From ddd53b24ffacda5179a66d01fa61c52b647c6735 Mon Sep 17 00:00:00 2001
From: 01Petard <1520394133@qq.com>
Date: Fri, 8 Nov 2024 21:19:09 +0800
Subject: [PATCH] =?UTF-8?q?doc:=20=E5=A4=87=E4=BB=BD=E6=96=87=E7=AB=A0?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/.vitepress/config.js | 1 +
...- \345\210\206\345\270\203\345\274\217.md" | 354 +++++++++++-----
...06\347\276\244\347\216\257\345\242\203.md" | 389 ++++++++++++++++++
3 files changed, 636 insertions(+), 108 deletions(-)
create mode 100644 "docs/\345\274\200\345\217\221/\346\220\255\345\273\272K8S\351\233\206\347\276\244\347\216\257\345\242\203.md"
diff --git a/docs/.vitepress/config.js b/docs/.vitepress/config.js
index cc4322e..3c16379 100644
--- a/docs/.vitepress/config.js
+++ b/docs/.vitepress/config.js
@@ -68,6 +68,7 @@ export default {
{text: '批量导出zip压缩包和Excel表格', link: '/开发/批量导出zip压缩包和Excel表格'},
{text: '阿里云OSS && 内容安全 Java实现参考代码', link: '/开发/阿里云OSS && 内容安全 Java实现参考代码'},
{text: '抖音评论区设计', link: '/开发/抖音评论区设计'},
+ {text: '搭建K8S集群环境', link: '/开发/搭建K8S集群环境'},
{
text: 'My Java Guide',
collapsed: false,
diff --git "a/docs/\345\274\200\345\217\221/My Java Guide/My Java Guide - \345\210\206\345\270\203\345\274\217.md" "b/docs/\345\274\200\345\217\221/My Java Guide/My Java Guide - \345\210\206\345\270\203\345\274\217.md"
index c9ba6f2..6def22e 100644
--- "a/docs/\345\274\200\345\217\221/My Java Guide/My Java Guide - \345\210\206\345\270\203\345\274\217.md"
+++ "b/docs/\345\274\200\345\217\221/My Java Guide/My Java Guide - \345\210\206\345\270\203\345\274\217.md"
@@ -830,7 +830,7 @@ Xxl-Job 支持多种任务分配策略,可以根据业务需求选择合适的
通过上述方法和技术手段,可以有效地应对大数据量任务的同时执行带来的挑战。
-# --------------分布式架构设计--------------
+# -----------------架构设计-----------------
# 例:讲一下分布式 ID 发号器的原理
@@ -1617,109 +1617,6 @@ public class WebMvcConfiguration extends WebMvcConfigurationSupport {
}
```
-# ------------容器化技术和CI/CD------------
-
-# Docker 的基本概念和工作原理
-
-Docker 是一种开源的容器化平台,允许开发者和运维人员以一致的方式部署应用程序。通过将应用程序及其所有依赖打包到一个单独的容器中,Docker 提供了一种便捷的方式来执行和移动应用程序。这种容器在任何符合所需条件的环境中都能保证其运行一致。
-
-工作原理上,Docker 利用 Linux 容器(LXC)的技术,并通过镜像(Image)、容器(Container)、仓库(Repository)等主要概念来实现应用的生命周期管理。具体来说,开发者首先创建一个 Docker 镜像,镜像是一个只读模板,包含应用程序及其运行所需的所有文件。然后,基于这个镜像,Docker 可以启动一个或多个容器,容器是镜像的运行实例。
-
-# Docker Compose 的主要用途是什么?
-
-Docker Compose 是用于定义和运行多容器 Docker 应用程序的工具。Compose 使用 YAML 文件定义服务、网络和卷,通过一条简单的命令 `docker-compose up` 就可以启动并运行整个配置的应用环境。
-
-举个例子,如果你有一个 web 应用,需要用到 MySQL 数据库,传统上你可能需要分别配置和运行这两个服务。而在 Docker Compose 中,你只需要创建一个 `docker-compose.yml` 文件,定义好 web 服务和 db 服务的配置,然后运行 `docker-compose up` 即可。
-
-# Docker 镜像的构建过程
-
-1. 编写 Dockerfile:其中包含了一系列的指令,描述了如何构建一个 Docker 镜像。
-2. 构建镜像:使用 `docker build` 命令,通过读取 Dockerfile 的内容,逐步执行其中的指令,最终生成一个 Docker 镜像。
-3. 保存镜像:构建完成的镜像会被保存到本地的 Docker 镜像库中,可以使用 `docker images` 命令查看。
-4. 发布镜像:如果需要共享镜像,可以将其推送到 Docker Hub 或其他镜像仓库,使用 `docker push` 命令完成发布。
-5. 使用镜像:最终用户可以使用 `docker run` 命令来启动基于该镜像的容器,完成应用的部署和运行。
-
-# Dockerfile 的作用
-
-1. 描述构建过程:Dockerfile 通过一系列的指令详细描述了构建镜像的步骤,包括基础镜像、环境配置、软件安装等。
-2. 保证一致性:同一个 Dockerfile 可以在不同环境下生成一致的镜像,确保应用运行环境的稳定和一致。
-3. 自动化构建:通过 Dockerfile,可以方便地实现镜像的自动化构建,简化了持续集成和持续部署(CI/CD)过程。
-4. 版本管理:Dockerfile 可以使用版本控制工具进行管理,方便回滚或跟踪更改记录。
-
-# 使用 Dockerfile 创建自定义镜像
-
-1. **编写 Dockerfile**:Dockerfile 是一个文本文件,包含了一系列指令,每个指令用来描述如何构建镜像。通常包括基础镜像的选择、复制文件、安装包以及配置环境等操作。
-2. **构建镜像**:使用 `docker build` 命令来构建镜像。
-
-简单示例:
-
-1. 创建一个名为 `Dockerfile` 的文件,内容如下:
-
-```dockerfile
-# 选择基础镜像
-FROM ubuntu:latest
-
-# 安装一些软件包
-RUN apt-get update && apt-get install -y python3 python3-pip
-
-# 设置工作目录
-WORKDIR /app
-
-# 复制当前目录下的文件到工作目录
-COPY .. /app
-
-# 安装 Python 依赖
-RUN pip3 install -r requirements.txt
-
-# 暴露端口
-EXPOSE 80
-
-# 设置容器启动时默认执行的命令
-CMD ["python3", "app.py"]
-```
-
-2. 运行构建命令,将 Dockerfile 构建为镜像:
-
-```bash
-docker build -t my_custom_image:latest .
-```
-
-# 如何优化容器启动时间?
-
-1. 使用较小的基础镜像:选择精简的基础镜像,例如 `alpine`,或其他定制过的轻量级基础镜像,例如 `scratch`。
-2. 减少镜像层数:每一层都会增加容器启动的开销,精简 Dockerfile,合并多个 `RUN` 命令,将有助于减少层数。
-3. 利用缓存:在构建镜像时尽量利用 Docker 的缓存功能,避免每次都重建镜像。
-4. 适当配置健康检查:配置适当的健康检查策略,让容器可以尽快转为运行状态,而不是卡在启动过程中。
-5. 本地化镜像:将常用的容器镜像保存在本地镜像库中,避免每次启动时从远程仓库拉取。
-
-# 如何实现容器之间的通信?
-
-1. **使用同一个网络:** 将多个容器连接到同一个 Docker 网络中,这样容器之间可以通过容器名称进行互相通信。
-2. **端口映射:** 将容器的端口映射到宿主机的端口,通过宿主机的 IP 和映射的端口进行通信。
-3. **Docker Compose:** 使用 Docker Compose 来编排多个服务,可以为每个服务定义网络,并对网络进行配置。
-4. **共享网络命名空间:** 通过创建共享网络命名空间的方式,使多个容器共享网络设置。
-
-## 如何实现资源限制?
-
-1. 为了限制容器使用的 CPU 数量,可以使用 `--cpu-shares` 或 `--cpus` 参数。
- - `--cpu-shares`:使用相对权重方式分配 CPU 资源。
- - `--cpus`:直接指定容器可使用的 CPU 核数。
-2. 为了限制容器使用的内存量,可以使用 `-m` 或 `--memory` 参数。
- - `--memory`:指定容器最大内存限制。
-
-举个简单的例子,如果我们希望某个容器最多使用一个CPU核心和 512MB 内存,可以使用以下命令:
-
-```shell
-docker run --cpus=1 --memory=512m [container_name]
-```
-
-# 如何使用 Jenkins 与 Docker 集成?
-
-1. 安装必要的插件:在 Jenkins 中,安装 Docker plugin 和 Pipeline plugin 等必要插件。
-2. 配置 Jenkins:配置环境,确保 Jenkins 可以访问 Docker 命令。
-3. 创建 Jenkins Pipeline:在 Jenkins 中创建一个 Pipeline 项目,并在 Pipeline Script 中编写构建、测试和部署的脚本,通常使用 Jenkinsfile。
-4. 运行与监控:配置好所有步骤后,运行 Pipeline 并监控执行过程,确保一切正常工作。
-
# ------------------消息队列------------------
# AMQP协议
@@ -1923,8 +1820,6 @@ AMQP 消息通常包含以下几个部分:
- **定义**:分区的备份,用于提高系统的可靠性和可用性。
- **用途**:当Leader失效时,可以切换到其他Replica继续提供服务。
-# ------------消息队列的底层设计------------
-
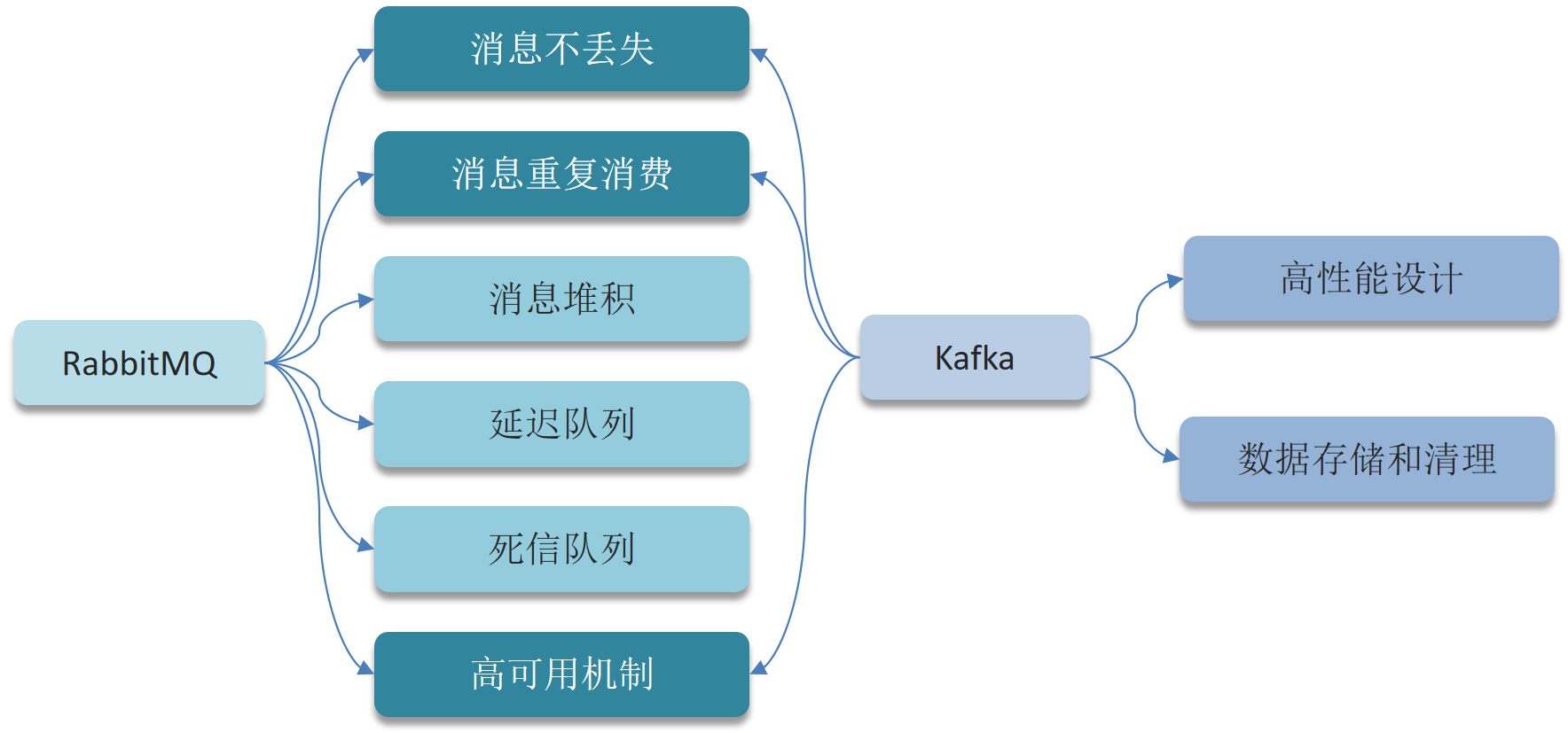 # 高可用设计
@@ -2645,8 +2540,6 @@ Netty中的参考计数(Reference Counting)是Netty为了管理内存而采
Netty通过使用`Selector`的`poll`方法,并结合`EventLoop`进行优化,避免了空轮询的情况。它会在没有事件时进行适当的休眠,减少CPU资源的浪费。
-#
# 高可用设计
@@ -2645,8 +2540,6 @@ Netty中的参考计数(Reference Counting)是Netty为了管理内存而采
Netty通过使用`Selector`的`poll`方法,并结合`EventLoop`进行优化,避免了空轮询的情况。它会在没有事件时进行适当的休眠,减少CPU资源的浪费。
-# ---------------*Netty底层原理*---------------
-
# Channel、ChannelHandlerContext
- **Channel**:表示一个连接,可以是服务器端或客户端的`SocketChannel`,它负责数据的读写。
