diff --git "a/docs/\345\274\200\345\217\221/My Java Guide/My Java Guide - \345\210\206\345\270\203\345\274\217.md" "b/docs/\345\274\200\345\217\221/My Java Guide/My Java Guide - \345\210\206\345\270\203\345\274\217.md"
index cf01e86..bb33d02 100644
--- "a/docs/\345\274\200\345\217\221/My Java Guide/My Java Guide - \345\210\206\345\270\203\345\274\217.md"
+++ "b/docs/\345\274\200\345\217\221/My Java Guide/My Java Guide - \345\210\206\345\270\203\345\274\217.md"
@@ -907,6 +907,10 @@ Snowflake 算法生成的 ID 是一个 64 位的整数,格式如下:
# 例:购物商城应对大流量、大并发的三类策略
+> 这其实是个缓存预热的问题,具体我已经写在了[My Java Guide - 缓存](./My%20Java%20Guide%20-%20缓存.md)中了,这里不多说了!
+>
+> 友情链接:[缓存预热和大流量冲击的应对策略](./My%20Java%20Guide%20-%20缓存.md#huancunyure)
+
**分流**
主要是将流量分散到不同的系统和服务上,以减轻单个服务的压力。常见的方法有水平扩展、业务分区、分片和动静分离。
diff --git "a/docs/\345\274\200\345\217\221/My Java Guide/My Java Guide - \346\225\260\346\215\256\345\272\223.md" "b/docs/\345\274\200\345\217\221/My Java Guide/My Java Guide - \346\225\260\346\215\256\345\272\223.md"
index f84250d..72abfc3 100644
--- "a/docs/\345\274\200\345\217\221/My Java Guide/My Java Guide - \346\225\260\346\215\256\345\272\223.md"
+++ "b/docs/\345\274\200\345\217\221/My Java Guide/My Java Guide - \346\225\260\346\215\256\345\272\223.md"
@@ -17,6 +17,61 @@ top_img: /img/Java-tutorials-by-GeeksForGeeks.png
