diff --git "a/4\355\214\200_week3_\354\243\274\354\227\260\354\247\204.md" "b/4\355\214\200_week3_\354\243\274\354\227\260\354\247\204.md"
new file mode 100644
index 0000000..0e1b4b5
--- /dev/null
+++ "b/4\355\214\200_week3_\354\243\274\354\227\260\354\247\204.md"
@@ -0,0 +1,185 @@
+# **로지스틱 회귀 & 확률적 경사 하강법**
+- **head ( ) :** 처음 5개 행 출력 메소드
+- **unique( )** : 판다스의 함수. 클래스들 출력해준다
+ ``` python
+ print(pd.unique(fish['Species']))
+
+ => ['Bream', 'Roach', 'Whitefish', 'Parkki', 'Perch']
+ ```
+
+- **classes_ :** KneighborsClassifier에서 **알파벳 순으로 정렬**된 타깃값 classes_속성에 저장됨
+
+- **predict_proba( )** : 클래스별 확률값 반환 메소드
+- **round( ) :** 넘파이의 함수. 기본으로 소수점 첫째 자리에서 반올림. 그러나 decimals 이용해서 소수점 아래 자릿수 지정 가능
+ ```python
+ import numpy as np
+
+ proba = kn.predict_proba(test_scaled[:5])
+
+ print(np.round(proba, decimals = 4))
+ # 소수점 네 번째 자리까지 표기
+ => [0. 0. 0.6667 0. 0.3333 0. 0.]
+ ```
+
+## **로지스틱 회귀**
+---
+이름은 회귀이지만 분류 모델. 선형 방정식을 학습한다.
+
+$$
+z = a * (weight) + b *(length) + d * (height) + e *(width) + f
+$$
+
+**1.** a, b, c, d, e 는 가중치이다.
+
+**2.** z는 음수 양수 상관없이 어떤 값도 가능하다.
+
+
+### **시그모이드 함수 (이중분류 때 사용)**
+z가 아주 큰 양수일 때 1이, 아주 큰 음수일 때 0이 되게 해주는 함수
+
+$$
+\frac {1} {1+e^-z}
+$$
+
+시그모이드 함수 출력 > 0.5 => **양성 클래스**
+
+시그모이드 함수 출력 <= 0.5 => **음성 클래스**
+
+- **불리언 인덱싱** : True False 값 전달해서 넘파이 배열 행 선택
+ ```python
+ bream_smelt_indexes = (train_target == 'Bream') or (train_target == 'Smelt')
+
+ train_bream_smelt = train_scaled[bream_smelt_indexes]
+
+ target_bream_smelt = target_scaled[bream_smelt_indexes]
+
+ => 도미와 빙어 값만 들어있게 된다
+ ```
+
+### **로지스틱 회귀 이진 분류 훈련 방법**
+``` python
+from sklearn.linear_model import LogisticRegression
+
+lr = LogisticRegression()
+
+lr.fit(train_bream_smelt, target_bream_smelt)
+
+print(lr.predict_proba(train_bream_smelt[:5]))
+=> [[0.99759855 0.00240145]]
+
+# 첫번째 열이 음성 클래스(0)에 대한 값 _ 알파벳 순
+# 두번째 열이 양성 클래스(1)에 대한 값 _ 알파벳 순
+
+print(lr.coef_, lr.intercept_)
+=> [[-0.4037798 -0.57620209 -0.66280298 -1.01290277 -0.73168947]] [-2.16155132]
+# 각각 다 가중치(계수)이다.
+
+decision = lr.decision_function(train_bream_smelt[:5])
+
+print(decisions)
+=> [-6.02927744 3.57123907 -5.26568906 -4.24321775 -6.0607117]
+# decision_function()은 z값 구해주는 메소드
+
+from scipy.special import expit
+
+print(expit(decisions))
+=> [0.00240145 0.97264817 0.00513928 0.01415798 0.00232731]
+
+# expit(z) 는 시그모이드 함수
+```
+
+### **로지스틱 회귀 다중 분류 방법**
+
+- **max_iter** : 반복횟수 지정. 기본값은 100. 에포크 횟수 지정
+
+- 계수의 제곱을 규제( L2 규제라고도 부름)
+- **C** : 규제 제어 매개변수. 작을수록 규제 커짐. 기본값 = 1
+- 다중 분류는 클래스마다 z 값 하나씩 계산. 가장 높은 z값 출력하는 클래스가 예측 클래스
+
+### **소프트맥스 함수(다중 분류에 이용)**
+여러 개의 선형 방정식의 출력값을 0~1사이로 압축 후 전체 합이 1 이 되도록 만듦
+
+$$
+e_ sum = e^z1 + e^z2 + ... + e^z7
+$$
+$$
+s1 = \frac{e^z1} {e_sum},
+s7 = \frac{e^z7} {e_sum}
+$$
+7개 모두 합하면 1
+
+```python
+from scipy.special import softmax
+
+proba = softmax(decision, axis = 1)
+# axis = 1 은 각 행마다 소프트맥스 계산하라는 것
+
+print(np.round(proba, decimals = 3))
+=> [0. 0.014 0.841 0. 0.136 0.007 0.003]
+```
+
+## **점진적 학습**
+---
+
+- **점진적 학습 :** 앞서 훈련한 모델 버리지 않고 새로운 데이터에 대해서만 조금씩 더 훈련하는 것
+- **확률적 :** '무작위하게', '랜덤하게'
+
+### **확률적 경사 하강법**
+1. 대표적인 점진적 학습 알고리즘
+2. 샘플 하나씩 선택해서 경사 내려가기
+
+- **에포크 :** 훈련 세트를 한 번 모두 사용하는 과정
+
+### **미니배치 경사 하강법**
+1. 무작위 여러개 샘플 사용해서 경사 내려가기
+
+### **배치 경사 하강법**
+1. 전체 샘플 사용해서 경사 내려가기
+
+## **손실함수**
+---
+1. 어떤 문제에서 머신러닝 알고리즘이 얼마나 엉터리인지를 측정하는 기준.
+
+2. 작을수록 굿.
+3. 미분 가능해야 함.
+
+### **로지스틱 손실 함수 ( 이진 분류에 사용 )**
+---
+
+**양성 클래스일 때 손실 =** -log(예측 확률)
+
+**음성 클래스일 때 손실 =** -log(1 - 예측 확률)
+
+### **크로스엔트로피 손실 함수 ( 다중 분류에 사용 )**
+---
+- **SGDClassifier :** 사이킷런에서 확률적 경사 하강법 제공하는 대표적 분류용 클래스
+
+- **loss :** 손실 함수 종류 지정
+
+```python
+from sklearn.linear_model import SGDClassifier
+
+sc = SGDClassifier(loss = 'log', max_iter = 10, random_state = 42)
+
+# loss = 'log'이므로 클래스마다 이진 분류 모델 만듦.
+# 에포크 10회
+```
+
+### **훈련된 모델 sc추가로 훈련 시키기**
+- **partial_fit()** 메소드 사용된다
+
+```python
+sc.partial_fit(train_scaled, train_target)
+```
+호출 할 때마다 1 에포크 이어서 훈련. 전달한 훈련 세트에서 1개씩 샘플 꺼내서 경하 하강법 단계 실행
+
+### **에포크와 과대/과소적합**
+에포크 횟수 적으면 => 과소적합
+
+에포크 횟수 너무 많으면 => 과대적합
+
+```python
+sc = SGDClassifier(loss = 'log', max_iter = 100, tol = None, random_state = 42)
+```
+SGDClassifier는 일정 에포크 동안 성능 향상 없으면 더 훈련하지 않고 자동으로 멈춤.
+- **tol :** 향상될 최솟값 지정
\ No newline at end of file
diff --git "a/5\355\214\200_\355\231\251\354\235\270\354\204\234.md" "b/5\355\214\200_\355\231\251\354\235\270\354\204\234.md"
deleted file mode 100644
index 8bad254..0000000
--- "a/5\355\214\200_\355\231\251\354\235\270\354\204\234.md"
+++ /dev/null
@@ -1,51 +0,0 @@
-# Chapter 03 회귀 알고리즘과 모델 규제
-
-### 03-1 k-최근접 이웃 회귀
-- Keywords
- - **회귀**: 임의의 수치(=타깃값)를 예측하는 문제
- - **k-최근접 이웃 회귀**: 가장 가까운 이웃 샘플들의 타깃값의 평균으로 예측하는 회귀 방법
- - **결정계수(R²)**: 회귀 문제의 성능 측정 도구. $R^2=1-\frac{\sum(타깃-예측)^2}{\sum(타깃-평균)^2}$
- - **과대적합**: (모델의 성능) 훈련 세트 > 테스트 세트
- - **과소적합**: (모델의 성능) 훈련 세트 < 테스트 세트, or 둘 다 낮을 때
-
-- Packages and Functions
- - scikit-learn
- - **KNeighborsRegressor**: k-최근접 이웃 회귀 모델을 만드는 클래스
- - **mean_absolute_error()**: 회귀 모델의 평균 절댓값 오차를 계산함.
- - numpy
- - **reshape()**: 배열의 크기를 바꿈
-
- `train_input = train_input.reshape(-1, 1)`
-
-### 03-2 선형 회귀
-- Keywords
- - **선형 회귀**: 특성과 타깃 사이의 관계를 가장 잘 나타내는 선형 방정식을 찾음.
- - **모델 파라미터**: 머신러닝 모델이 특성에서 학습한 파라미터(선형 회귀)
- - **다항 회귀**: 다항식을 사용한 선형 회귀
-
-- Packages and Functions
- - scikit-learn(.linear_model)
- - **LinearRegression**: 선형 회귀 모델을 만드는 클래스
- - **coef_** 속성: 특성에 대한 계수를 포함한 배열
- - **intercept_** 속성: 절편을 포함한 배열
-
-### 03-3 특성 공학과 규제
-- Keywords
- - **다중 회귀**: 여러 개의 특성을 사용하는 회귀 모델
- - **특성 공학**: 주어진 특성을 조합하여 새로운 특성을 만드는 작업
- - **변환기**: 특성을 만들거나 전처리하는 클래스
- - **규제**: 모델이 훈련 세트에 과대적합되지 않도록 하는 것(**릿지**와 **라쏘**는 선형 모델의 계수를 작게 만듦)
- - **하이퍼파라미터**: 머신러닝 알고리즘이 학습하지 않는 파라미터. 사람이 사전에 지정함.(릿지와 라쏘의 경우, 규제 강도 alpha 파라미터)
-
-- Packages and Functions
- - scikit-learn(.pre-processing)
- - **PolynomialFeatures**: 주어진 특성을 조합하여 새로운 특성을 만드는(변환기) 클래스.
- - **transform()**: fit() 메서드 다음에 사용되어 특성 공학을 수행함.
- - **get_feature_names()**: 특성 공학 결과가 각각 어떤 입력의 조합으로 만들어졌는지 표시함.
- - **StandardScaler**: 표준점수를 기반으로 데이터를 전처리하는(변환기) 클래스
- - scikit-learn(.linear_model)
- - **Ridge**: 릿지 회귀 모델을 훈련함.
- - **Lasso**: 라쏘 회귀 모델을 훈련함.
- - **pandas**: 데이터 분석 라이브러리
- - **read_csv()**: CSV 파일을 읽어 판다스 데이터프레임으로 변환함.
- - **to_numpy()**: 판다스 데이터프레임을 넘파이 배열로 변환함.
\ No newline at end of file
diff --git "a/week1/0\355\214\200_\355\231\215\352\270\270\353\217\231.md" "b/week1/0\355\214\200_\355\231\215\352\270\270\353\217\231.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/week1/1\354\243\274\354\260\250_\352\271\200\354\203\201\353\257\274.md" "b/week1/1\354\243\274\354\260\250_\352\271\200\354\203\201\353\257\274.md"
deleted file mode 100644
index 8f17256..0000000
--- "a/week1/1\354\243\274\354\260\250_\352\271\200\354\203\201\353\257\274.md"
+++ /dev/null
@@ -1,91 +0,0 @@
-# 발표 1주차
-
----
-
-발표자 : 서현빈
-
-일자 : 2022-03-17
-
----
-
-## 내용 정리
-
-### 인공지능이란?
-
-- **인공지능** : 사람처럼 학습하고 추론할 수 있는 지능을 가진 컴퓨터 시스템
-
-뇌의 뉴런의 개념으로 부터 출발하여 퍼셉트론 그리고 지금의 머신러닝에 이르기까지 점점 발전해옴
-
-대표적인 인물로는 프랑크 로젠블라트 등이 있다.
-
-### 기본적인 머신러닝(빙어 vs 도미)
-
-- 흔히들 사람들은 도미와 빙어를 길이와 무게만으로 분류 가능하다.
-
-- 마찬가지로 이 문제를 산점도를 바탕으로 한 그림으로 그려 해결해볼 수 있다.
-
- ```python
- import matplotlib.pyplot as plt //그래프를 그리는 패키지
-
- plt.scatter(bream_length, bream_weight) //산점도를 그리는 함수
-
- plt.xtable('length')
-
- plt.ylable('weight)')
-
- plt.show()
-
- //도미, 빙어의 데이터를 바탕으로 산점도 그래프를 그림
-
- plt.scatter(bream_length, bream_weight)
-
- plt.scatter(smelt_length, smelt_weight)
-
- plt.xlabel('length')
-
- plt.ylabel('weight')
-
- plt.show()
- ```
-
-
-학습 데이터를 통한 2차원 데이터를 제작하고 KNeighborsClassifier클래스의 fit()메서드로 훈련을 시켜보자
-
-k-최근접 이웃 알고리즘을 이용하는 것으로 새로운 물고기가 어느분포에 가까이 있냐에 따라 물고기의 종류를 결정한다.
-
-### 머신러닝 기초
-
-- 지도학습 : 훈련하기 위한 데이터와 정답(지도자)가 존재하는 특성을 가지는 학습
- - 훈련 데이터와 평가 데이터가 완전히 똑같지 않도록 설정해야 한다.
- - 그러나 데이터를 분류할 때 랜덤으로 뽑도록 해야한다.( 샘플링 편향 방지 )
-
-- 비지도 학습 : 지도자 없이 데이터의 분포 파악 또는 변형에 초점을 맞추는 학습
-
-### 전처리 기초
-
-- numpy : 데이터의 전처리에 주로 이용되는 라이브러리
-
- ```python
- import numpy as np
- ```
-
-- 넘파이의 np.column_stack()을 이용해 전달받은 튜플을 넘파이 배열로 변환해줌.
-
- ```python
- np.column_stack(([1,2,3], [4,5,6]))
- ```
-
-- 넘파이의 np.concatenate(), np.ones, np.zeros를 통해 타깃 데이터를 생성함.
- ```python
- fish_target= np.concatenate((np.ones(35), np.zeros(14)))
- ```
-
-- np.mean은 평균을 계산하고, np.std는 표준편차를 계산함.
- ```python
- mean = np.mean(train_input, axis=0)
- std = np.std(train_input, axis=0)
- ```
-
-표준점수 = (원본 – 평균)/표준편차 train_scaled = (train_input - mean) / std
-
-테스트 세트로 평가할 때도, 샘플을 훈련 세트와 동일한 평균과 표준편차로 변환해야 평가 가 능하고, 새로운 샘플도 동일함
\ No newline at end of file
diff --git "a/week1/1\354\243\274\354\260\250_\354\236\204\354\204\270\355\233\210.md" "b/week1/1\354\243\274\354\260\250_\354\236\204\354\204\270\355\233\210.md"
deleted file mode 100644
index 508bd9c..0000000
--- "a/week1/1\354\243\274\354\260\250_\354\236\204\354\204\270\355\233\210.md"
+++ /dev/null
@@ -1,60 +0,0 @@
-# Ch 01. 나의 첫 머신러닝
-___
-## 인공지능 vs 머신러닝 vs 딥러닝
-___
->인공지능은 머신러닝을 포함하는 개념이고, 머신러닝은 딥러닝을 포함하는 개념
-- __인공지능__
- 사람처럼 학습하고 추론할 수 있는 지능을 가진 컴퓨터 시스템을 만드는 기술
-- __머신러닝__
- 자동으로 데이터에서 규칙을 학습하는 알고리즘을 연구
-- __딥러닝__
- 머신러닝 알고리즘 중 인공 신경망을 기반으로 한 방법들
-___
-## k-최근접 이웃 알고리즘
-___
-> 어떤 데이터에 대한 답을 구할 때 주위의 다른 데이터를 보고 정답을 구하는 알고리즘
-- 용어
- - __특성__ : 데이터의 특징
- - __산점도__ : x, y축으로 이루어진 좌표계에 x, y의 관계를 표현한 그래프
- - __훈련__ : 데이터를 통해 모델이 규칙을 학습하는 과정
- - 함수
- - fit(훈련에 사용할 특성, 정답 데이터) : 모델을 훈련하는 함수
- - predict(특성) : 학습한 모델을 통해 예측하는 함수
- - score(특성, 정답) : 모델의 성능을 측정하는 함수
-
-# Ch 02. 데이터 다루기
-___
-## 지도학습이란?
-___
->머신러닝의 세 가지 종류: 지도학습, 비지도학습, 강화학습
-
-k-최근접 이웃 알고리즘은 지도학습에 속한다.
-지도학습은 훈련 데이터를 받아서 정답을 맞히면서 학습하는 과정이다
-
-___
-## 훈련 세트와 테스트 세트
-___
-> 머신러닝의 훈련 및 성능 평가를 위한 두 가지 데이터 세트
-
-훈련에 사용한 데이터는 성능 평가로 사용하면 안된다
-- __샘플링 편향__
- - 훈련 세트와 테스트 세트가 골고루 섞이지 않아 발생하는 현상
- - 골고루 섞기 위해 __numpy__ 사용
-___
-## numpy
-___
->python의 배열 라이브러리
-- 함수
- - seed(숫자) : 난수 생성을 위한 시드값을 지정하는 함수
- - arange() : 일정 간격의 정수 또는 실수 배열을 생성하는 함수
- - shuffle() : 주어진 배열을 무작위로 섞는 함수
-___
-## 데이터 전처리
-___
->알고리즘의 정확도를 위해 특성값을 일정한 기준으로 맞추어 주는 함수
-- 용어
- - __표준점수__ : 특성값이 평균에서 표준편차의 몇배만큼 떨어져 있는지 나타내는 척도
- - z=(특성값-평균)/(표준편차)
- - __브로드캐스팅__ : 크기가 다른 numpy 배열에서 자동으로 사칙 연산을 모든 행이나 열로 확장해서 수행하는 것
-- 주의할 점
- 훈련 세트를 변환한 방식 그대로 테스트 데이터를 변환해야 한다!
\ No newline at end of file
diff --git "a/week1/1\354\243\274\354\260\250_\354\236\245\354\244\200\354\230\244.md" "b/week1/1\354\243\274\354\260\250_\354\236\245\354\244\200\354\230\244.md"
deleted file mode 100644
index c1e40d1..0000000
--- "a/week1/1\354\243\274\354\260\250_\354\236\245\354\244\200\354\230\244.md"
+++ /dev/null
@@ -1,26 +0,0 @@
-**인공지능이란?**
-사람처럼 학습하고 추론할 수 있는 지능을 가진 컴퓨터 시스템
-
->Ex1) 강인공지능 : 사람과 비슷한 인공지능
-
->Ex2) 약인공지능 : 사람의 일을 보조하는 인공지능
-
-**인공지능의 학습**
->1. 머신러닝 : 자동으로 데이터에서 규칙 학습하는 알고리즘 연구 분야
-
->2. 딥러닝 : 머신러닝 알고리즘 중 심층신경망을 기반으로 한 방법
-
-##데이터 시각화
-1. 라이브러리 : matplotlib.pyplot을 사용.
-2. 내장 함수 : scatter() 산점도를 그리는 함수, xtable() x축의 변수를 설정하는 함수, ytable() y축의 변수를 설정하는 함수, show() 그래프를 출력하는 함수.
-
-##알고리즘
-1. 라이브러리 : sklearn.neighobrs 중에서 KNeighborsClassifier를 사용.
-2. 설명 : 근접한 데이터를 보고 다수를 차지하는 것을 정답으로 사용하는 머신러닝.
-3. 사용법 : KNeighborsClassifier(n_neighobrs=a) 근접한 a개의 데이터를 바탕으로 판단함.
-
-##머신러닝 구현하기
-1. 데이터 : 지도 학습 기준, 훈련 데이터와 테스트 데이터가 필요하며 데이터에 샘플이 올바르게 섞여 있지 않을 경우 샘플링 편향이 발생할 수 있다. *데이터는 사이킷런의 train_test_split을 이용하여 비율에 맞게 훈련과 테스트 데이터로 나눌 수 있다.*
-2. 사용 함수 : fit()을 이용하여 훈련 데이터를 학습 시키고 score를 통해 정확도를 출력하며 predict()를 이용해 테스트 데이터를 판별한다.(이진 분류의 경우)
-3. 시각화 : 산점도를 보면 x와 y의 범위가 다름을 알 수 있다. 따라서 데이터 전처리를 통해 특성값을 일정하게 맞춰주어야한다.
-
diff --git "a/week1/1\355\214\200_\354\206\241\354\242\205\353\252\205.md" "b/week1/1\355\214\200_\354\206\241\354\242\205\353\252\205.md"
deleted file mode 100644
index c01d7c6..0000000
--- "a/week1/1\355\214\200_\354\206\241\354\242\205\353\252\205.md"
+++ /dev/null
@@ -1,76 +0,0 @@
-## 1.머신러닝이란?
-
-1. AI: 학습하고 추론할 수 있는 지능을 가진 컴퓨터 시스템
-2. Machine Learning: 자동으로 규칙을 학습하는 알고리즘
-3. Deep Learning: 머신러닝의 기법중 하나로 인공 신경망을 사용하는 알고리즘
-
-> **AI >> Machine Learning >> Deep Learning**
----
-## 2. 머신러닝의 종류
-- 지도학습
- - KNN
- - 선형 회귀
- - 로지스터 회귀
- - SVM
- - 결정 트리
-- 비지도 학습
- - K-Mean
- - 주성분 분석
-- 강화 학습
-
-### 지도학습: 학습할 떄 정답이 주어지는 문제
-> 분류: 정답이 디지털적인것
-
-> 회귀: 정답이 아날로그적인것
-
-### 비지도학습: 학습할 때 정답이 주어지지 않고 데이터속에서 모델이 직접 규칙을 찾는 것
-
----
-
-## 3-1. KNN을 통한 도미 빙어 데이터 구분
-
- length = bream_length + smelt_length
- weight = bream_weight + smelt_weight
- fish_data = [[l, w] for l, w in zip(length, weight)]
-
-도미와 빙어 데이터를 합친 fish_data를 생성
-
- fish_target = [1]*35 + [0]*14
-
-도미와 빙어 데이터의 정답이 담겨있는 fish_target 생성
-
- kn = KNeighborClassifier()
- kn.fit(fish_data, fish target)
-
-KNN모델을 생성 후 학습
-
- kn.predict([[25, 150]])
- = array([0])
-
-> 올바르지 않은 값이 나온 이유?
-
-### ***weight와 length의 scale이 다르기 때문!***
-
----
-
-## 3-2. 데이터 전처리
-
-표준점수: 모든 데이터를 ***(값 - 평균) / 표준편차***로 나타내는 것
-
- mean = np.mean(train_input, axis = 0)
- std = np.std(trainn_input, axis = 0)
-
-numpy의 mean, std함수를 통해 평균, 표준편차 구하기
-
- train_scaled = (train_input - mean) / std
-
-전처리된 train_scaled값 구하기
-
- kn.fit(train_scaled, train_target)
- test_scaled = (test_input - mean) / std
- kn.score(test_scaled, test_target)
- = 1.0
-
-전처리된 훈련 샘플로 모델 재학습 후 마찬가지로 전처리된 test샘플로 score을 매기기
-
-***test 샘플을 전처리 할때는 훈련 샘플의 평균과 표준편차를 사용해야 한다!***
diff --git "a/week1/1\355\214\200_\354\230\244\353\217\231\355\233\210.md" "b/week1/1\355\214\200_\354\230\244\353\217\231\355\233\210.md"
deleted file mode 100644
index 6052c16..0000000
--- "a/week1/1\355\214\200_\354\230\244\353\217\231\355\233\210.md"
+++ /dev/null
@@ -1,145 +0,0 @@
-# KNN 알고리즘 개요
-
-- 개념 : 어떤 데이터가 주어지면 그 주변의 데이터를 살펴본 뒤 더 많은 데이터가 포함되어 있는 범주로 분류하는 방식
-- 특징 : 훈련 데이터를 저장하는 것이 훈련의 전부이다.
-
-
-
-
-
-# 혼공머신 - knn 알고리즘을 이용한 생선 분류
-
-## **데이터 살펴보기**
-
-
-
-왼쪽 영역에 분포하는 데이터가 빙어, 오른쪽 영역에 분포하는 데이터가 도미를 의미한다.
-
-앞으로 사용할 데이터를 다음과 같이 정의한다.
-
-```python
-length = bream_length + smelt_length
-weight = bream_weight + smel_weight
-
-fish_data = [[l, w]] for l,w in zip(length, weight)
-
-# 1: 도미, 2: 빙어
-# 35 개의 도미 데이터와 14개의 빙어 데이터를 사용한다.
-fish_target = [1]*35 + [0]*14
-
-```
-
-## knn 알고리즘을 이용한 도미 빙어 데이터 구분
-
-사이킷 런의 KneighborsClassifer 를 통해 knn 알고리즘을 사용할 수 있다.
-```python
-from sklearn.neighbors import KNeighborsClassifier
-
-# KNN 객체 생성
-kn = KNeighborsClassifier(n_neighbors=49)
-# fit() : 주어진 데이터로 알고리즘을 훈련
-kn.fit(fish_data, fish_target)
-# score() : 0~1 사이의 값 반환
-kn.score(fish_data, fish_target)
-```
-
-## **훈련 세트 & 데이터 세트 분리**
-
-혼공머신 Chapter1,2 에서는 다음의 두 가지 방식으로 훈련 데이터와 테스트 데이터를 분류한다.
-
-- 각 데이터의 index를 랜덤으로 정렬해서 데이터를 임의로 뽑아내는 방식으로 훈련 데이터와 테스트 데이터를 분류한다.
-- 사이킷런의 train_test_split 을 사용한다.
-
-두 번째 방식으로 데이터를 분리하는 것이 깔끔하다.
-
-```python
-from sklearn.model_selection import train_test_split
-
-train_input, test_input, train_target, test_target = train_test_split(fish_data, fish_target, random_state = 42)
-```
-
-## **데이터 학습**
-
-데이터 전처리를 거치지 않고 일단, train data / test data 분리 된 것을 훈련시켰을 때 다음과 같은 결과가 나온다.
-
-*코드*
-```python
-kn = KNeighborsClassifier()
-# train
-kn.fit(train_input, train_target)
-# test
-kn.score(test_input, test_target)
-
-# (25, 150) 특성 값을 가지는 데이터를 예측해보자.
-kn.predict([[25,150]]) >>> 결과값은 빙어(0) 를 가리킨다.
-
-# 최근접 이웃을 확인해보자.
-# import matplotlib.pyplot as plt
-plt.scatter(train_input[:, 0], train_input[:,1])
-plt.scatter(25, 150, marker='^')
-# 최근접 이웃 표시
-plt.scatter(train_input[indexes,0], train_input[indexes,1], marker='D')
-plt.show()
-```
-
-
-
-> 최근접 이웃 k = 5로 지정했을 때 과반수 이상의 3 개의 이웃이 빙어 데이터를 가리키므로 산접도 상 샘플 데이터는 도미에 가깝지만 빙어로 예측하게 된다. 이를 해결하기 위해 데이터 전처리 과정을 거쳐야 한다.
-
-
-
-## **데이터 전처리**
-
-z-표준점수 정규화 방법을 사용한다. 즉, 다음의 수식을 활용한다.
-
-$$z = \frac{자료 값 - 평균}{표준편차}$$
-
-*코드*
-```python
-# 평균, 표준편차
-# import nupmy as np
-mean = np.mean(train_input, axis=0)
-std = np.std(train_input, axis=0)
-
-# 전처리 데이터
-train_scaled = (train_input - mean) / std
-
-# 전처리 데이터로 모델 훈련
-plt.scatter(train_scaled[:,0], train_scaled[:,1])
-# 전처리 데이터와 마찬가지로 테스트 데이터도 전처리 해야됨.
-plt.scatter(25, 150,marker='^')
-plt.show()
-```
-*결과*
-
-
-> 빙어 데이터 와 샘플 데이터의 차이가 뚜렷해졌다.
-
-
-## **전처리 데이터로 모델 훈련**
-
-*코드*
-```python
-new_sample_scaled = ([25, 150] - mean) / std
-plt.scatter(train_scaled[:,0], train_scaled[:,1])
-plt.scatter(new_sample_scaled[0], new_sample_scaled[1])
-
-# 최근접 이웃 표시
-distances, indexes = kn.kneighbors([new_sample_scaled])
-plt.scatter(train_scaled[:,0], train_scaled[:,1])
-plt.scatter(new_sample_scaled[0], new_sample_scaled[1], marker='^')
-plt.scatter(train_scaled[indexes, 0], train_scaled[indexes, 1], marker='D')
-plt.show()
-
-```
-
-*결과*
-
-
-
-최근접 이웃 모두 도미 데이터 이미로 샘플 데이터 역시 '도미' 로 예측하게 된다.
-
-```python
-print(kn.predict([new_sample_scaled]))
->>> [1]
-```
diff --git "a/week1/1\355\214\200_\354\235\264\354\204\261\354\247\204.md" "b/week1/1\355\214\200_\354\235\264\354\204\261\354\247\204.md"
deleted file mode 100644
index 9fd9172..0000000
--- "a/week1/1\355\214\200_\354\235\264\354\204\261\354\247\204.md"
+++ /dev/null
@@ -1,665 +0,0 @@
-# 2022년 3월 17일 HAI 혼공머신 스터디 1조 발표
-### 발표자: 임정섭
-
-## __Contents__
-### Chapter 1
-- 인공지능 / 머신러닝 / 딥러닝 이란?
-- 왜 머신러닝인가?
-- 지도학습과 비지도 학습
-
-### Chapter 2
-- 머신러닝 예제(KNN 알고리즘을 이용한 생선 분류)
-
-
-
-## Chapter 1
-### 인공지능 / 머신러닝 / 딥러닝 이란?
-- 인간의 지능을 모방하는 기술 분야인 인공지능과 기계가 학습하는 과정을 통해 이를 구현하는 머신 러닝, 그리고 인공 신경망을 이용한 머신러닝 기법인 딥러닝이 있습니다.
-### 왜 머신러닝인가?
-- 결정에 필요한 로직이 한 분야, 작업에 한정되고, 규칙을 설계하려면 그 분야의 전문가들이 내리는 결정 방식에 대해 잘 알아야 합니다.
-### 지도학습과 비지도 학습
-- 지도 학습의 종류: KNN, 로지스틱 회귀, 신경망, 선형 회귀, SVM, 결정 트리
-- 비지도 학습의 종류: K-Mean, 주성분 분석
-- 이 외에도 강화 학습 등 다양한 종류가 있습니다.
-
-
-
-## Chapter 2
-### 머신러닝 예제(KNN 알고리즘을 이용한 생선 분류)
-
-#### 이 챕터에서는 사이킷런을 이용한 첫 머신 러닝 프로그램을 구현하는 과정을 설명합니다.
-
-
-
-### 1. 개발 환경 구축
----
-- 개발 환경으로는 손쉽게 머신 러닝 프레임워크를 구동하기 위해 Google Colab을 사용했습니다.
-- 프로젝트에 사용될 언어는 Python이며 Numpy, Matplotlib, Scikits-learn 라이브러리가 사용되었습니다.
-
-### 2. KNN 알고리즘 소개
----
-- KNN 알고리즘은 주어진 데이터가 있을 때 새로운 데이터의 라벨을 예측하는 회귀 알고리즘 중 하나입니다.
-- 새로운 데이터가 주어지면, 거리가 가장 가까운 몇 개의 데이터를 살펴본 뒤 가장 많은 데이터가 포함된 라벨이 새로운 데이터의 라벨이 됩니다.
-- 따로 훈련이 필요하지 않고, 데이터를 저장하는 과정이 전부라는 특징이 있습니다.
-
-### 3. 데이터 다루기 및 시각화
----
-- 이 프로젝트에서는 도미와 빙어라는 두 종류의 생선들의 데이터를 입력받아 새로 추가된 생선이 도미인지 빙어인지 구분하는 프로그램을 작성합니다.
-- 각 생선들은 길이와 무게라는 두 개의 특성을 지니고 있습니다.
-- matplotlib.pyplot을 이용하여 그래프 형태료 표현해볼 수 있습니다.
-- 도미를 찾는것을 1로, 빙어를 0으로 정의하여 라벨 데이터도 생성합니다.
-
-### 4. sklearn을 이용한 KNN 알고리즘
----
-- skleanr.neighbors에 포함된 KNeighborsClassifier 클래스를 활용합니다.
-- fit() 함수를 활용해 주어진 데이터로 알고리즘을 훈련시킵니다.
-- n_neighbors 파라미터를 조정하는 것을 통해 얼마나 많은 이웃들을 고려할지 정할 수 있습니다.
-
-### 5. 훈련 데이터와 테스트 데이터
----
-- 어떤 머신러닝 모델을 훈련할 때, 모든 데이터로 훈련시키는 것 보다는 전체 데이터에서 일부분을 테스트 데이터로 구분하여 훈련 과정에서 완전히 배제시키고 훈련이 끝난 모델에서 모델의 성능을 평가하는 방식으로 사용됩니다.
-- 이 프로젝트에서는 전체 데이터의 약 25%를 균일하게 뽑아서 테스트 데이터로 사용했습니다.
-
-### 6. 데이터 전처리
----
-- 도미와 빙어의 성질인 길이와 무게는 단위와 데이터 분포가 다르기 때문에 상대적으로 숫자가 더 큰 무게가 KNN 알고리즘에서 더 중요한 성질처럼 학습될 수 있습니다.
-- 그래서 무게와 길이 데이터를 각각 평균을 빼고 표준편차로 나누어 정규화하면 각각의 데이터가 편중되지 않게 반영될 수 있습니다.
-- 여기서 주의해야 할 점은 테스트 데이터의 성질이 훈련 과정에 반영되면 안 되기 때문에, 테스트 데이터를 전처리할 때에도 훈련 데이터의 성질(평균, 표준편차)를 사용해야 합니다.
-
-### __아래는 이번주 발표자분이 작성한 프로그램 실행 과정입니다.__
-
----
-
-
-
-# 혼공머신 1.3장 예제 - KNN 알고리즘을 이용한 생선 분류
-
-
-## 예제 데이터 준비
-
-
-```python
-# 도미 Data
-#특성1. 길이
-bream_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
- 31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
- 35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0]
-#특성2. 무게
-bream_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
- 500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
- 700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0]
-# 빙어 Data
-smelt_length = [9.8, 10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
-smelt_weight = [6.7, 7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]
-```
-
-## matplotlib 을 이용한 데이터 그래프 표현
-
-
-```python
-import matplotlib.pyplot as plt
-# 산점도 그래프 생성
-plt.scatter(bream_length, bream_weight)
-plt.scatter(smelt_length, smelt_weight)
-# x축
-plt.xlabel('length')
-# y축
-plt.ylabel('weight')
-plt.show()
-
-```
-
-
-## KNN 알고리즘을 이용한 도미 빙어 데이터 구분
-
-
-```python
-# 데이터 합치기
-length = bream_length + smelt_length
-weight = bream_weight + smelt_weight
-
-fish_data = [[l, w] for l,w in zip(length,weight)]
-print(fish_data)
-```
-
- [[25.4, 242.0], [26.3, 290.0], [26.5, 340.0], [29.0, 363.0], [29.0, 430.0], [29.7, 450.0], [29.7, 500.0], [30.0, 390.0], [30.0, 450.0], [30.7, 500.0], [31.0, 475.0], [31.0, 500.0], [31.5, 500.0], [32.0, 340.0], [32.0, 600.0], [32.0, 600.0], [33.0, 700.0], [33.0, 700.0], [33.5, 610.0], [33.5, 650.0], [34.0, 575.0], [34.0, 685.0], [34.5, 620.0], [35.0, 680.0], [35.0, 700.0], [35.0, 725.0], [35.0, 720.0], [36.0, 714.0], [36.0, 850.0], [37.0, 1000.0], [38.5, 920.0], [38.5, 955.0], [39.5, 925.0], [41.0, 975.0], [41.0, 950.0], [9.8, 6.7], [10.5, 7.5], [10.6, 7.0], [11.0, 9.7], [11.2, 9.8], [11.3, 8.7], [11.8, 10.0], [11.8, 9.9], [12.0, 9.8], [12.2, 12.2], [12.4, 13.4], [13.0, 12.2], [14.3, 19.7], [15.0, 19.9]]
-
-
-
-```python
-# 1 : 도미 / 2: 빙어
-fish_target = [1]*35 + [0]*14
-print(fish_target)
-```
-
- [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
-
-
-
-```python
-from sklearn.neighbors import KNeighborsClassifier
-```
-
-
-```python
-# KNN 객체 생성
-kn = KNeighborsClassifier()
-# fit() : 주어진 데이터로 알고리즘을 훈련
-kn.fit(fish_data, fish_target)
-# score() : 0~1 사이의 값 반환
-kn.score(fish_data, fish_target)
-```
-
-
-
-
- 1.0
-
-
-
-
-```python
-# predict
-kn.predict([[30,600]]) , kn.predict([[10,100]]) # (array([1]), array([0]))
-```
-
-
-
-
- (array([1]), array([0]))
-
-
-
-
-```python
-# n_neighbors
-kn49 = KNeighborsClassifier(n_neighbors=49)
-kn49.fit(fish_data, fish_target)
-print(kn49.score(fish_data, fish_target))
-print(35/49)
-```
-
- 0.7142857142857143
- 0.7142857142857143
-
-
-
-```python
-kn49.predict([[10, 100]])
-```
-
-
-
-
- array([1])
-
-
-
-
-```python
-plt.scatter(25, 500, marker='^')
-# 산점도 그래프 생성
-plt.scatter(bream_length, bream_weight)
-plt.scatter(smelt_length, smelt_weight)
-# x축
-plt.xlabel('length')
-# y축
-plt.ylabel('weight')
-plt.show()
-```
-
-
-
-
-
-## 훈련 세트 & 테스트 세트
-
-
-```python
-import numpy as np
-```
-
-#### Numpy vs List 속도 비교
-
-
-```python
-my_arr = np.arange(1000000)
-my_list = list(range(1000000))
-%time for _ in range(10): my_arr2 = my_arr * 2
-%time for _ in range(10): my_list2 = [x * 2 for x in my_list]
-```
-
- CPU times: user 14.1 ms, sys: 5.32 ms, total: 19.4 ms
- Wall time: 22.6 ms
- CPU times: user 763 ms, sys: 190 ms, total: 953 ms
- Wall time: 957 ms
-
-
-#### Numpy를 이용한 데이터 표현
-
-
-```python
-input_arr = np.array(fish_data)
-target_arr = np.array(fish_target)
-print(input_arr)
-print(target_arr)
-```
-
- [[ 25.4 242. ]
- [ 26.3 290. ]
- [ 26.5 340. ]
- [ 29. 363. ]
- [ 29. 430. ]
- [ 29.7 450. ]
- [ 29.7 500. ]
- [ 30. 390. ]
- [ 30. 450. ]
- [ 30.7 500. ]
- [ 31. 475. ]
- [ 31. 500. ]
- [ 31.5 500. ]
- [ 32. 340. ]
- [ 32. 600. ]
- [ 32. 600. ]
- [ 33. 700. ]
- [ 33. 700. ]
- [ 33.5 610. ]
- [ 33.5 650. ]
- [ 34. 575. ]
- [ 34. 685. ]
- [ 34.5 620. ]
- [ 35. 680. ]
- [ 35. 700. ]
- [ 35. 725. ]
- [ 35. 720. ]
- [ 36. 714. ]
- [ 36. 850. ]
- [ 37. 1000. ]
- [ 38.5 920. ]
- [ 38.5 955. ]
- [ 39.5 925. ]
- [ 41. 975. ]
- [ 41. 950. ]
- [ 9.8 6.7]
- [ 10.5 7.5]
- [ 10.6 7. ]
- [ 11. 9.7]
- [ 11.2 9.8]
- [ 11.3 8.7]
- [ 11.8 10. ]
- [ 11.8 9.9]
- [ 12. 9.8]
- [ 12.2 12.2]
- [ 12.4 13.4]
- [ 13. 12.2]
- [ 14.3 19.7]
- [ 15. 19.9]]
- [1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0
- 0 0 0 0 0 0 0 0 0 0 0 0]
-
-
-
-```python
-# random 으로 data 뽑기
-# seed 값 설정 시 일정한 random 값 생성
-np.random.seed(3)
-index = np.arange(49)
-np.random.shuffle(index)
-print(index)
-```
-
- [12 39 9 46 31 28 13 47 44 6 36 23 37 18 4 25 16 15 30 11 7 40 27 34
- 45 5 48 1 35 2 22 33 17 26 14 29 20 32 38 43 41 10 19 21 0 8 3 24
- 42]
-
-
-
-```python
-# train_data 생성하기
-train_input = input_arr[index[:35]]
-train_target = target_arr[index[:35]]
-
-# test_data 생성하기
-test_input = input_arr[index[35:]]
-test_target = target_arr[index[35:]]
-```
-
-
-```python
-plt.scatter(train_input[:,0], train_input[:,1])
-plt.scatter(test_input[:,0], test_input[:,1])
-plt.show()
-```
-
-
-
-
-
-```python
-# KNN 알고리즘으로 test_data 대입해보기
-kn = kn.fit(train_input, train_target)
-kn.score(test_input,test_target)
-```
-
-
-
-
- 1.0
-
-
-
-
-```python
-kn.predict([[20, 250]])
-```
-
-
-
-
- array([1])
-
-
-
-## 데이터 전처리
-
-
-```python
-# np.column_stack 을 이용한 fish_data 생성
-
-fish_data = np.column_stack((length, weight))
-print(fish_data[:10])
-```
-
- [[ 25.4 242. ]
- [ 26.3 290. ]
- [ 26.5 340. ]
- [ 29. 363. ]
- [ 29. 430. ]
- [ 29.7 450. ]
- [ 29.7 500. ]
- [ 30. 390. ]
- [ 30. 450. ]
- [ 30.7 500. ]]
-
-
-
-```python
-# np.zeros(), np.ones() : 0, 1 행렬 생성
-# fish_target
-fish_target = np.concatenate((np.ones(35), np.zeros(14)))
-print(fish_target)
-```
-
- [1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1.
- 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
- 0.]
-
-
-### 사이킷런으로 훈련 데이터와 테스트 데이터 나누기
-
-
-```python
-from sklearn.model_selection import train_test_split
-```
-
-
-```python
-train_input, test_input, train_target, test_target = train_test_split(fish_data, fish_target, random_state = 42)
-print(train_input, test_input, train_target, test_target)
-```
-
- [[ 30. 450. ]
- [ 29. 363. ]
- [ 29.7 500. ]
- [ 11.3 8.7]
- [ 11.8 10. ]
- [ 13. 12.2]
- [ 32. 600. ]
- [ 30.7 500. ]
- [ 33. 700. ]
- [ 35. 700. ]
- [ 41. 975. ]
- [ 38.5 920. ]
- [ 25.4 242. ]
- [ 12. 9.8]
- [ 39.5 925. ]
- [ 29.7 450. ]
- [ 37. 1000. ]
- [ 31. 500. ]
- [ 10.5 7.5]
- [ 26.3 290. ]
- [ 34. 685. ]
- [ 26.5 340. ]
- [ 10.6 7. ]
- [ 9.8 6.7]
- [ 35. 680. ]
- [ 11.2 9.8]
- [ 31. 475. ]
- [ 34.5 620. ]
- [ 33.5 610. ]
- [ 15. 19.9]
- [ 34. 575. ]
- [ 30. 390. ]
- [ 11.8 9.9]
- [ 32. 600. ]
- [ 36. 850. ]
- [ 11. 9.7]] [[ 32. 340. ]
- [ 12.4 13.4]
- [ 14.3 19.7]
- [ 12.2 12.2]
- [ 33. 700. ]
- [ 36. 714. ]
- [ 35. 720. ]
- [ 35. 725. ]
- [ 38.5 955. ]
- [ 33.5 650. ]
- [ 31.5 500. ]
- [ 29. 430. ]
- [ 41. 950. ]] [1. 1. 1. 0. 0. 0. 1. 1. 1. 1. 1. 1. 1. 0. 1. 1. 1. 1. 0. 1. 1. 1. 0. 0.