@@ -2814,3 +2707,248 @@ Netty中的Future和Promise是用于处理异步操作的结果和状态的。
3)多继承
抽象类只能单继承,接口可以有多个实现。
+
+# ------------容器化技术和CI/CD------------
+
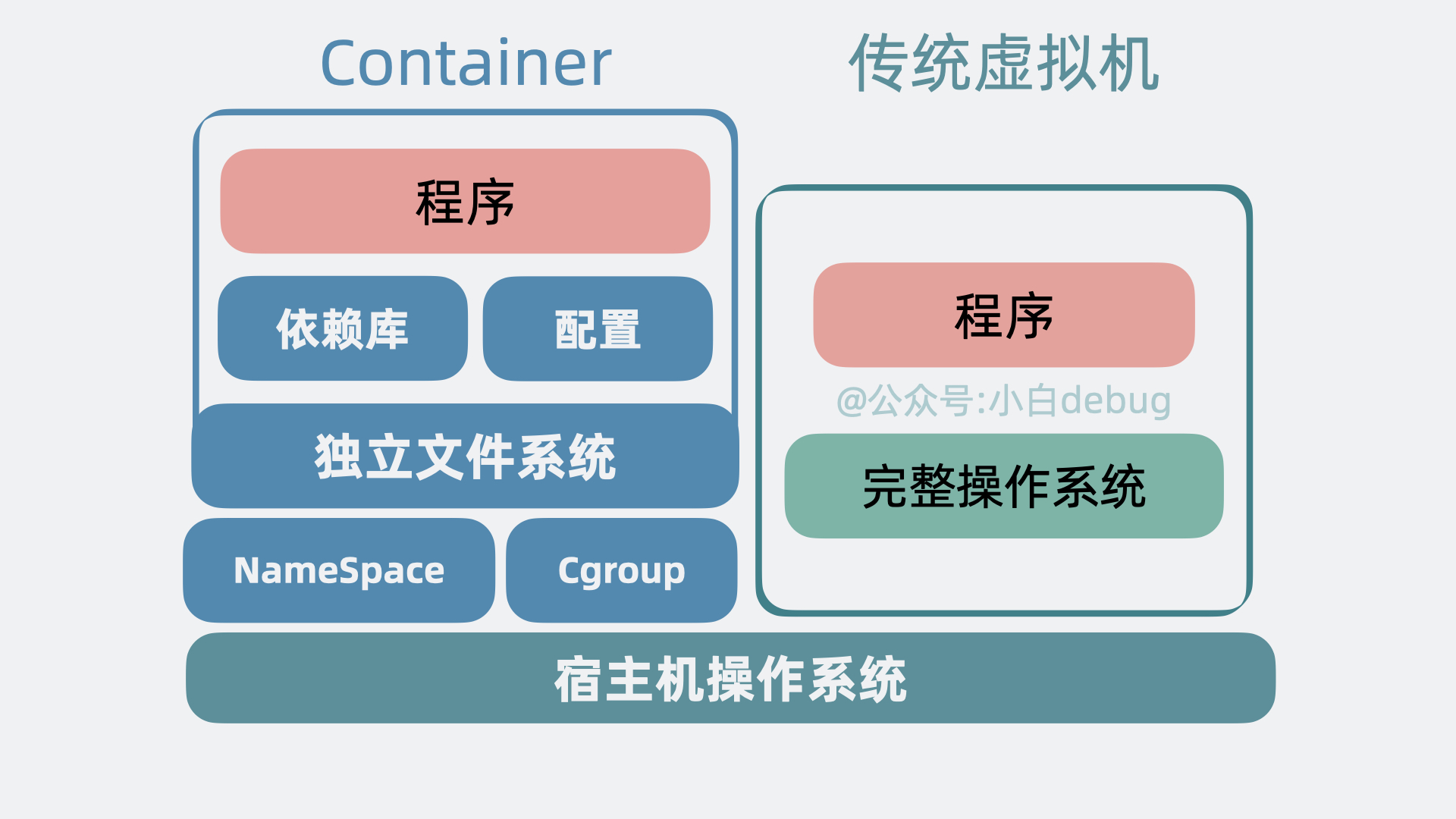
+# Docker 的基本概念和工作原理
+
+Docker 是一种开源的容器化平台,允许开发者和运维人员以一致的方式部署应用程序。通过将应用程序及其所有依赖打包到一个单独的容器中,Docker 提供了一种便捷的方式来执行和移动应用程序。这种容器在任何符合所需条件的环境中都能保证其运行一致。
+
+工作原理上,Docker 利用 Linux 容器(LXC)的技术,并通过镜像(Image)、容器(Container)、仓库(Repository)等主要概念来实现应用的生命周期管理。具体来说,开发者首先创建一个 Docker 镜像,镜像是一个只读模板,包含应用程序及其运行所需的所有文件。然后,基于这个镜像,Docker 可以启动一个或多个容器,容器是镜像的运行实例。
+
+# Docker Compose 的主要用途是什么?
+
+Docker Compose 是用于定义和运行多容器 Docker 应用程序的工具。Compose 使用 YAML 文件定义服务、网络和卷,通过一条简单的命令 `docker-compose up` 就可以启动并运行整个配置的应用环境。
+
+举个例子,如果你有一个 web 应用,需要用到 MySQL 数据库,传统上你可能需要分别配置和运行这两个服务。而在 Docker Compose 中,你只需要创建一个 `docker-compose.yml` 文件,定义好 web 服务和 db 服务的配置,然后运行 `docker-compose up` 即可。
+
+# Docker 镜像的构建过程
+
+1. 编写 Dockerfile:其中包含了一系列的指令,描述了如何构建一个 Docker 镜像。
+2. 构建镜像:使用 `docker build` 命令,通过读取 Dockerfile 的内容,逐步执行其中的指令,最终生成一个 Docker 镜像。
+3. 保存镜像:构建完成的镜像会被保存到本地的 Docker 镜像库中,可以使用 `docker images` 命令查看。
+4. 发布镜像:如果需要共享镜像,可以将其推送到 Docker Hub 或其他镜像仓库,使用 `docker push` 命令完成发布。
+5. 使用镜像:最终用户可以使用 `docker run` 命令来启动基于该镜像的容器,完成应用的部署和运行。
+
+# Dockerfile 的作用
+
+1. 描述构建过程:Dockerfile 通过一系列的指令详细描述了构建镜像的步骤,包括基础镜像、环境配置、软件安装等。
+2. 保证一致性:同一个 Dockerfile 可以在不同环境下生成一致的镜像,确保应用运行环境的稳定和一致。
+3. 自动化构建:通过 Dockerfile,可以方便地实现镜像的自动化构建,简化了持续集成和持续部署(CI/CD)过程。
+4. 版本管理:Dockerfile 可以使用版本控制工具进行管理,方便回滚或跟踪更改记录。
+
+# 使用 Dockerfile 创建自定义镜像
+
+1. **编写 Dockerfile**:Dockerfile 是一个文本文件,包含了一系列指令,每个指令用来描述如何构建镜像。通常包括基础镜像的选择、复制文件、安装包以及配置环境等操作。
+2. **构建镜像**:使用 `docker build` 命令来构建镜像。
+
+简单示例:
+
+1. 创建一个名为 `Dockerfile` 的文件,内容如下:
+
+```dockerfile
+# 选择基础镜像
+FROM ubuntu:latest
+
+# 安装一些软件包
+RUN apt-get update && apt-get install -y python3 python3-pip
+
+# 设置工作目录
+WORKDIR /app
+
+# 复制当前目录下的文件到工作目录
+COPY .. /app
+
+# 安装 Python 依赖
+RUN pip3 install -r requirements.txt
+
+# 暴露端口
+EXPOSE 80
+
+# 设置容器启动时默认执行的命令
+CMD ["python3", "app.py"]
+```
+
+2. 运行构建命令,将 Dockerfile 构建为镜像:
+
+```bash
+docker build -t my_custom_image:latest .
+```
+
+# 如何优化容器启动时间?
+
+1. 使用较小的基础镜像:选择精简的基础镜像,例如 `alpine`,或其他定制过的轻量级基础镜像,例如 `scratch`。
+2. 减少镜像层数:每一层都会增加容器启动的开销,精简 Dockerfile,合并多个 `RUN` 命令,将有助于减少层数。
+3. 利用缓存:在构建镜像时尽量利用 Docker 的缓存功能,避免每次都重建镜像。
+4. 适当配置健康检查:配置适当的健康检查策略,让容器可以尽快转为运行状态,而不是卡在启动过程中。
+5. 本地化镜像:将常用的容器镜像保存在本地镜像库中,避免每次启动时从远程仓库拉取。
+
+# 如何实现容器之间的通信?
+
+1. **使用同一个网络:** 将多个容器连接到同一个 Docker 网络中,这样容器之间可以通过容器名称进行互相通信。
+2. **端口映射:** 将容器的端口映射到宿主机的端口,通过宿主机的 IP 和映射的端口进行通信。
+3. **Docker Compose:** 使用 Docker Compose 来编排多个服务,可以为每个服务定义网络,并对网络进行配置。
+4. **共享网络命名空间:** 通过创建共享网络命名空间的方式,使多个容器共享网络设置。
+
+## 如何实现资源限制?
+
+1. 为了限制容器使用的 CPU 数量,可以使用 `--cpu-shares` 或 `--cpus` 参数。
+ - `--cpu-shares`:使用相对权重方式分配 CPU 资源。
+ - `--cpus`:直接指定容器可使用的 CPU 核数。
+2. 为了限制容器使用的内存量,可以使用 `-m` 或 `--memory` 参数。
+ - `--memory`:指定容器最大内存限制。
+
+举个简单的例子,如果我们希望某个容器最多使用一个CPU核心和 512MB 内存,可以使用以下命令:
+
+```shell
+docker run --cpus=1 --memory=512m [container_name]
+```
+
+# 如何使用 Jenkins 与 Docker 集成?
+
+1. 安装必要的插件:在 Jenkins 中,安装 Docker plugin 和 Pipeline plugin 等必要插件。
+2. 配置 Jenkins:配置环境,确保 Jenkins 可以访问 Docker 命令。
+3. 创建 Jenkins Pipeline:在 Jenkins 中创建一个 Pipeline 项目,并在 Pipeline Script 中编写构建、测试和部署的脚本,通常使用 Jenkinsfile。
+4. 运行与监控:配置好所有步骤后,运行 Pipeline 并监控执行过程,确保一切正常工作。
+
+# ----------------容器编排引擎----------------
+
+# Kubernetes 是什么?
+
+Kubernetes,它是 **Google **开源的神器,它介于**应用服务**和**服务器**之间,能够通过策略,协调和管理多个应用服务,只需要一个 **yaml** 文件配置,定义应用的部署顺序等信息,就能自动部署应用到各个服务器上,还能让它们挂了自动重启,自动扩缩容。
+
+# Kubernetes 解决的问题
+
+ +
+随着**应用服务变多**,需求也千奇百怪。有的应用服务不希望被外网访问到,有的部署的时候要求内存得大于 xxGB 才能正常跑。
+你每次都需要登录到各个服务器上,执行**手动**操作更新。不仅容易出错,还贼**浪费时间**。那么问题就来了,有没有一个办法,可以解决上面的问题?当然有,**没有什么是加一个中间层不能解决的,如果有,那就再加一层**。这次要加的中间层,叫 **Kubernetes**。
+
+
+
+随着**应用服务变多**,需求也千奇百怪。有的应用服务不希望被外网访问到,有的部署的时候要求内存得大于 xxGB 才能正常跑。
+你每次都需要登录到各个服务器上,执行**手动**操作更新。不仅容易出错,还贼**浪费时间**。那么问题就来了,有没有一个办法,可以解决上面的问题?当然有,**没有什么是加一个中间层不能解决的,如果有,那就再加一层**。这次要加的中间层,叫 **Kubernetes**。
+
+ +
+# 为什么要用 Kubernetes ?
+
+在[Kubernetes](https://kubernetes.io/)出现之前,我们一般都是使用Docker来管理容器化的应用。
+
+但是Docker只是一个单机的容器管理工具,它只能管理单个节点上的容器,当我们的应用程序需要运行在多个节点上的时候,就需要使用一些其他的工具来管理这些节点,比如Docker Swarm、Mesos、[Kubernetes](https://kubernetes.io/)等等。
+
+这些工具都是容器编排引擎,它们可以用来管理多个节点上的容器,但是它们之间也有一些区别:
+
+- Docker Swarm是Docker官方提供的一个容器编排引擎,它的功能比较简单,适合于一些小型的、简单的场景
+- Mesos和[Kubernetes](https://kubernetes.io/)则是比较复杂的容器编排引擎,Mesos是Apache基金会的一个开源项目
+- [Kubernetes](https://kubernetes.io/)是Google在2014年开源的,目前已经成为了CNCF(Cloud Native Computing Foundation)的一个顶级项目,基本上已经成为了容器编排引擎的事实标准了。
+
+# Kunbernetes 与 Docker之间的关系
+
+Kubernetes 与 Docker 之间的关系可以概括为互补关系,两者在容器化技术的不同层面发挥作用。
+
+## Docker
+
+Docker 是一个开源的容器化平台,它允许开发人员将应用程序及其依赖项打包到一个可移植的容器中,确保这些容器可以在任何支持 Docker 的环境中一致地运行。Docker 解决了开发、测试和生产环境之间的一致性问题,使得应用程序的开发、测试和部署过程更加一致和可靠。Docker 的主要组成部分包括:
+
+- **镜像**:包含了应用程序及其所需的所有依赖项的快照。
+- **容器**:基于镜像运行的实例,提供了一个隔离的环境来运行应用程序。
+- **仓库**:存储和分享镜像的地方,如 Docker Hub。
+
+## Kubernetes
+
+Kubernetes 是一个开源的容器编排系统,它用于自动化部署、扩展和管理容器化应用程序。Kubernetes 提供了一系列强大的功能,比如服务发现、负载均衡、滚动更新、自动恢复等,使得开发人员可以更加轻松地构建、部署和管理大规模容器化应用程序。Kubernetes 的核心概念包括:
+
+- **Pod**:Kubernetes 中最小的部署单位,它可以包含一个或多个容器,这些容器共享存储、网络等资源。
+- **Service**:一种抽象,定义了一组逻辑上的 Pod 和访问策略。
+- **Deployment**:用于管理应用程序的副本,确保指定数量的 Pod 始终处于运行状态。
+- **StatefulSet**:用于管理有状态的应用程序,保证每个 Pod 的唯一身份。
+
+## 关系
+
+1. **互补性**:Docker 和 Kubernetes 各自解决了容器化技术的不同方面。Docker 专注于单个容器的生命周期管理,而 Kubernetes 则关注多个容器的组织、管理和调度。
+2. **集成**:虽然 Kubernetes 可以使用多种容器运行时(如 containerd、CRI-O 等),但 Docker 是最常用的容器运行时之一。Kubernetes 可以直接使用 Docker 镜像,并通过其 Pod 概念管理 Docker 容器。
+3. **生态系统**:两者都拥有庞大的生态系统和社区支持,共同推动了容器技术的发展。
+
+## 实际应用
+
+在实际应用中,开发人员通常会使用 Docker 来构建和打包应用程序,然后使用 Kubernetes 来部署和管理这些容器化应用程序。这种结合使用的方式可以充分利用 Docker 和 Kubernetes 的各自优势,提高应用程序的开发、测试和部署效率。
+
+总之,Kubernetes 和 Docker 之间是互补而非竞争的关系。它们共同构成了现代云原生应用开发和部署的重要基石。
+
+
+
+# 为什么要用 Kubernetes ?
