特征维度范围内采用相同的卷积核参数进行运算,全局共享参数的连接方式可以使神经元之间的连接参数大大减少;局部卷积又叫平铺卷积(Tiled Convolution)或非共享卷积(Unshared Convolution),是局部连接与全卷积的折衷。四者的比较如表XX所示。
+ 表XX 卷积网络中连接方式的对比
-### 5.22.2 有哪些方法可以避免棋盘效应?
+| 连接方式 | 示意图 | 说明 |
+| :------: | :---: | :--- |
+| 全连接 |  | 层间神经元完全连接,每个输出神经元可以获取到所有输入神经元的信息,有利于信息汇总,常置于网络末层;连接与连接之间独立参数,大量的连接大大增加模型的参数规模。 |
+| 局部连接 |  | 层间神经元只有局部范围内的连接,在这个范围内采用全连接的方式,超过这个范围的神经元则没有连接;连接与连接之间独立参数,相比于全连接减少了感受域外的连接,有效减少参数规模 |
+| 全卷积 |  | 层间神经元只有局部范围内的连接,在这个范围内采用全连接的方式,连接所采用的参数在不同感受域之间共享,有利于提取特定模式的特征;相比于局部连接,共用感受域之间的参数可以进一步减少参数量。 |
+| 局部卷积 |  | 层间神经元只有局部范围内的连接,感受域内采用全连接的方式,而感受域之间间隔采用局部连接与全卷积的连接方式;相比与全卷积成倍引入额外参数,但有更强的灵活性和表达能力;相比于局部连接,可以有效控制参数量 |
-(1)第一种方法是用到的反卷积核的大小可被步长整除,从而避免重叠效应。与最近成功用于图像超分辨率的技术“子像素卷积”(sub-pixel convolution)等价。
-
+## 5.21 局部卷积的应用
-(2)另一种方法是从卷积操作中分离出对卷积后更高分辨率的特征图上采样来计算特征。例如,可以先缩放图像(最近邻插值或双线性插值),再卷积。
+并不是所有的卷积都会进行权重共享,在某些特定任务中,会使用不权重共享的卷积。下面通过人脸这一任务来进行讲解。在读人脸方向的一些paper时,会发现很多都会在最后加入一个Local Connected Conv,也就是不进行权重共享的卷积层。总的来说,这一步的作用就是使用3D模型来将人脸对齐,从而使CNN发挥最大的效果。
+
-
+截取论文中的一部分图,经过3D对齐以后,形成的图像均是152×152,输入到上述的网络结构中。该结构的参数如下:
-反卷积与不同缩放卷积方法都是线性操作,并可用矩阵去解释。对于每个输出窗口,反卷积操作的输入唯一,缩放卷积会以阻碍高频棋盘效应的方式来隐式地集中权重(weight-tying)。
+Conv:32个11×11×3的卷积核,
-#### 缩放卷积
+Max-pooling: 3×3,stride=2,
-缩放卷积为线性操作:假设原图像为A,经过插值后的图像为A+B;用卷积核C对插值缩放后的图像卷积,得到最终的图像 ,其中*为卷积操作。则可将缩放卷积分解为原图像卷积和插值增量图像卷积,或卷积的原图像和卷积的插值增量图像。
+Conv: 16个9×9的卷积核,
-C为卷积操作的卷积核。此时为上采样,理解为反卷积操作中的卷积核。
+Local-Conv: 16个9×9的卷积核,
-(1)最近邻缩放卷积
+Local-Conv: 16个7×7的卷积核,
-
+Local-Conv: 16个5×5的卷积核,
-发现,插值增量图像表示的矩阵为原图像表示的矩阵下移1行。可将原图像矩阵看成环形队列(队列最后1行的输出送入队列的第1行)。
+Fully-connected: 4096维,
-(2)双线性缩放卷积
+Softmax: 4030维。
-
+前三层的目的在于提取低层次的特征,比如简单的边和纹理。其中Max-pooling层使得卷积的输出对微小的偏移情况更加鲁棒。但不能使用更多的Max-pooling层,因为太多的Max-pooling层会使得网络损失图像信息。全连接层将上一层的每个单元和本层的所有单元相连,用来捕捉人脸图像不同位置特征之间的相关性。最后使用softmax层用于人脸分类。
+中间三层都是使用参数不共享的卷积核,之所以使用参数不共享,有如下原因:
-发现,插值增量图像可细分为原图像表示的矩阵下移1行后乘以1/2与原图像表示的矩阵上移1行后乘以1/2。
+(1)对齐的人脸图片中,不同的区域会有不同的统计特征,因此并不存在特征的局部稳定性,所以使用相同的卷积核会导致信息的丢失。
-## 5.23 CNN主要的计算瓶颈
+(2)不共享的卷积核并不增加inference时特征的计算量,仅会增加训练时的计算量。
+使用不共享的卷积核,由于需要训练的参数量大大增加,因此往往需要通过其他方法增加数据量。
-CNN的训练主要是在卷积层和子采样层的交互上,其主要的计算瓶颈是:
-* 1)前向传播过程:下采样每个卷积层的maps;
-* 2)反向传播过程:上采样高层子采样层的灵敏度map,以匹配底层的卷积层输出maps的大小;
-* 3)sigmoid的运用和求导。
+## 5.22 NetVLAD池化 (贡献者:熊楚原-中国人民大学)
-举例:
+NetVLAD是论文\[15\]提出的一个局部特征聚合的方法。
-对于第一和第二个问题,我们考虑的是如何用Matlab内置的图像处理函数去实现上采样和下采样的操作。对于上采样,imresize函数可以搞定,但需要很大的开销。一个比较快速的版本是使用Kronecker乘积函数kron。通过一个全一矩阵ones来和我们需要上采样的矩阵进行Kronecker乘积,就可以实现上采样的效果。对于前向传播过程中的下采样,imresize并没有提供在缩小图像的过程中还计算nxn块内像素的和的功能,所以没法用。一个比较好和快速的方法是用一个全一的卷积核来卷积图像,然后简单的通过标准的索引方法来采样最后卷积结果。例如,如果下采样的域是2x2的,那么我们可以用2x2的元素全是1的卷积核来卷积图像。然后再卷积后的图像中,我们每个2个点采集一次数据,y=x(1:2:end,1:2:end),这样就可以得到了两倍下采样,同时执行求和的效果。
+在传统的网络里面,例如VGG啊,最后一层卷积层输出的特征都是类似于Batchsize x 3 x 3 x 512的这种东西,然后会经过FC聚合,或者进行一个Global Average Pooling(NIN里的做法),或者怎么样,变成一个向量型的特征,然后进行Softmax or 其他的Loss。
-对于第三个问题,实际上有些人以为Matlab中对sigmoid函数进行inline的定义会更快,其实不然,Matlab与C/C++等等语言不一样,Matlab的inline反而比普通的函数定义更费时间。所以,我们可以直接在代码中使用计算sigmoid函数及其导数的真实代码。
+这种方法说简单点也就是输入一个图片或者什么的结构性数据,然后经过特征提取得到一个长度固定的向量,之后可以用度量的方法去进行后续的操作,比如分类啊,检索啊,相似度对比等等。
-## 5.24 卷积神经网络的经验参数设置
-对于卷积神经网络的参数设置,没有很明确的指导原则,以下仅是一些经验集合。
+那么NetVLAD考虑的主要是最后一层卷积层输出的特征这里,我们不想直接进行欠采样或者全局映射得到特征,对于最后一层输出的W x H x D,设计一个新的池化,去聚合一个“局部特征“,这即是NetVLAD的作用。
-1、learning-rate 学习率:学习率越小,模型收敛花费的时间就越长,但是可以逐步稳健的提高模型精确度。一般初始设置为0.1,然后每次除以0.2或者0.5来改进,得到最终值;
+NetVLAD的一个输入是一个W x H x D的图像特征,例如VGG-Net最后的3 x 3 x 512这样的矩阵,在网络中还需加一个维度为Batchsize。
-2、batch-size 样本批次容量:影响模型的优化程度和收敛速度,需要参考你的数据集大小来设置,具体问题具体分析,一般使用32或64,在计算资源允许的情况下,可以使用大batch进行训练。有论文提出,大batch可以加速训练速度,并取得更鲁棒的结果;
+NetVLAD还需要另输入一个标量K即表示VLAD的聚类中心数量,它主要是来构成一个矩阵C,是通过原数据算出来的每一个$W \times H$特征的聚类中心,C的shape即$C: K \times D$,然后根据三个输入,VLAD是计算下式的V:
-3、weight-decay 权重衰减:用来在反向传播中更新权重和偏置,一般设置为0.005或0.001;
+$$V(j, k) = \sum_{i=1}^{N}{a_k(x_i)(x_i(j) - c_k(j))}$$
-4、epoch-number 训练次数:包括所有训练样本的一个正向传递和一个反向传递,训练至模型收敛即可;(注:和迭代次数iteration不一样)
-总之,不是训练的次数越多,测试精度就会越高。会有各种原因导致过拟合,比如一种可能是预训练的模型太复杂,而使用的数据集样本数量太少,种类太单一。
+其中j表示维度,从1到D,可以看到V的j是和输入与c对应的,对每个类别k,都对所有的x进行了计算,如果$x_i$属于当前类别k,$a_k=1$,否则$a_k=0$,计算每一个x和它聚类中心的残差,然后把残差加起来,即是每个类别k的结果,最后分别L2正则后拉成一个长向量后再做L2正则,正则非常的重要,因为这样才能统一所有聚类算出来的值,而残差和的目的主要是消减不同聚类上的分布不均,两者共同作用才能得到最后正常的输出。
-## 5.25 提高泛化能力的方法总结(代码示例)
-本节主要以代码示例来说明可以提高网络泛化能力的方法。
-代码实验是基于mnist数据集,mnist是一个从0到9的手写数字集合,共有60000张训练图片,10000张测试图片。每张图片大小是28*28大小。目的就是通过各种手段,来构建一个高精度的分类神经网络。
-### 5.25.1 手段
-一般来说,提高泛化能力的方法主要有以下几个:
-> * 使用正则化技术
-> * 增加神经网络层数
-> * 使用恰当的代价函数
-> * 使用权重初始化技术
-> * 人为增广训练集
-> * 使用dropout技术
-
-### 5.25.2 主要方法
-下面我们通过实验结果来判断每种手段的效果。
-
-(1)普通的全连接神经网络
-网络结构使用一个隐藏层,其中包含100个隐藏神经元,输入层是784,输出层是one-hot编码的形式,最后一层是Softmax层。损失函数采用对数似然代价函数,60次迭代,学习速率η=0.1,随机梯度下降的小批量数据(mini-SGD)大小为10,没使用正则化。在测试集上得到的结果是97.8%,代码如下:
-```python
->>> import network3
->>> from network3 import Network
->>> from network3 import ConvPoolLayer, FullyConnectedLayer, SoftmaxLayer
->>> training_data, validation_data, test_data = network3.load_data_shared()
->>> mini_batch_size = 10
->>> net = Network([FullyConnectedLayer(n_in=784, n_out=100),
- SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
->>> net.SGD(training_data, 60, mini_batch_size, 0.1, validation_data, test_data)
-```
-(2)使用卷积神经网络 — 仅一个卷积层
-输入层是卷积层,卷积核大小是5*5,一共20个特征映射。最大池化层的大小为2*2。后面接一层100个隐藏神经元的全连接层。结构如图所示
-
-在这个结构中,我们把卷积层和池化层看做是训练图像的特征提取,而后的全连接层则是一个更抽象层次的特征提取,整合全局信息。同样设定是60次迭代,批量数据大小是10,学习率是0.1.代码如下,
-```python
->>> net = Network([
- ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),
- filter_shape=(20, 1, 5, 5),
- poolsize=(2, 2)),
- FullyConnectedLayer(n_in=20*12*12, n_out=100),
- SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
->>> net.SGD(training_data, 60, mini_batch_size, 0.1,
- validation_data, test_data)
-```
-经过三次运行取平均后,准确率是98.78%,提高得较多。错误率降低了1/3。
-
-(3)使用卷积神经网络 — 两个卷积层
-我们接着插入第二个卷积层,把它插入在之前结构的池化层和全连接层之间,同样是使用5*5的局部感受野,2*2的池化层。
-```python
->>> net = Network([
- ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),
- filter_shape=(20, 1, 5, 5),
- poolsize=(2, 2)),
- ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12),
- filter_shape=(40, 20, 5, 5),
- poolsize=(2, 2)),
- FullyConnectedLayer(n_in=40*4*4, n_out=100),
- SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
->>> net.SGD(training_data, 60, mini_batch_size, 0.1, validation_data, test_data)
-```
-这一次,准确率达到了99.06%。
-
-(4)使用卷积神经网络 — 两个卷积层+线性修正单元(ReLU)+正则化
-上面的网络结构,我们使用的是Sigmod激活函数,现在我们换成线性修正激活函数ReLU ,同样设定参数为60次迭代,学习速率η=0.03,使用L2正则化,正则化参数λ=0.1,代码如下:
-```python
->>> from network3 import ReLU
->>> net = Network([
- ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),
- filter_shape=(20, 1, 5, 5),
- poolsize=(2, 2),
- activation_fn=ReLU),
- ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12),
- filter_shape=(40, 20, 5, 5),
- poolsize=(2, 2),
- activation_fn=ReLU),
- FullyConnectedLayer(n_in=40*4*4, n_out=100, activation_fn=ReLU),
- SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
->>> net.SGD(training_data, 60, mini_batch_size, 0.03,
- validation_data, test_data, lmbda=0.1)
-```
-这一次,准确率达到了99.23%,超过了使用sigmoid激活函数的99.06%. ReLU的优势是当取最大极限时,梯度不会饱和。
-
-(5)卷积神经网络 —两个卷基层+线性修正单元(ReLU)+正则化+拓展数据集
-拓展训练集数据的一个简单方法是将每个训练图像由一个像素来代替,无论是上一个像素,下一个像素,或者左右的像素。其他的方法也有改变亮度,改变分辨率,图片旋转,扭曲,位移等。我们把50000幅图像人为拓展到250000幅图像。使用与第四小节一样的网络,因为我们训练时使用了5倍的数据,所以减少了过拟合的风险。
-```python
->>> expanded_training_data, _, _ = network3.load_data_shared(
- "../data/mnist_expanded.pkl.gz")
->>> net = Network([
- ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),
- filter_shape=(20, 1, 5, 5),
- poolsize=(2, 2),
- activation_fn=ReLU),
- ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12),
- filter_shape=(40, 20, 5, 5),
- poolsize=(2, 2),
- activation_fn=ReLU),
- FullyConnectedLayer(n_in=40*4*4, n_out=100, activation_fn=ReLU),
- SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
->>> net.SGD(expanded_training_data, 60, mini_batch_size, 0.03,
- validation_data, test_data, lmbda=0.1)
-```
-这次得到了99.37的训练正确率。
-
-(6)卷积神经网络 — 两个卷基层+线性修正单元(ReLU)+正则化+拓展数据集+继续插入额外的全连接层
-继续上面的网络,我们拓展全连接层的规模,使用300个隐藏神经元和1000个神经元的额精度分别是99.46%和99.43%.
-```python
->>> net = Network([
- ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),
- filter_shape=(20, 1, 5, 5),
- poolsize=(2, 2),
- activation_fn=ReLU),
- ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12),
- filter_shape=(40, 20, 5, 5),
- poolsize=(2, 2),
- activation_fn=ReLU),
- FullyConnectedLayer(n_in=40*4*4, n_out=100, activation_fn=ReLU),
- FullyConnectedLayer(n_in=100, n_out=100, activation_fn=ReLU),
- SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
->>> net.SGD(expanded_training_data, 60, mini_batch_size, 0.03,
- validation_data, test_data, lmbda=0.1)
-```
-这次取得了99.43%的精度。拓展后的网络并没有帮助太多。
-
-(7)卷积神经网络 — 两个卷基层+线性修正单元(ReLU)+拓展数据集+继续插入额外的全连接层+dropout技术
-dropout的基本思想就是在训练网络时随机的移除单独的激活值,使得模型更稀疏,不太依赖于训练数据的特质。我们尝试应用dropout到最终的全连接层(而不是在卷积层)。由于训练时间,将迭代次数设置为40,全连接层使用1000个隐藏神经元,因为dropout会丢弃一些神经元。Dropout是一种非常有效且能提高泛化能力,降低过拟合的方法!
-```python
->>> net = Network([
- ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),
- filter_shape=(20, 1, 5, 5),
- poolsize=(2, 2),
- activation_fn=ReLU),
- ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12),
- filter_shape=(40, 20, 5, 5),
- poolsize=(2, 2),
- activation_fn=ReLU),
- FullyConnectedLayer(
- n_in=40*4*4, n_out=1000, activation_fn=ReLU, p_dropout=0.5),
- FullyConnectedLayer(
- n_in=1000, n_out=1000, activation_fn=ReLU, p_dropout=0.5),
- SoftmaxLayer(n_in=1000, n_out=10, p_dropout=0.5)],
- mini_batch_size)
->>> net.SGD(expanded_training_data, 40, mini_batch_size, 0.03,
- validation_data, test_data)
-```
-使用dropout,得到了99.60%的准确率。
-
-(8)卷积神经网络 — 两个卷基层+线性修正单元(ReLU)+正则化+拓展数据集+继续插入额外的全连接层+弃权技术+组合网络
-组合网络类似于随机森林或者adaboost的集成方法,创建几个神经网络,让他们投票来决定最好的分类。我们训练了5个不同的神经网络,每个都大到了99.60%的准去率,用这5个网络来进行投票表决一个图像的分类。
-采用这种集成方法,精度又得到了微小的提升,达到了99.67%。
-
-## 5.26 CNN在CV与NLP领域运用的联系与区别?
-
-### 5.26.1 联系
-
-自然语言处理是对一维信号(词序列)做操作。
-计算机视觉是对二维(图像)或三维(视频流)信号做操作。
-
-### 5.26.2 区别
-
-自然语言处理的输入数据通常是离散取值(例如表示一个单词或字母通常表示为词典中的one hot向量),计算机视觉则是连续取值(比如归一化到0,1之间的灰度值)。CNN有两个主要特点,区域不变性(location invariance)和组合性(Compositionality)。
+输入与输出如下图所示:
-1. 区域不变性:滤波器在每层的输入向量(图像)上滑动,检测的是局部信息,然后通过pooling取最大值或均值。pooling这步综合了局部特征,失去了每个特征的位置信息。这很适合基于图像的任务,比如要判断一幅图里有没有猫这种生物,你可能不会去关心这只猫出现在图像的哪个区域。但是在NLP里,词语在句子或是段落里出现的位置,顺序,都是很重要的信息。
-2. 局部组合性:CNN中,每个滤波器都把较低层的局部特征组合生成较高层的更全局化的特征。这在CV里很好理解,像素组合成边缘,边缘生成形状,最后把各种形状组合起来得到复杂的物体表达。在语言里,当然也有类似的组合关系,但是远不如图像来的直接。而且在图像里,相邻像素必须是相关的,相邻的词语却未必相关。
+
-## 5.27 卷积神经网络凸显共性的方法?
-### 5.27.1 局部连接
-我们首先了解一个概念,感受野,即每个神经元仅与输入神经元相连接的一块区域。
-在图像卷积操作中,神经元在空间维度上是局部连接,但在深度上是全连接。局部连接的思想,是受启发于生物学里的视觉系统结构,视觉皮层的神经元就是仅用局部接受信息。对于二维图像,局部像素关联性较强。这种局部连接保证了训练后的滤波器能够对局部特征有最强的响应,使神经网络可以提取数据的局部特征;
-下图是一个很经典的图示,左边是全连接,右边是局部连接。
+中间得到的K个D维向量即是对D个x都进行了与聚类中心计算残差和的过程,最终把K个D维向量合起来后进行即得到最终输出的$K \times D$长度的一维向量。
-
+而VLAD本身是不可微的,因为上面的a要么是0要么是1,表示要么当前描述x是当前聚类,要么不是,是个离散的,NetVLAD为了能够在深度卷积网络里使用反向传播进行训练,对a进行了修正。
-对于一个1000 × 1000的输入图像而言,如果下一个隐藏层的神经元数目为10^6个,采用全连接则有1000 × 1000 × 10^6 = 10^12个权值参数,如此巨大的参数量几乎难以训练;而采用局部连接,隐藏层的每个神经元仅与图像中10 × 10的局部图像相连接,那么此时的权值参数数量为10 × 10 × 10^6 = 10^8,将直接减少4个数量级。
+那么问题就是如何重构一个a,使其能够评估当前的这个x和各个聚类的关联程度?用softmax来得到:
-### 5.27.2 权值共享
-权值共享,即计算同一深度的神经元时采用的卷积核参数是共享的。权值共享在一定程度上讲是有意义的,是由于在神经网络中,提取的底层边缘特征与其在图中的位置无关。但是在另一些场景中是无意的,如在人脸识别任务,我们期望在不同的位置学到不同的特征。
-需要注意的是,权重只是对于同一深度切片的神经元是共享的。在卷积层中,通常采用多组卷积核提取不同的特征,即对应的是不同深度切片的特征,而不同深度切片的神经元权重是不共享。相反,偏置这一权值对于同一深度切片的所有神经元都是共享的。
-权值共享带来的好处是大大降低了网络的训练难度。如下图,假设在局部连接中隐藏层的每一个神经元连接的是一个10 × 10的局部图像,因此有10 × 10个权值参数,将这10 × 10个权值参数共享给剩下的神经元,也就是说隐藏层中10^6个神经元的权值参数相同,那么此时不管隐藏层神经元的数目是多少,需要训练的参数就是这 10 × 10个权值参数(也就是卷积核的大小)。
+$$a_k = \frac{e^{W_k^T x_i + b_k}}{e^{W_{k'}^T x_i + b_{k'}}}$$
-
+将这个把上面的a替换后,即是NetVLAD的公式,可以进行反向传播更新参数。
-这里就体现了卷积神经网络的奇妙之处,使用少量的参数,却依然能有非常出色的性能。上述仅仅是提取图像一种特征的过程。如果要多提取出一些特征,可以增加多个卷积核,不同的卷积核能够得到图像不同尺度下的特征,称之为特征图(feature map)。
+所以一共有三个可训练参数,上式a中的$W: K \times D$,上式a中的$b: K \times 1$,聚类中心$c: K \times D$,而原始VLAD只有一个参数c。
-### 5.27.3 池化操作
+最终池化得到的输出是一个恒定的K x D的一维向量(经过了L2正则),如果带Batchsize,输出即为Batchsize x (K x D)的二维矩阵。
-池化操作与多层次结构一起,实现了数据的降维,将低层次的局部特征组合成为较高层次的特征,从而对整个图片进行表示。如下图:
+NetVLAD作为池化层嵌入CNN网络即如下图所示,
-
+
-## 5.28 全卷积与Local-Conv的异同点
+原论文中采用将传统图像检索方法VLAD进行改进后应用在CNN的池化部分作为一种另类的局部特征池化,在场景检索上取得了很好的效果。
-如果每一个点的处理使用相同的Filter,则为全卷积,如果使用不同的Filter,则为Local-Conv。
+后续相继又提出了ActionVLAD、ghostVLAD等改进。
-## 5.29 举例理解Local-Conv的作用
-并不是所有的卷积都会进行权重共享,在某些特定任务中,会使用不权重共享的卷积。下面通过人脸这一任务来进行讲解。在读人脸方向的一些paper时,会发现很多都会在最后加入一个Local Connected Conv,也就是不进行权重共享的卷积层。总的来说,这一步的作用就是使用3D模型来将人脸对齐,从而使CNN发挥最大的效果。
-
-截取论文中的一部分图,经过3D对齐以后,形成的图像均是152×152,输入到上述的网络结构中。该结构的参数如下:
+## 参考文献
-Conv:32个11×11×3的卷积核
+[1] 卷积神经网络研究综述[J]. 计算机学报, 2017, 40(6):1229-1251.
-max-pooling: 3×3,stride=2,
+[2] 常亮, 邓小明, 周明全,等. 图像理解中的卷积神经网络[J]. 自动化学报, 2016, 42(9):1300-1312.
-Conv: 16个9×9的卷积核,
+[3] Chua L O. CNN: A Paradigm for Complexity[M]// CNN a paradigm for complexity /. 1998.
-Local-Conv: 16个9×9的卷积核,
+[4] He K, Gkioxari G, Dollar P, et al. Mask R-CNN[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, PP(99):1-1.
-Local-Conv: 16个7×7的卷积核,
+[5] Hoochang S, Roth H R, Gao M, et al. Deep Convolutional Neural Networks for Computer-Aided Detection: CNN Architectures, Dataset Characteristics and Transfer Learning[J]. IEEE Transactions on Medical Imaging, 2016, 35(5):1285-1298.
-Local-Conv: 16个5×5的卷积核,
+[6] 许可. 卷积神经网络在图像识别上的应用的研究[D]. 浙江大学, 2012.
-Fully-connected: 4096维
+[7] 陈先昌. 基于卷积神经网络的深度学习算法与应用研究[D]. 浙江工商大学, 2014.
-Softmax: 4030维。
+[8] [CS231n Convolutional Neural Networks for Visual Recognition, Stanford](http://cs231n.github.io/convolutional-networks/)
-前三层的目的在于提取低层次的特征,比如简单的边和纹理。其中Max-pooling层使得卷积的输出对微小的偏移情况更加鲁棒。但不能使用更多的Max-pooling层,因为太多的Max-pooling层会使得网络损失图像信息。全连接层将上一层的每个单元和本层的所有单元相连,用来捕捉人脸图像不同位置特征之间的相关性。最后使用softmax层用于人脸分类。
-中间三层都是使用参数不共享的卷积核,之所以使用参数不共享,有如下原因:
+[9] [Machine Learning is Fun! Part 3: Deep Learning and Convolutional Neural Networks](https://medium.com/@ageitgey/machine-learning-is-fun-part-3-deep-learning-and-convolutional-neural-networks-f40359318721#.2gfx5zcw3)
-(1)对齐的人脸图片中,不同的区域会有不同的统计特征,因此并不存在特征的局部稳定性,所以使用相同的卷积核会导致信息的丢失。
+[10] cs231n 动态卷积图:
-(2)不共享的卷积核并不增加inference时特征的计算量,仅会增加训练时的计算量。
-使用不共享的卷积核,由于需要训练的参数量大大增加,因此往往需要通过其他方法增加数据量。
+[11] Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks[C]//Advances in neural information processing systems. 2012: 1097-1105.
+[12] Sun Y, Wang X, Tang X. Deep learning face representation from predicting 10,000 classes[C]//Computer Vision and Pattern Recognition (CVPR), 2014 IEEE Conference on. IEEE, 2014: 1891-1898.
-## 5.30 简述卷积神经网络进化史
+[13] 魏秀参.解析深度学习——卷积神经网络原理与视觉实践[M].电子工业出版社, 2018
-主要讨论CNN的发展,并且引用刘昕博士的思路,对CNN的发展作一个更加详细的介绍,将按下图的CNN发展史进行描述
+[14] Jianxin W U , Gao B B , Wei X S , et al. Resource-constrained deep learning: challenges and practices[J]. Scientia Sinica(Informationis), 2018.
-
+[15] Arandjelovic R , Gronat P , Torii A , et al. [IEEE 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) - Las Vegas, NV, USA (2016.6.27-2016.6.30)] 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) - NetVLAD: CNN Architecture for Weakly Supervised Place Recognition[C]// 2016:5297-5307.
- 1. 列表项
-http://mp.weixin.qq.com/s?__biz=MzI1NTE4NTUwOQ==&mid=2650324619&idx=1&sn=ca1aed9e42d8f020d0971e62148e13be&scene=1&srcid=0503De6zpYN01gagUvn0Ht8D#wechat_redirect
-CNN的演化路径可以总结为以下几个方向:
-> * 进化之路一:网络结构加深
-> * 进化之路二:加强卷积功能
-> * 进化之路三:从分类到检测
-> * 进化之路四:新增功能模块
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.1.jpg" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.1.jpg"
new file mode 100644
index 00000000..3e36b5e5
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.1.jpg" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.10.jpg" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.10.jpg"
new file mode 100644
index 00000000..bf73d3ee
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.10.jpg" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.11.jpg" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.11.jpg"
new file mode 100644
index 00000000..f08bd84f
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.11.jpg" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.12.jpg" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.12.jpg"
new file mode 100644
index 00000000..f1f4696a
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.12.jpg" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.13.jpg" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.13.jpg"
new file mode 100644
index 00000000..614ee0d4
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.13.jpg" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.14.jpg" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.14.jpg"
new file mode 100644
index 00000000..9ab176bb
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.14.jpg" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.15.jpg" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.15.jpg"
new file mode 100644
index 00000000..0166dcf8
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.15.jpg" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.16.jpg" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.16.jpg"
new file mode 100644
index 00000000..602c7a65
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.16.jpg" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.17.jpg" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.17.jpg"
new file mode 100644
index 00000000..c207c2cd
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.17.jpg" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.18.jpg" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.18.jpg"
new file mode 100644
index 00000000..35440710
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.18.jpg" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.19.jpg" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.19.jpg"
new file mode 100644
index 00000000..b93246b2
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.19.jpg" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.2.jpg" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.2.jpg"
new file mode 100644
index 00000000..8eea0b2f
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.2.jpg" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.3.jpg" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.3.jpg"
new file mode 100644
index 00000000..caa59035
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.3.jpg" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.4.jpg" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.4.jpg"
new file mode 100644
index 00000000..30ba7ba4
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.4.jpg" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.5.jpg" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.5.jpg"
new file mode 100644
index 00000000..2f99e164
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.5.jpg" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.6.jpg" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.6.jpg"
new file mode 100644
index 00000000..609998e9
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.6.jpg" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.7.jpg" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.7.jpg"
new file mode 100644
index 00000000..0ac364ae
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.7.jpg" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.8.jpg" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.8.jpg"
new file mode 100644
index 00000000..a05add55
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.8.jpg" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.9.jpg" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.9.jpg"
new file mode 100644
index 00000000..c715b0d2
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/6.9.jpg" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM1.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM1.png"
new file mode 100644
index 00000000..448438f5
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM1.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM10.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM10.png"
new file mode 100644
index 00000000..15a8daeb
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM10.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM11.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM11.png"
new file mode 100644
index 00000000..6cabdc5c
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM11.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM12.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM12.png"
new file mode 100644
index 00000000..a6bbe153
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM12.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM2.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM2.png"
new file mode 100644
index 00000000..f49c66e8
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM2.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM3.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM3.png"
new file mode 100644
index 00000000..4a0514b6
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM3.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM4.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM4.png"
new file mode 100644
index 00000000..c2f129a0
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM4.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM5.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM5.png"
new file mode 100644
index 00000000..06733d21
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM5.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM6.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM6.png"
new file mode 100644
index 00000000..965b7c0c
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM6.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM7.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM7.png"
new file mode 100644
index 00000000..e6e2595b
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM7.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM8.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM8.png"
new file mode 100644
index 00000000..03f50fba
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM8.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM9.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM9.png"
new file mode 100644
index 00000000..228098dc
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/LSTM9.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.1_1.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.1_1.png"
new file mode 100644
index 00000000..368cd799
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.1_1.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.1_1.vsd" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.1_1.vsd"
new file mode 100644
index 00000000..06b735da
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.1_1.vsd" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.2_1.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.2_1.png"
index 33b2c6a6..b6fecf97 100644
Binary files "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.2_1.png" and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.2_1.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.2_1.vsd" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.2_1.vsd"
new file mode 100644
index 00000000..13906f56
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.2_1.vsd" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.2_2.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.2_2.png"
new file mode 100644
index 00000000..8e429841
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.2_2.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.2_2.vsd" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.2_2.vsd"
new file mode 100644
index 00000000..38d407ea
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.2_2.vsd" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.1_1.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.1_1.png"
index e54ddb20..f378b3c4 100644
Binary files "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.1_1.png" and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.1_1.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.1_1.vsd" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.1_1.vsd"
new file mode 100644
index 00000000..ad24ad55
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.1_1.vsd" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.2_1.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.2_1.png"
index fb138c4a..b0a50032 100644
Binary files "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.2_1.png" and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.2_1.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.2_1.vsd" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.2_1.vsd"
new file mode 100644
index 00000000..6d0d7125
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.2_1.vsd" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.3_1.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.3_1.png"
index 7f80bc81..51ffefdf 100644
Binary files "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.3_1.png" and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.3_1.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.3_1.vsd" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.3_1.vsd"
new file mode 100644
index 00000000..63023bf8
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.3_1.vsd" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.4_1.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.4_1.png"
index bb72ba58..2893b568 100644
Binary files "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.4_1.png" and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.4_1.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.4_1.vsdx" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.4_1.vsdx"
new file mode 100644
index 00000000..aed23155
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.4_1.vsdx" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.4_2.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.4_2.png"
index bd62b394..ca3329ea 100644
Binary files "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.4_2.png" and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.4_2.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.4_2.vsdx" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.4_2.vsdx"
new file mode 100644
index 00000000..9a6ad422
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.4_2.vsdx" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.4_3.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.4_3.png"
index bbd1e296..a39ae760 100644
Binary files "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.4_3.png" and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.4_3.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.4_3.vsdx" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.4_3.vsdx"
new file mode 100644
index 00000000..be7ceb9b
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.4_3.vsdx" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.5_1.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.5_1.png"
index 9659ecc2..90454a4e 100644
Binary files "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.5_1.png" and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.5_1.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.5_1.vsdx" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.5_1.vsdx"
new file mode 100644
index 00000000..5dccfa42
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.5_1.vsdx" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.6_1.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.6_1.png"
index 899da6a9..1b11373c 100644
Binary files "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.6_1.png" and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.6_1.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.6_1.vsdx" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.6_1.vsdx"
new file mode 100644
index 00000000..e0df0ad9
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.6_1.vsdx" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.6_2.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.6_2.png"
index 038c1815..cb920ce6 100644
Binary files "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.6_2.png" and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.6_2.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.6_2.vsdx" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.6_2.vsdx"
new file mode 100644
index 00000000..892f40bf
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.6_2.vsdx" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.7_1.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.7_1.png"
index 5e72863d..271ed19c 100644
Binary files "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.7_1.png" and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.7_1.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.7_1.vsdx" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.7_1.vsdx"
new file mode 100644
index 00000000..74495301
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/figure_6.6.7_1.vsdx" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/rnnbp.png" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/rnnbp.png"
new file mode 100644
index 00000000..fc6ebf23
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/rnnbp.png" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/sigmoid.jpg" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/sigmoid.jpg"
new file mode 100644
index 00000000..1d5a2628
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/sigmoid.jpg" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/tanh.jpg" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/tanh.jpg"
new file mode 100644
index 00000000..cebe1b07
Binary files /dev/null and "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/img/ch6/tanh.jpg" differ
diff --git "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/\347\254\254\345\205\255\347\253\240_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN).md" "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/\347\254\254\345\205\255\347\253\240_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN).md"
index aef232d6..c5601a46 100644
--- "a/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/\347\254\254\345\205\255\347\253\240_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN).md"
+++ "b/ch06_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN)/\347\254\254\345\205\255\347\253\240_\345\276\252\347\216\257\347\245\236\347\273\217\347\275\221\347\273\234(RNN).md"
@@ -4,99 +4,133 @@
# 第六章 循环神经网络(RNN)
- Markdown Revision 2;
- Date: 2018/11/07
- Editor: 李骁丹-杜克大学
- Contact: xiaodan.li@duke.edu
-
- Markdown Revision 1;
- Date: 2018/10/26
- Editor: 杨国峰-中国农业科学院
- Contact: tectalll@gmail.com
-
-新增 https://blog.csdn.net/zhaojc1995/article/details/80572098
-RNN发展简述?
-为什么需要RNN?
-RNN的结构及变体
-标准RNN的前向输出流程?
-RNN的训练方法——BPTT?
-什么是长期依赖(Long-Term Dependencies)问题?
-LSTM 网络是什么?
-LSTM 的核心思想?
-如何逐步理解LSTM?
-常见的RNNs扩展和改进模型
-RNN种类?
-讲解CNN+RNN的各种组合方式 http://www.elecfans.com/d/775895.html
-RNN学习和实践过程中常常碰到的疑问
-## CNN和RNN的对比 http://www.elecfans.com/d/775895.html
-1、CNN卷积神经网络与RNN递归神经网络直观图
-2、相同点:
-2.1. 传统神经网络的扩展。
-2.2. 前向计算产生结果,反向计算模型更新。
-2.3. 每层神经网络横向可以多个神经元共存,纵向可以有多层神经网络连接。
-3、不同点
-3.1. CNN空间扩展,神经元与特征卷积;RNN时间扩展,神经元与多个时间输出计算
-3.2. RNN可以用于描述时间上连续状态的输出,有记忆功能,CNN用于静态输出
-3.3. CNN高级100+深度,RNN深度有限
-
-
-
-http://blog.csdn.net/heyongluoyao8/article/details/48636251
-
## 6.1 为什么需要RNN?
-http://ai.51cto.com/art/201711/559441.htm
-神经网络可以当做是能够拟合任意函数的黑盒子,只要训练数据足够,给定特定的x,就能得到希望的y,结构图如下:
-将神经网络模型训练好之后,在输入层给定一个x,通过网络之后就能够在输出层得到特定的y,那么既然有了这么强大的模型,为什么还需要RNN(循环神经网络)呢?
-他们都只能单独的取处理一个个的输入,前一个输入和后一个输入是完全没有关系的。但是,某些任务需要能够更好的处理序列的信息,即前面的输入和后面的输入是有关系的。
-比如,当我们在理解一句话意思时,孤立的理解这句话的每个词是不够的,我们需要处理这些词连接起来的整个序列; 当我们处理视频的时候,我们也不能只单独的去分析每一帧,而要分析这些帧连接起来的整个序列。
+ 时间序列数据是指在不同时间点上收集到的数据,这类数据反映了某一事物、现象等随时间的变化状态或程度。一般的神经网络,在训练数据足够、算法模型优越的情况下,给定特定的x,就能得到期望y。其一般处理单个的输入,前一个输入和后一个输入完全无关,但实际应用中,某些任务需要能够更好的处理序列的信息,即前面的输入和后面的输入是有关系的。比如:
-以nlp的一个最简单词性标注任务来说,将我 吃 苹果 三个单词标注词性为 我/nn 吃/v 苹果/nn。
+ 当我们在理解一句话意思时,孤立的理解这句话的每个词不足以理解整体意思,我们通常需要处理这些词连接起来的整个序列; 当我们处理视频的时候,我们也不能只单独的去分析每一帧,而要分析这些帧连接起来的整个序列。为了解决一些这样类似的问题,能够更好的处理序列的信息,RNN就由此诞生了。
-那么这个任务的输入就是:
+## 6.2 图解RNN基本结构
-我 吃 苹果 (已经分词好的句子)
+### 6.2.1 基本的单层网络结构
-这个任务的输出是:
+ 在进一步了解RNN之前,先给出最基本的单层网络结构,输入是x,经过变换Wx+b和激活函数f得到输出y:
-我/nn 吃/v 苹果/nn(词性标注好的句子)
+
-对于这个任务来说,我们当然可以直接用普通的神经网络来做,给网络的训练数据格式了就是我-> 我/nn 这样的多个单独的单词->词性标注好的单词。
+### 6.2.2 图解经典RNN结构
-但是很明显,一个句子中,前一个单词其实对于当前单词的词性预测是有很大影响的,比如预测苹果的时候,由于前面的吃是一个动词,那么很显然苹果作为名词的概率就会远大于动词的概率,因为动词后面接名词很常见,而动词后面接动词很少见。
+ 在实际应用中,我们还会遇到很多序列形的数据,如:
-所以为了解决一些这样类似的问题,能够更好的处理序列的信息,RNN就诞生了。
+- 自然语言处理问题。x1可以看做是第一个单词,x2可以看做是第二个单词,依次类推。
-## 6.1 RNN种类?
-https://www.cnblogs.com/rucwxb/p/8047401.html
-1. sequence-to-sequence:输入输出都是一个序列。例如股票预测中的RNN,输入是前N天价格,输出明天的股市价格。
+- 语音处理。此时,x1、x2、x3……是每帧的声音信号。
-2. sequence-to-vector:输入是一个序列,输出单一向量。
+- 时间序列问题。例如每天的股票价格等等。
-3. vector-to-sequence:输入单一向量,输出一个序列。
+ 其单个序列如下图所示:
-4.Encoder-Decoder:输入sequence-to-vector,称作encoder,输出vector-to-sequence,称作decoder。
+ 
-这是一个delay模型,经过一段延迟,即把所有输入都读取后,在decoder中获取输入并输出一个序列。这个模型在机器翻译中使用较广泛,源语言输在入放入encoder,浓缩在状态信息中,生成目标语言时,可以生成一个不长度的目标语言序列。
+ 前面介绍了诸如此类的序列数据用原始的神经网络难以建模,基于此,RNN引入了隐状态$h$(hidden state),$h$可对序列数据提取特征,接着再转换为输出。
-## RNN train的时候,Loss波动很大
-https://www.jianshu.com/p/30b253561337
-由于RNN特有的memory会影响后期其他的RNN的特点,梯度时大时小,learning rate没法个性化的调整,导致RNN在train的过程中,Loss是震荡起伏的……
-为了解决RNN的这个问题,在train的时候,可以有个clipping的方式,当梯度大于某个临界值,直接截断,用这个临界值作为梯度的大小,防止飞出去…(居然还能这么操作,66666)
+ 为了便于理解,先计算$h_1$:
-## 6.1 RNNs和FNNs有什么区别?
+ 
-1. 不同于传统的前馈神经网络(FNNs),RNNs引入了定向循环,能够处理输入之间前后关联问题。
-2. RNNs可以记忆之前步骤的训练信息。
-**定向循环结构如下图所示**:
+ 注:图中的圆圈表示向量,箭头表示对向量做变换。
-
+ RNN中,每个步骤使用的参数$U,W,b$相同,$h_2$的计算方式和$h_1$类似,其计算结果如下:
+
+ 
+
+ 计算$h_3$,$h_4$也相似,可得:
+
+ 
+
+ 接下来,计算RNN的输出$y_1$,采用$Softmax$作为激活函数,根据$y_n=f(Wx+b)$,得$y_1$:
+
+ 
+
+ 使用和$y_1$相同的参数$V,c$,得到$y_1,y_2,y_3,y_4$的输出结构:
+
+ 
+
+ 以上即为最经典的RNN结构,其输入为$x_1,x_2,x_3,x_4$,输出为$y_1,y_2,y_3,y_4$,当然实际中最大值为$y_n$,这里为了便于理解和展示,只计算4个输入和输出。从以上结构可看出,RNN结构的输入和输出等长。
+
+### 6.2.3 vector-to-sequence结构
+
+ 有时我们要处理的问题输入是一个单独的值,输出是一个序列。此时,有两种主要建模方式:
+
+ 方式一:可只在其中的某一个序列进行计算,比如序列第一个进行输入计算,其建模方式如下:
+
+
+
+ 方式二:把输入信息X作为每个阶段的输入,其建模方式如下:
+
+
+
+### 6.2.4 sequence-to-vector结构
+
+ 有时我们要处理的问题输入是一个序列,输出是一个单独的值,此时通常在最后的一个序列上进行输出变换,其建模如下所示:
+
+ 
+
+### 6.2.5 Encoder-Decoder结构
+
+ 原始的sequence-to-sequence结构的RNN要求序列等长,然而我们遇到的大部分问题序列都是不等长的,如机器翻译中,源语言和目标语言的句子往往并没有相同的长度。
+
+ 其建模步骤如下:
+
+ **步骤一**:将输入数据编码成一个上下文向量$c$,这部分称为Encoder,得到$c$有多种方式,最简单的方法就是把Encoder的最后一个隐状态赋值给$c$,还可以对最后的隐状态做一个变换得到$c$,也可以对所有的隐状态做变换。其示意如下所示:
+
+ 
-## 6.2 RNNs典型特点?
+ **步骤二**:用另一个RNN网络(我们将其称为Decoder)对其进行编码,方法一是将步骤一中的$c$作为初始状态输入到Decoder,示意图如下所示:
+
+ 
+
+方法二是将$c$作为Decoder的每一步输入,示意图如下所示:
+
+ 
+
+### 6.2.6 以上三种结构各有怎样的应用场景
+
+| 网络结构 | 结构图示 | 应用场景举例 |
+| -------- | :---------------------: | ------------------------------------------------------------ |
+| 1 vs N |  | 1、从图像生成文字,输入为图像的特征,输出为一段句子
2、根据图像生成语音或音乐,输入为图像特征,输出为一段语音或音乐 |
+| N vs 1 |  | 1、输出一段文字,判断其所属类别
2、输入一个句子,判断其情感倾向
3、输入一段视频,判断其所属类别 |
+| N vs M |  | 1、机器翻译,输入一种语言文本序列,输出另外一种语言的文本序列
2、文本摘要,输入文本序列,输出这段文本序列摘要
3、阅读理解,输入文章,输出问题答案
4、语音识别,输入语音序列信息,输出文字序列 |
+
+### 6.2.7 图解RNN中的Attention机制
+
+ 在上述通用的Encoder-Decoder结构中,Encoder把所有的输入序列都编码成一个统一的语义特征$c$再解码,因此,$c$中必须包含原始序列中的所有信息,它的长度就成了限制模型性能的瓶颈。如机器翻译问题,当要翻译的句子较长时,一个$c$可能存不下那么多信息,就会造成翻译精度的下降。Attention机制通过在每个时间输入不同的$c$来解决此问题。
+
+ 引入了Attention机制的Decoder中,有不同的$c$,每个$c$会自动选择与当前输出最匹配的上下文信息,其示意图如下所示:
+
+
+
+ **举例**,比如输入序列是“我爱中国”,要将此输入翻译成英文:
+
+ 假如用$a_{ij}$衡量Encoder中第$j$阶段的$h_j$和解码时第$i$阶段的相关性,$a_{ij}$从模型中学习得到,和Decoder的第$i-1$阶段的隐状态、Encoder 第$j$个阶段的隐状态有关,比如$a_{3j}$的计算示意如下所示:
+
+
+
+最终Decoder中第$i$阶段的输入的上下文信息 $c_i$来自于所有$h_j$对$a_{ij}$的加权和。
+
+其示意图如下图所示:
+
+
+
+ 在Encoder中,$h_1,h_2,h_3,h_4$分别代表“我”,“爱”,“中”,“国”所代表信息。翻译的过程中,$c_1$会选择和“我”最相关的上下午信息,如上图所示,会优先选择$a_{11}$,以此类推,$c_2$会优先选择相关性较大的$a_{22}$,$c_3$会优先选择相关性较大的$a_{33},a_{34}$,这就是attention机制。
+
+## 6.3 RNNs典型特点?
1. RNNs主要用于处理序列数据。对于传统神经网络模型,从输入层到隐含层再到输出层,层与层之间一般为全连接,每层之间神经元是无连接的。但是传统神经网络无法处理数据间的前后关联问题。例如,为了预测句子的下一个单词,一般需要该词之前的语义信息。这是因为一个句子中前后单词是存在语义联系的。
-2. RNNs中当前单元的输出与之前步骤输出也有关,因此称之为循环神经网络。具体的表现形式为当前单元(cell)会对之前步骤信息进行储存并应用于当前输出的计算中。隐藏层之间的节点连接起来,隐藏层当前输出由当前时刻输入向量和之前时刻隐藏层状态共同决定。
-3. 理论上,RNNs能够对任何长度序列数据进行处理。但是在实践中,为了降低复杂度往往假设当前的状态只与之前某几个时刻状态相关,**下图便是一个典型的RNNs**:
+2. RNNs中当前单元的输出与之前步骤输出也有关,因此称之为循环神经网络。具体的表现形式为当前单元会对之前步骤信息进行储存并应用于当前输出的计算中。隐藏层之间的节点连接起来,隐藏层当前输出由当前时刻输入向量和之前时刻隐藏层状态共同决定。
+3. 标准的RNNs结构图,图中每个箭头代表做一次变换,也就是说箭头连接带有权值。
+4. 在标准的RNN结构中,隐层的神经元之间也是带有权值的,且权值共享。
+5. 理论上,RNNs能够对任何长度序列数据进行处理。但是在实践中,为了降低复杂度往往假设当前的状态只与之前某几个时刻状态相关,**下图便是一个典型的RNNs**:

@@ -116,140 +150,395 @@ https://www.jianshu.com/p/30b253561337
4. 在某些情况下,隐藏层的输入还包括上一时刻隐藏层的状态,即隐藏层内的节点可以自连也可以互连。
5. 当前单元(cell)输出是由当前时刻输入和上一时刻隐藏层状态共同决定。
+## 6.4 CNN和RNN的区别 ?
+
+| 类别 | 特点描述 |
+| ------ | ------------------------------------------------------------ |
+| 相同点 | 1、传统神经网络的扩展。
2、前向计算产生结果,反向计算模型更新。
3、每层神经网络横向可以多个神经元共存,纵向可以有多层神经网络连接。 |
+| 不同点 | 1、CNN空间扩展,神经元与特征卷积;RNN时间扩展,神经元与多个时间输出计算
2、RNN可以用于描述时间上连续状态的输出,有记忆功能,CNN用于静态输出 |
+
+## 6.5 RNNs和FNNs有什么区别?
+
+1. 不同于传统的前馈神经网络(FNNs),RNNs引入了定向循环,能够处理输入之间前后关联问题。
+2. RNNs可以记忆之前步骤的训练信息。
+ **定向循环结构如下图所示**:
+
+
+
+
+
+## 6.6 RNNs训练和传统ANN训练异同点?
+
+**相同点**:
+
+1. RNNs与传统ANN都使用BP(Back Propagation)误差反向传播算法。
+
+**不同点**:
+
+1. RNNs网络参数W,U,V是共享的(具体在本章6.2节中已介绍),而传统神经网络各层参数间没有直接联系。
+2. 对于RNNs,在使用梯度下降算法中,每一步的输出不仅依赖当前步的网络,还依赖于之前若干步的网络状态。
+
+## 6.7 为什么RNN 训练的时候Loss波动很大
+ 由于RNN特有的memory会影响后期其他的RNN的特点,梯度时大时小,learning rate没法个性化的调整,导致RNN在train的过程中,Loss会震荡起伏,为了解决RNN的这个问题,在训练的时候,可以设置临界值,当梯度大于某个临界值,直接截断,用这个临界值作为梯度的大小,防止大幅震荡。
+
+## 6.8 标准RNN前向输出流程
+
+ 以$x$表示输入,$h$是隐层单元,$o$是输出,$L$为损失函数,$y$为训练集标签。$t$表示$t$时刻的状态,$V,U,W$是权值,同一类型的连接权值相同。以下图为例进行说明标准RNN的前向传播算法:
+
+ 
+
+对于$t$时刻:
+$$
+h^{(t)}=\phi(Ux^{(t)}+Wh^{(t-1)}+b)
+$$
+其中$\phi()$为激活函数,一般会选择tanh函数,$b$为偏置。
+
+$t$时刻的输出为:
+$$
+o^{(t)}=Vh^{(t)}+c
+$$
+模型的预测输出为:
+$$
+\widehat{y}^{(t)}=\sigma(o^{(t)})
+$$
+其中$\sigma$为激活函数,通常RNN用于分类,故这里一般用softmax函数。
+
+## 6.9 BPTT算法推导
+
+ BPTT(back-propagation through time)算法是常用的训练RNN的方法,其本质还是BP算法,只不过RNN处理时间序列数据,所以要基于时间反向传播,故叫随时间反向传播。BPTT的中心思想和BP算法相同,沿着需要优化的参数的负梯度方向不断寻找更优的点直至收敛。需要寻优的参数有三个,分别是U、V、W。与BP算法不同的是,其中W和U两个参数的寻优过程需要追溯之前的历史数据,参数V相对简单只需关注目前,那么我们就来先求解参数V的偏导数。
+$$
+\frac{\partial L^{(t)}}{\partial V}=\frac{\partial L^{(t)}}{\partial o^{(t)}}\cdot \frac{\partial o^{(t)}}{\partial V}
+$$
+RNN的损失也是会随着时间累加的,所以不能只求t时刻的偏导。
+$$
+L=\sum_{t=1}^{n}L^{(t)}
+$$
+
+$$
+\frac{\partial L}{\partial V}=\sum_{t=1}^{n}\frac{\partial L^{(t)}}{\partial o^{(t)}}\cdot \frac{\partial o^{(t)}}{\partial V}
+$$
+
+ W和U的偏导的求解由于需要涉及到历史数据,其偏导求起来相对复杂。为了简化推导过程,我们假设只有三个时刻,那么在第三个时刻 L对W,L对U的偏导数分别为:
+$$
+\frac{\partial L^{(3)}}{\partial W}=\frac{\partial L^{(3)}}{\partial o^{(3)}}\frac{\partial o^{(3)}}{\partial h^{(3)}}\frac{\partial h^{(3)}}{\partial W}+\frac{\partial L^{(3)}}{\partial o^{(3)}}\frac{\partial o^{(3)}}{\partial h^{(3)}}\frac{\partial h^{(3)}}{\partial h^{(2)}}\frac{\partial h^{(2)}}{\partial W}+\frac{\partial L^{(3)}}{\partial o^{(3)}}\frac{\partial o^{(3)}}{\partial h^{(3)}}\frac{\partial h^{(3)}}{\partial h^{(2)}}\frac{\partial h^{(2)}}{\partial h^{(1)}}\frac{\partial h^{(1)}}{\partial W}
+$$
+
+$$
+\frac{\partial L^{(3)}}{\partial U}=\frac{\partial L^{(3)}}{\partial o^{(3)}}\frac{\partial o^{(3)}}{\partial h^{(3)}}\frac{\partial h^{(3)}}{\partial U}+\frac{\partial L^{(3)}}{\partial o^{(3)}}\frac{\partial o^{(3)}}{\partial h^{(3)}}\frac{\partial h^{(3)}}{\partial h^{(2)}}\frac{\partial h^{(2)}}{\partial U}+\frac{\partial L^{(3)}}{\partial o^{(3)}}\frac{\partial o^{(3)}}{\partial h^{(3)}}\frac{\partial h^{(3)}}{\partial h^{(2)}}\frac{\partial h^{(2)}}{\partial h^{(1)}}\frac{\partial h^{(1)}}{\partial U}
+$$
+
+可以观察到,在某个时刻的对W或是U的偏导数,需要追溯这个时刻之前所有时刻的信息。根据上面两个式子得出L在t时刻对W和U偏导数的通式:
+$$
+\frac{\partial L^{(t)}}{\partial W}=\sum_{k=0}^{t}\frac{\partial L^{(t)}}{\partial o^{(t)}}\frac{\partial o^{(t)}}{\partial h^{(t)}}(\prod_{j=k+1}^{t}\frac{\partial h^{(j)}}{\partial h^{(j-1)}})\frac{\partial h^{(k)}}{\partial W}
+$$
+
+$$
+\frac{\partial L^{(t)}}{\partial U}=\sum_{k=0}^{t}\frac{\partial L^{(t)}}{\partial o^{(t)}}\frac{\partial o^{(t)}}{\partial h^{(t)}}(\prod_{j=k+1}^{t}\frac{\partial h^{(j)}}{\partial h^{(j-1)}})\frac{\partial h^{(k)}}{\partial U}
+$$
+
+整体的偏导公式就是将其按时刻再一一加起来。
+
+## 6.9 RNN中为什么会出现梯度消失?
+
+首先来看tanh函数的函数及导数图如下所示:
+
+
+
+sigmoid函数的函数及导数图如下所示:
+
+
+
+从上图观察可知,sigmoid函数的导数范围是(0,0.25],tach函数的导数范围是(0,1],他们的导数最大都不大于1。
+
+ 基于6.8中式(9-10)中的推导,RNN的激活函数是嵌套在里面的,如果选择激活函数为$tanh$或$sigmoid$,把激活函数放进去,拿出中间累乘的那部分可得:
+$$
+\prod_{j=k+1}^{t}{\frac{\partial{h^{j}}}{\partial{h^{j-1}}}} = \prod_{j=k+1}^{t}{tanh^{'}}\cdot W_{s}
+$$
+
+$$
+\prod_{j=k+1}^{t}{\frac{\partial{h^{j}}}{\partial{h^{j-1}}}} = \prod_{j=k+1}^{t}{sigmoid^{'}}\cdot W_{s}
+$$
+
+ **梯度消失现象**:基于上式,会发现累乘会导致激活函数导数的累乘,如果取tanh或sigmoid函数作为激活函数的话,那么必然是一堆小数在做乘法,结果就是越乘越小。随着时间序列的不断深入,小数的累乘就会导致梯度越来越小直到接近于0,这就是“梯度消失“现象。
+
+ 实际使用中,会优先选择tanh函数,原因是tanh函数相对于sigmoid函数来说梯度较大,收敛速度更快且引起梯度消失更慢。
+
+## 6.10 如何解决RNN中的梯度消失问题?
+
+ 上节描述的梯度消失是在无限的利用历史数据而造成,但是RNN的特点本来就是能利用历史数据获取更多的可利用信息,解决RNN中的梯度消失方法主要有:
+
+ 1、选取更好的激活函数,如Relu激活函数。ReLU函数的左侧导数为0,右侧导数恒为1,这就避免了“梯度消失“的发生。但恒为1的导数容易导致“梯度爆炸“,但设定合适的阈值可以解决这个问题。
+
+ 2、加入BN层,其优点包括可加速收敛、控制过拟合,可以少用或不用Dropout和正则、降低网络对初始化权重不敏感,且能允许使用较大的学习率等。
+
+ 2、改变传播结构,LSTM结构可以有效解决这个问题。下面将介绍LSTM相关内容。
+
+## 6.11 LSTM
+
+### 6.11.1 LSTM的产生原因
+
+ RNN在处理长期依赖(时间序列上距离较远的节点)时会遇到巨大的困难,因为计算距离较远的节点之间的联系时会涉及雅可比矩阵的多次相乘,会造成梯度消失或者梯度膨胀的现象。为了解决该问题,研究人员提出了许多解决办法,例如ESN(Echo State Network),增加有漏单元(Leaky Units)等等。其中最成功应用最广泛的就是门限RNN(Gated RNN),而LSTM就是门限RNN中最著名的一种。有漏单元通过设计连接间的权重系数,从而允许RNN累积距离较远节点间的长期联系;而门限RNN则泛化了这样的思想,允许在不同时刻改变该系数,且允许网络忘记当前已经累积的信息。
+
+### 6.11.2 图解标准RNN和LSTM的区别
+
+ 所有 RNN 都具有一种重复神经网络模块的链式的形式。在标准的 RNN 中,这个重复的模块只有一个非常简单的结构,例如一个 tanh 层,如下图所示:
+
+
+
+ LSTM 同样是这样的结构,但是重复的模块拥有一个不同的结构。不同于单一神经网络层,这里是有四个,以一种非常特殊的方式进行交互。
+
+
+
+
+
+注:上图图标具体含义如下所示:
+
+
+
+ 上图中,每一条黑线传输着一整个向量,从一个节点的输出到其他节点的输入。粉色的圈代表 pointwise 的操作,诸如向量的和,而黄色的矩阵就是学习到的神经网络层。合在一起的线表示向量的连接,分开的线表示内容被复制,然后分发到不同的位置。
-## 6.3 RNNs能干什么?
+### 6.11.3 LSTM核心思想图解
-RNNs在自然语言处理领域取得了巨大成功,如词向量表达、语句合法性检查、词性标注等。在RNNs及其变型中,目前使用最广泛最成功的模型是LSTMs(Long Short-Term Memory,长短时记忆模型)模型,该模型相比于RNNs,能够更好地对长短时依赖进行描述。
+ LSTM 的关键就是细胞状态,水平线在图上方贯穿运行。细胞状态类似于传送带。直接在整个链上运行,只有一些少量的线性交互。信息在上面流传保持不变会很容易。示意图如下所示:
+
+
+LSTM 有通过精心设计的称作为“门”的结构来去除或者增加信息到细胞状态的能力。门是一种让信息选择式通过的方法。他们包含一个 sigmoid 神经网络层和一个 pointwise 乘法操作。示意图如下:
+
+
+
+
+
+LSTM 拥有三个门,分别是忘记层门,输入层门和输出层门,来保护和控制细胞状态。
+
+**忘记层门**
+
+ 作用对象:细胞状态 。
+
+ 作用:将细胞状态中的信息选择性的遗忘。
+
+ 操作步骤:该门会读取$h_{t-1}$和$x_t$,输出一个在 0 到 1 之间的数值给每个在细胞状态$C_{t-1}$中的数字。1 表示“完全保留”,0 表示“完全舍弃”。示意图如下:
+
+
+
+**输入层门**
+
+ 作用对象:细胞状态
+
+ 作用:将新的信息选择性的记录到细胞状态中。
+
+ 操作步骤:
+
+ 步骤一,sigmoid 层称 “输入门层” 决定什么值我们将要更新。
+
+ 步骤二,tanh 层创建一个新的候选值向量$\tilde{C}_t$加入到状态中。其示意图如下:
+
+
+
+ 步骤三:将$c_{t-1}$更新为$c_{t}$。将旧状态与$f_t$相乘,丢弃掉我们确定需要丢弃的信息。接着加上$i_t * \tilde{C}_t$得到新的候选值,根据我们决定更新每个状态的程度进行变化。其示意图如下:
+
+
+
+**输出层门**
+ 作用对象:隐层$h_t$
+
+ 作用:确定输出什么值。
+
+ 操作步骤:
+
+ 步骤一:通过sigmoid 层来确定细胞状态的哪个部分将输出。
+
+ 步骤二:把细胞状态通过 tanh 进行处理,并将它和 sigmoid 门的输出相乘,最终我们仅仅会输出我们确定输出的那部分。
+
+其示意图如下所示:
+
+
+
+### 6.11.4 LSTM流行的变体
+
+**增加peephole 连接**
+
+ 在正常的LSTM结构中,Gers F A 等人提出增加peephole 连接,可以门层接受细胞状态的输入。示意图如下所示:
+
+
+
+**对忘记门和输入门进行同时确定**
+
+ 不同于之前是分开确定什么忘记和需要添加什么新的信息,这里是一同做出决定。示意图如下所示:
+
+
+
+**Gated Recurrent Unit**
+
+ 由Kyunghyun Cho等人提出的Gated Recurrent Unit (GRU),其将忘记门和输入门合成了一个单一的更新门,同样还混合了细胞状态和隐藏状态,和其他一些改动。其示意图如下:
+
+
+
+最终的模型比标准的 LSTM 模型要简单,也是非常流行的变体。
+
+## 6.12 LSTMs与GRUs的区别
+
+LSTMs与GRUs的区别如图所示:
+
+
+
+从上图可以看出,二者结构十分相似,**不同在于**:
+
+1. new memory都是根据之前state及input进行计算,但是GRUs中有一个reset gate控制之前state的进入量,而在LSTMs里没有类似gate;
+2. 产生新的state的方式不同,LSTMs有两个不同的gate,分别是forget gate (f gate)和input gate(i gate),而GRUs只有一种update gate(z gate);
+3. LSTMs对新产生的state可以通过output gate(o gate)进行调节,而GRUs对输出无任何调节。
+
+## 6.13 RNNs在NLP中典型应用?
-## 6.4 RNNs在NLP中典型应用?
**(1)语言模型与文本生成(Language Modeling and Generating Text)**
-给定一组单词序列,需要根据前面单词预测每个单词出现的可能性。语言模型能够评估某个语句正确的可能性,可能性越大,语句越正确。另一种应用便是使用生成模型预测下一个单词的出现概率,从而利用输出概率的采样生成新的文本。
+ 给定一组单词序列,需要根据前面单词预测每个单词出现的可能性。语言模型能够评估某个语句正确的可能性,可能性越大,语句越正确。另一种应用便是使用生成模型预测下一个单词的出现概率,从而利用输出概率的采样生成新的文本。
**(2)机器翻译(Machine Translation)**
-机器翻译是将一种源语言语句变成意思相同的另一种源语言语句,如将英语语句变成同样意思的中文语句。与语言模型关键的区别在于,需要将源语言语句序列输入后,才进行输出,即输出第一个单词时,便需要从完整的输入序列中进行获取。
+ 机器翻译是将一种源语言语句变成意思相同的另一种源语言语句,如将英语语句变成同样意思的中文语句。与语言模型关键的区别在于,需要将源语言语句序列输入后,才进行输出,即输出第一个单词时,便需要从完整的输入序列中进行获取。
**(3)语音识别(Speech Recognition)**
-语音识别是指给定一段声波的声音信号,预测该声波对应的某种指定源语言语句以及计算该语句的概率值。
+ 语音识别是指给定一段声波的声音信号,预测该声波对应的某种指定源语言语句以及计算该语句的概率值。
**(4)图像描述生成 (Generating Image Descriptions)**
-同卷积神经网络(convolutional Neural Networks, CNNs)一样,RNNs已经在对无标图像描述自动生成中得到应用。CNNs与RNNs结合也被应用于图像描述自动生成。
+ 同卷积神经网络一样,RNNs已经在对无标图像描述自动生成中得到应用。CNNs与RNNs结合也被应用于图像描述自动生成。

-## 6.5 RNNs训练和传统ANN训练异同点?
-**相同点**:
-1. RNNs与传统ANN都使用BP(Back Propagation)误差反向传播算法。
+## 6.13 常见的RNNs扩展和改进模型
-**不同点**:
-
-1. RNNs网络参数W,U,V是共享的,而传统神经网络各层参数间没有直接联系。
-2. 对于RNNs,在使用梯度下降算法中,每一步的输出不仅依赖当前步的网络,还依赖于之前若干步的网络状态。
-
-
-## 6.6 常见的RNNs扩展和改进模型
+### 6.13.1 Simple RNNs(SRNs)
-### 6.6.1 Simple RNNs(SRNs)
-
-1. SRNs是RNNs的一种特例,它是一个三层网络,其在隐藏层增加了上下文单元。下图中的**y**是隐藏层,**u**是上下文单元。上下文单元节点与隐藏层中节点的连接是固定的,并且权值也是固定的。上下文节点与隐藏层节点一一对应,并且值是确定的。
+1. SRNs是一个三层网络,其在隐藏层增加了上下文单元。下图中的y是隐藏层,u是上下文单元。上下文单元节点与隐藏层中节点的连接是固定的,并且权值也是固定的。上下文节点与隐藏层节点一一对应,并且值是确定的。
2. 在每一步中,使用标准的前向反馈进行传播,然后使用学习算法进行学习。上下文每一个节点保存其连接隐藏层节点上一步输出,即保存上文,并作用于当前步对应的隐藏层节点状态,即隐藏层的输入由输入层的输出与上一步的自身状态所决定。因此SRNs能够解决标准多层感知机(MLP)无法解决的对序列数据进行预测的问题。
-**SRNs网络结构如下图所示**:
+SRNs网络结构如下图所示:

-### 6.6.2 Bidirectional RNNs
+### 6.13.2 Bidirectional RNNs
-Bidirectional RNNs(双向网络)将两层RNNs叠加在一起,当前时刻输出(第t步的输出)不仅仅与之前序列有关,还与之后序列有关。例如:为了预测一个语句中的缺失词语,就需要该词汇的上下文信息。Bidirectional RNNs是一个相对较简单的RNNs,是由两个RNNs上下叠加在一起组成的。输出由前向RNNs和后向RNNs共同决定。**如下图所示**:
+ Bidirectional RNNs(双向网络)将两层RNNs叠加在一起,当前时刻输出(第t步的输出)不仅仅与之前序列有关,还与之后序列有关。例如:为了预测一个语句中的缺失词语,就需要该词汇的上下文信息。Bidirectional RNNs是一个相对较简单的RNNs,是由两个RNNs上下叠加在一起组成的。输出由前向RNNs和后向RNNs共同决定。如下图所示:

-### 6.6.3 Deep RNNs
+### 6.13.3 Deep RNNs
-Deep RNNs与Bidirectional RNNs相似,其也是又多层RNNs叠加,因此每一步的输入有了多层网络。该网络具有更强大的表达与学习能力,但是复杂性也随之提高,同时需要更多的训练数据。**Deep RNNs的结构如下图所示**:
+ Deep RNNs与Bidirectional RNNs相似,其也是又多层RNNs叠加,因此每一步的输入有了多层网络。该网络具有更强大的表达与学习能力,但是复杂性也随之提高,同时需要更多的训练数据。Deep RNNs的结构如下图所示:

-### 6.6.4 Echo State Networks(ESNs)
-ESNs(回声状态网络)虽然也是一种RNNs,但它与传统的RNNs相差较大。
-
-**ESNs具有三个特点**:
+### 6.13.4 Echo State Networks(ESNs)
+**ESNs特点**:
1. 它的核心结构为一个随机生成、且保持不变的储备池(Reservoir)。储备池是大规模随机生成稀疏连接(SD通常保持1%~5%,SD表示储备池中互相连接的神经元占总神经元个数N的比例)的循环结构;
-
2. 从储备池到输出层的权值矩阵是唯一需要调整的部分;
-
3. 简单的线性回归便能够完成网络训练;
-从结构上讲,ESNs是一种特殊类型的循环神经网络,其基本思想是:使用大规模随机连接的循环网络取代经典神经网络中的中间层,从而简化网络的训练过程。因此ESNs的关键是储备池。
+**ESNs基本思想**:
+
+ 使用大规模随机连接的循环网络取代经典神经网络中的中间层,从而简化网络的训练过程。
网络中的参数包括:
(1)W - 储备池中节点间连接权值矩阵;
(2)Win - 输入层到储备池之间连接权值矩阵,表明储备池中的神经元之间是相互连接;
(3)Wback - 输出层到储备池之间的反馈连接权值矩阵,表明储备池会有输出层来的反馈;
(4)Wout - 输入层、储备池、输出层到输出层的连接权值矩阵,表明输出层不仅与储备池连接,还与输入层和自己连接。
-Woutbias - 输出层的偏置项。
-对于ESNs,关键是储备池的四个参数,如储备池内部连接权谱半径SR(SR=λmax=max{|W的特征指|},只有SR <1时,ESNs才能具有回声状态属性)、储备池规模N(即储备池中神经元的个数)、储备池输入单元尺度IS(IS为储备池的输入信号连接到储备池内部神经元之前需要相乘的一个尺度因子)、储备池稀疏程度SD(即为储备池中互相连接的神经元个数占储备池神经元总个数的比例)。对于IS,待处理任务的非线性越强,输入单元尺度越大。该原则本质就是通过输入单元尺度IS,将输入变换到神经元激活函数相应的范围(神经元激活函数的不同输入范围,其非线性程度不同)。
-**ESNs的结构如下图所示**:
+(5)Woutbias - 输出层的偏置项。
+
+ ESNs的结构如下图所示:
+
-

-
-### 6.6.5 Gated Recurrent Unit Recurrent Neural Networks
-GRUs是一般的RNNs的变型版本,其主要是从以下**两个方面**进行改进。
+### 6.13.4 Gated Recurrent Unit Recurrent Neural Networks
+GRUs是一般的RNNs的变型版本,其主要是从以下两个方面进行改进。
-1. 序列中不同单词处(以语句为例)的数据对当前隐藏层状态的影响不同,越前面的影响越小,即每个之前状态对当前的影响进行了距离加权,距离越远,权值越小。
+1. 以语句为例,序列中不同单词处的数据对当前隐藏层状态的影响不同,越前面的影响越小,即每个之前状态对当前的影响进行了距离加权,距离越远,权值越小。
2. 在产生误差error时,其可能是由之前某一个或者几个单词共同造成,所以应当对对应的单词weight进行更新。GRUs的结构如下图所示。GRUs首先根据当前输入单词向量word vector以及前一个隐藏层状态hidden state计算出update gate和reset gate。再根据reset gate、当前word vector以及前一个hidden state计算新的记忆单元内容(new memory content)。当reset gate为1的时候,new memory content忽略之前所有memory content,最终的memory是由之前的hidden state与new memory content一起决定。