# -------------------数据库-------------------
+# 对 `last_updated` 字段意义的思考
+
+1. **数据同步和一致性。**在主从同步中,从数据库同步主数据库时,通过对比本地的 `last_updated` 和主节点的 `last_updated`,可以知道需要同步哪些数据
+2. **审计和追踪。**`last_updated` 字段可以帮助定位最后一次更新的时间,进而确定变动的来源和责任人。
+3. **并发控制(乐观锁)**。不必单独设置一个字段 `version`,但需要手动维护`last_updated`
+4. **数据备份和恢复**。在数据备份和恢复过程中,`last_updated` 字段可以用来判断哪些数据是最新的,哪些数据需要恢复。特别是在系统发生故障或数据丢失时,备份数据可能并非实时更新,因此需要依赖last_updated字段来进行增量恢复。
+5. **数据预热**。在处理定期批量更新操作时,系统只需要查询那些 `last_updated` 字段在某个时间范围内的数据,而不必每次都处理所有数据,减少了不必要的查询负担。
+
+# 对 `is_deleted` 字段意义的思考
+
+**我认为`is_deleted`字段是将错就错的妥协产物。**
+
+在业务表中增加is_delete 字段进行逻辑删除的做法在一定规模的系统中可能带来一些问题,因此通常更合理的做法是将历史或删除的数据迁移到归档表。以下是主要原因:
+
+1. 破坏数据模型
+
+  +
+ | 身份证号 | 姓名 | is_delete |
+ | :----------: | :--: | :-------: |
+ | 130102XXXXXX | 张三 | 0 |
+
+ | 身份证号 | 其他档案信息字段 | is_delete |
+ | :----------: | :--------------: | :-------: |
+ | 130102XXXXXX | ... | 0 |
+ | 130102XXXXXX | ... | 1 |
+
+2. 性能影响
+
+ 如果在业务表中使用 `is_delete` 字段来标记逻辑删除,查询时需要附加 `is_delete = false` 的条件,这会增加数据库的查询成本,尤其是数据量大的情况下,可能导致索引失效、查询性能下降
+
+ 业务表承担的是核心业务功能,通常会有很高的读写需求。如果删除的数据一直存在,业务表的体量会持续增大,不仅会影响查询效率,还会对数据存储和维护带来压力。
+
+3. 数据准确性和维护复杂性
+
+ 使用 `is_delete` 字段可能会导致误操作,比如查询中忘记加上过滤条件,容易引入逻辑错误,将已删除的数据也包括在结果中。
+
+ 对于一些数据库操作(如外键关联、唯一约束),逻辑删除可能无法简单适用,可能需要额外的处理,增加了维护难度。
+
+4. 优化考虑
+
+ 已删除的数据被视为“冷数据”,虽不允许删除,但仍需保存。可以考虑将这些数据迁移出去
+
+**正确的做法**
+
+宽表化归档数据
+