+
+在[Kubernetes](https://kubernetes.io/)出现之前,我们一般都是使用Docker来管理容器化的应用。
+
+但是Docker只是一个单机的容器管理工具,它只能管理单个节点上的容器,当我们的应用程序需要运行在多个节点上的时候,就需要使用一些其他的工具来管理这些节点,比如Docker Swarm、Mesos、[Kubernetes](https://kubernetes.io/)等等。
+
+这些工具都是容器编排引擎,它们可以用来管理多个节点上的容器,但是它们之间也有一些区别:
+
+- Docker Swarm是Docker官方提供的一个容器编排引擎,它的功能比较简单,适合于一些小型的、简单的场景
+- Mesos和[Kubernetes](https://kubernetes.io/)则是比较复杂的容器编排引擎,Mesos是Apache基金会的一个开源项目
+- [Kubernetes](https://kubernetes.io/)是Google在2014年开源的,目前已经成为了CNCF(Cloud Native Computing Foundation)的一个顶级项目,基本上已经成为了容器编排引擎的事实标准了。
+
+# Kunbernetes 与 Docker之间的关系
+
+Kubernetes 与 Docker 之间的关系可以概括为互补关系,两者在容器化技术的不同层面发挥作用。
+
+## Docker
+
+Docker 是一个开源的容器化平台,它允许开发人员将应用程序及其依赖项打包到一个可移植的容器中,确保这些容器可以在任何支持 Docker 的环境中一致地运行。Docker 解决了开发、测试和生产环境之间的一致性问题,使得应用程序的开发、测试和部署过程更加一致和可靠。Docker 的主要组成部分包括:
+
+- **镜像**:包含了应用程序及其所需的所有依赖项的快照。
+- **容器**:基于镜像运行的实例,提供了一个隔离的环境来运行应用程序。
+- **仓库**:存储和分享镜像的地方,如 Docker Hub。
+
+## Kubernetes
+
+Kubernetes 是一个开源的容器编排系统,它用于自动化部署、扩展和管理容器化应用程序。Kubernetes 提供了一系列强大的功能,比如服务发现、负载均衡、滚动更新、自动恢复等,使得开发人员可以更加轻松地构建、部署和管理大规模容器化应用程序。Kubernetes 的核心概念包括:
+
+- **Pod**:Kubernetes 中最小的部署单位,它可以包含一个或多个容器,这些容器共享存储、网络等资源。
+- **Service**:一种抽象,定义了一组逻辑上的 Pod 和访问策略。
+- **Deployment**:用于管理应用程序的副本,确保指定数量的 Pod 始终处于运行状态。
+- **StatefulSet**:用于管理有状态的应用程序,保证每个 Pod 的唯一身份。
+
+## 关系
+
+1. **互补性**:Docker 和 Kubernetes 各自解决了容器化技术的不同方面。Docker 专注于单个容器的生命周期管理,而 Kubernetes 则关注多个容器的组织、管理和调度。
+2. **集成**:虽然 Kubernetes 可以使用多种容器运行时(如 containerd、CRI-O 等),但 Docker 是最常用的容器运行时之一。Kubernetes 可以直接使用 Docker 镜像,并通过其 Pod 概念管理 Docker 容器。
+3. **生态系统**:两者都拥有庞大的生态系统和社区支持,共同推动了容器技术的发展。
+
+## 实际应用
+
+在实际应用中,开发人员通常会使用 Docker 来构建和打包应用程序,然后使用 Kubernetes 来部署和管理这些容器化应用程序。这种结合使用的方式可以充分利用 Docker 和 Kubernetes 的各自优势,提高应用程序的开发、测试和部署效率。
+
+总之,Kubernetes 和 Docker 之间是互补而非竞争的关系。它们共同构成了现代云原生应用开发和部署的重要基石。
+
+ +
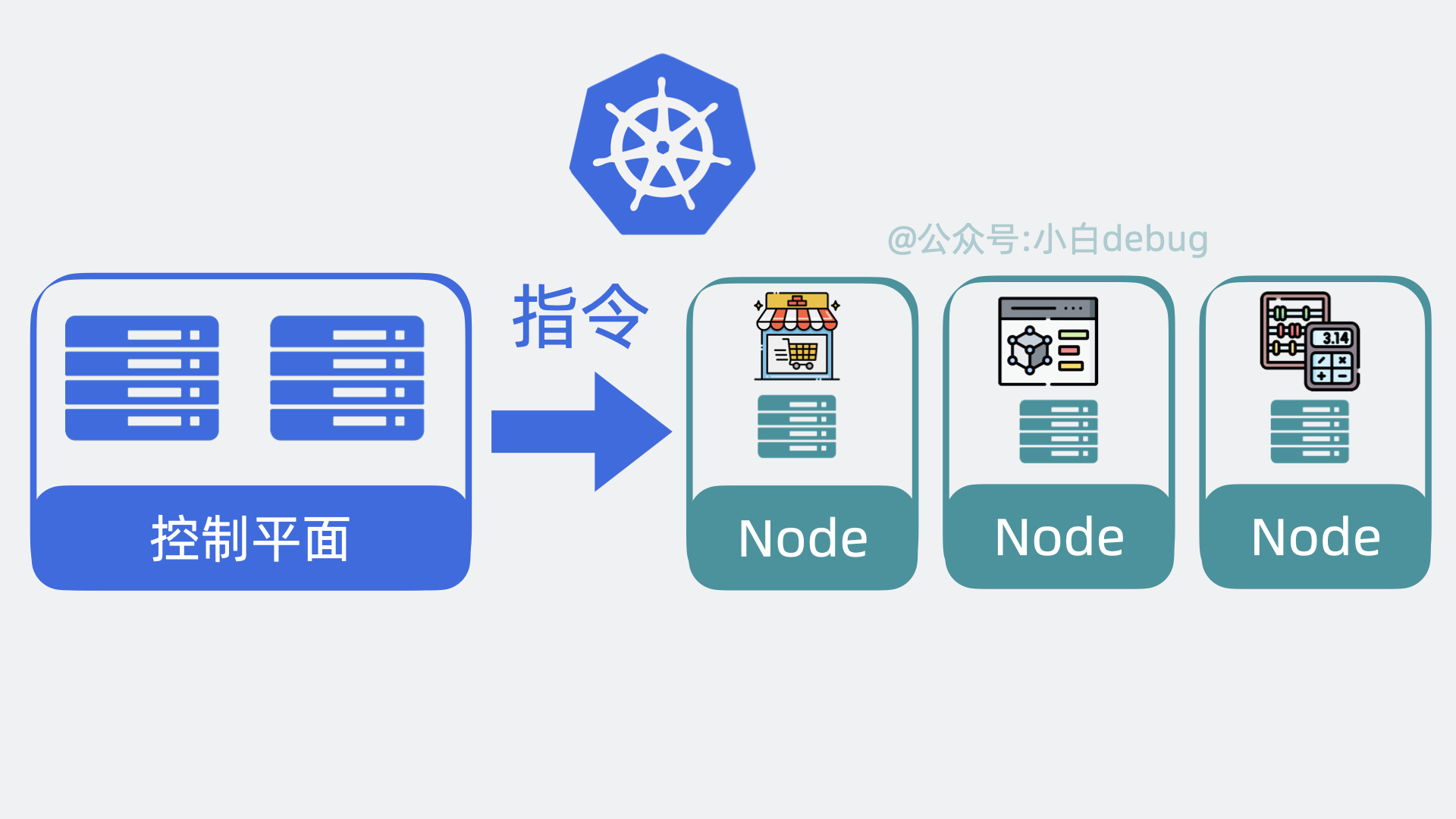
+# Kubernetes 架构原理
+
+为了实现上面的功能,Kubernetes 会将我们的服务器划为两部分,一部分叫**控制平面**(control plane,以前叫master),另一部分叫**工作节点**,也就是 **Node**。简单来说它们的关系就是老板和打工人, 用现在流行的说法就是训练师和帕鲁。控制平面负责控制和管理各个 Node,而 Node 则负责实际运行各个应用服务。
+
+
+
+# Kubernetes 架构原理
+
+为了实现上面的功能,Kubernetes 会将我们的服务器划为两部分,一部分叫**控制平面**(control plane,以前叫master),另一部分叫**工作节点**,也就是 **Node**。简单来说它们的关系就是老板和打工人, 用现在流行的说法就是训练师和帕鲁。控制平面负责控制和管理各个 Node,而 Node 则负责实际运行各个应用服务。
+
+ +
+我们依次看下这两者的内部架构。
+
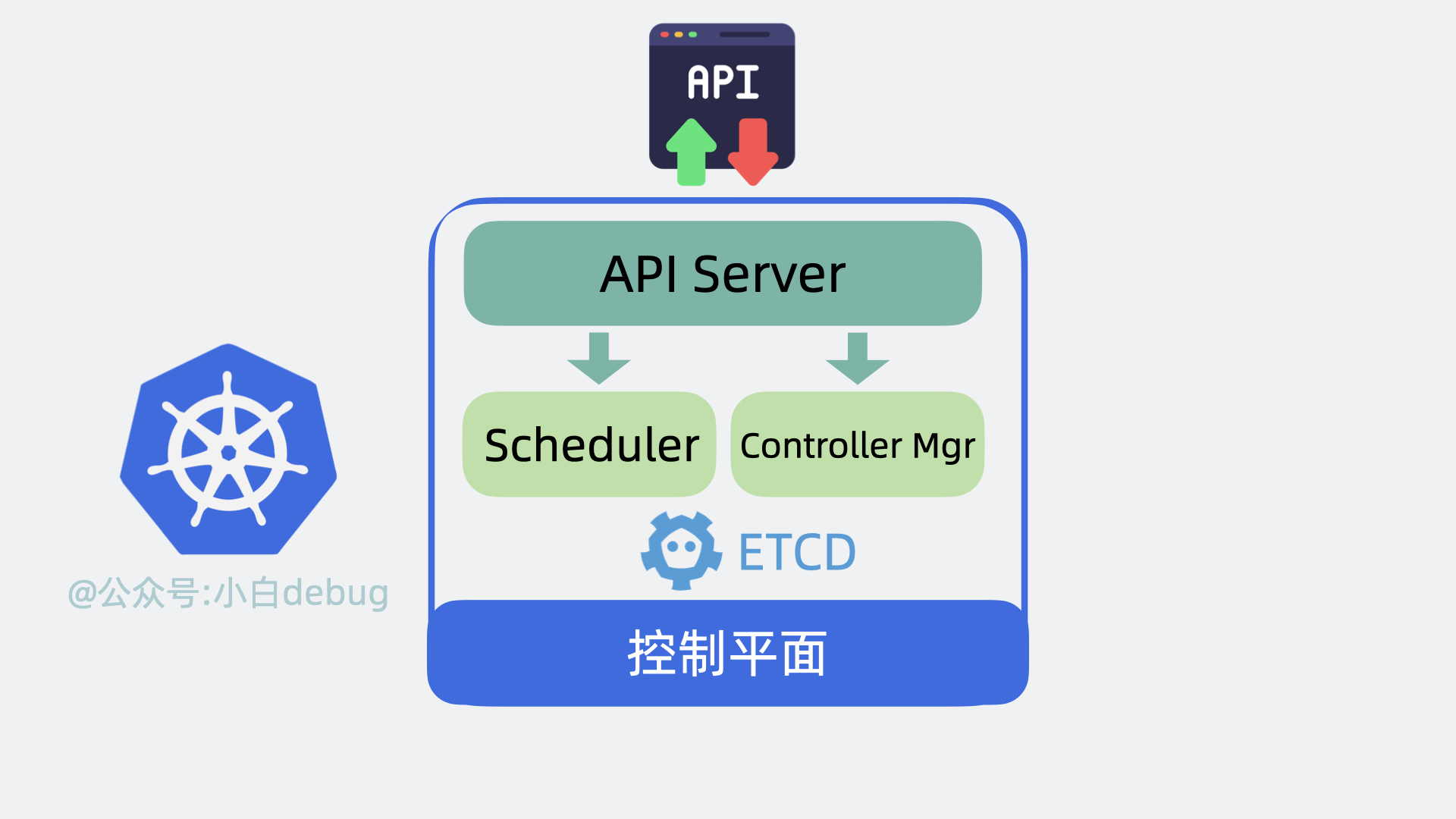
+## 控制平面内部组件
+
+- 以前我们需要登录到每台服务器上,手动执行各种命令,现在我们只需要调用 k8s 的提供的 api 接口,就能操作这些服务资源,这些接口都由 **API Server** 组件提供。
+- 以前我们需要到处看下哪台服务器 cpu 和内存资源充足,然后才能部署应用,现在这部分决策逻辑由 **Scheduler**(调度器)来完成。
+- 找到服务器后,以前我们会手动创建,关闭服务,现在这部分功能由 **Controller Manager**(控制器管理器)来负责。
+- 上面的功能都会产生一些数据,这些数据需要被保存起来,方便后续做逻辑,因此 k8s 还会需要一个**存储层**,用来存放各种数据信息,目前是用的 **etcd**,这部分源码实现的很解耦,后续可能会扩展支持其他中间件。
+
+以上就是控制平面内部的组件。
+
+
+
+我们依次看下这两者的内部架构。
+
+## 控制平面内部组件
+
+- 以前我们需要登录到每台服务器上,手动执行各种命令,现在我们只需要调用 k8s 的提供的 api 接口,就能操作这些服务资源,这些接口都由 **API Server** 组件提供。
+- 以前我们需要到处看下哪台服务器 cpu 和内存资源充足,然后才能部署应用,现在这部分决策逻辑由 **Scheduler**(调度器)来完成。
+- 找到服务器后,以前我们会手动创建,关闭服务,现在这部分功能由 **Controller Manager**(控制器管理器)来负责。