- 1. 0. 1. 1. 1. 0. 1. 1. 0. 1. 1. 0.] [1. 0. 0. 0. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
-
-
-### 수상한 도미 한마리
-
-
-```python
-kn = KNeighborsClassifier()
-# train
-kn.fit(train_input, train_target)
-# test
-kn.score(test_input, test_target)
-```
-
-
-
-
- 1.0
-
-
-
-
-```python
-# sample predict
-print(kn.predict([[25,150]]))
-```
-
- [0.]
-
-
-
-```python
-plt.scatter(train_input[:, 0], train_input[:,1])
-plt.scatter(25, 150, marker='^')
-plt.show()
-```
-
-
-
-
-
-
-```python
-# 최근접 이웃의 거리 및 index
-distances, indexes = kn.kneighbors([[25, 150]])
-print(indexes)
-print(distances)
-```
-
- [[12 29 5 19 4]]
- [[ 92.00086956 130.48375378 138.32150953 140.00603558 140.62090883]]
-
-
-
-```python
-plt.scatter(train_input[:, 0], train_input[:,1])
-plt.scatter(25, 150, marker='^')
-# 최근접 이웃 표시
-plt.scatter(train_input[indexes,0], train_input[indexes,1], marker='D')
-plt.show()
-```
-
-
-
-
-
-## 데이터 전처리 : x축, y축 기준 맞추기
-
-
-```python
-#평균, 표준편차
-mean = np.mean(train_input, axis=0)
-std = np.std(train_input, axis=0)
-
-print(mean, std)
-```
-
- [ 26.175 418.08888889] [ 10.21073441 321.67847023]
-
-
-
-```python
-# 전처리 데이터
-train_scaled = (train_input - mean) / std
-```
-
-### 전처리 데이터로 모델 훈련하기
-
-
-
-```python
-plt.scatter(train_scaled[:,0], train_scaled[:,1])
-# 전처리 데이터와 마찬가지로 테스트 데이터도 전처리 해야됨.
-plt.scatter(25, 150,marker='^')
-plt.show()
-```
-
-
-
-
-
-
-```python
-new_sample_scaled = ([25, 150] - mean) / std
-plt.scatter(train_scaled[:,0], train_scaled[:,1])
-plt.scatter(new_sample_scaled[0], new_sample_scaled[1])
-plt.show()
-```
-
-
-
-
-
-
-```python
-test_scaled = (test_input - mean) / std
-kn.fit(train_scaled, train_target)
-print(kn.score(test_scaled, test_target))
-print(kn.predict([new_sample_scaled]))
-```
-
- 1.0
- [1.]
-
-
-
-```python
-distances, indexes = kn.kneighbors([new_sample_scaled])
-plt.scatter(train_scaled[:,0], train_scaled[:,1])
-plt.scatter(new_sample_scaled[0], new_sample_scaled[1], marker='^')
-plt.scatter(train_scaled[indexes, 0], train_scaled[indexes, 1], marker='D')
-plt.show()
-```
-
-
-
-
-
-## 결정경계
-
-### 외부 라이브러리 불러오기
-
-
-```python
-import os, sys
-from google.colab import drive
-drive.mount('/content/drive')
-
-my_path = '/content/notebooks'
-# Colab Notebooks 안에 my_env 폴더에 패키지 저장
-#os.symlink('/content/drive/My Drive/Colab Notebooks/my_env', my_path)
-sys.path.insert(0, my_path)
-```
-
- Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount("/content/drive", force_remount=True).
-
-
-### mglearn 라이브러리를 사용하여 결정경계 확인
-
-
-
-```python
-import mglearn
-```
-
-
-```python
-mglearn.plots.plot_2d_separator(kn, train_scaled, fill=True, eps=0.5, alpha=0.5)
-mglearn.discrete_scatter(train_scaled[:,0], train_scaled[:,1], train_target)
-plt.scatter(new_sample_scaled[0], new_sample_scaled[1], marker='D')
-plt.show()
-```
-
-
-
-
-
-## 최적의 K 찾기
-
-
-```python
-# 훈련 정확도와 테스트 정확도를 저장할 리스트 선언
-training_accuracy = []
-testing_accuracy = []
-
-# neighbor 1~36 세팅
-neighbor_settings = range(1,37)
-for n_neighbor in neighbor_settings:
- kn = KNeighborsClassifier(n_neighbors=n_neighbor)
- kn.fit(train_input, train_target)
- training_accuracy.append(kn.score(train_input, train_target))
- testing_accuracy.append(kn.score(test_input, test_target))
-plt.plot(neighbor_settings, training_accuracy, label = '훈련 정확도')
-plt.plot(neighbor_settings, testing_accuracy, label = '테스트 정확도')
-plt.show()
-print(f'훈련 데이터에서 최적의 k 는 {training_accuracy.index(max(training_accuracy)) + 1}')
-print(f'테스트 데이터에서 최적의 k 는 {testing_accuracy.index(max(training_accuracy)) + 1}')
-
-
-```
-
-
-
-
- 훈련 데이터에서 최적의 k 는 1
- 테스트 데이터에서 최적의 k 는 1
-
diff --git "a/week1/1\355\214\200_\354\236\204\354\240\225\354\204\255.md" "b/week1/1\355\214\200_\354\236\204\354\240\225\354\204\255.md"
deleted file mode 100644
index ee4aeb9..0000000
--- "a/week1/1\355\214\200_\354\236\204\354\240\225\354\204\255.md"
+++ /dev/null
@@ -1,367 +0,0 @@
-## 혼공머신 1장, 2장 정리
-
-### 1\. 인공지능 / 머신러닝 / 딥러닝 이란?
-
-#### 인공지능
-
-인공지능은 사람처럼 학습하고 추론할 수 있는 지능을 가진 컴퓨터 시스템을 만드는 기술이다. 인공지능은 과거 암흑기를 거쳐 최근 컴퓨터 하드웨어의 발전으로 다시 한 번 각광받기 시작한다. 인공지능에는 강인공지능(인공일반지능)과 약인공지능으로 구분할 수 있다. 강인공지능은 사람과 구별하기 어려운 높은 레벨의 시스템이고, 약인공지능은 특정 분야에 특화되어 보조 역할을 하는 시스템이다.
-
-#### 머신러닝
-
-머신러닝은 규칙을 사람이 일일이 정하지 않고 자동으로 데이터에서 규칙을 학습하는 알고리즘을 연구하는 분야이다. 인공 지능의 하위 분야인 지능을 구현하기 위한 핵심 분야이다.
-
-#### 딥러닝
-
-딥 러닝은 학습하는 많은 방법 중 하나(머신 러닝의 하위 개념)이다. 딥 러닝은 신경망 학습으로, 인간이 결론을 내리는 방식과 유사한 논리 구조를 사용하여 데이터를 지속적으로 분석한다.
-
----
-
-### 2\. 왜 머신러닝인가?
-
-그렇다면 왜 머신러닝을 이용하여 규칙을 찾아야할까? '사람이 직접 규칙을 입력해서 프로그래밍을 만들면 되는 것 아닌가'라는 생각을 할 수 있지만 이런 경우 두 가지 단점이 생긴다.
-
-- 결정에 필요한 로직이 한 분야 or 작업에 국한됨.
-- 규칙을 설계하려면 그 분야 전문가들이 내리는 결정 방식에 대해 잘 알아야 한다.
-
-얼굴 인식을 예시로 들 수 있다. 컴퓨터가 인식하는 픽셀 방식이 사람이 얼굴을 인식하는 방법과 매우 다르기 때문에 사람이 직접 디지털 이미지에서 얼굴을 구성하는 것이 무엇인지를 일련의 규칙으로 표현하기가 근본적으로 불가능하다. 그러나 머신 러닝을 사용하여 알고리즘에 많은 얼굴 이미지를 제공하면 얼굴을 특정 요소(규칙)가 무엇 인지를 찾아낼 수 있다.
-
----
-
-### 3\. 지도학습 과 비지도 학습
-
-#### 지도학습
-
-지도학습이란 정답을 알려주면서 진행하는 학습이다. 학습 시 데이터와 함께 레이블(정답)이 항상 제공되어야 한다. 지도 학습의 예로는 분류와 회귀가 대표적이다. 대표적인 알고리즘으로 KNN , SVM, 선형 회귀, 로지스터 회귀, 신경망, 결정 트리가 있다.
-
-**장점**
-
-테스트할 때 데이터와 함께 제공하기 때문에 손쉽게 모델의 성능을 평가할 수 있다.
-
-**단점**
-
-데이터마다 레이블을 달기 위해 많은 시간을 투자해야한다.
-
-#### 비지도학습
-
-비지도학습이란 레이블 없이 데이터만 입력하여 진행하는 학습이다. 보통 데이터 자체에서 패턴을 찾아낼 때 사용한다. 비지도학습의 대표적인 예로는 군집화와 차원축소가 있다. 대표적인 알고리즘으로는 K-Mean, 주성분 분석이 있다.
-
-**장점**
-
-레이블을 제공할 필요가 없다.
-
-**단점**
-
-레이블이 없기 때문에 모델 성능을 평가하는 데에 어려움이 있다.
-
----
-
-### 4\. 머신러닝 예제 (KNN을 이용한 생선 분류)
-
-#### Colab 시작하기
-
-Colab은 구글에서 제공하는 서비스로, 웹브라우저에서 무료로 파이썬 프로그램을 테스트하고 저장할 수 있다. 이는 대화식 프로그래밍 환경인 주피터 노트북을 커스터마이징한 것이다. 구글의 클라우드와 연결되어 있기 때문에 초기 세팅(라이브러리 설치 등)이 필요 없고 컴퓨터 성능과 상관없이 프로그램을 실습할 수 있다.
-
-Colab 에는 코드 셀과 텍스트 셀을 지원한다. 코드 셀은 말 그대로 코드를 입력해서 바로 실행할 수 있다. (셀은 코랩에서 실행할 수 있는 최소 단위) 그리고 텍스트 셀은 마크다운 형식으로 주석처럼 사용가능하다.
-
-#### KNN이란?
-
-KNN 알고리즘은 가장 간단한 머신러닝 알고리즘으로, 훈련 데이터셋을 저장하여 모델을 만드는 과정이 전부이다. 새로운 입력 데이터에 대해 예측할 때, 알고리즘이 훈련 데이터셋에서 가장 가까운 데이터 포인터, '최근접 이웃'을 찾는다.
-
-#### 예제 데이터 준비하기
-
-```
-# 도미 Data
-#특성1. 길이
-bream_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
- 31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
- 35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0]
-#특성2. 무게
-bream_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
- 500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
- 700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0]
-# 빙어 Data
-smelt_length = [9.8, 10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
-smelt_weight = [6.7, 7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]
-```
-
-\* [데이터 출처](http://bit.ly/bream_list)
-
-예제의 데이터는 도미와 빙어 2 클래스(품종)로 이루어졌고 특성으로는 길이와 무게이다. (도미 sample 35개, 빙어 sample 14개)
-
-#### Matplotlib 으로 데이터 시각화하기
-
-맷플롯립 라이브러리를 이용하여 산점도 그래프를 그려보자.
-
-```
-import matplotlib.pyplot as plt
-# 산점도 그래프 생성
-plt.scatter(bream_length, bream_weight)
-plt.scatter(smelt_length, smelt_weight)
-# 예측 데이터 추가
-plt.scatter(25, 500, marker='^')
-# x축
-plt.xlabel('length')
-# y축
-plt.ylabel('weight')
-plt.show()
-```
-
-#### 데이터 다루기
-
-```
-length = bream_length + smelt_length
-weight = bream_weight + smelt_weight
-
-fish_data = [[l, w] for l,w in zip(length,weight)]
-print(fish_data)
-```
-
-파이썬의 리스트를 이용하여 도미와 빙어 길이와 무게 데이터를 각각 합친다. zip() 메서드는 나열된 리스트에서 원소를 하나씩 꺼내준다.
-
-#### 레이블 만들기
-
-```
-# 1 : 도미 / 2: 빙어
-fish_target = [1]*35 + [0]*14
-print(fish_target)
-```
-
----
-
-이제 본격적으로 sklearn 의 knn 알고리즘을 이용하여 데이터를 훈련시키고 예측해보자.
-
-#### 모델 생성 / 데이터 훈련 / 성능 측정 / 데이터 예측
-
-```
-from sklearn.neighbors import KNeighborsClassifier
-# KNN 객체 생성
-kn = KNeighborsClassifier()
-# fit() : 주어진 데이터로 알고리즘을 훈련
-kn.fit(fish_data, fish_target)
-# score() : 0~1 사이의 값 반환
-kn.score(fish_data, fish_target)
-# predict
-kn.predict([[30,600]]) , kn.predict([[10,100]]) # (array([1]), array([0]))
-```
-
-KNeighborsClassifier 객체는 KNN 알고리즘을 사용하기 위한 다양한 메서드를 포함하고 있다. 대표적으로 fit(), score(), predict() 등이 있다.
-
-#### n_neighbors
-
-KNN은 최근접 이웃을 찾을 때 n_neighbors를 통해 이웃을 몇 개나 찾을지 정할 수 있다. default 값은 5이다. n_neighbors 가 49(전체 데이터 수) 인 모델을 만들어보자.
-
-```
-# n_neighbors
-kn49 = KNeighborsClassifier(n_neighbors=49)
-kn49.fit(fish_data, fish_target)
-print(kn49.score(fish_data, fish_target))
-print(35/49)
-```
-
-n-neighbors=49 로 정하면 전체 데이터 수와 같기 때문에 데이터를 예측할 때 항상 도미로 분류한다.
-
----
-
-#### 훈련 세트 & 테스트 세트
-
-위 예제에서는 데이터 셋 구분 없이 전체 데이터를 학습시키고 정확도를 평가했다. 여기서 문제가 발생하는데, 훈련시킨 데이터를 테스트 데이터로 사용했기 때문에 정확성을 신뢰할 수 없다. (마치 정답을 미리 알려주고 시험을 보는 것과 같다.) 또한, 전체 데이터로 훈련시키면 정확한 평가를 위해 전체 데이터 외에 추가적인 데이터가 필요하다.
-
-그래서 데이터 셋이 있을 때 훈련 세트(데이터)와 테스트 세트(데이터)로 나눠서 모델을 생성하고 평가한다. 일반적으로 훈련 세트는 데이터 셋의 75%, 테스트 세트는 데이터 셋의 25% 로 설정하여 진행한다.
-
-#### Numpy 을 이용한 데이터 다루기
-
-이번에는 Numpy의 ndarray 를 이용해 데이터를 만들어보자.
-
-```
-import numpy as np
-input_arr = np.array(fish_data)
-target_arr = np.array(fish_target)
-print(input_arr)
-print(target_arr)
-```
-
-#### 샘플링 편향
-
-위 데이터는 index 0
-
-~34 까지는 도미 데이터, 35~
-
-48 까지는 빙어 데이터로 되어있다. 이처럼 훈련 세트와 테스트 세트에 샘플이 골고루 섞여 있지 않으면 샘플링이 한쪽으로 치우친 것을 샘플링 편향이라고 한다. 위 데이터는 샘플링 편향이 있기 때문에 앞 데이터를 가지고 훈련하고 뒤에 있는 데이터로 테스트하면 결과값이 도미로만 출력되는 문제가 있다. 이러한 문제를 해결하기 위해 무작위로 데이터를 섞을 필요가 있다. numpy 의 random 클래스를 이용해서 도미와 빙어가 골고루 섞인 데이터를 만들어보자.
-
-```
-# random 으로 data 뽑기
-# seed 값 설정 시 일정한 random 값 생성
-np.random.seed(3)
-index = np.arange(49)
-np.random.shuffle(index)
-print(index)
-```
-
-#### 훈련 데이터 / 테스트 데이터 생성 및 성능 평가
-
-우선, 훈련 데이터 개수를 35개, 테스트 데이터를 14개로 설정하겠습니다.
-
-```
-# train_data 생성하기
-train_input = input_arr[index[:35]]
-train_target = target_arr[index[:35]]
-
-# test_data 생성하기
-test_input = input_arr[index[35:]]
-test_target = target_arr[index[35:]]
-```
-
-다음으로 훈련 데이터와 테스트 데이터를 시각화 해보자.
-
-```
-plt.scatter(train_input[:,0], train_input[:,1])
-plt.scatter(test_input[:,0], test_input[:,1])
-plt.show()
-```
-
-이제 모델 성능 테스트를 해보자.
-
-```
-# KNN 알고리즘으로 test_data 대입해보기
-kn = kn.fit(train_input, train_target)
-kn.score(test_input,test_target)
-```
-
-1.0 이라는 100% 정확성 결과를 얻었다.
-
----
-
-### 5\. 데이터 전처리
-
-#### 사이킷런으로 훈련 데이터와 테스트 데이터 나누기
-
-위에서 random 함수를 이용하여 훈련 데이터와 테스트 데이터를 나눴다. 이 기능을 사이킷런에서 train_test_split() 함수를 이용하면 간단하게 훈련 데이터와 테스트 데이터를 나눌 수 있다.
-
-```
-from sklearn.model_selection import train_test_split
-train_input, test_input, train_target, test_target = train_test_split(fish_data, fish_target, random_state = 42)
-print(train_input, test_input, train_target, test_target)
-```
-
-return 순서로는 train_input(훈련 데이터), test_input(테스트 데이터), train_target(훈련 라벨), test_target(테스트 라벨) 순이다.
-
-#### Kneighbors 확인하기
-
-데이터 시각화
-
-```
-kn = KNeighborsClassifier()
-# train
-kn.fit(train_input, train_target)
-# test
-kn.score(test_input, test_target)
-# sample predict
-print(kn.predict([[25,150]]))
-plt.scatter(train_input[:, 0], train_input[:,1])
-plt.scatter(25, 150, marker='^')
-plt.show()
-```
-
-```
-# 최근접 이웃의 거리 및 index
-distances, indexes = kn.kneighbors([[25, 150]])
-print(indexes)
-print(distances)
-```
-
-kneighbors 를 이용하면 해당 샘플의 최근접 이웃과 그 거리 값을 얻을 수 있다.
-
-```
-plt.scatter(train_input[:, 0], train_input[:,1])
-plt.scatter(25, 150, marker='^')
-# 최근접 이웃 표시
-plt.scatter(train_input[indexes,0], train_input[indexes,1], marker='D')
-plt.show()
-```
-
-최근접 이웃을 확인했을 때 이상한 점을 확인할 수 있을 것이다. knn은 기본적으로 거리를 계산하는데 x축과 y축의 단위(스케일)가 다르기 때문에 이러한 문제가 발생했다. 그렇기 때문에 우리는 두 특성의 값을 일정한 기준으로 맞춰야 한다. 이를 데이터 전처리라 한다.
-
-데이터 전처리에서 많이 사용하는 방법 중 하나는 표준점수이다.
-
-> 표준 점수 = 데이터 값 - 평균 / 표준 편차
-
-표준 점수를 이용하여 데이터 전처리를 진행해보자.
-
-Numpy 의 평균, 표준편차 함수를 이용하여 값을 구한다.
-
-```
-#평균, 표준편차
-mean = np.mean(train_input, axis=0)
-std = np.std(train_input, axis=0)
-
-print(mean, std)
-```
-
-```
-# 전처리 데이터
-train_scaled = (train_input - mean) / std
-```
-
-Numpy의 브로드 캐스팅으로 기존 데이터를 표준 점수로 바꿔준다.
-
-이를 시각화 해보자.
-
-```
-new_sample_scaled = ([25, 150] - mean) / std
-plt.scatter(train_scaled[:,0], train_scaled[:,1])
-plt.scatter(new_sample_scaled[0], new_sample_scaled[1])
-plt.show()
-```
-
-x축과 y축의 스케일이 변경된 것을 확인할 수 있다.
-
-이제 최근접 이웃을 확인해보자.
-
-```
-distances, indexes = kn.kneighbors([new_sample_scaled])
-plt.scatter(train_scaled[:,0], train_scaled[:,1])
-plt.scatter(new_sample_scaled[0], new_sample_scaled[1], marker='^')
-plt.scatter(train_scaled[indexes, 0], train_scaled[indexes, 1], marker='D')
-plt.show()
-```
-
-이제 우리가 생각했던 것처럼 최근접 이웃을 선택한 것을 확인할 수 있다.
-
----
-
-### 6\. 결정경계
-
-가능한 모든 테스트 포인트의 예측을 xy 평면에 나타내어 각 포인트가 속한 클래스에 따라 평면에 색을 칠한다. 이를 결정 경계라 한다.
-
-```
-import mglearn
-mglearn.plots.plot_2d_separator(kn, train_scaled, fill=True, eps=0.5, alpha=0.5)
-mglearn.discrete_scatter(train_scaled[:,0], train_scaled[:,1], train_target)
-plt.scatter(new_sample_scaled[0], new_sample_scaled[1], marker='D')
-plt.show()
-```
-
-\* colab 에서 mglearn 을 import 하는 방법이 궁금하면 다음 [글](https://noapps-code.tistory.com/202)을 참고하길 바란다.
-
----
-
-### 7\. 최적의 k 찾기
-
-```
-# 훈련 정확도와 테스트 정확도를 저장할 리스트 선언
-training_accuracy = []
-testing_accuracy = []
-
-# neighbor 1~37 세팅
-neighbor_settings = range(1,37)
-for n_neighbor in neighbor_settings:
- kn = KNeighborsClassifier(n_neighbors=n_neighbor)
- kn.fit(train_input, train_target)
- training_accuracy.append(kn.score(train_input, train_target))
- testing_accuracy.append(kn.score(test_input, test_target))
-plt.plot(neighbor_settings, training_accuracy, label = '훈련 정확도')
-plt.plot(neighbor_settings, testing_accuracy, label = '테스트 정확도')
-plt.show()
-print(f'훈련 데이터에서 최적의 k 는 {training_accuracy.index(max(training_accuracy)) + 1}')
-print(f'테스트 데이터에서 최적의 k 는 {testing_accuracy.index(max(training_accuracy)) + 1}')
-```
diff --git "a/week1/1\355\214\200_\354\236\245\354\244\200\354\230\244.md" "b/week1/1\355\214\200_\354\236\245\354\244\200\354\230\244.md"
deleted file mode 100644
index c1e40d1..0000000
--- "a/week1/1\355\214\200_\354\236\245\354\244\200\354\230\244.md"
+++ /dev/null
@@ -1,26 +0,0 @@
-**인공지능이란?**
-사람처럼 학습하고 추론할 수 있는 지능을 가진 컴퓨터 시스템
-
->Ex1) 강인공지능 : 사람과 비슷한 인공지능
-
->Ex2) 약인공지능 : 사람의 일을 보조하는 인공지능
-
-**인공지능의 학습**
->1. 머신러닝 : 자동으로 데이터에서 규칙 학습하는 알고리즘 연구 분야
-
->2. 딥러닝 : 머신러닝 알고리즘 중 심층신경망을 기반으로 한 방법
-
-##데이터 시각화
-1. 라이브러리 : matplotlib.pyplot을 사용.
-2. 내장 함수 : scatter() 산점도를 그리는 함수, xtable() x축의 변수를 설정하는 함수, ytable() y축의 변수를 설정하는 함수, show() 그래프를 출력하는 함수.
-
-##알고리즘
-1. 라이브러리 : sklearn.neighobrs 중에서 KNeighborsClassifier를 사용.
-2. 설명 : 근접한 데이터를 보고 다수를 차지하는 것을 정답으로 사용하는 머신러닝.
-3. 사용법 : KNeighborsClassifier(n_neighobrs=a) 근접한 a개의 데이터를 바탕으로 판단함.
-
-##머신러닝 구현하기
-1. 데이터 : 지도 학습 기준, 훈련 데이터와 테스트 데이터가 필요하며 데이터에 샘플이 올바르게 섞여 있지 않을 경우 샘플링 편향이 발생할 수 있다. *데이터는 사이킷런의 train_test_split을 이용하여 비율에 맞게 훈련과 테스트 데이터로 나눌 수 있다.*
-2. 사용 함수 : fit()을 이용하여 훈련 데이터를 학습 시키고 score를 통해 정확도를 출력하며 predict()를 이용해 테스트 데이터를 판별한다.(이진 분류의 경우)
-3. 시각화 : 산점도를 보면 x와 y의 범위가 다름을 알 수 있다. 따라서 데이터 전처리를 통해 특성값을 일정하게 맞춰주어야한다.
-
diff --git "a/week1/2\355\214\200_\352\271\200\354\203\201\353\257\274.md" "b/week1/2\355\214\200_\352\271\200\354\203\201\353\257\274.md"
deleted file mode 100644
index 8f17256..0000000
--- "a/week1/2\355\214\200_\352\271\200\354\203\201\353\257\274.md"
+++ /dev/null
@@ -1,91 +0,0 @@
-# 발표 1주차
-
----
-
-발표자 : 서현빈
-
-일자 : 2022-03-17
-
----
-
-## 내용 정리
-
-### 인공지능이란?
-
-- **인공지능** : 사람처럼 학습하고 추론할 수 있는 지능을 가진 컴퓨터 시스템
-
-뇌의 뉴런의 개념으로 부터 출발하여 퍼셉트론 그리고 지금의 머신러닝에 이르기까지 점점 발전해옴
-
-대표적인 인물로는 프랑크 로젠블라트 등이 있다.
-
-### 기본적인 머신러닝(빙어 vs 도미)
-
-- 흔히들 사람들은 도미와 빙어를 길이와 무게만으로 분류 가능하다.
-
-- 마찬가지로 이 문제를 산점도를 바탕으로 한 그림으로 그려 해결해볼 수 있다.
-
- ```python
- import matplotlib.pyplot as plt //그래프를 그리는 패키지
-
- plt.scatter(bream_length, bream_weight) //산점도를 그리는 함수
-
- plt.xtable('length')
-
- plt.ylable('weight)')
-
- plt.show()
-
- //도미, 빙어의 데이터를 바탕으로 산점도 그래프를 그림
-
- plt.scatter(bream_length, bream_weight)
-
- plt.scatter(smelt_length, smelt_weight)
-
- plt.xlabel('length')
-
- plt.ylabel('weight')
-
- plt.show()
- ```
-
-
-학습 데이터를 통한 2차원 데이터를 제작하고 KNeighborsClassifier클래스의 fit()메서드로 훈련을 시켜보자
-
-k-최근접 이웃 알고리즘을 이용하는 것으로 새로운 물고기가 어느분포에 가까이 있냐에 따라 물고기의 종류를 결정한다.
-
-### 머신러닝 기초
-
-- 지도학습 : 훈련하기 위한 데이터와 정답(지도자)가 존재하는 특성을 가지는 학습
- - 훈련 데이터와 평가 데이터가 완전히 똑같지 않도록 설정해야 한다.
- - 그러나 데이터를 분류할 때 랜덤으로 뽑도록 해야한다.( 샘플링 편향 방지 )
-
-- 비지도 학습 : 지도자 없이 데이터의 분포 파악 또는 변형에 초점을 맞추는 학습
-
-### 전처리 기초
-
-- numpy : 데이터의 전처리에 주로 이용되는 라이브러리
-
- ```python
- import numpy as np
- ```
-
-- 넘파이의 np.column_stack()을 이용해 전달받은 튜플을 넘파이 배열로 변환해줌.
-
- ```python
- np.column_stack(([1,2,3], [4,5,6]))
- ```
-
-- 넘파이의 np.concatenate(), np.ones, np.zeros를 통해 타깃 데이터를 생성함.
- ```python
- fish_target= np.concatenate((np.ones(35), np.zeros(14)))
- ```
-
-- np.mean은 평균을 계산하고, np.std는 표준편차를 계산함.
- ```python
- mean = np.mean(train_input, axis=0)
- std = np.std(train_input, axis=0)
- ```
-
-표준점수 = (원본 – 평균)/표준편차 train_scaled = (train_input - mean) / std
-
-테스트 세트로 평가할 때도, 샘플을 훈련 세트와 동일한 평균과 표준편차로 변환해야 평가 가 능하고, 새로운 샘플도 동일함
\ No newline at end of file
diff --git "a/week1/2\355\214\200_\353\202\250\354\234\240\354\260\254.md" "b/week1/2\355\214\200_\353\202\250\354\234\240\354\260\254.md"
deleted file mode 100644
index 4abb3a6..0000000
--- "a/week1/2\355\214\200_\353\202\250\354\234\240\354\260\254.md"
+++ /dev/null
@@ -1,22 +0,0 @@
-# 회귀 알고리즘과 모델 규제
-## 회귀 알고리즘
-회귀 알고리즘은 **어떤 숫자를 예측**하는데 주로 사용된다
-- K-최근접 이웃 회귀 알고리즘
-- 선형 회귀 알고리즘
-- 다항 회귀 알고리즘
-## K-최근접 이웃 회귀 알고리즘
-- 분류와 똑같이 예측하려는 샘플에 가장 가까운 샘플 k개를 선택하여 이웃한 샘플의 수치들의 평균을 구해서 샘플의 수치를 예상
-- 하지만 훈련 데이터의 범위를 넘어가는 수의 경우 정확도 낮아진다.
-## 선형 회귀 알고리즘
-- 특성이 하나인 경우, 직선을 이용하여 학습한다.
-## 다항 회귀 알고리즘
-- 다항식을 활용하여 선형 회귀를 한다
-## 과소적합과 과대 적합
-### 과소적합
-- 훈련세트 보다 테스트세트의 점수가 높거나 두 점수가 모두 낮음
-- 모델이 너무 단순하거나 훈련 세트를 통해 적절히 훈련되지 않음
-### 과대적합
-- 훈련세트가 테스트에 비해 점수가 너무 큼
-- 모델이 훈련 세트에만 적합해짐
-> 과소적합이나 과대적합이 발생할 때에는 적절한 모델의 수정이 요구됨
-- 다중 회귀는 2개 이상의 특성을 사용하여 모델을 형성해 과소적합 문제 해결에 도움을 받는다.
diff --git "a/week1/2\355\214\200_\354\234\244\355\230\225\354\204\234.md" "b/week1/2\355\214\200_\354\234\244\355\230\225\354\204\234.md"
deleted file mode 100644
index 828e37a..0000000
--- "a/week1/2\355\214\200_\354\234\244\355\230\225\354\204\234.md"
+++ /dev/null
@@ -1,11 +0,0 @@
-# 혼공머신 1주차
-## 인공지능
-인공지능 : 사람처럼 학습하고 추론하는 컴퓨터 시스템
-### 머신러닝. 자동으로 데이터에서 규칙 학습하는 알고리즘 분야
-- 딥러닝: 인공신경망을 기반으로한 머신러닝 알고리즘
-- 지도 학습: 훈련데이터와 정답데이터 활용
-- 비지도 학습: 입력데이터만 사용해서 학습. 데이터 파악 및 변형에 유리
-## k-최근접 이웃 알고리즘 활용 머신러닝
-k-": 근접한 데이터를 보고 다수를 차지하는 것을 정답으로함
-- 무게, 길이의 데이터를 합쳐 리스트화함.
-- 사이킷런을 사용하기 위해 2차원 리스트로 변환
diff --git "a/week1/3\355\214\200_\352\271\200\353\217\231\354\227\260.md" "b/week1/3\355\214\200_\352\271\200\353\217\231\354\227\260.md"
new file mode 100644
index 0000000..30d74d2
--- /dev/null
+++ "b/week1/3\355\214\200_\352\271\200\353\217\231\354\227\260.md"
@@ -0,0 +1 @@
+test
\ No newline at end of file
diff --git "a/week1/3\355\214\200_\352\271\200\355\225\234\352\262\260.md" "b/week1/3\355\214\200_\352\271\200\355\225\234\352\262\260.md"
deleted file mode 100644
index 2f139fa..0000000
--- "a/week1/3\355\214\200_\352\271\200\355\225\234\352\262\260.md"
+++ /dev/null
@@ -1,38 +0,0 @@
-# 나의 첫 머신러닝
-## 인공지능과 머신러닝, 딥러닝
-인공지능 : 사람처럼 학습하고 추론할 수 있는 지능을 가진 컴퓨터 시스탬을 만드는 기술
-머신러닝 : 규칙을 일일이 프로그래밍하지 않아도 자동으로 데이터에서 규칙을 학습하는 알고리즘을 연구하는 분야
-딥러닝 : 머신러닝 알고리즘 중에 인공 신경망을 기반으로 한 방법들을 통칭
-## 코랩과 주피터 노트북
-코랩 : 구글 계정이 있으면 누구나 사용할 수 있는 웹 브라우저 기반의 파이썬 코드 실행 환경
-노트북 : 코드, 코드 실행 겨로가, 문서 모두 저장 가능
-구글 드라이브 : 구글이 제공하는 클라우드 파일 저장 서비스
-텍스트 셀에는 마크다운 사용 가능
-## 마켓과 머신러닝
-특성 : 데이터를 표현하는 하나의 성질
-훈련 : 머신러닝 알고리즘이 데이터에서 규칙을 찾는 과정
-k-최근접 이웃 알고리즘 : 가장 간단한 머신러닝 알고리즘. 전체 데이터를 메모리에 가지고 있는다.
-모델 : 알고리즘이 구현된 객체
-정확도 : 정확히 맞힌 개수/전체 데이터 개수
-1. matplotlib
-- scatter() : 산점도 그리기
-2. scikit-learn
-- KNeighborsClassifier() : k-최근접 이웃 분류 모델을 만드는 사이킷런 클래스
-- fit() : 사이킷런 모델 훈련
-- predict() : 모델 훈련 및 예측
-- score() : 훈련된 사이킷런 모델의 성능 측정
-# 데이터 다루기
-## 훈련 세트와 테스트 세트
-지도 학습 : 입력과 타깃을 전달하여 모델을 훈련한 다음 새로운 데이터를 예측하는 데 활용
-비지도 학습 : 타깃 데이터 X. 입력 데이터에서 어떤 특징을 찾는 데 주로 활용
-1. numpy
-- seed() : 난수를 생성하기 위한 정수 초깃값 지정
-- arrange() : 일정한 간격의 정수 또는 실수 배열 만들기
-- shuffle() : 주어진 배열 랜덤하게 섞기
-## 데이터 전처리
-데이터 전처리 : 머신러닝 모델에 훈련 데이터를 주입하기 전에 가공하는 단계
-표준점수 : 훈련 세트의 스케일을 바꾸는 대표적인 방법 중 하나
-브로드캐스팅 : 크기가 다른 넘파이 배열에서 자동으로 사칙 연산을 모든 행이나 열로 확장하여 수행하는 기능
-1. scikit-learn
-- train_test_split() : 훈련 데이터를 훈련 세트와 테스트 세트로 나눔
-- kneighbors() : k-최근접 이웃 객체의 메서드
\ No newline at end of file
diff --git "a/week1/3\355\214\200_\354\235\264\354\236\254\355\235\240.md" "b/week1/3\355\214\200_\354\235\264\354\236\254\355\235\240.md"
index 6ba35b1..cb13698 100644
--- "a/week1/3\355\214\200_\354\235\264\354\236\254\355\235\240.md"
+++ "b/week1/3\355\214\200_\354\235\264\354\236\254\355\235\240.md"
@@ -34,7 +34,7 @@
**노트북**은 프로그램 안에서 텍스트와 프로그램 코드를 자유롭게 작성할 수 있는 에디터 입니다.
**셀**은 노트북에서 실행할 수 있는 최소 단위입니다. 셀 안에 있는 내용을 한번에 실행하고 그 결과를 노트북으로 나타냅니다. 기존에 실행된 셀 내용이 다른 셀에서 실행할때 영향을 끼친다는 것이 노트북의 큰 특징입니다.
-###### 구글 코랩
+######구글 코랩
**구글 코랩**은 주피터 노트북을 커스터마이징 웹 브라우저에서 무료로 파이썬 프로그램을 테스트하고 저장할 수 있는 서비스 입니다. 클라우드 기반의 주피터 노트북 개발 환경을 가지고 있어 자신의 컴퓨터의 사양이 좋지 않아도 프로그램을 돌릴 수 있어 유용합니다.
@@ -88,7 +88,7 @@ predict( ) 메서드는 새로운 데이터의 정답을 예측하는 메소드
하지만 모든 데이터를 훈련을 넣고 모든 데이터를 넣고 테스트 해보는 것은 학습이 되어있는 데이터를 다시 처리하는 것 뿐이므로 성능을 제대로 평가 할 수 없습니다.
그래서 우리는 이 데이터를 훈련하는 데이터(train set)와 테스트하는 데이터(test set)로 나누어 모델 평가를 해야 합니다.
-###### 샘플링 편향
+######샘플링 편향
훈련 데이터와 테스트 데이터에는 다른 특징을 가지는 데이터들이 골고루 섞여져 있어야 합니다.
골고루 섞여져 있지 않은 경우, 샘플링이 한쪽으로 치우치게 되어 훈련을 할 때 한쪽에 편향된 결과가 만들어져 정확도에 영향을 끼칠수 있습니다. 이를 **샘플링 편향**이라고 부릅니다.
@@ -132,4 +132,4 @@ train_input, test_input, train_target, test_target = train_test_split(some_data,
````python
mean = np.mean(train_input, axis=0) #행을 따라(axis=0) 각 열의 평균값을 계산합니다.
std = np.std(trian_input, axis=0) #행을 따라(axis=0) 각 열의 표준편차를 계산합니다.
-````
+````
\ No newline at end of file
diff --git "a/week1/3\355\214\200_\354\241\260\353\252\205\352\265\254.md" "b/week1/3\355\214\200_\354\241\260\353\252\205\352\265\254.md"
deleted file mode 100644
index 1e12c66..0000000
--- "a/week1/3\355\214\200_\354\241\260\353\252\205\352\265\254.md"
+++ /dev/null
@@ -1,20 +0,0 @@
- 1주차에는 구글 코랩의 기본적인 사용법과 k-최근접 이웃 알고리즘을 공부했습니다.
-교재에서 배운 내용을 학습하는 것을 기본적으로 구글 코랩이라는 곳에서 하는데
-코드를 구글 클라우드에서 실행하기 때문에 본인이 사용하는 pc의 영향을 받지 않지만
-할당받은 메모리 안에서 코드 실행이 이루어져야하기 때문에 조금의 제한사항이 있습
-니다. 이 책의 커리큘럼을 따라가는데에는 무리가 없다고 합니다.
- 첫 머신러닝은 k-최근접 알고리즘을 학습하기 위해 샤이킷런에서 KNeighborsClassifier
-을 import하여 사용합니다. k-최근접 알고리즘을 이용하게 해주는 머신러닝 관련 class인
-걸로 이해하고 있습니다. KNeighborsClassifier(이하 kn)는 지도 학습에 해당하는데 이
-지도학습은 input과 target을 필요로 합니다. input에 대응하는 target을 학습한 후
-test set로 kn이 학습이 잘 되었는지 결정계수(Ch. 3)를 점수로 매깁니다. fit 명령어를
-이용하여 train하고 score 명령어로 점수를 매깁니다. 점수가 1에 가까울수록 훈련이
-잘 되었다고 볼 수 있습니다.
- kn은 제시된 데이터가 도미냐 빙어냐를 판별하기 위해 가장 가까운 이웃 5개를 그래프
-상 거리를 기준으로 선발하여 그 중 많은 쪽으로 판별합니다. 하지만 여기서 무게와
-너비 단위가 다르다는 이유로 산점도 그래프상으로 빙어인 데이터를 도미로 오판정하게
-됩니다. 이를 계기로 데이터 전처리라는 걸 공부하게 됩니다.
- 데이터 전처리는 모든 데이터를 평등하게 만들어줍니다. 여기서 배운 데이터 전처리는
-표준 점수라고 하는 것으로, {(데이터)-(평균)}/(표준편차)로 계산합니다. 이 표준 점수는
-train_input을 기준으로 구한 평균과 표준편차를 이용하여 train_input, test_input 둘 다를
-전처리해주어야 합니다. 이 과정을 통해 x축과 y축의 scale 문제가 해소될 수 있습니다.
\ No newline at end of file
diff --git "a/week1/4\355\214\200_week2_\354\243\274\354\227\260\354\247\204.md" "b/week1/4\355\214\200_week2_\354\243\274\354\227\260\354\247\204.md"
deleted file mode 100644
index fc2e6dd..0000000
--- "a/week1/4\355\214\200_week2_\354\243\274\354\227\260\354\247\204.md"
+++ /dev/null
@@ -1,205 +0,0 @@
-# **회귀 알고리즘과 모델 규제**
-## **K-최근접 이웃 회귀**
----
-* 주변 샘플 k개를 선택해 타깃값을 평균내서 타깃값을 예측하는 방법
-* 사이킷런 훈련 세트는 2차원 배열이어야 함
-```python
-test_array = np.array([1, 2, 3, 4])
-
-test_array = test_array.reshape(2, 2)
-
-print(test_array.shape)
-```
-1. 처음 [1, 2, 3, 4] 의 경우 크기는 (4, )이다. ( 1차원 배열 )
-
-2. reshape( )를 사용하면 크기가 (2, 2)로 변경 된다. ( 2차원 배열 )
-
-3. reshape( -1, 1 )을 하면 첫 번째 크기를 나머지 원소 개수로 채우고, 두 번째 크기는 1이 된다.
-
-* **KNeighborsRegressor** : k - 최근접 이웃 회귀 알고리즘 구현 클래스
-```python
-from sklearn.neighbors import KNeighborsRegressor
-
-knr = KNeighborsRegressor()
-
-kn.fit(train_input, train_target)
-```
-
-## **결정계수 ( $R^2$ )**
----
-```python
-print(knr.score(test_input, test_target))
-```
-결과값으로 0.992809406100639가 나온다.
-
-* **결정계수 ( $R^2$ )** : 위 결과값
-
-$$
-R^2 = 1 - \frac{(타깃 - 예측)^2의 합 }{ (타깃 - 평균)^2의 합}
-$$
-이와 같이 결정계수를 구할 수 있다.
-> * 평균 = 타깃 값들의 평균
-> * 결정계수는 분산 이용한 모델평가지표
-> * 독립변수로 설명할 수 있는 분산 / 전체분산 과 같다
-> * 독립변수들이 종속변수들을 얼마나 설명하는가
-> * 1에 가까울수록 좋은 모델
-
-## **타깃과 예측한 값 차이 구하기**
----
-* **mean_absolute_error :** 타깃과 예측의 절댓값 오차 평균 반환
-```python
-from sklearn.metrics import mean_absolute_error
-
-test_prediction = knr.predict(test_input)
-
-mae = mean_absolute_error(test_target, test_prediction)
-```
-다음과 같이 사용한다.
-
-## **과대적합 vs 과소적합**
----
-### **과대적합**
-* 훈련 세트에서 점수가 굉장히 좋은데, 테스트 세트에서 점수가 굉장히 나쁜 경우
-* 훈련 세트에만 잘 맞는 모델
-
-### **과소적합**
-* 훈련 세트보다 테스트 세트 점수가 더 놓은 경우
-* 두 점수 모두 낮은 경우
-
-
-### **과소적합이 일어나는 이유 :**
-* 모델이 너무 단순하여 훈련 세트에 적절히 훈련되지 않은 경우
-* 훈련 세트와 테스트 세트의 크기가 매우 작기 때문
-
-### **과소적합 해결 방법**
-모델을 조금 더 복잡하게 만들면 된다. K-최근접 이웃 알고리즘의 경우 K를 줄이면 된다.