+
+
+ | 身份证号 | 姓名 | is_delete |
+ | :----------: | :--: | :-------: |
+ | 130102XXXXXX | 张三 | 0 |
+
+ | 身份证号 | 其他档案信息字段 | is_delete |
+ | :----------: | :--------------: | :-------: |
+ | 130102XXXXXX | ... | 0 |
+ | 130102XXXXXX | ... | 1 |
+
+2. 性能影响
+
+ 如果在业务表中使用 `is_delete` 字段来标记逻辑删除,查询时需要附加 `is_delete = false` 的条件,这会增加数据库的查询成本,尤其是数据量大的情况下,可能导致索引失效、查询性能下降
+
+ 业务表承担的是核心业务功能,通常会有很高的读写需求。如果删除的数据一直存在,业务表的体量会持续增大,不仅会影响查询效率,还会对数据存储和维护带来压力。
+
+3. 数据准确性和维护复杂性
+
+ 使用 `is_delete` 字段可能会导致误操作,比如查询中忘记加上过滤条件,容易引入逻辑错误,将已删除的数据也包括在结果中。
+
+ 对于一些数据库操作(如外键关联、唯一约束),逻辑删除可能无法简单适用,可能需要额外的处理,增加了维护难度。
+
+4. 优化考虑
+
+ 已删除的数据被视为“冷数据”,虽不允许删除,但仍需保存。可以考虑将这些数据迁移出去
+
+**正确的做法**
+
+宽表化归档数据
+
+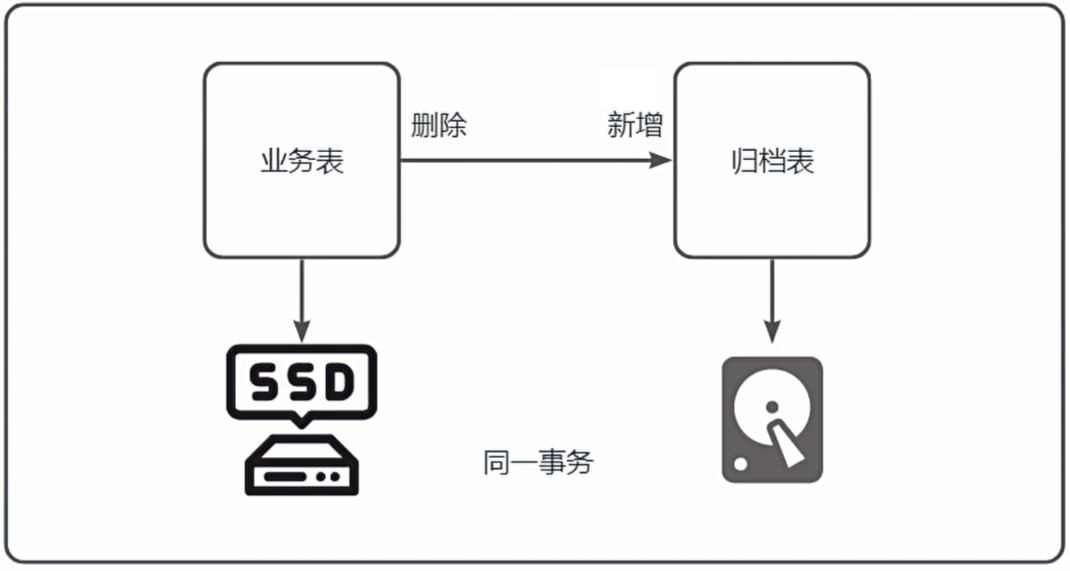 +
+档案归档表
+
+| 代理主键 | 身份证号 | 其他字段 | 删除时间 | 删除人id | 其他审计字段 |
+| :------: | :----------: | :------: | :------: | :------: | :----------: |
+| 1 | 130102XXXXXX | .. | ... | ... | ... |
+
# MySQL支持的存储引擎及其区别
**存储引擎**就是存储数据、建立索引、更新/查询数据等技术的实现方式 。存储引擎是基于表的,而不是基于库的,所以存储引擎也可被称为表类型。
@@ -453,13 +508,7 @@ SET SESSION sort_buffer_size = value; -- `value` 是以字节为单位的大小
调整 `sort_buffer_size` 可以影响排序操作的性能。如果设置得过小,可能导致频繁地将数据写入磁盘,从而降低性能;如果设置得过大,则可能消耗过多内存资源。
-# 对 `last_updated` 字段意义的思考
-1. **数据同步和一致性。**在主从同步中,从数据库同步主数据库时,通过对比本地的 `last_updated` 和主节点的 `last_updated`,可以知道需要同步哪些数据
-2. **审计和追踪。**`last_updated` 字段可以帮助定位最后一次更新的时间,进而确定变动的来源和责任人。