+- 上面的功能都会产生一些数据,这些数据需要被保存起来,方便后续做逻辑,因此 k8s 还会需要一个**存储层**,用来存放各种数据信息,目前是用的 **etcd**,这部分源码实现的很解耦,后续可能会扩展支持其他中间件。
+
+以上就是控制平面内部的组件。
+
+ +
+我们接下来再看看 Node 里有哪些组件。
+
+## Node 内部组件
+
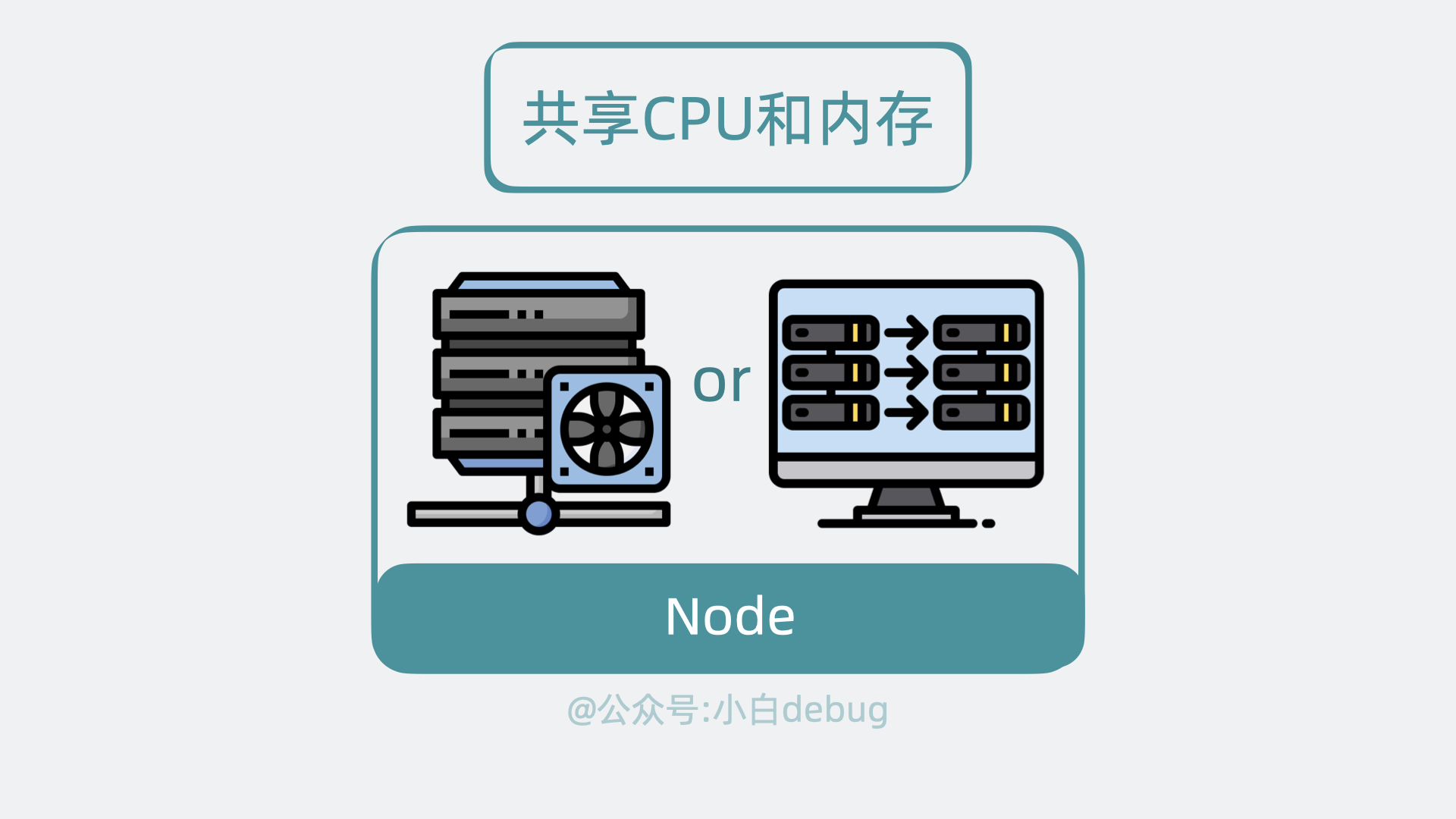
+Node 是实际的工作节点,它既可以是**裸机服务器**,也可以是**虚拟机**。它会负责实际运行各个应用服务。多个应用服务**共享**一台 Node 上的内存和 CPU 等计算资源。
+
+
+
+我们接下来再看看 Node 里有哪些组件。
+
+## Node 内部组件
+
+Node 是实际的工作节点,它既可以是**裸机服务器**,也可以是**虚拟机**。它会负责实际运行各个应用服务。多个应用服务**共享**一台 Node 上的内存和 CPU 等计算资源。
+
+ +
+在文章开头,我们聊到了部署多个应用服务的场景。以前我们需要上传代码到服务器,而用了 k8s 之后,我们只需要将服务代码打包成**Container Image**(容器镜像),就能一行命令将它部署。
+
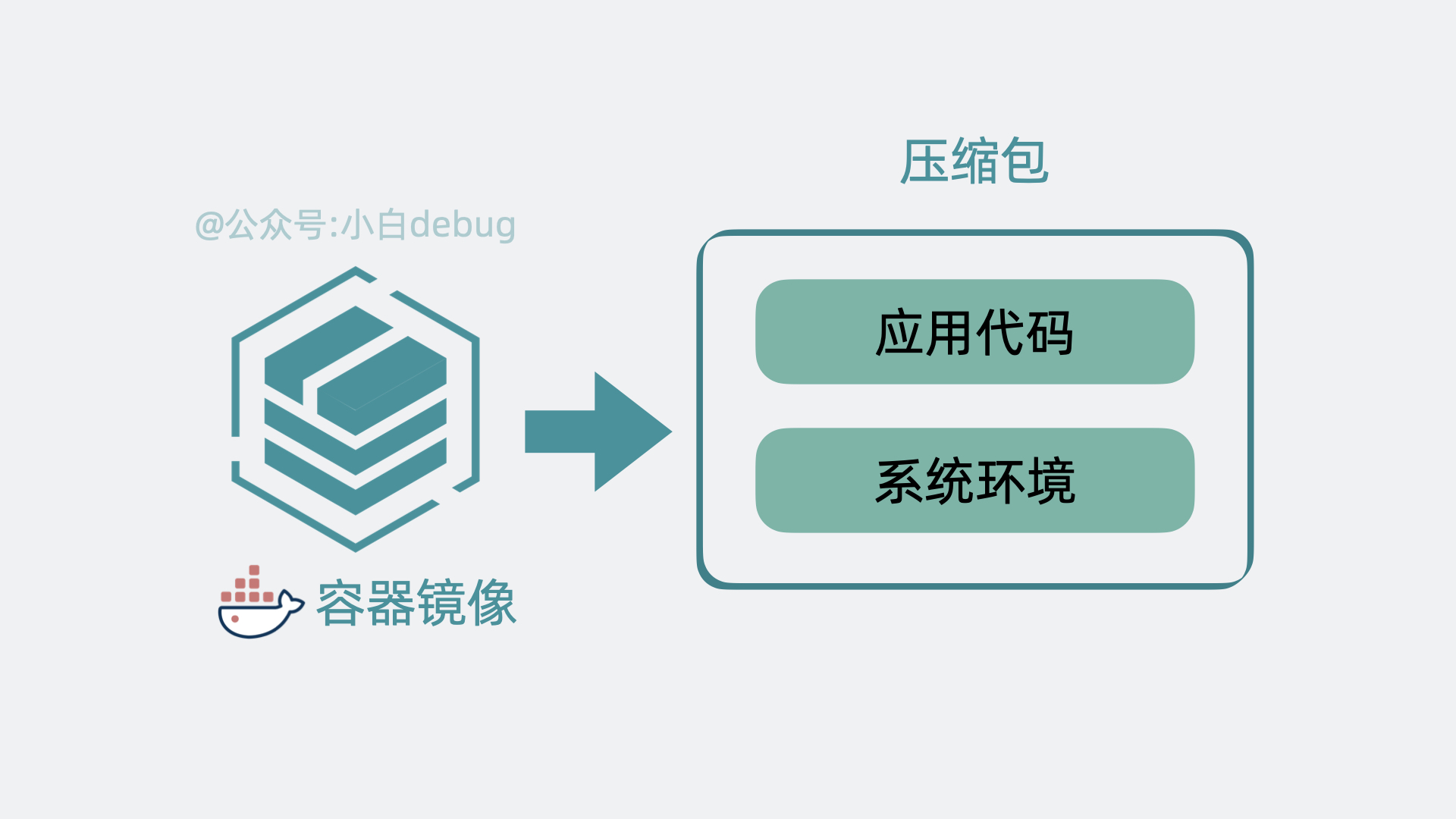
+如果你不了解容器镜像的含义,你可以简单理解为它其实就是将**应用代码**和依赖的**系统环境**打了个压缩包,在任意一台机器上解压这个压缩包,就能正常运行服务。为了下载和部署镜像,Node 中会有一个 **Container runtime** 组件。
+
+
+
+在文章开头,我们聊到了部署多个应用服务的场景。以前我们需要上传代码到服务器,而用了 k8s 之后,我们只需要将服务代码打包成**Container Image**(容器镜像),就能一行命令将它部署。
+
+如果你不了解容器镜像的含义,你可以简单理解为它其实就是将**应用代码**和依赖的**系统环境**打了个压缩包,在任意一台机器上解压这个压缩包,就能正常运行服务。为了下载和部署镜像,Node 中会有一个 **Container runtime** 组件。
+
+ +
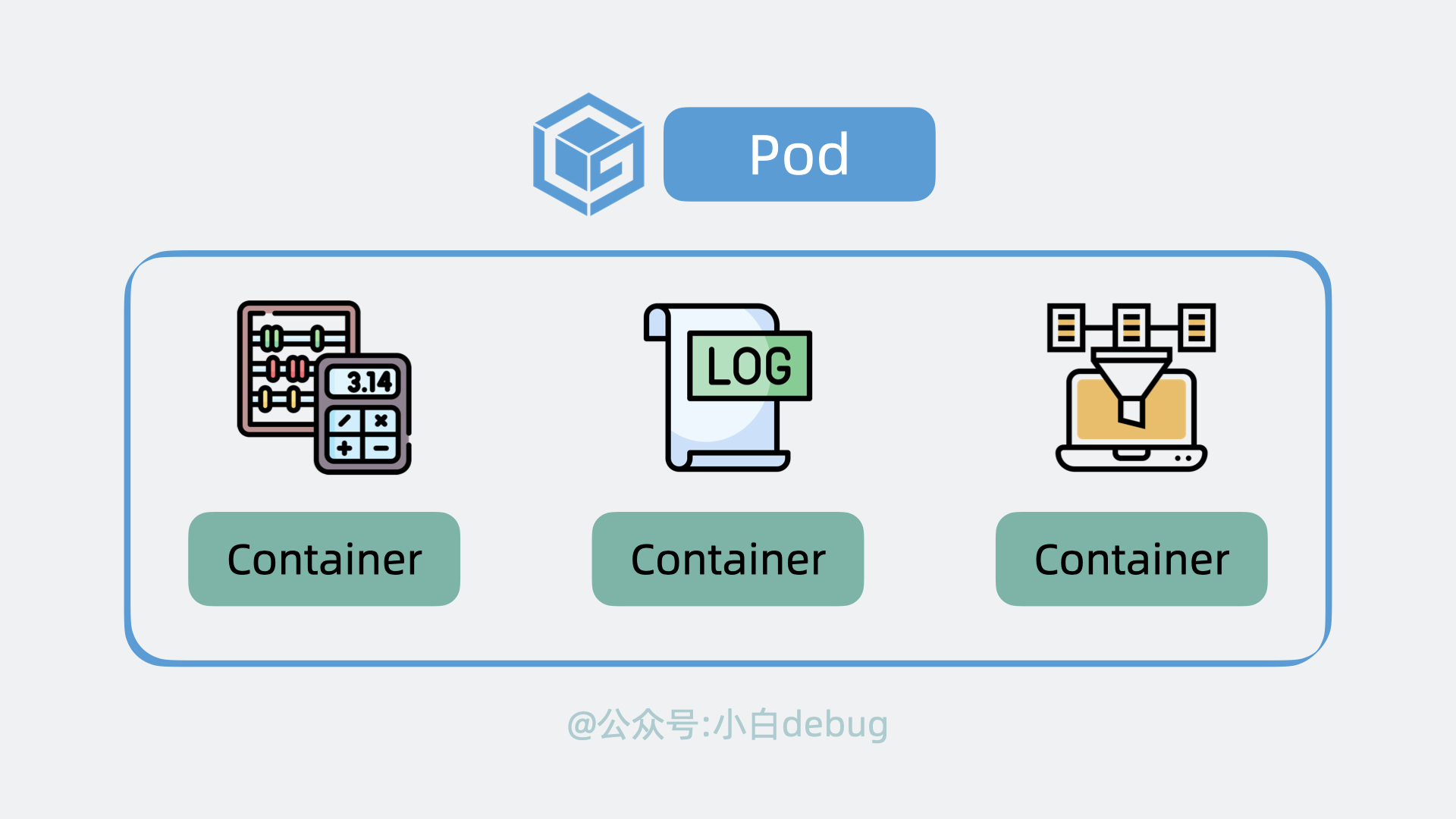
+每个应用服务都可以认为是一个 **Container**(容器), 并且大多数时候,我们还会为应用服务搭配一个日志收集器 Container 或监控收集器 Container,多个 Container 共同组成一个一个 **Pod**,它运行在 Node 上。
+
+
+
+每个应用服务都可以认为是一个 **Container**(容器), 并且大多数时候,我们还会为应用服务搭配一个日志收集器 Container 或监控收集器 Container,多个 Container 共同组成一个一个 **Pod**,它运行在 Node 上。
+
+ +
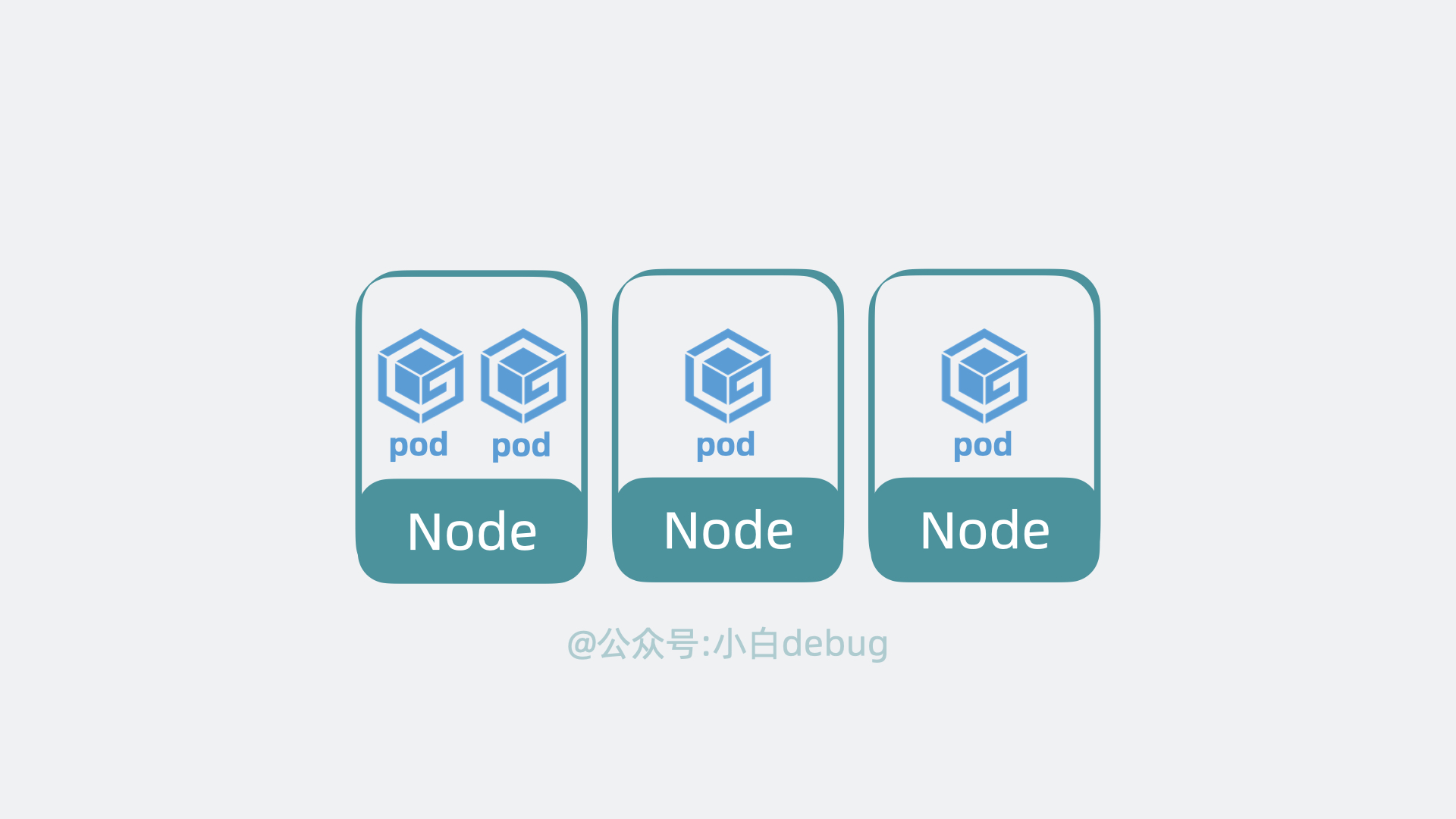
+k8s 可以将 pod 从某个 Node 调度到另一个 Node,还能以 pod 为单位去做重启和动态扩缩容的操作。
+所以说 **Pod 是 k8s 中最小的调度单位**。
+
+
+
+k8s 可以将 pod 从某个 Node 调度到另一个 Node,还能以 pod 为单位去做重启和动态扩缩容的操作。
+所以说 **Pod 是 k8s 中最小的调度单位**。
+
+ +
+另外,前面提到控制平面会用 **Controller Manager** (通过API Server)控制 Node 创建和关闭服务,那 Node 也得有个组件能接收到这个命令才能去做这些动作,这个组件叫 **kubelet**,它主要负责管理和监控 Pod。最后,Node 中还有个 **Kube Proxy** ,它负责 Node 的网络通信功能,有了它,外部请求就能被转发到 Pod 内。
+
+
+
+另外,前面提到控制平面会用 **Controller Manager** (通过API Server)控制 Node 创建和关闭服务,那 Node 也得有个组件能接收到这个命令才能去做这些动作,这个组件叫 **kubelet**,它主要负责管理和监控 Pod。最后,Node 中还有个 **Kube Proxy** ,它负责 Node 的网络通信功能,有了它,外部请求就能被转发到 Pod 内。
+
+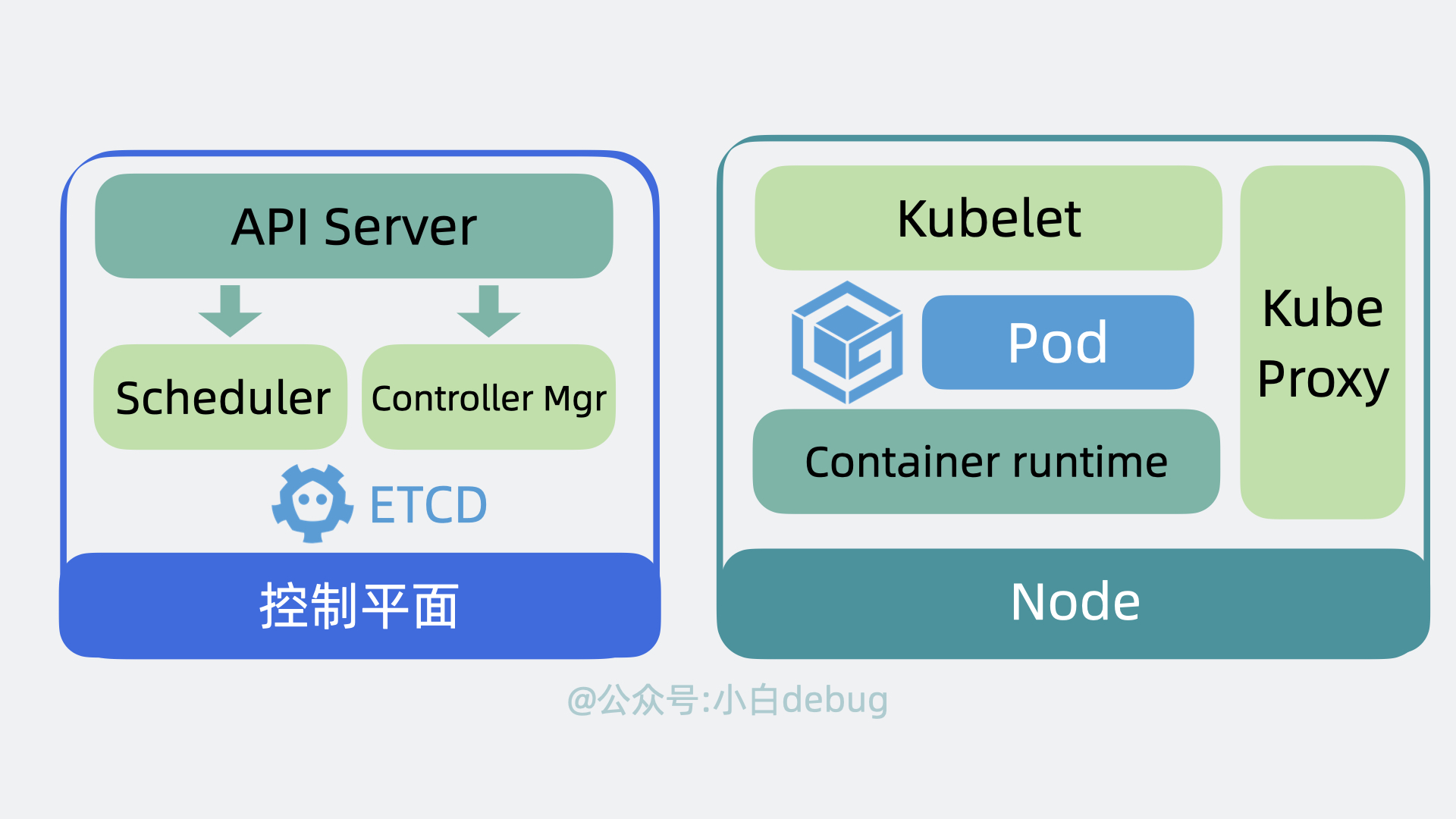 +
+# Cluster
+
+**控制平面和Node** 共同构成了一个 **Cluster**,也就是**集群**。在公司里,我们一般会构建多个集群, 比如测试环境用一个集群,生产环境用另外一个集群。同时,为了将集群内部的服务暴露给外部用户使用,我们一般还会部署一个入口控制器,比如 **Ingress 控制器(比如Nginx)**,它可以提供一个入口让外部用户访问集群内部服务。
+
+
+
+# Cluster
+
+**控制平面和Node** 共同构成了一个 **Cluster**,也就是**集群**。在公司里,我们一般会构建多个集群, 比如测试环境用一个集群,生产环境用另外一个集群。同时,为了将集群内部的服务暴露给外部用户使用,我们一般还会部署一个入口控制器,比如 **Ingress 控制器(比如Nginx)**,它可以提供一个入口让外部用户访问集群内部服务。
+
+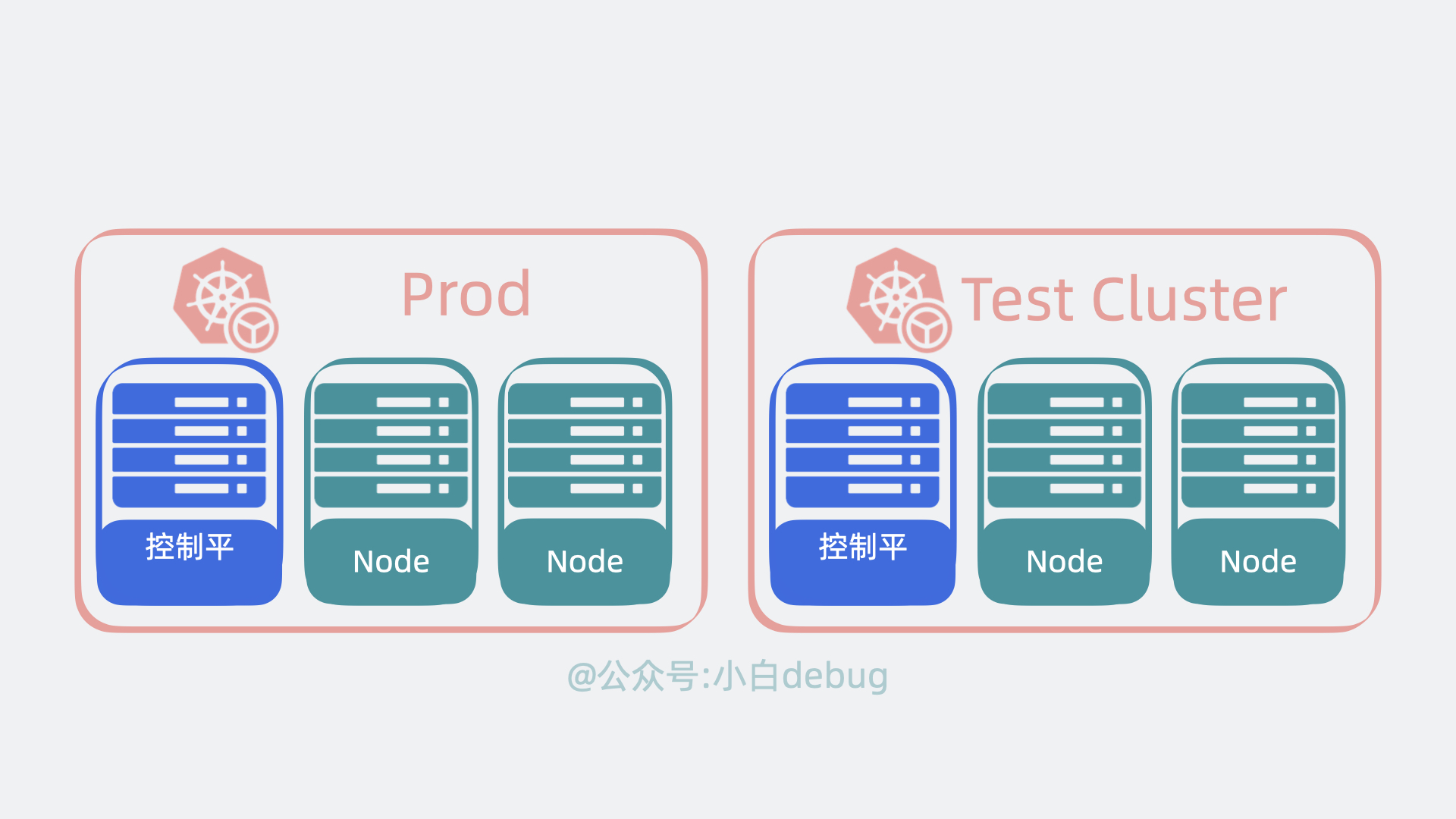 +
+# kubectl
+
+上面提到说我们可以使用 k8s 提供的 API 去创建服务,但问题就来了,这是需要我们自己写代码去调用这些 API 吗?答案是不需要,k8s 为我们准备了一个命令行工具 **kubectl**,我们只需要执行命令,它内部就会调用 k8s 的 API。
+
+
+
+# kubectl
+
+上面提到说我们可以使用 k8s 提供的 API 去创建服务,但问题就来了,这是需要我们自己写代码去调用这些 API 吗?答案是不需要,k8s 为我们准备了一个命令行工具 **kubectl**,我们只需要执行命令,它内部就会调用 k8s 的 API。
+
+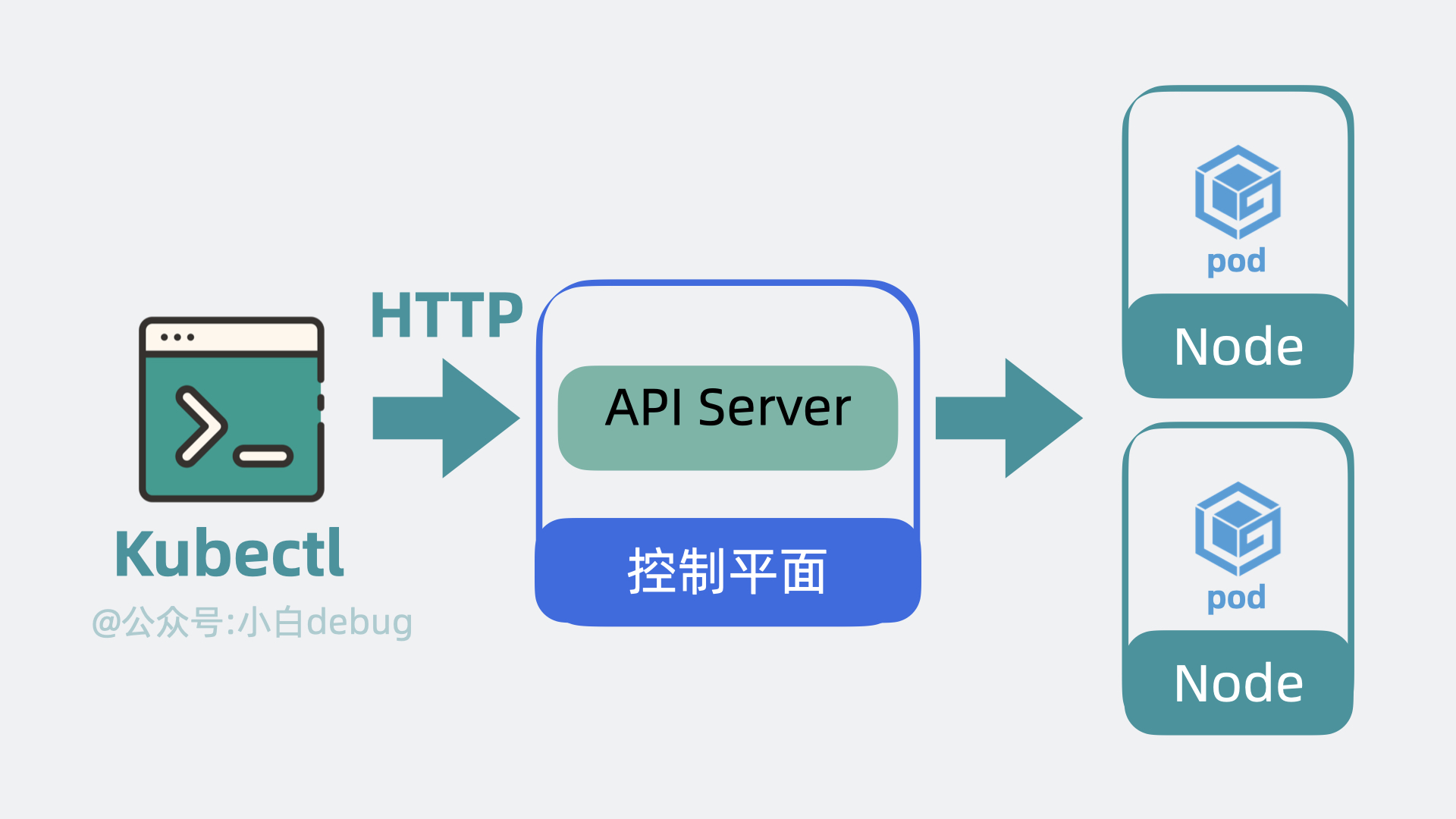 +
+接下来我们以部署服务为例子,看下 k8s 是怎么工作的。
+
+# 部署 Kubernetes 服务
+