-### 6.6.6 LSTM Netwoorks
-1. LSTMs是当前一种非常流行的深度学习模型。为了解决RNNs存在的长时记忆问题,LSTMs利用了之前更多步的训练信息。
-2. LSTMs与一般的RNNs结构本质上并没有太大区别,只是使用了不同函数控制隐藏层的状态。
-3. 在LSTMs中,基本结构被称为cell,可以把cell看作是黑盒用以保存当前输入之前Xt的隐藏层状态ht−1。
-4. LSTMs有三种类型的门:遗忘门(forget gate), 输入门(input gate)以及输出门(output gate)。遗忘门(forget gate)是用来决定 哪个cells的状态将被丢弃掉。输入门(input gate)决定哪些cells会被更新. 输出门(output gate)控制了结果输出. 因此当前输出依赖于cells状态以及门的过滤条件。实践证明,LSTMs可以有效地解决长序列依赖问题。**LSTMs的网络结构如下图所示**。
-
-
-
-LSTMs与GRUs的区别如图所示:
-
-
-从上图可以看出,二者结构十分相似,**不同在于**:
-1. new memory都是根据之前state及input进行计算,但是GRUs中有一个reset gate控制之前state的进入量,而在LSTMs里没有类似gate;
-
-2. 产生新的state的方式不同,LSTMs有两个不同的gate,分别是forget gate (f gate)和input gate(i gate),而GRUs只有一种update gate(z gate);
-
-3. LSTMs对新产生的state可以通过output gate(o gate)进行调节,而GRUs对输出无任何调节。
-
-### 6.6.7 Bidirectional LSTMs
+### 6.13.5 Bidirectional LSTMs
1. 与bidirectional RNNs 类似,bidirectional LSTMs有两层LSTMs。一层处理过去的训练信息,另一层处理将来的训练信息。
2. 在bidirectional LSTMs中,通过前向LSTMs获得前向隐藏状态,后向LSTMs获得后向隐藏状态,当前隐藏状态是前向隐藏状态与后向隐藏状态的组合。
-### 6.6.8 Stacked LSTMs
+### 6.13.6 Stacked LSTMs
1. 与deep rnns 类似,stacked LSTMs 通过将多层LSTMs叠加起来得到一个更加复杂的模型。
2. 不同于bidirectional LSTMs,stacked LSTMs只利用之前步骤的训练信息。
-### 6.6.9 Clockwork RNNs(CW-RNNs)
-CW-RNNs是较新的一种RNNs模型,该模型首次发表于2014年Beijing ICML。
-CW-RNNs是RNNs的改良版本,其使用时钟频率来驱动。它将隐藏层分为几个块(组,Group/Module),每一组按照自己规定的时钟频率对输入进行处理。为了降低RNNs的复杂度,CW-RNNs减少了参数数量,并且提高了网络性能,加速网络训练。CW-RNNs通过不同隐藏层模块在不同时钟频率下工作来解决长时依赖问题。将时钟时间进行离散化,不同的隐藏层组将在不同时刻进行工作。因此,所有的隐藏层组在每一步不会全部同时工作,这样便会加快网络的训练。并且,时钟周期小组的神经元不会连接到时钟周期大组的神经元,只允许周期大的神经元连接到周期小的(组与组之间的连接以及信息传递是有向的)。周期大的速度慢,周期小的速度快,因此是速度慢的神经元连速度快的神经元,反之则不成立。
+### 6.13.7 Clockwork RNNs(CW-RNNs)
+ CW-RNNs是RNNs的改良版本,其使用时钟频率来驱动。它将隐藏层分为几个块(组,Group/Module),每一组按照自己规定的时钟频率对输入进行处理。为了降低RNNs的复杂度,CW-RNNs减少了参数数量,并且提高了网络性能,加速网络训练。CW-RNNs通过不同隐藏层模块在不同时钟频率下工作来解决长时依赖问题。将时钟时间进行离散化,不同的隐藏层组将在不同时刻进行工作。因此,所有的隐藏层组在每一步不会全部同时工作,这样便会加快网络的训练。并且,时钟周期小组的神经元不会连接到时钟周期大组的神经元,只允许周期大的神经元连接到周期小的(组与组之间的连接以及信息传递是有向的)。周期大的速度慢,周期小的速度快,因此是速度慢的神经元连速度快的神经元,反之则不成立。
-CW-RNNs与SRNs网络结构类似,也包括输入层(Input)、隐藏层(Hidden)、输出层(Output),它们之间存在前向连接,输入层到隐藏层连接,隐藏层到输出层连接。但是与SRN不同的是,隐藏层中的神经元会被划分为若干个组,设为$g$,每一组中的神经元个数相同,设为$k$,并为每一个组分配一个时钟周期$T_i\epsilon\{T_1,T_2,...,T_g\}$,每一组中的所有神经元都是全连接,但是组$j$到组$i$的循环连接则需要满足$T_j$大于$T_i$。如下图所示,将这些组按照时钟周期递增从左到右进行排序,即$T_1
+
+[15] Deep Learning,Ian Goodfellow Yoshua Bengio and Aaron Courville,Book in preparation for MIT Press,2016;
+
+[16] http://colah.github.io/posts/2015-08-Understanding-LSTMs/
+
+[17] Greff K, Srivastava R K, Koutník J, et al. LSTM: A Search Space Odyssey[J]. IEEE Transactions on Neural Networks & Learning Systems, 2016, 28(10):2222-2232.
+
+[18] Yao K , Cohn T , Vylomova K , et al. Depth-Gated Recurrent Neural Networks[J]. 2015.
+
+[19] Koutník J, Greff K, Gomez F, et al. A Clockwork RNN[J]. Computer Science, 2014:1863-1871.
+
+[20] Gers F A , Schmidhuber J . Recurrent nets that time and count[C]// Neural Networks, 2000. IJCNN 2000, Proceedings of the IEEE-INNS-ENNS International Joint Conference on. IEEE, 2000.
+
+[21] Li S, Wu C, Hai L, et al. FPGA Acceleration of Recurrent Neural Network Based Language Model[C]// IEEE International Symposium on Field-programmable Custom Computing Machines. 2015.
+
+[22] Mikolov T , Kombrink S , Burget L , et al. Extensions of recurrent neural network language model[C]// Acoustics, Speech and Signal Processing (ICASSP), 2011 IEEE International Conference on. IEEE, 2011.
+
+[23] Graves A . Generating Sequences With Recurrent Neural Networks[J]. Computer Science, 2013.
+
+[24] Sutskever I , Vinyals O , Le Q V . Sequence to Sequence Learning with Neural Networks[J]. 2014.
+
+[25] Liu B, Lane I. Joint Online Spoken Language Understanding and Language Modeling with Recurrent Neural Networks[J]. 2016.
+
+[26] Graves A, Mohamed A R, Hinton G. Speech recognition with deep recurrent neural networks[C]// IEEE International Conference on Acoustics. 2013.
+
+[27] https://cs.stanford.edu/people/karpathy/deepimagesent/
+
+[28] Cho K, Van Merriënboer B, Gulcehre C, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation[J]. arXiv preprint arXiv:1406.1078, 2014.
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/ch7.md" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/ch7.md"
new file mode 100755
index 00000000..3d8a83fd
--- /dev/null
+++ "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/ch7.md"
@@ -0,0 +1,486 @@
+[TOC]
+
+# 第七章 生成对抗网络
+
+## 7.1 GAN基本概念
+### 7.1.1 如何通俗理解GAN?
+
+ 生成对抗网络(GAN, Generative adversarial network)自从2014年被Ian Goodfellow提出以来,掀起来了一股研究热潮。GAN由生成器和判别器组成,生成器负责生成样本,判别器负责判断生成器生成的样本是否为真。生成器要尽可能迷惑判别器,而判别器要尽可能区分生成器生成的样本和真实样本。
+
+ 在GAN的原作[1]中,作者将生成器比喻为印假钞票的犯罪分子,判别器则类比为警察。犯罪分子努力让钞票看起来逼真,警察则不断提升对于假钞的辨识能力。二者互相博弈,随着时间的进行,都会越来越强。那么类比于图像生成任务,生成器不断生成尽可能逼真的假图像。判别器则判断图像是否是真实的图像,还是生成的图像,二者不断博弈优化。最终生成器生成的图像使得判别器完全无法判别真假。
+
+### 7.1.2 GAN的形式化表达
+ 上述例子只是简要介绍了一下GAN的思想,下面对于GAN做一个形式化的,更加具体的定义。通常情况下,无论是生成器还是判别器,我们都可以用神经网络来实现。那么,我们可以把通俗化的定义用下面这个模型来表示:
+
+
+ 上述模型左边是生成器G,其输入是$z$,对于原始的GAN,$z$是由高斯分布随机采样得到的噪声。噪声$z$通过生成器得到了生成的假样本。
+
+ 生成的假样本与真实样本放到一起,被随机抽取送入到判别器D,由判别器去区分输入的样本是生成的假样本还是真实的样本。整个过程简单明了,生成对抗网络中的“生成对抗”主要体现在生成器和判别器之间的对抗。
+
+### 7.1.3 GAN的目标函数是什么?
+ 对于上述神经网络模型,如果想要学习其参数,首先需要一个目标函数。GAN的目标函数定义如下:
+
+$$
+\mathop {\min }\limits_G \mathop {\max }\limits_D V(D,G) = {\rm E}_{x\sim{p_{data}(x)}}[\log D(x)] + {\rm E}_{z\sim{p_z}(z)}[\log (1 - D(G(z)))]
+$$
+ 这个目标函数可以分为两个部分来理解:
+
+ 第一部分:判别器的优化通过$\mathop {\max}\limits_D V(D,G)$实现,$V(D,G)$为判别器的目标函数,其第一项${\rm E}_{x\sim{p_{data}(x)}}[\log D(x)]$表示对于从真实数据分布 中采用的样本 ,其被判别器判定为真实样本概率的数学期望。对于真实数据分布 中采样的样本,其预测为正样本的概率当然是越接近1越好。因此希望最大化这一项。第二项${\rm E}_{z\sim{p_z}(z)}[\log (1 - D(G(z)))]$表示:对于从噪声$P_z(z)$分布当中采样得到的样本,经过生成器生成之后得到的生成图片,然后送入判别器,其预测概率的负对数的期望,这个值自然是越大越好,这个值越大, 越接近0,也就代表判别器越好。
+
+ 第二部分:生成器的优化通过$\mathop {\min }\limits_G({\mathop {\max }\limits_D V(D,G)})$来实现。注意,生成器的目标不是$\mathop {\min }\limits_GV(D,G)$,即生成器不是最小化判别器的目标函数,二是最小化判别器目标函数的最大值,判别器目标函数的最大值代表的是真实数据分布与生成数据分布的JS散度(详情可以参阅附录的推导),JS散度可以度量分布的相似性,两个分布越接近,JS散度越小。
+
+### 7.1.4 GAN的目标函数和交叉熵有什么区别?
+
+ 判别器目标函数写成离散形式即为:
+$$
+V(D,G)=-\frac{1}{m}\sum_{i=1}^{i=m}logD(x^i)-\frac{1}{m}\sum_{i=1}^{i=m}log(1-D(\tilde{x}^i))
+$$
+
+ 可以看出,这个目标函数和交叉熵是一致的,即**判别器的目标是最小化交叉熵损失,生成器的目标是最小化生成数据分布和真实数据分布的JS散度**。
+
+-------------------
+[1]: Goodfellow, Ian, et al. "Generative adversarial nets." Advances in neural information processing systems. 2014.
+
+### 7.1.5 GAN的Loss为什么降不下去?
+
+ 对于很多GAN的初学者在实践过程中可能会纳闷,为什么GAN的Loss一直降不下去。GAN到底什么时候才算收敛?其实,作为一个训练良好的GAN,其Loss就是降不下去的。衡量GAN是否训练好了,只能由人肉眼去看生成的图片质量是否好。不过,对于没有一个很好的评价是否收敛指标的问题,也有许多学者做了一些研究,后文提及的WGAN就提出了一种新的Loss设计方式,较好的解决了难以判断收敛性的问题。下面我们分析一下GAN的Loss为什么降不下去?
+ 对于判别器而言,GAN的Loss如下:
+$$
+\mathop {\min }\limits_G \mathop {\max }\limits_D V(D,G) = {\rm E}_{x\sim{p_{data}(x)}}[\log D(x)] + {\rm E}_{z\sim{p_z}(z)}[\log (1 - D(G(z)))]
+$$
+ 从$\mathop {\min }\limits_G \mathop {\max }\limits_D V(D,G)$可以看出,生成器和判别器的目的相反,也就是说两个生成器网络和判别器网络互为对抗,此消彼长。不可能Loss一直降到一个收敛的状态。
+
+- 对于生成器,其Loss下降快,很有可能是判别器太弱,导致生成器很轻易的就"愚弄"了判别器。
+- 对于判别器,其Loss下降快,意味着判别器很强,判别器很强则说明生成器生成的图像不够逼真,才使得判别器轻易判别,导致Loss下降很快。
+
+ 也就是说,无论是判别器,还是生成器。loss的高低不能代表生成器的好坏。一个好的GAN网络,其GAN Loss往往是不断波动的。
+
+ 看到这里可能有点让人绝望,似乎判断模型是否收敛就只能看生成的图像质量了。实际上,后文探讨的WGAN,提出了一种新的loss度量方式,让我们可以通过一定的手段来判断模型是否收敛。
+
+### 7.1.6 生成式模型、判别式模型的区别?
+
+ 对于机器学习模型,我们可以根据模型对数据的建模方式将模型分为两大类,生成式模型和判别式模型。如果我们要训练一个关于猫狗分类的模型,对于判别式模型,只需要学习二者差异即可。比如说猫的体型会比狗小一点。而生成式模型则不一样,需要学习猫张什么样,狗张什么样。有了二者的长相以后,再根据长相去区分。具体而言:
+
+- 生成式模型:由数据学习联合概率分布P(X,Y), 然后由P(Y|X)=P(X,Y)/P(X)求出概率分布P(Y|X)作为预测的模型。该方法表示了给定输入X与产生输出Y的生成关系
+
+- 判别式模型:由数据直接学习决策函数Y=f(X)或条件概率分布P(Y|X)作为预测模型,即判别模型。判别方法关心的是对于给定的输入X,应该预测什么样的输出Y。
+
+ 对于上述两种模型,从文字上理解起来似乎不太直观。我们举个例子来阐述一下,对于性别分类问题,分别用不同的模型来做:
+
+ 1)如果用生成式模型:可以训练一个模型,学习输入人的特征X和性别Y的关系。比如现在有下面一批数据:
+
+| Y(性别) | | 0 | 1 |
+| --------- | ---- | ---- | ---- |
+| X(特征) | 0 | 1/4 | 3/4 |
+| | 1 | 3/4 | 1/4 |
+
+ 这个数据可以统计得到,即统计人的特征X=0,1….的时候,其类别为Y=0,1的概率。统计得到上述联合概率分布P(X, Y)后,可以学习一个模型,比如让二维高斯分布去拟合上述数据,这样就学习到了X,Y的联合分布。在预测时,如果我们希望给一个输入特征X,预测其类别,则需要通过贝叶斯公式得到条件概率分布才能进行推断:
+$$
+P(Y|X)={\frac{P(X,Y)}{P(X)}}={\frac{P(X,Y)}{P(X|Y)P(Y)}}
+$$
+ 2)如果用判别式模型:可以训练一个模型,输入人的特征X,这些特征包括人的五官,穿衣风格,发型等。输出则是对于性别的判断概率,这个概率服从一个分布,分布的取值只有两个,要么男,要么女,记这个分布为Y。这个过程学习了一个条件概率分布P(Y|X),即输入特征X的分布已知条件下,Y的概率分布。
+
+ 显然,从上面的分析可以看出。判别式模型似乎要方便很多,因为生成式模型要学习一个X,Y的联合分布往往需要很多数据,而判别式模型需要的数据则相对少,因为判别式模型更关注输入特征的差异性。不过生成式既然使用了更多数据来生成联合分布,自然也能够提供更多的信息,现在有一个样本(X,Y),其联合概率P(X,Y)经过计算特别小,那么可以认为这个样本是异常样本。这种模型可以用来做outlier detection。
+
+### 7.1.7 什么是mode collapsing?
+
+ 某个模式(mode)出现大量重复样本,例如:
+
+ 上图左侧的蓝色五角星表示真实样本空间,黄色的是生成的。生成样本缺乏多样性,存在大量重复。比如上图右侧中,红框里面人物反复出现。
+
+### 7.1.8 如何解决mode collapsing?
+
+方法一:**针对目标函数的改进方法**
+
+ 为了避免前面提到的由于优化maxmin导致mode跳来跳去的问题,UnrolledGAN采用修改生成器loss来解决。具体而言,UnrolledGAN在更新生成器时更新k次生成器,参考的Loss不是某一次的loss,是判别器后面k次迭代的loss。注意,判别器后面k次迭代不更新自己的参数,只计算loss用于更新生成器。这种方式使得生成器考虑到了后面k次判别器的变化情况,避免在不同mode之间切换导致的模式崩溃问题。此处务必和迭代k次生成器,然后迭代1次判别器区分开[8]。DRAGAN则引入博弈论中的无后悔算法,改造其loss以解决mode collapse问题[9]。前文所述的EBGAN则是加入VAE的重构误差以解决mode collapse。
+
+方法二:**针对网络结构的改进方法**
+
+ Multi agent diverse GAN(MAD-GAN)采用多个生成器,一个判别器以保障样本生成的多样性。具体结构如下:
+
+
+
+ 相比于普通GAN,多了几个生成器,且在loss设计的时候,加入一个正则项。正则项使用余弦距离惩罚三个生成器生成样本的一致性。
+
+ MRGAN则添加了一个判别器来惩罚生成样本的mode collapse问题。具体结构如下:
+
+
+
+ 输入样本$x$通过一个Encoder编码为隐变量$E(x)$,然后隐变量被Generator重构,训练时,Loss有三个。$D_M$和$R$(重构误差)用于指导生成real-like的样本。而$D_D$则对$E(x)$和$z$生成的样本进行判别,显然二者生成样本都是fake samples,所以这个判别器主要用于判断生成的样本是否具有多样性,即是否出现mode collapse。
+
+方法三:**Mini-batch Discrimination**
+
+ Mini-batch discrimination在判别器的中间层建立一个mini-batch layer用于计算基于L1距离的样本统计量,通过建立该统计量,实现了一个batch内某个样本与其他样本有多接近。这个信息可以被判别器利用到,从而甄别出哪些缺乏多样性的样本。对生成器而言,则要试图生成具有多样性的样本。
+
+## 7.2 GAN的生成能力评价
+
+### 7.2.1 如何客观评价GAN的生成能力?
+
+ 最常见评价GAN的方法就是主观评价。主观评价需要花费大量人力物力,且存在以下问题:
+
+- 评价带有主管色彩,有些bad case没看到很容易造成误判
+
+- 如果一个GAN过拟合了,那么生成的样本会非常真实,人类主观评价得分会非常高,可是这并不是一个好的GAN。
+
+因此,就有许多学者提出了GAN的客观评价方法。
+
+### 7.2.2 Inception Score
+
+ 对于一个在ImageNet训练良好的GAN,其生成的样本丢给Inception网络进行测试的时候,得到的判别概率应该具有如下特性:
+- 对于同一个类别的图片,其输出的概率分布应该趋向于一个脉冲分布。可以保证生成样本的准确性。
+- 对于所有类别,其输出的概率分布应该趋向于一个均匀分布,这样才不会出现mode dropping等,可以保证生成样本的多样性。
+
+ 因此,可以设计如下指标:
+$$
+IS(P_g)=e^{E_{x\sim P_g}[KL(p_M(y|x)\Vert{p_M(y)})]}
+根据前面分析,如果是一个训练良好的GAN,$p_M(y|x)$趋近于脉冲分布,$p_M(y)$趋近于均匀分布。二者KL散度会很大。Inception Score自然就高。实际实验表明,Inception Score和人的主观判别趋向一致。IS的计算没有用到真实数据,具体值取决于模型M的选择
+$$
+ 根据前面分析,如果是一个训练良好的GAN,$p_M(y|x)$趋近于脉冲分布,$p_M(y)$趋近于均匀分布。二者KL散度会很大。Inception Score自然就高。实际实验表明,Inception Score和人的主观判别趋向一致。IS的计算没有用到真实数据,具体值取决于模型M的选择。
+
+ **特点:可以一定程度上衡量生成样本的多样性和准确性,但是无法检测过拟合。Mode Score也是如此。不推荐在和ImageNet数据集差别比较大的数据上使用。**
+
+### 7.2.3 Mode Score
+
+ Mode Score作为Inception Score的改进版本,添加了关于生成样本和真实样本预测的概率分布相似性度量一项。具体公式如下:
+$$
+MS(P_g)=e^{E_{x\sim P_g}[KL(p_M(y|x)\Vert{p_M(y)})-KL(p_M(y)\Vert p_M(y^*))]}
+$$
+
+### 7.2.4 Kernel MMD (Maximum Mean Discrepancy)
+
+计算公式如下:
+$$
+MMD^2(P_r,P_g)=E_{x_r\sim{P_r},x_g\sim{P_g}}[\lVert\Sigma_{i=1}^{n1}k(x_r)-\Sigma_{i=1}^{n2}k(x_g)\rVert]
+$$
+ 对于Kernel MMD值的计算,首先需要选择一个核函数$k$,这个核函数把样本映射到再生希尔伯特空间(Reproducing Kernel Hilbert Space, RKHS) ,RKHS相比于欧几里得空间有许多优点,对于函数内积的计算是完备的。将上述公式展开即可得到下面的计算公式:
+$$
+MMD^2(P_r,P_g)=E_{x_r,x_r{'}\sim{P_r},x_g,x_g{'}\sim{P_g}}[k(x_r,x_r{'})-2k(x_r,x_g)+k(x_g,x_g{'})]
+$$
+MMD值越小,两个分布越接近。
+
+**特点:可以一定程度上衡量模型生成图像的优劣性,计算代价小。推荐使用。**
+
+### 7.2.5 Wasserstein distance
+
+ Wasserstein distance在最优传输问题中通常也叫做推土机距离。这个距离的介绍在WGAN中有详细讨论。公式如下:
+$$
+WD(P_r,P_g)=min_{\omega\in\mathbb{R}^{m\times n}}\Sigma_{i=1}^n\Sigma_{i=1}^m\omega_{ij}d(x_i^r,x_j^g)
+$$
+
+$$
+s.t. \Sigma_{i=1}^mw_{i,j}=p_r(x_i^r), \forall i;\Sigma_{j=1}^nw_{i,j}=p_g(x_j^g), \forall j
+$$
+
+ Wasserstein distance可以衡量两个分布之间的相似性。距离越小,分布越相似。
+
+**特点:如果特征空间选择合适,会有一定的效果。但是计算复杂度为$O(n^3)$太高**
+
+### 7.2.6 Fréchet Inception Distance (FID)
+
+ FID距离计算真实样本,生成样本在特征空间之间的距离。首先利用Inception网络来提取特征,然后使用高斯模型对特征空间进行建模。根据高斯模型的均值和协方差来进行距离计算。具体公式如下:
+$$
+FID(\mathbb P_r,\mathbb P_g)=\lVert\mu_r-\mu_g\rVert+Tr(C_r+C_g-2(C_rC_g)^{1/2})
+$\mu,C$分别代表协方差和均值。
+$$
+$\mu,C$分别代表协方差和均值。
+
+ **特点:尽管只计算了特征空间的前两阶矩,但是鲁棒,且计算高效。**
+
+### 7.2.7 1-Nearest Neighbor classifier
+
+ 使用留一法,结合1-NN分类器(别的也行)计算真实图片,生成图像的精度。如果二者接近,则精度接近50%,否则接近0%。对于GAN的评价问题,作者分别用正样本的分类精度,生成样本的分类精度去衡量生成样本的真实性,多样性。
+- 对于真实样本$x_r$,进行1-NN分类的时候,如果生成的样本越真实。则真实样本空间$\mathbb R$将被生成的样本$x_g$包围。那么$x_r$的精度会很低。
+- 对于生成的样本$x_g$,进行1-NN分类的时候,如果生成的样本多样性不足。由于生成的样本聚在几个mode,则$x_g$很容易就和$x_r$区分,导致精度会很高。
+
+**特点:理想的度量指标,且可以检测过拟合。**
+
+### 7.2.8 其他评价方法
+
+ AIS,KDE方法也可以用于评价GAN,但这些方法不是model agnostic metrics。也就是说,这些评价指标的计算无法只利用:生成的样本,真实样本来计算。
+
+## 7.3 其他常见的生成式模型有哪些?
+
+### 7.3.1 什么是自回归模型:pixelRNN与pixelCNN?
+
+ 自回归模型通过对图像数据的概率分布$p_{data}(x)$进行显式建模,并利用极大似然估计优化模型。具体如下:
+$$
+p_{data}(x)=\prod_{i=1}^np(x_i|x_1,x_2,...,x_{i-1})
+$$
+ 上述公式很好理解,给定$x_1,x_2,...,x_{i-1}$条件下,所有$p(x_i)$的概率乘起来就是图像数据的分布。如果使用RNN对上述依然关系建模,就是pixelRNN。如果使用CNN,则是pixelCNN。具体如下[5]:
+
+
+
+
+
+ 显然,不论是对于pixelCNN还是pixelRNN,由于其像素值是一个个生成的,速度会很慢。语音领域大火的WaveNet就是一个典型的自回归模型。
+
+### 7.3.2 什么是VAE?
+
+ PixelCNN/RNN定义了一个易于处理的密度函数,我们可以直接优化训练数据的似然;对于变分自编码器我们将定义一个不易处理的密度函数,通过附加的隐变量$z$对密度函数进行建模。 VAE原理图如下[6]:
+
+
+
+ 在VAE中,真实样本$X$通过神经网络计算出均值方差(假设隐变量服从正太分布),然后通过采样得到采样变量$Z$并进行重构。VAE和GAN均是学习了隐变量$z$到真实数据分布的映射。但是和GAN不同的是:
+
+- GAN的思路比较粗暴,使用一个判别器去度量分布转换模块(即生成器)生成分布与真实数据分布的距离。
+- VAE则没有那么直观,VAE通过约束隐变量$z$服从标准正太分布以及重构数据实现了分布转换映射$X=G(z)$
+
+**生成式模型对比**
+
+- 自回归模型通过对概率分布显式建模来生成数据
+- VAE和GAN均是:假设隐变量$z$服从某种分布,并学习一个映射$X=G(z)$,实现隐变量分布$z$与真实数据分布$p_{data}(x)$的转换。
+- GAN使用判别器去度量映射$X=G(z)$的优劣,而VAE通过隐变量$z$与标准正太分布的KL散度和重构误差去度量。
+
+## 7.4 GAN的改进与优化
+
+### 7.4.1 如何生成指定类型的图像——条件GAN
+
+ 条件生成对抗网络(CGAN, Conditional Generative Adversarial Networks)作为一个GAN的改进,其一定程度上解决了GAN生成结果的不确定性。如果在Mnist数据集上训练原始GAN,GAN生成的图像是完全不确定的,具体生成的是数字1,还是2,还是几,根本不可控。为了让生成的数字可控,我们可以把数据集做一个切分,把数字0~9的数据集分别拆分开训练9个模型,不过这样太麻烦了,也不现实。因为数据集拆分不仅仅是分类麻烦,更主要在于,每一个类别的样本少,拿去训练GAN很有可能导致欠拟合。因此,CGAN就应运而生了。我们先看一下CGAN的网络结构:
+
+ 从网络结构图可以看到,对于生成器Generator,其输入不仅仅是随机噪声的采样z,还有欲生成图像的标签信息。比如对于mnist数据生成,就是一个one-hot向量,某一维度为1则表示生成某个数字的图片。同样地,判别器的输入也包括样本的标签。这样就使得判别器和生成器可以学习到样本和标签之间的联系。Loss如下:
+$$
+\mathop {\min }\limits_G \mathop {\max }\limits_D V(D,G) = {\rm E}_{x\sim{p_{data}(x)}}[\log D(x|y)] + {\rm E}_{z\sim{p_z}(z)}[\log (1 - D(G(z|y)))]
+$$
+ Loss设计和原始GAN基本一致,只不过生成器,判别器的输入数据是一个条件分布。在具体编程实现时只需要对随机噪声采样z和输入条件y做一个级联即可。
+
+### 7.4.2 CNN与GAN——DCGAN
+
+ 前面我们聊的GAN都是基于简单的神经网络�构建的。可是对于视觉问题,如果使用原始的基于DNN的GAN,则会出现许多问题。如果输入GAN的随机噪声为100维的随机噪声,输出图像为256x256大小。也就是说,要将100维的信息映射为65536维。如果单纯用DNN来实现,�那么整个模型参数会非常巨大,而且学习难度很大(低维度映射到高维度需要添加许多信息)。因此,DCGAN就出现了。具体而言,DCGAN将传统GAN的生成器,判别器均采用GAN实现,且使用了一下tricks:
+
+- 将pooling层convolutions替代,其中,在discriminator上用strided convolutions替代,在generator上用fractional-strided convolutions替代。
+- 在generator和discriminator上都使用batchnorm。
+- 移除全连接层,global pooling增加了模型的稳定性,但伤害了收敛速度。
+- 在generator的除了输出层外的所有层使用ReLU,输出层采用tanh。
+- 在discriminator的所有层上使用LeakyReLU。
+
+网络结构图如下:
+
+
+### 7.4.3 如何理解GAN中的输入随机噪声?
+
+ 为了了解输入随机噪声每一个维度代表的含义,作者做了一个非常有趣的工作。即在隐空间上,假设知道哪几个变量控制着某个物体,那么僵这几个变量挡住是不是就可以将生成图片中的某个物体消失?论文中的实验是这样的:首先,生成150张图片,包括有窗户的和没有窗户的,然后使用一个逻辑斯底回归函数来进行分类,对于权重不为0的特征,认为它和窗户有关。将其挡住,得到新的生成图片,结果如下:
+
+此外,将几个输入噪声进行算数运算,�可以得到语义上进行算数运算的非常有趣的结果。类似于word2vec。
+
+
+### 7.4.4 GAN为什么容易训练崩溃?
+
+ 所谓GAN的训练崩溃,指的是训练过程中,生成器和判别器存在一方压倒另一方的情况。
+GAN原始判别器的Loss在判别器达到最优的时候,等价于最小化生成分布与真实分布之间的JS散度,由于随机生成分布很难与真实分布有不可忽略的重叠以及JS散度的突变特性,使得生成器面临梯度消失的问题;�可是如果不把判别器训练到最优,那么生成器优化的目标就失去了意义。因此需要我们小心的平衡二者,要把判别器训练的不好也不坏才行。否则就会出现训练崩溃,得不到想要的结果
+
+### 7.4.5 WGAN如何解决训练崩溃问题?
+
+ WGAN作者提出了使用Wasserstein距离,以解决GAN网络训练过程难以判断收敛性的问题。Wasserstein距离定义如下:
+$$
+L={\rm E}_{x\sim{p_{data}}(x)}[f_w(x)] - {\rm E}_{x\sim{p_g}(x)}[f_w(x)]
+$$
+通过最小化Wasserstein距离,得到了WGAN的Loss:
+
+- WGAN生成器Loss:$- {\rm E}_{x\sim{p_g}(x)}[f_w(x)]$
+- WGAN判别器Loss:$L=-{\rm E}_{x\sim{p_{data}}(x)}[f_w(x)] + {\rm E}_{x\sim{p_g}(x)}[f_w(x)]$
+
+从公式上GAN似乎总是让人摸不着头脑,在代码实现上来说,其实就以下几点:
+
+- 判别器最后一层去掉sigmoid
+- 生成器和判别器的loss不取log
+- 每次更新判别器的参数之后把它们的绝对值截断到不超过一个固定常数c
+
+### 7.4.6 WGAN-GP:带有梯度正则的WGAN
+
+ 实际实验过程发现,WGAN没有那么好用,主要原因在于WAGN进行梯度截断。梯度截断将导致判别网络趋向于一个二值网络,造成模型容量的下降。
+于是作者提出使用梯度惩罚来替代梯度裁剪。公式如下:
+$$
+L=-{\rm E}_{x\sim{p_{data}}(x)}[f_w(x)] + {\rm E}_{x\sim{p_g}(x)}[f_w(x)]+\lambda{\rm E}_{x\sim{p_x}(x)}[\lVert\nabla_x(D(x))\rVert_p-1]^2
+由于上式是对每一个梯度进行惩罚,所以不适合使用BN,因为它会引入同个batch中不同样本的相互依赖关系。如果需要的话,可以选择Layer Normalization。实际训练过程中,就可以通过Wasserstein距离来度量模型收敛程度了:
+
+上图纵坐标是Wasserstein距离,横坐标是迭代次数。可以看出,随着迭代的进行,Wasserstein距离趋于收敛,生成图像也趋于稳定。
+$$
+ 由于上式是对每一个梯度进行惩罚,所以不适合使用BN,因为它会引入同个batch中不同样本的相互依赖关系。如果需要的话,可以选择Layer Normalization。实际训练过程中,就可以通过Wasserstein距离来度量模型收敛程度了:
+
+ 上图纵坐标是Wasserstein距离,横坐标是迭代次数。可以看出,随着迭代的进行,Wasserstein距离趋于收敛,生成图像也趋于稳定。
+
+### 7.4.7 LSGAN
+
+ LSGAN(Least Squares GAN)这篇文章主要针对标准GAN的稳定性和图片生成质量不高做了一个改进。作者将原始GAN的交叉熵损失采用最小二乘损失替代。LSGAN的Loss:
+$$
+\mathop{\min }\limits_DJ(D)=\mathop{\min}\limits_D[{\frac{1}{2}}{\rm E}_{x\sim{p_{data}}(x)}[D(x)-a]^2 + {\frac{1}{2}}{\rm E}_{z\sim{p_z}(z)}[D(G(z))-b]^2]
+$$
+
+$$
+\mathop{\min }\limits_GJ(G)=\mathop{\min}\limits_G{\frac{1}{2}}{\rm E}_{z\sim{p_z}(z)}[D(G(z))-c]^2
+$$
+
+ 实际实现的时候非常简单,最后一层去掉sigmoid,并且计算Loss的时候用平方误差即可。之所以这么做,作者在原文给出了一张图:
+
+ 上面是作者给出的基于交叉熵损失以及最小二乘损失的Loss函数。横坐标代表Loss函数的输入,纵坐标代表输出的Loss值。可以看出,随着输入的增大,sigmoid交叉熵损失很快趋于0,容易导致梯度饱和问题。如果使用右边的Loss设计,则只在x=0点处饱和。因此使用LSGAN可以很好的解决交叉熵损失的问题。
+
+### 7.4.8 如何尽量避免GAN的训练崩溃问题?
+
+- 归一化图像输入到(-1,1)之间;Generator最后一层使用tanh激活函数
+- 生成器的Loss采用:min (log 1-D)。因为原始的生成器Loss存在梯度消失问题;训练生成器的时候,考虑反转标签,real=fake, fake=real
+- 不要在均匀分布上采样,应该在高斯分布上采样
+- 一个Mini-batch里面必须只有正样本,或者负样本。不要混在一起;如果用不了Batch Norm,可以用Instance Norm
+- 避免稀疏梯度,即少用ReLU,MaxPool。可以用LeakyReLU替代ReLU,下采样可以用Average Pooling或者Convolution + stride替代。上采样可以用PixelShuffle, ConvTranspose2d + stride
+- 平滑标签或者给标签加噪声;平滑标签,即对于正样本,可以使用0.7-1.2的随机数替代;对于负样本,可以使用0-0.3的随机数替代。 给标签加噪声:即训练判别器的时候,随机翻转部分样本的标签。
+- 如果可以,请用DCGAN或者混合模型:KL+GAN,VAE+GAN。
+- 使用LSGAN,WGAN-GP
+- Generator使用Adam,Discriminator使用SGD
+- 尽快发现错误;比如:判别器Loss为0,说明训练失败了;如果生成器Loss稳步下降,说明判别器没发挥作用
+- 不要试着通过比较生成器,判别器Loss的大小来解决训练过程中的模型坍塌问题。比如:
+ While Loss D > Loss A:
+ Train D
+ While Loss A > Loss D:
+ Train A
+- 如果有标签,请尽量利用标签信息来训练
+- 给判别器的输入加一些噪声,给G的每一层加一些人工噪声。
+- 多训练判别器,尤其是加了噪声的时候
+- 对于生成器,在训练,测试的时候使用Dropout
+
+## 7.3 GAN的应用(图像翻译)
+
+### 7.3.1 什么是图像翻译?
+ GAN作为一种强有力的生成模型,其应用十分广泛。最为常见的应用就是图像翻译。所谓图像翻译,指从一副图像到另一副图像的转换。可以类比机器翻译,一种语言转换为另一种语言。常见的图像翻译任务有:
+- 图像去噪
+- 图像超分辨
+- 图像补全
+- 风格迁移
+- ...
+
+ 本节将介绍一个经典的图像翻译网络及其改进。图像翻译可以分为有监督图像翻译和�无监督图像翻译:
+
+- 有监督图像翻译:原始�域与目标域存在一一对应数据
+- 无监督图像翻译:原始�域与目标域不存在一一对应数据
+
+### 7.3.2 有监督图像翻译:pix2pix
+ 在这篇paper里面,作者提出的框架十分简洁优雅(好用的算法总是简洁优雅的)。相比以往算法的大量专家知识,手工复杂的loss。这篇paper非常粗暴,使用CGAN处理了一系列的转换问题。下面是一些转换示例:
+
+
+ 上面展示了许多有趣的结果,比如分割图$\longrightarrow$街景图,边缘图$\longrightarrow$真实图。对于第一次看到的时候还是很惊艳的,那么这个是怎么做到的呢?我们可以设想一下,如果是我们,我们自己会如何设计这个网络?
+
+**直观的想法**?
+
+ 最直接的想法就是,设计一个CNN网络,直接建立输入-输出的映射,就像图像去噪问题一样。可是对于上面的问题,这样做会带来一个问题。**生成图像质量不清晰。**
+
+ 拿左上角的分割图$\longrightarrow$街景图为例,语义分割图的每个标签比如“汽车”可能对应不同样式,颜色的汽车。那么模型学习到的会是所有不同汽车的评均,这样会造成模糊。
+
+**如何解决生成图像的模糊问题**?
+
+ 这里作者想了一个办法,即加入GAN的Loss去惩罚模型。GAN相比于传统生成式模型可以较好的生成高分辨率图片。思路也很简单,在上述直观想法的基础上加入一个判别器,判断输入图片是否是真实样本。模型示意图如下:
+
+
+
+ 上图模型和CGAN有所不同,但它是一个CGAN,只不过输入只有一个,这个输入就是条件信息。原始的CGAN需要输入随机噪声,以及条件。这里之所有没有输入噪声信息,是因为在实际实验中,如果输入噪声和条件,噪声往往被淹没在条件C当中,所以这里直接省去了。
+
+### 7.3.3 其他图像翻译的tricks
+从上面两点可以得到最终的Loss由两部分构成:
+- 输出和标签信息的L1 Loss。
+
+- GAN Loss
+
+- 测试也使用Dropout,以使输出多样化
+ $$
+ G^*=arg\mathop {\min }\limits_G \mathop {\max }\limits_D \Gamma_{cGAN}(G,D)+\lambda\Gamma_{L1}(G)
+ $$
+
+ 采用L1 Loss而不是L2 Loss的理由很简单,L1 Loss相比于L2 Loss保边缘(L2 Loss基于高斯先验,L1 Loss基于拉普拉斯先验)。
+
+ GAN Loss为LSGAN的最小二乘Loss,并使用PatchGAN(进一步保证生成图像的清晰度)。PatchGAN将图像换分成很多个Patch,并对每一个Patch使用判别器进行判别(实际代码实现有更取巧的办法),将所有Patch的Loss求平均作为最终的Loss。
+
+### 7.3.4 如何生成高分辨率图像和高分辨率视频?
+
+ pix2pix提出了一个通用的图像翻译框架。对于高分辨率的图像生成以及高分辨率的视频生成,则需要利用更好的网络结构以及更多的先验只是。pix2pixHD提出了一种多尺度的生成器以及判别器等方式从而生成高分辨率图像。Vid2Vid则在pix2pixHD的基础上利用光流,时序约束生成了高分辨率视频。
+
+### 7.3.5 有监督的图像翻译的缺点?
+ 许多图像翻译算法如前面提及的pix2pix系列,需要一一对应的图像。可是在许多应用场景下,往往没有这种一一对应的强监督信息。比如说以下一些应用场景:
+
+以第一排第一幅图为例,要找到这种一一配对的数据是不现实的。因此,无监督图像翻译算法就被引入了。
+
+### 7.3.6 无监督图像翻译:CycleGAN
+**模型结构**
+
+ 总体思路如下,假设有两个域的数据,记为A,B。对于上图第一排第一幅图A域就是普通的马,B域就是斑马。由于A->B的转换缺乏监督信息,于是,作者提出采用如下方法进行转换:
+>a. A->fake_B->rec_A
+b. B->fake_A->rec_B
+
+ 对于A域的所有图像,学习一个网络G_B,该网络可以生成B。对于B域的所有图像,也学习一个网络G_A,该网络可以生成G_B。
+
+ 训练过程分成两步,首先对于A域的某张图像,送入G_B生成fake_B,然后对fake_B送入G_A,得到重构后的A图像rec_A。对于B域的某一张图像也是类似。重构后的图像rec_A/rec_B可以和原图A/B做均方误差,实现了有监督的训练。此处值得注意的是A->fake_B(B->fake_A)和fake_A->rec_B(fake_B->rec_A)的网络是一模一样的。下图是形象化的网络结构图:
+
+ cycleGAN的生成器采用U-Net,判别器采用LS-GAN。
+
+**Loss设计**
+
+ 总的Loss就是X域和Y域的GAN Loss,以及Cycle consistency loss:
+$$
+L(G,F,D_X,D_Y)=L_{GAN}(G,D_Y,X,Y)+L_{GAN}(F,D_X,Y,X)+\lambda L_{cycle}(G,F)
+$$
+整个过程End to end训练,效果非常惊艳,利用这一框架可以完成非常多有趣的任务
+
+### 7.3.7 多领域的无监督图像翻译:StarGAN
+
+cycleGAN模型较好的解决了无监督图像转换问题,可是这种单一域的图像转换还存在一些问题:
+
+- 要针对每一个域训练一个模型,效率太低。举例来说,我希望可以将橘子转换为红苹果和青苹果。对于cycleGAN而言,需要针对红苹果,青苹果分别训练一个模型。
+- 对于每一个域都需要搜集大量数据,太麻烦。还是以橘子转换为红苹果和青苹果为例。不管是红苹果还是青苹果,都是苹果,只是颜色不一样而已。这两个任务信息是可以共享的,没必要分别训练两个模型。而且针对红苹果,青苹果分别取搜集大量数据太费事。
+
+ starGAN则提出了一个多领域的无监督图像翻译框架,实现了多个领域的图像转换,且对于不同领域的数据可以混合在一起训练,提高了数据利用率
+
+## 7.4 GAN的应用(文本生成)
+
+### 7.4.1 GAN为什么不适合文本任务?
+
+ GAN在2014年被提出之后,在图像生成领域取得了广泛的研究应用。然后在文本领域却一直没有很惊艳的效果。主要在于文本数据是离散数据,而GAN在应用于离散数据时存在以下几个问题:
+
+- GAN的生成器梯度来源于判别器对于正负样本的判别。然而,对于文本生成问题,RNN输出的是一个概率序列,然后取argmax。这会导致生成器Loss不可导。还可以站在另一个角度理解,由于是argmax,所以参数更新一点点并不会改变argmax的结果,这也使得GAN不适合离散数据。
+- GAN只能评估整个序列的loss,但是无法评估半句话,或者是当前生成单词对后续结果好坏的影响。
+- 如果不加argmax,那么由于生成器生成的都是浮点数值,而ground truth都是one-hot encoding,那么判别器只要判别生成的结果是不是0/1序列组成的就可以了。这容易导致训练崩溃。
+
+### 7.4.2 seqGAN用于文本生成
+
+ seqGAN在GAN的框架下,结合强化学习来做文本生成。 模型示意图如下:
+
+
+在文本生成任务,seqGAN相比较于普通GAN区别在以下几点:
+
+- 生成器不取argmax。
+- 每生成一个单词,则根据当前的词语序列进行蒙特卡洛采样生成完成的句子。然后将句子送入判别器计算reward。
+- 根据得到的reward进行策略梯度下降优化模型。
+
+## 7.5 GAN在其他领域的应用
+
+### 7.5.1 数据增广
+
+ GAN的良好生成特性近年来也开始被用于数据增广。以行人重识别为例,有许多GAN用于数据增广的工作[1-4]。行人重识别问题一个难点在于不同摄像头下拍摄的人物环境,角度差别非常大,导致存在较大的Domain gap。因此,可以考虑使用GAN来产生不同摄像头下的数据进行数据增广。以论文[1]为例,本篇paper提出了一个cycleGAN用于数据增广的方法。具体模型结构如下:
+
+
+
+ 对于每一对摄像头都训练一个cycleGAN,这样就可以实现将一个摄像头下的数据转换成另一个摄像头下的数据,但是内容(人物)保持不变。
+
+### 7.5.2 图像超分辨与图像补全
+
+ 图像超分辨与补全均可以作为图像翻译问题,该类问题的处理办法也大都是训练一个端到端的网络,输入是原始图片,输出是超分辨率后的图片,或者是补全后的图片。文献[5]利用GAN作为判别器,使得超分辨率模型输出的图片更加清晰,更符合人眼主管感受。日本早稻田大学研究人员[6]提出一种全局+局部一致性的GAN实现图像补全,使得修复后的图像不仅细节清晰,且具有整体一致性。
+
+### 7.5.3 语音领域
+
+ 相比于图像领域遍地开花,GAN在语音领域则应用相对少了很多。这里零碎的找一些GAN在语音领域进行应用的例子作为介绍。文献[7]提出了一种音频去噪的SEGAN,缓解了传统方法支持噪声种类稀少,泛化能力不强的问题。Donahue利用GAN进行语音增强,提升了ASR系统的识别率。
+
+## 参考文献
+
+[1] Zheng Z , Zheng L , Yang Y . Unlabeled Samples Generated by GAN Improve the Person Re-identification Baseline in Vitro[C]// 2017 IEEE International Conference on Computer Vision (ICCV). IEEE Computer Society, 2017.
+
+[2] Zhong Z , Zheng L , Zheng Z , et al. Camera Style Adaptation for Person Re-identification[J]. 2017.
+
+[3] Deng W , Zheng L , Ye Q , et al. Image-Image Domain Adaptation with Preserved Self-Similarity and Domain-Dissimilarity for Person Re-identification[J]. 2017.
+
+[4] Wei L , Zhang S , Gao W , et al. Person Transfer GAN to Bridge Domain Gap for Person Re-Identification[J]. CVPR, 2017.
+
+[5] Ledig C , Theis L , Huszar F , et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network[J]. CVPR, 2016.
+
+[6] Iizuka S , Simo-Serra E , Ishikawa H . Globally and locally consistent image completion[J]. ACM Transactions on Graphics, 2017, 36(4):1-14.
+
+[7] Pascual S , Bonafonte A , Serrà, Joan. SEGAN: Speech Enhancement Generative Adversarial Network[J]. 2017.
+
+[8] Donahue C , Li B , Prabhavalkar R . Exploring Speech Enhancement with Generative Adversarial Networks for Robust Speech Recognition[J]. 2017.
+
+
+
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/ch7.pdf" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/ch7.pdf"
new file mode 100644
index 00000000..dc565cbe
Binary files /dev/null and "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/ch7.pdf" differ
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/7.1-gan_structure.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/7.1-gan_structure.png"
old mode 100644
new mode 100755
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/7.1.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/7.1.png"
new file mode 100644
index 00000000..54dc08bd
Binary files /dev/null and "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/7.1.png" differ
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/7.4.3-2.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/7.4.3-2.png"
new file mode 100644
index 00000000..d07fbf23
Binary files /dev/null and "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/7.4.3-2.png" differ
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/7.4.3.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/7.4.3.png"
new file mode 100644
index 00000000..7d88f093
Binary files /dev/null and "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/7.4.3.png" differ
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/Boundary_map.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/Boundary_map.png"
old mode 100644
new mode 100755
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/CGAN-ACGAN.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/CGAN-ACGAN.png"
new file mode 100644
index 00000000..eaf636d1
Binary files /dev/null and "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/CGAN-ACGAN.png" differ
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/CGAN\347\275\221\347\273\234\347\273\223\346\236\204.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/CGAN\347\275\221\347\273\234\347\273\223\346\236\204.png"
old mode 100644
new mode 100755
index 3b1633e7..07059a10
Binary files "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/CGAN\347\275\221\347\273\234\347\273\223\346\236\204.png" and "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/CGAN\347\275\221\347\273\234\347\273\223\346\236\204.png" differ
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/CycleGAN\346\250\241\345\236\213\347\244\272\346\204\217\345\233\276.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/CycleGAN\346\250\241\345\236\213\347\244\272\346\204\217\345\233\276.png"
new file mode 100644
index 00000000..4af9d521
Binary files /dev/null and "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/CycleGAN\346\250\241\345\236\213\347\244\272\346\204\217\345\233\276.png" differ
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/CycleGAN\347\273\223\346\236\234\344\276\213\345\255\220.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/CycleGAN\347\273\223\346\236\234\344\276\213\345\255\220.png"
new file mode 100644
index 00000000..984f3177
Binary files /dev/null and "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/CycleGAN\347\273\223\346\236\234\344\276\213\345\255\220.png" differ
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/DCGAN\347\273\223\346\236\204\345\233\276.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/DCGAN\347\273\223\346\236\204\345\233\276.png"
new file mode 100644
index 00000000..9a14e9ca
Binary files /dev/null and "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/DCGAN\347\273\223\346\236\204\345\233\276.png" differ
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/Domain Adaption.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/Domain Adaption.png"
new file mode 100644
index 00000000..73d9074f
Binary files /dev/null and "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/Domain Adaption.png" differ
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/GAN Appl.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/GAN Appl.png"
new file mode 100644
index 00000000..a5d3618c
Binary files /dev/null and "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/GAN Appl.png" differ
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/GAN overview.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/GAN overview.png"
new file mode 100644
index 00000000..7b49e5ae
Binary files /dev/null and "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/GAN overview.png" differ
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/GAN-semi-Supervised.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/GAN-semi-Supervised.png"
new file mode 100644
index 00000000..69b5d2aa
Binary files /dev/null and "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/GAN-semi-Supervised.png" differ
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/GAN_ALL.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/GAN_ALL.png"
new file mode 100644
index 00000000..37e78ec0
Binary files /dev/null and "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/GAN_ALL.png" differ
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/GAN\347\273\223\346\236\204\345\257\271\346\257\224.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/GAN\347\273\223\346\236\204\345\257\271\346\257\224.png"
new file mode 100644
index 00000000..88edcc67
Binary files /dev/null and "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/GAN\347\273\223\346\236\204\345\257\271\346\257\224.png" differ
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/InfoGAN.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/InfoGAN.png"
new file mode 100644
index 00000000..85b38829
Binary files /dev/null and "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/InfoGAN.png" differ
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/LSGAN\344\272\244\345\217\211\347\206\265\344\270\216\346\234\200\345\260\217\344\272\214\344\271\230\346\215\237\345\244\261\345\257\271\346\257\224\345\233\276.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/LSGAN\344\272\244\345\217\211\347\206\265\344\270\216\346\234\200\345\260\217\344\272\214\344\271\230\346\215\237\345\244\261\345\257\271\346\257\224\345\233\276.png"
new file mode 100644
index 00000000..18c7fc63
Binary files /dev/null and "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/LSGAN\344\272\244\345\217\211\347\206\265\344\270\216\346\234\200\345\260\217\344\272\214\344\271\230\346\215\237\345\244\261\345\257\271\346\257\224\345\233\276.png" differ
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/MAD_GAN.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/MAD_GAN.png"
new file mode 100644
index 00000000..ff18d938
Binary files /dev/null and "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/MAD_GAN.png" differ
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/MRGAN.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/MRGAN.png"
new file mode 100644
index 00000000..88f6e391
Binary files /dev/null and "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/MRGAN.png" differ
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/StackGAN PGAN.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/StackGAN PGAN.png"
new file mode 100644
index 00000000..21af4bc2
Binary files /dev/null and "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/StackGAN PGAN.png" differ
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/Triple-GAN.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/Triple-GAN.png"
new file mode 100644
index 00000000..802aa77a
Binary files /dev/null and "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/Triple-GAN.png" differ
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/VAE.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/VAE.png"
new file mode 100644
index 00000000..5f8309da
Binary files /dev/null and "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/VAE.png" differ
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/VAEGAN.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/VAEGAN.png"
new file mode 100644
index 00000000..631ab5b2
Binary files /dev/null and "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/VAEGAN.png" differ
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/Wass\350\267\235\347\246\273\351\232\217\350\277\255\344\273\243\346\254\241\346\225\260\345\217\230\345\214\226.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/Wass\350\267\235\347\246\273\351\232\217\350\277\255\344\273\243\346\254\241\346\225\260\345\217\230\345\214\226.png"
new file mode 100644
index 00000000..a2205ddf
Binary files /dev/null and "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/Wass\350\267\235\347\246\273\351\232\217\350\277\255\344\273\243\346\254\241\346\225\260\345\217\230\345\214\226.png" differ
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/coupleGAN.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/coupleGAN.png"
new file mode 100644
index 00000000..9cf596fc
Binary files /dev/null and "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/coupleGAN.png" differ
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/cycleGAN\346\225\260\346\215\256\345\242\236\345\271\277.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/cycleGAN\346\225\260\346\215\256\345\242\236\345\271\277.png"
new file mode 100644
index 00000000..e1466e5d
Binary files /dev/null and "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/cycleGAN\346\225\260\346\215\256\345\242\236\345\271\277.png" differ
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/f-divergence.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/f-divergence.png"
new file mode 100644
index 00000000..90bcf81f
Binary files /dev/null and "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/f-divergence.png" differ
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/lsgan loss compare.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/lsgan loss compare.png"
new file mode 100644
index 00000000..73645287
Binary files /dev/null and "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/lsgan loss compare.png" differ
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/lsgan\345\206\263\347\255\226\351\235\242\347\244\272\346\204\217\345\233\276.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/lsgan\345\206\263\347\255\226\351\235\242\347\244\272\346\204\217\345\233\276.png"
new file mode 100644
index 00000000..70473b67
Binary files /dev/null and "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/lsgan\345\206\263\347\255\226\351\235\242\347\244\272\346\204\217\345\233\276.png" differ
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/mode_dropping.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/mode_dropping.png"
new file mode 100644
index 00000000..de9feadb
Binary files /dev/null and "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/mode_dropping.png" differ
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/model_collpsing.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/model_collpsing.png"
new file mode 100644
index 00000000..6900aaac
Binary files /dev/null and "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/model_collpsing.png" differ
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/mv_boxes.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/mv_boxes.png"
new file mode 100644
index 00000000..a4304930
Binary files /dev/null and "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/mv_boxes.png" differ
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/part1.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/part1.png"
new file mode 100644
index 00000000..4513bd92
Binary files /dev/null and "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/part1.png" differ
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/part2-3.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/part2-3.png"
new file mode 100644
index 00000000..b2a7909d
Binary files /dev/null and "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/part2-3.png" differ
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/part4.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/part4.png"
new file mode 100644
index 00000000..491244f6
Binary files /dev/null and "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/part4.png" differ
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/pix2pixHD_Loss.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/pix2pixHD_Loss.png"
old mode 100644
new mode 100755
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/pix2pixHD\347\275\221\347\273\234\347\273\223\346\236\204.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/pix2pixHD\347\275\221\347\273\234\347\273\223\346\236\204.png"
old mode 100644
new mode 100755
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/pix2pix_Loss.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/pix2pix_Loss.png"
old mode 100644
new mode 100755
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/pix2pix\346\250\241\345\236\213\347\244\272\346\204\217\345\233\276.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/pix2pix\346\250\241\345\236\213\347\244\272\346\204\217\345\233\276.png"
old mode 100644
new mode 100755
index 1d11362a..51d7b87c
Binary files "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/pix2pix\346\250\241\345\236\213\347\244\272\346\204\217\345\233\276.png" and "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/pix2pix\346\250\241\345\236\213\347\244\272\346\204\217\345\233\276.png" differ
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/pix2pix\347\273\223\346\236\234\347\244\272\344\276\213.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/pix2pix\347\273\223\346\236\234\347\244\272\344\276\213.png"
old mode 100644
new mode 100755
index 22763192..ae64d636
Binary files "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/pix2pix\347\273\223\346\236\234\347\244\272\344\276\213.png" and "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/pix2pix\347\273\223\346\236\234\347\244\272\344\276\213.png" differ
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/pix2pix\350\257\255\344\271\211\345\234\260\345\233\276L1loss\347\273\223\346\236\234.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/pix2pix\350\257\255\344\271\211\345\234\260\345\233\276L1loss\347\273\223\346\236\234.png"
old mode 100644
new mode 100755
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/pixCNN.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/pixCNN.png"
new file mode 100644
index 00000000..08829af1
Binary files /dev/null and "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/pixCNN.png" differ
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/pixRNN.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/pixRNN.png"
new file mode 100644
index 00000000..fe9d5b34
Binary files /dev/null and "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/pixRNN.png" differ
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/readme.md" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/readme.md"
deleted file mode 100644
index f099ebf1..00000000
--- "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/readme.md"
+++ /dev/null
@@ -1,2 +0,0 @@
-Add the corresponding chapter picture under img/ch*
-��img/ch*�����Ӷ�Ӧ�½�ͼƬ
\ No newline at end of file
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/seqGAN\346\250\241\345\236\213.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/seqGAN\346\250\241\345\236\213.png"
new file mode 100644
index 00000000..121c8009
Binary files /dev/null and "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/seqGAN\346\250\241\345\236\213.png" differ
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/starGAN\345\212\240\345\205\245mask\347\244\272\346\204\217\345\233\276.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/starGAN\345\212\240\345\205\245mask\347\244\272\346\204\217\345\233\276.png"
new file mode 100644
index 00000000..0cd5d1f4
Binary files /dev/null and "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/starGAN\345\212\240\345\205\245mask\347\244\272\346\204\217\345\233\276.png" differ
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/starGAN\346\250\241\345\236\213\347\273\223\346\236\204.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/starGAN\346\250\241\345\236\213\347\273\223\346\236\204.png"
new file mode 100644
index 00000000..22ad0222
Binary files /dev/null and "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/starGAN\346\250\241\345\236\213\347\273\223\346\236\204.png" differ
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/two_trans_diff_dis_wgan.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/two_trans_diff_dis_wgan.png"
new file mode 100644
index 00000000..c2f2a04e
Binary files /dev/null and "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/two_trans_diff_dis_wgan.png" differ
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/two_trans_wgan.jpeg" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/two_trans_wgan.jpeg"
new file mode 100644
index 00000000..87961767
Binary files /dev/null and "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/two_trans_wgan.jpeg" differ
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/upsample.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/upsample.png"
old mode 100644
new mode 100755
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/\350\257\255\344\271\211\347\274\226\350\276\221.png" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/img/ch7/\350\257\255\344\271\211\347\274\226\350\276\221.png"
old mode 100644
new mode 100755
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/modify_log.txt" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/modify_log.txt"
deleted file mode 100644
index c5e0e582..00000000
--- "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/modify_log.txt"
+++ /dev/null
@@ -1,20 +0,0 @@
-该文件用来记录修改日志:
-<----shw2018-2018-10-25---->
-1. 新增章节markdown文件
-
-<----shw2018-2018-10-28---->
-1. 修改错误内容和格式
-2. 修改图片路径
-
-<----shw2018-2018-10-31---->
-1. 新增第九章文件夹,里面包括:
-img---->用来放对应章节图片,例如路径./img/ch9/ch_*
-readme.md---->章节维护贡献者信息
-modify_log---->用来记录修改日志
-第 * 章_xxx.md---->对应章节markdown文件
-第 * 章_xxx.pdf---->对应章节生成pdf文件,便于阅读
-其他---->待增加
-2. 修改readme内容
-3. 修改modify内容
-4. 修改章节内容,图片路径等
-
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/readme.md" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/readme.md"
index 5e5d42b4..985dccce 100644
--- "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/readme.md"
+++ "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/readme.md"
@@ -1,13 +1,22 @@
###########################################################
-### 深度学习500问-第 * 章 xxx
+### 深度学习500问-第 7 章 xxx
**负责人(排名不分先后):**
-牛津大学博士生-程泽华
-中科院研究生-郭晓锋
+xxx研究生-xxx(xxx)
+xxx博士生-xxx
+xxx-xxx
+郭晓锋-中科院-爱奇艺
**贡献者(排名不分先后):**
内容贡献者可自加信息
-###########################################################
+郭晓锋-中科院-爱奇艺
+
+
+
+Add the corresponding chapter picture under img/ch*
+在img/ch*下添加对应章节图片
+
+###########################################################
\ No newline at end of file
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/ref.bib" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/ref.bib"
deleted file mode 100644
index 86d0508a..00000000
--- "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/ref.bib"
+++ /dev/null
@@ -1,66 +0,0 @@
-@article{arjovsky2017towards,
- title={Towards principled methods for training generative adversarial networks},
- author={Arjovsky, Martin and Bottou, L{\'e}on},
- journal={arXiv preprint arXiv:1701.04862},
- year={2017}
-}
-@inproceedings{nowozin2016f,
- title={f-gan: Training generative neural samplers using variational divergence minimization},
- author={Nowozin, Sebastian and Cseke, Botond and Tomioka, Ryota},
- booktitle={Advances in Neural Information Processing Systems},
- pages={271--279},
- year={2016}
-}
-@article{choi2017stargan,
- title={Stargan: Unified generative adversarial networks for multi-domain image-to-image translation},
- author={Choi, Yunjey and Choi, Minje and Kim, Munyoung and Ha, Jung-Woo and Kim, Sunghun and Choo, Jaegul},
- journal={arXiv preprint},
- volume={1711},
- year={2017}
-}
-@article{isola2017image,
- title={Image-to-image translation with conditional adversarial networks},
- author={Isola, Phillip and Zhu, Jun-Yan and Zhou, Tinghui and Efros, Alexei A},
- journal={arXiv preprint},
- year={2017}
-}
-@article{radford2015unsupervised,
- title={Unsupervised representation learning with deep convolutional generative adversarial networks},
- author={Radford, Alec and Metz, Luke and Chintala, Soumith},
- journal={arXiv preprint arXiv:1511.06434},
- year={2015}
-}
-@inproceedings{long2015fully,
- title={Fully convolutional networks for semantic segmentation},
- author={Long, Jonathan and Shelhamer, Evan and Darrell, Trevor},
- booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
- pages={3431--3440},
- year={2015}
-}
-@article{murez2017image,
- title={Image to image translation for domain adaptation},
- author={Murez, Zak and Kolouri, Soheil and Kriegman, David and Ramamoorthi, Ravi and Kim, Kyungnam},
- journal={arXiv preprint arXiv:1712.00479},
- volume={13},
- year={2017}
-}
-@inproceedings{yi2017dualgan,
- title={DualGAN: Unsupervised Dual Learning for Image-to-Image Translation.},
- author={Yi, Zili and Hao (Richard) Zhang and Tan, Ping and Gong, Minglun},
- booktitle={ICCV},
- pages={2868--2876},
- year={2017}
-}
-@inproceedings{wu2018wasserstein,
- title={Wasserstein Divergence for GANs},
- author={Wu, Jiqing and Huang, Zhiwu and Thoma, Janine and Acharya, Dinesh and Van Gool, Luc},
- booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
- pages={653--668},
- year={2018}
-}
-@article{zhu2017unpaired,
- title={Unpaired image-to-image translation using cycle-consistent adversarial networks},
- author={Zhu, Jun-Yan and Park, Taesung and Isola, Phillip and Efros, Alexei A},
- journal={arXiv preprint},
- year={2017}
-}
\ No newline at end of file
diff --git "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/\347\254\254\344\270\203\347\253\240_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN).md" "b/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/\347\254\254\344\270\203\347\253\240_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN).md"
deleted file mode 100644
index 11783080..00000000
--- "a/ch07_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN)/\347\254\254\344\270\203\347\253\240_\347\224\237\346\210\220\345\257\271\346\212\227\347\275\221\347\273\234(GAN).md"
+++ /dev/null
@@ -1,403 +0,0 @@
-
-#
-# 7.1 什么是生成对抗网络
-## GAN的通俗化介绍
-
-生成对抗网络(GAN, Generative adversarial network)自从2014年被Ian Goodfellow提出以来,掀起来了一股研究热潮。GAN由生成器和判别器组成,生成器负责生成样本,判别器负责判断生成器生成的样本是否为真。生成器要尽可能迷惑判别器,而判别器要尽可能区分生成器生成的样本和真实样本。
-
-在GAN的原作[1]中,作者将生成器比喻为印假钞票的犯罪分子,判别器则类比为警察。犯罪分子努力让钞票看起来逼真,警察则不断提升对于假钞的辨识能力。二者互相博弈,随着时间的进行,都会越来越强。
-
-## GAN的形式化表达
-上述例子只是简要介绍了一下GAN的思想,下面对于GAN做一个形式化的,更加具体的定义。通常情况下,无论是生成器还是判别器,我们都可以用神经网络来实现。那么,我们可以把通俗化的定义用下面这个模型来表示:
-
-
-上述模型左边是生成器G,其输入是$z$,对于原始的GAN,$z$是由高斯分布随机采样得到的噪声。噪声$z$通过生成器得到了生成的假样本。
-
-生成的假样本与真实样本放到一起,被随机抽取送入到判别器D,由判别器去区分输入的样本是生成的假样本还是真实的样本。整个过程简单明了,生成对抗网络中的“生成对抗”主要体现在生成器和判别器之间的对抗。
-
-## GAN的目标函数
-对于上述神经网络模型,如果想要学习其参数,首先需要一个目标函数。GAN的目标函数定义如下:
-
-$$\mathop {\min }\limits_G \mathop {\max }\limits_D V(D,G) = {{\rm E}_{x\sim{p_{data}}(x)}}[\log D(x)] + {{\rm E}_{z\sim{p_z}(z)}}[\log (1 - D(G(z)))]$$
-
-这个目标函数可以分为两个部分来理解:
-
-判别器的优化通过$\mathop {\max}\limits_D V(D,G)$实现,$V(D,G)$为判别器的目标函数,其第一项${{\rm E}_{x\sim{p_{data}}(x)}}[\log D(x)]$表示对于从真实数据分布 中采用的样本 ,其被判别器判定为真实样本概率的数学期望。对于真实数据分布 中采样的样本,其预测为正样本的概率当然是越接近1越好。因此希望最大化这一项。第二项${{\rm E}_{z\sim{p_z}(z)}}[\log (1 - D(G(z)))]$表示:对于从噪声P_z(z)分布当中采样得到的样本经过生成器生成之后得到的生成图片,然后送入判别器,其预测概率的负对数的期望,这个值自然是越大越好,这个值越大, 越接近0,也就代表判别器越好。
-
-生成器的优化通过$\mathop {\min }\limits_G({\mathop {\max }\limits_D V(D,G)})$实现。注意,生成器的目标不是$\mathop {\min }\limits_GV(D,G)$,即生成器**不是最小化判别器的目标函数**,生成器最小化的是**判别器目标函数的最大值**,判别器目标函数的最大值代表的是真实数据分布与生成数据分布的JS散度(详情可以参阅附录的推导),JS散度可以度量分布的相似性,两个分布越接近,JS散度越小。
-
-
-## GAN的目标函数和交叉熵
-判别器目标函数写成离散形式即为$$V(D,G)=-\frac{1}{m}\sum_{i=1}^{i=m}logD(x^i)-\frac{1}{m}\sum_{i=1}^{i=m}log(1-D(\tilde{x}^i))$$
-可以看出,这个目标函数和交叉熵是一致的,即**判别器的目标是最小化交叉熵损失,生成器的目标是最小化生成数据分布和真实数据分布的JS散度**
-
-
--------------------
-[1]: Goodfellow, Ian, et al. "Generative adversarial nets." Advances in neural information processing systems. 2014.
-
-# 7.2 什么是图像翻译
-GAN作为一种强有力的生成模型,其应用十分广泛。最为常见的应用就是图像翻译。所谓图像翻译,指从一副图像到另一副图像的转换。可以类比机器翻译,一种语言转换为另一种语言。常见的图像翻译任务有:
-- 图像去噪
-- 图像超分辨
-- 图像补全
-- 风格迁移
-- ...
-
-本节将介绍一个经典的图像翻译网络及其改进。
-# 7.2.1 pix2pix�:图像翻译
-在这篇paper里面,作者提出的框架十分简洁优雅(好用的算法总是简洁优雅的)。相比以往算法的大量专家知识,手工复杂的loss。这篇paper非常粗暴,使用CGAN处理了一系列的转换问题。下面是一些转换示例:
-
-
-上面展示了许多有趣的结果,比如分割图$\longrightarrow$街景图,边缘图$\longrightarrow$真实图。对于第一次看到的时候还是很惊艳的,那么这个是怎么做到的呢?我们可以设想一下,如果是我们,我们自己会如何设计这个网络。
-
-## 如何做图像翻译?
-最直接的想法就是,设计一个CNN网络,直接建立输入-输出的映射,就像图像去噪问题一样。可是对于上面的问题,这样做会带来一个问题。**生成图像质量不清晰。**
-
-拿左上角的分割图$\longrightarrow$街景图为例,语义分割图的每个标签比如“汽车”可能对应不同样式,颜色的汽车。那么模型学习到的会是所有不同汽车的评均,这样会造成模糊。
-
-
-## 如何解决模糊呢?
-这里作者想了一个办法,即加入GAN的Loss去惩罚模型。GAN相比于传统生成式模型可以较好的生成高分辨率图片。思路也很简单,在上述直观想法的基础上加入一个判别器,判断输入图片是否是真实样本。模型示意图如下:
-
-
-
-上图模型和CGAN有所不同,但它是一个CGAN,只不过输入只有一个,这个输入就是条件信息。原始的CGAN需要输入随机噪声,以及条件。这里之所有没有输入噪声信息,是因为在实际实验中,如果输入噪声和条件,噪声往往被淹没在条件C当中,所以这里直接省去了。
-
-## 图像翻译的tricks
-从上面两点可以得到最终的Loss由两部分构成:
-- 输出和标签信息的L1 Loss。
-- GAN Loss
-- 测试也使用Dropout,以使输出多样化
-
-
-采用L1 Loss而不是L2 Loss的理由很简单,L1 Loss相比于L2 Loss保边缘(L2 Loss基于高斯先验,L1 Loss基于拉普拉斯先验)。
-
-GAN Loss为LSGAN的最小二乘Loss,并使用PatchGAN(进一步保证生成图像的清晰度)。PatchGAN将图像换分成很多个Patch,并对每一个Patch使用判别器进行判别(实际代码实现有更取巧的办法),将所有Patch的Loss求平均作为最终的Loss。
-
-
-
-# 7.2.2 pix2pixHD:高分辨率图像生成
-这篇paper作为pix2pix改进版本,如其名字一样,主要是可以产生高分辨率的图像。具体来说,作者的贡献主要在以下两个方面:
-- 使用多尺度的生成器以及判别器等方式从而生成高分辨率图像。
-- 使用了一种非常巧妙的方式,实现了对于同一个输入,产生不同的输出。并且实现了交互式的语义编辑方式
-## 如何生成高分辨率图像
-为了生成高分辨率图像,作者主要从三个层面做了改进:
-- 模型结构
-- Loss设计
-- 使用Instance-map的图像进行训练。
-### 模型结构
-
-生成器由两部分组成,G1和G2,其中G2又被割裂成两个部分。G1和pix2pix的生成器没有差别,就是一个end2end的U-Net结构。G2的左半部分提取特征,并和G1的输出层的前一层特征进行相加融合信息,把融合后的信息送入G2的后半部分输出高分辨率图像。
-
-判别器使用多尺度判别器,在三个不同的尺度上进行判别并对结果取平均。判别的三个尺度为:原图,原图的1/2降采样,原图的1/4降采样。显然,越粗糙的尺度感受野越大,越关注全局一致性。
-
-生成器和判别器均使用多尺度结构实现高分辨率重建,思路和PGGAN类似,但实际做法差别比较大。
-
-### Loss设计
-这里的Loss由三部分组成:
-- GAN loss:和pix2pix一样,使用PatchGAN。
-- Feature matching loss:将生成的样本和Ground truth分别送入判别器提取特征,然后对特征做Element-wise loss
-- Content loss:将生成的样本和Ground truth分别送入VGG16提取特征,然后对特征做Element-wise loss
-
-
-使用Feature matching loss和Content loss计算特征的loss,而不是计算生成样本和Ground truth的MSE,主要在于MSE会造成生成的图像过度平滑,缺乏细节。Feature matching loss和Content loss只保证内容一致,细节则由GAN去学习。
-### 使用Instance-map的图像进行训练
-pix2pix采用语义分割的结果进行训练,可是语义分割结果没有对同类物体进行区分,导致多个同一类物体排列在一起的时候出现模糊,这在街景图中尤为常见。在这里,作者使用个体分割(Instance-level segmention)的结果来进行训练,因为个体分割的结果提供了同一类物体的边界信息。具体做法如下:
-- 根据个体分割的结果求出Boundary map
-- 将Boundary map与输入的语义标签concatnate到一起作为输入
-Boundary map求法很简单,直接遍历每一个像素,判断其4邻域像素所属语义类别信息,如果有不同,则置为1。下面是一个示例:
-
-### 语义编辑
-不同于pix2pix实现生成多样性的方法(使用Dropout),这里采用了一个非常巧妙的办法,即学习一个条件(Condition)作为条件GAN的输入,不同的输入条件就得到了不同的输出,从而实现了多样化的输出,而且还是可编辑的。具体做法如下:
-
-- 首先训练一个编码器
-- 利用编码器提取原始图片的特征,然后根据Labels信息进行Average pooling,得到特征(上图的Features)。这个Features的每一类像素的值都代表了这类标签的信息。
-- 如果输入图像有足够的多,那么Features的每一类像素的值就代表了这类物体的先验分布。
-- 对所有输入的训练图像通过编码器提取特征,然后进行K-means聚类,得到K个聚类中心,以K个聚类中心代表不同的颜色,纹理等信息。
-- 实际生成图像时,除了输入语义标签信息,还要从K个聚类中心随机选择一个,即选择一个颜色/纹理风格
-
-这个方法总的来说非常巧妙,通过学习数据的隐变量达到控制图像颜色纹理风格信息。
-
-### 总结
-作者主要的贡献在于:
-- 提出了生成高分辨率图像的多尺度网络结构,包括生成器,判别器
-- 提出了Feature loss和VGG loss提升图像的分辨率
-- 通过学习隐变量达到控制图像颜色,纹理风格信息
-- 通过Boundary map提升重叠物体的清晰度
-
-可以看出,这篇paper除了第三点,都是针对性的解决高分辨率图像生成的问题的。可是本篇工作只是生成了高分辨率的图像,那对于视频呢?接下来会介绍Vid2Vid,这篇paper站在pix2pixHD的基础上,继续做了许多拓展,特别是针对视频前后帧不一致的问题做了许多优化。
-
-
-# 7.2.3 vid2vid:高分辨率视频生成
-待续。。。。
-
-
-## 7.1 GAN的「生成」的本质是什么?
-GAN的形式是:两个网络,G(Generator)和D(Discriminator)。Generator是一个生成图片的网络,它接收一个随机的噪声z,记做G(z)。Discriminator是一个判别网络,判别一张图片是不是“真实的”。它的输入是x,x代表一张图片,输出D(x)代表x为真实图片的概率,如果为1,就代表100%是真实的图片,而输出为0,就代表不可能是真实的图片。
-
-GAN*生成*能力是*学习分布*,引入的latent variable的noise使习得的概率分布进行偏移。因此在训练GAN的时候,latent variable**不能**引入均匀分布(uniform distribution),因为均匀分布的数据的引入并不会改变概率分布。
-
-## 7.2 GAN能做数据增广吗?
-GAN能够从一个模型引入一个随机数之后「生成」无限的output,用GAN来做数据增广似乎很有吸引力并且是一个极清晰的一个insight。然而,纵观整个GAN的训练过程,Generator习得分布再引入一个Distribution(Gaussian或其他)的噪声以「骗过」Discriminator,并且无论是KL Divergence或是Wasserstein Divergence,本质还是信息衡量的手段(在本章中其余部分介绍),能「骗过」Discriminator的Generator一定是能在引入一个Distribution的噪声的情况下最好的结合已有信息。
-
-训练好的GAN应该能够很好的使用已有的数据的信息(特征或分布),现在问题来了,这些信息本来就包含在数据里面,有必要把信息丢到Generator学习使得的结果加上噪声作为训练模型的输入吗?
-
-## 7.3 VAE与GAN有什么不同?
-1. VAE可以直接用在离散型数据。
-2. VAE整个训练流程只靠一个假设的loss函数和KL Divergence逼近真实分布。GAN没有假设单个loss函数, 而是让判别器D和生成器G互相博弈,以期得到Nash Equilibrium。
-
-## 7.4 有哪些优秀的GAN?
-
-### 7.4.1 DCGAN
-
-[DCGAN](http://arxiv.org/abs/1511.06434)是GAN较为早期的「生成」效果最好的GAN了,很多人用DCGAN的简单、有效的生成能力做了很多很皮的工作,比如[GAN生成�二次元萌妹](https://blog.csdn.net/liuxiao214/article/details/74502975)之类。
-关于DCGAN主要集中讨论以下问题:
-
-1. DCGAN�的contribution?
-2. DCGAN实操上有什么问题?
-
-效果好个人主要认为是引入了卷积并且给了一个非常�优雅的结构,DCGAN的Generator和Discriminator几乎是**对称的**,而之后很多研究都遵从了这个对称结构,如此看来学界对这种对称架构有极大的肯定。完全使用了卷积层代替全链接层,没有pooling和upsample。其中upsample是将low resolution到high resolution的方法,而DCGAN用��卷积的逆运算来完成low resolution到high resolution的操作,这简单的替换为什么成为提升GAN�稳定性的原因?
-
-
-�图中是Upsample的原理图,十分的直观,宛如�低分屏换高分屏。然而Upsample和逆卷积最大的不一样是Upsample其实只能放一样的颜色来填充,而逆卷积它是个求值的过程,也就是它�要算出一个具体值来,可能是一样的也可能是不一样的——如此,孰优孰劣高下立判。
-
-DCGAN提出了其生成的特征具有向量的计算特性。
-
-[DCGAN Keras实现](https://github.com/jacobgil/keras-dcgan)
-### 7.4.2 WGAN/WGAN-GP
-
-WGAN及其延伸是被讨论的最多的部分,原文连发两文,第一篇(Towards principled methods for training generative adversarial networks)非常solid的提了一堆的数学,一作Arjovsky克朗所的数学能力果然一个打十几个。后来给了第二篇Wasserstein GAN,可以说直接给结果了,和第一篇相比,第二篇更加好接受。
-
-然而Wasserstein Divergence真正牛逼的地方在于,几乎对所有的GAN,Wasserstein Divergence可以直接秒掉KL Divergence。那么这个时候就有个问题呼之欲出了:
-
-**KL/JS Divergence为什么不好用?Wasserstein Divergence牛逼在哪里?**
-
-**KL Divergence**是两个概率分布P和Q差别的**非对称性**的度量。KL Divergence是用来度量使用基于Q的编码来编码来自P的样本平均所需的额外的位元数(即分布的平移量)。 而**JS Divergence**是KL Divergence的升级版,解决的是**对称性**的问题。即:JS Divergence是对称的。并且由于KL Divergence不具有很好的对称性,将KL Divergence考虑成距离可能是站不住脚的,并且可以由KL Divergence的公式中看出来,平移量$\to 0$的时候,KL Divergence直接炸了。
-
-KL Divergence:
-$$D_{KL}(P||Q)=-\sum_{x\in X}P(x) log\frac{1}{P(x)}+\sum_{x\in X}p(x)log\frac{1}{Q(x)}=\sum_{x\in X}p(x)log\frac{P(x)}{Q(x)}$$
-
-JS Divergence:
-
-$$JS(P_1||P_2)=\frac{1}{2}KL(P_1||\frac{P_1+P_2}{2})$$
-
-**Wasserstein Divergence**:如果两个分配P,Q离得很远,完全没有重叠的时候,KL Divergence毫无意义,而此时JS Divergence值是一个常数。这使得在这个时候,梯度直接消失了。
-
-**WGAN从结果上看,对GAN的改进有哪些?**
-
-1. 判别器最后一层去掉sigmoid
-2. 生成器和判别器的loss不取log
-3. 对更新后的权重强制截断到一定范围内,比如[-0.01,0.01],以满足lipschitz连续性条件。
-4. 论文中也推荐使用SGD,RMSprop等优化器,不要基于使用动量的优化算法,比如adam。
-
-然而,由于D和G其实是各自有一个loss的,G和D是可以**用不同的优化器**的。个人认为Best Practice是G用SGD或RMSprop,而D用Adam。
-
-很期待未来有专门针对寻找均衡态的优化方法。
-
-**WGAN-GP的改进有哪些?**
-
-**如何理解Wasserstein距离?**
-Wasserstein距离与optimal transport有一些关系,并且从数学上想很好的理解需要一定的测度论的知识。
-
-### 7.4.3 condition GAN
-条件生成对抗网络(CGAN, Conditional Generative Adversarial Networks)作为一个GAN的改进,其一定程度上解决了GAN生成结果的不确定性。如果在Mnist数据集上训练原始GAN,GAN生成的图像是完全不确定的,具体生成的是数字1,还是2,还是几,根本不可控。为了让生成的数字可控,我们可以把数据集做一个切分,把数字0~9的数据集分别拆分开训练9个模型,不过这样太麻烦了,也不现实。因为数据集拆分不仅仅是分类麻烦,更主要在于,每一个类别的样本少,拿去训练GAN很有可能导致欠拟合。因此,CGAN就应运而生了。我们先看一下CGAN的网络结构:
-
-从网络结构图可以看到,对于生成器Generator,其输入不仅仅是随机噪声的采样z,还有欲生成图像的标签信息。比如对于mnist数据生成,就是一个one-hot向量,某一维度为1则表示生成某个数字的图片。同样地,判别器的输入也包括样本的标签。这样就使得判别器和生成器可以学习到样本和标签之间的联系。Loss如下:
-$$\mathop {\min }\limits_G \mathop {\max }\limits_D V(D,G) = {{\rm E}_{x\sim{p_{data}}(x)}}[\log D(x|y)] + {{\rm E}_{z\sim{p_z}(z)}}[\log (1 - D(G(z|y)))]$$
-Loss设计和原始GAN基本一致,只不过生成器,判别器的输入数据是一个条件分布。在具体编程实现时只需要对随机噪声采样z和输入条件y做一个级联即可。
-### 7.4.4 InfoGAN
-通过最大化互信息(c,c’)来生成同类别的样本。
-
-$$L^{infoGAN}_{D,Q}=L^{GAN}_D-\lambda L_1(c,c')$$
-$$L^{infoGAN}_{G}=L^{GAN}_G-\lambda L_1(c,c')$$
-
-### 7.4.5 CycleGAN
-
-**CycleGAN与DualGAN之间的区别**
-
-### 7.4.6 StarGAN
-目前Image-to-Image Translation做的最好的GAN。
-
-## 7.5 GAN训练有什么难点?
-由于GAN的收敛要求**两个网络(D&G)同时达到一个均衡**
-
-## 7.6 GAN与强化学习中的AC网络有何区别?
-强化学习中的AC网络也是Dual Network,似乎从某个角度上理解可以为一个GAN。但是GAN本身
-
-## 7.7 GAN的可创新的点
-GAN是一种半监督学习模型,对训练集不需要太多有标签的数据。我认为GAN用在Super Resolution、Inpainting、Image-to-Image Translation(俗称鬼畜变脸)也好,无非是以下三点:
-
-1. 更高效的无监督的利用卷积结构或者结合网络结构的特点�对特征进行**复用**。(如Image-to-Image Translation提取特征之后用loss量化特征及其share的信息以完成�整个特征复用过程)
-2. 一个高效的loss function来**量化变化**。
-3. 一个短平快的拟合分布的方法。(如WGAN对GAN的贡献等)
-
-当然还有一些非主流的方案,比如说研究latent space甚至如何优雅的加噪声,这类方案虽然很重要,但是囿于本人�想象力及实力不足,难以想到解决方案。
-
-## 7.8 如何训练GAN?
-判别器D在GAN训练中是比生成器G更强的网络
-
-Instance Norm比Batch Norm的效果要更好。
-
-使用逆卷积来生成图片会比用全连接层效果好,全连接层会有较多的噪点,逆卷积层效果清晰。
-
-## 7.9 GAN如何解决NLP问题
-
-GAN只适用于连续型数据的生成,对于离散型数据效果不佳,因此假如NLP方法直接应用的是character-wise的方案,Gradient based的GAN是无法将梯度Back propagation(BP)给生成网络的,因此从训练结果上看,GAN中G的表现长期被D压着打。
-## 7.10 Reference
-
-### DCGAN部分:
-* Radford, A., Metz, L., & Chintala, S. (2015). Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv preprint arXiv:1511.06434.
-* Long, J., Shelhamer, E., & Darrell, T. (2015). Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 3431-3440).
-* [可视化卷积操作](https://github.com/vdumoulin/conv_arithmetic)
-### WGAN部分:
-* Arjovsky, M., Chintala, S., & Bottou, L. (2017). Wasserstein gan. arXiv preprint arXiv:1701.07875.
-* Nowozin, S., Cseke, B., & Tomioka, R. (2016). f-gan: Training generative neural samplers using variational divergence minimization. In Advances in Neural Information Processing Systems (pp. 271-279).
-* Wu, J., Huang, Z., Thoma, J., Acharya, D., & Van Gool, L. (2018, September). Wasserstein Divergence for GANs. In Proceedings of the European Conference on Computer Vision (ECCV) (pp. 653-668).
-
-
-### Image2Image Translation
-* Isola P, Zhu JY, Zhou T, Efros AA. Image-to-image translation with conditional adversarial networks. arXiv preprint. 2017 Jul 21.
-* Zhu, J. Y., Park, T., Isola, P., & Efros, A. A. (2017). Unpaired image-to-image translation using cycle-consistent adversarial networks. arXiv preprint.(CycleGAN)
-* Choi, Y., Choi, M., Kim, M., Ha, J. W., Kim, S., & Choo, J. (2017). Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. arXiv preprint, 1711.
-* Murez, Z., Kolouri, S., Kriegman, D., Ramamoorthi, R., & Kim, K. (2017). Image to image translation for domain adaptation. arXiv preprint arXiv:1712.00479, 13.
-
-### GAN的训练
-* Arjovsky, M., & Bottou, L. (2017). Towards principled methods for training generative adversarial networks. arXiv preprint arXiv:1701.04862.
-
-
-
-
-# 生成模型和判别模型
-https://blog.csdn.net/u010358304/article/details/79748153
-原文:https://blog.csdn.net/u010089444/article/details/78946039
-
-# 生成模型和判别模型对比
-https://blog.csdn.net/love666666shen/article/details/75522489
-
-
-# 直观理解GAN的博弈过程
-https://blog.csdn.net/u010089444/article/details/78946039
-
-# GAN原理
-1.GAN的原理:
-
-GAN的主要灵感来源于博弈论中零和博弈的思想,应用到深度学习神经网络上来说,就是通过生成网络G(Generator)和判别网络D(Discriminator)不断博弈,进而使G学习到数据的分布,如果用到图片生成上,则训练完成后,G可以从一段随机数中生成逼真的图像。G, D的主要功能是:
-
-● G是一个生成式的网络,它接收一个随机的噪声z(随机数),通过这个噪声生成图像
-
-● D是一个判别网络,判别一张图片是不是“真实的”。它的输入参数是x,x代表一张图片,输出D(x)代表x为真实图片的概率,如果为1,就代表100%是真实的图片,而输出为0,就代表不可能是真实的图片
-
-训练过程中,生成网络G的目标就是尽量生成真实的图片去欺骗判别网络D。而D的目标就是尽量辨别出G生成的假图像和真实的图像。这样,G和D构成了一个动态的“博弈过程”,最终的平衡点即纳什均衡点.
----------------------
-作者:山水之间2018
-来源:CSDN
-原文:https://blog.csdn.net/Gavinmiaoc/article/details/79947877
-
-# GAN的特点
-2. GAN的特点:
-
-● 相比较传统的模型,他存在两个不同的网络,而不是单一的网络,并且训练方式采用的是对抗训练方式
-
-● GAN中G的梯度更新信息来自判别器D,而不是来自数据样本
-
-# GAN优缺点?
-
-3. GAN 的优点:
-
-(以下部分摘自ian goodfellow 在Quora的问答)
-
-● GAN是一种生成式模型,相比较其他生成模型(玻尔兹曼机和GSNs)只用到了反向传播,而不需要复杂的马尔科夫链
-
-● 相比其他所有模型, GAN可以产生更加清晰,真实的样本
-
-● GAN采用的是一种无监督的学习方式训练,可以被广泛用在无监督学习和半监督学习领域
-
-● 相比于变分自编码器, GANs没有引入任何决定性偏置( deterministic bias),变分方法引入决定性偏置,因为他们优化对数似然的下界,而不是似然度本身,这看起来导致了VAEs生成的实例比GANs更模糊
-
-● 相比VAE, GANs没有变分下界,如果鉴别器训练良好,那么生成器可以完美的学习到训练样本的分布.换句话说,GANs是渐进一致的,但是VAE是有偏差的
-
-● GAN应用到一些场景上,比如图片风格迁移,超分辨率,图像补全,去噪,避免了损失函数设计的困难,不管三七二十一,只要有一个的基准,直接上判别器,剩下的就交给对抗训练了。
-
-
-4. GAN的缺点:
-
-● 训练GAN需要达到纳什均衡,有时候可以用梯度下降法做到,有时候做不到.我们还没有找到很好的达到纳什均衡的方法,所以训练GAN相比VAE或者PixelRNN是不稳定的,但我认为在实践中它还是比训练玻尔兹曼机稳定的多
-
-● GAN不适合处理离散形式的数据,比如文本
-
-● GAN存在训练不稳定、梯度消失、模式崩溃的问题(目前已解决)
----------------------
-作者:山水之间2018
-来源:CSDN
-原文:https://blog.csdn.net/Gavinmiaoc/article/details/79947877
-版权声明:本文为博主原创文章,转载请附上博文链接!
-
-# 模式崩溃(model collapse)原因
-一般出现在GAN训练不稳定的时候,具体表现为生成出来的结果非常差,但是即使加长训练时间后也无法得到很好的改善。
-
-具体原因可以解释如下:GAN采用的是对抗训练的方式,G的梯度更新来自D,所以G生成的好不好,得看D怎么说。具体就是G生成一个样本,交给D去评判,D会输出生成的假样本是真样本的概率(0-1),相当于告诉G生成的样本有多大的真实性,G就会根据这个反馈不断改善自己,提高D输出的概率值。但是如果某一次G生成的样本可能并不是很真实,但是D给出了正确的评价,或者是G生成的结果中一些特征得到了D的认可,这时候G就会认为我输出的正确的,那么接下来我就这样输出肯定D还会给出比较高的评价,实际上G生成的并不怎么样,但是他们两个就这样自我欺骗下去了,导致最终生成结果缺失一些信息,特征不全。
----------------------
-作者:山水之间2018
-来源:CSDN
-原文:https://blog.csdn.net/Gavinmiaoc/article/details/79947877
-版权声明:本文为博主原创文章,转载请附上博文链接!
-
-# 为什么GAN不适合处理文本数据
-1. 文本数据相比较图片数据来说是离散的,因为对于文本来说,通常需要将一个词映射为一个高维的向量,最终预测的输出是一个one-hot向量,假设softmax的输出是(0.2, 0.3, 0.1,0.2,0.15,0.05)那么变为onehot是(0,1,0,0,0,0),如果softmax输出是(0.2, 0.25, 0.2, 0.1,0.15,0.1 ),one-hot仍然是(0, 1, 0, 0, 0, 0),所以对于生成器来说,G输出了不同的结果但是D给出了同样的判别结果,并不能将梯度更新信息很好的传递到G中去,所以D最终输出的判别没有意义。
-
-2. 另外就是GAN的损失函数是JS散度,JS散度不适合衡量不想交分布之间的距离。
-
-(WGAN虽然使用wassertein距离代替了JS散度,但是在生成文本上能力还是有限,GAN在生成文本上的应用有seq-GAN,和强化学习结合的产物)
----------------------
-作者:山水之间2018
-来源:CSDN
-原文:https://blog.csdn.net/Gavinmiaoc/article/details/79947877
-版权声明:本文为博主原创文章,转载请附上博文链接!
-
-# 训练GAN的一些技巧
-
-1. 输入规范化到(-1,1)之间,最后一层的激活函数使用tanh(BEGAN除外)
-
-2. 使用wassertein GAN的损失函数,
-
-3. 如果有标签数据的话,尽量使用标签,也有人提出使用反转标签效果很好,另外使用标签平滑,单边标签平滑或者双边标签平滑
-
-4. 使用mini-batch norm, 如果不用batch norm 可以使用instance norm 或者weight norm
-
-5. 避免使用RELU和pooling层,减少稀疏梯度的可能性,可以使用leakrelu激活函数
-
-6. 优化器尽量选择ADAM,学习率不要设置太大,初始1e-4可以参考,另外可以随着训练进行不断缩小学习率,
-
-7. 给D的网络层增加高斯噪声,相当于是一种正则
----------------------
-作者:山水之间2018
-来源:CSDN
-原文:https://blog.csdn.net/Gavinmiaoc/article/details/79947877
-版权声明:本文为博主原创文章,转载请附上博文链接!
-
-
-
-# 实例理解GAN实现过程
-https://blog.csdn.net/sxf1061926959/article/details/54630462
-
-# DCGAN、WGAN、WGAN-GP、LSGAN、BEGAN原理总结及对比
-https://blog.csdn.net/qq_25737169/article/details/78857788
-
-## DCGAN
-### DCGAN原理理解?
-### 优缺点?
-
-# GAN对噪声z的分布有要求吗?常用哪些分布?
-一般没有特别要求,常用有高斯分布、均匀分布。噪声的维数至少要达到数据流形的内在维数,才能产生足够的diversity,mnist大概是6维,CelebA大概是20维(参考:https://zhuanlan.zhihu.com/p/26528060)
-https://blog.csdn.net/witnessai1/article/details/78507065/
-
-# 现有GAN存在哪些关键属性缺失?
-http://www.elecfans.com/d/707141.html
-# 图解什么是GAN
-https://www.cnblogs.com/Darwin2000/p/6984253.html
-
-# GAN有哪些训练难点\原因及解决方案
-https://www.sohu.com/a/143961544_741733
-
-# 近年GAN有哪些突破口?
-https://baijiahao.baidu.com/s?id=1593092872607620265&wfr=spider&for=pc
diff --git "a/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/68747470733a2f2f6c656f6e6172646f617261756a6f73616e746f732e676974626f6f6b732e696f2f6172746966696369616c2d696e74656c6967656e63652f636f6e74.png" "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/68747470733a2f2f6c656f6e6172646f617261756a6f73616e746f732e676974626f6f6b732e696f2f6172746966696369616c2d696e74656c6967656e63652f636f6e74.png"
deleted file mode 100644
index 71a43bb5..00000000
Binary files "a/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/68747470733a2f2f6c656f6e6172646f617261756a6f73616e746f732e676974626f6f6b732e696f2f6172746966696369616c2d696e74656c6967656e63652f636f6e74.png" and /dev/null differ
diff --git "a/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/68747470733a2f2f6e6f74652e796f7564616f2e636f6d2f7977732f7075626c69632f7265736f757263652f636539303432353631643535333464386635373936303137.png" "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/68747470733a2f2f6e6f74652e796f7564616f2e636f6d2f7977732f7075626c69632f7265736f757263652f636539303432353631643535333464386635373936303137.png"
deleted file mode 100644
index a25a804c..00000000
Binary files "a/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/68747470733a2f2f6e6f74652e796f7564616f2e636f6d2f7977732f7075626c69632f7265736f757263652f636539303432353631643535333464386635373936303137.png" and /dev/null differ
diff --git "a/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.1.6.png" "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.1.6.png"
index 329ef069..acbbd3c4 100644
Binary files "a/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.1.6.png" and "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.1.6.png" differ
diff --git "a/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.2.1-1.png" "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.2.1-1.png"
new file mode 100644
index 00000000..84312cb0
Binary files /dev/null and "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.2.1-1.png" differ
diff --git "a/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.2.2-1.png" "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.2.2-1.png"
new file mode 100644
index 00000000..74a9a324
Binary files /dev/null and "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.2.2-1.png" differ
diff --git "a/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.2.2-2.png" "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.2.2-2.png"
new file mode 100644
index 00000000..65d312c9
Binary files /dev/null and "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.2.2-2.png" differ
diff --git "a/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.2.3-1.png" "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.2.3-1.png"
new file mode 100644
index 00000000..b6f0bbc6
Binary files /dev/null and "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.2.3-1.png" differ
diff --git "a/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.2.3-2.png" "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.2.3-2.png"
new file mode 100644
index 00000000..d6e67326
Binary files /dev/null and "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.2.3-2.png" differ
diff --git "a/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.2.3-3.png" "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.2.3-3.png"
new file mode 100644
index 00000000..acfc08ad
Binary files /dev/null and "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.2.3-3.png" differ
diff --git "a/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.2.3-4.png" "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.2.3-4.png"
new file mode 100644
index 00000000..aa42d7dd
Binary files /dev/null and "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.2.3-4.png" differ
diff --git "a/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.2.3-5.png" "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.2.3-5.png"
new file mode 100644
index 00000000..96ee4b70
Binary files /dev/null and "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.2.3-5.png" differ
diff --git "a/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.2.3-6.png" "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.2.3-6.png"
new file mode 100644
index 00000000..a083d9ba
Binary files /dev/null and "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.2.3-6.png" differ
diff --git "a/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.2.3-7.png" "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.2.3-7.png"
new file mode 100644
index 00000000..17430a16
Binary files /dev/null and "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.2.3-7.png" differ
diff --git "a/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.2.4-1.png" "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.2.4-1.png"
new file mode 100644
index 00000000..b7c7bbad
Binary files /dev/null and "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.2.4-1.png" differ
diff --git "a/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.2.4-2.png" "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.2.4-2.png"
new file mode 100644
index 00000000..a6caeae6
Binary files /dev/null and "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.2.4-2.png" differ
diff --git "a/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.2.4-3.png" "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.2.4-3.png"
new file mode 100644
index 00000000..82045aad
Binary files /dev/null and "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.2.4-3.png" differ
diff --git "a/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.2.4-4.png" "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.2.4-4.png"
new file mode 100644
index 00000000..f12913e9
Binary files /dev/null and "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.2.4-4.png" differ
diff --git "a/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.2.4-5.png" "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.2.4-5.png"
new file mode 100644
index 00000000..d337479e
Binary files /dev/null and "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/8.2.4-5.png" differ
diff --git "a/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/DSSD-01.png" "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/DSSD-01.png"
new file mode 100644
index 00000000..dc5af485
Binary files /dev/null and "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/DSSD-01.png" differ
diff --git "a/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/DSSD-02.png" "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/DSSD-02.png"
new file mode 100644
index 00000000..ca2622bf
Binary files /dev/null and "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/DSSD-02.png" differ
diff --git "a/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/DSSD-03.png" "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/DSSD-03.png"
new file mode 100644
index 00000000..b2b0f41c
Binary files /dev/null and "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/DSSD-03.png" differ
diff --git "a/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/FPN-01.png" "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/FPN-01.png"
new file mode 100644
index 00000000..5b16fef9
Binary files /dev/null and "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/FPN-01.png" differ
diff --git "a/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/FPN-02.png" "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/FPN-02.png"
new file mode 100644
index 00000000..8de57618
Binary files /dev/null and "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/FPN-02.png" differ
diff --git "a/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/FPN-03.png" "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/FPN-03.png"
new file mode 100644
index 00000000..862b5c7b
Binary files /dev/null and "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/FPN-03.png" differ
diff --git "a/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/FPN-04.png" "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/FPN-04.png"
new file mode 100644
index 00000000..ccdd8556
Binary files /dev/null and "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/FPN-04.png" differ
diff --git "a/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/M2Det-01.png" "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/M2Det-01.png"
new file mode 100644
index 00000000..c8ac8a86
Binary files /dev/null and "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/M2Det-01.png" differ
diff --git "a/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/M2Det-02.png" "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/M2Det-02.png"
new file mode 100644
index 00000000..cd5b582d
Binary files /dev/null and "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/M2Det-02.png" differ
diff --git "a/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/M2Det-03.png" "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/M2Det-03.png"
new file mode 100644
index 00000000..ed41990c
Binary files /dev/null and "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/M2Det-03.png" differ
diff --git "a/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/Mask R-CNN-01.png" "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/Mask R-CNN-01.png"
new file mode 100644
index 00000000..d3eb5e6d
Binary files /dev/null and "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/Mask R-CNN-01.png" differ
diff --git "a/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/Mask R-CNN-02.png" "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/Mask R-CNN-02.png"
new file mode 100644
index 00000000..69ae2426
Binary files /dev/null and "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/Mask R-CNN-02.png" differ
diff --git "a/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/Mask R-CNN-03.png" "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/Mask R-CNN-03.png"
new file mode 100644
index 00000000..e1de2caf
Binary files /dev/null and "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/Mask R-CNN-03.png" differ
diff --git "a/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/Mask R-CNN-04.png" "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/Mask R-CNN-04.png"
new file mode 100644
index 00000000..397b29b5
Binary files /dev/null and "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/Mask R-CNN-04.png" differ
diff --git "a/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/RFBNet-01.png" "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/RFBNet-01.png"
new file mode 100644
index 00000000..dda9a6cf
Binary files /dev/null and "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/RFBNet-01.png" differ
diff --git "a/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/RFBNet-02.png" "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/RFBNet-02.png"
new file mode 100644
index 00000000..d8566591
Binary files /dev/null and "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/RFBNet-02.png" differ
diff --git "a/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/RFBNet-03.png" "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/RFBNet-03.png"
new file mode 100644
index 00000000..f09c6379
Binary files /dev/null and "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/img/ch8/RFBNet-03.png" differ
diff --git "a/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/modify_log.txt" "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/modify_log.txt"
index 0eed1d29..386b09e2 100644
--- "a/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/modify_log.txt"
+++ "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/modify_log.txt"
@@ -26,4 +26,21 @@ modify_log---->用来记录修改日志
5. 新增所有论文链接
<----lp-2018-11-18---->
-1.修改SSD和YOLO系列
\ No newline at end of file
+1. 修改SSD和YOLO系列
+
+<----cfj-2018-12-09---->
+1. 新增8.1.4目标检测有哪些应用?
+2. 新增8.2节Two-Stage检测算法:FPN、Mask R-CNN
+3. 删除8.2节Two-Stage检测算法:RefineDet和Cascade R-CNN
+4. 新增8.3节One-Stage检测算法:DSSD和RFBNet
+5. 删除8.3节One-Stage检测算法:FSSD
+5. 修改8.4人脸检测章节序号
+6. 新增8.5节目标检测的技巧汇总
+7. 新增8.6节目标检测的常用数据集
+
+<----cfj-2019-12-21---->
+1. 新增SSD系列创新点
+2. 新增YOLO系列创新点
+
+<----cfj-2019-01-05---->
+1. 新增8.3节One-Stage检测算法:M2Det
diff --git "a/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/readme.md" "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/readme.md"
index 81c26276..1ed15ff0 100644
--- "a/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/readme.md"
+++ "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/readme.md"
@@ -5,8 +5,29 @@
**负责人(排名不分先后):**
上海大学研究生-陈方杰(wechat:cfj123456cfj,email:1609951733@qq.com)
-
**贡献者(排名不分先后):**
内容贡献者可自加信息
+目标检测负责人:**
+
+- 稿定科技计算机视觉工程师-刘鹏
+-
+- 上海大学硕士陈方杰:微信(cfj123456ccfj)邮箱(1609951733@qq.com)
+
+
+
+更新日志:**
+
+2019.01.05(陈方杰):新增8.3节One-Stage检测算法:M2Det
+
+2018.12.21(陈方杰):新增SSD系列创新点,新增YOLO系列创新点
+
+2018.12.09(陈方杰):新增目标检测有哪些应用,新增FPN、Mask R-CNN、DSSD和RFBNet算法,新增目标检测Tricks,新增目标检测的常用数据集,删除RefineDet、Cascade R-CNN和FSSD,修改人脸检测章节序号
+
+2018.11.18(陈方杰):修改第八章目标检测目录,新增目标检测基本概念,修改R-CNN、Fast R-CNN、RetinaNet,新增待完善论文FPN、RefineDet、RFBNet,以及新增所有论文链接。
+
+2018.11.18(刘鹏):新增人脸检测部分,修改ssd-yolo系列
+
+2018.11.18(刘鹏):修改SSD和YOLO系列
+
###########################################################
\ No newline at end of file
diff --git "a/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/\347\254\254\345\205\253\347\253\240_\347\233\256\346\240\207\346\243\200\346\265\213.md" "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/\347\254\254\345\205\253\347\253\240_\347\233\256\346\240\207\346\243\200\346\265\213.md"
index 9fcfa806..3e32fe78 100644
--- "a/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/\347\254\254\345\205\253\347\253\240_\347\233\256\346\240\207\346\243\200\346\265\213.md"
+++ "b/ch08_\347\233\256\346\240\207\346\243\200\346\265\213/\347\254\254\345\205\253\347\253\240_\347\233\256\346\240\207\346\243\200\346\265\213.md"
@@ -1,82 +1,14 @@
[TOC]
-**更新日志:**
-
-2018.11.18(陈方杰):修改第八章目标检测目录,新增目标检测基本概念,修改R-CNN、Fast R-CNN、RetinaNet,新增待完善论文FPN、RefineDet、RFBNet,以及新增所有论文链接。
-
-2018.11.18(刘鹏):新增人脸检测部分,修改ssd-yolo系列
-
-2018.11.18(刘鹏):修改SSD和YOLO系列
-
# 第八章 目标检测
-**目标检测负责人:**
-
-- 稿定科技计算机视觉工程师-刘鹏
-- 哈工大博士袁笛
-- 上海大学硕士陈方杰:微信(cfj123456ccfj)邮箱(1609951733@qq.com)
-
-**目录**
-
-8.1 基本概念
-
-8.1.1 什么是目标检测?
-
-8.1.2 目标检测要解决的核心问题
-
-8.1.2 目标检测算法
-
-8.2 Two Stage目标检测算法
-
-8.2.1 R-CNN
-
-8.2.2 Fast R-CNN
-
-8.2.3 Faster R-CNN
-
-8.2.4 R-FCN
-
-8.2.5 FPN
-
-8.2.6 Mask R-CNN
-
-8.2.7 RefineDet
-
-8.2.8 Cascade R-CNN
-
-8.3 One Stage目标检测算法
-
-8.3.1 SSD
-
-8.3.2 DSSD
-
-8.3.3 FSSD
-
-8.3.4 YOLOv1
-
-8.3.5 YOLOv2
-
-8.3.6 YOLO9000
-
-8.3.7 YOLOv3
-
-8.3.8 RetinaNet
-
-8.3.9 RFBNet
-
-8.3.10 M2Det
-
-Reference
-
-
-
## 8.1 基本概念
### 8.1.1 什么是目标检测?
-目标检测(Object Detection)的任务是找出图像中所有感兴趣的目标(物体),确定它们的类别和位置,是计算机视觉领域的核心问题之一。由于各类物体有不同的外观,形状,姿态,加上成像时光照,遮挡等因素的干扰,目标检测一直是计算机视觉领域最具有挑战性的问题。
+ 目标检测(Object Detection)的任务是找出图像中所有感兴趣的目标(物体),确定它们的类别和位置,是计算机视觉领域的核心问题之一。由于各类物体有不同的外观、形状和姿态,加上成像时光照、遮挡等因素的干扰,目标检测一直是计算机视觉领域最具有挑战性的问题。
-计算机视觉中关于图像识别有四大类任务:
+ 计算机视觉中关于图像识别有四大类任务:
**分类-Classification**:解决“是什么?”的问题,即给定一张图片或一段视频判断里面包含什么类别的目标。
@@ -98,57 +30,48 @@ Reference
3.目标可能有各种不同的形状。
-如果用矩形框来定义目标,则矩形有不同的宽高比。由于目标的宽高比不同,因此采用经典的滑动窗口+图像缩放的方案解决通用目标检测问题的成本太高。
-
-### 8.1.2 目标检测算法分类?
+### 8.1.3 目标检测算法分类?
基于深度学习的目标检测算法主要分为两类:
**1.Two stage目标检测算法**
-先进行区域生成(region proposal,RP)(一个有可能包含待检物体的预选框),再通过卷积神经网络进行样本分类。
+ 先进行区域生成(region proposal,RP)(一个有可能包含待检物体的预选框),再通过卷积神经网络进行样本分类。
-任务:特征提取—>生成RP—>分类/定位回归。
+ 任务:特征提取—>生成RP—>分类/定位回归。
-常见的two stage目标检测算法有:R-CNN、SPP-Net、Fast R-CNN、Faster R-CNN和R-FCN等。
+ 常见的two stage目标检测算法有:R-CNN、SPP-Net、Fast R-CNN、Faster R-CNN和R-FCN等。
**2.One stage目标检测算法**
-不用RP,直接在网络中提取特征来预测物体分类和位置。
+ 不用RP,直接在网络中提取特征来预测物体分类和位置。
-任务:特征提取—>分类/定位回归。
+ 任务:特征提取—>分类/定位回归。
-常见的one stage目标检测算法有:OverFeat、YOLOv1、YOLOv2、YOLOv3、SSD和RetinaNet等。
+ 常见的one stage目标检测算法有:OverFeat、YOLOv1、YOLOv2、YOLOv3、SSD和RetinaNet等。

-## 8.2 Two Stage目标检测算法
+### 8.1.4 目标检测有哪些应用?
-### 8.2.1 R-CNN
+ 目标检测具有巨大的实用价值和应用前景。应用领域包括人脸检测、行人检测、车辆检测、飞机航拍或卫星图像中道路的检测、车载摄像机图像中的障碍物检测、医学影像在的病灶检测等。还有在安防领域中,可以实现比如安全帽、安全带等动态检测,移动侦测、区域入侵检测、物品看护等功能。
-**标题:《Rich feature hierarchies for accurate object detection and semantic segmentation》**
-
-**时间:2014**
-
-**出版源:CVPR 2014**
-
-**主要链接**:
+## 8.2 Two Stage目标检测算法
-- arXiv:http://arxiv.org/abs/1311.2524
-- github(caffe):https://github.com/rbgirshick/rcnn
+### 8.2.1 R-CNN
-**R-CNN 创新点**
+**R-CNN有哪些创新点?**
-- 使用CNN(ConvNet)对 region proposals 计算 feature vectors。从经验驱动特征(SIFT、HOG)到数据驱动特征(CNN feature map),提高特征对样本的表示能力。
-- 采用大样本下(ILSVRC)有监督预训练和小样本(PASCAL)微调(fine-tuning)的方法解决小样本难以训练甚至过拟合等问题。
+1. 使用CNN(ConvNet)对 region proposals 计算 feature vectors。从经验驱动特征(SIFT、HOG)到数据驱动特征(CNN feature map),提高特征对样本的表示能力。
+2. 采用大样本下(ILSVRC)有监督预训练和小样本(PASCAL)微调(fine-tuning)的方法解决小样本难以训练甚至过拟合等问题。
注:ILSVRC其实就是众所周知的ImageNet的挑战赛,数据量极大;PASCAL数据集(包含目标检测和图像分割等),相对较小。
**R-CNN 介绍**
-R-CNN作为R-CNN系列的第一代算法,其实没有过多的使用“深度学习”思想,而是将“深度学习”和传统的“计算机视觉”的知识相结合。比如R-CNN pipeline中的第二步和第四步其实就属于传统的“计算机视觉”技术。使用selective search提取region proposals,使用SVM实现分类。
+ R-CNN作为R-CNN系列的第一代算法,其实没有过多的使用“深度学习”思想,而是将“深度学习”和传统的“计算机视觉”的知识相结合。比如R-CNN pipeline中的第二步和第四步其实就属于传统的“计算机视觉”技术。使用selective search提取region proposals,使用SVM实现分类。
-
+
原论文中R-CNN pipeline只有4个步骤,光看上图无法深刻理解R-CNN处理机制,下面结合图示补充相应文字
@@ -172,25 +95,10 @@ R-CNN在VOC 2007测试集上mAP达到58.5%,打败当时所有的目标检测