-3. **并发控制(乐观锁)**。不必单独设置一个字段 `version`,但需要手动维护`last_updated`
-4. **数据备份和恢复**。在数据备份和恢复过程中,`last_updated` 字段可以用来判断哪些数据是最新的,哪些数据需要恢复。特别是在系统发生故障或数据丢失时,备份数据可能并非实时更新,因此需要依赖last_updated字段来进行增量恢复。
-5. **数据预热**。在处理定期批量更新操作时,系统只需要查询那些 `last_updated` 字段在某个时间范围内的数据,而不必每次都处理所有数据,减少了不必要的查询负担。
#
+
+档案归档表
+
+| 代理主键 | 身份证号 | 其他字段 | 删除时间 | 删除人id | 其他审计字段 |
+| :------: | :----------: | :------: | :------: | :------: | :----------: |
+| 1 | 130102XXXXXX | .. | ... | ... | ... |
+
# MySQL支持的存储引擎及其区别
**存储引擎**就是存储数据、建立索引、更新/查询数据等技术的实现方式 。存储引擎是基于表的,而不是基于库的,所以存储引擎也可被称为表类型。
@@ -453,13 +508,7 @@ SET SESSION sort_buffer_size = value; -- `value` 是以字节为单位的大小
调整 `sort_buffer_size` 可以影响排序操作的性能。如果设置得过小,可能导致频繁地将数据写入磁盘,从而降低性能;如果设置得过大,则可能消耗过多内存资源。
-# 对 `last_updated` 字段意义的思考
-1. **数据同步和一致性。**在主从同步中,从数据库同步主数据库时,通过对比本地的 `last_updated` 和主节点的 `last_updated`,可以知道需要同步哪些数据
-2. **审计和追踪。**`last_updated` 字段可以帮助定位最后一次更新的时间,进而确定变动的来源和责任人。
-3. **并发控制(乐观锁)**。不必单独设置一个字段 `version`,但需要手动维护`last_updated`
-4. **数据备份和恢复**。在数据备份和恢复过程中,`last_updated` 字段可以用来判断哪些数据是最新的,哪些数据需要恢复。特别是在系统发生故障或数据丢失时,备份数据可能并非实时更新,因此需要依赖last_updated字段来进行增量恢复。
-5. **数据预热**。在处理定期批量更新操作时,系统只需要查询那些 `last_updated` 字段在某个时间范围内的数据,而不必每次都处理所有数据,减少了不必要的查询负担。
# ----------数据库-索引(MySQL)----------
diff --git "a/docs/\345\274\200\345\217\221/My Java Guide/My Java Guide - \347\274\223\345\255\230.md" "b/docs/\345\274\200\345\217\221/My Java Guide/My Java Guide - \347\274\223\345\255\230.md"
