diff --git "a/docs/\345\274\200\345\217\221/My Java Guide/My Java Guide - Java\345\237\272\347\241\200.md" "b/docs/\345\274\200\345\217\221/My Java Guide/My Java Guide - Java\345\237\272\347\241\200.md"
index cc57505..5661ec9 100644
--- "a/docs/\345\274\200\345\217\221/My Java Guide/My Java Guide - Java\345\237\272\347\241\200.md"
+++ "b/docs/\345\274\200\345\217\221/My Java Guide/My Java Guide - Java\345\237\272\347\241\200.md"
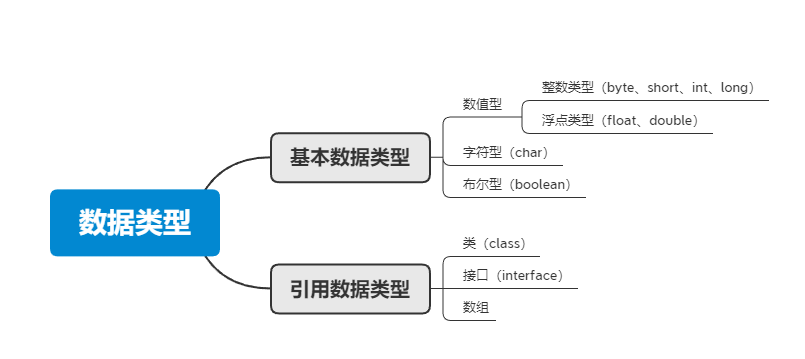
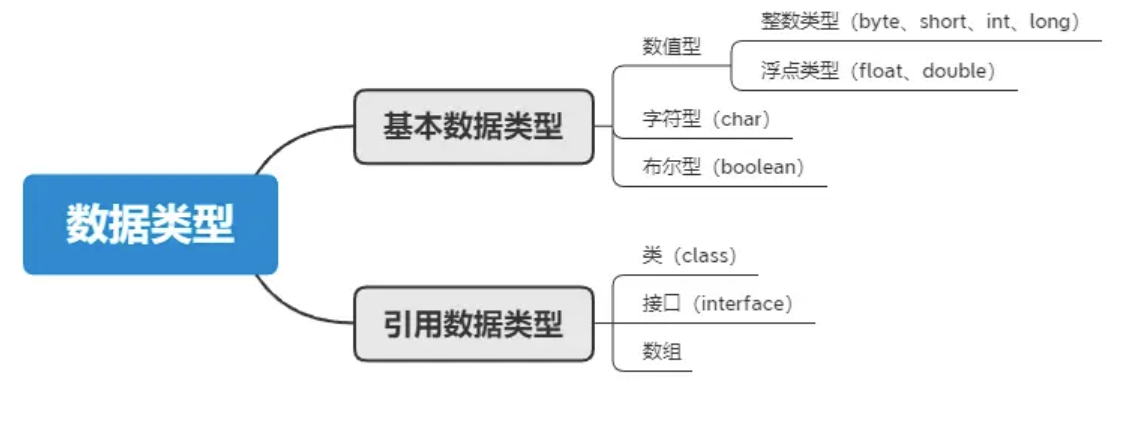
@@ -25,11 +25,11 @@ Java支持数据类型分为两类: 基本数据类型和引用数据类型。
- 字符型:char
- 布尔型:boolean
- +
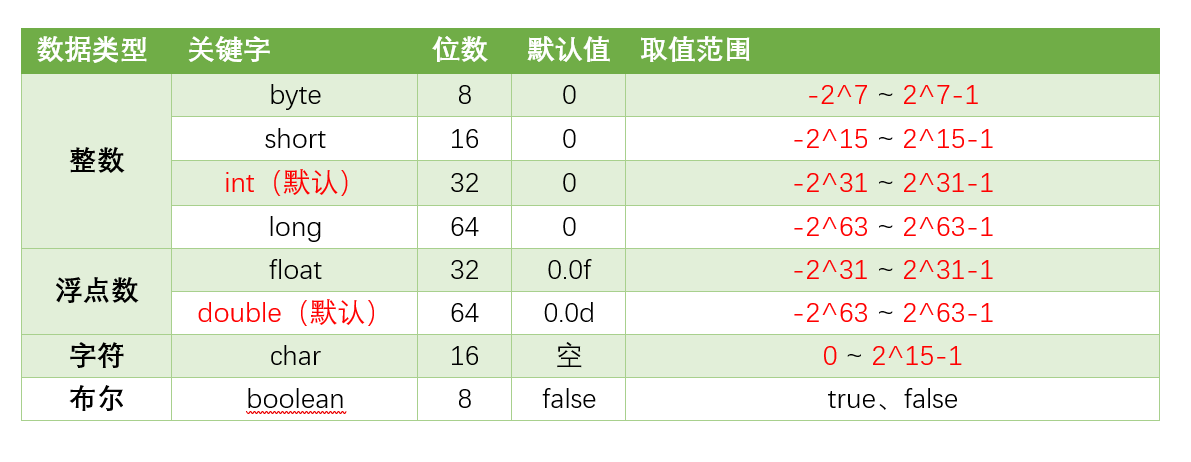
+ 8种基本数据类型的默认值、位数、取值范围,如下表所示:
-
8种基本数据类型的默认值、位数、取值范围,如下表所示:
- +
# String、StringBuffer 和 StringBuilder 的区别
diff --git "a/docs/\345\274\200\345\217\221/My Java Guide/My Java Guide - \345\210\206\345\270\203\345\274\217.md" "b/docs/\345\274\200\345\217\221/My Java Guide/My Java Guide - \345\210\206\345\270\203\345\274\217.md"
index 96765e4..cf01e86 100644
--- "a/docs/\345\274\200\345\217\221/My Java Guide/My Java Guide - \345\210\206\345\270\203\345\274\217.md"
+++ "b/docs/\345\274\200\345\217\221/My Java Guide/My Java Guide - \345\210\206\345\270\203\345\274\217.md"
@@ -2771,7 +2771,7 @@ Netty中的Future和Promise是用于处理异步操作的结果和状态的。
抽象类只能单继承,接口可以有多个实现。
-#
+
# String、StringBuffer 和 StringBuilder 的区别
diff --git "a/docs/\345\274\200\345\217\221/My Java Guide/My Java Guide - \345\210\206\345\270\203\345\274\217.md" "b/docs/\345\274\200\345\217\221/My Java Guide/My Java Guide - \345\210\206\345\270\203\345\274\217.md"
index 96765e4..cf01e86 100644
--- "a/docs/\345\274\200\345\217\221/My Java Guide/My Java Guide - \345\210\206\345\270\203\345\274\217.md"
+++ "b/docs/\345\274\200\345\217\221/My Java Guide/My Java Guide - \345\210\206\345\270\203\345\274\217.md"
@@ -2771,7 +2771,7 @@ Netty中的Future和Promise是用于处理异步操作的结果和状态的。
抽象类只能单继承,接口可以有多个实现。
-# ------------容器化技术和CI/CD------------
+# -----------------容器化技术----------------
# Docker 的基本概念和工作原理
@@ -2853,7 +2853,7 @@ docker build -t my_custom_image:latest .