-
-## **선형회귀**
-___
-* 사이킷럿에 LinearRegression 클래스에서 선형 회귀 알고리즘 사용
-```python
-from sklenar.linear_model import LinearRegression
-
-lr = LinearRegression()
-
-lr.fit(train_input, train_target)
-
-print(lr.predict([[50]]))
-```
-다음과 같이 사용한다.
-
- * **coef_ :** 기울기 ( 계수, 또는 가중치라고도 불림 )
- * **intercept_ :** y절편
-
- ## **다항회귀**
- ---
- * 최적의 곡선 찾기
- * 2차 방정식 그래프 그리려면 길이 제곱이 훈련에 추가 되어야 함
-```python
-train_poly = np.column_stack((train_input ** 2, train_input))
-test_poly = np.column_stack((test_input ** 2, test_input))
-```
-* 어떤 그래프를 훈련하든지, 타깃값은 그대로 사용한다.
-
-```python
-lr = LinearRegression()
-lr.fit(train_poly, train_target)
-
-print([[50 ** 2, 50]])
-```
-## **다중 회귀**
----
-* 여러 개의 **특성**을 사용한 선형 회귀
-
-* **특성 공학 :** 기존의 특성을 사용해 새로운 특성을 뽑아내는 작업
- > ex) '농어 길이' x '농어 높이'를 새로운 특성으로 만들기
-
-## **판다스**
----
-* 데이터 분석 라이브러리
-* **넘파이와 달리** 인터넷에서 데이터 바로 다운로드해서 사용 가능
-* 데이터 프라임 넘파이 배열로 바꾸는 거 가능
-* read_csv( '주소' ) 로 데이터 프라임 만들고, to_numpy()
-
-```python
-import pandas as pd
-
-df = pd.read_csv('https://bit.ly/perch_csv_data')
-perch_full = df.to_numpy()
-print(perch_full)
-# [[8.4, 2.11, 1.41],
-# [13.7, 3.53, 2. ]]
-# 위와 같이 여러 특성을 포함한 numpy로 바뀐다.
-```
-
-## **사이킷런 변환기**
----
-* **변환기:** 특성을 만들거나 전처리해주는 클래스
- > ex) PolynomialFeatures
-* **include_bias = False :** transform 할 때 1을 자동으로 추가하는 것을 방지
-* **transform() :** 특성 각자 그대로, 각자 제곱한 값, 서로서로 곱한 값 모두 포함
-* **polynomialFeatures(degree = 5) :** 5제곱까지 특성 만듦
-
-```python
-from sklearn.preprocessing import PolynomialFeatures
-
-poly = PolynomialFeatures()
-
-poly.fit([[2, 3]]) #훈련 해야 변환 가능
-print(poly.transform([[2,3]]))
-# [[1,2,3,4,6,9]] 가 나옴.
-# 2개 특성이 6개로 바뀜.
-```
-
-## **규제**
----
-* 훈련 세트에 과대적합되지 않도록 만드는 것
-* 선형 회귀 모델의 경우 특성에 곱해지는 계수 작게 만들기
-* 선형 회귀 모델에 규제 적용할 때, 계수 깂 크기가 특성마다 많이 다르면 공정한 제어 불가능하므로 정규화 필요
-* **StandardScaler :** 특성 표준점수로 바꿔주는 변환기
-
-```python
-from sklearn.preprocessing import StandardScaler
-
-ss = StandardScaler()
-ss.fit(train_poly)
-
-train_scaled = ss.transform(train_poly)
-test_scaled = ss.transform(test_poly)
-```
-
-### **Alpha**
-* Alpha는 매개변수로 규제 강도 조절
-
-* Alpha 값이 **크면** 규제 커지고 **과소적합** 유도
-* Alpha 값이 **작으면** 규제 작아지고 **과대적합** 유도
-* **하이퍼파라미터 :** 모델이 학습할 수 없고 사람이 알려줘야 하는 파라미터
-
-
-### **릿지 회귀**
-* 선형 회귀 모델에 규제를 추가한 모델
-* 계수를 제곱한 값을 기준으로 규제
-```python
-from sklearn.linear_model import Ridge
-
-ridge = Ridge()
-ridge.fit(train_scaled, test_scaled)
-```
-이와 같이 사용한다.
-
-### **라쏘 회귀**
-* 계수의 절댓값을 기준으로 규제 적용
-* 계수 크기 0으로 만들기 가능
-```python
-from sklearn.linear_model import Lasso
-
-lasso = Lasso()
-lasso.fit(train_scaled, test_scaled)
-```
-
-
-
-
-
-
-
diff --git "a/week1/4\355\214\200_\353\260\260\354\227\260\354\232\261.md" "b/week1/4\355\214\200_\353\260\260\354\227\260\354\232\261.md"
deleted file mode 100644
index d2c6730..0000000
--- "a/week1/4\355\214\200_\353\260\260\354\227\260\354\232\261.md"
+++ /dev/null
@@ -1,109 +0,0 @@
-# [1주차 과제] 4팀 배연욱
-
----
-
-### Chapter 1. 나의 첫 머신러닝
-
----
-
-**인공지능(artificial intelligence, AI)**은 사람처럼 학습하고 추론할 수 있는 지능을 가진 시스템을 만드는 기술이다.
-
-**인공지능**
-
-* 강인공지능
-* 약인공지능
-
-
-**머신러닝(machine learning, ML)**은 규칙을 프로그래밍하지 않아도 자동으로 데이터에서 규칙을 학습하는 알고리즘을 연구하는 분야. Scikit-learn이 대표적인 라이브러리이다.
-
-**머신러닝**
-
-* 지도학습
- * 분류
- * 회귀
-* 비지도학습
-* 강화학습
-
-
-**딥러닝(deep learning, DL)**은 인공 신경망이라고도 하며, TensorFlow, PyTorch가 대표적인 라이브러리이다.
-
-
-**인공지능**
-
-* **머신 러닝**
- * **딥러닝**
-
----
-
-**코랩(Colab)**은 구글 계정이 있으면 누구나 사용할 수 있는 웹 브라우저 기반의 Python 코드 실행 환경이다.
-
-**텍스트 셀에 사용할 수 있는 마크다운**
-
-
----
-
-**특성**은 데이터를 표현하는 하나의 성질이다.
-
-
-머신러닝 알고리즘이 데이터에서 규칙을 찾는 과정을 **훈련**이라고 한다. Scikit-learn에서는 fit() 메서드가 하는 역할이다.
-
-
-**k-최근접 이웃 알고리즘**은 가장 간단한 머신러닝 알고리즘 중 하나이다. 사실 어떤 규칙을 찾기보다는 전체 데이터를 메모리에 가지고 있는 것이 전부이다.
-
-
-머신러닝 프로그램에서는 알고리즘이 구현된 객체를 **모델**이라고 부른다. 종종 알고리즘 자체를 모델이라고 부르기도 한다.
-
-
-**정확도**는 정확한 답을 몇 개 맞혔는지를 백분율로 나타낸 값이다. Scikit-learn에서는 0~1 사이의 값으로 출력된다.
-> 정확도 = (정확히 맞힌 개수) / (전체 데이터 개수)
-
----
-
-### Chapter 2. 데이터 다루기
-
----
-
-**지도 학습**은 입력과 타깃을 전달하여 모델을 훈련한 다음 새로운 데이터를 예측하는 데 활용한다. 1장에서부터 사용한 k-최근접 이웃이 지도 학습 알고리즘이다.
-
-
-**비지도 학습**은 타깃 데이터가 없다. 따라서 무엇을 예측하는 것이 아니라 입력 데이터에서 어떤 특지을 찾는 데 주로 활용한다.
-
-
-**훈련 세트**는 모델을 훈련할 때 사용하는 데이터이다. 보통 훈련 세트가 클수록 좋다. 따라서 테스트 세트를 제외한 모든 데이터를 사용한다.
-
-
-**테스트 세트**는 전체 데이터에서 20~30%를 테스트 세트로 사용하는 경우가 많다. 전체 데이터가 아주 크다면 15%만 덜어내도 충분할 수 있다.
-
----
-
-**데이터 전처리**는 머신러닝 모델에 훈련 데이터를 주입하기 전에 가공하는 단계를 말한다. 때로는 데이터 전처리에 많은 시간이 소모되기도 한다.
-
-**데이터 전처리**
-
-* 이상치(outliers) 제거
-* 결측값(missing values) 처리
- 1. 결측값이 있는 행 제거 (.dropna() 사용)
- 2. 결측값 보강 (imputation)
- * 평균값 또는 중앙값 또는 최빈값으로 대체
- * 예측값으로 대체
-* Feature Scaling
- * 정규화(normalization)
- * 표준화(standardization)
-
-
-**표준점수**는 훈련 세트의 스케일을 바꾸는 대표적인 방법 중 하나이다. 표준점수를 얻으려면 특성의 평균을 빼고 표준편차로 나눈다. 반드시 훈련 세트의 평균과 표준편차로 테스트 세트를 바꿔야 한다.
-
-
-**브로드캐스팅**은 크기가 다른 NumPy 배열에서 자동으로 사칙 연산을 모든 행이나 열로 확장항여 수행하는 기능이다.
-
----
-
-### 기타 발표 내용 정리
-
----
-
-**교차 검증**
-
-* Holdout method
-* Leave-one-out cross validation
-* k-fold cross validation
diff --git "a/week1/4\355\214\200_\354\243\274\354\227\260\354\247\204.md" "b/week1/4\355\214\200_\354\243\274\354\227\260\354\247\204.md"
deleted file mode 100644
index dfbd83d..0000000
--- "a/week1/4\355\214\200_\354\243\274\354\227\260\354\247\204.md"
+++ /dev/null
@@ -1,110 +0,0 @@
-# **나의 첫 머신러닝 & 데이터 다루기**
-## 1. 인공지능, 머신러닝, 딥러닝이란 무엇인가
--------
-* **인공지능**
- >사람처럼 학습하고 추론할 수 있는 지능을 가진 컴퓨터 시스템을 만드는 기술
-
-* **머신러닝**
- > 규칙을 일일이 프로그래밍하지 않아도 자동으로 데이터에서 규칙을 학습하는 알고리즘을 연구하는 분야
-
-* **딥러닝**
- >머신러닝 알고리즘 중에 인공신경망을 기반으로 한 방법들
-
-## 2. 머신러닝의 종류
----
-* **지도학습( Supervised Learning )**
-
- > 훈련 데이터로부터 하나의 함수를 유추해내기 위한 기계 학습의 한 방법
-
-* **비지도학습( Unsupervised Learning)**
- > 정답 라벨이 없는 데이터를 비슷한 특징끼리 군집화하여 새로운 데이터에 대한 결과를 예측하는 기계학습의 한 방법
-
-* **강화학습( Reinforcement Learning )**
- > 현재의 상태에서 어떤 행동을 취하는 것이 최적인지를 학습하는 기계학습의 한 방법
-
- ## 3. matplotlib
----
-- 과학계산용 그래프 그려주는 패키지
-- scatter( ) : 산점도 그려주는 함수
-```python
-import matplotlib.pyplot as plt
-
-plt.scatter(bream_length, bream_weight)
-```
-이와 같이 사용한다.
-
-## 4. K - 최근접 이웃 알고리즘
----
-* 주위 다른 데이터를 바탕으로 현재 데이터를 판단하는 알고리즘
- > 거리 기반이며, 기본적으로 가까운 5개 데이터 참고함
-
-* KNeighborsClassifier : 사이킷런에 패키지에서 k-최근접 알고리즘 구현한 클래스
-* kneighbors( ) : 이웃 데이터들 찾아서 이웃들까지 거리와 이웃 인덱스 반환
- > kneighbors( 데이터 )
-* fit( ) : 훈련시키는 메서드
- > fit( 인풋 데이터, 정답 ) 순으로 작성
-* score( ) : 모델 평가하는 메서드
- > score( 인풋 데이터, 정답 ) 순으로 작성
-* predict( ) : 새로운 데이터 정답 예측하는 메서드
- > predict( 데이터 )
-
-```python
-from sklearn.neighbors import KNeighborsClassifier
-
-kn = KNeighborsClassifier()
-kn.fit( fish_data, fish_target )
-kn.score( fish_data, fish_target )
-kn.predict( [[30, 600]] )
-```
-이와 같이 사용한다.
-
-## 5. 넘파이 ( numpy )
----
-* 배열 라이브러리로, 고차원 배열을 쉽게 만들 수 있으며 간편한 도구들이 많아 쉽게 조작 가능
-
-* array( ) : 파이썬 리스트를 넘파이 배열로 바꾸기
-* arange( num ) : 0 ~ ( num - 1 )까지 1씩 증가하는 인덱스 만들어주는 함수
-* random.shuffle( ) : 주어진 배열 무작위로 섞는 함수
-* column_stack( ) : 전달받은 리스트들 각각 하나씩 원소 꺼내서 붙이기
-* concatenate( ) : 첫번째 차원을 따라 배열 연결해주는 함수
-
-```python
-import numpy as np
-
-input_arr = np.array( fish_data )
-index = np.arange( 49 )
-np.random.suffle( index )
-
-fish_data = np.column_stack((fish_length, fish_weight))
-fish_target = np.concatenate((np.ones(35), np.zeros(14)))
-```
-이와 같이 사용한다.
-
-## 6. train_test_split
----
-* 리스트나 배열을 비율에 맞게 훈련 세트와 테스트 세트로 나눠줌
-* 기본적으로 25%가 테스트 세트로 가지만, stratify에 타겟 데이터를 전달하면 클래스 비율에 따라 데이터 나눔 가능
-
-```python
-from sklearn.model_selection import train_test_split
-
-train_input, test_input, train_target, test_target = train_test_split(fish_data, fish_target, stratify = fish_target, random_state = 42)
-```
-1. fish_data가 비율에 따라 train_input, test_input으로 나뉨
-2. fish_target이 비율에 따라 train_target, test_target으로 나뉨
-
-## 7. 데이터 전처리
----
-* 특성의 스케일이 달라서 어느 한 쪽이 거리에 영향을 많이 미칠 경우, 대표적으로 표준점수로 값 변환
-
-* 표준점수 ( z ) = ( 데이터 - mean ) / std
-* np.mean( ) : 평균 계산
-* np.std( ) : 표준편차 계산
-
-```python
-mean = np.mean( train_input, axis = 0 )
-std = np.std( train_input, axis = 0 )
-
-train_scaled = ( train_input - mean ) / std
-```
-이와 같이 사용힌다.
diff --git "a/week1/4\355\214\200_\354\265\234\355\203\234\354\230\201.md" "b/week1/4\355\214\200_\354\265\234\355\203\234\354\230\201.md"
deleted file mode 100644
index 8a3112d..0000000
--- "a/week1/4\355\214\200_\354\265\234\355\203\234\354\230\201.md"
+++ /dev/null
@@ -1,81 +0,0 @@
-import matplotlib.pyplot as plt#그래프 그리기
-import numpy as np#라이브러리 넘파이
-
-fish_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
- 31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
- 35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0, 9.8,
- 10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
-fish_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
- 500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
- 700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0, 6.7,
- 7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9] # 데이터
-
-
-fish_data = [[l,w] for l, w in zip(fish_length,fish_weight)]# 2d 로 데이터 정렬
-
-fish_target = [1]*35 + [0]*14 #정답 데이터를 만듦. 1은 도미 2는 빙어
-
-input_arr = np.array(fish_data)
-target_arr = np.array(fish_target) #넘파이로 변환
-
-from sklearn.neighbors import KNeighborsClassifier # KNeighborsClassifier 라이브러리 호출
-
-kn = KNeighborsClassifier()
-
-np.random.seed(42)
-index = np.arange(49)
-np.random.shuffle(index) #데이터를 섞음
-
-train_input = input_arr[index[:35]]
-train_target = target_arr[index[:35]]
-print(input_arr[13], train_input[0])
-test_input = input_arr[index[35:]]
-test_target = target_arr[index[35:]] #데이터를 나누어 학습 데이터와 테스트 데이터 셋을 만듦
-
-kn = kn.fit(train_input, train_target) #학습
-kn.score(test_input, test_target)#평가
-kn.predict(test_input)
-test_target
-fish_data = np.column_stack((fish_length, fish_weight))# 데이터 합체
-fish_target = np.concatenate((np.ones(35), np.zeros(14)))#타깃 데이터 생성
-from sklearn.model_selection import train_test_split
-train_input, test_input, train_target, test_target = train_test_split(
- fish_data, fish_target, stratify=fish_target, random_state=42) #데이터 분류. split()함수를 통해 간단하게 가능
-print(test_target)
-kn.fit(train_input, train_target)#학습
-kn.score(test_input, test_target)
-plt.scatter(train_input[:,0], train_input[:,1])
-plt.scatter(25, 150, marker='^')
-plt.xlabel('length')
-plt.ylabel('weight')
-plt.show() #그래프 그리기
-distances, indexes = kn.kneighbors([[25, 150]])
-plt.scatter(train_input[:,0], train_input[:,1])
-plt.scatter(25, 150, marker='^')
-plt.scatter(train_input[indexes,0], train_input[indexes,1], marker='D')
-plt.xlabel('length')
-plt.ylabel('weight')
-plt.show()
-mean = np.mean(train_input, axis=0)
-std = np.std(train_input, axis=0) #거리를 표준화하기 위해 평균값과 분산을 구함
-print(mean, std)
-plt.scatter(train_scaled[:,0], train_scaled[:,1])
-plt.scatter(25, 150, marker='^')
-plt.xlabel('length')
-plt.ylabel('weight')
-plt.show() #그래프화
-new = ([25, 150] - mean) / std# 표준화
-plt.scatter(train_scaled[:,0], train_scaled[:,1])
-plt.scatter(new[0], new[1], marker='^')
-plt.xlabel('length')
-plt.ylabel('weight')
-plt.show()
-kn.fit(train_scaled, train_target) #새로 학습시킴
-test_scaled = (test_input - mean) / std
-distances, indexes = kn.kneighbors([new])
-plt.scatter(train_scaled[:,0], train_scaled[:,1])
-plt.scatter(new[0], new[1], marker='^')
-plt.scatter(train_scaled[indexes,0], train_scaled[indexes,1], marker='D')
-plt.xlabel('length')
-plt.ylabel('weight')
-plt.show()#데이터 전처리를 통해 더 확실한 정답을 구함
\ No newline at end of file
diff --git "a/week1/5\355\214\200_\352\271\200\353\217\231\354\232\260.md" "b/week1/5\355\214\200_\352\271\200\353\217\231\354\232\260.md"
deleted file mode 100644
index 26ed755..0000000
--- "a/week1/5\355\214\200_\352\271\200\353\217\231\354\232\260.md"
+++ /dev/null
@@ -1,114 +0,0 @@
-# Chap 1, 2
-
-## k-Nearest Neighbors
-
-### key words
-
-* 특성: 데이터를 표현하는 하나의 성질
-* 훈련: 머신러닝 알고리즘이 데이터의 규칙을 찾는 과정
-* k-Nearest Neighbors: 머신러닝 알고리즘 중 하나
-* 모델: 머신러닝 프로그램에서 알고리즘이 구현된 객체
-* 정확도: 머신러닝 알고리즘이 답을 맞힌 비율
-* matplotlib: 그래프와 차트를 그리는 모듈
-* scikit-learn: 머신러닝, 딥러닝 모델을 만드는 모듈
----
-```python
-bream_length = [25.4, 26.3, 26.5, ...]
-bream_weight = [242.0, 290.0, 340.0, ...]
-
-import matplotlib.pyplot as plt
-
-plt.scatter(bream_length, bream_weight)
-plt.xlabel('length')
-plt.ylabel('weight')
-plt.show()
-
-smelt_length = [9.8, 10.5, 10.6, ...]
-smelt_weight = [6.7, 7.5, 7.0, ...]
-
-plt.scatter(bream_length, bream_weight)
-plt.scatter(smelt_length, smelt_weight)
-plt.xlabel('length')
-plt.ylabel('weight')
-plt.show()
-```
-1. 도미와 빙어 데이터 준비
-2. matplotlib 모듈 불러오기
-3. matplotlib의 산점도 함수를 이용하여 데이터 분포 확인
----
-```python
-length = bream_length+smelt_length
-weight = bream_weight+smelt_weight
-
-fish_data = [[l, w] for l, w in zip(length, weight)]
-
-fish_target = [1]*35 + [0]*14
-
-from sklearn.neighbors import KNeighborsClassifier
-
-kn = KNeighborsClassifier()
-
-kn.fit(fish_data, fish_target)
-
-kn.score(fish_data, fish_target)
-```
-1. 도미와 빙어 데이터 합치기
-2. 사이킷런 패키지를 사용하기 위해 데이터를 2차원 리스트로 변환
-3. KNeighborsClassifier 클래스를 불러오기
-4. KNeighborsClassifier 클래스의 객체 만들기
-5. 주어진 데이터로 객체가 훈련
-6. 객체의 훈련이 잘 되었는지 정확도 확인
----
-```python
-plt.scatter(bream_length, bream_weight)
-plt.scatter(smelt_length, smelt_weight)
-plt.scatter(30, 600, marker='^')
-plt.xlabel('length')
-plt.ylabel('weight')
-plt.show()
-
-kn.predict([[30, 600]])
-
-kn49 = KNeighborsClassifier(n_neighbors=49)
-
-kn49.fit(fish_data, fish_target)
-kn49.score(fish_data, fish_target)
-print(35/49)
-```
-1. 산점도 그래프에서 (30, 600)의 위치 확인
-2. (30, 600)이 도미에 속하는지 빙어에 속하는지 예측
-3. n_neighbors이 49라면 예측값이 항상 도미가 됨
----
-## train sets & test sets
-```python
-train_input = fish_data[:35]
-train_target = fish_target[:35]
-test_input = fish_data[35:]
-test_target = fish_target[35:]
-
-kn = kn.fit(train_input, train_target)
-kn.score(test_input, test_target)
-```
-1. fish 데이터의 자르는 방법으로 train, test 데이터를 나눔
-2. train 데이터로 훈련하고 test 데이터로 검증
----
-```python
-import numpy as np
-
-input_arr = np.array(fish_data)
-target_arr = np.array(fish_target)
-
-np.random.seed(42)
-index = np.arange(49)
-np.random.shuffle(index)
-
-train_input = input_arr[index[:35]]
-train_target = target_arr[index[:35]]
-
-test_input = input_arr[index[:35]]
-test_target = target_arr[index[:35]]
-```
-1. numpy 모듈 불러오기
-2. numpy의 랜덤함수를 이용하여 0 ~ 48이 무작위 순서로 들어있는 리스트 만들기
-3. 앞의 리스트를 35개, 14개로 잘라 train, test 데이터를 넣음
----
\ No newline at end of file
diff --git "a/week1/5\355\214\200_\354\235\264\354\212\271\355\233\210.md" "b/week1/5\355\214\200_\354\235\264\354\212\271\355\233\210.md"
deleted file mode 100644
index 11f5858..0000000
--- "a/week1/5\355\214\200_\354\235\264\354\212\271\355\233\210.md"
+++ /dev/null
@@ -1,205 +0,0 @@
-# 혼자 공부하는 머신러닝
-## Ch 1. 나의 첫 머신러닝
-## Ch 2. 데이터 다루기
-
----
-### 인공지능과 머신러닝, 딥러닝
-
-- **인공지능**: 사람처럼 학습하고 추론할 수 있는 지능을 가진 시스템을 만드는 기술. 고도의 지능을 가진 **강인공지능**과 보조적 기능을 수행하는 **약인공지능**으로 구분할 수 있다.
-- **머신러닝**: 규칙을 프로그래밍하지 않아도 자동으로 데이터에서 규칙을 학습하는 알고리즘을 연구하는 분야
-- **딥러닝**: 머신러닝 알고리즘 중 **인공 신경망**을 기반으로 한 방법들을 통칭해 이르는 말
-
----
-### 머신러닝의 종류
-
-##### 지도 학습
-지도 학습은 훈련하기 위한 데이터와 정답을 필요로 함.
-
-##### 비지도 학습
-비지도 학습은 별도의 정답 없이 입력 데이터만 사용함. 무언가를 맞힐 순 없으나 데이터를 잘 파악하거나 변형하는데 도움을 준다.
-
-##### 강화 학습
-이 책에서 다루지 않음
-
----
-
-### k-최근접 이웃 알고리즘으로 도미와 빙어 구분하기
-
-#### 우리의 목표
-도미와 빙어의 무게, 길이 데이터를 학습하여 임의의 데이터가 주어지면 도미인지 빙어인지 구분하는 프로그램을 설계해보기
-
----
-
-### 용어 정리
-
-- **분류(Classification)**: 여러 개의 종류 중 하나를 구별해내는 문제
-- **클래스(Class)**: 분류 문제에서 "종류"에 해당함
-- **이진 분류(Binary Classification)**: 분류 문제 중에서도 두 가지 중 하나로 구별해내는 문제
-- **특성(Feature)**: 분류 과정에서 단서가 되는 요소. 우리의 상황에선 생선의 무게와 길이가 된다.
-
----
-
-### 용어 정리
-- **입력(input)**: 지도 학습에서 **넣어주는 데이터**에 해당함
-- **타깃(target):** 지도 학습에서 **정답**에 해당함
-- **훈련 데이터:** 입력과 타깃을 통틀어 부르는 말
-- **훈련 세트:** 지도 학습 모델을 학습시킬 때 사용하는 데이터 모음
-- **테스트 세트:** 학습된 모델을 검증할 때 사용하는 데이터 모음
-
----
-
-### 용어 정리: k-최근접 이웃 알고리즘
-데이터가 들어오면 훈련 데이터 중 인접한 $n$개의 데이터를 찾아 가장 많이 나타나는 클래스로 데이터를 분류하는 알고리즘
-
-Ex) 인접한 5개의 데이터가 도미 4개, 빙어 1개 였다면 이 데이터는 도미로 분류
-
----
-
-### 우리가 책에서 겪은 시행착오
-- 훈련 데이터는 항상 훈련 세트와 테스트 세트로 나누어 학습과 정확도 확인을 진행해야 한다
-- 훈련 데이터는 파이썬의 리스트보단 넘파이 배열로 관리하는 것이 빠르고 편리하다 (구현체가 C이기 때문 + 편리한 함수 제공)
-- 거리를 기반으로 한 머신러닝 알고리즘은 **데이터 전처리**가 필수적이다
-
----
-### 코드 되짚어보기: 모듈 불러오기
-```python
-import matplotlib.pyplot as plt
-import numpy as np
-from sklearn.neighbors import KNeighborsClassifier
-from sklearn.model_selection import train_test_split
-```
-파이썬에서 모듈을 불러올 땐 `import`와 `from ~ import`가 있다.
-
-`import`는 모듈 내 객체를 사용할 때 모듈의 이름을 밝혀야 한다.
-Ex) `module.title`
-
-`from ~ import`는 모듈의 객체를 본 코드로 복사해오는 개념이라 모듈의 이름을 밝히지 않아도 사용할 수 있다
-
----
-
-### 코드 되짚어보기: 데이터 전처리
-```python
-# 우리가 분류할 도미, 빙어 데이터 (도미: Bream, 빙어 Smelt)
-
-bream_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
- 31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
- 35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0]
-bream_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
- 500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
- 700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0]
-
-smelt_length = [9.8, 10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
-smelt_weight = [6.7, 7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]
-
-fish_length = bream_length + smelt_length
-fish_weight = bream_weight + smelt_weight
-```
-
-scikit-learn의 훈련 모델은 `[[특성1, 특성2, ...]]` 형식을 요구한다.
-
----
-
-### 코드 되짚어보기: 데이터 전처리
-```python
-# [길이, 무게] 를 담은 2차원 리스트 생성; [[l, w] for l, w in zip(fish_length, fish_weight)]와 동치, 하지만 더 빠름
-fish_data = np.column_stack((fish_length, fish_weight))
-
-# 타깃 데이터 생성; 도미는 0, 빙어는 1; [0] * 35 + [1] * 14와 동치이나 더 빠름
-fish_target = np.concatenate((np.ones(35), np.zeros(14)))
-```
-
-- `np.column_stack((list1, list2))`: `list1`과 `list2`를 일렬로 세워 나란히 붙임
-- `np.concatenate((array1, array2))`: `array1`과 `array2`를 서로 나란히 이음
-- `np.ones(x)`: 길이 x의 1로 채워진 배열을 반환
-
----
-
-### 코드 되짚어보기: 데이터 전처리
-
-```python
-# 훈련 세트와 테스트 세트 나누기
-# train_test_split: (입력 데이터, 타깃 데이터 + 랜덤 함수 시드 (선택))
-# 데이터의 25%를 떼어내 테스트 세트로 만들어준다
-train_input, test_input, train_target, test_target = train_test_split(fish_data, fish_target, stratify = fish_target, random_state = 42)
-```
-
-`scikit-learn`에선 훈련 세트와 테스트 세트를 쉽게 나누는 함수를 제공함.
-- `random_state`: 섞을 때 사용할 랜덤 함수 시드를 설정
-- `stratify`: 타깃 데이터를 넣으면 클래스가 고르게 섞이게 함
-
----
-
-### 코드 되짚어보기: 데이터 전처리
-가장 흔하게 사용하는 데이터 전처리 방법 중 하나는 **표준점수**로, 각 특성값이 평균에서 표준편차의 몇 배만큼 떨어져 있는지 나타낸다.
-
-$$ Z = \frac{x - m}{\sigma} $$
-
-$x$는 특성값, $m$은 평균, $\sigma$는 표준편차를 의미한다.
-
-```python
-mean = np.mean(train_input, axis = 0)
-std = np.std(train_input, axis = 0)
-```
-
----
-### 코드 되짚어보기: 데이터 전처리
-
-`np.mean`과 `np.std`에서의 `axis`인자는 순회 방향을 의미한다.
-
-C에서의 배열로 `a[n][m]`이 있다고 생각하면,
-`axis = 0`이면 m은 고정한 채 n을 0~n-1까지 변화시키며 더하고, 결과는 크기 m의 1차원 배열이다.
-`axis = 1`이면 n은 고정한 채 m을 0~m-1까지 변화시키며 더한다고 생각할 수 있다.
-
-같은 느낌으로 `a[n][m][k]`가 있다고 생각하면
-`axis = 2`이면 n과 m은 고정한 채 k를 0~k-1까지 변화시키면서 더하고, 결과는 크기 [n][m]의 2차원 배열이다.
-
----
-### 데이터 전처리: 넘파이 브로드캐스팅
-넘파이는 넘파이 배열에 대해 일괄적으로 계산을 해준다.
-```python
-# 넘파이의 브로드캐스팅; 넘파이 배열 사이에서 이루어지는 배열 연산
-train_scaled = (train_input - mean) / std
-```
-
----
-### 코드 되짚어보기: 데이터 전처리
-주의할 점은 테스트 세트 역시 훈련 세트의 표준편차와 평균으로 표준화 해야한다는 점이다.
-그렇지 않으면 표준화의 기준이 달라져 잘못된 결과가 나오기 때문이다.
-
-```python
-# 테스트 데이터의 표준화도 훈련 데이터의 평균과 표준편차로 이루어져야함; 스케일을 같게 해야하기 때문
-test_scaled = (test_input - mean) / std
-```
-
----
-### 코드 되짚어보기: 데이터 전처리
-표준화한 상태의 산점도를 살펴보자.
-```py
-new = ([25, 150] - mean) / std
-plt.scatter(train_scaled[:,0], train_scaled[:,1])
-plt.scatter(new[0], new[1], marker = '^')
-plt.xlabel('length')
-plt.ylabel('weight')
-plt.show()
-```
-
----
-### 데이터 전처리: 넘파이의 배열 인덱싱
-생소한 표현 `a[:,0]`이 눈에 띈다. 이는 넘파이에서 지원하는 다차원 배열 인덱싱이다.
-
-`a[m, n]`: C에서 a[m][n]와 동치이다.
-`a[m1:m2, n1:n2]`: 행 [m1, m2), 열 [n1,n2)에 해당하는 부분 배열
-
-따라서 `a[:,0]`은 모든 행, 인덱스 0에 해당하는 열로 이루어진 부분 배열을 반환한다.
-
----
-### 코드 되짚어보기: 모델 학습, 결과 도출
-```python
-kn = KNeighborsClassifier()
-kn.fit(train_scaled, train_target)
-print(kn.score(test_scaled, test_target))
-print(kn.predict([new]))
-```
-- `fit()`: 모델을 학습시킴
-- `score()`: 모델의 정확도를 0~1로 나타냄
-- `predict()`: 학습한 모델을 이용해 새로운 데이터의 정답을 도출 (매개변수로 리스트를 받음)
\ No newline at end of file
diff --git "a/week1/5\355\214\200_\355\231\251\354\235\270\354\204\234.md" "b/week1/5\355\214\200_\355\231\251\354\235\270\354\204\234.md"
deleted file mode 100644
index 16d77a0..0000000
--- "a/week1/5\355\214\200_\355\231\251\354\235\270\354\204\234.md"
+++ /dev/null
@@ -1,80 +0,0 @@
-# Chapter 01 나의 첫 머신러닝
-
-### 01-1 인공지능과 머신러닝, 딥러닝
-- **인공지능**: 사람처럼 학습하고 추론할 수 있는 지능형 시스템을 만드는 기술
- - **머신러닝**: 자동으로 데이터에서 규칙을 학습하는 알고리즘을 연구하는 분야
- - **딥러닝**: 인공 신경망을 기반으로 한 머신러닝 알고리즘
-
-### 01-2 코랩과 주피터 노트북
-- **코랩**: 웹 브라우저 기반의 파이썬 코드 실행 환경
-- **노트북**: 코랩의 프로그램 작성 단위. 코드와 실행 결과, 문서를 모두 저장할 수 있음.
-
-### 01-3 마켓과 머신러닝
-- Keywords
- - **특성**: 데이터를 표현하는 하나의 성질. ex) 생선 데이터의 특성 = 길이, 무게
- - **훈련**: 머신러닝 알고리즘이 데이터에서 규칙을 찾는 과정
- - **모델**: 머신러닝 프로그램에서 알고리즘이 구현된 객체
- - **정확도**: (맞힌 개수) / (전체 데이터 개수)
- - **k-최근접 이웃 알고리즘**: 데이터에 대한 답을 결정할 때, 해당 데이터 주위에 많은 데이터의 정답을 채택하는 머신러닝 알고리즘
-
-- Packages and Functions
- - Python Built-in Functions
- - **zip()**: 나열된 리스트에서 원소를 하나씩 꺼냄.
-
- `fish_data = [[l, w] for l, w in zip(length, weight)]`
-
- - **matplotlib**(.pyplot): 파이썬에서 데이터 시각화(차트, 플롯 등)에 사용됨.
- - **scatter()**: x축 값과 y축 값을 바탕으로 산점도를 그림.
- - **xlabel(), ylabel()**: 축 레이블을 설정함.
- - **show()**: 그래프를 화면에 표시함.
-
- - **scikit-learn**(.neighbors): 파이썬을 위한 머신러닝 라이브러리
- - **KNeighborsClassifier**: k-최근접 이웃 분류 모델을 만드는 클래스
- - **fit()**: 특성과 정답 데이터로 사이킷런 모델을 훈련함.
- - **predict()**: 특성 데이터 하나를 매개변수로 받아 모델의 예측 결과를 표시함.
- - **score()**: 훈련된 사이킷런 모델의 성능을 측정함. 분류 모델의 경우, predict() 메서드로 예측을 수행하고 정답과 비교하여 맞힌 비율을 반환함.
-
-# Chapter 02 데이터 다루기
-### 02-1 훈련 세트와 테스트 세트
-- Keywords
- - **지도 학습**: 입력과 타깃을 전달하여 모델을 훈련한 후 새로운 데이터를 예측함. ex) k-최급접 이웃 알고리즘
- - **비지도 학습**: 타깃 데이터가 주어지지 않으며, 입력 데이터에서 어떠한 특징을 찾음.
- - **훈련 세트**: 모델을 훈련할 때 사용하는 데이터
- - **테스트 세트**: 훈련한 모델을 평가할 때 사용하는 데이터
- - **슬라이싱**: 파이썬 리스트에서 제공하는 연산자로, 인덱스의 범위를 지정해 여러 개의 원소를 선택할 수 있음.
-
- `# fish_data의 0 ~ 4 인덱스 원소를 출력`
-
- `print(fish_data[0:5]) `
-
- - **배열 인덱싱**: numpy에서 제공하는 기능으로, 여러 개의 인덱스로 여러 개의 배열 원소를 선택할 수 있음.
-
- `#input_arr의 2번째와 4번째 샘플 출력`
-
- `print(input_arr[[1,3]])`
-
- - **샘플링 편향**: 훈련 세트와 테스트 세트에 샘플이 골고루 섞여 있지 않은 경우
-
-- Packages and Functions
- - **numpy**: 파이썬의 배열 라이브러리. 고차원의 배열을 쉽게 만들고 조작할 수 있음.
- - **shape**: numpy 배열 객체의 속성. 샘플 개수와 특성 개수에 대한 정보를 담고 있음.
- - **array()**: 파이썬 리스트를 numpy 배열로 바꿈.
- - **arange()**: 일정한 간격의 정수 또는 실수 배열을 만듦.
- - **shuffle()**: 배열을 무작위로 섞음.
-
-### 02-2 데이터 전처리
-- Keywords
- - **데이터 전처리**: 머신러닝 모델에 훈련 데이터를 입력하기 전에 가공하는 단계
- - **브로드캐스팅**: 크기가 다른 numpy 배열에서 자동으로 사칙 연산을 모든 행이나 열로 확장하여 수행하는 기능
- - **표준점수**: 훈련 세트의 스케일을 바꾸는 방법 중 하나. 각 데이터가 원점에서 몇 표준편차만큼 떨어져 있는지 나타냄.
-
-$$Z=\frac{X-M}{\sigma}$$
-
-- Packages and Functions
- - matplotlib(.pyplot)
- - **xlim(), ylim()**: 축 범위를 지정함.
- - scikit-learn(.model_selection)
- - **train_test_split()**: 훈련 데이터를 훈련 세트와 테스트 세트로 나눔. stratify 매개변수에 클래스 레이블이 담긴 배열(타깃 데이터)을 전달하면 클래스 비율에 맞게 훈련 세트와 테스트 세트를 나눔.
- - numpy
- - **column_stack()**: 전달받은 리스트를 일렬로 세워 차례대로 나란히 연결함.
- - **concatenate()**: 첫 번째 차원을 따라 배열을 연결함.
diff --git "a/week1/6\354\241\260_\352\271\200\353\257\274\354\244\200.md" "b/week1/6\354\241\260_\352\271\200\353\257\274\354\244\200.md"
new file mode 100644
index 0000000..11376f5
--- /dev/null
+++ "b/week1/6\354\241\260_\352\271\200\353\257\274\354\244\200.md"
@@ -0,0 +1,52 @@
+# Ch 1 . 나의 첫 머신러닝
+
++ 인공지능 / 머신러닝 / 딥러닝
+ * 인공지능
+ - 사람처럼 학습하고 추론할 수 있는 지능을 가진 컴퓨터 시스템을 만드는 기술
+ - 인공일반지능(강인공지능) : 인간의 어떠한 지적 업무를 모두 성공적으로 수행하는 지능
+ - 약인공지능 : 특정 영역에서만 활용 가능한 지능
+ * 머신러닝
+ - 데이터에서 자동으로 규칙을 학습하는 알고리즘
+ - 사이킷런(sklearn) 등 사용
+ * 딥러닝
+ - 머신러닝 알고리즘 중 인공신경망을 기반으로 한 방법
+ - Tensorflow, Pytorch 등 사용
++ 마크다운(Markdown)
+ - 텍스트 기반의 마크업 언어
+ - 구글 Colab 텍스트 셀 등 사용
++ K-최근접 이웃 알고리즘 (K-Nearest Neighbor)
+ * 정의
+ - 주위의 다른 데이터에서 다수를 차지하는 것으로 정답을 판단하는 분류(Classify) 알고리즘
+ - 사이킷런 라이브러리에서 KNeighborsClassifier 사용
+ + fit() : 훈련 데이터를 분류기에 입력하는 함수
+ + predict() : 평가 데이터를 기반으로 label값을 예측하는 함수
+ + score() : 훈련된 모델의 성능을 측정하는 함수
+ * 용어
+ - 특성 : 데이터의 특징
+ - 산점도 : x, y축으로 이루어진 죄표계에서 x, y의 관계를 표현하는 방법 (변수 혹은 특성 간의 관계 표현)
+ - 훈련 : 모델에 데이터를 전달하여 규칙을 학습하는 과정
+
+# Ch 2 . 데이터 다루기
+
++ 지도 학습
+ * 비지도 학습 (Unsupervised learning)
+ - 훈련하기 위한 train data 필요 (정답은 target)
+ - ex) K-최근접 이웃 알고리즘
+ * 지도 학습 (Supervised learning)
+ * 강화 학습 (Reinforcement learning)
+
++ 훈련 세트 및 테스트 세트
+ - 머신러닝 알고리즘의 성능 평가에 사용
+ - 훈련에 한 번 사용한 데이터를 통한 모델 평가는 적절하지 않음
+ * 샘플링 편향
+ - 훈련 세트와 테스트 세트의 샘플이 고르지 못해 샘플링이 한쪽으로 치우침
+ - 균일한 훈련 세트 및 테스트 세트 필요
+ - numpy 라이브러리 shuffle() 함수 등 사용
+
++ 데이터 전처리
+ - 데이터의 특성값을 일정 기준으로 통일해야 함
+ - 전처리를 진행하지 않으면 정확도 문제 발생 가능
+ * 표준점수 (z점수)
+ - 각 특성값이 평균에서 얼마나 떨어져 있는지 나타냄
+ - 표준편차의 몇 배만큼 떨어져 있는지 표시
+
\ No newline at end of file
diff --git "a/week1/6\355\214\200_\352\266\214\354\230\210\354\244\200.md" "b/week1/6\355\214\200_\352\266\214\354\230\210\354\244\200.md"
deleted file mode 100644
index 3f2009f..0000000
--- "a/week1/6\355\214\200_\352\266\214\354\230\210\354\244\200.md"
+++ /dev/null
@@ -1,49 +0,0 @@
-# 나의 첫 머신러닝
-## 인공지능 / 머신러닝 / 딥러닝
----
-+ ### 인공지능: 사람처럼 학습하고 추론 할 수 있는 지능을 가진 컴퓨터 시스템을 만드는 기술
- + 인공일반지능(강인공지능) / 약인공지능
-+ ### 머신러닝: 자동으로 데이터에서 규칙을 학습하는 알고리즘을 연구
-+ ### 딥러닝: 머신러닝 알고리즘 중 인공 신경망을 기반으로 한 방법들
-
-## K-최근접 이웃 알고리즘
----
-+ ### 용어 정리
- + 특성: 데이터의 특징
- + 산점도: x, y축으로 이뤄진 좌표계에 x, y의 관계를 표현하는 방법
- + 훈련: 모델에 데이터를 전달하여 규칙을 학습하는 과정
-
-+ ### 어떤 데이터에 대한 답을 구할 때 주위의 다른 데이터를 보고 다수를 차지하는 것을 정답으로 사용
-
-+ ### KNeighborsClassifier
- + fit(): 처음 두 매개변수로 훈련에 사용할 특성과 정답 데이터 전달, 훈련에 사용
- + predict(): 특성 데이터 하나만 매개변수로 받아 사이킷런 모델 훈련, 예측에 사용
- + score() 훈련된 사이킷런 모델의 성능 측정, predict()로 예측 수행 후 분류 모델일 경우 정답과 비교하여 올바르게 예측한 개수의 비율 반환
-
-
-## 데이터 다루기
----
-+ ### 지도 학습: 훈련하기 위한 훈련데이터와 정답데이터 모두 필요
-+ ### 훈련 세트
- + 머신러닝 알고리즘의 성능 평가 -> 테스트 세트 사용
- + 훈련에 사용한 데이터로 모델 평가는 적절하지 않다
-
-+ ### 셈플링 편향
- + 훈련세트와 테스트 세트에 샘플이 골고루 섞여 있지 않아 훈련 또는 결과를 도출해 내는데 방해가 됨
- + numpy로 데이터를 shuffle 하여 해결
-
-## numpy
----
-### 파이썬의 배열 라이브러리
-### 함수
-+ seed(): 난수 시드 설정
-+ arange(): 일정 간격의 정수 또는 실수 배열 생성
-+ shuffle(): 주어진 배열을 랜덤하게 섞음
-
-## 데이터 전처리
----
-### 데이터를 표현하는 기준이 같도록 일정한 기준으로 맞추어 주는 과정
-
-### 표준점수(Z점수)
-+ 각 특성값이 평균에서 표준편차의 몇 배만큼 떨어져 있는지를 나타냄
-+ 실제 특성값의 크기와 상관없이 동일한 조건으로 비교 가능
diff --git "a/week1/6\355\214\200_\354\236\204\354\204\270\355\233\210.md" "b/week1/6\355\214\200_\354\236\204\354\204\270\355\233\210.md"
deleted file mode 100644
index 508bd9c..0000000
--- "a/week1/6\355\214\200_\354\236\204\354\204\270\355\233\210.md"
+++ /dev/null
@@ -1,60 +0,0 @@
-# Ch 01. 나의 첫 머신러닝
-___
-## 인공지능 vs 머신러닝 vs 딥러닝
-___
->인공지능은 머신러닝을 포함하는 개념이고, 머신러닝은 딥러닝을 포함하는 개념
-- __인공지능__
- 사람처럼 학습하고 추론할 수 있는 지능을 가진 컴퓨터 시스템을 만드는 기술
-- __머신러닝__
- 자동으로 데이터에서 규칙을 학습하는 알고리즘을 연구
-- __딥러닝__
- 머신러닝 알고리즘 중 인공 신경망을 기반으로 한 방법들
-___
-## k-최근접 이웃 알고리즘
-___
-> 어떤 데이터에 대한 답을 구할 때 주위의 다른 데이터를 보고 정답을 구하는 알고리즘
-- 용어
- - __특성__ : 데이터의 특징
- - __산점도__ : x, y축으로 이루어진 좌표계에 x, y의 관계를 표현한 그래프
- - __훈련__ : 데이터를 통해 모델이 규칙을 학습하는 과정
- - 함수
- - fit(훈련에 사용할 특성, 정답 데이터) : 모델을 훈련하는 함수
- - predict(특성) : 학습한 모델을 통해 예측하는 함수
- - score(특성, 정답) : 모델의 성능을 측정하는 함수
-
-# Ch 02. 데이터 다루기
-___
-## 지도학습이란?