index c6c8cfe..72239c5 100644
--- "a/docs/\345\274\200\345\217\221/My Java Guide/My Java Guide - \347\274\223\345\255\230.md"
+++ "b/docs/\345\274\200\345\217\221/My Java Guide/My Java Guide - \347\274\223\345\255\230.md"
@@ -15,6 +15,8 @@ cover: /img/cache_logo.png
top_img: /img/Java-tutorials-by-GeeksForGeeks.png
---
+> 友情链接:[缓存预热和大流量冲击的应对策略](#huancunyure)
+
# -----------------缓存总述-----------------
缓存是一种用于提高数据访问速度和系统性能的技术。通过将频繁访问的数据存储在内存或其他快速访问介质中,缓存可以显著减少数据访问的延迟和减轻后端系统的负载。
@@ -564,6 +566,94 @@ Write Back 是计算机体系结构中的设计,比如 CPU 的缓存、操作
 +# 缓存预热和大流量冲击的应对策略{#huancunyure}
+
+大家都知道二八定律,也就是帕累托原则,它告诉我们80%的效果往往来自20%的原因。在互联网应用中,这也意味着80%的
+流量通常集中在20%的API上。对于刚启动或长时间未使用的应用系统来说,这种突然的大流量冲击可能会带来以下几个问题:
+
+1. **缓存未命中**:刚开始时,缓存里啥都没有,所有请求都要去后端数据库找数据,这就增加了系统的响应时间。
+2. **连接池耗尽**:短时间内大量请求可能导致连接池里的可用连接迅速用完,新的请求无法建立连接,从而引发错误。
+3. **资源竞争**:多个请求同时争夺有限的系统资源,可能导致资源争用和死锁问题。
+
+
+# 缓存预热和大流量冲击的应对策略{#huancunyure}
+
+大家都知道二八定律,也就是帕累托原则,它告诉我们80%的效果往往来自20%的原因。在互联网应用中,这也意味着80%的
+流量通常集中在20%的API上。对于刚启动或长时间未使用的应用系统来说,这种突然的大流量冲击可能会带来以下几个问题:
+
+1. **缓存未命中**:刚开始时,缓存里啥都没有,所有请求都要去后端数据库找数据,这就增加了系统的响应时间。
+2. **连接池耗尽**:短时间内大量请求可能导致连接池里的可用连接迅速用完,新的请求无法建立连接,从而引发错误。
+3. **资源竞争**:多个请求同时争夺有限的系统资源,可能导致资源争用和死锁问题。
+
+ +
+## 1. 收集日志分析热点API与热点数据
+