-**参考**
-
-[Amusi-R-CNN论文笔记](https://github.com/amusi/paper-note/blob/master/Object-Detection/R-CNN%E8%AE%BA%E6%96%87%E7%AC%94%E8%AE%B0.md)
-
### 8.2.2 Fast R-CNN
-**标题:《Fast R-CNN》**
-
-**时间:2015**
-
-**出版源:ICCV 2015**
-
-**主要链接:**
-
-- arXiv:https://arxiv.org/abs/1504.08083
-- github(Official):https://github.com/rbgirshick/fast-rcnn
-
-**Fast R-CNN 创新点**
+**Fast R-CNN有哪些创新点?**
1. 只对整幅图像进行一次特征提取,避免R-CNN中的冗余特征提取
2. 用RoI pooling层替换最后一层的max pooling层,同时引入建议框数据,提取相应建议框特征
@@ -199,11 +107,11 @@ R-CNN在VOC 2007测试集上mAP达到58.5%,打败当时所有的目标检测
**Fast R-CNN 介绍**
-Fast R-CNN是基于R-CNN和[SPPnets](https://arxiv.org/abs/1406.4729)进行的改进。SPPnets,其创新点在于计算整幅图像的the shared feature map,然后根据object proposal在shared feature map上映射到对应的feature vector(就是不用重复计算feature map了)。当然,SPPnets也有缺点:和R-CNN一样,训练是多阶段(multiple-stage pipeline)的,速度还是不够"快",特征还要保存到本地磁盘中。
+ Fast R-CNN是基于R-CNN和SPPnets进行的改进。SPPnets,其创新点在于计算整幅图像的the shared feature map,然后根据object proposal在shared feature map上映射到对应的feature vector(就是不用重复计算feature map了)。当然,SPPnets也有缺点:和R-CNN一样,训练是多阶段(multiple-stage pipeline)的,速度还是不够"快",特征还要保存到本地磁盘中。
-将候选区域直接应用于特征图,并使用ROI池化将其转化为固定大小的特征图块。以下是Fast R-CNN的流程图
+将候选区域直接应用于特征图,并使用RoI池化将其转化为固定大小的特征图块。以下是Fast R-CNN的流程图
-
+
**RoI Pooling层详解**
@@ -215,9 +123,9 @@ RoI Pooling 是Pooling层的一种,而且是针对RoI的Pooling,其特点是
RoI是Region of Interest的简写,一般是指图像上的区域框,但这里指的是由Selective Search提取的候选框。
-
+
-往往经过rpn后输出的不止一个矩形框,所以这里我们是对多个RoI进行Pooling。
+往往经过RPN后输出的不止一个矩形框,所以这里我们是对多个RoI进行Pooling。
**RoI Pooling的输入**
@@ -228,7 +136,7 @@ RoI是Region of Interest的简写,一般是指图像上的区域框,但这
在Fast RCNN中,指的是Selective Search的输出;在Faster RCNN中指的是RPN的输出,一堆矩形候选框,形状为1x5x1x1(4个坐标+索引index),其中值得注意的是:坐标的参考系不是针对feature map这张图的,而是针对原图的(神经网络最开始的输入)。其实关于ROI的坐标理解一直很混乱,到底是根据谁的坐标来。其实很好理解,我们已知原图的大小和由Selective Search算法提取的候选框坐标,那么根据"映射关系"可以得出特征图(featurwe map)的大小和候选框在feature map上的映射坐标。至于如何计算,其实就是比值问题,下面会介绍。所以这里把ROI理解为原图上各个候选框(region proposals),也是可以的。
-注:说句题外话,由Selective Search算法提取的一系列可能含有object的boudning box,这些通常称为region proposals或者region of interest(ROI)。
+注:说句题外话,由Selective Search算法提取的一系列可能含有object的bounding box,这些通常称为region proposals或者region of interest(ROI)。
**RoI的具体操作**
@@ -240,7 +148,7 @@ RoI是Region of Interest的简写,一般是指图像上的区域框,但这
3. 对每个sections进行max pooling操作
-这样我们就可以从不同大小的方框得到固定大小的相应 的feature maps。值得一提的是,输出的feature maps的大小不取决于ROI和卷积feature maps大小。ROI pooling 最大的好处就在于极大地提高了处理速度。
+这样我们就可以从不同大小的方框得到固定大小的相应 的feature maps。值得一提的是,输出的feature maps的大小不取决于ROI和卷积feature maps大小。RoI Pooling 最大的好处就在于极大地提高了处理速度。
**RoI Pooling的输出**
@@ -250,75 +158,50 @@ RoI是Region of Interest的简写,一般是指图像上的区域框,但这

-**参考**
-
-[Amusi-Fast R-CNN论文笔记](https://github.com/amusi/paper-note/blob/master/Object-Detection/Fast-R-CNN%E8%AE%BA%E6%96%87%E7%AC%94%E8%AE%B0.md)
-
### 8.2.3 Faster R-CNN
-**标题:《Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks》**
-
-**时间:2015**
-
-**出版源:NIPS 2015**
-
-**主要链接:**
-
-- arXiv:http://arxiv.org/abs/1506.01497
-- github(official, Matlab):https://github.com/ShaoqingRen/faster_rcnn
-- github(official, Caffe):https://github.com/rbgirshick/py-faster-rcnn
+**Faster R-CNN有哪些创新点?**
- Fast R-CNN依赖于外部候选区域方法,如选择性搜索。但这些算法在CPU上运行且速度很慢。在测试中,Fast R-CNN需要2.3秒来进行预测,其中2秒用于生成2000个ROI。Faster R-CNN采用与Fast R-CNN相同的设计,只是它用内部深层网络代替了候选区域方法。新的候选区域网络(RPN)在生成ROI时效率更高,并且以每幅图像10毫秒的速度运行。
- 
+Fast R-CNN依赖于外部候选区域方法,如选择性搜索。但这些算法在CPU上运行且速度很慢。在测试中,Fast R-CNN需要2.3秒来进行预测,其中2秒用于生成2000个ROI。Faster R-CNN采用与Fast R-CNN相同的设计,只是它用内部深层网络代替了候选区域方法。新的候选区域网络(RPN)在生成ROI时效率更高,并且以每幅图像10毫秒的速度运行。
+
- 图8.1.13 Faster R-CNN的流程图
- Faster R-CNN的流程图与Fast R-CNN相同,采用外部候选区域方法代替了内部深层网络。
- 
+图8.1.13 Faster R-CNN的流程图
+Faster R-CNN的流程图与Fast R-CNN相同,采用外部候选区域方法代替了内部深层网络。
+
- 图8.1.14
- **候选区域网络**
+图8.1.14
+**候选区域网络**
- 候选区域网络(RPN)将第一个卷积网络的输出特征图作为输入。它在特征图上滑动一个3×3的卷积核,以使用卷积网络(如下所示的ZF网络)构建与类别无关的候选区域。其他深度网络(如VGG或ResNet)可用于更全面的特征提取,但这需要以速度为代价。ZF网络最后会输出256个值,它们将馈送到两个独立的全连接层,以预测边界框和两个objectness分数,这两个objectness分数度量了边界框是否包含目标。我们其实可以使用回归器计算单个objectness分数,但为简洁起见,Faster R-CNN使用只有两个类别的分类器:即带有目标的类别和不带有目标的类别。
- 
+候选区域网络(RPN)将第一个卷积网络的输出特征图作为输入。它在特征图上滑动一个3×3的卷积核,以使用卷积网络(如下所示的ZF网络)构建与类别无关的候选区域。其他深度网络(如VGG或ResNet)可用于更全面的特征提取,但这需要以速度为代价。ZF网络最后会输出256个值,它们将馈送到两个独立的全连接层,以预测边界框和两个objectness分数,这两个objectness分数度量了边界框是否包含目标。我们其实可以使用回归器计算单个objectness分数,但为简洁起见,Faster R-CNN使用只有两个类别的分类器:即带有目标的类别和不带有目标的类别。
+
- 图8.1.15
- 对于特征图中的每一个位置,RPN会做k次预测。因此,RPN将输出4×k个坐标和每个位置上2×k个得分。下图展示了8×8的特征图,且有一个3×3的卷积核执行运算,它最后输出8×8×3个ROI(其中k=3)。下图(右)展示了单个位置的3个候选区域。
- 
+图8.1.15
+对于特征图中的每一个位置,RPN会做k次预测。因此,RPN将输出4×k个坐标和每个位置上2×k个得分。下图展示了8×8的特征图,且有一个3×3的卷积核执行运算,它最后输出8×8×3个ROI(其中k=3)。下图(右)展示了单个位置的3个候选区域。
+
- 图8.1.16
- 假设最好涵盖不同的形状和大小。因此,Faster R-CNN不会创建随机边界框。相反,它会预测一些与左上角名为锚点的参考框相关的偏移量(如x, y)。我们限制这些偏移量的值,因此我们的猜想仍然类似于锚点。
- 
+图8.1.16
+假设最好涵盖不同的形状和大小。因此,Faster R-CNN不会创建随机边界框。相反,它会预测一些与左上角名为锚点的参考框相关的偏移量(如x, y)。我们限制这些偏移量的值,因此我们的猜想仍然类似于锚点。
+
- 图8.1.17
- 要对每个位置进行k个预测,我们需要以每个位置为中心的k个锚点。每个预测与特定锚点相关联,但不同位置共享相同形状的锚点。
- 
+图8.1.17
+要对每个位置进行k个预测,我们需要以每个位置为中心的k个锚点。每个预测与特定锚点相关联,但不同位置共享相同形状的锚点。
+
- 图8.1.18
- 这些锚点是精心挑选的,因此它们是多样的,且覆盖具有不同比例和宽高比的现实目标。这使得我们可以用更好的猜想来指导初始训练,并允许每个预测专门用于特定的形状。该策略使早期训练更加稳定和简便。
- 
+图8.1.18
+这些锚点是精心挑选的,因此它们是多样的,且覆盖具有不同比例和宽高比的现实目标。这使得我们可以用更好的猜想来指导初始训练,并允许每个预测专门用于特定的形状。该策略使早期训练更加稳定和简便。
+
- 图8.1.19
- Faster R-CNN使用更多的锚点。它部署9个锚点框:3个不同宽高比的3个不同大小的锚点框。每一个位置使用9个锚点,每个位置会生成2×9个objectness分数和4×9个坐标。
+图8.1.19
+Faster R-CNN使用更多的锚点。它部署9个锚点框:3个不同宽高比的3个不同大小的锚点(Anchor)框。每一个位置使用9个锚点,每个位置会生成2×9个objectness分数和4×9个坐标。
### 8.2.4 R-FCN
-**标题:《R-FCN: Object Detection via Region-based Fully Convolutional Networks》**
-
-**时间:2016**
-
-**出版源:NIPS 2016**
-
-**主要链接:**
-
-- arXiv:https://arxiv.org/abs/1605.06409
-- github(Official):https://github.com/daijifeng001/r-fcn
-
-**R-FCN 创新点**
+**R-FCN有哪些创新点?**
R-FCN 仍属于two-stage 目标检测算法:RPN+R-FCN
-- Fully convolutional
-- 位置敏感得分图(position-sentive score maps)
+1. Fully convolutional
+2. 位置敏感得分图(position-sentive score maps)
> our region-based detector is **fully convolutional** with almost all computation shared on the entire image. To achieve this goal, we propose **position-sensitive score maps** to address a dilemma between translation-invariance in image classification and translation-variance in object detection.
@@ -329,23 +212,23 @@ ResNet-101+R-FCN:83.6% in PASCAL VOC 2007 test datasets
既提高了mAP,又加快了检测速度
假设我们只有一个特征图用来检测右眼。那么我们可以使用它定位人脸吗?应该可以。因为右眼应该在人脸图像的左上角,所以我们可以利用这一点定位整个人脸。如果我们还有其他用来检测左眼、鼻子或嘴巴的特征图,那么我们可以将检测结果结合起来,更好地定位人脸。现在我们回顾一下所有问题。在Faster R-CNN中,检测器使用了多个全连接层进行预测。如果有2000个ROI,那么成本非常高。R-FCN通过减少每个ROI所需的工作量实现加速。上面基于区域的特征图与ROI是独立的,可以在每个ROI之外单独计算。剩下的工作就比较简单了,因此R-FCN的速度比Faster R-CNN快。
-
+
图8.2.1 人脸检测
现在我们来看一下5×5的特征图M,内部包含一个蓝色方块。我们将方块平均分成3×3个区域。现在,我们在M中创建了一个新的特征图,来检测方块的左上角(TL)。这个新的特征图如下图(右)所示。只有黄色的网格单元[2,2]处于激活状态。在左侧创建一个新的特征图,用于检测目标的左上角。
-
+
图8.2.2 检测示例
我们将方块分成9个部分,由此创建了9个特征图,每个用来检测对应的目标区域。这些特征图叫做位置敏感得分图(position-sensitive score map),因为每个图检测目标的子区域(计算其得分)。
-
+
图8.2.3生成9个得分图
下图中红色虚线矩形是建议的ROI。我们将其分割成3×3个区域,并询问每个区域包含目标对应部分的概率是多少。例如,左上角ROI区域包含左眼的概率。我们将结果存储成3×3 vote数组,如下图(右)所示。例如,vote_array[0][0]包含左上角区域是否包含目标对应部分的得分。
-
+
图8.2.4
将ROI应用到特征图上,输出一个3x3数组。将得分图和ROI映射到vote数组的过程叫做位置敏感ROI池化(position-sensitive ROI-pool)。该过程与前面讨论过的ROI池化非常接近。
-
+
图8.2.5
将ROI的一部分叠加到对应的得分图上,计算V[i][j]。在计算出位置敏感ROI池化的所有值后,类别得分是其所有元素得分的平均值。
@@ -358,88 +241,133 @@ ResNet-101+R-FCN:83.6% in PASCAL VOC 2007 test datasets
图8.2.7
### 8.2.5 FPN
-**标题:《Feature Pyramid Networks for Object Detection》**
+**FPN有哪些创新点?**
-**时间:2016**
+1. 多层特征
+2. 特征融合
-**出版源:CVPR 2017**
+解决目标检测中的多尺度问题,通过简单的网络连接改变,在基本不增加原有模型计算量的情况下,大幅度提升小物体(small object)检测的性能。
-**主要链接:**
+在物体检测里面,有限计算量情况下,网络的深度(对应到感受野)与 stride 通常是一对矛盾的东西,常用的网络结构对应的 stride 一般会比较大(如 32),而图像中的小物体甚至会小于 stride 的大小,造成的结果就是小物体的检测性能急剧下降。传统解决这个问题的思路包括:
-- arXiv:https://arxiv.org/abs/1612.03144
+1. 图像金字塔(image pyramid),即多尺度训练和测试。但该方法计算量大,耗时较久。
+2. 特征分层,即每层分别预测对应的scale分辨率的检测结果,如SSD算法。该方法强行让不同层学习同样的语义信息,但实际上不同深度对应于不同层次的语义特征,浅层网络分辨率高,学到更多是细节特征,深层网络分辨率低,学到更多是语义特征。
-- [ ] TODO
+因而,目前多尺度的物体检测主要面临的挑战为:
-### 8.2.6 Mask R-CNN
+1. 如何学习具有强语义信息的多尺度特征表示?
+2. 如何设计通用的特征表示来解决物体检测中的多个子问题?如 object proposal, box localization, instance segmentation.
+3. 如何高效计算多尺度的特征表示?
-**标题:《Mask R-CNN》**
+FPN网络直接在Faster R-CNN单网络上做修改,每个分辨率的 feature map 引入后一分辨率缩放两倍的 feature map 做 element-wise 相加的操作。通过这样的连接,每一层预测所用的 feature map 都融合了不同分辨率、不同语义强度的特征,融合的不同分辨率的 feature map 分别做对应分辨率大小的物体检测。这样保证了每一层都有合适的分辨率以及强语义(rich semantic)特征。同时,由于此方法只是在原网络基础上加上了额外的跨层连接,在实际应用中几乎不增加额外的时间和计算量。作者接下来实验了将 FPN 应用在 Faster RCNN 上的性能,在 COCO 上达到了 state-of-the-art 的单模型精度。在RPN上,FPN增加了8.0个点的平均召回率(average recall,AR);在后面目标检测上,对于COCO数据集,FPN增加了2.3个点的平均精确率(average precision,AP),对于VOC数据集,FPN增加了3.8个点的AP。
-**时间:2017**
-**出版源:ICCV 2017**
-**主要链接:**
+
-- arXiv:https://arxiv.org/abs/1703.06870
+FPN算法主要由三个模块组成,分别是:
+1. Bottom-up pathway(自底向上线路)
+2. Lareral connections(横向链接)
+3. Top-down path(自顶向下线路)
-- github(Official):https://github.com/facebookresearch/Detectron
+
+**Bottom-up pathway**
+FPN是基于Faster R-CNN进行改进,其backbone是ResNet-101,FPN主要应用在Faster R-CNN中的RPN(用于bouding box proposal generation)和Fast R-CNN(用于object detection)两个模块中。
-- [ ] TODO
+其中 RPN 和 Fast RCNN 分别关注的是召回率(recall)和精确率(precision),在这里对比的指标分别为 Average Recall(AR) 和 Average Precision(AP)。
-### 8.2.7 RefineDet
+注:Bottom-up可以理解为自底向上,Top-down可以理解为自顶向下。这里的下是指low-level,上是指high-level,分别对应于提取的低级(浅层)特征和高级语义(高层)特征。
-**标题:《Single-Shot Refinement Neural Network for Object Detection》**
+Bottom-up pathway 是卷积网络的前向传播过程。在前向传播过程中,feature map的大小可以在某些层发生改变。一些尺度(scale)因子为2,所以后一层feature map的大小是前一层feature map大小的二分之一,根据此关系进而构成了feature pyramid(hierarchy)。
-**时间:2017**
+然而还有很多层输出的feature map是一样的大小(即不进行缩放的卷积),作者将这些层归为同一 stage。对于feature pyramid,作者为每个stage定义一个pyramid level。
-**出版源:CVPR 2018**
+作者将每个stage的最后一层的输出作为feature map,然后不同stage进行同一操作,便构成了feature pyramid。
-**主要链接:**
+具体来说,对于ResNets-101,作者使用了每个stage的最后一个残差结构的特征激活输出。将这些残差模块输出表示为{C2, C3, C4, C5},对应于conv2,conv3,conv4和conv5的输出,并且注意它们相对于输入图像具有{4, 8, 16, 32}像素的步长。考虑到内存占用,没有将conv1包含在金字塔中。
-- arXiv:https://arxiv.org/abs/1711.06897
-- github(Official):https://github.com/sfzhang15/RefineDet
+
+**Top-down pathway and lateral connections**
+Top-town pathway是上采样(upsampling)过程。而later connection(横向连接)是将上采样的结果和bottom-up pathway生成的相同大小的feature map进行融合(merge)。
-- [ ] TODO
+注:上采样尺度因子为2,因为为了和之前下采样卷积的尺度因子=2一样。上采样是放大,下采样是缩小。
-### 8.2.8 Cascade R-CNN
+具体操作如下图所示,上采样(2x up)feature map与相同大小的bottom-up feature map进行逐像素相加融合(element-wise addition),其中bottom-up feature先要经过1x1卷积层,目的是为了减少通道维度(reduce channel dimensions)。
-**标题:《Cascade R-CNN: Delving into High Quality Object Detection》**
+注:减少通道维度是为了将bottom-up feature map的通道数量与top-down feature map的通道数量保持一致,又因为两者feature map大小一致,所以可以进行对应位置像素的叠加(element-wise addition)。
-**时间:2017**
+
-**出版源:CVPR 2018**
+### 8.2.6 Mask R-CNN
-**主要链接:**
+**Mask R-CNN有哪些创新点?**
-- arXiv:https://arxiv.org/abs/1712.00726
-- github(Official):https://github.com/zhaoweicai/cascade-rcnn
+1. Backbone:ResNeXt-101+FPN
+2. RoI Align替换RoI Pooling
+Mask R-CNN是一个实例分割(Instance segmentation)算法,主要是在目标检测的基础上再进行分割。Mask R-CNN算法主要是Faster R-CNN+FCN,更具体一点就是ResNeXt+RPN+RoI Align+Fast R-CNN+FCN。
+
-- [ ] TODO
+**Mask R-CNN算法步骤**
-## 8.3 One Stage目标检测算法
+1. 输入一幅你想处理的图片,然后进行对应的预处理操作,或者预处理后的图片;
+2. 将其输入到一个预训练好的神经网络中(ResNeXt等)获得对应的feature map;
+3. 对这个feature map中的每一点设定预定个的RoI,从而获得多个候选RoI;
+4. 将这些候选的RoI送入RPN网络进行二值分类(前景或背景)和BB回归,过滤掉一部分候选的RoI;
+5. 对这些剩下的RoI进行RoI Align操作(即先将原图和feature map的pixel对应起来,然后将feature map和固定的feature对应起来);
+6. 对这些RoI进行分类(N类别分类)、BB回归和MASK生成(在每一个RoI里面进行FCN操作)。
- 我们将对单次目标检测器(包括SSD、YOLO、YOLOv2、YOLOv3)进行综述。我们将分析FPN以理解多尺度特征图如何提高准确率,特别是小目标的检测,其在单次检测器中的检测效果通常很差。然后我们将分析Focal loss和RetinaNet,看看它们是如何解决训练过程中的类别不平衡问题的。
-### 8.3.1 SSD
+**RoI Pooling和RoI Align有哪些不同?**
+
+ROI Align 是在Mask-RCNN中提出的一种区域特征聚集方式,很好地解决了RoI Pooling操作中两次量化造成的区域不匹配(mis-alignment)的问题。实验显示,在检测测任务中将 RoI Pooling 替换为 RoI Align 可以提升检测模型的准确性。
+
+在常见的两级检测框架(比如Fast-RCNN,Faster-RCNN,RFCN)中,RoI Pooling 的作用是根据预选框的位置坐标在特征图中将相应区域池化为固定尺寸的特征图,以便进行后续的分类和包围框回归操作。由于预选框的位置通常是由模型回归得到的,一般来讲是浮点数,而池化后的特征图要求尺寸固定。故RoI Pooling这一操作存在两次量化的过程。
+
+- 将候选框边界量化为整数点坐标值。
+- 将量化后的边界区域平均分割成 $k\times k$ 个单元(bin),对每一个单元的边界进行量化。
+
+事实上,经过上述两次量化,此时的候选框已经和最开始回归出来的位置有一定的偏差,这个偏差会影响检测或者分割的准确度。在论文里,作者把它总结为“不匹配问题(misalignment)”。
+
+下面我们用直观的例子具体分析一下上述区域不匹配问题。如下图所示,这是一个Faster-RCNN检测框架。输入一张$800\times 800$的图片,图片上有一个$665\times 665$的包围框(框着一只狗)。图片经过主干网络提取特征后,特征图缩放步长(stride)为32。因此,图像和包围框的边长都是输入时的1/32。800正好可以被32整除变为25。但665除以32以后得到20.78,带有小数,于是RoI Pooling 直接将它量化成20。接下来需要把框内的特征池化$7\times 7$的大小,因此将上述包围框平均分割成$7\times 7$个矩形区域。显然,每个矩形区域的边长为2.86,又含有小数。于是ROI Pooling 再次把它量化到2。经过这两次量化,候选区域已经出现了较明显的偏差(如图中绿色部分所示)。更重要的是,该层特征图上0.1个像素的偏差,缩放到原图就是3.2个像素。那么0.8的偏差,在原图上就是接近30个像素点的差别,这一差别不容小觑。
+
+
+
+为了解决RoI Pooling的上述缺点,作者提出了RoI Align这一改进的方法(如图2)。
+
+
+
+RoI Align的思路很简单:取消量化操作,使用双线性内插的方法获得坐标为浮点数的像素点上的图像数值,从而将整个特征聚集过程转化为一个连续的操作。值得注意的是,在具体的算法操作上,RoI Align并不是简单地补充出候选区域边界上的坐标点,然后将这些坐标点进行池化,而是重新设计了一套比较优雅的流程,如下图所示:
-**标题:《SSD: Single Shot MultiBox Detector》**
+1. 遍历每一个候选区域,保持浮点数边界不做量化。
-**时间:2015**
+2. 将候选区域分割成$k\times k$个单元,每个单元的边界也不做量化。
-**出版源:ECCV 2016**
+3. 在每个单元中计算固定四个坐标位置,用双线性内插的方法计算出这四个位置的值,然后进行最大池化操作。
-**主要链接:**
+这里对上述步骤的第三点作一些说明:这个固定位置是指在每一个矩形单元(bin)中按照固定规则确定的位置。比如,如果采样点数是1,那么就是这个单元的中心点。如果采样点数是4,那么就是把这个单元平均分割成四个小方块以后它们分别的中心点。显然这些采样点的坐标通常是浮点数,所以需要使用插值的方法得到它的像素值。在相关实验中,作者发现将采样点设为4会获得最佳性能,甚至直接设为1在性能上也相差无几。事实上,RoI Align 在遍历取样点的数量上没有RoI Pooling那么多,但却可以获得更好的性能,这主要归功于解决了mis alignment的问题。值得一提的是,我在实验时发现,RoI Align在VOC 2007数据集上的提升效果并不如在COCO上明显。经过分析,造成这种区别的原因是COCO上小目标的数量更多,而小目标受mis alignment问题的影响更大(比如,同样是0.5个像素点的偏差,对于较大的目标而言显得微不足道,但是对于小目标,误差的影响就要高很多)。
-- arXiv:https://arxiv.org/abs/1512.02325
-- github(Official):https://github.com/weiliu89/caffe/tree/ssd
+
-不同于前面的RCNN系列,SSD属于one-stage方法。SSD使用 VGG16 网络作为特征提取器(和 Faster R-CNN 中使用的 CNN 一样),将后面的全连接层替换成卷积层,并在之后添加自定义卷积层,并在最后直接采用卷积进行检测。在多个特征图上设置不同缩放比例和不同宽高比的default boxes(先验框)以融合多尺度特征图进行检测,靠前的大尺度特征图可以捕捉到小物体的信息,而靠后的小尺度特征图能捕捉到大物体的信息,从而提高检测的准确性和定位的准确性。如下图是SSD的网络结构图。
+
+
+## 8.3 One Stage目标检测算法
+
+我们将对单次目标检测器(包括SSD系列和YOLO系列等算法)进行综述。我们将分析FPN以理解多尺度特征图如何提高准确率,特别是小目标的检测,其在单次检测器中的检测效果通常很差。然后我们将分析Focal loss和RetinaNet,看看它们是如何解决训练过程中的类别不平衡问题的。
+
+### 8.3.1 SSD
+
+**SSD有哪些创新点?**
+
+1. 基于Faster R-CNN中的Anchor,提出了相似的先验框(Prior box)
+2. 从不同比例的特征图(多尺度特征)中产生不同比例的预测,并明确地按长宽比分离预测。
+
+不同于前面的R-CNN系列,SSD属于one-stage方法。SSD使用 VGG16 网络作为特征提取器(和 Faster R-CNN 中使用的 CNN 一样),将后面的全连接层替换成卷积层,并在之后添加自定义卷积层,并在最后直接采用卷积进行检测。在多个特征图上设置不同缩放比例和不同宽高比的先验框以融合多尺度特征图进行检测,靠前的大尺度特征图可以捕捉到小物体的信息,而靠后的小尺度特征图能捕捉到大物体的信息,从而提高检测的准确性和定位的准确性。如下图是SSD的网络结构图。

@@ -460,58 +388,43 @@ SSD在训练的时候只需要输入图像和图像中每个目标对应的groun
**3. 怎样得到预测的检测结果?**
-最后分别在所选的特征层上使用3x3卷积核预测不同default boxes所属的类别分数及其预测的边界框location。由于对于每个box需要预测该box属于每个类别的置信度(假设有c类,包括背景)和该box对应的预测边界框的location(包含4个值,即该box的中心坐标和宽高),则每个box需要预测c+4个值。所以对于某个所选的特征层,该层的卷积核个数为(c+4)x该层的default box个数.最后将每个层得到的卷积结果进行拼接。对于得到的每个预测框,取其类别置信度的最大值,若该最大值大于置信度阈值,则最大值所对应的类别即为该预测框的类别,否则过滤掉此框。对于保留的预测框根据它对应的先验框进行解码得到其真实的位置参数(这里还需注意要防止预测框位置超出图片),然后根据所属类别置信度进行降序排列,取top-k个预测框,最后进行NMS,过滤掉重叠度较大的预测框,最后得到检测结果。
-
-
+最后分别在所选的特征层上使用3x3卷积核预测不同default boxes所属的类别分数及其预测的边界框location。由于对于每个box需要预测该box属于每个类别的置信度(假设有c类,包括背景,例如20class的数据集合,c=21)和该box对应的预测边界框的location(包含4个值,即该box的中心坐标和宽高),则每个box需要预测c+4个值。所以对于某个所选的特征层,该层的卷积核个数为(c+4)x 该层的default box个数.最后将每个层得到的卷积结果进行拼接。对于得到的每个预测框,取其类别置信度的最大值,若该最大值大于置信度阈值,则最大值所对应的类别即为该预测框的类别,否则过滤掉此框。对于保留的预测框根据它对应的先验框进行解码得到其真实的位置参数(这里还需注意要防止预测框位置超出图片),然后根据所属类别置信度进行降序排列,取top-k个预测框,最后进行NMS,过滤掉重叠度较大的预测框,最后得到检测结果。
SSD优势是速度比较快,整个过程只需要一步,首先在图片不同位置按照不同尺度和宽高比进行密集抽样,然后利用CNN提取特征后直接进行分类与回归,所以速度比较快,但均匀密集采样会造成正负样本不均衡的情况使得训练比较困难,导致模型准确度有所降低。另外,SSD对小目标的检测没有大目标好,因为随着网络的加深,在高层特征图中小目标的信息丢失掉了,适当增大输入图片的尺寸可以提升小目标的检测效果。
### 8.3.2 DSSD
-**标题:《DSSD : Deconvolutional Single Shot Detector》**
-
-**时间:2017**
-
-**出版源:CVPR 2017**
-
-**主要链接:**
-
-- arXiv:https://arxiv.org/abs/1701.06659
-- github(Official):https://github.com/chengyangfu/caffe/tree/dssd
-
-
-
-
-- [ ] TODO
-
-### 8.3.3 FSSD
+**DSSD有哪些创新点?**
-**标题:《FSSD: Feature Fusion Single Shot Multibox Detector》**
+1. Backbone:将ResNet替换SSD中的VGG网络,增强了特征提取能力
+2. 添加了Deconvolution层,增加了大量上下文信息
-**时间:2017**
+为了解决SSD算法检测小目标困难的问题,DSSD算法将SSD算法基础网络从VGG-16更改为ResNet-101,增强网络特征提取能力,其次参考FPN算法思路利用去Deconvolution结构将图像深层特征从高维空间传递出来,与浅层信息融合,联系不同层级之间的图像语义关系,设计预测模块结构,通过不同层级特征之间融合特征输出预测物体类别信息。
-**出版源:None**
+DSSD算法中有两个特殊的结构:Prediction模块;Deconvolution模块。前者利用提升每个子任务的表现来提高准确性,并且防止梯度直接流入ResNet主网络。后者则增加了三个Batch Normalization层和三个3×3卷积层,其中卷积层起到了缓冲的作用,防止梯度对主网络影响太剧烈,保证网络的稳定性。
-**主要链接:**
+SSD和DSSD的网络模型如下图所示:
-- arXiv:https://arxiv.org/abs/1712.00960
+
+**Prediction Module**
+SSD直接从多个卷积层中单独引出预测函数,预测量多达7000多,梯度计算量也很大。MS-CNN方法指出,改进每个任务的子网可以提高准确性。根据这一思想,DSSD在每一个预测层后增加残差模块,并且对于多种方案进行了对比,如下图所示。结果表明,增加残差预测模块后,高分辨率图片的检测精度比原始SSD提升明显。
-- [ ] TODO
+
-### 8.3.4 YOLOv1
+**Deconvolution模块**
-**标题:《You Only Look Once: Unified, Real-Time Object Detection》**
+为了整合浅层特征图和deconvolution层的信息,作者引入deconvolution模块,如下图所示。作者受到论文Learning to Refine Object Segments的启发,认为用于精细网络的deconvolution模块的分解结构达到的精度可以和复杂网络一样,并且更有效率。作者对其进行了一定的修改:其一,在每个卷积层后添加批归一化(batch normalization)层;其二,使用基于学习的deconvolution层而不是简单地双线性上采样;其三,作者测试了不同的结合方式,元素求和(element-wise sum)与元素点积(element-wise product)方式,实验证明元素点积计算能得到更好的精度。
-**时间:2015**
+
-**出版源:CVPR 2016**
+### 8.3.3 YOLOv1
-**主要链接:**
+**YOLOv1有哪些创新点?**
-- arXiv:http://arxiv.org/abs/1506.02640
-- github(Official):https://github.com/pjreddie/darknet
+1. 将整张图作为网络的输入,直接在输出层回归bounding box的位置和所属的类别
+2. 速度快,one stage detection的开山之作
**YOLOv1介绍**
@@ -523,11 +436,9 @@ YOLO创造性的将物体检测任务直接当作回归问题(regression probl
事实上,YOLO也并没有真正的去掉候选区,而是直接将输入图片划分成7x7=49个网格,每个网格预测两个边界框,一共预测49x2=98个边界框。可以近似理解为在输入图片上粗略的选取98个候选区,这98个候选区覆盖了图片的整个区域,进而用回归预测这98个候选框对应的边界框。
-**下面以问答的形式展示YOLO中的一些实现细节:**
-
**1. 网络结构是怎样的?**
-YOLO网络借鉴了GoogleNet分类网络结构,不同的是YOLO使用1x1卷积层和3x3卷积层替代inception module。如下图所示,整个检测网络包括24个卷积层和2个全连接层。其中,卷积层用来提取图像特征,全连接层用来预测图像位置和类别概率值。
+YOLO网络借鉴了GoogLeNet分类网络结构,不同的是YOLO使用1x1卷积层和3x3卷积层替代inception module。如下图所示,整个检测网络包括24个卷积层和2个全连接层。其中,卷积层用来提取图像特征,全连接层用来预测图像位置和类别概率值。

@@ -572,24 +483,19 @@ YOLO最后采用非极大值抑制(NMS)算法从输出结果中提取最有
3.返回步骤2继续处理下一类对象。
-YOLO将识别与定位合二为一,结构简便,检测速度快,更快的Fast YOLO可以达到155FPS。相对于RNN系列, YOLO的整个流程中都能看到整张图像的信息,因此它在检测物体时能很好的利用上下文信息,从而不容易在背景上预测出错误的物体信息。同时YOLO可以学习到高度泛化的特征,能将一个域上学到的特征迁移到不同但相关的域上,如在自然图像上做训练的YOLO,在艺术图片上可以得到较好的测试结果。
+YOLO将识别与定位合二为一,结构简便,检测速度快,更快的Fast YOLO可以达到155FPS。相对于R-CNN系列, YOLO的整个流程中都能看到整张图像的信息,因此它在检测物体时能很好的利用上下文信息,从而不容易在背景上预测出错误的物体信息。同时YOLO可以学习到高度泛化的特征,能将一个域上学到的特征迁移到不同但相关的域上,如在自然图像上做训练的YOLO,在艺术图片上可以得到较好的测试结果。
由于YOLO网格设置比较稀疏,且每个网格只预测2个边界框,其总体预测精度不高,略低于Fast RCNN。其对小物体的检测效果较差,尤其是对密集的小物体表现比较差。
-### 8.3.5 YOLOv2
-
-**标题:《YOLO9000: Better, Faster, Stronger》**
-
-**时间:2016**
+### 8.3.4 YOLOv2
-**出版源:None**
+**YOLOv2 有哪些创新点?**
-**主要链接:**
+YOLOv1虽然检测速度快,但在定位方面不够准确,并且召回率较低。为了提升定位准确度,改善召回率,YOLOv2在YOLOv1的基础上提出了几种改进策略,如下图所示,可以看到,一些改进方法能有效提高模型的mAP。
-- arXiv:https://arxiv.org/abs/1612.08242
-- github(Official):https://pjreddie.com/darknet/yolov2/
-
-YOLOv1虽然检测速度快,但在定位方面不够准确,并且召回率较低。为了提升定位准确度,改善召回率,YOLOv2在YOLOv1的基础上提出了几种改进策略,如下图所示,可以看到,一些改进方法能有效提高模型的mAP.
+1. 大尺度预训练分类
+2. New Network:Darknet-19
+3. 加入anchor

@@ -639,12 +545,12 @@ YOLOv2借鉴了很多其它目标检测方法的一些技巧,如Faster R-CNN
**YOLOv2的训练**
YOLOv2的训练主要包括三个阶段。
-第一阶段:先在ImageNet分类数据集上预训练Darknet-19,此时模型输入为224*224,共训练160个epochs。
-第二阶段:将网络的输入调整为448*448,继续在ImageNet数据集上finetune分类模型,训练10个epochs,此时分类模型的top-1准确度为76.5%,而top-5准确度为93.3%。
+第一阶段:先在ImageNet分类数据集上预训练Darknet-19,此时模型输入为$224\times 224$,共训练160个epochs。
+第二阶段:将网络的输入调整为$448\times 448$,继续在ImageNet数据集上finetune分类模型,训练10个epochs,此时分类模型的top-1准确度为76.5%,而top-5准确度为93.3%。
第三个阶段:修改Darknet-19分类模型为检测模型,并在检测数据集上继续finetune网络。
-网络修改包括(网路结构可视化):移除最后一个卷积层、global avgpooling层以及softmax层,并且新增了三个3*3*2014卷积层,同时增加了一个passthrough层,最后使用1*1卷积层输出预测结果。
+网络修改包括(网路结构可视化):移除最后一个卷积层、global avgpooling层以及softmax层,并且新增了三个$3\times 3 \times 2014$卷积层,同时增加了一个passthrough层,最后使用$1\times 1$卷积层输出预测结果。
-### 8.3.6 YOLO9000
+### 8.3.5 YOLO9000
github:http://pjreddie.com/yolo9000/
@@ -677,20 +583,15 @@ WordTree中每个节点的子节点都属于同一个子类,分层次的对每
YOLO9000使用WordTree混合目标检测数据集和分类数据集,并在其上进行联合训练,使之能实时检测出超过9000个类别的物体,其强大令人赞叹不已。YOLO9000尤其对动物的识别效果很好,但是对衣服或者设备等类别的识别效果不是很好,可能的原因是与目标检测数据集中的数据偏向有关。
-### 8.3.7 YOLOv3
-
-**标题:《YOLOv3: An Incremental Improvement》**
+### 8.3.6 YOLOv3
-**时间:2018**
-
-**出版源:None**
-
-**主要链接:**
+YOLOv3总结了自己在YOLOv2的基础上做的一些尝试性改进,有的尝试取得了成功,而有的尝试并没有提升模型性能。其中有两个值得一提的亮点,一个是使用残差模型,进一步加深了网络结构;另一个是使用FPN架构实现多尺度检测。
-- arXiv:https://arxiv.org/abs/1804.02767
-- github(Official):https://github.com/pjreddie/darknet
+**YOLOv3有哪些创新点?**
-YOLOv3总结了自己在YOLOv2的基础上做的一些尝试性改进,有的尝试取得了成功,而有的尝试并没有提升模型性能。其中有两个值得一提的亮点,一个是使用残差模型,进一步加深了网络结构;另一个是使用FPN架构实现多尺度检测。
+1. 新网络结构:DarkNet-53
+2. 融合FPN
+3. 用逻辑回归替代softmax作为分类器
**1. YOLOv3对网络结构做了哪些改进?**
@@ -710,18 +611,7 @@ YOLOv3借鉴了FPN的思想,从不同尺度提取特征。相比YOLOv2,YOLOv
从YOLOv1到YOLOv2再到YOLO9000、YOLOv3, YOLO经历三代变革,在保持速度优势的同时,不断改进网络结构,同时汲取其它优秀的目标检测算法的各种trick,先后引入anchor box机制、引入FPN实现多尺度检测等。
-### 8.3.8 RetinaNet
-
-**标题:《Focal Loss for Dense Object Detection》**
-
-**时间:2017**
-
-**出版源:ICCV 2017(Best Student Paper Award)**
-
-**主要链接:**
-
-- arXiv:https://arxiv.org/abs/1708.02002
-- github(Official):https://github.com/facebookresearch/Detectron
+### 8.3.7 RetinaNet
**研究背景**
@@ -756,7 +646,7 @@ YOLOv3借鉴了FPN的思想,从不同尺度提取特征。相比YOLOv2,YOLOv
答:因为通过RPN阶段可以减少候选目标区域,而在分类阶段,可以固定前景与背景比值(foreground-to-background ratio)为1:3,或者使用OHEM(online hard example mining)使得前景和背景的数量达到均衡。
-**RetinaNet 创新点**
+**RetinaNet有哪些创新点?**
**概述:**
@@ -875,36 +765,60 @@ Table1是关于RetinaNet和Focal Loss的一些实验结果。(a)是在交叉

-### 8.3.9 RFBNet
+### 8.3.8 RFBNet
+
+**RFBNet有哪些创新点?**
+
+1. 提出RF block(RFB)模块
+
+RFBNet主要想利用一些技巧使得轻量级模型在速度和精度上达到很好的trade-off的检测器。灵感来自人类视觉的感受野结构Receptive Fields (RFs) ,提出了新奇的RF block(RFB)模块,来验证感受野尺寸和方向性的对提高有鉴别鲁棒特征的关系。RFBNet是以主干网络(backbone)为VGG16的SSD来构建的,主要是在Inception的基础上加入了dilated卷积层(dilated convolution),从而有效增大了感受野(receptive field)。整体上因为是基于SSD网络进行改进,所以检测速度还是比较快,同时精度也有一定的保证。
+
+**RFB介绍**
-**标题:《Receptive Field Block Net for Accurate and Fast Object Detection》**
+RFB是一个类似Inception模块的多分支卷积模块,它的内部结构可分为两个组件:多分支卷积层和dilated卷积层。如下图:
-**时间:2017**
+
-**出版源:ECCV 2018**
+**1.多分支卷积层**
+ 根据RF的定义,用多种尺寸的卷积核来实现比固定尺寸更好。具体设计:1.瓶颈结构,1x1-s2卷积减少通道特征,然后加上一个nxn卷积。2.替换5x5卷积为两个3x3卷积去减少参数,然后是更深的非线性层。有些例子,使用1xn和nx1代替nxn卷积;shortcut直连设计来自于ResNet和Inception ResNet V2。3.为了输出,卷积经常有stride=2或者是减少通道,所以直连层用一个不带非线性激活的1x1卷积层。
-**主要链接:**
+**2.Dilated 卷积层**
-arXiv:https://arxiv.org/pdf/1711.07767.pdf
+设计灵感来自Deeplab,在保持参数量和同样感受野的情况下,用来获取更高分辨率的特征。下图展示两种RFB结构:RFB和RFB-s。每个分支都是一个正常卷积后面加一个dilated卷积,主要是尺寸和dilated因子不同。(a)RFB。整体结构上借鉴了Inception的思想,主要不同点在于引入3个dilated卷积层(比如3x3conv,rate=1),这也是RFBNet增大感受野的主要方式之一;(b)RFB-s。RFB-s和RFB相比主要有两个改进,一方面用3x3卷积层代替5x5卷积层,另一方面用1x3和3x1卷积层代替3x3卷积层,主要目的应该是为了减少计算量,类似Inception后期版本对Inception结构的改进。
-github(Official):https://github.com/ruinmessi/RFBNet
+
+RFBNet300的整体结构如下图所示,基本上和SSD类似。RFBNet和SSD不同的是:1、主干网上用两个RFB结构替换原来新增的两层。2、conv4_3和conv7_fc在接预测层之前分别接RFB-s和RFB结构。
+
-- [ ] TODO
+### 8.3.9 M2Det
-### 8.3.10 M2Det
+**M2Det有哪些创新点?**
-**标题:《M2Det: A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network》**
+1. 提出了多层次特征金字塔网络(MLFPN)来构建更有效的特征金字塔,用于检测不同尺度的对象。
-**时间:**2018
+M2Det的整体架构如下所示。M2Det使用backbone和多级特征金字塔网络(MLFPN)从输入图像中提取特征,然后类似于SSD,根据学习的特征生成密集的边界框和类别分数,最后是非最大抑制(NMS)操作以产生最终结果。 MLFPN由三个模块组成:特征融合模块(FFM),简化的U形模块(TUM)和按基于尺度的特征聚合模块(SFAM)。 FFMv1通过融合骨干网络的特征图,将语义信息丰富为基本特征。每个TUM生成一组多尺度特征,然后交替连接的TUM和FFMv2提取多级多尺度特征。此外,SFAM通过按比例缩放的特征连接操作和自适应注意机制将特征聚合到多级特征金字塔中。下面介绍有关M2Det中三个核心模块和网络配置的更多详细信息。
-**出版源:**AAAI 2019
+
-**主要链接:**
+**FFMs**
-- arXiv:https://arxiv.org/abs/1811.04533
-- github(Official):https://github.com/qijiezhao/M2Det
+FFM融合了M2Det中不同层次的特征,这对于构建最终的多级特征金字塔至关重要。它们使用1x1卷积层来压缩输入特征的通道,并使用连接操作来聚合这些特征图。特别是,由于FFMv1以backbone中不同比例的两个特征图作为输入,因此它采用一个上采样操作,在连接操作之前将深度特征重新缩放到相同的尺度。同时,FFMv2采用基本特征和前一个TUM的最大输出特征图 - 这两个具有相同的比例 - 作为输入,并产生下一个TUM的融合特征。 FFMv1和FFMv2的结构细节分别如下图(a)和(b)所示。
+
+
+
+**TUMs**
+
+TUM不同于FPN和RetinaNet,TUM采用简化的U形结构,如上图(c)所示。编码器是一系列3x3,步长为2的卷积层.并且解码器将这些层的输出作为其参考特征集,而原始FPN选择ResNet主干网络中每个阶段的最后一层的输出。此外,在解码器分支的上采样层后添加1x1卷积层和按元素求和的操作,以增强学习能力并保持特征的平滑性。每个TUM的解码器中的所有输出形成当前级别的多尺度特征。整体而言,堆叠TUM的输出形成多层次多尺度特征,而前TUM主要提供浅层特征,中间TUM提供中等特征,后TUM提供深层特征。
+
+**SFAM**
+
+SFAM旨在将由TUM生成的多级多尺度特征聚合成多级特征金字塔,如下图所示。SFAM的第一阶段是沿着信道维度将等效尺度的特征连接在一起。聚合特征金字塔可以表示为$X = [X_1,X_2,...,X_i,...,X_L]$,其中
+$$X_i = Concat(X_{1i}, X_{2i}, ...., X_{Li}) \in R^{W_i \times H_i \times C}$$
+指的是尺度第i个最大的特征。这里,聚合金字塔中的每个比例都包含来自多级深度的特征。但是,简单的连接操作不太适合。在第二阶段,引入了通道注意模块,以促使特征集中在最有益的通道。在SE区块之后,使用全局平均池化来在挤压步骤中生成通道统计z∈RC。
+
+
## 8.4 人脸检测
@@ -946,7 +860,7 @@ github(Official):https://github.com/ruinmessi/RFBNet
(1)缩放图片大小。(不过也可以通过缩放滑动窗的方式,基于深度学习的滑动窗人脸检测方式效率会很慢存在多次重复卷积,所以要采用全卷积神经网络(FCN),用FCN将不能用滑动窗的方法。)
-(2)通过anchor box的方法(如图8.3所示,不要和图8.2混淆,这里是通过特征图预测原图的anchorbox区域,具体在facebox中有描述)。
+(2)通过anchor box的方法(如图8.3所示,不要和图8.2混淆,这里是通过特征图预测原图的anchor box区域,具体在facebox中有描述)。

@@ -964,7 +878,7 @@ github(Official):https://github.com/ruinmessi/RFBNet
原理类似,这里主要看anchorbox的最小box,通过可以通过缩放输入图片实现最小人脸的设定。
-### 8.4.4 如何定位人脸的位置
+### 8.4.4 如何定位人脸的位置?
(1)滑动窗的方式:
@@ -982,7 +896,7 @@ github(Official):https://github.com/ruinmessi/RFBNet
通过特征图映射到图的窗口,通过特征图映射到原图到多个框的方式确定最终识别为人脸的位置。
-### 8.1.5 如何通过一个人脸的多个框确定最终人脸框位置?
+### 8.4.5 如何通过一个人脸的多个框确定最终人脸框位置?

@@ -990,7 +904,7 @@ github(Official):https://github.com/ruinmessi/RFBNet
NMS改进版本有很多,最原始的NMS就是判断两个框的交集,如果交集大于设定的阈值,将删除其中一个框,那么两个框应该怎么选择删除哪一个呢? 因为模型输出有概率值,一般会优选选择概率小的框删除。
-### 8.1.6 基于级联卷积神经网络的人脸检测(Cascade CNN)
+### 8.4.6 基于级联卷积神经网络的人脸检测(Cascade CNN)
1. cascade cnn的框架结构是什么?
@@ -1082,12 +996,85 @@ $$
+## 8.5 目标检测的技巧汇总
+
+1. Data Augmentation
+2. OHEM
+3. NMS:Soft NMS/ Polygon NMS/ Inclined NMS/ ConvNMS/ Yes-Net NMS/ Softer NMS
+4. Multi Scale Training/Testing
+5. 建立小物体与context的关系
+6. 参考relation network
+7. 结合GAN
+8. 结合attention
+
+## 8.6 目标检测的常用数据集
+
+### 8.6.1 PASCAL VOC
+
+ VOC数据集是目标检测经常用的一个数据集,自2005年起每年举办一次比赛,最开始只有4类,到2007年扩充为20个类,共有两个常用的版本:2007和2012。学术界常用5k的train/val 2007和16k的train/val 2012作为训练集,test 2007作为测试集,用10k的train/val 2007+test 2007和16k的train/val 2012作为训练集,test2012作为测试集,分别汇报结果。
+
+### 8.6.2 MS COCO
+
+ COCO数据集是微软团队发布的一个可以用来图像recognition+segmentation+captioning 数据集,该数据集收集了大量包含常见物体的日常场景图片,并提供像素级的实例标注以更精确地评估检测和分割算法的效果,致力于推动场景理解的研究进展。依托这一数据集,每年举办一次比赛,现已涵盖检测、分割、关键点识别、注释等机器视觉的中心任务,是继ImageNet Chanllenge以来最有影响力的学术竞赛之一。
+
+相比ImageNet,COCO更加偏好目标与其场景共同出现的图片,即non-iconic images。这样的图片能够反映视觉上的语义,更符合图像理解的任务要求。而相对的iconic images则更适合浅语义的图像分类等任务。
+
+ COCO的检测任务共含有80个类,在2014年发布的数据规模分train/val/test分别为80k/40k/40k,学术界较为通用的划分是使用train和35k的val子集作为训练集(trainval35k),使用剩余的val作为测试集(minival),同时向官方的evaluation server提交结果(test-dev)。除此之外,COCO官方也保留一部分test数据作为比赛的评测集。
+
+### 8.6.3 Google Open Image
+
+ Open Image是谷歌团队发布的数据集。最新发布的Open Images V4包含190万图像、600个种类,1540万个bounding-box标注,是当前最大的带物体位置标注信息的数据集。这些边界框大部分都是由专业注释人员手动绘制的,确保了它们的准确性和一致性。另外,这些图像是非常多样化的,并且通常包含有多个对象的复杂场景(平均每个图像 8 个)。
+
+### 8.6.4 ImageNet
+
+ ImageNet是一个计算机视觉系统识别项目, 是目前世界上图像识别最大的数据库。ImageNet是美国斯坦福的计算机科学家,模拟人类的识别系统建立的。能够从图片识别物体。Imagenet数据集文档详细,有专门的团队维护,使用非常方便,在计算机视觉领域研究论文中应用非常广,几乎成为了目前深度学习图像领域算法性能检验的“标准”数据集。Imagenet数据集有1400多万幅图片,涵盖2万多个类别;其中有超过百万的图片有明确的类别标注和图像中物体位置的标注。
+## TODO
-## Reference
+- [ ] 目标检测基础知识:mAP、IoU和NMS等
+- [ ] 目标检测评测指标
+- [ ] 目标检测常见标注工具
+- [ ] 完善目标检测的技巧汇总
+- [ ] 目标检测的现在难点和未来发展
+
+## 参考文献
https://github.com/amusi/awesome-object-detection
https://github.com/hoya012/deep_learning_object_detection
https://handong1587.github.io/deep_learning/2015/10/09/object-detection.html
+
+https://www.zhihu.com/question/272322209/answer/482922713
+
+http://blog.leanote.com/post/afanti.deng@gmail.com/b5f4f526490b
+
+https://blog.csdn.net/hw5226349/article/details/78987385
+
+[1] Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2014: 580-587.
+
+[2] Girshick R. Fast r-cnn[C]//Proceedings of the IEEE international conference on computer vision. 2015: 1440-1448.
+
+[3] He K, Zhang X, Ren S, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE transactions on pattern analysis and machine intelligence, 2015, 37(9): 1904-1916.
+
+[4] Ren S, He K, Girshick R, et al. Faster r-cnn: Towards real-time object detection with region proposal networks[C]//Advances in neural information processing systems. 2015: 91-99.
+
+[5] Lin T Y, Dollár P, Girshick R, et al. Feature pyramid networks for object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 2117-2125.
+
+[6] He K, Gkioxari G, Dollár P, et al. Mask r-cnn[C]//Proceedings of the IEEE international conference on computer vision. 2017: 2961-2969.
+
+[7] Liu W, Anguelov D, Erhan D, et al. Ssd: Single shot multibox detector[C]//European conference on computer vision. Springer, Cham, 2016: 21-37.
+
+[8] Fu C Y, Liu W, Ranga A, et al. Dssd: Deconvolutional single shot detector[J]. arXiv preprint arXiv:1701.06659, 2017.
+
+[9] Redmon J, Divvala S, Girshick R, et al. You only look once: Unified, real-time object detection[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 779-788.
+
+[10] Redmon J, Farhadi A. YOLO9000: better, faster, stronger[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 7263-7271.
+
+[11] Redmon J, Farhadi A. Yolov3: An incremental improvement[J]. arXiv preprint arXiv:1804.02767, 2018.
+
+[12] Lin T Y, Goyal P, Girshick R, et al. Focal loss for dense object detection[C]//Proceedings of the IEEE international conference on computer vision. 2017: 2980-2988.
+
+[13] Liu S, Huang D. Receptive field block net for accurate and fast object detection[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 385-400.
+
+[14] Zhao Q, Sheng T, Wang Y, et al. M2Det: A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network[J]. arXiv preprint arXiv:1811.04533, 2018.
diff --git "a/ch09_\345\233\276\345\203\217\345\210\206\345\211\262/img/ch9/9-10-2.jpg" "b/ch09_\345\233\276\345\203\217\345\210\206\345\211\262/img/ch9/9-10-2.jpg"
deleted file mode 100644
index 2d1a937d..00000000
Binary files "a/ch09_\345\233\276\345\203\217\345\210\206\345\211\262/img/ch9/9-10-2.jpg" and /dev/null differ
diff --git "a/ch09_\345\233\276\345\203\217\345\210\206\345\211\262/img/ch9/9-10-2.png" "b/ch09_\345\233\276\345\203\217\345\210\206\345\211\262/img/ch9/9-10-2.png"
new file mode 100644
index 00000000..03d036ff
Binary files /dev/null and "b/ch09_\345\233\276\345\203\217\345\210\206\345\211\262/img/ch9/9-10-2.png" differ
diff --git "a/ch09_\345\233\276\345\203\217\345\210\206\345\211\262/img/ch9/COCO-01.png" "b/ch09_\345\233\276\345\203\217\345\210\206\345\211\262/img/ch9/COCO-01.png"
new file mode 100644
index 00000000..e9e4aef4
Binary files /dev/null and "b/ch09_\345\233\276\345\203\217\345\210\206\345\211\262/img/ch9/COCO-01.png" differ
diff --git "a/ch09_\345\233\276\345\203\217\345\210\206\345\211\262/img/ch9/Cityscapes-01.png" "b/ch09_\345\233\276\345\203\217\345\210\206\345\211\262/img/ch9/Cityscapes-01.png"
new file mode 100644
index 00000000..d29e608b
Binary files /dev/null and "b/ch09_\345\233\276\345\203\217\345\210\206\345\211\262/img/ch9/Cityscapes-01.png" differ
diff --git "a/ch09_\345\233\276\345\203\217\345\210\206\345\211\262/img/ch9/Instance-01.png" "b/ch09_\345\233\276\345\203\217\345\210\206\345\211\262/img/ch9/Instance-01.png"
new file mode 100644
index 00000000..e063a032
Binary files /dev/null and "b/ch09_\345\233\276\345\203\217\345\210\206\345\211\262/img/ch9/Instance-01.png" differ
diff --git "a/ch09_\345\233\276\345\203\217\345\210\206\345\211\262/img/ch9/VOC-01.png" "b/ch09_\345\233\276\345\203\217\345\210\206\345\211\262/img/ch9/VOC-01.png"
new file mode 100644
index 00000000..a0f02fdd
Binary files /dev/null and "b/ch09_\345\233\276\345\203\217\345\210\206\345\211\262/img/ch9/VOC-01.png" differ
diff --git "a/ch09_\345\233\276\345\203\217\345\210\206\345\211\262/img/ch9/semantic-01.png" "b/ch09_\345\233\276\345\203\217\345\210\206\345\211\262/img/ch9/semantic-01.png"
new file mode 100644
index 00000000..8223f766
Binary files /dev/null and "b/ch09_\345\233\276\345\203\217\345\210\206\345\211\262/img/ch9/semantic-01.png" differ
diff --git "a/ch09_\345\233\276\345\203\217\345\210\206\345\211\262/modify_log.txt" "b/ch09_\345\233\276\345\203\217\345\210\206\345\211\262/modify_log.txt"
index cffcd2de..4f180f95 100644
--- "a/ch09_\345\233\276\345\203\217\345\210\206\345\211\262/modify_log.txt"
+++ "b/ch09_\345\233\276\345\203\217\345\210\206\345\211\262/modify_log.txt"
@@ -34,11 +34,12 @@ modify_log---->用来记录修改日志
<----qjhuang-2018-11-9---->
1. 修改部分答案公式,链接
-<----qjhuang-2019-3-15---->
-1. 修改图片错别字
-
其他---->待增加
2. 修改readme内容
3. 修改modify内容
4. 修改章节内容,图片路径等
+<----cfj-2019-01-07---->
+
+1. 新增什么是图像分割?图像分割算法类别
+2. 新增图像分割数据集
\ No newline at end of file
diff --git "a/ch09_\345\233\276\345\203\217\345\210\206\345\211\262/readme.md" "b/ch09_\345\233\276\345\203\217\345\210\206\345\211\262/readme.md"
index 26409571..fc3e1b3e 100644
--- "a/ch09_\345\233\276\345\203\217\345\210\206\345\211\262/readme.md"
+++ "b/ch09_\345\233\276\345\203\217\345\210\206\345\211\262/readme.md"
@@ -6,9 +6,11 @@
电子科大研究生-孙洪卫(wechat:sunhwee,email:hwsun@std.uestc.edu.cn)
电子科大研究生-张越(wechat:tianyuzy)
华南理工研究生-黄钦建(wechat:HQJ199508212176,email:csqjhuang@mail.scut.edu.cn)
-中国农业科学院-杨国峰(wechat:tectal,email:yangguofeng@caas.cn)
+中国农业科学院-杨国峰()
+
+上海大学-陈方杰(wechat:cfj123456cfj,email:1609951733@qq.com)
**贡献者(排名不分先后):**
内容贡献者可自加信息
-###########################################################
+###########################################################
\ No newline at end of file
diff --git "a/ch09_\345\233\276\345\203\217\345\210\206\345\211\262/\347\254\254\344\271\235\347\253\240_\345\233\276\345\203\217\345\210\206\345\211\262.md" "b/ch09_\345\233\276\345\203\217\345\210\206\345\211\262/\347\254\254\344\271\235\347\253\240_\345\233\276\345\203\217\345\210\206\345\211\262.md"
index 992d4c79..ed8e264d 100644
--- "a/ch09_\345\233\276\345\203\217\345\210\206\345\211\262/\347\254\254\344\271\235\347\253\240_\345\233\276\345\203\217\345\210\206\345\211\262.md"
+++ "b/ch09_\345\233\276\345\203\217\345\210\206\345\211\262/\347\254\254\344\271\235\347\253\240_\345\233\276\345\203\217\345\210\206\345\211\262.md"
@@ -1,74 +1,64 @@
-
[TOC]
-```
-作者:scutan90
-编辑者:shw2018(UESTC_孙洪卫_硕,Wechat:sunhwee)
-提交:2018.10.25
-更新:2018.10.31
-```
-
# 第九章 图像分割
-## 9.1 传统的基于CNN的分割方法缺点?
+## 9.1 图像分割算法分类?
+
+图像分割是预测图像中每一个像素所属的类别或者物体。基于深度学习的图像分割算法主要分为两类:
+
+**1.语义分割**
+
+为图像中的每个像素分配一个类别,如把画面中的所有物体都指出它们各自的类别。
+
+
+
+**2.实例分割**
+
+与语义分割不同,实例分割只对特定物体进行类别分配,这一点与目标检测有点相似,但目标检测输出的是边界框和类别,而实例分割输出的是掩膜(mask)和类别。
+
+
+
+## 9.2 传统的基于CNN的分割方法缺点?
-
传统的基于CNN的分割方法:为了对一个像素分类,使用该像素周围的一个图像块作为CNN的输入,用于训练与预测,这种方法主要有几个缺点:
-
1)存储开销大,例如,对每个像素使用15 * 15的图像块,然后不断滑动窗口,将图像块输入到CNN中进行类别判断,因此,需要的存储空间随滑动窗口的次数和大小急剧上升;
-
2)效率低下,相邻像素块基本上是重复的,针对每个像素块逐个计算卷积,这种计算有很大程度上的重复;
-
3)像素块的大小限制了感受区域的大小,通常像素块的大小比整幅图像的大小小很多,只能提取一些局部特征,从而导致分类性能受到限制。
-
而全卷积网络(FCN)则是从抽象的特征中恢复出每个像素所属的类别。即从图像级别的分类进一步延伸到像素级别的分类。
-## 9.2 FCN
-
-### 9.2.1 FCN改变了什么?
-
-
-对于一般的分类CNN网络,如VGG和Resnet,都会在网络的最后加入一些全连接层,经过softmax后就可以获得类别概率信息。但是这个概率信息是1维的,即只能标识整个图片的类别,不能标识每个像素点的类别,所以这种全连接方法不适用于图像分割。
+## 9.3 FCN
-
+### 9.3.1 FCN改变了什么?
-
-而FCN提出可以把后面几个全连接都换成卷积,这样就可以获得一张2维的feature map,后接softmax获得每个像素点的分类信息,从而解决了分割问题,如图4。
+ 对于一般的分类CNN网络,如VGG和Resnet,都会在网络的最后加入一些全连接层,经过softmax后就可以获得类别概率信息。但是这个概率信息是1维的,即只能标识整个图片的类别,不能标识每个像素点的类别,所以这种全连接方法不适用于图像分割。
+ 而FCN提出可以把后面几个全连接都换成卷积,这样就可以获得一张2维的feature map,后接softmax层获得每个像素点的分类信息,从而解决了分割问题,如图4。

图 4
-### 9.2.2 FCN网络结构?
+### 9.3.2 FCN网络结构?
-
-FCN对图像进行像素级的分类,从而解决了语义级别的图像分割(semantic segmentation)问题。与经典的CNN在卷积层之后使用全连接层得到固定长度的特征向量进行分类(全联接层+softmax输出)不同,FCN可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷积层的feature map进行上采样, 使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生了一个预测, 同时保留了原始输入图像中的空间信息, 最后在上采样的特征图上进行逐像素分类。
-下图是语义分割所采用的全卷积网络(FCN)的结构示意图:
+ FCN对图像进行像素级的分类,从而解决了语义级别的图像分割(semantic segmentation)问题。与经典的CNN在卷积层之后使用全连接层得到固定长度的特征向量进行分类(全联接层+softmax输出)不同,FCN可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷积层的feature map进行上采样, 使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生了一个预测, 同时保留了原始输入图像中的空间信息, 最后在上采样的特征图上进行逐像素分类。
+ 下图是语义分割所采用的全卷积网络(FCN)的结构示意图:

-### 9.2.3 全卷积网络举例?
+### 9.3.3 全卷积网络举例?
-
-通常CNN网络在卷积层之后会接上若干个全连接层, 将卷积层产生的特征图(feature map)映射成一个固定长度的特征向量。以AlexNet为代表的经典CNN结构适合于图像级的分类和回归任务,因为它们最后都得到整个输入图像的一个概率向量,比如AlexNet的ImageNet模型输出一个1000维的向量表示输入图像属于每一类的概率(softmax归一化)。
+ 通常CNN网络在卷积层之后会接上若干个全连接层, 将卷积层产生的特征图(feature map)映射成一个固定长度的特征向量。以AlexNet为代表的经典CNN结构适合于图像级的分类和回归任务,因为它们最后都得到整个输入图像的一个概率向量。

-如图所示:
+如上图所示:
(1)在CNN中, 猫的图片输入到AlexNet, 得到一个长为1000的输出向量, 表示输入图像属于每一类的概率, 其中在“tabby cat”这一类统计概率最高, 用来做分类任务。
-(2)FCN与CNN的区别在于把CNN最后的全连接层转换成卷积层,输出的是一张已经Label好的图片, 而这个图片就可以做语义分割。
+(2)FCN与CNN的区别在于把CNN最后的全连接层转换成卷积层,输出的是一张已经带有标签的图片, 而这个图片就可以做语义分割。
(3)CNN的强大之处在于它的多层结构能自动学习特征,并且可以学习到多个层次的特征: 较浅的卷积层感知域较小,学习到一些局部区域的特征;较深的卷积层具有较大的感知域,能够学习到更加抽象一些的特征。高层的抽象特征对物体的大小、位置和方向等敏感性更低,从而有助于识别性能的提高, 所以我们常常可以将卷积层看作是特征提取器。
@@ -765,7 +755,7 @@ DenseNet的Block结构如上图所示。
1*1卷积核的目的:减少输入的特征图数量,这样既能降维减少计算量,又能融合各个通道的特征。我们将使用BottleNeck Layers的DenseNet表示为DenseNet-B。(在论文的实验里,将1×1×n小卷积里的n设置为4k,k为每个H产生的特征图数量)
-
+
上图是DenseNet网络的整体网络结构示意图。其中1*1卷积核的目的是进一步压缩参数,并且在Transition Layer层有个参数Reduction(范围是0到1),表示将这些输出缩小到原来的多少倍,默认是0.5,这样传给下一个Dense Block的时候channel数量就会减少一半。当Reduction的值小于1的时候,我们就把带有这种层的网络称为DenseNet-C。
@@ -777,3 +767,37 @@ DenseNet网络的优点包括:
- 更有效地利用了feature
- 一定程度上较少了参数数量
- 一定程度上减轻了过拟合
+
+## 9.12 图像分割的常用数据集
+
+### 9.12.1 PASCAL VOC
+
+VOC 数据集分为20类,包括背景为21类,分别如下:
+- Person: person
+- Animal: bird, cat, cow, dog, horse, sheep
+- Vehicle: aeroplane, bicycle, boat, bus, car, motorbike, train
+- Indoor: bottle, chair, dining table, potted plant, sofa, tv/monitor
+
+VOC 数据集中用于分割比赛的图片实例如下,包含原图以及图像分类分割和图像物体分割两种图(PNG格式)。图像分类分割是在20种物体中,ground-turth图片上每个物体的轮廓填充都有一个特定的颜色,一共20种颜色。
+
+
+
+### 9.12.2 MS COCO
+
+MS COCO 是最大图像分割数据集,提供的类别有 80 类,有超过 33 万张图片,其中 20 万张有标注,整个数据集中个体的数目超过 150 万个。MS COCO是目前难度最大,挑战最高的图像分割数据集。
+
+
+
+### 9.12.3 Cityscapes
+
+Cityscapes 是驾驶领域进行效果和性能测试的图像分割数据集,它包含了5000张精细标注的图像和20000张粗略标注的图像,这些图像包含50个城市的不同场景、不同背景、不同街景,以及30类涵盖地面、建筑、交通标志、自然、天空、人和车辆等的物体标注。Cityscapes评测集有两项任务:像素级(Pixel-level)图像场景分割(以下简称语义分割)与实例级(Instance-level)图像场景分割(以下简称实例分割)。
+
+
+
+TODO
+
+- [ ] 图像分割数据集标注工具
+- [ ] 图像分割评价标准
+- [ ] 全景分割
+- [ ] UNet++
+
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/img/ch11/readme.md" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/img/ch11/readme.md"
deleted file mode 100644
index f099ebf1..00000000
--- "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/img/ch11/readme.md"
+++ /dev/null
@@ -1,2 +0,0 @@
-Add the corresponding chapter picture under img/ch*
-��img/ch*�����Ӷ�Ӧ�½�ͼƬ
\ No newline at end of file
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/00864b9c79b810761fec244e89a0ea08.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/00864b9c79b810761fec244e89a0ea08.jpg"
new file mode 100644
index 00000000..cf8a5121
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/00864b9c79b810761fec244e89a0ea08.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/02cf7802ec9aabdccf710442cda04ccb.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/02cf7802ec9aabdccf710442cda04ccb.jpg"
new file mode 100644
index 00000000..b018e177
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/02cf7802ec9aabdccf710442cda04ccb.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/07e7da7afdea5c38f470b3a06d8137e2.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/07e7da7afdea5c38f470b3a06d8137e2.jpg"
new file mode 100644
index 00000000..8e6c2809
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/07e7da7afdea5c38f470b3a06d8137e2.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/0854b7278c50c5e2b0bbe61d273721c1.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/0854b7278c50c5e2b0bbe61d273721c1.jpg"
new file mode 100644
index 00000000..d34a3df7
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/0854b7278c50c5e2b0bbe61d273721c1.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/09cb64cf3f3ceb5d87369e41c29d34bf.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/09cb64cf3f3ceb5d87369e41c29d34bf.jpg"
new file mode 100644
index 00000000..7861d49b
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/09cb64cf3f3ceb5d87369e41c29d34bf.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/0b5d1ded61af9b38fedb2746a7dda23e.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/0b5d1ded61af9b38fedb2746a7dda23e.jpg"
new file mode 100644
index 00000000..e2dbeb68
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/0b5d1ded61af9b38fedb2746a7dda23e.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/0f3a57ffdefd178a4db06b52c2d53b58.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/0f3a57ffdefd178a4db06b52c2d53b58.jpg"
new file mode 100644
index 00000000..d4d7cb59
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/0f3a57ffdefd178a4db06b52c2d53b58.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/103de3658cbb97ad4c24bafe28f9d957.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/103de3658cbb97ad4c24bafe28f9d957.jpg"
new file mode 100644
index 00000000..6f940fa1
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/103de3658cbb97ad4c24bafe28f9d957.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542808441403.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542808441403.png"
new file mode 100644
index 00000000..ad0a0408
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542808441403.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542812321831.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542812321831.png"
new file mode 100644
index 00000000..c620942f
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542812321831.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542812440636.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542812440636.png"
new file mode 100644
index 00000000..c620942f
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542812440636.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542812748062.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542812748062.png"
new file mode 100644
index 00000000..e9d4896c
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542812748062.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542817257337.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542817257337.png"
new file mode 100644
index 00000000..47ca18f5
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542817257337.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542817481582.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542817481582.png"
new file mode 100644
index 00000000..cd1ff206
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542817481582.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542820738631.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542820738631.png"
new file mode 100644
index 00000000..96b03027
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542820738631.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542820752570.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542820752570.png"
new file mode 100644
index 00000000..65ed0664
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542820752570.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542820774326.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542820774326.png"
new file mode 100644
index 00000000..01864641
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542820774326.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542820797637.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542820797637.png"
new file mode 100644
index 00000000..8e378853
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542820797637.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542821989163.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542821989163.png"
new file mode 100644
index 00000000..46899e4c
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542821989163.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542822045307.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542822045307.png"
new file mode 100644
index 00000000..cea8d2a1
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542822045307.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542822087844.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542822087844.png"
new file mode 100644
index 00000000..168bdd04
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542822087844.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542822226596.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542822226596.png"
new file mode 100644
index 00000000..27ccbdce
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542822226596.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542822305161.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542822305161.png"
new file mode 100644
index 00000000..659e86f6
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542822305161.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542822326035.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542822326035.png"
new file mode 100644
index 00000000..7d0e2ef0
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542822326035.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542822355361.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542822355361.png"
new file mode 100644
index 00000000..7d0e2ef0
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542822355361.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542822398717.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542822398717.png"
new file mode 100644
index 00000000..c5282076
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542822398717.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542822474045.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542822474045.png"
new file mode 100644
index 00000000..c064b44c
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542822474045.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542822558549.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542822558549.png"
new file mode 100644
index 00000000..7f64fbb2
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542822558549.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542822578502.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542822578502.png"
new file mode 100644
index 00000000..fbfa2d82
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542822578502.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542822851294.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542822851294.png"
new file mode 100644
index 00000000..36f573b1
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542822851294.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542822971212.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542822971212.png"
new file mode 100644
index 00000000..62d24a6a
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542822971212.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542823019007.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542823019007.png"
new file mode 100644
index 00000000..14cf119d
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542823019007.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542823210556.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542823210556.png"
new file mode 100644
index 00000000..986273c6
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542823210556.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542823438846.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542823438846.png"
new file mode 100644
index 00000000..a3c4dbc3
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542823438846.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542823455820.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542823455820.png"
new file mode 100644
index 00000000..7cfd51d9
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542823455820.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542823474720.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542823474720.png"
new file mode 100644
index 00000000..08be3ab2
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542823474720.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542823505559.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542823505559.png"
new file mode 100644
index 00000000..82e1d52e
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542823505559.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542823539428.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542823539428.png"
new file mode 100644
index 00000000..65e6e43c
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542823539428.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542823589390.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542823589390.png"
new file mode 100644
index 00000000..e238a80e
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542823589390.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542823632598.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542823632598.png"
new file mode 100644
index 00000000..fda1ec56
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542823632598.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542823895008.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542823895008.png"
new file mode 100644
index 00000000..12b72750
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542823895008.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542824091867.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542824091867.png"
new file mode 100644
index 00000000..0657cb71
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542824091867.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542824195602.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542824195602.png"
new file mode 100644
index 00000000..9c60006d
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542824195602.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542824318155.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542824318155.png"
new file mode 100644
index 00000000..5d7ce48e
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542824318155.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542824486343.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542824486343.png"
new file mode 100644
index 00000000..54c6c93b
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542824486343.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542824497736.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542824497736.png"
new file mode 100644
index 00000000..9e385670
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542824497736.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542824918145.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542824918145.png"
new file mode 100644
index 00000000..149a39d6
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542824918145.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542825063804.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542825063804.png"
new file mode 100644
index 00000000..106d7143
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542825063804.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542825205225.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542825205225.png"
new file mode 100644
index 00000000..ce1afcb0
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542825205225.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542825237816.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542825237816.png"
new file mode 100644
index 00000000..cff94112
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542825237816.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542825575318.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542825575318.png"
new file mode 100644
index 00000000..93424754
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542825575318.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542825908870.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542825908870.png"
new file mode 100644
index 00000000..1e7e9057
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542825908870.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542825965528.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542825965528.png"
new file mode 100644
index 00000000..b98512b8
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542825965528.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542826334834.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542826334834.png"
new file mode 100644
index 00000000..db11e5a6
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542826334834.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542826461988.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542826461988.png"
new file mode 100644
index 00000000..ba7d28b3
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542826461988.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542826471739.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542826471739.png"
new file mode 100644
index 00000000..208995f0
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542826471739.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542826475517.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542826475517.png"
new file mode 100644
index 00000000..208995f0
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542826475517.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542826542007.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542826542007.png"
new file mode 100644
index 00000000..497b79f6
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542826542007.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542826743056.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542826743056.png"
new file mode 100644
index 00000000..1d0602a3
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542826743056.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542826809443.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542826809443.png"
new file mode 100644
index 00000000..87c80588
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542826809443.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542826826991.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542826826991.png"
new file mode 100644
index 00000000..44eb01be
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542826826991.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542827203409.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542827203409.png"
new file mode 100644
index 00000000..21240915
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542827203409.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542828076050.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542828076050.png"
new file mode 100644
index 00000000..0cb0dd01
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542828076050.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542828185735.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542828185735.png"
new file mode 100644
index 00000000..daee5556
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542828185735.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542828483223.png" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542828483223.png"
new file mode 100644
index 00000000..daee5556
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1542828483223.png" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1cb62df2f6209e4c20fe5592dcc62918.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1cb62df2f6209e4c20fe5592dcc62918.jpg"
new file mode 100644
index 00000000..58e52518
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1cb62df2f6209e4c20fe5592dcc62918.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1dffeb6986cf18354dafed0e1c08e09f.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1dffeb6986cf18354dafed0e1c08e09f.jpg"
new file mode 100644
index 00000000..4fcc13d2
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/1dffeb6986cf18354dafed0e1c08e09f.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/20c3e041d5f5fdd3eceec976060c8b89.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/20c3e041d5f5fdd3eceec976060c8b89.jpg"
new file mode 100644
index 00000000..ae460d6e
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/20c3e041d5f5fdd3eceec976060c8b89.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/2c8363bdbb6739578197ca68d05d362c.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/2c8363bdbb6739578197ca68d05d362c.jpg"
new file mode 100644
index 00000000..26483989
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/2c8363bdbb6739578197ca68d05d362c.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/3d0802d34834b3aa3a8290fc194bc5be.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/3d0802d34834b3aa3a8290fc194bc5be.jpg"
new file mode 100644
index 00000000..d1b06822
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/3d0802d34834b3aa3a8290fc194bc5be.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/3ea390bee08e90a87c4990322469592e.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/3ea390bee08e90a87c4990322469592e.jpg"
new file mode 100644
index 00000000..f4d1d73c
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/3ea390bee08e90a87c4990322469592e.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/40f2c27caa934c2d220d1d43ba0cef51.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/40f2c27caa934c2d220d1d43ba0cef51.jpg"
new file mode 100644
index 00000000..38ca9dec
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/40f2c27caa934c2d220d1d43ba0cef51.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/42d0f131b458659a0e642a3d0a156b09.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/42d0f131b458659a0e642a3d0a156b09.jpg"
new file mode 100644
index 00000000..cbb91921
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/42d0f131b458659a0e642a3d0a156b09.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/4761dc00b96100769281e7c90011d09b.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/4761dc00b96100769281e7c90011d09b.jpg"
new file mode 100644
index 00000000..9047608c
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/4761dc00b96100769281e7c90011d09b.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/4abacd82901988c3e0a98bdb07b2abc6.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/4abacd82901988c3e0a98bdb07b2abc6.jpg"
new file mode 100644
index 00000000..f3104a66
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/4abacd82901988c3e0a98bdb07b2abc6.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/4f913ade7e7a16426fd809f6ac0af7b2.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/4f913ade7e7a16426fd809f6ac0af7b2.jpg"
new file mode 100644
index 00000000..71f5203d
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/4f913ade7e7a16426fd809f6ac0af7b2.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/52de242e850347b9f0b7a7ad8dfa84b0.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/52de242e850347b9f0b7a7ad8dfa84b0.jpg"
new file mode 100644
index 00000000..61ae000b
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/52de242e850347b9f0b7a7ad8dfa84b0.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/5dc622ed6ec524048bee9be3da965903.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/5dc622ed6ec524048bee9be3da965903.jpg"
new file mode 100644
index 00000000..98d80ab5
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/5dc622ed6ec524048bee9be3da965903.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/5de65e5b7d2026c108b653d3ea60ffc2.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/5de65e5b7d2026c108b653d3ea60ffc2.jpg"
new file mode 100644
index 00000000..bde80b63
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/5de65e5b7d2026c108b653d3ea60ffc2.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/602723a1d3ce0f3abe7c591a8e4bb6ec.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/602723a1d3ce0f3abe7c591a8e4bb6ec.jpg"
new file mode 100644
index 00000000..1161226d
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/602723a1d3ce0f3abe7c591a8e4bb6ec.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/631e5aab4e0680c374793804817bfbb6.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/631e5aab4e0680c374793804817bfbb6.jpg"
new file mode 100644
index 00000000..516278d1
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/631e5aab4e0680c374793804817bfbb6.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/65162f4b973a249a4f9788b2af998bdb.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/65162f4b973a249a4f9788b2af998bdb.jpg"
new file mode 100644
index 00000000..91ab5bd4
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/65162f4b973a249a4f9788b2af998bdb.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/693ac94b61c21e30e846aa9ecfb1883c.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/693ac94b61c21e30e846aa9ecfb1883c.jpg"
new file mode 100644
index 00000000..0d593a5c
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/693ac94b61c21e30e846aa9ecfb1883c.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/6fe355b691b487cc87f5ba4afd2dda3d.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/6fe355b691b487cc87f5ba4afd2dda3d.jpg"
new file mode 100644
index 00000000..db3c3f05
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/6fe355b691b487cc87f5ba4afd2dda3d.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/71fcf4fee7500478ada89e52d72dcda1.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/71fcf4fee7500478ada89e52d72dcda1.jpg"
new file mode 100644
index 00000000..ae0f2cba
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/71fcf4fee7500478ada89e52d72dcda1.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/7caec88931b25c3a023021bccab48ae3.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/7caec88931b25c3a023021bccab48ae3.jpg"
new file mode 100644
index 00000000..6b1de455
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/7caec88931b25c3a023021bccab48ae3.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/857c3d2e84a6e9d5d31965252bcc9202.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/857c3d2e84a6e9d5d31965252bcc9202.jpg"
new file mode 100644
index 00000000..67ff11da
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/857c3d2e84a6e9d5d31965252bcc9202.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/8d017ade0d332c15d1a242a61fd447ec.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/8d017ade0d332c15d1a242a61fd447ec.jpg"
new file mode 100644
index 00000000..2d4b3d20
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/8d017ade0d332c15d1a242a61fd447ec.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/8d428fc8967ec734bd394cacfbfba40f.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/8d428fc8967ec734bd394cacfbfba40f.jpg"
new file mode 100644
index 00000000..06921fc4
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/8d428fc8967ec734bd394cacfbfba40f.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/93f17238115b84db66ab5d56cfddacdd.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/93f17238115b84db66ab5d56cfddacdd.jpg"
new file mode 100644
index 00000000..7359dfc0
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/93f17238115b84db66ab5d56cfddacdd.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/966b912ade32d8171f18d2ea79b91b04.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/966b912ade32d8171f18d2ea79b91b04.jpg"
new file mode 100644
index 00000000..ab01cce6
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/966b912ade32d8171f18d2ea79b91b04.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/9898eb379bf1d726962b5928cfed69b0.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/9898eb379bf1d726962b5928cfed69b0.jpg"
new file mode 100644
index 00000000..0a387aa6
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/9898eb379bf1d726962b5928cfed69b0.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/a1122fb92521b6d3c484d264560473dc.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/a1122fb92521b6d3c484d264560473dc.jpg"
new file mode 100644
index 00000000..ee85f853
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/a1122fb92521b6d3c484d264560473dc.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/a2a7e5cc9e4325b6f23d79efec9c51da.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/a2a7e5cc9e4325b6f23d79efec9c51da.jpg"
new file mode 100644
index 00000000..ff871c14
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/a2a7e5cc9e4325b6f23d79efec9c51da.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/a3db84158d9b6454adff88dbe4fa5d28.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/a3db84158d9b6454adff88dbe4fa5d28.jpg"
new file mode 100644
index 00000000..b074b8f6
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/a3db84158d9b6454adff88dbe4fa5d28.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/a814da5329927aca7b2a02cefb2e3f44.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/a814da5329927aca7b2a02cefb2e3f44.jpg"
new file mode 100644
index 00000000..a8346126
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/a814da5329927aca7b2a02cefb2e3f44.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/aa10d36f758430dd4ff72d2bf6a76a6c.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/aa10d36f758430dd4ff72d2bf6a76a6c.jpg"
new file mode 100644
index 00000000..c4dec113
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/aa10d36f758430dd4ff72d2bf6a76a6c.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/ab78b954fa6c763bdc99072fb5a1f670.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/ab78b954fa6c763bdc99072fb5a1f670.jpg"
new file mode 100644
index 00000000..32fb745d
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/ab78b954fa6c763bdc99072fb5a1f670.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/ad24cbd2e510f912a72a82a2acfe92de.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/ad24cbd2e510f912a72a82a2acfe92de.jpg"
new file mode 100644
index 00000000..b7388092
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/ad24cbd2e510f912a72a82a2acfe92de.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/b1630ca5d004d4b430672c8b8ce7fb90.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/b1630ca5d004d4b430672c8b8ce7fb90.jpg"
new file mode 100644
index 00000000..c888b75e
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/b1630ca5d004d4b430672c8b8ce7fb90.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/b4513fe8c46d8e429d9f5526fd66c57a.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/b4513fe8c46d8e429d9f5526fd66c57a.jpg"
new file mode 100644
index 00000000..d01eaf04
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/b4513fe8c46d8e429d9f5526fd66c57a.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/c8e12bd34619cf9e3111be3e728b3aa6.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/c8e12bd34619cf9e3111be3e728b3aa6.jpg"
new file mode 100644
index 00000000..90d544db
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/c8e12bd34619cf9e3111be3e728b3aa6.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/cf52633ba21fdb92e33853b80eb07ee0.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/cf52633ba21fdb92e33853b80eb07ee0.jpg"
new file mode 100644
index 00000000..73f3449b
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/cf52633ba21fdb92e33853b80eb07ee0.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/d8427680025580b726d99b1143bffd94.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/d8427680025580b726d99b1143bffd94.jpg"
new file mode 100644
index 00000000..ca87e066
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/d8427680025580b726d99b1143bffd94.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/dd15dfa395f495d41806595f58f3754d.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/dd15dfa395f495d41806595f58f3754d.jpg"
new file mode 100644
index 00000000..cb796618
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/dd15dfa395f495d41806595f58f3754d.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/e654d14df0b44ee4e8a0e505c654044b.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/e654d14df0b44ee4e8a0e505c654044b.jpg"
new file mode 100644
index 00000000..aae50871
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/e654d14df0b44ee4e8a0e505c654044b.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/f0cccba910e0833cb8455d4fe84a7dc8.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/f0cccba910e0833cb8455d4fe84a7dc8.jpg"
new file mode 100644
index 00000000..60008837
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/f0cccba910e0833cb8455d4fe84a7dc8.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/f852afecfb647f6b2727c4dcbabb1323.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/f852afecfb647f6b2727c4dcbabb1323.jpg"
new file mode 100644
index 00000000..c0894f84
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/f852afecfb647f6b2727c4dcbabb1323.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/fa08900e89bfd53cc28345d21bc6aca0.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/fa08900e89bfd53cc28345d21bc6aca0.jpg"
new file mode 100644
index 00000000..aaeabf7e
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/fa08900e89bfd53cc28345d21bc6aca0.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/fa99e7c6f1985ddc380d04d4eb3adf26.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/fa99e7c6f1985ddc380d04d4eb3adf26.jpg"
new file mode 100644
index 00000000..e12d19c4
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/fa99e7c6f1985ddc380d04d4eb3adf26.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/fcbe02803e45f6455a4602b645b472c5.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/fcbe02803e45f6455a4602b645b472c5.jpg"
new file mode 100644
index 00000000..1772f912
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/fcbe02803e45f6455a4602b645b472c5.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/fed8fcb90eedfa6d3c4b11464c3440cb.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/fed8fcb90eedfa6d3c4b11464c3440cb.jpg"
new file mode 100644
index 00000000..59eca95b
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/fed8fcb90eedfa6d3c4b11464c3440cb.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/ffdf5ed6d284f09e2f3c8d3e062c9bc2.jpg" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/ffdf5ed6d284f09e2f3c8d3e062c9bc2.jpg"
new file mode 100644
index 00000000..9206f709
Binary files /dev/null and "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/media/ffdf5ed6d284f09e2f3c8d3e062c9bc2.jpg" differ
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/modify_log.txt" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/modify_log.txt"
deleted file mode 100644
index c5e0e582..00000000
--- "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/modify_log.txt"
+++ /dev/null
@@ -1,20 +0,0 @@
-该文件用来记录修改日志:
-<----shw2018-2018-10-25---->
-1. 新增章节markdown文件
-
-<----shw2018-2018-10-28---->
-1. 修改错误内容和格式
-2. 修改图片路径
-
-<----shw2018-2018-10-31---->
-1. 新增第九章文件夹,里面包括:
-img---->用来放对应章节图片,例如路径./img/ch9/ch_*
-readme.md---->章节维护贡献者信息
-modify_log---->用来记录修改日志
-第 * 章_xxx.md---->对应章节markdown文件
-第 * 章_xxx.pdf---->对应章节生成pdf文件,便于阅读
-其他---->待增加
-2. 修改readme内容
-3. 修改modify内容
-4. 修改章节内容,图片路径等
-
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/readme.md" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/readme.md"
index 4ebe256b..fa0d10dd 100644
--- "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/readme.md"
+++ "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/readme.md"
@@ -1,14 +1,24 @@
###########################################################
-### 深度学习500问-第 * 章 xxx
+### 深度学习500问-第 7 章 xxx
**负责人(排名不分先后):**
xxx研究生-xxx(xxx)
xxx博士生-xxx
-xxx-xxx
+xxx-xxx
+
+中科院-王晋东
+郭晓锋-中科院-爱奇艺
**贡献者(排名不分先后):**
内容贡献者可自加信息
+郭晓锋-中科院-爱奇艺
+
+
+
+Add the corresponding chapter picture under img/ch*
+在img/ch*下添加对应章节图片
+
###########################################################
\ No newline at end of file
diff --git "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/\347\254\254\345\215\201\344\270\200\347\253\240_\350\277\201\347\247\273\345\255\246\344\271\240.md" "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/\347\254\254\345\215\201\344\270\200\347\253\240_\350\277\201\347\247\273\345\255\246\344\271\240.md"
index 0edeb8e3..f247a026 100644
--- "a/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/\347\254\254\345\215\201\344\270\200\347\253\240_\350\277\201\347\247\273\345\255\246\344\271\240.md"
+++ "b/ch11_\350\277\201\347\247\273\345\255\246\344\271\240/\347\254\254\345\215\201\344\270\200\347\253\240_\350\277\201\347\247\273\345\255\246\344\271\240.md"
@@ -1,15 +1,22 @@
[TOC]
-# 第十章 迁移学习
+# 第十一章 迁移学习
+ 本章主要简明地介绍了迁移学习的基本概念、迁移学习的必要性、研究领域和基本方法。重点介绍了几大类常用的迁移学习方法:数据分布自适应方法、特征选择方法、子空间学习方法、以及目前最热门的深度迁移学习方法。除此之外,我们也结合最近的一些研究成果对未来迁移学习进行了一些展望。并提供了一些迁移学习领域的常用学习资源,以方便感兴趣的读者快速开始学习。
-## 10.1 为什么需要迁移学习?(中科院计算所-王晋东)
+## 11.1 迁移学习基础知识
+
+### 11.1.1 什么是迁移学习?
+
+找到目标问题的相似性,迁移学习任务就是从相似性出发,将旧领域(domain)学习过的模型应用在新领域上。
+
+### 11.1.2 为什么需要迁移学习?
1. **大数据与少标注的矛盾**:虽然有大量的数据,但往往都是没有标注的,无法训练机器学习模型。人工进行数据标定太耗时。
2. **大数据与弱计算的矛盾**:普通人无法拥有庞大的数据量与计算资源。因此需要借助于模型的迁移。
3. **普适化模型与个性化需求的矛盾**:即使是在同一个任务上,一个模型也往往难以满足每个人的个性化需求,比如特定的隐私设置。这就需要在不同人之间做模型的适配。
4. **特定应用(如冷启动)的需求**。
-## 10.2 迁移学习的基本问题有哪些?(中科院计算所-王晋东)
+### 11.1.3 迁移学习的基本问题有哪些?
基本问题主要有3个:
@@ -17,7 +24,7 @@
- **What to transfer**: 给定一个目标领域,如何找到相对应的源领域,然后进行迁移?(源领域选择)
- **When to transfer**: 什么时候可以进行迁移,什么时候不可以?(避免负迁移)
-## 10.3 迁移学习有哪些常用概念?(KeyFoece)
+### 11.1.4 迁移学习有哪些常用概念?
- 基本定义
- **域(Domain)**:数据特征和特征分布组成,是学习的主体
@@ -41,7 +48,7 @@