3. **Docker Compose:** 使用 Docker Compose 来编排多个服务,可以为每个服务定义网络,并对网络进行配置。
4. **共享网络命名空间:** 通过创建共享网络命名空间的方式,使多个容器共享网络设置。
-## 如何实现资源限制?
+# 如何实现资源限制?
1. 为了限制容器使用的 CPU 数量,可以使用 `--cpu-shares` 或 `--cpus` 参数。
- `--cpu-shares`:使用相对权重方式分配 CPU 资源。
@@ -2867,9 +2867,11 @@ docker build -t my_custom_image:latest .
docker run --cpus=1 --memory=512m [container_name]
```
-# Jenkins
-## 自动发布的好处
+
+# ----------------自动化服务器---------------
+
+# 自动发布的好处
**CI/CD**:持续集成(CI)、持续交付(CD)
@@ -2885,7 +2887,7 @@ docker run --cpus=1 --memory=512m [container_name]
**自动发布真正的好处**:并不是单单**节省了多服务器的部署时间**,**免去人工编译、部署时可能发生的人为失误**,从而节省无意间浪费的成本。
-## Jenkins介绍
+# Jenkins介绍
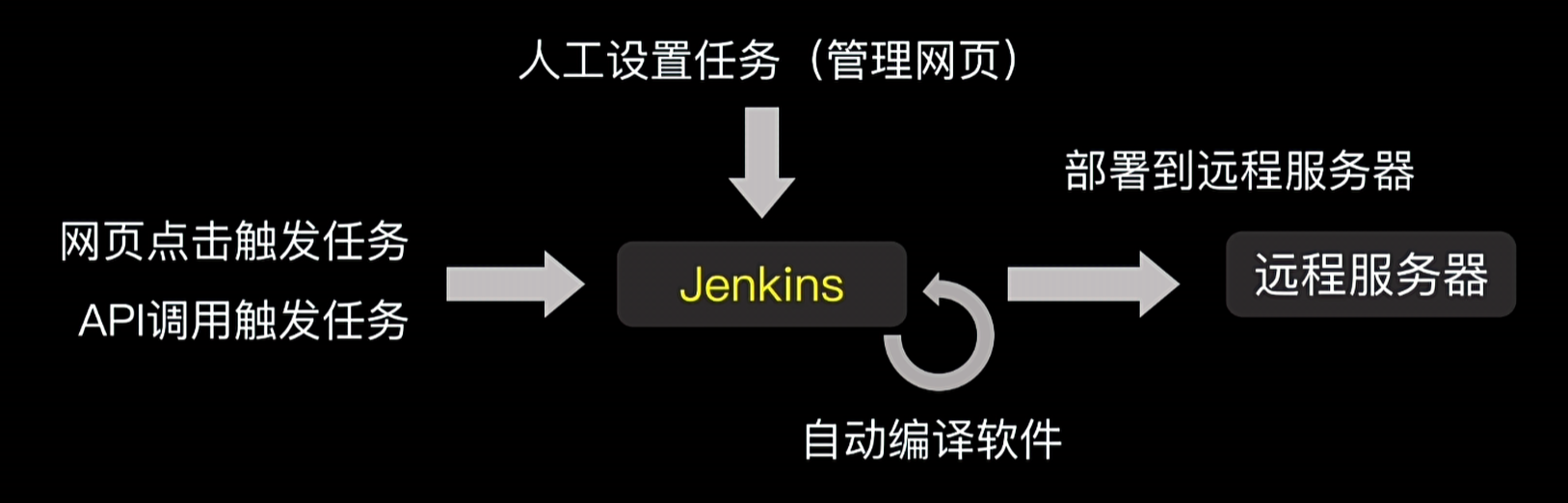
Jenkins是一个自动发布部署软件的系统,可以简单地将Jenkins理解为一个网站系统,在管理网站上,用户可以编排自动发布任务,可以实现代码下载-代码编译-文件发送-执行远程命令等场景,当条件触发时,Jenkins就会自动按预设任务进行编译部署。
@@ -2893,15 +2895,15 @@ Jenkins是一个自动发布部署软件的系统,可以简单地将Jenkins理
 -## Jenkins安装
+# Jenkins安装
使用[1Panel](https://1panel.cn/)一键安装
-## Jenkins发布流程配置
+# Jenkins发布流程配置
TODO
-## 如何使用 Jenkins 与 Docker 集成?
+# *如何使用 Jenkins 与 Docker 集成?*
1. 安装必要的插件:在 Jenkins 中,安装 Docker plugin 和 Pipeline plugin 等必要插件。
2. 配置 Jenkins:配置环境,确保 Jenkins 可以访问 Docker 命令。
diff --git "a/docs/\345\274\200\345\217\221/My Java Guide/My Java Guide - \347\274\223\345\255\230.md" "b/docs/\345\274\200\345\217\221/My Java Guide/My Java Guide - \347\274\223\345\255\230.md"
index 4286d6e..e99e987 100644
--- "a/docs/\345\274\200\345\217\221/My Java Guide/My Java Guide - \347\274\223\345\255\230.md"
+++ "b/docs/\345\274\200\345\217\221/My Java Guide/My Java Guide - \347\274\223\345\255\230.md"
@@ -15,7 +15,7 @@ cover: /img/cache_logo.png
top_img: /img/Java-tutorials-by-GeeksForGeeks.png
---
-#
-## Jenkins安装
+# Jenkins安装
使用[1Panel](https://1panel.cn/)一键安装
-## Jenkins发布流程配置
+# Jenkins发布流程配置
TODO
-## 如何使用 Jenkins 与 Docker 集成?