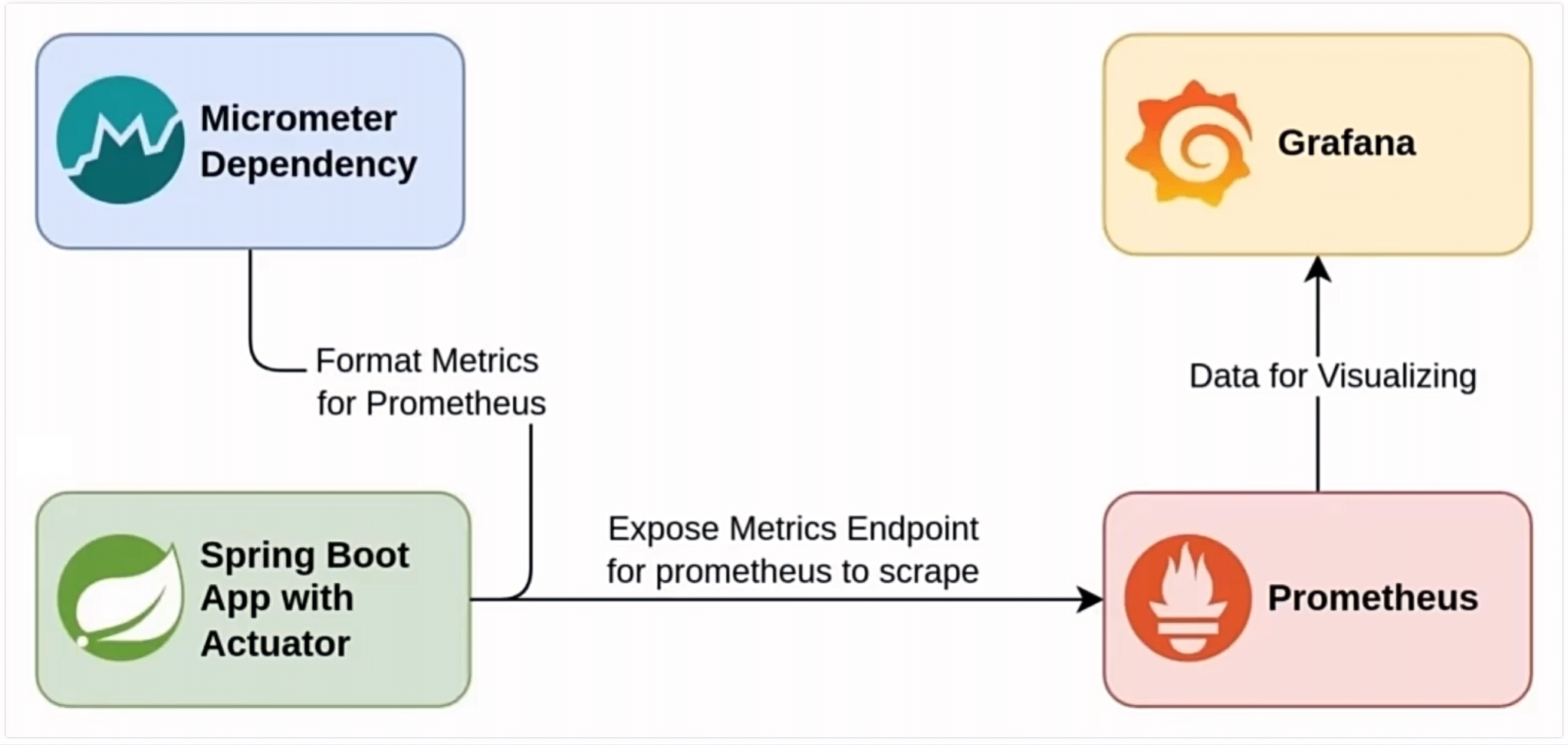
+要进行API预热,首先得知道哪些API是热点API,哪些数据是热点数据。这一步可以通过收集和分析系统日志来实现。常用的日志收集和分析工具有Prometheus和ELK(Elasticsearch, Logstash, Kibana)。
+
+**Prometheus :**
+
+1. **安装与配置**:在应用服务器上安装Prometheus,并配置监控目标,收集APl请求的响应时间、请求频率等指标。
+2. **数据采集**:Prometheus会定期从应用服务器上抓取指标数据,并存储在本地数据库中。
+3. **数据分析**:通过Prometheus的图形界面或查询语言PromQL,可以分析出哪些APl的请求频率最高,响应时间最长,从而确定热点API。
+
+
+
+## 1. 收集日志分析热点API与热点数据
+
+要进行API预热,首先得知道哪些API是热点API,哪些数据是热点数据。这一步可以通过收集和分析系统日志来实现。常用的日志收集和分析工具有Prometheus和ELK(Elasticsearch, Logstash, Kibana)。
+
+**Prometheus :**
+
+1. **安装与配置**:在应用服务器上安装Prometheus,并配置监控目标,收集APl请求的响应时间、请求频率等指标。
+2. **数据采集**:Prometheus会定期从应用服务器上抓取指标数据,并存储在本地数据库中。
+3. **数据分析**:通过Prometheus的图形界面或查询语言PromQL,可以分析出哪些APl的请求频率最高,响应时间最长,从而确定热点API。
+
+ +
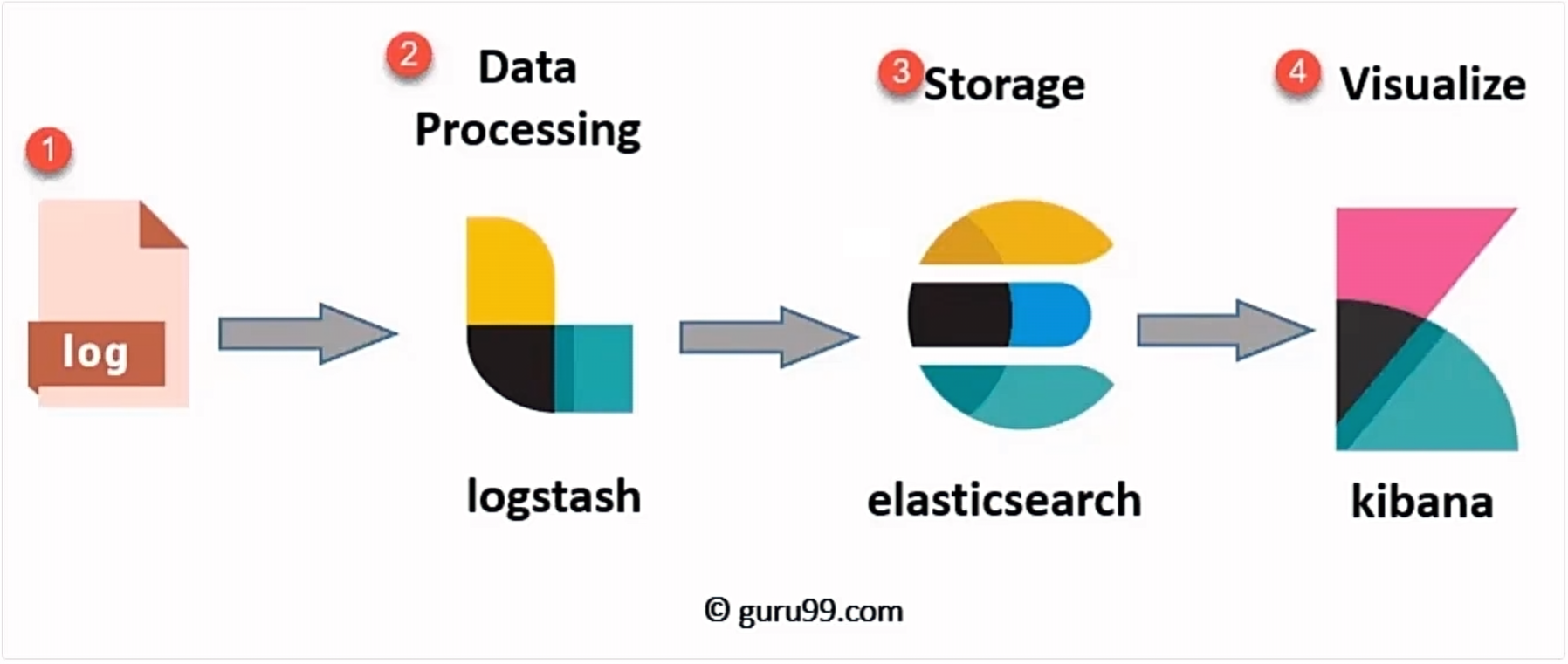
+**ELK:**通过日志的方式实现数据的离线分析(日志分析**Prometheus**其实也可以做,因为上面已经拿到了请求的API了 )
+
+1. **安装与配置**:安装Elasticsearch、Logstash和Kibana,配置Logstash从应用服务器上收集日志文件。
+2. **日志解析**:使用Logstash的过滤器解析日志文件,提取出APl请求的相关信息,如请求路径、响应时间等。
+3. **数据分析**:将解析后的日志数据存储在Elasticsearch中,通过Kibana的可视化工具进行分析,找出热点APl和热点数据。
+
+
+
+**ELK:**通过日志的方式实现数据的离线分析(日志分析**Prometheus**其实也可以做,因为上面已经拿到了请求的API了 )
+
+1. **安装与配置**:安装Elasticsearch、Logstash和Kibana,配置Logstash从应用服务器上收集日志文件。
+2. **日志解析**:使用Logstash的过滤器解析日志文件,提取出APl请求的相关信息,如请求路径、响应时间等。
+3. **数据分析**:将解析后的日志数据存储在Elasticsearch中,通过Kibana的可视化工具进行分析,找出热点APl和热点数据。