-## 10.4 迁移学习与传统机器学习有什么区别?(KeyFoece)
+### 11.1.5 迁移学习与传统机器学习有什么区别?
| | 迁移学习 | 传统机器学习 |
| -------- | -------------------------- | -------------------- |
@@ -50,8 +57,7 @@
| 建模 | 可以重用之前的模型 | 每个任务分别建模 |

-
-## 10.5 迁移学习的基本思路?(中科院计算所-王晋东)
+### 11.1.6 迁移学习的核心及度量准则?
**迁移学习的总体思路可以概括为**:开发算法来最大限度地利用有标注的领域的知识,来辅助目标领域的知识获取和学习。
@@ -61,7 +67,7 @@
**一句话总结: 相似性是核心,度量准则是重要手段。**
-## 10.6 迁移学习与其他概念的区别(Limber)
+### 11.1.7 迁移学习与其他概念的区别?
1. 迁移学习与多任务学习关系:
* **多任务学习**:多个相关任务一起协同学习;
@@ -69,83 +75,14 @@
2. 迁移学习与领域自适应:**领域自适应**:使两个特征分布不一致的domain一致。
3. 迁移学习与协方差漂移:**协方差漂移**:数据的条件概率分布发生变化。
-## 10.7 什么是多任务学习?
-在迁移学习中,从**任务A**里学习只是然后迁移到**任务B**。
-在多任务学习中,同时开始学习的,试图让**单个神经网络**同时做**几件事情**,然后希望这里每个任务都能帮到其他所有任务。
-> 指多个相关任务一起协同学习
-
-## 10.8 多任务学习有什么意义?
-1. 第一,如果你训练的一组任务,可以共用**低层次特征**。
-对于无人驾驶的例子,同时识别交通灯、汽车和行人是有道理的,这些物体有相似的特征,也许能帮你识别停车标志,因为这些都是道路上的特征。
-2. 第二,这个**准则没有那么绝对**,所以不一定是对的。
-但我从很多成功的多任务学习案例中看到,如果每个任务的数据量很接近,你还记得迁移学习时,你从任务学到知识然后迁移到任务,所以如果任务有**1百万个样本**,任务只有**1000个样本**,那么你从这**1百万个样本**学到的知识,真的可以帮你增强对更小数据集任务的训练。
-那么多任务学习又怎么样呢?在多任务学习中,你通常有更多任务而不仅仅是两个,所以也许你有,以前我们有**4个任务**,但比如说你要完成**100个任务**,而你要做多任务学习,尝试同时识别**100种不同类型的物体**。你可能会发现,每个任务大概有**1000个样本**。
-所以如果你专注加强单个任务的性能,比如我们专注加强第**100个任务**的表现,我们用表示,如果你试图单独去做这个最后的任务,你只有**1000个样本**去训练这个任务,这是**100项任务**之一,而通过在**其他99项任务**的训练,这些加起来可以一共有**99000个样本**,这可能大幅提升算法性能,可以提供很多知识来增强这个任务的性能。
-不然对于任务,只有**1000个样本**的训练集,效果可能会很差。如果有对称性,这**其他99个任务**,也许能提供一些数据或提供一些知识来帮到这**100个任务中**的每一个任务。所以第二点不是绝对正确的准则,但我通常会看的是如果你专注于单项任务,如果想要从多任务学习得到很大性能提升,那么其他任务加起来必须要有比单个任务大得多的数据量。
-要满足这个条件,其中一种方法是,比如右边这个例子这样,或者如果每个任务中的数据量很相近,但关键在于, 如果对于单个任务你已经有**1000个样本**了,那么对于所有其他任务,你最好有超过**1000个样 本**,这样其他任务的知识才能帮你改善这个任务的性能。
-3. 最后多任务学习往往在以下场合**更有意义**,当你可以训练一个足够大的神经网络,同时做好所有的工作,所以多任务学习的**替代方法**是为每个任务**训练一个单独的神经网络**。
-所以不是训练单个神经网络同时处理行人、汽车、停车标志和交通灯检测。你可以训练一个**用于行人检测的神经网络**,一个**用于汽车检测的神经网络**,一个**用于停车标志检测的神经网络**和一个**用于交通信号灯检测的神经网络**。
-那么研究员 Rich Carona 几年前发现的是什么呢?
-多任务学习会降低性能的唯一情况,和训练单个神经网络相比性能更低的情况就是你的神经网络还不够大。 但如果你可以训练一个足够大的神经网络,那么多任务学习肯定**不会或者很少**会**降低性能**,我们都希望它可以提升性能,比单独训练神经网络来单独完成各个任务**性能要更好**。
-4. 所以**这就是多任务学习**,在实践中,多任务学习的使用频率要低于迁移学习。
-我看到很多迁移学习的应用,你需要解决一个问题,但你的**训练数据很少**,所以你需要找一个数据很多的相关问题来**预先学习**,并将知识迁移到这个新问题上。
-但多任务学习比较少见,就是你需要同时处理很多任务,都要做好,你可以同时训练所有这些任务,也许计算机视觉是一个例子。
-在物体检测中,我们看到**更多**使用多任务学习的应用,其中一个神经网络尝试检测一大堆物体,比分别训练不同的神经网络检测物体**更好**。但我说,平均来说,目前迁移学习使用频率**更高**,比多任务学习频率**更高**,但两者都可以成为你的**强力工具**。
-5. 总结一下,多任务学习能让你训练一个神经网络来执行许多任务,这可以给你更高的性能,比单独完成各个任务更高的性能。
-但要**注意**,**实际上**迁移学习比多任务学习使用频率**更高**。
-我看到很多任务都是,如果你想解决一个机器学习问题,但你的数据集相对较小,那么迁移学习真的能帮到你,就是如果你找到一个相关问题,其中数据量要大得多,你就能以它为基础训练你的神经网络,然后迁移到这个数据量很少的任务上来。
-6. 今天我们学到了很多和迁移学习有关的问题,还有一些迁移学习和多任务学习的应用。
-但多任务学习,我觉得使用频率比迁移学习要少得多,也许其中一个例外是计算机视觉,物体检测。在那些任务中,人们经常训练一个神经网络同时检测很多不同物体,这比训练单独的神经网络来检测视觉物体要更好。但平均而言,我认为即使迁移学习和多任务学习工作方式类似。 实际上,我看到用迁移学习比多任务学习要更多,我觉得这是因为你很难找到那么多相似且数据量对等的任务可以用单一神经网络训练。
-再次,在计算机视觉领域,物体检测这个例子是最显著的例外情况。
-7. 所以这就是多任务学习,多任务学习和迁移学习都是你的工具包中的重要工具。
-最后,我想继续讨论端到端深度学习,所以我们来看下一个视频来讨论端到端学习。
-
-## 10.9 什么是端到端的深度学习?
-1. 深度学习中**最令人振奋**的最新动态之一就是端到端深度学习的兴起,那么端到端学习到底是什么呢?简而言之,以前有一些数据处理系统或者学习系统,它们需要多个阶段的处理。
-那么端到端深度学习就是**忽略所有这些不同的阶段**,用单个神经网络代替它。
-2. 而端到端深度学习就只需要把训练集拿过来,直接学到了和之间的函数映射,直接绕过了其中很多步骤。对一些学科里的人来说,这点相当难以接受,他们无法接受这样**构建AI系统**,因为有些情况,**端到端方法**完全**取代**了旧系统,某些投入了多年研究的中间组件也许已经**过时**了。
-
-## 10.10 端到端的深度学习举例?
-1. 这张图上是一个研究员做的人脸识别门禁,是百度的林元庆研究员做的。
-这是一个相机,它会拍下接近门禁的人,如果它认出了那个人,门禁系统就自动打开,让他通过,所以你不需要刷一个**RFID工卡**就能进入这个设施。
-系统部署在越来越多的中国办公室,希望在其他国家也可以部署更多,你可以接近门禁,如果它认出你的脸,它就直接让你通过,你不需要带RFID工卡。
-2. 我们再来看几个例子,比如机器翻译。
-传统上,机器翻译系统也有一个很复杂的流水线,比如英语机翻得到文本,然后做文本分析,基本上要从文本中提取一些特征之类的,经过很多步骤,你最后会将英文文本翻译成法文。
-因为对于机器翻译来说的确有很多(英文,法文)的数据对,端到端深度学习在机器翻译领域非常好用,那是因为在今天可以收集对的大数据集,就是英文句子和对应的法语翻译。
-所以在这个例子中,端到端深度学习效果很好。
-
-## 10.11 端到端的深度学习有什么挑战?
-1. 事实证明,端到端深度学习的挑战之一是,你可能需要大量数据才能让系统表现良好,比如,你只有**3000小时数据**去训练你的**语音识别系统**,那么传统的流水线效果真的很好。
-但当你拥有非常大的数据集时,比如**10,000小时数据**或者**100,000小时**数据,这样端到端方法突然开始很厉害了。所以当你的**数据集较小**的时候,传统流水线方法其实效果也不错,通常做得**更好**。
-2. 你需要**大数据集**才能让**端到端方法**真正发出耀眼光芒。如果你的数据量适中,那么也可以用中间件方法,你可能输入还是音频,然后绕过特征提取,直接尝试从神经网络输出音位,然后也可以在其他阶段用,所以这是往端到端学习迈出的一小步,但还没有到那里。
-
-## 10.13 端到端的深度学习优缺点?
-假设你正在搭建一个机器学习系统,你要决定是否使用端对端方法,我们来看看端到端深度学习的一些优缺点,这样你就可以根据一些准则,判断你的应用程序是否有希望使用端到端方法。
-
-这里是应用端到端学习的一些优点:
-1. 首先端到端学习真的只是让数据说话。所以如果你有足够多的数据,那么不管从 x 到 y 最适合的函数映射是什么,如果你训练一个足够大的神经网 络,希望这个神经网络能自己搞清楚,而使用纯机器学习方法,直接从到输入去训练的神经网 络,可能更能够捕获数据中的任何统计信息,而不是被迫引入人类的成见。
-例如,在语音识别领域,早期的识别系统有这个音位概念,就是基本的声音单元,如 cat 单词的“cat”的 Cu-、Ah-和 Tu-,我觉得这个音位是人类语言学家生造出来的,我实际上认为音位其实是语音学家的幻想,用音位描述语言也还算合理。但是不要强迫你的学习算法以音位为单位思考,这点有时没那么明显。如果你让你的学习算法学习它想学习的任意表示方式,而不是强迫你的学习算法使用音位作为表示方式,那么其整体表现可能会更好。
-2. 端到端深度学习的第二个好处就是这样,所需手工设计的组件更少,所以这也许能够简化你的设计工作流程,你不需要花太多时间去手工设计功能,手工设计这些中间表示方式。
-
-这里是应用端到端学习的一些缺点:
-1. 首先,它可能需要大量的数据。要直接学到这个到的映射,你可能需要大量数据。
-我们在以前的视频里看过一个例子,其中你可以收集大量子任务数据。
-比如人脸识别,我们可以收集很多数据用来分辨图像中的人脸,当你找到一张脸后,也可以找得到很多人脸识别数据。
-但是对于整个端到端任务,可能只有更少的数据可用。所以这是端到端学习的输入端,是输出端,所以你需要很多这样的数据,在输入端和输出端都有数据,这样可以训练这些系统。
-这就是为什么我们称之为端到端学习,因为你直接学习出从系统的一端到 系统的另一端。
-2. 另一个缺点是,它排除了可能有用的手工设计组件。
-机器学习研究人员一般都很鄙视手工设计的东西,但如果你没有很多数据,你的学习算法就没办法从很小的训练集数据中获得洞察力。
-所以手工设计组件在这种情况,可能是把人类知识直接注入算法的途径,这总不是一件坏事。
-我觉得学习算法有两个主要的知识来源,一个是数据,另一个是你手工设计的任何东西,可能是组件,功能,或者其他东西。
-所以当你有大量数据时,手工设计的东西就不太重要了,但是当你没有太多的数据时,构造一个精心设计的系统,实际上可以将人类对这个问题的很多 认识直接注入到问题里,进入算法里应该挺有帮助的。
-
-总结:
-1. 所以端到端深度学习的弊端之一是它把可能有用的人工设计的组件排除在外了,精心设计的人工组件可能非常有用,但它们也有可能真的伤害到你的算法表现。
-例如,强制你的算法以音位为单位思考,也许让算法自己找到更好的表示方法更好。
-所以这是一把双刃剑,可能有坏处,可能有好处,但往往好处更多,手工设计的组件往往在训练集更小的时候帮助更大。
-
-## 10.14 什么是负迁移?产生负迁移的原因有哪些?(中科院计算所-王晋东)
+Reference:
+
+1. [王晋东,迁移学习简明手册](https://github.com/jindongwang/transferlearning-tutorial)
+2. Ben-David, S., Blitzer, J., Crammer, K., Kulesza, A., Pereira, F., & Vaughan, J. W. (2010). A theory of learning from different domains. Machine learning, 79(1-2), 151-175.
+3. Tan, B., Song, Y., Zhong, E. and Yang, Q., 2015, August. Transitive transfer learning. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (pp. 1155-1164). ACM.
+
+### 11.1.8 什么是负迁移?产生负迁移的原因有哪些?
负迁移(Negative Transfer)指的是,在源域上学习到的知识,对于目标域上的学习产生负面作用。
产生负迁移的原因主要有:
@@ -154,14 +91,15 @@
负迁移给迁移学习的研究和应用带来了负面影响。在实际应用中,找到合理的相似性,并且选择或开发合理的迁移学习方法,能够避免负迁移现象。
-## 10.15 什么是迁移学习?
+### 11.1.9 迁移学习的基本思路?
+
+迁移学习的总体思路可以概括为:开发算法来最大限度地利用有标注的领域的知识,来辅助目标领域的知识获取和学习。
1. 找到目标问题的相似性,迁移学习任务就是从相似性出发,将旧领域(domain)学习过的模型应用在新领域上。
2. 迁移学习,是指利用数据、任务、或模型之间的相似性,将在旧领域学习过的模型,应用于新领域的一种学习过程。
3. 迁移学习**最有用的场合**是,如果你尝试优化任务B的性能,通常这个任务数据相对较少。
例如,在放射科中你知道很难收集很多射线扫描图来搭建一个性能良好的放射科诊断系统,所以在这种情况下,你可能会找一个相关但不同的任务,如图像识别,其中你可能用 1 百万张图片训练过了,并从中学到很多低层次特征,所以那也许能帮助网络在任务在放射科任务上做得更好,尽管任务没有这么多数据。
4. 迁移学习什么时候是有意义的?它确实可以**显著提高**你的**学习任务的性能**,但我有时候也见过有些场合使用迁移学习时,任务实际上数据量比任务要少, 这种情况下增益可能不多。
-
> 什么情况下可以使用迁移学习?
>
> 假如两个领域之间的区别特别的大,**不可以直接采用迁移学习**,因为在这种情况下效果不是很好。在这种情况下,推荐使用[3]的工作,在两个相似度很低的domain之间一步步迁移过去(踩着石头过河)。
@@ -176,3 +114,547 @@ Reference:
2. Ben-David, S., Blitzer, J., Crammer, K., Kulesza, A., Pereira, F., & Vaughan, J. W. (2010). A theory of learning from different domains. Machine learning, 79(1-2), 151-175.
3. Tan, B., Song, Y., Zhong, E. and Yang, Q., 2015, August. Transitive transfer learning. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (pp. 1155-1164). ACM.
+
+
+## 11.2 迁移学习的基本思路有哪些?
+
+ 迁移学习的基本方法可以分为四种。这四种基本的方法分别是:基于样本的迁移, 基于模型 的迁移, 基于特征的迁移,及基于关系的迁移。
+
+### 11.2.1 基于样本迁移
+
+ 基于样本的迁移学习方法 (Instance based Transfer Learning) 根据一定的权重生成规则,对数据样本进行重用,来进行迁移学习。图[14](#bookmark90)形象地表示了基于样本迁移方法的思想源域中存在不同种类的动物,如狗、鸟、猫等,目标域只有狗这一种类别。在迁移时,为了最大限度地和目标域相似,我们可以人为地提高源域中属于狗这个类别的样本权重。
+
+
+
+图 14: 基于样本的迁移学习方法示意图
+
+ 在迁移学习中,对于源域D~s~和目标域D~t~,通常假定产生它们的概率分布是不同且未知的(P(X~s~) =P(X~t~))。另外,由于实例的维度和数量通常都非常大,因此,直接对 P(X~s~) 和P(X~t~) 进行估计是不可行的。因而,大量的研究工作 [[Khan and Heisterkamp,2016](#bookmark267), [Zadrozny, 2004](#bookmark319), [Cortes et al.,2008](#bookmark242), [Dai et al., 2007](#bookmark243), [Tan et al.,2015](#bookmark302), [Tan et al., 2017](#bookmark303)] 着眼于对源域和目标域的分布比值进行估计(P(**X**t)/P(**X**s))。所估计得到的比值即为样本的权重。这些方法通常都假设P(**x**s) \<并且源域和目标域的条件概率分布相同(P(y\|x~s~)=*P*(y\|x~t~))。特别地,上海交通大学Dai等人[[Dai et al.,2007](#bookmark243)]提出了 TrAdaboost方法,将AdaBoost的思想应用于迁移学习中,提高有利于目标分类任务的实例权重、降低不利于目标分类任务的实例权重,并基于PAC理论推导了模型的泛化误差上界。TrAdaBoost方法是此方面的经典研究之一。文献 [[Huang et al., 2007](#bookmark264)]提出核均值匹配方法 (Kernel Mean atching, KMM)对于概率分布进行估计,目标是使得加权后的源域和目标域的概率分布尽可能相近。在最新的研究成果中,香港科技大学的Tan等人扩展了实例迁移学习方法的应用场景,提出 了传递迁移学习方法(Transitive Transfer Learning, TTL) [[Tan etal., 2015](#bookmark302)] 和远域迁移学习 (Distant Domain Transfer Learning,DDTL) [[Tan et al., 2017](#bookmark303)],利用联合矩阵分解和深度神经网络,将迁移学习应用于多个不相似的领域之间的知识共享,取得了良好的效果。
+
+ 虽然实例权重法具有较好的理论支撑、容易推导泛化误差上界,但这类方法通常只在领域间分布差异较小时有效,因此对自然语言处理、计算机视觉等任务效果并不理想。而基于特征表示的迁移学习方法效果更好,是我们研究的重点。
+
+### 11.2.2 基于特征迁移
+
+ 基于特征的迁移方法 (Feature based Transfer Learning) 是指将通过特征变换的方式互相迁移 [[Liu et al., 2011](#bookmark272), [Zheng et al.,2008](#bookmark327), [Hu and Yang, 2011](#bookmark263)],来减少源域和目标域之间的差距;或者将源域和目标域的数据特征变换到统一特征空间中 [[Pan et al.,2011](#bookmark288), [Long et al., 2014b](#bookmark278), [Duan et al.,2012](#bookmark248)],然后利用传统的机器学习方法进行分类识别。根据特征的同构和异构性,又可以分为同构和异构迁移学习。图[15](#bookmark93)很形象地表示了两种基于特 征的迁移学习方法。
+
+
+
+图 15: 基于特征的迁移学习方法示意图
+
+ 基于特征的迁移学习方法是迁移学习领域中最热门的研究方法,这类方法通常假设源域和目标域间有一些交叉的特征。香港科技大学的 Pan 等人 [[Pan et al.,2011](#bookmark288)] 提出的迁移 成分分析方法 (Transfer Component Analysis, TCA)是其中较为典型的一个方法。该方法的 核心内容是以最大均值差异 (Maximum MeanDiscrepancy, MMD) [[Borgwardt et al., 2006](#bookmark236)]作为度量准则,将不同数据领域中的分布差异最小化。加州大学伯克利分校的 Blitzer 等人 [[Blitzer et al., 2006](#bookmark235)] 提出了一种基于结构对应的学习方法(Structural Corresponding Learning,SCL),该算法可以通过映射将一个空间中独有的一些特征变换到其他所有空间中的轴特征上,然后在该特征上使用机器学习的算法进行分类预测。清华大学龙明盛等人[[Long et al.,2014b](#bookmark278)]提出在最小化分布距离的同时,加入实例选择的迁移联合匹配(Tran-fer Joint Matching, TJM) 方法,将实例和特征迁移学习方法进行了有机的结合。澳大利亚卧龙岗大学的 Jing Zhang 等人 [[Zhang et al., 2017a](#bookmark321)]提出对于源域和目标域各自训练不同 的变换矩阵,从而达到迁移学习的目标。
+
+### 11.2.3 基于模型迁移
+
+ 基于模型的迁移方法 (Parameter/Model based Transfer Learning) 是指从源域和目标域中找到他们之间共享的参数信息,以实现迁移的方法。这种迁移方式要求的假设条件是: 源域中的数据与目标域中的数据可以共享一些模型的参数。其中的代表性工作主要有[[Zhao et al., 2010](#bookmark324), [Zhao et al., 2011](#bookmark325), [Panet al., 2008b](#bookmark287), [Pan et al., 2008a](#bookmark286)]。图[16](#bookmark96)形象地 表示了基于模型的迁移学习方法的基本思想。
+
+
+
+图 16: 基于模型的迁移学习方法示意图
+
+ 其中,中科院计算所的Zhao等人[[Zhao et al., 2011](#bookmark325)]提出了TransEMDT方法。该方法首先针对已有标记的数据,利用决策树构建鲁棒性的行为识别模型,然后针对无标定数据,利用K-Means聚类方法寻找最优化的标定参数。西安邮电大学的Deng等人[[Deng et al.,2014](#bookmark245)] 也用超限学习机做了类似的工作。香港科技大学的Pan等人[[Pan etal., 2008a](#bookmark286)]利用HMM,针对Wifi室内定位在不同设备、不同时间和不同空间下动态变化的特点,进行不同分布下的室内定位研究。另一部分研究人员对支持向量机 SVM 进行了改进研究 [[Nater et al.,2011](#bookmark285), [Li et al., 2012](#bookmark269)]。这些方法假定 SVM中的权重向量 **w** 可以分成两个部分: **w** = **wo**+**v**, 其中 **w**0代表源域和目标域的共享部分, **v** 代表了对于不同领域的特定处理。在最新的研究成果中,香港科技大学的 Wei 等人 [[Wei et al., 2016b](#bookmark313)]将社交信息加入迁移学习方法的 正则项中,对方法进行了改进。清华大学龙明盛等人[[Long et al., 2015a](#bookmark275), [Long et al., 2016](#bookmark276), [Long etal., 2017](#bookmark280)]改进了深度网络结构,通过在网络中加入概率分布适配层,进一步提高了深度迁移学习网络对于大数据的泛化能力。
+
+### 11.2.4 基于关系迁移
+
+ 基于关系的迁移学习方法 (Relation Based Transfer Learning) 与上述三种方法具有截然不同的思路。这种方法比较关注源域和目标域的样本之间的关系。图[17](#bookmark82)形象地表示了不 同领域之间相似的关系。
+
+ 就目前来说,基于关系的迁移学习方法的相关研究工作非常少,仅有几篇连贯式的文章讨论: [[Mihalkova et al., 2007](#bookmark283), [Mihalkova and Mooney,2008](#bookmark284), [Davis and Domingos, 2009](#bookmark244)]。这些文章都借助于马尔科夫逻辑网络(Markov Logic Net)来挖掘不同领域之间的关系相似性。
+
+ 我们将重点讨论基于特征和基于模型的迁移学习方法,这也是目前绝大多数研究工作的热点。
+
+
+
+图 17: 基于关系的迁移学习方法示意图
+
+
+
+图 18: 基于马尔科夫逻辑网的关系迁移
+## 11.3 迁移学习的常用方法
+## 11.3 迁移学习的常见方法有哪些?
+
+### 11.3.1 数据分布自适应
+
+ 数据分布自适应 (Distribution Adaptation) 是一类最常用的迁移学习方法。这种方法的基本思想是,由于源域和目标域的数据概率分布不同,那么最直接的方式就是通过一些变换,将不同的数据分布的距离拉近。
+
+ 图 [19](#bookmark84)形象地表示了几种数据分布的情况。简单来说,数据的边缘分布不同,就是数据整体不相似。数据的条件分布不同,就是数据整体相似,但是具体到每个类里,都不太相似。
+
+
+
+图 19: 不同数据分布的目标域数据
+
+ 根据数据分布的性质,这类方法又可以分为边缘分布自适应、条件分布自适应、以及联合分布自适应。下面我们分别介绍每类方法的基本原理和代表性研究工作。介绍每类研究工作时,我们首先给出基本思路,然后介绍该类方法的核心,最后结合最近的相关工作介绍该类方法的扩展。
+
+### 11.3.2 边缘分布自适应
+
+ 边缘分布自适应方法 (Marginal Distribution Adaptation) 的目标是减小源域和目标域的边缘概率分布的距离,从而完成迁移学习。从形式上来说,边缘分布自适应方法是用P(X~s~)和 P(X~t~)之间的距离来近似两个领域之间的差异。即:
+
+ $DISTANCE(D~s~,D~t~)\approx\lVert P(X_s)-P(X_t)\Vert$ (6.1)
+
+ 边缘分布自适应对应于图[19](#bookmark84)中由图[19(a)](#bookmark101)迁移到图[19(b)](#bookmark83)的情形。
+
+### 11.3.3 条件分布自适应
+
+ 条件分布自适应方法 (Conditional Distribution Adaptation) 的目标是减小源域和目标域的条件概率分布的距离,从而完成迁移学习。从形式上来说,条件分布自适应方法是用 P(y~s~|X~s~) 和 P (y~t~|X~t~) 之间的距离来近似两个领域之间的差异。即:
+
+ $DISTANCE(D~s~,D~t~)\approx\lVert P(y_s|X_s)-P(y_t|X_t)\Vert$(6.8)
+
+ 条件分布自适应对应于图[19](#bookmark84)中由图[19(a)](#bookmark101)迁移到图[19(c)](#bookmark85)的情形。
+
+ 目前单独利用条件分布自适应的工作较少,这些工作主要可以在 [[Saito et al.,2017](#bookmark292)] 中找到。最近,中科院计算所的 Wang 等人提出了 STL 方法(Stratified Transfer Learning) [[Wang tal.,2018](#bookmark309)]。作者提出了类内迁移 (Intra-class Transfer)的思想。指出现有的 绝大多数方法都只是学习一个全局的特征变换(Global DomainShift),而忽略了类内的相 似性。类内迁移可以利用类内特征,实现更好的迁移效果。
+
+ STL 方法的基本思路如图所示。首先利用大多数投票的思想,对无标定的位置行为生成伪标;然后在再生核希尔伯特空间中,利用类内相关性进行自适应地空间降维,使得不同情境中的行为数据之间的相关性增大;最后,通过二次标定,实现对未知标定数据的精准标定。
+
+
+
+图 21: STL 方法的示意图
+### 11.3.4 联合分布自适应
+
+ 联合分布自适应方法 (Joint Distribution Adaptation) 的目标是减小源域和目标域的联合概率分布的距离,从而完成迁移学习。从形式上来说,联合分布自适应方法是用*P*(**x**s) 和P(**x**t)之间的距离、以及P(ys\|**x**s)和P(yt\|**x**t)之间的距离来近似两个领域之间的差异。即:
+
+ $DISTANCE(D~s~,D~t~)\approx\lVert P(X_s)-P(X_t)\Vert-\lVert P(y_s|X_s)-P(y_t|X_t)\Vert$(6.10)
+
+ 联合分布自适应对应于图[19](#bookmark84)中由图[19(a)](#bookmark101)迁移到图[19(b)](#bookmark83)的情形、以及图[19(a)](#bookmark101)迁移到
+图[19(c)](#bookmark85)的情形。
+
+### 11.3.4 概率分布自适应方法优劣性比较
+
+综合上述三种概率分布自适应方法,我们可以得出如下的结论:
+
+1. 精度比较: BDA \>JDA \>TCA \>条件分布自适应。
+2. 将不同的概率分布自适应方法用于神经网络,是一个发展趋势。图[23](#bookmark119)展示的结果表明将概率分布适配加入深度网络中,往往会取得比非深度方法更好的结果。
+
+
+
+图 22: BDA 方法的效果第二类方法:特征选择
+### 11.3.6 特征选择
+
+ 特征选择法的基本假设是:源域和目标域中均含有一部分公共的特征,在这部分公共的特征,源领域和目标领域的数据分布是一致的。因此,此类方法的目标就是,通过机器学习方法,选择出这部分共享的特征,即可依据这些特征构建模型。
+
+ 图 [24](#bookmark122)形象地表示了特征选择法的主要思路。
+
+
+
+图 23: 不同分布自适应方法的精度比较
+
+
+
+图 24: 特征选择法示意图
+
+ 这这个领域比较经典的一个方法是发表在 2006 年的 ECML-PKDD 会议上,作者提出了一个叫做 SCL 的方法 (Structural Correspondence Learning) [[Blitzer et al.,2006](#bookmark235)]。这个方法的目标就是我们说的,找到两个领域公共的那些特征。作者将这些公共的特征叫做Pivot feature。找出来这些Pivot feature,就完成了迁移学习的任务。
+
+
+
+图 25: 特征选择法中的 Pivot feature 示意图
+
+ 图 [25](#bookmark124)形象地展示了 Pivot feature 的含义。 Pivot feature指的是在文本分类中,在不同领域中出现频次较高的那些词。总结起来:
+
+- 特征选择法从源域和目标域中选择提取共享的特征,建立统一模型
+- 通常与分布自适应方法进行结合
+- 通常采用稀疏表示 \|\|**A**\|\|2,1 实现特征选择
+
+### 11.3.5 统计特征对齐方法
+
+ 统计特征对齐方法主要将数据的统计特征进行变换对齐。对齐后的数据,可以利用传统机器学习方法构建分类器进行学习。SA方法(Subspace Alignment,子空间对齐)[[Fernando et al.,2013](#bookmark249)]是其中的代表性成果。SA方法直接寻求一个线性变换**M**,将不同的数据实现变换对齐。SA方法的优化目标如下:
+
+
+
+则变换 **M** 的值为:
+
+
+
+可以直接获得上述优化问题的闭式解:
+
+
+
+ SA 方法实现简单,计算过程高效,是子空间学习的代表性方法。
+
+### 11.3.6 流形学习方法
+
+**什么是流形学习**
+
+ 流形学习自从 2000 年在 Science 上被提出来以后,就成为了机器学习和数据挖掘领域的热门问题。它的基本假设是,现有的数据是从一个高维空间中采样出来的,所以,它具有高维空间中的低维流形结构。流形就是是一种几何对象(就是我们能想像能观测到的)。通俗点说就是,我们无法从原始的数据表达形式明显看出数据所具有的结构特征,那我把它想像成是处在一个高维空间,在这个高维空间里它是有个形状的。一个很好的例子就是星座。满天星星怎么描述?我们想像它们在一个更高维的宇宙空间里是有形状的,这就有了各自星座,比如织女座、猎户座。流形学习的经典方法有Isomap、locally linear embedding、 laplacian eigenmap 等。
+
+ 流形空间中的距离度量:两点之间什么最短?在二维上是直线(线段),可在三维呢?地球上的两个点的最短距离可不是直线,它是把地球展开成二维平面后画的那条直线。那条线在三维的地球上就是一条曲线。这条曲线就表示了两个点之间的最短距离,我们叫它测地线。更通俗一点, 两点之间,测地线最短。在流形学习中,我们遇到测量距离的时候更多的时候用的就是这个测地线。在我们要介绍的 GFK 方法中,也是利用了这个测地线距离。比如在下面的图中,从 A 到 C 最短的距离在就是展开后的线段,但是在三维球体上看它却是一条曲线。
+
+
+
+图 28: 三维空间中两点之间的距离示意图
+
+ 由于在流形空间中的特征通常都有着很好的几何性质,可以避免特征扭曲,因此我们首先将原始空间下的特征变换到流形空间中。在众多已知的流形中, Grassmann 流形G(d) 可以通过将原始的 d 维子空间 (特征向量)看作它基础的元素,从而可以帮助学习分类 器。在 Grassmann流形中,特征变换和分布适配通常都有着有效的数值形式,因此在迁移学习问题中可以被很高效地表示和求解 [[Hamm and Lee,2008](#bookmark260)]。因此,利用 Grassmann流形空间中来进行迁移学习是可行的。现存有很多方法可以将原始特征变换到流形空间 中[[Gopalan et al., 2011](#bookmark257), [Baktashmotlagh et al.,2014](#bookmark230)]。
+
+ 在众多的基于流形变换的迁移学习方法中,GFK(Geodesic Flow Kernel)方法[[Gong et
+al., 2012](#bookmark255)]是最为代表性的一个。GFK是在2011年发表在ICCV上的SGF方法[[Gopalan et al.,
+2011](#bookmark257)]发展起来的。我们首先介绍SGF方法。
+
+ SGF 方法从增量学习中得到启发:人类从一个点想到达另一个点,需要从这个点一步一步走到那一个点。那么,如果我们把源域和目标域都分别看成是高维空间中的两个点,由源域变换到目标域的过程不就完成了迁移学习吗?也就是说, 路是一步一步走出来的。
+
+ 于是 SGF 就做了这个事情。它是怎么做的呢?把源域和目标域分别看成高维空间 (即Grassmann流形)中的两个点,在这两个点的测地线距离上取d个中间点,然后依次连接起来。这样,源域和目标域就构成了一条测地线的路径。我们只需要找到合适的每一步的变换,就能从源域变换到目标域了。图 [29](#bookmark133)是 SGF 方法的示意图。
+
+
+
+图 29: SGF 流形迁移学习方法示意图
+
+ SGF 方法的主要贡献在于:提出了这种变换的计算及实现了相应的算法。但是它有很明显的缺点:到底需要找几个中间点? SGF也没能给出答案,就是说这个参数d是没法估计的,没有一个好的方法。这个问题在 GFK 中被回答了。
+
+ GFK方法首先解决SGF的问题:如何确定中间点的个数d。它通过提出一种核学习的方法,利用路径上的无穷个点的积分,把这个问题解决了。这是第一个贡献。然后,它又解决了第二个问题:当有多个源域的时候,我们如何决定使用哪个源域跟目标域进行迁移? GFK通过提出Rank of Domain度量,度量出跟目标域最近的源域,来解决这个问题。图 [30](#bookmark134)是 GFK 方法的示意图。
+
+
+
+图 30: GFK 流形迁移学习方法示意图
+
+ 用Ss和St分别表示源域和目标域经过主成分分析(PCA)之后的子空间,则G可以视为所有的d维子空间的集合。每一个d维的原始子空间都可以被看作G上的一个点。因此,在两点之间的测地线{\$(t) :0 \< t \<1}可以在两个子空间之间构成一条路径。如果我 们令Ss = \$(0),St =\$(1),则寻找一条从\$(0)到\$(1)的测地线就等同于将原始的特征变换到一个无穷维度的空间中,最终减小域之间的漂移现象。这种方法可以被看作是一种从\$(0)到\$(1)的増量式“行走”方法。
+
+ 特别地,流形空间中的特征可以被表示为**z** =\$(t)T**x**。变换后的特征**Z**i和**Z**j的内积定义了一个半正定 (positive semidefinite) 的测地线流式核
+
+
+
+ GFK 方法详细的计算过程可以参考原始的文章,我们在这里不再赘述。
+
+### 11.3.7 什么是finetune?
+
+ 深度网络的finetune也许是最简单的深度网络迁移方法。**Finetune**,也叫微调、fine-tuning, 是深度学习中的一个重要概念。简而言之,finetune就是利用别人己经训练好的网络,针对自己的任务再进行调整。从这个意思上看,我们不难理解finetune是迁移学习的一部分。
+
+**为什么需要已经训练好的网络?**
+
+ 在实际的应用中,我们通常不会针对一个新任务,就去从头开始训练一个神经网络。这样的操作显然是非常耗时的。尤其是,我们的训练数据不可能像ImageNet那么大,可以训练出泛化能力足够强的深度神经网络。即使有如此之多的训练数据,我们从头开始训练,其代价也是不可承受的。
+
+ 那么怎么办呢?迁移学习告诉我们,利用之前己经训练好的模型,将它很好地迁移到自己的任务上即可。
+
+**为什么需要 finetune?**
+
+ 因为别人训练好的模型,可能并不是完全适用于我们自己的任务。可能别人的训练数据和我们的数据之间不服从同一个分布;可能别人的网络能做比我们的任务更多的事情;可能别人的网络比较复杂,我们的任务比较简单。
+
+ 举一个例子来说,假如我们想训练一个猫狗图像二分类的神经网络,那么很有参考价值的就是在 CIFAR-100 上训练好的神经网络。但是 CIFAR-100 有 100 个类别,我们只需要 2个类别。此时,就需要针对我们自己的任务,固定原始网络的相关层,修改网络的输出层以使结果更符合我们的需要。
+
+ 图[36](#bookmark148)展示了一个简单的finetune过程。从图中我们可以看到,我们采用的预训练好的网络非常复杂,如果直接拿来从头开始训练,则时间成本会非常高昂。我们可以将此网络进行改造,固定前面若干层的参数,只针对我们的任务,微调后面若干层。这样,网络训练速度会极大地加快,而且对提高我们任务的表现也具有很大的促进作用。
+
+
+
+图 36: 一个简单的 finetune 示意图
+**Finetune 的优势**
+
+ Finetune 的优势是显然的,包括:
+
+- 不需要针对新任务从头开始训练网络,节省了时间成本;
+- 预训练好的模型通常都是在大数据集上进行的,无形中扩充了我们的训练数据,使得模型更鲁棒、泛化能力更好;
+- Finetune 实现简单,使得我们只关注自己的任务即可。
+
+**Finetune 的扩展**
+
+ 在实际应用中,通常几乎没有人会针对自己的新任务从头开始训练一个神经网络。Fine-tune 是一个理想的选择。
+
+ Finetune 并不只是针对深度神经网络有促进作用,对传统的非深度学习也有很好的效果。例如, finetune对传统的人工提取特征方法就进行了很好的替代。我们可以使用深度网络对原始数据进行训练,依赖网络提取出更丰富更有表现力的特征。然后,将这些特征作为传统机器学习方法的输入。这样的好处是显然的: 既避免了繁复的手工特征提取,又能自动地提取出更有表现力的特征。
+
+ 比如,图像领域的研究,一直是以 SIFT、SURF 等传统特征为依据的,直到 2014 年,伯克利的研究人员提出了 DeCAF特征提取方法[[Donahue et al.,2014](#bookmark246)],直接使用深度卷积神经网络进行特征提取。实验结果表明,该特征提取方法对比传统的图像特征,在精度上有着无可匹敌的优势。另外,也有研究人员用卷积神经网络提取的特征作为SVM分类器的输 入[[Razavian et al.,014](#bookmark291)],显著提升了图像分类的精度。
+
+### 11.3.8 finetune为什么有效?
+
+ 随着 AlexNet [[Krizhevsky et al., 2012](#bookmark268)] 在 2012 年的 ImageNet大赛上获得冠军,深度学习开始在机器学习的研究和应用领域大放异彩。尽管取得了很好的结果,但是神经网络本身就像一个黑箱子,看得见,摸不着,解释性不好。由于神经网络具有良好的层次结构很自然地就有人开始关注,能否通过这些层次结构来很好地解释网络?于是,有了我们熟知的例子:假设一个网络要识别一只猫,那么一开始它只能检测到一些边边角角的东西,和猫根本没有关系;然后可能会检测到一些线条和圆形;慢慢地,可以检测到有猫的区域;接着是猫腿、猫脸等等。图 [32](#bookmark137)是一个简单的示例。
+
+
+
+图 32: 深度神经网络进行特征提取到分类的简单示例
+
+ 这表达了一个什么事实呢?概括来说就是:前面几层都学习到的是通用的特征(general feature);随着网络层次的加深,后面的网络更偏重于学习任务特定的特征(specific feature)。
+这非常好理解,我们也都很好接受。那么问题来了:如何得知哪些层能够学习到 general feature,哪些层能够学习到specific feature。更进一步:如果应用于迁移学习,如何决定该迁移哪些层、固定哪些层?
+
+ 这个问题对于理解神经网络以及深度迁移学习都有着非常重要的意义。
+
+ 来自康奈尔大学的 Jason Yosinski 等人 [[Yosinski et al., 2014](#bookmark318)]率先进行了深度神经网络可迁移性的研究,将成果发表在2014年机器学习领域顶级会议NIPS上并做了口头汇报。该论文是一篇实验性质的文章(通篇没有一个公式)。其目的就是要探究上面我们提到的几个关键性问题。因此,文章的全部贡献都来自于实验及其结果。(别说为啥做实验也能发文章:都是高考,我只上了个普通一本,我高中同学就上了清华)
+
+ 在ImageNet的1000类上,作者把1000类分成两份(A和B),每份500个类别。然后,分别对A和B基于Caffe训练了一个AlexNet网络。一个AlexNet网络一共有8层, 除去第8层是类别相关的网络无法迁移以外,作者在 1 到 7这 7层上逐层进行 finetune 实验,探索网络的可迁移性。
+
+ 为了更好地说明 finetune 的结果,作者提出了有趣的概念: AnB 和 BnB。
+
+ 迁移A网络的前n层到B (AnB) vs固定B网络的前n层(BnB)
+
+ 简单说一下什么叫AnB:(所有实验都是针对数据B来说的)将A网络的前n层拿来并将它frozen,剩下的8 - n层随机初始化,然后对B进行分类。
+
+ 相应地,有BnB:把训练好的B网络的前n层拿来并将它frozen,剩下的8 - n层随机初始化,然后对 B 进行分类。
+
+ **实验结果**
+
+ 实验结果如下图(图[33](#bookmark145)) 所示:
+
+ 这个图说明了什么呢?我们先看蓝色的BnB和BnB+(就是BnB加上finetune)。对 BnB而言,原训练好的 B 模型的前 3 层直接拿来就可以用而不会对模型精度有什么损失到了第4 和第5 层,精度略有下降,不过还是可以接受。然而到了第6 第第7层,精度居然奇迹般地回升了!这是为什么?原因如下:对于一开始精度下降的第4 第 5 层来说,确
+
+
+
+图 33: 深度网络迁移实验结果 1
+
+实是到了这一步,feature变得越来越specific,所以下降了。那对于第6第7层为什么精度又不变了?那是因为,整个网络就8层,我们固定了第6第7层,这个网络还能学什么呢?所以很自然地,精度和原来的 B 网络几乎一致!
+
+ 对 BnB+ 来说,结果基本上都保持不变。说明 finetune 对模型结果有着很好的促进作用!
+
+ 我们重点关注AnB和AnB+。对AnB来说,直接将A网络的前3层迁移到B,貌似不会有什么影响,再一次说明,网络的前3层学到的几乎都是general feature!往后,到了第4第5层的时候,精度开始下降,我们直接说:一定是feature不general 了!然而,到了第6第7层,精度出现了小小的提升后又下降,这又是为什么?作者在这里提出两点co-adaptation和feature representation。就是说,第4第5层精度下降的时候,主要是由于A和B两个数据集的差异比较大,所以会下降;至I」了第6第7层,由于网络几乎不迭代了,学习能力太差,此时 feature 学不到,所以精度下降得更厉害。
+
+ 再看AnB+。加入了 finetune以后,AnB+的表现对于所有的n几乎都非常好,甚至 比baseB
+(最初的B)还要好一些!这说明:finetune对于深度迁移有着非常好的促进作用!
+
+ 把上面的结果合并就得到了下面一张图 (图[34](#bookmark138)):
+
+ 至此, AnB 和 BnB 基本完成。作者又想,是不是我分 A 和 B 数据的时候,里面存在一些比较相似的类使结果好了?比如说A里有猫,B里有狮子,所以结果会好?为了排除这些影响,作者又分了一下数据集,这次使得A和B里几乎没有相似的类别。在这个条件下再做AnB,与原来精度比较(0%为基准)得到了下图(图[35](#bookmark139)):
+
+ 这个图说明了什么呢?简单:随着可迁移层数的增加,模型性能下降。但是,前3层仍然还是可以迁移的!同时,与随机初始化所有权重比较,迁移学习的精度是很高的!总之:
+
+- 深度迁移网络要比随机初始化权重效果好;
+
+
+- 网络层数的迁移可以加速网络的学习和优化。
+
+### 11.3.9 什么是深度网络自适应?
+
+**基本思路**
+
+ 深度网络的 finetune 可以帮助我们节省训练时间,提高学习精度。但是 finetune 有它的先天不足:它无法处理训练数据和测试数据分布不同的情况。而这一现象在实际应用中比比皆是。因为 finetune 的基本假设也是训练数据和测试数据服从相同的数据分布。这在迁移学习中也是不成立的。因此,我们需要更进一步,针对深度网络开发出更好的方法使之更好地完成迁移学习任务。
+
+ 以我们之前介绍过的数据分布自适应方法为参考,许多深度学习方法[[Tzeng et al.,2014](#bookmark307), [Long et al.,2015a](#bookmark275)]都开发出了自适应层(AdaptationLayer)来完成源域和目标域数据的自适应。自适应能够使得源域和目标域的数据分布更加接近,从而使得网络的效果更好。
+
+ 从上述的分析我们可以得出,深度网络的自适应主要完成两部分的工作:
+
+ 一是哪些层可以自适应,这决定了网络的学习程度;
+
+ 二是采用什么样的自适应方法 (度量准则),这决定了网络的泛化能力。
+
+ 深度网络中最重要的是网络损失的定义。绝大多数深度迁移学习方法都采用了以下的损失定义方式:
+
+
+
+ 其中,I表示网络的最终损失,lc(Ds,**y**s)表示网络在有标注的数据(大部分是源域)上的常规分类损失(这与普通的深度网络完全一致),Ia(Ds,Dt)表示网络的自适应损失。最后一部分是传统的深度网络所不具有的、迁移学习所独有的。此部分的表达与我们先前讨论过的源域和目标域的分布差异,在道理上是相同的。式中的A是权衡两部分的权重参数。
+
+ 上述的分析指导我们设计深度迁移网络的基本准则:决定自适应层,然后在这些层加入自适应度量,最后对网络进行 finetune。
+
+### 11.3.10 GAN在迁移学习中的应用
+
+生成对抗网络 GAN(Generative Adversarial Nets) [[Goodfellow et al.,2014](#bookmark256)] 是目前人工智能领域最炙手可热的概念之一。其也被深度学习领军人物 Yann Lecun 评为近年来最令人欣喜的成就。由此发展而来的对抗网络,也成为了提升网络性能的利器。本小节介绍深度对抗网络用于解决迁移学习问题方面的基本思路以及代表性研究成果。
+
+**基本思路**
+
+ GAN 受到自博弈论中的二人零和博弈 (two-player game) 思想的启发而提出。它一共包括两个部分:一部分为生成网络(Generative Network),此部分负责生成尽可能地以假乱真的样本,这部分被成为生成器(Generator);另一部分为判别网络(Discriminative Network), 此部分负责判断样本是真实的,还是由生成器生成的,这部分被成为判别器(Discriminator) 生成器和判别器的互相博弈,就完成了对抗训练。
+
+ GAN 的目标很明确:生成训练样本。这似乎与迁移学习的大目标有些许出入。然而,由于在迁移学习中,天然地存在一个源领域,一个目标领域,因此,我们可以免去生成样本的过程,而直接将其中一个领域的数据 (通常是目标域) 当作是生成的样本。此时,生成器的职能发生变化,不再生成新样本,而是扮演了特征提取的功能:不断学习领域数据的特征使得判别器无法对两个领域进行分辨。这样,原来的生成器也可以称为特征提取器
+(Feature Extractor)。
+
+ 通常用 Gf 来表示特征提取器,用 Gd 来表示判别器。正是基于这样的领域对抗的思想,深度对抗网络可以被很好地运用于迁移学习问题中。与深度网络自适应迁移方法类似,深度对抗网络的损失也由两部分构成:网络训练的损失lc*和领域判别损失Id:
+
+
+
+**DANN**
+
+Yaroslav Ganin 等人 [[Ganin et al., 2016](#bookmark251)]首先在神经网络的训练中加入了对抗机制,作者将他们的网络称之为DANN(Domain-Adversarial Neural Network)。在此研宄中,网络的学习目标是:生成的特征尽可能帮助区分两个领域的特征,同时使得判别器无法对两个领域的差异进行判别。该方法的领域对抗损失函数表示为:
+
+
+
+Id = max 其中的 Ld 表示为
+
+
+
+
+
+
+
+## 参考文献
+
+王晋东,迁移学习简明手册
+
+[Baktashmotlagh et al., 2013] Baktashmotlagh, M., Harandi, M. T., Lovell, B. C.,and Salz- mann, M. (2013). Unsupervised domain adaptation by domain invariant projection. In *ICCV,* pages 769-776.
+
+[Baktashmotlagh et al., 2014] Baktashmotlagh, M., Harandi, M. T., Lovell, B. C., and Salz- mann, M. (2014). Domain adaptation on the statistical manifold. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition*,pages 2481-2488.
+
+[Ben-David et al., 2010] Ben-David, S., Blitzer, J., Crammer, K., Kulesza, A., Pereira, F., and Vaughan, J. W. (2010). A theory of learning from different domains. *Machine learning,* 79(1-2):151-175.
+
+[Ben-David et al., 2007] Ben-David, S., Blitzer, J., Crammer, K., and Pereira, F. (2007). Analysis of representations for domain adaptation. In *NIPS*, pages 137-144.
+
+[Blitzer et al., 2008] Blitzer, J., Crammer, K., Kulesza, A., Pereira, F., and Wortman, J. (2008). Learning bounds for domain adaptation. In *Advances in neural information processing systems*, pages 129-136.
+
+[Blitzer et al., 2006] Blitzer, J., McDonald, R., and Pereira, F. (2006). Domain adaptation with structural correspondence learning. In *Proceedings of the 2006 conference on empirical methods in natural language processing*, pages 120-128. Association for Computational Linguistics.
+
+[Borgwardt et al., 2006] Borgwardt, K. M., Gretton, A., Rasch, M. J., Kriegel, H.-P., Scholkopf, B., and Smola, A. J. (2006). Integrating structured biological data by kernel maximum mean discrepancy. *Bioinformatics*, 22(14):e49-e57.
+
+[Bousmalis et al., 2016] Bousmalis, K., Trigeorgis, G., Silberman, N., Krishnan, D., and Erhan, D. (2016). Domain separation networks. In *Advances in Neural Information Processing Systems*, pages 343-351.
+
+[Cai et al., 2011] Cai, D., He, X., Han, J., and Huang, T. S. (2011). Graph regularized nonnegative matrix factorization for data representation. *IEEE Transactions on Pattern Analysis and Machine Intelligence*, 33(8):1548-1560.
+
+[Cao et al., 2017] Cao, Z., Long, M., Wang, J., and Jordan, M. I. (2017). Partial transfer learning with selective adversarial networks. *arXiv preprint arXiv:1707.07901*.
+
+[Carlucci et al., 2017] Carlucci, F. M., Porzi, L., Caputo, B., Ricci, E., and Bulo, S. R. (2017). Autodial: Automatic domain alignment layers. In International Conference on* Computer Vision.
+
+[Cook et al., 2013] Cook, D., Feuz, K. D., and Krishnan, N. C. (2013). Transfer learning for activity recognition: A survey. *Knowledge and information systems*, 36(3):537-556.
+
+[Cortes et al., 2008] Cortes, C., Mohri, M., Riley, M., and Rostamizadeh, A. (2008). Sample selection bias correction theory. In *International Conference on Algorithmic Learning Theory*, pages 38-53, Budapest, Hungary. Springer.
+
+[Dai et al., 2007] Dai, W., Yang, Q., Xue, G.-R., and Yu, Y. (2007). Boosting for transfer learning. In *ICML*, pages 193-200. ACM.
+
+[Davis and Domingos, 2009] Davis, J. and Domingos, P. (2009). Deep transfer via second- order markov logic. In *Proceedings of the 26th annual international conference on machine learning*, pages 217-224. ACM.
+
+[Denget al., 2014] Deng,W.,Zheng,Q.,andWang,Z.(2014).Cross-personactivityrecog-nition using reduced kernel extreme learning machine. *Neural Networks,* 53:1-7.
+
+[Donahue et al., 2014] Donahue, J., Jia, Y., et al. (2014). Decaf: A deep convolutional activation feature for generic visual recognition. In *ICML*, pages 647-655.
+
+[Dorri and Ghodsi, 2012] Dorri, F. and Ghodsi, A. (2012). Adapting component analysis. In *Data Mining (ICDM), 2012 IEEE 12th International Conference on*, pages 846-851. IEEE.
+
+[Duan et al., 2012] Duan, L., Tsang, I. W., and Xu, D. (2012). Domain transfer multiple kernel learning. *IEEE Transactions on Pattern Analysis and Machine Intelligence*, 34(3):465-479.
+
+[Fernando et al., 2013] Fernando, B., Habrard, A., Sebban, M., and Tuytelaars, T. (2013). Unsupervised visual domain adaptation using subspace alignment. In ICCV*, pages 29602967.
+
+[Fodor, 2002] Fodor, I. K. (2002). A survey of dimension reduction techniques. Center for Applied Scientific Computing, Lawrence Livermore National Laboratory*, 9:1-18.
+
+[Ganin et al., 2016] Ganin, Y., Ustinova, E., Ajakan, H., Germain, P., Larochelle, H., Lavi- olette, F., Marchand, M., and Lempitsky, V. (2016).Domain-adversarial training of neural networks. *Journal of Machine Learning
+Research*, 17(59):1-35.
+
+[Gao et al., 2012] Gao, C., Sang, N., and Huang, R. (2012). Online transfer boosting for object tracking. In *Pattern Recognition (ICPR), 2012 21st International Conference on*, pages 906-909. IEEE.
+
+[Ghifary et al., 2017] Ghifary, M., Balduzzi, D., Kleijn, W. B., and Zhang, M. (2017). Scatter component analysis: A unified framework for domain adaptation and domain generalization. *IEEE transactions on pattern analysis and machine intelligence*, 39(7):1414-1430.
+
+[Ghifary et al., 2014] Ghifary, M., Kleijn, W. B., and Zhang, M. (2014). Domain adaptive neural networks for object recognition. In *PRICAI*, pages 898-904.
+
+[Gong et al., 2012] Gong, B., Shi, Y., Sha, F., and Grauman, K. (2012). Geodesic flow kernel for unsupervised domain adaptation. In *CVPR*, pages 2066-2073.
+
+[Goodfellow et al., 2014] Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde- Farley, D., Ozair, S., Courville, A., and Bengio, Y. (2014). Generative adversarial nets. In *Advances in neural information processing systems*, pages 2672-2680.
+
+[Gopalan et al., 2011] Gopalan, R., Li, R., and Chellappa, R. (2011). Domain adaptation for object recognition: An unsupervised approach. In *ICCV*, pages 999-1006. IEEE.
+
+[Gretton et al., 2012] Gretton, A., Sejdinovic, D., Strathmann, H., Balakrishnan, S., Pontil, M., Fukumizu, K., and Sriperumbudur, B. K. (2012). Optimal kernel choice for large- scale two-sample tests. In *Advances in neural information processing systems*, pages 1205-1213.
+
+[Gu et al., 2011] Gu, Q., Li, Z., Han, J., et al. (2011). Joint feature selection and subspace learning. In *IJCAI Proceedings-International Joint Conference on Artificial Intel ligence*, volume 22, page 1294.
+
+[Hamm and Lee, 2008] Hamm, J. and Lee, D. D. (2008). Grassmann discriminant analysis: a unifying view on subspace-based learning. In *ICML*, pages 376-383. ACM.
+
+[Hou et al., 2015] Hou, C.-A., Yeh, Y.-R., and Wang, Y.-C. F. (2015). An unsupervised domain adaptation approach for cross-domain visual classification. In *Advanced Video and Signal Based Surveil lance (AVSS), 2015 12th IEEE International Conference on*,pages 1-6. IEEE.
+
+[Hsiao et al., 2016] Hsiao, P.-H., Chang, F.-J., and Lin, Y.-Y. (2016). Learning discriminatively reconstructed source data for object recognition with few examples. *IEEE*Transactions on Image Processing*, 25(8):3518-3532.
+
+[Hu and Yang, 2011] Hu, D. H. and Yang, Q. (2011). Transfer learning for activity recognition via sensor mapping. In *IJCAI Proceedings-International Joint Conference on Artificial Intelligence*, volume 22, page 1962, Barcelona, Catalonia, Spain. IJCAI.
+
+[Huang et al., 2007] Huang, J., Smola, A. J., Gretton, A., Borgwardt, K. M., Scholkopf, B., et al. (2007). Correcting sample selection bias by unlabeled data. *Advances in neural information processing systems*, 19:601.
+
+[Jaini et al., 2016] Jaini, P., Chen, Z., Carbajal, P., Law, E., Middleton, L., Regan, K., Schaekermann, M., Trimponias, G., Tung, J., and Poupart, P. (2016). Online bayesian transfer learning for sequential data modeling. In *ICLR 2017*.
+
+[Kermany et al., 2018] Kermany, D. S., Goldbaum, M., Cai, W., Valentim, C. C., Liang, H., Baxter, S. L., McKeown, A., Yang, G., Wu, X., Yan, F., et al. (2018). Identifying medical diagnoses and treatable diseases by image-based deep learning. *Cell*, 172(5):1122-1131.
+
+[Khan and Heisterkamp, 2016] Khan, M. N. A. and Heisterkamp, D. R. (2016). Adapting instance weights for unsupervised domain adaptation using quadratic mutual information and subspace learning. In *Pattern Recognition (ICPR), 2016 23rd International Conference on*, pages 1560-1565, Mexican City. IEEE.
+
+[Krizhevsky et al., 2012] Krizhevsky, A., Sutskever, I., and Hinton, G. E. (2012). Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems*, pages 1097-1105.
+
+[Li et al., 2012] Li, H., Shi, Y., Liu, Y., Hauptmann, A. G., and Xiong, Z. (2012). Crossdomain video concept detection: A joint discriminative and generative active learning approach. *Expert Systems with Applications*,
+39(15):12220-12228.
+
+[Li et al., 2016] Li, J., Zhao, J., and Lu, K. (2016). Joint feature selection and structure preservation for domain adaptation. In *Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence*, pages
+1697-1703. AAAI Press.
+
+[Li et al., 2018] Li, Y., Wang, N., Shi, J., Hou, X., and Liu, J. (2018). Adaptive batch normalization for practical domain adaptation. *Pattern Recognition*, 80:109-117.
+
+[Liu et al., 2011] Liu, J., Shah, M., Kuipers, B., and Savarese, S. (2011). Cross-view action recognition via view knowledge transfer. In *Computer Vision and Pattern Recognition (CVPR), 2011 IEEE Conference on*, pages 3209-3216, Colorado Springs, CO, USA. IEEE.
+
+[Liu and Tuzel, 2016] Liu, M.-Y. and Tuzel, O. (2016). Coupled generative adversarial networks. In *Advances in neural information processing systems*, pages 469-477.
+
+[Liu et al., 2017] Liu, T., Yang, Q., and Tao, D. (2017). Understanding how feature structure transfers in transfer learning. In *IJCAI*.
+
+[Long et al., 2015a] Long, M., Cao, Y., Wang, J., and Jordan, M. (2015a). Learning transferable features with deep adaptation networks. In *ICML*, pages 97-105.
+
+[Long et al., 2016] Long, M., Wang, J., Cao, Y., Sun, J., and Philip, S. Y. (2016). Deep learning of transferable representation for scalable domain adaptation. *IEEE Transactions on Knowledge and Data Engineering*,
+28(8):2027-2040.
+
+[Long et al., 2014a] Long, M., Wang, J., Ding, G., Pan, S. J., and Yu, P. S. (2014a). Adaptation regularization: A general framework for transfer learning.*IEEE TKDE, 26(5):1076-1089.
+
+[Long et al., 2014b] Long, M., Wang, J., Ding, G., Sun, J., and Yu, P. S. (2014b). Transfer joint matching for unsupervised domain adaptation. In *CVPR ,pages 1410-1417.
+
+[Long et al., 2013] Long, M., Wang, J., et al. (2013). Transfer feature learning with joint distribution adaptation. In *ICCV*, pages 2200-2207.
+
+[Long et al., 2017] Long, M., Wang, J., and Jordan, M. I. (2017). Deep transfer learning with joint adaptation networks. In *ICML*, pages 2208-2217.
+
+[Long et al., 2015b] Long, M., Wang, J., Sun, J., and Philip, S. Y. (2015b). Domain invariant transfer kernel learning. *IEEE Transactions on Knowledge and Data Engineering*, 27(6):1519-1532.
+
+[Luo et al., 2017] Luo, Z., Zou, Y., Hoffman, J., and Fei-Fei, L. F. (2017). Label efficient learning of transferable representations acrosss domains and tasks. In *Advances in Neural Information Processing Systems*, pages 164-176.
+
+[Mihalkova et al., 2007] Mihalkova, L., Huynh, T., and Mooney, R. J. (2007). Mapping and revising markov logic networks for transfer learning. In *AAAI*, volume 7, pages 608-614.
+
+[Mihalkova and Mooney, 2008] Mihalkova, L. and Mooney, R. J. (2008). Transfer learning by mapping with minimal target data. In *Proceedings of the AAAI-08 workshop on transfer learning for complex tasks*.
+
+[Nater et al., 2011] Nater, F., Tommasi, T., Grabner, H., Van Gool, L., and Caputo, B. (2011). Transferring activities: Updating human behavior analysis. In *Computer Vision Workshops (ICCV Workshops), 2011 IEEE International Conference on*, pages 17371744, Barcelona, Spain. IEEE.
+
+[Pan et al., 2008a] Pan, S. J., Kwok, J. T., and Yang, Q. (2008a). Transfer learning via dimensionality reduction. In *Proceedings of the 23rd AAAI conference on Artificial intelligence*, volume 8, pages 677-682.
+
+[Pan et al., 2008b] Pan, S. J., Shen, D., Yang, Q., and Kwok, J. T. (2008b). Transferring localization models across space. In *Proceedings of the 23rd AAAI Conference on Artificial Intelligence*, pages 1383-1388.
+
+[Pan et al., 2011] Pan, S. J., Tsang, I. W., Kwok, J. T., and Yang, Q. (2011). Domain adaptation via transfer component analysis. *IEEE TNN*, 22(2):199-210.
+
+[PanandYang, 2010] Pan,S.J.andYang,Q.(2010). A survey on transfer learning. IEEE TKDE*, 22(10):1345-1359.
+
+[Patil and Phursule, 2013] Patil, D. M. and Phursule, R. (2013). Knowledge transfer using cost sensitive online learning classification. *International Journal of Science and Research*, pages 527-529.
+
+[Razavian et al., 2014] Razavian, A. S., Azizpour, H., Sullivan, J., and Carlsson, S. (2014). Cnn features off-the-shelf: an astounding baseline for recognition. In *Computer Vision and Pattern Recognition Workshops (CVPRW), 2014 IEEE Conference on*, pages 512519. IEEE.
+
+[Saito et al., 2017] Saito, K., Ushiku, Y., and Harada, T. (2017). Asymmetric tri-training for unsupervised domain adaptation. In *International Conference on Machine Learning*.
+
+[Sener et al., 2016] Sener, O., Song, H. O., Saxena, A., and Savarese, S. (2016). Learning transferrable representations for unsupervised domain adaptation. In *Advances in Neural Information Processing Systems*, pages 2110-2118.
+
+[Shen et al., 2018] Shen, J., Qu, Y., Zhang, W., and Yu, Y. (2018). Wasserstein distance guided representation learning for domain adaptation. In *AAAI*.
+
+[Si et al., 2010] Si, S., Tao, D., and Geng, B. (2010). Bregman divergence-based regularization for transfer subspace learning. *IEEE Transactions on Knowledge and Data Engineering*, 22(7):929-942.
+
+[Silver et al., 2017] Silver, D., Schrittwieser, J., Simonyan, K., Antonoglou, I., Huang, A., Guez, A., Hubert, T., Baker, L., Lai, M., Bolton, A., et al. (2017). Mastering the game of go without human knowledge. *Nature*, 550(7676):354.
+
+[Stewart and Ermon, 2017] Stewart, R. and Ermon, S. (2017). Label-free supervision of neural networks with physics and domain knowledge. In *AAAI*, pages 2576-2582.
+
+[Sun et al., 2016] Sun, B., Feng, J., and Saenko, K. (2016). Return of frustratingly easy domain adaptation. In *AAAI*, volume 6, page 8.
+
+[Sun and Saenko, 2015] Sun, B. and Saenko, K. (2015). Subspace distribution alignment for unsupervised domain adaptation. In *BMVC*, pages 24-1.
+
+[Sun and Saenko, 2016] Sun, B. and Saenko, K. (2016). Deep coral: Correlation alignment for deep domain adaptation. In *European Conference on Computer Vision*, pages 443-450. Springer.
+
+[Tahmoresnezhad and Hashemi, 2016] Tahmoresnezhad, J. and Hashemi, S. (2016). Visual domain adaptation via transfer feature learning. *Knowledge and Information Systems*, pages 1-21.
+
+[Tan et al., 2015] Tan, B., Song, Y., Zhong, E., and Yang, Q. (2015). Transitive transfer learning. In *Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining*, pages 1155-1164. ACM.
+
+[Tan et al., 2017] Tan, B., Zhang, Y., Pan, S. J., and Yang, Q. (2017). Distant domain transfer learning. In *Thirty-First AAAI Conference on Artificial Intelligence*.
+
+[Taylor and Stone, 2009] Taylor, M. E. and Stone, P. (2009). Transfer learning for reinforcement learning domains: A survey. *Journal of Machine Learning Research*, 10(Jul):1633- 1685.
+
+[Tzeng et al., 2015] Tzeng, E., Hoffman, J., Darrell, T., and Saenko, K. (2015). Simultaneous deep transfer across domains and tasks. In *Proceedings of the IEEE International Conference on Computer Vision*, pages 4068-4076, Santiago, Chile. IEEE.
+
+[Tzeng et al., 2017] Tzeng, E., Hoffman, J., Saenko, K., and Darrell, T. (2017). Adversarial discriminative domain adaptation. In *CVPR*, pages 2962-2971.
+
+[Tzeng et al., 2014] Tzeng, E., Hoffman, J., Zhang, N., et al. (2014). Deep domain confusion: Maximizing for domain invariance. *arXiv preprint arXiv:1412.3474*.
+
+[Wang et al., 2017] Wang, J., Chen, Y., Hao, S., et al. (2017). Balanced distribution adaptation for transfer learning. In *ICDM*, pages 1129-1134.
+
+[Wang et al., 2018] Wang, J., Chen, Y., Hu, L., Peng, X., and Yu, P. S. (2018). Stratified transfer learning for cross-domain activity recognition. In *2018 IEEE International Conference on Pervasive Computing and Communications (PerCom)*.
+
+[Wang et al., 2014] Wang, J., Zhao, P., Hoi, S. C., and Jin, R. (2014). Online feature selection and its applications. *IEEE Transactions on Knowledge and Data Engineering*, 26(3):698-710.
+
+[Wei et al., 2016a] Wei, P., Ke, Y., and Goh, C. K. (2016a). Deep nonlinearfeature coding for unsupervised domain adaptation. In *IJCAI*, pages 2189-2195.
+
+[Wei et al., 2017] Wei, Y., Zhang, Y., and Yang, Q. (2017). Learning totransfer. *arXiv* preprint arXiv:1708.05629*.
+
+[Wei et al., 2016b] Wei, Y., Zhu, Y., Leung, C. W.-k., Song, Y., and Yang, Q. (2016b). Instilling social to physical: Co-regularized heterogeneous transfer learning. In *Thirtieth* AAAI Conference on Artificial Intelligence*.
+
+[Weiss et al., 2016] Weiss, K., Khoshgoftaar, T. M., and Wang, D. (2016). A survey of transfer learning. *Journal of Big Data*, 3(1):1-40.
+
+[Wu et al., 2017] Wu, Q., Zhou, X., Yan, Y., Wu, H., and Min, H. (2017). Online transfer learning by leveraging multiple source domains. *Knowledge and Information Systems*, 52(3):687-707.
+
+[xinhua, 2016] xinhua (2016). http://mp.weixin.qq.com/s?__biz=MjM5ODYzNzAyMQ==& mid=2651933920&idx=1\\&sn=ae2866bd12000f1644eae1094497837e.
+
+[Yan et al., 2017] Yan, Y., Wu, Q., Tan, M., Ng, M. K., Min, H., and Tsang, I. W. (2017). Online heterogeneous transfer by hedge ensemble of offline and online decisions. *IEEE transactions on neural networks and learning systems*.
+
+[Yosinski et al., 2014] Yosinski, J., Clune, J., Bengio, Y., and Lipson, H. (2014). How transferable are features in deep neural networks? In *Advances in neural information processing systems*, pages 3320-3328.
+
+[Zadrozny, 2004] Zadrozny, B. (2004). Learning and evaluating classifiers under sample selection bias. In *Proceedings of the twenty-first international conference on Machine learning*, page 114, Alberta, Canada. ACM.
+
+[Zellinger et al., 2017] Zellinger, W., Grubinger, T., Lughofer, E., Natschlager, T., and Saminger-Platz, S. (2017). Central moment discrepancy (cmd) for domain-invariant representation learning. *arXiv preprint arXiv:1702.08811*.
+
+[Zhang et al., 2017a] Zhang, J., Li, W., and Ogunbona, P. (2017a). Joint geometrical and statistical alignment for visual domain adaptation. In *CVPR*.
+
+[Zhang et al., 2017b] Zhang, X., Zhuang, Y., Wang, W., and Pedrycz, W. (2017b). Online feature transformation learning for cross-domain object category recognition. *IEEE transactions on neural networks and learning systems*.
+
+[Zhao and Hoi, 2010] Zhao, P. and Hoi, S. C. (2010). Otl: A framework of online transfer learning. In *Proceedings of the 27th international conference on machine learning (ICML- 10)*, pages 1231-1238.
+
+[Zhao et al., 2010] Zhao, Z., Chen, Y., Liu, J., and Liu, M. (2010). Cross-mobile elm based activity recognition. *International Journal of Engineering and Industries*, 1(1):30-38.
+
+[Zhao et al., 2011] Zhao, Z., Chen, Y., Liu, J., Shen, Z., and Liu, M. (2011). Cross-people mobile-phone based activity recognition. In *Proceedings of the Twenty-Second international joint conference on Artificial Intelligence (IJCAI)*, volume 11, pages 2545-2550. Citeseer.
+
+[Zheng et al., 2009] Zheng, V. W., Hu, D. H., and Yang, Q. (2009). Cross-domain activity recognition. In *Proceedings of the 11th international conference on Ubiquitous computing*, pages 61-70. ACM.
+
+[Zheng et al., 2008] Zheng, V. W., Pan, S. J., Yang, Q., and Pan, J. J. (2008). Transferring multi-device localization models using latent multi-task learning. In *AAAI*, volume 8, pages 1427-1432, Chicago, Illinois, USA. AAAI.
+
+[Zhuang et al., 2015] Zhuang, F., Cheng, X., Luo, P., Pan, S. J., and He, Q. (2015). Supervised representation learning: Transfer learning with deep autoencoders. In *IJCAI*,pages 4119-4125.
+
+[Zhuo et al., 2017] Zhuo, J., Wang, S., Zhang, W., and Huang, Q. (2017). Deep unsupervised convolutional domain adaptation. In *Proceedings of the 2017 ACM on Multimedia Conference*, pages 261-269. ACM.
diff --git "a/ch12_\347\275\221\347\273\234\346\220\255\345\273\272\345\217\212\350\256\255\347\273\203/img/ch12/readme.md" "b/ch12_\347\275\221\347\273\234\346\220\255\345\273\272\345\217\212\350\256\255\347\273\203/img/ch12/readme.md"
deleted file mode 100644
index f099ebf1..00000000
--- "a/ch12_\347\275\221\347\273\234\346\220\255\345\273\272\345\217\212\350\256\255\347\273\203/img/ch12/readme.md"
+++ /dev/null
@@ -1,2 +0,0 @@
-Add the corresponding chapter picture under img/ch*
-��img/ch*�����Ӷ�Ӧ�½�ͼƬ
\ No newline at end of file
diff --git "a/ch12_\347\275\221\347\273\234\346\220\255\345\273\272\345\217\212\350\256\255\347\273\203/\347\254\254\345\215\201\344\272\214\347\253\240_\347\275\221\347\273\234\346\220\255\345\273\272\345\217\212\350\256\255\347\273\203.md" "b/ch12_\347\275\221\347\273\234\346\220\255\345\273\272\345\217\212\350\256\255\347\273\203/\347\254\254\345\215\201\344\272\214\347\253\240_\347\275\221\347\273\234\346\220\255\345\273\272\345\217\212\350\256\255\347\273\203.md"
index e4f8210c..ee02c68c 100644
--- "a/ch12_\347\275\221\347\273\234\346\220\255\345\273\272\345\217\212\350\256\255\347\273\203/\347\254\254\345\215\201\344\272\214\347\253\240_\347\275\221\347\273\234\346\220\255\345\273\272\345\217\212\350\256\255\347\273\203.md"
+++ "b/ch12_\347\275\221\347\273\234\346\220\255\345\273\272\345\217\212\350\256\255\347\273\203/\347\254\254\345\215\201\344\272\214\347\253\240_\347\275\221\347\273\234\346\220\255\345\273\272\345\217\212\350\256\255\347\273\203.md"
@@ -3,44 +3,6 @@
# 第十二章 网络搭建及训练
-目录
-常用框架介绍
-常用框架对比(表格展示) 16个最棒的深度学习框架 https://baijiahao.baidu.com/s?id=1599943447101946075&wfr=spider&for=pc
-基于tensorfolw网络搭建实例
-CNN训练注意事项
-训练技巧
-深度学习模型训练痛点及解决方法 https://blog.csdn.net/weixin_40581617/article/details/80537559
-深度学习模型训练流程 https://blog.csdn.net/Quincuntial/article/details/79242364
-深度学习模型训练技巧 https://blog.csdn.net/w7256037/article/details/52071345
-https://blog.csdn.net/u012033832/article/details/79017951
-https://blog.csdn.net/u012968002/article/details/72122965
-
-深度学习几大难点 https://blog.csdn.net/m0_37867246/article/details/79766371
-
-## CNN训练注意事项
-http://www.cnblogs.com/softzrp/p/6724884.html
-1.用Mini-batch SGD对神经网络做训练的过程如下:
-
-不断循环 :
-
-① 采样一个 batch 数据( ( 比如 32 张 )
-
-②前向计算得到损失 loss
-
-③ 反向传播计算梯度( 一个 batch)
-
-④ 用这部分梯度迭代更新权重参数
-
-2.去均值
-
-去均值一般有两种方式:第一种是在每个像素点都算出3个颜色通道上的平均值,然后对应减去,如AlexNet。 第二种是在整个样本上就只得到一组数,不分像素点了,如VGGNet。
-3.权重初始化
-4.Dropout
-
-
-
-# 第十二章 TensorFlow、pytorch和caffe介绍
-
# 12.1 TensorFlow
## 12.1.1 TensorFlow是什么?
diff --git "a/ch13_\344\274\230\345\214\226\347\256\227\346\263\225/img/ch13/figure_13_18_1.png" "b/ch13_\344\274\230\345\214\226\347\256\227\346\263\225/img/ch13/figure_13_18_1.png"
index 8edafaf4..5d53edc7 100644
Binary files "a/ch13_\344\274\230\345\214\226\347\256\227\346\263\225/img/ch13/figure_13_18_1.png" and "b/ch13_\344\274\230\345\214\226\347\256\227\346\263\225/img/ch13/figure_13_18_1.png" differ
diff --git "a/ch13_\344\274\230\345\214\226\347\256\227\346\263\225/img/ch13/figure_13_19_1.png" "b/ch13_\344\274\230\345\214\226\347\256\227\346\263\225/img/ch13/figure_13_19_1.png"
index 4c283d61..0ada3972 100644
Binary files "a/ch13_\344\274\230\345\214\226\347\256\227\346\263\225/img/ch13/figure_13_19_1.png" and "b/ch13_\344\274\230\345\214\226\347\256\227\346\263\225/img/ch13/figure_13_19_1.png" differ
diff --git "a/ch13_\344\274\230\345\214\226\347\256\227\346\263\225/\347\254\254\345\215\201\344\270\211\347\253\240_\344\274\230\345\214\226\347\256\227\346\263\225.md" "b/ch13_\344\274\230\345\214\226\347\256\227\346\263\225/\347\254\254\345\215\201\344\270\211\347\253\240_\344\274\230\345\214\226\347\256\227\346\263\225.md"
index 88eae7fd..4641022b 100644
--- "a/ch13_\344\274\230\345\214\226\347\256\227\346\263\225/\347\254\254\345\215\201\344\270\211\347\253\240_\344\274\230\345\214\226\347\256\227\346\263\225.md"
+++ "b/ch13_\344\274\230\345\214\226\347\256\227\346\263\225/\347\254\254\345\215\201\344\270\211\347\253\240_\344\274\230\345\214\226\347\256\227\346\263\225.md"
@@ -4,222 +4,124 @@
# 第一十三章 优化算法
+## 13.1 如何解决训练样本少的问题
-## 13.1 CPU 和 GPU 的区别?
-
-
-**概念:**
+目前大部分的深度学习模型仍然需要海量的数据支持。例如 ImageNet 数据就拥有1400多万的图片。而现实生产环境中,数据集通常较小,只有几万甚至几百个样本。这时候,如何在这种情况下应用深度学习呢?
+(1)利用预训练模型进行迁移微调(fine-tuning),预训练模型通常在特征上拥有很好的语义表达。此时,只需将模型在小数据集上进行微调就能取得不错的效果。这也是目前大部分小数据集常用的训练方式。视觉领域内,通常会ImageNet上训练完成的模型。自然语言处理领域,也有BERT模型等预训练模型可以使用。
-CPU 全称是 central processing unit,CPU 是一块超大规模的集成电路,是一台计算机的运 算和控制核心,它的主要功能是解释计算机指令和处理计算机软件中的数据。
+(2)单样本或者少样本学习(one-shot,few-shot learning),这种方式适用于样本类别远远大于样本数量的情况等极端数据集。例如有1000个类别,每个类别只提供1-5个样本。少样本学习同样也需要借助预训练模型,但有别于微调的在于,微调通常仍然在学习不同类别的语义,而少样本学习通常需要学习样本之间的距离度量。例如孪生网络(Siamese Neural Networks)就是通过训练两个同种结构的网络来判别输入的两张图片是否属于同一类。
+ 上述两种是常用训练小样本数据集的方式。此外,也有些常用的手段,例如数据集增强、正则或者半监督学习等方式来解决小样本数据集的训练问题。
-
-GPU 全称是 graphics processing unit,GPU 是将计算机系统,所需要的显示信息进行转换 的驱动,并向显示器提供扫描信号,控制显示器的正确显示,是连接显示器和个人电脑主板的 重要元件,是人机对话的重要设备之一。
+## 13.2 深度学习是否能胜任所有数据集?
-
-**缓存:**
-
-CPU 有大量的缓存结构,目前主流的 CPU 芯片上都有四级缓存,这些缓存结构消耗了大 量的晶体管,在运行的时候需要大量的电力。反观 GPU 的缓存就很简单,目前主流的 GPU 芯 片最多有两层缓存。CPU 消耗在晶体管上的空间和能耗,GPU 都可以用来做成 ALU 单元,也 因此 GPU 比 CPU 的效率要高一些。
+深度学习并不能胜任目前所有的数据环境,以下列举两种情况:
-
-**响应方式:**
-
-对 CPU 来说,要求的是实时响应,对单任务的速度要求很高,所以就要用很多层缓存的 办法来保证单任务的速度。对 GPU 来说大家不关心第一个像素什么时候计算完成,而是都关 心最后一个像素什么时候计算出来,所以 GPU 就把所有的任务都排好,然后再批处理,这样 对缓存的要求就很低了。举个不恰当的例子,在点击 10 次鼠标的时候,CPU 要每一次点击都 要及时响应,而 GPU 会等第 10 次点击后,再一次性批处理响应。
+(1)深度学习能取得目前的成果,很大一部分原因依赖于海量的数据集以及高性能密集计算硬件。因此,当数据集过小时,需要考虑与传统机器学习相比,是否在性能和硬件资源效率更具有优势。
+(2)深度学习目前在视觉,自然语言处理等领域都有取得不错的成果。这些领域最大的特点就是具有局部相关性。例如图像中,人的耳朵位于两侧,鼻子位于两眼之间,文本中单词组成句子。这些都是具有局部相关性的,一旦被打乱则会破坏语义或者有不同的语义。所以当数据不具备这种相关性的时候,深度学习就很难取得效果。
-
-**浮点运算:**
-
-CPU 除了负责浮点整形运算外,还有很多其他的指令集的负载,比如像多媒体解码,硬 件解码等,所以 CPU 是个多才多艺的东西,而 GPU 基本上就是只做浮点运算的,也正是因为 只做浮点运算,所以设计结构简单,也就可以做的更快。另外显卡的 GPU 和单纯为了跑浮点 高性能运算的 GPU 还是不太一样,显卡的 GPU 还要考虑配合图形输出显示等方面,而有些专 用 GPU 设备,就是一个 PCI 卡上面有一个性能很强的浮点运算 GPU,没有显示输出的,这样 的 GPU 就是为了加快某些程序的浮点计算能力。CPU 注重的是单线程的性能,也就是延迟, 对于 CPU 来说,要保证指令流不中断,所以 CPU 需要消耗更多的晶体管和能耗用在控制部分, 于是CPU分配在浮点计算的功耗就会变少。GPU注重的是吞吐量,单指令能驱动更多的计算, 所以相比较而言 GPU 消耗在控制部分的能耗就比较少,因此也就可以把电省下来的资源给浮 点计算使用。
+## 13.3 有没有可能找到比已知算法更好的算法?
-
-**应用方向:**
-
-像操作系统这一类应用,需要快速响应实时信息,需要针对延迟优化,所以晶体管数量和能耗都需要用在分支预测,乱序执行上,低延迟缓存等控制部分,而这都是 CPU 的所擅长的。 对于像矩阵一类的运算,具有极高的可预测性和大量相似运算的,这种高延迟,高吞吐的架构 运算,就非常适合 GPU。
+在最优化理论发展中,有个没有免费午餐的定律,其主要含义在于,在不考虑具体背景和细节的情况下,任何算法和随机猜的效果期望是一样的。即,没有任何一种算法能优于其他一切算法,甚至不比随机猜好。深度学习作为机器学习领域的一个分支同样符合这个定律。所以,虽然目前深度学习取得了非常不错的成果,但是我们同样不能盲目崇拜。
-
-**浅显解释:**
-
-一块 CPU 相当于一个数学教授,一块 GPU 相当于 100 个小学生。
-
-第一回合,四则运算,一百个题。教授拿到卷子一道道计算。100 个小学生各拿一道题。 教授刚开始计算到第二题的时候,小学生就集体交卷了。
-
-第二回合,高等函数,一百个题。当教授搞定后。一百个小学生可能还不知道该做些什么。
-
-这两个回合就是 CPU 和 GPU 的区别了。
+优化算法本质上是在寻找和探索更符合数据集和问题的算法,这里数据集是算法的驱动力,而需要通过数据集解决的问题就是算法的核心,任何算法脱离了数据都会没有实际价值,任何算法的假设都不能脱离实际问题。因此,实际应用中,面对不同的场景和不同的问题,可以从多个角度针对问题进行分析,寻找更优的算法。
-## 13.2 如何解决训练样本少的问题
+## 13.4 什么是共线性,如何判断和解决共线性问题?
-
-要训练一个好的 CNN 模型,通常需要很多训练数据,尤其是模型结构比较复杂的时候, 比如 ImageNet 数据集上训练的模型。虽然深度学习在 ImageNet 上取得了巨大成功,但是一个 现实的问题是,很多应用的训练集是较小的,如何在这种情况下应用深度学习呢?有三种方法 可供读者参考。
+对于回归算法,无论是一般回归还是逻辑回归,在使用多个变量进行预测分析时,都可能存在多变量相关的情况,这就是多重共线性。共线性的存在,使得特征之间存在冗余,导致过拟合。
-
-(1)可以将 ImageNet 上训练得到的模型做为起点,利用目标训练集和反向传播对其进 行继续训练,将模型适应到特定的应用。ImageNet 起到预训练的作用。
-
-(2)如果目标训练集不够大,也可以将低层的网络参数固定,沿用 ImageNet 上的训练集 结果,只对上层进行更新。这是因为底层的网络参数是最难更新的,而从 ImageNet 学习得到 的底层滤波器往往描述了各种不同的局部边缘和纹理信息,而这些滤波器对一般的图像有较好 的普适性。
-
-(3)直接采用 ImageNet 上训练得到的模型,把最高的隐含层的输出作为特征表达,代 替常用的手工设计的特征。
+常用判断是否存在共线性的方法有:
-## 13.3 什么样的样本集不适合用深度学习?
+(1)相关性分析。当相关性系数高于0.8,表明存在多重共线性;但相关系数低,并不能表示不存在多重共线性;
-
-(1)数据集太小,数据样本不足时,深度学习相对其它机器学习算法,没有明显优势。
-
-(2)数据集没有局部相关特性,目前深度学习表现比较好的领域主要是图像/语音 /自然语言处理等领域,这些领域的一个共性是局部相关性。图像中像素组成物体,语音 信号中音位组合成单词,文本数据中单词组合成句子,这些特征元素的组合一旦被打乱, 表示的含义同时也被改变。对于没有这样的局部相关性的数据集,不适于使用深度学习算 法进行处理。举个例子:预测一个人的健康状况,相关的参数会有年龄、职业、收入、家 庭状况等各种元素,将这些元素打乱,并不会影响相关的结果。
+(2)方差膨胀因子VIF。当VIF大于5或10时,代表模型存在严重的共线性问题;
-## 13.4 有没有可能找到比已知算法更好的算法?
+(3)条件系数检验。 当条件数大于100、1000时,代表模型存在严重的共线性问题。
+通常可通过PCA降维、逐步回归法和LASSO回归等方法消除共线性。
+## 13.5 权值初始化方法有哪些?
-
-没有免费的午餐定理:
-
-图 13.4 没有免费的午餐(黑点:训练样本;白点:测试样本)
+在深度学习的模型中,从零开始训练时,权重的初始化有时候会对模型训练产生较大的影响。良好的初始化能让模型快速、有效的收敛,而糟糕的初始化会使得模型无法训练。
-
-对于训练样本(黑点),不同的算法 A/B 在不同的测试样本(白点)中有不同的表现,这表示:对于一个学习算法A,若它在某些问题上比学习算法B更好,则必然存在一些问题, 在那里B比A好。
-
-也就是说:对于所有问题,无论学习算法 A 多聪明,学习算法 B 多笨拙,它们的期望性 能相同。
-
-但是:没有免费午餐定力假设所有问题出现几率相同,实际应用中,不同的场景,会有不 同的问题分布,所以,在优化算法时,针对具体问题进行分析,是算法优化的核心所在。
+目前,大部分深度学习框架都提供了各类初始化方式,其中一般常用的会有如下几种:
+**1. 常数初始化(constant)**
-## 13.5 何为共线性, 跟过拟合有啥关联?
+ 把权值或者偏置初始化为一个常数。例如设置为0,偏置初始化为0较为常见,权重很少会初始化为0。TensorFlow中也有zeros_initializer、ones_initializer等特殊常数初始化函数。
-
-共线性:多变量线性回归中,变量之间由于存在高度相关关系而使回归估计不准确。
-
-产生问题:共线性会造成冗余,导致过拟合。
-
-解决方法:排除变量的相关性、加入权重正则。
+**2. 高斯初始化(gaussian)**
-## 13.6 广义线性模型是怎被应用在深度学习中?
+ 给定一组均值和标准差,随机初始化的参数会满足给定均值和标准差的高斯分布。高斯初始化是很常用的初始化方式。特殊地,在TensorFlow中还有一种截断高斯分布初始化(truncated_normal_initializer),其主要为了将超过两个标准差的随机数重新随机,使得随机数更稳定。
-
-深度学习从统计学角度,可以看做递归的广义线性模型。
-
-广义线性模型相对于经典的线性模型$(y=wx+b)$,核心在于引入了连接函数 $g(\cdot)$,形式变为: $y=g-1(wx+b)$。
-
-深度学习时递归的广义线性模型,神经元的激活函数,即为广义线性模型的链接函数。逻 辑回归(广义线性模型的一种)的 Logistic 函数即为神经元激活函数中的 Sigmoid 函数,很多 类似的方法在统计学和神经网络中的名称不一样,容易引起困惑。
+**3. 均匀分布初始化(uniform)**
-## 13.7 造成梯度消失的原因?
+ 给定最大最小的上下限,参数会在该范围内以均匀分布方式进行初始化,常用上下限为(0,1)。
+**4. xavier 初始化(uniform)**
+ 在batchnorm还未出现之前,要训练较深的网络,防止梯度弥散,需要依赖非常好的初始化方式。xavier 就是一种比较优秀的初始化方式,也是目前最常用的初始化方式之一。其目的是为了使得模型各层的激活值和梯度在传播过程中的方差保持一致。本质上xavier 还是属于均匀分布初始化,但与上述的均匀分布初始化有所不同,xavier 的上下限将在如下范围内进行均匀分布采样:
+$$
+[-\sqrt{\frac{6}{n+m}},\sqrt{\frac{6}{n+m}}]
+$$
+ 其中,n为所在层的输入维度,m为所在层的输出维度。
-
-神经网络的训练中,通过改变神经元的权重,使网络的输出值尽可能逼近标签以降低误差 值,训练普遍使用 BP 算法,核心思想是,计算出输出与标签间的损失函数值,然后计算其相 对于每个神经元的梯度,进行权值的迭代。
-
-梯度消失会造成权值更新缓慢,模型训练难度增加。造成梯度消失的一个原因是,许多激 活函数将输出值挤压在很小的区间内,在激活函数两端较大范围的定义域内梯度为 $0$。造成学 习停止。
-
-图 13.7 sigmoid 函数的梯度消失
+**6. kaiming初始化(msra 初始化)**
-## 13.8 权值初始化方法有哪些?
+ kaiming初始化,在caffe中也叫msra 初始化。kaiming初始化和xavier 一样都是为了防止梯度弥散而使用的初始化方式。kaiming初始化的出现是因为xavier存在一个不成立的假设。xavier在推导中假设激活函数都是线性的,而在深度学习中常用的ReLu等都是非线性的激活函数。而kaiming初始化本质上是高斯分布初始化,与上述高斯分布初始化有所不同,其是个满足均值为0,方差为2/n的高斯分布:
+$$
+[0,\sqrt{\frac{2}{n}}]
+$$
+ 其中,n为所在层的输入维度。
-
-权值初始化的方法主要有:常量初始化(constant)、高斯分布初始化(gaussian)、 positive_unitball 初始化、均匀分布初始化(uniform)、xavier 初始化、msra 初始化、双线性初 始化(bilinear)。
+除上述常见的初始化方式以外,不同深度学习框架下也会有不同的初始化方式,读者可自行查阅官方文档。
-
-**1. 常量初始化(constant)**
-
-把权值或者偏置初始化为一个常数,具体是什么常数,可以自己定义。
+## 13.5 如何防止梯度下降陷入局部最优解?
-
-**2. 高斯分布初始化(gaussian)**
-
-需要给定高斯函数的均值与标准差。
+梯度下降法(GD)及其一些变种算法是目前深度学习里最常用于求解凸优化问题的优化算法。神经网络很可能存在很多局部最优解,而非全局最优解。 为了防止陷入局部最优,通常会采用如下一些方法,当然,这并不能保证一定能找到全局最优解,或许能得到一个比目前更优的局部最优解也是不错的:
-
-**3. positive_unitball 初始化**
-
-让每一个神经元的输入的权值和为 $1$,例如:一个神经元有 $100$ 个输入,让这 $100$ 个输入
-的权值和为 $1$. 首先给这 $100$ 个权值赋值为在$(0,1)$之间的均匀分布,然后,每一个权值再 除以它们的和就可以啦。这么做,可以有助于防止权值初始化过大,从而防止激活函数(sigmoid 函数)进入饱和区。所以,它应该比较适合 simgmoid 形的激活函数。
+**(1)stochastic GD** /**Mini-Batch GD**
-
-**4. 均匀分布初始化(uniform)**
-
-将权值与偏置进行均匀分布的初始化,用 min 与 max 控制它们的的上下限,默认为$(0,1)$。
+ 在GD算法中,每次的梯度都是从所有样本中累计获取的,这种情况最容易导致梯度方向过于稳定一致,且更新次数过少,容易陷入局部最优。而stochastic GD是GD的另一种极端更新方式,其每次都只使用一个样本进行参数更新,这样更新次数大大增加也就不容易陷入局部最优。但引出的一个问题的在于其更新方向过多,导致不易于进一步优化。Mini-Batch GD便是两种极端的折中,即每次更新使用一小批样本进行参数更新。Mini-Batch GD是目前最常用的优化算法,严格意义上Mini-Batch GD也叫做stochastic GD,所以很多深度学习框架上都叫做SGD。
+**(2)动量 **
+ 动量也是GD中常用的方式之一,SGD的更新方式虽然有效,但每次只依赖于当前批样本的梯度方向,这样的梯度方向依然很可能很随机。动量就是用来减少随机,增加稳定性。其思想是模仿物理学的动量方式,每次更新前加入部分上一次的梯度量,这样整个梯度方向就不容易过于随机。一些常见情况时,如上次梯度过大,导致进入局部最小点时,下一次更新能很容易借助上次的大梯度跳出局部最小点。
-
-**5. xavier 初始化**
-
-对于权值的分布:均值为 $0$,方差为($1$ / 输入的个数)的均匀分布。如果我们更注重前
-向传播的话,我们可以选择 fan_in,即正向传播的输入个数;如果更注重后向传播的话,我们选择 fan_out, 因为在反向传播的时候,fan_out 就是神经元的输入个数;如果两者都考虑的话, 就选 average = (fan_in + fan_out) /$2$。对于 ReLU 激活函数来说,XavierFiller 初始化也是很适合。关于该初始化方法,具体可以参考文章1、文章2,该方法假定激活函数是线性的。
+**(3)自适应学习率 **
-
-**6. msra 初始化**
-
-对于权值的分布:基于均值为 $0$,方差为( $2$/输入的个数)的高斯分布;它特别适合 ReLU 激活函数,该方法主要是基于 Relu 函数提出的,推导过程类似于 xavier。
+ 无论是GD还是动量重点优化角度是梯度方向。而学习率则是用来直接控制梯度更新幅度的超参数。自适应学习率的优化方法有很多,例如Adagrad和RMSprop。两种自适应学习率的方式稍有差异,但主要思想都是基于历史的累计梯度去计算一个当前较优的学习率。
-
-**7. 双线性初始化(bilinear)**
-
-常用在反卷积神经网络里的权值初始化。
+## 13.7 为什么需要激活函数?
-## 13.9 启发式优化算法中,如何避免陷入局部最优解?
+(1)非线性:即导数不是常数。这个条件是多层神经网络的基础,保证多层网络不退化成单层线性网络。这也是激活函数的意义所在。
-
-启发式算法中,局部最优值的陷入无法避免。启发式,本质上是一种贪心策略,这也在客 观上决定了不符合贪心规则的更好(或者最优)解会错过。
-
-简单来说,避免陷入局部最优就是两个字:随机。
-
-具体实现手段上,可以根据所采用的启发式框架来灵活地加入随机性。比如遗传里面,可 以在交叉变异时,可以在控制人口策略中,也可以在选择父本母本样本时;禁忌里面,可以在 禁忌表的长度上体现,也可以在解禁策略中使用,等等。这些都要结合具体问题特定的算例集, 需要反复尝试摸索才行。参数的敏感性是一个问题,建议不要超过 $3$ 个参数,参数越不敏感越好。不同算例集用不同种子运行多次($100$ 次左右才有统计意义),统计平均性能即可。需注 意全局的随机重启通常来说不是一个好办法,因为等于主动放弃之前搜索结果,万不得已不要 用,或者就是不用。
+(2)几乎处处可微:可微性保证了在优化中梯度的可计算性。传统的激活函数如sigmoid等满足处处可微。对于分段线性函数比如ReLU,只满足几乎处处可微(即仅在有限个点处不可微)。对于SGD算法来说,由于几乎不可能收敛到梯度接近零的位置,有限的不可微点对于优化结果不会有很大影响[1]。
-
-**三个原则应该把握:越随机越好;越不随机越好;二者平衡最好。**
+(3)计算简单:非线性函数有很多。极端的说,一个多层神经网络也可以作为一个非线性函数,类似于Network In Network[2]中把它当做卷积操作的做法。但激活函数在神经网络前向的计算次数与神经元的个数成正比,因此简单的非线性函数自然更适合用作激活函数。这也是ReLU之流比其它使用Exp等操作的激活函数更受欢迎的其中一个原因。
-
-**1. 越随机越好**
-
-没有随机性,一定会陷入局部最优。为了获得更大的找到最优解的期望,算法中一定要有
-足够的随机性。具体体现为鲁棒性较好,搜索时多样性较好。算法的每一步选择都可以考虑加入随机性,但要控制好概率。比如,某个贪心策略下,是以概率 $1 $做某一动作,可以考虑将其 改为以概率 $0.999$ 做之前的操作,以剩余概率做其他操作。具体参数设置需调试。
+(4)非饱和性(saturation):饱和指的是在某些区间梯度接近于零(即梯度消失),使得参数无法继续更新的问题。最经典的例子是Sigmoid,它的导数在x为比较大的正值和比较小的负值时都会接近于0。更极端的例子是阶跃函数,由于它在几乎所有位置的梯度都为0,因此处处饱和,无法作为激活函数。ReLU在x>0时导数恒为1,因此对于再大的正值也不会饱和。但同时对于x<0,其梯度恒为0,这时候它也会出现饱和的现象(在这种情况下通常称为dying ReLU)。Leaky ReLU[3]和PReLU[4]的提出正是为了解决这一问题。