+# *如何使用 Jenkins 与 Docker 集成?*
1. 安装必要的插件:在 Jenkins 中,安装 Docker plugin 和 Pipeline plugin 等必要插件。
2. 配置 Jenkins:配置环境,确保 Jenkins 可以访问 Docker 命令。
diff --git "a/docs/\345\274\200\345\217\221/My Java Guide/My Java Guide - \347\274\223\345\255\230.md" "b/docs/\345\274\200\345\217\221/My Java Guide/My Java Guide - \347\274\223\345\255\230.md"
index 4286d6e..e99e987 100644
--- "a/docs/\345\274\200\345\217\221/My Java Guide/My Java Guide - \347\274\223\345\255\230.md"
+++ "b/docs/\345\274\200\345\217\221/My Java Guide/My Java Guide - \347\274\223\345\255\230.md"
@@ -15,7 +15,7 @@ cover: /img/cache_logo.png
top_img: /img/Java-tutorials-by-GeeksForGeeks.png
---
-# --------------------缓存总述--------------------
+# -----------------缓存总述-----------------
缓存是一种用于提高数据访问速度和系统性能的技术。通过将频繁访问的数据存储在内存或其他快速访问介质中,缓存可以显著减少数据访问的延迟和减轻后端系统的负载。
@@ -76,13 +76,12 @@ top_img: /img/Java-tutorials-by-GeeksForGeeks.png
2. **减轻负载**:减少后端系统的负载,提高系统的可用性和稳定性。
3. **提高用户体验**:加快数据访问速度,提升用户的使用体验。
4. **节省资源**:减少对计算和网络资源的消耗,降低运营成本。
-
5. **数据一致性问题**:缓存数据和后端数据源之间的数据一致性难以保证,可能导致数据不一致的问题。
6. **复杂性增加**:引入缓存机制会增加系统的复杂性,需要管理和维护缓存系统。
7. **内存占用**:缓存数据占用内存,如果管理不当可能导致内存溢出等问题。
8. **缓存击穿**:大量请求同时访问同一个缓存数据,导致缓存失效后的瞬间大量请求涌入后端系统,造成后端系统压力过大。
-# ------------------多级缓存架构------------------
+# --------------多级缓存架构--------------
**缓存是提升性能最直接的方法 多级缓存分为:客户端,应用层,服务层,数据层**
@@ -108,7 +107,7 @@ CDN是一项基础设施,一般由云服务厂商提供。
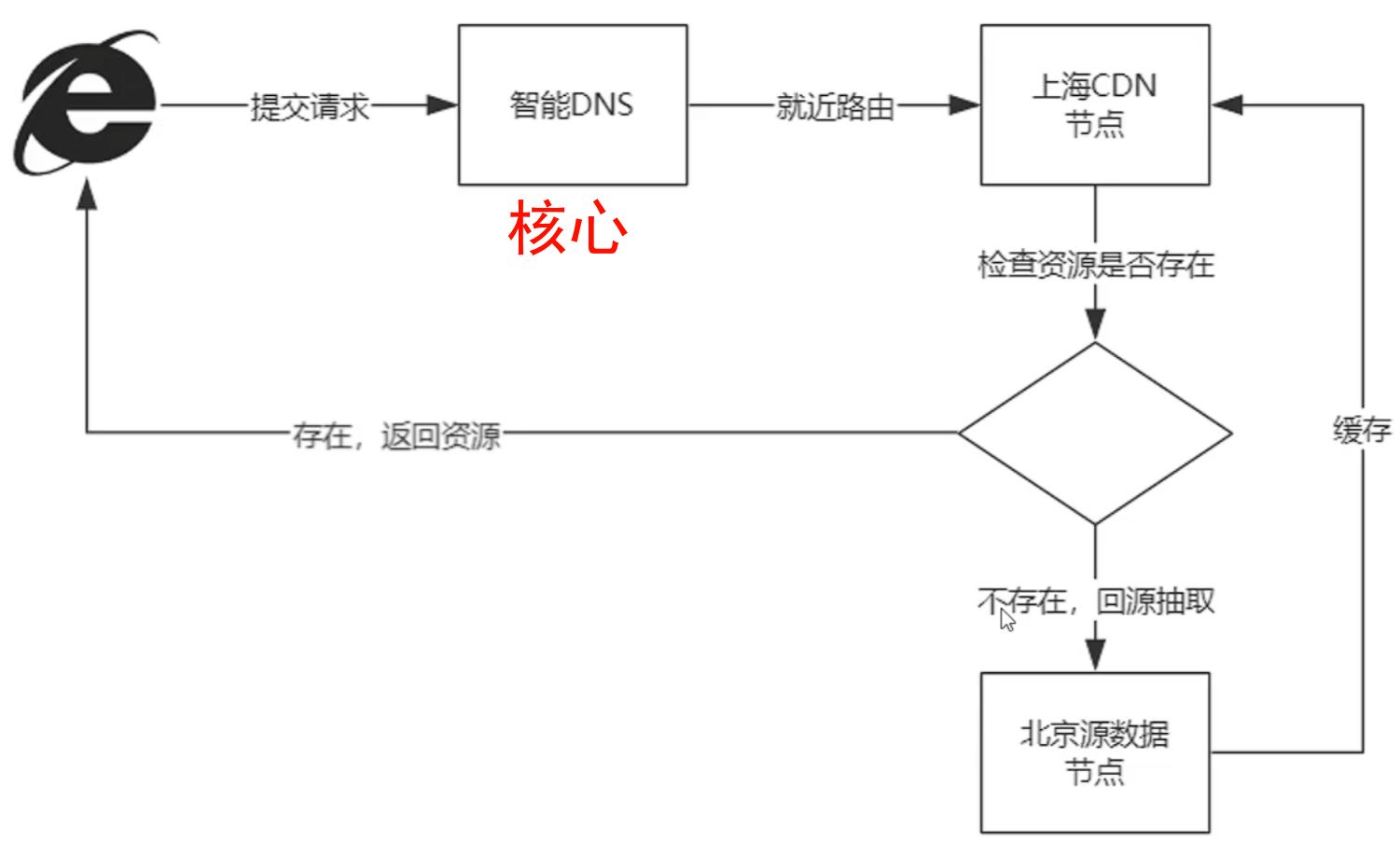
**CDN的核心技术**: 根据请求访问DNS节点, 自动转发到就近CDN节点,检查资源是否被缓存,若已缓存则返回资源否则回源数据节点提取,并缓存到就近CDN节点,再由就近CDN节点进行返回。
- +