-___
->머신러닝의 세 가지 종류: 지도학습, 비지도학습, 강화학습
-
-k-최근접 이웃 알고리즘은 지도학습에 속한다.
-지도학습은 훈련 데이터를 받아서 정답을 맞히면서 학습하는 과정이다
-
-___
-## 훈련 세트와 테스트 세트
-___
-> 머신러닝의 훈련 및 성능 평가를 위한 두 가지 데이터 세트
-
-훈련에 사용한 데이터는 성능 평가로 사용하면 안된다
-- __샘플링 편향__
- - 훈련 세트와 테스트 세트가 골고루 섞이지 않아 발생하는 현상
- - 골고루 섞기 위해 __numpy__ 사용
-___
-## numpy
-___
->python의 배열 라이브러리
-- 함수
- - seed(숫자) : 난수 생성을 위한 시드값을 지정하는 함수
- - arange() : 일정 간격의 정수 또는 실수 배열을 생성하는 함수
- - shuffle() : 주어진 배열을 무작위로 섞는 함수
-___
-## 데이터 전처리
-___
->알고리즘의 정확도를 위해 특성값을 일정한 기준으로 맞추어 주는 함수
-- 용어
- - __표준점수__ : 특성값이 평균에서 표준편차의 몇배만큼 떨어져 있는지 나타내는 척도
- - z=(특성값-평균)/(표준편차)
- - __브로드캐스팅__ : 크기가 다른 numpy 배열에서 자동으로 사칙 연산을 모든 행이나 열로 확장해서 수행하는 것
-- 주의할 점
- 훈련 세트를 변환한 방식 그대로 테스트 데이터를 변환해야 한다!
\ No newline at end of file
diff --git a/week1/images/2022-03-22-11-24-12.png b/week1/images/2022-03-22-11-24-12.png
deleted file mode 100644
index 2c257ae..0000000
Binary files a/week1/images/2022-03-22-11-24-12.png and /dev/null differ
diff --git a/week1/images/2022-03-22-11-33-30.png b/week1/images/2022-03-22-11-33-30.png
deleted file mode 100644
index 398164a..0000000
Binary files a/week1/images/2022-03-22-11-33-30.png and /dev/null differ
diff --git a/week1/images/2022-03-22-11-33-47.png b/week1/images/2022-03-22-11-33-47.png
deleted file mode 100644
index 398164a..0000000
Binary files a/week1/images/2022-03-22-11-33-47.png and /dev/null differ
diff --git a/week1/images/2022-03-22-11-34-17.png b/week1/images/2022-03-22-11-34-17.png
deleted file mode 100644
index e6adad8..0000000
Binary files a/week1/images/2022-03-22-11-34-17.png and /dev/null differ
diff --git a/week1/images/2022-03-22-14-17-45.png b/week1/images/2022-03-22-14-17-45.png
deleted file mode 100644
index 4c70f3f..0000000
Binary files a/week1/images/2022-03-22-14-17-45.png and /dev/null differ
diff --git a/week1/images/2022-03-22-14-24-50.png b/week1/images/2022-03-22-14-24-50.png
deleted file mode 100644
index 0213407..0000000
Binary files a/week1/images/2022-03-22-14-24-50.png and /dev/null differ
diff --git a/week1/images/2022-03-22-14-29-46.png b/week1/images/2022-03-22-14-29-46.png
deleted file mode 100644
index af19e7d..0000000
Binary files a/week1/images/2022-03-22-14-29-46.png and /dev/null differ
diff --git a/week1/images/2022-03-22-14-34-34.png b/week1/images/2022-03-22-14-34-34.png
deleted file mode 100644
index 81ea0bb..0000000
Binary files a/week1/images/2022-03-22-14-34-34.png and /dev/null differ
diff --git a/week1/markdown for text cells.png b/week1/markdown for text cells.png
deleted file mode 100644
index a36da51..0000000
Binary files a/week1/markdown for text cells.png and /dev/null differ
diff --git "a/week2/1\355\214\200_\354\206\241\354\242\205\353\252\205.md" "b/week2/1\355\214\200_\354\206\241\354\242\205\353\252\205.md"
deleted file mode 100644
index f229a17..0000000
--- "a/week2/1\355\214\200_\354\206\241\354\242\205\353\252\205.md"
+++ /dev/null
@@ -1,39 +0,0 @@
-# 회귀 알고리즘
-
-회귀 알고리즘이란?
-- 기존에 관찰된 변수들의 수치를 바탕으로 변수들 사이의 모형을 구해 적합도를
측정해내는 분석방법
-- 시간에 따라 변하는 데이터나 어떤 영향, 인과 관계 등을 모델링하여 통계적으로
예측하는데 사용될 수 있다.
-
-
-## 1. K-최근접 이웃 회귀
-
-- K-최근접 이웃 회귀 알고리즘은 분류 알고리즘과 동일하게 가장 가까운
-N개의 이웃을 선택하여 새로운 데이터의 특성을 예측하는 방식이다.
-
-- 새로운 데이터의 예측값은 가장 가까운 N개의 이웃의 특성 값의 평균이 되어 계산과정이 단순하지만
-***기존 데이터 범위를 넘어서는 경우 정확도가 떨어지는 단점이 있다.***
-
-## 2. 선형 회귀
-
-- 선형 회귀란 기존 데이터 X와 Y사이의 선형 관계를 모델링 하는 기법이다.
-Y = aX + b와 같은 선형 방정식 형태로 표현할 수 있다.
-이때 a를 계수(coefficient)라고 하고 b를 가중치(weight)라고 한다.
-- 다항 회귀란 Y를 X에 대한 다항식으로 표현하여 모델링하는 것을 말하는데,
-각각의 X에 대한 항을 서로 다른 변수로 생각하면 선형 방정식으로 표현이 가능하여
-선형 회귀와 동일하게 해결할 수 있다.
-
-> 다중회귀란 목표변수 Y를 여러 개의 독립된 변수 A, B, C, D ... 들의 관계로 나타내는 회귀 알고리즘이다.
-다항회귀는 하나의 독립변수 X를 형태를 바꾼것인데 다중회귀는 서로 독립된 변수라는 차이가 있다.
-
-## 3. 과대적합과 과소적합
-
-- 어떤 모델이 훈련 데이터의 성질에 너무 깊게 학습되어 훈련 데이터에대한 예측 성능은 매우 높지만
-새로운 데이터에 대해서는 매우 떠러어지는 경우를 과대적합(overfitting)이라고 한다.
-- 반대로 훈련데이터의 특성이 충분히 학습되지 않아 성능이 떨어지는
-경우는 과소적합(underfitting)이라고 한다.
-
-## 규제(릿지 & 라쏘)
-
-- 과대적합 문제를 막기 위해 모델이 과도하게 학습되는 것을 막는 규제를 적용할 수 있다.
-- 선형 회귀 모겔에 계수를 제곱한 기준으로 규제를 가한 모델을 릿지,
-절댓값을 기준으로 하면 라쏘라고 한다.
\ No newline at end of file
diff --git "a/week2/1\355\214\200_\354\230\244\353\217\231\355\233\210.md" "b/week2/1\355\214\200_\354\230\244\353\217\231\355\233\210.md"
deleted file mode 100644
index 4740dcd..0000000
--- "a/week2/1\355\214\200_\354\230\244\353\217\231\355\233\210.md"
+++ /dev/null
@@ -1,328 +0,0 @@
-# Notation
-
-## K-최근접 이웃 회귀
-
-- k-최근접 이웃 회귀 알고리즘은 가장 가까운 n 개의 이웃을 선택, 확률을 계산하여 새로운 데이터 특성을 예측하는 방식이다.
-- 계산 과정이 간단하지만 기존 데이터 범위를 넘어서는 경우 정확도가 매우 떨어진다.
-
-
-
-
-## 선형 회귀
-
-- 선형 회귀란 y = ax + b 와 같은 선형 방정식 형태로 표현. a 를 coefficient 라고 하고 b를 weight 라고 한다.
-- 다항 회귀란, y를 x에 대한 다항식으로 표현하여 모델링하는 것을 말한다. n차 방정식과 동일.
-
-
-## 다중 회귀
-
-- 다중 회귀란 목표 변수 y를 여러 개의 독립된 변수 a,b,c ... 들의 관계로 나타내는 알고리즘이다.
-- 다항 회귀는 독립변수 x의 차수가 n으로 높아진 것이며 다중 회귀는 이와 달리 서로 다른 독립 변수 a,b,c... 가 존재한다.
-
-
-
-
-## Overfitting vs. Underfitting
-
-- overfitting : 어떤 모델이 훈련 데이터의 성질에 너무 깊게 학습되어 훈련 데이터에 대한 예측 성능은 매우 높지만 새로운 데이터에 대해서 score 가 매우 떨어지는 현상.
-
-- underfitting : 훈련 데이터의 특성이 충분히 학습되지 않아 성능이 떨어지는 현상.
--
-
-## 규제(릿지&라쏘)
-
-- 오버피팅을 막기 위해 모델이 과도하게 학습되는 것을 규제를 통해 조절.
-- 계수를 제곱한 기준으로 규제를 가한 모델을 릿지, 절댓값을 기준으로 하면 라쏘 라고 한다.
-
-
-
-
-
-
-# 혼공머신 K-최근접 회귀 문제
-
-목표 : 농어 길이 데이터를 바탕으로 무게를 추론하는 회귀 모델을 학습.
-
-## 산점도로 데이터 살펴 보기
-
-(미리 준비된 'perch_length', 'perch_weight' 데이터 이용.)
-
-
-
-
-## train data & test data 분리
-
-```python
-from sklearn.model_selection import train_test_split
-train_input, test_input, train_target, test_target = train_test_split(
- perch_length, perch_weight, random_state=42
-)
-
-# column vector 로 input 데이터 조정.
-train_input = train_input.reshape(-1,1)
-test_input = test_input.reshape(-1,1)
-```
-
-## k-최근접 이웃 회귀 모델 훈련
-
-```python
-from sklearn.neighbors import KNeighborsRregressor
-knr = KNeighborsRegressor()
-knr.fit(train_input, train_target) # 모델 훈련
-
-# 모델을 결정계수로 평가.
-print(knr.score(test_input, test_target))
-
->>> 0.992809406101064
-
-# 이웃의 개수를 3으로 설정해서 모델을 조금 더 예민하게 조정.
-knr.fit(train_input, train_target)
-print(knr.score(train_input, train_target))
-print(knr.score(test_input, test_target))
-
->>> 0.9804899950518966
->>> 0.9746459963987609
-```
-
-## 선형 회귀 문제
-
-- k-최근접 이웃 회귀 모델로 예측하기 어려운 새로운 데이터를 사용할 수 있도록 선형 회귀 모델 사용.
-```python
-# 기존 데이터에 없는 50cm 농어 데이터, 100cm 농어 데이터
-knr.predict([[50]])
-
->>> array([1033.33333333])
-
-knr.predict([[100]])
-
->>> array([1033.33333333])
-```
-이웃 샘플이 동일 하기 때문에 같은 값으로 예측이 되는 문제 발생. 이런 문제를 선형 회귀를 통해 해결.
-
-
-## 선형 회귀 모델
-```python
-from sklearn.linear_model import LinearRegression
-lr = LinearRegression()
-
-# 선형 회귀 모델을 훈련합니다.
-lr.fit(train_input, train_target)
-
-# 15에서 50까지 1차 방정식 그래프를 그립니다.
-plt.plot([15,50], [15*lr.coef_ + lr.intercept_, 50*lr.coef_ + lr.intercept_])
-
-# 훈련 세트의 산점도를 그립니다.
-plt.scatter(train_input, train_target)
-
-# 50cm 농어 데이터를 따로 표시합니다.
-plt.scatter(50, lr.predict([[50]]), marker='^')
-plt.xlabel('length')
-plt.ylabel('weight')
-plt.show()
-```
-
-
-```python
-# 훈련 점수와 테스트 점수 비교
-print(lr.score(train_input, train_target))
-print(lr.score(test_input, test_target))
-
->>> 0.939846333997604
->>> 0.8247503123313558
-```
-
-모델이 train data에 과도하게 학습되었음을 알 수 있다. overfitting 발생.
-
-```python
-# 기존 데이터를 제곱한 값을 특성으로 추가.
-train_poly = np.column_stack((train_input ** 2, train_input))
-test_poly = np.column_stack((test_input ** 2, test_input))
-
-# 모델 훈련
-lr = LinearRegression()
-lr.fit(train_poly, train_target)
-
-# train score, test score 재확인
-print(lr.score(train_poly, train_target))
-print(lr.score(test_poly, test_target))
-
->>> 0.9706807451768623
->>> 0.9775935108325122
-```
-train score 와 test score 를 비교했을 때 이전 모델과는 다르게 overfitting 발생을 방지.
-
-
-# 특성 공학과 규제
-
-목표
-- 사이킷런의 다양한 도구를 활용하여 여러 특성을 사용한 다중 회귀 모델 구현
-- 복잡한 모델의 과대적합을 막기 위해 릿지와 라쏘 회귀 사용.
-
-## 데이터 준비
-
-앞서 사용했던 데이터에 특성이 하나 더 추가 된 'perch_full' 데이터 사용.
-```python
-import pandas as pd
-df = pd.read_csv('https://bit.ly/perch_csv_data')
-perch_full = df.to_numpy() # 판다스 -> 넘파이 배열
-```
-
-```python
-train_input, test_input, train_target, test_target = train_test_split(
- perch_full, perch_weight, random_state=42)
-```
-
-## PolynomialFeatures 클래스
-
-PolynomialFeatures 클래스의 경우, 입력한 특성 관련해서 (특성)^2, (특성1)*(특성2) 같은 새로운 특성들을 계산하여 제공한다.
-
-train_input 데이터를 해당 클래스에 통과시키면 다음과 같은 결과를 보인다.
-
-```python
-from sklearn.preprocessing import PolynomialFeatures
-poly = PolynomialFeatures(include_bias=False)
-
-poly.fit(train_input)
-train_poly = poly.transform(train_input)
-
-print(train_poly.shape)
-print(poly.get_feature_names())
-
->>> (42, 9) # 9개의 특성.
->>> ['x0', 'x1', 'x2', 'x0^2', 'x0 x1', 'x0 x2', 'x1^2', 'x1 x2', 'x2^2']
-```
-위의 train_poly 데이터를 사용해 선형 회귀 모델을 훈련시켜 본다.
-
-```python
-lr = LinearRegression()
-lr.fit(train_poly, train_target)
-
-print(lr.score(train_poly, train_target))
-print(lr.score(test_poly, test_target))
-
->>> 0.9903183436982124
->>> 0.9714559911594134
-```
-여전히 overfitting 현상이 남아 있다.
-
-특성의 개수를 추가시켜서 모델을 학습시켜 보자.
-
-```python
-# PolynomialFeatures 클래스의 degree 파라미터를 변경하여 특성의 개수를 추가합니다.
-poly = PolynomialFeatures(degree=5, include_bias=False)
-poly.fit(train_input)
-train_poly = poly.transform(train_input)
-test_poly = poly.transform(test_input)
-
-# 모델 훈련 및 score 평가
-lr.fit(train_poly, train_target)
-print(lr.score(train_poly, train_target))
-print(lr.score(test_poly, test_target))
-
->>> 0.9999999999938143
->>> -144.40744532797535
-```
-오히려 훈련 세트에 대해 너무 과대적합되므로 테스트 데이터에 대한 점수가 굉장히 낮게 나온다.
-
-
-## 규제
-
-각 특성을 정규화한 후 규제를 적용해보자.
-
-### 릿지 회귀
-```python
-from sklearn.preprocessing import StandardScaler
-ss = StandardScaler()
-ss.fit(train_poly)
-
-train_scaled = ss.transform(train_poly)
-test_scaled = ss.transform(test_poly)
-
-# 각 계수를 제곱한 값을 바탕으로 규제를 적용하는 릿지 회귀를 사용합니다.
-from sklearn.linear_model import Ridge
-ridge = Ridge()
-
-ridge.fit(train_scaled, train_target)
-print(ridge.score(train_scaled, train_target))
-print(ridge.score(test_scaled, test_target))
-
->>> 0.9896101671037343
->>> 0.979069397761539
-```
-score 사이 간의 차이가 줄어들었다. 최적의 규제깂을 확인해보자.
-```python
-train_score = []
-test_score = []
-
-alpha_list = [0.001, 0.01, 0.1, 1, 10, 100]
-for alpha in alpha_list:
- # 릿지 모델을 만듭니다.
- ridge = Ridge(alpha = alpha)
- # 릿지 모델을 훈련합니다.
- ridge.fit(train_scaled, train_target)
- # 훈련 점수와 테스트 점수를 저정합니다.
- train_score.append(ridge.score(train_scaled, train_target))
- test_score.append(ridge.score(test_scaled, test_target))
-
-plt.plot(np.log10(alpha_list), train_score)
-plt.plot(np.log10(alpha_list), test_score)
-plt.xlabel('log10(alpha)') #로그 스케일
-plt.ylabel('R^2')
-plt.show()
-```
-
-
-alpha = 0.1일 때 결정계수가 가장 큰 값을 보인다.
-
-```python
-# alpha=0.1을 사용하여 최종 학습 후 평가를 해 봅니다.
-ridge = Ridge(alpha=0.1)
-ridge.fit(train_scaled, train_target)
-
-print(ridge.score(train_scaled, train_target))
-print(ridge.score(test_scaled, test_target))
-
->>> 0.9903815817570368
->>> 0.9827976465386954
-```
-
-### 라쏘 회귀
-
-```python
-# 각 계수의 절대값을 바탕으로 규제를 적용하는 라쏘 회귀를 사용합니다.
-from sklearn.linear_model import Lasso
-lasso = Lasso()
-lasso.fit(train_scaled, train_target)
-
-print(lasso.score(train_scaled, train_target))
-print(lasso.score(test_scaled, test_target))
-
->>> 0.989789897208096
->>> 0.9800593698421884
-```
-alpha 조정을 통해 라쏘 회귀 역시 규제를 조절할 수 있다. 라쏘 회귀 역시 릿지 회귀에서와 동일한 과정을 거쳐 alpha 값에 따른 결정계수 그래프를 그려보면 다음과 같으며, 적절한 alpha 값을 찾을 수 있다.
-
-
-
-```python
-# 그래프에서 보이는 최적의 alpha 값 10을 적용해보자.
-lasso = Lasso(alpha=10)
-lasso.fit(train_scaled, train_target)
-
-print(lasso.score(train_scaled, train_target))
-print(lasso.score(test_scaled, test_target))
-
->>> 0.9888067471131867
->>> 0.9824470598706695
-```
-
-두 score 사이의 차이가 줄어들었다. overfitting을 어느 정도 조절하게 되었다.
-
-## 라쏘 회귀의 또다른 기능
-```python
-print(np.sum(lasso.coef_ == 0))
->>> 40
-```
-라쏘 회귀는 절댓값을 사용하기 때문에 특정 계수를 0으로 만들 수 있다. 위의 코드 결과는 훈련과정에서 0이 된 파라미터의 개수가 40개 임을 확인할 수 있다.
-
-55개의 특성 중 40개가 0이고 나머지 15개 weights 만이 실질적으로 사용되며 이러한 특징은 라쏘 모델을 유용한 특성을 골라내는 용도로도 사용할 수 있음을 보여준다.
\ No newline at end of file
diff --git "a/week2/1\355\214\200_\354\236\204\354\240\225\354\204\255.md" "b/week2/1\355\214\200_\354\236\204\354\240\225\354\204\255.md"
deleted file mode 100644
index 7ebf246..0000000
--- "a/week2/1\355\214\200_\354\236\204\354\240\225\354\204\255.md"
+++ /dev/null
@@ -1,376 +0,0 @@
-## 회귀 알고리즘
-
-### 1\. k - 최근접 이웃 회귀
-
-#### 회귀란?
-
-특정 클래스로 예측하는 분류와는 다르게, 임의의 수치를 예측하는 문제이다.
-
-#### k-최근접 이웃 회귀란?
-
-knn 알고리즘을 사용한 회귀방법으로 가장 가까운 이웃 샘플을 찾고 이 샘플들의 타깃값을 평균으로 예측한다.
-
-#### Data
-
-```
-# 농어 길이
-perch_length = np.array(
- [8.4, 13.7, 15.0, 16.2, 17.4, 18.0, 18.7, 19.0, 19.6, 20.0,
- 21.0, 21.0, 21.0, 21.3, 22.0, 22.0, 22.0, 22.0, 22.0, 22.5,
- 22.5, 22.7, 23.0, 23.5, 24.0, 24.0, 24.6, 25.0, 25.6, 26.5,
- 27.3, 27.5, 27.5, 27.5, 28.0, 28.7, 30.0, 32.8, 34.5, 35.0,
- 36.5, 36.0, 37.0, 37.0, 39.0, 39.0, 39.0, 40.0, 40.0, 40.0,
- 40.0, 42.0, 43.0, 43.0, 43.5, 44.0]
- )
-# 농어 무게
-perch_weight = np.array(
- [5.9, 32.0, 40.0, 51.5, 70.0, 100.0, 78.0, 80.0, 85.0, 85.0,
- 110.0, 115.0, 125.0, 130.0, 120.0, 120.0, 130.0, 135.0, 110.0,
- 130.0, 150.0, 145.0, 150.0, 170.0, 225.0, 145.0, 188.0, 180.0,
- 197.0, 218.0, 300.0, 260.0, 265.0, 250.0, 250.0, 300.0, 320.0,
- 514.0, 556.0, 840.0, 685.0, 700.0, 700.0, 690.0, 900.0, 650.0,
- 820.0, 850.0, 900.0, 1015.0, 820.0, 1100.0, 1000.0, 1100.0,
- 1000.0, 1000.0]
- )
-```
-
-```
-plt.scatter(perch_length, perch_weight)
-plt.xlabel('length')
-plt.ylabel('weight')
-plt.show()
-```
-
----
-
-#### 데이터 시각화
-
----
-
-#### 1차원 배열 -> 2차원 배열
-
-numpy의 reshpae() 메서드를 사용하여 데이터를 원하는 배열의 크기로 변경가능하다.
-
-```
-# 1차원 배열 -> 2차원 배열
-train_input = train_input.reshape(-1,1)
-test_input = test_input.reshape(-1,1)
-```
-
----
-
-#### 결정 계수
-
-분류에서는 정확도를 평가할 수 있지만 회귀에서는 수치로 반환하기 때문에 정확도를 구하기 어렵다. 그래서 회귀는 다른 값으로 평가하는데 이 점수를 결정계수라 한다. 결정계수는 다음과 같다.
-
-> R^2 = 1 - (타깃 - 예측)^2의 합 / (타깃 - 평균)^2의 합
-
-만약 타깃의 평균 정도를 예측하는 수준이면 R^2는 0에 가까워지고 예측이 타킷에 아주 가까워지면 1에 가까운 값이 된다.
-
-```
-from sklearn.neighbors import KNeighborsRegressor
-# k 최근접 이웃 회귀 모델
-knr = KNeighborsRegressor()
-# 훈련 - train_input 값은 2차원 배열만 가능
-knr.fit(train_input, train_label)
-knr.score(test_input, test_label)
-```
-
----
-
-#### MAE
-
-사이킷런에서 제공하는 mae (타깃과 예측값의 절대값 오차 평균)을 통해 예측값이 평균적으로 얼마 차이나는지 확인해보자.
-
-```
-from sklearn.metrics import mean_absolute_error
-# 예측
-test_prediction = knr.predict(test_input)
-# mae 계산
-mae = mean_absolute_error(test_label, test_prediction)
-print(mae)
-```
-
-대략 19 정도 평균적으로 차이나는 것을 확인할 수 있다.
-
----
-
-#### 과대적합 / 과소적합
-
-과대적합 : 훈련 세트에서는 점수가 굉장히 좋지만, 테스트 세트와 실전에서는 예측이 제대로 작동하지 않는 경우
-
-과소적합 : 모델이 너무 단순하여 훈련 세트에 적절히 훈련되지 않는 경우
-
-#### 과대적합 / 과소적합 테스트
-
-```
-knr = KNeighborsRegressor()
-# 5~45
-x = np.arange(5, 45).reshape(-1, 1)
-for n in [1, 5, 10]:
- knr.n_neighbors = n
- knr.fit(train_input, train_label)
- prediction = knr.predict(x)
- plt.scatter(train_input, train_label)
- plt.plot(x, prediction)
- plt.title('n_neighbors ={}'.format(n))
- plt.xlabel('length')
- plt.ylabel('weight')
- plt.show()
-```
-
----
-
-### 2\. 선형 회귀
-
-#### k - 최근접 이웃 한계
-
-예측하는 데이터가 훈련 세트의 범위를 벗어나면 엉뚱한 값을 예측한다.
-
-```
-print(knr.predict([[50]]))
-"""
-[[912.5]]
-"""
-```
-
-이러한 문제점을 해결하기 위해 선형 회귀를 이용한다.
-
----
-
-#### 선형 회귀란?
-
-특성과 타깃 사이의 관계를 가장 잘 나타내는 선형 방정식을 찾는 방법이다. 선형 회귀가 찾은 특성과 타깃 사이의 관계는 선형 방정식의 계수 또는 가중치(기울기, 절편)에 저장된다.
-
----
-
-#### 예시
-
-```
-from sklearn.linear_model import LinearRegression
-# 선형 회귀
-lr = LinearRegression()
-lr.fit(train_input, train_label)
-
-# 시각화
-plt.scatter(train_input, train_label)
-# 15~50 1차 방정식 그래프 그리기
-plt.plot([15, 50], [15*lr.coef_[0]+lr.intercept_[0], 50*lr.coef_[0]+lr.intercept_[0]])
-plt.scatter(50, 1241.8, marker='D')
-plt.show()
-```
-
-
-```
-print(lr.score(train_input, train_label))
-print(lr.score(test_input, test_label))
-```
-
-
-
----
-
-### 3\. 다항 회귀
-
-#### 다항 회귀란?
-
-다항 회귀는 다항식을 사용하여 특성과 타깃 사이의 관계를 나타내는 방법이다. 이 함수는 비선형, 선형 두 가지 모두 가능하다.
-
----
-
-#### 예시
-
-```
-train_poly = np.column_stack((train_input ** 2, train_input))
-test_poly = np.column_stack((test_input ** 2, test_input))
-lr = LinearRegression()
-lr.fit(train_poly, train_label)
-
-# 시각화
-# 15 ~ 49
-x = np.arange(15,50)
-plt.scatter(train_input, train_label)
-plt.plot(x, 1.01*x**2 - 21.6*x + 116.05)
-plt.scatter([50],[1574], marker='^')
-plt.show()
-```
-
-
----
-## 특성 공학과 규제
-
-### 1\. 다중 회귀
-
-#### 다중 회귀란?
-
-여러 개의 특성을 사용한 선형 회귀를 다중 회귀라 한다.
-
-#### 특성 공학이란?
-
-주어진 특성을 조합하여 새로운 특성을 만드는 일련의 작업 과정이다.
-
----
-
-#### Pandas 로 데이터 불러오기
-
-```
-import pandas as pd
-df = pd.read_csv('https://bit.ly/perch_csv_data')
-perch_full = df.to_numpy()
-```
-
-pandas 로 csv 데이터를 불러온 후 to\_numpy() 메서드를 통해서 배열로 변환한다.
-
-```
-perch_weight = np.array(
- [5.9, 32.0, 40.0, 51.5, 70.0, 100.0, 78.0, 80.0, 85.0, 85.0,
- 110.0, 115.0, 125.0, 130.0, 120.0, 120.0, 130.0, 135.0, 110.0,
- 130.0, 150.0, 145.0, 150.0, 170.0, 225.0, 145.0, 188.0, 180.0,
- 197.0, 218.0, 300.0, 260.0, 265.0, 250.0, 250.0, 300.0, 320.0,
- 514.0, 556.0, 840.0, 685.0, 700.0, 700.0, 690.0, 900.0, 650.0,
- 820.0, 850.0, 900.0, 1015.0, 820.0, 1100.0, 1000.0, 1100.0,
- 1000.0, 1000.0]
- )
-```
-
-```
-from sklearn.model_selection import train_test_split
-train_input, test_input, train_target, test_target = train_test_split(perch_full, perch_weight, random_state=42)
-```
-
----
-
-### 2\. 사이킷런 변환기
-
-사이킷런은 특성을 만들거나 전처리하기 위한 다양한 클레스를 제공하는데 이를 변환기라 한다.
-
-#### PolynomialFeatures()
-
-```
-from sklearn.preprocessing import PolynomialFeatures
-# poly
-poly = PolynomialFeatures()
-poly.fit([[2, 3]])
-print(poly.transform([[2, 3]]))
-
-# include_bias(절편) 포함 x
-poly = PolynomialFeatures(include_bias=False)
-
-poly.fit(train_input)
-train_poly = poly.transform(train_input)
-```
-
-#### 특성 확인
-
-```
-poly.get_feature_names_out()
-```
-여기서는 총 9가지의 특성이 있다.
-
----
-
-### 3\. 다중 회귀 모델 훈련하기
-
-```
-from sklearn.linear_model import LinearRegression
-
-lr = LinearRegression()
-lr.fit(train_poly, train_target)
-#degree = 5 -> 5제곱 까지 특성을 만듦
-poly = PolynomialFeatures(degree=5, include_bias=False)
-
-poly.fit(train_input)
-train_poly = poly.transform(train_input)
-test_poly = poly.transform(test_input)
-lr.fit(train_poly, train_target)
-print(lr.score(train_poly, train_target))
-```
-
----
-
-### 4\. 규제
-
-규제는 머신러닝 모델이 훈련 세트를 너무 과도하게 학습하지 못하도록 훼방하는 것을 말한다. 즉, 과대적합되지 않도록 만드는 작업이다. 선형 회귀 모델에서의 규제는 특성에 곱해지는 계수를 작게 만드는 것이다.
-
-```
-# 사이킷런의 변환기 중 하나
-from sklearn.preprocessing import StandardScaler
-
-ss = StandardScaler()
-ss.fit(train_poly)
-
-train_scaled = ss.transform(train_poly)
-test_scaled = ss.transform(test_poly)
-```
-
----
-
-#### 릿지란?
-
-규제가 있는 선형 회귀 모델 중 하나이며 선형 모델의 계수를 제곱한 값을 기준으로 규제를 한다.
-
-```
-from sklearn.linear_model import Ridge
-
-ridge = Ridge()
-ridge.fit(train_scaled, train_target)
-print(ridge.score(train_scaled, train_target))
-```
-
-#### 최적의 alpha 값 찾기
-
-```
-import matplotlib.pyplot as plt
-
-train_score = []
-
-alpha_list = [0.001, 0.01, 0.1, 1, 10, 100]
-for alpha in alpha_list:
- # 릿지 모델을 만듭니다
- ridge = Ridge(alpha=alpha)
- # 릿지 모델을 훈련합니다
- ridge.fit(train_scaled, train_target)
- # 훈련 점수와 테스트 점수를 저장합니다
- train_score.append(ridge.score(train_scaled, train_target))
- test_score.append(ridge.score(test_scaled, test_target))
-test_score = []
-
-# 시각화
-plt.plot(np.log10(alpha_list), train_score)
-plt.plot(np.log10(alpha_list), test_score)
-plt.xlabel('alpha')
-plt.ylabel('R^2')
-plt.show()
-```
-
----
-
-#### 라쏘란?
-
-또 다른 규제가 있는 선형 모델 회귀모델이다. 계수의 절댓값을 기준으로 규제를 한다. 릿지와 달리 계수 값을 아예 0으로 만들 수 있다.
-
-```
-from sklearn.linear_model import Lasso
-
-lasso = Lasso()
-lasso.fit(train_scaled, train_target)
-
-train_score = []
-test_score = []
-
-alpha_list = [0.001, 0.01, 0.1, 1, 10, 100]
-for alpha in alpha_list:
- # 라쏘 모델을 만듭니다
- lasso = Lasso(alpha=alpha, max_iter=10000)
- # 라쏘 모델을 훈련합니다
- lasso.fit(train_scaled, train_target)
- # 훈련 점수와 테스트 점수를 저장합니다
- train_score.append(lasso.score(train_scaled, train_target))
- test_score.append(lasso.score(test_scaled, test_target))
-
-# 시각화
-plt.plot(np.log10(alpha_list), train_score)
-plt.plot(np.log10(alpha_list), test_score)
-plt.xlabel('alpha')
-plt.ylabel('R^2')
-plt.show()
\ No newline at end of file
diff --git "a/week2/2\354\243\274\354\260\250_\352\271\200\354\203\201\353\257\274.md" "b/week2/2\354\243\274\354\260\250_\352\271\200\354\203\201\353\257\274.md"
deleted file mode 100644
index a7ee6d6..0000000
--- "a/week2/2\354\243\274\354\260\250_\352\271\200\354\203\201\353\257\274.md"
+++ /dev/null
@@ -1,67 +0,0 @@
-# 발표 2주차
-
----
-
-발표자 : 윤형서
-
-일자 : 2022-03-24
-
----
-
-## 내용 정리
-
-### 회귀 알고리즘
-
-- K-최근접 이웃 회귀 알고리즘
-- 선형 회귀 알고리즘
-- 다항 회귀 알고리즘
-
-### 회귀 알고리즘 훈련-KNeighborsRegressor(매서드)
-
-```python
-from sklearn.neighbors import KNeighborsRegressor
-
-
-knr = KNeighborsRegressor()
-
-knr.fit(trsin_input, train_target)
-print(knr.score(test_input, test_target))
-```
-
-0.9928094061010639 = 결정계수 R
-$$
-R^2 = 1 - \frac{(타깃-예측)^2의 합}{(타깃-평균)^2의 합}
-$$
-
-
-### 과소적합
-
-- 훈련세트보다 테스트 세트의 점수가 높거나 두 점수가 모두 낮음
-
-- 모델이 너무 단순하거나 훈련세트를 통해 적절히 훈련되지 않음
-
-
-### 과대적합
-
-- 훈련 세트가 테스트에 비해 점수가 너무 큼
-- 모델이 훈련 세트에만 적합해짐 - 과적합
-- 규제를 통해 훈련세트를 과도하게 학습하지 못하게 하여 방지(특성에 대한 계수를 줄임)
-- 선형 회귀 + 규제 : 릿지,라쏘
-
-### 릿지 회귀(sklearn)
-
-```python
-from sklearn.linear_model import Ridge
-ridge = Ridge()
-ridge.fit(train_scaled, train_target)
-print(ridge.score(train_scaled, train_target))
-```
-
-### 라쏘 회귀(sklearn)
-
-```python
-from sklearn.linear_model import Lasso
-lasso = Lasso()
-lasso.fit(train_scaled, train_target)
-print(lasso.score(train_scaled, train_target))
-```
diff --git "a/week2/2\354\243\274\354\260\250_\354\236\204\354\204\270\355\233\210.md" "b/week2/2\354\243\274\354\260\250_\354\236\204\354\204\270\355\233\210.md"
deleted file mode 100644
index 8a77cd4..0000000
--- "a/week2/2\354\243\274\354\260\250_\354\236\204\354\204\270\355\233\210.md"
+++ /dev/null
@@ -1,35 +0,0 @@
-## 회귀 알고리즘
->분류와 회귀의 차이점
-
-| 종류 | 특징 |
- | :---: | :---: |
-| __분류__ | 몇 개의 클래스 중 하나로 분류하는 문제|
-| __회귀__ | 임의의 숫자를 예측하는 문제|
-
-___
-## 과대 적합과 과소 적합
-
-| 종류 | 설명 | 그림 |
- | :---: | :---: | :---:|
-| __과대적합__ | 훈련 데이터에 과하게 최적화 훈련세트 점수 > 테스트세트 점수 ||
-| __과소적합__ |훈련 부족으로 모델이 너무 단순한 경우 훈련세트 점수 < 테스트세트 점수| 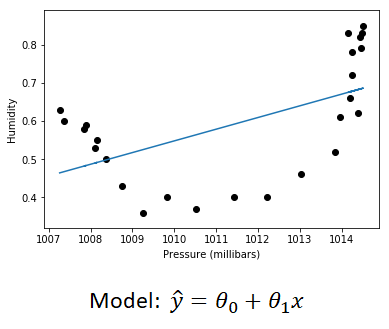|
-
-___
-## 선형 회귀와 다중 회귀
-| 종류 | 특징 | 그림 |
- | :---: | :---: | :---:|
-| __선형 회귀__ | 특성이 하나인 경우 어떠한 직선을 학습하는 알고리즘 학습 속도와 예측 속도가 빠름 데이터셋이 희소해도 예측값이 유의미 | |
-| __다중 회귀__ |특성이 여러 개인 경우의 회귀 특성이 2개인 경우 평면을 학습 특성이 너무 많은 경우 과대적합을 불러올 수 있음|
|
-| __다중 회귀__ |특성이 여러 개인 경우의 회귀 특성이 2개인 경우 평면을 학습 특성이 너무 많은 경우 과대적합을 불러올 수 있음|  -
-___
-## 규제
-> 머신러닝 모델이 훈련 세트를 너무 과도하게 학습하지 않도록 규제하는 것
- - 다중 회귀 모델에서는 특성에 곱해지는 계수를 작게 만듦
-
-| 종류 | 특징 |
- | :---: | :---: |
-| __릿지__ | 계수를 제곱한 값을 기준으로 규제를 적용|
-| __라쏘__ | 계수의 절댓값을 기준으로 규제를 적용|
-
-
-
diff --git "a/week2/2\354\243\274\354\260\250_\354\236\245\354\204\234\354\227\260.md" "b/week2/2\354\243\274\354\260\250_\354\236\245\354\204\234\354\227\260.md"
deleted file mode 100644
index 5e29f36..0000000
--- "a/week2/2\354\243\274\354\260\250_\354\236\245\354\204\234\354\227\260.md"
+++ /dev/null
@@ -1,36 +0,0 @@
-# Ch03. 회귀 알고리즘과 모델 규제
-## 회귀 알고리즘
-### k-최근접 이웃 회귀
-예측하려는 샘플에 가장 가까운 샘플 k개를 선택 > 이웃한 샘플의 타깃값의 평균으로 예측 타깃값 출력
-### 과대적합 / 과소적합
-* **과대적합**: 훈련 데이터에만 잘 맞게 과하게 최적화 > 실제 데이터와 잘 맞지 않음. (훈련 세트 점수 > 테스트 세트 점수)
-* **과소적함**: 모델이 너무 단순하여 적절히 훈련되지 않음. (ex. 훈련 세트의 크기가 매우 작음) (훈련 세트 점수 < 테스트 세트 점수)
-
-## 선형회귀
-* 특성이 하나인 경우 어떤 **직선**을 학습
-* 학습 속도 & 예측 빠름
-* 희소한 데이터셋에서도 유의미한 예측 값 도출 (KNN과의 차이)
-
-## 다중회귀
-* 여러 개의 특성을 사용한 선형 회귀
-* 특성이 2개인 다중 회귀는 평면을 학습
-* 테스트 데이터 개수에 비해 너무 많은 특성은 **과대적합**을 불러옴
-
-## 규제
-머신러닝 모델이 훈련 세트를 너무 과도하게 학습하지 못하도록 함.
-(선형 회귀 모델의 경우 특성에 곱해지는 계수(기울기)를 작게 만듦)
-* 선형 회귀 모델에 규제를 추가한 모델
-> 릿지(ridge): 계수를 제곱한 값을 기준으로 규제 적용
-```python
-from sklearn.linear_model import Ridge
-ridge = Ridge()
-ridge.fit(train_scaled, train_target)
-print(ridge.score(train_scaled, train_target))
-```
-> 라쏘(lasso): 계수의 절댓값을 기준으로 규제 적용
-```python
-from sklearn.linear_model import Lasso
-lasso = Lasso()
-lasso.fit(train_scaled, train_target)
-print(lasso.score(train_scaled, train_target))
-```
\ No newline at end of file
diff --git "a/week2/2\354\243\274\354\260\250_\354\236\245\354\244\200\354\230\244.md" "b/week2/2\354\243\274\354\260\250_\354\236\245\354\244\200\354\230\244.md"
deleted file mode 100644
index b6d1ec8..0000000
--- "a/week2/2\354\243\274\354\260\250_\354\236\245\354\244\200\354\230\244.md"
+++ /dev/null
@@ -1,28 +0,0 @@
-
-## ▷ 알고리즘 회귀
-* * *
-### ▶ 회귀란?
-> 두 변수 사이의 상관관계를 분석하는 방법을 말한다.
-### ▶ k-최근접 이웃 회귀
-> 예측하려는 샘플에 가장 가까운 샘플 k개를 선택한 뒤 샘플들의 클래스를 확인하여 다수의 클래스를 새로운 샘플의 클래스로 예측하는 회귀 알고리즘이다.
-### ▶ 결정계수
-> 분류의 경우 정확도로 성능을 나타내었지만 회귀는 값을 정확하게 맞출 수 없는 구조이기 때문에 결정 계수라는 것을 사용합니다.
-
-> 결정계수는 R^2 = 1 - { (타깃 - 예측)^2의 합 / (타깃 - 평균)^2의 합 }으로 계산합니다. 즉, 1에 가까울수록 예측이 타겟에 가깝다고 해석할 수 있습니다.
-### ▶ 과대적합과 과소적합
-> 1. 과대적합 : 훈련 세트 점수는 매우 좋으나 테스트 세트의 점수가 매우 나쁜 경우를 말한다. 다르게 해석하면 훈련 세트에만 잘 맞게 학습되어 테스트 세트에서 모델이 원하는 대로 작동하지 못하게 된 것이다.
-
-> 2. 과소적합: 훈련 세트보다 테스트 세트의 점수가 높거나 또는 훈련 세트, 테스트 세트 모두 점수가 낮게 나오는 경우를 말한다. 다르게 해석하면 모델이 단순하거나 훈련 세트가 너무 적어 훈련이 잘 이루어지지 않았다는 것이다.