+
+ +
+## 2. 将连接池的可用连接拉升到较高的水平线
+
+除了缓存预热外,还需要将连接池的可用连接拉升到较高的水平线,以应对突发大流量。
+
+**配置连接池参数:**
+
+1. **初始连接数**:设置连接池的初始连接数,确保在应用启动时就有一定数量的连接可用。**最佳实践:初始连接数=最大连接数**
+2. **最大连接数**:根据系统的最大负载能力,设置连接池的最大连接数。
+3. **连接超时时间**:设置合理的连接超时时间,避免连接长时间占用导致资源浪费。
+
+## 3. 初始化调度方式发送模拟API热点数据的访问请求
+
+确定了热点API和热点数据后,下一步就是在应用启动后通过初始化调度方式发送模拟API热点数据的访问请求,达到本地缓存与Redis分布式缓存预热的目的。
+
+**本地缓存预热:**
+
+1. **缓存初始化**:在应用启动时,通过初始化代码将热点数据加载到本地缓存中。比如,可以使用GuavaCache或Caffeine等缓存库。
+2. **缓存更新策略**:设置合理的缓存更新策略,如定时刷新或基于LRU(最近最少使用)算法自动淘汰旧数据。
+
+**分布式缓存预热:**
+
+1. **预热脚本**:编写预热脚本,通过HTTP客户端(如HttpClient或OkHttp)发送模拟请求,访问热点API。
+2. **数据加载**:在模拟请求中,确保热点数据被加载到分布式缓存中。
+3. **监控预热过程**:通过Prometheus或ELK监控预热过程中的各项指标,确保数据成功加载到缓存中。
+
+## 4. API对外提供服务后的预热与限流
+
+在API对外提供服务后,仍然需要通过WarmUp(预热)方式对API进行限流,做好进一步的接口预防工作。
+
+**WarmUp策略:**
+
+- 渐进式增加流量:在API对外提供服务的初期,通过限流策略逐渐增加流量,避免突然大量请求导致系统过载,AlibabaSentinel以内置此功能。
+
+
+
+## 2. 将连接池的可用连接拉升到较高的水平线
+
+除了缓存预热外,还需要将连接池的可用连接拉升到较高的水平线,以应对突发大流量。
+
+**配置连接池参数:**
+
+1. **初始连接数**:设置连接池的初始连接数,确保在应用启动时就有一定数量的连接可用。**最佳实践:初始连接数=最大连接数**
+2. **最大连接数**:根据系统的最大负载能力,设置连接池的最大连接数。
+3. **连接超时时间**:设置合理的连接超时时间,避免连接长时间占用导致资源浪费。
+
+## 3. 初始化调度方式发送模拟API热点数据的访问请求
+
+确定了热点API和热点数据后,下一步就是在应用启动后通过初始化调度方式发送模拟API热点数据的访问请求,达到本地缓存与Redis分布式缓存预热的目的。
+
+**本地缓存预热:**
+
+1. **缓存初始化**:在应用启动时,通过初始化代码将热点数据加载到本地缓存中。比如,可以使用GuavaCache或Caffeine等缓存库。