**CDN的使用**(aliyun):
@@ -120,13 +119,13 @@ CDN是一项基础设施,一般由云服务厂商提供。
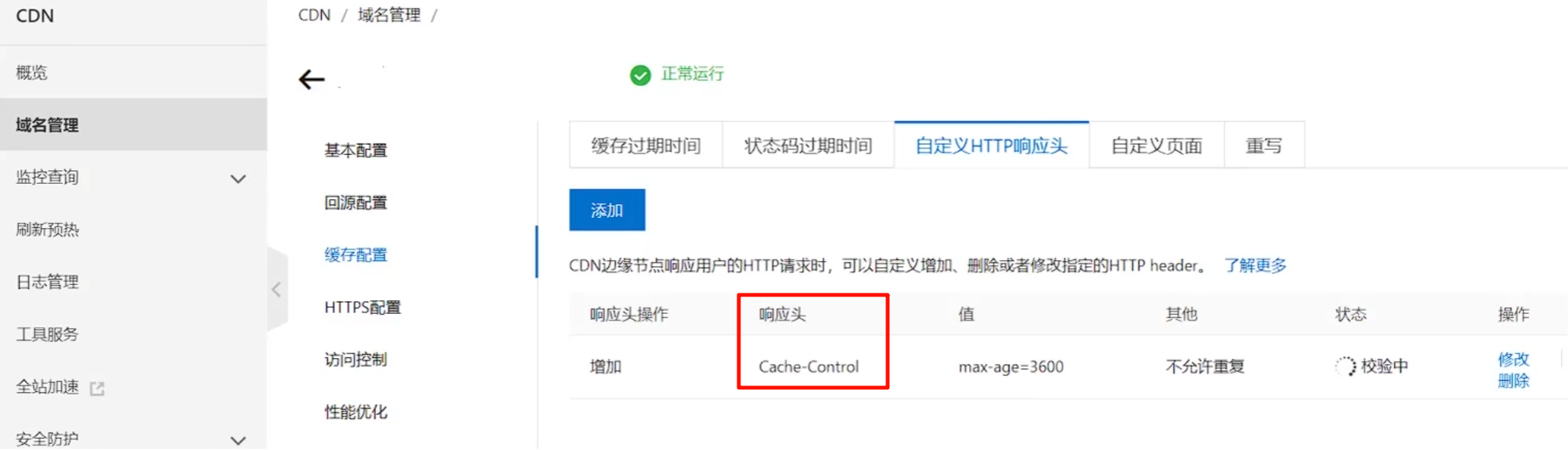
响应头的设置:`Expires` 设置时间,`Cache-Control` 设置时长。
-
+
**CDN的使用**(aliyun):
@@ -120,13 +119,13 @@ CDN是一项基础设施,一般由云服务厂商提供。
响应头的设置:`Expires` 设置时间,`Cache-Control` 设置时长。
- +
## Nginx(轻量级)
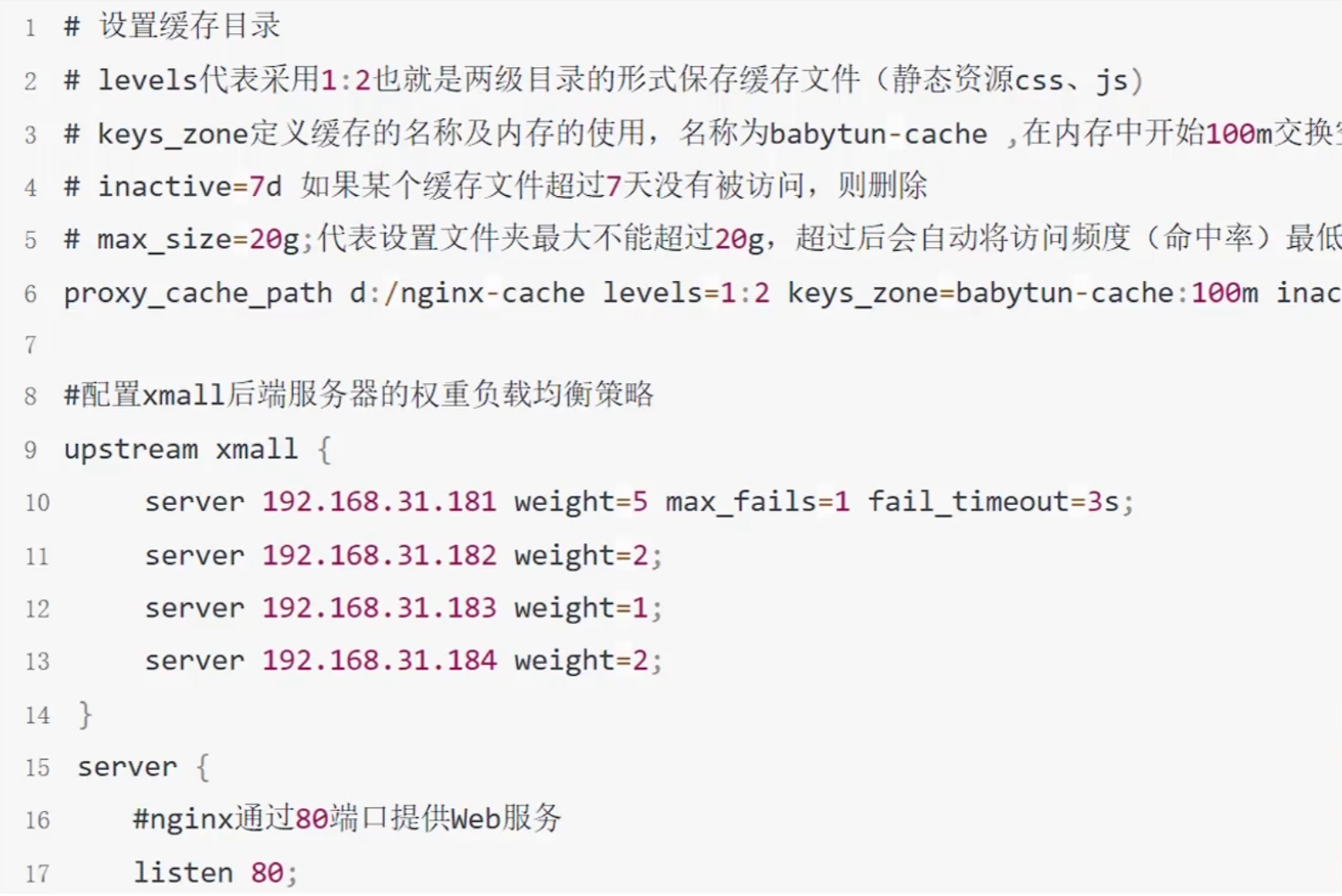
Nginx对Tomcat集群做软负载均衡,提供高可用性。有静态资源缓存和压缩功能(在本地缓存文件)
-
+
## Nginx(轻量级)
Nginx对Tomcat集群做软负载均衡,提供高可用性。有静态资源缓存和压缩功能(在本地缓存文件)
- +
+
 @@ -153,7 +152,7 @@ Nginx对Tomcat集群做软负载均衡,提供高可用性。有静态资源缓
@@ -153,7 +152,7 @@ Nginx对Tomcat集群做软负载均衡,提供高可用性。有静态资源缓
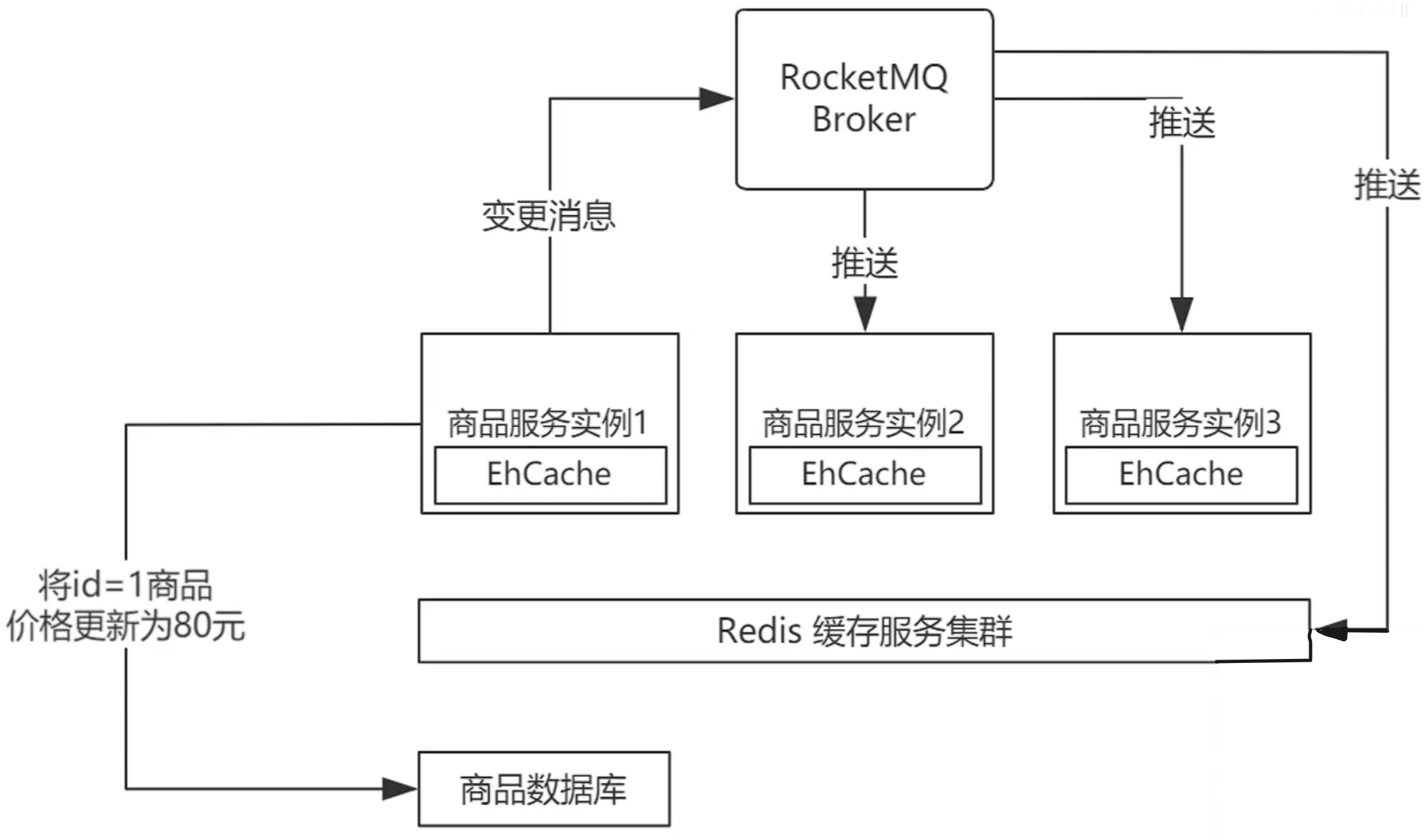 -#
-# ---------进程外缓存(SpringCache)---------
+# ---------------进程外缓存---------------
> 只适合单体项目,遇到分布式,一碰就碎!纯FW!