-* * *
-### ▶ 선형 회귀
-> 선형 회귀는 데이터들을 바탕으로 최적의 직선을 찾아 직선으로 예측하는 것을 말한다. 사이킷 런에서 선형 회귀를 하는 방법은 최소제곱법이다. 직선과 데이터들의 거리의 제곱의 합이 최소가 되는 직선을 최적의 직선으로 선택하는 방법이다.
-### ▶ 다항 회귀
-> 다항 회귀란 말 그대로 독립변수가 2개 이상인 선형 회귀를 말한다.
-### ▶ 다중 회귀
-> 다중 회귀는 특성이 2개 이상인 선형 회귀를 말한다.
-
-> #### ※ 특성 공학이란?
->> 기존의 특성을 이용해 새로운 특성을 뽑아내는 작업을 말한다.
-
-> #### ※ 규제란?
->> 모델이 훈련할 때 과대적합이 일어나지 않도록 하는 것이다. 선형 회귀 모델의 예로 가중치를 작게 만드는 일이다.
diff --git "a/week2/3\355\214\200_\352\271\200\353\217\231\354\227\260.md" "b/week2/3\355\214\200_\352\271\200\353\217\231\354\227\260.md"
new file mode 100644
index 0000000..49174e5
--- /dev/null
+++ "b/week2/3\355\214\200_\352\271\200\353\217\231\354\227\260.md"
@@ -0,0 +1,60 @@
+# 03 회귀 알고리즘과 모델 규제
+> 농어의 무게 예측하기
+---
+## 3-1 K-최근접 이웃 회귀
+
-
-___
-## 규제
-> 머신러닝 모델이 훈련 세트를 너무 과도하게 학습하지 않도록 규제하는 것
- - 다중 회귀 모델에서는 특성에 곱해지는 계수를 작게 만듦
-
-| 종류 | 특징 |
- | :---: | :---: |
-| __릿지__ | 계수를 제곱한 값을 기준으로 규제를 적용|
-| __라쏘__ | 계수의 절댓값을 기준으로 규제를 적용|
-
-
-
diff --git "a/week2/2\354\243\274\354\260\250_\354\236\245\354\204\234\354\227\260.md" "b/week2/2\354\243\274\354\260\250_\354\236\245\354\204\234\354\227\260.md"
deleted file mode 100644
index 5e29f36..0000000
--- "a/week2/2\354\243\274\354\260\250_\354\236\245\354\204\234\354\227\260.md"
+++ /dev/null
@@ -1,36 +0,0 @@
-# Ch03. 회귀 알고리즘과 모델 규제
-## 회귀 알고리즘
-### k-최근접 이웃 회귀
-예측하려는 샘플에 가장 가까운 샘플 k개를 선택 > 이웃한 샘플의 타깃값의 평균으로 예측 타깃값 출력
-### 과대적합 / 과소적합
-* **과대적합**: 훈련 데이터에만 잘 맞게 과하게 최적화 > 실제 데이터와 잘 맞지 않음. (훈련 세트 점수 > 테스트 세트 점수)
-* **과소적함**: 모델이 너무 단순하여 적절히 훈련되지 않음. (ex. 훈련 세트의 크기가 매우 작음) (훈련 세트 점수 < 테스트 세트 점수)
-
-## 선형회귀
-* 특성이 하나인 경우 어떤 **직선**을 학습
-* 학습 속도 & 예측 빠름
-* 희소한 데이터셋에서도 유의미한 예측 값 도출 (KNN과의 차이)
-
-## 다중회귀
-* 여러 개의 특성을 사용한 선형 회귀
-* 특성이 2개인 다중 회귀는 평면을 학습
-* 테스트 데이터 개수에 비해 너무 많은 특성은 **과대적합**을 불러옴
-
-## 규제
-머신러닝 모델이 훈련 세트를 너무 과도하게 학습하지 못하도록 함.
-(선형 회귀 모델의 경우 특성에 곱해지는 계수(기울기)를 작게 만듦)
-* 선형 회귀 모델에 규제를 추가한 모델
-> 릿지(ridge): 계수를 제곱한 값을 기준으로 규제 적용
-```python
-from sklearn.linear_model import Ridge
-ridge = Ridge()
-ridge.fit(train_scaled, train_target)
-print(ridge.score(train_scaled, train_target))
-```
-> 라쏘(lasso): 계수의 절댓값을 기준으로 규제 적용
-```python
-from sklearn.linear_model import Lasso
-lasso = Lasso()
-lasso.fit(train_scaled, train_target)
-print(lasso.score(train_scaled, train_target))
-```
\ No newline at end of file
diff --git "a/week2/2\354\243\274\354\260\250_\354\236\245\354\244\200\354\230\244.md" "b/week2/2\354\243\274\354\260\250_\354\236\245\354\244\200\354\230\244.md"
deleted file mode 100644
index b6d1ec8..0000000
--- "a/week2/2\354\243\274\354\260\250_\354\236\245\354\244\200\354\230\244.md"
+++ /dev/null
@@ -1,28 +0,0 @@
-
-## ▷ 알고리즘 회귀
-* * *
-### ▶ 회귀란?
-> 두 변수 사이의 상관관계를 분석하는 방법을 말한다.
-### ▶ k-최근접 이웃 회귀
-> 예측하려는 샘플에 가장 가까운 샘플 k개를 선택한 뒤 샘플들의 클래스를 확인하여 다수의 클래스를 새로운 샘플의 클래스로 예측하는 회귀 알고리즘이다.
-### ▶ 결정계수
-> 분류의 경우 정확도로 성능을 나타내었지만 회귀는 값을 정확하게 맞출 수 없는 구조이기 때문에 결정 계수라는 것을 사용합니다.
-
-> 결정계수는 R^2 = 1 - { (타깃 - 예측)^2의 합 / (타깃 - 평균)^2의 합 }으로 계산합니다. 즉, 1에 가까울수록 예측이 타겟에 가깝다고 해석할 수 있습니다.
-### ▶ 과대적합과 과소적합
-> 1. 과대적합 : 훈련 세트 점수는 매우 좋으나 테스트 세트의 점수가 매우 나쁜 경우를 말한다. 다르게 해석하면 훈련 세트에만 잘 맞게 학습되어 테스트 세트에서 모델이 원하는 대로 작동하지 못하게 된 것이다.
-
-> 2. 과소적합: 훈련 세트보다 테스트 세트의 점수가 높거나 또는 훈련 세트, 테스트 세트 모두 점수가 낮게 나오는 경우를 말한다. 다르게 해석하면 모델이 단순하거나 훈련 세트가 너무 적어 훈련이 잘 이루어지지 않았다는 것이다.
-* * *
-### ▶ 선형 회귀
-> 선형 회귀는 데이터들을 바탕으로 최적의 직선을 찾아 직선으로 예측하는 것을 말한다. 사이킷 런에서 선형 회귀를 하는 방법은 최소제곱법이다. 직선과 데이터들의 거리의 제곱의 합이 최소가 되는 직선을 최적의 직선으로 선택하는 방법이다.
-### ▶ 다항 회귀
-> 다항 회귀란 말 그대로 독립변수가 2개 이상인 선형 회귀를 말한다.
-### ▶ 다중 회귀
-> 다중 회귀는 특성이 2개 이상인 선형 회귀를 말한다.
-
-> #### ※ 특성 공학이란?
->> 기존의 특성을 이용해 새로운 특성을 뽑아내는 작업을 말한다.
-
-> #### ※ 규제란?
->> 모델이 훈련할 때 과대적합이 일어나지 않도록 하는 것이다. 선형 회귀 모델의 예로 가중치를 작게 만드는 일이다.
diff --git "a/week2/3\355\214\200_\352\271\200\353\217\231\354\227\260.md" "b/week2/3\355\214\200_\352\271\200\353\217\231\354\227\260.md"
new file mode 100644
index 0000000..49174e5
--- /dev/null
+++ "b/week2/3\355\214\200_\352\271\200\353\217\231\354\227\260.md"
@@ -0,0 +1,60 @@
+# 03 회귀 알고리즘과 모델 규제
+> 농어의 무게 예측하기
+---
+## 3-1 K-최근접 이웃 회귀
+
+
+### K-최근접 이웃 회귀
+ 회귀는 샘플을 여러개의 클래스 중 하나로 예측하는 분류와 달리 임의의 수치, 어떤 숫자를 예측하는 지도학습 알고리즘이다.
+ * ex) 내년도 경제성장률 예측하기, 농어의 무게 예측하기
+
+
+
+
+
+ k-최근접 이웃 회귀는 k-최근접 이웃 분류 알고리즘과 작동 원리가 비슷하다.
+예측하려는 샘플에 가장 가까운 샘플 k개를 선택하여 이 샘플들의 수치의 평균을 구하고 이 값이 예측 타깃값이 된다.
+
+### 결정 계수 $ R^2$ (*coefficient of determination*)
+회귀의 경우 모델의 정확도를 평가하는 점수로 **결정계수**라는 값을 사용한다.
+결정계수는 각 샘플의 타깃과 예측한 값의 차이를 제곱하여 더한 후, 타깃과 타깃 평균의 차이를 제곱하여 더한 값으로 나누는 것으로 계산된다.
+
+따라서 만약 모든 샘플을 타깃의 평균으로 예측한다면 결정계수는 0에 가까워지고, 타깃에 정확히 예측한다면 1에 가까운 값이 된다.
+
+### 과대적합 (*overfitting*) vs 과소적합 (*underfitting*)
+ **과대적합** 이란 훈련 세트에서는 점수가 높지만 테스트 세트에서는 상대적으로 점수가 낮은 상황이를 말한다. 한마디로 훈련 세트에만 잘 맞는 모델이라고 할 수 있다. 모델이 과대적합되었다면, 실전에 투입되어 새로운 샘플들에 대해 내린 모델의 예측은 정확도가 낮을 것이다.
+
+ **과소적합** 이란 반대로 훈련 세트에서의 점수보다 테스트 세트에서의 점수가 높거나 두 점수가 모두 낮은 경우이다. 이때는 모델이 너무 단순하여 훈련 세트에도 적절히 훈련되지 않은 경우이다.
+
+ 과대적합과 과소적합 모두 모델을 훈련시킬 때 경계해야하는 상황이며 모델이 훈련 세트와 테스트 세트에서 모두 적절한 점수가 나오도록 조정해야한다.
+
+
+## 3-2 선형 회귀
+
+
+### K-최근접 이웃의 한계
+ K-최근접 이웃 회귀모델은 가장 가까운 샘플을 찾아 타깃을 평균하므로 새로운 샘플이 훈련 세트의 범위를 벗어나는 경우 합당한 값을 예측할 수 없다.
+
+### 선형 회귀 (*liner regression*)
+**선형 회귀** 알고리즘은 이름에서 짐작할 수 있듯이 특성이 하나인 경우 어떤 직섭을 학습하는 알고리즘이다. 특성 $a$가 있고 이에 따라 타깃값 $y$를 예측한다면
+$y = ax + b$ 라는 직선을 찾는다.
+이때 모델이 찾은 $a$와 $b$값을 계수또는 가중치라고 부른다.
+
+### 다항 회귀 (*polynomial regression*)
+특성에 따른 타깃값이 직선의 형태를 띄지않을 때는 직선으로 타깃값을 예측하는데 어려움이 있다. 이럴 땐 특성을 제곱한 항을 추가하여 새로운 다항식을 만들 수 있는데 이 다항식을 사용한 선형 회귀를 **다항 회귀**라고 한다. 다항 회귀를 이용하면 특성에 따라 타깃값을 그래프에서 곡선형태로 예측할 수 있다.
+
+
+## 3-3 특성 공학과 규제
+
+
+### 다중 회귀 (*multiple regression*)
+ 여러 개의 특성을 사용한 선형 회귀를 **다중회귀**라고 한다.
+ 예를 들어 선형 회귀 모델이 2개의 특성을 사용하여 학습하면 직선이 아닌 평면을 학습하게 된다.
+ 따라서 생선의 길이 뿐만이 아니라 높이와 두께 등 다양한 특성을 사용하여 생선의 무게를 예측할 수 있게 된다. 이때 각 특성의 값들을 제곱하거나 서로 곱해서 또다른 특성을 만들어 더 복잡한 방정식을 학습할 수 있는데, 이처럼 기존의 특성을 사용해 새로운 특성을 뽑아내는 작업을 **특성 공학** (*feature engineering)* 이라 한다.
+
+### 규제 (*regularization*)
+**규제**는 머신러닝 모델이 훈련 세트를 너무 과도하게 학습하지 못하도록 제한을 두는 것이다. 즉 모델의 과대적합을 막는 역할을 한다. 선형 회귀 모델의 경우 특성에 곱해지는 계수를 작게 만드는 식으로 수행할 수 있다.
+
+선형 회귀 모델에 규제를 추가한 모델로는 **릿지**(*ridge*)와 **라쏘**(*lasso*)가 있다.
+릿지는 계수를 제곱한 값을 기준으로 규제를 적용하고, 라쏘는 계수의 절대값을 기준으로 규제를 적용한다. 일반적으로 릿지가 조금더 선호되며, 두 알고리즘 모두 계수의 크기를 줄이지만 라쏘는 아예 0으로 만들 수 있다.
+
\ No newline at end of file
diff --git "a/week2/3\355\214\200_\352\271\200\355\225\234\352\262\260.md" "b/week2/3\355\214\200_\352\271\200\355\225\234\352\262\260.md"
deleted file mode 100644
index b973e97..0000000
--- "a/week2/3\355\214\200_\352\271\200\355\225\234\352\262\260.md"
+++ /dev/null
@@ -1,38 +0,0 @@
-# 회귀 알고리즘과 모델 규제
-
-## k-최근접 이웃 회귀
-
-회귀 : 임의의 수치를 예측하는 문제. 타깃값도 임의의 수치가 된다.
-k-최근접 이웃 회귀 : k-최근접 이웃 알고리즘을 이용하여 회귀 문제를 해결. 가장 가까운 이웃 샘플을 찾고 이 샘플들의 타깃값을 평균하여 예측으로 삼음.
-결정계수(R^2) : 대표적인 회귀 문제의 성능 측정 도구. 1에 가까울수록 좋고, 0에 가깝다면 성능이 나쁜 모델.
-과대적합 : 모델의 훈련 세트 성능이 테스트 세트 성능보다 훨씬 높을 때
-과소적합 : 훈련 세트와 테스트 세트 성능이 모두 동일하게 낮거나 테스트 세트 성능이 오히려 더 높을 때
-
-1. scikit-learn
-
-- KNeighborsRegressor : k-최근접 이웃 회귀 모델을 만드는 사이킷런 클래스. n_neighbors 매개변수로 이웃의 개수를 지정(기본값 5).
-- mean_absolute_error() : 회귀 모델의 평균 절댓값 오차 계산. 첫 번째 매개변수는 타깃, 두 번째 매개변수는 예측값 전달. 타깃과 예측을 뺀 값을 제곱한 다음 전체 샘플에 대해 평균한 값을 반환
-
-2. numpy
-
-- reshape() : 배열의 크기를 바꾸는 메서드. 바꾸고자 하는 배열의 크기를 매개변수로 전달.
-
-## 선형 회귀
-
-선형 회귀 : 특성과 타깃 사이의 관계를 가장 잘 나타내는 선형 방정식 찾기
-
-- 선형 회귀가 찾은 특성과 타깃 사이의 관계는 선형 방정식의 계수 또는 가중치에 저장
- 모델 파라미터 : 선형 회귀가 찾은 가중치처럼 머신러닝 모델이 특성에서 학습한 파라미터
- 다항 회귀 : 다항식을 사용하여 특성과 타깃 사이의 관계를 나타냄. 비선형일 수 있지만 여전히 선형 회귀로 표현할 수 있음
-
-1. scikit-learn
-
-- LinearRegression : 사이킷런의 선형 회귀 클래스. coef* 속성에서는 특성에 대한 계수 포함, intercept* 속성에는 절편이 저장.
-
-## 특성 공학과 규제
-
-다중 회귀 : 여러 개의 특성을 사용하는 회귀 모델
-특성 공학 : 주어진 특성을 조합하여 새로운 특성을 만드는 일련의 작업 과정
-릿지 : 규제가 있는 선형 회귀 모델 중 하나이며 선형 모델의 계수를 작게 만들어 과대적합을 완화
-라쏘 : 릿지와 달리 계수 값을 아예 0으로 만들 수 있음
-하이퍼파라미터 : 머신러닝 알고리즘이 학습하니 않는 파라미터
diff --git "a/week2/3\355\214\200_\354\235\264\354\236\254\355\235\240.md" "b/week2/3\355\214\200_\354\235\264\354\236\254\355\235\240.md"
new file mode 100644
index 0000000..b05b26c
--- /dev/null
+++ "b/week2/3\355\214\200_\354\235\264\354\236\254\355\235\240.md"
@@ -0,0 +1,198 @@
+# 🖥️ 혼공머신 스터디 : 3장 요약
+#### 스터디 3조 이재흠 (@rethinking21, rethinking21@gmail.com)
+
+***
+## 챕터 3 회귀 알고리즘과 모델 규제 🐠🐟
+
+### 03-1. k-최근접 이웃 회귀 🎯
+
+###### * 분류와 회귀
+**분류(classification)** 는 미리 정의된 여러 클래스 레이블중 하나를 예측하는 과정입니다.
+지난 2챕터에서는 분류에 대해서 설명을 했으며, 이중 분류와 다중 분류에 대해서도 설명을 했습니다.
+
이와 달리, **회귀(regression)** 는 연속적인 숫자를 예측하는 과정입니다. 분류에서는 몇개의 정해진 클래스중 하나를 선택하여 결정을 하도록 짜여져 있지만,
+회귀는 대푯값이 클래스가 아니며, **연속성**을 띤 출력값을 지니게 됩니다.
+
+일반적으로 얻고자 하는 데이터의 값이 이름(ex. 생성종류, 이름)일 경우 분류를 이용하고, 데이터의 값이 숫자(키, 나이)일 경우 회귀를 사용합니다.
+
+###### * k-최근접 이웃 회귀 (k-NN Regression)
+
+
+
▲ k-최근접 이웃 회귀에 작동방식([🖼️ 이미지 출처][1])]
+
기존에 배운 k-최근접 이웃(k-NN, K-Nearest Neighbor)이 근처에 있는 k개의 데이터를 보고 속할 **그룹**을 판단해주는 알고리즘이었습니다.
+이와 달리 **k-최근접 이웃 회귀 (k-NN Regression)** 는 근처에 있는 k개의 데이터를 보고 그 값들의 **평균**을 반환하는 알고리즘입니다.
+
+
scikit-learn에 있는 클래스 KNeighborsRegressor를 이용해 k-최근접 이웃 회귀를 구현 할 수 있습니다.
+
+```python
+from sklearn.neighbors import KNeighborsRegressor
+
+knr = KNeighborsRegressor()
+knr.fit(train_input, train_target) #학습
+```
+
+###### * reshape()
+학습이나 훈련을 할때 1차원으로 나열되어있던 배열을 2차원으로 바꿔야 하는 상황이 생깁니다.
+이때 numpy 안에 있는 **reshpae()** 메서드를 이용해 바꾸려는 배열의 크기를 지정할 수 있습니다.
+
+```python
+import numpy as np
+
+test_array = np.array([1,2,3,4])
+print(test_array.shape) # (4,)
+test_array = test_array.reshape(2,2) #배열의 크기를 바꾸어줍니다.
+print(test_array.shape) #(2,2)
+```
+
+크기에 -1을 지정할 경우, 나머지 원소로 배열이 알아서 지정됩니다.
+```python
+import numpy as np
+
+print(test_array.shape) #(1000,)
+test_array = test_array.reshape(-1,1) #2차원 배열의 크기가 1인 상태로 고정되어 원소가 채워집니다.
+print(test_array.shape) #(1,1000)
+```
+
+###### * 결정계수 (R2)
+
+분류의 경우, 예측한 값들이 실제 값과 맞는지 안맞는지만 판단하면 되기에 모델을 평가하는데 무리가 없었습니다.
+하지만 회귀는 값을 연속적인 값을 가지고 있어 정확한 숫자를 맞힌다는 것은 거의 불가능합니다.
+이 경우 우리는 다른 평가방식을 택하는데, 그 중 **결정계수(coefficient of determination, R2)** 는 회귀에서 모델을 평가하는데 많이 쓰이는 평가방식중 하나입니다.
+
+
R2를 구하는 방법은 다음과 같습니다.
+
+
+
여기서 SSE는 회귀선에 위치한 값(추정 값)과 실제값의 차이(오차)의 제곱이며, SST는 실제 값 과 Y의 평균을 뺀 값의 제곱을 의미합니다.
+
+
R2는 회귀모형 내에서 설명변수 x로 설명할 수 있는 반응변수 y의 변동 비율입니다.
+
[❕ R2결정계수에 대한 더 자세한 설명][2]
+
scikit-learn에 있는 클래스 r2_score를 이용해 패키지를 통해 쉽게 사용할 수 있습니다.
+```python
+from sklearn.metrics import r2_score
+
+test_prediction = model.predict(test_input)
+r2_score(test_target, test_prediction) #결정계수
+```
+
+
+###### * MAE(mean absolute error)
+
+
+
+**MAE(mean absolute error)** 는 모든 절대 오차의 평균입니다.
+
scikit-learn에 있는 클래스 mean_absolute_error 패키지를 통해 쉽게 사용할 수 있습니다.
+```python
+from sklearn.metrics import mean_absolute_error
+
+test_prediction = model.predict(test_input)
+mae = mean_absolute_error(test_target, test_prediction) #MAE
+print(mae)
+```
+
+###### * 과대적합 vs 과소적합
+
+
+▲ 과대적합, 과소적합에 대한 설명 이미지([🖼️ 이미지 출처][3])]
+
+훈련세트에서 점수가 높게 나왔지만, 테스트 세트에서 점수가 매우 안좋게 나왔다면 모델이 훈련세트에 **과대적합(overfitting)** 되었다고 말합니다.
+
반면, 훈련세트와 테스트 세트가 동시에 낮거나 테스트 세트의 점수가 오히려 더 높은 경우, 모델이 훈련세트에 **과소적합(underfitting)** 되었다고 말합니다.
+
+### 03-2. 선형 회귀 🎢
+###### * k-최근접 이웃 회귀 (k-NN Regression)의 한계
+
+k-최근접 이웃 회귀 알고리즘은 직관적이며, 간단하기에 처음 머신러닝을 시작하기에 편리하지만, **데이터 밖의 범위**의 새로운 데이터에서는 예측이 불가능하다는 단점이 있습니다.
+
이해하기 쉽게 표를 이용하여 설명해봅시다.
+

+위 그래프는 훈련 데이터(점)에 따른 테스트 결과값(선)의 그래프입니다. 5~45 정도 까지는 어느정도 예측을 했지만, 50이상부터는 일직선으로 나와버리는 현상이 일어납니다.
+이는 알고리즘이 데이터에서 멀어질 때에도 k개의 '근처'에 있는 데이터를 보고 판단하기 때문에 생기는 현상입니다.
+
+###### * 선형 회귀 (linear regression)
+**선형회귀(linear regression)** 는 종속 변수 y와 여러 개의 독립 변수 x와의 선형 관계를 모델링하는 회귀분석 기법입니다.
+그중에 변수 x가 하나일 때를 **단순 선형 회귀(Simple Linear Regression)** 이라 부르기도 합니다.
+

+k-NN 회귀(주황색)과 달리 선형 회귀(파란색)은 주어진 훈련 데이터 범위 밖을 지나는 데이터도 예측이 가능하다는 특징이 있습니다.
+또한 훈련하는 속도가 빠르고 결과값을 내는데 시간이 좀 걸리는 k-nn과 달리, 선형회귀는 훈련 속도는 다소 느리지만(그래도 빠르긴 하다) 테스트 속도가 빠르다는 장점을 지니고 있습니다.
+
+이때 하나의 선형함수는 다음과 같이 표현할 수 있습니다.
+

+이때 w를 **가중치(weight)** , 별도로 더해지는 값 b를 **편향(bias)** 이라고 부릅니다.
+
+scikit-learn에서는 LinearRegression모델로 간편하게 선형회귀 모델을 만들 수 있습니다.
+```python
+from sklearn.linear_model import LinearRegression
+lr = LinearRegression()
+
+lr.fit(train_input, train_target)
+print(lr.predict([[50]]))
+print(lr.coef_) #학습된 선형함수의 계수(또는 가중치)를 불러옵니다. 이는 한개 일 수도 있고, 여러개 일 수도 있습니다.
+print(lr.intercept_) #학습된 선형함수의 편향을 불러옵니다.
+```
+
+선형회귀의 학습과정 중에는 경사하강법(Gradient Descent)이 나오긴 하지만, 이는 다른 챕터에서 다룰 예정입니다.
+
[❕ 선형회귀와 다중회귀& 경사하강법에 대한 간단한 설명(링크)][4]
+
+###### * 다항 회귀 (polynomial regression)
+**다항 회귀(polynomial regression)** 는 다항식을 이용한 선형 회귀로, 항이 2차, 3차, 제곱근일수도 있으며(로그함수 일 수도 있습니다!), 함수의 형태가 **비선형**이라는 특징이 있습니다.
+

+
+### 03-3. 특성 공학과 규제
+
+###### * 다중 회귀 (multiple regression, Multiple Linear Regression)
+여러개의 특성을 활용한 선형 회귀를 **다중 회귀(multiple regression, Multiple Linear Regression)** 라고 부릅니다.
+단순 선형 회귀와 달리 다중 회귀는 여러개의 특성을 사용한다는 차이점이 있습니다.
+

+
+다중 회귀에 사용되는 특성들 중에는 특성을 제곱한다던지 특성을 서로 곱하여 새로운 특성을 만드는 경우가 있습니다. 이처럼 기존의 특성을 이용하여 새로운 특성을 만들어 내는 작업을 **특성 공학(feature engineering)** 이라고 부릅니다.
+###### * 판다스(Pandas)와 사이킷런 변환기, 정규화 클래스
+**판다스(Pandas)** 는 파이썬의 유명한 데이터 분석 라이브러리입니다. 이중 **데이터프레임(dataframe)** 은 판다스의 핵심 데이터 구조입니다. 판다스를 이용해 .csv파일을 numpy 배열로 바꿀수도 있고, 웹사이트에 있는 데이터 구조를 불러올 수 있습니다.
+```python
+import pandas as pd
+df = pd.read_csv('website') #웹사이트에 있는 csv파일을 불러옵니다.
+perch_full = df.to_numpy() #데이터를 numpy 배열로 바꿔줍니다.
+```
+
+Scikit-learn에서는 특성을 새로 만들거나 전처리를 하기 위해 다양한 클래스를 제공하며, 이를 **변환기(transformer)** 라고 부릅니다.
+```python
+from sklearn.preprocessing import PolynomialFeatures
+
+poly = PolynomialFeatures(degree=4 ,include_bias=False) #degree = 몇차수까지를 특성으로 만들건지 결정합니다.
+poly.fit([[2,3]])
+print(poly.transform([[2,3]])) #[[2. 3. 4. 6. 9.]]
+
+```
+
+또한 Scikit-learn에서는 StandardScaler클래스를 통해 정규화를 쉽게 할 수 있습니다.
+```python
+from sklearn.preprocessing import StandardScaler
+ss = StandardScaler()
+ss.fit(train_data) # 정규화를 하기 위해 먼저 테스트 데이터를 넣습니다.
+train_scald = ss.transform(train_data) # 구한 값을 이용해 정규화를 진행합니다.
+test_scaled = ss.transform(test_poly) # 주의해야 할 것은 테스트 데이터를 '훈련'데이터로 정규화해야 한다는 것입니다.
+```
+
+###### * 규제(Regularization)
+**규제(Regularization)** 는 머신러닝 모델의 과대적합 문제를 피하기 위해서 너무 과도하게 학습하지 못하도록 만드는 것을 말합니다.
+선형 회귀 모델의 경우, 각 특성의 가중치의 크기를 작게 만들어 규제를 할 수 있습니다.
+
+###### * 릿지 회귀(Ridge Regression, L2 Regression)
+
+```python
+from sklearn.linear_model import Ridge
+ridge = Ridge(alpha=0.1) #알파값을 통해 언제가 가장 최적의 값이 되는지 찾아야 합니다.
+ridge.fit(train_scaled, train_target)
+ridge.score(test_scaled,test_target)
+```
+
+###### * 라쏘 회귀(Lasso Regression, L1 Regression)
+
+```python
+from sklearn.linear_model import Lasso
+lasso = Lasso(alpha=10) #알파값을 통해 언제가 가장 최적의 값이 되는지 찾아야 합니다.
+lasso.fit(train_scaled, train_target)
+lasso.score(test_scaled,test_target)
+```
+
+#### * 아직 규제쪽은 이해를 못했어요..🥺
+[1]: https://tensorflow.blog/파이썬-머신러닝/2-3-2-k-최근접-이웃/
+[2]: https://datalabbit.tistory.com/54
+[3]: https://towardsdatascience.com/overfitting-vs-underfitting-a-conceptual-explanation-d94ee20ca7f9
+[4]: https://wikidocs.net/21670
\ No newline at end of file
diff --git "a/week2/4\355\214\200_\352\271\200\353\217\204\355\230\204.md" "b/week2/4\355\214\200_\352\271\200\353\217\204\355\230\204.md"
new file mode 100644
index 0000000..6549d59
--- /dev/null
+++ "b/week2/4\355\214\200_\352\271\200\353\217\204\355\230\204.md"
@@ -0,0 +1,25 @@
+### 회귀: 두 변수 사이의 인과관계를 분서하는 방법
+### 분류vs회귀: 분류는 여러 클래스 중 하나로 분류하지만 회귀는 임의의 어떤 숫자로 예측한다.
+
+### 결정계수(R^2): 대표적인 회귀 문제의 성능 측정 지표, 1 - sum((실제-예측)^2)/sum((실제-평균)^2), 1에 가까울수록 성능이 좋다.
+### 결정계수 추가 설명: 결정계수는 분산을 이용한 지표로, 모델의 설명력을 나타낸다. 실제 타깃의 분산은 (설명할 수 없는 분산 + 설명할 수 있는 분산)으로 이루어지는데 (설명할 수 있는 분산/실제 타깃의 분산)이 결정계수이다. 독립변수가 많아질수록 설명할 수 있는 분산은 늘어나고 결국 종속변수와 별로 관련이 없는 독립변수가 추가해도 결정계수의 값은 증가하는 현상이 발생한다. 따라서 독립변수가 여러개일 때는 조정된 결정계수 값을 이용하여 비교해봐야한다.
+
+### 과대적합: 훈현 데이터에는 잘 맞지만 테스트 데이터에는 잘 맞지 않는 모델, 복잡한 모델에서 일어난다. Low Bias, High Variance
+### 과소적합: 훈련 데이터와 테스트 데이터 모두 잘 맞지 않는 모델, 단순한 모델에서 일어난다. High bias, Low Variance
+### 특성공학: 기존의 특성을 활용해 새로운 특성을 추출하는 작업 (X -> X^2)
+## K-최근접 이웃 회귀
+### K-최근접 알고리즘: 어떤 데이터를 분류하고 회귀할 때 근처에 있는 주위 다른 데이터를 이용하는 방법, K는 고려할 주위 데이터의 수를 의미함 (분류의 경우 주위 데이터 중 다수가 차지하는 클래스, 회귀는 주위 데이터의 결과값을 평균)
+### 단점: 훈련 데이터의 범위를 벗어난 데이터가 들어오면 값을 예측하기 힘들다.
+
+## 선형회귀
+### 선형회귀: 종속변수와 한 개 이상의 독립변수와의 선형관계를 모델링하여 분석하는 방법
+### 단순 선형회귀: 선형회귀에서 독립변수가 한 개일 경우
+### 다중 선형회귀: 선형회귀에서 독립변수가 여러 개일 경우
+### 다항회귀: 다항식을 이용한 선형회귀 (Y = wo + w1X + w2(X^2) + w3(X^3) + ...)
+
+### 규제: 모델이 과대적합되지 않도록 규제하는 방법
+## 릿지와 라쏘
+### 릿지: 선형회귀 모델에 alpha sum((계수)^2)을 더해 규제를 추가한 모델
+### 라쏘: 선형회귀 모델에 alpha sum(absolute(계수))를 더해 규제를 추가한 모델
+### 릿지의 경우 계수가 0이 될 수 없지만, 라쏘의 경우는 계수가 0이 되기도 한다. 일반적으로 릿지 모델을 조금 더 선호한다.
+
diff --git "a/week2/4\355\214\200_\354\265\234\355\203\234\354\230\201.md" "b/week2/4\355\214\200_\354\265\234\355\203\234\354\230\201.md"
deleted file mode 100644
index 1e083c0..0000000
--- "a/week2/4\355\214\200_\354\265\234\355\203\234\354\230\201.md"
+++ /dev/null
@@ -1,282 +0,0 @@
-# -*- coding: utf-8 -*-
-"""최근접회귀.ipynb
-
-Automatically generated by Colaboratory.
-
-Original file is located at
- https://colab.research.google.com/drive/1b6ZS4btE4uvG5IwZGKr-KNmlkmQSYadq
-"""
-
-import numpy as np
-
-perch_length = np.array(
- [8.4, 13.7, 15.0, 16.2, 17.4, 18.0, 18.7, 19.0, 19.6, 20.0,
- 21.0, 21.0, 21.0, 21.3, 22.0, 22.0, 22.0, 22.0, 22.0, 22.5,
- 22.5, 22.7, 23.0, 23.5, 24.0, 24.0, 24.6, 25.0, 25.6, 26.5,
- 27.3, 27.5, 27.5, 27.5, 28.0, 28.7, 30.0, 32.8, 34.5, 35.0,
- 36.5, 36.0, 37.0, 37.0, 39.0, 39.0, 39.0, 40.0, 40.0, 40.0,
- 40.0, 42.0, 43.0, 43.0, 43.5, 44.0]
- )
-perch_weight = np.array(
- [5.9, 32.0, 40.0, 51.5, 70.0, 100.0, 78.0, 80.0, 85.0, 85.0,
- 110.0, 115.0, 125.0, 130.0, 120.0, 120.0, 130.0, 135.0, 110.0,
- 130.0, 150.0, 145.0, 150.0, 170.0, 225.0, 145.0, 188.0, 180.0,
- 197.0, 218.0, 300.0, 260.0, 265.0, 250.0, 250.0, 300.0, 320.0,
- 514.0, 556.0, 840.0, 685.0, 700.0, 700.0, 690.0, 900.0, 650.0,
- 820.0, 850.0, 900.0, 1015.0, 820.0, 1100.0, 1000.0, 1100.0,
- 1000.0, 1000.0]
- )
-
-import matplotlib.pyplot as plt
-plt.scatter(perch_length, perch_weight)
-plt.xlabel('length')
-plt.ylabel('weight')
-plt.show()
-
-from sklearn.model_selection import train_test_split
-train_input, test_input, train_target, test_target = train_test_split(
- perch_length, perch_weight, random_state=42)
-train_input = train_input.reshape(-1, 1)
-test_input = test_input.reshape(-1, 1) #데이터의 모양을 2 차원으로 변경함
-
-from sklearn.neighbors import KNeighborsRegressor#kNeighborRegrssor호출
-
-knr = KNeighborsRegressor()
-knr.fit(train_input, train_target)
-
-knr.score(test_input, test_target)
-
-from sklearn.metrics import mean_absolute_error
-
-test_prediction = knr.predict(test_input)
-mae = mean_absolute_error(test_target, test_prediction)#오차 계산
-print(mae)
-
-print(knr.score(train_input, train_target))#과소 적합확인
-
-knr.n_neighbors = 3 #이웃의 수를 줄여 민감도를 높임
-knr.fit(train_input, train_target)
-print(knr.score(train_input, train_target))
-
-print(knr.score(test_input, test_target))# 과소적합 해결
-
-import numpy as np
-
-perch_length = np.array(
- [8.4, 13.7, 15.0, 16.2, 17.4, 18.0, 18.7, 19.0, 19.6, 20.0,
- 21.0, 21.0, 21.0, 21.3, 22.0, 22.0, 22.0, 22.0, 22.0, 22.5,
- 22.5, 22.7, 23.0, 23.5, 24.0, 24.0, 24.6, 25.0, 25.6, 26.5,
- 27.3, 27.5, 27.5, 27.5, 28.0, 28.7, 30.0, 32.8, 34.5, 35.0,
- 36.5, 36.0, 37.0, 37.0, 39.0, 39.0, 39.0, 40.0, 40.0, 40.0,
- 40.0, 42.0, 43.0, 43.0, 43.5, 44.0]
- )
-perch_weight = np.array(
- [5.9, 32.0, 40.0, 51.5, 70.0, 100.0, 78.0, 80.0, 85.0, 85.0,
- 110.0, 115.0, 125.0, 130.0, 120.0, 120.0, 130.0, 135.0, 110.0,
- 130.0, 150.0, 145.0, 150.0, 170.0, 225.0, 145.0, 188.0, 180.0,
- 197.0, 218.0, 300.0, 260.0, 265.0, 250.0, 250.0, 300.0, 320.0,
- 514.0, 556.0, 840.0, 685.0, 700.0, 700.0, 690.0, 900.0, 650.0,
- 820.0, 850.0, 900.0, 1015.0, 820.0, 1100.0, 1000.0, 1100.0,
- 1000.0, 1000.0]
- )
-
-from sklearn.model_selection import train_test_split
-
-
-train_input, test_input, train_target, test_target = train_test_split(# 훈련 세트와 테스트 세트 나눔
- perch_length, perch_weight, random_state=42)
-
-train_input = train_input.reshape(-1, 1)# 훈련 세트와 테스트 세트를 2차원 배열 변경
-test_input = test_input.reshape(-1, 1)
-
-from sklearn.neighbors import KNeighborsRegressor
-
-knr = KNeighborsRegressor(n_neighbors=3)
-
-knr.fit(train_input, train_target)
-
-print(knr.predict([[50]]))
-
-distances, indexes = knr.kneighbors([[50]])# 50cm 농어의 이웃
-
-plt.scatter(train_input, train_target)
-plt.scatter(train_input[indexes], train_target[indexes], marker='D')
-# 50cm 농어 데이터
-plt.scatter(50, 1033, marker='^')
-plt.xlabel('length')
-plt.ylabel('weight')
-plt.show()
-
-distances, indexes = knr.kneighbors([[100]])# 100cm 농어의 이웃
-
-plt.scatter(train_input, train_target)
-plt.scatter(train_input[indexes], train_target[indexes], marker='D')
-plt.scatter(100, 1033, marker='^')
-plt.xlabel('length')
-plt.ylabel('weight')
-plt.show()
-
-from sklearn.linear_model import LinearRegression
-
-lr = LinearRegression()
-lr.fit(train_input, train_target)
-
-print(lr.predict([[50]]))
-
-plt.scatter(train_input, train_target)
-
-plt.plot([15, 50], [15*lr.coef_+lr.intercept_, 50*lr.coef_+lr.intercept_])# 구한 그래프 표현
-
-plt.scatter(50, 1241.8, marker='^')# 50cm 농어 데이터
-plt.xlabel('length')
-plt.ylabel('weight')
-plt.show()
-
-print(lr.score(train_input, train_target))
-print(lr.score(test_input, test_target))
-
-train_poly = np.column_stack((train_input ** 2, train_input))
-test_poly = np.column_stack((test_input ** 2, test_input))
-
-lr = LinearRegression()
-lr.fit(train_poly, train_target)
-
-print(lr.predict([[50**2, 50]]))
-
-point = np.arange(15, 50)
-# 훈련 세트의 산점도를 그립니다
-plt.scatter(train_input, train_target) # 15에서 49까지 2차 방정식 그래프
-plt.plot(point, 1.01*point**2 - 21.6*point + 116.05)
-plt.scatter([50], [1574], marker='^')
-plt.xlabel('length')
-plt.ylabel('weight')
-plt.show()
-
-print(lr.score(train_poly, train_target))
-print(lr.score(test_poly, test_target))
-
-import pandas as pd
-
-df = pd.read_csv('https://bit.ly/perch_csv_data')# 판다를 통해 데이터를 가져옴
-perch_full = df.to_numpy()
-print(perch_full)
-
-perch_weight = np.array(
- [5.9, 32.0, 40.0, 51.5, 70.0, 100.0, 78.0, 80.0, 85.0, 85.0,
- 110.0, 115.0, 125.0, 130.0, 120.0, 120.0, 130.0, 135.0, 110.0,
- 130.0, 150.0, 145.0, 150.0, 170.0, 225.0, 145.0, 188.0, 180.0,
- 197.0, 218.0, 300.0, 260.0, 265.0, 250.0, 250.0, 300.0, 320.0,
- 514.0, 556.0, 840.0, 685.0, 700.0, 700.0, 690.0, 900.0, 650.0,
- 820.0, 850.0, 900.0, 1015.0, 820.0, 1100.0, 1000.0, 1100.0,
- 1000.0, 1000.0]
- )
-
-from sklearn.model_selection import train_test_split
-
-train_input, test_input, train_target, test_target = train_test_split(perch_full, perch_weight, random_state=42)
-
-from sklearn.preprocessing import PolynomialFeatures
-
-poly = PolynomialFeatures()
-poly.fit([[2, 3]])
-print(poly.transform([[2, 3]]))# 데이터의 수를 늘림
-
-poly = PolynomialFeatures(include_bias=False)
-
-poly.fit(train_input)
-train_poly = poly.transform(train_input)
-
-poly.get_feature_names_out()
-
-test_poly = poly.transform(test_input)
-
-from sklearn.linear_model import LinearRegression #규제 라이브러리
-
-lr = LinearRegression()
-lr.fit(train_poly, train_target)
-print(lr.score(train_poly, train_target))
-
-print(lr.score(test_poly, test_target))
-
-poly = PolynomialFeatures(degree=5, include_bias=False)
-
-poly.fit(train_input)
-train_poly = poly.transform(train_input)
-test_poly = poly.transform(test_input)
-
-lr.fit(train_poly, train_target)
-print(lr.score(train_poly, train_target))
-
-print(lr.score(test_poly, test_target))
-
-from sklearn.preprocessing import StandardScaler#규제 라이브러리
-
-ss = StandardScaler()
-ss.fit(train_poly)
-
-train_scaled = ss.transform(train_poly)
-test_scaled = ss.transform(test_poly)
-
-from sklearn.linear_model import Ridge # 릿지 방식의 규제
-
-ridge = Ridge()
-ridge.fit(train_scaled, train_target)
-print(ridge.score(train_scaled, train_target))
-
-print(ridge.score(test_scaled, test_target))
-
-import matplotlib.pyplot as plt
-
-train_score = []
-test_score = []
-
-alpha_list = [0.001, 0.01, 0.1, 1, 10, 100]
-for alpha in alpha_list:
- ridge = Ridge(alpha=alpha)
- ridge.fit(train_scaled, train_target)
- train_score.append(ridge.score(train_scaled, train_target))
- test_score.append(ridge.score(test_scaled, test_target))
-
-plt.plot(np.log10(alpha_list), train_score)
-plt.plot(np.log10(alpha_list), test_score)
-plt.xlabel('alpha')
-plt.ylabel('R^2')
-plt.show()
-
-ridge = Ridge(alpha=0.1)
-ridge.fit(train_scaled, train_target)
-
-print(ridge.score(train_scaled, train_target))
-print(ridge.score(test_scaled, test_target))
-
-from sklearn.linear_model import Lasso # 랏쏘 방식의 규제
-
-lasso = Lasso()
-lasso.fit(train_scaled, train_target)
-print(lasso.score(train_scaled, train_target))
-
-print(lasso.score(test_scaled, test_target))
-
-train_score = []
-test_score = []
-
-alpha_list = [0.001, 0.01, 0.1, 1, 10, 100]
-for alpha in alpha_list:
- lasso = Lasso(alpha=alpha, max_iter=10000)
- lasso.fit(train_scaled, train_target)
- train_score.append(lasso.score(train_scaled, train_target))
- test_score.append(lasso.score(test_scaled, test_target))
-
-plt.plot(np.log10(alpha_list), train_score)
-plt.plot(np.log10(alpha_list), test_score)
-plt.xlabel('alpha')
-plt.ylabel('R^2')
-plt.show()
-
-lasso = Lasso(alpha=10)
-lasso.fit(train_scaled, train_target)
-
-print(lasso.score(train_scaled, train_target))
-print(lasso.score(test_scaled, test_target))
-
-print(np.sum(lasso.coef_ == 0))
\ No newline at end of file
diff --git "a/week2/5\355\214\200_\352\271\200\353\217\231\354\232\260.md" "b/week2/5\355\214\200_\352\271\200\353\217\231\354\232\260.md"
deleted file mode 100644
index 1a1374f..0000000
--- "a/week2/5\355\214\200_\352\271\200\353\217\231\354\232\260.md"
+++ /dev/null
@@ -1,102 +0,0 @@
-# Chap 3
-## k-최근접 이웃 회귀
-지도 학습 알고리즘 = 분류 + 회귀
-분류: 샘플을 몇 개의 클래스 중 하나로 분류
-회귀: 임의의 어떤 숫자를 예측
-
-훈련 세트와 테스트 세트로 나누기
-```py
-from sklearn.model_selection import train_test_split
-train_input, test_input(), train_target, test_target = train_test_split(perch_length, perch_weight, random_state=42)
-```
-(42,) 배열을 (42,1)로 변환
-```py
-train_input = train_input.reshape(-1,1)
-test_input = test_input.reshape(-1,1)
-```
-결정계수: 회귀의 평가 결과
-```py
-knr = KNeighborsRegressor()
-knr.fit(train_input, train_target)
-print(knr.score(test_input, test_target))
-```
-평균 절댓값 오차
-```py
-test_prediction = knr.predict(test_input)
-mae = mean_absolute_error(test_target, test_prediction)
-```
-과대적합: 훈련 세트 점수는 좋지만 테스트 세트 점수가 나쁨
-과소적합: 훈련 세트보다 테스트 세트의 점수가 높거나 두 점수가 모두 너무 낮음
-
-## 선형 회귀
-k-최근접 이웃으로 샘플들의 경향성 반영이 잘 안되는 경우가 있음
-
-선형 회귀 모델
-```py
-from sklearn.linear_model import LinearRegression
-lr = LinearRegression()
-lr.fit(train_input, train_target)
-print(lr.predict([[50]]))
-```
-모델 파라미터
-```py
-print(lr.coef_, lr.intercept_)
-```
-다항 회귀
-```py
-train_poly = np.column_stack((train_input**2, train_input))
-test_poly = np.coulmn_stack((test_input**2, test_input))
-lr = LinearRegression()
-lr.fit(train_poly, train_target)
-print(lr.predic([[50**2, 50]]))
-```
-## 다중회귀
-특성 공학: 기존의 특성을 사용해 새로운 특성을 뽑아냄(농어 길이*농어 높이)
-판다스: 데이터 분석 라이브러리
-데이터프레임: 판다스의 핵심 데이터 구조
-
-변환기: 사이킷런이 제공하는 특성을 만들거나 전처리하기 위한 다양한 클래스
-```py
-from sklearn.preprocessing import PolynomialFeatures
-poly = PolynomialFeatures(include_bias=False)
-poly.fit(train_input)
-train_poly = poly.transform(train_input)
-print(train_poly.shape)
-poly.get_feature_names_out()
-test_poly = poly.transform(test_input)
-```
-다중 회귀 모델
-```py
-from sklearn.linear_model import LinearRegression
-lr = LinearRegression()
-lr.fit(train_poly, train_target)
-print(lr.score(train_poly, train_target), lr.score(test_poly, test_target))
-```
-정규화
-```py
-from sklearn.preprocessing import StandardScaler
-ss = StandardScaler()
-ss.fit(train_poly)
-train_scaled = ss.transform(train_poly)
-test_scaled = ss.transform(test_poly)
-```
-규제: 릿지 & 라쏘
-
-릿지 회귀
-```py
-from sklearn.linear_model import Ridge
-ridge = Ridge()
-ridge.fit(train_scaled, train_target)
-print(ridge.score(train_scaled, train_target))
-```
-alpha: 규제의 강도 조절(클수록 규제 강도가 세짐)
-하이퍼파라미터: 머신러닝 모델이 학습할 수 없고 사람이 알려줘야 하는 파라미터(매개변수)
-
-라쏘 회귀
-```py
-from sklearn.linear_model import Lasso
-lasso = Lasso()
-lasso.fit(train_scaled, train_target)
-print(lasso.score(train_scaled, train_target), lasso.score(test_scaled, test_target))
-```
-
diff --git "a/week2/5\355\214\200_\354\235\264\354\212\271\355\233\210.md" "b/week2/5\355\214\200_\354\235\264\354\212\271\355\233\210.md"
deleted file mode 100644
index d614c00..0000000
--- "a/week2/5\355\214\200_\354\235\264\354\212\271\355\233\210.md"
+++ /dev/null
@@ -1,35 +0,0 @@
-# 회귀 알고리즘과 모델규제
-## k-최근접 이웃 회귀
-인접한 원소 $n$개의 평균을 이용하여 임의의 데이터의 특성을 예측하는 알고리즘
-### 주요 메서드
-`reshape()`: 배열의 크기를 조정, 인자로 -1이 들어가면 자동으로 데이터를 맞춘다
-
-### 주요 용어
-- 결정계수: 회귀 분석에서 모델의 정확도를 평가하는 방법. 1에 가까울 수록 모델이 정확하다
-- 과대적합: 모델이 훈련 세트에선 정확하지만 테스트 세트에선 부정확하게 나올 때
-- 과소적합: 훈련 세트보다 테스트 세트의 점수가 높거나 두 점수 모두 낮을 때
-
-k-최근접 이웃 회귀에선 과대적합을 막기 위해선 비교하는 인접한 원소 $n$을 늘리고, 과소적합을 막기 위해선 $n$을 줄인다.