+首先我们需要编写 **YAML 文件**,在里面定义 Pod 里用到了哪些镜像,占用多少内存和 CPU 等信息。然后使用 kubectl 命令行工具执行 `kubectl apply -f xx.yaml` ,此时 kubectl 会读取和解析 YAML 文件,将解析后的对象通过 API 请求发送给 Kubernetes 控制平面内 的 **API Server**。API Server 会根据要求,驱使 **Scheduler** 通过 **etcd** 提供的数据寻找合适的 **Node**, **Controller Manager** 会通过 API Server 控制 Node 创建服务,Node 内部的 **kubelet** 在收到命令后会开始基于 **Container runtime** 组件去拉取镜像创建容器,最终完成 **Pod** 的创建。
+
+至此服务完成创建。
+
+
+
+接下来我们以部署服务为例子,看下 k8s 是怎么工作的。
+
+# 部署 Kubernetes 服务
+
+首先我们需要编写 **YAML 文件**,在里面定义 Pod 里用到了哪些镜像,占用多少内存和 CPU 等信息。然后使用 kubectl 命令行工具执行 `kubectl apply -f xx.yaml` ,此时 kubectl 会读取和解析 YAML 文件,将解析后的对象通过 API 请求发送给 Kubernetes 控制平面内 的 **API Server**。API Server 会根据要求,驱使 **Scheduler** 通过 **etcd** 提供的数据寻找合适的 **Node**, **Controller Manager** 会通过 API Server 控制 Node 创建服务,Node 内部的 **kubelet** 在收到命令后会开始基于 **Container runtime** 组件去拉取镜像创建容器,最终完成 **Pod** 的创建。
+
+至此服务完成创建。
+
+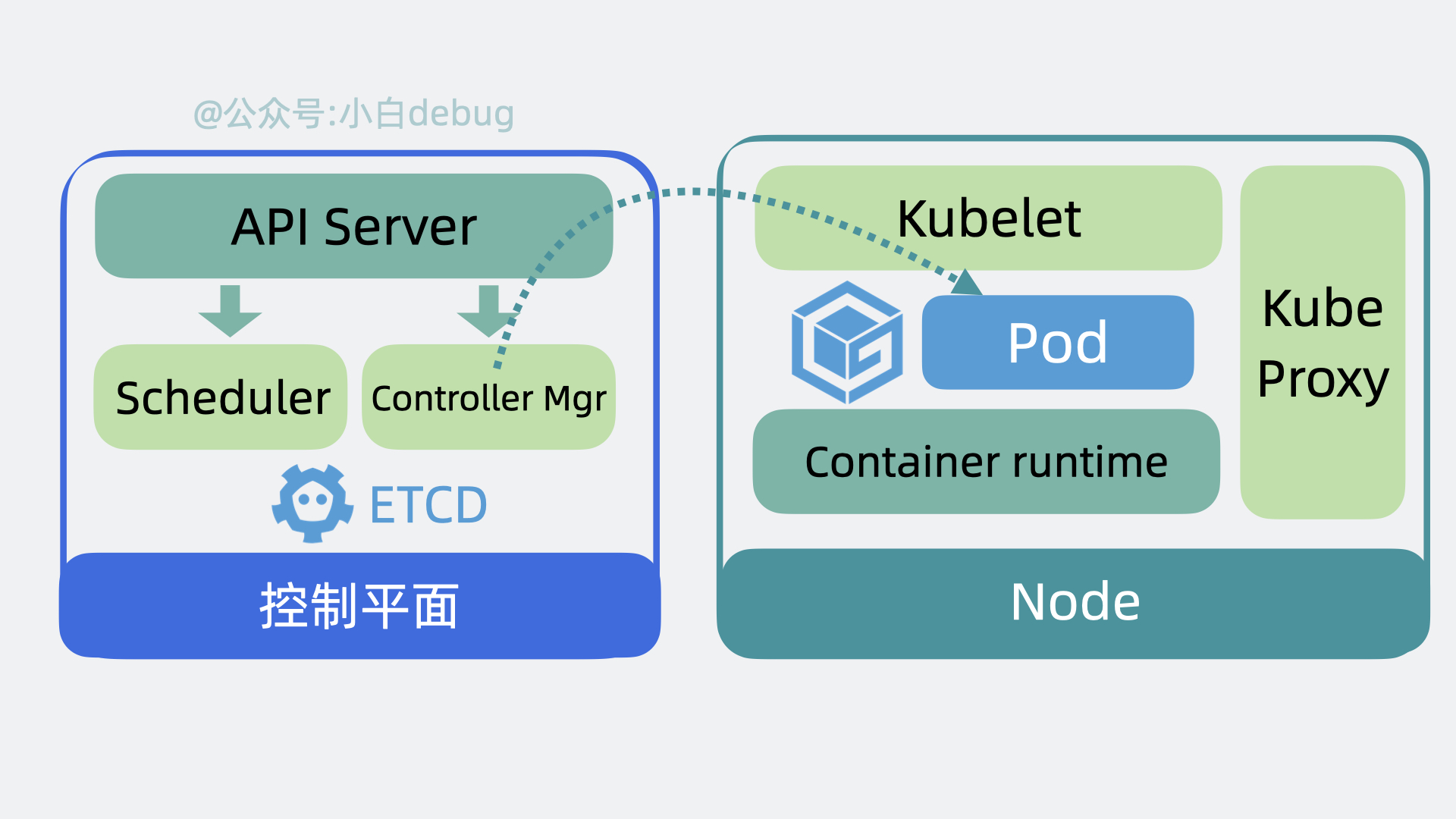 +
+整个过程下来,我们只需要写一遍 yaml 文件,和执行一次 kubectl 命令,比以前省心太多了!部署完服务后,我们来看下服务是怎么被调用的。
+
+# 调用 Kubernetes 服务
+
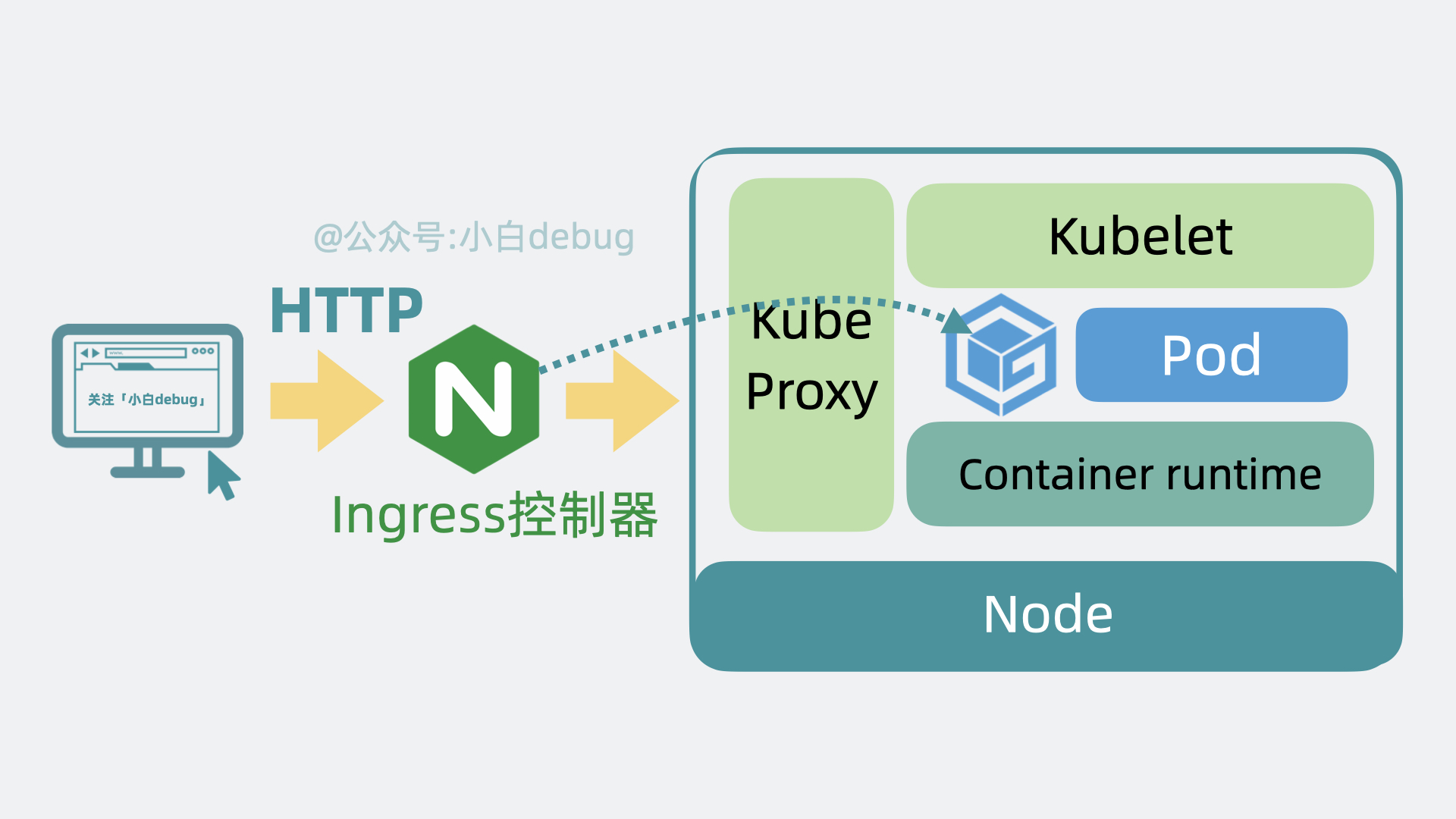
+以前外部用户小明,直接在浏览器上发送 http 请求,就能打到我们服务器上的 Nginx,然后转发到部署的服务内。用了 k8s 之后,外部请求会先到达 Kubernetes 集群的 Ingress 控制器,然后请求会被转发到 Kubernetes 内部的某个 Node 的 **Kube Proxy** 上,再找到对应的 pod,然后才是转发到内部**容器服务**中,处理结果原路返回,到这就完成了一次服务调用。
+
+
+
+整个过程下来,我们只需要写一遍 yaml 文件,和执行一次 kubectl 命令,比以前省心太多了!部署完服务后,我们来看下服务是怎么被调用的。
+
+# 调用 Kubernetes 服务
+
+以前外部用户小明,直接在浏览器上发送 http 请求,就能打到我们服务器上的 Nginx,然后转发到部署的服务内。用了 k8s 之后,外部请求会先到达 Kubernetes 集群的 Ingress 控制器,然后请求会被转发到 Kubernetes 内部的某个 Node 的 **Kube Proxy** 上,再找到对应的 pod,然后才是转发到内部**容器服务**中,处理结果原路返回,到这就完成了一次服务调用。
+
+ +
+到这里我们就大概了解了 k8s 的工作原理啦,它本质上就是应用服务和服务器之间的**中间层**,通过暴露一系列 API 能力让我们简化服务的部署运维流程。
+
+并且,不少中大厂基于这些 API 能力搭了自己的服务管理平台,程序员不再需要敲 kubectl 命令,直接在界面上点点几下,就能完成服务的部署和扩容等操作,是真的嘎嘎好用。
diff --git "a/docs/\345\274\200\345\217\221/\346\220\255\345\273\272K8S\351\233\206\347\276\244\347\216\257\345\242\203.md" "b/docs/\345\274\200\345\217\221/\346\220\255\345\273\272K8S\351\233\206\347\276\244\347\216\257\345\242\203.md"
new file mode 100644
index 0000000..19f4375
--- /dev/null
+++ "b/docs/\345\274\200\345\217\221/\346\220\255\345\273\272K8S\351\233\206\347\276\244\347\216\257\345\242\203.md"
@@ -0,0 +1,389 @@
+---
+搭建K8S集群环境
+---
+
+## 使用[minikube](https://minikube.sigs.k8s.io/)搭建kubernetes集群环境
+
+[minikube](https://minikube.sigs.k8s.io/)是一个轻量级的kubernetes集群环境,可以用来在本地快速搭建一个单节点的kubernetes集群,
+
+### 安装minikube
+
+也可以到官网直接下载安装包来安装:https://minikube.sigs.k8s.io/docs/start/
+
+```shell
+# macOS
+brew install minikube
+
+# Windows
+choco install minikube
+
+# Linux
+curl -LO https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64
+sudo install minikube-linux-amd64 /usr/local/bin/minikube
+```
+
+### 启动minikube
+
+```shell
+# 启动minikube
+minikube start
+```
+
+## 使用[Multipass](https://multipass.run/)和[k3s](https://k3s.io/)搭建kubernetes集群环境
+
+[minikube](https://minikube.sigs.k8s.io/)只能用来在本地搭建一个单节点的kubernetes集群环境,下面介绍如何使用[Multipass](https://multipass.run/)和[k3s](https://k3s.io/)来搭建一个多节点的kubernetes集群环境。
+
+### Multipass介绍
+