-
-**2. 越不随机越好**
-
-随机性往往是对问题内在规律的一种妥协。即没有找到其内在规律,又不知道如何是好, 为了获得更好的多样性,逼不得已加入随机。因此,对给定问题的深入研究才是根本:分辨出 哪些时候,某个动作就是客观上能严格保证最优的——这点至关重要,直接决定了算法性能。 最好的算法一定是和问题结构紧密相连的,范范地套用某个启发式的框架不会有出色的性能。 当然,如果不是追求性能至上,而是考虑到开发效率实现成本这些额外因素,则另当别论。
+(5)单调性(monotonic):即导数符号不变。这个性质大部分激活函数都有,除了诸如sin、cos等。个人理解,单调性使得在激活函数处的梯度方向不会经常改变,从而让训练更容易收敛。
-
-**3. 二者平衡最好**
-
-通常情况下,做好第一点,可以略微改善算法性能;做好第二点,有希望给算法带来质的提高。而二者调和后的平衡则会带来质的飞跃。
+(6)输出范围有限:有限的输出范围使得网络对于一些比较大的输入也会比较稳定,这也是为什么早期的激活函数都以此类函数为主,如Sigmoid、TanH。但这导致了前面提到的梯度消失问题,而且强行让每一层的输出限制到固定范围会限制其表达能力。因此现在这类函数仅用于某些需要特定输出范围的场合,比如概率输出(此时loss函数中的log操作能够抵消其梯度消失的影响[1])、LSTM里的gate函数。
-
-贪心是“自强不息”的精进,不放过任何改进算法的机会;多样性的随机是“厚德载物”的一分包 容,给那些目前看似不那么好的解一些机会。调和好二者,不偏颇任何一方才能使算法有出色 的性能。要把握这种平衡,非一朝一夕之功,只能在反复试验反思中去细细品味。
-
-要结合具体问题而言,范范空谈无太大用。
+(7)接近恒等变换(identity):即约等于x。这样的好处是使得输出的幅值不会随着深度的增加而发生显著的增加,从而使网络更为稳定,同时梯度也能够更容易地回传。这个与非线性是有点矛盾的,因此激活函数基本只是部分满足这个条件,比如TanH只在原点附近有线性区(在原点为0且在原点的导数为1),而ReLU只在x>0时为线性。这个性质也让初始化参数范围的推导更为简单[5][4]。额外提一句,这种恒等变换的性质也被其他一些网络结构设计所借鉴,比如CNN中的ResNet[6]和RNN中的LSTM。
-## 13.10 凸优化中如何改进 GD 方法以防止陷入局部最优解?
+(8)参数少:大部分激活函数都是没有参数的。像PReLU带单个参数会略微增加网络的大小。还有一个例外是Maxout[7],尽管本身没有参数,但在同样输出通道数下k路Maxout需要的输入通道数是其它函数的k倍,这意味着神经元数目也需要变为k倍;但如果不考虑维持输出通道数的情况下,该激活函数又能将参数个数减少为原来的k倍。
-
-在对函数进行凸优化时,如果使用导数的方法(如:梯度下降法/GD,牛顿法等)来寻找最优解,有可能陷入到局部最优解而非全局最优解。
-
-为了防止得到局部最优,可以对梯度下降法进行一些改进,防止陷入局部最优。
-
-但是请注意,这些方法只能保证以最大的可能找到全局最优,无法保证 $100\%$得到全局最优。
+(9)归一化(normalization):这个是最近才出来的概念,对应的激活函数是SELU[8],主要思想是使样本分布自动归一化到零均值、单位方差的分布,从而稳定训练。在这之前,这种归一化的思想也被用于网络结构的设计,比如Batch Normalization[9]。
-
-**(1)incremental GD/stochastic GD**
-
-在 GD 中,是需要遍历所有的点之后才计算 $w$ 的变化的;但是,在 stochastic GD 中,每输入一个点,就根据该点计算下一步的 $w$,这样,不仅可以从 batch training 变成 online training 方法,而且每次是按照单点的最优方向而不是整体的最优方向前进,从而相当于在朝目标前进的路上多拐了好多弯,有可能逃出局部最优。
-
-**(2)momentum 方法**
-
-momentum 相当与记忆住上一次的更新。在每次的更新中,都要加一个 $k$ 倍的上一次更新 量。这样,也不再是按照标准路线前进,每次的步骤都容易受到上一次的影响,从而可能会逃 出局部最优。另外,也会加大步长,从而加快收敛。
-## 13.11 常见的损失函数?
+## 13.6 常见的损失函数有哪些?
-
-机器学习通过对算法中的目标函数进行不断求解优化,得到最终想要的结果。分类和回归 问题中,通常使用损失函数或代价函数作为目标函数。
-
-损失函数用来评价预测值和真实值不一样的程度。通常损失函数越好,模型的性能也越好。
-
-损失函数可分为经验风险损失函数和结构风险损失函数。经验风险损失函数指预测结果和 实际结果的差别,结构风险损失函数是在经验风险损失函数上加上正则项。
+机器学习通过对算法中的目标函数进行不断求解优化,得到最终想要的结果。分类和回归问题中,通常使用损失函数或代价函数作为目标函数。
-
-下面介绍常用的损失函数:
+损失函数用来评价预测值和真实值不一样的程度。通常损失函数越好,模型的性能也越好。
+损失函数可分为**经验风险损失**和**结构风险损失**。经验风险损失是根据已知数据得到的损失。结构风险损失是为了防止模型被过度拟合已知数据而加入的惩罚项。
+
+下面介绍常用的损失函数:
+**(1)0-1 损失函数**
-**1)$0-1$ 损失函数**
-
-如果预测值和目标值相等,值为 $0$,如果不相等,值为 $1$:
+如果预测值和目标值相等,值为 0,如果不相等,值为 1:
$$
L(Y,f(x))=
\left\{
@@ -243,15 +145,15 @@ L(Y,f(x))=
$$
-**2)绝对值损失函数**
+**(2)绝对值损失函数**
-和 $0-1$ 损失函数相似,绝对值损失函数表示为:
+和 0-1 损失函数相似,绝对值损失函数表示为:
$$
L(Y,f(x))=|Y-f(x)|.
$$
-**3)平方损失函数**
+**(3)平方损失函数**
$$
L(Y|f(x))=\sum_{N}(Y-f(x))^2.
$$
@@ -260,16 +162,16 @@ $$
这点可从最小二乘法和欧几里得距离角度理解。最小二乘法的原理是,最优拟合曲线应该 使所有点到回归直线的距离和最小。
-**4)$log$ 对数损失函数**
+**(4)log 对数损失函数**
$$
L(Y,P(Y|X))=-logP(Y|X).
$$
-常见的逻辑回归使用的就是对数损失函数,有很多人认为逻辑回归的损失函数式平方损失, 其实不然。逻辑回归它假设样本服从伯努利分布,进而求得满足该分布的似然函数,接着取对 数求极值等。逻辑回归推导出的经验风险函数是最小化负的似然函数,从损失函数的角度看, 就是 $log$ 损失函数。
+常见的逻辑回归使用的就是对数损失函数,有很多人认为逻辑回归的损失函数式平方损失, 其实不然。逻辑回归它假设样本服从伯努利分布,进而求得满足该分布的似然函数,接着取对 数求极值等。逻辑回归推导出的经验风险函数是最小化负的似然函数,从损失函数的角度看, 就是 log 损失函数。
-**5)指数损失函数**
+**(5)指数损失函数**
指数损失函数的标准形式为:
$$
@@ -280,7 +182,7 @@ $$
例如 AdaBoost 就是以指数损失函数为损失函数。
-**6)Hinge 损失函数**
+**(6)Hinge 损失函数**
Hinge 损失函数的标准形式如下:
$$
@@ -288,7 +190,7 @@ L(y)=max(0, 1-ty).
$$
-其中 $y$ 是预测值,范围为$(-1,1)$, $t$ 为目标值,其为$-1$ 或 $1$。
+其中 y 是预测值,范围为(-1,1), t 为目标值,其为-1 或 1。
在线性支持向量机中,最优化问题可等价于:
$$
@@ -303,1080 +205,248 @@ $$
其中$l(wx_i+by_i))$是Hinge损失函数,$\lVert w^2 \rVert$可看做为正则化项。
-## 13.14 如何进行特征选择(feature selection)?
-
-### 13.14.1 如何考虑特征选择
-
-
-当数据预处理完成后,我们需要选择有意义的特征输入机器学习的算法和模型进行训练。通常来说,从两个方面考虑来选择特征:
-
-
-(1)特征是否发散:如果一个特征不发散,例如方差接近于 $0$,也就是说样本在这个特 征上基本上没有差异,这个特征对于样本的区分并没有什么用。
-
-(2)特征与目标的相关性:这点比较显见,与目标相关性高的特征,应当优选选择。除移除低方差法外,本文介绍的其他方法均从相关性考虑。
-
-### 13.14.2 特征选择方法分类
-
-
-根据特征选择的形式又可以将特征选择方法分为 $3$ 种:
-
-
-(1)Filter:过滤法,按照发散性或者相关性对各个特征进行评分,设定阈值或者待选择
-阈值的个数,选择特征。
-
-(2)Wrapper:包装法,根据目标函数(通常是预测效果评分),每次选择若干特征,或
-者排除若干特征。
-
-(3)Embedded:嵌入法,先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。类似于 Filter 方法,但是是通过训练来确定特征的优劣。
-
-### 13.14.3 特征选择目的
-
-
-(1)减少特征数量、降维,使模型泛化能力更强,减少过拟合;
-
-(2)增强对特征和特征值之间的理解。拿到数据集,一个特征选择方法,往往很难同时完成这两个目的。通常情况下,选择一种自己最熟悉或者最方便的特征选择方法(往往目的是降维,而忽略了对特征和数据理解的目的)。 本文将结合 Scikit-learn 提供的例子介绍几种常用的特征选择方法,它们各自的优缺点和问题。
-
-## 13.15 梯度消失/梯度爆炸原因,以及解决方法
-
-### 13.15.1 为什么要使用梯度更新规则?
-
-
-在介绍梯度消失以及爆炸之前,先简单说一说梯度消失的根源—–深度神经网络和反向传 播。目前深度学习方法中,深度神经网络的发展造就了我们可以构建更深层的网络完成更复杂 的任务,深层网络比如深度卷积网络,LSTM 等等,而且最终结果表明,在处理复杂任务上, 深度网络比浅层的网络具有更好的效果。但是,目前优化神经网络的方法都是基于反向传播的 思想,即根据损失函数计算的误差通过梯度反向传播的方式,指导深度网络权值的更新优化。 这样做是有一定原因的,首先,深层网络由许多非线性层堆叠而来,每一层非线性层都可以视 为是一个非线性函数 $f(x)$($f(x)$非线性来自于非线性激活函数),因此整个深度网络可以视为是一个复合的非线性多元函数:
-$$F(x)=f_n(\cdots f_3(f_2(f_1(x)*\theta_1+b)*\theta_2+b)\cdots)$$
-
-
-我们最终的目的是希望这个多元函数可以很好的完成输入到输出之间的映射,假设不同的输入,输出的最优解是$g(x)$ ,那么,优化深度网络就是为了寻找到合适的权值,满足 $Loss=L(g(x),F(x))$取得极小值点,比如最简单的损失函数:
-$$
-Loss = \lVert g(x)-f(x) \rVert^2_2.
-$$
-
-
-假设损失函数的数据空间是下图这样的,我们最优的权值就是为了寻找下图中的最小值点, 对于这种数学寻找最小值问题,采用梯度下降的方法再适合不过了。
-
-图 13.15.1
+## 13.7 如何进行特征选择(feature selection)?
-### 13.15.2 梯度消失、爆炸原因?
+### 13.7.1 特征类型有哪些?
-
-梯度消失与梯度爆炸其实是一种情况,看接下来的文章就知道了。两种情况下梯度消失经 常出现,一是在深层网络中,二是采用了不合适的损失函数,比如 sigmoid。梯度爆炸一般出 现在深层网络和权值初始化值太大的情况下,下面分别从这两个角度分析梯度消失和爆炸的原因。
+对象本身会有许多属性。所谓特征,即能在某方面最能表征对象的一个或者一组属性。一般地,我们可以把特征分为如下三个类型:
-
-(1)深层网络角度
-
-对激活函数进行求导,如果此部分大于 $1$,那么层数增多的时候,最终的求出的梯度更新 将以指数形式增加,即发生**梯度爆炸**,如果此部分小于 $1$,那么随着层数增多,求出的梯度更 新信息将会以指数形式衰减,即发生了**梯度消失**。
-
-从深层网络角度来讲,不同的层学习的速度差异很大,表现为网络中靠近输出的层学习的 情况很好,靠近输入的层学习的很慢,有时甚至训练了很久,前几层的权值和刚开始随机初始 化的值差不多。因此,梯度消失、爆炸,其根本原因在于反向传播训练法则,属于先天不足, 另外多说一句,Hinton 提出 capsule 的原因就是为了彻底抛弃反向传播,如果真能大范围普及, 那真是一个革命。
+(1)相关特征:对于特定的任务和场景具有一定帮助的属性,这些属性通常能有效提升算法性能;
-
-(2)激活函数角度
-
-计算权值更新信息的时候需要计算前层偏导信息,因此如果激活函数选择不合适,比如使用 sigmoid,梯度消失就会很明显了,原因看下图,左图是sigmoid的损失函数图,右边是其倒数的图像,如果使用 sigmoid 作为损失函数,其梯度是不可能超过 $0.25$ 的,这样经过链式求导之后,很容易发生梯度消失。
-
-图 13.15.2 sigmod函数与其导数
+(2)无关特征:在特定的任务和场景下完全无用的属性,这些属性对对象在本目标环境下完全无用;
-### 13.15.3 梯度消失、爆炸的解决方案
+(3)冗余特征:同样是在特定的任务和场景下具有一定帮助的属性,但这类属性已过多的存在,不具有产生任何新的信息的能力。
-
-**方案1-预训练加微调**
-
-此方法来自Hinton在2006年发表的一篇论文,Hinton为了解决梯度的问题,提出采取无监督逐层训练方法,其基本思想是每次训练一层隐节点,训练时将上一层隐节点的输出作为输入,而本层隐节点的输出作为下一层隐节点的输入,此过程就是逐层“预训练”(pre-training);在预训练完成后,再对整个网络进行“微调”(fine-tunning)。Hinton在训练深度信念网络(Deep Belief Networks中,使用了这个方法,在各层预训练完成后,再利用BP算法对整个网络进行训练。此思想相当于是先寻找局部最优,然后整合起来寻找全局最优,此方法有一定的好处,但是目前应用的不是很多了。
+### 13.7.2 如何考虑特征选择
-
-**方案2-梯度剪切、正则**
-
-梯度剪切这个方案主要是针对梯度爆炸提出的,其思想是设置一个梯度剪切阈值,然后更新梯度的时候,如果梯度超过这个阈值,那么就将其强制限制在这个范围之内。这可以防止梯度爆炸。
-
-另外一种解决梯度爆炸的手段是采用权重正则化(weithts regularization)比较常见的是l1l1正则,和l2l2正则,在各个深度框架中都有相应的API可以使用正则化。
+当完成数据预处理之后,对特定的场景和目标而言很多维度上的特征都是不具有任何判别或者表征能力的,所以需要对数据在维度上进行筛选。一般地,可以从以下两个方面考虑来选择特征:
-
-**方案3-relu、leakrelu、elu等激活函数**
-
-**Relu**
-
-思想也很简单,如果激活函数的导数为1,那么就不存在梯度消失爆炸的问题了,每层的网络都可以得到相同的更新速度,relu就这样应运而生。
-
-relu函数的导数在正数部分是恒等于1的,因此在深层网络中使用relu激活函数就不会导致梯度消失和爆炸的问题。
-relu的主要贡献在于:
-
-(1)解决了梯度消失、爆炸的问题
-
-(2)计算方便,计算速度快
-
-(3)加速了网络的训练
+(1)特征是否具有发散性:某个特征若在所有样本上的都是一样的或者接近一致,即方差非常小。 也就是说所有样本的都具有一致的表现,那这些就不具有任何信息。
-
-同时也存在一些缺点:
-
-(1)由于负数部分恒为0,会导致一些神经元无法激活(可通过设置小学习率部分解决);
-
-(2)输出不是以0为中心的。
+(2)特征与目标的相关性:与目标相关性高的特征,应当优选选择。
-
-**leakrelu**
-
-leakrelu就是为了解决relu的0区间带来的影响,其数学表达为:leakrelu$=max(k*x,0)$其中$k$是leak系数,一般选择$0.01$或者$0.02$,或者通过学习而来。
+### 13.7.3 特征选择方法分类
-
-**方案4-batchnorm**
-
-Batchnorm是深度学习发展以来提出的最重要的成果之一了,目前已经被广泛的应用到了各大网络中,具有加速网络收敛速度,提升训练稳定性的效果,Batchnorm本质上是解决反向传播过程中的梯度问题。Batchnorm全名是Batch Normalization,简称BN,即批规范化,通过规范化操作将输出信号$x$规范化到均值为$0$,方差为$1$保证网络的稳定性。
+根据特征选择的形式又可以将特征选择方法分为 3 种:
+(1)过滤法:按照发散性或者相关性对各个特征进行评分,设定阈值或者待选择阈值的个数,选择特征。
-
-**方案5-残差结构**
-
-事实上,就是残差网络的出现导致了Imagenet比赛的终结,自从残差提出后,几乎所有的深度网络都离不开残差的身影,相比较之前的几层,几十层的深度网络,在残差网络面前都不值一提,残差可以很轻松的构建几百层,一千多层的网络而不用担心梯度消失过快的问题,原因就在于残差的捷径(shortcut)部分。
+(2)包装法:根据目标函数(通常是预测效果评分),每次选择若干特征,或者排除若干特征。
-
-**方案6-LSTM**
-
-LSTM全称是长短期记忆网络(long-short term memory networks),是不那么容易发生梯度消失的,主要原因在于LSTM内部复杂的“门”(gates)。
+(3)嵌入法:先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。
-## 13.16 深度学习为什么不用二阶优化
+### 13.7.4 特征选择目的
-1. 二阶优化方法可以用到深度学习网络中,比如DistBelief,《Large-scale L-BFGS using MapReduce》.采用了数据并行的方法解决了海量数据下L-BFGS算法的可用性问题。
-2. 二阶优化方法目前还不适用于深度学习训练中,主要存在问题是:
-(1)最重要的问题是二阶方法的计算量大,训练较慢。
-(2)求导不易,实现比SGD这类一阶方法复杂。
-(3)另外其优点在深度学习中无法展现出来,主要是二阶方法能够更快地求得更高精度的解,这在浅层模型是有益的,但是在神经网络这类深层模型中对参数的精度要求不高,相反 相对而言不高的精度对模型还有益处,能够提高模型的泛化能力。
-(4)稳定性。题主要明白的一点事,越简单的东西往往越robust,对于优化算法也是这样。梯度下降等一阶算法只要步长不选太大基本都不会出问题,但二阶方法遍地是坑,数值稳定性啊等等。
+(1)减少特征维度,使模型泛化能力更强,减少过拟合;
-## 13.17 怎样优化你的深度学习系统?
+(2)降低任务目标的学习难度;
-
-你可能有很多想法去改善你的系统,比如,你可能想我们去收集更多的训练数据吧。或者你会说,可能你的训练集的多样性还不够,你应该收集更多不同姿势的猫咪图片,或者更多样化的反例集。或者你想再用梯度下降训练算法,训练久一点。或者你想尝试用一个完全不同的优化算法,比如Adam优化算法。或者尝试使用规模更大或者更小的神经网络。或者你想试试dropout或者正则化。或者你想修改网络的架构,比如修改激活函数,改变隐藏单元的数目之类的方法。
+(3)一组优秀的特征通常能有效的降低模型复杂度,提升模型效率
-
-当你尝试优化一个深度学习系统时,你通常可以有很多想法可以去试,问题在于,如果你做出了错误的选择,你完全有可能白费6个月的时间,往错误的方向前进,在6个月之后才意识到这方法根本不管用。比如,我见过一些团队花了6个月时间收集更多数据,却在6个月之后发现,这些数据几乎没有改善他们系统的性能。所以,假设你的项目没有6个月的时间可以浪费,如果有快速有效的方法能够判断哪些想法是靠谱的,或者甚至提出新的想法,判断哪些是值得一试的想法,哪些是可以放心舍弃的。
+## 13.8 梯度消失/梯度爆炸原因,以及解决方法
-
-我希望在这门课程中,可以教给你们一些策略,一些分析机器学习问题的方法,可以指引你们朝着最有希望的方向前进。这门课中,我会和你们分享我在搭建和部署大量深度学习产品时学到的经验和教训,我想这些内容是这门课程独有的。比如说,很多大学深度学习课程很少提到这些策略。事实上,机器学习策略在深度学习的时代也在变化,因为现在对于深度学习算法来说能够做到的事情,比上一代机器学习算法大不一样。我希望这些策略能帮助你们提高效率,让你们的深度学习系统更快投入实用。
+### 13.8.1 为什么要使用梯度更新规则?
-## 13.18 为什么要设置单一数字评估指标?
+目前深度学习的火热,其最大的功臣之一就是反向传播。反向传播,即根据损失评价函数计算的误差,计算得到梯度,通过梯度反向传播的方式,指导深度网络权值的更新优化。这样做的原因在于,深层网络由许多非线性层堆叠而来,每一层非线性层都可以视为是一个非线性函数,因此整个深度网络可以视为是一个复合的非线性多元函数:
+$$
+F(x)=f_n(\cdots f_3(f_2(f_1(x)*\theta_1+b)*\theta_2+b)\cdots)
+$$
+我们最终的目的是希望这个多元函数可以很好的完成输入到输出之间的映射,假设不同的输入,输出的最优解是g(x) ,那么,优化深度网络就是为了寻找到合适的权值,满足 Loss=L(g(x),F(x))取得极小值点,比如最简单的损失函数:
+$$
+Loss = \lVert g(x)-f(x) \rVert^2_2.
+$$
+假设损失函数的数据空间是下图这样的,我们最优的权值就是为了寻找下图中的最小值点, 对于这种数学寻找最小值问题,采用梯度下降的方法再适合不过了。
-
-无论你是调整超参数,或者是尝试不同的学习算法,或者在搭建机器学习系统时尝试不同手段,你会发现,如果你有一个单实数评估指标,你的进展会快得多,它可以快速告诉你,新尝试的手段比之前的手段好还是差。所以当团队开始进行机器学习项目时,我经常推荐他们为问题设置一个单实数评估指标。
+
-
-我发现很多机器学习团队就是这样,有一个定义明确的开发集用来测量查准率和查全率,再加上这样一个单一数值评估指标,有时我叫单实数评估指标,能让你快速判断分类器或者分类器更好。所以有这样一个开发集,加上单实数评估指标,你的迭代速度肯定会很快,它可以加速改进您的机器学习算法的迭代过程。
-
图 13.8.1
-## 13.19 满足和优化指标(Satisficing and optimizing metrics)
-
-
-要把你顾及到的所有事情组合成单实数评估指标有时并不容易,在那些情况里,我发现有时候设立满足和优化指标是很重要的,让我告诉你是什么意思吧。
-
-图 13.9.1
-
-
-假设你已经决定你很看重猫分类器的分类准确度,这可以是分数或者用其他衡量准确度的指标。但除了准确度之外,我们还需要考虑运行时间,就是需要多长时间来分类一张图。分类器需要$80$毫秒,需要$95$毫秒,C需要$1500$毫秒,就是说需要$1.5$秒来分类图像。
-
-
-你可以这么做,将准确度和运行时间组合成一个整体评估指标。所以成本,比如说,总体成本是,这种组合方式可能太刻意,只用这样的公式来组合准确度和运行时间,两个数值的线性加权求和。
-
-
-你还可以做其他事情,就是你可能选择一个分类器,能够最大限度提高准确度,但必须满足运行时间要求,就是对图像进行分类所需的时间必须小于等于$100$毫秒。所以在这种情况下,我们就说准确度是一个优化指标,因为你想要准确度最大化,你想做的尽可能准确,但是运行时间就是我们所说的满足指标,意思是它必须足够好,它只需要小于$100$毫秒,达到之后,你不在乎这指标有多好,或者至少你不会那么在乎。所以这是一个相当合理的权衡方式,或者说 将准确度和运行时间结合起来的方式。实际情况可能是,只要运行时间少于 100 毫秒,你的用 户就不会在乎运行时间是 100 毫秒还是 50 毫秒,甚至更快。
-
-
-通过定义优化和满足指标,就可以给你提供一个明确的方式,去选择“最好的”分类器。在 这种情况下分类器 B 最好,因为在所有的运行时间都小于 100 毫秒的分类器中,它的准确度最好。
-
-
-总结一下,如果你需要顾及多个指标,比如说,有一个优化指标,你想尽可能优化的,然 后还有一个或多个满足指标,需要满足的,需要达到一定的门槛。现在你就有一个全自动的方 法,在观察多个成本大小时,选出"最好的"那个。现在这些评估指标必须是在训练集或开发集 或测试集上计算或求出来的。所以你还需要做一件事,就是设立训练集、开发集,还有测试集。 在下一个视频里,我想和大家分享一些如何设置训练、开发和测试集的指导方针,我们下一个 视频继续。
-
-## 13.20 怎样划分训练/开发/测试集
-
-
-设立训练集,开发集和测试集的方式大大影响了你或者你的团队在建立机器学习应用方面取得进展的速度。同样的团队,即使是大公司里的团队,在设立这些数据集的方式,真的会让团队的进展变慢而不是加快,我们看看应该如何设立这些数据集,让你的团队效率最大化。
-
-
-我建议你们不要这样,而是让你的开发集和测试集来自同一分布。我的意思是这样,你们要记住,我想就是设立你的开发集加上一个单实数评估指标,这就是像是定下目标,然后告诉你的团队,那就是你要瞄准的靶心,因为你一旦建立了这样的开发集和指标,团队就可以快速迭代,尝试不同的想法,跑实验,可以很快地使用开发集和指标去评估不同分类器,然后尝试选出最好的那个。所以,机器学习团队一般都很擅长使用不同方法去逼近目标,然后不断迭代,不断逼近靶心。所以,针对开发集上的指标优化。
-
-
-所以我建议你们在设立开发集和测试集时,要选择这样的开发集和测试集,能够反映你未来会得到的数据,认为很重要的数据,必须得到好结果的数据,特别是,这里的开发集和测试集可能来自同一个分布。所以不管你未来会得到什么样的数据,一旦你的算法效果不错,要尝试收集类似的数据,而且,不管那些数据是什么,都要随机分配到开发集和测试集上。因为这样,你才能将瞄准想要的目标,让你的团队高效迭代来逼近同一个目标,希望最好是同一个目标。
-
-
-我们还没提到如何设立训练集,我们会在之后的视频里谈谈如何设立训练集,但这个视频的重点在于,设立开发集以及评估指标,真的就定义了你要瞄准的目标。我们希望通过在同一分布中设立开发集和测试集,你就可以瞄准你所希望的机器学习团队瞄准的目标。而设立训练集的方式则会影响你逼近那个目标有多快,但我们可以在另一个讲座里提到。我知道有一些机器学习团队,他们如果能遵循这个方针,就可以省下几个月的工作,所以我希望这些方针也能帮到你们。
-
-
-接下来,实际上你的开发集和测试集的规模,如何选择它们的大小,在深度学习时代也在变化,我们会在下一个视频里提到这些内容。
-
-## 13.21 如何划分开发/测试集大小
-
-
-你可能听说过一条经验法则,在机器学习中,把你取得的全部数据用$70/30$比例分成训练集和测试集。或者如果你必须设立训练集、开发集和测试集,你会这么分$60\%$训练集,$20\%$开发集,$20\%$测试集。在机器学习的早期,这样分是相当合理的,特别是以前的数据集大小要小得多。所以如果你总共有100个样本,这样$70/30$或者$60/20/20$分的经验法则是相当合理的。如果你有几千个样本或者有一万个样本,这些做法也还是合理的。
-
-
-但在现代机器学习中,我们更习惯操作规模大得多的数据集,比如说你有$1$百万个训练样本,这样分可能更合理,$98\%$作为训练集,$1\%$开发集,$1\%$测试集,我们用和缩写来表示开发集和测试集。因为如果你有$1$百万个样本,那么$1\%$就是$10,000$个样本,这对于开发集和测试集来说可能已经够了。所以在现代深度学习时代,有时我们拥有大得多的数据集,所以使用小于$20\%$的比例或者小于$30\%$比例的数据作为开发集和测试集也是合理的。而且因为深度学习算法对数据的胃口很大,我们可以看到那些有海量数据集的问题,有更高比例的数据划分到训练集里,那么测试集呢?
-
-
-总结一下,在大数据时代旧的经验规则,这个$70/30$不再适用了。现在流行的是把大量数据分到训练集,然后少量数据分到开发集和测试集,特别是当你有一个非常大的数据集时。以前的经验法则其实是为了确保开发集足够大,能够达到它的目的,就是帮你评估不同的想法,然后选出还是更好。测试集的目的是评估你最终的成本偏差,你只需要设立足够大的测试集,可以用来这么评估就行了,可能只需要远远小于总体数据量的$30\%$。
+### 13.8.2 梯度消失/爆炸产生的原因?
-
-所以我希望本视频能给你们一点指导和建议,让你们知道如何在深度学习时代设立开发和测试集。接下来,有时候在研究机器学习的问题途中,你可能需要更改评估指标,或者改动你的开发集和测试集,我们会讲什么时候需要这样做。
-
-## 13.22 什么时候该改变开发/测试集和指标?
-
-
-我们来看一个例子,假设你在构建一个猫分类器,试图找到很多猫的照片,向你的爱猫人士用户展示,你决定使用的指标是分类错误率。所以算法和分别有3%错误率和5%错误率,所以算法似乎做得更好。
+本质上,梯度消失和爆炸是一种情况。在深层网络中,由于网络过深,如果初始得到的梯度过小,或者传播途中在某一层上过小,则在之后的层上得到的梯度会越来越小,即产生了梯度消失。梯度爆炸也是同样的。一般地,不合理的初始化以及激活函数,如sigmoid等,都会导致梯度过大或者过小,从而引起消失/爆炸。
-
-但我们实际试一下这些算法,你观察一下这些算法,算法由于某些原因,把很多色情图像分类成猫了。如果你部署算法,那么用户就会看到更多猫图,因为它识别猫的错误率只有$3\%$,但它同时也会给用户推送一些色情图像,这是你的公司完全不能接受的,你的用户也完全不能接受。相比之下,算法有$5\%$的错误率,这样分类器就得到较少的图像,但它不会推送色情图像。所以从你们公司的角度来看,以及从用户接受的角度来看,算法实际上是一个更好的算法,因为它不让任何色情图像通过。
+下面分别从网络深度角度以及激活函数角度进行解释:
-
-那么在这个例子中,发生的事情就是,算法A在评估指标上做得更好,它的错误率达到$3\%$,但实际上是个更糟糕的算法。在这种情况下,评估指标加上开发集它们都倾向于选择算法,因为它们会说,看算法A的错误率较低,这是你们自己定下来的指标评估出来的。但你和你的用户更倾向于使用算法,因为它不会将色情图像分类为猫。所以当这种情况发生时,当你的评估指标无法正确衡量算法之间的优劣排序时,在这种情况下,原来的指标错误地预测算法A是更好的算法这就发出了信号,你应该改变评估指标了,或者要改变开发集或测试集。在这种情况下,你用的分类错误率指标可以写成这样:
+(1)网络深度
-
-但粗略的结论是,如果你的评估指标无法正确评估好算法的排名,那么就需要花时间定义一个新的评估指标。这是定义评估指标的其中一种可能方式(上述加权法)。评估指标的意义在于,准确告诉你已知两个分类器,哪一个更适合你的应用。就这个视频的内容而言,我们不需要太注重新错误率指标是怎么定义的,关键在于,如果你对旧的错误率指标不满意,那就不要一直沿用你不满意的错误率指标,而应该尝试定义一个新的指标,能够更加符合你的偏好,定义出实际更适合的算法。
+若在网络很深时,若权重初始化较小,各层上的相乘得到的数值都会0-1之间的小数,而激活函数梯度也是0-1之间的数。那么连乘后,结果数值就会变得非常小,导致**梯度消失**。若权重初始化较大,大到乘以激活函数的导数都大于1,那么连乘后,可能会导致求导的结果很大,形成**梯度爆炸**。
-
-所以方针是,如果你在指标上表现很好,在当前开发集或者开发集和测试集分布中表现很好,但你的实际应用程序,你真正关注的地方表现不好,那么就需要修改指标或者你的开发测试集。换句话说,如果你发现你的开发测试集都是这些高质量图像,但在开发测试集上做的评估无法预测你的应用实际的表现。因为你的应用处理的是低质量图像,那么就应该改变你的开发测试集,让你的数据更能反映你实际需要处理好的数据。
+(2)激活函数
+如果激活函数选择不合适,比如使用 sigmoid,梯度消失就会很明显了,原因看下图,左图是sigmoid的函数图,右边是其导数的图像,如果使用sigmoid作为损失函数,其梯度是不可能超过0.25的,这样经过链式求导之后,很容易发生梯度消失。
+
-
-但总体方针就是,如果你当前的指标和当前用来评估的数据和你真正关心必须做好的事情关系不大,那就应该更改你的指标或者你的开发测试集,让它们能更够好地反映你的算法需要处理好的数据。
+图 13.8.2 sigmod函数与其导数
-## 13.23 设置评估指标的意义?
+### 13.8.3 梯度消失、爆炸的解决方案
-
-评估指标的意义在于,准确告诉你已知两个分类器,哪一个更适合你的应用。就这个视频的内容而言,我们不需要太注重新错误率指标是怎么定义的,关键在于,如果你对旧的错误率指标不满意,那就不要一直沿用你不满意的错误率指标,而应该尝试定义一个新的指标,能够更加符合你的偏好,定义出实际更适合的算法。
+**1、预训练加微调**
+此方法来自Hinton在2006年发表的一篇论文,Hinton为了解决梯度的问题,提出采取无监督逐层训练方法,其基本思想是每次训练一层隐节点,训练时将上一层隐节点的输出作为输入,而本层隐节点的输出作为下一层隐节点的输入,此过程就是逐层“预训练”(pre-training);在预训练完成后,再对整个网络进行“微调”(fine-tunning)。Hinton在训练深度信念网络(Deep Belief Networks中,使用了这个方法,在各层预训练完成后,再利用BP算法对整个网络进行训练。此思想相当于是先寻找局部最优,然后整合起来寻找全局最优,此方法有一定的好处,但是目前应用的不是很多了。
-## 13.24 什么是可避免偏差?
+**2、梯度剪切、正则**
+梯度剪切这个方案主要是针对梯度爆炸提出的,其思想是设置一个梯度剪切阈值,然后更新梯度的时候,如果梯度超过这个阈值,那么就将其强制限制在这个范围之内。这可以防止梯度爆炸。
+另外一种解决梯度爆炸的手段是采用权重正则化(weithts regularization)比较常见的是L1和L2正则。
-
-[http://www.ai-start.com/dl2017/lesson3-week1.html](http://www.ai-start.com/dl2017/lesson3-week1.html
-)
+**3、ReLu、leakReLu等激活函数**
+(1)ReLu:其函数的导数在正数部分是恒等于1,这样在深层网络中,在激活函数部分就不存在导致梯度过大或者过小的问题,缓解了梯度消失或者爆炸。同时也方便计算。当然,其也存在存在一些缺点,例如过滤到了负数部分,导致部分信息的丢失,输出的数据分布不在以0为中心,改变了数据分布。
+(2)leakrelu:就是为了解决relu的0区间带来的影响,其数学表达为:leakrelu=max(k*x,0)其中k是leak系数,一般选择0.01或者0.02,或者通过学习而来。
-
-所以要给这些概念命名一下,这不是广泛使用的术语,但我觉得这么说思考起来比较流畅。就是把这个差值,贝叶斯错误率或者对贝叶斯错误率的估计和训练错误率之间的差值称为可避免偏差,你可能希望一直提高训练集表现,直到你接近贝叶斯错误率,但实际上你也不希望做到比贝叶斯错误率更好,这理论上是不可能超过贝叶斯错误率的,除非过拟合。而这个训练错误率和开发错误率之前的差值,就大概说明你的算法在方差问题上还有多少改善空间。
+**4、batchnorm**
+Batchnorm是深度学习发展以来提出的最重要的成果之一了,目前已经被广泛的应用到了各大网络中,具有加速网络收敛速度,提升训练稳定性的效果,Batchnorm本质上是解决反向传播过程中的梯度问题。Batchnorm全名是Batch Normalization,简称BN,即批规范化,通过规范化操作将输出信号x规范化到均值为0,方差为1保证网络的稳定性。
-
-可避免偏差这个词说明了有一些别的偏差,或者错误率有个无法超越的最低水平,那就是说如果贝叶斯错误率是$7.5\%$。你实际上并不想得到低于该级别的错误率,所以你不会说你的训练错误率是$8\%$,然后$8\%$就衡量了例子中的偏差大小。你应该说,可避免偏差可能在$0.5\%$左右,或者$0.5\%$是可避免偏差的指标。而这个$2\%$是方差的指标,所以要减少这个$2\%$比减少这个$0.5\%$空间要大得多。而在左边的例子中,这$7\%$衡量了可避免偏差大小,而$2\%$衡量了方差大小。所以在左边这个例子里,专注减少可避免偏差可能潜力更大。
+**5、残差结构**
+残差的方式,能使得深层的网络梯度通过跳级连接路径直接返回到浅层部分,使得网络无论多深都能将梯度进行有效的回传。
-## 13.25 什么是TOP5错误率?
+**6、LSTM**
+LSTM全称是长短期记忆网络(long-short term memory networks),是不那么容易发生梯度消失的,主要原因在于LSTM内部复杂的“门”(gates)。在计算时,将过程中的梯度进行了抵消。
-
-top1就是你预测的label取最后概率向量里面最大的那一个作为预测结果,你的预测结果中概率最大的那个类必须是正确类别才算预测正确。而top5就是最后概率向量最大的前五名中出现了正确概率即为预测正确。
+## 13.9 深度学习为什么不用二阶优化?
-
-ImageNet 项目是一个用于物体对象识别检索大型视觉数据库。截止$2016$年,ImageNet 已经对超过一千万个图像的url进行手动注释,标记图像的类别。在至少一百万张图像中还提供了边界框。自$2010$年以来,ImageNet 举办一年一度的软件竞赛,叫做 ImageNet 大尺度视觉识别挑战(ImageNet Large Scale Visual Recognition Challenge,ILSVRC)。主要内容是通过算法程序实现正确分类和探测识别物体与场景,评价标准就是Top-5 错误率。
+目前深度学习中,反向传播主要是依靠一阶梯度。二阶梯度在理论和实际上都是可以应用都网络中的,但相比于一阶梯度,二阶优化会存在以下一些主要问题:
+(1)计算量大,训练非常慢。
+(2)二阶方法能够更快地求得更高精度的解,这在浅层模型是有益的。而在神经网络这类深层模型中对参数的精度要求不高,甚至不高的精度对模型还有益处,能够提高模型的泛化能力。
+(3)稳定性。二阶方法能更快求高精度的解,同样对数据本身要的精度也会相应的变高,这就会导致稳定性上的问题。
-
-Top-5 错误率
-
-ILSRVRC(ImageNet 图像分类大赛) 比赛设置如下:$1000$类图像分类问题,训练数据集$126$万张图像,验证集$5$万张,测试集$10$万张(标注未公布)。评价标准采用 top-5 错误率——即对一张图像预测$5$个类别,只要有一个和人工标注类别相同就算对,否则算错。
+## 13.10 为什么要设置单一数字评估指标,设置指标的意义?
-## 13.26 什么是人类水平错误率?
+在训练模型时,无论是调整超参数,还是调整不同的模型算法,我们都需要一个有效的评价指标,这个评价标准能帮助我们快速了解新的尝试后模型的性能是否更优。例如在分类时,我们通常会选择选择准确率,当样本不平衡时,查准率和查全率又会是更好的评价指标。所以在训练模型时,如果设置了单一数字的评估指标通常能很快的反应出我们模型的改进是否直接产生了收益,从而加速我们的算法改进过程。若在训练过程中,发现优化目标进一步深入,现有指标无法完全反应进一步的目标时,就需要重新选择评估指标了。
-
-人类水平错误率的定义,就是如果你想要替代或估计贝叶斯错误率,那么一队经验丰富的医生讨论和辩论之后,可以达到$0.5\%$的错误率。我们知道贝叶斯错误率小于等于$0.5\%$,因为有些系统,这些医生团队可以达到$0.5\%$的错误率。所以根据定义,最优错误率必须在$0.5\%$以下。我们不知道多少更好,也许有一个更大的团队,更有经验的医生能做得更好,所以也许比$0.5\%$好一点。但是我们知道最优错误率不能高于$0.5\%$,那么在这个背景下,我就可以用$0.5\%$估计贝叶斯错误率。所以我将人类水平定义为$0.5\%$,至少如果你希望使用人类水平错误来分析偏差和方差的时候,就像上个视频那样。
+## 13.11训练/验证/测试集的定义及划分
-
-现在,为了发表研究论文或者部署系统,也许人类水平错误率的定义可以不一样,你可以使用1%,只要你超越了一个普通医生的表现,如果能达到这种水平,那系统已经达到实用了。也许超过一名放射科医生,一名医生的表现,意味着系统在一些情况下可以有部署价值了。
+训练、验证、测试集在机器学习领域是非常重要的三个内容。三者共同组成了整个项目的性能的上限和走向。
-## 13.27 可避免偏差、几大错误率之间的关系?
+训练集:用于模型训练的样本集合,样本占用量是最大的;
-
-要了解为什么这个很重要,我们来看一个错误率分析的例子。比方说,在医学图像诊断例子中,你的训练错误率是$5\%$,你的开发错误率是$6\%$。而在上一张幻灯片的例子中,我们的人类水平表现,我将它看成是贝叶斯错误率的替代品,取决于你是否将它定义成普通单个医生的表现,还是有经验的医生或医生团队的表现,你可能会用$1\%$或$0.7\%$或$0.5\%$。同时也回想一下,前面视频中的定义,贝叶斯错误率或者说贝叶斯错误率的估计和训练错误率直接的差值就衡量了所谓的可避免偏差,这(训练误差与开发误差之间的差值)可以衡量或者估计你的学习算法的方差问题有多严重。
+验证集:用于训练过程中的模型性能评价,跟着性能评价才能更好的调参;
-
-所以在这个第一个例子中,无论你做出哪些选择,可避免偏差大概是$4\%$,这个值我想介于……,如果你取$1\%$就是$4\%$,如果你取$0.5\%$就是$4.5\%$,而这个差距(训练误差与开发误差之间的差值)是$1\%$。所以在这个例子中,我得说,不管你怎么定义人类水平错误率,使用单个普通医生的错误率定义,还是单个经验丰富医生的错误率定义或经验丰富的医生团队的错误率定义,这是$4\%$还是$4.5\%$,这明显比都比方差问题更大。所以在这种情况下,你应该专注于减少偏差的技术,例如培训更大的网络。
+测试集:用于最终模型的一次最终评价,直接反应了模型的性能。
-## 13.28 怎样选取可避免偏差及贝叶斯错误率?
+在划分上,可以分两种情况:
-
-就是比如你的训练错误率是0.7%,所以你现在已经做得很好了,你的开发错误率是$0.8\%$。在这种情况下,你用$0.5\%$来估计贝叶斯错误率关系就很大。因为在这种情况下,你测量到的可避免偏差是$0.2\%$,这是你测量到的方差问题$0.1\%$的两倍,这表明也许偏差和方差都存在问题。但是,可避免偏差问题更严重。在这个例子中,我们在上一张幻灯片中讨论的是$0.5\%$,就是对贝叶斯错误率的最佳估计,因为一群人类医生可以实现这一目标。如果你用$0.7$代替贝叶斯错误率,你测得的可避免偏差基本上是$0\%$,那你就可能忽略可避免偏差了。实际上你应该试试能不能在训练集上做得更好。
+1、在样本量有限的情况下,有时候会把验证集和测试集合并。实际中,若划分为三类,那么训练集:验证集:测试集=6:2:2;若是两类,则训练集:验证集=7:3。这里需要主要在数据量不够多的情况,验证集和测试集需要占的数据比例比较多,以充分了解模型的泛化性。
-## 13.29 怎样减少方差?
+2、在海量样本的情况下,这种情况在目前深度学习中会比较常见。此时由于数据量巨大,我们不需要将过多的数据用于验证和测试集。例如拥有1百万样本时,我们按训练集:验证集:测试集=98:1:1的比例划分,1%的验证和1%的测试集都已经拥有了1万个样本。这已足够验证模型性能了。
-
-如果你的算法方差较高,可以尝试下面的技巧:
+此外,三个数据集的划分不是一次就可以的,若调试过程中发现,三者得到的性能评价差异很大时,可以重新划分以确定是数据集划分的问题导致还是由模型本身导致的。其次,若评价指标发生变化,而导致模型性能差异在三者上很大时,同样可重新划分确认排除数据问题,以方便进一步的优化。
-
-(1)增加训练数据:只要你可以获得大量数据和足够的算力去处理数据,这就是一种解决高方差问题最简单,最可靠的方式。
-
-(2)正则化(L2, L1, dropout):这种技巧减少方差的同时,增加了偏差。
-
-(3)提前停止(例如,根据开发集的错误率来提前停止梯度下降):这种技巧减少方差的同时增加的偏差。提前停止技巧很像正则化方法,一些论文作者也叫他正则化技巧。
-
-(4)特征选择来减少输入特征的数量或类型:这种技巧可能会处理好方差问题,但是同时会增大偏差。稍微减少特征数量(比如从1000个特征减少到900个特征)不太可能对偏差产生大的影响。大量减少特征数量(比如从$1000$减少到$100-$减少$10$倍)可能产生较大偏差,因为去掉了很多有用的特征。(注:可能会欠拟合)。在现代的深度学习中,数据量很大,人们对待特征选择的态度出现了转变,现在我们更加倾向于使用全部的特征,让算法自己选择合适的特征。但是当训练集比较小时,特征选择非常有用。
-
-(5)缩小模型(例如减少网络层数和神经元数量):谨慎使用。这种技巧可以减少方差,同时也可能增加偏差。然而,我并不推荐使用这种技巧来解决方差问题。添加正则化通常会获得更好的分类性能。缩小模型的优点在于减少计算成本,以更快的速度来训练模型。如果模型的训练速度非常重要,那么就想尽一切方法来缩小模型。但是如果目标是减少方差,不是那么在意计算成本,可以考虑添加正则化。
+## 13.12 什么是TOP5错误率?
-## 13.30 贝叶斯错误率的最佳估计
+通常对于分类系统而言,系统会对某个未知样本进行所有已知样本的匹配,并给出该未知样本在每个已知类别上的概率。其中最大的概率就是系统系统判定最可能的一个类别。TOP5则就是在前五个最大概率的类别。TOP5错误率,即预测最可能的五类都不是该样本类别的错误率。
-
-对于这样的问题,更好的估计贝叶斯错误率很有必要,可以帮助你更好地估计可避免偏差和方差,这样你就能更好的做出决策,选择减少偏差的策略,还是减少方差的策略。
+TOP5错误率通常会用于在类别数量很多或者细粒度类别的模型系统。典型地,例如著名的ImageNet ,其包含了1000个类别。通常就会采用TOP5错误率。
-## 13.31 举机器学习超过单个人类表现几个例子?
+## 13.13 什么是泛化误差,如何理解方差和偏差?
-
-现在,机器学习有很多问题已经可以大大超越人类水平了。例如,我想网络广告,估计某个用户点击广告的可能性,可能学习算法做到的水平已经超越任何人类了。还有提出产品建议,向你推荐电影或书籍之类的任务。我想今天的网站做到的水平已经超越你最亲近的朋友了。还有物流预测,从到开车需要多久,或者预测快递车从开到需要多少时间。或者预测某人会不会偿还贷款,这样你就能判断是否批准这人的贷款。我想这些问题都是今天的机器学习远远超过了单个人类的表现。
+一般情况下,我们评价模型性能时都会使用泛化误差。泛化误差越低,模型性能越好。泛化误差可分解为方差、偏差和噪声三部分。这三部分中,噪声是个不可控因素,它的存在是算法一直无法解决的问题,很难约减,所以我们更多考虑的是方差和偏差。
-
-除了这些问题,今天已经有语音识别系统超越人类水平了,还有一些计算机视觉任务,一些图像识别任务,计算机已经超越了人类水平。但是由于人类对这种自然感知任务非常擅长,我想计算机达到那种水平要难得多。还有一些医疗方面的任务,比如阅读ECG或诊断皮肤癌,或者某些特定领域的放射科读图任务,这些任务计算机做得非常好了,也许超越了单个人类的水平。
+ 方差和偏差在泛化误差上可做如下分解,假设我们的预测值为g(x),真实值为f(x),则均方误差为
+$$
+E((g(x)−f(x))2)
+$$
+这里假设不考虑噪声,g来代表预测值,f代表真实值,g¯=E(g)代表算法的期望预测,则有如下表达:
+$$
+\begin{align}
+E(g-f)^2&=E(g^2-2gf+f^2)
+\\&=E(g^2)-\bar g^2+(\bar g-f)^2
+\\&=E(g^2)-2\bar g^2+\bar g^2+(\bar g-f)^2
+\\&=E(g^2-2g\bar g^2+\bar g^2)+(\bar g-f)^2
+\\&=\underbrace{E(g-\bar g)^2}_{var(x)}+\underbrace{(\bar g-f)^2}_{bias^2(x)}
+\end{align}
+$$
+有上述公式可知,方差描述是理论期望和预测值之间的关系,这里的理论期望通常是指所有适用于模型的各种不同分布类型的数据集;偏差描述为真实值和预测值之间的关系,这里的真实值通常指某一个特定分布的数据集合。
-## 13.32如何改善你的模型?
+所以综上方差表现为模型在各类分布数据的适应能力,方差越大,说明数据分布越分散,而偏差则表现为在特定分布上的适应能力,偏差越大越偏离真实值。
-
-你们学过正交化,如何设立开发集和测试集,用人类水平错误率来估计贝叶斯错误率以及如何估计可避免偏差和方差。我们现在把它们全部组合起来写成一套指导方针,如何提高学习算法性能的指导方针。
+## 13.14 如何提升模型的稳定性?
-
-首先,你的算法对训练集的拟合很好,这可以看成是你能做到可避免偏差很低。还有第二件事你可以做好的是,在训练集中做得很好,然后推广到开发集和测试集也很好,这就是说方差不是太大。
-1. 总结一下前几段视频我们见到的步骤,如果你想提升机器学习系统的性能,我建议你们看看训练错误率和贝叶斯错误率估计值之间的距离,让你知道可避免偏差有多大。换句话说,就是你觉得还能做多好,你对训练集的优化还有多少空间。
+评价模型不仅要从模型的主要指标上的性能,也要注重模型的稳定性。模型的稳定性体现在对不同样本之间的体现的差异。如模型的方差很大,那可以从如下几个方面进行考虑:
-2. 然后看看你的开发错误率和训练错误率之间的距离,就知道你的方差问题有多大。换句话说,你应该做多少努力让你的算法表现能够从训练集推广到开发集,算法是没有在开发集上训练的。
+(1)正则化(L2, L1, dropout):模型方差大,很可能来自于过拟合。正则化能有效的降低模型的复杂度,增加对更多分布的适应性。
-3. 用尽一切办法减少可避免偏差
+(2)提前停止训练:提前停止是指模型在验证集上取得不错的性能时停止训练。这种方式本质和正则化是一个道理,能减少方差的同时增加的偏差。目的为了平衡训练集和未知数据之间在模型的表现差异。
-4. 比如使用规模更大的模型,这样算法在训练集上的表现会更好,或者训练更久。
+(3)扩充训练集:正则化通过控制模型复杂度,来增加更多样本的适应性。那增加训练集让模型适应不同类型的数据本身就是一种最简单直接的方式提升模型稳定的方法,也是最可靠的一种方式。 与正则有所不同的是,扩充数据集既可以减小偏差又能减小方差。
-5. 使用更好的优化算法,比如说加入momentum或者RMSprop,或者使用更好的算法,比如Adam。你还可以试试寻找更好的新神经网络架构,或者说更好的超参数。这些手段包罗万有,你可以改变激活函数,改变层数或者隐藏单位数,虽然你这么做可能会让模型规模变大。
+(4)特征选择:过高的特征维度会使模型过拟合,减少特征维度和正则一样可能会处理好方差问题,但是同时会增大偏差。但需要注意的是若过度删减特征,很可能会删除很多有用的特征,降低模型的性能。所以需要多注意删减的特征对模型的性能的影响。
-6. 或者试用其他模型,其他架构,如循环神经网络和卷积神经网络。
+## 13.15 有哪些改善模型的思路
-
-在之后的课程里我们会详细介绍的,新的神经网络架构能否更好地拟合你的训练集,有时也很难预先判断,但有时换架构可能会得到好得多的结果。
+改善模型本质是如何优化模型,这本身是个很宽泛的问题。也是目前学界一直探索的目的,而从目前常规的手段上来说,一般可取如下几点。
+### 13.15.1 数据角度
-## 13.33 理解误差分析
+增强数据集。无论是有监督还是无监督学习,数据永远是最重要的驱动力。更多的类型数据对良好的模型能带来更好的稳定性和对未知数据的可预见性。对模型来说,“看到过的总比没看到的更具有判别的信心”。但增大数据并不是盲目的,模型容限能力不高的情况下即使增大数据也对模型毫无意义。而从数据获取的成本角度,对现有数据进行有效的扩充也是个非常有效且实际的方式。良好的数据处理,常见的处理方式如数据缩放、归一化和标准化等。
-
-如果你希望让学习算法能够胜任人类能做的任务,但你的学习算法还没有达到人类的表现,那么人工检查一下你的算法犯的错误也许可以让你了解接下来应该做什么。这个过程称为错误分析,我们从一个例子开始讲吧。
+### 13.15.2 模型角度
-
-假设你正在调试猫分类器,然后你取得了$90\%$准确率,相当于$10\%$错误,,在你的开发集上做到这样,这离你希望的目标还有很远。也许你的队员看了一下算法分类出错的例子,注意到算法将一些狗分类为猫,你看看这两只狗,它们看起来是有点像猫,至少乍一看是。所以也许你的队友给你一个建议,如何针对狗的图片优化算法。试想一下,你可以针对狗,收集更多的狗图,或者设计一些只处理狗的算法功能之类的,为了让你的猫分类器在狗图上做的更好,让算法不再将狗分类成猫。所以问题在于,你是不是应该去开始做一个项目专门处理狗?这项目可能需要花费几个月的时间才能让算法在狗图片上犯更少的错误,这样做值得吗?或者与其花几个月做这个项目,有可能最后发现这样一点用都没有。这里有个错误分析流程,可以让你很快知道这个方向是否值得努力。
+模型的容限能力决定着模型可优化的空间。在数据量充足的前提下,对同类型的模型,增大模型规模来提升容限无疑是最直接和有效的手段。但越大的参数模型优化也会越难,所以需要在合理的范围内对模型进行参数规模的修改。而不同类型的模型,在不同数据上的优化成本都可能不一样,所以在探索模型时需要尽可能挑选优化简单,训练效率更高的模型进行训练。
-
-那这个简单的人工统计步骤,错误分析,可以节省大量时间,可以迅速决定什么是最重要的,或者最有希望的方向。实际上,如果你观察$100$个错误标记的开发集样本,也许只需要$5$到$10$分钟的时间,亲自看看这$100$个样本,并亲自统计一下有多少是狗。根据结果,看看有没有占到$5\%$、$50\%$或者其他东西。这个在$5$到$10$分钟之内就能给你估计这个方向有多少价值,并且可以帮助你做出更好的决定,是不是把未来几个月的时间投入到解决错误标记的狗图这个问题。
+### 13.15.3 调参优化角度
-
-所以总结一下,进行错误分析,你应该找一组错误样本,可能在你的开发集里或者测试集里,观察错误标记的样本,看看假阳性(false positives)和假阴性(false negatives),统计属于不同错误类型的错误数量。在这个过程中,你可能会得到启发,归纳出新的错误类型,就像我们看到的那样。如果你过了一遍错误样本,然后说,天,有这么多Instagram滤镜或Snapchat滤镜,这些滤镜干扰了我的分类器,你就可以在途中新建一个错误类型。总之,通过统计不同错误标记类型占总数的百分比,可以帮你发现哪些问题需要优先解决,或者给你构思新优化方向的灵感。在做错误分析的时候,有时你会注意到开发集里有些样本被错误标记了,这时应该怎么做呢?我们下一个视频来讨论。
+如果你知道模型的性能为什么不再提高了,那已经向提升性能跨出了一大步。 超参数调整本身是一个比较大的问题。一般可以包含模型初始化的配置,优化算法的选取、学习率的策略以及如何配置正则和损失函数等等。这里需要提出的是对于同一优化算法,相近参数规模的前提下,不同类型的模型总能表现出不同的性能。这实际上就是模型优化成本。从这个角度的反方向来考虑,同一模型也总能找到一种比较适合的优化算法。所以确定了模型后选择一个适合模型的优化算法也是非常重要的手段。
-## 13.34 为什么值得花时间查看错误标记数据?
+### 13.15.4 训练角度
-
-最后我讲几个建议:
-
-首先,深度学习研究人员有时会喜欢这样说:“我只是把数据提供给算法,我训练过了,效果拔群”。这话说出了很多深度学习错误的真相,更多时候,我们把数据喂给算法,然后训练它,并减少人工干预,减少使用人类的见解。但我认为,在构造实际系统时,通常需要更多的人工错误分析,更多的人类见解来架构这些系统,尽管深度学习的研究人员不愿意承认这点。
-
-其次,不知道为什么,我看一些工程师和研究人员不愿意亲自去看这些样本,也许做这些事情很无聊,坐下来看100或几百个样本来统计错误数量,但我经常亲自这么做。当我带领一个机器学习团队时,我想知道它所犯的错误,我会亲自去看看这些数据,尝试和一部分错误作斗争。我想就因为花了这几分钟,或者几个小时去亲自统计数据,真的可以帮你找到需要优先处理的任务,我发现花时间亲自检查数据非常值得,所以我强烈建议你们这样做,如果你在搭建你的机器学习系统的话,然后你想确定应该优先尝试哪些想法,或者哪些方向。
+很多时候我们会把优化和训练放一起。但这里我们分开来讲,主要是为了强调充分的训练。在越大规模的数据集或者模型上,诚然一个好的优化算法总能加速收敛。但你在未探索到模型的上限之前,永远不知道训练多久算训练完成。所以在改善模型上充分训练永远是最必要的过程。充分训练的含义不仅仅只是增大训练轮数。有效的学习率衰减和正则同样是充分训练中非常必要的手段。
-## 13.35 快速搭建初始系统的意义?
-
-一般来说,对于几乎所有的机器学习程序可能会有$50$个不同的方向可以前进,并且每个方向都是相对合理的可以改善你的系统。但挑战在于,你如何选择一个方向集中精力处理。即使我已经在语音识别领域工作多年了,如果我要为一个新应用程序域构建新系统,我还是觉得很难不花时间去思考这个问题就直接选择方向。所以我建议你们,如果你想搭建全新的机器学习程序,就是快速搭好你的第一个系统,然后开始迭代。我的意思是我建议你快速设立开发集和测试集还有指标,这样就决定了你的目标所在,如果你的目标定错了,之后改也是可以的。但一定要设立某个目标,然后我建议你马上搭好一个机器学习系统原型,然后找到训练集,训练一下,看看效果,开始理解你的算法表现如何,在开发集测试集,你的评估指标上表现如何。当你建立第一个系统后,你就可以马上用到之前说的偏差方差分析,还有之前最后几个视频讨论的错误分析,来确定下一步优先做什么。特别是如果错误分析让你了解到大部分的错误的来源是说话人远离麦克风,这对语音识别构成特殊挑战,那么你就有很好的理由去集中精力研究这些技术,所谓远场语音识别的技术,这基本上就是处理说话人离麦克风很远的情况。
+## 13.16 如何快速构建有效初始模型?
-
-建立这个初始系统的所有意义在于,它可以是一个快速和粗糙的实现(quick and dirty implementation),你知道的,别想太多。初始系统的全部意义在于,有一个学习过的系统,有一个训练过的系统,让你确定偏差方差的范围,就可以知道下一步应该优先做什么,让你能够进行错误分析,可以观察一些错误,然后想出所有能走的方向,哪些是实际上最有希望的方向。
+ 构建一个有效的初始模型能帮助我们快速了解数据的质量和确定模型构建的方向。构建一个良好的初始模型,一般需要注意如下几点:
-## 13.36 为什么要在不同的划分上训练及测试?
+ 1、了解"对手"。这里的“对手”通常是指数据,我们在得到数据时,第一步是需要了解数据特点和使用场合。了解数据特点能帮助我们快速定位如何进行建模。确定使用场合能帮助我们进一步确定模型需要优化的方向。数据特点一般需要了解例如数据集规模、训练集和验证集是否匹配、样本的分布是否均匀、数据是否存在缺失值等等。
-
-深度学习算法对训练数据的胃口很大,当你收集到足够多带标签的数据构成训练集时,算法效果最好,这导致很多团队用尽一切办法收集数据,然后把它们堆到训练集里,让训练的数据量更大,即使有些数据,甚至是大部分数据都来自和开发集、测试集不同的分布。在深度学习时代,越来越多的团队都用来自和开发集、测试集分布不同的数据来训练,这里有一些微妙的地方,一些最佳做法来处理训练集和测试集存在差异的情况,我们来看看。
-
-图 13.36 Cat app example
+ 2、站在巨人肩膀上。根据数据特点,我们通常能匹配到一个现有比较优秀的模型。这类模型都通常能在类似数据上表现出一个比较不错的性能。
-
-假设你在开发一个手机应用,用户会上传他们用手机拍摄的照片,你想识别用户从应用中上传的图片是不是猫。现在你有两个数据来源,一个是你真正关心的数据分布,来自应用上传的数据,比如右边的应用,这些照片一般更业余,取景不太好,有些甚至很模糊,因为它们都是业余用户拍的。另一个数据来源就是你可以用爬虫程序挖掘网页直接下载,就这个样本而言,可以下载很多取景专业、高分辨率、拍摄专业的猫图片。如果你的应用用户数还不多,也许你只收集到$10,000$张用户上传的照片,但通过爬虫挖掘网页,你可以下载到海量猫图,也许你从互联网上下载了超过$20$万张猫图。而你真正关心的算法表现是你的最终系统处理来自应用程序的这个图片分布时效果好不好,因为最后你的用户会上传类似右边这些图片,你的分类器必须在这个任务中表现良好。现在你就陷入困境了,因为你有一个相对小的数据集,只有$10,000$个样本来自那个分布,而你还有一个大得多的数据集来自另一个分布,图片的外观和你真正想要处理的并不一样。但你又不想直接用这$10,000$张图片,因为这样你的训练集就太小了,使用这$20$万张图片似乎有帮助。但是,困境在于,这$20$万张图片并不完全来自你想要的分布,那么你可以怎么做呢?
+ 3、一切从简。初始模型的作用在于迅速了解数据质量和特点,所以模型的性能通常不需要达到很高,模型复杂度也不需要很高。例如,做图像分类时,我们在使用预训练模型时,不需要一开始就使用例如ResNet152这类模型巨大,复杂度过高的模型。这在数据量较小时,很容易造成过拟合而导致出现我们对数据产生一些误导性的判断,此外也增加了额外训练构建时间。所以使用更小更简单的模型以及损失函数来试探数据是相比更明智的选择。
-
-这里有一种选择,你可以做的一件事是将两组数据合并在一起,这样你就有$21$万张照片,你可以把这$21$万张照片随机分配到训练、开发和测试集中。为了说明观点,我们假设你已经确定开发集和测试集各包含$2500$个样本,所以你的训练集有$205000$个样本。现在这么设立你的数据集有一些好处,也有坏处。好处在于,你的训练集、开发集和测试集都来自同一分布,这样更好管理。但坏处在于,这坏处还不小,就是如果你观察开发集,看看这$2500$个样本其中很多图片都来自网页下载的图片,那并不是你真正关心的数据分布,你真正要处理的是来自手机的图片。
+ 4、总比瞎猜强。构建模型的意义在于建立一个高效的模型,虽然初始模型我们不对性能做过高的要求。但前提在于必须要比随机猜测好,不然构建模型的意义就不存在了。
-
-我建议你走另外一条路,就是这样,训练集,比如说还是$205,000$张图片,我们的训练集是来自网页下载的$200,000$张图片,然后如果需要的话,再加上$5000$张来自手机上传的图片。然后对于开发集和测试集,这数据集的大小是按比例画的,你的开发集和测试集都是手机图。而训练集包含了来自网页的$20$万张图片,还有$5000$张来自应用的图片,开发集就是$2500$张来自应用的图片,测试集也是$2500$张来自应用的图片。这样将数据分成训练集、开发集和测试集的好处在于,现在你瞄准的目标就是你想要处理的目标,你告诉你的团队,我的开发集包含的数据全部来自手机上传,这是你真正关心的图片分布。我们试试搭建一个学习系统,让系统在处理手机上传图片分布时效果良好。缺点在于,当然了,现在你的训练集分布和你的开发集、测试集分布并不一样。但事实证明,这样把数据分成训练、开发和测试集,在长期能给你带来更好的系统性能。我们以后会讨论一些特殊的技巧,可以处理 训练集的分布和开发集和测试集分布不一样的情况。
+ 5、解剖模型。一旦确定了一个初始模型时,无论你对该模型多熟悉,当其面对一批新数据时,你永远需要重新去认识这个模型,因为你永远不确定模型内部到底发生了些什么。解剖模型一般需要在训练时注意误差变化、注意训练和验证集的差异;出现一些NAN或者INf等情况时,需要打印观察内部输出,确定问题出现的时间和位置;在完成训练后,需要测试模型的输出是否正确合理,以确认评价指标是否符合该数据场景。无论使用任何一种模型,我们都不能把它当做黑盒去看待。
-## 13.37 如何解决数据不匹配问题?
+## 13.17 如何通过模型重新观察数据?
-
-如果您的训练集来自和开发测试集不同的分布,如果错误分析显示你有一个数据不匹配的问题该怎么办?这个问题没有完全系统的解决方案,但我们可以看看一些可以尝试的事情。如果我发现有严重的数据不匹配问题,我通常会亲自做错误分析,尝试了解训练集和开发测试集的具体差异。技术上,为了避免对测试集过拟合,要做错误分析,你应该人工去看开发集而不是测试集。
+ 对于这个问题,与其说如何做,倒不如说这个问题是用来强调这样做的重要性。如何重新观察数据其实不难,而是很多读者,会忽略这一项过程的重要性。
-
-但作为一个具体的例子,如果你正在开发一个语音激活的后视镜应用,你可能要看看……我想如果是语音的话,你可能要听一下来自开发集的样本,尝试弄清楚开发集和训练集到底有什么不同。所以,比如说你可能会发现很多开发集样本噪音很多,有很多汽车噪音,这是你的开发集和训练集差异之一。也许你还会发现其他错误,比如在你的车子里的语言激活后视镜,你发现它可能经常识别错误街道号码,因为那里有很多导航请求都有街道地址,所以得到正确的街道号码真的很重要。当你了解开发集误差的性质时,你就知道,开发集有可能跟训练集不同或者更难识别,那么你可以尝试把训练数据变得更像开发集一点,或者,你也可以收集更多类似你的开发集和测试集的数据。所以,比如说,如果你发现车辆背景噪音是主要的错误来源,那么你可以模拟车辆噪声数据,我会在下一张幻灯片里详细讨论这个问题。或者你发现很难识别街道号码,也许你可以有意识地收集更多人们说数字的音频数据,加到你的训练集里。
+ 通过模型重新观察数据,不仅能让我们了解模型情况,也能让我们对数据质量产生进一步的理解。目前深度学习在监督学习领域成就是非常显著的。监督学习需要依赖大量的人为标注,人为标注很难确定是否使用的数据中是否存在错误标注或者漏标注等问题。这无论是哪种情况都会影响我们对模型的判断。所以通过模型重新验证数据质量是非常重要的一步。很多初学者,通常会忽略这一点,而导致出现对模型的一些误判,严重时甚至会影响整个建模方向。此外,对于若出现一些过拟合的情况,我们也可以通过观察来了解模型。例如分类任务,样本严重不平衡时,模型全预测到了一边时,其正确率仍然很高,但显然模型已经出现了问题。
-
-现在我知道这张幻灯片只给出了粗略的指南,列出一些你可以做的尝试,这不是一个系统化的过程,我想,这不能保证你一定能取得进展。但我发现这种人工见解,我们可以一起尝试收集更多和真正重要的场合相似的数据,这通常有助于解决很多问题。所以,如果你的目标是让训练数据更接近你的开发集,那么你可以怎么做呢?
-
-你可以利用的其中一种技术是人工合成数据(artificial data synthesis),我们讨论一下。在解决汽车噪音问题的场合,所以要建立语音识别系统。也许实际上你没那么多实际在汽车背景噪音下录得的音频,或者在高速公路背景噪音下录得的音频。但我们发现,你可以合成。所以假设你录制了大量清晰的音频,不带车辆背景噪音的音频,“The quick brown fox jumps over the lazy dog”(音频播放),所以,这可能是你的训练集里的一段音频,顺便说一下,这个句子在AI测试中经常使用,因为这个短句包含了从a到z所有字母,所以你会经常见到这个句子。但是,有了这个“the quick brown fox jumps over the lazy dog”这段录音之后,你也可以收集一段这样的汽车噪音,(播放汽车噪音音频)这就是汽车内部的背景噪音,如果你一言不发开车的话,就是这种声音。如果你把两个音频片段放到一起,你就可以合成出"the quick brown fox jumps over the lazy dog"(带有汽车噪声),在汽车背景噪音中的效果,听起来像这样,所以这是一个相对简单的音频合成例子。在实践中,你可能会合成其他音频效果,比如混响,就是声音从汽车内壁上反弹叠加的效果。
-
-但是通过人工数据合成,你可以快速制造更多的训练数据,就像真的在车里录的那样,那就不需要花时间实际出去收集数据,比如说在实际行驶中的车子,录下上万小时的音频。所以,如果错误分析显示你应该尝试让你的数据听起来更像在车里录的,那么人工合成那种音频,然后喂给你的机器学习算法,这样做是合理的。
+## 13.18 如何解决数据不匹配问题?
-
-现在我们要提醒一下,人工数据合成有一个潜在问题,比如说,你在安静的背景里录得$10,000$小时音频数据,然后,比如说,你只录了一小时车辆背景噪音,那么,你可以这么做,将这$1$小时汽车噪音回放$10,000$次,并叠加到在安静的背景下录得的$10,000$小时数据。如果你这么做了,人听起来这个音频没什么问题。但是有一个风险,有可能你的学习算法对这1小时汽车噪音过拟合。特别是,如果这组汽车里录的音频可能是你可以想象的所有汽车噪音背景的集合,如果你只录了一小时汽车噪音,那你可能只模拟了全部数据空间的一小部分,你可能只从汽车噪音的很小的子集来合成数据。
+### 13.18.1 如何定位数据不匹配?
-
-所以,总而言之,如果你认为存在数据不匹配问题,我建议你做错误分析,或者看看训练集,或者看看开发集,试图找出,试图了解这两个数据分布到底有什么不同,然后看看是否有办法收集更多看起来像开发集的数据作训练。
+ 数据不匹配问题是个不容易定位和解决的问题。这个问题出现总会和模型过拟合表现很相似,即在训练集上能体现非常不错的性能,但在测试集上表现总是差强人意但区别在于如果遇到是数据不匹配的问题,通常在用一批和训
+练集有看相同或者相似分布的数据上仍然能取得不错的结果。但很多时候,当测试集上结果表现很差时,很多初学
+者可能会直接将问题定位在模型过拟合上,最后对模型尝试各种方法后,性能却始终不能得到有效提升。当遇到这
+种情况时,建议先定位出是否存在数据不匹配的问题。最简单的验证方式就是可以从训练集中挑选出一部分数据作
+为验证集,重新划分后训练和验证模型表现。
-
-我们谈到其中一种办法是人工数据合成,人工数据合成确实有效。在语音识别中。我已经看到人工数据合成显著提升了已经非常好的语音识别系统的表现,所以这是可行的。但当你使用人工数据合成时,一定要谨慎,要记住你有可能从所有可能性的空间只选了很小一部分去模拟数据。
+### 13.18.2 举例常见几个数据不匹配的场景?
-
-所以这就是如何处理数据不匹配问题,接下来,我想和你分享一些想法就是如何从多种类型的数据同时学习。
+ 例如设计款识别物体的app时,实际场景的图片均来自于手机拍摄,而训练集确是来自于网上各类抓取下来的图
+片。例如在图像去噪、去模糊、去雾、超分辨率等图像处理场景时,由于大量数据的难以获取,因此都会采用人为
+假设合成的图像进行训练,这时候应用到实际场景中也容易出现不匹配的问题
-## 13.38 梯度检验注意事项?
+### 13.18.3 如何解决数据不匹配问题?
-
-首先,不要在训练中使用梯度检验,它只用于调试。我的意思是,计算所有值的是一个非常漫长的计算过程,为了实施梯度下降,你必须使用和 backprop来计算,并使用backprop来计算导数,只要调试的时候,你才会计算它,来确认数值是否接近。完成后,你会关闭梯度检验,梯度检验的每一个迭代过程都不执行它,因为它太慢了。
+ 数据不匹配是个很难有固定方法来解决的问题。这里提供几条供参考的途径:
+ 1、收集更多符合实际场最需要的数据。这似乎是最简单但也最难方式
+ 2、对结果做错误分析。找出数据集中出错的数据和正确数据之间的特点和区别,这对你无论是进行后续模型的分析或者是数据的处理提供非常有效的思路。注意,这里的数据集包括训练集和测试集
+ 3、数据集增强。数据集增强并不意味看数据集越大越好,其目的是丰富数据的分布以适应更多的变化当遇到数
+据不匹配时,对数据处理般可以有两种方式。其一,合成或处理更多接近需要的数据特点。其二,对所有数据包
+括实际场景数据都进行处理,将所有数据都统一到另一个分布上,统一出一种新的特点。
-
-第二点,如果算法的梯度检验失败,要检查所有项,检查每一项,并试着找出bug,也就是说,如果与$d\theta[i]$的值相差很大,我们要做的就是查找不同的$i$值,看看是哪个导致与的值相差这么多。举个例子,如果你发现,相对某些层或某层的或的值相差很大,但是的各项非常接近,注意的各项与和的各项都是一一对应的,这时,你可能会发现,在计算参数的导数的过程中存在bug。反过来也是一样,如果你发现它们的值相差很大,的值与的值相差很大,你会发现所有这些项目都来自于或某层的,可能帮你定位bug的位置,虽然未必能够帮你准确定位bug的位置,但它可以帮助你估测需要在哪些地方追踪bug。
+### 13.18.4 如何提高深度学习系统的性能
-
-第三点,在实施梯度检验时,如果使用正则化,请注意正则项。如果代价函数,这就是代价函数J的定义,等于与相关的函数的梯度,包括这个正则项,记住一定要包括这个正则项。
+ 当我们要试图提高深度学习系统的性能时,目前我们大致可以从三方面考虑:
-
-第四点,梯度检验不能与dropout同时使用,因为每次迭代过程中,dropout会随机消除隐藏层单元的不同子集,难以计算dropout在梯度下降上的代价函数J。因此dropout可作为优化代价函数的一种方法,但是代价函数J被定义为对所有指数极大的节点子集求和。而在任何迭代过程中,这些节点都有可能被消除,所以很难计算代价函数。你只是对成本函数做抽样,用dropout,每次随机消除不同的子集,所以很难用梯度检验来双重检验dropout的计算,所以我一般不同时使用梯度检验和dropout。如果你想这样做,可以把dropout中的keepprob设置为$1.0$,然后打开dropout,并寄希望于dropout的实施是正确的,你还可以做点别的,比如修改节点丢失模式确定梯度检验是正确的。实际上,我一般不这么做,我建议关闭dropout,用梯度检验进行双重检查,在没有dropout的情况下,你的算法至少是正确的,然后打开dropout。
+ 1、提高模型的结构,比如增加神经网络的层数,或者将简单的神经元单位换成复杂的 LSTM 神经元,比如在自然语言处理领域内,利用 LSTM 模型挖掘语法分析的优势。
-
-最后一点,也是比较微妙的一点,现实中几乎不会出现这种情况。当和接近0时,梯度下降的实施是正确的,在随机初始化过程中$……$,但是在运行梯度下降时,和变得更大。可能只有在和接近$0$时,backprop的实施才是正确的。但是当和变大时,它会变得越来越不准确。你需要做一件事,我不经常这么做,就是在随机初始化过程中,运行梯度检验,然后再训练网络,和会有一段时间远离$0$,如果随机初始化值比较小,反复训练网络之后,再重新运行梯度检验。
+ 2、改进模型的初始化方式,保证早期梯度具有某些有益的性质,或者具备大量的稀疏性,或者利用线性代数原理的优势。
-
-这就是梯度检验,恭喜大家,这是本周最后一课了。回顾这一周,我们讲了如何配置训练集,验证集和测试集,如何分析偏差和方差,如何处理高偏差或高方差以及高偏差和高方差并存的问题,如何在神经网络中应用不同形式的正则化,如正则化和dropout,还有加快神经网络训练速度的技巧,最后是梯度检验。这一周我们学习了很多内容,你可以在本周编程作业中多多练习这些概念。祝你好运,期待下周再见。
+ 3、选择更强大的学习算法,比如对度梯度更新的方式,也可以是采用除以先前梯度 L2 范数来更新所有参数,甚至还可以选用计算代价较大的二阶算法。
-## 13.39什么是随机梯度下降?
-
-随机梯度下降,简称SGD,是指梯度下降算法在训练集上,对每一个训练数据都计算误差并更新模型。
-对每一个数据都进行模型更新意味着随机梯度下降是一种[在线机器学习算法](https://en.wikipedia.org/wiki/Online_machine_learning)。
-
-优点:
-* 频繁的更新可以给我们一个模型表现和效率提升的即时反馈。
-* 这可能是最容易理解和实现的一种方式,尤其对于初学者。
-* 较高的模型更新频率在一些问题上可以快速的学习。
-* 这种伴有噪声的更新方式能让模型避免局部最优(比如过早收敛)。
+## 参考文献
-
-缺点:
-* 这种方式相比其他来说,计算消耗更大,在大数据集上花费的训练时间更多。
-* 频繁的更新产生的噪声可能导致模型参数和模型误差来回跳动(更大的方差)。
-* 这种伴有噪声的更新方式也能让算法难以稳定的收敛于一点。
-
-## 13.40什么是批量梯度下降?
-
-
-批量梯度下降对训练集上每一个数据都计算误差,但只在所有训练数据计算完成后才更新模型。
-
-对训练集上的一次训练过程称为一代(epoch)。因此,批量梯度下降是在每一个训练epoch之后更新模型。
-
-
-优点:
-* 更少的模型更新意味着比SGD有更高的计算效率。
-* 在一些问题上可以得到更稳定的误差梯度和更稳定的收敛点。
-* 误差计算和模型更新过程的分离有利于并行算法的实现。
-
-
-缺点:
-* 更稳定的误差梯度可能导致模型过早收敛于一个不是最优解的参数集。
-* 每一次epoch之后才更新会增加一个累加所有训练数据误差的复杂计算。
-* 通常来说,批量梯度下降算法需要把所有的训练数据都存放在内存中。
-* 在大数据集上,训练速度会非常慢。
-
-## 13.41什么是小批量梯度下降?
-
-
-小批量梯度下降把训练集划分为很多批,对每一批(batch)计算误差并更新参数。
-
-可以选择对batch的梯度进行累加,或者取平均值。取平均值可以减少梯度的方差。
-
-小批量梯度下降在随机梯度下降的鲁棒性和批量梯度下降的效率之间取得平衡。是如今深度学习领域最常见的实现方式。
-
-
-优点:
-* 比批量梯度下降更快的更新频率有利于更鲁棒的收敛,避免局部最优。
-* 相比随机梯度下降更具计算效率。
-* 不需要把所有数据放入内存中。
-
-
-缺点:
-* 小批量梯度下降给算法增加了一个超参数batch size。
-* 和批量梯度下降一样,每一个batch上的误差需要累加。
-
-## 13.42怎么配置mini-batch梯度下降
-
-
-Mini-batch梯度下降对于深度学习大部分应用是最常用的方法。
-
-Mini-batch sizes,简称为 “batch sizes”,是算法设计中需要调节的参数。比如对应于不同GPU或CPU硬件$(32,64,128,256,\cdots)$的内存要求。
-
-batch size是学习过程中的“滑块”。
-
-
-(1)较小的值让学习过程收敛更快,但是产生更多噪声。
-
-(2)较大的值让学习过程收敛较慢,但是准确的估计误差梯度。
-
-
-**建议1:batch size的默认值最好是$32$**
-
-batch size通常从1到几百之间选择,比如$32$是一个很好的默认值,超过$10$的值可以充分利用矩阵$*$矩阵相对于矩阵$*$向量的加速优势。
-[——Practical recommendations for gradient-based training of deep architectures, 2012](https://arxiv.org/abs/1206.5533)
-
-
-**建议2:调节batch size时,最好观察模型在不同batch size下的训练时间和验证误差的学习曲线**
-
-相比于其他超参数,它可以被单独优化。在其他超参数(除了学习率)确定之后,在对比训练曲线(训练误差和验证误差对应于训练时间)。
-
-
-**建议3:调整其他所有超参数之后再调整batch size和学习率**
-
-batch size和学习率几乎不受其他超参数的影响,因此可以放到最后再优化。batch size确定之后,可以被视为固定值,从而去优化其他超参数(如果使用了动量超参数则例外)。
-
-## 13.43 局部最优的问题
-
-
-在深度学习研究早期,人们总是担心优化算法会困在极差的局部最优,不过随着深度学习理论不断发展,我们对局部最优的理解也发生了改变。我向你展示一下现在我们怎么看待局部最优以及深度学习中的优化问题。
-
-图 13.43.1
-
-
-这是曾经人们在想到局部最优时脑海里会出现的图,也许你想优化一些参数,我们把它们称之为和,平面的高度
-就是损失函数。在图中似乎各处都分布着局部最优。梯度下降法或者某个算法可能困在一个局部最优中,而不会抵达
-全局最优。如果你要作图计算一个数字,比如说这两个维度,就容易出现有多个不同局部最优的图,而这些低维的图
-曾经影响了我们的理解,但是这些理解并不正确。事实上,如果你要创建一个神经网络,通常梯度为零的点并不是这
-个图中的局部最优点,实际上成本函数的零梯度点,通常是鞍点。
-
-图 13.43.2
-
-
-也就是在这个点,这里是和,高度即成本函数的值。
-
-图 13.43.3
-
-
-但是一个具有高维度空间的函数,如果梯度为$0$,那么在每个方向,它可能是凸函数,也可能是凹函数。如果你在$2$万维空间中,那么想要得到局部最优,所有的$2$万个方向都需要是这样,但发生的机率也许很小,也许是,你更有可能遇到有些方向的曲线会这样向上弯曲,另一些方向曲线向下弯,而不是所有的都向上弯曲,因此在高维度空间,你更可能碰到鞍点。
-
-图 13.43.4
-
-
-就像下面的这种:
-
-图 13.43.5
-
-
-而不会碰到局部最优。至于为什么会把一个曲面叫做鞍点,你想象一下,就像是放在马背上的马鞍一样,如果这是马,这是马的头,这就是马的眼睛,画得不好请多包涵,然后你就是骑马的人,要坐在马鞍上,因此这里的这个点,导数为$0$的点,这个点叫做鞍点。我想那确实是你坐在马鞍上的那个点,而这里导数为$0$。
-
-图 13.43.6
-
-
-所以我们从深度学习历史中学到的一课就是,我们对低维度空间的大部分直觉,比如你可以画出上面的图,并不能应用到高维度空间中。适用于其它算法,因为如果你有$2$万个参数,那么函数有$2$万个维度向量,你更可能遇到鞍点,而不是局部最优点。
-
-
-如果局部最优不是问题,那么问题是什么?结果是平稳段会减缓学习,平稳段是一块区域,其中导数长时间接近于$0$,如果你在此处,梯度会从曲面从从上向下下降,因为梯度等于或接近$0$,曲面很平坦,你得花上很长时间慢慢抵达平稳段的这个点,因为左边或右边的随机扰动,我换个笔墨颜色,大家看得清楚一些,然后你的算法能够走出平稳段(红色笔)。
-
-图 13.43.7
-
-
-我们可以沿着这段长坡走,直到这里,然后走出平稳段。
-
-图 13.43.8
-
-
-所以此次视频的要点是,首先,你不太可能困在极差的局部最优中,条件是你在训练较大的神经网络,存在大量参数,并且成本函数被定义在较高的维度空间。
-
-
-第二点,平稳段是一个问题,这样使得学习十分缓慢,这也是像Momentum或是RMSprop,Adam这样的算法,能够加速学习算法的地方。在这些情况下,更成熟的优化算法,如Adam算法,能够加快速度,让你尽早往下走出平稳段。
-
-
-因为你的网络要解决优化问题,说实话,要面临如此之高的维度空间,我觉得没有人有那么好的直觉,知道这些空间长什么样,而且我们对它们的理解还在不断发展,不过我希望这一点能够让你更好地理解优化算法所面临的问题。
-
-## 13.44 提升算法性能思路
-
-
-这个列表里提到的思路并完全,但是一个好的开始。
-
-我的目的是给出很多可以尝试的思路,希望其中的一或两个你之前没有想到。你经常只需要一个好的想法就能得到性能提升。
-
-如果你能从其中一个思路中得到结果,请在评论区告诉我。我很高兴能得知这些好消息。
-
-如果你有更多的想法,或者是所列思路的拓展,也请告诉我,我和其他读者都将受益!有时候仅仅是一个想法或许就能使他人得到突破。
-
-1. 通过数据提升性能
-2. 通过算法提升性能
-3. 通过算法调参提升性能
-4. 通过嵌套模型提升性能
-
-
-通常来讲,随着列表自上而下,性能的提升也将变小。例如,对问题进行新的架构或者获取更多的数据,通常比调整最优算法的参数能带来更好的效果。虽然并不总是这样,但是通常来讲是的。
-
-
-我已经把相应的链接加入了博客的教程中,相应网站的问题中,以及经典的Neural Net FAQ中。
-
-部分思路只适用于人工神经网络,但是大部分是通用的。通用到足够你用来配合其他技术来碰撞出提升模型性能的方法。
-OK,现在让我们开始吧。
-
-1. 通过数据提升性能
-
-
-对你的训练数据和问题定义进行适当改变,你能得到很大的性能提升。或许是最大的性能提升。
-
-
-以下是我将要提到的思路:
-
-获取更多数据、创造更多数据、重放缩你的数据、转换你的数据、特征选取、重架构你的问题
-
-
-1)获取更多数据
-
-你能获取更多训练数据吗?
-
-你的模型的质量通常受到你的训练数据质量的限制。为了得到最好的模型,你首先应该想办法获得最好的数据。你也想尽可能多的获得那些最好的数据。
-
-有更多的数据,深度学习和其他现代的非线性机器学习技术有更全的学习源,能学得更好,深度学习尤为如此。这也是机器学习对大家充满吸引力的很大一个原因(世界到处都是数据)。
-
-
-2) 创造更多数据
-
-上一小节说到了有了更多数据,深度学习算法通常会变的更好。有些时候你可能无法合理地获取更多数据,那你可以试试创造更多数据。
-
-如果你的数据是数值型向量,可以随机构造已有向量的修改版本。
-
-如果你的数据是图片,可以随机构造已有图片的修改版本(平移、截取、旋转等)。
-
-如果你的数据是文本,类似的操作……
-
-这通常被称作数据扩增(data augmentation)或者数据生成(data generation)。
-
-你可以利用一个生成模型。你也可以用一些简单的技巧。例如,针对图片数据,你可以通过随机地平移或旋转已有图片获取性能的提升。如果新数据中包含了这种转换,则提升了模型的泛化能力。
-
-这也与增加噪声是相关的,我们习惯称之为增加扰动。它起到了与正则化方法类似的作用,即抑制训练数据的过拟合。
-
-
-3)重缩放(rescale)你的数据
-
-这是一个快速获得性能提升的方法。 当应用神经网络时,一个传统的经验法则是:重缩放(rescale)你的数据至激活函数的边界。
-
-如果你在使用sigmoid激活函数,重缩放你的数据到0和1的区间里。如果你在使用双曲正切(tanh)激活函数,重缩放数据到-1和1的区间里。
-
-这种方法可以被应用到输入数据(x)和输出数据(y)。例如,如果你在输出层使用sigmoid函数去预测二元分类的结果,应当标准化y值,使之成为二元的。如果你在使用softmax函数,你依旧可以通过标准化y值来获益。
-
-这依旧是一个好的经验法则,但是我想更深入一点。我建议你可以参考下述方法来创造一些训练数据的不同的版本:
-
-归一化到0和1的区间。
-
-重放缩到-1和1的区间
-
-标准化(译者注:标准化数据使之成为零均值,单位标准差)
-
-然后对每一种方法,评估你的模型的性能,选取最好的进行使用。如果你改变了你的激活函数,重复这一过程。
-
-在神经网络中,大的数值累积效应(叠加叠乘)并不是好事,除上述方法之外,还有其他的方法来控制你的神经网络中数据的数值大小,譬如归一化激活函数和权重,我们会在以后讨论这些技术。
-
-
-4)数据变换
-
-这里的数据变换与上述的重缩放方法类似,但需要更多工作。你必须非常熟悉你的数据。通过可视化来考察离群点。
-
-猜测每一列数据的单变量分布。
-
-列数据看起来像偏斜的高斯分布吗?考虑用Box-Cox变换调整偏态。
-
-列数据看起来像指数分布吗?考虑用对数变换。
-
-列数据看起来有一些特征,但是它们被一些明显的东西遮盖了,尝试取平方或者开平方根来转换数据
-
-你能离散化一个特征或者以某种方式组合特征,来更好地突出一些特征吗?
-
-依靠你的直觉,尝试以下方法。
-
-你能利用类似PCA的投影方法来预处理数据吗?
-
-你能综合多维特征至一个单一数值(特征)吗?
-
-你能用一个新的布尔标签去发现问题中存在一些有趣的方面吗?
-
-你能用其他方法探索出目前场景下的其他特殊结构吗?
-
-神经网层擅长特征学习(feature engineering)。它(自己)可以做到这件事。但是如果你能更好的发现问题到网络中的结构,神经网层会学习地更快。你可以对你的数据就不同的转换方式进行抽样调查,或者尝试特定的性质,来看哪些有用,哪些没用。
-
-
-5)特征选择
-
-一般说来,神经网络对不相关的特征是具有鲁棒的(校对注:即不相关的特征不会很大影响神经网络的训练和效果)。它们会用近似于0的权重来弱化那些没有预测能力的特征的贡献。
-
-
-尽管如此,这些无关的数据特征,在训练周期依旧要耗费大量的资源。所以你能去除数据里的一些特征吗?
-
-有许多特征选择的方法和特征重要性的方法,这些方法能够给你提供思路,哪些特征该保留,哪些特征该剔除。最简单的方式就是对比所有特征和部分特征的效果。同样的,如果你有时间,我建议在同一个网络中尝试选择不同的视角来看待你的问题,评估它们,来看看分别有怎样的性能。
-
-或许你利用更少的特征就能达到同等甚至更好的性能。而且,这将使模型变得更快!
-
-或许所有的特征选择方法都剔除了同样的特征子集。很好,这些方法在没用的特征上达成了一致。
-
-或许筛选过后的特征子集,能带给特征工程的新思路。
-
-
-
-6)重新架构你的问题
-
-有时候要试试从你当前定义的问题中跳出来,想想你所收集到的观察值是定义你问题的唯一方式吗?或许存在其他方法。或许其他构建问题的方式能够更好地揭示待学习问题的结构。
-
-我真的很喜欢这个尝试,因为它迫使你打开自己的思路。这确实很难,尤其是当你已经对当前的方法投入了大量的时间和金钱时。
-
-但是咱们这么想想,即使你列出了3-5个可供替代的建构方案,而且最终还是放弃了它们,但这至少说明你对当前的方案更加自信了。
-
-看看能够在一个时间窗(时间周期)内对已有的特征/数据做一个合并。
-
-或许你的分类问题可以成为一个回归问题(有时候是回归到分类)。
-
-或许你的二元输出可以变成softmax输出?
-
-或许你可以转而对子问题进行建模。
-
-仔细思考你的问题,最好在你选定工具之前就考虑用不同方法构建你的问题,因为此时你对解决方案并没有花费太多的投入。除此之外,如果你在某个问题上卡住了,这样一个简单的尝试能释放更多新的想法。
-
-2. 通过算法提升性能
-
-
-机器学习当然是用算法解决问题。
-
-所有的理论和数学都是描绘了应用不同的方法从数据中学习一个决策过程(如果我们这里只讨论预测模型)。
-
-你已经选择了深度学习来解释你的问题。但是这真的是最好的选择吗?在这一节中,我们会在深入到如何最大地发掘你所选择的深度学习方法之前,接触一些算法选择上的思路。
-
-
-下面是一个简要列表:
-* 对算法进行抽样调查
-* 借鉴已有文献
-* 重采样方法
-
-下面我解释下上面提到的几个方法:
-
-
-1)对算法进行抽样调查
-
-其实你事先无法知道,针对你的问题哪个算法是最优的。如果你知道,你可能就不需要机器学习了。那有没有什么数据(办法)可以证明你选择的方法是正确的?
-
-
-让我们来解决这个难题。当从所有可能的问题中平均来看各算法的性能时,没有哪个算法能够永远胜过其他算法。所有的算法都是平等的,下面是在no free lunch theorem中的一个总结。
-
-
-或许你选择的算法不是针对你的问题最优的那个
-
-我们不是在尝试解决所有问题,算法世界中有很多新热的方法,可是它们可能并不是针对你数据集的最优算法。
-
-我的建议是收集(证据)数据指标。接受更好的算法或许存在这一观点,并且给予其他算法在解决你的问题上“公平竞争”的机会。
-
-抽样调查一系列可行的方法,来看看哪些还不错,哪些不理想。
-
-首先尝试评估一些线性方法,例如逻辑回归(logistic regression)和线性判别分析(linear discriminate analysis)。
-
-评估一些树类模型,例如CART, 随机森林(Random Forest)和Gradient Boosting。
-
-评估一些实例方法,例如支持向量机(SVM)和K-近邻(kNN)。
-
-评估一些其他的神经网络方法,例如LVQ, MLP, CNN, LSTM, hybrids等
-
-
-选取性能最好的算法,然后通过进一步的调参和数据准备来提升。尤其注意对比一下深度学习和其他常规机器学习方法,对上述结果进行排名,比较他们的优劣。
-
-
-很多时候你会发现在你的问题上可以不用深度学习,而是使用一些更简单,训练速度更快,甚至是更容易理解的算法。
-
-
-2)借鉴已有文献
-
-方法选择的一个捷径是借鉴已有的文献资料。可能有人已经研究过与你的问题相关的问题,你可以看看他们用的什么方法。
-
-你可以阅读论文,书籍,博客,问答网站,教程,以及任何能在谷歌搜索到的东西。
-
-写下所有的想法,然后用你的方式把他们研究一遍。
-
-这不是复制别人的研究,而是启发你想出新的想法,一些你从没想到但是却有可能带来性能提升的想法。
-
-发表的研究通常都是非常赞的。世界上有非常多聪明的人,写了很多有趣的东西。你应当好好挖掘这个“图书馆”,找到你想要的东西。
-
-
-3)重采样方法
-
-你必须知道你的模型效果如何。你对模型性能的估计可靠吗?
-
-深度学习模型在训练阶段非常缓慢。这通常意味着,我们无法用一些常用的方法,例如k层交叉验证,去估计模型的性能。
-
-
-或许你在使用一个简单的训练集/测试集分割,这是常规套路。如果是这样,你需要确保这种分割针对你的问题具有代表性。单变量统计和可视化是一个好的开始。
-
-
-或许你能利用硬件来加速估计的过程。例如,如果你有集群或者AWS云端服务(Amazon Web Services)账号,你可以并行地训练n个模型,然后获取结果的均值和标准差来得到更鲁棒的估计。
-
-
-或许你可以利用hold-out验证方法来了解模型在训练后的性能(这在早停法(early stopping)中很有用,后面会讲到)。
-
-
-或许你可以先隐藏一个完全没用过的验证集,等到你已经完成模型选择之后再使用它。
-
-而有时候另外的方式,或许你能够让数据集变得更小,以及使用更强的重采样方法。
-
-有些情况下你会发现在训练集的一部分样本上训练得到的模型的性能,和在整个数据集上训练得到的模型的性能有很强的相关性。也许你可以先在小数据集上完成模型选择和参数调优,然后再将最终的方法扩展到全部数据集上。
-
-
-或许你可以用某些方式限制数据集,只取一部分样本,然后用它进行全部的建模过程。
-
-3. 通过算法调参提升性能
-
-
-这通常是工作的关键所在。你经常可以通过抽样调查快速地发现一个或两个性能优秀的算法。但是如果想得到最优的算法可能需要几天,几周,甚至几个月。
-
-
-为了获得更优的模型,以下是对神经网络算法进行参数调优的几点思路:
-
-* 诊断(Diagnostics)
-* 权重初始化(Weight Initialization)
-* 学习速率(Learning Rate)
-* 激活函数
-* 网络拓扑(Network Topology)
-* 批次和周期(Batches and Epochs)
-* 正则化
-* 优化和损失
-* 早停法
-
-
-你可能需要训练一个给定“参数配置”的神经网络模型很多次(3-10次甚至更多),才能得到一个估计性能不错的参数配置。这一点几乎适用于这一节中你能够调参的所有方面。
-
-
-1)诊断
-
-如果你能知道为什么你的模型性能不再提高了,你就能获得拥有更好性能的模型。
-
-你的模型是过拟合还是欠拟合?永远牢记这个问题。永远。
-
-模型总是会遇到过拟合或者欠拟合,只是程度不同罢了。一个快速了解模型学习行为的方法是,在每个周期,评估模型在训练集和验证集上的表现,并作出图表。
-
-
-如果训练集上的模型总是优于验证集上的模型,你可能遇到了过拟合,你可以使用诸如正则化的方法。
-
-
-如果训练集和验证集上的模型都很差,你可能遇到了欠拟合,你可以提升网络的容量,以及训练更多或者更久。
-
-
-如果有一个拐点存在,在那之后训练集上的模型开始优于验证集上的模型,你可能需要使用早停法。
-
-经常画一画这些图表,学习它们来了解不同的方法,你能够提升模型的性能。这些图表可能是你能创造的最有价值的(模型状态)诊断信息。
-
-另一个有用的诊断是网络模型判定对和判定错的观察值。
-
-对于难以训练的样本,或许你需要更多的数据。
-
-或许你应该剔除训练集中易于建模的多余的样本。
-
-也许可以尝试对训练集划分不同的区域,在特定区域中用更专长的模型。
-
-
-2)权重初始化
-
-经验法则通常是:用小的随机数进行初始化。
-
-在实践中,这可能依旧效果不错,但是对于你的网络来说是最佳的吗?对于不同的激活函数也有一些启发式的初始化方法,但是在实践应用中并没有太多不同。
-
-固定你的网络,然后尝试多种初始化方式。
-
-记住,权重是你的模型真正的参数,你需要找到他们。有很多组权重都能有不错的性能表现,但我们要尽量找到最好的。
-
-
-尝试所有不同的初始化方法,考察是否有一种方法在其他情况不变的情况下(效果)更优。
-
-
-尝试用无监督的方法,例如自动编码(autoencoder),来进行预先学习。
-
-
-尝试使用一个已经存在的模型,只是针对你的问题重新训练输入层和输出层(迁移学习(transfer learning))
-
-需要提醒的一点是,改变权重初始化方法和激活函数,甚至优化函数/损失函数紧密相关。
-
-
-3)学习率
-
-调整学习率很多时候也是行之有效的时段。
-
-以下是可供探索的一些想法:
-
-
-实验很大和很小的学习率
-
-
-格点搜索文献里常见的学习速率值,考察你能学习多深的网络。
-
-
-尝试随周期递减的学习率
-
-
-尝试经过固定周期数后按比例减小的学习率。
-
-
-尝试增加一个动量项(momentum term),然后对学习速率和动量同时进行格点搜索。
-
-
-越大的网络需要越多的训练,反之亦然。如果你添加了太多的神经元和层数,适当提升你的学习速率。同时学习率需要和训练周期,batch size大小以及优化方法联系在一起考虑。
-
-
-4)激活函数
-
-你或许应该使用修正激活函数(rectifier activation functions)。他们也许能提供更好的性能。
-
-在这之前,最早的激活函数是sigmoid和tanh,之后是softmax, 线性激活函数,或者输出层上的sigmoid函数。我不建议尝试更多的激活函数,除非你知道你自己在干什么。
-
-尝试全部三种激活函数,并且重缩放你的数据以满足激活函数的边界。
-
-显然,你想要为输出的形式选择正确的传递函数,但是可以考虑一下探索不同表示。例如,把在二元分类问题上使用的sigmoid函数切换到回归问题上使用的线性函数,然后后置处理你的输出。这可能需要改变损失函数使之更合适。详情参阅数据转换那一节。
-
-
-5)网络拓扑
-
-网络结构的改变能带来好处。
-
-你需要多少层以及多少个神经元?抱歉没有人知道。不要问这种问题...
-
-那怎么找到适用你的问题的配置呢?去实验吧。
-
-
-尝试一个隐藏层和许多神经元(广度模型)。
-
-
-尝试一个深的网络,但是每层只有很少的神经元(深度模型)。
-
-
-尝试上述两种方法的组合。
-
-
-借鉴研究问题与你的类似的论文里面的结构。
-
-
-尝试拓扑模式(扇出(fan out)然后扇入(fan in))和书籍论文里的经验法则(下有链接)
-
-
-选择总是很困难的。通常说来越大的网络有越强的代表能力,或许你需要它。越多的层数可以提供更强的从数据中学到的抽象特征的能力。或许需要它。
-
-深层的神经网络需要更多的训练,无论是训练周期还是学习率,都应该相应地进行调整。
-
-
-6)Batches和周期
-
-batch size大小会决定最后的梯度,以及更新权重的频度。一个周期(epoch)指的是神经网络看一遍全部训练数据的过程。
-
-你是否已经试验了不同的批次batch size和周期数? 之前,我们已经讨论了学习率,网络大小和周期之间的关系。
-
-在很深的网络结构里你会经常看到:小的batch size配以大的训练周期。
-
-下面这些或许能有助于你的问题,也或许不能。你要在自己的数据上尝试和观察。
-
-
-尝试选取与训练数据同大小的batch size,但注意一下内存(批次学习(batch learning))
-
-
-尝试选取1作为batch size(在线学习(online learning))
-
-
-尝试用格点搜索不同的小的batch size(8,16,32,…)
-
-
-分别尝试训练少量周期和大量周期。
-
-
-考虑一个接近无穷的周期值(持续训练),去记录到目前为止能得到的最佳的模型。
-
-一些网络结构对batch size更敏感。我知道多层感知器(Multilayer Perceptrons)通常对batch size是鲁棒的,而LSTM和CNNs比较敏感,但是这只是一个说法(仅供参考)。
-
-
-7)正则化
-正则化是一个避免模型在训练集上过拟合的好方法。
-
-神经网络里最新最热的正则化技术是dropout方法,你是否试过?dropout方法在训练阶段随机地跳过一些神经元,驱动这一层其他的神经元去捕捉松弛。简单而有效。你可以从dropout方法开始。
-
-
-格点搜索不同的丢失比例。
-
-
-分别在输入,隐藏层和输出层中试验dropout方法
-
-
-dropout方法也有一些拓展,比如你也可以尝试drop connect方法。
-
-
-也可以尝试其他更传统的神经网络正则化方法,例如:
-
-
-权重衰减(Weight decay)去惩罚大的权重
-
-
-激活约束(Activation constraint)去惩罚大的激活值
-
-
-你也可以试验惩罚不同的方面,或者使用不同种类的惩罚/正则化(L1, L2, 或者二者同时)
-
-
-8)优化和损失
-
-最常见是应用随机梯度下降法(stochastic gradient descent),但是现在有非常多的优化器。你试验过不同的优化(方法)过程吗?随机梯度下降法是默认的选择。先好好利用它,配以不同的学习率和动量。
-
-
-许多更高级的优化方法有更多的参数,更复杂,也有更快的收敛速度。 好与坏,是不是需要用,取决于你的问题。
-
-
-为了更好的利用好一个给定的(优化)方法,你真的需要弄明白每个参数的意义,然后针对你的问题通过格点搜索不同的的取值。困难,消耗时间,但是值得。
-
-
-我发现了一些更新更流行的方法,它们可以收敛的更快,并且针对一个给定网络的容量提供了一个快速了解的方式,例如:
-* ADAM
-* RMSprop
-
-
-你还可以探索其他优化算法,例如,更传统的(Levenberg-Marquardt)和不那么传统的(genetic algorithms)。其他方法能够为随机梯度下降法和其他类似方法提供好的出发点去改进。
-
-
-要被优化的损失函数与你要解决的问题高度相关。然而,你通常还是有一些余地(可以做一些微调,例如回归问题中的均方误(MSE)和平均绝对误差(MAE)等),有时候变换损失函数还有可能获得小的性能提升,这取决于你输出数据的规模和使用的激活函数。
-
-
-9)Early Stopping/早停法
-
-一旦训练过程中出现(验证集)性能开始下降,你可以停止训练与学习。这可以节省很多时间,而且甚至可以让你使用更详尽的重采样方法来评估你的模型的性能。
-
-
-早停法是一种用来避免模型在训练数据上的过拟合的正则化方式,它需要你监测模型在训练集以及验证集上每一轮的效果。一旦验证集上的模型性能开始下降,训练就可以停止。
-
-
-如果某个条件满足(衡量准确率的损失),你还可以设置检查点(Checkpointing)来储存模型,使得模型能够继续学习。检查点使你能够早停而非真正的停止训练,因此在最后,你将有一些模型可供选择。
-
-4. 通过嵌套模型提升性能
-
-
-你可以组合多个模型的预测能力。刚才提到了算法调参可以提高最后的性能,调参之后这是下一个可以提升的大领域。
-
-事实上,你可以经常通过组合多个“足够好的”模型来得到优秀的预测能力,而不是通过组合多个高度调参的(脆弱的)模型。
-
-你可以考虑以下三个方面的嵌套方式:
-* 组合模型
-* 组合视角
-* 堆叠(Stacking)
-
-
-1)组合模型
-
-有时候我们干脆不做模型选择,而是直接组合它们。
-
-如果你有多个不同的深度学习模型,在你的研究问题上每一个都表现的还不错,你可以通过取它们预测的平均值来进行组合。
-
-模型差异越大,最终效果越好。例如,你可以应用非常不同的网络拓扑或者不同的技术。
-
-如果每个模型都效果不错但是不同的方法/方式,嵌套后的预测能力将更加鲁棒。
-
-每一次你训练网络,你初始化不同的权重,然后它会收敛到不同的最终权重。你可以多次重复这一过程去得到很多网络,然后把这些网络的预测值组合在一起。
-
-它们的预测将会高度相关,但是在那些难以预测的特征上,它会给你一个意外的小提升。
-
-
-2)组合视角
-
-同上述类似,但是从不同视角重构你的问题,训练你的模型。
-
-同样,目标得到的是效果不错但是不同的模型(例如,不相关的预测)。得到不同的模型的方法,你可以依赖我们在数据那一小节中罗列的那些非常不同的放缩和转换方法。
-
-你用来训练模型的转换方法越不同,你构建问题的方式越不同,你的结果被提升的程度就越高。
-
-简单使用预测的均值将会是一个好的开始。
-
-
-3)stacking/堆叠
-
-你还可以学习如何最佳地组合多个模型的预测。这称作堆叠泛化(stacked generalization),或者简短来说就叫堆叠。
-
-通常上,你使用简单线性回归方法就可以得到比取预测平均更好的结果,像正则化的回归(regularized regression),就会学习如何给不同的预测模型赋权重。基线模型是通过取子模型的预测均值得到的,但是应用学习了权重的模型会提升性能。
+[1] 冯宇旭, 李裕梅. 深度学习优化器方法及学习率衰减方式综述[J]. 数据挖掘, 2018, 8(4): 186-200.
\ No newline at end of file
diff --git "a/ch14_\350\266\205\345\217\202\346\225\260\350\260\203\346\225\264/img/ch14/14.14.png" "b/ch14_\350\266\205\345\217\202\346\225\260\350\260\203\346\225\264/img/ch14/14.14.png"
index cfc05bfe..5f0dd49c 100644
Binary files "a/ch14_\350\266\205\345\217\202\346\225\260\350\260\203\346\225\264/img/ch14/14.14.png" and "b/ch14_\350\266\205\345\217\202\346\225\260\350\260\203\346\225\264/img/ch14/14.14.png" differ
diff --git "a/ch14_\350\266\205\345\217\202\346\225\260\350\260\203\346\225\264/img/ch14/NASNet\347\232\204RNN\346\216\247\345\210\266\345\231\250.png" "b/ch14_\350\266\205\345\217\202\346\225\260\350\260\203\346\225\264/img/ch14/NASNet\347\232\204RNN\346\216\247\345\210\266\345\231\250.png"
new file mode 100644
index 00000000..d1f8f8b7
Binary files /dev/null and "b/ch14_\350\266\205\345\217\202\346\225\260\350\260\203\346\225\264/img/ch14/NASNet\347\232\204RNN\346\216\247\345\210\266\345\231\250.png" differ
diff --git "a/ch14_\350\266\205\345\217\202\346\225\260\350\260\203\346\225\264/img/ch14/NAS\346\220\234\347\264\242\347\255\226\347\225\245.png" "b/ch14_\350\266\205\345\217\202\346\225\260\350\260\203\346\225\264/img/ch14/NAS\346\220\234\347\264\242\347\255\226\347\225\245.png"
new file mode 100644
index 00000000..40f7cc23
Binary files /dev/null and "b/ch14_\350\266\205\345\217\202\346\225\260\350\260\203\346\225\264/img/ch14/NAS\346\220\234\347\264\242\347\255\226\347\225\245.png" differ
diff --git "a/ch14_\350\266\205\345\217\202\346\225\260\350\260\203\346\225\264/img/ch14/RNN\346\216\247\345\210\266\345\231\250.png" "b/ch14_\350\266\205\345\217\202\346\225\260\350\260\203\346\225\264/img/ch14/RNN\346\216\247\345\210\266\345\231\250.png"
new file mode 100644
index 00000000..958b60e0
Binary files /dev/null and "b/ch14_\350\266\205\345\217\202\346\225\260\350\260\203\346\225\264/img/ch14/RNN\346\216\247\345\210\266\345\231\250.png" differ
diff --git "a/ch14_\350\266\205\345\217\202\346\225\260\350\260\203\346\225\264/img/ch14/readme.md" "b/ch14_\350\266\205\345\217\202\346\225\260\350\260\203\346\225\264/img/ch14/readme.md"
deleted file mode 100644
index f099ebf1..00000000
--- "a/ch14_\350\266\205\345\217\202\346\225\260\350\260\203\346\225\264/img/ch14/readme.md"
+++ /dev/null
@@ -1,2 +0,0 @@
-Add the corresponding chapter picture under img/ch*
-��img/ch*�����Ӷ�Ӧ�½�ͼƬ
\ No newline at end of file
diff --git "a/ch14_\350\266\205\345\217\202\346\225\260\350\260\203\346\225\264/img/ch14/\345\257\274\346\225\260.png" "b/ch14_\350\266\205\345\217\202\346\225\260\350\260\203\346\225\264/img/ch14/\345\257\274\346\225\260.png"
deleted file mode 100644
index 4eb7ca20..00000000
Binary files "a/ch14_\350\266\205\345\217\202\346\225\260\350\260\203\346\225\264/img/ch14/\345\257\274\346\225\260.png" and /dev/null differ
diff --git "a/ch14_\350\266\205\345\217\202\346\225\260\350\260\203\346\225\264/img/ch14/\346\200\235\347\273\264\345\257\274\345\233\276.png" "b/ch14_\350\266\205\345\217\202\346\225\260\350\260\203\346\225\264/img/ch14/\346\200\235\347\273\264\345\257\274\345\233\276.png"
new file mode 100644
index 00000000..8ec2bfc3
Binary files /dev/null and "b/ch14_\350\266\205\345\217\202\346\225\260\350\260\203\346\225\264/img/ch14/\346\200\235\347\273\264\345\257\274\345\233\276.png" differ
diff --git "a/ch14_\350\266\205\345\217\202\346\225\260\350\260\203\346\225\264/modify_log.txt" "b/ch14_\350\266\205\345\217\202\346\225\260\350\260\203\346\225\264/modify_log.txt"
index 110a1976..ea1c0553 100644
--- "a/ch14_\350\266\205\345\217\202\346\225\260\350\260\203\346\225\264/modify_log.txt"
+++ "b/ch14_\350\266\205\345\217\202\346\225\260\350\260\203\346\225\264/modify_log.txt"
@@ -34,6 +34,11 @@
14.20 什么是神经网络架构搜索(NAS)
14.21 如何调试模型?
-<----shw2018-2018-11-15---->
+<----shw2018-2018-11-26---->
修改整体结构:modify by 王超锋
+增加思维导图
+<----shw2018-2018-12-9---->
+修改整体结构:modify by 王超锋
+修改思维导图
+调整结构,修改部分答案描述
\ No newline at end of file
diff --git "a/ch14_\350\266\205\345\217\202\346\225\260\350\260\203\346\225\264/\347\254\254\345\215\201\345\233\233\347\253\240_\350\266\205\345\217\202\346\225\260\350\260\203\346\225\264.md" "b/ch14_\350\266\205\345\217\202\346\225\260\350\260\203\346\225\264/\347\254\254\345\215\201\345\233\233\347\253\240_\350\266\205\345\217\202\346\225\260\350\260\203\346\225\264.md"
index 726308e0..be8d1ed3 100644
--- "a/ch14_\350\266\205\345\217\202\346\225\260\350\260\203\346\225\264/\347\254\254\345\215\201\345\233\233\347\253\240_\350\266\205\345\217\202\346\225\260\350\260\203\346\225\264.md"
+++ "b/ch14_\350\266\205\345\217\202\346\225\260\350\260\203\346\225\264/\347\254\254\345\215\201\345\233\233\347\253\240_\350\266\205\345\217\202\346\225\260\350\260\203\346\225\264.md"
@@ -11,17 +11,21 @@
> Updater: [sjsdfg](https://github.com/sjsdfg),王超锋
## 14.1 写在前面
- 关于训练深度学习模型最难的事情之一是你要处理的参数的数量。无论是从网络本身的层宽(宽度)、层数(深度)、连接方式,还是损失函数的超参数设计和调试,亦或者是学习率、批样本数量、优化器参数等等。这些大量的参数都会有网络模型最终的有效容限直接或者间接的影响。面对如此众多的参数,如果我们要一一对其优化调整,所需的无论是时间、资源都是不切实际。结果证实一些超参数比其它的更为重要,因此认识各个超参数的作用和其可能会造成的影响是深度学习训练中必不可少的一项重要技能。
+ 关于训练深度学习模型最难的事情之一是你要处理的参数的数量。无论是从网络本身的层宽(宽度)、层数(深度)、连接方式,还是损失函数的超参数设计和调试,亦或者是学习率、批样本数量、优化器参数等等。这些大量的参数都会有网络模型最终的有效容限直接或者间接的影响。面对如此众多的参数,如果我们要一一对其优化调整,所需的无论是时间、资源都是不切实际。结果证实一些超参数比其它的更为重要,因此认识各个超参数的作用和其可能会造成的影响是深度学习训练中必不可少的一项重要技能。
- 目前,超参数调整一般分为手动调整和自动优化超参数两种。本章节不会过多阐述所有超参数的详细原理,如果需要了解这部分,您可以翻阅前面的基础章节或者查阅相关文献资料。当然,下面会讲到的一些超参数优化的建议是根据笔者们的实践以及部分文献资料得到认知建议,并不是非常严格且一定有效的,很多研究者可能会很不同意某些的观点或有着不同的直觉,这都是可保留讨论的,因为这很依赖于数据本身情况。
+ 超参数调整可以说是深度学习中理论和实际联系最重要的一个环节。目前,深度学习仍存在很多不可解释的部分,如何设计优化出好的网络可以为深度学习理论的探索提供重要的支持。超参数调整一般分为手动调整和自动优化超参数两种。读者可先浏览思维导图,本章节不会过多阐述所有超参数的详细原理,如果需要了解这部分,您可以翻阅前面的基础章节或者查阅相关文献资料。当然,下面会讲到的一些超参数优化的建议是根据笔者们的实践以及部分文献资料得到认知建议,并不是非常严格且一定有效的,很多研究者可能会很不同意某些的观点或有着不同的直觉,这都是可保留讨论的,因为这很依赖于数据本身情况。
-## 14.2 超参数概述
+
-### 14.2.1 什么是超参数,参数和超参数的区别
+
+
+## 14.2 超参数概念
+
+### 14.2.1 什么是超参数,参数和超参数的区别?
区分两者最大的一点就是是否通过数据来进行调整,模型参数通常是有数据来驱动调整,超参数则不需要数据来驱动,而是在训练前或者训练中人为的进行调整的参数。例如卷积核的具体核参数就是指模型参数,这是有数据驱动的。而学习率则是人为来进行调整的超参数。这里需要注意的是,通常情况下卷积核数量、卷积核尺寸这些也是超参数,注意与卷积核的核参数区分。
-### 14.2.2 神经网络中包含哪些超参数
+### 14.2.2 神经网络中包含哪些超参数?
通常可以将超参数分为三类:网络参数、优化参数、正则化参数。
网络参数:可指网络层与层之间的交互方式(相加、相乘或者串接等)、卷积核数量和卷积核尺寸、网络层数(也称深度)和激活函数等。
@@ -30,9 +34,9 @@
正则化:权重衰减系数,丢弃法比率(dropout)
-### 14.2.3 模型优化寻找最优解和正则项之间的关系
+### 14.2.3 为什么要进行超参数调优?
- 网络模型优化调整的目的是为了寻找到全局最优解(或者相比更好的局部最优解),而正则项又希望模型尽量拟合到最优。两者通常情况下,存在一定的对立,但两者的目标是一致的,即最小化期望风险。模型优化希望最小化经验风险,而容易陷入过拟合,正则项用来约束模型复杂度。所以如何平衡两者之间的关系,得到最优或者较优的解就是超参数调整优化的目的。
+ 本质上,这是模型优化寻找最优解和正则项之间的关系。网络模型优化调整的目的是为了寻找到全局最优解(或者相比更好的局部最优解),而正则项又希望模型尽量拟合到最优。两者通常情况下,存在一定的对立,但两者的目标是一致的,即最小化期望风险。模型优化希望最小化经验风险,而容易陷入过拟合,正则项用来约束模型复杂度。所以如何平衡两者之间的关系,得到最优或者较优的解就是超参数调整优化的目的。
### 14.2.4 超参数的重要性顺序
@@ -43,7 +47,7 @@
- 最后,**Adam优化器的超参数、权重衰减系数、丢弃法比率(dropout)和网络参数**。在这里说明下,这些参数重要性放在最后**并不等价于这些参数不重要**。而是表示这些参数在大部分实践中**不建议过多尝试**,例如Adam优化器中的*β1,β2,ϵ*,常设为 0.9、0.999、10−8就会有不错的表现。权重衰减系数通常会有个建议值,例如0.0005 ,使用建议值即可,不必过多尝试。dropout通常会在全连接层之间使用防止过拟合,建议比率控制在[0.2,0.5]之间。使用dropout时需要特别注意两点:一、在RNN中,如果直接放在memory cell中,循环会放大噪声,扰乱学习。一般会建议放在输入和输出层;二、不建议dropout后直接跟上batchnorm,dropout很可能影响batchnorm计算统计量,导致方差偏移,这种情况下会使得推理阶段出现模型完全垮掉的极端情况;网络参数通常也属于超参数的范围内,通常情况下增加网络层数能增加模型的容限能力,但模型真正有效的容限能力还和样本数量和质量、层之间的关系等有关,所以一般情况下会选择先固定网络层数,调优到一定阶段或者有大量的硬件资源支持可以在网络深度上进行进一步调整。
-### 14.2.5 部分超参数如何影响模型性能
+### 14.2.5 部分超参数如何影响模型性能?
| 超参数 | 如何影响模型容量 | 原因 | 注意事项 |
| :----------------: | :------------------------------: | :----------------------------------------------------------: | :----------------------------------------------------------: |
@@ -62,7 +66,7 @@
| :----------------: | :----------------------------------------------------------: | :----------------------------------------------------------: |
| 初始学习率 | SGD: [1e-2, 1e-1]
momentum: [1e-3, 1e-2]
Adagrad: [1e-3, 1e-2]
Adadelta: [1e-2, 1e-1]
RMSprop: [1e-3, 1e-2]
Adam: [1e-3, 1e-2]
Adamax: [1e-3, 1e-2]
Nadam: [1e-3, 1e-2] | 这些范围通常是指从头开始训练的情况。若是微调,初始学习率可在降低一到两个数量级。 |
| 损失函数部分超参数 | 多个损失函数之间,损失值之间尽量相近,不建议超过或者低于两个数量级 | 这是指多个损失组合的情况,不一定完全正确。单个损失超参数需结合实际情况。 |
-| 批样本数量 | [1:1024] | 当批样本数量过大(大于6000)或者等于1时,需要注意学习策略或者BN的替代品。 |
+| 批样本数量 | [1:1024] | 当批样本数量过大(大于6000)或者等于1时,需要注意学习策略或者内部归一化方式的调整。 |
| 丢弃法比率 | [0, 0.5] | |
| 权重衰减系数 | [0, 1e-4] | |
| 卷积核尺寸 | [7x7],[5x5],[3x3],[1x1], [7x1,1x7] | |
@@ -80,8 +84,9 @@
3、监控训练和验证误差。首先很多情况下,我们忽略代码的规范性和算法撰写正确性验证,这点上容易产生致命的影响。在训练和验证都存在问题时,首先请确认自己的代码是否正确。其次,根据训练和验证误差进一步追踪模型的拟合状态。若训练数据集很小,此时监控误差则显得格外重要。确定了模型的拟合状态对进一步调整学习率的策略的选择或者其他有效超参数的选择则会更得心应手。
4、反向传播数值的计算,这种情况通常适合自己设计一个新操作的情况。目前大部分流行框架都已包含自动求导部分,但并不一定是完全符合你的要求的。验证求导是否正确的方式是比较自动求导的结果和有限差分计算结果是否一致。所谓有限差分即导数的定义,使用一个极小的值近似导数。
-
-
+$$
+f^{'}(x_0) = \lim_{n\rightarrow0}\frac{\Delta y}{\Delta x} = \lim_{n\rightarrow0}\frac{f(x_0+\Delta x -f(x_0))}{\Delta x}
+$$
### 14.3.2 为什么要做学习率调整?
@@ -89,7 +94,7 @@
### 14.3.3 学习率调整策略有哪些?
-通常情况下,大部分学习率调整策略都是衰减学习率,当然也有部分增大学习率的策略。这里结合TensorFlow的内置方法来举例。
+通常情况下,大部分学习率调整策略都是衰减学习率,但有时若增大学习率也同样起到奇效。这里结合TensorFlow的内置方法来举例。
1、**exponential_decay**和**natural_exp_decay**
@@ -123,15 +128,19 @@ polynomial_decay(learning_rate, global_step, decay_steps,
多项式衰减,计算如下:
-global_step = min(global_step,decay_steps)
+$$
+global setp = min(global step, decay steps)
+$$
-decayed_learning_rate = (learning_rate-end_learning_rate)*(1-global_step/decay_steps)^ (power)+end_learning_rate
+$$
+lr_{decayed} = (lr-lr_{end})*(1-{globalstep\over decaysteps})^{power} +lr_{end}
+$$
-有别去上述两种,多项式衰减则是在每一步迭代上都会调整学习率。主要看Power参数,若Power为1,则是下图中的红色直线;若power小于1,则是开1/power次方,为蓝色线;绿色线为指数,power大于1。
+有别于上述两种,多项式衰减则是在每一步迭代上都会调整学习率。主要看Power参数,若Power为1,则是下图中的红色直线;若power小于1,则是开1/power次方,为蓝色线;绿色线为指数,power大于1。