@@ -206,7 +205,7 @@ EhCache 支持本地缓存和分布式缓存,广泛应用于各种企业级应
- **Caffeine**:高性能的本地缓存库,适合对性能要求较高的场景,特别是单机应用。
- **EhCache**:支持本地缓存和分布式缓存,适合需要分布式缓存支持的企业级应用。
-# -------------进程内缓存(Redis)-------------
+# ---------------进程内缓存---------------
# 缓存的使用场景
@@ -358,7 +357,7 @@ pipeline(管道)使得客户端可以一次性将要执行的多条命令封
## 缓存击穿
-**缓存击穿**:key过期的时候,恰好这时间点对这个key有大量的并发请求过来,这些并发的请求可能会瞬间把DB压垮
+**缓存击穿**:key过期后,这个key有大量的并发请求过来,这些并发的请求可能会瞬间把DB压垮
**解决方案**:
@@ -369,7 +368,7 @@ pipeline(管道)使得客户端可以一次性将要执行的多条命令封
## 缓存雪崩
-**缓存雪崩**:是指在同一时段大量的缓存key同时效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。
+**缓存雪崩**:在同一时段,大量的缓存key同时效,或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。
**解决方案**:
@@ -515,27 +514,28 @@ LFU(Least Frequently Used):最少频率使用。会统计每个key的访问频
# 缓存更新策略
-- **Cache Aside(旁路缓存)策略**;
-- *Read/Write Through(读穿 / 写穿)策略;*(仅存在于理论中)
-- *Write Back(写回)策略;(仅存在于理论中)*
+- Cache Aside(旁路缓存)策略;
+- Read/Write Through(读穿 / 写穿)策略;
+- Write Back(写回)策略
+- Refresh (刷新) 策略:定期或在某些条件下清空缓存,强制从后端数据源重新加载数据。比如用户状态管理等。
-实际开发中,Redis 和 MySQL 的更新策略用的是 **Cache Aside**,另外两种策略应用不了。
+实际开发中,最常用的策略是 **Cache Aside**。
## Cache Aside(旁路缓存)策略
Cache Aside(旁路缓存)策略是最常用的,应用程序直接与「数据库、缓存」交互,并负责对缓存的维护,该策略又可以细分为「读策略」和「写策略」。
-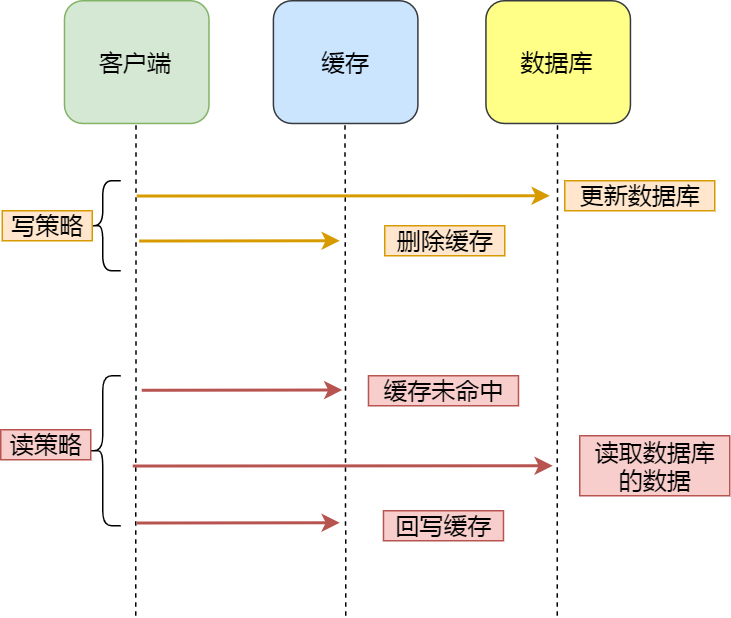 +
-## *Read/Write Through(读穿 / 写穿)策略*
+## Read/Write Through(读穿 / 写穿)策略
Read/Write Through(读穿 / 写穿)策略原则是应用程序只和缓存交互,不再和数据库交互,而是由缓存和数据库交互,相当于更新数据库的操作由缓存自己代理了。
