From fad3478ed987107ff51ee1b81c04e1e3d896dbed Mon Sep 17 00:00:00 2001
From: 01Petard <1520394133@qq.com>
Date: Mon, 25 Nov 2024 19:09:36 +0800
Subject: [PATCH] =?UTF-8?q?doc:=201=E3=80=81=E5=A4=87=E4=BB=BD=E6=96=87?=
=?UTF-8?q?=E7=AB=A0=EF=BC=9B?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
...e - \345\210\206\345\270\203\345\274\217.md" | 10 +++++++---
...\256\345\272\223\345\221\275\344\273\244.md" | 6 ++----
...\215\344\270\226\344\273\212\347\224\237.md" | 17 ++++++++++++-----
3 files changed, 21 insertions(+), 12 deletions(-)
diff --git "a/docs/\345\274\200\345\217\221/My Java Guide/My Java Guide - \345\210\206\345\270\203\345\274\217.md" "b/docs/\345\274\200\345\217\221/My Java Guide/My Java Guide - \345\210\206\345\270\203\345\274\217.md"
index 3f547c1..ba1cec2 100644
--- "a/docs/\345\274\200\345\217\221/My Java Guide/My Java Guide - \345\210\206\345\270\203\345\274\217.md"
+++ "b/docs/\345\274\200\345\217\221/My Java Guide/My Java Guide - \345\210\206\345\270\203\345\274\217.md"
@@ -1045,10 +1045,14 @@ public class SeckillController {
}
```
-# 例:如何设计一个订单超时取消功能?
+# 例:订单超时自动取消的功能
+
+1. **数据库层**:增加订单状态和过期时间字段,配合定时任务清理。
+2. 全局定时批量处理(存在延后取消问题)
+3. **服务层**:
+ 1. 基于**消息队列**延时特性(如RabbitMQ的TTL队列)。在订单创建后,向TTL队列投放定时任务,任务超时前付款就取消任务,任务超时后未付款就将该任务投放到死信队列,死信消费者来处理订单状态。
+ 2. 使用**分布式锁**配合ScheduledExecutorService。在订单创建时,启动一个定时任务,该任务会在预设的时间后尝试关闭订单。为了防止多个实例同时处理同一个订单,需要使用分布式锁来保证操作的原子性。
-1. 定时任务(存在延后取消问题)
-2. **使用MQ的延时任务**
# *例:统计某家店铺销量 top 50 的商品?
diff --git "a/docs/\345\274\200\345\217\221/\346\241\206\346\236\266/MySql\346\225\260\346\215\256\345\272\223\345\221\275\344\273\244.md" "b/docs/\345\274\200\345\217\221/\346\241\206\346\236\266/MySql\346\225\260\346\215\256\345\272\223\345\221\275\344\273\244.md"