-此外,需要注意的是参数cycle,cycle对应的是一种周期循环调整的方式,主要的目的在后期防止在一个局部极小值震荡,若跳出该区域或许能得到更有的结果。这里说明cycle的方式不止可以在多项式中应用,可配合类似的周期函数进行衰减,如下图。
+此外,需要注意的是参数cycle,cycle对应的是一种周期循环调整的方式。这种cycle策略主要目的在后期防止在一个局部极小值震荡,若跳出该区域或许能得到更有的结果。这里说明cycle的方式不止可以在多项式中应用,可配合类似的周期函数进行衰减,如下图。

@@ -162,7 +171,7 @@ cosine_decay_restarts(learning_rate, global_step, first_decay_steps,
t_mul=2.0, m_mul=1.0, alpha=0.0, name=None)
```
-余弦重启衰减,即余弦版本的cycle策略,作用与多项式衰减中的cycle相同。区别在于余弦重启衰减会重新回到初始学习率,拉长周期,而多项式版本则会逐周期衰减。
+余弦衰减,即余弦版本的cycle策略,作用与多项式衰减中的cycle相同。区别在于余弦重启衰减会重新回到初始学习率,拉长周期,而多项式版本则会逐周期衰减。

@@ -186,28 +195,11 @@ linear_cosine_decay(learning_rate, global_step, decay_steps,
### 14.3.4 极端批样本数量下,如何训练网络?
+ 极端批样本情况一般是指batch size为1或者batch size在6000以上的情况。这两种情况,在使用不合理的情况下都会导致模型最终性能无法达到最优甚至是崩溃的情况。
+ 在目标检测、分割或者3D图像等输入图像尺寸较大的场景,通常batch size 会非常小。而在14.2.4中,我们已经讲到这种情况会导致梯度的不稳定以及batchnorm统计的不准确。针对梯度不稳定的问题,通常不会太致命,若训练中发现梯度不稳定导致性能的严重降低时可采用累计梯度的策略,即每次计算完不反向更新,而是累计多次的误差后进行一次更新,这是一种在内存有限情况下实现有效梯度更新的一个策略。batch size过小通常对batchnorm的影响是最大的,若网络模型中存在batchnorm,batch size若只为1或者2时会对训练结果产生非常大的影响。这时通常有两种策略,一、若模型使用了预训练网络,可冻结预训练网络中batchnorm的模型参数,有效降低batch size引起的统计量变化的影响。二、在网络不是过深或者过于复杂时可直接移除batchnorm或者使用groupnorm代替batchnorm,前者不多阐释,后者是有FAIR提出的一种用于减少batch对batchnorm影响,其主要策略是先将特征在通道上进行分组,然后在组内进行归一化。即归一化操作上完全与batch size无关。这种groupnorm的策略被证实在极小批量网络训练上能达到较优秀的性能。当然这里也引入里group这个超参数,一般情况下建议不宜取group为1或者各通道单独为组的group数量,可结合实际网络稍加调试。
-### 14.3.5 为什么卷积核设计尺寸都是奇数
-
-主要原因有两点:
-
-- 保证像素点中心位置,避免位置信息偏移
-- 填充边缘时能保证两边都能填充,原矩阵依然对称
-
-### 14.3.6 权重共享的形式有哪些,为什么要权重共享
-
-权重共享的形式:
-
-- 深度学习中,权重共享最具代表性的就是卷积网络的卷积操作。卷积相比于全连接神经网络参数大大减少;
-- 多任务网络中,通常为了降低每个任务的计算量,会共享一个骨干网络。
-- 一些相同尺度下的结构化递归网络
-
-权重共享的好处:
-
- 权重共享一定程度上能增强参数之间的联系,获得更好的共性特征。同时很大程度上降低了网络的参数,节省计算量和计算所需内存(当然,结构化递归并不节省计算量)。此外权重共享能起到很好正则的作用。正则化的目的是为了降低模型复杂度,防止过拟合,而权重共享则正好降低了模型的参数和复杂度。
-
- 因此一个设计优秀的权重共享方式,在降低计算量的同时,通常会较独享网络有更好的效果。
+ 为了降低训练时间的成本,多机多卡的分布式系统通常会使用超大的batch size进行网络训练。同样的在14.2.4中,我们提到了超大batch size会带来梯度方向过于一致而导致的精度大幅度降低的问题。这时通常可采用层自适应速率缩放(LARS)算法。从理论认知上将,batch size增大会减少反向传播的梯度更新次数,但为了达到相同的模型效果,需要增大学习率。但学习率一旦增大,又会引起模型的不收敛。为了解决这一矛盾,LARS算法就在各层上自适应的计算一个本地学习率用于更新本层的参数,这样能有效的提升训练的稳定性。目前利用LARS算法,腾讯公司使用65536的超大batch size能将ResNet50在ImageNet在4分钟完成训练,而谷歌使用32768的batch size使用TPU能将该时间缩短至2分钟。
## 14.4 合理使用预训练网络
@@ -248,19 +240,23 @@ linear_cosine_decay(learning_rate, global_step, decay_steps,
劣势在于,分类模型和检测模型之间仍然存在一定任务上的差异:
- 1、检测模型能在多尺度上获取更高的收益;
+ 1、分类模型大部分训练于单目标数据,对同时进行多目标的捕捉能力稍弱,且不关注目标的位置,在一定程度上让模型损失部分空间信息,这对检测模型通常是不利的;
- 2、分类模型大部分训练于单目标数据,对同时进行多目标的捕捉能力稍弱;
+ 2、域适应问题,若预训练模型(ImageNet)和实际检测器的使用场景(医学图像,卫星图像)差异较大时,性能会受到影响;
- 3、分类模型并不关注目标的位置,在一定程度上让模型损失部分空间信息,这对检测模型通常是不利的。
+ 3、使用预训练模型就意味着难以自由改变网络结构和参数限制了应用场合。
-### 14.4.5 目标检测中如何从零开始训练?
+### 14.4.5 目标检测中如何从零开始训练(train from scratch)?
- 参考14.15提到的使用预训练模型训练检测模型的优劣势,有两个方案在实际实现中可能会更有效。
+ 结合FAIR相关的研究,我们可以了解目标检测和其他任务从零训练模型一样,只要拥有足够的数据以及充分而有效的训练,同样能训练出不亚于利用预训练模型的检测器。这里我们提供如下几点建议:
- 方案一、通常二阶段检测模型并未实现真正完全端对端的训练,因此二阶段模型会更难以训练。所以一阶段检测模型相较起来更适合从零训练,参考DSOD,使用DenseNet使用更多层次的特征将更适应训练。
+ 1、数据集不大时,同样需要进行数据集增强。
- 方案二、二阶段模型从零训练很难,而分类模型对于多目标、尺度并不敏感。因此仍然需要预训练模型的参数,这时借鉴DetNet训练一个专属于目标检测的模型网络,而参考分类模型的劣势,该专属网络应对多目标、尺度和位置拥有更强的适应性。
+ 2、预训练模型拥有更好的初始化,train from scratch需要更多的迭代次数以及时间训练和优化检测器。而二阶段模型由于并不是严格的端对端训练,此时可能需要更多的迭代次数以及时间,而一阶段检测模型训练会相对更容易些(例如DSOD以ScratchDet及)。
+
+ 3、目标检测中train from scratch最大的问题还是batch size过小。所以可采取的策略是增加GPU使用异步batchnorm增大batch size,若条件限制无法使用更多GPU时,可使用groupnorm代替batchnorm
+
+ 4、由于分类模型存在对多目标的捕捉能力弱以及对物体空间位置信息不敏感等问题,可借鉴DetNet训练一个专属于目标检测的模型网络,增强对多目标、尺度和位置拥有更强的适应性。
## 14.5 如何改善 GAN 的性能
@@ -327,23 +323,76 @@ GAN常用训练技巧
### 14.6.3 什么是神经网络架构搜索(NAS)
-2015至2017年间,是CNN网络设计最兴盛的阶段,大多都是由学者人工设计的网络结构。这个过程通常会很繁琐。其主要原因在于对不同模块组件的组成通常是个黑盒优化的问题,此外,在不同结构超参数以及训练超参数的选择优化上非凸优化问题,或者是个混合优化问题,既有离散空间又有连续空间。NAS(Neural Architecture Search)的出现就是为了解决如何通过机器策略和自动化的方式设计出优秀高效的网络。而这种策略通常不是统一的标准,不同的网络结合实际的需求通常会有不同的设计,比如移动端的模型会在效率和精度之间做平衡。目前的网络架构搜索通常会分为三个方面,搜索空间,搜索策略以及评价预估。链接 | https://www.paperweekly.site/papers/2249
+2015至2017年间,是CNN网络设计最兴盛的阶段,大多都是由学者人工设计的网络结构。这个过程通常会很繁琐。其主要原因在于对不同模块组件的组成通常是个黑盒优化的问题,此外,在不同结构超参数以及训练超参数的选择优化上非凸优化问题,或者是个混合优化问题,既有离散空间又有连续空间。NAS(Neural Architecture Search)的出现就是为了解决如何通过机器策略和自动化的方式设计出优秀高效的网络。而这种策略通常不是统一的标准,不同的网络结合实际的需求通常会有不同的设计,比如移动端的模型会在效率和精度之间做平衡。目前,NAS也是AUTOML中最重要的部分。NAS通常会分为三个方面,搜索空间(在哪搜索),搜索策略(如何搜索)及评价预估。
+
+- 搜索空间,即在哪搜索,定义了优化问题所需变量。不同规模的搜索空间的变量其对于的难度也是不一样的。早期由于网络结构以及层数相对比较简单,参数量较少,因此会更多的使用遗传算法等进化算法对网络的超参数和权重进行优化。深度学习发展到目前,模型网络结构越来越复杂,参数量级越来越庞大,这些进化算法已经无法继续使用。但若我们先验给定一些网络结构和超参数,模型的性能已经被限制在给定的空间,此时搜索的空间已变得有限,所以只需对复杂模型的架构参数和对应的超参数进行优化即可。
+
+- 搜索策略, 即如何搜索,定义了如何快速、准确找到最优的网络结构参数配置的策略。常见的搜索方法包括:随机搜索、贝叶斯优化以及基于模型的搜索算法。其中主要代表为2017 年谷歌大脑的使用强化学习的搜索方法。
+
+- 评价预估,定义了如何高效对搜索的评估策略。深度学习中,数据规模往往是庞大的,模型要在如此庞大的数据规模上进行搜索,这无疑是非常耗时的,对优化也会造成非常大的困难,所以需要一些高效的策略做近似的评估。 这里一般会有如下三种思路:
+
+ 一、使用些低保真的训练集来训练模型。低保真在实际中可以用不同的理解,比如较少的迭代次数,用一小部分数据集或者保证结构的同时减少通道数等。这些方法都可以在测试优化结构时大大降低计算时间,当然也会存在一定的偏差。但架构搜索从来并不是要一组固定的参数,而是一种优秀的模型结构。最终选取时,只需在较优秀的几组结构中进行全集训练,进行择优选取即可。
-- 搜索空间,定义了优化问题的变量,网络结构和超参数的变量定义有所不同,不同的变量规模对于算法的难度来说也不尽相同。早期很多工作都是用以遗传算法为代表的进化算法对神经网络的超参数和权重进行优化,因为当时的神经网络只有几层,每层十几个神经元,也不存在复杂的网络架构,参数很有限,可直接进行优化。而深度学习模型一方面有着复杂的网络结构,另一方面权重参数通常都以百万到亿来计,进化算法根本无法优化。但换个思路,假如我们找到了一组网络架构参数和对应的超参数,深度学习模型的性能其实是由这组参数来控制和决定的,所以只需要对复杂模型的架构参数和对应的超参数进行优化即可。
+ 二、使用代理模型。除了低保真的训练方式外,学者们提出了一种叫做代理模型的回归模型,采用例如插值等策略对已知的一些参数范围进行预测,目的是为了用尽可能少的点预测到最佳的结果。
-- 搜索策略, 搜索策略定义了使用怎样的算法可以快速、准确找到最优的网络结构参数配置。常见的搜索方法包括:随机搜索、贝叶斯优化、进化算法、强化学习、基于梯度的算法。其中,2017 年谷歌大脑的那篇强化学习搜索方法将这一研究带成了研究热点,后来 Uber、Sentient、OpenAI、Deepmind 等公司和研究机构用进化算法对这一问题进行了研究,这个 task 算是进化算法一大热点应用。
+ 三、参数级别的迁移。例如知识蒸馏等。用已训练好的模型权重参数对目标问题搜索,通常会让搜索拥有一个优秀的起点。由于积累了大量的历史寻优数据,对新问题的寻优将会起到很大的帮助。
-- 评价预估,类似于工程优化中的代理模型(surrogate model),因为深度学习模型的效果非常依赖于训练数据的规模,大规模数据上的模型训练会非常耗时,对优化结果的评价将会非常耗时,所以需要一些手段去做近似的评估。
+### 14.6.4 NASNet的设计策略
- 一种思路是用一些低保真的训练集来训练模型,低保真在实际应用可以有多种表达,比如训练更少的次数,用原始训练数据的一部分,低分辨率的图片,每一层用更少的滤波器等。用这种低保真的训练集来测试优化算法会大大降低计算时间,但也存在一定的 bias,不过选择最优的架构并不需要绝对数值,只需要有相对值就可以进行排序选优了;
+NASNet是最早由google brain 通过网络架构搜索策略搜索并成功训练ImageNet的网络,其性能超越所有手动设计的网络模型。关于NASNet的搜索策略,首先需要参考google brain发表在ICLR2017的论文《Neural Architecture Search with Reinforcement Learning》。该论文是最早成功通过架构搜索策略在cifar-10数据集上取得比较不错效果的工作。NASNet很大程度上是沿用该搜索框架的设计思想。
- 另一种主流思路是借鉴于工程优化中的代理模型,在很多工程优化问题中,每一次优化得到的结果需要经过实验或者高保真仿真(有限元分析)进行评价,实验和仿真的时间非常久,不可能无限制地进行评价尝试,学者们提出了一种叫做代理模型的回归模型,用观测到的点进行插值预测,这类方法中最重要的是在大搜索空间中如何选择尽量少的点预测出最优结果的位置;
+NASNet的核心思想是利用强化学习对搜索空间内的结构进行反馈探索。架构搜索图如下,定义了一个以RNN为核心的搜索控制器。在搜索空间以概率p对模型进行搜索采样。得到网络模型A后,对该模型进行训练,待模型收敛得到设定的准确率R后,将梯度传递给控制器RNN进行梯度更新。
- 第三种主流思路是参数级别的迁移,用之前已经训练好的模型权重参数对target问题进行赋值,从一个高起点的初值开始寻优将会大大地提高效率。在这类问题中,积累了大量的历史寻优数据,对新问题的寻优将会起到很大的帮助,用迁移学习进行求解,是一个很不错的思路;另一种比较有意思的思路叫做单次(One-Shot)架构搜索,这种方法将所有架构视作一个 one-shot 模型(超图)的子图,子图之间通过超图的边来共享权重。
+
+ 架构搜索策略流程
+RNN控制器会对卷积层的滤波器的尺寸、数量以及滑动间隔进行预测。每次预测的结果都会作为下一级的输入,档层数达到设定的阈值时,会停止预测。而这个阈值也会随着训练的进行而增加。这里的控制器之预测了卷积,并没有对例如inception系列的分支结构或者ResNet的跳级结构等进行搜索。所以,控制器需要进一步扩展到预测这些跳级结构上,这样搜索空间相应的也会增大。为了预测这些结构,RNN控制器内每一层都增加了一个预测跳级结构的神经元,文中称为锚点,稍有不同的是该锚点的预测会由前面所有层的锚点状态决定。
+
+ RNN控制器
+
+NASNet大体沿用了上述生成网络结构的机器,并在此基础上做了如下两点改进:
+
+1、先验行地加入inception系列和ResNet的堆叠模块的思想。其定义了两种卷积模块,Normal Cell和Reduction Cell,前者不进行降采样,而后者是个降采样的模块。而由这两种模块组成的结构可以很方便的通过不同数量的模块堆叠将其从小数据集搜索到的架构迁移到大数据集上,大大提高了搜索效率。
+
+
+
+ NASNet的RNN控制器
+
+2、对RNN控制进行优化,先验性地将各种尺寸和类型的卷积和池化层加入到搜索空间内,用预测一个卷积模块代替原先预测一层卷积。如图,控制器RNN不在预测单个卷积内的超参数组成,而是对一个模块内的每一个部分进行搜索预测,搜索的空间则限定在如下这些操作中:
+
+ • identity • 1x3 then 3x1 convolution
+ • 1x7 then 7x1 convolution • 3x3 dilated convolution
+ • 3x3 average pooling • 3x3 max pooling
+ • 5x5 max pooling • 7x7 max pooling
+ • 1x1 convolution • 3x3 convolution
+ • 3x3 depthwise-separable conv • 5x5 depthwise-seperable conv
+ • 7x7 depthwise-separable conv
+
+在模块内的连接方式上也提供了element-wise addition和concatenate两种方式。NASNet的搜索方式和过程对NAS的一些后续工作都具有非常好的参考借鉴意义。
+
+### 14.6.5 网络设计中,为什么卷积核设计尺寸都是奇数
+
+我们发现在很多大部分网络设计时都会使用例如3x3/5x5/7x7等奇数尺寸卷积核,主要原因有两点:
+
+- 保证像素点中心位置,避免位置信息偏移
+- 填充边缘时能保证两边都能填充,原矩阵依然对称
+
+### 14.6.6 网络设计中,权重共享的形式有哪些,为什么要权重共享
+
+权重共享的形式:
+
+- 深度学习中,权重共享最具代表性的就是卷积网络的卷积操作。卷积相比于全连接神经网络参数大大减少;
+- 多任务网络中,通常为了降低每个任务的计算量,会共享一个骨干网络。
+- 一些相同尺度下的结构化递归网络
+
+权重共享的好处:
+
+ 权重共享一定程度上能增强参数之间的联系,获得更好的共性特征。同时很大程度上降低了网络的参数,节省计算量和计算所需内存(当然,结构化递归并不节省计算量)。此外权重共享能起到很好正则的作用。正则化的目的是为了降低模型复杂度,防止过拟合,而权重共享则正好降低了模型的参数和复杂度。
+
+ 因此一个设计优秀的权重共享方式,在降低计算量的同时,通常会较独享网络有更好的效果。
diff --git "a/ch15_GPU\345\222\214\346\241\206\346\236\266\351\200\211\345\236\213/readme.md" "b/ch15_GPU\345\222\214\346\241\206\346\236\266\351\200\211\345\236\213/readme.md"
index d8afb155..ec9e6352 100644
--- "a/ch15_GPU\345\222\214\346\241\206\346\236\266\351\200\211\345\236\213/readme.md"
+++ "b/ch15_GPU\345\222\214\346\241\206\346\236\266\351\200\211\345\236\213/readme.md"
@@ -9,6 +9,6 @@
**贡献者(排名不分先后):**
-冯宝宝
+陈龙宇-重庆大学
###########################################################
diff --git "a/ch15_GPU\345\222\214\346\241\206\346\236\266\351\200\211\345\236\213/\347\254\254\345\215\201\344\272\224\347\253\240_\345\274\202\346\236\204\350\277\220\347\256\227\343\200\201GPU\345\217\212\346\241\206\346\236\266\351\200\211\345\236\213.md" "b/ch15_GPU\345\222\214\346\241\206\346\236\266\351\200\211\345\236\213/\347\254\254\345\215\201\344\272\224\347\253\240_\345\274\202\346\236\204\350\277\220\347\256\227\343\200\201GPU\345\217\212\346\241\206\346\236\266\351\200\211\345\236\213.md"
index c290b220..51b3b28e 100644
--- "a/ch15_GPU\345\222\214\346\241\206\346\236\266\351\200\211\345\236\213/\347\254\254\345\215\201\344\272\224\347\253\240_\345\274\202\346\236\204\350\277\220\347\256\227\343\200\201GPU\345\217\212\346\241\206\346\236\266\351\200\211\345\236\213.md"
+++ "b/ch15_GPU\345\222\214\346\241\206\346\236\266\351\200\211\345\236\213/\347\254\254\345\215\201\344\272\224\347\253\240_\345\274\202\346\236\204\350\277\220\347\256\227\343\200\201GPU\345\217\212\346\241\206\346\236\266\351\200\211\345\236\213.md"
@@ -11,20 +11,20 @@
异构计算是基于一个更加朴素的概念,”异构现象“,也就是不同计算平台之间,由于硬件结构(包括计算核心和内存),指令集和底层软件实现等方面的不同而有着不同的特性。异构计算就是使用结合了两个或者多个不同的计算平台,并进行协同运算。比如,比较常见的,在深度学习和机器学习中已经比较成熟的架构:CPU和GPU的异构计算;此外还有比较新的Google推出的协处理器(TPU),根据目的而定制的ASIC,可编程的FPGA等也都是现在在异构计算中使用比较多的协处理器。而,本章中会着重介绍和深度学习共同繁荣的图形加算器,也就是常说的GPU。
## 15.2 什么是GPGPU?
-GPU,就如名字所包含的内容,原本开发的目的是为了进行计算机图形渲染,而减少对于CPU的负载。由于图像的原始特性,也就是像素间的独立性,所以GPU在设计的时候就遵从了“单指令流多数据流(SIMD)”架构,使得同一个指令(比如图像的某种变换),可以同时在多一个像素点上进行计算,从而得到比较大的吞吐量,才能使得计算机可以实时渲染比较复杂的2D/3D场景。在最初的应用场景里,GPU并不是作为一种通用计算平台出现的,直到2007年左右,一家伟大的公司—NVIDIA将GPU带到通用计算的世界里,使得其可以在相对比较友好的编程环境(CUDA/OpenCL)里加速通用程序成了可能。从此之后,GPU通用计算(General Purpose Computing on GPU),也就是GPGPU就成了学界和工业界都频繁使用的技术,在深度学习爆发的年代里,GPGPU成了推动这股浪潮非常重要的力量。
+GPU,就如名字所包含的内容,原本开发的目的是为了进行计算机图形渲染,而减少对于CPU的负载。由于图像的原始特性,也就是像素间的独立性,所以GPU在设计的时候就遵从了“单指令流多数据流(SIMD)”架构,使得同一个指令(比如图像的某种变换),可以同时在多一个像素点上进行计算,从而得到比较大的吞吐量,才能使得计算机可以实时渲染比较复杂的2D/3D场景。在最初的应用场景里,GPU并不是作为一种通用计算平台出现的,直到2007年左右,一家伟大的公司将GPU带到通用计算的世界里,使得其可以在相对比较友好的编程环境(CUDA/OpenCL)里加速通用程序成了可能。从此之后,GPU通用计算,也就是GPGPU就成了学界和工业界都频繁使用的技术,在深度学习爆发的年代里,GPGPU成了推动这股浪潮非常重要的力量。
## 15.3 GPU架构简介
-GPU,图形显示芯片作为不同于CPU的设计逻辑和应用场景,有着非常不同的架构,理解 GPU 和 CPU 之间区别的一种简单方式是比较它们如何处理任务。CPU 由专为顺序串行处理而优化的几个核心组成,而 GPU 则拥有一个由数以千计的更小、更高效的核心(专为同时处理多重任务而设计)组成的大规模并行计算架构。本部分将简单介绍GPU究竟是如何架构,其中的计算核心有哪些特性。
+GPU,图形显示芯片作为不同于CPU的设计逻辑和应用场景,有着非常不同的架构,本部分将简单介绍GPU究竟是如何架构,其中的计算核心有哪些特性。
### 15.3.1 如何通俗理解GPU的架构?
首先,下图简单地展示了几个GPU不同于CPU的特性:
-* 计算核心: 图中的CPU,i7-5960X,Intel的第五代Broadwell架构,其中包括了8个CPU核心(支持16线程),也就是理论上可以有16个不同的运算同时进行。除了8个核心计算单元,大部分的芯片面积是被3级缓存,内存和控制电路占据了。同样的,来自NVIDIA的GTX980GPU,在差不多的芯片面积上,大部分是计算单元,16个SM,也就是流处理单元,每个流处理单元中包含着128个CUDA计算核心,所以总共来说,有2048个GPU运算单元,相应地这颗GPU理论上可以在一个时钟周期内可以进行2048次单精度运算。
+* 计算核心: 图中的CPU,i7-5960,Intel的第五代Broadwell架构,其中包括了8个CPU核心(支持16线程),也就是理论上可以有16个不同的运算同时进行。除了8个核心计算单元,大部分的芯片面积是被3级缓存,内存和控制电路占据了。同样的,来自Nvidia的GTX980GPU,在差不多的芯片面积上,大部分是计算单元,16个SM,也就是流处理单元,每个流处理单元中包含着128个CUDA计算核心,所以总共来说,有2048个GPU运算单元,相应地这颗GPU理论上可以在一个时钟周期内可以进行2048次单精度运算。

-* 计算核心频率:时钟频率,代表每一秒中内能进行同步脉冲次数,也是从一个侧面反映一个计算元件的工作速度。下图中对比了个别早期产品,比如Intel的X5650和几款NVIDIA的GPU。可以看出核心频率而言,CPU要远高于GPU。对于CPU而言,在不考虑能源消耗和制程工艺限制的情况下,追求更高的主频。但在GPU的设计中,采用了多核心设计,即使是提高一些频率,其实对于总体性能影像不会特别大。当然,其中还有能耗方面的考虑,避免发热过高,也进行了权衡。还有一个可能的原因是,在一个流处理器中的每个核心(CUDA核心)的运行共享非常有限的缓存和寄存器,由于共享内存也是有性能极限的,所以即使每个GPU核心频率提高,如果被缓存等拖累也是无法展现出高性能的。
+* 计算核心频率:时钟频率,代表每一秒中内能进行同步脉冲次数,也是从一个侧面反映一个计算元件的工作速度。下图中对比了个别早期产品,比如Intel的x5650和几款Nvidia的GPU。可以看出核心频率而言,CPU要远高于GPU。对于CPU而言,在不考虑能源消耗和制程工艺限制的情况下,追求更高的主频。但,在GPU的设计中,采用了多核心设计,即使是提高一些频率,其实对于总体性能影像不会特别大。当然,其中还有能耗方面的考虑,避免发热过高,也进行了权衡。还有一个可能的原因是,在一个流处理器中的每个核心(CUDA核心)的运行共享非常有限的缓存和寄存器,由于共享内存也是有性能极限的,所以即使每个GPU核心频率提高,如果被缓存等拖累也是无法展现出高性能的。

@@ -59,19 +59,11 @@ GPU整体的架构而言,某种意义上是同时支持以上两种并行模
深度学习在最近几年内出现的井喷现象背后也是GPU的存在和发展作为坚实的推动力量。
哪些场景使用GPU
-在涉及大型矩阵运算的时候使用GPU可以显著加速处理速度,由于GPU架构的独特设计,针对矩阵运算可以实现高速并行计算,极大提高计算速度。
-一般在高性能计算,机器学习,深度学习,图像渲染等等场景中会比较多的使用矩阵运算,使用GPU可以显著加快处理速度。
-在一般的深度学习训练中,通常来说使用GPU比使用CPU都有10倍以上的速度提升,所以几乎所有深度学习的研究者几乎都是在使用GPU进行训练。
ImageNet的例子
### 15.3.5 新图灵架构里的tensor core对深度学习有什么作用?
-我们知道在深度学习中,矩阵-矩阵乘法运算(BLAS GEMM)是神经网络训练和推理的核心,并且矩阵乘法运算占据了所有计算量的大部分,而Tensor core就是为了解决这个问题而推出的,它的出现极大的提高了计算效率,大大加速了深度学习的计算速度,对深度学习的发展具有极大意义。
-
-Tensor Core是Volta架构最重磅特性,是专门针对Deep Learning应用而设计的专用ASIC单元,实际上是一种矩阵乘累加的计算单元。(矩阵乘累加计算在Deep Learning网络层算法中,比如卷积层、全连接层等是最重要、最耗时的一部分。)Tensor Core可以在一个时钟周期内实现两个4×4矩阵乘法以及与另一个4×4矩阵加法。整个计算的个数,就是在一个时钟周期内可以实现64次乘和64次加。
-
-所以Tensor Core就是为了矩阵乘法的加速而设计的,使用具有Tensor Core的GPU来进行深度学习的训练会极大的提高训练速度。
## 15.4 CUDA 框架
@@ -86,10 +78,10 @@ Tensor Core是Volta架构最重磅特性,是专门针对Deep Learning应用而
GPU的性能主要由以下三个参数构成:
1. 计算能力。通常我们关心的是32位浮点计算能力。16位浮点训练也开始流行,如果只做预测的话也可以用8位整数。
-2. 显存大小。当模型越大,或者训练时的批量越大时,所需要的GPU显存就越多。
-3. 显存带宽。只有当显存带宽足够时才能充分发挥计算能力。
+2. 内存大小。当模型越大,或者训练时的批量越大时,所需要的GPU内存就越多。
+3. 内存带宽。只有当内存带宽足够时才能充分发挥计算能力。
-对于大部分用户来说,只要考虑计算能力就可以了。GPU显存尽量不小于4GB。但如果GPU要同时显示图形界面,那么推荐的显存大小至少为6GB。显存带宽通常相对固定,选择空间较小。
+对于大部分用户来说,只要考虑计算能力就可以了。GPU内存尽量不小于4GB。但如果GPU要同时显示图形界面,那么推荐的内存大小至少为6GB。内存带宽通常相对固定,选择空间较小。
下图描绘了GTX 900和1000系列里各个型号的32位浮点计算能力和价格的对比。其中价格为Wikipedia的建议价格。
@@ -97,16 +89,19 @@ GPU的性能主要由以下三个参数构成:
我们可以从图中读出两点信息:
-1. 在同一个系列里面,价格和性能大体上成正比。但后发布的型号性价比更高,例如980 Ti和1080 Ti。
+1. 在同一个系列里面,价格和性能大体上成正比。但后发布的型号性价比更高,例如980 TI和1080 TI。
2. GTX 1000系列比900系列在性价比上高出2倍左右。
如果大家继续比较GTX较早的系列,也可以发现类似的规律。据此,我们推荐大家在能力范围内尽可能买较新的GPU。
+对于RTX系列,新增了Tensor Cores单元及支持FP16,使得显卡的可选择范围更加多元。
+
### 15.5.2 购买建议
-##### 首先给出一些总体的建议
-最好的GPU整体(小幅度):Titan Xp
-综合性价比高,但略贵:GTX 1080 Ti,GTX 1070,GTX 1080
-性价比还不错且便宜:GTX 1060(6GB)
+首先给出一些总体的建议:
+
+性价比高但较贵:RTX 2070,GTX 1080 Ti
+
+性价比高又便宜:RTX 2060,GTX 1060(6GB)
当使用数据集> 250GB:GTX Titan X(Maxwell) ,NVIDIA Titan X Pascal或NVIDIA Titan Xp
@@ -114,25 +109,25 @@ GPU的性能主要由以下三个参数构成:
几乎没有钱,入门级:GTX 1050 Ti(4GB)
-做Kaggle比赛:GTX 1060(6GB)适用于任何“正常”比赛,或GTX 1080 Ti用于“深度学习竞赛”
+做Kaggle比赛:RTX 2070、GTX 1060(6GB)适用于任何“正常”比赛,GTX 1080 Ti(预算足够可以选择RTX 2080 Ti)用于“深度学习竞赛”
-计算机视觉研究员:NVIDIA Titan Xp;不要买现在新出的Titan X(Pascal或Maxwell)
+计算机视觉研究员:RTX 2080 Ti(涡轮散热或水冷散热较好,方便后期增加新的显卡)如果网络很深可以选择Titan RTX
-一名研究员人员:GTX 1080 Ti。在某些情况下,如自然语言处理,一个GTX 1070或GTX 1080已经足够了-检查你现在模型的内存需求
+一名NLP研究人员:RTX 2080 Ti,并使用FP16来训练
搭建一个GPU集群:这个有点复杂,另做探讨。
-刚开始进行深度学习研究:从GTX 1060(6GB)开始。根据你下一步兴趣(入门,Kaggle比赛,研究,应用深度学习)等等,在进行选择。目前,GTX 1060更合适。
+刚开始进行深度学习研究:从RTX 2060或GTX 1060(6GB)开始,根据你下一步兴趣(入门,Kaggle比赛,研究,应用深度学习)等等,再进行选择。目前,RTX 2060和GTX 1060都比较合适入门的选择。
-想尝试下深度学习,但没有过多要求:GTX 1050 Ti(4或2GB)
+想尝试下深度学习,但没有过多要求:GTX 1050 ti(4或2GB)
-目前独立GPU主要有AMD和NVIDIA两家厂商。其中NVIDIA在深度学习布局较早,对深度学习框架支持更好。因此,目前大家主要会选择NVIDIA的GPU。
+目前独立GPU主要有AMD和Nvidia两家厂商。其中Nvidia在深度学习布局较早,对深度学习框架支持更好。因此,目前大家主要会选择Nvidia的GPU。
-NVIDIA有面向个人用户(例如GTX系列)和企业用户(例如Tesla系列)的两类GPU。这两类GPU的计算能力相当。然而,面向企业用户的GPU通常使用被动散热并增加了内存校验,从而更适合数据中心,并通常要比面向个人用户的GPU贵上10倍。
+Nvidia有面向个人用户(例如GTX系列)和企业用户(例如Tesla系列)的两类GPU。这两类GPU的计算能力相当。然而,面向企业用户的GPU通常使用被动散热并增加了内存校验,从而更适合数据中心,并通常要比面向个人用户的GPU贵上10倍。
-如果你是拥有100台机器以上的大公司用户,通常可以考虑针对企业用户的NVIDIA Tesla系列。如果你是拥有10到100台机器的实验室和中小公司用户,预算充足的情况下可以考虑NVIDIA DGX系列,否则可以考虑购买如Supermicro之类的性价比比较高的服务器,然后再购买安装GTX系列的GPU。
+如果你是拥有100台机器以上的大公司用户,通常可以考虑针对企业用户的Nvidia Tesla系列。如果你是拥有10到100台机器的实验室和中小公司用户,预算充足的情况下可以考虑Nvidia DGX系列,否则可以考虑购买如Supermicro之类的性价比比较高的服务器,然后再购买安装GTX系列的GPU。
-NVIDIA一般每一两年发布一次新版本的GPU,例如2016年发布的是GTX 1000系列。每个系列中会有数个不同的型号,分别对应不同的性能。
+Nvidia一般每一两年发布一次新版本的GPU,例如2017年发布的是GTX 1000系列。每个系列中会有数个不同的型号,分别对应不同的性能。
## 15.6 软件环境搭建
深度学习其实就是指基于一套完整的软件系统来构建算法,训练模型。如何搭建一套完整的软件系统,比如操作系统的选择?安装环境中遇到的问题等等,本节做一个简单的总结。
@@ -146,7 +141,7 @@ NVIDIA一般每一两年发布一次新版本的GPU,例如2016年发布的是G
总之一句话,如果不熟悉Linux,就先慢慢熟悉,最终还是要回归到Linux系统来构建深度学习系统
### 15.6.2 常用基础软件安装?
-目前有众多深度学习框架可供大家使用,但是所有框架基本都有一个共同的特点,目前几乎都是基于Nvidia的GPU来训练模型,要想更好的使用NVIDIA的GPU,cuda和cudnn就是必备的软件安装。
+目前有众多深度学习框架可供大家使用,但是所有框架基本都有一个共同的特点,目前几乎都是基于Nvidia的GPU来训练模型,要想更好的使用Nvidia的GPU,cuda和cudnn就是必备的软件安装。
1. **安装cuda**
上文中有关于cuda的介绍,这里只是简单介绍基于Linux系统安装cuda的具体步骤,可以根据自己的需要安装cuda8.0或者cuda9.0,这两种版本的安装步骤基本一致,这里以最常用的ubuntu 16.04 lts版本为例:
1. 官网下载,地址
@@ -386,46 +381,48 @@ mxnet的最知名的优点就是其对多GPU的支持和扩展性强,其优秀
### 15.2.1 常用框架简介
-1,tensorflow:
+1. tensorflow:
tensorflow由于有google的强大背书,加上其优秀的分布式设计,丰富的教程资源和论坛,工业部署方便,基本很多人都是从tensorflow入门的
优点:google的强大背书,分布式训练,教程资源丰富,常见问题基本都可以在互联网中找到解决办法,工业部署方便
缺点: 接口混乱,官方文档不够简洁,清晰,
-2,keras:
+2. keras:
keras是一种高层编程接口,其可以选择不同的后端,比如tensorflow,therao等等
优点:接口简洁,上手快,文档好,资源多
缺点: 封装的太好了导致不理解其技术细节
-3,pytorch:
+3. pytorch:
-4,caffe2:
+4. caffe2:
caffe2是在caffe之后的第二代版本,同属于Facebook。。。
优点:支持模型的全平台部署,。。。。
缺点:使用人数相对较少,资源较少,和pytorch合并后应该会更受欢迎
-5,mxnet
+5. mxnet
mxnet是dmlc社区推出的深度学习框架,在2017年被亚马逊指定为官方框架
优点:支持多种语言,代码设计优秀,省显存,华人团队开发,中文社区活跃,官方复现经典论文推出gluoncv和gluonNLP模块,非常方便,拿来就可以用。
缺点:现在mxnet官方社区主要在推gluon接口,接口稍有混乱,坑较多,入手门槛稍高
-6,caffe:
+6. caffe:
目前很多做深度学习比较早的大厂基本都是在用caffe,因为在2013-2015年基本就是caffe的天下,并且caffe的代码设计很优秀,基本所有代码都被翻了很多遍了,被各种分析,大厂基本都是魔改caffe,基于caffe来进行二次开发,所在目前在很多大厂还是在使用caffe
优点:资源丰富,代码容易理解,部署方便
缺点:入门门槛高,文档较少
-###15.2.1 框架选型总结
-1,新手入门,首推pytorch,上手快,资源丰富,官方文档写的非常好(https://pytorch.org/tutorials/)
-2,目前工业部署,tensorflow是首选,资源丰富,并且在分布式训练这一块基本一家独大
-3,mxnet的gluon接口有比较丰富的中文资源(教程:zh.gluon.ai,论坛:discuss.gluon.ai),gluoncv模块(https://gluon-cv.mxnet.io),gluonNLP模块(https://gluon-nlp.mxnet.io)
+框架选型总结:
+1. 新手入门,首推pytorch,上手快,资源丰富,官方文档写的非常好(https://pytorch.org/tutorials/)
+2. 目前工业部署,tensorflow是首选,资源丰富,并且在分布式训练这一块基本一家独大
+3. mxnet的gluon接口有比较丰富的中文资源(教程:zh.gluon.ai,论坛:discuss.gluon.ai),gluoncv模块(https://gluon-cv.mxnet.io),gluonNLP模块(https://gluon-nlp.mxnet.io)
-##15.3 模型部署
+## 15.3 模型部署
我们一般都是通过python或者其他语言来编码训练模型,然后基于后端来进行部署
一般的框架都有自身的部署框架,比如tensorflow,pytorch,caffe2,mxnet等等
有一些框架是专门做推理部署使用的,比如
-(1)tensorRT
-
+ (1)tensorRT
(2)TVM
-
(3)ONNX
+
+ ## 相关文献
+ [1] Aston Zhang, Mu Li, Zachary C. Lipton, and Alex J. Smola. [《动手学深度学习》附录 购买GPU](https://github.com/d2l-ai/d2l-zh/blob/master/chapter_appendix/buy-gpu.md), 2019.
+ [2] Tim Dettmers. [Which GPU(s) to Get for Deep Learning: My Experience and Advice for Using GPUs in Deep Learning](http://timdettmers.com/2019/04/03/which-gpu-for-deep-learning/), 2019.
\ No newline at end of file
diff --git "a/ch16_\350\207\252\347\204\266\350\257\255\350\250\200\345\244\204\347\220\206(NLP)/img/ch16/readme.md" "b/ch16_\350\207\252\347\204\266\350\257\255\350\250\200\345\244\204\347\220\206(NLP)/img/ch16/readme.md"
deleted file mode 100644
index f099ebf1..00000000
--- "a/ch16_\350\207\252\347\204\266\350\257\255\350\250\200\345\244\204\347\220\206(NLP)/img/ch16/readme.md"
+++ /dev/null
@@ -1,2 +0,0 @@
-Add the corresponding chapter picture under img/ch*
-��img/ch*�����Ӷ�Ӧ�½�ͼƬ
\ No newline at end of file
diff --git "a/ch17_\346\250\241\345\236\213\345\216\213\347\274\251\343\200\201\345\212\240\351\200\237\345\217\212\347\247\273\345\212\250\347\253\257\351\203\250\347\275\262/17.8.1 NCNN\351\203\250\347\275\262.md" "b/ch17_\346\250\241\345\236\213\345\216\213\347\274\251\343\200\201\345\212\240\351\200\237\345\217\212\347\247\273\345\212\250\347\253\257\351\203\250\347\275\262/17.8.1 NCNN\351\203\250\347\275\262.md"
new file mode 100644
index 00000000..08ef3e99
--- /dev/null
+++ "b/ch17_\346\250\241\345\236\213\345\216\213\347\274\251\343\200\201\345\212\240\351\200\237\345\217\212\347\247\273\345\212\250\347\253\257\351\203\250\347\275\262/17.8.1 NCNN\351\203\250\347\275\262.md"
@@ -0,0 +1,986 @@
+### 17.8.1 NCNN部署
+
+##### 1.在电脑端使用ncnn实现分类(alexnet)
+
+s1,安装g++,cmake,protobuf,opencv
+
+
+
+s2,对源码进行编译
+
+```shell
+git clone https://github.com/Tencent/ncnn
+$ cd
+$ mkdir -p build
+$ cd build
+$ cmake ..
+$ make -j4
+```
+
+
+
+s3,准备caffe模型文件(alexnet)
+
+```
+deploy.prototxt
+snapshot_10000.caffemodel
+```
+
+alexnet [deploy.prototxt](https://github.com/BVLC/caffe/tree/master/models/bvlc_alexnet), [caffemodel](http://dl.caffe.berkeleyvision.org/bvlc_alexnet.caffemodel)
+
+
+
+s4,使用ncnn转换工具将旧caffe版本的prototxt和caffemodel转新版本
+
+将旧caffe版本的prototxt和caffemodel存放在caffe/build/tools目录下,执行如下命令完成转换
+
+```shell
+./upgrade_net_proto_text [old prototxt] [new prototxt]
+./upgrade_net_proto_binary [old caffemodel] [new caffemodel]
+```
+
+
+
+s5,将deploy.prototxt中输入层替换成input层(如果只读取一张图片将dim设置为1)
+
+```protobuf
+layer {
+ name: "data"
+ type: "Input"
+ top: "data"
+ input_param { shape: { dim: 1 dim: 3 dim: 227 dim: 227 } }
+}
+```
+
+
+
+s6,使用caffe2ncnn工具将caffe model转成ncnn model
+
+```shell
+./caffe2ncnn deploy.prototxt bvlc_alexnet.caffemodel alexnet.param alexnet.bin
+```
+
+在ncnn/build/tools目录下生成param和bin文件。
+
+
+
+s7,对模型参数进行加密
+
+```shell
+./ncnn2mem alexnet.param alexnet.bin alexnet.id.h alexnet.mem.h
+```
+
+在ncnn/build/tools目录下生成.param、.bin和.h文件。
+
+alexnet.param 网络的模型参数
+
+alexnet.bin 网络的权重
+
+alexnet.id.h 在预测图片的时候使用到
+
+
+
+s8,编写pc端代码(参考https://blog.csdn.net/qq_36982160/article/details/79929869)
+
+```c++
+#include
+#include
+#include
+#include"gesture.id.h"
+#include "net.h"
+//使用ncnn,传入的参数第一个是你需要预测的数据,第二个参数是各个类别的得分vector,注意传入的是地址,这样才能在这个函数中改变其值
+static int detect_squeezenet( float *data, std::vector& cls_scores) {
+ //实例化ncnn:Net,注意include "net.h",不要在意这时候因为找不到net.h文件而include报错,后文会介绍正确的打开方式
+ ncnn::Net squeezenet;
+
+ //加载二进制文件,也是照写,后面会介绍对应文件应该放的正确位置
+ int a=squeezenet.load_param("demo.param");
+ int b=squeezenet.load_param_bin("demo.bin");
+
+ //实例化Mat,前三个参数是维度,第四个参数是传入的data,维度的设置根据你自己的数据进行设置,顺序是w、h、c
+ ncnn::Mat in = ncnn::Mat(550, 8, 2, data);
+
+ //实例化Extractor
+ ncnn::Extractor ex = squeezenet.create_extractor();
+ ex.set_light_mode(true);
+ //注意把"data"换成你deploy中的数据层名字
+ int d= ex.input("data", in);
+
+ ncnn::Mat out;
+ //这里是真正的终点,不多说了,只能仰天膜拜nihui大牛,重点是将prob换成你deploy中最后一层的名字
+ int c=ex.extract("prob", out);
+
+ //将out中的值转化为我们的cls_scores,这样就可以返回不同类别的得分了
+ cls_scores.resize(out.w);
+ for (int j=0; j cls_scores; //用来存储最终各类别的得分
+ //这个函数的实现在上面,快去看
+ detect_squeezenet(data, cls_scores);
+ for (int i = 0; i < cls_scores.size(); ++i) {
+ printf("%c : %f\n", a[i],cls_scores[i]);
+ }
+
+ return 0;
+}
+```
+
+代码是最简单的ncnn使用场景,可以根据自己需求加入代码。
+
+
+
+s9,编译代码
+
+(1) 编写CMakeLists.txt
+
+在CMakeLists.txt增加如下两行代码
+
+```c
+add_executable(demo demo.cpp)
+target_link_libraries(demo ncnn)
+```
+
+CMakeLists.txt如下
+
+```
+find_package(OpenCV QUIET COMPONENTS core highgui imgproc imgcodecs)
+if(NOT OpenCV_FOUND)
+ find_package(OpenCV REQUIRED COMPONENTS core highgui imgproc)
+endif()
+
+include_directories(${CMAKE_CURRENT_SOURCE_DIR}/../src)
+include_directories(${CMAKE_CURRENT_BINARY_DIR}/../src)
+
+add_executable(squeezenet squeezenet.cpp)
+
+target_link_libraries(squeezenet ncnn ${OpenCV_LIBS})
+
+add_executable(fasterrcnn fasterrcnn.cpp)
+target_link_libraries(fasterrcnn ncnn ${OpenCV_LIBS})
+
+add_executable(demo demo.cpp)
+target_link_libraries(demo ncnn)
+
+add_subdirectory(ssd)
+```
+
+(2) 在ncnn根目录下CMakeLists.txt中编译examples语句的注释去掉
+
+```
+##############################################
+
+# add_subdirectory(examples)
+# add_subdirectory(benchmark)
+add_subdirectory(src)
+if(NOT ANDROID AND NOT IOS)
+add_subdirectory(tools)
+endif()
+```
+
+(3)ncnn/build目录下进行编译,生成demo可执行文件
+
+```
+make
+```
+
+
+
+s10,执行
+
+将生成的.param和.bin文件复制到ncnn/build/examples目录下,然后终端cd到ncnn/build/examples,执行:
+
+```
+./demo data_path1 data_path2
+```
+
+
+
+##### 2. Win x64 (Visual Studio Community 2017)
+
+s1,安装Visual Studio Community 2017
+
+```
+download Visual Studio Community 2017 from https://visualstudio.microsoft.com/vs/community/
+install it
+Start → Programs → Visual Studio 2017 → Visual Studio Tools → x64 Native Tools Command Prompt for VS 2017
+```
+
+s2,编译protobuf
+
+```powershell
+download protobuf-3.4.0 from https://github.com/google/protobuf/archive/v3.4.0.zip
+> cd
+> mkdir build-vs2017
+> cd build-vs2017
+> cmake -G"NMake Makefiles" -DCMAKE_BUILD_TYPE=Release -DCMAKE_INSTALL_PREFIX=%cd%/install -Dprotobuf_BUILD_TESTS=OFF -Dprotobuf_MSVC_STATIC_RUNTIME=OFF ../cmake
+> nmake
+> nmake install
+```
+
+s3,编译ncnn库
+
+```powershell
+> cd
+> mkdir -p build-vs2017
+> cd build-vs2017
+> cmake -G"NMake Makefiles" -DCMAKE_BUILD_TYPE=Release -DCMAKE_INSTALL_PREFIX=%cd%/install -DProtobuf_INCLUDE_DIR=/build-vs2017/install/include -DProtobuf_LIBRARIES=/build-vs2017/install/lib/libprotobuf.lib -DProtobuf_PROTOC_EXECUTABLE=/build-vs2017/install/bin/protoc.exe ..
+> nmake
+> nmake install
+
+pick build-vs2017/install folder for further usage
+```
+
+
+
+##### 3. Android端使用ncnn
+
+参考:
+
+https://blog.csdn.net/qq_33200967/article/details/82421089
+
+https://blog.csdn.net/qq_36982160/article/details/79931741
+
+s1,使用Android Studio安装ndk
+
+1)打开Android Studio,依次点击File->Settings->Appearance&Behavior->System Settings->Android SDK->SDK Tool,选中NDK,点击apply自动下载安装(如果安装成功会在SDK目录下生成ndk-bundle文件夹);
+
+2)配置ndk的环境变量
+
+ * 打开profile
+
+ ```shell
+ sudo vim /etc/profile
+ ```
+
+ * 在profile文件末尾添加ndk路径
+
+ ```shell
+ export NDK_HOME=sdkroot/ndk-bundle
+ PATH=$NDK_HOME:$PATH
+ ```
+
+ * 保存退出,使用source命令使环境变量生效
+
+ ```shell
+ source /etc/profile
+ ```
+
+ * 验证ndk是否配置成功
+
+ ```shell
+ ndk-build -v
+ ```
+
+
+
+s2,编译ncnn sdk
+
+通过如下命令编译ncnn sdk,会在ncnn/build-android下生成install文件夹,其中包括:include(调用ncnn所需的头文件)和lib(编译得到的ncnn库libncnn.a)
+
+```shell
+mkdir build-android
+cd build-android
+cmake -DCMAKE_TOOLCHAIN_FILE=$ANDROID_NDK/build/cmake/android.toolchain.cmake \
+ -DANDROID_ABI="armeabi-v7a" -DANDROID_ARM_NEON=ON \
+ -DANDROID_PLATFORM=android-14 ..
+make
+make install
+make package
+```
+
+参数设置请参考:https://github.com/Tencent/ncnn/wiki/cmake-%E6%89%93%E5%8C%85-android-sdk
+
+```
+ANDROID_ABI 是架构名字,"armeabi-v7a" 支持绝大部分手机硬件
+ANDROID_ARM_NEON 是否使用 NEON 指令集,设为 ON 支持绝大部分手机硬件
+ANDROID_PLATFORM 指定最低系统版本,"android-14" 就是 android-4.0
+```
+
+
+
+s3,对源码进行编译
+
+```shell
+git clone https://github.com/Tencent/ncnn
+$ cd
+$ mkdir -p build
+$ cd build
+$ cmake ..
+$ make -j4
+```
+
+
+
+s4,准备caffe模型文件(alexnet)
+
+```
+deploy.prototxt
+snapshot_10000.caffemodel
+```
+
+alexnet [deploy.prototxt](https://github.com/BVLC/caffe/tree/master/models/bvlc_alexnet), [caffemodel](http://dl.caffe.berkeleyvision.org/bvlc_alexnet.caffemodel)
+
+
+
+s5,使用ncnn转换工具将旧caffe版本的prototxt和caffemodel转新版本
+
+将旧caffe版本的prototxt和caffemodel存放在caffe/build/tools目录下,执行如下命令完成转换
+
+```shell
+./upgrade_net_proto_text [old prototxt] [new prototxt]
+./upgrade_net_proto_binary [old caffemodel] [new caffemodel]
+```
+
+
+
+s6,将deploy.prototxt中输入层替换成input层(如果只读取一张图片将dim设置为1)
+
+```protobuf
+layer {
+ name: "data"
+ type: "Input"
+ top: "data"
+ input_param { shape: { dim: 1 dim: 3 dim: 227 dim: 227 } }
+}
+```
+
+s7,使用caffe2ncnn工具将caffe model转成ncnn model
+
+```shell
+./caffe2ncnn deploy.prototxt bvlc_alexnet.caffemodel alexnet.param alexnet.bin
+```
+
+在ncnn/build/tools目录下生成param和bin文件。
+
+
+
+s8,对模型参数进行加密
+
+```shell
+./ncnn2mem alexnet.param alexnet.bin alexnet.id.h alexnet.mem.h
+```
+
+在ncnn/build/tools目录下生成.param、.bin和.h文件。
+
+alexnet.param 网络的模型参数
+
+alexnet.bin 网络的权重
+
+alexnet.id.h 在预测图片的时候使用到
+
+
+
+s9,开发安卓项目
+
+(1)在Android Studio上创建一个NCNN1,并选择Include C++ support
+
+
+
+(2)在main目录下创建assets目录,并将alexnet.param、alexnet.bin、label.txt拷贝其中
+
+(3)将include文件夹和 alexnet.id.h拷贝到cpp目录下
+
+(4)在main目录下创建jniLibs/armeabi-v7a/目录,并将alexnet.id.h 拷贝其中
+
+(5)在cpp文件夹下创建C++文件,用于加载模型和预测图片
+
+```C++
+#include
+#include
+#include
+#include
+#include
+// ncnn
+#include "include/net.h"
+#include "alexnet.id.h"
+#include
+#include
+static ncnn::UnlockedPoolAllocator g_blob_pool_allocator;
+static ncnn::PoolAllocator g_workspace_pool_allocator;
+static ncnn::Mat ncnn_param;
+static ncnn::Mat ncnn_bin;
+static ncnn::Net ncnn_net;
+extern "C" {
+// public native boolean Init(byte[] param, byte[] bin, byte[] words); JNIEXPORT jboolean JNICALL
+Java_com_example_ncnn1_NcnnJni_Init(JNIEnv *env, jobject thiz, jbyteArray param, jbyteArray bin) {
+ // init param
+ {
+ int len = env->GetArrayLength(param);
+ ncnn_param.create(len, (size_t) 1u);
+ env->GetByteArrayRegion(param, 0, len, (jbyte *) ncnn_param); int ret = ncnn_net.load_param((const unsigned char *) ncnn_param);
+ __android_log_print(ANDROID_LOG_DEBUG, "NcnnJni", "load_param %d %d", ret, len);
+ }
+
+ // init bin
+ {
+ int len = env->GetArrayLength(bin);
+ ncnn_bin.create(len, (size_t) 1u);
+ env->GetByteArrayRegion(bin, 0, len, (jbyte *) ncnn_bin);
+ int ret = ncnn_net.load_model((const unsigned char *) ncnn_bin);
+ __android_log_print(ANDROID_LOG_DEBUG, "NcnnJni", "load_model %d %d", ret, len);
+ }
+
+ ncnn::Option opt;
+ opt.lightmode = true;
+ opt.num_threads = 4;
+ opt.blob_allocator = &g_blob_pool_allocator;
+ opt.workspace_allocator = &g_workspace_pool_allocator;
+
+ ncnn::set_default_option(opt);
+
+ return JNI_TRUE;
+}
+
+// public native String Detect(Bitmap bitmap);
+JNIEXPORT jfloatArray JNICALL Java_com_example_ncnn1_NcnnJni_Detect(JNIEnv* env, jobject thiz, jobject bitmap)
+{
+ // ncnn from bitmap
+ ncnn::Mat in;
+ {
+ AndroidBitmapInfo info;
+ AndroidBitmap_getInfo(env, bitmap, &info);
+ int width = info.width; int height = info.height;
+ if (info.format != ANDROID_BITMAP_FORMAT_RGBA_8888)
+ return NULL;
+
+ void* indata;
+ AndroidBitmap_lockPixels(env, bitmap, &indata);
+ // 把像素转换成data,并指定通道顺序
+ in = ncnn::Mat::from_pixels((const unsigned char*)indata, ncnn::Mat::PIXEL_RGBA2BGR, width, height);
+ AndroidBitmap_unlockPixels(env, bitmap);
+ }
+
+ // ncnn_net
+ std::vector cls_scores;
+ {
+ // 减去均值和乘上比例
+ const float mean_vals[3] = {103.94f, 116.78f, 123.68f};
+ const float scale[3] = {0.017f, 0.017f, 0.017f};
+
+ in.substract_mean_normalize(mean_vals, scale);
+
+ ncnn::Extractor ex = ncnn_net.create_extractor();
+ // 如果时不加密是使用ex.input("data", in);
+ ex.input(mobilenet_v2_param_id::BLOB_data, in);
+
+ ncnn::Mat out;
+ // 如果时不加密是使用ex.extract("prob", out);
+ ex.extract(mobilenet_v2_param_id::BLOB_prob, out);
+
+ int output_size = out.w;
+ jfloat *output[output_size];
+ for (int j = 0; j < out.w; j++) {
+ output[j] = &out[j];
+ }
+
+ jfloatArray jOutputData = env->NewFloatArray(output_size);
+ if (jOutputData == nullptr) return nullptr;
+
+ env->SetFloatArrayRegion(jOutputData, 0, output_size, reinterpret_cast(*output)); // copy
+ return jOutputData;
+ }
+}
+}
+```
+
+(6)在项目包com.example.ncnn1下,修改MainActivity.java中的代码
+
+```java
+package com.example.ncnn1;
+import android.Manifest;
+import android.app.Activity;
+import android.content.Intent;
+import android.content.pm.PackageManager;
+import android.content.res.AssetManager;
+import android.graphics.Bitmap;
+import android.graphics.BitmapFactory;
+import android.net.Uri;
+import android.os.Bundle;
+import android.support.annotation.NonNull;
+import android.support.annotation.Nullable;
+import android.support.v4.app.ActivityCompat;
+import android.support.v4.content.ContextCompat;
+import android.text.method.ScrollingMovementMethod;
+import android.util.Log;
+import android.view.View;
+import android.widget.Button;
+import android.widget.ImageView;
+import android.widget.TextView;
+import android.widget.Toast;
+
+import com.bumptech.glide.Glide;
+import com.bumptech.glide.load.engine.DiskCacheStrategy;
+import com.bumptech.glide.request.RequestOptions;
+
+import java.io.BufferedReader;
+import java.io.FileNotFoundException;
+import java.io.IOException;
+import java.io.InputStream;
+import java.io.InputStreamReader;
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.List;
+
+public class MainActivity extends Activity {
+ private static final String TAG = MainActivity.class.getName();
+ private static final int USE_PHOTO = 1001;
+ private String camera_image_path;
+ private ImageView show_image;
+ private TextView result_text;
+ private boolean load_result = false; private int[] ddims = {1, 3, 224, 224};
+ private int model_index = 1;
+ private List resultLabel = new ArrayList<>();
+ private NcnnJni squeezencnn = new NcnnJni();
+
+ @Override
+ public void onCreate(Bundle savedInstanceState) {
+ super.onCreate(savedInstanceState);
+ setContentView(R.layout.activity_main);
+
+ try {
+ initSqueezeNcnn();
+ } catch (IOException e) {
+ Log.e("MainActivity", "initSqueezeNcnn error");
+ }
+
+ init_view();
+ readCacheLabelFromLocalFile();
+ }
+
+ private void initSqueezeNcnn() throws IOException {
+ byte[] param = null;
+ byte[] bin = null;
+
+ {
+ InputStream assetsInputStream = getAssets().open("mobilenet_v2.param.bin");
+ int available = assetsInputStream.available();
+ param = new byte[available];
+ int byteCode = assetsInputStream.read(param);
+ assetsInputStream.close();
+ }
+
+ {
+ InputStream assetsInputStream = getAssets().open("mobilenet_v2.bin");
+ int available = assetsInputStream.available();
+ bin = new byte[available];
+ int byteCode = assetsInputStream.read(bin);
+ assetsInputStream.close();
+ }
+
+ load_result = squeezencnn.Init(param, bin);
+ Log.d("load model", "result:" + load_result);
+ }
+
+ // initialize view
+ private void init_view() {
+ request_permissions();
+ show_image = (ImageView) findViewById(R.id.show_image);
+ result_text = (TextView) findViewById(R.id.result_text);
+ result_text.setMovementMethod(ScrollingMovementMethod.getInstance());
+ Button use_photo = (Button) findViewById(R.id.use_photo);
+
+ // use photo click
+ use_photo.setOnClickListener(new View.OnClickListener() {
+ @Override
+ public void onClick(View view) {
+ if (!load_result) {
+ Toast.makeText(MainActivity.this, "never load model", Toast.LENGTH_SHORT).show();
+ return;
+ }
+ PhotoUtil.use_photo(MainActivity.this, USE_PHOTO);
+ }
+ });
+ }
+
+ // load label's name
+ private void readCacheLabelFromLocalFile() {
+ try {
+ AssetManager assetManager = getApplicationContext().getAssets();
+ BufferedReader reader = new BufferedReader(new InputStreamReader(assetManager.open("synset.txt")));
+ String readLine = null;
+ while ((readLine = reader.readLine()) != null) {
+ resultLabel.add(readLine);
+ }
+ reader.close();
+ } catch (Exception e) {
+ Log.e("labelCache", "error " + e);
+ }
+ }
+
+ @Override
+ protected void onActivityResult(int requestCode, int resultCode, @Nullable Intent data) {
+ String image_path;
+ RequestOptions options = new RequestOptions().skipMemoryCache(true).diskCacheStrategy(DiskCacheStrategy.NONE);
+ if (resultCode == Activity.RESULT_OK) {
+ switch (requestCode) {
+ case USE_PHOTO:
+ if (data == null) {
+ Log.w(TAG, "user photo data is null");
+ return;
+ }
+ Uri image_uri = data.getData();
+ Glide.with(MainActivity.this).load(image_uri).apply(options).into(show_image);
+ // get image path from uri
+ image_path = PhotoUtil.get_path_from_URI(MainActivity.this, image_uri);
+ // predict image
+ predict_image(image_path);
+ break;
+ }
+ }
+ }
+
+ // predict image
+ private void predict_image(String image_path) {
+ // picture to float array
+ Bitmap bmp = PhotoUtil.getScaleBitmap(image_path);
+ Bitmap rgba = bmp.copy(Bitmap.Config.ARGB_8888, true);
+
+ // resize to 227x227
+ Bitmap input_bmp = Bitmap.createScaledBitmap(rgba, ddims[2], ddims[3], false);
+ try {
+ // Data format conversion takes too long
+ // Log.d("inputData", Arrays.toString(inputData));
+ long start = System.currentTimeMillis();
+ // get predict result
+ float[] result = squeezencnn.Detect(input_bmp);
+ long end = System.currentTimeMillis();
+ Log.d(TAG, "origin predict result:" + Arrays.toString(result));
+ long time = end - start; Log.d("result length", String.valueOf(result.length));
+ // show predict result and time
+ int r = get_max_result(result);
+ String show_text = "result:" + r + "\nname:" + resultLabel.get(r) + "\nprobability:" + result[r] + "\ntime:" + time + "ms";
+ result_text.setText(show_text);
+ } catch (Exception e) {
+ e.printStackTrace();
+ }
+ }
+
+ // get max probability label
+ private int get_max_result(float[] result) {
+ float probability = result[0];
+ int r = 0;
+ for (int i = 0; i < result.length; i++) {
+ if (probability < result[i]) {
+ probability = result[i];
+ r = i;
+ }
+ }
+ return r;
+ }
+
+ // request permissions
+ private void request_permissions() {
+ List permissionList = new ArrayList<>();
+ if (ContextCompat.checkSelfPermission(this, Manifest.permission.CAMERA) != PackageManager.PERMISSION_GRANTED) {
+ permissionList.add(Manifest.permission.CAMERA);
+ }
+
+ if (ContextCompat.checkSelfPermission(this, Manifest.permission.WRITE_EXTERNAL_STORAGE) != PackageManager.PERMISSION_GRANTED) {
+ permissionList.add(Manifest.permission.WRITE_EXTERNAL_STORAGE);
+ }
+
+ if (ContextCompat.checkSelfPermission(this, Manifest.permission.READ_EXTERNAL_STORAGE) != PackageManager.PERMISSION_GRANTED) {
+ permissionList.add(Manifest.permission.READ_EXTERNAL_STORAGE);
+ }
+
+ // if list is not empty will request permissions
+ if (!permissionList.isEmpty()) {
+ ActivityCompat.requestPermissions(this, permissionList.toArray(new String[permissionList.size()]), 1);
+ }
+ }
+
+ @Override
+ public void onRequestPermissionsResult(int requestCode, @NonNull String[] permissions, @NonNull int[] grantResults) {
+ super.onRequestPermissionsResult(requestCode, permissions, grantResults);
+ switch (requestCode) {
+ case 1:
+ if (grantResults.length > 0) {
+ for (int i = 0; i < grantResults.length; i++) {
+ int grantResult = grantResults[i];
+ if (grantResult == PackageManager.PERMISSION_DENIED) {
+ String s = permissions[i];
+ Toast.makeText(this, s + " permission was denied", Toast.LENGTH_SHORT).show();
+ }
+ }
+ }
+ break;
+ }
+ }
+}
+```
+
+(7)在项目的包com.example.ncnn1下,创建一个NcnnJni.java类,用于提供JNI接口,代码如下:
+
+```java
+package com.example.ncnn1;
+
+import android.graphics.Bitmap;
+
+public class NcnnJni {
+ public native boolean Init(byte[] param, byte[] bin);
+ public native float[] Detect(Bitmap bitmap);
+
+ static {
+ System.loadLibrary("ncnn_jni");
+ }
+}
+```
+
+(8)在项目的包com.example.ncnn1下,创建一个PhotoUtil.java类,这个是图片的工具类,代码如下:
+
+```java
+package com.example.ncnn1;
+
+import android.app.Activity;
+import android.content.Context;
+import android.content.Intent;
+import android.database.Cursor;
+import android.graphics.Bitmap;
+import android.graphics.BitmapFactory;
+import android.net.Uri;
+import android.provider.MediaStore;
+import java.nio.FloatBuffer;
+
+public class PhotoUtil {
+ // get picture in photo
+ public static void use_photo(Activity activity, int requestCode) {
+ Intent intent = new Intent(Intent.ACTION_PICK);
+ intent.setType("image/*");
+ activity.startActivityForResult(intent, requestCode);
+ }
+
+ // get photo from Uri
+ public static String get_path_from_URI(Context context, Uri uri) {
+ String result;
+ Cursor cursor = context.getContentResolver().query(uri, null, null, null, null);
+ if (cursor == null) {
+ result = uri.getPath();
+ } else {
+ cursor.moveToFirst();
+ int idx = cursor.getColumnIndex(MediaStore.Images.ImageColumns.DATA);
+ result = cursor.getString(idx);
+ cursor.close();
+ }
+ return result;
+ }
+
+ // compress picture
+ public static Bitmap getScaleBitmap(String filePath) {
+ BitmapFactory.Options opt = new BitmapFactory.Options();
+ opt.inJustDecodeBounds = true;
+ BitmapFactory.decodeFile(filePath, opt);
+
+ int bmpWidth = opt.outWidth;
+ int bmpHeight = opt.outHeight;
+
+ int maxSize = 500;
+
+ // compress picture with inSampleSize
+ opt.inSampleSize = 1;
+ while (true) {
+ if (bmpWidth / opt.inSampleSize < maxSize || bmpHeight / opt.inSampleSize < maxSize) {
+ break;
+ }
+ opt.inSampleSize *= 2;
+ }
+ opt.inJustDecodeBounds = false;
+ return BitmapFactory.decodeFile(filePath, opt);
+ }
+}
+```
+
+(9)修改启动页面的布局,修改如下:
+
+```xml
+
+
+
+
+
+
+
+
+
+
+
+
+```
+
+(10)修改APP目录下的CMakeLists.txt文件,修改如下:
+
+```
+# For more information about using CMake with Android Studio, read the
+# documentation: https://d.android.com/studio/projects/add-native-code.html
+
+# Sets the minimum version of CMake required to build the native library.
+
+cmake_minimum_required(VERSION 3.4.1)
+
+# Creates and names a library, sets it as either STATIC
+# or SHARED, and provides the relative paths to its source code.
+# You can define multiple libraries, and CMake builds them for you.
+# Gradle automatically packages shared libraries with your APK.
+set(ncnn_lib ${CMAKE_SOURCE_DIR}/src/main/jniLibs/armeabi-v7a/libncnn.a)
+add_library (ncnn_lib STATIC IMPORTED)
+set_target_properties(ncnn_lib PROPERTIES IMPORTED_LOCATION ${ncnn_lib})
+
+add_library( # Sets the name of the library.
+ ncnn_jni
+ # Sets the library as a shared library.
+ SHARED
+
+ # Provides a relative path to your source file(s).
+ src/main/cpp/ncnn_jni.cpp )
+
+# Searches for a specified prebuilt library and stores the path as a
+# variable. Because CMake includes system libraries in the search path by
+# default, you only need to specify the name of the public NDK library
+# you want to add. CMake verifies that the library exists before
+# completing its build.
+
+find_library( # Sets the name of the path variable.
+ log-lib
+
+ # Specifies the name of the NDK library that
+ # you want CMake to locate.
+ log )
+
+# Specifies libraries CMake should link to your target library. You
+# can link multiple libraries, such as libraries you define in this
+# build script, prebuilt third-party libraries, or system libraries.
+
+target_link_libraries( # Specifies the target library.
+ ncnn_jni
+ ncnn_lib
+ jnigraphics
+
+ # Links the target library to the log library
+ # included in the NDK.
+ ${log-lib} )
+```
+
+(11)修改APP目录下的build.gradle文件,修改如下:
+
+```
+apply plugin: 'com.android.application'
+
+android {
+ compileSdkVersion 28
+ defaultConfig {
+ applicationId "com.example.ncnn1"
+ minSdkVersion 21
+ targetSdkVersion 28
+ versionCode 1
+ versionName "1.0"
+ testInstrumentationRunner "android.support.test.runner.AndroidJUnitRunner"
+ externalNativeBuild {
+ cmake {
+ cppFlags "-std=c++11 -fopenmp"
+ abiFilters "armeabi-v7a"
+ }
+ }
+ }
+ buildTypes {
+ release {
+ minifyEnabled false
+ proguardFiles getDefaultProguardFile('proguard-android.txt'), 'proguard-rules.pro'
+ }
+ }
+ externalNativeBuild {
+ cmake {
+ path "CMakeLists.txt"
+ }
+ }
+
+ sourceSets {
+ main {
+ jniLibs.srcDirs = ["src/main/jniLibs"]
+ jni.srcDirs = ['src/cpp']
+ }
+ }
+}
+
+dependencies {
+ implementation fileTree(dir: 'libs', include: ['*.jar'])
+ implementation 'com.android.support:appcompat-v7:28.0.0-rc02'
+ implementation 'com.android.support.constraint:constraint-layout:1.1.3'
+ testImplementation 'junit:junit:4.12'
+ implementation 'com.github.bumptech.glide:glide:4.3.1'
+ androidTestImplementation 'com.android.support.test:runner:1.0.2'
+ androidTestImplementation 'com.android.support.test.espresso:espresso-core:3.0.2'
+}
+```
+
+(12)最后在配置文件中添加权限
+
+```xml
+
+
+```
+
+(13)编译完成
\ No newline at end of file
diff --git "a/ch17_\346\250\241\345\236\213\345\216\213\347\274\251\343\200\201\345\212\240\351\200\237\345\217\212\347\247\273\345\212\250\347\253\257\351\203\250\347\275\262/img/ch17/readme.md" "b/ch17_\346\250\241\345\236\213\345\216\213\347\274\251\343\200\201\345\212\240\351\200\237\345\217\212\347\247\273\345\212\250\347\253\257\351\203\250\347\275\262/img/ch17/readme.md"
deleted file mode 100644
index f099ebf1..00000000
--- "a/ch17_\346\250\241\345\236\213\345\216\213\347\274\251\343\200\201\345\212\240\351\200\237\345\217\212\347\247\273\345\212\250\347\253\257\351\203\250\347\275\262/img/ch17/readme.md"
+++ /dev/null
@@ -1,2 +0,0 @@
-Add the corresponding chapter picture under img/ch*
-��img/ch*�����Ӷ�Ӧ�½�ͼƬ
\ No newline at end of file
diff --git "a/ch17_\346\250\241\345\236\213\345\216\213\347\274\251\343\200\201\345\212\240\351\200\237\345\217\212\347\247\273\345\212\250\347\253\257\351\203\250\347\275\262/img/ch17/tensorRT1.png" "b/ch17_\346\250\241\345\236\213\345\216\213\347\274\251\343\200\201\345\212\240\351\200\237\345\217\212\347\247\273\345\212\250\347\253\257\351\203\250\347\275\262/img/ch17/tensorRT1.png"
new file mode 100644
index 00000000..7815e336
Binary files /dev/null and "b/ch17_\346\250\241\345\236\213\345\216\213\347\274\251\343\200\201\345\212\240\351\200\237\345\217\212\347\247\273\345\212\250\347\253\257\351\203\250\347\275\262/img/ch17/tensorRT1.png" differ
diff --git "a/ch17_\346\250\241\345\236\213\345\216\213\347\274\251\343\200\201\345\212\240\351\200\237\345\217\212\347\247\273\345\212\250\347\253\257\351\203\250\347\275\262/img/ch17/tensorRT2.png" "b/ch17_\346\250\241\345\236\213\345\216\213\347\274\251\343\200\201\345\212\240\351\200\237\345\217\212\347\247\273\345\212\250\347\253\257\351\203\250\347\275\262/img/ch17/tensorRT2.png"
new file mode 100644
index 00000000..7ef0e49c
Binary files /dev/null and "b/ch17_\346\250\241\345\236\213\345\216\213\347\274\251\343\200\201\345\212\240\351\200\237\345\217\212\347\247\273\345\212\250\347\253\257\351\203\250\347\275\262/img/ch17/tensorRT2.png" differ
diff --git "a/ch17_\346\250\241\345\236\213\345\216\213\347\274\251\343\200\201\345\212\240\351\200\237\345\217\212\347\247\273\345\212\250\347\253\257\351\203\250\347\275\262/img/ch17/tensorRT3.png" "b/ch17_\346\250\241\345\236\213\345\216\213\347\274\251\343\200\201\345\212\240\351\200\237\345\217\212\347\247\273\345\212\250\347\253\257\351\203\250\347\275\262/img/ch17/tensorRT3.png"
new file mode 100644
index 00000000..386e2bc8
Binary files /dev/null and "b/ch17_\346\250\241\345\236\213\345\216\213\347\274\251\343\200\201\345\212\240\351\200\237\345\217\212\347\247\273\345\212\250\347\253\257\351\203\250\347\275\262/img/ch17/tensorRT3.png" differ
diff --git "a/ch17_\346\250\241\345\236\213\345\216\213\347\274\251\343\200\201\345\212\240\351\200\237\345\217\212\347\247\273\345\212\250\347\253\257\351\203\250\347\275\262/img/ch17/\344\275\216\347\247\251\345\210\206\350\247\243\346\250\241\345\236\213\345\216\213\347\274\251\345\212\240\351\200\237.jpg" "b/ch17_\346\250\241\345\236\213\345\216\213\347\274\251\343\200\201\345\212\240\351\200\237\345\217\212\347\247\273\345\212\250\347\253\257\351\203\250\347\275\262/img/ch17/\344\275\216\347\247\251\345\210\206\350\247\243\346\250\241\345\236\213\345\216\213\347\274\251\345\212\240\351\200\237.jpg"
new file mode 100644
index 00000000..ef19bc31
Binary files /dev/null and "b/ch17_\346\250\241\345\236\213\345\216\213\347\274\251\343\200\201\345\212\240\351\200\237\345\217\212\347\247\273\345\212\250\347\253\257\351\203\250\347\275\262/img/ch17/\344\275\216\347\247\251\345\210\206\350\247\243\346\250\241\345\236\213\345\216\213\347\274\251\345\212\240\351\200\237.jpg" differ
diff --git "a/ch17_\346\250\241\345\236\213\345\216\213\347\274\251\343\200\201\345\212\240\351\200\237\345\217\212\347\247\273\345\212\250\347\253\257\351\203\250\347\275\262/img/ch17/\345\211\252\346\236\235\347\262\222\345\272\246\345\210\206\347\261\273.png" "b/ch17_\346\250\241\345\236\213\345\216\213\347\274\251\343\200\201\345\212\240\351\200\237\345\217\212\347\247\273\345\212\250\347\253\257\351\203\250\347\275\262/img/ch17/\345\211\252\346\236\235\347\262\222\345\272\246\345\210\206\347\261\273.png"
new file mode 100644
index 00000000..5a940cae
Binary files /dev/null and "b/ch17_\346\250\241\345\236\213\345\216\213\347\274\251\343\200\201\345\212\240\351\200\237\345\217\212\347\247\273\345\212\250\347\253\257\351\203\250\347\275\262/img/ch17/\345\211\252\346\236\235\347\262\222\345\272\246\345\210\206\347\261\273.png" differ
diff --git "a/ch17_\346\250\241\345\236\213\345\216\213\347\274\251\343\200\201\345\212\240\351\200\237\345\217\212\347\247\273\345\212\250\347\253\257\351\203\250\347\275\262/img/ch17/\347\275\221\347\273\234\350\222\270\351\246\217.png" "b/ch17_\346\250\241\345\236\213\345\216\213\347\274\251\343\200\201\345\212\240\351\200\237\345\217\212\347\247\273\345\212\250\347\253\257\351\203\250\347\275\262/img/ch17/\347\275\221\347\273\234\350\222\270\351\246\217.png"