+2. **缓存更新策略**:设置合理的缓存更新策略,如定时刷新或基于LRU(最近最少使用)算法自动淘汰旧数据。
+
+**分布式缓存预热:**
+
+1. **预热脚本**:编写预热脚本,通过HTTP客户端(如HttpClient或OkHttp)发送模拟请求,访问热点API。
+2. **数据加载**:在模拟请求中,确保热点数据被加载到分布式缓存中。
+3. **监控预热过程**:通过Prometheus或ELK监控预热过程中的各项指标,确保数据成功加载到缓存中。
+
+## 4. API对外提供服务后的预热与限流
+
+在API对外提供服务后,仍然需要通过WarmUp(预热)方式对API进行限流,做好进一步的接口预防工作。
+
+**WarmUp策略:**
+
+- 渐进式增加流量:在API对外提供服务的初期,通过限流策略逐渐增加流量,避免突然大量请求导致系统过载,AlibabaSentinel以内置此功能。
+
+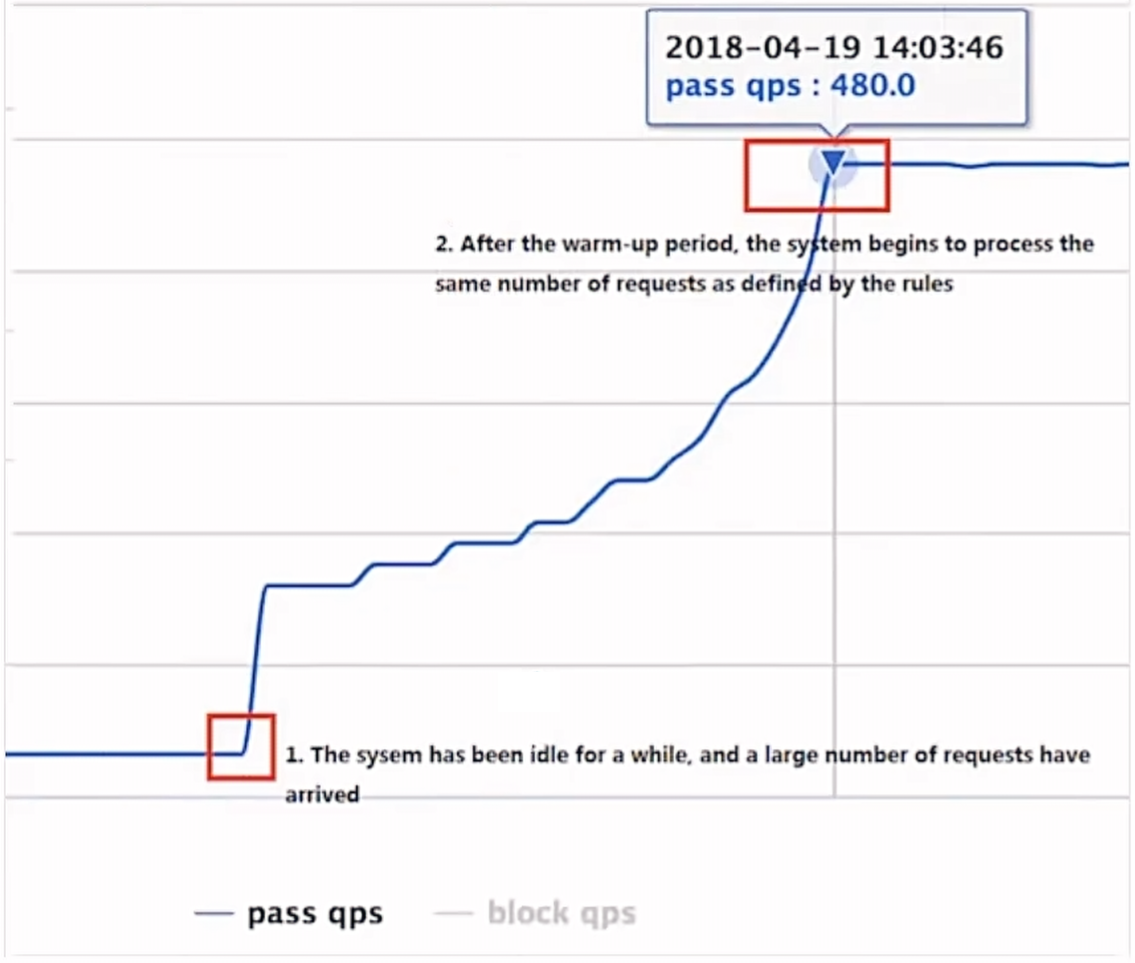 +
+- 动态调整限流阈值:根据系统的实时负载情况,动态调整限流阈值。
+
+## 5. 防止Redis被瞬时流量击垮的服务降级措施
+
+为了防止Redis被瞬时流量击垮,还需要做好服务降级的措施,确保系统的稳定性和可靠性。
+
+**服务降级策略:**
+
+- **缓存穿透**:数据库被大量请求直接访问。可以使用布隆过滤器或缓存空对象的方式来防止缓存穿透。
+- **缓存雪崩**:数据库被大量请求冲击。可以设置缓存的过期时间随机化,或者使用互备缓存机制。
+- **降级方案**:当Redis服务停止响应时,尝试读取本地缓存。如果本地缓存中也没有数据,可以返回默认值或提示用户稍后再试。
+
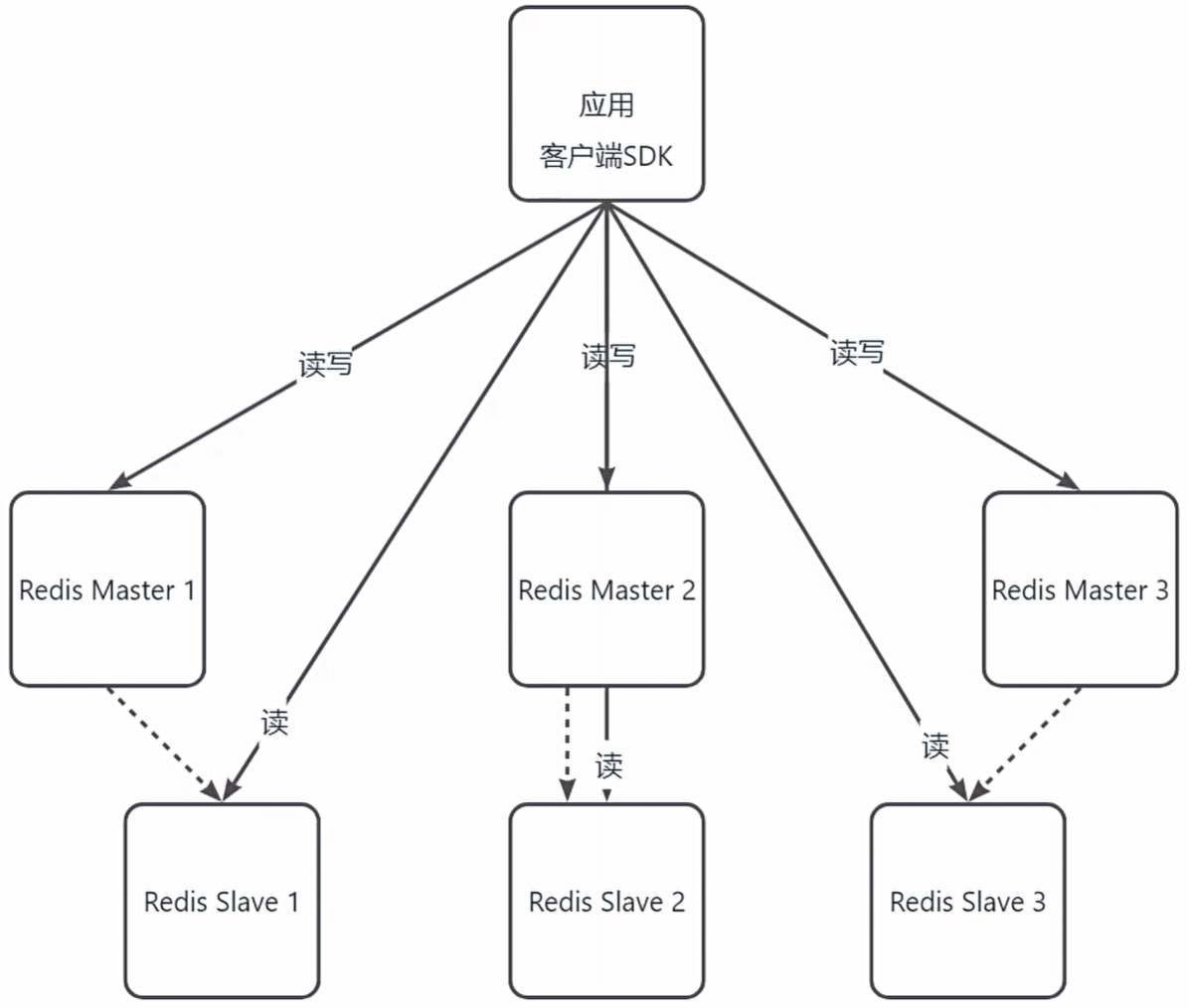
+**故障转移:**
+
+- **集群模式**:使用集群模式,将数据分散到多个节点上,提高系统的扩展性和容错能力。
+
+- **客户端负载均衡**:规避中心化设计
+
+
+
+- 动态调整限流阈值:根据系统的实时负载情况,动态调整限流阈值。
+
+## 5. 防止Redis被瞬时流量击垮的服务降级措施
+
+为了防止Redis被瞬时流量击垮,还需要做好服务降级的措施,确保系统的稳定性和可靠性。
+
+**服务降级策略:**
+
+- **缓存穿透**:数据库被大量请求直接访问。可以使用布隆过滤器或缓存空对象的方式来防止缓存穿透。
+- **缓存雪崩**:数据库被大量请求冲击。可以设置缓存的过期时间随机化,或者使用互备缓存机制。
+- **降级方案**:当Redis服务停止响应时,尝试读取本地缓存。如果本地缓存中也没有数据,可以返回默认值或提示用户稍后再试。
+
+**故障转移:**
+
+- **集群模式**:使用集群模式,将数据分散到多个节点上,提高系统的扩展性和容错能力。
+
+- **客户端负载均衡**:规避中心化设计
+
+  +
+
+
#
+
+
+
# ----------------分布式缓存----------------
# 主从同步