index 8685219..6ab3304 100644
--- "a/docs/\345\274\200\345\217\221/\346\241\206\346\236\266/MySql\346\225\260\346\215\256\345\272\223\345\221\275\344\273\244.md"
+++ "b/docs/\345\274\200\345\217\221/\346\241\206\346\236\266/MySql\346\225\260\346\215\256\345\272\223\345\221\275\344\273\244.md"
@@ -172,11 +172,9 @@ alter table 表名 drop primary key;
alter table 表名 drop constraint 约束名 (on 表名);
```
-复合主/外键内部是有顺序的,请注意!顺序由创建时决定
+复合主/外键内部是有顺序的,请注意!顺序由创建时决定
-
-
-单键可以和复合主键的单键相连,但是不建议这么做
+单键可以和复合主键的单键相连,但是不建议这么做
删除表
diff --git "a/docs/\345\274\200\345\217\221/\346\241\206\346\236\266/Netty\344\270\216NIO\347\232\204\345\211\215\344\270\226\344\273\212\347\224\237.md" "b/docs/\345\274\200\345\217\221/\346\241\206\346\236\266/Netty\344\270\216NIO\347\232\204\345\211\215\344\270\226\344\273\212\347\224\237.md"
index ebe1d86..2cf622a 100644
--- "a/docs/\345\274\200\345\217\221/\346\241\206\346\236\266/Netty\344\270\216NIO\347\232\204\345\211\215\344\270\226\344\273\212\347\224\237.md"
+++ "b/docs/\345\274\200\345\217\221/\346\241\206\346\236\266/Netty\344\270\216NIO\347\232\204\345\211\215\344\270\226\344\273\212\347\224\237.md"
@@ -59,7 +59,7 @@ public class IntBufferDemo {
运行后可以看到
- +
### 2.Buffer的基本原理
@@ -122,15 +122,16 @@ public class BufferDemo {
```
完成的输出结果为:
+
+
### 2.Buffer的基本原理
@@ -122,15 +122,16 @@ public class BufferDemo {
```
完成的输出结果为:
+
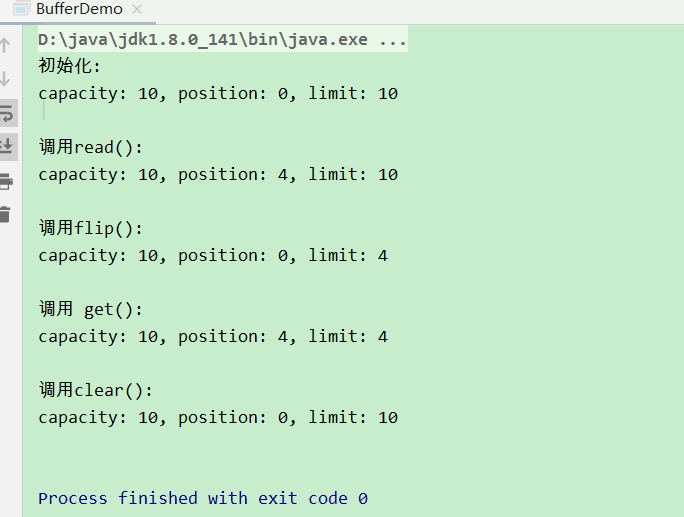 运行的结果我们可以看到,下面对以上结果进行图解,四个属性分别如图所示
-
运行的结果我们可以看到,下面对以上结果进行图解,四个属性分别如图所示
-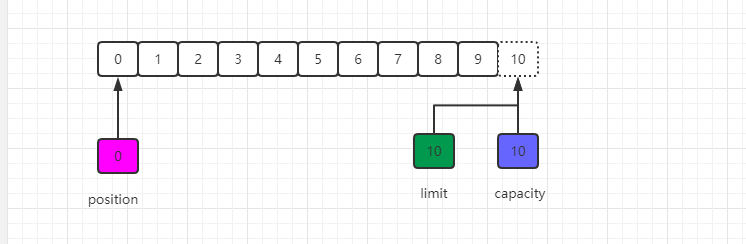 +
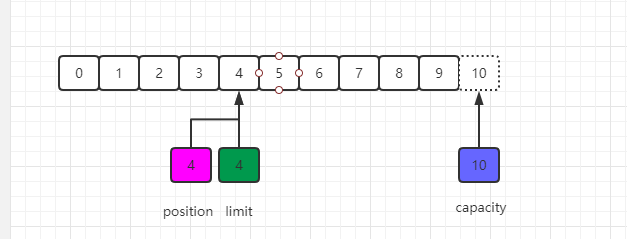
我们可以从通道中读取一些数据到缓冲区中,注意从通道读取数据,相当于往缓冲区中写入数据。如果读取4个自己的数据,则此时position的值为4,即下一个将要被写入的字节索引为4,而limit仍然是10,如下图所示:
-
+
我们可以从通道中读取一些数据到缓冲区中,注意从通道读取数据,相当于往缓冲区中写入数据。如果读取4个自己的数据,则此时position的值为4,即下一个将要被写入的字节索引为4,而limit仍然是10,如下图所示:
-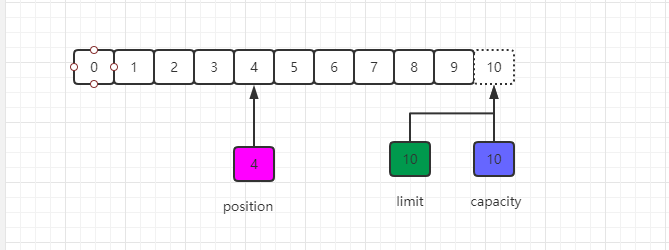 +
下一步把读取的数据写入到输出通道中,相当于从缓冲区中读取数据,在此之前,必去调用flip()方法,该方法将会完成两件事情:
1.将limit设置为当前的position值
@@ -138,10 +139,13 @@ public class BufferDemo {
由于position被设置为0,所以可以保证在下一步输出是读取到的是缓冲区中的第一个字节,而limit被设置为当前的position,可以保证读取的数据正好是之前写入到缓冲区中的数据, 如下图所示:
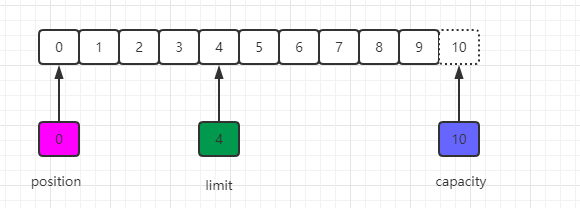
+
现在调用get()方法从缓冲区中读取数据写入到输出通道,这会导致position的增加而limit保持不变,但position不会超过limit的值,所以在读取我们之前写入到缓冲区中的4个自己之后,position和limit的值都为4,如下图所示:
+
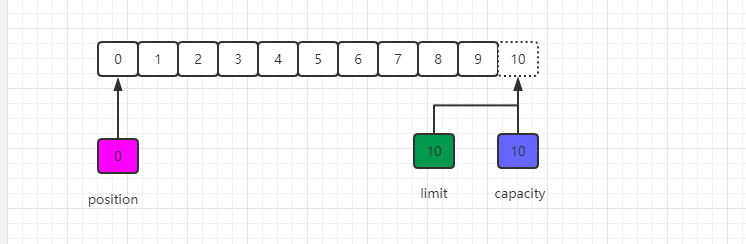
在从缓冲区读取数据完毕后,limit的值仍然保持在我们调用flip()方法的值,调用clear()方法能够把所有的状态变化为初始化的值,如下图所示:
+
### 3.缓冲区的分配
@@ -202,6 +206,7 @@ public class BufferSlice {
```
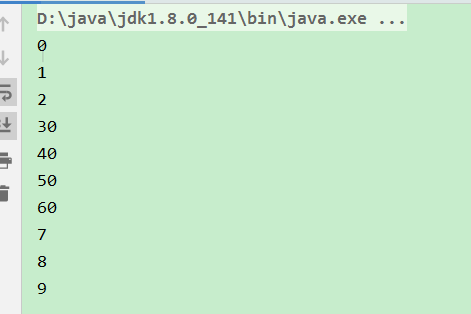
在该示例中,分配了一个容量大小为10的缓冲区,并在其中放入数据0-9,而在该缓冲区基础上又创建一个子缓冲区,并改变子缓冲区的内容,从最后输出的结果来看,只有子缓冲区“可见的”那部分数据发生了变化,并且说明子缓冲区与原缓冲区时数据共享的,输出结果如下所示:
+
### 5.只读缓冲区
@@ -303,7 +308,7 @@ public class MappedBuffer {
## 1.2选择器 Selector
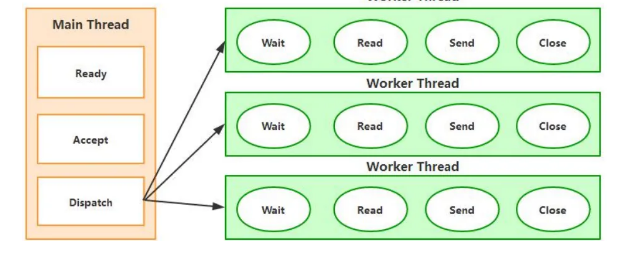
-传统的Server/Client模式基于TPR(Thread Request),服务器会为每个客户请求建立一个线程,由该线程单独负责处理一个客户请求。这种模式带来的一个问题就是线程数量的剧增,大量的线程会增大服务器的开销。大多数的实现为了避免这个问题,都采用了线程池模型,并设置线程池线程的最大数量,这又带来了新的问题,如果线程池中有200个线程,而有200个用户都在进行大文件下载,会导致第201用户的请求无法及时处理,即便第201个用户想请求一个几kb大小的页面,传统的Server/Client模式如下图所示
+传统的Server/Client模式基于TPR(Thread Request),服务器会为每个客户请求建立一个线程,由该线程单独负责处理一个客户请求。这种模式带来的一个问题就是线程数量的剧增,大量的线程会增大服务器的开销。大多数的实现为了避免这个问题,都采用了线程池模型,并设置线程池线程的最大数量,这又带来了新的问题,如果线程池中有200个线程,而有200个用户都在进行大文件下载,会导致第201用户的请求无法及时处理,即便第201个用户想请求一个几kb大小的页面,传统的Server/Client模式如下图所示:
@@ -342,4 +347,6 @@ NIO 中非阻塞 I/O 采用了基于 Reactor 模式的工作方式,I/O 调用