new file mode 100644
index 00000000..f7335726
Binary files /dev/null and "b/ch17_\346\250\241\345\236\213\345\216\213\347\274\251\343\200\201\345\212\240\351\200\237\345\217\212\347\247\273\345\212\250\347\253\257\351\203\250\347\275\262/img/ch17/\347\275\221\347\273\234\350\222\270\351\246\217.png" differ
diff --git "a/ch17_\346\250\241\345\236\213\345\216\213\347\274\251\343\200\201\345\212\240\351\200\237\345\217\212\347\247\273\345\212\250\347\253\257\351\203\250\347\275\262/\347\254\254\345\215\201\344\270\203\347\253\240_\346\250\241\345\236\213\345\216\213\347\274\251\343\200\201\345\212\240\351\200\237\345\217\212\347\247\273\345\212\250\347\253\257\351\203\250\347\275\262.md" "b/ch17_\346\250\241\345\236\213\345\216\213\347\274\251\343\200\201\345\212\240\351\200\237\345\217\212\347\247\273\345\212\250\347\253\257\351\203\250\347\275\262/\347\254\254\345\215\201\344\270\203\347\253\240_\346\250\241\345\236\213\345\216\213\347\274\251\343\200\201\345\212\240\351\200\237\345\217\212\347\247\273\345\212\250\347\253\257\351\203\250\347\275\262.md"
index 84aaef64..6b5c3344 100644
--- "a/ch17_\346\250\241\345\236\213\345\216\213\347\274\251\343\200\201\345\212\240\351\200\237\345\217\212\347\247\273\345\212\250\347\253\257\351\203\250\347\275\262/\347\254\254\345\215\201\344\270\203\347\253\240_\346\250\241\345\236\213\345\216\213\347\274\251\343\200\201\345\212\240\351\200\237\345\217\212\347\247\273\345\212\250\347\253\257\351\203\250\347\275\262.md"
+++ "b/ch17_\346\250\241\345\236\213\345\216\213\347\274\251\343\200\201\345\212\240\351\200\237\345\217\212\347\247\273\345\212\250\347\253\257\351\203\250\347\275\262/\347\254\254\345\215\201\344\270\203\347\253\240_\346\250\241\345\236\213\345\216\213\347\274\251\343\200\201\345\212\240\351\200\237\345\217\212\347\247\273\345\212\250\347\253\257\351\203\250\347\275\262.md"
@@ -4,93 +4,194 @@
# 第十七章 模型压缩及移动端部署
- Markdown Revision 1;
- Date: 2018/11/4
- Editor: 谈继勇
- Contact: scutjy2015@163.com
- updata:贵州大学硕士张达峰
+ 深度神经网络在人工智能的应用中,包括语音识别、计算机视觉、自然语言处理等各方面,在取得巨大成功的同时,这些深度神经网络需要巨大的计算开销和内存开销,严重阻碍了资源受限下的使用。本章总结了模型压缩、加速一般原理和方法,以及在移动端如何部署。
-## 17.1 为什么需要模型压缩和加速?
-(1)随着AI技术的飞速发展,越来越多的公司希望在自己的移动端产品中注入AI能力
+## 17.1 模型压缩理解
+
+ 模型压缩是指利用数据集对已经训练好的深度模型进行精简,进而得到一个轻量且准确率相当的网络,压缩后的网络具有更小的结构和更少的参数,可以有效降低计算和存储开销,便于部署再受限的硬件环境中。
+
+## 17.2 为什么需要模型压缩和加速?
+
+(1)随着AI技术的飞速发展,越来越多的公司希望在自己的移动端产品中注入AI能力。
(2)对于在线学习和增量学习等实时应用而言,如何减少含有大量层级及结点的大型神经网络所需要的内存和计算量显得极为重要。
-(3)智能设备的流行提供了内存、CPU、能耗和宽带等资源,使得深度学习模型部署在智能移动设备上变得可行。
-(4)高效的深度学习方法可以有效的帮助嵌入式设备、分布式系统完成复杂工作,在移动端部署深度学习有很重要的意义。
+(3)模型的参数在一定程度上能够表达其复杂性,相关研究表明,并不是所有的参数都在模型中发挥作用,部分参数作用有限、表达冗余,甚至会降低模型的性能。
+
+(4)复杂的模型固然具有更好的性能,但是高额的存储空间、计算资源消耗是使其难以有效的应用在各硬件平台上的重要原因。
+
+(5)智能设备的流行提供了内存、CPU、能耗和宽带等资源,使得深度学习模型部署在智能移动设备上变得可行。
+(6)高效的深度学习方法可以有效的帮助嵌入式设备、分布式系统完成复杂工作,在移动端部署深度学习有很重要的意义。
+
+## 17.3 模型压缩的必要性及可行性
+
+| 必要性 | 首先是资源受限,其次在许多网络结构中,如VGG-16网络,参数数量1亿3千多万,占用500MB空间,需要进行309亿次浮点运算才能完成一次图像识别任务。 |
+| -------- | ------------------------------------------------------------ |
+| 可行性 | 模型的参数在一定程度上能够表达其复杂性,相关研究表明,并不是所有的参数都在模型中发挥作用,部分参数作用有限、表达冗余,甚至会降低模型的性能。论文提出,很多的深度神经网络仅仅使用很少一部分(5%)权值就足以预测剩余的权值。该论文还提出这些剩下的权值甚至可以直接不用被学习。也就是说,仅仅训练一小部分原来的权值参数就有可能达到和原来网络相近甚至超过原来网络的性能(可以看作一种正则化)。 |
+| 最终目的 | 最大程度的减小模型复杂度,减少模型存储需要的空间,也致力于加速模型的训练和推测 |
+
+## 17.4 目前有哪些深度学习模型压缩方法?
+
+ 目前深度学习模型压缩方法主要分为更精细化模型设计、模型裁剪、核的稀疏化、量化、低秩分解、迁移学习等方法,而这些方法又可分为前端压缩和后端压缩。
+
+### 17.4.1 前端压缩和后端压缩对比
+
+| 对比项目 | 前端压缩 | 后端压缩 |
+| :--------: | :--------------------------------------------: | :------------------------------------------: |
+| 含义 | 不会改变原始网络结构的压缩技术 | 会大程度上改变原始网络结构的压缩技术 |
+| 主要方法 | 知识蒸馏、紧凑的模型结构设计、滤波器层面的剪枝 | 低秩近似、未加限制的剪枝、参数量化、二值网络 |
+| 实现难度 | 较简单 | 较难 |
+| 是否可逆 | 可逆 | 不可逆 |
+| 成熟应用 | 剪枝 | 低秩近似、参数量化 |
+| 待发展应用 | 知识蒸馏 | 二值网络 |
+
+### 17.4.2 网络剪枝
+
+深度学习模型因其**稀疏性**,可以被裁剪为结构精简的网络模型,具体包括结构性剪枝与非结构性剪枝。
+
+| 事项 | 特点 | 举例 |
+| ------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 非结构化剪枝 | 通常是连接级、细粒度的剪枝方法,精度相对较高,但依赖于特定算法库或硬件平台的支持 | Deep Compression [5], Sparse-Winograd [6] 算法等; |
+| 结构化剪枝 | 是filter级或layer级、粗粒度的剪枝方法,精度相对较低,但剪枝策略更为有效,不需要特定算法库或硬件平台的支持,能够直接在成熟深度学习框架上运行。 | 如局部方式的、通过layer by layer方式的、最小化输出FM重建误差的Channel Pruning [7], ThiNet [8], Discrimination-aware Channel Pruning [9];全局方式的、通过训练期间对BN层Gamma系数施加L1正则约束的Network Slimming [10];全局方式的、按Taylor准则对Filter作重要性排序的Neuron Pruning [11];全局方式的、可动态重新更新pruned filters参数的剪枝方法 [12];
https://blog.csdn.net/baidu_31437863/article/details/84474847 |
+
+如果按剪枝粒度分,从粗到细,可分为中间隐含层剪枝、通道剪枝、卷积核剪枝、核内剪枝、单个权重剪枝。下面按照剪枝粒度的分类从粗(左)到细(右)。
+
+
+
+(a)层间剪枝 (b)特征图剪枝 (c)k*k核剪枝 (d)核内剪枝
+
+| 事项 | 特点 |
+| -------------------- | ------------------------------------------------------------ |
+| 单个权重粒度 | 早期 Le Cun[16]提出的 OBD(optimal brain damage)将网络中的任意权重参数都看作单个参数,能够有效地提高预测准确率,却不能减小运行时间;同时,剪枝代价过高,只适用于小网络 |
+| 核内权重粒度 | 网络中的任意权重被看作是单个参数并进行随机非结构化剪枝,该粒度的剪枝导致网络连接不规整,需要通过稀疏表达来减少内存占用,进而导致在前向传播预测时,需要大量的条件判断和额外空间来标明零或非零参数的位置,因此不适用于并行计算 |
+| 卷积核粒度与通道粒度 | 卷积核粒度与通道粒度属于粗粒度剪枝,不依赖任何稀疏卷积计算库及专用硬件;同时,能够在获得高压缩率的同时大量减小测试阶段的计算时间.由 |
+
+从剪枝目标上分类,可分为减少参数/网络复杂度、减少过拟合/增加泛化能力/提高准确率、减小部署运行时间/提高网络效率及减小训练时间等。
+
+### 17.4.3 典型剪枝方法对比
+
+| 剪枝方法 | 修剪对象 | 修剪方式 | 效果 |
+| :----------------: | :--------: | :---------------: | :----------: |
+| Deep Compression | 权重 | 随机修剪 | 50倍压缩 |
+| Structured Pruning | 权重 | 组稀疏+排他性稀疏 | 性能提升 |
+| Network Slimming | 特征图通道 | 根据尺度因子修剪 | 节省计算资源 |
+| mProp | 梯度 | 修剪幅值小的梯度 | 加速 |
+
+### 17.4.4 网络蒸馏
+
+ 网络精馏是指利用大量未标记的迁移数据(transfer data),让小模型去拟合大模型,从而让小模型学到与大模型相似的函数映射.网络精馏可以看成在同一个域上迁移学习[34]的一种特例,目的是获得一个比原模型更为精简的网络,整体的框架图如图 4所示.
+
+
+
+### 17.4.5 前端压缩
-## 17.2 目前有哪些深度学习模型压缩方法?
-https://blog.csdn.net/wspba/article/details/75671573
-https://blog.csdn.net/Touch_Dream/article/details/78441332
+(1)知识蒸馏
-### 17.2.1 前端压缩
-(1)知识蒸馏(简单介绍)
-一个复杂的模型可以认为是由多个简单模型或者强约束条件训练而来,具有很好的性能,但是参数量很大,计算效率低,而小模型计算效率高,但是其性能较差。知识蒸馏是让复杂模型学习到的知识迁移到小模型当中,使其保持其快速的计算速度前提下,同时拥有复杂模型的性能,达到模型压缩的目的。但与剪枝、量化等方法想比,效果较差。(https://blog.csdn.net/Lucifer_zzq/article/details/79489248)
-(2)紧凑的模型结构设计(简单介绍)
-紧凑的模型结构设计主要是对神经网络卷积的方式进行改进,比如使用两个3x3的卷积替换一个5x5的卷积、使用深度可分离卷积等等方式降低计算参数量。
-(3)滤波器层面的剪枝(简单介绍)
-参考链接 https://blog.csdn.net/JNingWei/article/details/79218745 补充优缺点
-滤波器层面的剪枝属于非结构花剪枝,主要是对较小的权重矩阵整个剔除,然后对整个神经网络进行微调。此方式由于剪枝过于粗放,容易导致精度损失较大,而且部分权重矩阵中会存留一些较小的权重造成冗余,剪枝不彻底。
-### 17.2.2 后端压缩
-(1)低秩近似 (简单介绍,参考链接补充优缺点)
-在卷积神经网络中,卷积运算都是以矩阵相乘的方式进行。对于复杂网络,权重矩阵往往非常大,非常消耗存储和计算资源。低秩近似就是用若干个低秩矩阵组合重构大的权重矩阵,以此降低存储和计算资源消耗。
-优点:
+ 一个复杂模型可由多个简单模型或者强约束条件训练得到。复杂模型特点是性能好,但其参数量大,计算效率低。小模型特点是计算效率高,但是其性能较差。知识蒸馏是让复杂模型学习到的知识迁移到小模型当中,使其保持其快速的计算速度前提下,同时拥有复杂模型的性能,达到模型压缩的目的。
+(2)紧凑的模型结构设计
+ 紧凑的模型结构设计主要是对神经网络卷积的方式进行改进,比如使用两个3x3的卷积替换一个5x5的卷积、使用深度可分离卷积等等方式降低计算参数量。 目前很多网络基于模块化设计思想,在深度和宽度两个维度上都很大,导致参数冗余。因此有很多关于模型设计的研究,如SqueezeNet、MobileNet等,使用更加细致、高效的模型设计,能够很大程度的减少模型尺寸,并且也具有不错的性能。
+(3)滤波器层面的剪枝
+ 滤波器层面的剪枝属于非结构花剪枝,主要是对较小的权重矩阵整个剔除,然后对整个神经网络进行微调。此方式由于剪枝过于粗放,容易导致精度损失较大,而且部分权重矩阵中会存留一些较小的权重造成冗余,剪枝不彻底。 具体操作是在训练时使用稀疏约束(加入权重的稀疏正则项,引导模型的大部分权重趋向于0)。完成训练后,剪去滤波器上的这些 0 。
-* 可以降低存储和计算消耗;
+ 优点是简单,缺点是剪得不干净,非结构化剪枝会增加内存访问成本。
-* 一般可以压缩2-3倍;精度几乎没有损失;
+### 17.4.6 后端压缩
+(1)低秩近似
+ 在卷积神经网络中,卷积运算都是以矩阵相乘的方式进行。对于复杂网络,权重矩阵往往非常大,非常消耗存储和计算资源。低秩近似就是用若干个低秩矩阵组合重构大的权重矩阵,以此降低存储和计算资源消耗。
-缺点:
+| 事项 | 特点 |
+| :--- | :----------------------------------------------------------- |
+| 优点 | 可以降低存储和计算消耗;
一般可以压缩2-3倍;精度几乎没有损失; |
+| 缺点 | 模型越复杂,权重矩阵越大,利用低秩近似重构参数矩阵不能保证模型的性能 ;
超参数的数量随着网络层数的增加呈线性变化趋势,例如中间层的特征通道数等等。
随着模型复杂度的提升,搜索空间急剧增大。 |
-* 模型越复杂,权重矩阵越大,利用低秩近似重构参数矩阵不能保证模型的性能
+(2)未加限制的剪枝
-(2)未加限制的剪枝 (简单介绍,参考链接补充优缺点)
-剪枝操作包括:非结构化剪枝和结构化剪枝。非结构化剪枝是对神经网络中权重较小的权重或者权重矩阵进剔除,然后对整个神经网络进行微调;结构化剪枝是在网络优化目标中加入权重稀疏正则项,使部分权重在训练时趋于0。
+ 完成训练后,不加限制地剪去那些冗余参数。
-优点:
+| 事项 | 特点 |
+| ---- | ------------------------------------------------------------ |
+| 优点 | 保持模型性能不损失的情况下,减少参数量9-11倍;
剔除不重要的权重,可以加快计算速度,同时也可以提高模型的泛化能力; |
+| 缺点 | 极度依赖专门的运行库和特殊的运行平台,不具有通用性;
压缩率过大时,破坏性能; |
-* 保持模型性能不损失的情况下,减少参数量9-11倍;
+(3)参数量化
-* 剔除不重要的权重,可以加快计算速度,同时也可以提高模型的泛化能力;
+ 神经网络的参数类型一般是32位浮点型,使用较小的精度代替32位所表示的精度。或者是将多个权重映射到同一数值,权重共享。**量化其实是一种权值共享的策略**。量化后的权值张量是一个高度稀疏的有很多共享权值的矩阵,对非零参数,我们还可以进行定点压缩,以获得更高的压缩率。
+| 事项 | 特点 |
+| ---- | ------------------------------------------------------------ |
+| 优点 | 模型性能损失很小,大小减少8-16倍; |
+| 缺点 | 压缩率大时,性能显著下降;
依赖专门的运行库,通用性较差; |
+| 举例 | 二值化网络:XNORnet [13], ABCnet with Multiple Binary Bases [14],
Bin-net with High-Order Residual Quantization [15], Bi-Real Net [16];
三值化网络:Ternary weight networks [17], Trained Ternary Quantization [18];
+W1-A8 或 W2-A8量化: Learning Symmetric Quantization [19];
+INT8量化:TensorFlow-lite [20], TensorRT [21];
+其他(非线性):Intel INQ [22], log-net, CNNPack [23] 等;
+原文:https://blog.csdn.net/baidu_31437863/article/details/84474847 |
+| 总结 | 最为典型就是二值网络、XNOR网络等。其主要原理就是采用1bit对网络的输入、权重、响应进行编码。减少模型大小的同时,原始网络的卷积操作可以被bit-wise运算代替,极大提升了模型的速度。但是,如果原始网络结果不够复杂(模型描述能力),由于二值网络会较大程度降低模型的表达能力。因此现阶段有相关的论文开始研究n-bit编码方式成为n值网络或者多值网络或者变bit、组合bit量化来克服二值网络表达能力不足的缺点。 |
-缺点:
+(4)二值网络
-* 非结构化剪枝会增加内存访问成本;
+ 相对量化更为极致,对于32bit浮点型数用1bit二进制数-1或者1表示,可大大减小模型尺寸。
-* 极度依赖专门的运行库和特殊的运行平台,不具有通用性;
+| 事项 | 特点 |
+| ---- | ------------------------------------------------------------ |
+| 优点 | 网络体积小,运算速度快,有时可避免部分网络的overfitting |
+| 缺点 | 二值神经网络损失的信息相对于浮点精度是非常大;
粗糙的二值化近似导致训练时模型收敛速度非常慢 |
-* 压缩率过大时,破坏性能;
+(5)三值网络
-(3)参数量化 (简单介绍,参考链接补充优缺点)
-神经网络的参数类型一般是32位浮点型,使用较小的精度代替32位所表示的精度。或者是将多个权重映射到同一数值,权重共享
-优点:
+| 事项 | 特点 |
+| ---- | ------------------------------------------------------------ |
+| 优点 | 相对于二值神经网络,三值神经网络(Ternary Weight Networks)在同样的模型结构下可以达到成百上千倍的表达能力提升;并且,在计算时间复杂度上,三元网络和二元网络的计算复杂度是一样的。
例如,对于ResNet-18层网络中最常出现的卷积核(3x3大小),二值神经网络模型最多可以表达2的3x3次方(=512)种结构,而三元神经网络则可以表达3的3x3次方(=19683)种卷积核结构。在表达能力上,三元神经网络相对要高19683/512 = 38倍。因此,三元神经网络模型能够在保证计算复杂度很低的情况下大幅的提高网络的表达能力,进而可以在精度上相对于二值神经网络有质的飞跃。另外,由于对中间信息的保存更多,三元神经网络可以极大的加快网络训练时的收敛速度,从而更快、更稳定的达到最优的结果。 |
+| | |
-* 模型性能损失很小,大小减少8-16倍;
+### 17.4.6 低秩分解
-缺点:
+基于低秩分解的深度神经网络压缩与加速的核心思想是利用矩阵或张量分解技术估计并分解深度模型中的原始卷积核.卷积计算是整个卷积神经网络中计算复杂 度 最 高 的 计 算 操 作,通 过 分 解4D 卷积核张量,可以有效地减少模型内部的冗余性.此外对于2D的全 连 接 层 矩 阵 参 数,同样可以利用低秩分解技术进行处理.但由于卷积层与全连接层的分解方式不同,本文分别从卷积层和全连接层2个不同角度回顾与分析低秩分解技术在深度神经网络中的应用.
-* 压缩率大时,性能显著下降;
+在2013年,Denil等人[57]从理论上利用低秩分解的技术并分析了深度神经网络存在大量的冗余信
+息,开创了基于低秩分解的深度网络模型压缩与加速的新思路.如图7所示,展示了主流的张量分解后卷积 计 算.
-* 依赖专门的运行库,通用性较差;
+
-(4)二值网络 (简单介绍,参考链接补充优缺点)
-对于32bit浮点型数用1bit二进制数-1或者1表示。
-优点:
+(出自《深度神经网络压缩与加速综述》)
-* 网络体积小,运算速度快
+### 17.4.7 总体压缩效果评价指标有哪些?
+ 网络压缩评价指标包括运行效率、参数压缩率、准确率.与基准模型比较衡量性能提升时,可以使用提升倍数(speedup)或提升比例(ratio)。
-目前深度学习模型压缩方法的研究主要可以分为以下几个方向:
-(1)更精细模型的设计。目前很多网络基于模块化设计思想,在深度和宽度两个维度上都很大,导致参数冗余。因此有很多关于模型设计的研究,如SqueezeNet、MobileNet等,使用更加细致、高效的模型设计,能够很大程度的减少模型尺寸,并且也具有不错的性能。
-(2)模型裁剪。结构复杂的网络具有非常好的性能,其参数也存在冗余,因此对于已训练好的模型网络,可以寻找一种有效的评判手段,将不重要的connection或者filter进行裁剪来减少模型的冗余。
-(3)核的稀疏化。在训练过程中,对权重的更新进行诱导,使其更加稀疏,对于稀疏矩阵,可以使用更加紧致的存储方式,如CSC,但是使用稀疏矩阵操作在硬件平台上运算效率不高,容易受到带宽的影响,因此加速并不明显。
-(4)量化
-(5)Low-rank分解
-(6)迁移学习
+| 评价指标 | 特点 |
+| ---------- | ------------------------------------------------------------ |
+| 准确率 | 目前,大部分研究工作均会测量 Top-1 准确率,只有在 ImageNet 这类大型数据集上才会只用 Top-5 准确率.为方便比较 |
+| 参数压缩率 | 统计网络中所有可训练的参数,根据机器浮点精度转换为字节(byte)量纲,通常保留两位有效数字以作近似估计. |
+| 运行效率 | 可以从网络所含浮点运算次数(FLOP)、网络所含乘法运算次数(MULTS)或随机实验测得的网络平均前向传播所需时间这 3 个角度来评价 |
+### 17.4.8 几种轻量化网络结构对比
+
+| 网络结构 | TOP1 准确率/% | 参数量/M | CPU运行时间/ms |
+| :---------------: | :-----------: | :------: | :------------: |
+| MobileNet V1 | 70.6 | 4.2 | 123 |
+| ShuffleNet(1.5) | 69.0 | 2.9 | - |
+| ShuffleNet(x2) | 70.9 | 4.4 | - |
+| MobileNet V2 | 71.7 | 3.4 | 80 |
+| MobileNet V2(1.4) | 74.7 | 6.9 | 149 |
+
+### 17.4.9 网络压缩未来研究方向有哪些?
+
+网络剪枝、网络精馏和网络分解都能在一定程度上实现网络压缩的目的.回归到深度网络压缩的本质目的上,即提取网络中的有用信息,以下是一些值得研究和探寻的方向.
+(1) 权重参数对结果的影响度量.深度网络的最终结果是由全部的权重参数共同作用形成的,目前,关于单个卷积核/卷积核权重的重要性的度量仍然是比较简单的方式,尽管文献[14]中给出了更为细节的分析,但是由于计算难度大,并不实用.因此,如何通过更有效的方式来近似度量单个参数对模型的影响,具有重要意义.
+(2) 学生网络结构的构造.学生网络的结构构造目前仍然是由人工指定的,然而,不同的学生网络结构的训练难度不同,最终能够达到的效果也有差异.因此,如何根据教师网络结构设计合理的网络结构在精简模型的条件下获取较高的模型性能,是未来的一个研究重点.
+(3) 参数重建的硬件架构支持.通过分解网络可以无损地获取压缩模型,在一些对性能要求高的场景中是非常重要的.然而,参数的重建步骤会拖累预测阶段的时间开销,如何通过硬件的支持加速这一重建过程,将是未来的一个研究方向.
+(4) 任务或使用场景层面的压缩.大型网络通常是在量级较大的数据集上训练完成的,比如,在 ImageNet上训练的模型具备对 1 000 类物体的分类,但在一些具体场景的应用中,可能仅需要一个能识别其中几类的小型模型.因此,如何从一个全功能的网络压缩得到部分功能的子网络,能够适应很多实际应用场景的需求.
+(5) 网络压缩效用的评价.目前,对各类深度网络压缩算法的评价是比较零碎的,侧重于和被压缩的大型网络在参数量和运行时间上的比较.未来的研究可以从提出更加泛化的压缩评价标准出发,一方面平衡运行速度和模型大小在不同应用场景下的影响;另一方面,可以从模型本身的结构性出发,对压缩后的模型进行评价.
+
+(出自《深度网络模型压缩综述》)
+
+## 17.5 目前有哪些深度学习模型优化加速方法?
-## 17.3 目前有哪些深度学习模型优化加速方法?
https://blog.csdn.net/nature553863/article/details/81083955
+
+### 17.5.1 模型优化加速方法
+
模型优化加速能够提升网络的计算效率,具体包括:
(1)Op-level的快速算法:FFT Conv2d (7x7, 9x9), Winograd Conv2d (3x3, 5x5) 等;
(2)Layer-level的快速算法:Sparse-block net [1] 等;
@@ -98,38 +199,109 @@ https://blog.csdn.net/nature553863/article/details/81083955
原文:https://blog.csdn.net/nature553863/article/details/81083955
-## 17.4 影响神经网络速度的4个因素(再稍微详细一点)
+### 17.5.2 TensorRT加速原理
+
+https://blog.csdn.net/xh_hit/article/details/79769599
+
+ 在计算资源并不丰富的嵌入式设备上,TensorRT之所以能加速神经网络的的推断主要得益于两点:
+
+- 首先是TensorRT支持int8和fp16的计算,通过在减少计算量和保持精度之间达到一个理想的trade-off,达到加速推断的目的。
+
+- 更为重要的是TensorRT对于网络结构进行了重构和优化,主要体现在一下几个方面。
+
+ (1) TensorRT通过解析网络模型将网络中无用的输出层消除以减小计算。
+
+ (2) 对于网络结构的垂直整合,即将目前主流神经网络的Conv、BN、Relu三个层融合为了一个层,例如将图1所示的常见的Inception结构重构为图2所示的网络结构。
+
+ (3) 对于网络结构的水平组合,水平组合是指将输入为相同张量和执行相同操作的层融合一起,例如图2向图3的转化。
+
+
+
+
+
+
+
+ 以上3步即是TensorRT对于所部署的深度学习网络的优化和重构,根据其优化和重构策略,第一和第二步适用于所有的网络架构,但是第三步则对于含有Inception结构的神经网络加速效果最为明显。
+
+ Tips: 想更好地利用TensorRT加速网络推断,可在基础网络中多采用Inception模型结构,充分发挥TensorRT的优势。
+
+### 17.5.3 TensorRT如何优化重构模型?
+
+| 条件 | 方法 |
+| ---------------------------------------- | ------------------------------------------------------------ |
+| 若训练的网络模型包含TensorRT支持的操作 | 1、对于Caffe与TensorFlow训练的模型,若包含的操作都是TensorRT支持的,则可以直接由TensorRT优化重构 |
+| | 2、对于MXnet, PyTorch或其他框架训练的模型,若包含的操作都是TensorRT支持的,可以采用TensorRT API重建网络结构,并间接优化重构; |
+| 若训练的网络模型包含TensorRT不支持的操作 | 1、TensorFlow模型可通过tf.contrib.tensorrt转换,其中不支持的操作会保留为TensorFlow计算节点; |
+| | 2、不支持的操作可通过Plugin API实现自定义并添加进TensorRT计算图; |
+| | 3、将深度网络划分为两个部分,一部分包含的操作都是TensorRT支持的,可以转换为TensorRT计算图。另一部则采用其他框架实现,如MXnet或PyTorch; |
+
+### 17.5.4 TensorRT加速效果如何?
+
+以下是在TitanX (Pascal)平台上,TensorRT对大型分类网络的优化加速效果:
+
+| Network | Precision | Framework/GPU:TitanXP | Avg.Time(Batch=8,unit:ms) | Top1 Val.Acc.(ImageNet-1k) |
+| :-------: | :-------: | :-------------------: | :-----------------------: | :------------------------: |
+| Resnet50 | fp32 | TensorFlow | 24.1 | 0.7374 |
+| Resnet50 | fp32 | MXnet | 15.7 | 0.7374 |
+| Resnet50 | fp32 | TRT4.0.1 | 12.1 | 0.7374 |
+| Resnet50 | int8 | TRT4.0.1 | 6 | 0.7226 |
+| Resnet101 | fp32 | TensorFlow | 36.7 | 0.7612 |
+| Resnet101 | fp32 | MXnet | 25.8 | 0.7612 |
+| Resnet101 | fp32 | TRT4.0.1 | 19.3 | 0.7612 |
+| Resnet101 | int8 | TRT4.0.1 | 9 | 0.7574 |
+
+## 17.6 影响神经网络速度的4个因素(再稍微详细一点)
1. FLOPs(FLOPs就是网络执行了多少multiply-adds操作);
+
2. MAC(内存访问成本);
+
3. 并行度(如果网络并行度高,速度明显提升);
+
4. 计算平台(GPU,ARM)
-## 17.5 改变网络结构设计为什么会实现模型压缩、加速?
-### 1. Group convolution
-Group convolution最早出现在AlexNet中,是为了解决单卡显存不够,将网络部署到多卡上进行训练。Group convolution可以减少单个卷积1/g的参数量。
-假设输入特征的的维度为H \* W \* c1;卷积核的维度为h1 \* w1 \* c1,共c2个;输出特征的维度为 H1 \* W1 \* c2。
+
+
+## 17.7 压缩和加速方法如何选择?
+
+ 1)对于在线计算内存存储有限的应用场景或设备,可以选择参数共享和参数剪枝方法,特别是二值量化权值和激活、结构化剪枝.其他方法虽然能够有效的压缩模型中的权值参数,但无法减小计算中隐藏的内存大小(如特征图).
+ 2)如果在应用中用到的紧性模型需要利用预训练模型,那么参数剪枝、参数共享以及低秩分解将成为首要考虑的方法.相反地,若不需要借助预训练模型,则可以考虑紧性滤波设计及知识蒸馏方法.
+ 3)若需要一次性端对端训练得到压缩与加速后模型,可以利用基于紧性滤波设计的深度神经网络压缩与加速方法.
+ 4)一般情况下,参数剪枝,特别是非结构化剪枝,能大大压缩模型大小,且不容易丢失分类精度.对于需要稳定的模型分类的应用,非结构化剪枝成为首要选择.
+ 5)若采用的数据集较小时,可以考虑知识蒸馏方法.对于小样本的数据集,学生网络能够很好地迁移教师模型的知识,提高学生网络的判别性.
+ 6)主流的5个深度神经网络压缩与加速算法相互之间是正交的,可以结合不同技术进行进一步的压缩与加速.如:韩 松 等 人[30]结合了参数剪枝和参数共享;温伟等人[64]以及 Alvarez等人[85]结合了参数剪枝和低秩分解.此外对于特定的应用场景,如目标检测,可以对卷积层和全连接层使用不同的压缩与加速技术分别处理.
+
+参考《深度神经网络压缩与加速综述》
+
+## 17.8 改变网络结构设计为什么会实现模型压缩、加速?
+### 17.8.1 Group convolution
+ Group convolution最早出现在AlexNet中,是为了解决单卡显存不够,将网络部署到多卡上进行训练而提出。Group convolution可以减少单个卷积1/g的参数量。如何计算的呢?
+
+ 假设
+
+- 输入特征的的维度为$H*W*C_1$;
+- 卷积核的维度为$H_1*W_1*C_1$,共$C_2$个;
+- 输出特征的维度为$H_1*W_1*C_2$ 。
+
传统卷积计算方式如下:

传统卷积运算量为:
-
-```math
-A = H * W * h1 * w1 * c1 * c2
-```
+$$
+A = H*W * h1 * w1 * c1 * c2
+$$
Group convolution是将输入特征的维度c1分成g份,每个group对应的channel数为c1/g,特征维度H \* W \* c1/g;,每个group对应的卷积核的维度也相应发生改变为h1 \* w1 \* c1/9,共c2/g个;每个group相互独立运算,最后将结果叠加在一起。
Group convolution计算方式如下:

Group convolution运算量为:
-
-```math
+$$
B = H * W * h1 * w1 * c1/g * c2/g * g
-```
+$$
Group卷积相对于传统卷积的运算量:
-```math
+$$
\dfrac{B}{A} = \dfrac{ H * W * h1 * w1 * c1/g * c2/g * g}{H * W * h1 * w1 * c1 * c2} = \dfrac{1}{g}
-```
+$$
由此可知:group卷积相对于传统卷积减少了1/g的参数量。
-### 2. Depthwise separable convolution
+### 17.8.2. Depthwise separable convolution
Depthwise separable convolution是由depthwise conv和pointwise conv构成。
depthwise conv(DW)有效减少参数数量并提升运算速度。但是由于每个feature map只被一个卷积核卷积,因此经过DW输出的feature map不能只包含输入特征图的全部信息,而且特征之间的信息不能进行交流,导致“信息流通不畅”。
pointwise conv(PW)实现通道特征信息交流,解决DW卷积导致“信息流通不畅”的问题。
@@ -137,67 +309,70 @@ pointwise conv(PW)实现通道特征信息交流,解决DW卷积导致“信息
传统卷积计算方式如下:

传统卷积运算量为:
-```math
+$$
A = H * W * h1 * w1 * c1 * c2
-```
+$$
DW卷积的计算方式如下:

DW卷积运算量为:
-```math
+$$
B_DW = H * W * h1 * w1 * 1 * c1
-```
+$$
PW卷积的计算方式如下:

-```math
-B_PW = H_m * W_m * 1 * 1 * c1 * c2
-```
+
+$$
+B_PW = H_m * W_m * 1 * 1 * c_1 * c_2
+$$
Depthwise separable convolution运算量为:
-```math
-B = B_DW + B_PW
-```
+$$
+B = B_DW + B_PW
+$$
Depthwise separable convolution相对于传统卷积的运算量:
-```math
-\dfrac{B}{A} = \dfrac{ H * W * h1 * w1 * 1 * c1 + H_m * W_m * 1 * 1 * c1 * c2}{H * W * h1 * w1 * c1 * c2}
+$$
+\dfrac{B}{A} = \dfrac{ H * W * h_1 * w_1 * 1 * c_1 + H_m * W_m * 1 * 1 * c_1 * c_2}{H * W * h1 * w1 * c_1 * c_2}
-= \dfrac{1}{c2} + \dfrac{1}{h1 * w1}
-```
+= \dfrac{1}{c_2} + \dfrac{1}{h_1 * w_1}
+$$
由此可知,随着卷积通道数的增加,Depthwise separable convolution的运算量相对于传统卷积更少。
-### 3. 输入输出的channel相同时,MAC最小
+### 17.8.3 输入输出的channel相同时,MAC最小
**卷积层的输入和输出特征通道数相等时MAC最小,此时模型速度最快。**
-假设feature map的大小为h*w,输入通道c1,输出通道c2。
+假设feature map的大小为h*w,输入通道$c_1$,输出通道$c_2$。
已知:
-```math
-FLOPs = B = h * w * c1 * c2
-
-=> c1 * c2 = \dfrac{B}{h * w}
+$$
+FLOPs = B = h * w * c1 * c2
+=> c1 * c2 = \dfrac{B}{h * w}
+$$
-MAC = h * w * (c1 + c2) + c1 * c2
+$$
+MAC = h * w * (c1 + c2) + c1 * c2
+$$
-c1 + c2 \geq 2 * \sqrt{c1 * c2}
+$$
+=> MAC \geq 2 * h * w \sqrt{\dfrac{B}{h * w}} + \dfrac{B}{h * w}
+$$
-=> MAC \geq 2 * h * w \sqrt{\dfrac{B}{h * w}} + \dfrac{B}{h * w}
-```
根据均值不等式得到(c1-c2)^2>=0,等式成立的条件是c1=c2,也就是输入特征通道数和输出特征通道数相等时,在给定FLOPs前提下,MAC达到取值的下界。
-### 4. 减少组卷积的数量
+### 17.8.4 减少组卷积的数量
**过多的group操作会增大MAC,从而使模型速度变慢**
由以上公式可知,group卷积想比与传统的卷积可以降低计算量,提高模型的效率;如果在相同的FLOPs时,group卷积为了满足FLOPs会是使用更多channels,可以提高模型的精度。但是随着channel数量的增加,也会增加MAC。
FLOPs:
-```math
+$$
B = \dfrac{h * w * c1 * c2}{g}
-```
+$$
MAC:
-```math
+$$
MAC = h * w * (c1 + c2) + \dfrac{c1 * c2}{g}
-```
+$$
由MAC,FLOPs可知:
-```math
+$$
MAC = h * w * c1 + \dfrac{B*g}{c1} + \dfrac{B}{h * w}
-```
+$$
当FLOPs固定(B不变)时,g越大,MAC越大。
-### 5. 减少网络碎片化程度(分支数量)
+### 17.8.5 减少网络碎片化程度(分支数量)
**模型中分支数量越少,模型速度越快**
此结论主要是由实验结果所得。
以下为网络分支数和各分支包含的卷积数目对神经网络速度的影响。
@@ -206,19 +381,14 @@ MAC = h * w * c1 + \dfrac{B*g}{c1} + \dfrac{B}{h * w}

由实验结果可知,随着网络分支数量的增加,神经网络的速度在降低。网络碎片化程度对GPU的影响效果明显,对CPU不明显,但是网络速度同样在降低。
-### 6. 减少元素级操作
+### 17.8.7 减少元素级操作
**元素级操作所带来的时间消耗也不能忽视**
ReLU ,Tensor 相加,Bias相加的操作,分离卷积(depthwise convolution)都定义为元素级操作。
FLOPs大多数是对于卷积计算而言的,因为元素级操作的FLOPs相对要低很多。但是过的元素级操作也会带来时间成本。ShuffleNet作者对ShuffleNet v1和MobileNet v2的几种层操作的时间消耗做了分析,发现元素级操作对于网络速度的影响也很大。

-## 17.6 常用的轻量级网络有哪些?(再琢磨下语言和排版)
-* **SqueezeNet**
-* **MobileNet**
-* **ShuffleNet**
-* **Xception**
-
-### 1. SequeezeNet
+## 17.9 常用的轻量级网络有哪些?
+### 17.9.1 SequeezeNet
SqueenzeNet出自F. N. Iandola, S.Han等人发表的论文《SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and < 0.5MB model size》,作者在保证精度不损失的同时,将原始AlexNet压缩至原来的510倍。
#### 1.1 设计思想
在网络结构设计方面主要采取以下三种方式:
@@ -233,12 +403,13 @@ SqueezeNet提出一种多分支结构——fire model,其中是由Squeeze层

SqueezeNet整体网络结构如下图所示:

+
#### 1.3实验结果
不同压缩方法在ImageNet上的对比实验结果

由实验结果可知,SqueezeNet不仅保证了精度,而且将原始AlexNet从240M压缩至4.8M,压缩50倍,说明此轻量级网络设计是可行。
-### 2. MobileNet
+### 17.9.2 MobileNet
MobileNet 是Google团队于CVPR-2017的论文《MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications》中针对手机等嵌入式设备提出的一种轻量级的深层神经网络,该网络结构在VGG的基础上使用DW+PW的组合,在保证不损失太大精度的同时,降低模型参数量。
#### 2.1 设计思想
* 采用深度可分离卷积代替传统卷积
@@ -263,7 +434,7 @@ MobileNet的网络架构主要是由DW conv和PW conv组成,相比于传统卷

由上表可知,使用相同的结构,深度可分离卷积虽然准确率降低1%,但是参数量减少了6/7。
-### 3. MobileNet-v2
+### 17.9.3 MobileNet-v2
MobileNet-V2是2018年1月公开在arXiv上论文《Inverted Residuals and Linear Bottlenecks: Mobile Networks for Classification, Detection and Segmentation》,是对MobileNet-V1的改进,同样是一个轻量化卷积神经网络。
#### 3.1 设计思想
* 采用Inverted residuals
@@ -286,7 +457,7 @@ stride=2的conv不使用shot-cot,stride=1的conv使用shot-cut
* 网络架构

-### 4. Xception
+### 17.9.4 Xception
Xception是Google提出的,arXiv 的V1 于2016年10月公开《Xception: Deep Learning with Depthwise Separable Convolutions 》,Xception是对Inception v3的另一种改进,主要是采用depthwise separable convolution来替换原来Inception v3中的卷积操作。
#### 4.1设计思想
* 采用depthwise separable convolution来替换原来Inception v3中的卷积操作
@@ -298,7 +469,7 @@ Xception是Google提出的,arXiv 的V1 于2016年10月公开《Xception: Deep
feature map在空间和通道上具有一定的相关性,通过Inception模块和非线性激活函数实现通道之间的解耦。增多3\*3的卷积的分支的数量,使它与1\*1的卷积的输出通道数相等,此时每个3\*3的卷积只作用与一个通道的特征图上,作者称之为“极致的Inception(Extream Inception)”模块,这就是Xception的基本模块。

-### 5. ShuffleNet-v1
+### 17.9.5 ShuffleNet-v1
ShuffleNet 是Face++团队提出的,晚于MobileNet两个月在arXiv上公开《ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices 》用于移动端前向部署的网络架构。ShuffleNet基于MobileNet的group思想,将卷积操作限制到特定的输入通道。而与之不同的是,ShuffleNet将输入的group进行打散,从而保证每个卷积核的感受野能够分散到不同group的输入中,增加了模型的学习能力。
#### 5.1 设计思想
* 采用group conv减少大量参数
@@ -319,7 +490,7 @@ avg pooling和DW conv(s=2)会减小feature map的分辨率,采用concat增加
网络结构:

-### 6. ShuffleNet-v2
+### 17.9.6 ShuffleNet-v2
huffleNet-v2 是Face++团队提出的《ShuffleNet V2: Practical Guidelines for Ecient CNN Architecture Design》,旨在设计一个轻量级但是保证精度、速度的深度网络。
#### 6.1 设计思想
* 文中提出影响神经网络速度的4个因素:
@@ -346,9 +517,9 @@ depthwise convolution 和 瓶颈结构增加了 MAC,用了太多的 group,
* 采用split使得一部分特征直接与下面的block相连,特征复用(DenseNet)
-## 17.7 现有移动端开源框架及其特点
+## 17.10 现有移动端开源框架及其特点
-### 17.7.1 NCNN
+### 17.10.1 NCNN
1、开源时间:2017年7月
@@ -413,7 +584,7 @@ ANDROID_PLATFORM 指定最低系统版本,"android-14" 就是 android-4.0
-### 17.7.2 QNNPACK
+### 17.10.2 QNNPACK
全称:Quantized Neural Network PACKage(量化神经网络包)
@@ -439,25 +610,48 @@ QNNPACK 的输入矩阵来自低精度、移动专用的计算机视觉模型。

- 在量化矩阵-矩阵乘法中,8 位整数的乘积通常会被累加至 32 位的中间结果中,随后重新量化以产生 8 位的输出。常规的实现会对大矩阵尺寸进行优化——有时 K 太大无法将 A 和 B 的面板转入缓存中。为了有效利用缓存层次结构,传统的 GEMM 实现将 A 和 B 的面板沿 K 维分割成固定大小的子面板,从而每个面板都适应 L1 缓存,随后为每个子面板调用微内核。这一缓存优化需要 PDOT 为内核输出 32 位中间结果,最终将它们相加并重新量化为 8 位整数。
+ 1)优化了L1缓存计算,不需要输出中间结果,直接输出最终结果,节省内存带宽和缓存占用。
+
+具体分析:
- 由于 ONNPACK 对于面板 A 和 B 总是适应 L1 缓存的移动神经网络进行了优化,因此它在调用微内核时处理整个 A 和 B 的面板。而由于无需在微内核之外积累 32 位的中间结果,QNNPACK 会将 32 位的中间结果整合进微内核中并写出 8 位值,这节省了内存带宽和缓存占用。
+- 常规实现:在量化矩阵-矩阵乘法中,8位整数的乘积通常会被累加至 32 位的中间结果中,随后重新量化以产生 8 位的输出。遇到大矩阵尺寸时,比如有时K太大,A和B的面板无法直接转入缓存,此时,需利用缓存层次结构,借助GEMM将A和B的面板沿着K维分割成固定大小的子面板,以便于每个子面板都能适应L1缓存,随后为每个子面板调用微内核。这一缓存优化需要 PDOT 为内核输出 32 位中间结果,最终将它们相加并重新量化为 8 位整数。
+- 优化实现:由于 ONNPACK 对于面板 A 和 B 总是适应 L1 缓存的移动神经网络进行了优化,因此它在调用微内核时处理整个 A 和 B 的面板。而由于无需在微内核之外积累 32 位的中间结果,QNNPACK 会将 32 位的中间结果整合进微内核中并写出 8 位值,这节省了内存带宽和缓存占用。

-使整个 A、B 面板适配缓存帮助实现了 QNNPACK 中的另一个优化:取消了矩阵 A 的重新打包。矩阵 B 包含静态权重,可以一次性转换成任何内存布局,但矩阵 A 包含卷积输入,每次推理运行都会改变。因此,重新打包矩阵 A 在每次运行时都会产生开销。尽管存在开销,传统的 GEMM 实现还是出于以下两个原因对矩阵 A 进行重新打包:缓存关联性及微内核效率受限。如果不重新打包,微内核将不得不读取被潜在的大跨距隔开的几行 A。如果这个跨距恰好是 2 的许多次幂的倍数,面板中不同行 A 的元素可能会落入同一缓存集中。如果冲突的行数超过了缓存关联性,它们就会相互驱逐,性能也会大幅下降。幸运的是,当面板适配一级缓存时,这种情况不会发生,就像 QNNPACK 优化的模型一样。
+ 2)取消了矩阵 A 的重新打包。
-打包对微内核效率的影响与当前所有移动处理器支持的 SIMD 向量指令的使用密切相关。这些指令加载、存储或者计算小型的固定大小元素向量,而不是单个标量(scalar)。在矩阵相乘中,充分利用向量指令达到高性能很重要。在传统的 GEMM 实现中,微内核把 MR 元素重新打包到向量暂存器里的 MR 线路中。在 QNNPACK 实现中,MR 元素在存储中不是连续的,微内核需要把它们加载到不同的向量暂存器中。越来越大的暂存器压力迫使 QNNPACK 使用较小的 MRxNR 拼贴,但实际上这种差异很小,而且可以通过消除打包开销来补偿。例如,在 32 位 ARM 架构上,QNNPACK 使用 4×8 微内核,其中 57% 的向量指令是乘-加;另一方面,gemmlowp 库使用效率稍高的 4×12 微内核,其中 60% 的向量指令是乘-加。
+- 常规实现:
-微内核加载 A 的多个行,乘以 B 的满列,结果相加,然后完成再量化并记下量化和。A 和 B 的元素被量化为 8 位整数,但乘积结果相加到 32 位。大部分 ARM 和 ARM64 处理器没有直接完成这一运算的指令,所以它必须分解为多个支持运算。QNNPACK 提供微内核的两个版本,其不同之处在于用于乘以 8 位值并将它们累加到 32 位的指令序列。
+ 矩阵 B 包含静态权重,可以一次性转换成任何内存布局,但矩阵 A 包含卷积输入,每次推理运行都会改变。因此,重新打包矩阵 A 在每次运行时都会产生开销。尽管存在开销,传统的 GEMM实现还是出于以下两个原因对矩阵 A 进行重新打包:
+
+ a 缓存关联性及微内核效率受限。如果不重新打包,微内核将不得不读取被潜在的大跨距隔开的几行A。如果这个跨距恰好是 2 的许多次幂的倍数,面板中不同行 A 的元素可能会落入同一缓存集中。如果冲突的行数超过了缓存关联性,它们就会相互驱逐,性能也会大幅下降。
+
+ b 打包对微内核效率的影响与当前所有移动处理器支持的 SIMD 向量指令的使用密切相关。这些指令加载、存储或者计算小型的固定大小元素向量,而不是单个标量(scalar)。在矩阵相乘中,充分利用向量指令达到高性能很重要。在传统的 GEMM 实现中,微内核把 MR 元素重新打包到向量暂存器里的 MR 线路中。
+
+- 优化实现:
+
+ a 当面板适配一级缓存时,不会存在缓存关联性及微内核效率受限的问题。
+
+ b 在 QNNPACK 实现中,MR 元素在存储中不是连续的,微内核需要把它们加载到不同的向量暂存器中。越来越大的暂存器压力迫使 QNNPACK 使用较小的 MRxNR 拼贴,但实际上这种差异很小,而且可以通过消除打包开销来补偿。例如,在 32 位 ARM 架构上,QNNPACK 使用 4×8 微内核,其中 57% 的向量指令是乘-加;另一方面,gemmlowp 库使用效率稍高的 4×12 微内核,其中 60% 的向量指令是乘-加。微内核加载 A 的多个行,乘以 B 的满列,结果相加,然后完成再量化并记下量化和。A 和 B 的元素被量化为 8 位整数,但乘积结果相加到 32 位。大部分 ARM 和 ARM64 处理器没有直接完成这一运算的指令,所以它必须分解为多个支持运算。QNNPACK 提供微内核的两个版本,其不同之处在于用于乘以 8 位值并将它们累加到 32 位的指令序列。
2)**从矩阵相乘到卷积**

-简单的 1×1 卷积可直接映射到矩阵相乘,但对于具备较大卷积核、padding 或子采样(步幅)的卷积而言则并非如此。但是,这些较复杂的卷积能够通过记忆变换 im2col 映射到矩阵相乘。对于每个输出像素,im2col 复制输入图像的图像块并将其计算为 2D 矩阵。由于每个输出像素都受 KHxKWxC 输入像素值的影响(KH 和 KW 分别指卷积核的高度和宽度,C 指输入图像中的通道数),因此该矩阵的大小是输入图像的 KHxKW 倍,im2col 给内存占用和性能都带来了一定的开销。和 Caffe 一样,大部分深度学习框架转而使用基于 im2col 的实现,利用现有的高度优化矩阵相乘库来执行卷积操作。
+ 传统实现:
+
+ 简单的 1×1 卷积可直接映射到矩阵相乘
+
+ 但对于具备较大卷积核、padding 或子采样(步幅)的卷积而言则并非如此。但是,这些较复杂的卷积能够通过记忆变换 im2col 映射到矩阵相乘。对于每个输出像素,im2col 复制输入图像的图像块并将其计算为 2D 矩阵。由于每个输出像素都受 KHxKWxC 输入像素值的影响(KH 和 KW 分别指卷积核的高度和宽度,C 指输入图像中的通道数),因此该矩阵的大小是输入图像的 KHxKW 倍,im2col 给内存占用和性能都带来了一定的开销。和 Caffe 一样,大部分深度学习框架转而使用基于 im2col 的实现,利用现有的高度优化矩阵相乘库来执行卷积操作。
-Facebook 研究者在 QNNPACK 中实现了一种更高效的算法。他们没有变换卷积输入使其适应矩阵相乘的实现,而是调整 PDOT 微内核的实现,在运行中执行 im2col 变换。这样就无需将输入张量的实际输入复制到 im2col 缓存,而是使用输入像素行的指针设置 indirection buffer,输入像素与每个输出像素的计算有关。研究者还修改了矩阵相乘微内核,以便从 indirection buffer 加载虚构矩阵(imaginary matrix)A 的行指针,indirection buffer 通常比 im2col buffer 小得多。此外,如果两次推断运行的输入张量存储位置不变,则 indirection buffer 还可使用输入张量行的指针进行初始化,然后在多次推断运行中重新使用。研究者观察到具备 indirection buffer 的微内核不仅消除了 im2col 变换的开销,其性能也比矩阵相乘微内核略好(可能由于输入行在计算不同输出像素时被重用)。
+ 优化实现:
+
+ Facebook 研究者在 QNNPACK 中实现了一种更高效的算法。
+
+- 他们没有变换卷积输入使其适应矩阵相乘的实现,而是调整 PDOT 微内核的实现,在运行中执行 im2col 变换。这样就无需将输入张量的实际输入复制到 im2col 缓存,而是使用输入像素行的指针设置 indirection buffer,输入像素与每个输出像素的计算有关。
+- 研究者还修改了矩阵相乘微内核,以便从 indirection buffer 加载虚构矩阵(imaginary matrix)A 的行指针,indirection buffer 通常比 im2col buffer 小得多。
+- 此外,如果两次推断运行的输入张量存储位置不变,则 indirection buffer 还可使用输入张量行的指针进行初始化,然后在多次推断运行中重新使用。研究者观察到具备 indirection buffer 的微内核不仅消除了 im2col 变换的开销,其性能也比矩阵相乘微内核略好(可能由于输入行在计算不同输出像素时被重用)。
3)**深度卷积**
@@ -500,7 +694,7 @@ http://www.sohu.com/a/272158070_610300
支持移动端深度学习的几种开源框架
https://blog.csdn.net/zchang81/article/details/74280019
-### 17.7.3 Prestissimo
+### 17.10.3 Prestissimo
1、开源时间:2017年11月
@@ -566,7 +760,7 @@ https://blog.csdn.net/zchang81/article/details/74280019
-### 17.7.4 MDL(mobile-deep-learning)
+### 17.10.4 MDL(mobile-deep-learning)
1、开源时间:2017年9月(已暂停更新)
@@ -618,7 +812,7 @@ MDL 框架主要包括:**模型转换模块(MDL Converter)、模型加载
-### 17.7.5 Paddle-Mobile
+### 17.10.5 Paddle-Mobile
1、开源时间:持续更新,已到3.0版本
@@ -643,7 +837,7 @@ MDL 框架主要包括:**模型转换模块(MDL Converter)、模型加载
- 支持树莓派等arm-linux开发板
-### 17.7.6 MACE( Mobile AI Compute Engine)
+### 17.10.6 MACE( Mobile AI Compute Engine)
1、开源时间:2018年4月(持续更新,v0.9.0 (2018-07-20))
@@ -735,7 +929,7 @@ MACE 支持 TensorFlow 和 Caffe 模型,提供转换工具,可以将训练
-### 17.7.7 FeatherCNN
+### 17.10.7 FeatherCNN
1、开源时间:持续更新,已到3.0版本
@@ -756,7 +950,7 @@ MACE 支持 TensorFlow 和 Caffe 模型,提供转换工具,可以将训练
- 轻量级:编译后的 FeatherCNN 库的体积仅为数百 KB。
-### 17.7.8 TensorFlow Lite
+### 17.10.8 TensorFlow Lite
1、开源时间:2017年11月
@@ -788,10 +982,10 @@ Android Studio 3.0, SDK Version API26, NDK Version 14
步骤:
1. 将此项目导入到Android Studio:
- https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/lite/java/demo
+ https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/lite/java/demo
2. 下载移动端的模型(model)和标签数据(lables):
- https://storage.googleapis.com/download.tensorflow.org/models/tflite/mobilenet_v1_224_android_quant_2017_11_08.zip
+ https://storage.googleapis.com/download.tensorflow.org/models/tflite/mobilenet_v1_224_android_quant_2017_11_08.zip
3. 下载完成解压mobilenet_v1_224_android_quant_2017_11_08.zip文件得到一个xxx.tflite和labes.txt文件,分别是模型和标签文件,并且把这两个文件复制到assets文件夹下。
@@ -806,7 +1000,7 @@ Android Studio 3.0, SDK Version API26, NDK Version 14
-### 17.7.9 PocketFlow
+### 17.10.9 PocketFlow
1、开源时间:2018年9月
@@ -872,11 +1066,11 @@ ResNet-18 模型进行压缩时,取得了一致性的性能提升;当平均
[2] Jiaxiang Wu, Weidong Huang, Junzhou Huang, Tong Zhang,「Error Compensated Quantized SGD and its Applications to Large-scale Distributed Optimization」, In Proc. of the 35th International Conference on Machine Learning, ICML’18, Stockholm, Sweden, July 2018.
-### 17.7.10 其他几款支持移动端深度学习的开源框架
+### 17.10.10 其他几款支持移动端深度学习的开源框架
https://blog.csdn.net/zchang81/article/details/74280019
-### 17.7.11 MDL、NCNN和 TFLite比较
+### 17.10.11 MDL、NCNN和 TFLite比较
百度-MDL框架、腾讯-NCNN框架和谷歌TFLite框架比较。
@@ -905,7 +1099,7 @@ https://blog.csdn.net/zchang81/article/details/74280019
-## 17.8 移动端开源框架部署
+## 17.11 移动端开源框架部署
### 17.8.1 以NCNN为例
部署步骤
@@ -1593,3 +1787,15 @@ implementation 'com.github.bumptech.glide:glide:4.3.1'
增加常见的几个问题
+
+知识蒸馏(Distillation)相关论文阅读(1)——Distilling the Knowledge in a Neural Network(以及代码复现)
+
+## 参考文献
+
+
+
+
+
+
+
+
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-2-10-1.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-2-10-1.png"
new file mode 100644
index 00000000..bba0a92a
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-2-10-1.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-2-10-2.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-2-10-2.png"
new file mode 100644
index 00000000..d5f27493
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-2-10-2.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-2-2.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-2-2.png"
new file mode 100644
index 00000000..c96f96d1
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-2-2.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-2-3-1.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-2-3-1.png"
new file mode 100644
index 00000000..20f84f13
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-2-3-1.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-2-3-2.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-2-3-2.png"
new file mode 100644
index 00000000..69428894
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-2-3-2.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-2-4-1.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-2-4-1.png"
new file mode 100644
index 00000000..a7ecab70
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-2-4-1.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-2-4-2.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-2-4-2.png"
new file mode 100644
index 00000000..b5344fd5
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-2-4-2.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-2-5-1.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-2-5-1.png"
new file mode 100644
index 00000000..fba6a2cb
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-2-5-1.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-2-5-2.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-2-5-2.png"
new file mode 100644
index 00000000..d09a0598
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-2-5-2.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-2-6-1.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-2-6-1.png"
new file mode 100644
index 00000000..ff572fed
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-2-6-1.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-2-6-2.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-2-6-2.png"
new file mode 100644
index 00000000..459d8f58
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-2-6-2.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-2-9-1.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-2-9-1.png"
new file mode 100644
index 00000000..894619ea
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-2-9-1.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-2-9-2.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-2-9-2.png"
new file mode 100644
index 00000000..5fb2c8fe
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-2-9-2.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-2-9-3.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-2-9-3.png"
new file mode 100644
index 00000000..7d6b87a2
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-2-9-3.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-2-9-4.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-2-9-4.png"
new file mode 100644
index 00000000..1823c37b
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-2-9-4.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-4-1.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-4-1.png"
new file mode 100644
index 00000000..c9b2b301
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-4-1.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-4-2.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-4-2.png"
new file mode 100644
index 00000000..d83ca44e
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-4-2.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-4-3.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-4-3.png"
new file mode 100644
index 00000000..8cd85879
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-4-3.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-4-4.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-4-4.png"
new file mode 100644
index 00000000..20b25262
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-4-4.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-4-5.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-4-5.png"
new file mode 100644
index 00000000..65e2a95b
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-4-5.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-1-1.jpg" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-1-1.jpg"
new file mode 100644
index 00000000..ce72d401
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-1-1.jpg" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-2-1.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-2-1.png"
new file mode 100644
index 00000000..2fc769fd
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-2-1.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-2-2.jpg" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-2-2.jpg"
new file mode 100644
index 00000000..a5c404d9
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-2-2.jpg" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-4-1.jpg" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-4-1.jpg"
new file mode 100644
index 00000000..108edd53
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-4-1.jpg" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-4-2.jpg" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-4-2.jpg"
new file mode 100644
index 00000000..2fcc3f37
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-4-2.jpg" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-6-1.jpg" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-6-1.jpg"
new file mode 100644
index 00000000..b3817e63
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-6-1.jpg" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-6-1.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-6-1.png"
new file mode 100644
index 00000000..7e2b7b11
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-6-1.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-6-2.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-6-2.png"
new file mode 100644
index 00000000..b437a6aa
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-6-2.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-6-3.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-6-3.png"
new file mode 100644
index 00000000..2cf17a3e
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-6-3.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-6-4.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-6-4.png"
new file mode 100644
index 00000000..73156472
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-6-4.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-6-5.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-6-5.png"
new file mode 100644
index 00000000..83cf5c0e
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-6-5.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-6-6.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-6-6.png"
new file mode 100644
index 00000000..c198465a
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-6-6.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-7-1.jpg" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-7-1.jpg"
new file mode 100644
index 00000000..63499447
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-7-1.jpg" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-8-1.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-8-1.png"
new file mode 100644
index 00000000..8620334d
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-8-1.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-8-2.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-8-2.png"
new file mode 100644
index 00000000..b19086fa
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-8-2.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-9-0.jpg" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-9-0.jpg"
new file mode 100644
index 00000000..37385cea
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-9-0.jpg" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-9-1.jpg" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-9-1.jpg"
new file mode 100644
index 00000000..f6a93fda
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-5-9-1.jpg" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-2-1-0.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-2-1-0.png"
new file mode 100644
index 00000000..ff160df6
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-2-1-0.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-2-1-1.jpg" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-2-1-1.jpg"
new file mode 100644
index 00000000..31b15d6a
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-2-1-1.jpg" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-2-1.jpg" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-2-1.jpg"
new file mode 100644
index 00000000..4fb0e718
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-2-1.jpg" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-2-2.jpg" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-2-2.jpg"
new file mode 100644
index 00000000..ef4c4c01
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-2-2.jpg" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-2-3.jpg" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-2-3.jpg"
new file mode 100644
index 00000000..db8a435f
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-2-3.jpg" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-2-3.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-2-3.png"
new file mode 100644
index 00000000..b666a215
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-2-3.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-2-4.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-2-4.png"
new file mode 100644
index 00000000..70b5a0bf
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-2-4.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-2-5.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-2-5.png"
new file mode 100644
index 00000000..0bb8ea8c
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-2-5.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-3-0.jpg" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-3-0.jpg"
new file mode 100644
index 00000000..4911ed62
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-3-0.jpg" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-3-1.jpg" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-3-1.jpg"
new file mode 100644
index 00000000..a98cbc10
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-3-1.jpg" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-3-2.jpg" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-3-2.jpg"
new file mode 100644
index 00000000..eb0465c0
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-3-2.jpg" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-3-3.jpg" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-3-3.jpg"
new file mode 100644
index 00000000..793ff567
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-3-3.jpg" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-3-4.jpg" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-3-4.jpg"
new file mode 100644
index 00000000..be5c1723
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-3-4.jpg" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-3-5.jpg" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-3-5.jpg"
new file mode 100644
index 00000000..602c7afb
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-3-5.jpg" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-4-1.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-4-1.png"
new file mode 100644
index 00000000..593c9ece
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-4-1.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-4-2.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-4-2.png"
new file mode 100644
index 00000000..e2969c83
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-4-2.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-4-3.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-4-3.png"
new file mode 100644
index 00000000..8c7e0479
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-4-3.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-4-4.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-4-4.png"
new file mode 100644
index 00000000..97a00eeb
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-4-4.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-5-1.jpg" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-5-1.jpg"
new file mode 100644
index 00000000..db8a435f
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-5-1.jpg" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-5-2.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-5-2.png"
new file mode 100644
index 00000000..2584aed6
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-5-2.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-5-3.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-5-3.png"
new file mode 100644
index 00000000..7a4e5061
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-5-3.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-5-4.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-5-4.png"
new file mode 100644
index 00000000..e0c1fe2f
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-5-4.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-8-1.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-8-1.png"
new file mode 100644
index 00000000..169d0415
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-6-8-1.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-9-2-1.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-9-2-1.png"
new file mode 100644
index 00000000..71b6fb7b
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-9-2-1.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-9-2-2.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-9-2-2.png"
new file mode 100644
index 00000000..457fb048
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-9-2-2.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-9-3-1.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-9-3-1.png"
new file mode 100644
index 00000000..2c75bcef
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/18-9-3-1.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/\346\226\260\345\273\272\346\226\207\344\273\266\345\244\271/18-2-10-1.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/\346\226\260\345\273\272\346\226\207\344\273\266\345\244\271/18-2-10-1.png"
new file mode 100644
index 00000000..53c0fb5c
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/\346\226\260\345\273\272\346\226\207\344\273\266\345\244\271/18-2-10-1.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/\346\226\260\345\273\272\346\226\207\344\273\266\345\244\271/18-2-3-1.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/\346\226\260\345\273\272\346\226\207\344\273\266\345\244\271/18-2-3-1.png"
new file mode 100644
index 00000000..683b767c
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/\346\226\260\345\273\272\346\226\207\344\273\266\345\244\271/18-2-3-1.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/\346\226\260\345\273\272\346\226\207\344\273\266\345\244\271/18-2-4-1.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/\346\226\260\345\273\272\346\226\207\344\273\266\345\244\271/18-2-4-1.png"
new file mode 100644
index 00000000..5db66668
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/\346\226\260\345\273\272\346\226\207\344\273\266\345\244\271/18-2-4-1.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/\346\226\260\345\273\272\346\226\207\344\273\266\345\244\271/18-4-5.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/\346\226\260\345\273\272\346\226\207\344\273\266\345\244\271/18-4-5.png"
new file mode 100644
index 00000000..a43fd0c3
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/\346\226\260\345\273\272\346\226\207\344\273\266\345\244\271/18-4-5.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/\346\226\260\345\273\272\346\226\207\344\273\266\345\244\271/18-5-2-1.jpg" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/\346\226\260\345\273\272\346\226\207\344\273\266\345\244\271/18-5-2-1.jpg"
new file mode 100644
index 00000000..91e663f9
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/\346\226\260\345\273\272\346\226\207\344\273\266\345\244\271/18-5-2-1.jpg" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/\346\226\260\345\273\272\346\226\207\344\273\266\345\244\271/18-5-2-1.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/\346\226\260\345\273\272\346\226\207\344\273\266\345\244\271/18-5-2-1.png"
new file mode 100644
index 00000000..c733940b
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/\346\226\260\345\273\272\346\226\207\344\273\266\345\244\271/18-5-2-1.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/\346\226\260\345\273\272\346\226\207\344\273\266\345\244\271/18-5-2-2.png" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/\346\226\260\345\273\272\346\226\207\344\273\266\345\244\271/18-5-2-2.png"
new file mode 100644
index 00000000..ad296098
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/\346\226\260\345\273\272\346\226\207\344\273\266\345\244\271/18-5-2-2.png" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/\346\226\260\345\273\272\346\226\207\344\273\266\345\244\271/emnlp2018.pdf" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/\346\226\260\345\273\272\346\226\207\344\273\266\345\244\271/emnlp2018.pdf"
new file mode 100644
index 00000000..831a88f7
Binary files /dev/null and "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/img/\346\226\260\345\273\272\346\226\207\344\273\266\345\244\271/emnlp2018.pdf" differ
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/modify_log.txt" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/modify_log.txt"
new file mode 100644
index 00000000..2d077458
--- /dev/null
+++ "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/modify_log.txt"
@@ -0,0 +1 @@
+# 记录修改信息
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/readme.md" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/readme.md"
new file mode 100644
index 00000000..402b5ac2
--- /dev/null
+++ "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/readme.md"
@@ -0,0 +1,11 @@