-
-
-## 선형 회귀
-3-1장에서 다룬 모델은 만약 주어진 값이 학습한 데이터와 동떨어진 값일 경우 부정확한 값을 낸다는 단점이 존재한다. 데이터를 도시해보면 선형으로 어느정도 근사할 수 있음을 알 수 있고, `scikit-learn`에서는 선형회귀를 쉽게 할 수 있는 도구를 제공한다.
-
-일차식으로 근사할 수 없는 경우 다차식으로 근사시킬 수도 있다. 이를 다항 회귀라고 부르며 `LinearRegression` 객체에 제곱항을 추가한 데이터 세트를 넣어주기만 하면 다항 회귀를 진행해준다.
-
-## 특성 공학과 규제
-두 개 이상의 특성을 이용해 선형 회귀를 진행하는 것을 다중 회귀라고 한다. 모델을 학습시킬 때 각 특성을 곱해 또 다른 특성을 만들어 낼 수도 있는데, 이렇게 기존의 특성을 사용해 새로운 특성을 뽑아내는 작업을 특성공학이라고 부른다.
-
-### Pandas
-판다스는 데이터 분석 라이브러리 중 하나로, 데이터프레임이라는 데이터 구조를 지원한다. 넘파이의 배열과 유사하게 다차원 배열을 다루지만, 더 많은 기능을 제공한다.
-
-### 주요 메서드
-- `read_csv()`: 웹 상의 csv 파일을 읽는다
-- `to_numpy()`: 판다스의 배열을 넘파이의 배열로 바꾼다.
-- `fit()`: 새롭게 만들 특성 조합을 찾는다
-- `transform()`: 특성 조합을 토대로 데이터를 변환한다.
-
-### 릿지 회귀와 라쏘 회쉬
-릿지 회귀와 라쏘 회귀는 머신러닝 모델이 훈련 세트를 과도하게 학습하지 못하게끔 규제하는 수단 중 하나이다.
-릿지 회귀와 라쏘 회귀의 경우 alpha값을 조절해가며 정확도가 높은 규제 양을 조절하는 과정이 수반된다.
-
diff --git "a/week2/6\354\241\260_\352\271\200\353\257\274\354\244\2002.md" "b/week2/6\354\241\260_\352\271\200\353\257\274\354\244\2002.md"
new file mode 100644
index 0000000..661c4fb
--- /dev/null
+++ "b/week2/6\354\241\260_\352\271\200\353\257\274\354\244\2002.md"
@@ -0,0 +1,28 @@
+#Ch. 3
+
++ 회귀
+ 주어진 샘플을 몇 개의 범주 중 하나로 판단하는 분류와는 다르게, 회귀는 특정 값을 숫자로써 예측하는 방법이다.
+
++ K-최근접 이웃 분류
+ 1. 값을 구하려는 데이터와 가장 가까운 샘플 K개를 선택한다. 여기서 숫자 K는 반드시 홀수로 설정해야 한다.
+ 2. 선택된 K개의 샘플 중 다수를 차지하는 클래스를 데이터의 범주로 예측한다.
+
++ K-최근접 이웃 회귀
+ 1. 값을 구하려는 데이터와 가장 가까운 샘플 K개를 선택한다. 단, 분류와 다르게 클래스가 아니라 수치를 이용한다.
+ 2. 이웃한 샘플들의 평균값을 도출하여 데이터의 타깃값을 구한다.
+
++ 결정계수
+ R^2이라고도 불리는 결정계수는 각 샘플들의 타깃값과 예측값의 차이를 제곱하여 더한 후, 타깃과 평균의 차이를 제곱한 값들의 총합으로 나누어 도출되는 값이다. 예측값이 타깃값과 가까울수록 결정계수는 1에 가까워진다.
+
++ 과대적합 (overfitting)
+ 훈련 세트에서만 점수가 높고 테스트 세트에서는 점수가 낮은 경우, 즉 훈련 세트에 대해서만 과도하게 학습된 경우를 뜻한다.
+
++ 과소적합 (underfitting)
+ 훈련 세트보다 테스트 세트의 점수가 높은 경우, 혹은 두 점수 모두 낮은 경우, 즉 모델이 너무 단순하게 학습되어 훈련 세트에서조차 잘 학습되지 않은 경우를 뜻한다.
+
++ K-최근접 이웃 알고리즘의 한계
+ K-최근접 이웃 회귀는 가장 가까운 샘플들의 평균을 값으로 도출하는데, 새로 입력된 샘플이 훈련 데이터의 범위를 벗어나게 된다면 적절치 않은 값을 도출할 수 있다.
+
++ 선형 회귀 (linear regression)
+ 전체 데이터의 특성을 가장 잘 나타낼 수 있는 하나의 직선, 혹은 선형적인 그래프를 표현하는 알고리즘이다.
+
\ No newline at end of file
diff --git "a/week2/6\354\241\260_\352\271\200\353\257\274\354\244\2005.md" "b/week2/6\354\241\260_\352\271\200\353\257\274\354\244\2005.md"
new file mode 100644
index 0000000..ecec07d
--- /dev/null
+++ "b/week2/6\354\241\260_\352\271\200\353\257\274\354\244\2005.md"
@@ -0,0 +1,44 @@
+#Ch. 3
+
++ 회귀
+ 주어진 샘플을 몇 개의 범주 중 하나로 판단하는 분류와는 다르게, 회귀는 특정 값을 숫자로써 예측하는 방법이다.
+
++ K-최근접 이웃 분류
+ 1. 값을 구하려는 데이터와 가장 가까운 샘플 K개를 선택한다. 여기서 숫자 K는 반드시 홀수로 설정해야 한다.
+ 2. 선택된 K개의 샘플 중 다수를 차지하는 클래스를 데이터의 범주로 예측한다.
+
++ K-최근접 이웃 회귀
+ 1. 값을 구하려는 데이터와 가장 가까운 샘플 K개를 선택한다. 단, 분류와 다르게 클래스가 아니라 수치를 이용한다.
+ 2. 이웃한 샘플들의 평균값을 도출하여 데이터의 타깃값을 구한다.
+
++ 결정계수
+ R^2이라고도 불리는 결정계수는 각 샘플들의 타깃값과 예측값의 차이를 제곱하여 더한 후, 타깃과 평균의 차이를 제곱한 값들의 총합으로 나누어 도출되는 값이다. 예측값이 타깃값과 가까울수록 결정계수는 1에 가까워진다.
+
++ 과대적합 (overfitting)
+ 훈련 세트에서만 점수가 높고 테스트 세트에서는 점수가 낮은 경우, 즉 훈련 세트에 대해서만 과도하게 학습된 경우를 뜻한다.
+
++ 과소적합 (underfitting)
+ 훈련 세트보다 테스트 세트의 점수가 높은 경우, 혹은 두 점수 모두 낮은 경우, 즉 모델이 너무 단순하게 학습되어 훈련 세트에서조차 잘 학습되지 않은 경우를 뜻한다.
+
++ K-최근접 이웃 알고리즘의 한계
+ K-최근접 이웃 회귀는 가장 가까운 샘플들의 평균을 값으로 도출하는데, 새로 입력된 샘플이 훈련 데이터의 범위를 벗어나게 된다면 적절치 않은 값을 도출할 수 있다.
+
++ 선형 회귀 (linear regression)
+ 전체 데이터의 특성을 가장 잘 나타낼 수 있는 하나의 직선, 혹은 선형적인 그래프를 표현하는 알고리즘이다.
+
++ 다항 회귀
+ 다항식을 활용한 선형회귀. 차원이 늘어날수록 그래프(함수)의 계수 또한 늘어난다.
+
++ 다중 회귀 (multiple regression)
+ 여러 개의 특성을 이용한 선형 회귀 알고리즘.
+ - 특성 공학
+ 기존의 feature값에서 새로운 특성을 생성하는 작업. 기존의 feature 값 간의 곱이나 차이를 주로 사용한다.
+ - 규제
+ 조정 학습과 비슷한 방법. 훈련 세트에 대해 너무 과도하게 학습되는 것을 방지한다.
+ - 릿지 회귀(Ridge Regression)
+ 릿지 회귀식: 잔자제곱의 합 + 패널티 항의 합
+ 제약 조건에 가장 가까이 접근하는 RSS 값을 선택
+ - 라쏘 회귀
+ 기존의 선형회귀에서 추가적인 제약 조건을 부여한 알고리즘. MSE가 최소가 되도록 하는 가중치 및 편향을 탐색하고, 가중치들의 크기가 최소가 되도록 함.
+ * MSE (평균 제곱 오차)
+ 데이터와 모델의 함수가 얼마나 평균적으로 떨어져 있는지 보여주는 지표.
\ No newline at end of file
diff --git "a/week2/6\355\214\200_\352\266\214\354\230\210\354\244\200.md" "b/week2/6\355\214\200_\352\266\214\354\230\210\354\244\200.md"
new file mode 100644
index 0000000..f077982
--- /dev/null
+++ "b/week2/6\355\214\200_\352\266\214\354\230\210\354\244\200.md"
@@ -0,0 +1,54 @@
+# 로지스틱 회귀
+## -> 이름에 회귀가 들어가지만 회귀가 아님!(확률을 찾는 알고리즘)
+
+## 분류 알고리즘에는 무엇이 있을까?
+---
+> ## K-NeighborsClassifier
+* ### 최근접 이웃 몇개를 뽑아서, 각각의 클래스가 차지하는 비율이 곧 확률
+* ### 구현방법
+ ### 1. 데이터 불러오기 (pd.read_csv())
+ ### 2. 넘파이로 변환하기 (.to_numpy())
+ ### 3. 데이터 분리하기 (train_test_split())
+ ### 4. 데이터 표준화 (StandardScaler())
+ ### 5. 모델 만들기 (KNeighborsClassifier())
+
+> ## 로지스틱 회귀(Logistic Classifier)
+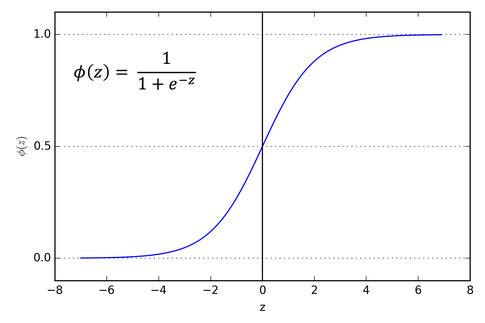
+* ### 치역이 0(0%)과 1(100%) 사이
+* ### 이중분류 (True/False)에서 사용
+* ### 0.5보다 크면 양성 클래스, 0.5보다 작으면 음성 클래스
+#
+* ### 구현방법
+ ### 1. 데이터 가공 (pd.read_csv(), .to_numpy())
+ ### 2. 불리언 인덱싱 (array['True'/'False'])
+ ### 3. 모델 만들기 (LogisticRegression())
+ ### 4. 모델 학습하기 (lr.fit())
+ ### 5. 모델 평가하기 (lr.predict(), predict_proba())
+
+---
+# 소프트맥스 함수
+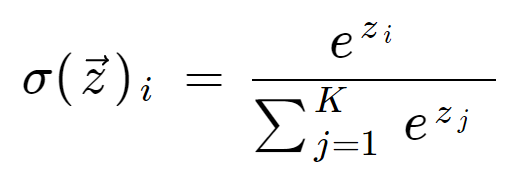
+* ### 모든 i에 대한 출력을 더하면 1(100%)
+* ### 다중 분류에서 사용
+
+---
+# 경사 하강법
+## 확률적 경사 하강법(Stochastic Gradient Descent, SGD)
+ * ### 훈련 세트에서 랜덤하게 샘플 하나를 골라 학습
+ * ### 이 과정을 훈련 세트의 수 만큼 사용하는 과정->에포크
+## 미니배치 경사 하강법(Mini-Batch Stochastic Gradient Descent, MSGD)
+ * ### 전체 데이터를 batch_size 개씩 나누어 학습
+## 배치 경사 하강법 (Batch Gradient Descent, BGD)
+ * ### 전체 데이터를 하나의 배치로 묶어 학습
+
+---
+# 손실 함수
+## 로지스틱 손실 함수
+ * ### 양성 클래스인 경우: -log(p)
+ * ### 음성 클래스인 경우: -log(1 - p)
+ * ### 이진 분류에서는 '이진' 크로스엔트로피 손실 함수
+ * ### 다중 분류에서는 크로스엔트로피 손실 함수
+## 평균 절댓값 오차
+ * ### 타깃에서 예측을 뺀 절댓값을 모든 샘플에 평균한 값
+## 평균 제곱 오차
+ * ### 타깃에서 예측을 뺸 값을 제곱한 다음 모든 샘플에 평균한 값
\ No newline at end of file
diff --git a/week2/images/2022-03-29-10-23-10.png b/week2/images/2022-03-29-10-23-10.png
deleted file mode 100644
index 3e3bdc0..0000000
Binary files a/week2/images/2022-03-29-10-23-10.png and /dev/null differ
diff --git a/week2/images/2022-03-29-10-27-49.png b/week2/images/2022-03-29-10-27-49.png
deleted file mode 100644
index d68aa59..0000000
Binary files a/week2/images/2022-03-29-10-27-49.png and /dev/null differ
diff --git a/week2/images/2022-03-29-10-32-28.png b/week2/images/2022-03-29-10-32-28.png
deleted file mode 100644
index 4c56dec..0000000
Binary files a/week2/images/2022-03-29-10-32-28.png and /dev/null differ
diff --git a/week2/images/2022-03-29-10-39-43.png b/week2/images/2022-03-29-10-39-43.png
deleted file mode 100644
index 6b286e9..0000000
Binary files a/week2/images/2022-03-29-10-39-43.png and /dev/null differ
diff --git a/week2/images/2022-03-29-11-11-19.png b/week2/images/2022-03-29-11-11-19.png
deleted file mode 100644
index cb7a64d..0000000
Binary files a/week2/images/2022-03-29-11-11-19.png and /dev/null differ
diff --git a/week2/images/2022-03-29-11-34-07.png b/week2/images/2022-03-29-11-34-07.png
deleted file mode 100644
index 44a365a..0000000
Binary files a/week2/images/2022-03-29-11-34-07.png and /dev/null differ
diff --git a/week2/images/2022-03-29-11-38-43.png b/week2/images/2022-03-29-11-38-43.png
deleted file mode 100644
index d2f37f7..0000000
Binary files a/week2/images/2022-03-29-11-38-43.png and /dev/null differ
diff --git "a/week2/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/03-1 MAE expain1.png" "b/week2/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/03-1 MAE expain1.png"
new file mode 100644
index 0000000..cce5951
Binary files /dev/null and "b/week2/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/03-1 MAE expain1.png" differ
diff --git "a/week2/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/03-1 R2 explain1.png" "b/week2/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/03-1 R2 explain1.png"
new file mode 100644
index 0000000..ba772e5
Binary files /dev/null and "b/week2/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/03-1 R2 explain1.png" differ
diff --git "a/week2/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/03-1 overunder explain1.png" "b/week2/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/03-1 overunder explain1.png"
new file mode 100644
index 0000000..ac46d3b
Binary files /dev/null and "b/week2/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/03-1 overunder explain1.png" differ
diff --git "a/week2/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/03-1k-NN Regression explain1.png" "b/week2/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/03-1k-NN Regression explain1.png"
new file mode 100644
index 0000000..f784074
Binary files /dev/null and "b/week2/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/03-1k-NN Regression explain1.png" differ
diff --git "a/week2/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/03-2 limit of k-NN Regression.png" "b/week2/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/03-2 limit of k-NN Regression.png"
new file mode 100644
index 0000000..a1036b6
Binary files /dev/null and "b/week2/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/03-2 limit of k-NN Regression.png" differ
diff --git "a/week2/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/03-2 linear regression explain1.png" "b/week2/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/03-2 linear regression explain1.png"
new file mode 100644
index 0000000..c1e6787
Binary files /dev/null and "b/week2/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/03-2 linear regression explain1.png" differ
diff --git "a/week2/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/03-2 linear regression explain2.png" "b/week2/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/03-2 linear regression explain2.png"
new file mode 100644
index 0000000..ac68645
Binary files /dev/null and "b/week2/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/03-2 linear regression explain2.png" differ
diff --git "a/week2/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/03-2 polynomial regression explain1.png" "b/week2/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/03-2 polynomial regression explain1.png"
new file mode 100644
index 0000000..e586b44
Binary files /dev/null and "b/week2/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/03-2 polynomial regression explain1.png" differ
diff --git "a/week2/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/03-3 multiple regression explain1.png" "b/week2/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/03-3 multiple regression explain1.png"
new file mode 100644
index 0000000..1593581
Binary files /dev/null and "b/week2/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/03-3 multiple regression explain1.png" differ
diff --git "a/week3/1\355\214\200_\354\230\244\353\217\231\355\233\210.md" "b/week3/1\355\214\200_\354\230\244\353\217\231\355\233\210.md"
new file mode 100644
index 0000000..bd9e5cb
--- /dev/null
+++ "b/week3/1\355\214\200_\354\230\244\353\217\231\355\233\210.md"
@@ -0,0 +1,212 @@
+# 이론 요약
+## 로지스틱 회귀
+
+- 로지스틱 회귀는 선형 방정식을 통해 학습하는 분류 모델이다.
+> ${z = a*( 특성1 ) + b*( 특성2 ) + ...}$
+- 시그모이드 함수를 통해 z 값을 0 과 1 사이로 만든다.
+- ## 시그모이드 함수 : ${\Phi ={\frac {1}{1+e^-z}}}$
+
+
+## 로지스틱 회귀 다중 분류
+
+- 로지스틱 회귀 함수는 이진 분류일 때 가장 강력한 성능을 발휘한다.
+- 또한, 다중 분류일 때는 시그모이드 함수가 아닌 소프트맥스 함수를 사용한다.
+
+
+## 소프트맥스 함수 : ${ y_i ={\frac {e^{z_i}}{\sum_{i=1}^K e^{z_i}}}}$
+- 소프트맥스 함수는 시그모이드 함수의 일반화 버전이다.
+- k 개의 클래스에 대해 확률을 계산하여 분류할 수 있다.
+
+
+## 손실함수, loss function
+- 어떤 문제에서 머신러닝 알고리즘이 얼마나 부정확한지 측정하는 기준
+- 머신러닝은 손실 함수 결과가 최솟값이 나오도록 모델을 최적화하는 것이 목표가 된다.
+- 로지스틱 손실함수는 '-log(예측확률)' 함수를 사용한다.
+
+
+## 경사하강법
+
+- Z = a*X0 + b*X1 + c*X2 + d 라고 할 때, 적절한 a,b,c,d 값을 찾기위한 최적화 알고리즘이다.
+- 샘플 X = [ X0, X1, X2 ] 라고 하면 Z 는 a,b,c,d 에 대한 함수로 표현 가능하고 이 a,b,c,d 값으 바꿔가면서 경사가 최소값일 때를 찾는 알고리즘이다.
+
+#### 확률적 경사 하강법 (Stochastic gradient descent)
+- 랜덤하게 하나의 샘플을 선택해 경사 하강법을 수행하는 방식
+
+#### 미니 배치 경사 하강법
+- 여러 개의 샘플을 사용해 경사 하강법을 수행하는 방식
+
+#### 배치 경사 하강법
+- 전체 샘플을 사용해 경사 하강법을 수행하는 방식
+
+
+# 혼공머신_예제
+
+## K-최근접 이웃 분류기의 확률 예측
+
+- ['Species'] 를 7개의 클래스로 설정(target_data)
+- 특성 5개: 길이, 높이, 두께, 대각선, 무게 (train_data)
+- train_test_split 으로 훈련 데이터, 테스트 데이터 분리
+- StandardScaler 클래스를 사용해 훈련 세트 및 테스트 세트 표준화 전처리
+
+```python
+import pandas as pd
+fish = pd.read_csv('https://bit.ly/fish_csv_data')
+# unqiue() 함수를 사용해서 어떤 종류의 생선이 있는지 확인
+print(pd.unique(fish['Species']))
+
+>>> ['Bream' 'Roach' 'Whitefish' 'Parkki' 'Perch' 'Pike' 'Smelt']
+
+# input data 설정
+fish_input = fish[['Weight', 'Length', 'Diagonal','Height','Width']].to_numpy()
+
+# target data 설정
+fish_target = fish['Species'].to_numpy()
+
+# 훈련 데이터, 테스트 데이터 분리
+from sklearn.model_selection import train_test_split
+train_input, test_input, train_target, test_target = train_test_split(
+ fish_input, fish_target, random_state=42)
+
+# 표준화 전처리
+from sklearn.preprocessing import StandardScaler
+ss = StandardScaler()
+ss.fit(train_input)
+train_scaled = ss.transform(train_input)
+test_scaled = ss.transform(test_input)
+```
+
+```python
+# 모델 생성 및 훈련
+from sklearn.neighbors import KNeighborsClassifier
+kn = KNeighborsClassifier(n_neighbors=3)
+kn.fit(train_scaled, train_target)
+```
+
+## 로지스틱 회귀로 이진 분류 수행
+
+- 데이터는 '도미'와 '빙어' 데이터를 사용.
+- 시그모이드 함수의 출력 0.5보다 크면 양성 클래스, 0.5와 같거나 작으면 음성 클래스.
+
+```python
+# 전체 데이터에서 boolean indexing 을 통해 도미와 빙어 데이터만 추출
+bream_smelt_indexes = (train_target == 'Bream') | (train_target == 'Smelt')
+train_bream_smelt = train_scaled[bream_smelt_indexes]
+target_bream_smelt = train_target[bream_smelt_indexes]
+
+# 로지스틱 회귀 모델 생성 및 훈련
+from sklearn.linear_model import LogisticRegression
+lr = LogisticRegression()
+lr.fit(train_bream_smelt, target_bream_smelt)
+```
+
+```python
+# 처음 5개 샘플의 클래스를 분류 및 예측 확률 출력
+print(lr.predict(train_bream_smelt[:5]))
+
+>>> ['Bream' 'Smelt' 'Bream' 'Bream' 'Bream']
+
+print(lr.predict_proba(train_bream_smelt[:5]))
+
+>>> [0.99759855 0.00240145]
+ [0.02735183 0.97264817]
+ [0.99486072 0.00513928]
+ [0.98584202 0.01415798]
+ [0.99767269 0.00232731]
+```
+
+## 로지스틱 회귀로 다중 분류 수행하기
+
+- 반복 횟수 (max_iter) = 1000 으로 설정
+- 계수의 제곱을 규제하는 L2 규제 적용
+
+```python
+# 다중 분류 모델 생성 및 훈련
+lr = LogisticRegression(C=20, max_iter=1000)
+lr.fit(train_scaled, train_target)
+```
+
+```python
+# 테스트 세트 처음 5개 샘플에 대한 분류, 예측 확률 출력
+print(lr.predict(test_scaled[:5]))
+
+>>> ['Perch' 'Smelt' 'Pike' 'Roach' 'Perch']
+
+# 예측 확률 출력
+proba = lr.predict_proba(test_scaled[:5])
+print(np.round(proba, decimals=3))
+
+>>> [0. 0.014 0.841 0. 0.136 0.007 0.003]
+ [0. 0.003 0.044 0. 0.007 0.946 0. ]
+ [0. 0. 0.034 0.935 0.015 0.016 0. ]
+ [0.011 0.034 0.306 0.007 0.567 0. 0.076]
+ [0. 0. 0.904 0.002 0.089 0.002 0.001]
+```
+
+```python
+# 처음 샘플 5개에 대한 z 값을 소프트맥스 함수에 통과시키기
+decision = lr.decision_function(test_scaled[:5])
+
+from scipy.special import softmax
+proba = softmax(decision, axis=1) # 열 기준, 행에 대해 소프트맥스 계산.
+print(np.round(proba, decimals=3))
+
+>>> [0. 0.014 0.841 0. 0.136 0.007 0.003]
+ [0. 0.003 0.044 0. 0.007 0.946 0. ]
+ [0. 0. 0.034 0.935 0.015 0.016 0. ]
+ [0.011 0.034 0.306 0.007 0.567 0. 0.076]
+ [0. 0. 0.904 0.002 0.089 0.002 0.001]
+```
+
+## SGDClassifier
+
+- 이진 분류의 경우, 이진 크로스엔트로피 손실 함수
+- 다중 분류의 경우, 크로스엔트로피 손실 함수
+- 경사 하강법 예제 데이터의 경우 앞선 7개 클래스에 대한 데이터를 그대로 사용한다.
+
+```python
+# SGDClassifier 로드
+from sklearn.linear_model import SGDClassifier
+
+# 손실함수: loss='log' 로지스틱, 에포크: max_iter=10
+sc =SGDClassifier(loss='log', max_iter=10, random_state=42)
+sc.fit(train_scaled, train_target)
+
+# score 출력
+print(sc.score(train_scaled, train_target))
+print(sc.score(test_scaled, test_target))
+
+>>> 0.773109243697479 // score 가 다소 낮게 나오는 경향이 있다.
+ 0.775
+```
+
+## epoch와 과대/과소적합
+
+- 확률적 경사 하강법을 사용한 모델은 epoch 횟수에 따라 과대/과소적합 현상이 나타난다.
+- epoch 횟수가 적으면 과소적합이 발생하며, epoch 가 너무 많으면 과대적합이 발생한다.
+- 과대적합이 시작되기 전 훈련을 멈추는 것을 'early stopping' 이라고 한다.
+- 예제에서는 np.unique() 함수로 7개 생선 클래스 목록(=classes) 을 만든다.
+- 과대적합이 발생하는 지점을 찾기 위해 epoch 1회 마다 train_score, test_score를 리스트로 logging 한다.
+- partial_fit() 메서드를 통해 모델을 훈련한다.
+
+```python
+# 모델 생성 및 훈련 준비
+import numpy as np
+sc = SGDClassifier(loss='log', random_state=42)
+train_score = []
+test_score = []
+classes = np.unique(train_target)
+
+# epochs= 300으로 설정하여 훈련
+for _ in range(0,300):
+ sc.partial_fit(train_scaled, train_target, classes=classes)
+ train_score.append(sc.score(train_scaled, train_target)) # train_score logging
+ test_score.append(sc.score(test_scaled, test_target)) # test_score logging
+
+# matplotlib 그래프로 확인
+import matplotlib.pyplot as plt
+plt.plot(train_score)
+plt.plot(test_score)
+plt.xlabel('epoch')
+plt.ylabel('accuracy')
+plt.show()
+```
\ No newline at end of file
diff --git "a/week3/1\355\214\200_\354\235\264\354\204\261\354\247\204.md" "b/week3/1\355\214\200_\354\235\264\354\204\261\354\247\204.md"
new file mode 100644
index 0000000..6da10ed
--- /dev/null
+++ "b/week3/1\355\214\200_\354\235\264\354\204\261\354\247\204.md"
@@ -0,0 +1,569 @@
+# 2022년 3월 31일 HAI 혼공머신 스터디 1조 발표
+### 발표자: 송종명
+
+## __Contents__
+### Chapter 4
+- 로지스틱 회귀
+- 로지스틱 회귀를 이용한 다중분류
+- 시그모이드 함수
+- 소프트맥스 함수
+- 경사 하강법
+
+
+
+## Chapter 4
+### 로지스틱 회귀
+- 로지스틱 회귀는 선형 방정식을 활용해 학습하는 분류 모델입니다.
+- 학습된 데이터를 바탕으로 새로운 데이터가 목표하는 클래스에 속하는지 아닌지를 시그모이드(sigmoid)함수를 활용하여 0~1 사이의 확률로 나타냅니다.
+
+### 로지스틱 회귀를 이용한 다중분류
+- 로지스틱 회귀는 이진 분류 문제를 해결할 때 성능이 가장 좋습니다.
+- 그래서 다중 분류 문제를 해결하기 위해서 이진 분류를 여러 번 하는 방식으로 계산합니다.
+- 다중분류일 때의 예측 결과는 단순 확률로 나타내기 어려우므로 확률분포를 만들어내는 소프트맥스 함수를 사용합니다.
+
+### 시그모이드 함수
+- 시그모이드 함수는 로짓(logit) 함수의 역함수입니다.
+- 로짓 함수는 두 확률의 확률비(odds)에 로그를 취한 함수를 말합니다.
+
+### 소프트맥스 함수
+- 소프트맥스 함수는 시그모이드 함수를 바이너리가 아닌 N에 대해서 확장한 함수입니다.
+- odds 함수를 클래스 개수가 K개일때로 일반화 한 뒤 양 변을 i=1 부터 i=k-1 까지 더하고 이 식을 P(Ck|X)에 대해 정리하면 소프트맥스 함수를 얻을 수 있습니다.
+- 소프트맥스 함수는 N개의 클래스에 속할 확률들을 나타내는 확률분포를 만들게 됩니다.
+
+### 경사 하강법
+- 경사 하강법은 각 파라미터들의 적절한 가중치를 찾기 위한 최적화 알고리즘입니다.
+- Z = A * x + B * y + C * z + D 라고 가정했을 때 파라미터 x, y, z 에 대한 가중치 A, B, C, D를 바꾸어가며 경사가 0이 되는 부분을 찾는 알고리즘입니다.
+- 이때 파라미터를 한 개만 사용할 경우 확률적 경사 하강법, 모든 X에 대해서 경사의 평균을 구하면 배치 경사 하강법, N개의 파라미터에 대해 평균을 내면 미니 배치 경사 하강법이라고 합니다.
+
+
+### __아래는 이번주 발표자분이 작성한 프로그램 실행 과정입니다.__
+
+
+
+
+# 로지스틱 회귀
+
+## 럭키백의 확률
+
+### 데이터 준비하기
+
+
+```python
+import pandas as pd
+
+fish = pd.read_csv('https://bit.ly/fish_csv_data')
+fish.head()
+```
+
+
+
+
+
+
+
+
+
+ |
+ Species |
+ Weight |
+ Length |
+ Diagonal |
+ Height |
+ Width |
+
+
+
+
+ | 0 |
+ Bream |
+ 242.0 |
+ 25.4 |
+ 30.0 |
+ 11.5200 |
+ 4.0200 |
+
+
+ | 1 |
+ Bream |
+ 290.0 |
+ 26.3 |
+ 31.2 |
+ 12.4800 |
+ 4.3056 |
+
+
+ | 2 |
+ Bream |
+ 340.0 |
+ 26.5 |
+ 31.1 |
+ 12.3778 |
+ 4.6961 |
+
+
+ | 3 |
+ Bream |
+ 363.0 |
+ 29.0 |
+ 33.5 |
+ 12.7300 |
+ 4.4555 |
+
+
+ | 4 |
+ Bream |
+ 430.0 |
+ 29.0 |
+ 34.0 |
+ 12.4440 |
+ 5.1340 |
+
+
+
+
+
+# 확률적 경사 하강법
+
+## SGDClassifier
+
+
+```python
+import pandas as pd
+
+fish = pd.read_csv('https://bit.ly/fish_csv_data')
+```
+
+
+```python
+fish_input = fish[['Weight','Length','Diagonal','Height','Width']].to_numpy()
+fish_target = fish['Species'].to_numpy()
+```
+
+
+```python
+from sklearn.model_selection import train_test_split
+
+train_input, test_input, train_target, test_target = train_test_split(
+ fish_input, fish_target, random_state=42)
+```
+
+
+```python
+from sklearn.preprocessing import StandardScaler
+
+ss = StandardScaler()
+ss.fit(train_input)
+train_scaled = ss.transform(train_input)
+test_scaled = ss.transform(test_input)
+```
+
+
+```python
+from sklearn.linear_model import SGDClassifier
+```
+
+
+```python
+sc = SGDClassifier(loss='log', max_iter=10, random_state=42)
+sc.fit(train_scaled, train_target)
+
+print(sc.score(train_scaled, train_target))
+print(sc.score(test_scaled, test_target))
+```
+
+ 0.773109243697479
+ 0.775
+
+
+ /mnt/disks/sdb/github/hg-mldl/.env/lib/python3.7/site-packages/sklearn/linear_model/_stochastic_gradient.py:700: ConvergenceWarning: Maximum number of iteration reached before convergence. Consider increasing max_iter to improve the fit.
+ ConvergenceWarning,
+
+
+
+```python
+sc.partial_fit(train_scaled, train_target)
+
+print(sc.score(train_scaled, train_target))
+print(sc.score(test_scaled, test_target))
+```
+
+ 0.8151260504201681
+ 0.85
+
+
+## 에포크와 과대/과소적합
+
+
+```python
+import numpy as np
+
+sc = SGDClassifier(loss='log', random_state=42)
+
+train_score = []
+test_score = []
+
+classes = np.unique(train_target)
+```
+
+
+```python
+for _ in range(0, 300):
+ sc.partial_fit(train_scaled, train_target, classes=classes)
+
+ train_score.append(sc.score(train_scaled, train_target))
+ test_score.append(sc.score(test_scaled, test_target))
+```
+
+
+```python
+import matplotlib.pyplot as plt
+
+plt.plot(train_score)
+plt.plot(test_score)
+plt.xlabel('epoch')
+plt.ylabel('accuracy')
+plt.show()
+```
+
+
+
+
+
+
+
+
+```python
+sc = SGDClassifier(loss='log', max_iter=100, tol=None, random_state=42)
+sc.fit(train_scaled, train_target)
+
+print(sc.score(train_scaled, train_target))
+print(sc.score(test_scaled, test_target))
+```
+
+ 0.957983193277311
+ 0.925
+
+
+
+```python
+sc = SGDClassifier(loss='hinge', max_iter=100, tol=None, random_state=42)
+sc.fit(train_scaled, train_target)
+
+print(sc.score(train_scaled, train_target))
+print(sc.score(test_scaled, test_target))
+```
+
+ 0.9495798319327731
+ 0.925
+
+
diff --git "a/week3/1\355\214\200_\354\236\204\354\240\225\354\204\255.md" "b/week3/1\355\214\200_\354\236\204\354\240\225\354\204\255.md"
new file mode 100644
index 0000000..d19321e
--- /dev/null
+++ "b/week3/1\355\214\200_\354\236\204\354\240\225\354\204\255.md"
@@ -0,0 +1,395 @@
+---
+
+## 로지스틱 회귀
+
+### 1\. 로지스틱 회귀란?
+
+선형 방정식을 사용한 분류 알고리즘이다. 선형 회귀와 달리 시그모이드 함수나 소프트맥스 함수를 사용하여 클래스 확률을 출력할 수 있다.
+
+#### 시그모이드 함수
+
+
+선형 방정식의 출력을 0~1 사이의 값으로 압축한다. z가 음의 무한으로 갈 수록 0에 가까워지고 양의 무한으로 갈 때 1에 가까워진다. 이는 이진 분류를 위해 사용한다.
+
+#### 소프트맥스 함수
+
+
+다중 분류에서 여러 선형 방정식의 출력 결과를 정규화하여 합이 1이 되도록 만든다.
+
+---
+
+### 2\. 로지스틱 회귀 예제 데이터 준비
+
+#### 데이터 불러오기
+
+```
+import pandas as pd
+
+fish = pd.read_csv('https://bit.ly/fish_csv_data')
+fish.head()
+# DF -> ndarray
+fish_input = fish[['Weight','Length','Diagonal','Height','Width']].to_numpy()
+fish_target = fish['Species'].to_numpy()
+```
+
+#### 고유값 확인하기
+
+unique() 메서드를 통해 특정 속성의 고유 값을 찾아보자.
+
+```
+print(pd.unique(fish['Species']))
+```
+
+이번 예제에서는 물고기 종(Species)의 고유 값을 출력했다.
+
+#### 데이터 셋 준비
+
+```
+from sklearn.model_selection import train_test_split
+
+train_input, test_input, train_target, test_target = train_test_split(
+ fish_input, fish_target, random_state=42)
+
+print(train_input.shape) #(119, 5)
+print(test_input.shape) #(40, 5)
+```
+
+#### 데이터 전처리
+
+```
+from sklearn.preprocessing import StandardScaler
+
+ss = StandardScaler()
+ss.fit(train_input)
+train_scaled = ss.transform(train_input)
+test_scaled = ss.transform(test_input)
+```
+
+---
+
+### 3\. k-최근접 이웃 분류기 확률 예측
+
+```
+from sklearn.neighbors import KNeighborsClassifier
+
+kn = KNeighborsClassifier(n_neighbors=3)
+kn.fit(train_scaled, train_target)
+
+print(kn.score(train_scaled, train_target))
+print(kn.score(test_scaled, test_target))
+
+# 분류 값 확인
+print(kn.classes_)
+"""
+['Bream' 'Parkki' 'Perch' 'Pike' 'Roach' 'Smelt' 'Whitefish']
+"""
+
+#테스트 데이터 5개 예측
+print(kn.predict(test_scaled[:5]))
+"""
+['Perch' 'Smelt' 'Pike' 'Perch' 'Perch']
+"""
+```
+
+#### 클래스별 확률 확인
+
+predict\_proba 메서드를 이용해서 각 샘플의 클래스별 확률을 확인할 수 있다.
+
+```
+import numpy as np
+
+proba = kn.predict_proba(test_scaled[:5])
+print(proba)
+#round(): 반올림 함수, deciamls 매개변수로 원하는 소수점까지 출력 가능
+print(np.round(proba, decimals=4))
+```
+
+#### 최근접 이웃 클래스 확인
+
+4번째 샘플의 최근접 이웃 클래스를 확인해보자.
+
+```
+distances, indexes = kn.kneighbors(test_scaled[3:4])
+print(train_target[indexes])
+"""
+[['Roach' 'Perch' 'Perch']]
+"""
+```
+
+---
+
+### 4\. 로지스틱 회귀
+
+#### 시그모이드 함수 그리기
+
+```
+import numpy as np
+import matplotlib.pyplot as plt
+
+z = np.arange(-5, 5, 0.1)
+phi = 1 / (1 + np.exp(-z))
+
+plt.plot(z, phi)
+plt.xlabel('z')
+plt.ylabel('phi')
+plt.show()
+```
+
+#### 로지스틱 회귀로 이진 분류
+
+불리언 인덱싱으로 Bream , Smelt 종만의 데이터를 불러오자.