I/O 速度非常慢,而在 Java 1.4 中推出了 NIO,这是一个面向块的 I/O 系统,系统以块的方式处理处理,每一个操作在
一步中产生或者消费一个数据库,按块处理要比按字节处理数据快的多。
-## 1.3 通道Channel
\ No newline at end of file
+## 1.3 通道Channel
+
+todo
\ No newline at end of file
+
下一步把读取的数据写入到输出通道中,相当于从缓冲区中读取数据,在此之前,必去调用flip()方法,该方法将会完成两件事情:
1.将limit设置为当前的position值
@@ -138,10 +139,13 @@ public class BufferDemo {
由于position被设置为0,所以可以保证在下一步输出是读取到的是缓冲区中的第一个字节,而limit被设置为当前的position,可以保证读取的数据正好是之前写入到缓冲区中的数据, 如下图所示:

+
现在调用get()方法从缓冲区中读取数据写入到输出通道,这会导致position的增加而limit保持不变,但position不会超过limit的值,所以在读取我们之前写入到缓冲区中的4个自己之后,position和limit的值都为4,如下图所示:
+

在从缓冲区读取数据完毕后,limit的值仍然保持在我们调用flip()方法的值,调用clear()方法能够把所有的状态变化为初始化的值,如下图所示:
+

### 3.缓冲区的分配
@@ -202,6 +206,7 @@ public class BufferSlice {
```
在该示例中,分配了一个容量大小为10的缓冲区,并在其中放入数据0-9,而在该缓冲区基础上又创建一个子缓冲区,并改变子缓冲区的内容,从最后输出的结果来看,只有子缓冲区“可见的”那部分数据发生了变化,并且说明子缓冲区与原缓冲区时数据共享的,输出结果如下所示:
+

### 5.只读缓冲区
@@ -303,7 +308,7 @@ public class MappedBuffer {
## 1.2选择器 Selector
-传统的Server/Client模式基于TPR(Thread Request),服务器会为每个客户请求建立一个线程,由该线程单独负责处理一个客户请求。这种模式带来的一个问题就是线程数量的剧增,大量的线程会增大服务器的开销。大多数的实现为了避免这个问题,都采用了线程池模型,并设置线程池线程的最大数量,这又带来了新的问题,如果线程池中有200个线程,而有200个用户都在进行大文件下载,会导致第201用户的请求无法及时处理,即便第201个用户想请求一个几kb大小的页面,传统的Server/Client模式如下图所示
+传统的Server/Client模式基于TPR(Thread Request),服务器会为每个客户请求建立一个线程,由该线程单独负责处理一个客户请求。这种模式带来的一个问题就是线程数量的剧增,大量的线程会增大服务器的开销。大多数的实现为了避免这个问题,都采用了线程池模型,并设置线程池线程的最大数量,这又带来了新的问题,如果线程池中有200个线程,而有200个用户都在进行大文件下载,会导致第201用户的请求无法及时处理,即便第201个用户想请求一个几kb大小的页面,传统的Server/Client模式如下图所示:

@@ -342,4 +347,6 @@ NIO 中非阻塞 I/O 采用了基于 Reactor 模式的工作方式,I/O 调用
I/O 速度非常慢,而在 Java 1.4 中推出了 NIO,这是一个面向块的 I/O 系统,系统以块的方式处理处理,每一个操作在
一步中产生或者消费一个数据库,按块处理要比按字节处理数据快的多。
-## 1.3 通道Channel
\ No newline at end of file
+## 1.3 通道Channel
+
+todo
\ No newline at end of file