+###########################################################
+
+### 深度学习500问-第十八章 后端分布式框架部署
+
+**负责人(排名不分先后):**
+中国平安-AI系统研究员-梁志成
+
+
+**贡献者(排名不分先后):**
+
+###########################################################
diff --git "a/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/\347\254\254\345\215\201\345\205\253\347\253\240_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257.md" "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/\347\254\254\345\215\201\345\205\253\347\253\240_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257.md"
new file mode 100644
index 00000000..54532c12
--- /dev/null
+++ "b/ch18_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257/\347\254\254\345\215\201\345\205\253\347\253\240_\345\220\216\347\253\257\346\236\266\346\236\204\351\200\211\345\236\213\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257.md"
@@ -0,0 +1,1954 @@
+[TOC]
+
+
+
+# 第十八章 后端架构选型及应用场景
+
+ Markdown Revision 1;
+ Date: 2018/11/11
+ Editor: 梁志成
+ Contact: superzhicheng@foxmail.com
+
+## 18.1 为什么需要分布式计算?
+
+ 在这个数据爆炸的时代,产生的数据量不断地在攀升,从GB,TB,PB,ZB.挖掘其中数据的价值也是企业在不断地追求的终极目标。但是要想对海量的数据进行挖掘,首先要考虑的就是海量数据的存储问题,比如Tb量级的数据。
+
+ 谈到数据的存储,则不得不说的是磁盘的数据读写速度问题。早在上个世纪90年代初期,普通硬盘的可以存储的容量大概是1G左右,硬盘的读取速度大概为4.4MB/s.读取一张硬盘大概需要5分钟时间,但是如今硬盘的容量都在1TB左右了,相比扩展了近千倍。但是硬盘的读取速度大概是100MB/s。读完一个硬盘所需要的时间大概是2.5个小时。所以如果是基于TB级别的数据进行分析的话,光硬盘读取完数据都要好几天了,更谈不上计算分析了。那么该如何处理大数据的存储,计算分析呢?
+
+ 一个很简单的减少数据读写时间的方法就是同时从多个硬盘上读写数据,比如,如果我们有100个硬盘,每个硬盘存储1%的数据 ,并行读取,那么不到两分钟就可以完成之前需要2.5小时的数据读写任务了。这就是大数据中的分布式存储的模型。当然实现分布式存储还需要解决很多问题,比如硬件故障的问题,使用多台主机进行分布式存储时,若主机故障,会出现数据丢失的问题,所以有了副本机制:系统中保存数据的副本。一旦有系统发生故障,就可以使用另外的副本进行替换(著名的RAID冗余磁盘阵列就是按这个原理实现的)。其次比如一个很大的文件如何进行拆分存储,读取拆分以后的文件如何进行校验都是要考虑的问题。比如我们使用Hadoop中的HDFS也面临这个问题,只是框架给我们实现了这些问题的解决办法,开发中开发者不用考虑这些问题,底层框架已经实现了封装。
+
+ 同样假如有一个10TB的文件,我们要统计其中某个关键字的出现次数,传统的做法是遍历整个文件,然后统计出关键字的出现次数,这样效率会特别特别低。基于分布式存储以后,数据被分布式存储在不同的服务器上,那么我们就可以使用分布式计算框架(比如MapReduce,Spark等)来进行并行计算(或者说是分布式计算),即:每个服务器上分别统计自己存储的数据中关键字出现的次数,最后进行一次汇总,那么假如数据分布在100台服务器上,即同时100台服务器同时进行关键字统计工作,效率一下子可以提高几十倍。
+
+## 18.2 目前有哪些深度学习分布式计算框架?
+
+### 18.2.1 PaddlePaddle
+
+ PaddlePaddle【1】是百度开源的一个深度学习平台。PaddlePaddle为深度学习研究人员提供了丰富的API,可以轻松地完成神经网络配置,模型训练等任务。
+官方文档中简易介绍了如何使用框架在
+
+- 线性回归
+- 识别数字
+- 图像分类
+- 词向量
+- 个性化推荐
+- 情感分析
+- 语义角色标注
+- 机器翻译
+
+等方面的应用
+
+ Github地址:https://github.com/PaddlePaddle/Paddle
+
+### 18.2.2 Deeplearning4j
+
+ DeepLearning4J(DL4J)【2】是一套基于Java语言的神经网络工具包,可以构建、定型和部署神经网络。DL4J与Hadoop和Spark集成,支持分布式CPU和GPU。
+
+ Deeplearning4j包括了分布式、多线程的深度学习框架,以及普通的单线程深度学习框架。定型过程以集群进行,也就是说,Deeplearning4j可以快速处理大量数据。Deeplearning4j在开放堆栈中作为模块组件的功能,使之成为为微服务架构打造的深度学习框架。
+
+ Deeplearning4j从各类浅层网络出发,设计深层神经网络。这一灵活性使用户可以根据所需,在分布式、生产级、能够在分布式CPU或GPU的基础上与Spark和Hadoop协同工作的框架内,整合受限玻尔兹曼机、其他自动编码器、卷积网络或递归网络。
+
+ Deeplearning4j在已建立的各个库及其在系统整体中的所处位置
+
+
+
+ Github地址:https://github.com/deeplearning4j/deeplearning4j
+
+### 18.2.3 Mahout
+
+ Mahout【3】是基于Hadoop的机器学习和数据挖掘的一个分布式框架。Mahout用MapReduce实现了部分数据挖掘算法,解决了并行挖掘的问题。
+
+ Mahout包含许多实现,包括聚类、分类、推荐过滤、频繁子项挖掘等。
+
+ Mahout算法库:
+
+
+
+ Mahout应用场景:
+
+
+
+ Github地址:https://github.com/apache/mahout
+
+### 18.2.4 Spark MLllib
+
+MLlib(Machine Learnig lib) 【4】是Spark对常用的机器学习算法的实现库,同时包括相关的测试和数据生成器。
+
+MLlib是MLBase一部分,其中MLBase分为四部分:MLlib、MLI、ML Optimizer和MLRuntime。
+
+- ML Optimizer会选择它认为最适合的已经在内部实现好了的机器学习算法和相关参数,来处理用户输入的数据,并返回模型或别的帮助分析的结果;
+- MLI 是一个进行特征抽取和高级ML编程抽象的算法实现的API或平台;
+- MLlib是Spark实现一些常见的机器学习算法和实用程序,包括分类、回归、聚类、协同过滤、降维以及底层优化,该算法可以进行可扩充;
+- MLRuntime 基于Spark计算框架,将Spark的分布式计算应用到机器学习领域。
+
+MLlib主要包含三个部分:
+
+- 底层基础:包括Spark的运行库、矩阵库和向量库
+- 算法库:包含广义线性模型、推荐系统、聚类、决策树和评估的算法
+- 实用程序:包括测试数据的生成、外部数据的读入等功能
+
+
+架构图
+
+
+ MLlib目前支持4种常见的机器学习问题: 分类、回归、聚类和协同过滤,MLlib在Spark整个生态系统中的位置如图下图所示。
+
+### 18.2.5 Ray
+
+ Ray【5】是加州大学伯克利分校实时智能安全执行实验室(RISELab)的研究人员针对机器学习领域开发的一种新的分布式计算框架,该框架旨在让基于Python的机器学习和深度学习工作负载能够实时执行,并具有类似消息传递接口(MPI)的性能和细粒度。
+
+ 增强学习的场景,按照原理定义,因为没有预先可用的静态标签信息,所以通常需要引入实际的目标系统(为了加快训练,往往是目标系统的模拟环境)来获取反馈信息,用做损失/收益判断,进而完成整个训练过程的闭环反馈。典型的步骤是通过观察特定目标系统的状态,收集反馈信息,判断收益,用这些信息来调整参数,训练模型,并根据新的训练结果产出可用于调整目标系统的行为Action,输出到目标系统,进而影响目标系统状态变化,完成闭环,如此反复迭代,最终目标是追求某种收益的最大化(比如对AlphoGo来说,收益是赢得一盘围棋的比赛)。
+
+ 在这个过程中,一方面,模拟目标系统,收集状态和反馈信息,判断收益,训练参数,生成Action等等行为可能涉及大量的任务和计算(为了选择最佳Action,可能要并发模拟众多可能的行为)。而这些行为本身可能也是千差万别的异构的任务,任务执行的时间也可能长短不一,执行过程有些可能要求同步,也有些可能更适合异步。
+
+ 另一方面,整个任务流程的DAG图也可能是动态变化的,系统往往可能需要根据前一个环节的结果,调整下一个环节的行为参数或者流程。这种调整,可能是目标系统的需要(比如在自动驾驶过程中遇到行人了,那么我们可能需要模拟计算刹车的距离来判断该采取的行动是刹车还是拐弯,而平时可能不需要这个环节),也可能是增强学习特定训练算法的需要(比如根据多个并行训练的模型的当前收益,调整模型超参数,替换模型等等)。
+
+ 此外,由于所涉及到的目标系统可能是具体的,现实物理世界中的系统,所以对时效性也可能是有强要求的。举个例子,比如你想要实现的系统是用来控制机器人行走,或者是用来打视频游戏的。那么整个闭环反馈流程就需要在特定的时间限制内完成(比如毫秒级别)。
+
+ 总结来说,就是增强学习的场景,对分布式计算框架的任务调度延迟,吞吐量和动态修改DAG图的能力都可能有很高的要求。按照官方的设计目标,Ray需要支持异构计算任务,动态计算链路,毫秒级别延迟和每秒调度百万级别任务的能力。
+
+ Ray的目标问题,主要是在类似增强学习这样的场景中所遇到的工程问题。那么增强学习的场景和普通的机器学习,深度学习的场景又有什么不同呢?简单来说,就是对整个处理链路流程的时效性和灵活性有更高的要求。
+
+Ray框架优点:
+
+- 海量任务调度能力
+- 毫秒级别的延迟
+- 异构任务的支持
+- 任务拓扑图动态修改的能力
+
+ Ray没有采用中心任务调度的方案,而是采用了类似层级(hierarchy)调度的方案,除了一个全局的中心调度服务节点(实际上这个中心调度节点也是可以水平拓展的),任务的调度也可以在具体的执行任务的工作节点上,由本地调度服务来管理和执行。
+与传统的层级调度方案,至上而下分配调度任务的方式不同的是,Ray采用了至下而上的调度策略。也就是说,任务调度的发起,并不是先提交给全局的中心调度器统筹规划以后再分发给次级调度器的。而是由任务执行节点直接提交给本地的调度器,本地的调度器如果能满足该任务的调度需求就直接完成调度请求,在无法满足的情况下,才会提交给全局调度器,由全局调度器协调转发给有能力满足需求的另外一个节点上的本地调度器去调度执行。
+
+ 架构设计一方面减少了跨节点的RPC开销,另一方面也能规避中心节点的瓶颈问题。当然缺点也不是没有,由于缺乏全局的任务视图,无法进行全局规划,因此任务的拓扑逻辑结构也就未必是最优的了。
+
+
+架构图
+
+
+任务调度图
+
+ Ray架构现状:
+
+- API层以上 的部分还比较薄弱,Core模块核心逻辑估需要时间打磨。
+- 国内目前除了蚂蚁金服和RISELab有针对性的合作以外,关注程度还很低,没有实际的应用实例看到,整体来说还处于比较早期的框架构建阶段。
+
+ Github地址:https://github.com/ray-project/ray
+
+### 18.2.6 Spark stream
+
+ 随着大数据的发展,人们对大数据的处理要求也越来越高,原有的批处理框架MapReduce适合离线计算,却无法满足实时性要求较高的业务,如实时推荐、用户行为分析等。 Spark Streaming是建立在Spark上的实时计算框架,通过它提供的丰富的API、基于内存的高速执行引擎,用户可以结合流式、批处理和交互试查询应用。
+
+ Spark是一个类似于MapReduce的分布式计算框架,其核心是弹性分布式数据集,提供了比MapReduce更丰富的模型,可以在快速在内存中对数据集进行多次迭代,以支持复杂的数据挖掘算法和图形计算算法。Spark Streaming【6】是一种构建在Spark上的实时计算框架,它扩展了Spark处理大规模流式数据的能力。
+
+ Spark Streaming的优势在于:
+
+- 能运行在100+的结点上,并达到秒级延迟。
+- 使用基于内存的Spark作为执行引擎,具有高效和容错的特性。
+- 能集成Spark的批处理和交互查询。
+- 为实现复杂的算法提供和批处理类似的简单接口。
+
+
+
+ Spark Streaming把实时输入数据流以时间片Δt (如1秒)为单位切分成块。Spark Streaming会把每块数据作为一个RDD,并使用RDD操作处理每一小块数据。每个块都会生成一个Spark Job处理,最终结果也返回多块。
+
+
+
+ 正如Spark Streaming最初的目标一样,它通过丰富的API和基于内存的高速计算引擎让用户可以结合流式处理,批处理和交互查询等应用。因此Spark Streaming适合一些需要历史数据和实时数据结合分析的应用场合。当然,对于实时性要求不是特别高的应用也能完全胜任。另外通过RDD的数据重用机制可以得到更高效的容错处理。
+
+### 18.2.7 Horovod
+
+ Horovod【7】 是 Uber 开源的又一个深度学习工具,它的发展吸取了 Facebook「一小时训练 ImageNet 论文」与百度 Ring Allreduce 的优点,可为用户实现分布式训练提供帮助。
+
+ Horovod 支持通过用于高性能并行计算的低层次接口 – 消息传递接口 (MPI) 进行分布式模型训练。有了 MPI,就可以利用分布式 Kubernetes 集群来训练 TensorFlow 和 PyTorch 模型。
+
+ 分布式 TensorFlow 的参数服务器模型(parameter server paradigm)通常需要对大量样板代码进行认真的实现。但是 Horovod 仅需要几行。下面是一个分布式 TensorFlow 项目使用 Horovod 的示例:
+
+
+ import tensorflow as tf
+ import horovod.tensorflow as hvd
+ # Initialize Horovod
+ hvd.init()
+ # Pin GPU to be used to process local rank (one GPU per process)
+ config = tf.ConfigProto()
+ config.gpu_options.visible_device_list = str(hvd.local_rank())
+ # Build model…
+ loss = …
+ opt = tf.train.AdagradOptimizer(0.01)
+ # Add Horovod Distributed Optimizer
+ opt = hvd.DistributedOptimizer(opt)
+ # Add hook to broadcast variables from rank 0 to all other processes during
+ # initialization.
+ hooks = [hvd.BroadcastGlobalVariablesHook(0)]
+ # Make training operation
+ train_op = opt.minimize(loss)
+ # The MonitoredTrainingSession takes care of session initialization,
+ # restoring from a checkpoint, saving to a checkpoint, and closing when done
+ # or an error occurs.
+ with tf.train.MonitoredTrainingSession(checkpoint_dir=“/tmp/train_logs”,
+ config=config,
+ hooks=hooks) as mon_sess:
+ while not mon_sess.should_stop():
+ # Perform synchronous training.
+ mon_sess.run(train_op)
+
+
+ 在该示例中,粗体文字指进行单个 GPU 分布式项目时必须做的改变:
+
+- hvd.init() 初始化 Horovod。
+- config.gpu_options.visible_device_list = str(hvd.local_rank()) 向每个 TensorFlow 流程分配一个 GPU。
+- opt=hvd.DistributedOptimizer(opt) 使用 Horovod 优化器包裹每一个常规 TensorFlow 优化器,Horovod 优化器使用 ring-allreduce 平均梯度。
+- hvd.BroadcastGlobalVariablesHook(0) 将变量从第一个流程向其他流程传播,以实现一致性初始化。如果该项目无法使用 MonitoredTrainingSession,则用户可以运行 hvd.broadcast_global_variables(0)。
+
+ 之后,可以使用 mpirun 命令使该项目的多个拷贝在多个服务器中运行:
+
+```
+$ mpirun -np 16 -x LD_LIBRARY_PATH -H
+server1:4,server2:4,server3:4,server4:4 python train.py
+```
+
+ mpirun 命令向四个节点分布 train.py,然后在每个节点的四个 GPU 上运行 train.py。
+
+ Github地址:https://github.com/uber/horovod
+
+### 18.2.8 BigDL
+
+ BigDL【9】是一种基于Apache Spark的分布式深度学习框架。它可以无缝的直接运行在现有的Apache Spark和Hadoop集群之上。BigDL的设计吸取了Torch框架许多方面的知识,为深度学习提供了全面的支持;包括数值计算和高级神经网络;借助现有的Spark集群来运行深度学习计算,并简化存储在Hadoop中的大数据集的数据加载。
+
+ BigDL优点:
+
+- 丰富的深度学习支持。模拟Torch之后,BigDL为深入学习提供全面支持,包括数字计算(通过Tensor)和高级神经网络 ; 此外,用户可以使用BigDL将预先训练好的Caffe或Torch模型加载到Spark程序中。
+- 极高的性能。为了实现高性能,BigDL在每个Spark任务中使用英特尔MKL和多线程编程。因此,在单节点Xeon(即与主流GPU 相当)上,它比开箱即用开源Caffe,Torch或TensorFlow快了数量级。
+- 有效地横向扩展。BigDL可以通过利用Apache Spark(快速分布式数据处理框架),以及高效实施同步SGD和全面减少Spark的通信,从而有效地扩展到“大数据规模”上的数据分析
+
+ BigDL缺点:
+
+- 对机器要求高 jdk7上运行性能差 在CentOS 6和7上,要将最大用户进程增加到更大的值(例如514585); 否则,可能会看到错误,如“无法创建新的本机线程”。
+- 训练和验证的数据会加载到内存,挤占内存
+
+ BigDL满足的应用场景:
+
+- 直接在Hadoop/Spark框架下使用深度学习进行大数据分析(即将数据存储在HDFS、HBase、Hive等数据库上);
+- 在Spark程序中/工作流中加入深度学习功能;
+- 利用现有的 Hadoop/Spark 集群来运行深度学习程序,然后将代码与其他的应用场景进行动态共享,例如ETL(Extract、Transform、Load,即通常所说的数据抽取)、数据仓库(data warehouse)、功能引擎、经典机器学习、图表分析等。
+
+### 18.2.9 Petastorm
+
+ Petastorm是一个由 Uber ATG 开发的开源数据访问库。这个库可以直接基于数 TB Parquet 格式的数据集进行单机或分布式训练和深度学习模型评估。Petastorm 支持基于 Python 的机器学习框架,如 Tensorflow、Pytorch 和 PySpark,也可以直接用在 Python 代码中。
+
+
+
+ 即使是在现代硬件上训练深度模型也很耗时,而且在很多情况下,很有必要在多台机器上分配训练负载。典型的深度学习集群需要执行以下几个步骤:
+
+- 一台或多台机器读取集中式或本地数据集。
+- 每台机器计算损失函数的值,并根据模型参数计算梯度。在这一步通常会使用 GPU。
+- 通过组合估计的梯度(通常由多台机器以分布式的方式计算得出)来更新模型系数。
+
+ 通常,一个数据集是通过连接多个数据源的记录而生成的。这个由 Apache Spark 的 Python 接口 PySpark 生成的数据集稍后将被用在机器学习训练中。Petastorm 提供了一个简单的功能,使用 Petastorm 特定的元数据对标准的 Parquet 进行了扩展,从而让它可以与 Petastorm 兼容。
+有了 Petastorm,消费数据就像在 HDFS 或文件系统中创建和迭代读取对象一样简单。Petastorm 使用 PyArrow 来读取 Parquet 文件。
+
+ 将多个数据源组合到单个表格结构中,从而生成数据集。可以多次使用相同的数据集进行模型训练和评估。
+
+
+
+ 为分布式训练进行分片
+在分布式训练环境中,每个进程通常负责训练数据的一个子集。一个进程的数据子集与其他进程的数据子集正交。Petastorm 支持将数据集的读时分片转换为正交的样本集。
+
+ Petastorm 将数据集的非重叠子集提供给参与分布式训练的不同机器
+
+ 本地缓存
+Petastorm 支持在本地存储中缓存数据。当网络连接速度较慢或带宽很昂贵时,这会派上用场。
+
+
+Github地址:https://github.com/uber/petastorm
+
+### 18.2.10 TensorFlowOnSpark
+
+ TensorFlowOnSpark【10】为 Apache Hadoop 和 Apache Spark 集群带来可扩展的深度学习。 通过结合深入学习框架 TensorFlow 和大数据框架 Apache Spark 、Apache Hadoop 的显着特征,TensorFlowOnSpark 能够在 GPU 和 CPU 服务器集群上实现分布式深度学习。
+
+ 满足的应用场景:
+为了利用TensorFlow在现有的Spark和Hadoop集群上进行深度学习。而不需要为深度学习设置单独的集群。
+
+
+
+
+
+ 优点:
+
+- 轻松迁移所有现有的TensorFlow程序,<10行代码更改;
+- 支持所有TensorFlow功能:同步/异步训练,模型/数据并行,推理和TensorBoard;
+- 服务器到服务器的直接通信在可用时实现更快的学习;
+- 允许数据集在HDFS和由Spark推动的其他来源或由TensorFlow拖动;
+- 轻松集成您现有的数据处理流水线和机器学习算法(例如,MLlib,CaffeOnSpark);
+- 轻松部署在云或内部部署:CPU和GPU,以太网和Infiniband。
+- TensorFlowOnSpark是基于google的TensorFlow的实现,而TensorFlow有着一套完善的教程,内容丰富。
+
+ 劣势:
+
+- 开源时间不长,未得到充分的验证。
+
+ Github 地址:https://github.com/yahoo/TensorFlowOnSpark
+
+## 18.3 如何进行实时计算?
+
+### 18.3.1 什么是实时流计算?
+
+ 所谓实时流计算,就是近几年由于数据得到广泛应用之后,在数据持久性建模不满足现状的情况下,急需数据流的瞬时建模或者计算处理。这种实时计算的应用实例有金融服务、网络监控、电信数据管理、 Web 应用、生产制造、传感检测,等等。在这种数据流模型中,单独的数据单元可能是相关的元组(Tuple),如网络测量、呼叫记录、网页访问等产生的数据。但是,这些数据以大量、快速、时变(可能是不可预知)的数据流持续到达,由此产生了一些基础性的新的研究问题——实时计算。实时计算的一个重要方向就是实时流计算。
+
+### 18.3.2 实时流计算过程
+
+
+
+ 我们以热卖产品的统计为例,看下传统的计算手段:
+
+- 将用户行为、log等信息清洗后保存在数据库中.
+- 将订单信息保存在数据库中.
+- 利用触发器或者协程等方式建立本地索引,或者远程的独立索引.
+- join订单信息、订单明细、用户信息、商品信息等等表,聚合统计20分钟内热卖产品,并返回top-10.
+- web或app展示.
+
+ 这是一个假想的场景,但假设你具有处理类似场景的经验,应该会体会到这样一些问题和难处:
+
+- 水平扩展问题(scale-out)
+显然,如果是一个具有一定规模的电子商务网站,数据量都是很大的。而交易信息因为涉及事务,所以很难直接舍弃关系型数据库的事务能力,迁移到具有更好的scale-out能力的NoSQL数据库中。
+
+ 那么,一般都会做sharding。历史数据还好说,我们可以按日期来归档,并可以通过批处理式的离线计算,将结果缓存起来。
+但是,这里的要求是20分钟内,这很难。
+
+- 性能问题
+这个问题,和scale-out是一致的,假设我们做了sharding,因为表分散在各个节点中,所以我们需要多次入库,并在业务层做聚合计算。
+
+ 问题是,20分钟的时间要求,我们需要入库多少次呢?10分钟呢?5分钟呢?实时呢?
+
+ 而且,业务层也同样面临着单点计算能力的局限,需要水平扩展,那么还需要考虑一致性的问题。
+所以,到这里一切都显得很复杂。
+
+- 业务扩展问题
+
+ 假设我们不仅仅要处理热卖商品的统计,还要统计广告点击、或者迅速根据用户的访问行为判断用户特征以调整其所见的信息,更加符合用户的潜在需求等,那么业务层将会更加复杂。
+也许你有更好的办法,但实际上,我们需要的是一种新的认知:
+这个世界发生的事,是实时的。
+所以我们需要一种实时计算的模型,而不是批处理模型。
+我们需要的这种模型,必须能够处理很大的数据,所以要有很好的scale-out能力,最好是,我们都不需要考虑太多一致性、复制的问题。
+
+ 那么,这种计算模型就是实时计算模型,也可以认为是流式计算模型。
+现在假设我们有了这样的模型,我们就可以愉快地设计新的业务场景:
+
+- 转发最多的微博是什么?
+- 最热卖的商品有哪些?
+- 大家都在搜索的热点是什么?
+- 我们哪个广告,在哪个位置,被点击最多?
+
+或者说,我们可以问:
+ 这个世界,在发生什么?
+
+ 最热的微博话题是什么?
+我们以一个简单的滑动窗口计数的问题,来揭开所谓实时计算的神秘面纱。
+假设,我们的业务要求是:
+统计20分钟内最热的10个微博话题。
+
+ 解决这个问题,我们需要考虑:
+
+- 数据源
+
+ 这里,假设我们的数据,来自微博长连接推送的话题。
+
+- 问题建模
+
+ 我们认为的话题是#号扩起来的话题,最热的话题是此话题出现的次数比其它话题都要多。
+比如:@foreach_break : 你好,#世界#,我爱你,#微博#。
+“世界”和“微博”就是话题。
+
+- 计算引擎采用storm
+
+- 定义时间
+
+ 时间的定义是一件很难的事情,取决于所需的精度是多少。
+根据实际,我们一般采用tick来表示时刻这一概念。
+在storm的基础设施中,executor启动阶段,采用了定时器来触发“过了一段时间”这个事件。
+如下所示:
+```
+(defn setup-ticks! [worker executor-data]
+ (let [storm-conf (:storm-conf executor-data)
+ tick-time-secs (storm-conf TOPOLOGY-TICK-TUPLE-FREQ-SECS)
+ receive-queue (:receive-queue executor-data)
+ context (:worker-context executor-data)]
+ (when tick-time-secs
+ (if (or (system-id? (:component-id executor-data))
+ (and (= false (storm-conf TOPOLOGY-ENABLE-MESSAGE-TIMEOUTS))
+ (= :spout (:type executor-data))))
+ (log-message "Timeouts disabled for executor " (:component-id executor-data) ":" (:executor-id executor-data))
+ (schedule-recurring
+ (:user-timer worker)
+ tick-time-secs
+ tick-time-secs
+ (fn []
+ (disruptor/publish
+ receive-queue
+ [[nil (TupleImpl. context [tick-time-secs] Constants/SYSTEM_TASK_ID Constants/SYSTEM_TICK_STREAM_ID)]]
+ )))))))
+```
+之前的博文中,已经详细分析了这些基础设施的关系,不理解的童鞋可以翻看前面的文章。
+每隔一段时间,就会触发这样一个事件,当流的下游的bolt收到一个这样的事件时,就可以选择是增量计数还是将结果聚合并发送到流中。
+bolt如何判断收到的tuple表示的是“tick”呢?
+负责管理bolt的executor线程,从其订阅的消息队列消费消息时,会调用到bolt的execute方法,那么,可以在execute中这样判断:
+```
+public static boolean isTick(Tuple tuple) {
+ return tuple != null
+ && Constants.SYSTEM_COMPONENT_ID .equals(tuple.getSourceComponent())
+ && Constants.SYSTEM_TICK_STREAM_ID.equals(tuple.getSourceStreamId());
+}
+```
+结合上面的setup-tick!的clojure代码,我们可以知道SYSTEM_TICK_STREAM_ID在定时事件的回调中就以构造函数的参数传递给了tuple,那么SYSTEM_COMPONENT_ID是如何来的呢?
+可以看到,下面的代码中,SYSTEM_TASK_ID同样传给了tuple:
+;; 请注意SYSTEM_TASK_ID和SYSTEM_TICK_STREAM_ID
+(TupleImpl. context [tick-time-secs] Constants/SYSTEM_TASK_ID Constants/SYSTEM_TICK_STREAM_ID)
+然后利用下面的代码,就可以得到SYSTEM_COMPONENT_ID:
+```
+ public String getComponentId(int taskId) {
+ if(taskId==Constants.SYSTEM_TASK_ID) {
+ return Constants.SYSTEM_COMPONENT_ID;
+ } else {
+ return _taskToComponent.get(taskId);
+ }
+ }
+```
+滑动窗口
+有了上面的基础设施,我们还需要一些手段来完成“工程化”,将设想变为现实。
+这里,我们看看Michael G. Noll的滑动窗口设计。
+
+
+
+Topology
+
+```
+ String spoutId = "wordGenerator";
+ String counterId = "counter";
+ String intermediateRankerId = "intermediateRanker";
+ String totalRankerId = "finalRanker";
+ // 这里,假设TestWordSpout就是我们发送话题tuple的源
+ builder.setSpout(spoutId, new TestWordSpout(), 5);
+ // RollingCountBolt的时间窗口为9秒钟,每3秒发送一次统计结果到下游
+ builder.setBolt(counterId, new RollingCountBolt(9, 3), 4).fieldsGrouping(spoutId, new Fields("word"));
+ // IntermediateRankingsBolt,将完成部分聚合,统计出top-n的话题
+ builder.setBolt(intermediateRankerId, new IntermediateRankingsBolt(TOP_N), 4).fieldsGrouping(counterId, new Fields(
+ "obj"));
+ // TotalRankingsBolt, 将完成完整聚合,统计出top-n的话题
+ builder.setBolt(totalRankerId, new TotalRankingsBolt(TOP_N)).globalGrouping(intermediateRankerId);
+```
+
+上面的topology设计如下:
+
+
+
+将聚合计算与时间结合起来
+前文,我们叙述了tick事件,回调中会触发bolt的execute方法,那可以这么做:
+
+```
+RollingCountBolt:
+ @Override
+ public void execute(Tuple tuple) {
+ if (TupleUtils.isTick(tuple)) {
+ LOG.debug("Received tick tuple, triggering emit of current window counts");
+ // tick来了,将时间窗口内的统计结果发送,并让窗口滚动
+ emitCurrentWindowCounts();
+ }
+ else {
+ // 常规tuple,对话题计数即可
+ countObjAndAck(tuple);
+ }
+ }
+
+ // obj即为话题,增加一个计数 count++
+ // 注意,这里的速度基本取决于流的速度,可能每秒百万,也可能每秒几十.
+ // 内存不足? bolt可以scale-out.
+ private void countObjAndAck(Tuple tuple) {
+ Object obj = tuple.getValue(0);
+ counter.incrementCount(obj);
+ collector.ack(tuple);
+ }
+
+ // 将统计结果发送到下游
+ private void emitCurrentWindowCounts() {
+ Map counts = counter.getCountsThenAdvanceWindow();
+ int actualWindowLengthInSeconds = lastModifiedTracker.secondsSinceOldestModification();
+ lastModifiedTracker.markAsModified();
+ if (actualWindowLengthInSeconds != windowLengthInSeconds) {
+ LOG.warn(String.format(WINDOW_LENGTH_WARNING_TEMPLATE, actualWindowLengthInSeconds, windowLengthInSeconds));
+ }
+ emit(counts, actualWindowLengthInSeconds);
+ }
+```
+
+上面的代码可能有点抽象,看下这个图就明白了,tick一到,窗口就滚动:
+
+
+
+```
+IntermediateRankingsBolt & TotalRankingsBolt:
+ public final void execute(Tuple tuple, BasicOutputCollector collector) {
+ if (TupleUtils.isTick(tuple)) {
+ getLogger().debug("Received tick tuple, triggering emit of current rankings");
+ // 将聚合并排序的结果发送到下游
+ emitRankings(collector);
+ }
+ else {
+ // 聚合并排序
+ updateRankingsWithTuple(tuple);
+ }
+ }
+```
+ 其中,IntermediateRankingsBolt和TotalRankingsBolt的聚合排序方法略有不同:
+
+IntermediateRankingsBolt的聚合排序方法:
+
+```
+ @Override
+ void updateRankingsWithTuple(Tuple tuple) {
+ // 这一步,将话题、话题出现的次数提取出来
+ Rankable rankable = RankableObjectWithFields.from(tuple);
+ // 这一步,将话题出现的次数进行聚合,然后重排序所有话题
+ super.getRankings().updateWith(rankable);
+ }
+```
+
+TotalRankingsBolt的聚合排序方法:
+
+```
+ @Override
+ void updateRankingsWithTuple(Tuple tuple) {
+ // 提出来自IntermediateRankingsBolt的中间结果
+ Rankings rankingsToBeMerged = (Rankings) tuple.getValue(0);
+ // 聚合并排序
+ super.getRankings().updateWith(rankingsToBeMerged);
+ // 去0,节约内存
+ super.getRankings().pruneZeroCounts();
+ }
+```
+
+而重排序方法比较简单粗暴,因为只求前N个,N不会很大:
+
+```
+ private void rerank() {
+ Collections.sort(rankedItems);
+ Collections.reverse(rankedItems);
+ }
+```
+
+ 结语
+
+ 下图可能就是我们想要的结果,我们完成了t0 - t1时刻之间的热点话题统计.
+
+
+
+## 18.4 如何进行离线计算?
+
+相对于实时计算,有充裕的时间进行运算挖掘
+
+**应用场景**
+
+- 用户流失预警系统
+- 基于用户购买的挽回系统
+- 用户特征和规则提取系统
+- 数据分析系统
+- 用户画像系统
+
+**流程**
+
+- 数据采集
+- 数据预处理
+- 数据建模
+- ETL
+- 数据导出
+- 工作流调度
+
+### 18.4.1 数据采集
+
+> Flume 收集服务器日志到hdfs
+>
+> ```
+> type=taildir taildir可以监控一个目录, 也可以用一个正则表达式匹配文件名进行实时收集
+> taildir=spooldir + exec + 支持断点续传
+> agent1.sources = source1
+> agent1.sinks = sink1
+> agent1.channels = channel1
+>
+> agent1.sources.source1.type = TAILDIR
+> agent1.sources.source1.positionFile = /var/log/flume/taildir_position.json
+> agent1.sources.source1.filegroups = f1 f2
+>
+> # 监控文件内容的改变
+>
+> agent1.sources.source1.filegroups.f1 = /usr/local/nginx/logs/example.log
+>
+> # 监控生成的文件
+>
+> agent1.sources.source1.filegroups.f1 = /usr/local/nginx/logs/.*log.*
+>
+> agent1.sources.source1.interceptors = i1
+> agent1.sources.source1.interceptors.i1.type = host
+> agent1.sources.source1.interceptors.i1.hostHeader = hostname
+>
+> # 配置sink组件为hdfs
+>
+> agent1.sinks.sink1.type = hdfs
+> agent1.sinks.sink1.hdfs.path=
+> hdfs://node-1:9000/weblog/flume-collection/%y-%m-%d/%H-%M_%hostname
+>
+> # 指定文件名前缀
+>
+> agent1.sinks.sink1.hdfs.filePrefix = access_log
+>
+> # 指定每批下沉数据的记录条数
+>
+> agent1.sinks.sink1.hdfs.batchSize= 100
+> agent1.sinks.sink1.hdfs.fileType = DataStream
+> agent1.sinks.sink1.hdfs.writeFormat =Text
+>
+> # 指定下沉文件按1G大小滚动
+>
+> agent1.sinks.sink1.hdfs.rollSize = 1024*1024*1024
+>
+> # 指定下沉文件按1000000条数滚动
+>
+> agent1.sinks.sink1.hdfs.rollCount = 1000000
+>
+> # 指定下沉文件按30分钟滚动
+>
+> agent1.sinks.sink1.hdfs.rollInterval = 30
+>
+> # agent1.sinks.sink1.hdfs.round = true
+>
+> # agent1.sinks.sink1.hdfs.roundValue = 10
+>
+> # agent1.sinks.sink1.hdfs.roundUnit = minute
+>
+> agent1.sinks.sink1.hdfs.useLocalTimeStamp = true
+>
+> # 使用memory类型channel
+>
+> agent1.channels.channel1.type = memory
+> agent1.channels.channel1.capacity = 500000
+> agent1.channels.channel1.transactionCapacity = 600
+>
+> # Bind the source and sink to the channel
+>
+> agent1.sources.source1.channels = channel1
+> agent1.sinks.sink1.channel = channel1
+> ```
+
+### 18.4.2 数据预处理
+
+> 数据预处理编程技巧
+>
+> - 对于本次分析无利用的数据 通常采用逻辑删除 建立标记位 通过01或者true false表示数据是否有效
+> - 对于最后一个字段不固定的情况 可以采用动态拼接的方式
+> - 静态资源过滤
+> - js css img (静态数据) 只关心真正请求页面的(index.html)
+> - data(动态数据)
+> - 在mr中,如果涉及小且频繁使用的数据,如何优化?
+> - 每次都从数据库查询 效率极低
+> - 可以通过数据结构保存在内存中 方便查询 一般在setup方法中进行初始化操作
+> - 关于mr程序输出文件名
+> - part-r-00000 表示是reducetask的输出
+> - part-m-00000 表示是maptask的输出
+
+### 18.4.3 数据建模
+
+> - 维度建模
+>
+> 专门适用于OLAP的设计模式存在着两种类型的表:事实表 维度表
+>
+> - 事实表:主题的客观度量 能够以记录主题为准 信息多不精准
+> - 维度表:看问题分析问题的角度 信息精但是不全 可跟事实表关系
+>
+> - 维度建模三种常见模型
+>
+> - 星型模型 一个事实表带多个维度表 维度之间没关系 数仓发展建立初期(一个主题)
+> - 雪花模型 一个事实表带多个维度表 维度之间可以继续关系维度 不利于维护 少用
+> - 星座模型 多个事实表带多个维度 有些维度可以共用 数仓发展后期(多个主题)
+>
+> 不管什么模型,在数仓中,一切有利于数据分析即可为,不用考虑数据冗余性和其他设计规范。
+>
+> - 模块设计–维度建模
+>
+> 在本项目中,因为分析主题只有一个(网站流量日志),所有采用星型模型
+> 事实表---->对应清洗完之后的数据
+> 维度表----->来自于提前通过工具生成 维度表范围要横跨事实表分析维度
+> 点击流模型属于业务模型数据 既不是事实表 也不是维度表 是为了后续计算某些业务指标方便而由业务指定
+>
+> - 宽表:为了分析,把原来表中某些字段属性提取出来,构成新的字段 也称之为明细表
+>
+> 窄表:没有扩宽的表 原始表
+> 宽表数据来自于窄表 insert(宽)+select (窄)
+> 总结:hive中,有几种方式可以创建出带有数据的表?
+>
+> - create+load data 创建表加载数据(内部表)
+>
+> - create +external +location 创建外部表指定数据路径
+>
+> - create+insert+select 表的数据来自于后面查询语句返回的结果
+>
+> - create+select 创建的表结构和数据来自于后面的查询语句
+>
+> ```
+> # -- hive内置解析url的函数
+>
+> parse_url_tuple(url,host path,query,queryvalue)
+>
+> # -- 通常用于把后面的表挂接在左边的表之上 返回成为一个新表
+>
+> a LATERAL VIEW b
+> LATERAL VIEW
+>
+> create table t_ods_tmp_referurl as SELECT a.*,b.* FROM ods_weblog_origin a LATERAL VIEW parse_url_tuple(regexp_replace(http_referer, "\"", ""), 'HOST', 'PATH','QUERY', 'QUERY:id') b as host, path, query, query_id;
+> ```
+>
+> - group by 语法限制
+>
+> ```
+> select count(*) as pvs from ods_weblog_detail t where datestr='20130918' group by t.hour
+>
+> select t.hour,count(*) as pvs from ods_weblog_detail t where datestr='20130918' group by t.hour
+>
+> # -- 在有group by的语句中,出现在select后面的字段要么是分组的字段要么是被聚合函数包围的字段。
+> 解决:
+> select t.day,t.hour,count(*) as pvs from ods_weblog_detail t where datestr='20130918' group by t.day,t.hour;
+> ```
+
+### 18.4.4 ETL
+
+> **宽表生成**
+>
+> - 生成ods+url解析表
+>
+> ```
+> create table t_ods_tmp_referurl as
+> SELECT a.*,b.*
+> FROM ods_weblog_origin a
+> LATERAL VIEW parse_url_tuple(regexp_replace(http_referer, "\"", ""), 'HOST', 'PATH','QUERY', 'QUERY:id') b as host, path, query, query_id;
+> ```
+>
+> - 生成ods+url+date解析表
+>
+> ```
+> create table t_ods_tmp_detail as
+> select b.*,substring(time_local,0,10) as daystr,
+> substring(time_local,12) as tmstr,
+> substring(time_local,6,2) as month,
+> substring(time_local,9,2) as day,
+> substring(time_local,11,3) as hour
+> From t_ods_tmp_referurl b;
+> ```
+>
+> - 综合
+>
+> ```
+> create table ods_weblog_detail(
+> valid string, --有效标识
+> remote_addr string, --来源IP
+> remote_user string, --用户标识
+> time_local string, --访问完整时间
+> daystr string, --访问日期
+> timestr string, --访问时间
+> month string, --访问月
+> day string, --访问日
+> hour string, --访问时
+> request string, --请求的url
+> status string, --响应码
+> body_bytes_sent string, --传输字节数
+> http_referer string, --来源url
+> ref_host string, --来源的host
+> ref_path string, --来源的路径
+> ref_query string, --来源参数query
+> ref_query_id string, --来源参数query的值
+> http_user_agent string --客户终端标识
+> )
+> partitioned by(datestr string);
+>
+> insert into table ods_weblog_detail partition(datestr='20130918')
+> select c.valid,c.remote_addr,c.remote_user,c.time_local,
+> substring(c.time_local,0,10) as daystr,
+> substring(c.time_local,12) as tmstr,
+> substring(c.time_local,6,2) as month,
+> substring(c.time_local,9,2) as day,
+> substring(c.time_local,12,2) as hour,
+> c.request,c.status,c.body_bytes_sent,c.http_referer,c.ref_host,c.ref_path,c.ref_query,c.ref_query_id,c.http_user_agent
+> from
+> (select a.*,b.*
+> from ods_weblog_origin a
+> LATERAL view
+> parse_url_tuple(regexp_replace(a.http_referer,"\"",""),'HOST','PATH','QUERY','QUERY_ID')b as ref_host, ref_path, ref_query, ref_query_id) c;
+> ```
+>
+> **DML分析**
+>
+> - 计算该处理批次(一天)中的各小时 pvs
+>
+> ```
+> select
+> t.month,t.day,t.hour,count(*)
+> from ods_weblog_detail t
+> where t.datestr='20130918'
+> group by t.month,t.day,t.hour;
+> ```
+>
+> - 计算每天的pvs
+>
+> ```
+> select t.month,t.day,count(*) from ods_weblog_detail t where t.datestr='20130918' group by t.month,t.day;
+>
+> select a.month,a.day,sum(a.pvs)
+> from
+> (
+> select
+> t.month as month,t.day as day,t.hour as hour,count(*) as pvs
+> from ods_weblog_detail t
+> where t.datestr='20130918'
+> group by t.month,t.day,t.hour
+> ) a
+> group by a.month,a.day;
+> ```
+>
+> 统计每小时各来访url产生的pvs
+>
+> ```
+> select
+> t.day,t.hour,t.http_referer,t.ref_host,count(*)
+> from ods_weblog_detail t
+> where datestr='20130918'
+> group by t.day,t.hour,t.http_referer,t.ref_host
+> having t.ref_host is not null;
+> ```
+>
+> - 统计每小时各来访host的产生的pv数并排序
+>
+> ```
+> select
+> t.month,t.day,t.hour,t.ref_host,count(*) as pvs
+> from ods_weblog_detail t
+> where datestr='20130918'
+> group by t.month,t.day,t.hour,t.ref_host
+> having t.ref_host is not null
+> order by t.hour asc ,pvs desc;
+> ```
+>
+> ```
+> 按照时间维度,统计一天内各小时产生最多pvs的来源(host)topN(分组Top)
+> select
+> a.month,a.day,a.hour,a.host,a.pvs,a.rmp
+> from
+> (
+> select
+> t.month as month,t.day as day,t.hour as hour,t.ref_host as host,count(*) as pvs,
+> row_number()over(partition by concat(t.month,t.day,t.hour) order by pvs desc) rmp
+> from ods_weblog_detail t
+> where datestr='20130918'
+> group by t.month,t.day,t.hour,t.ref_host
+> having t.ref_host is not null
+> order by hour asc ,pvs desc
+> )a
+> where a.rmp < 4;
+> ```
+>
+> 统计今日所有来访者平均请求的页面数。
+>
+> ```
+> select count(*)/count(distinct remote_addr) from ods_weblog_detail where datestr='20130918';
+>
+> select
+> sum(a.pvs)/count(a.ip)
+> from
+> (
+> select
+> t.remote_addr as ip,count(*) as pvs
+> from ods_weblog_detail t
+> where t.datestr='20130918'
+> group by t.remote_addr
+> ) a;
+> ```
+>
+> - 统计每日最热门的页面 top10
+>
+> ```
+> select
+> t.request,count(*) as counts
+> from ods_weblog_detail t
+> where datestr='20130918'
+> group by t.request
+> order by counts desc
+> limit 10;
+> ```
+>
+> - 每日新访客
+>
+> ```
+> select
+> today.ip
+> from
+> (
+> select distinct t.remote_addr as ip
+> from ods_weblog_detail t
+> ) today
+> left join history
+> on today.ip=history.ip
+> where history.ip is null;
+> ```
+>
+> - 查询今日所有回头访客及其访问次数(session)
+>
+> ```
+> select
+> remote_addr,count(session) as cs
+> from ods_click_stream_visit
+> where datestr='20130918'
+> group by remote_addr
+> having cs >1;
+> ```
+>
+> - 人均访问频次
+>
+> ```
+> select
+> count(session)/count(distinct remote_addr)
+> from ods_click_stream_visit
+> where datestr='20130918';
+> ```
+>
+> - 级联查询自join
+>
+> ```
+> select
+> rn.step as rnstep,rn.numbs as rnnumbs,rr.step as rrstep,rr.numbs as rrnumbs
+> from dw_oute_numbs rn
+> inner join
+> dw_oute_numbs rr;
+>
+> # -- 绝对转化
+>
+> select
+> a.rrstep,a.rrnumbs/a.rnnumbs
+> from
+> (
+> select
+> rn.step as rnstep,rn.numbs as rnnumbs,rr.step as rrstep,rr.numbs as rrnumbs
+> from dw_oute_numbs rn
+> inner join dw_oute_numbs rr
+> )a
+> where a.rnstep='step1';
+>
+> # -- 相对转化
+>
+> select
+> tmp.rrstep as step,tmp.rrnumbs/tmp.rnnumbs as leakage_rate
+> from
+> (
+> select rn.step as rnstep,rn.numbs as rnnumbs,rr.step as rrstep,rr.numbs as rrnumbs from dw_oute_numbs rn
+> inner join
+> dw_oute_numbs rr
+> ) tmp
+> where cast(substr(tmp.rnstep,5,1) as int)=cast(substr(tmp.rrstep,5,1) as int)-1;
+> ```
+
+### 18.4.5 数据导出
+
+> Sqoop可以对HDFS文件进行导入导出到关系型数据库
+> Sqoop 工作机制是将导入或导出命令翻译成 mapreduce 程序来实现。
+> 在翻译出的 mapreduce 中主要是对 inputformat 和 outputformat 进行定制
+> sqoop实际生产环境中 关于mysql地址 尽量不要使用: localhost 可用ip或者域名代替
+>
+> **导入**
+>
+> - mysql----->hdfs 导入的文件分隔符为逗号
+> - mysql----->hive
+> - 需要先复制表结构到hive 再向表中导入数据
+> - 导入的文件分隔符为 ‘\001’
+> - sqoop中增量导入的判断是通过上次导入到某个列的某个值来标识 的,这个值由用户自己维护,一般企业中选择不重复且自增长的主键最多,自增长的时间也可以。
+>
+> ```
+> # 导入mysql表到hdfs
+>
+> bin/sqoop import \
+> --connect jdbc:mysql://node-1:3306/userdb \
+> --username root \
+> --password 123 \
+> --target-dir /sqoopresult \
+> --table emp --m 1
+>
+> # 支持条件导入数据
+>
+> bin/sqoop import \
+> --connect jdbc:mysql://node-1:3306/userdb \
+> --username root \
+> --password 123 \
+> --where "id > 1202" \
+> --target-dir /sqoopresult/t1 \
+> --table emp --m 1
+>
+> # 将关系型数据的表结构复制到hive中
+>
+> bin/sqoop create-hive-table \
+> --connect jdbc:mysql://node-1:3306/userdb \
+> --table emp_add \
+> --username root \
+> --password 123 \
+> --hive-table default.emp_add_sp
+>
+> # 从关系数据库导入文件到hive中
+>
+> bin/sqoop import \
+> --connect jdbc:mysql://node-1:3306/userdb \
+> --username root \
+> --password 123 \
+> --table emp_add \
+> --hive-table default.emp_add_sp \
+> --hive-import \
+> --m 1
+>
+> # 增量导入
+>
+> bin/sqoop import \
+> --connect jdbc:mysql://node-1:3306/userdb \
+> --username root \
+> --password 123 \
+> --table emp_add \
+> --target-dir '/user/hive/warehouse/emp_add_sp' \
+> --incremental append \
+> --check-column id \
+> --last-value 1205 \
+> --fields-terminated-by '\001' \
+> --m 1
+> ```
+>
+>
+> **导出**
+>
+> - hdfs导出到mysql
+>
+> - 要先在mysql中手动创建对应的表结构
+>
+> ```
+> # hdfs文件导出到mysql
+>
+> bin/sqoop export \
+> --connect jdbc:mysql://node-1:3306/userdb \
+> --username root \
+> --password 123 \
+> --table employee \
+> --export-dir /hivedata/employee.txt \
+> --fields-terminated-by '\001'
+> ```
+
+### 18.4.6 工作流调度
+
+> azkaban工作流程
+>
+> - 配置job文件(注意文件的第一行头信息)
+> - 把job配置连同其他资源一起打成.zip压缩包
+> - 页面上创建工程project
+> - 上传.zip压缩包
+> - execute/schedule
+
+## 18.5 如何设计一个人机交互系统?
+
+### 18.5.1 什么是人机交互系统?
+
+ 人机交互系统(Human-computer interaction,简称HCI)是研究人与计算机之间通过相互理解的交流与通信,在最大程度上为人们完成信息管理,服务和处理等功能,使计算机真正成为人们工作学习的和谐助手的一门技术科学。
+
+ 通俗来讲,就是指人与计算机之间使用某种对话语言,以一定的交互方式,为完成确定任务的人与计算机之间的信息交换过程。
+
+ 目前工业界落地的产品包括阿里巴巴集团的云小蜜、天猫精灵;百度的UNIT、小度;小米的小爱同学;京东的叮咚智能音箱等。
+
+【产品图】
+
+人机交互发展阶段大致可分为四个阶段
+
+- 第一代人机交互技术:基于键盘和字符显示器的交互阶段
+- 第二代人机交互技术:基于鼠标和图形显示器的交互阶段
+- 第三代人机交互技术:基于多媒体技术的交互阶段
+- 第四代人机交互技术:人机自然交互与通信
+
+本章节重点介绍第四代人机交互技术,传统人机交互模型主要组成部分包括:
+
+1.多模态输入/输出:多模态输入/输出是第四代人机交互与通信的主要标志之一。多模态输入包括键盘、鼠标、文字、语音、手势、表情、注视等多种输入方式;而多模态输出包括文字、图形、语音、手势、表情等多种交互信息
+
+2.智能接口代理:智能接口代理是实现人与计算机交互的媒介
+
+3.视觉获取:视觉系统主要用于实时获取外部视觉信息
+
+4.视觉合成:使人机交互能够在一个仿真或虚拟的环境中进行,仿佛现实世界中人与人之间的交互
+
+5.对话系统:目前主要由两种研究趋势,一种以语音为主,另一种从某一特定任务域入手,引入对话管理概念,建立类似于人人对话的人机对话
+
+6.Internet信息服务:扮演信息交流媒介的角色
+
+7.知识处理:自动地提取有组织的,可为人们利用的知识
+
+本章节介绍的人机交互系统在传统人机交互功能基础上提供:
+
+- 对话管理:业界领先的自然语言交互系统,支持多意图自由跳转以及状态跟踪等技术
+- 意图识别:基于fasttext与textcnn、bert等nlp处理技术提供多意图识别框架以及策略
+- 实验系统:多重叠实验框架,支持流量多种划分方式以及灰度白名单功能
+- 分布式训练:基于k8s+tensorflow+kebuflow的分布式gpu训练集群
+- 日志分析:基于spark+flume等流式大数据处理成熟方案,提供在线日志分析系统
+- 语料平台:基于标注数据以及线上数据汇总的语料存储平台
+
+等功能。
+
+【架构设计图】
+
+
+### 18.5.2 如何设计人机交互系统的问答引擎算法架构?
+
+人机交互系统中的核心是问答引擎,引擎架构设计的好坏直接影响整个系统的用户体验,地位就像人的大脑。
+
+本章节介绍的问答引擎架构由预处理模块、检索模块、知识图谱、排序模块、用户画像组成。
+
+
+
+
+
+检索模块如果能完全命中语料库答案则直接返回,不在经过排序。
+
+ES检索和深度语义匹配是比较粗比较弱的召回模型,不用考虑用户问内部的相对顺序,也不用考虑用户问与匹配问之间的位置编码,ngram信息。精排解决这些问题,且有更强的拟合性,但精排涉及到效率问题,所以在此之前有实体对齐过滤一些明显不对的答案。
+
+回答不了的问题可以坐意图澄清或者转移到另一个问题。
+
+借鉴推荐系统的思想:
+
+1.粗排阶段根据用户长期兴趣画像召回相关度较高的答案,同时减轻精排阶段的压力
+
+2.精排阶段则根据粗排召回的答案列表,通过离线训练好的排序模型预测CTR,最终下发前Top N 个答案作为推荐结果。
+
+### 18.5.3 如何处理长难句?
+
+
+**长难句压缩**
+
+ 输入:“嗯你好,我之前06年的时候买了一个保险,嗯一年只交了518元,然后后面我就再也没有买了,是06年的事情,然后现在我打电话给那个服务热线吧,我想退保就是”
+
+ 输出:“我之前06年的时候买了保险,我想退保”
+
+ 输入:“一年半之前做过小腿骨折手术,现在已修复,只是固定钢板还没取,准备8月取,医生说也可以不取,不影响正常生活和工作,能否投保相互保?”
+
+ 输出:“做过腿骨折手术,不影响正常生活和工作,能否投保相互保?”
+
+
+**传统处理方案**
+
+- 语法树分析+关键词典
+
+步骤:
+
+1.通过标点或空格分割长句成若干个断句,然后对短句分类,去掉口水语句
+
+2.基于概率和句法分析的句子压缩方案,只保留主谓宾等核心句子成分。配合特定的关键词典,确保关键词被保留。
+
+
+**深度学习处理方案**
+
+- 文本摘要和句子压缩主流方法:一种是抽取式(extractive),另一种是生成式(abstractive)
+
+从传统的TextRank抽取式,到深度学习中采用RNN、CNN单元处理,再引入Attention、Self-Attention、机器生成摘要的方式,这些跟人类思维越来越像,都建立在对整段句子的理解之上,生成摘要的效果,常常让我们惊艳。
+
+注意:TextRank算法对较短的文本效果不好。
+
+### 18.5.4 如何纠错?
+
+- **字典纠错:字典+规则,特定数据驱动型纠错**
+
+
+
+- **通用纠错模型:神经网络模型,其他纠错保底**
+
+
+
+### 18.5.5 什么是指代消解?如何指代消解?
+
+ 指代消解,广义上说,就是在篇章中确定代词指向哪个名词短语的问题。按照指向,可以分为回指和预指。回指就是代词的先行语在代词前面,预指就是代词的先行语在代词后面。按照指代的类型可以分为三类:人称代词、指示代词、有定描述、省略、部分-整体指代、普通名词短语。
+
+1. 主谓关系SBV(subject-verb)
+1. 状中结构ADV(adverbial)
+1. 核心HED(head)
+1. 动宾关系VOB(verb-object)
+1. 标点 WP
+1. nhd:疾病,v:动词,vn:名动词 ,nbx:自定义专有名词,rzv:谓词性指示代词
+
+例子:
+
+ 输入1: 感冒/nhd 可以/v 投保/vn 相互保/nbx 吗/y?
+ 输入2: 那/rzv 癌症/nhd 呢/y?
+ 输出:癌症可以投保相互保吗?
+
+ 输入1:相互保很好
+ 输入2:这个产品比e生保好在哪?
+ 输出:相互保比e生保好在哪?
+
+ 输入1:相互保、e生保都是医疗险吗
+ 输入2:前者能报销啥
+ 输出:相互保能报销啥
+
+ 输入1:相互保、e生保都是医疗险吗
+ 输入2:第一种能报销啥
+ 输出:相互保能报销啥
+ 输入3:第二种呢
+ 输出:e生保能报销啥
+
+分析:
+
+ 感冒 --(SBV)--> 投保
+ 可以 --(ADV)--> 投保
+ 投保 --(HED)--> ##核心##
+ 相互保 --(VOB)--> 投保
+ 吗 --(RAD)--> 投保
+ ? --(WP)--> 投保
+
+实现思路:
+
+ 分词->词性标注->依存句法分析->主谓宾提取->实体替换/指代消解
+
+待消解项,先行语可通过句法分析找出。
+
+### 18.5.6 如何做语义匹配?
+
+- 孪生网络(Siamese network)
+
+孪生神经网络是一类包含两个或更多个相同子网络的神经网络架构。 这里相同是指它们具有相同的配置即具有相同的参数和权重。 参数更新在两个子网上共同进行。
+
+孪生神经网络在涉及发现相似性或两个可比较的事物之间的关系的任务中流行。 一些例子是复述评分,其中输入是两个句子,输出是它们是多么相似的得分; 或签名验证,确定两个签名是否来自同一个人。 通常,在这样的任务中,使用两个相同的子网络来处理两个输入,并且另一个模块将取得它们的输出并产生最终输出。 下面的图片来自Bromley et al (1993)【11】。 他们为签名验证任务提出了一个孪生体系结构。
+
+
+
+孪生结构之所以在这些任务中表现的比较好,有如下几个原因 :
+
+```
+1.子网共享权重意味着训练需要更少的参数,也就意味着需要更少的数据并且不容易过拟合。
+
+2.每个子网本质上产生其输入的表示。 (图片中的"签名特征向量")。如果输入是相同类型的,例如匹配两个句子或匹配两个图片,使用类似的模型来处理类似的输入是有意义的。 这样,就有了具有相同语义的表示向量,使得它们更容易比较。
+```
+
+问题回答,一些最近的研究使用孪生体系结构来评分问题和答案候选人之间的相关性[2]。 所以一个输入是一个问句,另一个输入是一个答案,输出和问题的答案是相关的。 问题和答案看起来不完全相同,但如果目标是提取相似性或它们之间的联系,孪生体系结构也可以很好地工作。
+
+- 交互矩阵(MatchPyramid)【12】
+
+对于文本匹配,基本思路如下述公式:
+$$
+match(T1,T2)=F(θ(T1),θ(T2))
+$$
+其中T为文本,函数θ代表将文本转换为对应的表示,函数F则代表两个文本表示之间的交互关系。
+由侧重点不同可分为表示方法与交互方法,即注重θ或者F,而MatchPyramid应属于后一种。
+
+基本方法:构建文本与文本的相似度矩阵,采用CNN对矩阵进行特征抽取,最后用softmax获得分类概率,评价方法为交叉熵。
+
+
+
+流程:
+
+- [x] 相似度矩阵
+
+由于CNN针对的是网格型数据,而文本显然属于序列数据,那么就有必要对数据进行转换,以下三种构建相似度矩阵的方法,其中距离矩阵使用点积的效果相对较好。
+
+- 0-1类型,每个序列对应的词相同为1,不同为0
+
+
+
+
+
+- cosine距离,使用预训练的Glove将词转为向量,之后计算序列对应的词的cosine距离
+
+
+
+- 点积,同上,但是将cosine距离改为点积
+
+ 
+
+- [x] 两层CNN
+
+
+后续利用两层的CNN对相似度矩阵进行特征抽取,这里要注意的是由于上一层的相似度矩阵shape不一致,在第一层CNN后面进行maxpool的时候,要使用动态pool,有没有其他的小trick就不可得知了。
+
+- [x] 两层MLP
+
+
+最后用两层的全连接对CNN的结果进行转换,使用softmax函数得到最终分类概率。
+
+> 作者使用论文中的模型,在kaggle的quora数据集中得到一个相当不错的分数,最终小组成绩达到了第四名。
+> 附实现地址:https://github.com/faneshion/MatchZoo
+
+### 18.5.7 如何在海量的向量中查找相似的TopN向量?
+
+- **Annoy搜索算法**
+
+ Annoy的目标是建立一个数据结构,使得查询一个点的最近邻点的时间复杂度是次线性。Annoy通过建立一个二叉树来使得每个点查找时间复杂度是O(log n)。 看下面这个图,随机选择两个点,以这两个节点为初始中心节点,执行聚类数为2的kmeans过程,最终产生收敛后两个聚类中心点。这两个聚类中心点之间连一条线段(灰色短线),建立一条垂直于这条灰线,并且通过灰线中心点的线(黑色粗线)。这条黑色粗线把数据空间分成两部分。在多维空间的话,这条黑色粗线可以看成等距垂直超平面。
+
+
+
+ 通过多次递归迭代划分的话,最终原始数据会形成类似下面这样一个二叉树结构。二叉树底层是叶子节点记录原始数据节点,其他中间节点记录的是分割超平面的信息。Annoy建立这样的二叉树结构是希望满足这样的一个假设: 相似的数据节点应该在二叉树上位置更接近,一个分割超平面不应该把相似的数据节点分割二叉树的不同分支上。
+
+ 总结:Annoy建立一个数据结构,使得查询一个向量的最近邻向量的时间复杂度是次线性
+
+ 步骤:随机选两个点聚类->超平面内分割->构造二叉树->构造多棵树->检索答案合并排序
+
+ 注意:第一次查询速度比较慢,是个近似算法,准确率逼近100%
+
+### 18.5.8 什么是话术澄清?
+
+ 问题有歧义或者匹配答案有置信度但不够高的时候触发话术澄清。简单来说,就是明确意图,意图不明确的时候可以反问用户以确认。
+
+
+
+ 意图图谱的节点代表一个个意图节点。这些“意图”之间的关系包括需求澄清(disambiguation)、需求细化(depth extension)、需求横向延展(breadth extension )等。在图所示例子中,当“阿拉斯加”的意思是“阿拉斯加州”时,与之关联的意图是城市、旅游等信息。当“阿拉斯加”的含义是“阿拉斯加犬”时,它延伸的意图是宠物狗、宠物狗护理,以及如何喂食等。
+
+### 18.5.9 如何对结果进行排序打分?
+
+- **DRMM+PACRR**【13】
+
+ **DRMM+PACRR**是针对文档相关性排序的新模型,这几种模型基于此前的DRMM模型。具体来说,DRMM 模型使用的是上下文无关的term encoding编码方式,改进模型则借鉴了PACRR的思想,融合了n-grams 和不同方式编码的上下文信息。
+
+ Context-sensitive Term Encodings构造qd相似度矩阵,卷积提取ngram信息。
+
+ 两层max-pooling获取最强相似信息并拼接。
+
+ 使用相同的MLP网络独立地计算每一个q-term encoding(矩阵的每一行)的分数,再通过一个线性层得到query与doc的相关性得分 。
+
+
+
+ github地址:https://github.com/nlpaueb/deep-relevance-ranking
+
+- **N-grams**
+
+ **N-grams**是机器学习中NLP处理中的一个较为重要的语言模型,常用来做句子相似度比较,模糊查询,以及句子合理性,句子矫正等。
+
+ 如果你是一个玩LOL的人,那么当我说“正方形打野”、“你是真的皮”,“你皮任你皮”这些词或词组时,你应该能想到的下一个词可能是“大司马”,而不是“五五开”。如果你不是LOL玩家,没关系,当我说“上火”、“金罐”这两个词,你能想到的下一个词应该更可能“加多宝”,而不是“可口可乐”。
+ **N-grams**正是基于这样的想法,它的第一个特点是某个词的出现依赖于其他若干个词,第二个特点是我们获得的信息越多,预测越准确。我想说,我们每个人的大脑中都有一个N-gram模型,而且是在不断完善和训练的。我们的见识与经历,都在丰富着我们的阅历,增强着我们的联想能力。
+ **N-grams**模型是一种语言模型(Language Model,LM),语言模型是一个基于概率的判别模型,它的输入是一句话(单词的顺序序列),输出是这句话的概率,即这些单词的联合概率(joint probability)。
+
+ **N-grams中的概率计算**
+
+ 假设我们有一个有n个词组成的句子$S=(w1,w2,...,wn)$ , 如何衡量它的概率呢?让我们假设,每个单词$wi$都要依赖于从第一个单词$w1$到它之前一个单词$wi−1$的影响:
+$$
+p(S)=p(w1w2...wn)=p(w1)p(w2|w1)...p(wn|wn1...w2w1)
+$$
+这个衡量方法有两个缺陷:
+
+- **参数空间过大**,概率$p(wn|wn-1...w2w1)$的参数有$O(n)$个。
+- **数据稀疏严重**,词同时出现的情况可能没有,组合阶数高时尤其明显。
+
+为了解决第一个问题,我们引入**马尔科夫假设(Markov Assumption)**:**一个词的出现仅与它之前的若干个词有关**。
+$$
+p(w1⋯wn)=∏p(wi∣wi−1⋯w1)≈∏p(wi∣wi−1⋯wi−N+1)
+$$
+如果一个词的出现仅依赖于它前面出现的一个词,那么我们就称之为 **Bi-gram**:
+$$
+p(S)=p(w
+1
+
+ w
+2
+
+ ⋯w
+n
+
+ )=p(w
+1
+
+ )p(w
+2
+
+ ∣w
+1
+
+ )⋯p(w
+n
+
+ ∣w
+n−1
+
+ )
+$$
+如果一个词的出现仅依赖于它前面出现的两个词,那么我们就称之为 **Tri-gram**:
+$$
+p(S)=p(w
+1
+
+ w
+2
+
+ ⋯w
+n
+
+ )=p(w
+1
+
+ )p(w
+2
+
+ ∣w
+1
+
+ )⋯p(w
+n
+
+ ∣w
+n−1
+
+ w
+n−2
+
+ )
+$$
+N-gram的$N$可以取很高,然而现实中一般 bi-gram 和 tri-gram 就够用了。
+
+那么,如何计算其中的每一项条件概率 $p(wn∣wn−1⋯w2w1) $答案是**极大似然估计(Maximum Likelihood Estimation,MLE)**,即数频数:
+$$
+p(w
+n
+
+ ∣w
+n−1
+
+ )=
+C(w
+n−1
+
+ )
+C(w
+n−1
+
+ w
+n
+
+ )
+$$
+
+$$
+p(w
+n
+
+ ∣w
+n−1
+
+ w
+n−2
+
+ )=
+C(w
+n−2
+
+ w
+n−1
+
+ )
+C(w
+n−2
+
+ w
+n−1
+
+ w
+n
+
+ )
+
+
+$$
+
+$$
+p(w
+n
+
+ ∣w
+n−1
+
+ ⋯w
+2
+
+ w
+1
+
+ )=
+C(w
+1
+
+ w
+2
+
+ ⋯w
+n−1
+
+ )
+C(w
+1
+
+ w
+2
+
+ ⋯w
+n
+
+ )
+
+
+$$
+
+**具体地**,以Bi-gram为例,我们有这样一个由三句话组成的语料库:
+
+
+
+容易统计,“I”出现了3次,“I am”出现了2次,因此能计算概率:
+$$
+p(am∣I)=
+3
+2
+$$
+同理,还能计算出如下概率:
+
+$p(I∣)=0.67p(do∣I)=0.33p(Sam∣am)=0.5p(not∣do)=1p(∣Sam)=0.5p(like∣not)=1 $
+
+
+
+### 18.5.10 如何评估人机交互系统的效果?
+
+ 人机交互系统可通过有效问题数量、推荐Top1答案的准确率、推荐Top3答案的准确率、有效问题响应的准确率、知识覆盖率等指标衡量其效果。
+
+| 类型 | 指标 | 收集方式收集方式 |
+| :----------: | :----------------: | :--------------: |
+| 问答评估指标 | 有效问题数 | 日志抽样统计 |
+| 问答评估指标 | Top1准确率 | 日志抽样统计 |
+| 问答评估指标 | Top3准确率 | 日志抽样统计 |
+| 问答评估指标 | 有效问题响应准确率 | 日志抽样统计 |
+| 问答评估指标 | 知识覆盖率 | 日志抽样统计 |
+
+| 类型 | 指标指标 | 计算公式 | 指标用途 | 收集方式 |
+| :------: | :------------: | :----------------------------------------------------------: | :------: | :--------: |
+| 总体指标 | 请求量占比 | FAQ、任务型、寒暄FAQ机器人的请求量/总请求量 | 运维 | 日志可得出 |
+| 总体指标 | 总用户量 | FAQ、任务型、寒暄引擎的独立访客数 | 运维 | 日志可得出 |
+| 总体指标 | 解决率 | (点击解决button量+不点击)/FAQ咨询重量=1-点击未解决button量/FAQ总咨询量 | 分析 | 日志可得出 |
+| 总体指标 | 未解决率 | 点击解决button/FAQ总咨询量=1-解决率 | 分析 | 日志可得出 |
+| 总体指标 | 转人工率 | FAQ转人工量/FAQ总咨询量 | 分析 | 日志可得出 |
+| 总体指标 | 任务达成率 | 业务办理成功量/业务办理请求量 | 分析 | 日志可得出 |
+| 总体指标 | 平均会话时长 | FAQ、任务、向量对话时长/总用户数 | 分析 | 日志可得出 |
+| 总体指标 | 平均对话轮数 | 总对话论数/总用户数 | 分析 | 日志可得出 |
+| 总体指标 | 断点问题分析 | 转空客问题 | 分析 | 日志可得出 |
+| 总体指标 | 无应答问题分析 | 机器人返回兜底话术的问题 | 分析 | 日志可得出 |
+| 总体指标 | 热点问题分析 | 问题咨询总量TopN | 分析 | 日志可得出 |
+
+## 18.6 如何设计个性化推荐系统?
+
+### 18.6.1 什么是个性化推荐系统?
+
+ 个性化推荐系统就是根据用户的历史,社交关系,兴趣点,上下文环境等信息去判断用户当前需要或潜在感兴趣的内容的一类应用。
+
+ 大数据时代,我们的生活的方方面面都出现了信息过载的问题:电子商务、电影或者视频网站、个性化音乐网络电台、社交网络、个性化阅读、基于位置的服务、个性化邮件、个性化广告.......逛淘宝、订外卖、听网络电台、看剧等等等。推荐系统在你不知不觉中将你感兴趣的内容推送给你,甚至有的时候,推荐系统比你本人更了解你自己。
+
+ 推荐系统的业务主要包括四个部分:
+
+- 物料组装:生产广告,实现文案、图片等内容的个性化
+
+- 物料召回:在大量内容中召回一个子集作为推荐的内容
+- 物料排序:将召回的子集的内容按照某种标准进行精细排序
+- 运营策略:加入一些运营策略进行一部分的重新排序,再下发内容
+
+ 推荐系统必须要实现收集与分析数据的功能。数据收集体现为:埋点、上报、存储。而数据分析则体现为:构造画像(用户与内容)、行为归因。
+
+ 推荐系统的算法体现在两部分:**召回、排序**。召回的算法多种多样:itemCF、userCF、关联规则、embedding、序列匹配、同类型收集等等。排序的算法可以从多个角度来描述,这里我们从一个宏观的角度来描述,即排序算法可以分成五个部分:**构造样本、设计模型、确定目标函数、选择优化方法、评估**。
+
+### 18.6.2 如何设计个性化推荐系统的推荐引擎架构?
+
+
+
+### 18.6.3 召回模块
+
+- 热点召回和人工运营:兜底策略
+- 用户画像(CB)召回:标签排序、倒排截取
+- CF召回算法:user-based算法和item-based算法
+
+- 如何做大规模在线用户CF召回?
+ - 离线计算每个用户的相似用户top k,存入cache
+ - 在线存储每个用户的点击记录
+ - 在线检索相似用户点击记录
+
+### 18.6.4 排序模块
+
+- 模型选择:LR、FM、GBDT、DNN ...
+
+| 复杂特征+简单模型 | 简单特征+复杂模型 |
+| ------------------------------------------ | -------------------- |
+| 线性模型:LR | 非线性模型:GBDT,DNN |
+| 训练快,解析性好 | 表达能力强,起点高 |
+| 在线预测简单 | 训练慢,解析性差 |
+| 人工构造大规模特征才能提升效果,后期难维护 | 容易过拟合,难优化 |
+
+- 排序算法演进
+
+ 
+
+### 18.6.5 离线训练
+
+- 离线训练流程
+
+ 
+
+- 如何线上实时反馈特征?
+
+ - 在线计算,与曝光日志一起上报,离线直接使用
+
+- 如何解决曝光不足问题?
+
+ - 使用CTR的贝叶斯平滑(CTR = 曝光次数 / 点击次数)【15】
+
+ > - 所有新闻自身CTR(r)服从Beta分布:
+ >
+ > 
+ >
+ > - 某一新闻,给定展示次数时和自身CTR,点击次数服从伯努利分布,曝光次数为I,点击次数为C:
+ >
+ > 
+ >
+ > - 对最大似然函数求解参数α,β,则i新闻CTR后验估计:
+ >
+ > 
+ >
+ > - 对曝光不足的做平滑,曝光充分的影响不大
+
+### 18.6.6 用户画像
+
+- 用户标签
+- 统计方法
+ - 用户feeds内行为,标签 计数(点击率),缺点:无法加入更多特征,不方便后续优化
+
+- 基于机器学习的方法
+ - 对用户长期兴趣建模
+ - LR模型
+ - 用户标签作为特征
+
+### 18.6.7 GBDT粗排
+
+- 为什么需要粗排?
+ - 快速筛选高质量的候选集
+ - 方便利用在线实时反馈特征
+- 如何做粗排的特征设计?
+ - 特征要相对稠密
+- 如何选择合适的算法模型?
+ - lightgbm
+ - xgboost
+ - lightgbm比xgboot速度更快;在线预测时,线程更安全
+
+### 18.6.8 在线FM精排
+
+- 为什么需要在线学习?
+
+ - feeds内容更新快
+ - 用户兴趣会随时间变化
+ - 排序模型需要快速反应用户的兴趣变化
+
+- **FM模型**
+
+ 
+ $$
+
+ $$
+
+ $$
+ 𝜎(𝑦)=1/(1+exp(−𝑦))
+ $$
+
+- **采用FTRL(Follow The Regularized Leader)更新模型**
+
+ - 算法概述
+
+ FTRL是一种适用于处理超大规模数据的,含大量稀疏特征的在线学习的常见优化算法,方便实用,而且效果很好,常用于更新在线的CTR预估模型。
+
+ FTRL算法兼顾了FOBOS和RDA两种算法的优势,既能同FOBOS保证比较高的精度,又能在损失一定精度的情况下产生更好的稀疏性。
+
+ FTRL在处理带非光滑正则项(如L1正则)的凸优化问题上表现非常出色,不仅可以通过L1正则控制模型的稀疏度,而且收敛速度快。
+
+ - 算法要点与推导
+
+ 
+
+ - 算法特性及优缺点
+
+ 在线学习,实时性高;可以处理大规模稀疏数据;有大规模模型参数训练能力;根据不同的特征特征学习率 。
+
+ FTRL-Proximal工程实现上的tricks:
+
+ 1.saving memory
+
+ ```
+ 方案1)Poisson Inclusion:对某一维度特征所来的训练样本,以p的概率接受并更新模型。
+ 方案2)Bloom Filter Inclusion:用bloom filter从概率上做某一特征出现k次才更新。
+ ```
+
+ 2.浮点数重新编码
+
+ ```
+ 1)特征权重不需要用32bit或64bit的浮点数存储,存储浪费空间。
+ 2)16bit encoding,但是要注意处理rounding技术对regret带来的影响(注:python可以尝试用numpy.float16格式)
+ ```
+
+ 3.训练若干相似model
+
+ ```
+ 1)对同一份训练数据序列,同时训练多个相似的model。
+ 2)这些model有各自独享的一些feature,也有一些共享的feature。
+ 3)出发点:有的特征维度可以是各个模型独享的,而有的各个模型共享的特征,可以用同样的数据训练。
+ ```
+
+ 4.Single Value Structure
+
+ ```
+ 1)多个model公用一个feature存储(例如放到cbase或redis中),各个model都更新这个共有的feature结构。
+ 2)对于某一个model,对于他所训练的特征向量的某一维,直接计算一个迭代结果并与旧值做一个平均。
+ ```
+
+ 5.使用正负样本的数目来计算梯度的和(所有的model具有同样的N和P)
+
+ 
+
+ 6.subsampling Training Data
+
+ ```
+ 1)在实际中,CTR远小于50%,所以正样本更加有价值。通过对训练数据集进行subsampling,可以大大减小训练数据集的大小。
+ 2)正样本全部采(至少有一个广告被点击的query数据),负样本使用一个比例r采样(完全没有广告被点击的query数据)。但是直接在这种采样上进行训练,会导致比较大的biased prediction。
+ 3)解决办法:训练的时候,对样本再乘一个权重。权重直接乘到loss上面,从而梯度也会乘以这个权重。
+ ```
+
+ - 适合场景
+
+ 点击率模型
+
+ - 案例
+
+ [https://www.kaggle.com/jiweiliu/ftrl-starter-code/output]()
+
+ https://github.com/Angel-ML/angel/blob/master/docs/algo/ftrl_lr_spark.md
+
+- 如何选择精排特征?
+
+ - 新增特征需保证已有特征索引不变
+ - 定期离线训练淘汰无用特征,防止特征无线膨胀
+ - 使用GBDT粗排预测的CTR分段结果作为特征
+
+### 18.6.9 算法介绍
+
+- 协同过滤算法
+
+ 协同过滤(Collaborative filtering, CF)算法是目前个性化推荐系统比较流行的算法之一。
+
+ 协同算法分为两个基本算法:**基于用户的协同过滤(UserCF)和基于项目的协同过滤(ItemCF)。**
+
+ 
+
+- 基于属性的推荐算法
+
+ - 基于用户标签的推荐
+
+ 统计用户最常用的标签,对于每个标签,统计被打过这个标签次数最多的物品,然后将具有这些标签的最热门的物品推荐给这个用户。这个方法非常适合新用户或者数据很少的冷启动,目前许多的app都会在新用户最初进入时让用户添加喜好标签方便为用户推送内容。
+
+ - 基于商品内容的推荐算法
+
+ 利用商品的内容属性计算商品之间的相似度,是物推物的算法。这种算法不依赖用户行为,只要获取到item的内容信息就可以计算语义级别上的相似性,不存在iterm冷启动问题。缺点就是不是所有iterm都可以非常容易的抽取成有意义的特征,而且中文一词多义和一义多词的复杂性也是需要攻克的一个难题。
+
+- 基于矩阵分解的推荐算法
+
+ 原理:根据已有的评分矩阵(非常稀疏),分解为低维的用户特征矩阵(评分者对各个因子的喜好程度)以及商品特征矩阵(商品包含各个因子的程度),最后再反过来分析数据(用户特征矩阵与商品特征矩阵相乘得到新的评分矩阵)得出预测结果;这是一个非常优雅的推荐算法,因为当涉及到矩阵分解时,我们通常不会太多地去思考哪些项目将停留在所得到矩阵的列和行中。但是使用这个推荐引擎,我们清楚地看到,u是第i个用户的兴趣向量,v是第j个电影的参数向量。
+
+ 
+
+ 所以我们可以用u和v的点积来估算x(第i个用户对第j个电影的评分)。我们用已知的分数构建这些向量,并使用它们来预测未知的得分。
+
+ 例如,在矩阵分解之后,Ted的向量是(1.4; .8),电影A的向量是(1.4; .9),现在,我们可以通过计算(1.4; .8)和(1.4; .9)的点积,来还原电影A-Ted的得分。结果,我们得到2.68分。
+
+ 
+
+- 基于热门内容的推荐算法
+
+ 为用户推荐流行度高的物品,或者说新热物品。例如最近北方天气突然降温,一大堆用户开始在淘宝搜索购买大衣或者羽绒服,淘宝就会为北方用户推荐大衣。55度杯新出时,所有人都会搜索购买,然后用户的瀑布流中就会出现55度杯。流行度算法很好的解决冷启动问题,但推荐的物品有限,不能很好的命中用户的兴趣点;其推荐列表通常会作为候补列表推荐给用户;在微博、新闻等产品推荐时是常用的方法。基本流程就是:确定物品的流行周期,计算物品在流行周期内的流行度,流行度高的物品作为被推荐的物品。
+
+### 18.6.10 如何评价个性化推荐系统的效果?
+
+- **准确率与召回率(Precision & Recall)**
+
+ 准确率和召回率是广泛用于信息检索和统计学分类领域的两个度量值,用来评价结果的质量。其中精度是检索出相关文档数与检索出的文档总数的比率,衡量的是检索系统的查准率;召回率是指检索出的相关文档数和文档库中所有的相关文档数的比率,衡量的是检索系统的查全率。
+
+
+
+ 一般来说,Precision就是检索出来的条目(比如:文档、网页等)有多少是准确的,Recall就是所有准确的条目有多少被检索出来了。
+
+ 正确率、召回率和 F 值是在鱼龙混杂的环境中,选出目标的重要评价指标。不妨看看这些指标的定义先:
+
+ 正确率 = 提取出的正确信息条数 / 提取出的信息条数
+
+ 召回率 = 提取出的正确信息条数 / 样本中的信息条数
+
+ 两者取值在0和1之间,数值越接近1,查准率或查全率就越高。
+
+ F值 = 正确率 * 召回率 * 2 / (正确率 + 召回率) (F 值即为正确率和召回率的调和平均值)
+
+ 不妨举这样一个例子:某池塘有1400条鲤鱼,300只虾,300只鳖。现在以捕鲤鱼为目的。撒一大网,逮着了700条鲤鱼,200只虾,100只鳖。那么,这些指标分别如下:
+
+ 正确率 = 700 / (700 + 200 + 100) = 70%
+
+ 召回率 = 700 / 1400 = 50%
+
+ F值 = 70% * 50% * 2 / (70% + 50%) = 58.3%
+
+ 不妨看看如果把池子里的所有的鲤鱼、虾和鳖都一网打尽,这些指标又有何变化:
+
+ 正确率 = 1400 / (1400 + 300 + 300) = 70%
+
+ 召回率 = 1400 / 1400 = 100%
+
+ F值 = 70% * 100% * 2 / (70% + 100%) = 82.35%
+
+ 由此可见,正确率是评估捕获的成果中目标成果所占得比例;召回率,顾名思义,就是从关注领域中,召回目标类别的比例;而F值,则是综合这二者指标的评估指标,用于综合反映整体的指标。
+
+ 当然希望检索结果Precision越高越好,同时Recall也越高越好,但事实上这两者在某些情况下有矛盾的。比如极端情况下,我们只搜索出了一个结果,且是准确的,那么Precision就是100%,但是Recall就很低;而如果我们把所有结果都返回,那么比如Recall是100%,但是Precision就会很低。因此在不同的场合中需要自己判断希望Precision比较高或是Recall比较高。如果是做实验研究,可以绘制Precision-Recall曲线来帮助分析。
+
+ **注意:准确率和召回率是互相影响的,理想情况下肯定是做到两者都高,但是一般情况下准确率高、召回率就低,召回率低、准确率高,当然如果两者都低,那是什么地方出问题了**。一般情况,用不同的阀值,统计出一组不同阀值下的精确率和召回率,如下图:
+
+
+
+**如果是做搜索,那就是保证召回的情况下提升准确率;如果做疾病监测、反垃圾,则是保准确率的条件下,提升召回。**
+
+所以,在两者都要求高的情况下,可以用F1值来衡量。
+
+
+
+公式基本上就是这样,但是如何算图中的A、B、C、D呢?**这需要人工标注,人工标注数据需要较多时间且枯燥,如果仅仅是做实验可以用用现成的语料。当然,还有一个办法,找个一个比较成熟的算法作为基准,用该算法的结果作为样本来进行比照**,这个方法也有点问题,如果有现成的很好的算法,就不用再研究了。
+
+- **综合评价指标(F-Measure)**
+
+ P和R指标有时候会出现的矛盾的情况,这样就需要综合考虑他们,最常见的方法就是F-Measure(又称为F-Score)。
+
+ F-Measure是Precision和Recall加权调和平均:
+
+
+
+ 当参数α=1时,就是最常见的F1,也即
+
+
+
+ 可知F1综合了P和R的结果,当F1较高时则能说明试验方法比较有效。
+
+- **E值**
+
+ E值表示查准率P和查全率R的加权平均值,当其中一个为0时,E值为1,其计算公式:
+
+
+
+ b越大,表示查准率的权重越大。
+
+- **平均正确率(Average Precision)**
+
+ 平均正确率表示不同查全率的点上的正确率的平均。
+
+- **AP和mAP(mean Average Precision)**
+
+ mAP是为解决P(准确率),R(召回率),F-measure的单点值局限性的。为了得到 一个能够反映全局性能的指标,可以看考察下图,其中两条曲线(方块点与圆点)分布对应了两个检索系统的准确率-召回率曲线 。
+
+ 
+
+ 可以看出,虽然两个系统的性能曲线有所交叠但是以圆点标示的系统的性能在绝大多数情况下要远好于用方块标示的系统。
+
+ 从中我们可以 发现一点,如果一个系统的性能较好,其曲线应当尽可能的向上突出。
+
+ 更加具体的,曲线与坐标轴之间的面积应当越大。
+
+ 最理想的系统, 其包含的面积应当是1,而所有系统的包含的面积都应当大于0。这就是用以评价信息检索系统的最常用性能指标,平均准确率mAP其规范的定义如下:
+
+ 
+
+- **ROC和AUC**
+
+ ROC和AUC是评价分类器的指标,上面第一个图的ABCD仍然使用,只是需要稍微变换。
+
+ 
+
+ ROC关注两个指标
+
+ ```
+ True Positive Rate( TPR ) = TP / [ TP + FN] ,TPR代表能将正例分对的概率
+ False Positive Rate( FPR ) = FP / [ FP + TN] ,FPR代表将负例错分为正例的概率
+ ```
+
+ 在ROC 空间中,每个点的横坐标是FPR,纵坐标是TPR,这也就描绘了分类器在TP(真正的正例)和FP(错误的正例)间的trade-off。ROC的主要分析工具是一个画在ROC空间的曲线——ROC curve。我们知道,对于二值分类问题,实例的值往往是连续值,我们通过设定一个阈值,将实例分类到正类或者负类(比如大于阈值划分为正类)。因此我们可以变化阈值,根据不同的阈值进行分类,根据分类结果计算得到ROC空间中相应的点,连接这些点就形成ROC curve。ROC curve经过(0,0)(1,1),实际上(0, 0)和(1, 1)连线形成的ROC curve实际上代表的是一个随机分类器。一般情况下,这个曲线都应该处于(0, 0)和(1, 1)连线的上方。如图所示。
+
+ 
+
+ 用ROC curve来表示分类器的performance很直观好用。可是,人们总是希望能有一个数值来标志分类器的好坏。
+
+ 于是**Area Under roc Curve(AUC)**就出现了。顾名思义,AUC的值就是处于ROC curve下方的那部分面积的大小。通常,AUC的值介于0.5到1.0之间,较大的AUC代表了较好的Performance。
+
+ AUC计算工具:
+
+ **P/R和ROC是两个不同的评价指标和计算方式,一般情况下,检索用前者,分类、识别等用后者。**
+
+
+
+### 18.6.11 个性化推荐系统案例分析
+
+ 在过去的十年中,神经网络已经取得了巨大的飞跃。如今,神经网络已经得以广泛应用,并逐渐取代传统的机器学习方法。 接下来,我要介绍一下YouTube如何使用深度学习方法来做个性化推荐。
+
+ 由于体量庞大、动态库和各种观察不到的外部因素,为YouTube用户提供推荐内容是一项非常具有挑战性的任务。
+
+ *YouTube的推荐系统算法由两个神经网络组成:一个用于候选生成,一个用于排序。如果你没时间仔细研究论文,可以看看我们下面给出的简短总结。* 【14】
+
+
+
+ 以用户的浏览历史为输入,候选生成网络可以显著减小可推荐的视频数量,从庞大的库中选出一组最相关的视频。这样生成的候选视频与用户的相关性最高,然后我们会对用户评分进行预测。
+
+ 这个网络的目标,只是通过协同过滤提供更广泛的个性化。
+
+ 
+
+ 进行到这一步,我们得到一组规模更小但相关性更高的内容。我们的目标是仔细分析这些候选内容,以便做出最佳的选择。
+
+ 这个任务由排序网络完成。
+
+ 所谓排序就是根据视频描述数据和用户行为信息,使用设计好的目标函数为每个视频打分,得分最高的视频会呈献给用户。
+
+
+
+ 通过这两步,我们可以从非常庞大的视频库中选择视频,并面向用户进行有针对性的推荐。这个方法还能让我们把其他来源的内容也容纳进来。
+
+
+
+ 推荐任务是一个极端的多类分类问题。这个预测问题的实质,是基于用户(U)和语境(C),在给定的时间t精确地从库(V)中上百万的视频类(i)中,对特定的视频观看(Wt)情况进行分类。
+
+## 18.7 参考文献
+
+【1】http://www.paddlepaddle.org/documentation/book/zh/0.11.0/05.recommender_system/index.cn.html
+
+【2】https://deeplearning4j.org/cn/compare-dl4j-torch7-pylearn.html
+
+【3】http://mahout.apache.org/
+
+【4】http://spark.apache.org/docs/1.1.0/mllib-guide.html
+
+【5】https://ray.readthedocs.io/en/latest/tutorial.html
+
+【6】http://spark.apache.org/streaming/
+
+【7】https://github.com/uber/horovod
+
+【8】https://software.intel.com/en-us/articles/bigdl-distributed-deep-learning-on-apache-spark
+
+【9】https://eng.uber.com/petastorm/
+
+【10】https://yahoo.github.io/TensorFlowOnSpark/
+
+【11】https://papers.nips.cc/paper/769-signature-verification-using-a-siamese-time-delay-neural-network.pdf
+
+【12】https://arxiv.org/pdf/1602.06359.pdf
+
+【13】http://www2.aueb.gr/users/ion/docs/emnlp2018.pdf
+
+【14】http://link.zhihu.com/?target=https://static.googleusercontent.com/media/research.google.com/ru//pubs/archive/45530.pdf
+
+【15】http://www.cs.cmu.edu/afs/cs/Web/People/xuerui/papers/ctr.pdf
+
+ ....
+
+ 未完待续!
+
+
\ No newline at end of file
diff --git a/qun5.png b/qun5.png
new file mode 100644
index 00000000..f5811573
Binary files /dev/null and b/qun5.png differ