-***1、Read Through 策略***
+**1、Read Through 策略**
先查询缓存中数据是否存在,如果存在则直接返回,如果不存在,则由缓存组件负责从数据库查询数据,并将结果写入到缓存组件,最后缓存组件将数据返回给应用。
-***2、Write Through 策略***
+**2、Write Through 策略**
当有数据更新的时候,先查询要写入的数据在缓存中是否已经存在:
@@ -548,7 +548,7 @@ Read/Write Through(读穿 / 写穿)策略原则是应用程序只和缓存
Read Through/Write Through 策略的特点是由缓存节点而非应用程序来和数据库打交道,在我们开发过程中相比 Cache Aside 策略要少见一些,原因是我们经常使用的分布式缓存组件,无论是 Memcached 还是 Redis 都不提供写入数据库和自动加载数据库中的数据的功能。而我们在使用本地缓存的时候可以考虑使用这种策略。
-## *Write Back(写回)策略*
+## Write Back(写回)策略
Write Back(写回)策略在更新数据的时候,只更新缓存,同时将缓存数据设置为脏的,然后立马返回,并不会更新数据库。对于数据库的更新,会通过批量异步更新的方式进行。
@@ -568,7 +568,7 @@ Write Back 是计算机体系结构中的设计,比如 CPU 的缓存、操作
# 主从同步
-
+
-## *Read/Write Through(读穿 / 写穿)策略*
+## Read/Write Through(读穿 / 写穿)策略
Read/Write Through(读穿 / 写穿)策略原则是应用程序只和缓存交互,不再和数据库交互,而是由缓存和数据库交互,相当于更新数据库的操作由缓存自己代理了。
-***1、Read Through 策略***
+**1、Read Through 策略**
先查询缓存中数据是否存在,如果存在则直接返回,如果不存在,则由缓存组件负责从数据库查询数据,并将结果写入到缓存组件,最后缓存组件将数据返回给应用。
-***2、Write Through 策略***
+**2、Write Through 策略**
当有数据更新的时候,先查询要写入的数据在缓存中是否已经存在:
@@ -548,7 +548,7 @@ Read/Write Through(读穿 / 写穿)策略原则是应用程序只和缓存
Read Through/Write Through 策略的特点是由缓存节点而非应用程序来和数据库打交道,在我们开发过程中相比 Cache Aside 策略要少见一些,原因是我们经常使用的分布式缓存组件,无论是 Memcached 还是 Redis 都不提供写入数据库和自动加载数据库中的数据的功能。而我们在使用本地缓存的时候可以考虑使用这种策略。
-## *Write Back(写回)策略*
+## Write Back(写回)策略
Write Back(写回)策略在更新数据的时候,只更新缓存,同时将缓存数据设置为脏的,然后立马返回,并不会更新数据库。对于数据库的更新,会通过批量异步更新的方式进行。