+[Multipass](https://multipass.run/)是一个轻量级的虚拟机管理工具,可以用来在本地快速创建和管理虚拟机,相比于VirtualBox或者VMware这样的虚拟机管理工具,[Multipass](https://multipass.run/)更加轻量快速,而且它还提供了一些命令行工具来方便我们管理虚拟机。
+
+> 官方网址: [https://Multipass.run/](https://multipass.run/)
+
+### 安装Multipass
+
+```shell
+# macOS
+brew install multipass
+
+# Windows
+choco install multipass
+
+# Linux
+sudo snap install multipass
+```
+
+### Multipass常用命令
+
+关于Multipass的一些常用命令我们可以通过`multipass help`来查看,这里只需要记住几个常用的命令就可以了
+
+```shell
+# 查看帮助
+multipass help
+multipass help
+
+# 创建一个名字叫做k3s的虚拟机
+multipass launch --name k3s
+
+# 在虚拟机中执行命令
+multipass exec k3s -- ls -l
+
+# 进入虚拟机并执行shell
+multipass shell k3s
+
+# 查看虚拟机的信息
+multipass info k3s
+
+# 停止虚拟机
+multipass stop k3s
+
+# 启动虚拟机
+multipass start k3s
+
+# 删除虚拟机
+multipass delete k3s
+
+# 清理虚拟机
+multipass purge
+
+# 查看虚拟机列表
+multipass list
+
+# 挂载目录(将本地的~/kubernetes/master目录挂载到虚拟机中的~/master目录)
+multipass mount ~/kubernetes/master master:~/master
+```
+
+Multipass有个问题,每次Mac升级之后Multipass的虚拟机都可能会被删除。
+
+```shell
+# 镜像位置
+/var/root/Library/Application Support/multipassd/qemu/vault/instances
+# 配置文件
+/var/root/Library/Application Support/multipassd/qemu/multipassd-vm-instances.json
+```
+
+## [k3s](https://k3s.io/)介绍
+
+[k3s](https://k3s.io/) 是一个轻量级的[Kubernetes](https://kubernetes.io/)发行版,它是 [Rancher Labs](https://www.rancher.com/) 推出的一个开源项目,旨在简化[Kubernetes](https://kubernetes.io/)的安装和维护,同时它还是CNCF认证的[Kubernetes](https://kubernetes.io/)发行版。
+
+### 创建和配置master节点
+
+首先我们需要使用multipass创建一个名字叫做k3s的虚拟机,
+
+```shell
+multipass launch --name k3s --cpus 2 --memory 8G --disk 10G
+```
+
+虚拟机创建完成之后,可以配置SSH密钥登录,不过这一步并不是必须的,即使不配置也可以通过`multipass exec`或者`multipass shell`命令来进入虚拟机,然后我们需要在master节点上安装[k3s](https://k3s.io/)。
+
+使用[k3s](https://k3s.io/)搭建kubernetes集群非常简单,只需要执行一条命令就可以在当前节点上安装[k3s](https://k3s.io/),打开刚刚创建的k3s虚拟机,执行下面的命令就可以安装一个[k3s](https://k3s.io/)的master节点。
+
+```shell
+# 安装k3s的master节点
+curl -sfL https://get.k3s.io | sh -
+
+# 国内可以使用ranher的镜像源来安装:
+curl -sfL https://rancher-mirror.rancher.cn/k3s/k3s-install.sh | INSTALL_K3S_MIRROR=cn sh -
+```
+
+安装完成之后,可以通过`kubectl`命令来查看集群的状态。
+
+```shell
+sudo kubectl get nodes
+```
+
+### 创建和配置worker节点
+
+接下来需要在这个master节点上获取一个token,用来作为创建worker节点时的一个认证凭证,它保存在`/var/lib/rancher/k3s/server/node-token`这个文件里面,我们可以使用`sudo cat`命令来查看一下这个文件中的内容。
+
+```shell
+sudo cat /var/lib/rancher/k3s/server/node-token
+```
+
+将TOKEN保存到一个环境变量中
+
+```shell
+TOKEN=$(multipass exec k3s sudo cat /var/lib/rancher/k3s/server/node-token)
+```
+
+保存master节点的IP地址
+
+```shell
+MASTER_IP=$(multipass info k3s | grep IPv4 | awk '{print $2}')
+```
+
+确认:
+
+```shell
+echo $MASTER_IP
+```
+
+使用刚刚的`TOKEN`和`MASTER_IP`来创建两个worker节点,并把它们加入到集群中
+
+```shell
+# 创建两个worker节点的虚拟机
+multipass launch --name worker1 --cpus 2 --memory 8G --disk 10G
+multipass launch --name worker2 --cpus 2 --memory 8G --disk 10G
+
+# 在worker节点虚拟机上安装k3s
+ for f in 1 2; do
+ multipass exec worker$f -- bash -c "curl -sfL https://rancher-mirror.rancher.cn/k3s/k3s-install.sh | INSTALL_K3S_MIRROR=cn K3S_URL=\"https://$MASTER_IP:6443\" K3S_TOKEN=\"$TOKEN\" sh -"
