You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
The `StreamingDataset` and `StreamingDataLoader` automatically make sure each rank receives the same quantity of varied batches of data, so it works out of the box with your favorite frameworks ([PyTorch Lightning](https://lightning.ai/docs/pytorch/stable/), [Lightning Fabric](https://lightning.ai/docs/fabric/stable/), or [PyTorch](https://pytorch.org/docs/stable/index.html)) to do distributed training.
@@ -139,6 +141,41 @@ Here you can see an illustration showing how the Streaming Dataset works with mu
139
141
140
142
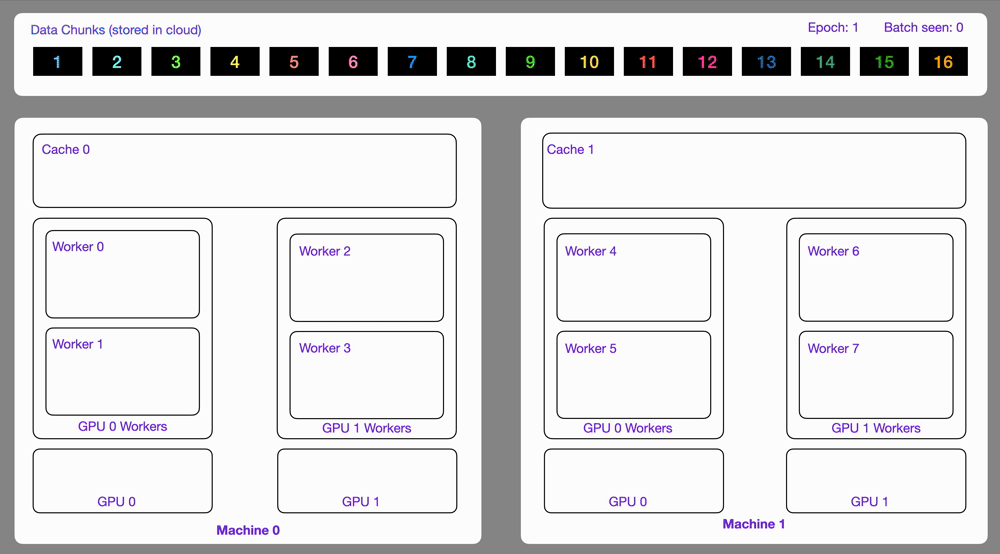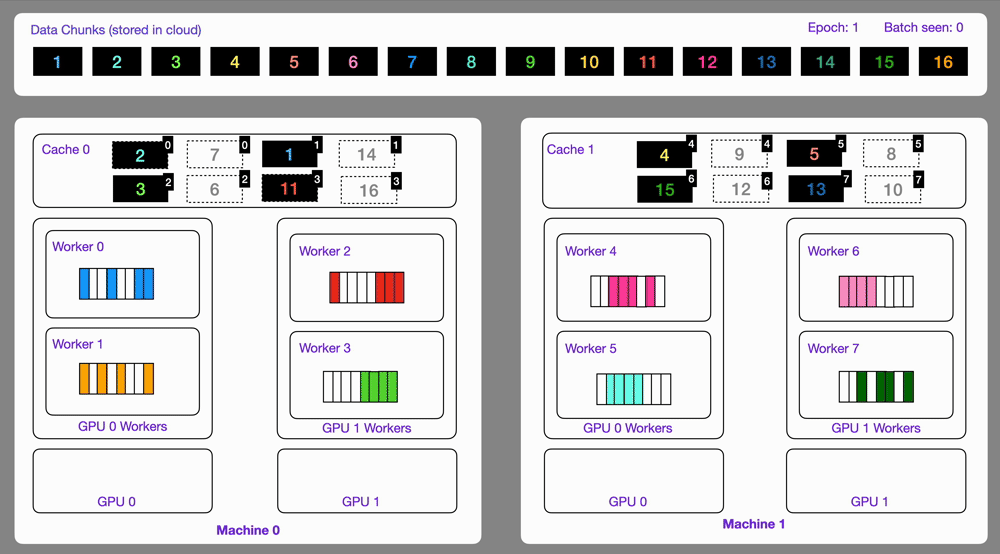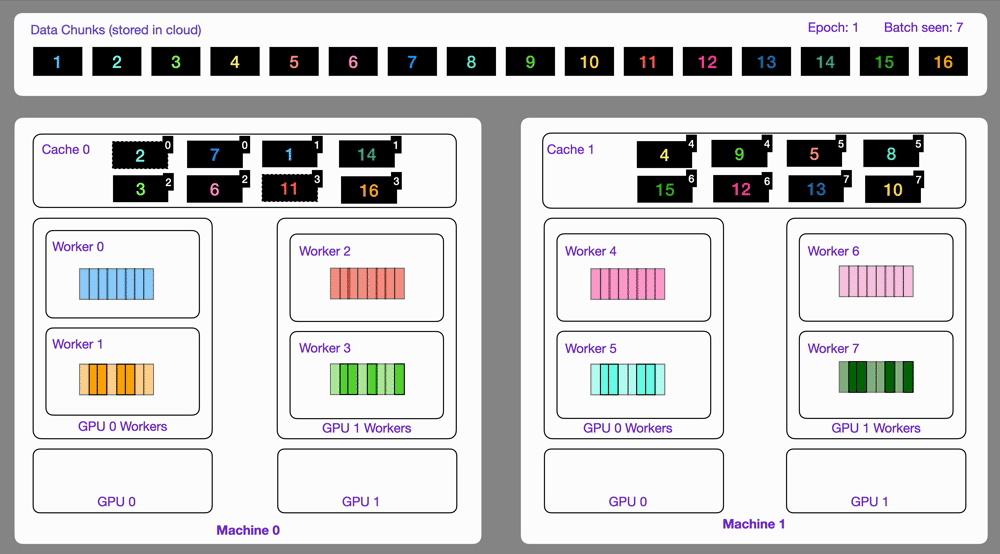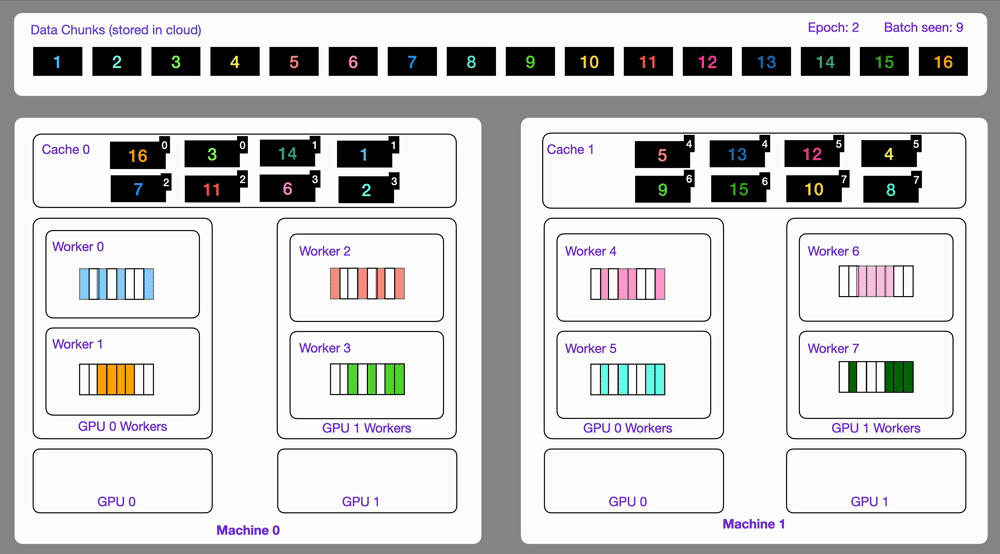
141
143
144
+
## Subsample and split your datasets
145
+
146
+
You can split your dataset with more ease with `train_test_split`.
147
+
148
+
```python
149
+
from litdata import StreamingDataset, train_test_split
150
+
151
+
dataset = StreamingDataset("s3://my-bucket/my-data") # data are stored in the cloud
152
+
153
+
print(len(dataset)) # display the length of your data
from litdata import StreamingDataset, train_test_split
172
+
173
+
dataset = StreamingDataset("s3://my-bucket/my-data", subsample=0.01) # data are stored in the cloud
174
+
175
+
print(len(dataset)) # display the length of your data
176
+
# out: 1000
177
+
```
178
+
142
179
## Access any item
143
180
144
181
Access the data you need, whenever you need it, regardless of where it is stored.
@@ -209,8 +246,7 @@ Easily experiment with dataset mixtures using the `CombinedStreamingDataset` cla
209
246
As an example, this mixture of [Slimpajama](https://huggingface.co/datasets/cerebras/SlimPajama-627B) & [StarCoder](https://huggingface.co/datasets/bigcode/starcoderdata) was used in the [TinyLLAMA](https://github.com/jzhang38/TinyLlama) project to pretrain a 1.1B Llama model on 3 trillion tokens.
210
247
211
248
```python
212
-
from litdata import StreamingDataset, CombinedStreamingDataset, StreamingDataLoader
213
-
from litdata.streaming.item_loader import TokensLoader
249
+
from litdata import StreamingDataset, CombinedStreamingDataset, StreamingDataLoader, TokensLoader
0 commit comments