+
+```
+# boolean indexing
+char_arr = np.array(['A', 'B', 'C', 'D', 'E'])
+print(char_arr[[True, False, True, False, False]]) # ['A' 'C']
+
+# boolean array
+bream_smelt_indexes = (train_target == 'Bream') | (train_target == 'Smelt')
+
+#boolean indexing
+train_bream_smelt = train_scaled[bream_smelt_indexes]
+target_bream_smelt = train_target[bream_smelt_indexes]
+```
+
+위 데이터를 바탕으로 로지스틱 회귀 훈련을 진행해보자.
+
+```
+from sklearn.linear_model import LogisticRegression
+
+lr = LogisticRegression()
+lr.fit(train_bream_smelt, target_bream_smelt)
+
+# 예측
+print(lr.predict(train_bream_smelt[:5]))
+"""
+['Bream' 'Smelt' 'Bream' 'Bream' 'Bream']
+"""
+print(lr.predict_proba(train_bream_smelt[:5]))
+"""
+[[0.99759855 0.00240145]
+ [0.02735183 0.97264817]
+ [0.99486072 0.00513928]
+ [0.98584202 0.01415798]
+ [0.99767269 0.00232731]]
+"""
+print(lr.classes_)
+"""
+['Bream' 'Smelt']
+"""
+# 가중치 구하기(계수, 기울기)
+print(lr.coef_, lr.intercept_)
+"""
+[[-0.4037798 -0.57620209 -0.66280298 -1.01290277 -0.73168947]] [-2.16155132]
+"""
+```
+
+위 계수로 z 값을 구한 뒤 시그모이드 함수에 대입해 확률을 구해보자.
+
+decision\_function()으로 z값을 구할 수 있다.
+
+```
+decisions = lr.decision_function(train_bream_smelt[:5])
+print(decisions
+"""
+[-6.02927744 3.57123907 -5.26568906 -4.24321775 -6.0607117 ]
+"""
+```
+
+scipy의 expit() 으로 시그모이드 함수에 z값을 대입해보자.
+
+```
+from scipy.special import expit
+
+print(expit(decisions))
+"""
+[0.00240145 0.97264817 0.00513928 0.01415798 0.00232731]
+"""
+```
+
+---
+
+#### 로지스틱 회귀로 다중 분류하기
+
+다중분류는 타깃 클래스가 2개 이상인 분류이다. 로지스틱 회귀는 다중 분류를 위해 소프트맥스 함수를 사용한다.
+
+C 값과 max\_iter 매개변수를 통해 규제 정도를 정할 수 있다.
+
+```
+lr = LogisticRegression(C=20, max_iter=1000)
+lr.fit(train_scaled, train_target)
+
+#과대적합 / 과소적합 확인
+print(lr.score(train_scaled, train_target))
+print(lr.score(test_scaled, test_target))
+
+# 테스트 샘플 확인
+print(lr.predict(test_scaled[:5]))
+"""
+['Perch' 'Smelt' 'Pike' 'Roach' 'Perch']
+"""
+
+# 클래스 확인
+print(lr.classes_) # ['Bream' 'Parkki' 'Perch' 'Pike' 'Roach' 'Smelt' 'Whitefish']
+
+# 테스트 샘플 확률 확인 (각 클래스별 확률 확인)
+proba = lr.predict_proba(test_scaled[:5])
+print(np.round(proba, decimals=3))
+"""
+[[0. 0.014 0.841 0. 0.136 0.007 0.003]
+ [0. 0.003 0.044 0. 0.007 0.946 0. ]
+ [0. 0. 0.034 0.935 0.015 0.016 0. ]
+ [0.011 0.034 0.306 0.007 0.567 0. 0.076]
+ [0. 0. 0.904 0.002 0.089 0.002 0.001]]
+"""
+
+# 가중치 확인
+print(lr.coef_.shape, lr.intercept_.shape)
+print(lr.coef_, lr.intercept_)
+"""
+(7, 5) (7,)
+[[-1.49002087 -1.02912886 2.59345551 7.70357682 -1.2007011 ]
+ [ 0.19618235 -2.01068181 -3.77976834 6.50491489 -1.99482722]
+ [ 3.56279745 6.34357182 -8.48971143 -5.75757348 3.79307308]
+ [-0.10458098 3.60319431 3.93067812 -3.61736674 -1.75069691]
+ [-1.40061442 -6.07503434 5.25969314 -0.87220069 1.86043659]
+ [-1.38526214 1.49214574 1.39226167 -5.67734118 -4.40097523]
+ [ 0.62149861 -2.32406685 -0.90660867 1.71599038 3.6936908 ]] [-0.09205179 -0.26290885 3.25101327 -0.14742956 2.65498283 -6.78782948
+ 1.38422358]
+"""
+
+# z 값 -> 소프트맥스 함수 대입해서 확률 구하기 (predict_proba 와 기능 동일)
+decision = lr.decision_function(test_scaled[:5])
+print(np.round(decision, decimals=2))
+
+from scipy.special import softmax
+
+proba = softmax(decision, axis=1)
+print(np.round(proba, decimals=3))
+"""
+[[0. 0.014 0.841 0. 0.136 0.007 0.003]
+ [0. 0.003 0.044 0. 0.007 0.946 0. ]
+ [0. 0. 0.034 0.935 0.015 0.016 0. ]
+ [0.011 0.034 0.306 0.007 0.567 0. 0.076]
+ [0. 0. 0.904 0.002 0.089 0.002 0.001]]
+"""
+```
+
+---
+
+### **참고 자료**
+
+**\[혼자 공부하는 머신러닝 + 딥러닝 4-1.ipynb\] : [https://colab.research.google.com/github/rickiepark/hg-mldl/blob/master/4-1.ipynb](https://colab.research.google.com/github/rickiepark/hg-mldl/blob/master/4-1.ipynb)**
+
+---
+
+## 확률적 강사 하강법
+
+### 1\. 확률적 강사 하강법이란?
+
+훈련 세트에서 샘플 하나씩 꺼내 손실 함수의 경사를 따라 최적의 모델을 찾는 알고리즘이다. 샘플을 하나씩 사용하지 않고 여러 개를 사용하면 미니배치 경사 하강법이 된다. 한 번에 전체 샘플을 사용하면 배치 경사 하강법이 된다.
+
+#### 이전 방법들과의 차이는?
+
+앞에서 배운 방법들은 이전에 훈련한 모델을 버리고 다시 새로운 모델을 훈련하는 방식이다. 만약 매번 데이터가 늘어나는 상황이라면 매번 새로운 모델을 만들어야 하는 것이다. 그래서 앞서 만든 모델에 새로운 훈련 데이터만 추가로 훈련하여 추가할 수 있는 방법을 **점진적 학습**이라고 한다.
+
+#### 손실 함수
+
+손실함수는 어떤 문제에서 머신러닝 알고리즘이 얼마나 엉터리인지를 측정하는 기준이다. 이는 확률적 강사 하강법이 최적화할 대상이다. 대부분의 문제에 잘 맞는 손실 함수가 이미 정의되어 있다. 이진 분류에는 로지스틱 회귀 손실 함수를 사용한다. 다중 분류에는 크로스엔트로피 손실 함수를 사용한다. 회귀 문제에서는 mse를 사용한다. 손실 함수에서도 로지스틱 회귀(시그모이드, 소프트맥스)에서 처럼 연속적인 값을 얻는 방법이 있다. 대표적으로 로지스틱 손실 함수, 크로스엔트로피 손실 함수 등이 있다.
+
+---
+
+### 2\. 확률적 강사 하강법 예제
+
+#### 데이터 불러오기 , 셋 분리, 전처리
+
+```
+import pandas as pd
+from sklearn.model_selection import train_test_split
+from sklearn.preprocessing import StandardScaler
+
+fish = pd.read_csv('https://bit.ly/fish_csv_data')
+fish_input = fish[['Weight','Length','Diagonal','Height','Width']].to_numpy()
+fish_target = fish['Species'].to_numpy()
+
+train_input, test_input, train_target, test_target = train_test_split(
+ fish_input, fish_target, random_state=42)
+
+ss = StandardScaler()
+ss.fit(train_input)
+train_scaled = ss.transform(train_input)
+test_scaled = ss.transform(test_input)
+```
+
+#### SGDClassifier
+
+SGDClassifier 객체를 만들 때는 2개의 매개변수(loss, max\_iter)를 넘겨준다. loss 는 손실함수 종류, max\_iter 는 에포크(전체 샘플을 모두 사용한 횟수) 횟수를 지정한다. loss 값으로는 hinge(default), svm 등 다양한 머신 러닝 알고리즘을 지원한다.
+
+```
+from sklearn.linear_model import SGDClassifier
+#loss = log -> 로지스틱 손실 함수
+sc = SGDClassifier(loss='log', max_iter=10, random_state=42)
+sc.fit(train_scaled, train_target)
+
+print(sc.score(train_scaled, train_target))
+print(sc.score(test_scaled, test_target))
+"""
+0.773109243697479
+0.775
+"""
+```
+
+#### 추가 훈련
+
+모델을 새로 만들지 않고 이어서 훈련할 때는 partial\_fit() 을 이용한다.
+
+```
+sc.partial_fit(train_scaled, train_target)
+
+print(sc.score(train_scaled, train_target))
+print(sc.score(test_scaled, test_target))
+"""
+0.8151260504201681
+0.85
+"""
+```
+
+정확도가 향상된 것을 확인할 수 있다. 따라서 모델을 여러 에포크에서 훈련할 필요성이 있다.
+
+#### 에포크 과대/과소적합
+
+에포크를 계속해서 진행할수록 과대적합이 일어날 것이다. 이를 그래프로 확인해보자.
+
+```
+import numpy as np
+import matplotlib.pyplot as plt
+
+
+sc = SGDClassifier(loss='log', random_state=42)
+
+train_score = []
+test_score = []
+
+classes = np.unique(train_target)
+
+#에포크 횟수 0~299
+for _ in range(0, 300):
+ sc.partial_fit(train_scaled, train_target, classes=classes)
+
+ train_score.append(sc.score(train_scaled, train_target))
+ test_score.append(sc.score(test_scaled, test_target))
+
+plt.plot(train_score)
+plt.plot(test_score)
+plt.xlabel('epoch')
+plt.ylabel('accuracy')
+plt.show()
+```
+
+과대적합이 시작하기 전에 훈련을 멈추는 것을 조기 종료라 한다. SGDClassifier는 일정 에포크 동안 성능이 향상되지 않으면 더 훈련하지 않고 자동으로 멈춘다.
+
+---
+
+### **참고 자료**
+
+**\[혼자 공부하는 머신러닝 + 딥러닝 4.2.ipynb\] : [https://colab.research.google.com/github/rickiepark/hg-mldl/blob/master/4-2.ipynb](https://colab.research.google.com/github/rickiepark/hg-mldl/blob/master/4-2.ipynb)**
\ No newline at end of file
diff --git "a/week3/3\354\243\274\354\260\250_\354\204\234\355\230\204\353\271\210.md" "b/week3/3\354\243\274\354\260\250_\354\204\234\355\230\204\353\271\210.md"
new file mode 100644
index 0000000..46c3d15
--- /dev/null
+++ "b/week3/3\354\243\274\354\260\250_\354\204\234\355\230\204\353\271\210.md"
@@ -0,0 +1,56 @@
+
+# Ch4 스터디
+
+###4-1. 로지스틱 회귀
+* K-최근접 이웃을 통한 확률 계산
+> - K-최근접 이웃 분류기로 클래스 비율을 통해 확률을 계산할 수 있다.
+> - 타깃 데이터에 2개 이상의 클래스가 포함된 문제인 '다중분류' 문제가 더 복잡해 질수록 확률이 어색해진다.
+* 로지스틱 회귀 : 선형방정식을 학습하는 분류 모델.
+
+ 사이킷런의 LogisticRegression 클래스를 사용한다.
+ > - max_iter : 반복 횟수를 지정해준다. 횟수가 적으면 경고가 발생한다.
+ > - C : 계수의 제곱을 얼마나 규제할 지를 지정해준다. 이를 L2규제라고 하며, 릿지 회귀에서의 alpha 매개변수와 비슷한 역할이다.
+ 값이 작을 수록 규제가 커진다.
+> - lf.coef_, lr.interceot로 로지스틱 회귀 모델이 학습한 방정식을 알 수 있다.
+
+* 불리언 인덱싱 : 넘파이 배열에 True, False 값을 전달하여 원하는 행만을 선택할 수 있다.
+
+* 로지스틱 회귀로 이진 분류하기 :
+
+ 확률을 나타내기 위해, 값을 0~1 사이의 값으로 바꾸어주는 시그모이드 함수(로지스틱 함수)를 사용한다.
+$$f(x) = {1 \over 1+e^{-z}}$$
+z가 무한하게 큰 음수일 경우 0에 가까워지고, z가 무한하게 큰 양수가 될 때는 1에 가까워진다. 함수의 출력이 0.5보다 크면 양성 클래스, 작으면 음성 클래스이다.
+
+* 로지스틱 회귀로 다중 분류하기 :
+
+ 다중분류는 클래스마다 결과값을 하나씩 계산한다. 이 때 소프트맥스 함수를 사용한다. 소프트맥스 함수는 여러 개의 선형 방정식의 출력값을 0~1로 압축하고, 전체의 합이 1이 되도록 한다.
+
+###4-2. 확률적 경사 하강법
+새로운 데이터가 계속해서 전달되는 경우, 데이터가 늘어날수록 훈련에 필요한 자원이 매우 늘어나고, 이전 데이터를 버린다면 중요한 데이터를 버릴 가능성도 있다.
+
+새로운 데이터에 대해서만 조금씩 더 훈련하는 방법을 점진적 학습이라고 하고, 대표적으로 확률적 경사 하강법이 있다.
+
+* 경사 하강법 :
+
+ 가장 가파른 길을 찾아 조금씩 내려와 원하는 지점에 도달하는 것이 목표이다. 이 때 가장 가파른 길은 훈련 세트에서 랜덤하게 하나의 샘플을 선택하여 찾는다.
+
+ > - 에포크 : 샘플을 하나하나 선택하면서 내려오다 훈련세트를 다 사용하게 되었을 때, 샘플을 다시 채워넣고 경사를 내려가는 사이클
+ > - 미니배치 경사 하강법 : 샘플을 한 번에 여러 개 선택하는 것
+ 것
+ > - 배치 경사 하강법 : 전체 데이터를 샘플로 사용하는 것
+
+* 손실 함수 : 경사 하강법에서 내려오는 길이 되는 함수이다.
+
+ 머신러닝 알고리즘이 얼마나 엉터리인지를 측정하는 기준이며, 값이 작을수록 좋다.
+ 비연속적인 값들을 연속적이게 만들어주어야(미분이 가능해야) 값을 하강시키면서 찾을 수 있다.
+
+ > - 로지스틱 손실 함수(이진 크로스엔트로피 손실 함수) : 샘플의 예측값을 양성 클래스와 음성 클래스로 구분하여 각각 -log를 씌워 연속적으로 만들어준다.
+ > - 크로스엔트로피 손실 함수 : 다중 분류에서 사용하는 손실 함수
+ > - 회귀에서는 평균 제곱 오차를 사용한다.
+
+* 에포크와 과대/과소 적합
+
+ 적은 에포크 횟수로 훈련한 모델은 과소적합, 많은 에포크 횟수로 훈련한 모델은 과대적합된 모델일 가능성이 높다.
+ > - 조기 종료 : 과대적합이 시작하기 전에 훈련을 멈추는 것.
+
+
diff --git "a/week3/3\354\243\274\354\260\250_\354\236\245\354\204\234\354\227\260.md" "b/week3/3\354\243\274\354\260\250_\354\236\245\354\204\234\354\227\260.md"
new file mode 100644
index 0000000..e292270
--- /dev/null
+++ "b/week3/3\354\243\274\354\260\250_\354\236\245\354\204\234\354\227\260.md"
@@ -0,0 +1,55 @@
+# k-최근접 이웃 회귀
+## 구현
+* 데이터 불러오기: pd.read_csv()
+* 넘파이로 변환: .to_numpy()
+* 데이터 분리하기: train_test_split()
+* 데이터 표준화: StandardScaler()
+* 모델 만들기: KneighborsClassfier()
+
+
+# 로지스틱 회귀
+## 로지스틱 함수
+$y=1/(1+e^(-x)) (x∈R, 0>> 과소 적합
+ * 에포크 횟수가 많음 >>> 과대 적합, 조기 종료를 통해 과대적합 방지
+## 미니배치 경사 하강법
+* 샘플을 하나씩 사용하지 않고 여러 개를 사용
+## 배치 경사 하강법
+* 한 번에 전체 샘플을 사용
+
+
+# 손실함수
+## 로지스틱 손실 함수
+* 타깃이 양성 클래스인 경우 >> -log(p) (p: 예측 확률)
+* 타깃이 음성 클래스인 경우 >> -log(1-p)
+* 이진 분류: 이진 크로스엔트로피 손실 함수,
+* 다중 분류: 크로스엔트로피 손실 함수
+## 평균 제곱/절댓값 오차
+* 평균 절댓값 오차: 타깃에서 예측을 뺀 절댓값을 모든 샘플에 평균한 값
+* 평균 제곱 오차: 타깃에서 뺸 값을 제곱한 다음 모든 샘플에 평균한 값
+ * 회귀 문제에서 많이 사용
+## 힌지
+* SGDClassifier() 함수 loss 매개변수의 기본값
+* (SGDClassifier(loss, max_iter, random_state)
+ * loss = ‘log’인 경우 로지스틱 회귀
+ * max_iter = epoch 횟수)
\ No newline at end of file
diff --git "a/week3/3\354\243\274\354\260\250_\354\236\245\354\244\200\354\230\244.md" "b/week3/3\354\243\274\354\260\250_\354\236\245\354\244\200\354\230\244.md"
new file mode 100644
index 0000000..4556442
--- /dev/null
+++ "b/week3/3\354\243\274\354\260\250_\354\236\245\354\244\200\354\230\244.md"
@@ -0,0 +1,33 @@
+
+## ▷ 다양한 분류 알고리즘
+* * *
+### ▶ 로지스틱 회귀
+> 이름은 회귀이지만 분류 모델입니다.
+> ex) z = a × (Weight) + b × (Length) + c × (Diagonal) + d × (Height) + e × (Width) + f, a, b, c, d, e는 가중치이며 다중 회귀를 위한 선형 방정식과 동일합니다. 여기서 z의 값은 무관하나 확률이 되려면 0~1 또는 0~100%가 되어야합니다. 이를 도와주는 것이 시그모이드 함수입니다.
+> #### ▶ 시그모이드 함수
+> > 시그모이드 함수는 다음과 같이 계산합니다. φ = 1/ 1+ e^(−z) 이 함수는 z값이 양의 무한대에 가까울수록 1에, 음의 무한대에 가까울수록 0에 수렴하게 됩니다. 아쉽게도 이중분류만 가능한 시그모이드 함수 다중 분류는 어떻게 함수를 이용할까요?
+> #### ▶ 소프트맥스 함수
+> > 소프트맥스 함수는 여러 개의 선 형 방정식의 출력값을 0~1 사이로 압축하고 전체 합이 1이 되도록 만드는 함수를 말합니다.
+### ▶ 확률적 경사 하강법
+> 하나의 샘플을 훈련 세트에서 랜덤하게 골라 가장 가파른 길을 찾는 방법을 말합니다.
+> #### ▶ 에포크
+> > 훈련 세트를 한 번 모두 사용하는 과정을 말합니다.
+> 다시 돌아가서 훈련 세트가 너무 많다면 에포크가 너무 커질 수 있습니다. 이럴 땐 하나의 샘플이 아닌 여러 개의 샘플을 이용하는 것이 좋습니다.
+> #### ▶ 미니 배치 경사 하강법
+> > 여러 개의 샘플을 이용하여 경사 하강법을 수행하는 방법입니다.
+> #### ▶ 배치 경사 하강법
+> > 모든 샘플을 이용하여 경사 하강법을 수행하는 방법입니다.
+### ▶ 손실함수
+> 어떤 문제에서 머신러닝 알고리즘이 얼마나 엉터리인지를 측정하는 기준입니다.
+> #### ▶ 로지스틱 손실 함수
+> > 양성 클래스(타깃 = 1)일 때 손실을 -log(예측 확률)로 계산하고 음성 클래스(타깃 = 0)일 때 손실은 -log(1-예측 확률)로 계산하는 함수입니다.
+> > 다른 이름으로는 이진 크로스엔트로피 손실 함수라고도 합니다.
+> > 이름 처럼 다중 분류에서는 크로스엔트로피 손실 함수를 사용할 수 있습니다.
+
+> 결정계수는 R^2 = 1 - { (타깃 - 예측)^2의 합 / (타깃 - 평균)^2의 합 }으로 계산합니다. 즉, 1에 가까울수록 예측이 타겟에 가깝다고 해석할 수 있습니다.
+### ▶ 에포크 과대적합과 과소적합
+> 에포크 횟수가 너무 적으면 과소적합, 많으면 과대적합이 일어날 수 있습니다. 이런 일을 방지하고자 모델을 조기 종료합니다.
+> #### ▶ 조기 종료
+> > 훈련 세트 점수는 에포크가 진행될수록 꾸준히 증가하지만 테스트 세트 점수는 어느 순간 감소하기 시작합니다. 바로 이 지점 이 모델이 과대적합되기 시작하는 곳입니다. 따라서 이렇게 과대적합이 시작하기 전에 훈련을 멈추는 것을 말합니다.
+
+
diff --git "a/week3/3\355\214\200_\352\271\200\353\217\231\354\227\260.md" "b/week3/3\355\214\200_\352\271\200\353\217\231\354\227\260.md"
new file mode 100644
index 0000000..74d91b7
--- /dev/null
+++ "b/week3/3\355\214\200_\352\271\200\353\217\231\354\227\260.md"
@@ -0,0 +1,43 @@
+# 04 다양한 분류 알고리즘
+> 럭키백의 확률 계산하기
+---
+## 4-1 로지스틱 회귀
+
+
+### 로지스틱 회귀 (*logistic regression*)
+ **로지스틱 회귀**는 이름은 회귀이지만 분류 모델이다. 이 알고리즘은 선형 회귀와 동일하게 다음과 같은 선형 방정식을 학습한다.
+ $z = a × (weight) + b × (length) + c ×(height)$
+
+ 여기서 $a, b, c$는 가중치 혹은 계수이다. 하지만 $z$는 실수의 값을 가지고 이것이 확률이 되려면 0\~1의 값을 가져야 한다. 따라서 z를 **시그모이드 함수** (*sigmoid function*)로 변환하여 확률값을 얻는다.
+ $$ϕ = \frac{1}{1+\frac{1}{z}}$$
+ $z$가 무한하게 큰 음수일 경우 이 함수는 0에 가까워지고, $z$가 무한하게 큰 양수일 때는 1에 가까워지므로 0\~1사이의 값을 얻을 수 있다.
+
+ 로지스틱 회귀를 사용하여 다중분류를 할 수도 있다.
+ 각 클래스마다 $z$값을 구한 후 **소프트맥스**(*softmax*)함수를 사용하여 7개의 $z$값을 총합이 1인 확률로 변환한다.
+
+
+## 4-2 확률적 경사 하강법
+
+
+### 점진적 학습
+ 훈련 데이터가 한번에 준비되는 것이 아닌 조금씩 전달될 때, 앞서 훈련한 모델을 버리지 않고 새로운 데이터에 대해서만 조금씩 더 훈련하는 방식을 **점진적 학습**또는 온라인 학습이라고 한다.
+
+
+### 확률적 경사 하강법 (*Stochastic Gradient Descent*)
+**확률적 경사 하강법**은 대표적인 점진적 학습 알고리즘이다.
+확률적 경사 하강법에서 경사 하강법은 모델이 얼마나 엉터리인지 판단하는 기준인 **손실 함수**(*loss function*)라 하는 수치를 줄이는 방향으로 학습한다는 의미이다. 또한 확률적이란 말은 '무작위하게'라는 의미를 포함하여, 확률적 경사 하강법은 훈련을 할 때 전체 샘플을 사용하지 않고 딱 하나의 샘플을 훈련 세트에서 랜덤하게 골라 손실 함수가 줄어드는 가장 가파른 길을 찾는 방식으로 훈련을 진행한다.
+이때 전체 훈련 세트를 한 번 모두 사용하는 과정을 **에포크**(*epoch*)라 하고 경사 하강법은 일반적으로 수십, 수백 번 이상 에포크를 수행한다.
+
+1개씩 말고 무작위로 여러개의 샘플을 사용해 경사 하강법을 수행하는 방식을 **미니배치 경사 하강법**(*minibatch gradient descent*)라 하고, 한 번에 전체 샘플을 사용하는 방법을 **배치 경사 하강법**(*batch gradient descent*)라 한다.
+
+
+이진 분류에서 사용하는 손실 함수를 **로지스틱 손실 함수**(*logistic loss function*) 또는 **이진 크로스엔트로피 손실 함수**(*binary cross-entropy loss function*)이라 하고, 다중 분류에서 사용하는 손실 함수를 **크로스엔트로피 손실 함수**라고 한다.
+
+
+### 에포크와 과대/과소적합
+경사 하강법을 사용한 모델은 에포크 횟수에 따라 과소적합이나 과대적합이 될 수 있다.
+에포크 횟수가 적으면 모델이 조금밖에 훈련하지 않아 훈련 세트와 테스트 세트에 잘 맞지 않는 과소적합된 모델이 될 가능성이 높고, 에포크 횟수가 너무 많으면 훈련 세트에 너무 잘 맞아 테스트 세트에는 정확도가 낮은 과대적합된 모델이 될 가능성이 높다.
+
+에포크가 진행됨에 따라 훈련 세트 점수는 꾸준히 증가하지만 테스트 세트 점수는 어느 순간 감소하기 시작하는데, 이 과대적합이 시작하는 지점 전에 훈련을 멈추는 것을 **조기종료**(*early stopping*)라고 한다.
+
+사이킷런에서 제공하는 **SGDClassifier** 모델은 *tol* 매개변수 값을 따라 일정 에포크 동안 성능이 향상되지 않으면 더 훈련하지 않고 자동으로 훈련을 종료한다.
\ No newline at end of file
diff --git "a/week3/3\355\214\200_\354\235\264\354\236\254\355\235\240.md" "b/week3/3\355\214\200_\354\235\264\354\236\254\355\235\240.md"
new file mode 100644
index 0000000..171e387
--- /dev/null
+++ "b/week3/3\355\214\200_\354\235\264\354\236\254\355\235\240.md"
@@ -0,0 +1,124 @@
+# 🖥️ 혼공머신 스터디 : 4장 요약
+#### 스터디 3조 이재흠 (@rethinking21, rethinking21@gmail.com)
+
+***
+## 챕터 4 다양한 분류 알고리즘 🎁
+
+### 04-1. 로지스틱 회귀 🐍
+
+###### 다중분류(multi-class classification)
+타깃 데이터에 2개 이상의 클래스가 포함된 문제를 **다중분류(multi-class classification)** 라고 부릅니다.
+이전에 배웠던 k-최근접 이웃 분류기를 통해 다중 분류를 수행 하실 수 있습니다.
+```python
+from sklearn.neighbors import KNeighborsClassifier
+kn = KNeighborsClassifier(n_neighbors=3)
+kn.fit(train_scaled. train_target)
+proba = kn.predict_proba(test_scaled[4])
+print(np.round(proba, decimals=4))
+```
+출력값에 보이는 결과는
+
+###### 로지스틱 회귀(logistic regression)
+
+**로지스틱 회귀(logistic regression)** 는 분류 모델로, 선형회귀와 동일하게 선형방정식을 학습합니다.
+확률은 0에서 1 사이의 값이어야 하기 때문에, 선형회귀는 확률을 표현하는 데에는 적절하지 않습니다
+
+
+▲ [🖼️ 이미지 출저][1]
+
**시그모이드 함수(sigmoid function)** 는 이를 해결해주는 함수입니다.
+이 함수는 무한히 음수값이 될 때는 0에 가까워지고, 무한히 양수값이 될 때는 1에 가까워집니다.
+
+
+Scikit-learn에서는 LogisticRegression 클래스를 이용하여 로지스틱 회귀모델을 이용할 수 있습니다.
+```python
+from sklearn.linear_model import LogisticRegression
+lr = LogisticRegression(C=20, max_iter=1000)
+lr.fit(train_data, target_data)
+```
+여기서 max_iter 매개변수는 반복횟수를 의미하고, C 매개변수는 LogisticRegression 클래스의 규제를 제어합니다.
+
+또한 Scipy의 expit이라는 함수를 통해 시그모이드 함수를 구현 할 수 있습니다.
+```python
+from scipy.special import expit
+print(expit(decisions))
+```
+
+###### 불리언 인덱싱(boolean indexing)
+넘파이 배열은 True, False 값을 전달하여 행을 선택 할 수 있습니다. 이를 **불리언 인덱싱(boolean indexing)** 이라고 부릅니다.
+
+```python
+import numpy as np
+char_arr = np.array(['A', 'B', 'C', 'D', 'E'])
+print(char_arr[[True, False, True, False, False]]) # ['A' 'C']
+```
+
+###### 소프트맥스 함수 (softmax function)
+
+로지스틱 회귀로 다중 분류를 수행할 때는 **소프트맥스(softmax)** 함수를 사용하여 확률로 변환합니다.
+
+
+
+scipy에서의 함수 softmax를 이용하여 소프트맥스 함수를 사용 할 수 있습니다.
+
+```python
+from scipy.special import softmax
+import numpy as np
+proba = softmax(decision, axis=1)
+print(np.round(proba, decimals=3))
+```
+
+### 04-2. 확률적 경사 하강법 ⛰️
+
+###### 경사하강법
+**경사하강법** 은 함수 값이 낮아지는 방향으로 독립 변수 값을 변형해 최소 함수 값을 갖도록 하는 방법을 말합니다. 보통 산에서 내려오는 것으로 비유를 많이 합니다.
+
경사하강법에서 조심해야 하는 부분은 step size입니다. 이 값이 너무 작을 경우 학습을 여러번 해도 온전히 학습이 안되는 문제가 발생 할 수 있으며, 반대로 값이 너무 클경우 제대로 학습이 되지 않는 문제가 발생합니다.
+

+

+▲[🖼️ 이미지 출처][2]
+
경사하강법에는 종류가 여러가지가 있습니다.
+
+먼저, 전체 데이터를 한번에 돌려서 경사하강법을 수행하는 **배치 경사 하강법(Batch Gradient Descent)** 가 있습니다.
+이 방법은 가장 안정적이지기도 하지만, 전체데이터를 사용하기에 컴퓨터 자원을 많이 소모한다는 단점이 있습니다.
+
+이와 달리 전체데이터중 한개를 무작위로 골라서 학습시키는 **확률적 경사 하강법(Stochastic Gradient Descent, SGD)** 이 있습니다.
+이 경우 학습속도가 빠르다는 장점이 있지만, 데이터가 말 그대로 확률적이기에 최소비용에 도달했는지 판단하는데 어려움이 있다는 단점이 존재합니다.
+
+전체 데이터 중에 여러개의 데이터를 뽑아와 학습시키는 방법도 있습니다. 이를 **미니배치 경사 하강법(minibatch Gradient Descent)** 라고 부릅니다.
+SGD의 노이즈를 줄이면서, 속도 또한 빠르다는 장점이 있기에 실전에서 많이 쓰이는 방법입니다.
+
+

+
+훈련세트를 한번 다 사용 하는 것을 **에포크(epoch)** 라고 합니다.
+또, **배치(batch)** 는 모델의 가중치를 한번 업데이트시킬 때 사용되는 샘플들의 묶음을 의미합니다.
+배치와 에포크를 조절해가며 학습의 효율을 조절해야 합니다.
+
+에포크를 많이 수행하게 되면 어느새 훈련/테스트 세트의 정확도가 낮아지는 현상이 발생합니다. 이는 과대적합이 된 경우로서 우리는 이 경우가 오지 전에 훈련을 종료해야 합니다.
+이를 **조기 종료(early stopping)** 라고 합니다.
+
+[❕ 경사하강법에 대한 자세한 내용][3]
+
+Scikit-learn에서 확률적 경사 하강법을 제공하는 대표적인 분류용 클래스는 SGDClassifier가 있습니다.
+```python
+from sklearn.linear_model import SGDClassifier
+sc = SGDClassifier(loss='log', max_iter=10, random_state=42)
+sc.fit(train_scaled, train_target)
+```
+여기서 max_iter는 수행할 에포크 횟수를 뜻합니다. loss는 추후의 나올 손실함수를 무엇으로 계산할 것인지를 정해주는 매개변수입니다.
+
+###### 손실함수(loss function)
+
+**크로스엔트로피 손실 함수(cross-entropy loss function)** 분류 모델이 얼마나 잘 수행되는지 측정하기 위해 사용되는 지표입니다.
+분류 과정에서 실제값과 예측값이 정확할수록 점점 0에 가까워지게 됩니다.
+
+**로지스틱 손실함수(logistic loss function)** 는 다중 분류를 위한 손실 함수인 크로스 엔트로피(cross entropy) 손실 함수를 이진 분류 버전으로 만든 것입니다.
+그래서 **이진 크로스엔트로피 손실 함수(binary cross-entropy loss function)** 이라고 불리기도 합니다.
+
+[❕ 로지스틱 손실 함수에 대한 더 자세한 내용][4]
+
+SGDClassifier 에서의 loss 매개변수의 기본값은 힌지손실입니다. **힌지 손실(hinge loss)** 는 **서포트 벡터 머신** 이라는 또 다른 머신러닝 알고리즘을 위한 손실함수입니다.
+
+
+[1]: https://velog.io/@yuns_u/Logistic-Regression
+[2]: https://hackernoon.com/life-is-gradient-descent-880c60ac1be8
+[3]: https://angeloyeo.github.io/2020/08/16/gradient_descent.html
+[4]: https://ukb1og.tistory.com/22
\ No newline at end of file
diff --git "a/week3/3\355\214\200_\354\241\260\353\252\205\352\265\254.md" "b/week3/3\355\214\200_\354\241\260\353\252\205\352\265\254.md"
new file mode 100644
index 0000000..a64fbe2
--- /dev/null
+++ "b/week3/3\355\214\200_\354\241\260\353\252\205\352\265\254.md"
@@ -0,0 +1,211 @@
+04-1 로지스틱 회귀
+=================
+
+>럭키백에서 각 생선들이 나올 확률 구하기
+
+앞에서 공부한 k-최근접 이웃으로 가까운 이웃의 비율을 계산해주는 모델을 이용하겠습니다.
+
+데이터 준비
+----------
+```python
+import pandas as pd
+fish = pd.read_csv('http://bit.ly/fish_csv_data')
+fish.head()
+```
+
+
+```python
+print(pd.unique(fish['Species']))
+```
+
+```pd.unique()``` 클래스로 데이터 프레임의 Species 열에 어떤 데이터가 있는지 출력하여 생선의 종류를 확인하였습니다.
+
+```python
+fish_input = fish[['weight', 'Length', 'Diagonal', 'Height', 'Width']].to_numpy()
+
+fish_target = fish['Species'].to_numpy()
+
+from sklearn.model_selection import train_split
+train_input, test_input, train_target, test_target = train_test_split(fish_input, fish_target, random_state=42)
+
+from sklearn.preprocessing import StandardScaler
+ss = StandardScaler()
+ss.fit(train_input)
+train_scaled = ss.transform(train_input)
+test_scaled = ss.transform(test_input)
+```
+fish_target는 각 인덱스에 해당하는 생선 종류에 대한 데이터를 넘파이 배열화시킨 것입니다.
+데이터를 훈련 세트와 테스트 세트로 나누어주었고, 데이터 전처리를 통해 표준점수화 하였습니다.
+
+k-최근접 이웃 분류기의 확률 예측
+----------
+>확률이 0.5 이상이면 양성 클래스로, 0.5 미만이면 음성 클래스로 판단한다.
+
+```python
+import numpy as np
+proba = kn.predict_proba(test_scaled[:5])
+print(np.round(proba, decimals=4))
+```
+```predict_proba()```로 각 클래스에 대해 모델이 예상한 확률을 나타낼 수 있습니다. 근데 이웃 3개에 대해 판단하므로, 확률이 1, 0.6666..., 0.3333..., 0 4개만 나타나서 좀 어색합니다.
+
+그래서 **로지스틱 회귀**를 이용하여 선형적인 확률 분포를 만들어보려 합니다. **시그모이드 함수**를 사용하면 가능합니다.
+
+
+
+로지스틱 회귀로 이진 분류
+-----------
+```python
+bream_smelt_indexes = (train_target == 'Bream') | (train_target == 'Smelt')
+train_bream_smelt == train_scaled[bream_smelt_indexes]
+target_bream_smelt = train_target[bream_smelt_indexes]
+```
+```bream_smelt_indexes``` 배열은 도미와 빙어일 경우 ```True``` 이고 그 외는 모두 ```False``` 값이 들어가 있습니다. 이 인덱스 배열을 이용하면 도미와 빙어 데이터만 골라낼 수 있습니다.
+
+이제 사이킷런에서 제공하는 로지스틱 회귀 메서드를 이용하여 모델 훈련 및 결과 확인을 해보겠습니다.
+
+```python
+from sklearn.linear_model import LogisticRegression
+
+lr = LogisticRegression()
+lr.fit(train_bream_smelt, target_bream_smelt)
+
+print(lr.predict_proba(train_bream_smelt[:5]))
+```
+
+```
+[[0.99759855 0.00240145]
+ [0.02735183 0.97264817]
+ [0.99486072 0.00513928]
+ [0.98584202 0.01415798]
+ [0.99767269 0.00232731]]
+ ```
+ 첫 번째 열이 음성클래스(Bream), 두 번째 열이 양성클래스(Smelt)에 대한 확률입니다.
+
+
+로지스틱 회귀로 다중 분류
+-------------
+```python
+lr = LogisticRegression(C=20, max_iter=1000)
+lr.fit(train_scaled, train_target)
+```
+```C```는 값이 작을수록 규제가 커지는 매개변수고, ```max_iter```가 반복 횟수를 지정해준느 매개변수입니다(기본값 100).
+
+```python
+proba = lr.predict_proba(test_scaled[:5])
+print(np.round(proba, decimals=3))
+```
+```
+[[0. 0.014 0.841 0. 0.136 0.007 0.003]
+ [0. 0.003 0.044 0. 0.007 0.946 0. ]
+ [0. 0. 0.034 0.935 0.015 0.016 0. ]
+ [0.011 0.034 0.306 0.007 0.567 0. 0.076]
+ [0. 0. 0.904 0.002 0.089 0.002 0.001]]
+ ```
+ 테스트 세트의 처음 5개 샘플에 대한 예측 확률입니다. 가장 높은 확률에 대응하는 생선을 예측합니다.
+
+ 데이터가 5개의 특성을 사용하므로 선형방정식의 계수가 5개입니다. 식은 7개입니다. 한 데이터에 대해 7개의 z값을 모두 도출해 **소프트맥스 함수**를 이용하여 7개의 z값을 확률로 변환합니다. 모델은 가장 높은 함수값을 가진 z값에 해당하는 생선으로 예측하게 되는 것입니다.
+
+ 확률적 경사 하강법
+ ===========
+ 데이터가 조금씩 공급될 때, 지속적인 학습을 위해 사용하는 방법입니다. 이를 위해서 앞서 훈련한 모델을 버리지 않고 새로운 데이터에 대해서만 훈련해야 합니다. 이를 **점진적 학습**이라고 합니다. 대표적인 점진적 학습 알고리즘은 **확률적 경사 하강법**입니다.
+
+ >훈련 세트의 데이터를 모두 사용하면 새로운 데이터를 훈련세트의 데이터에 채워준다.
+
+ 여기서 훈련세트를 한 번 모두 사용하는 과정을 에포크라고 합니다.
+
+ 
+
+ 로지스틱 손실 함수
+ ------
+ 
+여기서 양성 클래스 (타깃 = 1)일 때 예측 확률이 낮을수록 손실 함수의 크기가 매우 커집니다. 음성 클래스 (타깃 =0)에서는 반대로 예측 확률이 높을수록 손실 함수의 크기가 매우 커집니다. 이처럼 잘못된 예측을 할수록 손실 함수의 크기가 커지는 것을 확인할 수 있습니다. 그렇다면 손실 함수의 크기를 낮추는 것이 확률적 경사 하강법에서의 목표라고 볼 수 있겠습니다.
+
+SGDClassifier
+-------------
+```python
+import pandas as pd
+
+fish = pd.read_csv('https://bit.ly/fish_csv_data')
+
+fish_input = fish[['Weight','Length','Diagonal','Height','Width']].to_numpy()
+fish_target = fish['Species'].to_numpy()
+
+from sklearn.model_selection import train_test_split
+
+train_input, test_input, train_target, test_target = train_test_split(
+ fish_input, fish_target, random_state=42)
+
+from sklearn.preprocessing import StandardScaler
+
+ss = StandardScaler()
+ss.fit(train_input)
+train_scaled = ss.transform(train_input)
+test_scaled = ss.transform(test_input)
+```
+데이터를 훈련 세트와 테스트 세트로 분류하고 전처리까지 마쳤습니다.
+
+사이킷런에서 확률적 경사 하강법을 제공하는 대표적인 분류용 클래스는 **SGDClassifier**입니다.
+
+```python
+from sklearn.linear_model import SGDClassifier
+
+sc = SGDClassifier(loss='log', max_iter=10, random_state=42)
+sc.fit(train_scaled, train_target)
+```
+지금 에포크 횟수가 10으로 설정되어있는데(```max_iter```), 에포크 횟수가 부족하여 모델의 점수가 낮게 나옵니다.
+```python
+sc.partial_fit(train_scaled, train_target)
+```
+해당 클래스를 사용하면 1 에포크씩 훈련할 수 있고, 점수가 좀 오릅니다. 그럼 어디까지 반복해야 할지 정해주는 기준이 필요하겠습니다.
+
+에포크의 과대/과소적합
+-----
+에포크의 반복횟수가 많을수록 훈련세트를 과도하게 학습하여 **과대적합**이 일어날 것이고, 에포크를 적게 반복하면 **과소적합**이 일어날 것입니다. 이 현상을 막기 위해 그래프를 통해 적절한 에포크 횟수를 찾을 것입니다.
+
+```python
+import numpy as np
+
+sc = SGDClassifier(loss='log', random_state=42)
+
+train_score = []
+test_score = []
+
+classes = np.unique(train_target)
+
+for _ in range(0, 300):
+ sc.partial_fit(train_scaled, train_target, classes=classes)
+
+ train_score.append(sc.score(train_scaled, train_target))
+ test_score.append(sc.score(test_scaled, test_target))
+
+import matplotlib.pyplot as plt
+
+plt.plot(train_score)
+plt.plot(test_score)
+plt.xlabel('epoch')
+plt.ylabel('accuracy')
+plt.show()
+```
+```train_score```와 ```test_score```에 에포크마다 훈련 세트와 테스트 세트에 대한 점수가 기록됩니다.
+
+에포크를 300번 반복하였습니다.
+
+**matplotlib**을 통해 그린 그래프는 다음과 같습니다.
+
+
+
+그래프를 통해 훈련 세트 점수, 테스트 세트 점수 모두 적당히 높고, 차이가 그리 나지 않고, 훈련 세트 점수가 조금 더 높은 에포크는 100 점도로 보입니다.
+
+```python
+sc = SGDClassifier(loss='log', max_iter=100, tol=None, random_state=42)
+sc.fit(train_scaled, train_target)
+
+print(sc.score(train_scaled, train_target))
+print(sc.score(test_scaled, test_target))
+```
+```
+0.957983193277311
+0.925
+```
+
+최종적으로 적절한 에포크 100을 설정하여 모델을 학습시킨 결과입니다. 점수가 잘 나오는 것으로 확인됩니다.
\ No newline at end of file
diff --git "a/week3/5\355\214\200_\354\235\264\354\212\271\355\233\210.md" "b/week3/5\355\214\200_\354\235\264\354\212\271\355\233\210.md"
new file mode 100644
index 0000000..5b742b9
--- /dev/null
+++ "b/week3/5\355\214\200_\354\235\264\354\212\271\355\233\210.md"
@@ -0,0 +1,36 @@
+## 로지스틱 회귀
+분류 모델 중 하나로, 선형 회귀와 동일하게 선형 방정식을 학습한다. 방정식을 통해 나온 값을 다양한 함수에 대입하여 확률로 변환한다.