+ done
+```
+
+这样就完成了一个多节点的kubernetes集群的搭建。
+
+## 在线实验环境
+
+> [Killercoda](https://killercoda.com/)
+
+> [Play-With-K8s](https://labs.play-with-k8s.com/)
+
+## kubectl常用命令
+
+### 基础使用
+
+```shell
+# 查看帮助
+kubectl --help
+
+# 查看API版本
+kubectl api-versions
+
+# 查看集群信息
+kubectl cluster-info
+```
+
+### 资源的创建和运行
+
+```shell
+# 创建并运行一个指定的镜像
+kubectl run NAME --image=image [params...]
+# e.g. 创建并运行一个名字为nginx的Pod
+kubectl run nginx --image=nginx
+
+# 根据YAML配置文件或者标准输入创建资源
+kubectl create RESOURCE
+# e.g.
+# 根据nginx.yaml配置文件创建资源
+kubectl create -f nginx.yaml
+# 根据URL创建资源
+kubectl create -f https://k8s.io/examples/application/deployment.yaml
+# 根据目录下的所有配置文件创建资源
+kubectl create -f ./dir
+
+# 通过文件名或标准输入配置资源
+kubectl apply -f (-k DIRECTORY | -f FILENAME | stdin)
+# e.g.
+# 根据nginx.yaml配置文件创建资源
+kubectl apply -f nginx.yaml
+```
+
+### 查看资源信息
+
+```shell
+# 查看集群中某一类型的资源
+kubectl get RESOURCE
+# 其中,RESOURCE可以是以下类型:
+kubectl get pods / po # 查看Pod
+kubectl get svc # 查看Service
+kubectl get deploy # 查看Deployment
+kubectl get rs # 查看ReplicaSet
+kubectl get cm # 查看ConfigMap
+kubectl get secret # 查看Secret
+kubectl get ing # 查看Ingress
+kubectl get pv # 查看PersistentVolume
+kubectl get pvc # 查看PersistentVolumeClaim
+kubectl get ns # 查看Namespace
+kubectl get node # 查看Node
+kubectl get all # 查看所有资源
+
+# 后面还可以加上 -o wide 参数来查看更多信息
+kubectl get pods -o wide
+
+# 查看某一类型资源的详细信息
+kubectl describe RESOURCE NAME
+# e.g. 查看名字为nginx的Pod的详细信息
+kubectl describe pod nginx
+```
+
+### 资源的修改、删除和清理
+
+```shell
+# 更新某个资源的标签
+kubectl label RESOURCE NAME KEY_1=VALUE_1 ... KEY_N=VALUE_N
+# e.g. 更新名字为nginx的Pod的标签
+kubectl label pod nginx app=nginx
+
+# 删除某个资源
+kubectl delete RESOURCE NAME
+# e.g. 删除名字为nginx的Pod
+kubectl delete pod nginx
+
+# 删除某个资源的所有实例
+kubectl delete RESOURCE --all
+# e.g. 删除所有Pod
+kubectl delete pod --all
+
+# 根据YAML配置文件删除资源
+kubectl delete -f FILENAME
+# e.g. 根据nginx.yaml配置文件删除资源
+kubectl delete -f nginx.yaml
+
+# 设置某个资源的副本数
+kubectl scale --replicas=COUNT RESOURCE NAME
+# e.g. 设置名字为nginx的Deployment的副本数为3
+kubectl scale --replicas=3 deployment/nginx
+
+# 根据配置文件或者标准输入替换某个资源
+kubectl replace -f FILENAME
+# e.g. 根据nginx.yaml配置文件替换名字为nginx的Deployment
+kubectl replace -f nginx.yaml
+```
+
+### 调试和交互
+
+```shell
+# 进入某个Pod的容器中
+kubectl exec [-it] POD [-c CONTAINER] -- COMMAND [args...]
+# e.g. 进入名字为nginx的Pod的容器中,并执行/bin/bash命令
+kubectl exec -it nginx -- /bin/bash
+
+# 查看某个Pod的日志
+kubectl logs [-f] [-p] [-c CONTAINER] POD [-n NAMESPACE]
+# e.g. 查看名字为nginx的Pod的日志
+kubectl logs nginx
+
+# 将某个Pod的端口转发到本地
+kubectl port-forward POD [LOCAL_PORT:]REMOTE_PORT [...[LOCAL_PORT_N:]REMOTE_PORT_N]
+# e.g. 将名字为nginx的Pod的80端口转发到本地的8080端口
+kubectl port-forward nginx 8080:80
+
+# 连接到现有的某个Pod(将某个Pod的标准输入输出转发到本地)
+kubectl attach POD -c CONTAINER
+# e.g. 将名字为nginx的Pod的标准输入输出转发到本地
+kubectl attach nginx
+
+# 运行某个Pod的命令
+kubectl run NAME --image=image -- COMMAND [args...]