@@ -568,7 +568,7 @@ Write Back 是计算机体系结构中的设计,比如 CPU 的缓存、操作
# 主从同步
- +
+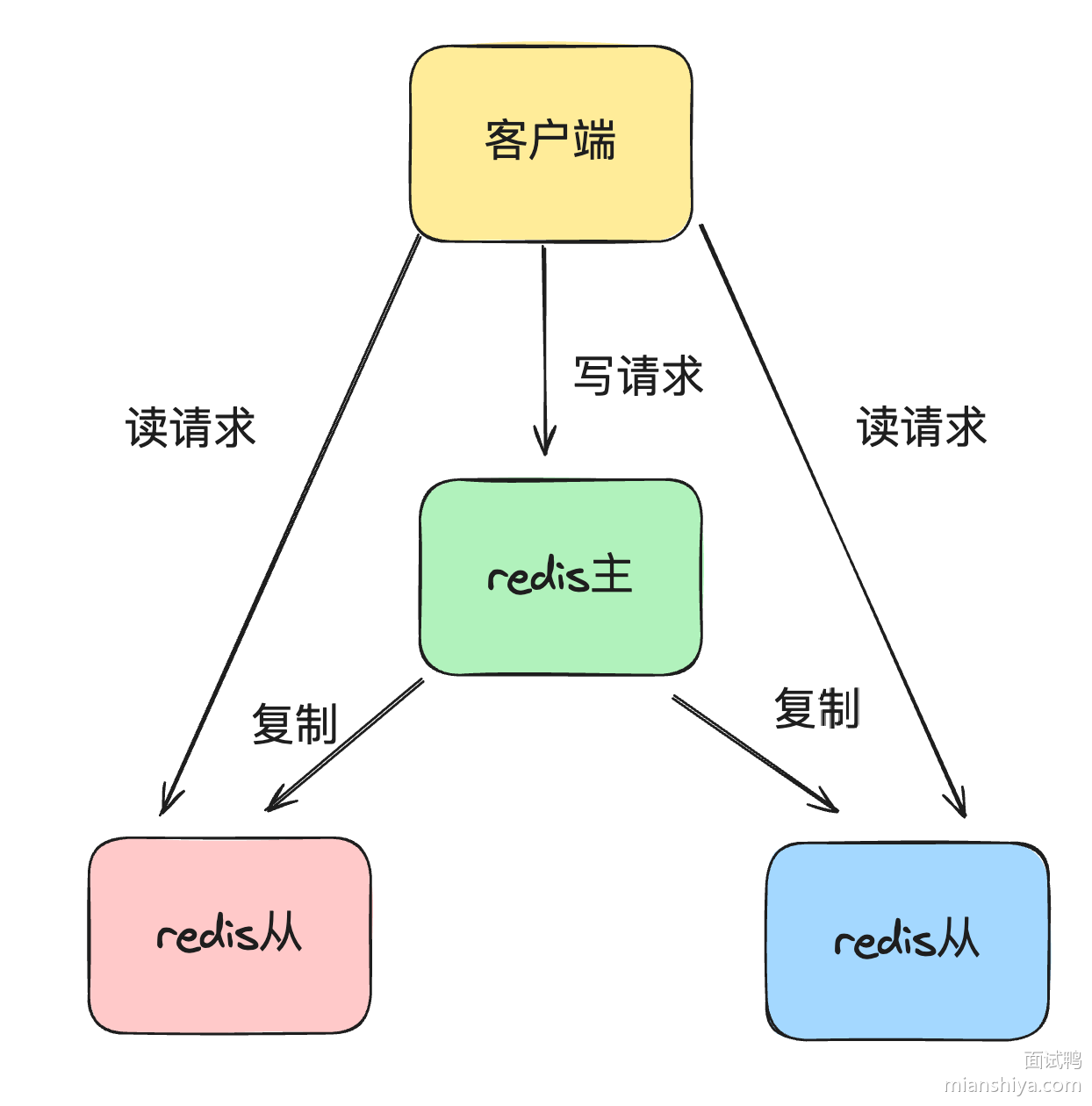 主从同步:单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,可以搭建主从集群,实现读写分离。一般都是一主多从,主节点负责写数据,从节点负责读数据,主节点写入数据之后,需要把数据同步到从节点中
@@ -576,7 +576,7 @@ Write Back 是计算机体系结构中的设计,比如 CPU 的缓存、操作
- 全量同步:从节点第一次与主节点建立连接的时候会使用全量同步
-
主从同步:单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,可以搭建主从集群,实现读写分离。一般都是一主多从,主节点负责写数据,从节点负责读数据,主节点写入数据之后,需要把数据同步到从节点中
@@ -576,7 +576,7 @@ Write Back 是计算机体系结构中的设计,比如 CPU 的缓存、操作
- 全量同步:从节点第一次与主节点建立连接的时候会使用全量同步
-  +
+ 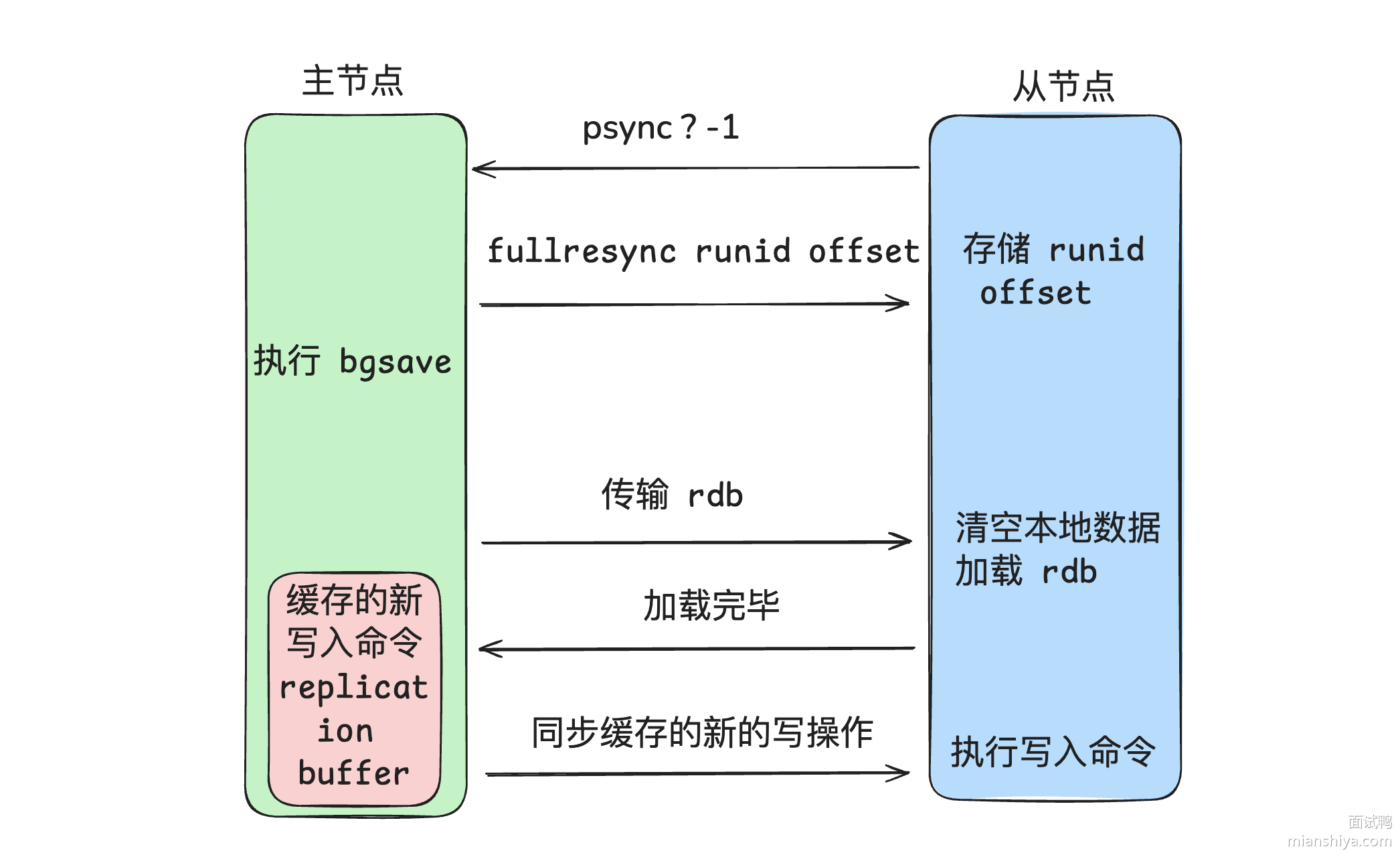 - 从节点请求主节点同步数据,其中从节点会携带自己的replication id和offset偏移量。
- 主节点判断是否是第一次请求,主要判断的依据就是,主节点与从节点是否是同一个replication id,如果不是,就说明是第一次同步,那主节点就会把自己的replication id和offset发送给从节点,让从节点与主节点的信息保持一致
@@ -586,7 +586,7 @@ Write Back 是计算机体系结构中的设计,比如 CPU 的缓存、操作
- 增量同步:当从节点服务重启之后,数据就不一致了,所以这个时候,从节点会请求主节点同步数据,主节点还是判断不是第一次请求,不是第一次就获取从节点的offset值,然后主节点从命令日志中获取offset值之后的数据,发送给从节点进行数据同步
-
- 从节点请求主节点同步数据,其中从节点会携带自己的replication id和offset偏移量。
- 主节点判断是否是第一次请求,主要判断的依据就是,主节点与从节点是否是同一个replication id,如果不是,就说明是第一次同步,那主节点就会把自己的replication id和offset发送给从节点,让从节点与主节点的信息保持一致
@@ -586,7 +586,7 @@ Write Back 是计算机体系结构中的设计,比如 CPU 的缓存、操作
- 增量同步:当从节点服务重启之后,数据就不一致了,所以这个时候,从节点会请求主节点同步数据,主节点还是判断不是第一次请求,不是第一次就获取从节点的offset值,然后主节点从命令日志中获取offset值之后的数据,发送给从节点进行数据同步
-  +
+ 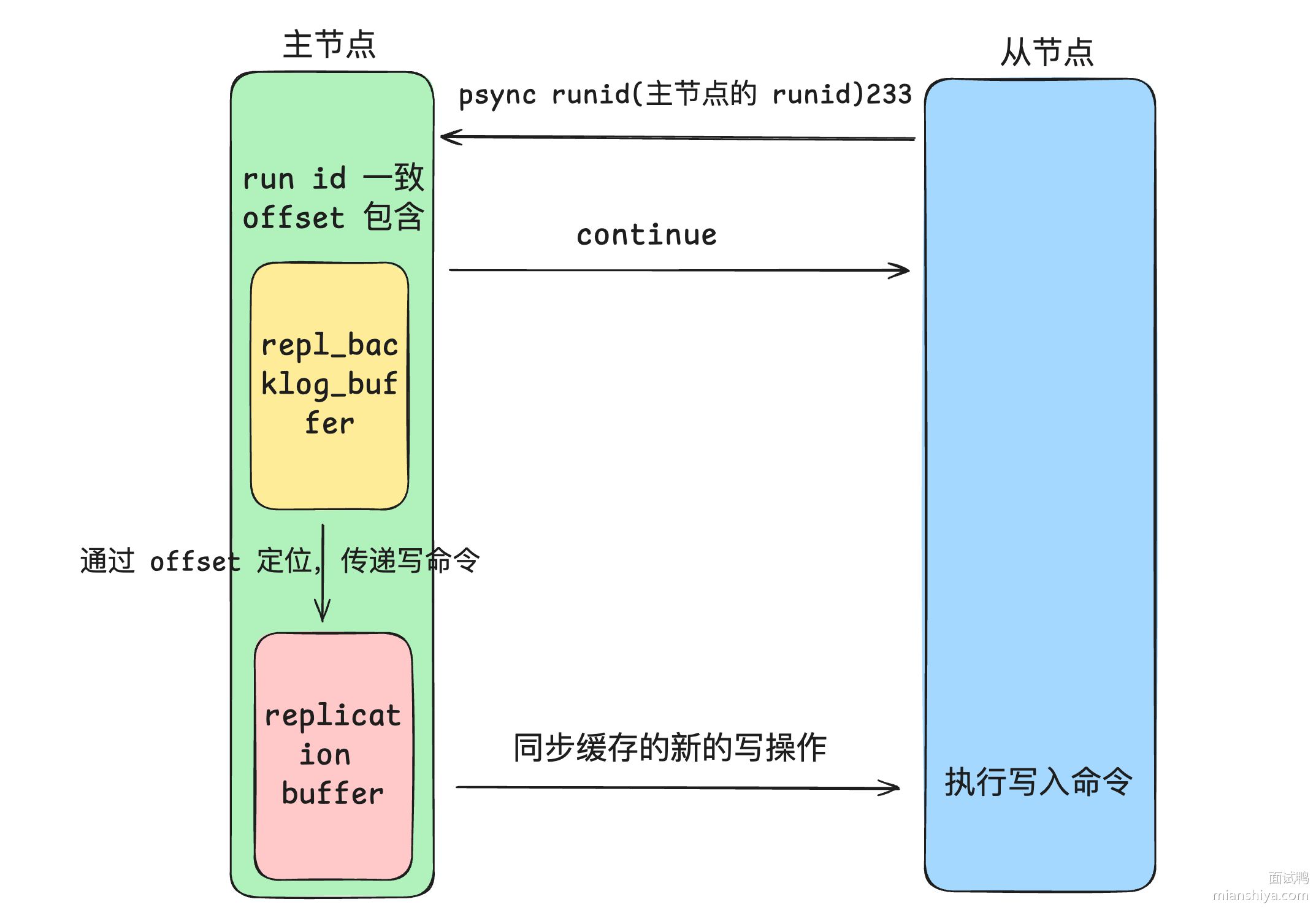 # 哨兵模式
# 哨兵模式