+
+- 시그모이드 함수: 선형 방정식의 출력을 0과 1 사이의 값으로 압축하여 이진 분류를 위해 사용함
+
+- 소프트맥스 함수: 다중 분류에서 여러 선형 방정식의 출력 결과를 정규화하여 합이 1이 되도록 만듦.
+
+### 주요 메서드
+
+- `LogisticRegression`: 로지스틱 회귀를 위한 클래스
+- `predict_proba()`: 이진 분류에선 음성/양성 클래스에 대한 확률을 반환, 다중 분류에선 모든 클래스에 대한 확률을 반환
+- `decision_function()`: 모델이 학습한 선형 방정식을 출력
+
+## 확률적 경사 하강법
+머신러닝 모델은 꾸준한 학습이 필요하다. 이를 위해 점진적인 학습을 진행해야하고, 대표적인 알고리즘으로 **확률적 경사 하강법**이 있다.
+
+**확률적 경사하강법**은 훈련 세트에서 샘플을 하나씩 꺼내 손실 함수의 경사를 따라 최적의 모델을 찾는 알고리즘이다.
+
+여기서 전체 데이터를 여러 샘플로 나눠 사용하면 **미니배치 경사 하강법**, 통채로 사용하면 **배치 경사 하강법**이 된다.
+
+- 에포크: 확률적 경사 하강법에서 전체 샘플을 모두 사용하는 한 번 반복을 의미한다.
+
+### 손실 함수
+확률적 경사 하강법이 최적화할 대상; 문제에 잘 맞는 손실 함수가 존재한다.
+
+- 이진 분류: 로지스틱 회귀 손실 함수
+- 다중 분류: 크로스 엔트로피 손실 함수
+- 회귀 문제: 평균 제곱 오차 손실 함수
+
+### 주요 메서드
+
+- `SGDClassifier`: 확률적 경사 하강법을 사용한 분류 모델을 생성
+- `SGDRegressor`: 확률적 경사 하강법을 사용한 회귀 모델을 생성
+
+
+
diff --git "a/week3/6\355\214\200_\352\271\200\353\257\274\354\244\200.md" "b/week3/6\355\214\200_\352\271\200\353\257\274\354\244\200.md"
new file mode 100644
index 0000000..e02a6de
--- /dev/null
+++ "b/week3/6\355\214\200_\352\271\200\353\257\274\354\244\200.md"
@@ -0,0 +1,26 @@
++ 로지스틱 회귀
+ 선형성을 가진 분류 알고리즘.
+
++ 시그모이드 함수 (sigmoid function)
+ z값이 음수인 경우에는 0에 수렴하고, 양수인 경우에는 1에 수렴하는 함수 그래프. 치역이 절대로 0과 1 사이의 범위를 벗어나지 않으므로, 이를 0%에서 100%의 확률로 환산할 수 있음.
+
++ 로지스틱 회귀를 이용한 다중 분류
+ 로지스틱 회귀를 이용한 이진 분류에서는 시그모이드 함수를 사용하지만, 로지스틱 회귀를 이용한 다중 분류에서는 소프트맥스 함수를 이용함.
+
++ 소프트맥스 함수 (softmax function)
+ 범주마다 z값을 하나씩 계산하여 가장 높은 z값의 범주를 반환함.
+
++ 옵티마이저: 확률적 경사 하강법
+ - 경사 하강법 (Gradient Descent)
+ 함수 그래프의 기울기를 이용한 점진적 학습 알고리즘. 손실 함수의 그래프의 기울기가 점점 낮아지는 방향으로 가면서 손실 점수를 줄임.
+ - 확률적 경사 하강법
+ 전체 훈련 샘플을 사용하지 않고 랜덤하게 하나의 샘플을 골라 경사 하강법을 진행. 하나의 샘플에서 경사 하강법이 진행 완료되면 다음 샘플로 랜덤하게 옮겨 다시 경사하강법 진행. 이런 식으로 전체 샘플에 대해 경사하강법 진행.
+ - 미니배치 경사하강법 (Minibatch Gradient Descent)
+ 확률적 경사 하강법과 다르게 여러 개의 샘플을 무작위로 선택해 경사 하강법 진행.
+ - 배치 경사 하강법 (Batch Gradient Descent)
+ 전체 샘플에 대해 한 번에 경사하강법 진행. 가장 안정적인 방법이나, 컴퓨팅 파워가 많이 필요하고, 데이터의 크기에 따라 에러 발생 가능.
++ 손실 함수 (Loss Function)
+ 머신러닝 알고리즘의 학습 결과가 얼마나 잘못되었는지 판단. 손실 함수의 결과값이 낮을수록 좋음.
+
++ 로지스틱 손실 함수 (Logistic Loss Function, 이진 크로스엔트로피 손실 함수)
+ 양성 클래스 (target = 1) 인 경우에는 -log(예측확률) 로 계산하고, 음성 클래스 (target = 0) 인 경우에는 -log(1-예측확률) 로 계산. 이렇게 된다면 예측 확률이 0에서 멀어질수록 손실값이 아주 큰 양수가 됨.
\ No newline at end of file
diff --git "a/week3/[3\354\243\274\354\260\250 \352\263\274\354\240\234] 4\355\214\200 \353\260\260\354\227\260\354\232\261.md" "b/week3/[3\354\243\274\354\260\250 \352\263\274\354\240\234] 4\355\214\200 \353\260\260\354\227\260\354\232\261.md"
new file mode 100644
index 0000000..2c3bfcc
--- /dev/null
+++ "b/week3/[3\354\243\274\354\260\250 \352\263\274\354\240\234] 4\355\214\200 \353\260\260\354\227\260\354\232\261.md"
@@ -0,0 +1,41 @@
+# [3주차 과제] 4팀 배연욱
+
+---
+
+### Chapter 4. 다양한 분류 알고리즘
+#### 04-1 로지스틱 회귀
+
+---
+
+* k-최근접 이웃은 주변 이웃의 클래스 비율을 확률로 출력한다.
+
+**로지스틱 회귀**는 선형 방정식을 사용한 분류 알고리즘이다. 선형 회귀와 달리 시그모이드 함수나 소프트맥스 함수를 사용하여 클래스 확률을 출력할 수 있다. 분류 알고리즘임에도 로지스틱 '회귀'라고 이름 붙여진 것은 그 기저 기술이 선형 회귀와 거의 같기 때문이다.
+
+**다중 분류**는 타깃 클래스가 2개 이상인 분류 문제이다. 로지스틱 회귀는 다중 분류를 위해 소프트맥스 함수를 사용하여 클래스를 예측한다.
+
+**시그모이드 함수**는 선형 방정식의 출력을 0과 1 사이의 값으로 압축하며 이진 분류를 위해 사용한다.
+
+
+**소프트맥스 함수**는 다중 분류에서 여러 선형 방정식의 출력 결과를 정규화하여 합이 1이 되도록 만든다.
+
+
+---
+
+#### 04-2 확률적 경사 하강법
+
+**점진적 학습**은 앞서 훈련한 모델을 버리지 않고 새로운 데이터에 대해서만 조금씩 더 훈련하는 방식이다. 온라인 학습이라고 불리기도 한다. 대표적인 점진적 학습 알고리즘이 확률적 경사 하강법이다.
+
+**확률적 경사 하강법**은 훈련 세트에서 샘플을 하나씩 꺼내 손실 함수의 경사를 따라 최적의 모델을 찾는 알고리즘이다. 샘플을 하나씩 사용하지 않고 여러 개를 사용하면 **미니배치 경사 하강법**이 된다. 한 번에 전체 샘플을 사용하면 **배치 경사 하강법**이 된다.
+
+* 신경망 모델은 확률적 경사 하강법이나 미니배치 경사 하강법을 사용한다.
+
+**손실 함수**는 확률적 경사 하강법이 최적화할 대상이다. 대부분의 문제에 잘 맞는 손실 함수가 이미 정의되어 있다. 이진 분류에는 로지스틱 회귀(또는 이진 크로스엔트로피) 손실 함수를 사용한다. 다중 분류에는 크로스엔트로피 손실 함수를 사용한다. 회귀 문제에는 평균 제곱 오차 손실 함수를 사용한다. 손실 함수는 미분 가능해야 한다.
+
+* 엄밀히 말하면 손실 함수는 샘플 하나에 대한 손실을 정의하고 비용 함수는 훈련 세트에 있는 모든 샘플에 대한 손실 함수의 합을 말한다.
+* 회귀의 손실 함수로는 평균 절댓값 오차(타깃에서 예측을 뺀 절댓값을 모든 샘플에 평균한 값) 또는 평균 제곱 오차(타깃에서 예측을 뺀 값을 제곱한 다음 모든 샘플에 평균한 값)를 많이 사용한다. 이 값이 작을수록, 즉 오차가 작을수록 좋은 모델이다.
+
+**힌지 손실**은 **서포트 벡터 머신**이라 불리는 다른 머신러닝 알고리즘을 위한 손실 함수이다.
+
+**에포크**는 확률적 경사 하강법에서 전체 샘플을 모두 사용하는 한 번 반복을 의미한다. 일반적으로 경사 하강법 알고리즘은 수십에서 수백 번의 에포크를 반복한다.
+
+**조기 종료**는 과대적합이 시작하기 전에 훈련을 멈추는 것이다.
\ No newline at end of file
diff --git "a/week3/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/04-1 logistic function.png" "b/week3/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/04-1 logistic function.png"
new file mode 100644
index 0000000..5868077
Binary files /dev/null and "b/week3/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/04-1 logistic function.png" differ
diff --git "a/week3/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/04-1 softmax function.png" "b/week3/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/04-1 softmax function.png"
new file mode 100644
index 0000000..246ee29
Binary files /dev/null and "b/week3/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/04-1 softmax function.png" differ
diff --git "a/week3/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/04-2 GD step size 01.gif" "b/week3/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/04-2 GD step size 01.gif"
new file mode 100644
index 0000000..b5486a2
Binary files /dev/null and "b/week3/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/04-2 GD step size 01.gif" differ
diff --git "a/week3/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/04-2 GD step size 02.gif" "b/week3/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/04-2 GD step size 02.gif"
new file mode 100644
index 0000000..6d0d5f0
Binary files /dev/null and "b/week3/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/04-2 GD step size 02.gif" differ
diff --git "a/week3/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/04-2 manyGDs.png" "b/week3/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/04-2 manyGDs.png"
new file mode 100644
index 0000000..dc6798f
Binary files /dev/null and "b/week3/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/04-2 manyGDs.png" differ
diff --git a/week3/img/output_13_0.png b/week3/img/output_13_0.png
new file mode 100644
index 0000000..6d056f4
Binary files /dev/null and b/week3/img/output_13_0.png differ
diff --git a/week3/img/output_18_0.png b/week3/img/output_18_0.png
new file mode 100644
index 0000000..05463e8
Binary files /dev/null and b/week3/img/output_18_0.png differ
diff --git a/week3/sigmoid function.png b/week3/sigmoid function.png
new file mode 100644
index 0000000..54a69f1
Binary files /dev/null and b/week3/sigmoid function.png differ
diff --git a/week3/softmax function.png b/week3/softmax function.png
new file mode 100644
index 0000000..4232026
Binary files /dev/null and b/week3/softmax function.png differ
diff --git "a/week4/3\355\214\200_\354\235\264\354\236\254\355\235\240.md" "b/week4/3\355\214\200_\354\235\264\354\236\254\355\235\240.md"
new file mode 100644
index 0000000..8272cc3
--- /dev/null
+++ "b/week4/3\355\214\200_\354\235\264\354\236\254\355\235\240.md"
@@ -0,0 +1,275 @@
+# 🖥️ 혼공머신 스터디 : 5장 요약
+#### 스터디 3조 이재흠 (@rethinking21, rethinking21@gmail.com)
+
+***
+## 챕터 5 트리 알고리즘 🌳
+
+### 05-1. 결정 트리 🍷
+
+###### 결정 트리 (Decision Tree)
+
+**결정 트리 (Decision Tree, 의사결정나무)** 각 노드마다 예/아니오 질문을 반복해가며 데이터를 정리하는 알고리즘입니다.
+이 모델은 분류와 회귀가 모두 가능하며 널리 사용되고 있는 모델 중 하나입니다. 또한 결정 트리는 데이터의 전처리(표준화)가 필요하지 않습니다.
+
+

+▲[🖼️ 이미지 출처][1]
+여기서 **노드(Node)** 는 질문이나 정답을 담은 상자를 뜻합니다.
+노드 안에 있는 질문에 의해 데이터가 흘러내려가게 되고, 흘러 내려간 데이터가 다른 노드에 도착하는 방법을 반복하며 데이터를 분류합니다.
+

+▲첫번째 줄은 노드의 조건을 의미합니다. 이 조건에 따라 데이터들이 다른 노드로 이동합니다.
+두번째 줄은 불순도(여기서는 지니불순도)를 의미합니다.
+세번째 줄은 노드를 지나간 샘플의 숫자를 의미합니다.
+마지막 줄은 노드를 지나간 데이터의 분포를 보여줍니다.
+
+Scikit-learn 에서는 **DecisionTreeClassifier** 클래스를 통해 결정 트리 분류 모델을 사용할 수 있고,
+**plot_tree** 함수를 통해 결정 트리 모델을 시각화할 수 있습니다.
+DecisionTreeRegressor 클래스는 결정 트리 회귀 모델입니다.
+```python
+from sklearn.tree import DecisionTreeClassifier
+import matplotlib.pyplot as plt
+from sklearn.tree import plot_tree
+
+dt = DecisionTreeClassifier(max_depth=3, random_state=42)
+dt.fit(train_scaled, train_target)
+
+plt.figure(figsize=(10,7))
+plot_tree(dt, max_depth=1, filled=True, feature_names=['alcohol', 'sugar', 'pH'])
+plt.show()
+```
+DecisionTreeClassifier의 매개변수 max_depth는 트리의 최대 깊이를 설정해줍니다.
+plot_tree의 매개변수 max_depth는 표시할 트리의 최대 깊이를 설정해주고, feature_names는 해당 요소의 이름을 표시해줍니다.
+
+이전에 배웠던 모델들은 '머신러낭 모델'을 모르는 사람에게 설명하기 어렵다는 단점이 있었습니다.
+하지만 **결정 트리** 는 그런 사람들에게 모델을 쉽게 설명할 수 있다는 장점을 지니고 있습니다.
+
+###### 불순도 (impurity) 와 정보이득 (Information Gain)
+
+**불순도(impurity)** 는 다양한 개체들이 얼마나 포함되어 있는가를 의미합니다. 불순도를 표시하는 방법에는 여러가지 방법이 있습니다.
+

+**지니 불순도(gini impurity)** 는 1에다가 각 분류 정도를 제곱한 것을 뺴는 방식으로 불순도를 측정합니다.
+값이 0이 될수록 순도가 높다는 의미입니다.
+
+

+**엔트로피 불순도(Entropy impurity)** 는 제곱이 아닌 로그를 사용하여 곱하는 방식을 사용합니다.
+
+이런 부모와 자식 노드의 불순도의 차이를 **정보 이득 (Information Gain)** 이라고 합니다.
+정보이득이 클수록 더 좋은 모델을 가집니다.
+
+[❕ 불순도와 정보이득에 대한 더 자세한 내용][2]
+
+### 05-2. 교차 검증과 그리드 서치 🔍
+
+###### 검증 세트 (validation set)
+
+우리는 데이터 세트를 훈련 세트와 테스트 세트로 나누는 작을 통해 모델의 과대적합 문제를 방지했습니다.
+하지만 이 방법은 모델이 테스트 세트에만 집중된다는 문제를 지니고 있습니다.
+그 결과 모델이 오히려 테스트 세트에 과대적합 될 수 있습니다.
+
+

+
이를 방지하기 위한 방법중에는 훈련세트 중 일부를 떼어낸 **검증 세트 (validation set)** 를 두어 모델을 평가하는 방법이 있습니다.
+
훈련 세트에서 모델을 훈련하고, 검증세트에서 모델을 평가하는 방식을 사용합니다. 테스트 세트는 이렇게 만들어진 모델을 마지막에 평가할 떄 사용합니다.
+
+###### 교차 검증 (cross validation)
+
+

+**교차 검증 (cross validation)** 은 훈련 세트를 몇개로 나누어서 그중 하나를 검증 세트로 두어 모델을 평가하는 방식입니다.
+이 방법을 이용하면 더 안정적인 검증 점수를 얻고 훈련에 더 많은 데이터를 사용 할 수 있게 됩니다.
+보통 5-폴드 교차 검증 이나 10-폴드 교차 검증을 사용합니다
+
+
Scikit-learn에서는 cross_validate으로 모델의 교차 검증을 수행할 수 있습니다.
+```python
+from sklearn.model_selection import cross_validate
+import numpy as np
+
+scores = cross_validate(model, train_input, train_target, cv=5) #cv는 데이터를 몇개 쪼갤건지를 의미합니다(기본값:5)
+print(scores)
+print(np.mean(scores['test_score']))
+```
+
+###### StratifiedKFold
+
+

+▲[🖼️ 이미지 출처][3]
+**KFold** 는 데이터 세트를 일정한 간격으로 나누어 사용하는 방식입니다.
+가장 간단한 방법이지만, 데이터 세트가 불균형할 경우, 모델 평가가 떨어지는 문제가 발생할 수 있습니다.
+
+
**StratifiedKFold** 는 이를 해결하기 위한 분할기로, 레이블의 데이터 분포도에 따라 데이터를 분할합니다.
+
+Scikit-learn에서는 StratifiedKFold를 통해 데이터 세트의 분할을 수행 할 수 있습니다.
+```python
+from sklearn.model_selection import StratifiedKFold
+import numpy as np
+
+splitter = StratifiedKFold(n_splits=10, shuffle=True, random_state=42)
+scores = cross_validate(model, train_input, train_target, cv=splitter)
+print(np.mean(scores['test_score']))
+```
+###### 하이퍼파라미터 튜닝
+
+모델이 학습 할 수 없어서 사용자가 직접 지정해줘야만 하는 파라미터를 **하이퍼마라미터** 라고 합니다.
+파라미터의 값이 두개일 경우, 한 파라미터에서 최적의 값을 찾아도, 다른 파라미터를 조정할때 달라지는 문제가 생깁니다.
+
+

+▲[🖼️ 이미지 출처][4]
+**그리드 서치(Grid Search)** 는 파라미터의 가능한 모든 경우의 수를 다 적용한 다음, 최적의 모델을 찾는 방법입니다.
+정말로 모든 경우의 수를 다 고려하기 때문에 시간이 오래 걸리며, 자원이 많이 필요합니다.
+
Scikit-learn 에서의 GridSearchCV를 이용해 그리드 서치를 사용하실 수 있습니다.
+```python
+from sklearn.model_selection import GridSearchCV
+import numpy as np
+
+params = {'min_impurity_decrease': np.arange(0.0001, 0.001, 0.0001),
+ 'max_depth': range(5, 20, 1),
+ 'min_samples_split': range(2, 100, 10)
+ } #파리미터를 여러개 넣을 수 있습니다.
+gs = GridSearchCV(model, params, n_jobs=-1) #n_jobs는 사용할 CPU코어 개수입니다.
+gs.fit(train_input, train_target)
+dt = gs.best_estimator_ # 그리드 서치를 통해 나온 결과중 가장 좋은 결과를 가져옵니다.
+print(dt.score(train_input, train_target))
+best_index = np.argmax(gs.cv_results_['mean_test_score']) # 가장 큰 값의 익덱스를 불러옵니다.
+print(gs.cv_results_['params'][best_index])
+```
+**랜덤 서치(Random Search)** 는 주어잔 파라미터 범위에 파라미터 값을 랜덤으로 주어 최적을 모델을 찾는 방법입니다.
+
Scikit-learn 에서의 RandomizedSearchCV를 이용해 랜덤 서치를 사용하실 수 있습니다.
+```python
+from sklearn.model_selection import RandomizedSearchCV
+from scipy.stats import uniform, randint
+
+params = {'min_impurity_decrease': uniform(0.0001, 0.001),
+ 'max_depth': randint(20, 50),
+ 'min_samples_split': randint(2, 25),
+ 'min_samples_leaf': randint(1, 25),
+ } #파라미터의 범위를 넣을 수 있습니다.
+gs = RandomizedSearchCV(model, params, n_iter=100, n_jobs=-1, random_state=42)
+gs.fit(train_input, train_target)
+print(gs.best_params_)
+dt = gs.best_estimator_ # 랜덤 서치를 통해 나온 결과중 가장 좋은 결과를 가져옵니다.
+print(dt.score(test_input, test_target))
+```
+
+[❕ 더 깊게 들어가고 싶다면..(링크)][5]
+[❕ 더어어 깊게 들어가고 싶다면..(링크)][6]
+
+### 05-3. 트리의 앙상블 🎄
+
+###### 정형데이터, 비정형데이터
+
+**정형 데이터** 는 정해진 규칙에 맞게 들어간 데이터 중에 수치 만으로 의미 파악이 쉬운 데이터들을 보통 말합니다.
+반면, 규칙적이지 않은 데이터는 **비정형 데이터** 라고 합니다.
+
+###### 앙상블 학습 (ensemble learning)
+**앙상블 학습(ensemble learning)** 은 여러 개의 분류기를 생성하고 그 분류기들의 예측을 결합시켜 더 정확한 예측을 내놓는 기법입니다.
+약한 모델을 여러개 두는 기법을 이용해 모델의 과대적합 문제를 해결할 수 있습니다.
+
+앙상블 학습은 보팅(Voting), 배깅(Bagging), 부스팅(Boosting)으로 유형을 나눌 수 있습니다.
+[❕ 앙상블 학습의 세가지 유형][7]
+
+###### 랜덤 포레스트 (Random Forest)
+
+

+▲[🖼️ 이미지 출처][8]
+**랜덤 포레스트(Random Forest)** 는 훈련을 통해 여러개의 결정 나무들을 생성한 다음, 그 나무들로 부터 예측값을 도출해내는 방법입니다.
+회귀의 경우 나무들의 평균값으로 계산하며, 분류의 경우 가장 많이 투표한 예측값으로 결론을 냅니다.
+
랜덤 포레스트는 샘플을 뽑을 때 샘플을 뽑고 다시 넣는 식으로 중복이 가능하게 샘플을 모읍니다.
+이를 **부트 스트랩 샘플(bootstrap sample)** 이라고 합니다.
+
+
Scikit-learn에서는 RandomForestClassifier를 통해 결정 트리 분류 모델을 사용할 수 있습니다.
+```python
+from sklearn.model_selection import cross_validate
+from sklearn.ensemble import RandomForestClassifier
+
+rf = RandomForestClassifier(n_jobs=-1, random_state=42)
+scores = cross_validate(rf, train_input, train_target, return_train_score=True, n_jobs=-1)
+rf.fit(train_input, train_target)
+```
+
+샘플중 부트스트랩 샘플에 포함되지 않고 남는 샘플이 있습니다.
+이 샘플을 **OBB(out of bag) 샘플** 이라고 합니다.
+이 샘플을 이용하여 부트스트랩으로 훈련한 결정 트리를 평가할 수 있습니다.
+
+```python
+rf = RandomForestClassifier(oob_score=True, n_jobs=-1, random_state=42)
+rf.fit(train_input, train_target)
+print(rf.oob_score_)
+```
+
+###### 엑스트라 트리 (Extra Trees)
+
+**엑스트라 트리(Extra Trees)** 는 랜덤 포레스트와 달리 부트스트랩 샘플을 사용하지 않습니다.
+대신 노드를 분할 할 때 무작위로 분할합니다.
+
Scikit-learn에서는 RandomForestClassifier를 통해 엑스트라 트리 분류 모델을 사용할 수 있습니다.
+```python
+from sklearn.ensemble import ExtraTreesClassifier
+
+et = ExtraTreesClassifier(n_jobs=-1, random_state=42)
+scores = cross_validate(et, train_input, train_target, return_train_score=True, n_jobs=-1)
+et.fit(train_input, train_target)
+```
+
+###### 부스팅 (Boost)
+
+
+**부스팅(Boost)** 은 가중치를 활용하여 분류기를 강화하며 만드는 모델입니다.
+처음 모델이 예측을 하면 그 예측 결과에 따라 데이터에 가중치가 부여되고, 부여된 가중치가 다음 모델에 영향을 줍니다.
+
+**그래디언트 부스팅(Gradient Boosting)** 은 경사하강법을 사용하여 트리를 앙상블에 추가합니다.
+
+```python
+from sklearn.ensemble import GradientBoostingClassifier
+
+gb = GradientBoostingClassifier(n_estimators=500, learning_rate=0.2, random_state=42) #n_estimators는 결정트리의 개수를 의미합니다.
+scores = cross_validate(gb, train_input, train_target, return_train_score=True, n_jobs=-1)
+```
+
+**Histogram-based Gradient Boosting** 은 입력 특성을 256개의 구간 (255개의 구간 + 누락구간 1개) 으로 나누는 방식을 사용합니다.
+
+특성값 중 누락된 값이 있어도 전처리를 안해도 된다는 장점이 있습니다.
+이런 장점 때문에, 정형 데이터를 다루는 머신러닝 알고리즘 중에 가장 높은 인기를 가지고 있는 알고리즘입니다.
+
+```python
+from sklearn.ensemble import HistGradientBoostingClassifier
+
+hgb = HistGradientBoostingClassifier(random_state=42)
+scores = cross_validate(hgb, train_input, train_target, return_train_score=True, n_jobs=-1)
+```
+
+**XGBoost (Extreme Gradient Boosting)** 은 Gradient Boosting이 병렬로 처리될 수 있게 만든 모델입니다.
+학습 속도가 빠르고 정확도가 높아 사람들이 많이 쓰는 모델 중 하나입니다.
+
+공식문서의 xgboost 라이브러리에서 XGBClassifier를 통해 모델을 사용할 수 있습니다.
+
[❕ XGBoost 공식 사이트][9]
+
[❕ XGBoost 공식 문서][10]
+```python
+from xgboost import XGBClassifier
+
+xgb = XGBClassifier(tree_method='hist', random_state=42)
+scores = cross_validate(xgb, train_input, train_target, return_train_score=True, n_jobs=-1)
+```
+
+**LightGBM** 은 학습속도가 빠르고 다른 부스팅 모델과 성능 차이가 별로 안나는 모델입니다.
+
+공식 문서에 따르면 일반적으로 10,000 건 이하의 데이터 세트를 다루는 경우 과적합 문제가 발생하기 쉽다는 단점이 있습니다.
+
+공식문서의 lightgbm 라이브러리에서 LGBMClassifier를 통해 모델을 사용할 수 있습니다.
+
[❕ LightGBM 공식 문서][11]
+```python
+from lightgbm import LGBMClassifier
+
+lgb = LGBMClassifier(random_state=42)
+scores = cross_validate(lgb, train_input, train_target, return_train_score=True, n_jobs=-1)
+```
+
+

+
+
+[1]: https://tensorflow.blog/파이썬-머신러닝/2-3-5-결정-트리/
+[2]: https://process-mining.tistory.com/106
+[3]: https://jhryu1208.github.io/data/2021/01/24/ML_cross_validation/
+[4]: https://link.springer.com/chapter/10.1007/978-3-030-05318-5_1
+[5]: https://carpe08.tistory.com/92
+[6]: https://daheekwon.github.io/bayesian-optimization/
+[7]: http://www.dinnopartners.com/__trashed-4/
+[8]: https://hleecaster.com/ml-random-forest-concept/
+[9]: https://xgboost.ai/
+[10]: https://xgboost.readthedocs.io/en/stable/
+[11]: https://lightgbm.readthedocs.io/en/latest/
\ No newline at end of file
diff --git "a/week4/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/05-1 Decision Tree Node.png" "b/week4/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/05-1 Decision Tree Node.png"
new file mode 100644
index 0000000..3146826
Binary files /dev/null and "b/week4/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/05-1 Decision Tree Node.png" differ
diff --git "a/week4/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/05-1 Decision Tree example1.png" "b/week4/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/05-1 Decision Tree example1.png"
new file mode 100644
index 0000000..c658211
Binary files /dev/null and "b/week4/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/05-1 Decision Tree example1.png" differ
diff --git "a/week4/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/05-1 Entropy impurity form.png" "b/week4/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/05-1 Entropy impurity form.png"
new file mode 100644
index 0000000..17f803d
Binary files /dev/null and "b/week4/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/05-1 Entropy impurity form.png" differ
diff --git "a/week4/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/05-1 Gini impurity form.png" "b/week4/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/05-1 Gini impurity form.png"
new file mode 100644
index 0000000..b410e44
Binary files /dev/null and "b/week4/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/05-1 Gini impurity form.png" differ
diff --git "a/week4/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/05-2 Cross Validation.jpg" "b/week4/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/05-2 Cross Validation.jpg"
new file mode 100644
index 0000000..bead630
Binary files /dev/null and "b/week4/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/05-2 Cross Validation.jpg" differ
diff --git "a/week4/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/05-2 Grid Search Random Search.png" "b/week4/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/05-2 Grid Search Random Search.png"
new file mode 100644
index 0000000..c4d0631
Binary files /dev/null and "b/week4/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/05-2 Grid Search Random Search.png" differ
diff --git "a/week4/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/05-2 Stratified cross validation.png" "b/week4/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/05-2 Stratified cross validation.png"
new file mode 100644
index 0000000..889a6be
Binary files /dev/null and "b/week4/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/05-2 Stratified cross validation.png" differ
diff --git "a/week4/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/05-2 Training set.png" "b/week4/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/05-2 Training set.png"
new file mode 100644
index 0000000..81eb4c8
Binary files /dev/null and "b/week4/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/05-2 Training set.png" differ
diff --git "a/week4/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/05-3 Boosting.png" "b/week4/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/05-3 Boosting.png"
new file mode 100644
index 0000000..2f0c276
Binary files /dev/null and "b/week4/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/05-3 Boosting.png" differ
diff --git "a/week4/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/05-3 Random Forest.png" "b/week4/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/05-3 Random Forest.png"
new file mode 100644
index 0000000..6a5a72e
Binary files /dev/null and "b/week4/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/05-3 Random Forest.png" differ
diff --git "a/week4/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/05-3 XGBoost and LightGBM.png" "b/week4/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/05-3 XGBoost and LightGBM.png"
new file mode 100644
index 0000000..2297e82
Binary files /dev/null and "b/week4/images/3\355\214\200_\354\235\264\354\236\254\355\235\240/05-3 XGBoost and LightGBM.png" differ
diff --git "a/week5/4\355\214\200_\354\235\264\354\236\254\355\235\240.md" "b/week5/4\355\214\200_\354\235\264\354\236\254\355\235\240.md"
new file mode 100644
index 0000000..100fb6e
--- /dev/null
+++ "b/week5/4\355\214\200_\354\235\264\354\236\254\355\235\240.md"
@@ -0,0 +1,172 @@
+# 🖥️ 혼공머신 스터디 : 6장 요약
+#### 스터디 4조 (new) 이재흠 (@rethinking21, rethinking21@gmail.com)
+
+***
+## 챕터 6 비지도 학습🍎🍍🍌
+
+### 05-1. 군집 알고리즘 🐝
+
+###### 비지도 학습 (unsupervised learning)
+
+
+**비지도 학습 (unsupervised learning)** 은 라벨이 없는 기존 데이터를 비슷한 특징끼리 군집화하여 새로운 데이터에 대한 결과를 예측하는 학습입니다.
+
+

+▲[🖼️ 이미지 출처][06-1_01]
+
+지도 학습의 경우, 데이터에 대한 라벨을 미리 주어 입력한 데이터에 대한 원하는 값이 미리 나와 있어야 합니다.
+이와 달리, 비지도 학습은 라벨을 미리 주지 않습니다.
+이는 데이터들을 분류하고, 분류한 데이터들의 특성(성격)을 파악하는걸 중점적으로 두기 위함입니다.
+
+
[❕ 비지도 학습에 대한 더 자세한 설명][06-1_02]
+
+###### 군집 (clustering) & 클러스터 (cluster)
+
+
+

+
+비슷한 샘플끼리 그룹으로 모으는 작업을 **군집 (clustering)** 이라고 합니다.
+군집은 대표적인 비지도 학습 작업중 하나입니다.
+군집 알고리즘에서 만든 그룹을 **클러스터 (cluster)** 라고 합니다.
+
+
[❕ 군집에 대한 더 깊은 내용][06-1_03]
+
+### 05-2. k-평균 📋
+
+###### k-평균 (k-means)
+
+**k-평균 알고리즘(K-means clustering algorithm)** 은 주어진 데이터를 k개의 클러스터로 묶는 알고리즘입니다.
+이 클러스터들의 평균값이 클러스터의 중심에 위치하기 때문에 **클러스터 중심 (cluster center)** 또는 **센트로이드 (centroid)** 라고 부르기도 합니다.
+
+k-평균 알고리즘을 구하는 방식은 다음과 같습니다.
+
+

+
+
1. 무작위로 k개의 클러스터 중심을 정합니다.
+
2. 각 샘플에서 가장 가까운 클러스터 중심을 찾아 해당 클러스터 샘플로 지정합니다.
+
3. 클러스터에 속한 샘플의 평균값으로 클러스터 중심을 변경합니다.
+
4. 클러스터 중심에 변화가 없을 떄까지 2번으로 돌아가 반복합니다.
+
+Scikit-learn에서는 sklearn.cluster 모듈아래 KMeans 클래스로 k-평균 알고리즘이 구현되어있습니다.
+
비지도 학습은 fit() 메서드에 타깃 데이터를 필요로 하지 않습니다.
+
+```python
+from sklearn.cluster import KMeans
+
+km = KMeans(n_clusters=3, random_state=42) # n_clusters는 클러스터의 개수를 의미합니다.
+km.fit(train_data)
+```
+
+fit() 메서드를 실행하였을 때 데이터가 어떤 클러스터에 속해 있는지는 다음과 같이 확인 할 수 있습니다.
+주의해야 할점은, 훈련 데이터는 2차원 배열(샘플개수, 너비×높이)로 변경해야 한다는 점입니다.
+```python
+
+import numpy as np
+
+km.labels__
+np.unique(km.labels__, return_counts=True)
+
+train_data[km.labels__==0] # 불리언 인덱싱을 통해 해당 클러스터가 가진 데이터들을 추출할 수 있습니다.
+```
+이때 나타나는 숫자값(0,1,2...)의 순서는 어떠한 의미도 담겨 있지 않습니다.
+
+
k-평균 알고리즘을 통해 최종적으로 얻은 클러스터 중심은 cluster_center 속성에 저장되어 있습니다.
+
+
[❕ k-평균 알고리즘에 대한 더 깊은 내용][06-2_01]
+
+###### 최적의 k찾기 : 엘보우 (elbow)
+
+k-평균 알고리즘의 단점 중 하나는 클러스터 개수를 사전에 지정해야 한다는 것 입니다.
+적절한 k값을 미리 정해 주어야 하지만, 비지도 학습이기에 실전에서는 몇개의 클러스터가 있는지를 알 수 없습니다.
+
+
적절한 클러스터의 개수를 찾기 위한 방법으로는 대표적으로 **엘보우 (elbow)** 방법이 있습니다.
+
+k-평균 알고리즘은 클러스터 중심과 속한 샘플 사이의 거리를 잴 수 있습니다.
+이떄 클러스터의 샘플들의 거리들을 합하여 샘플들이 얼마나 가깝게 모여있는지 나타낼 수 있습니다.
+이 값을 **이니셔 (inertia)** 라고 부릅니다.
+
일반적으로 클러스터의 개수가 늘어날수록 클러스터가 포함하고 있는 데이터의 수도 줄기 때문에 이니셔도 줄어듭니다.
+
+
엘보우 방법은 클러스터의 개수에 따른 이니셔의 변화를 관찰하여 최적의 클러스터 개수를 찾는 방법입니다.
+
+

+
+### 05-3. 주성분 분석 📊
+
+###### 차원과 차원 축소 (dimensionality reduction)
+
+머신러닝에서는 데이터가 가진 속성을 특성이라고 하며, 이를 **차원 (dimension)** 이라고도 부릅니다.
+
[❕ 머신러닝에서의 차원에 대한 더 자세한 설명][06-3_01]
+
+

+▲[🖼️ 이미지 출처][06-3_02]
+일반적으로, 특성이 더 많을 수록 데이터의 예측은 더 정확해질 것이라 생각합니다.
+하지만, 차원이 늘어날 수록 문제의 계산 시간이 더 길어지게 되고, 데이터간의 거리가 더 멀어지게 되어 빈공간이 증가하는 현상이 생깁니다.
+이를 **차원의 저주 (curse of dimensionality)** 라고 합니다.
+
+전 챕터에 본 데이터의 경우 특성값이 그리 많지는 않아 이런 현상이 가시적으로 나타나지는 않았습니다.
+하지만 그림의 경우, 각 픽셀의 정보마다 차원이 추가되기에 차원의 개수가 매우 많아지게 됩니다.
+예시인 과일 사진의 경우에도 10,000개의 픽셀이 있기에 차원이 10,000개라고 할 수 있습니다.
+
+차원의 저주 문제는 차원을 줄이는 방법으로 해결할 수 있습니다. 이를 **차원 축소 (dimensionality reduction)** 라고 합니다.
+
차원 축소에 이용되는 방법으로는 **투영(Projection)** 과 **매니폴드 학습(Manifold Learning)** 이 있습니다.
+이 챕터에서는 그중 투영 방법에 대해 소개합니다.
+
[❕ 더 다양한 차원 축소 방법][06-3_03]
+
[❕ 투영의 수학적인.. 접근?][06-3_04]
+
[❕ 매니폴드에 대한 더 자세한 내용][06-3_05]
+
+###### 주성분 분석 (principal component analysis, PCA)
+
+**주성분 분석 (principal component analysis, PCA)** 은 가장 보편적인 차원 축소 알고리즘 중 하나로,
+고차원의 데이터를 저차원의 데이터로 환원시키는 기법을 말합니다.
+이 기법은 고차원의 데이터를 시각화하는데 많이 사용하며, 데어터의 노이즈를 줄이고 싶을 때에도 이용되는 기법입니다.
+
+PCA의 경우, 분산을 최대로 보존할 수 있는 축을 선택하는 것이 정보를 가장 적게 손실할 수 있다고 가정하며 축을 정합니다.
+

+▲[🖼️ 이미지 출처][06-3_06]
+
+이 축을 정의하는 벡터 값을 **주성분 (principal component)** 이라고 하며, 이 주성분을 기준으로 데이터들을 투영하게 됩니다.
+
+
[❕ 차원 축소에 더 자세한 내용(주성분을 찾는 방법)][06-3_06]
+
+Scikit-learn 에서는 sklearn.decomposition 모듈 아래 PCA 클래스로 주성분 분석 알고리즘을 제공하고 있습니다.
+
+
+```python
+from sklearn.decomposition import PCA
+
+pca = PCA(n_components=50) # 주성분의 개수를 지정해야 합니다.
+pca.fit(train_data)
+```
+PCA 클래스의 객체를 만들 떄에는 n_components 매개변수에 주성분의 개수를 지정해야 합니다.
+또한 k-평균 알고리즘과 마찬가지로 비지도 학습이기 때문에 fit() 메서드에 타깃값을 제공하지 않습니다.
+
+```python
+pca.components_ # 주성분 값들입니다. 가장 분산이 큰 순서대로 정렬되어 있습니다.
+```
+
+

+
+transform() 메서드를 사용해 원래의 데이터를 주성분 개수의 차원으로 줄일 수 있습니다.
+
또한, inverse_transform() 메서드를 이용해 주성분 개수의 차원으로 이루어진 데이터를 원본 데이터로 복원할 수 있습니다.
+```python
+transform_data = pca.transform(train_data)
+inverse_data = pca.inverse_transform(transform_data)
+```
+
+주성분이 원본 데이터의 분산을 얼마나 잘 나타내었는지 측정한 값을 **설명된 분산(explained variance)** 이라고 합니다.
+```python
+pca.explained_variance_ratio_
+```
+
+[06-1_01]: https://towardsdatascience.com/a-brief-introduction-to-unsupervised-learning-20db46445283
+[06-1_02]: https://opentutorials.org/course/4548/28945
+[06-1_03]: https://www.secmem.org/blog/2019/05/17/clustering/
+
+[06-2_01]: https://mubaris.com/posts/kmeans-clustering/
+
+[06-3_01]: https://opentutorials.org/module/3653/22088
+[06-3_02]: https://for-my-wealthy-life.tistory.com/40
+[06-3_03]: https://box-world.tistory.com/61
+[06-3_04]: https://bskyvision.com/236
+[06-3_05]: https://junstar92.tistory.com/157
+[06-3_06]: https://butter-shower.tistory.com/210
\ No newline at end of file
diff --git "a/week5/images/4\355\214\200_\354\235\264\354\236\254\355\235\240/06-1 clustering explain.png" "b/week5/images/4\355\214\200_\354\235\264\354\236\254\355\235\240/06-1 clustering explain.png"
new file mode 100644
index 0000000..827d42d
Binary files /dev/null and "b/week5/images/4\355\214\200_\354\235\264\354\236\254\355\235\240/06-1 clustering explain.png" differ
diff --git "a/week5/images/4\355\214\200_\354\235\264\354\236\254\355\235\240/06-1 unsupervied learning explain.png" "b/week5/images/4\355\214\200_\354\235\264\354\236\254\355\235\240/06-1 unsupervied learning explain.png"
new file mode 100644
index 0000000..9e977b7
Binary files /dev/null and "b/week5/images/4\355\214\200_\354\235\264\354\236\254\355\235\240/06-1 unsupervied learning explain.png" differ
diff --git "a/week5/images/4\355\214\200_\354\235\264\354\236\254\355\235\240/06-2 elbow graph.png" "b/week5/images/4\355\214\200_\354\235\264\354\236\254\355\235\240/06-2 elbow graph.png"
new file mode 100644
index 0000000..2ed090e
Binary files /dev/null and "b/week5/images/4\355\214\200_\354\235\264\354\236\254\355\235\240/06-2 elbow graph.png" differ
diff --git "a/week5/images/4\355\214\200_\354\235\264\354\236\254\355\235\240/06-2 k-mean algorithm.gif" "b/week5/images/4\355\214\200_\354\235\264\354\236\254\355\235\240/06-2 k-mean algorithm.gif"
new file mode 100644
index 0000000..e4cb018
Binary files /dev/null and "b/week5/images/4\355\214\200_\354\235\264\354\236\254\355\235\240/06-2 k-mean algorithm.gif" differ
diff --git "a/week5/images/4\355\214\200_\354\235\264\354\236\254\355\235\240/06-3 PCA component fruit.png" "b/week5/images/4\355\214\200_\354\235\264\354\236\254\355\235\240/06-3 PCA component fruit.png"
new file mode 100644
index 0000000..b9ac99b
Binary files /dev/null and "b/week5/images/4\355\214\200_\354\235\264\354\236\254\355\235\240/06-3 PCA component fruit.png" differ
diff --git "a/week5/images/4\355\214\200_\354\235\264\354\236\254\355\235\240/06-3 PCA distance.gif" "b/week5/images/4\355\214\200_\354\235\264\354\236\254\355\235\240/06-3 PCA distance.gif"
new file mode 100644
index 0000000..474011b
Binary files /dev/null and "b/week5/images/4\355\214\200_\354\235\264\354\236\254\355\235\240/06-3 PCA distance.gif" differ
diff --git "a/week5/images/4\355\214\200_\354\235\264\354\236\254\355\235\240/06-3 curse of dimensionality.png" "b/week5/images/4\355\214\200_\354\235\264\354\236\254\355\235\240/06-3 curse of dimensionality.png"
new file mode 100644
index 0000000..fcce542
Binary files /dev/null and "b/week5/images/4\355\214\200_\354\235\264\354\236\254\355\235\240/06-3 curse of dimensionality.png" differ