+# e.g. 运行名字为nginx的Pod
+kubectl run nginx --image=nginx -- /bin/bash
+```
+
+## Portainer的安装和使用
+
+[Portainer](https://www.portainer.io/) 是一个轻量级的容器管理工具,可以用来管理Docker和Kubernetes,它提供了一个Web界面来方便我们管理容器。
+
+> 官方网址: https://www.portainer.io/
+
+### 安装Portainer
+
+```shell
+# 创建一个名字叫做portainer的虚拟机
+multipass launch --name portainer --cpus 2 --memory 8G --disk 10G
+```
+
+当然也可以直接安装在我们刚刚创建的master节点上,
+
+```shell
+# 在master节点上安装portainer,并将其暴露在NodePort 30777上
+kubectl apply -n portainer -f https://downloads.portainer.io/ce2-19/portainer.yaml
+```
+
+或者使用Helm安装
+
+```shell
+# 使用Helm安装Portainer
+helm upgrade --install --create-namespace -n portainer portainer portainer/portainer --set tls.force=true
+```
+
+然后直接访问 `https://localhost:30779/` 或者 `http://localhost:30777/` 就可以了,
+
+## Helm的安装和使用
+
+[Helm](https://helm.sh/) 是一个Kubernetes的包管理工具,可以用来管理Kubernetes的应用,它提供了一个命令行工具来方便我们管理Kubernetes的应用。
+
+> 官方网址: https://helm.sh/
+
+### 安装Helm
+
+使用包管理器安装:
+
+```shell
+# macOS
+brew install helm
+
+# Windows
+choco install kubernetes-helm
+# 或者
+scoop install helm
+
+# Linux(Debian/Ubuntu)
+curl https://baltocdn.com/helm/signing.asc | gpg --dearmor | sudo tee /usr/share/keyrings/helm.gpg > /dev/null
+sudo apt-get install apt-transport-https --yes
+echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/helm.gpg] https://baltocdn.com/helm/stable/debian/ all main" | sudo tee /etc/apt/sources.list.d/helm-stable-debian.list
+sudo apt-get update
+sudo apt-get install helm
+
+# Linux(CentOS/Fedora)
+sudo dnf install helm
+
+# Linux(Snap)
+sudo snap install helm --classic
+
+# Linux(FreeBSD)
+pkg install helm
+```
+
+使用脚本安装
+
+```shell
+curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3
+chmod 700 get_helm.sh
+./get_helm.sh
+```
+
+或者
+
+```shell
+curl https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 | bash
+```
\ No newline at end of file
+
+到这里我们就大概了解了 k8s 的工作原理啦,它本质上就是应用服务和服务器之间的**中间层**,通过暴露一系列 API 能力让我们简化服务的部署运维流程。
+
+并且,不少中大厂基于这些 API 能力搭了自己的服务管理平台,程序员不再需要敲 kubectl 命令,直接在界面上点点几下,就能完成服务的部署和扩容等操作,是真的嘎嘎好用。
diff --git "a/docs/\345\274\200\345\217\221/\346\220\255\345\273\272K8S\351\233\206\347\276\244\347\216\257\345\242\203.md" "b/docs/\345\274\200\345\217\221/\346\220\255\345\273\272K8S\351\233\206\347\276\244\347\216\257\345\242\203.md"
new file mode 100644
index 0000000..19f4375
--- /dev/null
+++ "b/docs/\345\274\200\345\217\221/\346\220\255\345\273\272K8S\351\233\206\347\276\244\347\216\257\345\242\203.md"
@@ -0,0 +1,389 @@
+---
+搭建K8S集群环境
+---
+
+## 使用[minikube](https://minikube.sigs.k8s.io/)搭建kubernetes集群环境
+
+[minikube](https://minikube.sigs.k8s.io/)是一个轻量级的kubernetes集群环境,可以用来在本地快速搭建一个单节点的kubernetes集群,
+
+### 安装minikube
+
+也可以到官网直接下载安装包来安装:https://minikube.sigs.k8s.io/docs/start/
+
+```shell
+# macOS
+brew install minikube
+
+# Windows
+choco install minikube
+
+# Linux
+curl -LO https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64
+sudo install minikube-linux-amd64 /usr/local/bin/minikube
+```
+
+### 启动minikube
+
+```shell
+# 启动minikube
+minikube start
+```
+
+## 使用[Multipass](https://multipass.run/)和[k3s](https://k3s.io/)搭建kubernetes集群环境
+
+[minikube](https://minikube.sigs.k8s.io/)只能用来在本地搭建一个单节点的kubernetes集群环境,下面介绍如何使用[Multipass](https://multipass.run/)和[k3s](https://k3s.io/)来搭建一个多节点的kubernetes集群环境。
+
+### Multipass介绍
+
+[Multipass](https://multipass.run/)是一个轻量级的虚拟机管理工具,可以用来在本地快速创建和管理虚拟机,相比于VirtualBox或者VMware这样的虚拟机管理工具,[Multipass](https://multipass.run/)更加轻量快速,而且它还提供了一些命令行工具来方便我们管理虚拟机。
+
+> 官方网址: [https://Multipass.run/](https://multipass.run/)
+
+### 安装Multipass
+
+```shell
+# macOS
+brew install multipass
+
+# Windows
+choco install multipass
+
+# Linux
+sudo snap install multipass
+```
+
+### Multipass常用命令
+
+关于Multipass的一些常用命令我们可以通过`multipass help`来查看,这里只需要记住几个常用的命令就可以了
+
+```shell
+# 查看帮助
+multipass help
+multipass help
+
+# 创建一个名字叫做k3s的虚拟机
+multipass launch --name k3s
+
+# 在虚拟机中执行命令
+multipass exec k3s -- ls -l
+
+# 进入虚拟机并执行shell
+multipass shell k3s
+
+# 查看虚拟机的信息
+multipass info k3s
+
+# 停止虚拟机
+multipass stop k3s
+
+# 启动虚拟机
+multipass start k3s
+
+# 删除虚拟机
+multipass delete k3s
+
+# 清理虚拟机
+multipass purge
+
+# 查看虚拟机列表
+multipass list
+
+# 挂载目录(将本地的~/kubernetes/master目录挂载到虚拟机中的~/master目录)
+multipass mount ~/kubernetes/master master:~/master
+```
+
+Multipass有个问题,每次Mac升级之后Multipass的虚拟机都可能会被删除。
+
+```shell
+# 镜像位置
+/var/root/Library/Application Support/multipassd/qemu/vault/instances
+# 配置文件
+/var/root/Library/Application Support/multipassd/qemu/multipassd-vm-instances.json
+```
+
+## [k3s](https://k3s.io/)介绍
+
+[k3s](https://k3s.io/) 是一个轻量级的[Kubernetes](https://kubernetes.io/)发行版,它是 [Rancher Labs](https://www.rancher.com/) 推出的一个开源项目,旨在简化[Kubernetes](https://kubernetes.io/)的安装和维护,同时它还是CNCF认证的[Kubernetes](https://kubernetes.io/)发行版。
+
+### 创建和配置master节点
+
+首先我们需要使用multipass创建一个名字叫做k3s的虚拟机,
+
+```shell
+multipass launch --name k3s --cpus 2 --memory 8G --disk 10G
+```
+
+虚拟机创建完成之后,可以配置SSH密钥登录,不过这一步并不是必须的,即使不配置也可以通过`multipass exec`或者`multipass shell`命令来进入虚拟机,然后我们需要在master节点上安装[k3s](https://k3s.io/)。
+
+使用[k3s](https://k3s.io/)搭建kubernetes集群非常简单,只需要执行一条命令就可以在当前节点上安装[k3s](https://k3s.io/),打开刚刚创建的k3s虚拟机,执行下面的命令就可以安装一个[k3s](https://k3s.io/)的master节点。
+
+```shell
+# 安装k3s的master节点
+curl -sfL https://get.k3s.io | sh -
+
+# 国内可以使用ranher的镜像源来安装:
+curl -sfL https://rancher-mirror.rancher.cn/k3s/k3s-install.sh | INSTALL_K3S_MIRROR=cn sh -
+```
+
+安装完成之后,可以通过`kubectl`命令来查看集群的状态。
+
+```shell
+sudo kubectl get nodes
+```
+
+### 创建和配置worker节点
+
+接下来需要在这个master节点上获取一个token,用来作为创建worker节点时的一个认证凭证,它保存在`/var/lib/rancher/k3s/server/node-token`这个文件里面,我们可以使用`sudo cat`命令来查看一下这个文件中的内容。
+
+```shell
+sudo cat /var/lib/rancher/k3s/server/node-token
+```
+
+将TOKEN保存到一个环境变量中
+
+```shell
+TOKEN=$(multipass exec k3s sudo cat /var/lib/rancher/k3s/server/node-token)
+```
+
+保存master节点的IP地址
+
+```shell
+MASTER_IP=$(multipass info k3s | grep IPv4 | awk '{print $2}')
+```
+
+确认:
+
+```shell
+echo $MASTER_IP
+```
+
+使用刚刚的`TOKEN`和`MASTER_IP`来创建两个worker节点,并把它们加入到集群中
+
+```shell
+# 创建两个worker节点的虚拟机
+multipass launch --name worker1 --cpus 2 --memory 8G --disk 10G
+multipass launch --name worker2 --cpus 2 --memory 8G --disk 10G
+
+# 在worker节点虚拟机上安装k3s
+ for f in 1 2; do
+ multipass exec worker$f -- bash -c "curl -sfL https://rancher-mirror.rancher.cn/k3s/k3s-install.sh | INSTALL_K3S_MIRROR=cn K3S_URL=\"https://$MASTER_IP:6443\" K3S_TOKEN=\"$TOKEN\" sh -"
+ done
+```
+
+这样就完成了一个多节点的kubernetes集群的搭建。
+
+## 在线实验环境
+
+> [Killercoda](https://killercoda.com/)
+
+> [Play-With-K8s](https://labs.play-with-k8s.com/)
+
+## kubectl常用命令
+
+### 基础使用
+
+```shell
+# 查看帮助
+kubectl --help
+
+# 查看API版本
+kubectl api-versions
+
+# 查看集群信息
+kubectl cluster-info
+```
+
+### 资源的创建和运行
+
+```shell
+# 创建并运行一个指定的镜像
+kubectl run NAME --image=image [params...]
+# e.g. 创建并运行一个名字为nginx的Pod
+kubectl run nginx --image=nginx
+
+# 根据YAML配置文件或者标准输入创建资源
+kubectl create RESOURCE
+# e.g.
+# 根据nginx.yaml配置文件创建资源
+kubectl create -f nginx.yaml
+# 根据URL创建资源
+kubectl create -f https://k8s.io/examples/application/deployment.yaml
+# 根据目录下的所有配置文件创建资源
+kubectl create -f ./dir
+
+# 通过文件名或标准输入配置资源
+kubectl apply -f (-k DIRECTORY | -f FILENAME | stdin)
+# e.g.
+# 根据nginx.yaml配置文件创建资源
+kubectl apply -f nginx.yaml
+```
+
+### 查看资源信息
+
+```shell
+# 查看集群中某一类型的资源
+kubectl get RESOURCE
+# 其中,RESOURCE可以是以下类型:
+kubectl get pods / po # 查看Pod
+kubectl get svc # 查看Service
+kubectl get deploy # 查看Deployment
+kubectl get rs # 查看ReplicaSet
+kubectl get cm # 查看ConfigMap
+kubectl get secret # 查看Secret
+kubectl get ing # 查看Ingress
+kubectl get pv # 查看PersistentVolume
+kubectl get pvc # 查看PersistentVolumeClaim
+kubectl get ns # 查看Namespace
+kubectl get node # 查看Node
+kubectl get all # 查看所有资源
+
+# 后面还可以加上 -o wide 参数来查看更多信息
+kubectl get pods -o wide
+
+# 查看某一类型资源的详细信息
+kubectl describe RESOURCE NAME
+# e.g. 查看名字为nginx的Pod的详细信息
+kubectl describe pod nginx
+```
+
+### 资源的修改、删除和清理
+
+```shell
+# 更新某个资源的标签
+kubectl label RESOURCE NAME KEY_1=VALUE_1 ... KEY_N=VALUE_N
+# e.g. 更新名字为nginx的Pod的标签
+kubectl label pod nginx app=nginx
+
+# 删除某个资源
+kubectl delete RESOURCE NAME
+# e.g. 删除名字为nginx的Pod
+kubectl delete pod nginx
+
+# 删除某个资源的所有实例
+kubectl delete RESOURCE --all
+# e.g. 删除所有Pod
+kubectl delete pod --all
+
+# 根据YAML配置文件删除资源
+kubectl delete -f FILENAME
+# e.g. 根据nginx.yaml配置文件删除资源
+kubectl delete -f nginx.yaml
+
+# 设置某个资源的副本数
+kubectl scale --replicas=COUNT RESOURCE NAME
+# e.g. 设置名字为nginx的Deployment的副本数为3
+kubectl scale --replicas=3 deployment/nginx
+
+# 根据配置文件或者标准输入替换某个资源
+kubectl replace -f FILENAME
+# e.g. 根据nginx.yaml配置文件替换名字为nginx的Deployment
+kubectl replace -f nginx.yaml
+```
+
+### 调试和交互
+
+```shell
+# 进入某个Pod的容器中
+kubectl exec [-it] POD [-c CONTAINER] -- COMMAND [args...]
+# e.g. 进入名字为nginx的Pod的容器中,并执行/bin/bash命令
+kubectl exec -it nginx -- /bin/bash
+
+# 查看某个Pod的日志
+kubectl logs [-f] [-p] [-c CONTAINER] POD [-n NAMESPACE]
+# e.g. 查看名字为nginx的Pod的日志
+kubectl logs nginx
+
+# 将某个Pod的端口转发到本地
+kubectl port-forward POD [LOCAL_PORT:]REMOTE_PORT [...[LOCAL_PORT_N:]REMOTE_PORT_N]
+# e.g. 将名字为nginx的Pod的80端口转发到本地的8080端口
+kubectl port-forward nginx 8080:80
+
+# 连接到现有的某个Pod(将某个Pod的标准输入输出转发到本地)
+kubectl attach POD -c CONTAINER
+# e.g. 将名字为nginx的Pod的标准输入输出转发到本地
+kubectl attach nginx
+
+# 运行某个Pod的命令
+kubectl run NAME --image=image -- COMMAND [args...]
+# e.g. 运行名字为nginx的Pod
+kubectl run nginx --image=nginx -- /bin/bash
+```
+
+## Portainer的安装和使用
+
+[Portainer](https://www.portainer.io/) 是一个轻量级的容器管理工具,可以用来管理Docker和Kubernetes,它提供了一个Web界面来方便我们管理容器。
+
+> 官方网址: https://www.portainer.io/
+
+### 安装Portainer
+
+```shell
+# 创建一个名字叫做portainer的虚拟机
+multipass launch --name portainer --cpus 2 --memory 8G --disk 10G
+```
+
+当然也可以直接安装在我们刚刚创建的master节点上,
+
+```shell
+# 在master节点上安装portainer,并将其暴露在NodePort 30777上
+kubectl apply -n portainer -f https://downloads.portainer.io/ce2-19/portainer.yaml
+```
+
+或者使用Helm安装
+
+```shell
+# 使用Helm安装Portainer
+helm upgrade --install --create-namespace -n portainer portainer portainer/portainer --set tls.force=true
+```
+
+然后直接访问 `https://localhost:30779/` 或者 `http://localhost:30777/` 就可以了,
+
+## Helm的安装和使用
+
+[Helm](https://helm.sh/) 是一个Kubernetes的包管理工具,可以用来管理Kubernetes的应用,它提供了一个命令行工具来方便我们管理Kubernetes的应用。
+
+> 官方网址: https://helm.sh/
+
+### 安装Helm
+
+使用包管理器安装:
+
+```shell
+# macOS
+brew install helm
+
+# Windows
+choco install kubernetes-helm
+# 或者
+scoop install helm
+
+# Linux(Debian/Ubuntu)
+curl https://baltocdn.com/helm/signing.asc | gpg --dearmor | sudo tee /usr/share/keyrings/helm.gpg > /dev/null
+sudo apt-get install apt-transport-https --yes
+echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/helm.gpg] https://baltocdn.com/helm/stable/debian/ all main" | sudo tee /etc/apt/sources.list.d/helm-stable-debian.list
+sudo apt-get update
+sudo apt-get install helm
+
+# Linux(CentOS/Fedora)
+sudo dnf install helm
+
+# Linux(Snap)
+sudo snap install helm --classic
+
+# Linux(FreeBSD)
+pkg install helm
+```
+
+使用脚本安装
+
+```shell
+curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3
+chmod 700 get_helm.sh
+./get_helm.sh
+```
+
+或者
+
+```shell
+curl https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 | bash
+```
\ No newline at end of file